/





































































































































































































































































































































































































































































































































































































































































































































































































Автор: Nicola M. Kumar-Chatterjee P.
Теги: programming data analysis
ISBN: 978-0-13-815047-1
Год: 2010




Текст
Related Books of Interest
DB2 9 for Linux,
UNIX, and Windows
DBA Guide, Reference, and
Exam Prep, Sixth Edition
Understanding DB2
Learning Visually with Examples,
Second Edition
by George Baklarz and Paul C. Zikopoulos
by Raul F. Chong, Xiaomei Wang,
Michael Dang, and Dwaine R. Snow
ISBN: 0-13-185514-X
ISBN: 0-13-158018-3
The sixth edition of this classic offers complete,
®
9 administra®
tion and development for Linux , UNIX®, and
Windows® platforms, as well as authoritative
preparation for the latest IBM®
exam. Written for both DBAs and developers,
IBM DB2 9 and DB2 9.5 provide breakthrough
capabilities for providing Information on Demand,
implementing Web services and Service Oriented
Architecture, and streamlining information management. Understanding DB2: Learning Visually
with Examples, Second Edition, is the easiest way
to master the latest versions of DB2 and apply their
full power to your business challenges.
Written by four IBM DB2 experts, this book
introduces key concepts with dozens of examples
drawn from the authors’ experience working
with DB2 in enterprise environments. Thoroughly
updated for DB2 9.5, it covers new innovations
ranging from manageability to performance and
XML support to API integration. Each concept is
presented with easy-to-understand screenshots,
diagrams, charts, and tables. This book is for
everyone who works with DB2: database administrators, system administrators, developers, and
consultants. With hundreds of well-designed review
questions and answers, it will also help profession-
ers all aspects of deploying and managing DB2 9,
including DB2 database design and development;
day-to-day administration and backup; deployment of networked, Internet-centered, and SOAbased applications; migration; and much more.
tips for optimizing performance, availability, and
value. Download Complete DB2 V9 Trial Version
Visit ibm.com/db2/9/download.html to download
a complete trial version of DB2, which enables
you to try out dozens of the most powerful
features of DB2 for yourself – everything from
pureXML™ support to automated administration
and optimization.
Listen to the author’s podcast at:
ibmpressbooks.com/podcasts
730, 731, or 736.
Listen to the author’s podcast at:
ibmpressbooks.com/podcasts
Sign up for the monthly IBM Press newsletter at
ibmpressbooks/newsletters
Related Books of Interest
Understanding
DB2 9 Security
By Rebecca Bond, Kevin Yeung-Kuen See,
Carmen Ka Man Wong, and
Yuk-Kuen Henry Chan
ISBN: 0-13-134590-7
Understanding DB2 9 Security is a comprehensive
guide to securing DB2 and leveraging the
powerful new security features of DB2 9.
Direct from a DB2 Security deployment expert
and the IBM DB2 development team, this book
gives DBAs and their managers a wealth of
security information that is available nowhere
else. It presents real-world implementation
scenarios, step-by-step examples, and expert
guidance on both the technical and human
sides of DB2 security.
This book’s material is organized to support you
through every step of securing DB2 in Windows,
Linux, or UNIX environments. You’ll start by
exploring the regulatory and business issues
driving your security efforts, and then master the
technological and managerial knowledge crucial
to effective implementation. Next, the authors
offer practical guidance on post-implementation
auditing, and show how to systematically
maintain security on an ongoing basis.
Mining the Talk
Unlocking the Business Value
in Unstructured Information
by Scott Spangler, and Jeffrey Kreulen
ISBN: 0-13-233953-6
In Mining the Talk, two leading-edge IBM
researchers introduce a revolutionary new
approach to unlocking the business value hidden
in virtually any form of unstructured data – from
word processing documents to websites, emails
to instant messages. The authors review the
business drivers that have made unstructured
data so important and explain why conventional
methods for working with it are inadequate.
Then, writing for business professionals – not
just data mining specialists – they walk step-bystep through exploring your unstructured data,
understanding it, and analyzing it effectively.
key areas: learning from your customer interactions; hearing the voices of customers when
they’re not talking to you; discovering the
“collective consciousness” of your own organization; enhancing innovation; and spotting emerging trends. Whatever your organization, Mining
the Talk offers you breakthrough opportunities to
become more responsive, agile, and competitive.
Listen to the author’s podcast at:
ibmpressbooks.com/podcasts
Visit ibmpressbooks.com
for all product information
Related Books of Interest
An Introduction to IMS
Meltz, Long, Harrington,
Hain, Nicholls
ISBN: 0-13-185671-5
A Practical Guide to
Trusted Computing
Enterprise Master Data
Management
by Allen Dreibelbis, Eberhard Hechler,
Ivan Milman, Martin Oberhofer, Paul van Run,
and Dan Wolfson
ISBN: 0-13-236625-8
Enterprise Master Data Management provides an
authoritative, vendor-independent MDM technical
reference for practitioners: architects, technical
analysts, consultants, solution designers, and
senior IT decision makers. Written by the IBM®
data management innovators who are pioneering
MDM, this book systematically introduces MDM’s
key concepts and technical themes, explains its
business case, and illuminates how it interrelates
with and enables SOA.
Challener, Yoder, Catherman,
Safford, Van Doorn
ISBN: 0-13-239842-7
Mainframe Basics for
Security Professionals
Pomerantz, Weele, Nelson, Hahn
ISBN: 0-13-173856-9
Service-Oriented
Architecture (SOA) Compass
Bieberstein, Bose, Fiammante,
Jones, Shah
ISBN: 0-13-187002-5
WebSphere Business
Integration Primer
Iyengar, Jessani, Chilanti
ISBN: 0-13-224831-X
Drawing on their experience with cutting-edge
projects, the authors introduce MDM patterns,
blueprints, solutions, and best practices published
nowhere else—everything you need to establish
a consistent, manageable set of master data, and
use it for competitive advantage.
Sign up for the monthly IBM Press newsletter at
ibmpressbooks/newsletters
Outside-in Software
Development
Kessler, Sweitzer
ISBN: 0-13-157551-1
This page intentionally left blank
DB2® pureXML®
Cookbook
Project
Management
with the
This page intentionally left blank
IBM WebSphere
[SUBTITLE ]
DB2® pureXML®
Cookbook
Deployment and Advanced
Master the Power of the IBM
Configuration
®
Hybrid Data Server
Roland Barcia, Bill Hines, Tom Alcott, and Keys Botzum
Matthias Nicola
Pav Kumar-Chatterjee
IBM Press
Pearson plc
Upper Saddle River, NJ • Boston • Indianapolis • San Francisco
New York • Toronto • Montreal • London • Munich • Paris • Madrid
Cape Town • Sydney • Tokyo • Singapore • Mexico City
Ibmpressbooks.com
The authors and publisher have taken care in the preparation of this book, but make no expressed or implied
warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for
incidental or consequential damages in connection with or arising out of the use of the information or
programs contained herein. Before you use any IBM or non-IBM or open-source product mentioned in this
book, make sure that you accept and adhere to the licenses and terms and conditions for any such product.
© Copyright 2010 by International Business Machines Corporation. All rights reserved.
Note to U.S. Government Users: Documentation related to restricted right. Use, duplication, or disclosure is
subject to restrictions set forth in GSA ADP Schedule Contract with IBM Corporation.
IBM Press Program Managers: Steven M. Stansel, Ellice Uffer
Cover design: IBM Corporation
Associate Publisher: Greg Wiegand
Marketing Manager: Kourtnaye Sturgeon
Publicist: Heather Fox
Acquisitions Editor: Bernard Goodwin
Managing Editor: Kristy Hart
Designer: Alan Clements
Project Editor: Andy Beaster
Copy Editor: Paula Lowell
Senior Indexer: Cheryl Lenser
Compositor: Gloria Schurick
Proofreader: Leslie Joseph
Manufacturing Buyer: Dan Uhrig
Published by Pearson plc
Publishing as IBM Press
IBM Press offers excellent discounts on this book when ordered in quantity for bulk purchases or special sales,
which may include electronic versions and/or custom covers and content particular to your business, training
goals, marketing focus, and branding interests. For more information, please contact:
U.S. Corporate and Government Sales
1-800-382-3419
corpsales@pearsontechgroup.com.
For sales outside the U.S., please contact:
International Sales
international@pearson.com.
The following terms are trademarks or registered trademarks of International Business Machines Corporation
in the United States, other countries, or both: IBM, the IBM logo, IBM Press, DB2, pureXML, z/OS, ibm.com,
WebSphere, System z, developerWorks, InfoSphere, DRDA, Rational, AIX, OmniFind, i5/OS, Lotus, and
DataPower. Microsoft, Windows, Microsoft Word, Microsoft Visual Studio, Visual Basic, and Visual C# are
trademarks of Microsoft Corporation in the United States, other countries, or both. UNIX is a registered
trademark of The Open Group in the United States and other countries. Linux is a registered trademark of
Linus Torvalds in the United States, other countries, or both. Java and all Java-based trademarks are
trademarks of Sun Microsystems, Inc., in the United States, other countries, or both. Other company, product,
or service names may be trademarks or service marks of others.
Library of Congress Cataloging-in-Publication Data
Nicola, Matthias.
DB2 PureXML cookbook : master the power of IBM’s hybrid data server / Matthias Nicola and
Pav Kumar-Chatterjee.
p. cm.
Includes indexes.
ISBN-13: 978-0-13-815047-1 (hardback : alk. paper)
ISBN-10: 0-13-815047-8 (hardback : alk. paper) 1. IBM Database 2. 2. XML (Document markup
language) 3. Database management. I. Kumar-Chatterjee, Pav. II. Title.
QA76.9.D3N525 2009
006.7’4—dc22
2009020222
All rights reserved. This publication is protected by copyright, and permission must be obtained from the
publisher prior to any prohibited reproduction, storage in a retrieval system, or transmission in any form or
by any means, electronic, mechanical, photocopying, recording, or likewise. For information regarding
permissions, write to:
Pearson Education, Inc.
Rights and Contracts Department
501 Boylston Street, Suite 900
Boston, MA 02116
Fax (617) 671 3447
ISBN-13: 978-0-13-815047-1
ISBN-10: 0-13-815047-8
Text printed in the United States on recycled paper at Edwards Brothers in Ann Arbor, Michigan.
First printing August 2009
I would like to dedicate this book to Scott and Carrie in the hope that it will
inspire them to work hard at school and to my mother who did not see the final
version, but who gave me unconditional support as only a mother can.
—Pav Kumar-Chatterjee
Contents
Chapter1
Introduction
1
1.1
1.2
1.3
1.4
1.5
Anatomy of an XML Document
Differences Between XML and Relational Data
Overview of DB2 pureXML
Benefits of DB2 pureXML over Alternative Storage Options for XML Data
XML Solutions to Relational Data Model Problems
1.5.1 When the Schema Is Volatile
1.5.2 When Data Is Inherently Hierarchical in Nature
1.5.3 When Data Represents Business Objects
1.5.4 When Objects Have Sparse Attributes
1.5.5 When Data Needs to be Exchanged
1.6 Summary
Chapter 2
2.1
2.2
2.3
2.4
2.5
Designing XML Data and Applications
Choosing Between XML Elements and XML Attributes
XML Tags versus Values
Choosing the Right Document Granularity
Using a Hybrid XML/Relational Approach
Summary
Chapter 3
Designing and Managing XML Storage Objects
3.1 Understanding XML Document Trees
3.2 Understanding pureXML Storage
3.3 XML Storage in DB2 for Linux, UNIX, and Windows
3.3.1 Storage Objects for XML Data
3.3.2 Defining Columns,Tables, and Table Spaces for XML Data
3.3.3 Dropping XML Columns
3.3.4 Improved XML Storage Format in DB2 9.7
3.4 Using XML Base Table Row Storage (Inlining)
3.4.1 Monitoring and Configuring XML Inlining
3.4.2 Potential Benefits and Drawbacks of XML Inlining
3.5 Compressing XML Data
3.6 Examining XML Storage Space Consumption
3.7 Reorganizing XML Data and Indexes
3.8 Understanding XML Space Management: A Comprehensive Example
3.9 XML in Range Partitioned Tables and MDC Tables
3.9.1 XML and Range Partitioning
3.9.2 XML and Multidimensional Clustering
3.10 XML in a Partitioned Database (DPF)
3.11 XML Storage in DB2 for z/OS
xi
2
4
7
10
11
12
12
12
13
13
13
15
15
19
22
24
25
27
28
30
33
33
36
40
40
41
43
47
48
51
53
54
57
57
58
59
60
xii
DB2 ® pureXML® Cookbook: Master the Power of the IBM® Hybrid Data Server
3.11.1 Storage Objects for XML Data
3.11.2 Characteristics of XML Table Spaces
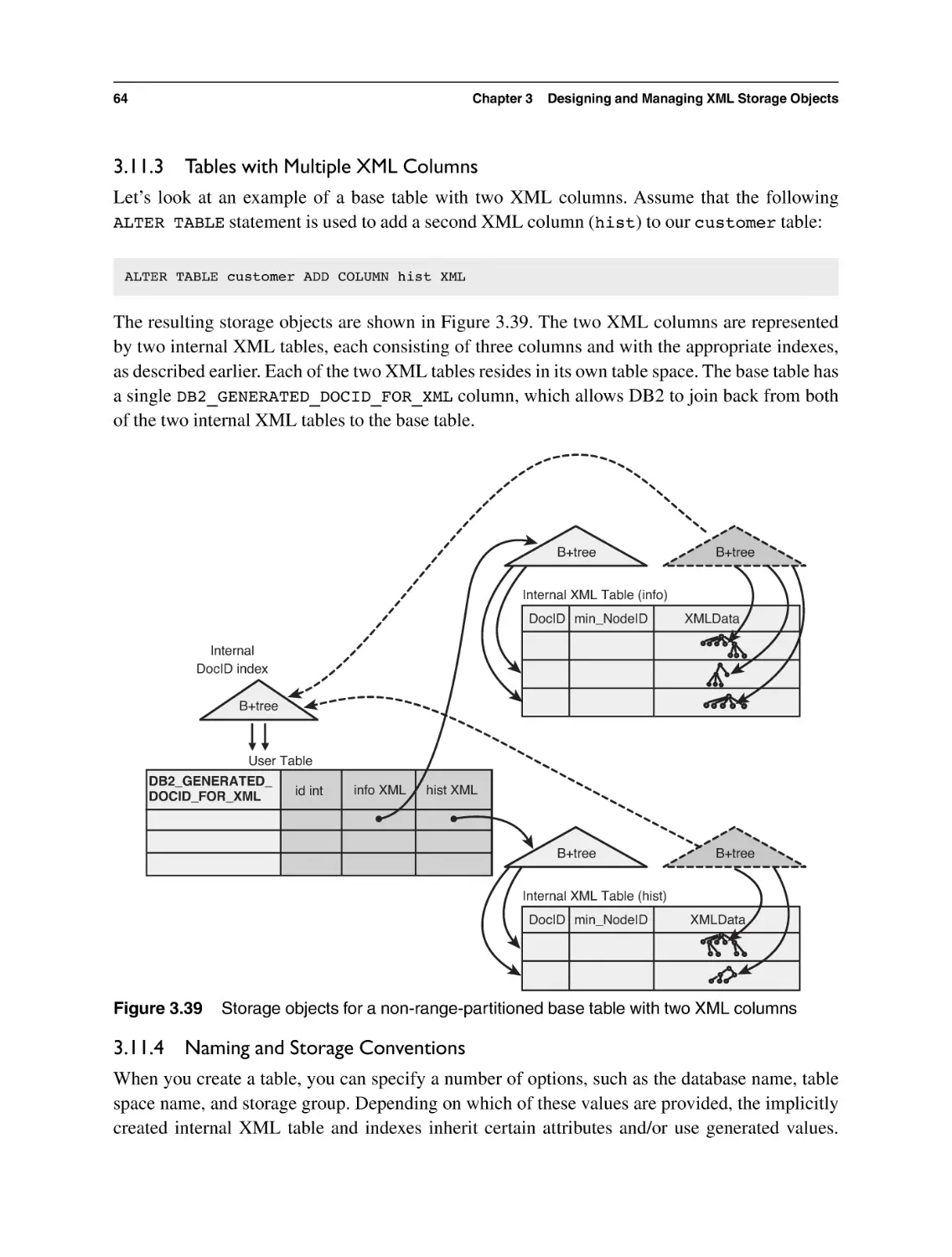
3.11.3 Tables with Multiple XML Columns
3.11.4 Naming and Storage Conventions
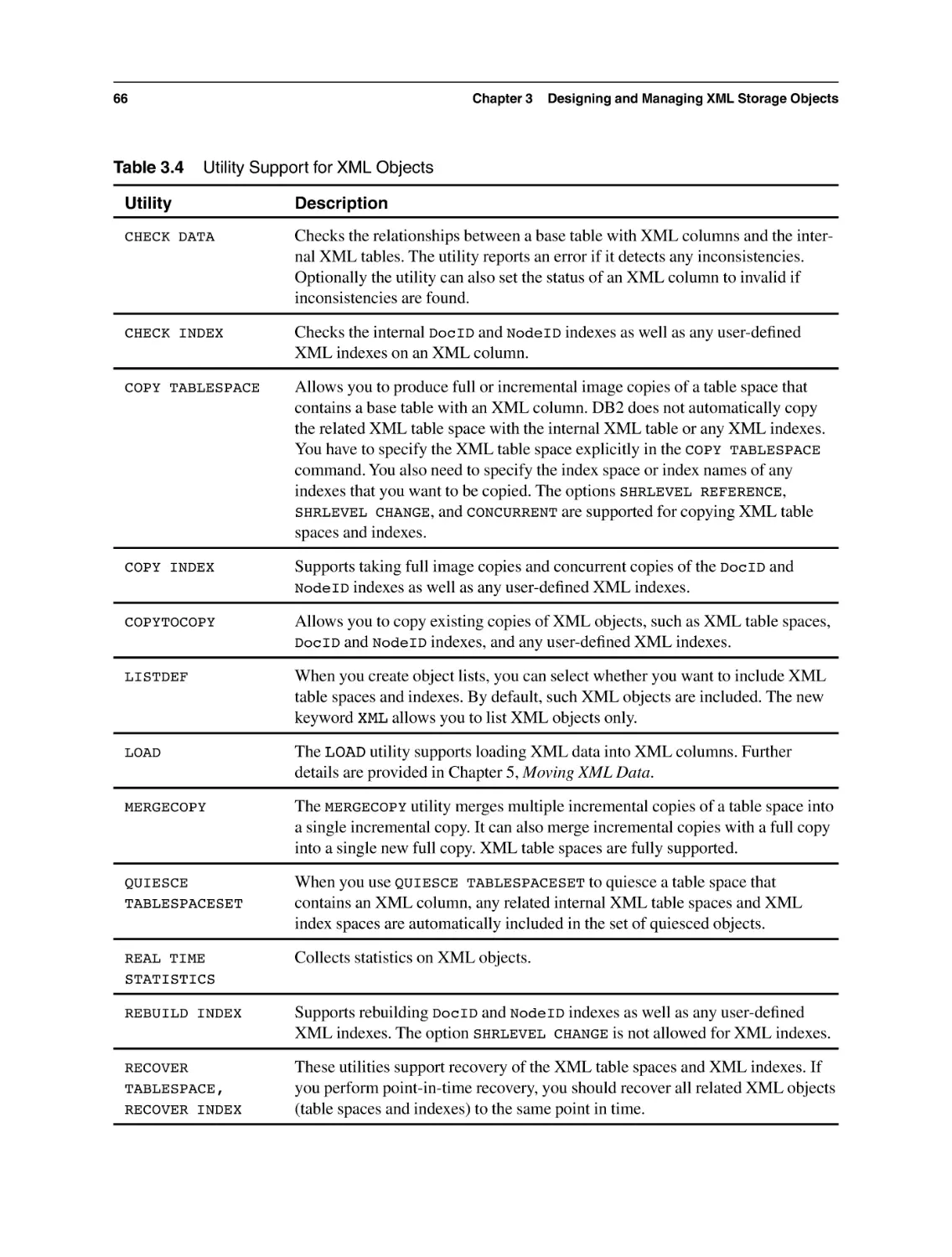
3.12 Utilities for XML Objects in DB2 for z/OS
3.12.1 REPORT TABLESPACESET for XML
3.12.2 Reorganizing XML Data in DB2 for z/OS
3.12.3 CHECK DATA for XML
3.13 XML Parsing and Memory Consumption in DB2 for z/OS
3.13.1 Controlling the Memory Consumption of XML Operations
3.13.2 Redirecting XML Parsing to zIIP and zAAP
3.14 Summary
Chapter 4
Inserting and Retrieving XML Data
4.1 Inserting XML Documents
4.1.1 Simple Insert Statements
4.1.2 Reading XML Documents from Files or URLs
4.2 Deleting XML Documents
4.3 Retrieving XML Documents
4.4 Handling Documents with XML Declarations
4.5 Copying Full XML Documents
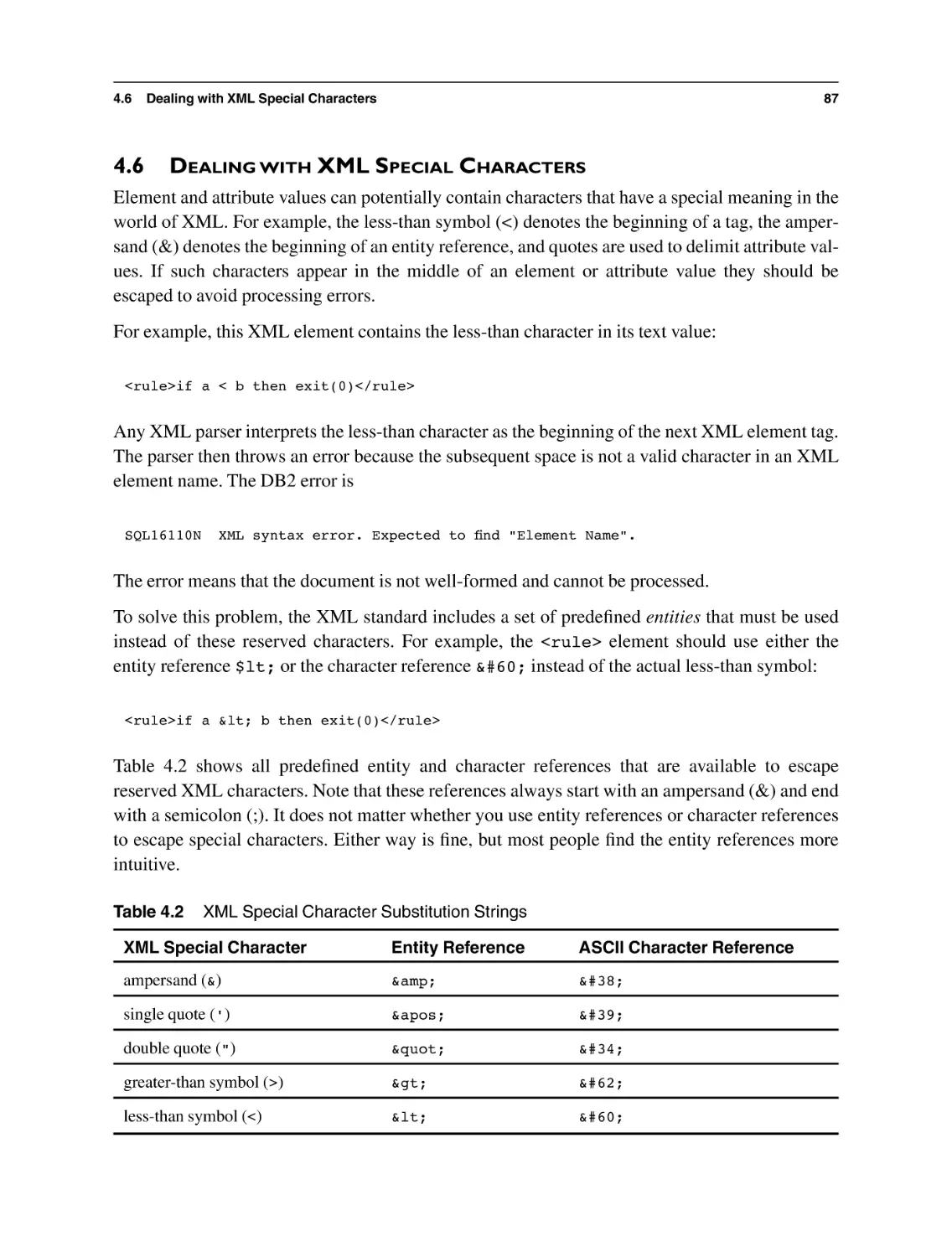
4.6 Dealing with XML Special Characters
4.7 Understanding XML Whitespace and Document Storage
4.7.1 Preserving XML Whitespace
4.7.2 Changing the Whitespace Default from “Strip” to “Preserve”
4.7.3 Storing XML Documents for Compliance
4.8 Summary
Chapter 5
Moving XML Data
5.1 Exporting XML Data in DB2 for Linux, UNIX, and Windows
5.1.1 Exporting XML Documents to a Single File
5.1.2 Exporting XML Documents as Individual Files
5.1.3 Exporting XML Documents as Individual Files with Non-Default Names
5.1.4 Exporting XML Documents to One or Multiple Dedicated Directories
5.1.5 Exporting Fragments of XML Documents
5.1.6 Exporting XML Data with XML Schema Information
5.2 Importing XML Data in DB2 for Linux, UNIX, and Windows
5.2.1 IMPORT Command and Input Files
5.2.2 Import/Insert Performance Tips
5.3 Loading XML Data in DB2 for Linux, UNIX, and Windows
5.4 Unloading XML Data in DB2 for z/OS
5.5 Loading XML Data in DB2 for z/OS
5.6 Validating XML Documents during Load and Insert Operations
5.7 Splitting Large XML Documents into Smaller Documents
5.8 Replicating and Publishing XML Data
61
63
64
64
65
67
68
69
71
71
72
73
75
76
76
79
82
83
85
86
87
89
91
93
94
95
97
98
98
100
102
102
104
105
106
107
108
109
111
114
116
116
118
Table of Contents
xiii
5.9 Federating XML Data
5.10 Managing XML Data with HADR
5.11 Handling XML Data in db2look and db2move
5.12 Summary
Chapter 6
Querying XML Data: Introduction and XPath
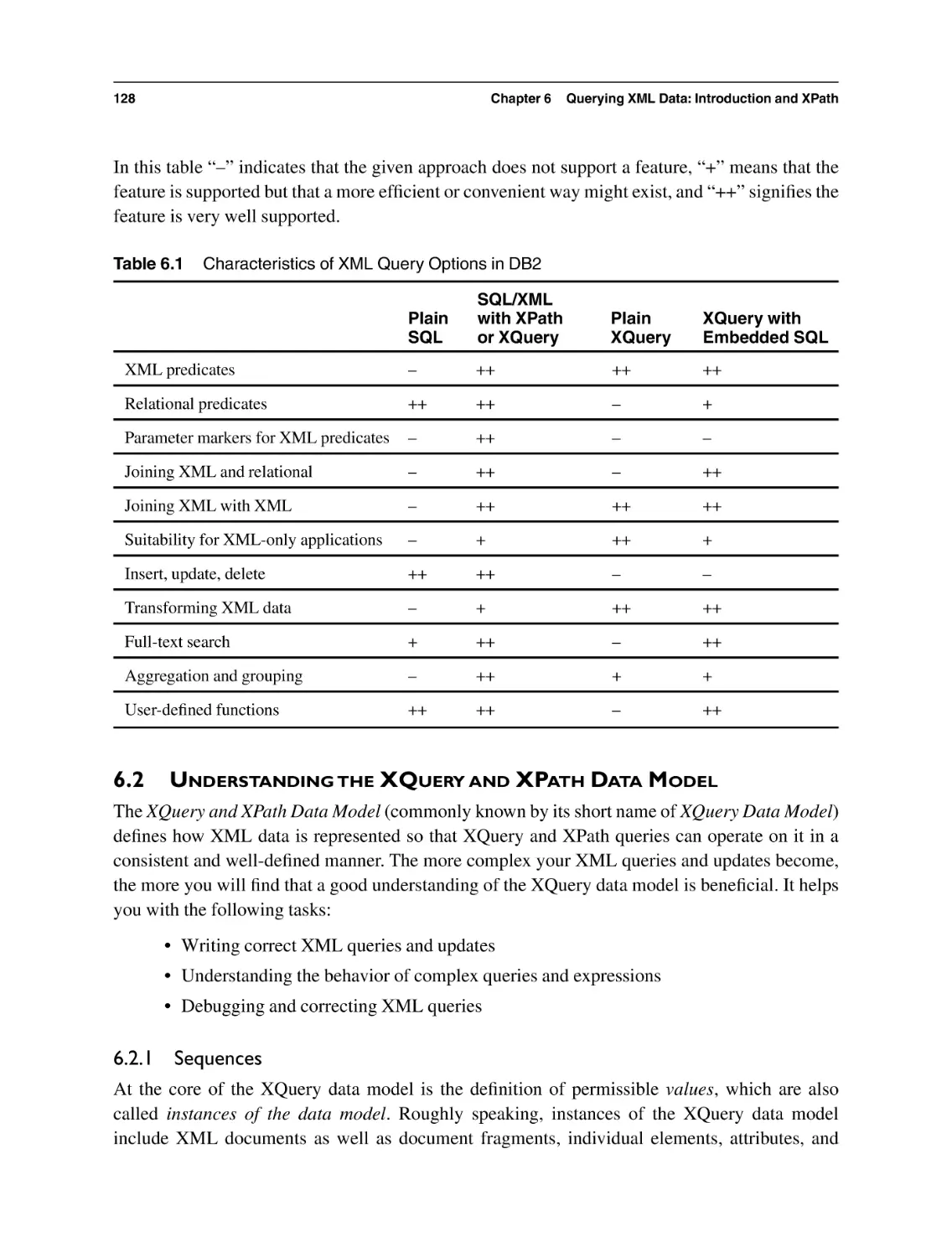
6.1 An Overview of Querying XML Data
6.2 Understanding the XQuery and XPath Data Model
6.2.1 Sequences
6.2.2 Sequence in, Sequence out
6.3 Sample Data for XPath, SQL/XML, and XQuery
6.4 Introduction to XPath
6.4.1 Analogy Between XPath and Navigating a File System
6.4.2 Simple XPath Queries
6.5 How to Execute XPath in DB2
6.6 Wildcards and Double Slashes
6.7 XPath Predicates
6.8 Existential Semantics
6.9 Logical Expressions with and, or, not()
6.10 The Current Context and the Parent Step
6.11 Positional Predicates
6.12 Union and Construction of Sequences
6.13 XPath Functions
6.14 General and Value Comparisons
6.15 XPath Axes and Unabbreviated Syntax
6.16 Summary
Chapter 7
Querying XML Data with SQL/XML
7.1 Overview of SQL/XML
7.2 Retrieving XML Documents or Document Fragments with XMLQUERY
7.2.1 Referencing XML Columns in SQL/XML Functions
7.2.2 Retrieving Element Values Without XML Tags
7.2.3 Retrieving Repeating Elements with XMLQUERY
7.3 Retrieving XML Values in Relational Format with XMLTABLE
7.3.1 Generating Rows and Columns from XML Data
7.3.2 Dealing with Missing Elements
7.3.3 Avoiding Type Errors
7.3.4 Retrieving Repeating Elements with XMLTABLE
7.3.5 Numbering XMLTABLE Rows Based on Repeating Elements
7.3.6 Retrieving Multiple Repeating Elements at Different Levels
7.4 Using XPath Predicates in SQL/XML with XMLEXISTS
7.5 Common Mistakes with SQL/XML Predicates
7.6 Using Parameter Markers or Host Variables
7.7 XML Queries with Dynamically Computed XPath Expressions
120
121
122
123
125
126
128
128
130
131
132
133
133
137
140
142
147
148
151
153
154
155
156
157
157
159
160
161
162
163
164
165
165
167
168
169
173
174
177
181
183
185
xiv
DB2 ® pureXML® Cookbook: Master the Power of the IBM® Hybrid Data Server
7.8 Ordering a Query Result Set Based on XML Values
7.9 Converting XML Values to Binary SQL Types
7.10 Summary
Chapter 8
Querying XML Data with XQuery
8.1 XQuery Overview
8.2 Processing XML Data with FLWOR Expressions
8.2.1 Anatomy of a FLWOR Expression
8.2.2 Understanding the for and let Clauses
8.2.3 Understanding the where and order by Clauses
8.2.4 FLWOR Expressions with Multiple for and let Clauses
8.3 Comparing FLWOR Expressions, XPath Expressions, and SQL/XML
8.3.1 Traversing XML Documents
8.3.2 Using XML Predicates
8.3.3 Result Set Cardinalities in XQuery and SQL/XML
8.3.4 Using FLWOR Expressions in SQL/XML
8.4 Constructing XML Data
8.4.1 Constructing Elements with Computed Values
8.4.2 Constructing XML Data with Predicates and Conditions
8.4.3 Constructing Documents with Multiple Levels of Nesting
8.4.4 Constructing Documents with XML Aggregation in SQL/XML Queries
8.5 Data Types, Cast Expressions, and Type Errors
8.6 Arithmetic Expressions
8.7 XQuery Functions
8.7.1 String Functions
8.7.2 Number and Aggregation Functions
8.7.3 Sequence Functions
8.7.4 Namespace and Node Functions
8.7.5 Date and Time Functions
8.7.6 Boolean Functions
8.8 Embedding SQL in XQuery
8.9 Using SQL Functions and User-Defined Functions in XQuery
8.10 Summary
Chapter 9
Querying XML Data:Advanced Queries &
Troubleshooting
9.1 Aggregation and Grouping of XML Data
9.1.1 Aggregation and Grouping Queries with XMLTABLE
9.1.2 Aggregation of Values within and across XML Documents
9.1.3 Grouping Queries in SQL/XML versus XQuery
9.2 Join Queries with XML Data
9.2.1 XQuery Joins between XML Columns
9.2.2 SQL/XML Joins between XML Columns
9.2.3 Joins between XML and Relational Columns
9.2.4 Outer Joins between XML Columns
186
187
188
189
190
191
191
193
194
195
197
197
198
200
201
202
202
204
206
207
208
212
214
215
218
220
222
224
226
227
229
230
233
233
234
236
237
239
240
242
248
250
Table of Contents
9.3 Case-Insensitive XML Queries
9.4 How to Avoid “Bad” Queries
9.4.1 Construction of Excessively Large Documents
9.4.2 “Between” Predicates on XML Data
9.4.3 Large Global Sequences
9.4.4 Multilevel Nesting SQL and XQuery
9.5 Common Errors and How to Avoid Them
9.5.1 SQL16001N
9.5.2 SQL16002N
9.5.3 SQL16003N
9.5.4 SQL16005N
9.5.5 SQL16015N
9.5.6 SQL16011N
9.5.7 SQL16061N
9.5.8 SQL16075N
9.6 Summary
Chapter 10 Producing XML from Relational Data
10.1 SQL/XML Publishing Functions
10.1.1 Constructing XML Elements from Relational Data
10.1.2 NULL Values, Missing Elements, and Empty Elements
10.1.3 Constructing XML Attributes from Relational Data
10.1.4 Constructing XML Documents from Multiple Relational Rows
10.1.5 Constructing XML Documents from Multiple Relational Tables
10.1.6 Comparing XMLAGG, XMLCONCAT, and XMLFOREST
10.1.7 Conditional Element Construction
10.1.8 Leading Zeros in Constructed Elements and Attributes
10.1.9 Default Tagging of Relational Data with XMLROW and XMLGROUP
10.1.10 GUI-Based Definition of SQL/XML Publishing Queries
10.1.11 Constructing Comments, Processing Instructions, and Text Nodes
10.1.12 Legacy Functions
10.2 Using XQuery Constructors with Relational Input
10.3 XML Declarations for Constructed XML Data
10.4 Inserting Constructed XML Data into XML Columns
10.5 Summary
Chapter 11 Converting XML to Relational Data
11.1 Advantages and Disadvantages of Shredding
11.2 Shredding with the XMLTABLE Function
11.2.1 Hybrid XML Storage
11.2.2 Relational Views over XML Data
11.3 Shredding with Annotated XML Schemas
11.3.1 Annotating an XML Schema
11.3.2 Defining Schema Annotations Visually in IBM Data Studio
xv
252
253
253
254
256
257
258
259
259
260
261
262
263
263
264
264
267
268
269
274
275
277
281
284
284
285
286
289
290
290
290
292
294
295
297
297
301
303
305
306
306
311
xvi
DB2 ® pureXML® Cookbook: Master the Power of the IBM® Hybrid Data Server
11.3.3 Registering an Annotated Schema
11.3.4 Decomposing One XML Document at a Time
11.3.5 Decomposing XML Documents in Bulk
11.4 Summary
Chapter 12 Updating and Transforming XML Documents
12.1 Replacing a Full XML Document
12.2 Modifying Documents with XQuery Updates
12.3 Updating the Value of an XML Node in a Document
12.3.1 Replacing an Element Value
12.3.2 Replacing an Attribute Value
12.3.3 Replacing a Value Using a Parameter Marker
12.3.4 Replacing Multiple Values in a Document
12.3.5 Replacing an Existing Value with a Computed Value
12.4 Replacing XML Nodes in a Document
12.5 Deleting XML Nodes from a Document
12.6 Renaming Elements or Atttributes in a Document
12.7 Inserting XML Nodes into a Document
12.7.1 Defining the Position of Inserted Elements
12.7.2 Defining the Position of Inserted Attributes
12.7.3 Insert Examples
12.8 Handling Repeating and Missing Nodes
12.9 Modifying Multiple XML Nodes in the Same Document
12.9.1 Snapshot Semantics and Conflict Situations
12.9.2 Converting Elements to Attributes and Vice Versa
12.10 Modifying XML Documents in Queries
12.11 Modifying XML Documents in Insert Operations
12.12 Modifying XML Documents in Update Cursors
12.13 XML Updates in DB2 for z/OS
12.14 Transforming XML Documents with XSLT
12.14.1 The XSLTRANSFORM Function
12.14.2 XML to HTML Transformation
12.15 Summary
Chapter 13 Defining and Using XML Indexes
13.1 Defining XML Indexes
13.1.1 Unique XML Indexes
13.1.2 Lean XML Indexes
13.1.3 Using the DB2 Control Center to Create XML Indexes
13.2 XML Index Data Types
13.2.1 VARCHAR(n)
13.2.2 VARCHAR HASHED
13.2.3 DOUBLE and DECFLOAT
13.2.4 DATE and TIMESTAMP
311
312
315
318
321
322
324
326
326
327
328
328
329
331
333
334
335
335
336
337
340
343
343
345
346
349
350
351
352
353
356
358
361
362
364
365
366
367
367
368
369
369
Table of Contents
13.3
13.4
13.5
13.6
13.7
13.8
13.9
13.2.5 Choosing a Suitable Index Data Type
13.2.6 Rejecting Invalid Values
Using XML Indexes to Evaluate Query Predicates
13.3.1 Understanding Index Eligibility
13.3.2 Data Types in XML Indexes and Query Predicates
13.3.3 Text Nodes in XML Indexes and Query Predicates
13.3.4 Wildcards in XML Indexes and Query Predicates
13.3.5 Using Indexes for Structural Predicates
XML Indexes and Join Predicates
XML Indexes on Non-Leaf Elements
Special Cases Where XML Indexes Cannot be Used
13.6.1 Special Cases with XMLQUERY
13.6.2 Parent Steps
13.6.3 The let and return Clauses
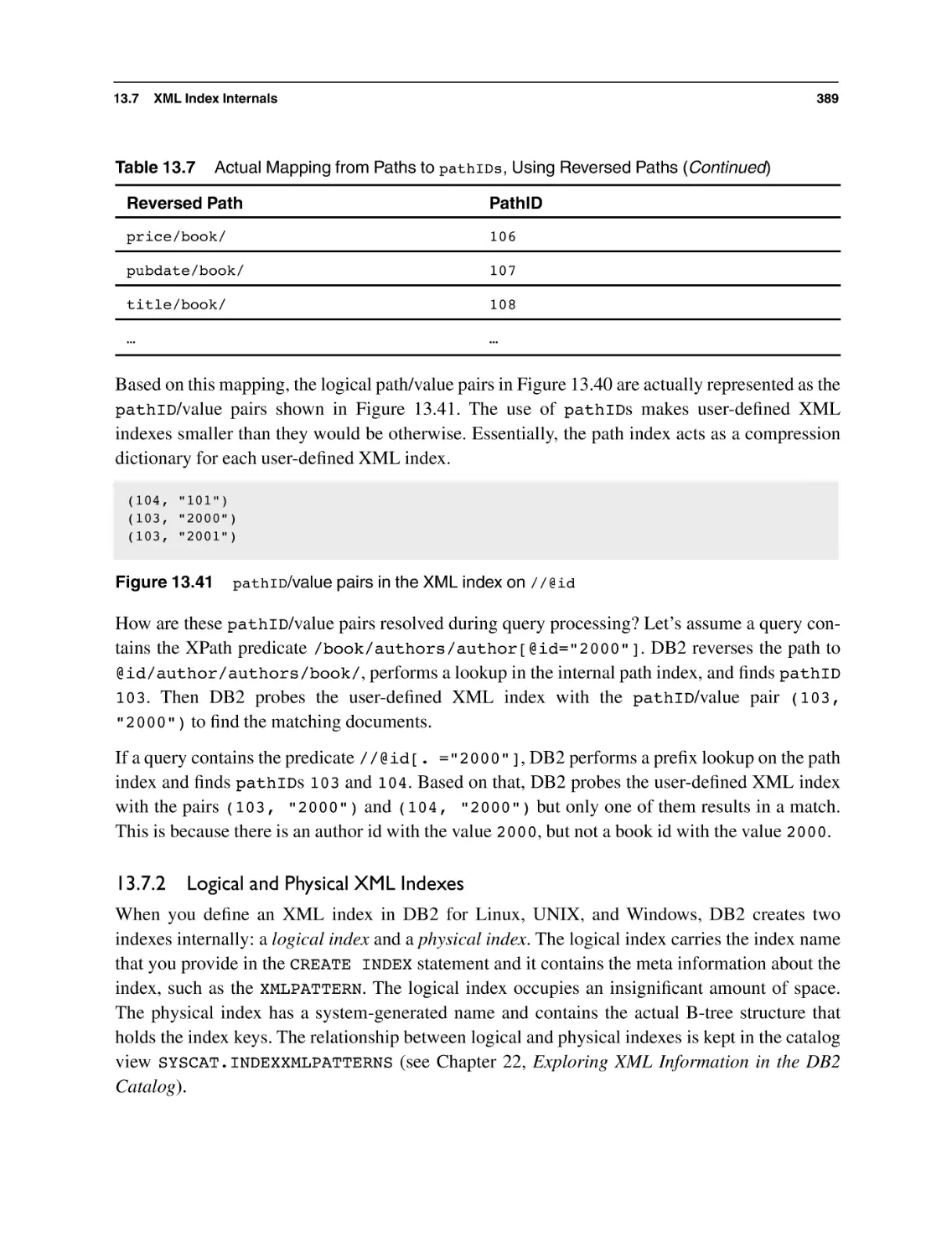
XML Index Internals
13.7.1 XML Index Keys
13.7.2 Logical and Physical XML Indexes
XML Index Statistics
Summary
Chapter 14 XML Performance and Monitoring
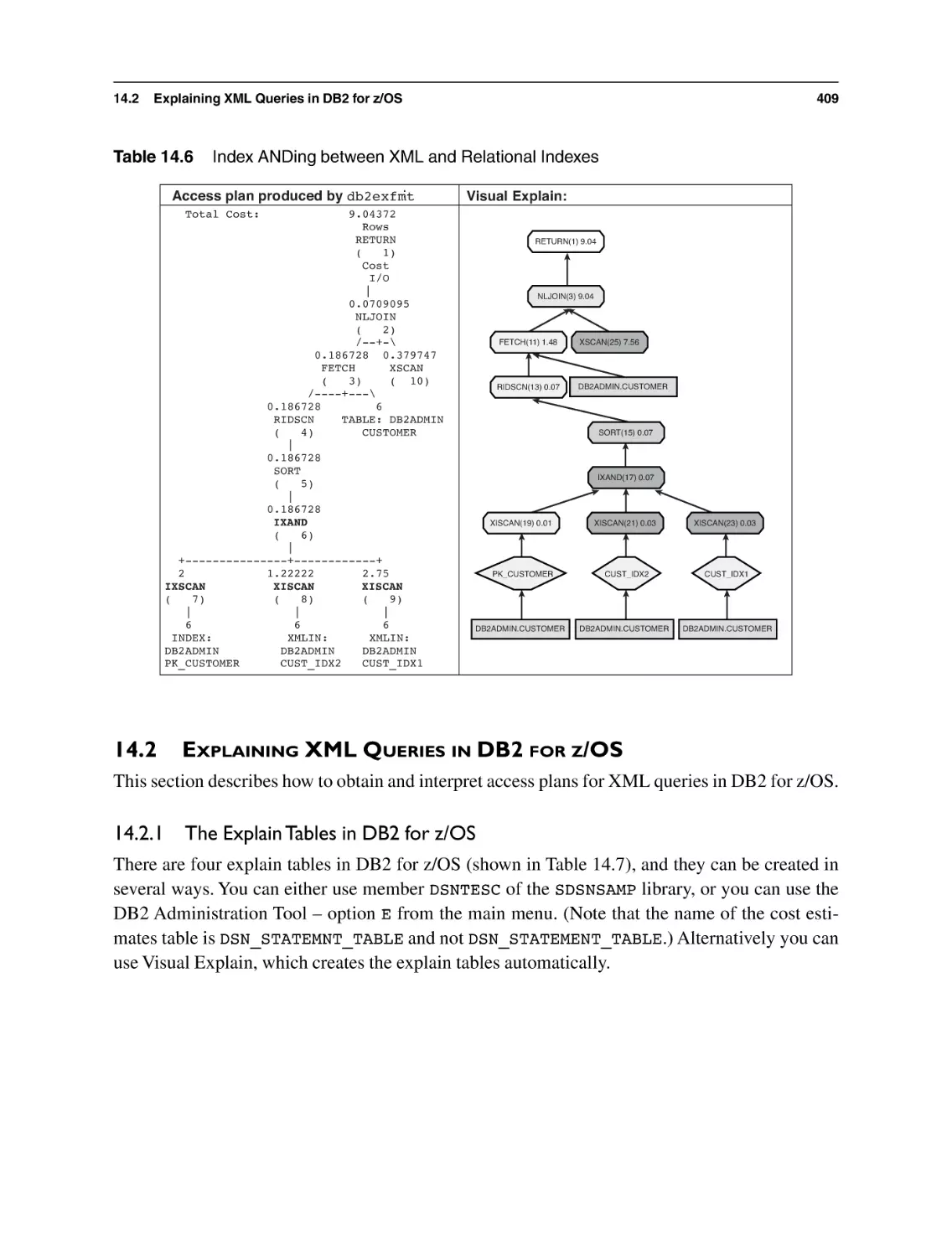
14.1 Explaining XML Queries in DB2 for Linux,UNIX, and Windows
14.1.1 The Explain Tables in DB2 for Linux, UNIX, and Windows
14.1.2 Using db2exfmt to Obtain Access Plans
14.1.3 Using Visual Explain to Display Access Plans
14.1.4 Access Plan Operators
14.1.5 Understanding and Analyzing XML Query Execution Plans
14.2 Explaining XML Queries in DB2 for z/OS
14.2.1 The Explain Tables in DB2 for z/OS
14.2.2 Obtaining Access Plan Information in SPUFI
14.2.3 Using Visual Explain to Display Access Plans
14.2.4 Access Plan Operators
14.2.5 Understanding and Analyzing XML Query Execution Plans
14.3 Statistics Collection for XML Data
14.3.1 Statistics Collection for XML Data in DB2 for z/OS
14.3.2 Statistics Collection for XML Data in DB2 for Linux, UNIX, and Windows
14.3.3 Examining XML Statistics with db2cat
14.4 Monitoring XML Activity
14.4.1 Using the Snapshot Monitor in DB2 for Linux, UNIX, and Windows
14.4.2 Monitoring Database Utilities
14.5 Best Practices for XML Performance
14.5.1 XML Document Design
14.5.2 XML Storage
xvii
369
371
373
373
374
375
376
377
379
383
385
385
385
386
387
387
389
390
393
395
396
396
397
400
401
403
409
409
410
411
413
414
417
417
418
419
424
424
427
428
428
429
xviii
DB2 ® pureXML® Cookbook: Master the Power of the IBM® Hybrid Data Server
14.5.3 XML Queries
14.5.4 XML Indexes
14.5.5 XML Updates
14.5.6 XML Schemas
14.5.7 XML Applications
14.6 Summary
Chapter 15 Managing XML Data with Namespaces
15.1 Introduction to XML Namespaces
15.1.1 Namespace Declarations in XML Documents
15.1.2 Default Namespaces
15.2 Exploring Namespaces in XML Documents
15.3 Querying XML Data with Namespaces
15.3.1 Declaring Namespaces in XML Queries
15.3.2 Using Namespace Declarations in SQL/XML Queries
15.3.3 Using Namespaces in the XMLTABLE Function
15.3.4 Dealing with Multiple Namespaces per Document
15.4 Creating Indexes for XML Data with Namespaces
15.5 Constructing XML Data with Namespaces
15.5.1 SQL/XML Publishing Functions and Namespaces
15.5.2 XQuery Constructors and Namespaces
15.6 Updating XML Data with Namespaces
15.6.1 Updating Values in Documents with Namespaces
15.6.2 Renaming Nodes in Documents with Namespace Prefixes
15.6.3 Renaming Nodes in Documents with Default Namespaces
15.6.4 Inserting and Replacing Nodes in Documents with Namespaces
15.7 Summary
Chapter 16 Managing XML Schemas
16.1 Introduction to XML Schemas and Their Usage
16.1.1 Valid Versus Well-Formed XML Documents
16.1.2 To Validate or Not to Validate,That Is the Question!
16.1.3 Custom Versus Industry Standard XML Schemas
16.2 Anatomy of an XML Schema
16.3 An XML Schema with Include and Import
16.4 Registering XML Schemas
16.4.1 Registering XML Schemas in the DB2 Command Line Processor
16.4.2 Registering XML Schemas from Applications via Stored Procedures
16.4.3 Registering XML Schemas from Java Applications via JDBC
16.4.4 Two XML Schemas Sharing a Common Schema Document
16.4.5 Error Situations and How to Resolve Them
16.5 Removing XML Schemas from the Schema Repository
430
432
433
434
434
435
437
437
439
442
444
447
448
451
452
454
456
460
460
462
463
464
465
467
468
469
471
472
473
474
474
476
479
483
484
486
488
489
490
492
Table of Contents
16.6 XML Schema Evolution
16.6.1 Schema Evolution Without Document Validation
16.6.2 Generic Schema Evolution with Document Validation
16.6.3 Compatible Schema Evolution with the UPDATE XMLSCHEMA Command
16.7 Granting and Revoking XML Schema Usage Privileges
16.8 Document Type Definitions (DTDs) and External Entities
16.9 Browsing the XML Schema Repository (XSR)
16.9.1 Tables and Views of the XML Schema Repository
16.9.2 Queries against the XML Schema Repository
16.10 XML Schema Considerations in DB2 for z/OS
16.11 Summary
Chapter 17 Validating XML Documents against XML Schemas
17.1
17.2
17.3
17.4
17.5
17.6
17.7
Document Validation Upon Insert
Document Validation Upon Update
Validation without Rejecting Invalid Documents
Enforcing Validation with Check Constraints
Automatic Validation with Triggers
Diagnosing Validation and Parsing Errors
Validation during Load and Import Operations
17.7.1 Validation against a Single XML Schema
17.7.2 Validation against Multiple XML Schemas
17.7.3 Using a Default XML Schema
17.7.4 Overriding XML Schema References
17.7.5 Validation Based on schemaLocation Attributes
17.8 Checking Whether an Existing Document Has Been Validated
17.9 Validating Existing Documents in a Table
17.10 Finding the XML Schema for a Validated Document
17.11 How to Undo Document Validation
17.12 Considerations for Validation in DB2 for z/OS
17.12.1 Document Validation Upon Insert
17.12.2 Document Validation Upon Update
17.12.3 Validating Existing Documents in a Table
17.12.4 Summary of Platform Similarities and Differences
17.13 Summary
Chapter 18 Using XML in Stored Procedures, UDFs, and Triggers
18.1 Manipulating XML in SQL Stored Procedures
18.1.1 Basic XML Manipulation in Stored Procedures
18.1.2 A Stored Procedure to Store XML in a Hybrid Manner
18.1.3 Loops and Cursors
18.1.4 A Stored Procedure to Update a Selected XML Element or Attribute
18.1.5 Three Tips for Testing Stored Procedures
xix
493
494
494
495
499
501
502
503
508
510
512
513
514
518
519
520
523
525
530
530
531
532
532
534
534
535
538
540
540
541
542
543
543
544
547
548
548
550
553
554
555
xx
DB2 ® pureXML® Cookbook: Master the Power of the IBM® Hybrid Data Server
18.2 Manipulating XML in User-Defined Functions
18.2.1 A UDF to Extract an Element or Attribute Value
18.2.2 A UDF to Extract the Values of a Repeating Element
18.2.3 A UDF to Shred XML Data to a Relational Table
18.2.4 A UDF to Modify an XML Document
18.3 Manipulating XML Data with Triggers
18.3.1 Insert Triggers on Tables with XML Columns
18.3.2 Delete Triggers on Tables with XML Columns
18.3.3 Update Triggers on XML Columns
18.4 Summary
Chapter 19 Performing Full-Text Search
19.1 Overview of Text Search in DB2
19.2 Sample Table and Data
19.3 Enabling a Database for the DB2 Net Search Extender
19.4 Managing Full-Text Indexes with the DB2 Net Search Extender
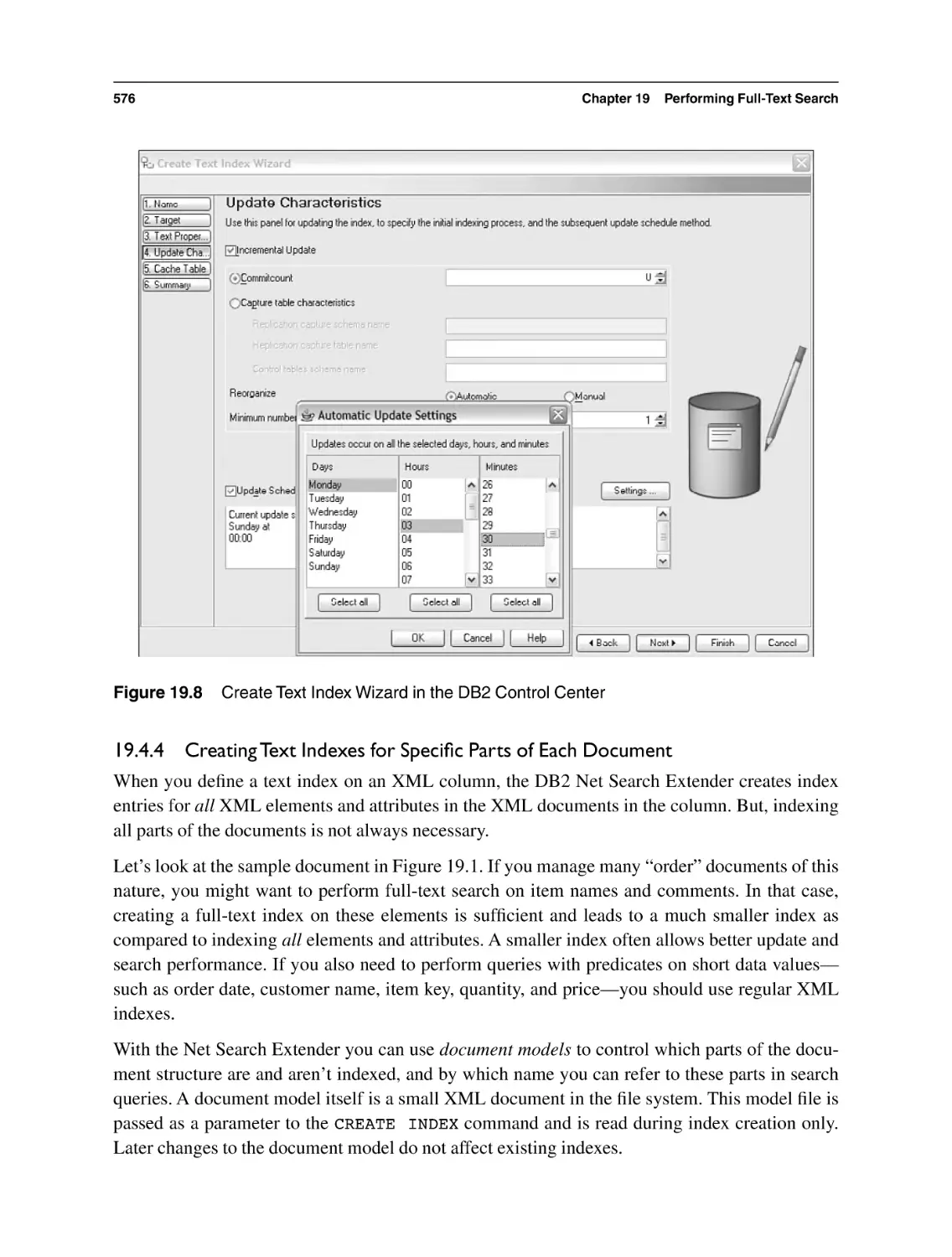
19.4.1 Creating Basic Text Indexes
19.4.2 Creating Text Indexes with Specific Storage Paths
19.4.3 Creating Text Indexes with a Periodic Update Schedule
19.4.4 Creating Text Indexes for Specific Parts of Each Document
19.4.5 Creating Text Indexes with Advanced Options
19.4.6 Updating and Reorganizing Text Indexes
19.4.7 Altering Text Indexes
19.5 Performing XML Full-Text Search with the DB2 Net Search Extender
19.5.1 Full-Text Search in SQL and XQuery
19.5.2 Full-Text Search with Boolean Operators
19.5.3 Full-Text Search with Custom Document Models
19.5.4 Advanced Search with Proximity, Fuzzy, and Stemming Options
19.5.5 Finding the Correct Match within an XML Document
19.5.6 Search Conditions on Sibling Branches of an XML Document
19.5.7 Text Search in the Presence of Namespaces
19.6 DB2 Text Search
19.6.1 Enabling a Database for DB2 Text Search
19.6.2 Creating and Maintaining Full-Text Indexes for DB2 Text Search
19.6.3 Writing DB2 Text Search Queries for XML Data
19.6.4 Full-Text Search with XPath Expressions
19.6.5 Full-Text Search with Wildcards
19.7 Summary of Text Search Administration Commands
19.8 XML Full-Text Search in DB2 for z/OS
19.9 Summary
556
557
557
558
559
561
562
563
564
564
567
568
570
571
572
572
573
574
576
578
579
580
581
581
583
585
586
587
588
588
590
590
591
592
593
594
594
596
596
Table of Contents
Chapter 20 Understanding XML Data Encoding
20.1 Understanding Internal and External XML Encoding
20.1.1 Internally Encoded XML Data
20.1.2 Externally Encoded XML Data
20.2 Avoiding Code Page Conversions
20.3 Using Non-Unicode Databases for XML
20.4 Examples of Code Page Issues
20.4.1 Example 1: Chinese Characters in a Non-Unicode Code Page ISO-8859-1
20.4.2 Example 2: Fetching Data from a Non-Unicode Code Database into a
Character Type Application Variable
20.4.3 Example 3: Encoding Issues with XMLTABLE and XMLCAST
20.4.4 Example 4: Japanese Literal Values in a Non-Unicode Database
20.4.5 Example 5: Data Expansion and Shrinkage Due to Code Page Conversion
20.5 Avoiding Data Loss and Encoding Errors in Non-Unicode Databases
20.6 Summary
Chapter 21 Developing XML Applications with DB2
21.1 The Value of DB2 pureXML for Application Development
21.1.1 Avoid XML Parsing in the Application Layer
21.1.2 Storing Business Objects in an Intuitive Format
21.1.3 Rapid Prototyping
21.1.4 Responding Quickly to Changing Business Needs
21.2 Using Parameter Markers or Host Variables
21.3 Java Applications
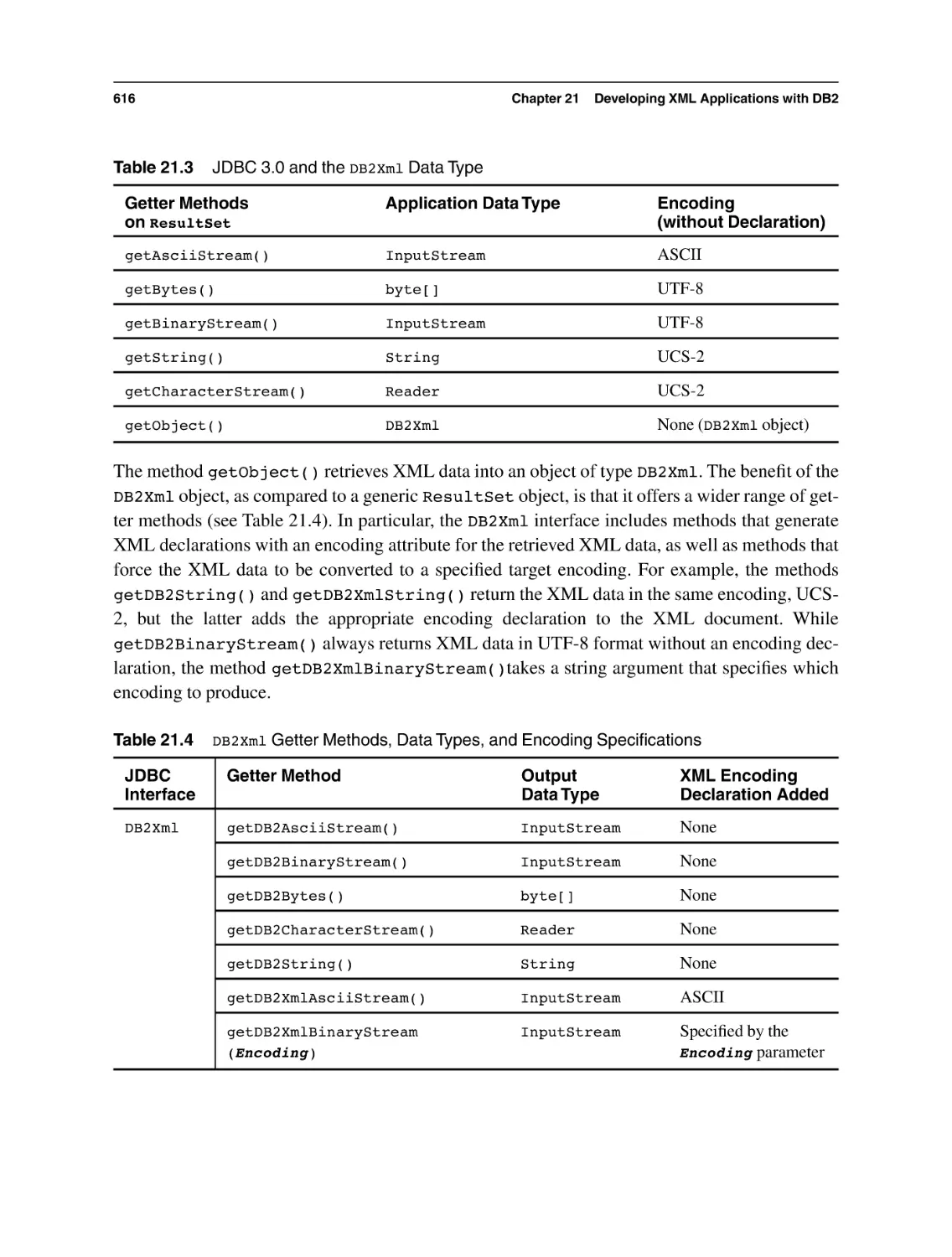
21.3.1 XML Support in JDBC 3.0
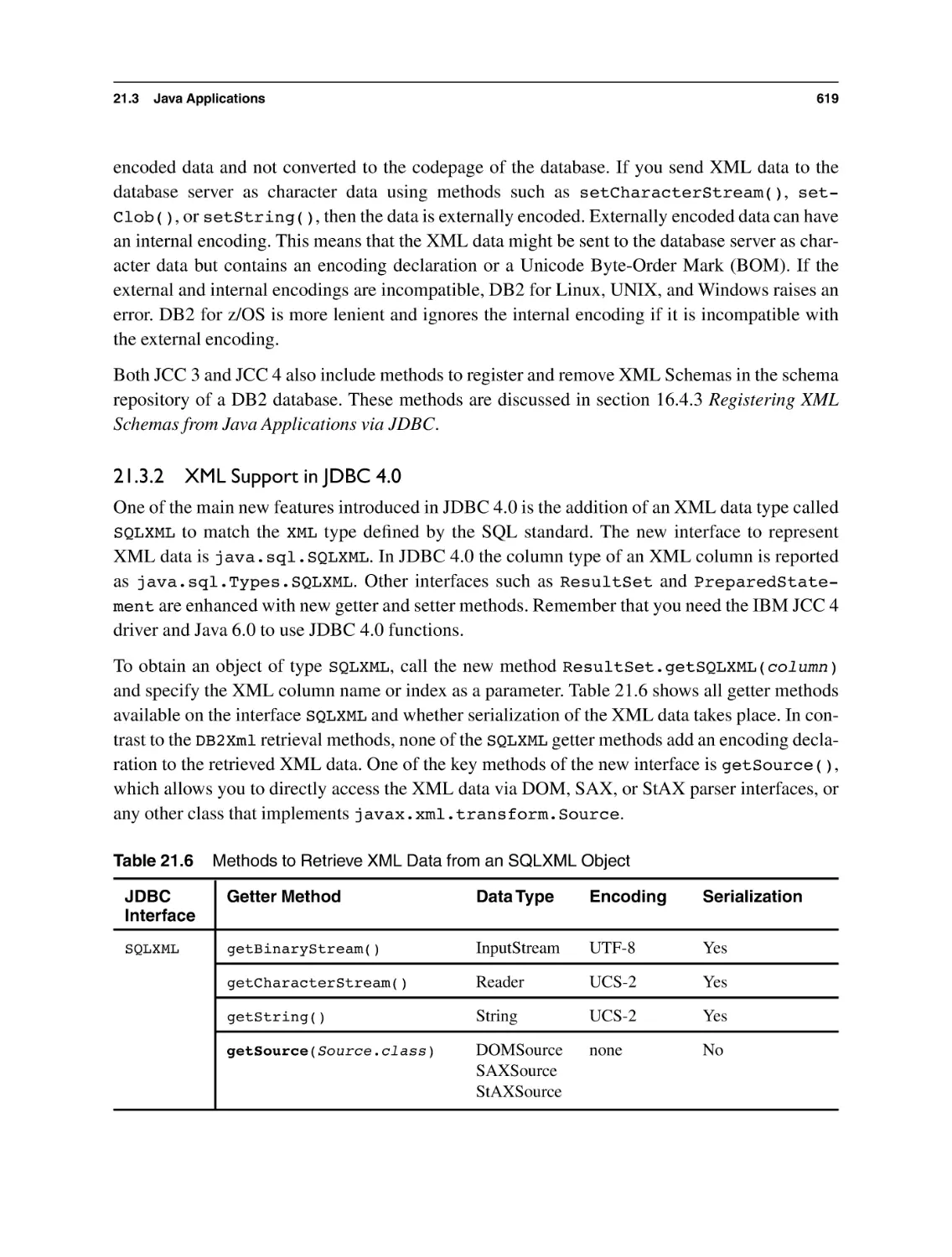
21.3.2 XML Support in JDBC 4.0
21.3.3 Comprehensive Example of Manipulating XML Data with JDBC 4.0
21.3.4 Creating XML Documents from Application Data
21.3.5 Binding XML Data to Java Objects
21.3.6 IBM pureQuery
21.4 .NET Applications
21.4.1 Querying XML Data in .NET Applications
21.4.2 Manipulating XML Data in .NET Applications
21.4.3 Inserting XML Data from .NET Applications
21.4.4 XML Schema and DTD Handling in .NET Applications
21.5 CLI Applications
21.6 Embedded SQL Applications
21.6.1 COBOL Applications with Embedded SQL
21.6.2 PL/1 Applications with Embedded SQL
21.6.3 C Applications with Embedded SQL
21.7 PHP Applications
xxi
597
599
599
600
601
601
602
602
603
604
605
605
606
606
609
610
610
612
612
613
613
615
615
619
621
627
629
629
631
632
633
635
636
636
639
640
643
645
647
xxii
DB2 ® pureXML® Cookbook: Master the Power of the IBM® Hybrid Data Server
21.8 Perl Applications
21.9 XML Application Development Tools
21.9.1 IBM Data Studio Developer
21.9.2 IBM Database Add-ins for Visual Studio
21.9.3 Altova XML Tools
21.9.4 <oXygen/>
21.9.5 Stylus Studio
21.10 Summary
Chapter 22 Exploring XML Information in the DB2 Catalog
22.1 XML-Related Catalog Information in DB2 for Linux, UNIX, and Windows
22.1.1 Catalog Information for XML Columns
22.1.2 The XML Strings and Paths Tables
22.1.3 The Internal XML Regions and Path Indexes
22.1.4 Catalog Information for User-Defined XML Indexes
22.1.5 Catalog Information for XML Schemas
22.2 XML-Related Catalog Information in DB2 for z/OS
22.2.1 Catalog Information for XML Storage Objects
22.2.2 Catalog Information for XML Indexes
22.2.3 Catalog Information for XML Schemas
22.3 Summary
Chapter 23 Test Your Knowledge—The DB2 pureXML Quiz
23.1 Designing XML Data and Applications
23.2 Designing and Managing Storage Objects for XML
23.3 Inserting and Retrieving XML Data
23.4 Moving XML Data
23.5 Querying XML
23.6 Producing XML from Relational Data
23.7 Converting XML to Relational Data
23.8 Updating and Transforming XML Documents
23.9 Defining and Using XML Indexes
23.10 XML Performance and Monitoring
23.11 Managing XML Data with Namespaces
23.12 XML Schemas and Validation
23.13 Performing Full-Text Search
23.14 XML Application Development
23.15 Answers
Appendix A Getting Started with DB2 pureXML
A.1 Exploring the Structure of XML Documents
A.1.1 Exploring XML Documents in the DB2 Control Center
A.1.2 Exploring XML Documents in the CLP
A.1.3 Exploring XML Documents in SPUFI
A.2 Tips for Running XML Operations in the CLP
650
651
652
656
656
658
659
659
661
661
661
662
663
664
667
667
667
671
672
673
675
675
677
680
681
682
686
687
688
689
692
693
694
696
697
700
703
703
703
704
705
706
Table of Contents
Appendix B The XML Sample Database
B.1
B.2
B.3
B.4
B.5
XML Sample Database on DB2 for Linux, UNIX, and Windows
XML Sample Tables on DB2 for z/OS
Table customer—Column info
Table product—Column description
Table purchaseorder—Column porder
Appendix C Further Reading
C.1 General Resources for All Chapters
C.2 Chapter-Specific Resources
C.3 Resources on the Integration of DB2 pureXML with Other Products
Index
xxiii
709
709
710
710
712
713
717
717
718
726
727
This page intentionally left blank
Foreword
n the years since E.F. Codd’s groundbreaking work in the 1970s, relational database systems have become ubiquitous in the business world. Today, most of the world’s business
data is stored in the rows and columns of relational databases. The relational model is ideally
suited to applications in which data has a relatively simple and uniform structure, and in which
database structure evolves much more slowly than data values.
I
With the advent of the Web, however, big changes began to occur in the database world, driven by
globalization and by dramatic reductions in the cost of storing, transmitting, and processing data.
Today, businesses are globally interconnected and exchange large volumes of data with customers, suppliers, and governments. Much of this data consists of things that do not fit neatly into
rows and columns, such as medical records, legal documents, incident reports, tax returns, and
purchase orders. The new kinds of data tend to be more heterogeneous than traditional business
data, having more variation and a more rapidly evolving structure.
In response to the changing requirements of business data, a new generation of standards have
appeared. XML has emerged as an international standard for the exchange of self-describing
data, unifying structured, unstructured, and semi-structured information formats. XML Schema
has been adopted as the metadata syntax for describing the structure of XML documents.
Industry-specific XML schemas have been developed for medical, insurance, retail, publishing,
banking, and other industries. XPath and XQuery have been adopted as standard languages for
retrieving and manipulating data in XML format, and new facilities have been added to the SQL
standard for interfacing between relational and XML data.
In DB2, the new generation of XML-related standards is reflected in pureXML, a broad new set of
XML functionality implemented in both DB2 for z/OS and DB2 for Linux, UNIX, and Windows.
pureXML bridges the gap between the XML and relational worlds and makes DB2 a true hybrid
database management system. DB2 pureXML stores and indexes XML data alongside relational
data in a highly efficient new storage format, and supports XML query languages such as XPath
and XQuery alongside the traditional SQL.
pureXML is perhaps the largest new package of functionality in the history of DB2, impacting
nearly every aspect of the system. The implementation of pureXML required deep changes in the
database kernel, optimization methods, database administrator tools, system utilities, and application programming interfaces. New facilities were added for registering XML schemas and
using them to validate stored documents. New kinds of statistics on XML documents had to be
gathered and exploited. Facilities for replicated, federated, and partitioned databases had to be
updated to accommodate the new XML storage format.
pureXML provides DB2 users with a new level of capability, but using this capability to full
advantage requires users to have a new level of sophistication. A new user of pureXML is
xxv
xxvi
DB2 ® pureXML® Cookbook: Master the Power of the IBM® Hybrid Data Server
confronted with many complex choices. What kinds of data should be represented in XML rather
than in normalized tables? How can data be converted between XML and relational formats?
How can a hybrid database be designed to take advantage of both data formats? What are the
most appropriate uses for SQL, XQuery, and XPath? What kinds of indexes should be maintained
on XML data? What is the XML equivalent of a NULL value? These and many other questions
are considered in detail in the DB2 pureXML Cookbook.
Matthias Nicola has been deeply involved in the design and implementation of DB2 pureXML
since its inception. As a Senior Engineer at IBM’s Silicon Valley Laboratory, his work has
focused on measuring and optimizing the performance of new storage and indexing techniques
for XML. After the release of pureXML, he worked with many IBM customers and business partners to create, deploy, and optimize XML applications for government, banking, telecommunications, retail, and other industries.
Pav Kumar-Chatterjee is a technical specialist with many years of experience in consulting with
IBM customers throughout the UK and Europe on developing and deploying DB2 and XML
solutions.
Through their work with customers, Matthias and Pav have learned how to explain concepts
clearly and how to identify and avoid common pitfalls in the application development process.
They have also developed a set of “best practices” that they have shared at numerous conferences,
classes, workshops, and customer engagements. Between them, Matthias and Pav have accumulated all the knowledge and experience you need to successfully create and deploy solutions
using DB2 pureXML. Their expertise is encapsulated in this book in the form of hundreds of
practical examples, tested and clearly explained. The book also includes a comprehensive set of
questions to test your understanding.
DB2 pureXML Cookbook includes both an introduction to basic XML concepts and a comprehensive description of the XML-related features of DB2 for z/OS and DB2 for Linux, UNIX, and
Windows. Chapters are organized around tasks that reflect the lifecycle of XML projects, including designing databases, loading and validating data, writing queries and updates, developing
applications, optimizing performance, and diagnosing problems. Each topic provides a clear progression from introductory material to more advanced concepts. The writing style is informal and
easy to understand for both beginners and experts.
If you are an application developer, database administrator, or system architect, this is the book
you need to gain a comprehensive understanding of DB2 pureXML.
Don Chamberlin
IBM Fellow, Emeritus
Almaden Research Center
April 10, 2009
Preface
n recent years XML has continued to emerge as the de-facto standard for data exchange,
because it is flexible, extensible, self-describing, and suitable for any combination of structured and unstructured data. With the increasing use of XML as a pervasive data format, there is a
growing need to store, index, query, update, and validate XML documents in database systems.
In response to this demand, IBM has developed sophisticated XML data management capabilities that are deeply integrated in the DB2 database system. This novel technology is called DB2
pureXML and is available in DB2 for z/OS and DB2 for Linux, UNIX, and Windows. With
pureXML, DB2 has evolved into a hybrid database system that allows you to manage both XML
and relational data in a tightly integrated manner.
I
The DB2 pureXML Cookbook provides the single most comprehensive coverage of DB2’s
pureXML functionality in DB2 for Linux, UNIX, and Windows as well as DB2 for z/OS. This
book is a “cookbook” because it is more than just a description of functions and features (“ingredients”). This book provides “recipes” that show you how to combine the pureXML ingredients
to efficiently perform typical user tasks for managing XML data. This book explains DB2
pureXML in more than 700 practical examples, including 250+ XQuery and SQL/XML queries,
taking you from simple introductions all the way to advanced scenarios, tuning, and troubleshooting.
Since the first release of DB2 pureXML in 2006 we have worked with numerous companies to
help them design, implement, optimize, and deploy XML applications with DB2. In this book we
have distilled our experience from these pureXML projects so that you can benefit from proven
implementation techniques, best practices, tips and tricks, and performance guidelines that are
not described elsewhere.
WHO SHOULD READ THIS BOOK?
This book is written for database administrators, application developers, IT architects, and everyone who wants to get a deep technical understanding of DB2’s pureXML technology and how to
use it most effectively. As a DBA you will learn, for example, how to design and manage XML
storage objects, how to index XML data, where to find XML-related information in the DB2 catalog, and how to mange XML with DB2 utilities. Application developers learn, among other
things, how to write XML queries and XML updates with XPath, SQL/XML, and XQuery, and
how to code XML applications with Java, .NET, C, COBOL, PL/1, PHP, or Perl.
This book is suitable for both beginners and experts. Each topic starts with simple examples,
which provide an easy introduction, and works towards advanced concepts and solutions to complex problems. Extensive XML knowledge is not required to read this book because it includes
the necessary introductions to XML, XPath, XQuery, XML Schema, and namespaces. These
xxvii
xxviii
DB2 ® pureXML® Cookbook: Master the Power of the IBM® Hybrid Data Server
concepts are explained through numerous examples that are easy to follow. We assume that you
have some experience with relational databases and SQL, but we show all the relevant DB2 commands that are required to work through the examples in this book. Appendix C, Further Reading, also contains links to additional educational material about both DB2 and XML.
COVERAGE OF DB2 FOR Z/OS AND DB2 FOR LINUX, UNIX, AND WINDOWS
IN THIS BOOK
The book describes DB2 pureXML on all supported platforms and versions, which at the time of
writing are DB2 9 for z/OS as well as DB2 9.1, 9.5, and 9.7 for Linux, UNIX, and Windows.
Many pureXML features and functions are identical across DB2 for Linux, UNIX, and Windows
and DB2 for z/OS.
Where platform-specific differences exist we point them out along the way. However, this book
does not intend to be a reference that lists all functions and features according to platform and
version of DB2. Instead, this book is a “cookbook” that focuses on concepts, examples, and best
practices. The capabilities in DB2 for z/OS and DB2 for Linux, UNIX, and Windows continue to
grow and converge over time. For the latest information on which feature is available in which
version, please consult the respective DB2 information center. DB2 for z/OS also continues to
deliver pureXML enhancements via APARs. Please look at APAR II14426, which is an informational APAR that summarizes and links all other XML-related APARs for DB2 on z/OS.
In our work with users who adopt DB2 pureXML we have made the following observation: Some
of the users who begin to use DB2 pureXML on Linux, UNIX, and Windows have little or no
prior experience with DB2. In contrast, most users who are interested in DB2 pureXML on z/OS
are already familiar with DB2 for z/OS in general. This difference is reflected in this book; that is,
we describe some DB2 concepts, such as monitoring or the use of DB2 utilities, in more detail for
DB2 for Linux, UNIX, and Windows than for DB2 for z/OS.
DO IT YOURSELF!
The best way to learn a new technology is hands-on. We strongly recommend that you download
DB2 Express-C, which is free, and try the concepts that you learn in this book in DB2’s sample
database. Appendixes A and B contain the necessary information to get you started.
DON’T HESITATE TO ASK QUESTIONS!
If any pureXML question is not covered in this book, the fastest way to get an answer is to post a
question in the DB2 pureXML forum at http://www.ibm.com/developerworks/forums/forum.
jspa?forumID=1423.
Whether you seek clarification about specific features or functions, or if you need help with a
tricky query, this forum is the right place to ask for help. You are also welcome to contact the
Preface
xxix
authors directly. If you want to discuss an XML project or if you have comments or feedback on
the material in this book—we will be happy to hear from you. Please contact Matthias at
mnicola@us.ibm.com and Pav at kumarp2@uk.ibm.com.
HOW THIS BOOK IS STRUCTURED
The DB2 pureXML Cookbook takes you through the different tasks and topics that you typically
encounter during the life cycle of an XML project. The structure of this book with its 23 chapters
is the following:
Planning
Chapter 1, Introduction, provides an overview of XML and its differences to relational data, and
discusses scenarios where XML has advantages over the relational model. This chapter also
includes a summary of the pureXML technology.
Chapter 2, Designing XML Data and Applications, covers fundamental XML design questions
such as choosing between XML elements and attributes, selecting an appropriate XML document
granularity, and deciding on a “good” mix of XML and relational data for your application.
Designing and Populating an XML Database
Chapter 3, Designing and Managing XML Storage Objects, first explains the tree representation of XML documents and how they are physically stored in DB2. Then it describes how to create and manage tables and table spaces for XML, including compression, reorganization, and
partitioning.
Chapter 4, Inserting and Retrieving XML Data, looks at “full document” operations such as
insert, delete, and retrieval of XML documents. This chapter also explains how to handle XML
declarations, white space, and reserved characters in XML documents.
Chapter 5, Moving XML Data, looks at importing, exporting, loading, replicating, and federating XML data in DB2. A technique to split large XML documents into smaller ones is also
demonstrated.
Querying XML Data
Chapter 6, Querying XML Data: Introduction and XPath, is the first of four chapters on querying XML data. This chapter provides an overview of the different options for querying XML,
introduces the XPath and XQuery data model, and describes the XPath language in detail. These
concepts are fundamental for the subsequent chapters.
xxx
DB2 ® pureXML® Cookbook: Master the Power of the IBM® Hybrid Data Server
Chapter 7, Querying XML Data with SQL/XML, explains how XPath can be included in SQL
statements with the SQL/XML functions XMLQUERY and XMLTABLE and the XMLEXISTS predicate. The use of SQL/XML is illustrated through a rich collection of examples and a discussion of
common mistakes and how to avoid them.
Chapter 8, Querying XML Data with XQuery, introduces the XQuery language, which is a
superset of XPath. Among other things, this chapter describes XQuery FLWOR expressions,
combinations of SQL and XQuery, and a comparison of XPath, XQuery, and SQL/XML.
Chapter 9, Querying XML Data: Advanced XML Queries and Troubleshooting, takes querying XML data to the expert level. It demonstrates how to perform grouping, aggregation, and
joins over XML data or a mix of XML and relational data. The troubleshooting section discusses
“bad” XML queries, common errors, and how to avoid both.
Converting, Updating, and Transforming
Chapter 10, Producing XML from Relational Data, begins the discussion of converting, updating, and transforming data. This chapter explains how to read relational data from existing database tables and construct XML documents from it.
Chapter 11, Converting XML to Relational Data, describes the opposite of Chapter 10, that is,
the process of decomposing or shredding XML documents into relational tables. Two shredding
methods are discussed, one using the XMLTABLE function and the other using annotated XML
Schemas.
Chapter 12, Updating and Transforming XML Documents, covers three techniques for updating XML documents: Full document replacement, XSLT transformations, and the XQuery
Update Facility that allows you to modify, insert, delete, or rename individual elements and
attributes within an XML document.
Performance and Monitoring
Chapter 13, Defining and Using XML Indexes, is one of two chapters dedicated to performance. It describes how to create XML indexes to improve query performance and explains
under which conditions query predicates can or cannot use XML indexes.
Chapter 14, Performance and Monitoring, looks at analyzing the performance of XML operations with particular emphasis on understanding XML query access plans. A summary of best
practices for XML performance in DB2 is also provided.
Preface
xxxi
Ensuring Data Quality
Chapter 15, Managing XML Data with Namespaces, introduces XML namespaces and
explains how they avoid naming conflicts and ambiguity, thus contributing to data quality. This
chapter illustrates how to index, query, update, and construct XML documents that contain namespaces.
Chapter 16, Managing XML Schemas, first describes how XML Schemas can constrain XML
documents in terms of their structure, element and attribute names, data types, and other characteristics. Then this chapter walks you through the concepts of registering, managing, and evolving XML Schemas in DB2.
Chapter 17, Validating XML Documents against XML Schemas, concentrates on the validation
of XML documents to ensure XML data quality in DB2. You can validate XML documents in
INSERT and UPDATE statements, queries, and import and load operations.
Application Development
Chapter 18, Using XML in Stored Procedures, UDFs, and Triggers, demonstrates how you can
implement application-specific processing logic with XML manipulation in SQL stored procedures, user-defined functions, and triggers.
Chapter 19, Performing Full-Text Search, describes how the DB2 Net Search Extender and
DB2 Text Search support efficient full-text search in collections of XML documents.
Chapter 20, Understanding XML Data Encoding, explains internal and external XML encoding, how DB2 determines and handles XML encoding, and how you can avoid code page conversion.
Chapter 21, Developing XML Application with DB2, contains techniques and best practices for
application programs that exchange XML data with the DB2 server. Code samples are provided
for Java, .NET, C, COBOL, PL/1, PHP, and Perl programmers.
Reference Material
Chapter 22, Exploring XML Information in the DB2 Catalog, is a guide to how XML storage
objects, XML indexes, and XML Schemas are listed in the database catalog.
Chapter 23, Test Your Knowledge—The DB2 pureXML Quiz, offers 82 questions to revisit specific topic areas.
The Appendixes list supporting information and further reading for each chapter.
This page intentionally left blank
Acknowledgments
Writing this book would not have been possible without the support from many people. For their
support and technical reviews we would like to thank Andrew Eisenberg, Andy Lai, Bert van der
Linden, Bob Harbus, Christian Daser, Cindy Saracco, Craig Mullins, Daniela Wersin, David
Salinero, Don Chamberlin, Guogen Zhang, Henrik Loeser, Holger Seubert, Ian Cook, Jan-Eike
Michels, Jason Cu, John Pickford, Lan Huang, Manfred Paessler, Mark Mezofenyi, Martin Sommerlandt, Paul Fletcher, Phil Nelson, Qi Jin, Shantanu Munkur, Stefan Momma, Susan Gausden,
Susan Malaika, Susan Visser, Susanne Englert, Thomas Fanghaenel, Tiffany Money, Tim Kiefer,
and Yuchu Tong. Thanks also to the many talented people in the DB2 pureXML development
team who have implemented this exciting technology that we have the privilege of writing about.
xxxiii
About the Authors
Matthias Nicola is a Senior Software Engineer for DB2 pureXML at IBM’s Silicon Valley Lab.
His work focuses on all aspects of XML in DB2, including XQuery, SQL/XML, XML storage,
indexing, and performance. Matthias also works closely with customers and business partners,
assisting them in the design, implementation, and optimization of XML solutions. Matthias has
published more than a dozen articles on various XML topics (see www.matthiasnicola.de) and is
a frequent speaker at DB2 conferences. Prior to joining IBM, Matthias worked on data warehousing performance for Informix Software. He received his doctorate in computer science from the
Technical University of Aachen, Germany.
Pav Kumar-Chatterjee has worked with DB2 since 1991 on DB2 for z/OS and since 2000 on
DB2 for Linux, UNIX, and Windows. He is currently employed by IBM as a technical sales specialist for Information Management in the United Kingdom. He has helped customers implement
the XML Extender product with DB2 V8 and has presented on DB2 and XML in the United
Kingdom and around Europe.
xxxiv
C
H A P T E R
1
Introduction
ML, the eXtensible Markup Language, is the standard format for exchanging information
between different systems, applications, and organizations. XML is also the underlying
data format for many web applications, Service-Oriented Architectures (SOA), and messagebased transaction processing systems. Enterprise application integration (EAI), enterprise information integration (EII), web services, the enterprise message bus (ESB), and standardization
efforts in many vertical industries all rely on XML as the underlying technology for data
exchange.
X
Organizations as well as entire industries have standardized XML Schemas to promote and simplify data exchange and are evolving those schemas to meet changing business needs. Many
industry-specific initiatives as well as regulatory requirements are driving the adoption of XML.
As more business transactions are conducted through web-based interfaces and electronic forms,
government agencies and commercial enterprises face increasing requirements for preserving
and post-processing the original transaction records. XML provides a straightforward means of
capturing and maintaining the data associated with such electronic transactions.
XML uses tags to define elements and attributes that hold business data. The element and attribute tags describe the intended meaning of the data items, and the nesting of the tags describes
hierarchical relationships between the data items. Hence, XML is a self-describing data format.
Data and metadata are tightly integrated in a vendor- and platform-independent format. These
properties make XML well-suited for data exchange. Additionally, new tags can be invented and
easily added. This extensibility allows XML to accommodate ever-evolving business needs.
XML is a flexible data model that is suited for any combination of structured, unstructured, and
semi-structured data. Also, XML documents can be modified and transformed, even into other
1
2
Chapter 1
Introduction
formats such as HTML. Furthermore, the consistency of XML documents can easily be verified
with an XML Schema. All this has become possible through widely available standards and tools
such as XML parsers, XSLT, XPath, XQuery, and XML Schema. They greatly relieve applications from the burden of dealing with proprietary data formats. In an era where message formats,
business forms, processes, and services change frequently, XML often reduces the cost and time
it takes to react to such changes and to maintain databases and application logic correspondingly.
Beyond XML for data exchange, enterprises are keeping large amounts of business-critical data
permanently in XML format. This practice has various reasons. Some businesses must retain
XML documents in their original format for auditing and regulatory compliance. Common examples include legal and financial documents as well as electronic forms. Another reason for using
XML as a permanent storage format is that XML can be a more suitable data model than a relational schema. If business objects are inherently complex, hierarchical, semi-structured, or highly
variable in nature, the flexibility of XML offers advantages over a rigorously defined relational
database schema. Accustomed to the benefits of mature relational databases, many users expect
the same capabilities for XML data, such as the ability to persist, query, index, update, and validate XML data with full ACID (Atomicity, Consistency, Isolation, Durability) compliance,
recoverability, high availability, and high performance. DB2 pureXML is the answer.
The subsequent discussion in this chapter is structured along the following topics:
• Brief introduction to XML as a data format (section 1.1)
• Differences between XML and relational data (section 1.2)
• Overview of DB2 pureXML and its capabilities for managing XML data (section 1.3)
• Advantages of DB2 pureXML over alternative storage options for XML (section 1.4)
• Sample scenarios where XML can offer advantages over relational data (section 1.5)
1.1
ANATOMY OF AN XML DOCUMENT
In this section we illustrate the most important parts of an XML document. A complete and
exhaustive discussion of the XML standard is outside the scope of this book. Pointers to textbooks and tutorials about XML are provided in Appendix C, Further Reading.
Let’s look at the XML document in Figure 1.1 as an example. The first line of the document contains the optional XML declaration. It indicates that this document follows the XML 1.0 standard, which is most commonly used. Besides XML 1.0, the only other version of XML is
currently XML 1.1, which is very rarely used. We only consider XML 1.0 in this book. The XML
declaration of the sample document in Figure 1.1 also carries an optional encoding declaration.
Encoding concepts are discussed in Chapter 20, Understanding XML Data Encoding.
1.1
Anatomy of an XML Document
3
An XML document consists of elements and their attributes. Each element consists of a start tag
and an end tag. These tags are enclosed in angle brackets. For example, the third line of the document shows a start tag <name> and an end tag </name>. Together they define a single XML element, the name element. The characters between the start and the end tag, Larry Menard,
represent the value or the content of this element. Every start tag of an element must have a corresponding end tag.
Elements can contain other elements, which means that tags can be nested. For example, the element addr contains the elements street, city, prov-state, and pcode-zip. Nesting builds
hierarchical structures and expresses relationships between the elements. Elements can occur multiple times, in which case they are called repeating elements. For example, the phone element is a
repeating element. It occurs multiple times because a single customer can have multiple phone
numbers. Nested and repeating elements express one-to-many relationships between data items.
<?xml version="1.0" encoding="UTF-8" ?>
XML and encoding declaration
Attribute
<customerinfo xmlns="http://posample.org" Cid="1005">
<name>Larry Menard</name>
<addr country="Canada">
Start tag of the root element
Namespace declaration
<street>223 NatureValley Road</street>
<city>Toronto</city>
<prov-state>Ontario</prov-state>
Element
Element value
(text node)
<pcode-zip>M4C 5K8</pcode-zip>
</addr>
Attribute name
<phone type="work">905-555-9146</phone>
<phone type="home">416-555-6121</phone>
<!--
this is comment -->
</customerinfo>
Attribute value
Comment
End tag of the root element
Figure 1.1 Anatomy of an XML document
Elements can also contain one or multiple attributes within their start tag. Attributes are used to
attach additional information to elements. They consist of an attribute name, the equal sign (=),
and a value in quotes. For example, the element addr has an attribute country whose value is
4
Chapter 1
Introduction
Canada. Similarly, each occurrence of the element phone has an attribute type. Attribute values
must be in quotes regardless of whether the value is considered a numeric or a string value.
For an XML document to be well-formed, it must have a single root element. The root element is
the outermost element and contains all the other elements of the document. The root element in
Figure 1.1 is customerinfo. It contains two attributes in its start tag, xmlns and Cid. The
attribute Cid is used here to represent the customer identification number. The attribute xmlns is
a reserved attribute and declares a namespace. Namespaces are optional and we defer their discussion to Chapter 15, Managing XML Data with Namespaces.
XML element and attribute names are case sensitive. The tags <name>, <Name> and <NAME> are
all completely distinct from each other. XML element and attribute names can contain letters,
numbers, and certain other characters such as the underscore. However, tag names must not start
with a number or punctuation character, must not start with the characters xml (or XML, xML, and
so on), and must not contain spaces.
The order in which elements appear in a document is significant. The order in which attributes
appear within the start tag of an element is not significant. In other words, elements are ordered,
attributes are not ordered. When to use elements and when to use attributes to represent certain
data items is a data modeling question and addressed in Section 2.1, Choosing Between XML
Elements and XML Attributes. Further discussion of XML documents and their hierarchical representation is provided in Section 3.1, Understanding XML Document Trees.
1.2
DIFFERENCES BETWEEN XML AND RELATIONAL DATA
For a comparison of XML and relational data, let’s consider the simple XML document and the
relational table in Figure 1.2. The relational table has six columns with fixed names and data
types. This table is a very strict and inflexible structure because every row in the table has to have
exactly the same format with the same number of columns and the same data types. It is not possible that one row in the table has more or fewer columns than the next. It is also not possible for
a column to have no data type or more than one data type. Each column has to have exactly one
fixed data type. Moreover, the structure and data types of the table are defined before any data is
inserted. Whenever data is inserted or retrieved from this table, the format of the rows is known
without looking at the actual data. The strict schema provides a lot of information about the data
and its format, which allows for very efficient access.
The XML document in the left side of Figure 1.2 represents similar data as the row in the table on
the right. With DB2 pureXML you can store, index, query, and update this XML document even
if there is no XML Schema that defines its structure or the data types of its elements. You may
have an XML Schema for this XML document, but you don’t have to. The document itself contains some meta information that describes the data items, but no further schema information is
necessary to store and query this document.
1.2
Differences Between XML and Relational Data
<customerinfo Cid=" 1003">
<name> Robert Shoemaker </name>
<addr>
<street> 845 Kean Street </street>
<city> Aurora</city>
</addr>
<phone> 905-555-7258 </phone>
</customerinfo>
5
CREATE TABLE address(cid INTEGER,
name VARCHAR(30),
street VARCHAR(40),
city VARCHAR(30),
email VARCHAR(50),
phone VARCHAR(20))
CID NAME
STREET
CITY
EMAIL PHONE
1003 Robert Shoemaker 845 Kean Street Aurora NULL 905-555-7258
Figure 1.2
XML document (left) and relational table (right)
Assume you receive information about another customer whose street name is 42 characters
long. Inserting this information into the relational table fails with an error that needs to be handled. This error can be desirable because it enforces a certain constraint, but it can also be undesirable because it prevents the new information from being stored and processed immediately.
Because XML allows more schema flexibility, a document with a 42-character street name can be
inserted without an error. The absence of an error can be desirable because it allows the data to be
stored immediately, but it can also be undesirable because the excessive length of the street value
goes undetected and can cause problems in later processing steps. Clearly, the flexibility of XML
needs to be used with care and only to the degree that is appropriate for a given application.
Optionally, you can choose to use an XML Schema that constrains the XML document as strictly
as the relational table in Figure 1.2. You could also choose to use a less stringent XML Schema.
For example, you could use an XML Schema that requires the Cid value to be an integer and the
name to not exceed 30 characters, leaving the data types of all other data items unconstrained.
You can choose the degree of schema flexibility that is right for your application.
Note that the relational table in Figure 1.2 contains a NULL value in the column email. In the
XML document, an email element is simply omitted if this customer does not have email.
Optional XML elements are another form of schema flexibility. Assume you receive information
about a customer where, unexpectedly, the name of his assistant is included. The assistant name
can easily be accommodated with an optional assistant element in an XML document. However, the relational table in Figure 1.2 does not allow the assistant name to be stored.
Next, let’s consider a schema change. Due to unforeseen changes in your business, you now need
to store multiple phone numbers per customer. Reacting to this change is simple with XML. The
document in the left side of Figure 1.3 simply uses multiple occurrences of the phone element.
The repeating phone elements represent the new one-to-many relationship between customers
and phones. Existing XPath queries that read phone elements do not change. Accommodating
6
Chapter 1
Introduction
multiple phone numbers per customer in the relational schema requires normalization, which is a
drastic schema change. Existing SQL queries must be modified to perform the proper join
between the two relational tables. Downtime and service interruptions are likely.
CREATE TABLE phones(cid INTEGER, phone VARCHAR(20))
<customerinfo Cid=" 1003">
<name> Robert Shoemaker </name>
<addr>
<street> 845 Kean Street </street>
<city> Aurora</city>
</addr>
<phone> 905-555-7258 </phone>
<phone> 416-555-2937 </phone>
</customerinfo>
CID
1003
1003
PHONE
905-555-7258
416-555-2937
CREATE TABLE address(cid INTEGER,
name VARCHAR(30),
street VARCHAR(40),
city VARCHAR(30),
email VARCHAR(50),
phone VARCHAR(20))
CID NAME
STREET
CITY
EMAIL PHONE
1003 Robert Shoemaker 845 Kean Street Aurora NULL 905-555-7258
Figure 1.3
A schema change in XML and relational data
Some of the key differences between XML and relational data are summarized in Table 1.1. The
flexibility of XML implies that examining and interpreting XML data can consume more computing resources than if the same data was stored in relational form. The reason is that information about the structure of the XML data needs to be discovered at runtime because a fixed
schema is not always present.
The relational data model relies on much more rigid schema definitions than XML. For a relational table in a database, the structure of a row and the size and data types of its columns are
known as soon as the table is created. Therefore, data access is more straightforward and can be
more efficient than for XML data. As such, relational data can provide very high performance but
might fail to meet application requirements for schema flexibility.
Table 1.1
Comparison of Relational and XML Data
Relational Data
XML Data
Highly structured, highly regular in nature
Semi-structured, can be highly variable in nature
Rows are flat
Data is hierarchical, can be arbitrarily nested
Fixed schema and metadata
Variable schema and metadata
Fixed number of columns per table
No fixed format, flexible number of elements and
attributes per document
Fixed data type for all values in a column
Data types are optional and can be variable
1.3
Overview of DB2 pureXML
Table 1.1
7
Comparison of Relational and XML Data (Continued)
Data format defined by DDL, known at query/
insert/update compile time
Data format not necessarily predefined, not known
until query/insert/update runtime
NULL values represent missing information
Optional elements and attributes can be omitted
Schema changes can be expensive
Schema changes are less expensive
In some cases, the nested and flexible structure of XML can offer performance benefits over relational schemas. Relational databases often require normalization to fit business data into flat, tabular structures. This normalization of complex business data requires transformation when data is
stored and retrieved, and often leads to multi-way join queries in relational databases. XML can
provide a more natural representation of complex business objects with all relevant relationships
represented in a single document. The hierarchies within an XML document are essentially precomputed joins between related data items.
1.3
OVERVIEW OF DB2 PUREXML
This section provides a condensed overview of the DB2 pureXML technology. It summarizes the
most important aspects of DB2 pureXML, which are described in more detail in the remainder of
this book.
At the core of DB2 pureXML is the data type XML, which has been added to the SQL type system
in the SQL:2003 standard. Database users can define tables that contain one or multiple columns
of type XML. In each row, a column of type XML contains either a well-formed XML document or
NULL. A table that contains one or more XML columns can also contain other columns, such as
INTEGER, VARCHAR, or DATE columns. Hence, users can define tables that hold both XML data
and traditional relational data in each row of the table. The integration of XML and relational data
is therefore very easy. It is also possible to create a table that only contains a single column of
type XML and no other columns.
DB2’s internal XML storage mechanism does not store XML data as text in large objects (LOBs)
and does not convert XML to relational format. When you insert or load XML documents into a
column of type XML, DB2 stores the XML documents in a parsed hierarchical format. Each XML
document is parsed only once; that is, when it is first inserted into an XML column. The parsed
storage format allows queries and updates to operate on XML data without XML parsing—a key
performance benefit. The maximum XML document size is 2GB.
You can use regular SQL statements to insert, delete, and update (replace) full XML documents.
XML insert, update, and delete operations are logged by default and XML data is always
buffered in the buffer pool. XML data participates in backup, restore, and recovery operations
just like traditional relational data in the database. XML data can be compressed, replicated, and
8
Chapter 1
Introduction
federated, and is allowed in range-partitioned tables, clustered tables (MDC), and partitioned
database environments (DPF). Partitioning keys and clustering keys must be relational columns.
All the critical database utilities support XML data, such as LOAD, UNLOAD, IMPORT, EXPORT,
RUNSTATS, REORG, BACKUP, RESTORE, and others. In DB2 for Linux, UNIX, and Windows,
XML columns are also supported by High Availability Disaster Recovery (HADR).
An XML Schema can be used to constrain XML documents, but the usage of XML Schemas is
optional in DB2. In particular, you do not need to provide an XML Schema to create a column of
type XML or to insert XML documents. DB2’s pureXML storage format does not depend on XML
Schemas. When you insert, update, or load XML documents, you can choose to validate the documents against one or multiple XML Schemas. If you choose to validate documents, the
validation and the association of schemas to documents happens on a per-document basis, not on
a per-column basis. DB2 does not require all documents in an XML column to belong to the same
XML Schema, although you can enforce that with triggers if you want. Since schema flexibility
is often a key reason for using XML, DB2 allows documents for multiple schemas, or multiple
versions of a schema, to coexist in a single XML column. XML Schema evolution is seamless
and does not require any database downtime. The use of XML Schemas for document validation
can help applications ensure XML data quality. However, there is no performance penalty if you
store XML documents without validation in DB2.
Although XML Schemas can constrain one XML document at a time, there is no standard or
XML technology yet to define constraints or referential integrity across XML documents or
across XML and relational data. However, when you insert XML documents into a table you can
choose to extract selected element or attribute values into relational columns. DB2 can perform
such value extraction as part of the INSERT statement, but it can also be automated with triggers.
Then you can define relational constraints, such as foreign keys and check constraints, on the
populated relational columns.
In DB2, XML data can be queried with XPath and SQL/XML, and in DB2 for Linux, UNIX, and
Windows, also with XQuery. The SQL/XML standard allows XPath and XQuery expressions to
be embedded in SQL statements so that XML and relational data can be queried together in a single query. Joins between XML columns or between XML and relational columns are possible.
The SQL/XML function XMLTABLE can be used to query XML data and return the result set in
relational format. Other SQL/XML functions support the opposite; that is, to query traditional
relational tables to construct and return XML documents that contain the data values.
To ensure high performance for XML queries, DB2 allows you to create XML indexes on specific XML elements and attributes that you specify with an XPath. Similar to the relational world,
it makes sense to index those XML elements and attributes that are frequently used in query predicates and join conditions. Although you can decide to index all elements and all attributes in all
documents in an XML column, you are not forced to do so. Indexing selected elements and attributes is often preferred. If you define an XML index on an optional element that, for example,
occurs in only 5% of the documents (rows), then the index is quite small because it contains
1.3
Overview of DB2 pureXML
9
entries only for those 5% of the documents and rows in the table. In contrast, relational indexes
always contain exactly one entry for each row in a table. If a query contains relational predicates
and XML predicates, DB2 can use a combination of XML and relational indexes to evaluate the
query.
DB2’s RUNSTATS utility can collect statistics for XML data which the DB2 optimizer uses to create efficient query execution plans. Although DB2 uses separate storage formats for XML and
relational data, DB2 only has a single processing engine and a single query compiler and optimizer that handle any mix of relational and XML queries. DB2’s EXPLAIN facility can be used to
examine the execution plans for XML queries just like for relational queries.
DB2 for Linux, UNIX, and Windows also supports XQuery Updates to modify, insert, delete, or
rename individual XML elements and attributes within an XML document. XSLT transformations as well as full-text search over XML data are also supported.
Access control as well as concurrency control (locking) for XML data happens on the level of full
documents. Since each XML document belongs to a row in a table, access control and concurrency control for a particular row determines the accessibility of the XML document in that row.
Access rights and privileges cannot be defined for individual elements within an XML document.
The XML data type can be used for more than just the definition of XML columns. For example,
you can define XML parameters and XML variables in SQL stored procedures and user-defined
function (UDFs). Such procedures and UDFs can contain XQuery or SQL/XML statements to
manipulate XML documents while they remain in DB2’s internal parsed format.
Application development for DB2 pureXML is based on existing but enhanced APIs. The traditional database APIs such as JDBC, ODBC/CLI, ADO.NET, or embedded SQL all support
XQuery and SQL/XML statements as well as the exchange of XML data between a DB2 server
and a client application. The JDBC 4.0 standard defines a new Java data type SQLXML to match
the data type XML defined by the SQL standard. Similarly you can define XML host variables in
COBOL, C, PL/1, and Assembler.
With DB2 pureXML, applications can often avoid XML parsing, because DB2 stores XML documents in a parsed format. The parsed storage allows you to extract or update document fragments or individual values without having to parse the XML data in your application.
Applications send appropriate XML query or update statements to DB2 instead of fetching and
parsing full documents. As a result, using DB2 pureXML leads to less application code, reduced
application complexity, and higher end-to-end performance.
Both the DB2 Control Center and IBM Data Studio support DB2 pureXML through a variety of
wizards and visual interfaces. For example, you can view the tree structure of XML documents,
create XML indexes with point-and-click into XML documents, design and register XML
Schemas, or build XQuery and SQL/XML statements with context assist in Data Studio’s statement editor.
10
Chapter 1
Introduction
1.4
BENEFITS OF DB2 PUREXML OVER ALTERNATIVE STORAGE OPTIONS
FOR XML DATA
Prior to the availability of DB2 pureXML, the two main storage options for XML data in relational databases are LOB storage and shredding:
• The LOB storage approach stores full XML documents in their textual form in character
or binary large object columns (CLOB or BLOB). Other columns in the same table typically contain document identification numbers or other information that helps applications to identify specific XML documents for retrieval or replacement. The main
problem of this approach is that the XML documents are stored as if they were arbitrary
pieces of text. The XML structure is ignored and not immediately visible. Therefore any
operation that needs to access individual elements or attributes in a document requires
XML parsing. For example, any query that extracts element values requires XML parsing at runtime. The resulting parsing overhead for query and update execution is a major
performance problem that renders LOB storage inadequate for most XML applications.
• Shredding (decomposing) XML documents into relational tables converts XML data
into relational format. Shredding first requires a design stage where an administrator
maps XML elements and attributes to relational columns. When XML documents are
inserted, they are parsed, broken up, and only their atomic data values are retained (see
Figure 1.4). These values are inserted into the relational target tables by a series of
INSERT statements. After an XML document has been shredded, its values are stored in
these tables without the original XML tags. Depending on the complexity of the XML
documents, shredding can require dozens or hundreds of relational tables to represent
all the hierarchical relationships among the original XML elements and attributes. In
many real-world XML applications this complexity is staggering such that even the
mapping task is considered prohibitively expensive or unfeasible. Queries over decomposed XML data often require multi-way SQL joins that tend to be difficult to develop
and tune. Changes or variability in the XML input format often break the mapping to the
relational database schema, which incurs time-consuming maintenance. A fixed schema
mapping that is costly to change negates the flexibility for which XML is typically used.
DB2 pureXML has been designed to overcome the problems that are inherent in LOB storage and
shredding. The advantages of DB2 pureXML and its native XML storage format include:
• Retaining awareness of the internal structure of the XML data: Contrary to LOB storage, DB2 pureXML stores XML in a parsed tree format that explicitly represents the
structure of each XML document. As a result, applications can query and update XML
data using XQuery, XPath, and SQL/XML without XML parsing at runtime. This is a
critical performance benefit. Additionally, query performance can be enhanced by creating indexes on specific elements and attributes in the XML documents.
1.5
XML Solutions to Relational Data Model Problems
LOB storage:
stores XML as text
XML
DOC
11
Shredding:
XML Relational
Schema
Mapping
DB2 pureXML:
stores XML as XML
XML
DOC
XML
DOC
Shredder
XML DOC
XML DOC
XML DOC
XML
Index
CLOB Column
regular relational tables
XML Column
Figure 1.4
DB2 pureXML and alternative XML storage options
• Keeping business objects intact: DB2 pureXML stores each XML document as a cohesive unit that belongs to one row in a table, providing a very intuitive storage and processing model for the application developer. In contrast, XML shredding scatters the
values of each XML document over a number of tables. Hence, shredding can result in
an unwieldy relational schema that is difficult to understand and inefficient for queries
and the reconstruction of XML documents.
• Schema flexibility: While shredding requires all XML documents to adhere to a single
XML Schema that is mapped to relational tables, DB2 pureXML can store documents
for variable or evolving schemas in the same XML column. The cost of schema evolution is much lower for DB2 pureXML than for a shredding approach.
• Faster application development: Because DB2 pureXML does not require any schema
mapping and uses a single XML column instead of complex relational schema, prototyping and designing applications can be much simpler with DB2 pureXML than with
shredding.
1.5
XML SOLUTIONS TO RELATIONAL DATA MODEL PROBLEMS
The data model that you use for your business data should allow for an easy and intuitive representation of your data and should efficiently support the most critical usage and access patterns. If
the data being modeled is naturally tabular, it is typically better to represent it in relational format
than as XML. However, there are cases where the relational model is not necessarily the best
choice and sometimes even a poor choice to hold your data. The following are some situations
where an XML representation tends to be more beneficial than the relational format.
12
Chapter 1
Introduction
1.5.1 When the Schema Is Volatile
Problem with relational data: If the schema of the data changes often, then a relational representation of the data is subject to costly relational schema changes. Although some forms of schema
modification are relatively painless in relational databases, such as adding a new column to a
table, other forms are more involved, such as dropping a column or changing the type of a column. Still other forms of schema modification are extremely difficult, such as normalizing one
table into multiple tables. Changing the tables means that the SQL statements in the applications
that access them must also be changed.
Solution with XML data: Portions of the schema that are volatile can be expressed as a single
XML column. The self-describing and extensible nature of XML allows seamless handling of
schema variability and evolution. Changes in the XML document format are accommodated
without changing tables or columns in the database and typically without breaking existing XML
queries.
1.5.2 When Data Is Inherently Hierarchical in Nature
Problem with relational data: Data that is inherently hierarchical or recursive is often difficult to
represent in relational schemas. Examples include a bill of materials, engineering objects, or biological data. A bill of materials explosion can be stored in a relational database but reconstructing
it in parts or in full might require recursive SQL.
Solution with XML data: Since XML is a hierarchical data model, it is a much more natural fit for
inherently hierarchical business data. Using XML allows simple, navigational data access to
replace complex set operations, which would be required if the same data was represented in tabular format.
1.5.3 When Data Represents Business Objects
Problem with relational data: If application data represents business objects, such as insurance
claim forms, then it is often beneficial to keep the data items that comprise a particular claim
together, instead of spreading them over a set of tables. This benefit is particularly important
when the individual data items of a claim form have no valid business meaning by themselves
and can only be interpreted in the context of the complete form. Normalizing the claims across
dozens of relational tables means that applications deal with a complex and unnatural fragmentation of their business data. Such normalization can increase complexity and the chance for errors.
Solution with XML data: XML enables you to represent even complex business objects as cohesive and distinct documents while still capturing all the relationships between the data items that
comprise the business object. Representing each claim form (business object) as a single XML
document in a single row of a table provides a very intuitive storage model for the application
developer and enables rapid application development.
1.6
Summary
13
1.5.4 When Objects Have Sparse Attributes
Problem with relational data: Some applications have a large number of possible attributes, most
of which are sparse; that is, they apply to very few objects. A classic example is a product catalog
where the number of different product attributes can be huge, including size, color, weight,
length, height, material, style, weave, voltage, resolution, water resistance, and a near endless list
of other properties. For any given product, only a subset of these attributes is relevant. One possible relational schema is to have one column per attribute, which means a very large percentage of
the cells in the table contain NULL values. Large numbers of NULLs are undesirable and can be
inefficient. A different relational approach for such sparse data is a three-column table that stores
several name/value pairs for each product ID. In this name/value pair approach, the attribute
names are not column names but values in a VARCHAR column. This design prevents relational
database systems from accurately estimating constraint selectivity and generating efficient query
plans. Finally, defining and enforcing constraints, such as uniqueness for a certain attribute, is
extremely difficult. Hence, data quality and integrity suffers.
Solution with XML data: The beauty of XML is that elements and attributes can be optional, so
they are simply omitted if they don’t apply for a specific product. Neither NULL values nor
name/value pairs are needed. The XML Schema can define a very large number of optional elements, but only few of them are used for any given object. While every row in a relational table
has to have the exact same columns, XML documents in an XML column can have different elements from one row to the next. Also, an XML index for an optional element is very small if this
element appears only in a small percentage of the documents (rows). This is a clear advantage
over relational indexes which have exactly one entry per row.
1.5.5 When Data Needs to be Exchanged
Problem with relational data: If you export a set of rows from a relational table and send them to
another application or organization, the recipient cannot interpret the data without additional
metadata that describes the columns. This separation of data from metadata in the relational
world poses a particular problem if your relational schema has changed since the last time you
sent data.
Solution with XML data: XML data is self-describing. The XML tags are metadata and describe
the values that they enclose. The nesting of XML elements further defines the relationship
between data items.
1.6
SUMMARY
XML, the extensible markup language, acts as a flexible and self-describing data format for data
exchange, web services, and service-oriented architectures. XML is also a hierarchical data
model that is inherently different from the relational model. While relational data processing is
14
Chapter 1
Introduction
based on rigorous and predefined schemas that allow for limited flexibility, XML is well-suited to
represent data with variable or evolving schemas. XML is also commonly used as a data format
for semi-structured data or to integrate structured and unstructured data.
Depending on the performance and flexibility requirements of particular applications, you will
find that in some cases XML is a better choice than a relational schema, and in other cases relational data has advantages over XML. Many scenarios also exist in which a hybrid approach, that
is, a mix of XML and relational data, is the best solution. Considerations for hybrid data models
are discussed further in the next chapter.
DB2 pureXML provides sophisticated capabilities for storing, indexing, querying, updating, and
validating XML documents. The pureXML technology and its native XML storage format provide significantly higher performance and flexibility than alternative storage options for XML
data, such as LOBs or shredding. DB2 pureXML also enables seamless integration of XML and
relational data.
C
H A P T E R
2
Designing XML Data
and Applications
his chapter looks at several design issues in the world of XML documents. Sometimes you
might get involved in the design of a specific format for your XML documents and you will
find that the design decisions made at this point can have a big impact on how your application
processes XML. Therefore, this is the first stage of XML application design. In many other cases,
the format of the XML documents that you need to process may have already been designed and
decided by the time you get involved. Many vertical industries and consortia define specific XML
Schemas to standardize the XML document formats that are used to exchange and process information within a particular industry. Some of them are discussed in Chapter 16, Managing XML
Schemas. Even if you work with a predefined XML format, there are still decisions to be made,
such as the most suitable granularity in which you should store XML documents or document
fragments.
T
In this chapter you learn
• How to choose between XML elements and attributes (section 2.1)
• How to represent data as XML values and metadata as XML tags (section 2.2)
• How to design documents with an appropriate size and scope (section 2.3)
• How to decide on a “good” mix of XML and relational data (section 2.4)
2.1
CHOOSING BETWEEN XML ELEMENTS AND XML ATTRIBUTES
A common question is when to use attributes and when to use elements, and whether this choice
affects performance. It turns out that this is much more of a data modeling question than a performance question. As such, this question is as old as SGML, the precursor of XML, and has been
15
16
Chapter 2
Designing XML Data and Applications
hotly debated with no universally accepted consensus. However, a key thing to remember is that
XML elements are more flexible than attributes because they can be repeated and nested.
Table 2.1 shows an example of an XML document with and without attributes. Both documents
logically represent the same business data. They contain information about a book called “Database Systems”, written by authors “John Doe” and “Peter Pan” who have id numbers 47
and 58 respectively, and the price of the book is 29, but there is no information in either document about the currency of the price.
In the document on the left of Table 2.1, price and title are child elements of the element
book, and the author id is a child element of the element author. This approach is certainly a
decent way of modeling the data. Alternatively, the document on the right has price and title
as attributes of the element book, and id as an attribute of the element author. In general, both
versions of the document, with and without attributes, can be reasonable choices. There is no
immediate way to decide whether one of the two document formats is “better” than the other.
Table 2.1
An XML Document with and without Attributes
XML document without attributes:
XML document with attributes:
<book>
<authors>
<author>
<id>47</id>
<name>John Doe</name>
</author>
<author>
<id>58</id>
<name>Peter Pan</name>
</author>
</authors>
<title>Database systems</title>
<price>29</price>
<keywords>
<keyword>SQL</keyword>
<keyword>relational</keyword>
</keywords>
</book>
<book price="29" title="Database systems">
<authors>
<author id="47">John Doe</author>
<author id="58">Peter Pan</author>
</authors>
<keywords>
<keyword>SQL</keyword>
<keyword>relational</keyword>
</keywords>
</book>
The document with attributes might be appealing because it is shorter. It contains 200 nonwhitespace characters as opposed to 248 in the document without attributes. An XML parser
needs to look at every single character of a document, which generally means that shorter documents can be parsed faster. This reduction in parsing times may matter if you are designing an
XML message format for very high-volume processing with near real-time performance requirements and throughput targets such as thousands of messages per second. However, many XML
applications do not fall into this category and performance should be a secondary concern during
XML modeling.
2.1
Choosing Between XML Elements and XML Attributes
17
More important is the flexibility and extensibility of the XML format, which is usually why XML
is chosen to begin with. In the example in Table 2.1, chances are that the format of the price
information eventually needs to be extended. This extension is easy in the document on the left
where price is an element. For example, you can add an attribute currency to the price element to make it more descriptive. Also, as the business expands to international markets, you can
easily repeat the price element multiple times to reflect the price of the book for different countries (see Figure 2.1).
<book>
<authors>
<author>
<id>47</id>
<name>John Doe</name>
</author>
<author>
<id>58</id>
<name>Peter Pan</name>
</author>
</authors>
<title>Database systems</title>
<price currency="GBP">29</price>
<price currency="JPY">5735</price>
<price currency="EUR">35.80</price>
<keywords>
<keyword>SQL</keyword>
<keyword>relational</keyword>
</keywords>
</book>
Figure 2.1 Document with multiple price elements
This extension of the price element has the very desirable property that XPath queries that
worked for the old document format continue to work without changes for the new format. For
example, the XPath /book/price returns the single price element from the document on the
left in Table 2.1, but also all three price elements with their currency information from the new
document format in Figure 2.1. This property helps to ensure seamless operation of applications
during such a schema evolution.
In the document on the right side of Table 2.1, where price is an attribute, such an extension is a
lot harder to make if you want to keep using attributes. The existing price attribute cannot be
extended to contain another nested attribute, and an attribute by the name of price can only
occur once for the book element. You could certainly remove the existing price attribute and
use price elements instead. This change implies that for older documents the XPath to the price
information is /book/@price whereas for newer books it is /book/price. Thus, this change is
invasive and indicates that you probably should have used elements to begin with.
In such a situation you should not use multiple price attributes with different names, as shown in
Figure 2.2. This design has a variety of undesirable consequences. First of all, XPath queries need
18
Chapter 2
Designing XML Data and Applications
to be changed each time you introduce a new currency to your business. Second, this design
makes it more complicated to retrieve all price information with a single query. Third, if your
queries use search conditions on the price attributes then you will have to define a separate XML
index for each currency, instead of just two indexes (on e for price and one for currency). These
problems stem from the fact that the currency information is part of your business data, not part
of the metadata. Hence, the currency should be a value and not part of a tag name. The use of tags
and values is discussed further in section 2.2.
<book priceGPB="29" priceJPY="5735"
priceEUR="35.80" title="Database systems">
...
</book>
Figure 2.2
Bad XML design with different names for price attributes
Also note that the XML standard specifies that elements are ordered while attributes are
unordered. For example, the three price elements in Figure 2.1 are in a fixed order, and this
order is guaranteed when the document is parsed, stored, queried, or otherwise processed. In contrast, the three price attributes in Figure 2.2 do not have a significant order within the book element. They could appear in a different order and the document would still be considered “the
same.” Hence, if the relative order among your data items is important, use elements instead of
attributes.
Although you could model all data without attributes, they can be a very intuitive choice for data
items that are known in advance to never repeat (per element) nor have any subfields. Attributes
contribute to somewhat shorter XML because they have only a single tag as opposed to elements,
which have a start tag and an end tag. Shorter attribute tags are at most a minor performance
bonus rather than an incentive to convert elements to attributes, especially when data modeling
considerations actually call for elements. In DB2, attributes can be used in queries, updates, predicates, and index definitions just as easily as elements. There is generally no significant performance difference between accessing or updating elements versus attributes when XML documents
are stored in DB2. Both elements and attributes can be defined as mandatory or optional in an
XML Schema.
As another example, let’s look at the XML document in Figure 2.3, which contains information
about a department with two employees. The document uses attributes for the department and
employee identifiers. This approach seems to make sense because each employee and department
will always have just one ID value. Furthermore, an element is used for the employee telephone
information, which allows an employee to have multiple occurrences of the phone element if
needed. It is also extensible in case you later need to break telephone numbers into fragments. For
example, the phone element could have child elements for country code, area code, and
extension, which would not be possible if phone was an attribute.
2.2
XML Tags versus Values
19
<dept deptID='PR27'>
<employee id='58043'>
<name>John Doe</name>
<phone>408-555-1212</phone>
<phone>408-463-4880</phone>
</employee>
<employee id='81822'>
<name>Peter Pan</name>
<phone>408-255-8587</phone>
<office>F589</office>
</employee>
</dept>
Figure 2.3 A sample XML document
The XML document in Figure 2.3 also raises another design question, which we discuss in section 2.3: Is it better to keep the information for all employees of a department in one document, or
is it better to have one XML document per employee?
2.2
XML TAGS VERSUS VALUES
The idea of XML as an extensible markup language is that the markup, which consists of all the
element and attribute tags, describes the enclosed data values. The ability to use custom tags for
markup makes XML a self-describing data format. The XML tags can also be considered metadata. Hence, XML documents conveniently combine data and metadata in a universally accepted
format. An important aspect of designing XML documents is to distinguish clearly between data
and metadata. The metadata should be represented as element and attribute names, the data as
element and attribute values. This approach is analogous to relational modeling, where table and
column names are metadata, and the values in the columns are the actual data.
In XML it’s almost always a bad idea to represent metadata as values instead of tags, or actual
data as tags instead of values. Let’s look at the examples in Table 2.2 and Table 2.3.
The document on the left side of Table 2.2 contains information about the brand, price, and year
of a car. The brand is Honda, the price is 5000, and the year is 1996. The terms “brand”, “price”,
and “year” constitute meta information for the values Honda, 5000, and 1996. Hence, Honda is a
data value, not metadata. Therefore it should be an XML element value, not an element name.
The XML document on the right side of Table 2.2 is a better representation of the same data.
There the term “brand” is used as an element name (meta information) for the value Honda.
Imagine yourself modeling the same data in a relational table. You would not use Honda as a column name in a table.
Avoiding business data in tag names has several advantages:
• If you are using an XML Schema, you don’t need to add new element definitions to your
XML Schema each time your business handles a new brand of car.
20
Chapter 2
Designing XML Data and Applications
• You can always use the XPath /car/brand to retrieve the brand from a particular car
document. Otherwise, if brand names are tags, many different or more complicated
XPath expressions are necessary.
• If you search for cars by brand then you can use XML indexes in a much simpler and
more intuitive manner if the brand names are element or attribute values rather than tag
names.
Table 2.2
Business Data as Tags Versus Values
Business data as element name
(not recommended):
<car>
<Honda>
<price>5000</price>
<year>1996</year>
</Honda>
</car>
Business data as element value
(recommended):
<car>
<brand>Honda</brand>
<price>5000</price>
<year>1996</year>
</car>
What happens if you use meta information, such as the terms “brand”, “price”, and “year”, as
values rather than element or attribute names? This is shown in the left side of Table 2.3 where the
XML document consists of very generic tag names, such as object, type, field, name, and
value. These tags are not very descriptive, which is contrary to the concept of XML as a selfdescribing data format. You see that the brand, price, and year of the car are represented by pairs,
which consist of a name and a value. However, the names are actually XML attribute values, not
descriptive tag names. This approach is commonly referred to as Name/Value Pairs (NVP), KeyValue Pairs (KVP), or Entity-Attribute-Value model (EAV).
Table 2.3
Name/Value Pairs (Metadata as Tags Versus Values)
Metadata as values, aka Name/Value Pairs (often bad): Metadata as element names (good):
<car>
<object type="car">
<brand>Honda</brand>
<field name="brand" value="Honda"/>
<price>5000</price>
<field name="price" value="5000"/>
<year>1996</year>
<field name="year" value="1996"/>
</car>
</object>
The Name/Value Pair approach to data modeling also sometimes appears in the relational world
when a table with three columns (id, name, and value) is used. This approach may seem attractive when dealing with entities that can have hundreds or thousands of attributes, but only a small
number of them apply to any individual entity. If you were to represent each possible attribute by
a column in a relational table, you might exceed the maximum row length or the maximum number of columns in a table. Nevertheless, the Name/Value Pairs approach has very significant and
inherent drawbacks, which are similar for XML and relational data. In particular:
2.2
XML Tags versus Values
21
• Defining business rules and constraints for Name/Value Pairs is very difficult and often
impossible. You cannot define an effective XML Schema to control and constrain this
type of XML data. If you use the “better” XML format shown in the right side of Table
2.3, an XML Schema can easily specify that the value of the price element has to be
greater than zero, and the value of the year element has to be a four-digit integer
between 1950 and 2099. In the Name/Value Pairs in the left column of Table 2.3, price
and year are represented by the same XML attribute called value. An XML Schema
does not allow you to specify that if there is an attribute called name with the value
price then the value of the attribute value in the same field element must be greater
than zero.
• Name/Value Pairs handle all data as strings (text). Since the attribute value can contain
arbitrary data values, it cannot be typed as INTEGER, DECIMAL, DATE, or TIMESTAMP.
Handling all data as strings leads to data quality issues because proper data types cannot
be enforced. Another consequence is that any indexes and comparisons have to treat the
data values as strings. If you search for cars with a price greater than “5000”, you will
also find cars with prices such as “600” or “900” because these strings are greater than
the string “5000”. You can solve this problem with appropriate cast operations in your
queries, but those usually preclude the use of indexes, which means performance suffers.
• Writing queries against Name/Value Pair data is very complex. As an example, assume
that you need to retrieve the years of all Honda cars that have a price greater than 5000.
The corresponding XPath expression for the Name/Value Pair data is shown in Figure
2.4, followed by the same query for the “regular” XML data in the right side of Table
2.3. The difference in complexity is striking, and it is even greater for more advanced
search queries.
-- XPath query to retrieve the years of all Honda cars with a
-- price greater than 5000 from Name/Value Pair XML data:
/object[@type="car" and
field[@name = "brand" and @value = "Honda"] and
field[@name = "price" and @value > "5000"]
]/field[@name="year"]/data(@value)
-- Same query for regular XML Data:
/car[brand="Honda" and price > 5000]/year
Figure 2.4
Complexity when querying Name/Value Pairs
22
2.3
Chapter 2
Designing XML Data and Applications
CHOOSING THE RIGHT DOCUMENT GRANULARITY
When you design your XML application, and in particular your XML document structure, you
may have a choice as to which business data is kept together in a single XML document. Is it better to keep a lot of data in a large XML document, or is it better to use many small documents
instead? The proper scope of any given document is a critical design decision. The general recommendation is to choose an XML document granularity such that one document represents one
logical business object from an application point of view. Another guideline is to use an XML
document granularity that matches the anticipated predominant granularity of data access or data
exchange. Very often the logical business objects match the predominant granularity of data
access, so these two guidelines lead to the same result.
What constitutes a small, medium, or large XML document? Very roughly, XML documents up
to 50KB are typically considered small, documents between 50KB and 1MB are often considered
medium, and documents of more than 1MB are considered large. Documents in the range of hundreds of Megabytes or a few Gigabytes are huge, relatively rare, and almost always the result of
combining a large number of smaller XML documents.
Let’s look at the example in Figure 2.5, which shows three design options to represent data for
several orders. Each order has a date, a customer name, and several parts, which have a
key, a quantity, and a price. Let’s assume that you have to store and manage these orders for
a particular application that treats each individual order as a separate logical business object. It
typically receives and processes one order at a time, and a single order is the predominant level of
access or transmission.
In case (a) on the left, multiple orders are combined in one large document (coarse granularity).
This approach can be useful when you need to archive or FTP a certain batch of orders, such as all
orders for the past week, for example. Storing this large document as-is in a database is only a
good idea if this batch in its entirety represents a meaningful business object to your application
and users. This is not the case in our example. Since our fictitious application typically reads and
writes one order at a time, storing many orders in a single large document would result in suboptimal performance. In general, combining many independent business objects in a single document is not recommended. DB2 uses indexes over XML data to filter on a per-document level.
Therefore, the finer the XML document granularity, the higher the potential benefit from indexbased access. Although DB2 pureXML helps you avoid a lot of XML parsing in the application
layer, some applications might still use a DOM parser to ingest XML documents and run into performance problems or failures if the documents are too large. Many XML design and editing
tools also use DOM parsers and are often unable to handle very large XML documents. Therefore, debugging and correcting XML documents is much easier if they are small.
In case (b), each order is a separate XML documents (medium granularity). This approach
matches the nature of the application and not only provides good performance but is also very
2.3
Choosing the Right Document Granularity
23
intuitive for the application developer. One row in the database contains one business object for
the application and no joins are required to retrieve all data for this object.
Case (c) on the right represents fine granularity. Each order and each part is stored as a separate
XML document. This approach can be a very good choice if each part information in itself is a
separate business object of interest and often accessed and processed independently from the
order it belongs to. In this example, however, part information has no real business meaning on its
own and is dependent on an order. For example, the quantity and the price of a part are relevant
only for a specific order. A different order can contain the same part with a different price and
quantity. Typically, an application always needs to see all parts of an order and would never
retrieve a part by itself without order information. Another reason why case (c) might not be useful is that having part and order information in separate documents would require joins between
them. These reasons make case (b) desirable because the XML documents already represent this
join in their structure.
(a)
<allorders>
<order date='2004-11-05'>
<customer>Doe</customer>
<part key='82' >
<quantity>5</quantity>
<price>5.00</price>
</part>
<part key='83' >
<quantity>11</quantity>
<price>19.95</price>
</part>
</order>
<order date=‘2004-11-06'>
<customer>Doe</customer>
<part key='19'>
<quantity>23</quantity>
<price>1.99</price>
</part>
<part key='83'>
<quantity>1</quantity>
<price>24.95</price>
</part>
</order>
</allorders>
(b)
<order date='2004-11-05'>
<customer>Doe</customer>
<part key='82' >
<quantity>5</quantity>
<price>5.00</price>
</part>
<part key='83' >
<quantity>11</quantity>
<price>19.95</price>
</part>
</order>
<order date='2004-11-06'>
<customer>Doe</customer>
<part key='19' >
<quantity>23</quantity>
<price>1.99</price>
</part>
<part key='83' >
<quantity>1</quantity>
<price>24.95</price>
</part>
</order>
(c)
<order date='2004-11-05'>
<customer>Doe</customer>
<part key='82'/>
<part key='83'/>
</order>
<order date=‘2004-11-06'>
<customer>Doe</customer>
<part key='19'/>
<part key='83'/>
</order>
<part key='82' >
<quantity>5</quantity>
<price>5.00</price>
</part>
<part key='83' >
<quantity>11</quantity>
<price>19.95</price>
</part>
<part key='19'>
<quantity>23</quantity>
<price>1.99</price>
</part>
<part key='83'>
<quantity>1</quantity>
<price>24.95</price>
</part>
Figure 2.5
Different document granularities
24
Chapter 2
Designing XML Data and Applications
In a nutshell, choose the XML document granularity with respect to the logical business objects
and the anticipated predominant granularity of access. When in doubt, it is usually better to lean
towards finer granularity and smaller XML documents.
2.4
USING A HYBRID XML/RELATIONAL APPROACH
XML is not the grand solution for all data management problems. As discussed in Chapter 1,
Introduction, XML can provide significant advantages if the structure of your data is highly variable, evolves over time, or is hard to represent in a simple relational schema. Also, if you receive
and send business objects in XML format, you can often improve performance and simplify
applications if you also store these objects in XML format. Storing XML objects in XML format
avoids complex mappings and costly transformations.
However, sometimes the best solution is to store some of your data in relational format and some
of your data in XML format, which is called hybrid storage. There are no definitive rules that
describe precisely how to determine the right mix of XML and relational data. The right mix
depends on the specific characteristics and requirements of a given application, or set of applications, that access the data. The following considerations can help you find the right design for
your application.
It is quite common that business objects such as orders, trades, sales records, customer records,
emails, and blog posts consist of a fixed header plus a highly variable body. The header contains
certain data fields that are common for all business objects of the same category. The body can be
very different from one business object to the next and can contain any of thousands of optional
attributes.
For example, a financial trade might contain a header with the trade ID, the trading date, and the
IDs of the two parties involved in the trade. Although these data items are present for every trade,
the elements in the body of the trade depend highly on the exact nature of this particular trade. In
this case, you might want to store the header fields in relational columns and the body in an XML
column of the same table.
Similarly, think of XML documents such as emails, blog posts, or CRM (customer relationship
management) records produced in a call center. CRM records often contain the customer name
and identifier, the date when the customer called in to report a problem, the name or ID of the
product or service that the customer needs help with, and most likely a unique identifier of the
CRM record itself. This data is very regular and structured with well-defined data types and can
easily be stored in relational columns. However, the body of a CRM record typically contains
semi-structured information with free text as well as interspersed data fields such as dates and a
user ID to track when and by whom new information gets appended. This semi-structured part of
the CRM record is better stored as a whole in an XML column.
2.5
Summary
25
If a business object arrives as an XML document, DB2 can extract selected element or attribute
values from the document as part of the INSERT statement, without any extra XML parsing. This
process is explained in more detail in Chapter 11, Converting XML to Relational Data.
The benefits of storing some data fields of a business object in relational format can include the
following:
• You can define primary key and foreign key constraints on relational columns, but not
on any elements or attributes in an XML column.
• You can define multi-column (composite key) indexes on two or more relational
columns, but you cannot define a composite key on two or more elements or attributes in
an XML column.
• Relational columns can be used to define range partitioning, hash partitioning, or multidimensional clustering for a table. These cannot be defined based on elements or attributes in an XML column.
• Queries can use regular relational SQL predicates for relational columns, which some
people find easier to use than XML predicates.
• If you use WebSphere Replication Server to replicate rows to another database server,
you can define filtering conditions on relational columns of the source so that rows are
selectively replicated only if they meet the specified condition. Such replication filters
cannot be specified on XML columns.
• Relational column values can be referenced in the definition of generated columns and
materialized views, but XML columns and individual XML elements and attributes
cannot.
2.5
SUMMARY
Designing an XML application begins with designing the XML data. The more appropriately you
design your XML data for your business needs and application, the easier it will be to process and
manage this XML data efficiently. Both your applications and your database will run best if the
scope and granularity of your XML documents match the logical business objects of your application as well as the most frequent granularity of data access or data exchange. Try to favor
smaller documents rather than larger documents. For the low-level design of your XML documents, keep in mind that XML elements are more flexible than attributes because they can be
repeated and nested. You often want to favor XML elements over attributes to ensure future
extensibility of your XML data. Also, make sure that meta information that describes your data is
represented by XML element and attribute names, not by values. Conversely, the actual data
items that your applications need to read and manipulate should be XML element and attribute
values, not XML tags. Remember the analogy to the columns in relational tables, where column
names represent metadata while the column content is your business data.
26
Chapter 2
Designing XML Data and Applications
Often you do not have the luxury to design your XML document format. Many XML applications are forced to consume and process XML documents in a format that has previously been
designed by other parties and cannot be changed. You can still choose to let DB2 split those documents into smaller fragments if that better matches the predominant granularity of access. Additionally, it can be advantageous to extract a few selected elements or attribute values from each
document into relational columns. Chapter 5, Moving XML Data and Chapter 11, Converting
XML to Relational Data explain DB2’s capabilities for splitting XML documents and hybrid
XML/relational storage.
C
H A P T E R
3
Designing and
Managing XML
Storage Objects
n this chapter we discuss how to create and configure a database, table spaces, and tables to
manage XML data. This discussion includes topics such as hierarchical XML storage
structures, XML compression and inlining, monitoring and measuring XML storage consumption, reorganization, and partitioning of tables and databases that contain XML data. The topics
in this chapter are organized as follows:
I
• Understanding XML document trees and their pureXML storage representation. These
concepts are platform independent (sections 3.1 and 3.2)
• Managing XML storage in DB2 for Linux, UNIX, and Windows (sections 3.3 through
3.10)
• Managing XML storage in DB2 for z/OS (sections 3.11 and 3.12)
• XML parsing and XML memory options specific to DB2 for z/OS (section 3.13)
When you create a database that will contain XML data, one of the first design choices is to
choose a code page. The recommended code page is UTF-8 Unicode. The benefits of Unicode are
explained in Chapter 20, Understanding XML Data Encoding.
It is also possible to manage XML in a non-Unicode database, which allows you to easily add
XML to existing databases that do not use UTF-8. DB2 9 for z/OS allows XML columns in databases and table spaces of any supported encoding. In DB2 9.5 and 9.7 for Linux, UNIX, and Windows, all new databases use UTF-8 as the default code page. However, you can specify a
non-Unicode code page in the CREATE DATABASE statement, if you want.
27
28
Chapter 3
Designing and Managing XML Storage Objects
DB2 9.1 for Linux, UNIX, and Windows is slightly more restrictive because pureXML is available only in UTF-8 encoded databases, and you must explicitly set the database code page to
UTF-8 in the USING CODESET clause of the CREATE DATABASE statement:
CREATE DATABASE mydb USING CODESET utf-8 TERRITORY us
Before we discuss how XML documents are physically stored in a DB2 database, let’s look at
how the XQuery Data Model defines XML document trees.
3.1
UNDERSTANDING XML DOCUMENT TREES
Since XML is a hierarchical data model, every XML document can be represented as a tree of
nodes. Any query or update of XML data traverses the hierarchical structure of the XML documents. This traversal can be done most efficiently if the XML documents are physically stored in
a hierarchical format. Therefore, DB2 for z/OS and DB2 for Linux, UNIX, and Windows store
XML documents as trees of nodes with parent-child relationships between the nodes. These trees
are defined by the XQuery Data Model (XDM) and described in this section. Further details of
the XQuery Data Model are covered in Chapter 6, Querying XML Data: Introduction and XPath.
Let’s look at the XML document in Figure 3.1 as an example. It is a simple document that contains information about a customer. The outermost element, customerinfo, is called the root
element. Its children are the elements name and addr as well as two occurrences of the element
phone. The element addr has an attribute country as well as four child elements: street,
city, state, and zip. Each phone element has an attribute called type.
<customerinfo>
<name>Jim Noodle</name>
<addr country="US">
<street>555 Bailey Ave</street>
<city>San Jose</city>
<state>CA</state>
<zip>95141</zip>
</addr>
<phone type="work">408-289-4136</phone>
<phone type="cell">408-710-7910</phone>
</customerinfo>
Figure 3.1
Sample XML document
Figure 3.2 shows the same XML document in its tree representation. Such a tree can be constructed by parsing a textual XML document with an XML parser. In general, an XML document
tree can have six different types of nodes. Element nodes, attribute nodes, text nodes, and the document node are the most common node kinds. They occur in the tree in Figure 3.2. Occasionally,
XML documents can also contain comment nodes and processing instruction nodes.
3.1
Understanding XML Document Trees
29
Every XML element of the document in Figure 3.1 is represented by an element node in the corresponding document tree in Figure 3.2.
The element nodes are white and rectangular. The textual value of each element is represented by
a separate text node, shown in gray. Attribute nodes are shown with a double border. An attribute
node contains all information about an attribute, including its value.
The XQuery Data Model also defines that each document tree has a document node, shown in
Figure 3.2 as a black circle. It is the topmost node and the parent of the root element. The document node is not visible in the textual representation of an XML document, only in its parsed
hierarchical format. You will see later in this book that the document node is sometimes important when you manipulate XML documents. For example, assume you cut off the addr branch
from the tree in Figure 3.2. This branch by itself does not have a document node and is therefore
not a valid document tree. Hence, inserting it as a document into an XML column would fail
unless you construct a new document node. Construction of a document node is shown in Chapter 5 (see section 5.7, Splitting Large XML Documents into Smaller Documents).
customerinfo
name
Jim Noodle
addr
country=US
street
555 Bailey Ave
Figure 3.2
city
San Jose
phone
state
CA
zip
type=work
408-289-4136
phone
type=cell
408-710-7910
95141
XML document tree
You might wonder why element values reside in separate text nodes while attribute values do not.
The main reason is that the child nodes of an element can be a mix of text nodes and other element nodes, which is known as mixed content. An attribute, however, has exactly one value and
never any child nodes, which makes attributes less extensible than elements. An element can have
multiple text node children but they cannot be adjacent siblings to each other.
As an example of mixed content and multiple text node children, consider the following two
XML documents, both of which contain a title element. In the first case the title has a single
text value and the corresponding tree representation is shown in Figure 3.3(a). The title element in the second document contains some text, “The ” and “ Cookbook” (note the spaces!), as
well as a child element bold.
30
Chapter 3
Designing and Managing XML Storage Objects
Figure 3.3(b) shows that this results in a mixed set of child nodes under the title element: two
text nodes and one child element (bold). The two text nodes “The ” and “ Cookbook” are separated by the element bold and are not adjacent children. If they were adjacent they would automatically collapse into a single text node.
(a)
(b)
<title>The DB2 pureXML Cookbook</title>
<title>The <bold>DB2 pureXML</bold> Cookbook</title>
title
title
The
bold
Cookbook
The DB2 pureXML Cookbook
DB2 pureXML
(a)
Figure 3.3
(b)
An example of mixed content
Note the XQuery Data Model defines the value of an XML element as the concatenation of all
text nodes in the subtree under that element. This concatenation is trivial for elements that have
only one text node. The value of the element state in Figure 3.2 is “CA”, and the value of
title in Figure 3.3(a) is “The DB2 pureXML Cookbook”. At the same time, the value of the
title element in Figure 3.3(b) is also “The DB2 pureXML Cookbook”, and the value of the element bold is “DB2 pureXML”. Similarly, the value of the addr element in Figure 3.2 is “555
Bailey AveSan JoseCA95141” (note that there is no space between Ave and San and also no
space between Jose and CA and 95141). The addr element is called a non-leaf element, and this
example shows that values of non-leaf elements are often not useful.
3.2
UNDERSTANDING PUREXML STORAGE
The document tree in Figure 3.2 illustrates the hierarchical format in which XML documents are
stored in DB2 (all platforms). When an XML document in its textual format is inserted or loaded
into an XML column, the DB2 server parses the XML document to produce the parsed hierarchical format that is stored on pages in a table space. This process is reversed when an application
retrieves an XML document from DB2. This reverse process is called serialization; that is, the
document tree is converted back into the text format of the XML document. You can think of
parsing and serialization as inverse operations.
3.2
Understanding pureXML Storage
31
The exact shape of a document tree in DB2’s storage layer depends on and can vary with each
individual instance document. It is not pre-defined based on an XML Schema, which allows DB2
to store documents with widely varying or evolving structures in the same XML column.
DB2 performs a variety of optimization when storing document trees on pages. For example, element and attribute names (also called tag names) are transparently replaced by unique 4-byte
integer numbers. Thus, DB2’s internal tree format looks actually more like Figure 3.4 than Figure
3.2. In addition to the integer number, each node can also contain other properties, such as information about namespaces and data types.
100
101
Jim Noodle
102
103=US
104
555 Bailey Ave
Figure 3.4
109
San Jose
116
106
CA
113
110=work
408-289-4136
116
110=cell
408-710-7910
95141
XML document tree with tag names replaced by integer values
The mapping from tag names to the so-called stringIDs is kept in the catalog table sysibm.
sysxmlstrings (see Figure 3.5). This mapping is database-wide, where each distinct tag name
and each distinct namespace URI has exactly one entry. For example, the phone element occurs
twice in the sample document and may occur millions of times across all the XML documents in
a database. Each occurrence is replaced with the same unique stringID, which is 116 in this
example. Hence, the phone element has only one entry in the mapping table. Consequently, the
mapping table is never larger than the number of distinct tag names in the database, which is typically a small number (several hundred to several thousand).
32
Chapter 3
Designing and Managing XML Storage Objects
STRING
STRINGID
IS_TEMPORARY
customerinfo
100
N
name
101
N
addr
102
N
country
103
N
street
104
N
city
109
N
state
106
N
zip
113
N
phone
116
N
type
110
N
…
…
…
Figure 3.5
Mapping tag names to integers in sysibm.sysxmlstrings
When a document is inserted and parsed, DB2 checks every tag name to see whether it is already
recorded in this mapping table. If it is not, a new entry is added to the mapping table. Otherwise
the existing stringID for the tag is used. Hence, inserts into the mapping table are very rare and
occur only for new elements that DB2 has never seen before in a given database. For example, if
you insert a million documents of similar structure, there is a good chance that only the first
document, or the first few documents, actually cause inserts into the sysibm.sysxmlstrings
catalog table.
Most of the time the mapping table is active as a lookup table and DB2 has a special purpose
mechanism and cache to ensure high lookup performance. DB2’s use of the mapping table leads
to significant performance benefits. First of all, it reduces the space that is required to represent
XML on pages in table spaces or buffer pools. Second, any query evaluation and traversal of
XML documents now operate on integers, not on strings, which is much faster.
Since the sysibm.sysxmlstrings table never grows very large, DB2 never deletes or updates
any entries in this table. This avoids lock contention on this table and enables high performance.
Even REORG or LOAD REPLACE of a user table does not reset the mapping table. Remember that
the mapping table contains entries for XML documents in the entire database, and not just for
XML documents in a single table. Excessive growth of the mapping table is not a concern,
because XML applications do not use an unbounded number of distinct tag names.
3.3
XML Storage in DB2 for Linux, UNIX, and Windows
33
The mapping table is really only for DB2’s internal operation and you cannot modify it. You can
however, read this table if you want to get a list of all tag names that ever existed in the database
(Figure 3.6). Since version 9.5, DB2 for Linux, UNIX, and Windows stores the tags in a binary
format to avoid code page problems in non-Unicode databases. Therefore you need to use the
function xmlbit2char to make the strings human-readable.
-- DB2 for z/OS and DB2 9 for Linux, UNIX, Windows:
SELECT *
FROM sysibm.sysxmlstrings;
-- DB2 for Linux, UNIX, and Windows, Version 9.5 and higher:
SELECT stringid, substr(sysibm.xmlbit2char(string),1,50),
is_temporary
FROM sysibm.sysxmlstrings;
Figure 3.6
Reading XML tag names from sysibm.sysxmlstrings
The column IS_TEMPORARY in sysibm.sysxmlstrings only exists in DB2 for Linux, UNIX,
and Windows. It indicates whether a tag name belongs to a document that is stored in an XML
column (IS_TEMPORARY = 'N') or to an element or attribute that has been newly constructed as
part of a query (IS_TEMPORARY = 'Y'). For example, a query that creates and returns a new element name that has never been seen in the database before also causes a new entry in the string
table. However this happens only upon its very first execution, after which the new tag is registered and known. You cannot delete or update entries in this catalog table.
3.3
XML STORAGE IN DB2 FOR LINUX, UNIX, AND WINDOWS
This and the following sections describe storage objects, such as tables and table spaces, for
XML data in DB2 for Linux, UNIX, and Windows. DB2 for z/OS uses similar but slightly different concepts, which are discussed in sections 3.11 through 3.12.
3.3.1
Storage Objects for XML Data
Whenever you define a table, DB2 creates one or multiple storage objects in a table space. For
example, a relational table structure is stored in a DAT (data) object. Any kind of index is stored as
an INX object. If your table contains a LOB column, DB2 creates a separate LOB object. And, if
your table contains one or multiple XML columns, there is an XDA (XML data area) object. For
SMS (system-managed space) table spaces, these objects appear as separate files in the file system. For DMS (database-managed space) table spaces, which are the default and recommended,
these objects are not visible but nevertheless exist in the DMS containers.
34
Chapter 3
Designing and Managing XML Storage Objects
WHAT IS A TABLE SPACE?
A table space is a storage structure that can contain relational
tables and indexes as well as large objects (LOBs) and XML
data. Table spaces enable you to specify where your data is
physically stored. They also allow you to assign different types
of data to different buffer pools in main memory, or to back up
and restore specific parts of your database.
Let’s look at this CREATE TABLE command as an example (note that no XML Schema is required
to define a table with a column of type XML. DB2’s XML storage is independent of any particular
XML Schema):
CREATE TABLE customer (id INTEGER, info XML)
The storage objects that DB2 creates and maintains for this table are illustrated in Figure 3.7. The
table with two columns is maintained in a DAT object. The XML column in this table does not
contain the actual XML documents that are inserted, but just logical pointers to them. The reason
is that XML documents can easily be too big to fit into a relational row on a single page. This
approach is similar to the storage of large objects (LOBs) in DB2. The main difference between
XML and LOBs is that XML is buffered in the buffer pool whereas LOBs are not.
By default, XML documents are stored in the XDA object. If a table has multiple XML columns,
all of them share the same XDA object. Whenever a document tree does not fit on a single page,
DB2 automatically and transparently breaks the tree into multiple subtrees, which are called
regions. Each region is then stored on a separate XDA page so a single document can span many
pages. Documents that fit on a single page consist of a single region. If documents are much
smaller than the page size, multiple regions (documents) can be stored on a single page so that no
space is wasted. DB2 allows you to store XML documents up to 2GB in size, which is large
enough for just about every application.
One regions index is created automatically by DB2 for each table that contains one or more XML
columns. In the catalog view syscat.indexes, every regions index is identified by the value
XRGN in the column INDEXTYPE. It is not a user-defined index and you cannot drop it. The regions
index contains one entry for each region of a document. If a document consists of multiple regions,
then these regions are represented by consecutive regions index entries. An XML document
pointer in the XML column in the DAT object points to a regions index entry that in turn points to
the “first” region of the corresponding document. This is the region that contains the root node of
the document. A short range scan on the regions index then provides pointers to the remaining
regions of the document. If a node A in a region has a child node B that is the topmost node of
3.3
XML Storage in DB2 for Linux, UNIX, and Windows
35
another region, node A contains information that points back into the regions index (not shown in
Figure 3.7). It points to the regions index entry that leads to the region with node B.
Also not shown in Figure 3.7 is that DB2 maintains a path index for every XML column. It contains one entry per unique path in the XML data and is therefore very small. More details on the
path index can be found in Chapter 13, Defining and Using XML Indexes.
Table Space
ID (INT)
1001
1000
1003
1005
INFO (XML)
Regions
Index
pages
INX Object
page
DAT Object
page
page
page
page
page
page
page
page
page
page
page
page
XDA Object
Figure 3.7
Storage objects involved with an XML column
Storing large documents as regions across pages has several advantages. First and foremost,
DB2’s proven infrastructure for managing pages works for XML data just like for relational data.
This includes table spaces, buffer pools, page cleaning, backup and restore, recovery, HADR, and
so on. If a document is large and spans many XDA pages and a query touches only part of the document, DB2 does not necessarily need to bring all pages of the document into the buffer pool.
DB2 always strives to split a document into the smallest possible number of regions. The regions
for one document are in most cases stored on physically consecutive pages. The way XML documents are broken into regions is completely transparent to the application and to the DBA. You
should never attempt to design XML documents with the goal of optimizing any aspect of how
DB2 stores the documents. You should model your XML data at the logical level to reflect your
business data and focus on the characteristics and requirements of your application, not on how
DB2 processes XML. Most applications are best served with large numbers of small documents,
where each XML document represents a separate business object.
36
3.3.2
Chapter 3
Designing and Managing XML Storage Objects
Defining Columns,Tables, and Table Spaces for XML Data
In DB2 for Linux, UNIX, and Windows, database-managed table spaces (DMS) provide higher
performance than system-managed table spaces (SMS) for relational data, and even more so for
XML read and write access. Since DB2 9, newly created table spaces are DMS by default. It is
also recommended to use DMS table spaces with automatic storage so that they grow as needed
without manual intervention.
A key aspect of physical database design is the page size of a table space. Measurements have
shown that the lower the number of regions (splits) per XML document the better the performance, especially for XML insert and full-document retrieval. If a document does not fit on a single
page, the number of splits per document depends on the page size (4KB, 8KB, 16KB, or 32KB).
The larger the page size of the table space the lower the number of regions per document. For
example, let’s say a given document gets split into forty regions across forty 4KB pages. Then it
might be possible to store the same document on only twenty 8KB pages, or ten 16KB, or five
32KB pages. If the XML documents are significantly smaller than the selected page size, no
space is wasted because multiple small documents can be stored on a single page. The impact of
the page size on the number of regions per document is illustrated in Figure 3.8. Since each
region requires one regions index entry, a larger page size that allows for fewer regions per document also leads to a smaller regions index.
4K Pages
8K Pages
….
32k Pages
Figure 3.8
The number of regions per document depends on the page size
3.3
XML Storage in DB2 for Linux, UNIX, and Windows
NOTE
37
Most XML applications perform best using 16KB or 32KB
pages.
16KB pages can provide good performance if most documents are quite small (for example, less
than 4KB) so that several documents fit on a page. Larger documents are better served by 32KB
pages. If you prefer to use a single page size for XML and relational data, or for data and indexes,
and you find that 32KB pages are too large for efficient access to relational data or indexes, then
16KB pages can be a good compromise.
Let’s look at some examples. Figure 3.9 shows how to define two table spaces, one with 4KB
pages and one with 32KB pages. These table spaces are used in the subsequent CREATE TABLE
statements and figures.
CREATE BUFFERPOOL bpsmall PAGESIZE 4k ;
CREATE BUFFERPOOL bplarge PAGESIZE 32k ;
CREATE TABLESPACE tbspace4k
PAGESIZE 4K
MANAGED BY AUTOMATIC STORAGE
BUFFERPOOL bpsmall ;
CREATE TABLESPACE tbspace32k
PAGESIZE 32K
MANAGED BY AUTOMATIC STORAGE
BUFFERPOOL bplarge ;
Figure 3.9
Creating table spaces with different page sizes
The CREATE TABLE statement shown in Figure 3.10 defines a table with an integer column and
an XML column using the table space with 32KB pages. It places XML data and relational data
into the same table space (see Figure 3.7). Consequently, they use the same page size and are
buffered in the same buffer pool. This default layout provides good performance for most
applications.
CREATE TABLE customer(id INTEGER, info XML)
IN tbspace32k;
Figure 3.10
Creating a table with an XML column in a named table space
If you have done a performance analysis and find that you need a large page size for XML data
but a small page size for relational data or indexes, you can use separate table spaces to achieve
this. When you define a table, you can direct “long” data (LOB and XML data) into a separate
table space with a different page size. The corresponding table definition and storage objects are
shown in Figure 3.11 and Figure 3.12, respectively. In this example, relational data is stored in a
38
Chapter 3
Designing and Managing XML Storage Objects
table space tbspace4k with page size 4KB and XML data is stored in a table space
tbspace32k with page size 32KB. If the table also contained a LOB column, the LOB data would
be stored in a separate LOB object in the table space tbspace32k. Pages of the LOB object are not
buffered in the buffer pool, whereas pages of the DAT, XDA, and INX objects are buffered.
CREATE TABLE customer(id INTEGER, info XML)
IN tbspace4k
LONG IN tbspace32k;
Figure 3.11
Storing XML and LOBs in a separate table space
tbspace4k
ID (INT)
1001
1000
1003
1005
INFO (XML)
Regions
Index
pages
INX Object
page
DAT Object
tbspace32k
page
page
page
page
page
page
page
page
page
page
page
page
XDA Object
Figure 3.12
Storage objects in a separate table spaces
If you had another table space named tbspace4kINX you could also direct the regions index as
well as any user-defined indexes into their own table space. This layout is shown in Figure 3.13
and Figure 3.14.
3.3
XML Storage in DB2 for Linux, UNIX, and Windows
39
CREATE TABLE customer(id INTEGER, info XML)
IN tbspace4k
INDEX IN tbspace4kINX
LONG IN tbspace32k;
Figure 3.13
Defining separate storage for indexes and XML data
tbspace4k
ID (INT)
1001
1000
1003
1005
tbspace4kINX
INFO (XML)
Regions
Index
pages
INX Object
page
DAT Object
tbspace32k
page
page
page
page
page
page
page
page
page
page
page
page
XDA Object
Figure 3.14
Separate table spaces for relational data, XML, and indexes
In general, the fewer distinct page sizes and buffer pools you create the easier it is to tune and
maintain your database. Therefore we recommend that you use different page sizes for XML and
relational data only if you have evidence that it improves the performance of your workload and
if you need this performance gain to meet the performance requirements of your application.
Otherwise there is benefit in keeping it simple. Dedicated measurements in a prototype and test
workload can help you make such decisions. Since DB2 9, new table spaces are by default large
table spaces, in which the number of rows per page is no longer limited to 255. Hence, you don’t
need to choose a small page size for relational data to ensure that pages are filled up and space
isn’t wasted.
40
3.3.3
Chapter 3
Designing and Managing XML Storage Objects
Dropping XML Columns
In DB2 9.1 and DB2 9.5 for Linux, UNIX, and Windows you cannot drop XML columns from a
table. To remove an XML column, create a new table without the XML column and use a “load
from cursor” to move data from the old table to the new table. Then drop the old table and rename
the new table so that it assumes the name of the old table. Alternatively, you can export data from
a table and then recreate and reload the table.
DB2 9.7 for Linux, UNIX, and Windows allows you to drop XML columns from a table with the
ALTER TABLE statement. If a table contains multiple XML columns you can only drop all XML
columns at the same time.
3.3.4
Improved XML Storage Format in DB2 9.7
DB2 9.7 uses a more optimized tree format for XML storage than prior releases. This improved
format is completely transparent to all database operations such as queries, inserts, updates,
indexing, and schema validation. The improved XML format is used only in tables that are created in DB2 9.7 or higher. When you migrate a table with XML data from DB2 9 or 9.5 to DB2
9.7, this XML data remains in its previous format and is not changed. Documents that you newly
insert or update in such a migrated table continue to be in the format of the previous DB2 release.
The previous and the improved storage format are not mixed within the XDA object of a table.
The new storage format has the following benefits:
• It is more compact and can reduce the space consumption of your XML data.
• It allows compression of XML data in the XDA object (see section 3.5).
• It allows you to use the function ADMIN_EST_INLINE_LENGTH to estimate the inline
length that would allow an XML document to be inlined (see section 3.4).
• It enables faster redistribution of XML data in a partitioned database; that is, you can
use the NOT ROLLFORWARD RECOVERABLE option in the REDISTRIBUTE command to
redistribute data in bulk and avoid logging.
If you have migrated a table with XML data from DB2 9 or 9.5 to DB2 9.7 and want to bring the
XML data into the new format, you need to create a new table and copy the data from the old to
the new table. You can use “load from cursor” for moving data from one table to another efficiently. Then you can drop the old table and rename the new table to the old table name.
Starting with DB2 9.7, copying and renaming a table can be done more elegantly and with minimal downtime by using the procedure SYSPROC.ADMIN_MOVE_TABLE. This procedure performs
an online table move, which means that table data is copied to a table object with the same name,
but not necessarily the same columns and storage characteristics. When the copying is complete,
the source table is briefly taken offline and its name is assigned to the new copy of the table. All
indexes of the table are also copied. During the copy phase, any updates, inserts, or deletes on the
3.4
Using XML Base Table Row Storage (Inlining)
41
source table are collected in a staging table and finally applied to the new table. An online table
move with XML data requires that the table has at least one unique index and does not participate
in foreign key constraints.
3.4
USING XML BASE TABLE ROW STORAGE (INLINING)
From DB2 9.5 for Linux, UNIX, and Windows onwards, XML documents that are small enough
to fit on a single page can be stored on the same page as the relational row that they belong to.
This capability is called base table row storage, or inlining. It means that the tree structure of an
XML document is no longer stored on a separate XDA page, but next to the relational data inside
the DAT object in the table space (Figure 3.16). XML inlining is currently not available in DB2
for z/OS.
Inlining needs to be explicitly enabled as a column option because it may or may not provide performance benefits. Before we discuss the performance trade-offs, Figure 3.15 shows how to create a table with inlined XML storage. You can add a column option INLINE LENGTH to the
definition of an XML column. In this example, any XML document that can be stored within
30,000 bytes is inlined. Documents that require more than 30,000 bytes are stored in the regular
way (on separate XDA pages). The inlining of some or all documents is handled by the DB2
engine and completely transparent to the application. DB2’s decision about whether a given document is within the inline length is based on the size of the document in DB2’s internal tree format, after XML parsing. The decision is not based on the length of the textual (serialized)
representation of the XML document. Inlined documents can be compressed, but the inlining
decision is based on their space requirement prior to compression.
CREATE TABLE customer(id INTEGER, info XML INLINE LENGTH 30000)
IN tbspace32k;
Figure 3.15
Table definition with inlined XML storage
The maximum allowed value for the inline length depends on the page size of the table space. As
a rule of thumb, the inline length has to be less than the page size minus the total length of the
other columns in the table and the overhead for the page header, and so on. For example, the maximum possible inline length in the example in Figure 3.15, where the table also contains an integer column and uses 32KB pages, is 32667 bytes.
If an XML document is updated it might become larger or smaller as a result of the update, which
affects inlining. The update may cause a previously inlined document to be moved from the DAT
object to the XDA object, or vice versa.
Figure 3.16 illustrates the storage objects in the table space when XML inlining is used. Three of
the four documents meet the inline length and are now stored as part of the relational rows on
pages in the DAT object. They do not have regions index entries. The document that belongs to the
42
Chapter 3
Designing and Managing XML Storage Objects
second row (id = 1000) is too large to be inlined. It is stored in the XDA object and spans three
pages, which are linked from the row in the DAT object via the regions index. Note that inlining
makes the DAT object larger, with larger and fewer rows per page. The XDA object has become
smaller and the regions index has fewer entries than without inlining.
Table Space: tbspace32k
ID (INT)
1001
INFO (XML)
Regions
Index
1000
page
pages
INX Object
1003
page
1005
page
page
page
page
page
page
page
DAT Object
XDA Object
Figure 3.16
Storage objects with XML inlining
The CREATE TABLE statement in Figure 3.17 creates the customer table in table space
tbspace4k, allows documents up to 3500 bytes to be inlined, and automatically directs larger
documents to the table space tbspace32k. In this case the inlining takes precedence over the
LONG IN clause. If a document is small enough to be inlined it will be part of the base table row
and stored on DAT pages in tbspace4k. Otherwise it is stored on XDA pages in tbspace32k.
CREATE TABLE customer(id INTEGER, info XML INLINE LENGTH 3500)
IN tbspace4k
LONG IN tbspace32k;
Figure 3.17
Another table definition with inlined XML storage
The inline length of an XML column can be changed with an ALTER TABLE statement, as shown
in Figure 3.18. This allows you to increase the inline length of an XML column, or to enable
inlining for an XML column that wasn’t previously defined with inlining.
3.4
Using XML Base Table Row Storage (Inlining)
43
ALTER TABLE customer
ALTER COLUMN info SET INLINE LENGTH 3600;
Figure 3.18
Changing the inline length of an XML column
The ALTER TABLE statement operation does not affect existing documents in the table, only documents that are inserted, loaded, or updated after the ALTER TABLE statement has been issued. If
you want existing documents to obey the newly set inline length, you need to update them with
themselves, as shown in Figure 3.19. Be aware that a bulk update of many XML documents can
require a lot of log space. You might have to perform a series of smaller updates and commit frequently to avoid running out of log space. After you use an UPDATE statement to move XML data
from the XDA object to the DAT object, you might want to reorganize the table to reclaim the
freed-up space in the XDA object (see section 3.7). However, reorganization by itself does not
move XML data from the XDA object to the DAT object.
UPDATE customer
SET info = info;
Figure 3.19
Updating existing documents to apply inlining
After you have specified an inline length for an XML column, you can only increase the inline
length, not reduce it. The only way to “undo” the inlining of XML documents is to copy the documents into a new table without inlining, drop the old table, and rename the new table to the old
table name. Starting with DB2 9.7 you can do this copying also with the procedure SYSPROC.
ADMIN_MOVE_TABLE.
3.4.1
Monitoring and Configuring XML Inlining
After you have set the inline length for an XML column, any newly inserted or updated document
is inlined if DB2’s internal tree representation of the document fits within the specified inline
length. The size of an XML document in DB2’s internal tree format depends on the actual document characteristics, such as the length of element names, the length of element values, the presence of namespaces, and other factors. In particular, the space required to store a document in an
XML column might be less than or greater than the size of the document in its textual representation. In DB2 9.5 and higher, the space requirement of most XML documents is between 70% and
150% of the space that they occupy in the file system. Therefore predicting whether a particular
document will or will not be inlined can be difficult. Similarly, choosing an inline length that
allows inlined storage of all or most documents can also be difficult.
To address this problem, DB2 9.7 for Linux, UNIX, and Windows introduced the scalar functions
ADMIN_IS_INLINED and ADMIN_EST_INLINE_LENGTH.
44
Chapter 3
Designing and Managing XML Storage Objects
The function ADMIN_IS_INLINED takes an XML column name as input, and returns
• 1 if the document in the current row of the XML column is inlined.
• 0 if the document in the current row of the XML column is not inlined.
• NULL if the XML column of the current row is NULL.
The query in Figure 3.20 shows how the function ADMIN_IS_INLINED can be used to examine a
table with inlining, like the one defined previously in Figure 3.17. The query reveals for every
document in the table whether or not it is inlined. The output indicates that the documents with
the relational id values 1000 and 1002 are inlined while the other documents are not inlined.
SELECT id, ADMIN_IS_INLINED(info) AS inlined
FROM customer;
ID
INLINED
---------------- ---------------1000
1
1001
0
1002
1
1003
0
1004
0
1005
0
6 record(s) selected.
Figure 3.20
Determining which documents are inlined
Since the query in Figure 3.20 can produce a lot of output when applied to a large table, you may
want to add a WHERE clause to retrieve the inlining status only for a subset of documents. Figure
3.21 uses the ADMIN_IS_INLINED function to compute the number of documents that are
inlined as well as the number of those that are not. The subselect in Figure 3.21 uses the clause
FETCH FIRST 1000 ROWS ONLY to obtain inlining information based on at most 1,000 documents. This can be useful if the input table is large and you want to use the first 1,000 documents
as a representative sample rather than scanning the entire table. Alternatively, you could use the
keywords TABLESAMPLE BERNOULLI(n) in the FROM clause of the subselect to sample n% of
all rows in the table.
3.4
Using XML Base Table Row Storage (Inlining)
45
SELECT COUNT(*) AS doc_count,
CASE WHEN inlined = 1 THEN 'Yes' ELSE 'No' END AS inlined
FROM (SELECT ADMIN_IS_INLINED(info) AS inlined
FROM customer
FETCH FIRST 1000 ROWS ONLY)
GROUP BY inlined;
DOC_COUNT
---------------2
4
INLINED
---------------Yes
No
2 record(s) selected.
Figure 3.21
Obtaining the number of inlined documents
The result in Figure 3.21 shows that only two out of six examined documents are inlined. This
raises the question of how much you would need to increase the inline length so that most or all of
the documents can be inlined. Similarly, you might have a table with an XML column for which
inlining is not yet enabled. You might wonder which inline length to use so that most or all of the
documents in that column get inlined. The function ADMIN_EST_INLINE_LENGTH is designed to
answer these questions.
The function ADMIN_EST_INLINE_LENGTH takes an XML column name as input, and returns
• The lowest inline length (in bytes) that would allow the XML document in the current
row to be inlined. This is an estimated value.
• –1 , if the document in the current row of the XML column is too large to be inlined for
the given page size.
• –2 , if the required inline length cannot be estimated for the document in the current row.
This is the case for any documents that have been inserted and stored prior to DB2 9.7
because DB2 9.7 uses a more optimized XML storage format (see section 3.3.4).
• NULL, if the XML column of the current row is NULL.
Figure 3.22 shows sample output of the function ADMIN_EST_INLINE_LENGTH. The values
returned depend on the actual XML data in the table. In this example, the output shows that the
first document (relational id = 1000) is already inlined and its actual size in DB2’s internal format is 770 bytes. The second document (id = 1001) is not inlined, but it can be inlined if the
inline length is increased to 2345 or larger. The document with id = 1005 cannot be inlined
because it is too large to fit on a single page together with the other columns in the table.
46
Chapter 3
Designing and Managing XML Storage Objects
SELECT id, ADMIN_IS_INLINED(info) AS inlined,
ADMIN_EST_INLINE_LENGTH(info) AS inline_length
FROM customer;
ID
INLINED
INLINE_LENGTH
---------------- ---------------- --------------1000
1
770
1001
0
2345
1002
1
796
1003
0
1489
1004
0
1910
1005
0
-1
6 record(s) selected.
Figure 3.22
Examining the required inlined length for specific XML documents
For a proposed inline length, such as 1500 bytes, the query in Figure 3.23 tells you how many
documents in the column would be inlined if this inline length was used.
SELECT COUNT(*) AS doc_count
FROM customer
WHERE ADMIN_EST_INLINE_LENGTH(info) BETWEEN 0 AND 1500;
DOC_COUNT
---------------3
1 record(s) selected.
Figure 3.23
Estimating the effectiveness of a proposed inline length
Figure 3.24 gives an example of a more comprehensive report on the distribution of document
sizes in a table. It shows that two documents require no more than 1000 bytes each, four documents can be stored in at most 2000 bytes each, five fit into 3000 bytes each, no potentially “inlinable” document is larger than 3000 bytes, and one document is too big to be inlined.
3.4
Using XML Base Table Row Storage (Inlining)
SELECT SUM(a) AS "<= 1000", SUM(b) AS "<= 2000",
SUM(c) AS "<= 3000", SUM(d) AS "> 3000",
SUM(e) AS "too big"
FROM(
SELECT CASE WHEN len > 0 AND len <= 1000 THEN 1 END
CASE WHEN len > 0 AND len <= 2000 THEN 1 END
CASE WHEN len > 0 AND len <= 3000 THEN 1 END
CASE WHEN len > 3000
THEN 1 END
CASE WHEN len = -1
THEN 1 END
FROM (
SELECT ADMIN_EST_INLINE_LENGTH(info) AS len
FROM customer) );
47
AS
AS
AS
AS
AS
a
b
c
d
e
,
,
,
,
<= 1000
<= 2000
<= 3000
> 3000
too big
----------- ----------- ----------- ----------- ----------2
4
5
0
1
1 record(s) selected.
Figure 3.24
Analyzing the distribution of document sizes
In Figure 3.24, if you replace ADMIN_EST_INLINE_LENGTH(info) with LENGTH(XMLSERIALIZE(info AS CLOB)) then you obtain information about the textual (serialized) size of the
documents instead of their parsed size inside DB2’s storage area.
Since inlined XML documents reside on regular data pages instead of XDA pages, their read and
write activity is reflected in the snapshot monitor counters for data pages, just like any other relational activity. Reads and writes to non-inlined XML documents affect XDA pages and are
reported in separate snapshot monitor counters, such as Buffer pool XDA logical reads as
opposed to Buffer pool data logical reads. This difference in page counters does not
affect performance, only the way you monitor XML activity in the database.
3.4.2
Potential Benefits and Drawbacks of XML Inlining
Inlining of XML data in the base table has several consequences that you should be aware of.
When in doubt, it is advisable to perform tests with your XML data and workload to determine
whether inlining is beneficial in your environment.
Potential benefits of inlining include
• Since inlined documents are stored on the relational data pages and never span more
than one such page, they do not require any regions index entries. If most or all of the
documents are inlined, the regions index will be very small. This saves storage space
and can improve performance.
48
Chapter 3
Designing and Managing XML Storage Objects
• Since inlined XML documents reside on the data pages of the table, they participate in
DB2’s prefetching. Prefetching can significantly improve the performance of queries
that read many documents from a table, but it is of little or no benefit to queries that
fetch only a single document.
• If you use DB2 9.5 or later and enable row compression, all inlined documents will be
compressed. This is the only way to compress XML data in DB2 9.5. If your system
tends to be I/O bound, compression can improve performance dramatically. Compression allows DB2 to use fewer I/O operations to read the same amount of data. Since
compressed data pages remain compressed in the buffer pool, a larger number of rows
(documents) are kept in your buffer pool.
Potential drawbacks of inlining are
• Since inlined documents are stored within the relational rows of the table, the row size is
a lot larger than without inlining. As a result, the number of rows that are stored on a single page is much lower. It can be as low as one row per page if most of your inlined documents occupy the majority of the page they each reside on. Queries that read data from
the non-XML columns of the table need to access a much larger number of pages than
without inlining. This can be detrimental for performance.
• XML queries and updates on inlined documents can use more temporary space at execution time than if the documents were not inlined. If the buffer pool for the temporary
table space is large enough then this does not necessarily incur additional physical I/O
and the performance impact is low to moderate. It is highly recommended to use a dedicated buffer pool for the temporary table space.
3.5
COMPRESSING XML DATA
The ability to compress XML data in DB2 depends on the version of DB2 you are using.
DB2 for z/OS compresses XML data if compression is enabled for the table space that contains
the table. Compression can be enabled with an ALTER TABLESPACE statement and then takes
effect after the first reorganization of the table space. Further details are provided in section 3.11.
DB2 for Linux, UNIX, and Windows supports XML compression as follows:
• DB2 9.1 does not support XML compression.
• DB2 9.5 allows you to compress all documents that are inlined.
• DB2 9.7 supports compression of inlined documents as well as those stored in the XDA
object. Compression of the XDA object is only supported for tables and XML columns
created in DB2 9.7, not for XML columns created in prior releases (see section 3.3.4).
3.5
Compressing XML Data
49
• DB2 9.7 also supports compression of user-defined XML indexes. They are compressed
automatically if the table itself is compressed, unless you alter them explicitly to disable
compression. The XML regions index is never compressed.
Figure 3.25 shows a CREATE TABLE statement that inlines XML documents of up to 30,000
bytes in size and enables compression. After the table is populated with an initial amount of data
(about 1 MB to 2 MB), a compression dictionary is automatically created and any subsequent
data that is inserted, loaded, or updated is subject to compression. The rows that were in the table
before the compression kicked in are not compressed until an offline reorganization of the table is
performed.
CREATE TABLE customer(id INTEGER, info XML INLINE LENGTH 30000)
IN tbspace32k COMPRESS YES;
Figure 3.25
Table definition with inlined XML storage and compression
In DB2 9.5, XML documents that are too large for inlining are excluded from compression
because only the DAT object is compressed, not the XDA object. In DB2 9.7, the table definition in
Figure 3.25 compresses all documents, including those that are not inlined. DB2 9.7 compresses
both the DAT and the XDA object and uses separate compression dictionaries for both.
Since DB2 9.5 you can use the administrative view sysibmadm.admintabcompressinfo to
check how well the data in a table is being compressed, as shown in Figure 3.26.
SELECT tabname, pages_saved_percent, bytes_saved_percent
FROM sysibmadm.admintabcompressinfo
WHERE tabname = 'CUSTOMER';
TABNAME
PAGES_SAVED_PERCENT BYTES_SAVED_PERCENT
---------- ------------------- ------------------CUSTOMER
67
67
1 record(s) selected.
Figure 3.26
Checking how well a table is compressed in DB2 9.5
In DB2 9.7, where the DAT and XDA storage objects are compressed separately, the view
sysibmadm.admintabcompressinfo has the additional column object_type. This column
allows you to examine the compression ratio of the DAT and XDA objects separately (Figure 3.27).
50
Chapter 3
Designing and Managing XML Storage Objects
SELECT tabname, object_type,
pages_saved_percent, bytes_saved_percent
FROM sysibmadm.admintabcompressinfo
WHERE tabname = 'CUSTOMER';
TABNAME
---------CUSTOMER
CUSTOMER
OBJECT_TYPE PAGES_SAVED_PERCENT BYTES_SAVED_PERCENT
----------- ------------------- ------------------DATA
67
67
XML
66
66
2 record(s) selected.
Figure 3.27
Checking how well a table is compressed in DB2 9.7
Additional information is available in the view sysibmadm.admintabinfo (Figure 3.28). Its
columns DICTIONARY_SIZE and XML_DICTIONARY_SIZE reveal the existence and size of the
compression dictionaries in the DAT and the XDA object, respectively. The column
XML_RECORD_TYPE has the value 2 if the table with the XML column was created in DB2 9.7
and allows XDA compression. It has the value 1 if the table was created prior to 9.7, and NULL if
the table does not have an XML column.
SELECT tabname, dictionary_size, xml_dictionary_size,
xml_record_type
FROM sysibmadm.admintabinfo
WHERE tabname = 'CUSTOMER';
TABNAME DICTIONARY_SIZE
XML_DICTIONARY_SIZE XML_RECORD_TYPE
-------- ----------------- -------------------- --------------CUSTOMER
7720
24048
2
1 record(s) selected.
Figure 3.28
Checking dictionary sizes
Compression information for tables and indexes is also available through the following table
functions, which can also estimate the gain from compressing a currently uncompressed table or
index:
• sysproc.admin_get_tab_compress_info in DB2 9.5
• sysproc.admin_get_tab_compress_info_v97 in DB2 9.7
• sysproc.admin_get_index_compress_info in DB2 9.7
You can also query the DB2 system catalog to get information about the compression ratio of
tables and indexes. This approach requires that you first use the RUNSTATS command to collect
statistics about the table:
RUNSTATS ON TABLE db2admin.customer AND INDEXES ALL
3.6
Examining XML Storage Space Consumption
51
Note that the RUNSTATS command requires a two-part table name, which consists of a relational
schema name (db2admin in this case) as well as table name (customer). After that, the queries
in Figure 3.29 retrieve compression information from the catalog. Note that the first query only
reports on the compression savings in the DAT object and ignores the XDA object. The second
query obtains compression information for all indexes on the customer table, and can only be
run in DB2 9.7 or higher. In Chapter 13, Defining and Using XML Indexes, you will learn that an
XML index consists of a logical and a physical index, and that the compression ratio is only
reported for the physical index.
SELECT tabname, avgrowcompressionratio, pctpagessaved
FROM
syscat.tables
WHERE tabname = 'CUSTOMER';
SELECT indname, tabname, indextype, pctpagessaved
FROM syscat.indexes
WHERE tabname = 'CUSTOMER';
Figure 3.29 Obtaining compression information from the system catalog
3.6
EXAMINING XML STORAGE SPACE CONSUMPTION
The space consumption of XML documents in a table space depends on a variety of factors,
including the structural characteristics of the documents, the ratio of tags to data values, the presence and number of namespaces, and the ratio of elements to attributes. In DB2 9 and 9.5 for
Linux, UNIX, and Windows the space consumption also depends on whether the documents are
validated against an XML Schema upon insert, load, or update. Validated documents can take
more space than non-validated documents due to type annotations, depending on the nature of the
XML Schema. This impact of validation on the space consumption does not exist in DB2 for
z/OS and has been removed in DB2 9.7 for Linux, UNIX, and Windows, too. Document validation is covered in Chapter 17, Validating XML Documents against XML Schemas.
In general, it is difficult to predict the exact amount of storage space that a particular document, or
a set of documents, will occupy in a DB2 table space. To get a reliable estimate you can insert a
representative set of documents into a table and check the number of pages occupied in DB2.
Clearly, if you use several hundred or thousand documents you get a better estimate than if you
use just a handful of documents.
You have multiple ways to check the number of pages used. In DB2 for Linux, UNIX, and Windows, one option is to use the list tablespaces command:
list tablespaces show detail
52
Chapter 3
Designing and Managing XML Storage Objects
This command reports the number of free and used pages for each table space. Figure 3.30 shows
sample output of the list tablespaces command for a table space named tbspace32k. You
see that the page size is 32KB and 1248 pages are occupied. Multiplying these two figures reveals
that the space consumption is 39MB. This is the total for all tables and indexes in the table space.
You might wonder why the number of usable pages is lower than the total number of pages in the
table space. That is because DB2 reserves some pages for free space management and other
housekeeping information.
Tablespace ID
Name
Type
Contents
State
Detailed explanation:
Normal
Total pages
Useable pages
Used pages
Free pages
High water mark (pages)
Page size (bytes)
Extent size (pages)
Prefetch size (pages)
Number of containers
Figure 3.30
=
=
=
=
=
5
TBSPACE32K
Database managed space
All permanent data. Large table space.
0x0000
=
=
=
=
=
=
=
=
=
2048
2016
1248
768
1312
32768
32
32
1
Detailed table space information
If you have multiple tables in one table space and prefer to see space information for each individual table, you can use the following commands where <dbname> is the name of your database:
update monitor switches using table on;
get snapshot for tables on <dbname>;
This command produces information for all tables that have been recently accessed. Figure 3.31
shows the information provided for the table customer. The number of used pages is reported
separately for data pages, index pages, and XDA pages.
Table Schema
Table Name
Table Type
Data Object Pages
Index Object Pages
Xda Object Pages
...
Figure 3.31
=
=
=
=
=
=
DB2ADMIN
CUSTOMER
User
27
32
192
Information from a table snapshot
3.7
Reorganizing XML Data and Indexes
53
If you are familiar with managing relational data in DB2 you might know that after using the
RUNSTATS utility on a table you can also obtain the number of pages for that table by querying
the DB2 system catalog as shown in Figure 3.32.
SELECT npages
FROM syscat.tables
WHERE tabname = 'CUSTOMER';
Figure 3.32
Obtaining the number of pages for a table
Beware that Figure 3.32 only reports the number of data
pages and does not include XDA or index pages. Hence, this number
can be misleading if a table includes XML columns. It is accurate only if
all documents in the table are inlined and reside on data pages only, not
on XDA pages.
NOTE
After you have determined how much space your XML documents occupy in DB2, you can compare that number to how much space the same documents consume in their textual format in the
file system. In DB2 9.5 and higher you find that the space consumption for most XML data is
between 70% and 150% of the space that they occupy in the file system. The exact ratio depends
on the characteristics of your documents. For example, since DB2’s internal storage format
replaces all XML tag names with four-byte integer values, documents with very long tag names
lose more characters when being stored in DB2 than documents with very short tag names.
3.7
REORGANIZING XML DATA AND INDEXES
When you delete or update XML documents, free space remains where the documents were previously stored. This space can be reused when other documents are inserted or updated. Hence,
there is little need to reorganize XML data if your workload is a somewhat balanced mix of
insert, update, and delete operations. You may wish to reorganize a table with XML data if many
update and delete operations have taken place and you want to reclaim space. Reorganization has
no impact on the tree structure in which XML documents are stored. Reorganization is performed
in DB2 for z/OS using the REORG utility (see section 3.12) and in DB2 for Linux, UNIX, and
Windows using the REORG command, which is discussed in this section.
The REORG command DB2 for Linux, UNIX, and Windows supports three operating modes, two
of which support reorganizing XML data:
• Offline REORG with no table access supports XML data.
• Offline REORG with read-only table access supports XML data.
54
Chapter 3
Designing and Managing XML Storage Objects
• Online REORG, also known as in-place REORG, which allows full read and write access
to the table. This reorganization mode is not supported for XML data.
The main effect of the REORG command on XML data is that the space left behind by deleted or
updated documents is reclaimed if the LONGLOBDATA option of the REORG command is used. If
the LONGLOBDATA option is omitted, only the DAT object and the indexes are reorganized while
the XDA object is ignored.
