/






















































































































































































































































































































































































































































































































































































































Автор: Боровиков В.
Теги: компьютерные технологии информационные машины машины для обработки данных программирование
ISBN: 5-272-00078-1
Год: 2003
Текст
СЕРИЯ
ЖЖЛ Ш 11 шгшЗ UJ кАмЩ^ I 11 О Iff ЛЛ 1
Е^пптер
f *
9
m *
V\ #
4
"• 9
Владимир Боровиков
ДЛЯ ПРОФЕССИОНАЛОВ
STXnSTICA
ИСКУССТВО
АНАЛИЗА ДАННЫХ
НА КОМПЬЮТЕРЕ
2-Е ИЗДАНИЕ
[^ПИТЕР
Москва - Санкт-Петербург - Нижний Новгород - Воронеж
Ростов-на-Дону - Екатеринбург - Самара
Киев - Харьков - Минск
2003
В. Боровиков
STATISTICA. Искусство анализа
данных на компьютере:
Для профессионалов
2-е издание
Главный редактор Е. Строганова
Заведующий редакцией //. Корнесв
Художник //. Биржаков
Корректор С. Беляева
Верстка Р. Гришанов
ББК 32.973.233
УДК 681.3.01
Боровиков В.
Б83 STATISTICA. Искусство анализа данных на компьютере: Для профессионалов.
2-е изд. (+CD). — СПб.: Питер, 2003. — 688 с: ил.
ISBN 5-272-00078-1
Во втором, исправленном и дополненном, издании книги, написанной известным
специалистом, научным директором компании StatSoft Russia, изложена концепция и технология
современного анализа данных на компьютере. На основе элементарных понятий описываются
углубленные методы анализа в системе STATISTICA (StatSoft) с многочисленными примерами из
экономики, маркетинга, рекламы, бизнеса, медицины, промышленности и других областей.
Второе издание дополнено описанием языка STATISTICA VISUAL BASIC. Книга адресована
самому широкому кругу читателей, желающих стать профессионалами в компьютерном анализе
данных.
К книге прилагается компакт-диск, включающий учебник StatSoft по анализу данных, учебник
по промышленной статистике, материалы обучающих курсов, демо-версии STATISTICA и SNN
(нейронные сети) и большое количество данных для обучения и проведения самостоятельных
исследований в STATISTICA и SNN
© ЗАО Издательский дом «Питер», 2003
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без
письменного разрешения владельцев авторских прав.
Информация, содержащаяся в данной книге, получена из источников, рассматриваемых издательством как надежные. Тем не
менее, имея в виду возможные человеческие или технические ошибки, издательство не может гарантировать абсолютную
точность и полноту приводимых сведений и не несет ответственности за возможные ошибки, связанные с использованием
книги.
ISBN 5-272-00078-1
ООО «Питер Принт». 196105, Санкт-Петербург, ул. Благодатная, д. 67в.
Лицензия ИД № 05784 от 07.09.01.
Налоговая льгота - общероссийский классификатор продукции ОК 005-93, том 2; 953005 - литература учебная.
Подписано в печать 11.08.03. Формат 70X100/16. Усл. п. л. 55,47. Доп. тираж 3000 экз. Заказ № 389.
Отпечатано с фотоформ в ФГУП «Печатный двор» им. А. М. Горького Министерства РФ по делам печати,
телерадиовещания и средств массовых коммуникаций.
197110, Санкт-Петербург, Чкаловский пр., 15.
Краткое содержание
Введение 13
Вступительное эссе: приглашение к анализу данных на компьютере 14
Глава 1. Краткая экскурсия по системе STATISTICA 44
Глава 2. Элементарные понятия анализа данных 105
Глава 3. Вероятностные распределения и их свойства 146
Глава 4. Подгонка вероятностных распределений к реальным данным 185
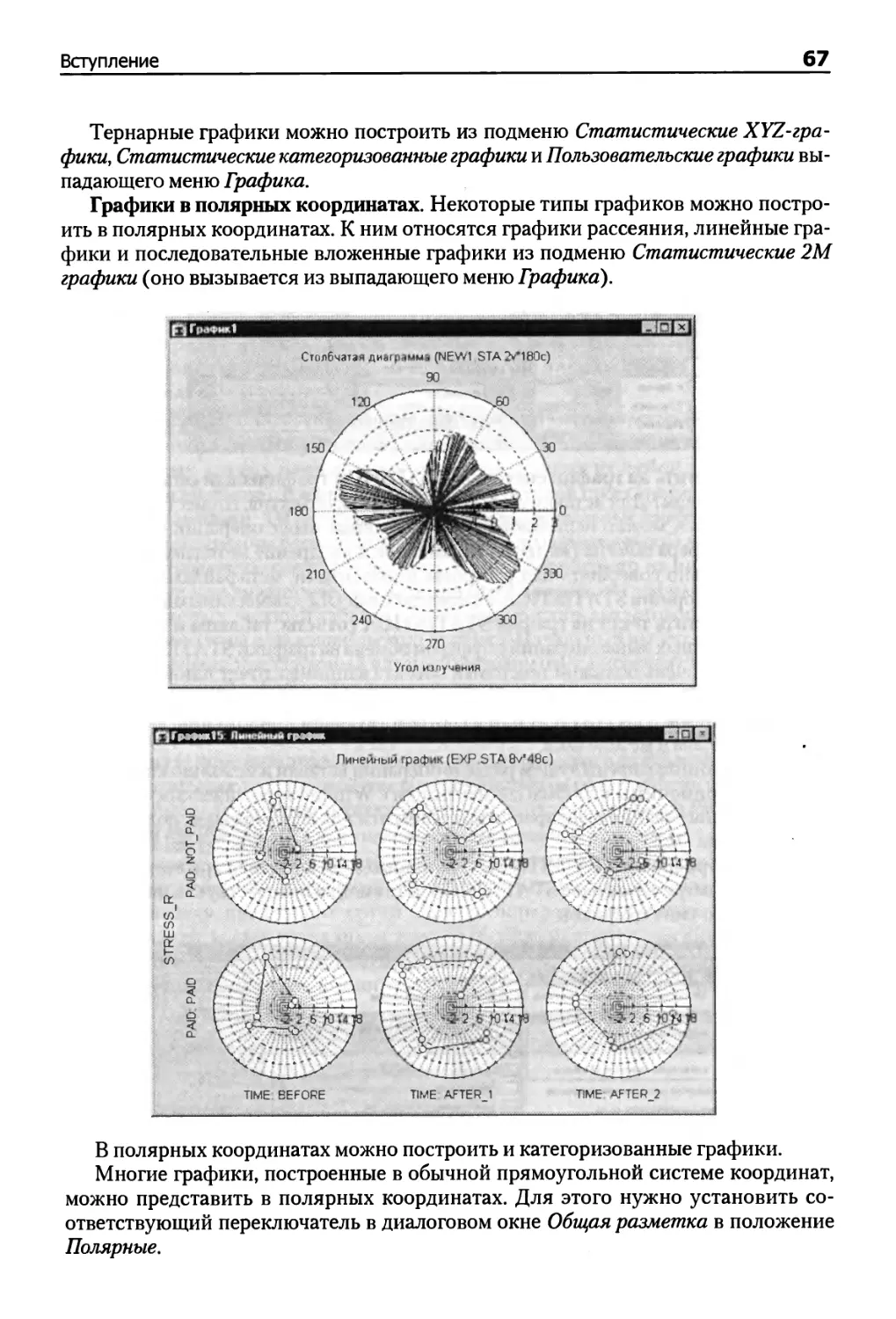
Глава 5. Двумерный визуальный анализ данных 210
Глава б. Трехмерный визуальный анализ данных 251
Глава 7. Визуальный анализ категоризованных данных 307
Глава 8. Пиктографики 333
Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA.... 341
Глава 10. Описательные статистики 409
Глава 11. Построение и анализ таблиц 429
Глава 12. Т-критерий сравнения средних в двух группах данных 487
Глава 13. Непараметрическая статистика 504
Глава 14. Анализ выживаемости 533
Глава 15. Анализ соответствий 561
Глава 16. Примеры анализа данных в системе STATISTICA 577
Глава 17. Нейронные сети 611
Глава 18. Язык STATISTICA VISUAL BASIC (SVB) 641
Приложение 1 667
Приложение 2 669
Приложение 3 677
Алфавитный указатель 687
Содержание
Введение 13
Вступительное эссе: приглашение к анализу данных на компьютере 14
Для кого эта книга? 40
Глава 1. Краткая экскурсия по системе STATTSTICA 44
Вступление 44
Командный язык STATISTICA (SCL) 76
Кнопки автозадач 80
Взгляд в будущее 84
Первые шаги в системе STATISTICA 85
Графический анализ таблиц сопряженности 97
Глава 2. Элементарные понятия анализа данных 105
Что такое переменная? 105
Простейшие описательные статистики 105
Свойства описательных статистик 107
Шкалы измерений ПО
Какие статистики выбирать? 111
Распределение переменной 112
Зависимости между переменными 112
Исследование связей между наблюдаемыми переменными в сравнении
с экспериментальными исследованиями 113
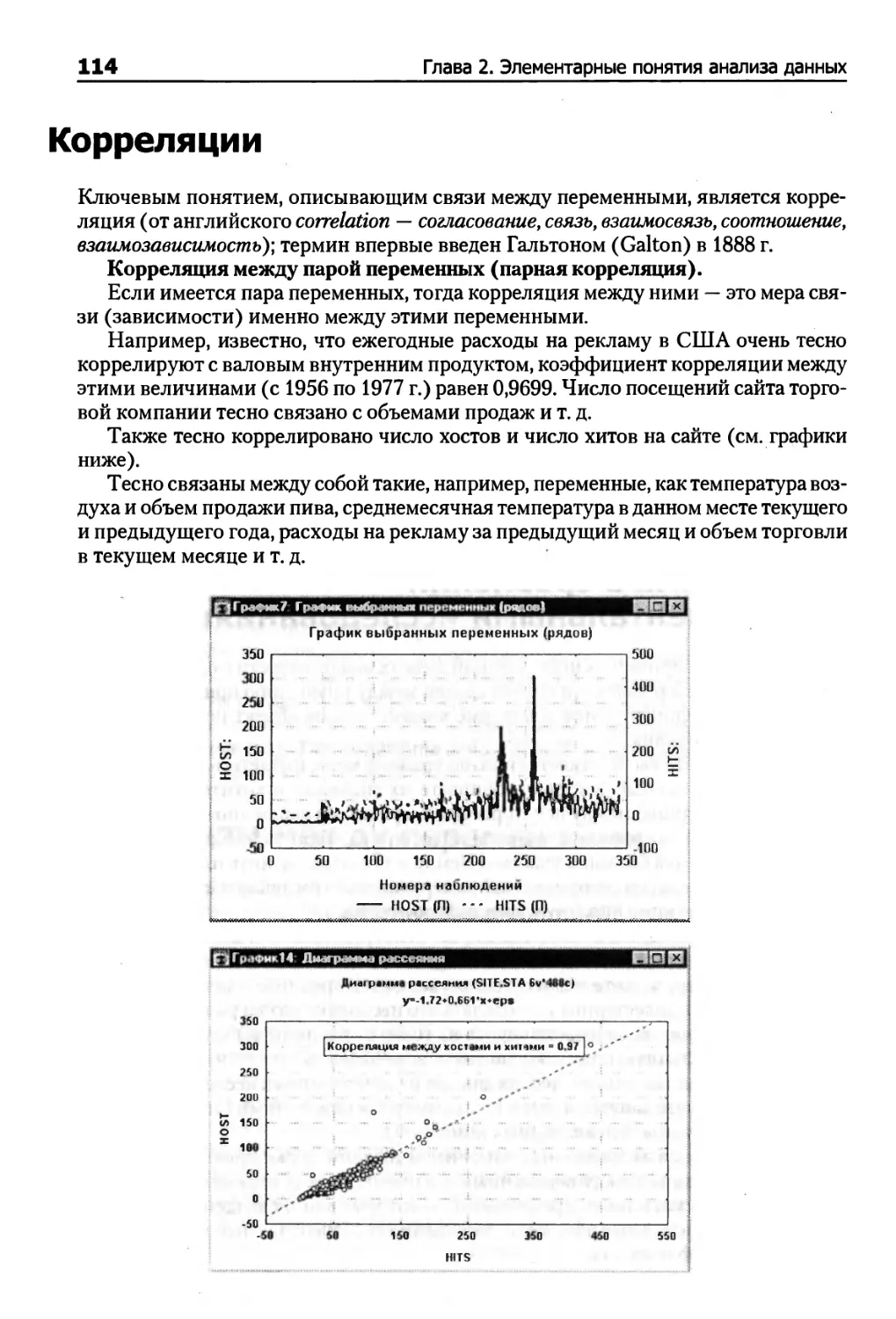
Корреляции 114
Почему зависимости между переменными являются важными 120
Зависимые и независимые переменные 121
Как измерить величину зависимости между переменными 122
Две черты зависимости между переменными 123
Что такое статистическая значимость (р-уровень)? 123
Как определить, является ли результат действительно значимым 124
Статистическая значимость и количество выполненных анализов 124
Величина зависимости между переменными в сравнении с надежностью зависимости 125
Почему более сильные зависимости между переменными являются более значимыми 125
Почему объем выборки влияет на значимость зависимости 125
Почему слабые зависимости могут быть значимо доказаны только на больших выборках 126
Можно ли рассматривать отсутствие связей как значимый результат? 127
Общая конструкция статистических тестов 127
Как вычисляется статистическая значимость 127
Содержание 7
Значимость коэффициента корреляции 128
Как определить, являются ли два коэффициента корреляции значимо различными 128
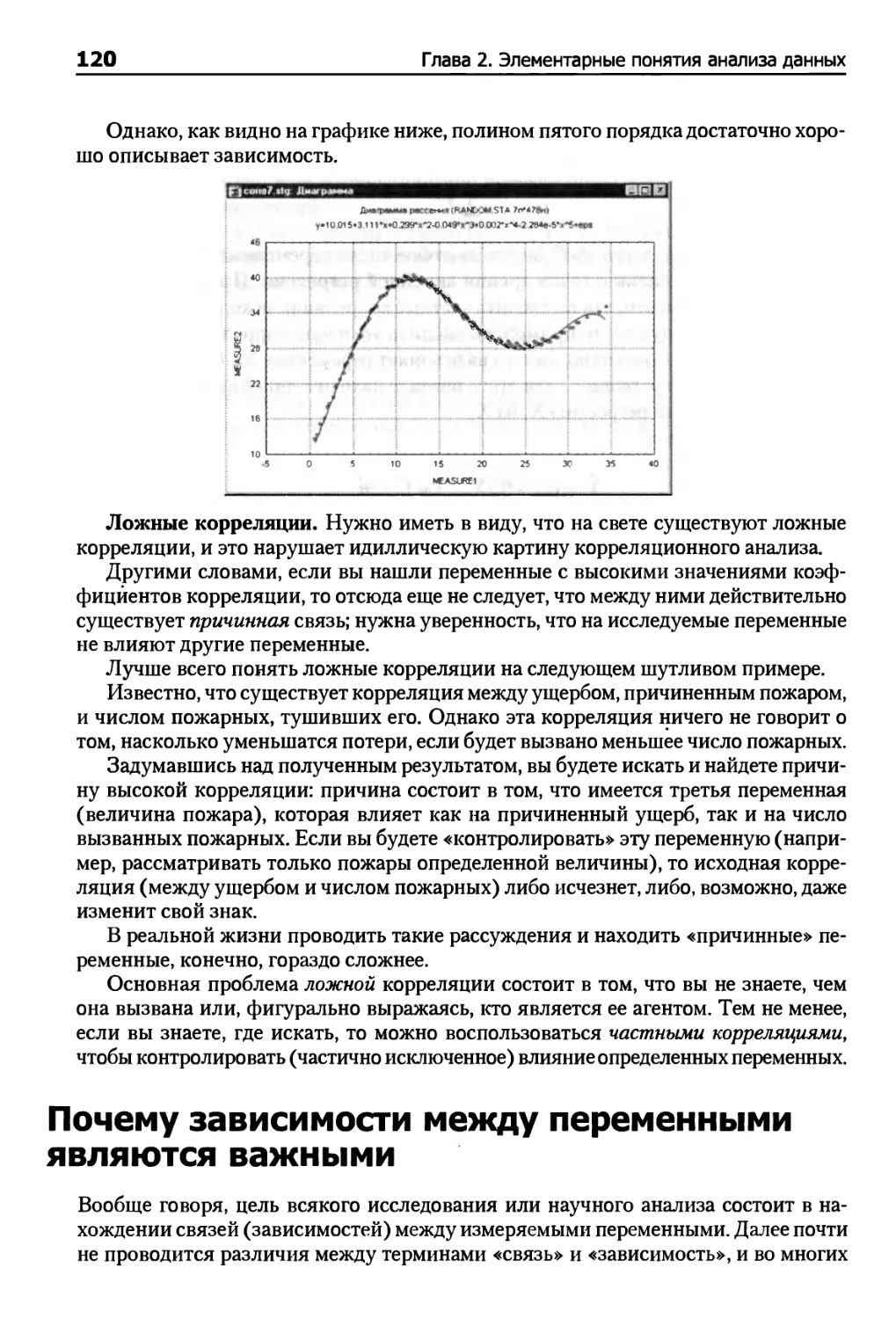
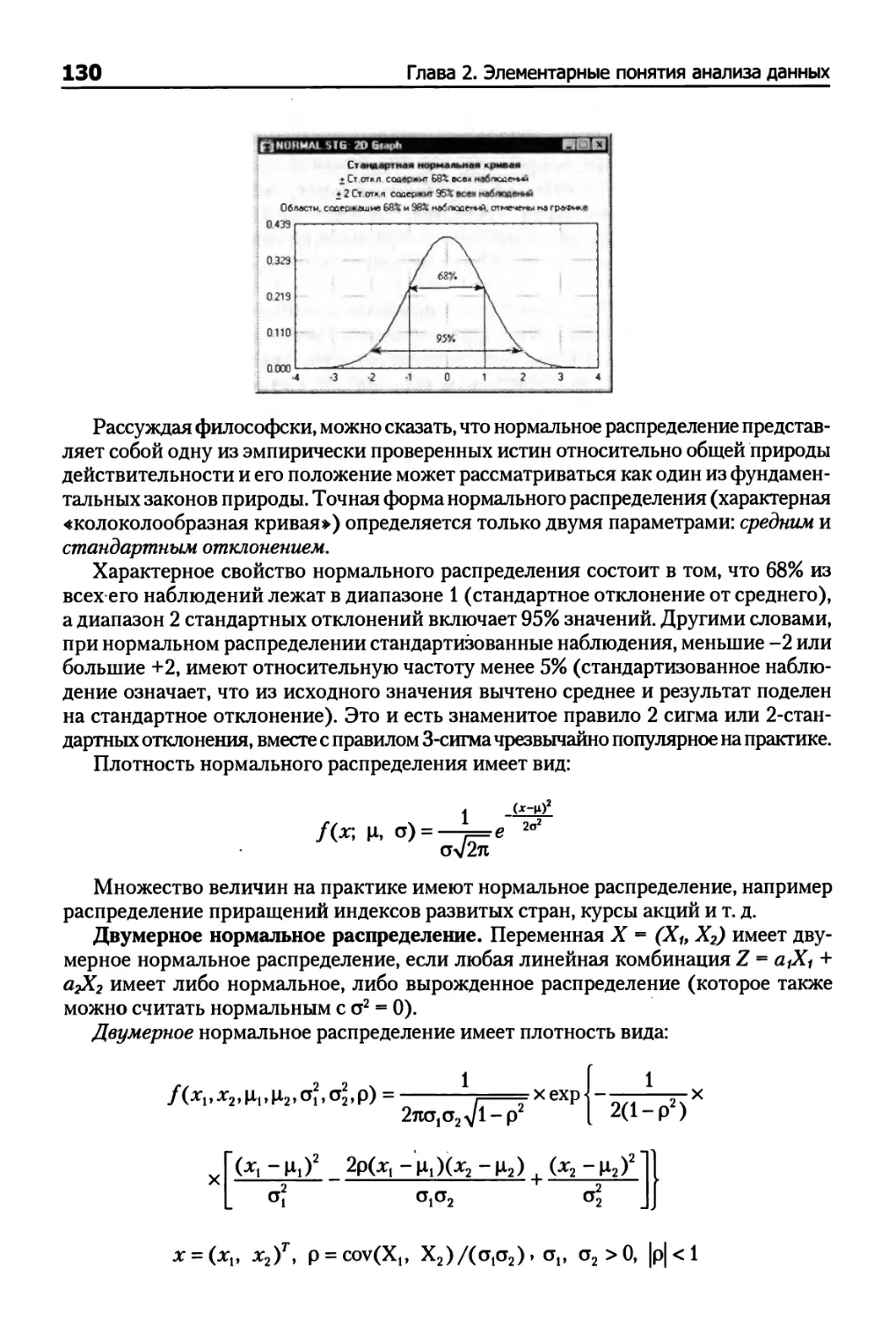
Почему важно нормальное распределение 129
Иллюстрация того, как нормальное распределение используется в статистических
рассуждениях 131
Как проверить нормальность наблюдаемых величин 131
Всели статистики критериев нормально распределены? 136
Как узнать последствия нарушений предположений нормальности? 137
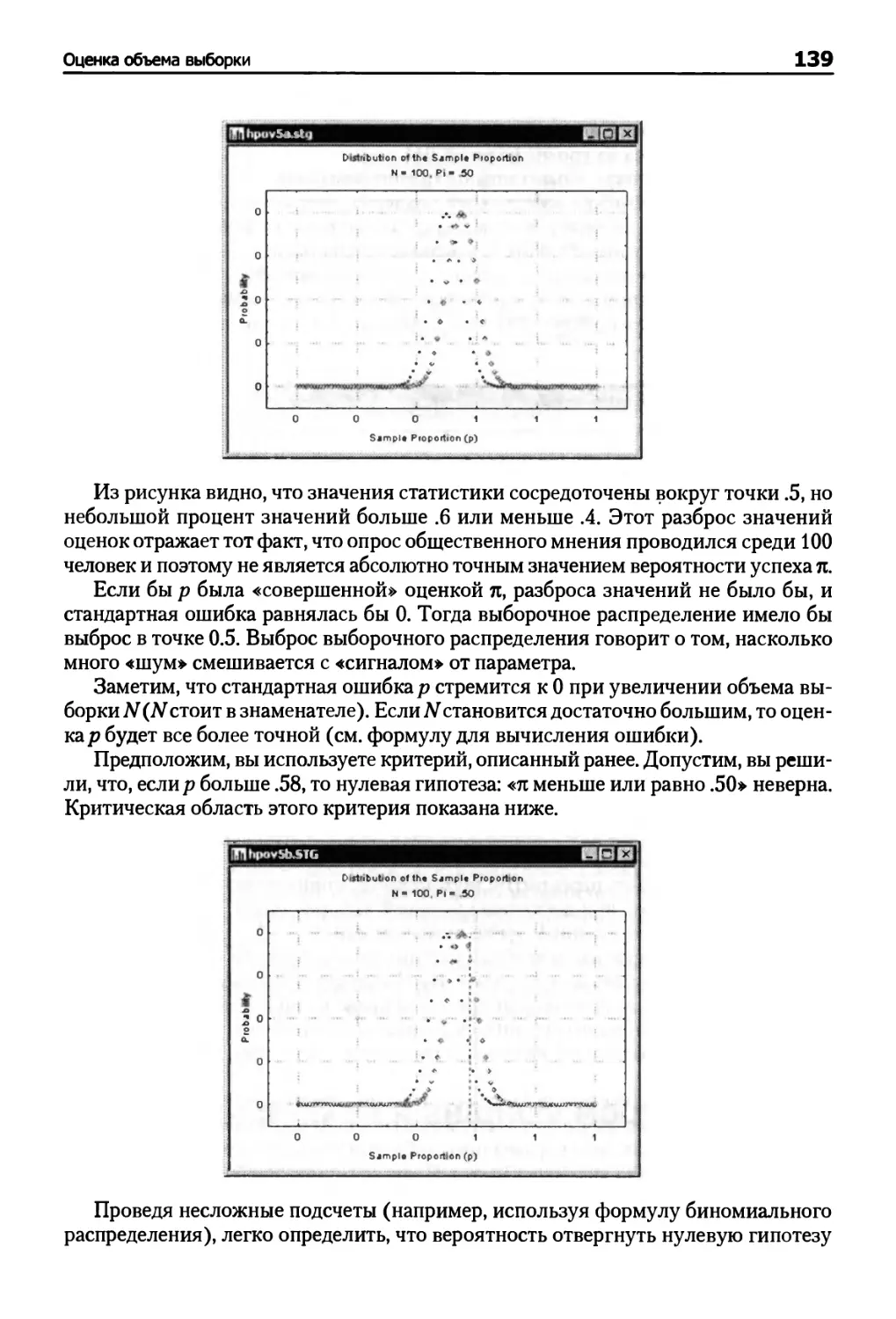
Оценка объема выборки 137
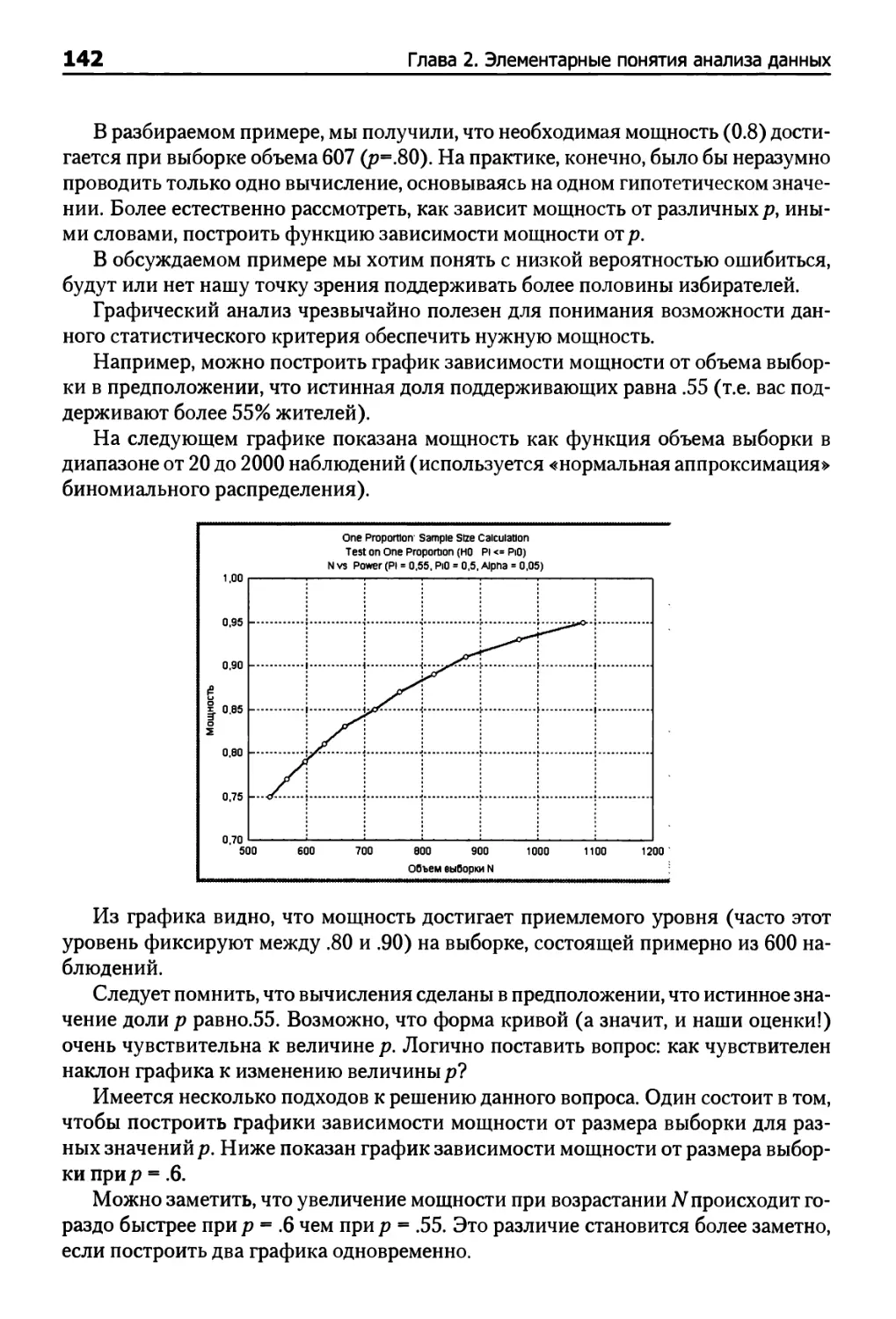
Визуальный подход к анализу мощности 141
Понижение размерности данных 144
Глава 3. Вероятностные распределения и их свойства 146
В чем состоит идея вероятностных рассуждений? 146
Нормальное распределение 147
Равномерное распределение 151
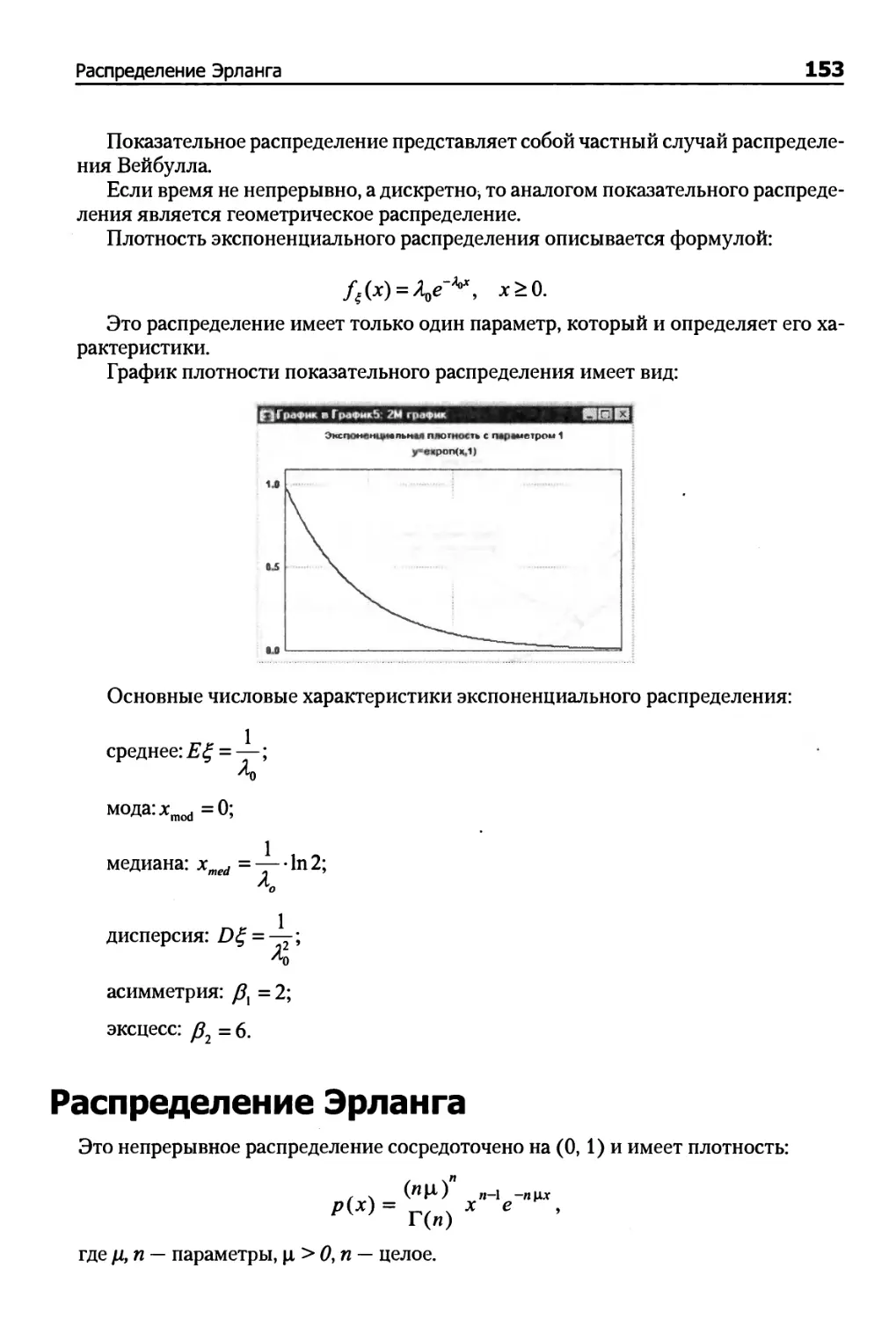
Экспоненциальное распределение ; 152
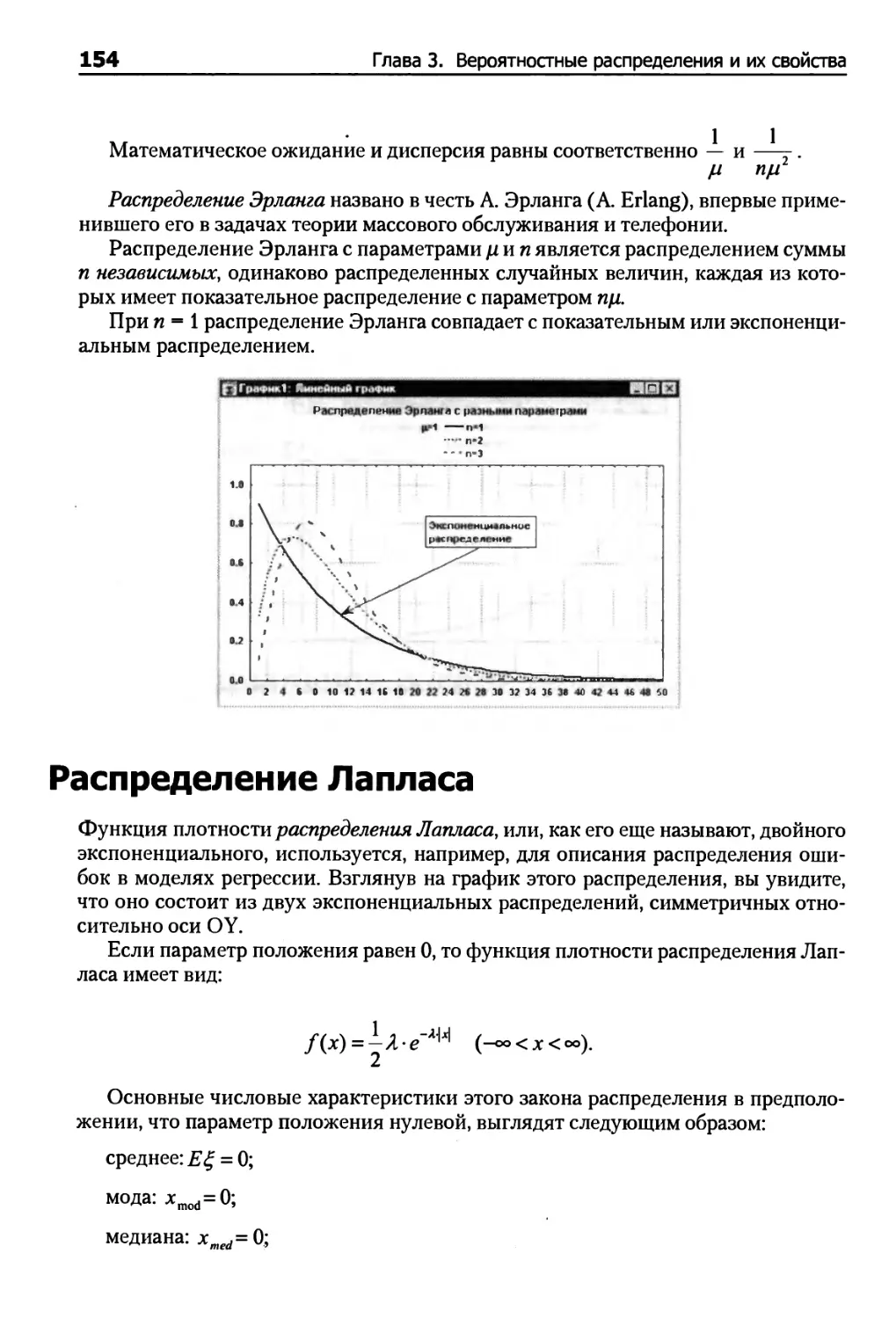
Распределение Эрланга 153
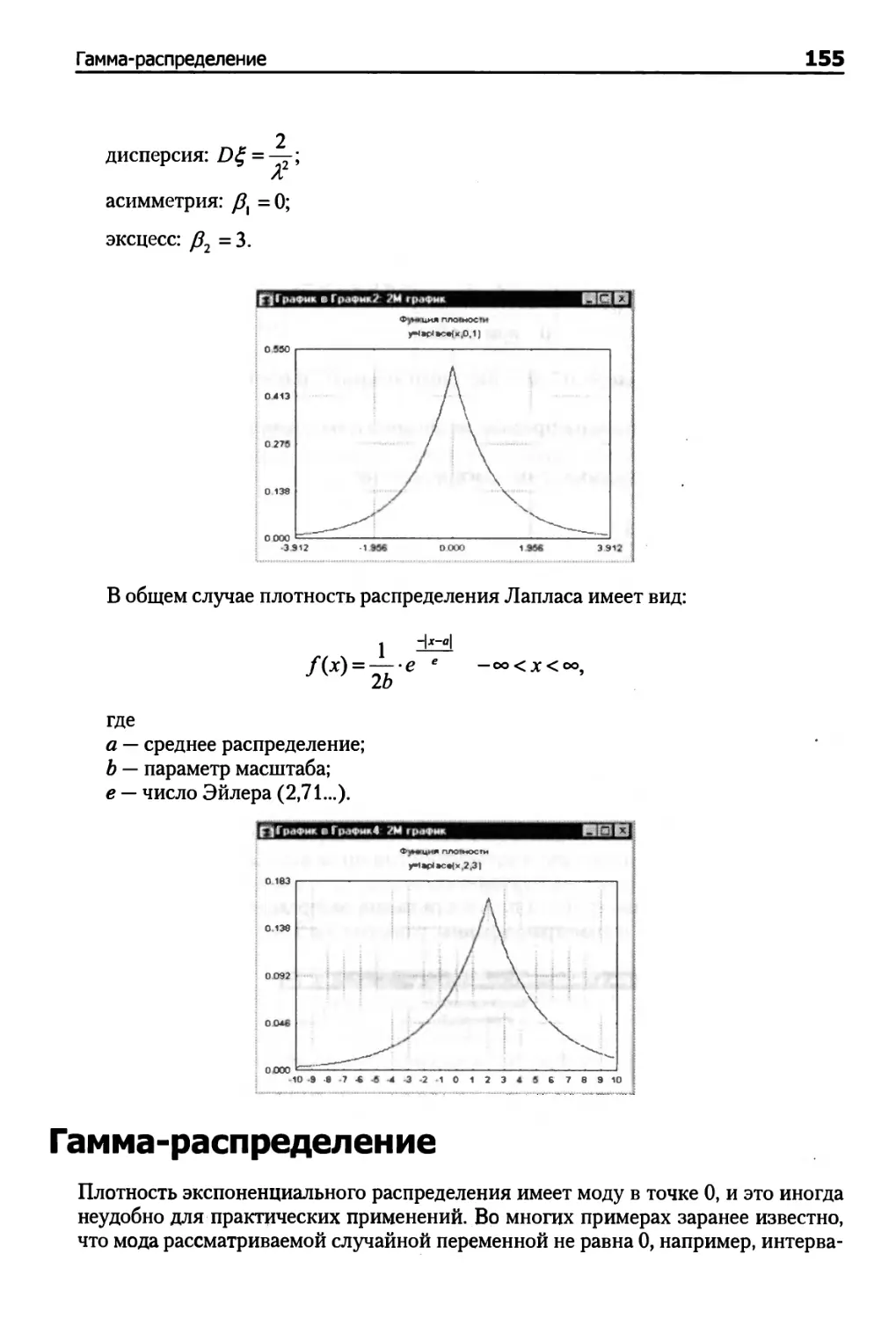
Распределение Лапласа 154
Гамма-распределение 155
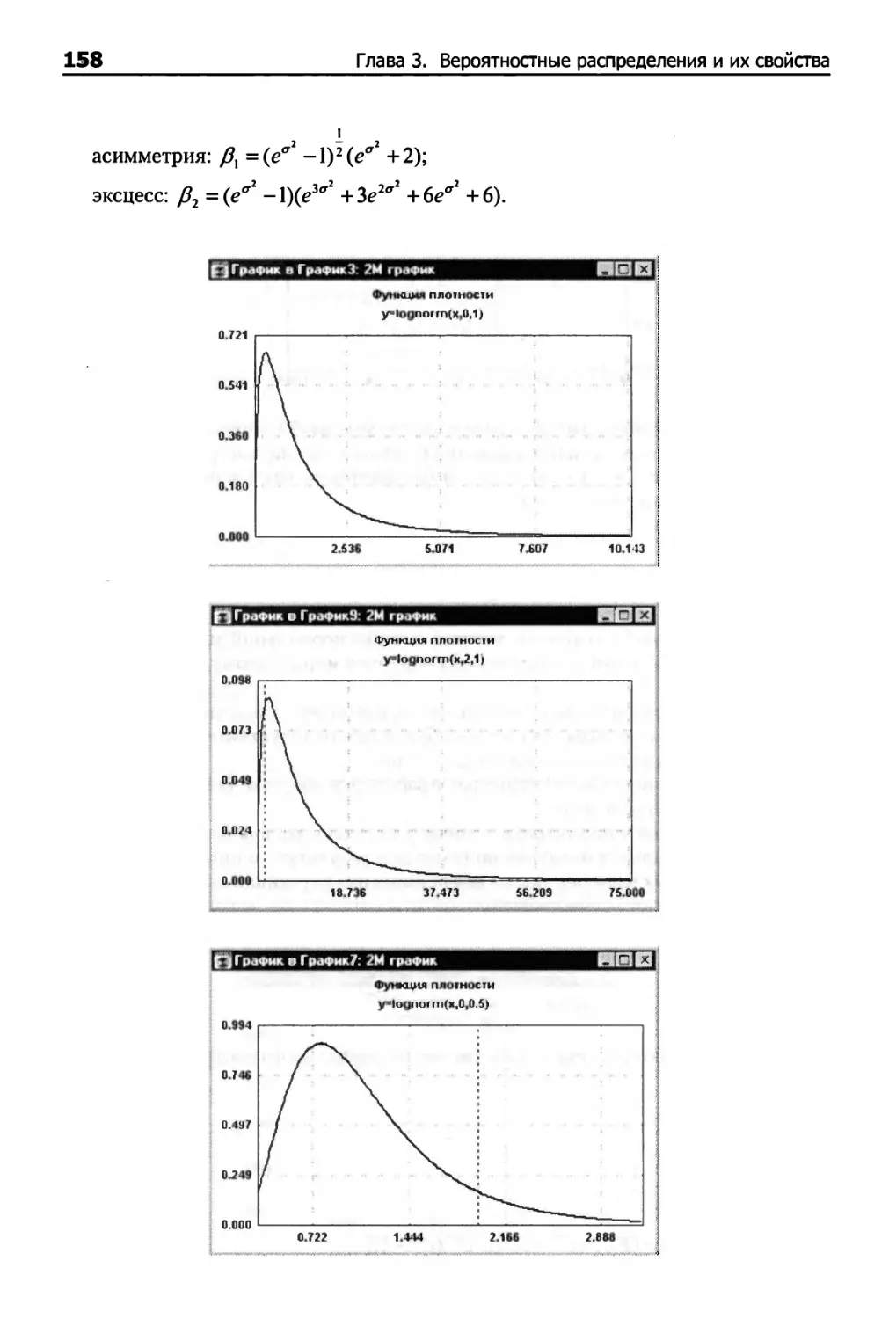
Логнормальное распределение 157
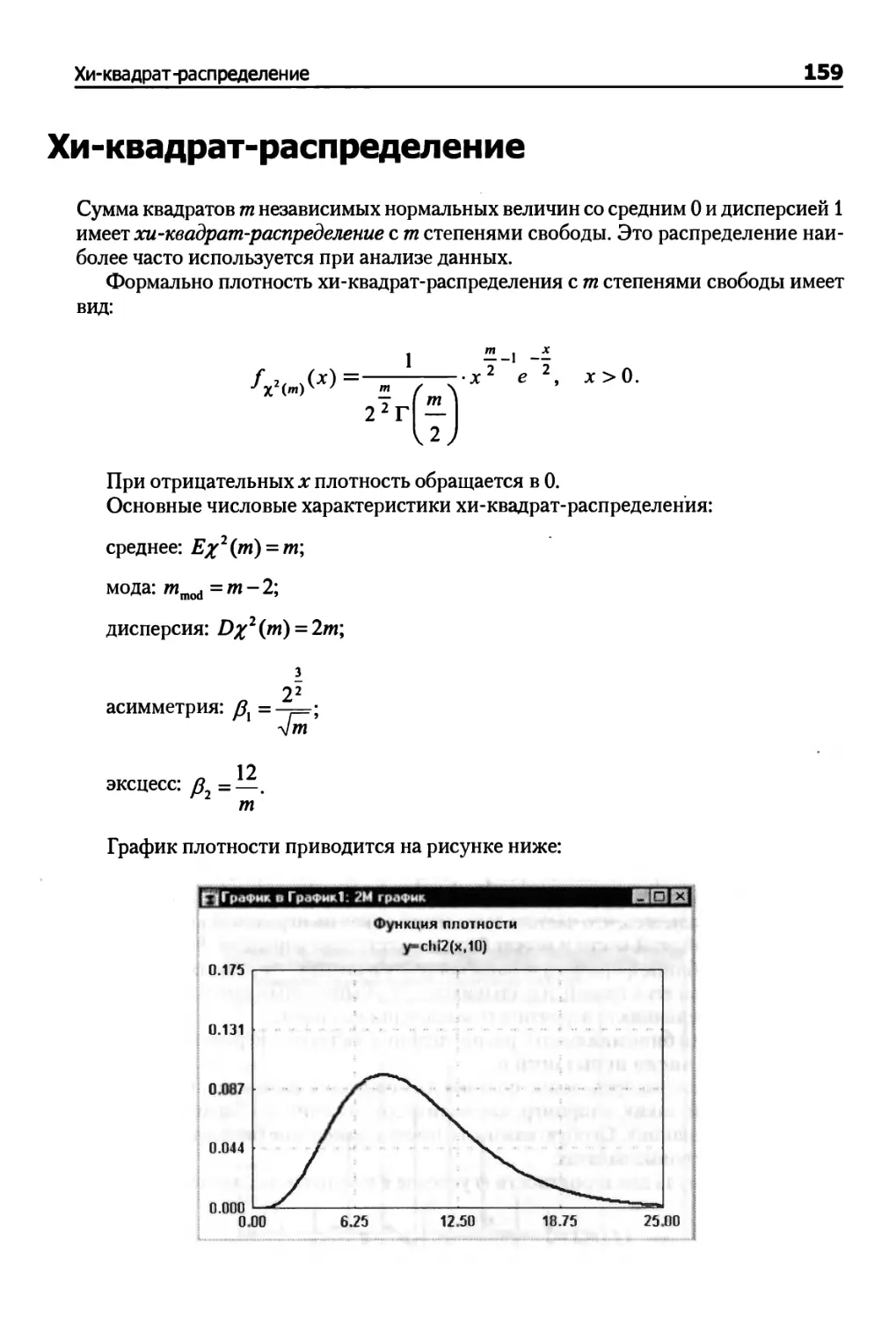
Хи-квадрат-распределение 159
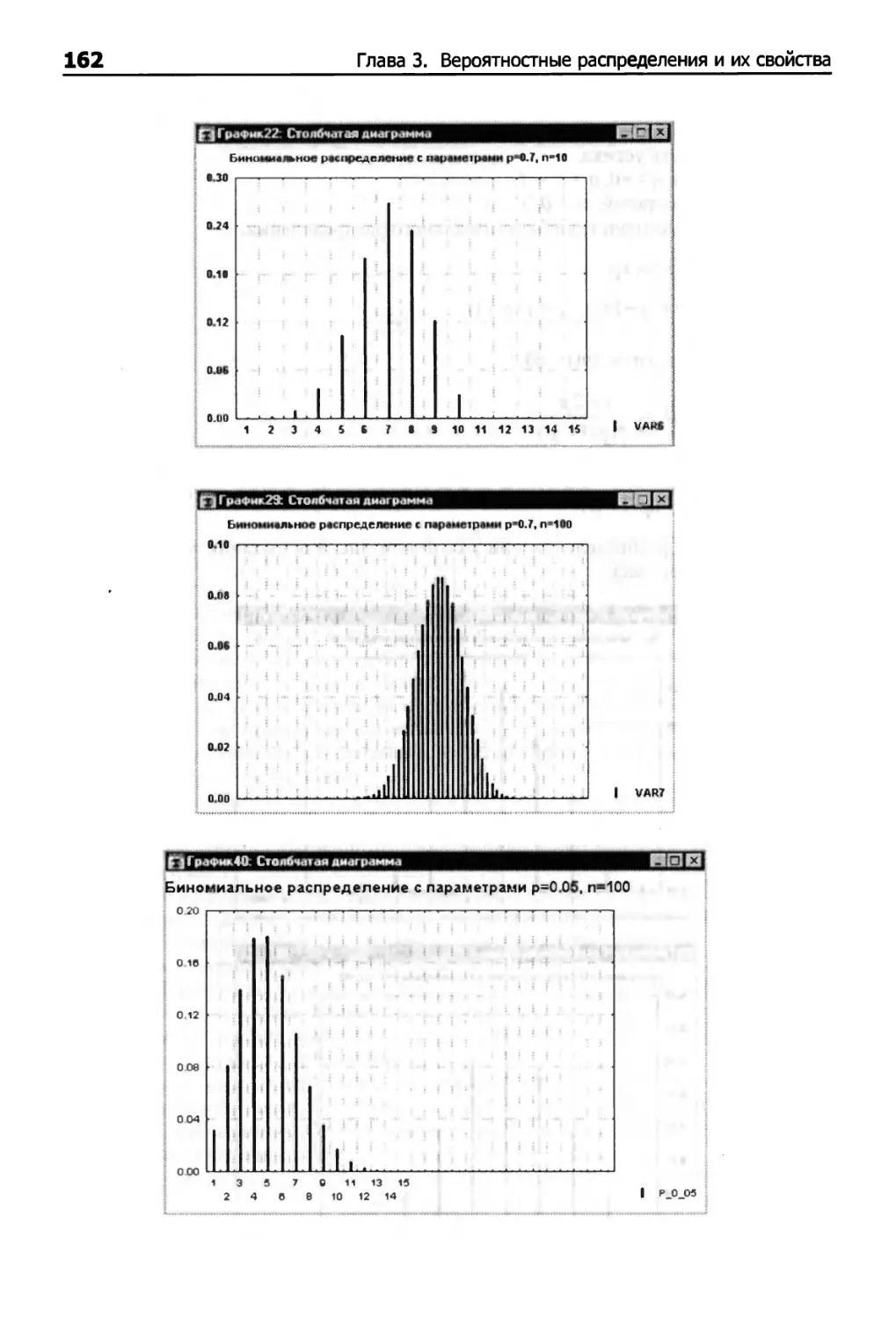
Биномиальное распределение 160
Распределение арксинуса 165
Отрицательное биномиальное распределение 166
Распределение Пуассона 167
Геометрическое распределение 170
Гипергеометрическое распределение ,.... 170
Полиномиальное распределение 171
Бета-распределение 171
Распределение экстремальных значений 172
Распределения Релея 172
Распределение Вейбулла 173
Распределение Парето 177
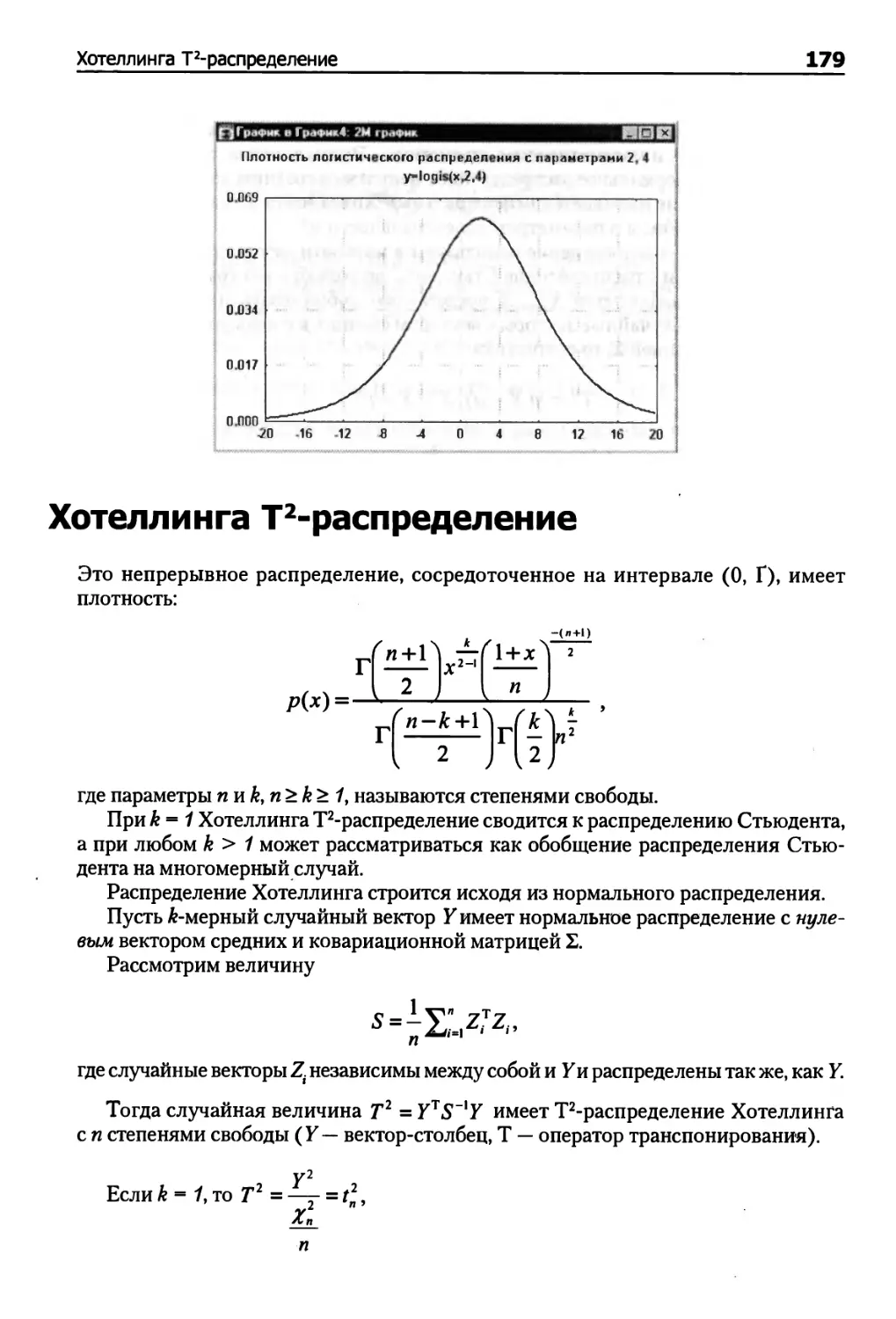
Логистическое распределение 178
Хотеллинга Т2-распределение 179
Распределение Максвелла 180
Распределение Коши 181
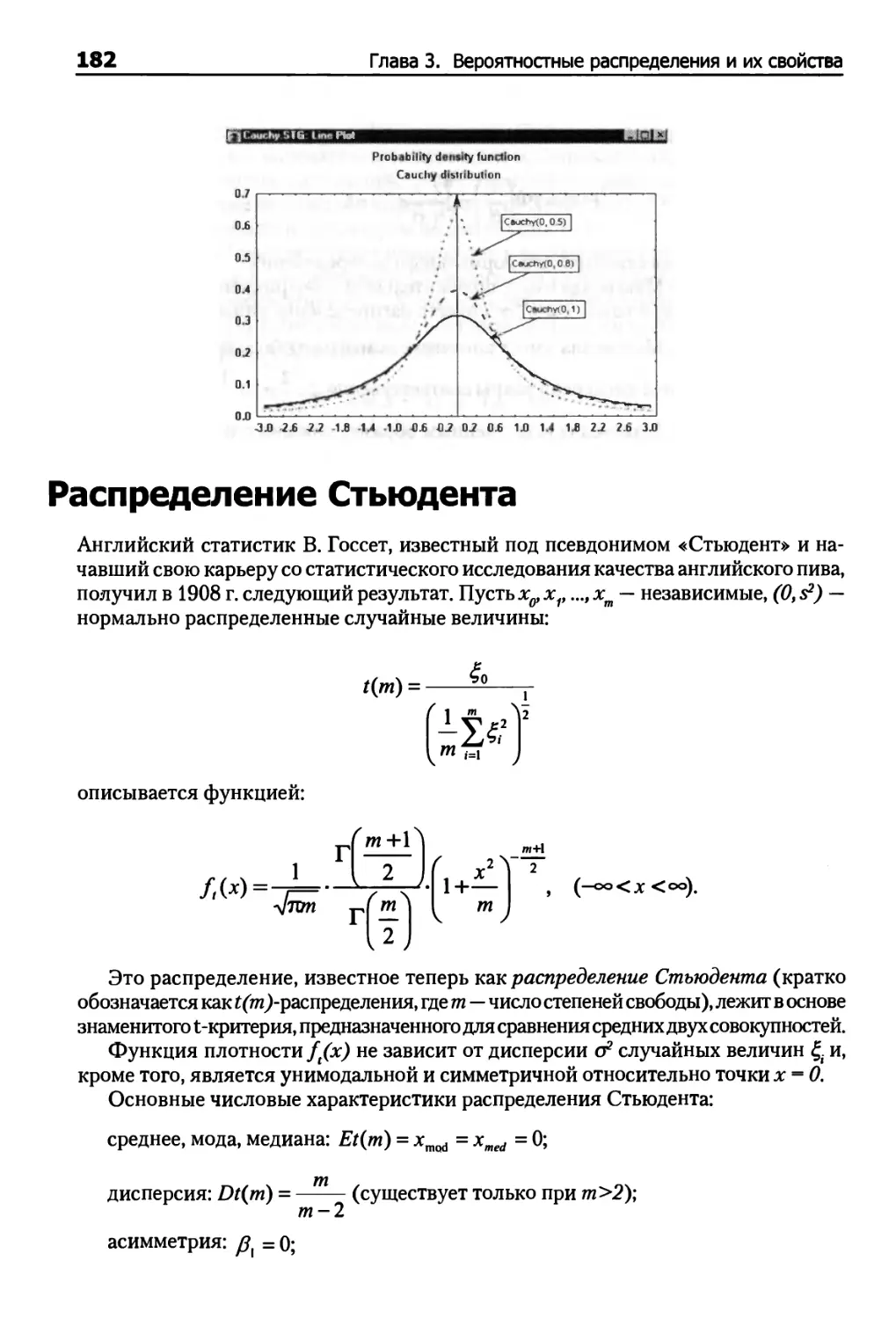
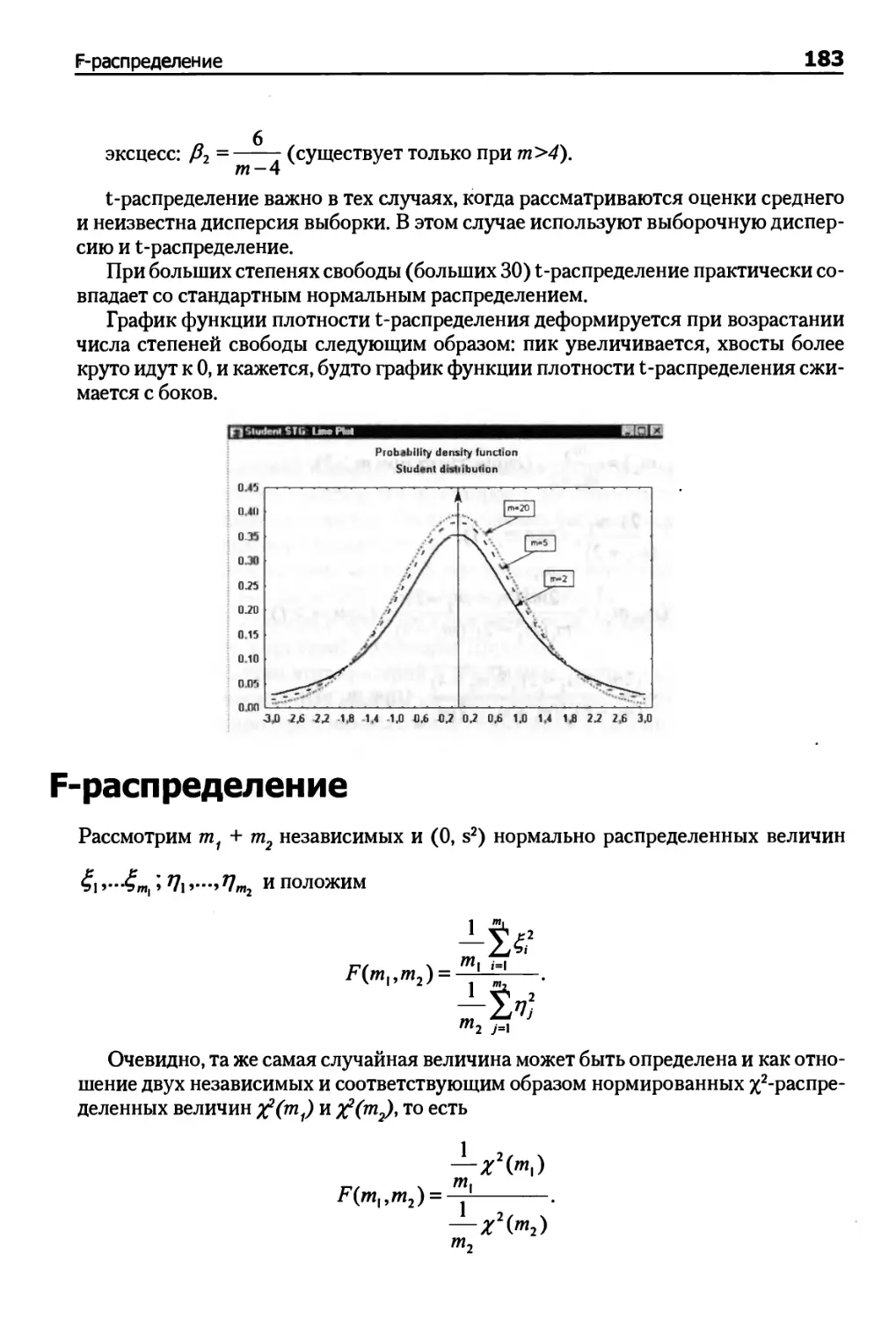
Распределение Стьюдента 182
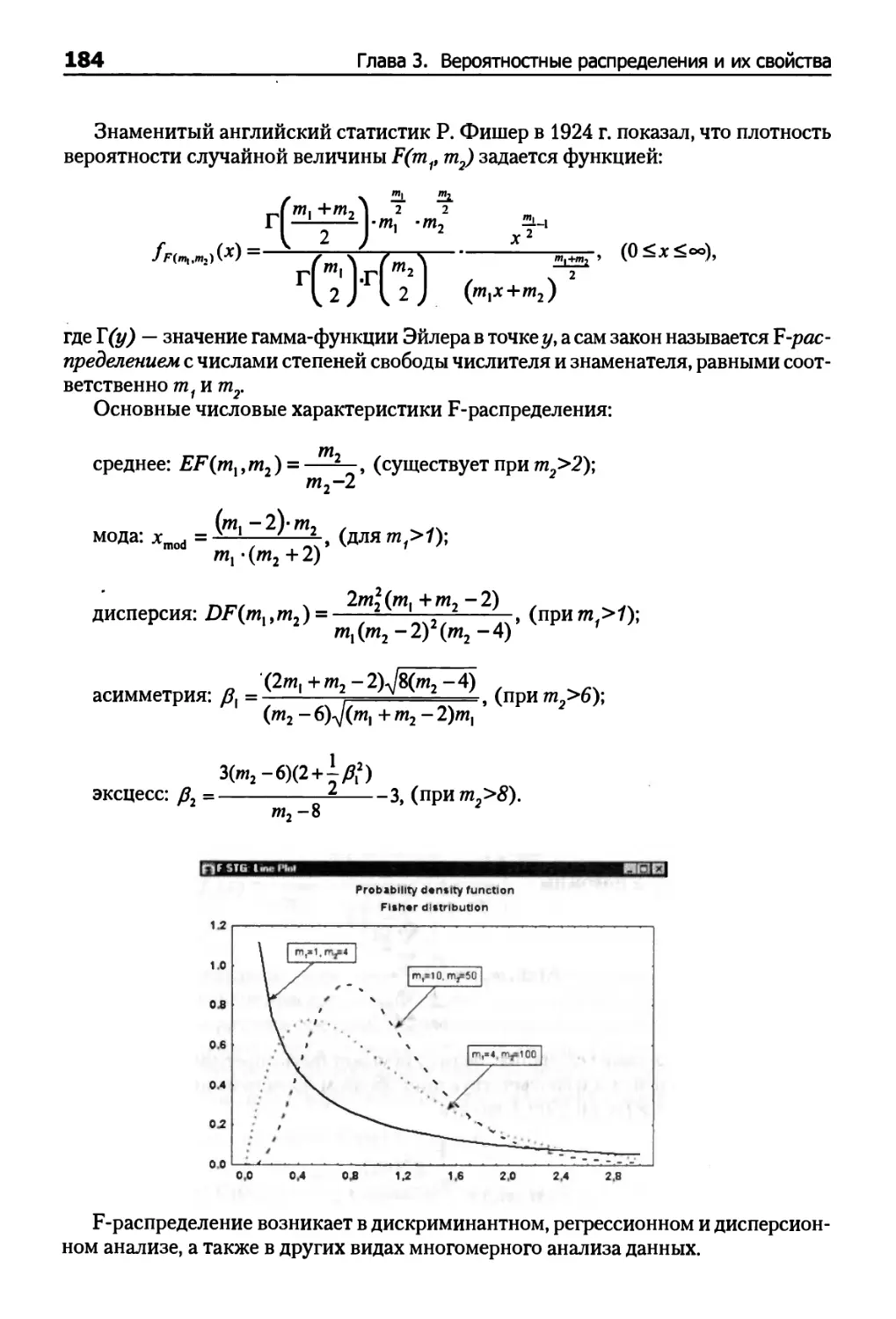
F-распределение 183
Глава 4. Подгонка вероятностных распределений к реальным данным 185
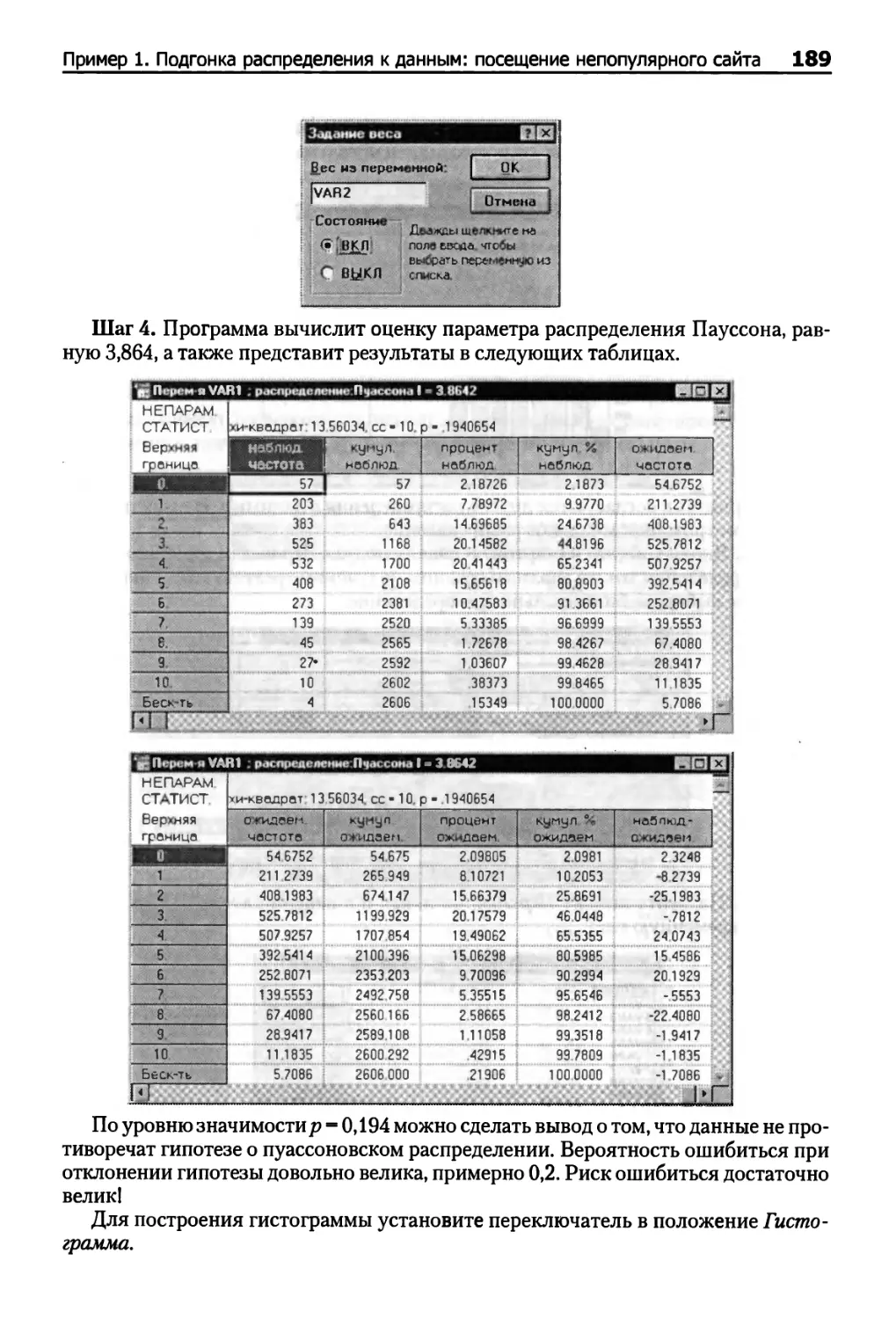
Пример 1. Подгонка распределения к данным: посещение непопулярного сайта 187
Пример 2. Подгонка распределения к данным: посещение популярного сайта 193
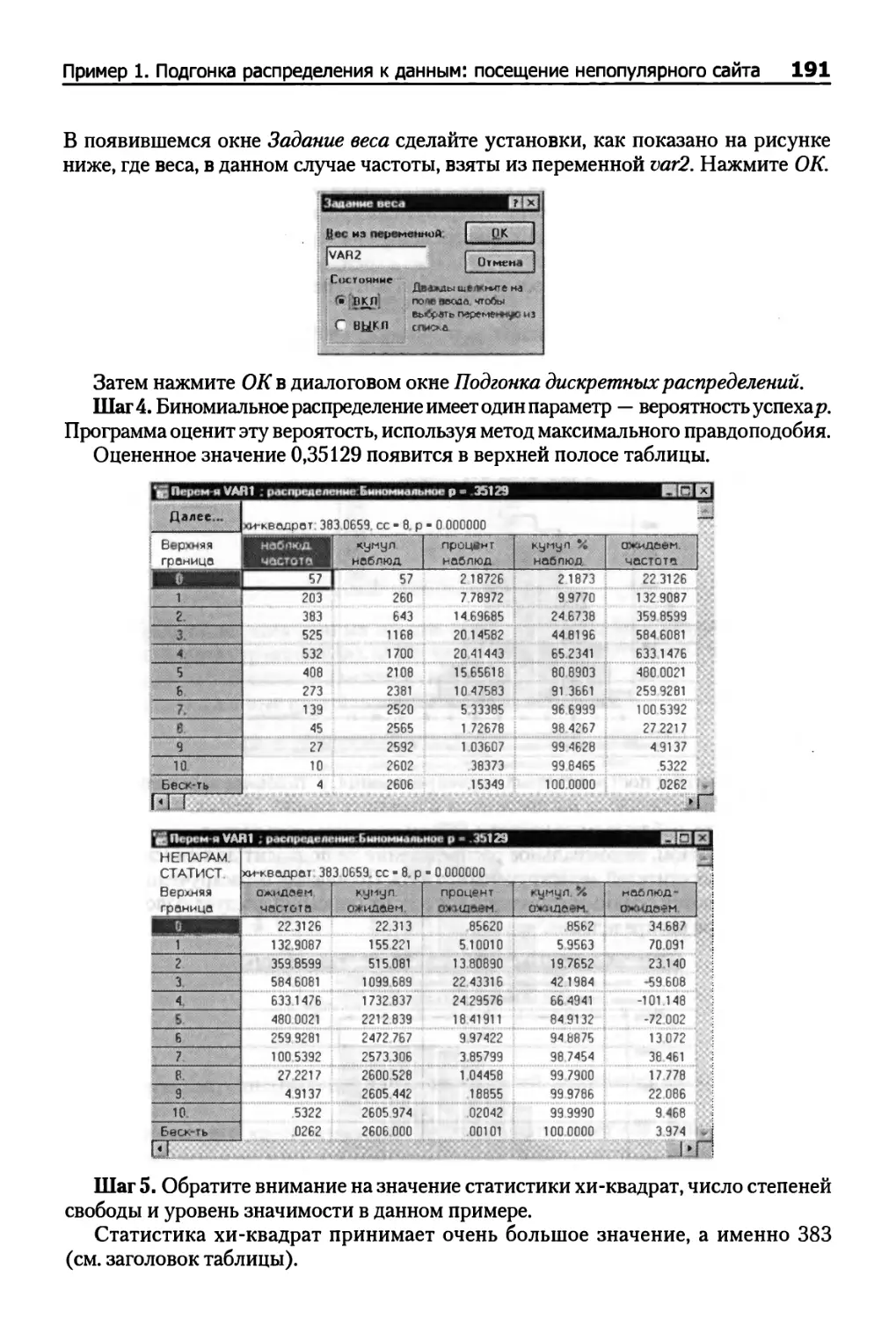
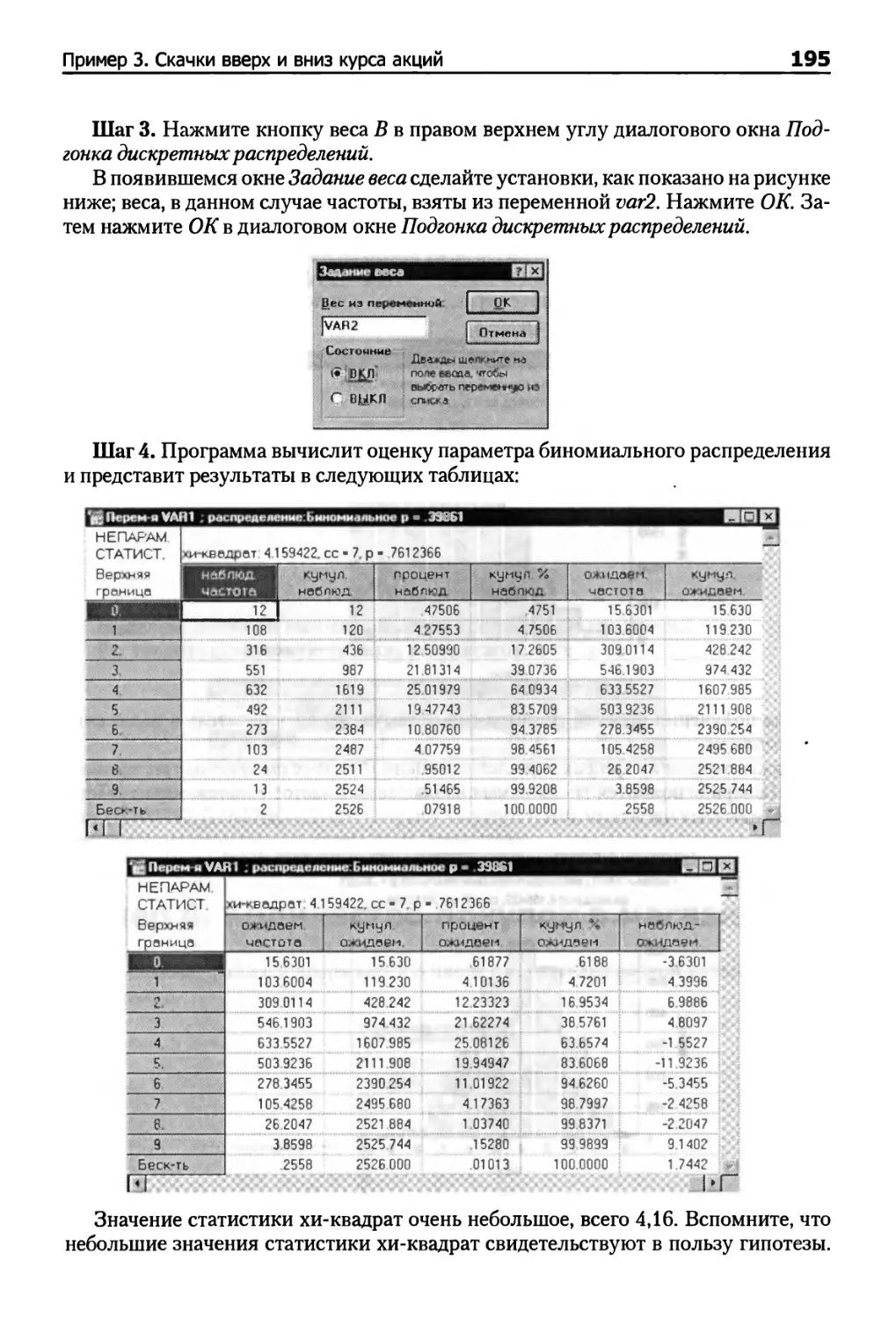
Пример 3. Скачки вверх и вниз курса акций 197
Пример 4. Количество покупок в магазине 197
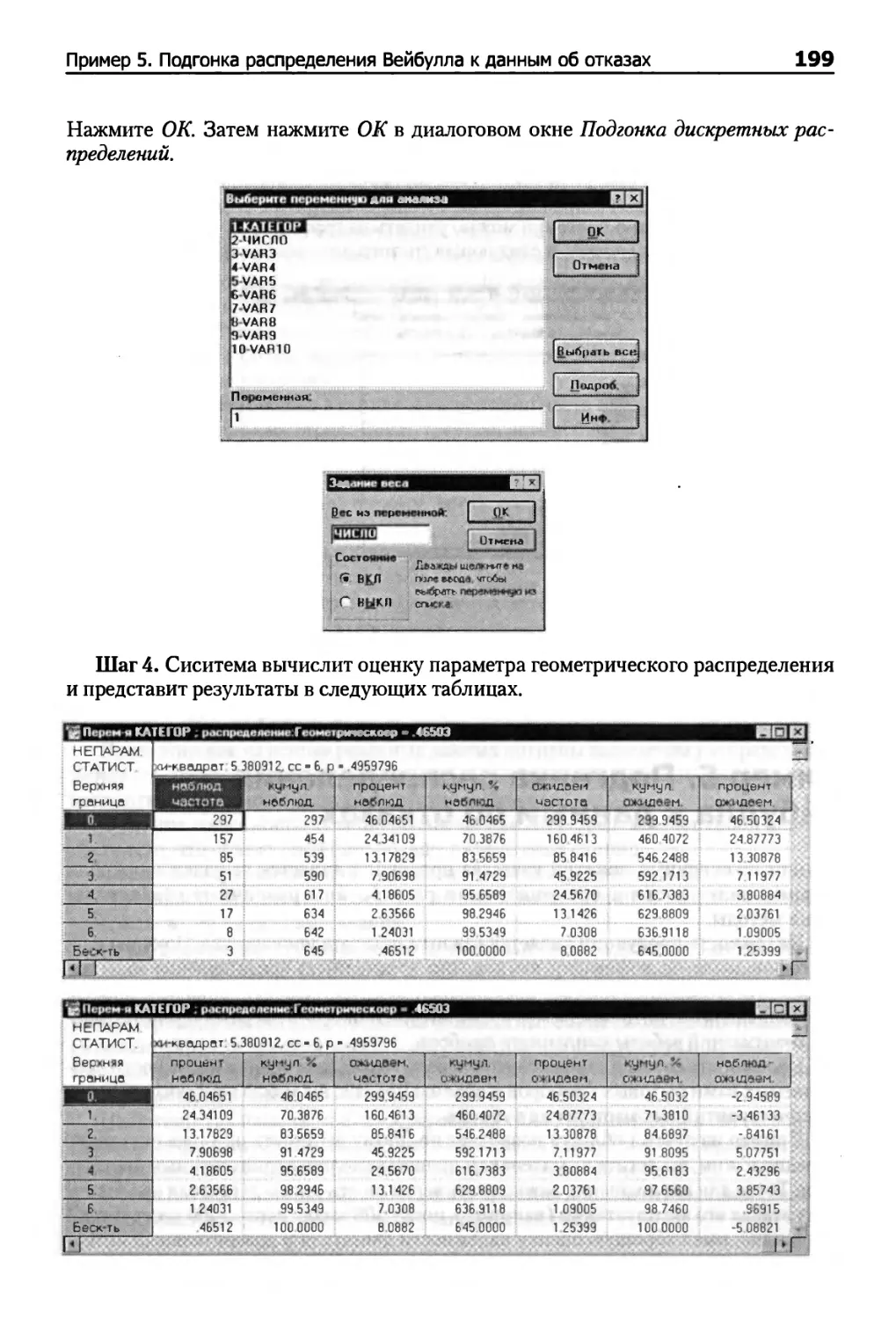
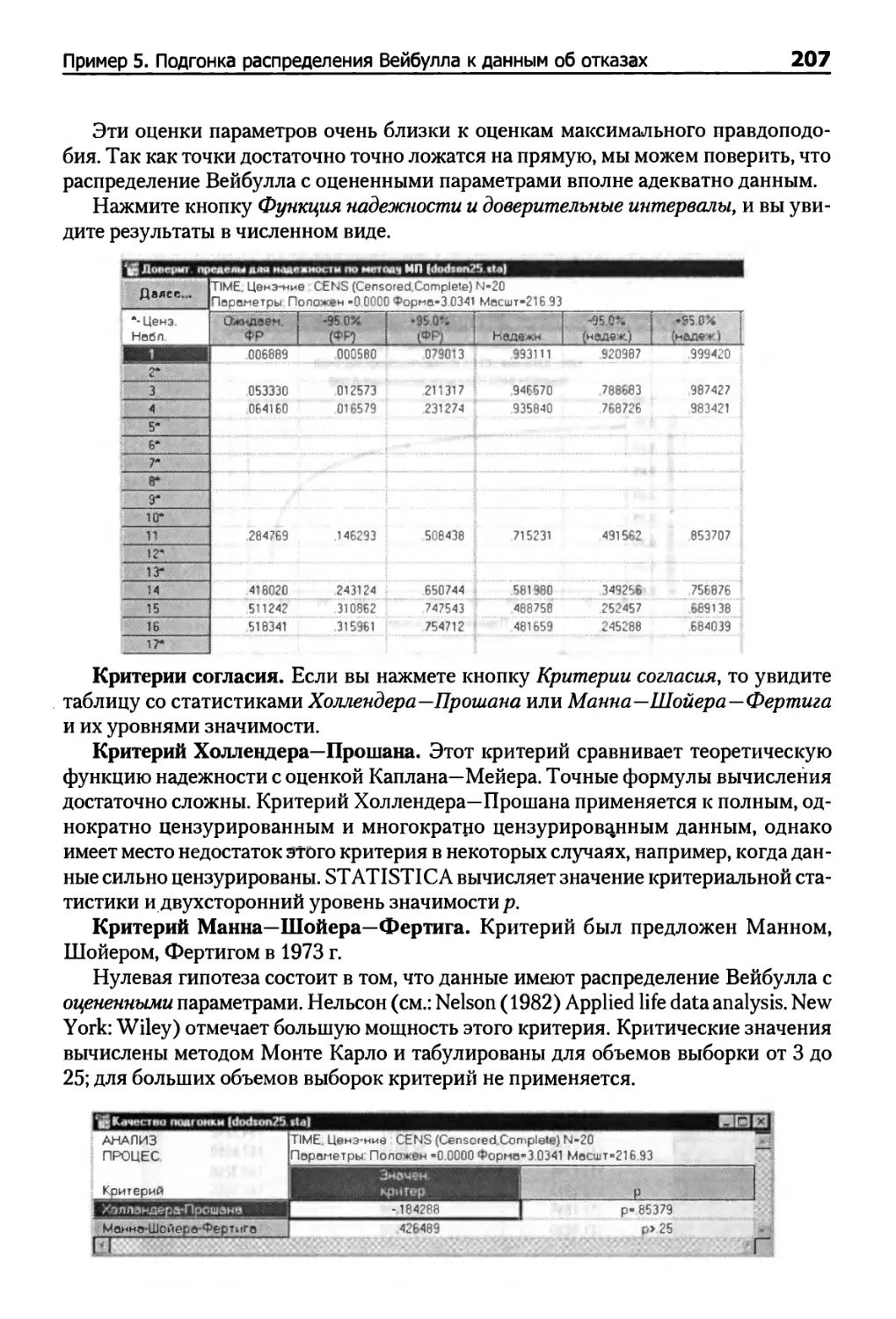
Пример 5. Подгонка распределения Вейбулла к данным об отказах 200
Глава 5. Двумерный визуальный анализ данных 210
Гистограммы 210
Гистограммы и описательные статистики 212
Группировка 213
8 Содержание
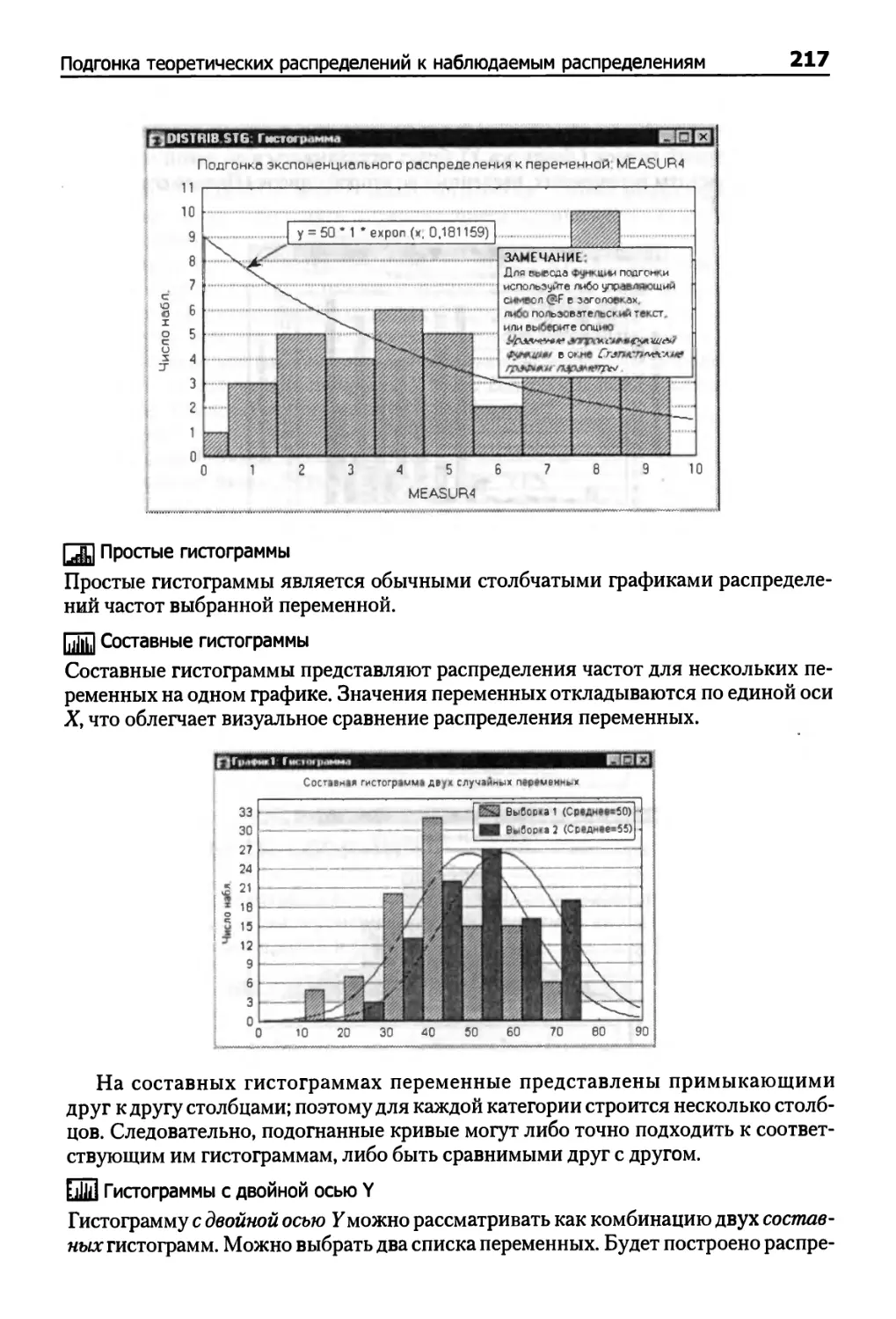
Подгонка теоретических распределений к наблюдаемым распределениям 216
Пересекающиеся категории 219
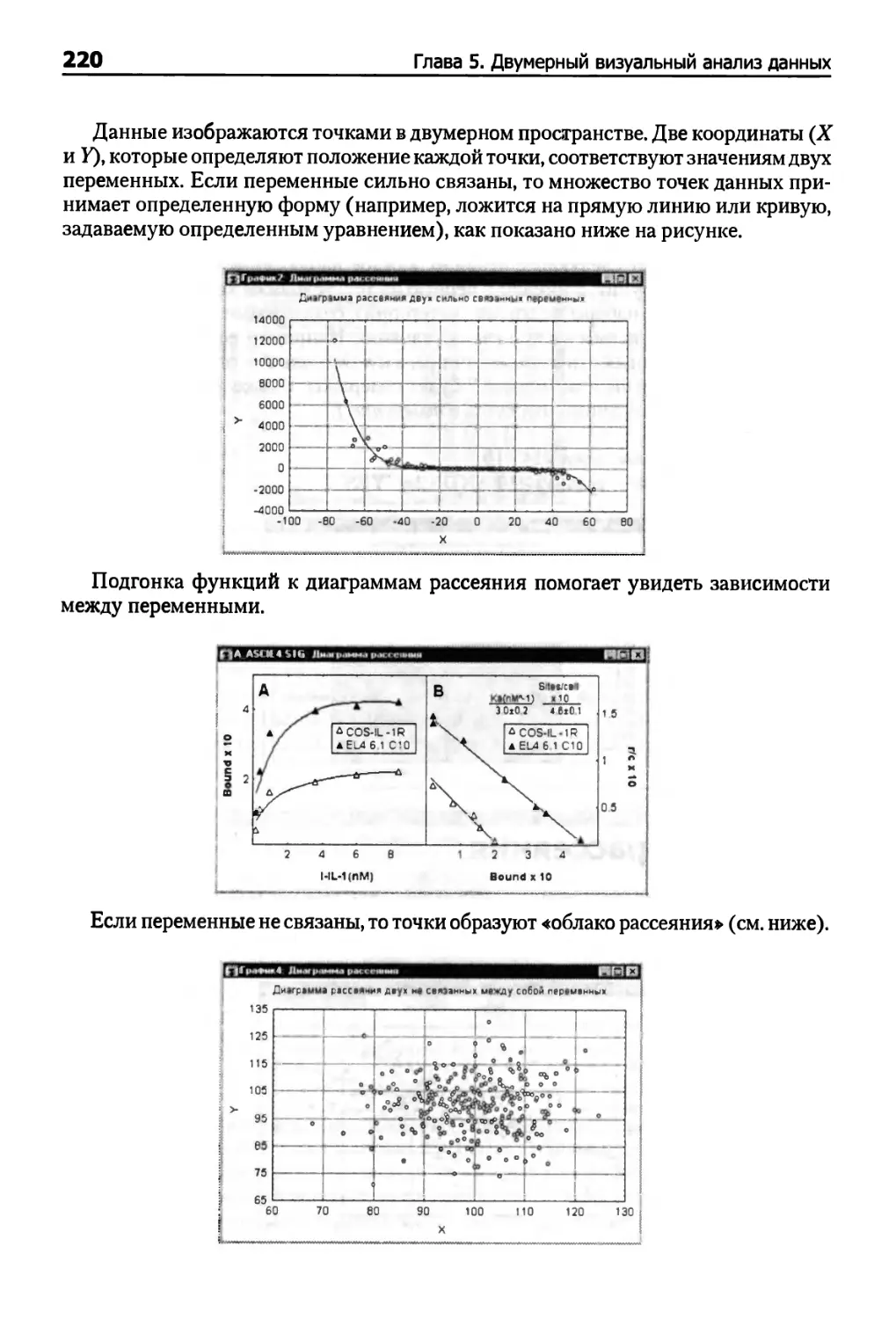
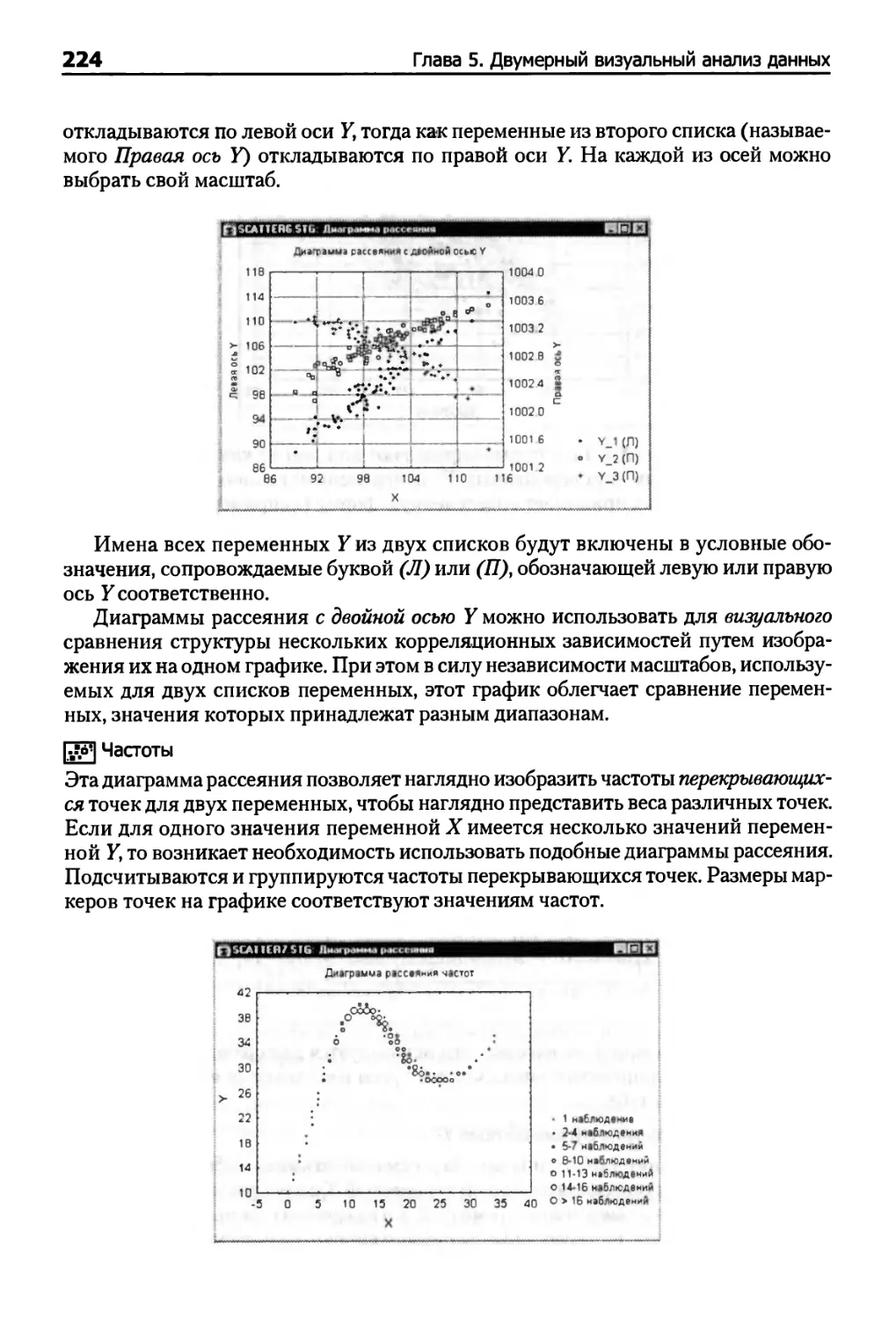
Диаграммы рассеяния 219
Однородность распределений двух переменных (формы зависимостей) 221
Выбросы 222
Диаграммы рассеяния с гистограммами 226
Диаграммы рассеяния с диаграммами размаха 226
Нормальные вероятностные графики 227
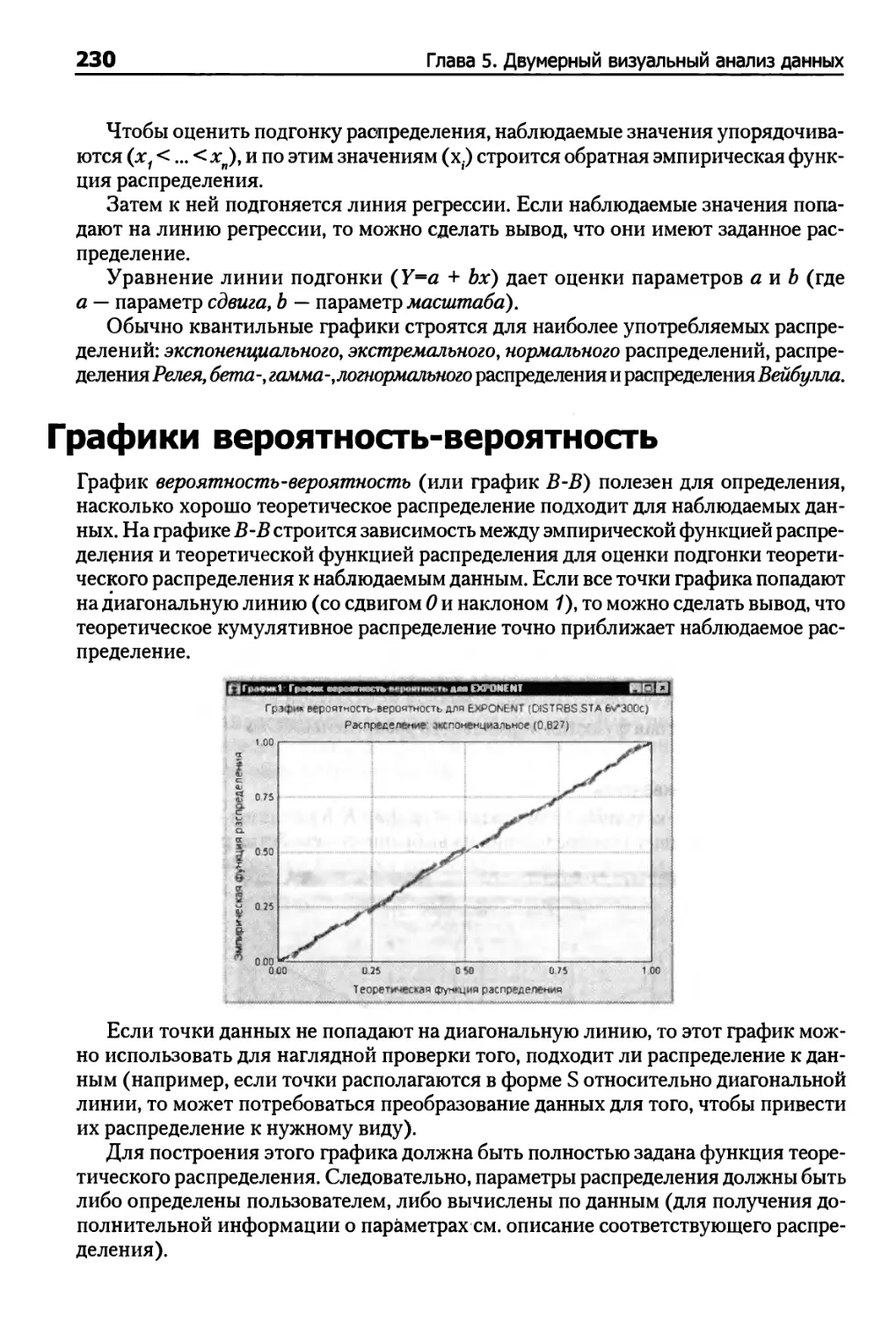
Графики вероятность — вероятность 230
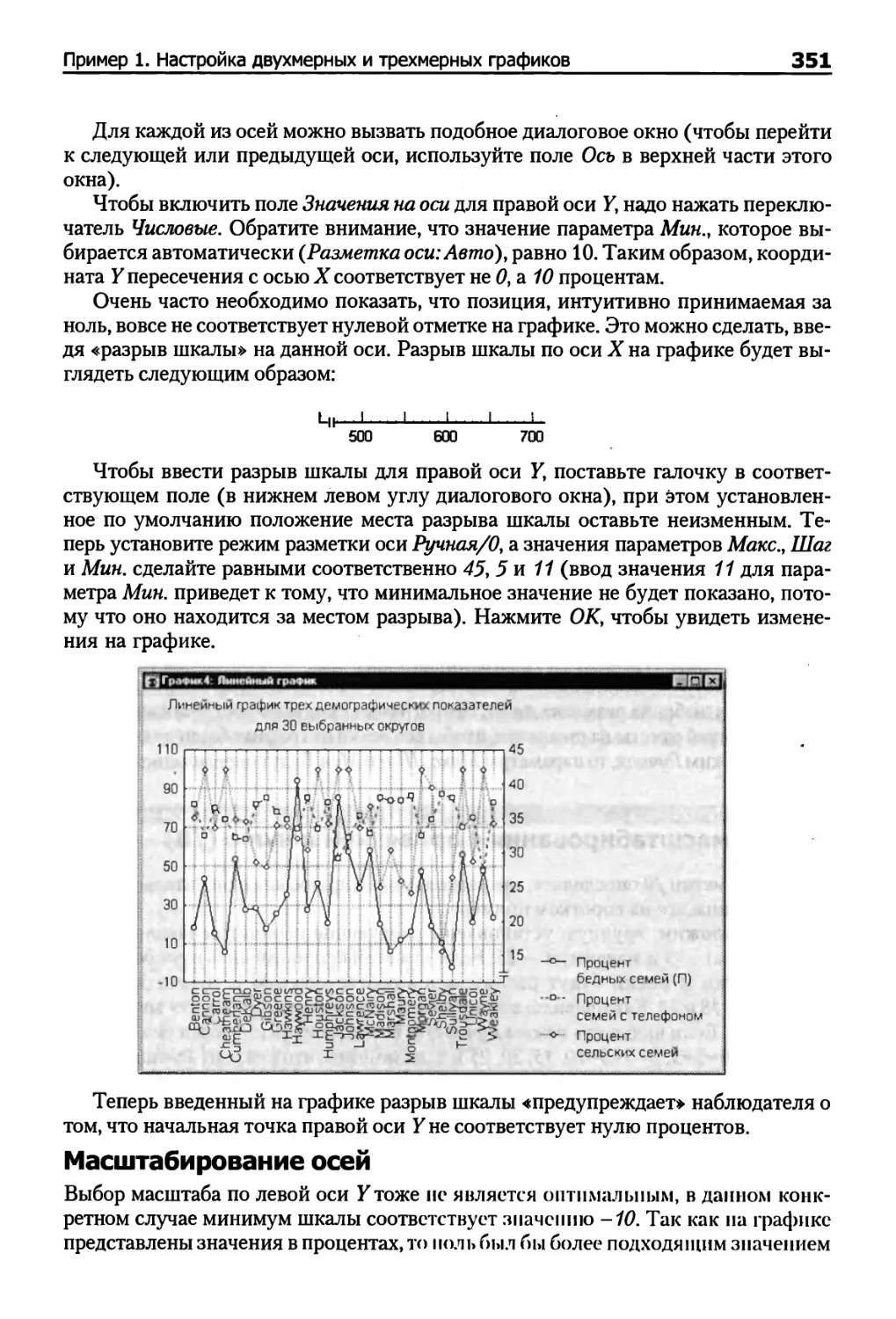
Диаграммы диапазонов 231
Диаграммы размаха 232
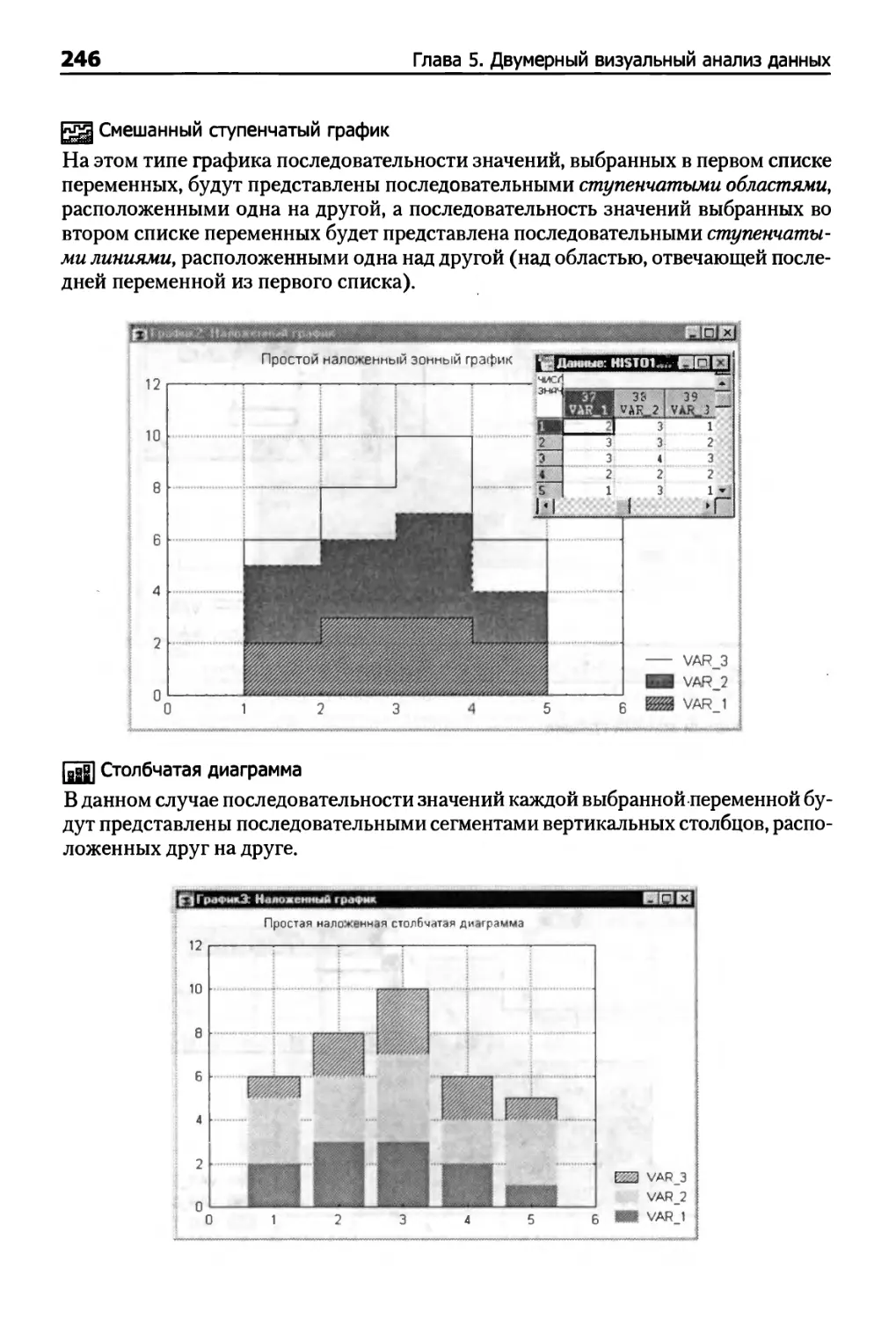
Столбчатые диаграммы , 234
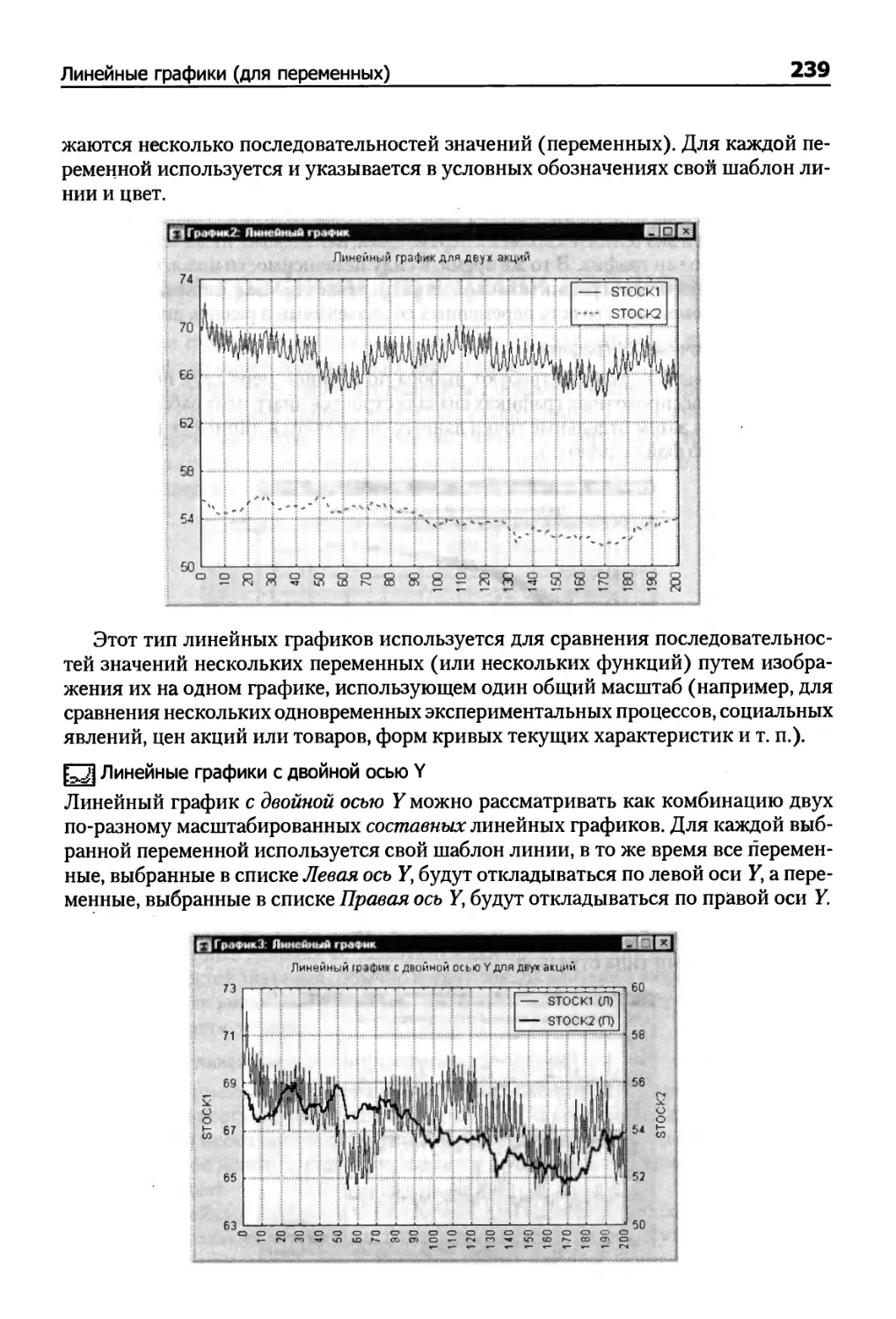
Линейные графики (для переменных) 236
Линейные графики (профили наблюдений) 241
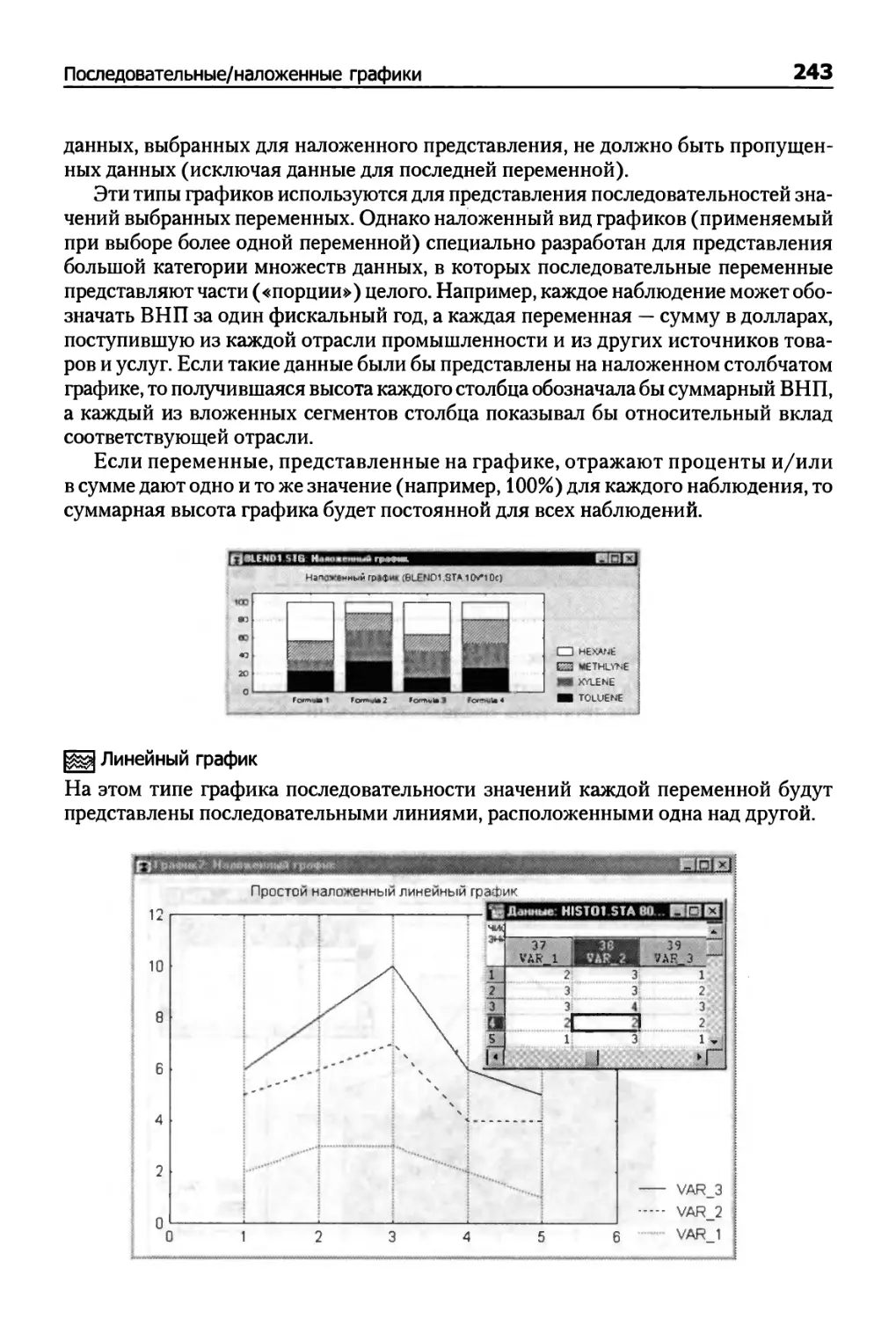
Последовательные/наложенные графики 242
Круговые диаграммы 247