The following command reorganizes the customer table including its XML data without allowing concurrent access to the table:
REORG TABLE customer ALLOW NO ACCESS LONGLOBDATA
To reorganize the customer table and its XML data and permit read-only access to the table during the REORG operation, issue this command:
REORG TABLE customer ALLOW READ ACCESS LONGLOBDATA
If you omit the ALLOW NO ACCESS or ALLOW READ ACCESS clause then ALLOW READ ACCESS
is the default for non-partitioned tables while ALLOW NO ACCESS is the default for partitioned
tables.
You can reorganize relational and XML indexes separately from the table. DB2 9 and 9.5 allow
you to reorganize XML indexes while users continue to have read-only access to the table. Use
the following command to reorganize indexes with read access:
REORG INDEXES ALL FOR TABLE customer ALLOW READ ACCESS
DB2 9.7 supports online reorganization for XML indexes, which means that applications have
read and write access to the table while indexes are being reorganized. Use the following command to reorganize indexes in online mode:
REORG INDEXES ALL FOR TABLE customer ALLOW WRITE ACCESS
3.8 UNDERSTANDING XML SPACE MANAGEMENT:
A COMPREHENSIVE EXAMPLE
This section walks you through a comprehensive example of XML space management in DB2 for
Linux, UNIX, and Windows. Let’s look at the example in Figure 3.33, which examines the effects
of XML inlining, compression, and reorganization on the storage objects of a table. The example
performs the following steps:
3.8
Understanding XML Space Management: A Comprehensive Example
55
1. Create a table
2. Import/Load XML data into the table
3. Get a snapshot to examine the number of pages used
4. Alter the table to enable inlining
5. Update all documents to physically move them from the XDA into the DAT object
6. Get a snapshot again to verify the increase of DAT pages
7. Reorganize the table to free up the empty XDA pages that got left behind after inlining
8. Get a snapshot to verify the reduction of XDA pages
9. Enable compression and reorganize the table again
10. Get a snapshot to verify the reduction of DAT pages after compression
Figure 3.33 shows the output of these steps when performed in the DB2 Command Line
Processor. We have truncated the output of the GET SNAPSHOT commands to only show the relevant portion. We have also added some comments [in italics and square brackets] as additional
explanations.
db2 => create table customer (id int, info XML) in TBSPACE32K;
DB20000I The SQL command completed successfully.
[import/load a batch of 20480 small documents]
db2 => select count(*) as num from customer;
num
----------20480
1 record(s) selected.
db2 => get snapshot for tables on sampxml;
Table Schema
Table Name
Table Type
Data Object Pages
Index Object Pages
Xda Object Pages
Rows Read
Rows Written
=
=
=
=
=
=
=
=
DB2ADMIN
CUSTOMER
User
60
38
[All XML data resides in the XDA object]
880
0
20480
db2 => alter table customer alter info set inline length 30000;
DB20000I The SQL command completed successfully.
[Altering the inline length does not affect existing documents.]
[Issue an update statement to rewrite all documents:]
Figure 3.33
(continues)
Examining the effects of XML inlining, compression, and reorganization
56
Chapter 3
Designing and Managing XML Storage Objects
db2 => update customer set info = info;
DB20000I The SQL command completed successfully.
db2 => get snapshot for tables on sampxml;
Table Schema
Table Name
Table Type
Data Object Pages
Index Object Pages
Xda Object Pages
=
=
=
=
=
=
DB2ADMIN
CUSTOMER
User
896
38
880
Rows Read
Rows Written
= 61435
= 40960
[XML docs have been inlined]
[Regions index pages are now empty]
[XDA pages are now empty, which we prove with
a reorg]
db2 => reorg table customer LONGLOBDATA ;
DB20000I The REORG command completed successfully.
db2 => get snapshot for tables on sampxml;
Table Schema
= DB2ADMIN
Table Name
= CUSTOMER
Table Type
= User
Data Object Pages
= 887
Index Object Pages = 5
[Regions index pages freed up]
Xda Object Pages
= 1
[XDA pages have been freed up]
Rows Read
= 122880
Rows Written
= 0
Table Reorg Information:
Reorg Type
=
Reclaiming
Table Reorg
Allow Read Access
Reorg Long Field LOB Data
[Enable compression:]
db2 => alter table customer compress yes;
DB20000I The SQL command completed successfully.
[Then reorg to actually compress the existing data in the table:]
db2 => reorg table customer resetdictionary;
DB20000I The REORG command completed successfully.
db2 => get snapshot for tables on sampxml;
Table Schema
Table Name
Table Type
Data Object Pages
Index Object Pages
Xda Object Pages
Rows Read
Rows Written
Figure 3.33
=
=
=
=
=
=
=
=
DB2ADMIN
CUSTOMER
User
106
[Compression ratio 8:1]
5
1
184320
0
Examining the effects of XML inlining, compression, and reorganization (Continues)
3.9
XML in Range Partitioned Tables and MDC Tables
57
Table Reorg Information:
Reorg Type
=
Reclaiming
[The reorg was a reclaiming reorg.]
Table Reorg
Allow Read Access
Reset Compression Dictionary
Reorg Data Only
Rows compressed
= 20480
Figure 3.33
3.9
Examining the effects of XML inlining, compression, and reorganization (Continued)
XML IN RANGE PARTITIONED TABLES AND MDC TABLES
Range partitioning (also known as table partitioning), as well as multidimensional clustering
(MDC), are methods for the storage organization of a database table in DB2 for Linux, UNIX,
and Windows. These methods can improve the performance and manageability of large tables.
Starting with DB2 9.7, XML columns are allowed in range partitioned tables and MDC tables.
3.9.1
XML and Range Partitioning
Range partitioning allows you to horizontally partition a table based on the values in one or multiple columns. Each partition is stored in a separate storage object and in its own table space,
which can significantly improve the manageability as well as the performance of large tables. For
example, if a table has a column of type DATE, such as an order date or a booking date, you could
choose to have all rows with dates in January in one partition, all rows for February in a second
partition, and so on. Alternatively you could decide to have one partition per week. Although
range partitioning by date is most common, you could also partition a table by product code, last
name, zip code, or other information.
Range partitioning has various benefits. For example, if a table is partitioned by date you can
attach (roll-in) a new partition with new data, and detach (roll-out) the oldest partition if that data
is no longer required in the table. This rolling in and rolling out of data allows you to make new
data available quickly. It also allows you to quickly remove old data without bulk delete operations that can be time consuming and require substantial logging overhead. After a partition has
been detached it is still available as a separate table if required for processing.
Additionally, if queries include predicates on the partitioning columns, the DB2 optimizer can
intelligently exclude non-relevant partitions from being scanned. This optimization is called partition elimination and improves performance.
The partitioning key has to consist of one or multiple relational columns; it cannot be an element
or an attribute in an XML column nor the whole XML column. The XML column is payload in
the rows of a range partitioned table, which can be very useful if you are managing very large
numbers of XML documents and need roll-in/roll-out capabilities for your XML data. For example, a tax processing system may store the filing date in a relational column and the tax return in
58
Chapter 3
Designing and Managing XML Storage Objects
an XML column. An order management system may store the order date in a relational column
and the actual order as XML. Figure 3.34 shows a sample of a range-partitioned order table with
one partition per quarter.
CREATE TABLE orders(id INT, orderdate DATE, order XML)
PARTITION BY RANGE(orderdate)
(PARTITION "1Q09" STARTING '1/1/2009',
PARTITION "2Q09" STARTING '4/1/2009',
PARTITION "3Q09" STARTING '7/1/2009',
PARTITION "4Q09" STARTING '10/1/2009' ENDING '12/31/2009');
Figure 3.34
A range-partitioned table with XML
Starting with DB2 9.7, indexes on range-partitioned tables can be defined as global or local
indexes. Prior to DB2 9.7, indexes on range-partitioned tables are always global indexes. A
global index consists of a single non-partitioned index structure for the entire table. A local index
has as many partitions as the table and each index partition contains index entries only for its corresponding table partition. This partitioning schema can improve the manageability of indexes on
partitioned tables when you need to roll data in or out, as compared to global indexes. Partitioned
indexes can be stored in a different or the same table space as the data partitions.
The internal regions index of a range-partitioned table is always a local (partitioned) index. If you
attach a new table partition to a table that contains an XML column, DB2 automatically uses the
regions index of the new table partition as a new regions index partition, without rebuilding the
regions index. Similarly, when you detach a table partition, the corresponding regions index partition becomes the regions index of the detached table.
The internal XML path index is always a global (non-partitioned) index even if the table is rangepartitioned. When you attach a new table partition to a table that contains an XML column, DB2
immediately maintains the path index for the target table. This behavior is different from other
non-partitioned indexes, which are maintained during SET INTEGRITY after the ATTACH operation. When the ATTACH operation is completed, the existing XML path index of the attached table
partition is dropped, because it is superseded by the updated non-partitioned path index on the
entire table. When you detach a partition of a table that contains an XML column, a new and separate path index is created for the detached partition, because the XML data in the detached table
is not accessible without a path index.
3.9.2
XML and Multidimensional Clustering
Multidimensional clustering (MDC) provides a method for clustering data in tables along one or
multiple dimensions. MDC tables can significantly improve query performance and reduce the
overhead of data maintenance operations such as inserting and deleting. Similar to range partitioning, an MDC table can contain one or multiple XML columns as payload. However, the table
cannot be clustered based on values in an XML column. The clustering key has to consist of one
or multiple relational columns.
3.10
XML in a Partitioned Database (DPF)
59
The table created in Figure 3.35 defines a table with sales data, including information about the
date, store, and product of the sale; plus additional details in an XML column. The table is clustered by date, storeid, and productid, which means that rows reside in the same blocks of
the table if they describe different sales of the same product in the same store and on the same
date.
CREATE TABLE sales(id INT, date DATE, storeid INT,
productid INT, details XML)
ORGANIZE BY DIMENSIONS(date, storeid, productid);
Figure 3.35
An MDC-table with XML
The way you use and manage range-partitioned tables or MDC tables is the same whether they
include XML columns or not. Since there are no XML-specific considerations for these storage
methods, we do not cover this topic in any more detail. The interested reader should refer to the
DB2 documentation or general DB2 database administration books for further information on
range-partitioning and multidimensional clustering.
3.10
XML IN A PARTITIONED DATABASE (DPF)
The Database Partitioning Feature (DPF) in DB2 for Linux, UNIX, and Windows allows you to
create a database that consists of multiple partitions. Each database partition, also known as a
node or database node, can reside on a physically separate server. It is also possible to have multiple database partitions on a single server. A database table can reside in a single partition or can
be distributed across multiple database nodes. When a table is assigned to multiple partitions, its
rows are randomly distributed across the partitions by a hash function. This data distribution
allows multiple processors and multiple machines to work in parallel to execute queries and other
processing tasks. Extensive parallelization allows you to run complex queries over large amounts
of data with shorter response times than in a single partition database. This benefit is particularly
important for data warehousing and complex analytical queries.
Starting with DB2 9.7, tables with XML columns can be created in a partitioned database to
enable parallel processing of XML data. You can also add XML columns to existing partitioned
tables in a DPF database. Designing, configuring, and managing a partitioned database is largely
the same whether it includes XML data or not. Hence, this section focuses on the XML-specific
consideration for partitioned databases.
To create a table in a partitioned database and distribute its data across a set of database partitions,
you need to take steps that are illustrated in Figure 3.36. If your table should be distributed across
the database partitions 1 through 16, create a database partition group with the corresponding
range of partition numbers. Then you create a buffer pool and a table space for this partition
group. Subsequently, any table that you create in this table space is distributed across the underlying database partitions. More precisely, each row that is added to the table is stored on exactly one
of the underlying database partitions. A single row never spans two or more partitions. Each row
60
Chapter 3
Designing and Managing XML Storage Objects
is assigned to one of the partitions by hashing on a distribution key. In Figure 3.36, the clause
DISTRIBUTE BY HASH specifies that the rows of the customer table are distributed based on
the values in the id column. The XML documents are distributed together with the rows that they
belong to. Each XML document resides in its entirety on exactly one partition.
-- create a database partition group
CREATE DATABASE PARTITION GROUP group1
ON DBPARTITIONNUMS (1 TO 16);
-- create a buffer pool for the partition group
CREATE BUFFERPOOL bp_group1 DATABASE PARTITION GROUP group1;
-- create a table space in the partition group
CREATE TABLESPACE ts_group1
IN DATABASE PARTITION GROUP group1
MANAGED BY AUTOMATIC STORAGE
BUFFERPOOL bp_group1
NO FILE SYSTEM CACHING;
-- create a table with a distribution key
CREATE TABLE customer(id INTEGER, info XML)
IN ts_group1 DISTRIBUTE BY HASH (id);
Figure 3.36
Creating storage objects in a partitioned database
A distribution key consists of one or multiple relational columns and cannot contain a LOB or
XML column. A table cannot be distributed by element or attribute values in an XML column.
You can, however, extract element or attribute values from XML documents, store them in a separate non-XML column, and use that column as the distribution key.
Any unique key or primary key of the table must contain all the distribution key columns. Since
XML values are not allowed in a distribution key, you cannot define unique XML indexes on a
table that is distributed across database partitions. The columns of the distribution key must be
included in the columns that make up any unique constraints.
3.11
XML STORAGE IN DB2 FOR Z/OS
Many of the concepts that are explained in the previous sections for DB2 on Linux, UNIX, and
Windows also apply to DB2 9 for z/OS. For example, the representation of XML documents in a
parsed tree format, replacing tag names with unique integer values, breaking large document
trees into regions, as well as the use of the XML data type to define columns in a table—all these
concepts are used in DB2 for z/OS as well. There are, however, differences in how these concepts
are implemented to fit well with table spaces and other infrastructure in DB2 for z/OS. These differences are explained in this section.
3.11
XML Storage in DB2 for z/OS
3.11.1
61
Storage Objects for XML Data
In DB2 9 for z/OS you can define XML columns in a table as easily as in DB2 for Linux, UNIX,
and Windows:
CREATE TABLE customer (id INTEGER, info XML)
Additionally, XML indexes can be defined on the XML column. The customer table appears to
applications as shown in Figure 3.37. An application sees exactly the columns that you defined,
including the XML column. Applications do not see or need to know that the physical storage of
this table’s data is different from its logical appearance.
XML index (user defined)
B+tree
id int
Figure 3.37
info XML
Logical view of a table with XML column and XML index
When a user table contains an XML column, an additional hidden column called DB2_
GENERATED_DOCID_FOR_XML of type BIGINT is automatically generated in addition to the
XML column. This column holds a unique identifier for the XML columns in a row. There is a
single DB2_GENERATED_DOCID_FOR_XML column even if the table contains multiple XML
columns. An index called the document ID index (or, DocID index) is automatically created on
this column. The column DB2_GENERATED_DOCID_FOR_XML is not included in the result set of
a “SELECT *” statement and should be considered as a DB2 internal column. The following
explains how this column is used by DB2 internally.
Similarly to DB2 for Linux, UNIX, and Windows, XML documents are not stored directly in the
XML column that you define in your user table. Instead, a separate internal XML table in its own
table space is created for each XML column in the user table (base table). The internal XML table
in DB2 for z/OS serves a similar purpose as the XDA object in DB2 for Linux, UNIX, and Windows, that is, XML documents are stored outside of the rows of the user table so that documents
up to 2GB in size can be managed. A single document can be physically split across multiple
rows in the XML table, but logically it belongs to a single row in the base table. These concepts
are illustrated in Figure 3.38.
62
Chapter 3
Designing and Managing XML Storage Objects
The internal XML table consists of three columns—DOCID (BIGINT), MIN_NODEID (VARCHAR),
and XMLDATA (VARBINARY). The DOCID column is used internally to automatically join the
XML table with the DB2_GENERATED_DOCID_FOR_XML column in the base table. The XMLDATA
column contains regions of XML documents in the pureXML parsed tree format, not in textual
format. Therefore the column type is VARBINARY. In any given row, the MIN_NODEID column
provides the lowest nodeID value of all nodes in the region that is stored in the XMLDATA column
of the same row. This helps DB2 to process documents efficiently, even if they span multiple
regions (multiple rows) in the internal XML table. The internal table is clustered by DOCID and
MIN_NODEID. Hence the regions of a large document are physically always stored in their logical
consecutive order.
A so-called NodeID index is defined on the internal XML table. Its key consists of the DOCID
value plus the largest nodeID of the region in the current row. The NodeID index allows for efficient access from a base table row to the corresponding document regions in the internal XML
table. These regions comprise the document that logically belongs to the base table row. When
you define an XML index on the XML column of your table, DB2 creates a physical B-Tree
index on the XMLDATA column in the internal XML table. The XML table is where the actual
XML data resides that is being indexed. When DB2 uses your XML index to evaluate an XML
predicate, it retrieves DOCID values from the internal XML table to join back to the base table.
For this reason, the base table has a DocID index on its DB2_GENRATED_DOCID_FOR_XML column (see Figure 3.38).
Internal
DocID index
Internal
NodeID index
B+tree
B+tree
XML index
(user defined)
B+tree
User Table
DB2_GENERATED_
DOCID_FOR_XML
Figure 3.38
id int
info XML
Internal XML Table
DocID min_NodeID
XMLData
Base table and XML table column relationships
Note that the XML column in the base table has the name (info) that was specified in the
CREATE TABLE statement. To speed up the search for specific XML elements, you can define
XML indexes on this info column, as shown in Figure 3.37. Internally, this results in a B-tree
index over the XMLDATA column in the internal XML table. XML indexes are discussed in further
detail in Chapter 13, Defining and Using XML Indexes.
3.11
XML Storage in DB2 for z/OS
3.11.2
63
Characteristics of XML Table Spaces
The page size of an internal XML table space is always 16KB, regardless of the page size of the
base table space. The internal XML table space therefore uses the buffer pool BP16K0 by default.
There is a new DSNZPARM subsystem parameter called TBSBPXML, which you can set to specify the default buffer pool to use for XML table spaces if you do not want to use BP16K0.
The storage structure and partitioning scheme of an internal XML table space depends on the
storage structure of the table space for the base table. If the base table resides in a simple, segmented, or partition-by-growth (PBG) table space, then the XML table space is automatically a
partition-by-growth table space. An internal XML table space is never a simple or segmented
table space.
If the base table space is partitioned or range-partitioned, then the internal XML table space is
also partitioned or range-partitioned, respectively. For example, if the base table space is partitioned into two parts, then the base table and the internal XML table also consist of two parts
each. The DocID index and the NodeID index are always created as non-partitioned indexes
(NPIs).
Table 3.1 summarizes the relationship between the storage structure of a base table space and the
storage structure of an internal XML table space that is implicitly created for an XML column in
the base table.
Table 3.1
Table Space Types for a Base Table and Internal XML Table
Base Table Space
Internal XML Table Space
Simple
Partition-by-growth
Segmented
Partition-by-growth
Partition-by-growth
Partition-by-growth
Partitioned
Range-partitioned
Range-partitioned
Range-partitioned
The internal XML table and table space also inherit certain attributes from the base table and
table space, such as TRACKMOD, ERASE, and LOCKMAX. In particular, an internal XML table space
inherits the COMPRESS YES parameter from the base table space, which allows compression of
XML data along with the other data in the same table. The COMPRESS attribute for an internal
XML table space can be altered by the ALTER TABLESPACE statement.
64
Chapter 3
3.11.3
Designing and Managing XML Storage Objects
Tables with Multiple XML Columns
Let’s look at an example of a base table with two XML columns. Assume that the following
ALTER TABLE statement is used to add a second XML column (hist) to our customer table:
ALTER TABLE customer ADD COLUMN hist XML
The resulting storage objects are shown in Figure 3.39. The two XML columns are represented
by two internal XML tables, each consisting of three columns and with the appropriate indexes,
as described earlier. Each of the two XML tables resides in its own table space. The base table has
a single DB2_GENERATED_DOCID_FOR_XML column, which allows DB2 to join back from both
of the two internal XML tables to the base table.
B+tree
B+tree
Internal XML Table (info)
DocID min_NodeID
XMLData
Internal
DocID index
B+tree
User Table
DB2_GENERATED_
DOCID_FOR_XML
id int
info XML
hist XML
B+tree
B+tree
Internal XML Table (hist)
DocID min_NodeID
Figure 3.39
3.11.4
XMLData
Storage objects for a non-range-partitioned base table with two XML columns
Naming and Storage Conventions
When you create a table, you can specify a number of options, such as the database name, table
space name, and storage group. Depending on which of these values are provided, the implicitly
created internal XML table and indexes inherit certain attributes and/or use generated values.
3.12
Utilities for XML Objects in DB2 for z/OS
65
Table 3.2 shows how certain attributes of the base table, XML table, and XML indexes are determined for a simple CREATE TABLE statement. Table 3.3 shows the corresponding information for
a table definition with an explicit database and table space name.
Table 3.2
Explicit and Generated Attributes for XML Objects
CREATE TABLE customer (id INTEGER, info XML)
Name
Database
Table Space Index Space Storage Group
Base Table
customer
generated
generated
SYSDEFLT
XML Table
generated
same as
base table
generated
SYSDEFLT
DocID Index
generated
generated
SYSDEFLT
generated
generated
SYSDEFLT
from create
index stmt
generated
from create index
stmt, or
(base table)
NodeID Index
(XML table)
User-defined
XML Indexes
SYSDEFLT
Table 3.3
Explicit and Generated Attributes for XML Objects
CREATE TABLE customer (id INTEGER, info XML) IN mydb.myts
Name
Database
Table Space Index Space Storage Group
Base Table
customer
mydb
myts
from database
XML Table
generated
mydb
generated
from database
DocID Index
generated
generated
from database
generated
generated
from database
from create
index stmt
generated
from create index
stmt, or derived
from the database
(base table)
NodeID Index
(XML table)
User-defined
XML Indexes
3.12
UTILITIES FOR XML OBJECTS IN DB2 FOR Z/OS
The XML storage objects discussed in the previous section are supported by all relevant utilities
in DB2 for z/OS. Table 3.4 provides an overview of the utility support for XML objects.
66
Table 3.4
Chapter 3
Designing and Managing XML Storage Objects
Utility Support for XML Objects
Utility
Description
CHECK DATA
Checks the relationships between a base table with XML columns and the internal XML tables. The utility reports an error if it detects any inconsistencies.
Optionally the utility can also set the status of an XML column to invalid if
inconsistencies are found.
CHECK INDEX
Checks the internal DocID and NodeID indexes as well as any user-defined
XML indexes on an XML column.
COPY TABLESPACE
Allows you to produce full or incremental image copies of a table space that
contains a base table with an XML column. DB2 does not automatically copy
the related XML table space with the internal XML table or any XML indexes.
You have to specify the XML table space explicitly in the COPY TABLESPACE
command. You also need to specify the index space or index names of any
indexes that you want to be copied. The options SHRLEVEL REFERENCE,
SHRLEVEL CHANGE, and CONCURRENT are supported for copying XML table
spaces and indexes.
COPY INDEX
Supports taking full image copies and concurrent copies of the DocID and
NodeID indexes as well as any user-defined XML indexes.
COPYTOCOPY
Allows you to copy existing copies of XML objects, such as XML table spaces,
DocID and NodeID indexes, and any user-defined XML indexes.
LISTDEF
When you create object lists, you can select whether you want to include XML
table spaces and indexes. By default, such XML objects are included. The new
keyword XML allows you to list XML objects only.
LOAD
The LOAD utility supports loading XML data into XML columns. Further
details are provided in Chapter 5, Moving XML Data.
MERGECOPY
The MERGECOPY utility merges multiple incremental copies of a table space into
a single incremental copy. It can also merge incremental copies with a full copy
into a single new full copy. XML table spaces are fully supported.
QUIESCE
TABLESPACESET
When you use QUIESCE TABLESPACESET to quiesce a table space that
contains an XML column, any related internal XML table spaces and XML
index spaces are automatically included in the set of quiesced objects.
REAL TIME
STATISTICS
Collects statistics on XML objects.
REBUILD INDEX
Supports rebuilding DocID and NodeID indexes as well as any user-defined
XML indexes. The option SHRLEVEL CHANGE is not allowed for XML indexes.
RECOVER
TABLESPACE,
RECOVER INDEX
These utilities support recovery of the XML table spaces and XML indexes. If
you perform point-in-time recovery, you should recover all related XML objects
(table spaces and indexes) to the same point in time.
3.12
Utilities for XML Objects in DB2 for z/OS
Table 3.4
67
Utility Support for XML Objects (Continued)
Utility
Description
REORG
TABLESPACE
Allows you to reorganize a base table space as well as all related XML table
spaces. The internal XML table spaces are not included automatically but must
be explicitly specified. Options such as SHRLEVEL CHANGE are supported.
REORG INDEX
Supports reorganization of XML indexes.
REPAIR
Supports XML table spaces and XML indexes.
REPORT
TABLESPACESET
All XML objects, such as XML table spaces and indexes are included in the set
of reported objects.
RUNSTATS
TABLESPACE,
RUNSTATS INDEX
The RUNSTATS utility gathers statistics for the base table space, XML table
spaces, DocID and NodeID indexes, and any user-defined XML indexes.
UNLOAD
Allows you to unload tables with XML columns. You only have to specify the
base table space and do not have to specify the internal XML table space explicitly. You cannot unload XML data from a copy. To ensure portability of
unloaded XML data, you should specify the UNICODE keyword and use
Unicode delimiter characters. The UNLOAD utility adds an XML declaration with
an encoding attribute to each XML document unless you unload the data in
UTF-8 CCSID 1208. For further detail on XML encodings, see Chapter 20,
Understanding XML Data Encoding.
3.12.1 REPORT TABLESPACESET for XML
You can identify the relationship between base tables and their related XML tables and XML
indexes by running the REPORT TABLESPACESET command. Figure 3.40 shows the output of
this command for the following table:
CREATE TABLE customer(id INT, info XML, info2 XML)
REPORT TABLESPACESET DSN00191.CUSTOMER
TABLESPACE SET REPORT:
TABLESPACE
TABLE
INDEXSPACE
INDEX
: DSN00191.CUSTOMER
: USER011.CUSTOMER
: DSN00191.IRDOCIDC
: USER011.I_DOCIDCUSTOMER
XML TABLESPACE SET REPORT:
TABLESPACE
: DSN00191.CUSTOMER
BASE TABLE
:
Figure 3.40
USER011.CUSTOMER
Running the REPORT TABLESPACESET command (Continues)
68
Chapter 3
COLUMN
:
XML TABLESPACE
:
XML TABLE
:
XML NODEID INDEXSPACE:
XML NODEID INDEX
:
COLUMN
:
XML TABLESPACE
:
XML TABLE
:
XML NODEID INDEXSPACE:
XML NODEID INDEX
:
Figure 3.40
3.12.2
Designing and Managing XML Storage Objects
INFO
DSN00191.XCUS0000
USER011.XCUSTOMER
DSN00191.IRNODEID
USER011.I_NODEIDXCUSTOMER
INFO2
DSN00191.XCUS0001
USER011.XCUSTOMER000
DSN00191.IRNO1UKC
USER011.I_NODEIDXCUSTOMER000
Running the REPORT TABLESPACESET command (Continued)
Reorganizing XML Data in DB2 for z/OS
You can use the DB2 for z/OS REORG utility to reorganize table spaces with XML data. You have
the option of either reorganizing just the base table space, or reorganizing just the internal XML
table spaces or both. You must explicitly list the table spaces that you want to reorganize.
If you are reorganizing XML table spaces, then you must specify the keyword WORKDDN and provide the specified temporary work file (the default work file is SYSUT1).
An example is shown in Figure 3.41, where the REORG statement specifies that DB2 is to reorganize the base table space CUSTOMER and XML table spaces XCUS0000 and XCUS0001. The names
of XML table spaces are known from running the REPORT TABLESPACESET command. The
command options in this reorganization tell DB2 to take an inline copy of the base table space
and gather statistics for all table spaces. Note, that the following options are not allowed in the
REORG statement for XML table spaces and base table spaces with XML columns: DISCARD,
REBALANCE or UNLOAD EXTERNAL.
//REORG
EXEC DSNUPROC,UID='KUMARP2.REORG',TIME=1440,
//
UTPROC='',
//
SYSTEM='ISC9',DB2LEV=DB2A
//SYSREC
DD DSN=KUMARP2.REORG.SYSREC,
//
DISP=(MOD,DELETE,CATLG),
//
UNIT=SYSDA,SPACE=(4000,(20,20),,,ROUND)
//SYSCOPY1 DD DSN=KUMARP2.REORG.SYSCOPY1,
//
DISP=(MOD,CATLG,CATLG),UNIT=SYSDA,
//
SPACE=(4000,(20,20),,,ROUND)
//SYSUT1
DD DSN=KUMARP2.REORG.SYSUT1,
//
DISP=(MOD,DELETE,CATLG),
//
UNIT=SYSDA,SPACE=(4000,(20,20),,,ROUND)
//SYSUT2
DD DSN=KUMARP2.REORG.SYSUT2,
//
DISP=(MOD,DELETE,CATLG),
//
UNIT=SYSDA,SPACE=(4000,(20,20),,,ROUND)
//SYSIN DD *
REORG TABLESPACE DSN00191.CUSTOMER
COPYDDN(SYSCOPY1)
Figure 3.41
Reorganizing XML tables in DB2 for z/OS (Continues)
3.12
Utilities for XML Objects in DB2 for z/OS
69
STATISTICS TABLE(ALL) INDEX(ALL)
REORG TABLESPACE DSN00191.XCUS0000
STATISTICS TABLE(ALL) INDEX(ALL)
WORKDDN(SYSUT1)
REORG TABLESPACE DSN00191.XCUS0001
STATISTICS TABLE(ALL) INDEX(ALL)
WORKDDN(SYSUT2)
/*
Figure 3.41
Reorganizing XML tables in DB2 for z/OS (Continued)
You can also use the LISTDEF utility to group the related table spaces together into a list and then
specify that list in the REORG statement.
3.12.3
CHECK DATA for XML
You can use the CHECK DATA utility to check the consistency between a base table with XML
columns and the related XML tables. If the base table space is not consistent with any related
XML table spaces, CHECK DATA reports an error. The default behavior of CHECK DATA is to
check both the base table and the XML table spaces. However, you can add the keywords SCOPE
REFONLY to check base tables only, or the keywords SCOPE AUXONLY to check only LOB and
XML objects. In its simplest form, as shown in Figure 3.42, CHECK DATA checks the XML relationships, the LOB relationships, and the base table space.
CHECK DATA TABLESPACE DSN00191.CUSTOMER
DSNUGUTC - CHECK DATA TABLESPACE DSN00191.CUSTOMER
XMLERROR REPORT
.02 DSNUKINP - TABLESPACE 'DSN00191.CUSTOMER' IS NOT
CHECK PENDING
Figure 3.42
Simple example of the CHECK DATA utility
Note that the table space name is the name of the base table space, not the name of the internal
XML table space. If the table space is not in check pending state, then the XML part of the table
space is okay.
Optionally you can also ask the CHECK DATA utility to invalidate any XML or LOB columns that
it finds to be inconsistent. The appropriate keywords are shown in Table 3.5.
70
Table 3.5
Chapter 3
Designing and Managing XML Storage Objects
CHECK DATA Error Keywords
Column in Error
Action Taken by CHECK DATA
Keyword
XML column
Report the error only
XMLERROR REPORT
Report the error and set the column in
error to an invalid status
XMLERROR INVALIDATE
Report the error only
LOBERROR REPORT
Report the error and set the column in
error to an invalid status
LOBERROR INVALIDATE
Report the error only
AUXERROR REPORT
Report the error and set the column in
error to an invalid status
AUXERROR INVALIDATE
LOB column
XML or LOB column
The keywords XMLERROR REPORT imply that an XML column check error is reported with a
warning message, and the base table space is set to the auxiliary check-pending status (ACHKP) .
The keywords XMLERROR INVALIDATE imply that an XML column check error is reported
along with a warning message, and the base table XML column is set to an invalid status. If an
XML column had an invalid status and is now correct, it is set to valid.
As an example, if you want to limit the scope of the utility to just checking XML and LOB
columns and reporting errors, you can use the job shown in Figure 3.43.
//CHECK
EXEC DSNUPROC,PARM='ISC9,CHCKUT',COND=(4,LT)
//SORTOUT DD UNIT=SYSDA,SPACE=(4000,(20,20),,,ROUND)
//SYSUT1
DD UNIT=SYSDA,SPACE=(4000,(50,50),,,ROUND)
//SYSERR
DD UNIT=SYSDA,SPACE=(4000,(20,20),,,ROUND)
//SYSIN
DD *
CHECK DATA TABLESPACE DSN00191.CUSTOMER
SCOPE AUXONLY
XMLERROR REPORT
/*
56.17 DSNUGUTC - OUTPUT START FOR UTILITY, UTILID = IANTEX
56.20 DSNUGTIS - PROCESSING SYSIN AS EBCDIC
56.22 DSNUGUTC - CHECK DATA TABLESPACE DSN00180.CUSTOMER SCOPE
AUXONLY XMLERROR REPORT
56.34 DSNUKDST - CHECKING TABLE KUMARP2.CUSTOMER
56.46 DSNUGSOR - SORT PHASE STATISTICS NUMBER OF RECORDS=3
ELAPSED TIME=00:00:00
56.47 DSNUKDAT - CHECK TABLE KUMARP2.CUSTOMER COMPLETE, ELAPSED
TIME=00:00:00
56.50 DSNUK001 - CHECK DATA COMPLETE,ELAPSED TIME=00:00:00
56.51 DSNUGBAC - UTILITY EXECUTION COMPLETE, HIGHEST RETURN
CODE=0
Figure 3.43
Running the CHECK DATA utility
3.13
XML Parsing and Memory Consumption in DB2 for z/OS
3.13
71
XML PARSING AND MEMORY CONSUMPTION IN DB2 FOR Z/OS
DB2 for z/OS has two parameters that allow you to limit the amount of memory used for XML
operations. DB2 for z/OS has also unique capabilities to offload XML parsing to System z Application Assist Processors (zAAP) and System z Integrated Information Processors (zIIP).
3.13.1
Controlling the Memory Consumption of XML Operations
Unlike DB2 for Linux, UNIX, and Windows, DB2 for z/OS allows you to limit the amount of
DB2 memory that is used for XML processing. For this purpose there are two new DSNZPARM
subsystem parameters: XMLVALA and XMLVALS (in the macro DSN6SYSP XMLVALA). Since XML
columns are defined without a maximum size per row, DB2 cannot estimate the amount of memory that it needs for processing SQL/XML and XPath queries before execution. If queries construct very large XML documents, the amount of memory that DB2 requires can grow very large.
You can set the XMLVALA and XMLVALS subsystem parameters to limit memory consumption.
• XMLVALA specifies the upper limit for the amount of memory (in KB) that each user
(thread) can use for processing XML data. The default is 204800 KB (200MB), the
maximum value is 2GB. The recommended value for this parameter is at least four
times the largest expected XML document size. The default value of 200MB is sufficient for most applications.
• XMLVALS specifies the upper limit for the amount of memory (in MB) that the entire
subsystem can use for processing XML data. The default is 10240 MB (10GB), the
maximum value is 50GB. The recommended value is the maximum number of concurrent threads multiplied by the value of XMLVALA.
When the system exceeds the maximum memory allowed per user or per system, the violating
SQL statement fails with SQLCODE -904. To track the memory usage for XML values and prevent the SQLCODE -904 from happening, the peak memory usage for XML has been added to
DB2 statistic record IFCID 2, DB2 accounting record IFCID 3, and the DB2 monitor trace
record IFCID 148. The DB2 statistic record provides the per-system peak memory usage for
XML. The DB2 accounting record and DB2 monitor trace records provide the per-user peak
memory usage for XML.
The DSNZPARM subsystem parameters LOBVALA and LOBVALS are applicable to XML processing if you move very large XML documents from your application to the DB2 server or in the
opposite direction (bind in and bind out). The general recommendation is to set LOBVALA to the
largest expected XML document size, and to set LOBVALS to the maximum number of concurrent
threads multiplied by the value of LOBVALA.
72
Chapter 3
3.13.2
Designing and Managing XML Storage Objects
Redirecting XML Parsing to zIIP and zAAP
XML insert, update, and load operations in DB2 for z/OS require XML parsing, which is performed by the z/OS XML System Services (XMLSS). XML System Services provides a systemlevel XML parser that is integrated in the base z/OS operating system. It can be used by system
components, middleware, and applications that need efficient XML parsing services. For further
information on XMLSS, see http://www.ibm.com/servers/eserver/zseries/zos/xml/.
XML parsing can be offloaded to zAAP and zIIP as follows:
• XML parsing can be redirected to zIIP and zAAP processors in z/OS V1.10.
• XML parsing can be redirected to zAAP processors in z/OS V1.9.
• With z/OS APAR OA20308, XML parsing is eligible for zAAP also in z/OS V1.8 and
V1.7.
• With z/OS APAR OA23828, XML parsing is eligible for zIIP also in z/OS V1.9 and
V1.8.
When you insert, update, or load XML data in DB2 for z/OS, only the XML parsing portion of
the processing is eligible for offloading. Depending on the size and complexity of the XML documents, between 10% and 50% of the total CPU time is spent on XML parsing and eligible for
offloading. Larger documents lead to a larger percentage of CPU consumption in the XML
parser. For further details, see http://www.ibm.com/support/techdocs/atsmastr.nsf/WebIndex/
WP101227.
Several important fixes and functional enhancements for pureXML in DB2 9 for z/OS have been
delivered via APARs. Table 3.6 lists some of the recommended APARs. For current information
on the latest APARs, please look at APAR II14426 and visit http://www.ibm.com/software/data/
db2/support/db2zos/.
Table 3.6
Relevant APARs for XML processing in DB2 9 for z/OS
APAR
Description
PK47594
XML load performance improvement
PK51571, PK51572, PK51573,
PK58914, PK57409
XMLTABLE support (see Chapter 7)
PK57158
XML index access path improvement
PK50575
zAAP accounting
PK55585, PK55831
Additional 13 XPath functions
PK50692
Change PGR DSSIZE for XML table space parts
PK55783
XML index exploitation for joins
3.14
Summary
73
Table 3.6
Relevant APARs for XML processing in DB2 9 for z/OS (Continued)
APAR
Description
PK68265
XML locking improvement
II14426
Info APAR to link together all pureXML-related APARs
3.14
SUMMARY
Although XML has a widely known character-based notation, it is also a hierarchical data model.
Every XML document can be represented as a tree of nodes. When you insert or load XML documents into an XML column in a DB2 table, the documents are parsed into a tree format. Such
document trees are stored on pages in a table space. As a result, DB2 can query XML data without XML parsing, which is a critical performance benefit. A table can have both XML and relational columns, but by default XML data is physically stored in a separate storage object. Internal
system indexes provide close linkage between the XML documents and the relational rows that
they belong to. These storage concepts are transparent to the user applications, which only see
logical tables that contain relational and XML columns.
Since XML documents are stored in pages in a table space, most DB2 functions and features
apply to XML data as for relational data. For example, buffering in the buffer pool, logging and
recovery, backup and restore, reorganization to reclaim free space, optional compression or partitioning of tables, and most database utilities are supported for XML and relational data in an integrated manner. Therefore, the database administrator can apply any existing DB2 knowledge also
to the management of XML data.
This page intentionally left blank
C
H A P T E R
4
Inserting and
Retrieving XML Data
n this chapter we discuss “full document” operations, such as insert, delete, and retrieval of
whole XML documents in DB2 tables. These are the most basic and most common operations for XML documents. Insert and retrieval operations are of particular interest. They involve
the conversion of textual XML data to DB2’s internal XML format upon insert, and the reverse
upon retrieval. This conversion from and to the character representation of XML requires handling of XML declarations, whitespace, and reserved characters. DB2 handles these matters automatically for you, but some options exist that allow you to customize its behavior if needed.
I
In this chapter you learn
• How to insert XML documents from application programs and the DB2 Command Line
Processor (section 4.1)
• How to utilize user-defined functions to read documents from the file system
(section 4.1.2)
• How to delete, retrieve, and copy XML documents in DB2 tables (sections 4.2
through 4.5)
• How to handle and escape reserved characters in XML documents (section 4.6)
• How to recognize different kinds of whitespace that can appear in XML documents and
what it means for XML document storage and retrieval (section 4.7)
We use the following sample table for the examples in this chapter:
CREATE TABLE shelf(id INTEGER, bookinfo XML)
75
76
4.1
Chapter 4
Inserting and Retrieving XML Data
INSERTING XML DOCUMENTS
XML documents can be placed into an XML column of a DB2 table with SQL INSERT statements or with the LOAD and IMPORT utilities, which are discussed in Chapter 5, Moving XML
Data. XML documents that already exist in a table can be replaced or modified using SQL
UPDATE statements, which we cover in Chapter 12, Updating and Transforming XML Documents. In this section we focus on SQL INSERT statements to add XML documents to a table.
An XML column in DB2 can only contain well-formed XML documents. A document is wellformed if it complies with the syntax rules for XML documents that we explained in section 1.1,
Anatomy of an XML Document. When you add an XML document to an XML column, DB2
invokes an XML parser which, among other things, verifies whether the document is wellformed. Documents that are not well-formed are rejected because they cannot be reliably
processed. You can, however, insert non well-formed documents as plain text into CLOB or VARCHAR columns. When you insert, load, or update XML documents you can optionally validate the
documents with an XML Schema (see Chapters 16, Managing XML Schemas and 17, Validating
XML Documents against XML Schemas).
4.1.1
Simple Insert Statements
You can insert an XML document into a table with SQL INSERT statements either via an API
from an application or from the DB2 Command Line Processor (CLP). The CLP is available for
DB2 for Linux, UNIX, and Windows and DB2 for z/OS. Other command interfaces such as
SPUFI or the Command Editor in the DB2 Control Center can also be used. We first look at
INSERT statements issued from the CLP, then at INSERT statements used through APIs.
When you insert an XML document through a command interface such as the CLP, the entire
document needs to be hardcoded in the INSERT statement as a string literal or read from the file
system with a user-defined function (UDF). Let’s look at the sample document in Figure 4.1. We
have added line breaks and indentation to make it easier to read.
<?xml version="1.0" encoding="UTF-8" ?>
<bookstore>
<book type="database">
<isbn>0131580183</isbn>
<title>Understanding DB2</title>
<author>Raul Chong</author>
</book>
</bookstore>
Figure 4.1
Document to be inserted into DB2
The statement that you can issue from the CLP to insert the document in Figure 4.1 into the
shelf table is shown in Figure 4.2. Note that the document is provided as a string value in the
INSERT statement. This string value has to be enclosed in single quotes.
4.1
Inserting XML Documents
77
INSERT INTO shelf
VALUES(4,'<?xml version="1.0" encoding="UTF-8" ?>
<bookstore>
<book type="database">
<isbn>0131580183</isbn>
<title>Understanding DB2</title>
<author>Raul Chong</author>
</book>
</bookstore>')
Figure 4.2
Inserting an XML document from the DB2 CLP
If an XML document contains a single quote in any of its element or attribute values (see Figure
4.3), then such quotes conflict with the quotes that the INSERT statement requires to mark the
beginning and end of the document. The single quote in the word “Don't” in the title element
would be interpreted as the closing quote and end of the string value that represents the document. This misinterpretation of the quote would lead to an error.
<?xml version="1.0" encoding="UTF-8" ?>
<bookstore>
<book type="general">
<isbn>0708823904</isbn>
<title>Don't cry for me sergeant major</title>
<author>Robert McGowan</author>
</book>
</bookstore>
Figure 4.3
Another document to be inserted into DB2
To avoid an error you should escape the single quote by using either two single quotes (Don''t)
or the predefined entity '. Figure 4.4 shows an INSERT statement with correct escaping of
the single quote. The single quote does not need to be escaped if you insert the document from an
application program and provide the document via a parameter marker or host variable. Escaping
special characters is discussed in more detail in section 4.6.
INSERT INTO shelf
VALUES(5,'<?xml version="1.0" encoding="UTF-8" ?>
<bookstore>
<book type="general">
<isbn>0708823904</isbn>
<title>Don't cry for me sergeant major</title>
<author>Robert McGowan</author>
</book>
</bookstore>')
Figure 4.4
Escaping single quotes ensures correct XML insertion from the CLP
78
Chapter 4
Inserting and Retrieving XML Data
The default processing mode for INSERT statements strips non-relevant whitespace from the
XML document. For example, the line breaks and indentation that you see in Figure 4.4 are
removed upon insert. You do not get them back when you retrieve the document, which is acceptable and actually desirable for most applications. Whitespace is typically not meaningful to an
application that processes the XML data, and removing whitespace saves storage space. If you
use digital signatures then it depends on the software that signs and verifies XML documents
whether the removal of whitespace affects the digital signatures. Although the XML signature
standard (http://www.w3.org/TR/xmldsig-core/) allows for whitespace to be removed, not every
signature software might be implemented that way. In case an application requires the preservation of whitespace, DB2 offers several options to do so. They are covered in section 4.7.
Hard-coding an XML document in an SQL INSERT statement is only feasible for simple tests
with individual documents that are very small. In most other cases it is better to insert XML documents from a variable in your application code, or from files in the file system. Inserting XML
from an application program typically uses parameter markers or host variables, as shown in Figure 4.5 and Figure 4.6. In these examples, the first parameter marker or host variable must be an
INTEGER value for the id column of the table shelf, and the second must be an XML document
for the XML column bookinfo.
INSERT INTO shelf(id, bookinfo)
VALUES(?,?)
Figure 4.5
Inserting an XML document using parameter markers
INSERT INTO shelf(id, bookinfo)
VALUES(:hostvar1, :hostvar2)
Figure 4.6
Inserting an XML document using host variables
Figure 4.7 shows a code snippet of a Java application that reads an XML document from a file
bookfile.xml, and inserts it into the XML column bookinfo in the table shelf. Additional
application code samples for various host languages and APIs are presented in Chapter 21, Developing XML Applications with DB2.
4.1
Inserting XML Documents
79
PreparedStatement insertStmt = null;
String sqls = null;
int id = 4;
File file = new File("bookfile.xml");
sqls = "INSERT INTO db2admin.shelf(id, bookinfo)
VALUES (?, ?)";
insertStmt = conn.prepareStatement(sqls);
insertStmt.setInt(1, id);
insertStmt.setBinaryStream(2, new FileInputStream(file),
(int)file.length());
insertStmt.executeUpdate();
Figure 4.7
Inserting an XML document from a JDBC application
If the XML documents you want to insert are located in files in a file system, you have two additional options:
• Use the DB2 IMPORT or LOAD utilities. See Chapter 5.
• Use a user-defined function (UDF) to read XML documents from files, which is
explained in the next section.
4.1.2
Reading XML Documents from Files or URLs
In DB2 for Linux, UNIX, and Windows you can use a set of convenient user-defined functions
(UDFs) to read XML documents from files or URLs. These UDFs do not come as part of a regular DB2 installation, but are available from the IBM developerWorks website at http://www.ibm.
com/developerworks/exchange/dw_entryView.jspa?externalID=635&categoryID=974.
The download package consists of 11 UDFs and one stored procedure, listed in Table 4.1. They
enable you to read XML documents from files, directories, directory trees, URLs, and ZIP files.
These functions provide a lot of flexibility in many situations. If you need to populate tables with
the greatest possible performance, also consider using the DB2 LOAD utility.
Table 4.1
List of UDFs
Function Name
Description
blobFromFile
Reads a file from the DB2 server’s file system and
returns the file contents as a BLOB. If this BLOB
contains a well-formed XML document, it can be
inserted into an XML column.
clobFromFile
Reads a file from the DB2 server’s file system and
returns the file contents as a CLOB. If this CLOB
contains a well-formed XML document, it can be
inserted into an XML column.
(continues)
80
Table 4.1
Chapter 4
Inserting and Retrieving XML Data
List of UDFs (Continued)
Function Name
Description
clobFromURL
Returns a CLOB from a URL.
blobFromURL
Reads a BLOB from a URL.
blobsFromZipURL,
clobsFromZipURL
Table functions that read a ZIP file from a URL and
return a table that contains each file from the ZIP in
a separate row, as a BLOB or CLOB, respectively.
blobsFromGzipURL,
clobsFromGzipURL
Table functions that read a gzipped tar file from a
URL and return a table that contains each file from
the tar archive in a separate row, as a BLOB or CLOB,
respectively.
directoryInfo
Returns a table with information about files in a
directory in the DB2 server’s file system.
directoryInfoRecursive
Returns a table with information about files in a
directory and its subdirectories.
urlFromFile
Returns a URL from a local file name.
insertXmlFromDir
Stored procedure that inserts all files with extension
.xml and .XML from a given directory into a DB2
table.
Many of these UDFs come in two versions that produce either a CLOB or a BLOB. Both types of
functions, CLOB and BLOB, can be used to insert XML documents into an XML column. However, inserting XML documents from a BLOB type is preferable to avoid code page conversion
issues. If you use a CLOB function to insert XML documents into an XML column, you might
introduce unnecessary code page conversion and might damage the data (see Chapter 20, Understanding XML Data Encoding). If you want to insert a file into a BLOB or VARCHAR FOR BIT
DATA column, you must use the BLOB version of the functions. If you want to insert a text file
from the file system into a CLOB or VARCHAR column, you must use a CLOB function.
The UDFs come in a package that needs to be installed with the following command:
db2 -td% -f XMLFromFile.clp
The script file XMLFromFile.clp in the package must be edited before running so that it contains the correct path to the correct directory where the package has been unpacked and where, as
a result, the file XMLFromFile.jar is located.
4.1
Inserting XML Documents
81
Let’s insert an XML document that is contained in the file C:\xml\book\book01.xml. The
INSERT statement in Figure 4.8 illustrates how to use the function blobFromFile to read the
file and use it as input for the INSERT statement.
INSERT INTO shelf(id, bookinfo)
VALUES(7,blobFromFile('c:\xml\book\book01.xml'))
Figure 4.8
Inserting a file with the blobFromFile function
If the UDF cannot find the specified file, the INSERT statement fails with the following error:
SQL0443N Routine "*FROMFILE" (specific name "") has returned an error
SQLSTATE with diagnostic text "java.io.FileNotFoundException:
c:\xml\book\book01.xml". SQLSTATE=38A00
The UDF directoryInfo is a table function and enables you to list the files in a specified directory. The function returns a table with one row for each file, and with columns for the filename,
size, timestamp, and other file attributes. You can write the query in Figure 4.9 to list file information for the directory c:\xml\book.
SELECT filename, size, modtime
FROM TABLE(directoryInfo('c:\xml\book'));
Figure 4.9
Query to list files in a directory
The function directoryInfo is particularly useful because it allows you to insert selected files
from a directory into a DB2 table. For example, the INSERT statement in Figure 4.10 uses the
directoryInfo function to read all files from the directory c:\xml that match the pattern
book%.xml and inserts them into an XML column. You can filter on file names or other file
attributes, as shown in the WHERE clause.
INSERT INTO shelf(bookinfo)
SELECT blobFromFile(filename)
FROM TABLE(directoryInfo('c:\xml'))
WHERE isDirectory = 0 AND filename LIKE 'book%.xml'
Figure 4.10
Inserting selected XML files from a directory
If the XML documents that you want to insert are bundled in a ZIP file, then you can use the table
function blobsFromZipURL to extract the files and insert them into the target table. This table
function returns the columns FILENAME, SIZE, COMPRESSEDSIZE, MODTIME, COMMENT and
DOC. You can use these columns to select specific documents for insertion, as in Figure 4.11.
82
Chapter 4
Inserting and Retrieving XML Data
Note that the ZIP file does not get unzipped in the file system. Instead, files are extracted and
inserted straight from the ZIP file.
INSERT INTO shelf(bookinfo)
SELECT doc FROM
TABLE(blobsFromZipURL(urlFromFile('c:\xml\book\allbook.zip')))
WHERE filename LIKE '%.xml'OR
filename LIKE '%.XML'
Figure 4.11
4.2
Inserting documents from a ZIP file
DELETING XML DOCUMENTS
There are two ways of removing XML documents from a table:
• You can delete entire rows from a table. These rows can be selected with predicates on
relational columns in a table or with predicates on XML elements and attributes in the
XML columns.
• You can delete just the XML document within a row by setting the XML column to
NULL. If you want to prevent NULL values in an XML column, declare the column as
NOT NULL, as you would for relational columns.
Figure 4.12 shows two SQL DELETE statements that remove rows with XML documents from a
table. The first DELETE statement removes the rows and documents from the shelf table where
the relational column id has the value 4. The second statement deletes all rows where the element isbn in the XML document in the bookinfo column has the value 1851588981. These
statements work in both DB2 for z/OS and DB2 for Linux, UNIX, and Windows.
DELETE FROM shelf
WHERE id = 4 ;
DELETE FROM shelf
WHERE XMLEXISTS('$c/bookstore/book[isbn="0131580183"]'
PASSING bookinfo AS "c") ;
Figure 4.12
Deleting rows with XML document
You can remove just an XML document (instead of the whole row) by setting the XML column
for a particular row to NULL, as in Figure 4.13. You cannot remove the XML document by assigning the empty string to the XML column (SET bookinfo =''). The empty string is not a wellformed XML document and is therefore rejected.
4.3
Retrieving XML Documents
83
UPDATE shelf
SET bookinfo = NULL
WHERE id = 3
Figure 4.13
4.3
Setting an XML column to NULL
RETRIEVING XML DOCUMENTS
The section describes how to retrieve full XML documents. In Chapters 6 through 9 on querying
XML data you learn how to retrieve or filter on individual elements or attributes in XML documents.
The easiest way to retrieve whole XML documents is to include an XML column name in the
SELECT list of an SQL query. The example in Figure 4.14 selects the relational column id and
the XML column bookinfo from the table shelf where the id is less than 10. This query
returns two columns that have the data types INTEGER and XML, respectively.
SELECT id, bookinfo
FROM shelf
WHERE id < 10
Figure 4.14
Selecting whole XML documents
The query in Figure 4.14 performs an implicit serialization of the XML documents to their textual representation. Implicit serialization means that when XML data is sent to the client, the
XML data is automatically converted to serialized (text) format and not returned in DB2’s internal hierarchical format. Implicit serialization does not change the data type, so the serialized
XML data is still returned as type XML.
When you retrieve data in the DB2 Command Line Processor, the display of LOBs and XML
documents is truncated. Only the first 4KB of each XML document are shown. If you want to
retrieve larger documents then you need to use the EXPORT command, explained in Chapter 5.
In a SELECT statement you can also use the function XMLSERIALIZE to perform explicit serialization. Explicit serialization means that the XML data is returned in text format and explicitly
converted to a non-XML data type. In DB2 for z/OS, XMLSERIALIZE allows you to return XML
documents as type BLOB, CLOB, and DBCLOB. DB2 for Linux, UNIX, and Windows allows CHAR
and VARCHAR as additional target types. Figure 4.15 shows three queries with explicit serialization. The first one returns the serialized XML document as a BLOB data type, and the second as
VARCHAR, and the third as a CLOB.
84
Chapter 4
Inserting and Retrieving XML Data
SELECT XMLSERIALIZE(bookinfo AS BLOB(100k)) FROM shelf;
SELECT XMLSERIALIZE(bookinfo AS VARCHAR(32000)) FROM shelf;
SELECT XMLSERIALIZE(bookinfo AS CLOB(1M)) FROM shelf;
Figure 4.15
Returning text with different data types
Implicit serialization is usually preferred, as it avoids unnecessary code page conversion where
possible. Explicit serialization can be useful if your query must return a non-XML data type to
the application. Explicit serialization to BLOB or CLOB can be beneficial for large documents,
because it allows your application to use LOB locators for retrieval. Retrieving XML data into
applications and potential code page issues are discussed in more detail in Chapter 20 and
Chapter 21.
For an application it is important to know the data types of the columns that it receives. You can
use the DESCRIBE command to obtain the column and type information for tables or query result
sets. DB2 for Linux, UNIX, and Windows allows you to execute the DESCRIBE command in the
Command Line Processor or from an application using the ADMIN_CMD administrative procedure. The DESCRIBE command returns information in result set format that can be processed by
the application just like any other SQL result set. In DB2 for z/OS, the statements DESCRIBE
TABLE, DESCRIBE OUTPUT, and DESCRIBE CURSOR can be embedded in an application program to read column and type information in an SQL descriptor area (SQLDA).
Figure 4.16 demonstrates the DESCRIBE command and its output in the CLP. You can see that the
data type of the bookinfo column is XML. The column length is zero because XML documents
are stored as trees, which have no notion of length. The maximum document size that can be
inserted, loaded, or retrieved is 2GB.
DESCRIBE TABLE shelf;
Column name
-----------ID
BOOKINFO
Figure 4.16
schema
--------SYSIBM
SYSIBM
Data type name Length
Scale Nulls
--------------- -------- ----- ----INTEGER
4
0 Yes
XML
0
0 Yes
Describing a table using the DESCRIBE command in the CLP
Figure 4.17 shows how to describe queries that return XML documents. The description of the
first query confirms that it returns the documents as type XML. The second query performs explicit
serialization, and the DESCRIBE command verifies that the target type is VARCHAR.
4.4
Handling Documents with XML Declarations
85
db2 => DESCRIBE SELECT id, bookinfo FROM shelf;
Number of columns: 2
SQL type
------------497
INTEGER
989
XML
Type length
----------4
0
Column name
--------------ID
BOOKINFO
Name length
----------2
8
db2 => DESCRIBE SELECT xmlserialize(info as varchar(30000))
AS mydoc FROM customer WHERE cid = 1003;
Number of columns: 1
SQL type
------------449
VARCHAR
Figure 4.17
4.4
Type length
----------30000
Column name
--------------MYDOC
Name length
----------5
Describing queries in the CLP
HANDLING DOCUMENTS WITH XML DECLARATIONS
In Figure 4.1 you saw that our sample document begins with an XML declaration:
<?xml version="1.0" encoding="UTF-8" ?>
An XML declaration is optional and not required for an XML document to be well-formed. If a
document has an XML declaration, the following rules apply:
• The XML declaration must be at the very beginning of the document and cannot be preceded by any characters or whitespace.
• The declaration must contain the version attribute. DB2 only allows XML version 1.0,
which is the only version of XML that is widely used.
• Optionally, the declaration can contain an encoding attribute (see Chapter 20).
A document with an XML declaration cannot be inserted into an XML column if any of these
rules are violated. For example, the VALUES clause in Figure 4.18 contains blanks after the single
quote and before the XML declaration, which leads to error SQL16168N.
INSERT INTO shelf VALUES(10,'
<?xml version="1.0"?>…
SQL16168N XML document contained an invalid XML declaration.
Reason code ="3". SQLSTATE=2200M.
Figure 4.18
Invalid whitespace preceding an XML declaration
86
Chapter 4
Inserting and Retrieving XML Data
When a document that contains an XML declaration is stored in DB2, the declaration is not preserved and not part of the stored document. Instead, an XML declaration can optionally be generated and added to each document upon retrieval from the database. The generation of XML
declarations is controlled by the application in ways that depend on the API that is used. Chapter
21 provides further details.
Independent from the specific API that an application uses, you can always force the generation
of an XML declaration by using the XMLSERIALIZE function with the option INCLUDING
XMLDECLARATION. Figure 4.19 serves as an example.
SELECT XMLSERIALIZE(bookinfo AS CLOB(1M)
INCLUDING XMLDECLARATION)
FROM shelf;
Figure 4.19
Retrieving an XML document with XML declaration
If you invoke the Command Line Processor of DB2 for Linux, UNIX, and Windows with the –d
option, an XML declaration is added to each XML value that is retrieved, even if the query does
not contain the XMLSERIALIZE function.
4.5
COPYING FULL XML DOCUMENTS
You can copy full XML documents from one table to another using an INSERT/SELECT statement as you normally would for relational data. In the example in Figure 4.20, a target table
(shelf2) is created and the XML documents from shelf are copied into it.
CREATE TABLE shelf2 LIKE shelf;
-INSERT INTO shelf2(id, info)
SELECT(id, info)
FROM shelf;
Figure 4.20
Manipulating full XML documents using INSERT/SELECT
XML data that is moved using the insert/select method remains in DB2’s internal tree format during the entire operation, which means that no XML parsing takes place. Thus, this method of
copying XML data is typically more efficient than using the DB2 EXPORT utility followed by the
LOAD utility. However, you can perform a LOAD FROM cursor, which requires no EXPORT,
avoids logging, and parallelizes the write operations into the target table. Chapter 5 describes the
processing of XML documents with the IMPORT, EXPORT, and LOAD utilities.
4.6
4.6
Dealing with XML Special Characters
87
DEALING WITH XML SPECIAL CHARACTERS
Element and attribute values can potentially contain characters that have a special meaning in the
world of XML. For example, the less-than symbol (<) denotes the beginning of a tag, the ampersand (&) denotes the beginning of an entity reference, and quotes are used to delimit attribute values. If such characters appear in the middle of an element or attribute value they should be
escaped to avoid processing errors.
For example, this XML element contains the less-than character in its text value:
<rule>if a < b then exit(0)</rule>
Any XML parser interprets the less-than character as the beginning of the next XML element tag.
The parser then throws an error because the subsequent space is not a valid character in an XML
element name. The DB2 error is
SQL16110N
XML syntax error. Expected to find "Element Name".
The error means that the document is not well-formed and cannot be processed.
To solve this problem, the XML standard includes a set of predefined entities that must be used
instead of these reserved characters. For example, the <rule> element should use either the
entity reference $lt; or the character reference < instead of the actual less-than symbol:
<rule>if a < b then exit(0)</rule>
Table 4.2 shows all predefined entity and character references that are available to escape
reserved XML characters. Note that these references always start with an ampersand (&) and end
with a semicolon (;). It does not matter whether you use entity references or character references
to escape special characters. Either way is fine, but most people find the entity references more
intuitive.
Table 4.2
XML Special Character Substitution Strings
XML Special Character
Entity Reference
ASCII Character Reference
ampersand (&)
&
&
single quote (')
'
'
double quote (")
"
"
greater-than symbol (>)
>
>
less-than symbol (<)
<
<
88
Chapter 4
Inserting and Retrieving XML Data
Let’s look at one more example, shown in Figure 4.21. This INSERT statement adds information
about another book to the table shelf. The title of the book is Helen's story about foxes
& rabbits. However, the ampersand (&) is a reserved character and needs to be represented
either by & or by &. Additionally you need to escape the single quote in the title if you
want to insert the document through the CLP as a string that must be enclosed in single quotes.
INSERT INTO shelf
VALUES (4,
'<bookstore>
<book>
<title>Helen's story about foxes & rabbits</title>
</book>
</bookstore>')
Figure 4.21
Inserting a document with two entity references
When you retrieve this document, what will the title look like? The simple test in Figure 4.22
reveals that the entity reference ' has been resolved into the actual single quote character.
However, the entity reference & has been preserved. The reason for the difference is that the
single quote is not a reserved character in XML. A document that has a single quote in an element
value is still well-formed and hence there is no need to retain the entity reference after the document has been inserted. The ampersand, however, is a reserved character and always has to be
escaped so that the document remains well-formed, which is crucial if your application uses an
XML parser to process the documents retrieved from DB2.
db2 => SELECT bookinfo FROM shelf WHERE id = 4;
<bookstore><book><title>Helen's story about foxes &
rabbits</title></book></bookstore>
1 record(s) selected.
Figure 4.22
Retrieving a document that contains entity references
If you extract the title element and cast its text value to the SQL type VARCHAR, then the actual
ampersand character appears in the output (see Figure 4.23). The functions XMLCAST and
XMLQUERY are explained in Chapter 7, Querying XML Data with SQL/XML.
4.7
Understanding XML Whitespace and Document Storage
89
db2 => SELECT XMLCAST(XMLQUERY('$BOOKINFO/bookstore/book/title')
AS VARCHAR(35)) as title
FROM shelf;
TITLE
-----------------------------------Helen's story about foxes & rabbits
1 record(s) selected.
Figure 4.23
4.7
Retrieving the title as SQL type VARCHAR
UNDERSTANDING XML WHITESPACE AND DOCUMENT STORAGE
Most XML documents contain whitespace, and its purpose is typically to improve readability.
According to the XML standard, whitespace is any of the following characters and their respective Unicode code points.
• space character (0x20)
• CR, carriage return (0x0D)
• LF, line feed (0x0A)
• tab (0x09)
The XML standard mandates that XML parsers must remove or replace any CR characters
(0x0D) that appear in an XML document. Any two-character sequence CR LF is replaced by a
single LF, and any CR character that is not followed by LF is also converted to a single LF.
Whitespace can occur at various places in an XML document. For example, the simple document
in Figure 4.24 contains whitespace in the following locations:
• Between the element name “a” and the attribute “x”
• On both sides of the “=” character that belongs to the attribute “x”
• Within the double quotes that enclose the value of the attribute “x”
• Between the start tag of element “a” and the start tag of element “b”
• Trailing whitespace within the start and end tag of element “b” and within the end tag of
element “a”
• Between the start and end tag of element “b”
• Between the end tag of element “b” and the start tag of element “c”
• Inside the text value of element “c”
• Between the end tag of element “c” and the end tag of element “a”
90
<a
Chapter 4
x
Figure 4.24
=
" 1">
<b
>
</b
>
<c>
2
Inserting and Retrieving XML Data
</c>
</a
>
A sample document with whitespace
The location of the whitespace matters. Depending on where a whitespace character occurs it is
considered one of four types of whitespace:
• Insignificant whitespace (trailing spaces in element or attributes names, spaces around
the equality [=] symbol of an attribute, and others)
• Significant whitespace (within attribute and elements values)
• Boundary whitespace (between one tag and the next, if no other characters occur there)
• Known whitespace (a single whitespace that precedes an attribute name)
Figure 4.25 shows the same XML document as in Figure 4.24 and identifies the four types of
whitespace. Note that the whitespace between the start and end tag of element “b” is considered
boundary whitespace and not significant whitespace, because there are no other non-whitespace
characters in the text value of element “b”. The whitespace in the text value of element “c” is significant, because there is another non-whitespace character (“2”) adjacent to this whitespace.
significant
known
<a
x
=
" 1"
>
<b
insignificant
Figure 4.25
significant
insignificant
>
</b
>
<c>
2
</c>
insignificant
</a
>
boundary
Different types of whitespace
XML parsers always remove all insignificant whitespace, which is not specific to DB2 but
required by the XML standard. The XML standard provides no option to preserve insignificant
whitespace during XML parsing. On the other hand, significant whitespace is always preserved
and there is no option to strip significant whitespace. Known whitespace is a single space
(U+0020) that separates an attribute name from a preceding element name or attribute. Known
whitespace is removed during XML parsing and not stored with the document. But, it gets reinjected during serialization when you retrieve the XML data in text format.
Boundary whitespace can be preserved or removed (stripped). Figure 4.26 shows two versions of
the sample document from Figure 4.25. In the first version, all insignificant and boundary whitespace has been stripped from the document. In the second version, insignificant whitespace has
been stripped but boundary whitespace has been preserved. In DB2, the default behavior is to
strip boundary whitespace, but you can choose to preserve boundary whitespace, if desired.
4.7
Understanding XML Whitespace and Document Storage
91
-- Document with boundary whitespace stripped:
<a x="1"><b/><c>
2
</c></a>
-- Document with boundary whitespace preserved:
<a x="1">
Figure 4.26
<b>
</b>
<c>
2
</c>
</a>
Sample document with and without boundary whitespace preserved
You can preserve boundary whitespace only if you insert
or update documents without validation against an XML Schema.
Validation always forces boundary whitespace to be stripped.
NOTE
4.7.1
Preserving XML Whitespace
DB2’s default behavior to strip boundary whitespace is desirable because it saves space on disk
and in memory. Additionally, whitespace is typically not meaningful for applications that consume XML data. Hence, this default is likely the right choice for your application. However, if
you encounter a case where boundary whitespace has to be preserved, DB2 supports three ways
to enable whitespace preservation. Ordered by their precedence, they are
• The special attribute xml:space inside XML documents
• The explicit strip/preserve whitespace option in the XMLPARSE function
• Changing the DB2 default behavior from “strip” to “preserve” with the CURRENT
IMPLICIT XMLPARSE OPTION (see section 4.7.2)
The XML standard defines the optional attribute xml:space that controls the stripping or preservation of whitespace. It can have the values preserve or default, where default means that
whitespace is stripped. This attribute can be included in any element in an XML document. It
affects the entire subtree under this element, unless it is overridden by other xml:space attributes at a deeper level of the document. If the xml:space attribute appears only in the root element of a document then it affects all boundary whitespace in the entire document. Any
xml:space attributes override any whitespace settings in the XMPARSE function or the CURRENT
IMPLICIT XMLPARSE OPTION.
The drawback of xml:space attributes is that they often do not occur in XML documents and it
can be time consuming to add them to every document before insertion into DB2. Also, when an
xml:space attribute is in place, its effect can only be changed by removing or modifying the
attribute in each document. Due to this lack of flexibility it is recommended not to use
xml:space attributes. Instead, use the explicit whitespace option in the XMPARSE function or the
CURRENT IMPLICIT XMLPARSE OPTION, which we explain later.
92
Chapter 4
Inserting and Retrieving XML Data
Let’s look at the four INSERT statements in Table 4.3 through Table 4.6. They all insert a document with whitespace such as indentation and line breaks. The right column in each table shows
the document and its whitespace after it has been retrieved from DB2. Run these INSERT statements in the CLP with the –t and the –q option (db2 –t –q). The –t option sets the semicolon
as the default statement terminator. The –q option ensures that the CLP, as an application program for DB2, does not remove new line characters or other whitespace when sending statements
to the DB2 server.
The INSERT statement in Table 4.3 does not specify any whitespace option, which implies that
all boundary whitespace is stripped. Since boundary whitespace includes line breaks, the document after retrieval is a continuous string without line breaks, spilling over multiple lines as
needed. Note that significant whitespace in the title element has been preserved; that is, the
spaces between the words This, is, a, space, and story.
Table 4.3
Inserting XML without Preserving Whitespace
INSERT statement:
Document after retrieval from DB2:
INSERT INTO shelf VALUES (10,
'<bookstore>
<book>
<isbn>1851586666</isbn>
<title>This is a space story</title>
</book>
</bookstore>')
<bookstore><book><isbn>1851586666</isbn><tit
le>This is a space story</title></book></bo
okstore>
The document that is inserted in Table 4.4 carries an xml:space attribute with the value
preserve, which means that all boundary whitespace in this document is preserved. Hence, when
you retrieve the document from DB2 all line breaks and indentation match the original document.
Table 4.4
Inserting an XML Document with xml:space Attribute
INSERT statement:
Document after retrieval from DB2:
INSERT INTO shelf VALUES (11,
'<bookstore xml:space="preserve">
<book>
<isbn>1851586666</isbn>
<title>This is a space story</title>
</book>
</bookstore>')
<bookstore xml:space="preserve">
<book>
<isbn>1851586666</isbn>
<title>This is a space story</title>
</book>
</bookstore>
The INSERT statement in Table 4.5 wraps the XMLPARSE function with the explicit PRESERVE
WHITESPACE clause around the document, which also preserves all boundary whitespace.
4.7
Understanding XML Whitespace and Document Storage
Table 4.5
93
Inserting an XML Document with the XMLPARSE Function
INSERT statement:
Document after retrieval from DB2:
INSERT INTO shelf
VALUES (12,XMLPARSE(DOCUMENT
'<bookstore>
<book>
<isbn>1851586666</isbn>
<title>This is a space story</title>
</book>
</bookstore>' PRESERVE WHITESPACE))
<bookstore>
<book>
<isbn>1851586666</isbn>
<title>This is a space story</title>
</book>
</bookstore>
The INSERT statement in Table 4.6 uses the XMLPARSE function with the STRIP WHITESPACE
option, and the document also carries the xml:space attribute in the book element. The effect is
that all boundary whitespace is stripped, except within the book element and its child elements.
The line breaks and indentation within the book element have been preserved according to the
xml:space attribute.
Table 4.6
Interaction between the XMLPARSE Function and xml:space Attribute
INSERT statement:
Document after retrieval from DB2:
INSERT INTO shelf
VALUES (13,XMLPARSE(DOCUMENT
'<bookstore>
<book xml:space="preserve">
<isbn>1851586666</isbn>
<title>This is a space story</title>
</book>
</bookstore>' STRIP WHITESPACE))
<bookstore><book xml:space="preserve">
<isbn>1851586666</isbn>
<title>This is a space story</title>
</book></bookstore>
4.7.2
Changing the Whitespace Default from “Strip” to “Preserve”
If you always need to preserve boundary whitespace you might find it tedious to ensure that all
applications always use the XMLPARSE function with the PRESERVE WHITESPACE option. In this
case it is easier to change DB2’s default behavior from STRIP WHITESPACE to PRESERVE
WHITESPACE and avoid using the XMLPARSE function. In DB2 for Linux, UNIX, and Windows,
the default behavior is controlled by a DB2 special register called CURRENT IMPLICIT
XMLPARSE OPTION. It enables you to specify the whitespace handling per session (connection).
You can change the default in several ways:
• Use the following statement from an application or the DB2 CLP:
SET CURRENT IMPLICIT XMLPARSE OPTION = 'PRESERVE WHITESPACE'
• For CLI applications, add the following entry to the db2cli.ini file:
CurrentImplicitXMLParseOption = 'PRESERVE WHITESPACE'
94
Chapter 4
Inserting and Retrieving XML Data
You can edit this file manually, or issue the UPDATE CLI CONFIGURATION command:
UPDATE CLI CONFIGURATION
FOR SECTION <dbname>
USING CurrentImplicitXMLParseOption '"PRESERVE WHITESPACE"'
• In CLI applications you can also use the function SQLSetConnectAttr() to set the
connection attribute SQL_ATTR_CURRENT_IMPLICIT_XMLPARSE_OPTION. It can be
set before or after establishing a connection.
Remember that the XMLPARSE function can always be used explicitly to override the default.
4.7.3
Storing XML Documents for Compliance
Many applications have the requirement that once they store an XML document they can get “the
same” document back. The key question is how the application defines “the same.” In many cases
“the same” means that all element and attribute tags, all element and attribute values, all comments, processing instructions and namespaces, and all significant whitespace have to be
returned in the same order and representation as in the original document. This notion of “the
same” is sometimes also called Document Object Model fidelity. It means that the structure and
data content of your XML documents is always preserved and reproducible, including digital signatures. DB2’s pureXML storage provides this fidelity.
Some applications may take their definition of “the same” one step further. They might require
that any XML document that they retrieve from a database is 100% byte-for-byte identical to the
one that was inserted, including all insignificant whitespace. To ensure that the documents are
byte-for-byte identical you must avoid XML parsing, because the output from an XML parser
does not always contain all bytes that were in the original document. This behavior is irrespective
of database storage, but inherent in how XML parsing is defined by the XML standard. For example, XML parsers are required by the XML standard to remove insignificant whitespace and normalize line endings. Otherwise they are not compliant.
If you require exact byte-for-byte retention of XML documents then an XML column, which
stores XML in a parsed format, should not be your only storage choice for the documents. You
should store a second copy of each document in a BLOB or VARCHAR FOR BIT column in the
same row. The parsed XML storage allows efficient querying while the binary copy is for auditing or compliance purposes. Note that character data types, such as CLOB or VARCHAR, do not
guarantee that documents are stored without any byte modifications, because character data can
be subject to code page conversion. Code page issues are explained in Chapter 20.
4.8
4.8
Summary
95
SUMMARY
The basic manipulation of XML documents in DB2 is easy. You can use the familiar SQL statements INSERT, SELECT, and DELETE to add, retrieve, and remove XML documents from an
XML column in a DB2 table. UPDATE statements can replace or modify XML documents, which
is further discussed in Chapter 12. In INSERT, SELECT, and UPDATE statements, applications can
use parameter markers and host variables to exchange XML documents with the DB2 server.
Code samples in various programming languages are provided in Chapter 21.
If you include an XML column name in the SELECT list of an SQL query, the column type in the
result set is XML and the XML documents are implicitly serialized to their textual representation
upon retrieval. Alternatively, the XMLSERIALIZE function allows you to perform explicit serialization. Explicit serialization means that the text form of the XML documents are returned in a
non-XML data type of your choosing, such as BLOB, CLOB, or VARCHAR. The XMLSERIALIZE
function can be used to force the generation of an XML declaration at the beginning of any document that you retrieve from DB2.
The XML standard defines several reserved characters as well as whitespace characters.
Reserved characters, such as the less-than sign (<) or the ampersand (&), cannot appear as-is in
the values of an XML document and must be properly escaped. XML documents can contain significant, insignificant, and boundary whitespace. Insignificant whitespace can occur within element tags, such as <book >, and must be removed during XML parsing, as defined in the XML
standard. Significant whitespace can occur in element and attribute values and is always preserved. Boundary whitespace, such as new line characters after XML elements, can be either preserved or stripped. DB2 strips boundary whitespace by default, but offers several ways to
preserve boundary whitespace, such as the PRESERVE WHITESPACE option in the XMLPARSE
function.
This page intentionally left blank
C
H A P T E R
5
Moving XML Data
his chapter looks at the different methods for moving large numbers of XML documents
into and out of the database. We also discuss moving XML data between databases with
federation and replication. These concepts apply to both DB2 for z/OS and DB2 for Linux,
UNIX, and Windows.
T
You can perform basic insert and retrieval of XML documents with SQL INSERT and SELECT
statements. However, for bulk processing of XML documents it is often more convenient and
more efficient to use the LOAD utility, which is available on all platforms, or the IMPORT utility in
DB2 for Linux, UNIX, and Windows. The tradeoff between insert, load, and import is the same
as for relational data. Some applications might have to issue an individual INSERT statement for
each XML document (row) as soon as it is received or generated to make new data instantly available for queries. In contrast, you might prefer to use the LOAD or IMPORT utilities if you receive a
large number of XML documents in bulk, or if you can afford to accumulate new documents for a
nightly batch operation.
There is a 2GB limit per document for moving data into and out of a DB2 database on any platform. This limit applies to large objects as well as XML documents.
In this chapter, we discuss the following topics:
• Exporting, importing, and loading XML documents in DB2 for Linux, UNIX, and Windows (sections 5.1, 5.2, and 5.3, respectively)
• Loading and unloading XML documents in DB2 for z/OS (sections 5.4 and 5.5)
• Document validation with XML Schemas during load or import (section 5.6)
97
98
Chapter 5
Moving XML Data
• Splitting large XML documents into smaller documents (section 5.7)
• XML support in replication, federation, HADR, db2look, and db2move (sections 5.8
through 5.11)
5.1
EXPORTING XML DATA IN DB2 FOR LINUX, UNIX, AND WINDOWS
You can use the EXPORT command in DB2 for Linux, UNIX, and Windows to move XML data,
or a mix of XML and relational data, from the database to the file system. In fact, the EXPORT
utility allows you to export the result of any query to the file system. If you are familiar with
exporting LOB data then you will find that exporting XML data is very similar.
In this section various options for exporting XML data are examined. We use a test table called
customer2, based on the customer table in the DB2 sample database. This test table is created
and populated using the two commands shown in Figure 5.1. It has one XML column while the
original customer table in the DB2 sample database has two XML columns, one of which is initially empty. It contains six rows, each with an XML document in the info column.
CREATE TABLE customer2 (cid INT, info XML);
INSERT INTO customer2
SELECT cid, info FROM customer;
Figure 5.1
Creating the test table to demonstrate the EXPORT command
Before you export data, you need to identify or create a directory into which the data will be
exported. Then you can use the EXPORT command in a number of different ways:
• Export XML documents and combine them into a single file (see section 5.1.1)
• Export XML documents as individual files (section 5.1.2)
• Export XML documents as individual files with non-default file names (section 5.1.3)
• Export XML documents to one or multiple dedicated directories (section 5.1.4)
• Export fragments of XML documents (section 5.1.5)
• Export XML documents with XML Schema information (section 5.1.6)
Let’s look at each of these in turn. Some of the examples are based on a Windows file system, others on a UNIX or Linux file system.
5.1.1
Exporting XML Documents to a Single File
The simplest form of the EXPORT command allows you to read all rows from a table, including
any XML columns (see Figure 5.2). The EXPORT command starts with the keywords EXPORT TO
plus the specification of the desired output file. In this example the output file is
5.1
Exporting XML Data in DB2 for Linux, UNIX, and Windows
99
c:\mydata\cust_exp.del in the Windows file system. The file name is followed by the keywords OF DEL to indicate that the type of the output file is delimited format. The remainder of the
EXPORT command is a query whose result set is exported. This query can be more complex than
the one shown in Figure 5.2. For example, it can also contain a WHERE clause to filter the exported
documents or any of the XML query functions discussed in Chapters 6 through 9.
EXPORT TO c:\mydata\cust_exp.del OF DEL
SELECT * FROM customer2;
Figure 5.2
Exporting all XML documents to a single file
The EXPORT command in Figure 5.2 produces two output files:
• cust_exp.del
(see Figure 5.3)
• cust_exp.del.001.xml
(see Figure 5.4)
The first file, cust_exp.del, is a delimited format flat file that holds the relational data of the
exported result set. The second file, cust_exp.del.001.xml, holds the XML data of the XML
column in the result set. By default, all XML documents from the XML column are concatenated
in this file.
The delimited format file, cust_exp.del, contains information that links the XML documents
to the rows that they belong to, as shown in Figure 5.3. More specifically, the delimited format
file contains one column for each column in the result set of the exported query. In this example it
contains two columns. The first column holds the integer values of the exported column cid. The
second column represents the exported column info and contains pointers to the corresponding
XML documents in the file cust_exp.del.001.xml. These pointers are XML elements known
as XML Data Specifiers (XDS). Each XML Data Specifier has three attributes: FIL, OFF, and
LEN. These attributes represent the file name that contains the XML data, the byte offset from
where a particular document starts, and the length of each XML document, respectively.
1000,"<XDS
1001,"<XDS
1002,"<XDS
1003,"<XDS
1004,"<XDS
1005,"<XDS
Figure 5.3
FIL='cust_exp.del.001.xml'
FIL='cust_exp.del.001.xml'
FIL='cust_exp.del.001.xml'
FIL='cust_exp.del.001.xml'
FIL='cust_exp.del.001.xml'
FIL='cust_exp.del.001.xml'
OFF='0' LEN='281' />"
OFF='281' LEN='283' />"
OFF='564' LEN='282' />"
OFF='846' LEN='408' />"
OFF='1254' LEN='412' />"
OFF='1666' LEN='421' />"
Content of the delimited format flat file cust_exp.del
The file cust_exp.del.001.xml contains all the XML documents from the exported XML
column concatenated together, as shown in Figure 5.4. The second of the six documents is highlighted in bold. As indicated in the DEL file, it begins at byte offset 281 and has a length of 283.
100
Chapter 5
Moving XML Data
You can actually count the characters in Figure 5.4 to verify that this is true. Also note that this
concatenation of documents does not produce a single well-formed document because a single
root element is missing.
<?xml version="1.0" encoding="UTF-8" ?><customerinfo Cid="1000"><
name>Kathy Smith</name><addr country="Canada"><street>5 Rosewood<
/street><city>Toronto</city><prov-state>Ontario</prov-state><pcod
e-zip>M6W 1E6</pcode-zip></addr><phone type="work">416-555-1358</
phone></customerinfo><?xml version="1.0" encoding="UTF-8" ?><cust
omerinfo Cid="1001"><name>Kathy Smith</name><addr country="Canada
"><street>25 EastCreek</street><city>Markham</city><prov-state>On
tario</prov-state><pcode-zip>N9C 3T6</pcode-zip></addr><phone typ
e="work">905-555-7258</phone></customerinfo><?xml version="1.0" e
ncoding="UTF-8" ?><customerinfo Cid="1002"><name>Jim Noodle</name
><addr country="Canada"><street>25 EastCreek</street><city>Markha
m</city><prov-state>Ontario</prov-state><pcode-zip>N9C 3T6</pcode
-zip></addr><phone type="work">905-555-7258</phone></customerinfo
><?xml version="1.0" encoding="UTF-8" ?><customerinfo Cid="1003">
<name>Robert Shoemaker</name><addr country="Canada"><street>1596
Baseline</street><city>Aurora</city><prov-state>Ontario</prov-sta
te><pcode-zip>N8X 7F8</pcode-zip></addr><phone type="work">905-55
5-7258</phone><phone type="home">416-555-2937</phone><phone type=
"cell">905-555-8743</phone><phone type="cottage">613-555-3278</ph
one></customerinfo>...
Figure 5.4
5.1.2
Content of the XML data file cust_exp.del.001.xml
Exporting XML Documents as Individual Files
In some situations exporting each XML document into a separate file can be desirable. To do this
you need to specify the clause MODIFIED BY with the option xmlinsepfiles. This is shown in
Figure 5.5.
EXPORT TO c:\mydata\cust_exp.del OF DEL
MODIFIED BY xmlinsepfiles
SELECT * FROM customer2;
Figure 5.5
Exporting XML documents as separate files
This EXPORT command produces n + 1 files where n is the number of XML documents in the
exported XML column. In our example it produces the following seven files in the directory
c:\mydata:
• cust_exp.del
• cust_exp.del.001.xml
• cust_exp.del.002.xml
• cust_exp.del.003.xml
5.1
Exporting XML Data in DB2 for Linux, UNIX, and Windows
101
• cust_exp.del.004.xml
• cust_exp.del.005.xml
• cust_exp.del.006.xml
The first file is the delimited format flat file that contains the relational data of the exported result
set together with pointers to the exported XML documents. These pointers (XML Data Specifiers) look different now because each XML document is exported as a separate file in the file system (see Figure 5.6). Offset and length are no longer required, just the file name of each
individual XML document. These file names are derived from the name of the delimited format
flat file and extended with an increasing number and the extension .xml. The file numbers start
with three digits and additional digits are used as needed when large numbers of documents are
exported.
1000,"<XDS
1001,"<XDS
1002,"<XDS
1003,"<XDS
1004,"<XDS
1005,"<XDS
Figure 5.6
FIL='cust_exp.del.001.xml'
FIL='cust_exp.del.002.xml'
FIL='cust_exp.del.003.xml'
FIL='cust_exp.del.004.xml'
FIL='cust_exp.del.005.xml'
FIL='cust_exp.del.006.xml'
/>"
/>"
/>"
/>"
/>"
/>"
Content of the delimited format flat file cust_exp.del
Remember that the examples in this chapter use the table customer2 which has an INTEGER
column and an XML column. The table customer, which is readily available in the DB2 sample
database, has an INTEGER column and two XML columns, info and history. Since the history column is initially empty (NULL), exporting all columns from the customer table leads to
odd-numbered file names—cust_exp.del.001.xml, cust_exp.del.003.xml, cust_
exp.del.005.xml, and so on. The even-numbered file names would be used for the documents
in the history column, but it is NULL and so these file names are not used.
The xmlinsepfiles option used in Figure 5.5 is just one of many possible options that can be
specified in the MODIFIED BY clause of the EXPORT command. Table 5.1 summarizes other
options relevant to XML data.
Table 5.1
XML Relevant Modifiers for the EXPORT Command
Modified by:
Description:
xmlinsepfiles
This option writes each XML document to a separate file. Without this
option, all documents are by default concatenated into a single file.
xmlnodeclaration
This option produces XML documents without an XML declaration. Without
this option the default behavior is that each exported XML document carries
an XML declaration with an encoding attribute, such as
<?xml version="1.0" encoding="UTF-8" ?>
(continues)
102
Chapter 5
Table 5.1
Moving XML Data
XML Relevant Modifiers for the EXPORT Command (Continued)
Modified by:
Description:
xmlchar
This option writes the exported XML documents in the character codepage.
The character codepage is the same as the application codepage unless the
codepage option of the EXPORT command is specified. Without the
xmlchar option, XML documents are by default written out in Unicode.
Chapter 20 provides a deeper discussion of code pages and XML document
encodings.
xmlgraphic
This option writes the exported XML documents in the UTF-16 code page
regardless of the application code page or the codepage modifier.
5.1.3
Exporting XML Documents as Individual Files with Non-Default Names
If you want the exported XML documents to have file names that are not based on the file name of
the delimited format flat file, use the XMLFILE clause of the EXPORT command to specify a different file name prefix. The command in Figure 5.7 exports the table customer2 and writes all
XML documents to separate files whose names start with custdoc.
EXPORT TO c:\mydata\cust_exp.del OF DEL
XMLFILE custdoc
MODIFIED BY xmlinsepfiles
SELECT * FROM customer2;
Figure 5.7
Exporting XML documents to files with custom file names
This command produces the following files:
• cust_exp.del
• custdoc.001.xml
• custdoc.002.xml
• custdoc.003.xml
• custdoc.004.xml
• custdoc.005.xml
• custdoc.006.xml
The XMLFILE clause can also be used without the xmlinsepfiles option; that is, all documents
are combined into a single file whose name starts with custdoc.
5.1.4
Exporting XML Documents to One or Multiple Dedicated Directories
The EXPORT command allows you to write the exported XML documents to a dedicated directory
that is different from the directory where the delimited format file is written to. To achieve this,
5.1
Exporting XML Data in DB2 for Linux, UNIX, and Windows
103
use the XML TO clause to specify an existing directory, as shown in Figure 5.8. This EXPORT command writes the delimited format flat file cust_exp.del to the directory /mydata, and the six
XML documents in six separate files to the directory /mydata/customer.
EXPORT TO /mydata/cust_exp.del OF DEL
XML TO /mydata/customer
MODIFIED BY xmlinsepfiles
SELECT * FROM customer2;
Figure 5.8
Exporting XML documents as individual files to a dedicated directory
If the XML TO clause specifies a list of multiple directories, as in Figure 5.9, the XML documents
are distributed evenly among them in a round-robin fashion.
EXPORT TO /mydata/cust_exp.del OF DEL
XML TO /mydata/cust1, /mydata/cust2
XMLFILE custdoc
MODIFIED BY xmlinsepfiles
SELECT * FROM customer2;
Figure 5.9
Exporting XML documents as separate files to multiple directories
This EXPORT command produces the following files:
• /mydata/cust1/custdoc.001.xml
• /mydata/cust1/custdoc.003.xml
• /mydata/cust1/custdoc.005.xml
• /mydata/cust2/custdoc.002.xml
• /mydata/cust2/custdoc.004.xml
• /mydata/cust2/custdoc.006.xml
You can later invoke the IMPORT or LOAD utility with the same two paths, /mydata/cust1 and
/mydata/cust2, to have DB2 read the same documents in the same round-robin fashion.
If you specify multiple target directories in the XML TO clause but omit the xmlinsepfiles
option, as in Figure 5.10, then the EXPORT utility concatenates the exported XML documents into
multiple large files, one per target directory.
EXPORT TO /mydata/cust_exp.del OF DEL
XML TO /mydata/cust1, /mydata/cust2
XMLFILE custdoc
SELECT * FROM customer2;
Figure 5.10
Exporting XML documents to multiple directories
104
Chapter 5
Moving XML Data
This EXPORT command produces the following three files:
• The delimited format flat file cust_exp.del in the directory /mydata
• A file called custdoc.001.xml in the directory /mydata/cust1
• A file called custdoc.002.xml in the directory /mydata/cust2
The exported XML documents are evenly distributed across the two files custdoc.001.xml and
custdoc.002.xml. The delimited format flat file cust_exp.del contains the rows shown in Figure 5.11. It reveals that the first, third, and fifth documents are stored in the file custdoc.
001.xml, while the second, fourth, and sixth documents are stored in custdoc.002.xml. Each
document is precisely identified by its offset and length.
1000,"<XDS
1001,"<XDS
1002,"<XDS
1003,"<XDS
1004,"<XDS
1005,"<XDS
Figure 5.11
5.1.5
FIL='custdoc.001.xml'
FIL='custdoc.002.xml'
FIL='custdoc.001.xml'
FIL='custdoc.002.xml'
FIL='custdoc.001.xml'
FIL='custdoc.002.xml'
OFF='0' LEN='281' />"
OFF='0' LEN='283' />"
OFF='281' LEN='282' />"
OFF='283' LEN='408' />"
OFF='563' LEN='412' />"
OFF='691' LEN='421' />"
Content of the delimited format flat file cust_exp.del
Exporting Fragments of XML Documents
Up to now we have looked at exporting whole documents. It is also possible to export document
fragments that may or may not be well-formed documents. To achieve this you can use the
EXPORT command with any XQuery or SQL/XML query, such as the ones that we discuss in
Chapters 6 through 9, which cover XML queries. Let’s consider the following examples.
The command in Figure 5.12 exports all phone elements from each of the six XML documents in
the info column of the table customer2. It writes six rows to the output files, one for each XML
document. Each row contains one or more phone elements, depending on the number of phone
elements in the respective document. If a row contains a sequence of multiple phone elements
without a common root element, then this value is not a well-formed XML document.
EXPORT TO /mydata/phones.del OF DEL
SELECT XMLQUERY('$INFO/customerinfo/phone')
FROM customer2;
Figure 5.12
Exporting document fragments
The query in the EXPORT command can also be an XPath or XQuery expression, as shown in Figure 5.13. Similar to the previous example in Figure 5.12, this command also exports all phone
5.1
Exporting XML Data in DB2 for Linux, UNIX, and Windows
105
elements from all six customer documents. However, it writes each phone element to a separate
row in the output file, even if multiple phone elements come from the same XML document.
This is because XQuery and SQL/XML queries that seem to be equivalent can produce result sets
with different cardinalities. For details, please refer to Chapter 8 (see section 8.3.3, Result Set
Cardinalities in XQuery and SQL/XML).
EXPORT TO /mydata/phones.del OF DEL
XQUERY db2-fn:xmlcolumn("CUSTOMER2.INFO")/customerinfo/phone;
Figure 5.13
5.1.6
Exporting document fragments as well-formed documents
Exporting XML Data with XML Schema Information
An XML column can contain XML documents that have been validated against one or multiple
XML Schemas when they were inserted or loaded. When you export validated XML documents,
the EXPORT utility can produce information that tells you for each document which XML
Schema it belongs to. This is achieved with the XMLSAVESCHEMA option in the EXPORT command. For each exported XML document that was validated against an XML Schema, the fully
qualified SQL identifier of that XML Schema is stored as an attribute (SCH) in the corresponding
XML Data Specifier (XDS). The SQL identifier of the XML Schema is the name under which you
registered the XML Schema in DB2. If the exported document was not validated against an XML
Schema or the schema no longer exists in the database, the SCH attribute is not included in the
corresponding XDS. Figure 5.14 shows the command to export documents with XML Schema
information.
EXPORT TO /mydata/cust_exp.del OF DEL
MODIFIED BY xmlinsepfiles
XMLSAVESCHEMA
SELECT * FROM customer2;
Figure 5.14
Exporting documents specifying the XML Schema
The delimited format flat file produced might look like the one in Figure 5.15. In this example it
shows that the first two documents were validated against the XML Schema with the SQL identifier DB2ADMIN.CUSTXSD. The third and the fifth documents were validated against schema
DB2ADMIN.CUSTXSD2, while the fourth and the sixth documents are not associated with any
XML Schema. This information reflects how documents were validated at insert time, if at all. If
you load or import the exported XML documents and use this delimited format flat file as input,
the documents can be validated against their respective XML Schemas, if those schemas exist in
the database.
106
Chapter 5
1000,"<XDS
1001,"<XDS
1002,"<XDS
1003,"<XDS
1004,"<XDS
1005,"<XDS
Figure 5.15
5.2
FIL='cust_exp.del.001.xml'
FIL='cust_exp.del.002.xml'
FIL='cust_exp.del.003.xml'
FIL='cust_exp.del.004.xml'
FIL='cust_exp.del.005.xml'
FIL='cust_exp.del.006.xml'
Moving XML Data
SCH='DB2ADMIN.CUSTXSD'/>"
SCH='DB2ADMIN.CUSTXSD'/>"
SCH='DB2ADMIN.CUSTXSD2'/>"
/>"
SCH='DB2ADMIN.CUSTXSD2'/>"
/>"
Content of the delimited format flat file cust_exp.del
IMPORTING XML DATA IN DB2 FOR LINUX, UNIX, AND WINDOWS
In DB2 9.1 for Linux, UNIX, and Windows you can use the IMPORT utility to move XML data
into an XML column. Since DB2 Version 9.5 you can also use the LOAD utility to load XML data.
The choice between IMPORT and LOAD is largely dependent on operating considerations, which
are similar for XML as for relational data:
• The LOAD utility typically performs better than the IMPORT utility because
• It operates at the DB2 page level, whereas the IMPORT utility operates at the row
level.
• The data loaded by the LOAD utility is not logged in the transaction log.
• The LOAD utility automatically parallelizes its workload.
• If you use the IMPORT utility, then the target table can be kept fully accessible to other
applications for insert and query operations at all times. In particular, you can start an
IMPORT operation while other queries on the table are in progress. The LOAD utility has
an online mode that allows queries (but no writes) against the target table while the
LOAD is in progress. However, queries that started prior to the LOAD must be quiesced
before a LOAD or online LOAD can be started.
• If you have triggers on the target table, then these are fired if the IMPORT utility is used,
but are not fired if the LOAD utility is used.
• Both the IMPORT and LOAD utilities can optionally perform XML Schema validation
and preserve whitespace in the XML documents.
The IMPORT and LOAD utilities can be viewed as inverse operations to EXPORT. In particular, the
IMPORT and LOAD utilities can directly consume the output produced by the EXPORT utility; that
is, a delimited format flat file that contains pointers to the XML documents that reside in one or
multiple separate files. If you want to IMPORT or LOAD data that wasn’t previously exported with
the EXPORT command, you need to produce a delimited format file that looks as if it had been
produced by the EXPORT utility.
5.2
Importing XML Data in DB2 for Linux, UNIX, and Windows
5.2.1
107
IMPORT Command and Input Files
Assume you want to use the IMPORT command to add new rows to the table customer2, and that
you have a directory c:\mydata in the file system that contains several files with XML documents that you want to import. This directory could contain thousands of files, but in this example
let’s assume that you just have two XML files called data2.xml and data3.xml, each containing a single XML document. You can produce a delimited format flat file, such as the file
data.del in Figure 5.16, which contains two columns. The first column holds INTEGER values
for the first column of the target table, and the second column holds pointers to the XML documents that you want to import into the second column of the target table.
2000,"<XDS FIL='data2.xml' />"
2001,"<XDS FIL='data3.xml' />"
Figure 5.16
Content of the delimited format input file data.del
With this delimited format input file you can execute the IMPORT command shown in Figure
5.17. It assumes that the file data.del as well as the XML documents data2.xml and
data3.xml are all located in the current directory. The keywords OF DEL indicate that the input
file data.del is of type delimited format.
IMPORT FROM data.del OF DEL
INSERT INTO customer2;
Figure 5.17
Importing XML documents
If the required files are not located in the local directory then you must provide appropriate paths.
For example, if the file data.del is located in the directory c:\mydata, and the XML documents are in the directory c:\mydata\myxml, then the IMPORT command in Figure 5.18 obtains
the files from the appropriate locations.
IMPORT FROM c:\mydata\data.del OF DEL
XML FROM c:\mydata\myxml
INSERT INTO customer2;
Figure 5.18
Importing XML documents from specific locations
Incorrect file paths in the IMPORT command are a very
common mistake, so you want to pay extra attention to them!
NOTE
If you need to load XML data that was previously exported to multiple directories, specify the list
of directories in the XML FROM clause. This clause corresponds to the XML TO clause of the
EXPORT command.
108
Chapter 5
Moving XML Data
If the two XML documents data2.xml and data3.xml happen to be concatenated as a single
file (for example, docs.xml), then the delimited format input file needs to specify offset and
length for each document, as in Figure 5.19. The first XML document starts at an offset of 0 bytes
into the file and is 281 bytes long. The second XML document starts at offset 281 and is 283 bytes
long, and so on for all XML documents that may be in the same file. Since it is tedious to determine the number of bytes of each document, such an input file with offsets and lengths is typically
only used if it is available from a previous EXPORT operation or generated by an application.
2000,"<XDS FIL='docs.xml' OFF='0' LEN='281' />"
2001,"<XDS FIL='docs.xml' OFF='281' LEN='283' />"
Figure 5.19
Input file for multiple concatenated documents
As an aside, what happens if you have more than one XML column in the target table? To populate a table with two XML columns, the delimited format input file has to contain two XML Data
Specifiers (XDS) per row, one for each XML column that you want to populate. Such an input file
is shown in Figure 5.20.
2000,"<XDS FIL='data2.xml' />","<XDS FIL='data2b.xml' />"
2001,"<XDS FIL='data3.xml' />","<XDS FIL='data3b.xml' />"
Figure 5.20
Input file to populate an integer column and two XML columns
When you import, insert, or load XML data, insignificant whitespace is by default automatically
stripped from the XML documents (see section 4.7, Understanding XML Whitespace and Document Storage). If you want to preserve whitespace, specify the XMLPARSE PRESERVE WHITESPACE clause in the IMPORT command (see Figure 5.21).
IMPORT FROM c:\mydata\cust_exp.del OF DEL
XML FROM c:\mydatadata
XMLPARSE PRESERVE WHITESPACE
INSERT INTO customer2;
Figure 5.21
5.2.2
Importing XML data into a table and preserving whitespace
Import/Insert Performance Tips
Several performance guidelines are common to all methods of populating a table with XML data.
If you have multiple user-defined XML indexes on a table, it is typically better to define them
before populating the table rather than creating them afterwards. It is better to define the indexes
before populating the table because during INSERT, LOAD, or IMPORT, each XML document is
processed only once to generate index entries for all XML indexes. However, if multiple CREATE
INDEX statements are issued, all documents in the XML column will be traversed multiple times,
once for each index.
5.3
Loading XML Data in DB2 for Linux, UNIX, and Windows
109
Even if you have not defined any indexes on the target table, DB2’s pureXML storage mechanism
transparently maintains regions and path indexes for efficient XML storage access (see Chapter
3, Designing and Managing XML Storage Objects). Take these indexes into account when determining buffer pool sizes.
Just as for relational data, you can issue the ALTER TABLE <tablename> APPEND ON command, which enables append mode for the table. New data is appended to the end of the table
instead of searching for free space on existing pages. This can provide for improved runtime performance of bulk inserts or import.
You can avoid logging if you use the ALTER TABLE <tablename> ACTIVATE NOT LOGGED
INITIALLY command. However, be warned that if there is a statement failure, the table will be
marked as inaccessible and must be dropped. This risk often prohibits using the NOT LOGGED
INITIALLY (NLI) option for incremental bulk inserts in production systems. The option can be
useful for the initial population of an empty table. Beware that NLI prevents concurrent
inserts/imports into a target table and that parallelism can yield higher performance than NLI.
If you use the IMPORT command, a small value for the COMMITCOUNT parameter tends to hurt
performance. Committing every 100 rows or more will perform better than committing every
row. An IMPORT command with an explicit COMMITCOUNT parameter is shown in Figure 5.22.
IMPORT FROM c:\mydata\data.del OF DEL
XML FROM c:\mydata
COMMITCOUNT 100
INSERT INTO customer2;
Figure 5.22
IMPORT command with COMMITCOUNT parameter
To achieve higher performance than provided by the IMPORT utility, consider using the LOAD utility instead, which automatically parallelizes its work.
5.3
LOADING XML DATA IN DB2 FOR LINUX, UNIX, AND WINDOWS
Since DB2 9.5 for Linux, UNIX, and Windows you can use the LOAD utility to move XML documents into a table. The key advantages of the LOAD utility are the same for XML as for relational
data. For example, the data is not logged and parallelism is automatically used to increase performance. DB2 determines a default degree of parallelism based on the number of CPUs and
table space containers.
The syntax for handling XML data in the LOAD command is the same as the XML-specific syntax
in the IMPORT command. For example, the only difference between the LOAD command in Figure
5.23 and the IMPORT command in Figure 5.18 is that the keyword IMPORT has been replaced by
the keyword LOAD.
110
Chapter 5
Moving XML Data
LOAD FROM c:\mydata\data.del OF DEL
XML FROM c:\mydata\myxml
INSERT INTO customer2;
Figure 5.23
Example of a LOAD command
The LOAD command has several optional parameters that can affect performance. DB2 automatically determines suitable values for these parameters, so you can usually obtain good load performance out-of-the-box without setting any parameters. If you want to try to improve load
performance, consider the following parameters:
• DATA BUFFER <buffer-size>—This parameter specifies the number of 4KB pages
(regardless of the degree of parallelism) to use as buffered space for transferring data
within the utility. The data buffers use the utility heap, whose size can be modified
through the util_heap_sz database configuration parameter. Large degrees of parallelism require a larger util_heap_sz.
• CPU_PARALLELISM <n>—This parameter specifies the number of threads that the
LOAD utility uses for parsing, converting, and formatting records.
• DISK_PARALLELISM <n>—This parameter specifies the number of threads that the
LOAD utility uses for writing data to the table space.
After a LOAD operation, the loaded table might be in SET INTEGRITY PENDING state in either
READ or NO ACCESS mode. This means that the table is only available for read or not available at
all. You can check whether the loaded table is in SET INTEGRITY PENDING status (also known
as CHECK PENDING status) by looking at the STATUS column of the catalog view
SYSCAT.TABLES and checking for a STATUS value equal to "C" (see Figure 5.24). The value
"C" means CHECK PENDING.
SELECT SUBSTR(tabschema,1,10) AS tabschema,
SUBSTR(tabname,1,10) AS tabname,
status
FROM
syscat.tables
WHERE status = 'C';
TABSCHEMA TABNAME
STATUS
---------- ---------- -----DB2ADMIN
CUSTOMER
C
Figure 5.24
Listing tables that are in CHECK PENDING state
One of the most common reasons why a table is placed in CHECK PENDING state after a LOAD
operation is that the table has check constraints or referential integrity constraints defined on it.
To take a table out of CHECK PENDING state, issue the SET INTEGRITY command:
5.4
Unloading XML Data in DB2 for z/OS
111
SET INTEGRITY FOR db2admin.customer2 IMMEDIATE CHECKED
DB2 performs minimal logging for the LOAD utility, because the operations are performed at the
DB2 page level and not the DB2 row level. If you have DB2 archive logging enabled (disabled by
default) and use the LOAD command, then the table will be placed in BACKUP PENDING status
after the load. After the load operation you have to take a backup of the table space containing the
table before you issue the SET INTEGRITY command.
An alternative to taking the backup is to specify the COPY YES option in the LOAD command.
This option instructs DB2 to perform a backup of the new data while it is being loaded, which
avoids the BACKUP PENDING state.
Another alternative is to specify the NONRECOVERABLE option in the LOAD command. This
option means the table space is not put in BACKUP PENDING state following the LOAD operation
and a copy of the loaded data does not have to be made during the load. However, it is not possible to recover the table by a subsequent roll forward action.
You can also move XML data from one table to another using the “load from cursor” option of
the LOAD utility. This option allows you to move data between tables without having to unload the
data first. In Figure 5.25 a cursor curs is declared. The subsequent LOAD command uses this cursor to move data from the table customer2 into table customer3. Loading XML data from a
cursor is supported for tables in the same database but not for moving XML data from one database to another (error SQL1407N).
DECLARE curs CURSOR FOR SELECT cid, info FROM customer ;
LOAD FROM curs OF CURSOR INSERT INTO customer3(cid,info) ;
Figure 5.25
5.4
Example of loading data from a cursor
UNLOADING XML DATA IN DB2 FOR Z/OS
You have two options for unloading data from DB2 for z/OS. You can either use the DSNTIAUL
utility or the UNLOAD utility. An example of using the DSNTIAUL utility to unload data from a
table called customer is shown in Figure 5.26.
The execution of the DSNTIAUL utility in Figure 5.26 produces two output files, pointed to by
SYSREC00 and SYSPUNCH. The SYSPUNCH sequential dataset contains the LOAD statement for
you to be able to load the unloaded data into a new table. The SYSREC00 sequential dataset contains the unloaded data, including the XML data.
112
Chapter 5
Moving XML Data
//DSNTIAUL EXEC PGM=IKJEFT01
//SYSPRINT DD SYSOUT=*
//SYSTSPRT DD SYSOUT=*
//SYSREC00 DD DSN=USER123.DSN8UNLD.SYSREC00,VOL=SER=P8P007,
//
UNIT=SYSDA,SPACE=(32760,(1000,500)),DISP=(,CATLG)
//SYSPUNCH DD DSN=USER123.DSN8UNLD.SYSPUNCH,
//
UNIT=SYSDA,SPACE=(800,(15,15)),DISP=(,CATLG),
//
RECFM=FB,LRECL=120,BLKSIZE=1200,VOL=SER=P8P007
//SYSTSIN DD *
DSN SYSTEM(ISC9)
RUN PROGRAM(DSNTIAUL) PLAN(DSNTIB91) PARMS('SQL') LIB('ISC910P8.RUNLIB.LOAD')
END
//SYSIN
DD *
SELECT * FROM CUSTOMER;
Figure 5.26
Unloading data using the DSNTIAUL utility
You can also use the UNLOAD utility to unload XML data. Remember that in DB2 for z/OS, the
XML data of an XML column always resides in an XML table space, separate from the base table
space. In the UNLOAD statement you just need to specify the base table space. You do not have to
specify the XML table space. An example is shown in Figure 5.27, where the data is unloaded in
delimited format.
Once you have determined the table space and database for the table you want to unload, you can
plug these values into the unload job as shown in Figure 5.27.
//UNLOAD
EXEC DSNUPROC,PARM='ISC9,IANTEX',COND=(4,LT)
//SORTLIB DD DSN=SYS1.SORTLIB,DISP=SHR
//SORTOUT DD UNIT=SYSDA,SPACE=(4000,(20,20),,,ROUND)
//DSNTRACE DD SYSOUT=*
//SYSPRINT DD SYSOUT=*
//SYSTSPRT DD SYSOUT=*
//SYSREC
DD DSN=USER123.UNLOAD.SYSREC,
//
DISP=(MOD,CATLG,CATLG),
//
UNIT=SYSDA,SPACE=(4000,(20,20),,,ROUND)
//SYSPUNCH DD DSN=USER123.UNLOAD.SYSPUNCH,
//
DISP=(MOD,CATLG,CATLG),
//
UNIT=SYSDA,SPACE=(4000,(20,20),,,ROUND)
//SYSIN
DD *
UNLOAD TABLESPACE DSN00191.CUSTOMER
DELIMITED CHARDEL X'22' COLDEL X'2C' DECPT X'2E'
FROM TABLE CUSTOMER
(CID
POSITION(*) INT,
INFO
POSITION(*) XML)
UNICODE
/*
Figure 5.27
Unloading data using the UNLOAD utility
5.4
Unloading XML Data in DB2 for z/OS
113
For maximum portability, you should specify UNICODE in the UNLOAD statement and use Unicode delimiter characters. If XML columns are not being unloaded in UTF-8 CCSID 1208, the
unloaded column values are prefixed with a standard XML encoding declaration that specifies the
encoding that is used.
If the table that you unload contains XML documents larger than 32KB, you need to use file reference variables (FRV) to unload the XML data to a separate partitioned data set (PDS) or hierarchical file system (HFS) file. Figure 5.28 shows unload to a PDS.
//SYSIN
DD *
TEMPLATE XMLHERE DSN 'USER123.&DB..&TS..UNLOAD' DSNTYPE(PDS)
UNIT(SYSDA)
UNLOAD DATA
DELIMITED CHARDEL X'22' COLDEL X'2C' DECPT X'2E'
FROM TABLE CUSTOMER
(CID INT, INFO VARCHAR(255) CLOBF XMLHERE) UNICODE
/*
Figure 5.28
SYSIN cards for unloading XML documents larger than 32KB
Let’s look at how the SYSIN cards in Figure 5.28 are constructed. The first two lines define a template with the name XMLHERE. The template declares the output naming pattern for the XML data
files. The variables &DB and &TS take the value of the database and table space where the XML
data is unloaded from. The parameter DSNTYPE specifies the type of volume for the unloaded
data. If PDS is specified, then this limits the output dataset to a single volume. This is also the
default if no DSNTYPE is specified. If the output should use multiple volumes, then you must
specify HFS. Next is the UNLOAD DATA statement. The line starting with DELIMITED defines how
the data is to be delimited. The last line specifies that the XML documents that are unloaded from
the XML column INFO are represented in the output data by file names of up to 255 characters.
The type VARCHAR(255) defines the data type of the XML file names, not of the actual XML
data. The keyword CLOBF tells UNLOAD to use File Reference Variables (FRV) and to store the
XML documents as CLOB files. You can also specify BLOBF or DBCLOBF as possible output file
formats. The template name XMLHERE tells UNLOAD to name the XML files according to the template that was defined in the first line. If you do not specify EBCDIC, ASCII, UNICODE, or
CCSID, the encoding scheme of the source data is preserved.
If the output PDS that will contain the XML documents does not exist, the job will create it for
you. The names of the output files are stored in the SYSREC data set as strings, as shown in Figure
5.29.
1000.USER123.DSN00201.XCUS0000.UNLOAD(B4C0WQCY)
1001.USER123.DSN00201.XCUS0000.UNLOAD(B4C0WQDR)
1002.USER123.DSN00201.XCUS0000.UNLOAD(B4C0WQEB)
...
Figure 5.29
Contents of SYSREC DS when unloading documents larger than 32KB
114
Chapter 5
Moving XML Data
You can see that the value of the relational column cid is the first part of each record. Each of the
output files pointed to by the remainder of the record contains an XML document. Note the random member name. If the dataset already contains members when the job is run, then the existing
members are not deleted, but new members (again with random names) are added. But the dataset
that SYSREC points to is overwritten with the new names.
The dataset pointed to by SYSPUNCH contains the statements that you need to put into a LOAD job,
as shown in Figure 5.30. Such a LOAD job is discussed in section 5.5.
LOAD DATA INDDN SYSREC
LOG NO RESUME YES
UNICODE CCSID(01208,01208,01208)
FORMAT DELIMITED COLDEL X'2C' CHARDEL X'22' DECPT
X'2E'
SORTKEYS
3
INTO TABLE "USER123"."CUSTOMER"
("CID"
POSITION(*) INTEGER,
"INFO" POSITION(*) VARCHAR CLOBF MIXED PRESERVE WHITESPACE)
Figure 5.30
5.5
Output SYSPUNCH DS when unloading records larger than 32KB
LOADING XML DATA IN DB2 FOR Z/OS
To load data into tables you use the LOAD utility, as shown in Figure 5.31. The data that was
unloaded in Figure 5.27 is being loaded into a new table called customer2. This table has an
INTEGER column and an XML column. Remember that only well-formed XML documents can
be loaded into an XML column.
//LOAD01
EXEC DSNUPROC,PARM='ISC9,IANTEX',COND=(4,LT)
//SORTLIB DD DSN=SYS1.SORTLIB,DISP=SHR
//SORTOUT DD UNIT=SYSDA,SPACE=(4000,(20,20),,,ROUND)
//SORTWK01 DD UNIT=SYSDA,SPACE=(4000,(20,20),,,ROUND)
//SORTWK02 DD UNIT=SYSDA,SPACE=(4000,(20,20),,,ROUND)
//SORTWK03 DD UNIT=SYSDA,SPACE=(4000,(20,20),,,ROUND)
//SORTWK04 DD UNIT=SYSDA,SPACE=(4000,(20,20),,,ROUND)
//DSNTRACE DD SYSOUT=*
//SYSPRINT DD SYSOUT=*
//SYSTSPRT DD SYSOUT=*
//MYSYSREC DD DSN=USER123.UNLOAD.SYSREC,DISP=SHR
//SYSUT1
DD UNIT=SYSDA,SPACE=(4000,(50,50),,,ROUND)
//SYSERR
DD UNIT=SYSDA,SPACE=(4000,(20,20),,,ROUND)
//SYSDISC DD UNIT=SYSDA,SPACE=(4000,(20,20),,,ROUND)
//SYSMAP
DD UNIT=SYSDA,SPACE=(4000,(20,20),,,ROUND)
//SYSIN
DD *
LOAD DATA INDDN (MYSYSREC)
LOG NO RESUME YES
UNICODE CCSID(01208,01208,01208)
FORMAT DELIMITED COLDEL X'2C' CHARDEL X'22' DECPT
X'2E'
SORTKEYS
3
INTO TABLE "USER123"."CUSTOMER2"
( "CID"
POSITION(*)
INTEGER ,
"INFO" POSITION(*)
XML PRESERVE WHITESPACE )
/*
Figure 5.31
Example of a DB2 for z/OS LOAD job
5.5
Loading XML Data in DB2 for z/OS
115
Note:
• If you have unloaded the data previously, using the jobs shown in Figure 5.26 or Figure
5.27, then the SYSIN records are the contents of the SYSPUNCH DD card in these jobs.
• The PRESERVE WHITESPACE option has been specified for the XML column. It can be
omitted, in which case the default behavior is not to preserve whitespace.
• If you omit the UNICODE CCSID line, then you get the following error: “RECORD (1)
WILL BE DISCARDED DUE TO 'CID' CONVERSION ERROR”. The Unicode input
data for FORMAT DELIMITED must be UTF-8, which is CCSID 1208.
• The COLDEL parameter specifies the column delimiter that is used in the input file. The
default value is a comma (,). For ASCII and UTF-8 data this is X'2C', and for EBCDIC
data it is a X'6B'. The CHARDEL parameter specifies the character string delimiter that is
used in the input file. The default value is a double quotation mark ("). For ASCII and
UTF-8 data this is X'22', and for EBCDIC data it is X'3F'. The DECPT parameter
specifies the decimal point character that is used in the input file. The default value is a
period (.). The default decimal point character is a period in a delimited file, X'2E' in
an ASCII or Unicode UTF-8 file.
When the XML data is loaded as a part of regular input records, specify XML as the input field
type. The target column must be an XML column. The LOAD utility treats XML columns as
variable-length data when loading XML directly from input records and expects a two-byte
length field preceding the actual XML value.
The internal XML tables are loaded when the base table is loaded. You cannot specify the name
of the internal XML table for load. You also cannot directly load the DocID column of the base
table space or specify a default value for an XML column.
You can load XML documents from regular input records if the total input record length is less
than 32KB. XML documents that don’t fit into 32KB input records must be loaded from separate
files. To achieve this you need to modify the SYSIN cards in Figure 5.31 with the one in Figure
5.30. The SYSREC input dataset is the dataset you specified in the UNLOAD job in Figure 5.27.
If you have documents larger than 32KB that come from a source other than a previous unload,
you can load these into a table as follows. As an example let us use a document called DOC01,
which is also the member name in a partitioned dataset called USER123.XMLLOAD. First you
need to edit the dataset pointed to by SYSREC and add the relational value for the Cid column of
the row, as shown next:
2000.USER123.XMLLOAD(DOC01)
You can now use exactly the same SYSIN cards as before to load this document into the table
customer2.
116
Chapter 5
Moving XML Data
Note that DB2 for z/OS does not compress an XML table space during the LOAD process. If the
XML table space is defined with COMPRESS YES, then you have to run a REORG to compress the
data.
5.6 VALIDATING XML DOCUMENTS DURING LOAD AND INSERT
OPERATIONS
When you use the LOAD or IMPORT utilities in DB2 for Linux, UNIX, and Windows to move a
large number of XML documents into a table, you can validate these documents against an XML
Schema. Simply add the clause XMLVALIDATE USING SCHEMA to the LOAD or IMPORT command, as illustrated in Figure 5.32.
LOAD FROM c:\mydata\load_customer.txt OF DEL
XML FROM c:\mydatadata
XMLVALIDATE USING SCHEMA db2admin.custxsd
INSERT INTO customer;
Figure 5.32
Performing XML Schema validation during LOAD
In DB2 for z/OS there is no XMLVALIDATE option for the LOAD utility but you can validate documents after loading them into a table. This and other validation topics are covered in Chapter 17,
Validating XML Documents against XML Schemas.
5.7
SPLITTING LARGE XML DOCUMENTS INTO SMALLER DOCUMENTS
Most programmers find it convenient and efficient to work with an XML document granularity
that matches the logical business objects of the application and the predominant granularity of
access. For example, a single document per purchase order, per trade, per contract, per tax return,
per customer, and so on is usually a good idea. Smaller documents can be manipulated more efficiently than larger ones. Also, indexed access and data retrieval is faster for smaller documents.
However, for a bulk transfer of XML data outside the database, such as FTP, it is often not convenient to handle thousands or millions of separate documents. Therefore, it is common to
receive large XML documents, often several hundred megabytes per file, which contain many
repeating blocks that represent independent objects. Many external XML tools fail, or have
severe problems, when you try to open such large XML documents, typically due to document
object model (DOM) parsing and memory limitations.
DB2 can ingest XML documents up to 2GB. Optionally, you can split them into smaller documents using the XMLTABLE function. The XMLTABLE function is discussed in detail in Chapter 7,
Querying XML Data with SQL/XML. Here we show one simple example of how it can split up
documents.
5.7
Splitting Large XML Documents into Smaller Documents
117
Assume you need to manage many XML documents with the following (simplified) structure:
<account>
<id>1</id>
<name>Heather</name>
<amount>12.34</amount>
</account>
You may receive many of these documents in one large file that has a root element <accounts>.
The root element is required for the file to be a well-formed document. Otherwise it cannot be
processed in DB2. The large file looks like this:
<accounts>
<account>
<id>1</id>
<name>Heather</name>
<amount>12.34</amount>
</account>
<account>
<id>2</id>
<name>Helen</name>
<amount>56.78</amount>
</account>
…
</accounts>
Your first step is to insert, import, or load this document into a staging table that has a column of
type XML, such as this one:
CREATE TABLE staging(xcol XML)
When this table contains the large document in a single row, you can read the document from the
staging table, split it into the individual account documents, and insert those into the following
target table:
CREATE TABLE accounts(acc XML)
To split the large document, use one of the two INSERT statements in Figure 5.33. Both accomplish the same thing; that is, they produce one row (document) in the target table for each
account element in the large input document. You must create an XML document node for each
newly created account document, either with the SQL/XML function XMLDOCUMENT, or with
the XQuery function document{}. The latter is only available in DB2 for Linux, UNIX, and
Windows. The first of the two statements in Figure 5.33 is suitable for DB2 for z/OS.
118
Chapter 5
Moving XML Data
INSERT INTO accounts(acc)
SELECT XMLDOCUMENT(x.val)
FROM staging,
XMLTABLE('$x/accounts/account' passing xcol as "x"
COLUMNS
val
XML
PATH
'.') AS x;
INSERT INTO accounts(acc)
SELECT x.val
FROM staging,
XMLTABLE('$XCOL/accounts/account'
COLUMNS
val
XML
PATH
'document{.}') AS x;
Figure 5.33
Splitting a large document
After the insert operation, select the data from accounts to verify that the large input document
has been split correctly (see Figure 5.34).
SELECT acc FROM accounts;
<account>
<id>1</id>
<name>Heather</name>
<amount>12.34</amount>
</account>
<account>
<id>2</id>
<name>Helen</name>
<amount>56.78</amount
</account>
2 record(s) selected.
Figure 5.34
Selecting the split documents from the target table
Instead of reading the large input file from a staging table, you can also pass it into the INSERT
statement in Figure 5.33 via a parameter marker. See Chapter 11, Converting XML to Relational
Data, for related examples. The input file can also be read from the file system with one of the
UDFs explained in section 4.1.2, Reading XML Documents from Files or URLs.
5.8
REPLICATING AND PUBLISHING XML DATA
In this section we briefly discuss how XML data can be replicated and published using WebSphere Replication Server and InfoSphere Data Event Publisher V9.5. This is applicable to DB2
for Linux, UNIX, and Windows and DB2 for z/OS. At the time of writing there is no support for
5.8
Replicating and Publishing XML Data
119
the XML data type in SQL replication. If you want to replicate XML data you must use
Q replication.
The XML data type is supported as a replication source for WebSphere Replication Server (Q
replication) from DB2 9.5 onwards. Note that
• Q replication uses WebSphere MQ as the message transport mechanism, and as such
there is a limit of around 100MB to the size of the XML document you can replicate.
• You cannot filter replication based on the contents of the XML documents.
• There is no automatic validation of XML documents by Q Apply at the target. If you
want to perform XML validation at the target, you can define a trigger to achieve that
(see section 17.5, Automatic Validation with Triggers).
• There is no replication of XML Schemas or schema registrations.
You can use WebSphere Replication Server (Q replication) to replicate tables containing XML
data type columns in a Unidirectional, Bidirectional, and peer-to-peer mode. It is outside the
scope of this book to describe the details of setting up Q replication. See the DB2 Information
Center for further details.
WebSphere Replication Server 9.7 has added additional XML capabilities in Q Apply for DB2
for z/OS and DB2 for Linux, UNIX, and Windows. Generally, Q Apply enables you to define custom SQL expressions to manipulate the data as it is integrated into the target database. These custom expressions can now include a selected set of XML functions such as XMLQUERY,
XMLPARSE, XMLSERIALIZE, XMLCAST, XMLVALIDATE, and XMLDOCUMENT. These functions
enable a wide range of useful XML document manipulations, including the following:
• Use XMLPARSE to replicate XML documents from VARCHAR columns to XML
columns.
• Use XMLSERIALZE to replicate XML documents from XML columns to CLOB or
BLOB columns
• Use XMLQUERY with an XPath expression to extract XML fragments (subtrees) from the
source documents. Add the XMLDOCUMENT function to create document nodes for the
XML fragments.
• Use XMLQUERY to extract individual XML element or attribute values from XML source
documents. Add XMLCAST to convert these XML values to SQL data types. (The
XMLTABLE function is not supported in Q Apply.)
• Use XMLQUERY to apply XQuery update expressions to the replicated document; for
example, to delete, add, or rename individual elements or attributes in the document.
• Use XMLVALIDATE to validate the documents with an XML Schema at the target
database.
120
5.9
Chapter 5
Moving XML Data
FEDERATING XML DATA
Database federation means that one DB2 database acts as a federated server that has access to
remote data sources. Remote data sources can include other DB2 databases, non-DB2 databases,
flat files, Excel files, message queues, and other sources. The purpose is that these remote data
sources appear in the federated DB2 server as if they are local DB2 tables. The federated server
provides applications with the illusion that all visible data resides in local relational tables. Federation hides the fact that some of this data is actually located at remote sources, which may or may
not be relational databases. The official product name for this functionality is InfoSphere Federation Server (formerly WebSphere Federation Server) although it is actually a DB2 feature.
Consider the scenario where one DB2 database acts as the federated server, and another DB2
database acts as a remote data source. Tables in the remote database can be registered as nicknames in the federated server. Subsequently they appear as if they were local tables. These tables
can contain columns of type XML. Federation allows an application to connect to just one database, the federated server, and have access to XML data in other DB2 databases.
You can federate XML data stored in XML columns in DB2 for Linux, UNIX, and Windows
using the DRDA wrapper. For a simple test with federation, two databases are required. Let’s
assume we have two databases, samplxml and samplsql, and that samplsql is the federated
server while samplxml is the remote data source. If the databases are not in the same instance,
which is often the case, you need to catalog the remote database in the federated server instance.
Figure 5.35 shows the steps to configure the federated system. The goal is to make the customer
table in the remote database samplxml locally visible in the database samplsql.
-- enable federation for the instance which contains
-- the federated server:
UPDATE DBM CFG USING federated yes;
db2stop;
db2start;
-- connect to the federate server database:
CONNECT TO samplsql;
-- create a DRDA wrapper:
CREATE WRAPPER DRDA
LIBRARY 'db2drda.dll';
-- register the other database (samplxml) as a data source
-- and assign the local name "remoteXML":
CREATE SERVER remoteXML
TYPE DB2/UDB VERSION '9.5' WRAPPER DRDA
AUTHID "db2admin" PASSWORD "*****"
OPTIONS( ADD DBNAME 'samplxml');
Figure 5.35
Configuring the federated server for access to a remote data source
5.10
Managing XML Data with HADR
121
-- register authentication credentials for the data source:
CREATE USER MAPPING FOR db2admin
SERVER remoteXML
OPTIONS ( ADD REMOTE_AUTHID 'db2admin',
ADD REMOTE_PASSWORD '*****');
-- create the local nickname "custtable" for the remote
-- table "customer":
CREATE NICKNAME custtable
FOR remoteXML.db2admin.customer;
Figure 5.35
Configuring the federated server for access to a remote data source (continued)
The remote database samplxml contains a table db2admin.customer, and this table is now
visible in the local database samplsql under the (nick)name custtable. After these steps, the
nickname custtable can be used as if it were a local DB2 table. You can check that the federation setup has worked by issuing an XQuery or SQL/XML query against the nickname, as shown
in Figure 5.36.
SELECT XMLQUERY('$INFO/customerinfo/name')
FROM custtable
WHERE cid = 1004;
<name>Matt Foreman</name>
1 record(s) selected.
Figure 5.36
Testing federated access to XML data
Any changes to the XML data at the data source are immediately reflected in any queries run
against the nickname. You can also perform updates against the nickname to change the remote
data at the data source. If your queries against the nickname contain XML predicates, such as
XMLEXISTS, these predicates are currently not pushed down for evaluation at the database
source. XML predicates in queries against nicknames are evaluated locally at the federated
server.
5.10
MANAGING XML DATA WITH HADR
You can use the High Availability Disaster Recovery (HADR) feature in DB2 for Linux, UNIX,
and Windows with XML columns in your tables. All relevant XML operations, such as INSERT,
UPDATE, and DELETE of XML data are captured to the DB2 log and shipped to the standby
database.
122
5.11
Chapter 5
Moving XML Data
HANDLING XML DATA IN DB2LOOK AND DB2MOVE
This section discusses the DB2 for Linux, UNIX, and Windows utilities db2look and db2move.
The db2look utility can be used to connect to an existing database and produce a script of Data
Definition Language (DDL) statements to recreate all objects in the database. The utility collects
the definitions of all tables, indexes, table spaces, and so on and writes them to a file, which
allows you (or IBM support) to produce an empty copy of the database. This copy can be helpful
for troubleshooting or testing purposes.
The following is an example of a typical invocation of the db2look utility at the operating system prompt to collect object definitions from the sampxml database:
db2look -d sampxml -e –l -o db2look.txt
The -e and -l parameters specify that the DDL statements for tables, views, indexes, buffer
pools, table spaces, and so on are to be extracted into the file specified by the –o parameter.
The output file db2look.txt automatically includes information for all XML columns and
XML indexes, but does not contain any information about XML Schemas that may exist in DB2’s
XML Schema Repository. You must specify the –xs option to also obtain XML Schema information:
db2look -d sampxml –e -l -xs -o db2look.txt -xdir c:\xml
The -xs option exports all files necessary to register XML Schemas and DTDs in a new database,
and generates appropriate commands for registering them. If you want to export XML Schemas
to a location other than the current directory, use the –xdir option to specify a different directory. This directory must exist before the command is run. The files that are written to this directory start with "doc_" or "md_". The "doc_" files contain the actual XML Schema documents.
The md_ files contain optional metadata about the XML Schemas. If you examine the output file
db2look.txt you find that the "doc_" files are used in the REGISTER XMLSCHEMA commands
and the "md_" files in the COMPLETE XMLSCHEMA commands (see Figure 5.37).
-- DDL Statements for XSR object "DB2ADMIN"."CUSTOMER"
REGISTER XMLSCHEMA "http://posample.org" FROM
c:\xml\xml\doc_562949953421312 AS "DB2ADMIN"."CUSTOMER";
COMPLETE XMLSCHEMA "DB2ADMIN"."CUSTOMER" WITH
c:\xml\xml\md_281474976710656;
Figure 5.37
Fragment of output from the db2look command
5.12
Summary
123
The db2move utility is also fully aware of XML data. The EXPORT option of the utility automatically includes XML data. The following command writes the contents of the database sampxml
to files:
db2move sampxml EXPORT
This command creates a set of output files for each table in the database. For the customer table,
the following files are produced in the local directory:
5.12
• tab3.ixf
(contains the relational data)
• tab3a.001.xml
(contains the XML data)
• tab3.msg
(contains any messages produced by the EXPORT utility)
SUMMARY
All of DB2’s data movement utilities and features support XML data and XML columns in DB2
tables. In particular, this support includes import, export, load, unload, replication, federation,
and high availability disaster recovery (HADR). The handling of XML data in the import, export,
load, and unload utilities is very similar to the handling of LOBs.
A common requirement is to split a large XML document into smaller documents, and this can be
achieved with the XMLTABLE function. Just remember that whenever you take a fragment of an
XML document and try to insert it into an XML column as an individual document, a new XML
document node needs to be added.
This chapter has provided you with the tools and skills to move XML data into and out of a DB2
database. The next four chapters deal with querying XML data that is stored in XML columns in
the database.
This page intentionally left blank
C
H A P T E R
6
Querying XML Data:
Introduction and
XPath
T
his is the first of four chapters that discuss methods for querying XML data. This chapter
lays the foundation for the next three chapters and discusses the following topics:
• Overview of the different options for querying XML data (section 6.1)
• The XPath and XQuery data model (section 6.2)
• The XPath language (sections 6.3 through 6.15)
XPath provides the basic means for traversing XML documents, evaluating predicates, and
retrieving XML values. XPath is at the very core of querying XML data in DB2 for z/OS and
DB2 for Linux, UNIX, and Windows. A good understanding of XPath and its data model is
essential for querying XML data in DB2. The subsequent chapters then expand on these fundamental concepts as follows:
• Chapter 7, Querying XML Data with SQL/XML, describes SQL/XML and how to
embed XPath in SQL statements.
• Chapter 8, Querying XML Data with XQuery, covers the XQuery language, which is a
superset of XPath.
• Chapter 9, Querying XML Data: Advanced Queries and Troubleshooting, covers
advanced XML queries with joins, aggregation, and case-insensitive predicates. It also
discusses common errors and guidelines for avoiding “bad” queries.
This book does not provide a formal and complete XPath and XQuery language reference that
covers all functions and features. We explain the most commonly used language features and how
they are supported in DB2. We focus on the practical use of these language features, not on their
125
126
Chapter 6
Querying XML Data: Introduction and XPath
formal definition. Appendix C, Further Reading, contains pointers to further reading about
XPath and XQuery.
To ease the introduction of the XML query languages, we defer the discussion of XML namespaces to Chapter 15, Managing XML Data with Namespaces.
6.1
AN OVERVIEW OF QUERYING XML DATA
The basic language to query XML data is XPath, which is a subset of XQuery. XQuery adds additional expressions and language constructs to XPath and supports more advanced queries.
XQuery and XPath have been standardized by the World Wide Web Consortium (W3C). Furthermore, the SQL:2006 standard includes functions that allow you to embed XQuery or XPath in
SQL statements. Figure 6.1 shows the relationships between XPath, SQL/XML, and XQuery.
Both XPath and XQuery are based on the same data model, which is called the XQuery 1.0 and
XPath 2.0 Data Model. This data model defines how XML data is represented so that XPath and
XQuery can operate on it. Section 3.1, Understanding XML Document Trees, already described
how the data model defines the tree representation of XML documents. Queries expressed in
XQuery or XPath typically traverse these XML document trees, evaluate predicates, and retrieve
XML values.
SQL/XML
ISO/IEC 9075-14:SQL/XML
XQUERY 1.0
Expressions
XPATH 2.0
http://www.w3.org/TR/xquery
http://www.w3.org/TR/xpath20
Functions & Operators
http://www.w3.org/TR/xquery-operators/
XQuery 1.0 and XPath 2.0 Data Model
http://www.w3.org/TR/query-datamodel/
Figure 6.1
Relationship between XQuery, XPath, and SQL/XML
With the languages shown in Figure 6.1 you can query your XML in any of the following five
ways:
• Plain SQL: allows full-document retrieval (see Chapter 4)
• SQL/XML: XPath embedded in SQL (see Chapters 7 and 9)
6.1
An Overview of Querying XML Data
127
• SQL/XML: XQuery embedded in SQL (see Chapters 8 and 9)
• XQuery as a stand-alone language (see section 6.5 and Chapters 8 and 9)
• SQL embedded in XQuery (see Chapters 8 and 9, sections 8.8, 8.9, and 9.2)
DB2 9 for z/OS does not support XQuery, which means that options 3, 4, and 5 are only available
in DB2 for Linux, UNIX, and Windows. This is not as big of a limitation as it might seem at first
sight. SQL/XML with embedded XPath expressions (option 2) is a very powerful combination
and sufficient for a very wide range of applications. Section 8.3, Comparing FLWOR Expressions, XPath Expressions, and SQL/XML, shows that many queries in XQuery notation can also
be expressed in SQL/XML with XPath.
Plain SQL without any XQuery or XPath is really only useful for full-document retrieval and
operations such as insert, delete, and update of whole documents. Selection of documents must
be based on non-XML columns in the same table.
XPath embedded in SQL statements provides very broad functionality. You can express predicates on XML columns, extract document fragments, pass parameter markers to XML predicates,
use full-text search, and perform efficient aggregation and grouping. This approach also allows
you to join XML columns or to combine and join XML with relational data. Most applications
are well served by this approach.
XQuery embedded in SQL statements offers the broadest functionality due to the increased
richness of XQuery over XPath. For example, XQuery provides advanced concepts such as direct
XML element constructors, conditional expressions, or nested iterations over XML nodes. If you
use DB2 for z/OS, note that some of the XQuery features that are not available in XPath can often
be compensated for by using SQL features. For example, you can often use a SQL CASE expression to achieve the same result as the XQuery if-then-else expression. Also, the SQL/XML
publishing functions can construct XML data much like the direct element constructors in
XQuery.
XQuery as a stand-alone language is a good option if your applications require querying and
manipulating of XML data only, and do not involve any relational data. Also, if you are migrating
from an XML-only database to DB2 and already have an existing XQuery workload, you might
prefer to stick with plain XQuery.
XQuery with embedded SQL can be a good choice if you want to leverage relational predicates
and indexes as well as full-text search to pre-filter the documents from an XML column that are
then input to an XQuery. SQL embedded in XQuery also allows you to run external functions and
UDFs on the XML data. But, queries with grouping, aggregations, and parameter markers are
typically better done in SQL/XML.
No matter what combination of SQL and XQuery you choose in one statement, DB2 uses a single
query compiler to produce and optimize a single execution plan for the entire query. Table 6.1
summarizes the respective advantages of the different options for querying XML data in DB2.
128
Chapter 6
Querying XML Data: Introduction and XPath
In this table “–” indicates that the given approach does not support a feature, “+” means that the
feature is supported but that a more efficient or convenient way might exist, and “++” signifies the
feature is very well supported.
Table 6.1
Characteristics of XML Query Options in DB2
Plain
SQL
SQL/XML
with XPath
or XQuery
Plain
XQuery
XQuery with
Embedded SQL
XML predicates
–
++
++
++
Relational predicates
++
++
–
+
Parameter markers for XML predicates
–
++
–
–
Joining XML and relational
–
++
–
++
Joining XML with XML
–
++
++
++
Suitability for XML-only applications
–
+
++
+
Insert, update, delete
++
++
–
–
Transforming XML data
–
+
++
++
Full-text search
+
++
–
++
Aggregation and grouping
–
++
+
+
User-defined functions
++
++
–
++
6.2
UNDERSTANDING THE XQUERY AND XPATH DATA MODEL
The XQuery and XPath Data Model (commonly known by its short name of XQuery Data Model)
defines how XML data is represented so that XQuery and XPath queries can operate on it in a
consistent and well-defined manner. The more complex your XML queries and updates become,
the more you will find that a good understanding of the XQuery data model is beneficial. It helps
you with the following tasks:
• Writing correct XML queries and updates
• Understanding the behavior of complex queries and expressions
• Debugging and correcting XML queries
6.2.1
Sequences
At the core of the XQuery data model is the definition of permissible values, which are also
called instances of the data model. Roughly speaking, instances of the XQuery data model
include XML documents as well as document fragments, individual elements, attributes, and
6.2
Understanding the XQuery and XPath Data Model
129
atomic values. A more precise definition follows shortly. A fundamental concept to remember is
that an XQuery always takes one instance of the data model as input, and produces another
instance of the data model as output.
Every instance of the XQuery data model is a sequence. A sequence is an ordered collection of
zero, one, or multiple items. An item is either an atomic value or a node.
Atomic values include strings, dates, integers, decimals, double precision numbers, and so on, as
defined by the XML Schema specification. Their types are xs:string, xs:date, xs:integer,
xs:decimal, xs:double, and so on.
Examples of atomic values are the following:
• 100 is an atomic value of type xs:integer.
• 1.5 and 3.145634785348 are atomic values of type xs:decimal.
• 1E8 is an atomic values of type xs:double.
• The strings “Peter” and “this is a cat” are atomic values of type xs:string.
• The expression xs:date("2009-05-09") converts a string into an atomic value of
type xs:date.
A node is either a document node, an element node, an attribute node, a text node, a comment
node, or a processing instruction node. An element node represents an XML element, an attribute
node represents an XML attribute, and so on. Element nodes can have children (child nodes) to
form hierarchies of nodes. An XML document is such a node hierarchy where the topmost node
is a document node. See section 3.1, Understanding XML Document Trees, and Figure 3.2, for
further details.
In the following list of examples, sequences are written as comma-separated lists of items, with
the whole list enclosed in parentheses and strings enclosed in double quotes. This is actually how
sequences can be constructed in XQuery.
• This sequence consists of four atomic values:
(100, "Peter", "This is a cat", 1.5)
• This is the empty sequence, which contains zero items:()
• This sequence contains one item, which is an atomic value:
("555 Bailey Avenue")
In the XQuery Data Model there is no difference between a single value and a sequence
of length 1 that contains that single value.
• Since sequences are ordered, the sequences (6, "F", 3) and (3, 6, "F") are different from each other.
130
Chapter 6
Querying XML Data: Introduction and XPath
• Sequences are never nested. Concatenating the sequences (1,2,3) and (4,5) produces the sequence (1,2,3,4,5), and not (1,2,3,(4,5)) or ((1,2,3),(4,5)).
A sequence is never an item in another sequence.
• The following is a sequence of three XML element nodes:
(<a></a>, <b>34</b>, <c><d>John</d></c>)
The first element (a) is empty. The second element (b) has a child node, which is a text
node with the atomic value 34. The third element (c) has a child node (d), which in turn
contains a text node with the value “John”.
• This next sequence contains one item, which is a node that has two child nodes. The two
child nodes are an attribute node (id) and another element node (name):
(<customer id="123"><name>John Doe</name></customer>)
• If you have a table T with an XML column XMLCOL, the XML documents in the column
XMLCOL can form a sequence. You see later in this chapter that the function
db2-fn:xmlcolumn("T.XMLCOL") produces exactly that sequence of documents
(section 6.5).
• Sequences can contain a mix of nodes and atomic items:
(167, <p>This is a cat</p>, "Peter",
<name><first>Peter</first></name>, 1.53E9 )
6.2.2
Sequence in, Sequence out
An XQuery always takes one sequence as input1, and produces another sequence as output. Let’s
look at some examples, before we introduce XPath and XQuery more formally in the next
sections.
In Figure 6.2, the input is a sequence that contains a single XML document. The output is a
sequence that contains a single text node; that is, the text value of the name element.
Input:
XQuery:
Output:
Figure 6.2
(<customer id="123"><name>John Doe</name></customer>)
/customer/name/text()
(John Doe)
XPath that returns a text node
In Figure 6.3, the input is a sequence of four XML documents. The XQuery is a path expression
that returns the text values of <b> elements that are child nodes of <a> elements. The result is a
sequence of three text nodes. Note that the third document in the input sequence does not contribute anything to the result of the query. This is because its element names do not match the element names in the XQuery:
1. You will see later that advanced XQuery expressions can even take multiple sequences as input. A join between two
columns is a typical example. For now, let’s keep things simple and assume a single input sequence.
6.3
Sample Data for XPath, SQL/XML, and XQuery
Input:
XQuery:
Output:
Figure 6.3
131
(<a><b>15</b></a>, <a><b>27</b></a>, <c><d>19</d></c>,
<a><b>Peter</b></a>)
/a/b/text()
(15, 27, Peter)
XPath that returns a sequence of multiple text nodes
The same input is used in Figure 6.4, but the XQuery returns a sequence of element nodes.
Input:
XQuery:
Output:
Figure 6.4
(<a><b>15</b></a>, <a><b>27</b></a>, <c><d>19</d></c>,
<a><b>Peter</b></a>)
/a/b
(<b>15</b>, <b>27</b>, <b>Peter</b>)
XPath that returns a sequence of multiple elements
The query in Figure 6.5 looks for <cstomer> elements. This may be intended or due to a misspelled tag name in the query. Either way, such elements are not found and so the empty sequence
is returned:
Input:
XQuery:
Output:
Figure 6.5
(<customer id="123"><name>John Doe</name></customer>)
/cstomer/name
()
Misspelled element in an XPath returns an empty sequence
In Figure 6.6 the input is a sequence with a single item, which is a well-formed XML document.
The output is a sequence of three atomic values:
Input:
XQuery:
Output:
Figure 6.6
(<a> <b>15</b> <b>27</b> <b>Peter</b> </a>)
/a/data(b)
(15, 27, Peter)
XPath that returns a sequence of atomic values
The difference between data(), which produces atomic values, and text(), which produces
text nodes in Figure 6.3, is explained in more detail in the next section. Now that you have an
understanding of the XQuery data model, let’s properly introduce the XQuery language. We start
with XPath, a subset of XQuery.
6.3
SAMPLE DATA FOR XPATH, SQL/XML, AND XQUERY
We use the two XML documents in Figure 6.7 as sample data to illustrate the concepts of XPath
in the remainder of this chapter. These documents also serve as the sample data for most of the
SQL/XML and XQuery examples in Chapters 7 and 8.
132
Chapter 6
Querying XML Data: Introduction and XPath
To be precise, the input for the XPath queries in this chapter is a sequence of two items, which are
the two documents in Figure 6.7. Remember that XPath is a subset of XQuery, so every XPath
takes a sequence of items as input and produces another sequence as output.
<customerinfo Cid="1003">
<name>Robert Shoemaker</name>
<addr country="Canada">
<street>845 Kean Street</street>
<city>Aurora</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N8X 7F8</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
<phone type="home">416-555-2937</phone>
<phone type="cell">905-555-8743</phone>
</customerinfo>
<customerinfo Cid="1004">
<name>Matt Foreman</name>
<addr country="Canada">
<street>1596 Baseline</street>
<city>Toronto</city>
<prov-state>Ontario</prov-state>
<pcode-zip>M3Z 5H9</pcode-zip>
</addr>
<phone type="work">905-555-4789</phone>
<phone type="home">416-555-3376</phone>
<assistant>
<name>Gopher Runner</name>
<phone type="home">416-555-3426</phone>
</assistant>
</customerinfo>
Figure 6.7
Two sample documents to demonstrate XPath navigation
In the following sections we explain XPath through a series of examples. Each example consists
of an XPath expression and its result, which is based on the input data in Figure 6.7. If the result
is a sequence of more than one item, each item is placed in a separate row. We first explain simple
XPath in generic terms, then how to run XPath in DB2, and finally additional XPath features such
as wildcards, predicates, logical expressions and so on. Unless otherwise noted, all XPath,
XQuery, and SQL/XML features (such as predicates, arithmetic, casting, built-in functions, and
so on) work the same way for elements and attributes.
6.4
INTRODUCTION TO XPATH
XPath provides the basic means for traversing XML documents, evaluating predicates, and
retrieving XML values. XPath is the bread and butter for querying XML data in DB2 for z/OS
and DB2 for Linux, UNIX, and Windows.
6.4
Introduction to XPath
6.4.1
133
Analogy Between XPath and Navigating a File System
The fundamental concept of using paths to navigate hierarchical structures is well known. Just
think of a file system on your personal computer or any Linux or UNIX machine. Most file systems have a root directory, which has subdirectories, which in turn have other subdirectories, and
so on. This defines a hierarchy of directories or folders. In a Windows file system the path
C:\WINDOWS\system32\drivers points to a specific folder in that hierarchy. A path in a
UNIX file system might be /home/sqllib/samples/xml. The path consists of multiple steps
that are delimited by the / character. The command cd /home/sqllib/samples/xml takes
you to this directory, which then becomes your current directory. We can also call it the current
context. From there you can use the command cd ../java/jdbc to navigate to the directory
/home/sqllib/samples/java/jdbc. The .. takes you to the parent of the current directory,
and from there the navigation continues down into the java/jdbc directory.
In the examples in the following sections you will find that using XPath to navigate the trees
formed by the nested elements and attributes of XML documents works in a strikingly similar
manner. Just like a path in a file system, an XPath expression consists of several steps that are separated by the slash (/) character. Each step typically navigates to another level of the hierarchy.
XPath also has the notion of a current context and also uses two dots (..) to indicate parent step
navigation. Unlike directories in a file system, XML elements can have multiple child elements
with the same name.
6.4.2
Simple XPath Queries
The XPath expression in Figure 6.8 starts its navigation at the root element customerinfo of
every XML document. From there it navigates to the name element, which is an immediate child
of customerinfo. The nodes identified by the last step of the XPath expression are considered
the result (or value) of the expression. Hence, the name elements that are children of customerinfo elements are returned from each document in the input sequence. Note that the second
input document also contains a name element that is not returned because it is a child of the
assistant element, which does not match the XPath expression in this example. The element
names customerinfo and name in this path expression effectively serve as so-called node tests.
This means that at each step the path expression only considers nodes that match the given element or attribute name.
XPath:
Output:
Figure 6.8
/customerinfo/name
<name>Robert Shoemaker</name>
<name>Matt Foreman</name>
XPath that returns name elements
If the first step of the XPath in Figure 6.8 was customer instead of customerinfo, as shown in
Figure 6.9, no nodes would be identified or returned. This is because the input data does not
134
Chapter 6
Querying XML Data: Introduction and XPath
contain a customer element at the beginning of any document. Consequently, there can be no
name element that is a child of customer. When an XPath expression returns an empty result
unexpectedly, a common reason is that tag names in the path are misspelled. Note that tag names
are case-sensitive, which means that /Customerinfo/Name would also return an empty result
for the sample data.
XPath:
Output:
Figure 6.9
/customer/name
Incorrect element name in an XPath returns an empty sequence
If you want to return the customer names without the XML tags <name> and </name>, you need
to explicitly navigate to the text node under the name element (see Figure 6.10). This query
returns a sequence of two text nodes. Although text() looks like a function, it is not and never
takes an argument. It is actually a node test that selects text nodes.
XPath:
Output:
Figure 6.10
/customerinfo/name/text()
Robert Shoemaker
Matt Foreman
XPath that returns text nodes of name elements
The same effect as in Figure 6.10 can be achieved with the string() function or the data()
function, as illustrated in Figure 6.11.
XPath:
Output:
Figure 6.11
/customerinfo/data(name)
Robert Shoemaker
Matt Foreman
XPath that returns the atomic values of name elements
The data() function computes the value of its argument and returns atomic values rather than
text nodes. In many cases, such as in Figure 6.10 and Figure 6.11, this makes no difference to
your application. The real difference between text() and data() or string() becomes
apparent when applied to non-leaf elements, such as addr. A non-leaf element is one that contains one or more child elements. The query in Figure 6.12 returns the empty sequence because
there are no text nodes that are immediate children of addr. The XPath in Figure 6.13, however,
returns the string value of each addr element. The string value of an element is defined as the
concatenation of all text nodes that appear in the subtree under the element. The concatenation
does not insert spaces or other delimiters.
XPath:
Output:
Figure 6.12
/customerinfo/addr/text()
Trying to retrieve text nodes from an element without text nodes
6.4
Introduction to XPath
XPath:
Output:
Figure 6.13
135
/customerinfo/string(addr)
845 Kean StreetAuroraOntarioN8X 7F8
1596 BaselineTorontoOntarioM3Z 5H9
Obtaining the string value of a non-leaf element
The query in Figure 6.13 can also use the function data() instead of string(). The differences
between string() and data() are subtle and not always relevant. For example, data() can
take a sequence of multiple items as input but string() cannot. If the input argument is an empty
sequence, data() returns an empty sequence but string() returns a string of length zero.
If you let an XPath expression point to a non-leaf node without using a function such as text(),
data(), or string(), the node is returned together with all the child nodes that it contains. This
is shown in Figure 6.14 where the XPath returns a sequence of two addr nodes, both of which
contain other nodes. Effectively, this allows you to extract entire fragments (subtrees) from your
XML documents.
XPath:
Output:
Figure 6.14
/customerinfo/addr
<addr country="Canada">
<street>845 Kean Street</street>
<city>Aurora</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N8X 7F8</pcode-zip>
</addr>
<addr country="Canada">
<street>1596 Baseline</street>
<city>Toronto</city>
<prov-state>Ontario</prov-state>
<pcode-zip>M3Z 5H9</pcode-zip>
</addr>
XPath that returns document fragments
Besides the four child elements street, city, prov-state, and pcode-zip, the addr element also has an attribute, country. The XPath language requires the use of the @ sign to distinguish attributes from elements in path expressions. The XPath in Figure 6.15 returns the values of
the country attributes. The function data() or string() is required in order to return attribute values in a query result.
XPath:
Output:
Figure 6.15
/customerinfo/addr/data(@country)
Canada
Canada
Using the data() function to return attribute values
136
Chapter 6
Querying XML Data: Introduction and XPath
Note that /customerinfo/addr/@country/text() would produce an empty result because
unlike elements, attributes never have separate text nodes. While text() produces text nodes,
data() and string() produce atomic values.
If you omit the data() function in Figure 6.15 and try to use /customerinfo/addr/@country
to return the attributes to your application, the XPath fails with an error (SQL16075N). This is
because without the data() function it tries to return the complete attribute nodes rather than just
their atomic value. But, attribute nodes can never be returned on their own. They always have to be
within an element. However, their values can be returned. The difference between the attribute
node and its value is that a node is a more complex entity that has properties such as a node name,
node kind, a value, and possibly a namespace.
The query Figure 6.16 returns the text nodes of all phone elements that are immediate children of
a customerinfo element. The result is a sequence of five items, three from the first and two
from the second of the input documents.
XPath:
Output:
Figure 6.16
/customerinfo/phone/text()
905-555-7258
416-555-2937
905-555-8743
905-555-4789
416-555-3376
Returning multiple text nodes from each document
This example also illustrates that each step in a path expression actually produces a sequence of socalled context nodes, which are input to the next step. The first step of the XPath in Figure 6.16 is
/customerinfo. For the input data, this step produces two customerinfo nodes, one from the
first and one from the second input document. The next step is /phone, which is executed once for
each of the two customerinfo nodes. For the first customerinfo node, the /phone step produces three phone elements and for the second customerinfo node it produces two phone elements. This makes a total of five nodes. The entire sequence of five nodes is input to the last step,
/text(). This step is executed once for each of the five nodes and produces their text nodes. Since
each of the phone elements has exactly one text node, the final cardinality of the result is five.
Figure 6.17 shows the result of a query that returns full phone elements and not just their text
nodes.
XPath:
Output:
Figure 6.17
/customerinfo/phone
<phone type="work">905-555-7258</phone>
<phone type="home">416-555-2937</phone>
<phone type="cell">905-555-8743</phone>
<phone type="work">905-555-4789</phone>
<phone type="home">416-555-3376</phone>
Returning multiple elements from each document
6.5
6.5
How to Execute XPath in DB2
137
HOW TO EXECUTE XPATH IN DB2
All the XPath queries in this chapter can be executed in DB2. Both DB2 for z/OS and DB2 for
Linux, UNIX, and Windows allow XPath expressions to be embedded in SQL. This is called
SQL/XML and is explained in Chapter 7, Querying XML Data with SQL/XML.
DB2 for Linux, UNIX, and Windows additionally supports XQuery as a stand-alone language
without any SQL required. All you need is a table with a column of type XML that contains one or
multiple XML documents. Let’s assume that you have the following table with an XML column
named info, and that it has two rows containing the two documents shown in Figure 6.7.
CREATE TABLE customer(id INTEGER, info XML)
To run XPath queries against the two documents in the table, you can use the same XPath expression as in the previous examples—with two additions. First, any XQuery or XPath query in DB2
for Linux, UNIX, and Windows starts with the keyword xquery to indicate that it’s not an SQL
statement. This keyword can be upper- or lowercase. Second, you need to reference the XML
column as the starting point (context) for the XPath. For this purpose DB2 offers the function
db2-fn:xmlcolumn(), which takes an XML column name as input and produces the sequence
of all documents in that column as output. The column name must be qualified by a table or view
name, which can optionally be qualified by an SQL schema name:
db2-fn:xmlcolumn('SQLSCHEMA.TABLENAME.XMLCOLUMNNAME')
Using the table and column name as well as the xquery keyword, you can run your first XPath
query in the DB2 Command Line Processor (see Figure 6.18). This query simply returns the
result of the db2-fn:xmlcolumn() function; that is, the sequence of all XML documents in the
info column. Remember that every XQuery takes a sequence of items as input and produces
another sequence of items as output. In this simple example, the input and output sequences are
identical. The query returns a single column of type XML and two rows, one row for each of our
two sample documents.
xquery db2-fn:xmlcolumn('CUSTOMER.INFO')
Figure 6.18
Executing XPath in DB2 for Linux, UNIX, and Windows
To verify that the query in Figure 6.18 returns a column of type XML you can describe it, just like
you would describe any SQL statement to check the number, names, and data types of the
columns in the result set (see Figure 6.19). The length of the XML data type is zero, because the
XML type is a hierarchical data format and there is no notion of length associated with a tree. In
contrast, the length of an INTEGER is 4 bytes, and that of a VARCHAR(100) is 100 bytes.
138
Chapter 6
Querying XML Data: Introduction and XPath
db2 => describe xquery db2-fn:xmlcolumn('CUSTOMER.INFO')
Column Information
Number of columns: 1
SQL type
------------988
XML
Type length
----------0
Column name
--------------------INFO
Name length
----------4
db2 =>
Figure 6.19
Describing an XQuery
You can run the query in Figure 6.18 in the DB2 Command Line Processor (CLP) or any other
interface, such as the Command Editor that’s part of the DB2 Control Center, IBM Data Studio,
or, for example, via JDBC from a Java application. When the XML type data is returned from the
DB2 server to any such client it is automatically serialized; that is, converted from DB2’s internal
tree format to XML text. The CLP displays at most 4,000 bytes of XML text per row. Any XML
column values shorter than this are padded with blanks. Any XML data beyond 4,000 bytes per
row is truncated in the CLP display. To avoid truncation and to see the full XML output, you
can use the DB2 EXPORT utility (see Chapter 5, Moving XML Data) or a tool such as IBM Data
Studio.
The table and column name in the db2-fn:xmlcolumn() function must be enclosed in either
single quotes or double quotes. They typically also need to be in uppercase. This is because DB2
table and column names default to uppercase, unless you use quotes in the CREATE TABLE statement to force a lowercase table or column name.
Now that you are familiar with the mechanics of running XPath in DB2, let’s run the XPath
expression previously shown in Figure 6.17. Simply append the path /customerinfo/phone
to the db2-fn:xmlcolumn() function, as shown in Figure 6.20. The result is exactly the same
as in Figure 6.17.
db2 => xquery db2-fn:xmlcolumn('CUSTOMER.INFO')/customerinfo/phone
<phone
<phone
<phone
<phone
<phone
type="work">905-555-7258</phone>
type="home">416-555-2937</phone>
type="cell">905-555-8743</phone>
type="work">905-555-4789</phone>
type="home">416-555-3376</phone>
5 record(s) selected.
db2 =>
Figure 6.20
Executing the query from Figure 6.17 in the DB2 Command Line Processor
6.5
How to Execute XPath in DB2
139
Remember that each step in a path expression produces a sequence of so-called context nodes that
are input to the next step. In the same manner, the db2-fn:xmlcolumn() function produces a
sequence of XML documents that are input to the first step of the XPath expression. Hence, the
XPath /customerinfo/phone is evaluated once for each document in the table. The result
items from all documents, in this case phone elements, are combined into a single sequence.
Each item is returned to the client as a separate row.
DB2 also offers the function db2-fn:sqlquery(), which is similar to db2-fn:xmlcolumn().
While db2-fn:xmlcolumn() takes an XML column name as input and produces the sequence
of all documents in that column as output, the function db2-fn:sqlquery() takes an SQL query
as input and produces as output the sequence of documents that are returned by that SQL statement. This SQL query can be any query, even with joins and subselects and so on, as long as it
returns a single column of type XML. Figure 6.21 is a simple example of a query that returns a
sequence of documents that are a subset of the documents in the XML column info.
xquery db2-fn:sqlquery("SELECT info FROM customer
WHERE id > 1003")
Figure 6.21
Producing a sequence of documents with an SQL query
The key difference between db2-fn:xmlcolumn() and db2-fn:sqlquery() is that db2fn:xmlcolumn() takes all documents in an XML column as the input for your XPath expression, while db2-fn:sqlquery() allows you to use relational predicates and so on to pre-filter
the set of documents that are input to the XPath query.
The embedded SQL statement is parsed by DB2’s SQL parser, which means that table and column names are automatically converted to uppercase. You can append any path expression to the
db2-fn:sqlquery() function to further process the returned documents. In Figure 6.22, the
XPath expression /customerinfo/phone is applied to the one XML document that is identified by the embedded SQL statement.
db2 => xquery db2-fn:sqlquery("select info from customer
where id = 1003")/customerinfo/phone
<phone type="work">905-555-7258</phone>
<phone type="home">416-555-2937</phone>
<phone type="cell">905-555-8743</phone>
3 record(s) selected.
db2 =>
Figure 6.22
Using db2-fn:sqlquery in the DB2 Command Line Processor
140
Chapter 6
Querying XML Data: Introduction and XPath
You can run any XPath expression that you see in this chapter simply by appending it to the db2fn:xmlcolumn() or db2-fn:sqlquery() functions and using the xquery keyword, as illustrated in the preceding figure. In the following sections we explain further features of the XPath
language and provide more examples. All of them can be run in DB2 for Linux, UNIX, and Windows just like you see in Figure 6.20 and Figure 6.22.
6.6
WILDCARDS AND DOUBLE SLASHES
XPath allows the use of the * as a wildcard character to match any element name, and @* to
match any attribute name. The XPath expression in Figure 6.23 uses the wildcard to return all elements that are immediate children of the assistant element. The assistant element occurs
only in the second of the two documents and has two child elements, name and phone.
XPath:
Output:
Figure 6.23
/customerinfo/assistant/*
<name>Gopher Runner</name>
<phone type="home">416-555-3426</phone>
Using a wildcard to select all child elements of assistant
The wildcard in the XPath expression in Figure 6.24 matches all elements that occur directly
under customerinfo. These are the elements name, addr, phone and in the second document
also assistant. The sequence of these elements is input to the last step of this XPath, /name.
In other words, the XPath then tries to find /customerinfo/name/name, /customerinfo/
addr/name, /customerinfo/phone/name, and /customerinfo/assistant/name. The
first three of these don’t exist and so only the assistant’s name is returned.
XPath:
Output:
Figure 6.24
/customerinfo/*/name
<name>Gopher Runner</name>
Using a wildcard to match any child element of customerinfo
The query in Figure 6.25 uses two wildcards, one to match any element at the second level of the
document hierarchy and one to match any element at the third level. The first wildcard matches
name, addr, phone, and assistant, as in the previous example. The next wildcard then
matches any child elements of these nodes. Only addr and assistant have child elements and
all of those are returned. The last two elements in the result, name and phone, are children of
assistant, which exists only for one of the two input documents. Customer phone elements
are not included in the result, because they are at the second instead of the third level of the document. The XPath expression /*/*/* would return the same result from the sample data.
6.6
Wildcards and Double Slashes
XPath:
Output:
Figure 6.25
141
/customerinfo/*/*
<street>845 Kean Street</street>
<city>Aurora</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N8X 7F8</pcode-zip>
<street>1596 Baseline</street>
<city>Toronto</city>
<prov-state>Ontario</prov-state>
<pcode-zip>M3Z 5H9</pcode-zip>
<name>Gopher Runner</name>
<phone type="home">416-555-3426</phone>
Using wildcards to return any element on the third level of the document
While * matches any element name, @* matches any attribute. The XPath in Figure 6.26 is similar to the one in Figure 6.25, but it returns any attribute at the third level of the documents
because it uses @* instead of * in the last step of the path expression. Additionally, the data()
function is used to return just the value of each attribute node. The sample data contains two
attributes on the third level of the document, /customerinfo/addr/@country and /customerinfo/phone/ @type. The addr and phone elements are matched by the * in the second
step of the XPath, and their attributes are matched by @* in the third step. Attributes of the assistant phone elements are not returned because they are at the fourth level.
XPath:
Output:
Figure 6.26
/customerinfo/*/data(@*)
Canada
work
home
cell
Canada
work
home
Using wildcards to return any attribute on the third level of the document
The examples clarify that a * is a wildcard for a tag name at a very specific level of the XML documents, and you need to use multiple wildcards to match arbitrary tags at multiple levels.
Another XPath construct that makes queries more general is the double slash (//). You can use it
to reach descendants at any level in a document tree. An example is shown in Figure 6.27. The
difference between a single slash (/) and a double slash (//) is that a / navigates exactly one
level further down in the document tree while a // navigates any number of levels down the tree.
In other words, a / navigates to an immediate child node while a // navigates to all descendant
nodes. Descendant nodes include child nodes, grandchild nodes, great-grandchild nodes, and
so on.
142
Chapter 6
Querying XML Data: Introduction and XPath
The XPath expression in Figure 6.27 consists of two steps. The first step navigates to the top-level
element customerinfo. All customerinfo nodes are input (context) for the second step. The
second step, //name, looks for name elements at any level in the document tree under a customerinfo node. It finds two name elements at the second level, /customerinfo/name, and
one name element at the third level, /customerinfo/assistant/name.
XPath:
Output:
Figure 6.27
/customerinfo//name
<name>Robert Shoemaker</name>
<name>Matt Foreman</name>
<name>Gopher Runner</name>
Selecting name elements at any level under customerinfo
Figure 6.27 shows some of the benefits and some of the dangers of the //. A benefit is that the //
allows you to easily navigate to all occurrences of a certain element, even if that element occurs at
multiple different levels of a document tree. Another benefit can be that it allows you to find a certain element in the documents even if you do not know its exact position and therefore are unable
to write a fully qualified XPath.
A danger of the // can be that it might select more data than you actually intended. If the goal of
the query in Figure 6.27 was to retrieve customer names only, then the result leads you to believe
that there are three customers and that Gopher Runner is one of them. This is incorrect because
Gopher Runner is the assistant to Matt Foreman and not a customer himself. Another disadvantage of the // is that it doesn’t specify a direct path to the desired nodes. This causes an XPath
processor, such as DB2, to search exhaustively through potentially large portions of a document.
For example, the query in Figure 6.27 requires DB2 to navigate into the addr branch of each document and examine each child element of addr to determine whether its element name is name.
A fully specified path without // avoids this overhead and yields better performance.
The // can also be used at the beginning of a path expression, such as //name, which for the
sample data returns the same result as the query in Figure 6.27. The XPath //* returns all elements from all input documents, because // navigates to any level of the document and *
matches any element at each of those levels. Similarly //data(@*) returns all attribute values
anywhere in the documents, and //text() returns all text nodes. Use such general expressions
with caution.
6.7
XPATH PREDICATES
The preceding XPath examples always return all matching nodes from the input documents. In
many cases it is desirable to use search conditions (predicates) to filter the data and only return
selected items. In XPath, predicates are always enclosed in square brackets and can appear in any
6.7
XPath Predicates
143
step of the path. In Figure 6.28, a predicate in square brackets is applied to the customerinfo
element, which is the first step of the path. Roughly speaking, this query returns the name of the
customer(s) whose Cid attribute is 1004. More precisely, the predicate checks for each
customerinfo element in the input data, whether the element has an attribute by the name of
Cid and whether the value of that attribute is 1004. If such a Cid attribute does not exist or if its
value is not 1004, the respective customerinfo element is excluded from further consideration.
Based on our input data, only the customerinfo element in the second document passes this
test. This element is now the context for the next steps of the navigation, /name/text(), and the
value Matt Foreman is returned.
XPath:
Output:
Figure 6.28
/customerinfo[@Cid=1004]/name/text()
Matt Foreman
Numeric predicate in an XPath expression
Instead of the equality comparison you can also use less than (<), greater than (>), less than or
equal (<=), greater than or equal (>=), and not equal (!=). More details on comparison operators
are provided in section 6.8.
In Figure 6.29, the predicate in square brackets is applied to the addr element to return the streets
of those customers who live in Toronto. If an addr element has a child element city whose
value is Toronto, the addr element is used as the context for the next navigation step, /street.
XPath:
Output:
Figure 6.29
/customerinfo/addr[city="Toronto"]/street
<street>1596 Baseline</street>
String predicate in an XPath expression
Remember that the value of an element is defined as the concatenation of all text nodes in the subtree underneath that element (see section 3.1, Understanding XML Document Trees). Since the
city element has only a single text node, the predicates [city="Toronto"] and [city/
text()="Toronto"] lead to the same result. Hence, in the vast majority of cases you do not
need to use /text() in predicates. The relatively rare case in which it can sometimes be useful
to use /text() in predicates is when the immediate children of an element are a mix of element
and text nodes. Such elements are said to have mixed content (see section 3.1).
If you want to return the city element instead of the street element, a possible XPath is
/customerinfo/addr[city="Toronto"]/city. The city element is referenced once to
evaluate the predicate and then a second time at the end of the path to return it.
144
Chapter 6
Querying XML Data: Introduction and XPath
NUMERIC VERSUS STRING COMPARISON
Note that the predicate [@Cid=1004] performs a numeric
comparison while the predicate [@Cid="1004"], with double
quotes around the literal value, performs a string comparison.
The difference between numeric and string comparison can
lead to different query results. For example, a string comparison would find that the string values “1E3” and “1000” are not
equal. But, a numeric comparison would confirm that the numbers 1E3 and 1000 are equal because 1E3 is the exponential
notation for 1000. Similarly, the string comparison “2” < “10” is
false, but the numeric comparison 2 < 10 is true.
Note also that the numeric comparison [@Cid=1004] fails
with an error (SQL16061N) at runtime if a document is encountered where the value of the Cid attribute is not a number.
A predicate expression within the square brackets can contain multiple steps to navigate to the
element or attribute whose value you want to check. For example, say you want to return the
name of all customers in Toronto. To develop this XPath expression from scratch, first start without the predicate and write down just the path to the element that you want to return:
/customerinfo/name
To restrict the result to customers in Toronto, a predicate on the city element is required. The
city element is a child of the addr element, which in turn is a child of customerinfo, so this
is where you need to apply the predicate:
/customerinfo[addr/city ="Toronto"]/name
The predicate [addr/city ="Toronto"] checks for each customerinfo element if it has a
child element addr that has a child element city whose value is Toronto. The customerinfo
nodes that fulfill this condition are then the input for the next step, /name. In other words, the
XPath step right after the predicate is /name and it continues navigation based on the element
before the predicate (customerinfo) and not based on any element inside the square brackets.
This is illustrated in Figure 6.30, where this XPath expression is shown with two branches. The
horizontal branch identifies the items that are to be returned (/customerinfo/name), and the
branch in the dotted box is the predicate.
addr
customerinfo
Figure 6.30
city = "Toronto"
name
Visualization of an XPath with a predicate
6.7
XPath Predicates
145
One XPath can contain multiple predicates, as illustrated in Figure 6.31, which returns the street
of the customer whose name is Matt Foreman and whose city is Toronto.
XPath:
Output:
/customerinfo[name="Matt Foreman"]/addr[city="Toronto"]/street
<street>1596 Baseline</street>
Figure 6.31
XPath with two predicates
When writing such a query from scratch, proper placement of the predicates is sometimes not
obvious if you are new to XPath. The recommendation is again to first write the XPath without
any predicates and only navigate to the element that you want to return (street). This simpler
XPath looks like this:
/customerinfo/addr/street
Now you can add filtering predicates for name and city. Since name is a child element of
customerinfo, insert a pair of square brackets right after customerinfo for the predicate:
/customerinfo[name="Matt Foreman"]/addr/street
The city element is a child of addr, so the square brackets for the second predicate come right
after addr in the path expression, and this completes the query in Figure 6.31:
/customerinfo[name="Matt Foreman"]/addr[city="Toronto"]/street
Again, visualizing this query as a branching expression might be helpful (see Figure 6.32).
name = "Matt Foreman"
city = "Toronto"
customerinfo
Figure 6.32
addr
street
Visualization of an XPath with two predicates
Note that a predicate expression in square brackets can contain a / or a // but typically never
starts with a / or a //. Consider the following XPath expression as an example:
/customerinfo[/name="Matt Foreman"]/addr/street
This XPath returns the empty sequence because the predicate [/name="Matt Foreman"] does
not use the current customerinfo element as context. That is, it does not look for name elements that are children of customerinfo. Instead, the / inside the square brackets causes it to
146
Chapter 6
Querying XML Data: Introduction and XPath
restart navigation at the very top of each document, but there is no document in the sample data
where the topmost element is name.
Figure 6.33 shows what can happen if you use // right at the beginning of a predicate expression
in square brackets. The intention of this query was to return all cell phones by looking at type
attributes anywhere under phone. However, the // inside the square brackets causes it to restart
navigation at the very top of each document. Hence, the actual meaning of this query is: Retrieve
all phone elements from a document if a type attribute with the value “cell” occurs anywhere in
the document. In other words, return all phone elements if one of them is a cell phone.
XPath:
Output:
/customerinfo/phone[//@type="cell"]
<phone type="work">905-555-7258</phone>
<phone type="home">416-555-2937</phone>
<phone type="cell">905-555-8743</phone>
Figure 6.33
Incorrect use of // in a predicate
If you know that the type attribute is a child of phone, you could simply remove the // from the
beginning of the predicate expression. Otherwise you can use a dot to force the // to only search
within the subtree (within the current context) of the respective phone element (see Figure 6.34).
The current context is explained in more detail in section 6.10.
XPath:
Output:
/customerinfo/phone[.//@type="cell"]
<phone type="cell">905-555-8743</phone>
Figure 6.34
Correct use of // in a predicate
Also note that the opening square bracket of a predicate can never follow immediately after a /
or a //. For example, the XPath /customerinfo/[name="Matt Foreman"] would fail with
an error (SQL16002N). A / starts a new step, which cannot begin with a predicate. A predicate
always has to be preceded by a context node (such as an element name) to which it is applied.
And finally, look at Figure 6.35, which uses an equality comparison without square brackets. This
is just a Boolean expression of the form A = B that returns either true or false. It is not a useful predicate to select specific parts of the customer data. In particular, this query does not return
the customer whose name is Matt Foreman. The query examines a sequence of name elements
and returns true if at least one of them is equal to Matt Foreman. This is called existential
semantics and is explained in the next section.
XPath:
Output:
/customerinfo/name="Matt Foreman"
true
Figure 6.35
A Boolean expression, not a filtering predicate
6.8
6.8
Existential Semantics
147
EXISTENTIAL SEMANTICS
When you use XPath, existential semantics (also known as existential quantification) is applied
automatically all the time. Roughly speaking, existential semantics means that the existence of at
least one matching node is sufficient for a predicate to evaluate to true. Let’s look at the query in
Figure 6.36 as an example. This query returns the name of those customers whose phone number
is 416-555-2937. But, both of the input documents contain several occurrences of the phone
element. Existential semantics means that the query in Figure 6.36 returns name elements that are
children of customerinfo elements that contain at least one child element phone whose value
is 416-555-2937. The existence of at least one matching phone element is sufficient to fulfill
the predicate. Existential semantics is a useful concept for querying XML data, because it defines
how to evaluate predicates on repeating elements (or more generally, on sequences of two or
more items).
XPath:
Output:
Figure 6.36
/customerinfo[phone="416-555-2937"]/name
<name>Robert Shoemaker</name>
At least one phone element must match, not all of them
Figure 6.37 shows another example of existential semantics. It includes a predicate that contains
nothing but the element name assistant. The predicate evaluates to true if this element exists
at the indicated position in the document tree; that is, as a child of the customerinfo element.
As a result, this query returns the name of those customers who have an assistant, no matter what
the assistant name or phone number is. The mere existence of an assistant element is what this
predicate is looking for. Such a predicate is called a structural predicate as opposed to a value
predicate, which performs a value comparison.
XPath:
Output:
Figure 6.37
/customerinfo[assistant]/name
<name>Matt Foreman</name>
A structural predicate
Similarly you can check for the existence of an attribute. The query in Figure 6.38 retrieves the
names of all customers who have a country attribute in the addr element.
XPath:
Output:
Figure 6.38
/customerinfo[addr/@country]/name
<name>Robert Shoemaker</name>
<name>Matt Foreman</name>
Return the name if a country attribute exists
Yet another example of existential semantics is illustrated in Figure 6.39 where the right side of
the predicate is a sequence of two atomic values. This predicate is true if there is at least one value
in this sequence that is equal to the value of the city element. If you are familiar with IN-list
queries in SQL, this is how you can do the same in XPath.
148
Chapter 6
XPath:
Output:
Figure 6.39
Querying XML Data: Introduction and XPath
/customerinfo[addr/city = ("Toronto","Aurora")]/name
<name>Robert Shoemaker</name>
<name>Matt Foreman</name>
Predicate is true if at least one of the values matches
What if a customer has several addresses so that addr/city evaluates to a sequence of multiple
city elements? In this case, existential semantics defines that the predicate is true if at least one
of these city elements is equal to at least one of the values on the right side.
Let’s look at the two sequences (1,2,3,4) and (7,8,2). The comparison (1,2,3,4) =
(7,8,2) evaluates to true because there is at least one item in the first sequence that is equal to at
least one item in the second sequence. This item is the number 2. What might seem counterintuitive at first is that the predicate (1,2,3,4) != (7,8,2) also evaluates to true! This is again
due to existential semantics, because there is at least one item in the first sequence that is not
equal to at least one item in the second sequence. Figure 6.40 shows the corresponding behavior
for the sample data. Remember that Robert Shoemaker lives in Aurora and Matt Foreman lives in
Toronto (see Figure 6.7). The XPath in Figure 6.40 returns Robert Shoemaker’s name because his
city (Aurora) is not equal to at least one item in the sequence on the right (Toronto). The same
applies to Matt Foreman whose city (Toronto) is not equal to Aurora.
XPath:
Output:
Figure 6.40
/customerinfo[addr/city != ("Toronto","Aurora")]/name
<name>Robert Shoemaker</name>
<name>Matt Foreman</name>
Predicate is true if at least one of the values does not match
The lesson here is that XPath’s existential semantics is not only applied to equality predicates but
also to range and inequality predicates for which the behavior is not immediately intuitive if the
left side or the right side evaluates to a sequence of more than one item. For example, the predicate in Figure 6.41 only involves sequences of exactly one item on either side of the != operator.
The behavior is intuitive and only Robert Shoemaker’s name is returned because he is the only
customer in our sample who does not live in Toronto.
XPath:
Output:
Figure 6.41
6.9
/customerinfo[addr/city != "Toronto"]/name
<name>Robert Shoemaker</name>
Not-equal predicate on single items
LOGICAL EXPRESSIONS WITH AND,
OR, NOT()
Similarly to SQL, XPath allows you to build more complex predicates with and, or, and not().
While and and or are logical operators, not() is a function that reverses the Boolean value of its
argument. XPath and XQuery are case-sensitive languages and all operators and functions have
to be written in lowercase.
6.9
Logical Expressions with AND, OR, NOT()
149
The query in Figure 6.42 uses the or operator to check whether there is an addr with a city element that has the value Toronto, or if there is an addr with a city element whose value is
Aurora. For the sample data, this returns the same result as in Figure 6.39. Note that when we say
“if there is” or “if there exists” we are hinting at the fact that existential semantic is always at play.
XPath:
Output:
Figure 6.42
/customerinfo[addr/city = "Toronto" or
addr/city ="Aurora"]/name
<name>Robert Shoemaker</name>
<name>Matt Foreman</name>
Disjunction of predicates (or-’ing)
The and operator is used in Figure 6.43 to select the names of customer whose city is Aurora
and whose country is Canada.
XPath:
Output:
Figure 6.43
/customerinfo[addr/city = "Aurora" and
addr/@country = "Canada"]/name
<name>Robert Shoemaker</name>
Conjunction of predicates (and-’ing)
The predicate in Figure 6.43 checks whether there is an addr element with a city child that has
the value Aurora, and whether there is also an addr element with a country attribute whose
value is Canada. In this case, both conditions are fulfilled by one and the same addr element. In
general, however, they could be fulfilled by two different addr elements; for example, if a customer had two addresses. This alludes to the next interesting example.
You might write the query in Figure 6.44 to find a customer whose work phone number is 416555-2937. Such a customer does not exist in our sample data, because 416-555-2937 is Robert
Shoemaker’s home phone number, not his work phone number. The predicate restricts the value
of the phone element to 416-555-2937, and the type attribute of the phone element to work.
Still, the name Robert Shoemaker is returned. This is because existential semantics applies to
both parts of the predicate. The first part of the predicate, phone = "416-555-2937", is true
because there is a phone element whose value is 416-555-2937. The second part of the predicate, phone/@type = "work", is also true because there also is a phone element whose type is
work. But, these two phone elements are not the same. The query result in Figure 6.44 is perfectly correct according to the existential semantics of XPath, but probably not what you wanted
to achieve with this query.
XPath:
Output:
Figure 6.44
/customerinfo[phone = "416-555-2937" and
phone/@type = "work"]/name
<name>Robert Shoemaker</name>
Two predicates matched by different phone elements!
150
Chapter 6
Querying XML Data: Introduction and XPath
To solve this issue you need to express the predicate such that both conditions are applied to the
same phone element. One way of doing this is shown in Figure 6.45 where nested square brackets are used. The outer square brackets describe a predicate that is applied to the customerinfo
elements. This predicate says that a customerinfo element should only be considered if a certain phone element exists among its children. The inner square brackets are used to further constrain these phone elements by applying a predicate to them. The inner predicate [text() =
"416-555-2937" and @type = "work"] says that the text value of the phone element has to
be 416-555-2937 and the type of the same phone element is work. Both parts of this inner
predicate are always applied together to the same phone element. Since no such customer exists
in our sample data, the correct result of the query is empty.
XPath:
/customerinfo[phone[text() = "416-555-2937" and
@type = "work"] ]/name
Output:
Figure 6.45
Nested predicates
Figure 6.46 provides another example of the use of the or operator. It returns the names of the
customers who have an assistant or a cell phone. Both of the customers are returned because one
of them has a cell phone and the other has an assistant.
XPath:
Output:
Figure 6.46
/customerinfo[assistant or phone/@type="cell"] ]/name
<name>Robert Shoemaker</name>
<name>Matt Foreman</name>
A structural predicate and a value predicate
The XPath expression in Figure 6.47 lists the names of those customers who don’t have an assistant. The not() function is used in the predicate to qualify the customerinfo elements that do
not have a child element with the name assistant.
XPath:
Output:
Figure 6.47
/customerinfo[not(assistant)]/name
<name>Robert Shoemaker</name>
Checking for the non-existence of an element
Next, let’s look at the following pair of queries (see Figure 6.48 and Figure 6.49) to clarify the
difference between using the not() function and the “not equal” comparison operator (!=). Due
to existential semantics, the query in Figure 6.48 returns the names of both customers. This is
because both of them have at least one phone number that is not equal to 416-555-2937. One
such non-matching phone element is enough to fulfill the predicate, even if other phone elements exist that do match this number.
6.10
The Current Context and the Parent Step
151
The query in Figure 6.49 returns a result that might be more desirable: the name of the customer
who does not have any phone element with the value 416-555-2937. The equality predicate
inside the not() function is subject to existential semantics; that is, at least one phone element
with this specific number has to exist. The outcome of this test is then negated with the not()
function. In other words, the two queries differ because
• The query in Figure 6.48 checks whether there is at least one phone that is not equal to
416-555-2937 (even if other phone elements are equal to this value).
• The query in Figure 6.49 checks whether there is not at least one phone that is equal to
416-555-2937 (that is, there is no phone that is equal to this value).
/customerinfo[phone != "416-555-2937"]/name
<name>Robert Shoemaker</name>
<name>Matt Foreman</name>
XPath:
Output:
Figure 6.48
/customerinfo[not(phone = "416-555-2937")]/name
<name>Matt Foreman</name>
XPath:
Output:
Figure 6.49
6.10
Predicate is true if at least one phone element does not match
Predicate is true if none of the phone elements match
THE CURRENT CONTEXT AND THE PARENT STEP
You probably know that in a file system the dot (.) denotes the current location in the file system,
and two dots (..) refer to the parent directory. The same notation exists in XPath to refer to the
current node when navigating a document tree, or to the parent of the current node. This is illustrated in Figure 6.50, which shows four versions of an XPath expression. All of them return the
same result from our input data; that is, the name element of the customers who live in Aurora.
For the discussion of these four XPath expressions you may want to refer to the document tree
shown in section 3.1, Understanding XML Document Trees. Also, remember that the node name
right before the square brackets of a predicate determines the input to the predicate and to the step
that immediately follows the predicate. For example, XPath (a) in Figure 6.50 first produces a
sequence of customerinfo elements. For each of these customerinfo elements the predicate
checks whether there is an addr element that has a child element city whose value is Aurora.
If so, the respective customerinfo element is input to the final step, /name, which returns the
child element name.
XPath (b) is different because the predicate is applied to addr, not to customerinfo. Hence,
this XPath first produces a sequence of addr elements, which are input to the predicate. Any
addr element that has a child element city with value Aurora is then input to the subsequent
152
Chapter 6
Querying XML Data: Introduction and XPath
step after the predicate. Since we want to return name elements, we need to navigate from addr
to name, which are siblings in our documents. Because an XML document tree has no direct links
between siblings, we use the parent step (..) to go one level up in the tree to their common parent, and from there to name.
XPath (a)
(b)
(c)
(d)
Output:
Figure 6.50
/customerinfo[addr/city = "Aurora"]/name
/customerinfo/addr[city = "Aurora"]/../name
/customerinfo/addr/city[. = "Aurora"]/../../name
/customerinfo/name[../addr/city = "Aurora"]
<name>Robert Shoemaker</name>
Four different ways to write a predicate and return the name element
In XPath (c) the predicate in square brackets is applied to city, which means that this XPath first
produces a sequence of city elements, which are used as input (as context nodes) to the predicate. The predicate [. = "Aurora"] uses the dot to refer to the current context, which in this
case is always a city element. Any city element for which the predicate is true is then input
(context) for the subsequent navigation after the predicate. If you want to return name elements,
you need to navigate from city to name, which are in different branches of the document. Hence
you need to navigate via the nearest common ancestor, which is customerinfo. Since city is a
grandchild of customerinfo, you need to go two levels up in the tree (/../..) before you can
reach the name element (/name).
XPath (d) is different from (a), (b), and (c) because there is no /name step after the predicate.
Instead, XPath (d) first navigates from customerinfo to name to produce a sequence of name
elements. The square brackets are applied to name, to filter the names that get returned. The predicate [../addr/city = "Aurora"] means that a name element is returned only if it has a parent that has a child element addr that has a child element city whose value is Aurora.
XPath (a) is the most preferable path expression among the four options in Figure 6.50, because it
avoids parent steps completely. Avoiding parent steps is good for performance and keeps queries
easy to understand.
Figure 6.51 shows four more XPath expressions. All of them return empty results because their
navigation doesn’t correspond to the structure of the sample data. The parent step in XPath (a) is
incorrect for the sample data because it navigates from customerinfo to name with an intermediate parent step as if name was a sibling of customerinfo, which is not the case. XPath (b)
tries to return name elements that are children of addr. But, no such name elements exist. Similarly, XPath (c) tries to return name elements that are children of the parent of city (that is, children of addr). Again, no such name elements exist. XPath (d) intends to return name elements
that have a child element addr with a city whose value is Aurora. But, this predicate is always
false for the sample data because addr is not a child of name.
6.11
Positional Predicates
XPath (a)
(b)
(c)
(d)
Output:
Figure 6.51
6.11
153
/customerinfo[addr/city = "Aurora"]/../name
/customerinfo/addr[city = "Aurora"]/name
/customerinfo/addr/city[. = "Aurora"]/../name
/customerinfo/name[addr/city = "Aurora"]
Four different XPath expressions that don’t match the sample data
POSITIONAL PREDICATES
So far you have used value predicates and structural predicates. Value predicates compare an element or attribute to a literal value such as a string or a number. Structural predicates don’t look at
values but at the structure of an XML document by checking for the existence of an element or
attribute by name.
Positional predicates can be used to select nodes based on the order in which they appear in a
document or, more generally, in a sequence. As shown in Figure 6.52, a positional predicate is
simply an integer number in square brackets. Both documents in the sample data contain multiple
phone elements, but this query only returns the first phone element from each document.
XPath:
Output:
Figure 6.52
/customerinfo/phone[1]
<phone type="work">905-555-7258</phone>
<phone type="work">905-555-4789</phone>
Positional predicate to select the first phone element
Similarly, the XPath in Figure 6.53 selects the third phone element under each customerinfo
element. In the sample data, the customer Robert Shoemaker has three phone numbers but Matt
Foreman has only two phones. Hence, the result only contains Robert’s third phone number and
none of Matt’s phone numbers.
XPath:
Output:
Figure 6.53
/customerinfo/phone[3]
<phone type="cell">905-555-8743</phone>
Positional predicate to select the third phone element
To obtain the last phone element from each document irrespective of the number of phone elements in any given document, use the function last() in the predicate. This function takes no
arguments but serves as an index to the last item in a sequence (see Figure 6.54).
154
Chapter 6
Querying XML Data: Introduction and XPath
/customerinfo/phone[last()]
<phone type="cell">905-555-8743</phone>
<phone type="home">416-555-3376</phone>
XPath:
Output:
Figure 6.54
Positional predicate to select the last phone element
Related to positional predicates is the function position(). It takes no arguments but returns
the position of the context item in the sequence that is being processed. For example, the positional predicate [3] is the same as the predicate [position() = 3].
6.12
UNION AND CONSTRUCTION OF SEQUENCES
Most of the XPath examples so far have returned one type of element, such as phone numbers or
names. Sometimes it is desirable to obtain multiple different elements or attributes from each
document. This can be achieved with the union operator, which is either written as the union
keyword or the pipe character: |. The XPath in Figure 6.55 uses the union operator in the last step
of the XPath, to combine the street and city elements into a single sequence. The result contains four elements, street and city from each of the two customers in the sample data. You
will later use SQL/XML to return the street and city in two separate columns, which can be a
more desirable return format (see Chapter 7, Querying XML Data with SQL/XML).
XPath:
Output:
Figure 6.55
/customerinfo/addr/(street|city)
<street>845 Kean Street</street>
<city>Aurora</city>
<street>1596 Baseline</street>
<city>Toronto</city>
XPath with a union operator
The union of sequences is similar to the construction of sequences. The comma is a sequence
constructor and in many cases it produces the same result as a union. For example, the XPath
/customerinfo/addr/(street,city)
returns the same result as the union in Figure 6.55. However, there are a couple of differences
between union and construction of sequences. The comma operator allows you to construct
sequences from atomic values. The | operator cannot take atomic values as input, it has to take
sequences of element or attribute nodes as input. Secondly, the union removes duplicate nodes
while the comma operator does not. The de-duplicating of the union is based on node identities,
not on node values. This means that two elements are not necessarily considered duplicates just
because they have the same element name and value. They are considered duplicates only if they
are indeed the same element from the same document.
6.13
General and Value Comparisons
155
In addition to the union operator there is also an intersect and an except operator. The
intersect operator produces the nodes that occur in both sequences, and the except operator
returns the nodes that are in the first but not the second sequence.
6.13
XPATH FUNCTIONS
If you look back at Figure 6.1 at the beginning of this chapter, you see that XPath and XQuery do
not only share the same data model but also a common set of functions and operators. Throughout this chapter we have used some of these functions such as data(), string(), and not().
XPath and XQuery provide a large number of built-in functions. These include aggregate functions such as count() and sum(), string functions such as contains() and substring(), as
well as numeric and other functions.
Figure 6.56, Figure 6.57, and Figure 6.58 provide examples of how to use functions in XPath
expressions. The count() function returns the number of nodes produced by the expression that
is provided as the function argument. Remember that Robert Shoemaker has three phone numbers and Matt Foreman has two. Other functions such as upper-case() and concat() behave
in intuitive ways.
XPath:
Output:
Figure 6.56
XPath:
Output:
Figure 6.57
XPath:
Output:
Figure 6.58
/customerinfo/count(phone)
3
2
Return the number of phone elements per document
/customerinfo/upper-case(name)
ROBERT SHOEMAKER
MATT FOREMAN
Convert the customer names to upper case
/customerinfo/concat(name," – ", addr/city)
Robert Shoemaker - Aurora
Matt Foreman - Toronto
Concatenate the customer name and city
Section 8.7, XQuery Functions, contains a more extensive discussion of XPath and XQuery functions. Additionally, Appendix C provides pointers to the complete reference of all supported
XPath and XQuery functions in DB2 for z/OS and DB2 for Linux, UNIX, and Windows.
156
6.14
Chapter 6
Querying XML Data: Introduction and XPath
GENERAL AND VALUE COMPARISONS
All the comparison operators that you have used so far (=, !=, <, <=, >, >=) are called general
comparisons because they allow you to compare sequences of zero, one, or multiple items. This
is based on existential semantics, as discussed in section 6.8. General comparisons provide a lot
of flexibility and serve you well in the vast majority of cases.
There are also value comparison operators, such as eq (equal), lt (less than), le (less than or
equal), gt (greater than), ge (greater or equal), and ne (not equal). Value comparisons are different from general comparisons because they can only compare single items. For example,
/customerinfo/addr[city eq "Toronto"] is a valid value comparison as long as there is
only one city element per addr. The query /customerinfo[phone eq "408-463-4963"]
will fail at runtime because the sample data contains multiple phone elements per customerinfo. The DB2 error message is
SQL16003N An expression of data type "( item(), item()+ )" cannot be used when the
data type "item()" is expected in the context.
The “( item(), item()+ )” is a regular expression that denotes a sequence of one item followed by one or more items. In total that’s two or more items. So this message is a very formal
way of saying that there is a sequence of multiple items (that is, multiple phone elements) when
only a single item was allowed.
In many cases you can work around this error by writing the XPath expression as /customerinfo/phone[. eq "408-463-4963"] because the dot always refers to exactly one of
the phone elements at a time. Another solution is to simply use a general comparison instead:
/customerinfo[phone = "408-463-4963"].
Another issue with value comparisons is that they perform string comparisons by default. For
example, the XPath /customerinfo/addr[pcode-zip lt 95123] will fail with the following message because it tries to use the lt operator with a numeric value (95123), instead of a
string value (“95123”).
SQL16003N An expression of data type "xs:integer" cannot be used when the data
type "xs:string" is expected in the context. SQLSTATE=10507
You can avoid this error by casting the pcode-zip element to xs:integer, such as
[xs:integer(pcode-zip) lt 95123], or by using a general comparison instead.
Value comparisons have one property that general comparisons do not have, and that is transitivity. If x eq y and y eq z then you are safe to conclude that y eq z is also true. This is not possible with the existential semantics of general comparisons for sequences. For example,
(1,2,3) = (3,4,5) and (3,4,5) = (5,6,7), but (1,2,3) != (5,6,7) because there is
no item in (1,2,3) that is equal to any item in (5,6,7).
6.16
Summary
157
In summary, the use of value comparisons opens up various opportunities for errors but in most
cases provides little gain. Most applications do not require transitivity and are well-served with
general comparisons. One potential benefit of value comparisons is that you can force errors if you
want to be alerted when data types or element occurrences are different than what you expect.
6.15
XPATH AXES AND UNABBREVIATED SYNTAX
We have introduced XPath through a series of practical examples. In a more formal introduction
you might read about XPath axes. An axis is the direction of movement when navigating through
a document. DB2 supports the child axis, the descendant axis, the attribute axis, the self axis, the
parent axis, and the descendant-or-self axis. We have used all of these axes in the examples in the
previous sections of this chapter. For example, the path /customerinfo/addr/@country
uses the child axis to navigate from customerinfo to its child element addr, and the attribute axis
to navigate from addr to its attribute country.
All XPath examples in this book use the so-called abbreviated XPath syntax, because it is simple,
easy to understand, and recommended. XPath also offers an unabbreviated syntax, which means
that the axes are spelled out explicitly in each step of an XPath. This is rarely used. For example:
Abbreviated: /customerinfo/addr/@country
Unabbreviated: /child::customerinfo/child::addr/attribute::country
Abbreviated: /customerinfo//phone
Unabbreviated: /child::customerinfo/descendant-or-self::node()/child::phone
In a nutshell, the unabbreviated XPath syntax is verbose, clumsy, and not used much in practice.
We recommend that you do not use it. We have explained it here merely so that you recognize it if
it ever crosses your path (no pun intended).
6.16
SUMMARY
XPath is the fundamental language for traversing XML documents, evaluating XML predicates,
and retrieving XML values. A thorough understanding of XPath is a prerequisite for querying
XML data in DB2 for z/OS and DB2 for Linux, UNIX, and Windows. Both SQL/XML and
XQuery involve XPath. Understanding XPath begins with understanding the XQuery and XPath
data model. This data model is inherently different from the relational model. The better you
understand the XQuery data model the easier it is for you to write XML queries.
Every value in the XQuery and XPath data model is a sequence of zero, one, or multiple items. An
item is either an atomic value or a node. Commonly used nodes include document nodes, element
nodes, attribute nodes, and text nodes. Element nodes can include child nodes to form hierarchies
158
Chapter 6
Querying XML Data: Introduction and XPath
of nodes, such as XML documents. Hence, a sequence of zero, one, or multiple XML documents
is a value in the XQuery and XPath data model. A sequence of individual elements, a sequence of
integer numbers, and so on are also values in the data model. Every XQuery or XPath query takes
a value of this data model as input and produces another value of the data model as output.
Most commonly an XPath expression consists of one or multiple steps, separated by a slash (/),
where each step is an element name or wildcard. This allows you to navigate into an XML document tree to select specific elements. If you want to select attribute nodes then the last step in a
path must be an attribute name that’s preceded by the @ sign. Since an XML document can contain elements that occur multiple times, a single XPath expression may select multiple nodes. At
each step an XPath can contain a predicate to restrict the search in the document. XPath predicates must be enclosed in square brackets.
The evaluation of XPath expressions and predicates is always based on existential semantics.
Roughly speaking, existential semantics means that the existence of at least one matching item is
sufficient for a predicate to evaluate to true. This is of particular importance when you query
XML documents with repeating elements. Repeating XML elements and existential semantics
are some of the most profound differences between the XML world and relational world.
In the following chapters you learn how to use XPath in SQL/XML and XQuery.
C
H A P T E R
7
Querying XML Data
with SQL/XML
he SQL language standard includes a variety of functions and features to process XML
data. This functionality is commonly referred to as SQL/XML. The SQL/XML functions
that allow you to embed XPath and XQuery expressions in SQL are of particular interest. These
functions enable you to use familiar SQL statements enriched with XPath expressions to query
XML data in a DB2 database. They also facilitate the simultaneous processing of XML and relational data in the same query. This marriage of two worlds, XML and relational, is extremely
powerful and versatile.
T
Although SQL/XML allows the integration of SQL and XQuery, this chapter focuses on the integration of SQL and XPath, which is supported in both DB2 for z/OS and DB2 for Linux, UNIX,
and Windows. The discussion of SQL/XML in this chapter assumes that you have a good understanding of XPath (see Chapter 6, Querying XML Data: Introduction and XPath). The examples
in this chapter also use the same two sample documents that were used throughout Chapter 6.
Please refer to Figure 6.7 in section 6.3, Sample Data for XPath, SQL/XML, and XQuery. All
examples are based on the following customer table:
CREATE TABLE customer(id INTEGER, info XML)
We assume that this table contains two rows with values 1003 and 1004 in the id column, and
the two documents from Figure 6.7 in the XML column info.
The remainder of this chapter is structured as follows:
• An overview of SQL/XML is given in section 7.1.
• The core SQL/XML functionality for extracting selected information from XML documents and defining XML predicates is covered in sections 7.2, 7.3, and 7.4.
159
160
Chapter 7
Querying XML Data with SQL/XML
• Common mistakes with SQL/XML predicates are highlighted in section 7.5.
• Parameter markers, dynamically computed XPath, sorting of XML data, and handling
of binary data are discussed in sections 7.6 through 7.9.
7.1
OVERVIEW OF SQL/XML
The term SQL/XML refers to the XML-specific features and functions in the SQL:2003 and
SQL:2006 standards. SQL/XML defines the following:
• The XML data type, which is a regular SQL type just like INTEGER or CHAR for example. SQL/XML defines the semantics of this type, not its storage format.
• Functions that convert XML type values to and from non-XML data types, such as
CHAR, VARCHAR, CLOB, and others. These functions are XMLSERIALIZE, XMLPARSE,
and XMLCAST.
• The function XMLVALIDATE for XML Schema validation and the predicate IS VALIDATED, which checks the validation status of an XML document or fragment.
• XML publishing functions, also sometimes called constructor functions, such as
XMLELEMENT, XMLATTRIBUTES, and XMLAGG, which allow you to construct new XML
documents or fragments. The input data for such XML construction can come from relational columns, from XML columns, or both. This topic is covered in Chapter 10,
Producing XML from Relational Data.
• Functions to embed XPath and XQuery in SQL statements. These functions are
XMLQUERY, XMLTABLE, and the XMLEXISTS predicate.
All of these SQL/XML functions are supported in DB2 for z/OS and DB2 for Linux, UNIX, and
Windows. In this chapter we focus on the following:
• XMLQUERY—A scalar function that is typically used in the SELECT clause of an SQL
query to extract XML fragments or values from an XML document.
• XMLTABLE—A table function that is used in the FROM clause of an SQL statement. It
reads one or multiple values from an XML document and returns them as a set of rows.
• XMLEXISTS—A predicate that is commonly used in the WHERE clause of an SQL statement to express predicates over XML data.
• XMLCAST—A function that converts individual XML values to SQL data types.
Now, let’s turn to examples to see how these functions work.
7.2
Retrieving XML Documents or Document Fragments with XMLQUERY
161
7.2 RETRIEVING XML DOCUMENTS OR DOCUMENT FRAGMENTS WITH
XMLQUERY
The simplest way of retrieving XML data with SQL is to include an XML column name in the
SELECT list of an SQL query. For example, the SQL statement in Figure 7.1 returns a single column of type XML (info) and two rows, one row for each of our two sample documents in the
customer table. Below the SQL statement in Figure 7.1 you see a corresponding XQuery that
returns the same result.
--SQL:
SELECT info
FROM customer;
--XQuery:
xquery db2-fn:xmlcolumn('CUSTOMER.INFO');
Figure 7.1
Retrieve all documents from the table
You can extend the SQL query in Figure 7.1 with other features of the SQL language, such as a
WHERE clause to select only specific rows (documents) from the table. This is shown in Figure
7.2, together with an equivalent XQuery for comparison.
--SQL:
SELECT info
FROM customer
WHERE id = 1003;
--XQuery:
xquery db2-fn:sqlquery('SELECT info FROM customer WHERE id = 1003');
Figure 7.2
Retrieve selected documents from the table
In many situations it is desirable not to retrieve full documents from the database, but just specific
XML elements, attributes, or fragments that are of interest. For example, if you only need to
retrieve the customer names, you can use the XMLQUERY function in the SELECT clause to extract
just that element (see Figure 7.3). The argument of the XMLQUERY function can be any XQuery or
XPath expression. This expression needs to know which column to operate on, because a table
could have multiple XML columns. The solution is to prefix the XPath with $INFO, a reference to
the XML column in our sample table. This reference has to be in uppercase and must start with
the $ sign (see section 7.2.1 for details).
The SQL/XML statement in Figure 7.3 uses SQL as the top-level language and has an embedded
XPath expression. Below it you see a corresponding XQuery that executes the same XPath
expression without the use of any SQL. The query result and performance is the same. In particular, note that the return type of the XMLQUERY function is always XML. We will later discuss cases
where SQL/XML can have advantages over XQuery and vice versa.
162
Chapter 7
Querying XML Data with SQL/XML
--SQL/XML:
SELECT XMLQUERY('$INFO/customerinfo/name')
FROM customer
--XQuery:
xquery db2-fn:xmlcolumn('CUSTOMER.INFO')/customerinfo/name;
--Output:
<name>Robert Shoemaker</name>
<name>Matt Foreman</name>
2 record(s) selected.
Figure 7.3
Extracting one element from each document
The XMLQUERY function in Figure 7.3 is a scalar function, which means that it takes one value as
input and produces one value as output. The XMLQUERY function is applied to one row at a time
and so its input value is always the XML document of the current row. The XMLQUERY function
typically never processes XML documents from multiple rows at the same time. Its output value
is the result of the XPath expression applied to the current document. This result is always a
sequence of zero, one, or more items. Such a sequence represents a single value (instance) of the
XQuery Data Model.
7.2.1
Referencing XML Columns in SQL/XML Functions
Figure 7.3 shows only one of three ways in which the XML column can be referenced inside the
XMLQUERY function. Here are all three ways in more detail:
• Direct reference of the XML column name as $INFO. This $INFO is an XQuery variable
that is implicitly bound to an XML column of the same name. This is only supported in
DB2 for Linux, UNIX, and Windows version 9.5 and higher. It only works if the XML
column name is unique across all tables that are referenced in the FROM clause. For
brevity we will use this notation in most of the examples in this chapter.
SELECT XMLQUERY('$INFO/customerinfo/name')
FROM customer;
• Explicit assignment of the XML column name to an alias of your choice, which is then
used as the context at the beginning of the XPath expression. This assignment is done in
the passing clause of the XMLQUERY function. It also allows you to qualify the column
name with its table name (passing customer.info AS "i") to avoid ambiguity.
The variable name $i has to be unique within each SQL/XML function, not across all
functions. You will later see that this passing clause also allows you to pass parameter
markers or expressions into the embedded XQuery. This is supported since version 9 of
DB2 for z/OS and DB2 for Linux, UNIX, and Windows.
7.2
Retrieving XML Documents or Document Fragments with XMLQUERY
163
SELECT XMLQUERY('$i/customerinfo/name' passing info as "i")
FROM customer;
-- query with two tables, both have an XML column "info":
SELECT XMLQUERY('$i/customerinfo/name' passing c1.info as "i"),
XMLQUERY('$i/customerinfo/name' passing c2.info as "i")
FROM customer c1, customer2 c2;
• No XQuery variable at the beginning of the XPath expression. Instead, the XML column
name is identified in the passing clause without assignment to a variable. This is only
supported in DB2 for z/OS.
SELECT XMLQUERY('/customerinfo/name' passing info)
FROM customer;
7.2.2
Retrieving Element Values Without XML Tags
There are several ways in which you can return the customer names without the element tags
<name></name> around them. One option is to use /text() in the XPath expression to only
return the text node of the name element, as in Figure 7.4 (a). The column in the query result set is
still of type XML. Alternatively, you can wrap the function XMLCAST() around the XMLQUERY
function to convert the XML result to a non-XML type, as in Figure 7.4 (b). XMLCAST() automatically removes the tags from the returned elements. The output is the same as from Figure 7.4
(a), except that the return type is VARCHAR(25) instead of XML.
--(a) SQL/XML:
SELECT XMLQUERY('$INFO/customerinfo/name/text()')
FROM customer;
--(b) SQL/XML:
SELECT XMLCAST(
XMLQUERY('$INFO/customerinfo/name')
AS VARCHAR(25))
FROM customer;
--Output:
Robert Shoemaker
Matt Foreman
2 record(s) selected.
Figure 7.4
Returning element values without tags
A common requirement is to retrieve multiple values from a document, such as the customers’
street and city, and to return them in separate columns of the same result row. Separate columns
can be produced by using multiple XMLQUERY functions in the SELECT clause (see Figure 7.5).
164
Chapter 7
Querying XML Data with SQL/XML
The same can be achieved with the XMLTABLE function, which is discussed later. Figure 7.5 also
shows that you can return a mix of relational columns and XML values.
SELECT id,
XMLQUERY('$INFO/customerinfo/addr/street/text()'),
XMLQUERY('$INFO/customerinfo/addr/city/text()')
FROM customer;
1003
1004
845 Kean Street
1596 Baseline
Aurora
Toronto
2 record(s) selected.
Figure 7.5
7.2.3
Returning multiple element values in separate columns
Retrieving Repeating Elements with XMLQUERY
The SQL/XML query in Figure 7.6 uses the path expression /customerinfo/phone, which
you know returns multiple elements from each of the two input documents. This SELECT statement produces one result row for each of the two input rows. Each result row contains the
sequence of phone numbers from the corresponding input document. Each of these two
sequences is returned as a string, which the consuming application then needs to break down.
However, such a sequence of two or more phone elements is not a well-formed XML document,
because a single common root element is missing. Hence, if your application uses an XML parser
to process this non-well-formed query result, it will fail with an error.
SELECT id, XMLQUERY('$INFO/customerinfo/phone')
FROM customer;
1003
1004
<phone type="work">905-555-7258</phone><phone type=
"home">416-555-2937</phone><phone type="cell">905555-8743</phone>
<phone type="work">905-555-4789</phone><phone type=
"home">416-555-3376</phone>
2 record(s) selected.
Figure 7.6
Returning a sequence of elements from each document
Figure 7.7 shows the same query with /text(), and you see that the result values in each
sequence are simply concatenated.
7.3
Retrieving XML Values in Relational Format with XMLTABLE
165
SELECT id, XMLQUERY('$INFO/customerinfo/phone/text()')
FROM customer;
1003
1004
905-555-7258416-555-2937905-555-8743
905-555-4789416-555-3376
2 record(s) selected.
Figure 7.7
Returning a sequence of text nodes from each document
The conclusion is that the XMLQUERY function is typically not very useful to return repeating elements. As a solution, use the XMLTABLE function, which is explained in the next section.
7.3
RETRIEVING XML VALUES IN RELATIONAL FORMAT WITH XMLTABLE
The XMLTABLE function is very versatile and one of the most powerful SQL/XML functions.
Let’s start with some simple examples of the XMLTABLE function and then get back to returning
the repeating phone elements in a more suitable format.
7.3.1
Generating Rows and Columns from XML Data
The query in Figure 7.8 uses the XMLTABLE function in the FROM clause. The XMLTABLE function
references the info column and is therefore implicitly joined with the table customer.
SELECT T.*
FROM customer,
XMLTABLE('$INFO/customerinfo'
COLUMNS
custID
INTEGER
PATH
custname
VARCHAR(20)
PATH
street
VARCHAR(20)
PATH
city
VARCHAR(16)
PATH
CUSTID
-----1003
1004
CUSTNAME
-------------------Robert Shoemaker
Matt Foreman
'@Cid',
'name',
'addr/street',
'addr/city') AS T;
STREET
-------------------845 Kean Street
1596 Baseline
CITY
-----------Aurora
Toronto
2 record(s) selected.
Figure 7.8
Using XMLTABLE to return XML values in relational columns
In DB2 for z/OS the XMLTABLE function must contain a PASSING clause to define the reference
to the XML column, like this:
XMLTABLE('$i/customerinfo' PASSING info AS "i"
166
Chapter 7
Querying XML Data with SQL/XML
The XMLTABLE function contains one row-generating XQuery expression and, in the COLUMNS
clause, multiple column-generating expressions. The row-generating expression is the XPath
$INFO/customerinfo and is applied to each XML document in the XML column and produces one or multiple rows per document. The row-generating expression produces one customerinfo element (fragment) per document. The output of the XMLTABLE function contains
one row for each of these customerinfo elements. The number of elements produced by the
row-generating XQuery expression determines the number of rows produced by the XMLTABLE
function.
The COLUMNS clause transforms XML data into relational format. Each of the entries in this
clause defines a column with a column name and an SQL data type. In Figure 7.8, the returned
rows have four columns named custID, custname, street, and city. The values for each column are extracted from the customerinfo fragments that are produced by the row-generating
expression, and then cast to the SQL data types. For example, the path addr/city is applied to
each customerinfo element to obtain the value for the column city. The row-generating
expression provides the context for the column-generating expressions. This means that the
column-generating expressions are not absolute paths, but relative to the row-generating expression. You can typically append the column-generating expressions to the row-generating expression to get an intuitive idea of what a given XMLTABLE function returns in its columns.
The result set of the XMLTABLE query can be treated like any SQL table. You can query and
manipulate it much like you use regular row sets or views. The column definitions in the
COLUMNS clause can use any SQL data type, such as INTEGER, DECIMAL, CHAR, DATE, and so on.
If an extracted XML value cannot be cast to the assigned SQL type, the query fails with an error
message.
DB2 for Linux, UNIX, and Windows also allows you to use the db2-fn:xmlcolumn() or
db2-fn:sqlquery() functions in the row-generating expression of the XMLTABLE function
(see Figure 7.9). In this case you omit the table name customer from the FROM clause. The query
result is the same as in Figure 7.8. (This is not available in DB2 for z/OS.)
SELECT T.*
FROM XMLTABLE('db2-fn:xmlcolumn("CUSTOMER.INFO")/customerinfo'
COLUMNS
custID
INTEGER
PATH '@Cid',
custname
VARCHAR(20)
PATH 'name',
street
VARCHAR(20)
PATH 'addr/street',
city
VARCHAR(16)
PATH 'addr/city') AS T;
Figure 7.9
Alternative syntax in DB2 for Linux, UNIX, and Windows
7.3
Retrieving XML Values in Relational Format with XMLTABLE
7.3.2
167
Dealing with Missing Elements
XML data can contain optional elements that are not present in all documents. For example, in
our sample data you can see that Robert Shoemaker does not have an assistant element. What
happens if the optional element assistant is referenced in the row-generating or a columngenerating expression, respectively? Let’s look at these two cases separately.
In Figure 7.10 the optional assistant element is referenced in the row-generating expression of
the XMLTABLE function. The query seeks to return the name and phone number of all assistants in
our customer data. Since the XMLTABLE function returns exactly one row for each node that is
produced by the row-generating expression, it does not return any rows for the documents that do
not contain an assistant element. Therefore, the query in Figure 7.10 returns the name and
phone number of Matt Foreman’s assistant, but no information from Robert Shoemaker’s XML
document where no assistant element is present. We will revisit this situation at the end of
section 7.3. in a more complex scenario.
SELECT T.*
FROM customer,
XMLTABLE('$i/customerinfo/assistant' PASSING info AS "i"
COLUMNS
a_name
VARCHAR(20) PATH 'name',
a_phone VARCHAR(20) PATH 'phone') AS T;
A_NAME
A_PHONE
-------------------- -------------------Gopher Runner
416-555-3426
1 record(s) selected.
Figure 7.10
Optional element in the row-generating expression
In Figure 7.11 the optional assistant element is referenced in a column-generating expression
of the XMLTABLE function. This query intends to return the customer name and the assistant name
from each document. For each document where the assistant element does not exist, the column expression assistant/name produces an empty sequence, which is automatically converted to a NULL value.
168
Chapter 7
Querying XML Data with SQL/XML
SELECT T.*
FROM customer,
XMLTABLE('$i/customerinfo' PASSING info AS "i"
COLUMNS
c_name
VARCHAR(20) PATH 'name',
a_name
VARCHAR(20) PATH 'assistant/name') AS T;
C_NAME
-------------------Robert Shoemaker
Matt Foreman
A_NAME
-------------------NULL
Gopher Runner
2 record(s) selected.
Figure 7.11
Optional element in a column-generating expression
If you prefer to generate a default value for missing elements instead of NULL values, use the
default clause to define a default value other than NULL. This is done in Figure 7.12.
SELECT T.*
FROM customer,
XMLTABLE('$i/customerinfo' PASSING info AS "i"
COLUMNS
c_name
VARCHAR(20) PATH 'name',
a_name
VARCHAR(20) default 'none'
PATH 'assistant/name') AS T;
C_NAME
-------------------Robert Shoemaker
Matt Foreman
A_NAME
-------------------none
Gopher Runner
2 record(s) selected.
Figure 7.12
7.3.3
Defining a default value for missing elements
Avoiding Type Errors
Be aware that every expression in the COLUMNS clause must return a value that can be cast to the
specified data type. Otherwise the XMLTABLE execution fails. Consider the following cases:
• Incompatible data types. For example, the query in Figure 7.8 fails when it encounters
an XML document where the Cid attribute has a non-numeric value, which cannot be
cast to INTEGER.
• String length. If the XMLTABLE function defines a column of type CHAR(n) or
VARCHAR(n), and the column-generating expression produces a string value that’s
longer than n, then either one of two things happen:
7.3
Retrieving XML Values in Relational Format with XMLTABLE
169
•
The value is truncated to n bytes, without warning or error. This truncation is mandated by the latest SQL/XML standard and implemented in DB2 for z/OS.
•
The query fails with error SQL16061N. This behavior was allowed by a previous
version of the SQL/XML standard and is still effective in DB2 for Linux, UNIX, and
Windows.
The following examples show how such cases can be handled. In Figure 7.13, the definition of
the custID column uses the XQuery if-then-else and castable expressions to check
whether the Cid attribute can indeed be cast to INTEGER, and returns -1 if not. The value for the
column custname is produced by the substring function so that only the first 20 characters of
the actual name are used. The column-generating expression for the city uses if-then-else
and the string-length function to test the length of the city value and returns an error flag if it
is too long. Such techniques can be useful if strict data types are not enforced with XML Schema
validation.
SELECT T.*
FROM customer,
XMLTABLE('$INFO/customerinfo'
COLUMNS
custID
INTEGER
PATH '(if (@Cid castable as xs:integer)
then @Cid else -1)',
custname
VARCHAR(20) PATH 'name/substring(.,1,20)',
street
VARCHAR(20) PATH 'addr/street',
city
VARCHAR(16) PATH
'addr/city/(if (string-length(.) <= 16)
then . else "Error!")') AS T;
Figure 7.13
7.3.4
Safeguarding against type errors in XMLTABLE
Retrieving Repeating Elements with XMLTABLE
Another error condition arises when a path expression in the COLUMNS clause returns a sequence
of two or more items. In this situation the XMLTABLE execution fails, because it is not possible to
convert a sequence of multiple XML values into a single atomic SQL value.
As an example, consider the phone element, which occurs multiple times per document. The following example produces a list of customer names with their phone numbers. The first attempt is
shown in Figure 7.14. This query fails with error message SQL16003N. This message means
that the query is trying to cast an XML sequence of multiple items to a single VARCHAR value,
which is not possible. The reason for this error is that phone returns multiple values per
customerinfo element.
170
Chapter 7
Querying XML Data with SQL/XML
SELECT T.*
FROM customer,
XMLTABLE('$INFO/customerinfo'
COLUMNS
custname VARCHAR(20) PATH 'name',
phone
VARCHAR(15) PATH 'phone') AS T;
SQL16003N An expression of data type "( item(), item()+ )"
cannot be used when the data type "VARCHAR_15" is expected in
the context. Error QName=err:XPTY0004. SQLSTATE=10507
Figure 7.14
Cannot map a sequence of multiple items to an SQL data type!
There are at least five ways to avoid this error:
• Return only one of multiple phone numbers (see Figure 7.15 and Figure 7.16)
• Return a list of multiple phone numbers in a single VARCHAR value (see Figure 7.17)
• Return a list of multiple phone numbers as an XML type (see Figure 7.18)
• Return multiple phone columns (see Figure 7.19)
• Return one row per phone number (see Figure 7.20)
To return only one of the phone numbers you can add a positional predicate [1] to the column
generating path expression, so that only the first phone element is returned (see Figure 7.15).
SELECT T.*
FROM customer,
XMLTABLE('$INFO/customerinfo'
COLUMNS
custname VARCHAR(20) PATH 'name',
phone
VARCHAR(12) PATH 'phone[1]') AS T;
Robert Shoemaker
Matt Foreman
905-555-7258
905-555-4789
2 record(s) selected.
Figure 7.15
Return only the first of multiple phone numbers
Alternatively, you could add a predicate on the type attribute of the phone element to only
return phones of a certain kind. The query in Figure 7.16 produces cell phone numbers only.
Since Matt Foreman doesn’t have a cell phone, a NULL value is returned instead. If there were a
customer who has multiple cell phones (that is, multiple phone elements where the type attribute has the value “cell”) the query would still fail with error SQL16003N.
7.3
Retrieving XML Values in Relational Format with XMLTABLE
171
SELECT T.*
FROM customer,
XMLTABLE('$INFO/customerinfo'
COLUMNS
custname VARCHAR(20) PATH 'name',
phone
VARCHAR(12) PATH 'phone[@type="cell"]') AS T;
Robert Shoemaker
Matt Foreman
905-555-7258
NULL
2 record(s) selected.
Figure 7.16
Return only one type of phone number
If you need to return all phone numbers, you can list them in a single column value. However,
VARCHAR(12) is too small for multiple phone numbers. Use VARCHAR(100) here, which can
hold multiple phone numbers separated by a comma, as shown in Figure 7.17. The function
string-join requires two parameters: a sequence of string values and a separator character. In
this example, the first parameter is the sequence of the phone element text nodes, and the second
parameter is the comma character “,”.
SELECT T.*
FROM customer,
XMLTABLE('$INFO/customerinfo'
COLUMNS
custname VARCHAR(20) PATH 'name',
phone
VARCHAR(100) PATH 'string-join(phone/text(),",")') AS T;
Robert Shoemaker
Matt Foreman
905-555-7258,416-555-2937,905-555-8743
905-555-4789,416-555-3376
2 record(s) selected.
Figure 7.17
Return a list of multiple phone numbers in a single VARCHAR value
Yet another option for dealing with multiple phone numbers is to return an XML sequence of
phone elements. To achieve this, the generated phone column needs to be of type XML. This
allows you to return any XML value as the result of the XPath expression. This value can be an
atomic value or a sequence of zero or more items. The query in Figure 7.18 returns one row per
customer with their phone elements as an XML sequence in the XML column phone. Such a
sequence of multiple elements is not a well-formed document, because a single common root element is missing. If you need to produce well-formed XML documents, you can wrap the
sequence of phone elements in a new root element. For example, you could change the path
expression in the COLUMNS clause from 'phone' to '<phones>{phone}</phones>'. This
notation is called direct element construction and explained in detail in section 8.4, Constructing
XML Data.
172
Chapter 7
Querying XML Data with SQL/XML
SELECT T.*
FROM customer,
XMLTABLE('$INFO/customerinfo'
COLUMNS
custname VARCHAR(20) PATH 'name',
phone
XML
PATH 'phone') AS T;
CUSTNAME
PHONE
---------------------- --------------------------------------Robert Shoemaker
<phone type="work">905-555-7258</phone>
<phone type="home">416-555-2937</phone>
<phone type="cell">905-555-8743</phone>
Matt Foreman
<phone type="work">905-555-4789</phone>
<phone type="home">416-555-3376</phone>
2 record(s) selected.
Figure 7.18
Return a list of multiple phone numbers as an XML type
The XMLTABLE function also allows you to return each phone number as a separate VARCHAR
value, by producing a fixed number of phone columns. The query in Figure 7.19 generates the
column custname for the customer name, plus three columns for phone numbers: phone1,
phone2, and phone3. Positional predicates are used to map the first phone element in a document to the column phone1, the second phone element to the column phone2, and the third
phone element to phone3.
SELECT T.*
FROM customer,
XMLTABLE('$INFO/customerinfo'
COLUMNS
custname
VARCHAR(20) PATH
phone1
VARCHAR(12) PATH
phone2
VARCHAR(12) PATH
phone3
VARCHAR(12) PATH
CUSTNAME
-------------------Robert Shoemaker
Matt Foreman
PHONE1
-----------905-555-7258
905-555-4789
'name',
'phone[1]',
'phone[2]',
'phone[3]') as T;
PHONE2
-----------416-555-2937
416-555-3376
PHONE3
-----------905-555-8743
NULL
2 record(s) selected.
Figure 7.19
Return multiple phone columns
An obvious drawback to this approach is that a variable number of items is mapped to a fixed
number of columns. This is a conceptual mismatch. A customer might have more phone numbers
than anticipated. Others might have fewer, which results in NULL values. But, depending on the
7.3
Retrieving XML Values in Relational Format with XMLTABLE
173
requirements of your application, mapping different occurrences of an element to different
columns in the result set can be a very useful query writing technique.
The fifth option for dealing with multiple phone elements per customer is to return them in
separate rows. In this case, you need to produce one row per phone number instead of one row
per customer. For that purpose, the XMLTABLE function in Figure 7.20 uses a different rowgenerating XPath expression: /customerinfo/phone. The number of elements identified by
this row-generating expression determines the number of rows produced by the XMLTABLE function. Since there is a one-to-many relationship between customers and phones, the customer
names get repeated for each of their phones.
Remember that the row-generating expression provides the context for the column-generating
path expressions. As the context now consists of phone elements and not customerinfo elements, the XPath expressions in the COLUMNS clause have changed accordingly. The path for the
custname column begins with a parent step (two dots) because name is a sibling of phone. The
path for the phone column is simply a dot, which denotes the current context and that is always
the current phone element.
SELECT T.*
FROM customer,
XMLTABLE('$INFO/customerinfo/phone'
COLUMNS
custname VARCHAR(20)
PATH '../name',
phone
VARCHAR(15)
PATH '.',
type
VARCHAR(10)
PATH '@type') AS T;
CUSTNAME
-------------------Robert Shoemaker
Robert Shoemaker
Robert Shoemaker
Matt Foreman
Matt Foreman
PHONE
--------------905-555-7258
416-555-2937
905-555-8743
905-555-4789
416-555-3376
TYPE
---------work
home
cell
work
home
5 record(s) selected.
Figure 7.20
7.3.5
Return one row per phone element
Numbering XMLTABLE Rows Based on Repeating Elements
The query in Figure 7.21 is the same as in Figure 7.20 except that the column seqno has been
added to the XMLTABLE function. The definition of this column does not consist of a data type and
a path, but just of the keywords FOR ORDINALITY. This produces a column of type BIGINT that
contains consecutive numbers for the rows produced by the row-generating expression of the
XMLTABLE function. This numbering automatically restarts at 1 for each input document,
174
Chapter 7
Querying XML Data with SQL/XML
because the rows generated from each document are numbered separately. These ordinality numbers reflect the order in which the values appeared in the corresponding input document.
SELECT T.*
FROM customer,
XMLTABLE('$INFO/customerinfo/phone'
COLUMNS
seqno
FOR ORDINALITY,
custname VARCHAR(20)
PATH '../name',
phone
VARCHAR(15)
PATH '.',
type
VARCHAR(10)
PATH '@type') AS T;
SEQNO
----1
2
3
1
2
CUSTNAME
-------------------Robert Shoemaker
Robert Shoemaker
Robert Shoemaker
Matt Foreman
Matt Foreman
PHONE
--------------905-555-7258
416-555-2937
905-555-8743
905-555-4789
416-555-3376
TYPE
---------work
home
cell
work
home
5 record(s) selected.
Figure 7.21
7.3.6
Add a sequence number for each generated row
Retrieving Multiple Repeating Elements at Different Levels
To allow for another interesting example, let’s assume that the customer Matt Foreman has multiple assistants, and each assistant can have multiple phone numbers, as shown in Figure 7.22.
<customerinfo Cid="1004">
<name>Matt Foreman</name>
<addr country="Canada">
<street>1596 Baseline</street>
<city>Toronto</city>
<prov-state>Ontario</prov-state>
<pcode-zip>M3Z 5H9</pcode-zip>
</addr>
<assistant>
<name>Gopher Runner</name>
<phone type="home">416-555-3426</phone>
<phone type="cell">416-911-1234</phone>
</assistant>
<assistant>
<name>Peter Browse</name>
<phone type="work">905-841-0701</phone>
<phone type="home">416-696-2620</phone>
</assistant>
</customerinfo>
Figure 7.22
Sample document
7.3
Retrieving XML Values in Relational Format with XMLTABLE
175
In the XML structure shown in Figure 7.22 there is a one-to-many relationship between
customers and assistants, and between assistants and phones. How can you produce a list
that includes customer names, assistant names, and assistant phone numbers? The trick is to use a
row-generating expression that navigates to the deepest repeating element, which is
/customerinfo/assistant/phone. This is shown in Figure 7.23. Based on the assistant
phone element, two consecutive parent steps are required to reach the customer’s name element,
and just one parent step to obtain the assistant name.
SELECT T.*
FROM customer,
XMLTABLE('$INFO/customerinfo/assistant/phone'
COLUMNS
custname VARCHAR(20)
PATH '../../name',
assistant VARCHAR(20)
PATH '../name',
a_phone
VARCHAR(12)
PATH '.') AS T;
CUSTNAME
-------------------Matt Foreman
Matt Foreman
Matt Foreman
Matt Foreman
ASSISTANT
--------------Gopher Runner
Gopher Runner
Peter Browse
Peter Browse
A_PHONE
-----------416-555-3426
416-911-1234
905-841-0701
416-696-2620
4 record(s) selected.
Figure 7.23
Navigate to the deepest repeating element first
Note that the result set in Figure 7.23 does not include any row for Robert Shoemaker. This is
because the XML document for Robert Shoemaker does not contain an assistant element.
Hence, the row-generating expression in this query never produces any rows for that input document. This is fine if the intention was to only list customers who have assistants. But, if you need
to list all customers even if they don’t have assistants, then the query in Figure 7.23 produces an
incomplete result.
Figure 7.24 shows one possible way in which you can include Robert Shoemaker in the result set.
The key idea is to extend the row-generating expression so that it produces a row for a customer
even if the assistant element does not exist. The new row-generating expression is
/customerinfo/(assistant/phone, .[not(assistant)]/name/text() )
It uses a sequence constructor, which was discussed in section 6.12, Union and Construction of
Sequences. The first expression in the sequence constructor, assistant/phone, produces
assistant phone elements if they exist. The second expression, .[not(assistant)]/name/
text(), produces the text node of the customer name if the assistant element does not exist.
176
Chapter 7
Querying XML Data with SQL/XML
The two expressions are mutually exclusive in the sense that for any given document only one of
them produces any items while the other produces an empty sequence. The existence of the
assistant element determines whether the first or the second expression produces any nodes.
The same behavior can be achieved with an if-then-else expression, which you may find
more intuitive:
/customerinfo/(if (assistant) then assistant/phone
else name/text() )
Since the XPath expressions in the COLUMNS clause are applied to the nodes produced by the rowgenerating expression, they now need to work for both assistant phone elements as well as customer name text nodes. We purposefully navigate to the text nodes of the name elements, because
they are on the same level of the document tree as the assistant phone elements. With this trick,
the paths in the column definition work for both. For example, the path ../../name always produces the customer name element, no matter whether the context node is an assistant phone element or customer name text node. Note that the predicate [../phone] was added to the column
expression for a_phone. This predicate ensures that the column a_phone is populated only
when the current node produced by the row-generating expression is a phone element, and not a
customer name text node.
SELECT T.*
FROM customer,
XMLTABLE('$INFO/customerinfo/(assistant/phone ,
.[not(assistant)]/name/text() )'
COLUMNS
custname VARCHAR(20)
PATH '../../name',
assistant VARCHAR(20)
PATH '../name',
a_phone
VARCHAR(12)
PATH '.[../phone]') AS T;
CUSTNAME
-------------------Robert Shoemaker
Matt Foreman
Matt Foreman
Matt Foreman
Matt Foreman
ASSISTANT
--------------NULL
Gopher Runner
Gopher Runner
Peter Browse
Peter Browse
A_PHONE
-----------NULL
416-555-3426
416-911-1234
905-841-0701
416-696-2620
5 record(s) selected.
Figure 7.24
Producing rows for missing elements
7.4
7.4
Using XPath Predicates in SQL/XML with XMLEXISTS
177
USING XPATH PREDICATES IN SQL/XML WITH XMLEXISTS
Most of the SQL/XML queries in the previous sections don’t have a WHERE clause. Therefore
they produce results from all documents (rows) in the customer table. One exception was Figure 7.2 in section 7.2, which uses a predicate on the relational id column as a document filter
(WHERE id = 1003). Your tables might have additional relational columns and you can use all
traditional SQL capabilities to formulate WHERE clauses with relational predicates or subqueries
to select rows (documents) from your table. However, you will also want to use XPath predicates
to filter query results based on values in the XML data, as discussed in section 6.7, XPath
Predicates.
The most typical way of using an XPath predicate in an SQL/XML statement is to include it in
the XMLEXISTS predicate. The XMLEXISTS predicate evaluates the embedded XPath or XQuery
expression one document (row) at a time. If the XPath returns a non-empty result, that is, a
sequence of one or more items, then XMLEXISTS returns TRUE and the corresponding row is
included in the result set. If the XPath does not return any items, that is, it returns an empty
sequence, then XMLEXISTS returns FALSE and the corresponding row is eliminated from the
result set.
Let’s look at Figure 7.25 to see how this works. Much like the XMLQUERY function, the
XMLEXISTS predicate references the info column of the customer table to evaluate the XPath
expression. For each row, the question is whether this XPath returns an empty or non-empty
result. In general, the XPath /customerinfo[addr/city = "Aurora"] returns customerinfo elements if they have an addr element with a city that has the value Aurora. Otherwise it
returns the empty sequence.
The first row in the customer table contains a document that has such a customerinfo element where addr/city equals Aurora. This means that the result of the XPath is non-empty,
so XMLEXISTS returns TRUE and the row is qualified for the result set. The XMLQUERY function in
the SELECT clause then extracts the name element and produces a result row.
The second row in our customer table contains a document where the city element does not
have the value Aurora. So the document has no customerinfo element that fulfills the predicate in square brackets. The XPath inside the XMLEXISTS predicate therefore returns the empty
sequence. This causes the XMLEXISTS predicate to return FALSE and the row is eliminated. Consequently, the XMLQUERY function is not applied to this second document and no further result
rows are produced.
178
Chapter 7
Querying XML Data with SQL/XML
SELECT XMLQUERY('$INFO/customerinfo/name')
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo[addr/city = "Aurora"]');
<name>Robert Shoemaker</name>
1 record(s) selected.
Figure 7.25
SQL/XML query with XMLEXISTS predicate in the WHERE clause
For comparison, the query in Figure 7.26 returns the same result as the one in Figure 7.25. The
difference is that the query in Figure 7.26 is a single XPath expression with no SQL involved. It
contains the filtering predicate in square brackets and defines the return value with the last step of
the path: /name. In Figure 7.25, the same processing is split across two XPaths in the SQL/XML
statement. The predicate is expressed with XMLEXISTS in the WHERE clause and its sole purpose
is the elimination of non-matching rows. The extraction (projection) of the name element happens separately in the XMLQUERY function in the SELECT clause. This is a common and useful
pattern of a SQL/XML query. The performance and execution plans of the queries in Figure 7.25
and Figure 7.26 are identical.
xquery db2-fn:xmlcolumn('CUSTOMER.INFO')/customerinfo[
addr/city = "Aurora"]/name;
Figure 7.26
XQuery that produces the same result as the query in Figure 7.25
If an XML index is defined on /customerinfo/addr/city, the queries in both Figure 7.25
and Figure 7.26 can use that index to speed up the evaluation of the predicate and to avoid a table
scan. The query in Figure 7.27 also returns the same result but cannot use an XML index and is an
example of how you should not write SQL/XML queries. It uses the XMLQUERY function in the
WHERE clause to extract the city element and the XMLCAST function to cast that value to VARCHAR(20). Then an SQL equality predicate is applied to this value. This works but is not recommended because the usage of functions in the WHERE clause prohibits index usage and leads to a
table scan. To express SQL/XML predicates, use XMLEXISTS instead.
SELECT XMLQUERY('$INFO/customerinfo/name')
FROM customer
WHERE XMLCAST( XMLQUERY('$INFO/customerinfo/addr/city')
AS VARCHAR(20)) = 'Aurora';
Figure 7.27
XMLQUERY in the WHERE clause is typically not recommended!
Any of the XPath predicates discussed in Chapter 6 can be used inside XMLEXISTS to filter XML
documents. This includes value predicates as well as structural predicates that check for the existence or non-existence of an element (see section 6.7) For example, the query in Figure 7.28
7.4
Using XPath Predicates in SQL/XML with XMLEXISTS
179
selects the id and name of all customers who have an assistant. The query in Figure 7.29 selects
the id and name of the customers who do not.
SELECT id, XMLQUERY('$INFO/customerinfo/name/text()')
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo[assistant]');
1004
Matt Foreman
1 record(s) selected.
Figure 7.28
A structural predicate checks for the existence of an element
SELECT id, XMLQUERY('$INFO/customerinfo/name/text()')
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo[not(assistant)]');
1003
Robert Shoemaker
1 record(s) selected.
Figure 7.29
A structural predicate with negation
You can also use XMLEXISTS in conjunction with the XMLTABLE function, as shown in Figure
7.30. In this example, the XMLEXISTS predicate selects one row from the customer table, and
only that one document is processed by the XMLTABLE function. Predicates in the columngenerating expressions of the XMLTABLE function, such as [@type="home"] in Figure 7.30, do
not affect the number of rows returned. This predicate only selects one out of multiple phone elements from each qualifying document. Hence, it is an intra-document predicate whose filtering
effect is restricted to items within a single document. In contrast, the XMLEXISTS predicate filters
rows from the entire table.
SELECT T.*
FROM customer,
XMLTABLE('$INFO/customerinfo'
COLUMNS
custname VARCHAR(20) PATH 'name',
phone
VARCHAR(12) PATH 'phone[@type="home"]') AS T
WHERE XMLEXISTS('$INFO/customerinfo[@Cid = 1003]');
Robert Shoemaker
416-555-2937
1 record(s) selected.
Figure 7.30
Predicates in an XMLTABLE column expression do not filter rows
180
Chapter 7
Querying XML Data with SQL/XML
The query in Figure 7.31 produces the same result as the query in Figure 7.30. It does not use
XMLEXISTS but an XPath predicate in the row-generating expression of the XMLTABLE function.
Remember that XMLTABLE is a table function that produces one row for each item returned by the
row-generating expression. Hence, a predicate in the row-generating expression eliminates rows
just like a predicate in XMLEXISTS does. For consistency across all your queries, you might
prefer to always use XMLEXISTS and not put predicates in the row-generating expression of
an XMLTABLE function. There is no significant performance difference between the queries in
Figure 7.30 and Figure 7.31.
SELECT T.*
FROM customer,
XMLTABLE('$INFO/customerinfo[@Cid = 1003]'
COLUMNS
custname VARCHAR(20) PATH 'name',
phone
VARCHAR(12) PATH 'phone[@type="home"]') AS T;
Figure 7.31
Predicates in a row-generating expression filter rows
You can also use regular SQL predicates on the relational columns produced by the XMLTABLE
function. In Figure 7.32, the XMLTABLE function returns the values of the /customerinfo/
name elements as a VARCHAR(20) column called custname. This column is then used in the
WHERE clause to restrict the result set to Robert Shoemaker.
SELECT T.*
FROM customer,
XMLTABLE('$INFO/customerinfo'
COLUMNS
custname VARCHAR(20) PATH 'name',
phone
VARCHAR(12) PATH 'phone[@type="home"]') AS T
WHERE custname = 'Robert Shoemaker';
Robert Shoemaker
416-555-2937
1 record(s) selected.
Figure 7.32
Using a relational predicate on a column generated by XMLTABLE
The query in Figure 7.32 is interesting because it applies a relational predicate to values that are
extracted from the /customerinfo/name elements in the XML column. DB2 9 for z/OS and
DB2 9.7 for Linux, UNIX, and Windows can exploit an XML index on /customerinfo/name
to evaluate this relational predicate. This capability is not available in DB2 9.1 and DB2 9.5 for
Linux, UNIX, and Windows.
7.5
Common Mistakes with SQL/XML Predicates
181
If you use multiple search conditions, it is generally better to combine them into a single XMLEXISTS instead of using multiple XMLEXISTS. Figure 7.33 shows both options, which return the
same result from our sample data.
SELECT XMLQUERY('$INFO/customerinfo/name')
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo[addr/city = "Aurora"]')
AND XMLEXISTS('$INFO/customerinfo[addr/@country = "Canada"]');
SELECT XMLQUERY('$INFO/customerinfo/name')
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo[addr/city = "Aurora"
and addr/@country = "Canada"]');
<name>Robert Shoemaker</name>
1 record(s) selected.
Figure 7.33
7.5
Using a single XMLEXISTS predicate is preferable
COMMON MISTAKES WITH SQL/XML PREDICATES
An easy mistake is to include the row-filtering predicate in the XMLQUERY function in the SELECT
clause and not in XMLEXISTS in the WHERE clause (see Figure 7.34). This query always returns as
many rows as there are rows in the customer table, which could be very many! This SQL statement does not include a WHERE clause and therefore never eliminates any rows. The XMLQUERY
function therefore produces a result for every row in the table. For customers living in Aurora it
returns their name; for all other customers it returns an empty sequence. If the customer table
contained one customer in Aurora and 100,000 customers who do not live in Aurora, this query
would return one name element plus 100,000 empty rows. This is not desirable.
SELECT XMLQUERY('$INFO/customerinfo[addr/city = "Aurora"]/name')
FROM customer;
<name>Robert Shoemaker</name>
[first result row]
[second result row (empty)]
2 record(s) selected.
Figure 7.34
Predicates in the SELECT list do not filter rows!
An XPath predicate expressed in XMLEXISTS in the WHERE clause can filter rows. A predicate in
the XMLQUERY function in the SELECT clause cannot filter rows. It can only restrict the output that
is produced from each XML document. This is further illustrated in Figure 7.35. The XMLEXISTS
182
Chapter 7
Querying XML Data with SQL/XML
predicate in the WHERE clause selects one row from the sample table; that is, the row with the document where the Cid attribute is 1003. The predicate [@type = "home"] in the XMLQUERY
function does not affect the number of rows returned. It only ensures that the result row contains
only the home phone number and not a list of all phone numbers of the selected customer.
SELECT XMLQUERY('$INFO/customerinfo/phone[@type = "home"]')
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo[@Cid = 1003]');
<phone type="home">416-555-2937</phone>
1 record(s) selected.
Figure 7.35
Only the XMLEXISTS predicate filters rows
Another easy mistake is to forget the square brackets in the XPath expression in the XMLEXISTS
predicate (see Figure 7.36). This comes back to the same issue as was discussed for the query in
Figure 6.35 in section 6.7. Without square brackets the XPath expression:
/customerinfo/addr/city = "Aurora"
is a Boolean predicate of the form A = B and always evaluates to either true or false. It never
evaluates to the empty sequence. The result is always a sequence that contains one item, and that
item is either the value true or the value false. Remember that XMLEXISTS eliminates a row
only if the XPath expression evaluates to the empty sequence. It truly performs an existence
check. If the XPath expression evaluates to a non-empty sequence, such as the sequence with the
single value true or false, XMLEXISTS does not eliminate the current row. Since the XPath
expression in the XMLEXISTS predicate in Figure 7.36 never produces an empty sequence, no
rows are ever eliminated and the result set contains as many rows as the customer table.
SELECT XMLQUERY('$INFO/customerinfo/addr/city)
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo/addr/city = "Aurora"');
<city>Aurora</city>
<city>Toronto</city>
2 record(s) selected.
Figure 7.36
An XMLEXISTS predicate without square brackets is not useful!
7.6
7.6
Using Parameter Markers or Host Variables
183
USING PARAMETER MARKERS OR HOST VARIABLES
All the queries with predicates that we have discussed so far use literal values to select specific
documents. But often it is preferable to use parameter markers or host variables instead. This
allows you to prepare (compile) a query only once and pass a different literal value for each execution of the query. This avoids recompiling the query for each execution. Very short database
queries often execute so fast that the time to compile and optimize them is a substantial portion of
their total response time. This is where parameter markers or host variables provide a significant
performance benefit.
Although you cannot use SQL-style parameter markers in XQuery, the SQL/XML functions
XMLQUERY, XMLTABLE, and XMLEXISTS allow you to pass SQL parameter markers as variables
into the embedded XQuery expression. This is recommended for applications with short and
repetitive queries.
Figure 7.37 shows two SQL/XML queries that select rows from the customer table where the
city element has a specific value. The queries use a parameter marker (?) and host variable,
respectively, instead of a literal string. The passing clause assigns the parameter or host variable
to the XPath variable c. In the XPath expression itself, this variable is used as $c. The dollar sign
is used to reference the variable, similar to how $INFO references the XML column. To ensure
proper typing it is recommended to cast the parameter marker or host variable to an appropriate
data type. Parameters that carry string values should always be cast to VARCHAR instead of CHAR;
otherwise they are padded with blanks, which are included in the string comparison and lead to
unexpected results. In XPath, trailing blanks are significant.
SELECT info
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo[addr/city = $c]')
passing cast(? as VARCHAR(25)) AS "c");
SELECT info
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo[addr/city = $c]')
passing cast(:hvar as VARCHAR(25)) AS "c");
Figure 7.37
XML predicates with parameter markers and host variables
The query in Figure 7.38 uses three parameter markers. One parameter appears in the XMLQUERY
function to select which type of phone number to extract. The other two parameters are in the
XMLEXISTS predicate to provide values that select customers in a specific city and country. Note
that the passing clause can contain a comma-separated list of multiple input parameters. The
same works with host variables.
184
Chapter 7
Querying XML Data with SQL/XML
SELECT XMLQUERY('$INFO/customerinfo/phone[@type = $p1]'
passing cast(? AS VARCHAR(10)) AS "p1")
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo[addr/city = $p2 and
addr/@country = $p3]')
passing cast(? AS VARCHAR(25)) AS "p2",
cast(? AS VARCHAR(30)) AS "p3");
Figure 7.38
XML predicates with multiple parameter markers
The SELECT statement in Figure 7.39 shows that you can also pass parameter markers or host
variables into the row-generating expression of the XMLTABLE function. Note that the SQL Standard does not allow a passing clause for the column-generating path expression in the
XMLTABLE function.
SELECT T.*
FROM customer,
XMLTABLE('$INFO/customerinfo[@Cid = $c]'
passing cast(:custid AS INTEGER) AS "c"
COLUMNS
custname VARCHAR(20) PATH 'name',
phone
VARCHAR(12) PATH 'phone[@type = "home"]')
AS T;
Figure 7.39
Using a host variable in the XMLTABLE function
If you also want to use a parameter to select the phone type, which is an intra-document predicate, you need to use an XMLQUERY function in the SELECT list (see Figure 7.40). The XMLCAST
function casts the phone number to the same SQL type as the XMLTABLE function did in Figure 7.39.
SELECT T.*,
XMLCAST(
XMLQUERY('$INFO/customerinfo/phone[@type = $t]'
passing cast(:type AS VARCHAR(10)) AS "t")
AS VARCHAR(20)) AS phone
FROM customer,
XMLTABLE('$INFO/customerinfo[@Cid = $c]'
passing cast(:custid AS INTEGER) AS "c"
COLUMNS
custname VARCHAR(20) PATH 'name') AS T;
Figure 7.40
A row-filtering and an intra-document predicate with host variables
7.7
7.7
XML Queries with Dynamically Computed XPath Expressions
185
XML QUERIES WITH DYNAMICALLY COMPUTED XPATH EXPRESSIONS
As you develop more and more sophisticated XML applications, you might encounter situations
where it is useful to not have a fixed hard-coded XPath in your query, but to dynamically compute
the XPath navigation steps at runtime. However, this is not immediately possible in SQL/XML.
Also, you cannot provide a parameter marker or variable with a value such as “/customerinfo/name” to an SQL/XML query and use this variable value as a path for XML navigation.
Some degree of flexibility can be achieved with dynamically prepared SQL/XML statements in a
stored procedure such as the one in Figure 7.41. The procedure takes two XPath expressions as
input, one to extract information from XML documents, the other to filter the XML documents
with a predicate. The stored procedure plugs these XPath expressions into an SQL/XML statement, which is then prepared and executed with a cursor. The procedure leaves the cursor open,
which allows the caller, such as your Java application or another stored procedure, to iterate over
the result set of the query.
CREATE PROCEDURE dynXMLquery (IN
IN
LANGUAGE SQL
BEGIN ATOMIC
XPathExtract VARCHAR(1024),
XPathFilter VARCHAR(1024) )
DECLARE sql VARCHAR(2048);
DECLARE c1 CURSOR with return to caller FOR stmt;
SET sql= 'SELECT XMLQUERY('' $INFO'|| XPathExtract || ' '' )
FROM customer
WHERE XMLEXISTS('' $INFO'|| XPathFilter || ' '' )';
PREPARE stmt FROM sql;
OPEN c1 ;
END #
Figure 7.41
Stored procedure to execute XPath dynamically
Since the body of a stored procedure can contain multiple statements, these statements have to be
separated by the semicolon character. Therefore you cannot use the semicolon as the terminating
character for the CREATE PROCEDURE statement. In this example we have chosen the # as the terminating character. If the procedure definition shown in Figure 7.41 is in a file create_proc.
sql then the following command issued at the OS prompt creates the procedure:
db2 -td# -f create_proc.sql
186
Chapter 7
Querying XML Data with SQL/XML
The following call statement invokes the stored procedure and passes two XPath expressions.
The XPath expressions are literal strings in this example, but they could also be passed as string
variables computed by an application or another stored procedure.
call dynXMLquery('/customerinfo/name',
'/customerinfo/addr[city="Aurora"]' )
7.8
ORDERING A QUERY RESULT SET BASED ON XML VALUES
One thing that distinguishes the XML data type from other SQL data types such as INTEGER,
VARCHAR, or DATE is that you cannot perform any SQL comparisons on values of type XML. Sorting of XML type values in an SQL ORDER BY clause is also not possible because sorting involves
comparisons. A value of type XML can be a complex nested XML document and there is no welldefined notion of equality, sort order, or collation among two or more XML documents. Therefore, the statements shown in Figure 7.42 are not meaningful and fail with errors. The error
messages indicate that the XML data type cannot be used in SQL comparison or sort operations.
SELECT id, info
FROM customer
ORDER BY info;
SQL20353N An operation involving comparison cannot use operand
"INFO" defined as data type "XML". SQLSTATE=42818
SELECT id, info
FROM customer
WHERE XMLQUERY('$INFO/customerinfo/addr/city') = 'Aurora';
SQL0401N The data types of the operands for the operation "="
are not compatible or comparable. SQLSTATE=42818
SELECT id, info
FROM customer
ORDER BY XMLQUERY('$i/customerinfo/name' passing info as "i");
SQL20353N An operation involving comparison cannot use operand
"Ordering column 1" defined as data type "XML". SQLSTATE=42818
Figure 7.42
Values of type XML cannot be compared or ordered
If you want to order a query result set by atomic values that are inside the XML documents in the
XML column, you need to cast them to an SQL type first. The functions XMLCAST and XMLTABLE
both perform conversion of XML values to SQL data types. The SELECT statements in Figure
7.43 successfully order the result set by the value of the customer name element.
7.9
Converting XML Values to Binary SQL Types
187
SELECT id, info
FROM customer
ORDER BY XMLCAST(
XMLQUERY('$i/customerinfo/name' passing info as "i")
AS VARCHAR(25)) ;
SELECT id, info
FROM customer,
XMLTABLE('$INFO/customerinfo/name'
COLUMNS
custname VARCHAR(25) PATH '.')
ORDER BY custname ;
Figure 7.43
Ordering a query result set based on converted XML values
Note that the XMLCAST function can only cast a single value at a time. If the first query in Figure
7.43 tried to order by /customerinfo/phone instead of /customerinfo/name, then the
XMLQUERY function would return a sequence of multiple phone elements and hence XMLCAST
fails. This is avoided by the use of XMLTABLE, which can iterate over repeating elements and cast
them one at a time.
7.9
CONVERTING XML VALUES TO BINARY SQL TYPES
Casting a value to a specific data type is possible only if the value is in the value space that the
data type represents. For example, casting the string “123” to data type INTEGER works because
123 is a valid integer number. However, the string “abc” cannot be cast to INTEGER because
alphanumeric character strings are not in the value space of the type INTEGER. The same concept
applies when you use the XMLTABLE or XMLCAST functions to cast values to BLOB or VARCHAR
FOR BIT DATA. Some values can be cast to a binary type, others cannot.
The SQL/XML standard defines how values from XML documents are cast to SQL data types. It
defines that a textual value in an XML document is first cast to an intermediate XQuery data type,
and then to the target SQL data type. To discuss what that means, let’s assume that a document
contains an element CCnumber, which contains binary data such as an encrypted credit card
number. Now consider the following XMLTABLE function:
XMLTABLE('$INFO/customerinfo'
COLUMNS
Custid
INTEGER
PATH '@Cid'
CCNumber
BLOB(2048)
PATH 'CCnumber' )
As per the SQL/XML standard, DB2 reads the textual value of the Cid attribute, casts this value
to the appropriate intermediate XQuery type, xs:integer, and then from xs:integer to the
SQL type INTEGER. The value space of the XQuery type xs:integer is larger than that of the
SQL type INTEGER and includes integers of 18 digits in length. Thus, if a value can be cast to
xs:integer, it does not automatically imply that the value can also be cast to SQL INTEGER.
188
Chapter 7
Querying XML Data with SQL/XML
For the second column, DB2 reads the textual value of the element CCNumber, casts this value to
the appropriate intermediate XQuery type (xs:base64Binary), and then from
xs:base64Binary to the SQL type BLOB(2048). The value space of xs:base64Binary is
the set of finite-length chains of binary octets. This means that a string can be cast to
xs:base64Binary only if it consists of a multiple of 8 bytes and does not contain any characters other than a-z, A-Z, 0-9, +, /, and =. Thus, if a cast to a binary SQL data type fails it’s likely
because the original value is not a valid binary XML value. For example, the ASCII string
“ABCD1234” can be cast to binary, but “ABCD12345” cannot because it has nine characters.
7.10
SUMMARY
SQL/XML enables you to embed XPath and XQuery expressions in SQL statements to query
XML and relational data in an integrated manner. Let’s quickly recapitulate the three most important functions for writing SQL/XML queries.
XMLQUERY is an SQL scalar function that is typically used in the SELECT clause of an SQL query.
It takes an XPath or XQuery expression as well as a reference to an XML column as input. For
each row, the expression in the XMLQUERY function is applied to the XML document in that row
and a single value of type XML is returned. This value is a sequence of zero, one, or multiple items.
These items can be, for example, XML elements or atomic values such as numbers or strings. An
XPath expression in an XMLQUERY function can contain predicates, but these predicates are only
applied within any given document. The XMLQUERY function processes one document at a time
and does not perform operations across multiple documents in multiple rows of the table.
XMLEXISTS is a predicate that is commonly used in the WHERE clause of an SQL statement to
express filtering conditions on an XML column. Like the XMLQUERY function, it takes an XPath
expression as well as a reference to an XML column as input, and is applied to one XML document at a time. The XMLEXISTS predicate returns false and removes the current row from the
result set, if the embedded XPath expression returns the empty sequence. The embedded XPath
expression should always include an XPath predicate that must be enclosed in square brackets.
XMLTABLE is a table function that is used in the FROM clause of an SQL statement. It reads one or
multiple values from an XML document and returns them as a set of relational rows. The
XMLTABLE function contains multiple XPath expressions; that is, one row-generating XPath
expression and one or multiple column-generating XPath expressions. The XMLTABLE function
generates one relational row for each XML element or attribute produced by the row-generating
expression. Since XML documents can contain optional as well as repeating elements, the
XMLTABLE function may produce zero, one, or multiple relational rows for each input document.
The column-generating expressions compute the values that are returned in each row. These
expressions are relative path expressions, based on the nodes identified by the row-generating
expression.
You will see further examples of these functions in the following chapters.
C
H A P T E R
8
Querying XML Data
with XQuery
his chapter takes the discussion of XML queries to the next level and builds upon the previous two chapters. Chapter 6, Querying XML Data: Introduction and XPath, introduced the
XPath and XQuery data model and described the XPath language. Chapter 7, Querying XML
Data with SQL/XML, demonstrated how SQL/XML allows you to embed XPath expressions in
SQL queries. Now we turn to XQuery, which is a query language for XML data and a superset of
XPath. Everything you have learned about XPath already counts towards your understanding of
XQuery. XQuery and XPath use a common data model, which was introduced in section 6.2,
Understanding the XQuery and XPath Data Model. Understanding this data model is very helpful for understanding XQuery. In this chapter we introduce XQuery through a series of examples
with focus on gaining a quick understanding and practical usage. This chapter is not meant to be
a complete and formal XQuery language reference. Appendix C, Further Reading, contains suggestions for further reading about XQuery. XQuery is supported in DB2 for Linux, UNIX, and
Windows, but not in DB2 9 for z/OS.
T
Many examples in this chapter use the same customerinfo sample documents that we used
throughout Chapters 6 and 7 (see Figure 6.7 in section 6.3, Sample Data for XPath, SQL/XML,
and XQuery). Section 8.5 then also introduces purchaseorder sample data, which is used to
illustrate the features presented in the second half of this chapter.
This chapter discusses the following topics:
• Overview of XQuery expressions (section 8.1)
• The XQuery FLWOR expression (section 8.2)
• Differences and similarities between XPath and FLWOR expression and SQL/XML statements (section 8.3)
189
190
Chapter 8
Querying XML Data with XQuery
• Constructing new XML documents with XQuery constructor expressions (section 8.4)
• XQuery data types, arithmetic expressions, and functions (sections 8.5 through 8.7)
• Using SQL queries and SQL functions within XQuery (sections 8.8 through 8.9)
8.1
XQUERY OVERVIEW
XQuery is a functional language. It consists of several different kinds of expressions, which can
be combined to compose more sophisticated expressions. Since XPath is a subset of XQuery, you
have already seen some of those expressions in the previous chapters. Some of the most important XQuery expressions include:
• Path expressions—Path expressions are used to locate nodes, such as XML elements
and attributes, in the tree structure of an XML document. XPath expressions were introduced in Chapter 6 and they continue to play an important role in XQuery.
• FLWOR expressions—FLWOR expressions allow you to iterate over the items in a
sequence to bind variables to intermediate query results. Such expressions are useful for
combining data from multiple XML documents or different parts of a single document.
The name FLWOR, pronounced “flower,” is based on the keywords for, let, where,
order by, and return. XQuery is a case-sensitive language and all keywords must be
written in lowercase. FLWOR expressions are discussed in sections 8.2 and 8.3.
• Constructor expressions—XQuery constructors can be used to create XML nodes,
such as elements and attributes, so that you can build new XML documents within a
query. This is explained in section 8.4.
• Cast expressions—A cast expression converts a value to a different data type. Section
8.5 provides details on XQuery data types, cast expressions, and potential type errors.
• Arithmetic expressions—XQuery has arithmetic operators for addition (+), subtraction (–), multiplication (*), division (div), integer division (idiv), and modulus (mod).
See section 8.6 for details.
• Comparison, logical, and conditional expressions—These expressions allow you to
formulate predicates to search for specific information. You have seen many of these
expressions in Chapter 6, especially in sections 6.7, 6.8, and 6.14. Conditional expressions are if-then-else expressions and already occurred in Chapter 7 in sections
7.3.3 and 7.3.6.
• Sequence expressions—With sequence expressions you can construct or combine
sequences. The construction and union of sequences was discussed in Chapter 6.12.
• Transform expressions—Transform expressions allow you to update or transform
existing XML documents. This is covered in Chapter 12, Updating and Transforming
XML Documents.
8.2
Processing XML Data with FLWOR Expressions
8.2
191
PROCESSING XML DATA WITH FLWOR EXPRESSIONS
The FLWOR expression is one of the most powerful and commonly used expressions in the
XQuery language. It is comparable to the SELECT-FROM-WHERE statement in the SQL language.
A significant difference is that an SQL SELECT statement operates on relational data (sets of
tuples) whereas the XQuery FLWOR expression operates on XML data. XML data is more formally described by the XQuery Data Model as sequences of atomic values and nodes, such as
XML element and attribute nodes (see section 6.2, Understanding the XQuery and XPath Data
Model).
8.2.1
Anatomy of a FLWOR Expression
Let’s first look at the generic syntax of the XQuery FLWOR expression (see Figure 8.1) and then
walk through concrete examples. In Figure 8.1, the DB2 keyword xquery indicates that this is
stand-alone XQuery and not an SQL statement. The body of the query contains the XQuery keywords for, let, where, order by, and return, which give the FLWOR expression its name.
The second line of the query is the for clause. It consists of the keyword for, a variable, the keyword in, and an expression such as a path expression. The for clause iterates over the sequence
of items that is produced by expression1. The let clause does not iterate but assigns the entire
sequence produced by expression2 to the variable $variable2. Similar to a SELECT statement in SQL, the where and order by clauses filter and sort the result set, which is then
returned (projected) in the return clause. A FLWOR expression must contain at least one for
clause or at least one let clause, and must contain a return clause. The where and order by
clauses are optional.
xquery
for $variable1 in expression1
let $variable2 := expression2
where expression3
order by expression4 [ascending|descending]
return expression3
Figure 8.1
The syntax of the XQuery FLWOR expression
Figure 8.2 shows a more concrete example of a FLWOR expression. It returns the phone elements
of all customers who live in Canada. The for clause contains a path expression that you are
already familiar with from Chapter 6. This path expression produces a sequence of customerinfo elements from the documents in the INFO column of the CUSTOMER table. The for clause
iterates over this sequence. In each iteration the variable $c is assigned the next item
(customerinfo element) in the sequence. The third line of the query contains the let clause. It
assigns the result of the path expression $c/phone to the variable $p. Since $c holds the
customerinfo element of the current iteration, $c/phone produces the sequence of phone elements for that customer. That entire sequence, which can contain multiple phone elements, is
assigned to $p.
192
Chapter 8
Querying XML Data with XQuery
xquery
for $c in db2-fn:xmlcolumn("CUSTOMER.INFO")/customerinfo
let $p := $c/phone
where $c/addr/@country = "Canada"
order by $c/@Cid descending
return $p;
Figure 8.2
The XQuery FLWOR expression
Next, the where clause evaluates the predicate $c/addr/@country = "Canada". This predicate evaluates to true if a country attribute exists that has the value Canada. If the predicate
evaluates to false, then the item of the current iteration is no longer considered in this query.
Unlike XMLEXISTS, the predicate in a where clause of a FLWOR expression does not require
square brackets. This is because the where clause checks whether the predicate evaluates to
true or false, while XMLEXISTS checks for the existence of any value or node. You can add
square brackets to the predicate in the where clause without changing the result of the query, for
example where $c/addr[@country = "Canada"]. The expression $c/addr[@country =
"Canada"] either evaluates to the empty sequence, in which case the predicate is false, or to a
sequence of one or multiple addr elements, in which case the predicate is true. Regardless of
the use of square brackets, the performance of this query can benefit from an XML index on
/customerinfo/addr/@country. Also, note that in general the where clause can contain
multiple predicates combined with and and or.
For each item that meets the condition in the where clause, the return clause is evaluated to
produce output (results). In Figure 8.2, the expression in the return clause is simply $p, which
holds the sequence of a customer’s phone elements. The order by clause reorders the items in
the iteration and causes the phone numbers of the customer with the largest value in the Cid
attribute to be returned first. The phone elements of any individual customer are returned in the
order in which they appear in the document. The result is shown in Figure 8.3.
<phone
<phone
<phone
<phone
<phone
type="work">905-555-4789</phone>
type="home">416-555-3376</phone>
type="work">905-555-7258</phone>
type="home">416-555-2937</phone>
type="cell">905-555-8743</phone>
Figure 8.3
Result of the queries in Figure 8.2 and Figure 8.4
A DB2 client, such as the DB2 Command Line Processor or a JDBC application, receives this
sequence of phone elements as a result set consisting of five rows in a single column of type XML.
An application can iterate over these rows just like it normally does for relational result sets. The
same query result can be produced by an SQL/XML statement, such as the one in Figure 8.4. It,
too, produces a single column of type XML.
8.2
Processing XML Data with FLWOR Expressions
193
SELECT T.phone
FROM customer,
XMLTABLE('$INFO/customerinfo/phone'
COLUMNS
custID
INTEGER
PATH '../@Cid',
phone
XML
PATH '.') AS T
WHERE XMLEXISTS('$INFO/customerinfo[addr/@country = "Canada"]')
ORDER BY T.custID DESC;
Figure 8.4
SQL/XML query that also produces the result in Figure 8.3
There are some analogies between FLWOR expressions and SQL SELECT statements. Both can
have an optional WHERE clause for filtering and an optional ORDER BY clause for sorting the
result. The projection and the format of the result are defined by the SELECT clause in SQL and
by the return clause in XQuery. The let and for clauses in XQuery roughly correspond to the
FROM clause in SQL, defining the source of the data.
8.2.2
Understanding the for and let Clauses
Every FLWOR expression has to have at least one for or let clause and must have a return
clause. The for and let clauses introduce new variables, which can subsequently be referred to
in other clauses of the FLWOR expression. However, for and let assign values to variables in different ways.
Figure 8.5 highlights the difference between the for and the let clause. This example is purposefully simplified to clearly reveal important concepts. It does not use a sequence of XML values from an XML column, but it constructs a sequence containing the atomic values 1, 5, and 3.
The first of the two FLWOR expressions in Figure 8.5 uses a for clause to iterate over these three
items. In the first iteration, the variable $i assumes the value 1, in the second iteration the value
5, and in the third iteration the value 3. In each iteration, the return clause constructs a new element called result whose value is the value of the variable $i. The query returns three results
rows, one for each item in the input sequence.
The second query in Figure 8.5 uses a let clause. Contrary to the for clause, it does not iterate
over the items in the sequence. Instead, it assigns the entire sequence to the variable $j. The
return clause then returns the entire sequence enclosed in the newly constructed result element. You can certainly choose a different name for that element, if you like.
194
Chapter 8
Querying XML Data with XQuery
db2 => xquery for $i in (1,5,3) return <result>{$i}</result>;
<result>1</result>
<result>5</result>
<result>3</result>
3 record(s) selected.
db2 => xquery let $j := (1,5,3) return <result>{$j}</result>;
<result>1 5 3</result>
1 record(s) selected.
Figure 8.5
8.2.3
The difference between for and let
Understanding the where and order by Clauses
Figure 8.6 shows two more versions of the previous query with the for clause. The first version
has an additional where clause to restrict the result set to values greater than 2. The second query
in Figure 8.6 adds an order by clause to return the result items in ascending order. Both the
where and the order by clause use the variable $i that is introduced in the for clause.
db2 => xquery for $i in (1,5,3)
where $i > 2
return <result>{$i}</result>;
<result>5</result>
<result>3</result>
2 record(s) selected.
db2 => xquery for $i in (1,5,3)
where $i > 2
order by $i
return <result>{$i}</result>;
<result>3</result>
<result>5</result>
2 record(s) selected.
Figure 8.6
The effect of the where and order by clauses
8.2
Processing XML Data with FLWOR Expressions
8.2.4
195
FLWOR Expressions with Multiple for and let Clauses
An XQuery FLWOR expression can contain multiple for or let clauses. Figure 8.7 shows two
nested for clauses that act similarly to nested loops in a programming language. The outer for
clause iterates over the sequence (1,5,3) and the inner for iterates over the sequence
("a","b"). For each iteration of the outer for clause, the inner for clause iterates over all the
items in its sequence. This generates the full Cartesian product between the input sequences. An
analogy in the SQL world is a SELECT statement with two tables in the FROM clause and no join
predicate.
db2 => xquery for $i in (1,5,3)
for $j in ("a","b")
return <result>{$i,$j}</result>;
<result>1
<result>1
<result>5
<result>5
<result>3
<result>3
a</result>
b</result>
a</result>
b</result>
a</result>
b</result>
6 record(s) selected.
Figure 8.7
Two nested for clauses produce a Cartesian product
The XQuery in Figure 8.8 also contains two nested for clauses. Their input sequences contain a
common item, the atomic value 5, which is identified by a join predicate in the where clause.
This is analogous to an SQL join. The difference is that SQL operates on sets of relational rows
while XQuery operates on sequences of items. In these examples the items are just atomic values
to allow for an easy introduction of the language. In the following sections we return to the customer sample data where the items are XML nodes, including elements, attributes, and full documents.
db2 => xquery for $i in (1,5,3)
for $j in (7,5)
where $i = $j
return <result>{$i,$j}</result>;
<result>5 5</result>
1 record(s) selected.
Figure 8.8
Two nested for clauses with a join predicate
Since the XQuery let clause does not iterate, it does not contribute to the generation of a Cartesian product of sequences. For example, the query in Figure 8.9 contains a for clause and two
let clauses. Each iteration of the for clause leads to one item in the query result. The return
196
Chapter 8
Querying XML Data with XQuery
clause constructs result elements. The value of each result element is the sequence of the
values of the variables $i, $j, and $k.
db2 => xquery for $i in (1,5,3)
let $j := ("a","b")
let $k := $i *2
return <result>{$i,$j,$k}</result>;
<result>1 a b 2</result>
<result>5 a b 10</result>
<result>3 a b 6</result>
3 record(s) selected.
Figure 8.9
A FLWOR expression with for and let clauses
All variable names in XQuery have to be preceded by the dollar sign ($). The XQuery standard
allows one or multiple spaces between the dollar sign and the beginning of the actual variables, so
that both $var and $ var are valid variable names. However, for readability and to avoid confusion it’s best to not use spaces. The same applies to hyphens. Note that $a-b and $ a-b are
valid variable names that happen to contain a hyphen. But, a – b is interpreted as an arithmetic
operation because there are spaces between the hyphen and the characters a and b.
LEARNING XQUERY
When it comes to learning a new language there is no better way than
learning by doing. We suggest that you download and install the latest
version of DB2 Express-C, which is free, so that you can run the
XQuery examples in this section hands-on. The examples show that
you can explore the behavior of XQuery even without any tables in the
database.We encourage you to extend and modify these examples and
to try other combinations of for, let, where, order by, and return
clauses.You may find that XQuery becomes intuitive quite quickly.
8.3 COMPARING FLWOR EXPRESSIONS, XPATH EXPRESSIONS, AND
SQL/XML
This section compares and examines XPath, FLWOR, and SQL/XML queries in several ways. We
look at traversing XML documents to extract specific elements, coding and placing XML predicates, result set cardinalities, and the integration of FLWOR expressions in SQL statements. We
discuss several examples of how “the same” query can be written in several different ways. By
“the same” we mean that the same result is returned from the sample data. The examples are not
exhaustive; that is, they do not show all possible ways in which a certain query can be written.
8.3
Comparing FLWOR Expressions, XPath Expressions, and SQL/XML
8.3.1
197
Traversing XML Documents
Figure 8.10 illustrates five different ways to retrieve the customer name elements. There is no significant performance difference between them, but for readability and maintainability it is a good
idea to use as simple a syntax as possible to express a query. Hence, options (4) and (5) are good
choices in Figure 8.10.
The first FLWOR expression in Figure 8.10 iterates over the customerinfo elements and binds
them to the variable $c, one at a time. The return clause then uses $c as the context to navigate
to the name element. The second FLWOR expression iterates directly over the name elements and
binds them to the variable $n, one at a time. The return clause then only emits the values of $n.
The navigation to the name element has shifted from the return clause to the for clause. The
third FLWOR expression iterates over the customer documents; that is, over the document nodes
that are at the top of each document tree. The return clause then navigates from these document
nodes, represented by $i, to the customerinfo/name elements. You will see shortly that the
decision of what to iterate over in the for clause makes a difference as soon as you add predicates to the query. The fourth expression is a simple XPath that returns the sequence of all name
elements. The fifth query is an SQL/XML statement that uses the XMLQUERY function to extract
the name elements.
--(1)
xquery
for $c in db2-fn:xmlcolumn("CUSTOMER.INFO")/customerinfo
return $c/name;
--(2)
xquery
for $n in db2-fn:xmlcolumn("CUSTOMER.INFO")/customerinfo/name
return $n;
--(3)
xquery
for $i in db2-fn:xmlcolumn("CUSTOMER.INFO")
return $i/customerinfo/name;
--(4)
xquery db2-fn:xmlcolumn("CUSTOMER.INFO")/customerinfo/name;
--(5)
SELECT XMLQUERY('$INFO/customerinfo/name')
FROM customer;
Figure 8.10
Five different ways to retrieve the customer name elements
198
8.3.2
Chapter 8
Querying XML Data with XQuery
Using XML Predicates
Figure 8.11 extends the sample queries of Figure 8.10 by adding a predicate to only return the
name of the customer whose Cid attribute has the value 1003. All five queries return the same
result. Again, the first two FLWOR expressions in Figure 8.11 differ in whether the step to the
name element happens in the for or the return clause. This difference affects the where clause,
which uses the variable from the for clause. If the for clause assigns the variable $i to
customerinfo elements, then the where clause can simply use the XPath $i/@Cid to access
the Cid attribute. This is because Cid is a child of customerinfo. The second FLWOR expression, however, binds the variable $i to name elements. This forces the where clause to use a parent step to navigate from $i to the Cid attribute. This is an extra navigation step, which makes
the second FLWOR expression slightly more expensive.
The third FLWOR expression shows that filtering predicates can not only be located in the where
clause but also in the XPath expression of the for clause. In fact, the entire query can again be
expressed as a single XPath, which is the fourth query. And finally, the fifth query is an
SQL/XML statement, which uses the XMLEXISTS predicate to properly include the filtering
condition.
--(1)
xquery
for $i in
db2-fn:xmlcolumn("CUSTOMER.INFO")/customerinfo
where $i/@Cid = 1003
return $i/name;
--(2)
xquery
for $i in
db2-fn:xmlcolumn("CUSTOMER.INFO")/customerinfo/name
where $i/../@Cid = 1003
return $i;
--(3)
xquery
for $c in
db2-fn:xmlcolumn("CUSTOMER.INFO")/customerinfo[@Cid = 1003]
return $c/name;
--(4)
xquery
db2-fn:xmlcolumn("CUSTOMER.INFO")/customerinfo[@Cid = 1003]/name;
--(5)
SELECT XMLQUERY('$INFO/customerinfo/name')
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo[@Cid = 1003]');
Figure 8.11
Five different ways to apply a predicate
8.3
Comparing FLWOR Expressions, XPath Expressions, and SQL/XML
199
The next example (Figure 8.12) shows four different queries that return phone elements whose
attribute type has the value cell. The first FLWOR expression uses two nested for clauses. The
outer for clause iterates over the customerinfo elements and assigns them to the variable $c.
The inner for clause uses the path $c/phone to iterate over the phone elements of the current
customer. For each such phone element, the where clause checks whether the type attribute has
the value cell. If so, the return clause returns that phone element.
The second FLWOR expression shows that the same query result can be achieved without nested
for clauses. It uses only a single for clause to iterate directly over the phone elements. The
predicate could be applied in the where clause, but this query adds the predicate to the return
clause. You will see later that predicates in the return clause can lead to different query results if
element construction is involved. The third query is a simple XPath without any FLWOR clauses.
The last query is an SQL/XML statement that uses the XMLTABLE function to produce one result
row per cell phone, just like the other queries.
--(1)
xquery
for $c in db2-fn:xmlcolumn("CUSTOMER.INFO")/customerinfo
for $p in $c/phone
where $p/@type = "cell"
return $p;
--(2)
xquery
for $i in db2-fn:xmlcolumn("CUSTOMER.INFO")/customerinfo/phone
return $i[@type = "cell"];
--(3)
xquery
db2-fn:xmlcolumn("CUSTOMER.INFO")/customerinfo/phone[
@type="cell"];
--(4)
SELECT T.phone
FROM customer,
XMLTABLE('$INFO/customerinfo/phone[@type="cell"]'
COLUMNS
phone
XML
PATH '.') as T;
Figure 8.12
Four different queries that return the same phone elements
NOTE An advantage of SQL/XML queries is that they can contain
parameter markers and host variables in their predicates, as discussed
in section 7.6.This is not possible when you use XQuery without SQL.
200
Chapter 8
8.3.3
Querying XML Data with XQuery
Result Set Cardinalities in XQuery and SQL/XML
Let’s look at result set cardinalities using the three queries in Figure 8.13 as examples. Each of
the three queries returns all five customer phone numbers, three from one of our sample documents and two from the other. The first query is an XPath expression that produces a sequence of
five text nodes, and each item in that sequence is returned as a separate result row. The second
query uses the XMLQUERY function and returns the same five phone numbers in two result rows.
The reason is that XMLQUERY is a scalar function in an SQL statement, and scalar functions
produce one value for each input row. In our example there are two input rows (documents) and
for each of them XMLQUERY produces one sequence of phone numbers. You can turn the items in
these sequences into separate rows only if you use a table function (as opposed to a scalar function), which generates a set of rows. This is what the XMLTABLE function does.
xquery
db2-fn:xmlcolumn("CUSTOMER.INFO")/customerinfo/phone/text();
905-555-7258
416-555-2937
905-555-8743
905-555-4789
416-555-3376
5 record(s) selected.
SELECT XMLQUERY('$INFO/customerinfo/phone/text()')
FROM customer;
905-555-7258416-555-2937905-555-8743
905-555-4789416-555-3376
2 record(s) selected.
SELECT T.phone
FROM customer,
XMLTABLE('$INFO/customerinfo/phone'
COLUMNS
phone
VARCHAR(20)
PATH '.') as T;
905-555-7258
416-555-2937
905-555-8743
905-555-4789
416-555-3376
5 record(s) selected.
Figure 8.13
Three different queries that return the same five phone numbers
8.3
Comparing FLWOR Expressions, XPath Expressions, and SQL/XML
201
A key difference between XPath or XQuery expressions
on the one hand and SQL/XML statements on the other is that XPath
and XQuery expressions always return a single column of type XML.
XQuery cannot return multiple columns in a result set or data types
other than XML. SQL/XML statements can read values from XML documents and return them as relational result sets that have multiple
columns and traditional SQL data types (see section 7.3, Retrieving XML
Values in Relational Format with XMLTABLE).
NOTE
The examples in this section have shown that many simple queries do not require XQuery FLWOR
expressions but can be written much simpler as plain XPath expressions. Indeed, many applications are well-served by combining XPath and SQL and do not necessarily require the extra
power of XQuery. However, XQuery has very valuable features that XPath alone does not provide. For example, construction of XML data and joins across multiple XML documents is not
possible with XPath alone. Section 8.4 and Chapter 9, Querying XML Data: Advanced Queries
and Troubleshooting, provide examples.
8.3.4
Using FLWOR Expressions in SQL/XML
Note that SQL/XML and XQuery are not mutually exclusive. Chapter 7 focused on examples that
combine XPath and SQL, which is supported both in DB2 for Linux, UNIX, and Windows and
DB2 for z/OS. In DB2 for Linux, UNIX, and Windows, the same SQL/XML functions can also
take more complex XQuery expressions as input, such as FLWOR expressions. Figure 8.14 shows
an example. It returns the name of the customer whose Cid attribute has the value 1003. Remember that the XMLEXISTS predicate is truly an existence check. If the XQuery or XPath expression
in the XMLEXISTS returns an empty sequence, then XMLEXISTS evaluates to FALSE and the current row is eliminated.
SELECT XMLQUERY('for $i in $INFO/customerinfo/name
return $i/text()')
FROM customer
WHERE XMLEXISTS('let $i := $INFO/customerinfo
where $i/@Cid = 1003
return $i');
Figure 8.14
Return the name of the customer whose Cid is 1003
If the same result can be achieved with simple XPath then for simplicity it is recommended to
avoid FLWOR expressions in SQL/XML functions. For example, the query in Figure 8.15 is simpler than the query in Figure 8.14 and returns an identical result set.
202
Chapter 8
Querying XML Data with XQuery
SELECT XMLQUERY('$INFO/customerinfo/name/text()')
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo[@Cid = 1003]');
Figure 8.15
A simpler query to return the same result as Figure 8.14
Figure 8.16 provides an example of how you should not integrate XQuery in SQL. The problem
with this query is that the predicate on the Cid attribute is included in the FLWOR expression in the
SELECT clause of the SQL statement. In this location, the predicate does not eliminate any rows
from the customer table. To work as expected, the predicate needs to be in the WHERE clause of
the SQL statement, using XMLEXISTS. This issue has been discussed in section 7.5, Common
Mistakes with SQL/XML Predicates.
SELECT XMLQUERY('for $i in $INFO/customerinfo/name
where $i/@Cid = 1003
return $i/text()')
FROM customer;
Figure 8.16
8.4
Do not place row-filtering predicates in the SELECT clause!
CONSTRUCTING XML DATA
Constructing XML data in XQuery is easy. You can simply type regular XML tags as part of your
XQuery. This method is called direct XML construction. For example, an XML element or document just by itself is already a valid XQuery expression. Figure 8.17 is a simple example where
the XQuery consists of nothing but a direct element constructor. The name of the constructed element is title and its value is the literal string Hello. The result of the XQuery is the constructed element itself. This cannot be done with XPath alone.
db2 => xquery <title>Hello</title>;
<title>Hello</title>
1 record(s) selected.
db2 =>
Figure 8.17
8.4.1
Constructing the element title with the value "Hello"
Constructing Elements with Computed Values
It is often desirable to generate XML elements whose values are dynamically computed during
query execution. Constructed elements can have computed values if they contain XQuery variables or other dynamic expressions. Such expressions must be enclosed in curly brackets and are
8.4
Constructing XML Data
203
often used in the return clause of a FLWOR expression. For example, the query in Figure 8.18
retrieves the name and city values, and returns this information in a newly constructed XML
document.
xquery
for $i in db2-fn:xmlcolumn("CUSTOMER.INFO")/customerinfo
where $i/@Cid = 1003
return <quickinfo>
<custname>{$i/name/text()}</custname>
<custcity>{$i/addr/city/text()}</custcity>
</quickinfo>;
<quickinfo><custname>Robert Shoemaker</custname><custcity>Auro
ra</custcity></quickinfo>
1 record(s) selected.
Figure 8.18
Construction of an XML document with dynamic values
Several things are noteworthy about Figure 8.18. The returned XML data uses XML element
names that do not exist in the XML documents that are stored in the table. In other words, the
query reads one XML format but returns another. This performs a transformation of the data.
Although XQuery is not always a substitute for XSLT (Extensible Stylesheet Language Transformations), it can carry out many transformations easily and efficiently.
In contrast to Figure 8.17, the values of the constructed elements in Figure 8.18 are not provided
as literal strings but computed by XPath expressions. These XPath expressions must be enclosed
in curly brackets to indicate that they are to be evaluated and not used as literal string values. If
you forget the curly brackets, the query result contains the actual path expressions, which is not
useful:
<quickinfo><custname>$i/name/text()</custname<custcity>$i/addr/city/text()</
custcity></quickinfo>
The XPath expressions within the constructed elements use /text() as the last step in the path.
This way they only retrieve the text node value of the name and city elements, but not the elements themselves. If you do not use /text() then the original XML elements name and city
are included in the constructed XML document. This behavior is demonstrated by the query in
Figure 8.19, which only constructs the quickinfo element and inserts the existing elements
name and city into it.
204
Chapter 8
Querying XML Data with XQuery
xquery
for $i in db2-fn:xmlcolumn("CUSTOMER.INFO")/customerinfo
where $i/@Cid = 1003
return <quickinfo>
{$i/name}{$i/addr/city}
</quickinfo>;
<quickinfo><name>Robert Shoemaker</name><city>Aurora</city></qui
ckinfo>
1 record(s) selected.
Figure 8.19
Expressions that include existing elements in constructed elements
You can produce the same query result with the SQL/XML statement in Figure 8.20. Since direct
element constructors are XQuery expressions, and any XQuery expression can be embedded in
SQL/XML, simply use direct element construction in the XMLQUERY function as needed. Adjust
the XPath expressions to use the INFO column as the starting point (context) for navigation. One
benefit of the SQL/XML query is that you can now use parameter markers or host variables in the
XMLEXISTS predicate, if desired.
SELECT XMLQUERY('<quickinfo>
{$INFO/customerinfo/name}
{$INFO/customerinfo/addr/city}
</quickinfo>')
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo[@Cid = 1003]');
Figure 8.20
8.4.2
Direct element constructors embedded in SQL/XML
Constructing XML Data with Predicates and Conditions
Both the content as well as the tag names of constructed elements can be controlled with predicates and conditional expressions (if-then-else). Let’s look at some examples.
In section 8.3 we compared various queries by moving navigation steps and predicates from one
clause to another. For example, the second FLWOR expression in Figure 8.12 iterates over phone
elements and applies a predicate in the return clause. This has a significant effect if element
construction comes into play, as in Figure 8.21. Since there is no predicate in the for or where
clauses, the query constructs a result document for every item of the iteration; that is, for every
phone element. If you prefer to produce one result per customer, then the for clause should iterate over customerinfo, not over phone. Second, the predicate that selects cell phones is within
the constructed element cellphone. This element is constructed regardless of the evaluation of
the predicate. Hence, the query result contains empty cellphone elements for every phone
number that’s not a cell phone.
8.4
Constructing XML Data
205
xquery
for $i in db2-fn:xmlcolumn("CUSTOMER.INFO")/customerinfo/phone
return <quickinfo>
{$i/../name}
<cellphone>{$i[@type="cell"]/text()}</cellphone>
</quickinfo>;
----------------------<quickinfo><name>Robert Shoemaker</name><cellphone/></quickinfo>
<quickinfo><name>Robert Shoemaker</name><cellphone/></quickinfo>
<quickinfo><name>Robert Shoemaker</name><cellphone>905-5558743</cellphone></quickinfo>
<quickinfo><name>Matt Foreman</name><cellphone/></quickinfo>
<quickinfo><name>Matt Foreman</name><cellphone/></quickinfo>
5 record(s) selected.
Figure 8.21
The effect of predicates within element constructors
The if-then-else expression in XQuery allows you to generate XML tags conditionally based
on value predicates. For each phone element, the query in Figure 8.22 creates an info element
that contains the customer Cid attribute as well as another element with the phone number. The
name of this element depends on the value of the type attribute of the original phone element. If
the type is cell, the constructed element is called cellphone. If the type is work, the constructed element is workphone, and so on. The nesting of the if-then-else expressions is
necessary because XQuery does not have an elseif or case construct.
xquery
for $i in db2-fn:xmlcolumn("CUSTOMER.INFO")/customerinfo/phone
return <info>
{$i/../@Cid}
{if ($i/@type="cell")
then <cellphone>{$i/text()}</cellphone>
else if ($i/@type="work")
then <workphone>{$i/text()}</workphone>
else if ($i/@type="home")
then <homephone>{$i/text()}</homephone>
else <phone>{$i/text()}</phone>
}
</info>;
<info
<info
<info
<info
<info
Cid="1003"><workphone>905-555-7258</workphone></info>
Cid="1003"><homephone>416-555-2937</homephone></info>
Cid="1003"><cellphone>905-555-8743</cellphone></info>
Cid="1004"><workphone>905-555-4789</workphone></info>
Cid="1004"><homephone>416-555-3376</homephone></info>
5 record(s) selected.
Figure 8.22
Conditional construction of XML elements
206
Chapter 8
Querying XML Data with XQuery
In Figure 8.22, note that the expression {$i/../@Cid} produces an attribute node. This attribute
automatically becomes an attribute of the parent element (info). Within an element constructor
such as <info></info>, it is mandatory that any such attribute nodes appear before any element nodes. The query in Figure 8.23 fails because the attribute expression {$i/@Cid} appears
after the element expression {$i/name}. Reverse the two and the query works fine.
xquery
for $i in db2-fn:xmlcolumn("CUSTOMER.INFO")/customerinfo
return <info>{$i/name}{$i/@Cid}</info>;
SQL16015N An element constructor contains an attribute node
named "Cid" that follows an XQuery node that is not an attribute
node.
Figure 8.23
8.4.3
Construction fails if attributes don’t appear first!
Constructing Documents with Multiple Levels of Nesting
Assume that you are asked to construct a summary document that contains names and phone
numbers, except home phones, for all Canadian customers, exactly as defined in Figure 8.24.
Note that the desired output is a single document, not one document per customer. Also, the customer names are requested to be attributes and not repeated for every phone number. This means
that you have to construct elements at three levels: the quickinfo element, which includes all
customers; then one contact element per customer at the second level; and finally one telephone element for every phone that’s not a home phone.
<quickinfo>
<contact name="Robert Shoemaker">
<telephone>905-555-7258</telephone>
<telephone>905-555-8743</telephone>
</contact>
<contact name="Matt Foreman">
<telephone>905-555-4789</telephone>
</contact>
</quickinfo>
Figure 8.24
Summary document with work and cell phone numbers
The query in Figure 8.25 constructs the document shown in Figure 8.24. The query begins with
the construction of the top-level quickinfo element. The for clause that iterates over the customers is within the construction of the quickinfo element to achieve the desired document
structure. This embedded FLWOR expression is enclosed in curly brackets because it needs to be
evaluated and should not be taken as a literal string value for the quickinfo element. The
return clause of the FLWOR expression produces one contact element per customer, with a
name attribute. Constructing this new attribute is straightforward. In place of the attribute value
the query simply uses the expression {$i/name/text()} to compute the desired attribute
value. Finally, the contact element includes another FLWOR expression that iterates over the
8.4
Constructing XML Data
207
phone elements of the current customer and produces one telephone element for every non-
home phone.
xquery
<quickinfo>{
for $i in db2-fn:xmlcolumn("CUSTOMER.INFO")/customerinfo
where $i/addr/@country = "Canada"
return <contact name="{$i/name/text()}">
{for $p in $i/phone
where $p/@type != "home"
return <telephone>{$p/text()}</telephone>
}
</contact>
}
</quickinfo>;
Figure 8.25
Construction of the document in Figure 8.24
Note how the structure of the XQuery expression in Figure 8.25 corresponds to the structure of
the generated document in Figure 8.24.
8.4.4
Constructing Documents with XML Aggregation in SQL/XML Queries
It is also possible to generate the document in Figure 8.24 with an SQL/XML statement, such as
the one in Figure 8.26. This query uses a subquery and XML aggregation to produce the desired
document structure. The XMLQUERY function in the subselect constructs the contact elements
much like the return clause in Figure 8.25. The extra challenge is to combine the contact elements for all customers into a single document. Without the XMLAGG function, the subquery
would produce each contact element in a separate row. The purpose of any aggregation function in SQL is to combine values from multiple rows into a single value. This is exactly what
XMLAGG does for values of type XML. It aggregates the generated contact elements into a single
XML sequence. This sequence is a value in a single row of a single column, called contactinfo. This column is of type XML and referenced in the outer SELECT clause to produce the content of the generated quickinfo element. More information on XMLAGG is provided in Chapter
10, Producing XML from Relational Data.
SELECT XMLQUERY('<quickinfo>{$CONTACTINFO}</quickinfo>')
FROM (
SELECT XMLAGG(
XMLQUERY('<contact name="{$INFO/customerinfo/name}">
{for $p in $INFO/customerinfo/phone
where $p/@type != "home"
return <telephone>{$p/text()}</telephone>
}
</contact>') ) as contactinfo
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo[addr/@country = "Canada"]'))
Figure 8.26
SQL/XML query to construct the document in Figure 8.24
208
Chapter 8
Querying XML Data with XQuery
You may find that constructing complex XML documents with nested and repeating elements is
often more intuitive in XQuery than SQL/XML. However, SQL/XML makes it easier to include
values from relational columns in the constructed XML data. As a simple example, let’s extend
the query in Figure 8.26 such that the value of the relational id column of the customer table is
shown as an attribute custid of the contact element. In SQL/XML, you can simply add the
custid attribute and reference the relational column with $ID, as shown in Figure 8.27. This
would be significantly more complex in the XQuery version of this query (refer to Figure 8.25),
involving the use of the function db2fn:sqlquery to embed an SQL/XML statement inside the
XQuery.
SELECT XMLQUERY('<quickinfo>{$CONTACTINFO}</quickinfo>')
FROM (
SELECT XMLAGG(
XMLQUERY('<contact name="{$INFO/customerinfo/name}"
custid = "{$ID}">
{for $p in $INFO/customerinfo/phone
where $p/@type != "home"
return <telephone>{$p/text()}</telephone>
}
</contact>') ) as contactinfo
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo[addr/@country = "Canada"]'))
Figure 8.27
Constructing an attribute with a value from a relational column
In this section we have described direct constructors for XML elements and attributes. Similarly
you can construct XML comments and processing instructions, if needed. When you have to construct XML data from a mix of XML and relational source values, the use of SQL/XML is recommended. Chapter 10 describes additional cases and capabilities for constructing XML data.
8.5
DATA TYPES, CAST EXPRESSIONS, AND TYPE ERRORS
For the discussion of XQuery types, cast operations, and arithmetic expressions we use the
purchaseorder table from the DB2 sample database. It has an XML column porder; Figure
8.28 shows one of the documents it contains. We assume the purchase order documents are
inserted into the table without schema validation.
8.5
Data Types, Cast Expressions, and Type Errors
209
<PurchaseOrder PoNum="5000"
OrderDate="2006-02-18"
Status="Unshipped">
<item>
<partid>100-100-01</partid>
<name>Snow Shovel, Basic 22 inch</name>
<quantity>3</quantity>
<price>9.99</price>
</item>
<item>
<partid>100-103-01</partid>
<name>Snow Shovel, Super Deluxe 26 inch</name>
<quantity>5</quantity>
<price>49.99</price>
</item>
</PurchaseOrder>
Figure 8.28
Sample document in the purchaseorder table
The data types used in the XQuery language consist of two sets of types:
• The built-in data types that are defined in the XML Schema specification. These XML
Schema types are in the namespace http://www.w3.org/2001/XMLSchema, which
has the pre-declared namespace prefix xs.
• The predefined types of XQuery, which are in the namespace http://www.w3.org/
2005/xpath-datatypes with the predeclared
prefix xdt.
Some of the most commonly used types include
• xs:integer
• xs:date
• xs:decimal
• xs:time
• xs:double
• xs:dateTime
• xs:string
• xs:duration
• xs:base64Binary
• xdt:dayTimeDuration
• xs:hexBinary
• xdt:yearMonthDuration
• xs:boolean
The complete list of XQuery data types is documented in the DB2 information center.
When you query the purchase order documents you probably want to treat the PoNum attribute as
a numeric value, the OrderDate as a date value, the Status as a character string, the price as a
decimal or double precision value, and so on. Luckily, most of that happens automatically. For
example, Figure 8.29 shows a query with two predicates, @PoNum = 5000 and @Status =
"Unshipped". Since the literal value 5000 is not in quotes, it is interpreted as a numeric value.
210
Chapter 8
Querying XML Data with XQuery
Thus, DB2 automatically casts the value of the attribute PoNum to xs:double to perform a
numeric comparison against the value 5000. No explicit casting is necessary. Similarly, the literal
value "Unshipped" is recognized as type xs:string, which causes the values of the attribute
Status also to be cast to xs:string for a textual comparison of the two.
xquery for $i in db2-fn:xmlcolumn("PURCHASEORDER.PORDER")
where $i/PurchaseOrder[@PoNum = 5000 and @Status = "Unshipped"]
return $i;
Figure 8.29
XQuery with a numeric predicate and a string predicate
However, occasionally it is necessary to convert a value to a specific data type. The query in Figure 8.30 tries to retrieve all purchase orders where the OrderDate is "2006-02-18". The literal
value in quotes is interpreted as a character string, which leads to a textual comparison using the
type xs:string. But textual comparisons do not follow the same semantics as date comparisons, so that the query in Figure 8.30 can potentially return a logically incorrect result. For
example, if the OrderDate value in the document in Figure 8.28 had a time zone indicator, then
this query with string comparison would not return that document.
xquery for $i in db2-fn:xmlcolumn("PURCHASEORDER.PORDER")
where $i/PurchaseOrder/@OrderDate = "2006-02-18"
return $i;
Figure 8.30
XQuery with a string comparison—not a date comparison!
Similarly, the query in Figure 8.31 returns the document in Figure 8.28 only because the literal
value in the query is cast to xs:date. The Z at the end of the date value is the time zone indicator
for UTC time. UTC stands for Coordinated Universal Time, which is the same as Greenwich
Mean Time. The string representation of this date value is different from the one in the document
in Figure 8.28, but when cast to xs:date they represent the same logical date. Also, if an XML
index of type DATE is defined on /PurchaseOrder/@OrderDate, the query in Figure 8.31 can
use the index, because the type of the predicate matches the type of the index, but the query in
Figure 8.30 cannot use the index.
xquery for $i in db2-fn:xmlcolumn("PURCHASEORDER.PORDER")
where $i/PurchaseOrder/@OrderDate = xs:date("2006-02-18Z")
return $i;
Figure 8.31
XQuery with a date comparison
In such cases, the casting has to be applied to the literal value. In Figure 8.32, the casting is
wrongly applied to the OrderDate attribute instead, and the query fails with error SQL16003N.
The problem is that the left side of the predicate is of type xs:date, while the right side is of type
xs:string. The leads to a type error at query runtime.
8.5
Data Types, Cast Expressions, and Type Errors
211
xquery for $i in db2-fn:xmlcolumn("PURCHASEORDER.PORDER")
where $i/PurchaseOrder/xs:date(@OrderDate) = "2006-02-18Z"
return $i;
SQL16003N An expression of data type "xs:string" cannot be used when the data type
"xs:date" is expected in the context. Error QName=err:XPTY0004. SQLSTATE=10507
Figure 8.32
Cannot compare xs:string to xs:date!
Similarly, the XQuery in Figure 8.33 also fails with a type error. The literal value 10 is numeric
because it is not in quotes. Hence, DB2 tries to perform a numeric comparison of type
xs:double. However, the value “Unshipped” of the Status attribute cannot be cast to any
numeric data type, so the comparison fails.
xquery for $i in db2-fn:xmlcolumn("PURCHASEORDER.PORDER")
where $i/PurchaseOrder/@Status > 10
return $i;
SQL16061N The value "Unshipped" cannot be constructed as, or cast
(using an implicit or explicit cast) to the data type "xs:double". Error
QName=err:FORG0001. SQLSTATE=10608
Figure 8.33
Cannot compare xs:string to xs:double!
What if you have some documents where the Status attribute contains numeric values and some
documents where it contains alphanumeric string values? In that case you might still want to use
the query in Figure 8.33 to find all orders whose Status has a numeric value greater than 10.
You can use the XQuery expression castable together with the if-then-else expression to
apply the numeric predicate only if the Status attribute of a given document is a valid integer
number. For all other documents the value false is produced to exclude them from the result set.
xquery for $i in db2-fn:xmlcolumn("PURCHASEORDER.PORDER")
where $i/PurchaseOrder/( if (@Status castable as xs:integer)
then (@Status > 10)
else false )
return $i;
Figure 8.34
XQuery with the expression castable
The SQL/XML statement in Figure 8.35 intends to read all purchase orders where the first item in
the order is less expensive than the second item. Clearly, the purchase order in Figure 8.28 should
be in the result set because the price of its first item is 9.99 while the price of the second item is
49.99. But, opposite to what you might expect, the predicate in Figure 8.35 does not select the
purchase order in Figure 8.28. Let’s examine why that is. First of all, note that the predicate
[item[1]/price < item[2]/price] does not include any literal value that could provide an
indication of the data type of the comparison. Hence, according to the XQuery standard, DB2
212
Chapter 8
Querying XML Data with XQuery
simply performs a string comparison, and the string “9.99” is greater than the string “49.99”.
In summary, the query in Figure 8.35 runs, but does not work the way you want.
SELECT porder
FROM purchaseorder
WHERE XMLEXISTS('$PORDER/PurchaseOrder[
item[1]/price < item[2]/price]');
Figure 8.35
String comparison between two elements in a document
The solution is to cast either the left side of the predicate, or the right side, or both to xs:double,
as shown in Figure 8.36. If at least one of the two operands is cast to a specific data type, then this
determines the data type of the comparison operation and DB2 tries to cast the other operand to
the same data type. Consequently, the query in Figure 8.36 performs a numeric comparison of the
two price elements and therefore includes the purchase order in Figure 8.28 in the result set, as
expected.
SELECT porder
FROM purchaseorder
WHERE XMLEXISTS('$PORDER/PurchaseOrder[
item[1]/xs:double(price) < item[2]/price]');
Figure 8.36
Numeric comparison between two elements in a document
Note that the casting functions, which are actually called type constructors, can only cast at most
one item at a time. The following expression would fail because one purchase order contains multiple item elements, and a sequence of two or more items cannot be cast to a double value.
xs:double($i/PurchaseOrder/item/price)
To cast all items in the sequence, use the type constructor at the end of the XPath expressions,
such as the following:
$i/PurchaseOrder/item/xs:double(price)
$i/PurchaseOrder/item/price/xs:double(.)
8.6
ARITHMETIC EXPRESSIONS
XQuery provides arithmetic operators for addition (+), subtraction (–), multiplication (*),
division (div), integer division (idiv), and modulus (mod). A subtraction operator must be preceded by whitespace if it could otherwise be interpreted as part of a variable or tag name. For
example, price-discount will be interpreted as a single name, but price -discount and
price - discount will be interpreted as arithmetic expressions between two separate items.
Arithmetic operators can be used with elements, attributes, or a mix of both.
8.6
Arithmetic Expressions
213
Figure 8.37 provides two examples, one in SQL/XML and one in XQuery notation. Both multiply the quantity and the price of each item in the purchase order that has PoNum=5000. Note
that the for clause of the XQuery iterates over item elements and computes the value of each
item separately.
SELECT T.id, T.itemvalue
FROM purchaseorder,
XMLTABLE('$PORDER/PurchaseOrder/item'
COLUMNS
id
VARCHAR(15) PATH 'partid',
value DECIMAL(9,2) PATH 'quantity * price') as T
WHERE XMLEXISTS('$PORDER/PurchaseOrder[@PoNum= 5000]');
ID
ITEMVALUE
--------------- ----------100-100-01
29.97
100-103-01
249.95
2 record(s) selected.
xquery for $i in db2-fn:xmlcolumn("PURCHASEORDER.PORDER")
/PurchaseOrder[@PoNum= 5000]/item
let $q := $i/quantity
let $p := $i/price
return <itemValue id="{$i/partid}">{$q * $p}</itemValue>;
<itemValue id="100-100-01">29.97</itemValue>
<itemValue id="100-103-01">249.95</itemValue>
2 record(s) selected.
Figure 8.37
SQL/XML and XQuery with arithmetic expression
The first step in evaluating an arithmetic expression is to evaluate its operands. If one of the
operands is an empty sequence, the result of the arithmetic expression is also an empty sequence.
If one of the operands is a sequence of more than one item, a type error is raised. This happens in
Figure 8.38. This query iterates over purchase orders, not over items. Since a purchase order typically has multiple items, the let clauses bind a sequence of multiple quantity elements to $q
and a sequence of multiple price elements to $p. This leads to an error in the multiplication in
the return clause.
xquery for $i in db2-fn:xmlcolumn("PURCHASEORDER.PORDER")
/PurchaseOrder[@PoNum= 5000]
let $q := $i/item/quantity
let $p := $i/item/price
return <itemValue id="{$i/item/partid}">{$q * $p}</itemValue>;
SQL16003N An expression of data type "( item(), item()+ )"
cannot be used when the data type "item()" is expected.
Figure 8.38
Operands in an arithmetic expression must be zero or one item
214
Chapter 8
Querying XML Data with XQuery
An error is also raised if one of the operands cannot be cast to xs:double. For example, if a
quantity element contains the string value “five” then the arithmetic expression fails at runtime.
XQuery provides a division operator (div) and an integer division operator (idiv). The latter
simply casts its result to type xs:integer. For example, the expression 5 div 2 returns the
value 2.5, whereas the expression 5 idiv 2 produces the value 2. The idiv operator always
rounds down to next integer value, which is forced by the cast to xs:integer. For testing purposes you can run XQuery expressions with cast and arithmetic operations in the DB2 Command
Line Processor, such as in Figure 8.39.
xquery xs:integer(3.9);
3
1 record(s) selected.
xquery
10 + 100 idiv 9;
21
1 record(s) selected.
Figure 8.39
8.7
Testing XQuery expressions in the CLP
XQUERY FUNCTIONS
The XQuery language provides a large number of built-in functions. These include aggregate
functions such as count and sum, string functions such as contains and starts-with, functions to manipulate date and timestamp values, numeric functions, and others. A complete discussion of all functions is beyond the scope of this book. Appendix C, Further References, contains
pointers to the complete reference of all supported XPath and XQuery functions in DB2 for z/OS
and DB2 for Linux, UNIX, and Windows.
In this section we list only a subset of the available XQuery functions to highlight those that are
most frequently used and have been found useful in DB2 pureXML production applications. We
provide some examples and encourage you to try more functions and queries hands-on with the
DB2 sample database. In general, all functions can be applied to elements as well as to attributes.
We categorize the discussion of XQuery functions as follows:
• String functions (section 8.7.1)
• Number and aggregation functions (section 8.7.2)
• Sequence functions (section 8.7.3)
8.7
XQuery Functions
215
• Node and namespace functions (section 8.7.4)
• Date and time functions (section 8.7.5)
• Boolean functions (section 8.7.6)
All XQuery functions belong to a default namespace that is always implicitly bound to the namespace prefix fn. Since it is a default namespace, the prefix can be omitted. For example, concat
and fn:concat refer to the same concatenation function.
8.7.1
String Functions
Some of the most commonly used string functions are listed in Table 8.1.
Table 8.1
Commonly Used String Functions
String Functions
Description
concat
The function fn:concat returns a string that is the concatenation of two or
more atomic values.
string-join
The function fn:string-join takes as input a sequence of string values
and a separator character. It returns a single string in which the input strings
are concatenated but separated by the separator character.
contains
The function fn:contains returns true if a string contains a given
substring.
matches
The function fn:matches returns true if a string matches a given regular
expression.
starts-with
The function fn:starts-with returns true if a string begins with a given
substring.
ends-with
The function fn:ends-with returns true if a string ends with a given
substring.
lower-case
The function fn:lower-case converts a string to lowercase.
upper-case
The function fn:upper-case converts a string to uppercase.
translate
The fn:translate function replaces selected characters in a string with
replacement characters.
string
The function fn:string returns the string representation of a value.
string-length
The function fn:string-length returns the length of a string.
substring
The function fn:substring returns a substring of a string, based on a start
position and a length. It is similar to the substr function in SQL.
substring-after
The function fn:substring-after returns the tail of the input string after
the first occurrence of a given search string.
(continues)
216
Chapter 8
Table 8.1
Querying XML Data with XQuery
Commonly Used String Functions (Continued)
String Functions
Description
substring-before
The function fn:substring-before returns the beginning of the input
string up to (but excluding) the first occurrence of a given search string.
tokenize
The function fn:tokenize breaks a string into a sequence of substrings.
normalize-space
The function fn:normalize-space strips leading and trailing whitespace
characters from a string and replaces each internal sequence of whitespace
characters with a single space character.
A simple example of the concat function is shown in Figure 8.40. Here, the concat function
has four arguments. The first and third arguments are literal string values, while the second and
fourth parameters are expressions based on the variable $i that is bound in the for clause.
xquery for $i in
db2-fn:xmlcolumn("PURCHASEORDER.PORDER")/PurchaseOrder/item
where $i/../@PoNum=5000
return concat("Order ",$i/../@PoNum," – Item ",$i/partid);
Order 5000 - Item 100-100-01
Order 5000 - Item 100-103-01
2 record(s) selected.
Figure 8.40
Concatenation of string literals and expressions
Figure 8.41 demonstrates three string functions. The query uses the concat function to concatenate the values of the attributes PoNum and Status into a single string. In the second column it
utilizes the string-join function to produce a list of partid values that are separated by the
semicolon. Note that the arguments of the concat functions are single values while the first
argument of the string-join function evaluates to a sequence of multiple elements. The contains function in the WHERE clause restricts the result set to purchase orders that have at least
one item whose name contains the word “Super”.
SELECT
XMLQUERY('$PORDER/PurchaseOrder/concat(@PoNum,@Status)')
AS id,
XMLQUERY('string-join($PORDER/PurchaseOrder/item/partid,";")')
AS items
FROM purchaseorder
WHERE
XMLEXISTS('$PORDER/PurchaseOrder/item[contains(name,"Super")]');
Figure 8.41
Query with three XQuery string functions
8.7
XQuery Functions
IDSTATUS
-----------------5000Unshipped
5001Shipped
5004Shipped
217
ITEMS
-----------------------------------------100-100-01;100-103-01
100-101-01;100-103-01;100-201-01
100-100-01;100-103-01
3 record(s) selected.
Figure 8.41
Query with three XQuery string functions (Continued)
XQuery functions can be nested. The query in Figure 8.42 returns the name of an item from purchase order 5000, if the item name contains a comma and contains the word Basic after the
comma. The function substring-after is the first argument of the contains function and
produces the part of the name after the comma. Thus, the contains function is applied only to
that second part of each item name.
SELECT XMLQUERY('$PORDER/PurchaseOrder/item[
contains(substring-after(name,","), "Basic")]/name')
FROM purchaseorder
WHERE XMLEXISTS('$PORDER/PurchaseOrder[@PoNum=5000]');
<name>Snow Shovel, Basic 22 inch</name>
1 record(s) selected.
Figure 8.42
Query with nested XQuery string functions
You can use the function tokenize to split a string into multiple smaller strings. For example,
the query in Figure 8.43 splits the values of the partid elements based on the occurrences of the
“-” character. The function returns the substrings as a sequence. Instead of using a single character to split the input string, you can also tokenize a string based on the occurrences of a substring
or regular expression.
xquery
db2-fn:xmlcolumn("PURCHASEORDER.PORDER")/PurchaseOrder[
@PoNum=5000]/item/tokenize(partid,"-");
100
100
01
100
103
01
6 record(s) selected.
Figure 8.43
Splitting a string into a sequence of separate items
218
Chapter 8
Querying XML Data with XQuery
Although the query in Figure 8.43 returns the tokenized substrings in separate rows, it can be
more useful to return them in separate columns instead, which happens in Figure 8.44. The query
in Figure 8.44 uses the XMLTABLE function to generate one row per order item. Each generated
row has an INTEGER column called OrderNo and an XML column called partid. The INTEGER
column contains the purchase order number (PoNum), and the XML column contains the
sequence of substrings produced by the tokenize function. In the SELECT clause, this XML
column is not returned as-is, but used as input to each of three XMLQUERY functions. They use
positional predicates [1], [2], and [3], respectively, to obtain the first, second, and third token
of the sequence separately.
SELECT T.orderno,
XMLCAST(XMLQUERY('$PARTID[1]') as CHAR(3)) as id1,
XMLCAST(XMLQUERY('$PARTID[2]') as CHAR(3)) as id2,
XMLCAST(XMLQUERY('$PARTID[3]') as CHAR(3)) as id3
FROM purchaseorder,
XMLTABLE('$PORDER/PurchaseOrder/item'
COLUMNS
OrderNo INTEGER
PATH '../@PoNum',
partid
XML
PATH 'tokenize(partid,"-")') as T
WHERE
XMLEXISTS('$PORDER/PurchaseOrder[@PoNum=5000]');
ORDERNO
------------5000
5000
ID1
--100
100
ID2
--100
103
ID3
--01
01
2 record(s) selected.
Figure 8.44
Splitting a string into separate columns
We encourage you to try other string functions on your own. For example, use the translate
function to change the delimiter in the partid values from 100-103-01 to 100/103/01. Or,
use the starts-with function to find all items whose name begins with the word “Snow”.
8.7.2
Number and Aggregation Functions
Let’s turn to numeric XQuery functions, some of which are shown in Table 8.2.
Table 8.2
Commonly Used Number and Aggregation Functions
Numeric and
Aggregation Functions
Description
sum
The function fn:sum returns the sum of the values in a sequence.
avg
The function fn:avg returns the average of the values in a sequence.
8.7
XQuery Functions
Table 8.2
219
Commonly Used Number and Aggregation Functions (Continued)
Numeric and
Aggregation Functions
Description
max
The function fn:max returns the maximum of the values in a sequence.
min
The function fn:min returns the minimum of the values in a sequence.
abs
The function fn:abs returns the absolute value of a numeric value.
round
The function fn:round returns the integer that is closest to the given
numeric value.
Figure 8.45 shows two XQuery expressions with number and string functions. The first one
returns the sum of item prices for each purchase order where the value of the Status attribute
starts with “Ship”. For example, this includes orders where the status is Shipped or Shipping.
A separate sum is computed for the items within each such purchase order. The second query
computes the average item price across all orders that match the starts-with predicate. A single average value is computed for these orders, because the XPath expression that produces the
sequence of purchase orders is the argument of the avg function.
xquery
db2-fn:xmlcolumn("PURCHASEORDER.PORDER")/PurchaseOrder[
starts-with(@Status,"Ship")]/sum(item/price);
73.97
33.97
59.98
33.97
4 record(s) selected.
xquery avg(
db2-fn:xmlcolumn("PURCHASEORDER.PORDER")/PurchaseOrder[
starts-with(@Status,"Ship")]/item/price );
18.3536363636364
1 record(s) selected.
Figure 8.45
The XQuery aggregation functions sum and avg
The same two queries can be coded in SQL/XML notation, as shown in Figure 8.46. They produce the same results as their counterparts in Figure 8.45. Note that the second SELECT statement
in Figure 8.46 uses the SQL function AVG, not the XQuery function avg.
220
Chapter 8
Querying XML Data with XQuery
SELECT XMLQUERY('$PORDER/PurchaseOrder/sum(item/price)')
FROM purchaseorder
WHERE
XMLEXISTS
('$PORDER/PurchaseOrder[starts-with(@Status,"Ship")]');
SELECT AVG(T.itemprice)
FROM purchaseorder,
XMLTABLE('$PORDER/PurchaseOrder/item'
COLUMNS
itemprice DECIMAL(9,2) PATH 'price') AS T
WHERE
XMLEXISTS('$PORDER/PurchaseOrder[starts-with(@Status,"Ship")]');
Figure 8.46
The XQuery functions sum and the SQL functions avg
In Figure 8.45 and Figure 8.46 you can replace the functions sum and avg with the function
count to obtain the number of elements rather than the sum or average of their values. Try it out.
8.7.3
Sequence Functions
The count function is not a numeric function but a sequence function (see Table 8.3) because it
counts the number of items in a sequence.
Table 8.3
Commonly Used Sequence Functions
Date and Time Functions
Description
count
The function fn:count returns the number of items in a sequence.
data
The function fn:data returns the input sequence but replaces any
nodes in the sequence with their values.
distinct-values
The function fn:distinct-values returns the distinct values in a
sequence. It is similar to the SQL function distinct.
deep-equal
The function fn:deep-equal compares two documents or sequences
and returns true if they meet the requirements for deep equality.
Roughly speaking, two documents or sequences are deep equal if every
aspect of their structure, values, and data type is equal.
empty
The function fn:empty returns true if the argument is an empty
sequence.
exactly-one
The function fn:exactly-one returns its argument if the argument
contains exactly one item.
zero-or-one
The function fn:zero-or-one returns its argument if the argument
contains one item or is an empty sequence.
one-or-more
The function fn:one-or-more returns its argument if the argument is
a sequence of one or more items.
8.7
XQuery Functions
Table 8.3
221
Commonly Used Sequence Functions (Continued)
Date and Time Functions
Description
last
The function fn:last takes no parameters but returns the number of
items in the sequence that is currently being processed. It is usually
used in a positional predicate to return the last item in a sequence.
position
The function fn:position returns the position of the context item in
the sequence that is currently being processed.
Figure 8.47 shows three examples that use sequence functions. The goal is to find all the different
values that Status attributes in purchase orders can have. The first XQuery in Figure 8.47
returns the value of the Status attribute from all purchase orders in the purchaseorder table.
It uses the function data to obtain the attribute values instead of the attribute nodes. The second
XQuery uses the distinct-values function to retrieve unique Status values only. The result
shows that the sample data contains two different spellings of the value Unshipped, one with
lowercase s and one with uppercase S. To address this, the third XQuery uses the string function
upper-case to convert all Status values to uppercase. The SQL/XML statement in Figure
8.48 produces the same result by using the SQL functions DISTINCT and UPPER.
xquery db2-fn:xmlcolumn("PURCHASEORDER.PORDER")
/PurchaseOrder/data(@Status);
Unshipped
Shipped
Shipped
UnShipped
Shipped
Shipped
6 record(s) selected.
xquery distinct-values(db2-fn:xmlcolumn("PURCHASEORDER.PORDER")
/PurchaseOrder/@Status);
Unshipped
Shipped
UnShipped
3 record(s) selected.
xquery distinct-values(db2-fn:xmlcolumn("PURCHASEORDER.PORDER")
/PurchaseOrder/upper-case(@Status));
UNSHIPPED
SHIPPED
2 record(s) selected.
Figure 8.47
Using the XQuery sequence functions data() and distinct-values()
222
Chapter 8
Querying XML Data with XQuery
SELECT DISTINCT(UPPER(T.stat))
FROM purchaseorder,
XMLTABLE('$PORDER/PurchaseOrder'
COLUMNS
stat VARCHAR(15) PATH '@Status') AS T;
Figure 8.48
Using the SQL function DISTINCT
The SQL/XML statement in Figure 8.49 returns the first and the last item of purchase order 5000
in two separate columns of type XML. The function last(), with no argument, returns the number of items in the sequence and therefore points to the last item.
SELECT XMLQUERY('$PORDER/PurchaseOrder/item[1]'),
XMLQUERY('$PORDER/PurchaseOrder/item[last()]')
FROM purchaseorder
WHERE XMLEXISTS('$PORDER/PurchaseOrder[@PoNum=5000]');
Figure 8.49
8.7.4
Positional predicates to obtain the first and last items
Namespace and Node Functions
Some commonly used namespace and node functions are listed in Table 8.4. The namespace
functions are discussed in Chapter 15, Managing XML Data with Namespaces.
Table 8.4
Commonly Used Namespace and Node Functions
Name and Node
Functions
Description
name
The function fn:name returns the name of a node, typically an element or
attribute name. The returned name includes the namespace prefix of the
node, if applicable.
local-name
The function fn:local-name returns the name of a node, but does not
include a namespace prefix.
namespace-uri
The function fn:namespace-uri returns the namespace URI of the given
node.
namespace-urifor-prefix
The function fn:namespace-uri-for-prefix returns the namespace
URI that is associated with a namespace prefix for an element.
in-scope-prefixes
The function fn:in-scope-prefixes returns a list of prefixes for all inscope namespaces of an element.
The functions name and local-name are very powerful because they allow access to element
and attribute names. In contrast, all previous queries in this chapter used element and attribute
8.7
XQuery Functions
223
names only to get to their values. As an example, the XMLTABLE function in Figure 8.50 iterates
over all the child elements of the item elements of purchase order 5000. For each child element
it returns the element’s name and value together with the PoNum of the purchase order. Note that
the row-generating expression ends with a wildcard that selects all child elements under item.
The expressions 'local-name(.)' and '.' in the column definitions use the dot to refer to
whatever the current child element is.
SELECT T.OrderNo, T.node, T.value
FROM purchaseorder,
XMLTABLE('$PORDER/PurchaseOrder/item/*'
COLUMNS
OrderNo INTEGER
PATH '../../@PoNum',
node
VARCHAR(10)
PATH 'local-name(.)',
value
VARCHAR(40)
PATH '.'
) AS T
WHERE XMLEXISTS('$PORDER/PurchaseOrder[@PoNum=5000]');
ORDERNO
NODE
VALUE
---------- ---------- -------------------------------------5000 partid
100-100-01
5000 name
Snow Shovel, Basic 22 inch
5000 quantity
3
5000 price
9.99
5000 partid
100-103-01
5000 name
Snow Shovel, Super Deluxe 26 inch
5000 quantity
5
5000 price
49.99
8 record(s) selected.
Figure 8.50
Producing a list of element names and values
Similarly you can use the function local-name to produce a list of all tags that occur in a given
document. This is shown in Figure 8.51. The row-generating expression of the XMLTABLE function is //(*, @*). To understand what this means, remember that //* selects all elements at all
levels of the document, and //@* selects all attributes at all levels of the document. In the expression //(*, @*) the parentheses and the comma construct a sequence that combines all elements
and all attributes at all levels. In short, the row-generating expression produces all elements and
attributes of the document. The column seq indicates the order in which the nodes appear in the
document, and the column node produces their names. The column type determines whether
the node is an attribute, an element, or a leaf element. The if-then-else expression uses the
node test self::attribute() which evaluates to true if the node is an attribute. The else
branch contains another if-then-else expression to check whether the current node has any
element children. If yes, it must be an element itself. Otherwise it’s considered a leaf-element.
224
Chapter 8
SELECT T.*
FROM purchaseorder,
XMLTABLE('$PORDER//(*, @*)'
COLUMNS
seq
FOR ORDINALITY,
node
VARCHAR(20)
PATH
type
VARCHAR(15)
PATH
'local-name(.)',
'if (self::attribute())
then "Attribute"
else (if (./*)
then "Element"
else "Leaf-Element")'
) AS T
WHERE XMLEXISTS('$PORDER/PurchaseOrder[@PoNum=5000]');
SEQ
NODE
----------- -----------------1 PurchaseOrder
2 PoNum
3 OrderDate
4 Status
5 item
6 partid
7 name
8 quantity
9 price
10 item
11 partid
12 name
13 quantity
14 price
TYPE
-----------------Element
Attribute
Attribute
Attribute
Element
Leaf-Element
Leaf-Element
Leaf-Element
Leaf-Element
Element
Leaf-Element
Leaf-Element
Leaf-Element
Leaf-Element
14 record(s) selected.
Figure 8.51
8.7.5
Querying XML Data with XQuery
Producing a list of all element and attribute names
Date and Time Functions
Some noteworthy date and time functions are listed in Table 8.5.
8.7
XQuery Functions
Table 8.5
225
Commonly Used Date and Time Functions
Date and Time Functions
Description
adjust-date-totimezone
The function fn:adjust-date-to-timezone adjusts an
xs:date value to a specific time zone, or removes the timezone
component from the value. Similar functions exist for xs:time
and xs:dateTime values.
current-date,
current-time,
current-dateTime
These functions return the current date, time, or date and time in
the UTC timezone (UTC = Coordinated Universal Time, which is
Greenwich Mean Time).
current-local-date,
current-local-time,
current-local-dateTime
These functions return the current date, time, or date and time in
the local time zone of the operating system, without time zone
indicator. (DB2 for Linux, UNIX, Windows, version 9.5 FP5,
and 9.7 FP1.)
dateTime
The function fn:dateTime constructs an xs:dateTime value
from an xs:date value and an xs:time value.
day-from-date
The function fn:day-from-date returns the day component of
an xs:date value. Similar functions exist to extract the months or
year from an xs:date value, or to extract the hours, minutes,
seconds, or timezone from xs:time or xs:dataTime values.
An example of an SQL/XML query that manipulates dates is shown in Figure 8.52. The goal of
the query is to list the identifier, order date, year, and age of all orders that are older than 90 days.
Let’s look at the predicate in the WHERE clause first. The predicate selects all orders whose
OrderDate attribute is less than the current date minus 90 days. The string literal P90D denotes a
duration of 90 days. The P is the duration indicator, and 90D specifies the length of the duration.
Similarly, the string P2DT5H45M could be used to denote a duration of 2 days, 5 hours, and 45
minutes. Any such duration string needs to be cast to the type xdt:dayTimeDuration to be
interpreted as a duration and not as xs:string. This casting allows you to subtract the duration
from the current date to produce a date in the past (90 days ago).
For each matching order, the XMLTABLE function in Figure 8.52 extracts the OrderDate, the
year portion of the date, and the age of the order. The age is calculated by subtracting the current
date from the order date. Subtraction of one date from another produces a duration. In this example, the returned durations are negative, because current-date() is always larger than any
existing OrderDate. The query result shows, for example, that purchase order 5000 has been
placed 1069 days prior to January 21, 2009.
226
Chapter 8
Querying XML Data with XQuery
SELECT poid, CURRENT DATE as today, T.odate, T.year, T.age
FROM purchaseorder,
XMLTABLE('$PORDER/PurchaseOrder'
COLUMNS
odate DATE
PATH '@OrderDate',
year CHAR(4) PATH 'year-from-date(@OrderDate)',
age
CHAR(15) PATH 'xs:date(@OrderDate) - current-date()'
) as T
WHERE XMLEXISTS('$PORDER/PurchaseOrder[@OrderDate <
current-date() - xdt:dayTimeDuration("P90D")]');
POID
----------5000
5001
5002
5003
5004
5006
TODAY
---------01/21/2009
01/21/2009
01/21/2009
01/21/2009
01/21/2009
01/21/2009
ODATE
---------02/18/2006
02/03/2005
02/29/2004
02/28/2005
11/18/2005
03/01/2006
YEAR
---2006
2005
2004
2005
2005
2006
AGE
----------P1069D
-P1449D
-P1789D
-P1424D
-P1161D
-P1058D
6 record(s) selected.
Figure 8.52
Using date types and functions
Note that current-date() produces the current date in UTC time. If you are living in California, where the local time is eight hours behind UTC, then from 4 p.m. onwards currentdate() gives you tomorrow’s date. New functions to produce the local date and time are being
added (refer to Table 8.5) but you can also use XQuery functions to adjust a date or a time to a
given time zone, such as in the following query:
xquery adjust-date-to-timezone(current-date(),
xdt:dayTimeDuration("-PT8H"));
8.7.6
Boolean Functions
And finally, XQuery Boolean functions are listed in Table 8.6. An example of using the function
fn:false is Figure 8.34 in section 8.5 of this chapter. The use of the function fn:not() was
discussed in the context of XPath in section 6.9. Please refer to these sections for examples.
Table 8.6
Commonly Used Boolean Functions
Boolean Functions
Description
not
The function fn:not returns false if the effective Boolean value of a
sequence is true, and true if the effective Boolean value of a sequence
is false.
false
The function fn:false returns the value false.
true
The function fn:true returns the value true.
8.8
8.8
Embedding SQL in XQuery
227
EMBEDDING SQL IN XQUERY
In section 6.5, How to Execute XPath in DB2, we explained how the function db2-fn:sqlquery lets you embed SQL in XPath queries. The same works in XQuery FLWOR expressions and
it allows you to include relational predicates in your XQuery. You can even pass parameters from
the outer XQuery to the embedded SQL statement. Remember that the embedded SQL statement
has to return a single column of type XML.
For the following examples, note that the table purchaseorder has several relational columns
that contain values extracted from the XML document in the same row.
CREATE TABLE purchaseorder(poid BIGINT, status VARCHAR(10),
custid BIGINT, orderdate DATE, porder XML);
An interesting pair of queries is shown in Figure 8.53. The first query is an SQL/XML statement
that uses the XMLQUERY function in the SELECT clause to compute the sum of the item prices of
any selected order. The WHERE clause restricts the result set to those orders in the table where the
relational column status has the value Unshipped, the column orderdate has the value
2006-02-18, and the order information in the XML column contains at least one item with a
price greater than 40. For each of these orders, the query computes the sum of all item prices.
The second query is a FLWOR expression that produces the same result from our sample data. Its
input is defined by the function db2-fn:sqlquery, which produces the sequence of XML documents that are selected by the embedded SQL statement. This allows you to use relational predicates in an XQuery. The XQuery iterates with the for clause over the PurchaseOrder
elements of these input documents. For each such element it evaluates the XML predicate on
price and returns the sum of item prices for any matching order.
SELECT XMLQUERY('$PORDER/PurchaseOrder/sum(item/price)')
FROM purchaseorder
WHERE status = 'Unshipped'
AND orderdate = '2006-02-18'
AND XMLEXISTS('$PORDER/PurchaseOrder/item[price > 40]');
xquery for $i in db2-fn:sqlquery("SELECT porder
FROM purchaseorder
WHERE status = 'Unshipped'
AND orderdate = '2006-02-18'"
)/PurchaseOrder
where $i/item[price >= 40]
return sum($i/item/price);
Figure 8.53
Two queries that produce the same result
There is typically no significant performance difference between the two queries in Figure 8.53.
Both can use an XML index on /PurchaseOrder/item/price and relational indexes on
status and orderdate at the same time.
228
Chapter 8
Querying XML Data with XQuery
Let’s extend the previous example slightly to illustrate parameter passing from XQuery to the
enclosed SQL statement. Assume you want to return all orders that have the same shipping status
and order date as the purchase order with number 5000. The XQuery in Figure 8.54 does that
easily. It uses the for and where clauses to select purchase order 5000 and assign it to the variable $i. The return clause then produces the sequence of all orders where the relational
columns status and orderdate have the same value as $i/@Status and $i/@OrderDate
respectively. The functions parameter(1) and parameter(2) can only be used in SQL statements inside the db2-fn:sqlquery function. They refer to the XQuery expressions that are
provided as additional arguments to the db2-fn:sqlquery function, according to the order in
which they appear. That is, $i/@Status is bound to parameter(1) and $i/@OrderDate to
parameter(2). Effectively, this is a self-join on the purchaseorder table.
xquery
for $i in db2-fn:xmlcolumn("PURCHASEORDER.PORDER")/PurchaseOrder
where $i/@PoNum = 5000
return db2-fn:sqlquery("SELECT porder
FROM purchaseorder
WHERE status = parameter(1)
AND orderdate = parameter(2)",
$i/@Status, $i/@OrderDate );
Figure 8.54
XQuery that contains an SQL statement with parameters
Figure 8.55 shows how you can code the same self-join in SQL/XML notation without any
XQuery concepts beyond XPath. The FROM clause contains two references to the purchaseorder table, p1 and p2. The alias p1 is used in the XMLTABLE function to find purchase order
5000 and to extract Status and OrderDate from it. These generated relational columns are
then joined with alias p2 in the WHERE clause to find all orders with the same status and date. The
queries in Figure 8.54 and Figure 8.55 look very different from each other, but the DB2 query
compiler generates the same execution plan for both.
SELECT p2.porder
FROM purchaseorder p1, purchaseorder p2,
XMLTABLE('$po1/PurchaseOrder[@PoNum = 5000]'
passing p1.porder as "po1"
COLUMNS
status
VARCHAR(10) PATH '@Status',
orderdate DATE
PATH '@OrderDate'
) AS T
WHERE p2.status = T.status
AND p2.orderdate = T.orderdate;
Figure 8.55
A different notation for the same self-join as in Figure 8.54
8.9
8.9
Using SQL Functions and User-Defined Functions in XQuery
229
USING SQL FUNCTIONS AND USER-DEFINED FUNCTIONS IN XQUERY
There are many built-in SQL functions that are not part of the XQuery language. For example,
functions such as sqrt (square root), rand (random number), or cos (cosine) are available as
SQL functions in DB2 but they are not available as built-in XQuery functions. Additionally you
might have developed your own user-defined functions (UDFs), either in the SQL Procedural
Language (SQP PL) or in an external programming language such as Java or C. It is possible to
use such functions from the SQL world within XQuery expressions. The trick is to use the db2fn:sqlquery function to embed SQL functions in XQuery.
Assume that you have a legacy application that processes partid values, which are product
identifiers, in a different format. For example, a partid such as 100-103-01 needs to be converted to 01(100)103. This is achieved by the UDF in Figure 8.56. It breaks a given partid
into its three pieces and assembles them in a different way to meet the requirements of the legacy
system.
CREATE FUNCTION convert(partid VARCHAR(15))
RETURNS VARCHAR(15)
BEGIN ATOMIC
DECLARE p1, p2, p3, new VARCHAR(10) DEFAULT '';
SET p1 = substr(partid,1,3);
SET p2 = substr(partid,5,3);
SET p3 = substr(partid,9,2);
SET new = p3||'('||p1||')'||p2;
RETURN new;
END#
Figure 8.56
User-defined function to convert product identifiers
The FLWOR expression in Figure 8.57 uses this UDF in its let clause to convert every partid in
purchase order 5000 to the different format. The db2-fn:sqlquery function contains an SQL
statement, which in this case is simply a VALUES clause. Since the result of the embedded SQL
statement must be of type XML, the XMLTEXT function is used to turn the VARCHAR result value
of the function convert into an XML text node. The convert function takes a single parameter,
which has to be cast to the input type of the function, that is, VARCHAR(15). The expression
$i/partid provides the actual value that is passed into the convert function.
230
Chapter 8
Querying XML Data with XQuery
xquery for $i in
db2-fn:xmlcolumn("PURCHASEORDER.PORDER")/PurchaseOrder/item
let $new := db2-fn:sqlquery("
VALUES(XMLTEXT(convert(CAST (parameter(1)as VARCHAR(15)))))",
$i/partid)
where $i/../@PoNum = 5000
return <out><old>{$i/partid/text()}</old><new>{$new}</new></out>;
<out><old>100-100-01</old><new>01(100)100</new></out>
<out><old>100-103-01</old><new>01(100)103</new></out>
2 record(s) selected.
Figure 8.57
Using an SQL UDF within an XQuery
You can use the db2-fn:sqlquery function anywhere where built-in XQuery functions are
allowed. Figure 8.58 gives you a couple of ideas. The first FLWOR expression uses the
db2-fn:sqlquery function in the construction of the element new. Note that it has to be in
curly brackets so that it gets properly evaluated and not treated as a literal string. The second
XQuery uses db2-fn:sqlquery in a path expression. The XPath in the return clause is
$i/PurchaseOrder/item/partid except that the db2-fn:sqlquery function is applied to
the last step, partid.
xquery for $i in
db2-fn:xmlcolumn("PURCHASEORDER.PORDER")/PurchaseOrder/item
where $i/../@PoNum = 5000
return <out><old>{$i/partid/text()}</old>
<new>{ db2-fn:sqlquery("
VALUES(XMLTEXT(convert(CAST(parameter(1) AS VARCHAR(15)))))",
$i/partid) }</new></out>;
xquery for $i in
db2-fn:xmlcolumn("PURCHASEORDER.PORDER")
where $i/PurchaseOrder/@PoNum = 5000
return $i/PurchaseOrder/item/db2-fn:sqlquery("
VALUES(XMLTEXT(convert(CAST(parameter(1) AS VARCHAR(15)))))",
partid);
Figure 8.58
8.10
Further examples of using the db2-fn:sqlquery function
SUMMARY
XQuery is a powerful query language for XML data. XPath is a subset of the XQuery language
and used in every XQuery expression that accesses XML documents. Hence, XPath is a critical
part of XQuery.
8.10
Summary
231
One of the most commonly used expressions in XQuery is the FLWOR expression, which is named
after its keywords for, let, where, order by, and return. The for clause of a FLWOR expression lets you iterate over documents, elements, attributes, atomics values, or any sequence of
items in the XQuery data model. In each iteration, a variable is assigned to the next item in the
sequence for further manipulation. The let clause allows you to assign an entire sequence, such
as an intermediate result, to a single variable. The where and order by clauses are used to filter
and sort the result of the FLWOR expression. The result is then returned by the return clause,
possibly with further manipulation. FLWOR expressions can express queries over sets of documents, perform joins across documents, and combine data from multiple XML documents or different parts of a single document into a query result.
Other important expressions in XQuery include constructor expressions, such as direct element
and attribute constructors, which are used to create XML nodes and construct new XML documents within a query. Conditional expressions (if-then-else) allow for advanced logic. Additionally, XQuery supports cast expressions, arithmetic expressions, logical and comparison
operators, and sequence and transform expressions. XQuery also offers a rich set of built-in functions, such as string functions, numeric functions, aggregation functions, and date and time
functions.
Not every XML application requires XQuery. Many applications are well-served with the combined power of XPath and SQL. In fact, many queries in XQuery notation can also be expressed
in SQL/XML with embedded XPath.
This page intentionally left blank
C
H A P T E R
9
Querying XML Data:
Advanced Queries &
Troubleshooting
n this chapter we discuss advanced XML query topics, common errors, and guidelines for
avoiding performance pitfalls. The examples include both XQuery and SQL/XML queries.
This chapter is organized along the following topics:
I
• Aggregation and grouping in XML queries (section 9.1)
• Joins between XML columns as well as joins between XML and relational data (section
9.2)
• XML queries with case-insensitive string predicates (section 9.3)
• Guidelines for avoiding common performance problem (section 9.4)
• Common errors in XML queries and how to resolve them (section 9.5)
9.1
AGGREGATION AND GROUPING OF XML DATA
The recommended and most efficient way to perform grouping and aggregation of XML data is
to use the XMLTABLE function to extract XML values to relational columns, and then to apply the
SQL GROUP BY clause and SQL aggregation functions to these columns. The XQuery 1.0 language by itself, specifically the FLWOR expression, does not have a GROUP BY clause. This shortcoming makes grouping more difficult in XQuery than SQL, although not entirely impossible.
In the following we discuss grouping and aggregation queries that use the purchase order sample
data as input. A sample document is shown in Figure 9.1.
233
234
Chapter 9
Querying XML Data: Advanced Queries & Troubleshooting
<PurchaseOrder PoNum="5000"
OrderDate="2006-02-18"
Status="Unshipped">
<item>
<partid>100-100-01</partid>
<name>Snow Shovel, Basic 22 inch</name>
<quantity>3</quantity>
<price>9.99</price>
</item>
<item>
<partid>100-103-01</partid>
<name>Snow Shovel, Super Deluxe 26 inch</name>
<quantity>5</quantity>
<price>49.99</price>
</item>
</PurchaseOrder>
Figure 9.1
9.1.1
Sample document in the purchaseorder table
Aggregation and Grouping Queries with XMLTABLE
As an example, let’s determine the number of purchase orders per year since 2004. This is done in
Figure 9.2. The XMLTABLE function together with the year-from-date function produces a
relational column year of type CHAR(4). This year column is then used in both the SELECT
clause and in the GROUP BY clause, as you normally would with relational columns. The relational COUNT() function produces the desired aggregation. The XMLEXISTS predicate in the
WHERE clause ensures that the query only looks at orders that were placed in 2004 or later.
SELECT year, COUNT(*) AS num_orders
FROM purchaseorder,
XMLTABLE('$PORDER/PurchaseOrder'
COLUMNS
year
CHAR(4) PATH 'year-from-date(@OrderDate)') AS T
WHERE
XMLEXISTS('$PORDER/PurchaseOrder[@OrderDate >=
xs:date("2004-01-01")]')
GROUP BY year;
YEAR NUM_ORDERS
---- ----------2004
1
2005
3
2006
2
3 record(s) selected.
Figure 9.2
Using SQL group by and aggregation on extracted XML values
9.1
Aggregation and Grouping of XML Data
235
This pattern of writing XML queries has been found very useful. The XMLTABLE function raises
selected values from the XML level to the SQL level, and then you can apply SQL functions and
groupings to these values as you normally do in purely relational queries. Let’s apply this pattern
to another business question.
What is the total value of shipped and unshipped items that were ordered in 2006? The answer is
computed by the query in Figure 9.3. To write this query, you might want to start with the WHERE
clause to restrict the orders to 2006. The path expression in the XMLEXISTS predicate navigates to
the OrderDate attribute and checks whether it is greater than or equal to the first day of 2006,
and less than or equal to the last day of 2006. Note that both dots in the predicate refer to the
OrderDate attribute, which is the current node in the navigation.
In the XMLEXISTS predicate, don’t use the year-fromdate function to restrict the orders to 2006 because that function
would prevent the use of an XML index that might exist on the OrderDate attribute.
NOTE
While the WHERE clause takes care of the filtering, the XMLTABLE function extracts the data items
needed to aggregate the value of shipped and unshipped items. For each item in an order it produces one row with the item price, quantity, and shipping status. This allows you to use SQL concepts to group by the status and to sum the item values. The value of an item in an order is the
item price multiplied by its quantity.
SELECT orderstatus, SUM(itemprice * itemqty) AS value
FROM purchaseorder,
XMLTABLE('$PORDER/PurchaseOrder/item'
COLUMNS
orderstatus VARCHAR(10) PATH 'upper-case(../@Status)',
itemprice
DECIMAL(9,2) PATH 'price',
itemqty
INTEGER
PATH 'quantity') AS T
WHERE
XMLEXISTS('$PORDER/PurchaseOrder/@OrderDate[
. >= xs:date("2006-01-01") and . <= xs:date("2006-12-31")]')
GROUP BY orderstatus;
ORDERSTATUS VALUE
----------- --------------------------------SHIPPED
149.87
UNSHIPPED
279.92
2 record(s) selected.
Figure 9.3
Total value of shipped and unshipped items in 2006
236
Chapter 9
Querying XML Data: Advanced Queries & Troubleshooting
If you need to obtain the total value of shipped and unshipped goods for all years and not just
2006, remove the WHERE clause, extract the year from the OrderDate attribute, and add the
year column to the SELECT and GROUP BY clauses (see Figure 9.4).
SELECT year, orderstatus, SUM(itemprice * itemqty) AS value
FROM purchaseorder,
XMLTABLE('$PORDER/PurchaseOrder/item'
COLUMNS
year
CHAR(4)
PATH 'year-from-date(../@OrderDate)',
orderstatus VARCHAR(10) PATH 'upper-case(../@Status)',
itemprice
DECIMAL(9,2) PATH 'price',
itemqty
INTEGER
PATH 'quantity') AS T
GROUP BY year, orderstatus;
YEAR
---2004
2005
2005
2006
2006
ORDERSTATUS VALUE
----------- --------------------------------SHIPPED
149.87
SHIPPED
263.90
UNSHIPPED
9.99
SHIPPED
149.87
UNSHIPPED
279.92
5 record(s) selected.
Figure 9.4
9.1.2
Grouping by multiple XML attributes
Aggregation of Values within and across XML Documents
The previous queries in Figure 9.3 and Figure 9.4 sum up the item values for shipped and
unshipped orders. They do not look at the value of individual orders, which would require the
item values within each order to be aggregated first. Let’s look at aggregated item values per
order with another business question.
What is the minimum, maximum, and average order value in 2005 and 2006? The query in Figure 9.5 answers this question. The value of an order is the sum of all of its item values, and an
item value is the item price multiplied by its quantity. The details of the XMLTABLE function are
critical for this computation. First of all, the row-generating expression in the XMLTABLE function
iterates over PurchaseOrder elements, not over item elements. For each order, the XMLTABLE
function produces two columns, containing the year and the value of the order, respectively.
The expression sum(item/(price * quantity)) in the definition of the value column is
noteworthy. Remember that the row-generating expression in the XMLTABLE function, in this
case $PORDER/PurchaseOrder, provides the context for the column-generating expressions.
Since one purchase order has usually multiple items, the expression item/(price * quantity) multiplies the price and the quantify of each item, and returns a sequence of as many
9.1
Aggregation and Grouping of XML Data
237
values as there are items in a given order. The surrounding sum function then aggregates these
item values to a single order value. This ensures that the entire column-generating expression
always returns a single value. The SELECT clause then uses these values to compute the min,
max, and average order value across all orders in 2005 and 2006.
SELECT year,
MIN(value) AS min,
CAST(AVG(value) AS decimal(6,2)) AS avg,
MAX(value) AS max
FROM purchaseorder,
XMLTABLE('$PORDER/PurchaseOrder'
COLUMNS
year CHAR(4)
PATH 'year-from-date(@OrderDate)',
value DECIMAL(5,2) PATH 'sum(item/(price * quantity))'
) AS T
WHERE XMLEXISTS('$PORDER/PurchaseOrder/@OrderDate[
. >= xs:date("2005-01-01") and . <= xs:date("2006-12-31")]')
GROUP BY year;
YEAR MIN
AVG
MAX
---- ------- -------- ------2005
9.99
91.29 139.94
2006 149.87
214.89 279.92
2 record(s) selected.
Figure 9.5
Aggregating values within and across XML documents
Note that the expression sum(item/(price * quantity)) in the COLUMNS clause of the
XMLTABLE function performs aggregation of values within a given document. The MIN, MAX, and
AVG functions in the SELECT clause perform aggregation of values across many documents.
9.1.3
Grouping Queries in SQL/XML versus XQuery
So far, all the grouping queries in this section have used SQL/XML notation to exploit the SQL
GROUP BY clause as well as SQL aggregation functions. The reason is that the XQuery language,
specifically the FLWOR expression, does not (yet) have a GROUP BY clause. This makes grouping
less intuitive in XQuery. As an example, look at Figure 9.6 and Figure 9.7, which show two different ways to determine how often each different item has been ordered. Figure 9.6 uses the
same pattern as before. For each item it extracts the partid and quantity values from the
XML data and exposes them as relational columns. Then the familiar SQL GROUP BY clause and
COUNT and SUM functions are applied. This shows, for example, that item 100-100-01 appears
in five orders with a total order quantity of 14 pieces.
238
Chapter 9
Querying XML Data: Advanced Queries & Troubleshooting
SELECT partid, COUNT(*) AS num_orders, SUM(qty) AS total_qty
FROM purchaseorder,
XMLTABLE('$PORDER/PurchaseOrder/item'
COLUMNS
partid VARCHAR(20) PATH 'partid',
qty
INTEGER
PATH 'quantity'
) as T
GROUP BY partid;
PARTID
NUM_ORDERS TOTAL_QTY
-------------------- ----------- ----------100-100-01
5
14
100-101-01
3
11
100-103-01
3
9
100-201-01
3
11
4 record(s) selected.
Figure 9.6
Preferred query pattern to group and aggregate XML values (SQL/XML)
Figure 9.7 shows an XQuery expression that performs the same grouping by means of a self-join.
The outermost for clause iterates over all distinct values of the partid element. Each distinct
partid value leads to one group in the query result. The first nested for clause (for $i) produces a sequence of all partid values, including duplicates. The outer for clause (for $p) uses
this sequence to obtain the four distinct values, 100-100-01, 100-101-01, and so on. In each
iteration, the variable $p is assigned to one of these distinct values. For each of these distinct values, the let clause and the return clause are evaluated. The let clause has a nested for clause
that produces the sequence of items whose partid matches the current distinct value $p.
xquery
for $p in distinct-values(
for $i in db2-fn:xmlcolumn("PURCHASEORDER.PORDER")
return $i/PurchaseOrder/item/partid/text()
)
let $items := (
for $j in db2-fn:xmlcolumn("PURCHASEORDER.PORDER")
return $j/PurchaseOrder/item[partid = $p]
)
return <part num_orders="{count($items)}"
total_qty="{sum($items/quantity)}">{$p}</part>;
<part
<part
<part
<part
num_orders="5"
num_orders="3"
num_orders="3"
num_orders="3"
total_qty="14">100-100-01</part>
total_qty="11">100-101-01</part>
total_qty="9">100-103-01</part>
total_qty="11">100-201-01</part>
4 record(s) selected.
Figure 9.7
Aggregation and grouping in XQuery is less intuitive and efficient
9.2
Join Queries with XML Data
239
For example, it can be the sequence of all items whose partid is 100-100-01. This sequence
is assigned to the variable $items. The return clause then constructs a result that shows the
partid ($p) as well as the count and total quantity of the items that have this partid.
Although Figure 9.7 is an educating example of a complex XQuery expression, it is not the recommended way of writing grouping queries. The SQL/XML statement in Figure 9.6 performs
much better and is more intuitive for most users.
9.2
JOIN QUERIES WITH XML DATA
For the discussion of join queries we use the product table and the purchaseorder table in the
sample database. Let’s review their column definitions as well as a sample document from their
respective XML columns (see Figure 9.8).
Each purchase order document contains one or multiple items with partid elements. These
partid values reference products in the product table. For each product, the pid is an XML
element in the product document and also stored as a relational column. This redundant storage
can be very useful. For example, it enables you to define a primary key index on the relational
pid column.
CREATE TABLE purchaseorder(
poid BIGINT,
status VARCHAR(10),
custid BIGINT,
orderdate DATE,
porder XML);
(2)
<PurchaseOrder PoNum="5000"
OrderDate="2006-02-18"
Status="Unshipped">
<item>
<partid>100-100-01</partid>
<name>Snow Shovel,Basic…</name>
<quantity>3</quantity>
<price>9.99</price>
</item>
<item>
<partid>100-103-01</partid>
<name>Snow Shovel,Super…</name>
<quantity>5</quantity>
<price>49.99</price>
</item>
</PurchaseOrder>
Figure 9.8
CREATE TABLE product(
pid VARCHAR(10),
name VARCHAR(128),
price DECIMAL(9,2),
promoprice DECIMAL(9,2),
promostart DATE,
(2) promoend DATE,
description XML);
<product pid="100-100-01">
<description>
<name>Snow Shovel,Basic…</name>
(1)
<details>Basic Snow Shovel,
22 inches wide, straight
handle with D-Grip
</details>
<price>9.99</price>
<weight>1 kg</weight>
</description>
</product>
(1)
Two tables for join queries
This sample data allows for two interesting types of joins:
• First, a join between the XML columns porder and description, indicated by the
two arrows labeled as (1) in Figure 9.8. This is an XML-to-XML join.
• Second, a join between the XML column porder and the relational column pid, indicated by arrows (2) in Figure 9.8. This is an XML-to-relational join.
240
Chapter 9
9.2.1
Querying XML Data: Advanced Queries & Troubleshooting
XQuery Joins between XML Columns
Let’s start with a simple join in XQuery notation. After that we show the same join in SQL/XML
notation. Assume you want to identify all products that have a weight of 3 kilograms and that are
part of any order in the purchaseorder table. The first condition (3 kg) requires a predicate on
the XML column description in the product table. The second condition (part of any order)
requires a join with the purchaseorder table. This join query is shown in Figure 9.9.
The typical pattern of a join in XQuery is a pair of nested for clauses, one for each of the two
tables. The variable $po iterates over purchase orders, and the variable $pr iterates over products. The predicate $pr/description/weight = "3 kg" restricts the products to those that
weigh 3 kilograms. The predicate $pr/@pid = $po/item/partid is the join predicate. It
requires the pid attribute of the product element to be equal to the partid of an item element
in a purchase order. The return clause returns the value of the pid attribute of any matching
product. The query produces three rows, each having the value 100-103-01. This is because the
product 100-103-01 weighs 3 kilograms and appears in three different purchase orders, as you
already saw in Figure 9.6 and Figure 9.7. In other words, this product has three join matches in
the purchaseorder table, and this leads to three result rows. This multiplication is not specific
to XML and you have probably observed it in relational join queries many times.
xquery
for $po in db2-fn:xmlcolumn("PURCHASEORDER.PORDER")/PurchaseOrder
for $pr in db2-fn:xmlcolumn("PRODUCT.DESCRIPTION")/product
where $pr/description/weight = "3 kg"
and $pr/@pid = $po/item/partid
return $pr/data(@pid);
100-103-01
100-103-01
100-103-01
3 record(s) selected.
Figure 9.9
Nested for clauses in XQuery to express a join
The two nested for clauses produce the Cartesian product between the input sequences, which
consist of purchase orders and products, respectively. An analogy in SQL is a SELECT statement
with two table names in the FROM clause. The join predicate in the where clause ensures that the
entire Cartesian product is not materialized. The order of the two for clauses does not matter and
does not determine the join order. The join order for the execution of the query is a cost-based
decision of the DB2 optimizer. To enable the use of an XML index to evaluate the join predicate,
cast the join keys to the appropriate data type:
9.2
Join Queries with XML Data
and
241
$po/item/partid/fn:string(.) = $pr/@pid/fn:string(.)
Chapter 13, Defining and Using XML Indexes, describes how to exploit XML indexes for join
queries and why the casting is necessary.
An interesting and important difference between XML and relational joins is the following. Note
that the query in Figure 9.9 returns the join key in the result set. A join key always exists in both
tables, and in relational joins you can select the join key from either of the two tables, with no difference in the result set. Figure 9.10 shows what can potentially happen if you try the same in an
XML join. The query in Figure 9.10 is the same as the one in Figure 9.9, except that the expression in the return clause is $po/item/partid to return the product identifier from the purchaseorder table instead of the product table. The result contains products that do not weigh
3 kilograms, such as 100-100-01. This result is semantically correct, but probably not what you
wanted. The reason for this behavior is at the heart of the fundamental difference between XML
and relational data. Relational rows are flat, but XML documents can be nested and can have
repeating elements. And in the example at hand, the join key partid is a repeating element. Note
that the variable $po iterates over purchase orders, and each purchase order can have multiple
item elements. Hence, the expression $po/item/partid represents a sequence of multiple
partid elements. The join predicate is satisfied if the identifier (@pid) of a given product
matches at least one of the partid values in an order. But, the return clause then returns all the
partids. In other words, the query is written to return all partid values in an order, irrespective of their value, if at least one of them matches a 3 kilogram product in the product table.
Once more, this is existential semantics at work (see section 6.8, Existential Semantics).
xquery
for $po in db2-fn:xmlcolumn("PURCHASEORDER.PORDER")/PurchaseOrder
for $pr in db2-fn:xmlcolumn("PRODUCT.DESCRIPTION")/product
where $pr/description/weight = "3 kg"
and $po/item/partid/fn:string(.) = $pr/@pid/fn:string(.)
return $po/item/partid/text();
100-100-01
100-103-01
100-101-01
100-103-01
100-201-01
100-100-01
100-103-01
7 record(s) selected.
Figure 9.10
Returning a repeating element from a join can be misleading
242
Chapter 9
Querying XML Data: Advanced Queries & Troubleshooting
The query result changes back to the three expected rows if the outer for clause iterates over
items instead of purchase orders (see Figure 9.11). The effect of this is that the join predicate
now checks the partid of each item element separately. Any item that does not match a 3 kilogram product is eliminated.
xquery
for $po in
db2-fn:xmlcolumn("PURCHASEORDER.PORDER")/PurchaseOrder/item
for $pr in db2-fn:xmlcolumn("PRODUCT.DESCRIPTION")/product
where $pr/description/weight = "3 kg"
and $po/partid/fn:string(.) = $pr/@pid/fn:string(.)
return $po/partid/text();
100-103-01
100-103-01
100-103-01
3 record(s) selected.
Figure 9.11
Iterate over repeating elements in the for clause
Next, let’s see how the same join query works in SQL/XML.
9.2.2
SQL/XML Joins between XML Columns
In this section we use SQL/XML instead of XQuery to identify all products that have a weight of
3 kilograms and that are part of any order in the purchaseorder table. Figure 9.12 and Figure
9.13 show two ways of writing this join in SQL/XML. Both queries return the same three product
identifiers as in Figure 9.11. The difference between the two queries in Figure 9.12 and Figure
9.13 is how the join condition is written. Look at their second XMLEXISTS predicate and pay particular attention to the square brackets. In Figure 9.12, the join predicate is of the form:
$DESCRIPTION/product[ join-condition ]
This predicate is expressed on the DESCRIPTION column of the product table. Thus,
XMLEXISTS checks whether there is a product element whose pid attribute is equal to a
partid in a purchase order document.
SELECT XMLQUERY('$DESCRIPTION/product/data(@pid)')
FROM purchaseorder, product
WHERE
XMLEXISTS('$DESCRIPTION/product/description[weight="3 kg"]')
AND XMLEXISTS('$DESCRIPTION/product[ @pid/fn:string(.) =
$PORDER/PurchaseOrder/item/partid/fn:string(.)]');
Figure 9.12
Join predicate in XMLEXISTS
9.2
Join Queries with XML Data
243
In Figure 9.13, the join predicate is of the form:
$PORDER/PurchaseOrder/item[ join-condition ]
This predicate is expressed on the PORDER column of the purchaseorder table. Thus, XMLEXISTS checks whether there is an item element whose partid element is equal to a pid attribute
in a product document.
SELECT XMLQUERY('$DESCRIPTION/product/data(@pid)')
FROM purchaseorder, product
WHERE
XMLEXISTS('$DESCRIPTION/product/description[weight="3 kg"]')
AND XMLEXISTS('$PORDER/PurchaseOrder/item[ partid/fn:string(.) =
$DESCRIPTION/product/@pid/fn:string(.) ]');
Figure 9.13
Join predicate in the opposite “direction” than Figure 9.12
Due to the XPath notation of predicates, the join conditions in Figure 9.12 and Figure 9.13 differ
in their “direction”; that is, in the order of their operands. In DB2 9 for z/OS and DB2 9.1 and 9.5
for Linux, UNIX, and Windows, this direction determines the join order. As a result, the predicate
in Figure 9.13 is typically preferable because its WHERE clause contains one predicate for the
product table and one predicate for the purchaseorder table. If proper indexes exist, this
query allows DB2 to use index access to both tables and avoid table scans completely. Prior to
DB2 9.7, Figure 9.12 cannot avoid a table scan on the purchaseorder table. In DB2 9.7, the
DB2 query compiler abstracts from the notation of the XPath predicate and chooses the appropriate join order based on cost estimates.
Since DB2 for z/OS does not yet allow column names as implicit variables in XPath, such as
$DESCRIPTION and $PORDER in the XMLEXISTS predicates in Figure 9.13, you need to use the
PASSING clause in these predicates, as demonstrated in Figure 9.14.
SELECT XMLQUERY('$DESCRIPTION/product/data(@pid)')
FROM purchaseorder, product
WHERE
XMLEXISTS('$d/product/description[weight="3 kg"]'
PASSING description as "d")
AND XMLEXISTS('$p/PurchaseOrder/item[ partid/fn:string(.) =
$d/product/@pid/fn:string(.) ]'
PASSING description as "d", porder as "p");
Figure 9.14
Join predicate with PASSING clause
Let’s extend the query in Figure 9.13 to make things more interesting. In particular, you might
want to return more information about the 3 kg products than just the product identifier. Assume
you want to extract the product ID and weight from the product document as well as the number,
244
Chapter 9
Querying XML Data: Advanced Queries & Troubleshooting
status, and date of the purchase orders where the product appears as an item. This is implemented
in Figure 9.15. Note that the WHERE clause is unchanged from Figure 9.13. To extract the desired
data values from the product and purchase order documents, you can use one XMLTABLE function
for each of the two tables. The result set confirms that product 100-103-01 is the only one that
weighs 3 kg, and it appears in purchase orders 5000, 5001, and 5004. Two of the three orders
with this product are already shipped.
SELECT T1.*, T2.*
FROM purchaseorder, product,
XMLTABLE('$DESCRIPTION/product'
COLUMNS
prodid
VARCHAR(15) PATH '@pid',
weight
VARCHAR(5)
PATH 'description/weight')
AS T1,
XMLTABLE('$PORDER/PurchaseOrder'
COLUMNS
ponum
INTEGER
PATH '@PoNum',
status
VARCHAR(15) PATH '@Status',
odate
DATE
PATH '@OrderDate')
AS T2
WHERE
XMLEXISTS('$DESCRIPTION/product/description[weight="3 kg"]')
AND XMLEXISTS('$PORDER/PurchaseOrder/item[ partid/fn:string(.) =
$DESCRIPTION/product/@pid/fn:string(.) ]');
PRODID
--------------100-103-01
100-103-01
100-103-01
WEIGHT PONUM
------ ----------3 kg
5000
3 kg
5001
3 kg
5004
STATUS
--------------Unshipped
Shipped
Shipped
ODATE
---------02/18/2006
02/03/2005
11/18/2005
3 record(s) selected.
Figure 9.15
SQL/XML join query with XMLTABLE functions
Note that the query in Figure 9.15 has a join predicate between the rows of the product and
purchaseorder tables. It does not have a join predicate between the rows produced by the two
XMLTABLE functions. This is not needed here, because both XMLTABLE functions produce exactly
one row per document; that is, one row for each row of the underlying tables. Hence, the join
predicate between the product and purchaseorder tables is sufficient.
Now let’s take a look at a slightly trickier case. Suppose you want to modify the query in Figure
9.15 so that it returns the item quantity and price from a matching purchase order instead of
the order status and date. To achieve this you need to modify the second XMLTABLE function to
extract the desired item information (see Figure 9.16). Since quantity and price occur per
item, with multiple items per purchase order, it seems reasonable to extend the row-generating
expression of the XMLTABLE function to iterate over $PORDER/PurchaseOrder/item. However, the result set seems wrong. For example, it suggests that product 100-103-01 appears two
9.2
Join Queries with XML Data
245
times in purchase order 5000, with quantities 3 and 5, and with two different prices. But from the
previous queries and sample data you know that this is not true. Only the second of the first two
rows in the result set is correct.
SELECT T1.*, T2.*
FROM purchaseorder, product,
XMLTABLE('$DESCRIPTION/product'
COLUMNS
prodid
VARCHAR(15) PATH '@pid',
weight
VARCHAR(5)
PATH 'description/weight')
AS T1,
XMLTABLE('$PORDER/PurchaseOrder/item'
COLUMNS
ponum
INTEGER
PATH '../@PoNum',
qty
INTEGER
PATH 'quantity',
price
DECIMAL(6,2) PATH 'price')
AS T2
WHERE
XMLEXISTS('$DESCRIPTION/product/description[weight="3 kg"]')
AND XMLEXISTS('$PORDER/PurchaseOrder/item[ partid/fn:string(.) =
$DESCRIPTION/product/@pid/fn:string(.) ]');
PRODID
--------------100-103-01
100-103-01
100-103-01
100-103-01
100-103-01
100-103-01
100-103-01
WEIGHT PONUM
QTY
PRICE
------ ----------- ----------- -------3 kg
5000
3
9.99
3 kg
5000
5
49.99
3 kg
5001
1
19.99
3 kg
5001
2
49.99
3 kg
5001
1
3.99
3 kg
5004
4
9.99
3 kg
5004
2
49.99
7 record(s) selected.
Figure 9.16
Misleading result due to multiple item elements per order
The reason for the misleading result set in Figure 9.16 is that the second XMLTABLE function produces multiple rows per purchase order. Although the query has a join predicate between the
product and purchaseorder tables, it has no join predicate between the rows produced by the
two XMLTABLE functions. Hence, the two XMLTABLE functions generate a Cartesian product that
produces misleading tuples in the result set. In particular, the product identifier and weight of a
product is combined with the quantity and price of all items of a purchase order, and not only
with the one item in the purchase order that actually matches. This produces additional and
“wrong” rows in the result set.
The solution is to use an additional predicate to remove these extraneous rows. This is a one-line
change in Figure 9.16. Augment the row-generating expression for purchase order items with a
predicate on partid and pass in the prodid produced by the other XMLTABLE function. Figure
9.17 shows the changed query and the desired result set.
246
Chapter 9
Querying XML Data: Advanced Queries & Troubleshooting
SELECT T1.*, T2.*
FROM purchaseorder, product,
XMLTABLE('$DESCRIPTION/product'
COLUMNS
prodid
VARCHAR(15) PATH '@pid',
weight
VARCHAR(5)
PATH 'description/weight')
AS T1,
XMLTABLE('$PORDER/PurchaseOrder/item[partid=$p]'
passing T1.prodid as "p"
COLUMNS
ponum
INTEGER
PATH '../@PoNum',
qty
INTEGER
PATH 'quantity',
price
DECIMAL(6,2) PATH 'price')
AS T2
WHERE
XMLEXISTS('$DESCRIPTION/product/description[weight="3 kg"]')
AND XMLEXISTS('$PORDER/PurchaseOrder/item[ partid/fn:string(.) =
$DESCRIPTION/product/@pid/fn:string(.) ]');
PRODID
--------------100-103-01
100-103-01
100-103-01
WEIGHT PONUM
QTY
PRICE
------ ----------- ----------- -------3 kg
5000
5
49.99
3 kg
5001
2
49.99
3 kg
5004
2
49.99
3 record(s) selected.
Figure 9.17
Using an extra predicate to filter the item elements per order
Alternatively, you can extend the second XMLTABLE function so that it produces partid values
as a column, and add the join condition T1.PRODID = T2.PARTID to the WHERE clause. This is
shown in Figure 9.18 and also produces the correct result.
SELECT T1.*, T2.ponum, T2.qty, T2.price
FROM purchaseorder, product,
XMLTABLE('$DESCRIPTION/product'
COLUMNS
prodid
VARCHAR(15) PATH '@pid',
weight
VARCHAR(5)
PATH 'description/weight')
AS T1,
XMLTABLE('$PORDER/PurchaseOrder/item'
COLUMNS
ponum
INTEGER
PATH '../@PoNum',
partid
VARCHAR(15) PATH 'partid',
qty
INTEGER
PATH 'quantity',
price
DECIMAL(6,2) PATH 'price')
AS T2
WHERE
XMLEXISTS('$DESCRIPTION/product/description[weight="3 kg"]')
AND XMLEXISTS('$PORDER/PurchaseOrder/item[ partid/fn:string(.) =
$DESCRIPTION/product/@pid/fn:string(.) ]')
AND T1.PRODID = T2.PARTID;
Figure 9.18
Correct result with multiple item elements per order
9.2
Join Queries with XML Data
247
Another way to write this join and produce the correct result is to use a single XMLTABLE function with an XQuery FLWOR expression. You see this in Figure 9.19, which no longer has any
XMLEXISTS predicates because all predicates are included in the FLWOR expression. Since the
product and purchaseorder tables appear in the FROM clause of the query, the FLWOR expression references their XML columns through the variables $DESCRIPTION and $PRODUCT. Since
you want to combine data from two different tables into joined result rows, the return clause of
the FLWOR expression has to construct XML fragments that combine the desired elements and
attributes. In Figure 9.19, this is the constructed element <result>, which contains attributes
and elements from each matching pair of product and purchase order documents. Remember that
in such a construction all attributes must appear before any child element. This is why @pid and
@PoNum are the first two items in <result>. The constructed <result> elements are input to
the COLUMNS clause where they are broken up into relational columns.
SELECT T.*
FROM purchaseorder, product,
XMLTABLE('for $pr in $DESCRIPTION/product
for $po in $PORDER/PurchaseOrder/item
where $pr/description/weight = "3 kg"
and $pr/@pid/fn:string(.) =
$po/partid/fn:string(.)
return
<result>
{$pr/@pid}
{$po/../@PoNum}
{$pr/description/weight}
{$po/quantity}
{$po/price}
</result>'
COLUMNS
prodid
VARCHAR(15) PATH '@pid',
weight
VARCHAR(5)
PATH 'weight',
ponum
INTEGER
PATH '@PoNum',
qty
INTEGER
PATH 'quantity',
price
DECIMAL(6,2) PATH 'price')
AS T;
Figure 9.19
Join query with FLWOR expression inside XMLTABLE
The advantage of the query in Figure 9.19 over the query Figure 9.18 is that the absence of
XMLEXISTS predicates makes it somewhat simpler. Also, the embedded FLWOR expression can
iterate over the repeating item elements and apply the join condition at that level. In Figure 9.18
the additional predicate T1.PRODID = T2.PARTID is required to achieve the same. A slight disadvantage of the query in Figure 9.19 is that you have to temporarily construct XML fragments in
the return clause, only to break them up again in the COLUMNS clause of the XMLTABLE function. This is fine for small result sets, but introduces overhead for large result sets. An advantage
of the query in Figure 9.18 is that it runs on all platforms, whereas the FLWOR expression in Figure 9.19 is not yet available in DB2 9 for z/OS.
248
Chapter 9
9.2.3
Querying XML Data: Advanced Queries & Troubleshooting
Joins between XML and Relational Columns
The product table holds the product identifier not only in each product’s XML document, but
also in the relational column pid. This allows us to illustrate XML-to-relational joins. Assume
that you want to find all orders placed in 2006 or later that contain items (products) whose promotional price is greater than 15. The corresponding SQL/XML query is shown in two versions
in Figure 9.20. The first version uses the passing clause to pass the XML column porder and
the relational column pid into the XMLEXISTS predicate. The second version omits the passing
clause and references these columns as implicit variables $PORDER and $PID. Either way, the key
mechanism of these XML-to-relational joins is that a relational value is referenced in the
XMLEXISTS predicate and compared to an XML element value. Both versions of the query
produce the same result and have the same execution plan. They can use relational indexes
on product.promoprice and purchaseorder.orderdate as well as an XML index on
/purchaseOrder/item/partid. They cannot use an index on the relational column
product.pid because this column is referenced in an XML predicate for which relational
indexes are not eligible.
-- with “passing” clause, for all platforms:
SELECT po.poid, po.orderdate, pr.pid, pr.price, pr.promoprice
FROM purchaseorder po, product pr
WHERE pr.promoprice > 15
AND po.orderdate >= '01/01/2006'
AND XMLEXISTS('$p/PurchaseOrder/item[partid = $prodid]'
passing po.porder as "p", pr.pid as "prodid");
-- without “passing” clause, for Linux, UNIX, and Windows:
SELECT po.poid, po.orderdate, pr.pid, pr.price, pr.promoprice
FROM purchaseorder po, product pr
WHERE pr.promoprice > 15
AND po.orderdate >= '01/01/2006'
AND XMLEXISTS('$PORDER/PurchaseOrder/item[partid = $PID]');
POID
--------5000
5006
ORDERDATE
---------02/18/2006
03/01/2006
PID
PRICE
PROMOPRICE
---------- --------------- --------------100-103-01
49.99
39.99
100-101-01
19.99
15.99
2 record(s) selected.
Figure 9.20
Join predicate between an XML and a relational column
The query in Figure 9.20 performs the XML-to-relational join by bringing the relational column
into the XML context; that is, into the XMLEXISTS predicate. In some cases it is possible to take
the opposite approach; that is, to bring the XML side of the join to the relational level and express
the join with a relational predicate. This is shown in Figure 9.21. In this query, the functions
9.2
Join Queries with XML Data
249
XMLCAST and XMLQUERY extract the value of the XML element partid and convert it to the relational data type VARCHAR(10). This allows the partid value to participate in a relational equality predicate with the column pr.pid. In our example, this query fails at runtime because a
purchase order has multiple items. As a result, the XMLQUERY function produces a sequence of
two or more elements. This causes the XMLCAST function to fail because it can only cast one
value at a time. However, this type of join predicate works fine if the XML element or attribute
that participates in the join condition occurs at most once per document. In that case DB2 can use
a relational index on product.pid to evaluate the join. It cannot use an XML index on
/PurchaseOrder/item/partid because the join comparison is a relational predicate, not an
XML predicate.
SELECT po.poid, po.orderdate, pr.pid, pr.price, pr.promoprice
FROM purchaseorder po, product pr
WHERE pr.promoprice > 15
AND po.orderdate >= '01/01/2006'
AND pr.pid = XMLCAST(
XMLQUERY('$PORDER/PurchaseOrder/item/partid')
AS VARCHAR(10));
SQL16003N An expression of data type "( item(), item()+ )"
cannot be used when the data type "VARCHAR_10" is expected in
the context.
Figure 9.21
Cannot cast a sequence of multiple items to an SQL data type
To avoid error SQL16003N, use the XMLTABLE function instead of XMLQUERY with XMLCAST (see
Figure 9.22). This produces a separate relational value for each partid element in an order, and
each of these values is checked in the join predicate pr.pid = T.partid.
SELECT po.poid, po.orderdate, pr.pid, pr.price, pr.promoprice
FROM purchaseorder po, product pr,
XMLTABLE('$PORDER/PurchaseOrder/item'
COLUMNS
partid VARCHAR(10) PATH 'partid') AS T
WHERE pr.promoprice > 15
AND po.orderdate >= '01/01/2006'
AND pr.pid = T.partid;
POID
--------5000
5006
ORDERDATE
---------02/18/2006
03/01/2006
PID
PRICE
PROMOPRICE
---------- --------------- --------------100-103-01
49.99
39.99
100-101-01
19.99
15.99
2 record(s) selected.
Figure 9.22
Using XMLTABLE to facilitate a relational join predicate
250
Chapter 9
Querying XML Data: Advanced Queries & Troubleshooting
A join between an XML column and a relational column is also possible if you use XQuery rather
than SQL/XML. Figure 9.23 shows the typical pattern of an XQuery join; that is, a nested pair of
for clauses. The first for clause iterates over the purchase order item elements. The second
for clause iterates over product elements of the description documents selected by the
embedded SQL query. The SQL query contains the join predicate, which is pid = parameter(1). This join predicate is expressed in relational terms, and the XML element $po/partid
is passed into the relational context as the parameter value. The return clause constructs
result elements to resemble the output of query Figure 9.22. One challenge is to get the relational column promoprice into the result. One possible solution is to use the db2-fn:
sqlquery function a second time in the return clause. The embedded SQL statement joins
back to the matching row of the product table and produces an XML element promo whose value
is the relational promoprice column.
xquery
for $po in
db2-fn:xmlcolumn("PURCHASEORDER.PORDER")/PurchaseOrder/item
for $pr in db2-fn:sqlquery("SELECT description
FROM product
WHERE promoprice > 15
AND pid = parameter(1)",
$po/partid)/product
where $po/../@OrderDate >= xs:date("2006-01-01")
return <result>
{$po/../@PoNum}
{$po/../@OrderDate}
<pid>{$po/partid/text()}</pid>
{$pr/description/price}
{db2-fn:sqlquery("SELECT XMLELEMENT(name ""promo"", promoprice)
FROM product
WHERE pid = parameter(1)",
$po/partid)}
</result>;
<result PoNum="5000" OrderDate="2006-02-18"><pid>100-103-01</pid>
<price>49.99</price> <promo>15.99</promo></result>
<result PoNum="5006" OrderDate="2006-03-01"><pid>100-101-01</pid>
<price>19.99</price> <promo>39.99</promo></result>
2 record(s) selected.
Figure 9.23
9.2.4
XQuery join between an XML column and a relational column
Outer Joins between XML Columns
Roughly speaking, an outer join between two tables includes all rows from one of the tables in
the join result, even if no match is found in the other table. You can formulate a left outer join or a
9.2
Join Queries with XML Data
251
right outer join to indicate which of the two tables has its rows retained in the result set. The SQL
language has specific keywords to write such outer join queries, but XQuery does not. Still, outer
joins can be expressed very naturally in XQuery. For example, assume you want to retrieve information from the product table for all products whose price is less than 100, and include order
dates if any of those products appear as items in purchase orders. This requires a left outer join
between the product and purchaseorder tables to return products even if they haven’t been
ordered. Figure 9.24 shows this outer join in XQuery notation. The trick is to include the join to
the purchaseorder table in the element construction of the return clause. The return clause
constructs the product information regardless of whether matching purchase orders exist or not.
If a product has matching orders, the order dates are included in the constructed document. Otherwise just the product information is returned, without order dates. This achieves the outer join
behavior. If you swap the two for clauses in Figure 9.24 then this reverses the row-preserving
side of the outer join from product to purchaseorder.
xquery
for $pr in db2-fn:xmlcolumn("PRODUCT.DESCRIPTION")/product
where $pr/description/price < 100
return
<productinformation>
{$pr}
{for $po in
db2-fn:xmlcolumn("PURCHASEORDER.PORDER")/PurchaseOrder
where $po/item/partid/fn:string(.) = $pr/@pid/fn:string(.)
return <orderdate>{$po/data(@PoNum)}</orderdate> }
</productinformation>;
Figure 9.24
Left outer join between product and purchaseorder
The query in Figure 9.25 achieves the same result as the one in Figure 9.24. The only difference is
that the inner for-where-return expression is now evaluated in a let clause and then referenced as $orderdates in the return clause.
xquery
for $pr in db2-fn:xmlcolumn("PRODUCT.DESCRIPTION")/product
let $orderdates := for $po in
db2-fn:xmlcolumn("PURCHASEORDER.PORDER")/PurchaseOrder
where $po/item/partid/fn:string(.) = $pr/@pid/fn:string(.)
return <orderdate>{$po/data(@PoNum)}</orderdate>
where $pr/description/price < 100
return
<productinformation>
{$pr}
{$orderdates}
</productinformation>;
Figure 9.25
Left outer join between product and purchaseorder, with let clause
252
Chapter 9
Querying XML Data: Advanced Queries & Troubleshooting
If you prefer to return the join result in relational format, you can plug the query from Figure 9.24
or Figure 9.25 into an XMLTABLE function of an SQL SELECT statement, similar to what we
illustrated in Figure 9.19.