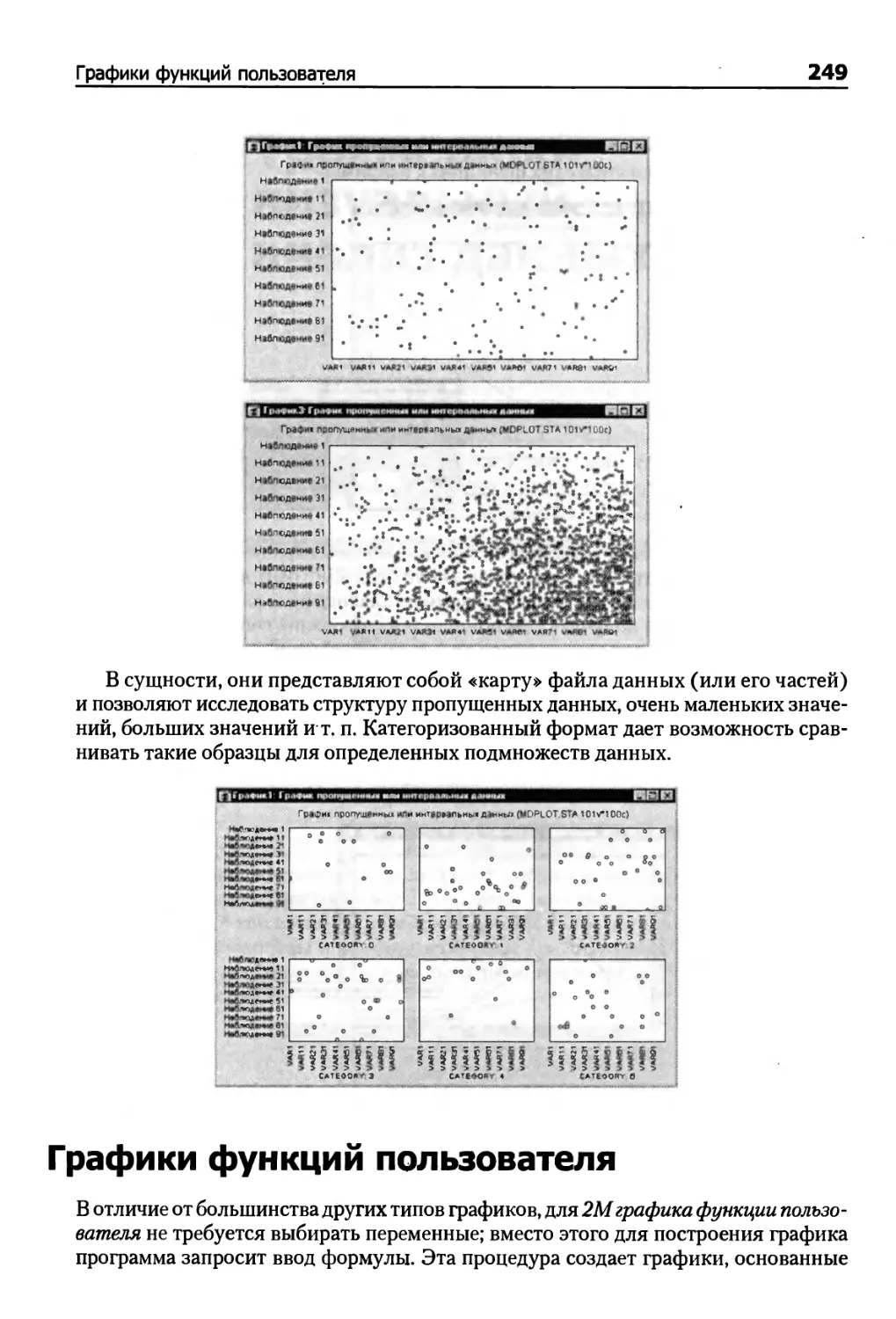
Диаграммы пропущенных значений и интервалов 248
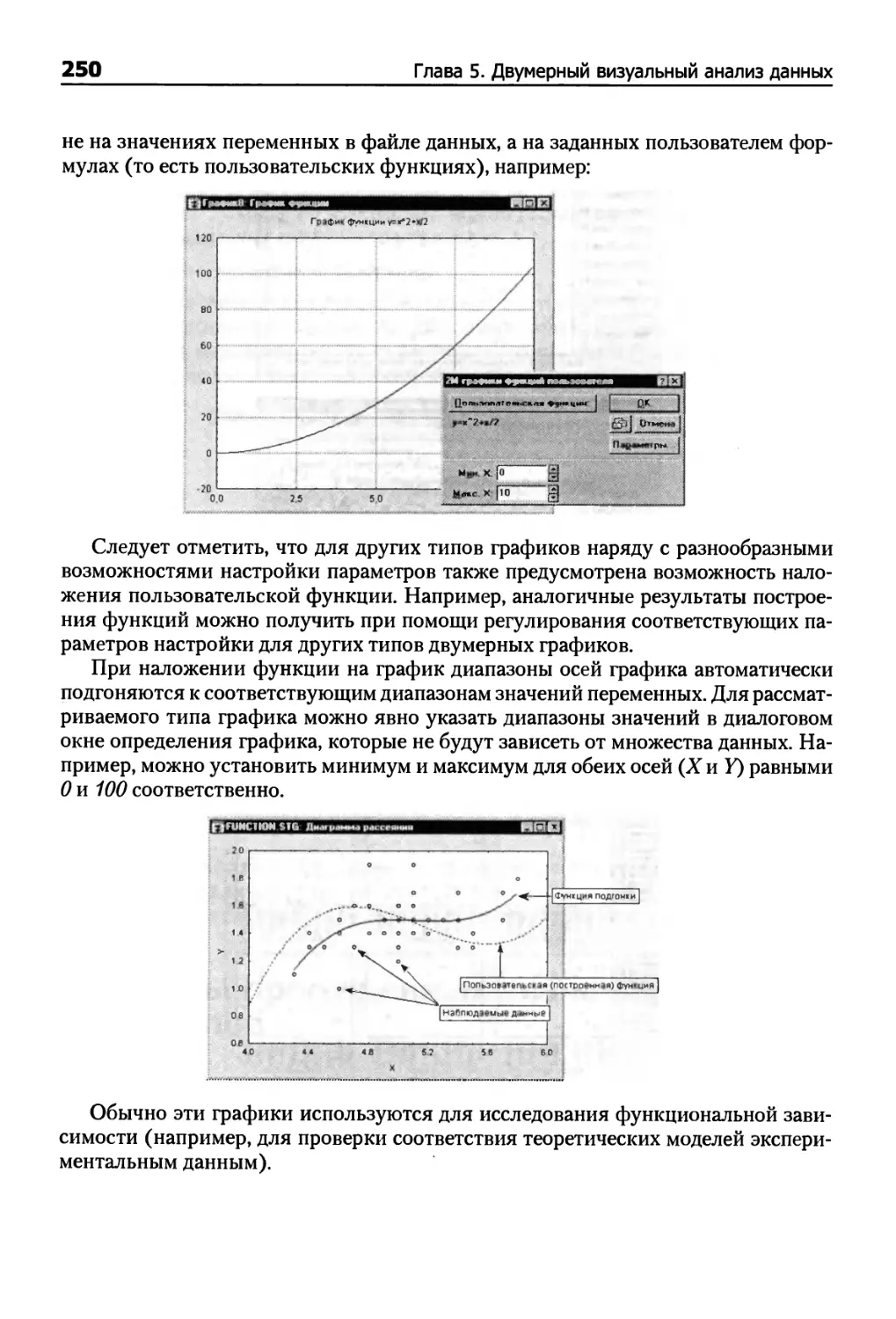
Графики функций пользователя 249
Глава 6. Трехмерный визуальный анализ данных 251
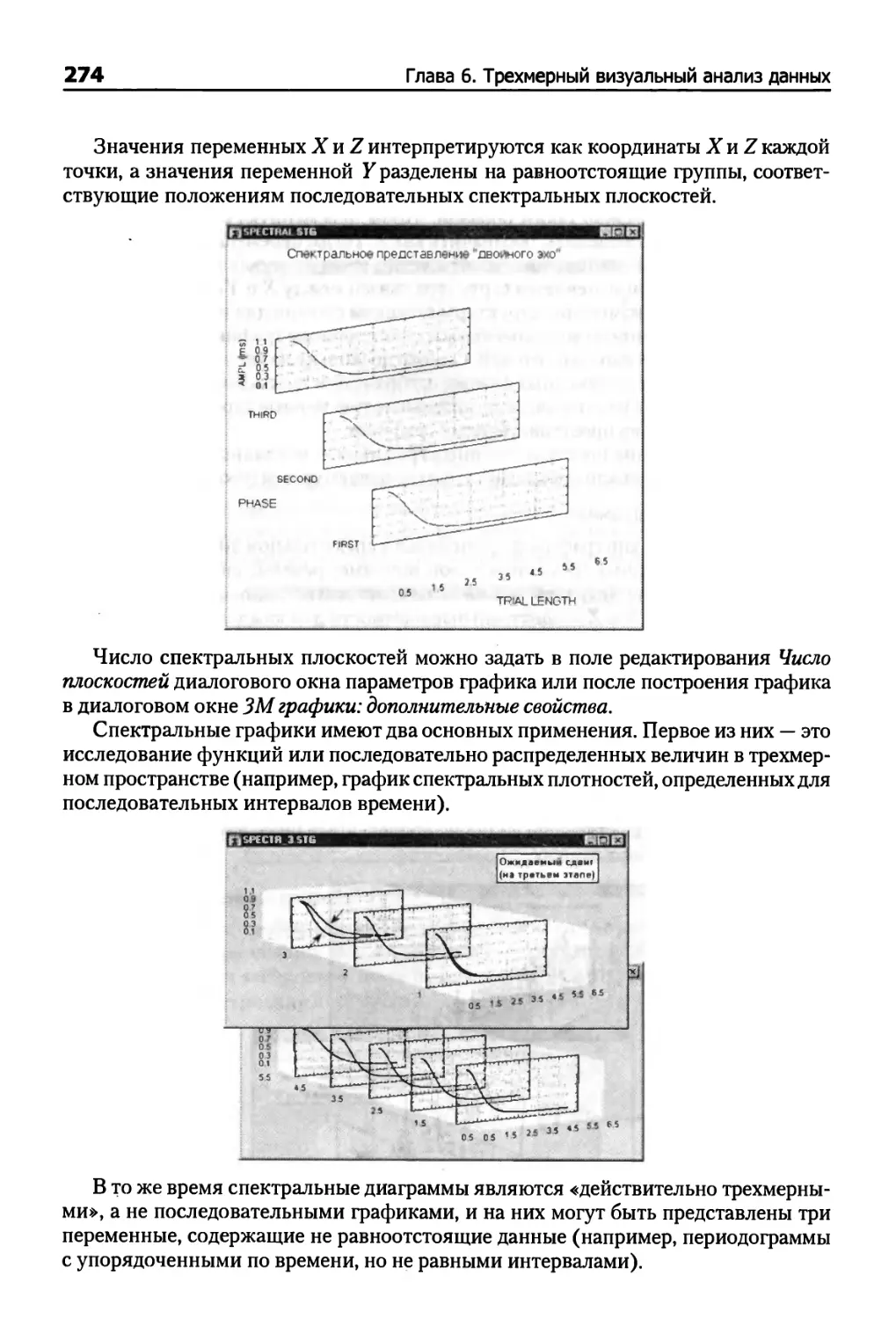
Гистограммы двух переменных 256
ЗМ диаграммы диапазонов 260
ЗМ диаграммы размаха 264
Трехмерные диаграммы рассеяния 269
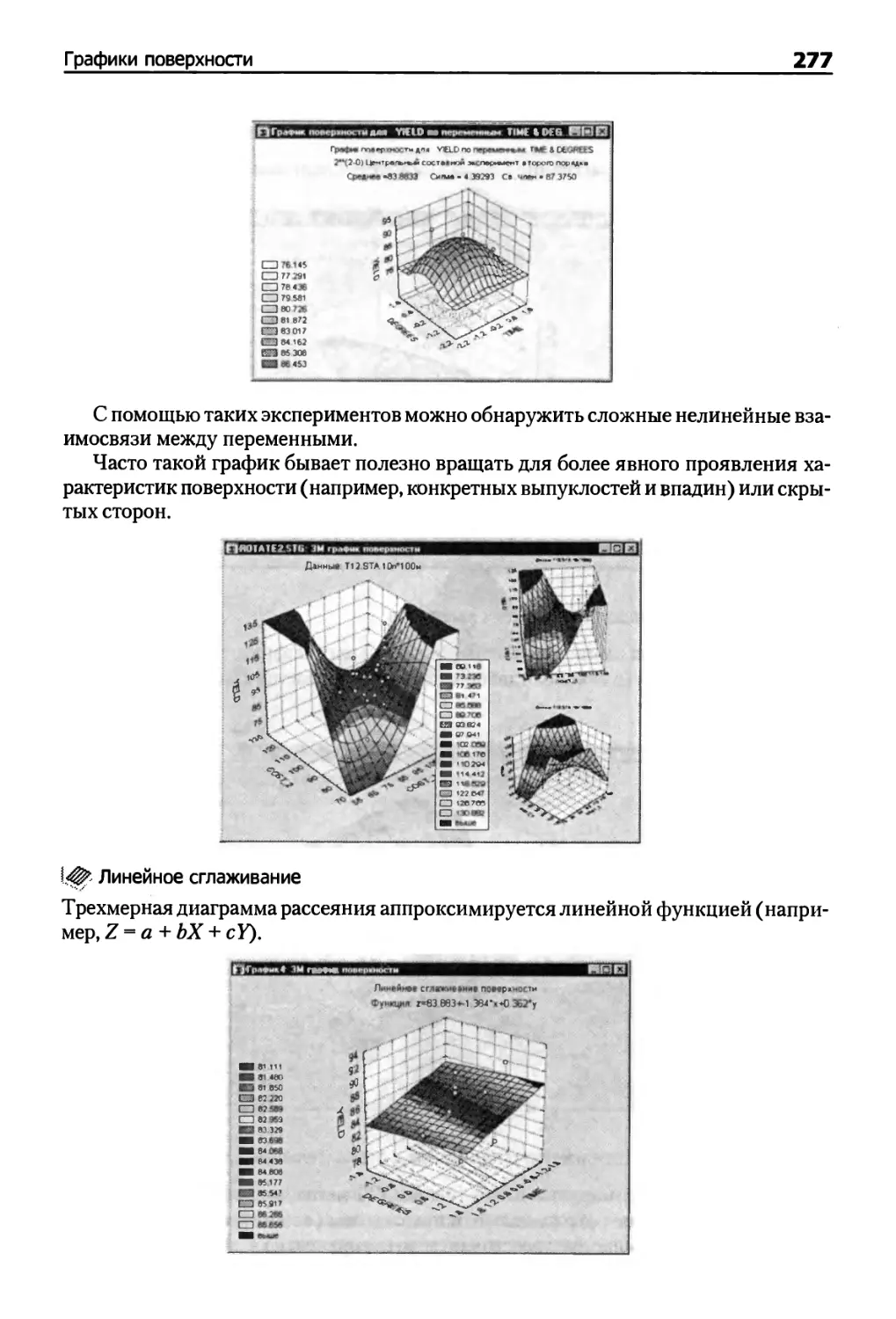
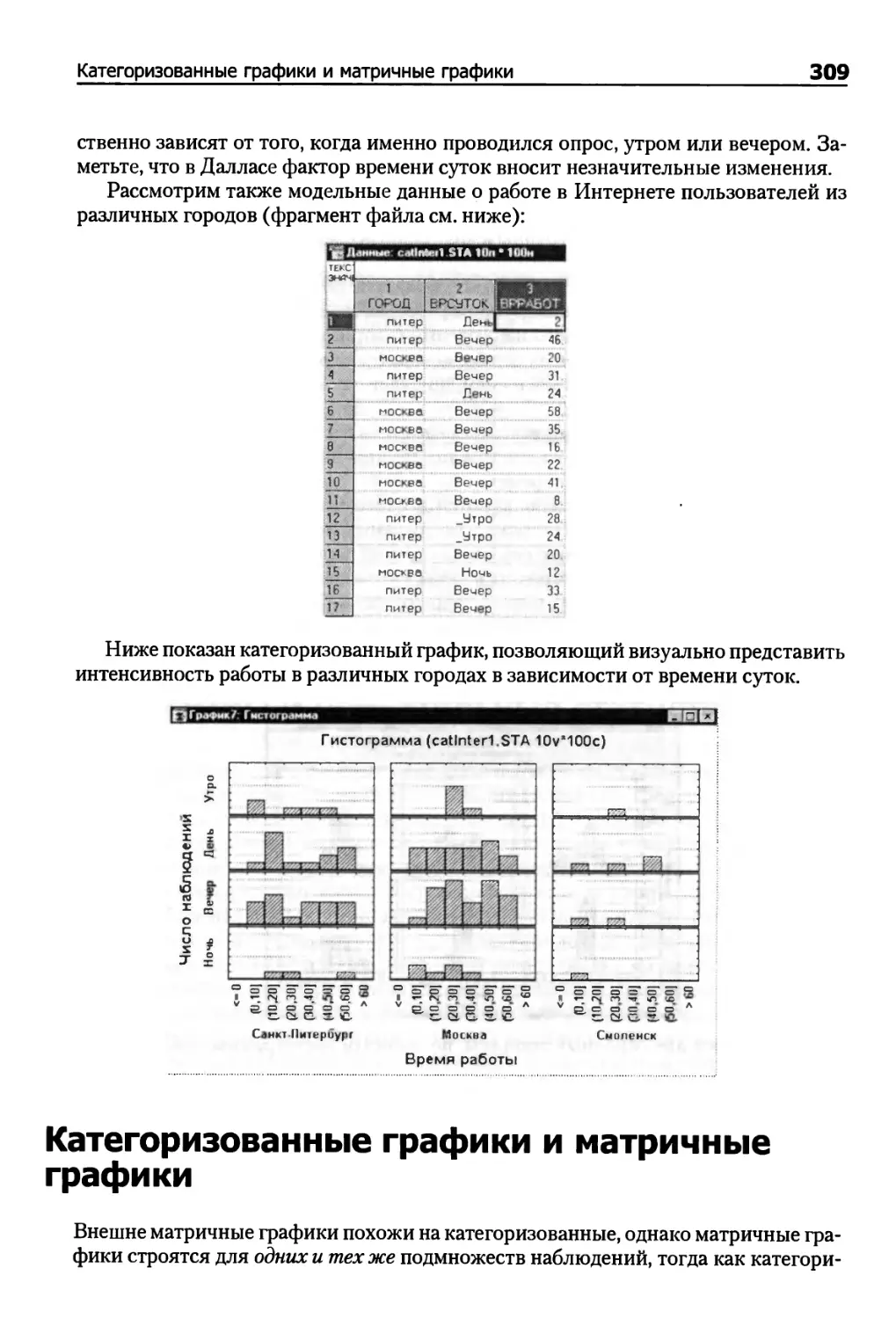
Графики поверхности 276
Карты линий уровня 280
Трассировочные графики 281
Тернарные графики 283
Трехмерные категоризованные графики 289
Категоризованные тернарные графики 293
Графики пользовательских функций 298
Матричные графики 299
Глава 7. Визуальный анализ категоризованных данных 307
Что такое категоризованные графики? 307
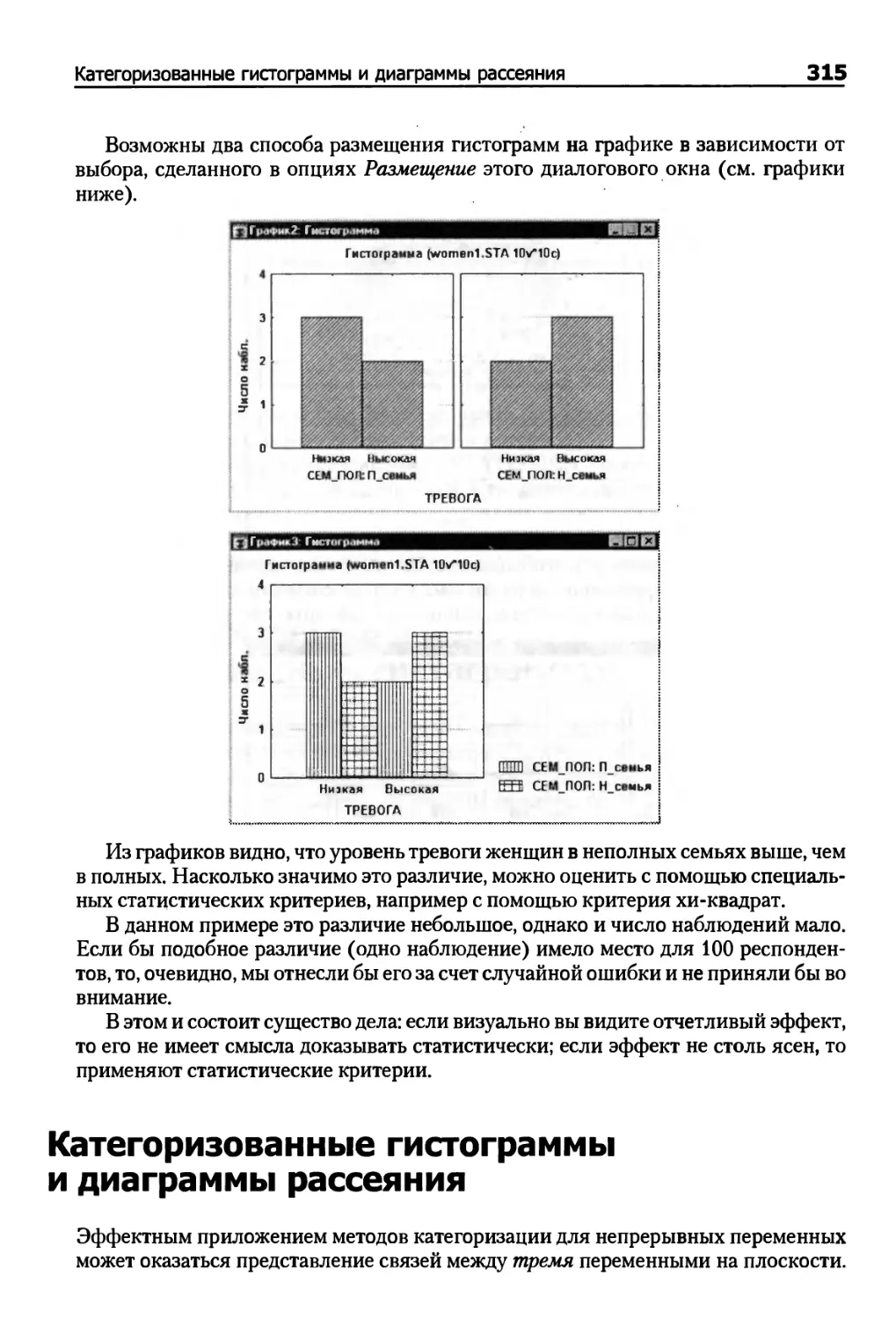
Категоризованные графики и матричные графики 309
Гистограммы и описательные статистики 311
Категоризация значений в каждой гистограмме 312
Категоризация значений в составных графиках 312
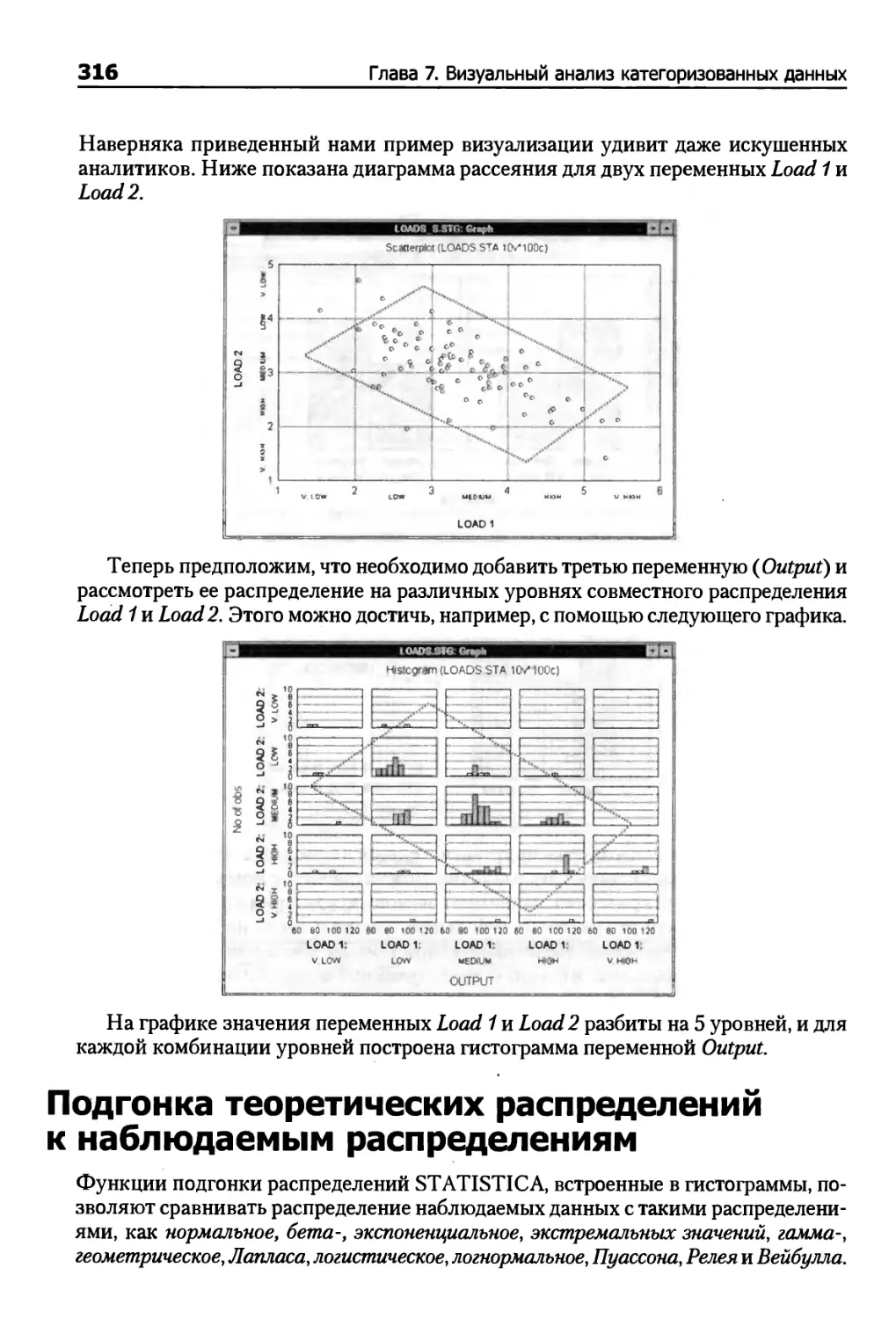
Категоризованные гистограммы и диаграммы рассеяния 315
Подгонка теоретических распределений к наблюдаемым распределениям 316
Подгонка распределений к множественным гистограммам 317
Категоризованные диаграммы рассеяния 318
Нелинейная зависимость 319
Категоризованные вероятностные графики 320
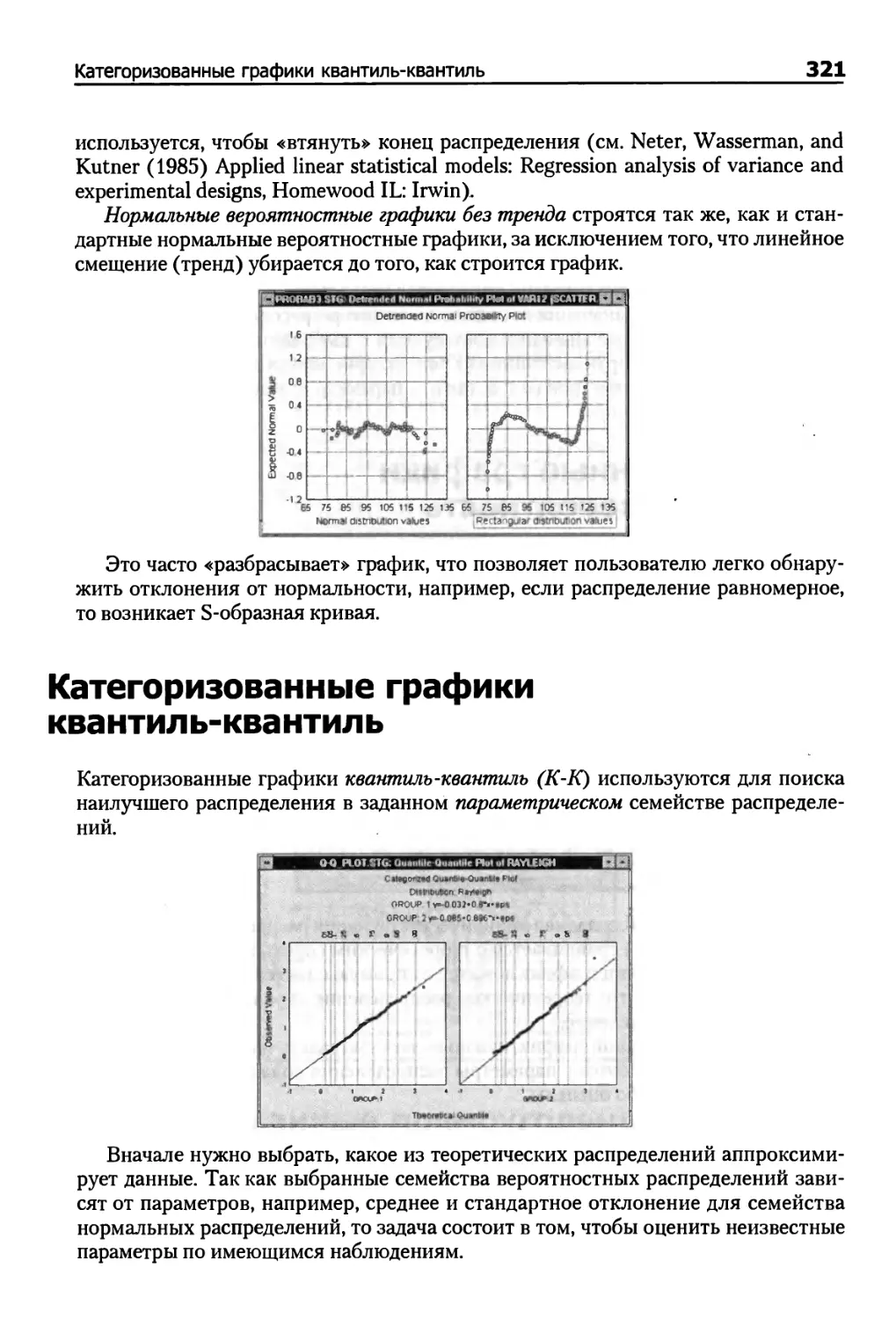
Категоризованные графики квантиль — квантиль 321
Категоризованные графики вероятность — вероятность 322
Категоризованные линейные графики 322
Методы сглаживания 323
Категоризованные прямоугольные диаграммы 323
Содержание 9
Связанные графики 325
Категоризованные круговые диаграммы 327
Круговые диаграммы рассеяния 328
Категоризованные диаграммы пропущенных данных и диаграммы диапазонов 329
Категоризованные трехмерные графики 329
Категоризованные тернарные графики 331
Глава 8. Пиктографики 333
Анализ пиктографиков 333
Классификация пиктографиков 334
Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA .... 341
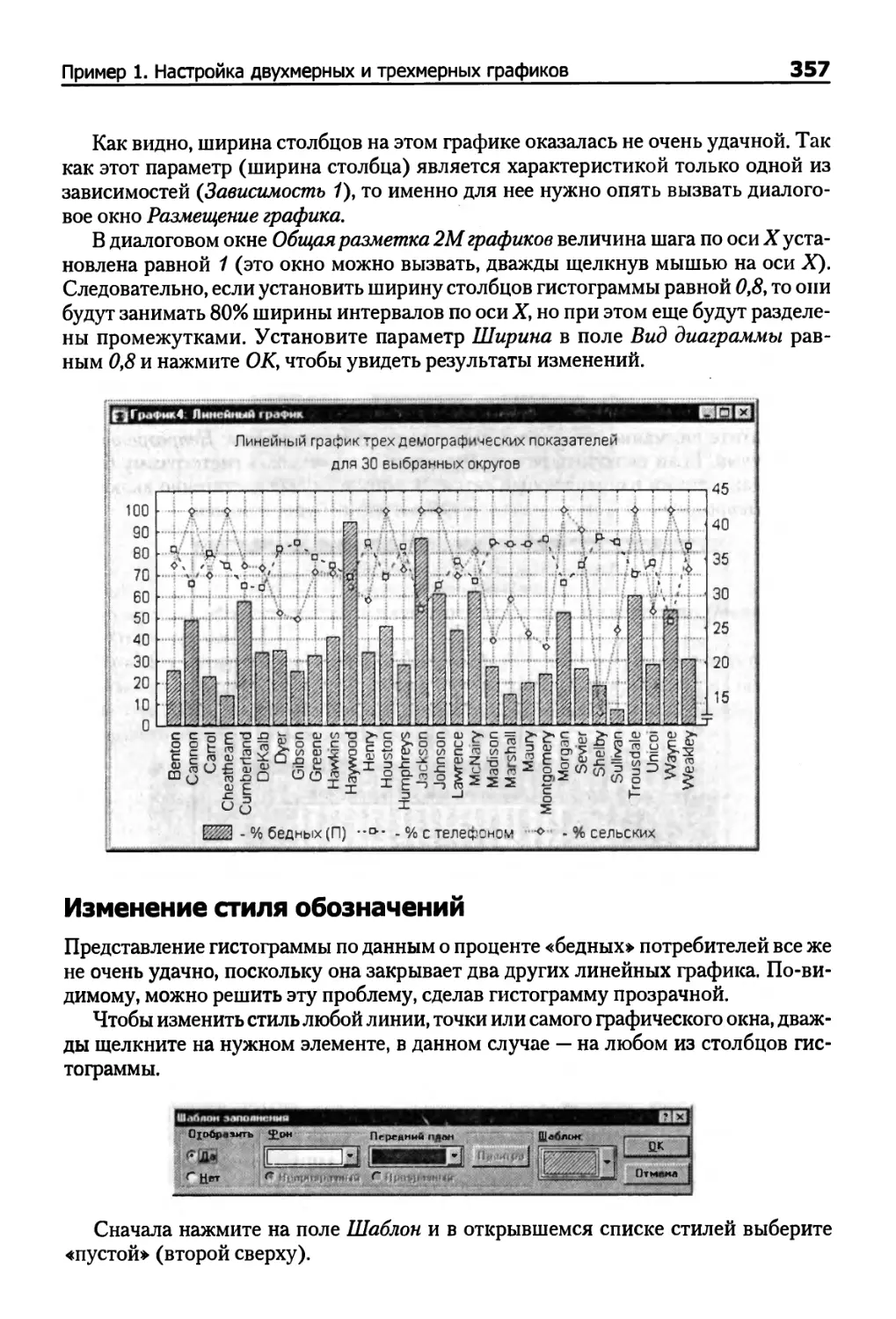
Пример 1. Настройка двумерных и трехмерных графиков 341
Настройка двумерных графиков 341
Настройка трехмерных графиков 361
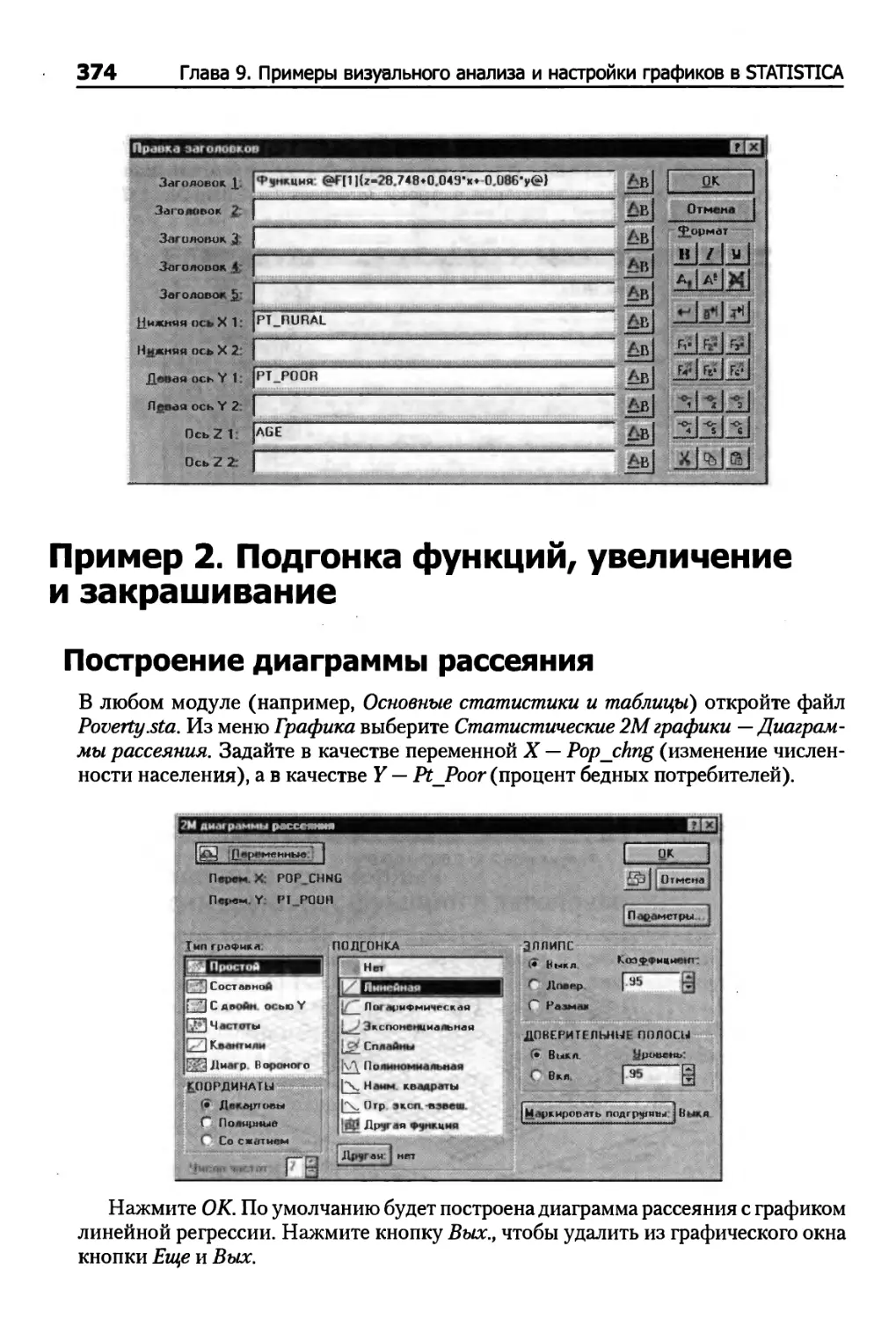
Пример 2. Подгонка функций, увеличение и закрашивание 374
Построение диаграммы рассеяния .- 374
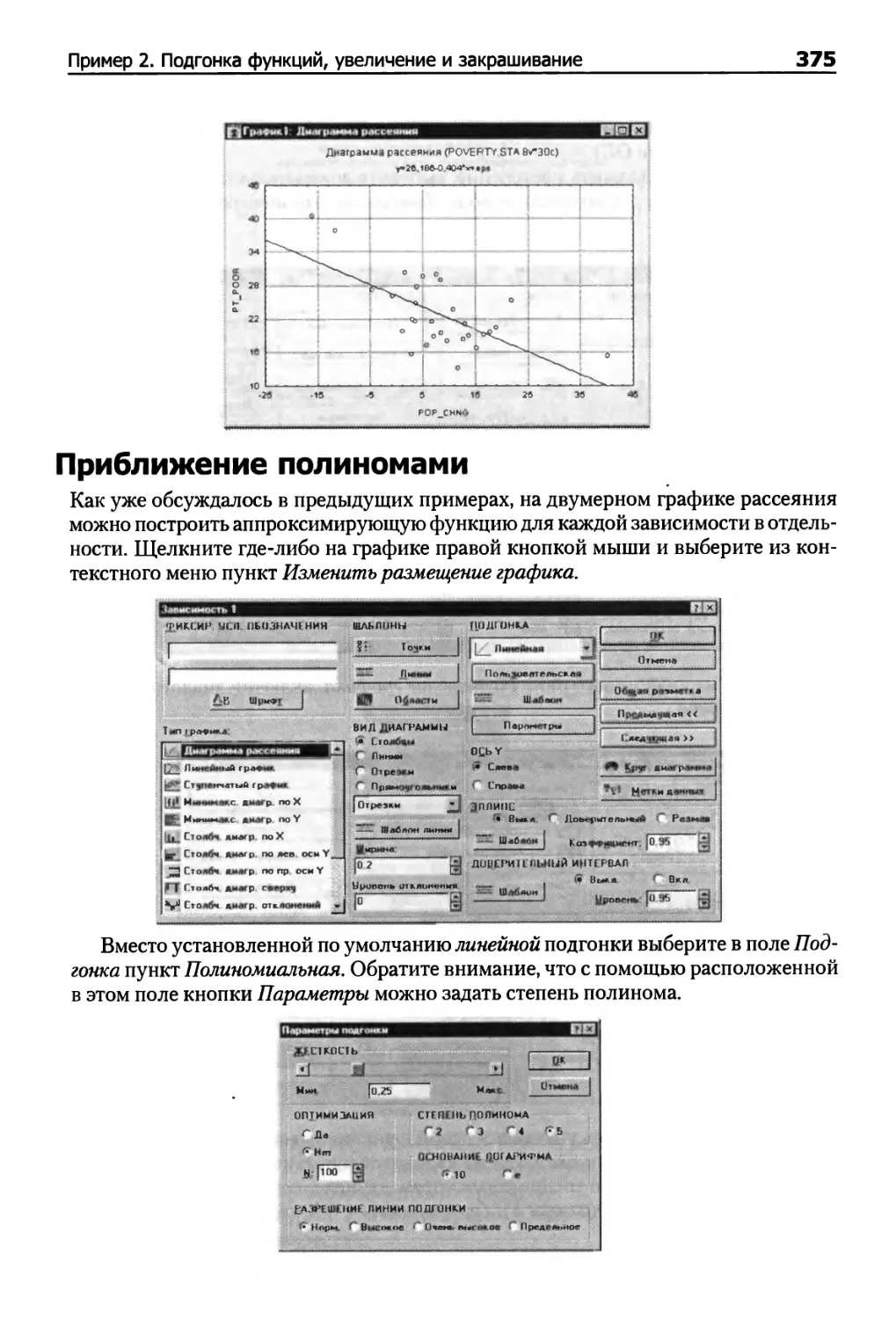
Приближение полиномами 375
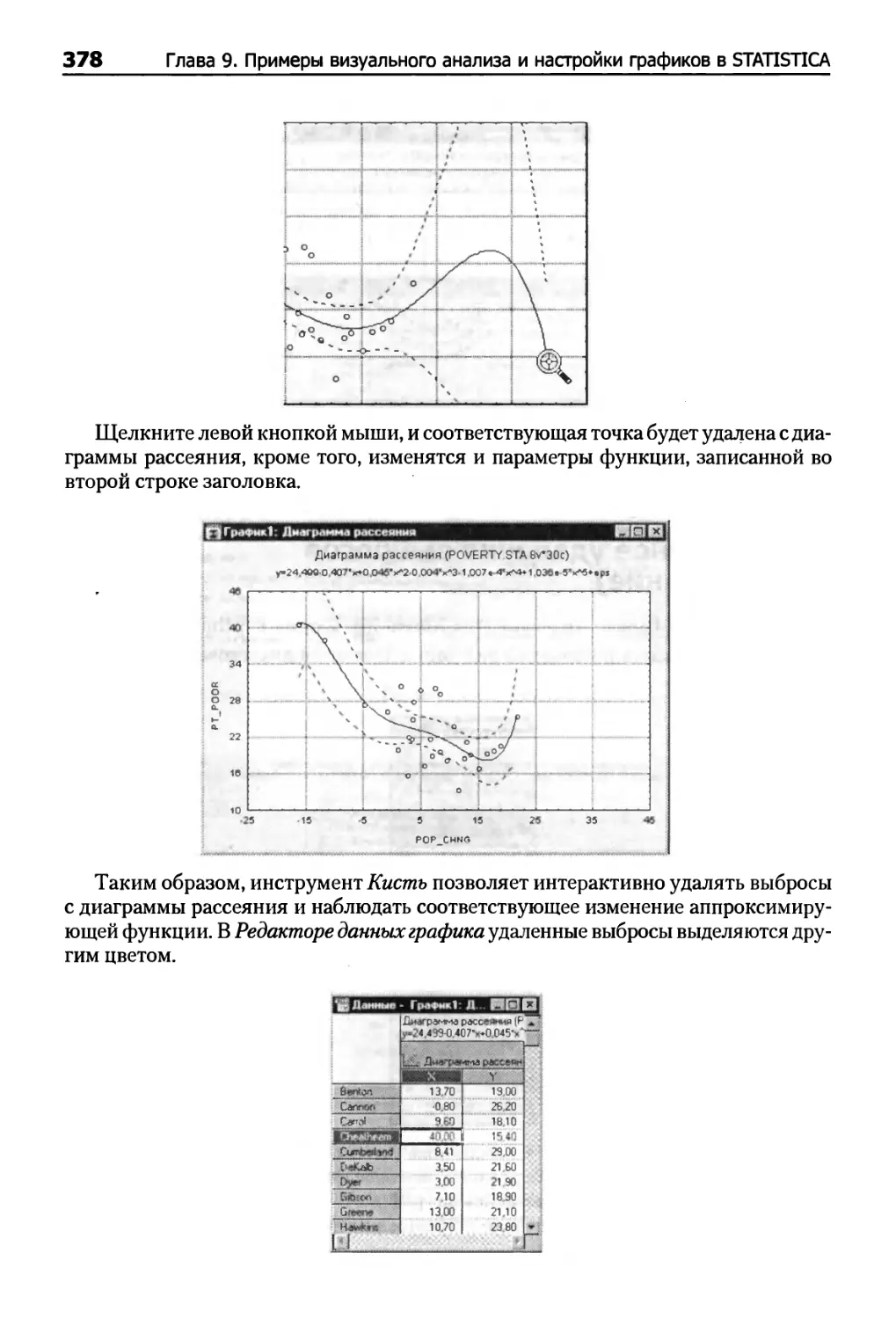
Интерактивное удаление выбросов (Закрашивание) 377
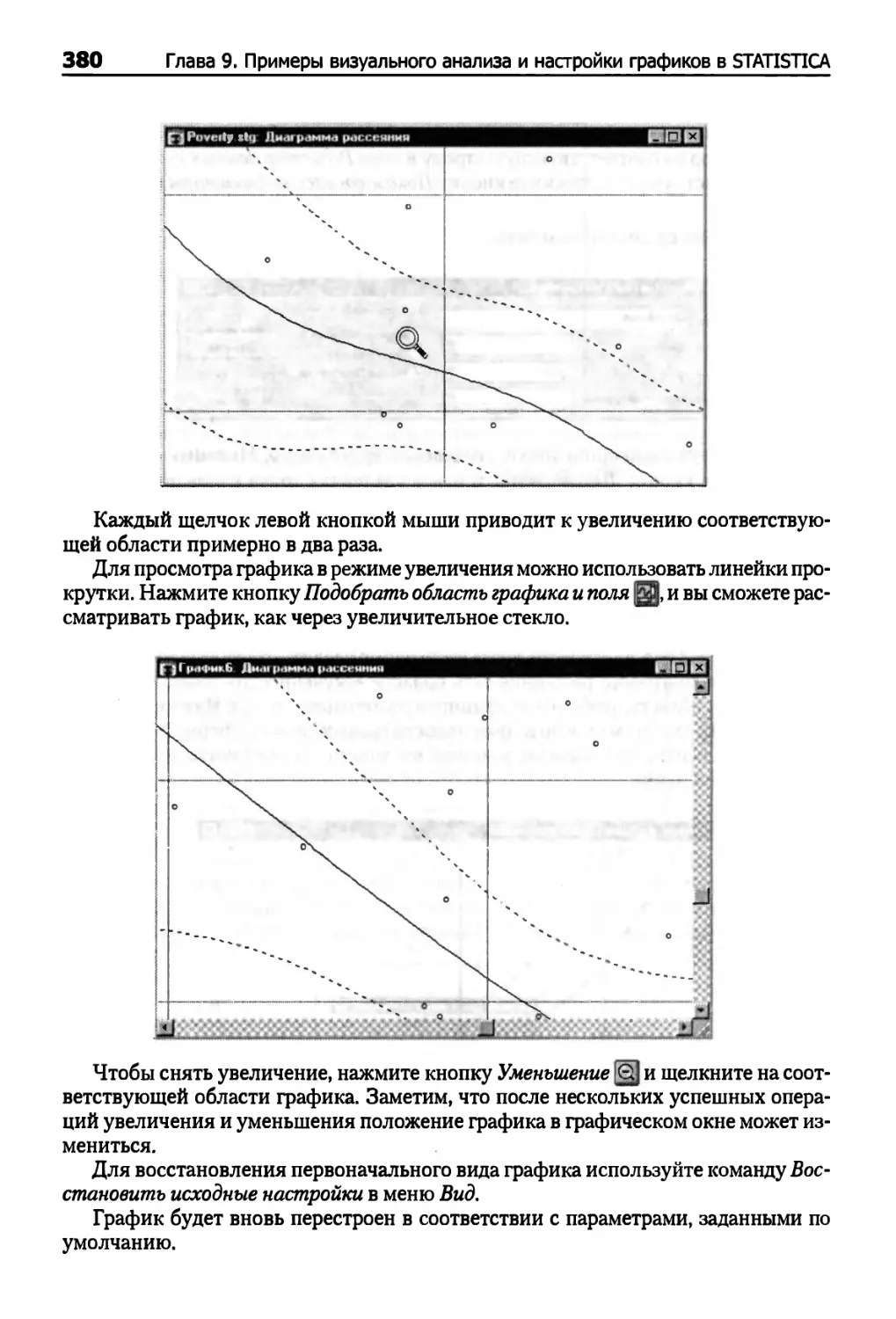
Увеличение 379
Рисование пользовательской функции 381
Добавление зависимости 382
Пример 3. Динамическое закрашивание (Кисть) 384
Файл данных 384
Построение матричного графика 384
Закрашивание в редакторе данных графика 386
Пример 4. Связывание и внедрение 387
Растровые изображения 387
Метафайлы Windows («картинки») 387
Собственный графический формат системы STATISTICA 388
Копирование и вставка графических объектов 388
Вставка в виде текста 391
Вставка в виде растрового изображения 391
Вставка в виде собственного графического объекта системы STATISTICA 393
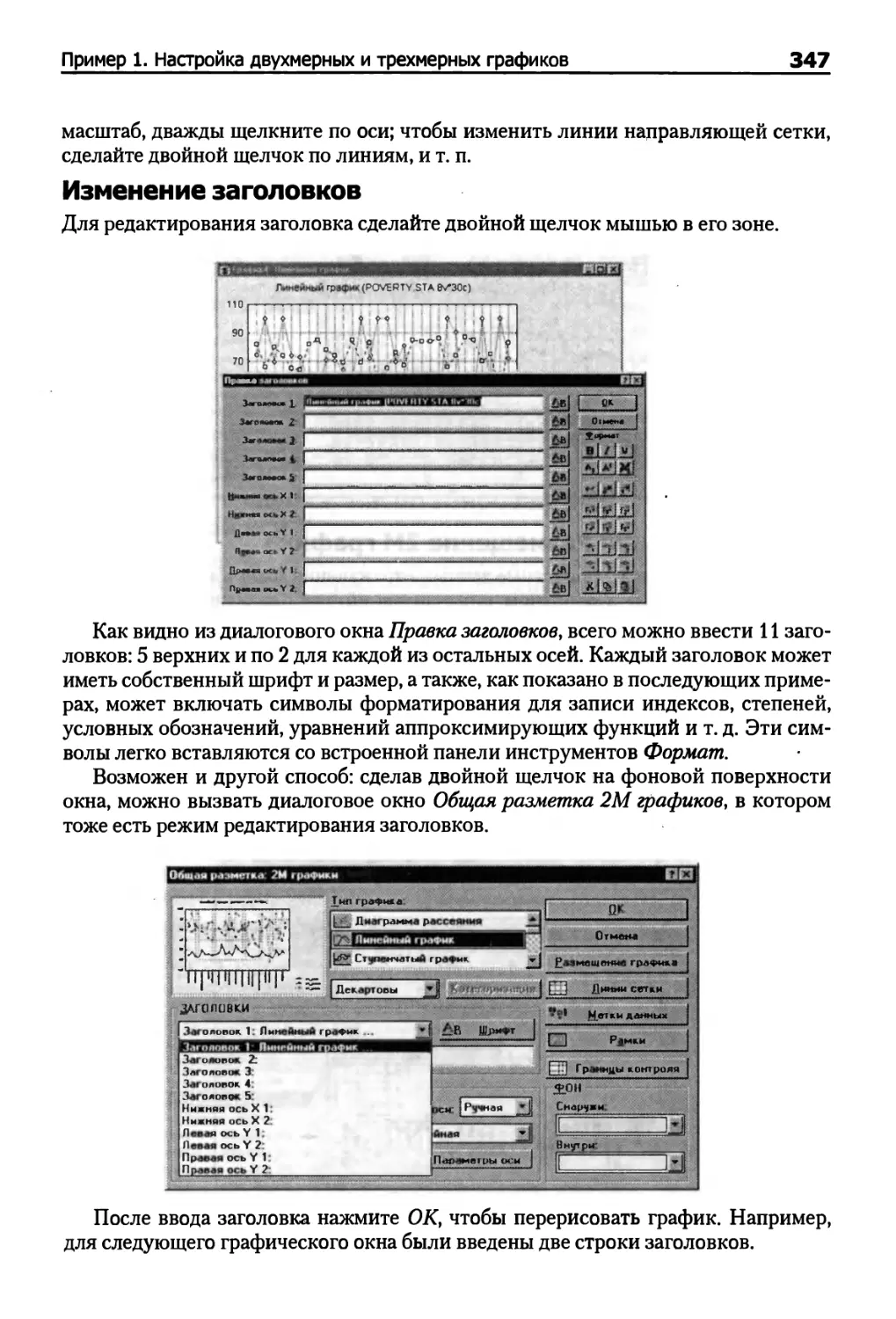
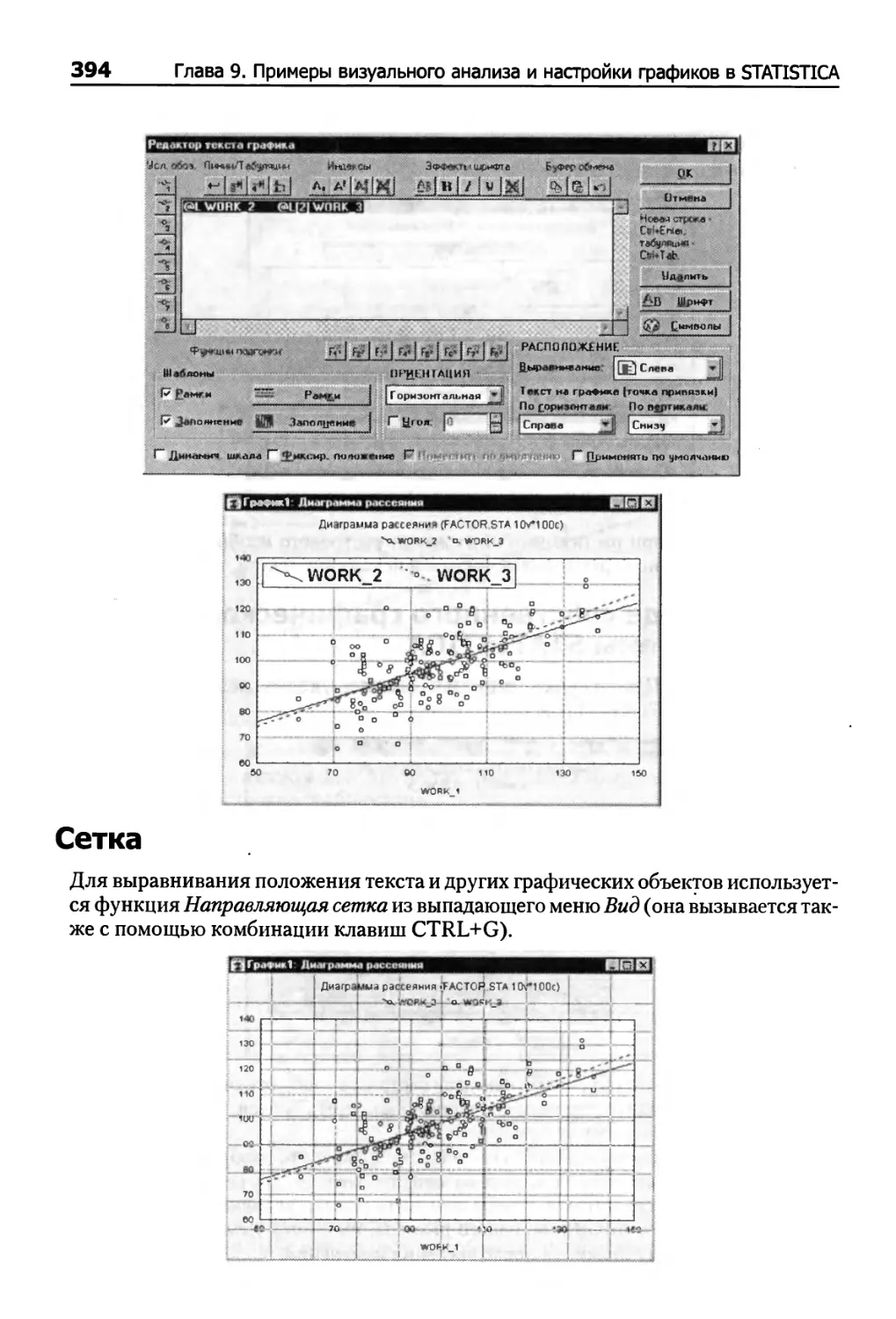
Сетка 394
Функции клиента и сервера в OLE 395
Создание трехмерной гистограммы 395
Внедрение диаграммы рассеяния 395
Редактирование внедренного графика 397
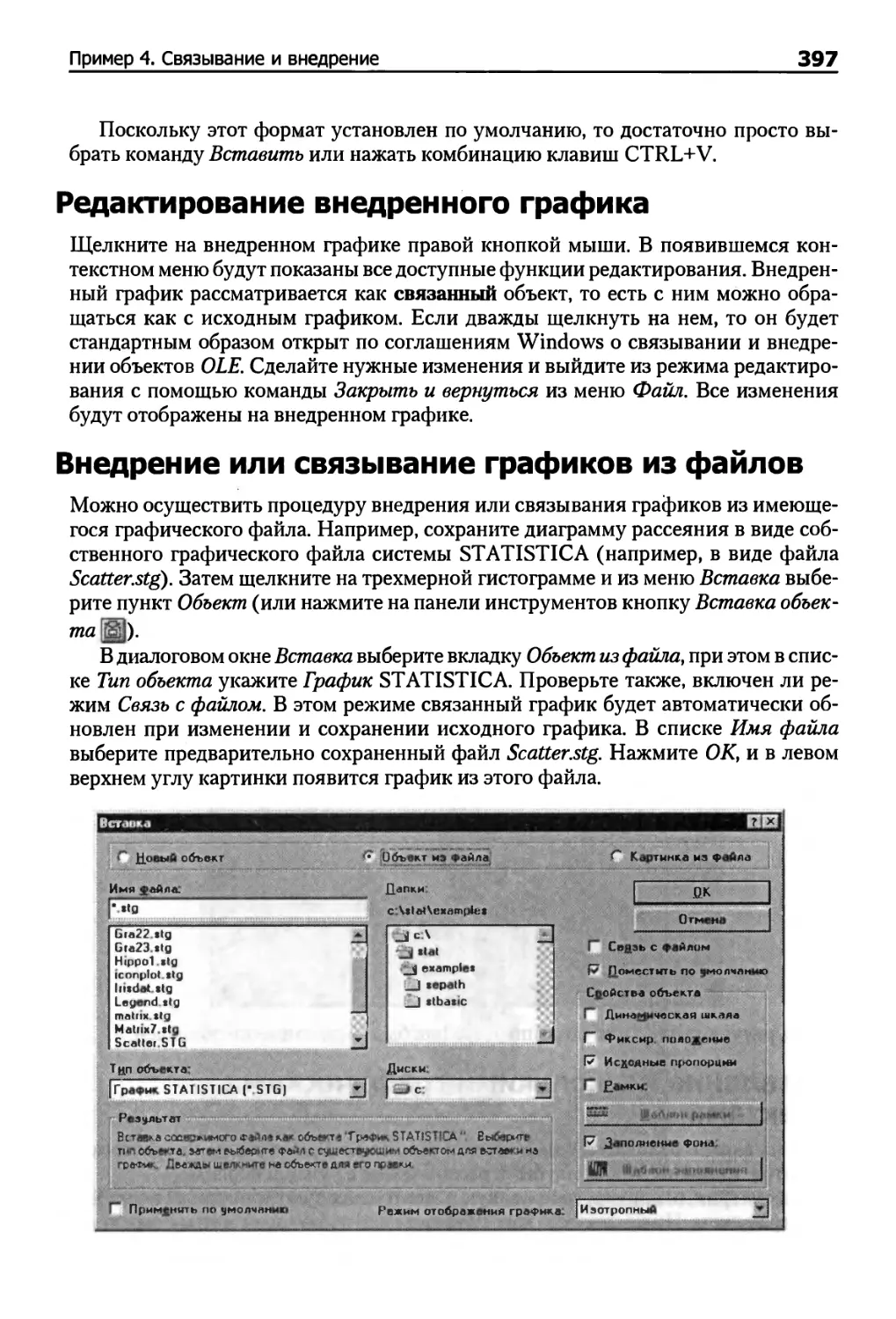
Внедрение или связывание графиков из файлов 397
Автоматическое обновление связанных графиков 398
Управление несколькими графическими объектами 398
Изменение очередности изображения графических объектов 399
Управление графиками системы STATISTICA в других приложениях Windows
средствами OLE 400
Связывание графика системы STATISTICA 401
Редактирование связанного графика 402
Пример 5. Добавление заданных пользователем статистических графиков в окно Галерея
графиков и в меню Графика 403
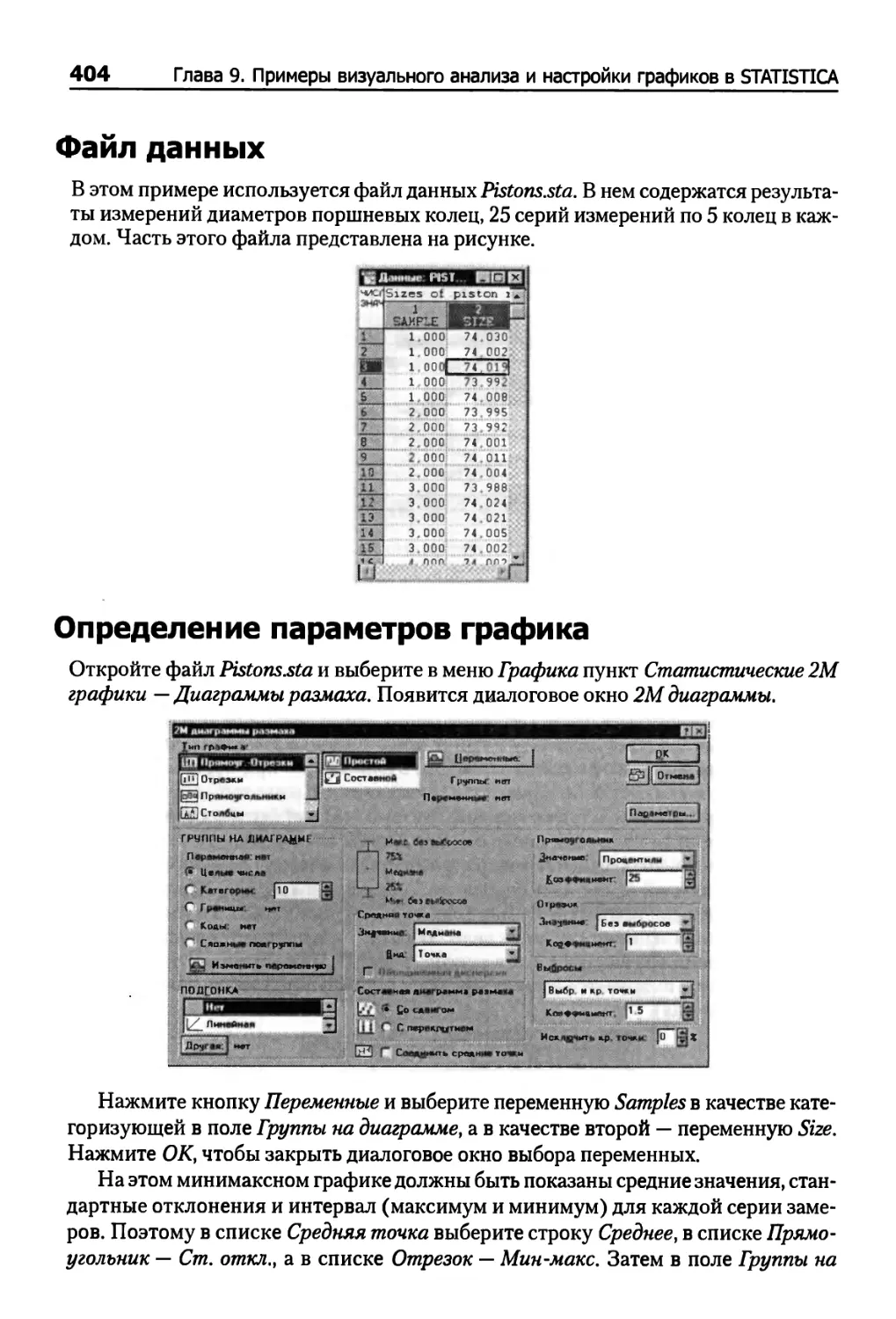
Файл данных 404
Определение параметров графика 404
10 Содержание
Создание нового графика пользователя 405
Выбор заданного пользователем графика 406
Просмотр и редактирование списка графиков пользователя 407
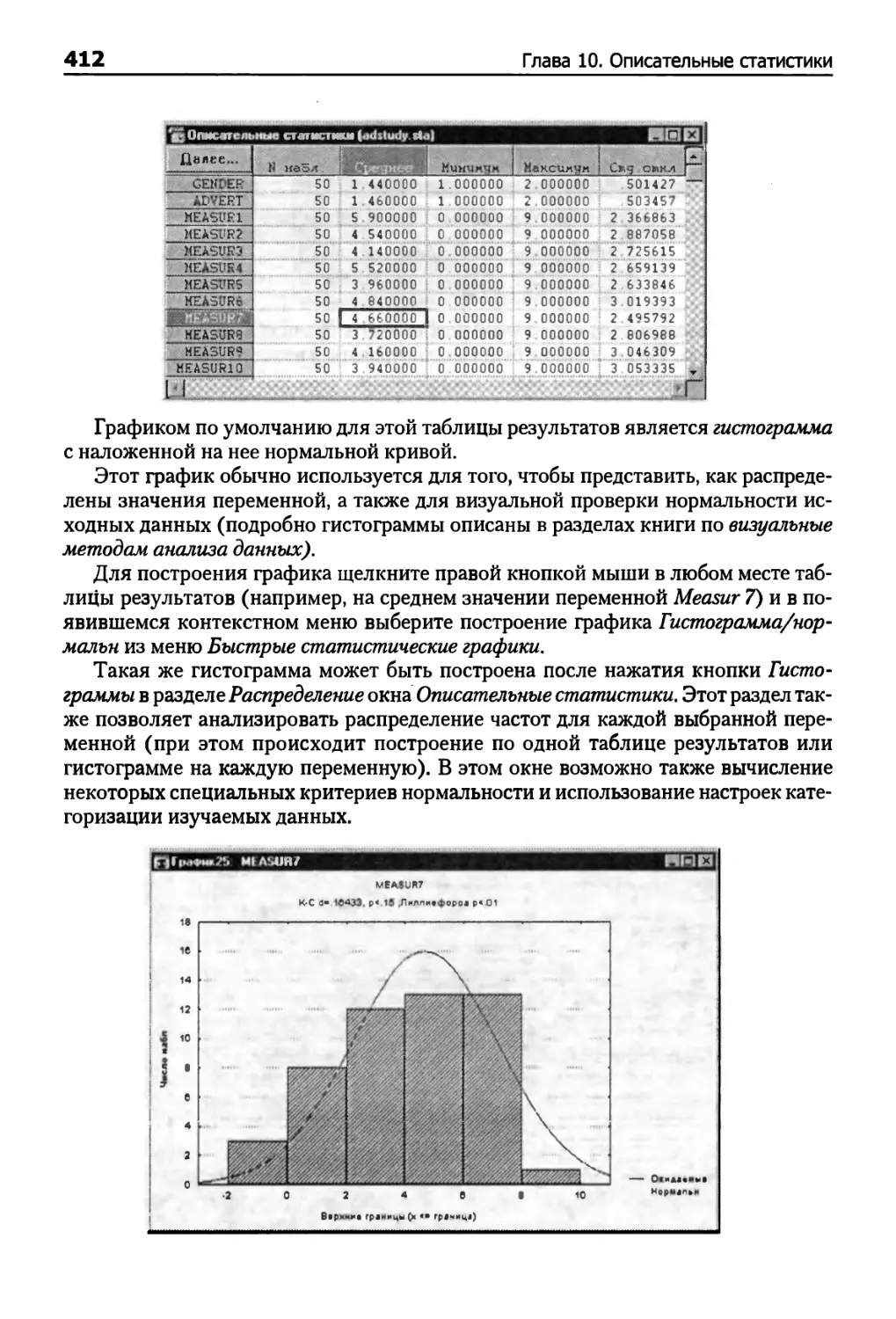
Глава 10. Описательные статистики 409
Корреляции 414
Вычисление описательных статистик для группированных данных 420
Внутригрупповые корреляции 424
Глава 11. Построение и анализ таблиц 429
Вводный обзор 429
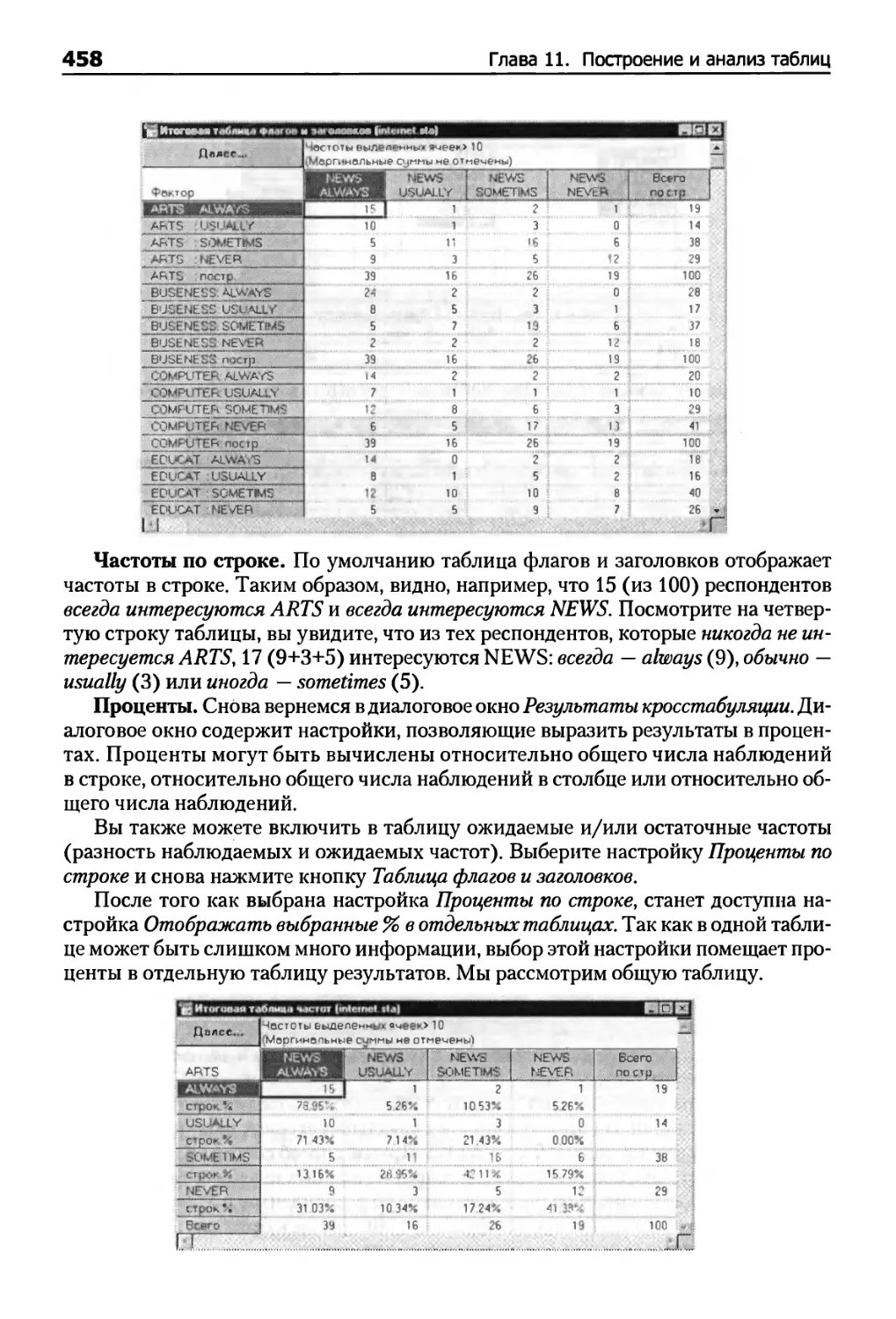
Таблицы частот 434
Таблицы сопряженности и таблицы флагов и заголовков 436
Таблицы флагов и заголовков 440
Статистики таблиц сопряженности 442
Статистики, основанные на рангах 445
Многомерные отклики и дихотомии 445
Многомерные отклики 445
Многомерные дихотомии 447
Кросстабуляция многомерных откликов и дихотомий 447
Парная кросстабуляция переменных с многомерными откликами 448
Средства построения таблиц системы STATISTICA 449
Таблицы частот 449
Таблицы сопряженности и таблицы флагов и заголовков 450
Многомерные отклики и дихотомии 451
Примеры 452
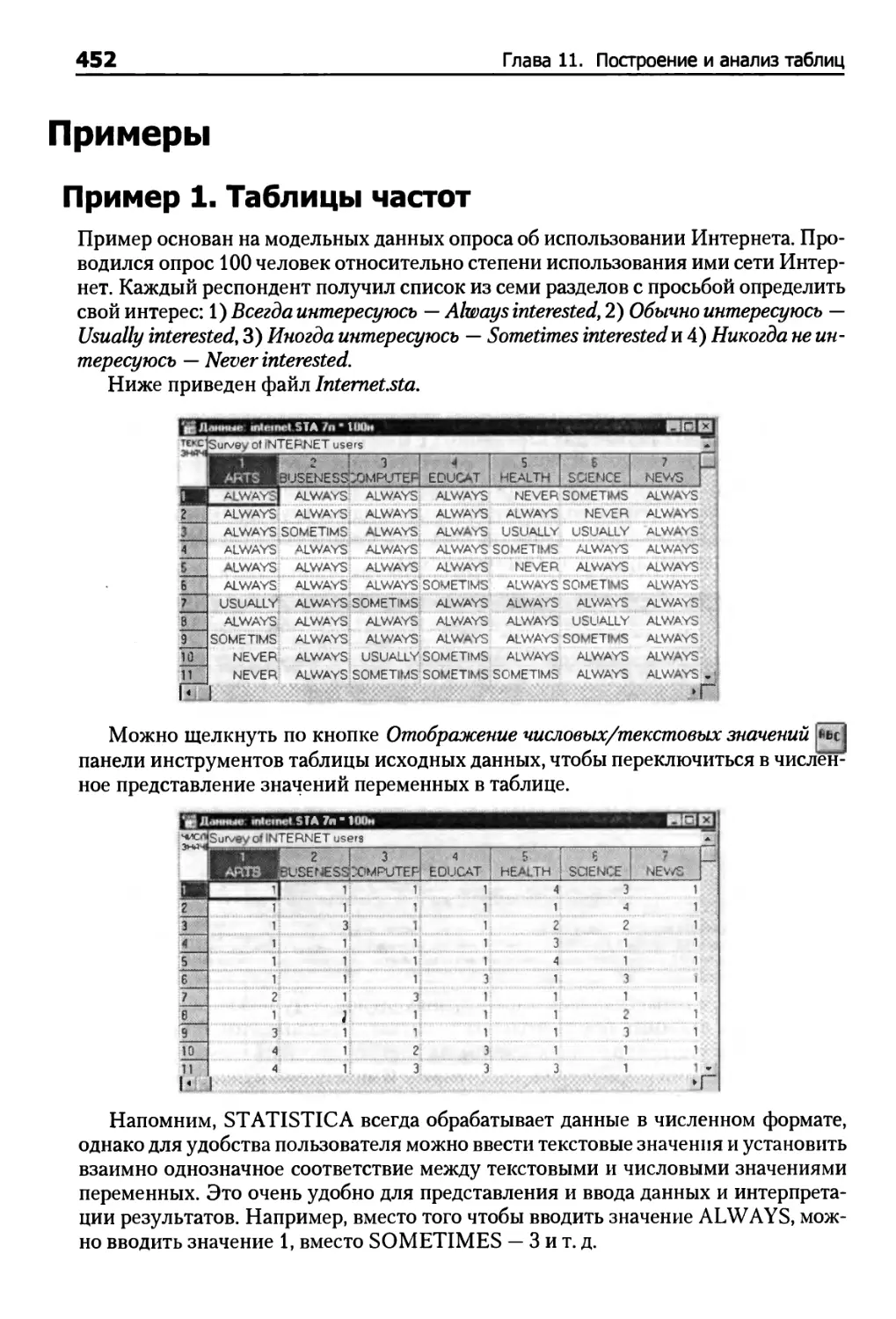
Пример 1. Таблицы частот 452
Пример 2. Таблицы флагов и заголовков 456
Пример 3. Таблицы сопряженности 461
Пример 4. Табулирование многомерных откликов и дихотомий 463
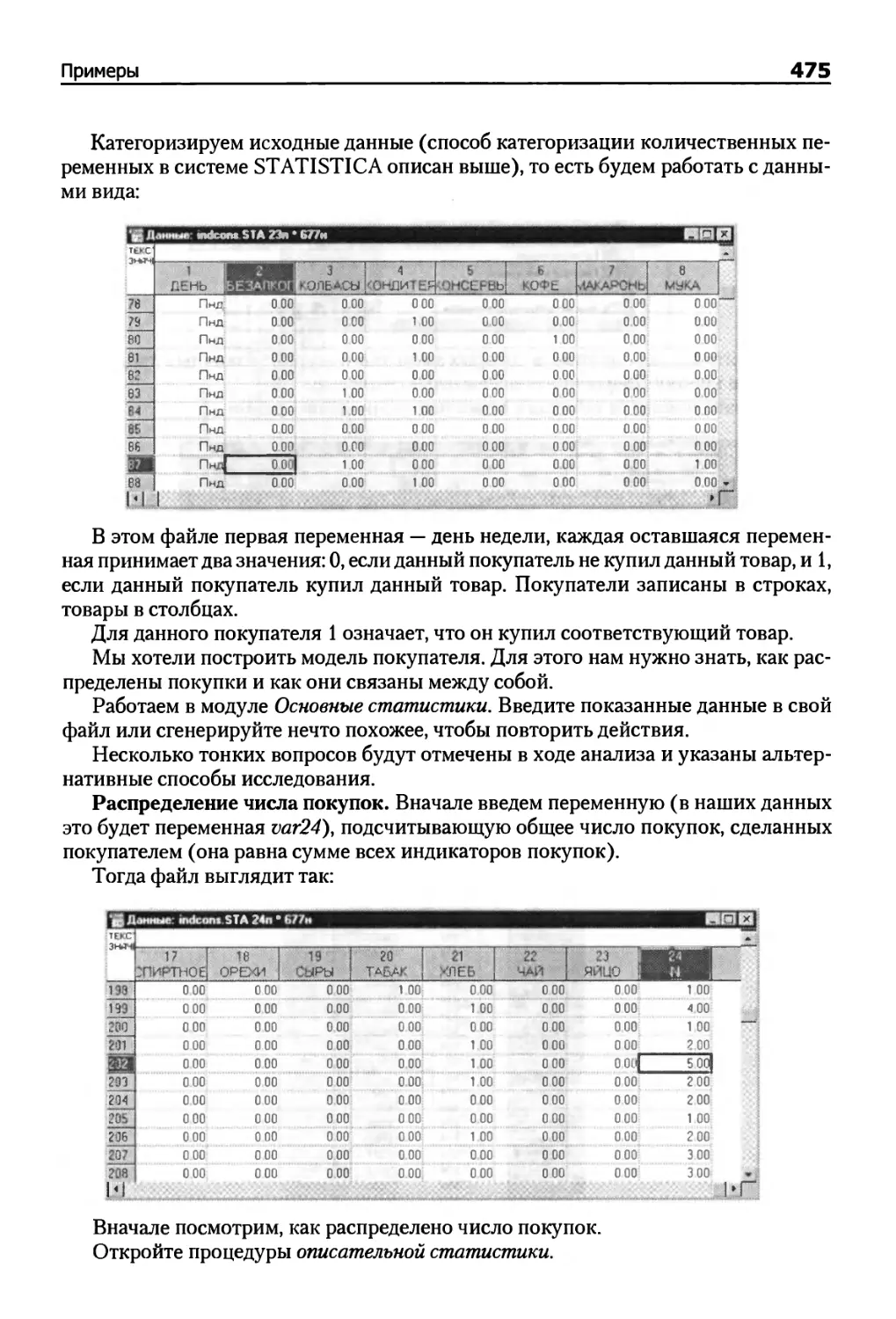
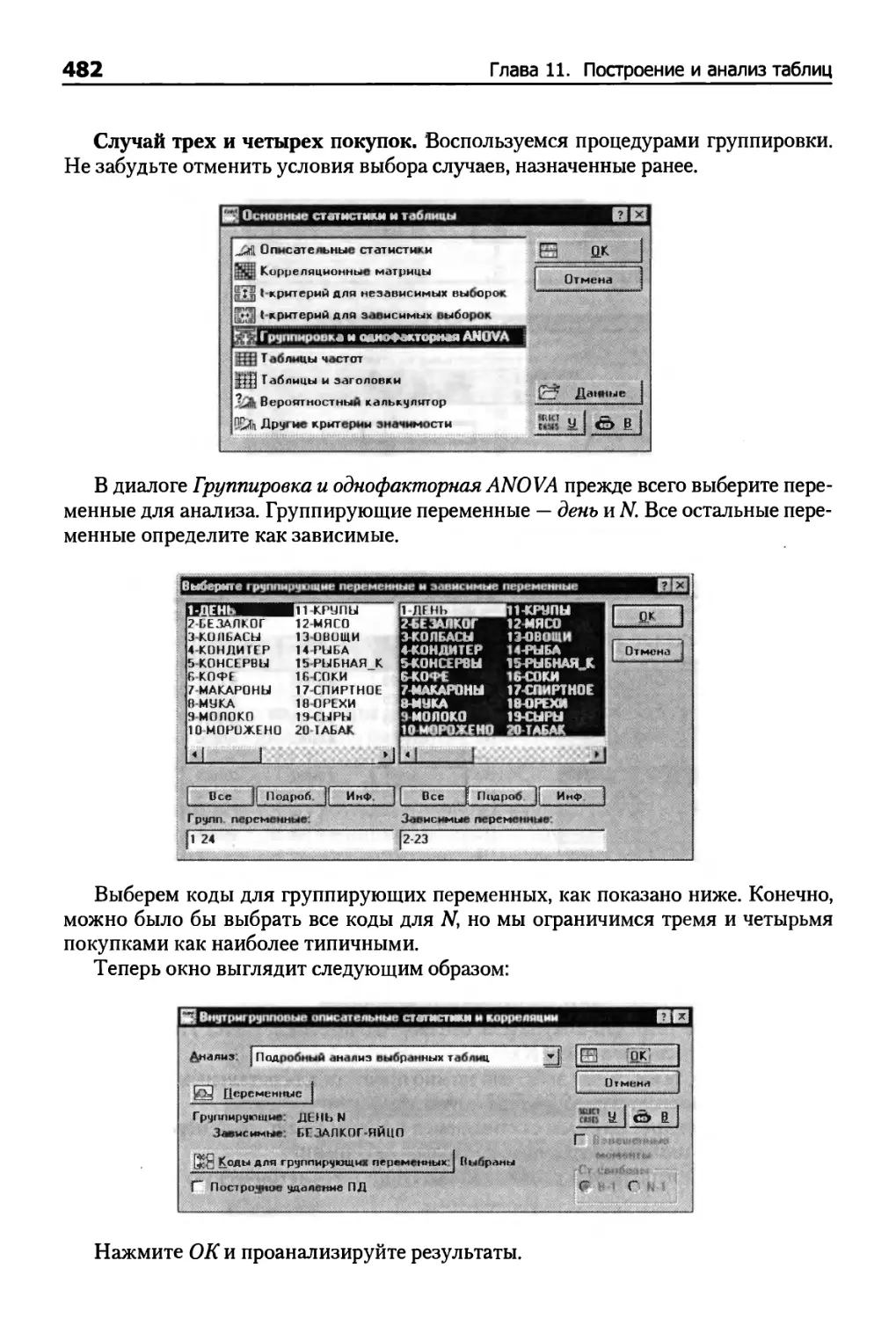
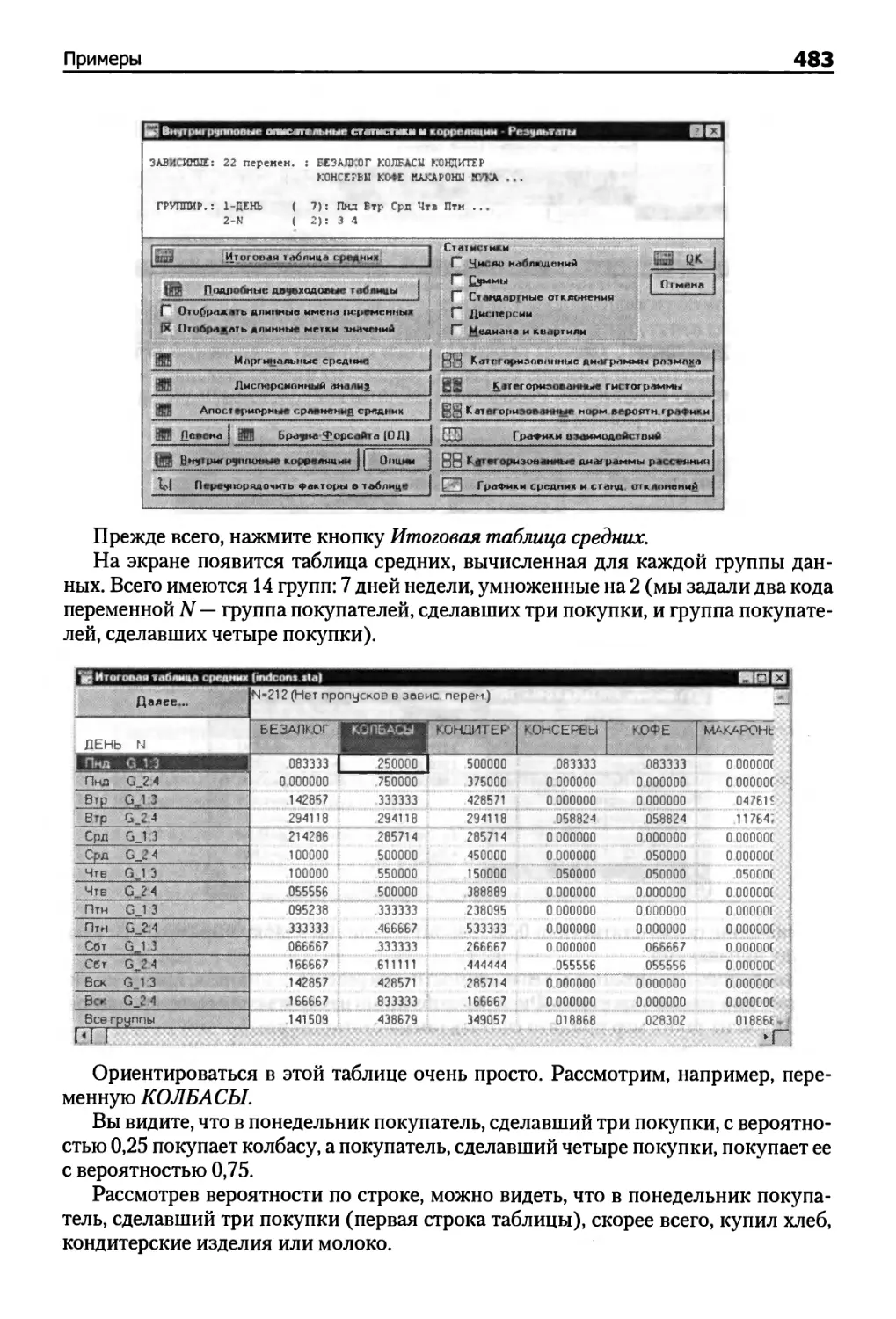
Пример (анализ продаж) 474
Глава 12. Г-критерий сравнения средних в двух группах данных 487
Г-критерий для независимых выборок 489
Формальное определение t-критерия 491
Г-критерий для зависимых выборок 492
Пример 1 493
Пример 2 495
Множественные сравнения 498
Однофакторный дисперсионный анализ и апостериорные сравнения средних 500
Глава 13. Непараметрическая статистика 504
Краткий обзор непараметрических процедур 504
Описание непараметрических процедур на примерах 507
Стартовая панель модуля Непараметрические статистики 507
Таблицы частот 2x2: статистики Хи/У/Фи-квадрат, Макнемара, точный критерий Фишера 508
Наблюдаемые частоты в сравнении с ожидаемыми 511
Корреляции (Спирмена R, тау Кендалла, Гамма) 512
Матричная диаграмма 515
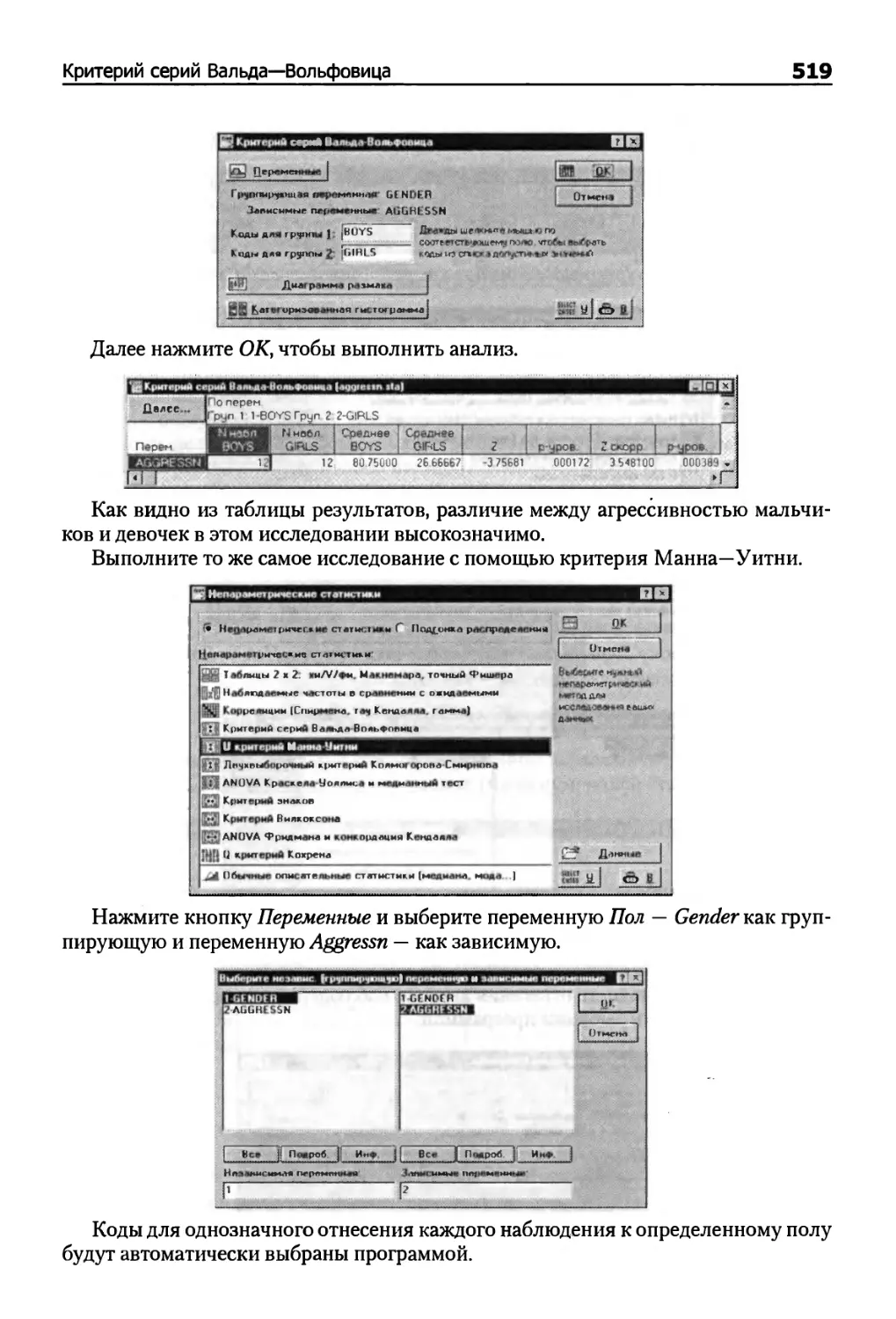
Критерий серий Вальда—Вольфовица 516
U-критерий Манна—Уитни 516
Содержание 11
Двухвыборочный критерий Колмогорова—Смирнова 517
Пример. Критерий серий Вальда—Вольфовица, Манна—Уитни U-критерий,
двухвыборочный критерий Колмогорова—Смирнова 517
ANOVA Краскела—Уоллиса и медианный тест 522
Критерий знаков 526
Критерий Вилкоксона 527
ANOVA Фридмана и коэффициент конкордации, или согласия, Кендалла 528
Q-критерий Кохрена 529
Описательные статистики 530
Медиана 530
Мода 530
Геометрическое среднее 531
Гармоническое среднее 531
Дисперсия и стандартное отклонение 531
Размах 531
Квартильный размах 531
Асимметрия 532
Эксцесс 532
Глава 14. Анализ выживаемости 533
Введение в анализ выживаемости 533
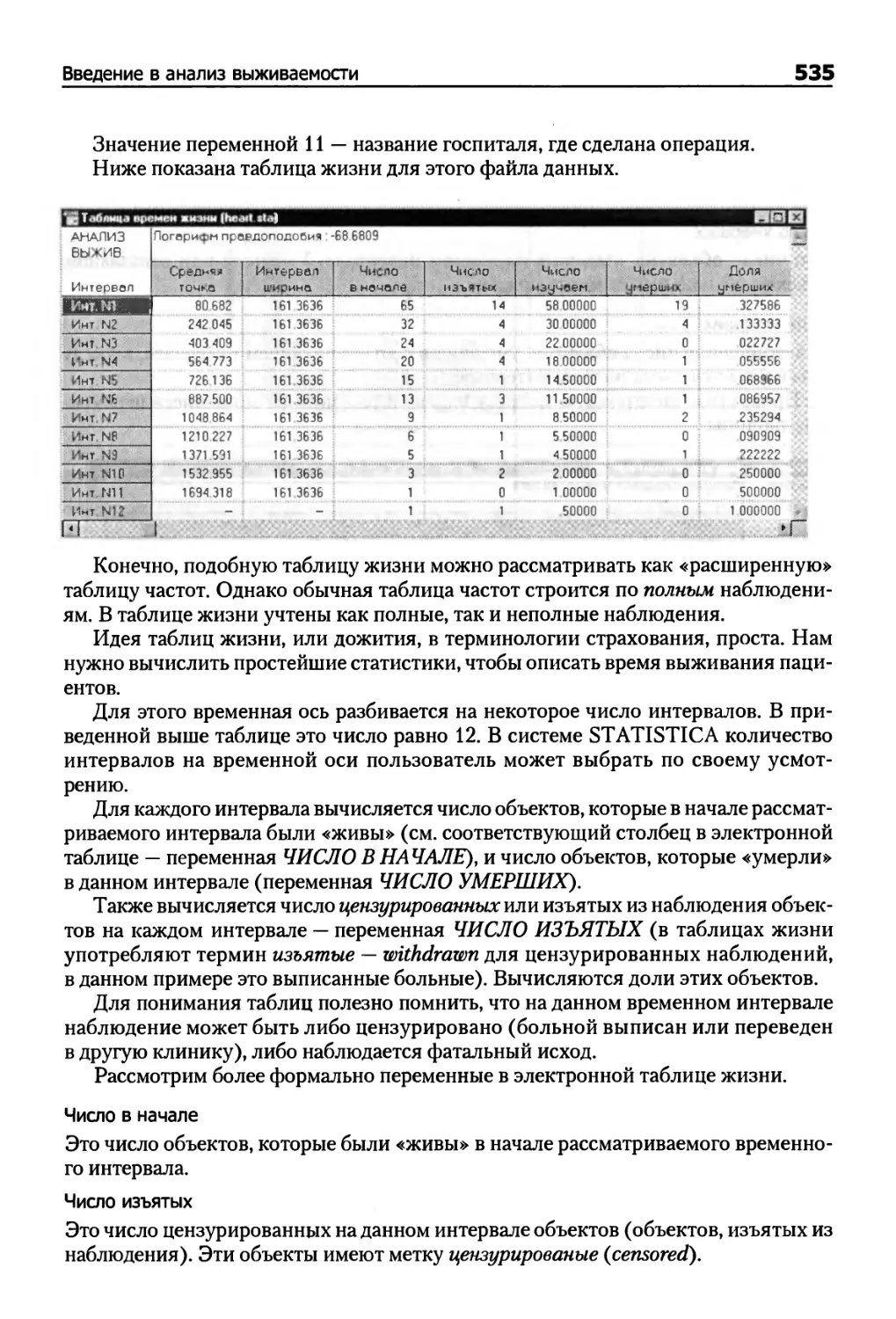
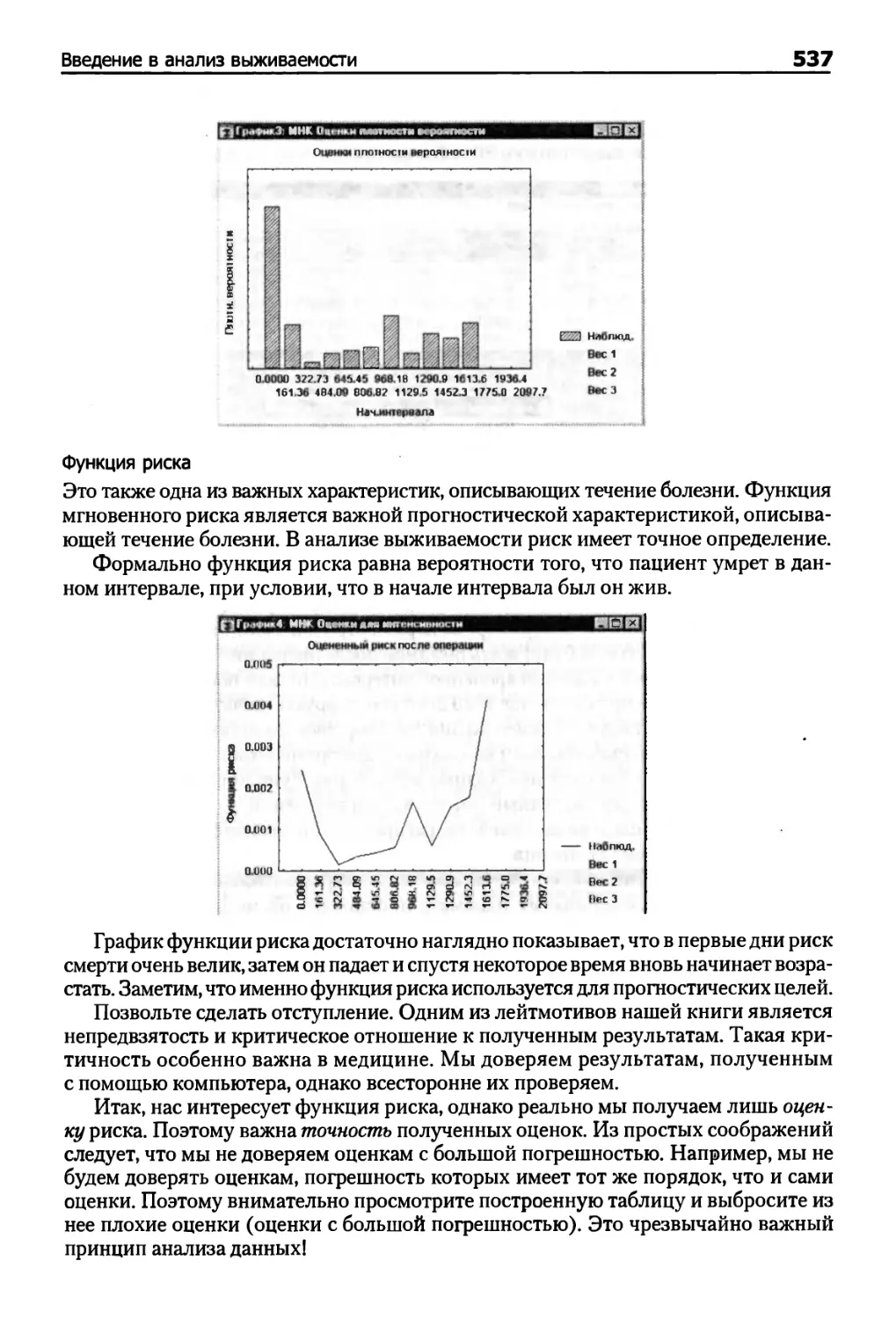
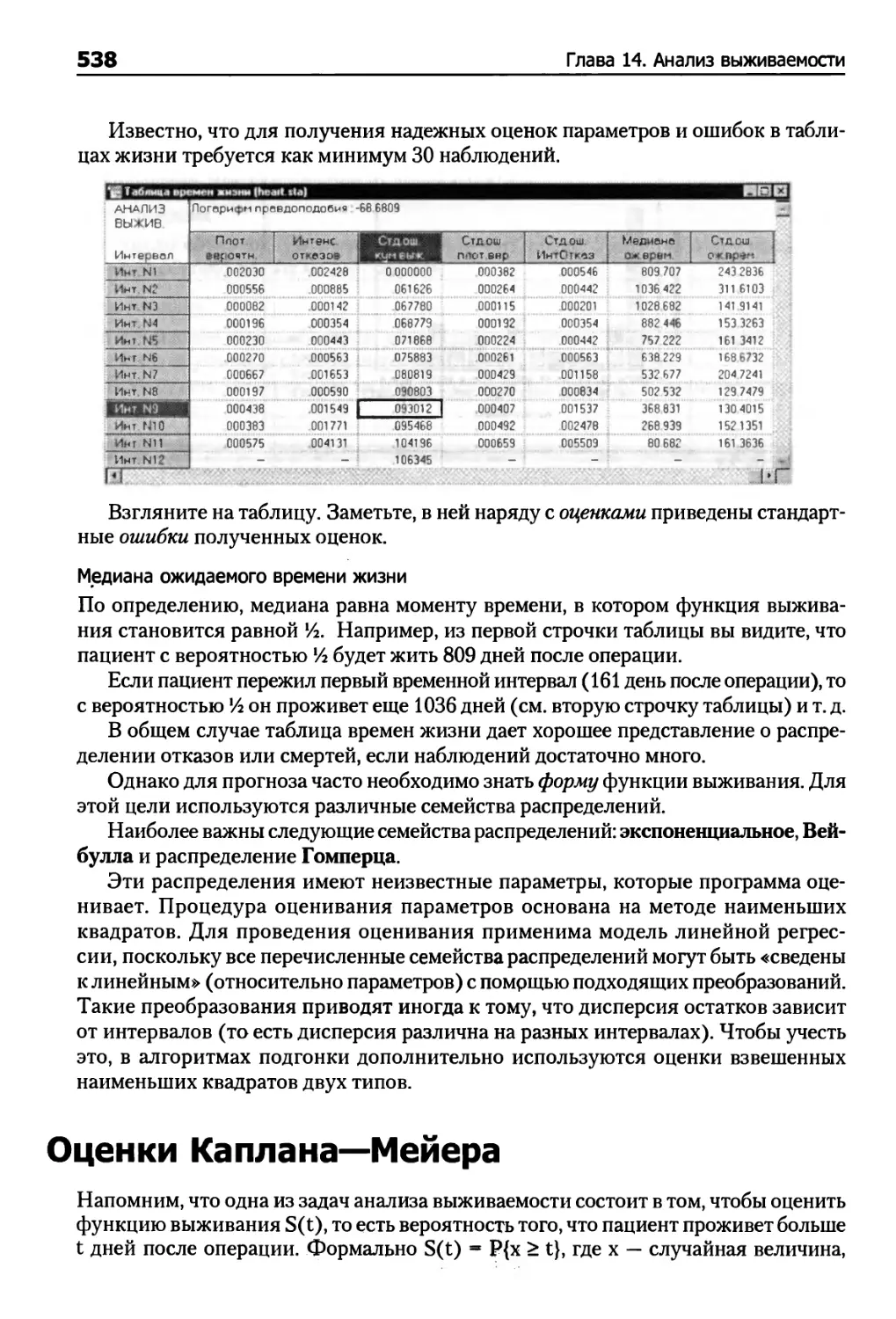
Таблицы времен жизни 534
Оценки Каплана—Мейера 538
Сравнение выживаемости в группах 541
Регрессионные модели в анализе выживаемости 543
Модель Кокса 544
Экспоненциальная регрессия 546
Нормальная и логнормальная регрессия ,.. 547
Обзор системы 548
Альтернативные процедуры 549
Пример 1. Таблицы времен жизни 550
Задание параметров анализа 550
Пример 2. Регрессионная модель Кокса 554
Задание параметров анализа 555
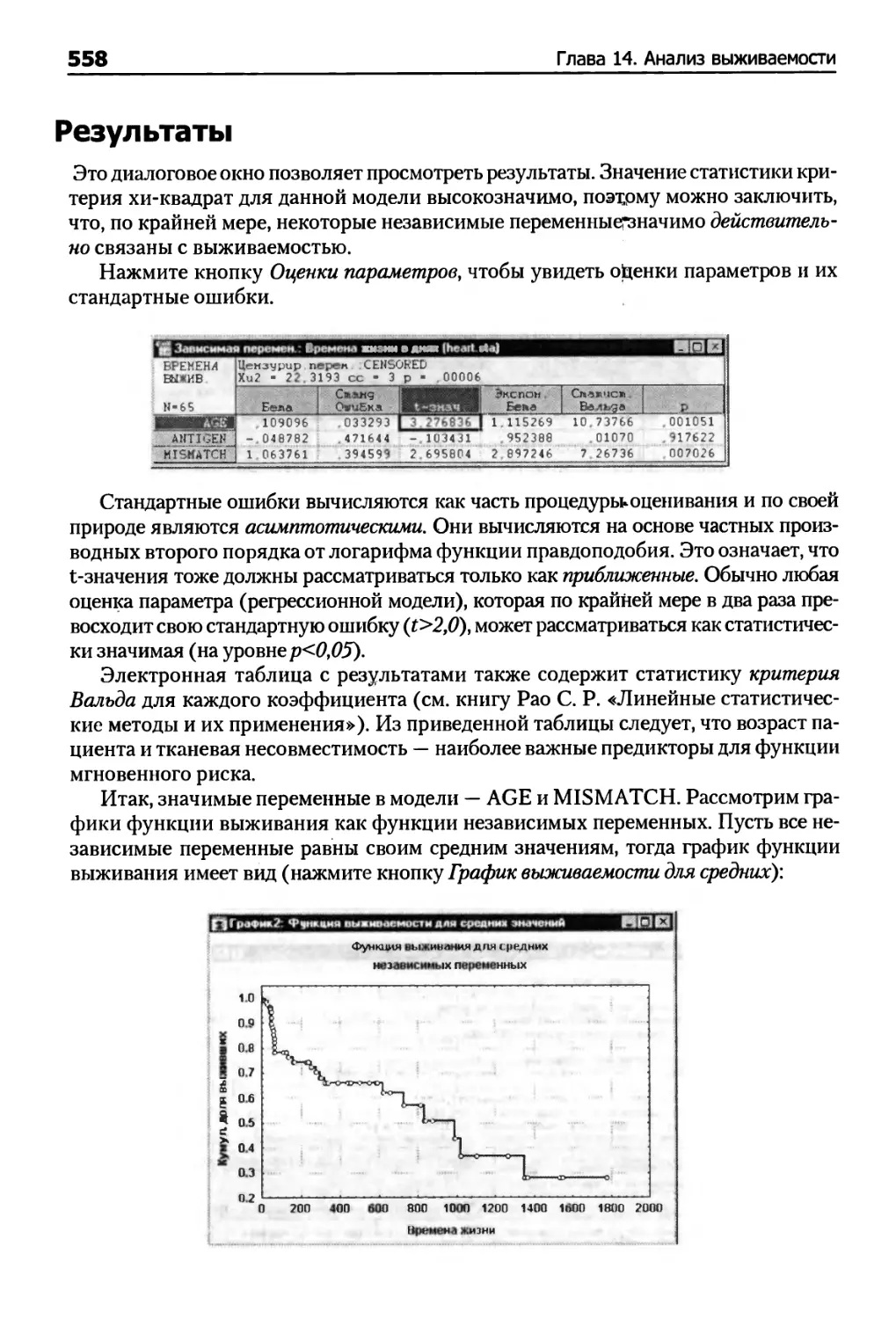
Оценивание параметров 556
Результаты 558
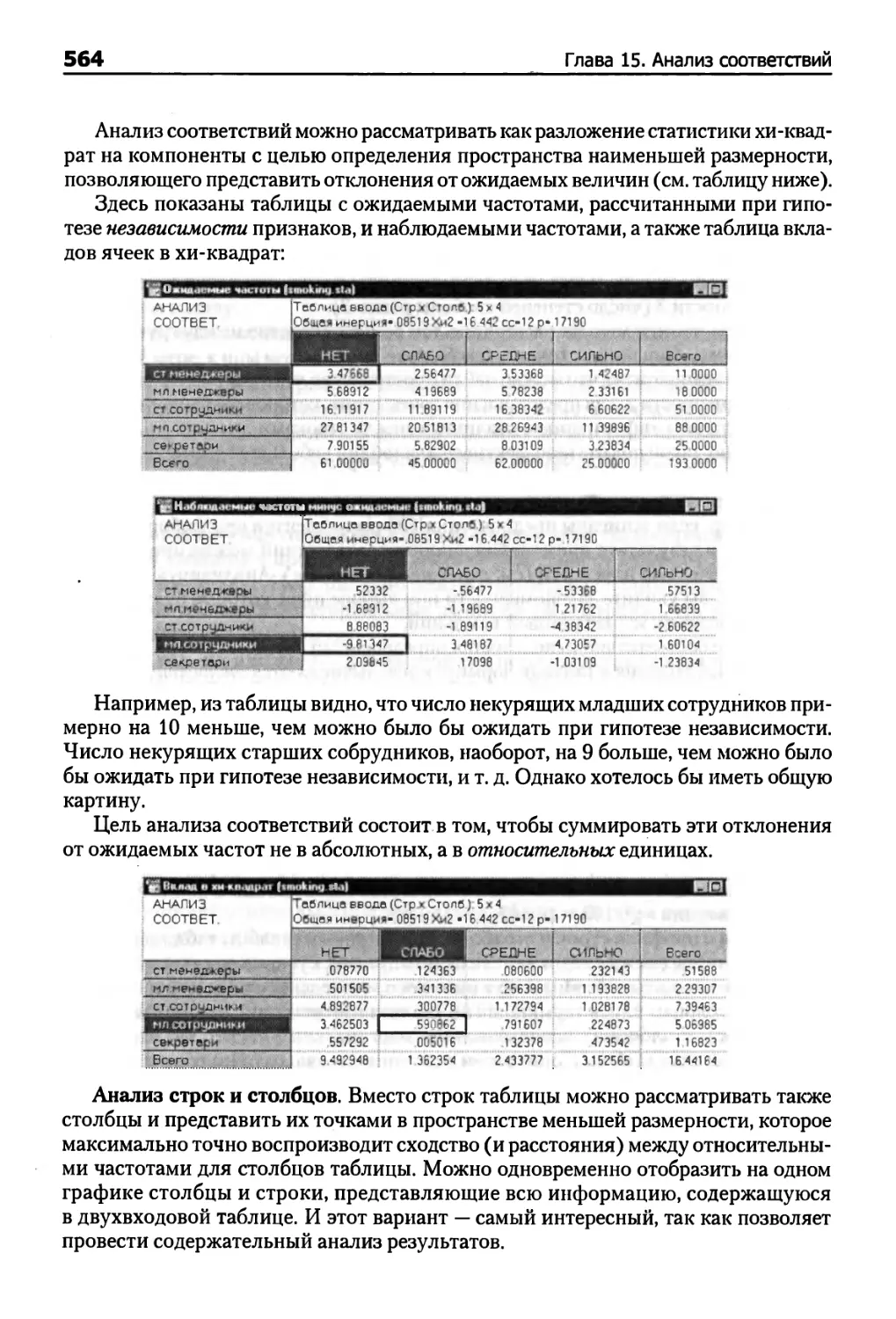
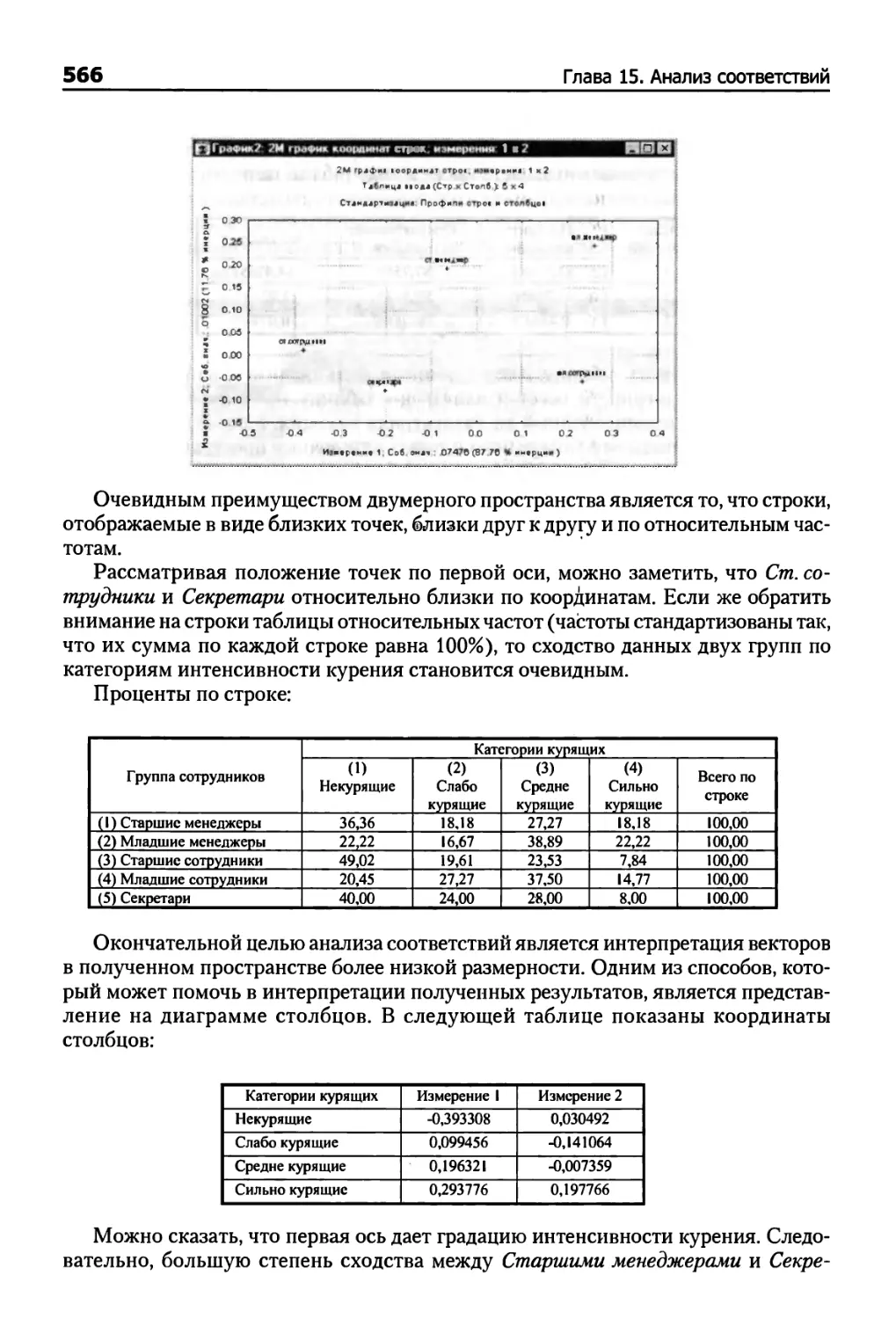
Глава 15. Анализ соответствий 561
Пример 1 (анализ курильщиков) 571
Пример 2 (анализ продаж) 574
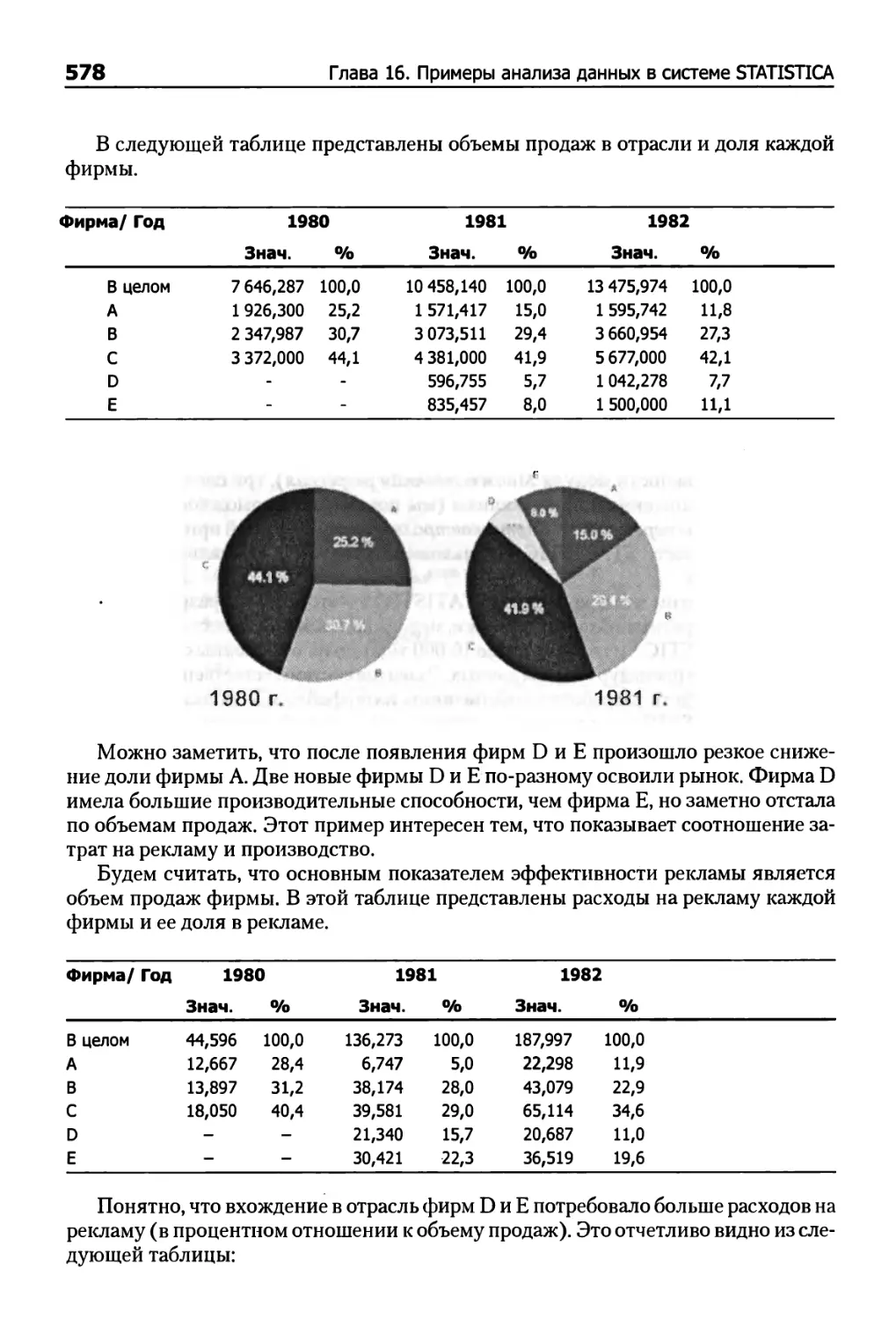
Глава 16. Примеры анализа данных в системе STATISTICA 577
Построение плана 589
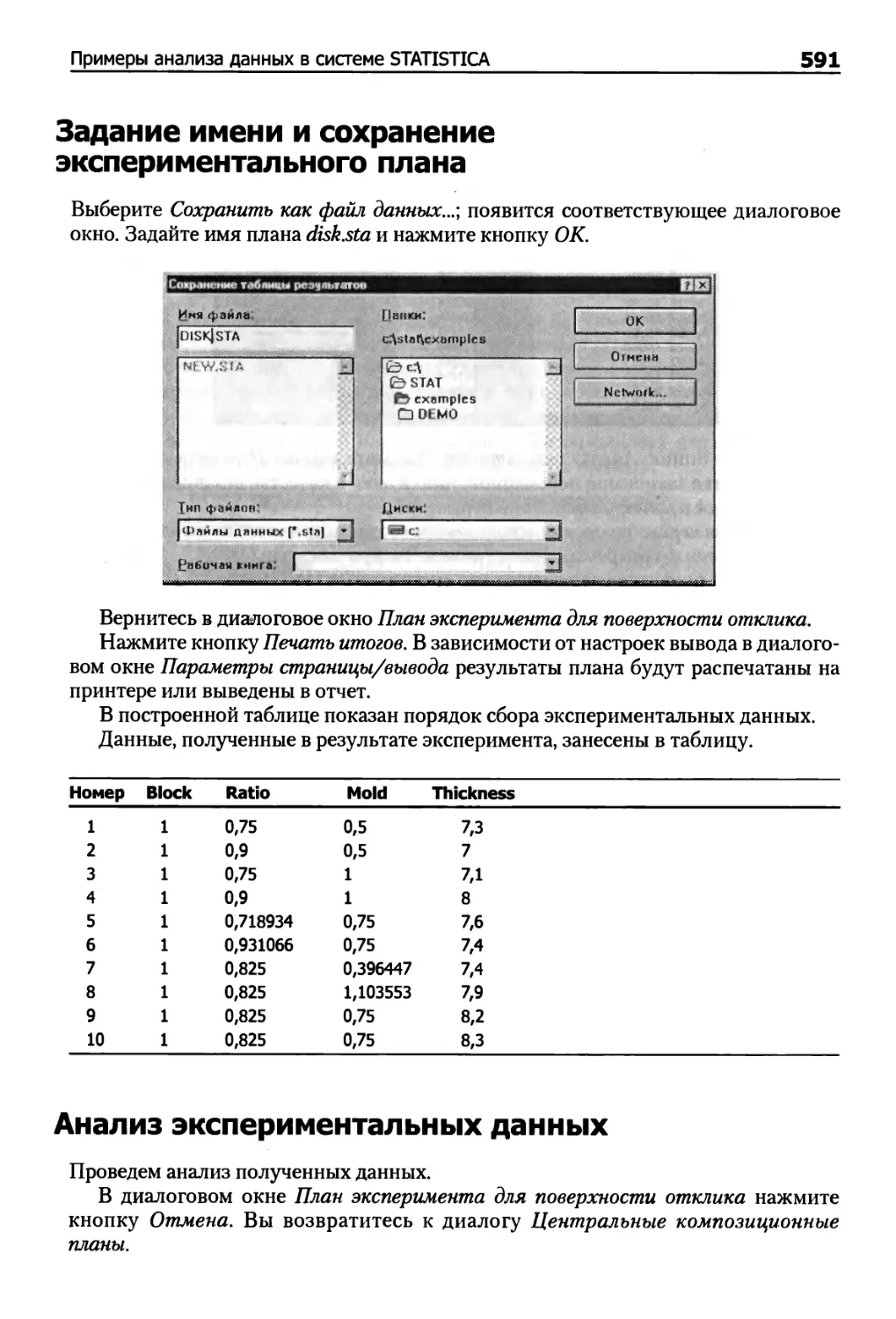
Задание имени и сохранение экспериментального плана 591
Анализ экспериментальных данных 591
Глава 17. Нейронные сети 611
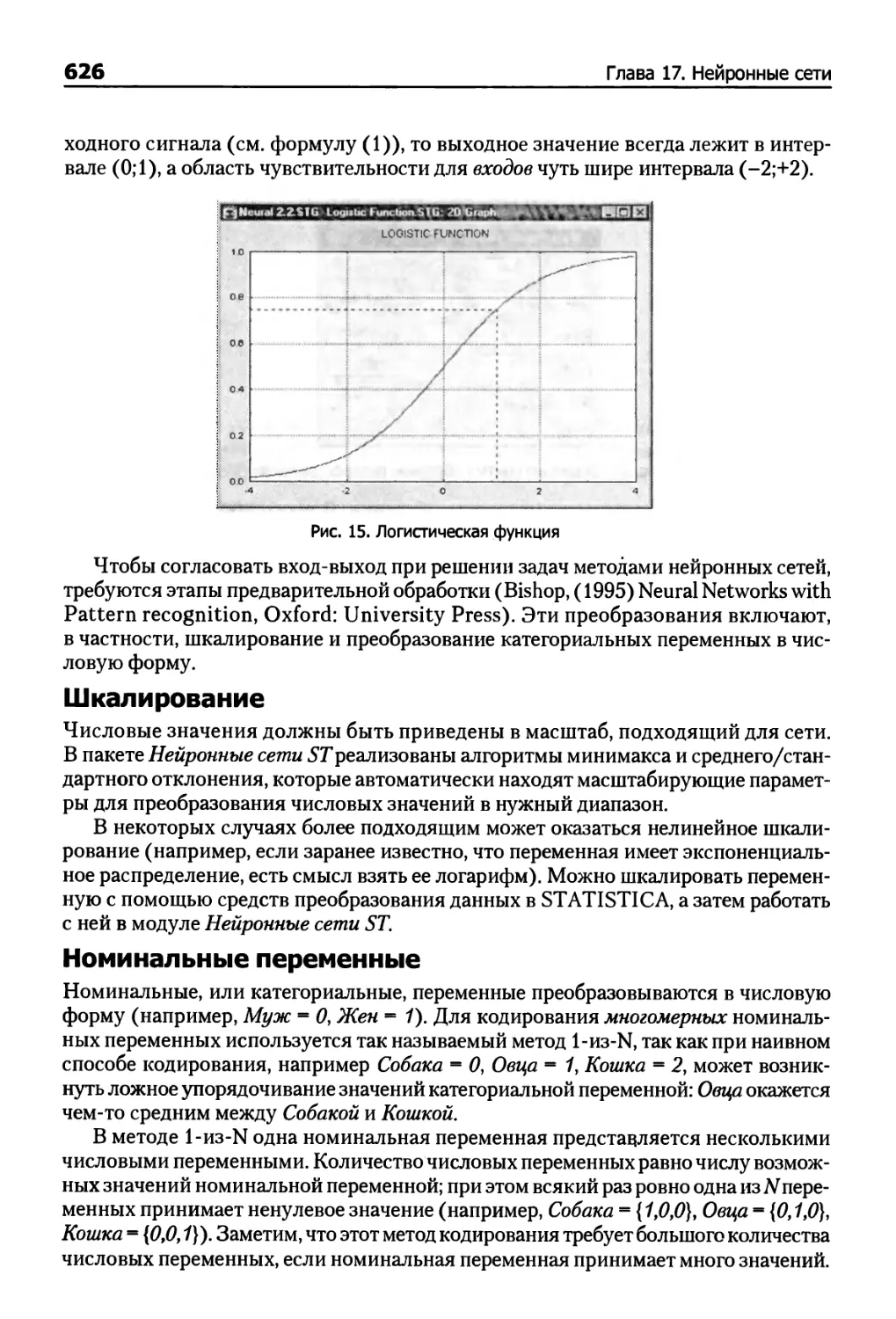
Пре/постпроцессирование 625
Оценка качества работы сети 627
Диалог в модуле Нейронные сети STATISTICA 627
Заключительные комментарии 636
12 Содержание
Глава 18. Язык STATISTICA VISUAL BASIC (SVB) 641
Структура языка STATISTICA Visual Basic 641
Запись макросов 642
Макрос анализа 642
Запись макроса анализа 643
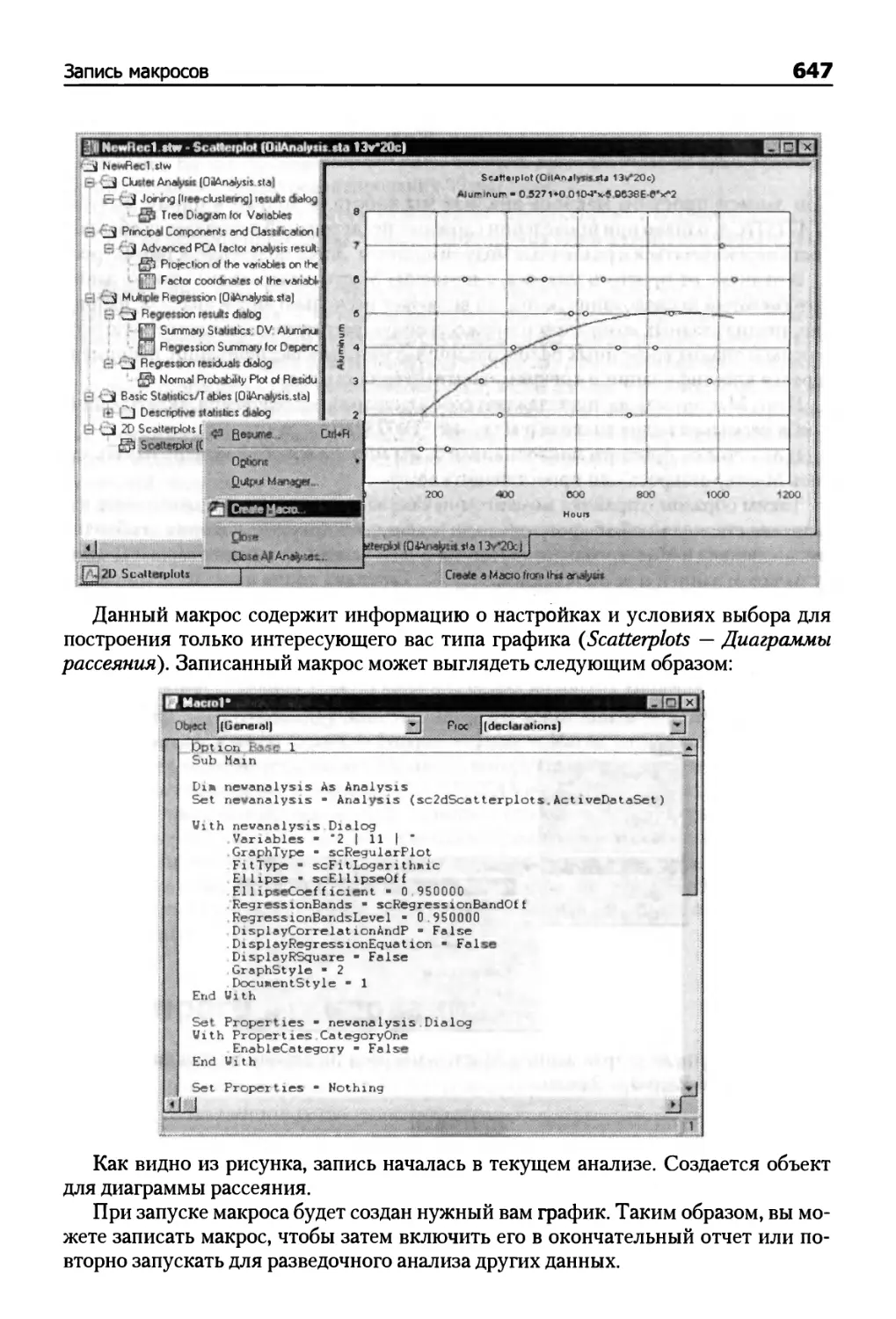
Создание графика 646
Мастер-макрос 648
Клавиатурные макросы 649
Среда программирования 649
Основные соглашения STATISTICA Visual Basic 650
Типы данных, массивы, функции 652
Операторы управления порядком выполнения команд 655
Глобальные переменные, передача аргументов по значению и по ссылке 656
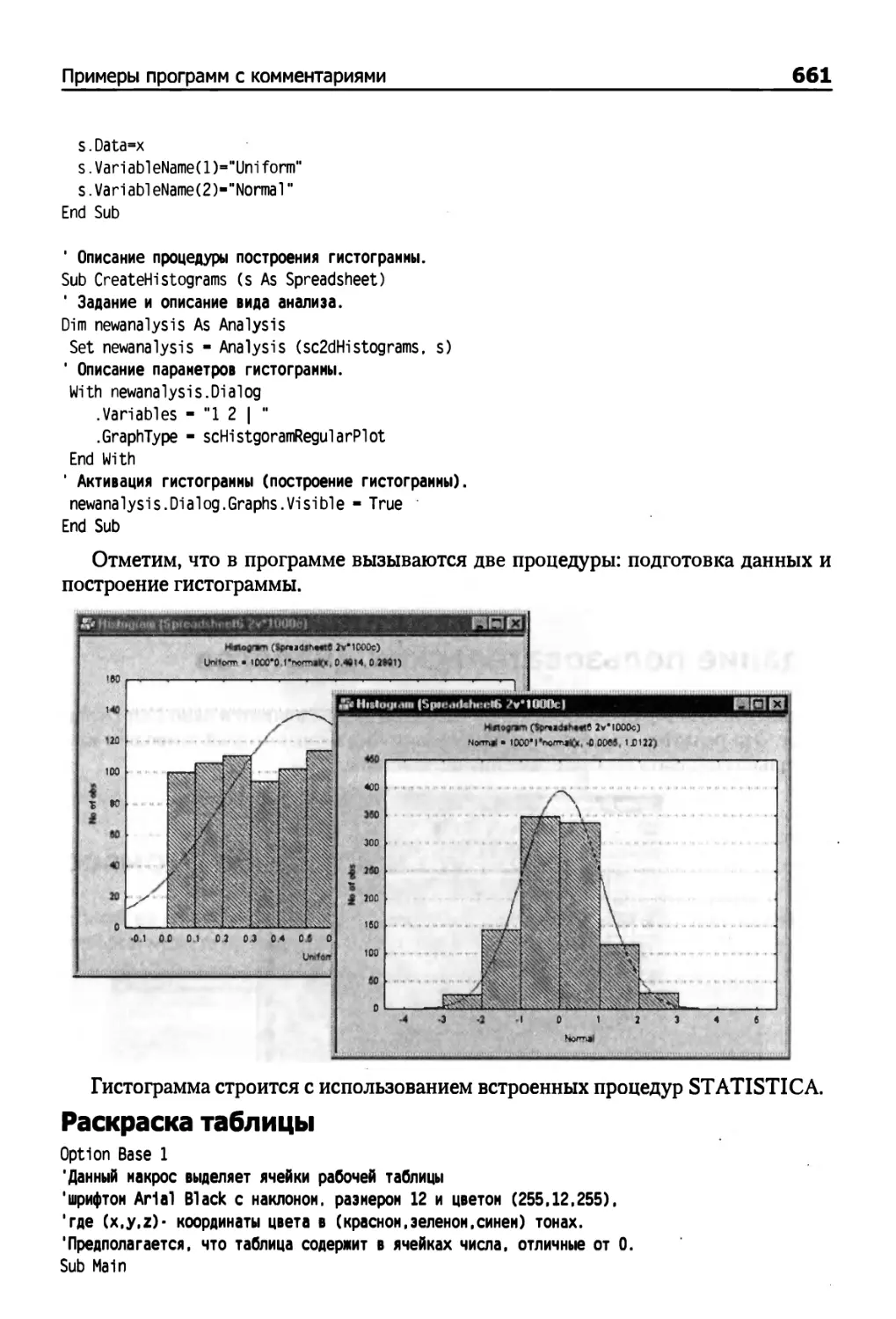
Примеры программ с комментариями 658
Пример: формирование коллекции таблиц данных 658
Создание таблицы данных и заполнение ее случайными числами 659
Вывод индикатора состояния 659
Построение гистограммы с подгонкой нормального распределения 660
Создание пользовательских диалогов 662
Просмотр объектов и функций 663
Приложение 1 667
Приложение 2 669
Приложение 3 677
Словарь терминов пакета SNN (версия 4.0) 677
Функции активации, реализованные в SNN 683
Функции ошибок, доступные в SNN 685
PSP-функции 686
Алфавитный указатель 687
Введение
В книге, написанной научным директором компании StatSoft Russia, изложена
концепция и технология современного анализа данных на компьютере. На основе
элементарных понятий описываются углубленные методы анализа в системе
STATISTICA (StatSoft), иллюстрированные многочисленными примерами из
экономики, маркетинга, рекламы, бизнеса, медицины, промышленности и других
областей. Большое внимание уделяется основным понятиям анализа данных,
разведочному анализу данных, группировке, анализу и построению таблиц —
важным этапам анализа данных, на которых формируются и проверяются
гипотезы о структуре данных и связях между ними.