9.3
CASE-INSENSITIVE XML QUERIES
The values of XML elements and attributes are by definition case sensitive. For example, if you
search <city> elements for the value “New York”, you will not find “NEW YORK” or “new
york” or “New york”. One way to solve this is to use the XQuery function fn:upper-case() to
convert both sides of the predicate to uppercase, as in Figure 9.26. In this query, the search string
is provided through a parameter marker, which is passed into the XML predicate as the variable
$c. Both $c and the value of the city element are converted to uppercase before comparison.
This makes the search case-insensitive, but performance may be suboptimal because the use of
such functions precludes the use of XML indexes.
SELECT XMLQUERY('$INFO/customerinfo/addr/city/text()')
FROM customer
WHERE XMLEXISTS('$XMLDOC/customerinfo/addr[fn:upper-case(city) =
fn:upper-case($c) ]'
PASSING CAST(? AS VARCHAR(15)) AS "c");
Figure 9.26
Case-insensitive predicate, which cannot use an XML index
Case-insensitive queries with index usage are possible as follows. DB2 for Linux, UNIX, and
Windows supports locale-aware Unicode collations since DB2 9.5 Fixpack 1. This allows you to
ignore case and/or accents. To create a database that is case-insensitive for all string comparisons,
use the collation UCA500R1 as in Figure 9.27.
CREATE DATABASE testdb
USING CODESET UTF-8 TERRITORY US
COLLATE USING UCA500R1_LEN_S2;
Figure 9.27
Create a case-insensitive database
UCA500R1 specifies that the default Unicode Collation Algorithm (UCA) based on the Unicode
standard version 5.0.0 is used in this database. The ordering of characters can be customized
using optional attributes. The attributes are separated by an underscore. The collation name
UCA500R1_LEN_S2 contains the attributes LEN and S2. LEN is the concatenation of L (language) and EN (ISO 639-1 language code for English). The second attribute S2 specifies the
strength level. Strength level 2 specifies that upper- versus lowercase is ignored but that accents
are not ignored. For example, cliche is equal to Cliche but not to cliché. Note that the collation does not change or convert your data, but only defines how string comparisons are
performed.
9.4
How to Avoid “Bad” Queries
253
If you define your database with a case-insensitive collation, all string comparisons and indexes
are automatically case-insensitive and the use of the upper-case function is not needed. Also,
the case of the search string no longer matters. Searching for “Beijing” or “BEIJING” returns the
same result. This applies to all relational and XML data in the entire database. It is not possible to
restrict the case insensitivity to specific tables or columns. The collation can only be defined
when the database is created. It cannot be altered later and cannot be specified per query or per
application. Hence, the collation is a far reaching and irreversible design decision for your
database.
Note that the case insensitivity only applies to element and attribute values, not to the tag names
themselves. XML tags and path expressions are still case sensitive. For example, the two XPath
expressions /customerinfo/city (lowercase “c”) and /Customerinfo/City (uppercase
“C”) are still different. The latter would not find any elements in our sample data, because the
<city> element in our sample data is spelled in lowercase.
9.4
HOW TO AVOID “BAD” QUERIES
One characteristic that SQL queries have in common with SQL/XML and XQuery is that logically the same query can be written in many different ways. But, just because a query can be written in a certain way does not mean that it should be written that way. You should write queries so
that they are intuitive, easy to understand, and easy for DB2 to optimize and process. Let’s look at
a few examples in this section.
9.4.1
Construction of Excessively Large Documents
The query in Figure 9.28 constructs a top-level element ShippedOrders and the content of this
element is the sequence of all order documents whose status is Shipped. Note that this query
returns a single large document that contains all qualifying orders. Whether this query is a good
idea depends on the number of shipped orders. Combining a small number of orders in a single
document is fine. However, the larger the number of shipped orders the more trouble you can
have with this query. First, returning many individual documents is more efficient than combining them into a single large document. Second, consuming applications often have trouble processing a document that’s tens or hundreds of megabytes in size, especially if the application uses
a DOM parser. And finally, if the constructed document exceeds 2GB in size then it cannot be
transmitted from the DB2 server to the client application. As a remedy, use a query such as in Figure 9.29 that returns each shipped order as a separate document. An application can easily concatenate them if needed. Alternatively you can use DB2’s EXPORT utility to write many
documents to a single large file on disk.
254
Chapter 9
Querying XML Data: Advanced Queries & Troubleshooting
xquery
<ShippedOrders>
{for $i in db2-fn:xmlcolumn("PURCHASEORDER.PORDER")
where $i/PurchaseOrder[@Status="Shipped"]
return $i
}
</ShippedOrders>;
Figure 9.28
Construction of a single large result document
xquery
for $i in db2-fn:xmlcolumn("PURCHASEORDER.PORDER")
where $i/PurchaseOrder[@Status="Shipped"]
return <ShippedOrder>{$i}><ShippedOrder>;
Figure 9.29
9.4.2
Returning many small documents is often more efficient
“Between” Predicates on XML Data
“Between” predicates are very common. For example, you might ask for all orders between
March and June, for all products with a weight between 1 and 5 kilograms, or for all customers
with a last name between “A” and “M.” The SQL language has the explicit between keyword to
formulate such predicates, but this does not exist in XPath or XQuery. Instead you can use a pair
of range predicates.
For example, the query in Figure 9.30 tries to retrieve all orders in 2006 or later that have items
with a price between 20 and 30. One purchase order is returned but it does not seem to match the
intention of the query. It contains two items, but neither one has a price between 20 and 30. And
yet, this document is a correct result for the query as it is written. Once again, this is due to existential semantics (see section 6.8) and the fact that item is a repeating element. The predicates
item/price >= 20 and item/price < 30 check whether an item element exists whose
price element has a value greater than or equal to 20, and if there also exists an item element
whose price is less than 30. But these two item elements do not have to be the same. In fact, the
selected purchase order fulfills the predicate item/price >= 20 because there is an item
whose price is 49.99. It also fulfills the predicate item/price < 30 because there is an item
whose price is 9.99.
9.4
How to Avoid “Bad” Queries
255
SELECT porder
FROM purchaseorder
WHERE XMLEXISTS('$PORDER/PurchaseOrder[@OrderDate > xs:date("2006-01-01")
and item/price >= 20
and item/price < 30 ]');
<PurchaseOrder PoNum="5000" OrderDate="2006-02-18" Status="Unshi
pped"><item><partid>100-100-01</partid><name>Snow Shovel, Basic
22 inch</name><quantity>3</quantity><price>9.99</price></item><i
tem><partid>100-103-01</partid><name>Snow Shovel, Super Deluxe 2
6 inch</name><quantity>5</quantity><price>49.99</price></item></
PurchaseOrder>
1 record(s) selected.
Figure 9.30
Wrong way to write a between predicate
Both SQL/XML statements in Figure 9.31 write the “between” condition correctly and ensure
that both range predicates are applied to the same item price. In the expression item/price[.
>= 20 and . < 30], both dots refer to the same price element. Hence, this query selects
orders that have at least one item with at least one price element whose value is indeed
between 20 and 30. (No such order exists in the sample database.) Based on this notation, DB2
knows that both range predicates are always applied to the same XML node. This allows DB2 to
evaluate both predicates with a single start-stop scan (start at 20, stop at 30) over an XML index
defined on the price element.
SELECT porder
FROM purchaseorder
WHERE XMLEXISTS('$PORDER/PurchaseOrder[@OrderDate > xs:date("2006-01-01")
and item/price[. >= 20 and . < 30]]');
SELECT porder
FROM purchaseorder
WHERE XMLEXISTS('$PORDER/PurchaseOrder[@OrderDate >
xs:date("2006-01-01")]/item/price[. >= 20 and . < 30]');
0 record(s) selected.
Figure 9.31
Correct way to write a between predicate
If each item element has at most one price element, then the expression item[price >= 20
and price < 30] also selects the correct query result. However, DB2 does not know that each
item has at most one price and therefore cannot apply a single start-stop index scan. Instead,
DB2 has to use two separate index scans plus an index ANDing operator to combine the result
(see Table 9.1). This is less efficient. Therefore it is always recommended to write “between”
256
Chapter 9
Querying XML Data: Advanced Queries & Troubleshooting
predicates with the “dot” (current context), as shown in Figure 9.31. Further details on XML
index usage and execution plans are provided in Chapters 13 and 14.
Table 9.1
Optimal (left) and Suboptimal Execution Plan (right)
price[. >= 20 and . < 30]
[price >= 20 and price < 30]
RETURN
|
NLJOIN
|
/-+-\
/
\
FETCH
XSCAN
|
/---+---\
/
\
RIDSCN
TABLE:
|
purchaseorder
SORT
|
XISCAN
20 <= price < 10
RETURN
|
NLJOIN
|
/-+-\
/
\
FETCH
XSCAN
|
/---+---\
/
\
RIDSCN
TABLE:
|
purchaseorder
SORT
|
IXAND
|
/-+-\
/
\
XISCAN
XISCAN
price >= 20 price < 30
Index
20 30
9.4.3
Index
20 30
Large Global Sequences
Figure 9.32 provides another example of how you should not write queries. The idea of this query
comes from a real XML application, but is changed here to fit the purchase order data. The query
starts with a let clause and assigns the sequence of all purchase order items in the table to the
variable $allitems. This is the first of multiple problems in this query. Unless the table is tiny,
the sequence in $allitems is typically very large. Using let to combine items from all (or
many) documents in the entire table often results in suboptimal performance.
The next step of the query, for $pid…, iterates over the distinct partid values of all the item
elements in the sequence $allitems. For each distinct partid it returns a constructed XML
element prod_info that contains the partid (produced by $pid) as well as the name and the
price of the item.
Note how the name and the price are obtained for each distinct partid; that is, for each value
of $pid. The variable $pid is used to probe back into the sequence $allitems to find all items
with a matching partid. This probe happens in the predicate $allitems[partid = $pid].
The same is done for price.
This coding is not straightforward, needlessly complex, and bad for performance. In particular,
the big sequence $allitems is a large temporary object and not indexed. Hence, the predicates
9.4
How to Avoid “Bad” Queries
257
in the return clause ([partid = $pid]) both require a sequential scan over all items in all
purchase orders, for each $pid. An analogy in the relational world would be a query that copies
all rows from a table to a temporary table, then performs a “select distinct” on that table to obtain
a set of keys, and then a table scan on the temp table for each of these keys.
xquery
let $allitems :=
( for $i in db2-fn:xmlcolumn("PURCHASEORDER.PORDER")
return $i/PurchaseOrder/item )
for $pid in distinct-values($allitems/partid)
order by $pid
return
<prod_info product = "{$pid}">
<name>{distinct-values($allitems[partid = $pid]/name)}</name>
<price>{distinct-values($allitems[partid = $pid]/price)}</price>
</prod_info>;
Figure 9.32
Expensive usage of large sequences
The result of the query in Figure 9.32 is simply the partid, name, and price for all distinct
items that occur in the purchase orders. The same result can be computed in a much easier way, as
shown in Figure 9.33. This query simply generates one tuple for each item element and uses the
SQL function DISTINCT to remove duplicates. In the original case, the performance improved
by two orders of magnitude. The rewritten query is also easier to understand.
SELECT distinct T.pid, T.name, T.price
FROM purchaseorder,
XMLTABLE('$PORDER/PurchaseOrder/item'
COLUMNS
pid
VARCHAR(10)
PATH
'partid',
name
VARCHAR(50)
PATH
'name',
price INTEGER
PATH
'price') as T;
Figure 9.33
9.4.4
Rewritten query avoids large intermediate sequences
Multilevel Nesting SQL and XQuery
A general guideline is to introduce only as much complexity in your queries as you really need.
For example, it is certainly possible to have an XQuery with an embedded SQL statement that has
an embedded XQuery, and so on. But, experience shows that nesting the two languages more
than one level deep is usually not needed to express the desired query logic. Therefore, we recommend using only one level of embedding XQuery into SQL or vice versa. As a result, queries
are easier to understand and to maintain, and often also easier to optimize and execute for DB2.
Figure 9.34 shows an example of an XQuery with an embedded SQL statement, which in turn has
embedded XQuery expressions in the XMLQUERY function and XMLEXSISTS predicate. The
258
Chapter 9
Querying XML Data: Advanced Queries & Troubleshooting
embedded SQL statement produces the purchase order elements from all orders that belong to
customer 1001 and whose PoNum attribute has the value 1002. For those orders, the XQuery
checks whether the Status is Shipped and returns all order items in a newly constructed element POitems. Using XQuery within the SQL statement and around the SQL statement is needlessly complex.
xquery
for $i in db2-fn:sqlquery("
SELECT XMLQUERY('$PORDER/PurchaseOrder')
FROM purchaseorder
WHERE custid =1001
AND XMLEXISTS('$PORDER/PurchaseOrder[@PoNum=5002]')
")
where $i[@Status="Shipped"]
return <POitems>{$i/item}</POitems>;
Figure 9.34
Unnecessary double-nesting of XQuery and SQL
To simplify the query in Figure 9.34, you can choose to either have all XML manipulation outside of the SQL query or all XML manipulation embedded within the SQL query. Both options
are demonstrated in Figure 9.35. In the first query in Figure 9.35, all XML operations are pulled
out of the SQL statement and into the surrounding XQuery. In the second query, all XML operations are pushed from the surrounding XQuery into the SQL statement.
xquery
for $i in db2-fn:sqlquery("SELECT porder
FROM purchaseorder
WHERE custid =1001")
where $i/PurchaseOrder[@PoNum = 5002 and @Status="Shipped"]
return <POitems>{$i/ PurchaseOrder/item}</POitems>;
SELECT XMLQUERY('<POitems>{$PORDER/PurchaseOrder/item}</POitems>')
FROM purchaseorder
WHERE custid =1001
AND XMLEXISTS('$PORDER/PurchaseOrder[@PoNum = 5002 and
@Status="Shipped"]');
Figure 9.35
9.5
Two simpler versions of the query in Figure 9.34
COMMON ERRORS AND HOW TO AVOID THEM
This section lists some common error messages that you might encounter when you run XML
queries. We discuss probable causes and ways to resolve the problems. DB2 has more than 250
XML-related error messages and we cannot discuss all of them here. Additionally, a specific error
message might have multiple different causes and we cannot describe all of them in this section.
Therefore we look at a few select queries, their errors, and how to fix them.
9.5
Common Errors and How to Avoid Them
259
Error messages related to XML processing have numbers in the 16000-range of messages and
SQL Codes. That is, the SQL Codes related to XML processing errors are -16000, -16001,
-16002, and so on. This is the same in DB2 for z/OS and DB2 for Linux, UNIX, and Windows.
Additionally, in DB2 for Linux, UNIX, and Windows the error messages for these SQL Codes
are numbered SQL16000N, SQL16001N, SQL16002N, and so on. Each error message raised by
a faulty XML query also contains an error code, such as err:XPDY0002, which is the error code
defined by the W3C. These error codes are listed at http://www.w3.org/2005/xqt-errors/, and you
can also search for them in the DB2 information center.
9.5.1 SQL16001N
Figure 9.36 and Figure 9.37 show queries that fail at compile time with error SQL16001N, which
indicates that an XPath or XQuery expression does not have a context; that is, the path does not
have a proper starting point. In Figure 9.36, INFO is not a valid context, because the XML column
name is only recognized if coded as a variable that starts with a $ sign ($INFO).
SELECT info
FROM customer
WHERE XMLEXISTS('INFO/customerinfo[name="Matt Foreman"]');
SQL16001N An XQuery expression starting with token "INFO" cannot
be processed because the focus component of the dynamic context
has not been assigned. Error QName=err:XPDY0002. SQLSTATE=10501
Figure 9.36
Use $INFO instead of INFO to avoid this error
In Figure 9.37, the path in the return clause starts with /addr, but no context is provided to
indicate from where this expression should navigate to the addr element. The correct coding in
this query is $c/addr instead of /addr.
xquery for $c in db2-fn:xmlcolumn("CUSTOMER.INFO")/customerinfo
return /addr[@country];
SQL16001N An XQuery expression starting with token "/" cannot
be processed because the focus component of the dynamic context
has not been assigned. Error QName=err:XPDY0002. SQLSTATE=10501
Figure 9.37
The path in the return clause should start with $c
9.5.2 SQL16002N
The error SQL16002N happens at compile time whenever the query parser encounters a keyword
or symbol that is unexpected or not recognized. This can happen in many different cases. The
query in Figure 9.38 fails because the uppercase keyword FOR is not valid. It has to be lowercase.
260
Chapter 9
Querying XML Data: Advanced Queries & Troubleshooting
xquery FOR $d IN db2-fn:xmlcolumn ("customer.info")/customerinfo
RETURN $d;
SQL16002N An XQuery expression has an unexpected token "d"
following "FOR $". Expected tokens may include: "".
Error QName=err:XPST0003. SQLSTATE=10505
Figure 9.38
The keywords for, in, and return must be lowercase
In Figure 9.39, the expression $INFO/customerinfo/ must not end with a slash (/). The slash
starts another step in the XPath expression and must be followed be an element name, attribute
name, wildcard (*), function name, and so on. Hence the empty string "" after the / is not
expected.
SELECT T.*
FROM customer,
XMLTABLE('$INFO/customerinfo/'
COLUMNS
name
VARCHAR(20) PATH 'name',
city
VARCHAR(20) PATH 'addr/city' ) as T;
SQL16002N An XQuery expression has an unexpected token ""
following "$INFO/customerinfo". Expected tokens may
include: "<StepExpr>".
Figure 9.39
To avoid this error remove the / after customerinfo
Furthermore, a slash cannot be followed by the square bracket that begins a predicate. Therefore
the square bracket in Figure 9.40 causes error SQL16002N.
SELECT XMLQUERY('$INFO/customerinfo/name')
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo/[addr/city = "Aurora"]');
SQL16002N An XQuery expression has an unexpected token "["
following "tomerinfo/". Expected tokens may include: "".
Figure 9.40
A predicate must not be preceded by a slash (/)
9.5.3 SQL16003N
Error SQL16003N happens during query execution; that is, at runtime and not at compile time. It
indicates that DB2 has encountered a value of a certain data type that is not valid in this situation.
The query in Figure 9.41 fails because a sequence of multiple phone elements cannot be cast to a
single SQL value. In this error message, the notation ( item(), item()+ ) is a regular
expression that represents a sequence of one item followed by one or more items. In total that’s
two or more items, but only a single item is allowed here.
9.5
Common Errors and How to Avoid Them
261
SELECT T.*
FROM customer,
XMLTABLE('$INFO/customerinfo'
COLUMNS
custname VARCHAR(20) PATH 'name',
phone
VARCHAR(15) PATH 'phone') AS T;
SQL16003N An expression of data type "( item(), item()+ )"
cannot be used when the data type "VARCHAR_15" is expected in
the context. Error QName=err:XPTY0004. SQLSTATE=10507
Figure 9.41
Cannot cast multiple phone numbers to a single VARCHAR value
Figure 9.42 shows a query that fails because it tries to compare a value of type xs:date with the
value "2006-02-18Z” of type xs:string, which is not allowed.
xquery for $i in db2-fn:xmlcolumn("PURCHASEORDER.PORDER")
where $i/PurchaseOrder/xs:date(@OrderDate) = "2006-02-18Z"
return $i;
SQL16003N An expression of data type "xs:string" cannot be used
when the data type "xs:date" is expected in the context.
Error QName=err:XPTY0004. SQLSTATE=10507
Figure 9.42
The string literal “2006-02-18Z” must be cast to xs:date
9.5.4 SQL16005N
The query in Figure 9.43 references a variable $c that has not been properly introduced. Normally, variables are introduced by assignment in a for or a let clause. Here, the for clause
defines the variable $b, which should be used instead of $c in the return clause.
xquery for $b in db2-fn:xmlcolumn("CUSTOMER.INFO")/customerinfo
return $c/name;
SQL16005N An XQuery expression references an element name,
attribute name, type name, function name, namespace prefix,
or variable name "c" that is not defined within the static
context. Error QName=err:XPST0008. SQLSTATE=10506
Figure 9.43
The variable $c has not been introduced
Figure 9.44 demonstrates a trickier case. The query tries to return a sequence of name and addr
elements, but it lacks parentheses. The expression return ($b/name, $b/addr) is correct
and avoids the error. The error message claims that the variable $b is not known. Clearly, $b has
been defined in the for clause, so the error is seemingly misleading or even wrong.
262
Chapter 9
Querying XML Data: Advanced Queries & Troubleshooting
xquery for $b in db2-fn:xmlcolumn("CUSTOMER.INFO")/customerinfo
return $b/name, $b/addr;
SQL16005N An XQuery expression references an element name,
attribute name,type name, function name, namespace prefix,
or variable name "b" that is notdefined within the static
context. Error QName=err:XPST0008. SQLSTATE=10506
Figure 9.44
Missing parentheses in the return clause
But, the error message in Figure 9.44 is correct. The comma in the return clause is the XQuery
comma operator, which constructs sequences. It has the lowest precedence of all operators.
Hence, the XQuery expression in Figure 9.44 defines a sequence of two expressions, which are
• for $b in db2-fn:xmlcolumn("CUSTOMER.INFO")/customerinfo
return $b/name
• $b/addr
In the first expression, $b is properly introduced in the for clause. In the second expression, $b is
not defined, which causes the error message. If you change the return clause to return
($b/name, $b/addr), the parentheses ensure that the comma operator only applies to
$b/name and $b/addr, and both of these expressions refer to $b defined in the for clause. The
use of the parentheses here is similar to parentheses in arithmetics, such as 3 * (2 + 3) to evaluate the + operator before the multiplication operator.
9.5.5 SQL16015N
When you construct elements with a direct element constructor, and you include a sequence of
expressions that provide the child nodes, attributes (if any) must come before elements in this
sequence.
xquery for $i in db2-fn:xmlcolumn("CUSTOMER.INFO")/customerinfo
return <info>{$i/name}{$i/@Cid}</info>;
SQL16015N An element constructor contains an attribute node
named "Cid" that follows an XQuery node that is not an attribute
node. QName=err:XQTY0024. SQLSTATE=10507
Figure 9.45
Within a constructed element, attributes must be first
9.5
Common Errors and How to Avoid Them
263
The error in Figure 9.45 is avoided if you construct the info element as
return <info>{$i/@Cid}{$i/name}</info>;
or as
return <info Cid="{$i/@Cid}”>{$i/name}</info>;
9.5.6 SQL16011N
The query in Figure 9.46 iterates over the distinct OrderDate values of the purchase order documents. The where clause tries to convert each of these values to xs:date for a proper date comparison with a literal value. But the expression raises error SQL16011N because $i contains an
atomic value and not an element or attribute node. An atomic value cannot be the input to a navigation step, such as the navigation step /xs:date(.). You can only navigate on nodes, not on
atomic values.
xquery for $i in distinct-values(
db2-fn:xmlcolumn("PURCHASEORDER.PORDER")/PurchaseOrder/@OrderDate
)
where $i/xs:date(.) < xs:date("2006-12-31")
return $i/.. ;
SQL16011N The result of an intermediate step expression in an
XQuery path expression contains an atomic value.
Error QName=err:XPTY0019. SQLSTATE=10507
Figure 9.46
Cannot navigate on an atomic value
If you remove the distinct-values function, then $i gets bound to OrderDate attribute
nodes, and the error is avoided. But removing the depulication can also change the query result.
Hence, the better way to avoid the error is to replace $i/xs:date(.) with xs:date($i) so
that there is no navigation step on $i.
9.5.7 SQL16061N
The XMLEXISTS predicate in Figure 9.47 checks whether the value of the Status attribute is 1.
The literal value 1 is interpreted as a number because it is not enclosed in quotes. To perform a
valid numeric comparison with this number, the value of the Status attribute is automatically
cast to xs:double. But, if the value is a string such as "Unshipped", this cast fails with error
SQL16061N.
264
Chapter 9
Querying XML Data: Advanced Queries & Troubleshooting
SELECT porder
FROM purchaseorder
WHERE XMLEXISTS('$PORDER/PurchaseOrder[@Status = 1]');
SQL16061N The value "Unshipped" cannot be constructed as, or
cast (using an implicit or explicit cast) to the data type
"xs:double"
Figure 9.47
Failure to cast an attribute value to a numeric type
9.5.8 SQL16075N
The query in Figure 9.48 tries to return the Status attribute node. When the query result is serialized to XML text, the serialization of the attribute node fails. It cannot exist by itself outside of
an element. The solution is to return the attribute value instead of the attribute node by using the
data() or string() function, such as $PORDER/PurchaseOrder/data(@Status).
Another solution is to wrap the XMLCAST function around the XMLQUERY function.
SELECT XMLQUERY('$PORDER/PurchaseOrder/@Status')
FROM purchaseorder;
SQL16075N The sequence to be serialized contains an item that is
an attribute node.
Figure 9.48
9.6
Cannot serialize an attribute node by itself
SUMMARY
The preferred way to write grouping and aggregation queries for XML data is to use the
XMLTABLE function. It allows you to extract XML values to relational columns and then to apply
the SQL GROUP BY clause and SQL aggregation functions to these columns. This pattern of writing XML queries provides a high degree of flexibility and allows you to reuse familiar SQL features in XML queries. The XMLTABLE function brings selected values from the XML level to the
SQL level so that you can apply any SQL expressions or functions to these values as you normally do in relational queries.
Efficient join queries between XML columns can be written in XQuery or SQL/XML. Either
way, remember that the join predicate requires casting to a specific data type. Otherwise an XML
index cannot be used to evaluate the predicate. When you use SQL/XML with a join condition in
an XMLEXISTS predicate, remember that in DB2 9.1 and 9.5 for Linux, UNIX, and Windows the
order of the operands in the join predicate determines the join order between the two tables. Consider the available indexes and check your queries’ execution plans to ensure an appropriate join
order, index usage, and adequate performance.
9.6
Summary
265
Observing a set of guidelines can help you avoid common pitfalls with XML queries. When you
write queries that construct new XML documents, be mindful of an appropriate document granularity and avoid creating excessively large documents.
When you write a pair of range predicates to express a “between” condition, remember to use the
current context (a dot) within the square brackets of the predicate, such as item/price[. >=
20 and . < 30]. This notation ensures that you get the semantically correct result and it allows
for an efficient execution plan with a single index scan.
A query pattern that can easily lead to poor performance is an XQuery let clause that builds a
single large sequence of elements from all (or many) documents in an XML column. A query
construct such as let $i := db2-fn:xmlcolumn("T.C")/xpath should generally be
avoided. An XQuery that contains such an expression can often be replaced by a much more efficient SQL/XML query with the XMLTABLE function.
This page intentionally left blank
C
H A P T E R
10
Producing XML from
Relational Data
ince XML has emerged as the de facto standard for data exchange, an increasing number of
organizations, applications, and interfaces expect to receive data in XML format. For
example, web services and enterprise service buses (ESBs) frequently use XML messages to
facilitate the information exchange between applications or services. XML is the fabric of
Service-Oriented Architectures (SOA). A frequent requirement is that new applications need to
consume existing relational data in XML format. Converting entire relational databases to XML
format is rarely feasible nor recommended. Instead, the preferred approach is to run queries
against the relational data and convert the result set to XML. This conversion from relational to
XML can be performed in the application layer, but it is often labor-intensive to develop and
maintain procedural application code that constructs XML. Letting the database engine convert
relational data to XML is easier and more efficient. Easier, because the construction of XML can
be defined in declarative SQL statements. More efficient, because DB2 can construct XML as
part of the query processing, which avoids repetitive calls to the database to obtain all required
values for an XML document.
S
This chapter explains how to write queries that read relational tables and return the result set in
XML format. There are two ways of writing such queries:
• The first approach uses the SQL/XML publishing functions, most of which have been
supported since Version 8 of both DB2 for z/OS and DB2 for Linux, UNIX, and Windows. This approach is explained in section 10.1.
• The second approach uses direct XML constructors of the XQuery language. This is
supported in DB2 9.1 and higher for Linux, UNIX, and Windows, and described in
section 10.2.
267
268
Chapter 10
Producing XML from Relational Data
For completeness, sections 10.3 and 10.4 cover the special topics of XML declarations and XML
document nodes for constructed XML documents.
Many examples in this chapter use the product table of the sample database. Figure 10.1 shows
the content of the relational columns of this table; the XML column description is omitted
and the column name is truncated for space. We demonstrate a variety of queries that construct
XML from this relational data.
SELECT pid, price, promoprice, promostart, promoend,
SUBSTR(name,1,15) AS name
FROM product;
PID
---------100-100-01
100-101-01
100-103-01
100-201-01
PRICE PROMOPRICE PROMOSTART PROMOEND
NAME
----- --------- ---------- ---------- --------------9.99
7.25 11/19/2004 12/19/2004 Snow Shovel,Bas
19.99
15.99 12/18/2005 02/28/2006 Snow Shovel,Del
49.99
39.99 12/22/2005 02/22/2006 Snow Shovel,Sup
3.99
- Ice Scraper,Win
4 record(s) selected.
Figure 10.1
10.1
The relational data in the product table
SQL/XML PUBLISHING FUNCTIONS
In this section we examine the SQL/XML publishing functions in DB2. These functions are also
known as “constructor” functions because they construct XML nodes, such as elements and
attributes, whose values are taken from relational columns. They are listed in Table 10.1 in the
order in which they are introduced in the following sections.
Table 10.1
SQL/XML Publishing Functions
Function
Purpose
XMLELEMENT
Constructs an XML element
XMLCONCAT
Concatenates two values of type XML
XMLFOREST
Constructs a sequence of XML elements
XMLATTRIBUTES
Constructs one or more XML attributes
XMLAGG
Aggregates XML values from multiple rows into a single XML value
XMLROW
Constructs XML elements with default tagging
XMLGROUP
Constructs and aggregates XML elements with default tagging
10.1
SQL/XML Publishing Functions
Table 10.1
269
SQL/XML Publishing Functions (Continued)
Function
Purpose
XMLCOMMENT
Constructs an XML comment
XMLPI
Constructs an XML processing instruction
XMLTEXT
Constructs an XML text node
XMLDOCUMENT
Constructs an XML document node
All of these functions are available in DB2 for z/OS and DB2 for Linux, UNIX, and Windows,
except XMLGROUP and XMLROW, which do not exist in DB2 for z/OS. XMLGROUP and XMLROW
merely serve as abbreviations for certain combinations of the other functions. Examples in section 10.1.9 show that the XML data constructed by XMLGROUP and XMLROW can also be constructed in DB2 for z/OS with the other publishing functions. All SQL/XML functions belong to
the relational schema SYSIBM.
10.1.1
Constructing XML Elements from Relational Data
The most commonly used XML publishing function is XMLELEMENT, which constructs an XML
element. In its simplest form, the XMLELEMENT function takes two arguments:
• The name of the XML element that you want to construct.
• An expression that provides the value of the constructed element. This expression
is often just the name of a relational column. Later you will also see that the
XMLELEMENT function can take multiple and complex expressions as input.
The SELECT statement in Figure 10.2 is a simple example of using the XMLELEMENT function.
For each row in the product table it constructs an XML element called pnum that contains the
value of the relational column pid. Each of the four constructed elements is a separate wellformed XML document. The return type of the XMLELEMENT function, and therefore of the column produced by the query in Figure 10.2, is XML.
SELECT XMLELEMENT(NAME "pnum", pid)
FROM product;
<pnum>100-100-01</pnum>
<pnum>100-101-01</pnum>
<pnum>100-103-01</pnum>
<pnum>100-201-01</pnum>
4 record(s) selected.
Figure 10.2
Constructing XML elements
270
Chapter 10
Producing XML from Relational Data
The query shown in Figure 10.3 is an extension of the query in Figure 10.2. It returns two columns
of type XML, each containing a constructed XML element for every row of the product table. The
values of the relational columns pid and price are returned as separate XML elements in separate columns. The optional AS clauses give each column a descriptive column name.
SELECT XMLELEMENT(NAME "pnum", pid) AS pnum_elem,
XMLELEMENT(NAME "cost", price) AS cost_elem
FROM product;
PNUM_ELEM
----------------------<pnum>100-100-01</pnum>
<pnum>100-101-01</pnum>
<pnum>100-103-01</pnum>
<pnum>100-201-01</pnum>
COST_ELEM
-----------------<cost>9.99</cost>
<cost>19.99</cost>
<cost>49.99</cost>
<cost>3.99</cost>
4 record(s) selected.
Figure 10.3
Constructing XML elements in separate columns
You can use the publishing function XMLCONCAT to combine the two constructed elements into a
single column of type XML, as shown in Figure 10.4. Each result row contains a sequence of two
XML elements that do not have a common root element and therefore do not form a well-formed
document.
SELECT XMLCONCAT(XMLELEMENT(NAME "pnum", pid),
XMLELEMENT(NAME "cost", price) ) AS twoelem
FROM product;
TWOELEM
----------------------------------------<pnum>100-100-01</pnum><cost>9.99</cost>
<pnum>100-101-01</pnum><cost>19.99</cost>
<pnum>100-103-01</pnum><cost>49.99</cost>
<pnum>100-201-01</pnum><cost>3.99</cost>
4 record(s) selected.
Figure 10.4
Concatenating two XML elements
To produce a well-formed document in each result row, use nested XMLELEMENT functions to construct a common root element. This is easy because one or multiple XMLELEMENT functions can be
arguments to another XMLELEMENT function. Figure 10.5 shows how to construct the root element
Product, which contains the two elements pnum and cost as child elements. Note that the nesting of the XMLELEMENT functions corresponds directly to the nesting of the generated XML elements in the result set of the query. The outer XMLELEMENT function constructs the root element
Product, which ensures that the generated XML documents are well-formed.
10.1
SQL/XML Publishing Functions
271
SELECT XMLELEMENT(NAME "Product",
XMLELEMENT(NAME "pnum", pid),
XMLELEMENT(NAME "cost", price)
) AS prod_doc
FROM product;
PROD_DOC
-----------------------------------------------------------<Product><pnum>100-100-01</pnum><cost>9.99</cost></Product>
<Product><pnum>100-101-01</pnum><cost>19.99</cost></Product>
<Product><pnum>100-103-01</pnum><cost>49.99</cost></Product>
<Product><pnum>100-201-01</pnum><cost>3.99</cost></Product>
4 record(s) selected.
Figure 10.5
Constructing XML documents with nested elements
If you want to add the promotional price as well as the start and end date of the promotion period
to each generated XML document, simply add additional XMLELEMENT functions as arguments to
the top-level XMLELEMENT function. This is illustrated in Figure 10.6. Due to the WHERE clause,
this query returns just one result row that contains an XML document with values from one of the
original relational rows in the product table. The DB2 Command Line Processor (CLP) displays this document as a single wrapping line. For readability, we also show the document with
added newline characters and indentation.
SELECT XMLELEMENT(NAME "Product",
XMLELEMENT(NAME "pnum", pid),
XMLELEMENT(NAME "cost", price),
XMLELEMENT(NAME "promoprice", promoprice),
XMLELEMENT(NAME "start", promostart),
XMLELEMENT(NAME "end", promoend)
)
FROM product
WHERE pid = '100-100-01';
-- Output as a single wrapped line:
<Product><pnum>100-100-01</pnum><cost>9.99</cost><promoprice>7.2
5</promoprice><start>2004-11-19</start><end>2004-12-19</end></Pr
oduct>
-- Output with newline characters and indentation:
<Product>
<pnum>100-100-01</pnum>
<cost>9.99</cost>
<promoprice>7.25</promoprice>
<start>2004-11-19</start>
Figure 10.6
Constructing XML documents with more nested elements (continues)
272
Chapter 10
Producing XML from Relational Data
<end>2004-12-19</end>
</Product>
1 record(s) selected.
Figure 10.6
Constructing XML documents with more nested elements (Continued)
Looking at the query in Figure 10.6, it is easy to realize that constructing larger XML documents
can require many nested XMLELEMENT functions. To keep queries short and easy to write, the
function XMLFOREST serves as an abbreviation for a sequence of XMLELEMENT functions. The
XMLFOREST function takes a list of arguments as input and constructs an XML element for each
argument. Each argument is a pair consisting of a relational column name or other expression and
the desired element name. The generated XML elements are all siblings of each other. As an
example, the query in Figure 10.7 produces the same result as the one in Figure 10.6. However,
you will soon see that XMLFOREST and XMLELEMENT have a different default behavior when
NULL values are involved (section 10.1.2).
SELECT XMLELEMENT(NAME "Product",
XMLFOREST(pid AS "pnum", price AS "cost",
promoprice AS "promoprice",
promostart AS "start", promoend AS "end" )
)
FROM product
WHERE pid = '100-100-01';
Figure 10.7
Constructing XML documents with the XMLFOREST function
The XMLFOREST function can abbreviate the query even further if you are willing to use the relational column names of the source table as default element names. In this case you can omit the
custom element names from the XMLFOREST function and only provide a list of relational column
names (see Figure 10.8). The default element names produced by XMLFOREST are in uppercase,
because uppercase is the default for SQL column names—unless you used lowercase column
names in double quotes in the CREATE TABLE statement. Producing default elements names
based on column names is not possible with the XMLELEMENT function.
SELECT XMLELEMENT(NAME "Product",
XMLFOREST(pid, price, promoprice, promostart, promoend)
)
FROM product
WHERE pid = '100-100-01';
<Product>
<PID>100-100-01</PID>
<PRICE>9.99</PRICE>
<PROMOPRICE>7.25</PROMOPRICE>
Figure 10.8
Using the XMLFOREST function with default element names
10.1
SQL/XML Publishing Functions
273
<PROMOSTART>2004-11-19</PROMOSTART>
<PROMOEND>2004-12-19</PROMOEND>
</Product>
1 record(s) selected.
Figure 10.8
Using the XMLFOREST function with default element names (Continued)
The document constructed in Figure 10.8 is very flat with only one level of nesting. However, you
might be required to generate XML documents that conform to a mandatory target format that
involves multiple levels of nesting. Suppose that all the promotion-related information has to be
nested under a separate PROMOTION element. Such a document structure is produced in Figure
10.9. Again, note that the nesting of the SQL/XML functions implies the nesting of elements in
the generated document. The top-level XMLELEMENT function, which constructs the PRODUCT
element, contains one XMLFOREST function and one XMLELEMENT function. The XMLFOREST
function constructs the elements PID and PRICE while the XMLELEMENT function generates the
element PROMOTION. This XMLELEMENT function includes another XMLFOREST function that
produces the child elements PROMOPRICE, PROMOSTART, and PROMOEND.
SELECT XMLELEMENT(NAME "PRODUCT",
XMLFOREST(pid, price),
XMLELEMENT(NAME "PROMOTION",
XMLFOREST(promoprice, promostart, promoend)
)
)
FROM product
WHERE pid = '100-100-01';
<PRODUCT>
<PID>100-100-01</PID>
<PRICE>9.99</PRICE>
<PROMOTION>
<PROMOPRICE>7.25</PROMOPRICE>
<PROMOSTART>2004-11-19</PROMOSTART>
<PROMOEND>2004-12-19</PROMOEND>
</PROMOTION>
</PRODUCT>
1 record(s) selected.
Figure 10.9
Constructing a document with multiple levels of nesting
Note that the XMLFOREST function that contained five column names in Figure 10.8 is broken into
two separate XMLFOREST functions in Figure 10.9. The reason is that in Figure 10.9 the elements
PROMOPRICE, PROMOSTART, and PROMOEND should be generated at a different level of the document than the elements PID and PRICE. A single XMLFOREST function always produces a
sequence of sibling elements for the same level in the document.
274
Chapter 10
Producing XML from Relational Data
10.1.2 NULL Values, Missing Elements, and Empty Elements
In Figure 10.1, which shows the relational data in the product table, you saw that one of the
rows contains NULL values in the columns promoprice, promostart, and promoend. If a
NULL value is input to an XMLELEMENT function, the default behavior is to generate an empty element. Figure 10.10 shows that the empty element <promoprice/> is constructed where the corresponding cell in the product table is NULL. This behavior is called “Empty on NULL.”
SELECT XMLELEMENT(NAME "Prod",
XMLELEMENT(NAME "PID", pid),
XMLELEMENT(NAME "promoprice", promoprice)
)
FROM product
WHERE price < 10;
<Prod><PID>100-100-01</PID><promoprice>7.25</promoprice></Prod>
<Prod><PID>100-201-01</PID><promoprice/></Prod>
2 record(s) selected.
Figure 10.10
The “Empty on NULL” behavior of the XMLELEMENT function
Alternatively, you may prefer to omit the <promoprice/> element from the generated document, so that NULL values result in missing elements rather than empty elements. This behavior is
called “NULL on NULL” and can be forced by inserting the keywords OPTION NULL ON NULL
into the XMLELEMENT function (see Figure 10.11).
SELECT XMLELEMENT(NAME "Prod",
XMLELEMENT(NAME "PID", pid),
XMLELEMENT(NAME "promoprice", promoprice
OPTION NULL ON NULL )
)
FROM product
WHERE price < 10;
<Prod><PID>100-100-01</PID><promoprice>7.25</promoprice></Prod>
<Prod><PID>100-201-01</PID></Prod>
2 record(s) selected.
Figure 10.11
The “NULL on NULL” option of the XMLELEMENT function
Beware that the default NULL handling of the XMLFOREST function is opposite to the behavior of
the XMLELEMENT function! This “mismatch” is defined by the SQL/XML standard and is not an
arbitrary choice made by DB2. By default, the XMLFOREST function does not construct elements
for NULL values (“NULL on NULL”) but you can specify OPTION EMPTY ON NULL to turn NULLs
into empty elements. Figure 10.12 illustrates this behavior.
10.1
SQL/XML Publishing Functions
275
SELECT XMLELEMENT(NAME "Prod",
XMLFOREST(pid, promoprice)
)
FROM product
WHERE price < 10;
<Prod><PID>100-100-01</PID><PROMOPRICE>7.25</PROMOPRICE></Prod>
<Prod><PID>100-201-01</PID></Prod>
2 record(s) selected.
SELECT XMLELEMENT(NAME "Prod",
XMLFOREST(pid, promoprice OPTION EMPTY ON NULL)
)
FROM product
WHERE price < 10;
<Prod><PID>100-100-01</PID><PROMOPRICE>7.25</PROMOPRICE></Prod>
<Prod><PID>100-201-01</PID><promoprice/></Prod>
2 record(s) selected.
Figure 10.12
“NULL on NULL” default and “Empty on NULL” option for XMLFOREST
If your relational data contains many NULL values,
the “NULL on NULL” behavior is usually preferable. This option
avoids large numbers of empty elements, which reduces the size
of the constructed documents and improves the performance of
the SQL/XML publishing queries.
NOTE
10.1.3
Constructing XML Attributes from Relational Data
XML attributes always belong to an XML element and can never appear by themselves. The construction of XML attributes is therefore always combined with the construction of an XML element. The function XMLATTRIBUTES creates one or multiple XML attributes and can only appear
as an argument to an XMLELEMENT function.
The arguments for the XMLATTRIBUTES function look just like the arguments for XMLFOREST;
that is, one or more relational column names or other expressions. While the XMLFOREST function uses such input to build a sequence of XML elements, the XMLATTRIBUTES function uses
this input to construct a sequence of XML attributes. Optionally, each argument can be associated
with a desired attribute name. If the attribute names are omitted, the relational column names of
the source table are used as default attribute names.
276
Chapter 10
Producing XML from Relational Data
The query in Figure 10.13 constructs an element called Product that contains the attributes
pnum and cost, which hold the values of the relational columns pid and price, respectively.
The Product element itself is an empty element (denoted by the slash at its end) because the
XMLELEMENT function contains no expression to provide element content.
SELECT XMLELEMENT(NAME "Product",
XMLATTRIBUTES(pid AS "pnum", price AS "cost") )
FROM product;
<Product
<Product
<Product
<Product
pnum="100-100-01"
pnum="100-101-01"
pnum="100-103-01"
pnum="100-201-01"
cost="9.99"/>
cost="19.99"/>
cost="49.99"/>
cost="3.99"/>
4 record(s) selected
Figure 10.13
Returning relational values as attributes
For each qualifying row of the product table, the query in Figure 10.14 constructs an XML document that consists of a mix of XML elements and attributes. The nesting of the XML constructor functions implies the nesting of the tags in the generated XML data. The root element
PRODUCT contains two attributes, PID and PRICE, whose names default to the names of the referenced relational columns. The PRODUCT element also contains a child element PROMOTION,
which in turn contains an attribute PROMOPRICE as well as two child elements generated by the
XMLFOREST function. When you specify the children of an XML element, attributes have to
come before any child elements. For example XMLATTRIBUTES(promoprice) is specified
before XMLFOREST(promostart, promoend) and it cannot be the other way round.
SELECT XMLELEMENT(NAME "PRODUCT",
XMLATTRIBUTES(pid, price),
XMLELEMENT(NAME "PROMOTION",
XMLATTRIBUTES(promoprice),
XMLFOREST(promostart, promoend)
) )
FROM product
WHERE pid = '100-100-01';
<PRODUCT PID="100-100-01" PRICE="9.99">
<PROMOTION PROMOPRICE="7.25">
<PROMOSTART>2004-11-19</PROMOSTART>
<PROMOEND>2004-12-19</PROMOEND>
</PROMOTION>
</PRODUCT>
1 record(s) selected.
Figure 10.14
Constructing a document with mix of elements and attributes
10.1
SQL/XML Publishing Functions
277
If an argument to XMLATTRIBUTES is NULL, no
attribute is constructed for that argument, and there is no option
to construct empty attributes for NULL values.
NOTE
Since an XML element cannot have two attributes with the same name, DB2 rejects any XMLATTRIBUTES function that tries to construct two attributes with identical names (SQL error
SQL0242N).
10.1.4
Constructing XML Documents from Multiple Relational Rows
So far all the examples in this chapter have constructed exactly one XML document for each
qualifying relational row. In other words, each selected relational row is turned into one corresponding document. However, it is often desirable to combine data from multiple relational rows
into a single XML document. For example, consider the relational data in the purchaseorder
table and note that there can be multiple orders per customer (see Figure 10.15).
SELECT poid, status, custid, orderdate
FROM purchaseorder;
POID
STATUS
CUSTID
ORDERDATE
-------------- --------- -------------- ---------5002 Shipped
1001 02/29/2004
5000 Unshipped
1002 02/18/2006
5003 Shipped
1002 02/28/2005
5006 Shipped
1002 03/01/2006
5001 Shipped
1003 02/03/2005
5004 Shipped
1005 11/18/2005
6 record(s) selected.
Figure 10.15
The relational data in the purchaseorder table
Suppose you have to construct one XML document with order information for each customer,
such as the documents shown in Figure 10.16. Customer 1001 has one order, but customer 1002
has three orders stored in three different rows of the table. The POID values of these three orders
are combined into a single document for customer 1002. This document represents the one-tomany relationship between customers and purchase orders through its hierarchical structure and
the repeated occurrence of the child element order.
278
Chapter 10
Producing XML from Relational Data
<CustOrders cid="1001">
<order>5002</order>
</CustOrders>
<CustOrders cid="1002">
<order>5000</order>
<order>5003</order>
<order>5006</order>
</CustOrders>
(...)
Figure 10.16
One document per customer with purchase order information
Producing the documents in Figure 10.16 requires grouping and aggregation of orders by customer. The function XMLAGG achieves this aggregation in Figure 10.17. This query contains the
SQL clause GROUP BY custid because the objective is to produce one XML document per customer. For each customer, the query constructs an element CustOrders with an attribute cid
that identifies the customer. For each CustOrders element, the XMLAGG function produces a single XML value. This value is a sequence of order elements that represent the orders of the
respective customer. Let’s zoom in on this to understand exactly how it works.
SELECT XMLELEMENT(name "CustOrders",
XMLATTRIBUTES(custid as "cid"),
XMLAGG(
XMLELEMENT(name "order", poid ) ) )
FROM purchaseorder
GROUP BY custid;
Figure 10.17
Using XMLAGG to aggregate order information per customer
XMLAGG is an aggregate function and it behaves much like any other SQL aggregate function,
such as SUM, AVG, MIN, MAX, or COUNT. Any such aggregate function, including XMLAGG, takes
values from multiple rows as input and produces a single output value. For example, the aggregate function AVG takes numeric values from multiple rows as input and produces a single
numeric output value. Similarly, the function MAX also takes values from multiple rows as input
and produces a single output value (see Figure 10.18). Correspondingly, XMLAGG takes XML values from multiple rows as input and produces a single XML output value. The single value that is
produced by AVG is the arithmetic mean of its input arguments. The single value produced by MAX
is the largest value of its input. And the single value produced by XMLAGG is an XML sequence
that combines the XML input arguments.
Remember that a value in the XQuery Data Model is always a sequence of zero or more items. In
Figure 10.18, XMLAGG takes three sequences as input; each of them contains one XML element.
The output of XMLAGG is a single sequence that contains three elements. Just like MAX is an aggregate function for date, string, or numeric values, XMLAGG is an aggregate function for XML type
values.
10.1
SQL/XML Publishing Functions
279
3 rows
5000
1 row, 1 value
MAX
5006
5003
5006
3 rows
5000
Figure 10.18
XMLELEMENT
<order>5000</order>
5003
<order>5003</order>
5006
<order>5006</order>
1 row, 1 value
XMLAGG
<order>5000</order>
<order>5003</order>
<order>5006</order>
The aggregation functions MAX and XMLAGG
There are further ways in which XMLAGG behaves like other SQL aggregate functions. The SQL
query in Figure 10.19(a) produces one value per group; that is, the maximum poid for each distinct custid value. Because custid appears in the SELECT clause and is not an argument to an
aggregate function, it must also appear in the GROUP BY clause. Without the GROUP BY clause, as
in Figure 10.19(b), the entire input table is one group and the aggregate function MAX is applied to
the entire table. Hence, the maximum poid value across all rows is returned. In this case,
custid must not appear in the SELECT list. All of these characteristics apply similarly to the
XMLAGG function. The query in Figure 10.17 corresponds to the query in Figure 10.19(a) because
the custid column appears in the SELECT clause but is not an argument of XMLAGG. Hence,
custid must also be specified in the GROUP BY clause and the query produces one document per
custid. The query in Figure 10.20 corresponds to Figure 10.19(b), because without a GROUP BY
clause XMLAGG aggregates order elements based on all rows in the table and returns a single
large document.
SELECT custid, MAX(poid) AS max
FROM purchaseorder
GROUP BY custid;
CUSTID MAX
------- -----1001
5002
1002
5006
1003
5001
1005
5004
SELECT MAX(poid) AS max
FROM purchaseorder;
MAX
------5006
1 record(s) selected.
4 record(s) selected.
(a)
Figure 10.19
(b)
Aggregation with and without grouping
280
Chapter 10
Producing XML from Relational Data
SELECT XMLELEMENT(name "CustOrders",
XMLAGG(XMLELEMENT(name "order", poid )) )
FROM purchaseorder;
<CustOrders>
<order>5000</order>
<order>5001</order>
<order>5002</order>
<order>5003</order>
<order>5004</order>
<order>5006</order>
</CustOrders>
1 record(s) selected.
Figure 10.20
Aggregation without grouping produces a single row
The query in Figure 10.21 is an extension of the one in Figure 10.17. The order elements that
are aggregated per customer are now ordered by the orderdate column in the product table.
This affects the order in which the order elements appear as child elements within each
CustOrders element. The query in Figure 10.21 also includes date attributes in the aggregated
order elements, although this is not a requirement for sorting them by orderdate. The order
elements can also contain nested child elements; that is, they can be the root of larger XML fragments that describe each order.
SELECT XMLELEMENT(name "CustOrders",
XMLATTRIBUTES(custid as "cid"),
XMLAGG(
XMLELEMENT(name "order",
XMLATTRIBUTES(orderdate AS "date"),
poid )
ORDER BY orderdate) )
FROM purchaseorder
WHERE custid IN (1001,1002)
GROUP BY custid;
<CustOrders cid="1001">
<order date="2004-02-29">5002</order>
</CustOrders>
<CustOrders cid="1002">
<order date="2005-02-28">5003</order>
<order date="2006-02-18">5000</order>
<order date="2006-03-01">5006</order>
</CustOrders>
2 record(s) selected.
Figure 10.21
XMLAGG with ORDER BY clause
10.1
SQL/XML Publishing Functions
10.1.5
281
Constructing XML Documents from Multiple Relational Tables
The previous section has described the construction of one XML document per customer. Each
document contains information for each of the customers’ orders. The XMLAGG function was used
to effectively convert the one-to-many relationship between customers and purchase orders into
nested repeating elements in the constructed documents. To further extend this scenario, recall
that there is also a one-to-many relationship between purchase orders and products (see section
9.2, Join Queries with XML Data). Each order contains multiple products (items). This permits
the construction of more detailed documents that not only have repeating order elements for
each customer but also repeating item elements for each order. Figure 10.22 shows an example
of a document that you might want to construct. It contains information about all orders that customer 1002 has placed. For each order, the purchase order identifier from the relational column
poid is provided as attribute oid, and the column orderdate as child element date. Additionally, the identifiers of all products in a purchase order are listed as item elements. Each item element also contains the promotional product price as an attribute, if applicable.
<CustOrders cid="1002">
<order oid="5000">
<date>2006-02-18</date>
<item promprice="7.25">100-100-01</item>
<item promprice="39.99">100-103-01</item>
</order>
<order oid="5003">
<date>2005-02-28</date>
<item promprice="7.25">100-100-01</item>
</order>
<order oid="5006">
<date>2006-03-01</date>
<item promprice="7.25">100-100-01</item>
<item promprice="15.99">100-101-01</item>
<item>100-201-01</item>
</order>
</CustOrders>
Figure 10.22
Document for customer 1002, with all related orders and all items per order
Note the two levels of nested and repeating elements in Figure 10.22. The root element
CustOrders contains a variable number of order elements, and each order element contains a
variable number of item elements. Two XMLAGG functions are required to construct this document structure, as shown in Figure 10.23.
The first and “outer” XMLAGG function in Figure 10.23 aggregates order elements per customer.
The second and “inner” XMLAGG function aggregates item elements per order. Note that the
XMLELEMENT function that constructs the order element contains four arguments:
• The constant “order” to specify the element name.
• An XMLATTRIBUTES function to construct the oid attribute.
282
Chapter 10
Producing XML from Relational Data
• An XMLEMENT function to construct the child element date.
• An expression that produces a single value of type XML to add further child elements.
This expression is a scalar subselect, which is a SELECT statement that produces exactly
one value (one row in one column).
The subselect is a query against the product table and retrieves the columns pid and promoprice. The WHERE clause of the subquery contains a join predicate to only read those rows from
the product table that match the items in a given purchase order. The join condition is
expressed between the XML column PORDER of the purchaseorder table and the PID column
of the product table. If there were relational join keys then this could be a regular relational join
predicate. The subselect constructs an item element for each product in a given purchase order
and then uses XMLAGG to aggregate these item elements into a single sequence. This sequence is
a single value of type XML, which ensures that the subselect is indeed a scalar subselect. Since the
subselect is an input argument to an XMLELEMENT function, it must produce a single value.
SELECT
XMLELEMENT(name "CustOrders",
XMLATTRIBUTES(po.custid as "cid"),
XMLAGG(
XMLELEMENT(name "order",
XMLATTRIBUTES(po.poid as "oid"),
XMLELEMENT(name "date", po.orderdate),
(SELECT XMLAGG(
XMLELEMENT(name "item",
XMLATTRIBUTES(promoprice as "promprice"),
pr.pid) )
FROM product pr
WHERE
XMLEXISTS('$PORDER/PurchaseOrder/item[partid = $PID]'))
) ) )
FROM purchaseorder po
WHERE po.custid = 1002
GROUP BY po.custid;
Figure 10.23
Constructing XML based on two relational tables
The query in Figure 10.23 constructs the document format in Figure 10.22 by nesting XML construction functions and subqueries according to the nested document structure that is to be produced. If the XML construction at each level of nesting becomes more complex, another way of
writing the same query can sometimes be helpful. The query in Figure 10.24 also produces the
document in Figure 10.22 but uses common table expressions for a somewhat more modular
approach to constructing XML data. The WITH clause defines one or multiple common table
expressions. Each such expression is a subquery whose result set can be referenced based on
assigned table and column names. You can also think of common table expressions as view definitions that can only be referenced in this query.
10.1
SQL/XML Publishing Functions
283
Common table expressions are a useful query pattern to construct XML data. The query in Figure
10.24 uses one common table expression for each collection of nested elements, starting with the
deepest level of the target document. The table expression items(pid, itemxml) is defined by
a subselect that constructs the item elements that you see in Figure 10.22. Later parts of the
query can obtain the item elements from the column itemxml and don’t need to be concerned
with how they were constructed. In the table expression items, each constructed item element
is paired with a pid to ease the selection of required items.
The second table expression in Figure 10.24, orders(custid, orderxml), constructs the
order elements and exposes them through the column orderxml. The order elements have to
include the appropriate item elements, which are selected from the previously defined table
expression items. No matter how complex the item elements are, the expression XMLAGG(i.
itemxml) combines them into a sequence. The join predicate ensures that only those items are
selected from the table expression items that belong to the current order.
The final construction of the CustOrders element is now much simpler in Figure 10.24 than in
Figure 10.23. Since the common table expressions items and orders have already constructed
the inner repeated elements item and order, the outermost SELECT clause of the query only has
to construct the element CustOrders, add any attributes, and use the expression XMLAGG(o.
orderxml) to aggregate all the order elements for the respective customer.
WITH
items (pid, itemxml) AS
(SELECT pid,
XMLELEMENT(name "item",
XMLATTRIBUTES(promoprice as "lowprice"),
pid)
FROM product),
orders (custid, orderxml) AS
(SELECT custid,
XMLELEMENT(name "order",
XMLATTRIBUTES(po.poid as "id"),
XMLELEMENT(name "date", po.orderdate),
(SELECT XMLAGG(i.itemxml)
FROM items i
WHERE
XMLEXISTS('$PORDER/PurchaseOrder/item[partid=$PID]')
)
)
FROM purchaseorder po )
SELECT XMLELEMENT(name "CustOrders",
XMLATTRIBUTES(o.custid as "cid"),
XMLAGG(o.orderxml))
FROM orders o
WHERE o.custid = 1002
GROUP BY o.custid;
Figure 10.24
XML construction with common table expressions
284
10.1.6
Chapter 10
Producing XML from Relational Data
Comparing XMLAGG, XMLCONCAT, and XMLFOREST
So far in this chapter you have seen examples that included the functions XMLAGG, XMLCONCAT,
and XMLFOREST. Among these three functions, XMLFOREST is the only one that constructs new
XML elements from relational input data. XMLAGG and XMLCONCAT both work with XML values
that have already been constructed by other functions. XMLAGG is the only function that combines
XML data from multiple rows into a single XML value in a single row. On the other hand,
XMLCONCAT and XMLFOREST do not aggregate and do not directly affect the cardinality of a
query result set. The differences and commonalities between these functions are summarized in
Table 10.2.
Table 10.2
Characteristics of XMLAGG, XMLCONCAT, and XMLFOREST
XMLAGG
XMLCONCAT
XMLFOREST
Constructs new XML elements
No
No
Yes
Concatenates input elements from two or
more columns
No
Yes
No
Can have two or more arguments
No
Yes
Yes
Aggregates a set of XML values
Yes
No
No
Combines XML from multiple rows into a
single XML value in one row
Yes
No
No
Input argument(s) must be of type XML
Yes
Yes
No
Is an abbreviation for multiple XMLELEMENT
functions
No
No
Yes
10.1.7
Conditional Element Construction
It is possible to construct XML elements or attributes based on conditions. Both tag names and
values can depend on conditions. For example, the query in Figure 10.25 uses an SQL CASE
expression to construct the element ShipPriority if the status of an order is “Unshipped”.
Otherwise it constructs the element status. The value of the element ShipPriority is determined by another CASE expression. If the order is more than 14 days old, the value of the element
ShipPriority is "high", otherwise it is "low".
SELECT XMLELEMENT(name "Order",
XMLATTRIBUTES(poid as "id"),
XMLELEMENT(name "Customer", custid),
CASE WHEN status='Unshipped'
THEN XMLELEMENT(name "ShipPriority",
CASE WHEN orderdate < current_date - 14 days
THEN 'high' ELSE 'low' END)
Figure 10.25
Conditional element construction with a CASE expression
10.1
SQL/XML Publishing Functions
285
ELSE XMLELEMENT(name "Status", status) END)
FROM purchaseorder
WHERE orderdate > '02/15/2006';
<Order id="5000">
<Customer>1002</Customer>
<ShipPriority>high</ShipPriority>
</Order>
<Order id="5006">
<Customer>1002</Customer>
<Status>Shipped</Status>
</Order>
2 record(s) selected.
Figure 10.25
10.1.8
Conditional element construction with a CASE expression (Continued)
Leading Zeros in Constructed Elements and Attributes
In DB2 Version 8, DB2 9.1, and DB2 9.5 for Linux, UNIX, and Windows, constructing XML elements or attributes from relational DECIMAL or DOUBLE values introduces leading zeros in the
constructed XML node. For example, the function XMLELEMENT(NAME "cost", price) produces elements such as this:
<cost>0000000000000000000000000009.99</cost>
The same applies to the XMLFOREST and XMLATTRIBUTES functions. These leading zeros are not
generated in DB2 for z/OS and DB2 9.7 for Linux, UNIX, and Windows. In prior versions of
DB2 for Linux, UNIX, and Windows, the zeros can be avoided by casting the numeric input values to type XML. The first part of Figure 10.26 shows the functions XMLELEMENT, XMLATTRIBUTES, and XMLFOREST that each take the DECIMAL column price as input. To avoid the leading
zeros, add the XMLCAST function as shown in the second part of Figure 10.26. Casting to data
type XML avoids the leading zeros, but the functions XMLFOREST and XMLATTRIBUTES do not
accept arguments of type XML. Therefore, a second XMLCAST function is required to convert the
number without the leading zeros to a character data type.
-- DB2 for z/OS and DB2 9.7 and higher:
XMLELEMENT(NAME "cost", price)
XMLATTRIBUTES(price AS "COST")
XMLFOREST(pid, price)
Figure 10.26
(continues)
Leading zeros in numeric output prior to DB2 9.7 for Linux, UNIX, and Windows
286
Chapter 10
Producing XML from Relational Data
-- DB2 9.5 and earlier:
XMLELEMENT(NAME "cost", XMLCAST(price AS XML))
XMLATTRIBUTES(XMLCAST(XMLCAST(price AS XML) AS VARCHAR(50))
AS "COST")
XMLFOREST(pid, XMLCAST(XMLCAST(price AS XML) AS VARCHAR(50))
AS PRICE)
Figure 10.26 Leading zeros in numeric output prior to DB2 9.7 for Linux, UNIX,
and Windows (Continued)
10.1.9
Default Tagging of Relational Data with XMLROW and XMLGROUP
In addition to the SQL/XML publishing functions discussed so far, DB2 for Linux, UNIX, and
Windows offers the functions XMLROW and XMLGROUP. These functions do not provide any new
capabilities but merely act as convenient abbreviations for combinations of the functions
XMLELEMENT, XMLATTRIBUTES, XMLFOREST, and XMLAGG. In particular, XMLROW and XMLGROUP are simple to use because they construct XML with a default structure and default tag
names. Let’s look at a few examples based on the relational data in Figure 10.27.
POID
-------5000
5001
5002
STATUS
CUSTID
---------- -------Unshipped
1002
Shipped
1003
Shipped
1001
Figure 10.27
A subset of the purchaseorder table
Figure 10.28 through Figure 10.33 show six queries with XMLROW and XMLGROUP. Each table
contains a second query that produces the same result. This comparison clarifies how XMLROW
and XMLGROUP are merely shortcuts for other SQL/XML functions. The right side of each table
shows the constructed XML data based on the relational input data in Figure 10.27.
The query in Figure 10.28 shows that XMLROW converts each row of the input table into an XML
element <row> that has child elements for each of the selected columns. The column names are
used as default element names. In DB2 for z/OS, where the function XMLROW is not available, you
can use XMLELEMENT plus XMLFOREST instead.
Optionally, XMLROW can produce attributes instead of child elements for the selected columns, as
shown in Figure 10.29.
The function XMLROW always generates one XML document in one result row for each qualifying
input row. All the queries shown here can certainly have WHERE clauses to restrict the result sets.
The function XMLGROUP differs from XMLROW in the cardinality of the produced result sets.
10.1
SQL/XML Publishing Functions
287
In particular, XMLGROUP is an abbreviation for XMLAGG plus XMLELEMENT and XMLFOREST and
combines data from multiple or all input rows into one XML document. Figure 10.30 shows an
example.
SELECT XMLROW(poid, status, custid)
FROM purchaseorder;
SELECT XMLELEMENT(name "row",
XMLFOREST(poid,
status,
custid) )
FROM purchaseorder;
<row>
<POID>5000</POID>
<STATUS>Unshipped</STATUS>
<CUSTID>1002</CUSTID>
</row>
<row>
<POID>5001</POID>
<STATUS>Shipped</STATUS>
<CUSTID>1003</CUSTID>
</row>
<row>
<POID>5002</POID>
<STATUS>Shipped</STATUS>
<CUSTID>1001</CUSTID>
</row>
3 record(s) selected.
Figure 10.28
Default tagging with XMLROW
SELECT XMLROW(poid, status, custid
OPTION AS ATTRIBUTES)
FROM purchaseorder;
SELECT XMLELEMENT(name "row",
XMLATTRIBUTES(poid,
status,
custid)
FROM purchaseorder;
)
<row POID="5000"
STATUS="Unshipped"
CUSTID="1002"/>
<row POID="5001"
STATUS="Shipped"
CUSTID="1003"/>
<row POID="5002"
STATUS="Shipped"
CUSTID="1001"/>
3 record(s) selected.
Figure 10.29
Default tagging with XMLROW, using attributes
288
Chapter 10
SELECT XMLGROUP(poid, status, custid)
FROM purchaseorder;
SELECT XMLELEMENT(name "rowset",
XMLAGG(
XMLELEMENT(name "row",
XMLFOREST(poid,
status,
custid))))
FROM purchaseorder;
Producing XML from Relational Data
<rowset>
<row>
<POID>5000</POID>
<STATUS>Unshipped</STATUS>
<CUSTID>1002</CUSTID>
</row>
<row>
<POID>5001</POID>
<STATUS>Shipped</STATUS>
<CUSTID>1003</CUSTID>
</row>
<row>
<POID>5002</POID>
<STATUS>Shipped</STATUS>
<CUSTID>1001</CUSTID>
</row>
</rowset>
1 record(s) selected.
Figure 10.30
Default tagging with XMLGROUP
Just like XMLROW, the function XMLGROUP also has an option to produce attributes instead of elements (see Figure 10.31).
SELECT XMLGROUP(poid, status, custid
OPTION AS ATTRIBUTES)
FROM purchaseorder;
SELECT XMLELEMENT(name "rowset",
XMLAGG(
XMLELEMENT(name "row",
XMLATTRIBUTES(poid,
status,
custid))))
FROM purchaseorder;
<rowset>
<row POID="5000"
STATUS="Unshipped"
CUSTID="1002"/>
<row POID="5001"
STATUS="Shipped"
CUSTID="1003"/>
<row POID="5002"
STATUS="Shipped"
CUSTID="1001"/>
</rowset>
1 record(s) selected.
Figure 10.31
Default tagging with XMLGROUP, using attributes
If you use a GROUP BY clause, the function XMLGROUP behaves just like the XMLAGG function.
One XML document is constructed for each group. The query in Figure 10.32 groups the result
by the status column, which contains the values Unshipped and Shipped. Therefore two documents are generated—one that contains shipped orders and one with unshipped orders.
10.1
SQL/XML Publishing Functions
SELECT XMLGROUP(poid, status, custid
OPTION AS ATTRIBUTES)
FROM purchaseorder
GROUP BY status;
SELECT XMLELEMENT(name "rowset",
XMLAGG(
XMLELEMENT(name "row",
XMLATTRIBUTES(poid,
status,
custid))))
FROM purchaseorder
;
GROUP BY status
289
<rowset>
<row POID="5000"
STATUS="Unshipped"
CUSTID="1002"/>
</rowset>
<rowset>
<row POID="5001"
"
STATUS="Shipped
CUSTID="1003"/>
<row POID="5002"
"
STATUS="Shipped
CUSTID="1001"/>
</rowset>
2 record(s) selected.
Figure 10.32
Default tagging and grouping with XMLGROUP
Both XMLGROUP and XMLROW have options that allow you to change the element names row and
rowset to custom names. The query in Figure 10.33 uses porder and Orders instead.
SELECT XMLGROUP(poid, status, custid
OPTION AS ATTRIBUTES
ROW "porder"
ROOT "Orders")
FROM purchaseorder
GROUP BY status;
SELECT XMLELEMENT(name "Orders",
XMLAGG(
XMLELEMENT(name "porder",
XMLATTRIBUTES(poid,
status,
custid))))
FROM purchaseorder
GROUP BY status;
Figure 10.33
10.1.10
<Orders>
<porder POID="5000"
STATUS="Unshipped"
CUSTID="1002"/>
</Orders>
<Orders>
<porder POID="5001"
STATUS="Shipped"
CUSTID="1003"/>
<porder POID="5002"
"
STATUS="Shipped
CUSTID="1001"/>
</Orders>
2 record(s) selected.
XMLGROUP with options for non-default tag names
GUI-Based Definition of SQL/XML Publishing Queries
Manual coding of SQL/XML publishing queries can become a complex task if you need to generate complex XML documents. IBM InfoSphere Data Architect, previously known as Rational
Data Architect (RDA), provides relief with a graphical user interface that lets you define the mapping from relational source tables to a target XML format, as shown in Figure 10.34. In the background, RDA generates an SQL/XML publishing statement that implements the desired
mapping. At the time of writing, this feature was not available in IBM Data Studio Developer.
290
Chapter 10
Figure 10.34
10.1.11
Producing XML from Relational Data
Relational to XML mapping in InfoSphere Data Architect (RDA)
Constructing Comments, Processing Instructions, and Text Nodes
The SQL/XML functions XMLCOMMENT, XMLPI, and XMLTEXT are available to construct comment nodes, processing instruction nodes, and text nodes, respectively. Most applications that
construct XML documents do not need to use these functions. Please refer to the DB2 Information Center or the latest DB2 SQL Reference if you require more details on these functions.
10.1.12
Legacy Functions
The legacy functions XML2CLOB and REC2XML are not part of the SQL/XML standard and have
been superseded by SQL/XML standard functions.
The function XML2CLOB was introduced in DB2 V8 to convert constructed XML data from type
XML to type CLOB. The SQL/XML function XMLSERIALIZE supersedes the XML2CLOB function.
It can convert XML type data to CLOB, BLOB, VARCHAR, or CHAR, and can optionally also control
the generation of XML declarations (see section 10.3). The function XML2CLOB is supported in
DB2 9.x for backward compatibility only. It is recommended to use XMLSERIALIZE instead of
XML2CLOB.
REC2XML is another legacy function that only exists for backward compatibility. It was intro-
duced to allow queries to retrieve relational rows in a default XML format. It is recommended
that you use the new functions XMLROW, XMLELEMENT, or XMLATTRIBUTES instead of REC2XML.
10.2
USING XQUERY CONSTRUCTORS WITH RELATIONAL INPUT
XQuery element and attribute constructors were introduced in section 8.4, Constructing XML
Data. They allow you to construct new XML elements and attributes and to nest them to build
new documents. In section 8.4 the constructed XML data contains values that are extracted from
10.2
Using XQuery Constructors with Relational Input
291
other XML documents. In this section we show how XQuery element and attribute constructors
can also use values from relational columns.
Consider Figure 10.35 as an example. Since XQuery element and attribute constructors are
XQuery expressions, just like XPath or FLWOR expressions, you can enclose them in an
XMLQUERY function in order to include them in an SQL statement. Direct element and attribute
constructors allow you to simply type the tags of XML documents that you want to construct
from each input row. Wherever you want a relational column to provide an attribute or element
value, simply use the column name as an uppercase variable and enclose it in curly brackets. This
turns the column name into an expression that is evaluated when the query executes.
In Figure 10.35, $POID, $ORDERDATE, and $STATUS refer to the relational columns poid,
orderdate, and status. The curly brackets ensure that the constructed elements and attributes
contain the column values, and not the column names.
SELECT XMLQUERY('<order id="{$POID}">
<details>
<date>{$ORDERDATE}</date>
<status>{$STATUS}</status>
</details>
</order>')
FROM purchaseorder
WHERE poid = 5000;
<order id="5000">
<details>
<date> 2006-02-18</date>
<status>Unshipped</status>
</details>
</order>
1 record(s) selected.
Figure 10.35
Using element constructors in a query
XQuery element and attribute constructors are not available in DB2 9 for z/OS, but you can
achieve the same construction with the SQL/XML publishing functions. For example, the query
in Figure 10.36 runs on all platforms and produces the same result as the query in Figure 10.35.
SELECT XMLELEMENT(name "order",
XMLATTRIBUTES(poid AS "id"),
XMLELEMENT(name "details",
XMLFOREST(orderdate AS "date", status AS "status")))
FROM purchaseorder
WHERE poid = 5000;
Figure 10.36
SQL/XML publishing functions that produce the same result as Figure 10.35
292
Chapter 10
Producing XML from Relational Data
The XQuery element and attribute constructors can be combined with the SQL/XML publishing
functions, which is useful if you want to construct documents that contain values from multiple
rows. Such aggregation is best done with the SQL/XML function XMLAGG. However, the XML
fragments that are being aggregated can be generated with XQuery constructor expressions, as
shown in Figure 10.37. The XMLQUERY function contains XQuery element and attribute constructors to produce the order elements. Since the result type of the XMLQUERY function is always
XML, it produces a valid input type for the XMLAGG function.
SELECT XMLELEMENT(name "CustOrders",
XMLAGG(
XMLQUERY('<order cid="{$CUSTID}" date="{$ORDERDATE}">
{$POID}
</order>') ))
FROM purchaseorder
WHERE custid IN (1001,1002)
GROUP BY custid;
<CustOrders>
<order cid="1001" date="2004-02-29">5002</order>
</CustOrders>
<CustOrders>
<order cid="1002" date="2005-02-28">5003</order>
<order cid="1002" date="2006-02-18">5000</order>
<order cid="1002" date="2006-03-01">5006</order>
</CustOrders>
2 record(s) selected.
Figure 10.37
10.3
SQL/XML publishing functions and XQuery constructor expressions
XML DECLARATIONS FOR CONSTRUCTED XML DATA
When you retrieve XML data from DB2, either from XML columns or constructed from relational columns, you might want each document to have an XML declaration with an encoding
attribute, such as
<?xml version="1.0" encoding="UTF-8"?>
The generation of XML declarations is controlled by the application that interacts with DB2.
Chapter 20, Understanding XML Data Encoding, and Chapter 21, Developing XML Applications
with DB2, provide further details.
Be aware that the DB2 Command Line Processor (CLP) is an application that by default retrieves
XML data without XML declarations. This default behavior can be changed. If you invoke the
10.3
XML Declarations for Constructed XML Data
293
CLP with the –d option, such as db2 –t –d, an XML declaration is added to each document that
you retrieve. During retrieval, DB2 also converts the XML data to the code page of the application, which can depend on your operating system. On AIX 5.3, constructed XML data retrieved
via the CLP may carry the XML declarations shown in Figure 10.38. Since each XML element
returned in Figure 10.38 is a separate XML document (one per row), each result row has its own
XML declaration.
SELECT XMLELEMENT(NAME "pnum", pid) AS pnum_elem
FROM product;
PNUM_ELEM
------------------------------------------------------------<?xml version="1.0" encoding="UTF-8"?><pnum>100-100-01</pnum>
<?xml version="1.0" encoding="UTF-8"?><pnum>100-101-01</pnum>
<?xml version="1.0" encoding="UTF-8"?><pnum>100-103-01</pnum>
<?xml version="1.0" encoding="UTF-8"?><pnum>100-201-01</pnum>
4 record(s) selected.
Figure 10.38
Constructed XML document with XML declarations
If you use SPUFI to run the same query on DB2 for z/OS, the result set may look like the one
shown in Figure 10.39.
<?xml
<?xml
<?xml
<?xml
version="1.0"
version="1.0"
version="1.0"
version="1.0"
encoding="IBM285"?><pnum>100-101-01</pnum>
encoding="IBM285"?><pnum>100-100-01</pnum>
encoding="IBM285"?><pnum>100-103-01</pnum>
encoding="IBM285"?><pnum>100-201-01</pnum>
DSNE610I NUMBER OF ROWS DISPLAYED IS 4
Figure 10.39
Result set with XML declarations in SPUFI
For ODBC and embedded SQL applications, DB2 for z/OS adds an XML declaration to the
returned XML data by default. For Java and .NET applications, the generation of an XML declaration depends on the methods used to retrieve the data (see Chapter 21).
Independent of the API and the platform that DB2 is running on, you can always control
(include/exclude) the generation of XML declarations with the XMLSERIALIZE function. To do
so, wrap the XMLSERIALIZE function around the XML type column that the query produces and
use the keywords EXCLUDING XMLDECLARATION or INCLUDING XMLDECLARATION as needed
(see Figure 10.40). The XMLSERIALIZE function also changes the return type of the constructed
XML data from type XML to a character or binary type. In DB2 for Linux, UNIX, and Windows
the target types of the XMLSERIALIZE function can be CLOB, BLOB, CHAR, and VARCHAR. DB2
for z/OS allows types CLOB and BLOB, and CLOB can further be cast to VARCHAR if the size
allows.
294
Chapter 10
Producing XML from Relational Data
SELECT XMLSERIALIZE(XMLELEMENT(NAME "pnum", pid)
AS CLOB(500) EXCLUDING XMLDECLARATION)
FROM product;
SELECT XMLSERIALIZE(XMLELEMENT(NAME "pnum", pid)
AS CLOB(500) INCLUDING XMLDECLARATION)
FROM product;
Figure 10.40
10.4
Using XMLSERIALIZE to suppress or include XML declarations
INSERTING CONSTRUCTED XML DATA INTO XML COLUMNS
The construction of XML data in DB2 composes an XML document tree that is internally represented in DB2’s parsed hierarchical XML format. All examples that we discussed in this chapter
so far return the constructed XML data to the application that issued the query. When XML data
is transferred from the DB2 server to a client application, the XML data is implicitly serialized;
that is, converted to its textual representation. You can also perform explicit serialization with the
XMLSERIALIZE function to choose a return type such as CLOB or VARCHAR and to control the
generation of an XML declaration. Either way, the XML data is sent to the application as text.
Instead of serializing a constructed document tree to text and returning it to the client, the document tree can also be inserted into an XML column. In section 3.1, Understanding XML Document Trees, we explained that the XQuery Data Model requires a document tree to have a
document node. The document node is the parent of the root element. A document node is not
visible in the textual representation of an XML document, and not automatically generated when
you construct XML data that is returned in text format to the application. However, a document
node must be added if you want to insert a constructed document into an XML column. The
SQL/XML function XMLDOCUMENT constructs such a document node.
Suppose you want to insert constructed XML documents into the following table:
CREATE TABLE orders(orderinfo XML)
Figure 10.41 shows the usage of the XMLDOCUMENT function as the outermost function for the construction of XML data. If you omit the XMLDOCUMENT function, the INSERT statement fails with
error SQL20345N The XML value is not a well-formed document with a single
root.
INSERT INTO orders(orderinfo)
SELECT XMLDOCUMENT(
XMLELEMENT(name "order",
XMLATTRIBUTES(poid AS "id"),
XMLFOREST(orderdate, status)) )
FROM purchaseorder;
Figure 10.41
Insert requires construction of an XML document node
10.5
Summary
295
A document node is equally required if you use XQuery direct element and attribute constructors
instead of the SQL/XML publishing functions. Figure 10.42 shows the insertion of a document
that is constructed in XQuery and a document node is added with the XMLDOCUMENT function.
INSERT INTO orders(orderinfo)
SELECT XMLDOCUMENT(
XMLQUERY('<order id="{$POID}">
<date>{$ORDERDATE}</date>
<status>{$STATUS}</status>
</order>') )
FROM purchaseorder;
Figure 10.42
XMLDOCUMENT plus XQuery constructors
Remember that XMLDOCUMENT is an SQL function. The XQuery language includes a corresponding document node constructor, document{ }, which you see used in Figure 10.43.
INSERT INTO orders(orderinfo)
SELECT XMLQUERY('document{<order id="{$POID}">
<date>{$ORDERDATE}</date>
<status>{$STATUS}</status>
</order>}')
FROM purchaseorder;
Figure 10.43
10.5
Constructing a document node in XQuery
SUMMARY
Developing and working with XML applications is not only about consuming and processing
XML data, but often also about creating and publishing XML data. In particular, generating
XML documents from existing data in relational tables is a common requirement.
Constructing XML data is supported through SQL/XML functions since version 8 of both DB2
for z/OS and DB2 for Linux, UNIX, and Windows. These SQL/XML publishing functions, also
sometimes called constructor functions, can be used in the SELECT clause of any valid SQL
query. They take the columns of a relational result set as input and produce XML data as output.
For example, the XMLELEMENT function constructs XML elements, the XMLATTRIBUTES function constructs XML attributes, and the XMLAGG function aggregates XML elements from multiple rows into XML documents. Remember that XMLAGG works much like any other SQL
aggregation function, taking multiple rows as input and producing a single row as output.
Just like XML elements are nested in the tree structure of an XML document, it is common to
nest the SQL/XML publishing functions to construct a correspondingly nested document structure. IBM InfoSphere Data Architect also provides a GUI interface to create SQL/XML publishing queries visually.
296
Chapter 10
Producing XML from Relational Data
In addition to the SQL/XML publishing functions, DB2 for Linux, UNIX, and Windows also
supports XQuery direct element and attribute constructors. They provide an alternative and
sometimes simpler way of constructing XML data from relational tables.
Any form of XML construction in DB2 produces data of type XML and is therefore fully compatible with all other pureXML features. For example, constructed XML documents can be
inserted into XML columns if they have an explicitly constructed XML document node at the top.
C
H A P T E R
11
Converting XML to
Relational Data
his chapter describes methods to convert XML documents to rows in relational tables. This
conversion is commonly known as shredding or decomposing of XML documents. Given
the rich support for XML columns in DB2 you might wonder in which cases it can still be useful
or necessary to convert XML data to relational format. One common reason for shredding is that
existing SQL applications might still require access to the data in relational format. For example,
legacy applications, packaged business applications, or reporting software do not always understand XML and have fixed relational interfaces. Therefore you might sometimes find it useful to
shred all or some of the data values of an incoming XML document into rows and columns of
relational tables.
T
In this chapter you learn:
• The advantages and disadvantages of shredding and of different shredding methods
(section 11.1)
• How to shred XML data to relational tables using INSERT statements that contain the
XMLTABLE function (section 11.2)
• How to use XML Schema annotations that map and shred XML documents to relational
tables (section 11.3)
11.1
ADVANTAGES AND DISADVANTAGES OF SHREDDING
The concept of XML shredding is illustrated in Figure 11.1. In this example, XML documents
with customer name, address, and phone information are mapped to two relational tables. The
documents can contain multiple phone elements because there is a one-to-many relationship
297
298
Chapter 11
Converting XML to Relational Data
between customers and phones. Hence, phone numbers are shredded into a separate table. Each
repeating element, such as phone, leads to an additional table in the relational target schema.
Suppose the customer information can also contain multiple email addresses, multiple accounts,
a list of most recent orders, multiple products per order, and other repeating items. The number of
tables required in the relational target schema can increase very quickly. Shredding XML into a
large number of tables can lead to a complex and unnatural fragmentation of your logical business objects that makes application development difficult and error-prone. Querying the shredded
data or reassembling the original documents may require complex multiway joins.
<customerinfo Cid="1003">
<name>Robert Shoemaker</name>
CID NAME
STREET
CITY
<addr country="Canada">
1003 Robert Shoemaker 845 Kean Street Aurora
<street>845 Kean Street</street>
<city>Aurora</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N8X 7F8</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
CREATE TABLE address(
<phone type="home">416-555-2937</phone>
cid INTEGER,
<phone type="cell">905-555-8743</phone>
name VARCHAR(30),
</customerinfo>
street VARCHAR(40),
city VARCHAR(30))
CID
1003
1003
1003
Figure 11.1
PHONETYPE
work
home
cell
PHONENUM
905-555-7258
416-555-2937
905-555-8743
CREATE TABLE phones(
cid INTEGER,
phonetype VARCHAR(10),
phonenum VARCHAR(20))
Shredding of an XML document
Depending on the complexity, variability, and purpose of your XML documents, shredding may
or may not be a good option. Table 11.1 summarizes the pros and cons of shredding XML data to
relational tables.
Table 11.1
When Shredding Is and Isn’t a Good Option
Shredding Can Be Useful When…
Shredding Is Not A Good Option When…
• Incoming XML data is just feeding an existing
relational database.
• Your XML data is complex and nested, and
difficult to map to a relational schema.
• The XML documents do not represent logical
business objects that should be preserved.
• Mapping your XML format to a relational
schema leads to a large number of tables.
• Your primary goal is to enable existing
relational applications to access XML data.
• Your XML Schema is highly variable or
tends to change over time.
• You are happy with your relational schema and
would like to use it as much as possible.
• Your primary goal is to manage XML
documents as intact business objects.
11.1
Advantages and Disadvantages of Shredding
Table 11.1
299
When Shredding Is and Isn’t a Good Option (Continued)
Shredding Can Be Useful When…
Shredding Is Not A Good Option When…
• The structure of your XML data is such that it
can easily be mapped to relational tables.
• You frequently need to reconstruct the
shredded documents or parts of them.
• Your XML format is relatively stable and
changes to it are rare.
• Ingesting XML data into the database at a
high rate is important for your application.
• You rarely need to reconstruct the shredded
documents.
• Querying or updating the data with SQL is
more important than insert performance.
In many XML application scenarios the structure and usage of the XML data does not lend itself
to easy and efficient shredding. This is the reason why DB2 supports XML columns that allow
you to index and query XML data without conversion. Sometimes you will find that your application requirements can be best met with partial shredding or hybrid XML storage.
• Partial shredding means that only a subset of the elements or attributes from each
incoming XML document are shredded into relational tables. This is useful if a relational application does not require all data values from each XML document. In cases
where shredding each document entirely is difficult and requires a complex relational
target schema, partial shredding can simplify the mapping to the relational schema
significantly.
• Hybrid XML storage means that upon insert of an XML document into an XML column,
selected element or attribute values are extracted and redundantly stored in relational
columns.
If you choose to shred XML documents, entirely or partially, DB2 provides you with a rich set of
capabilities to do some or all of the following:
• Perform custom transformations of the data values before insertion into relational
columns.
• Shred the same element or attribute value into multiple columns of the same table or different tables.
• Shred multiple different elements or attributes into the same column of a table.
• Specify conditions that govern when certain elements are or are not shredded. For example, shred the address of a customer document only if the country is Canada.
• Validate XML documents with an XML Schema during shredding.
• Store the full XML document along with the shredded data.
300
Chapter 11
Converting XML to Relational Data
DB2 9 for z/OS and DB2 9.x for Linux, UNIX, and Windows support two shredding methods:
• SQL INSERT statements that use the XMLTABLE function. This function navigates into
an input document and produces one or multiple relational rows for insert into a relational table.
• Decomposition with an annotated XML Schema. Since an XML Schema defines the
structure of XML documents, annotations can be added to the schema to define how elements and attributes are mapped to relational tables.
Table 11.2 and Table 11.3 discuss the advantages and disadvantages of the XMLTABLE method
and the annotated schema method.
Table 11.2
Considerations for the XMLTABLE Method
Advantages of the XMLTABLE Method
Disadvantages of the XMLTABLE Method
• It allows you to shred data even if you do
not have an XML Schema.
• For each target table that you want to shred
into you need one INSERT statement.
• It does not require you to understand the XML
Schema language or to understand schema
annotations for decomposition.
• You might have to combine multiple
INSERT statements in a stored procedure.
• It is generally easier to use than annotated
schemas because it is based on SQL and XPath.
• There is no GUI support for implementing the
INSERT statements and the required
XMLTABLE functions. You need to be familiar
with XPath and SQL/XML.
• You can use familiar XPath, XQuery, or SQL
functions and expressions to extract and
optionally modify the data values.
• It often requires no or little work during
XML Schema evolution.
• The shredding process can consume data
from multiple XML and relational sources,
if needed, such as values from DB2 sequences
or look-up data from other relational tables.
• It can often provide better performance than
annotated schema decompositions.
11.2
Shredding with the XMLTABLE Function
Table 11.3
301
Considerations for Annotated Schema Decomposition
Advantages of the Annotated
Schema Method
Disadvantages of the Annotated
Schema Method
• The mapping from XML to relational tables
can be defined using a GUI in IBM Data
Studio Developer.
• It does not allow shredding without an XML
Schema.
• If you shred complex XML data into a large
number of tables, the coding effort can be
lower than with the XMLTABLE approach.
• You might have to manually copy annotations
when you start using a new version of your
XML Schema.
• It offers a bulk mode with detailed diagnostics
if some documents fail to shred.
• Despite the GUI support, you need to be
familiar with the XML Schema language for
all but simple shredding scenarios.
• Annotating an XML Schema can be complex, if
the schema itself is complex.
11.2
SHREDDING WITH THE XMLTABLE FUNCTION
The XMLTABLE function is an SQL table function that uses XQuery expressions to create relational rows from an XML input document. For details on the XMLTABLE function, see Chapter 7,
Querying XML Data with SQL/XML. In this section we describe how to use the XMLTABLE function in an SQL INSERT statement to perform shredding. We use the shredding scenario in Figure
11.1 as an example.
The first step is to create the relational target tables, if they don’t already exist. For the scenario in
Figure 11.1 the target tables are defined as follows:
CREATE TABLE address(cid INTEGER, name VARCHAR(30),
street VARCHAR(40), city VARCHAR(30))
CREATE TABLE phones(cid INTEGER, phonetype VARCHAR(10),
phonenum VARCHAR(20))
Based on the definition of the target tables you construct the INSERT statements that shred
incoming XML documents. The INSERT statements have to be of the form INSERT INTO …
SELECT … FROM … XMLTABLE, as shown in Figure 11.2. Each XMLTABLE function contains a
parameter marker (“?”) through which an application can pass the XML document that is to be
shredded. SQL typing rules require the parameter marker to be cast to the appropriate data type.
The SELECT clause selects columns produced by the XMLTABLE function for insert into the
address and phones tables, respectively.
302
Chapter 11
Converting XML to Relational Data
INSERT INTO address(cid, name, street, city)
SELECT x.custid, x.custname, x.str, x.place
FROM XMLTABLE('$i/customerinfo' PASSING CAST(? AS XML) AS "i"
COLUMNS
custid
INTEGER
PATH '@Cid',
custname VARCHAR(30) PATH 'name',
str
VARCHAR(40) PATH 'addr/street',
place
VARCHAR(30) PATH 'addr/city' ) AS x ;
INSERT INTO phones(cid, phonetype, phonenum)
SELECT x.custid, x.ptype, x.number
FROM XMLTABLE('$i/customerinfo/phone'
PASSING CAST(? AS XML) AS "i"
COLUMNS
custid
INTEGER
PATH '../@Cid',
number
VARCHAR(15) PATH '.',
ptype
VARCHAR(10) PATH './@type') AS x ;
Figure 11.2
Inserting XML element and attribute values into relational columns
To populate the two target tables as illustrated in Figure 11.1, both INSERT statements have to be
executed with the same XML document as input. One approach is that the application issues both
INSERT statements in one transaction and binds the same XML document to the parameter markers for both statements. This approach works well but can be optimized, because the same XML
document is sent from the client to the server and parsed at the DB2 server twice, once for each
INSERT statement. This overhead can be avoided by combining both INSERT statements in a single stored procedure. The application then only makes a single stored procedure call and passes
the input document once, regardless of the number of INSERT statements in the stored procedure.
Chapter 18, Using XML in Stored Procedures, UDFs, and Triggers, demonstrates such a stored
procedure as well as other examples of manipulating XML data in stored procedures and userdefined functions.
Alternatively, the INSERT statements in Figure 11.2 can read a set of input documents from an
XML column. Suppose the documents have been loaded into the XML column info of the
customer table. Then you need to modify one line in each of the INSERT statements in Figure
11.2 to read the input document from the customer table:
FROM customer, XMLTABLE('$i/customerinfo' PASSING info AS "i"
Loading the input documents into a staging table can be advantageous if you have to shred many
documents. The LOAD utility parallelizes the parsing of XML documents, which reduces the time
to move the documents into the database. When the documents are stored in an XML column in
parsed format, the XMLTABLE function can shred the documents without XML parsing.
The INSERT statements can be enriched with XQuery or SQL functions or joins to tailor the
shredding process to specific requirements. Figure 11.3 provides an example. The SELECT clause
11.2
Shredding with the XMLTABLE Function
303
contains the function RTRIM to remove trailing blanks from the column x.ptype. The row-generating expression of the XMLTABLE function contains a predicate that excludes home phone
numbers from being shredded into the target table. The column-generating expression for the
phone numbers uses the XQuery function normalize-space, which strips leading and trailing
whitespace and replaces each internal sequence of whitespace characters with a single blank
character. The statement also performs a join to the lookup table areacodes so that a phone
number is inserted into the phones table only if its area code is listed in the areacodes table.
INSERT INTO phones(cid, phonetype, phonenum)
SELECT x.custid, RTRIM(x.ptype), x.number
FROM areacodes a,
XMLTABLE('$i/customerinfo/phone[@type != "home"]'
PASSING CAST(? AS XML) AS "i"
COLUMNS
custid
INTEGER
PATH '../@Cid',
number
VARCHAR(15) PATH 'normalize-space(.)',
ptype
VARCHAR(10) PATH './@type') AS x
WHERE SUBSTR(x.number,1,3) = a.code;
Figure 11.3
11.2.1
Using functions and joins to customize the shredding
Hybrid XML Storage
In many situations the complexity of the XML document structures makes shredding difficult,
inefficient, and undesirable. Besides the performance penalty of shredding, scattering the values
of an XML document across a large number of tables can make it difficult for an application
developer to understand and query the data. To improve XML insert performance and to reduce
the number of tables in your database, you may want to store XML documents in a hybrid manner. This approach extracts the values of selected XML elements or attributes and stores them in
relational columns alongside the full XML document.
The example in the previous section used two tables, address and phones, as the target tables
for shredding the customer documents. You might prefer to use just a single table that contains
the customer cid, name, and city values in relational columns and the full XML document with
the repeating phone elements and other information in an XML column. You can define the following table:
CREATE TABLE hybrid(cid INTEGER NOT NULL PRIMARY KEY,
name VARCHAR(30), city VARCHAR(25), info XML)
Figure 11.4 shows the INSERT statement to populate this table. The XMLTABLE function takes an
XML document as input via a parameter marker. The column definitions in the XMLTABLE function produce four columns that match the definition of the target table hybrid. The rowgenerating expression in the XMLTABLE function is just $i, which produces the full input
document. This expression is the input for the column-generating expressions in the COLUMNS
clause of the XMLTABLE function. In particular, the column expression '.' returns the full input
304
Chapter 11
Converting XML to Relational Data
document as-is and produces the XML column doc for insert into the info column of the target
table.
INSERT INTO hybrid(cid, name, city, info)
SELECT x.custid, x.custname, x.city, x.doc
FROM XMLTABLE('$i' PASSING CAST(? AS XML) AS "i"
COLUMNS
custid
INTEGER
PATH 'customerinfo/@Cid',
custname VARCHAR(30) PATH 'customerinfo/name',
city
VARCHAR(25) PATH 'customerinfo/addr/city',
doc
XML
PATH '.' ) AS x;
Figure 11.4
Storing an XML document in a hybrid fashion
It is currently not possible to define check constraints in DB2 to enforce the integrity between
relational columns and values in an XML document in the same row. You can, however, define
INSERT and UPDATE triggers on the table to populate the relational columns automatically whenever a document is inserted or updated. Triggers are discussed in Chapter 18, Using XML in
Stored Procedures, UDFs, and Triggers.
It can be useful to test such INSERT statements in the DB2 Command Line Processor (CLP). For
this purpose you can replace the parameter marker with a literal XML document as shown in Figure 11.5. The literal document is a string that must be enclosed in single quotes and converted to
the data type XML with the XMLPARSE function. Alternatively, you can read the input document
from the file system with one of the UDFs that were introduced in Chapter 4, Inserting and
Retrieving XML Data. The use of a UDF is demonstrated in Figure 11.6.
INSERT INTO hybrid(cid, name, city, info)
SELECT x.custid, x.custname, x.city, x.doc
FROM XMLTABLE('$i' PASSING
XMLPARSE(document
'<customerinfo Cid=”1001”>
<name>Kathy Smith</name>
<addr country=”Canada”>
<street>25 EastCreek</street>
<city>Markham</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N9C 3T6</pcode-zip>
</addr>
<phone type=”work”>905-555-7258</phone>
</customerinfo>') AS "i"
COLUMNS
custid
INTEGER
PATH 'customerinfo/@Cid',
custname VARCHAR(30) PATH 'customerinfo/name',
city
VARCHAR(25) PATH 'customerinfo/addr/city',
doc
XML
PATH '.' ) AS x;
Figure 11.5
Hybrid insert statement with a literal XML document
11.2
Shredding with the XMLTABLE Function
305
INSERT INTO hybrid(cid, name, city, info)
SELECT x.custid, x.custname, x.city, x.doc
FROM XMLTABLE('$i' PASSING
XMLPARSE(document
blobFromFile('/xml/mydata/cust0037.xml')) AS "i"
COLUMNS
custid
INTEGER
PATH 'customerinfo/@Cid',
custname VARCHAR(30) PATH 'customerinfo/name',
city
VARCHAR(25) PATH 'customerinfo/addr/city',
doc
XML
PATH '.' ) AS x;
Figure 11.6
Hybrid insert statement with a “FromFile” UDF
The insert logic in Figure 11.4, Figure 11.5, and Figure 11.6 is identical. The only difference is
how the input document is provided: via a parameter marker, as a literal string that is enclosed in
single quotes, or via a UDF that reads a document from the file system.
11.2.2 Relational Views over XML Data
You can create relational views over XML data using XMLTABLE expressions. This allows you to
provide applications with a relational or hybrid view of the XML data without actually storing the
data in a relational or hybrid format. This can be useful if you want to avoid the overhead of converting large amounts of XML data to relational format. The basic SELECT … FROM …
XMLTABLE constructs that were used in the INSERT statements in the previous section can also be
used in CREATE VIEW statements.
As an example, suppose you want to create a relational view over the elements of the XML documents in the customer table to expose the customer identifier, name, street, and city values. Figure 11.7 shows the corresponding view definition plus an SQL query against the view.
CREATE VIEW custview(id, name, street, city)
AS
SELECT x.custid, x.custname, x.str, x.place
FROM customer,
XMLTABLE('$i/customerinfo' PASSING info AS "i"
COLUMNS
custid
INTEGER
PATH '@Cid',
custname VARCHAR(30) PATH 'name',
str
VARCHAR(40) PATH 'addr/street',
place
VARCHAR(30) PATH 'addr/city' ) AS x;
SELECT id, name FROM custview WHERE city = 'Aurora';
ID
NAME
----------- -----------------------------1003 Robert Shoemaker
1 record(s) selected.
Figure 11.7
Creating a view over XML data
306
Chapter 11
Converting XML to Relational Data
The query over the view in Figure 11.7 contains an SQL predicate for the city column in the
view. The values in the city column come from an XML element in the underlying XML column. You can speed up this query by creating an XML index on /customerinfo/addr/city
for the info column of the customer table. DB2 9 for z/OS and DB2 9.7 for Linux, UNIX, and
Windows are able to convert the relational predicate city = 'Aurora' into an XML predicate
on the underlying XML column so that the XML index can be used. This is not possible in DB2
9.1 and DB2 9.5 for Linux, UNIX, and Windows. In these previous versions of DB2, include the
XML column in the view definition and write the search condition as an XML predicate, as in the
following query. Otherwise an XML index cannot be used.
SELECT id, name
FROM custview
WHERE XMLEXISTS('$INFO/customerinfo/addr[city = "Aurora"]')
11.3
SHREDDING WITH ANNOTATED XML SCHEMAS
This section describes another approach to shredding XML documents into relational tables. The
approach is called annotated schema shredding or annotated schema decomposition because it is
based on annotations in an XML Schema. These annotations define how XML elements and
attributes in your XML data map to columns in your relational tables.
To perform annotated schema shredding, take the following steps:
• Identify or create the relational target tables that will hold the shredded data.
• Annotate your XML Schema to define the mapping from XML to the relational tables.
• Register the XML Schema in the DB2 XML Schema Repository.
• Shred XML documents with Command Line Processor commands or built-in stored
procedures.
Assuming you have defined the relational tables that you want to shred into, let’s look at annotating an XML Schema.
11.3.1
Annotating an XML Schema
Schema annotations are additional elements and attributes in an XML Schema to provide mapping information. DB2 can use this information to shred XML documents to relational tables.
The annotations do not change the semantics of the original XML Schema. If a document is valid
for the annotated schema then it is also valid for the original schema, and vice versa. You can use
an annotated schema to validate XML documents just like the original XML Schema. For an
introduction to XML Schemas, see Chapter 16, Managing XML Schemas.
The following is one line from an XML Schema:
<xs:element name="street" type="xs:string" minOccurs="1"/>
11.3
Shredding with Annotated XML Schemas
307
This line defines an XML element called street and declares that its data type is xs:string
and that this element has to occur at least once. You can add a simple annotation to this element
definition to indicate that the element should be shredded into the column STREET of the table
ADDRESS. The annotation consists of two additional attributes in the element definition, as
follows:
<xs:element name="street" type="xs:string" minOccurs="1"
db2-xdb:rowSet="ADDRESS" db2-xdb:column="STREET"/>
The same annotation can also be provided as schema elements instead of attributes, as shown
next. You will see later in Figure 11.8 why this can be useful.
<xs:element name="street" type="xs:string" minOccurs="1">
<xs:annotation>
<xs:appinfo>
<db2-xdb:rowSetMapping>
<db2-xdb:rowSet>ADDRESS</db2-xdb:rowSet>
<db2-xdb:column>STREET</db2-xdb:column>
</db2-xdb:rowSetMapping>
</xs:appinfo>
</xs:annotation>
<xs:element/>
The prefix xs is used for all constructs that belong to the XML Schema language, and the prefix
db2-xdb is used for all DB2-specific schema annotations. This provides a clear distinction and
ensures that the annotated schema validates the same XML documents as the original schema.
There are 14 different types of annotations. They allow you to specify what to shred, where to
shred to, how to filter or transform the shredded data, and in which order to execute inserts into
the target tables. Table 11.4 provides an overview of the available annotations, broken down into
logical groupings by user task. The individual annotations are further described in Table 11.5.
Table 11.4
Overview and Grouping of Schema Annotations
If You Want to
Use This Annotation
Specify the target tables to shred into
db2-xdb:rowSet
db2-xdb:column
db2-xdb:SQLSchema
db2-xdb:defaultSQLSchema
Specify what to shred
db2-xdb:contentHandling
Transform data values while shredding
db2-xdb:expression
db2-xdb:normalization
db2-xdb:truncate
Filter data
db2-xdb:condition
db2-xdb:locationPath
(continues)
308
Table 11.4
Chapter 11
Converting XML to Relational Data
Overview and Grouping of Schema Annotations (Continued)
If You Want to
Use This Annotation
Map an element or attribute to multiple columns
db2-xdb:rowSetMapping
Map several elements or attributes to the
same column
db2-xdb:table
Define the order in which rows are inserted
into the target table, to avoid referential
integrity violations
db2-xdb:rowSetOperationOrder
db2-xdb:order
Table 11.5
XML Schema Annotations
Annotation
Description
db2-xdb:defaultSQLSchema
The default relational schema for the target tables.
db2-xdb:SQLSchema
Overrides the default schema for individual tables.
db2-xdb:rowSet
The table name that the element or attribute is
mapped to
db2-xdb:column
The column name that the element or attribute is
mapped to.
db2-xdb:contentHandling
For an XML element, this annotation defines how
to derive the value that will be inserted into the target column. You can chose the text value of just this
element (text), the concatenation of this element’s
text and the text of all its descendant nodes
(stringValue), or the serialized XML (including
all tages) of this element and all descendants
(serializeSubtree). If you omit this annotation,
DB2 chooses an appropriate default based on the
nature of the respective element.
db2-xdb:truncate
Specifies whether a value should be truncated if
its length is greater than the length of the target
column.
db2-xdb:normalization
Specifies how to treat whitespace—valid values are
whitespaceStrip, canonical, and
original
db2-xdb:expression
Specifies an expression that is to be applied to the
data before insertion into the target table.
11.3
Shredding with Annotated XML Schemas
Table 11.5
309
XML Schema Annotations (Continued)
Annotation
Description
db2-xdb:locationPath
Filters based on the XML context. For example, if it is a
customer address then shred to the cust table; if it is an
employee address then shred to the employee table.
db2-xdb:condition
Specifies value conditions so that data is inserted into a
target table only if all conditions are true.
db2-xdb:rowSetMapping
Enables users to specify multiple mappings, to the same or
different tables, for an element or attribute.
db2-xdb:table
Maps multiple elements or attributes to a single column.
db2-xdb:order
Specifies the insertion order of rows among multiple
tables.
db2-xdb:rowSetOperationOrder
Groups together multiple db2-xdb:order annotations.
To demonstrate annotated schema decomposition we use the shredding scenario in Figure 11.1 as
an example. Assume that the target tables have been defined as shown in Figure 11.1. An annotated schema that defines the desired mapping is provided in Figure 11.8. Let’s look at the lines
that are highlighted in bold font. The first bold line declares the namespace prefix db2-xdb,
which is used throughout the schema to distinguish DB2-specific annotations from regular XML
Schema tags. The first use of this prefix is in the annotation db2-xdb:defaultSQLSchema,
which defines the relational schema of the target tables. The next annotation occurs in the definition of the element name. The two annotation attributes db2-xdb:rowSet="ADDRESS" and
db2-xdb:column="NAME" define the target table and column for the name element. Similarly,
the street and city elements are also mapped to respective columns of the ADDRESS table. The
next two annotations map the phone number and the type attribute to columns in the PHONES
table. The last block of annotations belongs to the XML Schema definition of the Cid attribute.
Since the Cid attribute value becomes the join key between the ADDRESS and the PHONE table, it
has to be mapped to both tables. Two row set mappings are necessary, which requires the use of
annotation elements instead of annotation attributes. The first db2-xdb:rowSetMapping maps
the Cid attribute to the CID column in the ADDRESS table. The second db2-xdb:rowSet
Mapping assigns the Cid attribute to the CID column in the PHONES table.
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
elementFormDefault="qualified"
xmlns:db2-xdb="http://www.ibm.com/xmlns/prod/db2/xdb1" >
<xs:annotation>
<xs:appinfo>
<db2-xdb:defaultSQLSchema>db2admin</db2-xdb:defaultSQLSchema>
</xs:appinfo>
</xs:annotation>
Figure 11.8
Annotated schema to implement the shredding in Figure 11.1 (continues)
310
Chapter 11
Converting XML to Relational Data
<xs:element name="customerinfo">
<xs:complexType>
<xs:sequence>
<xs:element name="name" type="xs:string" minOccurs="1"
db2-xdb:rowSet="ADDRESS" db2-xdb:column="NAME"/>
<xs:element name="addr" minOccurs="1"
maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="street" type="xs:string"
minOccurs="1" db2-xdb:rowSet="ADDRESS"
db2-xdb:column="STREET"/>
<xs:element name="city" type="xs:string"
minOccurs="1" db2-xdb:rowSet="ADDRESS"
db2-xdb:column="CITY"/>
<xs:element name="prov-state" type="xs:string"
minOccurs="1" />
<xs:element name="pcode-zip" type="xs:string"
minOccurs="1" />
</xs:sequence>
<xs:attribute name="country" type="xs:string" />
</xs:complexType>
</xs:element>
<xs:element name="phone" minOccurs="0"
maxOccurs="unbounded" db2-xdb:rowSet="PHONES"
db2-xdb:column="PHONENUM">
<xs:complexType>
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="type" form="unqualified"
type="xs:string" db2-xdb:rowSet="PHONES"
db2-xdb:column="PHONETYPE"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:element>
</xs:sequence>
<xs:attribute name="Cid" type="xs:integer">
<xs:annotation>
<xs:appinfo>
<db2-xdb:rowSetMapping>
<db2-xdb:rowSet>ADDRESS</db2-xdb:rowSet>
<db2-xdb:column>CID</db2-xdb:column>
</db2-xdb:rowSetMapping>
<db2-xdb:rowSetMapping>
<db2-xdb:rowSet>PHONES</db2-xdb:rowSet>
<db2-xdb:column>CID</db2-xdb:column>
</db2-xdb:rowSetMapping>
</xs:appinfo>
</xs:annotation>
</xs:attribute>
</xs:complexType>
</xs:element>
</xs:schema>
Figure 11.8
Annotated schema to implement the shredding in Figure 11.1 (Continued)
11.3
Shredding with Annotated XML Schemas
11.3.2
311
Defining Schema Annotations Visually in IBM Data Studio
You can add annotations to an XML Schema manually, using any text editor or XML Schema
editor. Alternatively, you can use the Annotated XSD Mapping Editor in IBM Data Studio
Developer. To invoke the editor, right-click on an XML Schema name and select Open With,
Annotated XSD Mapping Editor. A screenshot of the mapping editor is shown in Figure
11.9. The left side of the editor shows the hierarchical document structure defined by the XML
Schema (Source). The right side shows the tables and columns of the relational target schema
(Target). You can add mapping relationships by connecting source items with target columns.
There is also a discover function to find probable relationships. Mapped relationships are represented in the mapping editor by lines drawn between source elements and target columns.
Figure 11.9
11.3.3
Annotated XSD Mapping Editor in Data Studio Developer
Registering an Annotated Schema
After you have created your annotated XML Schema you need to register it in the XML Schema
Repository of the database. DB2’s XML Schema Repository is described in detail in Chapter 16,
Managing XML Schemas. For the annotated schema in Figure 11.8 it is sufficient to issue the
REGISTER XMLSCHEMA command with its COMPLETE and ENABLE DECOMPOSITION options as
shown in Figure 11.10. In this example the XML Schema is assumed to reside in the file
/xml/myschemas/cust2.xsd. Upon registration it is assigned the SQL identifier db2admin.
cust2xsd. This identifier can be used to reference the schema later. The COMPLETE option of the
command indicates that there are no additional XML Schema documents to be added. The option
ENABLE DECOMPOSITION indicates that this XML Schema can be used not only for document
validation but also for shredding.
312
Chapter 11
Converting XML to Relational Data
REGISTER XMLSCHEMA 'http://pureXMLcookbook.org'
FROM '/xml/myschemas/cust2.xsd'
AS db2admin.cust2xsd COMPLETE ENABLE DECOMPOSITION;
Figure 11.10
Registering an annotated XML schema
Figure 11.11 shows that you can query the DB2 catalog view syscat.xsrobjects to determine whether a registered schema is enabled for decomposition (Y) or not (N).
SELECT SUBSTR(objectname,1,10) AS objectname,
status, decomposition
FROM syscat.xsrobjects ;
OBJECTNAME STATUS DECOMPOSITION
---------- ------ ------------CUST2XSD
C
Y
Figure 11.11
Checking the status of an annotated XML schema
The DECOMPOSITION status of an annotated schema is automatically changed to X (inoperative)
and shredding is disabled, if any of the target tables are dropped or a target column is altered. No
warning is issued when that happens and subsequent attempts to use the schema for shredding
fail. You can also use the following commands to disable and enable an annotated schema for
shredding:
ALTER XSROBJECT cust2xsd DISABLE DECOMPOSITION;
ALTER XSROBJECT cust2xsd ENABLE DECOMPOSITION;
11.3.4
Decomposing One XML Document at a Time
After you have registered and enabled the annotated XML Schema you can decompose XML
documents with the DECOMPOSE XML DOCUMENT command or with a built-in stored procedure.
The DECOMPOSE XML DOCUMENT command is convenient to use in the DB2 Command Line
Processor (CLP) while the stored procedure can be called from an application program or the
CLP. The CLP command takes two parameters as input: the filename of the XML document that
is to be shredded and the SQL identifier of the annotated schema, as in the following example:
DECOMPOSE XML DOCUMENT /xml/mydocuments/cust01.xml
XMLSCHEMA db2admin.cust2xsd VALIDATE;
The keyword VALIDATE is optional and indicates whether XML documents should be validated
against the schema as part of the shredding process. While shredding, DB2 traverses both the
XML document and the annotated schema and detects fundamental schema violations even if the
VALIDATE keyword is not specified. For example, the shredding process fails with an error if a
11.3
Shredding with Annotated XML Schemas
313
mandatory element is missing, even if this element is not being shredded and the VALIDATE keyword is omitted. Similarly, extraneous elements or data type violations also cause the decomposition to fail. The reason is that the shredding process walks through the annotated XML Schema
and the instance document in lockstep and therefore detects many schema violations “for free”
even if the XML parser does not perform validation.
To decompose XML documents from an application program, use the stored procedure XDBDECOMPXML. The parameters of this stored procedure are shown in Figure 11.12 and described in
Table 11.6.
>>-XDBDECOMPXML--(--rschema--,--xmlschemaname--,--xmldoc--,---->
>--documentid--,--validation--,--reserved--,--reserved--,------>
>--reserved--)------------------------------------------------><
Figure 11.12
Table 11.6
Syntax and parameters of the stored procedure XDBDECOMPXML
Description of the Parameters of the Stored Procedure XDBDECOMPXML
Parameter
Description
rschema
The relational schema part of the two-part SQL identifier of the annotated XML
Schema. For example, if the SQL identifier of the XML Schema is
db2admin.cust2xsd, then you should pass the string 'db2admin' to this
parameter. In DB2 for z/OS this value must be either 'SYSXSR' or NULL.
xmlschemaname
The second part of the two-part SQL identifier of the annotated XML Schema. If
the SQL identifier of the XML Schema is db2admin.cust2xsd, then you pass
the string 'cust2xsd' to this parameter. This value cannot be NULL.
xmldoc
In DB2 for Linux, UNIX, and Windows, this parameter is of type BLOB(1M)
and takes the XML document to be decomposed. In DB2 for z/OS this parameter is of type CLOB AS LOCATOR. This parameter cannot be NULL.
documentid
A string that the caller can use to identify the input XML document. The value
provided will be substituted for any use of $DECOMP_DOCUMENTID specified in
the db2-xdb:expression or db2-xdb:condition annotations.
validation
Possible values are: 0 (no validation) and 1 (validation is performed). This
parameter does not exist in DB2 for z/OS.
reserved
Parameters reserved for future use. The values passed for these arguments must
be NULL. These parameters do not exist in DB2 for z/OS.
314
Chapter 11
Converting XML to Relational Data
A Java code snippet that calls the stored procedure using parameter markers is shown in Figure 11.13
CallableStatement callStmt = con.prepareCall(
"call SYSPROC.XDBDECOMPXML(?,?,?,?,?, null, null, null)");
File xmldoc = new File("c:\mydoc.xml");
FileInputStream xmldocis = new FileInputStream(xmldoc);
callStmt.setString(1, "db2admin" );
callStmt.setString(2, "cust2xsd" );
// document to be shredded:
callStmt.setBinaryStream(3,xmldocis,(int)xmldoc.length() );
callStmt.setString(4, "mydocument26580" );
// no schema validation in this call:
callStmt.setInt(5, 0);
callStmt.execute();
Figure 11.13
Java code that invokes the stored procedure XDBDECOMPXML
While the input parameter for XML documents is of type CLOB AS LOCATOR in DB2 for z/OS, it
is of type BLOB(1M) in DB2 for Linux, UNIX, and Windows. If you expect your XML documents to be larger than 1MB, use one of the stored procedures listed in Table 11.7. These stored
procedures are all identical except for their name and the size of the input parameter xmldoc.
When you call a stored procedure, DB2 allocates memory according to the declared size of the
input parameters. For example, if all of your input documents are at most 10MB in size, the
stored procedure XDBDECOMPXML10MB is a good choice to conserve memory.
Table 11.7 Stored Procedures for Different Document Sizes (DB2 for Linux, UNIX,
and Windows)
Stored Procedure
Document Size
Supported since
XDBDECOMPXML
≤1MB
DB2 9.1
XDBDECOMPXML10MB
≤10MB
DB2 9.1
XDBDECOMPXML25MB
≤25MB
DB2 9.1
XDBDECOMPXML50MB
≤50MB
DB2 9.1
XDBDECOMPXML75MB
≤75MB
DB2 9.1
XDBDECOMPXML100MB
≤100MB
DB2 9.1
XDBDECOMPXML500MB
≤500MB
DB2 9.5 FP3
11.3
Shredding with Annotated XML Schemas
315
Table 11.7 Stored Procedures for Different Document Sizes (DB2 for Linux, UNIX,
and Windows) (Continued)
Stored Procedure
Document Size
Supported since
XDBDECOMPXML1GB
≤1GB
DB2 9.5 FP3
XDBDECOMPXML1_5GB
≤1.5GB
DB2 9.7
XDBDECOMPXML2GB
≤2GB
DB2 9.7
For platform compatibility, DB2 for z/OS supports the procedure XDBDECOMPXML100MB with the
same parameters as DB2 for Linux, UNIX, and Windows, including the parameter for validation.
11.3.5
Decomposing XML Documents in Bulk
DB2 9.7 for Linux, UNIX, and Windows introduces a new stored procedure called
XDB_DECOMP_XML_FROM_QUERY. It uses an annotated schema to decompose one or multiple
XML documents selected from a column of type XML, BLOB, or VARCHAR FOR BIT DATA. The
main difference to the procedure XDBDECOMPXML is that XDB_DECOMP_XML_FROM_QUERY
takes an SQL query as a parameter and executes it to obtain the input documents from a DB2
table. For a large number of documents, a LOAD operation followed by a “bulk decomp” can be
more efficient than shredding these documents with a separate stored procedure call for each document. Figure 11.14 shows the parameters of this stored procedure. The parameters commit_
count and allow_access are similar to the corresponding parameters of DB2’s IMPORT utility.
The parameters total_docs, num_docs_decomposed, and result_report are output
parameters that provide information about the outcome of the bulk shredding process. All
parameters are explained in Table 11.8.
>>--XDB_DECOMP_XML_FROM_QUERY--(--rschema--,--xmlschema--,-->
>--query--,--validation--,--commit_count--,--allow_access--,---->
>--reserved--,--reserved2--,--continue_on_error--,-------------->
>--total_docs--,--num_docs_decomposed--,--result_report--)--><
Figure 11.14
The stored procedure XDB_DECOMP_XML_FROM_QUERY
316
Table 11.8
Chapter 11
Converting XML to Relational Data
Parameters for XDB_DECOMP_XML_FROM_QUERY
Parameter
Description
rschema
Same as for XDBDECOMPXML.
xmlschema
Same as xmlschemaname for XDBDECOMPXML.
query
A query string of type CLOB(1GB), which cannot be NULL. The query must be
an SQL or SQL/XML SELECT statement and must return two columns. The first
column must contain a unique document identifier for each XML document in
the second column of the result set. The second column contains the XML
documents to be shredded and must be of type XML, BLOB, VARCHAR FOR BIT
DATA, or LONG VARCHAR FOR BIT DATA.
validation
Possible values are: 0 (no validation) and 1 (validation is performed).
commit_count
An integer value equal to or greater than 0. A value of 0 means the stored procedure does not perform any commits. A value of n means that a commit is performed after every n successful document decompositions.
allow_access
A value of 1 or 0. If the value is 0, then the stored procedure acquires an exclusive lock on all tables that are referenced in the annotated XML Schema. If the
value is 1, then the stored procedure acquires a shared lock.
reserved,
reserved2
These parameters are reserved for future use and must be NULL.
continue_on
_error
Can be 1 or 0. A value of 0 means the procedure stops upon the first document
that cannot be decomposed; for example, if the document does not match the
XML Schema.
total_docs
An output parameter that indicates the total number of documents that the procedure tried to decompose.
num_docs_
decomposed
An output parameter that indicates the number of documents that were
successfully decomposed.
result_report
An output parameter of type BLOB(2GB). It contains an XML document that
provides diagnostic information for each document that was not successfully
decomposed. This report is not generated if all documents shredded successfully. The reason this is a BLOB field (rather than CLOB) is to avoid codepage
conversion and potential truncation/data loss if the application code page is
materially different from the database codepage.
Figure 11.15 shows an invocation of the XDB_DECOMP_XML_FROM_QUERY stored procedure in
the CLP. This stored procedure call reads all XML documents from the info column of the
customer table and shreds them with the annotated XML Schema db2admin.cust2xsd. The
procedure commits every 25 documents and does not stop if a document cannot be shredded.
11.3
Shredding with Annotated XML Schemas
317
call SYSPROC.XDB_DECOMP_XML_FROM_QUERY
('DB2ADMIN', 'CUST2XSD', 'SELECT cid, info FROM customer',
0, 25, 1, NULL, NULL, '1',?,?,?) ;
Value of output parameters
-------------------------Parameter Name : TOTALDOCS
Parameter Value : 100
Parameter Name : NUMDOCSDECOMPOSED
Parameter Value : 100
Parameter Name : RESULTREPORT
Parameter Value : x''
Return Status = 0
Figure 11.15
Calling the procedure SYSPROC.XDB_DECOMP_XML_FROM_QUERY
If you frequently perform bulk shredding in the CLP, use the command DECOMPOSE XML DOCUMENTS instead of the stored procedure. It is more convenient for command-line use and performs
the same job as the stored procedure XDB_DECOMP_XML_FROM_QUERY. Figure 11.16 shows the
syntax of the command. The various clauses and keywords of the command have the same meaning as the corresponding stored procedure parameters. For example, query is the SELECT statement that provides the input documents, and xml-schema-name is the two-part SQL identifier
of the annotated XML Schema.
>>-DECOMPOSE XML DOCUMENTS IN----'query'----XMLSCHEMA------->
.-ALLOW NO ACCESS-.
>--xml-schema-name--+----------+--+-----------------+----------->
'-VALIDATE-' '-ALLOW ACCESS----'
>--+----------------------+--+-------------------+-------------->
'-COMMITCOUNT--integer-' '-CONTINUE_ON_ERROR-'
>--+--------------------------+--------------------------------><
'-MESSAGES--message-file-'
Figure 11.16
Syntax for the DECOMPOSE XML DOCUMENTS command
Figure 11.17 illustrates the execution of the DECOMPOSE XML DOCUMENTS command in the DB2
Command Line Processor.
DECOMPOSE XML DOCUMENTS IN 'SELECT cid, info FROM customer'
XMLSCHEMA db2admin.cust2xsd MESSAGES decomp_errors.xml ;
DB216001I The DECOMPOSE XML DOCUMENTS command successfully
decomposed all "100" documents.
Figure 11.17
Example of the DECOMPOSE XML DOCUMENTS command
318
Chapter 11
Converting XML to Relational Data
If you don’t specify a message-file then the error report is written to standard output. Figure
11.18 shows a sample error report. For each document that failed to shred, the error report shows
the document identifier (xdb:documentId). This identifier is obtained from the first column that
is produced by the SQL statement in the DECOMPOSE XML DOCUMENTS command. The error
report also contains the DB2 error message for each document that failed. Figure 11.18 reveals
that document 1002 contains an unexpected XML attribute called status, and that document
1005 contains an element or attribute value abc that is invalid because the XML Schema
expected to find a value of type xs:integer. If you need more detailed information on why a
document is not valid for a given XML Schema, use the stored procedure XSR_GET_PARSING_
DIAGNOSTICS, which we discuss in section 17.6, Diagnosing Validation and Parsing Errors.
<?xml version='1.0' ?>
<xdb:errorReport
xmlns:xdb="http://www.ibm.com/xmlns/prod/db2/xdb1">
<xdb:document>
<xdb:documentId>1002</xdb:documentId>
<xdb:errorMsg>SQL16271N Unknown attribute "status" at or
near line “1" in document "1002".</xdb:errorMsg>
</xdb:document>
<xdb:document>
<xdb:documentId>1005</xdb:documentId>
<xdb:errorMsg> SQL16267N An XML value "abc" at or near
line "1" in document "1005" is not valid according to
its declared XML schema type "xs:integer" or is outside
the supported range of values for the XML schema type
</xdb:errorMsg>
</xdb:document>
</xdb:errorReport>
Figure 11.18
11.4
Sample error report from bulk decomp
SUMMARY
When you consider shredding XML documents into relational tables, remember that XML and
relational data are based on fundamentally different data models. Relational tables are flat and
unordered collections of rows with strictly typed columns, and each row in a table must have the
same structure. One-to-many relationships are expressed by using multiple tables and join relationships between them. In contrast, XML documents tend to have a hierarchical and nested
structure that can represent multiple one-to-many relationships in a single document. XML
allows elements to be repeated any number of times, and XML Schemas can define hundreds or
thousands of optional elements and attributes that may or may not exist in any given document.
Due to these differences, shredding XML data to relational tables can be difficult, inefficient, and
sometimes prohibitively complex.
11.4
Summary
319
If the structure of your XML data is of limited complexity such that it can easily be mapped to
relational tables, and if your XML format is unlikely to change over time, then XML shredding
can sometimes be useful to feed existing relational applications and reporting software.
DB2 offers two methods for shredding XML data. The first method uses SQL INSERT statements
with the XMLTABLE function. One such INSERT statement is required for each target table and
multiple statements can be combined in a stored procedure to avoid repetitive parsing of the same
XML document. The shredding statements can include XQuery and SQL functions, joins to other
tables, or references to DB2 sequences. These features allow for customization and a high degree
of flexibility in the shredding process, but require manual coding. The second approach for shredding XML data uses annotations in an XML Schema to define the mapping from XML to relational tables and columns. IBM Data Studio Developer provides a visual interface to create this
mapping conveniently with little or no manual coding.
This page intentionally left blank
C
H A P T E R
12
Updating and
Transforming
XML Documents
T
his chapter describes techniques to update and transform XML documents. DB2 pureXML
supports three general techniques for modifying XML documents:
• Full document replacement, which allows an application to replace an existing XML
document with an updated document. It is up to the application to provide the new document. For DB2, this is a full-document operation. See section 12.1.
• The XQuery Update Facility, which is a standardized extension to XQuery that allows
you to modify, insert, or delete individual elements and attributes within an XML document. Such updates are also known as subdocument level updates, node-level updates,
or partial document updates. See sections 12.2 through 12.13.
• Extensible Stylesheet Language Transformation (XSLT), which lets you apply a style
sheet to an XML document to transform it into a different XML format, HTML format,
or some other user-defined format. See section 12.14.
The discussion in this chapter assumes that you are familiar with querying XML data as
described in Chapters 6 through 9. When you update an XML document you can optionally validate it against an XML Schema, either explicitly with the XMLVALIDATE function or automatically with a trigger. If the updated document does not comply with the specified XML Schema,
the update fails. The validation of XML documents upon insert and update is explained in Chapter 17, Validating XML Documents against XML Schemas.
321
322
12.1
Chapter 12
Updating and Transforming XML Documents
REPLACING A FULL XML DOCUMENT
You can use regular relational SQL UPDATE statements to replace a full XML document in a table
with a new document. This treats the XML document as a “black box” and does not modify individual elements or attributes. Your application needs to provide the new document, possibly after
reading an existing document and modifying it in the application.
An SQL UPDATE statement often has a WHERE clause to qualify one or more specific rows that
you want to update. When you replace one document with another, the UPDATE statement typically needs to select a single row. Otherwise multiple existing documents might get replaced by
the same new document, which is typically not what you want. You can use relational predicates,
XML predicates, or any combination of those to select the appropriate row in which you want to
update a document. Chapters 6 and 7 on querying XML data provide many examples of such
predicates.
In this section we look at UPDATE statements that perform full-document replacement with various different predicates to select the appropriate document:
• Predicate on the relational columns of the table
• Predicate on an XML element value
• Predicate on an XML attribute value
• Predicates on XML and relational values
We also show how to provide new documents via parameter markers and how to remove existing
documents by replacing them with a relational NULL value.
The UPDATE statement in Figure 12.1 replaces the existing XML document in the info column
with a new XML document, but only in the row where the relational column cid has the value
1000. The SET clause of the UPDATE statement performs the assignment of the new document to
the XML column info in the selected row.
UPDATE customer
SET info =
'<?xml version="1.0" encoding="UTF-8" ?>
<customerinfo Cid="1010">
<name>Larry Trotter</name>
<addr country="England">
<street>5 Rosewood</street>
<city>Winchester</city>
<prov-state>Hampshire</prov-state>
<pcode-zip>HU16 6666</pcode-zip>
</addr>
<phone type="work">416-555-1358</phone>
</customerinfo>'
WHERE cid = 1000;
Figure 12.1
Replacing a full XML document based on a relational value
12.1
Replacing a Full XML Document
323
In the example in Figure 12.1, the new XML document is provided as a literal value. More commonly you will use UPDATE statements in your application with parameter markers or host variables that carry the new XML document, as shown in Figure 12.2.
UPDATE customer SET info = ?
WHERE cid = 1000
UPDATE customer SET info = :hvar WHERE cid = 1000
Figure 12.2
Full document replacement with parameter marker or host variable
You can also use parameter markers or host variables to provide the relational value by which you
select the row where you want to replace the XML document (see Figure 12.3).
UPDATE customer SET info = ?
WHERE cid = ?
UPDATE customer SET info = :hvar1 WHERE cid = :hvar2
Figure 12.3
Full document replacement with parameter markers or host variables
Figure 12.4 shows UPDATE statements that use various different WHERE clauses to select the document that gets replaced in the SET clause of the statement. The new document is provided through
a parameter marker, but it could be a literal document as shown previously in Figure 12.1. The first
UPDATE in Figure 12.4 replaces the document where the name element has the value Larry
Trotter. Ideally there should be only one such document in the table. Otherwise all documents
where the name is Larry Trotter are replaced. Also, remember that the square brackets in the
XMLEXISTS predicate are important. If you omit them, all rows qualify and are updated.
The second UPDATE statement in Figure 12.4 uses a conjunction of an XML predicate and a relational predicate to qualify the document to be replaced. The third UPDATE statement uses an
XML predicate on the attribute Cid in the XML data. The fourth UPDATE statement replaces the
document of the customer whose work phone number is 416-555-1358. Note that the four
UPDATE statements only differ in their WHERE clauses, which you can code in many different
ways to select the desired document for replacement.
UPDATE customer
SET info = ?
WHERE XMLEXISTS('$INFO/customerinfo[name = "Larry Trotter"]');
UPDATE customer
SET info = ?
WHERE XMLEXISTS('$INFO/customerinfo[name = "Larry Trotter"]')
AND cid = 1000;
UPDATE customer
SET info = ?
WHERE XMLEXISTS('$INFO/customerinfo[@Cid = 1005]');
Figure 12.4
Full XML document replacement with various different WHERE clauses
324
Chapter 12
Updating and Transforming XML Documents
UPDATE customer
SET info = ?
WHERE XMLEXISTS('$INFO/customerinfo/phone[@type="work"
and text()="416-555-1358"]');
Figure 12.4
Full XML document replacement with various different WHERE clauses (Continued)
If you run the UPDATE statements shown in Figure 12.4 in DB2 for z/OS, remember that the
XMLEXISTS predicate always requires a PASSING clause, like this:
…WHERE XMLEXISTS('$i/customerinfo[@Cid = 1005]'
PASSING info AS "i")
You can also replace an existing XML document with a NULL value, which removes the document from the row without deleting the row:
UPDATE customer SET info = NULL WHERE cid = 1000
The disadvantage of full document replacement is that it is left to the application to provide a new
and possibly updated document. Often this means that an application has to read a document
from the database, parse and modify the document using application code, and then execute one
of the UPDATE statements discussed in this section to replace the original document with the
updated one. This process requires dedicated application logic as well as moving XML documents back and forth between the application and the DB2 server. This can be improved with
XQuery Updates, which are discussed next.
12.2
MODIFYING DOCUMENTS WITH XQUERY UPDATES
In many situations you want to make modifications to your XML documents and not just replace
one document with another. Since version 9.5, DB2 for Linux, UNIX, and Windows supports the
XQuery Update Facility, a standardized extension to XQuery that allows you to modify, insert, or
delete individual elements and attributes within an XML document. These capabilities make
updating XML data easier and provide better performance than performing full document
replacements.
XQuery Updates allow you to modify individual XML nodes, such as elements and attributes, in
the following ways:
• Replace the value of a node
• Replace a node with a new one
• Insert a new node (at a specific location, such as before or after a given node)
12.2
Modifying Documents with XQuery Updates
325
• Delete a node
• Rename a node
• Modify multiple nodes in a document in a single statement
• Update multiple documents in a single statement
To perform updates of an XML document, use the XQuery transform expression. This expression can start with the optional transform keyword and consists of three clauses: the copy
clause, the modify clause, and the return clause (Figure 12.5). The intuitive idea of the transform expression is that the copy clause assigns an input document from an XML column to a
variable, then the modify clause applies one or more modifications to that variable, and finally
the return clause produces the result of the transform expression. XQuery is a case-sensitive
language and all keywords have to be in lowercase, including copy, modify, and return.
.-transform-.
>>-+------------+-------------------------------------------------->
>--copy----$VariableName--:=--CopySourceExpression-+--------------->
>--modify--ModifyExpression---------------------------------------->
>--return--ReturnExpression----------------------------------------|
Figure 12.5
High-level syntax of the transform expression
Such XML modifications can be performed in an SQL UPDATE statement, in a query, or as part of
an INSERT statement (Figure 12.6). If you modify a document in a query, the query reads the
document from an XML column, changes it on-the-fly, and returns the modified document to the
application. This leaves the original version of the document in the DB2 table unchanged. If you
modify a document in an UPDATE statement, you make a permanent change to the data that is
stored in DB2. Such an UPDATE is logged in the DB2 transaction log and subject to all the transaction management concepts that also apply to relational updates, such as commit, rollback, and
recovery, when applicable. Concurrency control (locking) and logging happens at the full document level. You can also modify a new document at insert time if you include an XQuery transform expression in an SQL INSERT statement.
326
Chapter 12
Modify a document as part of a
query. The original document in
the database is not changed.
Make a permanent change
to a document in the database.
This UPDATE is logged.
XML
Document
Updating a
stored document
Figure 12.6
Updating and Transforming XML Documents
Modify a new document during
INSERT. The modified document
is inserted and logged.
XML
Document
XML
Document
XML
Document
XML
Document
Updating a returned
document upon retrieval.
Updating a new document
upon insert.
Three ways of modifying XML documents
The concepts of changing XML element or attribute values, inserting new elements, renaming
elements, and so on are independent from whether you do this in an UPDATE statement, in a
query, or in an INSERT statement. The following sections describe the capabilities of the XQuery
transform expressions and their usage in SQL UPDATE statements. Sections 12.10 and 12.11
then show how the same document modifications can be performed in queries and INSERT
statements.
12.3
UPDATING THE VALUE OF AN XML NODE IN A DOCUMENT
A simple and common kind of XML update is to change the value of a specific element or attribute node in an XML document.
12.3.1
Replacing an Element Value
As an example, assume you have to update the address of a customer to change the value of the
street element to “43 WestCreek”. Figure 12.7 shows the original document on the left and
the desired updated document on the right.
Original document
Updated document
<customerinfo Cid="1002">
<name>Jim Noodle</name>
<addr country="Canada">
<street>25 EastCreek</street>
<city>Markham</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N9C 3T6</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
</customerinfo>
<customerinfo Cid="1002">
<name>Jim Noodle</name>
<addr country="Canada">
<street>43 WestCreek</street>
<city>Markham</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N9C 3T6</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
</customerinfo>
Figure 12.7
Changing the value of an element
12.3
Updating the Value of an XML Node in a Document
327
The UPDATE statement that performs the desired modification of the document is shown in Figure
12.8. It assumes that the document to be updated resides in the info column of the customer
table in a row with the relational cid value 1002. The SET clause of the UPDATE statement assigns
a new value to the XML column info. This new value is produced by the XMLQUERY function,
which contains an XQuery transform expression. The copy clause refers to the original XML
column value ($INFO), and assigns the original document to the variable $mycust. Subsequently,
the modify clause manipulates this variable. The modify clause contains the update operation
replace value of to replace the value of the element street with the new string literal “43
WestCreek”. Finally, the variable $mycust, which contains the modified document, is returned
in the return clause of the transform expression.
UPDATE customer
SET info = XMLQUERY('
transform
copy $mycust := $INFO
modify do replace
value of $mycust/customerinfo/addr/street
with "43 WestCreek"
return $mycust ')
WHERE cid = 1002
Figure 12.8
Update statement to replace the value of an element
In Figure 12.8 and many other typical update cases, the right side of the copy clause is just the
variable that refers to the original document, in this case $INFO. The right side of the copy clause
could be a more complex expression, but it must always evaluate to a single node. It cannot be an
empty sequence or a sequence of more than one item. This single node can have descendants,
which means it can be (and often is) the root of a full XML document. In many update examples
you will also see that the return clause simply returns the variable that holds the modified document. However, the return clause could contain a more complex expression, including element
construction or a FLWOR expression. Updates with more complex expressions in the copy and the
return clauses are discussed in section 12.10.
Since the transform keyword is optional, it is omitted from here on.
12.3.2
Replacing an Attribute Value
Replacing an attribute value is just as easy as replacing an element value. The UPDATE statement
in Figure 12.9 changes the Cid attribute to the new value 1099. The entire UPDATE statement is
the same as in Figure 12.8 except that the path to the target node and the new value are different.
The literal value 1099 could be in double quotes but does not have to be because it can be interpreted as a number.
328
Chapter 12
Updating and Transforming XML Documents
UPDATE customer
SET info = XMLQUERY('
copy $mycust := $INFO
modify do replace
value of $mycust/customerinfo/@Cid
with 1099
return $mycust ')
WHERE cid = 1002
Figure 12.9
12.3.3
Replacing the value of an attribute
Replacing a Value Using a Parameter Marker
Often you will want to prepare and compile an UPDATE statement only once, and then pass in a
new value every time you execute it. This avoids recompiling the statement in the database server
for each execution. The mechanism to use parameters is the same as for SQL/XML queries. The
PASSING clause of the XMLQUERY function allows you to pass a SQL-style parameter marker
(“?”) as a variable ($z) into the XQuery expression (Figure 12.10). Note that XQuery variables
are case-sensitive. For example, $z and $Z are not the same. The query in Figure 12.10 also uses
a parameter marker in the WHERE clause to select the row to be updated.
UPDATE customer
SET info = XMLQUERY('
copy $newinfo := $INFO
modify do replace
value of $newinfo/customerinfo/phone
with $z
return $newinfo'
PASSING CAST(? AS VARCHAR(15)) AS "z")
WHERE cid = ?
Figure 12.10
Updating XML values with parameter markers
You can run the UPDATE statement in Figure 12.10 from an application, such as a Java program.
You would use JDBC statements to prepare and compile the statement, bind a value from an
application variable to the parameter marker, and then execute the statement.
12.3.4
Replacing Multiple Values in a Document
You can update multiple values in the same document in a single UPDATE statement. Figure 12.11
illustrates that the modify clause allows for a comma-separated list of update operations. The
entire list is enclosed in parentheses. This enables you to easily combine two or more update
operations in a single statement.
12.3
Updating the Value of an XML Node in a Document
329
UPDATE customer
SET info = XMLQUERY('
copy $newinfo := $INFO
modify
(do replace
value of $newinfo/customerinfo/addr/street
with "85 Leicester Rd" ,
do replace
value of $newinfo/customerinfo/addr/pcode-zip
with "W7B 8X1" )
return $newinfo ')
WHERE cid = 1002
Original document
Updated document
<customerinfo Cid="1002">
<name>Jim Noodle</name>
<addr country="Canada">
<street>25 EastCreek</street>
<city>Markham</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N9C 3T6</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
</customerinfo>
<customerinfo Cid="1002">
<name>Jim Noodle</name>
<addr country="Canada">
<street>85 Leicester Rd</street>
<city>Markham</city>
<prov-state>Ontario</prov-state>
<pcode-zip>W7B 8X1</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
</customerinfo>
Figure 12.11
Updating multiple values in a single UPDATE statement
If you want to update multiple values in a single UPDATE statement and use parameter markers
for all values, the PASSING clause of the XMLQUERY function needs to contain a list of typed
parameter markers together with the variable names that refer to them (see Figure 12.12).
UPDATE customer
SET info = XMLQUERY('
copy $newinfo := $INFO
modify
(do replace
value of $newinfo/customerinfo/addr/street
with $str,
do replace
value of $newinfo/customerinfo/addr/pcode-zip
with $zip )
return $newinfo'
PASSING CAST(? AS VARCHAR(30)) AS "str",
CAST(? AS VARCHAR(10)) AS "zip")
WHERE cid = 1002
Figure 12.12
12.3.5
Updating multiple values with parameter markers
Replacing an Existing Value with a Computed Value
The value that you use to update an existing element or attribute does not necessarily have to be a
fixed value but can be computed based on the existing values in the document. For example,
330
Chapter 12
Updating and Transforming XML Documents
assume that the customer documents can contain an element numorders that tracks the total
number of orders that a customer has placed. The UPDATE statement in Figure 12.13 increments
the value of the element numorders by 1.
UPDATE customer
SET info = XMLQUERY('
copy $newinfo := $INFO
modify do replace
value of $newinfo/customerinfo/numorders
with $newinfo/customerinfo/numorders + 1
return $newinfo ')
WHERE cid = 1002
Original document
Updated document
<customerinfo Cid="1002">
<name>Jim Noodle</name>
<addr country="Canada">
<street>25 EastCreek</street>
<city>Markham</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N9C 3T6</pcode-zip>
<customerinfo Cid="1002">
<name>Jim Noodle</name>
<addr country="Canada">
<street>25 EastCreek</street>
<city>Markham</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N9C 3T6</pcode-zip>
</addr>
<numorders>16</numorders>
</customerinfo>
</addr>
<numorders>17</numorders>
</customerinfo>
Figure 12.13
Incrementing the numeric value of an element
Similarly, the UPDATE statement in Figure 12.14 modifies the value of the element street by
appending an apartment number. It uses the XQuery function concat.
UPDATE customer
SET info = XMLQUERY('
copy $newinfo := $INFO
modify do replace
value of $newinfo/customerinfo/addr/street
with concat($newinfo/customerinfo/addr/street,
" Apt #4")
return $newinfo ')
WHERE cid = 1002
Figure 12.14
Appending an apartment number to the street
If you write more elaborate updates, you might find it tedious to repeat a long path such as
$newinfo/customerinfo/addr/street whenever you reference an existing node in the document. Figure 12.15 uses a let clause to assign this long path to the variable $s. Subsequently, the
do replace value clause uses $s multiple times instead of repeating the long path. Note that
the modify clause contains a FLWOR expression that only consists of the let and the return
clause while the for, where, and order by clauses are omitted. Hence, the XQuery expression
12.4
Replacing XML Nodes in a Document
331
in Figure 12.15 also contains two return clauses. The first one belongs to the let and its FLWOR
expression (bold font), and the second one is the return of the transform expression.
UPDATE customer
SET info = XMLQUERY('
copy $newinfo := $INFO
modify
let $s := $newinfo/customerinfo/addr/street
return do replace
value of $s
with concat($s, " Apt #4")
return $newinfo ')
WHERE cid = 1002
Figure 12.15
12.4
Using let to assign a long path to a short variable
REPLACING XML NODES IN A DOCUMENT
Suppose a customer has moved to a different city and you need to update the address in the XML
document that holds the customer’s information. You could write an UPDATE statement with
replace value of expressions to individually change the values of all elements and attributes
that make up the address of the customer (country, street, city, prov-state, and pcodezip). However, such an update can be lengthy and tedious to write. It can be a lot easier to simply
replace the existing addr element and all of its children with a new addr element. Such a
replacement of a node is done with a replace expression. The replace expression works differently from the replace value of expression. The former replaces the whole node (the old
node is deleted), whereas the latter replaces only the value of the target node. Figure 12.16 shows
an UPDATE statement that replaces the existing addr element and all of its child nodes with a new
addr fragment.
The structure of the new XML fragment does not have to be identical to the original one. Indeed,
the new address in Figure 12.16 contains the elements state and zipcode, which are different
from the original address. Similarly, you could decide to replace the original addr element and
all of its children, with a single email element, if you wanted to. If you choose to validate
updated documents with an XML Schema, the new structure of the document has to conform
with the XML Schema.
332
Chapter 12
Updating and Transforming XML Documents
UPDATE customer
SET info = XMLQUERY('
copy $newinfo := $INFO
modify do replace $newinfo/customerinfo/addr
with <addr country="United States">
<street>555 Bailey Avenue</street>
<city>San Jose</city>
<state>California</state>
<zipcode>95141</zipcode>
</addr>
return $newinfo ')
WHERE cid = 1002
Original document
Updated document
<customerinfo Cid="1002">
<name>Jim Noodle</name>
<addr country="Canada">
<street>25 EastCreek</street>
<city>Markham</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N9C 3T6</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
</customerinfo>
<customerinfo Cid="1002">
<name>Jim Noodle</name>
<addr country="United States">
<street>555 Bailey Avenue</street>
<city>San Jose</city>
<state>California</prov-state>
<zipcode>95141</zipcode>
</addr>
<phone type="work">905-555-7258</phone>
</customerinfo>
Figure 12.16
Replacing an element node
Note that the new addr fragment in the modify clause of the UPDATE statement in Figure 12.16
is not enclosed in single quotes because it is not a string value. Instead, the new addr element and
its children are constructed with direct element and attribute constructors (see section 8.4, Constructing XML Data). The XML value that provides the new address can also be computed with
an expression. For example, Figure 12.17 uses an XPath expression to obtain the addr element
from the customer whose Cid attribute has the value 1004. This address element replaces the
address of customer 1002.
UPDATE customer
SET info = XMLQUERY('
copy $newinfo := $INFO
modify do replace $newinfo/customerinfo/addr
with
db2-fn:xmlcolumn("CUSTOMER.INFO")/customerinfo[@Cid=1004]/addr
return $newinfo ')
WHERE cid = 1002
Figure 12.17
Updating multiple values in a single UPDATE statement
12.5
Deleting XML Nodes from a Document
12.5
333
DELETING XML NODES FROM A DOCUMENT
This section describes how to delete elements or attributes from a document. As an example, suppose that a phone number of a customer is invalid and you want to remove the entire phone element from the corresponding XML document. Figure 12.18 shows a first attempt at writing an
appropriate UPDATE statement. It looks much like the previous UPDATE statements except that the
updating expression is delete instead of replace value of. In the delete expression, simply
specify the path to the elements or attributes that you want to remove from the document.
UPDATE customer
SET info = XMLQUERY('
copy $newinfo := $INFO
modify do delete $newinfo/customerinfo/phone
return $newinfo')
WHERE cid = 1003
Original document
Updated document
<customerinfo Cid="1003">
<name>Robert Shoemaker</name>
<addr country="Canada">
<street>845 Kean Street</street>
<city>Aurora</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N8X 7F8</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
<phone type="home">416-555-2937</phone>
<phone type="cell">905-555-8743</phone>
</customerinfo>
<customerinfo Cid="1003">
<name>Robert Shoemaker</name>
<addr country="Canada">
<street>845 Kean Street</street>
<city>Aurora</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N8X 7F8</pcode-zip>
</addr>
</customerinfo>
Figure 12.18
Deleting an element
The document that is being updated in Figure 12.18 contains multiple phone elements, and the
delete expression removes all of them. If you don’t want to delete all occurrences of a repeating
element, add a predicate to the target path to delete only selected occurrences. For example, the
following delete expression removes a phone element only if its type attribute has the value
home:
do delete $newinfo/customerinfo/phone[type="home"]
This delete expression removes exactly one phone element from the original document in Figure 12.18, and leaves the other two phone elements untouched. In general, this expression can
delete zero, one, or multiple phone elements from a document, depending on how many phone
elements with type equal to home occur in a given document. Modifying repeating elements is
further discussed in section 12.8.
334
Chapter 12
Updating and Transforming XML Documents
Predicates in the update expression only serve to select
nodes within any given document. They do not help you to efficiently
find the documents that should be updated. Predicates that select documents for update must be placed in the WHERE clause of the SQL
UPDATE statement.They can include XMLEXISTS predicates.
NOTE
If you want to delete an attribute, such as country, simply use a delete expression with an
XPath that points to the attribute:
do delete $newinfo/customerinfo/addr/@country
You can also remove an entire XML fragment from an XML document. For example, the statement in Figure 12.19 deletes the entire addr element including all the child elements and attributes it contains.
UPDATE customer
SET info = XMLQUERY('
copy $newinfo := $INFO
modify
do delete $newinfo/customerinfo/addr
return $newinfo')
WHERE cid = 1002
Original document
Updated document
<customerinfo Cid="1002">
<name>Jim Noodle</name>
<addr country="Canada">
<street>25 EastCreek</street>
<city>Markham</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N9C 3T6</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
</customerinfo>
<customerinfo Cid="1002">
<name>Jim Noodle</name>
<phone type="work">905-555-7258</phone>
</customerinfo>
Figure 12.19
12.6
Deleting an XML fragment
RENAMING ELEMENTS OR ATTTRIBUTES IN A DOCUMENT
The rename expression enables you to change the name of an element or attribute. For example,
the statement in Figure 12.20 renames the addr element to address. The new element name
address is a string literal and must be enclosed in double quotes.
12.7
Inserting XML Nodes into a Document
335
UPDATE customer
SET info = XMLQUERY('
copy $new := $INFO
modify
do rename $new/customerinfo/addr as "address"
return $new ')
WHERE cid = 1002
Original document
Updated document
<customerinfo Cid="1002">
<name>Jim Noodle</name>
< addr country="Canada">
<street>25 EastCreek</street>
<city>Markham</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N9C 3T6</pcode-zip>
</ addr >
<phone type="work">905-555-7258</phone>
</customerinfo>
<customerinfo Cid="1002">
<name>Jim Noodle</name>
<address country="Canada">
<street>25 EastCreek</street>
<city>Markham</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N9C 3T6</pcode-zip>
</address>
<phone type="work">905-555-7258</phone>
</customerinfo>
Figure 12.20
Changing an element name
DB2 never allows you to update a document in a manner that violates the rules for well-formed
XML documents. For example, in an element such as <product xid="15" yid="107"> you
cannot rename the attribute xid to yid. This update operation is rejected because it would produce an element with two attributes that have the same name (yid), which is not permitted in any
XML document.
12.7
INSERTING XML NODES INTO A DOCUMENT
This section describes how to add element or attribute nodes to a document. When you insert a
new element or attribute into a document, you must specify the target position of the new node in
the document. We first discuss the positioning of inserted elements, then the positioning of
inserted attributes, and then look at several examples.
12.7.1
Defining the Position of Inserted Elements
Suppose you want to insert the new element <email>jnoodle@ibm.com</email> into the
XML document for customer Jim Noodle. You have to decide which existing element is going to
be the parent for the new email element. For example, you might decide that email is going to
be a child element of the root element customerinfo. This makes email a sibling of the elements name, addr, and phone. Then you can further choose the position of the email element
among its siblings. For example, should email appear before or after the addr element? Alternatively, you could decide that email is going to be a child element of addr and therefore becomes
a sibling of street, city, prov-state, and pcode-zip.
The insert operation in the modify clause allows you to add new nodes to an XML document.
It offers five ways to specify the position of the new node: into, as last into, as first
336
Chapter 12
Updating and Transforming XML Documents
into, after, and before. Examples of using these five options for a new element are listed in
Table 12.1.
Table 12.1
Five Options for Inserting an Element into a Document
Insert Operation
Position of the Inserted Node
insert <email>jnoodle@ibm.com</email>
into $new/customerinfo
email becomes a child element of
customerinfo. The position of email
among the existing children of
customerinfo is nondeterministic.
insert <email>jnoodle@ibm.com</email>
as last into $new/customerinfo
email becomes the last child element of
customerinfo.
insert <email>jnoodle@ibm.com</email>
as first into $new/customerinfo
email becomes the first child element of
customerinfo.
insert <email>jnoodle@ibm.com</email>
after $new/customerinfo/addr
email becomes a sibling of addr and
therefore a child of customerinfo. email
appears immediately after addr.
insert <email>jnoodle@ibm.com</email>
before $new/customerinfo/addr
email becomes a sibling of addr and a child
of customerinfo. email appears immediately before addr.
The path that defines the target location of the insert, such as $new/customerinfo or
$new/customerinfo/addr, has to produce exactly one node. If the path does not exist in the
document or if it exists more than once, the operation fails with error SQL16085N. If you look up
the explanation for SQL16085N you find that a common reason is described as “the target
node of an insert expression is not a single element node or document
node.” Beware that the words “not a single element node” do not necessarily imply that
more than one target node was found. It’s equally possible that no target node was found. “Not a
single element” means that either zero or more than one node was found, so you should
check for both cases when you encounter error SQL16085N. For example, if you misspell a tag
name in the target path, error SQL16085N is raised because no target node was found.
12.7.2
Defining the Position of Inserted Attributes
To insert a new attribute instead of an element, you have to use a computed attribute constructor.
It consists of the keyword attribute followed by the attribute name and an expression or constant that provides the attribute value. The same five insert options are available as for elements
and are shown in Table 12.2. The difference for attributes is that the operations into $new/
customerinfo, as last into $new/customerinfo, and as first into $new/
customerinfo all have the same effect. Their effect is that the new attribute becomes an attribute of the element customerinfo. Since the XML data model does not define a positional order
12.7
Inserting XML Nodes into a Document
337
among the attributes of an element, attributes are always unordered. Therefore the keywords
last, first, before, and after do not affect the position of attributes. If you insert an attribute
before or after $new/customerinfo/addr, the attribute becomes a sibling of addr and is
therefore added to the parent of addr, which is customerinfo.
Table 12.2
Five Options for Inserting a Attribute into a Document
Insert Operation
Position of the Inserted Node
insert attribute email {"jnoodle@ibm.com"}
into $new/customerinfo
In all three cases, email becomes an
attribute of customerinfo.
The position of email among the
existing attributes is undefined
because attributes are not ordered.
insert attribute email {"jnoodle@ibm.com"}
as last into $new/customerinfo
insert attribute email {"jnoodle@ibm.com"}
as first into $new/customerinfo
insert attribute email {"jnoodle@ibm.com"}
after $new/customerinfo/addr
In both cases, email becomes an
attribute of the parent of addr, which
is customerinfo.
insert attribute email {"jnoodle@ibm.com"}
before $new/customerinfo/addr
12.7.3
Insert Examples
For the following examples, assume that an email element has to be inserted into the XML document for Robert Shoemaker. This document is identified by the relational cid value 1003.
Figure 12.21 shows a first attempt at performing this update. The UPDATE statement fails with
errors message SQL20345N because the target path is specified as $new instead of $new/customerinfo. When the target path is $new, the email element is inserted as a sibling and not as a
child of the customerinfo element. The result is a sequence of two elements (customerinfo,
email), which is not a well-formed XML document. Since XML columns can only contain wellformed documents, the update fails. It fails for the same reason if you specify before $new/
customerinfo or after $new/customerinfo as the target position.
338
Chapter 12
Updating and Transforming XML Documents
UPDATE customer
SET info = XMLQUERY('
copy $new := $INFO
modify do insert <email>robert@ibm.com</email>
as last into $new
return $new')
WHERE cid = 1003
SQL20345N The XML value is not a well-formed document with a single
root element. SQLSTATE=2200L
Original document
Rejected XML value
<customerinfo Cid="1003">
<name>Robert Shoemaker</name>
<addr country="Canada">
<street>845 Kean Street</street>
<city>Aurora</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N8X 7F8</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
<phone type="home">416-555-2937</phone>
<phone type="cell">905-555-8743</phone>
</customerinfo>
<customerinfo Cid="1003">
<name>Robert Shoemaker</name>
<addr country="Canada">
<street>845 Kean Street</street>
<city>Aurora</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N8X 7F8</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
<phone type="home">416-555-2937</phone>
<phone type="cell">905-555-8743</phone>
</customerinfo>
<email>robert@ibm.com</email>
Figure 12.21
Cannot insert an element as a sibling of the root element
Figure 12.22 shows the corrected UPDATE statement and the correctly modified XML document.
You could similarly insert the email element as first into $new/customerinfo.
UPDATE customer
SET info = XMLQUERY('
copy $new := $INFO
modify do insert <email>robert@ibm.com</email>
as last into $new/customerinfo
return $new')
WHERE cid = 1003
Original document
Updated document
<customerinfo Cid="1003">
<name>Robert Shoemaker</name>
<addr country="Canada">
<street>845 Kean Street</street>
<city>Aurora</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N8X 7F8</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
<phone type="home">416-555-2937</phone>
<phone type="cell">905-555-8743</phone>
</customerinfo>
<customerinfo Cid="1003">
<name>Robert Shoemaker</name>
<addr country="Canada">
<street>845 Kean Street</street>
<city>Aurora</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N8X 7F8</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
<phone type="home">416-555-2937</phone>
<phone type="cell">905-555-8743</phone>
<email>robert@ibm.com</email>
</customerinfo>
Figure 12.22
Inserting a new element as the last element
12.7
Inserting XML Nodes into a Document
339
If you want the email element to appear in the document before the phone elements, you can
explicitly request it to be inserted before the first occurrence of any existing phone elements
using the positional predicate [1]. This is shown in Figure 12.23 where the positional predicate
selects exactly one phone element as the target location. If you omit the positional predicate, the
UPDATE statement fails with error SQL16085N. The statement in Figure 12.23 would also fail if
the document contained no phone elements.
UPDATE customer
SET info = XMLQUERY('
copy $new := $INFO
modify do insert <email>robert@ibm.com</email>
before $new/customerinfo/phone[1]
return $new')
WHERE cid = 1003
Original document
Updated document
<customerinfo Cid="1003">
<name>Robert Shoemaker</name>
<addr country="Canada">
<street>845 Kean Street</street>
<city>Aurora</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N8X 7F8</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
<phone type="home">416-555-2937</phone>
<phone type="cell">905-555-8743</phone>
</customerinfo>
<customerinfo Cid="1003">
<name>Robert Shoemaker</name>
<addr country="Canada">
<street>845 Kean Street</street>
<city>Aurora</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N8X 7F8</pcode-zip>
</addr>
<email>robert@ibm.com</email>
<phone type="work">905-555-7258</phone>
<phone type="home">416-555-2937</phone>
<phone type="cell">905-555-8743</phone>
</customerinfo>
Figure 12.23
Inserting a new element before an existing element
If you want to insert the email element after the last phone element but before any other elements that might appear at end of the document, specify the insert position to be after
$new/customerinfo/phone[last()].
As another example, Figure 12.24 shows an UPDATE statement that inserts the new email element as the first child of the addr element.
Alternatively, the UPDATE statement in Figure 12.25 inserts the email address as an attribute of the
addr element. In the updated document, the attribute email happens to appear before the attribute
country. But this order is not relevant and not guaranteed because XML attributes have no defined
order. If you change the target position of the inserted attribute to after $new/customerinfo/
addr/city or before $new/customerinfo/addr/@country, the updated document is still
the same as shown in Figure 12.25.
340
Chapter 12
Updating and Transforming XML Documents
UPDATE customer
SET info = XMLQUERY('
copy $new := $INFO
modify do insert <email>robert@ibm.com</email>
as first into $new/customerinfo/addr
return $new')
WHERE cid = 1003
Original document
Updated document
<customerinfo Cid="1003">
<name>Robert Shoemaker</name>
<addr country="Canada">
<street>845 Kean Street</street>
<city>Aurora</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N8X 7F8</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
<phone type="home">416-555-2937</phone>
<phone type="cell">905-555-8743</phone>
</customerinfo>
<customerinfo Cid="1003">
<name>Robert Shoemaker</name>
<addr country="Canada">
<email>robert@ibm.com</email>
<street>845 Kean Street</street>
<city>Aurora</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N8X 7F8</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
<phone type="home">416-555-2937</phone>
<phone type="cell">905-555-8743</phone>
</customerinfo>
Figure 12.24
Inserting a new element as the first child element of a target node
UPDATE customer
SET info = XMLQUERY('
copy $new := $INFO
modify do insert attribute email {"robert@ibm.com"}
into $new/customerinfo/addr
return $new')
WHERE cid = 1003
Original document
Updated document
<customerinfo Cid="1003">
<name>Robert Shoemaker</name>
<addr country="Canada">
<street>845 Kean Street</street>
<city>Aurora</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N8X 7F8</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
<phone type="home">416-555-2937</phone>
<phone type="cell">905-555-8743</phone>
</customerinfo>
<customerinfo Cid="1003">
<name>Robert Shoemaker</name>
<addr email="robert@ibm.com"
country="Canada">
<street>845 Kean Street</street>
<city>Aurora</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N8X 7F8</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
<phone type="home">416-555-2937</phone>
<phone type="cell">905-555-8743</phone>
</customerinfo>
Figure 12.25
12.8
Inserting an attribute
HANDLING REPEATING AND MISSING NODES
If a single XPath expression identifies multiple nodes in a single document, they are called
repeating nodes. In previous sections you saw that the XML document for Robert Shoemaker
contains multiple phone elements. Hence, the element phone is a repeating element and the path
/customerinfo/phone produces a sequence of more than one element node.
12.8
Handling Repeating and Missing Nodes
341
As defined by the XQuery Update standard, the delete expression is the only update operation
that can directly process multiple occurrences of a node. It simply deletes all of them, as you saw
in section 12.5. All other update expressions (replace, replace value of, rename, and
insert) require special attention when dealing with repeating nodes. The same applies to missing nodes. If you try to delete an element or attribute that does not exist, the delete expression performs no action and returns successfully. However, all other update expressions fail when they try
to modify an element or attribute that does not exist in the target document.
The UPDATE statement in Figure 12.26 tries to change the value of a phone element but fails. At
runtime, DB2 detects that there is more than one phone element in the target document and
returns error SQL16085N. You can type “? SQL16085N” at the DB2 command prompt to
find that the explanation for reason code XUTY0008 is that “the target node of a replace
expression is not a single node”. This reason code indicates that the target path
$new/customerinfo/phone has either produced multiple phone elements or none. However,
it must produce exactly one node for the update to be successful. The error prevents you from
updating multiple phone elements with the same number, which would not make sense. If no
phone element exists, the error ensures that you are not led to believe that the new phone number
was successfully written to the document.
UPDATE customer
SET info = XMLQUERY('
copy $new := $INFO
modify do replace
value of $new/customerinfo/phone
with "123-456-7890"
return $new ')
WHERE cid = 1003
SQL16085N The target node of an XQuery "replace value of" expression is not valid.
Error QName=err:XUTY0008. SQLSTATE=10703.
Figure 12.26
Trying to replace the value of a repeating element
If you know that there are multiple phone elements, a common way to avoid error SQL16085N is
to add a predicate to the target path to select exactly one phone element for update. As an example,
Figure 12.27 uses the predicate [@type="cell"] to only update the cell phone number.
UPDATE customer
SET info = XMLQUERY('
copy $new := $INFO
modify do replace
value of $new/customerinfo/phone[@type="cell"]
with "123-456-7890"
return $new ')
WHERE cid = 1003
Figure 12.27
Replacing one of multiple occurrences of an element
342
Chapter 12
Updating and Transforming XML Documents
Using the predicate in Figure 12.27 works well if every possible target document contains exactly
one phone element with a type attribute equal to cell. However, if a document does not contain a cell phone element, the UPDATE statement in Figure 12.27 still fails with error SQL16085N.
In that case, another option is to use the XQuery if-then-else expression, as shown in Figure
12.28. If a cell phone element exists then its value is replaced with a new value, else a new cell
phone element with the new number is inserted. This implements an “upsert” operation.
UPDATE customer
SET info = XMLQUERY('
copy $new := $INFO
modify if ($new/customerinfo/phone[@type="cell"])
then do replace value
of $new/customerinfo/phone[@type="cell"]
with "123-456-7890"
else do insert
<phone type="cell">123-456-7890</phone>
as last into $new/customerinfo
return $new ')
WHERE cid = 1001
Figure 12.28
Conditional update and insert of an element
The most resilient solution for handling both repeating and missing elements is a FLWOR expression
in the modify clause (see Figure 12.29). The for clause iterates over the target elements one at a
time, so that the replace value of expression in the return clause is always applied to exactly
one element. If you remove the condition where $j/@type = "cell", all phone elements are
updated with the same number "123-456-7890", regardless of their type. If a document does not
contain a cell phone or no phone elements at all, the return clause of the FLWOR expression is
never invoked so that the replace value of expression never fails due to a missing node.
In summary, the FLWOR expression in the modify clause enables an UPDATE statement to
• Modify multiple or all occurrences of a repeating node (without warning)
• Add predicates to select which occurrences of a repeating node to modify
• Silently proceed and return successfully even if a target node is not found
12.9
Modifying Multiple XML Nodes in the Same Document
343
UPDATE customer
SET info = XMLQUERY('
copy $new := $INFO
modify for $j in $new/customerinfo/phone
where $j/@type = "cell"
return do replace value of $j
with "123-456-7890"
return $new')
WHERE cid = 1000
Original document
Updated document
<customerinfo Cid="1003">
<name>Robert Shoemaker</name>
<addr country="Canada">
<street>845 Kean Street</street>
<city>Aurora</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N8X 7F8</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
<phone type="home">416-555-2937</phone>
<phone type="cell">905-555-8743</phone>
</customerinfo>
<customerinfo Cid="1003">
<name>Robert Shoemaker</name>
<addr country="Canada">
<street>845 Kean Street</street>
<city>Aurora</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N8X 7F8</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
<phone type="home">416-555-2937</phone>
<phone type="cell">123-456-7890</phone>
</customerinfo>
Figure 12.29
12.9
Iterating over the occurrences of a repeating element
MODIFYING MULTIPLE XML NODES IN THE SAME DOCUMENT
You can have multiple update operations for the same document in the modify clause of a single
UPDATE statement. However, you cannot rename, replace, or update the value of the same
node more than once. In this section we discuss examples where multiple combined update operations are or are not in conflict with each other.
12.9.1
Snapshot Semantics and Conflict Situations
The XQuery Update standard defines that all update operations in the modify clause are applied
independently from each other to the original document. They don’t see each others’ effects. This
is called snapshot semantics, which means that each update operation is logically applied to a
separate snapshot of the original document.
As an example, let’s look at the UPDATE statement in Figure 12.30, which contains two updating
expressions in the modify clause, separated by a comma. The first expression inserts an additional phone element. The second expression deletes all phone elements. The obvious question
is whether the newly inserted phone element is instantly removed by the delete expression, and
whether that depends on the order in which the insert and the delete operations appear in the
modify clause. As it turns out, the new phone element is not affected by the delete expression,
irrespective of the order in which the operations appear in the modify clause. Due to snapshot
344
Chapter 12
Updating and Transforming XML Documents
semantics, both the insert and the delete expressions in Figure 12.30 are independently
applied to a snapshot of the original document. Therefore the delete expression does not see the
newly inserted phone element and only removes the old phone elements that existed in the document prior to this update. Hence, there is no conflict between the insert and the delete
expression in Figure 12.30.
UPDATE customer
SET info = XMLQUERY('
copy $new := $INFO
modify( do insert <phone type="cell">777-555-3333</phone>
after $new/customerinfo/addr ,
do delete $new/customerinfo/phone )
return $new ')
WHERE cid = 1002
Original document
<customerinfo Cid="1002">
<name>Jim Noodle</name>
<addr country="Canada">
<street>25 EastCreek</street>
<city>Markham</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N9C 3T6</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
</customerinfo>
Figure 12.30
Updated document
<customerinfo Cid="1002">
<name>Jim Noodle</name>
<addr country="Canada">
<street>25 EastCreek</street>
<city>Markham</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N9C 3T6</pcode-zip>
</addr>
<phone type="cell">777-555-3333</phone>
</customerinfo>
Combining an insert and a delete operation
For comparison, let’s look at a different combination of an insert and a delete expression in
Figure 12.31. One of the expressions deletes the addr element, and the other expression inserts
a new POBox element into the addr element. Again, the order of the two operations in the
modify clause is irrelevant. Nevertheless, the two operations conflict with each other because
the delete expression removes the parent element (addr) of the newly inserted POBox element.
For this case, the language standard defines that delete “wins” over insert and the updated document has no addr or POBox elements. Be aware of these effects when you code complex
updates.
12.9
Modifying Multiple XML Nodes in the Same Document
345
UPDATE customer
SET info = XMLQUERY('
copy $new := $INFO
modify(
do delete $new/customerinfo/addr ,
do insert <POBox>15</POBox>
into $new/customerinfo/addr )
return $new ')
WHERE cid = 1002
Original document
<customerinfo Cid="1002">
<name>Jim Noodle</name>
<addr country="Canada">
<street>25 EastCreek</street>
<city>Markham</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N9C 3T6</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
</customerinfo>
Figure 12.31
12.9.2
Updated document
<customerinfo Cid="1002">
<name>Jim Noodle</name>
<phone type="cell">777-555-3333</phone>
</customerinfo>
A different combination of an insert and a delete operation
Converting Elements to Attributes and Vice Versa
The UPDATE statement in Figure 12.32 is another interesting example. It combines two insert
expressions and two delete expressions in a single statement. The objective is to turn the existing Cid attribute into an element called customerid, and the existing element name into an
attribute called custname . Four update operations are required to make this happen:
• Insert a customerid element and compute its value from the existing Cid attribute
• Insert a custname attribute and take its value from the existing name element
• Delete the existing Cid attribute
• Delete the existing name element
Again, the order of these four expressions in the modify clause does not matter. Snapshot semantics ensures that the four expressions are applied in isolation and produce the intended result. In
particular, the insert expressions see their own logical snapshots of the original document,
which enables them to read the Cid attribute and the name element even though these nodes are
being deleted at the same time.
346
Chapter 12
Updating and Transforming XML Documents
UPDATE customer
SET info = XMLQUERY('
copy $new := $INFO
modify(do insert <customerid>
{$new/customerinfo/data(@Cid)}
</customerid>
as first into $new/customerinfo ,
do insert attribute
custname {$new/customerinfo/name}
into $new/customerinfo,
do delete $new/customerinfo/@Cid,
do delete $new/customerinfo/name
)
return $new')
WHERE cid = 1002
Document before the update
Document after the update
<customerinfo Cid="1002">
<name>Jim Noodle</name>
<addr country="Canada">
<street>25 EastCreek</street>
<city>Markham</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N9C 3T6</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
</customerinfo>
<customerinfo custname=Jim Noodle">
<customerid>1002</customerid>
<addr country="Canada">
<street>25 EastCreek</street>
<city>Markham</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N9C 3T6</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
</customerinfo>
Figure 12.32
12.10
Turning an attribute into an element and vice versa
MODIFYING XML DOCUMENTS IN QUERIES
Throughout this chapter you have seen many examples of XQuery Update expressions (transform expressions) that are enclosed in an XMLQUERY function in the SET clause of an SQL
UPDATE statement. In this manner, they modify existing documents in the database with logging
and locking as needed. The exact same update expressions can also be used in an XMLQUERY
function in the SELECT clause of a query. This allows you to modify XML documents as you read
them from the database and return them to the application, without changing the original document in the table.
Figure 12.33 shows how any UPDATE statement in this chapter can be “converted” into a SELECT
statement that performs the same document modifications upon read rather than update of a document. This can be useful for various purposes. When you develop XQuery Update expressions it
is convenient to first test them as queries rather than updates. The queries show the modified documents immediately so you can easily check whether your update expressions did exactly what
you had intended. Secondly, the queries do not change your data on disk, which makes testing
much safer in case a miscoded update expression deletes data unintentionally.
12.10
Modifying XML Documents in Queries
347
If the XML data in your database is used by multiple applications or services, it is likely that not
all the consumers need or want to see the XML documents in the same shape and form. To
retrieve only certain parts of an XML document, it can sometimes be easier to delete one part of
the document while retrieving it, rather than to extract many different parts from a document
except one. Also, using insert into expressions in an XML query allows you to enrich an
XML document on-the-fly with XML fragments from other documents.
-- The UPDATE statement:
UPDATE customer
SET info = XMLQUERY('
copy $newinfo := $INFO
modify do replace value of
$newinfo/customerinfo/addr/pcode-zip
with "XXX XXX"
return $newinfo
')
WHERE cid = 1000 ;
-- Corresponding SELECT statement:
SELECT XMLQUERY('
copy $newinfo := $INFO
modify do replacevalue of
$newinfo/customerinfo/addr/pcode-zip
with "XXX XXX"
return $newinfo
')
FROM customer
WHERE cid = 1000 ;
Figure 12.33
Corresponding UPDATE and SELECT statements
You can write the SELECT statement in Figure 12.33 also as an XQuery, which is shown in Figure
12.34. The copy clause assigns the input document that is to be updated to the variable
$newinfo. The input document is produced by the function db2-fn:sqlquery, which contains an SQL query that retrieves exactly one document. The modify clause uses a replace
expression to modify the document.
xquery
copy $newinfo := db2-fn:sqlquery("SELECT info
FROM customer
WHERE cid=1000")
modify do replace
value of $newinfo/customerinfo/addr/pcode-zip
with "XXX XXX"
return $newinfo;
Figure 12.34
Replacing values in a document upon read
348
Chapter 12
Updating and Transforming XML Documents
You might find it more intuitive to use the XQuery transform expression in the return clause
of a FLWOR expression and to modify the documents that are selected by the for and where
clauses with XML predicates (see Figure 12.35).
xquery
for $i in db2-fn:xmlcolumn("CUSTOMER.INFO")
where $i/customerinfo/name = "Jim Noodle"
return
copy $newinfo := $i
modify do replace
value of $newinfo/customerinfo/addr/pcode-zip
with "XXX XXX"
return $newinfo;
Figure 12.35
XQuery transform expression in the return clause of a FLWOR
In the next example (Figure 12.36), the goal is to obtain the address for Matt Foreman, rename
the pcode-zip element to postalcode, and embed the modified address in a new element
called sendto. This example shows how it can sometimes be useful to have non-trivial expressions in the copy and the return clause of the transform expression. The copy clause navigates to the addr element because only that part of the document is to be modified and returned.
The return clause constructs a new element around the modified address.
xquery
for $i in db2-fn:xmlcolumn("CUSTOMER.INFO")/customerinfo
where $i/name = "Matt Foreman"
return
copy $newinfo := $i/addr
modify
do rename $newinfo/pcode-zip as "postalcode"
return <sendto>{$newinfo}</sendto> ;
<sendto>
<addr country="Canada">
<street>1596 Baseline</street>
<city>Toronto</city>
<prov-state>Ontario</prov-state>
<postalcode>M3Z 5H9</postalcode>
</addr>
</sendto>
1 record(s) selected.
Figure 12.36
Returning modified parts of an XML document
Figure 12.37 shows a particularly interesting example of inserting XML elements from one document into another. The query reads the document for customer 1002 from the customer table
and applies two changes to it. The first update expression inserts the partid elements of all the
12.11
Modifying XML Documents in Insert Operations
349
items that the customer has ever ordered, and the second update expression removes the customer’s phone numbers from the document. The partid elements are obtained with a subquery
from the purchaseorder table. The relational column cid of the customer table is passed as a
variable ($CID) into the embedded SQL query, which selects the order documents for the given
customer. The part IDs of all items (//item/partid) are extracted from each order document
and inserted at the end of the customer document. In this case the insert expression inserts a
sequence of elements, not just a single element.
SELECT XMLQUERY('
copy $new := $INFO
modify (
do insert db2-fn:sqlquery("SELECT porder
FROM purchaseorder
WHERE custid=parameter(1)",
$CID)//item/partid
as last into $new/customerinfo,
do delete $new/customerinfo/phone)
return $new')
FROM customer
WHERE cid = 1002;
<customerinfo Cid="1002">
<name>Jim Noodle</name>
<addr country="Canada">
<street>25 EastCreek</street>
<city>Markham</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N9C 3T6</pcode-zip>
</addr>
<partid>100-100-01</partid>
<partid>100-103-01</partid>
<partid>100-100-01</partid>
<partid>100-100-01</partid>
<partid>100-101-01</partid>
<partid>100-201-01</partid>
</customerinfo>
1 record(s) selected.
Figure 12.37
12.11
Inserting XML elements from one document into another
MODIFYING XML DOCUMENTS IN INSERT OPERATIONS
In addition to performing update operations when you select or update an XML document, you
can also apply changes to a document when you insert it into a table. As an example, assume an
application receives XML documents that contain phone numbers, but the application is not supposed to store these phone numbers in a shared database. You can write an INSERT statement that
takes an XML document as input, deletes the phone elements, and inserts the modified
350
Chapter 12
Updating and Transforming XML Documents
document into a table. Such an INSERT statement is shown in Figure 12.38. The target table is
called cust2 and is created as follows:
CREATE TABLE cust2 (cid INT, info XML)
The INSERT statement extracts the Cid attribute value from each input document and inserts it
into the relational cid column of the table. It also inserts the document without phone elements
into the XML column info. Note the use of the single dot on the right side of the copy expression. The dot refers to the full XML document provided by the row generating expression $i.
INSERT INTO cust2(cid, info)
SELECT x.custid, x.xdoc
FROM XMLTABLE('$i' PASSING CAST(? AS XML) AS "i"
COLUMNS
custid INTEGER PATH 'customerinfo/@Cid',
xdoc
XML
PATH 'copy $newinfo := .
modify
do delete
$newinfo/customerinfo/phone
return $newinfo'
) AS x
Figure 12.38
12.12
Deleting elements upon insertion
MODIFYING XML DOCUMENTS IN UPDATE CURSORS
As you would normally do for relational columns, you can declare a cursor FOR UPDATE of an
XML column and then issue an UPDATE statement with the clause WHERE CURRENT OF
cursorname. You can use such update cursors in your application programs or in stored procedures. Figure 12.39 shows sample code for a stored procedure that uses an update cursor to modify XML data.
(...)
DECLARE doc XML;
DECLARE c1 CURSOR FOR SELECT info FROM customer
FOR UPDATE OF info;
OPEN c1;
FETCH c1 INTO doc;
WHILE SQLCODE <> 100 DO
—(some processing logic here)
IF (condition) THEN
UPDATE customer
SET xmldoc = XMLQUERY('copy $new := $INFO
modify do delete
$new/customerinfo/phone
Figure 12.39
Updating XML documents in a cursor
12.13
XML Updates in DB2 for z/OS
WHERE CURRENT OF c1;
END IF;
351
return $new')
FETCH c1 INTO doc;
END WHILE;
CLOSE c1;
Figure 12.39
12.13
Updating XML documents in a cursor (Continued)
XML UPDATES IN DB2 FOR Z/OS
DB2 9 for z/OS does not currently support XML modifications other than full-document replacement. Enhanced XML update support is intended for a future release. For now, this leaves you
with two options whenever you want to update a piece of a document. One option is to read the
entire document into the application, modify it there, and replace the full document. The other
option is to perform XML construction with the SQL/XML publishing functions to mimic an
XML update. This means that you reconstruct the original document, using existing pieces if they
don’t change, and construct new elements where needed.
For example, assume you want to replace all existing phone elements in a customer document
with a new phone element. The UPDATE statement in Figure 12.40 achieves exactly that. It constructs the updated document in the following way. The first XMLELEMENT function produces the
root element customerinfo. This element contains the XML data produced by the subsequent
XMLQUERY and XMLELMENT functions. The XMLQUERY functions copy unchanged pieces of the
original document into the new document. They include the Cid attribute, the name element, and
the entire addr element with all its children. The existing phone element is not copied. In its
place a new phone element with a new value is constructed.
UPDATE customer
SET info =
XMLELEMENT(name "customerinfo",
XMLQUERY('$i/customerinfo/@Cid' PASSING info AS "i"),
XMLQUERY('$i/customerinfo/name' PASSING info AS "i"),
XMLQUERY('$i/customerinfo/addr' PASSING info AS "i"),
XMLELEMENT(Name "phone", XMLATTRIBUTES('home' as "type"),
'408-463-4963')
)
WHERE cid = 1000
Figure 12.40
Reconstructing an existing document with a new phone element
Before you execute the UPDATE statement in Figure 12.40 you can run a query that constructs the
same document (see Figure 12.41). This enables you to verify that the document construction
achieves the desired result.
352
Chapter 12
Updating and Transforming XML Documents
SELECT
XMLELEMENT(name "customerinfo",
XMLQUERY('$i/customerinfo/@Cid' PASSING info AS "i"),
XMLQUERY('$i/customerinfo/name' PASSING info AS "i"),
XMLQUERY('$i/customerinfo/addr' PASSING info AS "i"),
XMLELEMENT(Name "phone", XMLATTRIBUTES('home' as "type"),
'408-463-4963')
)
FROM customer
WHERE cid = 1000
Figure 12.41
12.14
Selecting an existing document with a new phone element
TRANSFORMING XML DOCUMENTS WITH XSLT
Let’s begin by reviewing some terms. XSL stands for eXtensible Stylesheet Language. XSLT
stands for XSL Transformation,which is a subset of XSL focusing on document transformations.
An XSLT style sheet contains the instructions to transform an existing XML document into a different format. The output of an XSL transformation can be a new XML document that has a different structure than the input document. The output can also be HTML or some non-XML
format such as a flat file. These options are illustrated in Figure 12.42.
Since version 9.5, DB2 for Linux, UNIX, and Windows supports the XSLTRANSFORM function to
perform XSL transformations in SQL statements. The input to an XSL transformation consists of
an XML document that you want to transform and the XSLT style sheet that defines the transformation. XSLT Version 1.0 is supported. Teaching XSLT is outside the scope of this book, but the examples in this section are kept simple so that you can follow along without deep XSLT knowledge.
XSLT
Style
Sheet 1
<dept bldg=“101”>
<employee id=“901”>
<name>John Doe</name>
<phone>408 555 1212</phone>
<office>344</office>
</employee>
</dept>
Figure 12.42
XSLT
Style
Sheet 2
XSLT
Style
Sheet 3
<emp name=“John Doe”>
<empNo>901</empNo>
<contact>
<phone>408 555 1212</phone>
<room>344</room>
</contact>
</emp>
John Doe;901;408 555 1212;344
HTML
Transforming XML
When should you use XSLT and when should you use XQuery Updates to modify an XML document? XQuery Updates typically perform better than XSL transformations because they do not
12.14
Transforming XML Documents with XSLT
353
incur any XML parsing costs of the target document. XQuery Updates are also particularly well
suited for transactional updates that modify small or moderate portions of a document (see Table
12.3). XSLT can have advantages if you need to convert XML documents into drastically different formats, including HTML. Also, XSLT has been around for much longer than XQuery
Updates, so you might have existing XSLT style sheets that you might want to use with the XML
data in DB2.
Table 12.3
When to Use XSLT or XQuery
XQuery Update
XSLT
Change, insert, delete specific elements/attributes (“point updates”)
+
–
High-performance database transactions
+
–
Produce custom XML formats for specific consumers
–
+
Format how XML data is rendered in a browser
–
+
If you decide to use XSLT, another consideration is whether to perform the XSLT processing in
the database layer (using DB2’s XSLTRANSFORM function), the mid-tier, or the application layer.
A big factor in this decision is where you want to incur the CPU consumption. XSLT processing
tends to be CPU intensive and the CPU cycles in the mid-tier or application layer may be less
expensive than the CPU cycles on the database server. In this case you may want to avoid XSLT
in the database server. On the other hand, performing XSLT transformations as part of a database
query over XML data can be very convenient. It avoids additional logic in the consuming applications and serves XML data directly in the format that a particular application requires.
12.14.1
The XSLTRANSFORM Function
In its most simple form the XSLTRANSFORM function has the following syntax:
XSLTRANSFORM(xmldocument USING xslstylesheet)
The first parameter, xmldocument, provides a well-formed XML document as data type XML,
CHAR, VARCHAR, CLOB, or BLOB. This is the document that is transformed using the XSL style
sheet specified in the second parameter, xslstylesheet. The style sheet can also be of type
XML, CHAR, VARCHAR, CLOB, or BLOB and must represent a valid XSLT 1.0 style sheet.
Let’s look at the examples in Figure 12.43. Both queries retrieve an XML document from the
info column of the customer table and apply a style sheet that is provided via a parameter
marker. SQL requires that the parameter marker is cast to an appropriate target type. In the first
query the style sheet is passed as a VARCHAR(1000) value, in the second query as an XML value.
The result type of the XSLTRANSFORM function is CLOB(2G). The result type is not XML because
there is no guarantee that the output of the transformation is an XML document.
354
Chapter 12
Updating and Transforming XML Documents
SELECT XSLTRANSFORM(info USING CAST(? AS VARCHAR(1000)) )
FROM customer
WHERE cid = 1000;
SELECT XSLTRANSFORM(info USING CAST(? AS XML) )
FROM customer
WHERE cid = 1000;
Figure 12.43
SQL queries with XSL transformation
Figure 12.44 shows that you can optionally specify a different result type, such as VARCHAR,
CHAR, or BLOB. In this example, the style sheet is passed into the XSLTRANSFORM function as
VARCHAR(1000), and the output of the transformation is of type VARCHAR(32000). You cannot
specify type XML as the output type.
SELECT XSLTRANSFORM(info USING CAST(? AS VARCHAR(1000))
AS VARCHAR(32000) )
FROM customer
WHERE cid = 1000
Figure 12.44
SQL query with XSL transformation and custom result type
If the XSL transformation produces a well-formed XML document and you have a strong reason
to return it to the application in a column of type XML, wrap the function XMLPARSE around the
XSLTRANSFORM function in the SELECT list. However, you typically can and should avoid the
XMLPARSE function because it introduces additional XML parsing overhead.
All the examples so far apply the XSL transformation as part of a query but do not modify the
original document in the table. You can use the XSL transformation function in an UPDATE statement to replace a document with a transformation of itself, as shown in Figure 12.45. The
UPDATE statement performs implicit XML parsing; that is, the VARCHAR(5000) result of
XSLTRANSFORM is automatically parsed to produce the required data type XML for the info column. The update fails if XSLTRANSFORM doesn’t produce a well-formed XML document.
UPDATE customer
SET info = XSLTRANSFORM(info USING CAST(? AS VARCHAR(5000)) )
WHERE cid = 1000
Figure 12.45
SQL UPDATE with XSL transformation
Optionally, the XSLTRANSFORM function can also accept a third parameter that provides
an XML document containing parameter values for the style sheet, which allows for more
flexibility.
12.14
Transforming XML Documents with XSLT
355
It is further possible to apply the XSLTRANSFORM function to just a portion of an XML document.
For example, assume you have a style sheet that transforms the address of a customer document.
The query in Figure 12.46 uses the XMLQUERY function to extract just the addr branch of the document and provides this as input to the XSLTRANSFORM function. The addr is then transformed
by a style sheet that is provided via parameter marker of type VARCHAR(3000).
SELECT XSLTRANSFORM(
XMLQUERY('$INFO/customerinfo/addr')
USING CAST(? AS VARCHAR(3000)) )
FROM customer
WHERE cid = 1000
Figure 12.46
SQL/XML query with XSL transformation of a document fragment
If you frequently need to perform XSL transformations, you might want to store the XSL style
sheets in a DB2 table instead of supplying them via a parameter marker. For example, you could
create the table in Figure 12.47 where each row contains an XSL style sheet (xsldoc) and an
INTEGER number (xslid) that serves as a style sheet identifier.