В книге изложены классические и современные методы анализа данных,
позволяющие получить всестороннее описание данных (например, в задачах массового
обследования и мониторинга), провести классификацию, найти закономерности и
зависимости между переменными, — иными словами, ответить на важные
вопросы, которые задает исследователь, впервые столкнувшийся с огромным массивом
информации.
Подробно описан визуальный анализ как первый этап сложного исследования, —
сотни типов графиков в STATISTICA, включая двумерные, трехмерные, категори-
зованные графики и пиктографики подробно рассмотрены с описанием опций и
настроек.
Все это делает книгу настольной для многочисленных пользователей STATISTICA.
Предлагаемая книга адресована самому широкому кругу читателей, желающих
стать профессионалами в анализе данных на STATISTICA в бизнесе, маркетинге,
финансах, управлении, экономике, промышленности, страховании, медицине и
других приложениях.
Книга дополнена компакт-диском, включающим последнюю версию
знаменитого учебника StatSoft по анализу данных, а также учебник по
промышленной статистике, материалы обучающих курсов, демо-версии STATISTICA и SNN
(нейронные сети), огромое количество данных для обучения и проведения
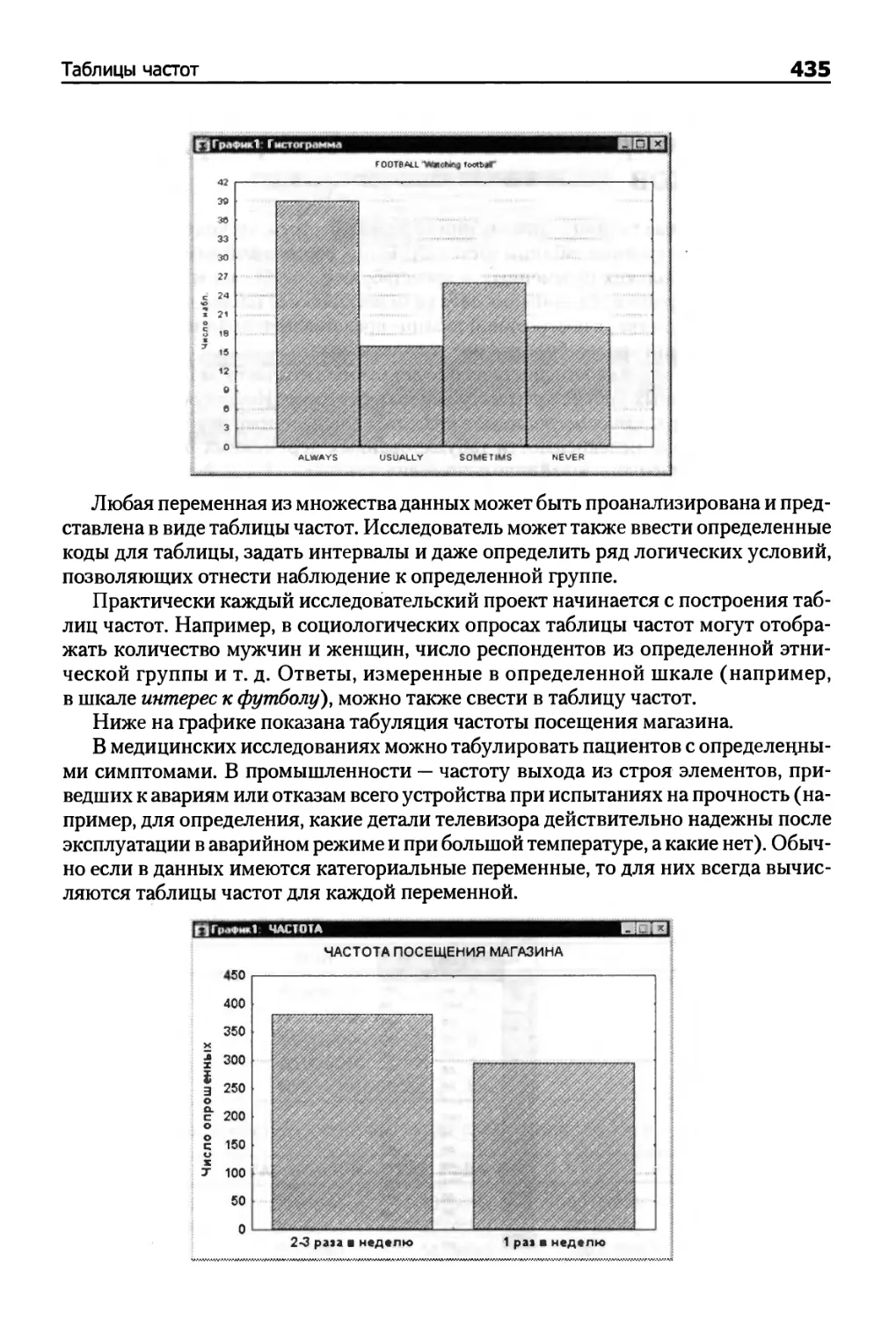
самостоятельных исследований в STATISTICA и SNN.
Во второе издание книги добавлены новые материалы, исправлены ошибки
первого издания, а также написана новая глава о языке STATISTICA VISUAL BASIC
(SVB), появившемся в 6-й версии STATISTICA. Кроме того, произведено
обновление диска с добавлением некоторых программ на SVB, снабженных
комментариями на русском языке.
Вступительное эссе:
приглашение к анализу
данных на компьютере
Окружающий нас мир насыщен информацией — разнообразные потоки данных
окружают нас, захватывая в поле своего действия, лишая правильного восприятия
действительности. Не будет преувеличением сказать, что информация становится
частью действительности и нашего сознания.
Без адекватных технологий анализа данных человек оказывается беспомощным
в жестокой информационной среде и скорее напоминает броуновскую частицу,
испытывающую жестокие удары со стороны и не имеющую возможности
рационально принять решение.
Статистика позволяет компактно описать данные, понять их структуру,
провести классификацию, увидеть закономерности в хаосе случайных явлений.
Удивительно, что даже простейшие методы визуального и разведочного анализа данных
позволяют существенно прояснить сложную ситуацию, первоначально
поражающую нагромождением цифр.
Особенность этой книги заключается в том, что в ней всесторонне, с
подробными примерами описано применение разнообразных методов анализа данных.
Вообще, наша идея состояла в том, чтобы вывалить из мешка различные
методы, написав своего рода популярную энциклопедию всевозможных методов
анализа данных, и позволить пользователю, применяя систему STATISTIC А,
свободно экспериментировать с этими методами, работая как с собственными данными,
так и с предлагаемыми нами. Мы дополнили книгу компакт-диском, на котором
записаны демо-версии системы STATISTICA, файлы данных, материалы курсов и
многое другое. Запустите диск и одновременно читайте книгу — это позволит
всесторонне освоить технологии анализа данных.
Мы описываем как классические методы анализа, так и современные, включая
нейронные сети, в частности, чрезвычайно интересный анализ соответствий,
позволяющий исследовать сложные многомерные таблицы, возникающие в экономике,
маркетинге, медицине и других областях. Даже традиционные методы мы стараемся
рассмотреть под новым углом зрения, акцентируя внимание на нестандартных
приложениях.
Визуальные методы анализа данных чрезвычайно важны, и мы посвящаем им
несколько глав. Многие явления, остающиеся за кадром, становятся отчетливыми,
если найти подходящее графическое представление.
Вступительное эссе: приглашение к анализу данных на компьютере
15
Например, на графике, приведенном ниже, мы видим два временных ряда: цены
на нефть в долларах за баррель и курс доллара по отношению к рублю за несколько
лет. Рассматривая график, вы видите, какие тенденции имеются в данных.
Конечно, это простейший вариант графического представления!
Далее вы можете перейти к построению более сложных моделей, однако первые
закономерности, найденные визуально, сохранятся и в углубленных моделях.
Именно поэтому мы уделяем визуализации столь большое внимание.
Множество практических примеров рассмотрено в данной книге. Чтобы
сделать изложение систематическим, мы начинаем с простейших понятий — которых,
к счастью, не так и много — и учимся говорить на языке анализа данных,
рассматривая простые и понятные всем примеры, постепенно развивая их до сложных
задач.
Мы не следим тщательно за строгим обоснованием методов, а просто говорим:
имеются такие-то методы и там-то их применение принесло успех. Если вы
желаете, попробуйте применить эти методы для анализа собственных данных и, быть
может, получите обнадеживающий результат.
Деты (и$ переменном: DATE )
- * * ЦЕНА Д.РУБЛЬ
Рис. 1. Динамика цены 1-го барреля нефти (в долларах) и реального курса доллара
(покупательной способности доллара, выраженной в рублях)
Но что значит обнадеживающий результат? Если из множества возможных
вариантов действий вы с большей вероятностью, чем ваш противник, выбираете
правильный вариант или добиваетесь более ясного понимания действительности,
«снимая» случайность, то, очевидно, вы находитесь в лучшей ситуации, чем ранее, когда
полагались на волю случая и отдавали себя во власть неопределенности.
Итак, разнообразие методов и обилие примеров — вот основная идея книги,
которая по этой причине может быть названа энциклопедией методов анализа и
областей их применения. Строгое обоснование методов — не наша цель, так как
многие интуитивно понятные методы и родились из решения практических задач и
лишь позднее получили строгое математическое обоснование, что никак не
уменьшает их прагматической ценности.
Для широкого круга пользователей полезно знать, где и какие методы
применялись на практике и когда привели к успеху, и мы хотим максимально развить
интуитивное представление пользователя об анализе данных, не предполагая наличия
16
Вступительное эссе: приглашение к анализу данных на компьютере
у него специальной подготовки. Таким образом, мы хотим познакомить читателя с
культурой анализа данных.
В качестве источника данных мы используем, например, Интернет и
иллюстрируем применение методов анализа на этих данных. Популярность Интернета
общеизвестна, но что нового может дать анализ данных в этой области? Вот один
из примеров. Вы производите поиск по различным ключевым словам в некоторых
поисковых системах и отмечаете количество ссылок; спрашивается, различаются
системы поиска или нет? Именно с такого рода примерами мы будем иметь дело.
Ниже приведены графики количества посетителей сайта. Спрашивается, как
строго доказать, что реклама имела успех? Правило 3-сигма позволяет оценить
эффективность рекламной кампании и, следовательно, работу менеджера по рекламе.
CTSITEGRF6STG ЛинеАмыв грв«мв
Число заходов иа сайт
Чмсяо н«6ямдеимм: 346
Среднее: 21.155
Максимум: Ж.—
Оамд. отклонение: 3«.4fS
° М Пиния среднего [ ж а ' Л " „ а т ' п
1 9 ГС 71 7Г 53 » * «I Я «3 «в
ДНИ
Рис. 2. Оценка эффективности рекламы
График спектральной плотности показывает, что в данных имеется отчетливая
периодичность с лагом 7, так как пик спектральной плотности приходится на 7 дней.
nSPECTRI STG: Спектр аиалиэ: HOST
Спектр, анализ: HOST
Число набл.: 72
ВесаХемминга: .0357 .2411 .4464 .2411 .0357
Рис. 3. График спектральной плотности
Вступительное эссе: приглашение к анализу данных на компьютере
17
График недельной составляющей позволяет увидеть, как изменяется (в
процентах) число посещений сайта в зависимости от дня недели. Исследуя разность
нагрузки Интернета в рабочие и выходные дни, можно оценить долю «домашних»
подключений к сети.
Подобного рода закономерности возникают в самых различных областях: в
торговле, бизнесе, промышленности, — важно уметь находить их и использовать в
своих целях.
flseasonl.STG: Гра+ переменны* HOST
Недельная составляющая посещений сайта компании
Сеаон. составл. (се*он * 7);
Понедельник Среда Пятница Воскресенье
Вторник Четверг Суббота
Рис. 4. Зависмость заходов на сайт от дней недели
Прогнозирование: представьте, что вы имеете данные ежемесячных продаж. Вам
нужно спрогнозировать продажи на текущий месяц. Как вам поступить? Вполне
разумный подход состоит в том, чтобы взять в качестве прогноза продажи
предыдущего месяца. Далее вы можете развить этот подход, использовать для прогноза
продажи нескольких предыдущих месяцев, усреднить их, например, с разными
весами. Как крайний случай, вы усредняете все продажи. Так из вполне
естественных рассуждений возникает метод скользящего среднего.
Если вы хотите учесть сезонный фактор, например прогнозировать продажи в
январе текущего года, используя информацию о продажах в январе предыдущего
года, то следует использовать сезонное скользящее среднее. Если вы хотите учесть
все продажи, но с разными весами, то используется экспоненциальное
сглаживание (exponential smoothing) с очевидными вариациями: сезонное или несезонное,
с трендом (отчетливо выраженной тенденцией) или без тренда. Обобщение
модели скользящего среднего приводит к моделям АРПСС — авторегрессии и
проинтегрированного скользящего среднего, или, в английской терминологии, ARIMA
(Autoregressive Integrated Moving Average).
Какую из этих моделей выбрать? Ответ: запустите STATISTICA и
поэкспериментируйте с различными моделями. Разбейте данные на две группы —
используйте данные второй группы для проверки качества прогноза (для проверки можно
оставить, например, пятую часть ряда). STATISTICA позволяет
экспериментировать с методами анализа, а это огромное достижение!
В тех ситуациях, когда классические методы не работают, можно испытать
нейронные сети. Мы рассматриваем их как полезный инструмент анализа, имеющий
свои достоинства и ограничения (см. главу 17).
18
Вступительное эссе: приглашение к анализу данных на компьютере
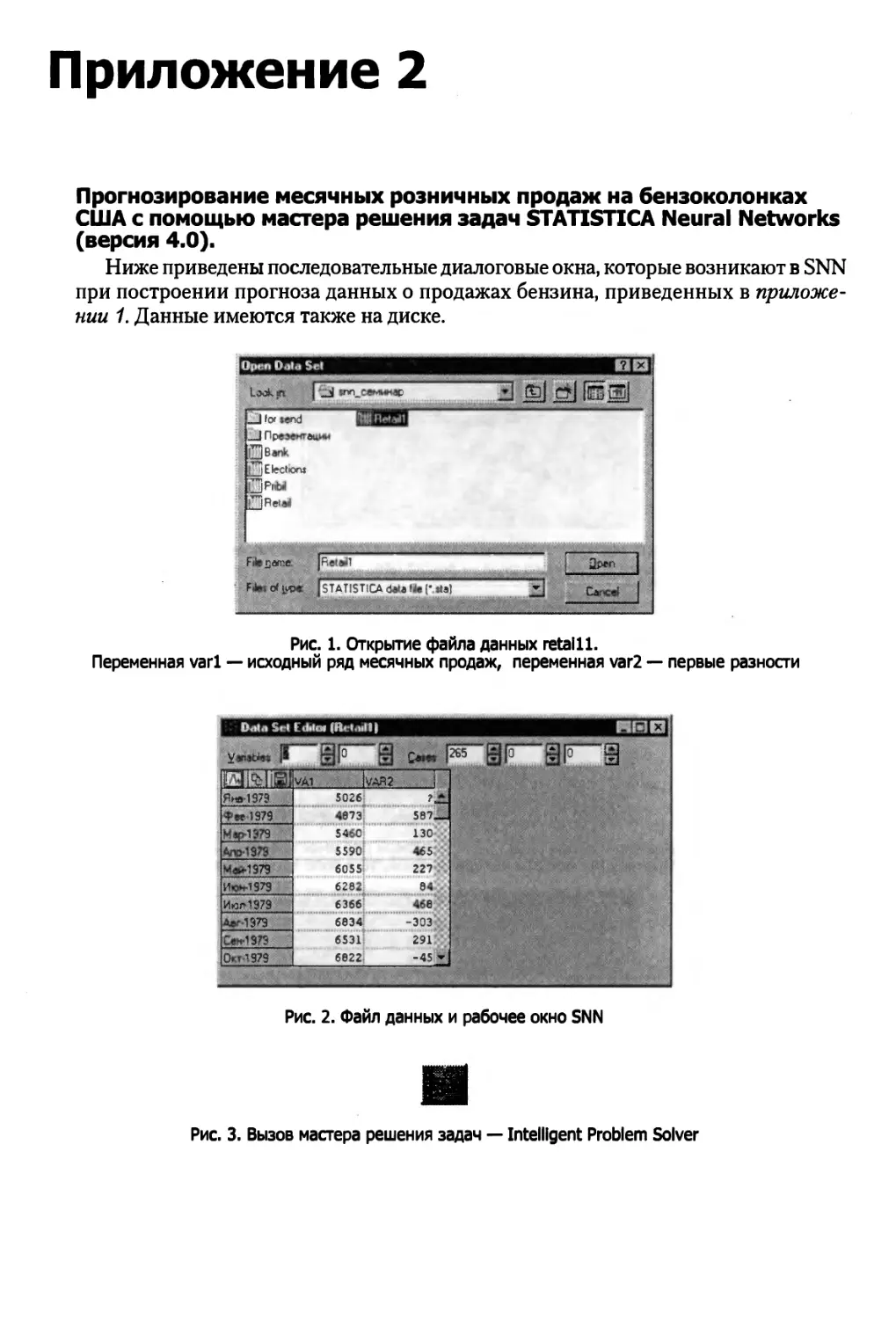
Вот типичный пример. Рассмотрим данные о розничных продажах бензина в
США (данные доступны на сайте www.economagJc.com в разделе Census Bureau:
Retail Sales by Kind of Business). В численном виде данные приведены в
приложении 1. Прогнозирование тех же данных с помощью нейронных сетей описано в
приложении 2.
На графике данные имеют вид:
Gagii'iii.-ir.i.i'f-ii'-.iii-.ii'iti^y-i'i1
Объем продаж автозаправочных станций
24000 |
S 12000
£ 8000
4006
Можно выделить
два временных интервала,
на которых динамика
показателя различается '
,^
vyvs
./W\<W
VI
лл/^W
Ш: !
гЛ
г^ СО ^-СЭ «- Гч гп «» ю 1Л-»«-' » W О ^- гм о *» ц-> ю
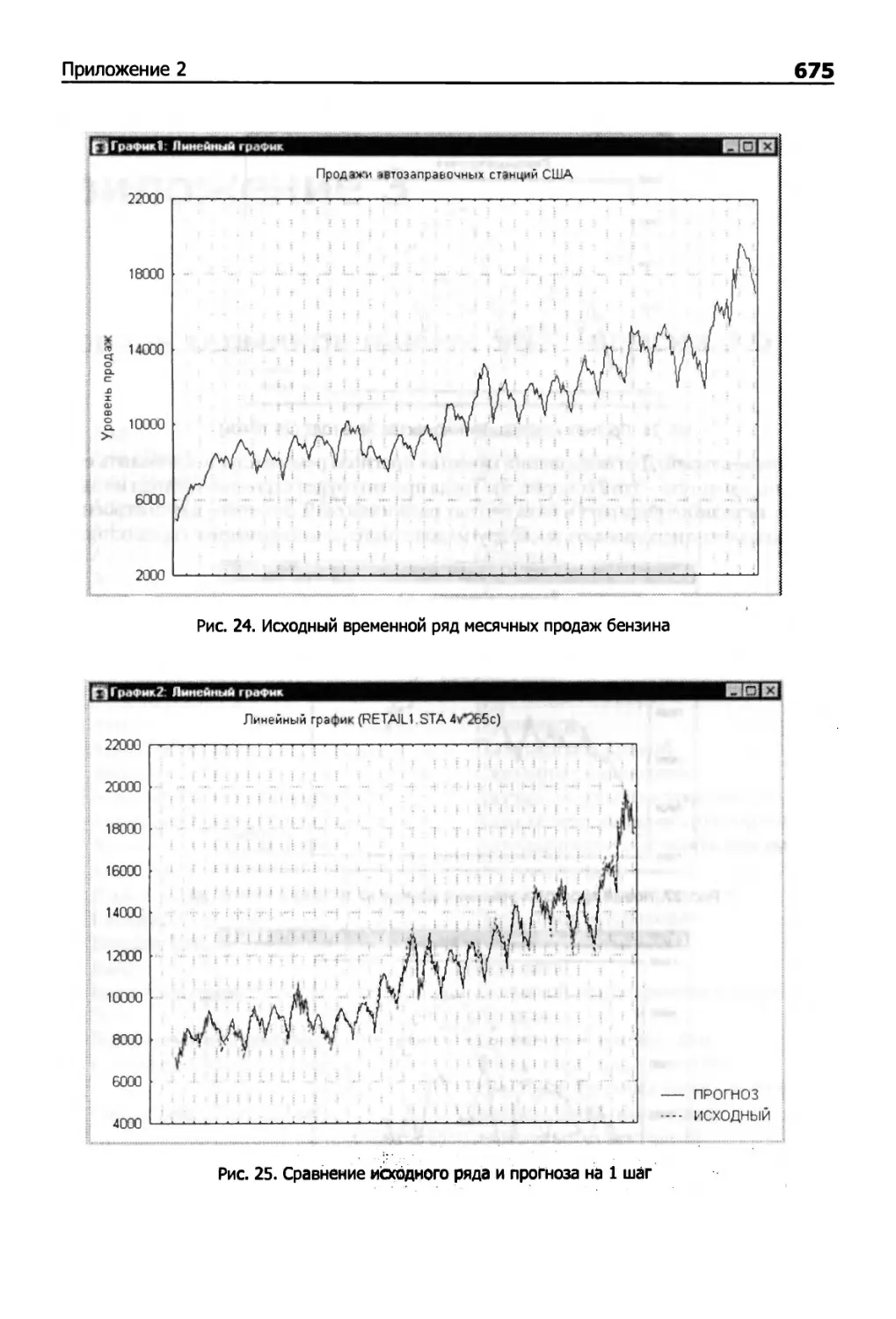
Рис. 5. Розничные продажи бензина в США
С помощью графика можно выделить два временных интервала, на которых
поведение ряда существенно различается.
Технологии прогнозирования, описанные в книге: Боровиков В. П., Ивченко Г. И.
«Прогнозирование в системе STATISTICA в среде Windows», M.: Финансы и
статистика, 2000, позволяют построить прогноз продаж бензина с помощью
моделей ARIMA — АРПСС (авторегрессии и проинтегрированного скользящего
среднего).
ffetftM квпиИ и» порвммтуо &>*tf j1 °
АРПСС (Бокс и Джмжмис) » ютокоиин
В
«М«*«НДЛЯ ЙИМА0М4ОЙ парвмвм* [р*лА
< »егмздЛл«р««ггмрам^*«»«пе0ем»««*,
| дауэдм щвжнит» по нам» Чтобы защитит» перв*и>му>
1<г^»1Ш1»1г<»мпрс«адюш1вгпрао6р«ао»*нмяу,дмж»м
щелкните и» соагмггстяуошеА строке в столбце Блок.
Рис. 6. Модуль анализ временных рядов в STATISTICA
Вступительное эссе: приглашение к анализу данных на компьютере
19
Г М«. лопфн+ц Г ipmmetmвегочикр Щ I & <:р«Э £|1;Кач«ооЛр . уточит*» д|
Р Р**«кя» 3, lUr.fi Щ По»«»о*:П 3 ;Г 2:|:: fcj < •••>-'••■•■ < •'•■• =:=-■ ^J
Vl Друтпрвибрстмашиигра&нц» I ; f 4:[
С ТотиыД (Мм*»*) Odawwm nn»wwr. fo"~ |
У НМММММ.Ч1
;rs:F
,r*F
Рис. 7. Построение прогноза продаж с помощью моделей АРПСС
UIJ.li.■ЦЩ.1М Я I.MJ 11.Ш НИШМ. ■■■■■ ВИ
Г^югьо>ы. Моде* IO.t 0 »1.0 1Ке «►•«>•■ члг i
Ис«од ПРОДАЖИ
Нечего исходны» 1ЭЗ комецмсходи 409
Прогмо) сотасмо
полученной мидепи
к
WV-Av^/'
vAvvVv'
лМУ
120 140 160 190 200 220 240 260 280 300 320 340 360 360 400 420 440
маОпюдаемь* • Пролом J 90 0000%
Рис. 8. Прогноз продаж бензина с помощью моделей АРПСС
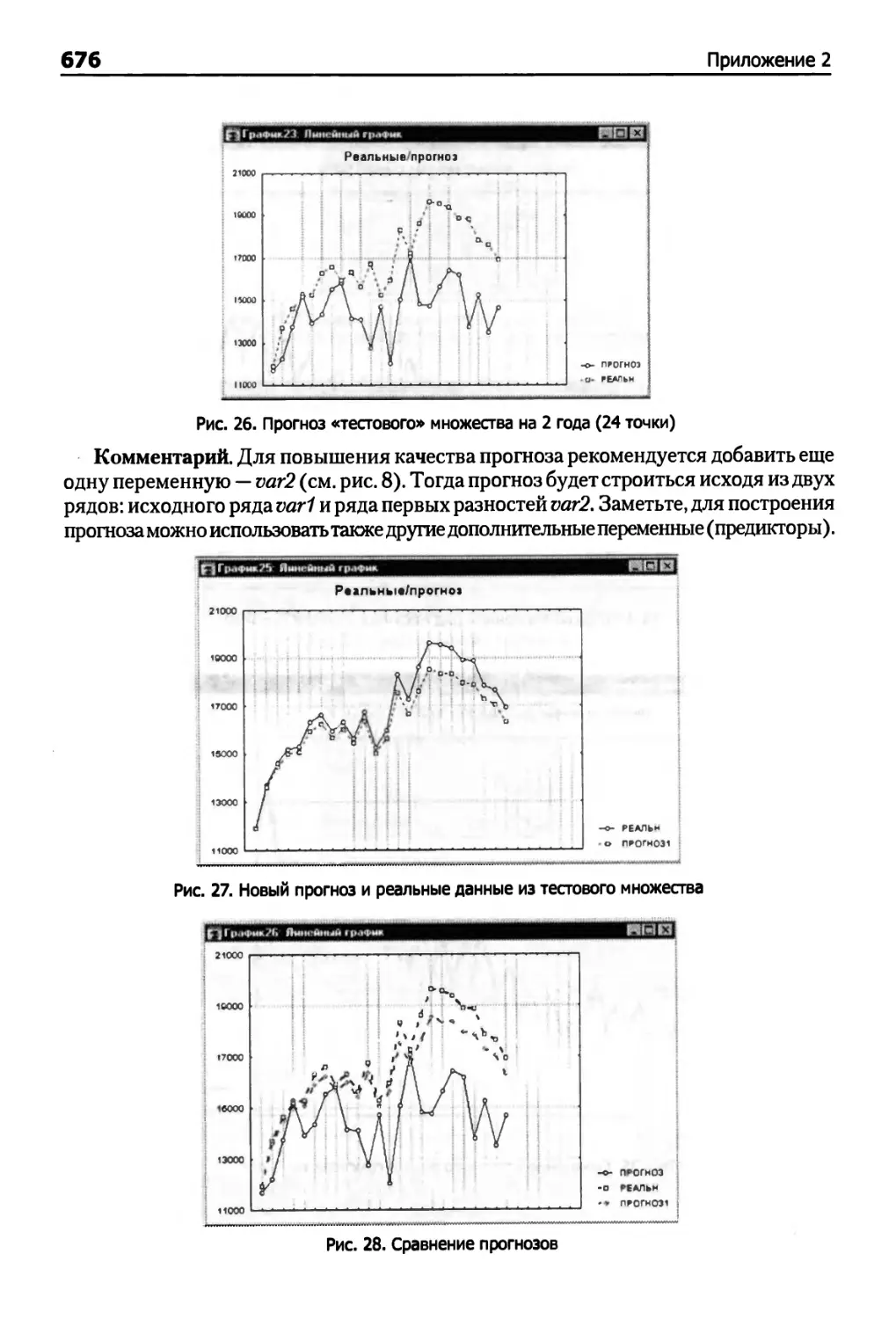
В качестве альтернативы можно использовать экспоненциальное сглаживание.
На следующих рисунках показан прогноз, построенный с помощью
экспоненциального сглаживания, который сравнивается с прогнозом на основе модели
ARIMA — АРПСС. Мы использовали часть данных для построения модели, а на
оставшихся данных сравнивали прогнозы.
inn mill hi ii in \\шшшшшшшшшшшшшшсшш
Рис. 9. Прогноз с помощью экспоненциального сглаживания
20
Вступительное эссе: приглашение к анализу данных на компьютере
■ ..101x1
График прогнозов экспоненциального сглажиеамия
и с помощью АР'МА модели
'. гншинп.м»
ЛН1МЛ модем»
У ^
■V'/"
И|Ю1НПЗ
Наблюдаемые :>ьспо»к>»<ииим,1
1.ГП»ЖИР 1МИРИ
Рис. 10. Сравнение прогнозов
Хотя в книге мы обращаем внимание на тонкие моменты исследования, более
важная наша задача — показать читателям, на какие результаты вообще можно
рассчитывать, применяя данный метод, и как избежать явных ошибок.
Итак, нам хотелось бы донести до читателя клише анализа данных: от
визуального анализа данных, описания данных с помощью простейших дескриптивных
статистик до сложных продвинутых методов, позволяющих понять структуру
данных, классифицировать данные и оценить связи между ними.
Ранее, до появления персональных компьютеров, анализ реальных данных был
чрезвычайно сложным, требующим больших интеллектуальных усилий делом, и
ни о каких технологиях не могло быть и речи. Это было дело небольшого круга
посвященных.
Благодаря таким системам, как STATISTICA, открылся путь к новым
технологиям анализа данных, максимально сокращающий рутинные процедуры и
делающий анализ максимально доступным для широкого круга пользователей.
На следующих рисунках показан типичный диалог в STATISTICA.
2«А* fjp*»*-* tm 4"*"* С*>*»« С«*ис 0»м* I
адшявге
гт
*«.-11П«Ч.я.,ятг,
Д |П»р»| наги и]НЫЦ|
7:оо
7:оо
7 400
■ЗКН за^г
П 118
о не
'JAW< '-bOlj'SV tOJ-tfc-'
15716 00 033 0 000
С*1-'
•.о
Ч «0
:isn
щвг
I Отие«« ]
Ш»(— «л.*.: [Г"| д.*. в.м. (о~~| Q
j»fw. ]
1.1 p»ft" {bw^&>$ |К£блй
Рис. 11. Рабочее окно STATISTICA с файлом данных о проблемных банках
Вступительное эссе: приглашение к анализу данных на компьютере
21
STATISTIC*
■з!
.;. л*.-|.»-.»м
;/W
*?.* ~*'rj:.<»< ouii, •г1>;чи:»Н1«.н i-i no i>.;umi.m4mi»(m Г~| Qfc
Лотт porpocom
робкт регрессия
f-l' ' I ' 1
|L2»
Отмсч*
Ш
i,J»t»t!Vtt^<««*«M<Vt* } '
Рис. 12. Логит-регрессия в STATISTICA — выбор метода оценивания
Задание начальных знамений
Конст.ВО ID
BANK 000001
f PR0TJ*P ] 0001
EQ_PERF jl
j OVJJQ p02
Ш
ok j
Отмена
0£щее значение :
0
1
±H l
Применить
га Модель: Логит регрессия (bank.sta)
НЕЛИН.
ОЦЕНИВ.
N = 182
шш
Зав.перем: BAD Потери: Макс правд
Ок.потери: 75.688258305 Хи2( 4)=52.208 р= 00000
Ко*к&:во
BANK
-2 6 '=» 2 О Б | 0000007 4 59557
0677422 1 000001 99 04430
1059 .151 95 94308
PROTLCAP 1 ECLPERF 1 OV^IIQ
Олн.несогл.-eg.иэм.
Оты.несогл.-размах
ы —
25 5 6 6 0 5 3 9
00026 1 0554
00301 103 8087
:.Г
Рис. 13. Задание начальных приближений и оценки параметров модели
22 Вступительное эссе: приглашение к анализу данных на компьютере
j£j График 11 Нормальный вероятностный график остатков НйЕЗ
НорЯМЛЬНЫИ |#рОЯТМОСТИЫИ ф1+ИС ОСТ1ТГ01
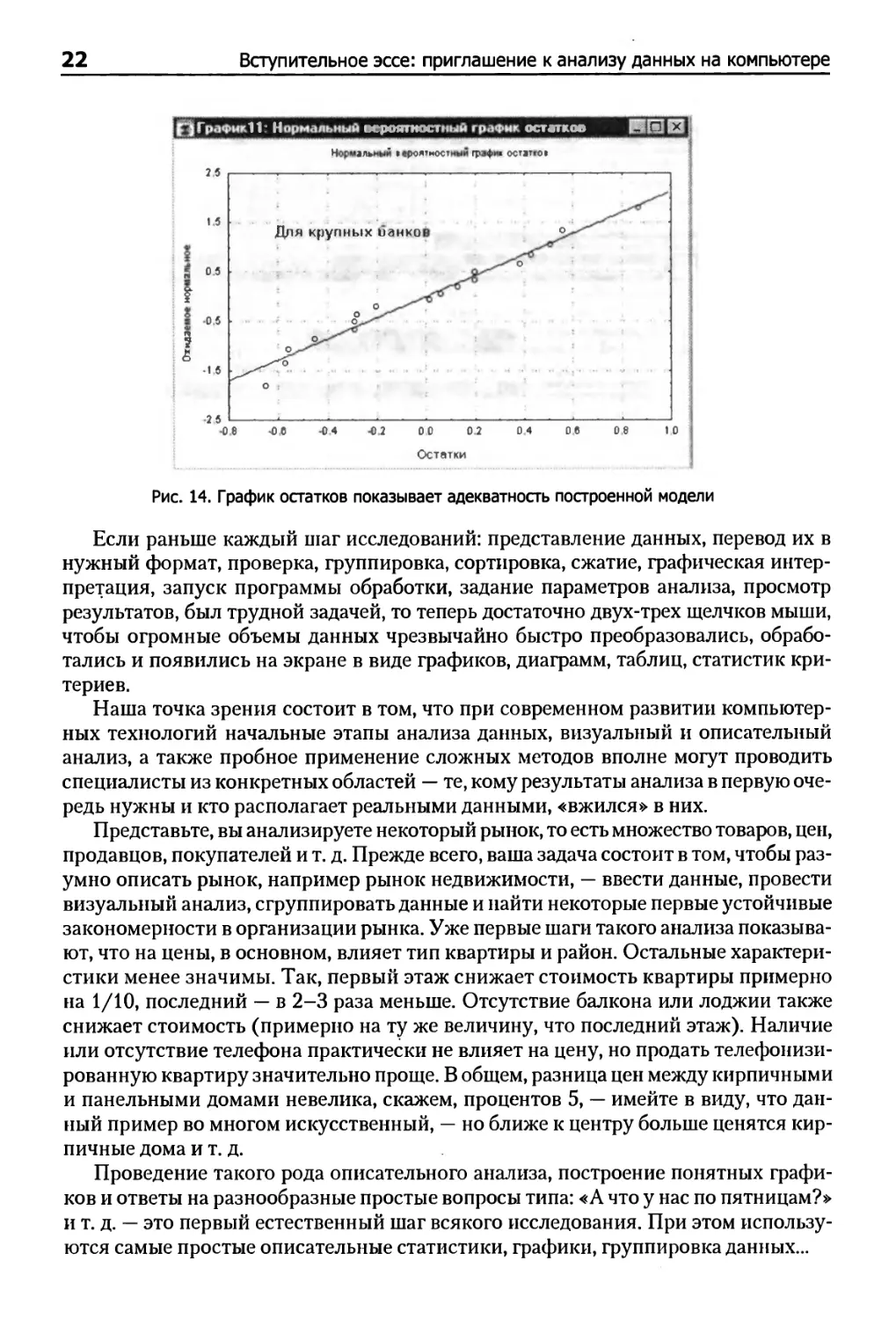
Рис. 14. График остатков показывает адекватность построенной модели
Если раньше каждый шаг исследований: представление данных, перевод их в
нужный формат, проверка, группировка, сортировка, сжатие, графическая
интерпретация, запуск программы обработки, задание параметров анализа, просмотр
результатов, был трудной задачей, то теперь достаточно двух-трех щелчков мыши,
чтобы огромные объемы данных чрезвычайно быстро преобразовались,
обработались и появились на экране в виде графиков, диаграмм, таблиц, статистик
критериев.
Наша точка зрения состоит в том, что при современном развитии
компьютерных технологий начальные этапы анализа данных, визуальный и описательный
анализ, а также пробное применение сложных методов вполне могут проводить
специалисты из конкретных областей — те, кому результаты анализа в первую
очередь нужны и кто располагает реальными данными, «вжился» в них.
Представьте, вы анализируете некоторый рынок, то есть множество товаров, цен,
продавцов, покупателей и т. д. Прежде всего, ваша задача состоит в том, чтобы
разумно описать рынок, например рынок недвижимости, — ввести данные, провести
визуальный анализ, сгруппировать данные и найти некоторые первые устойчивые
закономерности в организации рынка. Уже первые шаги такого анализа
показывают, что на цены, в основном, влияет тип квартиры и район. Остальные
характеристики менее значимы. Так, первый этаж снижает стоимость квартиры примерно
на 1/10, последний — в 2-3 раза меньше. Отсутствие балкона или лоджии также
снижает стоимость (примерно на ту же величину, что последний этаж). Наличие
или отсутствие телефона практически не влияет на цену, но продать
телефонизированную квартиру значительно проще. В общем, разница цен между кирпичными
и панельными домами невелика, скажем, процентов 5, — имейте в виду, что
данный пример во многом искусственный, — но ближе к центру больше ценятся
кирпичные дома и т. д.
Проведение такого рода описательного анализа, построение понятных
графиков и ответы на разнообразные простые вопросы типа: «А что у нас по пятницам?»
и т. д. — это первый естественный шаг всякого исследования. При этом
используются самые простые описательные статистики, графики, группировка данных...
Вступительное эссе: приглашение к анализу данных на компьютере
23
Далее, после разбиения жилья на однородные группы, возникают более
сложные аналитические вопросы, например, как влияет на стоимость типового жилья
появление элитных квартир? Или как повлияют большие продажи
муниципального жилья на цены? Как зависит спрос от сезонной составляющей? Как зависят
продажи от текущего строительства в городе? Мы рассмотрели рынок
недвижимости, но точно такие же методы применяются при исследовании других рынков:
финансового, фондовых, товарных, сырьевых...
Здесь нужно перейти от описательного анализа к более сложным
статистическим моделям, например регрессионным.
Любой рынок по существу своему многомерен, то есть описывается многими
параметрами, поэтому необходимо применять многомерные методы, например
факторный анализ, чтобы понять, какие факторы в основном влияют на цену
квартиры, многомерное шкалирование, деревья классификации и т. д. Для анализа
динамики цен и прогнозирования изменения цен в зависимости от времени
применяются методы анализа временных рядов.
Очень многие сложные задачи успешно решаются довольно простыми
статистическими методами. Например, известно, что краткосрочная финансовая
политика США строится на основе модели линейной регрессии с учетом сезонной
информации о финансах. Однако применение даже простых методов приносит эффект.
В бурно развивающейся отрасли средств телекоммуникации важно решать
следующие задачи:
О прогнозировать пиковые нагрузки в сети,
О оценивать недельные колебания нагрузки,
О рационально выбирать место строительства новой станции для
эффективного развития сети.
В принципе, задача рационального выбора места строительства станции может
быть решена с помощью методов множественной (многомерной)'регрессии. Она
вполне аналогична разбираемой нами задачи о строительстве атомной станции.
Оценка колебаний нагрузки сети в зависимости от дней недели решается с
помощью метода сезонной декомпозиции. Для прогнозирования нагрузки в сети можно
использовать модели авторегрессии и проинтегрированного скользящего среднего.
Регрессионные модели также используются для процентного выражения
прибыли магазина определенного типа в текущем году. В качестве регрессоров
используются величина спроса, качество товаров, рост доходов и др. (см. например,
статью Thurik A. R. A985). Retail margins during recession and growth, Econ. Lett., 17,
№ 3, p. 281-284, где даются расчеты по данным реальных наблюдений и
финансово-экономический анализ результатов).
Регрессия эффективно применяется для анализа экономической активности в
различных регионах.
Такая модель, например, с успехом применялась для анализа реальных данных
в Швеции. Степень вариации или изменчивости параметров модели для
различных муниципалитетов интерпретировалась как пространственная изменчивость,
а для эффективного оценивания неизвестных параметров принимались некоторые
априорные допущения о величине их изменения, см. например, работу Westlund
Anders H. A986) On econometric analysis of regional structural variability, Adv. Modell.
And Simul., 5, № 3, p. 25-44.
24
Вступительное эссе: приглашение к анализу данных на компьютере
Интересные результаты регрессии для прогнозирования доходов
телевизионных компаний в зависимости от трех факторов: числа продаваемых телевизоров,
общего числа рекламных объявлений и правительственных мер, ограничивающих
некоторую рекламу (например, рекламу сигарет), можно также получить с
помощью регрессионных моделей и т. д.
Мы употребили слово «регрессия», которое в анализе данных имеет почти
магическое значение и, возможно, отпугивает своей странностью многих.
Но что такое регрессия? В действительности, регрессия — это очень просто, и
если отбросить статистический жаргон, включающий такое малопонятное слово,
как «регрессия», то вы легко поймете, в чем здесь дело.
Представьте, вы изучаете годовой доход телевизионных компаний. «От чего он
может зависеть?» — спрашиваете вы себя и перечисляете следующие факторы, от
которых зависит доход: число зрителей, смотрящих ТВ, затраты на рекламу в год и
некоторые другие.
Тогда регрессия — это просто уравнение, в котором в левой части стоит
интересующая вас переменная, например годовой доход, а в правой число зрителей,
умноженное на некоторый коэффициент, плюс затраты на рекламу, умноженные
на другой коэффициент, плюс другие параметры. То есть вы имеете уравнение:
ДОХОД = А1 х ЧИСЛО_ЗРИТЕЛЕЙ + А2 х РЕКЛАМА+...
Итак, у вас есть просто зависимость одной переменной от других.
Замечательно, что все параметры (коэффициенты уравнения в правой части) рассчитываются
по реальным данным, а не назначаются умозрительно.
«А для чего мне нужна эта зависимость, выраженная в явном виде?» — спросите
вы. Предположим, вы расширили сеть кабельного телевидения, то есть увеличили
число зрителей, тогда вы можете спрогнозировать свой доход. Именно так и
поступал R. Sassone в исследовании, выполненном в 1978 году в США (данные были
получены частично от McCann-Erickson, Inc., частично от Television Bureau of
Advertising).
Аналогично вы можете спросить себя, каким образом изменятся внутренние
цены на нефть при изменении цен на международном рынке, и попытаться
ответить на этот вопрос с помощью регрессионного анализа. Типичная задача анализа
качества: вы имеете группы поставщиков сырья и показатели качества продукции.
Как зависит качество продукции от качества сырья?
Слово «регрессия» мы часто будем заменять словом «зависимость» и надеемся,
нас правильно поймут. Вообще, мы будем стараться максимально уходить от
статистического жаргона и выражаться доступным для каждого здравомыслящего человека
языком. Потому что наэтом языке изначально формулируются задачи анализа данных.
Известны сотни эффективных применений статистических методов и
регрессии, в том числе в экономике, маркетинге, финансах, медицине, промышленности
и т. д. Результаты выглядят очень простыми, естественными и впечатляющими.
Невозможно проведение актуарных расчетов без анализа конкретных данных —
клиента интересует реальный риск, а не виртуальный, так как от оценки риска
зависит конкретная процентная ставка и реальный платеж.
Важным полем применения статистических методов являются современные
системы электронной торговли. Успешные действия систем онлайновой торговли
требуют от фирм предсказания поведения индивидуальных покупателей.
Вступительное эссе: приглашение к анализу данных на компьютере
25
Крупнейшие фирмы, занимаясь электронной коммерцией, несут ежегодно
огромные убытки из-за того, что 5-10% покупателей меняют фирму или переходят
в пассивное состояние (см. Greg M. Allenby, Robert P. Leone and Lichung Jen A999).
A dynamic model of purchase timing with application to direct marketing, J. American
Statistical Association, v. 94, № 446, p. 365-374). Системы регистрации
электронной торговли позволяют зафиксировать моменты прихода каждого покупателя в
магазин, сумму сделки, количество товаров и другие параметры. Здесь уже все
готово для проведения статистического анализа. Важно спланировать его и провести
анализ системно.
Одна из возможных задач состоит, например, в том, чтобы оценить периоды
между покупками и изменить стратегию воздействия на покупателя — например,
провести более активную рекламную кампанию, если покупатель не обращается на
фирму в течение чрезмерно долгого времени.
Для описания интервалов времени между приходами посетителей в
электронный магазин можно использовать, например, гамма-распределение.
На модельных данных, отражающих реальную ситуацию, нами подробно
разбирается пример СУПЕРМАРКЕТ: от первичного, описательного анализа данных о
покупках в течение дня до углубленного анализа и получения неочевидных выводов.
Мы начинаем с корреляционной матрицы продаж:
[ф Данные coiil STA 6п * 6и
мясо
РЫБА
СПИРТНЫЕ НАЛИТКИ
ЧАР) "
ГОФЕ
К 1
коп
эасы.И
1 00[
lb
1 ми
1.'
Н
JM
P'U&A (СПИРТНЫЕ 1
16
i:
1 ЛП
IF,
14
1Г
1 00
....
ЧАИ J
11
1 00
1 ?
И
6
КОФЕ
\Г.\ х|
т
07
10
1Ь
11
I7
0A »
ч
Рис. 15. Корреляции между покупками различных товаров
Затем рассматриваются графики, исследуется вариабельность покупок в
зависимости от дней недели, применяется многомерный анализ, анализируется
потребительская корзина для различных категорий пользователей, различных дней
недели и т. д.
СПИРТНЫЕ НАШ ТКИ
Срд Ч1В П1И Сб1
ДЕНЬ НЕДЕ ПИ
Т~ *Ci. они!.
СЗ iCi.oui.
" Среднее
Рис. 16. Продажа спиртного в зависимости от дней недели
26
Вступительное эссе: приглашение к анализу данных на компьютере
1.Ц.1!|1|Д,|1Ш1Ц|.ШИ1Ш1.и11.Ы.1
Диаграмма размаха: КОЛЬАСА
Т"
■rU
1" !
''""
~т~
ПЖ2
Пид Bip Срд Чт Ши СО! Век
ДЕНЬ
~Г~ iCi. 01кл.
I'Z'J *Ci. ош.
г- Среднее
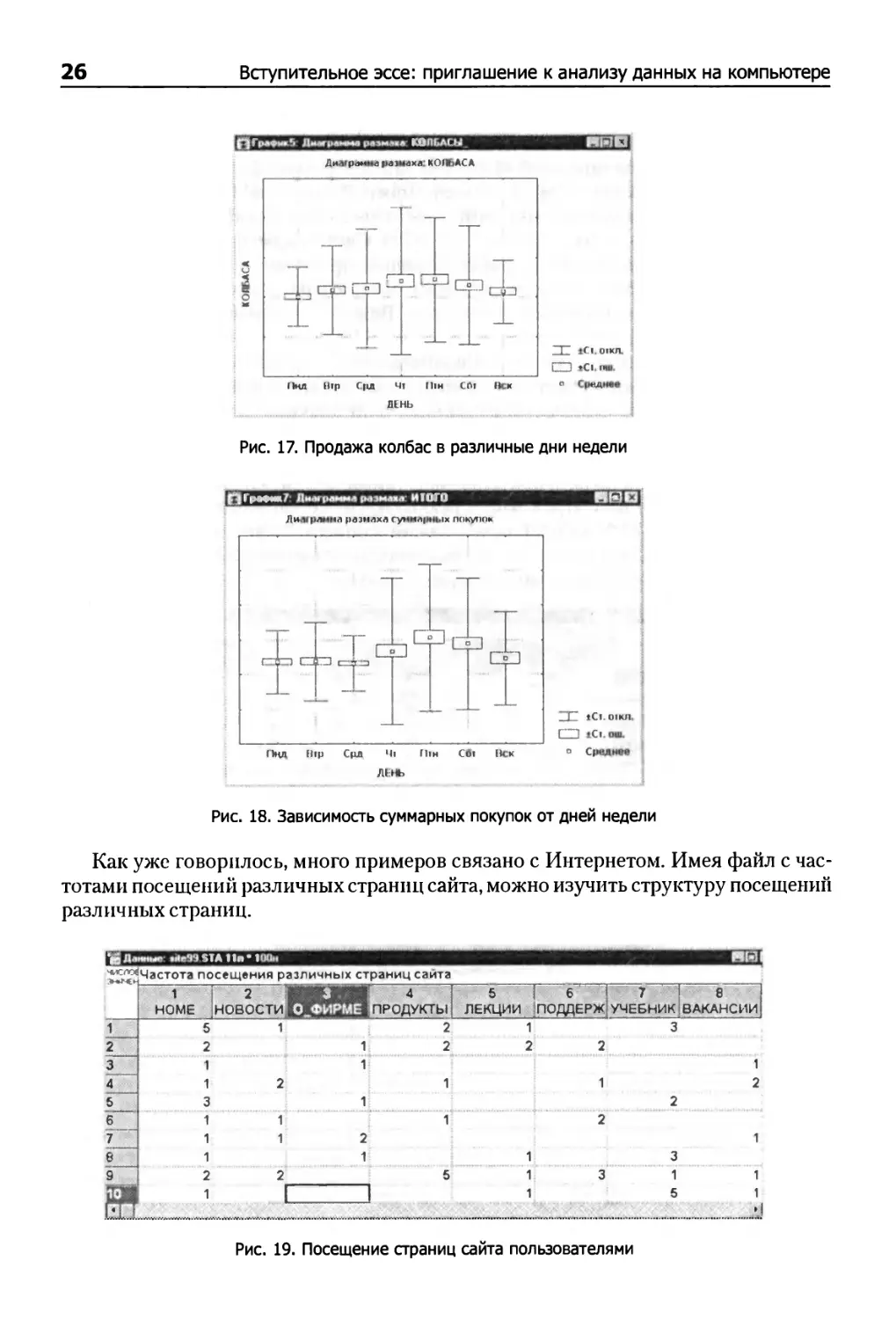
Рис. 17. Продажа колбас в различные дни недели
hlMli;i^'""ill 'll'r" "IJI'II'I
Диа! рамма размаха суммарных покупок
Рис. 18. Зависимость суммарных покупок от дней недели
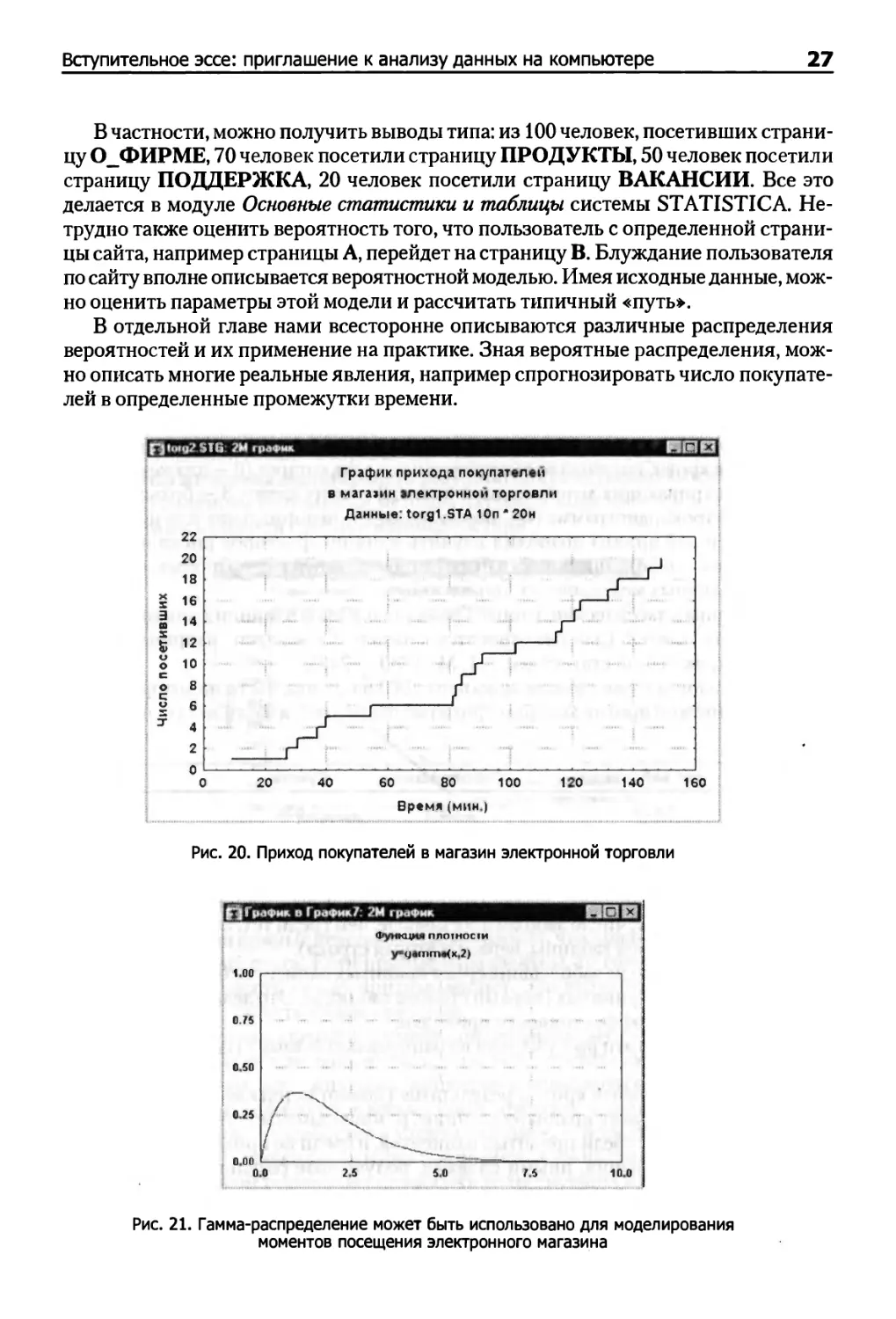
Как уже говорилось, много примеров связано с Интернетом. Имея файл с
частотами посещений различных страниц сайта, можно изучить структуру посещений
различных страниц.
\ти*
число*
1
2
3
4
б
6
7
6
9
Я
иные sile99STA11
Частота
1
НОМЕ
п- 100м
посещения различных страниц сайта
I
2 шаг
^новостижгдд:
5
2
1
1
3
1
1
1
2
1
1
2
1
1
2
I
• i
1
1
1
2
1
—I
4
ПРОДУКТЫ
2
2
1
1
5
б
ЛЕКЦИИ
1
2
1
1
1
6
ПОДДЕ
РЖ
2
1
2
3
7
нн
УЧЕБНИК
8
ВАКАНСИИ
3
1
2
2
1
3
1 1
б 1
\
Рис. 19. Посещение страниц сайта пользователями
Вступительное эссе: приглашение к анализу данных на компьютере
27
В частности, можно получить выводы типа: из 100 человек, посетивших
страницу 0_ФИРМЕ, 70 человек посетили страницу ПРОДУКТЫ, 50 человек посетили
страницу ПОДДЕРЖКА, 20 человек посетили страницу ВАКАНСИИ. Все это
делается в модуле Основные статистики и таблицы системы STATISTICA.
Нетрудно также оценить вероятность того, что пользователь с определенной
страницы сайта, например страницы А, перейдет на страницу В. Блуждание пользователя
по сайту вполне описывается вероятностной моделью. Имея исходные данные,
можно оценить параметры этой модели и рассчитать типичный «путь».
В отдельной главе нами всесторонне описываются различные распределения
вероятностей и их применение на практике. Зная вероятные распределения,
можно описать многие реальные явления, например спрогнозировать число
покупателей в определенные промежутки времени.
22
20
18
8 16
i и
| 12
S ю
с
о 8
х «
т 4
2
0
С
ПЗЕЗШЯ
S
) 20
График прихода покупателей
• магазин электронной торговли
Данные: torgl .8ТА 10п * 20н
I
_Н
40 60 80 100 120
Время (мин.)
140
■ ЛР1х1
1С
Ю
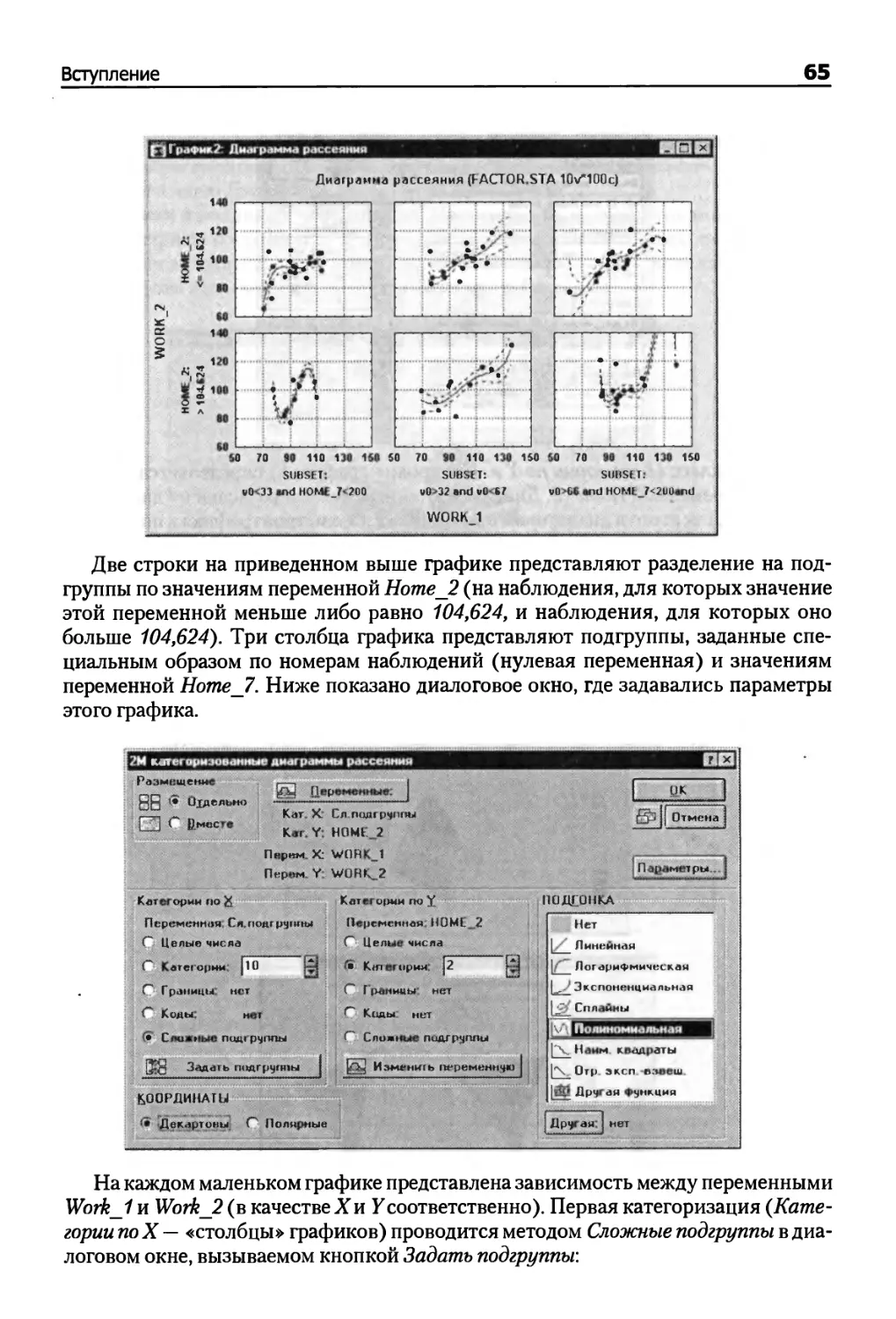
Рис. 20. Приход покупателей в магазин электронной торговли
ФуНМЦИЯ ПЛ01НОС1И
У«пт«<х,2)
1.1
Рис. 21. Гамма-распределение может быть использовано для моделирования
моментов посещения электронного магазина
28 Вступительное эссе: приглашение к анализу данных на компьютере
Общеизвестно применение статистики в медицине и фармакологии. Оценка
эффективности лекарств, классификация больных по степени тяжести заболевания,
исследование кардиограмм, самые разнообразные тесты, позволяющие
диагностировать пациентов на раннем этапе заболевания, и многие другие задачи хорошо
известны. Только математика открывает путь к доказательной медицине.
В знаменитом фрэмингхемском исследовании, выполненном в США
(см. Truett, J., Cornfield, J., and Kendall, W. A967). A Multivariate Analysis of the
Risk of Coronary Heart Disease in Framingham, Journal of Chronic Disease 20,
p. 511-524), статистический анализ применялся для оценивания зависимости риска
развития ишемической болезни сердца от семи факторов.
В этом исследовании в течение 12 лет были собраны данные о проявлениях
ишемической болезни у 1929 мужчин и 2540 женщин в возрасте от 30 до 62 лет. В
начале обследования все пациенты были здоровы. Факторами риска служили: возраст,
количество холестерина в крови, систолическое давление, вес, количество
гемоглобина в крови, количество выкуриваемых в день сигарет @ — для некурящих,
1 — для выкуривающих меньше одной пачки, 2 — одну пачку, 3 — больше одной
пачки), электрокардиограмма @ — нормальная, 1 — ненормальная или неясная).
Проведенный анализ позволил изучить влияние факторов риска на
развитие ишемической болезни сердца и стимулировал целый ряд подобных примеров
в самых различных медицинских приложениях.
Рассмотрим классические данные Гринвуда и Юла о влиянии прививки на
заболеваемость холерой (данные относятся к началу XX века, см., например,
Справочник по прикладной статистике, т. 1, М.: 1989, с. 245).
В приведенной ниже таблице показаны 2663 пациента, части из которых были
сделаны прививки против холеры (привитые пациенты), а части нет (непривитые
пациенты).
Привитые
Не привитые
Сумма
Не заболевшие
1625
1022
2 647
Заболевшие
5
11
16
Сумма
1630
1033
2 663
Что можно сказать, глядя на эту таблицу? Прежде всего, видно, что среди тех,
кто сделал прививку, число заболевших меньше, чем среди тех, кто не сделал
прививку (второй столбец таблицы, первая и вторая строка).
Кроме того, число не заболевших среди привитых пациентов больше, чем не
заболевших среди не привитых (первый столбец таблицы). Это делает
правдоподобным заключение об эффективности прививки.
Но как перевести эти рассуждения на рациональный язык? Имеется ли вообще
такой язык?
Представьте, нашелся критик результатов (нового метода лечения, нового
лекарства), который, заняв крайнюю позицию, резонно замечает, что и в том и в
другом случае, то есть и среди привитых пациентов, и среди не привитых, были
отмечены случаи заболевания, иными словами, полученные результаты носят чисто
случайный характер, и утверждение об эффективности прививки весьма
сомнительно.
Как рационально ответить на подобную критику?
Вступительное эссе: приглашение к анализу данных на компьютере
29
Лучше всего воспользоваться вероятностными рассуждениями и подходящим
статистическим критерием. Для такого рода таблиц, называемых таблицами
сопряженности, имеются специально разработанные критерии, например критерий хн-
квадрат и критерий Фишера, названный по имени знаменитого английского
статистика Р. А. Фишера.
Эти критерии измеряют силу связи между признаками (переменными)
таблицы, в данном примере между признаком прививка и признаком болезнь.
Для представленной выше таблицы величина статистики хи-квадрат равна 6,08,
что значимо на уровне 0,0136 (чтобы получить эти цифры, мы сделали два щелчка
мыши в системе STATISTICA).
Следовательно, с небольшой вероятностью ошибки (меньше 0,0136) вы можете
утверждать, что среди привитых пациентов количество заболевших существенно
меньше, чем среди непривитых. Поэтому вероятность того, что суждение критика
о неэффективности вакцины справедливо, равна всего 0,0136 (примерно один шанс
из 70). Ваша же оценка достоверности результатов существенно выше.
Весьма полезным визуальным методом изучения зависимостей между
признаками таблицы являются графики взаимодействий:
Гр«фим в
17М
1SM
13М
11М
! -
1 '»
SM
зм
1U
•1М
к вэаимо* ПРИВИВКА к БОЛЕЗНЬ ЯИЕЗ
»*имод.: ПРИВИВКА х БОЛЕЗНЬ
\
\
\
\
°V \
>W Ч
^v ч
Л.Ч
^у.
_
Не »«6олеяи Заболели
БОЛЕЗНЬ
-«- ПРИВИВКИ НЕТ
♦ г, ПРИВИВКА ЕСТЬ
Рис. 22. График зависимости БОЛЕЗНЬ — ПРИВИВКА
Здесь показаны две прямые, сооткетствующие категориям больных: привитые —
не привитые. Если прямые пересекаются, то говорят, что признаки
взаимодействуют, влияют друг на друга. Если прямые параллельны, то говорят, что
взаимодействия или зависимости между признаками нет. Это визуальный подход, точные
результаты дают статистические критерии.
Первые применения статистики в медицине, по-видимому, относятся к XVIII веку,
когда в Англии было замечено, что относительная частота смертности мужчин и
женщин одного возраста, живущих примерно в одинаковых условиях, из года в
год колеблется, но колеблется в весьма узких пределах. Самым интересным здесь
является замечание: «колеблется в узких пределах», — всем известно, что
колебания происходят, — неожиданным фактом являются узкие границы колебания, что
позволяет с большой точностью предсказать долю умерших в той или иной
категории населения и служит основой актуарных расчетов.
Итак, в случайном явлении — смертности или, наоборот, выживаемости людей —
была открыта устойчивая закономерность: относительная частота или доля для
30
Вступительное эссе: приглашение к анализу данных на компьютере
людей одного пола и близкого возраста примерно постоянна. А это удивительное
открытие, повлекшее за собой множество событий, в частности современное
страхование.
В современной медицине накопились огромные архивы данных, и их
исследование с помощью новых технологий чрезвычайно важная задача. STATISTICA
позволяет реализовать системный подход к анализу данных.
У каждого врача имеется собственный архив данных, отражающий
многолетний опыт его работы, — огромный массив знаний, имеющий большую
познавательную ценность.
Ценность этой ш1формации может быть многократно увеличена, если
воспользоваться методами анализа данных. И в этот момент на помощь врачу приходит
система STATISTICA, позволяющая перевести клинический опыт на язык
количественных оценок (подробнее о применении статистики в медицине см.: Ст. Гланц.
Медико-биологическая статистика. М, 1999).
В STATISTICA реализованы множество методов, чрезвычайно полезных
врачам для анализа их данных, в частности описательные статистики и таблицы,
анализ выживаемости, непараметрическая статистика, дискриминантиый анализ
и др.
Щ Анализ выживаемости и времен отказов
|ЕШ Таблицы и распределения времен жизни
|гг|/" Метод множительных оценок Каплана-Мейера
j!|1j Сравнение двух выборок
||Л Сравнение нескольких выборок
■ ВД Регрессионные модели 1
ИЕЗ
а ак
Отмена
(^? Данные
«ист и
сязи я.
& а
Рис. 23. Анализ выживаемости в системе STATISTICA
Анализ выживаемости позволяет проанализировать неполные или цензуриро-
ваниые данные, например, о выживаемости больных после операции (рис. 24).
к
h i
2
3
А
5
6
7
1«
Данные: HEART STA 11
Heort transplant data trc
■ци
JANUARY
MAY
AUG'JST
AUGUST
SEPTEMBR
OCTOBER
OCTOBER
.1
DAY
n " 65m
m Crowlev and Hu. stratitied
3
YEARJ
Г e
2
31
22
9
5
26
4
MONTHJ
68 JANUARY
68 MAY
68 MAY
68 OCTOBER
68 JANUARY
68 DECEMBER
68
JULY
5
DAY
21
5
17
i
14
8
7
6
YHARJ
7
:ensor£c
68:ensored
68:ensored
70 COMPLETE
68 COMPLETE
69:ensored
68 COMPLETE
72
COMPLETE
8
AGE
54
40
51
42
48
54
54
9
ANTI
0
0
0
0
0
0
0
10
MJ5MA
1 11
1 66
1 32
61
36
1 89
87
и ran I
~
и
HOSPITAL
HILLVIEW
HILLV1EW |
HILLVIEW !
ST_AND |
ST AND
ST.AND
BINER
Г
Рис. 24. Данные по трансплантации сердца
Одной из важных характеристик является функция выживаемости
(вероятности того, что пациент проживет t дней после операции. Для оценки функции
выживаемости по неполным данным используют так называемую оценку Каплана—Мей-
ера, которая может быть легко получена в STATISTICA (рис. 25).
Вступительное эссе: приглашение к анализу данных на компьютере
31
UIJII.NIII.MJII1II|I|I|.II||I|J.IJIUJI1
Функция выживаемости
о Завершен. + Цеизурироваииые
500 1000
Время жизни (дни)
2000
Рис. 25. Функция выживаемости после операции
Этот график легко «читается»: вы легко видите, например, что доля пациентов,
проживших больше 1000 дней, равна 0,4.
Можно сравнить функции выживаемости в разных больницах, для разных
возрастных групп (рис. 26).
iTid-r1, ,'м дл,',', .г Л", 11-1; 11И1 г' mi. -i,f м/1;, I in1 ij-iih^ к j -i
Кумулятивная доля выживших
о Завершен. + Цеизуририроваииые
0 400 800 1200 1600 2000
200 600 1000 1400 1800
Время (дни)
— HILLVIEW
■- ST_AND
•• BINER
Рис. 26. Сравнение выживаемости в разных группах
\ лштшттштт
<•* Неоараметрнчаоше тшшпт» С Подсоика р^уфтагтшт
Цепаремотрмчаоциа статистики: "'
В
о*
Таблицы 2 я 2: хи/V/e*. Мекиемара. точный Фмиера
Ш0 Наблюдаемые частоты ■ сравнении с ожидаемыми
Коррелядии (Спирмема, та*. К вид а л да. гамма)
И8 Критерий серий Вальда-Вояьфовида
метод для
нес*
щЩ Леу»еыборочный критерий Колиогороее-Смирнова
J5J AN OVA Краскела-Уоллиса и медианный тест
Критерия знаков
ДЗЛ Критерий Вилкоксома
(Jjjjj] AN0VA Фридмана и коикордадиа Кеидалла
Q критерий Кохрена
СЛ Обычные описательные статистики (медиана, мода...)
&
Рис. 27. Модуль Непараметрические статистики в системе STATISTICA
32
Вступительное эссе: приглашение к анализу данных на компьютере
Опишем еще одну важную область применения статистических методов —
современное высокотехнологичное производство.
Традиционную область применения статистического анализа данных составляет
промышленность.
Обычно любая машина или станок, используемые на производстве, позволяют
операторам производить настройки, чтобы воздействовать на качество
производимого продукта. Изменяя настройки, инженер стремится добиться максимального
эффекта, а также выяснить, какие факторы играют наиболее важную роль в
улучшении качества продукции. Использование этой информации позволяет
достигнуть оптимального качества в условиях данного производства.
Например, на производстве (см. например, книгу: Box, Draper A990), Empirical
model-building and response surfaces, New York: Wiley, 115) проводился
эксперимент по нахождению оптимальных условий для изготовления красителя ткани.
Качество красителя описывается насыщенностью, яркостью и стойкостью.
Другими словами, в этом эксперименте нам хотелось бы выявить факторы,
наиболее заметно (значимо) влияющие на яркость, насыщенность и стойкость
производимого красителя. В примере Бокса и Дрейпера рассматривается 6 различных
факторов, влияние которых оценивается с помощью так называемого плана2F0).
В данном плане первоначально рассматривались 6 факторов, принимающих 2
значения, то есть всего имелось 26 = 32 различных вариантов установок. Результаты
эксперимента выявили три наиболее важных фактора: Polysulfide (Полисульфид),
Time (Время) и Temperature (Температура).
Можно представить ожидаемое воздействие на интересующую нас переменную
(например, светостойкость окраски) в виде так называемой кубической
диаграммы, которая показывает ожидаемую (предсказываемую) среднюю стойкость
краски, нанесенной на ткань, на верхних и нижних уровнях каждого из трех факторов,
и определить те значения факторов, которые обеспечивают максимальное качество
продукции (рис. 28).
Рис. 28. Кубическая диаграмма показывает значимость факторов,
установленных на разных уровнях
Вступительное эссе: приглашение к анализу данных на компьютере
33
Глядя на эту диаграмму, легко можно понять, что наилучшее расположение
факторов для максимизации качества красителя следующее: Polysulfide установлен на
верхнем уровне HIGH, Time — на верхнем уровне LONG, Temperature — на верхнем
уровне HIGH. Таким образом, оптимум достигается на дальней вершине куба (см. рис. 28).
В описанном эксперименте присутствовало 6 факторов, нередки, однако, случаи,
когда очень много (до 100) различных факторов являются потенциально важными
на производстве, однако заранее вы не знаете, какие факторы важны, а какие нет. •
Специальные планы, например план Плакетта—Бермана или планы с матрицей
Адамара, позволяют эффективно «просеять» или, как говорят на статистическом
сленге, проскринировать большое число факторов, используя минимальное число
наблюдений.
Например, вы можете спланировать и проанализировать эксперимент со 127
факторами, используя всего 128 опытов, а затем оценить главный эффект каждого
фактора, определив, какие факторы играют доминирующую роль, а какие нет.
Выход продукта многих химических реакций является функцией времени и
температуры. К сожалению, эти переменные влияют на выход не линейно. Другими
словами, нельзя сказать: «чем больше продолжительность реакции, тем больше
выход» и «чем выше температура, тем больше выход». Цель экспериментатора
заключается в определении оптимального выхода или экстремальной точки
поверхности выхода, образованной двумя переменными: временем и температурой.
При проведении таких экспериментов используют так называемые
центральные композиционные планы, позволяющие инженерам-технологам оценить
поверхность регрессии (рис. 29 и 30) и найти экстремумы этой поверхности, или точки,
отвечающие заданному значению зависимой переменной.
Подобные планы применялись, например, для исследования ракетного топлива,
в состав которого входили три компоненты: связывающее вещество, окислитель и
горючее, а характеристикой качества являлась эластичность продукта (см. также
планы для смесей в модуле Планирование эксперимента в системе STATISTIC А).
Требовалось найти такие пропорции (доли) компонент, чтобы эластичность
достигала заданного значения (см. Kurotori I. S. A966). Experiment with mixtures of
components having lower bounds, Industrial Quality Control, № 2, p. 592-596).
■156 000
■I 60 000
■164 000
Ш 68 000
CU 72 000
CD 76 000
■I 80 000
■184 000
■I 86 000
■I 92 000
■I «bow
Fitted Surface. Variable YIELD
2 factors, 1 Blocks, 12 Runs, MS Re$idu«l=4 014637
DV YIELD Vield of process in grams
Рис. 29. Поверхность регрессии
34
Вступительное эссе: приглашение к анализу данных на компьютере
fti Г|*йфми I > Хъ*% Гркафш
ИЮ01Г1Графм*4 XYZ графи*
&ЩкШ& :Ц№¥&фМ$
WF113 i &Т№№&Ш£ЩржШ*
■Л -юго
■Л -OTfti
■■ о из
Вй -0 30)
О ооет
СП от
I 1 0 403
I ом?
Рис. 30. Визуальные методы STATISTICA при планировании экспериментов
Это типичные задачи планирования эксперимента, возникающие на
производстве, и система STATISTICA предоставляет эффективные методы их решения.
Ниже показаны методы планирования эксперимента, доступные в системе.
iMiiimiJi'iiiwHW-iiiuii
j£A Планы 2"|кр) (Бокса, Хаит ера и Хантера)
'0г
в
а*
2-х уровневые отсеивающие
Максимально несмешанные
(П лакетта-Бермана)
порядка 2"(к-р)
Отмена
с Планы 3""(к-р) и пианы Бокса Бенкена
Е Смешанные 2-х и 3-х «ровиевые
1^/ Центр, составные, нефакториые. поверхности отклика
;Ц| Латинские и греко-латинские квадраты
\£$\ Робастные планы Тагами
/§>, Планы для смесей и триангул.поверхности
Дли 4НвлИЗ* ПОЛНЫХ
Факторных планов/
иерархически вложенных
и с несЯа/чисированным
вложением, смешанных
моделей {со случайными
мх^ктами! см. также
модули Компонвитм
дисперсии и
Дисперсионный анализ
№
Планы для поверхностей с ограничениями и смесей
D- и А- (Т-) оптимальные планы
е-
Данные
& а
Рис. 31. Модуль планирования экспериментов в STATISTICA
Не менее важны в промышленности задачи контроля качества.
Для всех производственных процессов возникает необходимость установить
пределы характеристик изделия, в рамках которых произведенная продукция
удовлетворяет своему предназначению. Вообще говоря, существует два «врага»
качества продукции:
1. Уклонения от значений плановых спецификаций изделия.
2. Слишком высокая изменчивость реальных характеристик изделий
относительно значений плановых спецификаций, что говорит о
несбалансированности процесса.
Вступительное эссе: приглашение к анализу данных на компьютере 35
На более ранних стадиях отладки производственного процесса для
оптимизации этих двух показателей качества производства часто используются описанные
выше методы планирования эксперимента.
Методы контроля качества предназначены для построения процедур контроля
качества продукции в процессе ее производства, то есть текущего контроля
качества. Детальное описание принципов построения контрольных карт и подробные
примеры можно найти в работах: Buffa A972) Operation management: Problems and
models Crd ed), New York:Wiley, Duncan A974) Quality control and industrial statistics,
Homewood, IL: Richard D. Irwin, Grant and Leavenworth A980) Statistical quality
control Eth ed.) New York: McGraw-Hill, Juran and Gryna A988) Quality planning
and analysis Bnd ed.) New York: McGraw-Hill, Montgomery A985) Statistical quality
control New York: Wiley, Montgomery A991) Design and analysis of experiment
Crd ed.) New York: Wiley, Shirland A993) или Vaughn A974).
В качестве превосходного вводного курса, построенного на основе подхода
«как — чтобы», можно указать монографию Hart and Hart A989) Quantitative
methods for quality improvement. Milwaukee, WI: ASQC Quality Press.
Особенно интенсивно методы контроля качества используются в США,
Германии, Японии.
Общий подход к текущему контролю качества заключается в следующем.
В процессе производства из произведенной продукции или поступающего
сырья проводится отбор выборок изделий заданного объема. После этого на
специально разлинованной бумаге строятся диаграммы средних значений и
изменчивости выборочных значений плановых спецификаций в этих выборках и
рассматривается степень их близости к плановым значениям. Если диаграммы
обнаруживают наличие тренда выборочных значений или выборочные значения
оказываются вне заданных пределов, то считается, что процесс вышел из-под
контроля, и предпринимаются необходимые действия для того, чтобы найти
причину разладки.
Такие специальные карты называются контрольными картами Шухарта
(названные в честь W. A. Shewhart, который общепризнанно считается первым,
применившим их на практике в начале 30-х годов XX века).
Один из примеров карты Шухарта показан на рис. 33. Смысл этой карты ясен.
В последовательно поступающих партиях нефтепродуктов измерялась примесь
вредных веществ. Строятся два линейных графика: для средних и размахов
(разностей между максимальными и минимальными значениями выборки, что
характеризует изменчивость характеристик производственного процесса).
Вначале посмотрим на график средних. Если средние выходят за определенные
границы, то мы говорим о неудовлетворительном качестве сырья. На графике
средних значений партии неудовлетворительного качества имеют специальную
метку.
Далее рассматриваем график размахов. Размах — это разность между
максимальным и минимальным значением выборки. Прагматическая ценность этой
характеристики в том, что она служит мерой изменчивости. По расположению точек
на графике размахов принимают решение о случайности или систематичности
отклонения в качестве продукции.
Ниже показаны карты контроля качества, доступные в системе:
36
Вступительное эссе: приглашение к анализу данных на компьютере
^^С-ларта по альтариашамом) лрмамак)
£л^ U-парта по альтернативному признак)
j£23 Np-карта по ааьтарнапммощ признак)
[«. Р-карт а по а
5S Н 1<5> I
fc^l Карта Т2 Хотаялммга
гасивим-ларта**»
1> МА-карта дня
£3 EWMA-карта »м
Ь'Я Раграссмоииая контры
IZT1 Карта Парато
вывврип w карты.
Друи»пртищ)ы
. «литот» кчаст»» •-
Рис. 32. Контрольные карты системы STATISTICA
На практике могут возникнуть трудности при выборе наилучшей контрольной
карты. Чтобы сделать выбор осознанно, нужно учитывать специфику
производства, например, если исследуется концентрация определенных веществ в
химическом процессе в режиме реального времени, то сложно провести группировку
данных и следует применять карты для индивидуальных наблюдений. В отличие от
этого, в машиностроении при измерении параметров продукции, например
диаметров поршневых колец, легко разбить партию данных на подгруппы и применить
соответствующие Х- и R-карты (рис. 33).
Еще одной типичной проблемой, с которой сталкиваются инженеры по
контролю качества на производстве, является следующая: определить, сколько именно
изделий из партии (например, полученной от поставщика) необходимо
исследовать, чтобы с высокой степенью уверенности утверждать, что изделия всей партии
обладают приемлемым качеством.
Допустим, что у вашей автомобильной компании есть поставщик поршневых
колец для небольших двигателей, и ваша цель — разработать процедуру
выборочного контроля поршневых колец в присылаемых партиях, обеспечивающую
требуемое качество.
Процедуры выборочного контроля применяются в том случае, когда нужно
решить, удовлетворяет ли определенным спецификациям партия изделий, не изучая
при этом все изделия.
Ш11. LB1IIIH.
Гистограмма средних
Г4Л16 |
Срад-74.0012 G4.0012) Сигма проц.-.009786 (.009754;
f^w^^^T\:
Эти продукты не удовлетворяют
требуемому качеству!
Выборки
Р*~«хо1 ,мах Сред- 022760 (.0227*0) Сигма-.008466 (.008455) г
Рис. 33. Х- и R-карты Шухарта для группированных данных
Вступительное эссе: приглашение к анализу данных на компьютере 37
В силу природы проблемы — принимать или не принимать партию изделий —
эти методы иногда называют статистическим приемочным контролем (acceptance
sampling).
Очевидное преимущество выборочного контроля над полным, или сплошным,
контролем продукции состоит в том, что изучение только выборки (а не всей партии
целиком) требует меньше времени и финансовых затрат. В некоторых случаях
исследование изделия является разрушающим (например, испытание стали на
предельную прочность), и сплошной контроль уничтожил бы всю партию.
Наконец, с точки зрения управления производством отбраковка всей партии
или поставки от данного поставщика (на основании выборочного контроля)
вместо браковки лишь определенного процента дефектных изделий (на основании
сплошного контроля) часто заставляет поставщиков строже придерживаться
стандартов качества.
Если взять повторные выборки определенного объема из совокупности, скажем,
поршневых колец и вычислить их средние диаметры, то распределение этих
средних значений будет приближаться к нормальному распределению с определенным
средним значением и стандартным отклонением (или стандартной ошибкой; для
выборочных распределений термин «стандартная ошибка» предпочтительнее,
чтобы отличать изменчивость средних значений от изменчивости изделий в
генеральной совокупности).
К счастью, нет необходимости брать повторные выборки из совокупности,
чтобы оценить среднее значение и изменчивость (стандартную ошибку) выборочного
распределения. Располагая хорошей оценкой того, какова изменчивость
(стандартное отклонение, или сигма) в данной совокупности, можно вывести выборочное
распределение среднего значения. В принципе этой информации достаточно,
чтобы оценить объем выборки, необходимый для обнаружения некоторого изменения
качества (по сравнению с заданными спецификациями).
Обычно технические условия задают некий диапазон допустимых значений.
Например, считается приемлемым, если значения диаметров поршневых колец лежат
в пределах 74,0 мм ± 0,02 мм. Таким образом, нижняя граница допуска для данного
процесса равна 73,98; верхняя граница допуска — 74,02. Разность между верхней
границей допуска (ВГД) и нижней границей допуска (НГД) называется размахом
допуска.
Простейшим и самым естественным показателем пригодности
производственного процесса служит потенциальная пригодность. Она определяется как
отношение размаха допуска к размаху процесса; при использовании правила 3 сигма
данный показатель можно выразить в виде
Ср = (ВГД - НГД)/F х сигма).
Данное отношение выражает долю размаха кривой нормального распределения,
попадающую в границы допуска (при условии, что среднее значение
распределения является номинальным, то есть процесс центрирован).
В книге Bhote A988) World class quality, New York: AM A Membership Publications
отмечается, что до повсеместного внедрения методов статистического контроля
качества (до 1980 г.) обычное качество производственных процессов в США
составляло примерно Ср = 0,67. Иными словами, два хвоста кривой нормального распре-
38
Вступительное эссе: приглашение к анализу данных на компьютере
деления, каждый из которых содержал 33/2% общего количества изделий,
попадали за границы допуска.
В конце 80-х годов лишь около 30% производств в США находились на этом
или еще худшем уровне качества (см. Bhote, 1988, стр. 51). В идеале, конечно, было
бы хорошо, если бы этот показатель превышал 1, то есть хотелось бы достигнуть
такого уровня пригодности процесса, чтобы никакое (или почти никакое) изделие
не выходило за границы допуска. Любопытно, что в начале 80-х годов японская
промышленность приняла в качестве стандарта Ср = 1,33! Пригодность процесса,
требуемая для изготовления высокотехнологичных изделий, еще выше; компания
Minolta установила показатель Ср = 2,0 как минимальный стандарт для себя (Bhote,
1988, с. 53) и как общий стандарт для своих поставщиков.
Заметим, что высокая пригодность процесса обычно приводит к более низкой,
а не к более высокой себестоимости, если учесть затраты на рекламацию,
связанную с низким качеством производимой продукции.
Как правило, более высокое качество обычно приводит к снижению общей
себестоимости. Хотя издержки производства при этом увеличиваются, но убытки,
вызванные плохим качеством, например из-за рекламаций потребителей, потери
доли рынка и т. п., обычно намного превышают затраты на контроль качества.
На практике два или три хорошо спланированных эксперимента, проведенных
в течение нескольких недель, часто позволяют достичь высокого показателя Ср.
В качестве одного из интересных примеров применения статистики в
промышленности отметим задачу классификации сортов бензина, решаемую с помощью
дискриминантного анализа.
Важная роль статистики в управлении экономикой США отмечена в статье:
Moynihan D. Р. A999) Data and dogma in public policy, J. American Statistical
Association, v. 94, № 446, p. 359-364: «статистика, — по словам автора, — помогает
понять силы, воздействующие на экономику». Без статистики трудно выделить
основные факторы, влияющие на экономику, и предпринимать шаги, позволяющие
минимизировать неблагоприятные флуктуации рынка.
Разнообразные задачи могут быть решены с помощью статистики на
региональном уровне, начиная с задач описательной статистики, например цен на
потребительском рынке продуктов питания, зависимости внутрирегиональных цен от цен
в соседних регионах, ввоза товаров из других регионов в пределах экономической
территории региона, доходов населения, описания рынка труда, уровня жизни,
экологической ситуации, здравоохранения и т. д.
Также могут быть решены задачи оценки технического состояния
транспортных средств города, расчет налоговых льгот для осуществления инвестиций в
транспортную систему, классификация объектов незавершенного строительства,
классификация должников, классификация источников выбросов загрязняющих
веществ и множество других, где до сих пор применяются эмпирические
правила.
Методы множественной регрессии позволяют исследовать рынок
сельскохозяйственной продукции. В качестве примера укажем статью Honma Masayoshi, Hayami
Yujioro A986) Structure of agricultural protection in industrial countries, J. Int. Econ.,
20, №1-2, p. 115-129, в которой исследована система протекции 10 индустриально
развитых стран и дан социально-экономический анализ коэффициентов регрессии.
Известно, что сельскохозяйственная политика индустриально развитых стран ха-
Вступительное эссе: приглашение к анализу данных на компьютере
39
рактеризуется сильными протекционистскими (защитными) мерами в отношении
собственных производителей, иными словами, создаются такие торговые
ограничения и система управления ценами, которые позволяют собственным
производителям находиться в заведомо выгодном положении. Система протекции включает,
в частности, экспортные налоги и завышенные обменные курсы валют. Следствие
такой политики — дискриминационное положение сельскохозяйственных
производителей развивающихся стран и неравномерное распределение продовольствия
в мире. Подобные методы можно, конечно, применить и к изучению российского
рынка.
Как и все математические науки, статистика родилась из практики. Подобно
тому как древние египтяне после разливов Нила вынуждены были заново
измерять свои участки и для этого разработали начала геометрии, так и современные
люди, вовлеченные в стремительно меняющиеся потоки данных (Интернет,
газеты, ТВ, слухи, сплетни, мнения экспертов и т. д.), вынуждены анализировать их.
Для этого попросту нет ничего иного, кроме статистики и анализа данных.
Классическая математика имеет дело с детерминированными величинами и
принципиально не приспособлена для работы со случайными данными. Конечно,
мы стремимся интуитивно сузить пределы случайности, максимально уменьшить
неопределенность, но сделать это полностью не удается.
По-видимому, случайность является важным элементом мироздания:
выброшенные в открытый хаотически меняющийся мир, мы вынуждены либо
приспосабливаться к нему и побеждать, либо погибнуть или влачить жалкое существование, не
понимая ни сущности вещей, ни событий, происходящих в нем.
Ни у кого не вызывает сомнения, что при строительстве дома следует
использовать начальные знания геометрии. Попробуйте точно начертить прямоугольник на
участке земли, и вы увидите, что сделать это не так просто.
Как проверить, что начерченный четырехугольник действительно является
прямоугольником? Если вы не знаете, что диагонали прямоугольника равны, то
столкнетесь с непростой задачей.
Точно так же при исследовании сложных систем, хаотических явлений и
потоков информации вы применяете статистику, в которой для измерения
случайностей разработаны как простейшие, но очень полезные инструменты, подобные
циркулю и транспортиру, так и весьма тонкие и совершенные методы.
Интересен следующий пример, приведенный Ж. Бертраном в его курсе
«Исчисление вероятностей»: Некто, прогуливаясь в Неаполе, увидел человека из Базили-
каты, который держал пари, что теперь же выбросит 3 шестерки, бросив 3 игральные
кости... Удивительный человек из Базиликаты на глазах изумленной публики сделал
это, а затем повторил фокус 2, 3, 4 и 5 раз подряд... «Черт побери, — воскликнул
Некто, — кости же, конечно, налиты свинцом!» — и был прав, потому что
наблюдаемое событие, бросить 3 кости 5 раз подряд и каждый раз получать 3 шестерки,
имеет ничтожно малую вероятность, равную (A/6) х A/6 х A/6))А5 = 4,71 х 101.
Другими словами, он имел лишь 471 шанс из 10 х 1012 ошибиться в своем
заключении. Заметим, что склонность использовать случай в свою пользу была
свойственна еще египетским фараонам, в гробнице которых обнаружены игральные кости со
смещенными центрами тяжести.
Классическим, и вместе с тем забавным, является пример шевалье де Мере,
когда ставший известным в веках благодаря своей любознательности, азартный
40
Вступительное эссе: приглашение к анализу данных на компьютере
игрок спросил себя: стоит ли ему ставить на выпадение двух шестерок
одновременно при бросании двух костей 24 раза или нет? Его собственные вычисления
показали, что стоит, так как вероятность данного события при 24 бросках костей
больше 1/2. Как же он удивился, когда с течением времени обнаружил, что
постоянно оказывается в проигрыше! Оскорбленный игрок во всем обвинил статистику.
И только знаменитый Паскаль нашел, в чем состоит ошибка игрока: оказывается,
вероятность данного события 0,49 (меньше 0,5!), следовательно, в длинной серии
игр, состоящих в 24 подбрасываниях двух костей, выигрыш происходит лишь в 49%,
а не в более 50% игр, как ожидал де Мере.
В STATISTIC А эта задача, то есть вычисление вероятности выпадения двух
шестерок, решается несколькими щелчками мыши.
Интересно, что не стоит делать ставку на выпадение двух шестерок при 24
бросках пары костей, но стоит это делать при 25 бросках, так как вероятность
выпадения хотя бы раз пары костей при 25 бросках больше 1/2, следовательно, в длинной
серии игр игрок, поставивший на две шестерки, будет в выигрыше чаще, чем в
проигрыше. Если бы правила игры были изменены и проводилось 25 бросков, то в
длинной серии игр де Мере оказался бы в выигрыше.
Конечно, теперь этот пример кажется забавным. Современное взаимодействие
статистики с практикой много изощреннее, но суть остается той же: применяя
статистические методы, вы должны найти устойчивые закономерности в случайных
данных и воспользоваться ими с пользой для себя.
Применение даже простых статистических методов позволяет добиться
эффектов там, где непосвященные опускают руки.
Одной из таких задач является пересчет голосов при голосовании.
Предположим, что в ходе выборов один из кандидатов уступил другому несколько десятых
процентов голосов. Так как разница очень небольшая, то потерпевший неудачу
может усомниться в правильности подсчета и поставить вопрос о пересчете. Если
пересчет подтвердит результаты голосования, то, по закону, ему нужно будет
оплатить расходы, связанные с пересчетом. В противном случае он окажется
победителем. Формально, на языке статистики, эта задача сводится к проверке гипотезы о
неравенстве математических ожиданий двух биномиальных величин, см.
например, работу, Harris Bernard A988) Election recounting, Amer. Statis., 42, № 1, p. 66-68.
Для кого эта книга?
Книга рассчитана на самый широкий круг читателей, для которых важен анализ
данных: статистиков, экономистов, маркетологов, аналитиков, актуариев,
бизнесменов, инженеров, лиц, принимающих решения, и многих других.
Иными словами, она полезна тем, кто интуитивно понимает, что из анализа
данных можно извлечь реальную пользу. Всех их мы хотим научить искусству анализа
данных на компьютере.
Она также чрезвычайно полезна врачам, инженерам, научным работникам,
преподавателям и студентам.
Разбираемые нами примеры охватывают самый широкий спектр приложений.
Предлагаемая книга является синтезом двух частей: описания разнообразных
статистических методов — от элементарных понятий и принципов до возможных
Вступительное эссе: приглашение к анализу данных на компьютере
41
конкретных приложении, и описание анализа данных с помощью этих методов в
системе STATISTIC А в среде Windows и отражает многолетний опыт автора в этой
области.
Система STATISTICA включает в себя все известные методы статистического
анализа данных и позволяет сделать процесс анализа высокотехнологичным.
Методы, известные ранее по учебникам и научным публикациям, теперь доступны всем.
В книге содержится подробное описание основных возможностей системы
STATISTICA, описаны основные диалоговые окна и команды системы. Особое
внимание уделено новой технологии компьютерной обработки данных, максимально
совмещенной со стандартами Windows.
STATISTICA позволяет реализовать системный подход к анализу данных, в
частности, средствами STATISTICA можно создать свои модули анализа данных
(см. рис. 34). Дополненные методами визуального программирования, эти
средства открывают захватывающие перспективы.
Каждая глава книги наряду с примерами содержит большой справочный
материал. Книга написана в двух срезах — для неподготовленного пользователя,
впервые знакомящегося с методами анализа, и для тех, кто имеет специальную
математическую подготовку и опыт работы на компьютере.
Начнем мы с изложения элементарных понятий. Вообще эти понятия следует
разделить на два класса: понятия, относящиеся собственно к статистике, и
понятия, относящиеся к анализу данных. И здесь есть некоторая тонкость. В
статистических исследованиях, например в эконометрике (приложении методов статистики
в экономике), мы исходим из априорной экономической модели и пытаемся
оценить ее параметры. Это так называемый дедуктивный подход, в котором первична
модель, а данные используются для оценки неизвестных параметров и проверки
различных гипотез относительно модели. Здесь возникают понятия качества.оце-
нок, уровня значимости и т. д.
ЕЗЗШ
^я^явичшшвшмя.
Панели инструментов КНОПКИ АВТОЗАДАЧ
Панелям инструментов
КНОПКИ АВТОЗАДАЧ
можно присваивать
различные задачи,
от простых,
таких, как выбор
переменных или
добавление
комментариев,
до самых
сложных,
например, длинные
последовательности |
многозадачных
процедур...
ррррш
Рис. 34. Настройка STATISTICA на конкретный проект
42
Вступительное эссе: приглашение к анализу данных на компьютере
В анализе данных мы желаем исходить из данных как таковых, имея
минимум априорных идей относительно их структуры. Далее мы стремимся понять,
как организованы данные, какие переменные или группы переменных связаны
(коррелируют) между собой, иными словами, стремимся понять структуру данных,
исходя из них самих. Наиболее известная крайняя точка зрения этого подхода
выражена в лозунге Бензекри (Benzecri), одного из создателей анализа
соответствий: «Модель должна соответствовать данным, а не наоборот!» Насколько
правомерен такой подход, судить философам, но он существует и его нельзя отвергать.
Приверженцы анализа данных зачастую критикуют эконометрику, утверждая,
что она имеет дело с абстрактными гипотезами, которые никогда не работают на
практике.
В действительности, между этими направлениями нет бездонной пропасти —
известно, что анализ данных черпает свои идеи из классической статистики и
наоборот. Типичный пример — анализ соответствий, чисто индуктивный метод,
корни которого «тем не менее» лежат в математической статистике и свойствах
знаменитого критерия хи-квадрат, открытого Карлом Пирсоном.
Рис. 35. Рабочие окна STATISTICA
Пример индуктивного подхода можно найти в интересной статье F.-X. Micheloud,
бывшей долгое время доступной на сайте http://www.micheloud.eom/FXM/cor/e/genera.htm,
Вступительное эссе: приглашение к анализу данных на компьютере
43
где разведочный анализ данных (анализ соответствий) применяется к
исследованию уровня образования жителей Лозанны (Швейцария). Автор, не используя
прямо статистические рассуждения, работаете выборкой из 169 836 человек.
Спрашивается, а почему не с выборкой, состоящей из 100 человек? Очевидно, что для него
интерес представляют перманентные, или устойчивые, выводы. Но понять, с какой
выборкой нужно иметь дело, можно лишь с помощью теоретико-вероятностных и
статистических рассуждений.
В данной книге мы стремились синтезировать классические методы статистики
с методами анализа данных и таким образом открыть новые возможности для
исследователей.
Лейтмотивом нашей книги является утверждение, что невозможно умозрительно
научиться анализу данных. Если вы хотите овладеть анализом данных, вам следует
совместить основные принципы анализа данных с работой в системе STATISTIC А.
Ключевым является понятие технологии, совмещение идей (коуос,) с действием
(xexvaco), иными словами, вы не просто мыслите, но и производите с помощью
компьютера действия, которые усиливают и развивают ваши мысли.
Мы трактуем нейронные сети как развитие классических методов анализа.
Основное отличие состоит в том, что в нейронных сетях используется
специальный базис исходных функций, и собираются сложные многомерные зависимости
из элементарных одномерных функций, реализуемых нейронами. Таким образом,
вы можете использовать нейронные сети для построения сложных нелинейных
зависимостей или нелинейных классификаций, которые недоступны другим методам.
Формально нейронные сети могут быть изложены чисто математически, без
привлечения понятия нейрон, однако биологический язык и нейронная интерпретация
создают новую реальность, открывающую массу возможностей для исследователя.
Математическим основанием нейронных сетей является знаменитая теорема
Колмогорова, утверждающая, что сложные нелинейные функции могут быть
собраны на двухслойных или трехслойных сетях персептронов. В частности, если
нужно приблизить непрерывную /2-мерную функцию, то достаточно сети с одним
скрытым слоем, содержащим 2п + 1 нейрона. Никто не утверждает, что вам
удастся быстро построить нужную сеть, которая хорошо приближает сложную
зависимость на имеющихся реальных данных, однако заведомо невозможно сделать это
чисто умозрительно. Используя компьютерные технологии, вы можете испытать
как классические методы анализа, так и нейронные сети.
В нашем изложении мы опирались на фундаментальные тексты Кендалла М. Дж. и
Стьюарта А., особенно на их замечательную книгу Статистические выводы и связи.
М.: Наука, 1973.
Для описания функций распределения мы использовали фундаментальное
издание: Вероятность и математическая статистика, М.: Большая российская
энциклопедия, 1999.
В ряде случаев нам оказались полезными справочники:
Айвазян С. А., Енюков И. С, Мешалкин Л. Д. Прикладная статистика: основы
моделирования и первичная обработка данных. М.: Финансы и статистика, 1983.
Справочник по прикладной статистике под редакцией Э. Ллойда и У. Ледерма-
на, т. 1,2. М.: Финансы и статистика, 1989.
На этом позвольте закончить наш, возможно, слишком продолжительный
экскурс в анализ данных и перейти к систематическому изложению материала.
1 Краткая экскурсия
по системе
STATISTICA
Вступление
STATISTICA — это интегрированная система анализа и управления данными.
STATISTICA — это инструмент разработки пользовательских приложений в бизнесе,
экономике, финансах, промышленности, медицине, страховании и других областях.
STATISTICA легка в освоении и использовании.
Все аналитические инструменты, имеющиеся в системе, доступны
пользователю и могут быть выбраны с помощью альтернативного пользовательского
интерфейса. Пользователь может всесторонне автоматизировать свою работу, начиная
с применения простых макросов для автоматизации рутинных действий вплоть до
углубленных проектов, включающих, в том числе, интеграцию системы с другими
приложениями или Интернетом. Технология автоматизации позволяет даже
неопытному пользователю настроить систему на свой проект.
Процедуры системы STATISTICA имеют высокую скорость и точность вычислений.
Гибкая и мощная технология доступа к данным позволяет эффективно работать
как с таблицами данных на локальном диске, так и с удаленными хранилищами данных.
Система обладает следующими общепризнанными достоинствами:
О содержит полный набор классических методов анализа данных: от основных
методов статистики до продвинутых методов, что позволяет гибко
организовать анализ;
О является средством построения приложений в конкретных областях;
О в комплект поставки входят специально подобранные примеры,
позволяющие систематически осваивать методы анализа;
О отвечает всем стандартам Windows, что позволяет сделать анализ
высокоинтерактивным;
О система может быть интегрирована в Интернет;
О поддерживает web-форматы: HTML, JPEG, PNG;
О легка в освоении, и как показывает опыт, пользователи из всех областей
применения быстро осваивают систему;
О данные системы STATISTICA легко конвертировать в различные базы
данных и электронные таблицы;
О поддерживает высококачественную графику, позволяющую эффектно
визуализировать данные и проводить графический анализ;
Вступление
45
О является открытой системой: содержит языки программирования, которые
позволяют расширять систему, запускать ее из других
Windows-приложений, например, из Excel.
STATISTICA состоит из набора модулей, в каждом из которых собраны
тематически связные группы процедур. При переключении модулей можно либо
оставлять открытым только одно окно приложения STATISTICA, либо все вызванные
ранее модули, поскольку каждый из них может выполняться в отдельном окне (как
самостоятельное приложение Windows).
При исполнении модулей STATISTICA как самостоятельных приложений в
любой момент времени в любом модуле имеется прямой доступ к «общим» ресурсам
(таблицам данных, языкам BASIChSCL, графическим процедурам).
ш % ш © ш
Алели» Н«чр*м*гри*скм/ Wnptt/WHMt Ф«*тор»»* К/чстч»»*
МШИМвМОСТМ Р*СЛр*0*Л*НИЙ ДЫМНЫМИ «И«ЛИЭ «И4/МЭ
При инсталляции системы программа установки (Setup) создает на рабочем столе
группу приложений под названием STATISTICA и помещает туда значки окна
Переключатель модулей (пиктограмма STATISTICA — первая в группе, см. рис.),
модуля Основные статистики и таблицы и некоторых других программ (Help, Setup).
Пользователю может показаться более удобным запускать модули, щелкая по их
значкам на рабочем столе (вместо того чтобы пользоваться окном Переключатель
модулей); поэтому он, вероятно, захочет создать дополнительные пиктограммы для
модулей помимо тех, которые будут автоматически созданы программой установки
(Setup). Для того чтобы создать еще один значок в данной группе, следуйте
стандартной процедуре Windows (выберите пункт Новый в меню Файл в окне Диспетчер
программ (Program Manager) и создайте новый программный элемент).
Настройка системы STATISTICA. В системе предусмотрена возможность
настройки множества характеристик и интерфейса программы в соответствии с пред-
46
Глава 1. Краткая экскурсия по системе STATISTICA
почтениями пользователя. Можно изменить, например, процесс запуска, а именно —
отменить установленный по умолчанию полноэкранный режим, изменить вид
стартовой панели, панели инструментов, таблиц с данными и другие параметры.
Настройка общих параметров системы. Настройку общих параметров системы
можно изменить в любой момент работы с программой. Эти параметры определяют:
О общие аспекты поведения программы (максимизация окна STATISTICA при
запуске, Рабочие книги, инструмент Перетащить и отпустить — Drag-and-
Drop, автоматические связи между графиками и данными, многозадачный
режим и т. д.);
О режим вывода (например, автоматическая распечатка таблиц или графиков,
форматы отчетов, буферизация и т. д.);
О общий вид окна приложения (значки, панели инструментов и т. д.);
О вид окон документов (цвета, шрифты).
Каждый из этих параметров можно настроить в соответствующем окне, доступ
к которому осуществляется через меню Сервис. На следующих рисунках показаны
два примера таких окон.
ШгЩ
3
jTafeP***^!5
'Сядем доимы* пмймяиь (мм
Ог«г. гр9тшМ:\Авгго
: Поль* грщ*тшг.\Аягго
Щ
Л
Гр»»н*мШЦАато
ш$г$
'!ШМшШШ^
\ V Отмечяг» Рцйшри щтг%.
"**ШМ
\ Г" Соцттгь нашили* ^льпуооь^Щ.
Помцить сойм* яау 8 |
-•?'f*;"""' :,-А • -• -
(^Л «ТЯГ « .
^*Ж*
Йс]Эмпмр. ФР со срсмимм
"- ,-,frfift>t Г,-,л,„-„ Vftrt^.i,
И
Вступление
47
Все общие параметры могут быть настроены независимо от типа окна документа
(например, таблица или график), которое активно в данный момент.
Настройка пользовательского интерфейса. При работе с системой STATISTICA
имеется возможность настройки пользовательского интерфейса программы таким
образом, чтобы он стал более «продуманным» с точки зрения потребностей
конкретного пользователя.
В зависимости от требований задачи и личных предпочтений (а также
эстетических соображений) можно использовать разнообразные «режимы» и условия
работы программы.
48
Глава 1. Краткая экскурсия по системе STATISTICA
Поддержка нескольких различных конфигураций системы STATISTICA. До
внесения специальных изменений STATISTICA будет хранить все текущие
настройки и параметры по умолчанию.
То обстоятельство, что сведения о конфигурации системы хранятся в той же
папке, из которой вызывается программа STATISTICA, позволяет иметь в своем
распоряжении различные варианты конфигурации программы для разных
проектов или видов работ. Например, можно вызывать программу из разных папок на
диске, каждая из которых содержит определенный связный набор документов, и
для каждой из этих папок система может быть сконфигурирована со своими
настройками вывода, параметрами графиков по умолчанию и т. д. Можно создать
несколько значков STATISTICA в разных группах приложений на рабочем столе
Windows (каждая из которых соответствует определенному проекту или виду
работ) и задать для них различные значения в поле Рабочая директория {Working
Directory) (с помощью диалогового окна системы Windows Свойства программного
элемента {Program Item Properties)).
Многозадачность. STATISTICA поддерживает режим многозадачности
(между своими модулями или другими приложениями).
При обработке очень больших объемов информации или выполнении сложных
процедур анализа можно переключиться в другой модуль STATISTICA (или
другое приложение Windows), используя возможность вести процесс обработки
данных в фоновом режиме.
Работа в одном окне приложения STATISTICA (вместо многооконного
режима). Один из вариантов глобальной системной настройки пакета STATISTICA
позволяет пользователю задать режим, в котором по умолчанию будет работать про-
Вступление
49
грамма — в одном окне приложения или же как набор приложений (каждое в
своем окне). Одним из непосредственных следствий этого выбора будет то, в каком
режиме будет работать окно Переключатель модулей: при двойном щелчке на
имени модуля в этом окне выбранный модуль будет открываться либо вместо уже
открытого, либо для него будет открываться новое окно приложения, причем
предыдущее окно останется открытым.
Выбор того или другого режима работы производится в поле Переключение
модулей: режим одного приложения в диалоговом окне Параметры по умолчанию:
общие настройки (вызывается из меню Сервис). Если это поле отмечено, STATISTICA
будет работать в режиме одного приложения.
Режим одного приложения. При выбранном режиме одного окна приложения
переключение с одного модуля на другой будет происходить без открытия новых
окон. Новый модуль всякий раз будет открываться в том же самом окне, заменяя
предыдущий. Некоторые пользователи предпочтут именно такой «простой* режим
работы, поскольку весь анализ будет происходить в одном окне приложения, а
количество активных программ на рабочем столе будет минимальным.
Примерно такого же эффекта можно достичь, нажимая кнопку Закончить и
переключиться в диалоговом окне Переключатель модулей; при этом окно
приложения текущего модуля закроется, но не будет заменено новым окном; вместо этого
система откроет «следующее* окно приложения.
Режим нескольких приложений. Основное преимущество режима нескольких
приложений — возможность параллельного выполнения различных процедур
анализа (модули) в разных одновременно открытых окнах приложения. При этом мож-
50
Глава 1. Краткая экскурсия по системе STATISTICA
но переключаться между модулями, не закрывая предыдущие, и использовать все
преимущества работы с независимыми очередями таблиц результатов и графиков
для окон приложений разных модулей. Этот режим имеет очевидные
преимущества для большинства задач анализа данных и дает возможность использовать
различные методы анализа (и сравнивать полученные результаты).
Интерактивный анализ данных в STATISTICA. Система не требует, чтобы
пользователь еще до проведения анализа указал всю информацию, которую
следует вывести на экран. Ведь анализ даже простого плана может породить
большое число таблиц результатов и просто необозримое количество графиков,
поэтому при проведении реального анализа, до изучения основных результатов,
трудно представить, какие графики или таблицы следует анализировать в
первую очередь. Именно поэтому STATISTICA предоставляет пользователю
возможность выбрать определенные типы вывода и интерактивно провести
последовательные сравнения и моделирующий анализ уже после того, как данные обработаны
и получены основные результаты.
Количество выводимых окон также может быть настроено, чтобы не
перегружать экран компьютера.
Гибкие вычислительные процедуры STATISTICA и широкий выбор методов
графического представления данных любого типа открывают перед пользователем
безграничные возможности проведения разведочного анализа и проверки
статистических гипотез.
Какие возможности предоставляют рабочие книги. Рабочие книги помогают
организовывать наборы файлов (например, таблиц результатов, графиков, тек-
Вступление
51
стовых/графических отчетов, пользовательских программ и т. д.), которые были
созданы или использовались (например, просматривались) во время анализа
набора данных. Рабочие книги хранят список всех файлов, использовавшихся с
текущим набором данных.
Ш'ШИ
МЕШ
Строка
А dvetlising Effectiveness Study.
днформевлд о фвтидв ы примечания; ■.
мыт ленные данные. полученные при изучении
I рек ламы. Респонденты мужского и женского пола
отвечали на 23 вопроса, оценивая эффективность
Iрекламы по десятибалльной @-9) шкале. Данные
были собраны в мае и июне 1993 г. на территории
университета.
АвТО <•.••"•"• ■ ••■• ••• •-'"-. J-
Д Щ Файлы т*кут«* Рабочей книги: Цчереаь. |8 h
В
Ы!
Нашм*гвО|М;г<*
угобы начать. е>.
новой сгрокн
Нажмите СьИаЬ,
чтобы вставить
ID
0
D
D
0
D
0
C:\stat5\data\fiist100. sel
□ C:\stat5\data42d_gjaph.stg
□ C:\stat5\data\poly5.txt
C:\stat5\data\distibs.Mf я
□ C:\stat5\data\blank.stg
□ C:\stat5\eica«ples4hippo1.stg
□ C:\stat5\eigenval. stb
табуляции.
& Охкрмть
Кнопки 'Добавить*'
иУдв/мп»'
иамвнжтт список
Файлов Раб книги
Обновленный список этих файлов автоматически сохраняется с файлом
данных. Если поставить пометку в поле Авто Щ около имени файла, то он будет
автоматически открываться с текущим набором данных.
Ц«й* Омы» 8м Йсцлм .fmmn* &m*m.tp*m*■■&*»■.&** №■'
■ ■|Д|»1
ОСНОВНЫЕ
СТ4ТИСТ
.wfflSr
т&шл
.^«НЯвкС
\ 'ЯмПМг'
■>iauamii
1 00
- 17
- 19
- 04
- 08
02
26
05
•- 77
- 04
- 15
04
'№&*Г№*т<\ jbaww) щ
52
Глава 1. Краткая экскурсия по системе STATISTICA
Справочная система и интерактивное (электронное) руководство. Чтобы
получить дополнительную информацию о некоторых функциях системы, нажмите
клавишу справки (F1), когда выделена соответствующая команда или пункт меню.
STATISTICA содержит Электронное руководство — справочную информацию по
всем процедурам и функциям программы, доступную в контекстно-зависимом
режиме при нажатии клавиши F1 или кнопки справки |Щ в строке заголовка всех
диалоговых окон (справочник содержит свыше 10 мегабайт документации в сжатом
виде). Благодаря динамической организации Электронного руководства с помощью
гиперссылок (и различным возможностям его настройки), как правило, быстрее
использовать эту справочную систему, чем искать нужную информацию в
напечатанном виде. Справку также можно вызвать двойным щелчком на поле сообщений
строки состояния в нижней части окна приложения STATISTICA (в поле
сообщений тоже отображаются краткие комментарии о функциях выпадающих
меню или кнопках панели инструментов соответственно при выделений пункта
меню или нажатии кнопки).
Статистический советник. Статистический советник представляет собой
интерактивную справочную систему. После выбора пункта Советник из
выпадающего меню (Справка) программа задаст вам несложные вопросы о характере
решаемой проблемы и типе исходных данных, а затем предложит список наиболее
подходящих процедур (и объяснит, где их найти в системе STATISTICA).
; В эееисимости от ваших ответов на вопросы j сущности вашего исследования
j Ст*тисггшчфский сотпти* предложит им подходящи! статистически!
методы и их месгонехождение е системе STATISTICA Отвечайте не каждый
! вопрос, щелкая не соответствующем ответе. Если вы не уверены, кекой ответ
1 выбрать, щелкните не строке Допоптмш>ьн»я информации
j Вы котите
О) ОпииУь.щипачуiihflmn;> Дяпп-wi
B) Пвмци'ь mnamn imwywhri тктлъп мишл.
C) М1ЙТИ М<Г^йЫ,Ш^т^*Г<,й*MAi.ltUV. или
D) Вырулит» сшч1бгигл1 ж пвсмушлщнагаманшалп кати»?
-mi
Дополнительная информации
Если денные только что собрены, то сначала следует посмотреть соответствующие
итоговые статистики для каждой переменной Непримвр. нужно посчитать
респрвдаления частот, чтобы определить иийрссм.
Обычно денные собиреются, чтобы проварить определенные гипотезы или модели,
саманные с несколькими переменными Непримвр, можно выяснить, чаще ли
мужчины соглешвются с каким-либо вопросом енкеты. чем женщины Более
сложные гипотезы могут касаться зависимости параманных. например, линейная
она или нет
Если конкретных гипотез нет, в изучение проводится с исследовательскими
целями, то можно использовать некоторые приемы, которые помогут "прояснить'
денные, то есть нейти кластеры, шеблоны. и т д
Четвертая опция (контроль качества) показывает различные приемы, использувмыа
в промышленном контроле качестве, зксперимвнтах и енвлиза надежности
С помощью гиперссылок можно непосредственно перейти из раздела
Статистический советник к подробному описанию соответствующих статистических
методов и процедур в разделе Вводный обзор.
Мультимедийный учебник. CD-версия STATISTICA включает ряд
анимационных примеров, иллюстрирующих некоторые из наиболее часто используемых
возможностей STATISTICA. Эти примеры шаг за шагом показывают, как провести
типичный статистический анализ и построить графики. Полный список имеющихся
Вступление
53
в данной версии системы мультимедийных обзоров находится в подменю
Мультимедийный учебник выпадающего меню {Справка).
:. ±*я Qpwm fim А"»*> Ср»им £«жс-: fl*xo *■ '
Они» мхом tt*t**# t**t*tmo* й Г0»»иц4
Отофдаим» и tmmmm тёкшими «wxowft м t*etm
Неюл Пкжыат* и оглуетмгь и А*г«э#«»чю«
Иопо% whmhm fr+Дочий ммги
Г***** пофммгмдем*. егагяегмчкям*. вмомы»
Н«стро*«ими*»«и»гр*Фи«)» s
Р«амещ«ии> wwmh» rp—i»o»
Кмпш aero****
Ял« 3UT»TJCA«A$iC
Я»* Sa (К» »фшЛ lOMt STATIST КЛ|
быстры» «мам*» етлчстиш. Ucmsmi выбор* иаблам»*
6«жооь« ст«тмс*икм и грмики
: Зя^мгдодмервмиияиаиьм*»
Прмамвск. митр** мрр*и«мй fatftttf
Прммкг Дисперсно*»* »«ми»ДООД)
Пр»«р- iWptMh»i«eHrpa»HUN»c»»»
При *р: йлшю npcmoeo»
ГцИ#4(^ ПрОММИМ94МГЛ1ММфСФФМ1 )КСтрммВМГ09 * ЧКТЬ I
П<»»^»Пра>1»м1Д>««пл»1»о»»|1>»кеп1»1ла»к»«ч»ст>г
Отметим, что для запуска этих мультимедийных иллюстраций необходима
звуковая карта. Если ваша версия STATISTICA не содержит мультимедийный
учебник (или содержит лишь часть примеров), вы можете загрузить соответствующие
файлы из Интернета (http://www.statsoft.com) или заказать их в компании StatSoft.
Приложения. Все рассмотренные возможности (доступные в любой момент
работы с системой) могут служить весомой альтернативой или дополнением к
обычному интерактивному пользовательскому интерфейсу, поскольку они позволяют
автоматизировать рутинный процесс многократного выполнения одних и тех же,
в том числе весьма сложных, задач. Например, макрокоманда (вызываемая
щелчком мыши по кнопке на панели инструментов Кнопки автозадач или одним
нажатием клавиши) может содержать длинный список переменных, часто используемый
график, операцию внедрения и т. п.
Автоматические отчеты и автоматическая распечатка таблиц результатов.
Независимо от того, происходит ли обработка в пакетном режиме или интерактивно
запрашивается пользователем, может быть выбран режим вывода Автоотчет. Этот
режим позволяет автоматически, без каких-либо действий со стороны
пользователя распечатывать (или направлять в окно отчета или в файл) содержание всех окон
вывода, которые получаются в процессе анализа.
Режим автоматического вывода каждой строящейся на экране таблицы
результатов и/или графика может оказаться полезным не только для создания полного
54
Глава 1. Краткая экскурсия по системе STATISTICA
отчета о результатах анализа, но и при разведочном анализе данных, когда
возникает необходимость вернуться к предыдущему шагу и просмотреть результаты,
полученные на ранних этапах обработки данных. Для этого всю выходную
информацию (таблицы результатов и графики) можно направить во временное Окно
текста/вывода с прокруткой и уже затем в случае необходимости сохранить ее,
распечатать или скопировать в файл текстового редактора.
Автоматическая печать графиков. Режим автоматической печати всех
возникающих на экране графиков особенно полезен как средство пакетной графической
печати.
It i) \мл1*лн1 гимн hi» ИРчЕЗ
ь(ЖАШ&№,)&;.Ш8а*ЯЬ&
Описательные статистики (adstudy.sta)
Дммы* AO8TU0Y STA 2вп ' 90м
AdvartMng Ef f «divan*** 9u**y
fen** AOSTUOY 8TA 26n ' 60h
Adwrtemg ЕМвоНмпм* Study
|Переменная N иабл. Среднее Нинимум Накскнум Стд.откл.
HEA3UR1
HEA5UR2
HEA5UR3
HEASUP4
HEASUR5
50
50
50
50
50
5.900000
4.540000
4.140000
5.520000
Э.960000
0.00
0.00
0.00
0.00
0.00
9.000000
9.000000
9.000000
9.000000
9.000000
2.366863
2.887058
2.725615
2.659139
2.633846
* ^06 т uoy б та га^зд
у • в 232-2 0ЭВ*х*О в22'**20 1 Уж^ЭЮ 001 **»О.0О1 'х*в**р«
Как правило, печать графиков занимает довольно много времени. Поэтому
имеет смысл воспользоваться этим режимом для распечатки последовательности
(«каскада») графиков, получающихся при применении определенных методов анализа
(например, для зрительного представления конфигураций средних при
исследовании связей высших порядков в дисперсионном анализе необходим^ длинная
последовательность графиков, а для многомерных таблиц — каскад трехмерных
гистограмм для двух переменных).
Однако гораздо эффективнее направить создаваемую последовательность
графиков в Окно текста/вывода. В STATISTICA предусмотрена возможность
пакетной печати всех ранее сохраненных графиков и таблиц результатов; для этого
нужно выбрать пункт Печать файлов в выпадающем меню Файл.
Буфер обмена. Наиболее быстрый и во многих случаях наиболее простой
способ получения данных из других приложений Windows (например, электронных
таблиц) — это использование буфера обмена, который в STATISTICA
поддерживает специальные форматы данных, создаваемые такими приложениями, как MS Excel
или Lotus для Windows. Например, STATISTICA правильно интерпретирует
форматированные (например, 1 000 000 или $10) и текстовые значения. Буфер обмена
и преобразование файлов данных можно также использовать для экспорта данных
из системы STATISTICA в другие форматы. При импорте и экспорте данных
STATISTICA использует один и тот же набор форматов и типов данных.
Вступление
55
Функции импорта файлов. Файлы данных из приложений Windows и других
операционных систем также можно переводить в формат системы STATISTICA
с помощью функций импорта файлов, которые включают доступ ко всем базам
данных (через поддержку метода ODBC), а также возможности импорта
форматированных текстовых файлов и текстовых файлов свободного формата (ASCII).
Импорт файлов без использования буфера обмена имеет свои преимущества:
О он позволяет пользователю точно указать, как должен проводиться импорт
(например, выбирать из файлов диапазоны значений, импортировать или не
импортировать имена переменных, текстовые значения и имена наблюдений
и указывать способ их интерпретации);
О он предоставляет пользователю доступ к типам данных, которые
недоступны (или труднодоступны) при операциях с буфером обмена (например,
длинные метки значений или специальные коды пропущенных данных).
Связи DDE. STATISTICA поддерживает соглашения динамического обмена
данными (DDE), что позволяет динамически связывать диапазон данных в таблице
исходных данных с набором данных других приложений (Windows). Эта процедура
на самом деле гораздо проще, чем она может показаться, и ее легко освоить, не имея
технических знаний о механизме DDE, особенно при использовании команды
Установишь связь (вместо ввода описания связи). Связи DDE (динамического обмена
данными) можно установить между файлом-источником (сервером), например
электронной таблицей MS Excel, и файлом данных системы STATISTICA
(файлом-клиентом), так что при внесении изменений в файл-источник данные в
соответствующей части таблицы исходных данных STATISTICA (файле-клиенте)
будут автоматически обновляться.
56
Глава 1. Краткая экскурсия по системе STATISTICA
Обычно два файла динамически связываются в промышленных установках,
когда к последовательному порту компьютера, на котором находится файл данных
системы STATISTICA, подключено измерительное устройство (например, для
ежечасного автоматического обновления определенных измерений).
Связи DDE можно установить с помощью команды Установить связь
выпадающего меню Правка таблицы исходных данных или введя определение связи в
поле Длинное имя (метка, формула, связь): диалогового окна спецификаций
переменной.
ГГГх!
g^|JMEASUR1
^ 1>4рмн* ero*6.;J4 Щ 'Две.
!,\ ^.Л*.J\.v,.w.. v?T \/ ...<-^ Отмена
Дата
Время
Денежный
Проценты
Представление:
il'iliBUiliTT
1 000; -1 000
1000; A000)
1 000; A 000)
3h»l/cttwct^
ШО £р*Фики|
Данное имя {мипгк*. мм» или Формул* с Фшжцнямм}):
eExcel|c.\adiesultxls!r10c10:г40с15
ЕЗ
Id
Лря wptr Мет** Валовой «анод ь 199V Формулы *vt + v2:
С*»* фе>ссе|с:т*Ыг2<£:*«с4 = * Jvl>0ГА6С ♦ v3
Если связь установлена, то можно управлять ею в диалоговом окне Диспетчер
связей (вызывается с помощью команды Связи... выпадающего меню Правка).
111Щ'1ДН;1
шщ
Доносить сейчас!
Отменит*
Обновление» Лв1 pnbi ичоскоо
Нэменнт* сеяэ* 1
Форматы Дата и Время. В файлах данных системы (которые организованы
как базы данных) формат отображения значений применяется ко всей переменной,
а не к отдельным ячейкам (как в Excel). Поэтому значения, которые в Excel были
отформатированы как даты, в файле системы STATISTICA будут отображаться
как юлианские (целые) значения (например, 34092 вместо May 3, 1993), если для
соответствующих переменных не установлен формат Дата или Время.
Поддерживает ли STATISTICA интерфейс ODBC? Да, для того чтобы
реализовать эту возможность, существует список команд Импорт данных, который
вызывается из выпадающего меню Файл любого модуля. Интерфейс ODBC
STATISTICA включает возможности для объединения полей из нескольких
таблиц и предоставляет доступ к множеству файлов баз данных, включая форматы
больших и персональных компьютеров (например, dBASE для Windows, Paradox,
Sybase, Oracle, SAS и т. д.).
Вступление
57
IIWW'iPHIfflll
ЧМ
-ii-i
ВС
В С«м(«
Dl
В Didw DeUfa
D Ordeti
нпшнп
DSbpp«i
Ds
D
С«1«домт Ceiegotj ID
CeiegniM Омафйоп
Cwto—ti.Curt—t ID
Oid*t D*(«k.Pioduct ID
Oidw 0«шЬ Urn» Price
Oidw D*4«U QiunMy
$*
e»JMU«*C*Mb*
t«ll*
■-^^^^
leSSJtf
Щ^Ц/
Импорт через ODBC можно автоматизировать с помощью функции
ODBC/Шаблоны или программ на языке SCL.
Типы объектов. Если задан режим Новый объект, то тип создаваемого объекта
может быть выбран из списка приложений Windows, которые поддерживают
средства OLE. После выбора типа и нажатия кнопки ОК будет открыто окно
соответствующего приложения для создания нового объекта. Если задан режим Объект из
файла, то тип объекта для вставки также выбирается из списка приложений
Windows, поддерживающих средства OLE; после выбора типа будут показаны все
предварительно сохраненные файлы этого приложения. В режиме Картинка из
файла можно вставить объект, несовместимый с методом OLE, но записанный в
одном из графических форматов Windows: в формате метафайла (файл с
расширением *.wmf) или растрового изображения (файл с расширением *.Ьтр).
■ .IDJXlj
ПРОИЗВОДСТВО ВЕРТОЛЕТОВ
Связывание и внедрение. STATISTICA поддерживает средства OLE
(связывания и внедрения объектов) как в режиме клиента, так и в режиме сервера. Таким
образом, возможна не только динамическая настройка графиков STATISTICA в
других приложениях (режим сервера), но также внедрение и последующее
преобразование 01£-совместимых объектов других приложений (например, графиков
или таблиц) или собственных объектов в графики STATISTICA. Другими
словами, помимо присоединения внешних элементов к графикам STATISTICA с
помощью вставки можно обращаться непосредственно к объектам, содержащимся в
файле на диске (например, перетащить их непосредственно из окна Диспетчер
файлов или Проводник (Windows Explorer) и поместить на график STATISTICA).
58 Глава 1. Краткая экскурсия по системе STATISTICA
STATISTICA поддерживает как связанные (то есть динамически
присоединенные), так и внедренные (то есть статически «встроенные») объекты. При этом они
могут быть расположены в любом файле, созданном приложениями Windows,
включая файлы в собственном графическом формате STATISTICA (с расширением *.stg).
Более того, STATISTICA одновременно может являться как клиентом, так и
сервером в методе OLE, поддерживая при этом уникальную возможность создания
вложенных составных документов (до четвертого порядка включительно), то есть
документ STATISTICA с внедренным документом может быть, в свою очередь,
внедрен в другой документ этой системы.
Заметим, что каждый из этих двух способов присоединения {связывание и
внедрение) имеет свои преимущества и недостатки.
Связанные объекты. Графики со связанными объектами медленнее
перерисовываются, поскольку при этом могут быть задействованы связи с внешними
файлами. В то же время, эти графики обновляются автоматически (статус связей
может быть установлен в диалоговом окне Связи данных и графика, которое вызывается
из графического меню Правка), а это позволяет легко создавать составные
документы, которые включают именно «текущее» содержимое других файлов.
шшшшшшшшшшшшшшшшшшшшшщ
гтшштшхЕтхтшшшшшшшшш j fllc »
' [Авто Гра*м*1: Диаграмма размана Л •'• | I
I Ойщтть с*Лчшс \
I Щматсг» стлль [.
I Орвраат» отяа» [
Г ГршФт ■:■*'■■*■■"• ,.™^._.—...«* ** . ..
\ fp»«*«2:XYZграфик v ..../..' .
'] Обиоымлг»: <? Датом4ГУ1Н»ае«И1 '•••."-С Дру»цщ Г uawwpw»ar% ttpwiamio) j;
: Г Ив абив*«ять гра+иш. «ивдреимм» * тасаки* гра+и*
Вступление
59
Внедренные объекты. Графики с внедренными объектами перерисовываются
быстрее, чем со связанными объектами, поскольку здесь отсутствуют связи с
обновляемыми внешними файлами. Если дважды щелкнуть на внедренном объекте,
то будет вызвано приложение-сервер (то есть источник), в котором можно
изменить данный объект. При этом обновить внедренный объект можно двумя
способами: отредактировать его или заменить вручную.
В меню Правка можно настроить все параметры внешних объектов {связанных
или внедренных), а также их связи с другими компонентами графика. Кроме того,
щелкнув на объекте правой кнопкой мыши, можно выбрать нужные команды
настройки из контекстного меню. Единственным исключением является способ
присоединения объекта {связывание или внедрение), который определяется в момент
подключения файла (после этого только связанный объект можно преобразовать во
внедренный, но не наоборот (см. команду Преобразовать во внедренный из
выпадающего меню Правка)),
Настройка связанных или внедренных объектов OLE. Объекты OLE-графиков
STATISTICA могут быть отредактированы после двойного щелчка мышью на
объекте; при этом приложение-источник будет открыто в режиме сервера OLE
с готовым к редактированию объектом. Если этот объект является графиком
STATISTICA, то в текущем модуле откроется новое графическое окно, что позволит
системе одновременно выступать как в роли клиента, так и сервера.
Жт*> .+< ^ \ - -ЛАЛ , Г_ / '_">_ ;. -, Л : ■ pUH^rtPJ^jtEt^ ,^Ы<Ьрр;СМ^;
Когда редактирование завершено, можно применить любое из стандартных
соглашений OLE для выхода из режима сервера и обновления графика в системе
STATISTICA (используя команды Обновить, Обновить и вернуться к... и т. д.
60
Глава 1. Краткая экскурсия по системе STATISTICA
в выпадающем меню приложения Файл; эти команды доступны только в случае,
если приложение запущено в режиме сервера).
Графические форматы Метафайл и Растровое изображение. Для вставки
графического файла в приложения, не поддерживающие методы OLE,
используются команды Сохранить метафайл или Сохранить растровое изображение (из
выпадающего графического меню Файл). График в формате метафайла Windows
будет записан в файл с расширением *.wmf, а в формате растрового изображения —
с расширением *.Ьтр. Эти форматы, описанные в двух следующих параграфах, не
позволяют полностью реализовать все возможности настройки графиков
STATISTICA, но в то же время совместимы со всеми приложениями,
поддерживающими графические форматы Windows.
Что такое метафайл Windows? Графический формат Метафайл — это один из
стандартов для записи графических файлов (с расширением *.wmf) и их
представления в буфере обмена Windows. Он содержит картинку в виде описаний и
определений всех компонент графика и его атрибутов (например, элементов линий, их
цветов и шаблонов, шаблонов заполнения, описания текста и его параметров).
По сравнению со стандартом растрового изображения (см. ниже) формат
метафайла дает возможности более гибкой настройки 01£-несовместимых объектов в
приложениях Windows.
Цапример, при открытии метафайла в программе Microsoft Draw можно
«разложить» изображение графика, выделить и изменить отдельные линии, шаблоны
заполнения или цвета, а также отредактировать текст и изменить его атрибуты.
Однако не все приложения Windows полностью поддерживают все возможности
формата метафайла, доступные в системе STATISTICA. Некоторые параметры
графиков, записанных системой STATISTICA в этом формате, могут измениться при
их воспроизведении в других приложениях. Например, может исчезнуть поворот
некоторых шрифтов. Поэтому по возможности используйте графический формат
STATISTICA и методы OLE для работы с графиками в других приложениях,
чтобы иметь доступ ко всем возможностям настройки самой STATISTICA.
Вступление
61
Ограничения стандартного формата Метафайл Windows. Сложные
графические изображения, создаваемые системой STATISTICA, могут оказаться слишком
большими (по числу представленных точек данных) для записи в формате
метафайла, который по умолчанию используется системой Windows для большинства
операций по связыванию и внедрению графических объектов. В таких случаях
нужно использовать растровое изображение. За дополнительной информацией
обратитесь к Электронному руководству из диалогового окна. Дополнительные
параметры, которое вызывается из вкладки Графика диалогового окна Параметры
страницы/вывода.
Что такое формат растрового изображения? Формат Растровое изображение —
это второй стандартный графический формат системы Windows, который
используется для представления графических файлов (с расширением *.Ьтр) и передачи
изображения через буфер обмена (как и формат Метафайл). В этом формате не
сохраняются никакие дополнительные данные или параметры, кроме изображения самой
картинки.
В отличие от метафайла растровое изображение представляет собой
«пассивное» поточечное отображение графического окна. Возможности настройки такого
графика в других приложениях Windows очень ограничены. Обычно они
включают только операции растяжения, сжатия, вырезания, вставки и рисования поверх
графика. Как уже отмечалось выше, для работы с графиками в других
приложениях удобнее использовать запись в графическом формате STATISTICA и методы
OLE, чтобы иметь доступ ко всем возможностям настройки самой системы
STATISTICA.
Что такое собственный графический формат STATISTICA? Графические
файлы системы STATISTICA имеют расширение *.stg. Их основное отличие от
метафайлов и растровых изображений состоит в том, что они содержат не только
картинку, но и всю информацию, необходимую для настройки графика и анализа
данных. Здесь записаны все представленные на графике данные, их связи,
уравнения подгонки, параметры внедренных объектов, связи графиков и рисунков и т. п.
Записанные в таком формате графики можно впоследствии открыть в любом из
модулей системы STATISTICA для продолжения настройки и анализа данных.
Кроме того, их можно распечатать в пакетном режиме с помощью команды Печать
файлов из выпадающего меню Файл. Графические файлы в собственном формате
системы STATISTICA можно динамически связать с документами приложений
Windows с помощью методов OLE.
Экспорт через буфер обмена (вставка или специальная вставка методами
OLE). Использование буфера обмена — это самый быстрый способ экспорта
графика в другое приложение. При копировании в буфер обмена создается три
графических представления объекта: в собственном формате STATISTICA, в формате
метафайла Windows и в формате растрового изображения. Каждое из них может
быть использовано в других приложениях.
Графики системы STATISTICA могут присутствовать в других приложениях
(редакторах или электронных таблицах) как в качестве связанных, так и
внедренных объектов. При использовании методов OLE они сохраняют свою связь с
системой STATISTICA и, следовательно, могут интерактивно редактироваться в
рамках других приложений.
62
Глава 1. Краткая экскурсия по системе STATISTICA
Доступ ко всем данным графика. Данные, представленные на графиках системы,
можно непосредственно просматривать и изменять независимо от их типа во
встроенном Редакторе данных графика. Это могут быть исходные данные, части таблицы
результатов или ряд рассчитанных значений (например, вероятностный график).
Для каждого графика создается связанное с ним «дочернее» окно Редактора,
которое закрывается вместе со своим графическим окном. Редактор организован в
виде групп столбцов, представляющих отдельные зависимости данного графика
(см. следующий параграф).
швш
t«tt::fl»*» JN:fr—4* £«»» -1
1.1дЫ
шштошш^
Ш-ШЩ
Данные любого графика всегда доступны через
Редактор данных графика [(одним щелчком), даже
если это уже преооразованные значения
(например, для графика|квантиль-квантиль[).
JUttbiT **»м*хяЬ*Ш\
РУплЭТЧ
Audi
,?<«*'■'•,,:.
Corvette
Ctafe
Oodq»';'- •
-.£«*..
fed
Hond»
JftOu
Mtofc '"'
*«o«fet
Mfeub
|i)
|pi|fll,l,|l|!|J.'»Plf!iffWf^i
Линейный гр«фмк (CARS STA 5л'22н)
||m,'',Y '
~7щ ^n«
WkV,'T'':":Y,:
i m 1
looo ■ЕНИИНв^И^^р
'Ежи пишиw Грин* i ,'>,%;;
12 00 Иде«У1<»»,гврт>чм<Г';' У;
13 X •:: •;::' • • •;':;;:.: #'^l- ¥#::::;.- :.^45^?r
8w**iH^*W■ :'':':K3:;?
.9ммчмг^ naeotemy влом'''."
Огн»чг» выиьтш* бя»л
H1
K2
I9
)93
L9
L3
L8
120
)99
H1
H6
I3
)^2
)ое
ИИИ^ИИЕОГ*'
нАЖ>ине
X
1.00
200
ЗХ
400
5Х
6 00
7Х
8 00
9Х
1000
11Х
1200
13Х
14Х
Y
038
•0 09
•0 09
•0 21
0 97
•0 21
015
0 21
015
0 03
•4 23
050
•0 09
038
*
)
^;
п
выбранные д«*«>« (все) ►
Вступление
63
Категоризованные графики. Для создания категоризованных графиков данные
разбиваются на подгруппы. На одном изображении будет одновременно
представлено несколько графиков, по одному для каждой из заданных подгрупп.
Например, можно построить графики отдельно для субъектов мужского и женского пола,
разделить пациентов на группы женщин с высоким давлением, женщин с низким
давлением, мужчин с высоким давлением, разделить товары по качеству,
странам-производителям и т. п. Разбиение данных на однородные группы и исследование
связей между этими группами — чрезвычайно важный прием анализа данных.
шидиигдиг
** ^^^
■ JffM
Категоризованные графики широко применяются в системе STATISTICA:
О Они доступны в большинстве диалоговых окон с результатами анализа (эти
графики автоматически создаются в тех процедурах, где анализируются
группы или подгруппы данных, например при классификации, проверки
^-критериев, в дисперсионном, дискриминантном и непараметрическом анализе).
О Эти типы графиков присутствуют в списке Быстрые статистические
графики в контекстных меню всех таблиц исходных данных и таблиц
результатов.
О Их можно вызвать из списка Статистические графики (в выпадающем меню
Графика), при построении которых предлагается большой выбор различных
методов категоризации данных.
Методы категоризации, предлагаемые в системе STATISTICA, описаны в
следующем пункте.
64
Глава 1. Краткая экскурсия по системе STATISTICA
Каким образом задаются «категории» для категоризованных графиков? Итак,
вначале нужно разбить данные на группы. При построении категоризованных
графиков из диалоговых окон с результатами анализа подгруппы данных
определяются автоматически (поскольку такое разделение является частью исследования
данных). При построении статистических графиков предлагаются различные
способы задания подгрупп по одной или двум группирующим переменным. Кроме того,
разбиение на подгруппы может организовать сам пользователь, используя любые
комбинации переменных из текущего набора данных.
Существует несколько методов выделения категорий:
О по целым значениям группирующих переменных (Целые числа);
О разделением группирующих переменных на заданное число интервалов
(Категории)?
О разделением группирующих переменных на интервалы с заданными
граничными значениями (Границы);
О с помощью задания конкретных значений (кодов) группирующих
переменных (Коды);
О путем формирования сложных подгрупп (Сложные подгруппы); для этого
пользователь может ввести условия выбора наблюдений практически
неограниченной сложности и использовать значения любой переменной текущего
файла данных, как показано ниже.
На следующем рисунке показан достаточно сложный график, категоризован-
ный по двум признакам. При этом использован смешанный метод выделения
подгрупп. Категоризация по двум признакам означает, что элементы графика
располагаются как элементы двухвходовой таблицы, полученной после использования
двух различных методов категоризации.
ШВВШй
наша
ИВЕ
,1
140
120
100
§
оо
140
. <*•
| 100
00
00
Диаграмма рассеяния (FACTOR.STA ИЬПООс)
f ;
.........
•у*
Ф&:
•V*
Щ
...; ; \...Л
i .-Ж
..£**!* \
50 70 00 110 130 160 60 70 00 110 130 160 60 70 00 110 130 160
ГРУППА: ГРУППА: ГРУППА:
«0<33 «nd НОМЕ_7<200 v0>32 and «0<87 v0>*6 «nd HOME_7<200«nd
WORK 1
Вступление
65
Г|Графмк2 Диаграмма рас се
Диаграмма рассеяния (FACTOR.STA 10v00c)
121
ОС
о
«,3
■SI I""
•*/
#~
♦_*
Ш
• f^
>^
Ш
M 70 10 110 130 1S0 SO 70 M 110 130 1S0 SO 70 00 110 130 1S0
SUBSET: SUBSET: SUBSET:
vt<33 «nd HOME_7<2M vt>32 and «0<S7 «0>00 end HOME_7<200*nd
WORK 1
Две строки на приведенном выше графике представляют разделение на
подгруппы по значениям переменной Ноте_2 (на наблюдения, для которых значение
этой переменной меньше либо равно 104,624, и наблюдения, для которых оно
больше 104,624). Три столбца графика представляют подгруппы, заданные
специальным образом по номерам наблюдений (нулевая переменная) и значениям
переменной Ноте_7. Ниже показано диалоговое окно, где задавались параметры
этого графика.
2М категормэованмые д
MJ.4'l.'lll.MJJJiPI.I
£р Дереиетеце: }
; ЯЯ <• Отдельно .
**-? ВГ"**9 IUr.Y:H0ME_2
Перем,* WQRKJ
Лерем-Y: WORI^2 :
Категории пе&
Переменная: С*, полгрэолм
\ С Целые числе
: Г Категории: [То |
\ С
С Код**
<?
Задать подгруппы
нет
С Сложные naArpywM
КООРДИНАТЫ л :|
СИ!
OIL
м
I Па^метры...
Категории по £ ~
Переменная: HOHtJZ
С Целые числе
<?- Категории: [5
С Границы: нет
СКадмс
* ПОДОЖКА
Нет
\/ Линейная
\Г~ Логарме»мм««бская
\_J Экспоненциальная
\j/ Сплайны
О
т.
|'У Намм. квадраты
1*4. Отр зксп -взвеш.
\Ш Другая Функция
[Друелф
На каждом маленьком графике представлена зависимость между переменными
Work_1 и Work_2 (в качестве Хи Усоответственно). Первая категоризация
(Категории поХ— «столбцы» графиков) проводится методом Сложные подгруппы в
диалоговом окне, вызываемом кнопкой Задать подгруппы:
66
Глава 1. Краткая экскурсия по системе STATISTICA
ЕЕИШЗЕ
Потрут 1 ""•••" •- * -" : '-.
[Вкяюч . осям ^JiOTmMrfrWcoip^wwbl
[v0< 33 and Нотв^7< 200
П<мгрута2
Вкяюч . ее ям
: •=•- :
»8 ]ChnpfciTb/ctn>piiim|
|vO>32 and v0<67
Подгрута J
(Включ., ее ям.
"~~ — —
Н|Отк|мьт»/сояранмп^
|v0>66 and Hon»el7<20b :
Вкяюч., ее ям
^||Открыгь/со«р<нмт»|
тЩтт
Отмой*
ВТ
! & Oiiq*tt»pc«
£оХр*«4Т* ОС«
1-е
Печать
Каждая fttft/рдов 6»*миг
COOnMffut^OWffV ОДНОЙ
' категории {уровню) на
|сатагориэоввннон
трафика.
jJ
Второй класс {Категории по У или «строки» графиков) определяется
группирующей переменной Ноте_2. Диапазон этой переменной разделен на два равных
интервала. Для этого в диалоговом окне задания параметров графика в поле
Категории введено значение 2 (при этом распределение переменной Ноте_2 разделено
на две группы: наблюдения, для которых значения меньше либо равны 104,62, и
наблюдения со значениями данной переменной, большими этого числа).
Тернарные графики поверхности и карты линий уровня. При выводе
результатов анализа по составлению смесей в модуле Планирование эксперимента можно
построить тернарные графики в виде трехмерных поверхностей или карт линий
уровня.
ВШ! I' HL'l.f,',' II,'! 1ШШШШШШШШШШСШ\
Д*миы« mbdutt «U 25» * SOOc
Тр«яомло»юитмм ciMtb ф1.82 и ВД и результат (n«p vi€LD)
■10 010
М 0 980
в 1970
ЕЭ 2 981
CZ3 3 951
□ 4 941
В 5 931
■1 8 921
■Л 7 911
■1 в 902
ЦИННИИ
зва
ЕЕЯЭ1
Катргоригоаммый т»ри»рмыА гррфт (МК2 STA5V42c)
Тр*»омпом«мтм«й сьись 0<1. К2 и КЗ). AM провы
5
fJBJ
144$
1521
1596
ЕЭ 1672
CD
С=)
ffJBJ
pjaj
fjpj
■■
1747
1823
1898
1974
2 049
2125
Вступление
67
Тернарные графики можно построить из подменю Статистические
XYZ-графики, Статистические категоризованные графики и Пользовательские графики
выпадающего меню Графика.
Графики в полярных координатах. Некоторые типы графиков можно
построить в полярных координатах. К ним относятся графики рассеяния, линейные
графики и последовательные вложенные графики из подменю Статистические 2М
графики (оно вызывается из выпадающего меню Графика).
Угол излучения
Ш!ШШВ2ШШШШШШШШШШШШШШШШШШШЩ
Линейный график (EXP.STA 8v*48c)
TIME: BEFORE TIME AFTERJ TIME AFTER_2
В полярных координатах можно построить и категоризованные графики.
Многие графики, построенные в обычной прямоугольной системе координат,
можно представить в полярных координатах. Для этого нужно установить
соответствующий переключатель в диалоговом окне Общая разметка в положение
Полярные.
68
Глава 1. Краткая экскурсия по системе STATISTICA
Ш1Ю1Ш.Ш1М1Г.:11И
Линейный график (EXP.STA 8v'48c)
;\Y левая fi^ltr^m *ш ]ЛинеАная 3 ■' " '«Ц
JY правая V . •' " \. . «* j! Внмтрвг • • 1
■*»»' [0 g •• •• Щ Па|>ам>П1>«осй j ц =>|
.Верхняя
Как поместить на график системы STATISTICA графический объект из
другого приложения? Для вставки любых графических объектов, совместимых с
системой Windows, можно использовать все описанные выше операции вставки
посредством буфера обмена (включая связывание и внедрение методами OLE). Эти
операции можно совершать над растровыми объектами, метафайлами Windows,
графиками в формате STATISTICA, а также любыми OLE-совместимыми объектами.
Как поместить текст на график STATISTICA (отчеты, таблицы и т. п.)? С
помощью описанных выше операций с буфером обмена на графики STATISTICA
можно поместить очень большой текстовый объект (например, отчет длиной
несколько страниц). Этот текст редактируется и изменяется в окне Редактор текста
графика системы STATISTICA или в соответствующем приложении, которое
является сервером в методе OLE.
Все описанные в предыдущем разделе операции вставки и использования
буфера обмена применимы к любым совместимым с Windows графическим объектам,
а операции связывания и внедрения выполняются для всех объектов,
поддерживающих методы OLE.
Галерея графиков STATISTICA. С помощью этой кнопки открывается
диалоговое окно Галерея графиков STATISTICA. Эта кнопка присутствует в диалоговом
окне каждого типа графиков.
шшшвт
¥*Щ
раза
[$ГСтат.
Ьст«.
ЙСтат
&*Стат.
ЩСтет
ЗМ последовательные графики
XYZ графики
матричные графики
пиктог рафики
кетегориэоваииые графики
vtfS Размещение нескольких графиков
О П»ст
не графические окна
Q Пользовательские графики
2? Блоковые статистические графики
£9 Стат.
графики пользователя
? Обаор 1
? График |
Гистограммы J
1 •"[ Диаграммы рассеяния
Ов Диагр. рассеяния с гистограмме»»*
I л1И1ил1Ш!Й11ли1илп»м
|К; | Нормальные вероятностные графики
Г Графики квантиль квантиль
| | Графики вероятность вероятность
[ii'i] Диаграммы диапазонов
Диаграммы размаха
Столбчатые диаграммы
[^л] Линейные графики (для переменных)
(„У-1 Линейные графики (профили иаблюд ]
Последовательные/налож. графики
Ф£ Круговые диаграммы
Г', ) Диагр пропущ. знач. и интервалов <
I <* i
Отмена ]
Составные графики:
диаграммы рассеян**]
XV с диаграммами
размаха для X и У,
подгонхаи
сглаживание функции
на пи XV,
параметров
средним, медиан,
проиентилвй.
выбросов, крайним
точек, диапазонов бе»
Вступление
69
Отсюда быстро и легко вызываются все статистические и пользовательские
графики, пустые графические окна и статистические графики пользователя. Для
этого нужно выделить название нужного типа графика и дважды щелкнуть на нем
(или нажать кнопку ОК).
Пользовательские и статистические графики. Помимо специализированных
графиков, которые вызываются непосредственно из итогового диалогового окна
любой программы статистической обработки, существуют еще два основных типа
графиков, доступных из меню или панели инструментов любой таблицы:
пользовательские графики и статистические (и быстрые статистические) графики.
Главное различие между двумя основными типами графиков заключается в
источнике данных для отображения. Более подробно эти различия описаны в
следующих разделах.
Ш Ш (Ш Э1Ш Пользовательские графики. Пользовательский график дает
возможность отобразить любую заданную пользователем комбинацию значений из
таблиц исходных данных или таблиц результатов (а также из любой комбинации их
строк и/или столбцов). В меню предлагается пять типов таких графиков:
2Мпользовательские графики, ЗМпользовательские последовательные графики, ЗМ
пользовательские диаграммы рассеяния и поверхности, пользовательские матричные
графики и пользовательские пиктографики. При выборе одного из них открывается
соответствующее диалоговое окно, где для отображения на графике можно задать
диапазон данных текущей таблицы. Содержание этого диалогового окна зависит
от выбранного типа пользовательского графика. Начальный выбор данных для
построения графика, предлагаемый в этом диалоговом окне, определяется положением
курсора в текущей таблице. В каждом диалоговом окне пользовательского графика
при задании параметров предусмотрена возможность выбора определенного вида
графика (в рамках основного типа). Вид графика также можно подобрать и после
построения (с помощью диалоговых окон Общая разметка или Размещение графика,
которые открываются при двойном щелчке мышью на области фона графического
окна или при выборе соответствующей строки выпадающего меню Разметки).
S818? Ш? И§ £% Ё!Ш Статистические графики. В отличие от
пользовательских графиков, которые представляют собой средство наглядного отображения
числовых данных любых таблиц (исходных данных или результатов, см. выше),
статистические графики предлагают сотни заранее определенных типов графических
представлений, включающих аналитическое обобщение статистических данных. Они
вызываются из диалогового окна Галерея графиков, которое открывается с помощью
одноименной кнопки панели инструментов @ или из выпадающего меню Графика.
70
Глава 1. Краткая экскурсия по системе STATISTICA
При построении таких графиков используются значения непосредственно из
файла данных, которые не зависят от содержания текущей таблицы, выделения
блоков и положения курсора. При этом предлагаются либо стандартные методы
графического анализа исходных данных (различные графики разброса значений,
гистограммы, графики средних значений, например медиан), либо стандартные
аналитические методы исследований (графики нормальной плотности
распределения, вероятностные графики с исключенным трендом или графики
доверительных интервалов линий регрессии). При построении статистических графиков
программа учитывает условия выбора и веса наблюдений.
Шл Быстрые статистические графики. Наиболее широко используемые типы
статистических графиков (вызываемых из меню Графика, см. предыдущий
параграф) представлены в меню Быстрые статистические графики. Эти списки
графиков не предоставляют такой широкий спектр возможностей, как меню
Статистические графики, но в отличие от последних упрощают и ускоряют процедуру
построения графика. Быстрые статистические графики:
О вызываются из контекстных меню или с панели инструментов любой таблицы
(обычно они не требуют обращения к выпадающим меню или диалоговым окнам),
О не требуют от пользователя выбора переменных (этот выбор определяется
текущим положением курсора в таблице) и промежуточной настройки пара-
* метров (формат соответствующих графиков определяется по умолчанию).
При выборе пункта Быстрые статистические графики (с помощью кнопки на
панели инструментов |^ из контекстного меню или из выпадающего меню
Графика) появляется меню выбора статистического графика для текущей переменной
таблицы, то есть той, на которую в настоящий момент указывает курсор.
ешшшптгжшшяп^
Вступление
71
Если курсор не указывает ни на одну из переменных, то перед построением
любого графика из меню Быстрые статистические графики будет предложено выбрать
переменную из списка. При создании таких графиков система STATISTICA
учитывает текущие условия выбора и веса наблюдений.
Блоковые статистические графики. Эти типы (пользовательских) графиков
вызываются из пунктов контекстных меню Статистики блока по столбцам и
Статистики блока по строкам или из диалогового окна Галерея графиков.
Любой из этих вариантов дает возможность построить итоговый
статистический график для выделенного блока, чтобы сравнить значения в строках
(Статистики блока по строкам) или в столбцах таблицы (Статистики блока по
столбцам). Данный тип графиков похож на те пользовательские графики, на которых
отображаются данные текущего блока таблицы.
Другие специализированные графики. Помимо стандартного набора быстрых
статистических графиков некоторые таблицы позволяют строить и более
специализированные статистические графики (например, временные
последовательности в модуле Временные ряды, пиктографики регрессионных остатков, а также
контурные графики в модуле Кластерный анализ). Как уже упоминалось ранее,
специализированные графики, которые связаны не с конкретной таблицей
результатов, а с определенным методом анализа данных (например, графики
аппроксимирующих функций в модуле Нелинейное оценивание или средних в модуле
Дисперсионный анализ), вызываются непосредственно из диалогового окна с результатами
анализа (то есть из окна, содержащего выходные параметры используемого метода
обработки данных).
Настройка графика до и после его построения. Любые изменения параметров
графика в STATISTICA осуществляются из активного графического окна (после
отображения графика на экране). Как правило, сначала имеет смысл построить
график, приняв значения параметров по умолчанию, а затем уже вносить различные
изменения. Однако в тех редких случаях, когда построение графика занимает
слишком много времени (при создании сложных составных графических изображений
или обработке больших наборов данных), можно вмешаться в этот процесс, чтобы
72
Глава 1. Краткая экскурсия по системе STATISTICA
сделать необходимые настройки. Прервать рисование можно одним нажатием
клавиши или щелчком мыши в любом месте экрана, а затем продолжить его после
ввода необходимых изменений.
Предусмотрено два основных метода настройки графика — добавление и
редактирование пользовательских графических объектов, изменение структурных
элементов графика.
Применяются ли к различным типам графиков различные методы настройки?
Нет. Независимо от способа создания графика для его настройки и изменения
можно использовать любые возможности, предусмотренные в системе
STATISTICA. К любому графику можно добавить новый график, объединить его с другим
графиком, поместить в него связанный или внедренный объект. Кроме того, график
можно любым образом изменять, рисовать на нем и использовать различные методы
подгонки функций. Эти же методы настройки доступны при работе с графиками,
которые были предварительно сохранены и вызваны из дискового файла.
Настройка статистического графика до и после его построения. В разделе
Как настроить график STATISTICA показано, что большинство возможностей
настройки (сотни различных вариантов графического представления) доступны
непосредственно после построения графика. Для этого достаточно щелкнуть на
конкретном элементе графика или выбрать соответствующий пункт в диалоговых окнах
Общая разметка или Размещение графика, которые вызываются из выпадающего
меню Разметки.
В то же время, отдельные параметры, которые определяют источник данных,
нужно задать до построения графика, например переменные, метод категоризации,
значения меток, имена наблюдений, метки осей. В данном примере перед
построением графика нужно выбрать переменные и метод категоризации, а также при
необходимости задать значения некоторых параметров с помощью кнопки
Параметры (которая здесь не использована).
Теперь вернемся к нашему примеру. После построения графика при щелчке на
любом месте фона графического окна появится диалоговое окно Общая разметка,
в котором регулируются параметры общего расположения графика.
В этом окне можно изменить тип графика и задать построение карты линий
уровня (используйте для этого поле Тип графика). Кроме того, можно изменить пара-
Вступление
73
метр Число сечений с установленного по умолчанию со значением 15 х 15 на 25 х 25
(этот параметр определяет точность построения карты линий уровня):
После внесения изменений нажмите ОК, и вы увидите новый график:
ЫШНМШД
ЗМ мт«яц»оо1 ••**> ч*Ф* (cardtocl sui3v*30c)
£ Tfl 00 108 1» <ЗВ Т8 00 10В «О 1ЭВ
л' •UMtT.0fNDi№'MALr«ni}A*(<41 «UM(T «CMOf M-MAlf-Ml ЛО<>40
Тв 00 ЮЯ 1» 1ЭВ
187 773
- 306 4»
37363*
- ?«1 01в
Снова вернемся к диалоговому окну Общая разметка и выберем для типа
контурной линии значение Зона. Кроме того, в первые три строки заголовка графика
74
Глава 1. Краткая экскурсия по системе STATISTICA
поместим управляющие символы @F[1,1], @F[1,2] и @F[1,3], чтобы записать там
уравнения аппроксимирующей квадратичной функции для первой зависимости
(цифра 1 на месте первого параметра в квадратных скобках) для каждого из трех
отдельных графиков (цифры У, 2 и 3 в качестве вторых параметров):
3«гоямок1 ЭМя«т« .
3«гоаомж 2 Подгрупп*: v1>0
3«гоаомж Э
шжв
Ниш
ьХ1 MEASUR1
kYI MIASUR2
OcfcZI MCASUR3
Ь**««Мг}А«то
3
*рн
{юяпщкл tmmmmcm * шит*)
i»tut
I О» 4 «»f|1 3K>-4*123«33 2i
1 Ma 1 30 C««*onra4 Б(«йГ
liH.2 *f|1.1|
t<W3 #fM,?l
Trite 5
BoMmXI BL000_P1
11««VI BIOOO.P?
L*IIY2
21 CHOLCST
J Г*********
Для быстрейшего отображения и всестороннего форматирования уравнений
функций лучше использовать диалоговое окно Параметры, которое вызывается из
диалогового окна Статистические графики. Нажмите ОК, и вы увидите измененный график:
SubM oe<«MMALrtndAoe«4i z>74eesi*4«iyx-3«7«rvoxMi*xax-oiei*x
a*wr of»c»H**LF «4 доемо г«вэ вгг-4в авгх*т$ totvo гэв*х*».о о
&<mt OCfCCK-TCMALF РМв 12>»ЗЭ 48Гх-$Э S71VO 0t74*ii.01 36*tVO
На^удЕ*
ID 114 MS
£23 mw
C=) 15090»
CDieeon
■Ив77ТЭ
■120S43&
IB 223 836
■■ 241 616
IUMIT •INMM-'rCUALr
Вступление
75
Теперь можно продолжить знакомство с различными способами настройки
графика. Самый простой (и самый быстрый) способ изменения параметров какого-
либо элемента — это двойной щелчок на нем кнопкой мыши. Кроме того, с
помощью одного щелчка правой кнопкой мыши на данном объекте можно вызвать
соответствующее ему контекстное меню.
Например, при щелчке правой кнопкой мыши на одной из осей графика появится
показанное ниже контекстное меню, в котором предлагается выбор вариантов
настройки для данной оси:
ifiiHiKifjuiiiiim
на
ЭМ кяткщтао*—** (рафик (cardart .*• i3v*20e)
Panel А0€«41 х-748Л51*4.вЗЭ»х.2в7»7»у*ОД«1*х*х-0161,х
SU*«t OeceWHALP «nd AOC*0 2-63.627.48J96*x*7S 707VO 23fx*x*0 О
SubML OWCeR-TOOLe 2-4612903 4вГх.53 «71VO W7Vx-0.136»xVO
Щит *штФ и»цс*с::
00 106 120
SUtSIT «ENOfn-TtMALT
■■78182
■■96 364
■1114.S4S
ЕЭ 132 727
CD 150 909
tZD 189.091
■■167 273
■■205 455
■■223:636
■■241818
■■ »ыае
по-
На показанном ниже графике с помощью кнопки панели инструментов \
добраны другие пропорции графического окна, кроме того, изменен статус
условных обозначений с фиксированного на перемещаемый, а их текст отредактирован,
упорядочен и перемещен на другое место.
Iillf ,'И 1Г1ЫЗЗ
ЭМ K«Ten>|M»ta>**u графис (carded А* 1 ЭУ20с)
SubMt OeCW-HAAUTandAOe-41 2-748Л51*4ВЗЗ,х.28 797»у*004ГхЧ.01в1*х
Subaet OCICeR-'MALr and A06»40z-63 627-48 998*х-»75 707*у«0 23844*0 О
$Cto«t C©C«-T»MLP 2-48129*33 488*x-53 87^4) 097»x'x-0.138»x*y0
SUMf T OENOfiR-TEMALF
■1 78 182
■1 96 364
ГЯ 114545
Ш 132 727
■1 223 636
CZ3 150 909
CD 169 091
ШШ 187 273
ШШ 205 455
ШШ 241 818
ЩШ выше
Могут ли графики автоматически обновляться при изменении файла данных?
Да, могут. Все графики сохраняют связи с таблицей исходных данных, по которым
они построены. При этом, если обновление не происходит вручную и связи не
отменены, график автоматически обновляется при изменении исходных данных. Для
управления связями имеется специальное диалоговое окно Связи данных и
графика. Оно вызывается из выпадающего меню Графика.
76
Глава 1. Краткая экскурсия по системе STATISTICA
ВШВВШШМвааааааааааааааааШЕШ
! ?««"" &*** у-.. .•■:. . •.■•• •■:.:•. ...•■ |—;— :=.^.|%1
IApto График 16: Диаграмма размаха 'и .-тТ^-i *
; llbllLH!lllJ/PJ.J»llLHil'M/ll'l'>.l',P.lJJJ-l!ll|-lHH^IH | -у
:; ЛГлокир. Графмк12: ЗМ карта лммия уровня l,,,,,,.,,,,,,,^?****. I--.--
1 ]Авто График 11: Матричная диаграмма
: > J 06&мтъ сейчас )
I I И»»****"» сая»ь |
I . 1 Орераатъсааэ» 1
Графш^15: Диаграмме рассеяния : I
: j Cb*aWei&$J^ ••
. Обновжт^ Г A^OH«rir»eciu< (g ^fggt^ С ^юкщ>ошлть{шршьлтшю) \
• ; Г Аатообиоалеим* иамршшвго грабим б*У предварительного запроса
Г Не обиоаапп» rpa+шм. анадрсш»* а текущий график
Здесь можно установить автоматический режим связи, когда график
автоматически обновляется при изменении данных, по которым он построен. Можно также
задать режим Вручную или временно заблокировать связь. Кроме того, можно
установить режим Связь с текущим файлом данных и построить такой же график или
серию графиков для других файлов данных. Способ связи можно глобально
изменить с помощью команды выпадающего меню Сервис.
STATISTICA поддерживает и «вложенные» связи с другими приложениями.
Например, можно установить связь графика с данными электронной таблицы Excel 5
путем динамического обмена данными (DDE). При нажатии клавиши F9 для
пересчета таблицы Excel произойдет автоматическое обновление как данных этой
таблицы, так и соответствующего им графика в системе STATISTICA. См. также два
следующих пункта.
Графический формат STATISTICA. Графики и рисунки могут быть сохранены
в графическом формате STATISTICA в файле с расширением *.stg. Для этого
используются команды Сохранить и Сохранить как... из выпадающего меню Файл.
Именно этот формат рекомендуется для записи графического файла, если
предполагается в дальнейшем снова открывать его в системе STATISTICA или
присоединять к другим приложениям методами OLE. В отличие от других графических
форматов формат STATISTICA хранит не только саму картинку, но и Редактор
данных графика со всеми представленными на графике данными, все аналитические
параметры (уравнения подгонки, эллипсы и пр.), а также другие параметры,
позволяющие впоследствии продолжить анализ графических данных. Этот формат
наиболее удобен при связывании или внедрении графика в другой график STATISTICA.
Сохраненные в данном графическом формате файлы можно распечатать в пакетном
режиме с помощью команды Печать файлов из выпадающего меню Файл.
Командный язык STATISTICA (SCL)
STATISTICA содержит два встроенных языка программирования: STATISTICA
BASIC и SCL (командный язык). Оба языка предназначены для работы в среде
Командный язык STATISTICA (SCL)
11
STATISTICA и содержат встроенные операции для обращения к таблицам
исходных данных, таблицам результатов и графическим функциям.
Язык STATISTICA BASIC представляет собой простой и одновременно
достаточно мощный язык программирования. С его помощью можно создать широкий
спектр приложений, начиная от простых программ преобразования данных и
кончая сложными пользовательскими процедурами комплексного анализа и вывода
информации.
Этот язык программирования пригоден для решения больших вычислительных
задач, поскольку обрабатываемые массивы данных могут иметь до 8 измерений и
нет ограничений на размеры массивов. Таким образом, пользователь может
использовать всю доступную память и создавать процедуры, включающие операции с
большими многомерными матрицами.
Встроенный язык STATISTICA BASIC доступен в любой момент анализа
вместе с интегрированной средой, которая позволяет писать, редактировать, проверять,
отлаживать (предварительно прогонять) и выполнять программы.
Язык STATISTICA BASIC как обычный язык программирования поддерживает
циклические операции и условные переходы, функции и подпрограммы, а также
работу с динамическими библиотеками (DLL). В то же время, он «понимает»
структуру файлов данных системы STATISTICA и позволяет организовать
интерактивную обработку данных в среде самой системы с помощью пользовательских
диалоговых окон. С помощью этого языка пользователь может создавать свои
собственные сложные программы анализа данных, одновременно используя
готовые алгоритмы расчетов и построения графиков, предусмотренные в системе
STATISTICA.
Командный язык SCL (STATISTICA Command Language) предназначен для
организации пакетной обработки данных и создания собственных приложений на
основе процедур, содержащихся в системе STATISTICA. Для того чтобы
пользователь мог при этом реализовать собственные алгоритмы расчетов, предусмотрена
возможность интеграции языков STATISTICA BASIC и SCL.
Программы, написанные на встроенных языках системы STATISTICA,
доступны в любом модуле системы и на любом этапе анализа данных, при этом их
можно вызывать и выполнять как с помощью кнопок автозадач, так и
непосредственно из окна редактирования. Пользователь также имеет возможность создавать
собственные библиотеки функций и подпрограмм и таким образом значительно
расширять предлагаемый набор процедур обработки данных и представления
результатов.
Ввод и исполнение 5СХ-программ. STATISTICA может работать в «истинном»
пакетном режиме как система, управляемая командами, с помощью встроенного
языка управления приложениями SCL (STATISTICA Command Language),
доступного в любом модуле системы из выпадающего меню Анализ. Можно ввести
последовательность команд для выполнения определенных действий, а затем сколько
угодно раз исполнять ее в пакетном режиме.
Возможен и другой способ действий — использование диалогового окна
Мастер команд для быстрого выбора и ввода требуемого списка команд.
78
Глава 1. Краткая экскурсия по системе STATISTICA
Для написания и отладки «пакетов» команд используется интегрированная среда
языка SCL. Она включает текстовый редактор, совмещенный с окном Мастер
команд (см. иллюстрацию выше — кнопка Мастер команд на панели инструментов
Командный язык), систему помощи по синтаксису языка с примерами и
интегрированные средства проверки правильности программ (доступны из выпадающего
меню Сервис).
Пользовательские расширения языка SCL. Программы на языке SCL могут
включать не только предопределенные параметры и команды для выполнения
действий по статистической обработке, управлению и графическому выводу данных
(см. кнопки Справка: примеры и Справка: синтаксис на панели инструментов), но и
пользовательские «команды», определенные с помощью инструмента Назначить
клавиши {SendKeys) (в соответствии с правилами, принятыми в MS Visual BASIC).
Написанные таким образом программы могут выполнять, например, операции
с буфером обмена (Копировать, Вставить), менять параметры вывода, принятые
по умолчанию в различных процедурах, и выполнять другие функции.
SCL-программы могут также включать в себя программы и процедуры, написанные
на языке STATISTICA BASIC (языке STATISTICA, предназначенном для
преобразования данных и графиков и управления ими, который доступен из любого модуля
пакета). Например, определенные пользователем графические или вычислительные
процедуры на языке STATISTICA BASIC могут выполняться как часть пакета команд SCL.
Пользовательский интерактивный интерфейс для SCL-программ. Несмотря на
то что в командном языке SCL не заложен в непосредственном виде специальный
пользовательский интерактивный интерфейс, тем не менее для этих целей можно
использовать программы на языке STATISTICA BASIC, вызываемые из SCL-про-
Командный язык STATISTICA (SCL) 79
грамм, например для создания диалоговых окон, позволяющих выбирать
переменные, файлы данных и т. п. в ходе выполнения программы (см. примеры в
Электронном руководстве).
Исполняемый модуль STATISTICA. Командный язык содержит специальный
Исполняемый модуль, позволяющий разрабатывать приложения «под ключ»,
которые вызываются двойным щелчком на значке соответствующего
«пользовательского приложения» на рабочем столе Windows.
Эта возможность позволяет экономить время пользователя, когда многократно
повторяется одна и та же процедура или последовательность процедур анализа,
а также дает возможность использовать SCI-программы пользователями, которые
не знакомы с соглашениями системы STATISTICA.
riflliHWIPillHilHilin' ЛГИ' ДГ \\Ш2ШШШШШШШШШШШШШШШШШШШШШШШШШШШШШШШШШШШШШЖЗ
Чтобы создать такое приложение «под ключ», сначала нужно написать саму SCL-
программу и сохранить ее обычным образом (например, в файле ProgramLscl).
Затем в окне Диспетчер программ системы Windows нужно создать пиктограмму для
исполняемого модуля с именем Sta_run.exe (оно находится в папке STATISTICA
на диске).
Модуль
запуска
80
Глава 1. Краткая экскурсия по системе STATISTICA
В поле команд нужно задать имя SCL-программы, подлежащей исполнению
(например, d:\data\program1.scl). Теперь при щелчке мышью на этом значке будет
начинаться выполнение программы (в данном случае ProgramLscl). Описанным
способом можно создать любое количество пользовательских приложений, а с помощью
окна Диспетчер программ дать им содержательные имена, соответствующие тем
задачам анализа данных, которые эти приложения выполняют.
Проверка Ежедн.
и очистка итог
данных
Критерии
оптимизации
Кнопки автозадач
Кнопки автозадач — это всплывающая настраиваемая панель инструментов
(включить или выключить ее можно клавишами CTRL+M).
ИНИИНИТ
£*» Qpm* gw ftp*** fernm 4N4*J>»*** &£*8">*Л£
, ' -,-.'v • „ -л
КНОПКИ АВТОЗАДАЧ идеально
подходят для автоматизации работы.
Им можно присваивать:
Макрокоманды: созданные
в Редакторе макрокоманд
Макрокоманды: движения
мыши и нажатия клавиш
Программы из команд
STATISTICA (язык SCL)
Программы пользователей
на STATISTICA BASIC
Файлы STATISTICA
(данные, графики, отчеты...)
1
,л
А
•7
/
/
|| W^: J^iew»»» ^J]
f«W>lwr^J|
№ Orm 'J]
fe Гра+мш14 J
Нц'наё^
It
1 ^::-:
• »ii»w.«»|^S
• it IPP
$и*»г»»инг£р Ц&МШ *W**n |"""".
Кнопки на этой панели инструментов можно назначить/переопределить с
помощью кнопки Настройка... (или нажатия на соответствующую кнопку при
удерживаемой клавише CTRL). В диалоговом окне, которое при этом открывается,
можно присвоить имена уже имеющимся и новым кнопкам.
Кнопки автозадач
81
Перейдем к более систематическому изложению.
Часто при выполнении сложной задачи возникает необходимость выполнять
одну и ту же последовательность действий, например открывать ранее
сохраненные графики, данные или листинги программ. Постоянная потребность выполнять
мало относящиеся к основной работе операции может отнимать время или даже
раздражать. В системе STATISTICA предусмотрены возможности, которые
избавляют пользователя от однообразных операций и способствует созданию
комфортных условий работы.
Кнопки автозадач — это настраиваемая панель, которую в случае
необходимости вы легко можете убрать с экрана или снова восстановить (восстановить или
скрыть эту панель можно с помощью комбинации кнопок CTRL+M).
На панели «Кнопки автозадач» нажмите кнопку Настройка...
Откроется окно настройки кнопок автозадач. В центральной части окна
расположен столбец кнопок, позволяющий:
О Изменить или задать кнопку. Нажав на эту кнопку, вы можете задать
последовательность нажатий кнопок клавиатуры. Для организации такой
последовательности достаточно нажать кнопку Запись в правой части
диалогового окна. С этого момента система автоматически начнет запоминать и
переводить на язык команд ваши действия. Нажав, например, на
клавиатуре кнопку Alt, вы попадете в главное меню, по которому сможете
передвигаться с помощью стрелок и клавиши Enter. Свободно перемещаться
внутри диалоговых окон вам поможет клавиша Tab и т. д. Для окончания
записи нажмите CTRL+F3. В нижней части окна Настройка кнопок авто-
задач будут описаны кнопки перемещений по окнам и соответствующий им
синтаксис.
О Удалить кнопку. В любой момент вы можете удалить ставшую ненужной
кнопку.
О Задать последовательность функций или операций на Командном языке
STATISTICA (SCL).
О Использовать написанные на языке STATISTICA BASIC процедуры
вычислительного характера, преобразования данных, операции по управлению
данными, графические процедуры, а также процедуры, написанные на
любом другом языке программирования, вызываемые из STATISTICA BASIC.
О Открывать файлы данных и любые вспомогательные файлы системы
STATISTICA.
О Создавать и редактировать макрокоманды (последовательности нажатий
клавиш), соответствующие часто выполняемым процедурам, заданиям или
настройкам. Такие редактируемые команды можно вводить в текстовом виде
или, например, как последовательности движений мышью.
В каждом из описанных выше окон предусмотрена возможность создания
сочетаний «горячих клавиш». Вы можете назначить сочетание клавиши CTRL и любой
буквы от А до Z или цифры от 0 до 9. После сохранения этой установки вам будет
достаточно нажать определенную комбинацию клавиш, что будет равносильно
нажатию на кнопку автозадачи.
82 Глава 1. Краткая экскурсия по системе STATISTICA
Панель инструментов может быть глобальной или локальной и содержать
большие библиотеки пользовательских заданий и процедур. Локальная панель
инструментов связана с конкретным модулем или проектом. Имя открытой в данный
момент панели высвечивается в строке заголовка диалогового окна.
Настроенную панель инструментов Кнопки автозадач можно затем сохранить,
используя команды диалогового окна Настройка....
Панель инструментов Кнопки автозадач можно использовать как удобный
интерфейс для пользовательских расширений стандартных процедур.
Кнопки автозадач
31
1
Ее можно легко настроить так, чтобы она занимала очень мало места на экране.
Размеры панелей инструментов можно менять с помощью мыши:
■ни ihiiiiiiihmhiiihh ■шшшииииДшАяншм
Панель можно зафиксировать, переместив ее к границе окна приложения
системы STATISTICA, как показано на следующем рисунке.
тшшшжшвшт
шящ
84
Глава 1. Краткая экскурсия по системе STATISTICA
Как уже было отмечено, кнопки панели инструментов Кнопки автозадач можно
настроить или переназначить в диалоговом окне Настройка кнопок автозадач
(которое открывается с помощью кнопки Настройка... на панели инструментов).
Кроме того, отдельные кнопки можно отредактировать и/или переназначить
непосредственно в соответствующем окне настройки; для этого нужно щелкнуть мышью
по этой кнопке при нажатой клавише CTRL.
11 *%; *-Л ty00*1.V; 11
При этом откроется окно настройки данной конкретной кнопки.
Выбирая последний пункт контекстного меню, которое появляется по щелчку
правой кнопкой мыши где-либо на панели инструментов, можно быстро
переключаться между различными предварительно сохраненными панелями
инструментов Кнопки автозадач.
Взгляд в будущее
STATISTICA постоянно развивается, открывая новые возможности для
пользователей. Если говорить кратко, то развитие системы происходит в духе развития
современных Windows-технологий. Гибкая настраиваемость для задач конкретного
проекта, широкий набор статистических опций, доступных пользователю из
других приложений, глобальная интеграция с другими приложениями, например,
с помощью VB, C++, Java, оптимизация для Web и мультимедийных приложений —
ближайшие перспективы STATISTICA.
Первые шаги в системе STATISTICA
85
;j£fe £<* %tm Qebug fiui $tf»fc* frapht look Window #ф
;JQ Й* В j £*' Г& | Л Ча & ;^ : *> Я* M $4 AddtoWoikbook* AddtaR«poa* j «$ Ц?!
«lolxi
Hiyffil^ff^r^ ^gjxj
• ffifqlxn
OrderlO j CustomerlD
103X LILAS
10331IBONAP
10332 MEREP
10333 WARTH
10334 VICTE
10335 HUNGO
•'_j Workbook 1
•-: <j| 2D Box Plots A0 by
И Box Plot A0 by
В 'iJ Basic Statistics/Tat
!:■; ;,'^J Descrptive slat
ПУагЗПОЬу.
nvaf4A0by
П Vai5A0by
Vaf6A0by
J
:'lh{:»>4f
В таблицы с данными (мультимедийные электронные таблицы) можно будет
встраивать различные объекты: звук, фото и т. д.
Первые шаги в системе STATISTICA
Наше знакомство с системой STATISTICA, конечно, следует начать с ввода
данных. Вы увидите, как легко вводятся в STATISTICA самые разнообразные данные.
Предполагается, что система STATISTICA установлена на вашем компьютере и
вы последовательно повторяете описываемые действия.
В качестве конкретной области выберем медицинский пример.
Как вы уже знаете, исходные данные в системе STATISTICA организованы в
виде таблиц. Если у вас имеется опыт работы с электронными таблицами (типа MS
Excel), то вы быстро привыкнете к таблицам STATISTICA. Заметим, что
табличная структура данных STATISTICA позволяет естественно отобразить
большинство реальных данных.
Электронная таблица состоит из строк и столбцов. Столбцы таблицы
STATISTICA называются Variables — Переменные, а строки Cases — Наблюдения.
Например, в медицине наблюдения — это пациенты, переменные — пол, возраст,
дата поступления в больницу, дата диагноза, дата операции, перевода в другую
больницу, выписки и т. д. Вы можете представить такую таблицу как страницу
записной книжки врача, где строки — это, например, имена пациентов, столбцы —
характеристики (переменные, описывающие течение болезни).
86
Глава 1. Краткая экскурсия по системе STATISTICA
Для того чтобы создать таблицу с данными, проделайте следующее:
1. Запустите программу STATISTICA.
2. Откроется меню Статистических модулей (STATISTICA Module Switcher).
3. Выберите из меню модуль Основные статистики и таблицы и щелкните по
нему мышью.
4. Теперь вы находитесь в модуле Основные статистики и таблицы, в котором
можете выбрать любую статистическую процедуру, входящую в этот модуль.
Но поскольку у вас другая цель, просто щелкните мышью по кнопке Выход
(Cancel).
Итак, вы находитесь в рабочем окне модуля Основные статистики и таблицы
системы STATISTICA. В основном рабочем окне системы подведите курсор мыши
к строке меню Файл и щелкните левой кнопкой. В выпадающем меню выберите
команду Создать данные. На экране компьютера сразу же появляется окно
Создание данных (см. рисунок ниже).
В этом окне можно ввести имя файла, например medicine1.sta (файл может быть
назван и по-русски, однако по ряду причин целесообразнее использовать
английские имена).
Теперь поместите курсор мыши в поле File name — Имя файла и наберите с
клавиатуры нужное имя.
Создание данных имя Файла
S«v*jr< ,ij Examples
~зшшшш
LjSepath
Lj Sibasic
CJIOitems
£13x3
CQ Accident
B] Adapters
«I,,,,,,,-,;,,,,] •
£]Adstudy
C] Aggr essn
£jAlerfly
£)Ваюгю2
•CjBarotrop
£|Beverag2
С J Beverage
£] B»d_ptep
£] Bleach
£J Boston2
rj Bulbs
£]Cars
£] Center
£1 Center2
£] Circuits
rj Comfort
£J Compos*
£j Constrr
21
ffbhrnx U :.Imedone1 staj
§*v*
'•• Savearjtpp* .{Файлыданных (" sta)
Рабоч книг* 1
;
Cancel
После нажатия клавиши Enter на клавиатуре или кнопки Save программа
создаст пустую таблицу, содержащую 10 строк и 10 столбцов.
NIHJUIIII
1.
ш
Ш
ошэ
г
VAR2
10
УАШ8
>d
Первые шаги в системе STATISTICA
87
Вы легко можете увеличить или уменьшить как количество строк, так и
количество столбцов этой таблицы. Создайте в таблице столько строк и столбцов, сколько
нужно. Для этого используйте кнопки Щ^Н^^ЩИИ^^^Й на панели инструментов.
Нажмите, например, кнопку Наблюдения. После нажатия кнопки на экране
возникнет меню, предлагающее следующий выбор для наблюдений таблицы:
Добавить, Переместить, Копировать, Удалить, Ввести имена наблюдений. Выберите,
например, пункт Добавить, дважды щелкнув левой кнопкой мыши. Откроется окно,
в котором можно задать число наблюдений, добавляемых в таблицу:
вшев
Ъегттъ
Р-1
\ О* I 1 Опшм|1
Нажмите ОК, и количество строк (наблюдений) в таблице увеличится на 2, то
есть станет равным 12. Аналогичным образом измените число переменных в таблице.
В данном случае понадобятся 11 переменных. Нажмите кнопку Переменные на
панели инструментов. С помощью курсора мыши в выпадающем меню выберите пункт
Добавить. На экране появится окно, где выполните установки, как показано ниже.
Ърг—тьтст; JvARI О
Ямядышмкниг* Hi mm лкимаииоА. чтобы
Нажмите еще раз кнопку Наблюдения и выберите пункт меню Имена. На экране
появится диалоговое окно, в котором можно определить, сколько символов в
таблице будет зарезервировано для имен наблюдений. Раздвинуть поле для имен
наблюдений можно также с помощью мыши.
Сммгъ?
. югн
ЕЛ
ЕШЗ 1 ** 1
Итак, вы сделали первый шаг к достижению цели — создали электронную
таблицу, которая имеет 11 столбцов и 12 строк, а также место для ввода имен
наблюдений (см. рисунок).
ИХ
1 г р-*э 1 4 I * I * Г *■] - * J * П to
VAEV IVAR2 I У»ЙЗ ] У>А4 I УЛЮ 1 VW I УЛЙ? \ W9 \ УАЯ8 1 VAfflg
Теперь необходимо ввести название таблицы (ее заголовок) и имена переменных.
Вы работаете, используя мышь и клавиатуру. Запомните основной принцип: дважды
88
Глава 1. Краткая экскурсия по системе STATISTICA
щелкая мышью по полям заголовков, вы открываете диалоговые окна, позволяющие
вводить заголовки, описывать переменные и т. д. Введите заголовок таблицы. Для
этого дважды щелкните мышью на верхней строке таблицы, пустой строке, которая
находится над переменными. В появившемся окне введите заголовок таблицы.
информация о ♦•Лив и
|ФаАл создай Эрнстом Статистиком 15-го января
2000 года дня статьи "Учимся применять
(статистические методы** ...
Ца*миг*СМ*Сг4«
чтобы начать*?
новой строки
НаммятоСШТяЬ.
чтобы вставить
позицию
L*U табуляции.
£ B£ «>аАйы текущей РебочеА шлшпс, &ч*рея>; |32 |
£$ Оцрмть \
| Добаешь }
1 ШтвИ 1
Кнопки 'йобтигь'
и "Удалить*
Файлов Раб *н>сн
Наберите с клавиатуры заголовок, нажмите ОК. Введенный текст
отобразится в заголовке таблицы. В поле Информация о файле и примечания можно записать
дополнительную информацию, которая будет полезна при работе с файлом.
Аналогично редактируются имена переменных и наблюдений. Например,
чтобы ввести имена, необходимо дважды щелкнуть мышью в поле Имя наблюдения и в
появившемся окне ввести имена пациентов:
IIIIIJ.!J1IIJJI1HJ!I!U.1 .l|J!H
1; Рм
2.
^Г
■6
[^ж;
1\п*~~т*А
Для того чтобы описать переменную, необходимо дважды щелкнуть мышью по
ее имени — например, после щелчка по заголовку переменноШ (VAR1) откроется
окно, в котором можно задать ее имя (или переименовать ее), формат переменной,
метку, связь и т. д.
гта!
Имя: ЩВГ
БодПД; |9999
й*
3
Тит
ll.l.l.l.l.i.HH.l.U.ffil
Првдстлщденме: i »
j Щст парам, |
| Хв*СТ, 9Н6Ч. J
| Знач./стат ист. {
[38 £р*+шм |
1.000 000. 1.000 000
000 000 A000 0001
.000 000.A.000 000)
Двинкое»
я (метке.«
*!%*"»'
Ы
Примеры Weir** 6алоеоАлокоав1991 Формулы: »vtVv2.
Сея*»; <^Kce*r\!te*»i2c2.»4c4 - (vi >0ГАьГ »v3
Первые шаги в системе STATISTICA
89
Теперь заполните созданную таблицу данными. Данные вводятся непосредственно
с клавиатуры. Возможности экспорта, например в MS Word, мы обсудим позднее. Если
нужно ввести числовые данные, используйте клавиатуру и стрелки перемещения
курсора. Поставьте курсор на нужную ячейку таблицы и введите числовые данные.
Текстовые значения вводятся иначе. Подведите курсор к ячейке переменной с
текстовыми значениями и дважды щелкните мышью. В ячейке появится код 9999 — это код
пропущенных значений. Сотрите код, используя кнопку DEL на клавиатуре. Затем
введите нужное текстовое значение. В итоге можно получить следующую таблицу:
ТЕКСТОВЫЕ
Абремо»АИ.
Баранове 8 В
Горим АН
Гордом Д8.
Гущин AJ4
ЩкаЛИ-И
£мр«фо»ДЛ
Жукя»ЛР
Эаа*«яо*ЛГ,
3*порймф9*ИА
Иммо»А,&
ltf*L. „ ..
тшшшшшшшшшшшш
Поступление и выписка пациентов
MECRLV
январь
май
август
август
сентябрь
октябрь
октябрь
ноябрь
ноябрь
февраль
февраль
март
£ень
J
6
2
31
22
9
5
26
22
20
15
8
29
ГОД.1
68
68
68
68
68
68
68
68
68
69
69
69
МЕСЯЦЕВ
январь
май
май|
октябрь
январь
декабрь
июль
август
декабрь
февраль
ноябрь
май
Яд
21
25
7
14
8
7
29
13
25
29
7
ГОД.*
68
68
70
68
69
68
72
69
68
69
71
69
ПОЛ:
муж
жен
муж
муж
жен
муж
муж
муж
муж
жен
муж
ВОЗРАСТ
54
40
51
42
48
54
54
49
56
55
43
42
• .9, :
ГОРОД
Иваново
Иваново
Иваново
Калуга
Калуга
Калуга
Смоленск
Смоленск
Иваново
Иваново
Смоленск
Иваново
■ -1Р1
10 I 11
ANmjMfSMA
0
0
0
0
0
0
0
0
0
1
0
0
111
3
-i
166
1 32
61
36
1 89
87
112
2 05
2 76
1 13 •
138*j
♦
Таким образом, вы научились создавать таблицы и вводить в них данные.
Повторив несколько раз описанные действия с другими данными, вы прочно
закрепите полученные навыки.
Поскольку система STATISTICA является обычным Windows-приложением,
можно легко и быстро импортировать данные, полученные в системе STATISTICA,
в другое Windows-приложение, например в MS Word.
Лучше всего проделать это следующим образом: нажмите одновременно кнопки
ALT и F3. На экране вместо курсора мыши появится значок «прицел». Используя
мышь, поместите прицел в верхний левый угол таблицы. Затем нажмите левую кнопку
мыши, зафиксируйте прицел и, удерживая кнопку мыши, переместите прицел в
новое место таблицы. Выделенная часть таблицы будет отмечена прямоугольной
рамкой. После того как вы отпустите кнопку мыши, отмеченная часть таблицы будет
помещена в буфер обмена. Если теперь открыть нужный документ Word и набрать
на клавиатуре комбинацию кнопок CTRL и V, то выбранный сегмент таблицы будет
скопирован в документ.
Замечания. Вы работали в модуле Основные статистики и таблицы, подобным
же способом можно ввести данные в любом модуле системы STATISTICA. С точки
зрения общих возможностей по управлению данными, модули системы одинаковы.
В системе STATISTICA имеется специальный модуль Управление данными (Data
management), который содержит расширенные возможности, позволяющие
быстро создать электронную таблицу, объединить две таблицы, вырезать часть
таблицы, отсортировать наблюдения по какому-либо признаку: например, расположить
имена пациентов в алфавитном порядке или упорядочить их по возрасту и т. д.
(см. рисунок ниже).
Упражнение. Проведите сортировку данных файла medicine 1.sta по возрасту
пациентов и по городам. Используйте модуль Управление данными и опцию
Сортировка наблюдений.
90
Глава 1. Краткая экскурсия по системе STATISTICA
В*В Объединение дача •ейлов денных
РЗ Создание подмножестве из Файле даиньп
••••» Сортировке небе—опий
М Иэмонвнмв небвлдеюв!
м? Проверке имен и Форматов перемешали
■■т Проверке значений данных
W Стаидартиэадия перемешали
iMbti Зенена ПД средними
& йш
Г> ММ: создание нового файла
& ММ: открытие файле до
|ВРДАеТ%»<т1фЫ*Ъ»
STATISTICA
Еще один пример
Из переключателя модулей системы STATISTICA запустите модуль Основные
статистики и таблицы. Для этого выберите в меню модуль Основные статистики и
таблицы и щелкните по нему мышью. Модуль будет выбран из списка модулей.
Затем подведите курсор мыши к кнопке Переключиться в и нажмите ее.
Произойдет запуск системы STATISTICA, и на экране появится рабочее окно модуля
Основные статистики и таблицы. Именно в этом модуле мы будем работать.
еавжава
Н опер вметрическея статистике
Дисперсионный анализ (AN OVA/MAN OVA)
Множественная регрессия
Вр
Кластерный анализ
Управление данным»
Факторный анализ
Многомерное вжелировеиив
Деревья классификации
Анализ соответствий
ИечфШжчкяцмА набор
олмсаге/*»** автмогих.:'•'
многообраэмвтаблиц..;...-■
мнргомерны* otttiMtMk;.
t awrop ejpi ме дихотомии. '•
ptlKOCTcipCi«ifi COpBlIC -
табукюеаню данных
просмотр таблщ по слоям,
корреляции, t •критерии дм
I жмборок, проверка различий
корреляциям процентам.
многие другие возможности.
Вое быстры» статистики
доступы из помелей
йерекяажитьса i
Ж
уЦвмените к
| J^»tw» »> w toKW*mwi **i:» ft JI
Отмена
'трасс женщин
^ЗзЯжШ1жв1
П_семья|
Н семья
Н семья
Н семья
П семья
П_семья
П_семья
Н_семья
П_семья
Н_семья
ТРЕВОГА
Высокая
Низкая
Высокая
Низкая
Высокая
Низкая
Низкая
Высокая
Низкая
Высокая
Первые шаги в системе STATISTICA . 91^
В модуле Основные статистики и таблицы создайте файл данных, как
показано на рисунке.
В файле содержатся результаты опроса 10 женщин (данные являются
модельными) относительно их семейного положения и состояния уровня тревожности.
Первая переменная СЕМ_ПОЛ описывает семейное положение женщин. Эта
переменная принимает два значения: П_семья — полная семья, Н__семья — неполная семья.
Вторая переменная, ТРЕВОГА, описывает самооценку личностной тревожности
женщины. Она принимает два значения: низкая, высокая. Известно, что личностная
тревожность характеризуется устойчивой склонностью воспринимать жизненную
ситуацию как угрожающую (содержащую в себе тайную угрозу). Вы видите, что
первая опрошенная женщина — наблюдение номер 1 (первая строка в таблице) —
имеет полную семью и характеризует свое душевное состояние как тревожное.
Вторая опрошенная женщина — наблюдение номер 2 (вторая строка таблицы) —
имеет неполную семью и оценивает уровень своей тревожности как низкий и т. д.
Назовите этот файл womenLsta.
Заметьте, переменные в этом файле принимают текстовые значения, что
типично для социологических опросов.
Примите совет, позволяющий эффективнее организовать ввод текстовых
данных. Переменные принимают текстовые значения, и если каждый раз вводить текст
в таблицу, то это займет слишком много времени. Для удобства лучше
использовать численные значения, а затем перейти в текстовый режим, нажав кнопку на
панели инструментов. Удобно закодировать значения переменных. Покажем, как
это делается. Начнем с переменной СЕМ_ПОЛ. Дважды щелкните по ее заголовку
левой кнопкой мыши, и на экране отобразится окно Диспетчер текстовых
значений - СЕМ_ПОЛ.
В этом окне в колонке Текст наберите в первой строке П_семья, а в колонке
Число наберите 1. Это приведет к тому, что текстовому значению П_семья будет
присвоен код 1. Во второй строке Диспетчера текстовых значений наберите Н_семья,
а в колонке Число наберите 2 — текстовому значению Н_семья будет присвоен
код 2. Далее нажмите кнопку ОК.
92
Глава 1. Краткая экскурсия по системе STATISTICA
Теперь введите значения 1 в те ячейки переменной СЕМ_ПОЛ, в которых
должно стоять текстовое значение П_семья.
Введите значения 2 в те ячейки переменной СЕМ_ПОЛ, в которых должно
стоять текстовое значение Н семья.
^|Стр#сс ж#нщин
2
3
4
б
в
9
10
1|
2
2
2
1
1
1
2
1
2
I
Теперь достаточно нажать кнопку ||| на панели инструментов STATISTICA,
чтобы получить нужные текстовые значения.
Точно таким же образом введите текстовые значения в ячейку переменной ТРЕВОГА.
Итак, вы создали файл womenLsta. Теперь построим, исходя из этого файла
исходных данных, таблицу сопряженности. Это очень легко сделать в STATISTICA.
Шаг 1. Подведите курсор мыши к пункту Анализ. Щелкните по нему мышью.
В появившемся меню сделайте выбор: Стартовая панель.
Вы увидите различные виды анализа, которые доступны в модуле. Выберите
анализ: Таблицы и заголовки и нажмите кнопку ОК.
I М1-1!1 ЫЛГ111
JA Описательные статистики
Корреляционные матрицы
ft%B t-критерий для независимых выборок
fl£2l t-критерия для зависимым выборок
j£S Группировка и одио+акториая AN OVA
Таблицы частот
В а*
Отмена
Ijk ВероятностиыА калькулятор
Юн Другие критерии значимости
На экране появится окно Задайте таблицы.
Шаг 2. Сначала в строке Анализ выберите Таблицы сопряженности (возможен
вариант Таблицы флагов и заголовков).
ITTxl
Таблицы сопряженности
Миогомоашмм таблицы
Э)
таблицы Фдагши
заголовка» выверит* й—
cm**. ..
Первые шаги в системе STATISTICA
93
Шаг 3. Далее нажмите кнопку Задать таблицы. В появившемся окне выберите
переменные, которые будут табулированы в таблице. Эти переменные задают
разбиение исходных данных на группы, поэтому часто их называют также группирующими
переменными. В данном случае нужно табулировать значения переменных СЕМ_ПОЛ
и ТРЕВОГА.
Поэтому выберите их, как это показано на рисунке ниже.
шшшшшш
ми
itTxii
щопшм
'2-ТРЕВОГА
3-VAR3
4-VAR4
5-VAR5
6-VAR6
7-VAR7
8-VAR8
9-VAR9
10-VAR10
1 СЕМПОЛ
3-VAR3
4-VAR4
5-VAR5
6-VAR6
7VAR7
8-VAR8
9-VAR9
10-VAR10
1 СЕМ ПОЛ
2-ТРЕВОГА
3-VAR3
4-VAR4
5-VAR5
6-VAR6
7VAR7
8-VAR8
9VAR9
10VAR10
1 СЕМ ПОЛ
2-ТРЕВОГА
3VAR3
4VAR4
5VAR5
6-VAR6
7VAR7
8VAR8
9VAR9
10-VAR10
1-СЕМ ПОЛ
2-ТРЕВОГА
3-VAR3
4-VAR4
5-VAR5
B-VAR6
7-VAR7
8-VAR8
9VAR9
10-VAR10
1-СЕМ ПОЛ
2 ТРЕВОГА
3-VAR3
4VAR4
5VAR5
6-VAR6
7VAR7
8-VAR8
9VAR9
10VAR10
ГшП
Отмена!
|Пщ|и*|И»««4по«фо&|И»^^
Слисая1: СлисшиЬ СлиеокЗ: Слиеок4: Слисокб: СлисокБ:
F
Г
Заметьте, что вообще можно выбрать до 6 списков группирующих переменных,
что позволяет построить чрезвычайно сложные таблицы, содержащие гораздо
большее число переменных, чем в описываемом примере. Именно такие таблицы часто
возникают при массовых обследованиях, и их нужно уметь строить.
После выбора переменных нажмите кнопку ОК. Вы вновь вернетесь в
диалоговое окно, показанное на рисунке. Обратите внимание, что окно немного
изменилось: около надписи Число таблиц появилась цифра 1, потому что вы выбрали
переменные и попросили систему построить одну таблицу.
Шаг 4. Нажмите Enter на клавиатуре или кнопку ОК в верхнем правом углу
диалогового окна.
Система произведет вычисления и предложит посмотреть результат в окне
Результаты кросстабуляции.
швшшшшшшшшшшшшшшшш
ЩШ
БшЗ |Проа^ретъ итоговые те^лииы!
Тъбтць .jEAaro» t* *»>*•« йршок | ■ ]
Тебян** -■-.■ ;;;;;-.'
Р? £ыле*ить частоты к jlO
Г* Ojpemi шт чмпготы
Г Оетатрчцце частоты
Г* Проценты or общего числе
Г Проценты по строке
V Дронеиты по етолбаф
з! Ш лк
Отмена
, Катеторцаочмепые гистограммы
Грденкиешеииодейстеийчестот |
I Р? Ото^ражвт* д<
Г Включить прооумеццыв авишие
j-Статистшш для деелиоае!^.?**!*^^"-—~? -\, ;^j^"
] Г Пирсоне и М«П м-каадрет ' /1 \. —•—«
1 Г То<1ииЛ<1>и1еер»<йвтое<Мекиеыар*B»2| ' ^;
Г »иЦ>2те6лты1иГ4>емер1УиС . J 3«^ЧА^Е^Т»5«*ы«^цгш*«»гояо«сое
j Г Тад-ЬитагдКеилелл* » ярстучы если г»><Ч*умл*е сгео*»дереыви«»к
| Г" &oppoemut* Вшрмаш
Г" Иоа+ещненты неопределенности
3J4 гистограммы
•ннргими еиавемч, иеполудо» модель
ЛогяииейныАг»1дла,
Шаг 5. В окне Результаты кросстабуляции нажмите кнопку Просмотреть
итоговые таблицы. На экране появится следующая таблица сопряженности:
94
Глава 1. Краткая экскурсия по системе STATISTICA
Пшм&* {Частоты выделенных ячеек> 10
'::....■ ^ /{(Итоговые маргинальные не отмечены) j
Шкй I'llllMI " i и ii | ii и и |
СЕМ_ПОЛ ИИДВШИИ Высоко* j постр. I
ЩЩДИ^ ^ ^ ^
; Н-св*ья I 2 з 5 \
'/Всего „ mi J 5 5 10 !
Вы видите, что в этой таблице табулированы переменные СЕМ_ПОЛ и
ТРЕВОГА. На пересечении строк и столбцов стоят абсолютные значения, вычисленные
из исходного файла данных womenLsta.
Мы табулировали совместно значения двух переменных, СЕМ_ПОЛ и
ТРЕВОГА, и такое действие часто называется кросстабуляцией (от английского cross —
пересекать).
Из построенной таблицы, называемой на сленге таблицей сопряженности,
видно, что три женщины имеют полную семью и низкий уровень тревоги, две
женщины имеют неполную семью и низкий уровень тревоги и т. д. Если вас интересует
раздельная табуляция каждой переменной, посмотрите на крайний правый
столбец и нижнюю строку таблицы. Вы увидите, что всего среди опрошенных женщин
пять имели полную семью и пять — неполную семью; пять женщин имели высокий
уровень тревожности (см. крайний правый столбец), пять — низкий уровень
тревожности (см. нижнюю строку).
Часто возникает необходимость вместе с абсолютными значениями привести в
таблице проценты. Система STATISTICA позволяет выбрать те проценты,
которые требуются: например, только проценты по строке, или проценты по столбцу,
или проценты от общего количества, или же и те и другие.
Проценты по столбцу — это проценты, вычисленные относительно суммарного
значения частот по столбцу. Проценты по строке — это проценты, вычисленные
относительно суммарного значения частот по строке. Проценты от общего числа
вычисляются относительно суммы частот в таблице. Рассмотрим, как это делается.
Шаг 6. Нажмите кнопку Далее в верхнем левом углу таблицы (см. рисунок).
Вы вновь вернетесь в окно Результаты кросстабуляции.
Шаг 7. В окне Результаты кросстабуляции обратите внимание на опции в
правой части, объединенные в группу Таблицы.
Выберите, например, опцию Проценты от общего числа. Подведите курсор мыши
к соответствующему квадрату и щелкните мышью. В окне Результаты
кросстабуляции нажмите кнопку Просмотреть итоговые таблицы. На экране появится
следующая таблица:
Здесь рядом с абсолютными значениями появились относительные величины —
проценты, вычисленные от общего числа женщин, то есть от 10.
Первые шаги в системе STATISTICA
95
Итак, из таблицы видно (пожалуйста, проверьте!), что:
О 30% женщин имеют полную семью и низкий уровень тревоги (первая клетка
таблицы),
О 20% женщин имеют полную семью и высокий уровень тревоги (вторая
клетка таблицы),
О 20% женщин имеют неполную семью и низкий уровень тревоги,
О 30% женщин имеют неполную семью и высокий уровень тревоги.
Построенную таблицу можно отредактировать, изменить ее вид, надписи и т. д.
Шаг 8. Редактирование таблицы.
Дважды щелкните, например, по полю Всего % в построенной таблице. В
появившемся окне Имя строки таблицы результатов вместо Всего % введите %.
'■•i'i-iii.!.4'i*'.i. .'шав
JUL
Diwmi |
Вы получите таблицу вида:
Итого
Итого*
20 00% |
5
50 00°/.
5
50 00V.
Шаг 9. Построение отдельных таблиц с процентами.
Вернитесь вновь в окно Результаты кросстабуляции и обратите внимание на
опцию Отображать выбранные % в отдельных таблицах.
Сделайте следующие установки: выберите опцию Проценты от общего числа и
опцию Отображать выбранные % в отдельных таблицах. Затем нажмите кнопку
Просмотреть итоговые таблицы.
\ттж\\л\ж
ЁЗ Просмотреть итоговые твбймщУ |
.. ..'■'..■ W..J.!. ■■■■■■'I ■■ ■> ' ■■■■■ .'ДЧ1.1 'Ц .J. ■ Ь'.'. ..■.■■■■'.■■iL.'.'U1.'. U1. .'А Л^-.
\ Щ Подробные деавдодоеые таблицы | .
J Р? Отображать амины* метки анпаннЛ ;
Г" Вшшиить tyowyoifiMe itatMMiHi
> Статистики ляп двойное оным табли»-"•••"•■••:
1 Г" Пирсоне и М41 амлщмжрет -.■
\ Г Точный Фишере. Цетса. М ми юмора B
Г Фи B*2 таблицы) и Крамера V и С
Г" Т**Ь и тае-е Кенкаяле:":' •
i Г" Еамме
1 Г*:^оорвляцие Сяиривна '*•'•
Г" Соммере 4
) Г 1Соа.ФФи*м#нгы неопределенности
Р? Дыделить чистоты >: (То
' Г~ Одедаемые частоты
1 Г" Остаточные частоты
1рТ Проценты от общего числа
Р Проценты по строке
] Г" Проценты по столодэ
ш
шс
1 Отмена j
,i
Категориэоелииые гистограммы
{*Щ Граочаш еаоимодействия частот
ЗМ гистограммы
ЗАМЕЧАНИЕ. Те5лишф*аго»*эаголоеко»
доступны, если выбраны два списка переменным.
Чтобы вычислить микеаврет максимального
пражоослобия и проанализировать таблицы со
многими еисвамм, иопояьэу&ге модуль
Лог линейный анализ.
96
Глава 1. Краткая экскурсия по системе STATISTICA
Вы увидите две таблицы, одна из которых будет содержать только абсолютные
значения, а другая — проценты, вычисленные от общего количества опрошенных.
ЕШШШЯШШШЯШШШШШПШШЕШШШ
пшятл [частоты выдепемчых ячеек> Ю
Г-..:..:...:.:■ "••:: ^(Маргинальные суммы не отмечены)
СЕМ.ПОП
ЧЧРЧРЧР
тревогА
Нмэка*
30 00
"с^""] 20 00
'..'Итого " ' 1 50 00
Ш
ТРЕВОГА Щ
Высокая Щ
20 00 L
30 00
50 00
■Щ9Н
5000 1
50 00
100 00
Шаг 10. Создание автоотчета.
г* »*»»<» -слфюя t чтткъ\тшз¥?1щжшън*&(ж\нштг
rp—.-^-»-'-i-J-'^-^-J^-i-j
СТАТ. Итоговая таблица частот (womenl.sta)
ОСНОВНЫЕ Частоты выделенных ячеек> 10
Всего
по стр.
СТАТИСТ.
СЕМ_ПОЛ
П семыа
Всего *
Нсеныш
Всего *
Всего
Всего *
жи
ТРЕВОГА
Ннэкая
Э
30 00*
2
20.00*
5
50 004
ТРЕВОГА
Высокая
2
20.00*
Э
30.00*
5
50.00*
НЛ'ГММ HWII,' ШИ
{Частоты выделенных ячеек> 10
СЕМ_ПОЛ
5000* Греемы
50.00* —'
[(Маргинальные суммы не отмечены)
ТРЕВОГА
ТРЕВОГА
Высокая
0 Всу? 1
з
30 00%
2
20 00%
5
50 00%
2
20 00%
3
30 00%
5
50 00%
iC
_ _. >d
В системе STATISTICA имеется полезное средство подготовки отчета, которое
позволяет представить все полученные результаты в формате RTF; далее отчет
можно вывести на принтер, отредактировать и красиво распечатать.
Проделайте следующее: войдите в меню Вид и выберите опцию Окно текста/
вывода. Из построенных таблиц (они находятся в рабочем окне системы) выберите
ту, которую нужно сохранить для отчета. Щелкните по ней мышью. Вновь войдите
в меню Файл и выберите опцию Печать. Отмеченная таблица результатов будет
распечатана.
В этом окне можно, например, отредактировать таблицу и подготовить ее в том
формате, какой требуется для исследовательского отчета или статьи.
тггнуу
СТАТ. Итоговая таблица частот (women 1 л\ь\
ТРЕВОГА ТРЕВОГА ИТОГО
СЕМ ПОЛ Низкая Высокая
Абс.зи * Абс.зи * Абс.зи *
П_сеиыш 3 30.00* 2 20.00* 5 50.00*
Н_сеиья 2 20.00*
10 100.00*
51 J
Графический анализ таблиц сопряженности
97
Обратите внимание, что в процессе работы ни разу не использовался какой-либо
язык программирования, все действия носят интерактивный характер, и это
большое достоинство системы STATISTICA. Работать в ней так же просто, как,
например, в текстовом редакторе MS Word. В заключение вам предлагается упражнение,
которое закрепит полученные навыки.
Пример. Создайте в STATISTICA файл women2.sta. Для градации значений пе-
Шкала семейного положения
Шкала тревожности женщи-
Графический анализ таблиц сопряженности
Таблицы сопряженности позволяют компактно описывать данные. Они удобны и
требуют минимум комментариев, поэтому популярны среди врачей, социологов,
маркетологов. В системе STATISTICA очень легко строятся даже самые сложные
таблицы сопряженности.
Здесь мы рассмотрим, как визуализировать построенные таблицы, то есть
познакомимся со средствами STATISTICA, позволяющими графически
проанализировать таблицы. Визуально гораздо проще увидеть закономерности,
содержащиеся в таблицах. В примерах используются данные небольшого объема, чтобы можно
было отчетливо представить основные приемы работы. Представьте, в каком
сложном положении вы оказались, если бы имели дело с громадными таблицами, а
именно такие таблицы возникают на практике. «Делайте вслед за нами!» — по-прежнему
остается нашим главным девизом.
Итак, система STATISTICA запущена на компьютере, вы работаете в модуле
Основные статистики и таблицы (в английской версии STATISTICA модуль
Основные статистики и таблицы называется Basic Statistics and Tables).
Пример (продолжение)
Файл данных womenLsta, с которым вы работаете, открыт в рабочем окне.
Напомним, что в этом файле приведены результаты опроса 10 женщин (данные являются
модельными) относительно их семейного положения и уровня тревожности.
ременных используются более реалистичные шкалы,
женщины: одинокая, неполная семья, полная семья,
ны: низкая, умеренная, высокая.
1Ч
TtKC
энйч
1
к*
•
Е
10
иг
шшшшшшввяшшшш
Crptcc жфнщин
П_с#мья
Н„с#мья
Одиноки
Н_с#мья
П_с#мья
Одинокая
П_с#мья
Н_с#мья
П.сфмья
Н сфмья
2
ТРЕВОГА
it!
Низкая
Высокая
Ум#р#н
Низкая
Высокая
Низкая
Высокая
98
Глава 1. Краткая экскурсия по системе STATISTICA
атель модулей смет
НЛЩ11111!1!иЛ1]11И11111|1И1И
l£V
IteJ
Непараметрическая статистика
Дисперсионный анализ (AN OVA/MAN OVA)
Множественная регрессия
Временные ряды и прогнозирование
Кластерный анализ
Управление данными
Факторный анализ
л ДМОММЧОСКММ АМвИМЭ
Многомерное шкалирование
Деревья классификации
Анализ соответствий
•^v.^A.-jj.^v. v•:&s.•лV•:':^•1,:":
Дерек яючнться ш
Ж
Исчврпмвдящнй набор . ■■.■
описательных статистик,
; мисгоо6рдэи»тв$ли»;. • li
сопряжен юсти, таблицы
Флагов м заголовков,
многомерен отклики и
многомврныедикотоь*«. :•.
разносторонний сервис
табелирований данных, •
просмотр таблиц по слоям.
корр«лйцйяй(ритариид1м :
зависимых и независимы»*... /,.
выборок, проверка различий I
между дисперсиями,
корреляциями, процентами,
1*рс*гнс>стный калькулятор и
многие другие возможности
Все быстрые статистики
доступны из панелей
инструментов,
. Изменитьсписок.. J
Злкрьтеь « н'^^'лпЫт^ы;» #
Ж
Отмена
Первая переменная СЕМ_ПОЛ — семейное положение женщин. Эта переменная
принимает два значения: П_семья — полная семья, Н_семья — неполная семья.
Вторая переменная ТРЕВОГА — самооценка личностной тревожности
женщины. Она принимает два значения: низкая, высокая. Известно, что личностная
тревожность характеризуется устойчивой склонностью личности воспринимать
жизненную ситуацию как угрожающую. В данном упрощенном примере мы
использовали две степени тревожности: низкая и высокая.
Вы видите, что первая опрошенная женщина — наблюдение номер 1 (первая
строка в таблице) — имеет полную семью и характеризует свое состояние как
тревожное. Вторая опрошенная женщина — наблюдение номер 2 (вторая строка
таблицы) — имеет неполную семью и оценивает уровень тревожности как низкий
и т. д.
щ
h
2
3
4
б
6
7
е
9
10
■I ■ I IIIIII III в—
Стресс женщин
1
СЕМ^ПОЛ
П_семья|
Н семья
Н семья
Н семья
П семья
П семья
П семья
Н семья
П семья
Н_семья
ТРЕВОГА
Высокая
Низкая
Высокая
Низкая
Высокая
Низкая
Низкая
Высокая
Низкая
Высокая
Шаг 1. Подведите курсор мыши к пункту Анализ. Щелкните по нему мышью.
В появившемся меню сделайте выбор: Стартовая панель.
Выберите анализ: Таблицы и заголовки и нажмите кнопку ОК.
С помощью опций окна задания таблицы произведите табулировку
переменных СЕМ ПОЛ и ТРЕВОГА.
Графический анализ таблиц сопряженности
99
17ПП
~ш
••ST.?';'*,
&ft*iett»;J Таблицы сопряженности
В^'ЖТ
Океана;;J1
У< ОрЩ*Ют;ит тЬм^уЫжш1ЩНщю - :1"° Г Вз«;ейеи«м<
**&М&р1Ы
• ,A..L> , • VL..:JK:^k:^ •'
Шаг 2. После того как система построит таблицу, посмотрите внимательно на
окно Результаты кросстабуляции.
Обратите внимание на кнопки в правом нижнем углу диалогового окна
Результаты кросстабуляции.
в
finnriiiiivnacg
Щ
Р? OreftjMmerw
Г BlUMMMTI» njMMJMJHlffejH) Ц
Сттмспш» дд< дцррпцрпи т шб^щ г;;-/:;;: ул./ ;■;;
' Г" Теним* ^швр^Я^с*, Мемммео* B*2)
Г" Ух fifr2теб*т*| и fomeca V и С
| Г" Т«д-Ьит»гсKwMjiMi •;..
Г £*мме . t.- ^ ...
1Г* Го1 ■■«■ it •;*■«. ><ь •
итм неопределенное
£ы*еЛМТЬ «АбТеТЫ >! J10
Г~ Ржрлшшш частотм
Г Остетечные честагм
Р. Проценты оу ебжеге числе,
I Лрофеиты не строке >
Г Оротемтм по стелбед •■:
* I
Отмене
'•»
••£W
^М гметегреммы '
ЗАМЕЧАНИЕ. ГеглдоФявггеиэеголоем»
доступ м, о&ы аыбреиы дм $ямсЛ переменны*
Чтобы еычмеемгь мншеарет маяеймалного
лревдопдобия и проак**»<ч>е^ т*ол«*»со
мелки ■исв»11испоя>»»*гс иоду»
ЛоцмлейшеИ ноли». .
Шаг 3. В диалоговом окне Результаты кросстабуляции нажмите кнопку Кате-
горизованные гистограммы:
ITl График. 4 Kaief ориз гистограмма СЕМ ПОЛ х ТРЕВОГА
К«1егори$дис¥осремме: СЕМ.ПОЛ х ТРЕВОГА
Ни«кая Высокая
СЕМ_ПОЛ: П_«
Низкая Высокая
СЕМ_ПОЛ: Н_саиья
100
Глава 1. Краткая экскурсия по системе STATISTICA
Смысл этих гистограмм следующий: опрошенные женщины разбиты на две
группы (категории): женщины из полной семьи и женщины из неполной семьи.
Обычная гистограмма для этих переменных выглядит следующим образом:
Гисгограмма (women 1.S ТА 1№*10с) ]
j в г
: 5 f
j
! 4 к
||,
!
^ 1
Низкая Высокая
ТРЕВОГА
Здесь ясно видно, в чем состоит отличие категоризованных гистограмм от
обычных. На обычной гистограмме количество женщин с высокой и низкой
тревожностью одинаково. На категоризованной гистограмме количество женщин с высоким
уровнем тревожности в неполных семьях выше, чем в полных. Уровень
тревожности женщин в полных семьях ниже, чем уровень тревожности в неполных семьях.
Продолжение примера
Рассмотрим файл данных women2.sta. Для градации значений переменных мы
использовали более реалистичные шкалы: одинокая женщина, неполная семья,
полная семья. Шкала тревожности женщины: низкая, умеренная, высокая.
Шаг 1. Подведите курсор мыши к пункту Анализ. Щелкните по нему мышью.
В появившемся меню сделайте выбор: Стартовая панель.
Выберите Таблицы и заголовки и нажмите кнопку ОК.
Шаг 2. В строке Анализ выберите Таблицы сопряженности (возможен вариант
Таблицы флагов и заголовков).
Графический анализ таблиц сопряженности
101
Далее нажмите кнопку Задать таблицы. В появившемся окне выберите
переменные, которые будут табулированы в таблице (подробности см. выше). В
данном случае необходимо табулировать значения переменных СЕМ__ПОЛ и
ТРЕВОГА.
Нажмите кнопку Коды и выберите коды (значения) табулируемых
качественных признаков. В этом примере количество значений переменных увеличилось,
так как используется более точная шкала измерения.
Если вы хотите, чтобы табулировались все значения переменных, нажмите
кнопку Выбрать все в правом нижнем углу.
с£м_по л РИННШ
1Р£В0ГА:|'*Ниэ*«Г - "Высокая" "Умерен"
Тй»11.ммй;ч- сие
\Ъ*6рть wf\
Заметьте, что вообще можно выбрать любой набор кодов. Коды переменных
можно просмотреть, нажав кнопку Инф.
Например, переменная СЕМ_ПОЛ принимает следующие значения:
' (н*т длинного им*ин|
: ;0лмс«нмым
|.| N- % 10 ••>•< t •:. Г Й
: Ст откл •0,78881063774682
щ
Шаг 3. Нажмите Enter на клавиатуре или кнопку ОК в верхнем правом углу
диалогового окна.
STATISTICA произведет вычисления, табулирует данные и предложит
результат в окне Результаты кросстабуляцш (см. рисунок).
102
Глава 1. Краткая экскурсия по системе STATISTICA
онвивлз
швш
-*<&
ftTxl
81 г!<<Щш'|Гд11^<1
fc^l'jg^J^? *«-'*VLj<^^*%"^
F;jai^iwmii>CTd<>6t|^t:v,
fpj»^iiiNiiti^gacyiii» Wygr J
Г
x 34 fMCVQf fMMMM ''
Шаг 4. В окне Результаты кросстабуляции нажмите кнопку Просмотреть
итоговые таблицы. На экране появится таблица:
Шаг 5. Нажмите кнопку Далее в верхнем углу таблицы, и вы вернетесь в окно
результатов. В диалоговом окне Результаты кросстабуляции нажмите кнопку Ка-
тегоризованные гистограммы.
|Г|ГраФикЗ: Категориз гистограмма С1МП0Л к ТРЕВОГА BIRD
Кат«х>ри).тстофа«им: СЕМ_П0Л х ТРЕВОГА
IWOOtOH Г
сем_пол сипов»
Смысл гистограмм заключается в следующем: женщины разбиты на 3 группы
или категории: женщины из полной семьи, женщины из неполной семьи, одинокие
женщины (ср. с предыдущим примером). Для каждой группы построена отдель-
Графический анализ таблиц сопряженности
103
пая гистограмма, и все эти гистограммы собраны вместе на одном графике, что
позволяет визуально сравнить группы.
Шаг 6. В диалоговом окне Результаты кросстабуляции нажмите кнопку
ЗМ гистограммы.
На экране появится трехмерная гистограмма.
Смысл этой гистограммы следующий: составляются всевозможные
комбинации значений двух переменных: семейное положение и уровень тревожности, и под-
считывается, сколько раз встречалась каждая комбинация.
Трехмерная гистограмма очень наглядно воспроизводит таблицу
кросстабуляции. Вы положили таблицу на плоскость и в каждую клетку поставили по столбцу,
высота которого равна количеству наблюдений в клетке таблицы.
Если вас не устраивает ракурс построенной трехмерной гистограммы, можно
его изменить, воспользовавшись средствами системы. STATISTICA предлагает
удивительный инструмент работы с графиками. Например, их можно повернуть.
Нажмите кнопку Вращение, расположенную на панели инструментов.
На экране появится окно, в котором можно провести вращение и подобрать
нужную перспективу.
Для вращения графика используйте линейку прокрутки. Немного
поэкспериментируйте с ней. Сначала, например, с помощью мыши сдвиньте курсор
прокрутки в крайне левое положение. Вы увидите следующую картинку:
104
Глава 1. Краткая экскурсия по системе SWISTICA
11ЧЭ5Э1
ок .гош—гЪД
J
E±Jtf
Сдвиньте теперь курсор прокрутки правее:
ерслектинл и праще
Каждый раз, когда сдвигается курсор, происходит поворот графика. Выберите тот
вариант, который вас устраивает. Нажмите кнопку ОК. Нужный график появится на
экране.
Шаг 7. Построение графиков взаимодействий частот. В окне Результаты кросс-
табуляции нажмите кнопку Графики взаимодействий частот. На экране появится
график взаимодействий:
П f p,i<*
35
30
2.5
2.0
! м
05
00
-0 5
мкЬ 1 р.хрия нз<«имод (Л M III
Графм маимод.: СЕМ_П0Л х
°>
о. /
у^<^_
Нинам BwcctM
ТРЕВОГА
)Л х I PL ВША
ТРЕВОГА
Ь
VWptH
СВ*_П0Л
П.стя
сви.пол
Н_С«МкЯ
сви.поп
Одиноия
Смысл этого графика простой: он показывает, как взаимодействуют или как
связаны между собой частоты наблюдений из разных групп.
Все построенные графики показывают, что женщины из разных семей
различаются по уровню тревожности. Является ли это различие значимым, показывают
статистические тесты.
2 Элементарные
понятия
анализа данных
В этой главе предлагается краткое обсуждение элементарных статистических
понятий, лежащих в основе процедур в любой области статистического анализа
данных. Выбранные нами темы иллюстрируют основные допущения, принимаемые
в большинстве статистических методов для описания «численной природы»
действительности, а изложение ведется на языке, доступном для широкого круга
читателей.
Мы начнем с самых простых, интуитивно ясных понятий и рассмотрим связи
между ними, фактически представим описание языка, на котором говорят при
проведении анализа данных.
Что такое переменная?
Переменная (английский термин variable) — это то, что можно измерять,
контролировать или чем можно манипулировать в исследованиях. Иными словами,
переменная — это то, что варьируется, изменяется, а не является постоянным (от
английского корня var).
Например, измеряя давление или содержание лейкоцитов в крови, вы
получаете различные значения у разных пациентов или значения для одного и того же
пациента в разное время суток. Измеряя уровень осадков, получаете различные
значения в разные дни недели, а также различные значения в одни и те же дни в
разных точках географической карты.
Другие примеры переменных из разных областей: анкетные данные,
систолическое давление пациентов, количество лейкоцитов в крови, цена акций, товаров,
услуг, потребление, инвестиции, доход, государственные закупки товаров и услуг,
инструмент государственного регулирования (в экономике); рейтинг программ,
доля зрителей, количество посещений сайта (в рекламе); скорость, температура,
объем, масса в (физике) и т. д.
Очевидно, что это очень разные по своим свойствам переменные, и поэтому
можно сказать, что переменные отличаются характеристиками, в частности, той
ролью, которую они играют в исследованиях, типом измерений и т. д.
Простейшие описательные статистики
Так как значения переменных не постоянны, нужно научиться описывать их
изменчивость.
106
Глава 2. Элементарные понятия анализа данных
Для этого придуманы описательные или дескриптивные статистики: минимум,
максимум, среднее, дисперсия, стандартное отклонение, медиана, квартили, мода
и т. д.
Идея этих статистик очень проста: вместо того чтобы рассматривать все
значения переменной, а их может быть очень много (тысячи и миллионы), вначале
стоит просмотреть описательные статистики. Они дают общее представление о
значениях, которые принимает переменная.
Минимум и максимум — это минимальное и максимальное значения переменной.
Среднее — сумма значений переменной, деленная на п (число значений
переменной).
Дисперсия (от английского variance) и стандартное отклонение (от
английского standard deviation) — наиболее часто используемые меры изменчивости
переменной. Дисперсия меняется от нуля до бесконечности. Крайнее значение 0 означает
отсутствие изменчивости, когда значения переменной постоянны.
Стандартное отклонение вычисляется как корень квадратный из дисперсии. Чем
выше дисперсия или стандартное отклонение, тем сильнее разбросаны значения
переменной относительно среднего. Часто стандартное отклонение — более
удобная характеристика, так как измерена в тех же единицах, что исходная величина.
Медиана разбивает выборку на две равные части. Половина значений
переменной лежит ниже медианы, половина — выше.
Медиана дает общее представление о том, где сосредоточены значения
переменной, иными словами, где находится ее центр. В некоторых случаях, например
при описании доходов населения, медиана более удобна, чем среднее.
Квартили представляют собой значения, которые делят две половины выборки
(разбитые медианой) еще раз пополам.
Таким образом, медиана и квартили делят диапазон значений переменной на
четыре равные части.
Различают верхнюю квартиль, которая больше медианы и делит пополам
верхнюю часть выборки (значения переменной больше медианы), и нижнюю квартиль,
которая меньше медианы и делит пополам нижнюю часть выборки.
Нижнюю квартиль часто обозначают символом 25%, это означает, что 25%
значений переменной меньше нижней квартили.
Верхнюю квартиль часто обозначают символом 75%, это означает, что 75%
значений переменной меньше верхней квартили.
Мода представляет собой максимально часто встречающееся значение
переменной (иными словами, наиболее «модное» значение переменной), например
популярная передача на телевидении, модный цвет платья или марка
автомобиля и т. д.
С описательными статистиками связаны статистические графики, например
приведенный ниже график наглядно показывает, как распределены значения
переменной (подробнее см. главу Визуальный анализ данных):
Взгляните на график.
На графике приведены описательные статистики для переменной Уровень осад-
ков. Хорошо видно, как распределены значения переменной: от минимального
уровня A6 дюймов) до максимального уровня C9 дюймов).
Половина значений переменной лежит ниже 27,5 дюйма, то есть в половине
всех наблюдаемых месяцев уровень осадков был меньше 27,5 дюйма. Половина
Свойства описательных статистик
107
значений осадков лежит выше 27,5 дюйма, соответствуя тому, что в половине
наблюдаемых месяцев уровень осадков был выше 27,5 дюйма.
Осадки (■ дюймах
\
ВВННННОШШ:
А4?
40
38
36
34
32
30
28
26
24
22
20
18
16
14
о
_1_ Макс. «39
Мин. «16
ПЗ 76% «33.6
26%-21.5
° Медиана «27.5 j
Свойства описательных статистик
Введем формально определения простейших описательных статистик.
Среднее. Пусть имеется переменная X, тогда оценка среднего, или выборочное
среднее, вычисляется как среднее арифметическое наблюдаемых значений.
Выборочное среднее обычно обозначается X и читается «X с чертой». Формально имеем:
— 1 п
х = -£х,.
Выборочное среднее является той точкой, сумма отклонений наблюдений от
которой равна 0. Формально это записывается следующим образом:
Е(х-х,.) = о
Упражнение: используя определение среднего, убедитесь, что данное свойство
действительно имеет место, то есть сумма отклонений наблюдаемых значений от
среднего арифметического действительно равна 0.
Выборочное среднее — единственная точка, которая обладает данным
свойством, и это выделяет ее среди всех других.
Кроме того, выборочное среднее обладает еще одним замечательным свойством:
сумма квадратов расстояний между наблюдаемыми значениями и их средним
арифметическим является минимальным. Если вместо среднего арифметического взять
любую другую величину, то сумма квадратов расстояний между наблюдаемыми
значениями и этой величиной будет только больше, но никак не меньше.
Дисперсия. Выборочная дисперсия переменной X (термин впервые введен
Фишером, в 1918 г.) вычисляется по формуле
108
Глава 2. Элементарные понятия анализа данных
n-lfif
Обратите внимание на коэффициент в данной формуле, он равен п - 1, такая
оценка дисперсии является несмещенной (математическое ожидание несмещенной
оценки равно в точности значению оцениваемого параметра).
Стандартное отклонение равно корню квадратному из выборочной дисперсии.
Формально имеем:
Медиана выборки (термин был впервые введен Гальтоном, в 1882 г.) —
значение, которое разбивает выборку на две равные части. Половина наблюдений
лежит ниже медианы, и половина наблюдений лежит выше медианы.
Наблюдения упорядочивается по возрастанию: Х0)< ХB)< ... < X(w).
Полученная последовательность Х0) называется вариационным рядом, а ее элементы —
порядковыми статистиками. Если число наблюдений нечетно п = 2т + 1, то
медиана оценивается как X(m): med = Х(т).
Если число наблюдений четно п = 2т, то в качестве оценки медианы берется
величина (X(m) + X(m+1))/2.
Медиана обладает следующим замечательным свойством: сумма абсолютных
расстояний между точками выборки и медианой минимальна. С вариационным
рядом связано много важных статистик, например, спейсинги, представляющие
собой расстояния между соседними порядковыми статистиками.
Квантиль (термин был впервые использован Кендаллом в 1940 г.) выборки
представляет собой число хру ниже которого находится р-я часть (доли) выборки.
Например, квантиль 0,25 для некоторой переменной — это такое значение (хр),
ниже которого находится 25% значений переменной.
Аналогично квантиль 0,75 — это такое значение, ниже которого попадают
75% значений выборки.
Формально р-квантиль непрерывного распределения F определяется как
корень уравнения F(x) =p, 0<р< 1.
Квартили. Нижняя и верхняя квартили, от слова кварта — четверть (термин
впервые использовал Гальтон в 1882 г.), равны соответственно 25-й и 75-й процен-
тилям распределения.
25-я процентиль переменной — это значение, ниже которого располагаются
25% значений переменной.
Аналогично, 75-я процентиль равна значению, ниже которого расположено
75% значений переменной.
Итак, 3 точки — нижняя квартиль, медиана и верхняя квартиль — делят выборку
на 4 равные части.
У4 наблюдений лежит между минимальным значением и нижней квартилью,
У4 — между нижней квартилью и медианой, У4 — между медианой и верхней
квартилью, у4 — между верхней квартилью и максимальным значением выборки.
Квартальный размах. Квартальный размах переменных (термин был
впервые использован Галтоном в 1882 г.) равен разности значений 75-й процентили
Свойства описательных статистик
109
и 25-й процентили. Таким образом, это интервал, содержащий медиану, в который
попадает 50% наблюдений.
Мода. Мода (термин был впервые введен Пирсоном в 1894 г.) — это наиболее
часто встречающееся (наиболее модное) значение переменной.
Мода хорошо описывает, например, типичную реакцию водителей на сигнал
светофора о прекращении движения.
Классический пример использования моды — выбор размера выпускаемой
партии обуви или цвета обоев.
Если распределение имеет несколько мод, то говорят, что оно мультимодально
или многомодально (имеет два или более «пика»).
Мультимодальность распределения дает важную информацию о природе
исследуемой переменной.
Например, в социологических опросах, если переменная представляет собой
предпочтение или отношение к чему-то, то мультимодальность может означать,
что существуют несколько определенно различных мнений.
Мультимодальность также служит индикатором того, что выборка не является
однородной и наблюдения, возможно, порождены двумя или более
«наложенными» распределениями.
Асимметрия. Асимметрия, или коэффициент асимметрии (термин введен
Пирсоном в 1895 г.), является мерой несимметричности распределения. Если этот
коэффициент значительно отличается от 0, распределение является асимметричным
(несимметричным). Формально имеем:
-±(ХГХK
g - п%
51 - 3
Г \ jl Пг
\-l(xrxf\
|_"м J
Эксцесс. Эксцесс, или коэффициент эксцесса (термин впервые введен
Пирсоном в 1905 г.) измеряет остроту пика распределения. Оценка эксцесса, или
выборочный эксцесс, вычисляется по формуле:
-S(x.-xL
b2=YILjl1 7,
|-£(Х,.-ХJ|
гдеХ = 1у X,..
Асимметрия и эксцесс полезны для проверки нормальности данных.
Нормальное распределение симметрично, следовательно, коэффициент асимметрии равен 0.
Эксцесс нормального распределения также равен 0, поэтому по отклонениям
выборочного эксцесса и асимметрии от 0 можно судить о близости распределения
наблюдаемой переменной к нормальному. Известно, что распределение с более
острой вершиной, чем нормальное, в типичных случаях имеет положительный
эксцесс, а с более закругленной - отрицательный.
110
Глава 2. Элементарные понятия анализа данных
Шкалы измерений
Переменные различаются тем, «насколько хорошо» они могут быть измерены, или,
другими словами, как много измеряемой информации обеспечивает шкала их
измерений, поскольку в каждом измерении присутствует некоторая ошибка,
определяющая границы «количества информации», которую можно получить в данном
измерении.
Другим фактором, определяющим количество информации, содержащейся в
переменной, конечно, является тип шкалы, в которой проведено измерение. Вы
можете считать, что шкала — это просто линейка: очень грубая, менее грубая, точная.
Обычно используют следующие типы шкал измерений: (а) номинальная, (Ь)
порядковая (ординальная)', (с) интервальная, (d) относительная {шкала отношения).
Соответственно имеются четыре типа переменных: (а) номинальная, (Ь)
порядковая (ординальная), (с) интервальная и (d) относительная.
(a) Номинальные переменные используются только для качественной
классификации. Это означает, что данные переменные могут быть измерены только в
терминах принадлежности к некоторым существенно различным классам, при
этом вы не сможете определить количество или упорядочить эти классы.
Типичными примерами номинальных переменных являются фирма-произ-
• водитель, тип товара, признак (болен — здоров) и т. д. Часто номинальные
переменные называются категориальными. Близкими к ним являются кате-
горизованные переменные, то есть переменные, искусственно превращенные
в категориальные (см. ниже).
(b) Порядковые переменные позволяют ранжировать (упорядочить) объекты,
если указано, какие из них в большей или меньшей степени обладают
качеством, выраженным данной переменной. Однако они не позволяют
определить «на сколько больше» или «на сколько меньше» данного качества
содержится в переменной.
Порядковые переменные иногда также называют ординальными. Типичный
пример — социоэкрномический статус семьи. Мы понимаем, что верхний средний
уровень выше среднего уровня, однако сказать, что разница между ними равна,
допустим, 18%, мы не можем. Само расположение шкал в порядке возрастания их
информативности — номинальная, порядковая, интервальная — является хорошим
примером порядковой переменной. Например, можно сказать, что измерения в
номинальной шкале предоставляют меньше информации, чем в порядковой шкале, а в
порядковой — меньше, чем в интервальной. Однако невозможно придать термину
«меньше» точный количественный смысл или сравнить между собой эти различия.
Другой пример порядковой переменной — это интенсивность использования
определенного цвета в картине художника.
Категориальные и порядковые переменные особенно часто возникают при
анкетировании, так как естественно отражают характер мышления человека.
Например, измерение интенсивности посещения ресторанов можно проводить в
следующей шкале: не посещаю, посещаю редко, посещаю, посещаю часто.
Как легко понять, категориальные и порядковые шкалы часто используются
для описания качественных признаков.
(c) Интервальные переменные позволяют не только упорядочивать объекты
измерения, но и численно выражать и сравнивать различия между ними.
Какие статистики выбирать?
111
Такого рода переменные часто возникают в естественных науках, при снятии
показателей с физических приборов, в медицине и т. д. Например, температура,
измеренная в градусах по Фаренгейту или Цельсию, образует интервальную
шкалу. Вы можете не только сказать, что температура 40 градусов выше,
чем температура 30 градусов, но и то, что увеличение температуры с 20 до
40 градусов вдвое больше увеличения температуры от 30 до 40 градусов,
(d) Относительные переменные очень похожи на интервальные переменные.
В дополнение ко всем свойствам переменных, измеренных в интервальной
шкале, их характерной чертой является наличие определенной точки
абсолютного нуля, таким образом, для этих переменных являются
обоснованными утверждения типа: х в два раза больше, чем у. Например, температура по
Кельвину образует шкалу отношения, и вы можете не только утверждать,
что температура 200 градусов выше, чем 100 градусов, но и то, что она вдвое
выше. Интервальные шкалы (например, шкала Цельсия) не обладают
данным свойством шкалы отношения. Однако в большинстве статистических
процедур не делается тонкого различия между свойствами интервальных
шкал и шкал отношения.
Заметим, что всегда можно перейти от более богатой шкалы к менее богатой.
Так, непрерывные переменные можно искусственно превратить в категориальные,
то есть категоризовать.
Например, непрерывная переменная «рост человека в сантиметрах» может быть
превращена в порядковую переменную с градациями: низкий, средний, высокий
или очень низкий; низкий, средний, высокий, высокий*; или очень низкий,
средне-низкий, низкий, средний, высокий, очень высокий; для размера одежды
используют следующую порядковую шкалу: S, M, L, XL, XXL, XXXL, XXXXL и т. д.
Категоризованные данные часто представляют в виде частот наблюдений,
попавших в определенные категории или классы. Для описания категориальных
переменных полезной оказывается мода.
В реальной жизни, например при проведении массовых опросов, мы имеем все
типы переменных, представленных в одном исследовании.
Какие статистики выбирать?
Среднее и медиана оценивают положение центра выборки, вокруг которого
группируются значения переменной.
Среднее обладает рядом замечательных свойств. Однако эта оценка
чувствительна к выбросам, которые вносят в нее сдвиг. Чтобы избежать сдвига, иногда
используют взвешенное среднее (каждому значению переменной приписывают
определенный вес в соответствии с его важностью, а затем для взвешенных
наблюдений вычисляется обычное среднее).
Медиана является средней точкой вариационного ряда, поэтому она не так
чувствительна к выбросам.
В официальной статистике США именно медиана используется в качестве
оценки центральной точки доходов населения.
Если распределение несимметрично (сдвинуто влево или вправо), то медиана
и межквартильный размах могут дать больше информации о том, в какой области
концентрируются наблюдения.
112
Глава 2. Элементарные понятия анализа данных
Если медиана меньше среднего, то распределение сдвинуто вправо. Если
медиана больше среднего, то распределение сдвинуто влево.
Обычно имеется следующая схема выбора (при условии, что распределение
имеет одну моду). Если данные категоризованы, то используйте моду. Если не все
имеющиеся значения переменной представляют интерес, распределение
несимметрично и имеются выбросы, используйте медиану. В противном случае работайте
со средним.
Распределение переменной
Самый простой вопрос, который естественно задать, анализируя значения
переменной, — какова вероятность того, что переменная примет данное значение или
значение из данного интервала. Иными словами, мы интересуемся тем, как
распределены значения переменной.
Например, оценивается вероятность того, что брошенная монета выпадет
гербом, вероятность того, что пациент проживет дольше определенного времени, или
вероятность того, что доля дефектных изделий в партии меньше 95%.
Описательные статистики дают общую информацию о распределении
переменной. Например, медиана отражает то, что с вероятностью 0,5 значение переменной
будет больше данного значения или, наоборот, меньше этого значения.
Полный ответ дает функция распределения.
Пусть X — некоторая переменная, принимающая значения на прямой. Тогда
функция распределения этой переменной, обозначаемая F(x), есть вероятность того, что Х<х.
Для описания реальных явлений статистиками используются различные
распределения: нормальное, Стьюдента, хи-квадрат, Коши, биномиальное,
отрицательное биномиальное и др. Распределения вероятностей, возникающие на практике,
подробно описываются в отдельной главе.
Зависимости между переменными
Независимо от типа две или более переменных связаны (зависимы) между собой,
если наблюдаемые значения этих переменных распределены согласованным образом.
Другими словами, мы говорим, что переменные зависимы, если их значения
каким-то образом согласованы друг с другом в имеющихся наблюдениях.
Заметьте, мы не определяем, как именно происходит это согласование, возможно, его вовсе
нельзя записать в явном виде.
Например, переменные Пол и WCC (число лейкоцитов) могли бы
рассматриваться как зависимые, если бы большинство мужчин имело высокий уровень WCC,
а большинство женщин — низкий WCC, или наоборот. Итак, если бы у мужчин
число лейкоцитов в крови было бы больше, чем у женщин, то можно сделать
вывод: категориальная переменная Пол связана с переменной Число лейкоцитов.
Если вы измеряете температуру человека сверхточными датчиками, то
регистрируемые значения зависят от точки, в которой проводится измерение.
Рост человека очевидно связан с Весом, потому что обычно высокие индивиды
тяжелее низких; IQ (коэффициент интеллекта) связан с Количеством ошибок в тесте,
так как люди с высоким значением IQ, как правило, делают меньше ошибок, и т. д.
Исследование связей между наблюдаемыми переменными
113
Другими типичными примерами связей являются: зависимость между объемом
винчестера и его ценой. Если вы рассмотрите предложения в Интернете, то увидите,
что логарифмическая зависимость хорошо описывает связь цена — объем для
винчестеров, зависимость между длиной диагонали монитора и ценой монитора,
зависимость между зерном и длиной диагонали экрана. В том же ряду находятся:
зависимость между количеством транспортных средств и количеством аварий в городе,
зависимость между эластичностью спроса и доходов, числом преступлений против
собственности и душевым доходом, зависимость между количеством рассылок по
почте и посещений сайта и т. д. Более экзотическим примером является зависимость
рождаемости от дня недели.
Исследования зависимости между парой переменных, естественно,
распространяется на исследование зависимостей между переменной и списком переменных,
между двумя или несколькими множествами переменных и т. д. (цена монитора
зависит от фирмы-производителя, от диагонали, зерна, развертки, разрешения
и других параметров).
Исследование связей между наблюдаемыми
переменными в сравнении
с экспериментальными исследованиями
Большинство эмпирических исследований данных можно отнести к одному из двух
типов: либо это сбор данных и оценка связей между ними, либо прямой
эксперимент, в котором фиксируются некоторые воздействия на объект исследования и
регистрируется отклик.
В первом случае вы не влияете (или, по крайней мере, пытаетесь не влиять) на
какие-либо переменные, а только собираете их значения и хотите найти
зависимости (корреляции) между некоторыми измеренными переменными, например
между кровяным давлением и уровнем холестерина. Типичный пример здесь —
космическая съемка больших участков Земли и попытка оценить или
спрогнозировать урожайность (см., например, сайт американского госдепартамента с
данными о сельхозпродукции http://www.nass.usda.gov/census/).
В экспериментальных исследованиях вы непосредственно и целенаправленно
варьируете некоторые переменные и измеряете воздействия этих изменений на
объект. Например, можете искусственно увеличить кровяное давление, а затем
измерить уровень холестерина и проделать это несколько раз на ряде объектов.
В исследованиях зависимости спроса на товар от рекламы вы можете активно
менять свою рекламную политику, но такая возможность отсутствует при
исследовании большинства экономических данных в маркетинговых исследованиях, где
вы просто собираете данные, а затем находите связи между ними (типичный
пример — оценка доходов телевизионных компаний).
Анализ данных в экспериментальном исследовании также приходит к
вычислению «корреляций» между переменными, а именно между переменными, на
которые воздействуют, и теми переменными, на которые влияет воздействие. Тем не
менее экспериментальные данные потенциально снабжают исследователей более
качественной информацией.
114
Глава 2. Элементарные понятия анализа данных
Корреляции
Ключевым понятием, описывающим связи между переменными, является
корреляция (от английского correlation — согласование, связь, взаимосвязь, соотношение,
взаимозависимость); термин впервые введен Гальтоном (Galton) в 1888 г.