CREATE TABLE xslfile(xslid INTEGER PRIMARY KEY NOT NULL,
xsldoc CLOB(1M) )
Figure 12.47
Defining a table for XSLT style sheets
Such a table allows you to pull specific style sheets into an invocation of the XSLTRANSFORM
function, as shown in Figure 12.48. Remember that the style sheet can be of type XML, CHAR,
VARCHAR, CLOB, or BLOB.
SELECT XSLTRANSFORM(info USING
(SELECT xsldoc FROM xslfile WHERE xslid = 2) )
FROM customer
WHERE cid = 1004
Figure 12.48
Using an XSL style sheet from a DB2 table
There can be situations where different documents require transformation with different style
sheets. For example, different documents might belong to different versions of an XML Schema
or be consumed by different applications. You can add an INTEGER column xslid to the table
that contains your XML documents and use it to indicate which style sheet is appropriate for any
particular document. Then you can perform a join, as in Figure 12.49, to transform multiple documents against their respective style sheets.
356
Chapter 12
Updating and Transforming XML Documents
SELECT XSLTRANSFORM (info USING xsldoc)
FROM customer c, xslfile x
WHERE c.xslid = x.xslid
Figure 12.49
12.14.2
Joining style sheets and XML documents
XML to HTML Transformation
Assume you want to read the contents of an XML document in the info column of the customer table and produce the Cid, name, and street information in HTML format. Remember
that Cid is an attribute of the root element and that name and street are elements. The INSERT
statement in Figure 12.50 inserts a suitable XSL style sheet into the table xslfile.
INSERT INTO xslfile
VALUES (1,
'<?xml version="1.0" encoding="isO-8859-1"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<html>
<body>
<h2>The customer</h2>
<table border="1">
<tr bgcolor="#FFF00">
<th align="left">Cid</th>
<th align="left">Name</th>
<th align="left">Street</th>
</tr>
<xsl:for-each select="customerinfo">
<tr>
<td><xsl:value-of select="@Cid"/></td>
<td><xsl:value-of select="name"/></td>
<td><xsl:value-of select="addr/street"/></td>
</tr>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet>')
Figure 12.50
INSERT statement for the XSL transformation style sheet
Note that the XSL style sheet contains the required namespace declaration for the XSLT,
xmlns:xsl=http://www.w3.org/1999/XSL/Transform. If your XML data contains
namespaces, then they should be declared after the XSL function namespace.
After you have inserted your XSL style sheet you can select from the customer table using the
XSLTRANSFORM function, as in Figure 12.51. It produces an HTML page for the selected
customer. To produce an HTML page with information for multiple customers, this information
12.14
Transforming XML Documents with XSLT
357
needs to be aggregated in a single XML document (XMLAGG) and passed in the XSLTRANSFORM
function.
SELECT XSLTRANSFORM(info
USING (SELECT xsldoc FROM xslfile WHERE xslid = 1)
AS CLOB(1M))
FROM customer
WHERE cid = 1000;
<html>
<body>
<h2>The customers</h2>
<table border="1">
<tr bgcolor="#FFF00">
<th align="left">Cid</th>
<th align="left">Name</th>
<th align="left">Street</th>
</tr>
<tr>
<td>1000</td>
<td>Kathy Smith</td>
<td>5 Rosewood</td>
</tr>
</table>
</body>
</html>
1 record(s) selected.
Figure 12.51
Transforming XML to HTML in an SQL/XML query
If you copy the output from the query in Figure 12.51 into a file then you can use a web browser
to view the rendered HTML page, as illustrated in Figure 12.52.
Figure 12.52
HTML output rendered in a browser
Note that the HTML page produced in Figure 12.51 is quite static and hardcoded in the XSLT
style sheet. Only three values are dynamically extracted from the XML document and plugged
into the HTML code. The same HTML code can be produced with XML construction in an
XMLQUERY function in a SELECT statement (see Figure 12.53). This is more efficient than using
XSLT and consumes less CPU cycles. It’s an indication that XQuery, with its construction and
update capabilities, often allows you to avoid or replace XSLT processing and gain higher performance at the same time.
358
Chapter 12
Updating and Transforming XML Documents
SELECT XMLQUERY('
<html>
<body>
<h2>The customers</h2>
<table border="1">
<tr bgcolor="#FFF00">
<th align="left">Cid</th>
<th align="left">Name</th>
<th align="left">Street</th>
</tr>
<tr>
<td>{$INFO/customerinfo/data(@Cid)}</td>
<td>{$INFO/customerinfo/name/text()}</td>
<td>{$INFO/customerinfo/addr/street/text()}</td>
</tr>
</table>
</body>
</html>
')
FROM customer
WHERE cid = 1000
Figure 12.53
Producing HTML using direct XML constructors
Sometimes XQuery with construction or update expressions can achieve the same result as an XSLT style sheet. In that case it
is recommended to use XQuery—possibly embedded in SQL—rather
than XSLT. XQuery provides better performance than XSLT.
NOTE
12.15
SUMMARY
DB2 supports several methods to update or transform XML documents. A simple method is fulldocument replacement, which allows an application to replace an existing XML document with
an updated document. An application can read an XML document from the database, parse and
modify it with custom application code, and then use it in an UPDATE statement to replace the
original version of the document.
In DB2 for Linux, UNIX, and Windows, the XQuery Update Facility also enables you to modify,
insert, or delete individual elements and attributes within an XML document—without reading
the document into your application. This method often provides better performance than fulldocument replacement. XQuery Updates provide a standardized and declarative way to express
XML document modifications, which is more efficient and less error-prone than procedural custom code. XQuery Updates are most commonly embedded in SQL UPDATE statements to change
existing documents in the database. They can also be used in queries or SQL INSERT statements
12.15
Summary
359
to modify documents on their way into or out of the database. A single statement can contain a list
of multiple XQuery Update expressions to apply multiple modifications to a document. Keep in
mind that each individual XQuery Update expression modifies exactly one element or attribute at
a time, but you can iterate with a for clause to handle missing or repeating elements. You can
also use predicates and if-then-else expressions to code conditional updates or “upsert”
operations.
DB2 for Linux, UNIX, and Windows also supports XSL transformations that can transform an
XML document into a different XML format, HTML, or into a non-XML format. Optionally,
XSLT style sheets may contain parameters to make transformations more flexible and dynamic.
You can apply XSL transformations to full documents in queries, updates, and inserts, or to partial documents produced by an SQL/XML query.
This page intentionally left blank
C
H A P T E R
13
Defining and Using
XML Indexes
his chapter looks at defining and using XML indexes to improve performance. The main
reasons why you want to define indexes on XML data are the same as for relational data;
that is, to evaluate predicates efficiently and to avoid table scans. Just like you define relational
indexes on selected columns of a relational table, you define XML indexes on selected elements
and attributes within a single XML column of a table. In particular, XML indexes in DB2 do not
automatically index all the values in an XML column, but only the ones that you choose.
Although you can choose to index all elements and attributes, you should typically index just
those elements and attributes that are frequently used in predicates and join conditions.
T
XML and relational indexes also have other similarities. Both are physically implemented as
B-Tree structures. Whenever XML documents are inserted, updated, or deleted, the affected
XML indexes are immediately updated before the transaction commits. This behavior is known
as synchronous index maintenance. DB2 can also collect statistics for XML indexes and use them
to generate efficient access plans (also known as execution plans).
In this chapter we explain
• How to define XML indexes and their data types (sections 13.1 and 13.2)
• The usage of XML indexes to improve query performance (sections 13.3 through 13.5)
• Cases in which XML indexes cannot be used to evaluate query predicates (section 13.6)
• An inside look at XML index internals and statistics (sections 13.7 and 13.8)
361
362
13.1
Chapter 13
Defining and Using XML Indexes
DEFINING XML INDEXES
To illustrate XML indexes in this chapter, we use the following table:
CREATE TABLE books (id INT, bookinfo XML)
The XML column bookinfo contains the XML documents shown in Figure 13.1. Each document has a root element called book, and under that are three other elements: title, price, and
authors. Some of the documents have additional elements under book, such as the publication
date pubdate. Each authors element has one or more author child elements.
<book id="101" isbn="0-321-18060-7">
<title>International Pasta</title>
<price>31</price>
<pubdate>2005-02-14</pubdate>
<authors>
<author id="2000">Frank Peterson</author>
<author id="2001">Mary Smith</author>
</authors>
</book>
<book id="102" isbn="0-596-00252-1">
<title>Bedtime Stories</title>
<price>£32</price>
<authors>
<author id="2001">Mary Smith</author>
</authors>
</book>
<book id="103" isbn="1-59059-983-7">
<title>The Moon and I</title>
<price>33</price>
<authors>
<author id="2002">Tom Noodle</author>
</authors>
</book>
Figure 13.1
Sample documents in the books table
The first example of an XML index is the CREATE INDEX statement in Figure 13.2. As for relational indexes, you need to specify the table name (books) and the column (bookinfo) that you
want to index. At most one column can be specified in an XML index. The clause GENERATE
KEYS USING XMLPATTERN defines a path expression that identifies the elements or attributes
whose values you want to index. In this case, the title elements of all books are indexed.
Finally, an SQL data type indicates how the indexed values should be represented in the index. In
this index, the book titles are represented as VARCHAR(50) values.
CREATE INDEX idx1 ON books(bookinfo)
GENERATE KEYS USING XMLPATTERN '/book/title'
AS SQL VARCHAR(50)
Figure 13.2
Simple example of creating an XML index
13.1
Defining XML Indexes
363
The specification of a data type is a key difference from relational indexes. When you define a
relational index on a relational column, the data type of the column automatically defines the data
type of the index keys. When you index XML data, such as the title elements in this example,
the appropriate data type for the index keys is not known to DB2. This is because DB2 does not
force you to use a single fixed XML Schema for all documents in the XML column. The use of an
XML Schema is optional, and different documents in one column can potentially use different
XML Schemas. XML index data types are discussed in more detail in section 13.2.
As another example, consider the two indexes in Figure 13.3. The first one indexes the author
elements. Note that there can be multiple author elements per document. Hence, this index can
contain multiple index entries that point to the same row and document. As a result, the cardinality of the index can be larger than the cardinality of the table. The second index in Figure 13.3
indexes the pubdate element, which exists in only one of the three sample documents. This
index contains index entries only for those rows where the pubdate element exists. Therefore,
when you index an optional element that occurs only in a subset of the documents, the cardinality
of the index can be less than the cardinality of the table. As a result, the size of indexes on
optional elements can be quite small, depending on how frequently the element occurs in the
XML column.
CREATE INDEX idx2 ON books(bookinfo)
GENERATE KEYS USING XMLPATTERN '/book/authors/author'
AS SQL VARCHAR(50)
CREATE INDEX idx3 ON books(bookinfo)
GENERATE KEYS USING XMLPATTERN '/book/pubdate'
AS SQL DATE
Figure 13.3
XML indexes with a variable number of keys per row
In general, an XML index can contain zero, one, or multiple index entries per row (document).
This is different from relational indexes, which contain exactly one index entry for each row.
The XMLPATTERN in the index definition can contain XPath expressions and wildcards (* and
//) and can point to attributes or elements. XPath predicates or parent steps are not allowed in
the XMLPATTERN. If your XML data contains namespaces, then this also needs to be reflected in
the XMLPATTERN. Indexes with namespaces are explained in Chapter 15, Managing XML Data
with Namespaces.
The index in Figure 13.4 uses the XMLPATTERN //@id. For the sample data in Figure 13.1, this
pattern matches the book id attributes on the path /book/@id as well as the author id attributes
on the path /book/authors/author/@id. Hence, this index contains multiple entries per row
(document).
CREATE INDEX idx3 ON books(bookinfo)
GENERATE KEYS USING XMLPATTERN '//@id' AS SQL VARCHAR(10)
Figure 13.4
Indexing nodes at multiple paths
364
Chapter 13
Defining and Using XML Indexes
Figure 13.5 shows the most relevant parts of the CREATE INDEX statement syntax for XML
indexes in DB2 for z/OS and DB2 for Linux, UNIX, and Windows. Some details are omitted for
simplicity, such as namespaces and the rarely needed capabilities to index XML comments and
processing instructions. Note that DB2 for z/OS supports two data types for XML indexes, VARCHAR(n) and DECFLOAT, whereas DB2 for Linux, UNIX, and Windows supports all data types
shown in Figure 13.5, except DECFLOAT. XML index data types and the handling of invalid values are discussed in section 13.2. Unique indexes are covered in section 13.1.1.
>>-CREATE--+--------+--INDEX--index-name----------------------->
'-UNIQUE-'
>--ON table-name (xml-column-name)----------------------------->
>--GENERATE KEYS USING XMLPATTERN------------------------------>
.--------------------------------------------------.
↓
|
>--'----+-/--+--+-----+----+-| xml element name
|-+----+--'-->
'-//-' '--@--'
+-| xml attribute name |-+
+-- text() --------------+
'-- * -------------------'
>--AS-SQL--+-VARCHAR--+-(--integer--)-+-+---------------------->
|
'-HASHED--------' |
+-DOUBLE---------------------+
+-DECFLOAT-------------------+
+-DATE-----------------------+
'-TIMESTAMP------------------'
.-IGNORE INVALID VALUES-.
>------+-----------------------+--------------------|
'-REJECT INVALID VALUES-'
Figure 13.5
13.1.1
Syntax diagram for the XML clauses of the CREATE INDEX statement
Unique XML Indexes
You can use the UNIQUE keyword in the CREATE INDEX statement to enforce uniqueness across
and within all XML documents stored in a single XML column. The uniqueness of a node is
enforced using the index data type, the XML path to the node, and the value of the node after
being cast to the index data type. To enforce uniqueness of all author id attributes you can define
the index in Figure 13.6.
CREATE UNIQUE INDEX authorIdx ON books(bookinfo)
GENERATE KEY USING XMLPATTERN '/book/authors/author/@id'
AS SQL DOUBLE
Figure 13.6
Creating a unique index
13.1
Defining XML Indexes
365
The XMLPATTERN in a unique XML index cannot contain a wildcard (*) or a double slash (//).
The reason for this restriction is that enforcing uniqueness in an index with wildcard or double
slash can require probing the index multiple times for each value that is inserted. To avoid this
overhead, unique indexes have to be specified with fully qualified paths.
13.1.2
Lean XML Indexes
A lean index is one that defines the path to just the element or attribute that you want to index,
without including any additional elements or attributes that do not need to be indexed. A lean
index always requires a fully qualified path; that is, a path without a wildcard (*) or double slash
(//). As an example, suppose you often search for books and authors via the author id attribute.
Then you can define the index in Figure 13.7 where the path to the author id attributes has been
fully specified. This index is lean because no other nodes are included in the index than the ones
you intended to index.
CREATE INDEX idx1 ON books(bookinfo)
GENERATE KEY USING XMLPATTERN '/book/authors/author/@id'
AS SQL VARCHAR(30)
Figure 13.7
A lean index on author id attributes
Alternatively, you could decide to define the index in Figure 13.8, which uses the double slash (//)
to index id attributes anywhere in the document. This index is “heavier” than the previous one
because it contains index entries for the id attributes of the author and the book elements. If
you never search for books via their id attributes then including them in the index is wasted overhead. The size of the index as well as the cost to maintain it during insert, update, and delete operations is larger than necessary. For example, when a new document is inserted, it is more efficient
to navigate straight to /book/authors/author/@id to obtain the index keys than to traverse
the entire document tree to evaluate //@id.
CREATE INDEX idx2 ON books(bookinfo)
GENERATE KEY USING XMLPATTERN '//@id' AS SQL VARCHAR(30)
Figure 13.8
A “heavy” index on all id attributes
If you need to support queries that search by author id as well as queries that search by book id,
it is recommended to define two indexes, one on /book/authors/author/@id and one on
/book/@id. This approach provides better performance than a single index on //@id. When
defining indexes you should always try to use full-specified path expressions and avoid using
wildcards (*) or double slashes (//).
366
13.1.3
Chapter 13
Defining and Using XML Indexes
Using the DB2 Control Center to Create XML Indexes
The DB2 Control Center contains a Create Index Wizard to conveniently create indexes on elements or attributes in an XML column. In the Control Center, right-click on the folder Indexes
or on a table name and select Create and Index to bring up the Create Index Wizard shown in
Figure 13.9. In the wizard, first specify the schema and name of the table. Then click the radio
buttons to indicate that you want to index an XML column and whether you want to ignore or
reject invalid XML values in the index. The options Reject and Ignore are explained in section
13.2.6.
Figure 13.9
Creating an XML index using the DB2 Control Center
The wizard then lets you select an XML column before it takes you to the “3. XML Pattern” dialog shown in Figure 13.10. In the upper part of this dialog all existing XML indexes on the
selected column are listed. The lower part shows the tree structure of a sample document from the
XML column. In that tree, highlight the element or attribute that you want to index and click the
Add Index button. You are then presented with options to index either just the selected node,
which is the common and default case, or to index specific child or descendant nodes. When you
click OK, the new index is added to the list of indexes above where you can still edit any of the
index properties. You cannot alter any previously defined indexes in this dialog.
13.2
XML Index Data Types
Figure 13.10
367
The XML Pattern screen in the XML Create Index wizard
One of the key benefits of the wizard is that it creates the XMLPATTERN for you and includes the
appropriate declarations for any namespaces that might exist in the sample document from the
XML column. In the final steps of the wizard you can review the textual CREATE INDEX statement DDL statement before executing it.
13.2
XML INDEX DATA TYPES
In DB2 for Linux, UNIX, and Windows there are five data types for XML indexes: VARCHAR(n),
VARCHAR HASHED, DOUBLE, DATE, and TIMESTAMP. DB2 for z/OS supports two SQL data types
for XML indexes: VARCHAR(n) and DECFLOAT. The XML index data types and their respective
behaviors are discussed in this section.
13.2.1 VARCHAR(n)
The data type VARCHAR(n) is used to index string values that have a fixed maximum length. The
length n is a hard constraint. This means
• If you try to insert an XML document in which the indexed elements or attributes have a
368
Chapter 13
Defining and Using XML Indexes
value longer than n, the INSERT statement fails and the document is not inserted.
• An UPDATE statement fails if it tries to assign a value longer than n bytes to the node that
is indexed as VARCHAR(n).
• If you try to create a new index over an XML column that already contains XML documents, and if these documents contain nodes on the index path with values longer than
n, then the index is not created and the CREATE INDEX statement fails.
Note that the value n indicates bytes and not characters. If you are managing data in a code page
where each character is represented by multiple bytes, you need to choose the value n accordingly. The minimum value for n is 1. The maximum value for n is 1000 in DB2 for z/OS. In DB2
for Linux, UNIX, and Windows the maximum value for n depends on the page size, as shown in
Table 13.1.
Table 13.1
Maximum Key Length of a VARCHAR Index for a Given Page Size
Page size (KB)
Maximum value of n (in bytes)
4
817
8
1841
16
3889
32
7985
If you prefer to avoid the rejection of documents when they violate the specified VARCHAR length,
you can safely specify the maximum allowed length for the index keys, such as
VARCHAR(817) if your page size is 4KB. Using the maximum length does not waste any space,
because in each index entry only the actual size of the indexed value is allocated and not the full
817 bytes.
13.2.2 VARCHAR HASHED
The data type VARCHAR HASHED allows you to index character strings of arbitrary length. The
length of the indexed string has no limits. DB2 generates an eight-byte hash code over the entire
string and uses the hash code as the index key.
Hashed indexes are useful for string values that are longer than the values supported by VARCHAR(n) for the respective page size. Using the VARCHAR HASHED data type can also significantly reduce the space consumption of an index. For example, if you index an element whose
values are 100 bytes long, then in each entry a VARCHAR HASHED index uses 92 bytes less than a
VARCHAR(100) index. The disadvantage of a hashed index is that it can only be used for equality
predicates, but not for less-than and greater-than predicates. Figure 13.11 shows an example of an
index with VARCHAR HASHED as the index type.
13.2
XML Index Data Types
369
CREATE INDEX idx1 ON books(bookinfo)
GENERATE KEYS USING XMLPATTERN '/book/title'
AS SQL VARCHAR HASHED
Figure 13.11
Creating an index of type VARCHAR HASHED
13.2.3 DOUBLE and DECFLOAT
In DB2 for Linux, UNIX, and Windows, the data type DOUBLE is used to index any kind of
numeric values. DB2 for z/OS uses the data type DECFLOAT instead of DOUBLE. If a document is
inserted in which the indexed element or attribute has a value that cannot be cast to DOUBLE or
DECFLOAT, such as any alphanumeric string, the default behavior is that the document is inserted
but no index entry is added to the index. No warning or error is issued. This behavior is safe and
never leads to incomplete query results. Due to its data type, a DOUBLE or DECFLOAT index is
only used to evaluate numeric predicates where XML nodes with non-numeric values can never
be a possible match. Hence, non-numeric values can safely be omitted from the index.
If you want to reject documents that contain non-numeric values in the indexed path, you can do
so in DB2 for Linux, UNIX, and Windows with the REJECT INVALID VALUES clause of the
CREATE INDEX statement (see section 13.2.6).
13.2.4 DATE and TIMESTAMP
Use the types DATE and TIMESTAMP to index XML nodes with date or timestamp values, respectively. The SQL data type DATE is used to index XML values of type xs:date. The SQL data
type TIMESTAMP is used to index XML values of type xs:dateTime. Remember that
xs:dateTime values have the form yyyy-mm-ddThh:mm:ss.nnnnnn, as in <arrival>
2008-10-31T07:45:57.345332</arrival>. If you want to specify a time zone, then you
add a “Z” to the timestamp to signify UTC, or you can specify an offset from the UTC time
(GMT), for example <arrival>2008-10-31T07:45:57.345332+03:00</arrival>.
XML indexes of type DATE and TIMESTAMP behave just like DOUBLE indexes as far as invalid
values are concerned. If the value of an indexed element or attribute cannot be cast to the type of
the index, the document is inserted but no index entry is generated. In DB2 for Linux, UNIX, and
Windows you can choose to reject such documents if you use the REJECT INVALID VALUES
clause in the CREATE INDEX statement (see section 13.2.6).
13.2.5
Choosing a Suitable Index Data Type
The data type of relational indexes is always determined by the type of the indexed column. However, since DB2 does not force you to associate an XML Schema with an XML column, the data
types of XML elements or attributes are not predetermined. Thus, each XML index requires a
target type, and the type matters. Assume a price element has the value 9. A string predicate
370
Chapter 13
Defining and Using XML Indexes
"9" < "29" is false while a numeric comparison 9 < 29 is true. Similarly, the string predicate
"100" = "1E2" is false while a numeric comparison 100 = 1E2 is true. The literal 1E2 is a
valid value for the XML data type xs:double. Hence, you should use DOUBLE indexes
(DECFLOAT in z/OS) if you want semantically correct numeric comparisons.
Similar considerations apply to dates and timestamps when time zones are involved. You can
index date and timestamp values as VARCHAR(n), and query them with string comparisons, if
they have no time zone indicators or if all values are in the same time zone. This is the recommended approach in DB2 for z/OS. In DB2 for Linux, UNIX, and Windows you should use the
index data types DATE and TIMESTAMP instead. These data types ensure correct date and time
comparison even across time zones.
When you define XML indexes you might find yourself confronted with the following questions:
• How do you know whether the values of a certain element can always be cast to
DOUBLE, DATE, or TIMESTAMP?
• How do you know how large to make the VARCHAR(n) type?
The first and best place to look for the answer is the XML Schema associated with your XML
documents. If you do not have an XML Schema or if you prefer to explore the actual XML documents in an XML column, you can use some of the following queries.
To check the actual maximum length of an element’s value across many documents, use one of
the queries shown in Figure 13.12. Note that these queries can be expensive to run over a large
number of documents, so you might want to add a WHERE clause to the subselect. Avoid scanning
the entire table but just look at a representative subset of the documents.
SELECT MAX(LENGTH(title))
FROM
(SELECT XMLCAST(XMLQUERY('$BOOKINFO/book/title')
AS VARCHAR(50) ) AS title
FROM books);
SELECT MAX(len)
FROM
(SELECT
XMLCAST(XMLQUERY('$BOOKINFO/book/string-length(title)')
AS VARCHAR(500) ) AS len
FROM books);
Figure 13.12
Checking the maximum length of an element value
13.2
XML Index Data Types
371
Now let’s look at two queries that check whether the value of the price element is indeed
numeric in all documents. The first query tries to cast the values of all price elements to
DOUBLE:
SELECT COUNT( XMLCAST( XMLQUERY('$b/book/price'
PASSING bookinfo AS "b")
AS DOUBLE) )
FROM BOOKS
If all price elements are numeric, this query returns the count of all prices. Otherwise, if a nonnumeric value is encountered, the query fails with the following message:
SQL16061N The value "£32" cannot be constructed as, or cast (using an
implicit or explicit cast) to the data type "xs:double". Error
QName=err:FORG0001. SQLSTATE=10608
The following XQuery is somewhat smarter because it does not fail but returns all the documents
in which the price value is not castable to xs:double:
xquery for $i in db2-fn:xmlcolumn("BOOKS.BOOKINFO")/book
where not($i/price castable as xs:double)
return $i
13.2.6
Rejecting Invalid Values
DB2 for Linux, UNIX, and Windows provides the option to reject invalid values in XML indexes
of type DOUBLE, DATE, or TIMESTAMP. As an example, remember that each of the three sample
documents in Figure 13.1 contains a price element. These three price elements are
• <price>31</price>
• <price>£32</price>
• <price>33</price>
Note that the first and third price elements have a numeric value while the second price element has a non-numeric value because it contains the character £. Assume you create an index for
these price elements as type DOUBLE, shown in Figure 13.13. This index only contains entries
for the first and third price elements, not for the second price element whose value cannot be
cast to DOUBLE. Any documents where the price element does match the DOUBLE data type are
silently ignored.
CREATE INDEX idx1 ON books(bookinfo)
GENERATE KEY USING XMLPATTERN '/book/price'
AS SQL DOUBLE
Figure 13.13
Indexing the price elements as DOUBLE
372
Chapter 13
Defining and Using XML Indexes
Omitting non-numeric values from the index does not lead to incomplete query results. If a query
searches for books where the price is £32, then the literal value £32 in the predicate must be
enclosed in double quotes because it is not a numeric value: /book[price="£32"]. The double
quotes imply that "£32" is a string, not a number, which means that DB2 cannot use the DOUBLE
index to evaluate the predicate anyway. Therefore, the absence of the value £32 from the index in
Figure 13.13 does no harm and only saves space.
Depending on the nature of your application you might want to guarantee that if a certain element or attribute is indexed as DOUBLE, then all occurrences of that element or attribute are
indeed of type DOUBLE. In other words, you might want to enforce the index data type as a hard
constraint.
Figure 13.14 shows how you can enforce the index data type with the REJECT INVALID VALUES clause. Due to the REJECT INVALID VALUES clause, this CREATE INDEX statement fails
with error SQL20306N if the XML column contains one or more documents in which the price
element contains a value that cannot be cast to DOUBLE. Similarly, if an application tries to insert
a document where the price element has a non-numeric value, the INSERT statement fails with
error SQL20305N, reason code 5.
CREATE INDEX priceIdx ON books(bookinfo)
GENERATE KEY USING XMLPATTERN '/book/price'
AS SQL DOUBLE REJECT INVALID VALUES
Figure 13.14
Rejecting invalid DOUBLE values
The same concepts apply to indexes of type DATE or TIMESTAMP. Figure 13.15 creates an index
of type DATE on the pubdate element with the REJECT INVALID VALUES clause. This index
definition guarantees that the XML column never contains documents in which the
pubdate element contains a value that cannot be cast to type DATE.
CREATE INDEX idxpubdate ON books(bookinfo)
GENERATE KEY USING XMLPATTERN '/book/pubdate'
AS SQL DATE REJECT INVALID VALUES
Figure 13.15
Creating an index of type DATE
The REJECT INVALID VALUES clause does not affect which values are or aren’t included in the
XML index. The contents and structure of the index is exactly the same with or without this
clause. The REJECT INVALID VALUES clause only affects which documents are or aren’t
allowed to be stored in the XML column. Such constraints, and more complex ones, can also be
enforced with XML Schemas.
13.3
Using XML Indexes to Evaluate Query Predicates
13.3
373
USING XML INDEXES TO EVALUATE QUERY PREDICATES
In this section we discuss the usage of XML indexes to improve query performance. Let’s start
with an example. Suppose you want to write a query to return the authors of all books with a
given title and price range. Figure 13.16 shows how this query can be coded.
SELECT XMLQUERY('$BOOKINFO/book/authors')
FROM books
WHERE XMLEXISTS('$BOOKINFO/book[title = "DB2 9 New Features"
and price < 50]')
Figure 13.16
SQL/XML query with two predicates
Without any indexes, this query scans the entire bookinfo column, which is typically inefficient.
To define suitable XML indexes, you need to know which paths to index and which data types to
use for the indexes. The predicates in Figure 13.16 constrain the title and price elements,
which are identified by the paths /book/title and /book/price, respectively. Assuming that
book titles are always character values and prices always numeric values, these elements should
be indexed as VARCHAR and DOUBLE (or DECFLOAT) values, respectively. Figure 13.17 shows the
two corresponding index definitions. These indexes are eligible (can be used) to evaluate the
predicates in Figure 13.16.
CREATE INDEX idx1 ON books(bookinfo)
GENERATE KEYS USING XMLPATTERN '/book/title' AS SQL VARCHAR(50)
CREATE INDEX idx2 ON books(bookinfo)
GENERATE KEYS USING XMLPATTERN '/book/price' AS SQL DOUBLE
Figure 13.17
13.3.1
Creating a VARCHAR and a DOUBLE index for the query in Figure 13.16
Understanding Index Eligibility
Index eligibility deals with the question of whether a certain XML index can be used to answer a
given query predicate. This question is typically trivial in relational query processing. Any index
defined on a single relational column can be used to answer any equality or range predicate on
that column. This problem, however, is more difficult for XML columns and XML indexes. An
index on a relational column stores all values that appear in the indexed column, but an XML
index stores only values of nodes that match the XPath pattern and the data type in the index definition. Therefore, an XML index can be used (is eligible) to answer an XML query predicate
only if the index contains all XML nodes that satisfy the query predicate. To ensure this, the following three index eligibility conditions must be met:
• The data type of the index and of the predicate must be compatible.
• Text nodes must be handled consistently in the index and the predicate.
374
Chapter 13
Defining and Using XML Indexes
• The index must “contain” the query predicate; that is, the XMLPATTERN of the index
must be equally or less restrictive than the XPath in the predicate.
If these conditions are met for a given index and predicate, the DB2 optimizer is allowed to consider the index in the generation of the query execution plan. The optimizer then makes a costbased decision whether to use the index or not in order to minimize the execution time of the
query. If you encounter a situation where an index is not used that you think should be used, begin
your investigation with examining the index definition and the predicate to check whether the
three index eligibility conditions are met. To help you do this, we explain the three conditions
with examples in the following sections 13.3.2, 13.3.3, and 13.3.4, respectively.
13.3.2
Data Types in XML Indexes and Query Predicates
As we explained in section 13.2, the data type of an XML index matters because it determines the
type of comparisons that the index can support. For example, indexes of type VARCHAR support
general string comparisons but no numeric comparisons. Indexes of type DOUBLE or DECFLOAT
support numeric comparisons but no string comparisons, and so on. Remember that comparing
strings is different from comparing numbers. A string predicate such as "2" < "100" is false
while the numeric comparison 2 < 100 is true.
If you want to search for books whose price does not exceed a certain limit, an index on the
/book/price element can help query performance. Although price values tend to be numeric in
nature, you certainly have the choice to index them as DOUBLE or as VARCHAR, as shown in the
two rightmost columns of Table 13.2. However, note that value predicates in a query also have a
data type that is determined by the type of the literal value. A value in double quotes, such as
“29”, is always a string while a numeric value without quotes is interpreted as a number. The
Yes/No entries in Table 13.2 show that a string predicate can only be evaluated with an XML
index of type VARCHAR while a numeric predicate can only be evaluated with a numeric index
(DOUBLE in DB2 for Linux, UNIX, and Windows and DECFLOAT in DB2 for z/OS). In this sense,
the data type of the predicate and the data type of the index have to match.
Table 13.2
Index Eligibility for Numeric Versus String Predicates
Index definition
Predicate
$i/book[price < "29"]
$i/book[price < 29]
…USING XMLPATTERN
'/book/price'
AS SQL DOUBLE
No
Y es
…USING XMLPATTERN
'/book/price'
AS SQL VARCHAR(10)
Y es
No
As another example, consider the index of type DATE for the pubdate element (see Figure
13.18). This index can only be used for date predicates. The first of the two SELECT statements in
Figure 13.19 cannot use this index, because it performs a simple string comparison. It can only
use an index of type VARCHAR. The second SQL/XML statement in Figure 13.19 casts the literal
value to xs:date to perform a comparison with date semantics. This predicate can use the DATE
index in Figure 13.18.
13.3
Using XML Indexes to Evaluate Query Predicates
375
CREATE INDEX pubDateIndex ON books(bookinfo)
GENERATE KEYS USING XMLPATTERN '/book/pubdate' AS SQL DATE
Figure 13.18
An index of type DATE
SELECT *
FROM books
WHERE XMLEXISTS('$BOOKINFO/book[pubdate = "2009-06-30"]');
SELECT *
FROM books
WHERE XMLEXISTS('$BOOKINFO/book[pubdate=xs:date("2009-06-30")]');
Figure 13.19
13.3.3
Querying the pubdate element, with and without using an index of type DATE
Text Nodes in XML Indexes and Query Predicates
We have previously discussed text nodes in sections 3.1, Understanding XML Document Trees,
and 6.2, Understanding the XQuery and XPath Data Model. Remember that the value of an XML
element is defined as the concatenation of all text nodes in the subtree underneath that element.
Query predicates are almost always expressed on leaf elements; that is, elements at the lowest level
of the tree with at most one text node. For example, the price element has only a single text node
and therefore the predicates [price = 33] and [price/text() = 33] lead to the same result.
Hence, you usually do not need to use /text() in predicates. Therefore you should also not use
/text() in index definitions. If you do use /text() in a predicate, then you also need to use
/text() in the index that you are hoping to use. These rules are summarized in Table 13.3.
Table 13.3
Index Eligibility with Text Nodes
Index definition
Predicate
$i/book[price = 33]
$i/book[price/text() = 33]
…USING XMLPATTERN
'/book/price'
AS SQL DOUBLE
Yes
No
…USING XMLPATTERN
'/book/price/text()'
AS SQL DOUBLE
No
Yes
As a general guideline we recommend not to use /text() in predicates or index definitions.
There are cases when using /text() in predicates can be helpful, such as for non-leaf elements
whose immediate children are a mix of element and text nodes (this is called mixed content, see
section 3.1). However, this is a relatively rare case. For example, consider the following XML
document:
<title>This is a <bold>great</bold> book about XML</title>
376
Chapter 13
Defining and Using XML Indexes
For this document, the XPath pattern /title produces a single index entry with the value “This
is a great book about XML”, because the value of the title element is the concatenation
of all its descendant text nodes. In contrast, the XPath expression /title/text() creates two
index entries, one for the text node “This is a ” and one for the text node “ book about
XML”. Indexing of non-leaf elements is further discussed in section 13.5.
13.3.4
Wildcards in XML Indexes and Query Predicates
The use of // and * in predicates can affect the containment relationship between an index and a
query predicate. For example, the path expressions such as /book/@id and //@id are different.
The path /book/@id identifies all id attributes that are immediate children of the element book.
But, the path //@id identifies id attributes anywhere at any level of the XML documents,
including author id attributes. Thus, /book/@id identifies a subset of the attributes specified by
//@id. In this sense, //@id contains /book/@id but not the other way around. Now let’s look
at how this affects index eligibility. Consider Figure 13.20 as an example.
SELECT *
FROM books
WHERE XMLEXISTS('$i/book[@id = 101]' PASSING bookinfo AS "i")
Figure 13.20
Demonstrating index eligibility
Based on this query, Table 13.4 shows four different ways of writing the XPath predicate in the
XMLEXISTS. The two rightmost columns of the table represent two alternative index definitions,
and the rows in the table show which of the predicates can (Yes) or cannot (No) be evaluated by
either of the indexes.
Table 13.4
Index Eligibility with Wildcards in XML Indexes and Predicates
Index definition
Predicate
1
2
3
4
$i//*[@id = 101]
$i/book[@id = 101]
$i/book[@* = 101]
$i/*[@id = 101]
…USING XMLPATTERN
'/book/@id'
AS SQL DOUBLE
No
Yes
No
No
…USING XMLPATTERN
'//@id'
AS SQL DOUBLE
Yes
Yes
No
Yes
For the first predicate, the index on /book/@id is not eligible because it only contains id attributes that are immediate children of book. The index does not contain id attributes at any deeper
level, such as the author id attributes. However, an author id attribute with a value of 101 would
be a valid match for the predicate path $i//*/@id. Thus, if DB2 used the index on /book/@id
it might return an incomplete result. The second index on //@id is eligible because it contains all
id attributes at any level of the document, as required for the predicate.
13.3
Using XML Indexes to Evaluate Query Predicates
377
The second predicate specifies a full path to the id attribute, so both indexes are eligible. The first
index on /book/@id contains exactly what the predicate path is looking for; that is, book id
attributes. The second index on //@id contains even more, and is therefore also eligible.
The third predicate uses @* as a wildcard, such that it looks for any attribute of book with a value
of 101. Not only id attributes can fulfill this predicate, but for example, a document with value
101 in the attribute /book/@isbn is also a valid match. But, isbn attributes are not included in
either of the two indexes. Therefore, neither index is used because DB2 cannot risk returning
incomplete results for this predicate.
The fourth predicate $i/*[@id = 101] looks for id attributes under any root element, not just
book. If there is a document with a path /journal/@id, then it might satisfy the predicate, but
it is not included in the index on /book/@id. Therefore, this index cannot be used because DB2
would again risk returning an incomplete query result. However, the index on //@id contains
any id attribute, irrespective of the root element, so this index can be used.
In a nutshell, the DB2 query compiler always needs to be able to prove that the index is equally or
less restrictive than the predicate, so that it contains everything that the predicate is looking for.
Be aware that using wildcards in index definitions might inadvertently index more nodes than
needed. Wherever possible, it is recommended to use the exact path to the desired elements or
attributes in index definitions and queries, without wildcards. Very generic XML index patterns
such as //* or //text() are possible, but should be used with great caution.
NOTE An index on //* indexes all elements, including non-leaf
elements, which is typically not useful. An index on //* contains an
index entry even for the root element, and the key value is the concatenation of all text nodes in the document. Such a key value can easily exceed the length constraint of a VARCHAR(n) index so that the
document cannot be inserted.
13.3.5
Using Indexes for Structural Predicates
As we discussed in sections 6.8, Existential Semantics, and 7.4, Using XPath Predicates in
SQL/XML with XMLEXISTS, a structural predicate is one that checks for the existence of an element or attribute irrespective of its value.
As an example, let’s find the titles of those documents in the books table that have an explicit
publication date; that is, a pubdate element that exists under the book element. The corresponding query is shown in Figure 13.21. The XMLEXISTS predicate evaluates to true if a book element has at least one pubdate child element (existential semantics).
378
Chapter 13
Defining and Using XML Indexes
SELECT XMLQUERY('$b/book/title' PASSING bookinfo AS "b")
FROM books
WHERE XMLEXISTS('$b/book/pubdate' PASSING bookinfo AS "b")
Figure 13.21
Query with a structural predicate
To support the structural predicate in this query and avoid a table scan, you might want to create a
corresponding index of type VARCHAR, as shown in Figure 13.22.
CREATE INDEX pubdate_index ON books(bookinfo)
GENERATE KEY USING XMLPATTERN '/book/pubdate'
AS SQL VARCHAR(12)
Figure 13.22
Index for the pubdate element
DB2 9 for z/OS is able to use this index to evaluate the structural predicate in Figure 13.21. DB2
for Linux, UNIX, and Windows can also use the index to evaluate the predicate, provided that
you rewrite the structural predicate into a suitable value predicate. Figure 13.23 shows a slightly
rewritten query that returns all books that have a pubdate element with a value greater than the
empty string.
-- Query:
SELECT XMLQUERY('$b/book/title' PASSING bookinfo AS "b")
FROM books
WHERE XMLEXISTS('$b/book[pubdate > ""]' PASSING bookinfo AS "b")
-- Access Plan:
RETURN
( 1)
|
NLJOIN
(
2)
/-+-\
FETCH
XSCAN
( 3)
( 7)
/----+---\
RIDSCN
TABLE: DB2ADMIN
( 4)
BOOKS
|
SORT
( 5)
|
XISCAN
( 6)
|
XMLIN: DB2ADMIN
PUBDATE_INDEX
Figure 13.23
Query with a value predicate to mimic a structural predicate
13.4
XML Indexes and Join Predicates
379
The query uses a value predicate that is eligible to use the index in Figure 13.21. If a document
contains an empty pubdate element (<pubdate></pubdate>), the query does not return the
title of that document. If you want the predicate to also match empty pubdate elements,
change it to [pubdate >= ""].
The access plan in Figure 13.23 confirms that an XML index scan (XISCAN) is used to probe into
the PUBDATE_INDEX. This XISCAN produces the row IDs of those documents that match the
predicate. The FETCH operator then retrieves only the rows for those matching documents from
the table. After that, the XSCAN operator extracts the title elements from the qualifying documents. Note that the nested loop join (NLJOIN) right above the XSCAN is not a typical join operation. It merely facilitates the passing of document pointers to the XSCAN operator. For more
background on access plans, see Chapter 14, XML Performance and Monitoring.
13.4
XML INDEXES AND JOIN PREDICATES
In section 9.2, Join Queries with XML Data, we explained how to write joins between XML
columns. Index usage for join predicates requires special considerations. Let’s look at joining two
tables with XML columns. The first one is the books table that we have been using so far, and the
second one is a table called authors, containing author information. The authors table is created as follows and contains the two documents in Figure 13.24.
CREATE TABLE authors (authorinfo XML)
<author id="2001">
<name>Mary Smith</name>
<addr country="USA">
<street>555 Bailey Avenue</street>
<city>San Jose</city>
</addr>
<phone>
<areacode>408</areacode>
<number>4511234</number>
</phone>
</author>
<author id="2002">
<name>Tom Noodle</name>
<addr country="Canada">
<street>213 Rigatoni Road</street>
<city>Toronto</city>
</addr>
<phone>
<areacode>905</areacode>
<number>8110583</number>
</phone>
</author>
Figure 13.24
Sample documents in the authors table
380
Chapter 13
Defining and Using XML Indexes
Take a moment to compare the author documents to the book documents in Figure 13.1. You’ll
notice that Figure 13.24 contains information about two of the three authors who are referenced
in the book documents via their id attributes and names. Therefore, you can join the table
authors and books on the author id attribute.
Figure 13.25 shows such a join first in XQuery notation and then in the equivalent SQL/XML
syntax that also runs on DB2 for z/OS. Both queries return the same result. For each author listed
in the authors table, these queries retrieve the isbn numbers of the author’s publications from
the books table and return a small document with the isbn number, author id, and name.
Although only two authors are listed in the authors table, the queries in Figure 13.25 return
three rows because Mary Smith has published two books.
xquery
for $a in db2-fn:xmlcolumn("AUTHORS.AUTHORINFO")/author
for $b in db2-fn:xmlcolumn("BOOKS.BOOKINFO")/book
where $a/@id = $b/authors/author/@id
return
<pub>{$b/@isbn}{$a/@id}{$a/name/text()}</pub>;
SELECT XMLELEMENT(name "pub",
XMLQUERY('$b/book/@isbn' PASSING bookinfo as "b"),
XMLQUERY('$a/author/@id' PASSING authorinfo as "a"),
XMLQUERY('$a/author/name' PASSING authorinfo as "a") )
FROM books, authors
WHERE XMLEXISTS('$a/author[@id = $b/book/authors/author/@id ]'
PASSING bookinfo as "b", authorinfo as "a");
<pub isbn="0-321-18060-7" id="2001">Mary Smith</pub>
<pub isbn="0-596-00252-1" id="2001">Mary Smith</pub>
<pub isbn="1-59059-983-7" id="2002">Tom Noodle</pub>
3 record(s) selected.
Figure 13.25
A join between books and authors in XQuery and SQL/XML notation
The join predicates of the queries are highlighted in their where clauses. To improve the performance of these queries, it seems useful to define the indexes in Figure 13.26. Use DECLFOAT
instead of DOUBLE on DB2 for z/OS.
CREATE INDEX bookAuthorIdx ON books(bookinfo)
GENERATE KEY USING XMLPATTERN '/book/authors/author/@id'
AS SQL DOUBLE
CREATE INDEX authorIdx ON authors(authorinfo)
GENERATE KEY USING XMLPATTERN '/author/@id'
AS SQL DOUBLE
Figure 13.26
Indexes on author id attributes in the books and authors tables
13.4
XML Indexes and Join Predicates
381
However, the queries in Figure 13.25 cannot use either of these indexes to evaluate their join
predicates. The reason is that a join predicate does not contain a literal value that indicates the
data type of the comparison. Therefore, DB2 needs to look for matching author ids of any data
type, not just numeric values. For example, it is possible that an author has a non-numeric id
value, such as TN28, in both the authors and the books table. This value would be a valid join
match. However, the numeric indexes bookAuthorIdx and authorIdx do not contain alphanumeric values such as TN28. If DB2 used one of these indexes to evaluate the join predicate it
would not find author id TN28 and return an incomplete join result. Thus, DB2 cannot use those
indexes and resorts to a table scan to ensure a correct query result.
Note that changing the index data types to VARCHAR does not help but only reverses the problem.
VARCHAR indexes on the author ids allow DB2 to find alphanumeric join matches but might cause
DB2 to miss numeric join matches. For example, the values 2001 and 2.001E3 are identical
numeric values and should be recognized as a join match. However, the strings “2001” and
“2.001E3” are different and not identical in a VARCHAR index. Again, DB2 has no choice but to
perform a table scan to guarantee that it catches all possible join matches.
In many situations, you probably know that all the values that you join on are of a certain data
type. For example, in our book and author example, all the author ids are numeric, so it is perfectly safe to use the numeric indexes in Figure 13.26. In this case, you need to tell DB2 that you
want the join to be restricted to numeric comparisons. The way to do this is shown in Figure
13.27, where both sides of the join predicate use a cast to xs:double. The cast explicitly
excludes non-numeric matches from the join and allows DB2 to use the DOUBLE index in
Figure 13.26.
xquery
for $a in db2-fn:xmlcolumn("AUTHORS.AUTHORINFO")/author
for $b in db2-fn:xmlcolumn("BOOKS.BOOKINFO")/book
where $a/@id/xs:double(.) = $b/authors/author/@id/xs:double(.)
return
<pub>{$b/@isbn}{$a/@id}{$a/name/text()}</pub>;
Figure 13.27
XQuery with a join predicate and proper casting
You can write the same join in SQL/XML notation in two ways, as shown in Figure 13.28. They
differ in the “direction” of the join predicate in the XMLEXISTS.
SELECT XMLELEMENT(name "pub",
XMLQUERY('$b/book/@isbn' PASSING bookinfo as "b"),
XMLQUERY('$a/author/@id' PASSING authorinfo as "a"),
XMLQUERY('$a/author/name' PASSING authorinfo as "a") )
FROM books, authors
WHERE XMLEXISTS('$b/book/authors[author/@id/xs:double(.) =
$a/author/@id/xs:double(.) ]'
PASSING bookinfo as "b", authorinfo as "a");
Figure 13.28
SQL/XML query using join predicates
382
Chapter 13
Defining and Using XML Indexes
SELECT XMLELEMENT(name "pub",
XMLQUERY('$b/book/@isbn' PASSING bookinfo as "b"),
XMLQUERY('$a/author/@id' PASSING authorinfo as "a"),
XMLQUERY('$a/author/name' PASSING authorinfo as "a") )
FROM books, authors
WHERE XMLEXISTS('$a/author[@id/xs:double(.) =
$b/book/authors/author/@id/xs:double(.) ]'
PASSING bookinfo as "b", authorinfo as "a");
Figure 13.28
SQL/XML query using join predicates (Continued)
In DB2 9 for z/OS as well as DB2 9.1 and 9.5 for Linux, UNIX, and Windows, the queries in Figure 13.28 enforce different join orders, so they typically do not perform the same. It’s the join
predicate that determines the join order and the performance. In the first query, the predicate in
square brackets is applied to the expression starting with $b (column bookinfo). This allows
DB2 to use an index to access the books table. As a result, the query performs a table scan on the
authors table and then uses the index bookAuthorIdx to probe for matches into the books
table.
In the second query, the join condition is a predicate on the expression starting with $a (column
authorinfo), so DB2 can use an index to access the authors table. It performs a table scan on
the books table and then uses the index AuthorIdx to probe into the authors table. You typically want the table scan to be performed on the smaller table. Hence, the choice between these
two statements depends on the size of the books and authors tables. If the books table has
more rows than the authors table, then the first statement in Figure 13.28 is preferable.
DB2 9 for z/OS requires APAR PK55783 to use indexes for
the join predicates in Figure 13.28. Also see APAR II14426 for the latest
status.
NOTE
In DB2 9.7 for Linux, UNIX, and Windows, the join order is no longer determined by how the
join predicate inside XMLEXISTS is written. The DB2 compiler makes a cost-based decision to
choose the appropriate join order.
To summarize the advice for XML join queries, you should always cast join predicates to the type
of the XML index that should be used. Otherwise query semantics do not allow index usage. If
the XML index is defined as DOUBLE or DECFLOAT, cast the join predicate with xs:double. If
the XML index is defined as VARCHAR, cast the join predicate with fn:string, and so on as
shown in Table 13.5.
13.5
XML Indexes on Non-Leaf Elements
Table 13.5
383
Summary of Casting Rules for XML Join Predicates
Index Type
Cast Join Predicate Using
Comment
DOUBLE,
DECFLOAT
xs:double
For any numeric predicate
VARCHAR(n),
VARCHAR HASHED
fn:string
For any string predicates
DATE
xs:date
For any date predicate
TIMESTAMP
xs:dateTime
For any timestamp predicates
13.5
XML INDEXES ON NON-LEAF ELEMENTS
Non-leaf elements are elements that contain other elements. They are not at the bottom of a document tree. In contrast, a leaf element is at the lowest level of the document tree and only contains
at most a text node (see section 3.1, Understanding XML Document Trees).
In our author documents in this chapter, elements such as addr and phone are non-leaf elements
because they contain other elements. The addr element contains the elements street and city,
and the phone element contains the elements areacode and number. Let’s remind ourselves of
the document structure:
<author id="2001">
<name>Mary Smith</name>
<addr country="USA">
<street>555 Bailey Avenue</street>
<city>San Jose</city>
</addr>
<phone>
<areacode>408</areacode>
<number>4511234</number>
</phone>
</author>
In the majority of cases, indexes on non-leaf elements are not useful. For example, it does not
make sense to create an index on the non-leaf element /authors/addr. This index has one
index entry for the document above because there is one occurrence of the addr element. The
XML data model defines the value of a non-leaf element as the concatenation of all text nodes
(but not attributes) in the subtree under that element. Therefore, the index entry has the key value
“555 Bailey AvenueSan Jose”. Note that there is no space between Avenue and San Jose.
Since you normally do not query your data with such concatenated values, the index is typically
not helpful. If you need index support for predicates on the street and the city elements of the
address, you better define two separate indexes on these two leaf elements.
384
Chapter 13
Defining and Using XML Indexes
Now let’s look at a case where an index on a non-leaf element can make sense. For example,
assume that queries search authors sometimes by area code and sometimes by their full phone
number. In this case, you can define one XML index on the non-leaf element phone (Figure
13.29) and one on the element areacode (Figure 13.30).
CREATE INDEX phoneidx
ON authors(authorinfo)
GENERATE KEY USING XMLPATTERN '/author/phone' AS SQL DOUBLE
Figure 13.29
Index on a non-leaf element
For our preceding sample document, the value of the phone element is the concatenation of the
text nodes of the areacode and number elements: 4084511234. This concatenation is meaningful because the areacode and number elements do not have any further siblings that would
contribute to and obscure the concatenated value.
CREATE INDEX areaidx
ON authors(authorinfo)
GENERATE KEY USING XMLPATTERN '/author/phone/areacode'
AS SQL DOUBLE
Figure 13.30
Index on a leaf element
Figure 13.31 contains a predicate on the non-leaf element phone and can use the non-leaf index
on /author/phone.
SELECT authorinfo
FROM authors
WHERE XMLEXISTS('$AUTHORINFO/author[phone=4084511234]')
Figure 13.31
Query that uses an index on a non-leaf element
Figure 13.32 only constrains the areacode element and can use the index in Figure 13.30.
SELECT authorinfo
FROM authors
WHERE XMLEXISTS('$AUTHORINFO/author/phone[areacode=408]')
Figure 13.32
Query that uses an index on a leaf element
13.6
Special Cases Where XML Indexes Cannot be Used
13.6
385
SPECIAL CASES WHERE XML INDEXES CANNOT BE USED
This section discusses specific situations where XML indexes are not eligible for certain
predicates.
13.6.1
Special Cases with XMLQUERY
All the guidelines for XML index eligibility discussed in the previous sections apply to both
XQuery and SQL/XML queries. Additionally, there are some specific considerations for the
SQL/XML functions XMLQUERY and XMLEXISTS.
If you use XML predicates in the XMLQUERY function in the SELECT clause of an SQL statement,
then these predicates do not eliminate any rows from the result set and therefore cannot use an
index. Such predicates only apply to one document at a time and might return a (possibly empty)
fragment of a document. Thus, you should place any document and row-filtering predicates into
an XMLEXISTS predicate in the WHERE clause of the SQL/XML statement. Figure 13.33 provides
an example.
-- This query cannot use an index:
SELECT XMLQUERY('$BOOKINFO/book[@id = 101]/title')
FROM books;
-- This query can use an index:
SELECT XMLQUERY('$BOOKINFO/book/title')
FROM books
WHERE XMLEXISTS('$BOOKINFO/book[@id = 101]');
Figure 13.33
13.6.2
Index usage with XMLEXISTS versus XMLQUERY
Parent Steps
DB2 cannot use an index for predicates that occur under a parent step (“..”), such as the predicates on price in the two queries in Figure 13.34.
-- Query 1
SELECT bookinfo
FROM books
WHERE XMLEXISTS('$BOOKINFO/book/title[../price < 10]');
-- Query 2
xquery
for $b in db2-fn:xmlcolumn("BOOKS.BOOKINFO")/book/title
where $b/../price < 10
return $b ;
Figure 13.34
Queries with parent steps in the predicate don’t use indexes
386
Chapter 13
Defining and Using XML Indexes
This is not a significant limitation because you can always express these predicates without the
parent axis, as shown in Figure 13.35.
-- Query 3:
SELECT bookinfo
FROM books
WHERE XMLEXISTS('$BOOKINFO/book[price < 10]/title');
-- Query 4:
xquery
for $b in db2-fn:xmlcolumn("BOOKS.BOOKINFO")/book
where $b/price < 10
return $b/title ;
Figure 13.35
13.6.3
Queries without parent steps in the predicate can use indexes
The let and return Clauses
Be aware that predicates in XQuery let and return clauses do not filter result sets, and therefore they do not use indexes. The next two queries (Figure 13.36 and Figure 13.37) cannot use an
index because an element phone408 needs to be returned for every author, even if it is an empty
element for authors outside the 408 area code.
xquery
for $a in db2-fn:xmlcolumn("AUTHORS.AUTHORINFO")/author
let $p := $a/phone[areacode=408]//text()
return
<phone408>{$p}</phone408>
Figure 13.36
No index usage for predicates with let and element construction
The second example of a query that doesn’t use an index is Figure 13.37.
xquery
for $a in db2-fn:xmlcolumn("AUTHORS.AUTHORINFO")/author
return
<phone408>{$a/phone[areacode=408]//text()}</phone408>
Figure 13.37
No index usage for predicates with return and element construction
If you want the queries in Figure 13.36 and Figure 13.37 to use an XML index, you need to move
the predicate from the let or return clause into the where or for clause (see Figure 13.38).
Both queries in Figure 13.38 return the same result, which is different from the results produced
by the queries Figure 13.36 and Figure 13.37. The difference is that the queries in Figure 13.38
do not produce empty phone408 elements for customers whose area code is not 408. Instead,
such customers are not represented at all in the result.
13.7
XML Index Internals
387
xquery
for $a in db2-fn:xmlcolumn("AUTHORS.AUTHORINFO")/author
where $a/phone[areacode="408"]
return
<phone408>{$p//text()}</phone408>;
xquery
for $a in db2-fn:xmlcolumn("AUTHORS.AUTHORINFO")/author/phone[
areacode="408"]
return
<phone408>{$p//text()}</phone408>;
Figure 13.38
13.7
Queries that can use an index
XML INDEX INTERNALS
In this section we provide a glimpse at how XML indexes are implemented in DB2 for Linux,
UNIX, and Windows.
13.7.1
XML Index Keys
In general terms, an XML index is a mapping from path/value pairs to document ID (docID),
node ID (nodeID), and row ID (RID). For example, for the first document in Figure 13.1, the
index on //@id in Figure 13.39 contains the path/value pairs shown in Figure 13.40.
CREATE INDEX idx3 ON books(bookinfo)
GENERATE KEYS USING XMLPATTERN '//@id'
AS SQL VARCHAR(10)
Figure 13.39
Indexing nodes at multiple paths
(/book/@id, "101")
(/book/authors/author/@id, "2000")
(/book/authors/author/@id, "2001")
Figure 13.40
Path/Value pairs represented in the XML Index on //@id
The index maps each of these pairs to a docID, a nodeID, and a RID. The docID identifies the
document that contains the matching node. The nodeID identifies the matching node and region
within the document. The RID identifies the row that contains the matching document, similar to
RIDs in regular relational indexes.
To save space, the XML index contains pathIDs instead of the actual paths. The pathIDs are
integers that uniquely identify the actual paths in the XML data. To maintain the mapping from
paths to pathIDs, DB2 automatically creates one path index for each XML column. The path
388
Chapter 13
Defining and Using XML Indexes
index contains one entry for each distinct path that occurs in the XML column. The index maps
each distinct path to a unique pathID. Path indexes tend to be very small since they have only
one entry per unique path, even if the table is very large. In the catalog table syscat.indexes,
path indexes have the index type XPTH. Table 13.6 shows the logical mapping from paths to
pathIDs for the sample data in Figure 13.1.
Table 13.6
Logical Mapping from Paths to PathIDs
Path
PathID
/book
100
/book/@id
101
/book/authors
102
/book/authors/author
103
/book/authors/author/@id
104
/book/price
105
/book/pubdate
106
/book/title
107
/book/title/@isbn
108
…
…
In XPath, the use of the // is fairly common and qualifies the end of the path rather than the
beginning. For example, the path //@id identifies all paths that end in “@id”. To find these paths
more efficiently, the path index actually stores each path in reverse, from leaf to root, as indicated
in Table 13.7. The reverse paths allow DB2 to perform a simple prefix lookup to find all paths that
end in “@id”.
Table 13.7
Actual Mapping from Paths to pathIDs, Using Reversed Paths
Reversed Path
PathID
author/authors/book/
100
authors/book/
101
book/
102
@id/author/authors/book/
103
@id/book/
104
@isbn/title/book/
105
13.7
XML Index Internals
Table 13.7
389
Actual Mapping from Paths to pathIDs, Using Reversed Paths (Continued)
Reversed Path
PathID
price/book/
106
pubdate/book/
107
title/book/
108
…
…
Based on this mapping, the logical path/value pairs in Figure 13.40 are actually represented as the
pathID/value pairs shown in Figure 13.41. The use of pathIDs makes user-defined XML
indexes smaller than they would be otherwise. Essentially, the path index acts as a compression
dictionary for each user-defined XML index.
(104, "101")
(103, "2000")
(103, "2001")
Figure 13.41
pathID/value pairs in the XML index on //@id
How are these pathID/value pairs resolved during query processing? Let’s assume a query contains the XPath predicate /book/authors/author[@id="2000"]. DB2 reverses the path to
@id/author/authors/book/, performs a lookup in the internal path index, and finds pathID
103. Then DB2 probes the user-defined XML index with the pathID/value pair (103,
"2000") to find the matching documents.
If a query contains the predicate //@id[. ="2000"], DB2 performs a prefix lookup on the path
index and finds pathIDs 103 and 104. Based on that, DB2 probes the user-defined XML index
with the pairs (103, "2000") and (104, "2000") but only one of them results in a match.
This is because there is an author id with the value 2000, but not a book id with the value 2000.
13.7.2
Logical and Physical XML Indexes
When you define an XML index in DB2 for Linux, UNIX, and Windows, DB2 creates two
indexes internally: a logical index and a physical index. The logical index carries the index name
that you provide in the CREATE INDEX statement and it contains the meta information about the
index, such as the XMLPATTERN. The logical index occupies an insignificant amount of space.
The physical index has a system-generated name and contains the actual B-tree structure that
holds the index keys. The relationship between logical and physical indexes is kept in the catalog
view SYSCAT.INDEXXMLPATTERNS (see Chapter 22, Exploring XML Information in the DB2
Catalog).
390
Chapter 13
Defining and Using XML Indexes
When you collect statistics for tables and indexes with the RUNSTATS command, note that index
statistics are associated with the physical XML index, not the logical index. Since a physical
XML index is just a B-tree, the same statistics apply as for a relational B-tree index. For example,
you can examine the key cardinalities of an XML index with the query in Figure 13.42. This
query joins the catalog view SYSCAT.INDEXES, which contains the key cardinalities, with
SYSCAT.INDEXXMLPATTERNS, which maps logical to physical index names. This join allows
you to easily examine the key cardinalities based on a logical index name.
SELECT x.indname, pattern,
firstkeycard AS f1kc, first2keycard AS f2kc,
first3keycard AS f3kc, first4keycard AS f4kc,
fullkeycard AS fkc
FROM syscat.indexes i, syscat.indexxmlpatterns x
WHERE i.indname = x.pindname
AND x.indname = 'IDX3';
INDNAME
PATTERN
F1KC
F2KC
F3KC
F4KC
----------- ----------- ------ ------ ------ -----IDX3
//@id
2
6
7
7
1 record(s) selected.
Figure 13.42
Key cardinalities of XML index
To interpret the key cardinalities, remember that the first four parts of an XML index entry are
pathID, value, docID, and nodeID. Hence, the column firstkeycard in the catalog view
syscat.indexes contains the number of distinct pathIDs in the index. This number is the cardinality of the first key of the index. For our sample index on //@id and the sample data in Figure 13.1, the firstkeycard value is 2 because the index contains index entries for two paths,
/book/@id and /book/authors/author/@id. The column first2keycard indicates the
number of unique pathID/value pairs in the index. This number is 6, because our sample data
contains six distinct books ids and author ids. The column first3keycard shows the number of
distinct pathID/value/docID triplets. In our example, this number is 7 because one pathID/
value pair occurs in two different documents. The author with the id attribute 2001 appears in
two of the book documents. The first4keycard and fullkeycard are also 7.
13.8
XML INDEX STATISTICS
In this section we look at a more comprehensive example of XML index statistics in DB2 for
Linux, UNIX, and Windows. This example is based on the customer table of the DB2 sample
database. This table contains six rows with relational cid values from 1000 through 1005, and
six corresponding XML documents in the XML column info. Figure 13.43 shows one of these
documents. The others can be found in Appendix B, The XML Sample Database.
13.8
XML Index Statistics
391
<customerinfo Cid="1004">
<name>Matt Foreman</name>
<addr country="Canada">
<street>1596 Baseline</street>
<city>Toronto</city>
<prov-state>Ontario</prov-state>
<pcode-zip>M3Z 5H9</pcode-zip>
</addr>
<phone type="work">905-555-4789</phone>
<phone type="home">416-555-3376</phone>
<assistant><name>Gopher Runner</name>
<phone type="home">416-555-3426</phone>
</assistant>
</customerinfo>
Figure 13.43
A sample document
Let’s create two indexes on the info column, as shown in Figure 13.44. The first index is defined on
/customerinfo/phone to cover the customer phones only. The second index on //phone contains index entries for all phone elements, including assistant phones. The clause COLLECT
DETAILED STATISTICS specifies that index statistics are to be collected during the creation of the
index. Alternatively you can run the RUNSTATS command after the creation of the indexes.
CREATE INDEX custPhoneIdx ON customer(info)
GENERATE KEY USING XMLPATTERN '/customerinfo/phone'
AS SQL VARCHAR(50) COLLECT DETAILED STATISTICS
CREATE INDEX allPhoneIdx ON customer(info)
GENERATE KEY USING XMLPATTERN '//phone'
AS SQL VARCHAR(50) COLLECT DETAILED STATISTICS
Figure 13.44
Creating the test indexes
After creating these two indexes, let’s look at the index statistics. They are visible in the two catalog views, SYSCAT.INDEXES and SYSSTAT.INDEXES. Figure 13.45 retrieves the index key cardinalities together with index names and patterns from SYSSTAT.INDEXES.
SELECT SUBSTR(x.indname,1,10) AS log_index,
SUBSTR(x.pattern,1,20) AS pattern,
i.firstkeycard AS f1kc,
i.first2keycard AS f2kc,
i.first3keycard AS f3kc,
i.first4keycard AS f4kc,
i.fullkeycard
AS fkc
FROM sysstat.indexes i, syscat.indexxmlpatterns x
WHERE i.indname = x.pindname;
LOG_INDEX
PATTERN
F1KC F2KC F3KC F4KC FKC
------------- -------------------- ----- ----- ----- ----- ---CUSTPHONEIDX /customerinfo/phone
1
9
11
11
11
ALLPHONEIDX
//phone
2
11
13
13
13
2 record(s) selected.
Figure 13.45
Examining XML index statistics in the catalog view SYSSTAT.INDEXES
392
Chapter 13
Defining and Using XML Indexes
The columns firstkeycard, first2keycard, and so on are interpreted as follows:
• firstkeycard: number of distinct pathIDs
• first2keycard: number of distinct pathID/value pairs
• first3keycard: number of distinct pathID/value/docID triplets
• first4keycard: number of distinct pathID/value/docID/nodeID tuples
• fullkeycard: number of distinct index entries
Since the index custPhoneIdx covers the single XPath /customerinfo/phone, the
firstkeycard value is always 1 because the pathID is the same for all index entries. The index
allPhoneIdx on //phone has a firstkeycard value of 2, because it includes index entries for
phone elements on two different paths, /customerinfo/phone as well as /customerinfo/
assistant/phone.
To better understand the values first2keycard, first3keycard, and so on, look at the 13
phone elements that occur in the customer table and their distribution across documents (Table
13.8). Note that the phone numbers #10 and #13 are assistant phone numbers and only occur in
the index allPhoneIdx. Hence, first4keycard and fullkeycard are 13 for the index allPhoneIdx but 11 for the index custPhoneIdx.
Table 13.8
Summary of phone elements
cid Value
#
All phone Elements
1000
1
<phone type="work">416-555-1358</phone>
1001
2
<phone type="work">905-555-7258</phone>
1002
3
<phone type="work">905-555-7258</phone>
1003
4
5
6
7
<phone
<phone
<phone
<phone
1004
8
9
10
<phone type="work">905-555-4789</phone>
<phone type="home">416-555-3376</phone>
<phone type="home">416-555-3426</phone>
1005
11
12
13
<phone type="work">905-555-9146</phone>
<phone type="home">416-555-6121</phone>
<phone type="home">416-555-1943</phone>
type="work">905-555-7258</phone>
type="home">416-555-2937</phone>
type="cell">905-555-8743</phone>
type="cottage">613-555-3278</phone>
13.9
Summary
393
The first2keycard of the index custPhoneIdx has the value 9 because out of the eleven index
entries there are only nine distinct pathID/value pairs. The phone numbers #2, #3, and #4 have
identical values and paths. In other words, three of the six customers have the same work phone
number. For the same reason, the first2keycard of the index allPhoneIdx is 11. It contains
nine distinct customer phones and two distinct assistant phones. The first3keycard of both
indexes equals their fullkeycard because in our example the duplicate phone numbers are all
in different documents; that is, they have different docID values in the index.
13.9
SUMMARY
XML indexes are essential to ensure good performance for queries, updates, or delete statements
that contain predicates on XML columns. The syntax of the CREATE INDEX statement has been
extended to let you specify an XMLPATTERN. An XMLPATTERN is a simple XPath expression that
selects the elements or attributes that should be indexed.
XML indexes are different from relational indexes in several ways. An index on a relational column has exactly one index entry for each row in the table, and the data type of the index key is
determined by the type of the column. When you define an XML index on a specific XML element, this element may appear zero, one, or multiple times in any given document. Hence, an
XML index can have zero, one, or multiple index entries for each row in the table. As a result, an
XML index on an optional element that occurs only in very few documents can be very small and
efficient. Another difference to relational indexes is that XML elements and attributes do not necessarily have a predefined data type. Therefore, a target type needs to be specified in the CREATE
INDEX statement for an XML index.
Since XML indexes only contain values that match the specified XPath and data type, it is not
trivial whether an XML index can be used for a given XML predicate or not. Therefore you have
to consider the rules for XML index eligibility when you create indexes and write queries. If an
XML index is not used when you think it should be used, a common reason is that the data type of
the index is not compatible with the comparison operation in the query predicate. Another common reason is that the XMLPATTERN of the index is more restrictive (selects fewer XML nodes)
than the XPath in the predicate. Additionally, XML join predicates require casting to a specific
data type before they can use an XML index.
This page intentionally left blank
C
H A P T E R
14
XML Performance and
Monitoring
his chapter describes several ways in which you can monitor and analyze the performance
of XML operations such as queries, updates, or loading data. We look at query access plans
and the statistics you can collect about XML data. Finally, we provide a summary of best practices for XML performance.
T
Query performance is of particular importance to many applications and is covered in more than
one chapter in this book. Guidelines for writing efficient XQuery and SQL/XML queries are provided in Chapters 6 through 9 on querying XML data. Unless explicitly mentioned, the query
examples in these chapters reflect best practices for writing queries. The use of XML indexes to
improve query performance is discussed in Chapter 13, Defining and Using XML Indexes. Additional guidelines apply to queries and indexes when your XML data contains namespaces. These
guidelines are covered in Chapter 15, Managing XML Data with Namespaces.
A common theme for all XML queries is that you might have to examine their execution plan to
understand or improve their performance. When you run a query against a DB2 database, DB2
first invokes the query compiler and optimizer to generate an efficient execution plan (also called
an access plan) for the query. An execution plan consists of a set of operators that DB2 combines
to plan the execution of the query. Then the DB2 run-time engine executes this execution plan.
The access plan determines to a large degree how efficiently the query is processed. The DB2
explain facility lets you view the execution plan, which allows you to understand how DB2 executes the query and take corrective measures to improve the access plan, if needed. For example,
the execution plan tells you which tables are accessed via an index and which tables are scanned.
Table scans can often (but not always) be the reason for suboptimal performance. Hence, the
analysis of an execution plan can prompt you to revisit the usage of XML indexes for specific
tables.
395
396
Chapter 14
XML Performance and Monitoring
Note that the execution plan of a query depends on a variety of factors, including:
• The volume and characteristics of the data in the table, and the statistics collected with
the RUNSTATS command/utility
• The existence and characteristics of database objects such as indexes, triggers, constraints, views, and so on
• Database and database manager configuration parameters
• The way the query is written
A change in any of these factors can change the execution plan of the query.
This remainder of this chapter covers the following topics:
• How to obtain and analyze XML query access plans in DB2 for Linux, UNIX, and Windows (section 14.1)
• How to obtain and analyze XML query access plans in DB2 for z/OS (section 14.2)
• How to collect statistics for XML data and indexes (section 14.3)
• How to monitor XML activity (section 14.4)
• A summary of best practices for XML performance in DB2 (section 14.5)
14.1 EXPLAINING XML QUERIES IN DB2 FOR LINUX,
UNIX, AND WINDOWS
In this section we describe the DB2 explain facility and how you can use it to understand and
improve the performance of XML queries. Sections 14.1.1 through 14.1.3 describe the basic
usage of the DB2 explain facility. XML-specific query operators and execution plans are discussed in sections 14.1.4 and 14.1.5, respectively.
14.1.1
The Explain Tables in DB2 for Linux, UNIX, and Windows
Before you can capture explain information you need to create the explain tables. These are relational tables in which DB2 stores the explain information. To display explain information you
can either use the command-line tool db2exfmt (“explain format”) or the Visual Explain tool in
the DB2 Control Center or IBM Data Studio Developer. These tools transparently read the
explain tables as needed. An advantage of the command-line tool db2exfmt is that all explain
information for a given query is written to a single output file that you can easily share with others. For example, the db2exfmt output is the preferred format in which to send explain information to IBM support.
14.1
Explaining XML Queries in DB2 for Linux, UNIX, and Windows
397
If you use the Visual Explain tool, the explain tables are created for you when you use Visual
Explain for the first time. If you use the command-line tool db2exfmt then you need to create the
explain tables manually before you use db2exfmt for the first time. The DDL statements that
create the explain tables are contained in the file EXPLAIN.DDL, which is located in the directory
sqllib\misc. To create the explain tables, go to this directory and issue the following command:
db2 -tf EXPLAIN.DDL
The explain tables are created with a schema of the current DB2 user name, unless you set a specific schema with the SET CURRENT SCHEMA command prior to creating the explain tables. This
allows you to control who can use and share the tables.
14.1.2
Using db2exfmt to Obtain Access Plans
In DB2 for Linux, UNIX, and Windows you can use the command-line tool db2exfmt to view
access plans. There are several ways of doing this, and we present the most common ways here.
It’s a two-step process. The first step is to submit a query and capture its access plan information
in the explain tables. The second step is to use the db2exfmt tool to read the explain tables and
print the execution plan to a file or to the screen.
First Step: Capture Access Plan Information in the Explain Tables
DB2 has a special register called CURRENT EXPLAIN MODE, which controls the behavior of the
explain facility. Its default value is NO, which means that any XQuery or SQL statement executed
in the current session is not explained, just executed. You can change the value to YES, to execute
an XQuery or SQL query and capture its access plan information in the explain tables. Or you can
set it to EXPLAIN to only capture the access plan information in the explain tables without executing the query. Figure 14.1 shows an example of a DB2 Command Line Processor (CLP) session. Note that most people type lowercase commands in the CLP and the commands are not case
sensitive, except XQuery expressions. This session begins with setting the explain mode to
EXPLAIN. The subsequent SQL/XML query is not executed and only explained; that is, access
plan information is inserted into the explain tables. Then the explain mode is disabled, which
allows the second invocation of the SQL/XML query to be executed as usual. Figure 14.1 shows
SQL/XML statements but the same works for queries in XQuery notation.
398
Chapter 14
XML Performance and Monitoring
SET CURRENT EXPLAIN MODE explain;
DB20000I The SQL command completed successfully.
SELECT cid
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo/phone[. = "905-555-7258"
and @type = "work"]');
SQL0217W The statement was not executed as only Explain
information requests are being processed. SQLSTATE=01604
SET CURRENT EXPLAIN MODE no;
DB20000I The SQL command completed successfully.
SELECT cid
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo/phone[. = "905-555-7258"
and @type = "work"]');
CID
------------1001
1002
1003
3 record(s) selected.
Figure 14.1
Submitting a query with different explain modes
The SET CURRENT EXPLAIN MODE statement can be embedded in an application program or
issued interactively. It’s an executable statement that can be dynamically prepared. Also, you can
check the current setting of the explain mode using the command VALUES CURRENT EXPLAIN
MODE.
An alternative way to capture access plan information in the explain tables is to start the query
with the keywords EXPLAIN ALL FOR as in Figure 14.2. This does not execute the query, only
captures its access plan.
EXPLAIN ALL FOR
SELECT XMLQUERY('$INFO/customerinfo/name')
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo/phone[. = "905-555-7258"
and @type = "work"]')
Figure 14.2
Explaining an SQL/XML query
14.1
Explaining XML Queries in DB2 for Linux, UNIX, and Windows
399
The EXPLAIN ALL FOR statement also works for XQuery, but you need to enclose the XQuery in
single quotes and specify the xquery keyword, as in Figure 14.3.
EXPLAIN ALL FOR
xquery
'for $i in db2-fn:xmlcolumn ("CUSTOMER.INFO")/customerinfo
where $i/phone[. = "905-555-7258" and @type = "work"]
return $i/name'
Figure 14.3
Explaining an XQuery
Second Step: Produce the Execution Plan with db2exfmt
After the explain tables have been populated, run the db2exfmt utility at the OS prompt to read
and format this information to produce a human-readable execution plan. You can produce the
execution plan for the most recently explained query (that is, the query for which you have most
recently captured access plan information for) by invoking the utility as follows:
db2exfmt -d sampxml -1 -o myquery_explain.txt
The parameters in the command have the following meaning:
• -d provides the database name.
• -1 (minus one) indicates that you want to produce a plan for the most recently explained
query.
• -o (the letter o) to provide the optional output file name. If omitted, the output goes to
the screen.
It is also possible to produce access plans for previously explained queries. This requires you to
use the –w parameter instead of -1, to provide a timestamp of an explained query. This timestamp
must match a value in the column EXPLAIN_TIME in the explain table EXPLAIN_STATEMENT.
An example of such a command is shown here:
db2exfmt -d sampxml -w 2008-12-08-10.11.16.421002
Before we discuss the db2exfmt output, let’s look at how we can obtain execution plans with
Visual Explain. Then we discuss the output of db2exfmt and of Visual Explain together.
400
14.1.3
Chapter 14
XML Performance and Monitoring
Using Visual Explain to Display Access Plans
In DB2 for Linux, UNIX, and Windows you can invoke Visual Explain from the DB2 Control Center or from IBM Data Studio tools, such as Data Studio Developer and Data Studio Administrator.
To invoke Visual Explain from the DB2 Control Center, right-click on the database name and
select Explain Query…. You can then type, paste, or GET the query that you want to analyze.
Clicking OK causes the DB2 compiler to generate an execution plan and store it in the explain
tables. The graphical access plan is displayed as shown in the center of Table 14.1. You can click
on each operator in the plan to see more information about it.
In Data Studio you invoke Visual Explain from the Data Project Explorer pane. In a project
connected to a database you should first create an SQL script that contains a query. Then rightclick on the query name and select Visual Explain from the context menu, as shown in Figure
14.4. The access plan is then generated and displayed. These steps are the same whether you are
connected to DB2 for z/OS or DB2 for Linux, UNIX, and Windows. Data Studio can
produce execution plans for both. Right-click on any node in the explain tree for more detailed
numbers.
Figure 14.4
Using Visual Explain in Data Studio Developer
14.1
Explaining XML Queries in DB2 for Linux, UNIX, and Windows
401
Table 14.1 shows the execution plan for the query in Figure 14.2 when no eligible indexes are
present. The Control Center, Data Studio Developer, and db2exfmt produce slightly different
graphical representations of the same access plan. In general, each item in an explain graph is
either an operator or a data object such as a table or an index. Understanding access plans starts
with understanding the individual operators, which we discuss in the next section.
Table 14.1
Access Plan from db2exfmt and Visual Explain
Access plan produced Visual Explain (Control Center)
by db2exfmt
Visual Explain (Data Studio):
Total Cost: 60.5308
Rows
RETURN
(
1)
Cost
I/O
|
0.06462
NLJOIN
(
2)
60.5308
8
/--+-\
6
0.01077
TBSCAN
XSCAN
(
3)
(
4)
15.1444
7.5644
2
1
|
6
TABLE: DB2ADMIN
CUSTOMER
14.1.4
(1)RETURN
RETURN(1) 60.53
6
(2)NLJOIN
0.0646264
NLJOIN(3) 60.53
(3)TBSCAN
TBSCAN(5) 15.14
XSCAN(7) 7.56
6
(4)XSCAN
0.0107711
(00)CUSTOMER
DB2ADMIN
DB2ADMIN.CUSTOMER
The numbers, such as 15.14 for
TBSCAN, indicate the estimated
operator cost.
The numbers, such as 6 for
TBSCAN, show the estimated
number of rows.
Access Plan Operators
An execution plan consists of a set of operators that DB2 combines to execute your query,
update, insert, or delete statement. Table 14.2 shows the full list of operators. There are three
query operators that process XML documents and indexes, called XSCAN, XISCAN, and XANDOR.
Together with the existing operators, they allow DB2 to generate execution plans for XQuery and
SQL/XML queries.
Table 14.2
Query Operators in DB2 for Linux, UNIX, and Windows
Operator
Description
DELETE
Deletes rows from a table.
FETCH
Fetches rows from a table.
FILTER
Filters data.
(continues)
402
Chapter 14
Table 14.2
XML Performance and Monitoring
Query Operators in DB2 for Linux, UNIX, and Windows (Continued)
Operator
Description
GENROW
Used by DB2 to generate rows of data.
GRPBY
Groups rows.
HSJOIN
Performs a hash join in which the qualified rows from tables are hashed.
INSERT
Inserts rows into a table
IXAND
The ANDing of the results of multiple index scans.
IXSCAN
Scans or probes an index on relational data.
MSJOIN
Performs a merge-sort join.
NLJOIN
Performs a nested loop join.
RETURN
Returns data from a query.
RIDSCN
Scans a list of row identifiers (RIDs).
RPD
Retrieves data from a non-relational remote data source.
SHIP
Retrieves data from a remote data source.
SORT
Sorts rows or rowIDs from a table.
TBSCAN
Performs a table scan.
TEMP
Stores data in a temporary table.
TQ
A table queue, for parallelization of a query.
UNION
Concatenates streams of rows from multiple tables.
UNIQUE
Eliminates rows with duplicate values.
UPDATE
Updates data in the rows of a table.
XANDOR
Evaluates multiple predicates simultaneously with two or more XISCAN operators.
XISCAN
Scans or probes an index on XML data.
XSCAN
Navigates XML data to evaluate XPath expressions.
We describe the three XML-specific operators here and then look at how they work in an execution plan in the next section.
• XSCAN (XML Document Scan)
DB2 uses the XSCAN operator to traverse XML document trees and, if needed, to evaluate predicates and extract document fragments and values. XSCAN is not an “XML table
14.1
Explaining XML Queries in DB2 for Linux, UNIX, and Windows
403
scan.” The XSCAN operator typically processes one document at a time. For example, it
can appear in an execution plan after a table scan to process each of the documents, or in
conjunction with an XML index scan to process the documents identified by the index
access.
• XISCAN (XML Index Scan)
Like the existing relational index scan operator for relational indexes (IXSCAN), the
XISCAN operator performs lookups or scans on XML indexes. The XISCAN takes a
value predicate as input, which is always a path-value pair such as /book[price =
31] or where $i/book/price = 31. The XISCAN returns a set of row IDs and node
IDs. The row IDs identify the rows that contain the qualifying documents, and the node
IDs identify the qualifying nodes within these documents. The IDs are typically consumed by other operators, such as a FETCH or a XANDOR, as you will see shortly.
• XANDOR (XML Index ANDing)
The XANDOR operator evaluates two or more equality predicates simultaneously by driving multiple XISCANs. It returns the row IDs of those documents that satisfy all of these
predicates. However, DB2 does not use the XANDOR operator for range predicates, or
predicates that have a * or // in their XPath. For example, the predicates such as
//book[price = 31] and /book[price < 50] prohibit the use of the XANDOR
operator. In such cases the IXAND operator is used instead. The IXAND operator is also
used for relational index ANDing and for exploiting XML and relational indexes at the
same time. Whenever possible, avoid * and // in query predicates to allow the DB2
query optimizer to consider the use of the XANDOR operator.
14.1.5
Understanding and Analyzing XML Query Execution Plans
In this section we examine the execution plans for the query in Figure 14.5 when no index, one
XML index, or two XML indexes exist that the query can use. This query contains two predicates, one for the value of the phone element, and one for the value of the type attribute of the
phone element.
SELECT XMLQUERY('$INFO/customerinfo/name')
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo/phone[. = "905-555-7258"
and @type = "work"]')
Figure 14.5
An SQL/XML query with two predicates
Table 14.3 shows the access plan for this query when no suitable indexes are defined on the customer table. The best way to read an access plan is to start at the lowest left-most node in the
operator tree, which in this case is the table db2admin.customer. Since no index is available,
the customer table is input to the TBSCAN (table scan) operator. The TBSCAN reads all rows from
404
Chapter 14
XML Performance and Monitoring
the table. The NLJOIN (nested loop join) operator connects the TBSCAN with an XSCAN. For each
row, the NLJOIN operator passes a pointer to the corresponding XML document to the XSCAN
operator. This tells the XSCAN which XML documents to operate on. As such, the NLJOIN does
not act as a classical join with two input legs, but facilitates access to the XML data for the XSCAN
operator. For each document, the XSCAN operator traverses the document tree, evaluates the two
predicates, and extracts the name element if the predicates are satisfied. Each name element is
passed up through the NLJOIN operator to the RETURN operator. The RETURN operator returns the
result set to the calling application.
Table 14.3
Access Plan for the Query in Figure 14.5 without Index Usage
:
Access plan produced by db2exfmt
Total Cost: 60.5308
Rows
RETURN
(
1)
Cost
I/O
|
0.06462
NLJOIN
(
2)
60.5308
8
/--+-\
6
0.01077
TBSCAN
XSCAN
(
3)
(
4)
15.1444
7.5644
2
1
|
6
TABLE: DB2ADMIN
CUSTOMER
Visual Explain:
RETURN(1) 60.53
NLJOIN(3) 60.53
TBSCAN(5) 15.14
XSCAN(7) 7.56
DB2ADMIN.CUSTOMER
In the db2exfmt output, each operator in the plan is represented by five lines. The RETURN operator at the top serves as a legend and always reminds you what the five lines mean (see Figure
14.6). The number above each operator name is the estimated number of rows produced by the
operator. The number in parentheses below the operator name is the operator number within the
tree. The next two numbers are the estimated cost of the operation in timerons and the estimated
number of I/Os that the operator will perform. Beware that the estimated values are typically not
accurate if you haven’t recently used the RUNSTATS command to collect statistics on tables and
indexes.
14.1
Explaining XML Queries in DB2 for Linux, UNIX, and Windows
405
Estimated number of rows returned by the operator: Rows
6
Operator name:
RETURN
TBSCAN
Unique identifier of the operator in this plan:
(
(
Estimated cost of the operator:
Cost
Estimated I/O cost of the operator:
I/O
Figure 14.6
1)
3)
15.1444
2
Operator information in an execution plan
Let’s see how the access plan can change when an XML index is defined on the type attribute, as
shown in Figure 14.7. After defining the index, you should invoke the RUNSTATS command to
gather index statistics. Alternatively you can add the COLLECT STATISTICS clause to the CREATE INDEX statement.
CREATE INDEX cust_idx1 ON customer(info)
GENERATE KEYS USING XMLPATTERN '/customerinfo/phone/@type'
AS SQL VARCHAR(50)
Figure 14.7
Creating an index for the query in Figure 14.5
Table 14.4 shows the access plan that is obtained after creating the index in Figure 14.7. Again,
read the execution plan from the lower-left corner. The XISCAN operator probes the index with
the path-value pair (/customerinfo/phone/@type, work) and returns the row IDs for the
documents where the phone type is work. These row IDs are sorted to remove duplicates (if any)
and to optimize the subsequent I/Os to the table. The RIDSCN operator (row ID scan) then scans
these row IDs, triggers row prefetching, and passes the row IDs to the FETCH operator. For each
row ID, the FETCH operator reads the corresponding row from the table. The benefit of this plan is
that only a fraction of the rows in the table are retrieved; that is, only those where type is work.
This is a lot cheaper than a full table scan that reads every row. For each row fetched, the NLJOIN
passes a document pointer to the XSCAN operator, which processes the corresponding XML document. It evaluates the predicate on phone and, if the predicate is satisfied, extracts the name element. There might be many documents where this second predicate is not true, so the XSCAN
might still perform a lot of work to eliminate them from the result set. Thus, you might see even
better performance if the second predicate is also covered by an index.
406
Chapter 14
Table 14.4
XML Performance and Monitoring
Access Plan for the Query in Figure 14.5 with XML Index Usage
:
Access plan produced by db2exfmt
Total Cost:
Rows
RETURN
(
1)
Cost
I/O
|
0.212729
NLJOIN
(
2)
28.394
3.75
/-+-\
2.75
0.0773558
FETCH
XSCAN
(
3)
(
7)
7.5921
7.56433
1
1
/----+---\
2.75
6
RIDSCN
TABLE: DB2ADMIN
(
4)
CUSTOMER
0.0267987
0
|
2.75
SORT
(
5)
0.0263833
0
|
2.75
XISCAN
(
6)
0.0250255
0
|
6
XMLIN: DB2ADMIN
CUST_IDX1
Visual Explain:
28
RETURN(1) 28.39
NLJOIN(3) 28.39
FETCH(8) 7.59
RIDSCN(10) 0.03
XSCAN(16) 7.56
DB2ADMIN.CUSTOMER
SORT(12) 0.03
XISCAN(14) 0.03
CUST_IDX1
DB2ADMIN.CUSTOMER
Let’s create a second XML index to index the values of the phone element (see Figure 14.8). To
provide DB2 with statistics about this new index, either use the COLLECT STATISTICS clause in
the index definition, or run RUNSTATS after creating the index.
CREATE INDEX cust_idx2 ON customer(info)
GENERATE KEYS USING XMLPATTERN '/customerinfo/phone'
AS SQL VARCHAR(50) COLLECT STATISTICS
Figure 14.8
Creating a second index for the query in Figure 14.5
An access plan where both XML indexes are used is shown in Table 14.5.
14.1
Explaining XML Queries in DB2 for Linux, UNIX, and Windows
Table 14.5
407
Access Plan for Query with Two Indexes Defined on the Table
Access plan produced by db2exfmt
:
11.8536
Rows
RETURN
(
1)
Cost
I/O
|
0.212729
NLJOIN
(
2)
11.8536
1.56019
/--+-\
0.560185 0.379747
FETCH
XSCAN
(
3)
(
9)
4.28921
7.5644
0.560185
1
/----+---\
0.560185
6
RIDSCN
TABLE: DB2ADMIN
(
4)
CUSTOMER
0.0513969
0
|
0.560185
SORT
(
5)
0.0509815
0
|
0.560185
XANDOR
(
6)
0.0500511
0
/-----+-----\
1.22222
2.75
XISCAN
XISCAN
(
7)
(
8)
0.0250255
0.0250255
0
0
|
|
6
6
XMLIN: DB2ADMIN XMLIN: DB2ADMIN
CUST_IDX2
CUST_IDX1
Visual Explain:
Total Cost:
RETURN(1) 11.85
NLJOIN(3) 11.85
FETCH(10) 4.29
XSCAN(22) 7.56
RIDSCN(12) 0.05
DB2ADMIN.CUSTOMER
SORT(14) 0.05
XANDOR(16) 0.05
XISCAN(18) 0.03
CUST_IDX2
DB2ADMIN.CUSTOMER
XISCAN(20) 0.03
CUST_IDX1
DB2ADMIN.CUSTOMER
The execution plan in Table 14.5 contains two XISCAN operators (XML index scans), one for
each XML predicate. The XANDOR operator uses these XISCANs to alternately probe into the two
indexes to efficiently find the row IDs of the documents that match both predicates. The FETCH
operator then only retrieves these rows, thus minimizing I/O to the table. The rest of the query
execution works as in the previous plan in Table 14.4. The XANDOR is an XML-specific operator
that efficiently computes the intersection between multiple equality predicates.
It is important to understand that the existence of two eligible indexes does not automatically
imply that both indexes are always used. After the DB2 compiler has identified that the two
408
Chapter 14
XML Performance and Monitoring
indexes can be used, the DB2 optimizer makes a cost-based decision to determine whether both
indexes should be used. For example, the optimizer might choose the plan with one index over
the plan with two indexes if the second index does not significantly reduce the number of rows
fetched from the table. In such a case the cost of accessing the second index can be greater than
the savings in I/O to the table. Based on statistics gathered with the RUNSTATS command, the
optimizer tries to detect such cases and uses the execution plan that it deems most efficient.
Remember that DB2 does not use the XANDOR operator if the XPath expressions in the predicates
include wildcards (// , * ) or if at least one of the indexes evaluate a range comparison (such as >
or <). In such cases you will see the IXAND operator (index ANDing) instead of the XANDOR. Logically, both perform the same job but for different types of predicates and with different runtime
optimizations.
DB2 can also use the IXAND operator to perform index ANDing across XML and relational
indexes. For example, the query in Figure 14.9 is similar to the one in Figure 14.5 and contains
the additional relational predicate cid < 1002.
SELECT XMLQUERY('$INFO/customerinfo/name')
FROM customer
WHERE cid < 1002
AND XMLEXISTS('$INFO/customerinfo/phone[. = "905-555-7258"
and @type = "work"]')
Figure 14.9
Sample query with an additional relational predicate
Table 14.8 shows the execution plan for the query in Figure 14.9 (with some cost estimates
removed for brevity). Note the IXAND operator, which computes the intersection of the row IDs
produced by one relational index scan (IXSCAN) and two XML index scans (XISCAN). As a
result, the FETCH operator reads only those rows from the table that fulfill all three predicates.
Again, whether DB2 decides to use all three indexes or only a subset of them depends,
among other things, on the actual data in the table and the statistics that have been collected with
RUNSTATS.
14.2
Explaining XML Queries in DB2 for z/OS
Table 14.6
409
Index ANDing between XML and Relational Indexes
:
Access plan produced by db2exfmt
9.04372
Rows
RETURN
(
1)
Cost
I/O
|
0.0709095
NLJOIN
(
2)
/--+-\
0.186728 0.379747
FETCH
XSCAN
(
3)
( 10)
/----+---\
0.186728
6
RIDSCN
TABLE: DB2ADMIN
(
4)
CUSTOMER
|
0.186728
SORT
(
5)
|
0.186728
IXAND
(
6)
|
+---------------+------------+
2
1.22222
2.75
IXSCAN
XISCAN
XISCAN
(
7)
(
8)
(
9)
|
|
|
6
6
6
INDEX:
XMLIN:
XMLIN:
DB2ADMIN
DB2ADMIN
DB2ADMIN
PK_CUSTOMER
CUST_IDX2
CUST_IDX1
Visual Explain:
Total Cost:
14.2
RETURN(1) 9.04
NLJOIN(3) 9.04
FETCH(11) 1.48
XSCAN(25) 7.56
RIDSCN(13) 0.07
DB2ADMIN.CUSTOMER
SORT(15) 0.07
IXAND(17) 0.07
XISCAN(19) 0.01
XISCAN(21) 0.03
XISCAN(23) 0.03
PK_CUSTOMER
CUST_IDX2
CUST_IDX1
DB2ADMIN.CUSTOMER
DB2ADMIN.CUSTOMER
DB2ADMIN.CUSTOMER
EXPLAINING XML QUERIES IN DB2 FOR Z/OS
This section describes how to obtain and interpret access plans for XML queries in DB2 for z/OS.
14.2.1
The Explain Tables in DB2 for z/OS
There are four explain tables in DB2 for z/OS (shown in Table 14.7), and they can be created in
several ways. You can either use member DSNTESC of the SDSNSAMP library, or you can use the
DB2 Administration Tool – option E from the main menu. (Note that the name of the cost estimates table is DSN_STATEMNT_TABLE and not DSN_STATEMENT_TABLE.) Alternatively you can
use Visual Explain, which creates the explain tables automatically.
410
Chapter 14
Table 14.7
XML Performance and Monitoring
Explain Tables in DB2 for z/OS
Table Name
Description
PLAN_TABLE
Access path information for SQL statements, plans, and
packages
DSN_STATEMNT_TABLE
Cost estimates for SQL statements
DSN_STATEMENT_CACHE_TABLE
Statements in the dynamic statement cache
DSN_FUNCTION_TABLE
User-defined functions in SQL statements
14.2.2
Obtaining Access Plan Information in SPUFI
To gather explain information in SPUFI, prefix the query with the keywords EXPLAIN PLAN
SET QUERYNO, as shown in Figure 14.10. This assigns a number to the query, and this number is
used as a key in the explain tables, which helps you find the access plan information for this specific query in the explain tables.
EXPLAIN PLAN SET QUERYNO = 115 FOR
SELECT XMLQUERY('$i/customerinfo/name' PASSING info AS "i")
FROM customer
WHERE
XMLEXISTS('$i/customerinfo/phone[. = "905-555-7258"
and @type = "work"]' PASSING info AS "i")
Figure 14.10
Explaining a query in SPUFI
After running the EXPLAIN statement in Figure 14.10, use the SQL statement in Figure 14.11 to
read the explain tables and obtain information about the execution of the query. This query reads
the table PLAN_TABLE and selects all rows for the query with a QUERYNO value of 115. The column ACCESSTYPE describes the method that DB2 has chosen to access the customer table. The
relevant ACCESSTYPE values for XML queries are
• DX—An XML index scan on the index that is named in ACCESSNAME. It returns a list of
document identifiers (DOCIDs).
• DI—An intersection of multiple DOCID lists to return the final DOCID list.
• DU—A union of multiple DOCID lists to return the final DOCID list.
• M—Multiple index scans followed by an intersection or union of RID lists.
14.2
Explaining XML Queries in DB2 for z/OS
411
SELECT queryno, SUBSTR(tname,1,8) AS tname, accesstype,
SUBSTR(accessname,1,10) AS accessname, indexonly
FROM plan_table
WHERE queryno = 115 ;
---------+---------+---------+---------+---------+------QUERYNO TNAME
ACCESSTYPE ACCESSNAME INDEXONLY
---------+---------+---------+---------+---------+------115 CUSTOMER DX
CUST_IDX1
N
Figure 14.11
Querying the DB2 for z/OS PLAN_TABLE
Figure 14.12 shows how to examine the DSN_STATEMNT_TABLE table, which contains information about the estimated cost of SQL statements. You should check the value of the column
COST_CATEGORY. If the value is B, then one of the possible reasons is that the table cardinality is
missing. In this case, ensure that you have run the RUNSTATS utility against both the table space
containing the base table and the XML table space.
SELECT queryno, explain_time, stmt_type,
cost_category, SUBSTR(reason,1,20) AS reason, total_cost
FROM dsn_statemnt_table
WHERE queryno = 115 ;
--------+---------+---------+---------+---------+---------+----QUERYNO EXPLAIN_TIME
STMT_TYPE COST_CATEGORY
--------+---------+---------+---------+---------+---------+----115 2008-12-03-11.51.08.260000 SELECT
A
.
.
.
.
.
.
.
.
.--+---------+---------+---------+---------+-.REASON
TOTAL_COST
.--+---------+---------+---------+---------+-.
+0.9539343662063281E+02
Figure 14.12
14.2.3
Querying the DB2 for z/OS DSN_STATEMNT_TABLE
Using Visual Explain to Display Access Plans
You can obtain a visual representation of the access plan using either IBM Data Studio Developer
or IBM DB2 Optimization Service Center for DB2 for z/OS (OSC). Using Visual Explain in Data
Studio Developer is the same in DB2 for z/OS as for DB2 for Linux, UNIX, and Windows and
was discussed in section 14.1.3.
For DB2 for z/OS you can invoke Visual Explain from the OSC by double-clicking on a project
folder and then clicking on Identify Target Query, as shown in Figure 14.13.
412
Figure 14.13
Chapter 14
XML Performance and Monitoring
Invoking Visual Explain from the OSC
The next step is shown in Figure 14.14. Make sure the Query source pull-down list specifies
Text, then paste your query into the Query text panel and select Access Plan Graph from
the Tools pull-down menu.
Figure 14.14
Invoking Visual Explain from the OSC
14.2
Explaining XML Queries in DB2 for z/OS
413
The tool generates an access plan, such as the one in Figure 14.16. For each operator node in the
access graph, the small number in parentheses to the left of the operator name is the operator ID.
The value under the operator name is the cardinality.
14.2.4
Access Plan Operators
An access plan consists of a set of operators that DB2 combines to execute a query. Table 14.8
shows the query operators in DB2 for z/OS. Four query operators are specific to the processing of
XML documents and indexes: DIXSCAN, XIXAND, XIXOR, and XIXSCAN.
Table 14.8
Internal Query Operators for DB2 for z/OS
Operator
Description
BTBSCAN
A buffer table scan.
CORSUB
ACCESS
Access by a correlated subquery.
DELETE
Deletes selected rows from a table or a deletable view.
DFETCH
An operation called a direct fetch.
DIXSCAN
DOCID index access. Returns a RID for a given DOCID.
EXCEPTA
An EXCEPT ALL operation.
EXCEPT
The EXCEPT operation.
FETCH
DB2 fetches rows from a table using the RIDs from an IXSCAN or MIXSCAN.
FFETCH
Uses a fact table index to fetch fact table data in a pushdown star join.
FIXSCAN
Scans a fact table index during a pushdown star join.
INTERSECTA
The INTERSECT ALL operation.
INTERSECT
The INTERSECT operation.
INSERT
Indicates the insertion of rows into a table or an insertable view.
IXAND
Returns the intersection of two sorted ROWID lists.
IXOR
Returns the union of two sorted ROWID lists.
IXSCAN
A single-index scan.
MERGE
Merges multiple data streams into one data stream.
MIXSCAN
A multiple-index scan.
PARTITION
Separates one data stream into multiple data streams.
(continues)
414
Chapter 14
Table 14.8
XML Performance and Monitoring
Internal Query Operators for DB2 for z/OS (Continued)
Operator
Description
QB n
Denotes a query block (subquery), where n is the query block number.
RID FETCH
RID fetch access.
SIXSCAN
Sparse index scan.
SORTRID
Sorts the qualified index entries that result from an index scan.
TRUNCATE
Truncates a table; that is, deletes all rows.
UNION
The union of the results from two SELECT statements to form a single result table
that contains no duplicate rows.
UNIONA
The union of the results from two SELECT statements to form a single result table
that might contain duplicate rows.
UPDATE
Updates of one or more columns of the selected rows in a table.
WFSCAN
Scans a work file.
XIXAND
Returns the intersection of two sorted DOCID lists. Only those DOCIDs that exist in
both DOCID lists are included in the output.
XIXOR
Returns the union of two sorted DOCID lists. Any DOCID that exists in at least one of
the DOCID lists is included in the output. Duplicate DOCIDs are removed.
XIXSCAN
XML index access, returns the DOCID and NODEID pairs for a given key value.
14.2.5
Understanding and Analyzing XML Query Execution Plans
As an example, consider the query in Figure 14.15, which contains two predicates, one for the
value of the phone element, and one for the value of the type attribute of the phone element.
Let’s examine the access plan for this query when no index, one XML index, or two XML
indexes exist that support the predicates in this query.
SELECT cid
FROM customer
WHERE XMLEXISTS('$i/customerinfo/phone[. = "905-555-7258"
and @type = "work"]' PASSING info AS "i")
Figure 14.15
Sample query with two predicates
The left side of Figure 14.16 shows the access plan for this query when there is no eligible index.
In this case, DB2 performs a table scan. For each XML document in the info column, DB2 evaluates the XML predicates and returns the value of the cid column if the predicates are true.
14.2
Explaining XML Queries in DB2 for z/OS
415
The right side of Figure 14.16 shows the access plan for the query in Figure 14.15 when there is
an XML index for one of the two predicates in the query. It could be the index on /customerinfo/phone/@type that was defined earlier in Figure 14.17. Read the access plan from the
lowest leftmost node in the graph going upwards. The XIXSCAN operator (XML index scan)
probes the index CUST_IDX1 with the value "work" and returns the document identifiers
(DOCIDs) of all documents that match the predicate. This list of DOCIDs is input to the DIXSCAN
operator. For each DOCID, the DIXSCAN operator probes the DOCID index and returns the RID
(row identifier) of the corresponding base table row. That is the row that the matching XML document logically belongs to. The FETCH operator uses this RID to fetch the identified row from the
customer table.
(1)QUERY
(2)QB1
192
(1)QUERY
(3)FETCH
192
(2)QB1
384
(3)TBSCAN
(4)DIXSCAN
(8)CUSTOMER
384
192
768.0
(4)CUSTOMER
768.0
(5)XIXSCAN
(7)DOCID Index
192
(6)CUST_IDX
1408
Figure 14.16
Access plan without XML index (left) and with one XML index (right)
When two XML indexes are available, one for the predicate on type and one for the predicate on
phone (Figure 14.7 and Figure 14.8), DB2 may generate the access plan shown in Figure 14.17.
The plan contains two XIXSCAN operators, one for each predicate and corresponding index. Each
XIXSCAN produces a list of DOCIDs for those documents that match the respective predicate. The
XIXAND operator (XML index ANDing) computes the intersection of the two DOCID lists that it
receives as input. It produces a single DOCID list that contains the DOCIDs of those documents
that match both predicates. These DOCIDs are used by the DIXSCAN operator to obtain corresponding base table RIDs from the DOCID index. The MIXSCAN operator indicates that this part of the
access plan is a multiple-index access construct. Finally, the FETCH operator uses the generated
RIDs to read those rows from the customer table that have XML documents that match both
predicates.
416
Chapter 14
XML Performance and Monitoring
(1)QUERY
(2)QB1
21
(3)FETCH
21.3333
(4)MIXSCAN
(12)CUSTOMER
192
768.0
(5)DIXSCAN
21.3333
(6)XIXAND
(11)DOCID Index
21.3333
Figure 14.17
(7)XIXSCAN
(9)XIXSCAN
21.3333
21.3333
(8)CUST_IDX2
(10)CUST_IDX2
1408.0
1408.0
Access plan with two XML indexes
Figure 14.18 shows the rows in the PLAN_TABLE table for the same query and access plan as in
Figure 14.17. The ACCESSTYPE indicators DX correspond to the XIXSCAN nodes in Figure 14.17.
The ACCESSTYPE indicator DI represents the DIXSCAN and M indicates the multiple-index access
construct.
SELECT queryno, SUBSTR(tname,1,8) AS tname, accesstype,
SUBSTR(accessname,1,10) AS accessname, indexonly
FROM plan_table
WHERE queryno = 130 ;
---------+---------+---------+---------+---------+---QUERYNO TNAME
ACCESSTYPE ACCESSNAME INDEXONLY
---------+---------+---------+---------+---------+---130 CUSTOMER M
N
130 CUSTOMER DX
CUST_IDX2
Y
130 CUSTOMER DX
CUST_IDX1
Y
130 CUSTOMER DI
N
DSNE610I NUMBER OF ROWS DISPLAYED IS 4
Figure 14.18
Plan table information for an access plan with two XML indexes
14.3
Statistics Collection for XML Data
14.3
417
STATISTICS COLLECTION FOR XML DATA
The access plan that DB2 chooses for a given query is determined, among other things, by the
characteristics (statistics) of the data in the table and by the presence of eligible indexes. Statistics
can be collected with the RUNSTATS utility, which also collects statistics for XML data.
When you use the RUNSTATS utility you can choose to include or exclude XML data in the statistics collection process. It is generally recommended to include XML to provide the DB2 optimizer with maximum information. If you know that many UPDATE statements have modified the
relational columns of your table but not the XML column(s), you might prefer to refresh the statistics for the relational columns only. The RUNSTATS utility typically completes faster if XML
columns are excluded.
14.3.1
Statistics Collection for XML Data in DB2 for z/OS
When you use the RUNSTATS utility in DB2 for z/OS, you can specify which table spaces and
indexes to include. This gives you the option to run the utility for the base table space only, for the
XML table space only, or for both. To ensure the best possible query access plan, it is recommended
to run RUNSTATS on the base table space and the XML table space and all related indexes.
Figure 14.19 shows an example of a RUNSTATS job for the customer table. The customer table
is in table space DSN00201.CUSTOMER and the associated XML table space is DSN00201.
XCUS0000. You can find the name of the XML table space with the REPORT TABLESPACESET
utility (see section 3.12, Utilities for XML Objects in DB2 for z/OS). Also, you can use the
LISTDEF utility to group these database objects together into a list and then specify that list in the
RUNSTATS control statement.
//RUNSTATS EXEC DSNUPROC,PARM='ISC9,PKCTEX',COND=(4,LT)
//SORTLIB DD DSN=SYS1.SORTLIB,DISP=SHR
//SORTOUT DD UNIT=SYSDA,SPACE=(4000,(20,20),,,ROUND)
//DSNTRACE DD SYSOUT=*
//SYSUT1
DD UNIT=SYSDA,SPACE=(4000,(50,50),,,ROUND)
//SYSIN DD *
RUNSTATS TABLESPACE DSN00201.CUSTOMER
TABLE (ALL)
INDEX (ALL) KEYCARD
REPORT YES
RUNSTATS TABLESPACE DSN00201.XCUS0000
TABLE (ALL)
INDEX (ALL)
REPORT YES
/*
Figure 14.19
Running the RUNSTATS utility on DB2 for z/OS
When you run the RUNSTATS TABLESPACE utility on an XML table space, the keywords
COLGROUP, FREQVAL, and HISTOGRAM are ignored. The RUNSTATS INDEX utility also ignores the
keywords KEYCARD, FREQVAL, and HISTOGRAM for XML indexes and NodeID indexes.
418
Chapter 14
XML Performance and Monitoring
Statistics about user-defined XML indexes and the internal DOCID and NodeID indexes are similar to relational indexes and kept in the catalog table SYSIBM.SYSINDEXSTATS. For example,
the FIRSTKEYCARD of a user-defined XML index indicates the number of distinct values in the
indexed XML element or attribute. The XML index on /customerinfo/phone/@type has a
FIRSTKEYCARD value of 3, if the only values that appear in the type attribute are work, home, or
cell. The FIRSTKEYCARD of a user-defined XML index can be used as the COLCARD (column
cardinality) in the estimation of the filter factor of an XMLEXISTS predicate. Similarly, the
FIRSTKEYCARD of a NodeID index provides the number of distinct DOCID values in the corresponding XML table. These statistics allow DB2 to translate the filter factor of an XMLEXISTS
predicate on the internal XML table into a filter factor of the base table. Both filter factors help
DB2 to assess the cost of potential access plans and to choose the plan with the lowest estimated
cost.
14.3.2
Statistics Collection for XML Data in DB2 for Linux, UNIX, and Windows
In DB2 for Linux, UNIX, and Windows, the default behavior of the RUNSTATS command is to
collect statistics for all relational and XML columns of a table. Optionally, you can choose to
exclude XML columns and collect statistics for relational columns only. You can also gather statistics for the indexes of a table only, which ignores all XML and relational columns in the table.
Yet other options allow you to run RUNSTATS for individual columns or indexes only, by providing the column or index names. The syntax of the RUNSTATS command for some of these options
is shown in Figure 14.20.
-- Collect statistics for XML and relational columns:
RUNSTATS ON TABLE db2admin.customer;
-- Collect statistics for relational columns only:
RUNSTATS ON TABLE db2admin.customer EXCLUDING XML COLUMNS;
-- Collect statistics for the XML column “info” only:
RUNSTATS ON TABLE db2admin.customer ON COLUMNS(info);
-- Collect statistics for the XML index “cust_idx1” only:
RUNSTATS ON TABLE db2admin.customer
FOR INDEX db2admin.cust_idx1;
-- Collect statistics for XML and relational indexes only:
RUNSTATS ON TABLE db2admin.customer FOR INDEXES ALL;
-- Collect detailed statistics for XML and relational indexes:
RUNSTATS ON TABLE db2admin.customer FOR DETAILED INDEXES ALL;
-- Collect detailed statistics for all columns and all indexes:
RUNSTATS ON TABLE db2admin.customer WITH DISTRIBUTION
AND DETAILED INDEXES ALL;
Figure 14.20
Useful options of the RUNSTATS command
14.3
Statistics Collection for XML Data
419
The last RUNSTATS command in Figure 14.20 collects the most information and gives DB2 the
best basis for generating efficient execution plans. But, if you have added a new index to a table
with otherwise up-to-date statistics, it is sufficient to collect statistics only for that new index.
For relational data as well as XML data you can enable sampling to reduce the time for executing
RUNSTATS. On a large data set, the statistics from 10% of the data (or even less) are often still
representative of the total population. Whatever sampling percentage you choose, RUNSTATS
allows you to sample rows (Bernoulli sampling) or pages (system sampling). Row-level sampling
reads all data pages but considers only a percentage of the rows on each page. Page-level sampling reduces I/O since it reads only a percentage of the data pages. Thus, page sampling can
improve performance, especially if XML data is inlined into the data pages of a table.
Figure 14.21 shows examples of RUNSTATS with sampling. The first RUNSTATS command collects detailed index statistics, but for table statistics it samples 10% of the pages. In many cases,
this provides the optimizer with reasonably accurate statistics and completes much faster than
without sampling. The second command samples 15% of all rows, does not collect distribution
statistics, and also applies sampling to the computation of extended index statistics.
RUNSTATS ON TABLE myschema.customer WITH DISTRIBUTION
AND DETAILED INDEXES ALL TABLESAMPLE SYSTEM (10);
RUNSTATS ON TABLE myschema.customer
AND SAMPLED DETAILED INDEXES ALL TABLESAMPLE BERNOULLI (15);
Figure 14.21
14.3.3
RUNSTATS with sampling
Examining XML Statistics with db2cat
In DB2 for Linux, UNIX, and Windows, statistics for XML indexes are very similar to statistics
for relational indexes and visible in the catalog views SYSCAT.INDEXES and SYSSTAT.
INDEXES. XML index statistics are explained in section 13.8, XML Index Statistics.
In DB2 for Linux, UNIX, and Windows, statistics for XML columns are stored differently from
statistics for relational columns. While relational statistics are kept in catalog tables, XML statistics are stored internally in the packed descriptor of the user table that you collect statistics for. As
a result, you cannot see XML statistics in any catalog views and you cannot manually modify
them. However, the “Database Catalog Analysis and Repair Tool” (db2cat) allows you to read
the XML statistics from a table’s packed descriptor and write them to a text file. For example, the
following command writes the XML statistics from the customer table in database sampxml
and schema db2admin to the file xmlstats.txt:
db2cat -d sampxml -n customer -s db2admin -o xmlstats.txt
420
Chapter 14
XML Performance and Monitoring
In the output file, search for the string XML column statistics to get to the XML statistics.
Figure 14.22 shows excerpts from the output file after db2cat was run on the customer table
with 6,144 documents and sampled statistics. We simply inserted the six original customer documents 1,024 times. The db2cat output contains six sections:
1. General counters, such as number of documents, paths, and nodes, as well as minimum,
maximum, and average document size, and so on
2. Top-k Pathid node counts
3. Top-k Pathid doc counts
4. Top-k Pathid-Value node counts
5. Top-k Pathid-Value doc counts
6. Catch All Pathid-Value Bucket
In these sections Top-k means the top k number of occurrences, where k has a default value of
200. The node count of a given path or path-value pair is the number of nodes that match the path
or path-value pair in the XML column. The document count of a path or path-value pair refers to
the number of documents that contain the given path or path-value pair at least once. Examining
these statistics does not always lead to immediate actions that you can perform to improve query
performance. However, understanding the statistics gives you a glimpse of the information that
the DB2 optimizer considers for XML query optimization. It can also reveal characteristics of
your XML data that you didn’t know. More specifically, the db2cat output shows the following:
• No. NULL XML docs: The number of NULL values in the XML column.
• No. non-NULL XML docs: The number XML documents in the XML column.
• No. inlined docs: Number of documents that are inlined into the base table rows
when an INLINE LENGTH has been specified for the XML column in the CREATE
TABLE statement.
• Distinct Pathid count: The number of distinct paths that occur in the documents
in the XML column.
• Sum Node Counts: The total number of nodes (elements, attributes, and so on) across
all documents in the column.
• Sum Doc Counts: The sum of the document counts of all distinct paths. For example,
suppose the documents contain 10 distinct paths and 4 of these paths occur in 100 documents, and the other 6 paths occur in 200 documents each. Then Sum Doc Counts has
the value 1600; that is (4 × 100) + (6 × 200). As another example, if all distinct paths
occur at least once in each document, then Sum Doc Counts = No. non-NULL
XML docs x Distinct Pathid count.
14.3
Statistics Collection for XML Data
421
Note that if each distinct path occurs exactly once per document then Sum Node Counts
equals Sum Doc Counts. If Sum Node Counts is much greater than Sum Doc Counts
then this indicates that the documents contain many repeating elements.
• Top-k Pathid node counts: The top k most frequent paths (represented by their
path IDs) and the number of nodes that each of these paths identify. For each path, this is
the number of times that the path occurs in the XML data and it includes any repeated
occurrences within any documents. The value k determines how many frequent paths
are included in the statistics, similar to the NUM_FREQVALUES parameter for relational
data. The default value for k is 200, but can be changed with the DB2 registry variable
DB2_XML_RUNSTATS_PATHID_K. We suggest that you do not change this value unless
advised by IBM support.
• Top-k Pathid doc counts: The top k paths that occur in the most documents,
together with the number of documents that they occur in. If a path occurs multiple
times in a document, then this document is counted only once. As an example, consider
the path /customerinfo/phone. Suppose this path appears in the Top-k Pathid
doc counts with a document count of 100, and in the Top-k Pathid node counts
with a node count of 200. Then DB2 can deduce that each document contains on average two phone elements. This is valuable information, for example, to estimate the cost
of navigating a document with a certain path, or to estimate the number of rows produced by an XMLTABLE function.
• Top-k Pathid-Value node counts: The top k most frequent path-value pairs and
the number of times they occur. Consider again the path /customerinfo/phone as an
example. Since most phone numbers in the customer data are distinct, this path is
unlikely to appear among the most frequent path-value pairs. Elements that have a small
number of distinct values are more likely to appear. For example, the path-value pair
(/customerinfo/phone/@type, "work") can easily be among the most frequent
pairs, because most customers in our sample data have a work phone number.
• Top-k Pathid-Value doc counts: The top k path-value pairs that occur in the
most documents, and the number of documents that they occur in. If a path-value pair
occurs multiple times in a given document, then this document is counted only once.
The value k, which determines how many frequent path-value pairs are collected, is 200
by default but can be changed with the DB2 registry variable DB2_XML_RUNSTATS_
PATHVALUE_K.
• Catch All Pathid-Value Bucket: For each distinct path that leads to a text node or
attribute, the statistics include the number of distinct values on this path, the second
highest and lowest value on this path, as well as the node and document count. Depending on your XML data, this catch-all can contain thousands of entries, which is no reason for concern.
422
Chapter 14
++++++++++++++++++++++++++++++++++++++++
XML column statistics
++++++++++++++++++++++++++++++++++++++++
Column ID
= 1
No. NULL XML docs
= 0
No. non-NULL XML docs = 6144
Smallest XML doc size = 422
Largest XML doc size = 678
Avg XML doc size
= 544
No. inlined docs
= 0
---------------------------------------Catch All Pathid Bucket
---------------------------------------Distinct Pathid count = 23
Sum Node Counts
= 132096
Sum Doc Counts
= 116736
---------------------------------------Top-k Pathid node counts
---------------------------------------Max no. of path counts = 23
Cur no. of path counts = 23
Cnt( /root()/customerinfo/phone/text() ) = 11690
Cnt( /root()/customerinfo/phone/type ) = 11228
Cnt( /root()/customerinfo/phone ) = 10951
Cnt( /root()/customerinfo ) = 6144
Cnt( /root()/customerinfo/addr/country ) = 6658
Cnt( /root()/customerinfo/name/text() ) = 6526
Cnt( /root()/customerinfo/addr/pcode-zip/text() ) = 6354
Cnt( /root()/customerinfo/addr/city ) = 6314
Cnt( /root()/customerinfo/addr/street ) = 6248
Cnt( /root()/customerinfo/addr/city/text() ) = 6142
Cnt( /root()/customerinfo/addr/pcode-zip ) = 5931
Cnt( /root()/customerinfo/addr ) = 5905
Cnt( /root()/customerinfo/addr/street/text() ) = 5905
Cnt( /root()/customerinfo/addr/prov-state ) = 5891
Cnt( /root()/customerinfo/Cid ) = 5865
Cnt( /root()/customerinfo/addr/prov-state/text() ) = 5746
Cnt( /root()/customerinfo/name ) = 5733
Cnt( /root()/customerinfo/assistant/name ) = 2338
Cnt( /root()/customerinfo/assistant/name/text() ) = 2140
Cnt( /root()/customerinfo/assistant ) = 2127
Cnt( /root()/customerinfo/assistant/phone/text() ) = 1981
Cnt( /root()/customerinfo/assistant/phone/type ) = 1902
Cnt( /root()/customerinfo/assistant/phone ) = 1797
---------------------------------------Top-k Pathid doc counts
---------------------------------------Max no. of path counts = 23
Cur no. of path counts = 23
Cnt( /root()/customerinfo/name/text() ) = 6144
Cnt( /root()/customerinfo/addr/city ) = 6144
Cnt( /root()/customerinfo/phone/type ) = 6144
Cnt( /root()/customerinfo/addr/country ) = 6144
Cnt( /root()/customerinfo ) = 6144
Cnt( /root()/customerinfo/addr ) = 6144
Figure 14.22
Output of the db2cat utility
XML Performance and Monitoring
14.3
Statistics Collection for XML Data
Cnt( /root()/customerinfo/phone ) = 6144
Cnt( /root()/customerinfo/addr/prov-state ) = 6144
Cnt( /root()/customerinfo/addr/pcode-zip ) = 6117
Cnt( /root()/customerinfo/addr/city/text() ) = 6105
Cnt( /root()/customerinfo/name ) = 6094
Cnt( /root()/customerinfo/addr/prov-state/text() ) = 6070
Cnt( /root()/customerinfo/addr/pcode-zip/text() ) = 6035
Cnt( /root()/customerinfo/Cid ) = 5895
Cnt( /root()/customerinfo/addr/street/text() ) = 5872
Cnt( /root()/customerinfo/phone/text() ) = 5813
Cnt( /root()/customerinfo/addr/street ) = 5650
Cnt( /root()/customerinfo/assistant ) = 2370
Cnt( /root()/customerinfo/assistant/name ) = 2171
Cnt( /root()/customerinfo/assistant/phone/text() ) = 2136
Cnt( /root()/customerinfo/assistant/phone ) = 1973
Cnt( /root()/customerinfo/assistant/phone/type ) = 1973
Cnt( /root()/customerinfo/assistant/name/text() ) = 1868
---------------------------------------Top-k Pathid-Value node counts
---------------------------------------Max no. of path-value counts = 43
Cur no. of path-value counts = 43
Cnt( /root()/customerinfo/addr/country,6:Canada ) = 6144
Cnt( /root()/customerinfo/phone/type,4:work ) = 6024
Cnt( /root()/customerinfo/addr/city/text(),7:Toronto ) = 3159
Cnt( /root()/customerinfo/phone/type,4:home ) = 3030
Cnt( /root()/customerinfo/addr/city/text(),7:Markham ) = 2041
(...)
---------------------------------------Top-k Pathid-Value doc counts
---------------------------------------Max no. of path-value counts = 43
Cnt( /root()/customerinfo/addr/country,6:Canada ) = 6144
Cnt( /root()/customerinfo/phone/type,4:work ) = 6024
Cnt( /root()/customerinfo/addr/city/text(),7:Toronto ) = 3159
Cnt( /root()/customerinfo/phone/type,4:home ) = 3030
Cnt( /root()/customerinfo/assistant/phone/type,4:home ) = 2048
Cnt( /root()/customerinfo/addr/city/text(),7:Markham ) = 2041
(...)
---------------------------------------Catch All Pathid-Value Bucket
---------------------------------------Max no. of buckets = 12
Cur no. of buckets = 12
---------------------------------------PathID
= /root()/customerinfo/addr/city/text()
Distinct Value Cnt = 3
2nd Highest Key
= 7:Toronto
2nd Lowest Key
= 6:Aurora
Sum Node Cnt
= 6144
Sum Doc Cnt
= 6144
Data Type of Keys = String
---------------------------------------(...)
Figure 14.22
Output of the db2cat utility (Continued)
423
424
14.4
Chapter 14
XML Performance and Monitoring
MONITORING XML ACTIVITY
Since the pureXML capabilities are deeply integrated into the DB2 engine, the existing tools for
monitoring database activity also capture any XML-related activity in the system. The DB2 snapshot monitor, the event monitor, DB2 traces, CLI and JDBC traces, and so on can be used to analyze relational and XML operations. The general usage of these existing tracing and monitoring
tools has not changed with the introduction of XML. Therefore we do not discuss them in detail
and only look at the snapshot monitor in DB2 for Linux, UNIX, and Windows as an example.
14.4.1
Using the Snapshot Monitor in DB2 for Linux, UNIX, and Windows
Chapter 3, Designing and Managing XML Storage Objects, described the data, index, and XML
storage objects in a DB2 table space. These objects are abbreviated DAT, INX, and XDA respectively. The DB2 snapshot monitor counts read and write operations to each of these storage
objects separately, and reports them as data, index, and xda page counters. For XML data that
is inlined in the base table, XML reads and writes are included in the counters for the DAT object
rather than the XDA object. Any activity pertaining to XML indexes, including the regions index,
is reflected in the index counters.
The way you capture snapshot information in DB2 has not changed with the introduction of DB2
pureXML. There are six snapshot monitor switches that you can turn on and off to select the
information that is collected. These are listed in Table 14.9. The switches can be set at the application level (per connection) or globally at the database manager (instance) level. The instancelevel settings are persistent, but the application-level settings are only effective for the lifetime of
a specific connection to the database.
Table 14.9
Snapshot Monitor Switches
Monitor Switch
(Application Level)
DBM Parameter
(Instance Level)
Information
Provided
BUFFERPOOL
DFT_MON_BUFPOOL
Buffer pool activity information, number of
reads and writes
LOCK
DFT_MON_LOCK
Lock waits, lock wait time, deadlocks
SORT
DFT_MON_SORT
Number of sort operations and their behavior
STATEMENT
DFT_MON_STMT
XQuery and SQL statement information
TABLE
DFT_MON_TABLE
Table activity information
UOW
DFT_MON_UOW
Unit of work information
TIMESTAMP
DFT_MON_TIMESTAMP
Time and timestamp information
14.4
Monitoring XML Activity
425
The first command in Figure 14.23 enables the collection of bufferpool, statement, table, and timing information for the current connection. The command disables the collection of lock, sort,
and UOW information. These settings remain active until the current connection to the database
is terminated. The second command in Figure 14.23 sets the default monitor switches at the DB2
instance level. Any application that connects to a database inherits these settings. You can always
check the setting of the monitor switches by using the GET MONITOR SWITCHES command.
UPDATE MONITOR SWITCHES USING
BUFFERPOOL on LOCK off SORT off STATEMENT on TABLE on
UOW off TIMESTAMP on;
UPDATE DBM CFG USING DFT_MON_BUFPOOL on DFT_MON_LOCK off
DFT_MON_SORT off DFT_MON_STMT on DFT_MON_TABLE on
DFT_MON_UOW off DFT_MON_TIMESTAMP on;
Figure 14.23
Setting the snapshot monitor switches
After the collection of snapshot information is enabled, you typically use two commands to work
with the snapshot monitor:
• RESET MONITOR FOR DATABASE <dbname>
• GET SNAPSHOT FOR [ALL|DATABASE|BUFFERPOOLS|TABLES|
TABLESPACES|APPLICATIONS|LOCKS|...]
The RESET MONITOR command resets the monitor counters to zero. You should do this before
executing a query or a workload that you want to monitor. After the completion of the workload
that you want to monitor, execute the GET SNAPSHOT command to retrieve the collected information. The FOR clause in the GET SNAPSHOT command allows you to obtain snapshot counters
for the whole database or by buffer pool, table space, or application. It can also restrict the monitor information to tables, locks, and other areas of interest.
In a partitioned database (DPF), the snapshot monitor commands can optionally use either one of
these additional clauses:
• AT DBPARTITIONNUM <db-partition-number>
• GLOBAL
The clause AT DBPARTITIONNUM can be used to specify the database partition for which the
command should be executed. This allows you to update monitor switches or to get and reset
monitor information for individual database partitions in a DPF system. Alternatively, use the
keyword GLOBAL to affect all partitions.
Figure 14.24 provides an example of the GET SNAPSHOT command to display buffer pool information. You see the various snapshot monitor counters for the three different storage objects:
426
Chapter 14
XML Performance and Monitoring
data, index, and XDA. The interpretation of the new XDA counters is the same as the corresponding DAT and INX counters. For example, Buffer pool xda logical reads shows the number of XDA pages that have been requested from the buffer pool. Out of those, some pages were
not in the buffer pool and cause physical I/O to the table space. This is reflected in the counter
Buffer pool xda physical reads. A low ratio of XDA physical reads to XDA logical reads
indicates a high buffer pool hit ratio for XML data, which is desirable. The more XML documents are inlined in the base table, the more XML activity is reflected in the data counters
instead of the XDA counters.
GET SNAPSHOT FOR BUFFERPOOLS ON sampxml GLOBAL;
(...)
Buffer pool data logical reads
Buffer pool data physical reads
Buffer pool temporary data logical reads
Buffer pool temporary data physical reads
Buffer pool data writes
Buffer pool index logical reads
Buffer pool index physical reads
Buffer pool temporary index logical reads
Buffer pool temporary index physical reads
Buffer pool xda logical reads
Buffer pool xda physical reads
Buffer pool temporary xda logical reads
Buffer pool temporary xda physical reads
Buffer pool xda writes
Asynchronous pool data page reads
Asynchronous pool data page writes
Buffer pool index writes
Asynchronous pool index page reads
Asynchronous pool index page writes
Asynchronous pool xda page reads
Asynchronous pool xda page writes
(...)
Figure 14.24
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
10356
216
0
0
0
7901
14
0
0
71993
8414
0
0
0
19
0
0
0
0
932
0
Snapshot monitor output for buffer pools
Instead of using the GET SNAPSHOT command you can also run SQL queries against snapshot
table functions or administrative views to obtain the same snapshot information. Figure 14.25
shows an example. For further details on the snapshot views and table functions, refer to the DB2
documentation.
SELECT SUBSTR(db_name,1,10) AS dbname,
SUBSTR(bp_name,1,10) AS bpname,
pool_xda_l_reads, pool_xda_p_reads, pool_xda_writes,
pool_async_xda_reads, pool_async_xda_writes,
pool_async_xda_read_reqs, pool_temp_xda_l_reads,
pool_temp_xda_p_reads
FROM sysibmadm.snapbp
Figure 14.25
Selecting XDA information from the buffer pool administrative view
14.4
Monitoring XML Activity
427
If you get a snapshot FOR DATABASE or FOR APPLICATION, you will find a snapshot element
called Xquery statements executed (see Figure 14.26). This lets you gauge the activity of
native XQuery language requests. SQL/XML queries, which may contain XQuery embedded in
the functions XMLQUERY, XMLEXISTS and XMLTABLE, are included in the counter Select SQL
statements executed.
db2 get snapshot for database on sampxml | grep –i executed
Select SQL statements executed
Xquery statements executed
Update/Insert/Delete statements executed
DDL statements executed
Figure 14.26
14.4.2
=
=
=
=
5616
123
2513
2
Number of statement executions
Monitoring Database Utilities
When you use DB2 utilities such as LOAD or REORG to manage XML or relational data, it can be
helpful to monitor the progress or status of these utilities. In short, the monitoring of DB2 utilities
works for XML just like it does for relational data. There are no special considerations for XML
data. For example, in DB2 for z/OS you can use the DISPLAY UTILITY command as usual to
check the current status of utilities. In DB2 for Linux, UNIX, and Windows you can use commands such as LIST UTILITIES and LOAD QUERY as you normally do. If you are familiar with
these commands, then you can skip this section.
In DB2 for Linux, UNIX, and Windows you can monitor the progress of BACKUP, RESTORE,
RUNSTATS, REORG, and LOAD utilities. While any of these utilities are running in the DB2 engine,
you can list them with the LIST UTILITIES command. For more detailed information, use the
LIST UTILITIES SHOW DETAIL command. The information for each utility can include the
start time, description, throttling priority (if applicable), and progress information (if available).
You need to be in the SYSADM, SYSCTRL, or SYSMAINT group to execute this command.
Alternatively, you can use the administrative views SNAPUTIL and SNAPUTIL_PROGRESS to
obtain the same information as from the LIST UTILITIES command. Sample queries against
these views are shown in Figure 14.27.
428
Chapter 14
XML Performance and Monitoring
SELECT utility_type, utility_priority,
SUBSTR(utility_description, 1,70) AS utility_description,
SUBSTR(utility_dbname, 1, 20) AS utility_dbname,
utility_state, utility_invoker_type, dbpartitionnum
FROM sysibmadm.snaputil;
SELECT utility_id, progress_total_units,
progress_completed_units, dbpartitionnum
FROM sysibmadm.snaputil_progress;
Figure 14.27
List utility information using an administrative view
Some utilities (LOAD and REORG) have special monitoring capabilities. For example, you can
monitor LOAD operations using the LOAD QUERY command:
LOAD QUERY TABLE db2admin.customer
You can check the progress of table reorganizations in the SNAPTAB_REORG administrative view,
as shown in Figure 14.28.
SELECT SUBSTR(tabname, 1, 15) AS tab_name,
SUBSTR(tabschema, 1, 15) AS tab_schema,
reorg_phase,
SUBSTR(reorg_type, 1, 20) AS reorg_type,
reorg_status, reorg_completion, dbpartitionnum
FROM sysibmadm.snaptab_reorg
Figure 14.28
14.5
Checking the progress of a REORG using an administrative view
BEST PRACTICES FOR XML PERFORMANCE
This section summarizes important guidelines for achieving good XML performance in DB2.
They are categorized into areas, such as XML Document Design, XML Storage, XML Queries,
XML Indexes, XML Updates, XML Schemas, and XML Applications. Many of these best practices are further elaborated on in the relevant chapters in this book.
14.5.1
XML Document Design
Choose an appropriate XML document granularity.
If you can influence the design of XML documents, an important decision is how much information
to include per XML document. Ideally, one XML document should correspond to one logical business object, such as a purchase order, a product, a sale, a contract, a form, or a tax return. Typically,
this design results in XML documents that also match the predominant granularity of read, update,
14.5
Best Practices for XML Performance
429
delete, and insert operations, which is good for performance and simplifies application development. Combining many independent business objects into a single XML document is not usually
recommended. For more details, see section 2.3, Choosing the Right Document Granularity.
Design XML documents to serve your application, not to serve DB2.
The requirements of your applications should be the main driver for designing XML documents.
Design XML documents and XML Schemas such that they are intuitive and easy to use for your
applications and application developers. There are no recommended ways to optimize XML documents specifically for DB2’s storage, indexing, and querying capabilities. Instead, follow the
general XML design recommendation regarding document granularity and values versus metadata that we described in Chapter 2, Designing XML Data and Applications.
14.5.2
XML Storage
Use a large page size for XML.
Processing XML in DB2 typically performs best with large pages. This is why DB2 for z/OS uses
a fixed page size of 16KB for XML table spaces and you cannot change it. In DB2 for Linux,
UNIX, and Windows you can choose between page sizes 4KB, 8KB, 16KB, and 32KB. Page
sizes 16KB or 32KB are usually best for XML data. Pages sizes are further discussed in section
3.3.2, Defining Columns, Tables, and Table Spaces for XML Data.
Store XML data in a separate table space, if needed.
If your table contains a mix of XML and relational data, and you know that your relational data is
best served by a small page size, it can be useful to store XML in a separate table space from the
rest of the table. DB2 for z/OS does that by default and you cannot change it. In DB2 for Linux,
UNIX, and Windows you can use the LONG IN clause in a CREATE TABLE statement to assign
LOB and XML columns to a separate table space. This table space can use a different page size
and a separate buffer pool. Note that inlining XML into the base table prevents storing it in a separate table space. Tables spaces for XML data are explained in section 3.3.2, Defining Columns,
Tables, and Table Spaces for XML Data, and section 3.11, XML Storage in DB2 for z/OS.
Use DMS table spaces.
In DB2 for Linux, UNIX, and Windows you can use SMS or DMS table spaces. The I/O performance with XML data is typically better with DMS than with SMS table spaces. Since version 9.1,
DMS table spaces are the default and used by DB2’s automatic storage. Automatic storage is generally recommended. For details, see section 3.3.1, Storage Objects for XML Data.
Use XML inlining wisely.
In DB2 for Linux, UNIX, and Windows, inlining XML in the base table can provide several performance benefits. For example
430
Chapter 14
XML Performance and Monitoring
• Inlining is a prerequisite for XML compression in DB2 9.5, and compression can significantly reduce I/O bottlenecks.
• Inlining enables better prefetching for XML data, especially for queries that scan or
access many documents in a column.
• Inlining reduces the size and usage of the regions index.
But, be aware that inlining also increases the row length, and therefore it reduces the number of
rows per data page. This means that queries that access relational columns only might perform
worse than without inlining.
When you use inlining, best performance is often achieved if the temporary table space, such as
TEMPSPACE1, has its own dedicated buffer pool. For more information on inlining, please refer to
section 3.4, Using XML Base Table Row Storage (Inlining).
14.5.3
XML Queries
In XPath expressions, use fully specified paths as much as possible.
Fully qualified XPath expressions, such as /customerinfo/addr/city, provide DB2 with a
straight navigation path to the desired data. Expressions like /customerinfo/*/city or
//city require DB2 to traverse additional or all branches of an XML document tree, which is
more time consuming. If you know the exact paths of the elements or attributes that you are interested in, use the fully specified path and avoid * and // to achieve better performance. An XPath
such as //city should really only be used if the city element can occur on multiple different or
unknown paths in your documents. Further information is provided in section 6.6, Wildcards and
Double Slashes.
Remember that predicates in the XMLQUERY function do not filter rows or use XML indexes.
XMLQUERY is a scalar function and is applied to one document at a time. For example, the query:
SELECT XMLQUERY('$INFO/PurchaseOrder/item[price > 10]')
FROM purchaseorder
returns as many rows as there are in the purchaseorder table. The XMLQUERY function performs filtering only within each document and might produce empty result rows if the predicate is
not matched. Put the filtering condition into an XMLEXISTS predicate if you want to eliminate
rows from the result and use XML indexes. See section 7.5, Common Mistakes with SQL/XML
Predicates, for additional examples.
14.5
Best Practices for XML Performance
431
Use square brackets in XMLEXISTS predicates.
Remember that an XMLEXISTS predicate eliminates a row from the result set only if the embedded XQuery or XPath expression returns an empty result. Hence, the embedded search condition
must be enclosed in square brackets, like this:
WHERE XMLEXISTS('$INFO/PurchaseOrder/item[price > 10]')
Without the square brackets the enclosed expression would always produce a Boolean value
true or false. It would never produce an empty result, never filter any rows, and never use an
XML index. Section 7.4, Using XPath Predicates in SQL/XML with XMLEXISTS, provides further details and examples.
Write proper “between” predicates.
XQuery does not have a BETWEEN keyword like SQL does. Hence, “between” predicates
must be written as a pair of range predicates. A pair of range predicates is best written as
/purchaseorder/item/price[. > 10 and . < 20] rather than for example
/purchaseorder [item/price > 10 and item/price < 20]. The notation with the dots
(current context) ensures that you get the desired result and a better execution plan. For details on
this execution plan, see section 9.4.2, “Between” Predicates on XML Data.
In a DPF database, choose relational join predicates over XML join predicates, if possible.
This guideline applies to partitioned databases in DB2 for Linux, UNIX, and Windows. Queries
that join two or more tables in a partitioned database can often use better execution plans if the
join condition is expressed on relational columns rather than XML columns. One example is that
relational join conditions allow DB2 to recognize collocated joins. Collocated joins have the
property that matching rows from two tables reside at the same node (partition) of the partitioned
database. This allows the join to be computed within each node, without shipping rows between
nodes, which is desirable for performance. Another advantage is that DB2 has a greater choice of
join methods and repartitioning options for relational join predicates than for XML join predicates. Background on DPF is provided in section 3.10, XML in a Partitioned Database (DPF).
Cast XML join predicates to an appropriate XML data type to allow XML index usage.
Join predicates do not contain a literal value that DB2 can use to determine the data type of the
comparison. Hence, DB2 needs to look for join matches in any possible data type. This precludes
the use of XML indexes because they contain values for a single data type only. If you cast the
join predicate to a certain data type, then DB2 can consider using a corresponding index. For
example, the following join predicate allows the use of an XML index of type DOUBLE:
432
Chapter 14
XML Performance and Monitoring
XMLEXISTS('$BOOKINFO/book/authors[author/@id/xs:double(.) =
$AUTHORINFO/author/@id/xs:double(.) ]')
Joins are discussed in section 9.2, Join Queries with XML Data, and section 13.4, XML Indexes
and Join Predicates.
Use RUNSTATS for XML data and indexes.
Efficient query execution plans depend on up-to-date statistics about the data and objects in the
database. This is true for XML and relational queries alike. Refresh statistics whenever significant amounts of data have been inserted, deleted, or updated. See section 14.3, Statistics Collection for XML Data.
Increase the statement heap if you have very complex XML queries.
In DB2 for Linux, UNIX, and Windows, the size of the statement heap determines how much
memory DB2 can use for compiling and optimizing a query. When DB2 optimizes a query, it
generates a set of candidate execution plans, estimates the execution cost for each plan, and
chooses the plan with the lowest cost. For complex queries, DB2 might have to consider a large
number of candidate plans. DB2 issues warning SQL0437W (reason code 1) if the statement heap
is too small to consider a sufficient number of candidate plans. As a result, a suboptimal execution plan may be used. To solve this problem, increase the size of the statement heap (database
configuration parameter stmtheap) or reduce the optimization level (database configuration
parameter dft_queryopt). Appendix C contains links to general DB2 material where these
parameters are explained, such as the DB2 Information Center.
14.5.4
XML Indexes
Use fully specified path expressions in XML index definitions.
This recommendation is similar to XML queries. Fully specified path expressions in index definitions allow DB2 to perform more efficient index maintenance than index definitions that include
* or // in the XMLPATTERN. Additionally, fully specified paths ensure that you index only as
many XML nodes as needed, which is good for performance and avoids unnecessarily large
indexes. For examples, see section 13.1.2, Lean XML Indexes.
Use appropriate namespace declarations in XML index definitions.
If your XML data contains namespaces then XML index definitions need to contain either corresponding namespace declarations or namespace wildcards, which match any namespace. Otherwise the index does not contain the desired index entries and is not used for query processing.
Details can be found in section 15.4, Creating Indexes for XML Data with Namespaces.
14.5
Best Practices for XML Performance
433
Use VARCHAR HASHED indexes to your advantage.
DB2 for Linux, UNIX, and Windows supports XML indexes of type VARCHAR HASHED, which
can index strings of arbitrary length. Each index key is an 8-byte hash code of the indexed string
rather than the string value itself. This can save a lot of space if the indexed string values tend to
be long. For example, if you index an element <url> that contains URLs with average length of
80 characters, a VARCHAR HASHED index uses keys, which are 10 times smaller than those of a
VARCHAR(n) index. A VARCHAR HASHED index can only be used to evaluate equality predicates,
which, depending on the workload, may be sufficient. More information is available in section
13.2, XML Index Data Types.
Be aware of the overhead of reorganizing XML indexes.
Reorganizing XML indexes is more expensive than reorganizing relational indexes. Hence, the
time to reorganize all indexes for a table can be significantly increased if the set of indexes
includes XML indexes. Therefore you might find it advantageous to reorganize relational and
XML indexes separately and to explicitly refer to their index names in the REORG command.
Since version 9.7, DB2 for Linux, UNIX, and Windows also offers online index reorganization,
which keeps the table fully available during index reorganization and does not require a dedicated
maintenance window. Also see section 3.7, Reorganizing XML Data and Indexes.
At the time of writing, the DB2 design advisor (db2advis) does not yet recommend XML
indexes.
14.5.5
XML Updates
Combine multiple update operations in a single statement.
If you need to make multiple modifications to a given XML document, combine multiple update
operations in a single UPDATE statement rather than issuing multiple UPDATE statements. See
Chapter 12, Updating and Transforming XML Documents, for examples.
For best update performance, choose a small XML document granularity.
Modifications within an XML document tend to perform better for smaller documents (in the KB
range) rather than larger documents (in the MB range). Therefore, the previous guideline for
XML document granularity (section 14.5.1) is of particular importance. If best possible update
performance is critical for your application, try using a smaller document granularity. Consider
splitting large documents into multiple smaller documents upon insert, as discussed in section
5.7, Splitting Large XML Documents into Smaller Documents.
434
14.5.6
Chapter 14
XML Performance and Monitoring
XML Schemas
Avoid repetitive document validation.
Inserting or updating XML documents with validation consumes more CPU cycles than the same
operations without validation. The difference is small for simple XML Schemas, but can be significant for large and complex XML Schemas. The validation of XML documents can happen at
various layers in the IT stack. For example, incoming XML messages might get validated by the
enterprise service bus or application server. In this case, additional validation by the DB2 server
might not be necessary. Also, if XML documents are produced by a trusted application and you
know that the documents are always valid, XML inserts without validation can reduce the CPU
utilization on the database server. Further details are discussed in section 16.1.2, To Validate or
Not to Validate, That Is the Question! as well as Chapter 17, Validating XML Documents against
XML Schemas.
14.5.7
XML Applications
Use pureXML instead of XML parsing in the application.
Traditionally, XML applications perform a lot of XML parsing to manipulate XML documents.
For example, updating or extracting values from XML documents is commonly done with
application-level XML parsing. Much of this XML parsing can be avoided by using DB2
pureXML. DB2 stores XML in a parsed format, which allows value extractions, updates, and
other operations to be performed without XML parsing. This allows for simpler application code
and high end-to-end performance. For more information, see section 21.1.1, Avoid XML Parsing
in the Application Layer.
For short queries or OLTP applications, use SQL/XML statements with parameter
markers or host variables.
Very short database queries often execute so fast that the time to compile and optimize them is a
substantial portion of their total response time. Thus, it’s useful to compile them just once and
only pass literal values for each execution. The SQL/XML functions XMLQUERY, XMLTABLE, and
XMLEXISTS allow you to pass SQL parameter markers or host variables as XQuery variables into
the embedded XPath or XQuery expressions. Then you prepare or pre-compile the SQL/XML
statements just like regular SQL statements. This is recommended for applications with short and
repetitive queries. The same applies to short insert, update, and delete operations. You can see
examples in section 21.2, Using Parameter Markers or Host Variables.
Avoid code page conversion during XML insert and retrieval.
Code page conversion can be an expensive operation. If the code page of the application is different from the code page of the database, then any character data that is passed between the database and the application undergoes code page conversion. This transcoding can be avoided if
14.6
Summary
435
applications move XML data to and from the database in binary format, using binary type variables rather than character type variables. For example, in CLI when you use SQLBindParameter() to bind parameter markers to input data buffers, you should use SQL_C_BINARY data
buffers rather than SQL_C_CHAR or SQL_C_WCHAR. Similarly, when you insert XML data from a
Java application, provide the XML data as a binary stream (setBinaryStream) rather than as a
string (setString). Further details on code page implications can be found in section 20.2,
Avoiding Code Page Conversions.
For large result sets, use XMLSERIALIZE to exploit blocking cursors or LOB locators.
When an application retrieves a relational result set without XML columns, a blocking cursor can
be used for more efficient data transfer from the database server to the client. With a blocking cursor, a block of result rows is transferred to the client in a single operation, which is more efficient
than transferring one row at a time. By default, blocking cursors cannot be used when retrieving
XML type data. However, you can use the XMLSERIALIZE function to explicitly convert an XML
type column in the result to a VARCHAR column, which allows blocking. This can improve the
performance of queries that retrieve many small XML values, such as the following:
SELECT XMLSERIALIZE(XMLQUERY('$INFO/customerinfo/name')
AS VARCHAR(100) )
FROM customer
This approach works as long as the serialized XML data fits within the specified VARCHAR length,
which cannot exceed 32KB. The benefits of a blocking cursor can outweigh the cost of code page
conversion that may occur when retrieving XML data as a VARCHAR column. If you retrieve very
large XML documents from a database, XMLSERIALIZE … AS CLOB or AS BLOB enables you to
use LOB locators. XMLSERIALIZE is further discussed in section 4.3, Retrieving XML Documents, and section 4.4, Handling Documents with XML Declarations.
14.6
SUMMARY
DB2’s pureXML capabilities are tightly integrated with all of its relational features in the DB2
engine. Therefore, all existing performance guidelines for DB2 still apply when the database contains XML data. XML does not introduce a departure from the existing best practices for configuring, tuning, and monitoring DB2. If you are a DBA who is new to managing XML data in the
database, you can safely apply your experience and knowledge with relational data to the management of XML data. That’s always a good start. Additionally, a set of XML-specific performance tips are summarized in the previous section.
One of the key factors for XML query performance is the proper use of XML indexes. Hence,
DB2’s features for examining access plans are critical to check which indexes are or are not used
by a given query. Fortunately, all of DB2’s explain tools work for XML queries as for relational
queries. To help DB2 produce good access plans, use RUNSTATS to collect statistics for your
XML data.
436
Chapter 14
XML Performance and Monitoring
When you examine the access plans of XML queries, you will encounter several XML-specific
query operators, which DB2 uses in conjunction with relational query operators. In DB2 for
Linux, UNIX, and Windows, the XML operators are called XSCAN, XISCAN, and XANDOR. They
facilitate the traversal of XML documents (XSCAN) as well as the access (XISCAN) and join
(XANDOR) of XML indexes. In DB2 for z/OS, the XML operators are DIXSCAN, XIXAND, XIXOR,
and XIXSCAN. The XIXSCAN operator performs access to an XML index and produces document
identifiers (DOCIDs). The XIXAND and XIXOR operators are used to compute the union or intersection, respectively, of sets of such DOCIDs. The DIXSCAN operator takes a DOCID as input and
returns the RID of the row that a document belongs to. Examining and understanding XML query
execution plans is one of the most important parts of investigating XML query performance.
C
H A P T E R
15
Managing XML Data
with Namespaces
n the previous chapters you have learned how to store, index, query, construct, and update
XML documents in DB2. In those discussions we have assumed that the XML documents
do not contain namespaces. When XML namespaces are present, additional considerations are
required, which are described in this chapter. The discussion of namespaces is split into the following topics:
I
• Understanding namespaces and namespace declarations (section 15.1)
• Obtaining namespace information from XML documents (section 15.2)
• Writing XQuery and SQL/XML queries for XML data with namespaces (section 15.3)
• Defining and using XML indexes in the presence of namespaces (section 15.4)
• Generating XML documents with namespaces (section 15.5)
• Updating XML documents that contain namespaces (section 15.6)
15.1
INTRODUCTION TO XML NAMESPACES
XML namespaces are a W3C XML standard for providing uniquely named elements and attributes in an XML document. XML documents can contain elements and attributes that have the
same name but belong to different vocabularies (or domains). Such name conflicts can lead to
ambiguity when you use these elements and attributes. This ambiguity is resolved by assigning a
namespace to each vocabulary. All pureXML features in DB2 such as SQL/XML, XQuery, XML
indexes, and validation with XML Schemas support XML namespaces.
437
438
Chapter 15
Managing XML Data with Namespaces
As an example, consider the three XML elements in Figure 15.1. They all have the same element
name, title, but they probably have different meanings. The first element might be a job title,
the second element might be the title of a person, and the third could be the title of a book or a
movie. If an application is not able to distinguish between them and treats them all in the same
way, then processing errors or logically incorrect results are the likely consequence.
<title>Database Administrator</title>
<title>Mr</title>
<title>Lord of the Rings</title>
Figure 15.1
Three elements with identical names
Figure 15.2 shows the same three elements where namespace prefixes are used to avoid naming
collisions and prevent ambiguity. The prefix is separated from the original element name (which
is also called the local name) by a colon. The prefix has to appear in the start tag and the end tag
of an element. The namespace prefixes indicate that the three elements belong to different
domains.
<job:title>Database Administrator</job:title>
<person:title>Mr</person:title>
<movies:title>Lord of the Rings</movies:title>
Figure 15.2
Three elements with identical local names but distinct prefixes
As an analogy, think of relational schema names that can be used to qualify the names of relational tables or indexes. For example, in a DB2 database you can have two tables called
schema1.mytable and schema2.mytable. The schema names act as prefixes for the table
names and avoid ambiguity and name conflicts. To drive the analogy further, remember that a
relational schema name is typically used to group together multiple database objects, such as
tables and indexes, if they belong to the same application or logical domain. Similarly, a namespace is used to identify and group all XML tag names that belong to the same application
domain. Typically, an XML Schema defines the element and attribute names that can appear in
XML documents for a given application. Such an XML Schema often declares a so-called target
namespace, which means that all elements (and optionally also all attributes) that are defined in
the schema belong to this specific namespace. XML Schemas and their namespaces are explained
in Chapter 16, Managing XML Schemas.
There is more to namespaces than the prefixes for tag names. In particular, a namespace needs to
be declared and a prefix has to be assigned to a Universal Resource Identifier (URI) before it can
15.1
Introduction to XML Namespaces
439
be used. An XML namespace is identified by a URI, and a namespace prefix only acts as an
abbreviation or alias for the URI. The following strings are examples of URIs:
• http://www.DB2pureXML-Cookbook.org/
• ftp://ftp.is.co.za/rfc/rfc3986.txt
• urn:xmlns:bogus:partner1.0
• telnet://192.0.2.16:80/
URIs often have the style of Uniform Resource Locators (URLs) or Uniform Resource Names
(URNs). However, a URI does not retrieve data from the specified location. If a URI has the form
of a URL, the URL does not need to reference a real web page; it can be a “fake” URL that simply serves as an identifier. Namespace URIs and namespace prefixes are case sensitive and must
not contain spaces. Appendix C, Further Reading, contains pointers to more details on URIs.
There is no XML well-formedness rule that requires namespace names to be URIs. For example,
URIs that contain spaces (blanks) are invalid URIs but they do not affect the well-formedness of an
XML document. Therefore, you can insert XML documents that have spaces in their namespace
URIs. However, URIs with spaces cannot be declared in a query. This makes it difficult and sometimes impossible to query documents with such invalid URIs. Also, it is not possible to refer to
URIs with spaces in an xsi:schemaLocation attribute because the spaces would be interpreted
as delimiters for the URIs in the list. In short, you should never use spaces in namespace URIs.
15.1.1
Namespace Declarations in XML Documents
XML namespaces are declared in XML documents with the reserved attribute xmlns:prefix
where prefix is the namespace prefix that you want to use. The value of this reserved attribute
must be a URI. Figure 15.3 shows an XML document whose root element customerinfo contains a namespace declaration. You will later see that namespaces can be declared in any element,
not just the root element. The attribute xmlns:cust declares that cust is a namespace prefix
and bound to the URI http://posample.org. The prefix cust can therefore be used for the
customerinfo element and all other elements or attributes in the document that are descendants
of customerinfo. In Figure 15.3, all elements that carry the prefix cust belong to the namespace http://posample.org.
<cust:customerinfo xmlns:cust="http://posample.org" Cid="1000">
<cust:name>Kathy Smith</cust:name>
<cust:addr country="Canada">
<cust:street>5 Rosewood</cust:street>
<cust:city>Toronto</cust:city>
</cust:addr>
<cust:phone type="work">416-555-1358</cust:phone>
</cust:customerinfo>
Figure 15.3
Document with namespace and prefix declaration
440
Chapter 15
Managing XML Data with Namespaces
The attributes Cid and country in Figure 15.3 do not belong to any namespace because they do
not have a prefix and do not inherit the namespace of the element that they belong to. Since an
attribute always belongs to a specific element and cannot occur by itself, the namespace of the
attribute’s element is sufficient to avoid attribute ambiguity. Therefore attributes typically do not
need to be in a namespace and do not require prefixes. If you want to assign an attribute to a
namespace you must add a prefix to the attribute, like this:
<cust:addr cust:country="Canada">
Not every node in a document has to belong to the same namespace. For example, the document
in Figure 15.4 uses the namespace prefix c only for the elements customerinfo, name, and
phone. These elements belong to the namespace http://posample.org while the elements
addr, street, and city as well as the attributes Cid and country do not belong to any namespace.
<c:customerinfo xmlns:c="http://posample.org" Cid="1000">
<c:name>Kathy Smith</c:name>
<addr country="Canada">
<street>5 Rosewood</street>
<city>Toronto</city>
</addr>
<c:phone type="work">416-555-1358</c:phone>
</c:customerinfo>
Figure 15.4
Document in which some elements do not have a namespace
An XML document can contain multiple namespaces, as shown in Figure 15.5. This document
has a second namespace declaration located in the addr element. It assigns the prefix add to the
URI http://myAddresses.org. The addr element itself, as well as any descendent nodes
under addr, can use the prefix add to indicate that it belongs to the same namespace. However,
the elements customerinfo, name, and phone cannot use the prefix add because they are not
children of the addr element and therefore not in the scope of the namespace declaration that
defines the prefix add. Namespace prefixes can only be used in the subtree of the document for
which they are declared. For example, if you used the prefix add for the customerinfo element
in Figure 15.5, DB2 rejects the document upon insert with the error SQL16193N.
<c:customerinfo xmlns:c="http://posample.org" Cid="1000">
<c:name>Kathy Smith</c:name>
<add:addr xmlns:add="http://myAddresses.org" country="Canada">
<add:street>5 Rosewood</add:street>
<add:city>Toronto</add:city>
</add:addr>
<c:phone type="work">416-555-1358</c:phone>
</c:customerinfo>
Figure 15.5
Document with multiple namespaces
15.1
Introduction to XML Namespaces
441
If a document contains multiple namespaces, their prefixes must be distinct. Namespaces can
also be interleaved within a document, as in Figure 15.6. The namespace prefix c can be used for
the elements street and city, because they are in the scope of the namespace declaration for
the prefix c.
<c:customerinfo xmlns:c="http://posample.org" Cid="1000">
<c:name>Kathy Smith</c:name>
<add:addr xmlns:add="http://myAddresses.org" country="Canada">
<c:street>5 Rosewood</c:street>
<c:city>Toronto</c:city>
</add:addr>
<c:phone type="work">416-555-1358</c:phone>
</c:customerinfo>
Figure 15.6
Document with interleaved use of namespaces
Since XML has traditionally been used in web-based application, most people use URLs or
URNs to identify their namespaces. But there is nothing to stop you from using any other form of
string to name a namespace. For example, the following is a well-formed XML document:
<hh:customer xmlns:hh="HappyHolidays"></hh:customer>
The full name (also called the expanded name) of any element or attribute consists of two parts,
the local name and the namespace name. In the preceding example, the local name of the element
is customer and the namespace name is HappyHolidays. The notation hh:customer represents the full name where hh is a reference to HappyHolidays. When a namespace-compliant
XML processor, such as DB2, evaluates XPath expressions over XML data, elements and attributes are always identified by their full name and never by their local name alone. Full names are
used even when no namespaces are declared. In this case, the namespace part of a full name is
empty and cannot match a node name whose namespace is not empty.
Note that an attribute can be in a different namespace than the element it belongs to. In Figure
15.7, the attribute country belongs to the namespace http://custinfo.org, whereas the
element addr belongs to the namespace http://addr.org.
<c:customerinfo xmlns:c="http://custinfo.org" Cid="1000">
<c:name>Kathy Smith</c:name>
<a:addr xmlns:a="http://addr.org" c:country="Canada">
<street>5 Rosewood</street>
<city>Toronto</city>
</a:addr>
<c:phone type="work">416-555-1358</c:phone>
</c:customerinfo>
Figure 15.7
Attribute and element in different namespaces
442
15.1.2
Chapter 15
Managing XML Data with Namespaces
Default Namespaces
If all elements in a document belong to the same namespace, it is often useful to declare a default
namespace and avoid the use of prefixes. The namespace declared in Figure 15.8 is a default
namespace because the xmlns attribute does not assign a prefix to the URI. The default namespace applies to all elements in its scope. In Figure 15.8, the scope of the default namespace is the
entire document. The default namespace does not apply to attributes. The attributes Cid and
country do not belong to any namespace, only their respective elements do.
<customerinfo xmlns="http://posample.org" Cid="1000">
<name>Kathy Smith</name>
<addr country="Canada">
<street>5 Rosewood</street>
<city>Toronto</city>
</addr>
<phone type="work">416-555-1358</phone>
</customerinfo>
Figure 15.8
Document with a default namespace
You can also think of a default namespace as a namespace with an empty prefix. Every element
that has an empty prefix belongs to the default namespace.
A default namespace can be overridden by another default namespace at a lower level of the document. In the document in Figure 15.9, the addr element and all of its descendant elements
(street and city) belong to the default namespace http://myAddresses.org, which overrides the namespace http://posample.org. The phone element is a child of customerinfo
and belongs to the namespace http://posample.org.
<customerinfo xmlns="http://posample.org" Cid="1000">
<name>Kathy Smith</name>
<addr xmlns="http://myAddresses.org" country="Canada">
<street>5 Rosewood</street>
<city>Toronto</city>
</addr>
<phone type="work">416-555-1358</phone>
</customerinfo>
Figure 15.9
Document with two default namespaces
XML documents can contain a mix of default and prefix namespaces. In Figure 15.10, all elements that do not have a prefix belong to the default namespace http://posample.org. The
elements addr and street belong to the namespace http://myAddresses.org. Note that
the city element has no prefix. It does not inherit the namespace from its parent (addr) but
assumes the default namespace, http://posample.org.
15.1
Introduction to XML Namespaces
443
<customerinfo xmlns="http://posample.org"
xmlns:add="http://myAddresses.org" Cid="1000">
<name>Kathy Smith</name>
<add:addr country="Canada">
<add:street>5 Rosewood</add:street>
<city>Toronto</city>
</add:addr>
<phone type="work">416-555-1358</phone>
</customerinfo>
Figure 15.10
Document with a default namespace and prefixed namespace
Figure 15.11 shows the tree representation of the document in Figure 15.10. The shading of the
nodes indicates their namespace. The gray element nodes addr and street belong to the namespace http://myAddresses.org. The striped elements customerinfo, name, phone, and
city belong to the default namespace. The attribute nodes (double bordered, white background)
and text nodes (single bordered, white background) do not belong to any namespace. Note that a
document tree never contains attribute nodes for the reserved namespace attributes (xmlns). We
investigate this document further in section 15.2.
ccustomerinfo
ustomerinfo
Cid = 1006
n
name
ame
Kathy Smith
Figure 15.11
ph
on
e
hone
addr
country =
Canada
street
ccity
ity
5 Rosewood
Toronto
type = work
416-555-1358
Tree representation of the document in Figure 15.10
Figure 15.12 and Figure 15.13 illustrate additional important characteristics of namespaces and
element names. The three elements in Figure 15.12 might look different at first sight, but they
have identical names. Remember that the full (expanded) name of an element consists of two
parts, its local name and the namespace URI. For all three elements, the local name is addr, and
the namespace name is http://myAddresses.org. The fact that the first two elements have
different prefixes is not relevant. Both prefixes, x and y, are bound to the same namespace URI
and therefore represent the same namespace. In other words, x and y are aliases for the same
thing. The third addr element also belongs to the namespace http://myAddresses.org
because this is the declared default namespace. Prefixed namespaces and default namespaces are
444
Chapter 15
Managing XML Data with Namespaces
just two different mechanisms to declare that an element belongs to a certain namespace. The
resulting namespace of an element is the same if the URIs are the same.
<x:addr xmlns:x="http://myAddresses.org"></x:addr>
<y:addr xmlns:y="http://myAddresses.org"></y:addr>
<addr xmlns="http://myAddresses.org"></addr>
Figure 15.12
Three XML elements with identical names
Figure 15.13 shows three elements that have different full names, although they all have the same
local name (addr). The first two elements have identical namespace prefixes. This, however, is
irrelevant because in the first element the prefix x is assigned to a different URI than in the second
element. Hence, the namespace part of their full name is different. Note that these two elements
cannot appear in the same document. Within a document, the same prefix cannot be assigned to
two different namespace URIs. The third element also has the local name addr, but the namespace of its full name is empty.
<x:addr xmlns:x="http://myAddresses.org"></x:addr>
<x:addr xmlns:x="http://yourAddresses.org"></x:addr>
<addr></addr>
Figure 15.13
Three distinct XML elements
Whether two elements have the same name or not is always decided based on their full
(expanded) name and never based on their local name alone. Hence, an element addr without a
namespace is different from an element addr that has a namespace, just like elements addr and
phone are different. Since XML queries use path expressions that contain element names, the
proper usage of namespaces in queries is critical for obtaining correct query results.
15.2
EXPLORING NAMESPACES IN XML DOCUMENTS
If you are not certain about the namespaces in a particular document or about the namespace of a
particular node, you can use the XQuery functions in Table 15.1 to obtain namespace information
for specific elements or attributes. These functions are available in DB2 for Linux, UNIX, and
Windows.
15.2
Exploring Namespaces in XML Documents
Table 15.1
445
Commonly Used Namespace and Node Functions
Name and Node Functions
Description
name
Returns the name of a node, such as an element or attribute name.
The returned name includes a namespace prefix, if applicable.
local-name
Returns the local name of a node, without a namespace prefix.
namespace-uri
Returns the namespace URI of a given node.
in-scope-prefixes
Returns a list of prefixes for all in-scope namespaces of an
element.
namespace-uri-for-prefix
Returns the namespace URI that is associated with a given prefix
of an in-scope namespace of an element.
The query in Figure 15.14 is an example of how you can use these functions. The query iterates
over all elements in all documents in the XML column DOC in the table MYTABLE. For each element it returns a document with namespace information.
xquery for $i in db2-fn:xmlcolumn("MYTABLE.DOC")//*
return <element>
<local-name>{local-name($i)}</local-name>
<name>{name($i)}</name>
<namespace>{namespace-uri($i)}</namespace>
<in-scope-namespaces>
{for $j in in-scope-prefixes($i)
return <namespace prefix="{$j}">
{namespace-uri-for-prefix($j,$i)}
</namespace> }
</in-scope-namespaces>
</element>;
Figure 15.14
Collecting namespace information for all elements
Let’s use this query to obtain information about some of the elements of the XML document
shown in Figure 15.10. The namespace information for the elements customerinfo and
street is shown in Figure 15.15. The name and local-name of the customerinfo element are
identical because the element belongs to the default namespace http://posample.org, which
has no prefix (that is, an empty prefix). The in-scope namespaces are the namespaces in whose
scope the element is. Both namespaces http://posample.org and http://myAddresses.org are declared at the customerinfo element. Therefore, the customerinfo element is in the scope of both namespace declarations although it belongs to only one of them. Note
that the default namespace http://posample.org is associated with the empty prefix. We will
come back to the empty prefix of the default namespace when we discuss updates of XML documents with namespaces. (The third in-scope namespace with the prefix xml is pre-declared in
XQuery and always exists. You can ignore it for now.)
446
Chapter 15
Managing XML Data with Namespaces
<element>
<local-name>customerinfo</local-name>
<name>customerinfo</name>
<namespace>http://posample.org</namespace>
<in-scope-namespaces>
<namespace prefix="">http://posample.org</namespace>
<namespace prefix="add">http://myAddresses.org</namespace>
<namespace prefix="xml">http://www.w3.org/XML/1998/namespace
</namespace>
</in-scope-namespaces>
</element>
<element>
<local-name>street</local-name>
<name>add:street</name>
<namespace>http://myAddresses.org</namespace>
<in-scope-namespaces>
<namespace prefix="">http://posample.org</namespace>
<namespace prefix="add">http://myAddresses.org</namespace>
<namespace prefix="xml">http://www.w3.org/XML/1998/namespace
</namespace>
</in-scope-namespaces>
</element>
Figure 15.15
Partial output from the query in Figure 15.14
The second XML element described in Figure 15.15 has the local name street, the name
add:street, and the namespace http://myAddresses.org. Remember that the function
name returns the local name plus the namespace prefix of an element. The element street is in
the scope of the same namespaces as the element customerinfo and all other elements.
The query in Figure 15.16 shows another application of the XQuery functions in Table 15.1. For
each element, attribute, and text node the query returns a sequence number, the node kind, the
node name, the value of the node, and the namespace of the node. The output shown is produced
from the document in Figure 15.10. The sequence number represents depth-first order of the
nodes. Remember that the value of an element is defined as the concatenation of all descendant
text nodes. Text nodes do not have a name or a namespace.
If namespaces are declared in XML documents, then they also need to be declared in the queries
that run against them. If queries do not declare namespaces, then they might not find matching
elements and might produce empty result sets. The handling of namespaces in XML queries is
the topic of the next section.
15.3
Querying XML Data with Namespaces
447
SELECT x.seq, x.kind, x.node AS nodename,
SUBSTR(x.value,1,16) AS value, x.uri AS "Namespace URI"
FROM mytable,
XMLTABLE('$DOC//(*, @*,text())'
COLUMNS
seq
FOR ORDINALITY,
node
VARCHAR(35) PATH 'name(.)',
value VARCHAR(200) PATH 'substring(.,1,200)',
kind
VARCHAR(4)
PATH 'if (self::attribute())
then "ATTR"
else (if (self::text())
then "TEXT"
else "ELEM")',
uri
VARCHAR(50)
PATH 'namespace-uri(.)'
) AS x;
SEQ
--1
2
3
4
5
6
7
8
9
10
11
12
13
KIND
---ELEM
ATTR
ELEM
TEXT
ELEM
ATTR
ELEM
TEXT
ELEM
TEXT
ELEM
ATTR
TEXT
NODENAME
------------customerinfo
Cid
name
add:addr
country
add:street
city
phone
type
VALUE
---------------Kathy Smith5 Ros
1000
Kathy Smith
Kathy Smith
5 RosewoodToront
Canada
5 Rosewood
5 Rosewood
Toronto
Toronto
416-555-1358
work
416-555-1358
Namespace URI
----------------------http://posample.org
http://posample.org
http://myAddresses.org
http://myAddresses.org
http://posample.org
http://posample.org
13 record(s) selected.
Figure 15.16
15.3
Nodes and namespaces in the document in Figure 15.11
QUERYING XML DATA WITH NAMESPACES
Querying XML data always involves path expressions that navigate to specific elements or attributes in order to extract XML values or evaluate predicates. If the element and attribute names in a
path expression do not match the full names of the elements and attributes in the XML documents, then the query returns an empty result set.
Full names (expanded names) consist of namespace name and local name, and both must be specified in path expressions to match the element and attribute names in the documents. Therefore,
any XPath or XQuery expression can have a prolog that consists of one or more namespace declarations. This also applies to XPath expressions that are embedded in an SQL/XML function,
such as XMLQUERY, XMLTABLE, or XMLEXISTS. We first explain namespace declarations for
XQuery expressions in general, and then show their usage in SQL/XML queries.
448
Chapter 15
Managing XML Data with Namespaces
Many of the examples in the remainder of this chapter use customerinfo documents that contain one default namespace, such as the sample document in Figure 15.17. We assume that these
documents reside in the XML column info of the table customer2.
<customerinfo xmlns="http://posample.org" Cid="1000">
<name>Kathy Smith</name>
<addr country="Canada">
<street>5 Rosewood</street>
<city>Toronto</city>
<prov-state>Ontario</prov-state>
<pcode-zip>M6W 1E6</pcode-zip>
</addr>
<phone type="work">416-555-1358</phone>
</customerinfo>
Figure 15.17
15.3.1
Sample document with a namespace (table customer2)
Declaring Namespaces in XML Queries
Namespace declarations in a query can have one of the following two forms:
declare namespace cust="http://posample.org";
declare default element namespace "http://posample.org";
The first declaration declares a namespace with URI http://posample.org and prefix cust.
The second declaration defines a default namespace. The keywords default element namespace emphasize the fact that a default namespace only applies to elements, not to attributes. All
keywords must be in lowercase.
Each namespace declaration in a query must end with a semicolon (;). This syntax rule clashes
with the default termination character for statements and commands in the DB2 Command Line
Processor (CLP). To solve this conflict, invoke the DB2 CLP with the option –td# to use the #
character as the termination character (db2 –td#). You can choose another character instead of #
if you prefer.
Figure 15.18 shows an XQuery FLWOR expression with a default namespace declaration. This
declaration binds all element names in the query to the namespace http://posample.org. It
ensures that the element names used in the for, where, and return clauses have the same
namespace as the element names in the documents in table customer2 (see Figure 15.17). The
result set of the query contains name elements from two documents. Each of these elements is in
the namespace http://posample.org and therefore carries a namespace declaration. The
namespaces in the query result set are always determined by the namespaces in the original documents that you query.
15.3
Querying XML Data with Namespaces
449
xquery
declare default element namespace "http://posample.org";
for $c in db2-fn:xmlcolumn("CUSTOMER2.INFO")/customerinfo
where $c/addr/city= "Markham"
and $c/addr/@country = "Canada"
return $c/name #
<name xmlns="http://posample.org">Kathy Smith</name>
<name xmlns="http://posample.org">Jim Noodle</name>
2 record(s) selected.
Figure 15.18
XQuery with a default namespace declaration
Remember that a namespace with prefixes can achieve the same binding of element names to a
URI as a default namespace declaration. Hence, you can also write the query in Figure 15.18 with
namespace prefixes instead of a default namespace and obtain exactly the same result set. This is
shown in Figure 15.19. It does not matter whether the XML documents in the table use default
namespace declarations, namespace prefixes, or a mix of both. What matters exclusively is that
the same namespace URIs are declared in the query and the target document. Also, any namespace prefixes used in the query can be different from any prefixes in the XML documents, as
long as the prefixes are associated with the same URI.
The attribute country in the where clause of Figure 15.19 does not have a namespace prefix and
therefore matches the attribute’s empty namespace in the source document. Otherwise the attribute cannot be found and the where clause evaluates to false. The style of the namespace declaration (default versus prefixes) in the result elements is determined by how the namespace is
declared in the original document, not how the namespace is declared in the query.
xquery
declare namespace cust="http://posample.org";
for $c in db2-fn:xmlcolumn("CUSTOMER2.INFO")/cust:customerinfo
where $c/cust:addr/cust:city = "Markham"
and $c/cust:addr/@country = "Canada"
return $c/cust:name #
<name xmlns="http://posample.org">Kathy Smith</name>
<name xmlns="http://posample.org">Jim Noodle</name>
2 record(s) selected.
Figure 15.19
XQuery with namespace prefixes
The namespace declarations in Figure 15.18 and Figure 15.19 restrict the queries to one specific
namespace. However, there can be situations in which you want to query across multiple namespaces. For example, you can store documents for different versions of an XML Schema in the
450
Chapter 15
Managing XML Data with Namespaces
same XML column. These documents can carry different namespaces although the majority of
their structure and their local element names are identical. You can use wildcards instead of
namespace prefixes to match elements in any namespace and avoid namespace declarations. The
query in Figure 15.20 is an example. This query works equally well for the documents in Figure
15.17 and Figure 15.10, which differ in their namespaces. The namespace wildcards also match
the empty namespace. Thus, the query can even return name elements from customer documents
without any namespaces. Note that the query also uses a namespace wildcard for the country
element in the where clause. This wildcard enables the query to also retrieve data from customer
documents that may assign namespaces to attributes.
xquery
for $c in db2-fn:xmlcolumn("CUSTOMER2.INFO")/*:customerinfo
where $c/*:addr/*:city = "Markham"
and $c/*:addr/@*:country = "Canada"
return $c/*:name #
<name xmlns="http://posample.org">Kathy Smith</name>
<name xmlns="http://posample.org">Jim Noodle</name>
2 record(s) selected.
Figure 15.20
XQuery with namespace wildcards
Let’s summarize the characteristics of namespace wildcards in queries. Namespace wildcards
• Match any namespace, including the empty namespace
• Enable you to write queries without namespace declarations
• Relieve you from knowing the exact namespace URIs used in the XML documents
• Enable you to query XML documents across multiple namespaces
• Do not restrict data access and query results to a particular namespace
The flexibility and ease of use of namespace wildcards are very compelling advantages in many
application scenarios. However, one reason why you might not want to use namespace wildcards
is that they don’t restrict data access to a particular namespace. For example, if you intentionally
want to retrieve values from documents in one namespace but not others, namespace wildcards
cannot be used. Also, remember that the original purpose of namespaces is to avoid naming conflicts by pairing local names with URIs. However, namespace wildcards disregard the URIs and
reduce the comparison of nodes to local names. This can be either desirable or undesirable,
depending on the nature and requirements of a given application scenario.
15.3
Querying XML Data with Namespaces
15.3.2
451
Using Namespace Declarations in SQL/XML Queries
When you use XPath or XQuery expressions in the SQL/XML functions XMLQUERY and
XMLTABLE, or in the XMLEXISTS predicate, then these expressions can contain namespace declarations such as the ones discussed in the previous section. Figure 15.21 shows the same queries as
in the previous section but in SQL/XML notation. The first statement uses default namespaces,
the second uses namespace prefixes, and the third uses namespace wildcards. If you use namespace declarations, each XMLQUERY and XMLTABLE function and each XMLEXISTS predicate
must have its own declaration. There is no mechanism to declare namespaces just once for all
SQL/XML functions in the query. In SQL/XML queries, namespaces cannot be declared at the
SQL level outside of the SQL/XML functions. Within the same query, different SQL/XML functions can declare namespaces in different ways. For example, you can choose to define namespace prefixes in the XMLQUERY function and to declare a default namespace or use namespace
wildcards in the XMLEXISTS predicate of the same query.
SELECT XMLQUERY('
declare default element namespace "http://posample.org";
$INFO/customerinfo/name')
FROM customer2
WHERE XMLEXISTS('
declare default element namespace "http://posample.org";
$INFO/customerinfo/addr[city = "Markham" and
@country = "Canada"]') #
SELECT XMLQUERY('
declare namespace cust="http://posample.org";
$INFO/cust:customerinfo/cust:name')
FROM customer2
WHERE XMLEXISTS('
declare namespace cust="http://posample.org";
$INFO/cust:customerinfo/cust:addr[cust:city = "Markham"
and @country = "Canada"]') #
SELECT XMLQUERY('$INFO/*:customerinfo/*:name')
FROM customer2
WHERE XMLEXISTS('$INFO/*:customerinfo/*:addr[
*:city = "Markham" and @*:country = "Canada"]') #
Figure 15.21
Three different ways of handling namespaces in a query
The SQL/XML statements in Figure 15.21 can also be run
in DB2 for z/OS if you add the clause PASSING info AS "INFO" to
each XMLEXISTS predicate and XMLQUERY function.
NOTE
452
Chapter 15
15.3.3
Managing XML Data with Namespaces
Using Namespaces in the XMLTABLE Function
The XMLTABLE function is different from the XMLEXISTS predicate and the XMLQUERY function
because it contains multiple XQuery expressions and not just one. More specifically, it contains
one row-generating expression and one or multiple column-generating expressions, as explained
in section 7.3, Retrieving XML Values in Relational Format with XMLTABLE. For example, in
Figure 15.22 the row-generating XPath expression is $INFO/*:customerinfo[*:addr/
*:city="Markham"] and provides the context for the column-generating expressions @Cid,
*:name, and *:addr/*:city. In this example, most of these expressions use namespace wildcards because the source table customer2 contains documents with namespaces. No namespace
wildcard is required for the Cid attribute because it does not belong to any namespace. The result
set produced by the XMLTABLE function does not contain namespace declarations because the
result consists of non-XML data types that never contain namespaces.
SELECT x.id, x.name, x.zip
FROM customer2,
XMLTABLE('$INFO/*:customerinfo[*:addr/*:city="Markham"]'
COLUMNS
id
INTEGER
PATH '@Cid',
name VARCHAR(20) PATH '*:name',
zip
VARCHAR(15) PATH '*:addr/*:pcode-zip' ) AS x;
ID
----------1001
1002
NAME
-------------------Kathy Smith
Jim Noodle
ZIP
--------------N9C 3T6
N9C 3T6
2 record(s) selected.
Figure 15.22
XMLTABLE function with namespace wildcards
Instead of namespace wildcards, each XQuery expression in the XMLTABLE function can have its
own namespace declaration, as shown in Figure 15.23. These namespace declarations can differ
from each other, for example, if there are multiple namespaces within each XML document. You
don’t have to declare a namespace for the Cid attribute, which doesn’t belong to any namespace.
15.3
Querying XML Data with Namespaces
453
SELECT x.id, x.name, x.zip
FROM customer2,
XMLTABLE('declare default element namespace "http://posample.org";
$INFO/customerinfo[addr/city="Markham"]'
COLUMNS
id
INTEGER
PATH '@Cid',
name VARCHAR(20) PATH 'declare namespace c="http://posample.org";
c:name',
zip
VARCHAR(15) PATH 'declare namespace d="http://posample.org";
d:addr/d:pcode-zip' ) AS x #
Figure 15.23
XMLTABLE function with multiple namespace declarations
The query in Figure 15.23 repeats the namespace declaration three times even though there is
only one namespace URI. Fortunately, this repetition of namespace declarations can be avoided
with the SQL/XML function XMLNAMESPACES. It allows you to declare one or multiple namespaces inside an XMLTABLE function. These namespaces are global for all expressions in the
XMLTABLE function. Therefore, the query in Figure 15.23 can be rewritten as shown in Figure
15.24 where a single default namespace is declared for all XQuery expressions in the XMLTABLE
function. The query in Figure 15.24 returns the same result from the table customer2 as the
queries in Figure 15.22 and Figure 15.23. There is no significant performance difference between
these three queries.
SELECT x.id, x.name, x.city
FROM customer2,
XMLTABLE(XMLNAMESPACES(DEFAULT 'http://posample.org'),
'$INFO/customerinfo[addr/city="Markham"]'
COLUMNS
id
INTEGER
PATH '@Cid',
name VARCHAR(20) PATH 'name',
city VARCHAR(15) PATH 'addr/city' ) AS x;
Figure 15.24
Using XMLNAMESPACES to declare a default namespace
Be aware of the difference between the XMLNAMESPACES function and the declare namespace clauses that we used in previous queries. The clauses declare namespace and
declare default element namespace are part of the XQuery language and appear as a
prolog of an XQuery expression. In contrast, the XMLNAMESPACES function is part of the SQL
language and defined in the SQL/XML standard. It can appear only as an argument of the functions XMLTABLE, XMLELEMENT, and XMLFOREST.
454
15.3.4
Chapter 15
Managing XML Data with Namespaces
Dealing with Multiple Namespaces per Document
Writing XML queries becomes slightly more interesting if your XML documents contain multiple namespaces. As a sample document for this discussion we use the XML document that we
previously discussed in Figure 15.10 and Figure 15.11. For convenience it is repeated here in Figure 15.25. We assume that this one document is stored in table customer3.
<customerinfo xmlns="http://posample.org"
xmlns:add="http://myAddresses.org" Cid="1000">
<name>Kathy Smith</name>
<add:addr country="Canada">
<add:street>5 Rosewood</add:street>
<city>Toronto</city>
</add:addr>
<phone type="work">416-555-1358</phone>
</customerinfo>
Figure 15.25
Document with a default namespace and a prefix namespace
When you query documents that contain multiple namespaces, declaring a single default namespace in your query is not sufficient. One possible solution is to use namespace wildcards as discussed in the previous sections. Since those wildcards match any namespace, the queries are the
same for documents with one namespace, no namespace, or many namespaces. Hence, namespace wildcards are often a simple and resilient solution for namespace complexity.
If you want to query data in multiple specific namespaces instead of all namespaces, your queries
need to contain multiple namespace declarations. The query in Figure 15.26 selects the name element from the document in Figure 15.25 and verifies that the city element has the value
Toronto. A single namespace declaration is sufficient in the XMLQUERY function because all elements on the path /customerinfo/name belong to the same namespace. But, the XPath
expression in the XMLEXISTS predicate contains elements from two different namespaces, both
of which must be declared. You can either declare one default namespace and one namespace
with a prefix, or two namespaces with prefixes. The latter approach is taken in the XMLEXISTS
predicate in Figure 15.26. Note that the namespace prefixes declared in the query do not have to
match the prefixes in the XML document, only the namespace URIs have to match.
15.3
Querying XML Data with Namespaces
455
SELECT XMLQUERY('
declare default element namespace "http://posample.org";
$INFO/customerinfo/name')
FROM customer3
WHERE XMLEXISTS('
declare namespace p="http://posample.org";
declare namespace a="http://myAddresses.org";
$INFO/p:customerinfo/a:addr[p:city = "Toronto"]') #
<name xmlns="http://posample.org"
xmlns:add="http://myAddresses.org">Kathy Smith</name>
1 record(s) selected.
Figure 15.26
SQL/XML statement with multiple namespace declarations
The name element that is returned by the query in Figure 15.26 has two namespace declarations.
Those are all of the in-scope namespaces of the name element; that is, all namespaces that are
declared in the original XML document at the name element or at any of its ancestors in the document tree. Although the name element itself belongs to only one of those namespaces
(http://posample.org), it could potentially contain child elements that belong to other inscope namespaces. This is illustrated in Figure 15.27 where an XQuery returns the addr element.
The addr element contains the city element, which is in the default namespace of the original
document. This namespace of the city element is maintained in the query result because the
addr element contains declarations for all in-scope namespaces. Since namespaces are an integral component of XML element names, there is no mechanism to return XML elements without
their in-scope namespace declarations.
xquery
declare namespace p="http://posample.org";
declare namespace a="http://myAddresses.org";
for $i in db2-fn:xmlcolumn("CUSTOMER3.INFO")/p:customerinfo
where $i/a:addr/p:city = "Toronto"
return $i/a:addr #
<add:addr xmlns="http://posample.org"
xmlns:add="http://myAddresses.org"
country="Canada">
<add:street>5 Rosewood</add:street>
<city>Toronto</city>
</add:addr>
1 record(s) selected.
Figure 15.27
XQuery with multiple namespace declarations
456
Chapter 15
Managing XML Data with Namespaces
A query result does not contain namespace declarations if you retrieve text nodes instead of elements, or if you use the XMLTABLE function to convert XML values to relational data types. The
query in Figure 15.28 uses the XMLTABLE function with multiple namespaces declared in the
XMLNAMESPACES function.
SELECT x.id, x.name, x.city
FROM customer3,
XMLTABLE(XMLNAMESPACES('http://posample.org' as "p",
'http://myAddresses.org' as "a"),
'$INFO/p:customerinfo[a:addr/p:city="Toronto"]'
COLUMNS
id
INTEGER
PATH '@Cid',
name VARCHAR(20) PATH 'p:name',
city VARCHAR(15) PATH 'a:addr/p:city' ) AS x ;
ID
NAME
CITY
----------- -------------------- --------------1000 Kathy Smith
Toronto
1 record(s) selected.
Figure 15.28
15.4
Using the XMLNAMESPACES function with XMLTABLE
CREATING INDEXES FOR XML DATA WITH NAMESPACES
The discussion of querying XML data with namespaces has shown that proper declaration of
namespaces in XML queries is critical to retrieving the desired data. Queries that do not declare
namespaces correctly or do not use namespace wildcards typically return empty result sets.
Equivalent concepts apply to XML indexes. If you define an XML index on XML documents that
contain namespaces, the index definition needs to account for the namespaces. Otherwise the
index definition might not match any XML nodes and will be empty. The remainder of this section assumes that you are already familiar with XML indexes and the conditions for index eligibility, as discussed in Chapter 13, Defining and Using XML Indexes.
As an example, let’s continue working with the table customer2, which contains XML documents with a single namespace (Figure 15.17). Suppose you frequently look up customers’ information based on their phone number. An index on the phone element can help speed up such
searches. However, the index in Figure 15.29 is not suitable because it only builds index entries
for phone elements that do not belong to any namespace. Therefore, this index does not contain
index entries for documents with a namespace such as the one in Figure 15.17. When a query
searches for phone elements in a specific namespace, or if it uses wildcards to search in any
namespace, the index in Figure 15.29 is not eligible.