Корреляция между парой переменных (парная корреляция).
Если имеется пара переменных, тогда корреляция между ними — это мера
связи (зависимости) именно между этими переменными.
Например, известно, что ежегодные расходы на рекламу в США очень тесно
коррелируют с валовым внутренним продуктом, коэффициент корреляции между
этими величинами (с 1956 по 1977 г.) равен 0,9699. Число посещений сайта
торговой компании тесно связано с объемами продаж и т. д.
Также тесно коррелировано число хостов и число хитов на сайте (см. графики
ниже).
Тесно связаны между собой такие, например, переменные, как температура
воздуха и объем продажи пива, среднемесячная температура в данном месте текущего
и предыдущего года, расходы на рекламу за предыдущий месяц и объем торговли
в текущем месяце и т. д.
еннмх (рядов)
щвшашяшшшаж
График выбранных переменных (рядов)
i500
J3U
300
250
200
£ 150
х 100
50
0
50
hi**»—
±№t
■
1
■ Lj
яжШ№
_, . , ._
Libl!1 '
ЧЩк:
.
400
300
200 £
100
о
50 100 150 200 250 300 350
Номера наблюдений
HOST (Л) - - - HITS (П)
■100
Itll'N-HIUlllW"
Диет рамма рассеяния (S1TE.STA fcV4Mc)
y--1.72*0.001 *x*ep*
350
300
250
200
* 150 [
О
X 100
50
0
-50
I Корреляция между хостами и хит «ми - 0.97
150 250
HITS
Корреляции
115
Корреляция между парой переменных называется парной корреляцией.
Статистики предпочитают говорить о коэффициенте парной корреляции, который
изменяется в пределах от -1 до +1.
В зависимости от типа шкалы, в которой измерены переменные, используют
различные виды коэффициентов корреляции.
Если исследуется зависимость между двумя переменными, измеренными
в интервальной шкале, наиболее подходящим коэффициентом будет
коэффициент корреляции Пирсона г (Pearson, 1896), называемый также линейной
корреляцией, так как он отражает степень линейных связей между переменными. Эта
корреляция наиболее популярна, поэтому часто, когда говорят о корреляции, имеют
в виду именно корреляцию Пирсона.
Итак, коэффициент парной корреляции изменяется в пределах от -1 до +1.
Крайние значения имеют особенный смысл. Значение -1 означает полную
отрицательную зависимость, значение +1 означает полную положительную
зависимость, иными словами, между наблюдаемыми переменными имеется точная
линейная зависимость с отрицательным или положительным коэффициентом.
Значение 0,00 интерпретируется как отсутствие корреляции.
Корреляция определяет степень, с которой значения двух переменных
пропорциональны друг другу. Это можно проследить, анализируя графики (см. ниже).
На графике в левом верхнем углу значения парного коэффициента
корреляции равны 0,0, на графике в правом верхнем углу коэффициент корреляции
постепенно увеличивается и становится равным 0,3.
На нижних графиках коэффициент корреляции увеличивается и становится
равным 0,6 и 0,9. Обратите внимание на то, как меняется наклон прямой линии и
как группируются точки вокруг этой прямой.
ншшешипязшш
MEASURE3vt. MEASURE4
103 i . г . !
102
101
100
MEASURE3
Заметьте, что чем ближе коэффициент корреляции к крайнему значению 1, тем
теснее группируются данные вокруг прямой. Та же картина наблюдалась бы и при
116
Глава 2. Элементарные понятия анализа данных
отрицательных значениях корреляции, только наклон прямой, вокруг которой
группируются значения переменных, был бы отрицательным.
При значении коэффициента корреляции, равном ±1, точки точно легли бы на
прямую линию, а это означает, что между данными имеется точная линейная
зависимость.
Внимательно посмотрите на эти графики. Корреляция — важное понятие,
постарайтесь привыкнуть к нему и научиться визуально определять по
расположению данных, насколько тесно они коррелированы.
Говорят, что две переменные положительно коррелированы, если при
увеличении значений одной переменной увеличиваются значения другой переменной.
Две переменные отрицательно коррелированны, если при увеличении одной
переменной другая переменная уменьшается (см. рисунки выше).
Говорят, что корреляция высокая, если на графике зависимость между
переменными можно с большой точностью представить прямой линией (с
положительным или отрицательным наклоном).
Если коэффициент корреляции равен 0, то отсутствует отчетливая тенденция
в совместном поведении двух переменных, точки располагаются хаотически вокруг
прямой линии (см. график в левом верхнем углу).
Важно, что коэффициент корреляции — безразмерная величина и не зависит
от масштаба измерения. Например, корреляция между ростом и весом будет
одной и той же независимо от того, проводились ли измерения в дюймах и футах или
в сантиметрах и килограммах.
Проведенная прямая (см. графики), вокруг которой группируются значения
переменных, называется прямой регрессии, или прямой, построенной методом
наименьших квадратов. Последний термин связан с тем, что сумма квадратов
расстояний (вычисленная по оси Y) от наблюдаемых точек до прямой действительно
является минимальной из всех возможных.
Формально коэффициент корреляции г12 Пирсона между переменными Yp Y2
вычисляется следующим образом:
ra =r(Y„Y2) = -Hp = —
JJCYu-Y^xCYa-Y,)''
V Ып
где Yt — среднее переменной Yt, Y2 — среднее переменной Y2.
Если переменные измерены в интервальной шкале, то используются ранговые
корреляции, которые будут рассмотрены ниже.
Для анализа зависимостей категориальных переменных обычно используют
таблицы сопряженности и соответствующие статистики, например хи-квадрат,
V-квадрату точный критерий Фишера, статистика фи-квадрат (альтернатива
корреляции) и др.
Если требуется измерить связи между списками переменных, используются
следующие типы корреляции:
О множественная корреляции: измерение зависимости между одной
переменной и несколькими переменными;
Корреляции
117
О каноническая корреляция: измерение зависимостей между двумя множества -
ми переменных;
О частные корреляции.
Если вычисляется корреляция между значениями одной переменной,
сдвинутыми на некоторый лаг, то говорят об автокорреляции.
Ранговые корреляции.
Ранговые корреляции основаны на рангах, которые соответствуют номеру
наблюдения в вариационном ряде. Если ваши данные ранжированы, то вы можете
воспользоваться ранговыми корреляциями.
Формально ранговый коэффициент корреляции Спирмена между
переменными Yp Y2 вычисляется следующим образом:
£(R,-R)(S,-S)
ТУ _ \=П
R|2" ~П Z Г" •
X(R,-RJE(S,-SJ
V i=n
где R, — ранг наблюдения Ylb S, — ранг наблюдения Y2j.
Сравнив эту формулу с формулой корреляции Пирсона, приведенной выше,
вы быстро поймете, что корреляция Спирмена является прямым аналогом
корреляции Пирсона. Заменив в формуле Пирсона наблюдения рангами, вы получите
корреляцию Спирмена. Большие значения рангового коэффициента корреляции
свидетельствуют против гипотезы о независимости переменных Yh Y2.
Частные корреляции. При исследовании «взаимозависимостей» переменных
часто возникают следующие трудности: если одна величина коррелирована с
другой, то это может быть всего лишь отражением того факта, что обе эти величины
коррелированы с некоторой третьей величиной или с совокупностью величин,
которые, грубо говоря, остаются за кадром и не введены в исследование. Указанная
ситуация приводит к рассмотрению условных корреляций между двумя
величинами при фиксированныхзначениях остальных величин. Это так называемые
частные корреляции.
Если корреляция между двумя величинами уменьшается, когда мы фиксируем
некоторую третью случайную величину, то это означает, что взаимозависимость
исходных величин возникает частично под воздействием этой величины; если же
частная корреляция равна нулю или очень мала, то мы делаем вывод, что их
взаимозависимость целиком обусловлена собственным воздействием и никак не
связана с новой величиной.
Наоборот, если частная корреляция больше первоначальной корреляции
между двумя величинами, то мы заключаем, что третья величина ослабила исходную
связь.
Еще одна тонкость состоит в том, что следует помнить — корреляция не есть
причинность. Иными словами, установив корреляцию двух величин, мы не имеем
права безапелляционно говорить о наличии причинной связи между ними:
некоторая совершенно отличная от рассматриваемых в анализе величина может быть
источником этой корреляции. Как при обычной корреляции, так и при частных
118
Глава 2. Элементарные понятия анализа данных
корреляциях предположение о причинности должно всегда иметь также
собственные основания, иными словами, соответствовать природе вещей.
Эти интуитивно ясные представления полезно иметь в виду при
интерпретации частных корреляций.
Рассмотрим вначале тройку переменных Yb Y2, Y3. Формально коэффициент
частной корреляции г12.3 между переменными Yb Y2 в предположении, что
переменная Y3 фиксирована, имеет вид:
г _ Г12 ~ Г13Г23
V * ~ Г13 V* ~ Г23
аналогично коэффициент частной корреляции г13.2 между переменными Yp Y3
в предположении, что переменная Y2 фиксирована, имеет вид:
г _ Г13 ~ Г12Г23
VI ~ Г12 V1 ~ Г23
и коэффициент частной корреляции г231 между переменными Y2, Y3 в
предположении, что переменная Yt фиксирована, имеет вид:
г _ Г23 ~ Г12Г13
23,1" ТГ^ТГ7^
Заметьте, эти формулы вполне симметричные, точкой отделяются переменные,
значения которых фиксированы.
Множественная корреляция. Лучше всего понять множественную корреляцию,
а также частные корреляции, с точки зрения регрессии, где они возникают
естественно из самого существа задачи и обобщаются на любое число переменных.
Рассмотрим вначале три переменные: переменную Y и переменные Хь Х2.
Переменную Y будем называть зависимой, переменные Xt, X2 независимыми.
Предположим, что между Y и Xt, X2 имеется линейная зависимость вида:
У: =P0+P1X1|. + P2X2j+eJ., г = 1,...,я(*),
где е, — независимые случайные ошибки с нулевым средним, РРР2,Р3
—неизвестные параметры. Хорошо известно, что в широких предположениях
оптимальными оценками неизвестных параметров в уравнении (*) являются оценки метода
наименьших квадратов (мнк-оценки). Обозначим мнк-оценки через Р0, рр Р2. Эти
оценки замечательны тем, что сумма квадратов расстояний между наблюдениями
Yj и плоскостью (*) минимальна.
Формально подставив мнк-оценки в (*) получаем значения Yn г = 1,...,п .
Теперь коэффициент множественной корреляции между Y и Xt, X2 можно
определить как обычный коэффициент корреляции Пирсона между Y и Y .
Заметим, что квадрат коэффициента множественной корреляции называется
коэффициентом множественной детерминации и показывает, какая доля
вариации (изменчивости, вариабельности) переменной Y объясняется с помощью
линейной зависимости Y и Xt, X2. Формально для коэффициента детерминации имеем:
Корреляции
119
г2 _ /=1
rYY
i=i
Это определение легко обобщается на любое число переменных.
Частные корреляции с точки зрения линейной регрессии. Продолжим наши
рассуждения и покажем, как вычислить частные корреляции исходя из уравнения
регрессии. Пусть нужно, например, вычислить частную корреляцию между Y
и Xi. Идея проста — очевидно, на эту связь влияет переменная Х2. Следовательно,
это влияние нужно устранить, для этого вначале находим линейную регрессию Y
на Х2, затем находим регрессию Xt на Х2.
Формально имеем:
i^.=p01+p02x2l., i = i я
XU =PlO + Pl2*2i» « = 1,---,Я
Теперь рассмотрим остатки {Yi -У{)у(Хи - Хи), г = 1,...,я. В соответствии с
общей идеей частная корреляция между Y и Xi есть обычная парная корреляция
Пирсона между переменными (У - Y),(Xt - Х{).
Эти рассуждения легко распространяются на любое число переменных.
Нелинейные зависимости между переменными. Корреляция Пирсона г
хорошо подходит для описания линейной зависимости. Отклонения от линейности
увеличивают общую сумму квадратов расстояний от регрессионной прямой, даже если
она представляет «истинные» и очень тесные зависимости между переменными.
Поэтому хорошим тоном после вычисления корреляций является построение
диаграмм рассеяния, которые позволяют понять, действительно ли между двумя
исследуемыми переменными имеется связь.
Например, показанная ниже высокая корреляция плохо описывается линейной
функцией.
ниша
иш
MEASURE1 v* MEASURE2 (Построч уд*л»«« ПД)
MEASURE2 - 37 474 . J23S4 • MEASURE1
Копил*** г "-3194
120
Глава 2. Элементарные понятия анализа данных
Однако, как видно на графике ниже, полином пятого порядка достаточно
хорошо описывает зависимость.
шшшштвшшшшшшшшшшшшшшшшшзшщ
Диаграмма рассей» (RAMMX STA 7п«478м)
у-10 0150 111 *х»0 299*х*2-0 049*x»3»0 0О2*х«4.2 284e-5,x«6*eps j
46
40
34
22
10
• 5 0 5 Ю 15 ГО 2$ 30 36 40
MIASURC1
Ложные корреляции. Нужно иметь в виду, что на свете существуют ложные
корреляции, и это нарушает идиллическую картину корреляционного анализа.
Другими словами, если вы нашли переменные с высокими значениями
коэффициентов корреляции, то отсюда еще не следует, что между ними действительно
существует причинная связь; нужна уверенность, что на исследуемые переменные
не влияют другие переменные.
Лучше всего понять ложные корреляции на следующем шутливом примере.
Известно, что существует корреляция между ущербом, причиненным пожаром,
и числом пожарных, тушивших его. Однако эта корреляция ничего не говорит о
том, насколько уменьшатся потери, если будет вызвано меньшее число пожарных.
Задумавшись над полученным результатом, вы будете искать и найдете
причину высокой корреляции: причина состоит в том, что имеется третья переменная
(величина пожара), которая влияет как на причиненный ущерб, так и на число
вызванных пожарных. Если вы будете «контролировать» эту переменную
(например, рассматривать только пожары определенной величины), то исходная
корреляция (между ущербом и числом пожарных) либо исчезнет, либо, возможно, даже
изменит свой знак.
В реальной жизни проводить такие рассуждения и находить «причинные»
переменные, конечно, гораздо сложнее.
Основная проблема ложной корреляции состоит в том, что вы не знаете, чем
она вызвана или, фигурально выражаясь, кто является ее агентом. Тем не менее,
если вы знаете, где искать, то можно воспользоваться частными корреляциями,
чтобы контролировать (частично исключенное) влияние определенных переменных.
Почему зависимости между переменными
являются важными
Вообще говоря, цель всякого исследования или научного анализа состоит в
нахождении связей (зависимостей) между измеряемыми переменными. Далее почти
не проводится различия между терминами «связь» и «зависимость», и во многих
Зависимые и независимые переменные
121
ситуациях они рассматриваются как синонимы, хотя поклонники строгих
определений, возможно, усмотрят в этом вольность.
Заметим, что не существует иного способа представления знания, кроме как
в терминах зависимостей между количествами или качествами.
Таким образом, развитие знаний всегда заключается в нахождении новых
зависимостей между переменными. Исследование корреляций по существу состоит
в измерении таких зависимостей непосредственным образом. Тем не менее
экспериментальное исследование не является в этом смысле чем-то отличным.
Например, отмеченное экспериментальное сравнение WCC у мужчин и женщин может
быть описано как поиск связи между двумя переменными: Пол и WCC.
Назначение статистики состоит в том, чтобы помочь оценить зависимости между
переменными. Действительно, множество статистических процедур может быть
рассмотрено в терминах оценки различных типов взаимосвязей между переменными. Итак,
специалиста по статистике прежде всего интересует оценка связи между
измеренными переменными.
Зависимые и независимые переменные
В повседневной жизни мы хорошо понимаем, что одни величины зависят от
других, например потребление, конечно, зависит от дохода, цена квартиры — от
площади, число посетителей магазина зависит от количества рекламных объявлений,
предпочтение в выборе платья связано с содержимым кошелька, число
посетителей ресторана зависит от времени суток и т. д.
Проведем более строго различие между независимыми и зависимыми
переменными. Независимыми переменными называются переменные, которые
варьируются исследователем, тогда как зависимые переменные — это переменные, которые
измеряются или регистрируются. Очевидно, варьируя интенсивность рекламной
рассылки, вы можете наблюдать изменение спроса и потока посетителей в магазин;
в этом примере интенсивность рекламы — независимая переменная, поток
посетителей — зависимая. Изменяя рекламную кампанию, вы можете заставить
покупателя перейти из пассивного состояния (спячки) в активное и т. д. В электронной
торговле очень важна оценка момента перехода покупателя из категорий пассивный,
активный, суперактивный, чтобы иметь возможность влиять на этот процесс.
На первый взгляд может показаться, что проведение .этого различия создает
путаницу в терминологии, поскольку, как иногда говорят в шутку студенты, «все
переменные зависят от чего-нибудь». Тем не менее, однажды отчетливо проведя
это различие, вы поймете его необходимость.
Термины зависимая и независимая переменная применяются в
экспериментальном исследовании, где экспериментатор манипулирует некоторыми
переменными, и в этом смысле они «независимы» от реакций, свойств, намерений и т. д.,
присущих объектам исследования. Некоторые другие переменные, как предполагается,
должны «зависеть» от действий экспериментатора или от экспериментальных
условий. Иными словами, зависимость проявляется в ответной реакции исследуемого
объекта, ее можно назвать откликом объекта на воздействие, поэтому термин
отклик (response) также иногда используется как синоним зависимой переменной.
122
Глава 2. Элементарные понятия анализа данных
Отчасти в противоречии с данным разграничением понятий находится
использование их в исследованиях, где вы не варьируете независимые переменные, а только
приписываете объекты к «экспериментальным группам», основываясь на
некоторых их априорных свойствах. Например, если в эксперименте мужчины
сравниваются с женщинами относительно числа лейкоцитов (WCC), то Пол можно назвать
независимой переменной, a WCC — зависимой переменной; вложения в рекламу
является независимой (варьируемой) переменной, а число клиентов — зависимой и т. д.
Как измерить величину зависимости
между переменными
Статистиками разработано много различных мер, позволяющих оценить или
измерить степень зависимости между наблюдаемыми переменными.
Выбор определенной меры в конкретном исследовании зависит от числа
включенных в анализ переменных, используемых шкал измерения, природы
зависимостей и т. д. Большинство этих мер, тем не менее, подчиняется одному общему
принципу: они являются попыткой оценить наблюдаемую зависимость, сравнивая ее с
«максимально возможной зависимостью» между рассматриваемыми переменными.
Обычный способ выполнить такие оценки заключается в том, чтобы
посмотреть, как варьируются значения переменных, и затем подсчитать, какая часть всей
имеющейся вариации может быть объяснена наличием «общей» («совместной»)
вариации двух (или более) переменных.
Проще говоря, сравнивается то, «что есть общего в этих переменных», с тем,
«что потенциально было бы у них общего, если бы переменные были абсолютно
зависимы». Рассмотрим простой пример.
Пусть в вашей выборке средний показатель (число лейкоцитов) WCC равен 100
для мужчин и 102 для женщин. Следовательно, вы могли бы сказать, что отклонение
каждого индивидуального значения от общего среднего A01) содержит
компоненту, связанную с полом субъекта, и средняя величина ее равна 1. Это значение,
таким образом, представляет некоторую меру зависимости между переменными
Пол и WCC. Конечно, это очень бедная мера, так как она не дает никакой
информации о том, насколько велика эта компонента, скажем, относительно общего
изменения значений WCC. Рассмотрим две крайние возможности:
(а) Если все значения WCCy мужчин были бы точно равны 100, а у женщин 102,
то все отклонения значений от общего среднего в выборке всецело
объяснялись бы полом. Поэтому вы могли бы сказать, что пол абсолютно
коррелирует с WCC, иными словами, 100% наблюдаемых различий между субъектами в
значениях WCC объясняются полом субъектов.
(б) Если же значения WCC лежат в пределах 0-1000, то та же самая разность B)
между средними значениями WCC у мужчин и женщин, обнаруженная в
эксперименте, составляла бы столь малую долю общей вариации, что полученное
различие считалось бы пренебрежимо малым. Например, введение в
рассмотрение еще одного субъекта могло бы изменить разность или даже изменить ее знак.
Поэтому хорошая мера зависимости должна принимать во внимание полную
изменчивость индивидуальных значений в выборке и оценивать зависимость
по тому, насколько эта изменчивость объясняется изучаемой зависимостью.
Что такое статистическая значимость (р-уровень)?
123
Две черты зависимости между переменными
Можно отметить два самых простых свойства зависимости между переменными:
(а) величину зависимости и (Ь) надежность зависимости.
(а) Величина. Величину зависимости легче понять и измерить, чем надежность.
Например, если любой мужчина в вашей выборке имел значение WCC выше,
чем любая женщина, то вы можете сказать, что величина зависимости между
двумя переменными (Пол и WCC) очень высокая. Другими словами, вы
могли бы предсказать значения одной переменной по значениям другой.
(б) Надежность («истинность»). Надежность взаимозависимости — менее
наглядное понятие, чем величина зависимости, однако чрезвычайно важное.
Оно непосредственно связано с репрезентативностью той определенной
выборки, на основе которой строятся выводы. Другими словами, надежность
говорит, насколько вероятно, что зависимость, подобная найденной, будет
вновь обнаружена (подтвердится) на данных другой выборки, извлеченной
из той же самой популяции. Следует помнить, что конечной целью почти
никогда не является изучение данной конкретной выборки; выборка
представляет интерес лишь постольку, поскольку она дает информацию обо всей
популяции. Если ваше исследование удовлетворяет некоторым специальным
критериям (об этом будет сказано позже), то надежность найденных
зависимостей между переменными выборки можно количественно оценить и
представить с помощью стандартной статистической меры (называемой р-уров-
нем, или статистическим уровнем значимости, см. следующий раздел).
Что такое статистическая значимость
(р-уровень)?
Статистическая значимость результата представляет собой оцененную меру
уверенности в его правильности.
Говоря проще, не на статистическом жаргоне, уровень значимости показывает,
насколько значим для вас полученный результат. Предположим, вы врач,
исследующий пациента. Проводя всесторонние исследования (измеряя давление, беря
анализы крови и т. д.), вы приходите к выводу, что пациент с большой
вероятностью болен, следовательно, полученные результаты значимы.
Выражаясь формально, уровень значимости, или, как еще говорят,р-уровень, —
это показатель, находящийся в убывающей зависимости от надежности
результата. Более высокий р-уровень соответствует более низкому уровню доверия к
найденной в выборке зависимости между переменными. Именно р-уровень
представляет собой вероятность ошибки, связанной с распространением
наблюдаемого результата на всю популяцию. Например, р-уровень = 0,05 (то есть 1/20)
показывает, что имеется 5%-я вероятность того, что найденная в выборке зависимость
между переменными является лишь случайной особенностью данной выборки.
Иначе говоря, если данная зависимость в популяции отсутствует, а вы многократно
проводите подобные эксперименты, то примерно в одном из двадцати повторений
124
Глава 2. Элементарные понятия анализа данных
эксперимента можно ожидать такой же или более сильной зависимости между
изучаемыми переменными. Во многих исследованиях р-уровенъ, равный 0,05,
рассматривается как «приемлемая граница» уровня ошибки.
На уровень значимости можно посмотреть с другой стороны. Предположим, что
вы врач и выдвигаете гипотезу: пациент болен. Тогда, если вы назначили уровень
0,05, то в среднем в 5 случаях из 100 будете совершать ошибку (то есть принимать
неправильную гипотезу — признавать человека больным, когда на самом деле он
здоров).
Как определить, является ли результат
действительно значимым
Не существует никакого способа избежать произвола при принятии решения о том,
какой уровень значимости следует действительно считать «значимым». Однако...
Однако статистическую значимость можно перевести в потери (например,
финансовые), используя подходящую функцию потерь. Представьте, что вы
многократно принимаете решение, то есть проверяете гипотезу о направлении
изменения курса акций, выбрав некоторый уровень значимости, тогда уменьшение
денег в вашем кошельке покажет ошибочность вашего выбора.
Выбор определенного уровня значимости, выше которого результаты
отвергаются как ложные, является достаточно произвольным. На практике окончательное
решение обычно зависит от того, был ли результат предсказан априори (то есть до
проведения опыта) или обнаружен апостериорно, в результате многих анализов
и сравнений, выполненных с множеством данных, а также по традиции,
имеющейся в данной области исследований.
Обычно, что во многих областях результату = 0,05 является приемлемой
границей статистической значимости, однако следует помнить, что этот уровень все еще
включает довольно большую вероятность ошибки E%). Результаты, значимые на
уровне р = 0,01, обычно рассматриваются как статистически значимые, а результаты
с уровнем р = 0,005 илир = 0,001 как высокозначимые. Но следует понимать, что в
данной классификации уровней значимости имеется произвол и это является
всего лишь неформальным соглашением, принятым на основе практического опыта.
Статистическая значимость и количество
выполненных анализов
Понятно, что чем большее число анализов вы провели над некоторыми группами
данных, тем большее число результатов среди них имеют шанс удовлетворить
выбранному уровню значимости. Например, если вычисляются корреляции
между 10 переменными (то есть имеется 45 различных коэффициентов корреляции),
можно ожидать, что примерно 2 коэффициента корреляции A на каждые 20)
случайно окажутся значимыми на уровне р = 0,05, даже если переменные совершенно
случайны и некоррелированы в популяции. Иными словами, имея серию
экспериментов, вы всегда можете подтасовать результаты, выбирая только те опыты,
результаты которых подтверждают вашу гипотезу.
Почему объем выборки влияет на значимость зависимости
125
Некоторые статистические методы, включающие множественные, то есть
многократные, сравнения и, следовательно, имеющие хороший шанс повторить
такого рода ошибки, используют специальную корректировку, или поправку, на общее
число сравнений. Тем не менее многие статистические методы (особенно простые
методы разведочного анализа данных) не предлагают какого-либо способа
решения этой проблемы. Поэтому исследователь должен с осторожностью оценивать
надежность неожиданных находок. Многие примеры, обсуждаемые в данном
руководстве, предлагают специальные советы по поводу того, как это сделать.
Величина зависимости между переменными
в сравнении с надежностью зависимости
Величина и надежность представляют собой две различные характеристики
зависимостей между переменными. Тем не менее нельзя сказать, что они совершенно
независимы. В общем, можно утверждать, что чем больше величина зависимости
(связи) между переменными в выборке обычного объема, тем она надежней.
Почему более сильные зависимости между
переменными являются более значимыми
Если предполагать отсутствие зависимости между соответствующими
переменными в популяции, то с наибольшей вероятностью следует ожидать, что в
исследуемой выборке связь между этими переменными также будет отсутствовать.
Таким образом, чем более сильная зависимость обнаружена в выборке, тем менее
вероятно, что этой зависимости нет в популяции, из которой она извлечена. Как
можно заметить, величина зависимости и значимости тесно связаны между собой,
и можно попытаться вывести значимость из величины зависимости и наоборот.
Однако указанная связь между зависимостью и значимостью имеет место только
при фиксированном объеме выборки, поскольку при различных объемах выборки
одна и та же зависимость может оказаться как высокозначимой, так и не значимой
вовсе (см. следующий раздел).
Почему объем выборки влияет
на значимость зависимости
Общая идея статистических методов состоит в том, чтобы по некоторой части
популяции вынести суждения о свойствах популяции в целом. Именно такого рода
результаты и представляют основной интерес, так как являются объективными.
Если количество наблюдений невелико, то есть выборка из популяции мала,
то соответственно имеет место малое количество возможных комбинаций значений
этих переменных и, таким образом, вероятность случайно обнаружить комбинацию
значений, показывающую сильную зависимость, относительно высока. Рассмотрим
следующий пример. Если вы исследуете зависимость двух переменных {Пол: муж-
126
Глава 2. Элементарные понятия анализа данных
чина/женщина и WCC: высокий/низкий) и имеете только 4 субъекта в выборке
B мужчины и 2 женщины), то вероятность того, что чисто случайно вы найдете
100%-ю зависимость между двумя переменными, равна 1/8. А именно вероятность
того, что оба мужчины имеют высокий WCC, а обе женщины — низкий WCC, или
наоборот, равна 1/8. Теперь рассмотрим вероятность подобного совпадения для
100 субъектов; легко видеть, что эта вероятность равна практически нулю.
Рассмотрим более общий пример. Представим популяцию, в которой среднее
значение WCC для мужчин и женщин одно и то же. Если теперь вы начнете
повторять эксперимент, состоящий в извлечении пары случайных выборок (одна —
мужчины, другая — женщины) и вычислении разности выборочных средних WCC для
каждой пары, то в большинстве экспериментов результат будет близок к 0. Однако
время от времени будут встречаться пары выборок, в которых различие между
мужчинами и женщинами будет существенно отличаться от 0. Как часто будет это
происходить? Чем меньше объем выборки в каждом эксперименте, тем более
вероятно появление таких ложных результатов, которые показывают
существование зависимости между полом и WCC в данных, полученных из популяции, где
такая зависимость на самом деле отсутствует.
Почему слабые зависимости могут быть
значимо доказаны только на больших
выборках
Предыдущий пример показывает, что если зависимость между переменными
«объективно» (другими словами, в популяции) мала, не существует иного способа
проверить такую зависимость, кроме как исследовать выборку достаточно
большого объема. Даже если ваша выборка совершенно репрезентативна, эффект не
будет статистически значимым, если выборка мала. Аналогично, если зависимость
«объективно» (в популяции) очень сильная, то она может быть обнаружена с
высокой значимостью даже на очень маленькой выборке. Рассмотрим следующий
иллюстративный пример. Если монета слегка несимметрична и при подбрасывании
орел выпадает чаще решки (например, 60% против 40%), то 10 подбрасываний
монеты было бы недостаточно, чтобы убедить кого бы то ни было, что монета
асимметрична, даже если был бы получен совершенно репрезентативный
результат, 6 орлов и 4 решки.
Не следует ли отсюда, что 10 подбрасываний вообще не могут доказать что-
либо? Нет, не следует, потому что если эффект в принципе очень сильный, 10
подбрасываний может быть вполне достаточно. Представьте, что монета настолько
несимметрична, что всякий раз, когда вы ее бросаете, выпадает орел. Если вы
бросаете такую монету 10 раз и всякий раз выпадает орел, большинство людей сочтут
это убедительным доказательством того, что с монетой что-то не то.
Другими словами, это послужило бы убедительным доказательством того, что
в популяции, состоящей из бесконечного числа подбрасываний этой монеты, орел
будет встречаться чаще, чем решка. Таким образом, если зависимость сильная, она
может быть обнаружена с высоким уровнем значимости даже на малой выборке.
Как вычисляется статистическая значимость
127
Можно ли рассматривать отсутствие связей
как значимый результат?
Чем слабее зависимость между переменными, тем большего объема требуется
выборка, чтобы значимо ее обнаружить. Например, представьте, как много бросков
монеты необходимо сделать, чтобы доказать, что отклонение от равных
вероятностей составляет только 0,000001%! Таким образом, необходимый минимальный
размер выборки возрастает, когда степень эффекта, который нужно доказать,
убывает. Когда эффект близок к 0, необходимый объем выборки для его отчетливого
доказательства приближается к бесконечности. Другими словами, если зависимость
между переменными почти отсутствует, объем выборки, необходимый для ее
значимого обнаружения, почти равен объему всей популяции, который
предполагается бесконечным. Статистическая значимость представляет вероятность того, что
подобный результат был бы получен при проверке всей популяции в целом.
Таким образом, все, что получено после тестирования всей популяции, было бы по
определению значимым на наивысшем возможном уровне, и это относится ко всем
результатам типа «нет связи».
Общая конструкция статистических тестов
Так как конечная цель большинства статистических тестов состоит в оценке
зависимости между переменными, большинство статистических тестов следует
некоторому общему принципу. Говоря техническим языком, эти тесты представляют
собой отношение групповой изменчивости к полной изменчивости. Например,
такой тест может представлять собой отношение той части изменчивости WCC,
которая определяется полом, к полной изменчивости WCC (вычисленной для
объединенной выборки мужчин и женщин). Это отношение обычно называется
отношением объясненной вариации к полной вариации.
В статистике термин объясненная вариация не обязательно означает, что вы даете
ей «теоретическое объяснение». Он используется только для обозначения общи
вариации рассматриваемых переменных, то есть для указания на то, что часть
вариации одной переменной «объясняется» определенными значениями другой
переменной, и наоборот.
Как вычисляется статистическая значимость
Предположим, вы уже вычислили меру зависимости между двумя переменными
(как объяснялось выше). Следующий вопрос, стоящий перед вами: насколько
значима эта зависимость? Например, является ли 40% объясненной дисперсии
между двумя переменными достаточным, чтобы считать зависимость значимой?
Ответ будет таким: в зависимости от обстоятельств. Именно значимость зависит в
основном от объема выборки. Как уже объяснялось, в очень больших выборках
даже очень слабые зависимости между переменными будут значимыми, в то время
как в малых выборках даже очень сильные зависимости не являются надежными
128
Глава 2. Элементарные понятия анализа данных
(значимыми). Таким образом, для того чтобы определить уровень статистической
значимости, вам нужна функция, которая представляла бы зависимость между
«величиной» и «значимостью» зависимости между переменными для каждого
объема выборки. Данная функция указала бы вам точно, насколько вероятно
получить зависимость данной величины (или больше) в выборке данного объема, в
предположении, что в популяции такой зависимости нет. Другими словами, эта
функция давала бы вам уровень значимости (р-уровень) и, следовательно,
вероятность ошибочно отклонить предположение об отсутствии данной зависимости в
популяции. Эта «альтернативная» гипотеза (состоящая в том, что нет
зависимости в популяции) обычно называется нулевой гипотезой. Было бы идеально, если
бы функция, вычисляющая вероятность ошибки, была линейна и имела только
различные наклоны для разных объемов выборки. К сожалению, эта функция
существенно более сложная и не всегда одна и та же. Тем не менее в большинстве
случаев ее форма известна, и это можно использовать для определения уровней
значимости при исследовании выборок заданного размера. Большинство этих
функций связано с очень важным классом, называемым нормальным.
Значимость коэффициента корреляции
Допустим, вы оценили коэффициент корреляции между двумя переменными.
Очевидно, чем больше по абсолютной величине значение коэффициента, тем больше
вероятность, что между переменными имеется связь, то есть с тем меньшей
вероятностью ошибки можно отвергнуть гипотезу об отсутствии связи между переменными.
Иными словами, чем больше абсолютное значение коэффициента корреляции,
тем более обоснованно опровергается гипотеза, что между переменными нет
связи. Спрашивается: какие именно значения значимы?
Ответ зависит как от величины коэффициента корреляции, так и от объема
выборки, по которой он вычислен.
Например, анализируя данные о годовых урожаях в Восточной Англии за 20 лет,
Фишер вычислил коэффициент корреляции между годовым урожаем пшеницы и
осенним уровнем дождей. Этот коэффициент, как и ожидалось, оказался
отрицательным (чем выше уровень осенних осадков, тем меньше урожай, то есть
переменные отрицательно коррелированны) и равным... 0,629, что значимо на уровне 0,01.
Если бы выборочный коэффициент корреляции оказался равен 0,45, то
результат был бы значим на уровне 0,1, но незначим на уровне 0,01, и т. д.
Как определить, являются ли
два коэффициента корреляции
значимо различными
Имеется критерий, позволяющий оценить значимость различия между двумя
коэффициентами корреляции. Результат применения критерия зависит не только
от величины разности этих коэффициентов, но и от объема выборок и величины
Почему важно нормальное распределение
129
самих этих коэффициентов. Вообще говоря, в соответствии с общим принципом
надежность коэффициента корреляции увеличивается с увеличением его
абсолютного значения; относительно малые различия между большими
коэффициентами могут быть значимыми. Например, разница 0,10 между двумя
корреляциями может не быть значимой, если коэффициенты равны 0,15 и 0,25, хотя
для той же выборки разность 0,10 может оказаться значимой для
коэффициентов 0,80 и 0,90.
В системе STATISTICA имеется специальное средство — статистический
калькулятор — в диалоговом окне Другие критерии значимости, доступном из
стартовой панели модуля Основные статистики и таблицы. Калькулятор
позволяет быстро сравнить коэффициенты корреляции, вычисленные по разным
выборкам.
Бк Основные статистики и таблицы
^fl Описательные статистики
ЩЦ Корреляционные матрицы
Iftfj (критерий для независимых выборок
[>2j I критерий для зависимых выборок
jff[ Группировка и однофакторная AN0VA
Щ} Таблицы частот
${\\ Таблицы и заголовки
IjJn Вероятностный калькулятор
ИЯ Другие критерии значимости
В ак
Отмена
Ё? Данные
& Л
Другие критерии значимости
Г~ Печатать результаты после каждого вычисления
Различие между двумя коэффициентами корреляции
т 1: f80 g Nl.flOO j|
~ I
Отмене
.0100
I 'Вычислить,
f£ рШ Щ N2: (ТОО
Различие между двумя средними (нормальное распределение)
Г Односторонний I ,уп7ГДГтшп1
<• Двусторонний
Ст.откл.
Щ р: 1.0000 | Вычислить |j
С Односторонний
(• Двусторонний
С Ь (о" Щ Ст.откл. [Г
Г" Среднее выборки 1 в сравнении со средним популяции 2
Различие между двумя пропорциями -—-.......> ....:^;^.:
р: i.oooo r 0*hoct°pohh>* L.SgyiSP!!?,-!
(* Двусторонний
Пр.1;[
50
a M1:[Y5 щ
Rp.^fbo Э N2:fT5 Э
Почему важно
нормальное распределение
Нормальное распределение (термин был впервые введен Гальюном в 1889 г.),
иногда называемое гауссовским, важно по многим причинам. Распределение большого
числа статистик является нормальным или может быть получено из нормального
с помощью некоторых преобразований.
130
Глава 2. Элементарные понятия анализа данных
Стандартная нормальная кривая
♦ Ст опт содержит G8X всем иаблюаеиий
♦ 2 Ст 0ТК.Л содержит 95* все» наблюдении
Области, содержащие S8X и 96% маблюаемий. отмечены на графике
0 329
0219
0110
0000
^/
/ б8% \
95%
\
Рассуждая философски, можно сказать, что нормальное распределение
представляет собой одну из эмпирически проверенных истин относительно общей природы
действительности и его положение может рассматриваться как один из
фундаментальных законов природы. Точная форма нормального распределения (характерная
«колоколообразная кривая») определяется только двумя параметрами: средним и
стандартным отклонением.
Характерное свойство нормального распределения состоит в том, что 68% из
всех его наблюдений лежат в диапазоне 1 (стандартное отклонение от среднего),
а диапазон 2 стандартных отклонений включает 95% значений. Другими словами,
при нормальном распределении стандартизованные наблюдения, меньшие -2 или
большие +2, имеют относительную частоту менее 5% (стандартизованное
наблюдение означает, что из исходного значения вычтено среднее и результат поделен
на стандартное отклонение). Это и есть знаменитое правило 2 сигма или 2-стан-
дартных отклонения, вместе с правилом 3-ситаа чрезвычайно популярное на практике.
Плотность нормального распределения имеет вид:
f(x\ \i, a) =
1
aV27i
' 2о2
Множество величин на практике имеют нормальное распределение, например
распределение приращений индексов развитых стран, курсы акций и т. д.
Двумерное нормальное распределение. Переменная X - (Хь Х2) имеет
двумерное нормальное распределение, если любая линейная комбинация Z - Я/Х, +
а-^Х2 имеет либо нормальное, либо вырожденное распределение (которое также
можно считать нормальным со2в 0).
Двумерное нормальное распределение имеет плотность вида:
f(xl,x2,\il,\i2,G2,o22,p) =
1
21юха2^\-рЛ
• х ехр <
1
2A-Р2)
(х, - щJ 2р(*, - ^)(х, - ц2) (х2 - \i2J
ст,а9
x = (xv х2)Т, p = cov(Xp Х2)/(а,а2). ар а2>0, |р|<1
Как проверить нормальность наблюдаемых величин
131
где р — корреляция переменных Хь Х2, щ, <*i — среднее и стандартное отклонения
переменной Хь \i2, c2 — среднее и стандартное отклонения переменной Х2.
Заметим, что двумерное нормальное распределение легко обобщить на
многомерное нормальное распределение.
График двумерного распределения показан ниже:
Иллюстрация того, как нормальное
распределение используется
в статистических рассуждениях
Напомним пример, обсуждавшийся ранее, когда пары выборок мужчин и женщин
выбирались из совокупности, в которой среднее значение WCC для мужчин и
женщин было в точности одно и то же. Хотя наиболее вероятный результат таких
экспериментов (одна пара выборок на эксперимент) состоит в том, что разность
между средними WCCдля мужчин и женщин для каждой пары близка к 0, время от времени
появляются пары выборок, в которых эта разность существенно отличается от 0. Как
часто это происходит? Если объем выборок достаточно большой, то разности
«нормально распределены» и, зная форму нормальной кривой, вы можете точно
рассчитать вероятность случайного получения результатов, представляющих различные
уровни отклонения среднего от 0, — значения гипотетического для всей популяции.
Если вычисленная вероятность настолько мала, что удовлетворяет принятому
заранее уровню статистической значимости, то можно сделать лишь один вывод: ваш
результат лучше описывает свойства популяции, чем «нулевая гипотеза». Следует
помнить, что нулевая гипотеза рассматривается только по техническим
соображениям как начальная точка, с которой сопоставляются эмпирические результаты.
Как проверить нормальность
наблюдаемых величин
При проверке нормальности выборки часто руководствуются следующим
принципом Фишера: «Отклонения от нормального вида, если только они не слишком
заметны, можно обнаружить лишь для больших выборок, однако сами по себе эти
отклонения вносят малое отличие в статистические критерии и другие вопросы»,
(см. например, Справочник по прикладной статистике под редакцией Э. Ллойда
и У. Линдермана, М: Финансы и статистика, 1989, с. 270).
132
Глава 2. Элементарные понятия анализа данных
На практике для проверки нормальности обычно применяют визуальные
методы, например гистограммы, нормальные вероятностные графики или
численные методы с помощью оценки коэффициентов асимметрии и эксцесса;
используется также критерий хи-квадрат.
Пример (проверка нормальности с помощью оценок коэффициентов
асимметрии и эксцесса).
Рассмотрим классические данные Р. Фишера о количестве осадков в одном из
районов Англии (см. Fisher R. А. A970). Statistical methods for research workers,
15-th edition, Macmillan):
2
J
4
Б
e
7
8
В
10
t!
\2
!3
14
15
1$
f?
18
19
20
2Л
гг
23
24
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
12
33
34
35
36
37
38
39
0
0
3
3
3
3
2
К
A
7
4
8
3
6
7
4
4
4
3
3
0
1
m...i
Далее приводится последовательность действий, которую лучше всего
повторить, используя систему STATISTICA.
Шаг 1. Создайте файл STATISTICA и введите в него данные, представленные
в таблице. В первом столбце приведено количество осадков в дюймах. Во втором
столбце записана частота, с которой данное значение встречалось в измерениях.
Например, уровень 16 дюймов наблюдался 1 раз, уровень 17 дюймов — 0 раз,
уровень 18 дюймов — 0 раз и т. д.
Шаг 2. Запустите модуль Основные статистики и таблицы.
Шаг 3. В стартовой панели модуля выберите Основные статистики и нажмите
ОК.
Корреляционные матрицы
(-критерия для независимых выборок
U2J I-критерия для зависимых выборок
jfX Группировка и одно+акторная AN OVA
9Ш Таблицы частот
ЩЦ Таблицы и заголовки
%Л Вероятностный калькулятор
№д Другие критерии значимости
&'
ц[ &> а
Как проверить нормальность наблюдаемых величин
133
Шаг 4. В появившемся окне Описательные статистики нажмите кнопку
Переменные и выберите переменную УРОВЕНЬ.
LE
HiiTlHiuir
Iflliilli
|дЗ Переменные. I УРОВЕНЬ
|дк;1
Подробные описательные статистики
Отмена
Опции
Г~ Построчное мдалвиме ПД
Г~ Отображать длинные имена переменных
Г~ Вычислении с повышенной точностью
Статистики
Г Медиана м доартидм
Г Доверит, границы средни* I . и» jj\ g> fl,j
*
Интервал: J95.
VI Друнв статистики
|х В зе. моменты
Or свободы
<* 8-1 Г - N-1
Распределение -
ЙВ Т аблм&ы частот
Гистограммы
Г
г
Г i
Офтмровка
; <• Число интервалов: [75 Э
С Целые интервалы (категории)
smi
а
□
г> <
и -
tr:- -
■••■■уюм1*<* 1*ъ:***4\-> <>.■
>MsV**&0*'Ht*# »*>>оч'(!
'■ , ■Г№Ор*У.Ш>Г>Ы>- ?•-•;>:•
>.< >>;*>«*>«•> ©е}>{/.¥< *»*•■:« >♦»•
• >•••.;♦***♦«« jl >\ ;•■№»>
*«****«« |(ТГ^
.„■;,»>;.••< : •.-:.
>*~Kt>-v •'
,,<:>^5<, :,>,,,
^1® *■-,•
71^:V,-.
- 1 ВВ ' -
1 сто <
- 1 88
— .|Ю'-<
- - |88>>»
••••.,,. | ig?
*>>}>ЧИ
^< W
( Л{-*^
"{»>«
'>*v ^*>*х<- 4 ><<*П >'<*<****>• i-Л i*An>Hf> |
, «>? »»'<fW , ^Лф*» >•* 5« >»*<{>< J
<>«v *)««•(•»****'! < и'*?<Г',< Xrw?* j
>ft^**Mi-}r' W(«i<,»»»tf <-f>>4*»^*b« j
* v</ <<JJv- ДО »« {><>»>« <M «. >ч' , < <>¥<(<*!
'%* rm-({!ip**i*.iM j
Шаг 5. Далее в правом верхнем углу окна нажмите кнопку В. В появившемся
окне Задание веса выберите вес из переменной ЧАСТОТА. Нажмите ОК.
Дмчды щелкните м*
(• Bjyi rww еесса. чтобы
выбрать переменную из
Г ВЫ*Л стек*
Шаг 6. Нажмите кнопку Другие статистики и дайте указание системе, что вам
нужно вычислить асимметрию и эксцесс, а также их стандартные ошибки (см.
рисунок).
Gьдм..».«шо1
ftce
Чи< ло илЛоод^кй N
Г Среднее
f~ £ч»*ь»«
Г MftUHitlU
Г" ClfiMA«»t"»*>0 1
г л---■■.-.• и«
Г" Oj...;.,! ■•• «'
i Т> - » ' • .■ •
! " Мимь.у- • .«
Г HMktiMft и оно
Г" Ре змея
Г* Кдв41ТИ<|«>»1Ьи4
fx Асимм«хрмя
fx Дигаясг
fx (.т«»ш<ч""->и .
[х Стандартное <
|»лин«*
U*0> ,
(..„..-И.,
•.HH4N
If
**•
* ж. .
нме «нлртидм
рлзыл*
шил*,,
цк ]
(О
|»:Л..С1Л
г?Г|>ММ
.имела лисцесс*
134
Глава 2. Элементарные понятия анализа данных
Шаг 7. Нажмите ОК в окне Статистики и далее нажмите ОК в появившемся
окне Описательные статистики. Следующая таблица с результатами появится на
экране:
Из этой таблицы видно, что по абсолютной величине оценки асимметрии и
эксцесса имеют тот же порядок, что их ошибки. Следовательно, ни одна из
полученных величин не значима. Поэтому можно сказать, что данные согласованы с
гипотезой нормальности.
Продолжение примера (использование критерия хи-квадрат для проверки
нормальности).
Мы работаем с теми же данными по осадкам, что и в предыдущем примере.
Шаг 1. Запустите модуль Непараметрические статистики.
В стартовой панели модуля выберите опцию Подгонка распределения.
Так как нужно проверить согласие данных с нормальным распределением, в
списке Непрерывные распределения выберите Нормальное. Далее нажмите кнопку ОК.
шшт
вша
ЕЩ
;Г Н|Д|ч1Цгц||Щр1и
£;V-'-'^>%i **•''> v •,*•<. ' * '
x ... Д»
ftl
Шаг 2. В появившемся диалоговом окне Подгонка непрерывных распределений
нажмите кнопку Переменные и выберите переменную УРОВЕНЬ. Нажмите ОК.
шшшштшшшшш
J2 ЧАСТОТА
(ЗЛ/АЯЭ
44-VAR4
J5VAR5
tt-VAR6
J7VAR7
I8-VAR8
! J9-VAR9
llO-VARIO
ГуП
1522Е2^^2Я
4-*—* *
W
Шаг 3. Далее в правом верхнем углу окна нажмите кнопку В. Выберите веса из
переменной ЧАСТОТА.
Как проверить нормальность наблюдаемых величин
135
Шаг 4. В диалоговом окне Подгонка непрерывных распределений нажмите кнопку
ОК.
На экране появится следующая электронная таблица с результатами:
LIIIJ.IMLIUII.II.imUl.lJ.U.IJMiJllll.l
|статистика Копм-См d -0399655. р ■
ги-кввдрвт 5 093237. ее ■ 6. р ■ 5319227 (ст ев скор
• процент
маблюд.
частота
0
1
1
6
9
14
30
41
58
71
79
86
89
90
90
0 00000
1 11111
0 00000
5 55556
3 33333
5 55556
17 77778
12 22222
18 88889
14 44444
8 88889
7 77778
3 33333
1 11111
0 00000
0 0000
11111
11111
6 6667
10 0000
15 5556
33 3333
45 5556
64 4444
78 8889
87 7778
95 5556
98 8889
100 0000
100 0000
10964
29009
84542
2 07955
4 31762
7 56682
11 19396
13 97860
14 73523
1311186
9 84881
6 24468
3 34222
1 50990
82558 *
Во второй строке заголовка таблицы показано значение статистики хи-квадрат
и уровень значимости/? = 0,532.
Снова мы можем сказать, что данные согласованы с гипотезой нормальности.
Результат согласуется с тем, который был получен в первой части примера,
когда в качестве критерия нормальности использовались коэффициенты асимметрии
и эксцесса.
ЗАМЕЧАНИЕ
В первой строке заголовка таблицы указаны значения статистики Колмогорова—Смирнова. Этот
критерий также можно использовать для проверки нормальности. Результат также незначим.
136
Глава 2. Элементарные понятия анализа данных
Посмотрим на результаты в графическом виде.
Шаг 5. В диалоговом окне Подгонка непрерывных распределений нажмите кнопку
График.
На экране появится гистограмма значений переменной Осадки. Из графика
также видно хорошее согласие данных с нормальным распределением.
УРОВЕНЬ . распределение Нормальное
УРОВЕНЬ
статистика Колм-См. d «.0399656. р ■ на.
х и-квадрат: 5.093237, ее ■ 6, р ■ .5319227 (ее. скор.)
20, ■ ■ ■ ■—■ ■ ■ ■
Ш ML
ill11
l£±_J
1214161820 2224 2628 3032 3436 3840 42
Группа (■•рх. границы)
Ожидаемы*
Этот классический пример иллюстрирует схему действий в системе STATIS-
TICA при проверке нормальности данных.
Все ли статистики критериев нормально
распределены?
Не все, но большинство из них либо имеют нормальное распределение (особенно
при большом числе наблюдений), либо имеют распределение, связанное с
нормальным и вычисляемое на основе нормального, такое как t, Fили хи-квадрат. Обычно
эти статистики требуют, чтобы анализируемые переменные сами были нормально
распределены в совокупности, то есть удовлетворяли бы «предположению».
Многие наблюдаемые переменные действительно нормально распределены, что
является еще одним аргументом в пользу того, что нормальное распределение
представляет «фундаментальный закон». Проблема может возникнуть при попытке
применить тесты, основанные на предположении нормальности, к данным, не
являющимся нормальными. В подобных случаях вы можете выбрать одно из двух.
Во-первых, вы можете использовать альтернативные «непараметрические»
тесты (или так называемые «свободно распределенные тесты»), особенно полезные,
если число наблюдений мало.
Как альтернативу во многих случаях вы можете все же использовать тесты,
основанные на предположении нормальности, если уверены, что объем выборки
достаточно велик.
Последняя возможность основана на чрезвычайно важном принципе,
позволяющем понять популярность тестов, основанных на нормальности: при
возрастании объема выборки форма распределения статистики критерия приближается к
нормальной, даже если распределение исследуемых переменных не является
нормальным. Этот принцип называется центральной предельной теоремой.
Оценка объема выборки
137
Как узнать последствия нарушений
предположений нормальности?
Хотя многие утверждения предыдущих параграфов можно доказать
математически, некоторые из них не имеют теоретического обоснования и могут быть
продемонстрированы только эмпирически, с помощью так называемых экспериментов
Монте-Карло. В этих экспериментах большое число выборок генерируется на
компьютере, а результаты, полученные из этих выборок, анализируются с помощью
различных тестов. Этим способом можно эмпирически оценить тип и величину
ошибок или смещений, которые вы получаете, когда нарушаются определенные
теоретические предположения используемых тестов, например, вы можете
искусственно изменить распределение выборки, сделать его отличным от нормального
и проверить результат.
Монте-Карловские исследования интенсивно использовались для того, чтобы
оценить, насколько тесты, основанные на предположении нормальности,
чувствительны к различным нарушениям предположений нормальности.
Общий вывод этих исследований состоит в том, что последствия нарушения
предположения нормальности менее фатальны, чем первоначально
предполагалось. Хотя эти выводы не означают, что предположения нормальности можно
игнорировать, они увеличили общую популярность тестов, основанных на
нормальном распределении.
Оценка объема выборки
В большинстве ситуаций на практике у нас нет доступа ко всей популяции
(генеральной совокупности) в целом (например, популяция слишком большая, процесс
измерения слишком дорог и т. д.). Таким образом, мы имеем дело с ограниченным
объемом данных — выборкой, и поставлены перед необходимость принимать
решение относительно всей популяции на основе лишь выборочных данных. Для
того чтобы оценить некоторую характеристику популяции, которую назовем
параметром, мы строим выборку и вычисляем на ее основе некоторую статистику,
которую рассматриваем как оценку искомого параметра.
Представьте, вы врач и вас интересует доля людей с данным заболеванием или
вы политик и вас интересует доля людей, поддерживающих вашу позицию. Пусть ваш
избирательный округ — большой город, в котором проживают около 1 500 000
человек, имеющих право голоса. В данном случае интересующий параметр я, доля
всех людей, поддерживающих вас. Как понять, насколько велика эта доля? Вы
можете поступить следующим образом: выбрать наудачу группу людей и
выяснить их мнение. Назовем выбранную группу выборкой, а количество элементов
в ней (в данном случае людей) объемом выборки. Число людей (N) в выборке
будет относительно небольшим в сравнении со всей популяцией. Опросив
людей в выборке, вы получите не точное значение интересующего вас параметра я,
а оценку — обозначим ее через р.
138
Глава 2. Элементарные понятия анализа данных
Формально р вычисляется так: p=N1/N, где N1 — число людей,
поддерживающих вашу кандидатуру, N — объем выборки.
Эквивалентная формула имеет вид:
p = p(N) = ^/N (*)
£, = 1, если 2-й респондент поддерживает вас, ^ = 0 в противном случае.
Возникает вопрос: какова точность этой оценки? В зависимости от ответа на данный
вопрос вы предпримете то или иное действие.
Очевидно, что параметр я не будет равен в точности оценки р. Величина
отклонения р от я называется ошибкой.
Таким образом, в любой построенной по выборке оценке содержится ошибка,
точная величина которой неизвестна, в противном случае вы могли бы точно
вычислить значение параметра, что в принципе невозможно сделать, имея дело с частью
популяции, то есть с выборкой.
В общем, можно сказать, чем больше объем выборки N, тем меньше ошибка
оценки. Если вам нужно точное решение относительно параметра р, вам необходимо
взять N достаточно большим, чтобы ошибка была «разумно малой», например,
опросить всех жителей города. Если N слишком мало, то мало шансов получить
хорошую оценку.
С другой стороны, если взять объем выборки N слишком большим, улучшение
точности оценки окажется незначительным. Итак, если N «достаточно большое»,
чтобы обеспечить приемлемый уровень точности, то дальнейшее увеличение объема
данных не приводит к неоправданной трате времени и средств.
Таким образом, ключевым вопросом является: какой уровень точности будет
иметь оценка для данного объема выборки?, а также связанный с ним: какой
размер выборки нужно иметь, чтобы достичь приемлемого уровня точности?
Выборочное распределение представляет собой распределение статистики
критерия в повторных выборках.
Рассмотрим выборочную оценку р, построенную по выборке объема N в
предположении, что значение я в точности равно .50. Статистическая теория
утверждает, что р имеет биномиальное распределение (как сумма независимых
случайных величин, принимающих два значения: 1 или 0).
Это распределение при достаточно больших N в силу теоремы
Муавра—Лапласа, являющейся частным случаем центральной предельной теоремы,
приближается к нормальному распределению со средним я и стандартным отклонением,
вычисляемым по формуле:
o = yJn(l-n)/N .
Заметим, что часто полезной оказывается оценка: а < 1 / 2^1 / N.
Предположим, что объем выборки N равен 100. Тогда распределение/? имеет
следующий вид (напомним, мы считаем, что я = .5):
Оценка объема выборки
139
Distribution of th« Sjmpl* Proportion
N- 100. Pi- .50
0 0 1
Sjmpl* Proportion (p)
Из рисунка видно, что значения статистики сосредоточены вокруг точки .5, но
небольшой процент значений больше .6 или меньше .4. Этот разброс значений
оценок отражает тот факт, что опрос общественного мнения проводился среди 100
человек и поэтому не является абсолютно точным значением вероятности успеха я.
Если бы р была «совершенной» оценкой я, разброса значений не было бы, и
стандартная ошибка равнялась бы 0. Тогда выборочное распределение имело бы
выброс в точке 0.5. Выброс выборочного распределения говорит о том, насколько
много «шум» смешивается с «сигналом» от параметра.
Заметим, что стандартная ошибка/? стремится к 0 при увеличении объема
выборки N (N стоит в знаменателе). Если N становится достаточно большим, то
оценка р будет все более точной (см. формулу для вычисления ошибки).
Предположим, вы используете критерий, описанный ранее. Допустим, вы
решили, что, если р больше .58, то нулевая гипотеза: «я меньше или равно .50» неверна.
Критическая область этого критерия показана ниже.
ИЩЬрс
1 °
1 °
1 <в
2 о
1 о
1 £
0
1 °
vbh.SIfj
Distribution of tb« Sjmpl* Proportion
N ■ 100. Pi ■ .50
Л *.
• v •
* *
tow»>«wwun4v4auM»«<<4&*v
ы
с
y
VK
0 0 0 11
Sjmplt Proportion (p)
R@E3
1
Проведя несложные подсчеты (например, используя формулу биномиального
распределения), легко определить, что вероятность отвергнуть нулевую гипотезу
140
Глава 2. Элементарные понятия анализа данных
при п = .50 равна .044. Следовательно, для выбранного решающего правила
ошибка I рода а находится на уровне не ниже .044.
Теперь важно понять, какова мощность этого критерия.
Предположим, что 55% избирателей поддерживают политика, то есть я = .55
и нулевая гипотеза не верна. В этом случае правильное решение состоит в том,
чтобы отвергнуть нулевую гипотезу в пользу альтернативы.
На рисунке ниже показано выборочное распределениер при условии, что п = .55.
Ясно, что политики принимают верные решения, поддерживаемые большинством,
только в очень малом проценте случаев. Вероятность того, что р больше .58, равна
только .241.
Нечего и говорить, что нет смысла проводить эксперимент, в котором ваша
точка зрения верна только в 24.1% опытов! В таком случае говорят, что критерий
значимости имеет «недостаточную мощность, чтобы обнаружить 5%-ное отклонение
от нулевой гипотезы».
Суть проблемы лежит в ширине этих двух распределений (при различных
гипотезах). Если объем выборки становится большим, то стандартная ошибка доли
уменьшается и область перекрытия двух распределений соответственно
уменьшается. Таким образом, при достаточно большой выборке можно найти критерий с
высокой мощностью и данным уровнем значимости а.
Следующие рассуждения вообще типичны при проверке гипотез. Назовем
исходную гипотезу «нулевая гипотеза» — Н0. Например, доля поддерживающих
политика выше 0.5 или прививка от гриппа привела к снижению заболеваемости.
Для проверки гипотезы мы организуем сбор данных, извлекаем выборку.
Используя статистическую теорию, видим, что гипотеза Н0, вероятно, неверна и должна
быть отвергнута.
Отвергая Н0, мы обосновываем то, во что верим. Эта ситуация, типичная во
многих областях приложения, отвергая нулевую гипотезу, вы подтверждаете теорию.
Нулевая гипотеза либо справедлива, либо ошибочна, и статистическая
процедура недвусмысленно указывает на это. Нулевая гипотеза либо отвергается, либо
не отвергается.
Следовательно, до проведения эксперимента вы постулируете, что имеют место
только 4 возможности, показанные ниже:
Визуальный подход к анализу мощности
141
Решение
Но
н,
Верная гипотеза
Но
Правильное
принятие
Ошибка
1рода
а
н,
Ошибка
II рода
Р
Правильное
отвержение
Как вы видите, применение статистического критерия приводит к ошибкам двух
видов.
Конечно, идеальным вариантом было бы уменьшение обеих ошибок (первого и
второго рода), однако реальное положение вещей такое, что при фиксированном
объеме выборки этого достичь нельзя. Поэтому мы фиксируем уровень а и
стараемся сделать ошибку второго рода C как можно меньше.
Обычно считается, что ошибка первого рода а должна принимать значение .05
или ниже, тогда как ошибка второго рода C должна быть столь малой, насколько
это возможно при фиксированном уровне ошибки первого рода.
«Статистическая мощность», которая по определению равна 1 - C (единица
минус ошибка второго рода), соответственно, должна быть максимально высокой.
Идеальный вариант, когда мощность равна, по крайней мере, .80, чтобы
обнаружить разумные отклонения от нулевой гипотезы.
Поставим вопрос: какой объем выборки N необходим, чтобы достичь разумно
высокой мощности в ситуации, когда а фиксировано на разумно низком уровне.
Конечно, можно опытным путем установить нужный объем выборки,
например, используя метод Монте-Карло. Однако программное обеспечение позволяет
это сделать автоматически с помощью нескольких движений мыши. Модуль
STATISTICA Анализ мощности предлагает различные аналитические и
графические процедуры, позволяющие представить зависимость между мощностью и
размером выборки. При работе с модулем Анализ мощности предполагается, что вы
будете применять хорошо известный лги-квадрат-критерий чаще, чем точный
биномиальный критерий.
Например, предположим, что в обсуждаемом нами примере политик хочет
достичь мощности .80 при я равном .55. Используя выборку объема 607, он получит
на выходе мощность, равную .8009. (Реальный уровень Альфа этого критерия
равен .0522.)
Визуальный подход к анализу мощности
Основные этапы проведения анализа мощности и вычисления объема выборки
состоят в следующем: определяется нулевая гипотеза и альтернативы, выбирается
критерий и исследуется мощность и требуемый объем выборки для обнаружения
данным критерием эффекта на разумном уровне.
142 Глава 2. Элементарные понятия анализа данных
В разбираемом примере, мы получили, что необходимая мощность @.8)
достигается при выборке объема 607 (р=.80). На практике, конечно, было бы неразумно
проводить только одно вычисление, основываясь на одном гипотетическом
значении. Более естественно рассмотреть, как зависит мощность от различных р}
иными словами, построить функцию зависимости мощности от р.
В обсуждаемом примере мы хотим понять с низкой вероятностью ошибиться,
будут или нет нашу точку зрения поддерживать более половины избирателей.
Графический анализ чрезвычайно полезен для понимания возможности
данного статистического критерия обеспечить нужную мощность.
Например, можно построить график зависимости мощности от объема
выборки в предположении, что истинная доля поддерживающих равна .55 (т.е. вас
поддерживают более 55% жителей).
На следующем графике показана мощность как функция объема выборки в
диапазоне от 20 до 2000 наблюдений (используется «нормальная аппроксимация»
биномиального распределения).
One Proportion: Sample Size Calculation
Test on One Proportion (HO: Pi <= PIO)
N vs. Power (Pi = 0.55. PiO = 0.5. Alpha = 0.05)
1.00
0.95
0.90
g
| 0.85
о
2
0.80
0.75
0.70
500 600 700 800 900 1000 1100 1200
Объем выборки N
Из графика видно, что мощность достигает приемлемого уровня (часто этот
уровень фиксируют между .80 и .90) на выборке, состоящей примерно из 600
наблюдений.
Следует помнить, что вычисления сделаны в предположении, что истинное
значение доли р равно.55. Возможно, что форма кривой (а значит, и наши оценки!)
очень чувствительна к величине р. Логично поставить вопрос: как чувствителен
наклон графика к изменению величины р?
Имеется несколько подходов к решению данного вопроса. Один состоит в том,
чтобы построить графики зависимости мощности от размера выборки для
разных значений р. Ниже показан график зависимости мощности от размера
выборки при р- .6.
Можно заметить, что увеличение мощности при возрастании N происходит
гораздо быстрее при р = .6 чем при р = .55. Это различие становится более заметно,
если построить два графика одновременно.
Визуальный подход к анализу мощности
143
Tlhpovbbd.STG
Ttst on Ont Proportion ( HO: Pi <- PC )
Power v» N (Pi - О 0. PiO - О 5. Alphj - О Об)
500 1000 1500
Sjmplt Sizt(N)
iHlhpovbbb.STG
Ttft on Ont Proportion ( MO: Pi <■ PiO )
Power ws N (PiO - 0 6. Alphj - 0 05)
500 1000 1500
Sjmplt Sizt (N)
Для данного уровня мощности график зависимости объема выборки отр
показывает чувствительность объема выборки к величине р. На следующем графике
показана зависимость объема выборки N, позволяющей достичь мощности .90 для
различных значений р, когда при нулевой гипотезе р = .50.
lHbpovbt(.SICj
Ttst on Ont Proportion (HO: Pi ■ PiO)
N v» Pi (Alphj • 0 05. PrO • 0 5. Power «0 0)
r
S. 800
i eoo
i
8 400
Population Proportion (Pi)
144
Глава 2. Элементарные понятия анализа данных
Из графика видно, как быстро уменьшается N дляр изменяющихся от .55 до .60.
Таким образом, чтобы надежно обнаружить различие .05 (от значения при нулевой
гипотезе .50), требуется взять объем выборки N больше 800, но, чтобы надежно
обнаружить различие .10 требуется всего лишь 200 (см. значение ЛГпри р = 0.6).
Очевидно, гораздо лучше быть осведомленным заранее о точности критерия, чем
оказаться поставленным перед фактом некорректности исследования и ошибки
при принятии решения.
В заключении сделаем замечание общего характера. Результат применения
критерия значимости заключается в утверждении — принять или отвергнуть нулевую
гипотезу. Такой подход часто не устраивает тех исследователей, кто
рассматривает нулевую гипотезу не как утверждение об отсутствии эффекта или нулевого
эффекта, а интересуется тем, насколько велик эффект, чем в точности он равен нулю
или нет. Таким образом, приходится ставить одну, две или три звездочки после
результатов в таблице, или приводить соответствующие р-уровни.
Вероятностные уровни иногда могут ввести в заблуждение относительно «силы»
результата, особенно когда они представлены без дополнительной информации.
Например, если в таблице дисперсионного анализа один эффект имел р-уровень
.019, а другой р уровень .048, то утверждение, что первый эффект сильнее второго,
возможно, будет ошибочным. Для правильной интерпретации полученного
результата необходима дополнительная информация. Чтобы понять это, предположим,
что некто установил р уровень .001. Это могло быть результатом слабого эффекта
и чрезмерно большого объема выборки, либо сильного эффекта в популяции и
умеренного объема выборки, либо очень сильного эффекта и малого объема
выборки. Аналогично,/? уровень .075 можно интерпретировать как комбинацию очень
сильного и малой выборки, либо незначительного эффекта и гигантской выборки.
Отсюда ясно, что следует внимательно сравнивать р-уровни и принимать во
внимание объем выборки и точность эксперимента.
Понижение размерности данных
Исследователи из различных областей часто сталкиваются с данными большой
размерности, иными словами, с таблицами данных, в которых много переменных
(столбцов). Естественное желание исследователя разумно сократить число
переменных, вводя новые переменные и объединяя некоторые переменные в одну.
Конечно, хотелось, чтобы эти новые переменные имели определенный смысл и
допускали разумную интерпретацию, а не вводились чисто формально.
Если вы хотите понизить размерность непрерывных данных, то можете
воспользоваться методами факторного анализа. Аналогом факторного анализа для
категориальных переменных является анализ соответствий, в котором роль компонент
дисперсии играют компоненты статистики хи-квадрат.
В анализе главных компонент определяются попарно ортогональные
направления максимальной вариации исходных данных, после чего данные
проектируются на подпространство меньшей размерности, порожденное найденными
компонентами. Далее эти компоненты могут рассматриваться как новые переменные,
Визуальный подход к анализу мощности
145
к которым применяются обычные методы многомерного анализа, например,
регрессионный анализ.
Для того чтобы понять основную идею, рассмотрим две зависимые
непрерывные переменные. Зависимость между двумя переменными можно обнаружить с
помощью двумерной диаграммы рассеяния. Полученная путем подгонки линия
регрессии дает графическое представление зависимости. Если определить новую
переменную на основе линии регрессии, изображенной на этой диаграмме, то такая
переменная будет включить в себя наиболее существенные черты обеих
коррелированных переменных. Итак, фактически, вы сократили число переменных и
заменили две зависимые переменные одной переменной.
Если вы имеете три зависимые переменные, то аналогичным образом можете
построить трехмерную диаграмму рассеяния и вновь провести линию регрессии,
вдоль которой разброс данных максимальный. После того, как вы нашли линию
регрессии, для которой дисперсия максимальна, вокруг нее остается некоторый
разброс данных, поэтому процедуру естественно повторить.
В анализе главных компонент именно так и поступают: после выделения
первого фактора определяется следующий фактор, максимизирующий остаточную
вариацию и т. д.
Таким образом, последовательно выделяются главные компоненты, которые по
самому способу построения оказываются некоррелированными или
ортогональными. Эта идея естественно распространяется на любое число переменных.
«~ Вероятностные
^у распределения
и их свойства
Случай является одним из наиболее загадочных явлений на свете, он внезапно
возникает и так же внезапно исчезает, — столь внезапно, что не позволяет нам
проникнуть в свою сущность. Только в XX веке математики научились оперировать
с вероятностью, хотя отдельные задачи о подсчете шансов в азартных играх
рассматривались еще в XV-XVI веках. Древние греки, приучившие нас к
количественному взгляду на мир, пришли бы в ужас, если бы узнали, что мы научились с
помощью теории вероятностей вычислять шансы и оценивать, какие события более
вероятны, а какие менее вероятны, например в актуарных расчетах или азартных
играх.
Знаменитые итальянские математики Кардано, Пачоли и Тарталья, а вслед за
ними Паскаль, Ферма, Гюйгенс в XVII веке разрабатывали все более и более
изощренные способы подсчета вероятностей в разнообразных игровых задачах и в
популярных лотереях. Их изобретательность была поистине удивительной!
Используя ограниченный и, на наш взгляд, примитивный язык, они смогли объяснить
глубокие явления. Существенное движение вперед произошло в тот момент, когда
прозорливые умы вдруг осознали, что очень схожие вероятностные законы
возникают в разных, на первый взгляд, задачах.
В чем состоит идея вероятностных
рассуждений?
Первый, самый естественный шаг вероятностных рассуждений заключается в
следующем: если вы имеете некоторую переменную, принимающую значения
случайным образом, то вам хотелось бы знать, с какими вероятностями эта переменная
принимает определенные значения. Совокупность этих вероятностей как раз и
задает распределение вероятностей. Например, имея игральную кость, можно a priori
считать, что с равными вероятностями 1/6 она упадет на любую грань. И это
происходит при условии, что кость симметричная. Если кость несимметричная, то
можно определить большие вероятности для тех граней, которые выпадают чаще,
а меньшие вероятности — для тех граней, которые выпадают реже, исходя из
опытных данных. Если какая-то грань вообще не выпадает, то ей можно присвоить ве-
Нормальное распределение
147
роятность 0. Это и есть простейший вероятностный закон, с помощью которого
можно описать результаты бросания кости. Конечно, это чрезвычайно простой
пример, но аналогичные задачи возникают, например, при актуарных расчетах,
когда на основе реальных данных рассчитывается реальный риск при выдаче
страхового полиса.
В этой главе мы рассмотрим вероятностные законы, наиболее часто
возникающие на практике.
Графики этих распределений можно легко построить в STATISTICA.
Нормальное распределение
Нормальное распределение вероятностей особенно часто используется в
статистике. Нормальное распределение дает хорошую модель для реальных явлений, в
которых:
1) имеется сильная тенденция данных группироваться вокруг центра;
2) положительные и отрицательные отклонения от центра равновероятны;
3) частота отклонений быстро падает, когда отклонения от центра становятся
большими.
Механизм, лежащий в основе нормального распределения, объясняемый с
помощью так называемой центральной предельной теоремы, можно образно описать
следующим образом. Представьте, что у вас имеются частицы цветочной пыльцы,
которые вы случайным образом бросили в стакан воды. Рассматривая отдельную
частицу под микроскопом, вы увидите удивительное явление — частица
движется. Конечно, это происходит, потому что перемещаются молекулы воды и
передают свое движение частицам взвешенной пыльцы.
Но как именно происходит движение? Вот более интересный вопрос. А это
движение очень причудливо!
Имеется бесконечное число независимых воздействий на отдельную частицу
пыльцы в виде ударов молекул воды, которые заставляют частицу двигаться по весьма
странной траектории. Под микроскопом это движение напоминает многократно и
хаотично изломанную линию. Эти изломы невозможно предсказать, в них нет никакой
закономерности, что как раз и соответствует хаотическим ударам молекул о частицу.
Взвешенная частица, испытав удар молекулы воды в случайный момент времени,
меняет направление своего движения, далее некоторое время движется по инерции,
затем вновь попадает под удар следующей молекулы и т. д. Возникает удивительный
бильярд в стакане воды!
Поскольку движение молекул имеет случайное направление и скорость, то
величина и направление изломов траектории также совершенно случайны и
непредсказуемы. Это удивительное явление, называемое броуновским движением, открытое
в XIX веке, заставляет нас задуматься о многом.
Если ввести подходящую систему и отмечать координаты частицы через
некоторые моменты времени, то как раз и получим нормальный закон. Более точно,
смещения частицы пыльцы, возникающие из-за ударов молекул, будут
подчиняться нормальному закону.
148
Глава 3. Вероятностные распределения и их свойства
Впервые закон движения такой частицы, называемого броуновским, на
физическом уровне строгости описал А. Эйнштейн. Затем более простой и интуитивно
ясный подход развил Ленжеван.
Математики в XX веке посвятили этой теории лучшие страницы, а первый шаг
был сделан 300 лет назад, когда был открыт простейший вариант центральной
предельной теоремы.
В теории вероятности центральная предельная теорема, первоначально
известная в формулировке Муавра и Лапласа еще в XVII веке как развитие знаменитого
закона больших чисел Я. Бернулли A654-1705) (см. Я. Бернулли A713), Ars
Conjectandi), в настоящее время чрезвычайно развилась и достигла своих высот
в современном принципе инвариантности, в создании которого существенную
роль сыграла русская математическая школа. Именно в этом принципе находит
свое строгое математическое объяснение движение броуновской частицы.
Идея состоит в том, что при суммировании большого числа независимых
величин (ударов молекул о частицы пыльцы) в определенных разумных условиях
получаются именно нормально распределенные величины. И это происходит
независимо, то есть инвариантно, от распределения исходных величин. Иными словами, если
на некоторую переменную воздействует множество факторов, эти воздействия
независимы, относительно малы и слагаются друг с другом, то получаемая в итоге
величина имеет нормальное распределение.
Например, практически бесконечное количество факторов определяет вес
человека (тысячи генов, предрасположенность, болезни и т. д.). Таким образом, можно
ожидать нормальное распределение веса в популяции всех людей.
Если вы финансист и занимаетесь игрой на бирже, то, конечно, вам известны
случаи, когда курсы акций ведут себя подобно броуновским частицам, испытывая
хаотические удары многих факторов.
(Н| График! 2 Линейный график
ННИ
Броуновское движение
X
Нормальное распределение
149
Г$ ГрафмкБ Линейный график
Броуиовско# движ#ни#
Формально плотность нормального распределения записывается так:
ф(х;я,а2) =
л/2я~-а
(х-аГ
' 2а2
г2_1
где а и о * — параметры закона, интерпретируемые соответственно как среднее
значение и дисперсия данной случайной величины (ввиду особой роли нормального
распределения мы будем использовать специальную символику для обозначения
его функции плотности и функции распределения). Визуально график
нормальной плотности — это знаменитая колоколообразная кривая.
Соответствующая функция распределения нормальной случайной величины
£(<я,сг2) обозначается Ф(х; <я,сг2) и задается соотношением:
ФО; д,а ) =РЩа^)< jc}=
-\/2я -а
X
(*-fl)
2а2
dt.
Нормальный закон с параметрами а = О и с2 = 1 называется стандартным.
Обратная функция стандартного нормального распределения, примененная к
величине 2, 0<z<1, называется пробит-преобразованием z, или просто пробитом z.
Воспользуйтесь вероятностным калькулятором STATISTICA, чтобы по х
вычислить 2 и наоборот.
Основные характеристики нормального закона:
среднее, мода, медиана: Е% = xmod = xmed = a\
дисперсия: D% = а2;
асимметрия: р{ = 0;
эксцесс: J32 = 0;
150
Глава 3. Вероятностные распределения и их свойства
Центральные моменты порядка k > s:
О при к = 2/и-1,
1-3-... •Bт-\)а2т при к = 2т,
т =3, 4,.
Из формул видно, что нормальное распределение описывается двумя параметрами:
а — mean — среднее;
а — stantard deviation — стандартное отклонение, читается: «сигма».
Иногда стандартное отклонение называют среднеквадратическим
отклонением, но это уже устаревшая терминология.
Приведем некоторые полезные факты относительно нормального распределения.
Среднее значение определяет меру расположения плотности. Плотность
нормального распределения симметрична относительно среднего. Среднее
нормального распределения совпадает с медианой и модой (см. графики).
«.
ллг»
0 110
/"
/
/
/
1.D
"\
\
\
ч
•10 1 t •
Плотность нормального распределения с дисперсией 1 и средним 1
а—ним
•Ю1
им
1007
0000
/
/
/
/
,*
/
► •»
"X
: \
J \
|
N
X
■^
Плотность нормального распределения со средним 0 и дисперсией 0,01
ВПйШШШЗШ
Плотность нормального распределения со средним 0 и дисперсией 4
Равномерное распределение
151
При увеличении дисперсии плотность нормального распределения
расплывается или растекается вдоль оси ОХ, при уменьшении дисперсии она, наоборот,
сжимается, концентрируясь вокруг одной точки — точки максимального значения,
совпадающей со средним значением. В предельном случае нулевой дисперсии
случайная величина вырождается и принимает единственное значение, равное
среднему.
Полезно знать правила 2- и 3-сигма, или 2- и 3-стандартных отклонений,
которые связаны с нормальным распределением и используются в разнообразных
приложениях. Смысл этих правил очень простой.
Если от точки среднего или, что то же самое, от точки максимума плотности
нормального распределения отложить вправо и влево соответственно два и три
стандартных отклонения B- и 3-сигма), то площадь под графиком нормальной
плотности, подсчитанная по этому промежутку, будет соответственно равна 95,45%
и 99,73% всей площади под графиком (проверьте на вероятностном калькуляторе
STATISTICA!).
Другими словами, это можно выразить следующим образом: 95,45% и 99,73%
всех независимых наблюдений из нормальной совокупности, например
размеров детали или цены акций, лежит в зоне 2- и 3-стандартных отклонений от
среднего значения.
Равномерное распределение
Равномерное распределение полезно при описании переменных, у которых каждое
значение равновероятно, иными словами, значения переменной равномерно
распределены в некоторой области.
Ниже приведены формулы плотности и функции распределения равномерной
случайной величины, принимающей значения на отрезке [а, Ь].
/<(*) =
FJx) =
при а<х<Ь;
Ъ-а
[О при х<аи х>Ь.
О при х<а;
х-а
Ь-а
1 при х>Ь.
при а<х<Ь\
Из этих формул легко понять, что вероятность того, что равномерная
случайная величина примет значения из множества [с, d\ с [а, Ь], равна (d — с)/(Ь — а).
Положим а - О, Ъ - 1. Ниже показан график равномерной плотности
вероятности, сосредоточенной на отрезке [0,1].
152
Глава 3. Вероятностные распределения и их свойства
02
Ojl 1 1 1
2 1 0 1 ?
Числовые характеристики равномерного закона:
г.* а + Ь
среднее, медиана: Eg = xmed = ;
дисперсия: D% = —;
асимметрия: Д = 0;
эксцесс: р2 =-1,2.
Экспоненциальное распределение
Имеют место события, которые на обыденном языке можно назвать редкими. Если
Т— время между наступлениями редких событий, происходящих в среднем с
интенсивностью X, то величина Г имеет экспоненциальное распределение с
параметром X (лямбда). Экспоненциальное распределение часто используется для описания
интервалов между последовательными случайными событиями, например
интервалов между заходами на непопулярный сайт, так как эти посещения являются
редкими событиями.
Это распределение обладает очень интересным свойством отсутствия
последействия, или, как еще говорят, марковским свойством, в честь знаменитого
русского математика Маркова А. А., которое можно объяснить следующим образом.
Если распределение между моментами наступления некоторых событий является
показательным, то распределение, отсчитанное от любого момента t до
следующего события, также имеет показательное распределение (с тем же самым параметром).
Иными словами, для потока редких событий время ожидания следующего
посетителя всегда распределено показательно независимо от того, сколько времени
вы его уже ждали.
Показательное распределение связано с пуассоновским распределением: в
единичном интервале времени количество событий, интервалы между которыми
независимы и показательно распределены, имеет распределение Пуассона. Если
интервалы между посещениями сайта имеют экспоненциальное распределение, то
количество посещений, например в течение часа, распределено по закону Пуассона.
Распределение Эрланга
153
Показательное распределение представляет собой частный случай
распределения Вейбулла.
Если время не непрерывно, а дискретно, то аналогом показательного
распределения является геометрическое распределение.
Плотность экспоненциального распределения описывается формулой:
Это распределение имеет только один параметр, который и определяет его
характеристики.
График плотности показательного распределения имеет вид:
f*| Г рафик в График5 ?М график
Экспоненциальны плотность с параметром 1
уекрогЦМ)
Основные числовые характеристики экспоненциального распределения:
среднее: Ед = —;
M^a:^mod=°;
медиана: xmed = — In 2;
дисперсия: £>£ = — ;
Я1
асимметрия: Д = 2;
эксцесс: f} = 6.
Распределение Эрланга
Это непрерывное распределение сосредоточено на @, 1) и имеет плотность:
(лц)" „ч _n]ix
Р(Х)=Г(П)Х 6 '
где /г, п — параметры, \х > 0, п — целое.
154
Глава 3. Вероятностные распределения и их свойства
Математическое ожидание и дисперсия равны соответственно — и —г-.
ju nju
Распределение Эрланга названо в честь А. Эрланга (A. Erlang), впервые
применившего его в задачах теории массового обслуживания и телефонии.
Распределение Эрланга с параметрами \i и п является распределением суммы
п независимых, одинаково распределенных случайных величин, каждая из
которых имеет показательное распределение с параметром п/л.
При п - 1 распределение Эрланга совпадает с показательным или
экспоненциальным распределением.
Распределение Эрланга с разными параметрами
и-1 —п-1
п-2
- - • п-3
• 2 4 I S 1t 12 14 11 1t 2t 22 24 2С 2t М 32 34 М М 4t 42 44 4* 4t SI
Распределение Лапласа
Функция плотности распределения Лапласа, или, как его еще называют, двойного
экспоненциального, используется, например, для описания распределения
ошибок в моделях регрессии. Взглянув на график этого распределения, вы увидите,
что оно состоит из двух экспоненциальных распределений, симметричных
относительно оси OY.
Если параметр положения равен 0, то функция плотности распределения
Лапласа имеет вид:
f(x) = h-e-MA
(-<»<JC<°°).
Основные числовые характеристики этого закона распределения в
предположении, что параметр положения нулевой, выглядят следующим образом:
среднее: Е% = 0;
м°Да: *mod=°;
медиана: xmed=0;
Гамма-распределение
155
дисперсия: Dg = —;
Я
асимметрия: fi{ = 0;
эксцесс: J32=3.
UIIHU>IUUUIIWJ ЩЦ-ПИ
Функция плотности
уН*р!»оЦж,0,1)
0960
0413
0 276
0 138
0000
-
У
^,^'
1
1
/
/
\
\
\
\
S
\
Xv
"~^—-
В общем случае плотность распределения Лапласа имеет вид:
/М = — -е е -оо<Д:<оо,
2о
где
а — среднее распределение;
Ь — параметр масштаба;
е — число Эйлера B,71...).
-10 9 8 7 •€ б 4 3 2 1 О 1 2 3 4 5 6 7 8 9 10
Гамма-распределение
Плотность экспоненциального распределения имеет моду в точке 0, и это иногда
неудобно для практических применений. Во многих примерах заранее известно,
что мода рассматриваемой случайной переменной не равна 0, например, интерва-
156
Глава 3. Вероятностные распределения и их свойства
лы между приходами покупателей в магазин электронной торговли или заходами
на сайт имеют ярко выраженную моду. Для моделирования таких событий
используется гамма-распределение.
Плотность гамма-распределения имеет вид:
JA(a,b)\X) ~
-хаЧе-Ьх
Па)
О при х<0
при О < х < °°;
где Г — Г-функция Эйлера, а > О — параметр «формы» и b > О — параметр
масштаба.
В частном случае имеем распределение Эрланга и экспоненциальное
распределение.
Основные характеристики гамма-распределения:
среднее: Еу(а,Ъ) = —\
о
м°да: *mod = —г- (пРи а *!);
дисперсия: Dy(a9b) = —;
Ъ
асимметрия: j3{ =-=;
_2_
л/я
эксцесс: р2=—%
а
Ниже приведены два графика плотности гамма-распределения с параметром
масштаба, равным 1, и параметрами формы, равными 3 и 5.
fj График в График 1 ?М график
Функцил пленное 1и
y~g«mm«(x,3)
Логнормальное распределение
157
I и in ii ii ^m
ФуНМДИЯ ПЯ01ИОС1И
y*g«mm*(x,5)
1.75
0.50
1.25
0.00 I -^ 1 11LLJ
1.0 2.5 5.1 7.5 10.1 !
Полезное свойство гамма-распределения: сумма любого числа независимых
гамма-распределенных случайных величин (с одинаковым параметром масштаба Ь)
yl(al9b) + y2(a2,b) + --- + yn(an9b) также подчиняется гамма-распределению, но
с параметрами я, + я 2 + • • • + я „ иЬ.
Логнормальное распределение
Случайная величина h называется логарифмически нормальной, или логнормаль-
ной, если ее натуральный логарифм AпА) подчинен нормальному закону
распределения.
Логнормальное распределение используется, например, при моделировании
таких переменных, как доходы, возраст новобрачных или допустимое отклонение от
стандарта вредных веществ в продуктах питания.
Итак, если величина х имеет нормальное распределение, то величина у = ех имеет
логнормальное распределение.
Если вы подставите нормальную величину в степень экспоненты, то легко
поймете, что логнормальная величина получается в результате многократных
умножений независимых величин, так же как нормальная случайная величина есть
результат многократного суммирования.
Плотность логнормального распределения имеет вид:
(lnjc-lnaJ
/*(*) =-г— е~ 2°2 *
1 л/2я ох
Основные характеристики логарифмически нормального распределения:
среднее: Ег/ = ае2 ;
Mojx^xmod=ae-a2;
медиана: xmed = a;
дисперсия: D7j = (E7jJ(ea2 -X) = a2ea\eal -1);
158
Глава 3. Вероятностные распределения и их свойства
асимметрия: /?, =(еа -1J(еа +2);
эксцесс: р2=(е°2 -\)(еъ°2 + Ъе2°2 + 6е°2 +6)
|"| График в Г рафик. 3 2М график
0.721
Функция плотности
y-k>gnorm(x,0,1)
ИНЕЗ
€% График в ГрафикЭ: 2М график
нгас
Функция плотности
y-lognor m(x, 2,1)
Г^График в График/: 2М график
ВИС
Функция плотности
y-lognorm(x,0,0.5)
0.994
0.497
0.000
0.722
1.444 2.186 2.888
Хи-квадрат-распределение
159
Хи-квадрат-распределение
Сумма квадратов т независимых нормальных величин со средним 0 и дисперсией 1
имеет хи-квадрат-распределение с т степенями свободы. Это распределение
наиболее часто используется при анализе данных.
Формально плотность хи-квадрат-распределения с т степенями свободы имеет
вид:
-W*) =
1
*М1
/я, _*
.7" „ 2
х2 е % jc > 0.
При отрицательных х плотность обращается в 0.
Основные числовые характеристики хи-квадрат-распределения:
среднее: Ех2{т)-т\
мода: 7nmod=/n-2;
дисперсия: Dx2{m) = 2т;
з
22
асимметрия: Д =—=;
4т
12
эксцесс: р2 =—.
/п
График плотности приводится на рисунке ниже:
£"! График о График! 2М графи
Функция плотности
y-chi2(x,10)
0.175
0.131
0.087
0.044
0.000
0.00
625
12.50
18.75
■ЧГ-Ш
25.00 :
160
Глава 3. Вероятностные распределения и их свойства
ШЗШВШВШЕВШ
Probability densNu function
Chi2 distribution
0.3
02
0.1
/,
/ \
/ ''
/
m-2
v-
4<
F«l
У
\.
--.....
|m-17 [
2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36
Биномиальное распределение
Биномиальное распределение является наиболее важным дискретным
распределением, которое сосредоточено всего лишь в нескольких точках. Этим точкам
биномиальное распределение приписывает положительные вероятности. Таким
образом, биномиальное распределение отличается от непрерывных распределений
(нормального, хи-квадрат и др.), которые приписывают нулевые вероятности
отдельно выбранным точкам и называются непрерывными.
Лучше понять биномиальное распределение можно, рассмотрев следующую игру.
Представьте, что вы бросаете монету. Пусть вероятность выпадения герба естьр,
а вероятность выпадения решки есть q = 1 - р (мы рассматриваем самый общий
случай, когда монета несимметрична, имеет, например, смещенный центр
тяжести—в монете сделана дырка).
Выпадение герба считается успехом, а выпадение решки — неудачей. Тогда
число выпавших гербов (или решек) имеет биномиальное распределение.
Отметим, что рассмотрение несимметричных монет или неправильных
игральных костей имеет практический интерес. Как отметил Дж. Нейман в своей
изящной книге «Вводный курс теории вероятностей и математической статистики»,
люди давно догадались, что частота выпадений очков на игральной кости зависит
от свойств самой этой кости и может быть искусственно изменена. Археологи
обнаружили в гробнице фараона две пары костей: «честные» — с равными
вероятностями выпадения всех граней, и фальшивые — с умышленным смещением центра
тяжести, что увеличивало вероятность выпадения шестерок.
Параметрами биномиального распределения являются вероятность успеха
р (q = 1 - р) и число испытаний п.
Биномиальное распределение полезно для описания распределения
биномиальных событий, таких, например, как количество мужчин и женщин в случайно
выбранных компаниях. Особую важность имеет применение биномиального
распределения в игровых задачах.
Точная формула для вероятности т успехов в п испытаниях записывается так:
/(>") =
т\-(п—т)\
•Р 'Я
Биномиальное распределение
161
где
р — вероятность успеха;
q равно 1-р,р, q>~0,p + q - 1;
п — число испытаний, т = 0,1 ...т.
Основные характеристики биноминального распределения:
среднее: Evp{n) = пр\
М0Даxmod: P(n + \)-\<xmod <р{п +1);
дисперсия: D vp (п) = прA - р);
1-2р
асимметрия: р =
^прA-р)'
эксцесс: Д = 1"М1-Р)
прA-р)
График этого распределения при различном числе испытаний п и
вероятностях успеха р имеет вид:
^тишишяш
тштттттт
шШШШМвЩ/шшйЛшшлшшм
Бмиомиы»1юа реслредеяеиме с г
0 24
0.20
0 10
0.12
ом
| 0.04
. 1
мреминреми р-#Д n»1i
.!:...
12Э460710 10
wtmtsstrru
1 V**3
Бимомивлымм распределение с пер#мв1ремм p"#.J, n*i§
L24
t.2t
Ml
•.12
t.M
M4
Mt
I
■ I I
•
■
-
«
_.
\
\
I
II. I
| VAftt
162
Глава 3. Вероятностные распределения и их свойства
Биномиальное распределение с пар ■тирами р»*.7, n-1i
•.24
Mt
М2
t.M
t.M
. I
Ll_ _J
1 2 3 4 S I 7 • S It 11 12 13 14 15 I VARe
bll'MIIUIHIIIilWir—
Биномиальное распределение с параме1рами p"t.7, na1tt
; Ml i
I VAR7
(Г)! рафик40 Столбчатая диаграмма
Биномиально* распределение с параметрами р«0.0$, п-100
I Р_0_05
Биномиальное распределение *од
Биномиальное распределение связано с нормальным распределением и
распределением Пуассона (см. ниже); при определенных значениях параметров при
большом числе испытаний оно превращается в эти распределения. Это легко
продемонстрировать с помощью STATISTIC А.
Например, рассматривая график биномиального распределения с
параметрами р=0,7, п = 100 (см. рисунок), мы использовали STATISTICA BASIC, — вы
можете заметить, что график очень похож на плотность нормального распределения
(так оно и есть на самом деле!).
График биномиального распределения с параметрами р=0f05f n = 100 очень
похож на график пуассоновского распределения.
Как уже было сказано, биномиальное распределение возникло из наблюдений
за простейшей азартной игрой — бросание правильной монеты. Во многих
ситуациях эта модель служит хорошим первым приближением для более сложных игр и
случайных процессов, возникающих при игре на бирже. Замечательно, что
существенные черты многих сложных процессов можно понять, исходя из простой
биномиальной модели.
Например, рассмотрим следующую ситуацию.
Отметим выпадение герба как 1, а выпадение решки — минус 1 и будем
суммировать выигрыши и проигрыши в последовательные моменты времени. На
графиках показаны типичные траектории такой игры при 1000 бросков, при 5000
бросков и при 10 000 бросков. Обратите внимание, какие длинные отрезки времени
траектория находится выше или ниже нуля, иными словами, время, в течение
которого один из игроков находится в выигрыше в абсолютно справедливой игре,
очень продолжительно, а переходы от выигрыша к проигрышу относительно
редки, и это с трудом укладывается в неподготовленном сознании, для которого
выражение «абсолютно справедливая игра» звучит как магическое заклинание. Итак,
хотя игра и справедлива по условиям, поведение типичной траектории вовсе не
справедливо и не демонстрирует равновесия!
Конечно, эмпирически этот факт известен всем игрокам, с ним связана
стратегия, когда игроку не дают уйти с выигрышем, а заставляют играть дальше.
Результаты бросаний правильной монеты A000 бросков)
30
20
10
S 0
-10
-20
-30
0 100 200 300 400 500 600 700 800 900 1000
164
Глава 3. Вероятностные распределения и их свойства
ал
Результаты бросаний правильной монеты E000 бросков)
сшш;
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
шмшштн
■ JDlxi
Результаты бросаний правильной монеты A5000 бросков)
100 г
0 2000 4000 6000 8000 10000 12000 14000
1000 3000 5000 7000 9000 11000 13000 15000
Рассмотрим количество бросков, в течение которых один игрок находится в
выигрыше (траектория выше 0), а второй — в проигрыше (траектория ниже 0). На
первый взгляд кажется, что количество таких бросков примерно одинаково. Однако
(см. захватывающую книгу: Феллер В. Введение в теорию вероятностей и ее
приложения. М: Мир, 1984, с.106) при 10 000 бросках идеальной монеты (то есть для
испытаний Бернулли ср - q - 0,5, п-10 000) вероятность того, что одна из сторон
будет лидировать на протяжении более 9 930 испытаний, а вторая — менее 70,
превосходит 0,1.
Удивительно, что в игре, состоящей из 10 000 бросаний правильной монеты,
вероятность того, что лидерство поменяется не более 8 раз, превышает 0,14, а
вероятность более 78 изменений лидерства приблизительно равна 0,12.
Итак, мы имеем парадоксальную ситуацию: в симметричном блуждании
Бернулли «волны» на графике между последовательными возвращениями в нуль (см.
графики) могут быть поразительно длинными. С этим связано и другое
обстоятельство, а именно то, что для Тп/п (доли времени, когда график находится выше
оси абсцисс) наименее вероятными оказываются значения, близкие к 1/2.
Распределение арксинуса
165
Математиками был открыт так называемый закон арксинуса, согласно которо-
Т
му при каждом 0 < а <1 вероятность неравенства — <а, где Т п — число
п
шагов, в течение которых первый игрок находится в выигрыше, стремится к
1 с dx 2 . г-
— \ , =— arcsiiWfl.
7CJo ^X(l-X) 1С
Распределение арксинуса
Это непрерывное распределение сосредоточено на интервале @,1) и имеет
плотность:
Функция распределения имеет вид:
F{x) = 2я " arcsin
Распределение арксинуса связано со случайным блужданием. Это
распределение доли времени, в течение которого первый игрок находится в выигрыше при
бросании симметричной монеты, то есть монеты, которая с равными
вероятностями S падает на герб и решку. По-другому такую игру можно рассматривать как
случайное блуждание частицы, которая, стартуя из нуля, с равными
вероятностями делает единичные скачки вправо или влево. Так как скачки частицы —
выпадения герба или решки — равновероятны, то такое блуждание часто называется
симметричным. Если бы вероятности были разными, то мы имели бы несимметричное
блуждание.
График плотности распределения арксинуса приведен на следующем рисунке:
•0.1 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.0 1.0 1.1 |
Доля времени
166
Глава 3. Вероятностные распределения и их свойства
Самое интересное — это качественная интерпретация графика, из которой
можно сделать удивительные выводы о сериях выигрышей и проигрышей в
справедливой игре. Взглянув на график, вы можете заметить, что минимум плотности
находится в точке 0,5. «Ну и что?!» — спросите вы. Но если вы задумаетесь над этим
наблюдением, то вашему удивлению не будет границ! Оказывается, определенная
как справедливая, игра в действительности вовсе не такая справедливая, как может
показаться на первый взгляд.
Траектории симметричного случайного, в которых частица равное время
проводит как на положительной, так и на отрицательной полуоси, то есть правее или
левее нуля, являются как раз наименее вероятными. Переходя на язык игроков,
можно сказать, что при бросании симметричной монеты игры, в которых игроки
находятся равное время в выигрыше и проигрыше, наименее вероятны.
Напротив, игры, в которых один игрок значительно чаще находится в
выигрыше, а другой соответственно в проигрыше, являются наиболее вероятными.
Удивительный парадокс!
Чтобы рассчитать вероятность того, что доля времени т, в течение которой
первый игрок находится в выигрыше, лежит в пределах от t1 до t2> нужно из значения
функции распределения F(t2) вычесть значение функции распределения F(t1).
Формально получаем:
P{tKx<t2} - F(t2) - F(t1).
Опираясь на этот факт, можно вычислить с помощью STATISTIC А, что при 10 000
шагов частица остается на положительной стороне более чем 9930 моментов
времени с вероятностью 0,1, то есть, грубо говоря, подобное положение будет наблюдаться
не реже чем в одном случае из десяти (хотя, на первый взгляд, оно кажется
абсурдным; см. замечательную по ясности заметку Ю. В. Прохорова «Блуждание Бернул-
ли» в энциклопедии «Вероятность и математическая статистика», с. 42-43, М.:
Большая российская энциклопедия, 1999).
Отрицательное
биномиальное распределение
Это дискретное распределение, приписывающее целым точкам k = 0, 1,2,...
вероятности:
Рк=Р{Х = к}=Скг+к_1ргA-р)к>где0<р<1,г>0.
Отрицательное биномиальное распределение встречается во многих приложениях.
При целом г > 0 отрицательное биномиальное распределение интерпретируется
как распределение времени ожидания r-го «успеха» в схеме испытаний Бернулли
с вероятностью «успеха» р, например, количество бросков, которые нужно сделать
до второго выпадения герба, в этом случае оно иногда называется распределением
Паскаля и является дискретным аналогом гамма-распределения.
При г - 1 отрицательное биномиальное распределение совпадает с
геометрическим распределением.
Распределение Пуассона
167
Если Y — случайная величина, имеющая распределение Пуассона со случайным
параметром А, который, в свою очередь, имеет гамма-распределение с плотностью
1
вд
х"'хе'ах9 л: > 0, // > 0,
то Убудет иметь отрицательно биномиальное распределение с параметрами г = \х
а
и р =
Распределение Пуассона
Распределение Пуассона иногда называют распределением редких событий.
Примерами переменных, распределенных по закону Пуассона, могут служить: число
несчастных случаев, число дефектов в производственном процессе и т. д.
Распределение Пуассона определяется формулой:
/(*) =
XхНеосновные характеристики пуассоновской случайной величины:
среднее: Ev0 =Я;
дисперсия: Dv0 =Л;
1
асимметрия: Д =
эксцесс: /?2 =—.
л/Г
Распределение Пуассона связано с показательным распределением и с
распределением Бернулли.
Если число событий имеет распределение Пуассона, то интервалы между
событиями имеют экспоненциальное или показательное распределение.
График распределения Пуассона:
Распределение Пуассона с параметром 5
1.
.1.1 1..
2 Э 4 9 в 7 • 0 10 11 12 13 14 15 16 17 II 10 20 I ПУАССОН
168
Глава 3. Вероятностные распределения и их свойства
Сравните график пуассоновского распределения с параметром 5 с графиком
распределения Бернулли прир=^=0,5, п=100.
Вы увидите, что графики очень похожи. В общем случае имеется следующая
закономерность (см., например, превосходную книгу: Ширяев А. Н. Вероятность.
М: Наука, с. 76): если в испытаниях Бернулли п принимает большие значения,
а вероятность успеха р относительно мала, так что среднее число успехов
(произведение п нар) и не мало и не велико, то распределение Бернулли с параметрами п,
р можно заменить распределением Пуассона с параметром Я - п х р.
Распределение Пуассона широко используется на практике, например, в
картах контроля качества как распределение редких событий.
В качестве другого примера рассмотрим следующую задачу, связанную с
телефонными линиями и взятую из практики (см.: Феллер В. Введение в теорию
вероятностей и ее приложения. М: Мир, 1984, с. 205, а также Molina E. С. A935) Probability
in engineering, Electrical engineering, 54, p. 423-427; Bell Telephone System Technical
Publications Monograph B-854). Эту задачу легко перевести на современный язык,
например на язык мобильной связи, что и предлагается сделать заинтересованным
читателям.
Задача формулируется следующим образом. Пусть имеется две телефонные
станции — А и В.
Телефонная станция А должна обеспечить связь 2000 абонентов со станцией В.
Качество связи должно быть таким, чтобы только 1 вызов из 100 ждал, когда освободится
линия.
Спрашивается: сколько нужно провести телефонных линий, чтобы обеспечить
заданное качество связи? Очевидно, что глупо создавать 2000 линий, так как
длительное время многие из них будут свободными. Из интуитивных соображений ясно, что,
по-видимому, имеется какое-то оптимальное число линий N Как рассчитать это
количество?
Начнем с реалистической модели, которая описывает интенсивность
обращения абонента к сети, при этом заметим, что точность модели, конечно, можно
проверить, используя стандартные статистические критерии.
Итак, предположим, что каждый абонент использует линию в среднем 2
минуты в час и подключения абонентов независимы (однако, как справедливо замечает
Феллер, последнее имеет место, если не происходит некоторых событий,
затрагивающих всех абонентов, например войны или урагана).
Тогда мы имеем 2000 испытаний Бернулли (бросков монеты) или
подключений к сети с вероятностью успеха р-2/60-1/30.
Нужно найти такое N, когда вероятность того, что к сети одновременно
подключается больше N пользователей, не превосходит 0,01. Эти расчеты легко
можно решить в системе STATISTICA.
Решение задачи на STATISTICA.
Шаг 1. Откройте модуль Основные статистики. Создайте файл binomtsta,
содержащий 110 наблюдений. Назовите первую переменную БИНОМ, вторую
переменную - ПУАССОН.
Шаг 2. Дважды щелкнув мышью на заголовке БИНОМ, откройте окно
Переменная 1 (см. рисунок). Введите в окно формулу, как показано на рисунке. Нажмите
кнопку ОК.
Распределение Пуассона
169
Шаг 3. Дважды щелкнув мышью на заголовке ПУАССОН, откройте окно
Переменная 2 (см. рис.)
Введите в окно формулу, как показано на рисунке. Обратите внимание, что
мы вычисляем параметр Я распределения Пуассона по формуле Я - п Хр.
Поэтому Я - 2000 х 1/30. Нажмите кнопку ОК.
:-1Щ^
j-MPoitton(vO. 86 67)
При»йгй«тк* taw**«зла• 1991 - Фт&ы «vl *v2r
STATISTICA рассчитает вероятности и запишет их в созданный файл.
ш
щ
р
17932915481441
14962154195493
12349862619553
10083994221371;
08144974069924
06507644413006.
05143167109724
04020781452994;
03109338172823
02378544881279
01799915279134
16824907605534
14033911041369
11585546029094
09465649818746
07653676714149
06124512732208
04850142615164
03801225878085
02948407549279
02263376934871
01719675893199
00731161583547
00530040965263
00380185793569
00269833777141:
'00189511542052:
00709273651699
00517334853803
00373553209677
00267042798121
00189009414657
170
Глава 3. Вероятностные распределения и их свойства
Шаг 4. Прокрутите построениую таблицу до наблюдений с номером 86. Вы
увидите, что вероятность того, что в течение часа из 2000 пользователей сети
одновременно работают 86 или более, равна 0,01347, если используется биномиальное
распределение.
Вероятность того, что в течение часа из 2000 пользователей сети одновременно
работают 86 или более человек, равна 0,01293, если используется пуассоновское
приближение для биномиального распределения.
Так как нам нужна вероятность не более 0,01, то 87 линий будет достаточно,
чтобы обеспечить нужное качество связи.
Близкие результаты можно получить, если использовать нормальное
приближение для биномиального распределения (проверьте это!).
Заметим, что В. Феллер не имел в своем распоряжении систему STATISTICA
и использовал таблицы для биномиального и нормального распределения.
С помощью таких же рассуждений можно решить следующую задачу,
обсуждаемую В. Феллером. Требуется проверить, больше или меньше линий
потребуется для надежного обслуживания пользователей при разбиении их на 2 группы
по 1000 человек в каждой.
Оказывается, при разбиении пользователей на группы потребуется
дополнительно 10 линий, чтобы достичь качества того же уровня.
Можно также учесть изменение интенсивности подключения к сети в течение дня.
Геометрическое распределение
Если проводятся независимые испытания Бернулли и подсчитывается количество
испытаний до наступления следующего «успеха», то это число имеет
геометрическое распределение. Таким образом, если вы бросаете монету, то число
подбрасываний, которое вам нужно сделать до выпадения очередного герба, подчиняется
геометрическому закону.
Геометрическое распределение определяется формулой:
f(x) = p-(l-Py-\
гдер — вероятность успеха, х= 1,2,3...
Название распределения связано с геометрической прогрессией.
Итак, геометрическое распределение задает вероятность того, что успех
наступил на определенном шаге.
Геометрическое распределение представляет собой дискретный аналог
показательного распределения. Если время изменяется квантами, то вероятность успеха в
каждый момент времени описывается геометрическим законом. Если время
непрерывно, то вероятность описывается показательным или экспоненциальным законом.
Гипергеометрическое распределение
Это дискретное распределение вероятностей случайной величины Ху
принимающей целочисленные значения т = 0, 1,2,..., п с вероятностями:
Бета-распределение
171
N
где N, M и п — целые неотрицательные числа uM<N,n<N.
Гипергеометрическое распределение обычно связано с выбором без
возвращения и определяет, например, вероятность найти ровно т черных шаров в
случайной выборке объема п из генеральной совокупности, содержащей N шаров, среди
которых М черных и N - М белых (см., например, энциклопедию «Вероятность и
математическая статистика», М.: Большая российская энциклопедия, с. 144).
Математическое ожидание гипергеометрического распределения не зависит от N и
совпадает с математическим ожиданием /л = пр соответствующего биномиального
распределения.
2 N-n
Дисперсия гипергеометрического распределения с = npq + не превос-
N -\
ходит дисперсии биномиального распределения npq. При N—> °° моменты любого
порядка гипергеометрического распределения стремятся к соответствующим
значениям моментов биномиального распределения.
Это распределение чрезвычайно часто возникает в задачах, связанных с
контролем качества.
Полиномиальное распределение
Полиномиальное у или мультиномиальное, распределение естественно обобщает
распределение. Если биномиальное распределение возникает при бросании
монеты с двумя исходами (решетка или герб), то полиномиальное распределение в(?зни-
кает, когда бросается игральная кость и имеется больше двух возможных исходов.
Формально — это совместное распределение вероятностей случайных величин
X1t...,Xk> принимающих целые неотрицательные значения n1f...,nk, удовлетворяющие
условию п1 + ... + nk = п, с вероятностями:
ПХх=п, хк=пк}—^—р?...р?, PjZ0,Y.Pj=l. (*)
и,/...и к! J
Название «полиномиальное распределение» объясняется тем, что
мультиномиальные вероятности возникают при разложении полинома (р1 + ... + р^1.
Бета-распределение
Бета-распределение имеет плотность вида:
/p(a„a2)W-
Г(а1+а2) _а,-1л ча2-1
*а,"'A-;с)а2~' приО<х<\',
Цах)Т\а2)
О для остальных значений х.
172
Глава 3. Вероятностные распределения и их свойства
Стандартное бета-распределение сосредоточено на отрезке от 0 до 1. Применяя
линейные преобразования, бета-величину можно преобразовать так, что она будет
принимать значения на любом интервале.
Основные числовые характеристики величины, имеющей бета-распределение:
среднее: Efl(a{, а2) = ——
м°Да: *mod = — г (пРи а1>1иа2> 1);
а, + а2 — 2
дисперсия: В/г(а,,а2) = 2'*2 ;
асимметрия: д =_1J 1/Л/ ' 1—.
(a,+a2+2)V^
эксцесс: А = 3(д, + *2 + 1)[2(а, + а,)' +«,«,(«, + *2 -Q] _3.
а1а2(а1+а2+2)(а,+а2+3)
Распределение экстремальных значений
Распределение экстремальных значений (тип I) имеет плотность вида:
1 *~* —
f(x) = --e ь -е'е " -оо<х<оо9Ь>0,
где
в — параметр положения;
Ъ — параметр масштаба;
е — число Эйлера B,71...).
Это распределение иногда также называют распределением крайних значений.
Распределение экстремальных значений используется при моделировании
экстремальных событий, например уровней наводнений, скоростей вихрей,
максимума индексов рынков ценных бумаг за данный год и т. д.
Это распределение используется в теории надежности, например для описания
времени отказа электрических схем, а также в актуарных расчетах.
Распределения Релея
Распределение Релея имеет плотность вида:
1 *~в *~°
f(x) = --e b -е~* ь -оо<х<оо9Ь>0,
Распределение Вейбулла
173
где Ь — параметр масштаба.
Распределение Релея сосредоточено в интервале от 0 до бесконечности. Вместо
значения О STATISTICA позволяет ввести другое значение порогового параметра,
которое будет вычтено из исходных данных перед подгонкой распределения Релея.
Следовательно, значение порогового параметра должно быть меньше всех
наблюдаемых значений.
Если две переменные у1 и у2 являются независимыми друг от друга и
нормально распределены с одинаковой дисперсией, то переменная х = ^]у? + у\ будет иметь
распределение Релея.
Распределение Релея используется, например, в теории стрельбы.
£**|1 рафик о График. 4 ?М график.
HWE2
Плотность распределения Ре лед
y-rtyteigh(x,1)
0.667
0.S00
0.334
8.167
0.000
0.0 0.2 0.4 0.1 0.0 1.0 1.2 1.4 1.6 1.8 2.0 2.2 2.4 2.1 2.0 3.0
Распределение Вейбулла
Распределение Вейбулла названо в честь шведского исследователя Валодди
Вейбулла (Waloddi Weibull), применявшего это распределение для описания времен
отказов разного типа в теории надежности.
Формально плотность распределения Вейбулла записывается в виде:
Лф) = \Ша-хе*^, />0.
Иногда плотность распределения Вейбулла записывается также в виде:
/w=Hf)c °~x'b>
0, о 0,
где
Ь — параметр масштаба;
с — параметр формы;
е — константа Эйлера B,718...).
174
Глава 3. Вероятностные распределения и их свойства
Параметр положения. Обычно распределение Вейбулла сосредоточено на
полуоси от 0 до бесконечности. Если вместо границы 0 ввести параметр а, что часто
бывает необходимо на практике, то возникает так называемое трехпараметричес-
кое распределение Вейбулла.
Распределение Вейбулла интенсивно используется в теории надежности и
страховании.
Как описывалось выше, экспоненциальное распределение часто используется
как модель, оценивающая время наработки до отказа в предположении, что
вероятность отказа объекта постоянна. Если вероятность отказа меняется с течением
времени, применяется распределение Вейбулла.
При с = 1 или, в другой параметризации, при а = 1 распределение Вейбулла,
как легко видеть из формул, переходит в экспоненциальное распределение, а при
а = 2 — в распределение Релея.
Разработаны специальные методы оценки параметров распределения
Вейбулла (см. например, книгу: Lawless A982) Statistical models and methods for lifetime
data, Belmont, CA: Lifetime Learning, где описаны методы оценивания, а также
проблемы, возникающие при оценке параметра положения для трехпараметричес-
кого распределения Вейбулла).
Часто при проведении анализа надежности необходимо рассматривать
вероятность отказа в течение малого интервала времени после момента времени t при
условии, что до момента t отказа не произошло.
Такая функция называется функцией риска, или функцией интенсивности
отказов, и формально определяется следующим образом:
„@= т
\-F(t)
где
h(t) — функция интенсивности отказов или функция риска в момент времени t;
f(t) — плотность распределения времен отказов;
F(t) — функция распределения времен отказов (интеграл от плотности по
интервалу [0, ф.
В общем виде функция интенсивности отказов записывается так:
Л@ = Я0саа-\
где к0>0иа>0 — некоторые числовые параметры.
При ос = 1 функция риска равна константе, что соответствует нормальной
эксплуатации прибора (см. формулы).
При а < 1 функция риска убывает, что соответствует приработке прибора.
При а > 1 функция риска убывает, что соответствует старению прибора.
Типичные функции риска показаны на графике.
Распределение Вейбулла
175
тшшшшшшт
Функция риска, модулируемая распределениями Вейбулла
с различными параметрами
Функция риска, моделируемая распределениями Вейбулла
с различными параметрами
130 г
120
110
100
90
§ 80
70
во
50
40 I
|*-°-т|
I—И
.
li-U ,
10
12
ТМЕ
Ниже показаны графики плотности распределения Вейбулла с различными
параметрами. Нужно обратить внимание на три области значений параметра ос:
1. сс<1,
2. ос=1,
3. а>1.
В первой области функция риска убывает (период настройки), во второй
области функция риска равна константе, в третьей области функция риска возрастает.
Вы легко поймете сказанное на примере покупки нового автомобиля: вначале
идет период адаптации машины, затем длительный период нормальной
эксплуатации, далее детали автомобиля изнашиваются и функция риска выхода его из
строя резко возрастает.
Важно, что все периоды эксплуатации можно описать одним и тем же
семейством распределения. В этом и состоит идея распределения Вейбулла.
176
Глава 3. Вероятностные распределения и их свойства
| Плотность распределения Вембулле с переме?реми 10,6
j y-wett>uN(x,1ltM)
I 0.207 .
1.166
1.113
0.062
0.000
7.100 0.607
Плотность распределит* Веиоуяля с переметремм 1,2
ywe*buM<K,V,t)
0.043
0.700
0.472
1230
0J00
1.0 1.6 2.0 2.6 3.0 3.6 4.0 4.6 6.0
Плотное* распределения ВейОулле с переметремм 1,0.0
ywe4butt(M,M,l)
2.762
0.000
Приведем основные числовые характеристики распределения Вейбулла.
Среднее: Е\ = к" Г 1+- ;
Распределение Парето
177
мода:*т0A =1
О, если а <1;
-1 1
i а( 1V
к и— ,
если а >1;
дисперсия: D% = X
ГЦ-
сс
-Г2
момент &-го порядка: тк = Eq = Х0 • Г
1
1 +
ч а
fi+*
1 а
здесь Г(г) — так называемая гамлш-функция Эйлера, T(z) = \x"~le~"dx.
Распределение Парето
В различных задачах прикладной статистики довольно часто встречаются так
называемые усеченные распределения.
Например, это распределение используется в страховании или в
налогообложении, когда интерес представляют доходы, которые превосходят некоторую
величину со-
W = P{£<*} = 1-|^|,
а
лм=-
Основные числовые характеристики распределения Парето:
ос
среднее: Е = cQ (существует при а> 1);
а-1
мода:*тоA=с0;
медиана: xmed =2a -с0;
дисперсия: Z)£ =
а
(а-1J(а-2)
cl (существует при а>2);
178
Глава 3. Вероятностные распределения и их свойства
а
Момент &-го порядка: Е%к = cl (существует при a>k).
а-к
V% График, в График.5 2М графи
Функция плотности
yp»r*to{x,2)
Графикб: 2М график
Функция плотности
y«p»r*to(x.10)
Логистическое распределение
Логистическое распределение имеет функцию плотности:
-(*-«)
f(x) = — -e b
*/W 2b
-(x-a)
l + в b
где
a — параметр положения;
b — параметр масштаба;
e — число Эйлера B,71...).
Хотеллинга Т2-распределение
179
итим\шл1шиш1штт
Плотность логистического распределения с параметрами 2, 4
y-logis(x,2,4)
0.069 |
0.052
0.034
0.017
0.000
20 .16 12 -8 4 0 4
12 16 20
Хотеллинга Т2-распределение
Это непрерывное распределение, сосредоточенное на интервале @, Г), имеет
плотность:
Г
п+\Л
г2-\
'и-А;+П
(О 7
и/
где параметры nnkyn>k>1y называются степенями свободы.
При k e 1 Хотеллинга Т2-распределение сводится к распределению Стьюдента,
а при любом k > 1 может рассматриваться как обобщение распределения
Стьюдента на многомерный случай.
Распределение Хотеллинга строится исходя из нормального распределения.
Пусть ^-мерный случайный вектор У имеет нормальное распределение с
нулевым вектором средних и ковариационной матрицей 2.
Рассмотрим величину
где случайные векторы Z. независимы между собой и У и распределены так же, как У.
Тогда случайная величина Т2 = YTS'lY имеет Т2-распределение Хотеллинга
с п степенями свободы (У— вектор-столбец, Т — оператор транспонирования).
Если k - У, то Т2 = -
Т = '-
п
180
Глава 3. Вероятностные распределения и их свойства
где случайная величина tn имеет распределение Стьюдента с п степенями свободы
(см. «Вероятность и математическая статистика», Энциклопедия, с. 792).
Если У имеет нормальное распределение с ненулевым средним, то
соответствующее распределение называется нецентральным Хотеллинга Т2-распределением
с п степенями свободы и параметром нецентральности v.
Хотеллинга Т2-распределение используют в математической статистике в той
же ситуации, что и ^-распределение Стьюдента, но только в многомерном случае.
Если результаты наблюдений X1t..., Хп представляют собой независимые, нормально
распределенные случайные векторы с вектором средних \х и невырожденной
ковариационной матрицей X, то статистика
T2=n(X-M)TS-l(X-M),
где х = 1 2 Xt и S = —Х (Х{ -Х)(Х, -Х)\
Я , , /2—1
имеет Хотеллинга Т2-распределение с п - 1 степенями свободы.
Этот факт положен в основу критерия Хотеллинга.
В STATISTIC А критерий Хотеллинга доступен, например, в модуле Основные
статистики и таблицы (см. приведенное ниже диалоговое окно).
Распределение Максвелла
Распределение Максвелла возникло в физике при описании распределения
скоростей молекул идеального газа.
Это непрерывное распределение сосредоточено на @, «>) и имеет плотность:
-х2
pw=.(I4^. °>°- (*)
уя а
Распределение Коши
181
Функция распределения имеет вид:
F(x)
[а) \п а
2а
4U 1
е -I,
где Ф(х) — функция стандартного нормального распределения.
Распределение Максвелла имеет положительный коэффициент асимметрии и
единственную моду в точке х = 42с (то есть распределение унимодально).
Распределение Максвелла имеет конечные моменты любого порядка; матема-
/~2 ^7г — 8
тическое ожидание и дисперсия равны соответственно 2J—<т и <т2.
\к к
Распределение Максвелла естественным образом связано с нормальным
распределением.
Если Хг Х2, Х3 — независимые случайные величины, имеющие нормальное
распределение с параметрами 0 и о2, то случайная величина ^Jx? + Х\ + Х\ имеет
распределение Максвелла. Таким образом, распределение Максвелла можно
рассматривать как распределение длины случайного вектора, координаты которого в
декартовой системе координат в трехмерном пространстве независимы и нормально
распределены со средним 0 и дисперсией о2.
Распределение Коши
У этого удивительного распределения иногда не существует среднего значения,
так как плотность его очень медленно стремится к нулю при увеличении х по
абсолютной величине. Такие распределения называют распределениями с
тяжелыми хвостами. Если вам нужно придумать распределение, не имеющее
среднего, то сразу называйте распределение Коши.
Распределение Коши унимодально и симметрично относительно моды, которая
одновременно является и медианой, и имеет функцию плотности вида:
п с2+(х-аJ
f(x) = -'-rr7 ^"' -00<х<00>
где с > 0 — параметр масштаба и а — параметр центра, определяющий
одновременно значения моды и медианы.
Интеграл от плотности, то есть функция распределения, задается
соотношением:
_. ч l l , х-а
F(x) = — + — arcth .
2 п с
182
Глава 3. Вероятностные распределения и их свойства
ItlCTiTHFWPMTl
0.7
0.6
0.5
0.4
0.3
02
0.1
п п
шшшшшшшшшшшшшшшшшшшшиш
Probability density function
Cauchy distribution
i
/ -
• /
\
|C«ucfty@,0S) |
|Cauchy@,0 8)|
*JS^
4 \t [caucfty@,1)|
-3.0 2£ 22 1.8 1.4 -1.0 Л.6 4J.2 0.2 0.6 1.0 1.4 1.8 22 2£ 3.0
Распределение Стьюдента
Английский статистик В. Госсет, известный под псевдонимом «Стьюдент» и
начавший свою карьеру со статистического исследования качества английского пива,
получил в 1908 г. следующий результат. Пусть х0> xv..., хт — независимые, @, s2) —
нормально распределенные случайные величины:
t(m) =
описывается функцией:
/,(*) =
(-оо<^<оо).
Это распределение, известное теперь как распределение Стьюдента (кратко
обозначается как £(т)-распределения, где т — число степеней свободы), лежит в основе
знаменитого t-критерия, предназначенного для сравнения средних двух совокупностей.
Функция плотности ft(x) не зависит от дисперсии о2 случайных величин £. и,
кроме того, является унимодальной и симметричной относительно точки х = 0.
Основные числовые характеристики распределения Стьюдента:
среднее, мода, медиана: Et(m) = xmQd = xmed = 0;
дисперсия: Dt(m) =
асимметрия: /3=0;
т
т-2
(существует только при т>2);
F-распределение
183
эксцесс: Р2 т (существует только при т>4).
т —4
t-распределение важно в тех случаях, когда рассматриваются оценки среднего
и неизвестна дисперсия выборки. В этом случае используют выборочную
дисперсию и t-распределение.
При больших степенях свободы (больших 30) t-распределение практически
совпадает со стандартным нормальным распределением.
График функции плотности t-распределения деформируется при возрастании
числа степеней свободы следующим образом: пик увеличивается, хвосты более
круто идут к 0, и кажется, будто график функции плотности t-распределения
сжимается с боков.
11ИМИ11Ш
l.lalx
Probability density function
Student distribution
3fl 2,6 2Л Л» 1.4 1,0 Я.6 Q2 0,2 0,6 1,0 1,4 1,8 22 2,6 3,0
F-распределение
Рассмотрим т1 + m2 независимых и @, s2) нормально распределенных величин
£lv..£m,;77lv..,77m2 И ПОЛОЖИМ
-!-£«■
1 А 2*
г»/ \ "Ч /=1
F(ml9m2) = —*—
Очевидно, та же самая случайная величина может быть определена и как
отношение двух независимых и соответствующим образом нормированных
^-распределенных величин ^(т^ и tf(m2), то есть
F(m]9m2) = —L
— X\rnx)
— Z2(m2)
184
Глава 3. Вероятностные распределения и их свойства
Знаменитый английский статистик Р. Фишер в 1924 г. показал, что плотность
вероятности случайной величины F(m1f m2) задается функцией:
JF(m.,i
F(mltm2)
Л т, +т2 12 2
г ~т~^ г 'щ Дч
(*) = / Ч / \ —^ХГ, @<*<~),
{тЛАтЛ
\2) \2) (mtx+m.
)
где Т(у) — значение гамма-функции Эйлера в точке у, а сам закон называется
Y-распределением с числами степеней свободы числителя и знаменателя, равными
соответственно тп1 и тп2.
Основные числовые характеристики F-распределения:
среднее: EF(jnx,m2) = ——, (существуетприт>2)\
т2-2
м°Да: *mod =
_(т1-2)-т2
тх -(т2+2)
, (длят,>7);
__, ч 2/w, (/w, +/w9 — 2) , .ч
дисперсия: DF(ml9m2) = — 2 , (приту>7);
т1(т2-2У(т2-4)
„ Bm.+m2-2)J&(m2-4) , _ч
асимметрия: /?, = -—■ l v l , (прит2>б);
(Щ-Щ(т\ +гп2-2)тх
эксцесс: J32 = -
3(т2-6)B + 1д2)
w2-8
2 3, (прит2>5).
■Jcrfxl
1.2
1.0
0J
0.6
0.4
0.2
0.0
\ Im,x
V '
■ \ '
/
.. 1. Л .. . . . .
.т,=4
/
Probability dontlty function
Flthor distribution
]
[m,=10. m,=50 I
\ |т1ж4. ^Г
■■■V
4. - N
00 |
0,0 0,4 0,8 1,2 1,6 2.0 2,4 2,8
F-распределение возникает в дискриминантном, регрессионном и
дисперсионном анализе, а также в других видах многомерного анализа данных.
Подгонка
4 вероятностных
распределений
к реальным данным
Подгонкой (английский термин fitting) называют аналитические процедуры,
позволяющие подобрать распределение, которое с достаточной степенью точности
описывает наблюдаемые данные. Типы различных распределений описаны выше
в главе Вероятностные распределения.
Итак, имея значения переменной X, мы проверяем гипотезу, согласно которой
распределение X описывается вероятностным законом F.
Одним из популярных и простых критериев согласия наблюдаемых данных с
гипотезой является критерий хи-квадрат Пирсона.
Мы сформулируем этот критерий в общем виде, потому что в дальнейшем он
используется в нескольких задачах: как критерий согласия, критерий
однородности и критерий проверки независимости признаков в таблицах сопряженности
(см. главу 11).
Итак, пусть проводится п независимых испытаний, в результате которых
наблюдаются частоты (пи ... щ) попарно несовместных исходов (Хь ... X*),
составляющих полную группу событий, щ + ... + щ - п. Например, вы можете
представить себе, что бросаете игральную кость (кость имеет шесть граней, следовательно
k - 6, исходы 1, 2, 3, 4, 5, 6 — выпадающие очки) или наблюдаете независимые
реализации случайной величины, область изменения которой разбита на k>l
непересекающихся интервалов. Обозначим вероятность появления f-ro исхода в
каждом испытании через р,:
i-l9...k9pi+...+pk-l9pi>0.
Формально статистика хи -квадрат вычисляется так:
k
хи-квадрат = V (щ -nptJ /npi
/»i
Заметим, что иногда используют также греческое обозначение %2 для
статистики хи-квадрат.
Предположим, вам нужно проверить гипотезу Н0: р - р°, где р - (рь ... рО,
Р° ■ (р°ь... Р°к). Альтернативой является гипотеза, согласно которой эти
вероятности неравны, иными словами, Hi: p Ф р°.
186
Глава 4. Подгонка вероятностных распределений к реальным данным
Для проверки гипотезы Н0 против альтернативы Hi мы вычисляем статистику
хи-квадрат при значениях р = р°(то есть при гипотезе Н0). Затем, выбираем уровень
значимости а, и находим 1 - а квантиль %2 распределения с к - 1 степенью
свободы. Обозначим данную квантиль через %2 ^ к. Тогда критическая область
критерия Пирсона уровня а имеет вид:
Г к 1
[ /=1 J
Таким образом, если мы, наблюдая (пь... nk), получаем значение статистики х2,
превышающее уровень х2 i-cu, то отвергаем гипотезу Н0 в пользу альтернативы Нь
в противном случае гипотезу не отвергаем.
Обычно критерий хи-квадрат используют при числе наблюдений п > 50,
я,>5, г = 1,... k.
Заметим, что при проверке гипотезы, согласно которой случайная величина X
имеет распределение F, вероятности p°jможно вычислять по формуле:p°f= F(Xf) -
F(X, _ 0, где [X,-, Х,_ 0, i-й интервал группировки.
Взглянув на формулу, вы легко поймете, что статистика хи-квадрат разумно
сравнивает наблюдаемые и ожидаемые частоты. Статистика принимает значения
от нуля до бесконечности. Чем меньше значение статистики хи-квадрат, тем более
вероятно, что гипотеза верна, чем больше значение статистики хи-квадрат, тем
меньше вероятность того, что гипотеза соответствует данным.
Итак, статистика хи-квадрат — это разумная мера согласия (соответствия)
данных с гипотезой. Конечно, вы можете предложить собственную меру, например,
вместо квадрата в приведенной формуле использовать модуль или четвертую
степень, однако известно, что критерий Пирсона обладает свойством оптимальности.
Замечательно, что выборочное распределение статистики хи-квадрат при
гипотезе приближенно является распределением хи-квадрат с числом степеней
свободы k - 1 (число интервалов группировки минус 1) и не зависит от закона F.
Точность приближения, грубо говоря, зависит от числа наблюдений (что вполне
естественно).
Если у вас имеется много данных, объем выборки большой, вы можете считать,
что статистика хи-квадрат имеет в точности распределение хи-квадрат, и
рассчитать вероятность ошибки, связанной с отклонением правильной гипотезы.
Тонкости применения:
О ячейки, в которых ожидаемые при гипотезе частоты меньше 5, следует
объединять (так как ухудшается качество аппроксимации распределения
критериальной статистики распределением хи-квадрат);
О если проверяется параметрическая гипотеза и параметры распределения
оцениваются по данным, то число степеней свободы критерия хи-квадрат
равно k-m- 1, где т — число параметров вероятностной модели, которые
должны быть оценены по тем же данным, что и проверяемая гипотеза.
В системе STATISTICA все необходимые вычисления и поправки на число
степеней свободы производятся автоматически.
Пример 1. Подгонка распределения к данным: посещение непопулярного сайта 187
ример 1. Подгонка распределения
данным: посещение непопулярного сайта
Рассмотрим данные о числе посетителей нераскрученного сайта.
Е
ЧИ(
1*
*>
Г\
*
9
10
11
1
$
lllilllflfll
нПосетители
ПЕШ
сейте
1 •■■■ :;.:V'<1.:^ ":^:":^^^^Н
1 °
1
2
I 3
4 А
3 5
I 6
3 7
] 8
3 9
10
11
12
57
203
383
525
532
408
273
139
45
27
10
4
1
1|
Из файла видно, что за 57 часов сайт не посетило ни одного человека
(первая строка файла), за 203 часа — на сайте находился 1 человек (вторая строка),
за 383 часа — 2 человека и т. д.
Спрашивается, какой вероятностный закон описывает эти данные?
Графически данные представляются в виде:
ШШШШШ
Переменная, описывающее число посетителей (переменная varl), принимает
дискретные значения.
Проведем анализ в модуле Непараметрические статистики и подгонка
распределений.
Шаг 1. Откройте модуль Непараметрические статистики и подгонка распределений.
Выберите опцию Подгонка распределения.
В окне Дискретные распределения выберите распределение Пуассона (дважды
щелкните мышью).
188
Глава 4. Подгонка вероятностных распределений к реальным данным
ш
щщ
*^'Птутл рфщтщ тштрШ'^ »»Щ
X
Отмаи*
|— Равномерное
\_J Экспоненциальное
|/\. Гамма
1/V Логиормальиое
1/\. Хм квадрат
1*С Друме ...
Д|»жрат<>ме |мюпре*в*#ни*
L.. Геометрическое
|А Бериуяяи
<J*S >
■ л
- АЯЬТврнвТМвНЛЯ
Иодгойка''
распределен^
аоступн*{1}»мйв|р»
Анадопршдеоо»
{мргодм*&
правдоподобия для
' Р*СПРвАвлФИИЙ
экстремального, вата
раолр«в«л*нии,и2|
•Сгетисттаск** -
графиках fB^K-O,
|3)«номдоАи«*#; ;•
ыжие
в
as а! ва|
Шаг 2. На экране появится следующее окно:
fc.v-A.^ ■ Ау ■■ ■ ^й=... ■■<■•? ч. ,.VA:г.■■■■:=■■■■ -й
^МЙШНК ШИЧМЯР^*
4* ъ#рх±Ы±*ьш*ш*шшш
\!§&J!№
{ТрШ+Ш* Д tflttftltNlilll '1X31 (l| IMM Ж *;
I С-.Относительные частоты ОД;:
Нажмите кнопку Переменная и выберите переменную шг7 для анализа.
шз
J2-VAR2
!]3-VAR3
I4-VAR4
15-VAR5
гб-УАЯб
IJ7-VAR7
J8-VAR8
I9-VAR9
: J10-VAR10
1*..^>&*х*...,.\..г
Й1оорат»всё|
ДоДроО 1
ЦиФ.
Шаг 3. Нажмите кнопку веса Б, расположенную в правом верхнем углу
диалогового окна Подгонка дискретных распределений.
В появившемся окне Задание веса сделайте установки, как показано на рисунке
ниже; веса, в данном случае частоты, взяты из переменной var2. Нажмите ОК.
Затем нажмите О К в диалоговом окне Подгонка дискретных распределений.
Пример 1. Подгонка распределения к данным: посещение непопулярного сайта 189
LLSy rxJ " ч, v^ v. ^Д**Щ ;
Шаг 4. Программа вычислит оценку параметра распределения Пауссона,
равную 3,864, а также представит результаты в следующих таблицах.
НЕПАРАМ.
СТАТИСТ
Верхняя
раница
i-квадрат: 13 56034, се ■ 10, р ■ .1940654
М
..куиул..'
иаблюд
процент*
наблюд
ноблкш.
ожидаем,
частота
.•V" <к 1
гл •v>< -
.г
:n^v*^
***$. .^- •
6;
7,
•а г-'
& •.; • •
т-
'Весить/,
203
383
525
532
408
273
139
45
27-
10
4
57
260
643
1168
1700
2108
2381
2520 ;
2565 !
2592
2602
2606
2.18726
778972
14 69685
2014582
20 41443
15.65618
10.47583
533385
1 72678
103607
38373
15349
21873
99770
246738
44.8196
65 2341
80.8903
91.3661
966999
984267 !
994628
99 8465
100 0000
546752 |
211 2739
408.1983
525 7812
5079257
392.5414
252.8071
139 5553 :: ']
67.4080 . I
28 9417 |
111835 ;
5 7086 ~i
*И* Перем и VAH1 . распре
НЕПАРАМ
СТАТИСТ
Верхняя
раница
Ьси-квадрат 13 56034, ее ■ 10, р ■ 1940654
*!♦>-
«zife^^'»'
mmftmm у
'•Ъл&^&'Щ
Ы\№У>??
ЬффгФ^
54 6752
211 2739
408.1983
525.7812
507 9257
3925414
252 8071
139.5553
67.4080
28 9417
11.1835
5.7086
54.675
265 949
674147
1199.929
1707.854
2100.396
2353203
2492758
2560166
2589.108
2600292
2606.000
2 09805
810721
15.66379
2017579
19.49062
15.06298
9.70096
5.35515
2 58665
1.11058
.42915
.21906
2 0981
10.2053
25.8691
460448
65.5355
80.5985
902994
956546
982412
99.3518
99.7809
100.0000
I пчЛф.^Л i ' ' "
2 3248
-8 2739
-25.1983
-7812
240743
154586
201929
-5553
-224080
-1 9417
-1.1835
-1.7086 И
По уровню значимостир = 0,194 можно сделать вывод о том, что данные не
противоречат гипотезе о пуассоновском распределении. Вероятность ошибиться при
отклонении гипотезы довольно велика, примерно 0,2. Риск ошибиться достаточно
велик!
Для построения гистограммы установите переключатель в положение
Гистограмма.
190
Глава 4. Подгонка вероятностных распределений к реальным данным
Нажмите кнопку График в диалоговом ощне Подгонка дискретных
распределений. На экран будет выведена гистограмма с наложенным графиком ожидаемых
пуассоновских частот.
Орем я VAR1; раачикмтмиЕПуксома I -18642
юмаадрап 1154034. ее - 10, р - .1940654
600 г
Проверим, как согласуются другие распределения с данными. В качестве
примера рассмотрим биномиальное распределение.
Шаг 1. Вновь войдите в стартовую панель модуля. Проведем для
биномиального, распределения тот же анализ и сравним полученные результаты. В окне
Распределение выберите биномиальное распределение.
С JU Ь иj»4iniSiim^:.
Г JUL
С (hmvutvwum чивгты ft)
Шаг 2. Нажмите кнопку Переменные и, как и в первом случае, выберите для
анализа переменную varl.
Шаг 3. В случае биномиального распределения также необходимо задать веса
наблюдениям. Нажмите кнопку веса В в правом верхнем углу диалогового окна.
Пример 1. Подгонка распределения к данным: посещение непопулярного сайта 191
В появившемся окне Задание веса сделайте установки, как показано на рисунке
ниже, где веса, в данном случае частоты, взяты из переменной var2. Нажмите ОК.
IjT адм
ч • Диады щмкнмг* w ^
•'■ \.ножямоачтобы '
.'•.1 ******■■..•.'
Затем нажмите ОК в диалоговом окне Подгонка дискретных распределений.
Шаг 4. Биномиальное распределение имеет один параметр — вероятность успеха/?.
Программа оценит эту вероятость, используя метод максимального правдоподобия.
Оцененное значение 0,35129 появится в верхней полосе таблицы.
h МИп'И^ИН^Ч,- 'II ,!' 11'г ,■!
д»*«*
1хи-квадрвт 383.0659, ее - 8. р - 0 000000
процент
наблюл.
наблюл
ожидаем,
частоте
I,-.'--.
. ,г
.'.■л*ч-*лъ-.
-Ъ4*-'.г?>ь ■:
■ %• ■ -
* а
?♦ *
б.
9.
m
Бвск*ть
203
383
525
532
408
273
139
45
27
10
4
ЗП
57
260
643
1168
1700
2108
2381
2520
2565
2592
2602
2606
218726
7 78972
14 69685
2014582
20.41443
15.65618
10 47583
533385
1 72678
1 03607
38373
15349
21873
9 9770
24 6738
448196
65.2341
80 8903
91 3661
96 6999
98 4267
99 4628
99 8465
100 0000
22 3126
132 9087
3598599
5846081
6331476
480 0021
259 9281
100 5392
27 2217
49137
5322
0262
Шаг 5. Обратите внимание на значение статистики хи-квадрат, число степеней
свободы и уровень значимости в данном примере.
Статистика хи-квадрат принимает очень большое значение, а именно 383
(см. заголовок таблицы).
192 Глава 4. Подгонка вероятностных распределений к реальным данным
Число степеней свободы равно 8 (количество интервалов группировки минус
один оцененный параметр).
Из заголовка таблицы также следует, что гипотезу о согласии данных с
биномиальным распределением можно отвергнуть на уровне 0,0000. Иными словами,
отвергая гипотезу о биномиальном распределении, мы рискуем ошибиться с
практически нулевой вероятностью.
Таким образом, делаем вывод: данные абсолютно не согласуются с
биномиальным распределением.
Тот же результат можно увидеть, конечно, и на графике.
Нажав кнопку График (см. окно Подгонка дискретныхраспределений), постройте
гистограмму и график накопленных (кумулятивных) частот (выберите
соответствующие опции в правой части окна).
1т11ГмЧ11П'!111|;л111Л||:т^|11Ч':1|;1м;|г:11*Дт1иа
П«ри-1 VAR1 : рлспр«А«л«ми« Бимоиилльмо* р- .39120
хи-1МАрлт: 383.0060. со - 8. р - 0 00ООО0
Для того чтобы построить график распределения, установите переключатель в
положение Кумулятивное распределение и нажмите кнопку График.
Как видите, наблюдаемые частоты далеки от ожидаемых частот.
Таким образом, биномиальное распределение не подходит для описания
данных о числе посетителей нераскрученного сайта. Посещения нераскрученного сайта
по сути являются редкими событиями, и для их описания следует использовать
пуассоновское распределение.
айв
П«р«»1 VAR1 : рлопр«мл«ии«*иио«илльио« р- 36120
хи-олдрлт 383 0060. оо - 8. р - 0 ОООООО
3460780 10
Группл
Пример 2. Подгонка распределения к данным: посещение популярного сайта 193
ример 2. Подгонка распределения
данным: посещение популярного сайта
В течение нескольких сотен часов регистрировалось число посетителей
популярного сайта. Результаты приведены в таблице:
^Посетители сайте
г
4
S-
6
8
9
10
1
2
3
А
5
6
7
8
9
10
11
й v
;VVAR£.:,V •
12 .
108'
316
551
632
492 -
273
103.
24
13
2
Интерпретация этих данных проста: за 12 часов сайт не пометило ни одного
человека (первая строка файла), за 108 часов — на сайте находился 1 человек
(вторая строка), за 316 часов — 2 человека и т. д.
Графически данные представляются в следующем виде:
ItllHII'lllillUIIUIiyilllllB'llllliy'lHilllllllllllM^
Перем-я VAR1; распрядблениегБиномиальиое р - .Э9861
ЮМВДЦИ!: 4.159422, СС - 7, р - .7612366
700
Переменная, описывающая число посетителей, принимает дискретные
значения.
Спрашивается, какой вероятностный закон описывает эти данные?
Проведем анализ в модуле Непараметрические статистики и подгонка
распределений.
Шаг 1. Откройте модуль Непараметрические статистики и подгонка
распределений.
Выберите опцию Подгонка распределения.
194 Глава 4. Подгонка вероятностных распределений к реальным данным
В окне Дискретные распределения выберите биномиальное распределение
(дважды щелкните мышью).
IK Подгонка распределения
С Непараметрические статистики <•*
Непрерывные распределения:
|— Равномерное
|_.'' Экспоненциальное
|,А ^ Гамма
]Л>, Лог нормальное
\/\ Хи-квадрат
j Другие ...
Дискретные распределения:
ШЯ Биномиальное
Ji, Пуассона
'pli,,. Геометрическое
[А Бернчлли
Альтернативная
подгонке
распределений
доступна: A]е моду»
Анализ процессов
(метод макс,
греедоподобиядл*
распределений
Вейбуллз,
экстремального, бете
распределения..^ B)
в Статистических
графиках (В-В.МС),
C) в модуле Анализ
выживаемости.
&JL
Шаг 2. На экране появится следующее окно:
Ifjj Подгонка дискретным распределений
Саслредеяеиие: | Биномиальное
В йеременная:|УАВ1
, Чис^о груше рО
Нижняя граница: |0
Веэдияя граница: |М.
ЗЗамечвык Табулирование Пай тя£l I
данным основано на первых 6 V$rz Avr,JLmJ
значащих цифрах;
используйте ОСНО0НЫЕ
СТАТИСТИКИ для построения
стандартной таблицы частот. & ft
Отмена
Чисдо испытаний: |10. Щ
Критерий согласия Колмогорове-Смирноеа
! (i Цат. J."
С Да (грчгашроеаиные)
С Да (непрерывное)
График
График распределения
| •. (•• Гистограмма
С ^чмчлятиеное распределение
График исходных частот иди X
(• <£астоты по строкам
С Относительные частоты [X]
Нажмите кнопку Переменные и выберите переменную varl для анализа.
Выберите перемени*» д;
J2VAR2
3VAR3
4VAR4
5VAR5
J6VAR6
7-VAR7
J8VAR8
9-VAR9
10VAR10
Г^п
Отмене]
| Выбрать все)
Додроб. J
IT
ЙНФ.
Пример 3. Скачки вверх и вниз курса акций
195
Шаг 3. Нажмите кнопку веса В в правом верхнем углу диалогового окна
Подгонка дискретных распределений.
В появившемся окне Задание веса сделайте установки, как показано на рисунке
ниже; веса, в данном случае частоты, взяты из переменной var2. Нажмите ОК.
Затем нажмите ОК в диалоговом окне Подгонка дискретных распределений.
1 Задание веса ВЕЗ!
:>ft#c и» паремчтой: | flK } |
1VAR2 | Огнен*!
^IfifiSi поле eeooa. чтобы
t _ ! выорвгь переменную иэ !
СВЬЦСЯ |описк* л.
Шаг 4. Программа вычислит оценку параметра биномиального распределения
и представит результаты в следующих таблицах:
t-IIH'll'li'i.lllB-N'lil'^l^nil'lll'III'l.Tflil-ll'Ill
квадрат 4159422, ее ■ 7, р - .7612366
НЕПАРАМ
СТАТИСТ.
Верхняя
границе
процент •.
йаб
толкуй^;?;
иавякмх
ожидаем;
частоте
кумул.
ожидаем.
^ат:.Д-\:лЛ
2. ■■..:■.■.
3.
4.
5.
':•' 6.-
7.
8.
9.
Бвск-ть
108
316
551
632
492
273
103
24
13
2
[хи-квадрат 4.159422, се- 7, р-.7612366
шПеремяУАН! . распределение Бином
НЕ ПАРАМ
СТАТИСТ
Верхняя
граница
"И-
1
12
120
436
987
1619
2111
2384
2487
2511
2524
2526
ие Бино
.47506
427553
1250990
21 81314
25 01979
19 47743
10 80760
4 07759
.95012
.51465
.07918
миальное р-
.4751
47506
17 2605
39 0736
64 0934
835709
94 3785
98 4561
99 4062
999208
100 0000
39861
156301
103 6004
3090114
5461903
6335527
503 9236
2783455
105 4258
26 2047
3.8598
2558
15 630
119230
428 242
974 432
1607 985
2111 908
2390 254
2495 680
2521 884
2525 744
2526 000
•
(ЯЩПЕЗВ
ожидаем,
частоте
куму л.
ожидаем.
процент-
ожидаем.
куму я. %
ожидаем
наблюд-
ожидаем
2.
Беск-ть
га—
156301
103 6004
3090114
5461903
6335527
503 9236
2783455
105 4258
262047
38598
.2558
15630
119230
428 242
974.432
1607985
2111 908
2390254
2495 680
2521 884
2525744
2526 000
61877
410136
1223323
21.62274
25 08126
19.94947
11.01922
417363
1.03740
.15280
01013
6188
4 7201
16 9534
385761
63.6574
836068
94.6260
98.7997
99.8371
99 9899
100 0000
-3.6301
43996
69886
4.8097
-1.5527
-11 9236
-5.3455
-24258
-2 2047
91402
1 7442
>г
Значение статистики хи-квадрат очень небольшое, всего 4,16. Вспомните, что
небольшие значения статистики хи-квадрат свидетельствуют в пользу гипотезы.
196 Глава 4. Подгонка вероятностных распределений к реальным данным
Вопрос, что такое большое и что такое небольшое значение статистики, снимается
понятием уровня значимости.
По уровню значимости р = 0,7612366 окончательно заключаем, что данные
хорошо согласуются с гипотезой о биномиальном распределении.
Мы настоятельно рекомендуем вам еще раз прочитать ту часть главы
Элементарные понятия, где обсуждается понятие статистического критерия.
Проиллюстрируем приведенные выше таблицы графиком кумулятивного
распределения. Для этого установите переключатель в положение Кумулятивное
распределение и нажмите кнопку График.
1т11ГмЧ|1||||1|иши^1^н1у;11|г||'1,1чиЯг|йщ
Перемя VAR1; распределение:Биномиалыюе р - .39861
хм квадрат: 4.159422, ее - 7, р - .7612366
3000 ,
Ожидаемые
Для получения простой гистограммы установите переключатель в положение
Гистограмма.
Нажмите кнопку График в диалоговом окне Подгонка дискретных
распределений. На экране появится гистограмма наблюдаемых частот с наложенным
графиком ожидаемых частот.
\ЗШШШШШЖ
^ш
Перем-я VAR1; распределемие:Биномиальное р - .39861
хи-юадрат: 4.159422, се - 7, р - .7612366
700 |
Ожидаемые
В качестве легкого упражнения мы рекомендуем вам попробовать подогнать
пуассоновское распределение к данным о числе посетителей популярного сайта.
Пример 4. Количество покупок в магазине
197
Пример 3. Скачки вверх и вниз курса акций
Ниже показан фрагмент файла, содержащего колебания курса акций в течение дня.
Единица показывает, что курс пошел вверх (скачок вверх), 0 — курс акций
пошел вниз (скачок вниз).
В течение дня таких скачков может быть несколько сотен. Выдвигается
гипотеза, что частота тех и других скачков одинакова. Как быстро проверить эту гипотезу
в системе STATISTICA?
1000
0000
0 000
0 000
Toool
1000
1000
1000
0 000
1.000
0 000
1.000
0 000
0 000
Выделите данные и вызовите Быстрые основные статистики.,
Вы увидите следующую таблицу результатов:
Точечная оценка частоты появления 1 равна 0,39, 95% доверительный
интервал: @,292732,0,487268). Следовательно, гипотеза о том, что частота скачков уровня
вверх и вниз одинакова, должна быть отвергнута.
Пример 4. Количество покупок в магазине
Ниже показан файл с информацией о числе покупателей разной категории в
супермаркете.
Шёх*>
г
Ч 2971
157
85
51
27
17
198 Глава 4. Подгонка вероятностных распределений к реальным данным
Мы разбили покупателей на классы по числу сделанных покупок.
К категории 0 относятся покупатели, сделавшие не более 4 покупок, к
категории 1 — покупатели, сделавшие 5-6 покупок, к категории 2 — покупатели,
сделавшие 7-8 покупок, и т. д.
Найдем вероятностный закон, который описывает эти данные. Вы можете
подготовить файл данных и повторить за нами все действия.
Шаг 1. Откройте модуль Непараметрические статистики и подгонка распределений.
Выберите опцию Подгонка распределения. В окне Дискретные распределения
выберите геометрическое распределение (дважды щелкните на его названии
мышью).
BBS
I у| х
С Недареметрические статистики <? Поди
Непрерывные распределения:
оике распределения
U*
[■— Равномерное
\_J Экспоненциальное
[Л „ Гамма
|/У_ Л or нормальное
|Л„ Хи-квалрат
IX4 Др^мв ...
Дискретные распределения:
| .illli, Биномиальное
l.;i„, Пуассона
11.1 111. Вернул ли
| Огаеиа . _ |
Альтернативная
подгонка
распределений
достали* A) в модуле
Анали» процессов
(метод макс
правдоподобий дли
распределении
Вейбулл*.
экстремального, бета
распределения. Д B]
• Статистических
графиках fB-0, **},
C} в модуле Анализ
& W
ёа]
Шаг 2. На экране появится следующее окно:
дискретных распределений
£аспред олеине: ] Геометрическое
jg {Тереме*и»ая:| КАТЕГОР
3 Замечание: Таоа/июеени*
«*»**•* оснрвено на первых 8
Нижняя гранил.»: \0
Вердняя границе: у
Параметр р:} 4650324
Критерий согласия Колмогороеа-Сиириоеа
С Да (группированные)
С Не. (непрерывное)
значащих цифрах;
используйте ОСНОВНЫЕ
СТАТИСТИКИ для построения i ш„ \
СЭ К]шв Ml
j Отмена
Граенех распределения ~
(• Гистограмма
С .Кумулятивное распределение
График исяоднык частот или X
(• Н*ст0ты по строкам
С Относительные частоты [Х\
Нажмите кнопку Переменные и выберите переменную КАТЕГОР для анализа.
Шаг 3. Нажмите кнопку веса В в правом верхнем углу диалогового окна
Подгонка дискретных распределений.
В появившемся окне Задание веса сделайте установки, как показано на
рисунке ниже; веса (в данном случае — частоты) взяты из переменной ЧИСЛО.
Пример 5. Подгонка распределения Вейбулла к данным об отказах
199
Нажмите ОК. Затем нажмите ОК в диалоговом окне Подгонка дискретных
распределений.
Ныберите переменим» для анализа
АШШШГ
|2 ЧИСЛО
3VAR3
4VAR4
SVAR5
J6VAR6
I7-VAR7
8VAR8
9-VAR9
10-VAR10
Г¥~1
Отмена |
]В,ы6р«ть аса)
1 П«Ф<* |
НнФ.
Шаг 4. Сиситема вычислит оценку параметра геометрического распределения
и представит результаты в следующих таблицах.
ерем я KAILI UP . р<
шзшшзшш
|хи-квадрат 5 380912. ее - 6. р » 4959796
Еащ
нбблюд.
Пр0ЦвНТ
; НввЛЮД,
кумул. %
иаблюа
ожидаем
частоте
'куму п.
ожидаем
процент
ожидаем.
1.
1
г
4, "<
5.
в.
Бфск-ть
297 |
157
85
51
27
17
8
3
|.м»*й:Д.
297
454
539
590
617
634
642
645
4604651
24 34109
1317829
790698
418605
2 63566
1 24031
46512
460465
70 3876
83 5659
91 4729
95 6589
98 2946
99 5349
100 0000
299 9459
160 4613
85 8416
45 9225
24 5670
131426
7 0308
8 0882
299 9459
460 4072
546 2488
5921713
616 7383
629 8809
636 9118
6450000
4650324
24 87773
13 30878
711977
380884
2 03761
1 09005
1 25399 ^
£
ы* Перем н КАТ ЕГОР . pi
шш
[хи-квадрат; 5.380912. се ■ 6. р ■ 4959796
процент
наблюл.
ч куну л. Н
наблюл.
ожидаем
частоте
кумул.
ожидаем
процент
ожидаем.
кумул,?*
ожидаем.
наблкш,-
ожидаем.
веск-rw
4604651
24 34109
1317829
7 90698
4 18605
2 63566
1 24031
46512
46 0465
703876
83 5659
91 4729
95 6589
98 2946
99 5349
100 0000
299 9459
1604613
858416
45 9225
24 5670
131426
70308
80882
299 9459
460 4072
546 2488
5921713
616 7383
629 8809
636 9118
645 0000
4650324
2487773
13 30878
711977
3 80884
2 03761
1 09005
1 25399
46 5032
71.3810
84 6897
91 8095
956183
97 6560
98 7460
100 0000
-2 94589
-3 46133
-84161
5 07751
2 43296
3.85743
96915
-5 08821 у
200 Глава 4. Подгонка вероятностных распределений к реальным данным
По уровню значимости р в 0,4959796 можно сделать вывод, что данные
совместимы с гипотезой о геометрическом распределении.
Иными словами, наш риск ошибиться составляет примерно 50%, если мы
отвергаем гипотезу.
Визуально качество подгонки можно увидеть на графике.
Нажмите кнопку График, и следующая гистограмма появится на экране:
hll'f'.Mrlll^'llMHI'lJI^I'ri
ЗВЗЕШ
КАТЕГОР; распределение • Геомефич. параметр - .46503
хиквадраг 5.380912, ее - в, р - .4959796
350 ,
— Ожидаемые
Вы можете попробовать другие распределения для описания этих данных и
убедиться, что они очень плохо подходят к ним.
Итак, геометрическое распределение вполне адекватно описывает число
покупателей разных категорий в супермаркете.
Пример 5. Подгонка распределения
Вейбулла к данным об отказах
Одним из основных понятий качества продукции является ее надежность. Для
оценки надежности и времени жизни разработаны различные
статистические методы.
Надежность продукции является важным показателем качества. Покупая
магнитофон, пылесос, кофеварку, вы, конечно, хотите иметь представление об их
надежности. Особенный интерес представляет количественная оценка надежности,
позволяющая оценить ожидаемое время жизни, или, в инженерных терминах,
время безотказной работы купленного прибора.
Надежность связана с маркетинговой политикой, зная оценки надежности
продаваемых вами бытовых приборов и объемы продаж, вы можете рассчитать
количество гарантийных мастерских в городе.
Пример из другой области позволяет по-иному взглянуть на ту же ситуацию.
Предположим, вы летите на маленьком личном самолете с единственным
двигателем. Тогда для вас жизненно важно знать вероятность отказа двигателя на
различных этапах его эксплуатации (например, после 500 часов, после 1000 часов и т. д.)
Очевидно, имея хорошую оценку надежности двигателя и доверительный интер-
Пример 5. Подгонка распределения Вейбулла к данным об отказах
201
вал, можно принять рациональное решение о том, когда следует заменить
двигатель или отправить его на капитальный ремонт. Конечно, вы можете положиться
на волю случая и летать, сколько угодно, однако цель нашей книги — научить вас
рационально анализировать случайность.
Обычно времена жизни описываются распределением Вейбулла (см.
предыдущую главу), поэтому одним из основных этапов статистических процедур,
связанных с оценкой надежности, является оценка параметров этого распределения.
Для большинства исследуемых приборов функция интенсивности отказов имеет
форму U-образной кривой: на ранней стадии жизни изделия риск выхода из строя
(отказ) достаточно велик, далее интенсивность отказов уменьшается до
определенного предела (оптимальный режим функционирования), затем вновь
увеличивается из-за износа изделия.
Например, автомобили в начале эксплуатации часто имеют несколько мелких
дефектов и выходят из строя. После того как автомобиль прошел обкатку, риск
поломки существенно уменьшается. Затем интенсивность отказов (выходов из
строя) возрастает, достигая своего максимального значения, например, после 20 лет
эксплуатации и 250 000 миль пробега, когда практически любой автомобиль
выходит из строя.
Распределение Вейбулла позволяет гибко моделировать возникающие на
практике функции интенсивности отказов.
Задавая разные параметры распределения, можно получить практически
любые функции риска.
Ранняя фаза кривой аппроксимируется распределением Вейбулла с
параметром формы меньше У, постоянная фаза — распределением Вейбулла с параметром
формы 1, а фаза старения или износа моделируется распределением Вейбулла с
параметром формы больше 1.
После того как на основе реальных данных оценены параметры распределения
Вейбулла, можно вычислить различные характеристики надежности, например,
когда откажет заданная доля тестируемых приборов.
Функция надежности, обычно обозначаемая R(t), представляет собой
вероятность того, что объект проживет больше t временных единиц.
Формально функция надежности определяется равенством R(t)=1-F(t), где
F— функция распределения времени жизни. Иногда функция надежности
называется также функцией выживания.
Цензурирование. В большинстве исследований по надежности не все
объекты завершаются отказами. Иными словами, к концу исследования известно, что
определенное количество приборов не отказало, но исследование завершено и
точные времена жизни этих приборов неизвестны. Такие наблюдения
называются неполными, или цензурированными. Заметим, что цензурирование может
осуществляться разными способами, так же как имеется много различных планов
тестирования приборов.
Например, так называемое цензурирование типа I применяется в ситуации,
когда заранее фиксируется время наблюдения отказов (допустим, мы берем 100 ламп
и оканчиваем эксперимент, например, после 120 часов после начала).
В этом случае время эксперимента фиксировано, и число отказавших
(перегоревших) ламп представляет собой случайную величину.
202 Глава 4. Подгонка вероятностных распределений к реальным данным
При цензурировании типа II заранее определяется доля отказов, но время
наблюдения не ограничивается (например, мы проводим эксперимент, пока не
выйдут из строя 50% компьютеров при данных критических условиях). Очевидно, что
при таком подходе время, в течение которого проводится эксперимент, является
случайной величиной.
Можно задать также направление цензурирования. При испытании
компьютеров или ламп цензурирование происходит в правом направлении по временной
оси (правое цензурирование), потому что исследователь точно фиксирует начало
эксперимента и знает, что неотказавшие компьютеры будут еще жить некоторое
время после окончания эксперимента. Другой вариант возникает, когда
исследователю неизвестно начало времени жизни объекта, например врачу известен
момент поступления пациента в госпиталь с данным диагнозом, но неизвестен
момент, когда данный диагноз был поставлен, и тем более неизвестно, когда болезнь
началась. Такое цензурирование называется левым.
Конечно, если тестируются старые компьютеры или мониторы, то это тоже
пример левого цензурирования, так как не известен момент начала их эксплуатации.
Наконец, возможны ситуации, в которых цензурирование происходит в
различные моменты времени (многократное цензурирование) или только в один
момент времени (однократное цензурирование).
Возвращаясь к эксперименту с тестированием компьютеров в экстремальных
условиях, заметим, что если эксперимент заканчивается в определенный момент
времени, то мы имеем однократное цензурирование.
Конечно, имеются нетривиальные ситуации, например, данные, собранные
директором фирмы по продаже подержанных копировальных аппаратов.
Балансируя между необходимостью продаж и выдачей гарантий покупателю, ему следует
рационально организовать процесс продаж.
Рассмотрим, как оцениваются параметры распределения Вейбулла в системе
STATISTICA при простейшем правом однократном цензурировании. Данные
содержатся в файле Dodson25.sta.
Case
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
TIME
42.1
77.8
83.3
88.7
101.8
105.9
117.0
126.9
138.7
148.9
151.3
157.3
163.8
177.2
194.3
195.6
207.0
215.3
217.4
258.8
CENSORING
Censored
Complete
Censored
Censored
Complete
Complete
Complete
Complete
Complete
Complete
Censored
Complete
Complete
Censored
Censored
Censored
Complete
Censored
Complete
Censored
Пример 5. Подгонка распределения Вейбулла к данным об отказах
203
Запустите модуль Анализ процессов и повторите вслед за нами наши действия.
I HIHMWIIHil'k
за производственных процессов
f-4-J Пианы выборочного контроля для различных распределений
Шр Анализ пригодности процесса и доверительные интервалы
jj Повторяемость и воспроизводимость измерений
надежности, времена отказов и распределение Вейбулла
0 Данные I
Ц1 Аft \
Шаг 1. Откройте файл Dodson25.sta, затем выберите Анализ Вейбулла... на
стартовой панели.
т Данньи
TEtJDodson A991), р.
X
TIHE
щ
L
1
1
1
8.
£
Щ
Та]
и
ii
ill
Щ
I
42,
77,
83,
88,
101,
105,
117,
126,
138,
148,
151,
157,
163,
177,
194,
195,
207,
100
800
300
700
800
900
000
900
700
900
300
300
800
200
300
600
000
Censore<
Complete
Censored
Censored
Complete
Complete
Complete
Complete
Complete
Complete
Censored
Complete
Complete
Censored
Censored
Censored
ComDlete
IJ.I!ll.|ILI.Ili.LIIIHl!H.IJI!l.liJ.«I.IJIJ.IJ.IJUI.LHIIJ).l.l!IIIJ.H!l!lll
Тип внавмае-*-—■■■■^■■~~
О Третированные j
С. ВероотностныЛ график распределения ВеЙбдоа (дашше необязательны)
|<У Список переценим! с j
\Q 10|Йв''Н откаадеКд^еЛначало и коне*) иди «есть (доты)
! Н.. ft*
Охиеиа
ft отказов и индикатор денеярйроа^ания): | ffm Щ \ & &
Времена отказов: TIME
Индикатор двнздриооеания: CENS
:^;г^::ж<
£рдполных наблюдений: rCensoiedM
й,..,,. :;f ^V- Код авнзарироаашпак наблюдении: ["Complete"
Г Прибавить констант) к нулевым t откааоо/ценээр. | i
Задайте коды
паяных и
.;. цензурированием
— меблшеиии, .
— По^ячаниюна
>m Нулевые времена
|3 отказов и • >Т
цензурирования
204
Глава 4. Подгонка вероятностных распределений к реальным данным
Рассмотрим опции окна.
Тип анализа.
Исходные данные — используйте этот диалог, если вы анализируете исходные
времена отказов с цензурированием или без него.
Группированные данные — используйте диалог для исследования
агрегированных или табулированных времен отказов, например таблиц жизни.
Распределение Вейбулла, вероятностный график — открывается диалоговое
окно, в котором вы можете построить вероятностный график распределения
Вейбулла, аналогичный нормальному вероятностному графику (графику на
нормальной вероятностной бумаге в старой терминологии).
В данном примере используйте анализ исходных данных.
Времена отказов — эта опция выбирается в том случае, когда данные содержат
действительные времена отказов.
Единственная переменная для времен отказов (жизни), переменные с началом
и концом, переменные с датами — опция выбирается в тех случаях, когда данные
содержат даты с началом или концом каждого наблюдения. Из файла данных
программа вычислит разность между временем конца и временем начала, чтобы
получить чистые времена отказов для каждого наблюдения, и затем подгонит к ним
распределение Вейбулла.
Если выбран Список переменных с временами, программа ожидает ввода одной
или нескольких переменных с временами отказов и дополнительного ввода
индикатора цензурирования (группирующей) переменной, которая позволяет
определить, какие времена полные, а какие цензурированы.
Если выбрана опция Одна t отказов, две (начало и конец) или шесть (даты), то
вы можете в первом списке переменных: 1) выбрать одну переменную с временами
отказов, 2) выбрать две переменные с временами начала и конца (наблюдения
объекта), 3) выбрать 6 переменных, которые также будут рассматриваться как
времена начала и конца (как и в случае 2 выше). Эти 6 переменных рассматриваются
как месяц, день, год начала и как месяц, день, год окончания испытания.
Выберите переменные для анализа, цензурирующие переменные (индикаторы
цензурирования) и коды. Затем нажмите ОК; по умолчанию программа вычислит
оценки максимального правдоподобия параметров для двухпараметического
распределения Вейбулла и перейдет в диалоговое окно Результаты анализа
Вейбулла. Заметим, что если оценки максимального правдоподобия не существуют,
процедура использует 0, 1, 1 для оценки параметров положения, формы и масштаба
соответственно.
Близкие процедуры содержатся в модуле Анализ выживаемости; для нецензу-
рированных или полных данных можно использовать визуальные методы
графики Квантиль-квантиль и Вероятность-вероятность (см. главу Визуальные
методы анализа).
Выберите переменную Time, содержащую времена отказов, и переменную Cens —
индикатор цензурирования.
Эта переменная содержит два значения, показывающие, полностью или нет
наблюдались изделия до момента отказа. Заметим, что такая ситуация (наличие двух
типов наблюдений) отличается от той, с которой мы имели дело в модуле непа-
Пример 5. Подгонка распределения Вейбулла к данным об отказах
205
раметрические статистики. Точно с такими же типами наблюдений мы имеем
дело в модуле анализ выживаемости.
Коды для полных и цензурированных наблюдений.
Эта опция доступна, если выбран индикатор цензурирования. Определите коды
или текстовые значения для полных (нецензурированных) и неполных
(цензурированных ) наблюдений. Чтобы просмотреть все коды соответствующей
переменной, дважды щелкните на поле ввода. Первые два различных значения,
обнаруженных в индикаторе цензурирования, используются по умолчанию как коды для
полных и цензурированных данных соответственно.
Выберите Complete для полных времен и Censored для цензурированных
времен. Нажмите ОК, чтобы начать анализ.
Опция: Прибавить пост, к нулевым t отказов/цензур, значениям.
Распределение Вейбулла ограничено слева, это означает, что все значения
выборки должны быть больше параметра положения, по умолчанию равного 0. Если
опция выбрана, программа перед подгонкой или построением графика заменит
нулевые времена отказов константой из поля. Если опция не выбрана, все наблюдения
с нулевыми временами отказов исключаются из анализа (рассматриваются как
пропущенные данные).
Шаг 2. По умолчанию программа вычислит оценки максимального
правдоподобия для двухпараметрического распределения Вейбулла, предполагая, что
параметр положения равен 0. В окне Результаты анализа эти оценки можно увидеть в
зоне Значения/оценки текущих параметров.
fjjfi Результаты лнили.ы Нейбцллн (исходные данные)
Перемен.: TIME
Ценз-кие: CEN3
N набл. : 20
Отказы: Censored Ценэурир: Complete
Отказы: 9 D5.0%) Ценэурир: 11 E5.04)
VI Форма* масштаб I \Л Форма, масштаб.
М аисимиашоа чнсшо итаращ,ий^ J50
■?V,г.< г.; W^^h^octicJ 00001 Щ
шшлы*,^тшиишнылмшт ft f<гГ""''■ К'?У:*'"**&£*
Wf^ft^i^fiTiMf. ^iEatMii
Ориона!
Настройки действуют ыт т#ф*ж
с*рЬ*ге*толмюАл*шанокМГ1& O^vi'--.'■■>■■>'■ ■■
3itayiiwii/tmaHiw oapaMtfrpoa *
:S£&&3
Параметр положаии* 10
Параметр форм* |3.03409674
Параметр масштаба:" 1216.92726489 SI ]
ffl ; ПараметруJM^flofcмиЫрйк*. \
950
• Q: t отрада и Щ\. | В fo**» P*^^^^|f|i
Фужния надежности
(• Маде.пр*адопоАо6м«|
С Нелараметричаские
^^■„и^.
^%^Щ¥Щ/^^Щщ %Фщр*.ЩщЩ*^^Р •>
^арематр ломдонйяг
;й
О , Гра»1ас«аангца^цц^ ,
> Фянади* рмска {тхшсшШь\0
1Э<У Врем*/от1?аааы*^
•f»«^#?
•л5 Г^'Щ^;^$Ш1
., jjwjiHjji^^ii^wi^iiiwAiiiw wiiii iwwiii mi in тпмутщшмят h'iiiMjiihi!ГмиГ 1
206 Глава 4. Подгонка вероятностных распределений к реальным данным
Оценки параметров. Окно результатов позволяет интерактивно провести
подгонку к данным распределения Вейбулла с различными параметрами.
После того как вы нажмете кнопку Форма & масштабу программа считает
текущее значение параметра положения и вычислит оценки максимального
правдоподобия параметров формы и масштаба.
Если вы нажмете кнопку Форма, масштаб, положение, программа вычислит
оценки максимального правдоподобия для трехпараметрического семейства.
В любом случае оценки будут отображены в полях значения/оценки текущих
параметров.
Шаг 3. Просмотр результатов. Все опции, доступные в окне результатов на
текущих значениях параметров, указаны в полях значения/оценки текущих
параметров независимо от того, определены эти параметры пользователем или
оценены программой (например, методом максимального правдоподобия). Однако
стандартные ошибки функции надежности можно вычислить только для оценок
максимального правдоподобия.
Оценки максимального правдоподобия двухпараметрического распределения
Вейбулла равны 3,034 и 216,9 для параметров формы и масштаба (см. рисунок).
Вы можете сравнить эти оценки с оценками, построенными с помощью
графиков: выберите опцию Непараметрические в рамке Дов. интервалы (нижний левый
угол). Тогда все графики будут построены на основе непараметрических
(ранговых) оценок функции распределения F(t), и результирующий график может быть
использован для оценки параметров распределения Вейбулла. Нажмите кнопку
График распределения и постройте график.
£*$ График! График распределения при оценке надежности метод НОЮЕЗ
TIME; Ценз-нив: CENS (Censored.Comptete) N-20
Лин. ф-ция: у--16.322+3.034 *x+eps Дов. интервал: 95.0%
Параметры: Положен -0.0000 Форма-3.0341 Масшт-216.93
Этот график показывает наблюдаемые времена отказов, линейную подгонку и
95%-й непараметрический доверительный интервал функции надежности (более
точно, log-log-преобразование; доверительный интервал показан
прерывистой линией).
Оценки параметров формы и масштаба вычисляются из коэффициента
наклона и свободного члена линейной подгонки: параметр формы равен коэффициенту
наклона, параметр масштаба оценивается как exp(-intercept/slope).
Пример 5. Подгонка распределения Вейбулла к данным об отказах
207
Эти оценки параметров очень близки к оценкам максимального
правдоподобия. Так как точки достаточно точно ложатся на прямую, мы можем поверить, что
распределение Вейбулла с оцененными параметрами вполне адекватно данным.
Нажмите кнопку Функция надежности и доверительные интервалы, и вы
увидите результаты в численном виде.
'-'ii'ii.if'iiii^i'iii'iriiJiii-M^i^mi
TIME. Ценэ-ние CENS (Censored.Complete) N-20
|Пораметры Положен -0 0000 Формо-3 0341 Масшт-216 93
ЭР)
000580
012573
016579
♦95.0%;
JSEL
Нодажн
-95.0%
(надеж.)
♦95 0%
(надеж)
079013
211317
231274
993111
946670
935840
920987
788683
768726
987427
Э83421
243124
310862
315961
508438
650744
747543
754712
715231
581980
488758
481659
491562
349256
252457
245288
853707
756876
689138
684039
Критерии согласия. Если вы нажмете кнопку Критерии согласия, то увидите
таблицу со статистиками Холлендера—Прогиана или Манна—Шойера—Фертига
и их уровнями значимости.
Критерий Холлендера—Прошана. Этот критерий сравнивает теоретическую
функцию надежности с оценкой Каплана—Мейера. Точные формулы вычисления
достаточно сложны. Критерий Холлендера—Прошана применяется к полным,
однократно цензурированным и многократно цензуриров^нным данным, однако
имеет место недостаток этого критерия в некоторых случаях, например, когда
данные сильно цензурированы. STATISTICA вычисляет значение критериальной
статистики и двухсторонний уровень значимости р.
Критерий Манна—Шойера—Фертига. Критерий был предложен Манном,
Шойером, Фертигом в 1973 г.
Нулевая гипотеза состоит в том, что данные имеют распределение Вейбулла с
оцененными параметрами. Нельсон (см.: Nelson A982) Applied life data analysis. New
York: Wiley) отмечает большую мощность этого критерия. Критические значения
вычислены методом Монте Карло и табулированы для объемов выборки от 3 до
25; для больших объемов выборок критерий не применяется.
зж
АНАЛИЗ
ПРОЦЕС
TIME. Ценэ-ние CENS (Censored.Complete) N-20
Параметры Положен -0 0000 Форме-3 0341 Мвсшт-216 93
МаинвЧиойер»4)ертиго
Ш
р-85379
р>25
208 Глава 4. Подгонка вероятностных распределений к реальным данным
Шаг 4. Оценки параметра положения. Хотя подгонка двухпараметрического
распределения Вейбулла кажется очень хорошей, предположим, что у вас
имеются некоторые доводы в пользу того, что параметр положения больше 0. Иными
словами, вы уверены, что имеется интервал, в течение которого вероятности
отказов нет. Оценим этот параметр положения. Нажмите кнопку R-квадрат и
параметр положения. Этот график показывает зависимость коэффициента
детерминации R-квадрат ©т параметра положения.
Параметр положения и R2
TIME; Цем-ние: CENS (Centored,Complete) N-20
MaiccR2-.9454 Параметр положения: 5.000
10 15 20 25
Параметр положения
Далее нажмите кнопку Форма, масштаб, положение, чтобы вычислить оценки
максимального правдоподобия для трехпараметрического распределения Вейбулла.
Для этих данных лучше применять более простую двухпараметрическую
модель с параметром положения, равным 0.
Шаг 5. Процентили и доверительные интервалы. Нажмите кнопку Проценти-
ли и доверительный интервал, чтобы построить таблицу с процентными точками
функции надежности.
'^4ШЙ^^
&•*;**
ЩШЩйЩ
>ШШ&ь
^ifrw"^-
75.5931
81.5016
66.6969
91.3767
956561
996190
103.3240
1068141'
110.1223
113.2745
116.2913
1191895
121.9830
22 3916
31.5837
38.6205
44 5459
497635
544795
588162
62.8530
666449
70.2319
716441
76.9046
80.0319
83.0409
859439
88.7509
101 3052
113 7979
121 9878
128 2793
133 4817
137.9731
1419626
145 5792
148 9079
152.0084
1549242
157.6880
160 3250
162 8555
165 2956
167.6586
Пример 5. Подгонка распределения Вейбулла к данным об отказах
209
Таблица содержит процентили с приращением 1%: 1, 2,3,4 и т. д.
Прокрутив таблицу, вы увидите, например, что оценка медианы равна 192,2,
а 95% доверительный интервал имеет границы от 154,9996 до 238,437.
Другими словами, можно ожидать, что 50% отказов происходит до момента
времени t= 192,2 (с соответствующим доверительным интервалом).
Двумерный
визуальный
анализ данных
Двумерный, сокращенно — 2М визуальный анализ, — это визуальный анализ
данных на плоскости. В двумерном визуальном анализе используются разнообразные
гистограммы, диаграммы рассеяния, вероятностные графики, линейные графики,
диаграммы диапазонов, размахов, круговые диаграммы, столбчатые диаграммы,
последовательные графики (графики последовательных значений) и т. д.,
позволяющие увидеть специфику данных.
Гистограммы
50 60 70 80 90 100 110 120 130 140 150
Термин гистограмма ввел Карл Пирсон в 1895 году. Гистограммы позволяют
увидеть, как распределены значения переменных по интервалам группировки,
то есть как часто переменные принимают значения из различных интервалов.
Особенно полезен этот график для большого числа наблюдений, например
больше 100.
Гистограммы
211
Гистограмма наглядно показывает, какие значения или диапазоны значений
исследуемой переменной являются наиболее частыми, насколько сильно они
различаются между собой, как сконцентрировано большинство наблюдений вокруг
среднего, является распределение симметричным или нет, имеет ли оно одну моду или
несколько мод, то есть является мультимодальным.
На простой гистограмме отображаются частоты значений одной переменной, а на
составной можно отобразить одновременно частоты нескольких переменных.
Например, показанная ниже составная гистограмма позволяет увидеть, как
меняется соотношение между покупками мяса и колбасы в супермаркете. Из нее
также видно, что доля колбас и мяса в дорогих покупках (на сумму более 300 рублей)
минимальна.
Ы11 ,411411! 3
■ JDlxl
Гистограмма покупок ■ магнии*
• 5
Hiiilitli
И КОЛБАСЫ_
sssa мясо
1ШШ итого
Изменяя интервал группировки, можно провести более точную сегментацию
рынка.
шпвшвев
675
450
<-5О0
СУММА ПОКУПОК
212
Глава 5. Двумерный визуальный анализ данных
швввшяпва
■ Jolxli
Гисюграмма
<- 250 E00,7501
B50.500] >750
СУММА ПОКУПОК
'Xt>v3 ^
1Ла-у^.
СШМДПСЖУГКЖ
С помощью гистограмм можно проверить наличие у распределения тяжелых
хвостов, что важно для актуарных расчетов.
Гистограммы дают возможность визуально оценить сходство наблюдаемых
распределений с теоретическими или ожидаемыми распределениями.
Гистограмма, или распределение частот значений переменной по интервалам,
представляет интерес по следующим причинам:
О по форме распределения можно охарактеризовать природу исследуемой
переменной (например, наличие двух мод — наиболее высоких столбцов
гистограммы, или, как говорят, бимодальность распределения может означать,
что выборка неоднородна и состоит из наблюдений, принадлежащих двум
различным генеральным совокупностям);
О многие статистики критериев основаны на определенных предположениях
о виде распределения, например, на предположении нормальности;
гистограммы помогают визуально проверить выполнение этих предположений.
Часто первый шаг визуального анализа нового множества данных состоит в
построении гистограмм для всех переменных. При этом выбираются различные по
величине интервалы группировки.
Гистограммы и описательные статистики
Хотя некоторые (числовые) описательные статистики легче воспринимать в виде
таблиц, общую форму распределения значений переменной лучше исследовать на
графике.
Группировка
213
График дает качественную информацию о распределении, которая не может
быть полностью выражена каким-то одним численным показателем.
Например, общее асимметричное распределение дохода может показывать, что
большинство людей имеют доход, находящийся гораздо ближе к минимальному,
нежели к максимальному значению.
Хотя эта информация содержится в коэффициенте асимметрии, ее легче
понять и запомнить визуально.
ЫМИ'Щ'МЦЦЧ
ДОХОД СНМЬИ: ОКРУГ WILLBURN. ОСЕНЫ 993 г
по
...
1
«
пир
к
—
п
" '" " " - - - --
1 » »
• '
,
мм
На гистограммах также могут быть заметны «провалы», которые несут важную
информацию о социальном расслоении группы покупателей или об аномалиях
распределения дохода, вызванных, например, недавней налоговой реформой.
Часто гистограммы применяются в маркетинге для сегментации рынка.
Группировка
Все окна Статистические графики системы STATISTICA, позволяющие строить
гистограммы, содержат стандартный набор методов задания при построении
гистограмм интервалов группировки. Диапазон значений переменной разбивается на
интервалы (если переменная непрерывная) или категории (если переменная
категориальная), для которых подсчитываются частоты, изображаемые в виде
отдельных столбцов.
Р'ЦИШ'!!!1!
>50
<45;50)
D0.451
05,40)
i g GO*]
; 5 С**)
: $ B0.25)
5 05.20]
5 00.15)
E.10)
@j5)
<-0
С
J JJLLi J i i LJ
Щ\
i
i
Ю a
0 Э
0 4I
i i
1
! I i !
! | | I
i ' i
! ! i ! - I
0 5
0 8
0 71
0 80 9
0 1С
Ю11
Ip'pfjlul
1 1
t
Щ5ЖЙ
|
1
on
Ю13
I J I I
I i li
I i ] :
j I
] l
I :
! I ^
i ' ! I i
Mi
I j ! 1 I
С 14
Ю1£
0 180 170
Число Н*ВЛ
214
Глава 5. Двумерный визуальный анализ данных
Например, можно построить гистограмму, на которой каждый столбец будет
соответствовать интервалу из 10 единиц шкалы, используемой для представления
переменной. Если минимальное значение равно 0, а максимальное — 120, то будет
создано 12 столбцов. Кроме того, можно сделать так, чтобы весь диапазон
значений переменной был разделен на указанное число интервалов равной длины
(например, 10); в последнем случае, если минимальное значение равно 0, а
максимальное — 120, каждый интервал будет равен 12 единицам шкалы. Можно выбрать
и более сложный метод группировки. Например, можно применить неравные
диапазоны с заданными пользователем границами, чтобы создать более понятные
диапазоны или объединить выброс и увеличить читаемость средней части
гистограммы. Диапазоны можно также создать, определив критерии включения и
исключения с помощью логических операторов (например, первый столбец
гистограммы может представлять людей, которые за последний год летали на
самолете более 10 раз и не более 50% этих поездок связано с бизнесом и т. д.).
Пример. Продвинутые возможности для визуализации группировки имеются
в модуле Основные статистики и таблицы (см. диалоговое окно Таблицы частот).
Шаг 1. Запустите модуль Основные статистики и таблицы. Откройте файл
данных adstudy.sta из папки Examples. Внесите в этот файл следующие изменения:
в пятой, седьмой и двенадцатой строке введите новое значение SPRITE в
переменную ADVERT (см. рисунок).
Теперь эта переменная принимает 3 значения: PEPSI, COKE, SPRITE.
шшшщшвшшт
[OtHDEl
*♦ ***•*
■Ш*^Шко9п-
С. Ивуег
P. Yotjmg
W riynd
4.tm*&-;
Advertising Effectiveness Study.
■4>
Я£1йЯК*9
ntk9\
HALE PEPSI
HALE COKE
TEHALE COKE
HALE PEPSI
HALE SPRITE
TEHALE COKE
TEHALE SPRITE
HALE PEPSI
ГЕНАЬЕ PEPSI
HALE PEPSI
TEHALE PEPSI
haleJsprite!
9
6
9
7
7
6
7
9
7
6
4
7
1
7
8
9
1
0
4
9
8
6
6
3
6
1
2
6
0
3
2
2
2
6
3
8
8
9
5
2
8
2
6
3
8
5
7
Шаг 2. В стартовой панели выберите диалог Таблицы частот и нажмите кнопку ОК.
| .»IIJ.i.liJ.liilHiICgJ^——7
Jjt Описательные статистики
Корреляционные матрицы
j7| t-критерия для независимы* выборок
%н% t-критерия для зависимых выборок
25 Группировка и одиофакториая AN OVA
Таблицы и заголовки
ЗА Вероятностный калькулятор
\\SJk Друие критерии значимости
ЕГ
Ртиона J
&>А-
jSSjJ&i
Шаг 3. В диалоговом окне Таблицы частот нажмите кнопку Переменные и
выберите первые 3 переменные из файла данных.
Группировка
215
Шаг 4.
дом с ней.
Выберите опцию Заданные группирующие коды и нажмите кнопку ря-
ршвшшшяшшшшш
(gg Q«>aHW—; ) 6EN0ER-MCASUR!
1* 1ДО
J»
I» ..
Шаг 5. В появившемся диалоговом окне выберите те значения переменных,
которые вы хотели бы отобразить на гистограммах. Сделайте это, например, так, как
показано на рисунке.
6SMDER: MALE FEMALE
AOVCRT:jPEPSI CORE
MCASUBI: 0 5
Q*
"UhtllMt»J
Шаг 6. Сделав выбора нажмите кнопку OK в окне Коды для выбранных
переменных.
После этого вы вернетесь в диалоговое окно Таблицы частот.
Шаг 7. В диалоговом окне Таблицы частот нажмите кнопку Гистограммы.
Вы увидите появляющиеся одну за одной гистограммы на вашем экране.
Обратите внимание, что на графике отбражаются не все значения переменных, а только
те, что выбраны вами.
GENOEffc Gemtor of the аиЬде» (May 1S, 19M).
Цаяьм штегории
216
Глава 5. Двумерный визуальный анализ данных
?1 ADVfcHT Ad shown
зашшжшкшш
АО VERT: Ad shown to the subjects (M«y 15,1SW).
Целые категории
П'Р^Фик?? MIASIIH1
ПН
C_1:2 G_1:3
Целые категории
Подгонка теоретических распределений
к наблюдаемым распределениям
STATISTIC А позволяет сравнивать распределение наблюдаемых данных с
распределениями: нормальное, бета- экспоненциальное, экстремальное, гамма-
геометрическое, Лапласа, логистическое, логнормальное, Пуассона, Релея, Вейбулла.
Q3BBBD
■ Jnlxli
Гистограмма (RANDOM2 STA 7V478C)
у-478* 1 • normal (х. 17 0711.6 538)
2 4 б 8 10 12 14 16 18 20 22 24 26 28 30 32 34
I 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35
CATEGORY
Подгонка теоретических распределений к наблюдаемым распределениям 217
еашшягаяи
■ Jntxll
Подгонке экспоненциального распределения к переменной: MEASUR4
| Простые гистограммы
Простые гистограммы является обычными столбчатыми графиками
распределений частот выбранной переменной.
[Д Составные гистограммы
Составные гистограммы представляют распределения частот для нескольких
переменных на одном графике. Значения переменных откладываются по единой оси
X, что облегчает визуальное сравнение распределения переменных.
На составных гистограммах переменные представлены примыкающими
друг к другу столбцами; поэтому для каждой категории строится несколько
столбцов. Следовательно, подогнанные кривые могут либо точно подходить к
соответствующим им гистограммам, либо быть сравнимыми друг с другом.
ШЯ Гистограммы с двойной осью Y
Гистограмму с двойной осью У можно рассматривать как комбинацию двух
составных гистограмм. Можно выбрать два списка переменных. Будет построено распре-
218
Глава 5. Двумерный визуальный анализ данных
деление частот для каждой выбранной переменной, но частоты переменных,
введенных в первый список {Левая ось У), будут откладываться по левой оси У, в то
время как частоты переменных, введенных во второй список {Правая ось У), — по
правой оси У.
ншннишп
i.'ibixji
Гистограмма с дюймом осью V
MEASURE2 (Л) \ щ
MEASURE3(П)
■ 1
И
-и
II
г
шй
§1
ill
wwwn
ш
ш
Имена всех переменных из двух списков будут включены в условные обозначе-
ния,-сопровождаемые буквой Л или Я, обозначающей левую или правую ось У
соответственно. Этот график полезен для визуального сравнения распределений
переменных с разными частотами.
[5\] Висячие столбцы
Гистограмма висячих столбцов является изысканным визуальным способом
проверки нормальности распределения переменной, который помогает наглядно
определить области, где возникают расхождения между наблюдаемыми и
нормальными частотами.
I'tll'r-l'I'I'HI'lll'll'fllU.B
fllblxl
В отличие от обычного способа наложения на гистограмму нормальной
кривой, гистограмма висячих столбцов предлагает альтернативный способ, когда
столбцы, представляющие наблюдаемые частоты для последовательных
диапазонов значений, «подвешиваются» к нормальной кривой. Если исследуемое
распределение приближенно нормальное, то нижние стороны подвешенных
прямоугольников ложатся на одну прямую.
Диаграммы рассеяния
219
Пересекающиеся категории
В системе STATISTICA можно задать логические условия выделения подгрупп.
Формально могут возникнуть пересекающиеся подмножества (одно и то же
наблюдение попадает в разные группы).
Однако действует следующее правило: каждое наблюдение будет помещено
только в одну подгруппу, а именно в первую из тех, условиям которой оно
удовлетворяет. Поэтому наборы подгрупп (категорий), создаваемые по таким
правилам, не будут пересекаться ни при каких условиях. Например, если к подгруппе 1
множества опрошенных отнесены мужчины, а к подгруппе 2 — опрошенные
старше 30 лет, то полученная подгруппа 2 будет содержать только женщин (старше
30 лет), так как все мужчины окажутся в подгруппе 1.
Пример:
Подгруппа 1:Включ., если:\1<=10
Подгруппа 2: Включ., если: vl>10 AND v2 = 'YES'
ЫШИИ'ИШ'Н
Диаграммы рассеяния
Двумерные диаграммы рассеяния используются для визуального исследования
зависимости между двумя переменными X и У (например, весом и ростом человека,
рекламой и объемом продаж и т. д.).
220
Глава 5. Двумерный визуальный анализ данных
Данные изображаются точками в двумерном пространстве. Две координаты (X
и У), которые определяют положение каждой точки, соответствуют значениям двух
переменных. Если переменные сильно связаны, то множество точек данных
принимает определенную форму (например, ложится на прямую линию или кривую,
задаваемую определенным уравнением), как показано ниже на рисунке.
ИЕЯИЯЕ2ЭЕ
ЕВШ
Диаграмма рассеяния двух сильно связанных пареиаиных
14000
12000
10000
8000
6000
4000
2000
0
-2000
•4000
;......
■ -
I
0 V
._.]-— i—l- i—; —
: i ' i
—4—4- j—-
::x::j:::{z:
т
-t
1
— 4 1—!_...— ;..-._.!.. _]У%-
! I ; I ! ! ;
-100 -80 -60 -40
20 40 60 80
Подгонка функций к диаграммам рассеяния помогает увидеть зависимости
между переменными.
Если переменные не связаны, то точки образуют «облако рассеяния» (см. ниже).
Однородность распределений двух переменных (формы зависимостей) 221
Однородность распределений двух
переменных (формы зависимостей)
Диаграммы рассеяния обычно используются для визуального исследования
зависимости двух переменных (например, кровяного давления и уровня холестерина),
поскольку они предоставляют больше информации, чем простое значение
коэффициента корреляции.
Например, отсутствие однородности в выборке, для которой была подсчитана
корреляция, может исказить значение коэффициента корреляции.
Предположим, вычисления производились для данных из различных
экспериментальных групп, но этот факт не был учтен, то есть группировка не
проводилась. Можно предположить, что экспериментальные действия в одной из групп
увеличили значения обеих коррелированных переменных, и таким образом,
данные из каждой группы образуют отдельное «облако» на диаграмме рассеяния (как
показано на рисунке ниже).
В этом примере высокая корреляция обусловлена наличием двух групп и не
отражает действительный характер связи (точнее, ее отсутствие) между
переменными.
ООщзякорреляция г - 86410
_4о I ■ • • ' « ■ 1 :•
-40 -20 0 20 40 60 80 100?
При наличии определенных предположений о структуре данных и
информации, а также о возможном способе разделения на группы попробуйте рассчитать
корреляции отдельно для каждого подмножества наблюдений или используйте
категоризованную диаграмму рассеяния.
Другой проблемой, которая может быть исследована на диаграммах рассеяния,
является нелинейность. Для исследования нелинейной зависимости между
переменными не существует «автоматических» или простых в употреблении методов.
Коэффициент корреляции Пирсона оценивает только линейные зависимости
и именно по этой причине часто называется линейным; некоторые
непараметрические критерии, такие как коэффициент корреляции Спирмена R, могут
оценивать нелинейную зависимость, но только монотонную.
Исследование диаграмм рассеяния позволяет определять формы зависимостей,
чтобы потом можно было выбрать подходящий тип преобразования данных для
их «линеаризации» или выбора подходящего нелинейного уравнения подгонки
(например, вместо линейной зависимости использовать полиномиальную).
222
Глава 5. Двумерный визуальный анализ данных
Выбросы
Другое важное преимущество диаграмм рассеяния состоит в том, что они
позволяют находить «выбросы» (нетипичные данные), которые искусственным образом
увеличивают или уменьшают («смещают») коэффициент корреляции.
1тШ1Ш1111Т1Ш11ШЬ
Корреляция г = 82842
Сильная корреляция обусловлена единственным выбросом
Даже один выброс может значительно увеличить коэффициент корреляции
между двумя переменными. Диаграмма рассеяния позволяет обнаруживать такие
аномалии.
Например, корреляция между двумя переменными на рисунке была бы близка
к 0 при отсутствии выброса. Наличие этого выброса «искусственно» увеличивает
значение корреляции.
Средство Кисть позволяет интерактивно удалять выбросы и непосредственно
наблюдать за изменением аппроксимирующей функции или линии регрессии.
ЩЩ Простые диаграммы рассеяния
Простая диаграмма рассеяния визуализирует зависимость между двумя
переменными Хи У (например, весом и высотой). Данные изображаются точками в
двумерном пространстве, где оси соответствуют переменным.
Выбросы
223
Простая диаграмма рассеяния (высота и аес)
210
205
200
195
S 190
о
ш 185
180
175
170
165
■- ■■- 8 ° °
— - . .* о- °в. о- ** ° - 9-
;г."
145
155
165 175
ВЫСОТА 00
185
195
Две координаты (X и У), которые определяют положение каждой точки,
соответствуют значениям двух переменных. Если переменные сильно связаны, то
множество точек данных принимает определенную форму (например, прямой линии
или кривой). Если связи нет, то точки образуют «облако».
|^р| Составные диаграммы рассеяния
В отличие от простой диаграммы рассеяния, на которой одна переменная
представлена по горизонтальной, а вторая — по вертикальной оси, составная
диаграмма рассеяния включает несколько зависимостей: значения одной переменной (X)
откладываются по горизонтальной оси, а по вертикальной оси откладываются
значения нескольких переменных (У). Для каждой переменной У используется
разный цвет и вид точек.
Составная диаграмма рассеяния
[-..
л Л
!...
I
•°-.§
•set-
• ■♦о
••••
^ОЛ*
.да--
■jjti;
;°o°22 B°S
Oo- - - - - i
'lilt»»'"»
r r !
°B°°
„B
-1
r*t • ♦
40 45 50 55 60 65 70 75
• Y1
о Y2
* Y3
Диаграмма рассеяния составного типа используется для сравнения структуры
нескольких корреляционных зависимостей путем изображения их на одном
графике в одном масштабе.
ЕЦ] Диаграммы рассеяния с двойной осью Y
Диаграмму рассеяния такого типа можно рассматривать как комбинацию двух
составных диаграмм рассеяния для одной переменной X и двух различных множеств
переменных У. Для независимой переменной Xи каждой из переменных Устроится
диаграмма рассеяния, но переменные из первого списка (называемого Левая ось У)
224
Глава 5. Двумерный визуальный анализ данных
откладываются по левой оси У, тогда как переменные из второго списка
(называемого Правая ось У) откладываются по правой оси У. На каждой из осей можно
выбрать свой масштаб.
Диаграмма рассеяния с двойной осью Y
Y_1 (Л)
Y_2 (П)
Y_3 (П)
Имена всех переменных У из двух списков будут включены в условные
обозначения, сопровождаемые буквой (Л) или G7), обозначающей левую или правую
ось У соответственно.
Диаграммы рассеяния с двойной осью У можно использовать для визуального
сравнения структуры нескольких корреляционных зависимостей путем
изображения их на одном графике. При этом в силу независимости масштабов,
используемых для двух списков переменных, этот график облегчает сравнение
переменных, значения которых принадлежат разным диапазонам.
\£?\ Частоты
Эта диаграмма рассеяния позволяет наглядно изобразить частоты
перекрывающихся точек для двух переменных, чтобы наглядно представить веса различных точек.
Если для одного значения переменной X имеется несколько значений
переменной У, то возникает необходимость использовать подобные диаграммы рассеяния.
Подсчитываются и группируются частоты перекрывающихся точек. Размеры
маркеров точек на графике соответствуют значениям частот.
Диаграмма рассеяния частот
• 1 наблюдение
• 2-4 наблюдения
• 5-7 наблюдений
о 6-10 наблюдений
о 11-13 наблюдений
о 14-16 наблюдений .
40 О > 16 наблюден!
Выбросы
225
РП Квантили
На графиках квантилей изображается зависимость между квантилями двух
переменных, позволяющая визуально оценить сходство эмпирических распределений
каждой переменной.
UIMLJIIiMf
а рассеяния квантиль к ват иль
Диаграмма рассеяния квантиль-квантиль (IRISDAT.STA5V150C)
y=-8,102*2,0rx*eps
Если точки данных ложатся на линию регрессии, то можно сделать вывод, что
две переменные имеют одинаковое распределение.
ggg Диаграмма Вороного
Эта особая диаграмма рассеяния одной переменной является в большей степени
аналитическим средством, нежели просто методом графического представления
данных. Пространство разделяется на области точек, максимально близких к
наблюдаемым точкам, иными словами можно сказать, что строятся зоны влияния
точек.
ВШПШВШЕШЕ
Мозаике Вороного
226
Глава 5. Двумерный визуальный анализ данных
Обратите внимание, что на изображенной выше диаграмме оси одинаково
масштабированы (минимум = 0, максимум = 10) и пропорции диаграммы таковы,
что обе оси имеют приблизительно одинаковую длину. Разбиения для мозаичной
диаграммы Вороного будут рассчитаны в предположении равных длин (и
масштабов) осей; таким образом, пропорции диаграммы и масштабирование по умолчанию
(например, автоматическое) могут привести к искаженной мозаичной диаграмме
Вороного.
Способы использования этого метода сильно зависят от областей
исследования, однако во многих случаях к этой диаграмме полезно добавлять
дополнительные измерения, используя категоризацию и выбор сложных подгрупп.
Диаграммы рассеяния с гистограммами
Этот тип статистических графиков представляет собой составной график с
зависимостью между двумя переменными и распределениями частот для каждой
переменной.
1ЯШ1ЧИ1|Ц1||Ц111ЛШЛ.Ч.Щ1Щ.ЧЛ11Л11
Диаграмма рассеяния с гистограммами ARISDAT STA 5V150с)
-±Л*т 1
^2ш.
°яЪо СО
««ft*« ■ •■-
0.0 09 1.0 1.9 2.0 29 3.0 Э.9 4.0 49 9.0 9.9 00 0.9 70 79 0 18 Эв
График состоит из простой .диаграммы рассеяния двух заданных переменных
(X и У) и гистограмм распределений частот для переменных X и Y, изображенных
соответственно вдоль осей X и У диаграммы рассеяния.
Диаграммы рассеяния с диаграммами
размаха
Этот тип статистических графиков представляет собой составной график с
зависимостью между двумя переменными и распределениями значений каждой из двух
выборок (включая выбросы и экстремальные значения). Такой график особенно
полезен при проверке по указанному пользователем критерию, являются ли
отдельные точки данных выбросами или экстремальными значениями и можно ли
их удалить из выборки. График состоит из простой диаграммы рассеяния двух
указанных переменных (X и У) и диаграмм размаха для переменных X и У,
изображенных соответственно вдоль осей X и У диаграммы рассеяния.
Нормальные вероятностные графики
227
{явавшпв
Диаграмма рассеяния с диаграммами размаха (FACTOR STA 1 0v*1 00c)
Нормальные вероятностные графики
Эти графики позволяют визуально исследовать, насколько распределение данных
близко к нормальному.
ихи
щш!тштшштяшт
Нормальный |ероятностный график
для нормальной переменной
90 110
Наблюдаемое значение
Нормальный вероятностный график
Стандартный нормальный вероятностный график строится следующим
образом. Сначала все значения переменной ранжируются. По рангам рассчитываются
Z-значения (значения стандартного нормального распределения) в
предположении. Значение z. для^-го ранга переменной с N наблюдениями вычисляется
по формуле:
2. = F-'[Cx;-l)/CxW+l)],
где F1 — это обратная функция стандартного нормального распределения
(преобразовывающая нормальную вероятность р в нормальное значение z).
Значения z откладываются по оси У, наблюдения — по оси X. Если
наблюдаемые значения распределены нормально, то все значения на графике должны
попасть на прямую линию. Если значения не являются нормально
распределенными, то будет наблюдаться отклонение от прямой.
228
Глава 5. Двумерный визуальный анализ данных
Нормальный мроятностный график \
i нормально распределенной переменной (с постоянной вероятностью) \
3 5 7
Наблюдаемое значение
На этом графике можно визуально обнаружить выбросы.
Если наблюдается очевидное несовпадение и данные располагаются
относительно линии определенным образом (например, в виде буквы 5), то перед
применением статистических методов, для которых существенное значение имеет
нормальность распределения, необходимо каким-то образом преобразовать
переменные (например, логарифмическое преобразование часто используется для того,
чтобы «втянуть» конец распределения).
Полунормальный вероятностный график
Полунормальный вероятностный график строится тем же образом, что и
стандартный нормальный вероятностный график, с тем отличием, что рассматривается лишь
положительная часть нормальной кривой. Следовательно, по оси Убудут
откладываться только положительные нормальные значения. В частности,
полунормальное вероятностное значение z. для7-го упорядоченного значения (ранга)
переменной с N наблюдениями вычисляется так:
2. = F~l[Ce х ЛГ+3 х;-1)/F х ЛГ+1)],
где F~{ — снова обратная функция нормального распределения.
lilllfJIIII'MHIlllll, I'M'J flf I'■".,.I,II,I НЛ 11,1 illl
Полунормальный мроятностный график
для нормальной переменной
::]::
.:.:.
i -1
■- - \ в ■} ■- ■
...... -i^8. L^^.
J\J±^f*\... | 1 Г .1
10 15 20 25
Наблюдаемое значение
Этот график часто используется для исследования распределения остатков, если
нужно игнорировать знак остатка, когда интерес вызывает распределение
абсолютных остатков независимо от их знака.
Нормальные вероятностные графики
229
Нормальный вероятностный график с исключенным трендом
Нормальный вероятностный график с исключенным трендом строится тем же
образом, что и стандартный нормальный вероятностный график, с тем отличием, что
перед созданием графика удаляется линейный тренд.
t-il.HIU !;ЧШ1'№1'- ГТ'Г' I'J'hll'^l," 1Г",,' 1J1 MII'IJI1!—ЛдГНТ
Нормальный вероятностный график \
для на нормально распределенной переменной (с постоянной вероятностью) I
3 5 7
Наблюдаемое значение
В частности, на этом графике каждое значение (X) стандартизируется
вычитанием среднего и делением на соответствующее стандартное отклонение (s).
Нормальное вероятностное значение с исключенным трендом z. для у го
упорядоченного значения (ранга) переменной с п наблюдениями вычисляется так:
г. - F~l[C х;-1)/C х JV+1)] - (х-среднее)Д
где.?-1 — это обратная функция нормального распределения, а5 — стандартное
отклонение.
Графики квантиль-квантиль
График квантиль-квантиль (или кратко — график К-К) полезен для нахождения
наиболее подходящего распределения из выбранного семейства распределений.
ItlUM'iirM'llMI'Hl'lll'llliilNIIl
График квантиль-квантиль для WEI8ULL (DISTRBS STA 8V300c)
Распределение: ВейОулла A)
у»0,013*>1.024«*м»р8
2 4
Теоретическая квантиль
Вначале выбирается семейство распределений, внутри которого производится
подгонка.
230
Глава 5. Двумерный визуальный анализ данных
Чтобы оценить подгонку распределения, наблюдаемые значения
упорядочиваются {х1 <... < хп), и по этим значениям (х.) строится обратная эмпирическая
функция распределения.
Затем к ней подгоняется линия регрессии. Если наблюдаемые значения
попадают на линию регрессии, то можно сделать вывод, что они имеют заданное
распределение.
Уравнение линии подгонки (У=я + Ьх) дает оценки параметров а и Ь (где
а — параметр сдвига, Ъ — параметр масштаба).
Обычно квантильные графики строятся для наиболее употребляемых
распределений: экспоненциального, экстремального, нормального распределений,
распределения Релея, бета-, гамма-,логнормального распределения и распределения Вейбулла.
Графики вероятность-вероятность
График вероятность-вероятность (или график В-В) полезен для определения,
насколько хорошо теоретическое распределение подходит для наблюдаемых
данных. На графике В-В строится зависимость между эмпирической функцией
распределения и теоретической функцией распределения для оценки подгонки
теоретического распределения к наблюдаемым данным. Если все точки графика попадают
на диагональную линию (со сдвигом 0 и наклоном У), то можно сделать вывод, что
теоретическое кумулятивное распределение точно приближает наблюдаемое
распределение.
иаШ'Ш11,Ш|^
График вероятность-вероятность для EXPONENT (DISTRBS STA 6V300c)
Распределение экспоненциальное @.827)
0 25 0 50 075
Теоретическая функция распределения
Если точки данных не попадают на диагональную линию, то этот график
можно использовать для наглядной проверки того, подходит ли распределение к
данным (например, если точки располагаются в форме S относительно диагональной
линии, то может потребоваться преобразование данных для того, чтобы привести
их распределение к нужному виду).
Для построения этого графика должна быть полностью задана функция
теоретического распределения. Следовательно, параметры распределения должны быть
либо определены пользователем, либо вычислены по данным (для получения
дополнительной информации о параметрах см. описание соответствующего
распределения).
Диаграммы диапазонов
231
Вообще говоря, если наблюдаемые точки имеют выбранное распределение с
соответствующими параметрами, то они попадут на прямую линию на графике В-В.
Заметьте, что для получения используемых здесь оценок параметров (для
наиболее подходящего распределения из семейства распределений) также можно
применять график квантиль-квантиль.
Диаграммы диапазонов
На диаграммах диапазонов представлены диапазоны значений или столбцы
ошибок, относящиеся к определенным точкам данных, в форме прямоугольников или
отрезков. В отличие от стандартных диаграмм размаха, диапазоны или столбцы
ошибок не вычисляются по данным, а определяются исходными значениями
выбранных переменных.
ШППЕШШЕЗЕ2
ЕсШ'
Диаграмма диапазонов для переменной V2 (цена BNM)
66 |
62 I
58 I
54
50
46 I
tJI.I:.1:1; .; ! !..: : :
tj1:..! !.! ! I i ! | i ! !
12 3 4 5
7 8 9 10 11 12 13 14
День торгов
ZL Верх/ниж
о засечки
Обычно горизонтальные диаграммы диапазонов используются для
изображения временных промежутков, а не изменчивости; их также рекомендуется
использовать, если у диапазонов очень длинные метки, потому что на горизонтальных
диаграммах диапазонов метки не нужно переносить (как в случае, когда длинные
метки расположены вдоль оси X).
I IIIIIМИНИIIIII ГНИ I ■■■■■■—1
Средние температуры (макс в июле) и
крайние значения температур для выбранных городов
Wichita
Dubuque
Oes Moines
Indianapolis
Chicago
Boise
Honululu
Atlanta
Miami
Key west
Jacksonville
Washington
Wilmington
Harford
Denver
San Francisco
LosANgeles
Little Rock
Phoenix
Juneau
Mongomery
Mobile
Вертикальные диаграммы диапазонов часто используются для представления
данных рынка, торговли и т. д.
232
Глава 5. Двумерный визуальный анализ данных
Диаграмма диапазонов (STOCKS STA 7И200с)
122Ш
I 1 I I I I I II I I I I
Диаграммы размаха
На диаграммах размаха (термин введен Тьюки в 1970 году), или так называемых
графиках ящики-усы, диапазоны значений выбранной переменной (или
переменных) строятся отдельно для групп наблюдений, определяемых значениями кате-
горизующей или группирующей переменной.
Центр (например, медиана или среднее) и статистики диапазонов или
вариации (например, квартили, стандартные ошибки или стандартные отклонения)
вычисляются для каждой группы наблюдений.
uaut
Средние обчамы продаж по округам
140
130
Выбрось
со
И 10°
go
tpwmm*
10ЧП
60
jj<T .
:fi:
1|J::.
i
-t
ft
__ ____\^
T
i
о
4
i
8
_4-._-r ...
HZ Макс баэ аыбросоа;
Мии баз аыбросоа
CD 75%
25%
NORTH SOUTH WEST EAST CENTRAL ° М«Аиаи»
На графике может быть представлено более одной зависимой переменной для
возможности сравнения распределений результатов соответствующих измерений
по группам.
Распрадаламие даум иэмарамим • трал rpynnai <
мадиака; прямоугольник 29%, 73%; отрозос: мим баз аыбросоа. uaic баз аыбросоа \
о
■ JL
т
А
• о
1 ^^
т
А
^
:т
Диаграммы размаха
233
Диаграмма размаха
4UU0
3500
3000
2500
2000
1500
1000
500
0
■500
|
1 а 1
CD 25%-75%
Если изменить разметку осей, то можно увидеть следующую картину:
Диаграмма размаха
1000
900
800
700 I
600
500
400
300
200
100
О '
....?=
bL_^_J
ZH
cz_
□ 254-75%
о Медиана
Из этой диаграммы размахов видно (данные носят модельный характер,
но в них отражена реальная ситуация), как распределены покупки колбасы и мяса
в супермаркете в течение дня. Диаграмма СУММА показывает, как распределена
сумма всех покупок, сделанных клиентами.
Очевидно, что вариабельность покупок колбас больше вариабельности
покупки мяса. Половина покупателей производят покупку колбас в очень узком
диапазоне (типичный покупатель).
Диаграммы диапазонов отличаются от диаграмм размаха тем, что для диаграмм
диапазонов диапазоны для построения определяются значениями выбранных
переменных (например, одна переменная содержит минимальные значения
диапазонов, а другая — максимальные значения диапазонов), в то время как для
диаграмм размаха диапазоны вычисляются по исходным значениям переменной
(например, стандартные отклонения, стандартные ошибки или исходные диапазоны).
Как правило, диаграммы размаха применяются в двух случаях: а) для
сравнения диапазонов значений отдельных выборок или категорий наблюдений
(например, типичная минимаксная диаграмма для акций или товаров или
агрегированные диаграммы последовательностей данных с диапазонами) и б) для сравнения
распределений или вариаций результатов в отдельных группах или выборках
234
Глава 5. Двумерный визуальный анализ данных
(например, диаграммы размаха, представляющие среднее в виде точки внутри
прямоугольника, стандартные ошибки — в виде прямоугольника, а стандартные
отклонения от среднего — в виде более узкого прямоугольника или отрезка).
Диаграммы размаха, показывающие вариацию значений, дают возможность
визуализировать и быстро оценить силу зависимости между группирующей и
зависимой переменными. В частности, предполагая, что зависимая переменная
распределена нормально, и зная, какая часть наблюдений попадает в интервал,
например, ±1 или ±2 стандартных отклонения от среднего, можно легко оценить
результаты эксперимента и показать, что около 95% наблюдений в
экспериментальной группе 1 принадлежат к диапазону, отличному от диапазона значений, куда
попадают примерно 95% наблюдений в группе 3.
[Р71 Простые диаграммы размаха
Простые диаграммы размаха используются для представления и исследования
диапазонов значений переменной при категоризации с помощью другой переменной.
Когда выбрано более одной зависимой (то есть У) переменной, будет построена
последовательность графиков (по одному для каждой выбранной зависимой
переменной).
И Составные диаграммы размаха
В отличие от простых диаграмм размаха, на которых представлены диапазоны
значений одной переменной, составная диаграмма размаха изображает (на одном
графике) диапазоны значений нескольких переменных.
■Jolx!
Диаграмма paauaia объемов продаж по округам
Медиана. Прямоуг 25%. 75%. Отрезок Мим без выбросов. Маге без выбросов
■ Медиана, продажи 1991
а Мвдиаиа. продажи 19921
Для каждой переменной используется и указывается в условных обозначениях
свой маркер точек, шаблон заполнения и цвет. Этот тип диаграмм размаха
используется для сравнения диапазонов значений нескольких переменных (или
нескольких функций) путем представления их на одном графике, использующем общие
шкалы (например, сравнение нескольких одновременных экспериментальных
процессов, социальных явлений, цен акций или товаров, форм кривых текущих
характеристик и т. п.).
Столбчатые диаграммы
2М столбчатые диаграммы представляют собой последовательности
значений в виде столбцов (одно наблюдение представлено одним столбцом). Если вы-
Столбчатые диаграммы
235
брано более одной переменной, то каждая диаграмма может быть изображена
отдельно или все диаграммы могут быть представлены на одном графике в виде групп
столбцов (одна группа для каждого наблюдения). Например, для этого множества
данных будет построена следующая столбчатая диаграмма.
ОБЪЕМЫ ПРОДАЖ (РАЗДЕЛЕНИЕ УСЛУГ)
Следует отметить, что для изображения столбцов ошибок, связанных с
отдельными измерениями (например, стандартных ошибок, вычисленных по данным или
зафиксированным ранее границам диапазона), следует использовать диаграммы
диапазонов или диаграммы размаха.
СТД Простые столбчатые диаграммы
Для выбранной переменной строится простая столбчатая диаграмма (если
выбрано более одной переменной, то для каждой переменной из списка строится
отдельный график).
Столбчатая диаграмма
236
Глава 5. Двумерный визуальный анализ данных
|Д Составные столбчатые диаграммы
На составных столбчатых диаграммах (на одном двумерном графике) показаны
группы столбцов для многих переменных (одному наблюдению соответствует одна
группа); один столбец группы представляет одну из выбранных переменных.
Benton
Cannon
Carrol Cumberland
Cheatheam
Ш PT.POOR
OHD PT.PHONE
Ш PT RURAL
Значения всех исследуемых переменных откладываются по единой оси У (или
оси X, если выбрана горизонтальная ориентация), что облегчает сравнение
анализируемых переменных.
Линейные графики (для переменных)
2М линейные графики представляют собой двумерные линейные графики одной
или многих переменных, на которых отдельные точки соединены линиями.
Линейные графики дают простой способ наглядного представления
последовательности большого числа значений (например, рыночных цен на акции за некоторое
число дней); ХУ-графики трассировочного типа (см. ниже) могут быть
использованы для изображения пути (вместо последовательности).
Линейные графики (для переменных)
237
Линейные графики могут также быть построены для непрерывных функций,
теоретических распределений и т. п. Ниже показано несколько таких графиков.
PJ ( роФик.4 Граф nept
ЦЕНА НА НЕФТЬ Моширов М б«реяь)
5*г
• ГЧ ^ •
gssssssss
<ы^ тгы ^т f*^ ^
si?
Даты (и* переменной: DATE)
tsssssssslssslsslssisiis
Даты (и» переменной: DATE)
• - - ЦЕНА Д.РУБЛЬ
Если имеется лишь несколько наблюдений, то лучше использовать
вертикальную столбчатую диаграмму, хотя значительным исключением из этого правила
являются графики различий между средними некоторого количества групп.
Криеея операционных характеристик
Границы контроля ВГК * 3 0000*Сигме. НГК«.3 000*Сигме
. .. L, ^ .
■ г*?*Гч^.
:.. : >^Ч ■>...:
V\\\ \ '-•
' * №■; ' N^
•••• *■■■ v-\\ ■••*■■■'■
• i- \v\.\\; ^х
Vх- V ^
v*:V^
•>*.v.
■*.
•vv-V ^^
ч-:-^ .>>n
^T^irt
>»»
■ ifll—
—
.
i-
*^«.
—
-..
■^
^
--
- «.
__
....
....
••
-;
, ^
....
100 200 300 400 5 00 600
Отношение стенд, отклон для старого и ноаого процессов (переменней
- • NO
-•• N-2
— N-S
SIZE)
238
Глава 5. Двумерный визуальный анализ данных
Если в последовательности очень много наблюдений и они различаются, то
необходимо сглаживание для обнаружения общей структуры последовательности
данных. Простейшей формой сглаживания является агрегирование, когда вместо
исходных данных изображаются средние последовательных множеств из п
наблюдений. На агрегированных линейных графиках диапазоны значений
изображаются отрезками.
О 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95 Ю0 !
Агрегирование также может быть использовано в качестве средства
уменьшения количества точек, дающего возможность представить на одном графике
больше данных, чем в любом другом случае (при данном разрешении монитора или
принтера).
|37| Простые линейные графики
Простые линейные графики используются для представления и исследования
последовательностей значений (обычно когда порядок значений является существенным ).
ОЗВШИаВВШШВ
График переменной SERIES.G
Число пассажире»! за месяц (• 1000)
: _J Li l JLLi JL1JJLA
Также типично применение линейных последовательных графиков при
построении графиков непрерывных функций, таких как функции подгонки или
теоретические распределения. Заметьте, что пустая ячейка данных (то есть
пропущенные данные) «разрывает» линию.
|gffl Составные линейные графики
В отличие от простых линейных графиков, на которых представлена
последовательность значений одной переменной, на составном линейном графике изобра-
Линейные графики (для переменных)
239
жаются несколько последовательностей значений (переменных). Для каждой
переменной используется и указывается в условных обозначениях свой шаблон
линии и цвет.
R8S88S888gg8§S8S88§
Этот тип линейных графиков используется для сравнения
последовательностей значений нескольких переменных (или нескольких функций) путем
изображения их на одном графике, использующем один общий масштаб (например, для
сравнения нескольких одновременных экспериментальных процессов, социальных
явлений, цен акций или товаров, форм кривых текущих характеристик и т. п.).
QI Линейные графики с двойной осью Y
Линейный график с двойной осью У можно рассматривать как комбинацию двух
по-разному масштабированных составных линейных графиков. Для каждой
выбранной переменной используется свой шаблон линии, в то же время все
переменные, выбранные в списке Левая ось У, будут откладываться по левой оси У, а
переменные, выбранные в списке Правая ось У, будут откладываться по правой оси У.
240
Глава 5. Двумерный визуальный анализ данных
Имена всех переменных будут указаны в условных обозначениях вместе с
буквой (Л) для переменных, относящихся к левой оси У, и с буквой G7) для
переменных, относящихся к правой оси У.
Линейный график с двойной осью У можно использовать для сравнения
последовательностей значений нескольких переменных, накладывая их линейные
представления на один график. В то же время, в силу независимости шкал,
используемых для двух осей, этот график может облегчить сравнение «не сравнимых» другим
способом переменных (то есть переменных со значениями в разных диапазонах).
[/у] Трассировочные XY-графики
Трассировочные XY-графики требуют выбора по крайней мере двух переменных
{X и У). На трассировочных графиках сначала строится диаграмма рассеяния двух
переменных, а затем отдельные точки данных соединяются линией (в порядке их
считывания из файла данных).
В этом смысле трассировочные графики визуализируют «путь»
последовательного процесса (движение, изменение явления во времени и т. п.).
li?H Агрегированные линейные графики
Агрегированные линейные графики изображают последовательность средних для
последовательных подмножеств выбранной переменной. Можно выбрать число
последовательных наблюдений, по которым будет вычислено среднее (параметр
Индекс), а при необходимости диапазон значений в каждом подмножестве будет
выделен значками типа отрезков.
\ Arptmpot-ениыЙ лмиейный график трех процессов
Линейные графики (профили наблюдений) 241
Агрегированные линейные графики используются для представления и исследова-
I ния последовательностей большого числа значений. Следует отметить, что в модуле
Временные ряды содержится большой набор процедур сглаживания и фильтрации
данных (например, скользящее среднее, скользящая медиана, 4253Н-фильтр и др.).
Линейные графики (профили наблюдений)
2М линейные графики (профили наблюдений) представляют собой двумерные
линейные графики одной и нескольких переменных.
В отличие от простых линейных графиков, где значения одной переменной
изображаются в виде одной линии (отдельные точки данных соединены линией), на
линейных графиках профилей наблюдений значения выбранных переменных для
наблюдения (строки) изображаются в виде одной линии (то есть один линейный
график создается для каждого выбранного наблюдения).
\ Линейный график (NEWSTA lOfMOc) ]
$
! "
; 44
\
'■ IS
\
' 3JQ
\
\ "
' 2Л
МТ&ШВ<е PRUDCNCE SOOABLITY ММЮТОСвМ WTWOVWICN
Линейные графики профилей наблюдений дают возможность наглядно
представить значения для наблюдения (например, значения для нескольких критериев).
Q Простые линейные графики (профили наблюдений)
Простые линейные графики используются для представления и исследования
последовательностей значений (обычно когда порядок значений является
существенным). Обратите внимание, что пустая ячейка данных (то есть пропущенные
данные) «разрывает» линию.
ISffl Составные линейные графики (профили наблюдений)
В отличие от простых графиков профилей наблюдений, на которых представлена
последовательность значений одной переменной, на составном линейном графике
изображаются несколько последовательностей значений (переменных). Для
каждой переменной используется и указывается в условных обозначениях свой
шаблон линии и цвет.
Этот тип линейных графиков используется Для сравнения последовательностей
значений нескольких переменных (или нескольких функций) путем изображения
их на одном графике, использующем один общий масштаб (например, для сравне-
242
Глава 5. Двумерный визуальный анализ данных
ния нескольких одновременных экспериментальных процессов, социальных
явлений, цен акций или товаров, форм кривых текущих характеристик и т. п.).
Последовательные/наложенные графики
Все типы графиков из этой группы используются для представления
последовательностей значений. В этом отношении они сходны с линейными графиками.
Фактически если для построения выбрана только одна переменная, то отображение
данных будет идентично представлению на линейных графиках. В то же время,
наложенные графики позволяют реализовать более разнообразные способы
графического представления (зонные, ступенчатые, столбчатые диаграммы и др.).
Единственное значительное различие между представлениями данных на
рассматриваемом типе графиков и на линейных графиках проявляется, когда для
построения выбирается более одной переменной. На линейных графиках каждая
переменная будет построена независимо от других; так, например, если две
переменные имеют одинаковые значения для наблюдения 3, то в этой точке (наблюдение 3)
две линии пересекутся или перекроются. В то же время, наложенные графики
«складывают» соответствующие значения последовательных переменных (из
выбранного списка).
Объединенный доход из трех источников
[ ^ ^ ^ д ^ ^ ^ ] I Е2Я sources
Так, на этом графике точка, отвечающая наблюдению 3 для второй
переменной, будет соответственно выше, чем для первой переменной. Переменные
складываются в том порядке, в каком они были выбраны.
Благодаря такому наложенному представлению значений последовательных
переменных линии (или шаги, области, столбцы и т. д.) последовательных
переменных никогда не будут перекрываться, если они больше 0.
Такая интерпретация влечет ограничение, касающееся пропущенных значений
в изображаемом множестве данных. А именно — положение каждой точки данных
на графике для каждой последовательной переменной (из выбранного списка)
является суммой ее значений и соответствующих значений (то есть значений для
того же наблюдения) всех «предшествующих» переменных в списке.
Следовательно, если хотя бы одно из предшествующих значений пропущено, сумму нельзя
вычислить, и график в этой точке будет «разорван». Таким образом, во множествах
Последовательные/наложенные графики
243
данных, выбранных для наложенного представления, не должно быть
пропущенных данных (исключая данные для последней переменной).
Эти типы графиков используются для представления последовательностей
значений выбранных переменных. Однако наложенный вид графиков (применяемый
при выборе более одной переменной) специально разработан для представления
большой категории множеств данных, в которых последовательные переменные
представляют части («порции») целого. Например, каждое наблюдение может
обозначать ВНП за один фискальный год, а каждая переменная — сумму в долларах,
поступившую из каждой отрасли промышленности и из других источников
товаров и услуг. Если такие данные были бы представлены на наложенном столбчатом
графике, то получившаяся высота каждого столбца обозначала бы суммарный ВНП,
а каждый из вложенных сегментов столбца показывал бы относительный вклад
соответствующей отрасли.
Если переменные, представленные на графике, отражают проценты и/или
в сумме дают одно и то же значение (например, 100%) для каждого наблюдения, то
суммарная высота графика будет постоянной для всех наблюдений.
НаложанмыА графи* (BLEN01 .ЭТА 10*4 Ос)
ЩЩ Линейный график
На этом типе графика последовательности значений каждой переменной будут
представлены последовательными линиями, расположенными одна над другой.
! ""'■■-•-.! — var_3
| \ ! | \ | | VAR_2
О 1 2 3 4 5 6 "■■ VARJ
244 Глава 5. Двумерный визуальный анализ данных
|jg Зонный график
На этом типе графика последовательности значений каждой переменной будут
представлены последовательными областями, расположенными одна на другой.
.1 н mi \\\\uv\]\шшашшшшшшишшшшшшшшшяшши,
JU3J1 Смешанный линейный график
На этом типе графика последовательности значений, выбранных в первом списке
переменных, будут представлены последовательными областями,
расположенными одна на другой, а последовательности значений, выбранных во втором
списке переменных, будут представлены последовательными линиями,
расположенными одна над другой (над областью, отвечающей последней переменной из
первого списка).
хшшжшшшшшвшшшшшшшшшшшшш^
Простой смешанный линейный график
Последовательные/наложенные графики
245
| Ступенчатый график
На этом типе графиков последовательности значений каждой переменной будут
представлены последовательными ступенчатыми линиями, расположенными одна
над другой.
|-ЦЩ»ЦЦШ1
шпаЩ
Простой наложенный ступенчатый график
| Ступенчатый зонный график
На этом типе графиков последовательности значений каждой переменной будут
представлены последовательными ступенчатыми областями, расположенными
одна на другой.
шинии
па
Простой ступенчатый зонный график
! 10
246
Глава 5. Двумерный визуальный анализ данных
Ей| Смешанный ступенчатый график
На этом типе графика последовательности значений, выбранных в первом списке
переменных, будут представлены последовательными ступенчатыми областями,
расположенными одна на другой, а последовательность значений выбранных во
втором списке переменных будет представлена последовательными
ступенчатыми линиями, расположенными одна над другой (над областью, отвечающей
последней переменной из первого списка).
ggg] Столбчатая диаграмма
В данном случае последовательности значений каждой выбранной переменной
будут представлены последовательными сегментами вертикальных столбцов,
расположенных друг на друге.
шшшшшпшшшшяшшшшашшшшщ
Простая наложенная столбчатая диаграмма
: 12
Круговые диаграммы
247
Круговые диаграммы
Круговая диаграмма (термин был впервые использован Хаскеллом в 1922 году)
является одним из наиболее часто используемых графиков для представления
пропорций. В зависимости от выбранного типа графика на круговой диаграмме
будут изображаться или исходные значения, или частоты особых категорий
значений (как те, которые можно изобразить на гистограмме).
Щ* Круговые диаграммы частот
В отличие от круговой диаграммы значений этот тип круговой диаграммы (иногда
называемой частотной круговой диаграммой) интерпретирует данные так же, как
и гистограмма. Все значения выбранной переменной группируются по
выбранному методу категоризации, а затем относительные частоты изображаются в виде
круговых секторов пропорциональных размеров.
и 11ЛШННИШ! шшшяшшшшшшшшшшштсшм
Круговая диаграмма предпочтений типов быстрого питания
НттЫмдт, 4i.2 %
Расположение значений, представленных на графике, зависит от метода
категоризации и происходит по той же схеме, что и для гистограмм.
Щ Круговые диаграммы значений
Последовательность значений переменной будет изображена в виде
последовательных круговых секторов; размер каждого сектора будет пропорционален
соответствующему значению. Значения должны быть больше 0 (нулевое и
отрицательные значения не могут быть представлены в виде круговых секторов).
Круговая диаграмма эиачвиий
метками секторов являются значения и соответствующие проценты
248
Глава 5. Двумерный визуальный анализ данных
Этот простой тип круговой диаграммы (иногда называемый круговой
диаграммой данных) интерпретирует данные самым непосредственным образом: одно
наблюдение соответствует одному сектору. Шаблоны круговых секторов,
используемые для этого графика по умолчанию, можно регулировать в диалоговом окне
Шаблоны специальных графиков по умолчанию.
Щ Многоцветные столбчатые диаграммы
Многоцветная столбчатая диаграмма служит для изображения того же типа
данных, что и описанная выше круговая диаграмма значений, однако
последовательные значения выражены высотами вертикальных столбцов (разных цветов и
видов), а не площадями круговых секторов.
Откуда поступают деньги
ИСТ0ЧИИ1И ллатажай за
мазиачаимыа ла«аретаа • США
Откуда поступают деньги
Источии(и платежей за
назначенные лмаретаа • США
Преимущество этих диаграмм перед круговыми диаграммами состоит в том,
что они дают возможность более точного сравнения представленных значений
(например, трудно сравнивать маленькие круговые секторы, если они не являются
соседними).
Этот тип графика может также иметь преимущества перед простыми
гистограммами (где для всех столбцов используется один цвет и шаблон
заполнения) в случаях, когда требуется быстрая идентификация определенных столбцов.
Диаграммы пропущенных значений
и интервалов
Диаграммы пропущенных значений и интервалов дают возможность исследовать
шаблон расположения или распределение пропущенных данных и/или заданных
пользователем точек «вне диапазона» текущего множества (или подмножества)
наблюдений.
Этот график применяется в разведочном анализе данных для определения
количества пропущенных данных (и/или данных «вне диапазона»), а также для
выяснения, является ли их распределение более или менее случайным или в их
расположении можно обнаружить некоторую закономерность.
Графики функций пользователя
249
itimiiHiiiwiii
Графин
Наблюдение 1
Нвблед»>т§11
Наблюдение 21
Наблюдение 31
Наблюдаиие 41
Наблюдем** 51
НабЛЮД*ИИе61 J.
Наблюден** 71
Наблюдай** 81
Наблюдение 91
или интервальных денных (MOFLOT 8TA101VI 00с)
. Г ~ .• t . •
VAR1 VAJM1 VAA21 VAR31 VAJU1 VAR61 VAAC1 VAK71 VAR01 VAK&1
WlllJIIIHHHIIIIllil'IIHnilll'lJ'llillMHLIIH
Го*фик пропущенных или интервальных данных (MOPLOT STA101V100с)
Неблюдение
Наблюдай**
Наблюдение 91
VAM1 VAH11 УАЮ1 VAK31 VA*41 VAJW1 УАЙ61 УАЛ71 VAR81 УАЯ01
В сущности, они представляют собой «карту» файла данных (или его частей)
и позволяют исследовать структуру пропущенных данных, очень маленьких
значений, больших значений и т. п. Категоризованный формат дает возможность
сравнивать такие образцы для определенных подмножеств данных.
График пропущенных или интервальных данных (MDPLOT STA1 oi v*1 00c)
Наело****) 41 ,
;h3SS23J[
isSHHiii iiiiiiHSi пшт
Набпюдаии*1
нЯюа«ииа31
«EKE?,
нЯяхттЫ
САТ1ФОКГ 1
Г5~
CATCOOftY. 2
МШНП! Щ1ШШ iliiliiiil
Графики функций пользователя
В отличие от большинства других типов графиков, для 2Мграфика функции
пользователя не требуется выбирать переменные; вместо этого для построения графика
программа запросит ввод формулы. Эта процедура создает графики, основанные
250
Глава 5. Двумерный визуальный анализ данных
не на значениях переменных в файле данных, а на заданных пользователем
формулах (то есть пользовательских функциях), например:
Ы1Ш1И1Ш11
miiwini'iin'iii
д. ,'{^Ди4иММ*4МЙми1
\?-9**?&тЯ /.<•••■;.:.: {
•"'-• ' •'"•'" '
ЫфукЬШ
Ж-
щямшш
ЛИ*-»- 1!
, &\ &УММ»|;
; Ящ1ктр>«..|
Следует отметить, что для других типов графиков наряду с разнообразными
возможностями настройки параметров также предусмотрена возможность
наложения пользовательской функции. Например, аналогичные результаты
построения функций можно получить при помощи регулирования соответствующих
параметров настройки для других типов двумерных графиков.
При наложении функции на график диапазоны осей графика автоматически
подгоняются к соответствующим диапазонам значений переменных. Для
рассматриваемого типа графика можно явно указать диапазоны значений в диалоговом
окне определения графика, которые не будут зависеть от множества данных.
Например, можно установить минимум и максимум для обеих осей (X и У) равными
О и 100 соответственно.
стттигя1д,|1Р.111Р.|. ■■■■niiiiijiiiiiH
о
.' о yS*^ ООО
0
^
*/"*—
Г t
|Пользо1ательская
] наблюдаемые данные
\
•{функция подгонки |
<
(построенная) функция[
1 \
\
Обычно эти графики используются для исследования функциональной
зависимости (например, для проверки соответствия теоретических моделей
экспериментальным данным).
6
Трехмерный
визуальный
анализ данных
Трехмерный визуальный анализ позволяет анализировать данные в трехмерном
пространстве, например, строить трехмерное изображение последовательностей
исходных данных (наблюдений) для одной или нескольких выбранных переменных.
Выбранные переменные представляются по оси Y, последовательные наблюдения — по
оси X, а значения переменных (для данного наблюдения) откладываются по оси Z,
как показано ниже:
t%m -щщш -Щ!штшшшшш*$1Ш№-;;
ЗМ последовательный график
И 10
4 п
1| 14
Б00|
500
000
1 -1 PI *1
HEIGHT 1
12.000
13.000
15.000*
Такие трехмерные графики используются для визуализации последовательностей
значений нескольких переменных. По своей идее они сходны с составными
линейными графиками, с тем лишь отличием, что для ЗМ диаграмм исходных данных ленты,
линии, параллелепипеды и другие трехмерные представления значений каждой
переменной не перекрываются (как на двумерном графике), а «раздвигаются» в
трехмерной перспективе.
lilll'li'llliTI.'OIIJfllfirV,1
ЗМ посл»домт»Лкмым гр»фи« (PAY-PLAN STA 20V1 ?С)
252 Глава 6. Трехмерный визуальный анализ данных
ЗМ диаграммы исходных данных применяются как для отображения
данных, так и для аналитических исследований. Наиболее типичным приложением
ЗМ диаграмм исходных данных является наглядное представление имеющейся
информации (например, о ценах, о росте населения, о взаимосвязи объемов
продаж и прибыли). Такие графики позволяют просто и эффектно представить
последовательности наблюдений, таких, например, как различные типы
временных рядов.
I н innIImi in ■■■■■■■■■■ ini I
Основное преимущество трехмерных представлений перед двумерными
составными линейными графиками заключается в том, что для некоторых множеств
данных при объемном изображении легче распознавать отдельные
последовательности значений. При выборе подходящего угла зрения с помощью,
например, интерактивного вращения линии графика не будут перекрываться или
«попадать друг на друга», как часто бывает на составных линейных двумерных
графиках.
Трехмерные диаграммы также используются в аналитических целях при
исследовании входных данных, имеющих матричный формат.
ГП5Ш
I
Для интерактивного просмотра поперечных сечений таких трехмерных
представлений можно использовать метод динамического расслоения.
TRIAL 21 (all braces removed except for Q-12)
Трехмерный визуальный анализ данных
253
Заметьте, что для детального исследования изображения отдельные
зависимости (то есть переменные) на графике можно выборочно выделить цветом. Для
этого нужно нажать левую кнопку мыши в любом месте выбранной зависимости.
Гистограмм Atyi мр«м*ниы1 ACHTEMS.STA ICVIOOc)
Процесс «просвечивания» дает возможность временно отобразить (с помощью
подсветки) целые серии данных, даже если они почти полностью закрыты
другими данными.
Столбчатая диаграмма
Этот последовательный график представляет отдельные значения одной или
нескольких серий данных по оси Хв виде серий трехмерных столбцов
(параллелепипедов). Все серии отделены друг от друга промежутками вдоль оси У. Высота
каждого столбца по оси Z отвечает значению соответствующей точки данных.
Простая ЗМ диаграмма размаха
254
Глава 6. Трехмерный визуальный анализ данных
Щ Блоковая диаграмма
Этот последовательный график представляет отдельные значения одной или
нескольких серий данных по оси X в виде серий «трехмерных блоков». Все серии
отделены друг от друга промежутками вдоль оси Y. Высота начала каждого блока
по оси Z отвечает значению соответствующей точки данных.
|Ц Ленточная диаграмма
Эта диаграмма представляет отдельные значения одной или нескольких серий
данных, по оси Хв виде серий «лент» в трехмерном пространстве.
шш
Простая ЗМ ленточная диаграмма
Все серии отделены друг от друга промежутками вдоль оси Y. Высота начала
каждой ленты по оси Z отвечает значению соответствующей точки данных.
Щ| Линейный график
Этот последовательный график представляет отдельные значения одной или
нескольких серий данных по оси X в виде ряда непрерывных линий в трехмерном
пространстве.
Простой ЗМ линейньм графим
Трехмерный визуальный анализ данных
255
Все серии отделены друг от друга промежутками на оси Y. Высота начала
каждой линии по оси Z отвечает значению соответствующей точки данных.
|Ц Диаграмма всплесков
Данный последовательный график представляет отдельные значения одного или
нескольких наборов данных по оси X в виде серий «всплесков» (точек с
перпендикулярами, опущенными на плоскость основания).
Простая ЗМ диаграмма всплесков
Все серии отделены друг от друга промежутками вдоль оси Y. Высота каждого
перпендикуляра по оси Z отвечает соответствующему значению серии.
[ Дискретная карта линии уровня
Этот последовательный график можно рассматривать как двумерную проекцию
ЗМ ленточной диаграммы.
'•"» !"•»■■""»
Асига
Honda
ISUZU
Nissan
MitSub
Olds
vw
Ford
Buick
Chrysler
Dodge
Eagle
Corvette
Porsche
Toyota
Audi
BMW
Mercedes
vorvo
Mazda
Pontiac
Saab
'•£ &£* *4 *•'
PRICE
Совместные
ACCELER
результаты
BRAKING
НИ^^Ии ill ,i i ii i i
^^|^^^^^^^Ш
&*4 .* .p »щдщ|
^Шв^^^^ГГ^^^Т^
HANDLING MILAGE
ИЕЕш
CD -3331
□ 2 833
□ 2 1Э4
tZ3 1 4ЭО
C3-0737
Е2Э о сев
В oeeo I
■ 13SB
I H 2067
■ 27X
На этом графике каждая точка данных представлена в виде прямоугольной
области; значениям (или диапазону значений) точек данных соответствуют
различные цвета или шаблоны (цветовые шаблоны описаны справа от графика).
Значения из одной серии представлены по оси Х> а сами серии откладываются по
оси Y.
256
Глава 6. Трехмерный визуальный анализ данных
Щ График поверхности
На последовательном графике к точкам исходных данных подгоняется
сглаженная сплайнами поверхность.
Простой последовательный график поверхности
Последовательные значения каждой серии откладываются по оси Х> а сами
последовательные серии представлены на оси Y.
ИМ Карта линий уровня
Карта линий уровня представляет собой двумерную проекцию сглаженной
сплайнами поверхности, подогнанной к исходным данным.
Простая карта линий уровня
Последовательные значения каждой серии откладываются по оси Х> а сами
последовательные серии представлены на оси У.
Гистограммы двух переменных
Трехмерные, или ЗМ, гистограммы двух переменных используются для
визуализации табулированных значений двух переменных или для визуализации таблиц
сопряженности двух переменных. Их можно рассматривать как сочетание двух
простых гистограмм (то есть гистограмм одной переменной), соединенных таким
образом, чтобы можно было исследовать частоты совместного появления значений
двух переменных.
Гистограммы двух переменных
257
I.IIII.UII1IIUIIHII. „1.Ц.Ш11!.11Ш1Л111
Гистограмма д»ух переменных (SPORTS.STA 14V100с)
Распределение частот на трехмерных гистограммах вызывает интерес по двум
причинам:
О по форме распределения можно сделать вывод о природе исследуемой
переменной (например, если распределение бимодально, то можно предположить,
что выборка не является однородной и состоит из наблюдений,
принадлежащих двум совокупностям, которые приблизительно нормально
распределены);
О многие статистики основаны на определенных предположениях о
распределениях анализируемых переменных; ЗМ гистограммы двух переменных
помогают проверить выполнение этих предположений для пары переменных.
ЗМ гистограммы и кросстабуляции
ЗМ гистограммы двух переменных предоставляют ту же информацию, что и
таблицы сопряженности. Хотя некоторые (числовые) данные по частотам легче
воспринимать в виде таблицы, общая форма и глобальные описательные характеристики
распределения двух переменных легче исследовать на графике.
Более того, график дает качественную информацию о распределении, которую
нельзя полностью выразить каким-то одним показателем. Например,
асимметричное распределение двух переменных — скрытых откликов и времени
реакции (в эксперименте измерения времени реакции) — может проистекать из
изменений поведения субъектов при усталости.
Mg"\il'*'li
Ж
jh-sJ
258
Глава б. Трехмерный визуальный анализ данных
Категоризация значений
Все процедуры построения гистограмм имеют стандартный набор методов
категоризации, или разбиения наблюдений на группы. Систематично методы
категоризации изложены в отдельной главе.
Согласно этим методам, диапазон значений каждой из двух выбранных для
графика переменных разбивается на категории (классы), для которых подсчитыва-
ются частоты, отображаемые в виде отдельных трехмерных столбцов.
Например, можно построить трехмерную гистограмму, на которой каждый
столбец будет соответствовать 10 единицам шкалы, используемой для переменной; если
минимальное значение равно 0, а максимальное равно 120, то будет построено 12
рядов столбцов. В качестве другого примера можно разделить диапазон значений
переменных на определенное число равных интервалов (например, 10); в
последнем случае, если минимум равен 0, а максимум равен 120, то каждый интервал
будет равен 12 единицам шкалы. Существует возможность проводить и более
сложную категоризацию.
Так можно создать неравные интервалы группировки, задавая их границы
(например, для создания легко интерпретируемой картинки или для связывания
выбросов и улучшения представления средней части гистограммы, в которой
сосредоточена большая часть наблюдений). Диапазоны также могут быть созданы с
помощью логических выражений (например, первый столбец гистограммы может
представлять людей, которые в прошлом году путешествовали самолетом более
10 раз, и тех, кто проводит более 20% времени в деловых поездках и т. п.).
Различные способы категоризации на одном графике
Для каждой из двух переменных, распределение которых представлено на
графике, могут быть использованы различные методы категоризации, как показано на
следующей ЗМ гистограмме двух переменных значений времени реакции и
условий эксперимента.
РАСПРЕДЕЛЕНИЕ
ВРЕМЕНИ РЕАКЦИИ
усямал:
ooiniiit урмамь.
■ мрааяьим «•»•. '
■ аи*мя мм
(
В частности, на этом графике распределение времен реакции (непрерывной
переменной, категоризованной путем разделения всего диапазона значений на 12
интервалов равной длины) представлено для трех условий эксперимента
(дискретной переменной с тремя уровнями, имеющими разные метки: Основной — BASEy
Нормальный — NORMAL и Двойной — DOUBLE).
Запомните, все элементы графика можно изменить, щелкнув, например, на нем
правой кнопкой мыши и вызвав контекстное меню графиков.
Гистограммы двух переменных
259
£*ьа«.тнр<«*г«> ваиим* грмь#« v.
Сглаживание распределений двух переменных
Процедуры сглаживания для ЗМ гистограмм двух переменных позволяют
подгонять поверхности к трехмерным изображениям данных частот двух переменных.
Так, например, каждая трехмерная гистограмма может быть превращена в
сглаженную поверхность. Это представление нецелесообразно использовать для
простых категоризованных данных (таких, как изображенная выше гистограмма).
РАСПРЕДЕЛЕНИЕ
ВРЕМЕНИ РЕАКЦИИ (А12)
условия:
- основной уровень,
- нормальная доза,
- двойная доза
Однако этот способ может оказаться ценным средством для исследования
сложной структуры частот.
1-IdIkI
УРОВНИ НАСЫЩЕНИЯ (мг/смл) x ЧИСЛО ОГРАНИЧЕНИЙ
...,-- т—Т СГЛАЖЕННАЯ ГИСТОГРАММА
^
А***^
ОБОЗНАЧЕНИЯ
ГП
из
CZD
□
си
сиз
УШ
шз
вш
вв
0 545
0 991
1 436
1 882
2 327
2 773
3 218
3 664
4 109
4 555
260
Глава 6. Трехмерный визуальный анализ данных
Он позволяет обнаруживать закономерности, менее заметные на стандартной
трехмерной гистограмме, например «волнистую» поверхность на показанном выше
рисунке.
ЗМ диаграммы диапазонов
Подобно статистическим 2М диаграммам диапазонов трехмерные диаграммы
диапазонов отображают диапазоны значений или столбцы ошибок, соответствующих
определенным точкам данных.
ЗМ диаграмм* диапазоне* (RAN0ES1 STA1 evi 4c)
I
Диапазоны или столбцы ошибок не вычисляются по данным, а определяются
исходными значениями выбранных переменных. Для каждого наблюдения
строится один диапазон или столбец ошибок. Переменные диапазона можно понимать
как абсолютные значения или как значения, отвечающие отклонениям от средней
точки. На графике можно представить одну или несколько переменных.
В основном диаграммы диапазонов используются для изображения: а)
диапазонов значений для отдельных элементов анализа (наблюдений, выборок и т. д.)
или б) вариации значений в отдельных группах или выборках (последнее имеет
смысл, когда величины вариации получены при независимых измерениях; иначе
более целесообразно использовать ЗМ диаграммы размаха, которые вычисляют
вариацию для выборок, представленных на графике). Некоторые из этих
приложений кратко описаны в разделе ЗМдиаграммы размаха.
Основное различие между диаграммами диапазонов и диаграммами размаха
состоит в том, что на диаграммах диапазонов все значения, определяющие
диапазоны («средние точки», минимум и максимум), не вычисляются по данным, а
являются исходными значениями переменных.
Когда на графике нужно представить только одну переменную, обычно
достаточно воспользоваться 2М диаграммой диапазонов; на этом графике также можно
представить несколько переменных (путем сдвига изображений так, что для
каждого наблюдения будет отображено последовательно столько диапазонов, сколько
переменных используется для анализа). Тем не менее ЗМ диаграмма диапазонов
часто является более подходящим способом представления диапазонов нескольких
ЗМ диаграммы диапазонов
261
переменных на одном графике, так как она не «разбивает» строки пиктограмм,
представляющих отдельные классы или переменные.
Дизгоамма диапазонов (RANGES 1 sta 16VUc)
После создания графика можно изменить его расположение и вид отдельных
элементов. Для этого нужно открыть диалоговое окно Общая разметка: ЗМграфики
(с помощью двойного щелчка мышью на фоне графика или из графического
выпадающего меню Разметки) или диалоговое окно Размещение ЗМ графика (с
помощью команды контекстного меню, вызываемого правой кнопкой мыши для
конкретной зависимости, или из графического выпадающего меню Разметки).
|5 Точечные диапазоны
На статистической ЗМ последовательной диаграмме диапазонов такого типа
диапазоны изображены в виде маркеров точек (соединенных линией).
Для каждого наблюдения строится один диапазон. Переменные диапазона
можно понимать как абсолютные значения или как значения, отвечающие отклонениям
от средней точки в зависимости от текущего значения параметра Тип (значения
диапазона).
262
Глава 6. Трехмерный визуальный анализ данных
Граничные диапазоны
На статистической ЗМ последовательной диаграмме диапазонов такого типа
диапазоны представлены двумя непрерывными линиями (верхние и нижние
диапазоны). Средние точки изображены в виде маркеров точек, соединенных линией.
tsmaaQEHSSzeasss
ЕШШ
ЗМ диаграмма диап*эоиоа (RANGES1 STA 16v*Uc)
Переменные диапазона можно понимать как абсолютные значения или как
значения, отвечающие отклонениям от центральной точки, в зависимости от
текущего значения параметра Тип (значения диапазона).
Щ Диапазоны ошибок
На статистической ЗМ последовательной диаграмме диапазонов такого типа
средние точки изображены в виде маркеров точек, а диапазоны — в виде столбцов
ошибок. Для каждого наблюдения строится один столбец ошибок.
JfHti-l'IWllWII
it-flii lih'iiiY
ОвШ;
ЗМ диаграмма диапазонов (RANGES1 STA 16v*14c)
I Диапазоны ошибок
Переменные диапазона можно понимать как абсолютные значения или как
значения, отвечающие отклонениям от центральной точки, в зависимости от
текущего значения параметра Тип (значения диапазона).
j Диапазоны двойных лент
На статистической ЗМ последовательной диаграмме диапазонов такого типа
диапазоны представлены двумя лентами (верхние и нижние диапазоны).
ЗМ диаграммы диапазонов
263
I.HHMI шпини тли и...