15.4
Creating Indexes for XML Data with Namespaces
457
CREATE INDEX idx1 ON customer2(info)
GENERATE KEYS USING XMLPATTERN '/customerinfo/phone'
AS SQL VARCHAR(30) #
Figure 15.29
Creating an index without namespace handling
Similar to XML queries, there are three ways to handle namespaces in XML index definitions:
• Declare and use a namespace prefix in the XMLPATTERN (Figure 15.30)
• Declare a default namespace prefix in the XMLPATTERN (Figure 15.31)
• Use namespace wildcards in the XMLPATTERN (Figure 15.32)
The syntax for namespace declarations in indexes is the same as for namespace declarations in
queries. Figure 15.30 defines an index on phone elements in the namespace http://posample.org. The namespace prefix is irrelevant and does not have to match the prefixes used in the
XML documents or queries. What matters is that the namespace URI of the index matches the
namespace URI in the XML documents and your queries.
CREATE INDEX idx2 ON customer2(info)
GENERATE KEYS USING XMLPATTERN
'declare namespace ns="http://posample.org";
/ns:customerinfo/ns:phone'
AS SQL VARCHAR(30) #
Figure 15.30
Creating an index with namespace prefixes
The index idx3 in Figure 15.31 declares the same URI as a default namespace, and therefore
does not use prefixes in the XML pattern /customerinfo/phone. The index definitions in
Figure 15.30 and Figure 15.31 are equivalent. Both indexes contain entries for the same phone
elements and can be used for the same queries. There is no preference for either one because they
are just different notations for the same index.
CREATE INDEX idx3 ON customer2(info)
GENERATE KEYS USING XMLPATTERN
'declare default element namespace "http://posample.org";
/customerinfo/phone'
AS SQL VARCHAR(30) #
Figure 15.31
Creating an index with a default element namespace
The index definition in Figure 15.32 uses namespace wildcards to match customer phone elements in any namespace. This index is different from the previous two because it can contain
index entries for phone elements from multiple different namespaces, including the empty
namespace. If the info column contains documents that are structurally the same but have different namespaces, then this index contains information for all of them.
458
Chapter 15
Managing XML Data with Namespaces
CREATE INDEX idx4 ON customer2(info)
GENERATE KEYS USING XMLPATTERN '/*:customerinfo/*:phone'
AS SQL VARCHAR(30) #
Figure 15.32
Creating an index with namespace wildcards
The set of queries that an index can be used for, that is, the index eligibility, depends on how you
handle namespaces in queries and index definitions. Figure 15.33 shows four queries that might
be able to use some of the four XML indexes that we have discussed. The first query defines and
uses a namespace prefix, the second query uses a default namespace, and the third query contains
namespace wildcards. The fourth query looks for phone elements that do not have a namespace,
which is the same as having an empty namespace.
--Query 1 (namespace with prefix):
SELECT info
FROM customer2
WHERE XMLEXISTS('declare namespace n="http://posample.org";
$INFO/n:customerinfo[n:phone = "416-555-1358"]')#
--Query 2 (default namespace):
SELECT info
FROM customer2
WHERE XMLEXISTS('
declare default element namespace "http://posample.org";
$INFO/customerinfo[phone = "416-555-1358"]')#
--Query 3 (namespace wildcards):
SELECT info
FROM customer2
WHERE XMLEXISTS('$INFO/*:customerinfo[*:phone="416-555-1358"]')#
--Query 4 (no namespace):
SELECT info
FROM customer2
WHERE XMLEXISTS('$INFO/customerinfo[phone = "416-555-1358"]')#
Figure 15.33
Four ways of handling namespaces in query predicates
Table 15.2 summarizes which queries can use which of the indexes. The four queries in Figure
15.33 are represented by four rows in the table. The four XML indexes in Figure 15.29 through
Figure 15.32 correspond to the four columns in the table. The entries marked Y in the table indicate that a certain index is eligible to evaluate a certain query.
15.4
Creating Indexes for XML Data with Namespaces
Table 15.2
459
Index Eligibility with Namespaces in XML Indexes and Predicates
Index Definition
Query
Query 1 (namespace prefixes)
Query 2 (default namespace)
Query 3 (namespace wildcard)
Query 4 (no namespace)
idx1
(no
namespace)
N
N
N
Y
idx2
(namespace
prefix)
Y
Y
N
N
idx3
(default
namespace)
Y
Y
N
N
idx4
(namespace
wildcards)
Y
Y
Y
Y
The index idx1 cannot be used for query 1, 2, and 3. The reason is that these queries look for
phone elements that have a namespace, but index idx1 contains entries for phone elements that
do not have a namespace.
The rows for query 1 and query 2 have identical entries, and the columns for indexes idx2 and
idx3 also have identical entries. This is because declaring namespace prefixes and declaring a
default namespace are equivalent. They are just two different notations for the same thing and
you can use either one without affecting index matching.
The indexes idx2 and idx3 can be used for query 1 and 2 but not for query 3, which uses namespace wildcards, or query 4, which uses no namespaces. The reason is that these indexes contain
entries for the one specific namespace that query 1 and 2 are searching for. Indexes idx2 and
idx3 do not contain index entries for phone elements in any namespace or no namespace.
Index idx4 with namespace wildcards is eligible for all four queries. Since it contains index
entries for any namespace, it certainly includes index entries for the specific namespace that
query 1 and 2 are searching for. Remember that namespace wildcards also match missing or
empty namespaces. Therefore, index idx4 can be used to evaluate query 4.
XML attributes often do not belong to a namespace and they never belong to a default namespace. The Cid attribute in the document in Figure 15.17 is an example. To index such an attribute, ensure that you account for the namespace of the element that the attribute belongs to. Three
options are shown in Figure 15.34. A fourth option is to use the XMLPATTERN /*:customerinfo/@*:Cid, which even matches Cid attributes that are in any or no namespace.
460
Chapter 15
Managing XML Data with Namespaces
CREATE INDEX idxcid ON customer2(info)
GENERATE KEYS USING XMLPATTERN
'declare namespace n="http://posample.org";
/n:customerinfo/@Cid' AS SQL DOUBLE #
CREATE INDEX idxcid ON customer2(info)
GENERATE KEYS USING XMLPATTERN
'declare default element namespace "http://posample.org";
/customerinfo/@Cid' AS SQL DOUBLE #
CREATE INDEX idxcid ON customer2(info)
GENERATE KEYS USING XMLPATTERN
'/*:customerinfo/@Cid' AS SQL DOUBLE #
Figure 15.34
15.5
Creating an index on an attribute
CONSTRUCTING XML DATA WITH NAMESPACES
In Chapter 10, Producing XML from Relational Data, you learned how to construct XML documents from existing relational data. The generated XML documents do not contain any namespaces unless you explicitly construct namespace declarations and prefixes as needed. In this
section we first explain how to construct namespaces when you use the SQL/XML publishing
functions in DB2 for z/OS or DB2 for Linux, UNIX, and Windows. Then we describe how to create namespaces when you use direct element and attribute constructors in XQuery in DB2 for
Linux, UNIX, and Windows.
15.5.1
SQL/XML Publishing Functions and Namespaces
The SQL/XML function XMLNAMESPACES can be an argument to the XMLELEMENT and XMLFOREST functions and allows you to construct one or multiple namespace declarations for the
constructed documents. These namespace declarations are visible in any nested XML construction so that you do not need to construct the same namespace in every nested publishing function.
Note that the XMLNAMESPACES function itself does not declare a namespace. It constructs namespace declarations, which in turn declare namespaces in the generated documents.
The query in Figure 15.35 is an example that is slightly extended from the examples shown in
section 10.1.1, Constructing XML Elements from Relational Data. It contains the XMLNAMESPACES function to construct a default namespace declaration for the entire generated document.
The XMLNAMESPACES function is an argument of the XMLELEMENT function that constructs the
root element PRODUCT. Therefore, the default namespace applies to all XML elements in the constructed document. If present, the XMLNAMESPACES function has to be the second argument of
the XMLELEMENT function; that is, it appears after the element name but before any XMLATTRIBUTES function.
15.5
Constructing XML Data with Namespaces
461
SELECT XMLELEMENT(NAME "PRODUCT",
XMLNAMESPACES(DEFAULT 'http://myproduct.net'),
XMLATTRIBUTES(pid),
XMLELEMENT(NAME "PRICE", price),
XMLELEMENT(NAME "PROMOTION",
XMLATTRIBUTES(promoprice),
XMLFOREST(promostart, promoend) ) )
FROM product
WHERE pid = '100-100-01';
<PRODUCT xmlns="http://myproduct.net" PID="100-100-01">
<PRICE>9.99</PRICE>
<PROMOTION PROMOPRICE="7.25">
<PROMOSTART>2004-11-19</PROMOSTART>
<PROMOEND>2004-12-19</PROMOEND>
</PROMOTION>
</PRODUCT>
1 record(s) selected.
Figure 15.35
Constructing default namespace declaration
For another example, suppose that the constructed PROMOTION element and all its child elements
have to be in the separate namespace http://mypromo.net. This can be achieved in several
ways. One approach is to use a second XMLNAMESPACES function as an argument to the XMLELEMENT function that constructs the PROMOTION element. This XMLNAMESPACES function constructs a new default namespace that overrides the top-level default namespace (see Figure
15.36).
SELECT XMLELEMENT(NAME "PRODUCT",
XMLNAMESPACES(DEFAULT 'http://myproduct.net'),
XMLATTRIBUTES(pid),
XMLELEMENT(NAME "PRICE", price),
XMLELEMENT(NAME "PROMOTION",
XMLNAMESPACES(DEFAULT 'http://mypromo.net'),
XMLATTRIBUTES(promoprice),
XMLFOREST(promostart, promoend) ) )
FROM product
WHERE pid = '100-100-01';
<PRODUCT xmlns="http://myproduct.net" PID="100-100-01">
<PRICE>9.99</PRICE>
<PROMOTION xmlns="http://mypromo.net" PROMOPRICE="7.25">
<PROMOSTART>2004-11-19</PROMOSTART>
<PROMOEND>2004-12-19</PROMOEND>
</PROMOTION>
</PRODUCT>
Figure 15.36
Constructing multiple default namespace declarations
462
Chapter 15
Managing XML Data with Namespaces
Another option for producing a different namespace for part of the document is to construct
multiple namespace declarations in a single XMLNAMESPACES function at the top of the document. The query in Figure 15.37 constructs a default namespace declaration for the URI
http://myproduct.net as well as a namespace prefix declaration for the URI http://
mypromo.net with the prefix promo. In the nested XMLELEMENT and XMLFOREST functions the
prefix promo is explicitly added to the generated element names to assign certain elements to that
namespace. All other elements belong to the default namespace.
SELECT XMLELEMENT(NAME "PRODUCT",
XMLNAMESPACES(DEFAULT 'http://myproduct.net',
'http://mypromo.net' AS "promo" ),
XMLATTRIBUTES(pid),
XMLELEMENT(NAME "PRICE", price),
XMLELEMENT(NAME "promo:PROMOTION",
XMLATTRIBUTES(promoprice),
XMLFOREST(promostart AS "promo:PROMOSTART",
promoend AS "promo:PROMOEND") ) )
FROM product
WHERE pid = '100-100-01';
<PRODUCT xmlns="http://myproduct.net"
xmlns:promo="http://mypromo.net" PID="100-100-01">
<PRICE>9.99</PRICE>
<promo:PROMOTION PROMOPRICE="7.25">
<promo:PROMOSTART>2004-11-19</promo:PROMOSTART>
<promo:PROMOEND>2004-12-19</promo:PROMOEND>
</promo:PROMOTION>
</PRODUCT>
Figure 15.37
15.5.2
Constructing multiple namespace declarations
XQuery Constructors and Namespaces
The direct element and attribute constructors of the XQuery language were introduced in section
8.4, Constructing XML Data, and further elaborated on in section 10.2, Using XQuery Constructors with Relational Input. Direct element and attribute constructors allow you to simply type the
tags of the XML documents the way you want them to be constructed and nested. In the same
manner you can type namespace declarations into the start tags of element constructors the way
you want them to appear in the document. This is shown by the three queries in Figure 15.38,
which construct the same XML documents as the queries in Figure 15.35, Figure 15.36, and Figure 15.37 in the previous section, respectively.
Remember that element and attribute values can be obtained from XML or relational columns
and are specified by expressions in curly brackets. A simple and common type of expression is a
relational column name used as an uppercase variable that starts with a $ sign, such as $PID.
15.6
Updating XML Data with Namespaces
463
SELECT XMLQUERY('
<PRODUCT xmlns="http://myproduct.net" PID="{$PID}">
<PRICE>{$PRICE}</PRICE>
<PROMOTION PROMOPRICE="{$PROMOPRICE}">
<PROMOSTART>{$PROMOSTART}</PROMOSTART>
<PROMOEND>{$PROMOEND}</PROMOEND>
</PROMOTION>
</PRODUCT>')
FROM product
WHERE pid = '100-100-01';
SELECT XMLQUERY('
<PRODUCT xmlns="http://myproduct.net" PID="{$PID}">
<PRICE>{$PRICE}</PRICE>
<PROMOTION xmlns="http://mypromo.net"
PROMOPRICE="{$PROMOPRICE}">
<PROMOSTART>{$PROMOSTART}</PROMOSTART>
<PROMOEND>{$PROMOEND}</PROMOEND>
</PROMOTION>
</PRODUCT>')
FROM product
WHERE pid = '100-100-01';
SELECT XMLQUERY('
<PRODUCT xmlns="http://myproduct.net"
xmlns:promo="http://mypromo.net" PID="{$PID}">
<PRICE>{$PRICE}</PRICE>
<promo:PROMOTION PROMOPRICE="{$PROMOPRICE}">
<promo:PROMOSTART>{$PROMOSTART}</promo:PROMOSTART>
<promo:PROMOEND>{$PROMOEND}</promo:PROMOEND>
</promo:PROMOTION>
</PRODUCT>')
FROM product
WHERE pid = '100-100-01';
Figure 15.38
15.6
Three ways of constructing namespace in XQuery
UPDATING XML DATA WITH NAMESPACES
In this section we discuss the handling of namespaces when you update XML documents with
XQuery update expressions in DB2 for Linux, UNIX, and Windows. This section assumes that
you are familiar with XML updates, which were discussed in Chapter 12, Updating and Transforming XML Documents.
When you update XML data that contains namespaces, you must specify namespace declarations
in the XQuery Update expressions. Otherwise the elements or attributes that you want to update
are not found, which typically causes UPDATE statements to fail. As we explained in Chapter 12,
replacing a node, replacing the value of a node, renaming a node, and inserting a node fails if the
464
Chapter 15
Managing XML Data with Namespaces
target path in the XQuery Update expression does not exist in the document that you try to
update. Only the delete operation behaves differently. If you try to delete an element or attribute
that does not exist in the document, the UPDATE statement succeeds and the document remains
unchanged.
Let’s look at some examples based on the sample document in Figure 15.17.
15.6.1
Updating Values in Documents with Namespaces
The document in Figure 15.17 contains a default namespace, which applies to all elements. The
UPDATE statement in Figure 15.39 does not declare an appropriate namespace. Hence, the target
path $new/customerinfo/phone[@type = "home"] produces an empty sequence and the
statement fails.
UPDATE customer2
SET info = XMLQUERY('
copy $new := $INFO
modify do replace
value of $new/customerinfo/phone[@type = "work"]
with "123-456-7890"
return $new')
WHERE cid = 1000 #
SQL16085N The target node of an XQuery "replace value of"
expression is not valid. Error QName=err:XUTY0008.
Figure 15.39
Update expression without namespace declaration
There are three ways to avoid this error, as shown in Figure 15.40. The first UPDATE statement in
Figure 15.40 declares an appropriate default element namespace that applies to all elements in
the update expression. The second statement defines and uses the namespace prefix po to achieve
the same effect. Note that the prefix is not used for the attribute type, which does not belong to
any namespace in the document that is being updated. The third statement in Figure 15.40 uses
namespace wildcards to match elements in any namespace, including the empty namespace.
UPDATE customer2
SET info = XMLQUERY('
declare default element namespace "http://posample.org";
copy $new := $INFO
modify do replace
value of $new/customerinfo/phone[@type = "work"]
with "123-456-7890"
return $new')
WHERE cid = 1000 #
Figure 15.40
Update expression with proper namespace handling
15.6
Updating XML Data with Namespaces
465
UPDATE customer2
SET info = XMLQUERY('
declare namespace po="http://posample.org";
copy $new := $INFO
modify do replace
value of $new/po:customerinfo/po:phone[@type = "work"]
with "123-456-7890"
return $new')
WHERE cid = 1000 #
UPDATE customer2
SET info = XMLQUERY('
copy $new := $INFO
modify do replace
value of $new/*:customerinfo/*:phone[@type = "work"]
with "123-456-7890"
return $new')
WHERE cid = 1000 #
Figure 15.40
15.6.2
Update expression with proper namespace handling (Continued)
Renaming Nodes in Documents with Namespace Prefixes
Additional attention is required when you rename elements or attributes that belong to a namespace. Renaming elements in a document with a default namespace behaves differently from
renaming elements in a document with namespace prefixes.
First consider a document with namespace prefixes, such as the original document in Figure 15.41,
and suppose you want to rename the element addr as address. The UPDATE statement declares
the correct namespace and uses the namespace prefix po in the target path. However, the new name
“address” in the rename expression is a local name without a namespace. As a result, the original element with the local name addr and the namespace URI http://posample.org is
renamed to the local name address and an empty namespace.
If the intention is to change the local name of an element but not to change its namespace, then
the new name provided in the rename expression must be a full name consisting of the correct
namespace and the new local name. For example, the UPDATE statement in Figure 15.42 adds the
declared namespace prefix po to the new element name. Due to this prefix, the new name
“po:address” contains the same namespace as the original element addr and all other elements in the document. The updated document now has two different prefixes for the same namespace URI. This is not a problem because what matters are the identical URIs, irrespective of the
prefixes, and that all elements belong to the same namespace as intended.
466
Chapter 15
Managing XML Data with Namespaces
UPDATE customer2
SET info = XMLQUERY(
'declare namespace po="http://posample.org";
copy $new := $INFO
modify do rename $new/po:customerinfo/po:addr as "address"
return $new')
WHERE cid = 1000 #
Original document
Updated document
<c:customerinfo xmlns:c="http://posample.org" <c:customerinfo xmlns:c="http://posample.org"
Cid="1000">
Cid="1000">
<c:name>Kathy Smith</c:name>
<c:name>Kathy Smith</c:name>
<c:addr country="Canada">
<address country="Canada">
<c:street>5 Rosewood</c:street>
<c:street>5 Rosewood</c:street>
c:city>Toronto</c:city>
<c:city>Toronto</c:city>
<<c:prov-state>Ontario</c:prov-state>
<c:prov-state>Ontario</c:prov-state>
<c:pcode-zip>M6W 1E6</c:pcode-zip>
<c:pcode-zip>M6W 1E6</c:pcode-zip>
</address>
</c:addr>
</c:customerinfo>
</c:customerinfo>
Figure 15.41
Renaming an element in a document with namespace prefixes
UPDATE customer2
SET info = XMLQUERY(
'declare namespace po="http://posample.org";
copy $new := $INFO
modify do rename $new/po:customerinfo/po:addr as "po:address"
return $new')
WHERE cid = 1000 #
Original document
Updated document
<c:customerinfo xmlns:c="http://posample.org" <c:customerinfo xmlns:c="http://posample.org"
Cid="1000">
Cid="1000">
<c:name>Kathy Smith</c:name>
<c:name>Kathy Smith</c:name>
<po:address xmlns:po="http://posample.org"
<c:addr country="Canada">
country="Canada">
<c:street>5 Rosewood</c:street>
<c:street>5 Rosewood</c:street>
<c:city>Toronto</c:city>
<c:city>Toronto</c:city>
<c:prov-state>Ontario</c:prov-state>
<c:pcode-zip>M6W 1E6</c:pcode-zip>
<c:prov-state>Ontario</c:prov-state>
<c:pcode-zip>M6W 1E6</c:pcode-zip>
</c:addr>
</c:customerinfo>
</po:address>
</c:customerinfo>
Figure 15.42
Using a namespace prefix in the new element name
Introducing the second namespace prefix in the updated document can be avoided only if the
UPDATE statement declares the same namespace prefix as the original document (see Figure
15.43). Another solution is to declare the correct default namespace in the UPDATE statement.
15.6
Updating XML Data with Namespaces
467
UPDATE customer2
SET info = XMLQUERY(
'declare namespace c="http://posample.org";
copy $new := $INFO
modify do rename $new/c: customerinfo/c: addr as "c:address "
return $new')
WHERE cid = 1000 #
Original document
Updated document
<c:customerinfo xmlns:c="http://posample.org" <c:customerinfo xmlns:c="http://posample.org"
Cid="1000">
Cid="1000">
<c:name>Kathy Smith</c:name>
<c:name>Kathy Smith</c:name>
<c:address country="Canada">
<c:addr country="Canada">
<c:street>5 Rosewood</c:street>
<c:street>5 Rosewood</c:street>
<c:city>Toronto</c:city>
<c:city>Toronto</c:city>
<c:prov-state>Ontario</c:prov-state>
<c:prov-state>Ontario</c:prov-state>
<c:pcode-zip>M6W 1E6</c:pcode-zip>
<c:pcode-zip>M6W 1E6</c:pcode-zip>
</c:address>
</c:addr>
</c:customerinfo>
</c:customerinfo>
Figure 15.43
15.6.3
Same namespace prefix in the update statement and document
Renaming Nodes in Documents with Default Namespaces
Now let’s look at renaming elements in a document with a default namespace, such as the one in
Figure 15.44. Remember that a default namespace has no prefix, which is the same as an empty
prefix.
<customerinfo xmlns="http://posample.org" Cid="1000">
<name>Kathy Smith</name>
<addr country="Canada">
<street>5 Rosewood</street>
<city>Toronto</city>
<prov-state>Ontario</prov-state>
<pcode-zip>M6W 1E6</pcode-zip>
</addr>
<phone type="work">416-555-1358</phone>
</customerinfo>
Figure 15.44
Sample document with a default namespace
Let’s again rename the element addr as address. The UPDATE statement in Figure 15.45
declares the correct namespace and uses the namespace prefix po in the target path. The new
name “address” in the rename expression is a local name without a namespace and without a
prefix; that is, both namespace and prefix of the new name are empty. This causes a conflict
because in the target document the empty prefix is already associated with the default namespace
http://posample.org and cannot also be associated with the empty namespace at the same
time. Therefore the update fails and error SQL16088N is returned.
468
Chapter 15
Managing XML Data with Namespaces
UPDATE customer2
SET info = XMLQUERY(
'declare namespace po="http://posample.org";
copy $new := $INFO
modify do rename $new/po:customerinfo/po:addr as "address"
return $new')
WHERE cid = 1000 #
SQL16088N A "rename" expression has a binding of a namespace
prefix "" to namespace URI "", introduced to an element named
"addr", that conflicts with an existing namespace binding of the
same prefix to a different URI in the in-scope namespaces
of that element node. Error QName=err:XUDY0023. SQLSTATE=10708
Figure 15.45
Renaming an element can cause namespace conflicts.
To avoid the error in Figure 15.45, the new element name in the rename expression must be in
the same namespace as the default namespace of the target document. There are two ways to
achieve this:
• Add the declared namespace prefix po to the new element name, so that it matches the
namespace in the document:
rename $new/po:customerinfo/po:addr as "po:address"
This rename expression clearly ensures that po:addr and po:address are in the same
namespace and only the local name of the element is changed, without interfering with
its namespace.
• In the UPDATE statement, declare the namespace http://posample.org as a default
namespace instead of a namespace with prefix. The new name “address” then assumes
this default namespace and matches the namespace in the target document.
15.6.4
Inserting and Replacing Nodes in Documents with Namespaces
When you insert elements or attributes into a document, or if you replace existing nodes with new
nodes, similar namespace considerations apply as for renaming elements. For example, if you
want to insert the new element <email>kathy@ibm.com</email> into a document, be aware
of the namespace for this new element. The UPDATE statement in Figure 15.46 declares a namespace with a prefix but does not use the prefix for the new element. Therefore the new email element does not belong to any namespace, which is equivalent to the empty namespace. In the
updated document the element therefore contains the empty namespace declaration xmlns="".
This undeclares the default namespace of the document and ensures that the email element does
not belong to the default namespace. Chances are that this is not what you wanted.
15.7
Summary
469
UPDATE customer2
SET info = XMLQUERY(
'declare namespace po="http://posample.org";
copy $new := $INFO
modify do insert <email>kathy@ibm.com</email>
as last into $new/po:customerinfo
return $new')
WHERE cid = 1000 #
Original document
<customerinfo xmlns="http://posample.org"
Cid="1000">
<name>Kathy Smith</name>
<addr country="Canada">
<street>5 Rosewood</street>
<city>Toronto</city>
<prov-state>Ontario</prov-state>
<pcode-zip>M6W 1E6</pcode-zip>
</addr>
</customerinfo>
Figure 15.46
Updated document
<customerinfo xmlns="http://posample.org"
Cid="1000">
<name>Kathy Smith</name>
<addr country="Canada">
<street>5 Rosewood</street>
<city>Toronto</city>
<prov-state>Ontario</prov-state>
<pcode-zip>M6W 1E6</pcode-zip>
<email xmlns="">kathy@ibm.com</email>
</addr>
</customerinfo>
Inserting an element without a namespace
In most cases you probably want the new email element to belong to the default namespace of
the target document. You achieve this in one of two ways:
• Add the declared namespace prefix po to the new element name, so that it matches the
namespace in the document:
do insert <po:email>kathy@ibm.com</po:email>
• In the UPDATE statement, declare the namespace http://posample.org as a default
namespace instead of a namespace with prefix. The new email element then assumes
this default namespace and matches the namespace in the target document.
Other insert, replace, and rename scenarios with namespaces are variations of the cases that
we have discussed. We encourage you to work with the DB2 sample database hands-on and to
test out these and other update scenarios. XML namespaces are often perceived as a difficult area
in the XML world, and some hands-on experiments are the best way to become comfortable with
them.
15.7
SUMMARY
XML namespaces are a standard that allows the designer of XML documents or XML Schemas
to define unique element and attribute names and to group them together into a well-defined
vocabulary of XML tags. Namespaces greatly help to avoid conflicts between tag names in XML
documents that come from multiple sources. The full name of an XML element or attribute
always consists of a namespace and a local name. If an XML element does not belong to a namespace then the namespace part of its name is empty.
470
Chapter 15
Managing XML Data with Namespaces
When you use XPath expressions to query, index, or update XML documents that contain namespaces, then these XPath expressions must contain namespace declarations. Otherwise they do
not identify any nodes in the XML documents. You can declare a namespace with a prefix and use
that prefix for every element name that belongs to that namespace. Alternatively, you can declare
a default namespace that applies to all elements in the XPath expression without the use of prefixes. Remember that a default namespace never applies to attributes. You can also use namespace
wildcards (*:) to match elements regardless of their namespace. Namespace wildcards can be
very convenient to avoid namespace declarations altogether. However, if you have a mix of documents from multiple namespaces and you want to query only documents in one specific namespace, then you must declare that specific namespace and cannot use wildcards.
Namespaces are closely related to XML Schemas. An XML Schema can define a target namespace to declare that all elements (and optionally also all attributes) defined in the schema belong
to this specific namespace. This and other aspects of XML Schemas are explained in the next
chapter.
C
H A P T E R
16
Managing XML
Schemas
ML Schemas are commonly used to define what XML documents are allowed to look like
in terms of their structure, element and attribute names, data types, and other document
characteristics. Due to their rich capabilities for defining XML document constraints, XML
Schemas are the preferred instrument for enforcing XML data quality. The XML Schema language is a widely adopted standard and supported in many tools and middleware software products. The use of XML Schemas in DB2 is optional and we will explain when and how to use
them.
X
Our discussion of XML Schemas is split into two chapters. This chapter introduces XML
Schemas and focuses on registering and managing them in DB2. Chapter 17, Validating XML
Documents against XML Schemas, then elaborates further on the use of XML Schemas to validate XML documents in operations such as insert, load, or update.
This chapter is organized along the following topics:
• Introduction to XML Schemas and considerations for their usage (section 16.1)
• A detailed look at two XML Schemas, a simple one (section 16.2) and a more complex
one that consists of multiple schema documents (section 16.3)
• Registering and removing XML Schemas in DB2’s XML Schema Repository (sections
16.4 and 16.5)
• XML Schema evolution (section 16.6)
• Usage privileges for XML Schemas in DB2 (section 16.7)
• Document Type Definitions (DTDs) and external entities (section 16.8)
471
472
Chapter 16
Managing XML Schemas
• Understanding and querying the tables in the XML Schema Repository (section 16.9)
• Additional considerations for managing XML Schemas in DB2 for z/OS (section 16.10)
Although we provide an introduction to XML Schemas in this chapter, a complete coverage of all
aspects and facets of XML Schemas is beyond the scope of this book. Instead we focus on DB2’s
capabilities for handling XML Schemas. References to detailed resources about XML Schemas
in general are provided in Appendix C, Further Reading.
16.1
INTRODUCTION TO XML SCHEMAS AND THEIR USAGE
Roughly speaking, an XML Schema is a specific type of XML document that defines the characteristics and structure of other XML documents. An XML Schema can be used to define some or
all of the following:
• The allowed element and attribute names as well as the structure in which these elements and attributes can be nested.
• The namespace(s) that all the defined elements and/or attributes belong to.
• Mandatory or optional occurrences of elements and attributes. For example, you can
define that each customerinfo document has to have a name element, and that phone
elements are optional.
• The minimum and/or maximum number of occurrences of an element in a document.
For example, you can define that a customer cannot have more than one name, but that
multiple phone numbers are allowed.
• The allowed data types for some or all of the elements and attributes in a document. For
example, you can define the customer name to be a string of at most 30 characters, and
the customer ID to be a positive integer.
• The allowed pattern for certain values. For example, you can define that the value of the
phone element has to be of the form xxx-xxx-xxxx.
• Derived or complex data types for your elements and attributes, as well as default values. An example of a derived data type is an integer type restricted to the range of values
from 1 to 100.
• The exclusive choice between two or more elements. For example, you can define that a
customer can have a secretary element or an assistant element, but not both.
• That certain branches of the document can contain any elements, even if they are not
defined in the XML Schema. This flexibility allows documents to be extensible and still
compliant with the XML Schema.
The preceding list is not exhaustive, as there are many more aspects of a document that can be
defined or constrained in an XML Schema. Three very important concepts of XML Schemas are
16.1
Introduction to XML Schemas and Their Usage
473
• The degree to which an XML Schema defines the characteristics of XML documents
can be very loose to allow for a lot of flexibility, or very strict to tightly control the XML
data in every aspect, or anything in between.
• The use of XML Schemas is optional. You can use XML Schemas but you don’t have to.
There is no penalty in terms of DB2 performance or functionality if you don’t use an
XML Schema.
• XML Schemas define constraints that are applied to one XML document at a time.
Today there is no standardized notation or method that defines constraints across multiple XML documents.
16.1.1
Valid Versus Well-Formed XML Documents
If a document complies with a given XML Schema, then this document is valid with respect to
that particular schema. If you have two different XML Schemas, a given document might be valid
with respect to one schema but not the other. The process of determining whether an XML document is valid for a given XML Schema is called validation or schema validation. Validation is an
optional part of XML parsing. An XML parser can parse an XML document with or without
comparing it to an XML Schema. Parsing with schema validation consumes more CPU cycles
than without. Hence, validation can have a performance impact, especially in CPU-bound environments.
Be aware of the difference between a valid and a well-formed XML document. A well-formed
document does not have to comply with any particular XML Schema. A document is well-formed
if the XML syntax of the document is correct. For example, all start tags must have a corresponding end tag, elements must be properly nested, attribute values must be in quotes, no reserved
characters are used, and so on. A document is well-formed if it can be parsed by an XML parser
without errors. If a document is not well-formed then it’s not considered an XML document.
XML documents that are not well-formed cannot be processed and need to be corrected or discarded. If you attempt to insert a non–well-formed document into an XML column in DB2, the
document will be rejected with an error message that indicates why the document isn’t wellformed. The complete list of formal requirements for a document to be well-formed is given at
http://www.w3.org/TR/xml.
A document is valid if it is well-formed and it complies with a particular XML Schema. Hence,
validity is stronger than well-formedness. Every valid document is also a well-formed document.
A document cannot be valid if it is not well-formed.
XML Schemas are often used to define agreed-upon ways to exchange information between
organizations or between departments and applications within a single company. You can often
view an XML Schema as a contract that says “if you give me data in this specific format, then I
know how to deal with it.”
474
16.1.2
Chapter 16
Managing XML Schemas
To Validate or Not to Validate,That Is the Question!
Whenever you insert, load, or update an XML document into a table you can choose to validate
the document against an XML Schema. You can also choose to validate XML documents in
queries. The decision whether to perform validation depends on various factors.
You may want to validate XML documents in DB2 if you receive the documents from an unreliable source and you need to ensure that the data that enters your database adheres to a specific
schema. Validation is also a good way to ensure that XML documents in DB2 are still valid after
they have been updated by an application program. If your applications expect documents that
comply with a specific schema, then validation is important to avoid application errors.
You might prefer to avoid schema validation in DB2 if you receive XML documents from a
trusted source. For example, if XML documents are inserted and updated by internal applications
that have been well-tested, validation can often be avoided to reduce CPU consumption. Another
common scenario is that XML documents are validated in other layers of your infrastructure,
such as the application server, the enterprise service bus, or a message broker. If that already
guarantees documents to be valid, then additional validation in DB2 might not be required.
16.1.3
Custom Versus Industry Standard XML Schemas
Where do XML Schemas come from? There are multiple answers to this question. You can certainly write your own XML Schema to constrain XML data according to the requirements of
your application. In this context you might wonder whether the XML Schema should be defined
by the DBAs or by the application designer. Clearly, the XML Schema needs to be defined to
meet the application requirements and should be designed primarily by people with subjectmatter knowledge of the application. An XML Schema should not be defined in an attempt to
optimize how documents are stored and processed in DB2. DB2 pureXML is designed to handle
XML data for any XML Schema. Modeling business data with an XML Schema happens at the
logical level and needs to focus on the business requirements of your application, not on how
DB2 processes XML. Applications typically process business objects such as orders, tax returns,
medical records, newspaper articles, insurance claims, patents, or others. Most applications work
best if each individual business object is represented by a separate XML document, which often
leads to a large number of small XML documents. Just like DB2 can handle relational tables with
large numbers of rows efficiently, DB2 pureXML is well-suited to manage large collections of
XML documents.
Designing XML Schemas is best done with design tools such as IBM Data Studio, IBM Rational
Application Developer, or Altova XMLSPY, which are described in Chapter 21, Developing XML
Applications with DB2. Such tools also allow you to generate an XML Schema based on existing
XML documents.
16.1
Introduction to XML Schemas and Their Usage
475
In many cases you won’t have the luxury to define your own XML format with an XML Schema.
Other organizations or business partners might already have established a specific XML format
that you are required to consume. Today, every major vertical industry has defined one or multiple XML Schemas to standardize the data and data exchange formats in that particular industry.
Some of them are listed in Table 16.1.
Table 16.1
Industry Standard XML Schemas
Name
Industry
Purpose/Comment
FpML
Financial
Derivatives trading
FIXML
Financial
Securities
UNIFI (ISO 20022) Financial
SEPA (Single Euro Payments Area)
SwiftXML
Financial
Financial messaging
MISMO
Financial
Loans and mortgages
Origo
Financial
Life insurance and pensions
ACORD
Insurance
Document standard in the insurance sector
HL7
Health Care
Document standard for medical and clinical data
CDISC
Health Care
Clinical laboratory data
ARTS
Retail
General retail
STAR
Retail
Automotive retail
NewsML
Media/Publishing
Creation, transfer, delivery of news
DITA
Media/Publishing
Darwin Information Typing Architecture
DOCBOOK
Media/Publishing
Document authoring
SVG
Media/Publishing
Scalable Vector Graphics
GJXDM
Government
Global Justice XML Data Model
TAX1120
Government
IRS e-File Form 1120, for corporate tax
NIEM
Government
National Information Exchange Model
OTA
Travel
OpenTravel Alliance
PIDX
Energy
Petroleum Industry Data Exchange
OAGIS
Cross-Industry
Business object documents (BODs)
476
Chapter 16
Managing XML Schemas
IBM has developed packages with sample scripts for a variety of these industry standards XML
Schemas. These packages give you a jumpstart for registering these XML Schemas and validating sample documents. They are available at http://www.alphaworks.ibm.com/tech/purexml/
download.
16.2
ANATOMY OF AN XML SCHEMA
An XML Schema can consist of one or multiple schema documents, each of which is an XML
document with special characteristics. Let’s first look at the simple XML Schema
customer.xsd in Figure 16.1, which consists of a single schema document. The XML instance
document in Figure 16.2 is valid with respect to this XML Schema.
The first four lines of the XML Schema in Figure 16.1 contain the root element xs:schema and
several namespace declarations. The declaration xmlns:xs="http://www.w3.org/
2001/XMLSchema" binds the namespace prefix xs to the XML Schema URI. All elements in the
schema, such as schema, complexType, element, attribute, and so on, are prefixed with
xs: to indicate that they have a specific meaning, as defined in the XML Schema specification of
the W3C (see link in Appendix C, Further Reading). This use of the XML Schema
namespace and the use of the elements that belong to this namespace make the XML document in
Figure 16.1 an XML Schema rather than a regular XML instance document. In fact, the namespace URI http://www.w3.org/2001/XMLSchema refers to the schema for XML Schemas,
which defines what XML Schemas can look like.
The target namespace defined in the second line of Figure 16.1 indicates that all the elements
declared in this XML Schema belong to a specific namespace; that is, the namespace with the
URI http://pureXMLcookbook.org. XML documents that want to be compliant with this
schema have to declare this namespace (see Figure 16.2 as an example).
The fourth line of the schema, elementFormDefault="qualified", mandates that not only
globally but also locally declared elements need to be qualified with a namespace when they
appear in an instance document. You’ll see in a minute what that means.
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://pureXMLcookbook.org"
xmlns="http://pureXMLcookbook.org"
elementFormDefault="qualified" >
<xs:complexType name="phoneType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="type" type="xs:string" use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
Figure 16.1
The XML Schema customer.xsd
16.2
Anatomy of an XML Schema
477
<xs:complexType name="addrType">
<xs:sequence>
<xs:element name="street" type="xs:string"/>
<xs:element name="city" type="xs:string"/>
<xs:element name="prov-state" type="xs:string"/>
<xs:element name="pcode-zip" type="xs:string"/>
</xs:sequence>
<xs:attribute name="country" type="xs:string"/>
</xs:complexType>
<xs:complexType name="assisType">
<xs:sequence>
<xs:element name="name" type="xs:string"/>
<xs:element name="phone" type="phoneType"
minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
</xs:complexType>
<xs:element name="customerinfo">
<xs:complexType>
<xs:sequence>
<xs:element name="name" type="xs:string"/>
<xs:element name="addr" type="addrType"/>
<xs:element name="phone" type="phoneType"
minOccurs="0" maxOccurs="unbounded"/>
<xs:element name="assistant" type="assisType"
minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="Cid" type="xs:integer" />
</xs:complexType>
</xs:element>
</xs:schema>
Figure 16.1
The XML Schema customer.xsd (Continued)
The body of the XML Schema in Figure 16.1 consists of four main blocks. The first three of them
start with xs:complexType because they define complex data types that are used later in the
schema. The first of these complex types is called phoneType. The declaration of phoneType
says that an element of this type will have simple content (no child elements). In this example,
phone elements have a value of type xs:string and an attribute called type whose data type is
also xs:string. This attribute is not optional. It’s required because it is declared with
use="required".
The second complex type defines the addrType. This type of declaration says that an element of
type addrType has to contain a sequence of exactly four child XML elements. The child elements must have the names street, city, prov-state, and pcode-zip. All of them are of
type xs:string, which means they can contain any text value. These four elements are declared
as an xs:sequence, which means they have to occur in the specified order. The addrType further defines that an element of this type can have an optional attribute called country of type
xs:string.
478
Chapter 16
Managing XML Schemas
The elements street, city, prov-state, and pcode-zip are considered local elements,
because their definition is local to the complex type addrType and not visible elsewhere.
Although the addrType is globally declared, the elements inside it are locally declared. The
declaration elementFormDefault="qualified" at the top of the schema requires these elements to be qualified by the target namespace when they appear in an instance document. This is
true in Figure 16.2, which uses a default namespace that qualifies all elements in the document.
The third complex type is the assisType. It declares that an element of type assisType
• Must have a child element called name of type xs:string.
• Can have zero or more child elements called phone that must be of type phoneType,
which was defined earlier. The schema attribute minOccurs="0" indicates that the
phone element is optional.
If an element is declared without explicit minOccurs or maxOccurs indicators then the default
value is 1, which means the element has to occur exactly once.
The fourth and last block in this schema defines that a document that wants to be compliant with
this schema has to have a root element customerinfo. This customerinfo element is globally
declared in the schema. It must have at least two child elements. They have to be name of type
xs:string, and addr of type addrType, which were defined earlier. The customerinfo element can, optionally, also contain any number of phone and assistant elements, which have
to be of type phoneType and assisType respectively. If they exist, all assistant elements
have to appear after any phone elements, as mandated by the XML Schema construct
xs:sequence. Finally, the customerinfo element can also contain the optional attribute Cid
of type xs:integer.
Given the XML Schema shown in Figure 16.1, a valid XML document is shown in Figure 16.2.
<customerinfo xmlns="http://pureXMLcookbook.org" Cid="1004">
<name>Matt Foreman</name>
<addr country="Canada">
<street>1596 Baseline</street>
<city>Toronto</city>
<prov-state>Ontario</prov-state>
<pcode-zip>M3Z 5H9</pcode-zip>
</addr>
<phone type="work">905-555-4789</phone>
<phone type="home">416-555-3376</phone>
<assistant>
<name>Gopher Runner</name>
<phone type="home">416-555-3426</phone>
</assistant>
</customerinfo>
Figure 16.2
A valid document for the XML Schema customer.xsd
16.3
An XML Schema with Include and Import
16.3
479
AN XML SCHEMA WITH INCLUDE AND IMPORT
In many real-world applications, XML data and hence XML Schemas are a lot more complex
than the one shown in Figure 16.1. To make the design and handling of complex XML Schemas
easier, it is often desirable to divide their content among several schema documents. This
approach is similar to application programs whose source code is divided across a number of distinct files, or modules, which can be included into other files as needed to build more complex
applications. In the same manner, an XML Schema can consist of multiple schema documents.
As an example, let’s take the schema in Figure 16.1 and move the definition of phone elements
and addresses into separate schema documents, phone.xsd and addr.xsd.
Figures 16.3 shows the schema document phone.xsd, which only declares the complex type
phoneType. This schema document declares a global type but does not define any global elements and therefore cannot be used by itself for any validation. It can only serve as a module that
is used in other schemas.
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:complexType name="phoneType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="type" type="xs:string" use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:schema>
Figure 16.3
Content of the schema document phone.xsd
The schema document addr.xsd in Figure 16.4 is conceptually different from phone.xsd. One
difference is that it declares a global element (addr) and not just a complex type. Therefore, this
schema document can be used by itself to validate XML documents. For example, the document
in Figure 16.5 is a valid instance document for addr.xsd. Another notable property of the
schema document in Figure 16.4 is that it defines its own target namespace. You will see shortly
that this makes a difference when this schema document is used as a module in a larger schema.
Also note that the XML document in Figure 16.5 declares the default namespace http://
pureXMLcookbook.org/addr for all its elements. This namespace is the target namespace
defined in addr.xsd and required for the document to be valid for this schema. Remember that
attributes never belong to a default namespace.
480
Chapter 16
Managing XML Schemas
<xs:schema targetNamespace="http://pureXMLcookbook.org/addr"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns="http://pureXMLcookbook.org/addr"
elementFormDefault="qualified">
<xs:element name="addr">
<xs:complexType>
<xs:sequence>
<xs:element name="street" type="xs:string"/>
<xs:element name="city" type="xs:string"/>
<xs:element name="prov-state" type="xs:string"/>
<xs:element name="pcode-zip" type="xs:string"/>
</xs:sequence>
<xs:attribute name="country" type="xs:string"/>
</xs:complexType>
</xs:element>
</xs:schema>
Figure 16.4
Content of the schema document addr.xsd
A valid document for the XML Schema in Figure 16.4 is shown in Figure 16.5.
<addr xmlns="http://pureXMLcookbook.org/addr" country="Canada">
<street>1 Young Street</street>
<city>Toronto</city>
<prov-state>Ontario</prov-state>
<pcode-zip>M5W-IE6</pcode-zip>
</addr>
Figure 16.5
A valid document for addr.xsd
You can now write a schema document that uses both phone.xsd and addr.xsd as building
blocks. Such a schema document is customer2.xsd in Figure 16.6. The line <xs:include
schemaLocation="phone.xsd"/>
includes the schema document phone.xsd. This
xs:include element makes all definitions and declarations in phone.xsd locally available in
customer2.xsd. Subsequently, the phoneType can be used as if it was defined locally.
All elements in the included schema document (phone.xsd) automatically take on the namespace of the including schema document (customer2.xsd). Therefore the include mechanism
can only be used to pull in a schema document that does not define a target namespace or whose
target namespace is the same as the target namespace in the including schema.
The xs:import element allows you to pull in a schema document that defines a target namespace that is different from the target namespace in the including schema. The import mechanism
enables schema components from different target namespaces to be used together, and hence
enables the validation of XML documents that combine structures from multiple namespaces. In
the XML Schema literature you will find further subtle differences between xs:include and
xs:import. For example, strictly speaking xs:include includes a schema document, but
xs:import imports a namespace.
16.3
An XML Schema with Include and Import
481
In Figure 16.6, customer2.xsd uses xs:import to make locally available the definition of the
addr element from the namespace http://pureXMLcookbook.org/addr. Since this is a new
namespace, customer2.xsd assigns the prefix address to it, so that objects from this namespace can be properly qualified. This prefix is used further down in the schema document where
the line <xs:element ref="address:addr"/> references the addr element that is globally
defined in addr.xsd.
We call the schema document customer2.xsd the primary schema document because it is at the
top of the hierarchy of the include and import dependencies among several schema documents.
Note that the included and imported schema documents themselves can also include or import
other schema documents. Include dependencies within any given namespace must not be circular.
Import relationships between namespaces are allowed to be circular.
<xs:schema targetNamespace="http://pureXMLcookbook.org"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns="http://pureXMLcookbook.org"
xmlns:address="http://pureXMLcookbook.org/addr"
elementFormDefault="qualified">
<xs:include schemaLocation="phone.xsd"/>
<xs:import namespace="http://pureXMLcookbook.org/addr"
schemaLocation="addr.xsd"/>
<xs:complexType name="assisType">
<xs:sequence>
<xs:element name="name" type="xs:string" minOccurs="0" />
<xs:element name="phone" type="phoneType"
minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
</xs:complexType>
<xs:element name="customerinfo">
<xs:complexType>
<xs:sequence>
<xs:element name="name" type="xs:string"/>
<xs:element ref="address:addr"/>
<xs:element name="phone" type="phoneType"
minOccurs="0" maxOccurs="unbounded"/>
<xs:element name="assistant" type="assisType"
minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="Cid" type="xs:integer" />
</xs:complexType>
</xs:element>
</xs:schema>
Figure 16.6
Schema document customer2.xsd refers to other schema documents.
The relationship between the schema documents customer2.xsd, phone.xsd, and addr.xsd
is illustrated in Figure 16.7.
482
Chapter 16
Managing XML Schemas
Customer2.xsd
phone.xsd
Figure 16.7
<xs:schema targetNamespa...
xmlns:xs=...
<xs:include phone.xsd …
<xs:import addr.xsd …
...
</xs:schema>
addr.xsd
Multiple XML Schema documents comprise one XML Schema
The XML document in Figure 16.8 is valid with respect to the XML Schema customer2.xsd.
The document declares http://pureXMLcookbook.org as the default element namespace.
Since the addr element comes from a different namespace, the document also declares the namespace http://pureXMLcookbook.org/addr and assigns it the prefix address. This prefix is
used for the addr element and all its children to override the default namespace. Since the
schema combines declarations from two different namespaces, the same must be reflected in the
instance document that is valid for this schema. The schema document phone.xsd did not define
its own namespace, and therefore the phone elements in the instance document belong to the
default namespace. This namespace is the target namespace of the schema document customer2.xsd, which includes phone.xsd.
<customerinfo xmlns="http://pureXMLcookbook.org" Cid="1004"
xmlns:address="http://pureXMLcookbook.org/addr">
<name>Matt Foreman</name>
<address:addr country="Canada">
<address:street>1596 Baseline</address:street>
<address:city>Toronto</address:city>
<address:prov-state>Ontario</address:prov-state>
<address:pcode-zip>M3Z 5H9</address:pcode-zip>
</address:addr>
<phone type="work">905-555-4789</phone>
<phone type="home">416-555-3376</phone>
<assistant>
<name>Gopher Runner</name>
<phone type="home">416-555-3426</phone>
</assistant>
</customerinfo>
Figure 16.8
A valid document for the XML Schema customer2.xsd
If you are designing your own XML Schema, you will find yourself confronted with many design
options; for example, when and how to use namespaces and how many, whether to declare global
or local elements, global or local types, how to keep schemas extensible, how to version XML
Schema documents, and other trade-offs. We chose not to cover these topics in this book, but
refer you to the XML Schema best practices at the following URL:
http://www.xfront.com/BestPracticesHomepage.html.
16.4
Registering XML Schemas
16.4
483
REGISTERING XML SCHEMAS
Before you can use XML Schemas in a DB2 database to validate XML documents, you need to
register them in the XML Schema Repository (XSR). The XSR consists of several tables in the
DB2 catalog. Registering an XML Schema means that the schema as well as meta information
about the schema are inserted into these catalog tables. Registering XML Schemas ensures fast
and reliable access to the schemas for document validation. During schema registration, each
XML Schema is parsed and stored in a binary representation in the DB2 catalog. When the
schema is later used for document validation, it does not have to be parsed again, which is a significant performance benefit. DB2 does not support document validation with XML Schemas that
are located in the file system or at some URL on the web—all XML Schemas must be registered
with DB2. Once an XML Schema is registered in the XSR, the schema is also called an XSR
Object. The XSR catalog tables and views in DB2 for z/OS and DB2 for Linux, UNIX, and Windows are described in detail in section 16.9.
Since an XML Schema can generally consist of multiple schema documents, the registration
process takes the following steps:
1. Register the primary schema document and assign a unique identifier for the XML
Schema.
2. Add additional schema documents that are included or imported. The same schema
identifier is used in this step to indicate that these additional schema documents belong
to the primary schema document that was registered in step 1. The additional schema
documents can be added in any order, independent from the import and include dependencies that exist among them.
3. Complete the schema registration. In this step DB2 verifies the correctness of the
schema and checks whether all schema documents that are referenced in xs:include
or xs:import declarations have been added.
If an XML Schema consists of just a single schema document, then these three steps can be collapsed into a single command.
An XML Schema is typically given two kinds of identifiers at schema registration time:
• A relational SQL identifier, for example db2admin.custxsd
• A schema location URI, which can be any arbitrary string of 1000 bytes or less, such as
myschema\customer.xsd or http://pureXMLcookbook.org/customer.xsd
The schema location URI does not have to reflect the actual location or filename of the XML
Schema. It is up to you to choose a schema location URI that provides a meaningful indication of
the identity and/or location of the XML Schema.
484
Chapter 16
Managing XML Schemas
In section 17.1, Document Validation Upon Insert, you will see that you can reference an XML
Schema in one of the following ways in order to use it for the validation of an XML document:
• By the relational SQL identifier of the XML Schema, which must be unique
• By the schema location URI provided when the schema was registered, if this URI is
unique in the XSR
• By the target namespace in the primary schema document, if this namespace is unique in
the XSR
• By the combination of target namespace and schema location URI, if this pair of values
is unique in the XSR
Referencing XML Schemas by their SQL identifiers is recommended in most cases, because
these identifiers are always unique and for most users they are an intuitive way of referring to
database objects. The use of namespaces and schema locations can be useful if you want to allow
XML documents to use schema location hints to dynamically select XML Schemas for validation
(see Chapter 17, Validating XML Documents against XML Schemas).
Depending on the complexity of your XML Schemas, you might need to increase the application
heap size (applheapsz) of your DB2 for Linux, UNIX, and Windows database. To register very
complex XML Schemas on 32-bit Windows systems, the DB2 agent stack size (agent_
stack_sz) might also need to be increased.
You can register and manage XML Schemas with commands in the DB2 Command Line Processor (CLP) or with equivalent stored procedures from an application. Both methods are available
in DB2 for z/OS and in DB2 for Linux, UNIX, and Windows. Note that DB2 for z/OS offers a
Command Line Processor through UNIX System Services (USS).
16.4.1
Registering XML Schemas in the DB2 Command Line Processor
Let’s first look at registering the XML Schema in Figure 16.1, which consists of just a single XML
Schema document. After that we show how to register an XML Schema that consists of multiple
schema documents, like the one in Figure 16.6 .
Figure 16.9 shows a single REGISTER XMLSCHEMA command that registers the XML Schema
customer.xsd from Figure 16.1 in the DB2 XML Schema Repository. Let’s look at this command line by line:
1. The first line of the command specifies the schema location URI of the schema, which is
specified as the string customer.xsd. We choose this value because it can be helpful to
identify this schema among others. But, any other string value could be used here.
2. The second line specifies the directory (c:\xml\myschemas) and filename
(customer.xsd) of the actual schema document that is being registered.
16.4
Registering XML Schemas
485
3. The third line assigns a relational SQL identifier to the schema. This identifier is a twopart name consisting of a relational schema name (db2admin) and an identifier for this
specific XML Schema (custxsd).
In DB2 for z/OS, the relational schema name must be SYSXSR or default to SYSXSR. If
the relational schema name is omitted then it defaults to the CURRENT SQLID, which
must be SYSXSR in this case.
4. The fourth line indicates that this completes the registration and no further schema documents are required.
REGISTER XMLSCHEMA 'customer.xsd'
FROM 'FILE:c:\xml\myschemas\customer.xsd'
AS db2admin.custxsd
COMPLETE;
Figure 16.9
Registering an XML Schema that consists of one schema document
If the XML Schema is made up of more than one XML Schema document, such as customer2.xsd in Figure 16.6, then the schema registration process consists of multiple steps. First
you need to register the primary XML Schema document using the REGISTER XMLSCHEMA command, as shown in Figure 16.10. The second step adds the schema document phone.xsd. The
third step adds the schema document addr.xsd. The fourth and last step completes the registration. The COMPLETE command checks that all links in the include and import declarations are
resolvable, and that the total XML Schema document is consistent. After completing the schema
registration you might want to grant the USAGE privilege to PUBLIC (see section 16.7).
REGISTER XMLSCHEMA 'customer2.xsd'
FROM 'FILE:c:\xml\myschemas\customer2.xsd'
AS db2admin.custxsd2;
ADD XMLSCHEMA DOCUMENT TO db2admin.custxsd2
ADD 'phone.xsd' FROM 'FILE:c:\xml\myschemas\phone.xsd';
ADD XMLSCHEMA DOCUMENT TO db2admin.custxsd2
ADD 'addr.xsd' FROM 'FILE:c:\xml\myschemas\addr.xsd';
COMPLETE XMLSCHEMA db2admin.custxsd2;
Figure 16.10
Registering an XML Schema that consists of multiple schema documents
Note that the clause ADD 'phone.xsd' in the ADD XMLSCHEMA command does not refer to the
filename of the schema document on disk, but to how the schema document is referenced in the
including schema. Since the including schema customer2.xsd contains the line
<xs:include schemaLocation="phone.xsd"/>
486
Chapter 16
Managing XML Schemas
you have to use 'phone.xsd' in the ADD clause here. If customer2.xsd was different and
contained the line
<xs:include schemaLocation="http://PhoneSchema"/>
then you would use ADD 'http://PhoneSchema' instead of ADD 'phone.xsd' in the ADD
XMLSCHEMA command. This handling of schema location values is independent of the actual filename, which is specified separately in the FROM clause.
16.4.2
Registering XML Schemas from Applications via Stored Procedures
The XML Schema registration that was performed with CLP commands in the previous section
can also be achieved with stored procedure calls from an application. For each of the three commands that were used in the previous section there is a corresponding stored procedure (see Table
16.2). In DB2 for z/OS, these stored procedures run in a WLM stored procedure address space.
Table 16.2
XSR Commands and Stored Procedures to Register XML Schemas
Command Line Processor Commands
Stored Procedure
REGISTER XMLSCHEMA
SYSPROC.XSR_REGISTER
ADD XMLSCHEMA DOCUMENT
SYSPROC.XSR_ADDSCHEMADOC
COMPLETE XMLSCHEMA
SYSPROC.XSR_COMPLETE
The two stored procedure calls in Figure 16.11 register the XML Schema customer.xsd from
Figure 16.1. The first call invokes the XSR_REGISTER procedure and passes five parameters: the
relational schema name (db2admin), the schema identifier (custxsd), the schema location URI
(customer.xsd), and a host variable of type BLOB(30M), which contains the actual schema
document that you want to register. A fifth parameter can optionally be used to provide an XML
document with descriptive information about this schema document, but the example simply
passes NULL instead, to not make use of this option.
The second stored procedure call (CALL XSR_COMPLETE) completes the registration and expects
the relational schema name and the schema identifier in its first and second parameter, respectively. The third parameter allows for an optional document with meta information about the
schema. For example, you can use this parameter if you want to store a description of your
schema along with the schema itself. DB2 makes no use of this metadata but allows your application to provide and refer to this information if desired. The fourth parameter can either be 0 or 1,
depending on whether the schema will be used for validation only (0), or also for decomposition
(1). Decomposition is discussed in Chapter 11, Converting XML to Relational Data.
16.4
Registering XML Schemas
487
CALL XSR_REGISTER('db2admin',
'custxsd',
'customer.xsd',
:primarySchemaDocument,
NULL);
CALL XSR_COMPLETE('db2admin',
'custxsd',
NULL,
0);
Figure 16.11
Registering an XML Schema that consists of one schema document
NOTE If you use these stored procedures in DB2 for z/OS then the
relational schema name, if provided, has to be SYSXSR. If omitted, it will
default to SYSXSR.
If an XML Schema consists of multiple schema documents, then one or multiple invocations of
the procedure XSR_ADDSCHEMADOC should be used to add additional schema documents before
calling the procedure XSR_COMPLETE. Figure 16.12 shows two calls to XSR_ADDSCHEMADOC to
add the schema documents phone.xsd and addr.xsd to the schema, similar to what was discussed for Figure 16.10.
CALL XSR_REGISTER('db2admin',
'custxsd2',
'customer2.xsd',
:primarySchemaDocument,
NULL);
CALL XSR_ ADDSCHEMADOC('db2admin',
'custxsd2',
'customer.xsd',
:SchemaDocumentPhone,
NULL);
CALL XSR_ ADDSCHEMADOC('db2admin',
'custxsd2',
'customer.xsd',
:SchemaDocumentAddr,
NULL);
CALL XSR_COMPLETE('db2admin',
'custxsd2',
NULL,
0);
Figure 16.12
Registering an XML Schema that consists of multiple schema documents
488
16.4.3
Chapter 16
Managing XML Schemas
Registering XML Schemas from Java Applications via JDBC
The JDBC driver for DB2 for z/OS and DB2 for Linux, UNIX, and Windows provides the method
connection.registerDB2XMLSchema, which can be called from a Java application to register
an XML Schema. The major difference from the commands and stored procedures discussed in the
previous sections is how schemas are registered that consist of multiple schema documents. The
registerDB2XMLSchema method can take an array of schema documents as input so that all
components of a complex XML Schema are registered in a single call. This means there is no need
for separate “ADDSCHEMADOC” calls for each component of a multidocument schema.
There are two forms of the registerDB2XMLSchema method: one that takes XML Schema documents as input from InputStream objects, and one that takes XML Schema documents as a
String. The sample snippet of Java code in Figure 16.13 illustrates the use of the registerDB2XMLSchema method with input streams. It performs the same schema registration as previously shown in Figure 16.10 and Figure 16.12.
String RelSchema = "SYSXSR";
String SchemaIdentifier = "CUSTXSD2";
String[] xmlSchemaLocations = new String[] {
"customer2.xsd", "phone.xsd", "addr.xsd" };
FileInputStream[] xmlSchemaDocuments =
new FileInputStream[] {
new FileInputStream("c:\xml\myschemas\customer2.xsd "),
new FileInputStream("c:\xml\myschemas\phone.xsd"),
new FileInputStream("c:\xml\myschemas\addr.xsd") };
int[] xmlSchemaDocumentsLengths = new int[] {
(int)xmlSchemaDocuments[0].getChannel().size(),
(int)xmlSchemaDocuments[1].getChannel().size(),
(int)xmlSchemaDocuments[2].getChannel().size()
InputStream[] xmlSchemaDocumentsProperties = null;
int[] xmlSchemaDocumentsPropertiesLengths = null;
InputStream xmlSchemaProperties = null;
int xmlSchemaPropertiesLength = 0;
boolean isUsedForShredding = false;
connection.registerDB2XmlSchema(
ReldSchema,
SchemaIdentifier,
xmlSchemaLocations,
xmlSchemaDocuments,
xmlSchemaDocumentsLengths,
xmlSchemaDocumentsProperties,
xmlSchemaDocumentsPropertiesLengths,
xmlSchemaProperties,
xmlSchemaPropertiesLength,
isUsedForShredding);
Figure 16.13
Registering an XML Schema via JDBC
};
16.4
Registering XML Schemas
16.4.4
489
Two XML Schemas Sharing a Common Schema Document
The import and include mechanisms of XML Schema allow you to build schemas in a modular
fashion. Section 16.3 described an XML Schema that consists of three schema documents. The
primary schema document customer2.xsd referenced the schema documents phone.xsd and
addr.xsd to reuse existing definitions for phone numbers and addresses.
The schema documents phone.xsd and addr.xsd can also be used in other XML Schemas. For
example, you can have a primary schema document supplier.xsd to define the structure of
XML documents that contain supplier information. If you want supplier addresses to obey the
same address structure as previously defined in addr.xsd, you can import addr.xsd into the
schema supplier.xsd. This works just like you previously imported addr.xsd into customer2.xsd in Figure 16.6. As a result, customer2.xsd and supplier.xsd now both rely on
addr.xsd as a schema component. They share a common schema document.
When you register the XML Schema documents customer2.xsd and supplier.xsd, you
need to add the schema document addr.xsd twice (see Figure 16.14 ), once to participate in the
customer schema, and once to participate in the supplier schema. Hence, the XML Schema
Repository now contains two copies of the schema document addr.xsd. Although
customer2.xsd and supplier.xsd logically share addr.xsd as a common schema document, DB2 requires separate physical copies of the shared document. Registering separate copies
of addr.xsd is a good thing, because it allows you to drop, update, or version the customer and
the supplier schemas independently from each other, if you have to.
REGISTER XMLSCHEMA 'customer2.xsd'
FROM 'FILE:c:\xml\myschemas\customer2.xsd'
AS db2admin.custxsd2;
ADD XMLSCHEMA DOCUMENT TO db2admin.custxsd2
ADD 'phone.xsd' FROM 'FILE:c:\xml\myschemas\phone.xsd';
ADD XMLSCHEMA DOCUMENT TO db2admin.custxsd2
ADD 'addr.xsd' FROM 'FILE:c:\xml\myschemas\addr.xsd';
COMPLETE XMLSCHEMA db2admin.custxsd2;
REGISTER XMLSCHEMA 'supplier.xsd'
FROM 'FILE:c:\xml\myschemas\supplier.xsd'
AS db2admin.suppxsd;
ADD XMLSCHEMA DOCUMENT TO db2admin.suppxsd
ADD 'addr.xsd' FROM 'FILE:c:\xml\myschemas\addr.xsd';
COMPLETE XMLSCHEMA db2admin.suppxsd;
Figure 16.14
Two XML Schemas sharing a common schema document (addr.xsd)
490
Chapter 16
Managing XML Schemas
The dependencies between schemas and their included or imported schema documents are
recorded in the catalog view SYSCAT.XSROBJECTHIERARCHIES in DB2 for Linux, UNIX, and
Windows, and the catalog table SYSIBM.XSROBJECTHIERARCHIES in DB2 for z/OS. The result
of the query in Figure 16.15 reveals the fact that both the customer and the supplier schemas
depend on the schema document whose schema location is addr.xsd. The column HTYPE represents the type of hierarchy, where P indicates the primary schema document and D flags other
(non-primary) schema documents that belong to the schema.
SELECT SUBSTR(o.objectname,1,25) AS schema, h.htype,
SUBSTR(h.schemalocation,1,35) AS schema_component
FROM syscat.xsrobjecthierarchies h, syscat.xsrobjects o
WHERE h.objectid = o.objectid;
SCHEMA
------------------CUSTXSD2
CUSTXSD2
CUSTXSD2
SUPPXSD
SUPPXSD
HTYPE
----P
D
D
P
D
SCHEMA_COMPONENT
----------------------------------customer2.xsd
phone.xsd
addr.xsd
supplier.xsd
addr.xsd
5 record(s) selected.
Figure 16.15
Dependencies between schemas and their components (DB2 for LUW)
DB2 for z/OS uses tables instead of catalog views, as summarized in section 16.9. Hence, the
query in Figure 16.15 would be written for DB2 for z/OS as shown in Figure 16.16, with the differences highlighted in bold font.
SELECT SUBSTR(o.objectname,1,25) AS schema, h.htype,
SUBSTR(h.schemalocation,1,35) AS schema_component
FROM sysibm.xsrobjecthierarchies h, sysibm.xsrobjects o
WHERE h.xsrobjectid = o.xsrobjectid;
Figure 16.16
16.4.5
Dependencies between schemas and their components (DB2 for z/OS)
Error Situations and How to Resolve Them
When you register an XML Schema, DB2 parses the schema and verifies that it complies with the
XML Schema standard. If a schema consists of multiple schema documents, this verification
happens in the COMPLETE step of the registration process. In this step, all import and include
dependencies are verified and the information from all schema documents is compiled into a single binary XML Schema grammar that allows fast document validation at runtime.
DB2 reports appropriate errors if any of the schema documents are not well-formed or if they
don’t form a correct XML Schema. In this case it is recommended to use an XML Schema editor,
16.4
Registering XML Schemas
491
such as the ones in IBM Data Studio Developer or Altova XMLSPY, to review and correct the
schema.
Let’s briefly look at two specific errors that you might find difficult to resolve if an XML Schema
consists of a large number of schema documents.
First, consider SQL error SQL20329N, which can occur in the COMPLETE step of the registration
process:
SQL20329N The completion check for the XML schema failed because
one or more XML schema documents is missing. One missing XML
schema document is identified by "LOCATION" as "assistant.xsd".
SQLSTATE=428GI
This error happens when a schema document with schema location URI assistant.xsd cannot
be found in the XML Schema Repository, but another schema document tries to include it with an
xs:include specification such as the following:
<xs:include schemaLocation="assistant.xsd"/>
A typical reason for this error is that the missing schema document was added to the XSR, using
the ADD XMLSCHEMA DOCUMENT command or the XSR_ADDSCHEMADOC stored procedure, but a
schema location URI other than assistant.xsd was specified. To avoid this error, make sure
that schema documents are always registered with the same schema location value that other
schema documents use to refer to it in xs:include elements.
Next, consider SQL error SQL20340N, which can also occur in the COMPLETE step of a schema
registration:
SQL20340N The XML schema "DB2ADMIN.CUSTOMER2" includes at least
one XML schema document in namespace "http://pureXMLcookbook.org"
with component ID "58546795155936256" that is not connected to the
other XML schema documents in the same namespace using an
include or redefine. SQLSTATE=22534
This error can arise when two or more schema documents in your XML Schema declare the same
target namespace, which is http://pureXMLcookbook.org in this example. All of those schema
documents must be connected via xs:include specifications. It can be helpful to visualize all
xs:include dependencies as a graph on a piece of paper, with a node for each schema document
and an arrow for each xs:include that links two schema documents. In this graph, all the nodes
that represent schema documents with the same target namespace declaration must be connected.
Otherwise error SQL20340N is raised. Use the big integer component ID shown in the error message to identify the disconnected schema document using a query such as the following:
SELECT schemalocation, targetnamespace
FROM syscat.xsrobjectcomponents
WHERE componentid = 58546795155936256;
492
16.5
Chapter 16
Managing XML Schemas
REMOVING XML SCHEMAS FROM THE SCHEMA REPOSITORY
In DB2 for Linux, UNIX, and Windows, you can remove XML Schemas, DTDs, and external
entities from the XML Schema Repository using the DROP XSROBJECT command. For example,
to drop the XML Schema db2admin.custxsd, issue the command:
DROP XSROBJECT db2admin.custxsd
If you drop an XML Schema then all schema documents that belong to that schema are removed
from the XSR in a cascading manner. Any check constraints that reference the schema are also
dropped. If you have any triggers, views, or packages that reference the object, then these are
marked as inoperative or invalid.
In DB2 for z/OS you use a stored procedure SYSPROC.XSR_REMOVE to drop schemas. The following stored procedure call removes the schema custxsd:
CALL SYSPROC.XSR_REMOVE('SYSXSR','CUSTXSD')
As an alternative to the DROP XSROBJECT command and the XSR_REMOVE procedure, you can
also use the JDBC method Connection.deregisterDB2XMLObject in your Java application.
You can drop an XML Schema even if there are XML documents in the database that have been
validated against that schema. In DB2, XML Schemas are not assigned to an entire table or XML
column because that would be too restrictive and prevents schema variability within an XML column. Instead, the relationship between XML Schemas and XML instance documents is managed
on a per-document basis (see Chapter 17). If you use DB2 for Linux, UNIX, and Windows, then
the fact that a document has been validated against a certain schema is automatically recorded
with the document itself in DB2’s XML storage. The XML document continues to carry the ID of
the schema that it has been validated against, even if that schema gets dropped.
In DB2 for z/OS the relationship between documents and a schema is not externalized. To make
this relationship explicit, you can insert a schema identifier into an extra column of your table
alongside each XML document.
DB2 has no built-in mechanism that prevents you from dropping a schema even if documents validated with this schema still exist in the database. This is a conscious DB2 design decision
because such a mechanism would require extra processing for every single XML insert, delete,
and update operation, and it is better to avoid this overhead.
In DB2 for Linux, UNIX, and Windows you can use the query in Figure 16.17 to determine the
number of documents in the customer table that have been validated against the XML Schema
db2admin.custxsd. The function XMLXSROBJECTID takes the XML column name as input. It
returns DB2’s internal ID number of the XML Schema that the document in the current row was
16.6
XML Schema Evolution
493
validated against, even if that schema was subsequently dropped. This schema ID joins to the
catalog table SYSCAT.XSROBJECTS where the relational SQL identifier of the schema
(db2admin.custxsd) is stored. The function XMLXSROBJECTID returns zero if the document
was not validated.
SELECT count(*)
FROM customer a, syscat.xsrobjects b
WHERE XMLXSROBJECTID(a.info) = b.objectid
AND b.objectschema = 'DB2ADMIN'
AND b.objectname = 'CUSTXSD';
Figure 16.17
Finding documents that were validated with a given XML Schema
DB2’s internal unique identification number of an XML Schema is created when you register a
schema and it is stored in the column OBJECTID of the catalog view SYSCAT.XSROBJECTS. The
OBJECTID cannot be changed. When an XML document is validated against an XML Schema in
DB2 for Linux, UNIX, and Windows, this unique identifier (and not the XML Schema name) is
stored with the XML document.
If you drop an XML Schema and then register the same or a different schema under the same
name, it will be assigned a different internal identification number. The query in Figure 16.17
will then no longer return the same result. The function XMLXSROBJECTID will continue to return
the internal ID of the schema that was dropped and is now missing from SYSCAT.XSROBJECTS.
This behavior makes sense for the following reason. If you drop one schema and then register a
different schema under the same name, any XML documents that are valid against the dropped
schema are not necessarily valid against the new schema. These documents are not automatically
revalidated against the new schema. If you revalidate them explicitly then the documents will
obtain the internal object ID of the new schema and lose the OBJECTID of their previous schema.
In other words, if a document is validated multiple times, it retains only the OBJECTID of the
XML Schema in the most recent validation.
If you have been using a certain version of your XML Schema and you want to start using an
updated version of the schema, then you should consider the UPDATE XMLSCHEMA command. It
enables you to perform compatible schema evolution and is described in the next section.
16.6
XML SCHEMA EVOLUTION
One of main reasons for using XML is its flexibility and extensibility. XML as a data format
enables you to react quickly to changing business needs. When products, services, processes, or
other parts of your business change, this change typically needs to be reflected in the data that you
capture, store, and process. For example you might have to allow for additional data items to be
included in your XML documents. As a result, you are likely to keep enhancing your XML
Schema that defines your XML data. This process leads to new versions of your XML Schema. In
the following sections we describe three approaches of dealing with such XML Schema evolution.
494
16.6.1
Chapter 16
Managing XML Schemas
Schema Evolution Without Document Validation
If you are not using your XML Schemas to validate documents in DB2, schema evolution at the
database level is easy. Without validation, DB2 is schema agnostic and allows you to insert any
kind of well-formed XML documents into an XML column. You don’t even have to register any
XML Schemas in DB2. At any point in time your application can decide to switch the document
format and insert XML documents that comply with a new version of your XML Schema. The
documents can be inserted into the same XML column as before. In this scenario DB2 is unaware
of the fact that the new documents belong to a different XML Schema than the documents that
were inserted previously. To help your application distinguish which documents belong to which
version of your XML, you may decide to add an integer column to your table so you can record
the version number of the schema for every document that is inserted or updated.
16.6.2
Generic Schema Evolution with Document Validation
XML Schema evolution becomes more interesting if you perform validation in DB2. If you register each version of your XML Schema in DB2 for Linux, UNIX, and Windows and use it for document validation, a situation like the one in Figure 16.18 evolves. The same situation evolves in
DB2 for z/OS, except that the relationship between validated documents and their schemas is not
externally visible. But, you can maintain a schema identifier in a separate column of your user
table to make the relationship between documents and schemas explicit.
You start out by registering the initial version of your XML Schema in DB2, using the name customerV1xsd. At that time DB2 assigns an internal OBJECTID to this schema. In the example in
Figure 16.18 this is the number 53521. For a while your application works with just this one XML
Schema. Several XML documents are inserted into the customer table and validated against the
schema customerV1xsd. These are the documents with the id values 1, 2, and 3 in Figure 16.18.
If you apply the function XMLXSROBJECTID to any of these documents, you will always obtain
the value 53521. This value links the documents to the schema they were validated with.
After some time your business requires you to change or extend your XML Schema. You create
the second version of your XML Schema and register it as customerV2xsd in DB2. For DB2
this is an entirely different schema and a new OBJECTID is assigned (33496). From this point
onwards you validate all new XML documents against the new version of your schema. In Figure
16.18, these are the documents 4 and 5. The function XMLXSROBJECTID() will reveal that these
documents point back to schema customerV2xsd. Eventually, you find yourself required to
make yet another schema evolution step. You register the third version of your schema as customerV3xsd and validate new documents against this latest version of your schema.
Note that the introduction of new schemas (or schema versions) does not require old documents
to be revalidated against the new schema. Such “bulk validation” can be done in DB2 (see Chapter 17) but it is often a very time-consuming operation and therefore usually avoided.
16.6
XML Schema Evolution
495
Table: customer
id
1
2
3
4
info
xmlxsrobjectid
SYSCAT.XSROBJECTS
OBJECTID
OBJECTSCHEMA
OBJECTNAME
53521
db2admin
customerV1xsd
33496
db2admin
customerV2xsd
70472
db2admin
customerV3xsd
...
5
6
7
Figure 16.18
XML documents validated against different versions of a schema
In the scenario depicted in Figure 16.18 , the XML Schema Repository contains the history of
your XML Schema versions and each document is correctly linked to its corresponding version
of your XML Schema. For additional comfort you can certainly add an integer column version
to the customer table to explicitly record the schema version with each row (document).
The advantage of managing schema evolution as shown in Figure 16.18 is that no version of your
XML Schema is required to be backward compatible with any previous version. The schema
customerV2xsd would be backward compatible with customerV1xsd if every document that
was valid for customerV1xsd is also valid for customerV2xsd. For example, if the
difference between the two versions is only that customerV2xsd defines additional optional elements, then customerV2xsd is backward compatible with customerV1xsd. However, if customerV2xsd declares new mandatory elements that did not exist in customerV1xsd, then this is a
non-compatible schema evolution. In this case, documents that were valid for customerV1xsd
will no longer be valid for customerV2xsd. Both compatible and non-compatible schema evolution is possible with the schema evolution approach described in this section.
A disadvantage of this approach can be that a number of different schema versions are explicitly
distinguished and managed in the database and the application. Depending on the details of your
application, this complexity may or may not be easy to handle.
16.6.3
Compatible Schema Evolution with the UPDATE XMLSCHEMA Command
It is very common that a new version of a schema is backward compatible to the previous version
of the schema. Backward compatible means that any document that is valid for the previous version is also valid for the new version of the schema. In this case, DB2 9.5 for Linux, UNIX, and
Windows allows you to replace (update) the old version of the schema with the new version.
After this operation, only the new version of the schema remains in DB2’s XML Schema Repository, and all documents that had been validated against the previous version of the schema now
appear as if they had been validated against the new version. This schema replacement allows you
to continue to work with a single XML Schema, instead of two.
496
Chapter 16
Managing XML Schemas
Updating an old schema with a compatible new schema is a quick operation in the DB2 catalog.
The existing XML documents are not revalidated, updated, examined, or touched in any way.
DB2 only compares the old with the new schema to verify that they are compatible. If they are
compatible, the UPDATE XMLSCHEMA command succeeds; otherwise it fails. The new schema
assumes the name and the OBJECTID of the old schema, and thus seamlessly takes its place.
Now let’s look at a compatible schema evolution step by step.
1. Create a table:
create table customer(id integer, info XML);
2. Register the initial version of your XML Schema under the name custxsd:
REGISTER XMLSCHEMA 'customerV1.xsd'
FROM 'FILE:c:\xml\myschemas\customerV1.xsd'
AS db2admin.custxsd
COMPLETE;
3. Insert any number of documents into the table and validate them against the schema
custxsd. The situation in your database now looks like Figure 16.19. There is
one schema listed in the XSROBJECTS catalog view, and if you apply the function
XMLXSROBJECTID() to any of the validated documents it always returns the OBJECTID
of that one XML Schema.
Table: customer
id
1
2
3
Figure 16.19
info
xmlxsrobjectid
SYSCAT.XSROBJECTS
OBJECTID
OBJECTSCHEMA
OBJECTNAME
53521
db2admin
custxsd
...
Three documents, validated with XML Schema custxsd
4. No matter how many documents are already stored in the table and validated against
custxsd, at some point your application might have to start using a new but compatible
version of your XML Schema, custxsd_V2. Register this schema just like you registered the previous schema:
REGISTER XMLSCHEMA 'customerV2.xsd'
FROM 'FILE:c:\xml\myschemas\customerV2.xsd'
AS db2admin.custxsd_V2
COMPLETE;
16.6
XML Schema Evolution
497
5. Figure 16.20 shows that the new version of your schema appears as a separate entry in
the schema repository. It has a different name and OBJECTID than the first version.
Table: customer
id
info
xmlxsrobjectid
1
2
3
Figure 16.20
SYSCAT.XSROBJECTS
OBJECTID
OBJECTSCHEMA
OBJECTNAME
53521
db2admin
custxsd
33496
db2admin
custxsd_V2
...
A second schema has been registered.
If you want to perform compatible schema evolution, no
documents should be validated against the new schema custxsd_V2
before the UPDATE XMLSCHEMA command has been issued !
NOTE
6. Perform the UPDATE XMLSCHEMA command to replace the old schema with the new one:
UPDATE XMLSCHEMA db2admin.custxsd
WITH db2admin.custxsd_V2
DROP NEW SCHEMA;
Alternatively, you can use the stored procedure XSR_UPDATE or the JDBC method Connection.updateDB2XmlSchema to achieve the same effect. After this command, the
situation in your database looks much like it did before you registered the new schema
(see Figure 16.19 ). What happened? The content of the new version of your schema has
been used to overwrite the content of the old version. This operation has temporarily
produced two copies of the new schema, one under the name custxsd and one under
the name custxsd_V2. But, the DROP NEW SCHEMA clause of the UPDATE XMLSCHEMA
command has automatically removed the schema with the name custxsd_V2 and
OBJECTID 33496. A single copy of the new XML Schema remains, registered under the
name and OBJECTID of the old schema. Therefore your application can seamlessly continue to reference the old schema name (custxsd) to validate new documents against
the new version of the schema. Since applications do not need to start using a different
schema name, schema evolution is possible without interruption to live applications.
Note that the single remaining copy of the XML Schema now carries the schema location of the new version of the schema (customerV2.xsd). This can be helpful if new
documents use this value in their schema location attributes to reference a schema.
However, when registering the new version of your schema you can specify the same
schema location as for the previous version, if you prefer to keep the same value.
498
Chapter 16
Managing XML Schemas
7. Insert additional documents and validate them with the schema named custxsd, as you
did prior to the schema evolution. The old schema name custxsd now identifies the
new schema. As shown in Figure 16.21, both old and new documents carry the OBJECTID of the same schema.
Table: customer
id
info
xmlxsrobjectid
1
2
SYSCAT.XSROBJECTS
OBJECTID
OBJECTSCHEMA
OBJECTNAME
53521
db2admin
custxsd
...
3
4
5
Figure 16.21
Documents inserted after updating the schema
If the two XML Schemas referenced in the UPDATE XMLSCHEMA command are not compatible,
DB2 produces error message SQL20432N and indicates which of the ten compatibility rules in
Table 16.3 has been violated. The compatibility rules ensure that the new schema is not more
restrictive than the old schema. Backward compatibility implies that the new schema cannot
remove any element, attribute, or type declarations that are present in the old schema. This is
required so that any document that was valid for the old schema is automatically valid in the new
schema.
Table 16.3
Conditions for XML Schema Compatibility
Rule
Description
(1) Attributes
Attributes in the old XML Schema must also be present in the new XML
Schema. Also, the new XML Schema cannot contain required attributes unless
they are already included in the old XML Schema. Only optional attributes
may be added to the schema.
(2) Elements
Elements in the old XML Schema must also be present in the new XML
Schema. Also, the new XML Schema cannot contain required elements unless
they are already included in the old XML Schema. Only optional elements
may be added to the schema.
16.7
Granting and Revoking XML Schema Usage Privileges
Table 16.3
499
Conditions for XML Schema Compatibility (Continued)
Rule
Description
(3) Simple type conflict
The value range of a simple type in the new XML Schema must be equal or
larger than the value range of the same simple type in the old XML Schema.
For example, if the customer name is restricted to a string of 20 characters in
the old schema and the new schema allows 30 characters, that’s a backward
compatible schema change. However, if the old schema defines the “year” to
be a four-digit integer value and new schema defines “year” as a two-digit
integer, then this is not backward compatible.
(4) Incompatible type
The data type of an element or attribute in the new XML Schema must be
equal or more inclusive than the data type of the same element or attribute in
the old schema. For example, if an element “postal code” is defined as
xs:integer in the old schema and as xs:string in the new schema,
then this is compatible because every integer is a valid string.
(5) Mixed content vs.
not mixed content
If the old XML Schema declares an element such that it can contain mixed
content, then the same element must also be allowed to contain mixed content
in the new schema. Mixed content is explained in section 3.1 Understanding
XML Document Trees.
(6) Nillable vs.
not nillable
If the attribute nillable in an element declaration of the original XML
Schema is turned on, it must also be turned on in the new XML Schema.
(Note that the attribute nillable is rarely used and should not be used as an
equivalent to “nullable” columns in relational tables. Use optional elements
and attributes to allow for missing values.)
(7) Removed element
Global elements declared in the old XML Schema must also be present in the
new XML Schema, and must not be declared as “abstract.”
(8) Removed type
If the old XML Schema contains a global type that is derived from another
type, the global type must also be present in the new XML Schema.
(9) Simple to complex
A complex type that contains simple content in the old XML Schema cannot
contain complex content in the updated XML Schema.
(10) Simple content
Simple types defined in the old XML Schema and in the new XML Schema
must be based on the same built-in data types.
16.7
GRANTING AND REVOKING XML SCHEMA USAGE PRIVILEGES
In DB2 for z/OS no privileges are associated with XML Schemas. After an XML Schema is registered, any user can reference that schema to validate XML documents.
In DB2 for Linux, UNIX, and Windows, the USAGE privilege for an XML Schema is automatically granted to the user who registers the schema in the XSR. If you want to allow other database
users to use the XML Schema, you need to explicitly grant USAGE of the XML Schema to
PUBLIC using the following command:
500
Chapter 16
Managing XML Schemas
GRANT USAGE ON XSROBJECT db2admin.custxsd TO PUBLIC
The XML Schema to grant usage on is referenced by its SQL identifier (db2admin.custxsd)
that was assigned during schema registration. Note that PUBLIC is currently the only user to
whom the usage of an XSR object can be granted. If you try to grant usage to a specific user or
DB2 role, the GRANT command fails with error SQL0104N. If you do not grant USAGE of the
XML Schema to PUBLIC, then a user trying to access the XML Schema for validation will
receive the following error message:
SQL0551N "<user>" does not have the privilege to perform operation "Validation" on
object "<object-name>". SQLSTATE=42501.
If an XML Schema consists of multiple documents, then the user who registers the primary
schema document (through the XSR_REGISTER stored procedure, for example) must also be the
user who adds additional XML Schema documents and completes the registration process.
You can revoke the USAGE privilege for an XML Schema with the command:
REVOKE USAGE ON XSROBJECT db2admin.custxsd FROM PUBLIC
The query in Figure 16.22 checks the usage authorizations for all XML Schemas in DB2 for
Linux, UNIX, and Windows databases. The result shows that user DB2ADMIN has usage authorization for the XML Schemas with the identifiers custxsd2 and supplier because this user has
registered these schemas. Additionally, the third row in the result shows that user DB2ADMIN has
run the GRANT USAGE command to authorize PUBLIC to use the schema custxsd2. The catalog
views XSROBJECTAUTH and XSROBJECTS are explained in detail in section 16.9.
SELECT SUBSTR(a.grantor,1,10) AS grantor,
SUBSTR(a.grantee,1,10) AS grantee,
SUBSTR(b.objectname,1,10) AS xmlschema,
a.usageauth
FROM syscat.xsrobjectauth a, syscat.xsrobjects b
WHERE a.objectid = b.objectid;
GRANTOR
---------SYSIBM
SYSIBM
DB2ADMIN
GRANTEE
---------DB2ADMIN
DB2ADMIN
PUBLIC
XMLSCHEMA
---------CUSTXSD2
SUPPLIER
CUSTXSD2
USAGEAUTH
--------G
G
Y
3 record(s) selected.
Figure 16.22
Checking the usage authorization for XML Schemas
16.8
Document Type Definitions (DTDs) and External Entities
16.8
501
DOCUMENT TYPE DEFINITIONS (DTDS) AND EXTERNAL ENTITIES
Prior to the emergence of the XML Schema as the de facto standard for constraining XML document structures, DTDs (Document Type Definitions) were frequently used to define and constrain
XML data. Although DTDs are still being used in some applications areas, such as publishing,
XML Schemas are by far the most common choice for defining and validating XML documents.
Therefore DB2 does currently not support validation of XML documents against DTDs, only validation against XML Schemas. Almost every DTD can easily be converted into an equivalent
XML Schema. You can find free and commercial tools for this conversion on the Internet.
Note that DTDs have a variety of shortcomings as compared to XML Schemas, including the
following:
• With DTDs you cannot define data types such as integer, decimal, date, and so on for
your XML elements and attributes.
• DTDs do not allow you to define and reuse complex element types.
• DTDs do not allow you to declare one specific XML element to be the root element.
Since all element definitions in a DTD are global, any defined element can be interpreted as a valid root element. As a result, a DTD can typically not force documents to
have a specific root element.
• Occurrence indicators in DTDs are limited to + (one or more occurrences), ? (exactly
one occurrence), and * (zero or more occurrences). DTDs do not allow you to specify,
for example, that an element has to occur at least 2 and at most 5 times.
• It is practically impossible to define, manage, and validate namespaces with DTDs.
• DTDs themselves are not written in XML notation.
Although DB2 does not support DTD validation, DB2 for Linux, UNIX, and Windows allows
you to register DTDs in the XML Schema Repository (XSR). If your XML documents contain
references to an external DTD, then this DTD must be registered in the XSR. The DTD can define
default values for attributes or so-called entities, which can be referenced in the XML documents.
To store a correct representation of such documents, DB2 accesses the DTD in the XSR to check
for default attribute values and to resolve entity references as needed.
DB2 for z/OS only allows internal DTDs. Internal DTDs are embedded inside an XML instance
document and therefore do not need to be registered in the XSR. If an internal DTD is present,
default attribute values are applied and entity references in the document are resolved. DB2 for
z/OS also tolerates XML documents that contain a reference to an external DTD, but never reads
or processes external DTDs.
Figure 16.23 shows an XML document that references an external DTD as well as an entity
&mycity; in the city element. In DB2 for Linux, UNIX, and Windows, this XML document
cannot be inserted into a DB2 database unless the DTD customer.dtd is registered in DB2’s
XSR.
502
Chapter 16
Managing XML Schemas
<?xml version="1.0" standalone="no" ?>
<!DOCTYPE customerinfo SYSTEM "customer.dtd">
<customerinfo Cid="1004">
<name>Matt Foreman</name>
<addr country="Canada">
<street>1596 Baseline</street>
<city>&mycity;</city>
<prov-state>Ontario</prov-state>
<pcode-zip>M3Z 5H9</pcode-zip>
</addr>
</customerinfo>
Figure 16.23
A document with reference to a DTD
The following REGISTER XSROBJECT command adds the DTD customer.dtd to the XSR:
REGISTER XSROBJECT 'customer.dtd'
FROM 'file:c:/xml/DTDs/customer.dtd' AS db2admin.custdtd
Alternatively, DB2 also offers the stored procedure XSR_DTD to register DTDs from an application program via an API. For the document in Figure 16.23, the registered DTD has to contain a
line with an internal entity definition for the entity mycity, such as
<!ENTITY mycity "Markham, Greater Toronto Area">
When the XML document is inserted into an XML column, DB2 examines the referenced DTD
in the XSR. This enables DB2 to replace the entity reference &mycity; with the string value
"Markham, Greater Toronto Area", which is defined in the entity declaration in the DTD.
For further details on DTDs, internal entities, and external entities, please see http://www.
w3schools.com/DTD and http://www.w3schools.com/dtd/dtd_entities.asp.
16.9
BROWSING THE XML SCHEMA REPOSITORY (XSR)
The XML Schema Repository (XSR) consists of several catalog tables, which allow you to query
information about the XML Schemas that are registered. You cannot add, change, or remove
information from the XML Schema Repository through SQL statements. All modifications are
made through the XSR commands or stored procedures, which allow you to register, drop, or
update XML Schemas.
In DB2 for Linux, UNIX, and Windows the XSR tables, views, and stored procedures are created
when a database in created.
In DB2 for z/OS the XSR tables, views, stored procedures, and functions need to be created
explicitly using the installation job DSNTIJSG or the migration job DSNTIJNX. By default the
XSR tables are created in DSNXSR.SYSXSR using STOGROUP SYSDEFLT. To create and use the
16.9
Browsing the XML Schema Repository (XSR)
503
XSR you need to have Java 5 or later installed and a WLM environment set up. The XSR stored
procedures and UDFs run in the WLM address space. The procedure XSR_COMPLETE uses Java
to compile XML Schema Documents (XSDs) into a binary schema representation for efficient
document validation in INSERT and UPDATE statements. In Appendix C you find a link to the
DB2 for z/OS XSR Setup and Troubleshooting Guide.
16.9.1
Tables and Views of the XML Schema Repository
DB2 for Linux, UNIX, and Windows provides catalog views in the SYSCAT schema for easier
browsing of the XSR tables. DB2 for z/OS provides similar information through catalog tables in
schema SYSIBM, which have the same names as the catalog views in DB2 for Linux, UNIX, and
Windows. The table and view names are summarized in Table 16.4 . Note that in DB2 for z/OS,
BLOB columns reside in separate auxiliary tables.
Table 16.4
Tables and Views of the XML Schema Repository
DB2 for Linux, UNIX, and
Windows Catalog Views
(Schema: SYSCAT)
DB2 for Linux, UNIX, and
Windows Catalog Tables
(Schema: SYSIBM)
DB2 for z/OS
Catalog Table
(Schema: SYSIBM)
XSROBJECTS
SYSXSROBJECTS
XSROBJECTS + BLOBs in
XSROBJECTGRAMMAR and
XSROBJECTPROPERTY
XSROBJECTCOMPONENTS
SYSXSROBJECTCOMPONENTS
XSROBJECTCOMPONENTS +
BLOBs in XSRCOMPONENT
and XSRPROPERTY
XSROBJECTHIERARCHIES
SYSXSROBJECTHIERARCHIES
XSROBJECTHIERARCHIES
XSROBJECTDEP
SYSXSROBJECTDEP
-
XSROBJECTAUTH
SYSXSROBJECTAUTH
-
XDBMAPGRAPHS
SYSXDBMAPGRAPHS
-
XDBMAPSHREDTREES
SYSXDBMAPSHREDTREES
-
The XSR catalog views in DB2 for Linux, UNIX, and Windows provide the following information, which is also visualized in Figure 16.24. In DB2 for z/OS, this information exists in the corresponding catalog tables.
• SYSCAT.XSROBJECTS—This is the main view, which contains one row for every XML
Schema that is registered. The row holds the OBJECTID of the schema, its name, target
namespace, schema location, and other meta information. The actual schema documents
(XSD files) are not in this view, but in SYSCAT.XSROBJECTCOMPONENTS.
504
Chapter 16
Managing XML Schemas
• SYSCAT.XSROBJECTCOMPONENTS—An XML Schema can consist of one or multiple
schema documents, also called components. SYSCAT.XSROBJECTCOMPONENTS therefore contains one or multiple rows for each XML Schema listed in SYSCAT.
XSROBJECTS. Each row describes one schema document. SYSCAT.XSROBJECTCOMPONENTS has a column COMPONENT of type BLOB(30M), which contains the actual
schema document in binary format.
• SYSCAT.XSROBJECTHIERARCHIES—This view contains information about the hierarchical relationships between an XML Schema and its components.
• SYSCAT.XSROBJECTDEP—This view lists dependencies, if any, between XML
Schemas and other database objects. Currently, there is only one kind of dependency
that is being recorded, and that is for XML Schemas that are enabled for decomposition
(shredding). Such schemas depend on the target tables that are used for shredding.
• SYSCAT.XSROBJECTAUTH—Each row in this view represents a user or a group that has
been granted the USAGE privilege on a particular XSR object, such as an XML Schema.
• SYSCAT.XDBMAPGRAPHS and SYSCAT.XDBMAPSHREDTREES—These two views contain information when an XML Schema has been annotated with mapping information
that can be used to shred XML data into relational tables. The so-called annotated
schema shredding or decomposition is discussed in Chapter 11.
XSROBJECTAUTH
GRANTOR
GRANTORTYPE
GRANTEE
GRANTEETYPE
OBJECTID
USAGEAUTH
XSROBJECTDEP
OJECTID
OJECTIDSCHEMA
OJECTNAME
BTYPE
BSCHEMA
BMODULENAME
BNAME
BMODULEID
TABAUTH
Figure 16.24
XSROBJECTCOMPONENTS
XSROBJECTS
OBJECTID
OJECTIDSCHEMA
OJECTNAME
TARGETNAMESPACE
SCHEMALOCATION
OBJECTINFO
OBJECTTYPE
OWNER
OWNERTYPE
CREATE_TIME
ALTER_TIME
STATUS
DECOMPOSITION
REMARKS
OBJECTID
OJECTIDSCHEMA
OJECTNAME
COMPONENTID
TARGETNAMESPACE
SCHEMALOCATION
COMPONENT
CREATE_TIME
STATUS
XSROBJECTHIERARCHIES
OBJECTID
COMPONENTID
HTYPE
TARGETNAMESPACE
SCHEMALOCATION
DB2’s XML Schema Repository
The following tables provide more detail on the columns in these catalog views.
16.9
Browsing the XML Schema Repository (XSR)
Table 16.5
Object
505
SYSCAT.XSROBJECTS—Each Row Represents an XML Schema Repository
Column Name
Data Type
Description
OBJECTID
BIGINT
Unique generated identifier for an XSR object
OBJECTSCHEMA
VARCHAR(128)
Schema name of the XSR object
OBJECTNAME
VARCHAR(128)
Unqualified name of the XSR object
TARGETNAMESPACE
VARCHAR(1001)
String identifier for the target namespace
SCHEMALOCATION
VARCHAR(1001)
String identifier for the schema location, or system
identifier
OBJECTINFO
XML
Optional metadata document describing the object
OBJECTTYPE
CHAR(1)
XSR object type
D = DTD
E = External Entity
S = XML Schema
OWNER
VARCHAR(128)
Authorization ID under which the XSR object was
registered
OWNERTYPE
CHAR(1)
S = The owner is the system
U = The owner is an individual user
CREATE_TIME
TIMESTAMP
Time at which the object was registered
ALTER_TIME
TIMESTAMP
Time at which the object was last updated (replaced)
STATUS
CHAR(1)
Registration status
C = Complete
I = Incomplete
R = Replace
T = Temporary
DECOMPOSITION
CHAR (1)
Indicates whether decomposition (shredding) is
enabled for this XML Schema
N = Not enabled
X = Inoperative
Y = Enabled
REMARKS
VARCHAR(254)
User-provided comments, or null
In DB2 for z/OS, the corresponding catalog table is called SYSIBM.XSROBJECTS and the first
three columns are called XSROBJECTID, XSROBJECTSCHEMA, and XSROBJECTNAME. Its
TARGETNAMESPACE column is an integer and is the value of the STRINGID column in
506
Chapter 16
Managing XML Schemas
SYSIBM.SYSXMLSTRINGS where the target namespace URI of the primary XML Schema document is stored. Similarly, its SCHEMALOCATION column is an integer and also a pointer into
SYSIBM.SYSXMLSTRINGS where the schema location URI of the primary XML Schema document is stored. See Chapter 3 for more information on SYSIBM.SYSXMLSTRINGS.
Table 16.6 SYSCAT.XSROBJECTCOMPONENTS—Each Row Represents an XSR Object
Component, Such as a Schema Document
Column Name
Data Type
Description
OBJECTID
BIGINT
Unique generated identifier for an XSR object
OBJECTSCHEMA
VARCHAR(128)
Schema name of the XSR object
OBJECTNAME
VARCHAR(128)
Unqualified name of the XSR object.
COMPONENTID
BIGINT
Unique generated identifier for an XSR object
component
TARGETNAMESPACE
VARCHAR(1001)
String identifier for the target namespace
SCHEMALOCATION
VARCHAR(1001)
String identifier for the schema location
COMPONENT
BLOB (30M)
External representation of the component. Actual
schema documents are stored here
CREATE_TIME
TIMESTAMP
Time at which the XSR object component was
registered
STATUS
CHAR (1)
Registration status
C = Complete
I = Incomplete
In DB2 for z/OS, the TARGETNAMESPACE and SCHEMALOCATION columns again hold integer
values that point into SYSIBM.SYSXMLSTRINGS.
Table 16.7 SYSCAT.XSROBJECTHIERARCHIES—Each Row Represents the Hierarchical
Relationship between an XSR Object and Its Components
Column Name
Data Type
Description
OBJECTID
BIGINT
Identifier for an XSR object
COMPONENTID
BIGINT
Identifier for an XSR component
HTYPE
CHAR (1)
Hierarchy type
D = Document
N = Top-level namespace
P = Primary document
TARGETNAMESPACE
VARCHAR(1001)
Identifier for the component’s target namespace
SCHEMALOCATION
VARCHAR(1001)
Identifier for the component’s schema location
16.9
Browsing the XML Schema Repository (XSR)
507
In DB2 for z/OS the corresponding catalog table is called SYSIBM.XSROBJECTHIERARCHIES and
the first two columns are called XSROBJECTID and XSRCOMPONENTID. As in the XSROBJECTS table,
the TARGETNAMESPACE and SCHEMALOCATION columns are integer values.
Table 16.8 SYSCAT.XSROBJECTDEP—Each Row Represents a Dependency of an XSR
Object on Some Other Object
Column Name
Data Type
Description
OBJECTID
BIGINT
Unique generated identifier for an XSR object
OBJECTSCHEMA
VARCHAR(128)
Schema name of the XSR object
OBJECTNAME
VARCHAR(128)
Unqualified name of the XSR object
BTYPE
CHAR(1)
Type of object on which there is a dependency, such
as T if the schema depends on a table into which the
schema shreds
BSCHEMA
VARCHAR(128)
Schema name of the object on which there is a
dependency
BNAME
VARCHAR(128)
Unqualified name of the object on which there is a
dependency. For routines (BTYPE = 'F'), this is the
specific name
TABAUTH
SMALLINT
If BTYPE = 'O', 'S', 'T', 'U', 'V', 'W', or 'v',
encodes the privileges on the table or view that are
required by a dependent trigger; null value otherwise
Table 16.9 SYSCAT.XSROBJECTAUTH—Each Row Represents a User or Group That Has
Been Granted the USAGE Privilege on a Particular XSR Object
Column Name
Data Type
Description
GRANTOR
VARCHAR (128)
Grantor of the privilege
GRANTORTYPE
CHAR (1)
S = Grantor is the system
U = Grantor is an individual user
GRANTEE
VARCHAR (128)
Holder of the privilege
GRANTEETYPE
CHAR (1)
G = Grantee is a group
R = Grantee is a role
U = Grantee is an individual user
OBJECTID
BIGINT
Identifier for the XSR object
USAGEAUTH
CHAR (1)
Privilege to use the XSR object and its components
N = Not held
Y = Held
G = Granted
508
Chapter 16
Table 16.10
XDB Map
Managing XML Schemas
SYSCAT.XDBMAPGRAPHS—Each Row Represents a Schema Graph for an
Column Name
Data Type
Description
OBJECTID
BIGINT
Unique generated identifier for an XSR object
OBJECTSCHEMA
VARCHAR(128)
Schema name of the XSR object
OBJECTNAME
VARCHAR(128)
Unqualified name of the XSR object
SCHEMAGRAPHID
INTEGER
Schema graph identifier, which is unique within an
XDB map identifier
NAMESPACE
VARCHAR(1001)
Identifier for the namespace URI of the root element
ROOTELEMENT
VARCHAR(1001)
Identifier for the element name of the root element
Table 16.11 SYSCAT.XDBMAPSHREDTREES—Each Row Represents a Shred Tree for a
Particular Schema Graph.
Column Name
Data Type
Description
OBJECTID
BIGINT
Unique generated identifier for an XSR object
OBJECTSCHEMA
VARCHAR(128)
Schema name of the XSR object
OBJECTNAME
VARCHAR(128)
Unqualified name of the XSR object
SCHEMAGRAPHID
INTEGER
Schema graph identifier, which is unique within
an XDB map identifier
SHREDTREEID
INTEGER
Shred tree identifier, which is unique within an
XDB map identifier
MAPPINGDESCRIPTION
CLOB(1M)
Diagnostic mapping information
16.9.2
Queries against the XML Schema Repository
You can use regular SQL to query the tables or views of the XML Schema Repository. This
allows you to retrieve any type of information about the XML Schemas and their schema documents in the repository. We provide a few examples of useful XSR queries in this section, based
on the XSR catalog views in DB2 for Linux, UNIX, and Windows. You can run these queries also
in DB2 for z/OS if you change the table names (and in some cases column names) to their corresponding equivalents in DB2 for z/OS. The examples also include sample output that the queries
produce after registering the schemas in section 16.4.4, where two XML Schemas share a common schema document.
16.9
Browsing the XML Schema Repository (XSR)
509
The query in Figure 16.25 lists all XML Schemas in the XSR, showing the relational schema they
belong to, their SQL identifier, their target namespace, and status. The STATUS column tells you
that the registration of both XML Schemas is complete. The substr function is used to limit the
column width in the output of the DB2 Command Line Processor.
SELECT SUBSTR(objectschema,1,10) AS rel_schema,
SUBSTR(objectname,1,10) AS identifier,
SUBSTR(targetnamespace,1,35) AS tgt_namespace,
status
FROM syscat.xsrobjects;
REL_SCHEMA
---------DB2ADMIN
DB2ADMIN
IDENTIFIER
---------CUSTXSD2
SUPPLIER
TGT_NAMESPACE
----------------------------------http://pureXMLcookbook.org
http://pureXMLcookbook.org/supplier
STATUS
-----C
C
2 record(s) selected.
Figure 16.25
Listing all XML Schemas in the XML Schema Repository
The query in Figure 16.26 can be used to list all XML Schemas and their internal OBJECTID.
This OBJECTID is stored with every XML document that is validated against the respective XML
Schema.
SELECT SUBSTR(objectschema,1,10) AS rel_schema,
SUBSTR(objectname,1,10) AS xml_schema,
objectid
FROM syscat.xsrobjects;
REL_SCHEMA
---------DB2ADMIN
DB2ADMIN
XML_SCHEMA OBJECTID
---------- -------------------SUPPLIER
39969446692943104
CUSTXSD2
38562071809389824
2 record(s) selected.
Figure 16.26
Listing XML Schemas and their OBJECTIDs
Since an XML Schema can consist of multiple schema documents (components), the query in
Figure 16.27 is useful to list all of these components with their schema location and the overall
XML Schema that they belong to. You also see the internal COMPONENTID that DB2 has assigned
to each schema document. The schema document addr.xsd has been registered twice, once for
the customer schema and once for the supplier schema. The two copies of addr.xsd are distinguished by different COMPONENTIDs.
510
Chapter 16
Managing XML Schemas
SELECT SUBSTR(objectname,1,10) AS schema,
componentid,
-- SUBSTR(targetnamespace,8,35) AS tgt_namespace,
SUBSTR(schemalocation, 1,35) AS schema_location
-- , create_time
FROM syscat.xsrobjectcomponents
ORDER BY create_time;
SCHEMA
---------CUSTXSD2
CUSTXSD2
CUSTXSD2
SUPPLIER
SUPPLIER
COMPONENTID
----------------38843546786100480
39125021762811136
39406496739521792
40250921669653760
40532396646364416
SCHEMA_LOCATION
----------------------------------customer2.xsd
phone.xsd
addr.xsd
supplier.xsd
addr.xsd
5 record(s) selected.
Figure 16.27
Listing all schema documents (components)
The query in Figure 16.28 provides similar information, but also reveals exactly which components are primary schema documents. Those are flagged with a P in the HTYPE column and are at
the top of the import/include hierarchy of an XML Schema.
SELECT SUBSTR(o.objectname,1,25) AS schema,
h.htype,
SUBSTR(h.schemalocation,1,35) AS schema_location
FROM syscat.xsrobjecthierarchies h, syscat.xsrobjects o
WHERE h.objectid = o.objectID;
SCHEMA
------------------------CUSTXSD
CUSTXSD
CUSTXSD
SUPPXSD
SUPPXSD
HTYPE
----P
D
D
P
D
SCHEMA_LOCATION
-------------------------------customer2.xsd
phone.xsd
addr.xsd
supplier.xsd
addr.xsd
5 record(s) selected.
Figure 16.28
16.10
Listing primary schema documents
XML SCHEMA CONSIDERATIONS IN DB2 FOR Z/OS
Where XML Schema management differs between DB2 for z/OS and DB2 for Linux, UNIX, and
Windows, we have explicitly mentioned the respective platform throughout this chapter. Let’s
summarize the main platform similarities and differences:
16.10
XML Schema Considerations in DB2 for z/OS
511
• Both DB2 for z/OS and DB2 for Linux, UNIX, and Windows have an XML Schema
Repository that allows you to register XML Schemas. Schemas that consist of multiple
schema documents are also supported. The schemas can then be used for document
validation.
• Neither DB2 for z/OS nor DB2 for Linux, UNIX, and Windows support validation with
document type definitions (DTDs). We recommend that you use XML Schemas instead.
• The XML Schema Repository in DB2 for Linux, UNIX, and Windows consists of catalog tables plus catalog views. In general, DB2 for z/OS does not use catalog views, but
the same information is available in catalog tables. See Table 16.4 in section 16.9.1.
• DB2 for z/OS keeps the object ID and name of an XML Schema in the columns XSROBJECTID and XSROBJECTNAME of the catalog table SYSIBM.XSROBJECTS. DB2 for
Linux, UNIX, and Windows also keeps them in the columns OBJECTID and OBJECTNAME of the corresponding catalog view SYSCAT.XSROBJECTS.
• When you register an XML Schema in DB2 for Linux, UNIX, and Windows you can
optionally assign it to a relational schema of your choice. In DB2 for z/OS, this relational schema has to be SYSXSR.
• DB2 for z/OS provides a stored procedure XSR_REMOVE to drop XML Schemas. In DB2
for Linux, UNIX, and Windows you use the DROP XSROBJECT command.
• The function XMLXSROBJECTID is only supported in DB2 for Linux, UNIX, and Windows. It takes an XML document as input, such as an XML column name, and returns
the OBJECTID of the XML Schema that the document was validated against. If you need
similar capabilities in DB2 for z/OS you should maintain a schema identifier in a separate column of your user table.
• At the time of writing, compatible schema evolution with the UPDATE XMLSCHEMA
command or the XSR_UPDATE procedure is only available in DB2 for Linux, UNIX, and
Windows.
• Using XML Schemas in DB2 9 for z/OS requires Java JDK 1.5 or above installed with
DB2 as well as the WLM environment setup for C stored procedures and Java stored
procedures.
• If you are installing DB2 9 for z/OS, installation job DSNTIJSG creates the tables and
stored procedures that support XML Schema management. This job is part of the DB2
installation process. If you are migrating to DB2 9, run job DSNTIJNX after DB2 is in
new-function mode to create the tables and stored procedures for XML Schema support.
These objects must exist before the JDBC method registerDB2XMLSchema can be
used.
512
16.11
Chapter 16
Managing XML Schemas
SUMMARY
XML Schemas provide rich capabilities to constrain XML documents. For example, an XML
Schema can specify which elements and attributes are allowed to appear in a document, the order
and nesting in which they may appear, the data types for their values, or that some elements are
optional while others are mandatory. A process called validation can check whether an XML
document complies with a given XML Schema.
The use of XML Schemas in DB2 is optional. The decision to use XML Schemas depends on
your application requirements to verify inserted or updated documents with an XML Schema. If
you receive XML documents from a trusted source you may decide to avoid validation in DB2
and save the extra CPU cost. A trusted source can be, for example, an application server that
already validates incoming XML documents so that additional validation in DB2 might not be
necessary.
If you decide to enforce XML data quality at the database level, you need to register the required
XML Schema(s) in DB2’s XML Schema Repository (XSR). The XSR is a set of tables in DB2
for the storage and management of XML Schemas. Schema registration can be performed with
DB2 Command Line Processor commands, stored procedure calls, or from a Java application
with specific JDBC methods.
Products, services, and processes tend to change over time in most enterprises. Often, such
changes need to be reflected in the data that is captured and processed. Such changes lead to
schema evolution. DB2 allows you to migrate from one version of an XML Schema to the next
without any downtime, no matter how different the schemas are. High schema flexibility is one of
the big advantages of XML data over relational data.
The next chapter describes how registered XML Schemas can be used to validate XML documents in insert, update, or load operations and how you can find the XML Schema for a given
document and vice versa.
C
H A P T E R
17
Validating XML
Documents against
XML Schemas
n Chapter 16, Managing XML Schemas, you learned how to register XML Schemas in
DB2’s XML Schema Repository (XSR). In this chapter we explain the validation of XML
documents using these XML Schemas. Remember that document validation is optional in DB2
and that there is no penalty in terms of DB2 performance or functionality if you don’t use an
XML Schema. Document validation is also called schema validation because an XML Schema is
used to validate XML documents. DB2 offers a variety of features to manage the validation of
XML documents. You can
I
• Validate individual documents when you insert or update them (sections 17.1 and 17.2)
• Validate documents without rejecting invalid documents (section 17.3)
• Define check constraints to make document validation mandatory (section 17.4)
• Use triggers to automatically validate every document that is inserted or updated
(section 17.5)
• Get detailed information on parsing and validation errors (section 17.6)
• Validate batches of documents when you load or import them (section 17.7)
• Check and validate existing XML documents in your database (sections 17.8 and 17.9)
• Find the XML Schema for a given XML document, or find all documents for a given
XML Schema (section 17.10)
• Undo document validation, to disassociate an XML document from an XML Schema
(section 17.11)
Additionally, section 17.12 highlights some of the specific considerations for document validation in DB2 for z/OS.
513
514
17.1
Chapter 17
Validating XML Documents against XML Schemas
DOCUMENT VALIDATION UPON INSERT
In DB2 for Linux, UNIX, and Windows you can use the SQL/XML function XMLVALIDATE to
validate an XML document when you insert or update it. In DB2 for z/OS, the validation function
is called DSN_XMLVALIDATE. The parameters and usage for DSN_XMLVALIDATE are similar to
XMLVALIDATE, and any differences are described in section 17.12.
Let’s look at some examples using the same table as in the previous chapter:
CREATE TABLE customer(id INTEGER, info XML)
Figure 17.1 shows several INSERT statements as you would use them in an application program.
The question marks denote parameter markers to which the application binds data values that are
used in an INSERT statement. The first INSERT statement does not perform validation. It simply
contains two parameter markers to insert one value into each of the two columns in the table.
When this INSERT is executed, the value of the second parameter has to be a well-formed XML
document.
The second INSERT statement wraps the XMLVALIDATE function around the parameter marker
for the XML column. This tells DB2 to validate the XML document as part of the insert operation. The clause ACCORDING TO XMLSCHEMA ID specifies the identifier of the XML Schema
that should be used for validation. This is the identifier that you provided when you initially registered the XML Schema. It allows you to force validation against this particular XML Schema.
If the inserted XML document is valid with respect to this schema, the INSERT succeeds, otherwise the INSERT fails with an error code that indicates why the document is not valid.
The third INSERT statement works much like the second one, except that the schema identifier is
not hard-coded but provided by the application through another parameter marker.
The fourth INSERT statement identifies the XML Schema by the URI of its target namespace
instead of its relational identifier. This approach can sometimes be more intuitive if the application usually identifies XML Schemas by URI rather than by DB2-specific identifiers. However,
the URI must uniquely identify an XML Schema in the XML Schema Repository; otherwise, the
INSERT fails with error SQL20335N.
If the target namespace is not unique among your registered schemas, but the combination of
namespace and schema location is, then you can reference the schema as in the fifth INSERT
statement.
17.1
Document Validation Upon Insert
515
If an XML Schema has no target namespace then you can also reference it just by its schema
location that you provided when you registered the Schema. In this case you use the keywords NO
NAMESPACE LOCATION in the XMLVALIDATE function. These keywords are used in the sixth
INSERT statement in Figure 17.1 and require the schema location to be unique in the XSR.
-- (1) insert without validation:
INSERT INTO customer(id, info) VALUES (?,?);
-- (2) insert with validation, using the schema's SQL identifier:
INSERT INTO customer(id, info) VALUES (?, XMLVALIDATE(?
ACCORDING TO XMLSCHEMA ID db2admin.custxsd) );
-- (3) obtaining the schema identifier as a parameter
INSERT INTO customer(id, info) VALUES (?, XMLVALIDATE(?
ACCORDING TO XMLSCHEMA ID ?) );
-- (4) referencing the schema by its target namespace:
INSERT INTO customer(id, info) VALUES (?, XMLVALIDATE(?
ACCORDING TO XMLSCHEMA URI 'http://pureXMLcookbook.org') );
-- (5) referencing the schema by its namespace and schema location
INSERT INTO customer(id, info) VALUES (?, XMLVALIDATE(?
ACCORDING TO XMLSCHEMA URI 'http://pureXMLcookbook.org'
LOCATION 'customer.xsd') );
-- (6) referencing a schema without a target namespace
INSERT INTO customer(id, info) VALUES (?, XMLVALIDATE(?
ACCORDING TO XMLSCHEMA NO NAMESPACE
LOCATION 'customer.xsd') );
-- (7) relying on schemaLocation hints in the XML documents:
INSERT INTO customer(id, info) VALUES (?, XMLVALIDATE(?) );
Figure 17.1
Insert statements with and without schema validation
The seventh and last INSERT statement in Figure 17.1 uses the XMLVALIDATE function without
specifying any particular XML Schema. In this case, DB2 looks at the incoming XML document
to determine the XML Schema that should be used for validation. In particular, DB2 looks for a
schemaLocation attribute whose value must be a pair of two URIs. The first URI is the target
namespace of the XML Schema, and the second URI is the schema location that you specified
when you registered the schema. The XML document in Figure 17.2 has such a schemaLocation attribute. The target namespace is originally declared in the XML Schema, such as the one
in Figure 16.1. The location URI was given to the XML Schema during registration in Figure
16.9. (See also section 15.1, Introduction to XML Namespaces, for more information on URIs.)
516
Chapter 17
Validating XML Documents against XML Schemas
<customerinfo xmlns="http://pureXMLcookbook.org"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://pureXMLcookbook.org
customer.xsd"
Cid="1004">
<name>Matt Foreman</name>
<addr country="Canada">
<street>1596 Baseline</street>
<city>Toronto</city>
<prov-state>Ontario</prov-state>
<pcode-zip>M3Z 5H9</pcode-zip>
</addr>
<phone type="work">905-555-4789</phone>
</customerinfo>
Figure 17.2
An XML document with a schemaLocation attribute
Considering the options in Figure 17.1, there is no single best way to identify an XML Schema.
People with a strong relational database background often prefer to reference a schema by its
SQL identifier. This identifier is the OBJECTNAME in the catalog view syscat.xsrobjects.
XML-oriented people might prefer to reference a schema by its target namespace, schema location, or both. Either way, the effect is the same. Figure 17.3 shows how to look up a schema’s target namespace and schema location in the XML Schema Repository. In DB2 for z/OS this query
would use the table sysibm.xsrobjects.
SELECT SUBSTR(objectschema,1,10) AS rel_schema,
SUBSTR(objectname,1,10) AS name,
SUBSTR(schemalocation,1,15) AS schemalocation,
SUBSTR(targetnamespace,1,30) AS tgt_namespace
FROM syscat.xsrobjects
WHERE objectname = 'CUSTXSD';
REL_SCHEMA NAME
SCHEMALOCATION TGT_NAMESPACE
---------- ---------- --------------- -------------------------DB2ADMIN
CUSTXSD
customer.xsd
http://pureXMLcookbook.org
1 record(s) selected.
Figure 17.3
Retrieving schema information for a given schema name
If you want to test document validation with INSERT statements in the DB2 Command Line
Processor (CLP), you can include a literal XML document instead of a parameter marker (see
Figure 17.4). This method works for any of the types of INSERT statements in Figure 17.1. The
XMLPARSE function converts the textual XML document, which is a string, into the XML data
type. This data type conversion is required because the XMLVALIDATE function expects a value of
type XML as input. If a parameter marker is used instead of a literal string value, then this type
conversion happens automatically, does not require the XMLPARSE function, and is hence also
known as implicit parsing.
17.1
Document Validation Upon Insert
517
INSERT INTO customer(id, info)
VALUES (1007, XMLVALIDATE(XMLPARSE (document
'<?xml version="1.0" encoding="UTF-8" ?>
<customerinfo Cid="1007">
<name>Kathy Smith</name>
<addr country="Canada"><street>5 Rosewood</street>
<city>Toronto</city>
<prov-state>Ontario</prov-state>
<pcode-zip>M6W 1E6</pcode-zip>
</addr>
<phone type="work">416-555-1358</phone>
</customerinfo>')
ACCORDING TO XMLSCHEMA ID db2admin.custxsd));
Figure 17.4
Validating a literal document against an XML Schema
Validation always implies that boundary whitespace is
stripped, not preserved, in both DB2 for z/OS and DB2 for Linux,
UNIX, and Windows. You cannot insert, update, or load documents
with schema validation and preserve whitespace at the same time. If an
XML Schema defines default values for elements or attributes, these
values get inserted into the document during validation.
NOTE
When you insert a document with schema validation and the document does not comply with the
schema, DB2 returns an error code. The INSERT statement fails and the document is rejected. For
example, if an element name is misspelled (such as citys rather than city) or has the wrong
case (such as City rather than city) and DB2 cannot find a corresponding element definition in
the XML Schema, it issues the following error:
SQL16196N XML document contains an element "citys" that is not correctly specified.
Reason code = "37" SQLSTATE=2200M.
There are dozens of different error codes for the various types of schema violations, and all of
them belong to SQLSTATE 2200M. See the DB2 Information Center for all error codes.
In general, applications are in control of the INSERT statements that they send to the database
server. They can choose whether to use the XMLVALIDATE function and which XML Schema to
reference for validation. Document validation with the XMLVALIDATE function in INSERT statements is a decentralized and application-driven approach to ensuring data quality. This approach
offers a lot of flexibility and can be useful in dynamic and heterogeneous application environments. In other situations more centralized control is desirable. One way to achieve a more centralized control is to allow inserting and updating of XML documents only through stored
procedures that are centrally defined at the database server. Alternatively, you can define check
constraints and triggers, which are discussed in sections 17.4 and 17.5, respectively.
518
17.2
Chapter 17
Validating XML Documents against XML Schemas
DOCUMENT VALIDATION UPON UPDATE
When an XML document is modified there is a chance that it is no longer valid for a given XML
Schema. If you don’t trust applications to modify documents in a valid manner, you may want to
perform validation each time a document is updated. Even if a document has been validated upon
INSERT, it does not get automatically revalidated upon UPDATE. The explicit use of the XMLVALIDATE function in UPDATE statements is required—unless a validation trigger is defined.
Figure 17.5 shows four UPDATE statements with parameter markers. The first statement performs
a full-document replacement without validation. Even if the original document was validated and
associated with an XML Schema in the XML Schema Repository, the new document is not associated with any XML Schema after this UPDATE statement is executed.
The second and third UPDATE statements also perform full-document replacement but they use
the XMLVALIDATE function around the parameter marker to enforce validation of the new document. This is analogous to the use of XMLVALIDATE in Figure 17.1. The fourth UPDATE statement
uses the XMLQUERY function and an XQuery Update expression to only change the value of the
element pcode-zip. The XQuery Update expression takes the existing document as input
($INFO) and produces a modified document. The XMLVALIDATE function ensures that the modified document is valid against an XML Schema whose identifier is provided through a parameter
marker.
UPDATE customer
SET info = ?
WHERE id = 1003;
UPDATE customer
SET info = XMLVALIDATE(? ACCORDING TO XMLSCHEMA ID db2admin.custxsd)
WHERE id = 1003;
UPDATE customer
SET info = XMLVALIDATE(? ACCORDING TO XMLSCHEMA URI ?)
WHERE id = 1003;
UPDATE customer
SET info = XMLVALIDATE( XMLQUERY('
copy $new := $INFO
modify do
replace value of $new/*:customerinfo/*:addr/*:pcode-zip
with "95123"
return $new')
ACCORDING TO XMLSCHEMA ID ?)
WHERE id = 1003;
Figure 17.5
Update statements with and without XML Schema validation
17.3
Validation without Rejecting Invalid Documents
519
Similarly, Figure 17.6 shows an UPDATE statement that replaces an existing document with a new
document that is provided as a literal value rather than through a parameter marker.
UPDATE customer
SET info = XMLVALIDATE(XMLPARSE(DOCUMENT
'<customerinfo Cid="1007">
<name>Kathy Smith</name>
<addr country="Canada">
<street>5 New Street</street>
<city>Toronto</city>
<prov-state>Ontario</prov-state>
<pcode-zip>M6W 1E6</pcode-zip>
</addr>
<phone type="work">416-555-1358</phone>
</customerinfo>')
ACCORDING TO XMLSCHEMA ID db2admin.custxsd)
WHERE id = 1007;
Figure 17.6
17.3
XML update with a literal document and validation
VALIDATION WITHOUT REJECTING INVALID DOCUMENTS
You might have an application where rejecting invalid XML documents with an error is not the
appropriate course of action. In this case you may wish to store the invalid document anyway so
that it doesn’t get lost. At the same time you can record the fact that the document is invalid
together with the reason for the schema violation. This can be done if the INSERT statement is
encapsulated in a stored procedure with exception handling. Figure 17.6 creates such a stored
procedure along with an exception table customer_invalid that has a status column to hold
error information for invalid documents. This stored procedure takes the same input parameters
as the INSERT statements in the previous section: an id number and an XML document. Optionally it could take a schema identifier as a third parameter, but in this example we use the fixed
schema db2admin.custxsd.
The actual body of the procedure consists merely of the INSERT statement at its end. This statement tries to insert the row into the customer table, using the XMLVALIDATE function for validation of the XML document. If this succeeds, the procedure exits and no further action is taken.
If the document is invalid for the specified XML Schema, this INSERT statement fails and the
declared exception handler kicks in. The exception handler is an EXIT handler, which means that
in case of a validation error (SQLSTATE 2200M), the statements in the BEGIN-END block of the
handler are executed before the procedure exits. The handler first uses the GET DIAGNOSTICS
statement to obtain the error message for the failed INSERT statement. Then it inserts the id
value and the XML document without validation into the table customer_invalid, and places
the error message into the status column of the same row. This method allows you to retain the
invalid documents and re-examine them at a later time. They must be well-formed, but don’t have
to be valid.
520
Chapter 17
Validating XML Documents against XML Schemas
CREATE TABLE customer_invalid(id INTEGER,
info XML,
status VARCHAR(300))#
CREATE PROCEDURE myinsert(IN id INTEGER, IN doc XML)
LANGUAGE SQL
BEGIN
DECLARE errormsg
VARCHAR(300);
DECLARE errortoken VARCHAR(50);
DECLARE INVALID_DOCUMENT CONDITION FOR '2200M';
DECLARE EXIT HANDLER FOR INVALID_DOCUMENT
BEGIN
GET DIAGNOSTICS EXCEPTION 1
errortoken = DB2_TOKEN_STRING,
errormsg
= MESSAGE_TEXT;
INSERT INTO customer_invalid(id, info, status)
VALUES(id, doc, errormsg);
END;
INSERT INTO customer(id, info)
VALUES(id, XMLVALIDATE(doc ACCORDING TO XMLSCHEMA
ID db2admin.custxsd));
END #
Figure 17.7
Stored procedure to handle and record validation errors
Since the body of a stored procedure can contain multiple statements, these statements have to be
separated by the semicolon character. Therefore, the CLP cannot use the semicolon as the terminating character for the CREATE PROCEDURE statement. In this example we have chosen the # as
the terminating character. If the procedure definition shown in Figure 17.7 is in a file
create_insert_proc.sql then the following command issued at the OS prompt creates the
procedure:
db2 -td# -f create_insert_proc.sql
The option –td# tells the CLP that the # sign is used as the terminating character.
17.4
ENFORCING VALIDATION WITH CHECK CONSTRAINTS
The explicit use of the XMLVALIDATE function in INSERT and UPDATE statements leaves document validation under the control of the individual applications. Applications can choose whether
to perform validation and which of the XML Schemas in the XSR to reference. One way to
restrict this flexibility and to enforce validation is through the use of check constraints. Another is
the use of triggers, discussed in the next section.
17.4
Enforcing Validation with Check Constraints
521
In DB2 for Linux, UNIX, and Windows you can use check constraints that force applications to
validate XML documents during insert and update, and to reference specific schemas for validation. Such constraints prevent non-validated documents from entering an XML column. DB2 for
z/OS currently does not support this feature.
The ALTER TABLE statement in Figure 17.8 defines a simple check constraint with the IS
VALIDATED predicate. The constraint, which is named val_customer, is defined on the XML
column info of the customer table, and requires all XML documents in this column to be validated. This constraint means that applications cannot perform INSERT or UPDATE operations on
the XML column without using the XMLVALIDATE function. However, applications still have the
freedom to choose any registered XML Schema for validation.
ALTER TABLE customer
ADD CONSTRAINT val_customer
CHECK (info IS VALIDATED)
Figure 17.8
Adding a constraint to enforce validation against any XML Schema
A check constraint itself does not perform validation. It only rejects INSERT or UPDATE statements that do not perform validation. Validation needs to be performed with the XMLVALIDATE
function in INSERT and UPDATE statements as explained in the previous sections. The check constraint ensures that validation is no longer optional for the info column. If an application tries to
insert or update an XML document without using XMLVALIDATE, DB2 returns the following
error message:
SQL0545N The requested operation is not allowed because a row does not satisfy the
check constraint "CUSTOMER.VAL_CUSTOMER". SQLSTATE=23513.
You cannot add the check constraint in Figure 17.8 if the info column of the customer table
already contains documents that have not been validated. In this case, the ALTER TABLE statement fails with the following message:
SQL0544N The check constraint "VAL_CUSTOMER" cannot be added because the table
contains a row that violates the constraint. SQLSTATE=23512
The query in Figure 17.9 identifies the documents in the info column that have not been validated. Section 17.9 explains how to validate or revalidate documents that are already in the table.
SELECT id
FROM customer
WHERE info IS NOT VALIDATED
Figure 17.9
Finding non-validated documents
522
Chapter 17
Validating XML Documents against XML Schemas
To constrain an XML column even more, you might want to enforce document validation not just
against any XML Schema, but against a specific XML Schema. This is possible since DB2 9.5 for
Linux, UNIX, and Windows where the IS VALIDATED predicate can have an optional ACCORDING TO XMLSCHEMA clause (Figure 17.10). This clause allows you to specify a particular registered XML Schema either by its identifier or URI.
ALTER TABLE customer
ADD CONSTRAINT val_customer
CHECK (info IS VALIDATED
ACCORDING TO XMLSCHEMA ID db2admin.custxsd)
Figure 17.10
A constraint to enforce validation against a specific XML Schema
The constraint in Figure 17.10 forces all applications to always validate XML documents in
INSERT and UPDATE statements against the schema db2admin.custxsd. The ALTER TABLE
statement fails if there are already documents in the column that haven’t been validated against
this specific schema.
Forcing all applications to use the same XML Schema, and the same version of that XML
Schema, can sometimes be too restrictive. There may be cases when you want to store XML documents for several different XML Schemas in one XML column. In this case you can create a
check constraint with a list of allowed schemas. For example, the constraint in Figure 17.11
allows applications to insert and update XML documents as long as the XMLVALIDATE function
is used to validate them against any of the three schemas listed in the constraint definition.
ALTER TABLE customer
ADD CONSTRAINT val_customer
CHECK (info IS VALIDATED
ACCORDING TO XMLSCHEMA IN (ID db2admin.custxsd,
ID db2admin.custxsd_V2,
ID db2admin.custxsd_V3) )
Figure 17.11
A constraint to enforce validation against one of several schemas
You cannot alter a constraint. If you want to change it you have to drop it and re-create it. To drop
a constraint, use the DROP CONSTRAINT option of the ALTER TABLE command:
ALTER TABLE customer DROP CONSTRAINT val_customer
Check constraints are evaluated after the INSERT/UPDATE statement is processed, and after any
triggers have fired. If a check constraint is violated, the current transaction is rolled back and an
error is raised. Check constraints can be very useful, but they do not relieve the application from
using the XMLVALIDATE function in INSERT and UPDATE operations. This relief can be achieved
with triggers, which are discussed in the next section.
17.5
Automatic Validation with Triggers
523
When you examine an existing database, you may want to find out whether any such constraints
are defined. This is easily done by querying the SYSCAT.CHECKS catalog view, as shown in Figure 17.12.
SELECT SUBSTR(constname,1,15) AS constraint_name,
SUBSTR(tabname,1,10) AS tabname,
SUBSTR(text,1,90) AS text
FROM
syscat.checks;
CONSTRAINT_NAME TABNAME
TEXT
--------------- ---------- ----------------------------------VAL_CUSTOMER
CUSTOMER
INFO IS VALIDATED ACCORDING TO
XMLSCHEMA IN (ID DB2ADMIN.CUSTXSD)
Figure 17.12
17.5
Listing check constraints
AUTOMATIC VALIDATION WITH TRIGGERS
Triggers allow you to perform automatic document validation in DB2 even if applications do not
use the XMLVALIDATE function in INSERT or UPDATE statements. Specifically, you can create
BEFORE triggers that inject the XMLVALIDATE function any time an INSERT or UPDATE statement is processed.
Figure 17.13 shows the definition of a BEFORE INSERT trigger on the customer table. This trigger fires for every INSERT statement on the customer table. The third line of the trigger definition declares that the new row that is being inserted can be referenced as a variable called
newrow. In general, the body of a trigger is a block of one or multiple statements between the
keywords BEGIN and END. The trigger in Figure 17.13 uses only a single SET statement. It
replaces the value of the XML column info in the new row with the same value validated by the
XMLVALIDATE function. In other words, the SET statement ensures that a new XML document is
not inserted as is, but goes through the XMLVALIDATE function first. If the new document is valid
against the schema db2admin.custxsd, the INSERT succeeds. Otherwise it fails with an error
message detailing the error.
CREATE TRIGGER validate_customer_ins
BEFORE INSERT ON customer
REFERENCING NEW AS newrow
FOR EACH ROW MODE DB2SQL
BEGIN ATOMIC
SET newrow.info = XMLVALIDATE(newrow.info
ACCORDING TO XMLSCHEMA ID db2admin.custxsd);
END #
Figure 17.13
A BEFORE trigger for document validation upon insert
524
Chapter 17
Validating XML Documents against XML Schemas
Similar to the stored procedure in Figure 17.7, the body of a trigger can contain multiple statements, which have to be terminated with the semicolon character. Therefore you have to use a different character to terminate the CREATE TRIGGER statement itself, such as the # used in this
example.
The trigger in Figure 17.13 ensures automatic validation only for new document inserts. You typically require a second similar trigger that automates validation when documents are updated. An
example of an update trigger is shown in Figure 17.14.
The trigger in Figure 17.13 applies the XMLVALIDATE function regardless of whether the original
INSERT statement that fired the trigger contains an XMLVALIDATE function or not. This trigger
always overrides any validation that the application may have specified in its INSERT and
UPDATE statements. This behavior can be desirable for maximum control at the database level.
If you want to allow for more flexibility you can define a conditional trigger with a WHEN clause
(see Figure 17.14). This clause ensures that the trigger is executed only if the new XML document is not being validated with an XMLVALIDATE function in the original INSERT or UPDATE
statement. Simply put, this trigger validates whenever the application does not specify validation,
but it never overrides the validation that the application may have specified. For example, you can
use such a conditional trigger to allow applications to use any registered XML Schema for validation. At the same time the trigger ensures that documents are validated with a default schema if
the application does not specify any validation in its INSERT and UPDATE statements. Additionally you can restrict an application’s choice of schema with a check constraint.
CREATE TRIGGER validate_customer_upd
BEFORE UPDATE OF info ON customer
REFERENCING NEW AS newrow
FOR EACH ROW MODE DB2SQL
WHEN (newrow.info IS NOT VALIDATED)
BEGIN ATOMIC
SET newrow.info = XMLVALIDATE(newrow.info
ACCORDING TO XMLSCHEMA ID db2admin.custxsd);
END #
Figure 17.14
A conditional UPDATE trigger for validation
If you want to enforce that a document is valid for multiple schemas you can have multiple SET
statements in the trigger, such as in Figure 17.15. Upon insert of a document, this trigger performs validation first with the schema custxsd, then with the schema custxsd_V2. The insert
succeeds only if both validations are successful, in which case the validated and stored document
will reference the schema it was last validated with (custxsd_V2).
17.6
Diagnosing Validation and Parsing Errors
525
CREATE TRIGGER insert_customer_ins2
BEFORE UPDATE OF info ON customer
REFERENCING NEW AS newrow
FOR EACH ROW MODE DB2SQL
BEGIN ATOMIC
SET newrow.info = XMLVALIDATE(newrow.info
ACCORDING TO XMLSCHEMA ID db2admin.custxsd);
SET newrow.info = XMLVALIDATE(newrow.info
ACCORDING TO XMLSCHEMA ID db2admin.custxsd_V2);
END #
Figure 17.15
Triggered validation with multiple schemas
Beware that validation against multiple XML
Schemas can significantly increase the CPU consumption.Try to
combine the multiple schemas into a single schema for more
efficient validation.
NOTE
17.6
DIAGNOSING VALIDATION AND PARSING ERRORS
If a document fails to validate against an XML Schema, DB2 produces an appropriate error message that might, depending on the message, contain a reason code that indicates the cause of the
schema violation. If you insert or update a document without validation, errors are also raised if
the document is not well-formed.
Depending on the size and complexity of your documents or XML Schema it can sometimes be
difficult to identify the exact spot in your document that causes the validation or parsing error.
To help you understand and resolve validation and parsing errors, DB2 for Linux, UNIX, and
Windows has introduced a stored procedure called XSR_GET_PARSING_DIAGNOSTICS. It is
included in DB2 9.5 since Fixpack 3 as well as in DB2 9.7. It is not available for DB2 9.1.
If an XML document is not well-formed or invalid for a given XML Schema, invoke the
XSR_GET_PARSING_DIAGNOSTICS procedure with the document and optionally the XML
Schema as input. The procedure produces detailed error information, including:
• The line and column number of the error position in the textual XML document
• An XPath that points to the error location in the document, if possible
• The original error message, reason code, and any applicable error tokens
Figure 17.16 shows the syntax and parameters of the XSR_GET_PARSING_DIAGNOSTICS procedure, and Table 17.1 explains the parameters.
526
Chapter 17
Validating XML Documents against XML Schemas
>>-XSR_GET_PARSING_DIAGNOSTICS--(--document--,--relschema--,-->
>--xmlSchemaName--,--schemaLocation--,--implicitValidation-,-->
>--errorReport--,--errorCount--)-----------------------------><
Figure 17.16
Table 17.1
Syntax of the stored procedure XSR_GET_PARSING_DIAGNOSTICS
Parameters of the Procedure XSR_GET_PARSING_DIAGNOSTICS
Parameter
Purpose
document
The XML document, provided as a BLOB(30M). Cannot be NULL.
relschema,
xmlSchemaName
Two optional input parameters of type VARCHAR(128) that provide the
two part SQL identifier of an XML Schema. For example, if the XML
Schema is db2admin.custxsd, then relschema should receive the value
db2admin and xmlSchemaName the value custxsd.
schemaLocation
The schema location URI that you specified when you registered the schema.
This is an optional alternative way to specify an XML Schema for validation.
It can be NULL.
implicitValidation
Input parameter, must be either 0 or 1, cannot be NULL.
1 means that the document is validated against the schema that is specified
by an xsi:schemaLocation attribute within the XML document itself.
0 means that the document is validated against the schema identified by
relschema.xmlSchemaName, and if relschema and
xmlSchemaName are NULL then the document is not validated.
errorReport
An output parameter of type VARCHAR(32000) that contains the error information in XML format.
errorCount
Output parameter for the number of reported errors (INTEGER).
In Figure 17.17 you see a sample invocation of the XSR_GET_PARSING_DIAGNOSTICS procedure in the DB2 Command Line Processor (CLP) as well as the error report produced. The input
document is cast to BLOB to match the parameter type of the stored procedure. Since no XML
Schema information is provided, this invocation of the procedure only reports well-formedness
errors. Note that the closing tag of the name element is misspelled in the document. The error
report reveals that the problem is at character 24 in line 2 of the document, in the element identified by /customerinfo/name.
17.6
Diagnosing Validation and Parsing Errors
CALL xsr_get_parsing_diagnostics(
BLOB('<customerinfo Cid="1008">
<name>Kathy Smith</nam>
<addr country="Canada"><street>5 Rosewood</street>
<city>Toronto</city>
<prov-state>Ontario</prov-state>
<pcode-zip>M6W 1E6</pcode-zip>
</addr>
<phone type="work">416-555-1358</phone>
</customerinfo>'),'','','',0,?,?);
Value of output parameters
-------------------------Parameter Name : ERRORDIALOG
Parameter Value :
<ErrorLog>
<XML_FatalError parser="XML4C">
<errCode>202</errCode>
<errDomain>http://apache.org/xml/messages/XMLErrors</errDomain>
<errText>Expected end of tag 'name'</errText>
<lineNum>2</lineNum>
<colNum>24</colNum>
<location>/customerinfo/name</location>
<schemaType></schemaType>
<tokenCount>1</tokenCount>
<token1>name</token1>
</XML_FatalError>
<DB2_Error>
<sqlstate>2200M<sqlstate/>
<sqlcode>-16129<sqlcode/>
<errText>[IBM][CLI Driver][DB2/AIX64] SQL16129N XML document
expected end of tag "name". SQLSTATE=2200M<errText/>
</DB2_Error>
</ErrorLog>
Parameter Name : ERRORCOUNT
Parameter Value : 1
Figure 17.17
Obtaining an error report for an XML parsing error
If you use the procedure XSR_GET_PARSING_DIAGNOSTICS in the DB2 Command Line Processor with a hardcoded XML
NOTE
document as input, as shown in Figure 17.17, make sure that you invoke
the CLP with the -q option (db2 -q -t).Without the -q option the
input document is always treated as a single long line so that any error
is always reported to be in line 1. This is because by default the CLP
strips all new-line characters from any submitted input before sending it
to the DB2 server. The -q option forces the CLP to retain all whitespace and new-line characters, which ensures that the line and column
information in the error report are correct.
527
528
Chapter 17
Validating XML Documents against XML Schemas
Figure 17.18 illustrates an invocation of the XSR_GET_PARSING_DIAGNOSTICS procedure that
checks a document for validation errors against the XML Schema db2admin.custxsd. That’s
the same XML Schema as we used in Chapter 16 (see Figure 16.1 in section 16.2, Anatomy of an
XML Schema). The relevant parts of that XML Schema are repeated in Figure 17.19.
CALL xsr_get_parsing_diagnostics(
BLOB('<customerinfo xmlns="http://pureXMLcookbook.org"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://pureXMLcookbook.org
customer.xsd"
Cid="5D8k17">
<name>Kathy Smith</name>
<addr country="Canada"><street>5 Rosewood</street>
<city>Toronto</city>
<pcode-zip>M6W 1E6</pcode-zip>
<prov-state>Ontario</prov-state>
</addr>
<phone>416-555-1358</phone>
</customerinfo>'),'db2admin','custxsd','',1,?,?);
Figure 17.18
Obtaining an error report for schema validation
The excerpts of the XML Schema show that the Cid attribute must have a value of type
xs:integer, and that the pcode-zip element has to be the last child element of addr. The
document in Figure 17.18 does not comply with these rules and schema validation fails.
(…)
<xs:complexType name="addrType">
<xs:sequence>
<xs:element name="street" type="xs:string"/>
<xs:element name="city" type="xs:string"/>
<xs:element name="prov-state" type="xs:string"/>
<xs:element name="pcode-zip" type="xs:string"/>
</xs:sequence>
<xs:attribute name="country" type="xs:string"/>
</xs:complexType>
(…)
<xs:attribute name="Cid" type="xs:integer" />
Figure 17.19
Excerpts of the XML Schema from Figure 16.1
Figure 17.20 shows the error report for the document in Figure 17.18. At the bottom of the error
report, note that the error count is 2. The error report shows both validation errors, while regular
validation in DB2 would produce an error message only for the first of the two errors (shown in
element <DB2_Error>). The first error explains that the value 5D8k17 in line 5 of the XML document does match the data type in the XML Schema. The second error reveals that the element
pcode-zip in the document violates a so-called content model in the XML Schema, which
17.6
Diagnosing Validation and Parsing Errors
529
defines that pcode-zip must be last in the following sequence of elements: ((street,city,
prov-state),pcode-zip).
Value of output parameters
-------------------------Parameter Name : ERRORDIALOG
Parameter Value :
<ErrorLog>
<XML_Error parser="XML4C">
<errCode>238</errCode>
<errDomain>http://apache.org/xml/messages/XML4CErrors
</errDomain>
<errText>Datatype error: Type:InvalidDatatypeValueException,
Message:Value '5D8k17' does not match regular expression
facet '[+\-]?[0-9]+'.</errText>
<lineNum>5</lineNum>
<colNum>22</colNum>
<location></location>
<schemaType>http://www.w3.org/2001/XMLSchema:anyType
</schemaType>
<tokenCount>2</tokenCount>
<token1>5D8k17</token1>
<token2>13</token2>
</XML_Error>
<XML_Error parser="XML4C">
<errCode>7</errCode>
<errDomain>http://apache.org/xml/messages/XMLValidity
</errDomain>
<errText>Element 'pcode-zip' is not valid for content model:
'((street,city,prov-state),pcode-zip)'</errText>
<lineNum>11</lineNum>
<colNum>10</colNum>
<location>/customerinfo/addr</location>
<schemaType>http://www.w3.org/2001/XMLSchema:string</schemaType>
<tokenCount>2</tokenCount>
<token1>pcode-zip</token1>
<token2>31</token2>
</XML_Error>
<DB2_Error>
<sqlstate>2200M<sqlstate/>
<sqlcode>-16210<sqlcode/>
<errText>[IBM][CLI Driver][DB2/AIX64] SQL16210N XML document
contained a value "5D8k17" that violates a facet constraint.
Reason code = "13". SQLSTATE=2200M<errText/>
</DB2_Error>
</ErrorLog>
Parameter Name : ERRORCOUNT
Parameter Value : 2
Figure 17.20
Error report for a document that fails schema validation
530
17.7
Chapter 17
Validating XML Documents against XML Schemas
VALIDATION DURING LOAD AND IMPORT OPERATIONS
DB2’s LOAD and IMPORT utilities allow you to efficiently move large numbers of XML documents into a table. These utilities are discussed in Chapter 5, Moving XML Data. The LOAD utility
in DB2 for z/OS does not yet support XML Schema validation. Hence, this section focuses on the
LOAD and IMPORT utilities in DB2 for Linux, UNIX, and Windows.
Both LOAD and IMPORT have options to validate XML documents against XML Schemas. In fact,
both utilities offer the same options and the same command syntax for XML Schema handling. In
this chapter we focus on the IMPORT utility, but all demonstrated options can be used identically
with the LOAD utility. These options include
• Validate all imported or loaded documents against a single XML Schema (section
17.7.1)
• In a single IMPORT or LOAD command, validate different documents against different
XML Schemas (section 17.7.2)
• Specify a default XML Schema for IMPORT or LOAD to also validate documents for
which no specific XML Schema is explicitly declared in the delimited format input file
(section 17.7.3)
• Disable validation for some of the XML Schemas specified in the input file (section
17.7.4)
• Selectively validate documents against a different schema than the one specified in the
input file (also in section 17.7.4)
• Validate documents against XML Schemas that are referenced in schema location attributes in the XML documents (section 17.7.5)
17.7.1 Validation against a Single XML Schema
When you import or load a set of XML documents, simply add the clause XMLVALIDATE USING
SCHEMA to the LOAD or IMPORT command and specify the SQL identifier of the XML Schema
that you want to use for validation. This is illustrated in the IMPORT command in Figure 17.21
and the LOAD command in Figure 17.22. The file load_customer.txt is a delimited format file
(DEL), which contains one line for each row that is being processed. This file contains values for
relational columns but no XML data for XML columns. For XML columns, it contains references
to separate XML files, which are located in the directory that is specified in the XML FROM clause.
IMPORT FROM c:\xml\load_customer.txt OF DEL
XML FROM c:\xml
XMLVALIDATE USING SCHEMA db2admin.custxsd
INSERT INTO customer
Figure 17.21
Performing XML Schema validation during IMPORT
17.7
Validation during Load and Import Operations
531
LOAD FROM c:\xml\load_customer.txt OF DEL
XML FROM c:\xml
XMLVALIDATE USING SCHEMA db2admin.custxsd
INSERT INTO customer
Figure 17.22
Performing XML Schema validation during LOAD
The XMLVALIDATE clause and its various options are identical for the LOAD and IMPORT commands. All subsequent examples therefore only show the IMPORT command.
17.7.2 Validation against Multiple XML Schemas
There can be cases when you don’t want to validate all documents in a single LOAD or IMPORT
operation against the same XML Schema. In this case you might be able to group your XML documents into multiple sets, one for each XML Schema. Then you can issue several individual
LOAD or IMPORT commands to load each set separately, each time specifying the appropriate
XML Schema.
DB2 also allows you to use multiple XML Schemas in a single LOAD or IMPORT command. This
requires explicit schema references in the delimited format input file. Figure 17.23 shows three
lines of a delimited format input file. Each line contains two entries, one for each of the two
columns. The first entry is an integer value for the id column of the customer table; the second
entry is an XML Data Specifier (XDS) that carries two attributes. The first attribute (FIL) points to
an XML file that is to be imported, and the second attribute (SCH) provides the SQL identifier of
an XML Schema. As a result, each XML document can be validated against a different XML
Schema.
2000,"<XDS FIL='data2.xml' SCH='DB2ADMIN.CUSTXSD1' />"
2001,"<XDS FIL='data3.xml' SCH='DB2ADMIN.CUSTXSD2' />"
2002,"<XDS FIL='data4.xml' SCH='DB2ADMIN.CUSTXSD1' />"
Figure 17.23
Schema identifiers in the delimited format input file
The input file in Figure 17.23 tells DB2 to use the XML Schema CUSTXSD1 to validate the XML
documents contained in files data2.xml and data4.xml, and the schema CUSTXSD2 to validate the XML document data3.xml. Additionally you need to include the XMLVALIDATE
USING XDS clause in the IMPORT or LOAD command (see Figure 17.24). Otherwise the SCH
attributes in the input are ignored and no validation is performed.
IMPORT FROM c:\xml\load_customer.txt OF DEL
XML FROM c:\xml
XMLVALIDATE USING XDS
INSERT INTO customer
Figure 17.24
Performing XML Schema validation during IMPORT with multiple schemas
532
Chapter 17
Validating XML Documents against XML Schemas
What happens if the delimited format input file contains schema references (SCH attributes) but
you use the XMLVALIDATE USING SCHEMA <schemaID> clause in the LOAD or IMPORT command? In this case the XML Schema specified in the XMLVALIDATE USING SCHEMA clause
takes precedence, all documents are validated against that one schema, and the SCH attributes in
the input file are ignored.
For a large number of documents you normally don’t create the delimited format input file manually—you may have an application or script that creates it for you. Also, note that DB2’s EXPORT
utility can export tables (or subsets of a table defined by a query) to the file system. When you
export XML data, the EXPORT utility automatically generates a delimited format file and optionally includes SCH attributes with schema identifiers for all documents that have been validated.
Samples of the output produced by EXPORT are shown in Figure 17.23, Figure 17.25, and
Figure 17.27.
17.7.3 Using a Default XML Schema
When schema references are included in the delimited format input file, it is possible that not
every XDS has a SCH attribute (see Figure 17.25). In this case, the LOAD and IMPORT commands
allow you to specify a default schema for those records that do not have a SCH attribute in the
input file.
2000,"<XDS FIL='data2.xml' />"
2001,"<XDS FIL='data3.xml' SCH='DB2ADMIN.CUSTXSD2' />"
2002,"<XDS FIL='data4.xml' />"
Figure 17.25
Schema identifiers in the delimited format input file
The IMPORT command in Figure 17.26 contains the DEFAULT option in the XMLVALIDATE
USING XDS clause to indicate that any input documents that don’t have a schema reference in the
XDS must be validated against the schema custxsd1.
IMPORT FROM c:\xml\load_customer.txt OF DEL
XML FROM c:\xmldata
XMLVALIDATE USING XDS DEFAULT db2admin.custxsd1
INSERT INTO customer
Figure 17.26
Specifying a default schema for validation
Note that the DEFAULT clause takes precedence over the IGNORE and MAP clauses (discussed in
the next sections).
17.7.4 Overriding XML Schema References
Assume you need to import XML data using the delimited format input file in Figure 17.27. This
input file contains references to XML Schemas custxsd1, custxsd2, and custxsd3.
17.7
Validation during Load and Import Operations
2000,"<XDS
2001,"<XDS
2001,"<XDS
2002,"<XDS
Figure 17.27
FIL='data2.xml'
FIL='data3.xml'
FIL='data3.xml'
FIL='data4.xml'
SCH='DB2ADMIN.CUSTXSD1'
SCH='DB2ADMIN.CUSTXSD3'
SCH='DB2ADMIN.CUSTXSD2'
SCH='DB2ADMIN.CUSTXSD1'
533
/>"
/>"
/>"
/>"
Schema identifiers in the delimited format input file
Let’s say you only want to validate the documents that reference schema custxsd1, but not the
documents that reference custxsd2 or custxsd3. One reason could be that you received the
input data but you only have schema custxsd1 and not the other two. Another reason could be
that the documents for schemas custxsd2 and custxsd3 are already known to be valid and you
want to save the CPU cycles of validating them again.
In such cases you can add the IGNORE keyword with a list of schema identifiers to the XMLVALIDATE USING XDS clause. An example is shown in Figure 17.28. It tells DB2 to perform validation based on the schemas specified in the SCH attributes, but not to validate any documents that
reference any of the schemas listed in the IGNORE clause.
IMPORT FROM c:\xml\tab.txt OF DEL
XML FROM c:\xmldata
XMLVALIDATE USING XDS IGNORE (db2admin.custxsd2,
db2admin.custxsd3)
INSERT INTO customer
Figure 17.28
Disabling validation for selected XML Schemas
Instead of ignoring certain XML Schemas you can also override them with a different schema.
The MAP clause allows you to specify alternate XML Schemas to use in place of those specified
by the SCH attributes in the delimited format input file. The MAP clause specifies a list of one or
more XML Schema pairs, where each pair represents a mapping from one XML Schema to
another. The first XML Schema in the pair represents a schema that is referenced by an SCH
attribute in an XDS. The second XML Schema in the pair represents the schema that should be
used to perform validation. An example is shown in Figure 17.29, where the IMPORT command
uses the schema custxsd1 whenever it sees schema custxsd2 or custxsd3 in an SCH attribute
in the input file.
IMPORT FROM c:\xml\tab.txt OF DEL
XML FROM c:\xmldata
XMLVALIDATE USING XDS
MAP ((db2admin.custxsd2, db2admin.custxsd1),
(db2admin.custxsd3, db2admin.custxsd1))
INSERT INTO customer
Figure 17.29
Import with validation against “mapped” XML Schemas
534
Chapter 17
Validating XML Documents against XML Schemas
The following usage rules apply:
• If an XML Schema is present in the left side of a schema pair in the MAP clause, it cannot
also be specified in the IGNORE clause.
• If an XML Schema is present in the right side of a schema pair in the MAP clause, it will
not be subsequently ignored if listed in the IGNORE clause.
• An XML Schema cannot be mapped more than once. It cannot appear on the left side of
more than one schema pair.
• Schema mappings in the MAP clause are non-transitive. For example, assume schema
custxsd3 is mapped to schema custxsd2, and assume a second pair maps schema
custxsd2 to schema custxsd1; then schema custxsd1 will not be used instead of
schema custxsd3.
17.7.5 Validation Based on schemaLocation Attributes
The IMPORT command in Figure 17.30 contains the clause XMLVALIDATE USING SCHEMALOCATION HINTS. This clause indicates that each XML document in the input file is to be validated
against the XML Schema that is referenced by the optional xsi:schemaLocation attribute
within the document. An xsi:schemaLocation attribute, which is also called a schema location hint, contains a pair of target namespace and schema location. This pair can identify an XML
Schema that you have previously registered in the XML Schema Repository. Earlier in this chapter, Figure 17.2 showed an XML document with an xsi:schemaLocation attribute.
IMPORT FROM c:\xml\load_customer.txt OF DEL
XML FROM c:\xmldata
XMLVALIDATE USING SCHEMALOCATION HINTS
INSERT INTO customer
Figure 17.30
Validation with schema location hints
17.8 CHECKING WHETHER AN EXISTING DOCUMENT HAS BEEN
VALIDATED
DB2 allows you to check whether an XML document that is stored in a table has previously been
validated. This can be done in a couple of ways. In DB2 for Linux, UNIX, and Windows you can
use the IS VALIDATED predicate, which works similarly to the IS NULL predicate that you
might already be familiar with. The query in Figure 17.31 checks every XML document in the
info column of the customer table and returns YES if the document has been validated, and NO
otherwise.
17.9
Validating Existing Documents in a Table
535
SELECT id,
CASE WHEN info IS VALIDATED THEN 'YES' ELSE 'NO' END
AS isvalid
FROM customer
Figure 17.31
Checking which documents in a table have been validated
The query in Figure 17.32 is very similar but uses a WHERE clause with an XMLEXISTS predicate
to check the validation status only of the document(s) where the customer name is Matt Foreman.
SELECT CASE WHEN info IS VALIDATED THEN 'YES' ELSE 'NO' END
AS isvalid
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo[name = "Matt Foreman"]')
Figure 17.32
Checking whether a specific document has been validated
To perform similar checks in DB2 for z/OS you need to maintain an additional column in your
user table. The column can contain 0 or 1 to indicate whether the document has been validated.
Alternatively you can store the OBJECTID of the XML Schema in a BIGINT column. Then you
can easily query this column to determine which schema a given XML document belongs to.
17.9
VALIDATING EXISTING DOCUMENTS IN A TABLE
You might encounter a situation where you already have XML documents stored in an XML column and want to validate them against an XML Schema. Maybe they were never validated and
you want to validate them now. Or, maybe they had been validated when they were inserted, but
now you want to validate them against a new schema. Either way, the validation of existing documents can be achieved with SELECT or UPDATE statements.
Let’s look at the update process first. Figure 17.33 shows an UPDATE statement that replaces a
document with a validated copy of itself. The WHERE clause uses a relational predicate to identify
a single row in the customer table. In this row, the XML document in the info column is
replaced with the result of the XMLVALIDATE function. The XMLVALIDATE function itself also
takes the info column as input. If the document is not valid against the specified XML Schema,
the update fails. Otherwise the document is replaced with itself and the OBJECTID of the XML
Schema gets attached to the document. This links the document to its schema. The function
XMLXSROBJECTID can take the document or any part of it as input, and returns the OBJECTID of
the schema that the document was validated against (see section 17.10).
536
Chapter 17
Validating XML Documents against XML Schemas
UPDATE customer
SET info = XMLVALIDATE(info ACCORDING TO XMLSCHEMA ID db2admin.custxsd)
WHERE id = 1000
Figure 17.33
Validating an existing document
The UPDATE statement in Figure 17.34 is similar to that in Figure 17.33, but has a different predicate in the WHERE clause. It tries to validate all documents in the XML column that have not been
validated before. This update works as expected if all those documents are valid against the specified XML Schema. However, the problem with this UPDATE statement is that it fails and rolls
back as soon as the first invalid document is encountered. The reason for this behavior is that the
SQL/XML standard requires the XMLVALIDATE function to raise an error if validation fails. You
will see later how error handling in a stored procedure can circumvent this problem (see Figure
17.38).
UPDATE customer
SET info = XMLVALIDATE(info ACCORDING TO XMLSCHEMA ID db2admin.custxsd)
WHERE info IS NOT VALIDATED
Figure 17.34
Validating multiple existing documents
Beware that a bulk update with validation of a large number of documents can take a significant
amount of time. All affected documents are rewritten in the table space and logged. If you are
only interested in a Yes/No answer whether certain documents are valid for a given schema, and if
you don’t require the relationship between documents and schema to be permanently recorded in
the database, then a SELECT statement can be used instead of an UPDATE statement. The query in
Figure 17.35 reads XML documents from the info column for all customers whose city is
Toronto. At the same time it uses the XMLVALIDATE function in the SELECT clause to validate
the documents upon retrieval. The query fails at runtime as soon as one document is retrieved that
is not valid for the specified schema.
SELECT XMLVALIDATE(info ACCORDING TO XMLSCHEMA ID db2admin.custxsd)
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo[addr/city = "Toronto"]')
Figure 17.35
Retrieving and validating documents at the same time
If the validation is performed in a stored procedure, an exception handler can catch and handle
the validation failure. Figure 17.36 shows a simple stored procedure that takes a single XML document as input and returns 1 if the document is valid and 0 if it is not valid. If the input document
17.9
Validating Existing Documents in a Table
537
is not valid for the specified schema, the exit handler catches the error that is raised by XMLVALIDATE and sets the output parameter isvalid to 0.
CREATE PROCEDURE validate(IN doc XML, OUT isvalid INTEGER)
LANGUAGE SQL
BEGIN
DECLARE INVALID_DOCUMENT CONDITION FOR '2200M';
DECLARE EXIT HANDLER FOR INVALID_DOCUMENT
SET isvalid = 0;
IF (XMLVALIDATE(doc ACCORDING TO XMLSCHEMA
ID db2admin.custxsd) IS VALIDATED)
THEN SET isvalid = 1;
END IF;
END #
Figure 17.36
Stored procedure to validate an existing document
The stored procedure in Figure 17.36 can be called from an application or from other stored procedures that manipulate XML documents. You can also call it in the DB2 Command Line Processor, if the first parameter of the stored procedure call is a query that produces a single XML
document. This is illustrated in Figure 17.37, where the XML document with id = 1003 from
the customer table is passed to the stored procedure for validation. The output shows that the
output parameter isvalid has the value 1, which means that the document is valid.
db2 =>
call validate((SELECT info FROM customer WHERE id = 1003),?)
Value of output parameters
-------------------------Parameter Name : ISVALID
Parameter Value : 1
Return Status = 0
db2 =>
Figure 17.37
Testing the validation stored procedure in the CLP
The stored procedure in Figure 17.38 is designed to perform the same task as the UPDATE statement in Figure 17.34. That is, it validates all documents in the XML column that have not been
validated before. The major difference is that this stored procedure does not fail and abort when
the first invalid document is encountered. Instead, it loops over the XML documents and uses a
CONTINUE handler to count invalid documents instead of raising an error. Alternatively, you
could change the CONTINUE handler to write the id values of the invalid documents to a separate
table, or take any other appropriate action.
538
Chapter 17
Validating XML Documents against XML Schemas
CREATE PROCEDURE bulkvalidate(OUT num_invalid_docs INTEGER)
LANGUAGE SQL
BEGIN
DECLARE count INTEGER DEFAULT 0;
DECLARE INVALID_DOCUMENT CONDITION FOR '2200M';
DECLARE CONTINUE HANDLER FOR INVALID_DOCUMENT
SET count = count + 1;
FOR doc AS cur1 CURSOR FOR
SELECT id, info
FROM customer
WHERE info IS NOT VALIDATED
FOR UPDATE OF INFO
DO
UPDATE customer
SET info = XMLVALIDATE(info ACCORDING TO XMLSCHEMA
ID db2admin.custxsd)
WHERE CURRENT of cur1;
END FOR;
SET num_invalid_docs = count;
END#
Figure 17.38
17.10
Stored procedure to validate multiple existing documents
FINDING THE XML SCHEMA FOR A VALIDATED DOCUMENT
DB2 for Linux, UNIX, and Windows also allows you to determine which XML Schema was used
to validate a particular XML document. Every XML Schema that is registered in DB2 is
assigned an internal identification number of type BIGINT. You can see this number in the column OBJECTID of the catalog view SYSCAT.XSROBJECTS. Whenever an XML document is validated against an XML Schema, the unique identifier (OBJECTID) is stored with the XML
document.
The scalar function XMLXSROBJECTID takes an XML document as input and returns the OBJECTID of the XML Schema that was used to validate the XML document. If the input document
hasn’t been validated, the value 0 is returned.
There are several interesting uses of the function XMLXSROBJECTID. One is to find the XML
Schema that was used to validate a specific document. Another is finding all documents that have
been validated against a particular XML Schema.
Figure 17.39 shows how to use the function XMLXSROBJECTID in the WHERE clause of an SQL
statement to join with the OBJECTID column in the catalog view syscat.xsrobjects.
Together with the predicate on the relational id column, this retrieves information about the
schema that was used to validate the document with id 1003. Instead of the relational predicate
you can certainly also use an XMLEXISTS predicate to qualify one or multiple XML documents
based on the contents of the XML document itself.
17.10
Finding the XML Schema for a Validated Document
539
SELECT c.id,
SUBSTR(x.objectschema,1,10) AS xmlschema_schema,
SUBSTR(x.objectname,1,10)
AS xmlschema_name
FROM customer c, syscat.xsrobjects x
WHERE XMLXSROBJECTID(c.info) = x.OBJECTID
AND c.id = 1003;
ID
XMLSCHEMA_SCHEMA XMLSCHEMA_NAME
--------------- ---------------- -------------1003 DB2ADMIN
CUSTXSD
Figure 17.39
Finding schema information for a given XML document
There is no hard dependency between a document and
the XML Schema it was validated against. This means that an XML
Schema can be dropped from the XML Schema Repository even if the
database contains documents that were validated against this schema.
Those documents continue to carry the OBJECTID of the XML
Schema even after the schema is dropped.The OBJECTID now points
to a non-existing XML Schema, which has no impact other than
the obvious; that is, you won’t find the schema that belongs to these
documents.
NOTE
While the query in Figure 17.39 finds the XML Schema for a given document, the query in Figure 17.40 finds the documents that were validated with a given XML Schema. Again, the function
XMLXSROBJECTID facilitates the join between the customer table and the XML Schema Repository. The second and the third predicates select the particular XML Schema db2admin.
custxsd for which the query finds all corresponding XML documents.
SELECT c.id
FROM customer c, syscat.xsrobjects x
WHERE XMLXSROBJECTID(c.info) = x.OBJECTID
AND x.objectschema = 'DB2ADMIN'
AND x.objectname = 'CUSTXSD'
Figure 17.40
Finding documents for given XML Schema, using XMLXSROBJECTID
Since DB2 9.5 for Linux, UNIX, and Windows you can also use the IS VALIDATED predicate
with the ACCORDING TO clause, as shown in Figure 17.41.
SELECT c.id
FROM customer c
WHERE c.info IS VALIDATED ACCORDING TO
XMLSCHEMA ID db2admin.custxsd
Figure 17.41
Finding documents for given XML Schema, using IS VALIDATED
540
Chapter 17
Validating XML Documents against XML Schemas
If you use multiple XML Schemas to validate documents within a single XML column, and
if you frequently need to run queries that relate documents to schemas, consider storing the
OBJECTID in an additional column of your table with an index on it. This additional column can
greatly improve the performance of finding schemas and documents that relate to each other. In
DB2 for z/OS, such an extra column is the only way to correlate documents to schemas.
17.11
HOW TO UNDO DOCUMENT VALIDATION
It is possible to make a validated XML document look and behave as if it had never been validated. When you “undo” the validation, the linkage between the document and any XML Schema
is removed, because the OBJECTID of an XML Schema is no longer associated with the document. All it takes is to update the validated document with itself and reparse it without validation.
You will probably rarely have to do this, but we want to show that it is possible if needed. It only
applies to DB2 for Linux, UNIX, and Windows.
You “remove validation” from a document with an UPDATE statement and the XMLSERIALIZE
and XMLPARSE functions as shown in Figure 17.42. This statement serializes the stored document
tree back to text format and then parses it again to produce DB2’s internal tree format, but without validation (assuming you don’t have triggers that enforce validation). The document now
looks like it has never been validated.
UPDATE customer
SET info = XMLPARSE(DOCUMENT XMLSERIALIZE(info AS CLOB(5000)))
WHERE id = 1000
Figure 17.42
Undoing validation disassociates a document from its schema
Note that the XMLSERIALIZE function requires you to use a character type, such as VARCHAR or
CLOB, that is large enough to temporarily hold the serialized document.
17.12
CONSIDERATIONS FOR VALIDATION IN DB2 FOR Z/OS
Throughout this chapter you have seen many ways in which the function XMLVALIDATE can be
used in DB2 for Linux, UNIX, and Windows to validate XML documents against an XML
Schema. The equivalent function in DB2 9 for z/OS is called SYSFUN.DSN_XMLVALIDATE. The
main difference between the two is that DSN_XMLVALIDATE must be an argument to the XMLPARSE function. The other difference is that DSN_XMLVALIDATE does not use an ACCORDING TO
XMLSCHEMA clause to identify an XML Schema, but a regular parameter instead. The following
sections provide examples.
17.12
Considerations for Validation in DB2 for z/OS
17.12.1
541
Document Validation Upon Insert
The DSN_XMLVALIDATE function can take either two or three input parameters. The first parameter is the XML document that you want to validate. It must be of type CLOB or BLOB with a maximum size of 250MB, or of type VARCHAR with a maximum size of 32KB.
If you are using DSN_XMLVALIDATE with two parameters, then the second parameter has to be
the SQL identifier of the XML Schema that you want to use for validation. This parameter cannot
be NULL. Figure 17.43 shows two INSERT statements that use DSN_XMLVALIDATE with two
parameters. The first statement provides the XML document as a parameter marker, and the second uses a host variable. Both specify that the document is to be validated against the XML
Schema SYSXSR.CUSTXSD. An error is returned if an XML Schema with this identifier is not
found in DB2’s XML Schema Repository (XSR).
INSERT INTO customer(id, info)
VALUES (?, XMLPARSE( DOCUMENT
SYSFUN.DSN_XMLVALIDATE(
(CAST ? AS CLOB), 'SYSXSR.CUSTXSD') ) );
INSERT INTO customer(id, info)
VALUES (:id, XMLPARSE( DOCUMENT
SYSFUN.DSN_XMLVALIDATE(
:document_hv, 'SYSXSR.CUSTXSD') ) );
Figure 17.43
Referencing the XML Schema by its SQL identifier
If you are using DSN_XMLVALIDATE with three parameters, then the second and third parameters
must be the target namespace and the schema location of the XML Schema that you want to use
for validation (see Figure 17.44). This combination of target namespace and schema location
must uniquely identify an XML Schema that is registered in the XSR, otherwise an error is
raised. If you use DSN_XMLVALIDATE with three parameters, the second and/or the third parameter can be NULL. In this case DB2 still looks for a corresponding XML Schema in its XML
Schema Repository. If both parameters are NULL, DB2 expects to find exactly one schema in the
XSR whose target namespace and schema location are NULL. DB2 for z/OS does not infer the
schema from a schema location attribute inside the XML document that you want to validate.
INSERT INTO customer(id, info)
VALUES (?, XMLPARSE( DOCUMENT SYSFUN.DSN_XMLVALIDATE(
(CAST ? AS CLOB),
'http://pureXMLcookbook.org',
NULL ) ) );
INSERT INTO customer(id, info)
VALUES (?, XMLPARSE( DOCUMENT SYSFUN.DSN_XMLVALIDATE(
:document_hv,
'http://pureXMLcookbook.org',
'customer.xsd' ) ) );
Figure 17.44
(continues)
Referencing the XML Schema by target namespace and schema location
542
Chapter 17
Validating XML Documents against XML Schemas
INSERT INTO customer(id, info)
VALUES (:id, XMLPARSE( DOCUMENT SYSFUN.DSN_XMLVALIDATE(
:document_hv,
NULL,
'customer.xsd' ) ) );
INSERT INTO customer(id, info)
VALUES (:id, XMLPARSE( DOCUMENT SYSFUN.DSN_XMLVALIDATE(
:document_hv,
NULL,
NULL ) ) );
Figure 17.44
(Continued)
Referencing the XML Schema by target namespace and schema location
The previous examples provided either the SQL identifier of the XML Schema, or the target
namespace and schema location as string literals. Alternatively you can provide them through
parameter markers or host variables. The first INSERT statement in Figure 17.45 uses the
DSN_XMLVALIDATE function with two parameter markers. The first provides the document to
validate and the second provides the SQL identifier of the XML Schema. The second parameter
cannot provide an actual XML Schema document for validation, because DB2 only validates
against schemas that were previously registered in the XSR. The second INSERT statement in
Figure 17.45 uses DSN_XMLVALIDATE with three host variables, which means that the schema is
being identified by target namespace and schema location.
INSERT INTO customer(id, info)
VALUES (?, XMLPARSE( DOCUMENT
SYSFUN.DSN_XMLVALIDATE(
(CAST ? as CLOB), ?) ) );
INSERT INTO customer(id, info)
VALUES (:id, XMLPARSE( DOCUMENT SYSFUN.DSN_XMLVALIDATE(
:document_hv,
:tgtnamespace_hv,
:schemalocation_hv) ) );
Figure 17.45
Providing schema identification via parameter markers or host variables
The DSN_XMLVALIDATE function can only be used as a parameter to the XMLPARSE function, and
in that case the XMLPARSE function cannot use the PRESERVE WHITESPACE clause. Validation
always implies that boundary whitespace is stripped, not preserved, in both DB2 for z/OS and
DB2 for Linux, UNIX, and Windows.
17.12.2
Document Validation Upon Update
If you use SQL UPDATE statements in DB2 for z/OS to replace existing documents, the
DSN_XMLVALIDATE function allows you to validate the new document as part of the update
17.12
Considerations for Validation in DB2 for z/OS
543
process. In the previous sections you have seen various different ways in which you can provide
input to the DSN_XMLVALIDATE function. All of them work in UPDATE statements as well, as in
Figure 17.46.
UPDATE customer
SET info = XMLPARSE( DOCUMENT SYSFUN.DSN_XMLVALIDATE(
:document_hv, 'SYSXSR.CUSTXSD') ) )
WHERE id = 1003
Figure 17.46
17.12.3
DSN_XMLVALIDATE in an UPDATE statement
Validating Existing Documents in a Table
There may be situations where you already have XML documents stored in an XML column and
want to validate them against an XML Schema. For example, the query in Figure 17.47 selects all
documents for customers in Toronto and validates them upon retrieval. Remember that the
DSN_XMLVALIDATE function requires the input document to be of type CLOB or BLOB. However,
the column info in our customer table is of type XML. Therefore, at the time of writing, the function XMLSERIALIZE is required to convert the XML documents to type CLOB or BLOB.
SELECT XMLPARSE( DOCUMENT SYSFUN.DSN_XMLVALIDATE(
XMLSERIALIZE(info AS CLOB), 'SYSXSR.CUSTXSD') ) )
FROM customer
WHERE XMLEXISTS('$i/customerinfo/addr[city = "Toronto"]'
PASSING info AS "i");
Figure 17.47
Validating existing documents in a table
The query in Figure 17.47 parses and validates all matching documents, which requires more
CPU cycles than simply retrieving the documents without reparsing them. The query raises an
error as soon as one document is encountered that is not valid against the schema
SYSXSR.CUSTXSD. You can capture and handle this error in a stored procedure, similar to how it
is discussed in section 17.9.
17.12.4
Summary of Platform Similarities and Differences
Table 17.2 provides a summary of the differences in validation functionality between DB2 for
z/OS and DB2 for Linux, UNIX, and Windows. This comparison is a point-in-time snapshot and
subject to change. Over time, the supported features in the DB2 for z/OS and DB2 for Linux,
UNIX, and Windows continue to converge.
544
Table 17.2
Chapter 17
Validating XML Documents against XML Schemas
Summary of Platform Similarities and Differences
Feature
DB2 for Linux, UNIX,
and Windows
DB2 for z/OS
Document validation for INSERT
and UPDATE operations
Yes
Yes
Validation function
XMLVALIDATE
DSN_XMLVALIDATE; always
has to be an argument of the
XMLPARSE function.
Can reference XML Schema by its
SQL identifier
Yes
Yes
Can reference XML Schema by
target namespace and schema
location
Yes
Yes
Can validate existing documents
in a table
Yes
Yes
Can perform validation in stored
procedures
Yes
Yes
Validation support in the LOAD
utility
Yes
You can validate documents
after LOAD.
Link between documents and
schemas is stored with each
validated document
Yes*
You can maintain this
information in a separate
column of the user table.
IS VALIDATED predicate to
Yes*
You can get this information
from a separate column
in the user table where you
record the schema ID for each
document.
check whether a document has
been validated
Function XMLXSROBJECTID to
find documents for a given schema,
or vice versa
Yes*
*If you query the relationship between documents and schemas often, you might want to maintain this information (the
schema ID for any given document) in a separate column that is indexed to ensure good performance.
17.13
SUMMARY
Validating XML documents against XML Schemas is the best way to enforce XML data quality
in the database. However, document validation is optional in DB2 and there is no performance or
functional penalty if you don’t use an XML Schema. If you choose to validate documents, you
typically do so when you insert, update, or load them. Existing documents in the database can
17.13
Summary
545
also be validated in queries. An XML column can contain a mix of validated and non-validated
documents, and different documents in a column can be validated with different schemas. In DB2
you are not forced to assign a single XML Schema to an entire XML column.
There are two general approaches for document validation in DB2:
• Application-centric: Applications use the XMLVALIDATE (or DSN_XMLVALIDATE)
function in their INSERT and UPDATE statements. This makes validation a distributed
responsibility and provides maximum flexibility.
• Database-centric: The database uses triggers and check constraints to enforce validation on a per-XML-column basis.
These application- and database-centric techniques can also be combined to implement a custom
validation strategy that meets specific requirements.
This page intentionally left blank
C
H A P T E R
18
Using XML in Stored
Procedures, UDFs, and
Triggers
tored procedures, user-defined functions (UDFs), and triggers are database objects that
encapsulate processing steps to retrieve or manipulate data in the database. They can contain multiple statements that are invoked and executed as a single unit. They are typically used to
implement application-specific logic. Stored procedures and UDFs can be implemented in the
SQL Procedure Language (SQL PL) or in external languages such as Java, C, or COBOL. The
benefits of stored procedures and UDFs include:
S
• Reduced coding labor due to the creation of reusable processing modules
• Richer processing capabilities in the databases by defining custom logic and functions
• Improved performance and reduced network traffic because stored procedures and
UDFs are executed close to the data; that is, in the database engine
Stored procedures are executed with CALL statements, which can be issued from an application
program, from another stored procedure, from a UDF, or from a trigger. UDFs are used in SQL
statements just like you use predefined SQL functions.
Triggers are executed automatically when an insert, delete, or update operation happens on a
specified table. Triggers are used to implement automated reactions to data modifications and to
enforce data integrity rules within the database. The benefits of stored procedures, UDFs, and
triggers apply equally to the processing of XML data and relational data.
In this chapter we discuss the following topics:
• Manipulating XML data in stored procedures (section 18.1)
• Manipulating XML data in user-defined functions (section 18.2)
• Manipulating XML data in triggers (section 18.3)
547
548
Chapter 18
Using XML in Stored Procedures, UDFs, and Triggers
For general background on stored procedures, UDFs, triggers, and the SQL Procedure Language,
please consult the resources listed in the Appendix C, Further Reading.
18.1
MANIPULATING XML IN SQL STORED PROCEDURES
Stored procedures are a powerful tool for application development. They allow you to define simple or complex multi-statement operations and processing logic that can be invoked with a single
call from the application. Stored procedures can encapsulate and hide complex data manipulation
from the client application. Since stored procedures are executed in the database server, they can
process data without moving it to the client, which is often beneficial for performance.
In previous chapters you have already seen several examples where stored procedures implement
specific tasks:
• Section 7.7, Figure 7.41: Stored procedure to execute XPath dynamically
• Section 17.3, Figure 17.7: Stored procedure to handle and record validation errors
• Section 17.9, Figure 17.36: Stored procedure to validate an existing document
• Section 17.9, Figure 17.38: Stored procedure to validate multiple existing documents
DB2 for Linux, UNIX, and Windows allows you to use the XML data type not just to define
columns in a table, but also to declare input and output parameters as well as variables in stored
procedures and user-defined functions. Stored procedures can therefore manipulate XML documents in their parsed format without incurring additional XML parsing, which is a major performance benefit.
Variables of data type XML can be manipulated in stored procedures much like variables of other
types. For example, XML variables can receive their value through statements such as a SET
statement or a SELECT INTO statement. The only restriction is that XML variables and XML
input parameters lose their value upon a COMMIT or ROLLBACK operation. If you want to use an
XML variable or parameter after a ROLLBACK or COMMIT statement, you need to assign new
values to them first. Otherwise error SQL1354N is raised.
The best way to use XPath or XQuery expressions in stored procedures is to embed them in the
SQL/XML functions XMLQUERY, XMLTABLE, or XMLEXISTS. These can be used in stored procedure statements and accept variables of type XML in their PASSING clause. You can also use
XQuery without SQL in stored procedures, but only with dynamic cursors. Static XQuery is not
allowed.
18.1.1
Basic XML Manipulation in Stored Procedures
Let’s look at Figure 18.1 to become familiar with the basic capabilities of handling XML data in
stored procedures. The table addrtable is defined in addition to the customer table that we
18.1
Manipulating XML in SQL Stored Procedures
549
have been using. The stored procedure has one input parameter and one output parameter, both
are of type XML. Additionally, the procedure declares the variables id and address of type
INTEGER and XML, respectively. The first SET statement extracts the Cid attribute from the input
document, converts it to INTEGER, and assigns it to the variable id. Note that the input parameter
custDoc is passed into the XMLQUERY function. Next is the SELECT-INTO statement, which
demonstrates two important capabilities. First, the INTO clause is used to assign an XML value to
the XML output parameter olddoc. Second, the variable id is passed into the XMLEXISTS predicate so that only the matching document is retrieved from the customer table. The last part of
the stored procedure shows that you can use the XMLEXISTS predicate directly in an IF statement. It checks whether the address in the input document is in Canada. If this is true then the
SET statement extracts the addr element of the document and assigns it to the XML variable
address. Subsequently the address and the id variables are inserted into the table
addrtable.
CREATE TABLE addrtable(id INTEGER, addr XML)#
CREATE PROCEDURE processDoc(IN custDoc XML, OUT oldDoc XML)
BEGIN ATOMIC
DECLARE id
INTEGER;
DECLARE address XML;
SET id = XMLCAST(XMLQUERY('$d/customerinfo/@Cid'
PASSING custDoc AS "d") as INTEGER);
SELECT info INTO olddoc
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo[@Cid = $x]'
PASSING id AS "x");
IF XMLEXISTS('$d/customerinfo/addr[@country = "Canada"]'
PASSING custDoc AS "d")
THEN
SET address = XMLQUERY('$d/customerinfo/addr'
PASSING custDoc AS "d");
INSERT INTO addrtable(id, addr)
VALUES(id, XMLDOCUMENT(address));
END IF;
END #
Figure 18.1
Stored procedure with basic XML manipulation
Since the body of a stored procedure can contain multiple statements, these statements have to be
separated by the semicolon character. This use of the semicolon conflicts with the fact that the
semicolon is also the default terminating character for statements in the DB2 Command Line
Processor (CLP). The same applies to user-defined functions and triggers. To avoid problems you
need to use a different terminating character in the CLP. For example, in Figure 18.1 the # is used
as the terminating character for the CREATE PROCEDURE statement. You must invoke the CLP
550
Chapter 18
Using XML in Stored Procedures, UDFs, and Triggers
with the td# option to set the #, or any other character of your choosing, as the statement terminator. If the CREATE PROCEDURE statement in Figure 18.1 is in a file create_proc.sql then
the following command issued at the OS prompt creates the procedure:
db2 -td# -f create_proc.sql
18.1.2
A Stored Procedure to Store XML in a Hybrid Manner
Let’s look at a common use case for a stored procedure. Assume you want to store the customer
sample documents in a hybrid fashion. You might decide to keep the address information as
XML, because you expect it to be of variable format over time, but you want to store customer
name and phone information in relational columns. Since each customer can have multiple phone
numbers (one-to-many relationship), the phone numbers have to be stored in a separate table with
a proper join key. That join key can be a number generated by a sequence for each new XML document that comes in. A sequence is a database object that produces a stream of unique values.
Figure 18.2 shows the definition of the target tables and the sequence.
CREATE TABLE cust (id INTEGER, name VARCHAR(20), addr XML);
CREATE TABLE phone(id INTEGER, type VARCHAR(20),
number VARCHAR(20));
CREATE SEQUENCE id_seq START WITH 1 INCREMENT BY 1 CACHE 100;
Figure 18.2
Table and sequence definition for hybrid storage
The stored procedure in Figure 18.3 takes a customer XML document as an input parameter.
Note that this parameter is of type XML. Each time the procedure is called, it uses the NEXTVAL
expression to pull a new id value from the sequence. Then it uses two INSERT statements with
XMLTABLE functions to extract the required values for insert into the target tables cust and
phone. The first insert produces one row per customer, the second produces one row per phone
element. The same id value is used for inserts into both tables to ensure referential integrity.
Instead of using the sequence, the id could also be passed as a parameter from the calling application, or extracted from the document.
CREATE PROCEDURE insertCustomer(IN custDoc XML, OUT id INTEGER)
BEGIN ATOMIC
SET id = NEXTVAL FOR id_seq;
INSERT INTO cust(id, name, addr)
SELECT id, T.name, T.address
FROM XMLTABLE('$d/customerinfo' PASSING custDoc AS "d"
COLUMNS
name
VARCHAR(20) PATH 'name',
address XML
PATH 'document{addr}' ) as T;
Figure 18.3
Stored procedure for hybrid XML inserts
18.1
Manipulating XML in SQL Stored Procedures
551
INSERT INTO phone (id, type, number)
SELECT id, T.type, T.num
FROM XMLTABLE('$d/customerinfo/phone' PASSING custDoc AS "d"
COLUMNS
type
VARCHAR(20)
PATH '@type',
num
VARCHAR(20)
PATH '.') AS T;
END #
Figure 18.3
Stored procedure for hybrid XML inserts (Continued)
With the stored procedure in Figure 18.3 in place, an application should use the stored procedure
call call insertCustomer(?) to insert new customer documents and never use direct
INSERT statements. If all inserts are performed through this stored procedure, the relational and
XML data in the tables are always consistent. You can have similar stored procedures for update
and delete operations. The stored procedures can also contain additional business logic or data
manipulation.
A challenging situation occurs when the stored procedure in Figure 18.3 fails with the following
error message, where <value> is a data value in the input document that cannot be cast to the
data type VARCHAR(20):
SQL16061N The value
<value> cannot be constructed as, or cast (using an implicit or explicit
cast) to the data type "VARCHAR_20".
Error QName=err:FORG0001. SQLSTATE=10608.
Note that the XMLTABLE functions in the stored procedure cast the customer name, phone type,
and phone number to VARCHAR(20). However, the error message does not specify which one of
them caused the problem. In this simple example, a quick look at the <value> might reveal
which XML element or attribute caused the error. However, in more complex cases it is often difficult to identify which element or attribute is responsible for the error. The solution is to add code
to the stored procedure to catch the SQL error, obtain the offending <value>, look for it in the
input document, and return the name of the XML element or attribute that caused the problem.
This logic is coded in Figure 18.4.
The INSERT statements in the procedure in Figure 18.4 are the same as previously in Figure 18.3.
The difference in Figure 18.4 is the error handling. The procedure declares SQLSTATE 10680 as
a condition, and an exit handler to take appropriate action when this condition occurs. This action
is enclosed in a separate BEGIN-END block and only executed when the declared error happens.