ЗМ диаграмма диапазонов (RANGES1 STA 1&V*i4c)
Переменные диапазона можно понимать как абсолютные значения или как
значения, отвечающие отклонениям от средней точки в зависимости от
текущего значения параметра Тип (значения диапазона). Средние точки на графике
не изображаются (они могут быть показаны на одном из первых трех типов
диаграмм диапазонов).
«Летящие ящики»
На статистической ЗМ последовательной диаграмме диапазонов такого типа
диапазоны представлены в виде «летящих ящиков». Ящики не закреплены на
плоскости, а как бы парят в пространстве. В ряде случаев такие графики чрезвычайно
эффектны для зрительного восприятия.
2E3SS
СьШШ|
ЗМ диаграмма диапазонов (RANGES1 STA 16v*Uc)
Переменные диапазона можно понимать как абсолютные значения или как
значения, отвечающие отклонениям от средней точки, в зависимости от
текущего значения параметра Тип (значения диапазона). Средние точки на графике
не изображаются (они могут быть показаны на одном из первых трех типов
диаграмм диапазонов).
| «Летящие блоки»
На статистической ЗМ последовательной диаграмме диапазонов такого типа
диапазоны представлены «летящими блоками».
264
Глава 6. Трехмерный визуальный анализ данных
ЗМ диаграмм» диапазонов (PAN6ES1 STA 16v*Uc)
ееш
Переменные диапазона можно понимать как абсолютные значения или как
значения, отвечающие отклонениям от средней точки, в зависимости от текущего
значения параметра Тип (значения диапазона). Средние точки на графике не
изображаются (они могут быть показаны на одном из первых трех типов диаграмм диапазонов).
ЗМ диаграммы размаха
Подобно статистическим 2М диаграммам размаха на ЗМ диаграммах размаха
диапазоны значений выбранной переменной строятся отдельно для групп
наблюдений, определяемых значениями категоризующей (группирующей) переменной.
Центральная тенденция (например, медиана или среднее) и диапазон или
вариационные статистики (например, квартили, стандартные ошибки или стандартные
отклонения) вычисляются для каждой группы наблюдений, а стиль изображения
определяется Типом графика.
iiiiiiiiiHHMrrrn
ЗМ диаграмма размаха
Медиана. Размах 26%. 75%
*.~^
ЗМ диаграммы диапазонов отличаются от ЗМ диаграмм размаха тем, что на
диаграммах диапазонов диапазоны представлены значениями выбранных
переменных (например, одна переменная содержит минимальные значения диапазонов,
а другая — максимальные значения диапазонов), а для диаграмм размаха
диапазоны вычисляются по значениям переменных (например, стандартные отклонения,
стандартные ошибки или минимальные и максимальные значения).
ЗМ диаграммы размаха
265
Как правило, диаграммы размаха используются в двух случаях: а) для
изображения диапазонов значений для отдельных наблюдений или выборок (например,
типичная минимаксная диаграмма для акций или товаров или агрегированные
последовательные графики данных с диапазонами) или б) для изображения
вариации значений в отдельных группах или выборках (например, диаграммы размаха,
изображающие медиану или среднее для каждой выборки в виде точки внутри
«летящего» столбца ошибок, а также стандартные ошибки или квартальный размах,
представленные в виде «летящих ящиков»; см. рисунок ниже).
ЫШ.В.Ш! ГГЧГТЧ""!
■ Jbfxl
Результаты экспаримамта 2А
Медиана. Рима* 26%. 75%
Диаграммы размаха, показывающие вариацию значений, легко позволяют
оценить и «интуитивно представить» силу связи между группирующей переменной и
одной или несколькими зависимыми переменными. В частности, предполагая, что
зависимые переменные нормально распределены, и зная, какая часть наблюдений
попадает, например, в интервал ±1 или ±2 стандартных отклонения от среднего,
можно легко понять результаты эксперимента и сделать вывод, что, например,
результаты примерно в 95% наблюдений в экспериментальной группе 1 принадлежат
диапазону, отличному от диапазона значений порядка 95% наблюдений в группе 2.
Когда на графике нужно представить только одну переменную, обычно
достаточно воспользоваться 2М диаграммой размаха; на этом графике можно также
представить несколько переменных (путем сдвига изображений отдельных «ящиков»
так, что для каждого наблюдения будет изображено последовательно столько
«ящиков», сколько переменных используется для анализа). Тем не менее для
представления нескольких переменных на одном графике более подходящей является
ЗМ диаграмма размаха, так как она не «разбивает» строки пиктограмм для каждой
переменной. Например, это часто делает более ясной схему расположения средних
и стандартных отклонений или квартальных размахов в выбранных категориях.
266
Глава 6. Трехмерный визуальный анализ данных
| Граничные диапазоны
На статистической ЗМ диаграмме размаха вычисленные по исходным данным
диапазоны (например, квартили) представлены двумя непрерывными линиями
(верхние и нижние диапазоны).
liM^llillWI1",1 ТГ
ЗМ диаграмма размаха (CLASSES STA6v*50c)
Медиана. Размах 25%. 75%
Средние точки (средние значения или медианы) отображаются маркерами
точек и соединены линиями.
(Д Диапазоны ошибок
На статистической ЗМ диаграмме размаха такого типа средние точки
(вычисленные по данным средние значения или медианы) изображены маркерами точек,
а вычисленные диапазоны (например, квартили) представлены столбцами
ошибок.
ьшш,н1'Ь1ивав
ЗМ диаграмма размаха
Медиана, Размах Среднее • Ст откл. Среднее * Ст откп
ггш:ь
Диапмоны ошибок
Для каждого уровня независимой (группирующей) переменной рисуется один
столбец ошибок.
j Точечные диапазоны
На статистической ЗМ диаграмме размаха такого типа средние точки и
вычисленные диапазоны (например, квартили) представлены тройками маркеров точек
(соединенных линией).
ЗМ диаграммы размаха
267
Ш11ЖШ11Г1
ansa
ЗМ диаграмма разили (CLASSES STA6v*S0c)
Мадиама, Размах 25%. 75%
Для каждого уровня независимой (группирующей) переменной строится одна
тройка значений.
[ Диапазоны двойных лент
На статистической ЗМ диаграмме размаха такого типа вычисленные диапазоны
(например, квартили) представлены двумя лентами (верхние и нижние диапазоны).
ЗМ диаграмма размаха (CLASSES STA 6v*50c)
Срадмв»,Раэмам Ср«дм»#-Ст ош.Сради***Ст ош
На диаграмме этого типа средние точки не изображаются. Чтобы их показать,
необходимо перейти к одному из первых трех типов диаграмм размаха (см. выше).
; «Летящие ящики»
На статистической ЗМ диаграмме размаха этого типа вычисленные диапазоны
(например, квартили) представлены в виде «летящих ящиков».
ЗМ диаграмма pwuaia (CLASSES STA 6у*50с)
Медиана, Размах Мим . Макс
268
Глава 6. Трехмерный визуальный анализ данных
На диаграмме средние точки не изображаются. Чтобы их показать, необходимо
перейти к одному из первых трех типов диаграмм размаха.
Щ «Летящие блоки»
На статистической ЗМ диаграмме размаха вычисленные диапазоны (например,
квартили) представлены в виде «летящих блоков».
ЗМ диаграмма размаха (CLASSES STA6**51ir)
Мадмача Разин Мин . Маге
"Лотящио" блоки I >
На диаграмме средние точки не изображаются. Чтобы их показать, необходимо
перейти к одному из первых трех типов диаграмм размаха.
ItIiIIIUUII'I irflLJMLI
ЗМ диаграмма р
Медиан*
24 Г
20
1в
\г
в
4
1 '• "*
*х"***\ •
^^>i*A\ -
л*>**\
,^\
лх**° ^~
»ua.a (CLASSES STA6»-50c) j
Разма. Мин Мак <
• ' ' ' >
НгЧг^ . |
{мшШ' '
в-lTTW > ("Летящие" блоки j
к!Ги м Ы'\ л
Если увеличить установленное по умолчанию значение поля Х@%), то между
отдельными «летящими блоками» появятся разрывы, как показано выше на графике.
x|ff Всплески
При выборе этого режима точечные диапазоны или столбцы ошибок будут
соединены с основанием графика линиями.
ItI.'HiMHIIJI'III.IiIWIII
ЗМ диаграмма разиаи
Модиама. Раэиа! 5%. 95*
80Г ,
Трехмерные диаграммы рассеяния
269
Трехмерные диаграммы рассеяния
Трехмерные диаграммы рассеяния (называемые также XYZдиаграммами рассеяния)
представляют собой наиболее простой тип трехмерных зависимостей. Как правило,
они используются для визуализации связей между непрерывными переменными.
Д**ыв WSDATSTA5V 150с (Fisher, 1936)
LENGTH ft WflOTN Of Sf PALS AND Pf TALS C types О
7*{
a*
««•И 1ИЙА1.ГГ A •»•«*«
Хотя можно найти различные применения трехмерных диаграмм рассеяния,
тем не менее их основное преимущество состоит в наглядном представлении
сложных взаимосвязей между несколькими переменными.
Рассмотрим простой пример из области маркетинга. Предположим, за
определенный период времени (в различное время суток) проводились исследования цены
и предложения товара. Если построить на графике значения трех этих
переменных {Price, Supply и Hour), то можно выявить сложные многомерные
интерактивные связи, которые практически невозможно обнаружить при численном анализе
данных.
яшшшшшшшшшшштяшшшшшяшшшшш
^^^^^^Г-ТЯ«-Ч|
JPPLY vs. PRICE vs. HOUR OF TRADING
о
1.11
0»
*, о7
1°>
о
о о о
СХЕМАТИЧЕСКОЕ 1 i
ИЗОБРАЖЕНИЕ
"ШАБЛОНА"
' °o / о e e /o I
t .' 9 ° / ■ ■ 0 |
; o:o ° / о !
о °o o" -'<'•'> ° о
г О ><■ ■ ' -.« ■ -.* ,
0$ \ оч •-■"ч* ~" о "■'.. - ' '>. 1
W-;'i>>>. .- ••.;.-■ ".-'о':-. !
** >t " ' ' ~ ' J^s
: ч^^■■■--••>/•>>,^;, 1
псо?там?08АШОс 1 i
0 ЧИСЛО СДЕЛОК (ml П-2Н) | |
270
Глава 6. Трехмерный визуальный анализ данных
Например, можно установить, что взаимосвязь усиливается во второй
половине дня (становится теснее связь между ценой и предложением товара). Однако по
форме графика также видно, что эта связь не сохраняется при низком уровне
предложения (то есть при малых значениях переменной Supply). Часто такие сложные
взаимосвязи легче выявить на графике, чем при использовании численных
методов, особенно в случае криволинейных зависимостей.
Выделение кластеров и подмножеств на выборке из неоднородной совокупности
Существует и другая область разведочного анализа данных, где могут быть
полезны XYZ диаграммы рассеяния. Это те случаи, когда ожидается наличие групп
наблюдений, которые могут быть выявлены только при исследовании
распределения одновременно по трем переменным. Например, на следующей XYZ диаграмме
рассеяния показаны «классические» данные по классификации ирисов (Fisher, 1936;
файл Irisdatsta), которые вклютают наблюдения различных видов ирисов.
ГЗСШД ГЧ1 1'Ч!11,1Ш!1Ш2ШШИИИИадЕЗ|
Данные IRISDAT.STA 5v • 150с (the 'classic* IRIS data set. Fisher 1936)
LENOTH l WIDTH OF SEPALS AND PETALS C types of Ins)
Из графика видно, что, построив зависимость ширины лепестков от их длины и
ширины чашелистиков, можно сделать вывод о том, что выборка неоднородна.
ЫШИИИЦ Iff. ИМ fJ^JJ, ,111Ж11111ЖДИИМИШ1
: Данные. IR1SOAT.STA Sv * 160с (the 'class*' IRIS data set. Fisher 1936)
LENOTH * WIDTH OF SEPALS AND PETALS C types of Ins)
На приведенном выше графике, где подмножества маркированы, легко
выделить различные виды ирисов.
Изучение результатов многомерного анализа
Часто XYZ диаграммы рассеяния используются в статистике для наглядного
представления результатов многомерных методов исследования, таких как факторный
Трехмерные диаграммы рассеяния
271
анализ и многомерное шкалирование. Например, построение на трехмерном
графике наблюдений с метками, являющихся трехмерным решением задачи
многомерного шкалирования, может помочь в определении величин и классификации
отдельных наблюдений.
Ок(
1
о»
QQQQI
эмчате
'I
0.2
&%
4-«
шттшяшт
шШШшшшшшшшшшшшшшшшшшшш^^шшшшшшшшшшшип II
льная конфигурация (файл данных NATIONS STA, ЗМ решение)
Г
1
<* ^ч^
^>^Чу^
о^^
о-*"
Ч,
« и» Т
°ECYPT ° f
i ° 1:
RUSSIA
YUGOSLA»
'. CONGO i
СивАр
с 1 FRANCE ' ■
9
■"AM. f !
' ° J^ -**
Чг ' j>^^ ^
^v, ' _->^*^>'^*»,*ь
Вращение
Общая проблема трехмерных диаграмм рассеяния — перекрывающиеся точки,
которые затрудняют изучение графика. В некоторых случаях при очень большом
числе наблюдений график почти невозможно понять, если смотреть на него под
одним углом зрения. Поэтому при исследовании таких трехмерных графиков
особенно полезно показанное ниже интерактивное вращение изображения на экране.
272
Глава б. Трехмерный визуальный анализ данных
| Диаграмма рассеяния
Этот простой тип XYZ диаграммы рассеяния отражает взаимосвязь между тремя
или более переменными в трехмерном пространстве, при этом каждой точке
соответствует тройка координат X, YnZ.
Простая ЗМ диаграмма расояиия
Заметьте, если выбрано более одной переменной Z, то будет построено несколько
XYZ диаграмм рассеяния для различных наборов данных (соответствующих
нескольким переменным Z), которые будут маркированы разными значками.
fjyQJSSEDE
66 [
г*\
шшшш
'. ' ; х 1 ■ .' ' •
осе»» 0^,
' 7 1' ;Lt
■ с
[■■ ,
??°" «, ' '
•.Г.-; '<
ЩШШШШ Ц Ц |
1 Данные набор 1
из файла даиньгх
IRANDSTA/n^TBH ||
о MEASURE3
о MEASURE4
о MEASURE5 i
♦ MEASURES |
|Ц Пространственный график
С помощью этого графика можно реализовать различные способы представления
ЗМ диаграммы рассеяния. Для этого предусмотрена возможность расположения
плоскости Х-У на выбранном пользователем уровне вертикальной оси Z (которая
проходит через середину плоскости).
ЗМ диаграмма рассммия (SPIRAL STA 1№*44м)
VAR_3 (Z) 5 5
сжэ
Трехмерные диаграммы рассеяния
273
Хотя пространственные графики используются для тех же типов данных, что
и XYZ диаграммы рассеяния, их представление может облегчить исследование
некоторых трехмерных наборов данных. Рекомендуется сопоставлять данные
отдельным осям на графике таким образом, чтобы переменную, структуру связей
которой необходимо выделить, обозначить как Z. Тогда, перемещая плоскость XY
вдоль оси Zh интерактивно вращая изображение, можно попробовать найти такой
уровень Z, на котором изменяется структура связей между X и У (или X, YnZ).
Если ожидаемое изменение структуры слишком сложно для его исследования
в одном «сечении», можно воспользоваться спектральным графиком, который
позволяет наблюдать несколько сечений. Однако поскольку на спектральных
графиках представлен набор двумерных сжатых изображений трехмерных данных, здесь
могут быть потеряны некоторые действительные трехмерные характеристики,
которые наблюдаются на пространственных графиках.
Другое приложение пространственных графиков — наглядное представление
плотности и направленности отклонений от определенного уровня (уровня отклонений).
||$ Спектральная диаграмма
Первоначально этот тип графиков применялся в спектральном анализе для
исследования нестационарных временных рядов, например речевых сигналов. На
горизонтальных осях можно откладывать частоты спектра и последовательные
временные интервалы, а на оси Z — спектральные плотности для каждого интервала.
На этом типе графиков трехмерное пространство разделено на области, в
которых данные «сжаты» в соответствующие спектральные плоскости. Обратите
внимание, что для построения функциональных зависимостей (таких как в
спектральном анализе) необходимо упорядочить данные таким образом, чтобы переменная
У содержала категоризующую информацию (то есть была группирующей переменной).
Спектральные диаграммы имеют явные преимущества перед обычными ЗМ
диаграммами рассеяния, когда необходимо исследовать, каким образом изменяется
взаимосвязь между двумя переменными при различных значениях третьей
переменной. Это преимущество ясно видно на приведенных ниже двух изображениях
одного и того же набора данных.
274
Глава 6. Трехмерный визуальный анализ данных
Значения переменных X и Z интерпретируются как координаты X и Z каждой
точки, а значения переменной Y разделены на равноотстоящие группы,
соответствующие положениям последовательных спектральных плоскостей.
Е 09
* 07
£ 05
1 03
• < 01
THIRD
. PHASE
Спект
ральное представление "двойного эхо"
v==--=^
SECOND
~v
FIRST
35 <* "
15 25
05 5
TRIAL LENGTH
l.loixri
65
Число спектральных плоскостей можно задать в поле редактирования Число
плоскостей диалогового окна параметров графика или после построения графика
в диалоговом окне ЗМ графики: дополнительные свойства.
Спектральные графики имеют два основных применения. Первое из них — это
исследование функций или последовательно распределенных величин в
трехмерном пространстве (например, график спектральных плотностей, определенных для
последовательных интервалов времени).
В то же время спектральные диаграммы являются «действительно
трехмерными», а не последовательными графиками, и на них могут быть представлены три
переменные, содержащие не равноотстоящие данные (например, периодограммы
с упорядоченными по времени, но не равными интервалами).
Трехмерные диаграммы рассеяния
275
Другое применение данных графиков — «расслоение» (или «сжатие») диаграмм
рассеяния для выявления скрытых структур при разведочном анализе данных.
In^«:
Е
ш в
1:
о
5 *'
SCA1 Ml,
«0
. •*'
.-lb-;
п
SATURATION (mfl/cm'
\
J
с
JO
)
*А* •
■ $-'
• ♦ •
• ,J
'
игао!
FITHRCPUCATION
Аяммые собрамы
АО смены Фм/ътров
•* !
" WEIGHT
Если предполагается согласованная взаимосвязь между тремя переменными и
особенно если ожидается, что связь между двумя переменными (XhZ) различна
на разных уровнях третьей переменной (У), то для исследования этого явления
вполне можно использовать спектральные графики. Упростить анализ поможет
выбор числа спектральных плоскостей (см. выше) и интерактивное вращение.
Заметим, что практически такой же ряд двумерны» изображений можно
получить с помощью категоризованных графиков рассеяния, где X и Z —
отображаемые переменные, а У— категоризующая переменная, разбитая на несколько
интервалов (число которых равно числу спектральных плоскостей). Если вас
интересуют подробности расположения данных на отдельных спектральных
плоскостях, то проще использовать категоризованные диаграммы рассеяния (по
сравнению с трехмерными спектральными графиками). Однако с помощью таких
категоризованных графиков нельзя получить цельное трехмерное представление
исследуемых данных, которое может быть полезно для понимания их структуры.
Спектральные диаграммы можно использовать для исследования
однородности, поскольку такое свойство, как однородность, трудно изучать на других типах
графиков (например, можно исследовать зависимость дисперсии от значений
переменной У или распределения выбросов).
[ Диаграмма отклонений
На этом типе графиков точки данных (заданные координатами X, У и Z)
представлены в виде «отклонений» от определенного базового уровня на оси Z.
В
Простая диаграмм* отклонений
(Точки данным показаны как отклонения от г«100)
276
Глава 6. Трехмерный визуальный анализ данных
Диаграммы отклонений похожи на пространственные графики. Однако на них,
в отличие от последних, «плоскость отклонений» «невидима» и не обозначена
положением плоскости Х-У (эти оси здесь всегда находятся в стандартном нижнем
положении). С помощью диаграммы отклонений можно исследовать природу
трехмерных наборов данных, изображая их в виде отклонений от произвольного
(горизонтального) уровня. Как упоминалось выше, такой метод «сечения» может
выявить динамические связи между исследуемыми переменными.
Графики поверхности
Для построения поверхности используется подгонка по точкам трехмерного
графика рассеяния. Такое представление, как и ЗМ диаграммы рассеяния, позволяет
выявить скрытую структуру данных и взаимосвязи между тремя переменными.
ЗМ Ф*«« пмюяиостм (AOSTUDV 8TA 25fTS<M
Графики поверхности используются в разведочном анализе данных, как и
описанные в предыдущем разделе трехмерные диаграммы рассеяния. Кроме того, они
полезны для наглядного представления результатов анализа, таких как подгонка
пользовательской функции или кластерный анализ.
В промышленной статистике графики поверхности обычно используются для
представления центрального композиционного плана эксперимента. Здесь
экспериментатором задаются конкретные систематические значения двух (или более)
переменных для оценки их влияния на некоторые зависимые переменные,
представляющие интерес (например, прочность синтетической ткани).
IiIIIL ■IL'JIUIIII.'liHlllllllNII. II,11,111 llllllJiHjNlIf,!,1!! IJIIIIII'll'llllilliUlJ.J „I'"III IHUIiJulfll
Граф,* nottpxMOCTK «ля УЕВ no парам» ■»■« TX > DtOWgS I \ Греф» поверхности «л« VgLDno nap >.,»■ »i,i TH€ > C«*«S
2"B-0) Зассларияаит naptore пор«дм I 2**B-0) Централ*»** еост»§иои *спаримаит »торогопоо*А«а
Сра*иаа-«4 733Э Силум-965Э20 С§ч«ви-МИО0 I Cpa*«aa »вЭ «33 Сигма ■ 4 ЗЮ93 Ci члаи • вт 3750
Графики поверхности
277
i.m-i ■.i.i.iJ.ii.iiiiiiiimjiiin..i..j.iuiiJ.! ПШ1 im.ii,. juui
Греф.* поверхности дп« YElb no переменч» TMC A 06GPEES
□ 76145
□ 77 291
□ 78 436
1 179 581
□ 80 726
□ 81 872
ЕЭ 83 017
Ш 84 162
вгэкэоб
■■86 453
2**B-0) Цв»<тр«'ъ*««>| составной мспарммент • торого пор*А«в
Среднее -63 8633 Смпм - 4 Э929Э С* чпеи . 87 3750 |
9*1
в»
5*
'..!•• r"'!--:t! -H ' ■• j
s^fSraOPSwfeb*
^^^v7\/0?vrm?>8^
k ХлЛАлЛЗгс**^"^
V. V^A^P^" * ]
N* iS. " J*&\. ' ^^ 1
\%<^>
* o.>^>'
С помощью таких экспериментов можно обнаружить сложные нелинейные
взаимосвязи между переменными.
Часто такой график бывает полезно вращать для более явного проявления
характеристик поверхности (например, конкретных выпуклостей и впадин) или
скрытых сторон.
ЫИНИНДШП
■ .IQlxil
Дяммы* T12.STA10W100*
*Ц4
"^<+ .
о>4'
Швеи*
Ш 7эгэв
Ш 77Э8Э
eaei <71
□ ввавв
□ еотов
■193 874
а в7 041
а 1свош
a loe 17©
а но 294
а П4 412
а П89ВО
О 122 647
О 12в7вв
О 130882
■ tuut
(.<#> Линейное сглаживание
Трехмерная диаграмма рассеяния аппроксимируется линейной функцией
(например, Z = a + bX + cY).
Iilll, HIT ,1Я
КЗЗШ]
Л***ймот сгмживамм помрхиостм
Фумю**: z*83.8834»1 384*nO 362*y
f'f "'*""'"">••■•••
H 81111
H 81 480
■181850
Ю 62.220
□ 82 5W
CD 82 969
■183 329
Bl 83898
■184088
В184 4Э8
■184 808
■186.177
■185 547
EZ3 85 917
CD 86286
CD 86 «58
9*
90
*
fi
r»
278
Глава 6. Трехмерный визуальный анализ данных
^ Квадратичное сглаживание
Трехмерная диаграмма рассеяния аппроксимируется полиномом второго порядка.
Квадратичное сглаживание поверхности
Функция z-87.375-1.384%-Ю362*у-2144*х*х-4 875*х>3094»
■■ 76.603
■177308
■I 76.409
Ш 79212
ОвОЯ15
CZJ 60*19
■B61J622
■162.425
■1 83226
■164.031
■184 834
■185637
■186440
Ш 67243
£3 88.046
□ 66.649
а Сглаживание методом наименьших квадратов
Поверхность аппроксимируется методом наименьших квадратов с весами,
зависящими от расстояния (влияние отдельных точек уменьшается с расстоянием до
поверхности).
тштшштшштш^^
11 lliniiililMLfl
: вШ 4.824
■: Ш 0.353
; шш 1529
ES3 2.706
СП 3.682
СП 5.059
: РЛ 6235
■■ 7.412
■■ 8.566
■1 9.765
■110941
: Ш12116
; ■113294
ЕЕЗ 14.471
СП15А47
CZJ16824
■1 аыия
Сглаживание по методу наименьших квадратов
•г УЧрщ^^^^^в^^^
18ГГ1 тШШШ*
1*|
ф
г
# в
^ г
^Я^Ш^ШШшш ' \
^^ШЯ^^^шшВшэ£Я1^^^ш ■_
Щг^ЩЯШу*
1- 1|Ш»/./о/7^кТ. /о:
>-
с» ^ ^
.inixji
<Щ* Экспоненциально взвешенное сглаживание с отрицательным показателем
Поверхность аппроксимируется в координатах XYZ методом экспоненциально
взвешенного сглаживания с отрицательным показателем (влияние каждой точки
экспоненциально уменьшается с расстоянием до поверхности).
Графики поверхности
279
ЫГ",'1111II1,! СД
1'£Тп1»||
Экспо»«мцимьно-ммш«имо« сглажгаани*
■1-0182
■I 1636
■1 3456
ШЗ 5 273
□ 7091
CD 8909
■110 727
■1 12 545
■114 364
■1 16162
I4& Сглаживание сплайнами
Поверхность в координатах XYZ аппроксимируется бикубическими сплайнами.
IillУ,' 1ШII", I1 ЩЩШШШШШШШШШШШШЩ
Сглажимим сгмкАиами
■I 3642
■I 5077
■I 6513
ШЭ 7949
CZJ 9386
ЕЗ 10821
■I 12257
■113.692
■I 15.128
■1 16.564
us« Другая функция
Можно самостоятельно задать математическое выражение для описания поверхности.
. М -2401
Ш-2Д68
' Н| .1733
• ЕЭ-1»7
О и ом
■ CZ3-07»
. Ш-оэм
м-оово
■1 0774
: Ш 0400
• ■■ ojo
: ■§ ют
■■ 1412
1 да it46
: CD 22»
CD 261S
; Ш~~
5
ЗМ гр*фмк помркностм (FILE3.STA WWSSn)
i«2*»in(x)* 94ot(*)+.3"*in<yL\7*cot(y)
...,-!-та; +;"г..-.г>
3-S 1
75
и
аз
.1.5
Л
' • /А' |щ\;--| '•-- г
^^ННМЕ^ЛРювАокзЯХ^^^НнМк
' ^ ^Р^^ВёЕИ^ЯНИШ^И^НРШ!
гКЭ^^Нйпз^ЧВКЛ'-кол.:/ .
.•-^^З^ЯИаа^жЧквг4^ .
•4*^^11 ^^^^•^**Ц*^|^^^;^'*^>^^
^^?ч?^^^г]Г
~^>-Z>
"-ч1
'. J
i
^О
^
**** чв» 3
Обратите внимание, что заданная таким образом поверхность не будет
аппроксимировать данные, а будет просто нарисована поверх них.
280
Глава б. Трехмерный визуальный анализ данных
Карты линий уровня
Карты линий уровня создаются путем подгонки трехмерной функции
поверхности к трехмерной диаграмме рассеяния. Получившиеся в результате контурные
линии (то есть линии равной «высоты») проектируются на плоскость X-Y.
ищдП
■ -IQlx||
Д»ииы« CONTOUR STA 5v • 150с
Подобно графикам поверхности, карты линий уровня используются для
выявления взаимосвязей между тремя переменными.
Как и графики, описанные в предыдущих пунктах (трехмерные диаграммы
рассеяния и поверхности), карты линий уровня находят свое применение в
исследовательском анализе данных.
2ЭНПШВЖ
■ J»M
фтт~
iSSKKft—JBS5353fCT^r
Трассировочные графики
281
Кроме того, они полезны для наглядного представления результатов
исследований, таких как подгонка пользовательской функции. Они менее эффективны
по сравнению с графиками поверхности (описанными ранее) для быстрого
наглядного представления полной пространственной структуры данных. Однако
преимущество состоит в том, что карты дают возможность с большой точностью
исследовать форму поверхности. Карты линий уровня представляют собой серию
неискаженных горизонтальных «сечений» поверхности.
Трассировочные графики
Как и на ЗМ диаграммах рассеяния, каждая точка данных на трассировочных
графиках располагается в трехмерном пространстве в соответствии со значениями
переменных X, У и Z (которые интерпретируются как координаты). Затем эти
точки последовательно соединяются линией (в соответствии с их расположением в
файле данных), чтобы показать «след» (трассу) какого-либо процесса (например,
движения, изменения чего-либо со временем и т. п.).
Даммы*: SPlRAl.STA 10п**4н
Наилучшим примером трассировочного графика является траектория объекта
в трехмерном пространстве.
В общем случае с помощью трассировочных графиков можно изучать
процессы, при которых переменные изменяются одновременно в трех измерениях при
последовательном наблюдении.
ДШЯВЮДИ ШИН III II1 ИЩЩШШУМИ
Характеристическая спираль
282
Глава 6. Трехмерный визуальный анализ данных
Отличие нескольких трассировочных графиков состоит только в том, что на
них можно отображать одновременно ряд «траекторий» для списка переменных Z
Трассировочный график процессов А1 А5
ШИЕЕШ1
*\ fvT^^
4 Г ffjj-
Г\^
-о- А1
-о- А2
A3
-— АД
-— А5
Примером набора данных, который можно сравнить с траекторией, служит
любой многомерный временной ряд. Предположим, в большом городе каждый
месяц в течение нескольких лет измерялись температура, уровень загрязнения и
содержание озона в воздухе. Так как эти переменные по своей природе цикличны
(например, зимой в северном полушарии холодно), то возникает характерная
картина, которая, в то же время, имеет сложную структуру. С помощью таких
графиков можно также изучать зависимость от времени цен на товары или
макроэкономических показателей.
Другое приложение таких графиков — это создание точных «трехмерных
рисунков» (с помощью задания координат в трехмерном пространстве) для таких
объектов, как границы контроля или выделенные области. Обычно трехмерные
объекты, нарисованные с помощью трассировочных графиков, можно вращать и
изменять в перспективе. Обратите внимание, что такие объекты не могут быть
нарисованы в интерактивном режиме, поскольку не существует способа контроля
третьей размерности («глубины»).
Рисование "перспективы" с помощью трассировочных графиков
ЕЭШ&
Если какое-либо наблюдение содержит пропущенные данные (например, не все
три координаты X, Yи Z, а только две из них), то линия трассировочного графика
будет разорвана. Это свойство можно использовать для создания отдельных
объектов (как показано ниже).
Тернарные графики 283
гтгтт^ртж. шили и ни. tffmwHTTW-^
Рисование нескольких сегментов
Тернарные графики
Тернарные графики используются для исследования связей между несколькими
переменными, когда сумма значений переменных постоянна для всех наблюдений.
Обычно такие графики применяются при экспериментальном исследовании
зависимости отклика от относительного содержания трех компонент смеси
(например, трех химических соединений), при этом соотношение компонент изменяется
с целью определения его оптимального значения.
Тфрмвриый график (MDOURE5.STA 4л~12н)
valOSti+MTy+l ВВГиОВВ*жфу*0 364*z«0.42V*
На тернарных графиках для построения зависимости четырех (или более)
переменных (компонент X, Y и Z и откликов V1, V2 и т. д.) используется
треугольная система координат на плоскости (тернарные диаграммы рассеяния или линии
уровня) или в пространстве (тернарные трехмерные диаграммы рассеяния или
поверхности). При построении тернарного графика относительная доля каждой
компоненты (для каждого наблюдения) ограничена их общей постоянной суммой
(например, 1). При создании графика масштаб долей по умолчанию изменяется
таким образом, чтобы эта сумма была равна 1 для каждого наблюдения.
Предположим, имеется смесь, состоящая из трех компонент: Л, В и С. Любая
трехкомпонентная смесь может быть обозначена точкой в треугольной системе
координат, заданной тремя переменными.
284
Глава 6. Трехмерный визуальный анализ данных
Например, возьмем 6 следующих трехкомпонентных смесей:
А
I
0
0
0.5
0.5
0
В
0
1
0
0.5
0
0.5
С 1
0
0
1
0
0.5
0.5
1.11111.1.1111М11И1Ш1!11111.Ш1..1111.11ЦП.11ЯИМ1
Тернарный график (NEW STA Юп'Юи)
♦0 5.5}
(.5.5.01
Ю.1 Л}
Сумма компонент в каждой смеси составляет 1,0, и эти значения могут
рассматриваться как доли. Если отобразить эти данные на обычной трехмерной диаграмме
рассеяния, то окажется, что они образуют треугольник в пространстве. Правильной
смеси будут соответствовать только точки, находящиеся внутри треугольника, где
сумма значений компонент равна 1. Поэтому для отображения соотношений
компонент достаточно просто построить треугольник на плоскости.
Три компоненты представлены осями, которые проходят из вершины
треугольника до середины противоположного основания (медианами треугольника),
и положение каждой точки определяется значениями, отложенными по
соответствующим осям. Присмотревшись к графику, вы легко заметите, что в вершинах
треугольника имеется лишь одна ненулевая компонента смеси, тогда как на сторонах
треугольника — две компоненты не равны нулю, а одна компонента нулевая.
iiiiii'iiiiiniiui мдявша
Тернарный график
(
| (.5Л.5)/ч^
(NEW STA 10л10н)
f «0.0.1)
| Ось компоненты "С" |
JX {0.5.5}
£ | Ось компоненты "8" ]
••ад г ,S.L ■ р-,щ \
Тернарные графики
285
Тернарные графики можно проиллюстрировать следующим примером,
рассмотренным в работе Вайнера (Wainer, 1995).
Тесты Национального бюро по развитию образования (National Assessment of
Educational Progress (NAЕР)) для студентов показали наличие трех уровней
образованности: Высшее/Профессиональное (AdVanced/Prvficient), Среднее (Basic) и
Неполное среднее (Below Basic). Результаты, полученные в различных регионах,
могут быть изображены на тернарном графике, где по каждой из трех осей отложена
доля студентов соответствующего уровня образованности.
На показанном выше графике (Wainer, 1995) видно, что 37% студентов штата
Айова (Iowa) имеют Высшее (AdVanced) или Профессиональное (Proficient)
образование, 44% — Среднее (Basic) и 19% — Неполное среднее (Below Basic). Для
сравнения, только 1% студентов Вирджинских островов (Virgin Islands) имеют Высшее
(AdVanced) или Профессиональное (Proficient) образование, 12% — Среднее (Basic)
и 87% — Неполное среднее (Below Basic).
Вайнер также обсуждает другое интересное применение графиков в
треугольных координатах. Подобный график был использован для изучения доли голосов,
отданных за каждую из трех британских политических партий на всеобщих
выборах в 1987 и 1992 гг. Заинтересованные читатели найдут подробную информацию
в работе: Wainer A995). Visual re delations, Chance, 8, p. 48-54.
Ill 2M диаграмма рассеяния
На этих графиках треугольная система координат используется для построения
зависимости трех (или более) переменных (компонент X, Y и Z) на плоскости.
ы111|шШп1111Уг11^111]Ш1Ш1имгВ1а
Тернарный графи* - 2М диаграмма рассеяния
COMPONENT С
COMPONENT A
COMPONENTВ
286
Глава 6. Трехмерный визуальный анализ данных
На приведенном графике изображены точки, соответствующие долям
переменных-компонент (X, Y и Z).
Щ ЗМ диаграмма рассеяния
На этом типе тернарных графиков в треугольной системе координат в трехмерном
пространстве строится зависимость четырех (или более) переменных (компонент
X, У и Zn откликов V1y V2 и т. д.) — тернарные трехмерные диаграммы рассеяния
или графики поверхности.
шиаш
Тернарный график* ЗМ диаграмма рассаяиия
1
IV^
На этом тернарном графике отклики ( V1, V2 и т. д.), соответствующие
определенным долям переменных-компонент (X, У и Z), откладываются в виде высот точек.
Щ Поверхность
Здесь на трехмерном тернарном графике поверхность представляет собой
результат подгонки к набору данных из четырех координат.
Тарнариый граф*! • Поверхность
■
■
■в
о
□
□
н
н
н
н
■
4300
4 700
4Q0O
5 100
9300
9300
9 700
9000
в 100
в 300
• шт
Щ| Карта линий
В данном типе тернарных графиков трехмерная поверхность (подогнанная к
набору данных из четырех координат) проектируется на плоскость в виде линий
уровня.
ItlllBN'HllMIW
MllllllHM«laNl
Тарнарный график • Карта пиний
COMPONENT С
4 700
4000
5 100
зэоо
6 300
5700
0000
0 100
еэоо
Тернарные графики
287
Д Зонная карта
На этом типе тернарных графиков трехмерная поверхность (подогнанная к
набору данных) проектируется на плоскость в виде карты зон.
I IIII III I II —■■
Тернарный графи» • Карта линий уроаия (зоны)
COMPONENT С
С OMPONE NT A COMPONE NT 8
III Трассировочный график
В данном случае можно исследовать связи между четырьмя и более переменными
(X, YyZn V1, V2 и т. д.) с помощью соединения точек на графике в той
последовательности, в какой они расположены в файле данных.
fCTM.JI|imiJll!>JJ!!llJJJJ..JIlimi!illlHlMMJoixl|
Тернарный графи* • Трассировочный графил I
Кроме перечисленных выше вариантов, после построения графика в
диалоговом окне Общая разметка можно также выбрать следующие типы графиков.
ЛЦ Пространственный график
Этот тип тернарных графиков предлагает особенный метод представления
трехмерных диаграмм рассеяния с использованием плоскости Х- Y-Z (определенной в
треугольной системе координат), которая располагается на заданном
пользователем уровне вертикальной оси У(эта ось проходит через середину плоскости).
UUIKIIillMlllliyJIIf.N'llllf.tifllliHMJuial
Тернарный графи» • Простраистаамыый графш
М 4 500
Н 4 700
Н 4 900
Н 5100
ЕЭ 5Э00
□ 5 500
□ 5 700
Н 5 900
■I 6 100
Н 6Э00
Н 6 500
Н 6 700
Н 1ыш»
288
Глава 6. Трехмерный визуальный анализ данных
Уровень расположения плоскости X-Y-Zможно подобрать таким образом,
чтобы разделить пространство X-Y-Z нз. значимые части (например, для выделения
различной структуры связей переменных).
ЦЦ Диаграмма отклонений
Эта диаграмма похожа на пространственный график, но на ней не отображается
плоскость, от которой отсчитываются отклонения.
fTffBII'llHIIIIIII-llil'JIILtillllllll,
ТариармыА график • Диаграмма отклонений
trf'f
■ft \
Подгонка
Приведенные ниже четыре уравнения регрессии можно использовать для
подгонки зависимостей на тернарных графиках. Обратите внимание, что уравнения
получены из стандартных полиномов с учетом ограничения на значения компонент
(X, У, Z), сумма которых для каждого наблюдения равна постоянной величине
(например, 1,0).
Простейшая модель первого порядка:
V=a + blxX+b2xY+b3xZ
с ограничением Х+ Y+Z= 1, может быть построена с помощью умножения
коэффициента а на 1=X+Y+Z\
V=axX+ax Y+axZ +bix X+Ь2х Y+b3xZ
Это выражение можно упростить:
V- (а+Ы) х X + (а+Ь2) х Y + (а+ЬЗ) х Z
или записать таким образом:
V=bYxX+bTxY+b34xZ
Ниже перечислены доступные в STATISTICS функции полиномиальной регрессии:
О Линейное сглаживание (полином первой степени):
V=b\xX+b2xY+b3xZ
О Квадратичное сглаживание (полином второй степени):
V=b\xX + b2xY+b3xZ+b\2xXxY+b\3xXxZ + b23xYxZ
О Полное кубическое сглаживание:
V=b\xX+b2xY+b3xZ+b\2xXxY+b\3xXxZ+b23xYxZ+b\2xX x
Ух (X-Y) + b\3xXxZx (X-Z) + Ь23 х YxZx(Y-Z) + М23хХх УхZ
Трехмерные категоризованные графики
289
О Специальное кубическое сглаживание:
V=b\xX+b2xY+b3xZ+b\2xXxY+b\3xXxZ+b23xYxZ+b\23xXxYxZ
Трехмерные категоризованные графики
Этот тип статистических графиков позволяет создавать трехмерные
категоризованные диаграммы рассеяния (и трассировочные графики), карты линий уровня и
поверхности. При этом используются заданные категории выбранной переменной
или другие способы логической группировки наблюдений.
lifiMWWU
fn'liV.IIIHHrCT^T
ЗМ пространственный график по Temperature
X(слева) Прочность 1
Y(справа) Прочность 2
2 (верти*) Сопротивляемость
High
На графике представлена та же информация, что и на трехмерном графике
рассеяния, графике поверхности или карте линий уровня, за исключением того, что
здесь для каждой заданной пользователем группы или категории показан свой
график. Основной смысл таких графиков — упростить сравнение групп или
категорий, отражающих связи между тремя или более переменными.
В общем случае трехмерные XYZ графики отображают динамические связи
между тремя переменными. С помощью различных способов категоризации данных
можно исследовать связи в определенных группах данных.
Например, положительная взаимосвязь между возрастом, состоянием
здоровья и удовлетворенностью жизнью наблюдается при опросе женщин, но не мужчин.
Соотношение между Age (X). Health Status (Y). и Life Satisfaction (Z)
GENDER MALE z = б 572«0 356**-0 52Гу
GENDER FEMALE 2 = 3 008-Ю Э86*к«0 09в*у
**
GENDER
MALE
GENDER
FEMALE
■i
^ш
■i
■i
ИЯ
ЕШ
ПЗ
m
rsa
BB
■i
■i
■i
■■
■■
■■
1 948
2 359
2 771
3 182
3 593
4005
4 416
4 828
5 239
5 651
6 062
6 474
6885
7296
7 708
8119
290
Глава 6. Трехмерный визуальный анализ данных
Поскольку категории создаются с помощью логических условий, которые
определяют подгруппы, то можно пойти дальше и построить другие графики —
разделив группу мужчин на одиноких или разведенных и женатых, можно
выделить в отдельную группу одиноких мужчин с высокими доходами и т. п.
Из приведенных ниже категоризованных графиков поверхности (и
соответствующих им карт линий уровня) можно сделать заключение о том, что задание
величины допусков на приборе не влияет на исследуемую взаимосвязь между
результатами измерений (Dependl, Depend2 и Height), за исключением случаев, когда эта
величина <3.
Имеет смысл только диапазон допуска <-3 (Т STA 277гГ29000м)
ш
Дипамш «аптс*а
4W>
Дипамш аапума
a ei
Дипамм аол*с*а
A4 1С]
it
fl
О 12 1
Долам» аолума
AС 18|
ESS!
ч^> 1
Дигамм аол»со
Дотах». аоя,со
П2.14]
Дипамм аол*"
• 18
I
Иногда карты линий уровня легче анализировать, чем графики поверхности
(что хорошо видно из следующего примера).
EEE3I
Имеет смысл только диапазон допуска <-3 (Т STA 277гГ29000м)
Таким образом, ЗМ категоризованные графики представляют собой мощный
исследовательский инструмент для изучения сложных взаимосвязей между
переменными и группами наблюдений.
|jj Категоризованная ЗМ диаграмма рассеяния
На этом типе графиков отображаются связи между тремя переменными
(представляющими координаты X, У и Z (вертикаль) в трехмерном пространстве), разде-
Трехмерные категоризованные графики
291
ленными на категории с помощью группирующей переменной или путем
задания подгрупп.
паи
iliTiiijiiiiiinm,Biilifiii'Hiiliimuiiiy.iitin.HifO
Уровень Discharge от Weight и Saturation
Четыре сегмента
Й
'!-■
'''•'■V
I: hit II
Х**Ч5>
|Ц Категоризованный пространственный график
В данном случае в одном графическом окне строится несколько
пространственных графиков (для групп категоризованных данных).
гшшпш imjmui 11, ,■ дедш
Уровень Discharge от Weight и Saturation
Четыре сегмента
HI Категоризованная спектральная диаграмма
На этом типе графика трехмерное пространство разделено на области, в которых
данные «сжаты» в соответствующие спектральные плоскости.
Уровень Discharge от Weight и Saturation
Четыре сегмента
ШУ
292
Глава 6. Трехмерный визуальный анализ данных
ЛР Категоризованная диаграмма отклонений
На этом типе графиков точки данных (заданные координатами X, У и Z)
представлены в виде «отклонений» от определенного базового уровня на оси Z
1.1пЫ|
Уроммь Discharge от Wnght и S»tu'»lion
ЧфТырв CtfMtMT»
tATUMATKM
\ Категоризованный график поверхности
С помощью этой функции будет построена поверхность (методом сглаживания
или по заданному математическому выражению) для категоризованных данных.
Уроммь D<»ch»rgt от Wtighl и Situation
Ч#тыр# с*гм»мт»
Карта линий уровня
Карта линий уровня — это проекция трехмерной поверхности на двумерную
плоскость. На ней линиями обозначены одинаковые «высоты» (равные значения
переменной Z).
вши
IJoMl
СЛ<ХЯ 0*OUP.l
r^
ОЖХР 0*OUP_3
О «фи. Cf ACTOR 6TA 1 Tp'JOOh)
Ч»»ш сгп*ж
ow<x»> о*ол>_г
43 <8S
«03*0
S6Q00
»2?Э
OMMP OROUPJ
Категоризованные тернарные графики
293
| Зонная карта
На таком графике одинаковые «высоты» (значения переменной Z) на
поверхности (зоны между контурными линиями одинаковой высоты, см. предыдущий тип
графика) показаны областями одинакового цвета и вида.
имлпА пилит!и..щ ц
■ -1оЫ
ЭМ категоризомнный график CFACT0R STA17п*200н)
Отр эксп-1звеш стаж
120 ,
30 45
OROUP1 OROUP.3
Категоризованные тернарные графики
Категоризованные тернарные графики используются для исследования
взаимосвязей между тремя и более переменными, когда три из них представляют собой
компоненты смеси для каждого значения группирующей переменной (то есть
между ними существует жесткая связь, заключающаяся в том, что их значения в сумме
дают постоянную величину для всех наблюдений).
IfilUlHIIlvi1 Д
Тернарным график (DENSITY STA 5п*500н)
г,.„**« IDlNSIIYSTASn-bOlM
tcmpcrat г*'с TtMPtRAT гв'с
TEMPERAT 20-С ^0 2К'ш^27УуОПГг.|45ri>0M4YM304Yf9S74V|'t
TEMPERAT 22- С v. 0 ИГш-О 347', 0 М'г.У KtV,.1 W4V|.2 СГ,'1 9 Wi'i'i
TEMPERAT 24-С v. 0Ю2*ш-0 40У, 0022't'O 33tV,.l W2VlI22«Y*-3*M"«V»
TEMPERAT 2«'C v.0 02«*i-O0SrfO27S,:0 52r.VO22«,i-:O75V».t775,iY:
TEMPERAT »C v.0*ri 005^.0274": 10в4,ш,,.0$О,ш,»1077,,,»ЧI25,ш,|*»
294
Глава 6. Трехмерный визуальный анализ данных
5ШШШПЯШН
Тернарный график (DEN8ITY 8ТА 5гГ500м)
TEMPERAT: 2tPC v*0.2l5^*0 273V0.1iy2«1 Дбв^уОМД^М 304«Г**5.в74-*Тг
TEMPERAT: 22»C 4MM81V0.347Y0.1M*2*1.161*xV1.184VZ«2123V^5.195Vyi
TEMPERAT: 24»С vMM02^0.403>0.022^*O.331YV1.3MVz*1.22eV2-3 259W2
TEMPERAT. 28* С ^O.028V0 ОвГуО 276^0 527VV0 226Y2-0.75VM 775VT2
TEMPERAT: 28*C ¥*0.187>0 051V0.274«M 084W0.613V2-1 077V2-0.125VV*l
На тернарных графиках для построения зависимости четырех (или более)
переменных (компонентов X, Y и Z и откликов V7, V2 и т. д.) используется
треугольная система координат на плоскости (тернарные диаграммы рассеяния или
линии уровня) или в пространстве (тернарные трехмерные диаграммы
рассеяния или поверхности). При построении тернарного графика относительная доля
каждой компоненты (для каждого наблюдения) ограничена их общей
постоянной суммой (например, 1). По умолчанию при создании графика масштаб долей
изменяется таким образом, что эта сумма для каждого наблюдения становится
равной 1. В вершинах треугольника имеется только одно ненулевое значение
компонент смеси.
На категоризованных тернарных графиках для каждого уровня группирующей
переменной (или заданной пользователем подгруппы) строится отдельный
график. Все эти графики располагаются в одном графическом окне для сравнения
групп данных (категорий).
Обычно такие графики используются в экспериментах, где отклик зависит от
относительного содержания трех компонент (например, трех различных
химических соединений). Причем это соотношение варьируется с целью определения
его оптимального значения (например, при исследовании смесей). Эти типы
графиков могут быть также использованы в том случае, когда необходимо сравнить
группы или категории данных при наличии жестко заданной связи между
переменными.
ЩЩ_ Категоризованная 2М диаграмма рассеяния
На таких графиках треугольная система координат используется для
построения зависимости трех (или более) переменных (компонент X, Y и Z) на
плоскости.
Категоризованные тернарные графики
295
i'Jabti
шал ?М диаграмма рассеяния
0СТЕЯО1 » П
ТЕМР1ЛАТ Я С
схтспш
ТЕМРСЯАТ ЭОС
Здесь изображены точки, представляющие собой доли переменных-компонент
(X, YnZ).
Щ 3M диаграмма рассеяния
Для данного типа тернарных графиков в треугольной системе координат в
трехмерном пространстве строится зависимость четырех (или более) переменных
(компонент X, У и Zh откликов V1, V2 и т. д.) (тернарные трехмерные диаграммы
рассеяния или графики поверхности).
паоЕшшп
ПЩИИЩННШЯИ
TfMFCHAT MC
\
* о '
ТОИРСПАТ »С
■■■■■иимшиишившишиг^ге**1»!
■и^и^ии^и^ииШ^ШШ
I" jfi ••• '
ПМРСЖАТ ЯС 1
\ IV ?■ l \
TtMPCTAT Я С
На этом тернарном графике отклики (V1, V2 и т. д.), соответствующие
определенным долям переменных-компонент (X, У и Z), откладываются в виде высот точек.
|gl Поверхность
Здесь на трехмерном тернарном графике поверхность представляет собой
результат подгонки к набору данных из четырех координат.
296
Глава 6. Трехмерный визуальный анализ данных
ЦЦ Карта линий
В этом типе тернарных графиков трехмерная поверхность (подогнанная к
4-мерному набору данных) проектируется на плоскость в виде линий уровня.
сашш
Катагоризоааммал тармармал карта пиний уровня
оссяог остслсм
ССТЕЯО' «« 21
тсмр«лат тес
сстерш
остслы ss г)
TCMPf ЛАТ Я С
остсяаг
Щ Зонная карта
В данном случае трехмерная поверхность (подогнанная к 4-координатному
набору данных) проектируется на плоскость в виде карты зон.
вшшт
Категоризоеаммал тармармал карта областей
ОСТЕМШ OCTtRQJ
CCTTR01 И 21
TCMPWAT П С
<х*г*аг
CCTCRQi SS 21
ЧМРСЯДТ Я С
0СТСПО2
I Трассировочный график
С помощью таких графиков можно исследовать связи между четырьмя и более
переменными (X, У, Zn V1} V2 и т. д.) путем соединения точек в той
последовательности, в какой они расположены в файле данных.
Категориэоеаммый тармармый трассировочный график
Категоризованные тернарные графики
297
Щ Пространственный график
Этот тип тернарных графиков реализует специальный метод представления
трехмерных диаграмм рассеяния с использованием плоскости Х- Y-Z (определенной в
треугольной системе координат), которая располагается на заданном уровне
вертикальной оси У (эта ось проходит через середину плоскости).
Категори»оеаииый тернарный пространственным график
Ък£*
темреват го с
ТЕМРЕВАТ П С
ТЕМРЕВАТ » С
ТЕМРЕВАТ 39 С
Уровень расположения плоскости Х- Y-Z можно подобрать таким образом,
чтобы разделить пространство X-Y-Z на значимые части (например, для выделения
различной структуры связей переменных).
Щ Диаграмма отклонений
Эта диаграмма похожа на пространственный график (см. выше), но на ней не
отображается плоскость, от которой отсчитываются отклонения.
тшшшшшшшяшшшшшшж
Категоригоеаииая тернарная диаграмма отклонений
temperat го с
£>
ТЕМРЕВАТ 30 С
Подгонка
Приведенные ниже четыре уравнения регрессии можно использовать для
подгонки данных на статистических, категоризованных или пользовательских
тернарных графиках. Обратите внимание, что эти уравнения получены из стандартных
полиномов с учетом ограничения на значения компонент (X, У, Z), сумма которых
для каждого наблюдения равна постоянной величине (например, 1,0). Например,
простая модель первого порядка:
V=a + blxX + b2xY+b3xZ
298
Глава 6. Трехмерный визуальный анализ данных
с ограничением X+y+Z=l может быть построена с помощью умножения
коэффициента а на 1 =Х+ Y+Z:
V=axX + axY+axZ+blxX + b2xY+b3xZ
Это выражение можно упростить:
V= (а+Ы)хХ+(а+Ь2) х У + (я+63) xZ
или записать таким образом:
V=bV хХ+62' хУ+63'xZ
Ниже показаны доступные функции полиномиальной регрессии:
О Линейное сглаживание (полином первой степени):
V=blxX + b2xY+b3xZ
О Квадратическое сглаживание (полином второй степени):
V=blxX+b2xY+b3xZ+bl2xXxY+bl3xXxZ+b23xYxZ
О Полное кубическое сглаживание:
V=blxX+b2xY+b3xZ + bl2xXxY+bl3xXxZ+b23xYxZ +
612 хХх Ух (X-Y) + b\3xXxZx (X-Z) + 623х YxZx (Y-Z) + 6123 хХх YxZ
О Специальное кубическое сглаживание:
У=61хХ + 62х У+63 xZ +612 хХхУ+613 xXxZ +623 xyxZ +
6123xXxyxZ
Можно задать пользовательскую функцию. Однако такие функции не
подгоняются к данным, а лишь накладываются на график.
Графики пользовательских функций
В отличие от других типов графиков, здесь не нужно выбирать переменные.
Вместо этого программа попросит вас ввести формулу для построения графика. В этом
режиме можно построить график не по значениям переменных файла данных, а по
заданной пользователем формуле (то есть отобразить пользовательскую функцию),
например:
Г»—ш »учм« (AOSTUDVST* ЗбпЧОн) ]
Матричные графики
299
На данном типе графика можно в явном виде задать диапазон изменения
переменных. Например, можно задать минимальное и максимальное значения для обеих
осей (X и У) равными соответственно 0 и 100.
Есть два основных варианта применения графиков функций, заданных
пользователем.
Наиболее очевидный — исследование конкретной функциональной
зависимости (например, проверка соответствия данных конкретной теоретической модели
исследуемого процесса или явления).
Другое направление — это разведочный анализ данных, когда необходимо
изучить форму функциональной зависимости в различных диапазонах значений
аргумента.
Следующим шагом такого исследования, конечно, является статистическая
проверка качества подгонки функции к конкретным данным.
Матричные графики
Матричные графики используются для графического представления зависимостей
между переменными некоторого множества в виде матрицы обычных двумерных
графиков. Чаще всего в качестве матричных графиков используются диаграммы
рассеяния, их можно рассматривать как метод визуализации корреляционных
матриц исследуемых переменных.
П SCATTER STG Корреятцж {SCATTER STА 80п00и)
Диаграммы рассеяния для 5 испытаний
.cgqQoq-c
ТЕ6Т_3
'•C^si основные
^-^ТГ^ СТАТИСТ.
..— .Л*
вшв
г^Ш
Отмеченные корреляции $н«чимы »м уровне р <.060
М*1М (Построчное удаление ПЖ)
**»П*
TOTJ»
■ЯШ
TEST 5
тшл I test j
.71 -.73
.78 1.М И
.73 И 1.М
.43 .46 -.31
.05 .07 -.07
i&№j
.43 .06
.46 .07
-.31 -.07
1.М .17
.17 1.00
На приведенном графике для каждой пары переменных построена диаграмма
рассеяния с изображенной на ней прямой линейной регрессии.
Матрицы диаграмм рассеяния могут быть не только квадратными (как на
приведенном рисунке), но и прямоугольными, если были выбраны два списка
переменных (по аналогии с прямоугольными матрицами корреляции). Если исполь-
300
Глава 6. Трехмерный визуальный анализ данных
зуется квадратная матрица, то на диагонали вместо диаграмм рассеяния будут
построены гистограммы для соответствующих переменных.
Подобные графики предоставляют эффективный способ визуального анализа
зависимостей между исследуемыми переменными. Например, с их помощью из
набора переменных легко выделить переменные, которые не коррелируют с
другими переменными.
11 НШШШ'М, |'|4HF.HU.llli < IИШ——ЕШШ!
Корреляции между 5 объектами
1ТЕМ_1
~р^
^Ж!
Ж
:******".!
1ТЕМ_2
--00000—
\*%М&.
\ >*&£?-:
П0~
Раслеределение оОьекта 4 отлично от
нормального, а его соотношение
с ддоими объектами нелинейна
ГГЕМ_3
1 -Ffflrw,
у&&^
рш^
т
ITEM 4
ILL...
г^^х;
Г ITEM_3
Матрицы линейных графиков
Рассмотренные выше матрицы диаграмм рассеяния обычно используются для
графического представления зависимостей между некоторыми случайными
переменными. Для изображения многоступенчатых процессов применяются, как правило,
матрицы линейных графиков.
1И1МШ11 НИШ \ЩЩ У1ИШ1,НДШШ,ИИДШ11
График 5 временных рядов от Time,
логарифма Time и кв. корня из Time
Например, на построенных матричных графиках изображено несколько
различных зависимостей переменной У (состояние процесса) от одной переменной X
(времени); таким образом, на одном рисунке может быть построено сразу
несколько изучаемых процессов (временных рядов).
Типичным применением матричных графиков является одновременное
изображение на одном графике распределений анализируемых переменных и
зависимостей между ними.
Матричные графики
301
i.iiiii.iiui.iiiiu!i.i.i.iiiiiii.iiiiiiii.iuiiimnji!HiiM
I.IdMI
WORKJ 1
WORK 2 1
WORK_3 1
Hoeevjl
Jflk._|
MOe8Y_2|
NOME J ~|
.BqQbQo.. I
HO€_2 |
моме_з1
MTCCEL 2 1
WORK J 1
.eelaj
X
^
j№ |
^
5и
•#1
•$Й
•#]
-?*и
^
Матричная диаграмма (FACTOR.STA ЮпМООн)
умолк_2 1
j£\
y\
Ж\
s&\
s&
ГТ^
■w)
Щ
~W\
**'
W0RK_3 1
..Ото. J
■ж\
5^
\/A
\*&\
^
p^fj
h$&"|
L***]
\j&
H068YJ 1
•-Г
#r\
^
И
ЙЕ
c#"
W
$r
X
^
Hoeev_2 1
.оЙв...
ш
w\
И
и
[71
И
и
f#j
0
[Z
MOMEJ 1
.bJbQo.J
ф&!Г
''ф\
Wr\
#^:
•J**"'
x
**r
jf
I3ft"
H0ME.2
*$aH
5f]
"ГРуС
H^J
L^'1
5?;
7
w
w_
\**F
M0ME_3 j
'5*ver*
|4ijS^|
£$H
[J^l
H
\/\
[^
ЙЕ
мкса 1 I
.Ж. |
#]
>j
#j
>1
Й
Й
я
и
Г/]
^
MfcCEL 2 1
«#1
'^f'\
&\
У\
^
$&
#:
#
^
[/
Это бывает полезно при выборе масштаба измерений или проведении
разведочного анализа данных (например, обработка анкет, экономической информации,
данных о контролируемом процессе и т. д.).
liH^IHAimillil'i'lHIII'fllHlilH
IHANDOM S1A ЛГ4/Ни|
Нелинейные зависимости
(Матрица рассеяния 5x5)
mm
;i&
<=Т!
тЪ"
"¥
m
ЗсасваоосасаЫ
При проведении разведочного анализа данных бывает необходимо изучить
влияние отдельных наблюдений, удовлетворяющих некоторому условию, на общий
вид зависимости между переменными. Это можно сделать с помощью логических
условий выделения подмножества наблюдений для построения матричного
графика.
302
Глава б. Трехмерный визуальный анализ данных
11.1 II', .1,1'111,114.,
Ma три** диацимм» («BOAT STA Sn*1 SOi)
чкн
т
7к'
т.
№.
#?
И
i
-#*
f
*
*Ч
• vM*SCTOSAa and *ИИ
4 «С-ЛЛМЯМС and <«<1М
• Н-ТОШаМ/апй^ИИ
| Матрица рассеяния
На этом матричном графике представлены двумерные диаграммы рассеяния, на
каждой из которых значения переменной из строки используются в качестве
координат X, а значения переменных из столбца — в качестве координат У
1ЙШМИШЙ
ваонш!
Квадратная матрица рассеяния
И
Ш
ЯИЯШШПШаЗШ
Прямоугольная матрица рассеяния
Ft!
L..!.i
L i.
Гистограммы, изображающие распределения каждой переменной,
расположены на главной диагонали матрицы (в квадратных матрицах) или по краям (в
прямоугольных матрицах).
| Матрица линий
При выборе этого типа графика создается матрица линейных (то есть
непоследовательных) ХУ-графиков (подобно матричной диаграмме рассеяния), на
которых отдельные точки соединены линиями в порядке их появления в
файле данных.
Гистограммы, изображающие распределения каждой переменной,
располагаются на главной диагонали матрицы (в квадратных матрицах) или по краям
(в прямоугольных матрицах).
Матричные графики
303
::№Ш *Ш»Ш*& iff L£* £?А 't 8w*tCW Я W КЗ
Квадратная матрица линий
VAR1
SJlQOOOOj
/ J
/у]
1.0
F
1Л1.1..11|1и.|1Ц||Ши1.||,.Ц|,!1И05Ш|
Прямоугольная матрица линий
DDLJoa.
odddJqdl
OOQOQtlOQ
dQQQDDQ
Q_0_QQQy
| Матрица столбцов
На этом графике матрица состоит из столбчатых диаграмм, на которых
представлены проекции отдельных точек данных на ось X (показывающие распределение
максимальных значений).
| Ы*<ъюш(# шШШШйпЖШШ&ЪШЧЫ"'
Квадратная матрица столбцов
-UIIJ.I|J.I.I.|l|JI.UIJUIIIIIUI»liWTM
Прямоугольная матрица столбцов
:еlsl.il
U00.0J
ввтЛт
yQOQQQQ
jlil.i
..ggill
G_Q_0QQU
a Si
Гистограммы, изображающие распределения каждой переменной,
расположены на главной диагонали матрицы (в квадратных матрицах) или по краям (в
прямоугольных матрицах).
Подгонка функции к данным
\/ Линейная подгонка
Линейная функция (Y = а + ЬХ) подгоняется к точкам каждой двумерной
диаграммы рассеяния. Параметры а, Ъ оцениваются методом наименьших квадратов.
Заметьте, что прямая не проходит через наблюдаемые точки, а располагается
максимально близко к ним (выбором а, Ь минимизируется сумма квадратов
расстояний от точек до прямой). То же относится к другим линиям (см. ниже).
304
Глава 6. Трехмерный визуальный анализ данных
ЫРЛ.ЛНШ 'IHIUIII.IMIMI
Матрица рассеяния с линейной подгонкой
VAR1
1_1йВВ000
^П
*>^\
^\
\.^\
VAR2 I
Q_Q_QQQ0i
U^
\'У
[>Г^\
FF
I VAP3 I
| bbOqbJJ
\^\
[•^
\^-
\^f
VAR4
\(*~ Логарифмическая подгонка
К данным подгоняется логарифмическая функция вида:
y = qX[lognx]+b,
где основание логарифма (п) выбирается пользователем (по умолчанию
используется натуральный логарифм по основанию е, где е = 2,71...).
KIPJJ HI ИМ.. I .111111 UHIT^l
Матрица рассеяния с логарифмической г>одгомгой
VAR1
1_УВ0В000|
/^~\
^-г\
У^"\
|^И
I VAK2 I
|0_0_BB0UU
\^<\
\^\
\^\
[>^\
1 v*'
\/^
[ VAP3 ]
[qqIqbJ-OJ
\>г^\
|.^>г
VAR4
0000_и000
\=£J_ Экспоненциальная подгонка
По данным подбирается экспоненциальная функция вида:
у = bx exp(qxx)
Матрица рассеяния с экспоненциальной подгонкой
VAP1
1_1в0ОВ00
>^'\
^\
^'\
1^1
| VAR2 1
0_0_000li
\^\
\^У\
\^\
\г^\
1 VAP3 I
1ав1вв-1-1
.^
U^"
.-^
\^Г
VAP4
1oqqb_UqqD
Матричные графики
305
\&{ Подгонка сплайнами
В данном случае производится сглаживание данных бикубическими
сплайнами.
lilillilWIflliHIM'WIil
Матрица рассеяния с подгонкой сплайнами
VAR1
VAR2
0_В_00й1
VAR4
|ч/\ Полиномиальная подгонка
Здесь методом наименьших квадратов данные аппроксимируются
полиномом вида
у = bn + btxx + bnxx2+ b0xx3+...+ Ъ ххп,
J 0 1 I 3 п '
где я есть степень полинома A<я<6). Степень полинома может быть выбрана.
lillflllll.ll|l|lllll|'fnll!4lllliHI,ll'mMII
Матрица рассеяния с экспоненциальной подгонкой
VAR2
й_0_000|
VAR3
[4v Подгонка методом наименьших квадратов
Кривая подгоняется к координатам данных с помощью процедуры сглаживания
методом взвешенных относительно расстояния наименьших квадратов (влияние
отдельных точек уменьшается с увеличением горизонтального расстояния от
соответствующих точек на кривой).
306
Глава б. Трехмерный визуальный анализ данных
Матрица рассеяния с подгонкой наименьшими квадратами
VAR1 1
I.Ibbbbbb 1
^~~*\
/
~~ /И
/j^_\
~^П
/^
\^У\
VAR2
0_0_000ii
1 ~~~71
[<<^7liJ
1 /1
\^^
\г—/\
Г~~~У\
\( \
VAR3
оо1вв-1_1
Г~~уП
|./^^~-
L^ll
1 ^-""l
\/ I
1 ' /1
1/^^
VAR4
|0Q0Q_UQqO | [
1*4, Экспоненциально взвешенное сглаживание
Кривая подгоняется к координатам X, У данных с помощью процедуры
экспоненциально взвешенного сглаживания с отрицательным показателем.
blnlllll'lllllll'IIIIBIiLlBIIIIIIBIIJIIIIllllllll
Матрица рассеяния с экспоненциально-взвешенной
с отрицательным показателем подгонкой
VAR1
1-1вввооо 1
/^~\
.—^1
у^\
| v/1
——^
[ VAR2 1
0_0_000ii
U-^1
Lx
. i^'l
|r<"^- 1
И"Л
VAR3
|оо1вв-1-11
i-^^l
^^
\^^
\/^~
\-^
I VAR4
100O0_iaai
Влияние отдельных точек уменьшается с увеличением горизонтального
расстояния от соответствующих точек на кривой.
7 Визуальный анализ
категоризова н н ых
данных
Как всегда, мы начинаем главу с обзора всевозможных графиков, преследуя
очевидную цель — дать читателю максимально полное представление о способах
визуализации категоризованных данных с тем, чтобы привести к осознанному, а не
спонтанному выбору необходимого метода. Дополнительный материал и
примеры содержатся также в других главах по визуальному анализу.
Вначале поймем идею категоризованных графиков.
Что такое категоризованные графики?
Категоризованные графики, также называемые Casement plots (см.
фундаментальный труд по визуализации Chambers, et al., A983) Graphical methods for data analysis.
Belmont, CA: Wadsworth), позволяют визуализировать категоризованные данные,
иными словами, данные, разбитые на группы (категории) с помощью одной или
нескольких группирующих (категоризующих) переменных (от английского
categorized variables — категориальные переменные). В качестве группирующих
переменных обычно используют категориальные (см. описание типов переменных
в главе Элементарные понятия).
Отметим, что разбиение данных на группы и проведение анализа внутри групп
является чрезвычайно важным приемом анализа, постоянно используемом в
практической работе. Например, известный прием сегментации рынка представляет
собой частный случай категоризации.
Итак, с помощью группирующих переменных наблюдения из исходного файла
данных разбиваются на несколько однородных групп (например, клиенты
супермаркета разбиваются по уровню дохода или по признаку: имеет — не имеет
машину), и для каждой группы строится свой график, показывающий специфику данных.
Так как групп несколько, то создаются серии двумерных и трехмерных графиков
(гистограммы, диаграммы рассеяния, линейные графики, графики поверхности и др.),
по одному для каждой выбранной группы — category случаев (непересекающихся
подмножества наблюдений). Например, такими группами могут быть пользователи
Интернет из Нью-Йорка, Чикаго, Далласа или Москвы, Санкт-Петербурга и Смоленска.
Такие «составные» графики помещаются последовательно, один за другим, на экране
компьютера, позволяя сравнивать данные в каждой группе (например, в группе
городов или среди клиентов с разным уровнем дохода). Часто удобно собрать
категоризованные графики в один составной график, для чего в STATISTICA имеются все
необходимые средства.
308
Глава 7. Визуальный анализ категоризованных данных
Для выбора групп обычно предоставляется широкий набор опций, наиболее
типичная из которых использует категоризующю переменную, то есть переменную,
производящую разбиения на группы своими собственными значениями, например,
переменная Город — City с тремя значениями Нью-Йорк — New York, Чикаго — Chicago
и Даллас — Dallas,
На следующем графике показаны гистограммы модельной переменной,
измеряющей уровень стресса жителей в трех городах США.
Взглянув на графики, можно сделать вывод, что стресс людей, живущих в
Далласе, более равномерно распределен, чем стресс жителей Нью-Йорка или Чикаго
(данные носят модельный характер).
H.$togr»m JJ2 S»*reporled STRESS J„
CITY
DALLAS
Очевидно, что вместо одной группирующей переменной можно использовать
две или больше. Далее показаны графики с двумя группирующими переменными.
Такие категоризованные графики можно рассматривать как «кросстабуляцию»
или «сопряжение» графиков (сравните с таблицами сопряженности). На них
каждая из зависимостей представлена на пересечение одного уровня одной
группирующей переменной (например, Город — City) и одного уровня другой
группирующей переменной (например, Время — Time). Таким образом, имеем 6 графиков
C уровня переменной Город умножить на 2 уровня переменной Время).
Histogram J_12 StN-rtporttd STRESS J„
CTTY CITY CITY
NEW.YORK CHICAGO DALLAS
Добавление второго фактора (второй группирующей переменной) показывает,
что схемы сообщений о стрессах в Нью-Йорке и Чикаго на самом деле очень
сильно различаются, если принять во внимание Время опроса. Иными словами, суще-
Категоризованные графики и матричные графики
309
ственно зависят от того, когда именно проводился опрос, утром или вечером.
Заметьте, что в Далласе фактор времени суток вносит незначительные изменения.
Рассмотрим также модельные данные о работе в Интернете пользователей из
различных городов (фрагмент файла см. ниже):
ГОРОД
ВРСУТОК
1L
1Н_
II
11
IL
i6_
17
питер
питер
москва
питер
питер
москва
москва
москва
москва
москва
москва
питер
питер
питер
москва
питер
питер
День^
Вечер
Вечер
Вечер
День
Вечер
Вечер
Вечер
Вечер
Вечер
Вечер
_Утро
_Утро
Вечер
Ночь
Вечер
Вечер
1Щ2^9
46
20
31
24
58
35
16
22
41
8
28
24
20
12
33
15
Ниже показан категоризованный график, позволяющий визуально представить
интенсивность работы в различных городах в зависимости от времени суток.
itiriJimiiHMi'PiiiB
Гистограмма (catlnteri.STA 10v*100c)
■ JQlxl
ir
1 GO
О
wrm
Г7ГГ77Л УТЛ \
? E Ч Ч E 5* 8 8 ? Щ! ц ц[Ц! ц % S
Санкт Питер бург Москва
Время работы
Л-
т im
Ж
т т
Г КТ7Э
?fulfils
v *SS8f£
Смоленск
Категоризованные графики и матричные
графики
Внешне матричные графики похожи на категоризованные, однако матричные
графики строятся для одних и тех же подмножеств наблюдений, тогда как категори-
310
Глава 7. Визуальный анализ категоризованных данных
зованные графики строятся для разных, более того, непересекающихся групп
наблюдений.
Наличие непересекающейся группы наблюдений и составляет главную
особенность категоризованных графиков. Собственно, идея в том и состоит, чтобы
разбить данные на естественные группы и визуально исследовать зависимости между
группами.
В категоризованных графиках нужно указывать, по меньшей мере, одну
группирующую переменную — grouping variable, которая содержит информацию о
групповой принадлежности каждого наблюдения (например, Чикаго — Chicago,
Даллас — Dallas). Эта группирующая переменная не будет непосредственно включена
в график, не будет отображаться на нем, но будет служить критерием разбиения
наблюдений на группы.
Выше мы познакомились с категоризованными гистограммами —
гистограммами, построенными отдельно для каждой группы наблюдений, определяемой
значениями группирующей переменной.
В основном гистограммы используются для того, чтобы исследовать
распределение значений переменных. Например, гистограммы показывают, какие
конкретно значения или диапазоны значений исследуемой переменной встречаются
наиболее часто, как отличаются значения в разных интервалах, сосредоточено или нет
наибольшее число наблюдений вокруг среднего или медианы, имеет ли место
симметрия распределения и т. д.
Гистограммы также используются для оценки сходства (согласия)
наблюдаемого или эмпирического распределения с теоретическим распределением.
Существуют две основные причины, по которым гистограммы представляют
интерес.
О С помощью гистограммы можно выяснить существо исследуемой
переменной (например, как распределены пользователи Интернета по возрасту, полу,
профессии, просматриваемым сайтам).
О Множество статистик основано на определенных предположениях о
распределении анализируемых переменных, например, временные интервалы
между заходами на сайт могут иметь гамма-распределение, и гистограмма
помогает проверить эти предположения.
Гистограммы и описательные статистики
311
Если вы описали тип распределения переменных, то можете построить
математическую модель и провести нужные расчеты.
Часто в качестве первого шага в анализе нового набора данных следует
построить гистограммы для всех переменных и всех наблюдений и далее подходящим
образом их категоризовать.
Гистограммы и описательные статистики
Категоризованные гистограммы — Categorized Histograms предоставляют
информацию, схожую с описательными статистиками (например, среднее, медиана,
минимальное значение, максимальное значение и т. д.). Несмотря на то что
некоторые (числовые) описательные статистики легче читаются в таблице, общий вид и
глобальные описательные статистики проще исследовать визуально.
График предоставляет качественную информацию о распределении, которая
не может быть полностью представлена одним или двумя параметрами.
Например, общее асимметричное распределение дохода может показывать, что
большинство людей имеет доход, который гораздо ближе к минимальному
значению диапазона дохода, чем к максимальному. Кроме того, при разбиении по
половому или этническому признаку эта характеристика распределения дохода может
оказаться более выраженной в определенных подгруппах. Хотя эта информация
будет содержаться в коэффициенте асимметрии (для каждой подгруппы) при
представлении в графическом виде на гистограмме, она обычно распознается и
запоминается более легко.
Имея свой сайт, вы анализируете статистику посещений и по гистограмме
определяете пик интереса к сайту в течение суток.
Гистограмма может также показать «изгибы», которые представляют важную
информацию об определенной социальной стратификации исследуемого
поколения или аномалий в распределении дохода в конкретной группе, вызванной,
например, налоговой реформой.
312
Глава 7. Визуальный анализ категоризованных данных
Категоризация значений в каждой
гистограмме
Все процедуры гистограмм, доступные в STATISTICA, предоставляют большой
набор способов разбиения данных на группы.
Эти методы категоризации разделяют весь диапазон значений переменной (от
минимума до максимума, если переменная числовая) на некоторое число групп
или диапазонов, для которых подсчитываются частоты (просто считается
количество значений, попавших в данный диапазон). Далее полученные частоты
представляются на графике в виде отдельных столбцов или полос.
Например, можно создать гистограмму, на которой каждый столбец будет
представлять диапазон из 10 единиц шкалы, которая используется для представления
переменной; если минимальное значение равно 0, а максимальное — 120, то будет
создано 12 столбцов. Кроме того, можно сделать так, чтобы весь диапазон
значений переменной был разделен на указанное число интервалов равной длины
(например, 10); в последнем случае, если минимальное значение равно 0, а
максимальное — 120у каждый интервал будет равен 12 единицам шкалы.
Имеются опции, которые поддерживают более сложные категоризации,
например, позволяют создать неравные диапазоны с заданными пользователем
границами для каждого диапазона (чтобы создать более понятные диапазоны или
объединить выброс и увеличить читаемость средней части гистограммы). Диапазоны
можно также создать, определив критерии включения и исключения с помощью
логических операторов (например, первый столбец гистограммы может
представлять людей, которые за последний год летали на самолете более 10 раз, причем не
более 50% этих поездок были связаны с бизнесом).
Категоризация значений в составных
графиках
Составные графики можно создать для уровней категоризующей переменной
(например, переменной пол или переменной стресс, характеризующей различные
уровни стресса).
Категоризация значений в составных графиках
313
Значения непрерывных переменных (например, возраст, доход, цена) можно
разбить на заданное число интервалов или создать группы наблюдений с
помощью логических условий.
шшшвшшшш
Error Scores Dy Treatment
The distribution of
error scores is clearly
different for females
Treatment does not seem
to effect tnis difference
Последняя возможность особенно эффективна, так как позволяет провести
разбиение на группы с помощью «правил», которые используют более одной
переменной, с заданием логических соотношений между этими переменными
(например, таким способом можно выбрать группу, состоящую из всех людей мужского
пола старше 30 лет и играющих в гольф и не любящих попсу).
В качестве еще одного примера рассмотрим данные, характеризующие стресс
женщин. Значения первой переменной описывают семейное положение
опрошенных женщин, значения второй переменной измеряют уровень тревоги. Известно,
что личностная тревожность представляет собой устойчивую склонность
личности воспринимать жизненную ситуацию как угрожающую и реагировать на нее
соответствующим образом (см., например, Кокс Т. A981) Стресс). Обычно
используют шкалу тревожности: низкая тревожность, умеренная и высокая. Для простоты
ограничимся шкалой «низкая — высокая» тревожность. Файл данных показан
ниже.
тем!
:зняЧ
enl STA 1Un - Шн
Стресс женщин
СЕМ ПОЛ;
,Л2; •
1к
2
1
J.
%
10
EGA
П_семья
Н_семья
Н.семья
Н_семья
П.семья
П_семья
П_семья
Н_семья
П_семья
Н семья
Высокая
Низкая
Высокая]
Низкая
Высокая
Низкая
Низкая
Высокая
Низкая
Высокая
Откройте окно Галерея графиков, в котором выберите статистические катего-
ризованные графики (левое меню) и гистограммы (правое меню). Сделав выбор,
нажмите кнопку ОК.
314
Глава 7. Визуальный анализ категоризованных данных
Wtffl
\ПР Стат. 2М график*
№JF Стат. ЗМ посяедоеате/
1£* Стат. XYZ графики
Стат
$2 Стат. пиктографики
QQ Диаграммы рассеяния
Нормальные вероятностные графики
OQ Графики каеитияь-кеектияь
|(Х] Графики ■
Ли
О Пустые графические с
£3 Пояь:
яоковые статистические графики
SJ Стат. графики пользователя
? Обеор I "•' $•] "'
1 ^ 1
Отмена
Гистограммы чlcт0г
гммграьфиы)
строятся отдально
дд* каждой
XX Круооые диаграммы
|СХЗ Д"*П>- nponyaiwiiH эиеч
№§ Категориэоеаииые XYZ графики
Категориэоееииые тернарные графики
Ш'ООрвКЭЮГСЯ
>|илис]
*)д*я
cpHjuanwnuftfpyn
В появившемся далее окне нажмите кнопку Переменные, чтобы выбрать
переменные для графика.
Выберем в качестве группирующей переменной семейное положение
женщины. Значения этой переменной разбивают данные на две группы: женщины,
живущие в полной семье, и женщины, живущие в неполной семье, включая одиноких
женщин. Анализируемой переменной будет переменная тревога, выбранная в
третьем столбце.
штштшшт
ъщуцщхптлшшял
2ТРЕ80ГА
3VAR3
4VAR4
5VAR5
6VAR6
7VAR7
B-VAR8
9VAR9
10VAR10
1-СЕМ ПОЛ
2ТРЕ80ГА
3VAR3
4VAR4
5-VAR5
6VAR6
7VAR7
8VAR8
9VAR9
10-VAR10
1 СЕМ ПОЛ
Ullllllll нИ»
3VAR3
4VAR4
5VAR5
6VAR6
7VAR7
8VAR8
9VAR9
10-VAR10
Категории по X: Категории по V: Переменные:
Далее сделайте установки для настройки графика, как показано в окне 2Мка-
тпегоризованные гистограммы.
ъжхттттттш
Qj3 С Диве?»
Ло«1сош«:|
У^: "к^х^шцпоя
' . К«т. Y: ифГ -
■
ittxii
JEL
g» ]] Отмена)
ЬиетармпвХ •- ;:--;--jKaWopHMneX
: Пера» яичаш; CEMJIOfl
. С
■;гг|
С Коде
С
«жа
II
С.^атфгорик [То"
г
Ж
ГИСТОГРАММА
' Перящцц»; ТРЕВОГА
• <• йштлл «мем Р* Дето
Г Накоялемиечастот гОоьУ:|м J
Г Интервал междя стояками Г* Показать проценты
д:^.-а:ж:у:...у:::аи>та-rrrr-vrifiM"iVi-i v -r •ir-v"..-:.-:jmw::::M-V4---'-iinv »«;цць»;и.ч.тл
Категоризованные гистограммы и диаграммы рассеяния
315
Возможны два способа размещения гистограмм на графике в зависимости от
выбора, сделанного в опциях Размещение этого диалогового окна (см. графики
ниже).
Низкая Высокая
ТРЕВОГА
\Ш СЕМ_ПОЛ: Псвмь* i
EH СЕМ_ПОЛ: Н_свмья j
Из графиков видно, что уровень тревоги женщин в неполных семьях выше, чем
в полных. Насколько значимо это различие, можно оценить с помощью
специальных статистических критериев, например с помощью критерия хи-квадрат.
В данном примере это различие небольшое, однако и число наблюдений мало.
Если бы подобное различие (одно наблюдение) имело место для 100
респондентов, то, очевидно, мы отнесли бы его за счет случайной ошибки и не приняли бы во
внимание.
В этом и состоит существо дела: если визуально вы видите отчетливый эффект,
то его не имеет смысла доказывать статистически; если эффект не столь ясен, то
применяют статистические критерии.
Категоризованные гистограммы
и диаграммы рассеяния
Эффектным приложением методов категоризации для непрерывных переменных
может оказаться представление связей между тремя переменными на плоскости.
316
Глава 7. Визуальный анализ категоризованных данных
Наверняка приведенный нами пример визуализации удивит даже искушенных
аналитиков. Ниже показана диаграмма рассеяния для двух переменных Load 1 и
Load 2.
Теперь предположим, что необходимо добавить третью переменную (Output) и
рассмотреть ее распределение на различных уровнях совместного распределения
Load 1 и Load 2. Этого можно достичь, например, с помощью следующего графика.
LOAD 2
V LOW
1П
IM
Histogram (LOADS STA 1CV100O
{'■•■•.... ■ .
,.•"
Ltd-'-1
I JU I
k-
[•::: - ::
2? 8
« 4
:;--*"*--.d
■Ь"нй H
Iff!
k.
■:.-._:: |
l 1Ш1 1
i jrfL 1
!-'-:.d
.•'
1 rmT,
60 80 100 120 60 60 100 120 60 80 100 120 60 80 100 120 60 80 100 120
LOA01: LOA0 1: LOAD 1: LOAD 1: LOAD 1:
V LOW LOW MEDIUM MlOH V HlOH
OUTPUT
На графике значения переменных Load 1 и Load 2 разбиты на 5 уровней, и для
каждой комбинации уровней построена гистограмма переменной Output.
Подгонка теоретических распределений
к наблюдаемым распределениям
Функции подгонки распределений STATISTICA, встроенные в гистограммы,
позволяют сравнивать распределение наблюдаемых данных с такими
распределениями, как нормальное, бета-, экспоненциальное, экстремальных значений, гамма-,
геометрическое, Лапласа, логистическое, логнормальное, Пуассона, Релея и Вейбулла.
Подгонка распределений к множественным гистограммам
317
11Ж1Ш11Ц|||||11.1.1111МЦи.|111Ш111111
Histogram wttn Normal Curve for 2 Groups
v &8.&8j£88SSR Л v &8.&&&8JSSSR л
Control Group Eiptrimtntal Group
Test Score
Это наиболее часто возникающие на практике распределения, и проверка
согласия с ними данных иногда представляет интерес.
Обратите внимание, что программа STATISTIC А также включает
специальный модуль подгонки распределения (см. Непараметрическая статистика и
подгонка распределений), который предоставляет широкий набор теоретических
функций распределения, графиков и статистик для проверки согласия исходных
данных с выбранным распределением.
Подгонка распределений
к множественным гистограммам
Несколько архаичный термин «множественный» в анализе данных часто
эквивалентен слову «несколько» или «много», таким образом, множественная гистограмма
означает всего лишь, что несколько гистограмм отображены на одном графике.
При построении нескольких гистограмм на одном графике переменные
представлены смежными полосами, поэтому для каждой группы (обычно построенной
вдоль горизонтальной оси X) строится несколько полос.
Аппроксимирующие кривые могут либо точно соответствовать гистограммам,
либо быть сравнимыми друг с другом.
шшшшшшшт
MuHipl» Histogram
г - я^ЛлЧЩ 1
Hv I
Ш
н I
0
Щ 1
|\\
\|
ЕЗЗ CLASS A
ess class в
Н CLASS С
Н CLASS D
Гч^.
Поскольку множественные гистограммы создаются для визуального сравнения
распределений в разных группах, например мужчин и женщин (а не для анализа
качества подгонки для отдельных переменных), то STATISTICA использует вто-
318
Глава 7. Визуальный анализ категоризованных данных
рое решение: ожидаемая теоретическая кривая будет «прикреплена» к числовым
значениям (а не к меткам групп) оси X. На практике это обычно не влияет на
объяснение графика, то есть очевидное отклонение переменной от ожидаемого
распределения по-прежнему будет очевидно.
Если вам нужно «прикрепить» функции распределения к меткам групп, то
можно изменить соответствующие формулы, так что подогнанные распределения
будут сдвинуты по оси X, чтобы компенсировать сдвиг столбцов гистограмм.
Категоризованные диаграммы рассеяния
2М диаграммы рассеяния используются для визуализации зависимости между
двумя переменными X и У (например, вес и рост, цена и качество). В диаграммах
рассеяния отдельные данные представлены точками в двумерном пространстве. Две
координаты (X и У), определяющие расположение каждой точки, соответствуют
определенным значениям двух переменных.
Если две переменные сильно связаны, то точки имеют некоторую
систематическую форму (например, группируются вдоль прямой линии или гладкой
кривой). Если переменные не связаны, то точки образуют круглое «облако» (более
подробно см. главу Элементарные понятия).
Readings of 2 Gages m 6 Locations
Категоризованные диаграммы рассеяния предоставляют мощные
исследовательские и аналитические методы исследования соотношений между двумя и
более переменными в различных подгруппах.
Cattgonztd Scatltrplot
Groups 1-16
(Л
* Ц\ т ...^НI щ и-^И 1 ш ,,-f) 1 ш -Л
PRESSURE
Нелинейная зависимость
319
60 70 60 90 100 ПО 120 130 140 60 70 80 90 100 110 IS 130 140
Malt*
Performance 1
Нелинейная зависимость
Нелинейность — это другая сторона зависимости между переменными, которую
можно исследовать на диаграммах рассеяния. Для измерения нелинейных
зависимостей между переменными не существует простых в использовании тестов:
стандартный коэффициент корреляции Пирсона г позволяет измерять линейную
зависимость, а некоторые непараметрические корреляции, такие как корреляция
Спирмена R, позволяют измерять также монотонные нелинейные связи.
Исследование диаграмм рассеяния дает возможность определить форму
зависимости, так что в дальнейшем можно выбрать соответствующее преобразование
данных, чтобы «линеаризовать» зависимость или выбрать соответствующее
уравнение для нелинейного оценивания.
т
ттштгшшшшт
R«l*0««h<p of 2 M«»*ur«m*nt« m 3 OfOup»
ЕЩ
. ^яМ&? ■**>**-*
M«t*ur«m*nl \
Sceeerpiot Prediction of Final Pertormanct by Gfade
GRADE. А у - 0.1344).Т2Г 1-1 ^ee-l*2»1 Л1ГI АЭЧ)Л11-l*44) J4Tl***tp»
GRADE: В у - 0.241*1 ХЖ'хЛ И4*1*24).10Г 1Лв»1>*0в*1А4-0.1§2*1Л**#р»
GRADE: Су- 4XЯA-^ЛЩrx^OO\Чrx•W>M^x*УOarx*A4Mrx^Ъ+^*%
GRADE: D у • 0 OJ7*OAJri4>.4661t*2.0.00rжЛЭ*0ЛГ1Л*»0.0Г1Л6*«р*
320
Глава 7. Визуальный анализ категоризованных данных
Категоризованные вероятностные графики
С помощью категоризованных вероятностных графиков можно определить,
насколько близко распределение переменной следует нормальному распределению
в различных подгруппах.
ъшшш
Detrended Могли» РгооаойЛу Plot varS
ii
*-*-
{с
•1 4
——г Н.^ 1.
-——J I л I
Категоризованные нормальные вероятностные графики представляют
эффективный инструмент для проверки нормальности распределения данных в отдельных
группах.
I^QDBSQDDOD
Normal Probabftty Plot by Group
Final Performance Scores m Eacn E>$«nment* Group
65 75 85 95 105 115 125 1Э5 65 75 95 95 105 115 125 1Э5
Normal dutnoubon values Rectangular distribution values
Если подгонка в основном неверна и данные образуют какую-либо ясную форму
(например, букву 5) вокруг прямой линии, то переменную, возможно, необходимо
каким-то образом преобразовать до того, как она будет использована в процедуре,
предполагающей нормальность (например, логарифмическое преобразование часто
Категоризованные графики квантиль-квантиль
321
используется, чтобы «втянуть» конец распределения (см. Neter, Wasserman, and
Kutner A985) Applied linear statistical models: Regression analysis of variance and
experimental designs, Homewood IL: Irwin).
Нормальные вероятностные графики без тренда строятся так же, как и
стандартные нормальные вероятностные графики, за исключением того, что линейное
смещение (тренд) убирается до того, как строится график.
Detrended Normal Prooaoility Plot
■j£*/V*4
66 75 85 96 105 115 126 135 55 75 86 96 105 115 125 1Э5
Normal distribution values Pectangjiar distributor! values
Это часто «разбрасывает» график, что позволяет пользователю легко
обнаружить отклонения от нормальности, например, если распределение равномерное,
то возникает S-образная кривая.
Категоризованные графики
квантиль-квантиль
Категоризованные графики квантиль-квантиль (К-К) используются для поиска
наилучшего распределения в заданном параметрическом семействе
распределений.
DtttntxAon Ravtwe*
OROUP 1у»-00Э2»ОГх*»р»
oroup. 2 г-о 065 «о eervw
88-3 « * «8 9 58-« « Г «8
/
Thtwelieel OutnM*
Вначале нужно выбрать, какое из теоретических распределений
аппроксимирует данные. Так как выбранные семейства вероятностных распределений
зависят от параметров, например, среднее и стандартное отклонение для семейства
нормальных распределений, то задача состоит в том, чтобы оценить неизвестные
параметры по имеющимся наблюдениям.
322
Глава 7. Визуальный анализ категоризованных данных
Чтобы оценить аппроксимацию или качество подгонки наблюдаемых данных
теоретическим распределением, наблюдаемые значения переменной (х1 < ... < хп)
упорядочиваются, строится вариационный ряд, а затем эти значения (лг.) строятся
по обратной функции распределения вероятности, обозначенной как F1 (точнее,
F~1 (г - rankad/n + п X где F~1 зависит от распределения, a rankad. и nad. задаются
пользователем).
На графиках проверка согласия проводится визуально.
Если наблюдаемые значения попадают на линию регрессии, то можно сделать
вывод, что наблюдаемые значения согласуются с выбранным распределением.
Уравнение аппроксимирующей линии ( Y=a + их, приводится в заголовке АЧК*-гра-
фика) дает оценки параметров {а и 6, где а — параметр положения, Ъ — параметр
масштаба) распределения.
Категоризованные графики
вероятность-вероятность
Категоризованные графики вероятность-вероятность (В-В) используются для
определения того, насколько хорошо определенное теоретическое распределение
аппроксимирует наблюдаемые данные.
CaUgonzad ProbabiMy РгоЬаЫПу Plot
Ditlnbutwn B«D
ош оде аш a»e too om on oao ore «o
Th«o*tical cumuUti* fetnbuhon
На В-В-графике наблюдаемая эмпирическая функция распределения (доля
значений переменной < х) сравнивается с теоретическим (предполагаемым)
распределением. Если все точки графика ложатся на прямую с тангенсом угла наклона 1,
то можно заключить, что теоретическое распределение хорошо аппроксимирует
эмпирическое распределение.
Чтобы построить такой график, нужно полностью задать теоретическую
функцию распределения. Поэтому параметры распределения должны либо быть
заданы пользователем, либо оценены.
Категоризованные линейные графики
На линейных графиках отдельные точки соединены линиями. Линейные графики
предоставляют простой способ визуального представления последовательности
большого числа значений (например, уровня цен на бирже за несколько дней).
Категоризованные прямоугольные диаграммы
323
Опция категоризованных линейных графиков — Line Plots используется, если
нужно посмотреть эти данные, разбитые группирующей переменной на группы
(например, цены при закрытии по понедельникам, вторникам и т. д.) или другими
логическими критериями, включая одну или более переменных (например, цены
при закрытии только в те дни, когда индекс на двух других биржах и Dow Jones
поднялся по сравнению с остальными расценками при закрытии).
Short-Term Bank Balances. U S Capital oy Quarter (X11Q Cnart G2)
|]*,<^r.tp-.u^44-f:iJ
2nd Quarter |
itJt.i-t'P
Г... i ».
, t-;-,-i-|
SiiliiiHHiHi Sii8l2HtiiUtS
iH-TA4i;l
:ГГ?1**- .......
H+*
S8igi2iitil8H8 SliSiiSitiUSsc
-o- D l> Hwl И dHwwtw wMn ««r«w—
• 01. ttnm SI mum«ncee wMwui м«мпи
■*- 01a. Final hhomI ftlor»
В системе STATISTICA можно экспериментировать с различными стилями
визуализации категоризованных последовательностей значений, изменяя Тип
графика — Graph Type в диалоговом окне Разметка графика — Plot Layout.
Методы сглаживания
Процедуры сглаживания доступны также и для категоризованных линейных
графиков, например, как показано на следующем рисунке:
О S Ю 1S » И 30 * 40 45 Ю И «О О S 10 15 » И » Эв 40 45 50 55 «0
Sequential Meawrement Sequential Measurement
No Shock Random Shock
Категоризованные прямоугольные
диаграммы
На прямоугольных диаграммах — Box Plots (термин впервые использовал
известный статистик Тьюки (Tukey) в 1970 г. — см.: Tukey J.W. A972) Some graphic
and semigraphic displays. In7 Statistical Papers in Honor of George W. Snedecor;
324
Глава 7. Визуальный анализ категоризованных данных
ed. Т. A. Bancroft, Arnes, I A: Iowa State University Press, p. 293—316) диапазоны
значений выбранной переменной (или нескольких переменных) строятся отдельно
для групп наблюдений, определенных значениями категоризующих переменных.
Положение центра данных (медианы или среднего) и диапазон вокруг него,
а также, например, квартили, стандартные ошибки или стандартные отклонения
вычисляются для каждой группы наблюдений.
На приведенном графике видны выбросы (в данном случае точки, отстоящие
больше или меньше, чем в 1,5 раза по отношению в межквартильному диапазону):
имвшашдш
Categorized Box Plot
*l
11
$&&$\
га
\у*н
Si*4
fijfj
i$j?
~1~ NorvOutli«r Мак
Non-Outlur Mm
CD 75%
25%
<> Median
о Outliers (*i 5 *
Interqu^i-tiie Pang»)
SAMPLE ID A lo 4)
Однако на следующем графике нет очевидного выброса или экстремальных
значений.
BARLEY HEEDS НО RAIH. Во* Plot (BARLEY STA 7v*9000c)
IE NorvOutlur M.n/Mix CZI 75% • M«d.»n
15ШРШШ11AШ{||аа1й;йШ
jjlllllllllll
MiJiHMiHiHffliH
IMiffllSlifflliMIJSil
COUNTRY
SWEDEN
COUNTRY
UK.
COUNTRY
FRANCE
virr
COUNTRY
GERMANY
COUNTRY
POLAND
J=
Для прямоугольных диаграмм существует два типа приложений: а) отображение
диапазонов значений для отдельных объектов наблюдений (например, обычная
минимаксная диаграмма — MIN-MAXplot для акций или товаров, или составные
последовательные графики — sequence data plots с диапазонами) и б) отображение
изменчивости данных в отдельных группах или примерах (например, диаграммы «ящики
и усы» или диаграммы размахов, в которых среднее — это точка внутри «ящика»,
плюс-минус стандартная ошибка «ящик», а плюс-минус стандартное отклонение от
среднего — более узкий «ящик», или, как иногда говорят, пара «усов»).
Прямоугольные диаграммы позволяют быстро вычислить и «интуитивно
представить» силу связи между группирующей и зависимой переменной.
Предполагая, что зависимая переменная распределена нормально, и зная,
какая часть наблюдений попадает, например, в ±1 или ±2 стандартных отклонения
от среднего, можно легко вычислить результаты эксперимента и сказать, напри-
Связанные графики 325
мер, что около 95% наблюдений в экспериментальной группе 1 принадлежат
диапазону, отличному от 95% наблюдений группы 2.
Кроме того, можно строить так называемые усеченные средние значения (trimmed
means), исключая заданный пользователем процент наблюдений из
экстремальных значений.
Связанные графики
pjjl «Ящики и усы», или диаграммы размаха
Этот тип статистических категоризованных графиков по умолчанию помещает
«ящик» вокруг центра (то есть среднего или медианы), который представляет
собой выделенный диапазон (то есть стандартную ошибку, стандартное отклонение,
минимакс или константу), и «усы» снаружи «ящика», которые отображают
другой выбранный тип диапазона.
! ; 1 I ', \ 1 О >*%
varM SeaM Sy**o*c v«rM SimM Sy**otc X%
Mtltt F«m«l«t ■ m<t.
Reasoning
Ширину «ящика» и засечек «усов», конечно, можно менять.
laTffi «Усы», или диаграммы диапазонов
В этом типе прямоугольных диаграмм диапазон (то есть внутригрупповая
стандартная ошибка, стандартное отклонение, минимакс или константа) представлен
«усами» (отрезком прямой с засечками на обоих концах).
щшшшшавяшшшиш^шшшшщ
Final Results oyGenaer
V«rM S«M Sy**o*C V«M S«M Sv**e«C NorvOH» Mn
MdM F«m«l«f ■ Г1ЦЩ-
Reasoning
И «Ящики», или прямоугольники
В этом типе прямоугольных диаграмм вокруг средней точки (то есть среднего
группы или медианы) помещается «ящик», который представляет выбранный диапа-
326
Глава 7. Визуальный анализ категоризованных данных
зон (внутригрупповая стандартная ошибка, стандартное отклонение, минимакс или
константа).
11ШШ<И1Ш1П1111ШШ1ШЦ
Final Results by Gender
i:
q:
Reasoning
(jg| Столбцы
В этом виде прямоугольных диаграмм для представления средней точки
(среднего группы или медианы) используются вертикальные столбцы.
ШШШШП11111Ш111МФ
Final Resu«s by Gender
140 г
120
100
80
I E 60
;..,.t .....
2
Males
2 3
Ftmaltt
НОГ^ОМШШ>
Reasoning
Можно создавать другие типы прямоугольных диаграмм, изменяя типы
зависимостей соответствующих компонент графиков.
Категоризованные круговые диаграммы
327
Верхние и нижние засечки
В этом виде прямоугольных диаграмм «засечки» на «усах» не симметричны, а
сдвинуты влево, представляя традиционный график «цен на акции».
Вож Plol (EXP STA 8v8c)
10
14
10
в
2
i i
|...1...т...
И! мах
BEFORE AFTERJ AFTER_2 BEFORE AFTERJ AFTER.2
OROUP: EXPERIMENTAL GROUP CONTROL
TIME
Категоризованные круговые диаграммы
Круговые диаграммы являются одним из наиболее часто используемых форматов
графиков, которые используются для представления пропорций или значений
переменных.
Market Shares of ACME Stores in Selected Markets
Kansas City
Major Competitors
a - Jones Mart
В - Shopping Empire
С - Shopping ideas
D- East Cost Wares
E - Discount Outlet
F • Mikes Mall
Построенные категоризованные круговые диаграммы всегда будут
рассматриваться как частотные —frequency круговые диаграммы (в противоположность
круговым диаграммам данных). Этот тип круговых диаграмм иногда называют
частотной круговой диаграммой — frequency pie chart.
Относительные частоты представлены как секторы круга пропорциональных
размеров. Поэтому круговые диаграммы предоставляют альтернативный
гистограммам метод визуализации данных.
328
Глава 7. Визуальный анализ категоризованных данных
Секторы круга можно пометить числовыми или текстовыми значениями;
метки могут включать непосредственные или относительные значения частот.
Круговые диаграммы рассеяния
Полезным приложением категоризованных круговых диаграмм является
представление относительной частоты распределения переменной в каждой точке
совместного распределения двух других переменных. Следующий график наверняка
удивит вас.
шшш
* *
* т
3 •
3 -
а •
сз -
сз •
э «
э -
n ~
•
и
1
ШШШШ7\
ш
L1 correlates with L2. and L1*L2 affect the QUALITY [
Ф
©
Ф
•
И
2
©
©
©
Ф
Ф
•
11
J
©
©
©
©
•
©
U
4
©
Ф
©
©
©
©
и
1
О
ф
ф
ф
©
и
1
о
о
©
©
©
и
7
о 1
О
о о о
© ©
о 1
©
и
•
QUALITY:
О нюн
ф мсошм
ф LOW
И И
• 11 1
Обратите внимание, круги нарисованы только в тех «местах», в которых есть
данные. Поэтому приведенный выше график выглядит как диаграмма рассеяния
(переменных L1 и L2) с отдельными кругами в качестве указателей точек.
Кроме информации, содержащейся в простой диаграмме рассеяния, каждый
круг показывает относительное распределение третьей переменной на
соответствующем месте (например, Низкое — Low, Среднее — Medium, Высокое качество — High
Quality).
Категоризованные трехмерные графики
329
Представленный график служит прекрасным образцом совмещения диаграмм
рассеяния и круговых диаграмм. Он также показывает, в каком направлении
следует двигаться в визуальном анализе данных, чтобы получить действительно
эффективный результат.
Категоризованные диаграммы пропущенных
данных и диаграммы диапазонов
Эти графики позволяют определить шаблон распределения пропущенных данных
и заданных пользователем точек, лежащих «вне диапазона», для каждой
категории наблюдений.
Mawngor Rang» Ml «tat ГМХЧ.СТ STA 101v*10Oc)
См Я
Сам Л
Сам 91
Сам 01
Сам»1
Сам 01
• ' \ о
0 о "
fc, °<.о
т
оо в 1.
—s—в
' «У
МШШП iiMiiififf Н?ШШ!
САТЮОЯТ О
НШШ1! iiffiifiif siifififii
САТ1О0ЯТ Э
CATI90*V в
Подобные графики используются в разведочном анализе для того, чтобы
определить протяженность и «выход из диапазона» данных.
В большинстве процедур пропущенные данные удаляются, используя
попарное или построчное удаление пропущенных данных или подстановку среднего
значения вместо пропуска.
Категоризованные трехмерные графики
К этому типу относятся трехмерные диаграммы рассеяния (пространственные
графики, спектральные графики, диаграммы отклонения и трассировочные
графики), диаграммы линий уровня и графики поверхности для наборов случаев,
заданных определенными группами выбранной переменной или группами,
определенными заданными пользователем условиями выбора случая (наборы можно
определить с помощью логических выражений, использующих любые переменные
текущего набора данных).
Информация, представленная на этом графике, в точности та же, что и на нека-
тегоризованной трехмерной диаграмме рассеяния, или диаграмме линий уровня,
или графике поверхности, за исключением того, что для каждой заданной
пользователем группы наблюдений строится один график.
330 Глава 7. Визуальный анализ категоризованных данных
Основное назначение данного графика — облегчить сравнение групп или
категорий независимо от соотношений между тремя или более переменными.
|ХAИ1) Ftbnc Strength 1 I
Y (nyhl) Fabric Strength 2
|Z (vertical) Cruth Rt«nl»nct j
Hign Low
В основном трехмерные XYZ графики обобщают соотношения между тремя
переменными. Различные способы, которыми могут быть категоризованы данные,
позволяют посмотреть состав этих соотношений с помощью какого-либо другого
критерия (например, групповой принадлежности).
_ИН^ННН
Щ7Щ
1 Ooiythe TOLIHAWCI <-J matter* (TSTA277V29000C)
ш
TOlXftANCI «*M«C
ИХ
ш
ТОИЛАИС1 ЯАММ
ТОИЛЛМС1 MAN»!
Г* 1в|
ш
ТОС1ЯАМС1 ПАИ»!
О 3|
т
ТОСЯНАИС! ЯАМ«4
•VUI
т
TOCMANCI HANOI
ре 1*1
ш
TOlf (UNCI ЯАМ41
ш
TOHftAMCf MAM«f
ш
TOUIUNCI KAN
> 1*
I
1
ни
Заметьте, что эффект более заметен, если переключиться на режим
отображения линий уровня.
Категоризованные тернарные графики
331
ГГАПУПСА: B»tk toMci w»4 Tttta»
_Ш1
т.
САТЮСАСДС
«^
ш<
'У >:U,
CAT1Q8UWCSG
Щ
<Л
CAT1MUW.CSG £*]
J.
jlL
. It
CAT10SP€C«C
CAnotuacsc
«]1
^? ^ ^ ^
^ ^ ^ ^
^ ^ ^ ^
шштл \
Щ
Н '14 -Ь С
S Й #•
& С в- й
V>*^- V*^£- V^.^5- V1?
Категоризованные тернарные графики
Категоризованные тернарные графики можно использовать для исследования
соотношений между компонентами смеси, сумма значений которых равна
константе, для каждого уровня группирующей переменной.
AAA
шШ.
В *гя
5 S«
■В чи
■В Лот
пмгстдт »• с т»шггь4виг^2тгг*иг.-^а*;;4П^чТ7Ч-шЧ;
to^wat if с ^•mr.4»rr«j»«4i»4>.>««ir«-n«rrl^4ar«vi
TEMWRATWC *-01»11МK4Гуо1МТ1 H14V1 IWVMinYMIMVy»
TEMPSRAT ?4*C *»010J*»0 40J>00ir*»0 33lW1 J6?Vfl ?MVr3?W*Yz
T6MPERAT WC *»0 02T»-0OMV0Jrr>-0 5inrVO2?ev*Of5Vl-1 **Y*
TEMPf RAT JTC*0 11Г*.0О51 V0 JT4«M <*4**V011 ГУМ OfРуЧ-О 1 MiryT
332
Глава 7. Визуальный анализ категоризованных данных
На тернарных графиках для построения четырех (или более) переменных
(компоненты Х} Y и Z, отклики V1, V2 и т. д.) в двух (тернарные диаграммы рассеяния
или линии уровня) или трех измерениях (тернарные графики поверхности)
используются треугольные системы координат.
В-категоризованных тернарных графиках для каждого уровня группирующей
переменной (или заданного пользователем набора данных) строится один
составной график, и все составные графики отображаются на одном экране, чтобы
можно было производить сравнения наборов данных (групп).
Типичным приложением этих графиков является эксперимент с результатами,
зависящими от относительных пропорций компонентов, входящих, например, в
состав нового лекарства, моющего вещества или духов, которые варьируются с
целью определения оптимального состава.
Этот тип графиков также можно использовать в случаях, когда соотношения
между связанными переменными нужно сравнить внутри групп данных.
8
Пиктографики
На статистических пиктографиках наблюдения или отдельные испытания
представлены в виде символов со многими элементами.
4
*****
£
т
ъ-
т
ивг»п
Ifin
Выбор*» по округам
i*i[7|*!!*i
1*- 1«п» "*"■ °л*»п
Oar* AtV>% &»!•* Mud*
••гтоьг Arelw ёмин* t*r*or
*>:
■№
3
Условные обозначения
(ПОЧвСОвОЙ ПР#П1в)
Потребление
Розничная продаж*
Домашнее юэяйстде
Занятость
пресулиость
Обраэоааиие
налоги
Стоимость недвижимости
Кечестао жизни
□ Сильный рост
■'.'.'; Умеренный рост
или мат роста
Основная идея использования пиктографиков состоит в представлении
отдельных наблюдений в виде некоторых графических объектов, где значения
переменных соответствуют определенным свойствам или размерам этих объектов (как
правило, одно наблюдение равно одиному объекту). Это соответствие таково, что
внешний вид объекта изменяется в зависимости от набора значений.
Даииыа ICONS STABOn* 30м
Условные обозначения
(почвеоаойстрелм)
Потребление
Домашнее хоэяйстао
Занятость
Преступность
Образование
налоги
Стоимость недвижимости
Качество жмзни
Таким образом, появляется возможность однозначно «идентифицировать»
объекты по набору значений. Изучение таких пиктограмм помогает обнаружить
специфические наборы простых соотношений и взаимосвязей между переменными.
Анализ пиктографиков
В идеальном случае анализ пиктографиков осуществляется в пять этапов.
1) Определяется порядок анализируемых переменных. Очень часто наилучшим
решением является случайная последовательность. Можно также
попробовать ввести переменные в порядке их расположения в уравнении
множественной регрессии в зависимости от величины их факторньйс нагрузок на
интерпретируемый коэффициент или использовать аналогичные
многомерные методы. Это иногда позволяет упростить и сделать «однородным»
общий вид пиктограмм, чтобы облегчить задачу распознавания не слишком
334
Глава 8. Пиктографики
отличающихся друг от друга картинок. В то же время, использование таких
методов может усложнить задачу поиска некоторых взаимозависимостей.
На этом этапе невозможно дать никаких универсальных рекомендаций,
кроме совета попробовать самый быстрый метод (случайный выбор порядка)
до того, как применять более сложные методы.
2) Проводится поиск любых возможных закономерностей, таких как сходство
между группами пиктограмм, выбросы или специфические соотношения
между элементами пиктограмм (например, «если на пиктограмме звезды
первые два луча длинны, то один или два луча с другой стороны
пиктограммы обычно коротки»). На этом этапе рекомендуется использовать
пиктографики кругового типа.
3) Обнаруженные закономерности описываются в терминах используемых
переменных.
4) Для проверки найденной структуры соотношений переменные
сопоставляются с другими элементами пиктограмм. Например, можно попытаться
переместить связанные элементы пиктограммы ближе друг к другу, чтобы
упростить дальнейшее сравнение. В некоторых случаях в конце этого этапа
рекомендуется исключить из рассмотрения переменные, не вносящие
заметного вклада в исследуемую структуру.
5) Для проверки и количественной оценки обнаруженной зависимости или хотя
бы некоторых ее параметров используется, например, регрессионный
анализ, нелинейное оценивание, дискриминантный или кластерный анализ.
Классификация пиктографиков
Большинство пиктографиков можно отнести к одному из двух типов: круговому
или последовательному.
Круговые пиктограммы
Круговые пиктографики {звезды, лучи, многоугольники) имеют форму
«велосипедного колеса», где значения переменных изображаются в виде расстояний между
центром («втулкой») пиктограммы и ее углами.
Такие пиктограммы полезны при поиске взаимозависимостей между
переменными, поскольку они хорошо отличаются и идентифицируются по внешнему виду,
который в свою очередь определяется конфигурацией значений изучаемых переменных.
Сродни* J
АЛЛ»
; *
St Maarten
: *
St Lucia
Пучши* Карибски* остром
>нач«мия по 6 порммтрам (по чкоаоА стреле)
*V«-I
2ф:
St Johns
Jamaica
Martinique
St юоэ Barbae»
^ ^ 1
St Croot С ос ото j
Классификация пиктографиков
335
Чтобы перевести эти «приблизительные соответствия» на язык конкретной
модели (в терминах соотношений между переменными) или чтобы проверить
конкретные предположения, полезно переключиться на один из последовательных
пиктографиков, использование которых может оказаться более эффективным в том
случае, когда уже известно, что нужно искать.
Последовательные пиктограммы
На последовательных пиктографиках {столбцы, профили, линейные графики)
отдельные пиктограммы представляют собой небольшие последовательные
графики (разных типов).
ГИППЧНТЯПР
tlllMiT*¥IIMlC
Среди
Агиоа
ill
St Maarten
L_L
St Lucia
шяшшшшшатттятттш^шшшшш
HiiM» iliilllMllihMMiiliBUSMBW
Лучшие Карибе*)* остро»*
*e значения по 6 napautTpMi (no часом
(Столбцы)
it. 1 . i Г
St jonns St Kins
If! 1 Jl 1
Jamaica St Croix
L i
Martinique
Л стрелке)
Barbados
II.
Cocomo 1
Значения следующих друг за другом переменных отображаются на этих
графиках расстоянием между основанием пиктограммы и последовательно идущими
точками последовательности (например, высоты столбцов на показанном выше
рисунке). Такие графики могут быть не столь эффективными на начальном этапе
анализа, поскольку пиктограммы могут не слишком отличаться друг от друга.Тем
не менее, как было указано выше, они могут пригодиться для проверки
определенной гипотезы или для описания модели в терминах соотношений между
конкретными переменными.
Круговые диаграммы
Пиктографики в виде круговых диаграмм занимают промежуточное место между
пиктографиками двух упомянутых выше типов; все пиктограммы имеют
одинаковую форму (круг) и разделены на последовательно идущие друг за другом части в
соответствии со значениями переменных, следующих друг за другом.
гяшчвпгплмя
iHlllliWlUMm
Ср#дми«
лЬ
(9
Ааюа
St Maarten
. \9
St Lucia
Лучшие Карибски* остро* а
значения по 6 параметрам (по часовой стрелка) I
(Круговые диаграммы)
-f-V ifaa.
•
St Jonns
(J
Jamaica
Martinique
St К1П5
St Cro«
/Ш \
W i
Bamaaos j
Cocomo
336
Глава 8. Пиктографики
Несмотря на их форму, с точки зрения функционального использования, такие
пиктографики скорее можно отнести к разряду последовательных.
«Лица Чернова»
Этот тип пиктограмм образует отдельную категорию. Разные наблюдения здесь
схематично представлены в виде лиц. При этом выбранные переменные
соответствуют конкретным элементам (чертам) лица.
В силу уникальных свойств таких диаграмм некоторые исследователи
рассматривают их в качестве основного многомерного метода исследований,
способного выявить скрытые взаимосвязи между переменными, которые невозможно
было бы отыскать, применяя любой другой метод. Это утверждение, однако, очень
похоже на преувеличение.
пшшшшшшшшшшшшшшшшшшшщ
Лучшие Карибские острова |
Средние значения по 6 параметрам (по часовой стрелке) I
(Лица Мерное.)
: ф <ф Ф ф \
Агиоа St Johns St Kitts Barbados I
St Maarten Jamaica St Crow Cocomo j
: <& ®
St Lucia Martinique I
Заметим, что метод «Лиц Чернова» довольно сложен, а его использование
требует проведения большого числа экспериментов по сопоставлению черт лица с
исходными данными.
Пиктографики применяются, как правило, в двух случаях: 1) когда нужно
выявить характерные зависимости или группы наблюдений и 2) когда необходимо
исследовать предположительно сложные взаимосвязи между несколькими
переменными. В первом случае пиктографики используются для классификации
наблюдений аналогично кластерному анализу.
Предположим, было проведено анкетирование артистов с целью изучения их
личных качеств. Пиктографики помогут определить, существуют ли естественные
группы артистов, отличающиеся определенными закономерностями полученных
баллов за ответы на различные вопросы. Например, может оказаться, что
некоторые артисты — чрезвычайно творческие личности, при этом они
недисциплинированны и независимы, в то время как представители второй группы хорошо
образованны, дисциплинированны и уделяют большое внимание успеху у публики.
Второй тип применений — исследование связей между несколькими
переменными — больше напоминает факторный анализ, то есть его можно использовать
при исследовании вопроса о зависимости переменных. Предположим, изучалось
мнение группы людей о различных марках автомобилей. Несколько человек
заполнили детальные анкеты, оценивая различные свойства различных
автомобилей. В файле данных записаны средние оценки по каждому из свойств
(рассматриваемых как переменные) для каждого из автомобилей (рассматриваемых
как наблюдения).
Классификация пиктографиков
337
При изучении «Лиц Чернова» (где каждое лицо представляет мнение об одном
из автомобилей) может оказаться, что улыбающиеся лица обычно имеют большие
уши, при этом если цене соответствует «величина» улыбки, а динамическим
качествам — размер ушей, это «открытие» означает, что быстрые машины дороги.
Разумеется, это очень простой пример, однако при анализе реальных данных
применение этого метода может сделать более очевидными сложные взаимосвязи между
переменными.
«Лица Чернова»
На данном типе диаграмм для каждого наблюдения рисуется отдельное «лицо».
Значениям выбранных переменных ставятся в соответствие форма и размеры
конкретных черт лица (например, длина носа, угол наклона бровей, ширина лица).
Iilll" ' 1111 НИ" I1 шшяяяшшяшшяша
Лица Чернова
Acura Audi BMW Buick Corvette Chrvsler Dodge
Ф ® § ® ® ® §
Eagle Ford Honda Isuzu Mazda Mercedes Mltsub i
®
Nissan
§
Olds
§
Pontiac
#
Porsche
Ф
Saab
§
Toyota
§
wv
Звезды
График с пиктограммами в виде звезд — это пиктографик кругового типа. На
таких графиках для каждого наблюдения рисуется отдельная пиктограмма в виде
звезды, при этом относительные значения выбранных переменных для каждого
наблюдения представляются длинами соответствующих лучей (порядок
следования которых зафиксирован: по часовой стрелке начиная от луча, направленного
вертикально вверх). Концы лучей соединяются линиями.
''■""""""Ill
; ^27
Acura
Dodge
Mercedes
Saao
Звезды
Audi
Eagle
2а
MltSUO
Toyota
BMW
л
Ford
Nissan
VW
Buick
Е7
Honda
Olds
VOrVO
A
Corvette
^7
isuzu
Pontiac
23
Chrysler
Mazda
A
Porscne
338
Глава 8. Пиктографики
Лучи
График с пиктограммами в виде лучей — это пиктографик кругового типа. На нем
для каждого наблюдения рисуется отдельная пиктограмма, напоминающая
солнце, при этом все лучи имеют одинаковую длину и каждый из них представляет
одну из выбранных переменных (порядок следования которых зафиксирован: по
часовой стрелке, начиная от луча, направленного вертикально вверх). Точки на
лучах, определяемые относительными значениями соответствующих переменных,
соединяются ломаной линией.
inn mm 11 иншаавд——
Лучи
Acura
i *
Dodge
] тк
Mercedes
*
Saab
Audi
•к
Eagle
-к
MltSUO
-b
Toyota
BMW
*
Ford
Ж
Nissan
-k
vw
Buick
*
Honda
^r
Olds
*
votvo
~k
Corvette
-k
isuzu
-h
Pontiac
Chrysler
~h
Mazaa
-k
Porsche
[ Многоугольники
График с пиктограммами в виде многоугольников — это пиктографик кругового
типа. Здесь для каждого наблюдения рисуется пиктограмма в виде
многоугольника. Относительные значения выбранных переменных для каждого наблюдения
представлены расстояниями, отсчитываемыми от центра диаграммы до
последовательно идущих вершин многоугольника (по часовой стрелке, начиная с
направления вертикально вверх).
■ Jolxll
Многоугольники
Corvette Chrysler
Oodge
Eagle
Toyota
Круговые диаграммы
Графики с пиктограммами в виде круговых диаграмм — это пиктографики
кругового типа (см. предыдущий раздел). Значения переменных для каждого
наблюдения изображаются в виде секторов (по часовой стрелке, начиная с направления
вертикально вверх). При этом относительные значения выбранных переменных
определяют углы раствора соответствующих секторов.
Классификация пиктографиков
339
i лит шишшши.шши
Ualsfl
Круговые диафаммы
Acura Audi BMW Buick Corvette Chrysler
# • • Ф Ф Ф
Isuzu
Ф
Nissan Olds
ф
Dodge Eagle Ford Honda Isuzu Mazda
Mercedes Mitsuo Nissan Olds Pontiac Porsche
Saao Toyota WV Volvo
м% Столбцы
График с пиктограммами в виде столбцов — это пиктографик последовательного
типа. Для каждого наблюдения рисуется отдельный график; относительные
значения выбранных переменных соответствуют высотам последовательных
столбцов.
iiir и и,' 11^,и1дди—^—нежа
Столбцы
I -8I1B allL ailla ll8eO.lL ilia
Acura Audi BMW Buick Corvette Chrysler
] ilia 1 L „ll .Ills ll EJll
Dodge
! illia
Eagle Ford
.lis ills
Honda isuzu Mazda ]
.IIS illJ ill
Mercedes Mrtsub Nissan Olds Pontiac Porsche ]
Nllln-IlL iIIsJIIb
Saab Toyota wv Volvo i
Линии
Графики с пиктограммами в виде линий являются пиктографиками
последовательного типа.
l-IDixij
Mercedes Mitsuo Nissan Olds Pontiac Porsche
Saab Toyota WV Volvo
340
Глава 8. Пиктографики
Для каждого наблюдения рисуется отдельная ломаная линия; при этом
относительные значения выбранных переменных для каждого наблюдения
соответствуют высотам последовательных точек излома.
*£* Профили
Графики с пиктограммами в виде профилей — это пиктографики
последовательного типа (см. предыдущий раздел). Для каждого наблюдения рисуется
отдельный график. Относительные значения выбранных переменных соответствуют
высотам последовательных пиков сечения, ограниченного снизу базовой линией.
I in in iii пни w \шшяшшшшашшшв\
Профили I
Acura Audi BMW Buick Corvette Cnrysier
9
Примеры визуального
анализа и настройки
графиков
в STATISTICA
Пример 1. Настройка двумерных
и трехмерных графиков
В данном примере описываются способы настройки графиков в системе
STATISTICA с использованием диалоговых окон Общая разметка и Размещение
графика.
Настройка двумерных графиков
В примере использован файл Poverty.sta из набора примеров, поставляемых с
системой STATISTICA, в котором содержатся сравнительные данные результатов
переписи 1960 году по 30 случайно выбранным округам США. В качестве
названий элементов введены названия округов. Ниже показана часть файла.
POVERTY STA8n» ЗОн
(Predictors of poverty
■^■^^^Н ■№ "-' '2. •:'':-::;^v
vk • -^ -*r ■■'..
•'•'••:-Л'::::-
ХШШ'Ф.
•■ 7-
HI3E3
*$•
•.".'••;*..
.*:£№*»
-1
Cannon
Carrot
Cnftttheeflt
Cumber**
DiK«to
Dytr
ОЫоп .
Or****
HiwKnft"
Htywowf
Htray .
-.8
9.6
40.0
8.4
3.5
3.0
7.1
13.0
10.7
-16.2
6.6
LLL
400
710
1610
500
640
920
1890
3040
2730
1850
2920
1070
19.0
26,2
18.1
15.4
29.0
21.6
21.9
18.9
21.1
23.8
40.5
21.6
1,09
1.01
,40
.93
.92
.59
.63
.49
.71
.93
.51
.80
82
66
80
. „ „ .