The exit handler obtains the error information and uses the SUBSTR function to extract the
offending <value> and data type from it. Then it uses the XQuery expression $d//(*,@*)
[data(.) = $v]/local-name() to obtain the name of the element or attribute that contains
the offending value. In this expression, $d represents the XML document and $v the value to
552
Chapter 18
Using XML in Stored Procedures, UDFs, and Triggers
look for. The first part of the expression, $d//(*,@*), iterates over all elements and attributes in
the document. For each of those, the predicate [data(.) = $v] checks whether the value of
the element or attribute matches the <value> from the error message. If the predicate is true,
then the last step of the expression, /local-name(), obtains the name of the element or attribute. The whole expression is an argument of the function string-join, which produces a
comma-separated list in case more than one node with the matching value is found in the
document.
CREATE PROCEDURE insertCustomer(IN custDoc XML, OUT id INTEGER,
OUT MESSAGE_TEXT VARCHAR(300))
BEGIN ATOMIC
DECLARE vErrMsg
VARCHAR(300);
DECLARE vValue
VARCHAR(100);
DECLARE vNode
VARCHAR(100);
DECLARE vType
VARCHAR(100);
DECLARE vTokenString VARCHAR(100);
DECLARE XMLTABLE_CAST_FAILURE CONDITION FOR SQLSTATE '10608';
DECLARE EXIT HANDLER FOR XMLTABLE_CAST_FAILURE
BEGIN
-- retrieve error message and token string
GET DIAGNOSTICS EXCEPTION 1
vTokenString = DB2_TOKEN_STRING,
vErrMsg = MESSAGE_TEXT;
SET vValue = SUBSTR(vErrMsg, 23, POSSTR(vErrMsg, '" ')-23);
SET vType
= SUBSTR(vTokenString, LENGTH(vValue)+2);
-- find xml nodes whose values match the error token
SET vNode = XMLCAST(XMLQUERY('
string-join($d//(*,@*)[data(.) = $v]/local-name(),",")'
PASSING custDoc AS "d", vValue AS "v") AS VARCHAR(100));
-- create message text
SET MESSAGE_TEXT =
'Failed to cast the value "' || vValue || '", at element or
attribute "' || vNode || '", to type "' || vType || '".';
END ;
SET id = NEXTVAL FOR id_seq;
INSERT INTO cust(id, name, addr)
SELECT id, T.name, T.address
FROM XMLTABLE('$d/customerinfo' PASSING custDoc AS "d"
COLUMNS
name
VARCHAR(20) PATH 'name',
address XML
PATH 'document{addr}' ) as T;
Figure 18.4
Stored procedure for hybrid XML inserts with error handling
18.1
Manipulating XML in SQL Stored Procedures
553
INSERT INTO phone (id, type, number)
SELECT id, T.type, T.num
FROM XMLTABLE('$d/customerinfo/phone' PASSING custDoc AS "d"
COLUMNS
type
VARCHAR(20)
PATH '@type',
num
VARCHAR(20)
PATH '.') AS T;
SET MESSAGE_TEXT = 'Insert successful.';
END #
Figure 18.4
18.1.3
Stored procedure for hybrid XML inserts with error handling (Continued)
Loops and Cursors
The example in Figure 18.5 shows that you can easily loop over the elements and attributes from
one or multiple XML documents. The stored procedure takes an XML document as input and
uses a SELECT statement with an XMLTABLE function to produce one row for each phone element. The FOR statement is used to iterate over these rows. When a FOR statement is executed, a
cursor is implicitly declared such that each iteration of the FOR loop fetches the next row from the
result set until there are no rows left. For each row, the statements in the DO clause of the FOR
statement are executed. An IF-THEN-ELSE statement inserts the phone information into the
table cellphones if the phone type is cell, and into the table landlines otherwise. To keep
stored procedures simple, we recommend the use of FOR statements instead of explicit cursor
declarations whenever possible.
CREATE TABLE cellphones(id INTEGER, number VARCHAR(20))#
CREATE TABLE landlines(id INTEGER, number VARCHAR(20))#
CREATE PROCEDURE processPhones(IN custDoc XML)
BEGIN ATOMIC
FOR phone AS
SELECT T.id, T.type, T.num
FROM XMLTABLE('$d/customerinfo/phone' PASSING custDoc AS "d"
COLUMNS
id
INTEGER
PATH '../@Cid',
type
VARCHAR(5) PATH '@type',
num
VARCHAR(20) PATH '.') as T
DO
IF phone.type='cell'
THEN INSERT INTO cellphones(id,number)
VALUES(phone.id, phone.num);
ELSE INSERT INTO landlines(id, number)
VALUES(phone.id, phone.num);
END IF;
END FOR;
END #
Figure 18.5
FOR loop over repeating XML elements
554
Chapter 18
Using XML in Stored Procedures, UDFs, and Triggers
You can also use XQuery without SQL in stored procedures, but not in a FOR statement or any
static manner. You have to construct the XQuery dynamically as a string and prepare and open it
as a dynamic cursor. In Figure 18.5 an XQuery string is assigned to the variable xqr. Note that
the query string includes the value of the input parameter city. The query is then prepared and
opened as a CURSOR WITH RETURN TO CALLER. With this cursor definition, the result sequence
of the XQuery becomes the result set of the stored procedure. The procedure does not fetch from
or close the cursor, which allows the calling application to iterate over the result of the query.
Alternatively you could decide to have a WHILE loop with a FETCH statement in the stored procedure itself to process the result set.
CREATE PROCEDURE cityphones(IN city VARCHAR(20))
BEGIN ATOMIC
DECLARE xqr VARCHAR(2048);
DECLARE c1
CURSOR WITH RETURN TO CALLER FOR stmt;
SET xqr = 'xquery for $i in db2-fn:xmlcolumn("CUSTOMER.INFO")
where $i/customerinfo/addr[city="'|| city ||'"]
return $i/customerinfo/phone';
PREPARE stmt FROM xqr;
OPEN c1;
END #
Figure 18.6
18.1.4
Dynamic cursor for an XQuery
A Stored Procedure to Update a Selected XML Element or Attribute
The stored procedure in Figure 18.7 changes the value of a selected XML node in a document.
The input parameters to the procedure are an XML document, the path to the node that is to be
updated, and the new value of the node. The parameter for the XML document is declared as
INOUT, so that the updated document is returned. The procedure constructs an XQuery update
expression in an XMLQUERY function. The input parameter xpath provides the target path for the
replace clause. Additionally, the document and the new value are passed as parameters into the
XQuery Update expression. The statement OPEN c1 USING mydoc, value binds the procedure parameters mydoc and value to the parameters markers in the XMLQUERY function.
CREATE PROCEDURE updateXPath (INOUT mydoc XML,
IN xpath VARCHAR(1024),
IN value VARCHAR(128))
BEGIN ATOMIC
DECLARE sql VARCHAR(2048);
DECLARE c1 CURSOR FOR stmt;
SET sql = 'VALUES XMLQUERY(''
copy $new := $original
modify do replace value of $new' || xpath ||'
Figure 18.7
Stored procedure to update a selected XML element or attribute
18.1
Manipulating XML in SQL Stored Procedures
555
with $value
return $new ''
PASSING XMLCAST(? AS XML) AS "original",
CAST(? AS VARCHAR(1024)) AS "value") ';
PREPARE stmt FROM sql;
OPEN c1 USING mydoc, value;
FETCH c1 INTO mydoc;
CLOSE c1;
END #
Figure 18.7
18.1.5
Stored procedure to update a selected XML element or attribute (Continued)
Three Tips for Testing Stored Procedures
The following three tips seem to be not as widely known as they should be, but they are extremely
useful.
Tip 1: How to Test Stored Procedures in the CLP
It is often very useful to test stored procedures in the CLP without having to have application
code that calls the procedure and passes an XML document as input. You can simply import your
test documents into a DB2 table, such as testdocs, and use an SQL fullselect as the input
parameter in the stored procedure call in the CLP. Make sure that the fullselect produces exactly
one row with one column of type XML, as shown in Figure 18.8. The second parameter is a question mark as a placeholder for the output parameter oldDoc.
CREATE TABLE testdocs(id INTEGER NOT NULL PRIMARY KEY, doc XML);
IMPORT FROM testdata.del OF DEL INSERT INTO testdocs;
CALL processDoc( (SELECT doc FROM testdocs WHERE id = 3),? );
Figure 18.8
Testing a stored procedure
Tip 2: How to Get the Execution Plan of a Stored Procedure
If a stored procedure does not perform well then it can be useful to examine the execution plans
of queries or other statements in the stored procedure. One approach is to copy individual statements from the stored procedure and to explain them separately. However, it can happen that a
statement has a different execution plan when it is compiled in the context of a stored procedure
than when it is compiled by itself. In DB2 for Linux, UNIX, and Windows you can use the following approach to explain the statements within a stored procedure.
1. Establish a connection to the database.
2. Create explain tables if they do not already exist (see section 14.1.1, The Explain Tables
in DB2 for Linux, UNIX, and Windows).
556
Chapter 18
Using XML in Stored Procedures, UDFs, and Triggers
3. Issue the following command at the OS prompt to enable the capturing of execution
plans when stored procedures are created in the current session:
db2 "CALL SYSPROC.SET_ROUTINE_OPTS('EXPLAIN ALL')"
4. If a CREATE PROCEDURE statement is the only statement in a file called create_
proc.sql, and if the statement is terminated with the # character, create the procedure
with the following command at the OS prompt:
db2 -td# -f create_proc.sql
5. Use the db2exfmt utility to write the execution plan to a file such as myprocplan.txt:
db2exfmt -d <dbname> -1 -o myprocplan.txt
The output file will contain separate explain information for each statement in the stored
procedure.
If you want to check whether the capturing of explain information for stored procedures
is enabled, use the following SELECT statement:
SELECT GET_ROUTINE_OPTS() FROM sysibm.sysdummy1
To revert to not explaining stored procedures, use this statement:
db2 "CALL SYSPROC.SET_ROUTINE_OPTS('EXPLAIN NO')"
Tip 3: How to Profile a Stored Procedure
IBM Data Studio Developer contains a very useful stored procedure profiler that can provide
information about the runtime performance of a procedure. For each statement in the stored procedure, the profile reveals the number of executions, the elapsed time, CPU time, and other
optional metrics such as the number of rows read or written, or the number of logical and physical
page reads. This information is extremely helpful to understand the behavior of a complex stored
procedure and to discover which parts of a procedure are particularly expensive to run.
If you have a Data Development Project in Data Studio and a stored procedure in the Stored
Procedures folder of the Data Project Explorer, right-click on the procedure name and choose
Run Profiling. The same context menu also has a command to invoke the stored procedure
debugger, which is another helpful tool for the development of stored procedures in DB2 for
Linux, UNIX, and Windows, and DB2 for z/OS.
18.2
MANIPULATING XML IN USER-DEFINED FUNCTIONS
DB2 9.7 for Linux, UNIX, and Windows allows you to use the XML data type in user-defined
functions (UDFs). UDFs can have XML type parameters and variables and can contain SQL/XML
statements that manipulate XML data. Most of these capabilities are similar to the XML support
in stored procedures. An important difference between UDFs and stored procedures is that UDFs
can be used in SQL statements while stored procedures can only be invoked with a CALL statement. In this section we discuss several examples of UDFs that manipulate XML data.
18.2
Manipulating XML in User-Defined Functions
18.2.1
557
A UDF to Extract an Element or Attribute Value
The function getname in Figure 18.9 takes an XML document as input and returns a value of
type VARCHAR(25). The body of the function consists of a single RETURN statement. It contains
the functions XMLCAST and XMLQUERY to extract the name element and convert it to VARCHAR(25). The PASSING clause of the XMLQUERY function passes the function’s input parameter
doc into the XPath expression. Below the function you see an SQL statement that invokes the
function in its SELECT clause. The use of the UDF allows an application to retrieve customer
names without having to code the actual XPath expression and SQL/XML functions.
CREATE FUNCTION getname(doc XML)
RETURNS VARCHAR(25)
LANGUAGE SQL CONTAINS SQL NO EXTERNAL ACTION DETERMINISTIC
BEGIN ATOMIC
RETURN XMLCAST(XMLQUERY('$d/customerinfo/name'
PASSING doc AS "d")
AS VARCHAR(25));
END #
SELECT getname(info) AS name
FROM customer
WHERE cid = 1002 #
NAME
------------------------Jim Noodle
1 record(s) selected.
Figure 18.9
Scalar UDF to extract an element value
Such a scalar UDF also enables you to create a table with a generated column whose value is
automatically computed based on the XML documents in an XML column:
CREATE TABLE custinfo(info XML, name VARCHAR(25) GENERATED
ALWAYS AS (getname(info)));
The function in Figure 18.9 is a scalar function, which means it returns a single value. If you
want to use a similar function to extract a repeating element then a table function instead of a
scalar function can be more appropriate. This is shown next.
18.2.2
A UDF to Extract the Values of a Repeating Element
Figure 18.10 demonstrates a function that extracts the phone elements from a given document.
Since a customer document can have multiple phone elements, the return type of the UDF is a
table. This UDF is therefore a table function. The structure of the returned table is defined in the
second line of the CREATE FUNCTION statement. The body of the function contains a RETURN
statement that includes an SQL/XML query that produces the rows and columns of the result table.
558
Chapter 18
Using XML in Stored Procedures, UDFs, and Triggers
Below the function you see an SQL query that uses the UDF. Since this UDF is a table function, it
is used in a table expression in the FROM clause of the SELECT statement. The result set of the
query includes two columns from the UDF plus the cid column from the customer table.
CREATE FUNCTION getphone(doc XML)
RETURNS TABLE(type VARCHAR(10), number VARCHAR(20))
BEGIN ATOMIC
RETURN
SELECT type, number
FROM XMLTABLE('$d/customerinfo/phone' PASSING doc AS "d"
COLUMNS
type
VARCHAR(10) PATH '@type',
number VARCHAR(20) PATH '.') ;
END #
SELECT cid, p.type, p.number
FROM customer, TABLE(getphone(info)) p
WHERE cid = 1004#
CID
---------------1004
1004
TYPE
---------work
home
NUMBER
-------------------905-555-4789
416-555-3376
2 record(s) selected.
Figure 18.10
Table UDF to extract repeating element values
You can certainly use multiple UDFs in a single query, as illustrated by the query in Figure 18.11.
SELECT getname(info) AS name, p.type, p.number
FROM customer, TABLE(getphone(info)) p
WHERE cid IN (1004, 1005)
NAME
------------------------Matt Foreman
Matt Foreman
Larry Menard
Larry Menard
TYPE
---------work
home
work
home
NUMBER
-------------------905-555-4789
416-555-3376
905-555-9146
416-555-6121
4 record(s) selected.
Figure 18.11
18.2.3
Using a scalar UDF and a table UDF in a query
A UDF to Shred XML Data to a Relational Table
A table function can also help you shred XML data into a relational table. Suppose you want to
populate the following target table:
18.2
Manipulating XML in User-Defined Functions
559
CREATE TABLE address(cid INTEGER, name VARCHAR(30),
street VARCHAR(40), city VARCHAR(30))
To shred XML documents into this table, you can create a table function that takes an XML document as input and returns a set of rows with columns that match the target table. Figure 18.12
defines such a function.
CREATE FUNCTION extractcols(doc XML)
RETURNS TABLE(cid INT, name VARCHAR(30),
street VARCHAR(40), city VARCHAR(30))
BEGIN ATOMIC
RETURN SELECT x.custid, x.custname, x.str, x.city
FROM XMLTABLE('$d/customerinfo' PASSING doc AS "d"
COLUMNS
custid
INTEGER
PATH '@Cid',
custname VARCHAR(30) PATH 'name',
str
VARCHAR(40) PATH 'addr/street',
city
VARCHAR(30) PATH 'addr/city' ) AS x ;
END #
Figure 18.12
Table function to extract several elements and attributes
You can then include this table function in an INSERT-INTO-SELECT-FROM statement. The first
INSERT statement in Figure 18.13 reads XML documents from the XML column info of the
customer table and shreds them into the address table. The function extractcols takes the
XML column info as input and produces relational rows for insert into the target table. The
second INSERT statement in Figure 18.13 shreds an XML document that is provided by an application through the parameter marker in the FROM clause.
INSERT INTO address(cid, name, street, city)
SELECT e.cid, e.name, e.street , e.city
FROM customer c,
TABLE(extractcols(c.info)) e
WHERE c.cid < 1050;
INSERT INTO address(cid, name, street, city)
SELECT e.cid, e.name, e.street , e.city
FROM TABLE(extractcols(cast(? as XML))) e ;
Figure 18.13
18.2.4
Using a table function to shred XML documents
A UDF to Modify an XML Document
Chapter 12, Updating and Transforming XML Documents, describes XQuery Update expressions
that allow you to change the value of an element or attribute, or to insert, rename, or delete elements and attributes in a document. It can be convenient to encapsulate such update expressions
in a user-defined function, which then serves as a much simpler update interface for database
applications.
560
Chapter 18
Using XML in Stored Procedures, UDFs, and Triggers
Using the customer documents in the sample database as an example, suppose you want to simplify the task of updating a selected phone element in a document. You could code the UDF in
Figure 18.14, which has the following input parameters:
• doc: the XML document that is to be updated
• phonetype: a string such as “cell” or “work” to indicate which phone is to be
updated
• number: the new telephone number
The function returns the input document where the phone element with the matching type
attribute has been given the new value.
CREATE FUNCTION updatephone(doc XML, phonetype VARCHAR(8),
number VARCHAR(12) )
RETURNS XML
BEGIN ATOMIC
RETURN XMLQUERY('
copy $new := $p1
modify do replace value of
$new/customerinfo/phone[@type=$p2] with $p3
return $new'
PASSING doc AS "p1", phonetype as "p2", number as "p3");
END #
Figure 18.14
Scalar UDF to modify an XML document
If an application wants to change the work phone number of customer 1002 to the new value
408-463-4963, it can simply issue the UPDATE statement in Figure 18.15 and does not need to
be concerned with the details of the underlying XQuery Update expression.
UPDATE customer
SET info = updatephone(info, 'work', '408-463-4963')
WHERE cid = 1002
Figure 18.15
UPDATE statement with a scalar UDF
Remember that the update expression “replace value of” fails if the target path ($new/customerinfo/phone[@type=$p2]) does not produce exactly one node. In other words, the invocation of the UDF in Figure 18.15 leads to an error if the document for customer 1002 does not
contain a phone element whose type attribute has the value work. Therefore you might want to
perform an “upsert” operation (update or insert). An “upsert” operation updates the phone element if it exists and inserts a new phone element otherwise. This logic is coded in the UDF in
Figure 18.16 with an XQuery if-then-else expression. The else branch constructs a new
phone element with a type attribute, and the variables $p2 and $p3 provide the values for this
18.3
Manipulating XML Data with Triggers
561
attribute and element, respectively. Within such attribute and element constructors the variables
$p2 and $p3 have to be in curly brackets.
CREATE FUNCTION upsert_phone(doc XML, phonetype VARCHAR(8),
number VARCHAR(12) )
RETURNS XML
BEGIN ATOMIC
RETURN XMLQUERY('copy $new := $p1
modify
if ($new/customerinfo/phone[@type = $p2])
then do replace value of
$new/customerinfo/phone[@type = $p2]
with $p3
else do insert <phone type="{$p2}">{$p3}</phone>
as last into $new/customerinfo
return $new'
PASSING doc AS "p1", phonetype as "p2", number as "p3");
END #
Figure 18.16
18.3
Scalar UDF to update or insert an XML element (“upsert”)
MANIPULATING XML DATA WITH TRIGGERS
A trigger defines a set of operations that are performed in response to an INSERT, UPDATE, or
DELETE statement on a specified table. For example, a trigger can perform updates to other
tables, automatically generate or change values for inserted or updated rows, or invoke functions
and stored procedures. When an INSERT, UPDATE, or DELETE statement activates a trigger, the
operations that are executed by the trigger can reference the column values of the rows that are
being inserted, updated, or deleted. So-called transition variables allow you to reference the new
column values provided in INSERT and UPDATE statements, or the old values that are removed by
DELETE or UPDATE statements.
You can define triggers on tables with XML columns, and you can also define UPDATE triggers on
individual XML columns in a table. Transition variables in triggers do not allow you to access the
old or new value of an XML column, which is true in DB2 for z/OS and DB2 for Linux, UNIX,
and Windows. But, the transition variables allow you to reference the old or new value of nonXML columns in the same row, such as primary key values. Therefore, triggers can still be used
for effective XML manipulation, as you will see in the examples in this section.
DB2 for Linux, UNIX, and Windows has one exception where it is possible to reference the new
value of an XML column as a transition variable. The exception is that the new value of an XML
column can be used in the XMLVALIDATE function to trigger the validation of a document that is
being inserted or updated. Such a validation trigger was shown in section 17.5, Automatic Validation with Triggers.
562
18.3.1
Chapter 18
Using XML in Stored Procedures, UDFs, and Triggers
Insert Triggers on Tables with XML Columns
Let’s look at an example in which triggers maintain the hybrid storage of incoming XML data.
Suppose you receive XML documents such as the customer documents in the sample database.
For reasons explained in section 2.4, Using a Hybrid XML/Relational Approach, you might
decide to store the full document in a column of type XML and to extract a few selected element
values into relational columns. For example, you might want to use relational columns to store
the customer name and city as well as the type and number of the customer phones. Figure 18.17
defines the appropriate target tables. Since a customer document can contain multiple phone elements, the phone information is stored in a separate table together with a join key.
CREATE TABLE cust(cust_id
name
city
info
INTEGER NOT NULL PRIMARY KEY
GENERATED ALWAYS AS IDENTITY,
VARCHAR(30),
VARCHAR(25),
XML )#
CREATE TABLE phones(cust_id
type
number
Figure 18.17
INTEGER NOT NULL,
VARCHAR (5),
VARCHAR (15) )#
Tables for hybrid XML storage
Next you can define a trigger that automatically populates the relational columns in both tables
whenever an XML document is inserted into the info column with an INSERT statement, such
as the following:
INSERT INTO cust(info) VALUES(?)
An appropriate insert trigger is shown in Figure 18.18. The trigger is fired after a new row is
inserted into the cust table but before the INSERT statement commits. The transition variable
newrow can be used to reference the column values of the newly inserted row, except for the
XML column. For example, newrow.cust_id identifies the generated primary key value of the
inserted row. This primary key value allows subselects in the trigger to identify the newly inserted
row in the table and to extract the desired element values from the new XML document in that
row. Since the XML document cannot be accessed through the transition variable, the trigger
accesses the document directly in the table based on the primary key that it finds in the transition
variable. The body of the trigger contains an UPDATE statement and an INSERT statement. The
UPDATE statement populates the columns name and city in the newly inserted row. The INSERT
statement adds rows to the phones table, one row for each phone element in the new document.
These rows include the primary key cust_id of the cust table so that the relationship between
phones and customers is properly maintained.
18.3
Manipulating XML Data with Triggers
563
CREATE TRIGGER cust_insert
AFTER INSERT ON cust
REFERENCING NEW AS newrow
FOR EACH ROW MODE DB2SQL
BEGIN ATOMIC
UPDATE cust
SET (name, city) =
(SELECT X.name, X.city
FROM cust, XMLTABLE('$INFO/customerinfo'
COLUMNS
name VARCHAR(30) PATH 'name',
city VARCHAR(20) PATH 'addr/city') AS X
WHERE cust.cust_id = newrow.cust_id )
WHERE cust.cust_id = newrow.cust_id;
INSERT INTO phones(cust_id, type, number)
SELECT cust.cust_id, P.type, P.number
FROM cust, XMLTABLE('$INFO/customerinfo/phone'
COLUMNS
type
VARCHAR(5) PATH '@type',
number VARCHAR(15) PATH '.') AS P
WHERE cust.cust_id = newrow.cust_id;
END#
Figure 18.18
18.3.2
Insert trigger
Delete Triggers on Tables with XML Columns
Let’s continue with the preceding example. In addition to the insert trigger you also need a delete
trigger that removes the correct rows from the phones table whenever rows are deleted from the
cust table. Figure 18.19 shows such a delete trigger. The transition variable oldrow provides
access to the cust_id values of the rows deleted in the cust table. These values allow the trigger to delete the corresponding rows in the phones table that have the same cust_id value.
CREATE TRIGGER delete_cust
AFTER DELETE ON cust
REFERENCING OLD AS oldrow
FOR EACH ROW MODE DB2SQL
BEGIN ATOMIC
DELETE FROM phones
WHERE phones.cust_id = oldrow.cust_id;
END#
Figure 18.19
Delete trigger
564
Chapter 18
18.3.3
Using XML in Stored Procedures, UDFs, and Triggers
Update Triggers on XML Columns
To complete our example, let’s examine the update trigger in Figure 18.20. It maintains the relational columns in the cust and phones tables whenever the info column in the cust table is
updated. Note that an update of a customer document might have changed, added, or removed
one or multiple phone elements. Thus, the only way to reliably update the phones table is to
issue a DELETE followed by an INSERT statement. The UPDATE, DELETE, and INSERT statements in this trigger are the same as in the previous triggers.
CREATE TRIGGER update_cust
AFTER UPDATE OF info ON cust
REFERENCING NEW AS newrow
FOR EACH ROW MODE DB2SQL
BEGIN ATOMIC
UPDATE cust
SET (name, city) =
(SELECT X.name, X.city
FROM cust, XMLTABLE('$INFO/customerinfo'
COLUMNS
name VARCHAR(30) PATH 'name',
city VARCHAR(20) PATH 'addr/city') AS X
WHERE cust.cust_id = newrow.cust_id )
WHERE cust.cust_id = newrow.cust_id;
DELETE FROM phones
WHERE phones.cust_id = newrow.cust_id;
INSERT INTO phones(cust_id, type, number)
SELECT cust.cust_id, P.type, P.number
FROM cust, XMLTABLE('$INFO/customerinfo/phone'
COLUMNS
type
VARCHAR(5) PATH '@type',
number VARCHAR(15) PATH '.') AS P
WHERE cust.cust_id = newrow.cust_id;
END#
Figure 18.20
18.4
Update trigger
SUMMARY
Stored procedures, user-defined functions (UDFs), and triggers are very powerful tools to customize or automate data processing steps for your specific application. DB2 for Linux, UNIX,
and Windows allows you to create stored procedures and UDFs with input parameters, output
parameters, and variables of type XML. Such procedures and functions can contain XQuery and
SQL/XML statements to query and manipulate XML data.
The benefit of using the XML data type for parameters and variables is that DB2 keeps the XML
data internally in the pureXML parsed tree format. This format enables stored procedures and
18.4
Summary
565
UDFs to process XML much more efficiently than a textual XML representation in VARCHAR or
CLOB parameters would allow. For example, a UDF can read and manipulate data from an XML
column without XML parsing because the data stays in DB2’s internal XML storage format. If an
application passes an XML document to a stored procedure via an XML type parameter, the document is parsed only once upon entry into the procedure. Any subsequent processing steps within
the procedure do not require XML parsing. Hence, the XML data type support in stored procedures
and UDFs is a significant performance benefit for any custom XML processing logic that you
implement.
You can also define triggers on tables with XML columns to implement automated actions that
are executed when XML documents are inserted, deleted, or updated. In a trigger, transitional
variables give you access to the relational values of the affected rows, but not to the old or new
value of an affected XML column. In the body of a trigger you can use the relational primary key
values of the affected rows to find and access the corresponding XML documents in the table and
perform any required operation on them.
Stored procedures have been found very useful to encapsulate and hide XML processing from
application programs. This reduces application complexity and improves end-to-end performance because SQL/XML statements in DB2 procedures can perform many XML processing tasks
more efficiently and with less code than application programs.
This page intentionally left blank
C
H A P T E R
19
Performing Full-Text
Search
ML applications and data can often be classified in one of two ways: predominantly datacentric or predominantly document- or content-centric. For example, the processing of
orders, sales, or trades is typically data-centric while the management of contracts, emails, or
news articles is document-centric. Content-centric XML documents often contain significant
amounts of free-flow text, including full sentences and paragraphs. Such full text is rare in datacentric XML, which tends to contain atomic data values such as names, dates, prices, quantities,
or addresses. Therefore, full-text search is more commonly required for querying content-centric
XML than data-centric XML documents.
X
There are also applications that exhibit characteristics of both, data- and document-oriented
XML processing. In fact, it is a particular strength of XML to serve as a single format for any
combination of data and content. For example, plain text comments can be part of an order, or a
description can be part of a product detail record. Wherever individual data items consist of more
than one word, and whenever you need to search for substring matches, full-text search can be the
right solution.
The following topics are discussed in this chapter:
• Overview of full-text search capabilities in DB2 (section 19.1)
• Sample table and documents used in this chapter (section 19.2)
• The DB2 Net Search Extender (sections 19.3 through 19.5)
• DB2 Text Search (section 19.6)
• Summary of text search administration commands (section 19.7)
• Comments on full-text search in DB2 for z/OS (section 19.8)
567
568
Chapter 19
Performing Full-Text Search
19.1 OVERVIEW OF TEXT SEARCH IN DB2
DB2 offers two technologies to perform full-text search. Both of them handle plain text, HTML
and XML data, as well as document formats such as PDF and Microsoft Word.
• The DB2 Net Search Extender (NSE) has been providing powerful text search capabilities since DB2 8 for Linux, UNIX, and Windows. The Net Search Extender is XML
aware and fully functional with the new XML column type in DB2 9 and higher. The
DB2 Net Search Extender continues to provide reliable and mature text search in DB2
with proven scalability and performance.
• DB2 Text Search is new text search functionality that is based on the technology in the
open source project Lucene. The same technology is also used in IBM OmniFind Text
Search Server for DB2 z/OS (see section 19.8). DB2 Text Search became first available
in DB2 9.5 for Linux, UNIX, and Windows, Fixpack 1. Its features and performance
continue to be improved in subsequent releases. DB2 Text Search in DB2 9.5 is just the
beginning of integrating OmniFind text search capabilities into DB2 on all platforms.
In a given DB2 database you can use either the DB2 Net Search Extender or DB2 Text Search,
not both. The DB2 Net Search Extender and DB2 Text Search can coexist in the same database
instance, but only one of them can be enabled for a given database. You will find that many DB2
Text Search features and most of its administration commands are identical or similar to those of
the DB2 Net Search Extender.
The DB2 Net Search Extender and DB2 Text Search have several design principles in common:
• A table in which one or multiple columns are indexed for text search must have a primary key. The primary key values of the table are used in the text index to correlate text
search results from the text index back to the rows in the table. Consequently, the finest
granularity of text search results is a row (a document).
• When a text index is created, triggers and a staging table (also known as a log table) are
also automatically created in DB2. Any insert, update, or delete on the indexed table
fires a trigger that in turn writes corresponding information about the data changes into
the staging table. The content of this staging table is read to update the text index, and is
subsequently deleted.
• Text indexes are maintained asynchronously; that is, not in the context of the original
insert, update, or delete statements. Updates of the text index are either explicitly
invoked with an UPDATE INDEX command, or they happen regularly on a predefined
schedule.
Table 19.1 summarizes the most important commonalities and differences between the DB2 Net
Search Extender and DB2 Text Search as of DB2 Version 9.5 Fixpack 1.
19.1 Overview of Text Search in DB2
Table 19.1
569
Comparing the DB2 Net Search Extender and DB2 Text Search
Feature
DB2 Net Search
Extender
DB2 Text
Search
Separate Text Search Install
Yes
No, part of DB2 install
DPF Support
Yes (on AIX)
No
Command line interface
Yes
Yes
Administration also through the
DB2 Control Center
Yes
No
Administration also through stored
procedures
No
Yes
DB2 Backup includes text index
No
No
Asynchronous index updates
Yes
Yes
Synchronous index updates
No
No
Index updates: manual or scheduled
Both
Both
Document models—to index only a
subsection (part) of each XML document
Yes
No
Multiple text indexes per column
Yes
No
Indexes on views and nick names
Yes
No
Stop words (avoid indexing irrelevant words,
such as "a", "or", and "the")
Yes, optional
No
SQL function: contains
Yes
Yes
XQuery function:
No
Yes
Support for XML namespaces
Limited
No
Can limit the result set size
Yes
Yes
Boolean search (and, or, and not operators
for text predicates)
Yes
(and: &, or: |)
Yes
(and: &&, or: ||)
Wildcards in search predicates
Yes
Yes
Search with escape characters
Yes
Yes
Stemming (reduces search word to its
base form)
Yes, optional
Yes, implicitly
Synonym search (Thesaurus)
Yes
Yes
db2-fn:xmlcolumn-contains
(continues)
570
Chapter 19
Table 19.1
Performing Full-Text Search
Comparing the DB2 Net Search Extender and DB2 Text Search (Continued)
Feature
DB2 Net Search
Extender
DB2 Text
Search
Weighted search
Yes
Yes
Fuzzy search
Yes
No
Proximity search
Yes
No
Ranking/scoring of result set items
Yes
Yes
Case-sensitive search
Yes
No
Linguistic processing (search for linguistic
variations of the search term)
English only
All supported languages
19.2 SAMPLE TABLE AND DATA
In the remainder of this chapter we use the following sample table and data to illustrate the text
search capabilities in DB2 (see Figure 19.1). You will see that it does not take magic to perform
efficient XML full-text search in DB2.
CREATE TABLE orders (id INTEGER NOT NULL PRIMARY KEY, doc XML)
id
1
2
doc
<order date="2007-11-05">
<customer>Wendy Witch</customer>
<item key="82">
<name>Crystal Ball, Deluxe Edition</name>
<quantity>5</quantity>
<price>95.00</price>
<comment>Customer requested extra wrapping.</comment>
</item>
<item key="83">
<name>Magic Potion, 300ml flask</name>
<quantity>10</quantity>
<price>19.95</price>
<comment>Await further shipping instructions.</comment>
</item>
</order>
<order date="2007-11-29">
<customer>William Wizard</customer>
<item key="55">
<name>Magician's Hat, Black</name>
<quantity>1</quantity>
<price>75.00</price>
<comment>Must be big enough for the rabbit.</comment>
</item>
<item key="56">
<name>White Rabbit</name>
<quantity>1</quantity>
<price>295.00</price>
<comment>Extra soft fur and extra white.</comment>
</item>
</order>
Figure 19.1
Sample table and data
19.3 Enabling a Database for the DB2 Net Search Extender
571
Note that the second document contains a single quote in the name of the first item. This quote is
not a problem if you import or load the document, or insert with a parameter marker. But, if you
execute an insert statement in the DB2 Command Line Processor (CLP) with a literal XML document in the statement, a single quote in an XML value conflicts with the single quotes that
enclose the document string. Hence, the first of the three insert statements in Figure 19.2 fails.
You can escape the single quote either by using two single quotes or by using the corresponding
entity reference (').
--incorrect:
INSERT INTO orders VALUES(1, '<name>Magician's Hat</name>');
--correct:
INSERT INTO orders VALUES(2, '<name>Magician''s Hat</name>');
INSERT INTO orders VALUES(3, '<name>Magician's Hat</name>');
Figure 19.2
Inserting XML data with quotes in the CLP
19.3 ENABLING A DATABASE FOR THE DB2 NET SEARCH EXTENDER
The DB2 Net Search Extender (NSE) requires a separate install in addition to the regular DB2
install. Appendix C, Further Reading, contains links to information about downloading and
installing the NSE. After installation you can start and stop the Net Search Extender instances
services much like you start and stop a DB2 server. You have to be the DB2 instance owner to
issue the following commands at the OS prompt:
db2text start
db2text stop [force]
The optional keyword force can be used to forcibly stop the NSE even if there are processes still
holding locks or if caching for an index is still activated. Be careful with the use of the force
option. If you perform db2text stop force while an index update or reorg is in progress, the
text index may get damaged and might have to be rebuilt entirely.
After starting the DB2 Net Search Extender instance services, the first step is to enable a database
for text search. Execute the following command at the OS prompt to enable the database
<dbname> for text search:
db2text ENABLE DATABASE FOR TEXT CONNECT TO <dbname>
As for the majority of the db2text commands, you can optionally provide a user name and password for authentication to the database:
db2text ENABLE DATABASE FOR TEXT CONNECT TO <dbname>
USER <username> USING <password>
572
Chapter 19
Performing Full-Text Search
The ENABLE DATABASE command creates UDFs, stored procedures, and the following tables
and views in the default table space of the database:
• db2ext.dbdefaults: Contains default values for text search configuration
parameters
• db2ext.textindexformats: Stores the list of supported index formats and the currently used document models
• db2ext.indexconfiguration: Stores index configuration parameters
• db2ext.textindexes: Keeps track of all text indexes
Similarly, you can disable the DB2 Net Search Extender for a database with the following command,
which removes the NSE tables, views, and UDFs, and drops all NSE indexes for that database.
db2text DISABLE DATABASE FOR TEXT [force] CONNECT TO <dbname>
USER <username> USING <password>
19.4 MANAGING FULL-TEXT INDEXES WITH THE DB2 NET SEARCH
EXTENDER
The DB2 Net Search Extender allows you to define one or multiple text indexes per column. It also
allows you to index only a certain section of each document instead of indexing all elements and
attributes in a document. Such partial indexing leads to fewer index entries per document, smaller
text indexes, and better index update and search performance. The following sections illustrate the
CREATE INDEX command and its various options for the DB2 Net Search Extender.
19.4.1 Creating Basic Text Indexes
Issued at the OS command prompt, the following command creates a text index with the name
orderIdx on the column doc in the table orders in the database <dbname>:
db2text "CREATE INDEX orderIdx FOR TEXT ON orders(doc)
CONNECT TO <dbname> USER <username> USING <password>"
Depending on the operating system and configuration of your command shell, enclosing the command parameter for db2text in double quotes might be necessary, as shown in this example.
Specifying a user name and a password for authentication to the database is optional. The table
orders must have a primary key; otherwise, a text index cannot be created. The column doc
must be of type XML or any character or binary column type, such as CHAR, VARCHAR, CLOB,
BLOB, DBCLOB, GRAPHIC, or VARCHAR FOR BIT DATA.
Unlike relational indexes in DB2, the CREATE INDEX statement for a text index defines an index
but does not actually build the text index. An UPDATE INDEX command is required after the
CREATE INDEX statement to perform the initial index build (see section 19.4.6).
19.4
Managing Full-Text Indexes with the DB2 Net Search Extender
573
For each text index, the Net Search Extender creates a log table and an event table as well as triggers on the user table. Upon insert, delete, update, or import of data, the triggers fire and write
change information into the log table, which is later used to update the index. The event table contains information about index updates and potential problems, such as invalid document formats.
If you use the DB2 LOAD utility to move documents into your table, the triggers don’t fire and
incremental indexing of the loaded documents does not happen. Therefore, it is recommended to
use the DB2 IMPORT utility, which activates the triggers. If you insist on using LOAD for performance reasons, then it is your own responsibility to fill the log table appropriately before issuing
the next UPDATE INDEX command.
The names of the log table and event table are system-generated. DB2 also creates views on these
tables to allow easy inspection of the information. Use the SQL statement in Figure 19.3 to obtain
the schema and view names for the index called orderIdx.
SELECT eventviewschema, eventviewname,
logviewschema, logviewname
FROM db2ext.textindexes
WHERE indname = 'ORDERIDX'
Figure 19.3
Obtaining names of the event and log views for a given text index
19.4.2 Creating Text Indexes with Specific Storage Paths
The previous examples used default locations for the text index and the index building work area.
The work area is used to hold temporary files that are created when text indexes are built or
updated. The default locations are defined in the table DB2EXT.DBDEFAULTS and are typically in
/sqllib/db2ext/indexes. This default location is often not a good place for large text
indexes. The command in Figure 19.4 specifies that the index is created in the file system
/data/index while temporary NSE files are written to /data/temp. Additionally, the log and
event tables are placed in the table space named nse_tspace instead of the default user table
space.
db2text "CREATE INDEX orderIdx FOR TEXT ON orders(doc)
INDEX DIRECTORY /data/index
WORK DIRECTORY /data/temp
ADMINISTRATION TABLES IN nse_tspace
CONNECT TO <dbname>"
Figure 19.4
Text index with non-default storage locations
The DB2 instance owner needs to have read, write, and execute permissions for the index and the
work directory. In a DPF system these directories have to exist on every physical node. For best
performance, the index and work directories should be allocated on RAID arrays that allow high
I/O throughput.
574
Chapter 19
Performing Full-Text Search
PERFORMANCE TIP
When a text index is created or updated, potentially large amounts of
data might have to be moved from the work directory to the index
directory. If the index directory and the work directory are located in
different file systems, then this move is an expensive copy operation. If
the index and work directory are located within the same file system,
an inexpensive rename operation can be performed instead of a copy.
Hence, for best performance it is highly recommended that the index
and work directory share the same file system.
The disk space required for an index depends on the amount and type of data that is being indexed
and on the length of the primary key in the user table. Since the primary key is part of the index,
short keys such as INTEGER or TIMESTAMP are preferable over long keys, such as CHAR(128).
As a rule of thumb you should reserve at least 0.7 times as much space for the text index as the
size of the data volume you want to index. The work area can require two to three times as much
space as the raw data.
19.4.3
Creating Text Indexes with a Periodic Update Schedule
By default a text index is not updated automatically. You have to use the explicit UPDATE INDEX
command whenever you want to refresh the text index, or configure the index for regularly scheduled index updates. The CREATE INDEX statement in Figure19.5 defines a text index that is automatically refreshed four times a day. The string D(*)H(0,6,12,18)M(30) means that the
index is updated every day at 0:30, 6:30, 12:30, and 18:30 hours.
db2text "CREATE INDEX orderIdx FOR TEXT ON orders(doc)
UPDATE FREQUENCY D(*)H(0,6,12,18)M(30)
CONNECT TO <dbname>"
Figure 19.5
Text index with automatic periodic updates
Alternatively, the string D(1,2,3,4,5)H(*)M(0,15,30,45) would mean that the index gets
updated Monday through Friday every 15 minutes. You will see later that there is also an ALTER
INDEX command in which you can use the UPDATE FREQUENCY clause to define or change automatic updates for existing indexes.
System load considerations and the time it takes for an
index update to finish should be the guiding factors for choosing an
appropriate update interval that is not too short. An update interval of
one minute is almost always the wrong thing to do.
NOTE
19.4
Managing Full-Text Indexes with the DB2 Net Search Extender
575
Depending on your application, you might want to avoid index maintenance at the scheduled
times if there was only an insignificant number of changes to your data since the last time the
index was updated. Figure 19.6 creates an index that is updated every 30 minutes if there are at
least 50 document changes queued up in the log table. If there are less than 50 changes in the log
table, the index is not updated. After 30 minutes, the scheduler checks again whether 50 or more
changes have accumulated.
db2text "CREATE INDEX orderIdx FOR TEXT ON orders(doc)
UPDATE FREQUENCY D(*)H(*)M(0, 30)
UPDATE MINIMUM 50
CONNECT TO <dbname>"
Figure 19.6
Text index with automatic updates when “enough” new rows are available
Such a combination of UPDATE FREQUENCY and UPDATE MINIMUM allows you to define an
index update schedule in which the index is updated more frequently when there are many
changes in the base table and less frequently if there are fewer changes. If omitted, the default
value for UPDATE MINIMUM is 1.
Instead of updating the index incrementally you can also choose to always re-create the index
from scratch. Figure 19.7 defines an index that is recreated entirely every night at 2 a.m.
db2text "CREATE INDEX orderIdx FOR TEXT ON orders(doc)
UPDATE FREQUENCY D(*)H(2)M(0)
RECREATE INDEX ON UPDATE
CONNECT TO <dbname>"
Figure 19.7
Text index with automatic re-create
If you define an index with the RECREATE option, no log table and no triggers are created for this
index. Use this option with caution as rebuilding a large text index can take a long time.
Note that the DB2 Control Center allows you to administrate the DB2 Net Search Extender and to
configure the update behavior of text indexes. When you right-click on a database name you are
presented with the option to enable the database for text search. A right-click on the index folder
of a database lets you create regular relational indexes but also text indexes. A multi-step wizard
guides you through the text index definition and allows you to change default parameters such as
index location and update characteristics. Figure 19.8 illustrates step 4 of the Create Text Index
Wizard, where you can set the frequency of automatic updates. The settings selected in Figure
19.8 result in a CREATE INDEX statement with the clause UPDATE FREQUENCY D(1) H(3)
M(30).
576
Chapter 19
Figure 19.8
19.4.4
Performing Full-Text Search
Create Text Index Wizard in the DB2 Control Center
Creating Text Indexes for Specific Parts of Each Document
When you define a text index on an XML column, the DB2 Net Search Extender creates index
entries for all XML elements and attributes in the XML documents in the column. But, indexing
all parts of the documents is not always necessary.
Let’s look at the sample document in Figure 19.1. If you manage many “order” documents of this
nature, you might want to perform full-text search on item names and comments. In that case,
creating a full-text index on these elements is sufficient and leads to a much smaller index as
compared to indexing all elements and attributes. A smaller index often allows better update and
search performance. If you also need to perform queries with predicates on short data values—
such as order date, customer name, item key, quantity, and price—you should use regular XML
indexes.
With the Net Search Extender you can use document models to control which parts of the document structure are and aren’t indexed, and by which name you can refer to these parts in search
queries. A document model itself is a small XML document in the file system. This model file is
passed as a parameter to the CREATE INDEX command and is read during index creation only.
Later changes to the document model do not affect existing indexes.
19.4
Managing Full-Text Indexes with the DB2 Net Search Extender
577
Figure 19.9 shows a simple document model for documents like the ones in Figure 19.1. This
document model declares that only item names and comments are indexed. Every XML document model starts with the element XMLModel, which includes one or multiple XMLFieldDefinition elements. Each XMLFieldDefinition assigns a name to a locator. The locator is
a simple XPath expression that defines which elements, attributes, or subtrees to index. The locator can contain XPath wildcards (*), namespace prefixes, the XPath union operator (|), and the
XPath descendant-and-self axis, which is also known as the “double slash” (//).
<?xml version="1.0"?>
<XMLModel>
<XMLFieldDefinition name="iName"
locator="/order/item/name"/>
<XMLFieldDefinition name="iComments"
locator="/order/item/comment"/>
</XMLModel>
Figure 19.9
A simple document model
If the document model is stored in the file itemModel.xml, then the following command defines
a full-text index for item names and comments:
db2text "CREATE INDEX orderIdx FOR TEXT ON orders(doc)
FORMAT XML DOCUMENTMODEL XMLModel IN itemModel.xml
CONNECT TO <dbname>"
Note that you might have to specify a full file system path to the model file. The document model
in Figure 9.10 declares that all elements under /order/item are indexed, except for the items
quantity and price, which are explicitly excluded. Depending on the actual data in the XML
column, and on the existence of other elements under /order/item, this document model can
index more information than the previous one in Figure 19.9. However, for the sample documents
in Figure 19.1, both document models index exactly the item name and comment. We will later
use these document models in text search queries.
<?xml version="1.0"?>
<XMLModel>
<XMLFieldDefinition name="item" locator="/order/item/*" />
<XMLFieldDefinition name="excl1" locator="/order/item/quantity
exclude="yes"/>
<XMLFieldDefinition name="excl2" locator="/order/item/price"
exclude="yes"/>
</XMLModel>
Figure 19.10
A document model with exclude
578
19.4.5
Chapter 19
Performing Full-Text Search
Creating Text Indexes with Advanced Options
The CREATE INDEX statement can use the optional INDEX CONFIGURATION clause to set one or
multiple additional configuration parameters for the index. The index definition can also specify a
transformation function that is applied to each document before indexing. Let’s look at some
examples.
Stop words are words that occur frequently but have little relevance for text search. In the English
language, frequent stop words are "a", "or", "in", "the", and so on. By default the DB2 Net
Search Extender includes stop words in the text index, which can increase the index size and
reduce the precision of the search results. Therefore you might want to ignore stop words. In the
CREATE INDEX command in Figure 19.11, the index configuration parameter IndexStopWords
0 advises the Net Search Extender not to index stop words.
db2text "CREATE INDEX orderIdx FOR TEXT ON orders(doc)
LANGUAGE PT_BR
UPDATE FREQUENCY D(*)H(2)M(0)
INDEX CONFIGURATION (IndexStopWords 0, UpdateDelay 30,
IgnoreEmptyDocs)
CONNECT TO <dbname>"
Figure 19.11
Text index with update delay and exclusion of stop words and empty documents
The Net Search Extender installation includes text files with lists of stop words for more than 20
languages. These stop word files cannot (easily) be edited. The LANGUAGE clause in Figure 19.11
specifies that the documents are assumed to be in Brazilian Portuguese, which implies that the
stop words to ignore are in the file /sqllib/db2ext/resources/PT_BR.tsw. The use of stop
words is language specific and works best if all documents that are indexed are in the same
language.
In Figure 19.11, the index configuration parameter UpdateDelay 30 specifies that at the time of
incremental update, which is 2 a.m. in this example, only entries older than 30 seconds are taken
from the log table. Any change records younger than 30 seconds are processed on the next incremental update. This deferral avoids lost updates when user transactions that modify the base table
overlap with the starting point of the incremental update. Therefore, the UpdateDelay parameter should be set to the maximum expected duration of a user write transaction on the table that
the index was created on.
The index configuration parameter IgnoreEmptyDocs specifies that rows where the indexed
column is empty or NULL are not represented in the index. If you index a column that has a significant percentage of NULL values, this option can reduce the size of the index.
Figure 19.12 shows a text index definition that applies a function functionname to the values in
the column that is being indexed. This function can be any built-in or user-defined function but it
must produce a single value of type XML or any character or binary data type. A transformation
19.4
Managing Full-Text Indexes with the DB2 Net Search Extender
579
function can be useful to transform, extend, or shorten the data before it is passed to the indexer.
Beware that a complex or inefficient transformation can have a drastic impact on the performance
of building or updating a text index.
db2text "CREATE INDEX orderIdx
FOR TEXT ON orders(functionname(doc))
CONNECT TO <dbname> USER <username> USING <password>"
Figure 19.12
19.4.6
Text index with transformation function
Updating and Reorganizing Text Indexes
Unlike relational indexes in DB2, the CREATE INDEX statement for a text index only defines an
index, but it does not actually build the index structure. The index is built, and subsequently
updated, when a scheduled index update takes place or when the explicit UPDATE INDEX command is issued. For example, after defining a new text index with the name orderIdx, you might
want to run this command to build the index immediately:
db2text "UPDATE INDEX orderIdx FOR TEXT CONNECT TO <dbname>"
For large text indexes you may wish to check the progress of the index update process. The
CONTROL LIST ALL LOCKS command displays information about the locks currently held for a
specific index or database:
db2text "CONTROL LIST ALL LOCKS FOR DATABASE <dbname>
INDEX orderIdx CONNECT TO <dbname>"
If there is an update lock, this command also prints the number of documents that have been
processed so far.
The DB2 Net Search Extender continuously monitors the quality of the index structure and determines whether a reorganization of the index is recommended. If periodic index updates are
scheduled they also automatically reorganize the index when needed. These automatic reorganizations relieve the DBA from the decision when to reorganize and ensure decent index performance over time. If you choose to disable automatic index reorganization you need to specify
REORGANIZE MANUAL in the CREATE INDEX statement, as in Figure 19.13.
db2text "CREATE INDEX orderIdx FOR TEXT ON orders(doc)
UPDATE FREQUENCY D(*)H(1,13)M(0) UPDATE MINIMUM 100
REORGANIZE MANUAL
CONNECT TO <dbname>"
Figure 19.13
A text index without automatic reorganization
580
Chapter 19
Performing Full-Text Search
Note that the manual reorganization property of a text index can only be set in the CREATE
INDEX statement and cannot be altered later. Hence, this option should be used with care. We recommend that you use the default, which is automatic reorganization.
If you decide not to rely on automatic reorganization you should manually reorganize the index
from time to time. You can use the following SQL statement to check whether reorganization for
a given index is recommended:
SELECT reorg_suggested
FROM db2ext.textindexes
WHERE indname = 'ORDERIDX'
The following UPDATE INDEX command forces reorganization of an index explicitly:
db2text "UPDATE INDEX orderIdx FOR TEXT REORGANIZE
CONNECT TO <dbname>"
19.4.7
Altering Text Indexes
The ALTER INDEX command allows you to change the update frequency of the index and work
directories for a particular text index. Figure 19.14 shows three sample commands. The first command sets the update frequency of the text index, such that it is updated every hour if at least 100
text documents have been changed. The second command disables automatically scheduled
index updates. The third command moves the index and work directories to a new storage location. The index is locked and cannot be used for queries while the storage areas are being moved.
db2text "ALTER INDEX orderIdx FOR TEXT
UPDATE FREQUENCY D(*)H(*)M(0) UPDATE MINIMUM 100
CONNECT TO <dbname>"
db2text "ALTER INDEX orderIdx FOR TEXT
UPDATE FREQUENCY NONE
CONNECT TO <dbname>"
db2text "ALTER INDEX orderIdx FOR TEXT
INDEX DIRECTORY /newstorage/index
WORK DIRECTORY /newstorage/temp
CONNECT TO <dbname>"
Figure 19.14
Three ALTER INDEX commands for text indexes
19.5
Performing XML Full-Text Search with the DB2 Net Search Extender
581
19.5 PERFORMING XML FULL-TEXT SEARCH WITH THE DB2 NET SEARCH
EXTENDER
The DB2 Net Search Extender offers three methods for performing full-text search:
• SQL scalar functions: contains, score, numberofmatches
These functions are seamlessly integrated into SQL and provide the most flexible
approach for text search. You can use these functions as you would use any other functions in SQL queries. The DB2 query optimizer estimates the selectivity of CONTAINS
predicates and uses this information to generate efficient access plans for SQL queries
that include text search.
• Text search table function: A key benefit of the DB2 Net Search Extender table function is that it allows full-text search on views. It returns a set of primary key values from
the text index that you need to join with the base table to obtain the actual search results.
• Text search stored procedure: The DB2 Net Search Extender stored procedure can
perform high-performance search against a predefined in-memory cache of user data.
This type of search cannot be used in arbitrary SQL queries and does not allow automatic update of the text index.
In the remainder of this section we focus on text search with the SQL scalar functions since they
are the most flexible and most commonly used search method. They are suitable in the majority
of application scenarios and the only way to perform text search on partitioned tables in a DPF
database. Unless otherwise noted, the following examples all use the following simple text index
without a custom document model:
db2text "CREATE INDEX orderIdx FOR TEXT ON orders(doc)
CONNECT TO <dbname>"
19.5.1
Full-Text Search in SQL and XQuery
The scalar functions CONTAINS, SCORE, and NUMBEROFMATCHES take two arguments: a column
name and a set of search criteria, such as search terms and additional conditions on them. For
each row in the column, the function CONTAINS returns the value 1 if the document in the row
matches the search criteria, and 0 otherwise. The query in Figure 19.15 returns all the rows from
the orders table where the XML document in the column doc contains the word Deluxe. For
the sample data in Figure 19.1, only the first of the two rows is returned.
SELECT doc
FROM orders
WHERE CONTAINS(doc, ' "Deluxe" ') = 1
Figure 19.15
Find all documents that contain the word Deluxe
582
Chapter 19
Performing Full-Text Search
Note that the search condition, which can be more complex than a single word, is enclosed in single quotes. The search term Deluxe itself is enclosed in double quotes.
The query in Figure 19.16 looks for documents that have two or more occurrences of the word
rabbit. The function NUMBEROFMATCHES returns an integer value that indicates how often the
search term occurs in a given document. The function SCORE returns a DOUBLE value indicating
how well a document meets the search conditions relative to other documents in the same index.
Among other things, the score is calculated based on the ratio between the number of matches
found in the document and the document’s size. The query in Figure 19.16 returns
the documents in order of decreasing relevance. However, only the second of the two rows in Figure 19.1 matches the search condition. Text search is case-insensitive by default, which is why
two occurrences of the word rabbit are found in the second document of our sample data.
SELECT SCORE(doc, ' "rabbit" ') AS score, doc
FROM orders
WHERE NUMBEROFMATCHES(doc, ' "rabbit" ') >= 2
ORDER BY score DESC
Figure 19.16
Find documents that contain the word rabbit at least twice
Since these queries are regular SQL statements they can be arbitrarily extended with relational
predicates, joins, aggregation, and other language constructs.
Since the functions CONTAINS, SCORE, and NUMBEROFMATCHES belong to the SQL domain you
cannot use them in XQuery directly. Also, the fn:contains function in the XQuery language
does not exploit any text indexes. Instead, use the db2-fn:sqlquery function to include text
search in an XQuery. The query in Figure 19.17 returns the customer element from all orders
that contain the word Deluxe:
xquery
for $i in db2-fn:sqlquery("SELECT doc
FROM orders
WHERE CONTAINS(doc, ' ""Deluxe"" ') = 1")/order
return $i/customer
Figure 19.17
Simple text search in XQuery
Since XML data has more structure than regular plain text in VARCHAR or CLOB columns, you can
apply the text search condition to specific elements, attributes, or subtrees through the use of
XPath. The search condition (still in single quotes) now consists of two parts: a section and a
search term. The section defines where to look for the search term. The section is separated from
the search term by any amount of whitespace. The XPath can contain only the child axis (/), the
attribute axis (@), and namespace prefixes. The query in Figure 19.18 retrieves order documents
in which any item name contains the word Deluxe.
19.5
Performing XML Full-Text Search with the DB2 Net Search Extender
583
SELECT doc
FROM orders
WHERE CONTAINS(doc, 'SECTION("/order/item/name") "Deluxe" ') = 1
Figure 19.18
Text search along a specific XPath in your XML data
Wildcard search is a technique to match words or phrases in your data that are not exactly the
same as the search terms that you provide in the query. Searching with wildcards is very intuitive.
You can use the underscore character “_” to match any single character in a word, and the percent
sign “%” to match any sequence of multiple characters. Both queries in Figure 19.19 find documents where the word Deluxe appears in an item name. The second of the two queries also
matches documents with words such as Delete or Departure in an item name.
SELECT doc
FROM orders
WHERE CONTAINS(doc, ' SECTION("/order/item/name") "De_uxe" ')=1;
SELECT doc
FROM orders
WHERE CONTAINS(doc, ' SECTION("/order/item/name") "De%e" ')=1;
Figure 19.19
19.5.2
Text search queries with wildcards
Full-Text Search with Boolean Operators
The DB2 Net Search Extender supports the Boolean operators AND (&), OR (|), and NOT. You can
use these operators with and without sections in the search conditions.
Figure 19.20 shows two equivalent queries that return all documents that contain the word
Deluxe or the word Crystal or both in any item name. The second of the two queries is logically equivalent to the first because a list of search terms implicitly uses the OR operator.
SELECT doc
FROM orders
WHERE CONTAINS(doc,'SECTION("/order/item/name")
"Deluxe" | "Crystal" ')=1;
SELECT doc
FROM orders
WHERE CONTAINS(doc,'SECTION("/order/item/name")
("Deluxe","Crystal") ')=1;
Figure 19.20
Find documents that contain the words Deluxe or Crystal or both
584
Chapter 19
Performing Full-Text Search
In contrast, the query in Figure 19.21 identifies the documents that contain both Deluxe and
Crystal in an item name.
SELECT doc
FROM orders
WHERE CONTAINS(doc,' SECTION("/order/item/name")
"Deluxe" & "Crystal" ') = 1
Figure 19.21
Find documents that contain two search terms in a specific element
The queries in Figure 19.22, which use the Boolean operator AND between two section expressions, have a different meaning than the query in Figure 19.21. While the previous query returns
documents where Deluxe and Crystal appear in the same item name, the queries in Figure
19.22 also return documents, where Deluxe and Crystal occur in different item names.
Remember that a single order can contain multiple items and those items can have different
names. The second query in Figure 19.22 is logically equivalent to the first, but it is typically less
efficient because it calls the contains UDF twice.
SELECT doc
FROM orders
WHERE CONTAINS(doc,'SECTION("/order/item/name") "Deluxe"
& SECTION("/order/item/name") "Crystal" ')=1;
SELECT doc
FROM orders
WHERE CONTAINS(doc, ' SECTION("/order/item/name") "Deluxe" ')=1
AND
CONTAINS(doc, ' SECTION("/order/item/name") "Crystal" ')=1;
Figure 19.22
Two equivalent queries that are different from Figure 19.21
The Boolean operators also work without using a section in the search condition. Figure 19.23
shows a query that returns all documents that contain words that start with Magic or Crystal
but that do not contain the word Potion. Only the second of the two documents in Figure 19.1 is
returned. This query uses parentheses to force a certain evaluation order of the Boolean operators.
The OR (|) is evaluated before the AND (&). Without the parentheses the AND is evaluated first,
because AND has precedence over OR, as in regular Boolean logic.
SELECT doc
FROM orders
WHERE CONTAINS(doc,'("Magic%" | "Crystal%") & NOT "Potion" ')=1
Figure 19.23
Combining the Boolean operators OR (|), AND (&), and NOT
19.5
Performing XML Full-Text Search with the DB2 Net Search Extender
19.5.3
585
Full-Text Search with Custom Document Models
If you always restrict the text search to item names and item comments in the documents then the
use of a custom document model can help reduce the size of the index and improve performance.
Let’s revisit the document model and index definition from section 19.4.4, which are repeated
here for convenience in Figure 19.24 and Figure 19.25, respectively.
<?xml version="1.0"?>
<XMLModel>
<XMLFieldDefinition name="iName"
locator="/order/item/name"/>
<XMLFieldDefinition name="iComments"
locator="/order/item/comment"/>
</XMLModel>
Figure 19.24
Document model, stored in the file /models/itemModel.xml
db2text "CREATE INDEX orderIdx FOR TEXT ON orders(doc)
FORMAT XML DOCUMENTMODEL XMLModel IN /models/itemModel.xml
CONNECT TO <dbname>"
Figure 19.25
Text index based on the document model in Figure 19.24
With this document model in the index definition you can simply use the name of an XMLFieldDefinition to identify the section of the document in which you want to search. For example,
the first query in Figure 19.26 returns documents that contain the word Deluxe in the item name
without specifying the actual XPath to the item name element. The second query returns documents where the word Deluxe appears in the item name or in the item comment.
SELECT doc
FROM orders
WHERE CONTAINS(doc, ' SECTION("iName") "Deluxe" ') = 1;
SELECT doc
FROM orders
WHERE CONTAINS(doc, ' SECTION("iName") "Deluxe"
| SECTION("iComment") "Deluxe" ') = 1;
Figure 19.26
Focused search queries that reference sections of a document by name
If you always want to search across item name and comment without distinguishing between the
two, then it is even simpler to use the document model with the XPath union operator (|) in
Figure 19.27. Then you can run the simplified query in Figure 19.28 to search across item name
and comment.
586
Chapter 19
Performing Full-Text Search
<?xml version="1.0"?>
<XMLModel>
<XMLFieldDefinition name = "NameComment"
locator = "/order/item/(name|comment)" />
</XMLModel>
Figure 19.27
Document model with the XPath union operator (|)
SELECT doc
FROM orders
WHERE CONTAINS(doc, ' SECTION("NameComment") "Deluxe" ') = 1
Figure 19.28
19.5.4
Query that uses the document model in Figure 19.27
Advanced Search with Proximity, Fuzzy, and Stemming Options
Proximity search allows you to search for words that appear within the same sentence in a larger
piece of text in an XML text node. The query in Figure 19.29 retrieves documents where the word
rabbit occurs in the same sentence as the phrase big enough. It does not matter whether rabbit occurs before or after big enough.
SELECT doc
FROM orders
WHERE CONTAINS(doc, ' SECTION("/order/item/comment") "rabbit"
IN SAME SENTENCE AS "big enough" ') = 1
Figure 19.29
Proximity search
Stemming means that the DB2 Net Search Extender looks for words that have the same stem (or
base form) as the search term. When the query in Figure 19.30 is executed, the search term
wrapped is first reduced to its stem wrap. Then the query returns documents that contain words
such as wrap, wrapping, wraps, and so on in an item comment. Stemming is language dependent and currently only supported for English.
SELECT doc
FROM orders
WHERE CONTAINS(doc, ' SECTION("/order/item/comment")
STEMMED FORM OF "wrapped" ') = 1
Figure 19.30
Text search with stemming
Fuzzy search allows you to look for words that are spelled similarly to the search term that you
provide. Specify a value between 1 and 100 to indicate the desired degree of similarity, where 100
requires an exact match and anything below 100 is increasingly fuzzy, which helps you overcome
spelling mistakes in the data or search terms. The query in Figure 19.31 retrieves documents
19.5
Performing XML Full-Text Search with the DB2 Net Search Extender
587
where the word wrapping occurs in an item comment although the search term wraping is
spelled with a single p.
SELECT doc
FROM orders
WHERE CONTAINS(doc, ' SECTION("/order/item/comment")
FUZZY FORM OF 85 "wraping" ') = 1
Figure 19.31
19.5.5
Fuzzy search
Finding the Correct Match within an XML Document
All the sample queries discussed so far have retrieved a full document or row when a match was
found in the document. But, since there can be multiple items per order, you might want to read
only those items from an order document that actually match the text search condition.
For example, the query in Figure 19.32 is not suitable to retrieve the items that contain the word
Crystal in their name. The WHERE clause qualifies an entire row, and the XMLQUERY function in
the SELECT clause extracts all items from the matching document. Hence, this query returns two
items from the sample data in Figure 19.1, the Crystal Ball and the Magic Potion. Both belong to
the same document but only the Crystal Ball matches the search condition.
SELECT XMLQUERY('$DOC/order/item')
FROM orders
WHERE CONTAINS(doc,'SECTION("/order/item/name") "Crystal" ')=1
Figure 19.32
This query does not find the correct match within a document.
To extract the desired item only, the XMLQUERY function must include a filtering condition based
on the XQuery function fn:contains. The query in Figure 19.33 uses the Net Search Extender
predicate CONTAINS in the WHERE clause to access the index and to find matching documents.
The XQuery function fn:contains in the SELECT clause does not use the text index and only
searches within any document that matches the WHERE clause.
SELECT XMLQUERY('$DOC/order/item[fn:contains(name, "Crystal")]')
FROM orders
WHERE CONTAINS(doc,'SECTION("/order/item/name") "Crystal" ')=1
Figure 19.33
This query finds the correct match within a document
If the number of matching documents is moderate, then the overhead of the additional fn:contains predicate in the XMLQUERY function is relatively small, because it is applied only to those
documents that already match the WHERE clause. The XQuery function fn:contains does not
support fuzzy search, proximity search, stemming, or other advanced search options. Hence, such
techniques cannot be used to find a specific item within a document.
588
19.5.6
Chapter 19
Performing Full-Text Search
Search Conditions on Sibling Branches of an XML Document
Assume you want to find order documents that contain the string Magic in an item name and the
string fur in the comment of the same item. In other words, you have two text search conditions
and a positional relationship between them. The conditions are required to match elements (or
branches) that are rooted under a common parent, which is the item element in this example. The
query in Figure 19.34 comes to mind but it does not represent the desired search semantics.
SELECT doc
FROM orders
WHERE CONTAINS(doc,'SECTION("/order/item/name") "Magic%"
& SECTION("/order/item/comment") "fur%" ')=1
Figure 19.34
Query with predicates that can match different item elements
This query returns both documents from the sample table in Figure 19.1 although only the first
document has an item with the string Magic in the item name and the string fur in the same
item’s comment. The problem with this query is that the sections /order/item/name and
/order/item/comment can match different items in the same document. The second document in Figure 19.1 contains one item whose name starts with Magic and a different item where
the string fur occurs in the comment. This document is a valid match for the query in Figure
19.34 but not what we wanted.
The DB2 Net Search Extender by itself is not sufficient to fully express the desired query. You
need to add additional XPath predicates with XMLEXISTS to properly constrain the name and the
comment of the same item, as in Figure 19.35. The additional fn:contains predicates within
XMLEXISTS do not use any index but they narrow down the intermediate result set from the Net
Search Extender text predicates and index.
SELECT doc
FROM orders
WHERE CONTAINS(doc, 'SECTION("/order/item/name") "Magic%"
& SECTION("/order/item/comment") "fur%" ')=1
AND XMLEXISTS('$DOC/order/item[fn:contains(name,"Magic") and
fn:contains(comment,"fur")]')
Figure 19.35
19.5.7
Extra predicates force both predicates to match the same item element
Text Search in the Presence of Namespaces
The DB2 Net Search Extender has simple support for namespaces. It does not allow you to
declare namespaces in the CONTAINS predicates, but you can use namespace prefixes in XPath
expressions when you specify a document section. Let’s consider the sample data in Figure 19.36
where the first document has a namespace with an explicit prefix ns, the second document uses a
default namespace, and the third document has no namespace at all.
19.5
Performing XML Full-Text Search with the DB2 Net Search Extender
id
1
2
3
589
doc
<ns:order xmlns:ns="http://www.witchcraft.org"
date="2007-11-05">
<ns:customer>Wendy Witch</ns:customer>
<ns:item key="82">
<ns:name>Crystal Ball, Deluxe Edition</ns:name>
<ns:quantity>1</ns:quantity>
<ns:price>95.00</ns:price>
<ns:comment>Customer needs extra wrapping.</ns:comment>
</ns:item>
</ns:order>
<order xmlns="http://www.witchcraft.org"
date="2007-11-05">
<customer>Wendy Witch</customer>
<item key="82">
<name>Crystal Ball, Deluxe Edition</name>
<quantity>1</quantity>
<price>95.00</price>
<comment>Customer needs extra wrapping.</comment>
</item>
</order>
<order date="2007-11-05">
<customer>Wendy Witch</customer>
<item key="82">
<name>Crystal Ball, Deluxe Edition</name>
<quantity>1</quantity>
<price>95.00</price>
<comment>Customer needs extra wrapping.</comment>
</item>
</order>
Figure 19.36
Sample data with namespaces
To illustrate text search with namespaces, let’s look for documents where the word Crystal
appears in an item name. All three documents in Figure 19.36 contain this word, but they differ in
their namespaces.
Now consider the two queries in Figure 19.37. The first query uses exactly the same namespace
prefix as the first document in Figure 19.36. Hence, only this document (with ID 1) is returned:
The second query does not use namespace prefixes in the section specification and returns the
second and the third document from Figure 19.36. The Net Search Extender does not distinguish
between a default namespace and no namespace. A document with a default namespace is treated
as if there was no namespace. Consequently, the Net Search Extender does not recognize that the
first two documents in Figure 19.36 are equivalent in terms of their namespaces. The Net search
Extender merely treats namespace prefixes as if they were parts of the local element names and
ignores namespace declarations and URIs.
590
Chapter 19
Performing Full-Text Search
-- returns only the first document:
SELECT doc
FROM orders
WHERE CONTAINS(doc,'SECTION("/ns:order/ns:item/ns:name")
"Crystal" ')=1;
-- returns the second and third document:
SELECT doc
FROM orders
WHERE CONTAINS(doc,'SECTION("/order/item/name") "Crystal" ')=1;
Figure 19.37
19.6
Two queries against the sample data with namespaces
DB2 TEXT SEARCH
DB2 Text Search is new text search functionality based on the technology in the open source
project Lucene, which is also used in OmniFind. The DB2 Net Search Extender and DB2 Text
Search can coexist in the same database instance, but only one of them can be used for a given
database. You will find that many DB2 Text Search features and most of its administration commands are identical or very similar to those of the DB2 Net Search Extender. Therefore we do not
repeat all of these commands and features but focus predominantly on those that are different in
DB2 Text Search. Section 19.7 provides a summary and comparison of the most relevant administrative commands for DB2 Text Search and the DB2 Net Search Extender.
19.6.1
Enabling a Database for DB2 Text Search
The first step to using DB2 Text Search is to start the DB2 Text Search instance service. You must
be the DB2 instance owner to run the following command at the OS prompt:
db2ts START FOR TEXT
Next you enable a database for text search operations. Issue the following command to enable the
database <dbname>:
db2ts ENABLE DATABASE FOR TEXT CONNECT TO <dbname>
This command is identical to the corresponding command for the DB2 Net Search Extender,
except that the executable db2ts is used instead of db2text. Optionally you can provide a username and password for authentication to the database:
db2ts ENABLE DATABASE FOR TEXT CONNECT TO <dbname>
USER <username> USING <password>
19.6
DB2 Text Search
591
The ENABLE DATABASE command creates the following tables and views in the default table
space of the database:
• SYSIBMTS.TSDEFAULTS: Contains default values for text search configuration
parameters
• SYSIBMTS.TSINDEXES: Contains one row with meta information for each text index
• SYSIBMTS.TSLOCKS: Contains dynamic information about database and index locks
• SYSIBMTS.TSCONFIGURATION: Contains index-level configuration parameters
• SYSIBMTS.TSCOLLECTIONNAMES: Associates text index names to internal collection
names
Similarly, you can disable DB2 Text Search for a database, which removes these tables and
views, with the following command:
db2ts DISABLE DATABASE FOR TEXT [FORCE] CONNECT TO <dbname>
[USER <username> USING <password>]
This command removes all tables and views in the SYSIBMTS schema. Use the optional keyword
FORCE to forcibly drop text indexes from the database. If this option is not specified and text
indexes still exist for this database, the command fails. You can also use the separate DROP
INDEX command to remove text indexes.
19.6.2
Creating and Maintaining Full-Text Indexes for DB2 Text Search
DB2 Text Search allows you to define at most one index per column. The index contains entries
for the entire document in the column, which is why you never need more than one text index per
column. You cannot use a document model to index only certain sections of each document. The
following examples illustrate the CREATE INDEX command for DB2 Text Search.
The following command creates a text index with the name orderIdx on the column doc in the
table orders in the database <dbname>:
db2ts "CREATE INDEX orderIdx FOR TEXT ON orders(doc)
CONNECT TO <dbname>"
Depending on the operating system and configuration of your command shell, you might have to
enclose the command parameter for db2ts in double quotes, as shown in this example. The table
orders must have a primary key. The column doc must be of type XML or any character or
binary column type, such as CHAR, VARCHAR, CLOB, BLOB, DBCLOB, GRAPHIC, or VARCHAR FOR
BIT DATA.
592
Chapter 19
Performing Full-Text Search
The preceding CREATE INDEX statement uses the same syntax as in the DB2 Net Search Extender, except that the executable is db2ts instead of db2text. As for the DB2 Net Search Extender, the CREATE INDEX statement for a text index defines an index but does not actually build the
text index. An UPDATE INDEX command is required after the CREATE INDEX statement to physically populate the index. Additional options in the CREATE INDEX syntax, such as defining an
update frequency or update minimum, are also the same for DB2 Text Search and the DB2 Net
Search Extender. Other administrative commands, such as UPDATE INDEX, DROP INDEX, and so
on are also common for the DB2 Text Search and the DB2 Net Search Extender.
19.6.3
Writing DB2 Text Search Queries for XML Data
DB2 Text Search allows you to write search queries with CONTAINS predicates much like the
DB2 Net Search Extender. Additionally, DB2 Text Search supports the function db2-fn:
xmlcolumn-contains, which enables you to perform full-text search in XQuery without any
use of SQL.
The query in Figure 19.38 returns the customer information from all orders that contain the word
Deluxe anywhere in the document. The syntax of this query is the same as for the DB2 Net
Search Extender.
SELECT XMLQUERY('$DOC/order/customer')
FROM orders
WHERE CONTAINS(doc, ' "Deluxe" ') = 1
Figure 19.38
SQL-based text search with the CONTAINS function
Applications that use XQuery only and prefer to avoid using SQL can write the same query with
the function db2-fn:xmlcolumn-contains, which is an extension of the regular
db2fn:xmlcolumn function. In addition to the XML column name it takes a search argument as
a second input parameter, as in Figure 19.39.
xquery
for $i in db2-fn:xmlcolumn-contains('ORDERS.DOC', ' "Deluxe" ')
return $i/order/customer
Figure 19.39
XQuery-based text search with the db2-fn:xmlcolumn-contains function
While db2-fn:xmlcolumn('ORDERS.DOC') returns all XML documents from the column
DOC in the ORDERS table, the db2-fn:xmlcolumn-contains function returns in this example
only those documents that contain the word Deluxe.
19.6
DB2 Text Search
19.6.4
593
Full-Text Search with XPath Expressions
DB2 Text Search differs from the DB2 Net Search Extender in the syntax for searching within a
specific path of your XML documents. Figure 19.40 shows two equivalent queries and compares
the respective syntax. Both queries return all order documents that have an item with a name that
contains the word Deluxe.
-- DB2 Net Search Extender query:
SELECT doc
FROM orders
WHERE CONTAINS(doc, 'SECTION("/order/item/name") "Deluxe" ') = 1;
-- DB2
Text Search query:
SELECT doc
FROM orders
WHERE CONTAINS(doc,
'@xpath:''/order/item/name[. contains("Deluxe")]'' ')=1;
Figure 19.40
Comparison of DB2 Text Search and NSE query syntax
Note that the syntax for DB2 Text Search includes the contains function also within the square
brackets of the XPath predicate. The dot that precedes the keyword contains is the current
XPath context and refers to the name element. Alternatively you can include the name element
itself in the square brackets, as shown in Figure 19.41, which produces the same result.
SELECT XMLQUERY('$DOC/order/customer')
FROM orders
WHERE CONTAINS(doc,
'@xpath:''/order/item[name contains("Deluxe")]'' ')=1;
Figure 19.41
DB2 Text Search query with XPath
The query in Figure 19.41 also uses the XMLQUERY function in the SELECT clause to extract and
return only the customer element from the matching documents. The same can be coded in
XQuery notation, as shown in Figure 19.42.
xquery
for $i in db2-fn:xmlcolumn-contains('ORDERS.DOC',
'@xpath:''/order/item[name contains("Deluxe")]'' ')
return $i/order/customer;
Figure 19.42
Text search in XQuery
The XPath navigation in the search argument can contain the child axis (/), the attribute axis (@),
the descendent-or-self axis (//), a reference to the current context node (.), and of course element
and attribute names. Wildcards (*) are not allowed.
594
19.6.5
Chapter 19
Performing Full-Text Search
Full-Text Search with Wildcards
While the DB2 Net Search Extender uses the underscore (_) to denote a single character wildcard
and the percent sign (%) as a multicharacter wildcard, DB2 Text Search uses the question mark
(?) and the star (*) instead. The two queries in Figure 19.43 illustrate the use of these wildcards.
The first query returns documents that contain words such as Deluxe with an arbitrary character
at the third position of the word. The second query also matches documents that contain words
such as Delete or Departure.
SELECT doc
FROM orders
WHERE CONTAINS(doc,' "De?uxe" ')=1;
SELECT doc
FROM orders
WHERE CONTAINS(doc,' "De*e" ')=1;
Figure 19.43
DB2 Text Search queries with wildcards
Note that wildcards at the beginning of a search term, such
as ?eluxe or *eluxe, often reduce query performance and should be
avoided.
NOTE
DB2 Text Search offers a variety of additional search capabilities that are not specific to XML but
applicable to text search in general. For example, you can add the + and – signs to specific search
terms to indicate that they are required or prohibited in the search results. If a query contains multiple search terms, DB2 Text Search also allows you to add boost modifiers to some of them to
give them stronger weighting in the search. Refer to the DB2 documentation for more details.
19.7
SUMMARY OF TEXT SEARCH ADMINISTRATION COMMANDS
Table 19.2 summarizes the most important commands for administrating the DB2 Net Search
Extender and DB2 Text Search. The commands are grouped according to their scope, such as the
entire DB2 instance, a single database, or a specific table or index.
19.7
Summary of Text Search Administration Commands
Table 19.2
595
Summary of Text Index Administration Commands
NSE / db2ts
Command
Comment
Instance Level Commands
db2text
START
db2ts
START FOR TEXT
db2text
STOP
db2ts
STOP FOR TEXT
db2ts
CLEANUP FOR TEXT
Start text search service
Stop text search service
Removes obsolete text search objects
Database Level Commands
db2ts /
db2text
ENABLE DATABASE FOR TEXT
CONNECT TO <dbname>
Enable full-text search
db2ts /
db2text
DISABLE DATABASE FOR
TEXT CONNECT TO <dbname>
Disable full-text search
db2text
CONTROL {clear|list} ALL
LOCKS FOR {DATABASE
<dbname> | INDEX
<indname>}
List or remove text index locks
db2ts
CLEAR COMMAND LOCKS [for
index <indname>] FOR TEXT
Force the removal of text index locks
Table/Index Level Commands
db2ts /
db2text
CLEAR EVENTS FOR INDEX
<indname> FOR TEXT
Delete events from event tables
db2ts /
db2text
CREATE INDEX <indname>
FOR TEXT ON <tabname>
(<colname>)
Add a text index
db2ts /
db2text
DROP INDEX <indname>
FOR TEXT
Remove a text index
db2ts /
db2text
ALTER INDEX <indname>
FOR TEXT…
Change index update options
db2ts /
db2text
UPDATE INDEX <indname>
FOR TEXT
Manually invoke index update
db2text
UPDATE INDEX <indname>
FOR TEXT REORGANIZE
Reorganize the text index
596
19.8
Chapter 19
Performing Full-Text Search
XML FULL-TEXT SEARCH IN DB2 FOR Z/OS
To perform XML full-text search in DB2 for z/OS, use the IBM OmniFind Text Search Server for
DB2 for z/OS. This text search functionality is very similar to DB2 Text Search for DB2 on
Linux, UNIX, and Windows, which is also based on Omnifind (see section 19.6). The XML
structure in the XML data is indexed in the IBM OmniFind Text Search Server for DB2 for z/OS
after parsing the data through an XML parser. Then you can use the CONTAINS function and the
supported XPath query syntax to perform XML full-text search. For example, the DB2 Text
Search queries in Figure 19.38, Figure 19.40, Figure 19.41, and Figure 19.43 are also supported
by the IBM OmniFind Text Search Server for DB2 for z/OS. The functionality and syntax of
search conditions are identical. Differences exist in the installation and administration of the Text
Search Server. For example, creating and updating full-text indexes for DB2 for z/OS is performed via stored procedures such as SYSPROC.SYSTS_CREATE and SYSPROC.SYSTS_
UPDATE. Links to further information are provided in Appendix C.
19.9
SUMMARY
Unlike data-oriented XML, content-oriented XML documents represent predominantly textual
information, such as emails, news, contracts, patents, or web content. Processing such XML data
often requires full-text search.
The existing DB2 Net Search Extender as well as the new DB2 Text Search capabilities allow
you to create full-text indexes over XML documents or other text documents that are stored in
XML columns or LOB and character columns. When you insert, update, or delete an XML document, text indexes are not updated immediately. Instead, the data changes are captured in a staging table and periodically used to refresh the text index. This is known as asynchronous index
maintenance. You can configure how frequently a text index gets refreshed.
When a text index is in place you can use text search predicates in SQL, XQuery, and SQL/XML
queries. The search predicates can range from simple search terms to complex predicates with
Boolean operators, fuzzy search, stemming, linguistic search, proximity search, and other
options. A single query can contain text search predicates as well as regular relational and XML
predicates at the same time.
C
H A P T E R
20
Understanding XML
Data Encoding
I
n this chapter you will learn
• How DB2 identifies and handles the encoding of your XML data
• Best practices to avoid encoding problems
DB2 for z/OS and DB2 for Linux, UNIX, and Windows always store XML data in UTF-8 Unicode, irrespective of the original code page of your XML data or application and regardless of the
database code page. If your XML data is in a different encoding, DB2 will automatically perform
code page conversion to UTF-8 before storing it. When you retrieve XML data from DB2 you
can obtain it in UTF-8 or automatically in the code page of your application. In most cases all
code page conversion is fully transparent to your application, especially if you stick to using Unicode for your data, application, and database code page. If you use non-Unicode code pages,
there are certain situations in which code page conversion occurs and can lead to data loss. Data
loss can occur when characters in one code page cannot be represented in another.
There is a significant trend towards Unicode in the industry. For example, the application code
page of Java and .NET applications is always Unicode (UTF-16).
If you want to use the pureXML capabilities in DB2 9.1 for Linux, UNIX, and Windows, the
database code page must be UTF-8. To create a UTF-8 Unicode database with the name demo in
DB2 9.1, issue the following command:
CREATE DATABASE demo USING CODESET utf-8 TERRITORY us
Since DB2 9.5 for Linux, UNIX, and Windows, the default code page for a new database is
always UTF-8, so you can safely omit the USING CODESET clause. DB2 9.5 also allows you to
use pureXML in non-Unicode databases.
597
598
Chapter 20
Understanding XML Data Encoding
DB2 for z/OS allows you to define and use XML columns regardless of the encoding scheme of
the database or table space. For example, you can add an XML column to an EBCDIC, ASCII, or
UNICODE table. The encoding schema of the table space does not affect the storage of the XML
documents, which are always stored in UTF-8. All other data of the same table remains EBCDIC,
ASCII, or UNICODE.
Many XML encoding considerations are identical for DB2 for z/OS and DB2 for Linux, UNIX,
and Windows. In the remainder of this chapter we refer to “DB2” without indication of platform
unless there is platform-specific behavior or syntax that deserves attention.
WHAT IS UNICODE?
Unicode is a universal character encoding standard for the representation of text in computer systems. Unicode assigns a universally unique
number to every character in every language, independent from any
hardware, operating system, software, or programming language. Before
the advent of Unicode, hundreds of different and often conflicting
encoding schemes were used. Unicode defines a single consistent
encoding for all of the world’s characters, including all European alphabets such as Greek and Cyrillic, Middle-Eastern left-to-right scripts, and
all commonly used Asian alphabets. Unicode also covers accented characters (such as é and ñ), punctuation marks as well as mathematical and
technical symbols, and hieroglyphs.
WHAT IS UTF-8?
UTF-8, UTF-16, and UTF-32 are the three Unicode Transformation Formats defined by the Unicode standard.They are different ways to represent the same Unicode character codes in bits and bytes.As indicated
by their names, they use 8-bit, 16-bit, or 32-bit units. UTF-32 represents
every Unicode character as a single 32-bit code unit. UTF-16 is a variable-length encoding, which represents the most commonly used characters in only 16 bit, and all others in pairs of two 16-bit code units.This
approach saves space over UTF-32. Finally, UTF-8 encodes any Unicode
character in 1 to 4 bytes. The number of bytes used depends on the
character. For example, UTF-8 represents the widely used ASCII characters in just one byte (8 bits) each, which saves space over UTF-16.
UTF-8 is the default encoding for XML.
The predecessor of UTF-16 is USC-2, which is a fixed-length encoding
that represents each character in 2 bytes. USC-2 is a subset of UTF-16
and the default encoding in Java applications prior to Java 1.5 (J2SE 5.0),
where support for UFT-16 was introduced.
20.1
Understanding Internal and External XML Encoding
20.1
599
UNDERSTANDING INTERNAL AND EXTERNAL XML ENCODING
XML differs from other types of data because it can be internally encoded, externally encoded, or
both. This difference matters when you move XML data from your application to DB2 (INSERT,
UPDATE, IMPORT, or LOAD) and when you retrieve XML data from DB2 (using SELECT or
EXPORT). Internally encoded means that the encoding of your XML data can be derived from the
data itself, as defined in the XML standard. In contrast, externally encoded means that the encoding of the data is derived from the application code page.
When an XML document is inserted, DB2 identifies its encoding. Whether DB2 treats your XML
data as internally encoded or externally encoded depends on the data type of the application variables or parameter markers that you use to exchange XML data with DB2. If your application
uses character type variables for XML then the data is considered externally encoded; that is, in
the application code page. If you use binary application data types then the XML data is considered internally encoded and the application code page is irrelevant.
DB2 for Linux, UNIX, and Windows detects the application code page automatically from the
operating system. For example, in Linux and UNIX it detects the locale setting. You can use the
DB2 registry variable DB2CODEPAGE to override the automatically detected application code
page and specify a different application code page. Overriding the automatically detected application code page is rarely required and can cause unpredictable results if you set an inappropriate
code page. Therefore we recommend that you do not set the DB2CODEPAGE registry variable
unless you have a strong reason for it.
20.1.1
Internally Encoded XML Data
The XML standard defines that the internal encoding of XML data is determined based on three
items, which may or may not exist in a given XML document. Any XML parser, including the
one in DB2, determines the internal encoding based on these items. They are
• A Unicode Byte-Order Mark (BOM): A Unicode Byte-Order Mark is a specific
sequence of bytes that represents the Unicode special character U+FEFF (“zero-width
no-break space”). If a BOM exists, it is located at the very beginning of an XML document. The BOM character is represented differently in UTF-8, UTF-16, or UTF-32.
This allows an XML parser (DB2) to recognize the BOM and use it to infer whether the
encoding of the document is UTF-8, UTF-16, or UTF-32. Appendix C, Further Reading, contains pointers to more detailed information.
• An XML declaration containing an encoding declaration: The XML declaration is
an optional line at the beginning of an XML document, and can contain an optional
attribute named encoding. This attribute is known as the encoding declaration. For
example, the following XML declaration contains an encoding declaration:
600
Chapter 20
Understanding XML Data Encoding
<?xml version=”1.0” encoding=”UTF–8” ?>
Encoding Declaration
XML Declaration
DB2 uses the value of the encoding attribute in the XML declaration to determine the
encoding of the XML document.
Note: If the XML document has a BOM and an encoding declaration, they must match.
If the BOM indicates a different encoding than the encoding declaration, DB2 rejects
the XML data with the following error: SQL16168N XML document contains an
invalid XML declaration. Reason code = "7".
To look up reason code “7,” you can issue the command “? SQL16168N” at the DB2
CLP. You will find that reason code “7” means that the specified document encoding was
invalid or contradicts the automatically sensed encoding. In that case you should either
remove the BOM, or the XML declaration, or both.
• An XML declaration without an encoding declaration: Since the encoding declaration is optional, an XML declaration may show the XML version number only, like this:
<?xml version="1.0">
If there is such an XML declaration and no BOM or encoding declaration, then DB2
inspects the XML declaration to determine the encoding in the following alternative
way. If the XML declaration consists of single-byte ASCII characters, then the encoding
of the document is UTF-8. If the XML declaration is in double-byte ASCII characters,
the encoding is UTF-16.
If an XML document has no BOM and no XML declaration at all, then DB2 interprets
the document as UTF-8.
20.1.2
Externally Encoded XML Data
Your XML data has an external encoding if you use character data types (instead of binary data
types) to hold the data in your application. Beware that externally encoded XML data might also
contain an internal encoding, which is the case when an XML document in a character data type
contains an encoding declaration.
If you try to store externally encoded XML data, DB2 for Linux, UNIX, and Windows checks
whether an internal encoding exists. If your XML data has an internal and an external encoding
that are not Unicode, the internal encoding must match the external encoding. Otherwise DB2 for
20.3
Using Non-Unicode Databases for XML
601
Linux, UNIX, and Windows rejects the XML data with error SQL16103N. If the external and the
internal encoding are Unicode encodings, DB2 ignores the internal encoding.
DB2 for z/OS does not enforce consistency of the internal and external encoding. If the internal
and external encoding information are different, the external encoding takes precedence although
character conversion might have occurred on the data and there might be data loss. Hence, it is
strongly recommended to avoid a mismatch between internal and external encoding.
20.2
AVOIDING CODE PAGE CONVERSIONS
Avoiding code page conversions helps reduce CPU consumption and prevents unintentional data
loss or data truncation. To avoid code page problems, it is recommended to use internally
encoded XML data, not externally encoded XML. This means it is recommended to handle XML
data in your application in binary data types rather than character data types.
For example, when you insert XML data into DB2 and use the function SQLBindParameter()
in CLI applications to bind a parameter marker to an XML document, you should use
SQL_C_BINARY data buffers rather than SQL_C_CHAR, SQL_C_DBCHAR, or SQL_C_WCHAR.
When inserting XML data from Java applications, reading in the XML data as a binary stream
(setBinaryStream) is preferred over character strings (setString). Similarly, if your Java
application receives XML from DB2 and writes it to a file, code page conversion can occur if the
XML is written as non-binary data.
20.3
USING NON-UNICODE DATABASES FOR XML
In DB2 9 for z/OS and DB2 9.5 for Linux, UNIX, and Windows you can use any database code
page to manage XML data using the pureXML capabilities. It does not have to be Unicode. While
Unicode is recommended, using a non-Unicode database code page can be desirable due to special application requirements. In some cases, you might have existing databases in a non-Unicode
code page and you might want to add XML data to such a database.
DB2 always stores and processes XML data in Unicode (UTF-8) even if the database code page
(or in DB2 for z/OS the table space encoding) is different. XML parsing, storage, serialization as
well as XML query execution and comparisons are all performed in UTF-8. In contrast, SQL data
is always stored and processed in the database code page. Therefore, a non-Unicode database
causes code page conversion whenever a query combines SQL and XML data, or casts SQL type
data to XML, or XML type data to SQL types. This code page conversion can only be avoided if
the database code page is UTF-8, the same for SQL and XML data.
Figure 20.1 illustrates code page considerations with XML data in DB2. If your application uses
character type variables to hold XML data, the data will be converted from the application code
page to the database code page upon insert into DB2 (indicated by arrow 1). Then DB2 converts
602
Chapter 20
Understanding XML Data Encoding
the XML data from the database code page to UTF 8 for XML parsing and storage (arrow 2).
Similarly, if you use character type application variables for retrieving XML data, the XML will
be converted from UTF-8 to the database code page and then to the application code page.
These code page conversions between application code page and database code page can be
avoided in two ways:
• Use binary (or XML) instead of character type variables for XML data in your application. This is illustrated by arrow 3 in Figure 20.1.
• Use the same code page for your database and your application. This avoids conversion
between database and application code page.
In both cases, DB2 still converts the XML data to UTF-8 if it isn’t in UTF-8 already.
DB2 Application
DB2 database
database code page
application
code page
1
2
Character data
Binary data type
XML data type
Figure 20.1
3
pureXML
Storage
UTF-8
Code page conversions
If you avoid code page conversions between application and database code pages, then you avoid
risking data loss. It is possible that characters in your application code page cannot be represented in the database code page, or vice versa. In this case DB2 introduces substitution characters into the data and issues an error or warning. The next section illustrates these issues in
various examples.
20.4
EXAMPLES OF CODE PAGE ISSUES
Let’s look at some examples of code page conversion issues.
20.4.1
Example 1: Chinese Characters in a Non-Unicode Code Page ISO-8859-1
Assume a database in DB2 for Linux, UNIX, and Windows has been created with the nonUnicode code page ISO-8859-1:
CREATE DATABASE test USING CODESET ISO-8859-1 TERRITORY us;
20.4
Examples of Code Page Issues
603
An application uses a character data type (for example, SQL_C_DBCHAR in CLI, or setString
in Java) to insert the document in Figure 20.2, which contains Chinese characters.
<book>
<title>Romance of the Three Kingdoms</title>
<nativeTitle>
</nativeTitle>
<author>
<firstname>Lou</firstname>
<lastname>Guanzhong</lastname>
<nativeName>
</nativeName>
</author>
</book>
Figure 20.2
XML document with Chinese characters
This document will be converted from whatever the application code page is to the database code
page, which is ISO-8859-1. The Chinese characters cannot be represented in ISO-8859-1 and
will be replaced by a substitution character. For ISO-8859-1, the substitution character is the
hexadecimal hex character 0x1A, which is usually displayed as a question mark (‘?’). Hence, the
document will be stored as shown in Figure 20.3.
<book>
<title>Romance of the Three Kingdoms</title>
<nativeTitle>????</nativeTitle>
<author>
<firstname>Lou</firstname>
<lastname>Guanzhong</lastname>
<nativeName>???</nativeName>
</author>
</book>
Figure 20.3
Document with substitution characters
As you see in Figure 20.3, the native title and the native author name are lost. The DB2 Command
Line Processor (CLP) shows “?” instead of the substitution character 0x1A. You can avoid this
data loss in two ways:
• Use binary instead of character type variables for XML in the application.
• Use UTF-8 as the database code page, or any other code page that can represent Chinese
characters.
20.4.2 Example 2: Fetching Data from a Non-Unicode Code Database into a
Character Type Application Variable
A database in DB2 for Linux, UNIX, and Windows has been created with the non-Unicode code
page ISO-8859-1. An application has used a binary application variable to insert the document
604
Chapter 20
Understanding XML Data Encoding
with Chinese characters (see Figure 20.4). The Chinese characters are preserved. The table name
is books and the XML column name is doc.
Assume the query in Figure 20.4 is used to fetch XML data into a character type application
variable:
SELECT XMLQUERY('$DOC/book/nativeTitle')
FROM books
Figure 20.4
Retrieving the Element nativeTitle
Since the query result is fetched into a character type variable, it is first converted from UTF-8
(XML storage) to the database code page, which cannot represent Chinese characters. Thus, this
query fails with the following error:
SQL20412N Serialization of an XML value resulted in characters that could not be
represented in the target encoding.
To avoid this error, use a binary instead of a character type variable to bind out the XML value to
the application, or use a database code page that can represent Chinese characters, such as
UTF-8.
20.4.3
Example 3: Encoding Issues with XMLTABLE and XMLCAST
This example uses the same database scenario as in example 2. Assume the query in Figure 20.5
is submitted to the database to retrieve the native title and author information. The XMLTABLE
function in this query extracts XML values and converts them to SQL VARCHAR values in the
database code page (ISO-8859-1). Since Chinese characters cannot be represented in this code
page, the VARCHAR values will contain the substitution character instead. This substitution also
applies if XMLCAST is used to convert the data to VARCHAR. To avoid this problem, create the database in a code page that can represent the Chinese characters.
SELECT x.*
FROM books,
XMLTABLE('$DOC/book'
COLUMNS
NativeTitle VARCHAR(50)
NativeAuthor VARCHAR(50)
Figure 20.5
PATH '/nativeTitle',
PATH '//nativeName') AS x
Return the native title and author as VARCHAR values
20.4
Examples of Code Page Issues
20.4.4
605
Example 4: Japanese Literal Values in a Non-Unicode Database
Assume a database has the non-Unicode code page ISO-8859-1 and that the query in Figure
20.6 is issued. Note that it contains the Japanese character “ ” as a literal value in the XML
predicate.
SELECT *
FROM items
WHERE XMLEXISTS('$DOC/item[name = "
Figure 20.6
"] ')
A query with a Japanese character
The query text will be converted to the database code page. As a result, the Japanese character
will be replaced by the substitution character 0x1A, which is not a valid character for an XQuery
expression. Hence, DB2 returns the following error, which would not occur in a Unicode
database:
SQL16002N: An XQuery expression has an unexpected token "0x1A" following "=".
20.4.5 Example 5: Data Expansion and Shrinkage Due to Code Page Conversion
A database has been created with the Unicode encoding UTF-8. The database contains XML
documents that include Korean characters. A Java application connects to the database to read
XML data. The application code page is UTF-16. The application uses the method ResultSet.getString to bind XML data from the database to a String type variable. Since String
is a character data type, code page conversion from the DB2 storage format (UTF-8) to the application code page (UTF-16) is performed. There is no data loss because UTF-16 can represent all
the same characters as UTF-8 (and vice versa). However, some Korean characters are represented
by 3 bytes in UTF-8; that is, 3 × 8 bit, while the same characters may use only 16 bit in UTF-16.
In other words, the same character requires more space in UTF-8 than in UTF-16.
Hence, when you retrieve a Korean character string from a UTF-8 database to a String variable
in a UTF-16 application, the resulting string length in the application (in bytes) might be smaller
than in the database. Conversely, if you hold a Korean character string in a character type variable
in your UTF-16 application and the length is, for example, 20 bytes, inserting this string into a
CHAR(20) column in a UTF-8 database may fail. The reason is that the same string might require
more bytes in UTF-8 than in UTF-16. If the same character string was part of an XML document
that is inserted into an XML column, the data expansion does not lead to a failure because there is
no length restriction associated with an XML column (other than the 2GB maximum size per
document).
606
Chapter 20
Understanding XML Data Encoding
20.5 AVOIDING DATA LOSS AND ENCODING ERRORS IN NON-UNICODE
DATABASES
The previous section has shown some of the problems that can occur when character type variables are used to insert (bind in) or fetch (bind out) XML data from a non-Unicode database.
Encoding errors and data loss can happen. Again, using a Unicode database and handling XML
with binary data types in your application is the best way to avoid these problems.
If you have to use a non-Unicode database then you can still avoid many problems by using
binary instead of character types in your application when you insert or retrieve XML data. In
DB2 9.5 and 9.7 for Linux, UNIX, and Windows you can use the database configuration parameter ENABLE_XMLCHAR to prevent applications from inserting XML data via character data types.
By default, this parameter is set to ON [YES] to allow the use of character types. Use the following command to block any inserts of character type data into XML columns:
db2 UPDATE DB CFG FOR <dbname> USING enable_xmlchar off
Subsequently, XML inserts with character type variables or parameter markers are rejected with
error message SQL20429N:
SQL20429N The XML operation is not allowed on strings that are not FOR BIT DATA on
this database.
This error ensures that data loss due to character substitution cannot occur upon insert. Applications will need to use binary data types to avoid this error and to avoid character substitutions.
When ENABLE_XMLCHAR is set to OFF, you cannot insert XML data in plain text through the
DB2 CLP.
20.6
SUMMARY
The character representation of an XML document can have an internal encoding, an external
encoding, or both. The internal encoding is determined by the document itself, through an encoding declaration or a Unicode byte order mark. The external encoding of a document is the same as
the application code page, if the application code holds XML data in character (string) type variables. If an application holds XML data in binary type variables then there is no external encoding, only an internal encoding.
It is recommended to create DB2 databases with UTF-8 as the database code page. DB2 always
stores XML data in UTF-8 encoding, even if the database code page is not UTF-8. For your application it is recommended to use binary data types for XML data to avoid external encoding.
External encoding leads to additional code page conversion when your application exchanges
20.6
Summary
607
XML data with the DB2 server—except when the application code page and the database code
page are UTF-8. Code page conversion can lead to data loss if characters in one code page cannot
be represented in another code page.
Understanding XML encoding concepts is important for XML application development and the
passing of XML data through APIs between database server and applications.
This page intentionally left blank
C
H A P T E R
21
Developing XML
Applications with DB2
A
pplication development encompasses all the tasks that go beyond the mere creation and
maintenance of database objects. Typical application development tasks include
• Developing application code in a programming language such as Java or COBOL and
managing all interactions with the database through APIs such as JDBC.
• Designing and maintaining XML artifacts such as XML Schemas and XSLT style sheets
with XML application development tools.
• Developing database stored procedures and user-defined functions (see Chapter 18).
• Writing queries in SQL, XQuery, or SQL/XML as well as writing INSERT, DELETE,
and UPDATE statements. (See Chapters 6 through 9 and Chapter 12).
XML application development often deals with moving XML data between the database server
and a client application. Codepage conversion issues can arise when the database and the application have different codepages. The discussion in this chapter assumes that you are familiar with
key concepts from Chapter 20, Understanding XML Data Encoding, such as XML declarations,
encoding declarations, internal encoding, and external encoding.
You can use a wide variety of programming languages and APIs to write DB2 pureXML applications, including the following:
• Assembler
• C or C++ (embedded SQL or DB2 CLI)
• COBOL
• Java (JDBC or SQLJ)
609
610
Chapter 21
Developing XML Applications with DB2
• C# and Visual Basic (.NET)
• Perl
• PHP
• PL/1
• Ruby, and the Ruby on Rails framework
In this chapter we discuss application programming with DB2 pureXML for a subset of these languages and APIs. In particular, this chapter covers the following topics:
• The value of DB2 pureXML for application development (section 21.1)
• Parameter markers and host variables in SQL/XML (section 21.2)
• Java applications for DB2 pureXML (section 21.3)
• .NET applications for DB2 pureXML (section 21.4)
• CLI applications for DB2 pureXML (section 21.5)
• COBOL, PL/1, and C applications for DB2 pureXML (section 21.6)
• PHP applications for DB2 pureXML (section 21.7)
• Perl applications for DB2 pureXML (section 21.8)
• XML application development tools (section 21.9)
Each section assumes that the reader is already familiar with the programming language or API
that is being discussed. Emphasis is placed on the special considerations for XML manipulation
and interaction with a DB2 pureXML database. A more general introduction to the listed languages and APIs is beyond the scope of this book.
The code samples in this chapter are based on the customer table:
CREATE TABLE customer(cid INTEGER, info XML)
21.1
THE VALUE OF DB2 PUREXML FOR APPLICATION DEVELOPMENT
As an application developer, you will find that the pureXML features in DB2 provide significant
value for XML application development. For example, rapid prototyping, flexibility, and avoiding XML parsing in the application are common benefits.
21.1.1
Avoid XML Parsing in the Application Layer
Traditionally, applications that need to manipulate XML documents often read full documents
from the file system or CLOB columns into memory. They then use an XML Document Object
Model (DOM) parser to gain access into the documents. The drawback of DOM parsing is that
the entire XML document is represented in memory as a tree. This tree can be five to ten times
21.1
The Value of DB2 pureXML for Application Development
611
larger than the original XML file, which can be acceptable if you process small documents, one
or a few at a time. However, memory consumption poses a significant problem if you manipulate
large documents or many at the same time. Additionally, the CPU consumption of XML parsing
is a common performance problem. Also, DOM manipulation requires specific skill and results in
additional non-trivial application code that needs to be maintained over time.
As an alternative, Simple API for XML (SAX) parsers and Streaming API for XML (StAX) parsers
alleviate the memory consumption problem because they are event- and stream-based interfaces
that give the application access to only a part of the XML document at a time. They are faster and
consume less memory than DOM parsers because they do not hold the entire document in memory. However, the CPU overhead remains. Navigating through an XML document with a SAX or
StAX parser requires extra coding because you cannot easily go backwards in a stream of events.
Hence, it’s the application’s responsibility to intelligently buffer any part of the document that it
might need to revisit. You should avoid this complexity as much as possible.
Another disadvantage of DOM-, SAX-, and StAX-based XML document manipulation is that
these APIs allow you to process only one document at a time. Querying or updating many XML
documents based on specific search criteria requires additional coding and processing overhead.
With DB2 pureXML, applications can often avoid XML parsing, because DB2 parses XML documents only once, at insert time, and stores them in a parsed hierarchical format. The parsed storage allows you to extract or update document fragments or individual values without having to
parse the XML data in your application. Applications send appropriate XML query or update
statements to DB2 instead of fetching and parsing full documents. As a result there is less application code, reduced application complexity, and higher end-to-end performance. Additionally,
DB2 can efficiently execute XML queries and updates over large collections of XML documents
without XML parsing and without additional application code. In particular, DB2’s XML indexes
can evaluate search conditions and find matching documents quickly.
Let’s consider further examples of how DB2 pureXML avoids XML processing in the application
code:
• Assume your application receives an XML document and needs to insert specific values
from the document into relational columns of a DB2 table. You could parse the XML
document in the application, extract the values, and issue a traditional INSERT statement to DB2. However, letting DB2 do this work is often easier and more efficient. Simply issue an INSERT statement with an XMLTABLE function and provide the document as
a parameter.
• Assume your application receives a very large document and you want to split it into
smaller documents and insert those into DB2. Although you could split the document
with an XML parser in your application, it is again easier and more efficient to let DB2
do the work in an INSERT statement with an XMLTABLE function.
612
Chapter 21
Developing XML Applications with DB2
• Assume your application needs to read certain values from one or several XML documents that are stored in DB2. You should use DB2’s SQL/XML and XQuery features
instead of performing XML parsing of full documents in the application.
• Assume you need to generate XML documents from data in several relational tables.
You could write custom application code to read the relational values and construct
XML data. However, it is often faster and simpler to use declarative SQL/XML construction queries and avoid the extra coding work in your application.
In situations where applications still require access to XML data through DOM or SAX APIs,
they can use the new JDBC 4.0 features, which are covered later in this chapter.
21.1.2
Storing Business Objects in an Intuitive Format
If application data represents business objects, such as insurance claim forms, then it is often beneficial to keep all data items that comprise a particular claim together instead of spreading them
over a set of tables. Often the individual data items of a claim form have no valid business meaning on their own and can only be interpreted in the context of the complete form. Normalizing the
claims across dozens of relational tables means that applications (and application developers)
deal with a complex and unnatural fragmentation of the business data. This fragmentation often
increases application complexity, development costs, and the chance for errors. It also introduces
the need for multi-way join queries to reassemble the original business objects.
DB2 pureXML allows you to manage complex business objects as cohesive and distinct documents while still capturing all the relationships between the data items that comprise the business
object. Representing each claim form (business object) as a single XML document in a single
row of a table provides a very intuitive storage model for the application developer and data analyst. The same applies to other business objects, such as orders, trades, tax returns, travel reservations, or medical records.
21.1.3
Rapid Prototyping
Designing a data model and a corresponding relational database schema can be a timeconsuming and complicated task that is subject to a variety of design decisions. How far do you
normalize the data? What should be the join keys between the tables? Where can you assume a
one-to-one relationship between data items and where do you have to account for one-to-many
relationships? Will each of your products belong to just one category, or to multiple? Which
columns and data types will you need in a given table? Will the product identifiers always be
numeric or do you need to prepare for alphanumeric IDs?
In the early stages of application prototyping there is often incomplete information to make all
these decisions. Additional information and requirements tend to keep trickling in so that the initial data model and relational schema is subject to frequent early changes. These changes take
21.2
Using Parameter Markers or Host Variables
613
time and require SQL statements in the application prototype to be modified and tested. This
overhead is undesirable when the goal of the prototyping project is not (yet) to produce an optimal data model but to showcase requested application functionality quickly.
With DB2 pureXML, many of the relational design decisions can be postponed. You can choose
XML as the data format for your application prototype and store evolving XML formats in a column of type XML in a DB2 database. The usage of a fixed XML Schema is not required. You can
build an application prototype quickly without having to define data types or decide on one-toone and one-to-many relationships. XML gives you the flexibility to leave these things undefined
at the database level. As a result, you can prototype more rapidly and be more resilient to changing requirements.
Note, however, that the flexibility of XML for rapid prototyping does not mean that you can or
should develop production applications without carefully thinking about data design and database schema design. Let’s consider an example. If you model information about customers and
their addresses and phone numbers, then eventually you should define precisely whether a customer can have one or more than one phone number. This decision affects applications that consume the data. The key benefit of XML is that when you make this decision, changing a
one-to-one relationship to a one-to-many relationship is much easier in an XML Schema than in a
relational schema. Using XML allows you to make this change without modifying or adding any
database tables.
To be very clear, the benefit of XML is that many types of schema changes are easier and less
costly than in a fully relational database design. Using XML does not imply that you can ignore
design decisions indefinitely.
21.1.4
Responding Quickly to Changing Business Needs
The same flexibility that enables more rapid prototyping also enables you to react faster to
change requests. Data fields can be added or removed, data types can be changed, one-to-one
relationships can evolve to one-to-many, all without any modifications to the underlying database
schema. XML queries are very resilient to such changes. For example, an XPath expression such
as /customerinfo[phone = "123-456-7890"] is independent from whether there is a oneto-one or a one-to-many relationship between customers and phone numbers. In general DB2
pureXML reduces the overhead incurred by schema and application changes as compared to a
fully relational database schema.
21.2
USING PARAMETER MARKERS OR HOST VARIABLES
Very short database queries as well as INSERT, UPDATE, and DELETE statements can execute so
fast that the time to compile and optimize them is a substantial portion of their total response
time. Thus, it is useful to write statements with parameter markers or host variables instead of
614
Chapter 21
Developing XML Applications with DB2
literal predicate values. Parameter markers and host variables are placeholders for literal values
and can be replaced by actual values without having to recompile the statement. This mechanism
allows you to compile (“prepare”) a statement only once and pass different literal predicate values for each execution.
Host variables are regular programming language variables that are referenced within SQL statements. Host variables are used in embedded SQL applications written for example in C, COBOL,
PL/1, or Assembler. Parameters markers are not variables, but there are specific API functions to
bind values of programming language variables to parameter markers.
You cannot use SQL-style parameter markers or traditional host variables in XQuery. However,
the SQL/XML functions XMLQUERY, XMLTABLE, and XMLEXISTS allow you to bind SQL parameter markers or host variables to XQuery variables in an XQuery expression. This is recommended for applications with short and repetitive queries. Figure 21.1 shows an XQuery and an
SQL/XML query with hardcoded literal values in their predicates. In contrast, the queries in Figure 21.2 use a parameter marker (?) and a host variable (:hostvar), respectively, to avoid compilation of the query for each execution with a different search value. You should cast the
parameter marker or host variable to an appropriate data type.
xquery
for $t in db2-fn:xmlcolumn('CUSTOMER.INFO')/customerinfo
where $t/addr/zip = 12345
return $t
SELECT info
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo/addr[zip=12345]')
Figure 21.1
Two XML queries with hard-coded literal values in the predicate
SELECT info
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo/addr[zip=$x]'
PASSING CAST(? AS integer) AS "x")
SELECT info
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo/addr[zip=$x]'
PASSING CAST(:hostvar AS integer) AS "x")
Figure 21.2
SQL/XML queries with parameter marker and host variable
21.3
Java Applications
21.3
615
JAVA APPLICATIONS
The Java programming language and its database interface JDBC are very popular choices for
XML application development. IBM provides a single driver that supports both the JDBC and the
SQLJ interfaces of the Java language. This driver is called IBM Data Server Driver for JDBC and
SQLJ, also known as JCC (Java Common Client). It is a JDBC type 2 and type 4 driver and can
connect to DB2 on all platforms. The type 2 driver is deprecated and you should use the type 4
driver.
An installation of DB2 9.1 for Linux, UNIX, and Windows includes JCC 3, which supports
JDBC 3.0. DB2 9.5 for Linux, UNIX, and Windows includes JCC 4, which supports JDBC 3.0
and a subset of JDBC 4.0. Note that JCC 4 and JDBC 4.0 require Java 6.0. The JAR files
db2jcc.jar and db2jcc4.jar are also included in the latest DB2 Client or can be downloaded
at http://www.ibm.com/software/data/db2/java/. Table 21.1 provides a summary of
the JCC drivers.
Table 21.1
DB2’s Support for JDBC 3.0 and 4.0
DB2
Version
JCC
Driver
JDBC
Support
JAR
File
Minimum Java
Level Required
DB2 9.1
JCC 3
JDBC 3.0
db2jcc.jar
1.4
DB2 9.5 and higher
JCC 4
JDBC 3.0 and 4.0
db2jcc4.jar
6.0
IBM’s JCC 3 driver provides the proprietary XML data type DB2Xml because the JDBC 3.0 standard does not define an XML data type. The JDBC 4.0 standard introduces an XML data type
called SQLXML, which is supported by the JCC 4 driver (see Table 21.2).
Table 21.2
XML Data Type Support in JCC 3 and JCC 4
JCC
Driver
JDBC
Java Interface
for XML Data
Java Constant for
the XML Data Type
JCC 3
JDBC 3.0
com.ibm.db2.jcc.DB2Xml
java.sql.Types.OTHER
JCC 4
JDBC 4.0
java.sql.SQLXML
java.sql.Types.SQLXML
21.3.1
XML Support in JDBC 3.0
To retrieve XML data from a DB2 database into your JDBC 3.0 application, use the Java standard
interface ResultSet as you normally would for relational data. The interface ResultSet offers
various getter methods to retrieve XML data from the current result row into an application variable. Table 21.3 lists those methods together with the data type and encoding of their output.
Remember that UCS-2 is a subset of UTF-16. The methods in Table 21.3 do not add an encoding
declaration to the retrieved XML data and are also available in JCC 4.
616
Table 21.3
Chapter 21
Developing XML Applications with DB2
JDBC 3.0 and the DB2Xml Data Type
Getter Methods
on ResultSet
Application Data Type
Encoding
(without Declaration)
getAsciiStream()
InputStream
ASCII
getBytes()
byte[]
UTF-8
getBinaryStream()
InputStream
UTF-8
getString()
String
UCS-2
getCharacterStream()
Reader
UCS-2
getObject()
DB2Xml
None (DB2Xml object)
The method getObject() retrieves XML data into an object of type DB2Xml. The benefit of the
DB2Xml object, as compared to a generic ResultSet object, is that it offers a wider range of getter methods (see Table 21.4). In particular, the DB2Xml interface includes methods that generate
XML declarations with an encoding attribute for the retrieved XML data, as well as methods that
force the XML data to be converted to a specified target encoding. For example, the methods
getDB2String() and getDB2XmlString() return the XML data in the same encoding, UCS2, but the latter adds the appropriate encoding declaration to the XML document. While
getDB2BinaryStream() always returns XML data in UTF-8 format without an encoding declaration, the method getDB2XmlBinaryStream()takes a string argument that specifies which
encoding to produce.
Table 21.4
DB2Xml Getter Methods, Data Types, and Encoding Specifications
JDBC
Interface
Getter Method
Output
Data Type
XML Encoding
Declaration Added
DB2Xml
getDB2AsciiStream()
InputStream
None
getDB2BinaryStream()
InputStream
None
getDB2Bytes()
byte[]
None
getDB2CharacterStream()
Reader
None
getDB2String()
String
None
getDB2XmlAsciiStream()
InputStream
ASCII
getDB2XmlBinaryStream
(Encoding)
InputStream
Specified by the
Encoding parameter
21.3
Java Applications
Table 21.4
617
DB2Xml Getter Methods, Data Types, and Encoding Specifications (Continued)
JDBC
Interface
Getter Method
Output
Data Type
XML Encoding
Declaration Added
DB2Xml
getDB2XmlBytes(Encoding)
byte[]
Specified by the
Encoding parameter
getDB2XmlCharacterStream()
Reader
ISO-10646-UCS-2
getDB2XmlString()
String
ISO-10646-UCS-2
Figure 21.3 shows usage examples for some of the getter methods in Table 21.3 and Table 21.4.
The last three Java calls in Figure 21.3 call getter methods on the DB2Xml object that was previously retrieved from the ResultSet.
import com.ibm.db2.jcc.DB2Xml;
ResultSet rs = statement.executeQuery(
"SELECT XMLQUERY('$INFO/customerinfo/name')
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo[addr/zip = 95123]') ");
rs.next();
//***** getter methods on ResultSet: *****
//retrieve XML into a UTF-8 byte array:
byte[] xmlBytes = rs.getBytes(1); // 1 is the column index
//retrieve XML as a UCS-2 string variable:
String xmlString = rs.getString(1);
//retrieve XML as a DB2Xml object:
DB2Xml xmlObj = (DB2Xml) rs.getObject(1);
//***** getter methods on DB2Xml: *****
//retrieve XML from the DB2Xml object as a string
//with encoding declaration for UCS-2:
String xmlString = xmlObj.getDB2XmlString();
//retrieve XML from the DB2Xml object as a UTF-8 binary stream:
InputStream inStream = xmlObj.getDB2BinaryStream();
//retrieve XML from the DB2Xml object as a binary stream,
//converted to the target encoding EUC_JP:
InputStream inStream = xmlObj.getDB2XmlBinaryStream("EUC-JP");
Figure 21.3
JDBC methods to retrieve XML data from a query result set
618
Chapter 21
Developing XML Applications with DB2
If your application does not need to manipulate the XML data in character string format, you
should retrieve XML as binary data with methods such as getBytes(), getBinaryStream(),
getDB2Bytes(), or getDB2XmlBinaryStream("UTF-8"). Using these methods avoids
unnecessary conversion of the XML data from UTF-8 to UTF-16.
An object of type DB2Xml cannot be updated or used to update an XML value in the database. If
you want to update or insert data into an XML column, use one of the setter methods of the interface PreparedStatement. Table 21.5 lists these methods and their input data types. The
method setSQLXML is not available on PreparedStatement until JDBC 4.0 but listed here
already for completeness.
Table 21.5
Methods to Insert or Update XML Data
JDBC Interface
Setter Method
Input Data Type
PreparedStatement
setAsciiStream()
setBinaryStream()
setBlob()
setBytes()
setCharacterStream()
setClob()
setString()
setObject()
InputStream
InputStream
Blob
byte[]
Reader
Clob
String
byte[], Blob, Clob, DB2Xml,
InputStream, Reader, String
SQLXML (new in JDBC 4.0)
setSQLXML
The code sample in Figure 21.4 shows how to insert XML data from a file into the info column
of the customer table using the setter method setBinaryStream().
String sql = "INSERT INTO customer(cid, info) VALUES (?,?)";
PreparedStatement stmt = connection.prepareStatement(sql);
File binFile = new File("customer1013.xml");
InputStream stream = new FileInputStream(binFile);
stmt.setInt(1, 1013);
stmt.setBinaryStream(2, stream, (int) binFile.length());
stmt.execute();
Figure 21.4
Inserting an XML document from a Java application
It is recommended that you send XML data to the database server as binary data, using the methods setBinaryStream(), setBlob(), or setBytes(). Binary data is treated as internally
21.3
Java Applications
619
encoded data and not converted to the codepage of the database. If you send XML data to the
database server as character data using methods such as setCharacterStream(), setClob(), or setString(), then the data is externally encoded. Externally encoded data can have
an internal encoding. This means that the XML data might be sent to the database server as character data but contains an encoding declaration or a Unicode Byte-Order Mark (BOM). If the
external and internal encodings are incompatible, DB2 for Linux, UNIX, and Windows raises an
error. DB2 for z/OS is more lenient and ignores the internal encoding if it is incompatible with
the external encoding.
Both JCC 3 and JCC 4 also include methods to register and remove XML Schemas in the schema
repository of a DB2 database. These methods are discussed in section 16.4.3 Registering XML
Schemas from Java Applications via JDBC.
21.3.2
XML Support in JDBC 4.0
One of the main new features introduced in JDBC 4.0 is the addition of an XML data type called
SQLXML to match the XML type defined by the SQL standard. The new interface to represent
XML data is java.sql.SQLXML. In JDBC 4.0 the column type of an XML column is reported
as java.sql.Types.SQLXML. Other interfaces such as ResultSet and PreparedStatement are enhanced with new getter and setter methods. Remember that you need the IBM JCC 4
driver and Java 6.0 to use JDBC 4.0 functions.
To obtain an object of type SQLXML, call the new method ResultSet.getSQLXML(column)
and specify the XML column name or index as a parameter. Table 21.6 shows all getter methods
available on the interface SQLXML and whether serialization of the XML data takes place. In contrast to the DB2Xml retrieval methods, none of the SQLXML getter methods add an encoding declaration to the retrieved XML data. One of the key methods of the new interface is getSource(),
which allows you to directly access the XML data via DOM, SAX, or StAX parser interfaces, or
any other class that implements javax.xml.transform.Source.
Table 21.6
Methods to Retrieve XML Data from an SQLXML Object
JDBC
Interface
Getter Method
Data Type
Encoding
Serialization
SQLXML
getBinaryStream()
InputStream
UTF-8
Yes
getCharacterStream()
Reader
UCS-2
Yes
getString()
String
UCS-2
Yes
getSource(Source.class)
DOMSource
SAXSource
StAXSource
none
No
620
Chapter 21
Developing XML Applications with DB2
An example of the getSource() method is shown in Figure 21.5. The sample code retrieves the
XML column info for the customer with a cid value of 1000. On the ResultSet object, it
fetches the first result row with resultSet.next(). Then it retrieves the XML document as a
SAXSource and creates a SAX parser for it. The same is possible for DOM and StAX parsers and
demonstrated in section 21.3.3.
ResultSet resultSet = statement.executeQuery(
"SELECT info FROM customer WHERE cid=1000");
resultSet.next();
// retrieve an SQLXML object from the ResultSet
SQLXML sqlxml = resultSet.getSQLXML(1); // 1 is column index
// create a SAX parser from the SQLXML object
SAXSource source = sqlxml.getSource(SAXSource.class);
XMLReader reader = source.getXMLReader();
// configure parser and start parsing
ContentHandler myHandler = ...;
reader.setContentHandler(myHandler);
reader.parse(source.getInputSource());
Figure 21.5
Retrieving XML Data into a SAX parser in JDBC 4.0
Just like JDBC 3.0, XML inserts and updates in JDBC 4.0 are performed with setter methods on
the PreparedStatement interface, as listed in Table 21.5. JDBC 4.0 adds one new setter
method called setSQLXML to PreparedStatement. This method allows you to bind an object
of type SQLXML to a parameter marker for update or insert into an XML column. The SQLXML
object itself can be set with the setter methods listed in Table 21.7. In particular, you can use the
method setResult to assign a DOM, SAX, or StAX representation of an XML document to the
SQLXML object. Thus, if your application manipulates XML documents in one of these common
formats, it does not need to serialize the XML data to its textual representation before using the
XML data in an INSERT or UPDATE statement.
Table 21.7
JDBC
Interface
SQLXML
Methods to Insert and Update XML Data from an SQLXML Object
Setter Method
Input Data Type
Encoding
Serialized
Input data
Internal
External
External
None
Yes
Yes
Yes
No
setBinaryStream()
OutputStream
setCharacterStream()
Writer
setString(String)
String
setResult(Result.class)
DOMResult
SAXResult
StAXResult
21.3
Java Applications
621
The code sample in Figure 21.6 prepares an INSERT statement for the customer table and creates an SQLXML object that will be inserted. The code shows how two of the four methods in Table
21.7 can be used to set the SQLXML object. If you call setCharacterStream() on the SQLXML
object you obtain a Writer that you can work with to assign or assemble the new
document as a character string. Alternatively, if you call setResult(DOMResult.class) you
obtain a DOMResult, which allows you to assign or construct a DOM tree to define the
document that is inserted into the DB2 table. No matter which way you set the SQLXML object,
call setSQLXML on the PreparedStatement to assign the SQLXML object to the parameter
marker for the XML column. The next section provides another coding example with
JDBC 4.0. Further details can also be found at http://java.sun.com/javase/6/docs/
api/java/sql/ SQLXML.html.
String sql = "INSERT INTO customer(cid, info) VALUES (?,?)";
PreparedStatement stmt = connection.prepareStatement(sql);
SQLXML sqlxml = connection.createSQLXML();
//Create a writer to write into the SQLXML object
Writer xmlWriter = sqlxml.setCharacterStream();
xmlWriter.write(xmldocumentString);
xmlWriter.close();
//Or, create a DOM as input for the SQLXML object
DOMResult domResult = sqlxml.setResult(DOMResult.class);
domResult.setNode(xmldocumentDOM);
//Bind the SQLXML object to the prepared statement and execute
stmt.setInt(1, 1097);
stmt.setSQLXML(2, sqlxml);
stmt.execute();
Figure 21.6
21.3.3
Inserting XML data with JDBC 4.0
Comprehensive Example of Manipulating XML Data with JDBC 4.0
Although DB2 pureXML enables you to avoid a lot of XML parsing in the application layer,
access to XML documents through the DOM, SAX, or StAX APIs can still be useful, depending
on the design and requirements of your application.
SAX, StAX, and DOM are complementary APIs for XML processing. DOM is a tree-based interface that holds the complete XML document in memory and allows easy navigation and manipulation of the XML nodes. SAX and StAX represent an XML document as a stream of events that
the application consumes through callbacks. They are stream-based and consume less memory
than DOM parsers because they do not hold the entire document in memory. StAX differs from
SAX in the way the application accesses the XML data. StAX is a “pull” API because the application asks the parser for the next piece of information from the parsed XML document. SAX is a
“push” API because the application receives events as data is encountered within the source document. StAX was added in JDK 6; in JDK 5 it is available as a separate JAR.
622
Chapter 21
Developing XML Applications with DB2
The following sample code demonstrates how to use JDBC 4.0 to exchange XML data with a
DB2 database. It also illustrates the use of an SQLXML object with SAX, StAX, and DOM parsers.
Comments are embedded throughout the code to explain how it works.
package test;
import
import
import
import
import
import
import
import
import
import
java.io.IOException;
java.io.OutputStreamWriter;
java.io.StringReader;
java.sql.Connection;
java.sql.DriverManager;
java.sql.PreparedStatement;
java.sql.ResultSet;
java.sql.SQLException;
java.sql.SQLXML;
java.sql.Statement;
import
import
import
import
import
import
import
import
import
import
javax.xml.stream.XMLStreamConstants;
javax.xml.stream.XMLStreamException;
javax.xml.stream.XMLStreamReader;
javax.xml.stream.XMLStreamWriter;
javax.xml.transform.dom.DOMResult;
javax.xml.transform.dom.DOMSource;
javax.xml.transform.sax.SAXResult;
javax.xml.transform.sax.SAXSource;
javax.xml.transform.stax.StAXResult;
javax.xml.transform.stax.StAXSource;
import
import
import
import
import
import
import
org.w3c.dom.Document;
org.xml.sax.ContentHandler;
org.xml.sax.InputSource;
org.xml.sax.SAXException;
org.xml.sax.XMLReader;
org.xml.sax.helpers.DefaultHandler;
org.xml.sax.helpers.XMLReaderFactory;
/* This class demonstrates some of the new SQLXML interfaces in
* JDBC 4.0. The code shows how to use SQLXML to
* read/write XML directly from/to SAX, StaX and DOM parsers.
*/
public class JDBC4FeatureTest {
// query to be executed by all methods
private String queryString =
"SELECT info FROM customer " +
"WHERE XMLEXSIST('$INFO/customerinfo[@Cid = 1000]')";
// connection to database
private Connection con;
public JDBC4FeatureTest() {
// obtain database connection
Class.forName("com.ibm.db2.jcc.DB2Driver").newInstance();
con = DriverManager.getConnection("jdbc:db2:SAMPLE");
}
Figure 21.7
A comprehensive example of XML manipulation with JDBC 4.0
21.3
Java Applications
public static void main(String[] args) {
JDBC4FeatureTest test = new JDBC4FeatureTest();
test.DbToSaxParser();
test.DbToDomTree();
test.DbToStaxParser();
test.SaxParserToDb();
test.DomTreeToDb();
test.StaxParserToDb();
}
/**
* This method executes a query against a database to obtain
* an XML document. The SQLXML type is used to pass the XML
* document to a SAX parser. In this example, the parser
* simply writes the document content to a stream.
*/
private void DbToSaxParser() {
try {
// create and execute statement
Statement stmt = con.createStatement();
ResultSet rs = stmt.executeQuery(queryString);
if (rs.next()) {
// if statement execution returned a document
// load query result into SQLXML object
SQLXML sqlxml = rs.getSQLXML(1);
// create SAX parser from SQLXML object
SAXSource source = sqlxml.getSource(SAXSource.class);
XMLReader parser = source.getXMLReader();
// configure SAX parser
DefaultHandler eventHandler = new SimpleSaxOutput(
new OutputStreamWriter(System.out));
parser.setContentHandler(eventHandler);
// parse document obtained from database
parser.parse(source.getInputSource());
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* This method executes a query against a database to obtain
* an XML document. The SQLXML type is used to pass the XML
* document to a DOM parser. In this example, the document
* content is simply written from the DOM tree to System.out.
*/
private void DbToDomTree() {
try {
// create and execute statement
Statement stmt = con.createStatement();
Figure 21.7
A comprehensive example of XML manipulation with JDBC 4.0 (Continued)
623
624
Chapter 21
Developing XML Applications with DB2
ResultSet rs = stmt.executeQuery(queryString);
if (rs.next()) {
// if statement execution returned a document
// load query result into SQLXML object
SQLXML sqlxml = rs.getSQLXML(1);
// obtain DOM tree from SQLXML object
DOMSource source = sqlxml.getSource(DOMSource.class);
// create document object from DOMSource
Document document = (Document) source.getNode();
// process DOM tree
SimpleDomOutput.writeDomTree(document,
new OutputStreamWriter(System.out));
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* This method executes a query against a database to obtain
* an XML document. The SQLXML type is used to pass the XML
* document to a StAX parser. In this example, the parser
* iterates over all elements and writes all address
* information to the standard output stream.
*/
private void DbToStaxParser() {
try {
// create and execute statement
Statement stmt = con.createStatement();
ResultSet rs = stmt.executeQuery(queryString);
if (rs.next()) {
// if statement execution returned a document
// load query result into SQLXML object
SQLXML sqlxml = rs.getSQLXML(1);
// get XMLStreamReader from SQLXML object
StAXSource source = sqlxml.getSource(StAXSource.class);
XMLStreamReader parser = source.getXMLStreamReader();
// output: iterate over all elements and skip elements
// that are not descendants of the "addr" element
boolean addr = false;
for (int event = parser.next();
event != XMLStreamConstants.END_DOCUMENT;
event = parser.next()) {
switch (event) {
case XMLStreamConstants.START_ELEMENT:
if (parser.getLocalName().equals("addr")) {
addr = true;
System.out.println("new address:");
Figure 21.7
A comprehensive example of XML manipulation with JDBC 4.0 (Continued)
21.3
Java Applications
}
break;
case XMLStreamConstants.END_ELEMENT:
if (parser.getLocalName().equals("addr")) {
addr = false;
}
break;
case XMLStreamConstants.CHARACTERS:
if (addr) {
System.out.println(parser.getText());
}
break;
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* This method uses the contentHandler of the SQLXML object to
* build a document that is then stored in the database.
*/
private void SaxParserToDb() {
try {
// prepare statement to insert an xml document
PreparedStatement prepStmt = con
.prepareStatement("INSERT INTO customer(cid, info) " +
"VALUES(1,?)");
// create an SQLXML SAXResult object as a bridge between
// SAX parser and the DB2 database
SQLXML sqlxml = con.createSQLXML();
SAXResult saxResult = sqlxml.setResult(SAXResult.class);
// get the content handler that builds the document
ContentHandler contentHandler = saxResult.getHandler();
// create a SAX parser to parse the document
XMLReader parser = XMLReaderFactory.createXMLReader();
// parse a document (in this case from a simple string)
// to trigger all necessary events in the contentHandler
parser.setContentHandler(contentHandler);
parser.parse(new InputSource(new StringReader(
"<customerinfo Cid=\"1\" " +
"<name>Linda Meyers</name>"
+ "<addr country=\"USA\">"
+ "<street>555 Bailey Ave</street>"
+ "<city>San Jose</city>"
+ "</addr>"
+
"<phone type=\"cell\">123-654-7896"
+ "</phone>"
+ "</customerinfo>")));
Figure 21.7
A comprehensive example of XML manipulation with JDBC 4.0 (Continued)
625
626
Chapter 21
Developing XML Applications with DB2
// execute the prepared statement to insert the
// new xml document
prepStmt.setSQLXML(1, sqlxml);
prepStmt.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* This method creates an XML document as a DOM tree.
* The DOM tree is then attached to an SQLXML object
* and inserted into the database.
*/
public void DomTreeToDb() {
try {
// prepare statement to insert an xml document
PreparedStatement prepStmt = con
.prepareStatement("INSERT INTO customer(cid, info) " +
"VALUES(2,?)");
// create SQLXML object as a bridge between DOM tree and DB2
SQLXML sqlxml = con.createSQLXML();
DOMResult domResult = sqlxml.setResult(DOMResult.class);
// create document DOM tree (done in another class)
Document document = CreateCustomer.createCustomerDom();
// attach the DOM tree to the SQLXML object
domResult.setNode(document);
// execute the prepared statement to insert the document
prepStmt.setSQLXML(1, sqlxml);
prepStmt.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* This method creates an XML document using an XMLStreamWriter.
* The document is then attached to an SQLXML object
* and inserted into the database.
*/
public void StaxParserToDb() {
try {
// prepare statement to insert an xml document
PreparedStatement prepStmt = con.prepareStatement
("INSERT INTO customer(cid, info) VALUES(3,?)");
// create SQLXML object as a bridge between StAX and DB
SQLXML sqlxml = con.createSQLXML();
Figure 21.7
A comprehensive example of XML manipulation with JDBC 4.0 (Continued)
21.3
Java Applications
627
StAXResult staxResult =
sqlxml.setResult(StAXResult.class);
// obtain the stream writer from StAXResult
XMLStreamWriter streamWriter =
staxResult.getXMLStreamWriter();
// create document and write into the stream
// (done in another class)
CreateCustomer.createCustomerStax(streamWriter);
// execute the prepared insert statement
prepStmt.setSQLXML(1, sqlxml);
prepStmt.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
}
Figure 21.7
21.3.4
A comprehensive example of XML manipulation with JDBC 4.0 (Continued)
Creating XML Documents from Application Data
If your application holds information in application variables and you want to combine this data
into an XML document, you can write code to do so. Creating documents is not difficult and can
be done with different XML APIs, such as DOM, SAX, or StAX.
The sample code in Figure 21.8 shows how to use the DOM API to construct the following XML
simple document:
<customerinfo Cid="1047">
<name>John Doe</name>
<phone type="home">123-456-7890</phone>
</customerinfo>
In this code sample, the element and attributes values are obtained from hard-coded String variables. They could also come from a file, a web service, user input from a website, or other sources.
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Text;
…
String
String
String
String
customerID = "1047";
customerName = "John Doe";
phoneNumberType = "home";
phoneNumber = "123-456-7890";
DocumentBuilderFactory factory =
DocumentBuilderFactory.newInstance();
Figure 21.8
Constructing XML as a DOM tree in Java
628
Chapter 21
Developing XML Applications with DB2
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.newDocument();
Element root = document.createElement("customerinfo");
Element name = document.createElement("name");
Element phone = document.createElement("phone");
Text nameValue = document.createTextNode(customerName);
Text phoneValue = document.createTextNode(phoneNumber);
name.appendChild(nameValue);
phone.setAttribute("type", phoneNumberType);
phone.appendChild(phoneValue);
root.setAttribute("Cid", customerID);
root.appendChild(name);
root.appendChild(phone);
document.appendChild(root);
Figure 21.8
Constructing XML as a DOM tree in Java (Continued)
The sample code in Figure 21.9 creates the same XML document as in the previous example by
using the StAX API and calling a sequence of write commands on a given StreamWriter.
import
import
import
import
import
…
javax.xml.parsers.DocumentBuilder;
javax.xml.parsers.DocumentBuilderFactory;
javax.xml.parsers.ParserConfigurationException;
javax.xml.stream.XMLStreamException;
javax.xml.stream.XMLStreamWriter;
OutputStream out = new FileOutputStream("customer1001.xml");
XMLOutputFactory factory = XMLOutputFactory.newInstance();
XMLStreamWriter writer = factory.createXMLStreamWriter(out);
streamWriter.writeStartDocument();
streamWriter.writeStartElement("customerinfo");
streamWriter.writeAttribute("Cid", "1047");
streamWriter.writeStartElement("name");
streamWriter.writeCharacters("John Doe");
streamWriter.writeEndElement();
streamWriter.writeStartElement("phone");
streamWriter.writeAttribute("type", "home");
streamWriter.writeCharacters("123-456-7890");
streamWriter.writeEndElement();
streamWriter.writeEndElement();
streamWriter.writeEndDocument();
streamWriter.flush();
streamWriter.close();
Figure 21.9
Constructing an XML Document with StAX in Java
21.3
Java Applications
21.3.5
629
Binding XML Data to Java Objects
In the previous sections we explained how to access an XML document from a Java application
using the XML parser interfaces DOM, SAX, and StAX. Each of these APIs requires manual
coding in order to process the XML elements and attributes and assign them to application variables, or vice versa. Alternatively, you can use frameworks that automatically perform a mapping
between XML documents and Java objects. This mapping is known as XML data binding. It
enables your application to abstract from the actual tree structure of XML documents and instead
work directly with the data content of those documents in Java object. Popular XML mapping
frameworks for Java include JAXB, JiBX, Castor, XMLBeans, and XStream. Their detailed discussion is beyond the scope of this book, but Appendix C, Further Reading, contains pointers to
further information.
In general, the process of binding XML data to Java objects consists of two phases. First you provide an XML Schema or DTD to the mapping framework. Based on the XML structure in the
schema and predefined mapping rules, the framework then generates a set of Java class definitions. In the second phase you can convert an XML document to instances of these Java classes,
and vice versa. The process of serializing a Java object into an XML document is called
marshalling. The reserve process of building a Java object from an XML document is called
unmarshalling. Some of the available mapping frameworks, such as XStream, do not require the
initial setup phase with an XML Schema. XStream is driven exclusively by XML instance documents and converts any given XML document into an appropriate Java object, based on predefined mapping rules.
XML data-binding frameworks can be useful when retrieving XML documents through object
relational mapping frameworks, such as IBM pureQuery.
21.3.6
IBM pureQuery
IBM pureQuery is a set of database tools designed to simplify the development of database applications in Java. pureQuery includes an object relational mapping (ORM) framework that aims to
relieve Java developers from some of the tediousness associated with JDBC programming. For
example, given a database table, pureQuery generates Java classes that represent the table data
and contain SQL statements to convert relational data to Java variables. Generating Java classes
from database tables is a bottom-up approach. The generated mapping code contains methods
and SQL statements for basic create, read, update, and delete operations (CRUD). For the
customer table in the sample database, pureQuery generates two Java classes:
• The Java Bean Customer.java, which contains a field for each column in the
customer table
• The mapping class CustomerData.java, which contains the SQL statements in the
form of Java annotations
630
Chapter 21
Developing XML Applications with DB2
Figure 21.10 shows excerpts from both classes.
public interface CustomerData {
// Select all CUSTOMERs
@Select(sql = "SELECT CID, INFO"
+ " FROM CUSTOMER")
Iterator<Customer> getCustomers();
// Select CUSTOMER by parameters
@Select(sql = "SELECT CID, INFO"
+ " FROM CUSTOMER"
+ " WHERE CID = ?")
Customer getCustomer(long cid);
...
public class Customer {
// Class variables
protected int cid;
protected String info;
...
Figure 21.10
Java classes generated by pureQuery
Based on these classes, a Java application can make the following calls to retrieve information
about specific customers, such as the customer with the relational cid value 1004:
Customer customer = CustomerData.getCustomer(1004);
This code allows you to access table columns in a purely object-oriented fashion. You can retrieve
or update fields of the Java Bean and do not need to write JDBC code or SQL statements. pureQuery also supports the reverse approach; that is, generating table definitions and the corresponding mapping classes based on a group of Java objects (top-down approach).
In both the top-down and bottom-up approach the generated mapping classes contain standard
SQL statements that an application programmer or DBA can see and modify if required. Modifying the statements can sometimes be useful for SQL optimization and customization. In contrast,
many other ORM frameworks use proprietary query languages that hide the actual SQL statements from the application developer because SQL gets generated at runtime only.
As shown in Figure 21.10, pureQuery exposes an XML column as a Java String variable. It
does not support XML data binding as described in section 21.3.5. However, pureQuery can be
extended so that individual nodes within an XML document are accessible to the Java application. This extension can be achieved in several ways and in the following we outline three possible methods.
21.4
NET Applications
631
Use pureQuery with the XMLTABLE Function
You can customize the generated SQL SELECT statements to contain an XMLTABLE function. The
XMLTABLE function enables you to select specific XML nodes and return them as relational
columns. Using this approach, the default ORM functionality of pureQuery can be leveraged.
After updating the SQL statement to include the XMLTABLE function, the pureQuery code generator needs to be run again to generate a Java Bean that corresponds to the columns returned by the
query. This approach minimizes data transfer between the database and the application because
only selected XML node values are fetched.
Use pureQuery with a Data-Binding Framework Such as JAXB
pureQuery offers extension points that allow you to customize result set handling. Given the generated SQL query that selects an XML column, you can write an extension that uses an XML data
binding library such as JAXB to transform XML data from a query result set into Java objects.
First you need to use the JAXB library to generate Java classes based on the customer XML
Schema. Then you implement a pureQuery RowHandler that uses JAXB methods to unmarshall
an XML document from a result row into instances of the previously generated Java classes.
Finally, you register the custom RowHandler class with pureQuery by passing it as an argument
to the method that executes the SQL query. This approach relieves you from defining the mapping in XMLTABLE functions and encapsulates the mapping in the RowHandler class. The drawback of this approach is that complete documents are transferred from the database to the client
application, even though the client might only be interested in certain XML elements.
Use pureQuery with an Application-Level XML Parser
The third approach places the XML to Java mapping into the Java Bean. You can add fields and
corresponding getter and setter methods to the bean to return XML element and attribute values
of interest, such as customer name or customer phone. These new methods need to use an XML
parser, such as DOM, to parse and extract values from the default info column. However, similar to the JAXB approach, it involves sending the complete XML document from the database to
the client. This can have a negative effect on performance due to XML serialization on the DB2
side and extraneous parsing at the client side. This XML parsing is avoided in the first approach
with the XMLTABLE function that exploits DB2’s parsed XML storage format.
Appendix C contains pointers to more detailed resources covering application development with
pureQuery.
21.4
.NET APPLICATIONS
If you want to access XML or relational data in a DB2 database from your .NET application, you
need an ADO.NET data provider. IBM provides three data providers for .NET applications:
632
Chapter 21
Developing XML Applications with DB2
• DB2 .NET Data Provider
• OLE DB .NET Data Provider
• ODBC .NET Data Provider
All three providers are installed as part of the DB2 Application Development Client. Among
them, the DB2 .NET Data Provider is the recommended data provider for use with DB2 family
databases. It provides access to databases in DB2 for Linux, UNIX, and Windows and DB2 for
z/OS. It has a more extensive set of APIs, fewer restrictions, and provides better performance
than the OLE DB and ODBC .NET Data Providers. It is a “managed” provider, which means that
it runs entirely within the Common Language Runtime (CLR), and does not translate requests to
native OLE or ODBC APIs.
The DB2 .NET Data Provider classes are located in the .NET namespaces IBM.Data.DB2 and
IBM.Data.DB2Types. One class of particular interest in the namespace IBM.Data.DB2Types
is the class DB2Xml, which represents XML data from a DB2 database.
21.4.1
Querying XML Data in .NET Applications
Let’s start with a simple example. The sample code in Figure 21.11 shows how to retrieve XML
data using the class DB2Xml. The code executes an SQL/XML query against the customer table
and retrieves the addr fragment from the XML document. The method DB2Command.ExecuteReader() executes the query. The ExecuteReader() method is used whenever a result
set is expected, as in this case. The result set class is DB2DataReader. The DB2DataReader
class allows you to loop through the result set and access the columns of the current row based on
the column index and the column data type. The method DB2DataReader.GetDB2Xml()
retrieves data from the XML column in the result set. This method returns an object of type
DB2Xml.
using System;
using IBM.Data.DB2;
using IBM.Data.DB2Types;
…
public static void readXmlColumn()
{
try {
DB2Command cmd = DB2Connection.CreateCommand();
cmd.CommandText = "SELECT XMLQUERY('$INFO/customerinfo/addr')
FROM customer
WHERE cid = 1003";
DB2DataReader reader = cmd.ExecuteReader();
DB2Xml doc;
String xmlString;
while(reader.Read())
Figure 21.11
Retrieving XML data in a C# .NET application
21.4
NET Applications
{
633
doc = reader.GetDB2Xml(0); // 0: index for first column
xmlString = doc.GetString();
Console.WriteLine(xmlString);
}
reader.Close();
} catch (Exception e) {
Console.WriteLine(e.Message);
}
Retrieving XML data in a C# .NET application (Continued)
Figure 21.11
The class DB2Xml offers several different methods for retrieving XML data. The sample code in
Figure 21.11 uses the method getString(). Table 21.8 lists all available methods on the
DB2XML class.
Table 21.8
Methods of the Class DB2Xml
IBM.Data.DB2Types.DB2Xml
GetBytes()
Returns the contents of the DB2Xml object instance as a UTF-8 byte array
GetString()
Returns the contents of the DB2Xml object instance as a UTF-16 string
GetXMLReader()
Returns an XmlReader for the contents of the DB2Xml object instance
More details on XMLReader follow.
The use of the class DB2Xml is recommended but not mandatory to retrieve XML data into a .NET
application. For example, you can also use the methods GetString(), GetBytes(), and
GetXMLReader() directly on the DB2DataReader class to obtain data from an XML column.
However, using the class DB2Xml is preferred because it can provide performance optimizations
and in future DB2 versions it might be enhanced with advanced methods for handling XML data.
Queries in XQuery notation can be executed in .NET applications just like SQL statements, but must
be prepended with the keyword xquery. For example, the CommandText property in Figure 21.11 could just as well be assigned a FLWOR expression instead of an SQL statement, like this:
cmd.CommandText = "xquery
for $i in db2-fn:xmlcolumn(""CUSTOMER.INFO"")
where $i/customerinfo/@Cid = 1003
return $i/customerinfo/addr";
21.4.2
Manipulating XML Data in .NET Applications
Note that the query in Figure 21.11 retrieves only the addr piece of an XML document and not
the whole document. Since DB2 stores XML in a parsed format, the query can return fragments
or individual values from the XML document without additional XML parsing. This query
provides a significant performance benefit compared to reading the whole document into your
634
Chapter 21
Developing XML Applications with DB2
application code and extracting the desired values there. Use DB2’s pureXML query capabilities
to avoid costly XML manipulation in your application as much as possible.
If you do need to manipulate XML documents in your application code, you can use the .NET
classes XMLReader or XMLDocument. The XmlDocument class implements the XML Document Object Model (DOM) to provide an in-memory tree representation of an XML document. It
enables the navigation and editing of a document. The XMLReader class provides an eventbased, forward-only, and read-only access to XML data, which is similar to a Java StAX parser
(see section 21.3). You can obtain an XMLReader object from an XML column in a result set as
illustrated by the code snippet in Figure 21.12. The while loop iterates over the result set and
obtains an XMLReader object for each XML document produced by the query. You can then
operate on each XMLReader object as you normally would.
DB2Command cmd = DB2Connection.CreateCommand();
cmd.CommandText = "SELECT info FROM customer
WHERE XMLEXISTS('$INFO/customerinfo/addr[
city = \"Toronto\"]')";
DB2DataReader reader = cmd.ExecuteReader();
DB2Xml doc;
XmlReader myXMLReaderObject;
while(reader.Read())
{
doc = reader.GetDB2Xml(0); // 0: index for first column
myXMLReaderObject = doc.GetXmlReader();
// do something with myXMLReaderObject
myXMLReaderObject.Close();
}
reader.Close();
Figure 21.12
Obtaining an XmlReader from a DB2Xml object
If you execute a query that returns at most one XML document then you can obtain an
XMLReader object with the shortcut shown in Figure 21.13. This code sample calls the method
ExecuteXMLReader() directly on the DB2Command object. The method ExecuteXMLReader() does not contain a parameter for the column index. Instead, it assumes that the command returns a single row with a single column that contains an XML document.
DB2Command cmd = DB2Connection.CreateCommand();
cmd.CommandText = "SELECT info FROM customer WHERE cid=1003";
XmlReader myXMLReaderObject = cmd.ExecuteXmlReader();
Figure 21.13
Obtaining an XmlReader from a DB2Command object
If you prefer to manipulate an XML document as a DOM, you can obtain an XMLDocument
object from an XMLReader by calling:
XMLDocument.load(myXMLReaderObject).
21.4
NET Applications
635
While the XMLDocument object provides read and write access to the XML document via the
DOM API, an XPathDocument object provides fast read-only access. You can use the method
DB2XmlAdapter.fillSQL() to read XML data from the database into an instance of an XPathDocument object. The DB2 Express-C Developer Handbook listed in Appendix C contains further examples.
21.4.3
Inserting XML Data from .NET Applications
Let’s turn to inserting XML data from a .NET application into DB2. The sample code in Figure
21.14 shows how to insert a row with an XML document into the info column of the customer
table. In this example, the INSERT statement also extracts the XML attribute Cid from the XML
document and inserts it into the relational column cid. The sample code reads the XML document from a file, but could obtain it from any other source. You need to set the data type and value
of the parameter before using the method cmd.Parameters.Add to bind the parameter to the
INSERT statement. The method DB2Command.ExecuteNonQuery() executes the INSERT
statement. ExecuteNonQuery() is used when no result set is expected, as in this case. The customer ID number for the relational id column is extracted by DB2 from the XML document at
insert time.
using System;
using IBM.Data.DB2;
using IBM.Data.DB2Types;
…
try {
DB2Command cmd = DB2Connection.CreateCommand();
cmd.CommandText =
"INSERT INTO customer(cid, info)
SELECT X.id, X.info
FROM XMLTABLE ('$d' passing cast(? as XML) as "d"
COLUMNS
cid INTEGER PATH 'customerinfo/@Cid',
info XML
PATH '.' ) AS X";
string XMLFile = "customer.xml";
DB2Parameter p1 = cmd.CreateParameter();
p1.DB2Type = DB2Type.XML;
p1.Value = File.OpenRead(XMLFile);
cmd.Parameters.Add(p1);
cmd.Prepare();
cmd.ExecuteNonQuery();
} catch (Exception e) {
Console.WriteLine(e.Message);
}
Figure 21.14
Inserting XML data from a C# .NET application
636
Chapter 21
Developing XML Applications with DB2
The sample code in Figure 21.14 sets the value of the input parameter p1 to the result of reading
from a file, which returns a FileStream. Alternatively, DB2Parameter.Value can also be
assigned a value of type String, Byte[], XmlReader, or DB2Xml.
21.4.4
XML Schema and DTD Handling in .NET Applications
The DB2 .NET Data Provider includes a number of methods that allow you to manage XML
Schemas and DTDs in DB2 from within your .NET application (Table 21.9). For example, there
are methods to register an XML Schema or a DTD in the XML Schema Repository (XSR) of a
DB2 database. Corresponding methods to drop objects from the XSR are also provided. Other
methods allow you to obtain DB2’s internal identification number of an XML Schema (XSROBJECTID) and to retrieve the XML Schema documents for a given XSROBJECTID.
Table 21.9
.NET Methods for XML Schema and DTD Handling
DB2Connection.RegisterXmlSchema
Registers an XML Schema in the database
DB2Connection.DropXmlSchema
Drops an XML Schema in the database
DB2DataReader.GetDB2XsrObjectId
Creates an instance of a DB2XsrObjectId
from XML column data
DB2DataReader.GetXmlSchemaCollection
Returns an XmlSchemaCollection object of
all the schema documents for the given
DB2XsrObjectId
DB2Connection.RegisterDTD
Registers a DTD in the database
DB2Connection.DropDTD
Drops a DTD in the database
When you develop .NET applications you might also be interested in the DB2 Add-on for Visual
Studio .NET. This add-on is a collection of GUI tools that assist you with database and XMLrelated tasks. For more details, refer to section 21.9.2.
21.5
CLI APPLICATIONS
The DB2 Call Level Interface (CLI) is a callable SQL interface to a DB2 database server. CLI is
an application programming interface for C and C++ applications and an alternative to embedded
dynamic SQL. Unlike embedded SQL, CLI does not require host variables or a precompiler.
CLI applications can retrieve, insert, and update XML data using the CLI SQL type SQL_XML.
This data type corresponds to the XML type in DB2 that is used to define columns in tables or
input and output parameters for stored procedures and user-defined functions. In your CLI application you can bind the SQL_XML type to the binary C type SQL_C_BINARY or to the character
types SQL_C_CHAR, SQL_C_WCHAR, and SQL_C_DBCHAR. We recommend that you use the
21.5
CLI Applications
637
C type SQL_C_BINARY rather than a character data type to avoid code page conversion. Code
page conversion incurs overhead and can lead to the loss of data when character code pages are
not fully compatible. Chapter 20, Understanding XML Data Encoding, provides more details on
this issue.
Figure 21.15 shows a CLI code fragment to insert a row into the customer table. The INSERT
statement contains two parameters, one for the relational column cid and one for the XML column info. The CLI function SQLBindParameter() binds the application variable custid to
the first parameter marker, and the character buffer xmldoc to the second. Note that the second
call to SQLBindParameter(), which binds the XML document to a parameter marker, specifies
the C type SQL_C_BINARY and the SQL type SQL_XML.
char xmldoc[32000];
integer length;
SQLSMALLINT custid = 1099;
// assume that "xmldoc" contains the input document
length = strlen (xmldoc);
// allocate a statement handle:
SQLHANDLE stmt;
SQLAllocHandle(SQL_HANDLE_STMT, connection, &stmt);
// prepare the insert statement:
SQLPrepare(stmt, "INSERT INTO customer(cid, info)
VALUES(?,?)", SQL_NTS);
// bind parameter values and execute the statement:
SQLBindParameter(stmt, 1, SQL_PARAM_INPUT, SQL_C_SHORT,
SQL_SMALLINT, 0, 0, &custid, 0, NULL);
SQLBindParameter(stmt, 1, SQL_PARAM_INPUT, SQL_C_BINARY,
SQL_XML, 0, 0, xmldoc, 32000, &length);
SQLExecute(stmt);
Figure 21.15
CLI code fragment to insert an XML document
Figure 21.16 shows a CLI code fragment that issues an SQL/XML query with a parameter
marker against the customer table. The query retrieves the addr element for the customers that
live in a specific zip code. The function SQLBindParameter() binds the variable zipcode to
the query parameter. The function SQLBindCol() binds the string buffer xmldoc to the XML
column that the query returns. Remember that the function XMLQUERY always returns a column
of type XML. The target data type in the call to SQLBindCol() is specified as SQL_C_BINARY to
ensure that the XML data is returned in UTF-8 and not converted to the application code page.
638
Chapter 21
Developing XML Applications with DB2
char xmldoc[32000];
integer length;
char zipcode[10];
length = sizeof (xmldoc);
// Prepare the query:
SQLPrepare(stmt, "
SELECT XMLQUERY('$INFO/customerinfo/addr')
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo/addr[zip = $z]'
PASSING cast(? as VARCHAR(10) as \"z\"))
", SQL_NTS);
SQLBindParameter(stmt, 1, SQL_PARAM_INPUT, SQL_C_CHAR,
SQL_CHAR, 10, 0, zipcode, 10, NULL);
// Now execute the query for zip code N9C 3T6
strcpy(zipcode, "N9C 3T6");
SQLExecute(stmt);
// Bind the returned XML column and fetch the first row:
SQLBindCol(stmt, 1, SQL_C_BINARY, xmldoc, &length, NULL);
SQLFetch (stmt);
Figure 21.16
CLI code fragment to read an XML document fragment
The default behavior for a CLI application is that each XML value that is retrieved from the database is given an XML declaration with an encoding attribute. For example, the first row returned
by the query in Figure 21.16 could look like this:
<?xml version="1.0" encoding="UTF-8" ?>
<addr country="Canada">
<street>25 EastCreek</street>
<city>Markham</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N9C 3T6</pcode-zip>
</addr>
You can choose to omit the XML declaration in one of three ways:
• Use the function SQLSetStmtAttr() to set the statement attribute SQL_ATTR_XML_
DECLARATION to 0 per statement.
• Use the function SQLSetConnectAttr() to set the connection attribute SQL_ATTR_
XML_DECLARATION to 0, per connection. This attribute affects any statement handles
allocated after the value is changed.
• For a specific database, set the CLI/ODBC configuration keyword XMLDeclaration in
the db2cli.ini file to 0. This setting affects all DB2 CLI and ODBC applications that
access the database.
21.6
Embedded SQL Applications
639
XML queries in XQuery notation can be issued and executed in CLI applications just like SQL
statements. An XQuery must be prepended with the keyword xquery.
21.6
EMBEDDED SQL APPLICATIONS
Embedded SQL applications are different from CLI, .NET, PHP, or JDBC applications because
they can use host variables and static SQL in addition to dynamic SQL with parameter markers.
While dynamic SQL statements are compiled at application runtime, static SQL is compiled by a
precompiler that reads the application source code and converts embedded SQL statements into
DB2 API calls. The precompiler produces a modified version of your application source code as
well as access plans that are stored as a package in the database.
Embedded SQL applications declare host variables in the application source code to exchange
data with the DB2 server. For XML data, DB2 provides six new XML types for host variables in
Assembler, C, C++, COBOL, and PL/1 applications. These XML types are based on LOB types for
variables and files. The six XML types and their encoding properties are listed in Table 21.10.
The XML host variable types are compatible with the XML data type in DB2. To avoid codepage
conversion issues, XML AS BLOB is preferred over XML AS CLOB and XML as DBCLOB.
Table 21.10
XML Types for Host Variables
Type Declaration
Encoding
SQL TYPE IS XML AS CLOB
XML data that is encoded in the application codepage
(externally encoded)
SQL TYPE IS XML AS BLOB
XML data that is internally encoded
SQL TYPE IS XML AS DBCLOB
XML data that is encoded in the application graphic
codepage (externally encoded)
SQL TYPE IS XML AS CLOB_FILE
XML data in a file that is encoded in the application
codepage (externally encoded)
SQL TYPE IS XML AS BLOB_FILE
XML data in a file that is internally encoded
SQL TYPE IS XML AS DBCLOB_FILE
XML data in a file that is encoded in the application
graphic codepage (externally encoded)
Remember that XML data is stored in DB2 in the UTF-8 codepage. If an embedded SQL application retrieves XML data into a host variable of type XML AS CLOB, the XML data is converted
from UTF-8 to the code page of the application. An XML declaration is added to the retrieved
XML data and it contains an encoding attribute that indicates the application codepage. This
behavior guarantees that external and internal encoding of the retrieved XML data are consistent.
The internal and external encoding might be inconsistent if you retrieve XML data into a host
variable of type CLOB, instead of XML AS CLOB.
640
Chapter 21
Developing XML Applications with DB2
When you retrieve XML data into a host variable of type XML AS BLOB, which is the preferred
method, the XML data is not converted to the application codepage and remains in UTF-8. The
retrieved XML data is internally encoded but not externally encoded, and includes an XML declaration where the encoding attribute indicates UTF-8:
<?xml version = "1.0" encoding = "UTF-8"?>
Irrespective of the type of the host variable, you can use the function XMLSERIALIZE to avoid the
generation of an XML declaration. Let’s consider the queries in Figure 21.17 as an example. Both
queries retrieve XML documents from the XML column info. The column produced by the first
query is of type XML and can be bound to a host variable that has an XML type such as XML AS
BLOB or XML AS CLOB. The second query serializes the XML documents explicitly to data type
BLOB, which has two effects. First, no XML declaration is generated for the documents unless
you add the optional keywords INCLUDING XMLDECLARATION to the XMLSERIALIZE function.
Second, since the returned column type is not XML, it cannot be bound to a host variable that has
an XML type such as XML AS BLOB. This column must be bound to a host variable of type BLOB.
SELECT info
FROM customer;
SELECT XMLSERIALIZE(info as BLOB)
FROM customer;
Figure 21.17
Using XMLSERIALIZE to avoid an XML declaration
There is no support for static XQuery. If you try to precompile an XQuery statement, DB2 produces an error. You can execute XQuery only if the XQuery expression is embedded in an SQL
statement through SQL/XML functions such as XMLQUERY or XMLTABLE.
The following sections provide examples of manipulating XML data in COBOL, PL/1, and C
applications with host variables and embedded SQL statements. Although these three languages
differ in the syntax for host variable declarations, the SQL and SQL/XML statements shown are
not host language specific. We therefore present slightly different examples for COBOL, PL/1,
and C to provide a larger overall set of samples.
21.6.1
COBOL Applications with Embedded SQL
Enterprise COBOL 4.1 for z/OS has enhanced its XML features. For example, it enables COBOL
applications to parse and extract values from XML documents, populate COBOL data structures
with values from XML documents, validate XML documents, and generate XML documents
from application data. However, when you develop COBOL applications for use with DB2
pureXML, it is often better to exploit DB2’s XML capabilities than to manipulate XML in the
application code (see section 21.1.1).
21.6
Embedded SQL Applications
641
In a COBOL application, the declaration of a host variable with the name MYDOCUMENT, data type
XML AS BLOB, and maximum size of 1MB, looks like this:
01
MYDOCUMENT USAGE IS SQL TYPE IS XML AS BLOB(1M).
On z/OS, an XML host variable of type XML AS BLOB(1M) or XML AS CLOB(1M) is converted
by the DB2 precompiler into the following variable in your application:
01 MYDOCUMENT.
02 MYDOCUMENT-LENGTH
PIC 9(9) COMP.
02 MYDOCUMENT-DATA.
49 FILLER PIC X(32767).
49 FILLER PIC X(32767).
.
.
.
49 FILLER PIC X(32).
The XML type variable is declared in chunks of 32,767 bytes or less. In this example, the variable
of size 1MB is represented by 32 chunks of 32,767 bytes plus one chunk of 32 bytes (32 × 32767
+ 32 = 1,048,576 = 1MB). If the variable is of type XML AS DBCLOB, it is declared in chunks of
32,767 or fewer double-byte characters.
The sample COBOL code in Figure 21.18 shows declarations of XML host variables and their
usage in INSERT, SELECT, and UPDATE statements. The INSERT statement contains the literal
value 1006 for the CID column of the customer table, but it could also include a subselect with
an XMLTABLE function to extract the Cid attribute value from the XML document.
*** Host variable declarations
EXEC SQL BEGIN DECLARE SECTION END-EXEC.
01 MYDOC
USAGE IS SQL TYPE IS XML as BLOB(50K).
01 MYDOC2 USAGE IS SQL TYPE IS XML AS CLOB(1M).
01 MYCLOB USAGE IS SQL TYPE IS CLOB(10K).
EXEC SQL END DECLARE SECTION END-EXEC.
*** Insert a document into an XML column.
EXEC SQL INSERT INTO CUSTOMER(CID, INFO)
VALUES (1006, :MYDOC)
END-EXEC.
*** Update an XML column with an XML AS CLOB variable
EXEC SQL UPDATE CUSTOMER
SET INFO = :MYDOC2
WHERE XMLEXISTS('$i/customerinfo[@Cid = 1004]'
PASSING info as "i")
END-EXEC.
Figure 21.18
COBOL code to read and write XML data (continues)
642
Chapter 21
Developing XML Applications with DB2
*** Retrieve the addr fragment of an XML document into
*** an XML AS BLOB host variable. The XML data is in UTF-8
*** and has an XML declaration with encoding attribute.
EXEC SQL SELECT XMLQUERY('$i/customerinfo/addr'
PASSING info as "i")
INTO :MYDOC
FROM CUSTOMER
WHERE XMLEXISTS('$i/customerinfo[@Cid = 1003]'
PASSING info as "i")
END-EXEC.
*** Retrieve an XML document into a CLOB variable. The XML
*** data is converted to the application code page and
*** has no XML declaration.
EXEC SQL SELECT XMLSERIALIZE(INFO AS CLOB(10K))
INTO :MYCLOB
FROM CUSTOMER
WHERE XMLEXISTS('$i/customerinfo[@Cid = 1005]'
PASSING info as "i")
END-EXEC.
Figure 21.18
COBOL code to read and write XML data (Continued)
In many situations you might not want to retrieve full XML documents or document fragments
into LOB variables. Instead it can be very useful to extract individual values from an XML document and read them into dedicated variables. The code sample in Figure 21.19 uses an SQL/XML
statement with the XMLTABLE function to extract the values of the name, street, and city elements into corresponding host variables. The query also uses a host variable in the XMLEXISTS
predicate to select information for one specific customer.
EXEC
01
01
01
01
EXEC
SQL BEGIN DECLARE SECTION END-EXEC.
name
pic x(30).
street
pic x(35).
city
pic x(20).
cid
pic s9(4) comp-5.
SQL END DECLARE SECTION END-EXEC.
MOVE 1005 TO cid.
EXEC SQL SELECT X.custname, X.str, X.city
INTO :name, :street, :city
FROM CUSTOMER,
XMLTABLE('$i/customerinfo' PASSING info AS "i"
COLUMNS
custname VARCHAR(30) PATH 'name',
str
VARCHAR(35) PATH 'addr/street',
city
VARCHAR(20) PATH 'addr/city' ) as X
WHERE XMLEXISTS('$i/customerinfo[@Cid = $c]'
PASSING CAST(:cid AS INTEGER) AS "c")
END-EXEC.
Figure 21.19
Extracting XML values into host variables in COBOL
21.6
Embedded SQL Applications
21.6.2
643
PL/1 Applications with Embedded SQL
In a PL/1 application, the declaration of a host variable with the name MYDOCUMENT, data type
XML AS BLOB, and maximum size of 100KB, looks like this:
DCL MYDOCUMENT SQL TYPE IS XML AS BLOB (100K);
The DB2 precompiler takes this declaration as input and generates the following variable in your
application:
DCL
1
2
2
MYDOCUMENT,
MYDOCUMENT_LENGTH BIN FIXED(31),
MYDOCUMENT_DATA,1
3
MYDOCUMENT_DATA1 (3) CHAR(32767),
3
MYDOCUMENT_DATA2 CHAR(4099);
The precompiler generates the same application variable if the host variable was declared as XML
AS CLOB(100K). The XML type variable, which has a size of 100K in this example, is represented by an array of strings of length 32,767. Since 100K is not evenly divisible by 32,767, an
additional character string is declared to hold the remainder. 100K is 102,400 bytes and allocated
as three chunks of 32,767 bytes, totaling 98,301 bytes, plus a string of 4,099 bytes (98,301 +
4,099 = 102,400). If the variable is of type XML AS DBCLOB, the precompiler declares chunks of
16,383 double-bytes plus an additional character string for the remainder.
Figure 21.20 shows a PL/1 program that inserts data from an XML AS BLOB host variable into an
XML column. It also shows the retrieval of XML data into an XML AS BLOB host variable and a
CLOB host variable, respectively.
/* Host variable declarations */
EXEC SQL BEGIN DECLARE SECTION;
DCL MYDOC SQL TYPE IS XML AS BLOB (100K),
MYCLOB SQL TYPE IS CLOB(10K);
CID
BIN FIXED(31),
EXEC SQL END DECLARE SECTION;
*** Insert a document into an XML column and extract the cid
*** attribute into the CID column of the table:
EXEC SQL INSERT INTO CUSTOMER(CID, INFO)
SELECT id, doc
FROM XMLTABLE('$i' PASSING CAST(:MYDOC AS XML) AS "i"
COLUMNS
id
INTEGER
PATH 'customerinfo/@Cid',
doc XML
PATH '.') as X;
Figure 21.20
PL/1 code to insert and select XML data (continues)
644
Chapter 21
Developing XML Applications with DB2
*** Retrieve an XML document into an XML AS BLOB host variable.
*** The XML data is in UTF-8 and has an XML declaration.
EXEC SQL SELECT CID, INFO
INTO :CID, :MYDOC
FROM CUSTOMER
WHERE XMLEXISTS('$i/customerinfo[@Cid = 1003]'
PASSING info as "i");
*** Retrieve a piece of an XML document into a CLOB variable.
*** The XML data is converted to the application code page
*** and has no XML declaration.
EXEC SQL SELECT XMLSERIALIZE(XMLQUERY('$i/customerinfo/addr'
PASSING info as "i")
AS CLOB(10K))
INTO :MYCLOB
FROM CUSTOMER
WHERE XMLEXISTS('$i/customerinfo[@Cid = 1005]'
PASSING info as "i");
Figure 21.20
PL/1 code to insert and select XML data (Continued)
If you do not want to retrieve full XML documents from DB2 you can use the XMLTABLE function to extract individual values from XML documents into host variables. This technique is illustrated by the code sample in Figure 21.21. The query shown also uses a host variable in the
XMLTABLE function to select a specific XML document in the table. Alternatively, an XMLEXISTS
predicate can be used.
EXEC SQL BEGIN DECLARE SECTION;
DCL cid
BIN FIXED(31),
name
CHAR(30) VAR,
phone CHAR(15) VAR,
city
CHAR(20) VAR;
EXEC SQL END DECLARE SECTION;
/* assume phone holds the number for a specific customer */
EXEC SQL SELECT X.id, X.custname, X.city
INTO :cid, :name, :city
FROM CUSTOMER,
XMLTABLE('$i/customerinfo[phone = $p]' PASSING
info AS "i", CAST(:phone AS VARCHAR(15)) AS "p"
COLUMNS
id
INTEGER
PATH '@Cid',
custname VARCHAR(30) PATH 'name',
city
VARCHAR(20) PATH 'addr/city' ) as X;
Figure 21.21
Extracting XML values into host variables in PL/1
21.6
Embedded SQL Applications
21.6.3
645
C Applications with Embedded SQL
In a C application with embedded SQL, the declaration of a host variable with the name MYDOCUMENT, a data type of XML AS BLOB, and a maximum size of 1MB, looks like this:
SQL TYPE IS XML AS BLOB(1M) MYDOCUMENT;
An XML host variable of type XML AS BLOB(1M) or XML AS CLOB(1M) is converted by the
DB2 precompiler into the following variable in your application:
struct
{ unsigned long length;
char data[1048576];
} MYDOCUMENT;
The code sample in Figure 21.22 illustrates the use of an XML AS CLOB host variable to insert
XML data into an XML column. The XML data is externally encoded in the code page of the
application because it is passed to DB2 in a character variable. When the INSERT statement is
processed, the XML document is converted to the database codepage and then to UTF-8, which is
the codepage for all XML storage. If the database codepage is not UTF-8, intermediate conversion
to the database codepage can be avoided if you use XML AS BLOB instead of XML AS CLOB.
EXEC SQL BEGIN DECLARE SECTION;
SQL TYPE IS XML AS CLOB(10K) mydoc;
CHAR docstring[5000];
EXEC SQL END DECLARE SECTION;
/* Create an XML document */
strcpy (docstring, "<customerinfo cid=\"1055\">"
"<name>John Doe</name>"
"<phone type=\"cell\">408-463-4963</phone>"
"</customerinfo>");
/* Set the data and length of the host variable mydoc */
strcpy(mydoc.data, docstring);
mydoc.length = strlen(docstring) + 1;
/* Insert the document */
EXEC SQL INSERT INTO customer(cid, info)
VALUES (1101, :mydoc);
Figure 21.22
Inserting an XML document with embedded SQL in C
The code sample in Figure 21.23 uses a cursor and an SQL/XML statement to retrieve the phone
elements where the type is work for all customers who live in Berlin. Each phone element is
returned in UTF-8 format with its start tag and end tag. If you want to obtain the phone number in
a CHAR variable without the XML tags, declare the host variable myphone as CHAR and change
the query to return a VARCHAR column using the XMLTABLE or XMLCAST function.
646
Chapter 21
Developing XML Applications with DB2
EXEC SQL INCLUDE SQLCA;
EXEC SQL BEGIN DECLARE SECTION;
SQL TYPE IS XML AS BLOB(1K) myphone;
CHAR city[20];
CHAR phonetype[10];
EXEC SQL END DECLARE SECTION;
strcpy (city, "Berlin");
strcpy (phonetype, "work");
/* Declare a cursor for a SQL/XML query */
EXEC SQL DECLARE cur1 CURSOR FOR
SELECT XMLQUERY('$i/customerinfo/phone[@type= $t]' PASSING
info as "i", CAST(:phonetype AS VARCHAR(15))as "t")
FROM customer
WHERE XMLEXISTS('$i/customerinfo[addr/city = $c]' PASSING
info as "i", CAST(:city AS VARCHAR(15))as "c");
/* Open the cursor and fetch all rows */
EXEC SQL OPEN cur1;
while( sqlca.sqlcode == SQL_RC_OK )
{
EXEC SQL FETCH cur1 INTO :myphone;
/* Consume and process the fetched phone elements here*/
}
EXEC SQL CLOSE cur1;
Figure 21.23
Retrieving XML elements with embedded SQL in C
When you develop a C application with embedded SQL for use with a database in DB2 for Linux,
UNIX, and Windows, you can also execute queries in XQuery notation without SQL. You execute XQuery dynamically, not statically, as demonstrated in Figure 21.24. The statement string
must begin with the keyword xquery. You can then prepare and execute the query like a dynamic
SQL statement.
EXEC SQL INCLUDE SQLCA;
EXEC SQL BEGIN DECLARE SECTION;
CHAR stmt[2000];
SQL TYPE IS XML AS BLOB(10K) mydoc;
EXEC SQL END DECLARE SECTION;
sprintf( stmt, "xquery
for $i in db2-fn:xmlcolumn(\"CUSTOMER.INFO\")
where $i/customerinfo/addr[city = \"Aurora\"]
return <cust>{$i/name}{$i/phone}</cust>" );
EXEC SQL PREPARE st1 FROM :stmt;
EXEC SQL DECLARE cur1 CURSOR FOR st1;
EXEC SQL OPEN cur1;
Figure 21.24
Executing XQuery in a C application with embedded SQL
21.7
PHP Applications
647
while( sqlca.sqlcode != 100 )
{
EXEC SQL FETCH cur1 INTO :mydoc;
/* Display results */
}
EXEC SQL CLOSE cur1;
Figure 21.24
21.7
Executing XQuery in a C application with embedded SQL (Continued)
PHP APPLICATIONS
PHP is an interpreted programming language that has gained increasing popularity for the development of Web applications. PHP is a modular language that allows for extensions to provide
additional or customized functionality in the language. For example, PHP 5 includes new extensions for processing XML data such as SimpleXML, XMLReader, and XMLWriter. SimpleXML
lets you convert an XML document into an object that can be processed with normal property
selectors and array iterators. Other extensions for PHP facilitate read and write access to databases so that you can easily create a dynamic database-driven Web application. PHP is a programming language not only for distributed platforms. IBM also offers a port of PHP 5.1 to the
z/OS UNIX System Services platform (see Appendix C for the URL).
IBM offers two PHP extensions for database access, called ibm_db2 and pdo_ibm. You can use
either extension to access data in a DB2 family database from your PHP application. Both extensions are included as part of the IBM Data Server Client but can also be downloaded from the
PHP Extension Community Library (PECL) at http://pecl.php.net/.
The extension pdo_ibm is a driver for PHP Data Objects (PDO) and offers access to DB2 databases through the standard object-oriented database interface introduced in PHP 5.1.
The extension ibm_db2 offers a procedural application programming interface (API) for database operations such as CREATE, INSERT, SELECT, and UPDATE and also provides access to the
database metadata. The complete list of all DB2 PHP functions in this extension is documented at
http://www.php.net/manual/en/ref.ibm-db2.php, which is an excellent reference if
you develop PHP applications for DB2. You can compile the ibm_db2 extension with either PHP
4 or PHP 5. The following examples all use the ibm_db2 extension.
Figure 21.25 shows the code to insert an XML document into the info column of the customer
table. The customer table also contains an INTEGER column called cid. The value for this column is extracted from the XML document by DB2 as part of the INSERT statement. The application does not need to parse the XML document to extract this value before performing the insert.
In this example, the XML document to insert is retrieved from a file and assigned to the variable
$mydoc. The function db2_bind_param() binds the document to the parameter marker of the
prepared INSERT statement. Note that the third parameter of the function db2_bind_param()
is a variable name “mydoc” as a string literal rather than the variable $mydoc itself. After you
648
Chapter 21
Developing XML Applications with DB2
have called db2_prepare() once, you can call db2_bind_param() and db2_execute()
repeatedly to insert multiple documents. The function db2_execute() always returns either
true or false to indicate the success or failure of the statement execution.
// Read the XML document from the file into a variable
$mydoc = file_get_contents("customer.xml");
// Create a string that holds the INSERT statement:
$insert = "INSERT INTO customer
SELECT T.cid, T.info
FROM XMLTABLE ('$d' passing cast(? as XML) as "d"
COLUMNS
cid INTEGER PATH 'customerinfo/@Cid',
info XML
PATH '.' ) AS T";
// Create a prepared statement:
$stmt = db2_prepare($connection, $insert);
// Bind the XML file object to the first parameter marker:
db2_bind_param($stmt, 1, "mydoc", DB2_PARAM_IN);
// Execute the statement:
$success = db2_execute($stmt);
if ($success) {
print "New customer inserted.";
}
Figure 21.25
PHP code to insert an XML document
Figure 21.26 shows the code to execute an XQuery against the customer table. The query
retrieves the complete XML document for each customer who lives in Aurora. Since XQuery
does not use SQL style parameter markers, there is no benefit in preparing an XQuery statement.
The query string is executed directly with the db2_exec() function, which returns a statement
resource if the execution was successful. The function db2_fetch_array() returns each result
row as an array indexed by column position. Since XQuery always returns a single column, you
only need to access the first element of the array at index 0. By default, the result cursor is a forward-only cursor that returns the next row of the result set for each fetch call.
// Build a query string
$query = "xquery for $i in db2-fn:xmlcolumn('CUSTOMER.INFO')
where $i/customerinfo/addr/city = 'Aurora'
return $i";
// Execute the xquery
$stmt = db2_exec($connection, $query);
Figure 21.26
PHP code to execute an XQuery
21.7
PHP Applications
649
// Loop through the result set
while($row = db2_fetch_array($stmt)){
printf("$row[0]\n");
}
Figure 21.26
PHP code to execute an XQuery (Continued)
If you prefer to retrieve only particular information for a customer instead of the complete XML
document, let DB2 extract the values for you and avoid costly XML parsing in your PHP code. In
Figure 21.27 , an XMLTABLE function is used to extract name, street, and city information for the
customer Jim Noodle. Note that the XMLTABLE function contains a predicate and a parameter
marker for the customer name that selects a specific document. The parameter marker allows you
to prepare the query just once but execute it many times, each time with a different customer
name as input. Preparing the query only once avoids repeated compilation at the DB2 server and
saves CPU cycles. In this example the result is fetched with the function db2_fetch_
object(). While db2_fetch_array() returns each result row as an array, db2_fetch_
object() allows you to access the columns of the result set as properties of a result row object.
// Build a query string:
$query = "SELECT T.custname, T.street, T.city
FROM customer,
XMLTABLE('$INFO/customerinfo[name = $n]'
PASSING cast(? as VARCHAR(25)) as "n"
COLUMNS
custname VARCHAR(20) PATH 'name',
street
VARCHAR(20) PATH 'addr/street',
city
VARCHAR(16) PATH 'addr/city') AS T";
// Create a prepared statement:
$stmt = db2_prepare($connection, $query);
// Bind a value to the parameter marker:
$searchname = "Jim Noodle"
db2_bind_param($stmt, 1, "searchname", DB2_PARAM_IN);
// Execute the query:
$success = db2_execute($stmt);
// Loop through the result set:
if ($success) {
while($row = db2_fetch_object($stmt)){
printf("$row-> custname , $row->street , $row->city\n");
}
}
Figure 21.27
PHP code to extract selected elements from a document
650
21.8
Chapter 21
Developing XML Applications with DB2
PERL APPLICATIONS
The DB2 Perl driver (called DBD::DB2) allows you to query and manipulate XML data in a DB2
database. Use DBD::DB2 version 1.6 or higher. For example, you can insert XML documents
from a Perl application into a column of type XML. You can also send XQuery or SQL/XML
queries to DB2 and retrieve the XML data in the result set either as a BLOB or a Record. Note that
the DBD::DB2 driver supports only dynamic SQL, not static SQL. For information about the
DB2 Perl Database Interface and information on how to download the latest DBD::DB2 driver, go
to http://search.cpan.org/~ibmtordb2/.
The Perl code in Figure 21.28 connects to the database, prepares two queries, and fetches their
results as a Record and BLOB respectively. The example assumes that a DB2 database with the
name perldb contains the customer table.
#!/usr/bin/perl
use DBI;
my $dbname='dbi:DB2:perldb';
my $dbuser='';
my $password='';
my $dbhandle = DBI->connect($dbname, $dbuser, $password)
or die "Connection failed: $DBI::errstr";
### Statement 1: SQL/XML query to extract customers names
### for a given zip code:
$stmt1 = q(
SELECT XMLQUERY('$INFO/customerinfo/name')
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo/addr[zip = $z]'
PASSING CAST(? as VARCHAR(10)) as "z")
);
### Statement 2: XQuery to retrieve the address
### for a certain customer:
$stmt2 = q(
xquery for $i in db2-fn:xmlcolunm("CUSTOMER.INFO")/customerinfo
where $i/name = "Matt Foreman"
return $i/addr
);
### Prepare and execute Statement 1, fetch result as a record:
my $zipcode = '95141';
$stmthandle = $dbhandle->prepare($stmt1);
$stmthandle->bind_param(1,$zipcode);
$stmthandle->execute();
#associate a variable with the output column
$stmthandle->bind_col(1,\$custname);
while ($stmthandle ->fetch)
Figure 21.28
Querying XML data in a Perl application
21.9
XML Application Development Tools
{
}
651
print $custname ; print "\n";
### Prepare and execute Statement 2, and fetch result as a BLOB
$dbhandle->{LongReadLen} = 0;
$stmthandle = $dbhandle->prepare($stmt2)
$stmthandle->execute();
my $offset = 0;
my $buffer="";
#Retrieve the results and print on the screen
while($stmthandle->fetch()) {
while( $buffer = $stmthandle->blob_read(1,$offset,1000000)) {
print "\n";
print $buffer;
$offset+=length($buffer);
$buffer="";
}
}
Figure 21.28
Querying XML data in a Perl application (Continued)
For XML document manipulation, such as extracting values or modifying documents, it is recommended that you use DB2’s XQuery and SQL/XML capabilities as much as possible. If you
do need to perform additional XML manipulation in your Perl application, consider using one of
the popular XML modules, such XML::Simple, XML::LibXML, XML::SAX, and XML::DOM.
These and others can be found on the CPAN website.
21.9
XML APPLICATION DEVELOPMENT TOOLS
A variety of tools from various vendors exist to help you develop XML applications. You should
use your favorite IDE (Integrated Development Environment) for the programming language that
you are using, such as Eclipse for Java development, or Visual Studio for .NET development.
Some of these IDEs have XML-specific capabilities or allow you to design and test stored procedures. In some cases you might need additional tools for the design and manipulation of XML
artifacts such as XML Schemas, XML documents, and XSLT style sheets. This section provides
an overview of the following XML and application development tools that support DB2
pureXML particularly well:
• IBM Data Studio Developer
• IBM Database Add-ins for Visual Studio
• Altova XML Tools (XMLSpy, MapForce, StyleVision, and DatabaseSpy)
• <oXygen/>
• Stylus Studio
652
21.9.1
Chapter 21
Developing XML Applications with DB2
IBM Data Studio Developer
IBM Data Studio Developer provides a suite of integrated tools for database administrators and
application developers. Data Studio Developer is based on the Eclipse framework and supports a
variety of databases, including DB2 for z/OS and DB2 for Linux, UNIX, and Windows. Using
Data Studio Developer, you can develop and test SQL, XQuery, and SQL/XML queries as well as
SQL and Java stored procedures. You can also generate and deploy data-centric Web services and
develop and optimize Java applications. Data Studio Developer also supports database administration tasks, such as creating and altering database objects, managing privileges, and generating
DDL statements. A profiler for SQL stored procedures allows you to get detailed performance
information for each statement in a stored procedure, including elapsed time, CPU time, and the
number of logical and physical I/O operations performed.
IBM Data Studio Developer also supports the design and manipulation of XML artifacts, such as
XML columns, XML documents, XML Schemas, XSLT style sheets, and XML queries and
updates.
Figure 21.29 shows a screenshot of Data Studio Developer with the Data Project Explorer and
Database Explorer on the left, the Editor in the top center, the Outline View on the right, and the
Output and Properties panel below the Editor and Outline View. The Database Explorer shows
information about the database SAMPXML. There are folders for buffer pools, schemas, and other
types of database objects. The Schemas folder is opened and allows access to the database objects
for the database schema MNICOLA. One of the tables in this schema, CUSTOMER, has been opened
to view sample content. The Output panel shows the three columns of the table, CID, INFO, and
HISTORY. The columns INFO and HISTORY are XML columns and each of their rows carries a
little button with three dots. You can click this button to show the XML document from that row
and column in the Editor and Outline view above. Then you can view or modify the XML document and save it back into the database. Note that the editor for XML documents offers a Design
and Source view. Figure 21.29 shows the Source view.
Figure 21.30 illustrates the Design view of the XML Editor. The Design view shows the nested
structure of the XML elements and attributes together with their values. A right-click on any node
in the document structure opens a context menu with applicable actions. The context menu is
being used to add another phone element before the existing phone element.
21.9
XML Application Development Tools
Figure 21.29
653
Browsing and viewing XML columns in Data Studio Developer
Data Studio Developer allows you to design new XML Schemas or edit existing schemas that you
import from the file system or open from DB2’s XML Schema Repository. The center of Figure
21.31 shows the Source View of the XML Schema Editor. The editor uses syntax highlighting to
improve the readability of the XML Schema. Simultaneously, the Outline view shows the structure
of the XML Schema in a tree format together with data types, occurrence indicators, and other
details of the items in the schema. You can edit the XML Schema in the Design or Source View
of the editor, as well as in the Outline view on the right. A context menu is being used to change the
number of allowed occurrences of the element pcode-zip. If you design or modify an XML
Schema you can subsequently register it in the XML Schema Repository of a DB2 database.
654
Figure 21.30
Chapter 21
Developing XML Applications with DB2
XML document viewer and editor in Data Studio Developer
Data Studio Developer also supports the creation of XML queries and XML updates. Figure
21.32 shows the SQL and XQuery editor. If you press CTRL-SPACE, the context assist allows you
to choose from a list of query and function templates. At the top of the editor a template of an
XMLTABLE query has already been inserted. It provides a skeleton that you can fill out with actual
table names, column names, and path expressions. It ensures that all required clauses and keywords are in place. Such templates exist for SQL/XML and XQuery as well as for XQuery
Update expressions.
21.9
XML Application Development Tools
Figure 21.31
XML Schema editor in Data Studio Developer
Figure 21.32
Query editor with content assist for SQL/XML and XQuery
655
656
21.9.2
Chapter 21
Developing XML Applications with DB2
IBM Database Add-ins for Visual Studio
If your primary environment for application development is Microsoft Visual Studio 2005 or
Visual Studio 2008, we recommend that you use the IBM Database Add-ins for Visual Studio.
These add-ins are a collection of features and wizards that integrate into your Visual Studio
development environment. They simplify your work with a DB2 database and the design of DB2
tables, indexes, schemas, queries, and applications. When you install the DB2 Server or the DB2
client, you will be presented with an option to install the IBM Database Add-ins for Visual Studio. Alternatively you can download them at http://www.ibm.com/software/data/db2/
windows/dotnet.html.
The IBM Database Add-ins for Visual Studio provide the following capabilities for developing
XML applications for DB2:
• Support of the XML data type in the Visual Studio table and stored procedure designer
• XML data visualization using Visual Studio’s built-in XML document designer and
editor
• A wizard to create XML indexes, with automatic generation of namespace declarations
• XQuery and SQL/XML query designer with syntax colorization and auto-completion
• Integration of the DB2 XML Schema Repository and the .NET XML Schema editor
• Register, edit, and drop XML Schemas in the DB2 XML Schema Repository
• Validation of XML documents with XML Schemas
• Compare and “diff” XML Schemas
• Visual design of annotated XML Schemas with a mapping editor
• Generation of sample XML documents from an XML Schema
• XML data transformation using XSLT
• XML data import and export
21.9.3
Altova XML Tools
Altova is one of the leading vendors for XML design, editing, and mapping tools. Their flagship
tools XMLSpy, MapForce, StyleVision, and DatabaseSpy have been enhanced so that relational
as well as XML data and schemas in DB2 can be manipulated. Altova tools support working with
DB2 for z/OS and DB2 for Linux, UNIX, and Windows. The tools connect to a DB2 database and
allow you to add, browse, edit, update, or convert XML and relational data. Any potential error
messages produced by DB2 are retrieved and displayed in the message pane of Altova’s GUI, so
you can take corrective action.
21.9
XML Application Development Tools
657
XMLSpy
XMLSpy is one of the most popular XML editors and offers a full IDE for working with all
XML-related technologies, including XML instance documents, XML Schemas, XQuery, XSLT,
XPath, and more. XMLSpy’s deep integration with DB2 pureXML allows you to
• Edit, debug, and profile XQuery statements against XML data in DB2 databases. Query
results are then available for further manipulation in XMLSpy.
• Visualize the database structure and query DB2 tables using SQL, SQL/XML, and
XQuery statements.
• Read XML data from DB2, edit it, and store it back in DB2 with optional schema validation.
• Manage XML Schemas in DB2’s XML Schema Repository. For example, you can
design new schemas in XMLSpy and register them in DB2, or read existing XML
Schemas from DB2, edit them, and save them back into DB2.
• Transform XML data for use in other applications.
MapForce
MapForce is a graphical data mapping and conversion tool to define and maintain relationships
between XML, databases, flat files, EDI, and web services. These capabilities help you integrate
these artifacts in a service-oriented architecture (SOA) or custom data integration application.
MapForce allows DB2 users to
• Map XML data, flat files, EDI, and so on directly to and from DB2 databases by assigning an XML Schema to the data using a drag-and-drop interface.
• Access, preview, and integrate database data.
• Define and deploy filtering of database sources within data mapping projects.
• Graphically build web services that retrieve or write data in DB2 databases.
StyleVision
StyleVision is a visual stylesheet creation tool that allows you to render XML and relational data
as HTML, PDF, Word, RTF, OOXML, and electronic forms. DB2 users can use StyleVision to
• Create XSLT and XSL:FO stylesheets to publish XML and relational data using dragand-drop interfaces and other features.
• Produce multiple output documents in HTML, Word/RTF, and PDF for publishing and
exchanging data from a DB2 pureXML database.
658
Chapter 21
Developing XML Applications with DB2
DatabaseSpy
DatabaseSpy is a database query and design tool. It allows you to
• Graphically view and modify database tables and their relationships as well as XML
Schemas.
• Manage XML Schemas that are registered in the database.
• Write SQL queries with code completion and syntax coloring.
• Organize frequently used queries into project files.
For further information on these tools and their capabilities for DB2 pureXML, please refer to the
following information:
• Website: Altova Tools for DB2 pureXML,
http://www.altova.com/IBM_DB2_9_pureXML.html,
http://www.altova.com/features_db2.html
• White Paper: Integration of Altova Tools with IBM DB2 pureXML,
http://www.altova.com/whitepapers/ibm.pdf
• Tutorial: Using the Altova Tools with IBM DB2 pureXML,
http://www.ibm.com/developerworks/db2/library/long/dm-0712kogan/
21.9.4
<oXygen/>
<oXygen/> is a complete XML editor with tools for XML authoring, XML conversion, XML
Schema and DTD manipulation, Relax NG and Schematron development, as well as SOAP and
WSDL testing. Additionally, <oXygen/> allows you to develop and debug XPath, XSLT, and
XQuery. <oXygen/> can connect to XML repositories via WebDAV, Subversion (SVN), and FTP
interfaces, and has support to browse and query databases. The <oXygen/> suite of XML tools is
available as a stand-alone application and as a plug-in for Eclipse.
<oXygen/> offers support for DB2 pureXML that allows you to
• Register and manage XML Schemas in the XML Schema Repository of a DB2 database.
• Export XML or relational data from DB2 tables to XML output format.
• Add, delete or edit data in DB2 tables. If any database constraints are violated, proper
error messages allow you to correct the problem.
• Open XML documents from DB2 XML columns in the <oXygen/> XML editor, modify
the XML data, and save it back to the database.
• Validate existing XML data in DB2 against an XML Schema.
• Run SQL (including DDLs), SQL/XML, and XQuery against data in DB2 tables.
21.10
Summary
659
For further information and instructions to configure the DB2 support in <oXygen/>, see
http://www.oxygenxml.com/IBM_DB2_XML_support.html.
21.9.5
Stylus Studio
Stylus Studio is a complete development environment for working with XML documents, XPath
and XQuery, XSLT, XSL:FO, EDI, XML Schemas and DTDs, XHTML, XML mapping and publishing, and Web services. It offers functionality to assist with the design, debugging, and maintenance of these artifacts that are commonly used in and around XML applications.
Additionally, Stylus Studio supports a separate XQuery processor, called DataDirect
(http://www.xquery.com/), which allows you to query relational data in DB2 using the
XQuery language. DataDirect converts XQuery into SQL statements that are then executed
against relational tables in DB2. Depending on your application you might find it more natural to
query relational DB2 data directly in SQL, and use DB2’s XQuery and SQL/XML capabilities to
query XML data in DB2 databases.
Stylus Studio also allows you to use XML and relational data in DB2 as input for publishing and
reporting with XSLT and XSL:FO. For further details on Stylus Studio, see http://www.
stylusstudio.com/ibm_db2.html.
21.10
SUMMARY
You can use a wide range of programming languages and APIs to develop applications on top of
DB2 pureXML. Many popular languages are supported, such as Java, COBOL, C, PL/1, PHP,
Perl, or the .NET languages C# and Visual Basic. The newer versions of the database APIs for
these languages support the XML data type as well as XQuery and SQL/XML statements.
In most languages you can define application variables of type XML that simplify the data
exchange between the application code and XML columns in DB2. XML documents can also be
inserted or retrieved with character or binary application variables. However, beware of code
page issues when you use character type variables in your application. In DB2, all XML data
stored is in UTF-8 format. If you retrieve XML documents into binary application variables, the
UTF-8 encoding is preserved. If you retrieve XML documents into character variables, the documents are converted to the code page of the application.
Not every query on an XML column returns XML data. For example, SQL/XML queries that use
the XMLTABLE function can extract individual values from XML documents and convert them to
traditional SQL data types such as INTEGER, DECIMAL, DATE, or VARCHAR. Your application
can process the result set of such queries just like it normally does for relational queries. Such
extraction queries also exploit the parsed storage format of DB2 pureXML; that is, they extract
XML values without XML parsing.
660
Chapter 21
Developing XML Applications with DB2
XML parsing is a central topic in XML application development. The general recommendation is
to avoid XML parsing in your application as much as possible. Many common XML processing
tasks can be done with DB2’s pureXML capabilities more efficiently and simpler than with custom application code.
There are tools from various vendors to help you develop XML applications. Depending on the
tool that you choose you might find capabilities such as visual XML Schema design, validation of
documents against schemas, generation of XML Schemas from sample data and vice versa,
design and testing of XSLT style sheets, building and debugging of XQuery expressions, and
many other useful features. Some of the available tools offer DB2-specific support, such as direct
access to DB2 tables or DB2’s XML Schema Repository.
C
H A P T E R
22
Exploring XML
Information in the
DB2 Catalog
I
n this chapter we summarize the DB2 catalog information related to managing XML data
in DB2. This discussion is split into two sections:
• XML information in the catalog views in DB2 for Linux, UNIX, and Windows
(section 22.1)
• XML information in the catalog tables in DB2 for z/OS (section 22.2)
22.1
XML-RELATED CATALOG INFORMATION IN DB2 FOR LINUX, UNIX,
AND WINDOWS
With the introduction of pureXML in DB2, several existing catalog tables have been augmented
with XML-related information and several catalog tables have been added. All of these tables are
discussed in the following sections.
22.1.1
Catalog Information for XML Columns
When a table with an XML column is created, this event is recorded in the catalog views
SYSCAT.TABLES and SYSCAT.COLUMNS and their underlying tables. The view SYSCAT.
COLUMNS contains one entry for each column in a table. XML columns are shown as type XML
(see Figure 22.1).
Base table inlining for XML columns was introduced in DB2 9.5 for Linux, UNIX, and Windows. Hence, for an XML column in DB2 9.5 and higher, the column INLINE_LENGTH in the
view SYSCAT.COLUMNS shows the inline length of that XML column. An inline length of 0
means that the column is not inlined. In DB2 9.7, the column PCTINLINED was added. If statistics have been collected for the table, this column shows the percentage of XML documents that
661
662
Chapter 22
Exploring XML Information in the DB2 Catalog
are inlined. With an inline length of 500 bytes, 63% of the documents in the XML column INFO
are inlined in the example in Figure 22.1. Inlined XML storage is discussed in section 3.4, Using
XML Base Table Row Storage (Inlining).
SELECT SUBSTR(tabname,1,10) AS tabname,
SUBSTR(colname,1,10) AS colname,
SUBSTR(typename,1,10) AS type ,
inline_length,
pctinlined
FROM syscat.columns
WHERE tabname ='CUSTOMER' ;
TABNAME
---------CUSTOMER
CUSTOMER
CUSTOMER
Figure 22.1
COLNAME
---------CID
INFO
HISTORY
TYPE
INLINE_LENGTH PCTINLINED
---------- ------------- ---------BIGINT
0
-1
XML
500
63
XML
0
0
Querying the catalog view SYSCAT.COLUMNS
22.1.2 The XML Strings and Paths Tables
Two system tables contain information about the XML tags and paths that occur in the XML data
that is stored in the database. Both tables contain DB2’s internal information and are not meant to
be queried by user applications or database administrators.
The system table SYSIBM.SYSXMLSTRINGS was discussed in section 3.2, Understanding
pureXML Storage. It contains the database-wide mapping from XML tag names to the stringIDs
that are used in DB2’s internal XML representation. The table consists of three columns, shown
in Figure 22.2.
DESCRIBE TABLE sysibm.sysxmlstrings ;
Column name
---------------STRINGID
STRING
IS_TEMPORARY
Data type
Column
schema
Data type
Length
Scale Nulls
--------- ----------- ---------- ----- -----SYSIBM
INTEGER
4
0 No
SYSIBM
VARCHAR
1001
0 No
SYSIBM
CHARACTER
1
0 No
3 record(s) selected.
Figure 22.2
Description of the catalog table SYSIBM.SYSXMLSTRINGS
Figure 22.3 shows how you can query the catalog table SYSIBM.SYSXMLSTRINGS. Since the
STRING column contains the tag names in hexadecimal form, you need to convert them to character strings, using the function SYSIBM.XMLBIT2CHAR.
22.1
XML-Related Catalog Information in DB2 for Linux, UNIX, and Windows
663
SELECT stringid,
SUBSTR(SYSIBM.XMLBIT2CHAR(string),1,50), is_temporary
FROM sysibm.sysxmlstrings;
Figure 22.3
Querying the table SYSIBM.SYSXMLSTRINGS
The second system table is called SYSIBM.SYSXMLPATHS. It maps paths to pathIDs, much like
the table SYSXMLSTRINGS maps tags to stringIDs. The table contains three columns, as shown in
Figure 22.4. The paths are stored in a binary format.
Column name
-------------PATHID
PATHTYPE
PATH
Figure 22.4
22.1.3
Data type
schema
--------SYSIBM
SYSIBM
SYSIBM
Column
Data type
Length
Scale Nulls
--------------- ---------- ----- ----INTEGER
4
0 No
CHARACTER
1
0 No
VARCHAR
1000
0 No
Columns in the catalog table SYSIBM.SYSXMLPATHS
The Internal XML Regions and Path Indexes
When you create a table with one or more XML columns, one XML path index is automatically
created for each XML column. DB2 also creates a single XML regions index for all XML
columns in a table (see section 3.3, XML Storage in DB2 for Linux, UNIX, and Windows). These
internal indexes associated with XML columns are distinct from XML indexes defined by you.
Table 22.1 shows the possible values for the column INDEXTYPE in the catalog view
SYSCAT.INDEXES where all indexes are recorded. The XML path index has an INDEXTYPE of
XPTH, and the XML regions index is indicated by XRGN. They are internal indexes for use by DB2
and do not appear in query execution plans. The index types XVIL and XVIP stand for the logical
and physical representation of a user-defined XML index (discussed in the next section).
Table 22.1
Column INDEXTYPE in the catalog view SYSCAT.INDEXES
Column Name
Data Type
Description
INDEXTYPE
CHAR (4)
Type of index:
BLOK—Block index
CLUS—Clustering index (controls the physical
placement of newly inserted rows)
DIM—Dimension block index
REG—Regular index
XPTH—XML path index
XRGN—XML regions index
XVIL—Index over XML column (logical)
XVIP—Index over XML column (physical)
664
Chapter 22
22.1.4
Exploring XML Information in the DB2 Catalog
Catalog Information for User-Defined XML Indexes
In the DB2 catalog you find that a user-defined XML index is internally represented by a logical
index and a physical index. The corresponding index types in SYSCAT.INDEXES are XVIL and
XVIP, respectively (refer to Table 22.1). The logical index contains just the index definition,
while the physical index contains the actual B-tree structure. The purpose of this separation is to
leave room and flexibility for more advanced indexing implementations in the future. For example, it is conceivable that a single logical index can be represented by multiple physical B-trees.
But, up to DB2 9.7, there is a one-to-one relationship between logical and physical indexes.
For each index that you define there are two entries in SYSCAT.INDEXES. The name of the logical index is the name you specified in the CREATE INDEX statement. It is also the name that
appears in an access plan. The physical index name is system generated and cannot be influenced.
You can list the indexes for the customer table as shown in Figure 22.5.
SELECT SUBSTR(indschema,1,10) AS indschema,
SUBSTR(indname,1,20) AS indname,
SUBSTR(tabschema,1,10) AS tabschema,
SUBSTR(tabname,1,10) AS tabname,
indextype AS type
FROM syscat.indexes
WHERE tabname = 'CUSTOMER';
INDSCHEMA
---------SYSIBM
SYSIBM
SYSIBM
DB2ADMIN
DB2ADMIN
SYSIBM
INDNAME
-------------------SQL080729100207180
SQL080729100207390
SQL080729100207420
PK_CUSTOMER
CUST_CID_XMLIDX
SQL080729100209890
TABSCHEMA
---------DB2ADMIN
DB2ADMIN
DB2ADMIN
DB2ADMIN
DB2ADMIN
DB2ADMIN
TABNAME
---------CUSTOMER
CUSTOMER
CUSTOMER
CUSTOMER
CUSTOMER
CUSTOMER
TYPE
----XRGN
XPTH
XPTH
REG
XVIL
XVIP
6 record(s) selected.
Figure 22.5
Listing the indexes for a table
The first row in the result set in Figure 22.5 shows the XML regions index of the customer table
(XRGN). The next two rows show the two path indexes of the customer table. There are two path
indexes because the customer table in the DB2 sample database has two XML columns, info
and history (see Figure 22.1). Further, the query result shows a regular relational index (REG)
and a user-defined XML index called CUST_CID_XMLIDX, which is the logical XML index
name. The index with the name SQL080729100209890 is the corresponding physical index,
which is not obvious unless you consult the new catalog view SYSCAT.INDEXXMLPATTERNS.
This catalog view contains the relationships between physical and logical XML indexes. Figure
22.6 shows how to find the XML physical index for a given logical index name.
22.1
XML-Related Catalog Information in DB2 for Linux, UNIX, and Windows
665
SELECT SUBSTR(indname,1,20) AS indname,
SUBSTR(pindname,1,20) AS pindname
FROM syscat.indexxmlpatterns
WHERE indname = 'CUST_CID_XMLIDX';
INDNAME
PINDNAME
-------------------- -------------------CUST_CID_XMLIDX
SQL080729100209890
Figure 22.6
Listing the physical index name for a given logical index name
Table 22.2 summarizes the columns of the catalog view SYSCAT.INDEXXMLPATTERNS.
Table 22.2
SYSCAT.INDEXXMLPATTERNS
Column Name
Data Type
Nullable
INDSCHEMA
VARCHAR(128)
Relational schema name of the logical index
INDNAME
VARCHAR(128)
Unqualified name of the logical index
PINDNAME
VARCHAR(128)
Unqualified name of the physical index
PINDID
SMALLINT
Identifier for the physical index
TYPEMODEL
CHAR(1)
Q = SQL DATA TYPE (Ignore invalid values)
R = SQL DATA TYPE (Reject invalid values)
DATATYPE
VARCHAR(128)
Name of the data type
HASHED
CHAR(1)
Indicates whether the value is hashed
N = Not hashed
Y = Hashed
LENGTH
SMALLINT
VARCHAR(n) length; 0 otherwise
PATTERNID
SMALLINT
Identifier for the pattern
PATTERN
CLOB(2M)
Y
Description
XMLPATTERN used in the index definition
The column PATTERN contains the XPath expression that was used in the XMLPATTERN clause of
the XML index definition. The query in Figure 22.7 reveals the XMLPATTERN and data type that
were used in the CREATE INDEX command of the index CUST_PHONES_XMLIDX.
666
Chapter 22
Exploring XML Information in the DB2 Catalog
SELECT SUBSTR(indname,1,20) AS indname,
SUBSTR(pattern,1,30) AS pattern,
SUBSTR(datatype,1,10) AS datatype,
length
FROM syscat.indexxmlpatterns
WHERE indname = 'CUST_PHONES_XMLIDX';
INDNAME
PATTERN
DATATYPE
LENGTH
------------------- -------------------- ---------- -----CUST_PHONES_XMLIDX /customerinfo/phone VARCHAR
25
Figure 22.7
Obtaining information about an XML index
The view SYSCAT.INDEXXMLPATTERNS does not contain a column for the table name. To list all
XML index definitions for a specific table, use a join between the views SYSCAT.INDEXXMLPATTERNS and SYSCAT.INDEXES (see Figure 22.8).
SELECT SUBSTR(p.indname,1,20) AS indname,
SUBSTR(p.pattern,1,80) AS pattern,
SUBSTR(p.datatype,1,10) AS datatype
FROM syscat.indexxmlpatterns p,
syscat.indexes i
WHERE p.indschema = i.indschema
AND p.indname = i.indname
AND i.tabname = 'CUSTOMER';
INDNAME
-------------------CUST_CID_XMLIDX
CUST_NAME_XMLIDX
CUST_PHONES_XMLIDX
CUST_PHONET_XMLIDX
Figure 22.8
PATTERN
-------------------------/customerinfo/@Cid
/customerinfo/name
/customerinfo/phone
/customerinfo/phone/@type
DATATYPE
---------DOUBLE
VARCHAR
VARCHAR
VARCHAR
Listing all XML index definitions for a given table
When you issue the RUNSTATS command to collect statistics for an XML index you can use
either the logical or the physical index name, as shown in Figure 22.9. No matter which name you
use, statistics are only recorded for and associated with the physical XML index. XML index statistics are explained in Chapter 13, Defining and Using XML Indexes.
RUNSTATS ON TABLE db2admin.customer
FOR INDEXES db2admin.cust_cid_xmlidx;
RUNSTATS ON TABLE db2admin.customer
FOR INDEXES sysibm.SQL080729100209890;
Figure 22.9
Running RUNSTATS on an XML index
22.2
XML-Related Catalog Information in DB2 for z/OS
22.1.5
667
Catalog Information for XML Schemas
A set of catalog tables and views have been introduced to manage XML Schemas and Document
Type Definitions (DTDs). Collectively, these tables and views are called the XML Schema
Repository (XSR). The XSR also includes commands and stored procedures to add, update, and
remove XML Schemas in the XSR. There is one XSR per database. The information in the XML
Schema Repository is exposed to the user through seven catalog views:
• SYSCAT.XSROBJECTS
• SYSCAT.XSROBJECTCOMPONENTS
• SYSCAT.XDBMAPGRAPHS
• SYSCAT.XSROBJECTAUTH
• SYSCAT.XSROBJECTDEP
• SYSCAT.XSROBJECTHIERARCHIES
• SYSCAT.XDBMAPSHREDTREES
These catalog views, their content, and the commands to manage XML Schemas are described in
Chapter 16, Managing XML Schemas.
22.2
XML-RELATED CATALOG INFORMATION IN DB2 FOR Z/OS
Some of the XML-related catalog tables in DB2 for z/OS are similar to the corresponding catalog
views in DB2 for Linux, UNIX, and Windows. For example, DB2 for z/OS has an XML Schema
Repository (XSR) just like DB2 for Linux, UNIX, and Windows. XML columns, tables, and
table spaces are also recorded in the DB2 for z/OS catalog tables. Remember, that when a table is
created with an XML column, DB2 for z/OS automatically creates an XML table space, an XML
table, a node ID index, and document ID index. All of these are listed in catalog tables.
22.2.1
Catalog Information for XML Storage Objects
The catalog table SYSIBM.SYSXMLRELS contains one row for each XML column. The entries in
this table correlate XML columns to the user tables that they logically belong to and to the internal XML tables where they are physically stored. Table 22.3 explains the columns of this catalog
table.
668
Table 22.3
Chapter 22
Exploring XML Information in the DB2 Catalog
SYSIBM.SYSXMLRELS
Column
Data Type
Description
TBOWNER
VARCHAR(128) NOT NULL
Schema or qualifier of the base table.
TBNAME
VARCHAR(128) NOT NULL
Name of the base table.
COLNAME
VARCHAR(128) NOT NULL
Name of the XML column in the base table.
XMLTBOWNER
VARCHAR(128) NOT NULL
Schema or qualifier of the internal XML table.
XMLTBNAME
VARCHAR(128) NOT NULL
Name of the internal XML table.
XMLRELOBID
INTEGER NOT NULL
Internal identifier of the relationship between the
base table and the XML table.
IBMREQD
CHAR(1) NOT NULL
The value Y indicates that the row came from the
machine-readable material (MRM) tape.
CREATEDTS
TIMESTAMP NOT NULL
Time when the XML table was created.
RELCREATED
CHAR(1) NOT NULL
The release of DB2 that is used to create the
object.
The table SYSIBM.SYSXMLSTRINGS acts as DB2’s internal dictionary of XML tags. Each row
contains an XML tag and the corresponding unique integer ID that DB2 uses to compress XML
data (see Table 22.4). The tag can be an element name, attribute name, namespace prefix, or a
namespace URI. DB2’s internal use of this table is illustrated in Chapter 3, Designing and Managing XML Storage Objects.
Table 22.4
SYSIBM.SYSXMLSTRINGS
Column
Data Type
Description
STRINGID
INTEGER NOT NULL
GENERATED ALWAYS
AS IDENTITY
STRING.
Unique ID for the XML tag in the column
STRING
VARCHAR(1000)
NOT NULL
The XML tag.
IBMREQD
CHAR(1)
NOT NULL
A value of Y indicates that the row came from the
basic machine-readable material (MRM) tape.
There are also existing catalog tables that have been augmented with information about XML
objects. For example, the catalog table SYSIBM.SYSTABLES contains one row for every table in
the database. Its column TYPE has the value P if the table is an internal XML table (see Table
22.5). This value allows you to distinguish explicitly created user tables from implicitly created
XML tables.
22.2
XML-Related Catalog Information in DB2 for z/OS
Table 22.5
669
Column TYPE in the catalog table SYSIBM.SYSTABLES
Column Name
Data Type
TYPE
CHAR(1)
NOT NULL
Description
Type of object:
A—Alias
C—Clone table
G—Created global temporary table
M—Materialized query table
P—Implicit table created for XML columns
T—Table
V—View
X—Auxiliary table
You can list tables and internal XML tables using the query in Figure 22.10. The output shows the
base table (type T) and the internal XML table (type P). Note that internal XML table names
always start with an X.
SELECT SUBSTR(creator,1,10) AS creator,
SUBSTR(name,1,30) AS name,
type
FROM sysibm.systables
WHERE name like '%CUST%' #
---------+---------+---------+--------CREATOR
NAME
TYPE
---------+---------+---------+--------USER011
CUSTOMER
T
USER011
XCUSTOMER
P
Figure 22.10
Listing XML tables in DB2 for z/OS
When you create a table with an XML column in DB2 for z/OS, DB2 automatically assigns
names to the internal tables and table spaces that physically store the XML columns. You cannot
influence their names. DB2 assigns a table space name of the form xxxxyyyy, where xxxx is the
first four characters of your table name, and yyyy is a number that guarantees uniqueness. The
example in Figure 22.11 creates a table called customer, which contains a relational column and
three XML columns. The query in Figure 22.11 shows the table and table space names for the
customer table and the three internal XML tables that are created, one for each XML column in
the customer table.
670
Chapter 22
Exploring XML Information in the DB2 Catalog
CREATE TABLE customer (id INT, info XML, info2 XML, info3 XML);
SELECT SUBSTR(name,1,15) AS tabname,
SUBSTR(tsname,1,15) AS tsname,
type
FROM sysibm.systables
WHERE name LIKE '%CUST%' #
---------+---------+---------+---------+---TABNAME
TSNAME
TYPE
---------+---------+---------+---------+---CUSTOMER
CUSTOMER
T
XCUSTOMER
XCUS0000
P
XCUSTOMER000
XCUS0001
P
XCUSTOMER001
XCUS0002
P
DSNE610I NUMBER OF ROWS DISPLAYED IS 4
Figure 22.11
Table spaces for a table with three XML columns in DB2 for z/OS
Another useful way to retrieve information about a table and its related XML table spaces is
shown in Figure 22.12.
SELECT SUBSTR(X.xmltbowner, 1, 15) AS owner,
SUBSTR(X.xmltbname, 1, 20) AS name,
T.type, T.dbname, T.tsname
FROM SYSIBM.SYSTABLES T, SYSIBM.SYSXMLRELS X
WHERE X.tbname = 'CUSTOMER'
AND T.name = X.xmltbname
AND T.creator = X.xmltbowner ;
Figure 22.12
Listing XML table spaces in DB2 for z/OS
The catalog table SYSIBM.SYSTABLESPACE contains one row for every table space in the database. A row that represents an internal XML table space has the value P in the column TYPE, and
the value X in the column LOCKRULE (see Table 22.6).
Table 22.6
Columns TYPE and LOCKRULE in the table SYSIBM.SYSTABLESPACE
Column Name
Data Type
Description
TYPE
CHAR(1) NOT NULL
WITH DEFAULT
P—Implicit table space created for XML columns.
(…)
LOCKRULE
CHAR(1)
NOT NULL
Lock size of the table space:
A—Any
L—Large object (LOB)
P—Page
R—Row
S—Table space
T—Table
X—Implicitly created XML table space
22.2
XML-Related Catalog Information in DB2 for z/OS
22.2.2
671
Catalog Information for XML Indexes
The catalog table SYSIBM.SYSINDEXES contains one row for every index. The value V in the
column IX_EXTENSION_TYPE indicates a user-defined XML index while the value N identifies
DB2’s internal node ID index (see Table 22.7).
Table 22.7
Column IX_EXTENSION_TYPE in the table SYSIBM.SYSINDEXES
Column Name
Data Type
Description
IX_EXTENSION_TYPE
CHAR(1)
NOT NULL WITH
DEFAULT
Identifies the type of extended index
N—Node ID index
S—Index on a scalar expression
T—Spatial index
V—XML index
blank—Simple index
You can list all user-defined XML indexes with the query in Figure 22.13.
SELECT ixcreator, ixname, tbname
FROM sysibm.sysindexes
WHERE ix_extension_type = 'V'
Figure 22.13
Listing XML indexes in DB2 for z/OS
If you want to check which XML elements and attributes are indexed you need to examine the
XPath expressions that were used in the XMLPATTERN clause of your XML index definitions. The
XMLPATTERN of an XML index is listed in the column DERIVED_FROM of the catalog table
SYSIBM.SYSKEYTARGETS. In the same table, the column CARDF contains the number of distinct
documents that are indexed (see Table 22.8).
Table 22.8
Columns DERIVED_FROM and CARDF in the table SYSIBM.SYSKEYTARGETS
Column Name
Data Type
Description
DERIVED_FROM
VARCHAR(4000)
NOT NULL
For an XML index, this column contains the XML
pattern that generates the key values.
For an index on a scalar expression, this column
contains the text of the scalar expression that
generates the keys.
For any other indexes, this column is empty.
CARDF
FLOAT
NOT NULL
The number of distinct values for the key.
For a user-defined XML index, this value is collected
for the second key target (the DOCID). For all other
key targets of an XML index, the value is -2. The
value is also -2 if the index is an internal XML node
ID index.
672
Chapter 22
Exploring XML Information in the DB2 Catalog
The example in Figure 22.14 illustrates how the XMLPATTERN used in a CREATE INDEX statement can subsequently be retrieved from the catalog table SYSIBM.SYSKEYTARGETS. Note that
the table SYSKEYTARGETS can contain multiple rows for a given index, and only the row with
KEYSEQ=1 contains the XMLPATTERN. Similarly, the cardinality of the DOCIDs is listed in the
column CARDF where KEYSEQ=2.
CREATE INDEX cust_idx2 ON customer(info)
GENERATE KEYS USING XMLPATTERN '/customerinfo/phone'
AS SQL VARCHAR(50) #
SELECT
SUBSTR(IXNAME,1,10) AS ixname,
SUBSTR(DERIVED_FROM,1,22) AS xmlpattern,
SUBSTR(TYPENAME,1,10) AS typename,
LENGTH
FROM SYSIBM.SYSKEYTARGETS
WHERE IXNAME = 'CUST_IDX2' AND KEYSEQ=1 #
---------+---------+---------+---------+---------+---------+IXNAME
XMLPATTERN
TYPENAME
LENGTH
---------+---------+---------+---------+---------+---------+CUST_IDX2
/customerinfo/phone
VARCHAR
50
Figure 22.14
22.2.3
Obtaining the XMLPATTERN for an existing XML index
Catalog Information for XML Schemas
Table 22.9 provides a summary of the XML Schema Repository tables, which are new in DB2 9
for z/OS. They are explained in more detail in Chapter 16, Managing XML Schemas.
Table 22.9
XML Schema Repository Tables in DB2 for z/OS
Table Name
Description
SYSIBM.XSROBJECTS
Contains one row for each registered XML Schema.
Rows in this table can only be changed using
the DB2-supplied XSR stored procedures and
commands.
SYSIBM.XSROBJECTGRAMMAR
An auxiliary table for the BLOB column GRAMMAR in
SYSIBM.SYSXSROBJECTS. This table is in LOB table
space SYSXSRA1.
SYSIBM.XSROBJECTPROPERTY
An auxiliary table for the BLOB column PROPERTIES
in SYSIBM.SYSXSROBJECTS. This table is in LOB
table space SYSXSRA2.
22.3
Summary
Table 22.9
673
XML Schema Repository Tables in DB2 for z/OS (Continued)
Table Name
Description
SYSIBM.XSROBJECTCOMPONENTS
Contains one row for each component (schema document) of an XML Schema. Rows in this table can only
be changed using the DB2-supplied XSR stored procedures and commands.
SYSIBM.XSRCOMPONENT
Auxiliary table for the BLOB column COMPONENT in
SYSIBM.SYSXSROBJECTCOMPONENTS. This table is in
LOB table space SYSXSRA3.
SYSIBM.XSRPROPERTY
An auxiliary table for the BLOB column COMPONENT in
SYSIBM.SYSXSROBJECTCOMPONENTS. This table is in
LOB table space SYSXSRA3.
SYSIBM.XSROBJECTHIERARCHIES
Contains one row for each component (document) of an
XML Schema to record the XML Schema document
hierarchy.
22.3
SUMMARY
With the introduction of pureXML in DB2, several new types of database objects can exist in a
database. Depending on the platform, they can include XML columns, XML tables, XML table
spaces, XML Schemas, as well as user-defined and system-defined XML indexes. New catalog
tables have been introduced and existing catalog tables extended to store appropriate metadata
about these new objects. As a result, users can run catalog queries to learn about the existing
XML objects much like they normally do for relational objects.
This page intentionally left blank
C
H A P T E R
23
Test Your Knowledge—
The DB2 pureXML
Quiz
his chapter contains multiple choice questions based on the content of the book. You can
use these questions to test your knowledge and revisit specific topic areas. Each question
comes with four or five possible answers, (a) through (e). There is exactly one correct answer,
unless otherwise stated. The solutions are at the end of the chapter. Many questions apply to both
DB2 for z/OS and DB2 for Linux, UNIX, and Windows. Questions that are platform-specific
mention the applicable platform explicitly.
T
There is an official IBM pureXML Technical Mastery Test that you can take to certify your DB2
pureXML expertise. Further information on that test is available at http://www.ibm.com/
certify/mastery_tests/objM34.shtml.
The questions in this chapter are different from the questions in the mastery test, but cover many
of the same topics.
23.1
DESIGNING XML DATA AND APPLICATIONS
1.
Which of the elements shown is well-formed?
(a) <name title=Mr></name>
(b) <name title="Mr"><name>
(c) <name title="Mr"><name/>
(d) <name title=Mr><name/>
(e) <name title="Mr"></name>
675
676
Chapter 23
2.
Test Your Knowledge—The DB2 pureXML Quiz
When choosing the size and granularity of XML documents that you want to store in
DB2, which guideline is correct?
(a) Choose the XML document granularity with respect to the logical business
objects and the anticipated predominant granularity of access.
(b) Try to make the stored XML documents as large as possible.
(c) Choose the XML document granularity depending on the page size of the table.
(d) Try to keep all XML documents between 100KB and 1MB since smaller or
larger documents tend to yield lower performance.
(e) Try to make the stored XML documents as small as possible.
3.
When should you use elements or attributes in your XML documents?
(a) Always use XML elements because attributes are supported in XML only for
backward compatibility.
(b) Attributes are often better for non-Unicode values.
(c) There are no clear rules, but elements are more flexible. They can be repeated and
nested.
(d) Attributes are for numeric data only.
(e) Answers (b) and (c).
4.
You want to encode information about a product. The product is a blue jacket of size
42. Which of the following three XML formats is preferable?
Format 1
<product>
<Jacket>
<size>42</size>
<color>blue</color>
</Jacket>
</product>
Format 2
<product>
<type>Jacket</type>
<size>42</size>
<color>blue</color>
</product>
Format 3
<product>
<field name="type"
value="Jacket">
<field name="size"
value="42">
<field name="color"
value="blue">
</product>
(a) All three options are equally good.
(b) Format 1.
(c) Format 2.
(d) Format 3.
(e) Format 2 and Format 3 are the best options, and equally preferable.
23.2
Designing and Managing Storage Objects for XML
5.
677
What is the maximum XML document size that you can insert into or read from a DB2
table?
(a) Depends on the page size.
(b) 4KB.
(c) 2GB.
(d) 64KB.
(e) There is no upper size limit.
23.2
DESIGNING AND MANAGING STORAGE OBJECTS FOR XML
6.
What is the value of the title element in the following XML document?
<title>The <bold>DB2 pureXML</bold> Cookbook</title>
(a) The <bold>DB2 pureXML</bold> Cookbook
(b) <title>The <bold>DB2 pureXML</bold> Cookbook</title>
(c) The DB2 pureXML Cookbook
(d) TheDB2pureXMLCookbook
(e) The title element has no value as such—it is a construct.
7.
How do you create an XML column called info in a DB2 table?
(a) CREATE TABLE cust(info XML)
(b) CREATE TABLE cust(info XML_TYPE)
(c) CREATE TABLE cust(info XML AS CLOB)
(d) CREATE TABLE cust(info XML(n)) where n is the maximum length of the
documents.
(e) You cannot create an XML column directly. You need to create a table with a primary key column first (column name DOCID, data type BIGINT) and then use the
ALTER TABLE command to add an XML column.
8.
In DB2 for Linux, UNIX, and Windows, can you store XML columns in a separate
table space?
(a) No. XML columns are stored in the same table space as the rest of the table.
(b) Yes. The CREATE TABLE statement now has a clause XML IN <tablespace>.
(c) Yes. If the CREATE TABLE statement has the clause LONG in <tablespace>,
then XML is stored in the long table space.
(d) Yes. A new XML clause in the CREATE DATABASE statement allows for this.
(e) Yes—if the CREATE TABLESPACE statement has the clause ALLOW XML DATA.
678
Chapter 23
9.
Test Your Knowledge—The DB2 pureXML Quiz
In DB2 for z/OS, when a base table is created with an XML column, an additional
internal XML table is created automatically. How many columns does this internal
table have?
(a) 1
(b) 3
(c) 5
(d) As many columns as there are XML columns in the base table
(e) As many columns as there are total columns in the base table
10. In DB2 for z/OS, which page size is used for the internal XML table?
(a) The same page size as the base table space
(b) 8KB
(c) 32KB
(d) 16KB
(e) 128KB, which is a new page size in DB2 9 and used for XML data only
11. In DB2 for Linux, UNIX, and Windows, when is a Regions index created?
(a) Every time you create an index on an XML column.
(b) When you create more than one index on an XML column.
(c) When you create an index consisting of more than one element.
(d) One Regions index is created automatically for each XML column when a table
is created.
(e) One Regions index is created automatically for each table that contains one or
more XML columns.
12. In DB2 for Linux, UNIX, and Windows, what does base table row storage or inlining
mean?
(a) It means that all XML data is stored in a DMS table space regardless of what was
specified when the table space was created.
(b) It means that all XML data is stored in a SMS table space regardless of what was
specified when the table space was created.
(c) It means that all data in a specified table is copied into the bufferpool when the
database is activated. This table is defined as being inlined in the bufferpool.
(d) It means that XML documents are stored next to the relational data on pages of
the DAT object of the table space.
(e) It means that relational column values are stored within an XML document in the
same row.
23.2
Designing and Managing Storage Objects for XML
679
13. Which of the following statements are correct about DB2 for z/OS?
(a) Each internal XML table resides in a “partition by growth” (PBG) table space,
whenever the base table is simple, segmented, partitioned, or partitioned by
growth.
(b) An internal XML table is clustered by DOCID and MIN_NODEID.
(c) The DocID index and the NodeID indexes are always created as non-partitioned
indexes.
(d) An internal XML table space inherits the COMPRESS YES parameter from the
base table space.
(e) All of the above.
14. In DB2 for Linux, UNIX, and Windows, how do you reorganize XML data?
(a) You use the REORG utility in either “online” or “offline” mode.
(b) You can only use the REORG utility in “offline” mode and have to specify the keyword LONGLOBDATA in the REORG command.
(c) You can use the REORG utility in “online” mode but have to specify the keyword
INCLUDEXML in the REORG command.
(d) You do not need to reorganize the tables as the data is not relational and therefore
does not require reorganizing.
(e) There is a new utility called REORG_XML, which has been specifically introduced
to deal with XML data (as the structure of XML data is different from relational
data).
15. In DB2 9.7 for Linux, UNIX, and Windows, are XML columns allowed in range
partitioned tables and MDC tables?
(a) Yes in both
(b) Only in range partitioned tables
(c) Only in MDC tables
(d) Yes, but only in a partitioned database (DPF)
(e) No; not allowed in either
16. In DB2 for z/OS, the column DB2_GENERATED_DOCID_FOR_XML is automatically
created in each table with an XML column. How can you query this column?
(a) You can select from it just like any other column in the table.
(b) It is an internal column and you cannot select from it.
680
Chapter 23
Test Your Knowledge—The DB2 pureXML Quiz
(c) You cannot use SELECT * to view the contents of the column, but have to name
the column explicitly in the SELECT statement.
(d) You cannot select from the column, but have to use the UNLOAD utility to view the
contents.
(e) You can view the contents using the CHECKDATA utility.
17. In DB2 for z/OS, which are the new ZPARM parameters that allow you to limit the
amount of DB2 memory used for XML processing? Select two answers.
(a) MEMXMLA
(b) MEMXMLS
(c) XMLMEM
(d) XMLVALA
(e) XMLVALS
23.3
INSERTING AND RETRIEVING XML DATA
18. According to the XML standard, which of the following is NOT considered a whitespace character?
(a) space
(b) carriage return
(c) line feed
(d) tab
(e) backspace
19. Which of the following characters may not appear in an XML element value, unless
they are properly escaped? There are two correct answers.
(a) ampersand (&)
(b) question mark (?)
(c) the “at” sign (@)
(d) pound/hash sign (#)
(e) less-than symbol (<)
20. Which of the following statements about INSERT statements is NOT correct?
(a) You can insert XML documents into an XML column using parameter markers.
(b) You can insert XML documents into an XML column using host variables.
23.4
Moving XML Data
681
(c) You can insert XML documents only if their encoding is UTF-8.
(d) You can insert XML documents from a CLOB column into an XML column.
(e) You can insert XML documents and choose whether to strip or preserve
whitespace.
21. When you insert an XML document with an XML declaration, can there be whitespace preceding the XML declaration in the document (as shown in the following)?
INSERT INTO myshelf VALUES(10,'
<?xml version="1.0"?>…
(a) Yes, the spaces are ignored.
(b) No, the insert will fail.
(c) Yes, but only if you do not validate the document with an XML Schema.
(d) Yes, if the spaces are declared as a namespace.
(e) Yes, provided the DB2 registry variable CURRENT IMPLICIT XMLPARSE
OPTION is set to STRIP WHITESPACE.
23.4
MOVING XML DATA
22. Which of the following statements are correct about the LOAD utility in DB2 for z/OS?
There are two correct answers.
(a) The LOAD utility treats XML columns as variable-length data when loading XML
directly from input records, and expects a two-byte length field preceding the
actual XML value.
(b) By default, the LOAD utility preserves whitespace when loading XML data.
(c) XML documents that don’t fit into 32KB input records can be loaded from separate files.
(d) When loading XML data, you need to specify the name of the internal XML table
in the load job.
(e) The LOAD utility does not check whether the input documents are well-formed.
23. Which function can split a large XML document into smaller XML documents?
(a) XMLSPLIT
(b) XMLSERIALIZE
(c) XMLSHRED
(d) XMLTABLE
(e) SUBSTR
682
Chapter 23
Test Your Knowledge—The DB2 pureXML Quiz
24. The Export utility in DB2 for Linux, UNIX, and Windows supports which of the
following options for exporting XML data? There are two correct answers.
(a) Relational and XML columns of a table can be exported side by side into a single
data file.
(b) Exported XML documents can be written to individual files, with one file per
XML document.
(c) Exported XML documents can be concatenated to produce several large files,
with one file per output directory.
(d) If an XML column contains documents for multiple XML Schemas, the Export
utility can produce one data file per schema, with each file containing the
documents for a given schema.
(e) If an XML column contains documents that have been validated, the XML
Schemas for the exported documents can optionally be written to a separate file.
23.5
QUERYING XML
25. Which of the following statements is true?
(a) DB2 allows XPath expressions to be embedded in SQL, based on the SQL/XML
standard.
(b) DB2 allows XPath expressions to be embedded in SQL, using DB2 proprietary
functions.
(c) DB2 allows the use of XPath expressions only for XML documents that have
been successfully validated with an XML Schema.
(d) DB2 allows the use of XPath in SQL SELECT statements, but not in INSERT,
UPDATE, or DELETE statements.
(e) Both (a) and (d) are correct.
26. Why is the following type of query typically not useful?
SELECT XMLQUERY('$p/customerinfo/addr[pcode-zip = "95141"]'
PASSING info AS "p")
FROM customer
(a) It can never use an index to evaluate the predicate on pcode-zip.
(b) It returns as many result rows as there are rows in table customer.
(c) It returns empty rows for those documents where pcode-zip is not 95141.
(d) There is no predicate in a WHERE clause to allow filtering of rows.
(e) All of the above.
23.5
Querying XML
683
27. What does the following query return?
SELECT description
FROM product
WHERE XMLEXISTS('$p/product/id = 178'
PASSING description AS "p")
(a) Nothing. Zero rows are returned because the syntax of the predicate is invalid.
(b) All documents where the product id element in the XML column description
has the value 178.
(c) All documents described in (b), as well as empty rows for those XML documents
were product id is not 178.
(d) All documents from table product.
(e) NULL.
28. Consider the following XML document:
<customerinfo Cid="1099">
<name>Matt Foreman</name>
<addr type="Work">
<street>12 Short Lane</street>
<city>Toronto</city>
</addr>
<addr type="Home">
<street>1596 Baseline</street>
<city>Toronto</city>
</addr>
</customerinfo>
Which of the following XPath expressions returns <name>Matt Foreman</name>?
(1) /customerinfo[addr/city="Toronto"]/name
(2) /customerinfo[.//city="Toronto"]/name
(3) //addr[city="Toronto"]/../customerinfo/name
(4) /customerinfo/addr[/city="Toronto"]/../name
(5) //name[..//city="Toronto"]
(a) All of the above
(b) All of the above, except (3)
(c) (1), (2), and (4)
(d) (1), (2), and (5)
(e) (3) and (4)
684
Chapter 23
Test Your Knowledge—The DB2 pureXML Quiz
29. Assume the two documents shown below are stored in the XML column doc of table
tab. Which of the documents are returned by the query below?
Document A
<Test>
<A>
</A>
<A>
</A>
</Test>
<B>5</B>
<C>
</C>
<F>6</F>
Document B
<Test>
<A>
</A>
</Test>
<B>5</B>
<C>
<F>6</F>
</C>
SELECT doc
FROM tab
WHERE XMLEXISTS('$i/Test/A[B=5 and C/F=6]'
PASSING doc AS "i")
(a) Document A
(b) Document B
(c) Both documents
(d) Neither document
30. Which of the following are valid functions in DB2 for Linux, UNIX, and Windows?
There are two correct answers.
(a) db2-fn:xmlcolumn
(b) db2-fn:sqlquery
(c) db2-fn:columnxml
(d) db2-fn:xmldocument
(e) db2-fn:sqlxml
31. Which of the following are not XQuery keywords? There are two correct answers.
(a) for
(b) let
(c) when
(d) order by
(e) result
23.5
Querying XML
685
32. What happens if you run the following query against an XML document where the
value of the XML element pcode-zip is the string “NE1 XQ7”?
SELECT info
FROM customer
WHERE XMLEXISTS('$INFO/customerinfo/addr[pcode-zip = 95141]')
(a) No data is returned from the document. The query succeeds but returns zero
rows.
(b) The document is selected and returned.
(c) The query is rejected at compile time due to a data type mismatch in the
predicate.
(d) The query fails at runtime when it tries to compare the string value of the pcodezip element to the numeric value 95141.
(e) All of the above can happen, depending on the XML Schema being used.
33. Consider the following table, queries, and results. If you run both queries, what results
will you get back?
Table tab
mycol (XML)
<a>
<b> 1 </b>
<b> 2 </b>
</a>
<a>
<b> 3 </b>
<b> 4 </b>
</a>
Query A:
XQUERY
for $i in db2-fn:xmlcolumn("TAB.MYCOL")/a/b
return $i
Query B:
SELECT XMLQUERY('$col/a/b' PASSING tab.mycol AS "col" )
FROM tab
686
Chapter 23
Result Set 1
<b> 1 </b>
<b> 2 </b>
<b> 3 </b>
<b> 4 </b>
Test Your Knowledge—The DB2 pureXML Quiz
Result Set 2
<b> 1 </b><b> 2 </b>
<b> 3 </b><b> 4 </b>
(a) Both queries return results set 1 (four rows).
(b) Both queries return results set 2 (two rows).
(c) Query A returns result set 1, query B result set 2.
(d) Query A returns result set 2, query B result set 1.
(e) Both queries return nothing (because no namespace is specified).
23.6
PRODUCING XML FROM RELATIONAL DATA
34. You can use the XMLFOREST function as an abbreviation for which function?
(a) XMLATTRIBUTES
(b) XMLCONCAT
(c) XMLAGG
(d) XMLCOMMENT
(e) XMLELEMENT
35. Which function supersedes the function XML2CLOB, which was introduced in DB2 V8
to convert constructed XML data from type XML to type CLOB?
(a) XMLDOCUMENT
(b) XMLCOMMENT
(c) XMLSERIALIZE
(d) XMLTEXT
(e) XML2CHAR
36. Which SQL/XML function can have an optional ORDER BY clause?
(a) XMLATTRIBUTES
(b) XMLCONCAT
(c) XMLAGG
(d) XMLFOREST
(e) XMLELEMENT
23.7
Converting XML to Relational Data
687
37. Assume that pid and name are relational columns in a table. Which of the following is
correct usage of XQuery direct element and attribute constructors to construct an element with an attribute?
(a) <product pid={$PID}>{$NAME}</product>
(b) <product pid="{$pid}">{$name}</product>
(c) <product pid="$pid">$name</product>
(d) <product pid={"$PID"}>{$NAME}</product>
(e) <product pid="{$PID}">{$NAME}</product>
23.7
CONVERTING XML TO RELATIONAL DATA
38. Which statement about shredding is NOT true?
(a) You can perform transformations of the data values before insert into relational
columns.
(b) You can shred the same element or attribute value into at most one column.
(c) You can shred multiple different elements or attributes into the same column of a
table.
(d) You can specify conditions that govern when certain elements are or are not
shredded.
(e) You can validate XML documents with an XML Schema during shredding.
39. Which SQL/XML function(s) can you use to shred XML into relational data?
(a) DECOMP_XML
(b) XMLSHRED
(c) XMLDECOMP
(d) XMLTABLE
(e) Both (b) and (d)
40. When you annotate an XML Schema for shredding, what is the purpose of the
annotation db2-xdb:normalization?
(a) It ensures that relational target tables are fully normalized before shredding.
(b) It converts all XML values to data type xs:string before insertion into relational tables.
(c) It specifies how to treat whitespaces in the XML documents that are shredded.
(d) It converts XML fragments to canonical XML format.
(e) It converts all XML attributes to elements before shredding.
688
Chapter 23
Test Your Knowledge—The DB2 pureXML Quiz
41. Which schema annotation do you use to define multiple mappings for the same XML
element or attribute?
(a) db2-xdb:multimap
(b) db2-xdb:contentHandling
(c) db2-xdb:expression
(d) db2-xdb:rowSetMapping
(e) db2-xdb:condition
42. Can you create a relational view over XML data?
(a) Yes
(b) No
(c) Yes, provided that the XML data has been validated
(d) Yes, but the view has to be written in XQuery
(e) Yes, but only with the XML View Wizard in IBM Data Studio Developer
23.8
UPDATING AND TRANSFORMING XML DOCUMENTS
43. In DB2 for Linux, UNIX, and Windows, which two keywords are not valid in an
XQuery transform expression? There are two correct answers.
(a) copy
(b) remove
(c) return
(d) modify
(e) append
44. Consider this XML document:
<alpha x="1"><beta>2</beta></alpha>
What will this document look like when a new node is inserted with the following
insert operation?
23.8
Updating and Transforming XML Documents
689
insert attribute y {3} after $new/alpha/beta
(a) <alpha x="1" y="3"><beta>2</beta></alpha>.
(b) <alpha y="3" x="1"><beta>2</beta></alpha>.
(c) <alpha x="1"><beta y="3">2</beta></alpha>.
(d) <alpha x="1"><beta>2</beta><y>3</y></alpha>.
(e) Both (a) and (b) are possible since the ordering of attributes does not matter.
45. What is the return type of the function XSLTRANSFORM?
(a) CLOB(2G)
(b) BLOB(2G)
(c) XML
(d) VARCHAR(32000)
(e) INTEGER (either 0 or 1, depending on the success of the transformation)
23.9
DEFINING AND USING XML INDEXES
46. When you create an XML index in DB2 for Linux, UNIX, and Windows, which of the
following SQL types is not a valid index type?
(a) VARCHAR HASHED
(b) DOUBLE
(c) INTEGER
(d) DATE
(e) TIMESTAMP
47. In DB2 for z/OS, which data type do you use to define an XML index for numeric
data?
(a) DOUBLE
(b) DECFLOAT
(c) FLOAT
(d) REAL
(e) DECIMAL
690
Chapter 23
Test Your Knowledge—The DB2 pureXML Quiz
48. An XML index is defined as ‘/product/name’ AS VARCHAR(40). What happens
when you insert a document with a product name larger then 40 bytes?
(a) This product name will be indexed by a hash value.
(b) The insert succeeds but there will be no index entry for this document. A warning
is issued.
(c) The insert succeeds but there will be no index entry for this document. No warning is issued.
(d) The insert fails with an error and the document is rejected.
(e) The insert succeeds, and the first 40 bytes of the product name are used as the
index key (lookup in a VARCHAR index is by prefix anyway).
49. If you define an XML index on /product/pid as data type DOUBLE or DECFLOAT,
what is the default behavior if you insert a document with a product id of PX25?
(a) This product pid will be indexed by a hash value.
(b) The insert succeeds but there will be no index entry for this document. A warning
is issued.
(c) The insert succeeds but there will be no index entry for this document. No warning is issued.
(d) The insert fails with an error and the document is rejected.
(e) It depends on whether the document was validated, and on the schema type for
/product/pid.
50. Which index is eligible to evaluate the following query?
SELECT XMLQUERY('$i/customerinfo/name'
PASSING info AS "i")
FROM customer
WHERE XMLEXISTS('$i/customerinfo[@Cid < "1005"]'
PASSING info AS "i")
CREATE INDEX idx1 ON customer(info) GENERATE KEY USING…
(a) XMLPATTERN '/customerinfo/@Cid' AS SQL DECFLOAT
(b) XMLPATTERN '//@Cid' AS SQL VARCHAR(8)
(c) XMLPATTERN '/customerinfo/@Cid' AS SQL VARCHAR HASHED
(d) All of the above
(e) Answers (b) and (c)
23.9
Defining and Using XML Indexes
691
51. Consider the following table and indexes:
CREATE TABLE tab(doc XML)
CREATE INDEX idx1 ON tab(doc)
GENERATE KEY USING XMLPATTERN '/product/id' AS SQL DECFLOAT
CREATE INDEX idx2 ON tab(doc)
GENERATE KEY USING XMLPATTERN '/product/name' AS SQL
VARCHAR(40)
Which of the two indexes can DB2 use to evaluate the following query?
SELECT doc
FROM tab
WHERE XMLEXISTS('$p/product[id = 178] and
$p/product[name = "T42p"]'
PASSING doc AS "p")
(a) None, because a Boolean expression in XMLEXISTS never returns an empty
sequence.
(b) Only idx1.
(c) Only idx2.
(d) Both.
(e) Both, but only if the document has been validated against a schema.
52. Given the query and the indexes shown in the following, which indexes can the query use?
SELECT XMLQUERY('$i/book[@id = 101]/title'
PASSING bookinfo AS "i")
FROM books
CREATE INDEX idx1 ON books(bookinfo)
GENERATE KEY USING XMLPATTERN '/book/title' AS SQL VARCHAR(50)
CREATE INDEX idx2 ON books(bookinfo)
GENERATE KEY USING XMLPATTERN '/book/@id' AS SQL DOUBLE
(a) idx1.
(b) idx2.
692
Chapter 23
Test Your Knowledge—The DB2 pureXML Quiz
(c) Neither, because XML predicates in the XMLQUERY function in the SELECT
clause do not eliminate any rows from the result set and therefore cannot use an
index.
(d) Both idx1 and idx2.
(e) Both, but only if the document has been validated.
23.10
XML PERFORMANCE AND MONITORING
53. In DB2 for Linux, UNIX, and Windows, what are the three access plan operators for
XML processing? There are three correct answers.
(a) XMLSCAN
(b) XISCAN
(c) XSCAN
(d) XJOIN
(e) XANDOR
54. In DB2 for z/OS there are four new access plan operators for XML processing. Which
of the following is NOT one of them?
(a) XIXSCAN
(b) XSCAN
(c) XIXOR
(d) DIXSCAN
(e) XIXAND
55. Does the RUNSTATS command collect statistics for XML columns?
(a) No.
(b) Yes. However, the optimizer does not yet use these statistics.
(c) Yes, but only for XML data that has been validated against XML Schemas.
(d) Yes. The RUNSTATS command collects statistics for XML data, but not for XML
indexes.
(e) Yes. The RUNSTATS command collects statistics for XML data and for XML
indexes.
23.10
XML Performance and Monitoring
693
56. In DB2 for Linux, UNIX, and Windows, what is XANDOR?
(a) A Boolean operator in the XQuery language standard.
(b) A new query operator that is only used for joins between relational and XML
data.
(c) An SQL/XML function to express XQuery joins.
(d) A new query operator over XML indexes, used if the query has two or more
equality predicates.
(e) A built-in function for XML parsing.
57. In DB2 for Linux, UNIX, and Windows, what does the XSCAN operator do?
(a) XSCAN is the same as TBSCAN, but for XML data.
(b) XSCAN, or cross-scan, is used to compute a join between two XML documents.
(c) XSCAN navigates XML documents, evaluates predicates, and extracts XML
pieces if needed.
(d) XSCAN scans an XML index to evaluate a predicate.
(e) XSCAN scans an XML document and shreds it into relational tables.
58. In DB2 for z/OS, what is DIXSCAN?
(a) Access to an XML index of type DECFLOAT.
(b) XML index access that returns the DOCID and NODEID pairs for a given key
value.
(c) Directed access to an XML index that was not defined with ALLOW REVERSE
SCANS.
(d) It represents a scan of XML documents.
(e) An operator for DOCID index access that returns a RID for a given DOCID.
23.11
MANAGING XML DATA WITH NAMESPACES
59. In XML documents, XML namespaces are declared with which reserved attribute?
(a) xmlnamespace
(b) declare
(c) nsxml
(d) default
(e) xmlns
694
Chapter 23
Test Your Knowledge—The DB2 pureXML Quiz
60. Which of the following is an invalid URI?
(a) http://www.DB2pureXMLCookbook.org/
(b) ftp://ftp.is.co.za/rfc/rfc3986.txt
(c) urn:xmlns:bogus:partner1.0
(d) telnet://192.0.2.16:80/
(e) http://www.DB2 pureXML Cookbook.org/
61. Which statement about default namespaces is correct?
(a) A default namespace always applies to all XML elements, regardless of actual
namespace declarations in an XML document.
(b) The default namespace does not assign a namespace prefix to a URI.
(c) There can be at most one default namespace in an XML document.
(d) A default namespace guarantees that all elements and attributes in a document
are in the same namespace, even if some elements have prefixes.
(e) A default namespace only applies if documents have been validated against an
XML Schema that defines the default namespace.
62. Consider the following XML document:
<p:product
xmlns:p="http://myuri"><p:name>p595<p:name></p:product>
How can you declare a namespace in an XML query to retrieve information from this
document?
(a) declare namespace xyz="http://myuri"
(b) declare default namespace "http://myuri"
(c) declare default element namespace "http://myuri"
(d) declare namespace p="http://anyuri"
(e) Both (a) and (c) are correct.
23.12
XML SCHEMAS AND VALIDATION
63. Do you need an XML Schema to store XML documents in a DB2 XML column?
(a) Yes, so that DB2 knows how to store the XML documents efficiently.
(b) No. XML Schemas are optional.
(c) Only if you want to use XQuery on your XML data.
(d) No, but there will be no query optimization without a schema.
(e) Both (b) and (d) are correct.
23.12
XML Schemas and Validation
695
64. Is a valid document always also a well-formed document?
(a) Always
(b) Never
(c) Depends on the contents of the XML Schema
(d) Depends on the contents of the XML document
(e) Depends on the setting of the DB2 registry variable DB2_VALID_XML
65. An XML Schema can consist of how many separate schema documents?
(a) There can only be 1 schema document per XML Schema.
(b) At most two: a primary and a secondary schema document.
(c) 32.
(d) 256.
(e) An XML Schema can consist of an arbitrary number of schema documents.
66. Which command do you use to add an XML Schema to the XML Schema Repository?
(a) REGISTER XSROBJECT
(b) INSERT XMLSCHEMA
(c) ADD XMLSCHEMA
(d) REGISTER XMLSCHEMA
(e) CREATE XMLSCHEMA
67. In DB2 for z/OS, which of the following is true about the relational schema name in
the SQL identifier of an XML Schema?
(a) It has to be either omitted or be the value SYSIBM.
(b) It can be the name of any defined schema in DB2.
(c) It can be any name you have previously registered in the XML Schema Repository.
(d) It has to be either omitted or be the value SYSXSR.
(e) It has to be the user id of the user performing the registration.
68. Is it possible to store XML documents for multiple XML Schemas in the same XML
column?
(a) Yes, but only if the documents are inserted without validation.
(b) Yes, but only if the documents are inserted with validation.
(c) Yes, regardless of validation.
(d) No, documents for different XML schemas have to be stored in separate XML
columns.
(e) Only if the different XML Schemas are backwards compatible.
696
Chapter 23
Test Your Knowledge—The DB2 pureXML Quiz
69. What do the functions XMLVALIDATE and DSN_XMLVALIDATE return if an XML document is valid against the specified XML schema?
(a) 0
(b) 1
(c) true
(d) The DOCID of the document
(e) The document itself
70. What do the functions XMLVALIDATE and DSN_XMLVALIDATE return if an XML
document is NOT valid against the specified XML schema?
(a) 0
(b) –1
(c) false
(d) An error
(e) A warning
23.13
PERFORMING FULL-TEXT SEARCH
71. If you want to issue DB2 Net Search Extender commands, you need to prefix them
with which of the following?
(a) db2nse
(b) db2ns
(c) db2txt
(d) db2text
(e) db2ts
72. Which of the following is true about the CREATE INDEX command in Net Search
Extender indexes?
(a) As soon as the command completes any query can use the index.
(b) In the CREATE INDEX command you can specify whether the index will be maintained synchronously or asynchronously.
(c) The CREATE INDEX command builds the index in the location defined by the
DB2 registry variable DB2_NSE_PATH.
(d) The CREATE INDEX command can be issued in the DB2 Command Line Processor or via JDBC calls.
(e) After the CREATE INDEX command you need to issue the UPDATE INDEX command before queries can use the index.
23.13
Performing Full-Text Search
697
73. Can you enable the DB2 Net Search Extender and DB2 Text Search in the same database?
(a) Yes
(b) No
(c) Depends on the DB2 registry setting DB2_DUAL_TEXT_SEARCH
(d) Yes, but a search query can only use one or the other, not both at the same time
(e) Yes, but only in UNICODE databases
74. When you use DB2 Text Search, how many text indexes are allowed per column?
(a) 64
(b) 1
(c) As many as you like (within storage limits)
(d) Depends on the text search parameter DB2TS_MAX_INDEXES
(e) 2—one for values and one for structural information
23.14
XML APPLICATION DEVELOPMENT
75. Which of the following statements is correct?
(a) DB2 pureXML allows you to reduce or completely avoid XML parsing in your
application and reduces application complexity.
(b) DB2 pureXML allows you to reduce or completely avoid XML parsing in your
application at the price of greater coding complexity.
(c) DB2 pureXML allows you to reduce your application complexity by introducing
additional XML parsing in the application layer.
(d) DB2 pureXML improves application performance because it never performs
XML parsing.
(e) DB2 pureXML applications manipulate XML data in the same way as an application that stores XML in CLOB columns.
76. In which language can you NOT use host variables of type XML?
(a) C , C++
(b) COBOL
(c) PL/1
(d) Fortran
(e) Assembler
698
Chapter 23
Test Your Knowledge—The DB2 pureXML Quiz
77. JDBC 4.0 introduces a new application data type to handle XML data. What is the
name of this data type?
(a) XML
(b) SQLXML
(c) XMLDOCUMENT
(d) XMLFILE
(e) DOM
78. In DB2 for Linux, UNIX, and Windows, you can use the XML data type for which of
the following? There are two correct answers.
(a) Parameters in SQL stored procedures, but not for variables
(b) Parameters and variables in SQL stored procedures
(c) Parameters and variables in SQL user-defined functions, but not as a return type
(d) Parameters, variables, and return type of SQL user-defined functions
(e) Parameters and variables in SQL user-defined scalar or table functions, and
return type of SQL user-defined scalar functions, but not as return type of a table
function
79. What is the internal encoding of an XML document?
(a) The internal encoding is always UTF-8.
(b) The internal encoding is always UTF-16.
(c) The internal encoding is the same as the application code page when XML data is
held in character type variable in the application.
(d) The internal encoding is the same as the database codepage.
(e) The internal encoding is determined by a Unicode Byte-Order Mark or an XML
declaration with encoding attribute.
23.14
XML Application Development
699
80. Which statements are true about an XML declaration such as the following? There are
two correct answers.
<?xml version="1.0" encoding="UTF-8" ?>
(a) The XML declaration is optional and not required for an XML document to be
well-formed.
(b) An XML declaration must always contain an encoding attribute.
(c) An XML declaration is not stored as part of a document, but can be generated
when XML data is retrieved by an application.
(d) The XML declaration of a document must match the XML declaration of its
XML Schema.
(e) The XML declaration must be a separate line at the beginning of the document;
that is, it must end with a new-line character.
81. Which DB2-specific JDBC methods allow you to specify a target encoding for the
XML data you retrieve from DB2? There are two correct answers.
(a) DB2Xml.getDB2XmlBinaryStream()
(b) DB2Xml.getDB2XmlCharacterStream()
(c) DB2Xml.getDB2BinaryStream()
(d) DB2Xml.getDB2CharacterStream()
(e) DB2Xml.getDB2XmlBytes()
82. Which of the following is a valid declaration of an XML host variable?
(a) SQL TYPE IS XML AS CLOB(n) <hostvar_name>
(b) SQL TYPE IS XML AS BLOB(n) <hostvar_name>
(c) SQL TYPE IS XML AS CLOB_FILE <hostvar_name>
(d) SQL TYPE IS XML AS DBCLOB_FILE <hostvar_name>
(e) All of the above
700
23.15
Chapter 23
Test Your Knowledge—The DB2 pureXML Quiz
ANSWERS
Question Answer
Chapter/Section in this Book with Further Information
1
(e)
1.1, Anatomy of an XML Document
2
(a)
2.3, Choosing the Right Document Granularity
3
(c)
2.1, Choosing Between XML Elements and XML Attributes
4
(c)
2.2, XML Tags Versus Values
5
(c)
3.3.1, Storage Objects for XML Data
6
(c)
3.1, Understanding XML Document Trees
7
(a)
3.3.2, Defining Columns, Tables, and Table Spaces for XML Data
8
(c)
3.3.2, Defining Columns, Tables, and Table Spaces for XML Data
9
(b)
3.11, XML Storage in DB2 for z/OS
10
(d)
3.11, XML Storage in DB2 for z/OS
11
(e)
3.3.1, Storage Objects for XML Data
12
(d)
3.4, Using XML Base Table Row Storage (Inlining)
13
(e)
3.11, XML Storage in DB2 for z/OS
14
(b)
3.7, Reorganizing XML Data and Indexes
15
(a)
3.9, XML in Range-Partitioned Tables and MDC Tables
16
(b)
3.11, XML Storage in DB2 for z/OS
17
(d)(e)
3.11, XML Storage in DB2 for z/OS
18
(e)
4.7, Understanding XML Whitespace and Document Storage
19
(a)(e)
4.6, Dealing with XML Special Characters
20
(c)
4, Inserting and Retrieving XML Data and 20, Understanding XML Data
Encoding
21
(b)
4.7.1, Preserving XML Whitespace
22
(a)(c)
5.5, Loading XML Data in DB2 for z/OS
23
(d)
5.7, Splitting Large XML Documents into Smaller Documents
24
(b)(c)
5.1, Exporting XML Data in DB2 for Linux, UNIX, and Windows
25
(a)
6.5, How to Execute XPath in DB2
26
(e)
7, Querying XML Data with SQL/XML
27
(d)
7.5, Common Mistakes with SQL/XML Predicates
23.15
Answers
701
Question Answer
Chapter/Section in this Book with Further Information
28
(d)
6.7, XPath Predicates
29
(b)
7, Querying XML Data with SQL/XML
30
(a)(b)
6.5, How to Execute XPath in DB2
31
(c)(e)
8.1, XQuery Overview
32
(d)
6.14, General and Value Comparisons
33
(c)
7, Querying XML Data with SQL/XML
34
(e)
10.1, SQL/XML Publishing Functions
35
(c)
10.1.12, Legacy Functions
36
(c)
10.1, SQL/XML Publishing Functions
37
(e)
10.2, Using XQuery Constructors with Relational Input
38
(b)
11, Converting XML to Relational Data
39
(d)
11.2, Shredding with the XMLTABLE Function
40
(c)
11.3, Shredding with Annotated XML Schemas
41
(d)
11.3, Shredding with Annotated XML Schemas
42
(a)
11.2.2, Relational Views over XML Data
43
(b)(e)
12.2, Modifying Documents with XQuery Updates
44
(e)
12.7, Inserting XML Nodes into a Document
45
(a)
12.14, Transforming XML Documents with XSLT
46
(c)
13.1, Defining XML Indexes
47
(b)
13.2, XML Index Data Types
48
(d)
13.2, XML Index Data Types
49
(c)
13.2, XML Index Data Types
50
(b)
13.2, XML Index Data Types
51
(a)
13, Defining and Using XML Indexes
52
(c)
13.6.1, Special Cases with XMLQUERY
53
(b), (c), (e)
14.1.4, Access Plan Operators
54
(b)
14.1.4, Access Plan Operators
55
(e)
14.3, Statistics Collection for XML Data
702
Chapter 23
Test Your Knowledge—The DB2 pureXML Quiz
Question Answer
Chapter/Section in this Book with Further Information
56
(d)
14.1.4, Access Plan Operators
57
(c)
14.1.4, Access Plan Operators
58
(e)
14.1.4, Access Plan Operators
59
(e)
15.1.1, Namespace Declarations in XML Documents
60
(e)
15.1, Introduction to XML Namespaces
61
(b)
15.1.2, Default Namespaces
62
(e)
15.3, Querying XML Data with Namespaces
63
(b)
16.1, Introduction to XML Schemas and Their Usage
64
(a)
16.1.1, Valid Versus Well-Formed XML Documents
65
(e)
16.1.1, Valid Versus Well-Formed XML Documents
66
(d)
16.4, Registering XML Schemas
67
(d)
16.4.1, Registering XML Schemas in the DB2 Command Line Processor
68
(c)
17, Validating XML Documents against XML Schemas
69
(e)
17, Validating XML Documents against XML Schemas
70
(d)
17, Validating XML Documents against XML Schemas
71
(d)
19, Performing Full-Text Search
72
(b)
19.4, Managing Full-Text Indexes with the DB2 Net Search Extender
73
(b)
19, Performing Full-Text Search
74
(b)
19.6.2, Creating and Maintaining Full-Text Indexes for DB2 Text Search
75
(a)
21, Developing XML Applications with DB2
76
(d)
21, Developing XML Applications with DB2
77
(b)
21, Developing XML Applications with DB2
78
(b) (d)
18, Using XML in Stored Procedures, UDFs, and Triggers
79
(e)
20.1, Understanding Internal and External XML Encoding
80
(a)(c)
20.1, Understanding Internal and External XML Encoding
81
(a)
21, Developing XML Applications with DB2
82
(e)
21, Developing XML Applications with DB2
A
P P E N D I X
A
Getting Started with
DB2 pureXML
his appendix explains how to explore XML data in DB2 and how to run basic commands in
the DB2 Command Line Processor (CLP) and SPUFI. Note that the CLP is not only available for DB2 for Linux, UNIX, and Windows but also for DB2 for z/OS as an application that
requires Unix System Services.
T
A.1
EXPLORING THE STRUCTURE OF XML DOCUMENTS
Before you can start writing XML queries or updates you need to know the structure of the XML
documents. A good approach is to look at one or several representative sample documents. You
can use the DB2 Control Center, IBM Data Studio, or commands issued in the CLP or SPUFI to
view the structure of XML documents.
A.1.1
Exploring XML Documents in the DB2 Control Center
Figure A.1 shows the DB2 Control Center view of the first XML document in the info column
of the customer table. The Source View and Tree View tabs let you switch between a textual
and a hierarchical view of the XML document.
703
704
Appendix A
Figure A.1
Getting Started with DB2 pureXML
Viewing XML documents in the DB2 Control Center
Similar capabilities for exploring XML documents are available in IBM Data Studio Developer.
For details and screenshot see section 21.9.1.
A.1.2
Exploring XML Documents in the CLP
To explore XML data in a command-line interface, issue a query that selects one or several rows
from an XML column, as shown in Figure A.2. The FETCH FIRST 1 ROWS ONLY option can be
used to conveniently limit the output. The SQL statement in Figure A.2 can be issued from the
CLP or from SPUFI. Unless you explicitly request DB2 to preserve whitespace, XML documents
are stored without line breaks. Hence, each XML document that you retrieve can be a single
wrapping line.
SELECT info
FROM customer FETCH FIRST 1 ROWS ONLY;
<customerinfo Cid="1000"><name>Kathy Smith</name><addr country="
Canada"><street>5 Rosewood</street><city>Toronto</city><prov-sta
te>Ontario</prov-state><pcode-zip>M6W 1E6</pcode-zip></addr><pho
ne type="work">416-555-1358</phone></customerinfo>
Let’s add line breaks and indentation to the above to make it easier to read:
Figure A.2
Selecting one XML document from a table
A.1
Exploring the Structure of XML Documents
705
<customerinfo Cid="1000">
<name>Kathy Smith</name>
<addr country="Canada">
<street>5 Rosewood</street>
<city>Toronto</city>
<prov-state>Ontario</prov-state>
<pcode-zip>M6W 1E6</pcode-zip>
</addr>
<phone type="work">416-555-1358</phone>
</customerinfo>
Figure A.2
Selecting one XML document from a table (continued)
You can see that the root element is customerinfo and has an attribute called Cid. The child
elements of customerinfo are the name, addr, and phone elements. Under the addr element
are the street, city, prov-state, and pcode-zip elements. The phone element has an
attribute called type.
A.1.3
Exploring XML Documents in SPUFI
For DB2 for z/OS you might prefer to use SPUFI rather than the CLP. If you use SPUFI to
retrieve and examine XML documents you might need to change the MAX CHAR FIELD setting in
the SPUFI defaults panel to be larger than the character length of the XML document. In Figure
A.3 the value has been set to 2000. (In this figure, the right side of the SPUFI output has been
truncated to fit the page.)
Output format characteristics:
14 MAX NUMERIC FIELD ===> 33
15 MAX CHAR FIELD .. ===> 2000
16 COLUMN HEADING .. ===> NAMES
Figure A.3
(Maximum width for numeric fi
(Maximum width for character
(NAMES, LABELS, ANY or BOTH)
Changing the SPUFI settings for MAX CHAR FIELD
XML and XPath are case-sensitive, so you need to ensure that CAPS are turned off. Also ensure
that the terminal session CCSID setting is consistent with the application encoding scheme,
because “[” and “]” have different code points in different code pages. If the CCSID settings are
not consistent, then the query in Figure A.4 fails with error SQLCODE 16002.
SELECT cid, info
FROM customer
WHERE XMLEXISTS('$i/customerinfo/addr[city="Toronto"]'
PASSING info AS "i")
Figure A.4
Sample query on DB2 for z/OS
706
A.2
Appendix A
Getting Started with DB2 pureXML
TIPS FOR RUNNING XML OPERATIONS IN THE CLP
The Command Line Processor (CLP) in DB2 for Linux, UNIX, and Windows offers various
options that are useful when you run XQuery, SQL/XML, or INSERT and UPDATE statements
with XML data. These options are listed in Table A.1.
Table A.1
CLP Options That Are Useful for XML
Option
Purpose
-i
Displays the XML results produced by an XQuery with indentation and line breaks for
better readability (pretty print). Without this option, XML data is returned as a continuous
string without line breaks. This option only works for XQuery, not for SQL/XML.
-d
Generates an XML declaration at the beginning of every XML document or XML value
that is returned. Without -d, XML declarations are omitted.
-q
Preserves all whitespace in any command that is executed. Without the -q option, the DB2
CLP strips newline characters before sending your command to the DB2 server. This
option matters when you insert XML documents through the CLP and want to preserve
whitespace (see Chapter 4 for details).
-td#
The -td option defines a character as the statement terminator. In this case the statement
termination character is set to #. If just the -t option is used, the default statement termination character is the semicolon (;), which can conflict with namespace declarations or
statements in CREATE PROCEDURE, CREATE FUNCTION, or CREATE TRIGGER
statements.
Here are three examples of invoking the CLP from an operating system prompt:
• db2 -i -t invokes the CLP with pretty print for XQuery results and using the semicolon as the statement terminator.
• db2 -d -td% invokes the CLP with the percent sign as the statement terminator and
enables XML declarations in XML query results.
• db2 -q -i -td# invokes the CLP with whitespace preservation, pretty print for
XQuery results, and the # character as the statement terminator.
On Windows, the CLP needs to be invoked from an operating system prompt in a DB2 command
window.
In Figure A.5, a CLP session is invoked with db2 -i -td#. Since a termination character is
used, you can enter multiline commands at the db2=> prompt. For example, you can cut and
paste a multiline statement from a text file into the CLP. To complete and submit the command,
type the termination character, which is # in the example in Figure A.5, and press Enter.
A.1
Exploring the Structure of XML Documents
Figure A.5
Using the DB2 CLP with a non-default termination character
Figure A.6 shows how output of the command in Figure A.5 is returned with pretty print:
<customerinfo Cid="1002">
<name>
Jim Noodle
</name>
<addr country="Canada">
<street>
25 EastCreek
</street>
<city>
Markham
</city>
<prov-state>
Ontario
</prov-state>
<pcode-zip>
N9C 3T6
</pcode-zip>
</addr>
<phone type="work">
905-555-7258
</phone>
</customerinfo>
1 record(s) selected.
Figure A.6
CLP output from an XQuery when the -i option is used
707
708
Appendix A
Getting Started with DB2 pureXML
Note that the CLP returns XML data as a 4KB character column. Documents larger than 4KB are
truncated. Use the DB2 EXPORT command if you want to retrieve full documents larger than 4KB
through the CLP (see Chapter 5, Moving XML Data).
If you have DB2 commands or SQL statements in a text file, you can execute these commands
and statements by providing the text file as an input parameter to the CLP (-f). Figure A.7 shows
two examples. The first line executes the commands in the file Q2.txt and assumes that each
statement in the file is terminated with the semicolon as the default termination character (-t).
The -v option produces verbose output. The second line executes the commands in the file
Q3.sql and expects these commands to end with the # character.
db2 -t -v -f Q2.txt
db2 -td# -f Q3.sql
Figure A.7
Executing the commands in the files Q2.txt and Q3.sql
A
P P E N D I X
B
The XML Sample
Database
hroughout this book we often use the XML sample database that comes with DB2 for
Linux, UNIX, and Windows. This appendix describes how to create the sample database,
shows some of its content, and explains how to set up sample tables in DB2 for z/OS.
T
B.1
XML SAMPLE DATABASE ON DB2 FOR LINUX, UNIX, AND WINDOWS
Issue the following command at the OS prompt to create the sample database with the database
name samplxml:
db2sampl -name sampxml -xml
Without the -name option the default database name is sample. The -xml flag is required to create tables with XML data in the sample database. The relational database schema used for these
tables is the user ID of the person who issued the db2sampl command.
In the examples in this book we use the tables customer, purchaseorder, and product. The
columns in these tables are shown in Table B.1. The XML column history in the customer
table does not contain any data when the sample database is initially created.
709
710
Appendix B
Table B.1
The XML Sample Database
Sample Database Tables on DB2 for Linux, UNIX, and Windows
Table Name
Column Name
Column Type
CUSTOMER
CID
INFO
HISTORY
BIGINT
XML
XML
PURCHASEORDER
POID
STATUS
CUSTID
ORDERDATE
PORDER
COMMENTS
BIGINT
VARCHAR(10)
BIGINT
DATE
XML
VARCHAR(1000)
PRODUCT
PID
NAME
PRICE
PROMOPRICE
PROMOSTART
PROMOEND
DESCRIPTION
VARCHAR(10)
VARCHAR(128)
DECIMAL(30,2)
DECIMAL(30,2)
DATE
DATE
XML
Since DB2 9.1 Fixpack 7 and DB2 9.5 Fixpack 4, the XML data in the customer, product, and
purchaseorder tables of the sample database no longer contain namespaces. This makes it easier to get started with querying, updating, and indexing XML data. The suppliers table in the
sample database still contains namespaces.
B.2
XML SAMPLE TABLES ON DB2 FOR Z/OS
In DB2 for z/OS, The installation job DSNTEJ1 creates five tables with XML columns. These
tables are in the relational schema DSN8910 and are named PRODUCT, CUSTOMER, PURCHASEORDER, CATALOG, and SUPPLIERS. These tables are not populated by the installation job.
There are several ways to populate some of these tables. For example, if you have a DB2 for
Linux, UNIX, and Windows installation, such as the free DB2 Express-C, you can create the
sample database and select or export the data from there. The data can then be imported or
inserted into the z/OS tables using SUPFI or an import job.
The PDF document “DB2 Version 9.1 for z/OS XML Guide” (SC18-9858) provides the DDL and
three INSERT statements with XML data for a table called MYCUSTOMER. You can copy and paste
these statements into SPUFI to build a sample table to work with.
B.3
TABLE CUSTOMER—COLUMN INFO
The customer table contains the following six documents.
B.3
Table customer—Column info
711
<customerinfo Cid="1000">
<name>Kathy Smith</name>
<addr country="Canada">
<street>5 Rosewood</street>
<city>Toronto</city>
<prov-state>Ontario</prov-state>
<pcode-zip>M6W 1E6</pcode-zip>
</addr>
<phone type="work">416-555-1358</phone>
</customerinfo>
<customerinfo Cid="1001">
<name>Kathy Smith</name>
<addr country="Canada">
<street>25 EastCreek</street>
<city>Markham</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N9C 3T6</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
</customerinfo>
<customerinfo Cid="1002">
<name>Jim Noodle</name>
<addr country="Canada">
<street>25 EastCreek</street>
<city>Markham</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N9C 3T6</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
</customerinfo>
<customerinfo Cid="1003">
<name>Robert Shoemaker</name>
<addr country="Canada">
<street>1596 Baseline</street>
<city>Aurora</city>
<prov-state>Ontario</prov-state>
<pcode-zip>N8X 7F8</pcode-zip>
</addr>
<phone type="work">905-555-7258</phone>
<phone type="home">416-555-2937</phone>
<phone type="cell">905-555-8743</phone>
<phone type="cottage">613-555-3278</phone>
</customerinfo>
<customerinfo Cid="1004">
<name>Matt Foreman</name>
<addr country="Canada">
<street>1596 Baseline</street>
<city>Toronto</city>
<prov-state>Ontario</prov-state>
<pcode-zip>M3Z 5H9</pcode-zip>
(continues)
712
Appendix B
The XML Sample Database
</addr>
<phone type="work">905-555-4789</phone>
<phone type="home">416-555-3376</phone>
<assistant>
<name>Gopher Runner</name>
<phone type="home">416-555-3426</phone>
</assistant>
</customerinfo>
<customerinfo Cid="1005">
<name>Larry Menard</name>
<addr country="Canada">
<street>223 NatureValley Road</street>
<city>Toronto</city>
<prov-state>Ontario</prov-state>
<pcode-zip>M4C 5K8</pcode-zip>
</addr>
<phone type="work">905-555-9146</phone>
<phone type="home">416-555-6121</phone>
<assistant>
<name>Goose Defender</name>
<phone type="home">416-555-1943</phone>
</assistant>
</customerinfo>
B.4
TABLE PRODUCT—COLUMN DESCRIPTION
The product table contains the following four documents.
<product pid="100-100-01">
<description>
<name>Snow Shovel, Basic 22 inch</name>
<details>Basic Snow Shovel, 22 inches wide, straight handle with
D-Grip</details>
<price>9.99</price>
<weight>1 kg</weight>
</description>
</product>
<product pid="100-101-01">
<description>
<name>Snow Shovel, Deluxe 24 inch</name>
<details>A Deluxe Snow Shovel, 24 inches wide, ergonomic curved
handle with D-Grip</details>
<price>19.99</price>
<weight>2 kg</weight>
</description>
</product>
<product pid="100-103-01">
<description>
<name>Snow Shovel, Super Deluxe 26 inch</name>
(continues)
B.5
Table purchaseorder—Column porder
713
<details>Super Deluxe Snow Shovel, 26 inches wide, ergonomic
battery heated curved handle with upgraded D-Grip</details>
<price>49.99</price>
<weight>3 kg</weight>
</description>
</product>
<product pid="100-201-01">
<description>
<name>Ice Scraper, Windshield 4 inch</name>
<details>Basic Ice Scraper 4 inches wide, foam handle</details>
<price>3.99</price>
</description>
</product>
B.5
TABLE PURCHASEORDER—COLUMN PORDER
The purchaseorder table contains the following six documents.
<PurchaseOrder PoNum="5000" OrderDate="2006-02-18" Status="Unshipped">
<item>
<partid>100-100-01</partid>
<name>Snow Shovel, Basic 22 inch</name>
<quantity>3</quantity>
<price>9.99</price>
</item>
<item>
<partid>100-103-01</partid>
<name>Snow Shovel, Super Deluxe 26 inch</name>
<quantity>5</quantity>
<price>49.99</price>
</item>
</PurchaseOrder>
<PurchaseOrder PoNum="5001" OrderDate="2005-02-03" Status="Shipped">
<item>
<partid>100-101-01</partid>
<name>Snow Shovel, Deluxe 24 inch</name>
<quantity>1</quantity>
<price>19.99</price>
</item>
<item>
<partid>100-103-01</partid>
<name>Snow Shovel, Super Deluxe 26 inch</name>
<quantity>2</quantity>
<price>49.99</price>
</item>
<item>
<partid>100-201-01</partid>
<name>Ice Scraper, Windshield 4 inch</name>
<quantity>1</quantity>
<price>3.99</price>
(continues)
714
Appendix B
The XML Sample Database
</item>
</PurchaseOrder>
<PurchaseOrder PoNum="5002" OrderDate="2004-02-29" Status="Shipped">
<item>
<partid>100-100-01</partid>
<name>Snow Shovel, Basic 22 inch</name>
<quantity>3</quantity>
<price>9.99</price>
</item>
<item>
<partid>100-101-01</partid>
<name>Snow Shovel, Deluxe 24 inch</name>
<quantity>5</quantity>
<price>19.99</price>
</item>
<item>
<partid>100-201-01</partid>
<name>Ice Scraper, Windshield 4 inch</name>
<quantity>5</quantity>
<price>3.99</price>
</item>
</PurchaseOrder>
<PurchaseOrder PoNum="5003" OrderDate="2005-02-28" Status="UnShipped">
<item>
<partid>100-100-01</partid>
<name>Snow Shovel, Basic 22 inch</name>
<quantity>1</quantity>
<price>9.99</price>
</item>
</PurchaseOrder>
<PurchaseOrder PoNum="5004" OrderDate="2005-11-18" Status="Shipped">
<item>
<partid>100-100-01</partid>
<name>Snow Shovel, Basic 22 inch</name>
<quantity>4</quantity>
<price>9.99</price>
</item>
<item>
<partid>100-103-01</partid>
<name>Snow Shovel, Super Deluxe 26 inch</name>
<quantity>2</quantity>
<price>49.99</price>
</item>
</PurchaseOrder>
<PurchaseOrder PoNum="5006" OrderDate="2006-03-01" Status="Shipped">
<item>
<partid>100-100-01</partid>
<name>Snow Shovel, Basic 22 inch</name>
<quantity>3</quantity>
<price>9.99</price>
(continues)
B.5
Table purchaseorder—Column porder
</item>
<item>
<partid>100-101-01</partid>
<name>Snow Shovel, Deluxe 24 inch</name>
<quantity>5</quantity>
<price>19.99</price>
</item>
<item>
<partid>100-201-01</partid>
<name>Ice Scraper, Windshield 4 inch</name>
<quantity>5</quantity>
<price>3.99</price>
</item>
</PurchaseOrder>
715
This page intentionally left blank
A
P P E N D I X
C
Further Reading
T
C.1
his appendix contains links to useful resources, grouped by chapter.
GENERAL RESOURCES FOR ALL CHAPTERS
The DB2 9.5 and 9.7 for Linux, UNIX, and Windows Information Centers:
• http://publib.boulder.ibm.com/infocenter/db2luw/v9r5/index.jsp
• http://publib.boulder.ibm.com/infocenter/db2luw/v9r7/index.jsp
The DB2 9 for z/OS Information Center:
• http://publib.boulder.ibm.com/infocenter/dzichelp/v2r2/index.jsp
If any pureXML question is not answered in this book, the fastest way to get an answer is to post
a question in the DB2 pureXML forum:
• http://www.ibm.com/developerworks/forums/forum.jspa?forumID=1423
The IBM developerWorks Wiki for DB2 XML has a variety of technical articles on DB2
pureXML:
• http://www.ibm.com/developerworks/wikis/display/db2xml/Technical+Papers+and
+Articles
Download DB2 Express-C, which is free to use, deploy, and distribute:
• http://www.ibm.com/software/data/db2/express/download.html
717
718
C.2
Appendix C
Further Reading
CHAPTER-SPECIFIC RESOURCES
Chapter 1: Introduction
New to DB2? Start here!
• http://www-128.ibm.com/developerworks/wikis/pages/viewpage.action?pageId=2658
New to XML? Start here!
• http://www.ibm.com/developerworks/xml/newto/
• http://www.w3schools.com/
Good books about XML in general include the following:
• XML in a Nutshell, 3rd Edition, by Elliotte Rusty Harold and Scott Means (O’Reilly,
ISBN 0-596-00764-7)
• Beginning XML, 4th Edition, by David Hunter et al. (Wrox, ISBN 0-470-11487-8)
• Professional XML, by Bill Evjen et al. (Wrox, ISBN 0-471-77777-3)
Chapter 2: Designing XML Data and Applications
Three very interesting blog entries on the problems with Name/Value pairs in data modeling. The
authors look at it from a relational point of view, but similar problems apply to Name/Value pairs
in XML notation.
• http://decipherinfosys.wordpress.com/2007/01/29/name-value-pair-design/
• http://geekswithblogs.net/darrengosbell/articles/KVPsInDatabaseDesign.aspx
• http://www.ibridge.be/?p=15
Further discussion of the design question “elements versus attributes” can be found in the developerWorks article “Principles of XML design: When to use elements versus attributes”. . .
• http://www.ibm.com/developerworks/xml/library/x-eleatt.html
. . . and in a section of the w3schools.com website:
• http://www.w3schools.com/DTD/dtd_el_vs_attr.asp
Chapter 3: Designing and Managing XML Storage Objects
These “best practices” articles provide excellent guidelines for database storage, range partitioning, multidimensional clustering, and other physical database design topics in DB2 for Linux,
UNIX, and Windows:
• “Best Practices—Database Storage”
• “Best Practices—Physical Database Design”
• “Best Practices—Data Life Cycle Management”
C.2
Chapter-Specific Resources
719
They are available at http://www.ibm.com/developerworks/data/bestpractices/.
For deeper information on the pureXML implementation in DB2 for z/OS, read this paper by
Guogen Zhang:
• http://www.geocities.com/zhanggene/pub/ScalableNativeXMLDB.pdf
Chapter 4: Inserting and Retrieving XML Data
The DB2 for Linux, UNIX, and Windows Exchange is a place where users and IBMers share
code samples, scripts, examples, and other goodies. Here is where you can get the UDFs that are
explained in Chapter 4.
• http://www.ibm.com/developerworks/exchange/dw_categoryView.jspa?categoryID=974&showAll=true
For deep details on reserved characters in XML, whitespace, attribute normalization, digital signatures, and more, try these links:
• http://www.w3.org/TR/REC-xml/#sec-white-space
• http://www.w3.org/TR/REC-xml/#sec-line-ends
• http://www.w3.org/TR/2002/REC-xmldsig-core-20020212/
Chapter 5: Moving XML Data
The only place that has additional information on moving XML data into and out of DB2 databases is the DB2 Information Center:
• http://publib.boulder.ibm.com/infocenter/db2luw/v9r5/topic/com.ibm.db2.luw.
xml.doc/doc/c0024120.html
• http://publib.boulder.ibm.com/infocenter/dzichelp/v2r2/topic/com.ibm.db29.doc.
ugref/db2z_loaddataxmlcolumns.htm
• http://publib.boulder.ibm.com/infocenter/dzichelp/v2r2/topic/com.ibm.db29.doc.
xml/db2z_xmlutil.htm
Chapters 6, 7, 8, and 9: Querying XML Data
If you are new to XPath and XQuery then the tutorials at w3schools.com are highly recommended for a quick introduction:
• http://www.w3schools.com/xpath/default.asp
• http://www.w3schools.com/xquery/default.asp
The ultimate book on XQuery by Don Chamberlin et al. is XQuery from the Experts: A Guide to
the W3C XML Query Language:
• http://www.amazon.com/XQuery-Experts-Guide-Query-Language/dp/0321180607
720
Appendix C
Further Reading
Relational views over XML (using the XMLTABLE) are helpful to “Create business reports for
XML Data with Cognos 8 BI and DB2 pureXML”:
• http://www.ibm.com/developerworks/db2/library/techarticle/dm-0811saracco/
The exercise “XQuery use cases converted to SQL/XML in DB2 9 for z/OS” shows examples of
how easy it is to work around the lack of XQuery in DB2 for z/OS:
• http://www.ibm.com/developerworks/wikis/download/attachments/2500/
XQueryUseCases.zip
The complete reference of all supported XPath and XQuery functions can be found in the DB2
for z/OS information center (search for “Descriptions of XPath functions”) and the DB2 for
Linux, UNIX, and Windows information center (search for “Functions by category”):
• http://publib.boulder.ibm.com/infocenter/dzichelp/v2r2/topic/com.ibm.db29.doc.
xml/db2z_xpxqfunctionreference.htm
• http://publib.boulder.ibm.com/infocenter/db2luw/v9r5/topic/com.ibm.db2.luw.xml.
doc/doc/xqrfncategory.html
The specifications of the XPath and XQuery standards are a tough read if you are new to querying
XML data, but very valuable when you get more advanced and dig deeper into the details of the
language:
• http://www.w3.org/TR/xpath20/
• http://www.w3.org/TR/xquery
The built-in functions in XPath and XQuery are defined and formally specified in:
• http://www.w3.org/TR/xquery-operators/
Chapter 10: Producing XML from Relational Data
If you wonder where the SQL/XML Publishing functions are covered in the DB2 documentation,
take a look at the SQL Reference for DB2 for z/OS and DB2 for Linux, UNIX, Windows, Version
8 or higher.
IBM Rational Data Architect provides a graphical mapping tool to construct XML from relational tables and generates SQL/XML publishing queries for you. Further details are available in
an article and a tutorial:
• http://www.ibm.com/developerworks/db2/library/techarticle/dm-0710kokkat/
• http://www.ibm.com/developerworks/edu/dm-dw-dm-0609bittner-i.html
C.2
Chapter-Specific Resources
721
Chapter 11: Converting XML to Relational Data
Mayank’s article, “From DAD to annotated XML schema decomposition,” helps you migrate
from the XML Extender to the new shredding capabilities in DB2 9.x:
• http://www.ibm.com/developerworks/db2/library/techarticle/dm-0604pradhan/
The article “Shred XML documents using DB2 pureXML” provides a useful comparison of
shredding techniques with examples:
• http://www.ibm.com/developerworks/db2/library/techarticle/dm-0801ledezma/
Interested in a case study on shredding XML with DB2? Take a look at this article:
• http://www.ibm.com/developerworks/data/library/techarticle/dm-0804nicola/
Chapter 12: Updating and Transforming XML Documents
The implementation of XQuery Updates in DB2 for Linux, UNIX, and Windows is based on the
following W3C specification of the XQuery Update Facility:
• http://www.w3.org/TR/2006/WD-xqupdate-20060711/
The formal documentation of the XQuery Update facility in DB2 starts here:
• http://publib.boulder.ibm.com/infocenter/db2luw/v9r5/topic/com.ibm.db2.luw.xml.
doc/doc/xqrupdcontainer.html
An introduction to XSLT:
• http://www.w3schools.com/xsl/default.asp
Chapter 13: Defining and Using XML Indexes
The article “On the Path to Efficient XML Queries” describes in more detail how the semantics of
the XQuery and SQL/XML languages affect the eligibility of XML indexes for XML queries:
• http://www.vldb.org/conf/2006/p1117-balmin.pdf
Chapter 14: XML Performance and Monitoring
Some of the most common questions about XML performance are answered in the article “A performance comparison of DB2 9 pureXML with CLOB and shredded XML storage”:
• http://www.ibm.com/developerworks/db2/library/techarticle/dm-0612nicola/
XML Database Benchmark: Transaction Processing over XML (TPoX):
• http://tpox.sourceforge.net/
722
Appendix C
Further Reading
If your queries are included in a stored procedure, here is how to collect the access plan for a
stored procedure in DB2 for Linux, UNIX, and Windows:
• http://www-01.ibm.com/support/docview.wss?uid=swg21279292
The white paper “DB2 9 and z/OS XML System Services Synergy Update” by Judy Ruby-Brown
and Akiko Hoshikawa contains a lot of z/OS-specific performance and monitoring information
for pureXML. Highly recommended for mainframe users:
• http://www.ibm.com/support/techdocs/atsmastr.nsf/WebIndex/WP101227
More information on the IBM DB2 Optimization Service Center for DB2 for z/OS:
• http://www.ibm.com/software/data/db2/zos/downloads/osc.html
Chapter 15: Managing XML Data with Namespaces
There is nothing DB2-specific about managing XML data with namespaces. The better you
understand namespace in general, the easier it is to work with namespaces in DB2. The following
are our Top 3 resources on XML namespaces:
• http://www.w3schools.com/XML/xml_namespaces.asp
• http://www.rpbourret.com/xml/NamespacesFAQ.htm
• http://www.w3.org/TR/REC-xml-names/
Chapter 16: Managing XML Schemas and Chapter 17: Validating XML Documents
against XML Schemas
The XML Schema Primer. This document is intended to be an easily readable description of
how XML Schemas work. It is less formal and less abstract than the official XML Schema
specification:
• http://www.w3.org/TR/xmlschema-0/
An even simpler introduction is this tutorial:
• http://www.w3schools.com/schema/default.asp
An excellent collection of best practices for designing XML Schemas:
• http://www.xfront.com/BestPracticesHomepage.html
The complete and formal specification of the XML Schema language consists of two parts. The
first part is on structures, the second part is on data types:
• http://www.w3.org/TR/xmlschema-1/, http://www.w3.org/TR/xmlschema-2/
C.2
Chapter-Specific Resources
723
If you like O’Reilly books, then their XML Schema book by Eric van der Vlist is a good choice to
learn all about XML Schema. (O’Reilly Media, ISBN: 0596002521):
• http://oreilly.com/catalog/9780596002527/
Definitive XML Schema is written by Priscilla Walmsley, an XML expert and member of the W3C
XML Schema Working Group from 1999 to 2004 (Prentice Hall, ISBN: 0130655678):
• http://www.datypic.com/books/defxmlschema/
The XML Schema Companion by Neil Bradley is another very accessible XML Schema guide
(Addison-Wesley, ISBN: 0321136179):
• http://www.amazon.com/XML-Schema-Companion-Neil-Bradley/dp/0321136179
Sample scripts and demonstrations of using industry standard XML Schemas with DB2, XQuery,
web services, Atom feeds, and forms:
• http://www.alphaworks.ibm.com/tech/purexml/download
• http://www.ibm.com/developerworks/wikis/display/db2xml/IndustryFormatsAndServicesWithpureXML
The DB2 for z/OS XSR Setup and Troubleshooting Guide can be found on this page:
• http://www.ibm.com/developerworks/wikis/display/db2xml/DB2+for+zOS+pureXML
Chapter 18: Using XML in Stored Procedures, UDFs, and Triggers
The most complete reference on SQL stored procedures, user-defined functions, and triggers is
the following book:
DB2 SQL PL: Essential Guide for DB2 UDB on Linux, UNIX, Windows, i5/OS, and z/OS, 2nd
Edition, IBM Press, ISBN 0-13-147700-5:
• http://www.ibmpressbooks.com/bookstore/product.asp?isbn=0131477005
This article provides fundamental performance guidelines for SQL stored procedures:
• http://www.ibm.com/developerworks/data/library/techarticle/0306arocena/
0306arocena.html
Chapter 19: Performing Full-Text Search
Information about downloading and installing the DB2 Net Search Extender:
• http://www.ibm.com/software/data/db2/9/download.html
• ftp://ftp.software.ibm.com/ps/products/db2/info/vr95/pdf/en_US/cteu9e951.pdf
724
Appendix C
Further Reading
Tuning the Performance of Full-Text Indexing in the DB2 Net Search Extender
• http://www.ibm.com/developerworks/wikis/download/attachments/1824/DB2+
NSE+indexing+performance.pdf
Key Concepts of IBM OmniFind Text Search for DB2 for z/OS:
• http://publib.boulder.ibm.com/infocenter/dzichelp/v2r2/topic/com.ibm.db29.doc.
srchz/srchz_keyconcepts.htm
Documentation of the IBM OmniFind Text Search Server for DB2 for z/OS:
• http://publib.boulder.ibm.com/infocenter/dzichelp/v2r2/topic/com.ibm.db29.doc.
srchz/dsntsk11.pdf
Chapter 20: Understanding XML Data Encoding
Useful information about Unicode:
• http://www.unicode.org/faq/ , http://en.wikipedia.org/wiki/Unicode, and
http://www.utf-8.com/
More detailed information on Unicode Byte Order Marks and the automatic detection of character encodings in XML documents:
• http://www.w3.org/TR/REC-xml/#sec-guessing
• http://en.wikipedia.org/wiki/Byte-order_mark
• http://unicode.org/faq/utf_bom.html#BOM
Chapter 21: Developing XML Applications with DB2
“DB2 Express-C: The Developer Handbook for XML, PHP, C/C++, Java, and .NET”:
• http://www.redbooks.ibm.com/abstracts/sg247301.html
The official Java documentation of the SQLXML interface in JDBC 4.0:
• http://java.sun.com/javase/6/docs/api/java/sql/SQLXML.html
Data bindings between XML and Java objects:
• http://www.ibm.com/developerworks/library/x-databdopt/index.html
Introduction to pureQuery:
• http://www.ibmdatabasemag.com/dbadmin/showArticle.jhtml?articleID=207801106
Handle pureXML data in Java applications with pureQuery:
• http://www.ibm.com/developerworks/data/library/techarticle/dm-0901rodrigues/
C.2
Chapter-Specific Resources
725
DeveloperWorks article “Develop proof-of-concept .NET applications, Part 1: Create database
objects in DB2 Viper using .NET”:
• http://www.ibm.com/developerworks/edu/dm-dw-dm-0605xia-i.html
“Develop proof-of-concept .NET applications, Part 4: Wire your application to DB2 pureXML
data”:
• http://www.ibm.com/developerworks/edu/dm-dw-dm-0608xia-i.html
Build a DB2 pureXML application in a day:
• http://www.ibm.com/developerworks/db2/library/techarticle/dm-0812malaika/
XML manipulation in COBOL 4.1 is documented in Chapters 28 and 29 of the COBOL Programming Guide (SC23-8529-00):
• http://publibfp.boulder.ibm.com/epubs/pdf/igy3pg40.pdf
All DB2 PHP functions in the extension ibm_db2 are documented here:
• http://www.php.net/manual/en/ref.ibm-db2.php
PHP 5.1.2 for the z/OS UNIX System Services platform:
• http://www.ibm.com/servers/eserver/zseries/zos/unix/ported/php/index.html
Resources for developing Perl application with DB2:
• http://www.ibm.com/developerworks/data/library/techarticle/dm-0512greenstein/
• http://www.ibm.com/software/data/db2/perl
• http://search.cpan.org/~ibmtordb2/
Resources for developing XML applications in Perl:
• http://www.ibm.com/developerworks/xml/library/x-xmlperl1.html
• http://www.ibm.com/developerworks/xml/library/x-xmlperl2.html
• http://www.ibm.com/developerworks/xml/library/x-xmlperl3.html
DB2 and pureXML with Ruby on Rails:
• http://www.ibm.com/developerworks/db2/library/techarticle/dm-0706chun/index.html
• http://www.alphaworks.ibm.com/tech/db2onrails
• http://antoniocangiano.com/2008/02/08/essential-guide-to-the-ruby-driver-for-db2/
Chapter 22: Exploring XML Information in the DB2 Catalog
Refer to the DB2 Information Center for details on the DB2 catalog.
726
Appendix C
Further Reading
C.3
RESOURCES ON THE INTEGRATION OF DB2 PUREXML
WITH OTHER PRODUCTS
IBM Data Studio Developer 2.1 is available from:
• http://www.ibm.com/software/data/studio/
• http://www.ibm.com/developerworks/spaces/datastudio
Lotus Forms, XForms, and DB2 pureXML:
• http://www.ibm.com/developerworks/wikis/download/attachments/1824/
LotusFormsXFormsandDB2pureXML.pdf
WebSphere DataPower and DB2 pureXML:
• http://www.ibm.com/developerworks/db2/library/techarticle/dm-0805malaika3/
• http://www.ibm.com/developerworks/db2/library/techarticle/dm-0805malaika3/
Universal Services for pureXML using Data Web Services:
• http://www.ibm.com/developerworks/db2/library/techarticle/dm-0805malaika/
Creating business reports for XML data with Cognos BI and DB2 pureXML:
• http://www.ibm.com/developerworks/db2/library/techarticle/dm-0811saracco/
Using industry standard data formats with WebSphere ESB and DB2 pureXML:
• http://www.ibm.com/developerworks/websphere/techjournal/0706_elhilaly/
0706_elhilaly.html
DB2 pureXML and Altova XMLSPY:
• http://www.altova.com/whitepapers/ibm.pdf
DeveloperWorks article, “DB2 and Rational: Working together, Part 1: Introduction to DB2
development with Rational Application Developer”:
• http://www.ibm.com/developerworks/edu/dm-dw-dm-0512eaton-i.html
IBM InfoSphere Data Architect (previously know as Rational Data Architect):
• http://www.ibm.com/developerworks/downloads/r/rda/learn.html?S_
TACT=105AGX28&S_CMP=DLMAIN
Index
Symbols
& (ampersand), escaping 88
* (asterisk) as wildcard
character, 140, 594
@ (at sign) in XPath, 135
@* XPath wildcard, 140
, (comma) operator, construction of sequences, 154
$ (dollar sign)
in XML column
references, 161
XQuery variable
names, 196
. (dot), current context in
XPath, 151-153
// (double slash)
in XPath, 141-142
in XPath predicates, 146
!= (not equal) comparison
operator, not( ) function
versus, 150
% (percent sign) in wildcard
searches, 583
.. (parent directory) in file system navigation, 133
.. (parent step) in XPath,
151-153
| (pipe) character
union of sequences, 154
as XPath union
operator, 585
? (question mark) as wildcard
character, 594
; (semicolon)
in namespace
declarations, 448
in stored procedures, 549
’ (single quotes),
escaping, 571
/ (slash)
in file system
navigation, 133
in XPath, 141
in XPath predicates, 145
_ (underscore character) in
wildcard searches, 583
A
abbreviated syntax in
XPath, 157
access control, 9
access plans. See execution
plans
ADD XMLSCHEMA
command, 485
727
adjust-date-to-timezone
function (XQuery), 226
ADMIN_EST_INLINE_
LENGTH function, 45-47
ADMIN_IS_INLINED
function, 44-45
ADO.NET data providers, list
of, 631
aggregate functions, 278
aggregation. See also
grouping
XML construction with,
207-208
of XML data, 233-239
within and across
documents, 236-237
XMLTABLE function,
234-236
with XMLAGG function
(SQL/XML), 277-283
aggregation functions in
XQuery, 218-220
ALTER INDEX command
(DB2 Net Search Extender),
580
altering text indexes
with DB2 Net Search
Extender, 580
Altova XML tools, 656-658
728
ampersand (&), escaping 88
AND operator, 149
in full-text searches, 584
annotated schema shredding,
306-318
advantages/disadvantages
of, 301
annotating XML Schema,
306-310
defining annotations
in Data Studio
Developer, 311
registering annotated
schemas, 311-312
shredding multiple XML
documents, 315-318
shredding single XML
documents, 312-315
Annotated XSD Mapping
Editor, 311
APAR II14426, xxvi
APARs, list of, 72-73
APIs, 9
application code page, 599
application development, 609
CLI applications, 636-639
embedded SQL
applications, 639-647
C applications with,
645-647
COBOL applications
with, 640-642
PL/1 applications with,
643-644
for DB2 pureXML, 9
host variables, 613-614
Java applications,
615-631
JDBC 3.0, XML
support in, 615-619
JDBC 4.0, example
usage, 621-627
JDBC 4.0, XML
support in, 619-621
pureQuery, 629-631
XML data binding, 629
XML documents,
creating from application data, 627-628
Index
.NET applications, 631-636
ADO.NET data
providers, list of, 631
inserting XML data
from, 635
manipulating XML data
in, 633-635
querying XML data in,
632-633
XML Schema and DTD
handling, 636
parameter markers, 613-614
Perl applications, 650-651
PHP applications, 647-649
pureXML, benefits of,
610-613
tools for
Altova XML tools,
656-658
IBM Data Studio Developer, 652-653, 655
IBM Database Add-ins
for Visual Studio, 656
list of, 651
<oXygen/>, 658-659
Stylus Studio, 659
application layer, avoiding
parsing in, 610-612
application-centric
validation, 545
applications (XML), best
practices, 434-435
arithmetic expressions, 190
in XQuery, 212-214
asterisk (*) as wildcard
character, 140, 594
atomic values (XQuery Data
Model), 129
attaching partitions, 57
attribute axis, 157
attribute constructors
(XQuery), 290-292
attribute expressions, XML
construction with, 206
attribute nodes, 29, 129
attribute values versus, 136
attribute values, attribute nodes
versus, 136
attributes
in path expressions, 135
XPath wildcards for, 141
attributes (objects),
sparse, 13
attributes (XML), 2-4. See also
nodes
constructing from
relational data, 275-277
converting to/from XML
elements, 345-346
elements versus, 15-19
extracting value of, 557
full names, 441, 443-444
index creation and, 459
indexing, 8
inserting, defining
position for, 336-337
namespaces and, 440-441
optional, 13
renaming, 334-335
updating with stored
procedures, 554-555
values, replacing,
327-328
automatic updates for text
indexes, 574-576
axes in XPath, 157
B
BACKUP PENDING
status, 111
backward compatibility of
XML Schema versions,
495-498
base table row storage. See
inlining
BEFORE triggers, 523
Bernoulli sampling, 419
best practices for XML
performance, 428-435
between predicates, 431
in XML queries, 254-256
binary data as internally
encoded, 618
binary data types, 606
Index
binary SQL types, converting
XML values to, 187-188
binding. See XML data
binding
BLOB data type, inserting
XML documents 80
blobFromFile UDF, 81
blobsFromZipURL UDF,
81-82
blocking cursors, 435
BOM (Byte-Order Mark), 599
Boolean expressions,
predicates versus, 146
Boolean functions in
XQuery, 226
Boolean operators in full-text
searches, 583-584
boost modifiers, 594
boundary whitespace, 90-91
preserving 91-93
bulk shredding of XML
documents, 315-318
business data. See data
business objects
data representation of,
12-13
storage of, 612
Byte-Order Mark (BOM), 599
C
C applications with embedded
SQL, 645-647
Call Level Interface. See CLI
application development
cardinality of XML
indexes, 363
Cartesian products, 240
case-insensitive XML queries,
252-253
cast expressions, 190
in XQuery, 208-212
castable XQuery
expression, 211
casting. See converting
729
catalog tables (DB2 for z/OS),
XML-related, 667-673
for XML indexes, 671-672
XML Schema Repository
(XSR), 503-508, 672
for XML storage objects,
667-670
catalog views (DB2 for Linux,
UNIX, and Windows),
XML-related, 661-667
SYSCAT.COLUMNS,
661-662
SYSCAT.INDEXES,
663-664
SYSCAT.INDEXXMLPATTERNS, 664-666
SYSIBM.SYSXMLPATHS,
663
SYSIBM.SYSXMLSTRINGS, 662-663
XML Schema Repository
(XSR), 503-508, 667
change requests, response time
for, 613
character data, as externally
encoded, 619
character data types, blocking
usage of, 606
character encoding. See XML
encoding
character references,
list of, 87
character type application variables, fetching non-Unicode
data into, 603-604
check constraints, 8,
520-523
CHECK DATA utility, 69-70
CHECK INDEX utility, 66
CHECK PENDING status, 110
child axis, 157
Chinese characters in code
page ISO-8859-1 (code page
conversion example),
602-603
CLI (Call Level Interface)
application development,
636-639
CLOB data type, inserting
XML documents 80
CLP (Command Line
Processor)
DESCRIBE command,
84-85
escaping quotes in, 571
input parameters, text files
as, 708
INSERT statements, 76-77
registering XML Schemas
in, 484-486
retaining whitespace, 527
terminating characters,
changing, 549
testing stored
procedures, 555
truncated XML document
display 83
viewing XML documents,
704-705
XML declarations,
inserting 86
XML options
list of, 706
usage examples,
706-707
coarse granularity of XML
documents, 22
COBOL applications with
embedded SQL, 640-642
code page conversions, 597
avoiding, 601
examples of, 602-605
with non-Unicode database
code pages, 601-602
performance considerations,
434
code pages, selecting, 27
column references
dollar sign ($) in, 161
in XMLQUERY function,
162-163
columns (XML)
dropping, 40
generating from XML data,
165-166
730
inserting constructed XML
data into, 294-295
comma (,) operator, construction of sequences, 154
Command Line Processor. See
CLP
commands for full-text
searches, list of, 594-595
comment nodes,
constructing, 290
common table expressions,
282-283
comparison expressions, 190
comparison operations in
predicates, 143
comparison operators
numeric versus string
comparison, 144
in XPath, 156-157
compatibility. See backward
compatibility
compliance, data storage
for, 94
components. See schema
documents
compression
of XML data, 48-51
XML space management
example, 54-57
computed values
replacing values in XML
documents with, 329-331
XML construction with,
202-204
concat function (XQuery),
215-216
concat( ) function, 155
concatenation of text
nodes, 30
concurrency control, XML
documents, 9
conditional expressions, 190
XML construction with, 205
conditional triggers, 524
conditional XML element construction, 284-285
leading zeros in, 285-286
Index
configuring XML inlining,
43-47
constraints on XML
documents, 8, 520-523
constructing XML data. See
converting relational data
to XML data; XML
construction
construction of sequences in
XPath, 154-155
constructor expressions, 190
constructor functions. See publishing functions (SQL/XML)
constructors (XQuery),
290-292
XML namespaces and,
462-463
contains function (XQuery),
216-217, 587
CONTAINS scalar function,
581-583
content-centric XML
documents, 567
context (file system
navigation), 133
context nodes, 136, 139
convert function, 229
converting. See also
shredding
relational data to XML
data, 267
inserting in XML
columns, 294-295
with SQL/XML
publishing functions,
268-290
XML declarations for,
292-294
with XQuery constructors, 290-292
XML elements to/from
XML attributes, 345-346
XML values to binary SQL
types, 187-188
COPY TABLESPACE
utility, 66
copying XML documents 86
COPYTOCOPY utility, 66
count( ) function, 155
Creat Index Wizard, 366-367
CREATE INDEX command
(DB2 Text Search), 591-592
CREATE INDEX command
(DB2 Net Search Extender),
572-579
advanced options, 578-579
with automatic updates,
574-576
for parts of documents,
576-577
with specific storage paths,
573-574
CREATE INDEX statement,
362-364
current context in XPath,
151-153
current directory (file system
navigation), 133
CURRENT IMPLICIT
XMLPARSE OPTION
register 93
current-date function
(XQuery), 225-226
current-dateTime function
(XQuery), 225
current-time function
(XQuery), 225
cursors
loading from, 111
in stored procedures,
553-554
update cursors, modifying
XML documents in,
350-351
custom document models, fulltext searches with,
585-586
custom XML Schemas,
industry standard XML
Schemas versus, 474-476
customer table (XML sample
database), contents of,
710-712
Index
D
data, distinguishing from metadata, 19-21. See also relational data; XML data
data binding (XML)
to Java objects, 629
pureQuery and, 631
data exchange, metadata
for, 13
data expansion/shrinkage (code
page conversion example),
605
data function (XQuery), 221
data loss due to XML
encoding, avoiding, 606
data models. See also design
decisions
XML data, when to use,
11-13
XQuery 1.0 and XPath 2.0
Data Model, 126-131
sequence construction,
128-130
sequence input/output,
130-131
data providers, list of, 631
data storage. See storage
Data Studio, support for DB2
pureXML, 9
Data Studio Developer,
652-655
defining schema
annotations, 311
profiling stored
procedures, 556
data types (SQL)
BLOB, inserting XML
documents, 80
CLOB, inserting XML
documents, 80
converting XML values
to binary SQL types,
187-188
DESCRIBE command,
84-85
index eligibility and,
374-375
731
type errors, avoiding in
XMLTABLE function,
168-169
XML, 7-9, 160
for XML indexes, 367-372
DATE, 369
DECFLOAT, 369
DOUBLE, 369
rejecting invalid
values, 371-372
selecting, 369-371
TIMESTAMP, 369
VARCHAR HASHED,
368-369
VARCHAR(n), 367-368
in XQuery, 208-212
data types (Java), SQLXML, 9
data( ) function, 134-135
data-centric XML
documents, 567
database code page,
non-Unicode database usage,
601-602
database nodes. See
partitioned databases
Database Partitioning Feature
(DPF), 59-60
database utilities,
monitoring, 427-428
database-centric
validation, 545
databases
disabling
for DB2 Net Search
Extender, 572
for DB2 Text
Search, 591
enabling
for DB2 Net Search
Extender, 571-572
for DB2 Text Search,
590-591
XML sample database. See
XML sample database
DatabaseSpy, 658
DataDirect, 659
date comparisons, string
comparisons versus,
210-211
date functions in XQuery,
224-226
DATE index data type, 369
DB2 .NET Data Provider, 632
DB2 Control Center
Creat Index Wizard,
366-367
support for DB2
pureXML, 9
viewing XML documents,
703-704
DB2 Express-C, 196
DB2 for Linux, UNIX, and
Windows, xxvi
explain facility, 396-409
exporting XML
documents, 98-106
importing XML
documents, 106-109
index implementation,
387-390
loading XML documents,
109-111
snapshot monitor,
424-427
statistics collection in,
418-419
validation in, DB2 for z/OS
versus, 543-544
XML compression, 48
XML index data types, 367
XML index statistics,
390-393
XML sample database,
creating, 709-710
XML Schemas in, 510-511
XML storage, 33-41
in DB2 9.7 release,
40-41
dropping XML
columns, 40
storage objects, types of,
33-35
table space page size,
36-39
732
XML-related catalog views,
661-667
SYSCAT.COLUMNS,
661-662
SYSCAT.INDEXES,
663-664
SYSCAT.INDEXXMLPATTERNS, 664-666
SYSIBM.SYSXMLPATHS, 663
SYSIBM.SYSXMLSTRINGS, 662-663
XML Schema
Repository (XSR), 667
DB2 9.1 for Linux, UNIX,
and Windows, XML
encoding, 597
DB2 9.5 for Linux, UNIX,
and Windows, XML
encoding, 597
DB2 9.7 for Linux, UNIX, and
Windows, optimized XML
storage format, 40-41
DB2 for z/OS, xxvi
explain facility, 409-416
full-text searches in, 596
loading XML documents,
114-116
statistics collection in,
417-418
unloading XML
documents, 111-114
updating XML documents
in, 351-352
validation in, 540-544
DB2 for Linux, UNIX,
and Windows versus,
543-544
for existing XML
documents, 543
with INSERT statement,
541-542
with UPDATE
statement, 542-543
XML compression, 48
XML encoding, 598
XML index data types, 367
Index
XML sample database,
creating, 710
XML Schemas in, 510-511
XML storage, 60-73
limiting memory
consumption, 71
multiple XML
columns, 64
naming conventions,
64-65
offloading XML
parsing, 72-73
storage objects, types of,
61-62
table space
characteristics, 63
utilities for, 65-70
XML-related catalog tables,
667-673
for XML indexes,
671-672
XML Schema Repository (XSR), 672
for XML storage objects,
667-670
DB2 Net Search Extender
administration commands,
list of, 594-595
altering text indexes, 580
creating text indexes,
572-579
DB2 Text Search versus,
568-570
disabling databases for, 572
enabling databases for,
571-572
performing full-text
searches, 581-590
reorganizing text indexes,
579-580
updating text indexes,
579-580
DB2 pureXML. See pureXML
DB2 Text Search, 590
administration commands,
list of, 594-595
creating text indexes,
591-592
DB2 Net Search Extender
versus, 568-570
disabling databases
for, 591
enabling databases for,
590-591
performing full-text
searches, 592-594
db2-fn:sqlquery function, 139,
166, 227, 229-230, 582
db2-fn:xmlcolumn( )
function, 137, 166
db2-fn:xmlcolumn-contains
function, 592
db2cat utility, 419-423
db2exfmt command-line tool,
396-399
db2look utility, XML
documents and, 122
db2move utility, XML
documents and, 123
DB2Xml class (.NET),
632-633
DB2Xml object (JDBC 3.0),
benefits of, 616
DECFLOAT index data
type, 369
declarations (XML), 2,
599-600
in CLI applications, 638
for constructed XML data,
292-294
in embedded SQL
applications, 639
handling documents with,
85-86
declaring namespaces, 4
XML, 439-441
in SQL/XML, 451
in XML indexes,
456-460
in XMLTABLE function,
452-453
in XQuery, 448-450
XSLT, 356
DECOMPOSE XML
DOCUMENT command, 312
Index
DECOMPOSE XML
DOCUMENTS command,
317-318
decomposing. See shredding
dedicated directories,
exporting XML documents
to, 102-104
default namespaces (XML),
renaming nodes in, 467-468
default tagging of relational
data, 286-289
default whitespace
preservation option,
changing 93-94
default XML namespaces,
442-444
default XML Schemas,
validation against with LOAD
and IMPORT
utilities, 532
defining XML indexes,
362-367
delete expression
(XQuery), 333
DELETE operator (execution
plans), 401
DELETE statement, 82-83
delete triggers, 563
deleting
XML documents, 82-83
XML nodes, 333-334
delimited format files, 99
descendant axis, 157
descendant nodes, 141
descendant-or-self axis, 157
DESCRIBE command 84-85
describing queries, 137
design decisions, XML
documents, 15-25, 428-429
elements versus attributes,
15-19
granularity, 22-24
hybrid storage, 24-25
performance, role of, 16
tags versus values, 19-21
detaching partitions, 57
DFETCH operator (execution
plans), 413
733
digital signatures, effect of
stripping whitespace on, 78
direct element construction,
171
direct element/attribute
constructors (XQuery), XML
namespaces and, 462-463
direct XML construction, 202
directories, exporting XML
documents to, 102-104
directoryInfo UDF, 81
disabling
annotated schemas for
shredding, 312
databases
for DB2 Net Search
Extender, 572
for DB2 Text
Search, 591
distinct-values function
(XQuery), 221
distribution keys, 60
document ID index, 61
document models, 576-577
custom document models,
full-text searches with,
585-586
document nodes, 29, 129
constructing, 294-295
Document Object Model
(DOM) parsers, 610
Document Object Model
fidelity, 94
document trees (XML), 28-30
storage of, 30-33
Document Type Definitions
(DTDs), 501-502
document validation. See
validation
document-centric XML
documents. See contentcentric XML
documents (XML)
access control, 9
attribute values, replacing,
327-328
checking for validation,
534-535
constraints, 8
constructing
from multiple relational
rows, 277-280
from multiple relational
tables, 281-283
content-centric versus
data-centric, 567
copying, 86
creating from Java
application data,
627-628
db2look utility and, 122
db2move utility and, 123
deleting, 82-83
description of, 2-4
design decisions, 15-25,
428-429
elements versus
attributes, 15-19
granularity, 22-24
hybrid storage, 24-25
performance, role of, 16
tags versus values,
19-21
document trees, 28-30
storage of, 30-33
element values, replacing,
326-327
elements/attributes, renaming, 334-335
escaping special
characters, 87-89
exporting, 98-106
to dedicated directories,
102-104
fragments of documents,
104-105
to multiple files,
100-102
to single file, 98-100
with XML Schema
information, 105-106
federating, 120-121
importing, 106-109
input files and, 107-108
performance tips,
108-109
734
Index
indexing, 8
inserting, 76-82
from files, 79-82
INSERT statement,
76-79
loading
in DB2 for Linux,
UNIX, and Windows,
109-111
in DB2 for z/OS,
114-116
modifying
in insert operations,
349-350
in queries, 346-349
in update cursors,
350-351
with XQuery Update
Facility, 324-326
namespace declarations,
439-441
namespace usage examples,
444-447
nodes
deleting, 333-334
inserting, 335-340
modifying multiple,
343-346
repeating/missing,
340-343
replacing, 331-332
parameter markers, replacing values with, 328
parsing, 9
avoiding in application
layer, 610-612
publishing, 118-119
queries on, 8-9
removing validation, 540
replacing, 322-324
multiple values in,
328-329
values with computed
values, 329-331
replicating, 118-119
retaining invalid, 519-520
retrieving, 83-85, 161-165
shredding, 10
advantages/
disadvantages of,
297-301
with annotated schema
shredding, 306-318
with XMLTABLE
function, 301-306
splitting, 116-118
storage. See XML storage
transforming with XSLT,
352-358
traversing, 197
unloading, 111-114
updating, 433
in DB2 for z/OS,
351-352
with UDFs, 559-561
valid documents
determining XML
Schemas for, 538-540
well-formed documents
versus, 473
validation. See validation
viewing structure of,
703-705
well-formed, 76
whitespace, 89-94
changing default preservation option 93-94
preserving, 91-93
types of, 90
with XML declarations,
handling, 85-86
dollar sign ($)
in XML column
references, 161
XQuery variable
names, 196
DOM (Document Object
Model) parsers, 610
dot notation in XPath,
151-153
DOUBLE index data type, 369
double slash (//)
in XPath, 141-142
in XPath predicates, 146
DPF (Database Partitioning
Feature), 59-60
DROP XSROBJECT
command, 492
dropping
check constraints, 522
XML columns, 40
DSNTIAUL command,
111-112
DSN_XMLVALIDATE
function, 541-543
DTDs (Document Type
Definitions), 501-502
in .NET applications,
handling, 636
registering, 501
dynamic XPath expressions,
185-186
E
EAV (Entity-Attribute-Value
model). See Name/Value Pairs
editing (Data Studio Developer)
queries, 654
XML Schemas, 653
element constructors
(XQuery), 290-292
element nodes, 29-30, 129
element values, returning without XML tags, 163-164
elements (XML), 2-4. See also
nodes
attributes versus, 15-19
constructing from
relational data, 269-273
conditional construction,
284-286
empty, missing, NULL
elements, 274-275
converting to/from XML
attributes, 345-346
extracting repeating
values, 557-558
extracting value of, 557
full names, 441-444
Index
indexing, 8
inserting, defining
position for, 335-336
leaf elements, 383
non-leaf elements, XML
indexes on, 383-384
optional elements
handling in XMLTABLE
function, 167-168
schema flexibility of, 5
renaming, 334-335
repeating elements
numbering rows based
on, 173-174
returning multiple,
174-176
returning with
XMLQUERY function,
164-165
returning with
XMLTABLE function,
169-173
schema flexibility of, 5
root elements, 28
updating with stored
procedures, 554-555
values
replacing, 326-327
as text node
concatenations, 30
XPath wildcards for, 140
embedded SQL application
development, 639-647
C applications with,
645-647
COBOL applications with,
640-642
PL/1 applications with,
643-644
embedding SQL in XQuery,
227-228
empty elements (relational
data), converting to XML
data, 274-275
“Empty on NULL”
behavior, 274
735
enabling
annotated schemas for
shredding, 312
databases
for DB2 Net Search
Extender, 571-572
for DB2 Text Search,
590-591
encoding (XML). See also
Unicode
code page conversions
avoiding, 601
examples of, 602-605
code pages, selecting, 27
data loss, avoiding, 606
embedded SQL application
development and, 639
external encoding,
599-601
internal encoding,
599-600
non-Unicode database
usage, 601-602
overview, 597
encoding declaration, 599
enforcing validation
with check constraints,
520-523
with triggers, 523-525
entities (XML), 87, 501
entity references, list of 87
Entity-Attribute-Value model
(EAV). See Name/Value Pairs
error codes
explained, 258-264
SQL0104N, 500
SQL0242N, 277
SQL0401N, 186
SQL0443N 81
SQL0544N, 521
SQL0545N, 521
SQL0551N, 500
SQL1354N, 548
SQL1407N, 111
SQL16001N, 259
SQL16002N, 146,
259-260, 605
SQL16003N, 156,
169-170, 210, 213,
249, 260-261
SQL16005N, 261-262
SQL16011N, 263
SQL16015N, 262-263
SQL16061N, 144, 169, 211,
263-264, 551
SQL16075N, 136, 264
SQL16085N, 336, 339,
341-342
SQL16088N, 467
SQL16103N, 601
SQL16110N 87
SQL16168N, 600
SQL16168N 85
SQL16193N, 440
SQL16196N, 517
SQL16267N, 318
SQL16271N, 318
SQL20329N, 491
SQL20335N, 514
SQL20340N, 491
SQL20345N, 294, 337
SQL20353N, 186
SQL20412N, 604
SQL20429N, 606
SQL20432N, 498
SQLCODE -904, 71
SQLCODE 16002, 705
SQLSTATE 2200M, 519
error handling
for registered XML
Schemas, 490-491
in stored procedures,
551-553
for validation/parsing
errors, 525-529
escaping
ampersand (&), 88
less-than character (<), 87
quotes (’), 77, 88, 571
special characters, 87-89
except operator, 155
exchanging data. See data
exchange
736
executing
stored procedures, 547
triggers, 547
UDFs, 547
execution plans, 395-396
obtaining
with db2exfmt
command-line tool,
397-399
with SPUFI, 410-411
with Visual Explain tool,
400-401,
411-413
operators, list of,
401-403, 413-414
of stored procedures,
555-556
usage examples, 403-409,
414-416
existential semantics, 241,
254, 377
logical expressions
and, 149
in XPath, 147-148
existing XML documents,
validating, 535-538
in DB2 for z/OS, 543
expanded names of XML
elements/attributes,
441-444
explain facility
in DB2 for Linux, UNIX,
and Windows, 396-409
db2exfmt command-line
tool, 397-399
execution plan
operators, 401-403
explain tables,
396-397
usage examples,
403-409
Visual Explain tool,
400-401
in DB2 for z/OS, 409-416
execution plan
operators, 413-414
explain tables,
409-410
Index
SPUFI, 410-411
usage examples,
414-416
Visual Explain tool,
411-413
explain tables
in DB2 for Linux, UNIX,
and Windows, 396-397
in DB2 for z/OS, 409-410
EXPLAIN utility, 9
explaining stored procedure
statements, 555-556
explicit serialization, 83, 294
EXPORT command, 98-106
exporting XML documents,
98-106
to dedicated directories,
102-104
fragments of documents,
104-105
to multiple files, 100-102
to single file, 98-100
with XML Schema
information, 105-106
extensibility
in design decisions, 17
of XML, 1
eXtensible Markup Language.
See XML
eXtensible Stylesheet
Language Transformation.
See XSLT
eXtensible Stylesheet
Language. See XSL
external DTDs, 501
external encoding of character
data, 619
external XML encoding,
599-601
extracting
repeating XML element values, 557-558
XML element/attribute
values, 557
F
-f CLP option, 708
federating XML documents,
120-121
FETCH operator (execution
plans), 401
file paths. See paths
file system navigation, 133
files, inserting XML
documents from, 79-82
FILTER operator (execution
plans), 401
filtering conditions on
XMLQUERY function, 587
fine granularity of XML
documents, 23
flexibility
in design decisions, 17
of XML Schema, 5-6
FLWOR expressions,
190-196
comparing with XPath and
SQL/XML, 196-202
for and let clauses,
compared, 193-194
for and let clauses, nested,
195-196
handling repeating/
missing XML nodes, 342
join queries in, 247
in SQL/XML, 201-202
syntax of, 191-193
where and order by
clauses, 194
for clause (FLWOR
expressions)
let clause versus, 193-194
nested, 195-196
fragments of XML documents,
exporting, 104-105
full names of XML
elements/attributes, 441,
443-444
full-text searches
DB2 for z/OS, 596
DB2 Net Search Extender
administration
commands, list of,
594-595
Index
altering text
indexes, 580
creating text indexes,
572-579
DB2 Text Search versus,
568-570
disabling databases
for, 572
enabling databases for,
571-572
performing searches,
581-590
reorganizing text
indexes, 579-580
updating text indexes,
579-580
DB2 Text Search, 590
administration
commands, list of,
594-595
creating text indexes,
591-592
disabling databases
for, 591
enabling databases for,
590-591
performing searches,
592-594
sample table for examples,
570-571
fullselect (SQL), 555
functions
XPath, 155
XQuery, 214-226
Boolean functions, 226
date and time functions,
224-226
namespace and node
functions, 222-224
numeric and aggregation
functions,
218-220
sequence functions,
220-222
string functions,
215-218
fuzzy searches, 586-587
737
G
general comparison operators
in XPath, 156
generated column, 557
GENROW operator (execution
plans), 402
GET SNAPSHOT
command, 425
global declarations in XML
Schemas, 478
global indexes, 58
global sequences,
performance optimization,
256-257
GRANT command, 499
granting XML Schema usage
privileges, 499-500
granularity of XML
documents, 22-24, 428, 433
grouping XML data, 233-239.
See also aggregation
in SQL/XML versus
XQuery, 237-239
XMLTABLE function,
234-236
GUI for defining SQL/XML
publishing functions,
289-290
H
HADR (High Availability
Disaster Recovery), 121
hashed indexes, 368
help. See technical support
hierarchical data, 12
hierarchical format, XML
document trees, 28-30
High Availability Disaster
Recovery (HADR), 121
host variables, 183-184,
613-614
INSERT statements 78
performance considerations,
434
HSJOIN operator (execution
plans), 402
HTML. See XML to HTML
transformation
hybrid storage, 24-25, 299,
303-305
with stored procedures,
550-553
I
IBM Data Server Driver for
JDBC and SQLJ. See JCC
IBM Data Studio Developer,
652-655
IBM Database Add-ins for
Visual Studio, 656
IBM OmniFind Text
Search Server for DB2
for z/OS, 596
IBM pureXML Technical
Mastery Test, 675
ibm_db2 PHP extension, 647
identifiers for XML Schemas,
483, 516
ignoring stop words, 578
implicit parsing, 516
implicit serialization,
83, 294
implicit XML parsing, 354
IMPORT command, 106-109
input files and, 107-108
LOAD command
versus, 106
performance tips, 108-109
triggers and, 573
validating XML documents,
116, 530-534
against default XML
Schemas, 532
against multiple XML
Schemas, 530-532
against single XML
Schema, 530-531
overriding XML Schema
references, 532-534
schema location
hints, 534
738
importing
schema documents in XML
Schemas, 479-482
XML documents, 106-109
input files and, 107-108
performance tips,
108-109
in-scope namespaces,
445, 455
in-scope-prefixes
function, 445
including schema documents in
XML Schemas, 479-482
index directories, locating with
work directories, 574
index eligibility, 373-374
data types and, 374-375
parent steps and, 385-386
text nodes and, 375-376
wildcards and, 376-377
XML namespaces and,
458-459
XMLQUERY and, 385
XQuery let and return
clauses, 386-387
indexes
catalog tables for,
671-672
logical, 664-666
path indexes, 663
physical, 664-666
on range-partitioned
tables, 58
regions indexes, 663
reorganization, 54
text indexes (DB2 Net
Search Extender)
altering, 580
creating, 572-579
reorganizing, 579-580
updating, 579-580
user-defined XML,
664-666
on XML documents, 8
indexes (XML)
best practices, 432-433
cardinality of, 363
Index
creating
with DB2 Control
Center, 366-367
with XML namespaces,
456-460
data types for, 367-372
DATE, 369
DECFLOAT, 369
DOUBLE, 369
rejecting invalid
values, 371-372
selecting, 369-371
TIMESTAMP, 369
VARCHAR HASHED,
368-369
VARCHAR(n), 367-368
DB2 for Linux, UNIX,
and Windows implementation, 387-390
defining, 362-367
explain facility. See explain
facility
join predicates and, 379-383
lean indexes, 365
logical and physical
indexes, 389-390
on non-leaf elements,
383-384
parent steps and, 385-386
path indexes for, 387-389
query predicates and,
373-379
relational indexes
versus, 361
statistics, 390-393
for structural predicates,
377-379
unique indexes, 364-365
in XMLQUERY, 385
XQuery let and return
clauses, 386-387
industry standard XML
Schemas, custom XML
Schemas versus, 474-476
InfoSphere Data Architect,
289-290
InfoSphere Federation
Server, 120
inlining, 41-48, 429-430
benefits of, 47-48
drawbacks of, 48
monitoring and
configuring, 43-47
viewing percentage of,
661-662
XML space management
example, 54-57
input, sequences as, 130-131
input files, IMPORT command
and, 107-108
input parameters (CLP), text
files as, 708
input parameters (XML) in
stored procedures, 548
insert operations, modifying
XML documents in,
349-350
INSERT statement, 76-79
copying XML
documents, 86
preserving whitespace,
92-93
validation, 514-517
in DB2 for z/OS,
541-542
XMLTABLE function,
shredding XML
documents with, 301-306
insert triggers, 562-563
inserting
constructed XML data into
XML columns, 294-295
nodes in XML documents
with namespaces,
468-469
XML data from .NET
applications, 635
XML documents, 76-82
from files, 79-82
INSERT statement,
76-79
XML nodes, 335-340
insignificant whitespace 90
instances of the data
model, 128
Index
integer division in
XQuery, 214
integration, resources for information, 726
internal DTDs, 501
internal encoding
of binary data, 618
XML encoding, 599-600
intersect operator, 155
INTERSECT operator
(execution plans), 413
invalid XML documents,
retaining, 519-520
invalid XML index data type
values, rejecting, 371-372
ISO-8859-1, Chinese
characters in (code page
conversion example),
602-603
items (XQuery Data
Model), 129
J
Japanese literal values in nonUnicode database
(code page conversion
example), 605
Java application
development, 615-631
JDBC 3.0, XML support in,
615-619
JDBC 4.0, 9
example usage,
621-627
XML support in,
619-621
pureQuery, 629-631
XML data binding, 629
XML documents, creating
from application data,
627-628
Java applications
inserting XML documents
from, 78-79
registering XML Schemas
from, 488
739
JCC (Java Common
Client), 615
JDBC
registering XML Schemas
with, 488
support for, 615
JDBC 3.0, XML support in,
615-619
JDBC 4.0, 9
example usage, 621-627
XML support in, 619-621
join predicates, XML indexes
and, 379-383
join queries, 239
outer joins, 250-252
in SQL/XML, 242-247
XML-to-relational joins,
248-250
in XQuery, 240-242
joins
best practices, 431
XML versus relational data,
7, 241
K
key cardinalities in XML
indexes, 390
Key-Value Pairs (KVP). See
Name/Value Pairs
known whitespace 90
Korean character code page
conversion example, 605
KVP (Key-Value Pairs). See
Name/Value Pairs
L
last function (XQuery), 222
last( ) function, 153
leading zeros in conditional
XML element construction,
285-286
leaf elements, 383
lean XML indexes, 365
left outer joins, 250
legacy functions
(SQL/XML), 290
less-than character (<),
escaping, 87
let clause (FLWOR expressions)
for clause versus, 193-194
nested, 195-196
let clause (XQuery), index
eligibility and, 386-387
Linux. See DB2 for Linux,
UNIX, and Windows
list tablespaces command, 51
LIST UTILITIES
command, 427
LISTDEF utility, 69
LOAD command, 109-111,
114-116
IMPORT command
versus, 106
triggers and, 573
validating XML
documents, 116, 530-534
against default XML
Schemas, 532
against multiple XML
Schemas, 530-532
against single XML
Schema, 530-531
overriding XML Schema
references, 532-534
schema location
hints, 534
LOAD QUERY command, 428
loading XML documents
in DB2 for Linux, UNIX,
and Windows, 109-111
in DB2 for z/OS, 114-116
LOB storage
pureXML storage versus,
10-11
for XML data, 10
local declarations in XML
Schemas, 478
local indexes, 58
local names of XML
elements/attributes,
441-444
local-name function
(XQuery), 223
740
locale-aware Unicode
collations, 252
locators, 577
locking XML documents, 9
logical expressions, 190
in XPath, 148-151
logical indexes, 664-666
XML indexes, 389-390
loops in stored procedures,
553-554
M
manipulating XML data. See
XML manipulation
MapForce, 657
mapping
path indexes for XML
indexes, 387-389
paths to pathIDs, 663
relational data to XML data,
GUI-based
definition, 289-290
tag names to stringIDs,
31-33
XML data to relational data.
See annotated schema
shredding
XML Schema pairs, 533
XML tags to
stringIDs, 662
marshalling, 629
MDC (multidimensional
clustering), 58-59
medium granularity of XML
documents, 22
memory consumption,
limiting in DB2 for
z/OS, 71
metadata
distinguishing from data,
19-21
for data exchange, 13
missing elements (relational
data), converting to XML
data, 274-275. See also
optional elements
Index
missing XML nodes,
handling, 340-343
mixed content, 143
in XML document trees,
29-30
modifying. See also updating
multiple XML nodes,
343-346
XML documents
in insert operations,
349-350
in queries, 346-349
in update cursors,
350-351
with XQuery Update
Facility, 324-326
monitoring
performance, 424
of database utilities,
427-428
with snapshot monitor,
424-427
XML inlining, 43-47
moving. See exporting; importing; inserting; loading;
unloading
multidimensional clustering
(MDC), 58-59
multiple documents,
constructing from queries,
253-254
multiple files, exporting XML
documents to, 100-102
multiple for/let clauses
(FLWOR expressions),
195-196
multiple namespaces in XML
documents, 440-441
multiple nesting levels, XML
construction with, 206-207
multiple node values in XML
documents, replacing,
328-329
multiple relational rows,
constructing XML
documents from, 277-280
multiple relational tables,
constructing XML
documents from, 281-283
multiple repeating elements,
returning, 174-176
multiple schema documents in
XML Schemas, 479-482
multiple table spaces,
performance and, 37
multiple XML columns
in DB2 for z/OS, 64
populating, 108
multiple XML documents,
shredding, 315-318
multiple XML namespaces,
querying XML documents
with, 454-456
multiple XML nodes,
modifying, 343-346
multiple XML Schemas,
validation
with LOAD and IMPORT
utilities, 530-532
with triggers, 524
N
Name/Value Pairs (NVP),
20-21
namespace functions
in XQuery, 222-224
namespaces (XML), 437-439
constructing XML data
with, 460-463
creating indexes with,
456-460
declaring, 4, 439-441
for XSLT, 356
default, 442-444
full-text searches and,
588-590
querying XML data with,
447-456
updating XML data with,
463-469
usage examples, 444-447
Index
XML indexes and, 432
in XML sample database
tables, 710
naming conventions
XML storage in DB2
for z/OS, 64-65
XML tags, 4
nested for/let clauses (FLWOR
expressions), 195-196
nested predicates, 150
nested XQuery functions, 217
nesting
SQL and XQuery, 257-258
XML tags, 3
XMLELEMENT functions,
270-273
nesting levels, XML
construction with, 206-207
.NET application
development, 631-636
ADO.NET data providers,
list of, 631
inserting XML data
from, 635
manipulating XML data in,
633-635
querying XML data in,
632-633
XML Schema and DTD
handling, 636
Net Search Extender. See DB2
Net Search Extender
node functions in XQuery,
222-224
node tests, 133
NodeID index, 62
nodes. See also partitioned
databases
attribute nodes, attribute
values versus, 136
context nodes, 136, 139
descendant nodes, 141
document nodes,
constructing, 294-295
inserting/replacing in XML
documents with namespaces, 468-469
741
renaming
in XML documents with
default namespaces,
467-468
in XML documents with
prefixed namespaces,
465-467
text nodes, index
eligibility and, 375-376
types of, 28
values, replacing
with computed values,
329-331
multiple values,
328-329
with parameter
markers, 328
in XML documents
deleting, 333-334
inserting, 335-340
modifying multiple,
343-346
repeating/missing,
340-343
replacing, 331-332
XQuery Data Model, 129
non-leaf elements, 30, 134
XML indexes on, 383-384
non-Unicode databases
avoiding data loss in, 606
for XML data management,
601-602
normalization, 7
of business objects, 12
not equal (!=) comparison
operator, not( ) function
versus, 150
NOT operator in full-text
searches, 584
not( ) function, 148, 150
not equal (!=) comparison
operator versus, 150
NSE. See DB2 Net Search
Extender
NULL, setting XML columns
to, 82
NULL elements (relational
data), converting to XML
data, 274-275
“NULL on NULL” behavior,
274
numbering rows based on
repeating elements,
173-174
NUMBEROFMATCHES
scalar function, 581-583
numeric comparisons, string
comparisons versus, 144,
211-212
numeric functions in XQuery,
218-220
NVP (Name/Value Pairs),
20-21
O
octets, 188
offloading XML parsing in
DB2 for z/OS, 72-73
OmniFind Text Search Server
for DB2 for z/OS, 596
one-to-many relationships,
XML elements, 3
online table moves, 40
operators (for execution
plans), 395
list of, 401-403, 413-414
usage examples, 403-409,
414-416
optimization of queries,
253-258
between predicates,
254-256
large global sequences,
256-257
nesting SQL and XQuery,
257-258
single versus multiple
document construction,
253-254
optional attributes (XML), 13
742
optional elements (XML)
handling in XMLTABLE
function, 167-168
schema flexibility of, 5
OR operator, 149-150
in full-text searches,
583-584
order by clause (FLWOR
expressions), 194
ordering result sets by XML
values, 186-187
outer joins, 250-252
output, sequences as, 130-131
overriding XML Schema
references in LOAD and
IMPORT utilities, 532-534
<oXygen/>, 658-659
P
page size
of table spaces, 36-39
for XML storage, 429
page-level sampling, 419
pairs (XML Schemas),
mapping, 533
parameter markers, 183-184,
613-614
INSERT statements 78
performance
considerations, 434
replacing values with, 328
parent axis, 157
parent of current directory (file
system navigation), 133
parent steps
index eligibility and,
385-386
in XPath, 151-153
parsing, 30
avoiding in application
layer, 610-612
error handling, 525-529
implicit parsing, 516
pureQuery and, 631
valid versus well-formed
XML documents, 473
Index
XML documents, 9
offloading in DB2
for z/OS, 72-73
performance
considerations, 434
with special
characters 88
partial shredding, 299
partition elimination, 57
PARTITION operator
(execution plans), 413
partitioned databases, 59-60
partitioning, range, 57-58
path expressions, 190
path indexes, 35, 58, 663
for XML indexes, 387-389
pathIDs, mapping to paths, 663
paths
in IMPORT command, 107
mapping to pathIDs, 663
storage paths for text
indexes, 573-574
pdo_ibm PHP extension, 647
percent sign (%) in wildcard
searches, 583
performance
best practices, 428-435
explain facility
in DB2 for Linux,
UNNIX, and Windows,
396-409
in DB2 for z/OS,
409-416
importing XML
documents, 108-109
LOAD command, 110
mapping tag names to
stringIDs, 32
monitoring, 424
of database utilities, 427428
with snapshot monitor,
424-427
multiple table spaces
and, 37
partition elimination, 57
query optimization, 253-258
between predicates,
254-256
large global sequences,
256-257
nesting SQL and
XQuery, 257-258
single versus multiple
document construction,
253-254
role in design decisions, 16
text indexes and, 574
of XSLT processing, 353
Perl application
development, 650-651
PHP application
development, 647-649
physical indexes, 664-666
physical XML indexes,
389-390
pipe (|) character
union of sequences, 154
as XPath union
operator, 585
PL/1 applications with embedded SQL, 643-644
plain SQL (XML data
queries), 127
position( ) function, 154
positional predicates in XPath,
153-154
positional relationships in
search conditions, 588
positioning
inserted XML attributes,
336-337
inserted XML elements,
335-336
predicates
in FLWOR expressions, 192
join predicates, XML
indexes and, 379-383
query examples of,
198-199
query predicates, XML
indexes and, 373-379
structural predicates, XML
indexes for, 377-379
Index
usage with SQL/XML,
177-181
common mistakes,
181-182
XML construction with,
204-205
in XPath, 142-146
dot notation, 151-153
existential semantics,
147-148
logical expressions,
148-151
positional predicates,
153-154
prefixed namespaces (XML),
438-439
mixing with default XML
namespaces, 442
renaming nodes in,
465-467
PreparedStatement interface
(JDBC 3.0), 618
preserving whitespace, 91-93
changing default, 93-94
during import, 108
validation and, 517
pretty print, CLP option
for, 707
primary schema
documents, 481
privileges for XML Schema
usage, granting/revoking,
499-500
processing instruction nodes,
constructing, 290
product table (XML sample
database), contents of,
712-713
profiling stored
procedures, 556
prototyping, XML flexibility
for, 612-613
proximity searches, 586
publishing functions
(SQL/XML), 160, 268-290
combining with XQuery
constructors, 292
743
empty, missing, NULL
elements, 274-275
GUI-based definition,
289-290
legacy functions, 290
list of, 268
XML namespaces and,
460-462
XMLAGG, 277-283
XMLAGG, XMLCONCAT,
XMLFOREST compared,
284
XMLATTRIBUTES,
275-277
XMLCOMMENT, 290
XMLCONCAT, 270
XMLELEMENT, 269-273
XMLFOREST, 272-273
XMLGROUP, 286-289
XMLPI, 290
XMLROW, 286-289
XMLTEXT, 290
publishing XML documents,
118-119
purchaseorder table (XML
sample database), contents of,
713-714
pureQuery, 629-631
pureXML
for application
development, benefits
of, 610-613
functionality of,
xxiii-xxiv, 7-10
quiz, 675-702
XML data storage methods
versus, 10-11
Q
Q Apply, 119
-q CLP option, 527, 706
Q replication, 119
queries. See also querying
XML data
against XSR (XML Schema
Repository), 508-510
editing in Data Studio
Developer, 654
query predicates, XML indexes
and, 373-379
querying XML data, 8-9
best practices, 430-432
case-insensitive queries,
252-253
error codes, 258-264
execution plans, 395-396
explain facility
in DB2 for Linux,
UNIX, and Windows,
396-409
in DB2 for z/OS,
409-416
grouping and aggregation,
233-239
in SQL/XML versus
XQuery, 237-239
within and across
documents, 236-237
XMLTABLE function,
234-236
join queries, 239
in SQL/XML, 242-247
in XQuery, 240-242
outer joins, 250-252
XML-to-relational joins,
248-250
methods of, 126-127
in .NET applications,
632-633
overview, 126-128
performance optimization,
253-258
between predicates,
254-256
large global sequences,
256-257
nesting SQL and
XQuery, 257-258
single versus multiple
document construction,
253-254
744
Index
sample data for examples,
131-132
SQL/XML, 159-160
converting XML values
to binary SQL types,
187-188
dynamic XPath
expressions, 185-186
host variables,
183-184
namespace declarations,
451
ordering result sets,
186-187
overview, 160
parameter markers,
183-184
performance considerations, 434
retrieving XML
documents, 161-165
retrieving XML values in
relational format,
165-176
XPath predicate usage,
177-182
with XML namespaces,
447-456
XPath
axes, 157
comparison operators,
156-157
construction of
sequences, 154-155
data( ) function,
134-135
dot notation, 151-153
double slash (//),
141-142
empty results, reasons
for, 134
executing in DB2,
137-140
existential semantics,
147-148
file system navigation
analogy, 133
functions, 155
logical expressions,
148-151
node tests, 133
positional predicates,
153-154
predicates, 142-146
simple query examples,
133-136
slash (/), 141
string( ) function, 135
text( ) node test, 134
unabbreviated
syntax, 157
union of sequences,
154-155
wildcards, 140-141
XQuery
arithmetic expressions,
212-214
attribute expressions
in XML construction,
206
comparing FLWOR
expressions, XPath,
SQL/XML, 196-202
computed value
XML construction,
202-204
conditional expressions
in XML
construction, 205
data types, cast
expressions, type
errors, 208-212
direct XML
construction, 202
embedding SQL in,
227-228
FLWOR expressions,
191-196
functions, 214-226
modifying XML
documents in,
346-349
multiple nesting levels in
XML construction,
206-207
namespace and node
functions, 445
namespace declarations,
448-450
overview, 190
predicates in XML
construction,
204-205
SQL functions and
UDFs in, 229-230
XML aggregation in
XML construction,
207-208
XQuery Data Model,
128-131
sequence construction,
128-130
sequence input/output,
130-131
question mark (?) as wildcard
character, 594
questions. See technical
support
quiz on pureXML, 675-702
quotes (’), escaping, 77,
88, 571
R
range partitioning, 57-58
rapid prototyping, 612-613
RDA (Rational Data
Architect), 289
REAL TIME STATISTICS
utility, 66
REC2XML function
(SQL/XML), 290
RECOVER INDEX utility, 66
RECOVER TABLESPACE
utility, 66
referencing
XML columns. See XML
column references
XML Schemas, 484
referential integrity of XML
documents, 8
regions, 34-35
page size and, 36
Index
regions indexes, 34, 58, 663
REGISTER XMLSCHEMA
command, 311, 484
registering
annotated schemas, 311-312
DTDs, 501
XML Schemas, 483-491
in CLP (command-line
processor), 484-486
error handling for,
490-491
identifiers, 483
with JDBC, 488
with shared schema
documents, 489-490
steps in, 483
with stored procedures,
486-487
relational data
converting to XML
data, 267
inserting in XML
columns, 294-295
with SQL/XML
publishing functions,
268-290
XML declarations for,
292-294
with XQuery constructors, 290-292
converting XML
documents to
advantages/
disadvantages, 297-301
with annotated schema
shredding, 306-318
with XMLTABLE
function, 301-306
generating Java classes
from, 629-631
hybrid storage, 24-25
XML versus, 4-7
when to use XML data,
11-13
XML-to-relational joins,
248-250
745
relational format, retrieving
XML values in, 165-176
relational indexes, XML
indexes versus, 361
relational joins, XML joins
versus, 241
relational views over XML
data, 305-306
relationships,
one-to-many, 3
removing. See also deleting;
stripping
validation from XML
documents, 540
XML Schemas from XSR,
492-493
renaming
nodes
in XML documents with
default namespaces,
467-468
in XML documents with
prefixed namespaces,
465-467
XML elements/attributes,
334-335
REORG command, 53-54,
68-69
reorganizing
text indexes with DB2
Net Search Extender,
579-580
XML indexes, 433
XML space management
example, 54-57
XML table data, 53-54,
68-69
repeating elements (XML), 3
extracting values of,
557-558
numbering rows based on,
173-174
returning
multiple elements,
174-176
with XMLQUERY
function, 164-165
with XMLTABLE
function, 169-173
schema flexibility of, 5
repeating XML nodes,
handling, 340-343
replace expression
(XQuery), 331
replacing. See also updating
nodes in XML documents
with namespaces,
468-469
XML attribute values,
327-328
XML documents, 322-324
XML element values,
326-327
XML node values
with computed values,
329-331
multiple node values,
328-329
with parameter
markers, 328
XML nodes, 331-332
replicating XML documents,
118-119
REPORT TABLESPACESET
utility, 67-68
reserved characters. See
special characters
RESET MONITOR
command, 425
resources for information,
717-726
on Altova XML tools, 658
response time for change
requests, 613
result set cardinalities,
200-201
result sets, ordering by XML
values, 186-187
ResultSet interface
(JDBC 3.0), 615
retaining
invalid XML documents,
519-520
whitespace in CLP, 527
746
retrieving
XML documents, 83-85,
161-165
XML values in relational
format, 165-176
return clause (XQuery), index
eligibility and, 386-387
RETURN operator (execution
plans), 402
returning element values
without XML tags, 163-164
revised XML Schemas. See
XML Schema evolution
REVOKE command, 500
revoking XML Schema usage
privileges, 499-500
RIDSCN operator (execution
plans), 402
right outer joins, 251
root elements (XML), 4, 28
row-level sampling, 419
rows
generating from XML data,
165-166
numbering based on
repeating elements,
173-174
RPD operator (execution
plans), 402
RUNSTATS INDEX utility, 67
RUNSTATS TABLESPACE
utility, 67
RUNSTATS utility, 9, 50, 417,
666
in DB2 for Linux, UNIX,
and Windows, 418-419
in DB2 for z/OS, 417-418
S
sample database. See XML
sample database
sampling in statistics
collection, 419
SAX (Simple API for XML)
parsers, 611
Index
scalar functions, 162, 200, 557
for full-text searches,
581-583
scalar subselects, 282
schema documents, 476
multiple schema
documents in XML
Schemas, 479-482
sharing between XML
Schemas, 489-490
schema location hints in LOAD
and IMPORT
utilities, 534
schema names, comparison
with XML namespaces, 438
schema validation. See
validation
schemas (XML). See also
XML Schema
best practices, 434
volatility of, 12
SCORE scalar function,
581-583
search conditions. See also
predicates
parts of, 582
positional relationships in,
588
search term (in search
conditions), 582
searches. See full-text searches
section (in search
conditions), 582
SELECT statement, retrieving
XML documents, 83-85
selecting
code pages, 27
XML index data types,
369-371
self axis, 157
self-describing data format,
XML as, 19
self-joins, 228
semicolon (;)
in namespace
declarations, 448
in stored procedures, 549
sequence constructors, 175
sequence expressions, 190
sequence functions in XQuery,
220-222
sequences, 550
constructing, 128-130
global sequences,
performance optimization,
256-257
as input/output, 130-131
in XPath, 154-155
serialization, 30, 83, 138
SET INTEGRITY
command, 110
SET INTEGRITY PENDING
status, 110
sharing schema documents
between XML Schemas,
489-490
SHIP operator (execution
plans), 402
shredding
pureXML storage versus,
10-11
XML data with UDFs,
558-559
XML documents, 10
advantages/disadvantages of, 297-301
with annotated schema
shredding, 306-318
with XMLTABLE
function, 301-306
sibling branches, search
conditions on, 588
significant whitespace 90
Simple API for XML (SAX)
parsers, 611
SimpleXML PHP
extension, 647
single documents,
constructing from queries,
253-254
single quotes (’), escaping, 77,
88, 571
size. See granularity
Index
slash (/)
in file system
navigation, 133
in XPath, 141
in XPath predicates, 145
snapshot monitor, 424-427
snapshot semantics, 343-345
SNAPTAB_REORG
administrative view, 428
SNAPUTIL administrative
view, 427
SNAPUTIL_PROGRESS
administrative view, 427
SORT operator (execution
plans), 402
sparse attributes, 13
special characters, escaping,
87-89
splitting XML documents,
116-118
SPUFI
execution plans,
obtaining, 410-411
viewing XML
documents, 705
SQL. See also SQL/XML
embedding in XQuery, 127,
227-228
nesting with XQuery,
257-258
scalar functions for
full-text searches,
581-583
stored procedures. See
stored procedures
for XML data queries, 127
SQL functions in XQuery,
229-230
SQL statements, embedding
XPath/XQuery in, 127
SQL/XML, 8, 159-160
comparing with FLWOR
expressions and XPath,
196-202
converting XML values
to binary SQL types,
187-188
747
dynamic XPath
expressions, 185-186
FLWOR expressions in,
201-202
grouping queries in,
XQuery versus, 237-239
host variables, 183-184
INSERT statement,
validation on, 514-517
join queries, XML-to-XML
joins, 242-247
namespace declarations,
451
ordering result sets,
186-187
overview, 160
parameter markers,
183-184
performance considerations,
434
publishing functions,
268-290
combining with XQuery
constructors, 292
empty, missing, NULL
elements, 274-275
GUI-based definition,
289-290
legacy functions, 290
list of, 268
XML namespaces and,
460-462
XMLAGG, 277-283
XMLAGG, XMLCONCAT, XMLFOREST
compared, 284
XMLATTRIBUTES,
275-277
XMLCOMMENT, 290
XMLCONCAT, 270
XMLELEMENT,
269-273
XMLFOREST, 272-273
XMLGROUP, 286-289
XMLPI, 290
XMLROW, 286-289
XMLTEXT, 290
UPDATE statement,
validation on, 518-519
XML aggregation, XML
construction with,
207-208
XML documents,
retrieving, 161-165
XML values, retrieving
in relational format,
165-176
XPath and XQuery
versus, 201
XPath predicate usage,
177-181
common mistakes,
181-182
SQL0104N error code, 500
SQL0242N error code, 277
SQL0401N error code, 186
SQL0443N error code 81
SQL0544N error code, 521
SQL0545N error code, 521
SQL0551N error code, 500
SQL1354N error code, 548
SQL1407N error code, 111
SQL16001N error code, 259
SQL16002N error code, 146,
259-260, 605
SQL16003N error code, 156,
169-170, 210, 213, 249,
260-261
SQL16005N error code,
261-262
SQL16011N error code, 263
SQL16015N error code,
262-263
SQL16061N error code, 144,
169, 211, 263-264, 551
SQL16075N error code,
136, 264
SQL16085N error code, 336,
339, 341-342
SQL16088N error code, 467
SQL16103N error code, 601
SQL16110N error code 87
SQL16168N error code, 600
SQL16168N error code 85
748
SQL16193N error code, 440
SQL16196N error code, 517
SQL16267N error code, 318
SQL16271N error code, 318
SQL20329N error code, 491
SQL20335N error code, 514
SQL20340N error code, 491
SQL20345N error code,
294, 337
SQL20353N error code, 186
SQL20412N error code, 604
SQL20429N error code, 606
SQL20432N error code, 498
SQLCODE -904 error code, 71
SQLCODE 16002 error
code, 705
SQLSTATE 2200M error
code, 519
SQLXML interface
(JDBC 4.0), 619-621
SQLXML Java data type, 9
star. See asterisk (*)
starts-with function
(XQuery), 218
statement heap, size of, 432
statistics
db2cat utility, 419-423
RUNSTATS utility, 417
in DB2 for Linux,
UNIX, and Windows,
418-419
in DB2 for z/OS,
417-418
for XML indexes, 390-393
StAX (Streaming API for
XML) parsers, 611
stemming in full-text searches,
586
steps (file system
navigation), 133
stop words, ignoring, 578
storage. See also data storage
of business objects, 612
for compliance 94
hybrid XML data storage
with stored procedures,
550-553
Index
pureXML versus
alternative XML storage
methods, 10-11
of XML document trees,
30-33
XML storage, 429-430
in DB2 for Linux,
UNIX, and Windows,
33-41
in DB2 for z/OS, 60-73
inlining, 41-48
MDC (multidimensional
clustering), 58-59
partitioned databases,
59-60
range partitioning, 57-58
space consumption of,
51-53
space management
example, 54-57
storage objects
catalog tables for, 667-670
in DB2 for Linux, UNIX,
and Windows, types of,
33-35
in DB2 for z/OS, types of,
61-62
storage paths for text indexes,
573-574
stored procedures, 548-556
benefits of, 547
for dynamic XPath
expressions, 185-186
executing, 547
for hybrid XML data
storage, 550-553
loops and cursors,
553-554
registering XML Schemas
with, 486-487
retaining invalid XML
documents, 519-520
for shredding XML
documents, 313-315
testing, 555-556
updating XML
elements/attributes,
554-555
Streaming API for XML
(StAX) parsers, 611
string comparisons
case-insensitivity,
252-253
date comparisons versus,
210-211
numeric comparisons
versus, 144, 211-212
string functions in XQuery,
215-218
string( ) function, 135
string-join function, 171, 216
stringIDs, mapping
tag names to, 31-33
to XML tags, 662
stripping whitespace, 78
changing default, 93-94
structural predicates, 147, 153
XML indexes for, 377-379
structure of XML documents,
viewing, 703-705
style sheets. See XSLT
StyleVision, 657
Stylus Studio, 659
subselects, 282
substring-after function
(XQuery), 217
synchronous index
maintenance, 361
syntax of FLWOR
expressions, 191-193
SYSCAT.COLUMNS catalog
view, 661-662
SYSCAT.INDEXES catalog
view, 663-664
SYSCAT.INDEXXMLPATTERNS catalog view,
664-666
SYSCAT.XDBMAPGRAPHS
catalog view, 504, 508, 667
SYSCAT.XDBMAPSHREDTREES catalog view,
504, 508, 667
SYSCAT.XSROBJECTAUTH
catalog view, 504, 507, 667
Index
SYSCAT.XSROBJECTCOMPONENTS catalog
view, 504, 506, 667
SYSCAT.XSROBJECTDEP
catalog view, 504, 507, 667
SYSCAT.XSROBJECTHIERARCHIES catalog
view, 504, 506, 667
SYSCAT.XSROBJECTS
catalog view, 503, 505, 667
SYSIBM.SYSINDEXES
catalog table, 671
SYSIBM.SYSKEYTARGETS
catalog table, 671-672
SYSIBM.SYSTABLES catalog
table, 668-670
SYSIBM.SYSTABLESPACE
catalog table, 670
SYSIBM.SYSXMLPATHS
catalog view, 663
SYSIBM.SYSXMLRELS
catalog table, 667-668
SYSIBM.SYSXMLSTRINGS
catalog table, 668
SYSIBM.SYSXMLSTRINGS
catalog view, 662-663
SYSIBMTS.TSCOLLECTIONNAMES table, 591
SYSIBMTS.TSCONFIGURATION table, 591
SYSIBMTS.TSDEFAULTS
table, 591
SYSIBMTS.TSINDEXES
table, 591
SYSIBMTS.TSLOCKS
table, 591
SYSIN cards, unloading large
XML documents, 113
SYSSTAT.INDEXES catalog
view, 391
system sampling, 419
System z Application Assist
Processors (zAAP), 71-72
System z Integrated
Information Processors
(zIIP), 71-72
749
T
table functions, 200, 557
table partitioning. See range
partitioning
table spaces
characteristics in DB2 for
z/OS, 63
defined, 34
page size, 36-39
XML storage, 51-53, 429
tables. See also catalog tables
online table moves, 40
reorganizing XML data,
53-54, 68-69
XML columns,
dropping, 40
in XML sample database
in DB2 for Linux,
UNIX, and
Windows, 710
in DB2 for z/OS, 710
tags (XML), 1-4
mapping to stringIDs,
31-33, 662
returning element values
without, 163-164
values versus, 19-21
target namespaces, 438
for XML Schemas, 476
TBSCAN operator (execution
plans), 402
technical support, xxvi.
See also resources for
information
TEMP operator (execution
plans), 402
terminating characters
changing, 549
CLP option for, 706
test on pureXML, 675-702
testing stored procedures,
555-556
text files as input parameters
for CLP, 708
text indexes (DB2 Net Search
Extender)
altering, 580
creating, 572-579,
591-592
reorganizing, 579-580
updating, 579-580
text nodes, 29-30
concatenation, 30
constructing, 290
index eligibility and,
375-376
text searches. See DB2 Text
Search; full-text searches
text( ) node test, 134
time functions in XQuery,
224-226
time zone indicators, 210
TIMESTAMP index data type,
369
tokenize function (XQuery),
217-218
TQ operator (execution plans),
402
transform expression
(XQuery), 190, 325
XML attribute values,
replacing, 327-328
XML element values,
replacing, 326-327
XML node values,
replacing
with computed values,
329-331
multiple values,
328-329
with parameter
markers, 328
transformation functions, 579
transforming
XML documents, 352-358
with XQuery, 203
transition variables, 561
transitivity of value
comparisons, 156
translate function
(XQuery), 218
traversing XML
documents, 197
750
trees of nodes, 28-30
storage of, 30-33
triggers, 523-525, 561-564
delete triggers, 563
executing, 547
IMPORT utility and, 573
insert triggers, 562-563
LOAD utility and, 573
update triggers, 564
troubleshooting
empty XPath query
results, 134
SQL/XML predicates,
181-182
truncated XML document
display, 83
avoiding, 138
type constructors, 212
type errors
avoiding in XMLTABLE
function, 168-169
in XQuery, 208-212
U
UCA (Unicode Collation Algorithm), 252
UDFs (user-defined functions),
547, 556-561
benefits of, 547
executing, 547
extracting
repeating XML element
values, 557-558
XML element/attribute
values, 557
inserting XML documents
from files, 79-82
shredding XML data,
558-559
updating XML documents,
559-561
in XQuery, 229-230
unabbreviated syntax in
XPath, 157
underscore character (_) in
wildcard searches, 583
Index
Unicode
explained, 598
locale-aware collations, 252
UTF-8, 27, 597-598
UTF-16, 598
UTF-32, 598
Unicode Byte-Order Mark
(BOM), 599
Unicode Collation Algorithm
(UCA), 252
union keyword, 154
union of sequences in XPath,
154-155
UNION operator (execution
plans), 402
union operator (|) in XPath, 585
UNIONA operator (execution
plans), 414
UNIQUE operator (execution
plans), 402
unique XML indexes, 364-365
Universal Resource Identifier
(URI), 438-439
UNIX. See DB2 for Linux,
UNIX, and Windows
UNLOAD utility, 67, 112
unloading XML documents,
111-114
unmarshalling, 629
update cursors, modifying
XML documents in, 350-351
UPDATE INDEX command
(DB2 Net Search Extender),
579-580
UPDATE operator (execution
plans), 414
UPDATE statement. See also
XQuery Update Facility
replacing XML documents,
322-324
validation, 518-519,
542-543
update triggers, 564
UPDATE XMLSCHEMA
command, XML Schema
evolution with, 495-498
updating. See also modifying;
replacing
text indexes
automatic updates,
574-576
with DB2 Net Search
Extender, 579-580
XML data with XML
namespaces, 463-469
XML documents, 433
in DB2 for z/OS,
351-352
with UDFs, 559-561
XML elements/attributes
with stored procedures,
554-555
upper-case function
(XQuery), 221
upper-case( ) function, 155
“upsert” operations, 342, 560
URI (Universal Resource
Identifier), 438-439
USC-2, 598
user-defined functions.
See UDFs
user-defined XML indexes,
664-666
UTF-8, 27, 597-598
UTF-16, 598
UTF-32, 598
utilities
monitoring performance of,
427-428
XML support in DB2 for
z/OS, 65-67
CHECK DATA utility,
69-70
REORG utility, 68-69
REPORT TABLESPACESET utility,
67-68
V
-v CLP option, 708
valid XML documents
determining XML Schemas
for, 538-540
Index
well-formed documents
versus, 473
validation, 8, 473
application-centric versus
database-centric, 545
checking XML documents
for, 534-535
in DB2 for z/OS, 540-544
DB2 for Linux, UNIX,
and Windows versus,
543-544
for existing XML
documents, 543
with INSERT statement,
541-542
with UPDATE
statement, 542-543
dropped XML Schemas
and, 493
during loading or
importing, 116
during shredding
process, 312
enforcing
with check constraints,
520-523
with triggers, 523-525
error handling, 525-529
of existing XML
documents, 535-538
on INSERT, 514-517
with LOAD and IMPORT
utilities, 530-534
against default XML
Schemas, 532
against multiple XML
Schemas, 530-532
against single XML
Schema, 530-531
overriding XML Schema
references, 532-534
schema location
hints, 534
performance considerations,
434
removing from XML
documents, 540
751
retaining invalid XML
documents, 519-520
space consumption
and, 51
on UPDATE, 518-519
when to use, 474
whitespace preservation
and, 517
XML Schema evolution
with/without, 494-495
value comparison operators in
XPath, 156-157
value predicates, 147, 153
values
attribute values, attribute
nodes versus, 136
of repeating XML
elements, extracting,
557-558
updating in XML
documents with
namespaces, 464-465
of XML attributes
extracting, 557
replacing, 327-328
of XML elements
extracting, 557
replacing, 326-327
of XML nodes, replacing
with computed values,
329-331
multiple values,
328-329
with parameter
markers, 328
values (XML)
converting to binary SQL
types, 187-188
ordering result sets by,
186-187
retrieving in relational
format, 165-176
tags versus, 19-21
values (XQuery Data
Model), 128
VARCHAR HASHED index
data type, 368-369, 433
VARCHAR(n) index data type,
367-368
variables
host variables, 613-614
in stored procedures, 548
viewing XML document
structure, 703-705
views. See catalog views;
relational views
Visual Explain tool, 396
execution plans, obtaining,
400-401, 411-413
Visual Studio, IBM
Database Add-ins for
Visual Studio, 656
volatility of schema, 12
W
WebSphere Replication
Server, 119
well-formed XML documents,
4, 76
valid documents
versus, 473
where clause (FLWOR
expressions), 194
whitespace
in XML documents, 89-94
changing default preservation option, 93-94
data storage for
compliance, 94
preserving, 91-93
types of, 90
preserving
during import, 108
validation and, 517
retaining in CLP, 527
stripping, 78
wildcard searches, 583
wildcards
in full-text searches, 594
index eligibility and,
376-377
752
for namespace queries,
449-450
in XPath, 140-141
Windows. See DB2 for Linux,
UNIX, and Windows
work directories, locating with
index directories, 574
X
XANDOR operator (execution
plans), 402-403
XDBDECOMPXML stored
procedure, 313-314
XDB_DECOMP_XML_
FROM_QUERY stored
procedure, 315-317
XDS (XML Data
Specifiers), 99
XISCAN operator (execution
plans), 403
XIXAND operator (execution
plans), 414
XIXOR operator (execution
plans), 414
XIXSCAN operator (execution
plans), 414
XML (eXtensible Markup
Language), 1
application development.
See application
development
applications, best
practices, 434-435
attributes. See attributes
(XML)
CLP options
list of, 706
usage examples, 706-707
documents. See documents
(XML)
for data exchange, 1
for data storage, 2
pureXML versus
alternative storage
methods, 10-11
Index
indexes. See indexes (XML)
monitoring performance,
424
of database utilities,
427-428
with snapshot monitor,
424-427
namespaces. See namespaces (XML)
performance. See
performance
pureXML. See pureXML
relational data versus, 4-7
when to use XML data,
11-13
reorganizing table data,
53-54, 68-69
schemas, best practices, 434
as self-describing data
format, 19
as standard, xxiii, xxv, 1
tags. See tags (XML)
values
converting to binary
SQL types, 187-188
ordering result sets by,
186-187
retrieving in relational
format, 165-176
tags versus, 19-21
XML 1.0 standard, 2
XML 1.1 standard, 2
XML aggregation. See
aggregation
XML column references. See
column references (XML)
XML columns. See columns
(XML)
XML compression. See
compression
XML construction
with attribute
expressions, 206
with computed values,
202-204
with conditional
expressions, 205
direct XML
construction, 202
with multiple nesting
levels, 206-207
with predicates, 204-205
with XML aggregation,
207-208
with XML namespaces,
460-463
XML data
converting relational data
to, 267
inserting in XML
columns, 294-295
with SQL/XML
publishing functions,
268-290
XML declarations for,
292-294
with XQuery constructors, 290-292
generating rows/columns
from, 165-166
querying. See querying
XML data
statistics collection
in DB2 for Linux,
UNIX, and Windows,
418-419
in DB2 for z/OS,
417-418
with db2cat utility,
419-423
truncation, avoiding, 138
XML data binding
to Java objects, 629
pureQuery and, 631
XML Data Specifiers
(XDS), 99
XML data type, 7-9, 160
XML declarations. See
declarations (XML)
XML document trees, 28-30
storage of, 30-33
XML encoding. See encoding
(XML); Unicode
Index
XML joins, relational joins
versus, 7, 241
XML manipulation
in .NET applications,
633-635
in stored procedures,
548-556
hybrid XML data
storage, 550-553
loops and cursors,
553-554
testing, 555-556
updating XML
elements/attributes,
554-555
with triggers, 561-564
delete triggers, 563
insert triggers,
562-563
update triggers, 564
in UDFs, 556-561
extracting repeating
XML element values,
557-558
extracting XML
element/attribute
values, 557
shredding XML data,
558-559
updating XML
documents, 559-561
XML predicates. See
predicates
XML publishing functions. See
publishing functions
(SQL/XML)
XML sample database
creating, 709-710
customer table contents,
710-712
product table contents,
712-713
purchaseorder table
contents, 713-714
XML Schema, xxiii, 2, 471
annotated schema
shredding, 306-318
753
advantages/disadvantages of, 301
annotating XML
Schema, 306-310
defining annotations
in Data Studio
Developer, 311
registering annotated
schemas, 311-312
shredding multiple XML
documents, 315-318
shredding single XML
documents, 312-315
custom versus industry
standard, 474-476
DB2 for z/OS versus DB2
for Linux, UNIX, and
Windows, 510-511
determining for validated
XML documents,
538-540
DTDs versus, 501
editing in Data Studio
Developer, 653
exporting
information with
db2look utility, 122
XML documents
containing, 105-106
flexibility of, 5-6
granting/revoking usage
privileges, 499-500
identifiers, 516
with multiple schema
documents, 479-482
in .NET applications,
handling, 636
as optional in DB2, 8
parts of, 476-478
reasons for using, 472-473
referencing, 484
registering, 483-491
in CLP (command-line
processor), 484-486
error handling for,
490-491
identifiers, 483
with JDBC, 488
with shared schema
documents, 489-490
steps in, 483
with stored procedures,
486-487
removing from XSR,
492-493
target namespaces, 438
valid versus well-formed
XML documents, 473
validation. See validation
when to validate, 474
XML Schema evolution,
493-498
with document validation,
494-495
with UPDATE
XMLSCHEMA command, 495-498
without document
validation, 494
XML Schema Repository
(XSR), 483, 502-503, 667,
672. See also registering
XML Schemas
catalog tables/views,
503-508
queries against, 508-510
registering annotated
schemas, 311-312
XML storage, 429-430
for compliance 94
in DB2 for Linux, UNIX,
and Windows, 33-41
dropping XML
columns, 40
in DB2 9.7 release,
40-41
storage objects, types of,
33-35
table space page size,
36-39
in DB2 for z/OS, 60-73
CHECK DATA utility,
69-70
limiting memory
consumption, 71
754
multiple XML
columns, 64
naming conventions,
64-65
offloading XML
parsing, 72-73
REORG utility, 68-69
REPORT TABLESPACESET utility,
67-68
storage objects, types of,
61-62
table space characteristics, 63
utilities for, 65-67
inlining, 41-48
benefits of, 47-48
drawbacks of, 48
monitoring and
configuring, 43-47
MDC (multidimensional
clustering), 58-59
partitioned databases,
59-60
range partitioning, 57-58
space consumption of,
51-53
space management
example, 54-57
XML System Services
(XMLSS), 72
XML to HTML transformation, 356-358
XML-related catalog tables,
667-673
for XML indexes, 671-672
XML Schema Repository
(XSR), 672
for XML storage objects,
667-670
XML-related catalog views,
661-667
SYSCAT.COLUMNS,
661-662
SYSCAT.INDEXES,
663-664
Index
SYSCAT.INDEXXMLPATTERNS, 664-666
SYSIBM.SYSXMLPATHS,
663
SYSIBM.SYSXMLSTRINGS, 662-663
XML Schema Repository
(XSR), 667
XML-to-relational joins, 239,
248-250
XML-to-XML joins, 239
outer joins, 250-252
in SQL/XML, 242-247
in XQuery, 240-242
XML2CLOB function
(SQL/XML), 290
xml:space attribute, 91-92
XMLAGG function
(SQL/XML), 160, 207,
277-283
XMLCONCAT,
XMLFOREST
compared, 284
XMLATTRIBUTES function
(SQL/XML), 160, 275-277
XMLCAST function, 119, 160,
163, 186-187
code page conversion
example, 604
XMLCOMMENT function
(SQL/XML), 290
XMLCONCAT function
(SQL/XML), 270
XMLAGG, XMLFOREST
compared, 284
XmlDocument class
(.NET), 634
XMLDOCUMENT function,
117, 119, 294-295
XMLELEMENT function
(SQL/XML), 160, 268-273,
460-462
XMLEXISTS predicate, 160,
177-182, 188, 431
XMLFOREST function
(SQL/XML), 272-273
XMLAGG, XMLCONCAT
compared, 284
XMLGROUP function
(SQL/XML), 286-289
XMLNAMESPACES function,
453, 460-462
XMLPARSE function, 92-93,
119, 160, 354
XMLPATTERN function in
index definitions, 363
XMLPI function (SQL/XML),
290
XMLQUERY function, 119,
160-165, 188, 430
filtering conditions, 587
index eligibility and, 385
returning
element values without
XML tags, 163-164
repeating elements,
164-165
XML column references in,
162-163
XMLReader class (.NET), 634
XMLROW function
(SQL/XML), 286-289
XMLSERIALIZE function,
83, 86, 119, 160, 293,
435, 640
XMLSpy, 657
XMLSS (XML System
Services), 72
XMLTABLE function, 160,
165-176, 188
advantages/disadvantages
of, 300
aggregation and grouping
queries, 234-236
code page conversion
example, 604
generating rows/columns
from XML data, 165-166
namespace declarations,
452-453
numbering rows based
on repeating elements,
173-174
optional elements,
handling, 167-168
Index
pureQuery and, 631
returning
multiple repeating
elements, 174-176
repeating elements,
169-173
shredding XML documents
with, 301-306
splitting XML documents,
116-118
type errors, avoiding,
168-169
XMLTEXT function
(SQL/XML), 290
XMLVALIDATE function,
119, 160, 514-519, 535-536
XMLXSROBJECTID
function, 492, 535, 538-539
XPath, xxiii, 8, 126.
See also XQuery
axes, 157
comparing with FLWOR
expressions and
SQL/XML, 196-202
comparison operators,
156-157
construction of sequences,
154-155
data( ) function, 134-135
dot notation, 151-153
double slash (//), 141-142
dynamic expressions,
185-186
embedding in SQL
statements, 127
empty results, reasons
for, 134
executing in DB2,
137-140
existential semantics,
147-148
file system navigation
analogy, 133
full-text searches in, 582
functions, 155
logical expressions,
148-151
755
node tests, 133
positional predicates,
153-154
predicates, 142-146
usage with SQL/XML,
177-182
sample data for examples,
131-132
simple query examples,
133-136
slash (/), 141
SQL/XML versus, 201
string( ) function, 135
text( ) node test, 134
unabbreviated syntax, 157
union of sequences,
154-155
union operator (|), 585
wildcards, 140-141
XPath expressions
best practices, 430
full-text searches
with, 593
XPath queries, design
decisions and, 17-18
XQuery, xxiii, 8, 126. See also
XPath
arithmetic expressions,
212-214
attribute expressions in
XML construction, 206
“between” predicates, 431
computed value XML
construction, 202-204
conditional expressions in
XML construction, 205
constructors, 290-292
XML namespaces and,
462-463
contains function, 587
data types, cast expressions,
type errors, 208-212
direct XML construction,
202
with embedded SQL, 127
embedding
in SQL statements, 127
SQL in, 227-228
FLWOR expressions,
191-196
comparing with XPath
and SQL/XML,
196-202
join queries in, 247
full-text searches,
582, 592
functions, 214-226
Boolean functions, 226
date and time functions,
224-226
namespace and node
functions, 222-224
numeric and aggregation
functions, 218-220
sequence functions,
220-222
string functions,
215-218
grouping queries in,
SQL/XML versus,
237-239
join queries, XML-to-XML
joins, 240-242
let and return clauses, index
eligibility and, 386-387
modifying XML documents
in, 346-349
multiple nesting levels
in XML construction,
206-207
namespace and node
functions, 445
namespace declarations,
448-450
nesting with SQL,
257-258
outer joins, 250-252
overview, 190
predicates in XML
construction, 204-205
sample data for examples,
131-132
SQL functions and UDFs
in, 229-230
SQL/XML versus, 201
756
as stand-alone
language, 127
in stored procedures, 554
XML aggregation in XML
construction, 207-208
XSLT versus, 353
XQuery 1.0 and XPath 2.0
Data Model, 126, 128-131
sequences
constructing, 128-130
as input/output,
130-131
xquery keyword, 137
XQuery Update Facility, 9,
324-326
XML attribute values,
replacing, 327-328
XML element values,
replacing, 326-327
XML elements/attributes,
renaming, 334-335
XML node values,
replacing
with computed values,
329-331
multiple values, 328-329
with parameter
markers, 328
Index
XML nodes
deleting, 333-334
inserting, 335-340
modifying multiple,
343-346
repeating/missing,
340-343
replacing, 331-332
XSCAN operator (execution
plans), 402
XSL (eXtensible Stylesheet
Language), 352
XSLT (eXtensible Stylesheet
Language Transformation),
352-358
XML to HTML transformation, 356-358
XQuery versus, 353
XSLTRANSFORM
function, 353-356
XSLTRANSFORM function,
352-356
XSR (XML Schema
Repository), 483, 502-503,
667, 672. See also
registering XML Schemas
catalog tables/views,
503-508
queries against, 508-510
registering DTDs, 501
removing XML Schemas
from, 492-493
XSR Objects, 483
XSR_GET_PARSING_
DIAGNOSTICS stored
procedure, 525-528
Y–Z
z/OS. See DB2 for z/OS
zAAP (System z Application
Assist Processors), 71-72
zeros, leading zeros in XML
element construction,
285-286
zIIP (System z Integrated
Information Processors),
71-72