65
64
82
85
78
74
75.
100
70.
'. !1 °°
74
73.
52.
50.
71.
71.
64.
58.
33,5.
32.8
33.4:'
27,8
27,9
33,2^
30.8
32.4
29.2
28.7
25.1
35.9
360
193
3080
592
2
230
3978
9816
1137
992
10723 .J
3129^1
Предположим, что необходимо построить график, отражающий информацию
о количестве семей, живущих ниже уровня бедности (PtJPoor), о количестве
жителей, имеющих телефоны (Pt_Phone), и о количестве сельского населения
(Pt_Rural). Для начала построим несколько линейных графиков.
342 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
Построение нескольких линейных графиков
по умолчанию
В любом из модулей системы STATISTICA откройте файл Poverty.sta. Затем с
помощью кнопки Галерея графиков Q (или из основного меню Графика) выберите
пункт Статистические 2М графики — Линейные графики (для переменных).
ДО Стат. ЭМ посяодовате
f££ Стат. XYZ графики
I Стат. матричные графики
|ф£Стат. пиктографией
|Ц£ Стат. катетеризованные графики
графики |
lei*
£3 Пястые графические окна
IQD Гистограммы
1[^] Диаграммы ра
Qjj Диагр. рассеяния с гистограммами
01 Диагр. рассеяния с диагр. размаха
ЕыЗ Нормальные вероятностные графики
JL••';■ I Графики кваитияь-кваитияь
11 I Графики вероятность вероятность
|0?Э Диаграммы диапазонов
О Диаграммы размена
JQ Столбчатые
Уди
ШВШшШШ
itjff] Линейные графики (профили неб вид.)*
Посведоватеяы
££ Кряговые диаграммы
|Г**1 Диагр. пропящ. знач. i
:&{$#&&
Появится диалоговое окно 2М линейные графики.
Затем нажмите кнопку Переменные и выберите три переменные для
построения зависимостей PtJPoor, Pt_Phone и Pt_Rural (чтобы выбирать переменные в
произвольном порядке, при нажатии на имя переменной удерживайте нажатой
клавишу CTRL).
В поле Тип графика приведен список доступных для построения линейных
графиков. По умолчанию выбирается первая строка списка (простой линейный
график одной переменной). Если в данный момент нажать ОК, то для каждой из
переменных будет построен один график, то есть три отдельных графика
последовательно, один за другим после нажатия кнопки Еще в графическом окне.
Пример 1. Настройка двухмерных и трехмерных графиков
343
«fiilHljipjpiuf
Так как цель данного примера — воспроизвести все три зависимости на одном
графике, в диалоговом окне 2Млинейные графики необходимо выбрать строку
Составной. Тогда диалоговое окно 2Млинейные графики будет выглядеть следующим
образом:
HJ.I'IMIflllW
ЕШ
fi*
¥§^й^Чъ '^—l
Для вывода установленного по умолчанию графика нажмите (Ж
itiiwrnan;
110
90
70
50
30
10
-10
1-lolxi
Линайный график (POVERTY 8TA 8V30C)
I ' ' t ' ' I 1 ■
.PHONE 1
• •■ PT_RURAL I
344 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
Удаление кнопок Еще и Выход
Если продолжить работу с данным конкретным графиком, может возникнуть
необходимость убрать кнопки Еще и Вых. из левого верхнего угла графического окна.
Для этого нужно нажать на кнопку Вых. (после нажатия кнопки Еще вновь
появится диалоговое окно 2Млинейные графики).
Изменение размеров (пропорций) графического окна
Показанный выше график имеет размеры, установленные по умолчанию. При
изменении размеров графического окна оно по умолчанию сохраняет свои
пропорции, то есть вертикальные и горизонтальные размеры меняются одновременно. Этот
режим (установленный по умолчанию) действует до тех пор, пока нажата кнопка
|Ш Фиксировать пропорции. Если нажать кнопку Изменить пропорции |Ц то так
называемый коэффициент разрешения может быть изменен — например,
графическое окно можно сделать квадратным:
HESHEEZaSZ
Линейный график (POVERTY STA 8V30c)
110 <■■■■■■■■■■■■■
M - r О i « »» n ' i i e «
V*-\ j ♦•'to -6^.- ■/*** • •,...©•*
fl DO " ♦ О ° fl
PT_P00R
PT.PHONE
PT RURAL
Отметим, что установки по умолчанию для пропорций графического окна
могут быть изменены в диалоговом окне Отображение графика (оно вызывается из
выпадающего меню Вид).
Прерывание построения графика
Программа автоматически перерисовывает график, чтобы отобразить на нем
изменения, внесенные вами. Для сложных графиков с несколькими зависимостями
процесс перерисовывания занимает определенное время.
Рисование графика можно прервать, щелкнув левой клавишей мыши где-либо
на экране. Программа закончит рисование текущего элемента, затем песочные часы
исчезнут и полный контроль над настройкой всех параметров будет возвращен
пользователю. Как правило, в этом случае график оказывается незаконченным.
Завершить процесс перерисовывания можно, слегка изменив размеры
графического окна или сделав любые другие изменения, требующие перерисовывания
графика.
Пример 1. Настройка двухмерных и трехмерных графиков
345
Просмотр данных
Нажмите кнопку Qj на панели инструментов, чтобы вызвать Редактор данных
графика. Это можно сделать и другими способами, например:
1) выбрав команду Редактировать данные из выпадающего меню Разметки или
2) щелкнув правой кнопкой мыши где-либо на фоновой поверхности графика,
на каком-либо условном обозначении или на одной из линий, а затем
выбрав строку контекстного меню Редактировать данные графика.
Напомним, что на двумерных графиках каждая зависимость (в данном случае
линия) представлена парой столбцов X и У. Каждая пара Х-У соответствует точке
на графике. В этом редакторе можно изменять данные, удалять точки, добавлять
строки или новые зависимости; все сделанные изменения будут отражены на
графике после того, как будет нажата кнопка Перерисовать или кнопка Выйти+пере-
рисовать на панели инструментов. Кроме того, в меню имеется много
возможностей для изменения представления чисел в Редакторе данных графика. К примеру,
346 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
нажмите кнопку Ширина столбца [
ширины.
), чтобы вызвать диалоговое окно Настройка
Введите число 3 в поле Десятичные разряды и нажмите ОК.
n»*i*b* гр#»** (POVERTY STA 8v30c)
Щ?5Щ^
M^L
C*vw
СтЫ
CHmumi*
Owbwiend
0«*
to* **
Siwon
йтю
H»*k* .
Нщыьой
2.000 1
3,000
4,000
5,000
6,000
7,000
6,000
9,000
10,000
11.000
12.000 ]
hLL...
iiiiL
.J9.000
26,200
18.100
15,400
29,000
21.600
21,900
18.900
21,100
23,800
40.500
21,600
Ш
■' W_PH0«-
. tK.^>>
1,000
2,000
3,000
4,000
5,000
6,000
7,000
8.000
9,000
10,000
11.000
12,000
„Л,^,
82,000
66,000
90,000
74,000
65,000
64,000
82.000
85.000
78,000
74.000
69,000
85,000
Jfc
rum*
.tbiMkfifoi
1.000
2.000
3.000
4,000
5.000
6.000
7.000
8.000
9.000
10,000
11.000
12.000
■%.
74,800
ioo.ooo
69.700
100,000
74,000
73.100
52.300
49.600
71,200
70,600
64,200
58,300
Теперь все данные в редактируемой таблице имеют три десятичных знака.
Можно изменить также шрифт и размер шрифта (используйте меню Сервис — Экран).
Для продолжения работы с графиком щелкните в любом месте графического
окна, чтобы вынести его на передний план (сделать активным), или закройте
Редактор данных графика.
Основные соглашения по настройке графиков
Средства настройки графиков доступны из выпадающих меню Правка и
Разметки, а также с клавиатуры (кроме того, они могут быть записаны в виде
макрокоманд и/или поставлены в соответствие кнопкам на панели инструментов Кнопки
автозадач). Кроме того, есть способы быстрого изменения элементов графика, не
требующие выполнения большого количества действий (нажатия кнопок мыши,
выбора меню и т. д.). Существуют два основных правила редактирования
графиков.
О Для выбора конкретного способа настройки объекта (или элемента
графика) щелкните правой кнопкой мыши на этом объекте и выберите тип
настройки из контекстного меню.
О Чтобы получить доступ к наиболее общим (установленным по умолчанию)
способам настройки объекта (или элемента графика), дважды щелкните по
объекту.
Например, чтобы изменить тип линии, дважды щелкните на соответствующей
линии; для изменения заголовка дважды щелкните по заголовку; чтобы изменить
Пример 1. Настройка двухмерных и трехмерных графиков
347
масштаб, дважды щелкните по оси; чтобы изменить линии направляющей сетки,
сделайте двойной щелчок по линиям, и т. п.
Изменение заголовков
Для редактирования заголовка сделайте двойной щелчок мышью в его зоне.
шшшшшшшшшшшшшшшшшшшшшшшшшшжшщ
Как видно из диалогового окна Правка заголовков, всего можно ввести 11
заголовков: 5 верхних и по 2 для каждой из остальных осей. Каждый заголовок может
иметь собственный шрифт и размер, а также, как показано в последующих
примерах, может включать символы форматирования для записи индексов, степеней,
условных обозначений, уравнений аппроксимирующих функций и т. д. Эти
символы легко вставляются со встроенной панели инструментов Формат.
Возможен и другой способ: сделав двойной щелчок на фоновой поверхности
окна, можно вызвать диалоговое окно Общая разметка 2М графиков, в котором
тоже есть режим редактирования заголовков.
После ввода заголовка нажмите ОК, чтобы перерисовать график. Например,
для следующего графического окна были введены две строки заголовков.
348 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
ыглцнии'иц
Линейный график трех демографических показателей
для 30 выбранных округов
110
90
70
50
30
d
■ Дх1
-о- PT.POOR
•■о- РТ PHONE
о РТ RURAL
Диалоговое окно Размещение 2М графика
Как видно из графика, процентные данные, отражающие долю «бедных»
потребителей, расположены в основном ниже значений для переменных Pt_Phone и
Pt_Rural Для каждой из зависимостей масштаб может быть подобран отдельно и
указан на левой или правой оси У. Можно добиться «лучшего представления»
переменной Pt^Poor, если установить для нее отдельный масштаб вдоль правой оси
У, включив при этом автоматический режим оптимального масштабирования.
Основные параметры отдельных зависимостей (в данном случае линейных
графиков) задаются в диалоговом окне Размещение графика, причем для каждой из
них открывается отдельное окно. Чтобы вызвать его для переменной PtJPoor,
щелкните правой кнопкой мыши где-либо несоответствующей линии (или на
условном обозначении этой зависимости).
слов
j Линейный график трех демографических показателей
| дпя 30 выбранных округов
| 110 | ......... . Р-, ,■,.,,.,,,,,;,
90
70
' 50
j
\ 30
i
\
\ 10
\ -10
i
* *
в Ъ-о
с
о <
Затем выберите строку контекстного меню Изменить размещение зависимое-
гпи(ей).
Пример 1. Настройка двухмерных и трехмерных графиков
349
дошр, дел. обозначения -
\ |PT_POOR
ITTxl!
1..,_..,„. г
£ft ■****
уЁ£ Ступенчатый график
|Ц|1 Мииимакс диагр. по X
]■£ Мииимакс. диагр. по Y
ill»* Стодбч диагр. поХ
]|а* Стодбч. дмагр. по два оси Y.
IJ3 Стодбч. диагр. по пр. оси Y
|РТ Стодбч. диагр сееркч
JV* Стодбч. диагр. отклонения ■
•ид диаграммы
:«СТ«Л*ЩЫ ,
;Н-:Я1М11;;^.'- "
: Г ПрДМОГОДЫДЖЫ
|отрв»ки |; ; аШпс
- - -<■• - *t# - * *
доверительный интервал
<* Вмжд.
Построение графика, масштабированного
вдоль правой оси Y
Практически в центре появившегося диалогового окна находится поле,
обозначенное как Ось Y. Состояние переключателей этого поля определяет, относительно
какой из осей Убудет построен график. Пометьте поле Справа, чтобы график
переменной Pt__Poor масштабировался вдоль правой оси Y.
Изменение фиксированных условных обозначений
В левом верхнем углу диалогового окна находится поле Фиксир. усл. обозначения.
Тест в этом поле определяет обозначение данной зависимости на графике. Далее
в этом примере это условное обозначение будет преобразовано в
пользовательский текст, который может быть помещен в любую область графического окна.
Пока же заменим имеющееся обозначение более информативным (например,
Процент), а затем во второй строке условного обозначения запишем бедные семьи G7).
(П) добавлено, чтобы показать, что этот график относится к правой оси Y. Это
добавление будет сделано автоматически, если в момент создания графика
установить параметр С двойн. осью Y.
ГгТх1|
£ИШМ» УСЛ. ОБОЗНАЧЕНИЯ ™ ШАБЛОНЫ
ПОДГОНКА
! Процент
|П)
А»
1 th.'
1т
т
Тоэдм
'• Дчиим
Обдаете
1
il
Tt*ig>i»H»at
ЬУ, Диаграмма рассеяния
1,,-Ml J.H.UJMI —
Й"* Ступенчатый гравии
[fit Мииммакс. диагр. по X
Мииммакс. диагр. по Y
III! Стодбч. диагр. по X
fcj» Стодбч. диагр. по два. оси Y_J
J3 Стодбч. диагр. по пр. оси Y
f^f Стодбч. диагр. сверх*
•в** Стодбч. диагр. отклонения «| ■
■■1Г:.йг9*9т. ;. \<i$:
< С. ПрД1 мегояы—ш
ВИД ДИАГРАММЫ
Штреэки
Л_
' Тишид^ттштолшЛ f
Отмене
■абдви
Л:.***
И,
ОСЬУ
П|>»и<дудад<< |
Сдадаатая »
*fl Метки <
аядаюс
С*р«
ДОВЕРИТЕЛЬНЫЙ ИНТЕРВАЛ
Г'кА
'I
350 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
Для того чтобы изменить обозначения других зависимостей, для каждой из них
также необходимо вызвать диалоговое окно Размещение 2М графика. Например, чтобы
вызвать диалоговое окно Размещение 2М графика для второй переменной (Pt_Phone),
нажмите на кнопку Следуюгцая » (в правом верхнем углу диалогового окна). Теперь
введите другое Фиксир. усл. обозначение и сделайте то же самое для следующей
зависимости. Закончив изменения, нажмите ОКи вернитесь к графическому окну.
шшливЕшггшшшшшшшшшшшшшшшшшшшшшшз.
Процент
бедных семей (П)
Процент
семей с телефоном
Процент
сельских семей
Изменение обозначений осей
Как и было задумано, на графике произошло два изменения. Во-первых, длинные
условные обозначения стали более информативными и, во-вторых, график
«процента бедных семей» стал более растянутым вдоль оси Y. Поскольку эта
зависимость построена теперь вдоль правой оси У, то на этой оси должны быть и
соответствующие обозначения. Если сделать двойной щелчок на правой оси У, то появится
диалоговое окно Параметры оси: Y правая.
Линейный график трех демографических показателей
для 30 выбранных округов
Пример 1. Настройка двухмерных и трехмерных графиков 351
Для каждой из осей можно вызвать подобное диалоговое окно (чтобы перейти
к следующей или предыдущей оси, используйте поле Ось в верхней части этого
окна).
Чтобы включить поле Значения на оси для правой оси У, надо нажать
переключатель Числовые. Обратите внимание, что значение параметра Мин., которое
выбирается автоматически {Разметка оси: Авто), равно 10. Таким образом,
координата У пересечения с осью X соответствует не 0, а 10 процентам.
Очень часто необходимо показать, что позиция, интуитивно принимаемая за
ноль, вовсе не соответствует нулевой отметке на графике. Это можно сделать,
введя «разрыв шкалы» на данной оси. Разрыв шкалы по оси X на графике будет
выглядеть следующим образом:
L„ I I I I |_
500 600 700
Чтобы ввести разрыв шкалы для правой оси У, поставьте галочку в
соответствующем поле (в нижнем левом углу диалогового окна), при этом
установленное по умолчанию положение места разрыва шкалы оставьте неизменным.
Теперь установите режим разметки оси Ручная/0, а значения параметров Макс, Шаг
и Мин. сделайте равными соответственно 45, 5 и 11 (ввод значения 11 для
параметра Мин. приведет к тому, что минимальное значение не будет показано,
потому что оно находится за местом разрыва). Нажмите ОК, чтобы увидеть
изменения на графике.
Теперь введенный на графике разрыв шкалы «предупреждает» наблюдателя о
том, что начальная точка правой оси Уне соответствует нулю процентов.
Масштабирование осей
Выбор масштаба по левой оси У тоже не является оптимальным, в данном
конкретном случае минимум шкалы соответствует значению -10. Так как на графике
представлены значения в процентах, то ноль был бы более подходящим значением
352 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
для минимума. Сделав двойной щелчок на левой оси У, вызовем диалоговое окно
Параметры оси: Yлевая.
Предусмотрено несколько режимов разметки оси: Авто, Авто/0, Ручная и
Ручная/О. Если выбрана разметка Лето, то программа сама выбирает минимальный и
максимальный отчеты на шкале так, чтобы все точки на графике были видны. Если
выбрать режим Ручная, то параметры Макс, Шаг и Мин. будут определяться
пользователем.
Режим масштабирования с привязкой к нулю (/0)
Режим разметки /0 определяет, где расположена «привязка» относительной
шкалы. Объясним это на коротком примере.
Предположим, вручную установлены следующие параметры шкалы:
минимум — 3, шаг — 5 и максимум — 25. Если для этой оси применить ручную
разметку, то метки и риски будут расположены соответственно в точках 3, 3+5=5,
3+5+5= 13,18 и 23. Как правило, желательно иметь «четкую привязку» меток
шкалы к нулю. Если включить режим Ручная/О, то метки и риски на оси окажутся на
позициях 0+5=5, 0+5+5= 10,15,20,25 и т. д. Заметим, что режимы Ручная с
параметром Мин., равным 0, и Ручная/0 {Manual/0) эквивалентны.
Для рассматриваемого в примере графика наиболее подходящий разметкой (так
как все значения представлены в процентах) будет следующая: Ручная/0 со
значением параметра Мин., равным 0, с параметром Шаг, равным 10, и параметром Макс,
равным 109. Установите эти значения и нажмите ОК, чтобы увидеть изменения на
графике.
Пример 1. Настройка двухмерных и трехмерных графиков
353
ШЕПЕЯЖПЕ
Линейный график трех демографических показателей
для 30 выбранных округов
с с ртэио jr, с а» его >с </> с с а> >
fopScTRftLoccofco^ooub
о
2
Процент
бедных семей (П)
Процент
семей с телефоном
Процент
сельских семей
Перемещение условных обозначений
Введенные нами условные обозначения оставляют на графике много свободного
места. В системе STATISTIC А условные обозначения могут быть как
фиксированными (закрепленными, как в настоящий момент на данном графике), так и
преобразованными в пользовательский текст, который можно перемещать,
редактировать, как и другие графические объекты. Щелкните правой кнопкой мыши на
условных обозначениях и выберите пункт Переместить условные обозначения из
контекстного меню.
шмшшшшшшшшшшшшшш
Линейный график трех демографических показателей
для 30 выбранных округов
■ JQlxl
2£
О^а+ст^у^ь» обр»!»>«■« |
семем е телефоном
Процент
сельских семей
354 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
тшшшвшшшишшш^ш^шшшшшшшшщ
Линейный график трех демографических показателей
для 30 выбранных округов
Теперь условные обозначения преобразованы в пользовательский текст, а
место, где они ранее располагались, занято графиком. Чтобы вернуться в
фиксированный режим, щелкните правой кнопкой мыши где-либо на фоновой
поверхности окна и в контекстном меню выберите Фиксированные условные обозначения
(например, можно поместить в свободном месте над условными обозначениями
какой-нибудь поясняющий текст).
Условные обозначения в заголовках
Для удаления какого-либо пользовательского объекта, такого, например, как текст,
выделите его (щелкнув по нему кнопкой мыши) и нажмите клавишу Del (или
выберите команду Вырезать объект из меню, вызываемую правой кнопкой мыши).
Теперь откройте диалоговое окно Общая разметка 2М графиков. Для этого
сделайте двойной щелчак где-либо на фоновой поверхности графика (или выберите
пункт Общая разметка из контекстного меню после щелчка правой кнопкой мыши
на фоновой поверхности графического окна).
Удачным местом для условных обозначений была бы нижняя область
графического окна Нажмите на стрелку в поле Заголовки и выберите строку Нижняя осьХ2.
Пример 1. Настройка двухмерных и трехмерных графиков
355
Управляющие символы
Специальное форматирование текста на графиках системы STATISTIC А
осуществляется с помощью последовательности управляющих символов, которая всегда
начинается символом @. Эти управляющие символы позволяют включать индексы,
степени, подчеркивание и т. п. в любой заголовок или пользовательский текст. Для
включения в текст условного обозначения используется следующая
последовательность управляющих символов: @L[номер зависимости]. Например, если написать в
поле заголовка @L[1], то в самом заголовке на графике будет показано условное
обозначение первой из зависимостей. Теперь в поле заголовка Нижняя ось Х2
введите следующую строку: @L[1]-% Poor (П) @L[2]-% Phone @L[3]-% Rural.
ншпвЕягша
ШтЩ
-—-"■'■"" ■"""' Ъш грлиржж
11|Ч||!||Нф':^~
уголовки
\.^. Диаграмма рассеяния
fc£J Ступенчатый график «J рк
Декартовы Hj .^»*г<3>*а?ири*} [71 Я»*
flK
tl
1 Нижняя ось X 2: @L|1 ] X Pool .
~jjj ^» ир*^т
*9> М«тш деичьпс
|@Ц1] X Роем (П) <*Ц2)Х Phone @ЦЗ] X Rmal
оси
ГП
Рам**
M**fetf31 g Р<ан«Г1и1оас1Ру«иая jjj> Струве
[ЛП] Границы контроля ]
I Y еяеве „^ (^ jg Ти№ | Пмнейная
]Y справа
- Сверх, М|*: 1°
3
П% Параметры оси
Внутри;
э
Нажмите (Ж, чтобы увидеть изменения на графике.
;1т1МШ'1Н-
да
Линейный график трех демографических показателей
для 30 выбранных округов
СС75С-0-а)г; С I) l^-D >С W С С HI >С= >>С )г. > С О) q О) >
и<3
?^5|
-% бедных (П) о-- -%стелефоном -■•»■•■ -% сельских
Отметим, что тот же результат можно получить, не удаляя обычный текст
условного обозначения, а переформатировав его (например, в одну строку текста)
и поместив в нижнюю часть графика (предварительно увеличив нижний отступ,
356 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
чтобы для дополнительного текста было достаточно места, как это сделано в
последующих примерах).
Представление графиков различных типов
Попробуем представить данные о проценте «бедных» потребителей не в виде
линейного графика, а в виде гистограммы. Тип всех зависимостей на графике может
быть одновременно изменен в диалоговом окне Общая разметка 2М графиков.
Изменить тип одной зависимости можно в ее диалоговом окне Размещение графика.
Вызовите диалоговое окно Размещение графика для первой зависимости
(% Poor), щелкнув на ее условном обозначении (или на самой линии) правой
кнопкой мыши и выбрав пункт Изменить размещение зависимости (ей).
Теперь щелкните на значке Столбч. диагр. по X в поле Тип графика, а затем
нажмите ОК, чтобы увидеть изменения на графике.
ишз
;ДОКСИР» ОСЛ. ОБОЗНАЧЕНИЯ
j Процент
\[& Диаграмма рассеяимя j4
У££ Ступенчатый график
1Ш Мииимекс. диагр. по X
Hfr Мииимакс. диагр. no Y
{ц| Столбч. диагр. по X
У»:ч Столбч. диагр. по пев. оси Y__
JJJjJ Столбч. диагр. по пр. оси Y
гП* Столбч. диагр. сверх)
■р* Столбч. диагр. отклонений <г
ШАБЛОНЫ
Области
ВИД ДИАГРАММЫ
(• Столбцы
С Линии ,
С Отрезки
Ц0ДГ0Н1СА
Нет
1
Пользовательская
Отмене
Шаблон
Общая разметка
Параметры
Предыдущая «
•0£bY
•<* Слева
Сяедшдщея» )
^ Кру- диаграмма
О Прлмоуольникн ;; С Справа j »., Ы!„яылтшш
| Отрезки 2$ ЭЛЛИПС г :- •"-"""--
<• Выкл. С Доверительный С Размах
Ширина:
ргг—
^ Шаблон
Козооццнент: 10 95
Щ ДОйЕРИТЕЛЬНЫЙ ИНТЕРВАЛ
• " , :.-.x<^.Bwk«..-v
5^ Шаблон I ■';.;:.;-
.C>iwt
ЩшШ"
100
90
80
70
60
50
40
30
20
10
0
Линейный график трех демографических показателей
для 30 выбранных округов
<> *
ч; • Р. •
5Ю.-о-° 5 P"-q
45
40
35
30
25
J20
15
Е
S3
>бедных(П)
j с телефоном о- - % сельских
Пример 1. Настройка двухмерных и трехмерных графиков
357
Как видно, ширина столбцов на этом графике оказалась не очень удачной. Так
как этот параметр (ширина столбца) является характеристикой только одной из
зависимостей (Зависимость У), то именно для нее нужно опять вызвать
диалоговое окно Размещение графика.
В диалоговом окне Общая разметка 2М графиков величина шага по оси X
установлена равной 1 (это окно можно вызвать, дважды щелкнув мышью на оси X).
Следовательно, если установить ширину столбцов гистограммы равной 0,8, то они
будут занимать 80% ширины интервалов по оси Ху но при этом еще будут
разделены промежутками. Установите параметр Ширина в поле Вид диаграммы
равным 0У8 и нажмите ОК, чтобы увидеть результаты изменений.
ПШПШШШЕИ^^ШШ^^^ШШШШШШШШ*}\
Линейный график трех демографических показателей
§И - % бедных (П) ••°" - % с телефоном •■•*•■ - % сельских
Изменение стиля обозначений
Представление гистограммы по данным о проценте «бедных» потребителей все же
не очень удачно, поскольку она закрывает два других линейных графика.
По-видимому, можно решить эту проблему, сделав гистограмму прозрачной.
Чтобы изменить стиль любой линии, точки или самого графического окна,
дважды щелкните на нужном элементе, в данном случае — на любом из столбцов
гистограммы.
Сначала нажмите на поле Шаблон и в открывшемся списке стилей выберите
«пустой» (второй сверху).
358 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
*P*i^*№lWn *ii&? 'А8&
Обратите внимание, что теперь стали доступны два режима: Непрозрачный и
Прозрачный. Если включить режим Прозрачный, то «сквозь» гистограмму будут
видны даже линии направляющей сетки. В данном случае достаточно включить
режим Непрозрачный. Теперь нажмите ОК, и график будет изменен.
вГ"|1р<К>м*4 Пикейный гра+м*
Линейный график трех демографических показателей
для 30 выбранных округов
100
90
80
70
60
50
40
30
20
10
0
Ч/о V <>.'..
О o.rf
а
S6IS**fcS
Я о
is
OJ 1Л ТЭ £■> С
Я • Yd 'Л
/ о \, *•' • - to- • •
rj О О
П
ш
л i
о £ t и ^ * 2 5 £ ел ,л э^Э
S-3
^1^:
I 1 - % бедных (П) -°-- - % с телефоном
^;
- % сельских
Настройку шаблонов линий, точек, заголовков, обозначений осей и других
элементов графика можно продолжить (для этого нужно дважды щелкнуть мышью
на соответствующем элементе).
Сохранение графика
Для сохранения итогового графика воспользуйтесь кнопкой Сохранить файл Щ
на панели инструментов или выберите пункт Сохранить из основного меню Файл.
Графические файлы системы STATISTICA (с расширением *.stg) используют свой
графический формат, который сохраняет все сделанные настройки. Поэтому
после открытия графического файла его настройку можно продолжить с того самого
места, где она была прекращена. График может быть записан и в других форматах,
таких как Метафайл или Растровое изображение^
В формате Растрового изображения график представляется в виде
последовательности точек, поэтому редактировать его заголовки или условные обозначения
будет уже невозможно.
Пример 1. Настройка двухмерных и трехмерных графиков
359
Формат метафайл Windows сохраняет некоторую «структурную» информацию
о графике (текст, обозначения и др.), и его можно редактировать в некоторых
других приложениях.
Печать графика (предварительный просмотр
печатной страницы)
В любой момент график может быть напечатан с помощью команды Печать
графика из меню Файл, при этом появляется диалоговое окно Печать графика.
DBBBB
Принтер: Текущий принтер (HP latmJtt 6t
(реи' ustftvERSHP u а
|LPT1:JJ
fl*
Zl
J ь*т'
Г Падет» • фа*4
Примечание Дли печати иогроврачнмс обьфкпт для i ия сгори
драйверов принтер» иаобюаимо ждем* рмн» Я«нвГ¥ШрмФТОб
Т а»Турв в графическом режима*.
на
Можно распечатать график, минуя этот этап, с помощью кнопки Печать
панели инструментов.
Чтобы посмотреть, как график будет располагаться на странице, и установить
нужные поля, можно включить режим Предварительный просмотр из основного
меню Файл. При этом появится диалоговое окно Предварительный просмотр.
Чтобы увидеть размеры полей, нажмите на кнопку Поля.
Дчип» 11 Поав } Закрыт* j Лк#вв«р| ? I
■да«л
Ш1Р
№|рН||Ч|1!1Ш«|»«)«И
Поля можно установить, переместив соответствующую линию в нужное
положение. Обратите внимание, что выбор Альбомной ориентации в меню Принтер
приведет к автоматическому изменению диалогового окна Предварительный просмотр.
360 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
Линейной 'сэфи« 'ре« демографически» показа'еяеи
ДЛЯ 30 вЬ<вр«нмЫ1« 0«Ру!Хв
шЬ
ПЗ - % Оедиьи (П) о - ч с телефоном о -Ч сельских
*
Размеры этого окна можно изменять, используя в том числе и полноэкранный
режим просмотра.
Просмотр графика в том виде, как он будет напечатан
(режим WYSIWYG)
При настройке сложных графиков желательно, чтобы пропорции графического
окна на экране в точности соответствовали тем, которые сформируются при его
печати. Такой режим получил название WYSIWYG (What You See Is What You Get).
Из меню Вид выберите пункт Пропорции страницы при печати, чтобы сделать
пропорции графика соответствующими печатной странице. Например, если в
диалоговом окне Принтер предварительно выбрана Книжная ориентация, то на
экране появится соответствующее изображение графика.
Линфйный график трех демографически» понэаилай
для 301ыбранных сирутси
45
] • % бедных (П) • о • . % с телефоном ♦ - % сельских
Пример 1. Настройка двухмерных и трехмерных графиков
361
Теперь все введенные ранее параметры графика показаны на экране именно
так, как они будут напечатаны.
Настройка трехмерных графиков
В этом примере, как и для двумерных графиков, будет использован файл Poverty.sta.
Создание и настройка трехмерного графика рассеяния проводится с помощью
диалоговых окон Общая разметка ЗМ графиков и Размещение графика.
Создание графика по умолчанию
Из Галереи графиков или меню Графика выберите пункт
СтатистическиеXYZграфики — Диаграммы рассеяния. Появится диалоговое окно ЗМ диаграммы
рассеяния.
4$$ Пространственный график
Спектральная диаграмма
JjJJ' Диаграмма отклонении
Нажмите на кнопку Переменные и выберите в качестве X переменную Pt_Poot%
в качестве У — Pt_Rural} а в качестве Z — Age (средний возраст в соответствующем
округе). Затем нажмите на кнопку Параметры. Появится диалоговое окно
Статистические графики: параметры. Для того чтобы на графике были показаны
названия округов, задайте режим Имена наблюдений в поле Метки наблюдений.
наблюдения
я*
ОПТИМИЗАЦИЯ
; (• Вымечена
ОТОБРАЗИТЬ:
Метки наблюдений • • •
I (• Нет Г Имена наблюдении С Ларем.: |РОР_СН*
Р? lexer май деты на ост
ftf Уравнение алпроксимируощеи функции
Р А/трокс. Функция в вмяв пользовательского текста
: Г Длинные «слоеные ооознеченмя подгрупп
Г Заголовок задания: |
Г Заголовок графика: I *___«____________
Нисдо десятичных знаков в «алией категория: [3 W
Другие параметры настроили
Р? Всо"|Гат^лто|в7л| наиааягся в диелоговь» окнах Х^шая
•■••■•~*?ятегя разметка'и Раэмеше>*« графике'.
6*
которые вызываются из графического
окна
Отмена ]
ОРИЕНТАЦИЯ ОСЕЙ X-Y
<е* Стандартная .; С Обратная
СИСТЕМА КООРДИНАТ 2М ГРАФИКА:
: (• Декартова С Поеярнал С Со сжатием
ПОДИНОМИАЛЬНАЯ ПОДГОНКА
. Порядок полинома: Г 2 С 3 Г 4 (• 5
: ЛОГАРИФМИЧЕСКАЯ ПОДГОНКА
Основание: (• 10 Г в
Р? {{оказать кнопки не последнем графике
Показать индикатор состояния: | Авто 7|
Добавить к меню как график пользователя
Затем нажмите ОК, чтобы вернуться к диалоговому окну ЗМ диаграммы
рассеяния.
362 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
!&SW*»«fe
ф Пространственный гра+нк
ДО Спектральная диаграмме •****.
£$ Диаграмма отклонения
4№КЛвйЛ*<Нв'
I
Снова нажмите ОК, чтобы построить трехмерную диаграмму рассеяния.
Нажмите Вых. для удаления кнопок Еще и Вых.
шшакашггввв
ЗМ диаграмма рассеяния (POVERTY STA 8V30c)
Чтобы избежать наложения меток (как это произошло на данном графике),
можно использовать режим Фильтры изображения.
Просмотр данных графика
Как и в предыдущих примерах, для начала посмотрим данные графика. Для этого
надо вызвать Редактор данных графика. Например, щелкните правой кнопкой
мыши на какой-либо из точек и выберите Редактировать данные для зависимости (ей)
или нажмите кнопку Редактор данных графика (Щ на панели инструментов. В
Редакторе данных графика показаны три столбца (X, Y и Z) для каждой зависимости.
ШИРДЛИ1№|Т||*!и
Cannon
Cwl
ChaathaajR
Cunte!**
D*4fc
От
G**rt
Qs—r+ '
*****
Hayy»OOd
Ноту
Houtton
LJ
ЗМ диаграмме рассеями«
19.00
26.20
18.10
15.40
29.00
21.60
21.90
18.90
21.10
23.80
40.50
21 60
25.40
(POVERTY'
i*p#«*p«»*»«*r
::. У
74.80
100.00
69 70
100 00
74.00
7310
52.30
49.60
71.20
70 60
64 20
58 30
100 00
2
33 50
32.80
33 40
27 80
27 90
33 20
30 80
32 40
23.20
28.70
25Ю
35 30
31 40
Ж
■**
Пример 1. Настройка двухмерных и трехмерных графиков
363
В данном случае это одна зависимость. При выборе более чем одной
переменной Z в диалоговом окне ЗМ диаграммы рассеяния в Редакторе данных графика
будет несколько зависимостей из трех колонок.
Как обычно, на этом этапе данные можно изменять, добавлять новые
зависимости, изменять представление данных в редакторе и шрифты.
Редактирование меток наблюдений
Предположим, что особый интерес представляют округа Jackson и Shelby. В
данный момент на графике трудно что-либо разобрать, поскольку многие названия
перекрываются. Поэтому нужно удалить все не представляющие интереса метки,
чтобы «упорядочить» график.
Для редактирования меток точек:
1) дважды щелкните на одной из них или
2) щелкните на любой из них правой кнопкой мыши, выберите пункт
Изменишь размещение зависимости (ей), в появившемся диалоговом окне
Размещение графика выберите пункт Метки данных.
В любом из этих случаев появится диалоговое окно Метки точек данных.
! г * ■ • ■
fl* t
Отмой»
&%*i№
Для обозначения точек на графике помимо Текстовых меток можно
использовать и значения координате, Yили Zили любую их комбинацию. Чтобы вызвать
диалоговое окно Правка текстовых меток, нажмите кнопку Правка.
1
2
3
4
5
6
\7
8
9
10
11
12
13
Н
i^enton
Cannon
Carrol
Cheatheam
Cumberland
OeKalb
Dyer
Gibson
Greene
Hawkins
Haywood
Henry
Houston
Humphreys
4
Д;
%
'*i
j
.:.!
Удалите все метки, Kpouejackson и Shelby.
364 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
III" ИНЬГ " IUI
14
15
16
17
18
19
20
21
22
23
24
25
26
27
Jackson
Shelby
1
±1
J
zl
там
rJjdi2J
Нажмите ОК, снова появится диалоговое окно Метки точек данных. Чтобы
увеличить размер шрифта (например, выбрать Arial полужирный 12), нажмите
кнопку Шрифт.
РЯД
АаВЬБбЯя
Ярмфг TftMT*». Ои испой»»»пся turn imh»i
как я«»кр«и. гж и и* принтер.
Нажмите ОК, чтобы увидеть изменения на графике.
ЗМ диаграмма рассеяния (POVERTY STA 8V30c)
Jackson
Теперь здесь хорошо видны две конкретные точки.
Пример 1. Настройка двухмерных и трехмерных графиков
365
Редактирование заголовков
Как и в предыдущих примерах, для редактирования заголовка дважды щелкните
на нем мышью. Появится диалоговое окно Правка заголовков.
Правка заголовков
'>. 4*ГвйЬвО*2^ ||ЗМ диаграмма рассеяния (POVERTY ST A 8v0c) Aft|
•1ШШГ^
3*^i'<-w ^r
;>:0а»22:" j
Ниже показаны несколько возможных заголовков.
Г*|ГраФик1 JM диаграмма рассеяния
HREI
Демографические данные по 30 выбранным округам
Диаграмма рассеяния возраст и процент бедных и сельских семей
Изменение масштаба
Как и в предыдущих примерах, по двум горизонтальным осям выбран не очень
удобный масштаб. Поскольку переменная Pt_Rural выражена в процентах, то
более подходящим здесь был бы интервал от 0 до 100 (а не от 10 до НО). Дважды
щелкните на этой оси, чтобы вызвать диалоговое окно Параметры оси: Y.
366 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
1«в|и -
%
Вставить
"И'; Псмюдоми*
3
точки («мш*]
Мине: |
•*C f
Г" Обратная ммим
"Si
"Hi
В поле Разметка оси выберите режим Ручная с параметрами Мин. = 0, Шаг = 20
и Л/якс. - 100.
Вращение трехмерного графика
Все трехмерные графики в системе STATISTICA могут быть повернуты в
пространстве вокруг любой из трех осей. Также может быть изменена перспектива.
Выберите команду Вращать из меню Вид. Появится диалоговое окно Перспектива и
вращение. Другим способом это окно можно вызвать, нажав кнопку Вращение
графика (ЛУ на панели инструментов.
tim4^\ii?m:^mfv^mi'm^mmt^
Демографические данные по 30 выбранным округам
Диаграмма рассеяния возраст и процент бедны» и сепьски* семей
Пиктограмма (упрощенное изображение графика) позволяет предварительно
наблюдать за изменяющейся ориентацией графика и перспективой.
Для вращения графика в горизонтальной плоскости используется
горизонтальная линейка прокрутки, для вращения в вертикальной плоскости — правая
линейка прокрутки (вверх-вниз). Левая линейка используется для управления
перспективой. Перспектива определяет, насколько «близко» находится трехмер-
Пример 1. Настройка двухмерных и трехмерных графиков
367
ный график. Далее на рисунке представлен крайний случай, когда левая линейка
прокрутки установлена в самое верхнее положение. Мы видим график словно через
сильную широкоугольную линзу.
шшшшшашшвш
i.iaixil
Демографические данные по 30 выбранным округам
Диаграмма рассеяния: возраст и процент бедных и сельских семей
На следующем графике перспектива выключена (левая линейка прокрутки
находится в самом нижнем положении). График виден как бы через телеобъектив.
iTirfl;il4iiJi!iirim;i|li
■ -1П1Х1
Демографические данные по 30 выбранным округам
Диаграмма рассеяния возраст и процент бедных и сельских семей
... ■ ' Jacktorv
*гь <^;
Когда нужные пространственная ориентация и перспектива наконец выбраны,
закройте диалоговое окно Перспектива и вращение. График будет перерисован.
Диалоговое окно Размещение графика
Для вызова диалогового окна Размещение графика щелкните правой кнопкой мыши
где-либо на поверхности графического окна. Из контекстного меню выберите пункт
Изменить размещение графика.
368 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
В диалоговом окне Размещение графика проводится настройка параметров
конкретной зависимости. Например, с помощью кнопки Точки можно изменить
значки на диаграмме рассеяния. (Напомним, что это диалоговое окно вызывается
также, если дважды щелкнуть на любой точке графика.)
Выберите, как показано выше, в качестве значков треугольники и установите
ихразмер равным 8 (поле Точки). Затем нажмите ОК, чтобы закрыть окно Шаблон
точки. Теперь нажмите кнопку Перпендикуляр.
Здесь можно выбрать стиль для вертикальных линий, которые соединяют
точки с плоскостью X-Y. Чтобы увидеть изменения на графике, выберите сплошную
линию. Нажмите ОК, а затем еще раз ОК в диалоговом окне Размещение графика.
Все эти изменения появятся на графике, как показано ниже.
Демографические данные по 30 выбранным округам I
Диаграмма рассеяния возраст и процент бедных и сельских семей
Пример 1. Настройка двухмерных и трехмерных графиков
369
Диалоговое окно Общая разметка ЗМ графиков
Теперь сделайте двойной щелчок где-либо на поверхности графика, чтобы вызвать
диалоговое окно Общая разметка.
По обычным правилам, установленным в системе STATISTICA, функции
этого диалогового окна относятся ко всему графику в целом. Смысл большинства из
них понятен по названиям.
Подгонка поверхности к диаграмме рассеяния
Выберем, к примеру, в поле Тип графика строку График поверхности для того,
чтобы заменить диаграмму рассеяния. Заметьте, что изображение в левом верхнем
углу тоже изменилось и соответствует новому типу графика. Нажмите ОК, чтобы
перерисовать график.
HIIIL'IB ГГЧЩ'ЖЦШ
Демографические данные по 30 выбранным округам
Диаграмма рассеяния: возраст и процент бедных и сельских семей
■I 22,961
■I 23,921
■I 24,992
■1 25,942
О 26,903
(ZD 27,784
Ш 29.724
Ш 29,695
■I 30,645
■I 31.606
370 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
В диалоговом ошеЗМ графики? дополнительные свойства, которое вызывается
с помощью двойного щелчка на поверхности графика, выбираются параметры
подгонки поверхности.
Во-первых, на приведенном выше графике метка Shelby «затенена»
поверхностью. ШтрихоJ^f здесь можно изШени-рь или сделать поверхность полностью
прозрачной. Нажмите кнопку Показагрь сцрытое, чтобы сделать поверхность
прозрачной, то есть чтобы сделать видимым все, что находится за ней. В результате
поверхность на графике станет «сетчатой». Нажмите ОК, чтобы закрыть это
диалоговое окно. Теперь на маленьком графике в диалоговом окне Общая разметка
будут видны результаты изменений.
17ЛП1
стиль поверхности-
W-' 1 А* 1
j| fHt> |
ET^|Cz33i22S2.
Лето ' Sfmm *»t»mttbo
_ И ^Ы)НТУРПОВЕРХН0СТИ\ Г. Ирщ» у
I20 Щ *er2*- ' Чцслоспектральных плоскьсглЛ:[5 |
Перемещение условных обозначений
Удалите из графического окна условное обозначение поверхности, которое теперь
потеряло смысл. Щелкните правой кнопкой мыши на каком-либо условном
обозначении и выберите в контекстном меню пункт Удалить условные обозначения
линий уровня.
шшашвмшж
IJaMl
Демографические данные по 30 выбранным округам
Диаграмма рассеяния: возраст и процент бедных и сельских семей
<**>
»s> #
Пример 1. Настройка двухмерных и трехмерных графиков
371
Число сечений поверхности
Число сечений, по которым строится данная поверхность, устанавливается в
диалоговом окне Общая разметка. Чтобы вызвать его, дважды щелкните по
поверхности графического окна. Измените параметры Число сечений для Хи Уна 30 и 30.
Для более точной подгонки поверхности в поле Подгонка (поверхности и
контуры) выберите пункт Сглаживание сплайнами. Теперь график будет выглядеть
следующим образом.
ГЗ График 1 ЗМ диаграмма рассеян
■ -1PIXI
Демографические данные по 30 выбранным округам
Диаграмма рассеяния: возраст и процент бедных и сельских семей
<v*
Обратите внимание на то, что показанный выше график повернут так, чтобы
поверхность была лучше видна.
Изменение пропорций осей
(пропорции трехмерной ячейки)
По умолчанию трехмерный график располагается в кубической ячейке, то есть
длины всех осей для него равны. Иногда желательно изменить эти пропорции.
Например, на этом графике хотелось бы «растянуть» точки вдоль плоскости X-Y.
Другими словами, хотелось бы удлинить осиХи У относительно оси Z. Это можно
сделать с помощью диалогового окна ЗМграфики: дополнительные свойства,
которое уже использовалось в этом примере.
Снова вызовите диалоговое окно Общая разметка и нажмите кнопку Дополни-
тельно... (заметьте, что прежде это окно вызывалось с помощью двойного щелчка
мышью). Затем введите в поле Пропорции осей X: 2 и Y: 2.
Нажмите (Ж, чтобы закрыть окно ЗМ графики: дополнительные свойства, и
снова ОК, чтобы закрыть окно Общая разметка.
Обратите внимание на то, что такой же результат можно получить, оставив без
изменения значения для X и У (то есть У), но изменив значение для Z с 1 до 0,5.
372 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
тшт
чтшшш
УРЯ ЗРЕНИЯ
ПРОПОРЦИИ ОСЕЙ
X: F.287436 g !;..£ JT"
Y! |э 287344 Щ
2; 7.221119
•2t-
СТИЛЬ ПОВЕРХНОСТИ |——-1
&«ртяк <8, 3*г*нвнивя С Слммшюя ■ ^ ■*
i]]c*"*[i
[ЩРОВНИ ПОВЕРХНОСТИ/КОНТУРА
J:(»Arra Нис«> уровне* |l 0 Щ
ЛИНИИ ПОВЕРХНОСТИ КОНТУР ПОВЕРХНОСТИ ,: С Дмпм
• < « ' >ц 1! ! Раостоту от 'цмн, 2: I
rlF^^^^ilm^M^^^ ц*""
шшяииши
^■^мвнвшвявШвшкзшз
Демографические данные по 30 выбранным округам
Диаграмма рассеяния: возраст и процент бедных и сельских семей
36!
34
32
S 30
m 28
2в
2*
'"'
Г ^\
*^* к-^,^^
^^
и§^
"Ч-,
Представление трехмерных
аппроксимирующих функций в заголовках
Предположим, хотелось бы найти простую линейную взаимосвязь между долей
бедных потребителей, долей сельского населения и средним возрастом. Можно
аппроксимировать данные плоскостью, а полученные линейные оценки
параметров вынести в заголовок графика.
Дважды щелкните на фоновой поверхности графического окна. Появится
диалоговое окно Общая разметка. В поле Подгонка (поверхности и контуры)
выберите пункт Линейное сглаживание, а параметр Число сечений верните к значениям,
установленным по умолчанию (X: 15 и Y: 15). Нажмите (Ж, чтобы вернуться
к графическому окну.
Управляющие символы
С помощью управляющих символов может быть настроен практически любой текст
на графике (заголовки, метки, пользовательский текст и др.). К примеру, текст
может включать индексы, показатели степени, подчеркивания и т. д. Для появле-
Пример 1. Настройка двухмерных и трехмерных графиков
373
ния в заголовке графика уравнения аппроксимирующей функции одной из
зависимостей используйте следующие управляющие символы @F[номер зависимости].
Дважды щелкните на первом заголовке, в строку Заголовок 1 введите текст
Функция: @F[1]n нажмите ОК.
ШВШВ
!щф*»*мя: ели
PT.RURAL
IjpfPOOR
^..лЩ
Теперь вернитесь к диалоговому окну Правка заголовков; запись в нем
изменилась: {z=28.748+0.049*x+0.086*y@}. Этот текст можно редактировать, менять его
шрифт и т. п.
Обратите внимание, что часть текста заголовка внутри фигурных скобок ({}),
ограниченная символами @, автоматически обновляется системой STATISTICA;
она изменится, например, если отредактировать данные или уравнение функции.
После удаления фигурных скобок и символов @ эта запись будет восприниматься
как обычный текст.
t*^ Г рафик 1 ЗМ дискрс
Функция z=28,748+-0,086*x+0,049*y
374 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
Функция 9П1 ]<z-28.748*0.049-k*-0.086X?) f ju^w^ewi»*e«w?tf4
У | lYl IVlYrnrtTfl-ffriYir -llVlVll
RURAL
PT_POOR
E
Y.ftWiitttrr.
ешййй;.;" ;:,, .,.
Пример 2. Подгонка функций, увеличение
и закрашивание
Построение диаграммы рассеяния
В любом модуле (например, Основные статистики и таблицы) откройте файл
Poverty, sta. Из меню Графика выберите Статистические 2М графики
—Диаграммы рассеяния. Задайте в качестве переменной X — Popjchng (изменение
численности населения), а в качестве У — Pt_Poor (процент бедных потребителей).
>ша^ШШ
|Г7П Составной
ВЕН
\г ■' | Квантили
Диагр. Вороного
1С
[^ Экспоненциальная
[^Сплайны
КЛ Поямюмиаяьная
|Х Нами, квадраты
12ч. Отр. эксл.-взаем.
ДО Другая «дикция
• :%*.:^;<2":у^
Я|Цг**1 нет ''^Яг*' '
Нажмите OK По умолчанию будет построена диаграмма рассеяния с графиком
линейной регрессии. Нажмите кнопку Вых., чтобы удалить из графического окна
кнопки Еще и Вых.
Пример 2. Подгонка функций, увеличение и закрашивание
375
I.U..H, ,Ш1,,., 1ЯШт
Диаграмма рассеяния (POVERTY STA 8V30O
у-2в.1ев-0.4ОГ'*»»р«
Приближение полиномами
Как уже обсуждалось в предыдущих примерах, на двумерном графике рассеяния
можно построить аппроксимирующую функцию для каждой зависимости в
отдельности. Щелкните где-либо на графике правой кнопкой мыши и выберите из
контекстного меню пункт Изменить размещение графика.
■тга|
3&И1ХИР WCit ОБОЗНАЧЕНИЯ
ШАБЛОНЫ
IS! T«*m
ПОДГОНКА
3
Пот^мж*
£в ш*т
О&ллсяы
1г
Тип£р**»«к
ЩВР
S
S3
Н? Степеичатый гра»«»
Ц£ Мммимакс дмагр по X
имммаяс. дмагр по Y
liji СтоабЧ дмагр. по X
gj£ СтоябЧ дмагр. по нее. <
Д СтоябЧ дмагр.
(ПГ Стоабч. дмагр.
V* Стоабч. дмагр.
пр. осм Y
*ид диаграммы
(• Столбам
СПшш > Н°Р>У
СОгр*тм \*~
Параметры
Л_
ОИщат рмиетда
[ .Прууущаяi<_< |
#* Spy, дмагцми<■[
I Отреяки
ЩмрмжС
|0 2
«• Мабави I
I ДОВЕРИТЕЛЬНЫЙ ИНТЕРВАЛ
"■!
Г Вид.
Вместо установленной по умолчанию линейной подгонки выберите в поле
Подгонка пункт Полиномиальная. Обратите внимание, что с помощью расположенной
в этом поле кнопки Параметры можно задать степень полинома.
ОПТИМИЗАЦИЯ
Я; 100
< СТЕПЕНЬ ЦОЯИНОМА
Г2 Га ..Г4 <?*
; ОСНОВАНИЕ ДОГАРИФМА
г?ю гФ
РАЗРЕШЕНИЕ ЛИНИИ ПОДГОНКИ •• •
*•" Нарм. Г Выеадае Г Очам» емеадее Г Преданное
376 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
По умолчанию используется полином 5-й степени. Теперь закройте это
диалоговое окно (нажмите ОК).
Прежде чем продолжить построение, выберите доверительный интервал. Для
этого установите переключатель в поле Доверительный интервал в положение
Вкл.
ШВЕЗЗЯЙ
£ИКСИР. УСЛ. ОБОЗНАЧЕНИЯ
АВ ШриФх 1
\УЪ Линейный график
$** Ступенчатый график
jfjft Минимакс. диагр. по X
Минимакс. диагр. по Y
iltl Столб*, диагр. по X
Ьг Столбч. диагр. по лее. оси Y..
JU Столбч. диагр. по пр. оси Y
рГ Стоябч. диагр. сверху
' Стоябч. диагр. отклонений
ШАБЛОНЫ
: ft» Тоуи
££ Дмиии
йОДГОНКА ,
|\А Полиномиальна! ^9>
м
itfxii
"Zll
ИДЯ Области
ВИД ДИАГРАММЫ
<* Стояокы
С Линии
С Отрезки
С Прямоугольники
J 1 Пользовательская }
Отмена
Шаблон
J
Обцая разметка
Параметры
Предыдущая« }
OfibY
Сяедяощая »
- #*> &рул диаграмме j
С Справа
Отрезки *;|;
j££ • Шаблон ДИИ1И1 [j
-Si Цеткида
Ширина:
02
ЭЛЛИПС
<• Выкл. С Доверительный С Раамах
S2; Шаблон | Коэффициент: fo95 Ц
г ДОВЕРИТЕЛЬНЫЙ ИНТЕРВАЛ " ~
, С Выкл. <? вид.
\ ^2. Шаблон
Ярове!»»: |0 95
Выйдите из диалогового окна Размещение графика, включив диалоговое окно
Общая разметка.
шшшешпшш
ГЩ
J^^'i^irill. ~ 1нп графика:
%М
|Ш! Диаграмма рассеяния
1J2S Линейный график
jjlftf Ступенчатый график
fl*
Отмене
{графике
ЗАГОЛОВКИ
| Заголовок 1: Диаграмма рассея.
Декартовы »| К*гилг<>ри»-гаич | f^l Динии сетки |
t **1 Цетки данных |
гам
j Диаграмма рассеяния (POVERTY STA 8v'30c)
0CJ4 -
CD
Рамки
.... QT} Границы контроля j
Макс,: [**§ Разметка оси: \**™ ZJ . '■ Ь*Р***
| Y слева 1ас р"П Q Тип:] Линейная " Ч ' I1 ЗЗ
j Y справа
а
Сверку Мми': F* 0 ТП Параметры оси
|н£ри:
а
Здесь видно, что запись уравнения новой функции автоматически
обновляется, потому что во второй строке заголовка введен специальный управляющий
символ @F[1] (использование специальных управляющих символов для
форматирования рассматривалось в примере 2). Теперь нажмите (Ж, чтобы увидеть результат
на графике.
Пример 2. Подгонка функций, увеличение и закрашивание
377
1,Ш.М|И1,|Щ|Ц|мшяир.
Диаграмма рассеяния (POVERTY STA8v*30c)
у25.864.0.в7,к*0.ОО2,хЛ2*4.313«-4,к-9*в.Звв#-5,«М.1 ТвЭф-в'.^*»?!
В итоге в заголовок помещены оценки параметров функции, а на графике
показана 95% доверительная полоса.
Интерактивное удаление выбросов
(Закрашивание)
Нажмите кнопку панели инструментов Кисть [QJ. Форма курсора изменится и
будет соответствовать показанной на кнопке. Появится диалоговое окно
Закрашивание.
ЕВ5ВЗЯШШ1
iimiiiH»VHj'¥" »
РА.
Зависимость 1
3
| С Огшщтп* Mtfep -
!*
Выберите режим Операция — Выключить (чтобы исключить из рассмотрения
закрашенные точки) и включите режим Автообновление, как показано выше
(чтобы действия кисти сразу отображались на графике).
Теперь подведите курсор к точке в правом нижнем углу графика, чтобы она
оказалась в центре перекрестья.
378 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
Щелкните левой кнопкой мыши, и соответствующая точка будет удалена с
диаграммы рассеяния, кроме того, изменятся и параметры функции, записанной во
второй строке заголовка.
Диаграмма рассеяния (POVERTY STA 8v*30c)
y-24.4Q00.407,**0.045,**20.0CW,xA3-1.007г4'х*«**1.030» 5'*»«*«pf
Таким образом, инструмент Кисть позволяет интерактивно удалять выбросы
с диаграммы рассеяния и наблюдать соответствующее изменение
аппроксимирующей функции. В Редакторе данных графика удаленные выбросы выделяются
другим цветом.
fiento* ' •"
Carttw*
Carrol
■ IJU."Hl»ieJ.JOl
Диаграмма рассеяния (Р
у-24.499-0.407-х*0.045-хЛ
(Ж::Д«втв)
13.70
•0.80
9 60
кпайа1 4:i-v:
Cumberland
DeKdb
Dyer
6fe$or>
Greene
H**ttt
Ш
8.41
3.50
3.00
7.10
13.00
10.70
*4t pttttMH
• • -Y- •
19.00
26.20
18.10
IS 40
29.00
21.60
21.90
18.90
21.10
23.80
XI
ZJi
Пример 2. Подгонка функций, увеличение и закрашивание
379
Чтобы «снять выделение» точки (то есть поместить ее обратно на график),
поместите курсор на соответствующую строку в окне Редактор данных графика и на
его панели инструментов нажмите кнопку Показать идентификаторы точек
графика Щ.
В появившемся диалоговом окне:
1Ж1ШШТТР1г111
ШТЩ
Um*# jCheathee»
■■х."а<...^<:"-'^>п^>1жг
■А"Длл:-й ■- у
^
измените статус выбранной точки. Выделение будет снято. Нажмите на панели
инструментов кнопку |Пврдр«с*>е*ть1 и ранее удаленная точка вновь появится на
графике.
Увеличение
Увеличение — это весьма полезный инструмент для подробного изучения
выбранной области графика, в частности, когда необходимо удалить отдельные точки. Если,
например, на диаграмме рассеяния есть области «скученности» точек, то можно
увеличить эту область, чтобы идентифицировать отдельные точки. Нажмите кнопку
Увеличение (<§j, при этом курсор на поверхности графика примет форму лупы.
Подведите его к центру той области, которую вы хотели бы увеличить, и щелкните
левой кнопкой мыши.
Если щелкнуть левой кнопкой мыши еще раз, то данная область снова
увеличится.
380 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
шшшмшшвшшшшш
°
N. О ^ ч ч
:Л'"'; • " в
; ч * ^ О
ННШЙМНЙННННСжЗЖ^)
i
j
'Чч О ]
' * * ч ^\ !
m.Tl , -шиЛ ,„■ J
Каждый щелчок левой кнопкой мыши приводит к увеличению
соответствующей области примерно в два раза.
Для просмотра графика в режиме увеличения можно использовать линейки
прокрутки. Нажмите кнопку Подобрать область графика и поля QQ, и вы сможете
рассматривать график, как через увеличительное стекло.
Чтобы снять увеличение, нажмите кнопку Уменьшение (€Ц и щелкните на
соответствующей области графика. Заметим, что после нескольких успешных
операций увеличения и уменьшения положение графика в графическом окне может
измениться.
Для восстановления первоначального вида графика используйте команду
Восстановить исходные настройки в меню Вид.
График будет вновь перестроен в соответствии с параметрами, заданными по
умолчанию.
Пример 2. Подгонка функций, увеличение и закрашивание
381
Пропорции прш %4j0 при п
' eytortwKvw
НвЛрашММИЙС***
:■' OW4
0*в
рСССЯмий (POVERTY STA 8И30О
ШШШЕЕ^а
Диаграмма рассеяния (POVERTY STA 8V30c)
y«24 J0e0.407,K*0.04e*xA2 0.CXL,x*3-1.007t-4V*4»1.03et-5,x*e*tpf
Рисование пользовательской функции
Снова вызовите диалоговое окно Размещение графика и нажмите в нем кнопку
Пользовательская. Откроется диалоговое окно Задание функции пользователя.
Задайте, например, экспоненциальную функцию: у = 25.183*ехр(-0.016*х).
Е
^ -* ■ ; '
ш
Ж
ЕВ|
•Принте няи. -^у.^,^. ,~..,■.„■..-.,..-. г
Д>у-*римзммю>юст»с4ргущиг<иХ :y»2>*iinW '• Л*"*»
I Трепwpjwoи»юимост»скгунтптчнХыУ;г:*Ъ»*вЫ^ . j .—
Операторы ♦."-*;•>>»<<» о «nd la (not ~ |J l~~
К«мст»«ты Р>-11415.:Ы,Ы*&П& to
•; К«ммвмгари»ог<№ля*геят«1чм)йемпйгой:»4(А2;ео1мчп1
' Основ** «^икцмс Л», «ceot, *c*v «ct«i e«. «eeh
, до, teg. toald fajuiainurt*. «9t Ш*ЛшЬ,- ./;,--'■ <"■'
i ***, идем♦ иИ**?*"?!' «к •*■*•" •w ''•'•■■ v-w- • •;•• • * •• -• •
? r***p»*ne»«* Mtbinom. Much* d©, ««on.***»
*. aamma. tfewfc feet**, log», kv*«m. помм! ..|..
р«Шо, poU$on. Kilfgh» tmos«. ttafeJ I g*
: Mxi«iTvp»*rftoeU^fcn^taM^.icr^ * .,.-*-""'
f, tgaiwr* доо. ikpiaoc, logic lognonn wwi*l ^v>: ran
<p«e(a jpowtcrt. iuefcigH. «rfuderi. *wfeJ ' |MB[
i Обрягиые 4>?«iu«c «bete, veaucty. *ch»2. *емроп : "'""
**dtm*. vf. vgmma. vtaptoc*, vtooij. viognotm
vncwnal, vpveto. v«*4*gh. vtluefan». vwahl
: Дм рвэмь* »«*♦«*« и* рахых мг«гори». грьфшт мспо/мдйгк :°
! <рмрп1Н#дгврпЙ1.^илм#5»арпП.и<01аеп|1Д^
flwtpw»
25.183'в«р( 0jI6'«J
382 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
Нажмите ОКв этом диалоговом окне и в диалоговом окне Размещение графика.
Заданная функция будет нарисована на графике (соответственно будет обновлен
и заголовок).
Обратите внимание, что в данном случае функция просто накладывается на
график. Чтобы найти пользовательскую аппроксимирующую функцию для
данной зависимости, необходимо использовать модуль Нелинейное оценивание.
Диаграмма рассеяния (POVERTY STA 8V30c)
y-25.iey«xp<-o.oiea>o
Добавление зависимости
Для каждой зависимости на графике можно найти только одну
аппроксимирующую функцию (или наложить на нее только одну функцию). Поэтому для
построения нескольких функций нужно создать дополнительные зависимости. Для
этого выполните следующие действия.
Нажмите кнопку Редактор данных графика (Щ (или вызовите его другим
упоминавшимся выше способом). Из меню Правка выберите пункт Добавить зависимость.
В этом диалоговом окне сохраните все установки по умолчанию (нажмите ОК).
При этом будет добавлена новая зависимость (в показанном ниже Редакторе
данных графика добавлены два пустых столбца).
ВЗИРИРН
Irflriiiiirii
Сшровп
С**
СЬмЛмт
Cumberiand
0*#*
Оу*
Gbw*
&#**
H«*»tt
Hqifwood :
H«rw
ыЛ
тми
мям
i «
Диагр»»м рассеямм (POVERTY STA8v30c|~
у-25.183-е«р(Д016*х| —Jj
LIjBm^ix
1370
-0.80
9.60
40.00
8.41
3.50
3.00
710
13 00
1070
1620
6.60
. .:«ХЪ\
1 19,00
26.20
18.10
15.40
29.00
21.60
21.90
1890
21.10
23,80
40.50
21,60
^ Диаграмм» pexwii
• ГХ>Г-:
,•: .-у :•,
L
I
и
Пример 2. Подгонка функций, увеличение и закрашивание
383
Теперь щелкните правой кнопкой мыши на первом столбце и из контекстного
меню выберите пункт Размещение графика. В этом диалоговом окне для
зависимости 1 снова выберите полиномиальную подгонку. Затем нажмите кнопку
Следующая ». Появится диалоговое окно Размещение графика для второй (новой)
зависимости. --•
ШТЩ
&ИКСИР. «СП. ОБОЗНАЧЕНИЯ
L
бе
•4 <i:f.<
(ШАБЛОНЫ
\ \v Toy*
ДОДГОНКА
Нет
Лг
J!L
Т\от$!пт*гтт>с**л
0£**стм . f{
Ttajt £fMH*MftAX у *"*
Пврамггрм
3
р
ИУ Ступенчатым график
(|Ц Нимммакс. дмагр. по X
М шишаке, дмагр. по Y
bill Стоабч дмагр по X
|а»" Столбч. дмагр. по лее
Д Столбч. дмагр. по пр.
I(Т Стоябч. дмагр. саархч
*У* Стоябч дмагр отклонения
ocmY.
>cmY
гВИД ДИАГРАММЫ , .-. ^ „,—- . ,
t(» СТОЛО** -1- — • - i СяОДЖЕ»*»>> |
! С Пряиоур<1>11мк>1 j/^ 1
'Отразим 2J ЭЯДИПС ~ :гТ™
; *j' Л Вмк*> Г Дмицмгммш» Г
; Ш {руг. диаграмм*
i""*1* v*\ '
|*1* MjffftM;
. ДОВЕРИТЕЛЬНЫЙ ИНТЕРВАЛ
2SS ■абмм]
<?8ы
С#дяМу
Здесь выберите пункт Другая функция и снова определите ее следующим
образом: у = 25.183*ехр(-0.016*х).
8мдмт« фяижкмк
у-25 183*вхр@ 016*х)
Закройте диалоговое окно Задание функции пользователя и откройте
диалоговое окно Общая разметка. В этом диалоговом окне Общая разметка: 2М графики
выберите в списке Заголовки строку Заголовок 3. Пользуясь введенными ранее
правилами, запишите в качестве заголовка: Функция 2: @F[2].
Для построения графика нажмите ОК:
\штшткшш
Диаграмма рассеяния (POVERTY.STA 8v*30c)
Функция 2 у = 25,18Э'ехр(-0,016*к)
«в i
POP_CHNO
384 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
Теперь на графике изображены как пользовательская функция, так и
подгоночный полином.
Пример 3. Динамическое закрашивание
(Кисть)
Как правило, режим Динамическое закрашивание используется на матричных
графиках для пробного анализа данных. При этом вместо закрашивания
определенного диапазона значений переменной (с целью исследования влияния различных
областей на функцию распределения) можно ввести автоматическое движение
кисти (в форме прямоугольника или лассо) и наблюдать «результат».
Область закрашивания определяется на одном из графиков матрицы и
автоматически перемещается вдоль него (горизонтально, вертикально или в обоих
направлениях). Когда в область закрашивания попадают группы точек этого
графика, то выделяются соответствующие точки на всех других графиках матрицы.
Файл данных
В этом примере использован файл данных IrisdaLsta с классическим отчетом
Фишера A936). В нем приведены данные о длине и ширине лепестков и
чашелистиков трех сортов ирисов (Setosa, Versicol, Virginic). Часть этого файла приведена
ниже.
ТЕКСТС
f£»
*, •«,•■•
6 ;•
Г,'.,;.,
%;„,
«ft?.
EC
Fisher A936) ins data length & width of sepals and petals
Ш+11ШЩ S&PAUMO
[ 5.0) 3.3
6.4 2.8
:'»C<*-*;c.W*
1.4
5.6
6.5 23 4.6
6.7 3.1 5.6
6.3 2.8 5.1
4.6 3.4 1,4
6,9 3.1 5,1
6.2 72 4.5
5.* 3.2 4.8
4.6 3.6
1.0
3 types of Ins ™
ретА1У«р 1 «щурь
.2 SETOSA
22 VIRGINIC j
1.5 VERSICOL
2.4 VIRGINIC
1.5 VIRGINIC
.3 SETOSA
2,3 VIRGINIC
1.5 VERSICOL
1.8 VERSICOL j
2 SETOSA
m
Построение матричного графика
Откройте файл данных IrisdaLsta, выберите из Галереи графиков или меню
Графика пункт Статистические матричные графики. Появится диалоговое окно
Матричные графики.
С помощью кнопки Переменные выберите все переменные. Нажмите ОК,
чтобы закрыть диалоговое окно выбора переменных. В поле Подгонка выберите
строку Линейная. Снова нажмите ОК для построения матричного графика и удалите
кнопки Вых. и Еще, нажав кнопку Вых.
Пример 3. Динамическое закрашивание (Кисть)
385
Матричная диаграмма ARISDAT STA5v*150c)
Aff^ 11 •^■ЙЛ''' II PETAUEN || .4^11| ~~Т
*j+*\ || . «гиМ^*-» II У —свУиед II iH^^ J J r
^i^ll>^ II V^L™ II >^
Нажмите кнопку (Щ панели инструментов. Появится диалоговое окно
Закрашивание. Затем в качестве типа wwcmw выберите Прямоугольник и включите режим
Движение (см. следующий рисунок).
386 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
Курсор примет форэду перекрестья. Теперь на одном из графиков матрицы
можно выбрать прямоугольную область. Для исследования и сравнения связей между
четырьмя характеристиками ирисов (Sepallen, Sepalwid, Petallen и Petalwid) трех
различных сортов (Setosa, Virginic и Versicol) выберите одну группу точек на
правом верхнем графике (представляющем один из сортов).
Когда вы отпустите кнопку мыши, прямоугольник начнет периодическое
движение по этому графику. При этом на всех остальных графиках будут выделяться
соответствующие точки.
■ Jplxll
Матричная диаграмма (IRlSDAT STA5v*l50c)
SEMUfN 1
<^^ч
~^**\
и*^
Й»г1
[ IfMLWIO 1
F^CTl
р^
\у^\
г^^*ч
1 *F»*Xt*
|Q_»Dq=
1^1
1 ^\
Ir- !
1и^1
p^-^Wkji:
1 >^l
1 freiwio 1
1 ..—s-1
Ш
ш
\^
и
Ш11ТТЦ
0_l__Q
ШпШЩ
Матричная диаграмма 0RISDAT STA 5v'150c)
aDBEl.
Ж
**^
Ж.
jDa».
л*а*-
^
^
Jn.
^
^
L^H^
>**
'FTM.WIO
Id
Btd
Г PF3
Omm |
r
= o*iw i
Lb ^ д л««
- «r-r jj
im «»«.»«■■■«
!4.i I""
Скорость и направление движения при динамическом закрашивании задаются
в диалоговом окне Движение.
Такая динамическая визуализация позволяет выявить разнообразие связей для
каждого сорта ирисов. Например, когда прямоугольная область закрашивания
проходит через первую группу (как показано выше), то выделение соответствующих
точек позволяет судить о различной величине и направлении связи между
параметрами Sepalwid и Petallen, Sepalwid и Petalwid.
Закрашивание в редакторе данных графика
В системе STATISTICA применяются два метода закрашивания: с
использованием инструмента Кисть Я в графическом окне или соответствующей кнопки в Ре-
Пример 4. Связывание и внедрение
387
дакторе данных графика. Если точки данных выбраны в режиме закрашивания (то
есть маркированы, помечены, выключены или подсвечены), то их координаты
представлены различными цветами в Редакторе данных графика.
Этот Редактор предоставляет «командную» среду, где можно напрямую
присваивать атрибуты точкам, не выбирая их предварительно, а используя кнопки панели
инструментов, диалоговое окно Идентификаторы точек на графике, контекстные
меню или команды выпадающего меню Правка. Таким образом, операции
закрашивания имеют здесь тот же статус, что и режим Автообновление в процедуре
закрашивания. При этом текущая операция будет выполняться после каждого
выбора атрибута, и точки, заданные с помощью курсора (как отдельные точки, так и
выделенные блоки), будут сразу же маркироваться, помечаться, выделяться и т. д.
Заметим, что точки данных графика могут иметь больше одного атрибута
(например, они могут быть одновременно маркированы и подсвечены), при этом в
Редакторе данных графика они отличаются лишь различными цветами и в
соответствии с этим отображаются на обновленном графике (после нажатия кнопки
Перерисовать или Выйти и перерисовать).
О В Редакторе данных графика можно управлять атрибутами точек (маркиро -
ванная, помеченная, выключенная или подсвеченная) с помощью
специальных кнопок панели инструментов или команд меню.
О Точки данных (значения), выбранные с помощью закрашивания (то есть
маркированные, помеченные, выключенные или подсвеченные), отображаются в
Редакторе данных графика различными цветами.
Пример 4. Связывание и внедрение
В этом примере будет показано, как поместить график системы STATISTICA в
другое графическое окно или в какое-либо приложение Windows, используя
средства OLE. При вырезании (удалении) или копировании графика или другого
выделенного объекта (такого как пользовательский текст, метки, вставки или
рисунки) он помещается в буфер обмена (Clipboard).
Для совместимости с другими приложениями Windows помимо объекта в
собственном графическом формате системы STATISTICA в буфер копируется
метафайл, а также растровое и текстовое представления.
Растровые изображения
В растровом изображении не хранятся никакие логические (структурные)
компоненты графика. При вставке в другой график оно просто передает образованное из
точек (пикселов) отображение графического окна.
Метафайлы Windows («картинки»)
В отличие от растрового изображения, этот формат сохраняет некоторые
структурные компоненты графика. Формат метафайла Windows хранит картинку в виде
набора описаний или определений всех компонент графика и их параметров
388 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
(например, сегментов линий, шаблонов заполнения, текста и его характеристик
и пр.). Поэтому формат метафайла предоставляет более гибкие возможности для
настройки и преобразования графика в других приложениях Windows.
Например, открыв график в формате метафайла в программе Microsoft Draw,
его можно «разобрать», выделить и изменить отдельные линии, заполнение,
цвета, отредактировать текст и изменить его параметры и т. п. Заметим, что не все
программы обеспечивают возможность полноценного редактирования
метафайлов, например, программа Microsoft Draw не поддерживает режим вращения текста.
Собственный графический формат системы
STATISTICA
Записанный в этом формате график при вставке его в другое графическое окно
сохраняет все свои структурные компоненты и объекты таким образом, что они
распознаются системой STATISTICA. Поэтому при копировании или обмене
графическими объектами (или целыми графиками) между окнами этот формат
выбирается по умолчанию, чтобы в дальнейшем можно было продолжить
редактирование (включая настройки графиков системы STATISTICA в других приложениях,
куда они помещаются средствами OLE).
Копирование и вставка графических объектов
В этом примере использован файл данных Factor.sta. Откройте этот файл в одном
из модулей системы STATISTICA (например, в модуле Основные статистики и
таблицы). Из меню Графика или Галерея графиков выберите пункт
Статистические 2Мграфики — Диаграммы рассеяния. В диалоговом окне 2М диаграммы
рассеяния в поле Тип графика: выберите строку Составной. Затем нажмите на кнопку
Переменные и выберите в качестве переменной X — Work_1> a Work_2 и Work_3 —
в качестве переменных Y. Нажмите ОК, чтобы закрыть диалоговое окно выбора
переменных.
Нажмите ОК, и на экране появится график.
Пример 4. Связывание и внедрение
389
HWTJI'PIMriHWJI'l!
Диаграмма рассеяния (FACTOR STA1 0v*1 00c)
^0 'a work.3
Щелкните правой кнопкой мыши на одном из условных обозначений и
выберите из контекстного меню пункт Переместить условные обозначения.
Диаграмма рассеяния (FACTOR 8TA10V*100c)
Теперь условные обозначения преобразованы в пользовательский текст. Если
дважды щелкнуть на них, то в Редакторе текста графика можно будет увидеть
текст условных обозначений и управляющие символы.
*.тмитшшш1мттш1*т
"ЯЗ
В окне редактора уберите из текста символ перевода строки (поместите курсор
в конец первой строки и нажмите клавишу Del). Две строчки в записи условных
обозначений превратятся в одну. Можно поместить четыре дополнительных
пробела между условными обозначениями первой и второй зависимости и заменить сим-
390 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
волы табуляции (@Т[6]) пробелами. Поскольку условные обозначения не
уместятся в одну строку, то табулятор не сможет гарантировать одинаковый интервал
между символами и текстом.
Щ
m. woRK_?es ei|2j work_3
Щ\
Ш
Ш
шг
^^^Г^ММ-Ы\шШы\ыК-%\шМш
в
зй
Нажмите ОК, чтобы увидеть на графике измененные условные обозначения.
Диаграмма рассеяния (FACTOR STA10V100с)
о
г
0 оо
° В
' 1
о
* о
о °
. ...о
о
*JA
-^1
оо
о ° о
о
о 1
"! ' ............ ff 4
Зо влК^о о
T^l»' ;
°о 8 °° о
о ° о
1 >0v WORK_2 'о. WORK_3 I
Текст расположен не в центре рамки, потому что в первоначальной записи
условных обозначений присутствовали символы межстрочного интервала (@S).
Дважды щелкните на условных обозначениях и удалите символы @5. Нажмите
ОК, чтобы вернуться к графическому окну.
Теперь дважды щелкните на условных обозначениях в виде пользовательского
текста, затем нажмите CTRL+C или кнопку Я, чтобы скопировать
пользовательский текст в буфер обмена, и закройте Редактор текста графика.
Диаграмма рассеяния (FACTOR STA 10V100с)
Пример 4. Связывание и внедрение
391
Вставка в виде текста
С помощью двойного щелчка на заголовке графика вызовите диалоговое окно
Правка заголовков. Для вставки поместите курсор на пустое поле Заголовок 2 и нажмите
комбинацию клавиш CTRL+V или кнопку [Щ1 на встроенной панели инструментов.
Ш
2Ш£
: Загоаач*!;
, £ Jet W0RK_2
Дмаграина рассеяния (FACTOR.STA lOv'IOOc)
OK
Г7Тх1|
3
eL|2| W0RK_3
>X#JWORK_1
>X2: |
ДвмйОсьУ1: J
Левая ось Y 2: [
Qpa*M«e»Y1: J
Паевая oc* Y 2: Г
Ы ...._
Ag|.
fie)
Отмена
Нажмите (Ж, чтобы увидеть итоговый график.
Iillf|lll4'"r,l"i4hll,l
Диаграмма рассеяния (FACTOR STA 10V100с)
>V WO"K_2 о. WO*K_3
Теперь условные обозначения помещены в заголовок.
Вставка в виде растрового изображения
Чтобы выделить условные обозначения в виде пользовательского текста, снова
щелкните мышью, поместив над ними курсор. Затем из меню Правка выберите
команду Вырезать (можно осуществить эту операцию и другими способами: с
помощью комбинации клавиш CTRL+X, кнопки панели инструментов или команды
Вырезать контекстного меню). Согласно пояснениям во введении к данному
примеру теперь пользовательский текст помещен в буфер обмена в четырех разных
форматах: как обычный текст, как растровое изображение, как метафайл и как
собственный графический объект системы STATISTICA.
Из меню Правка выберите режим Специальная вставка.
В диалоговом окне Специальная вставка выберите формат Растровое
изображение. Включите режим Поместить по умолчанию.
392 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
.. • ■ !,i» >.I.inIад;мдй >iw«ни >
ввцн
ШБ : ,
J>o.wokk_2 awoWK.3|iMa расСвяния (FACTOR STA 10V100c)
^Ot WORK.2 " o. WO«K_3
140 i
WORKJ
Теперь вставка имеет вид обычных условных обозначений в виде
пользовательского текста, но на самом деле это не так. Программа воспринимает ее как набор
точек, то есть растровое изображение.
Щелкните на объекте правой кнопкой мыши и выберите из контекстного меню
пункт Свойства объекта (или дважды щелкните на объекте, или выделите объект
и нажмите комбинацию клавиш ALT+ENTER).
В появившемся диалоговом окне удалите метку около слов Исходные
пропорции (чтобы можно было менять размеры объекта, не заботясь о сохранении перво-
Пример 4. Связывание и внедрение
393
начальных пропорций). После закрытия этого диалогового окна объект можно
перемещать и изменять его размеры.
Диаграмма рассеяния (FACj растягивание растровых рисунков
искажает изображение
(например, данный текст)
WORKJ
Очевидно, что при растяжении или сжатии растрового изображения каждая
точка соответственно перемещается, вызывая искажение текста.
Вставка в виде собственного графического
объекта системы STATISTICA
Выберите из меню Правка пункт Специальная вставка, а затем режим Внутреннее
описание системы STATISTICA.
ШВВШШЕВВШЯ
Диаграмма рассеяния (FACTOR STA1 0v*1 00c)
"ЧХ. WORK_2 * о. WORK_3
Первоначально этот объект выглядит как растровое изображение. Дважды
щелкните на нем. Вы увидите, что размеры шрифта изменить нельзя. Вместо этого
откроется окно Редактор текста графика.
Таким образом, система STATISTICA воспринимает это изображение как
собственный графический объект и, следовательно, позволяет его редактировать
любыми доступными средствами. Чтобы изменить размер условных обозначений,
необходимо выбрать Шрифт большего размера, например Anal Bold 20. Ниже
показан график, получившийся после внесения изменений.
394 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
Йиммяг
;:Г:г?&й^
twcT н* графике fro-
|P£iMKN ";38ЯК Р«*М ■ : |ИIГоризонтальная *\-
\ '•• ••.- ■ ■ ■ ■.■.■ ■■■!■■ ■.■_■ ■ о■ ■ ■ ■ ■ ■...... „пил.!;:I. .п.,..,.-. ...п i л, ..и тт.л л»[ррюшгтт*::<- Попарптля* ,
Г* Дцнаии*. «мим!"Г"Здеир» яо*ож«ми»: Р ftwMewrwvrm дочт* »и*> Г*Дрттатсть поуио^иаомо
Диаграмма рассеяния (FACTOR STA 10V100с)
>Оч WORK.2 * о. WORK_3
130
120
110
100
on
Ж)
70
|^WORK_2 -*-.. WORK_3|
<...
0
0
0 -*»*&
.—Г^ о
У " О
о
-° ;-о-оЛй i
о ° о; °о
-Jgcg&g Оо-.У. ..0о,..Р
*й*1 ■■.•«-.■
о о ° 0
О О
о
9
ft).
0
' ls*~
"о— ;
о
о
о
Сетка
Для выравнивания положения текста и других графических объектов
используется функция Направляющая сетка из выпадающего меню Вид (она вызывается
также с помощью комбинации клавиш CTRL+G).
| Диаграмма рассеяния .ТACTOR STA 10у*100с)
>0kV*CRK_3 ♦ -•«■■ wosK_a -
Пример 4. Связывание и внедрение
395
Имеющаяся на графике сетка позволяет очень точно размещать различные
объекты (например, текст). Эта сетка не выводится на печать. Удалить ее можно,
снова выбрав пункт Направляющая сетка (то есть удалив метку около названия
функции или нажав комбинацию клавиш CTRIAG).
Для настройки сетки (ее начала и интервалов) нажмите кнопку панели
инструментов §Ц или выберите из меню Вид команду Прикрепить к сетке. При этом также
появится возможность прикреплять к узлам сетки объекты (для точного размещения).
При перемещении и изменении размеров объектов режим прикрепления к
сетке можно легко включать и выключать клавишей TAB.
Функции клиента и сервера в OLE
Теперь удалите все графические объекты, помещенные в этом примере, на
диаграмму рассеяния. Сам этот график будет вставлен в трехмерную гистограмму. Этот
пример продемонстрирует, как система STATISTICA может являться
одновременно клиентом и сервером в методе OLE.
Создание трехмерной гистограммы
Из меню Графики выберите пункт Статистические ЗМ последовательные
графики — Гистограммы двух переменных. Выберите в качестве переменных Work_1 и
Work_2. Нажмите ОК для построения гистограммы двух переменных.
Внедрение диаграммы рассеяния
Щелкните на предыдущем изображении диаграммы рассеяния. Затем из меню
Правка выберите команду Копировать (или нажмите комбинацию клавиш
396 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
CTRL+C). Снова щелкните на гистограмме и теперь из меню Правка выберите
пункт Специальная вставка.
Как и в случае пользовательского текста, возможен выбор из нескольких
графических (файловых) форматов. При выборе формата Растровое изображение
изменение размеров внедренного графика, как и в случае пользовательского текста,
приводит к искажению изображения (см. ниже).
UIHnilJlHI4MI',ilflHlII,llU"Jlllri
*Щ&0^
Выберем вместо этого собственный графический формат системы STATISTICA.
Ржзшввяшвр»
Mm in i it*"mMAmnmm
4WVVWU
^wm«x (FACTOR STA 1<V100c)
ъшФШ,
Пример 4. Связывание и внедрение
397
Поскольку этот формат установлен по умолчанию, то достаточно просто
выбрать команду Вставить или нажать комбинацию клавиш CTRL+V.
Редактирование внедренного графика
Щелкните на внедренном графике правой кнопкой мыши. В появившемся
контекстном меню будут показаны все доступные функции редактирования.
Внедренный график рассматривается как связанный объект, то есть с ним можно
обращаться как с исходным графиком. Если дважды щелкнуть на нем, то он будет
стандартным образом открыт по соглашениям Windows о связывании и
внедрении объектов OLE. Сделайте нужные изменения и выйдите из режима
редактирования с помощью команды Закрыть и вернуться из меню Файл. Все изменения
будут отображены на внедренном графике.
Внедрение или связывание графиков из файлов
Можно осуществить процедуру внедрения или связывания графиков из
имеющегося графического файла. Например, сохраните диаграмму рассеяния в виде
собственного графического файла системы STATISTICA (например, в виде файла
Scatter.stg). Затем щелкните на трехмерной гистограмме и из меню Вставка
выберите пункт Объект (или нажмите на панели инструментов кнопку Вставка объек-
таЩ).
В диалоговом окне Вставка выберите вкладку Объект из файла, при этом в
списке Тип объекта укажите График STATISTICA. Проверьте также, включен ли
режим Связь с файлом. В этом режиме связанный график будет автоматически
обновлен при изменении и сохранении исходного графика. В списке Имя файла
выберите предварительно сохраненный файл Scatter.stg. Нажмите ОК, и в левом
верхнем углу картинки появится график из этого файла.
398 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
. " ******* &<**>*•»«*СПЖ«г» «•»*«*) Ц.
Ф^ЗР*?*
Автоматическое обновление связанных графиков
Теперь вернемся к диаграмме рассеяния и удалим весь пользовательский текст и
заголовки (выделим их щелчком мыши, а затем нажмем Del или используем
команду Вырезать в меню Правка).
l«imji|M«IMI!li».I.IIII.IJ.IU4Jlll)l
шх (FACTORSTA 10»*100е)
Ш0Ф
На рисунке видно, что связанный график был автоматически обновлен.
Управление несколькими графическими
объектами
Если на экране находятся одновременно несколько непрозрачных графических
объектов, то важно, чтобы они были расположены в нужном порядке.
Рассмотрим, например, построенную ранее трехмерную гистограмму с
внедренным графиком. Ниже показан этот график после добавления к нему стрелки и
пользовательского текста.
Пример 4. Связывание и внедрение
399
В данном случае желательно нарисовать стрелку и пользовательский текст
поверх связанного графика, потому что иначе они не будут видны. В настоящий
момент элементы графика изображены в правильной последовательности. Но в
следующем параграфе просто с целью демонстрации мы покажем, каким образом вынести
этот график на передний план, то есть нарисовать его в последнюю очередь.
Изменение очередности изображения
графических объектов
Кнопки панели инструментов Вынести на передний план и Перенести на задний
план Ю1^1 предназначены для соответствующего перемещения выбранных
(выделенных) графических объектов. Щелкните на связанном графике, чтобы выделить
его, а затем нажмите кнопку Вынести на передний план.
Гистогрятм дшух мрммимых
Теперь внедренный график закрывает стрелку и часть пользовательского
текста. Можно снова поместить его на задний план (в исходное состояние), нажав
кнопку Перенести на задний план.
400 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
Управление графиками системы STATISTICA
в других приложениях Windows средствами OLE
В этом примере будет показано, как связать график системы STATISTICA с
другим приложением Windows, используя метод Связывания и внедрения объектов
(OLE). В данном случае график будет связан с документом, предназначенным для
редактирования в программе Microsoft Word. Связанный таким образом график
системы STATISTICA может редактироваться внутри другого приложения с
использованием инструментов настройки системы STATISTICA (если это
приложение поддерживает средства OLE).
Сначала построим в системе STATISTICA приведенный ниже график.
Предположим, данный график необходимо включить в документ,
редактируемый в программе Microsoft Word. Ниже показана та часть «отчета», в которую
должен быть помещен график.
ЫоМ
«60 G0,80] (90,100) A10;120) A30,140]
F0;70) (80.90) A00.110] A20:130] » 140
WORKJ
При исследовании удовлетворенности работой и досугом было получено
несколько неожиданных результатов Однако перед представлением
интерпретаций полученных результатов будут рассмотрены
распределения ключевых итоговых показателей П
И
Респредепение переменной W0PK_f можно представить следующим
обрезом 4I
1
Распределение этой итоговой переменной близко к нормальному
распределению 1
Пример 4. Связывание и внедрение
401
График системы STATISTICA нужно вставить между вторым и третьим
абзацами текста (после слов следующим образом:).
Связывание графика системы STATISTICA
Сначала откройте систему STATISTICA и постройте необходимый график
(например, такой, как показано выше). Затем скопируйте его с помощью комбинации
клавиш CTRL+C или команды Копировать из меню Правка.
Переключитесь на документ Word и поместите курсор в то место, с которым
должен быть связан график (в конец второго абзаца). В программе Microsoft Word
выберите из меню Правка пункт Специальная вставка.
ш
("{•дож
| Рисунок
Том**»* рисунок
|Алпарвтно-немеисимыи точечном рисунок
[метафайл window (EMF)
Р;-/-?'<!:'^;'.:''-^^
~j: Г^шц»'4И»к»..:;.::
•» ППыъ! <WHew»ecrwoрц»ацю»*т»«п> м*График ?.:v?*^4&^4<*&«i
Редактор Microsoft Word распознал в буфере обмена график системы
STATISTICA. Следовательно, по умолчанию график будет помещен в документ
как График STATISTICA. Для вставки графика нажмите ОК.
Обратите внимание, что таким же образом можно просто вставить график в
документ (нажав CTRL+V), поскольку формат График STATISTICA стоит первым
в списке форматов буфера обмена (Clipboard).
Mi«^^^
m
щтщмШЧ»'
=*S
интерпретаций по пуме иных результатов будут рассмотрены
распределения ключевых итоговых показателей П
Распределение переменной WORK_ 1 можно представить следующим
образом Ц
Итогом* гистограмм» для п»р»м«ййой W0RK_1
30 г
I
i
ы
МйШаШ
60 G0.80] (90.1001 A10,120) A30140)
(80.70] (80.90] A00.110] A20.130] » 140
WORKJ f
Распределение этой итоговой переменной близко к нормальному
распределению П
пгз^шгу^ * j»wrj8ri
г^жутч;
rriw wtmm шр>:як1|1тш№ш
402 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
Редактирование связанного графика
Предположим, вы решили включить в показанный выше график краткое
описание переменной Work_1. Для редактирования графика дважды щелкните по нему,
при этом автоматически запустится система STATISTICA, где будет открыто
данное графическое окно. Можно убедиться, что при этом здесь в меню Файл
появились новые пункты.
= 60 G0.80) (90.100) A10.120) A30.140)
F0.70) (80.90) A00.110) A20.130) > 140
WORKJ
Обратите внимание, что система STATISTICA «знает», что данный график
внедрен в документ Microsoft Word. Таким образом, сделав необходимые настройки,
можно закрыть систему STATISTICA и вернуться в Word (Закрыть и
вернуться...), обновить график в программе Word и продолжить редактирование в системе
STATISTICA (Обновить...) или выйти из системы STATISTICA и вернуться в
программу Word (если график был изменен, то система STATISTICA спросит, нужно
ли обновить его в документе Word).
Предположим/к графику добавлен следующий пользовательский текст.
iriii'rifiiiini.fiHi'itiMi-f.ia'.fi
Итоговая гистограмма для переменной WORK_1
30fi
«=60 G0.801 (90.100] A10.1201 A30.140|
F0.70] (80.90] A00.110] A20.130] »140
WORKJ
В меню Файл выберите команду Выйти и вернуться в Microsoft Word. Теперь
в документе Word содержится обновленный график.
Пример 5. Добавление заданных пользователем статистических графиков 403
Я'ЯИПГИТМШ
'.ТЭ**** 0»** ** lw*,« '**«» 6mm 1*им Оки» J fflOwe
П£мш2Г
'нтррпретации rvjnyj* нньг»-ре1упь*^в'оудутра^с"мс*трш>г ;'':ч ::
распределения кпючевы* итоговых показателей Ц
Ра<: пред с пение переменной WWK_ f mowmo представить спедующим
образа Ц
Итого»»* mtion»ut«>y<» п»р«м«Ш'ОД WORK_1
«i«ra>i»i
00| A10 1 Ml A30.1*01
A00 1101 A201ИЧ «1*0
Распределение этой итоговой переменной бпиэко * мормапьюму
распредепениюЦ
id» i Nitt
w mv** ctt *•«
Как видно из рисунка, на графике, внедренном в документ Word, присутствует
новый текст.
Пример 5. Добавление заданных
пользователем статистических графиков
в окно Галерея графиков и в меню Графика
STATISTICA позволяет включать в пункт меню Графика дополнительные типы
графиков, определенные пользователем. Это очень удобно при построении
типовых графиков с конкретными параметрами настройки. Кроме того, определенные
пользователем графики, а также типовые настройки могут быть поставлены в
соответствие кнопкам на панели инструментов Кнопки автозадач.
Предположим, что в процессе контроля качества обычно производится 25 серий
измерений, в каждой из которых берется по 5 образцов продукции. При этом
каждый раз по этим данным строится минимаксная диаграмма одного и того же типа.
В этом случае для экономии времени целесообразно включить этот конкретный тип
графика со всеми его настройками в список графиков, определяемых
пользователем. Этот список вызывается из меню Графика (в подпункте Статистические
графики пользователя).
шттт&ьшш
ft> ■**»«* »wimi»
404 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
Файл данных
В этом примере используется файл данных Pistons.sta. В нем содержатся
результаты измерений диаметров поршневых колец, 25 серий измерений по 5 колец в
каждом. Часть этого файла представлена на рисунке.
ГчЕ
HHOlSizes of
ЭНЙЧ
Щг,
5"!!
Hi
in
£>•
JsL
T.^i
I*
>* и
АР
Ж
UL
iL
i$
Q.
1 x'J
SAKPtE 9
1.000
1.000
i.ooo[
1.000
1.000.
2.000
2.000
2.000
2.000
2.000
3.000
3.000
3.000
3.000
3.000
л nnn
ИСЕИ]
piston iT|
74.030;
74.002:
74.0191
73.992
74.008;;
73.995
73.992
74.001
74.011
74.004
73.988,
74.024/
74.021: i
74.005
74.002 .
Определение параметров графика
Откройте файл Pistons.sta и выберите в меню Графика пункт Статистические 2М
графики — Диаграммы размаха. Появится диалоговое окно 2М диаграммы.
шшщщ
ЕШ]
щшг;"
ЦП Состою* ^Г^щ тт:^;Ш-Щ &.$$&
Нажмите кнопку Переменные и выберите переменную Samples в качестве кате-
горизующей в поле Группы на диаграмме, а в качестве второй — переменную Size.
Нажмите ОК, чтобы закрыть диалоговое окно выбора переменных.
На этом минимаксном графике должны быть показаны средние значения,
стандартные отклонения и интервал (максимум и минимум) для каждой серии
замеров. Поэтому в списке Средняя точка выберите строку Среднее, в списке
Прямоугольник — Ст. откл.у а в списке Отрезок — Мин-макс. Затем в поле Группы на
Пример 5. Добавление заданных пользователем статистических графиков 405
диаграмме поставьте переключатель в положение Коды, нажмите кнопку Задать
коды и выберите их значения с 1 по 25. И наконец, нажмите кнопку Параметры и
установите режим Текст или даты на осях. Закройте диалоговое окно
Статистические графики: параметры. Теперь диалоговое окно 2М диаграммы размаха
выглядит следующим образом:
ж
[7>Л Отрезки
Прямоугольники JLJ
\Щ Столбцы
-■-группы иаШ^гранйё^
;ф ntp*M*MM^SAMr^;..•••.■:■'..
* С Km* •' *т".'.•>';•'.•
^.^ • -•••-•• "■■■■"■■
ш
J:.
[523 СоставноА
-. Груюы; SAMPU
'■■"••■•'•'.••''/••"•.:■•''';•. ,'•>•' ПерамчндЛ: SI2K •
■J, » )
ffi [| Отмена |
CpiwieeCt.oTKA :
Срелй^т^шУ^--
.1?
•■х..*:?*Г • 1
|Ст. откя.
il!
31
jСреднее
Г ОбЧедмидинеядоядрсия ]
31МЦМНИИК 1 Мин-макс
л!
]Друел:|нет
'■"Щ *. £а сденгом ^ ;f # -:.)
■ '| 1 j Г C'CntiMjKftMnieM^--^:-'; / -.]
B3 Г Сояяццит» средни» то«иш
{Выбр. и кр. точки
15
Mc**^^ToW |Г|
Создание нового графика пользователя
Все эти настройки могут быть сохранены в виде пользовательского графика,
который представляет собой таблицу графических стилей. Нажмите кнопку
Параметры и снова откройте диалоговое окно Статистические графики: параметры.
0*;
[ОПТИМИЗАЦИЯ ~
'| Су ftUMMMOl j/,"-:-'
i j: ftjMWi^&*»*** н/ р"» Щ] \ • &*: I*
^ОТОБР^ТЬ;:"
[<• НетГ Име»«наЛлюде«мй С Ляре*.; (SAMPLE
j.) |У|1е»^млм'деУы'н4'^мц
ГУ1
;Н>$ЛЮДЕНИЯ"^^.д^ :
'■ Ж Шов иабдвдетд ; *«^»сдвдие*гое**©Ы1акХ№«ая
еая..^ ждагеяаа.; -pga*^ й Размещение rpe**dV г- \
□ |«1Гор(ыв»*«>^«тОйИ1»грАФичесг.ог<> L Отмен» J
У : owe. "'•'
|Р
елороогимиругшеД «нуждим
ГА«1рокс4^нк4«я.етв
М Длинные «слоеные
| Г Заголовок «дммик j
• Г* Зеголоео* срвФнкд: J
••"::•;... (• Стдндартнал • . О Обратная
СИСТЕМА КООРДИНАТ 2* ГРАФИКА:f-
■■<• Дек «ртов* Г Полярная С Со сжатиям
ПОЛИНОМИАЛЬНАЯ ПОДГОНКА
! Порядок, полинома: С 2 ГЗ С 4 «5
годыммктпмьсдого гедсг»,.,««. ~.......— -^
'"'"'" ордгр^-!Й;:#:^ ПОДГОНКА
<• 10 Г в
• (ST £|ок«9«ть киопкм на последнем графика
категорий: ]3Щ
Показать индикатор состояния: |Авто HI
Добавить к >
Нажмите кнопку Добавить к меню как график пользователя, при этом
откроется диалоговое окно Новый график пользователя.
406 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
РОэ*ттъгр—т***т
В данном примере установите режим Сохранить текущие переменные с
определением графика. (Здесь можно изменить имя файла и каталог, в котором он
должен быть сохранен.) В поле ввода Название пункта меню введите название
графика для его обозначения в списке меню Графика (в подпункте Статистические
графики пользователя). Назовите этот тип графика, например, Контроль качества.
Закройте это диалоговое окно (нажмите ОК)> и заданная диаграмма будет
построена.
П Ср»*м»#*Ст crin
2 4 б • 10 12 14 18 И 20 22 24
SAMPLE
Выбор заданного пользователем графика
Закройте модуль системы STATISTICA, в котором вы работали, а затем откройте
его опять. Если открывать модуль с помощью кнопки Переключатель модулей
системы STATISTICA, то все его настройки вновь будут установлены по
умолчанию. Откройте файл Pistons.sta, если он еще не открыт по умолчанию.
Предположим, что этот файл теперь содержит новые данные, полученные по той же схеме
(то есть в первой переменной записаны 25 идентификационных кодов, а во
второй — результаты измерений). Чтобы построить этот предварительно
определенный пользователем график, выберите в меню Графика подпункт Статистические
графики пользователя.
Со1<»спю»р<опра»елош^стдг |
ЗМ помри юсп» (по*» homhww поуоимн
П|«тогр4*ик8о«хн*6лк!вений 1
Как видно, к этому списку добавлен ранее сохраненный график пользователя
Контроль качества (в том случае, если вы не добавляли в это меню другие
графики, график Контроль качества может оказаться единственным в этом списке).
Теперь выберите его, при этом появится диалоговое окно 2М диаграммы размаха.
Пример 5. Добавление заданных пользователем статистических графиков 407
шшяшаа
ШгЩ
В этом диалоговом окне сохранены и автоматически воспроизведены все
настройки, включая выбор переменных и кодов. Чтобы построить график,
подобный предыдущему, достаточно нажать ОК.
Диаграмма размаха (PISTONS STA 2V125с)
74.04
7403
74.02
74.01
74.00
73.00
7Э.ев
73.07
73.00
г 0 11 13 15 17 10 21 23 25
8 10 12 14 18 18 20 22 24
m
Млс
Мим
CD cptA*tt*CT
о
CptAntt-Ст
CptftMtt
oti
отт
Просмотр и редактирование списка графиков
пользователя
Для просмотра и редактирования списка доступных графиков пользователя
выберите в меню Сервис пункт Пользовательские графики.
Чтобы уюрщючит» <У*ссж гркцко», вмените ймемиг* I
(фИДОСТрвК&«ВК«М«*К1««Г»*?ОММ»СТ« .. i ' . и ,1
меяад строками. *ум шявп** «• ламмтмт*
408 Глава 9. Примеры визуального анализа и настройки графиков в STATISTICA
Можно изменить порядок графиков в списке. Для этого нужно выбрать строку
(строки) для перемещения и щелкнуть на новом месте расположения. Кроме того,
можно добавить новые графики (если они предварительно сохранены как
графики пользователя в файле с расширением *.sug)y изменить названия или присвоить
их заново. Ненужные графики можно удалить.
Удаление графика из списка на данном этапе не означает удаление файла,
содержащего параметры графика (файла с расширением *.sug). Операция Удалить
стирает имя графика из инициализационного файла системы STATISTICA
Statist.ini. Позже этот график снова может быть занесен в инициализационный файл
(с помощью кнопки Добавить), и опять появится в меню Графики пользователя.
Описательные
статистики
Дескриптивные, или описательные, статистики рассматривались в главе
Элементарные понятия анализа данных. Здесь мы покажем, как вычисляются
дескриптивные статистики, и уделим особое внимание описательным статистикам для
группированных данных.
Дескриптивные статистики очень важны, так как они позволяют в удобной
компактной форме описать исходные данные. Представьте, вы издаете журнал и вам нужно
описать читательскую аудиторию. Вы проводите анкетирование читателей и
просите их указать: пол, возраст, уровень образования, доход и другие параметры. Затем вы
вычисляете описательные статистки и находите, что основную аудиторию
составляют мужчины в возрасте от 32 до 47 лет, имеющие доход свыше а долларов,
образование высшее, женщины от 27 до 35 лет, имеющие доход свыше Ь долларов, образование
среднее и т. д. Разнообразные графики помогают вам визуально представить
результаты, которые являются основой для проведения издательской политики и анализа.
Заметим, что различные способы построения таблиц, описанные в главе 11,
также чрезвычайно полезны для анализа подобных данных.
Мы будем работать с файлом Adstudy.sta, который находится в папке Examples
и поставляется вместе с системой STATISTICA. Этот файл выбран специально
для того, чтобы вы могли повторить наши действия и далее самостоятельно
проводили описательный анализ собственных данных, так как позволяют установить
связь между, например, возрастной категорией и читаемым материалом.
Файл Adstudy.sta содержит 25 переменных и 50 наблюдений. Эти данные были
собраны путем социологического опроса в одном рекламном исследовании, где
мужчины и женщины оценивали качество двух рекламных роликов.
Каждому респонденту случайным образом предлагался на просмотр один из
двух рекламных роликов (ADVERT: 1 - Coke*, 2 - Pepsi*). Затем респонденты
оценивали привлекательность рекламы по 23 различным шкалам (с Меры 1 — Measur 1
до Меры 23 — Measur 23).
В каждой из шкал респонденты могли дать ответы по десятибалльной шкале,
то есть выставить от 0 до 9 баллов. Пол респондента кодировался: 1 —
МУЖЧИНА, 2 - ЖЕНЩИНА.
Нажмите кнопку Описательные статистики. Далее нажмите кнопку
Переменные и выберите переменные для анализа.
ю
410
Глава 10. Описательные статистики
<£«** Qpmk« |иа &*то £pt+*A fiojartc flwo j
■ Jtfixj
AI)SIUDYSTA?bn-bOM
шишштшшвт
Advertising Effectiveness Study
2* [Г] Щ Ц S Г 6 ] 7 [ a 19 1 10 ] 11 j 12 I 13 I 1.
►Г
" |въаоя8Ы1СЛ ~ }8мбор:8ЫКЛ |В*с£ЫКЛ (
В данном случае выберите все переменные. После нажатия ОК в окне выбора
переменных диалоговое окно Описательные статистики будет выглядеть
следующим образом:
H'L'lliHil-lWII'lil'l
ЁЗ Дар» иии»—: | ВСЕ
Подобные опмсетел
i статистики
ОПЦИИ •:•••.••:•.: ;",v ;■;•;•••.;•■■■;. ■:■;
Г Построчное удаление ПД
Г* Отображать А****** и» юна перемети»
Г* Вычисления с поеымюнмои точиостыо.
■ Распределение -""■* -—' ^—-- ~—=• '—-* •-—=-=--
Статистики -— -■..-■.— .
Р Медиана и доартили
V Доверит, гренмды средни»
Иитереал: ]95^[Ц*
VI Драхме статистики I
IB №1
Отмене
Ittl&ftl
,'£* .е-ео<ск«ш
Программы
j Г* Ожидаемые нормальные частоты ■'■■'■';■.
\ Г »^»итерие ■*пмро-«ижа W •'
£р*лпмро»к*
(• Число интереелое: |10
С Целые интерееем (категории)|.
\ЙЩ Диеп>ме»вр*дмааадляос»я паранаткд 1, §§ ^агоридооыиело диаграммы раамава
□
□
- 1 '.. *Г!."! "" '"""'. "I"!!! .""j
Нормальные еероодмостиые графики ]
Полуиормальныа вероятностные греелеш |
ГП Нормальные еероетиостмые граечеш бее тренда |
ЕВ32И
iIi/ЗМ
рассеяния || с именами ] §§ Матричный |
рассеяния ][ с именами | 1^ Поеедоюсть ]
,ЕЩ
88
1§
Катвгормэоеанные графики средник |
Кахегориооеаниые гистограммы |
(Сатегориеоеаниые нормальные графики |
881Сатегори9оеанные диаграмме! рассеяния ]
18?
ЗМ гистограммы j
По умолчанию таблицы результатов окна Описательные статистики
содержат средние значения, число наблюдений без пропусков N, стандартные
отклонения, а также минимальные и максимальные значения для выбранных переменных.
С помощью кнопки У задаются условия выбора наблюдений.
Описательные статистики
411
* о < ><ш >»N0TAN0Oft £*
>7<t OB *VttS4 <nf *<>0
В окне Условия выбора наблюдений можно задать правила выбора наблюдений
из файла данных. Таким образом, будут анализироваться не все наблюдения, а
только те, которые удовлетворяют заданным условиям.
Кнопка В позволяет ввести веса, таким образом могут быть введены, например,
группированные данные (см. пункт Как проверить нормальность наблюдаемых
величин в главе Элементарные понятия анализа).
222!!!!ЭВЭЭЗННННВННСЕЕЕЗ
Д*С И» tWpliWIHOft | Щ 1
1к« :Т5=Т
'. ЯИПРФЪ Л((ЯМЯИИМ М>
Г дал огмж*
Нажмите кнопку Другие статистики, чтобы открыть окно Статистики, в
котором можно выбрать различные описательные статистики.
Вы можете выбрать любой набор статистик из предложенного списка. В нашем
примере оставьте выбор статистик, сделанный по умолчанию, и нажмите кнопку
Подробные описательные статистики для построения таблицы результатов.
I % ХЬ ШI УСА: frrwm***:Ы4в-Шт * ** *M*wix*
Г* Сттшщптш nmilkn <и>'«
Г 9 * яйшчт.грттщ* mm е
Г ОштЛттттт*,мт.т,шч» # ы,
Г К»мг. шц» ишидт» К—м» Г Нмшни*
cm" "w"*:':'*'"::*' * Г Кмтммм*имм>
1ЙН| Диаграмма рммщадяк
га
i ым«ц||пча омом тктттящт
Дмгм* «не*»*»»** сгеияикк i
:(fH С- *и
мыв имтямммы fnwrwoDMtl
fcwiiHX» гмствгр w<m
у fwnwrp^HNM
412
Глава 10. Описательные статистики
ADVERT
MEASWRl
XEA5UR3
ХЕА51ШЗ
MEASUR4
KEASURS
HEA5UR9
HE4S0R1Q
50
50
50
50
50
50
50
50
50
50
50
SO
440000
460000
900000
540000
140000
520000
960000
840000
4 660000
3 720000
4 160000
3 940000
000000
000000
000000
000000
000000
000000
000000
000000
000000
000000
.000000
000000
000000
000000
000000
000000
000000
000000
000000
000000
000000
000000
000000
000000
501427
503457
2 366863
2 887058
2 725615
2 659139
2 633846
3.019393
2 495792
2 806988
3.046309
3 053335
Графиком по умолчанию для этой таблицы результатов является гистограмма
с наложенной на нее нормальной кривой.
Этот график обычно используется для того, чтобы представить, как
распределены значения переменной, а также для визуальной проверки нормальности
исходных данных (подробно гистограммы описаны в разделах книги по визуальные
методам анализа данных).
Для построения графика щелкните правой кнопкой мыши в любом месте
таблицы результатов (например, на среднем значении переменной Measur 7) и в
появившемся контекстном меню выберите построение графика Гистограмма/нор-
мальн из меню Быстрые статистические графики.
Такая же гистограмма может быть построена после нажатия кнопки
Гистограммы в разделе Распределение окна Описательные статистики. Этот раздел
также позволяет анализировать распределение частот для каждой выбранной
переменной (при этом происходит построение по одной таблице результатов или
гистограмме на каждую переменную). В этом окне возможно также вычисление
некоторых специальных критериев нормальности и использование настроек
категоризации изучаемых данных.
ал
■ klDIXll
MEA8UR7
К-С d« 16433. р< 16 ,Л*лли#фороа p« 01
Ожим«иы«
Норимльм
ицы(х <■ граница)
Описательные статистики
413
Окно Описательные статистики предлагает большое количество графических
процедур для проведения визуального анализа распределений переменных и
корреляций между ними. Например, нажмите кнопку 2Мрассеяния (с именами),
чтобы получить наглядное представление о характере зависимости между двумя
переменными.
При использовании опции с именами программа располагает на диаграмме
имена наблюдений рядом с соответствующими им точками. Вы можете построить
матрицу диаграмм рассеяния, нажав кнопку Матричный.
гтшят
штш^шшшшяш^яшшштяшшштшштшшттшшлттшяттш^шттт
flllimiliimwMiiiiiiriiiiiii^^
2М диаграмма рассеяния
MEASUR1vs MEASUR2
9
7
:
> ОС
и 5
: Z
{ 3
j 1
Р Squre С Mayer
О О
М Quick J Owen 0 Leno
О О О
М ONei В Quaie A Sm*h
О О О
Е Bynurn L.Hosen F East H Morrow N Segal
0 0 0 0 0
J Oury R Irving M Crow J Harper
0 0 0 О
U. Andy S Brd
0 0
R.Jerm К Small C.CW
О 0 0
T.Bush F.Wnd 1 Ned 0 Bos«
0 0 0 0
0 Hogen M West
0 0
I Mynard D Young M Oood
0 0 0
1 1 3.5 7
MEASUR1
D Frynd
0
M Brown
0
N Luce
0
S Reber
0
J Liu
0
J.Baker
0
9
—■' ''
HHLbJJbUUmJI
11 I
UIIIII..|llllWlll!llll.|l|l|lii|IUIIIIIlHai.miLI ■
Корреляции (C0BBS.8TA 21п*400м)
Ш-Q
J^>"
•V?"
ОСУУ0УС_о
Кнопка Поверхность предназначена для построения поверхности в
пространстве (по умолчанию второго порядка), приближающей значения выбранных
переменных.
414
Глава 10. Описательные статистики
U».H..|l|lLl.l.UJ.IH!l.liJl.lJ.I.I.IJII.I.I.l.l.lU
Поверхность второго поряака
VAR1 vs VAR2 vs VAR3
Н 98.621
Н 99 059
Ш 99.497
Ш 99 935
CZ3 100 372
I 1100 81
Ш 101 248
Н 101 686
tm 102124
Н Ю2 562
Также возможно построение категоризованных диаграмм размаха, гистограмм,
диаграмм рассеяния и вероятностных графиков.
Наконец, есть возможность построить ЗМ гистограммы двух переменных для
изучения двумерного распределения выбранных переменных.
Этот график обычно используется для описательных целей, а также при
проведении разведочного анализа данных; однако иногда он может быть полезен при
проверке нормальности двумерного распределения.
ьншиниг
S
MEASURE I MMEASURE2
ЗН гистограмм* для : HIASURI1 и HIASURI2
Число мабл.
Корреляции
Корреляции измеряют степень зависимости между переменными. В файле
данных имеем несколько шкал (переменные Measur 1 — Measur23).
Вначале проверим, не коррелируют ли между собой оценки в различных
шкалах, другими словами, не измеряют ли некоторые шкалы, по сути, одни и те же
Корреляции
415
свойства объекта. Если окажется, что некоторые шкалы зависимы, мы просто
сократим анкету, выбросив из нее лишние пункты.
Вначале вычислим корреляции по всем наблюдениям, далее рассмотрим внут-
ригрупповые корреляции, то есть корреляции внутри групп. Вообще, вычисление
корреляций наряду с группировкой и построением таблиц — стандартный первый
шаг всякого исследования, связанного с анализом данных.
В стартовой панели Основные статистики и таблицы выберите процедуру
Корреляционные матрицы и щелкните ОК (или можете просто дважды щелкнуть на
процедуре Корреляционные матрицы).
|Ш критерии Л*» не»
ЕЭ t-*P**epMft для j
jJJ Группировка и одио+акториая AN OVA
Таблицы частот
Таблицы и заголовки
\lSMk Вероятностный калькулятор
0Е*\ Другие критерии значимости
: {У Данные
жш&&{
После выбора этой процедуры откроется диалоговое окно Корреляции
Пирсона.
£3 Корреляции Пирсона
jj5jj Клтцьнтрт* [<*т спмсо*|:■ {И Прдмочс метро** (ем списка) ■■ | [В • jfijcf >' }
:'' ■ . vi:''^^"'V U^y**}* "
ДВ Сохранить матриц [
Отмена |
ц|ав
Отображать - •**—~~*-.а*~-
(• &орв\ метраже, (еше*.:
я\ 11 рТ Построчно* удойна*» П Д
С Корр. мвтрицч (отоорвжлть рм N) \\Г Отображатьммниыеимена nepeetj
Г Подробичю тебанач реауцгто»
Е3 2М
• -- ■_ ^ ,:r :^;#|pf
3 Матричный I 39 Катетор. янаграша* рассеяния
1^3М
j taJE" Поверхность
ЗМ гмстогрлммы
]Ь*в1*^*эн>мддеик«)ррелйииии^
модул Клаогерный еиалиь Да* начислений множественной корреляции и частные коррелят *сг»яьэ^г#
модуль Мнс>«роаг§енна«реги»осий. ' ^?:.Д-^''--К'''
Вы можете выбрать переменные как из одного списка (то есть матрица будет
квадратной), так и из двух списков (прямоугольная матрица).
В данном примере для простоты выберем все переменные для анализа. Однако
следует помнить, что корреляции Пирсона больше подходят для переменных,
измеренных в количественных шкалах.
Для номинальных переменных, таких как GENDER, ADVERT, применяются
другие методы исследования зависимости (см. главу Построение и анализ
таблиц).
Итак, хотя формально корреляции вычисляются для всех переменных, мы
сосредоточим свое внимание на корреляциях между Measur 1 — Measur 23.
416
Глава 10. Описательные статистики
г auvi н г
I Ml ASIJII1
4MIASUH?
SMI AMIII.1
Ь MlASUH4
/MIA'.UHS
В MLASUHB
«JMIASUH/
10MIASUHB
II Ml Л",НИМ
i? mi asiihio
Доироб.
»» t
Нажмите OK, чтобы вернуться в диалоговое окно Корреляции Пирсона,
ж-.\-™ъ&ш**<&
си
:< ОСНОВНЫЕ ]Омм«чемиые корреляции значимы не уровне р < .05000 $
II СТАТИСТ |Н'50 (Построчное удаление ПД) Та
Вы можете указать уровень значимости {альфа — 0,05 по умолчанию) для
выделения значимых коэффициентов корреляции в таблице результатов.
Чтобы изменить уровень альфа, щелкните по кнопке Параметры на панели
инструментов таблицы результатов и откройте диалоговое окно Уровень
значимости. Введите в это окно уровень значимости 0,001 и щелкните ОК.
Шш
177x1
■• Веедите жимишь яиееммовзд {еяьфв! ami jmmmjmmimr \ OOll
ев в*
Корреляции 417
Легко обнаружить высокие корреляции (например, корреляция между
Мерой 5 — Measure и Мерой 9 — Measur 9 равна — 0,47).
Такая высокая отрицательная корреляция показывает, что две шкалы оценок
могут измерять одну и ту же характеристику зрительного восприятия рекламы
(хотя одна мера этой характеристики возрастающая, а другая — убывающая).
Две опции из диалогового окна Корреляции Пирсона позволяют получить
таблицу данных с коэффициентами корреляции, а также более подробными
статистиками (например, р-значение, число пар N, ^-коэффициент детерминации, £-зна-
чения и т. д.).
Когда вы выберете установку Корр. матрицу (отображать р и N), вместе с
коэффициентами корреляции будут также выведены р-значения и число пар N
наблюдений, по которым они вычислены. Данная опция полезна, если в данных есть
пропуски и нужно точно знать объем выборки.
Выбор опции
Подробную таблицу результатов в диалоговом окне Корреляции Пирсона
возможен только при выборе 20 или меньше переменных для анализа, так как для
каждой корреляции автоматически будет выводиться большое количество
информации. После выбора этой опции будет построена таблица результатов, содержащая
соответствующие описательные статистики, коэффициенты корреляции,
^-значения и число пар N, а также наклон и отрезок регрессии для каждой переменной.
418
Глава 10. Описательные статистики
Эту опцию следует использовать только для отдельных корреляций (но не для
подробного анализа), потому что в этом формате для каждого коэффициента
корреляции будут заняты 22 ячейки таблицы результатов; таким образом, для
матрицы корреляций 20x20 получится таблица результатов с 8800 ячейками.
Вы видите, что корреляция между Measur 5 и Measur 9 действительно значима
(р=.0006). Это говорит о том, что ошибка, связанная с принятием гипотезы о
независимости, составляет 6 из 10 000.
После того как получена оценка корреляций, посмотрим зависимости на графиках.
Чтобы визуализировать значения корреляций между переменными, можно
построить график корреляций. Если щелкнуть по соответствующему коэффициенту
корреляции (-0,47) правой кнопкой мыши, то появится меню:
■■■■■■■■■■■■■■пщщ!
[Отмеченные корреляции значимы на уровне р < 00100^*
(Построчное удаление ПД)
доШЩШящдарШЁ&яЩ
10
-SL
12 1 00 05 03 -.08 - 07
-.33 ; 05 1.00 00 23 09
1-27 03 00 1 00 08 -.01
ЩЩШШШШГШШШШ
£3 Ошь**»мье*и* графики »
JA Быстрые основ»** crimen**...
Ш Сп<11иФйк*ииистфйбцД~'
1 Иместро**..
ф Нвжиромгьаыдоянио»
Ю ^<по/нигы'сгвиа«рти^>омт1»б«1сж *
Ы Стлгистикябяокл по столбцам >
gQJ Сw>cn*w блекл по строкам • ►
X Ы*ж* СМ«Х
(& £рпиров«г^ CW+C
(& Концхимп» содержание ,
ф Bcr<***> V*.**-*
0 О^^сшгь Del
1 03
l 1.00
; 05
l - 09
17
! 11
1 - 02
: 15
. -.11
11
jSH
Теперь перейдите в подменю Быстрые статистические графики и выберите
Диаг. рассеяиия/довер.
Будет построен график с параметрами, заданными по умолчанию (диаграмма
рассеяния для выбранного коэффициента корреляции с прямой регрессии,
доверительная полоса 95% и уравнение регрессии в заголовке).
QBE
Дме#.*
Отмеченные корреляции значимы но уровне р < 01000
N■50 (Построчное удаление ПД)
MEASUftlO
:MEASUfm
:MEASUR1?
KCASUR13
MEASUR14
MEASUR15
MEASUfit?
MEASUftlj
MEASUFH8
MEASUR19
-24
09
-01
-12
14
-21
11
25
00
06
j йшрт+* р*т т* йпл MEASUflS
g 2U гметогр»** no MEASUftS
ДО г>югогр»»« n»ME*SUft$
3 /Wjj«wM»<>ft3M4rtno^ftASW»$ '/"
I Вямигностньй гдоик по М£А$Ш$
> Q<*«h^M€ASW5mM£ASU*3
J Ыятр"**я «натр»*» рассмим...
p 00
03
15
08
07
h 32
23
22
16
02
Unix»
-07
09
-01
03
1 00
05 *Д
-09
17
11
-02
15
-11
11 <*
>П
Корреляции
419
ft STATISTICS Основные ст.
файл Оравкд Вид Встаем £«амвткм ^н**© Графика £*р*ис Qkho 2
l.lfflxl
гёШИ^ГА^ШУ* $ |Д Ш*Ш*
шм
Шштшш
Advertising Effectiveness Study.
Г|»1Й»|#«*Ш»Й f«**ив* »»?
Д*дее...
Этмеменные корреляции значимы на уровне р < 01000
sj-50 (Построчное удаление ПД)
В. Brown
С. Науес
В. «est
Ь. Young
S. Bird
Ь. Flypd
J. Oeen
HAI
tehai Перемен
hai MEASUR7J
hai MEASUR8
TEHAI JJgJj^Jgj0|
[fehai M£ASUR10:
hai MEASUR11
tehai MEASUR12
C. Clint
G. Вовв
hi I
l.».M.!l!IHlU.UII:L|llMII.UIIlLII.UJ.I.[i|!I.IJWHPi
MEASUR9 v» MEASUR5 (Постро^юе давление ПД)
MEASUR5 - 5 Б404 • .4039 ■ MEASUR9
Корреляция г ■ • 4672
пл| яга а г
В. Мог со v I hai MEASUR13
Г. E*st fehai MEASURE
hai MEASUR1& |
hai MEASUR16 2
hai MEASUR1? 2
MEASUR18
MEASUR13
ко-
loo о
[■" ' - .О О О . • О *
г-^-^_ *'•••? ° *
V О <^""^^-_" °" " - - О О О
I ° "°" ""■"•-.. '"° • - -
L . . о "^--T^S"-—^_©
| О о "* -.. о ♦■
[■ о -о • о о* %--.-р-
I о о о о
3 5 7
MEASUR9
Регрессия
95*дое*р
\1ШШШШ№Ш1*\\
{Готов*
* |в*ак*ПРИНТТг* |Вы6ор.ВЫКЛ |ВасВЫМ1 [
Мы вернемся к этому примеру и рассмотрим зависимость между Measur 5 и
Measur 9 для группированных данных.
А сейчас опишем некоторые возможности для настройки построенного
графика зависимости.
Если вы щелкнете где-нибудь на свободном месте снаружи осей графика,
появится меню глобальных опций.
l..l,..nvi,UII.LI.lllllll.LII,l,LI,i Ml >Ц1М ,,,,!■
HIASUR9 v§ HIASUBS (Построчно* ул*л«мм« ПД)
MASVRS - 5.6404 - .4039 * HIA3UH9
Корреляция: г ■ -4672
HjpWHHT» ра»«ш«*и графим..
■йшжмралвгъй—*т ура»**-,- •
Задать щнйсиъ трюьцл/дрм''.,.
о о Мстив**» а—та «она-•. '■<■
-5^"' Врана* объект.*.
в' * •. Вставить
о {атававатьтраздах,
Л1чат*гра«*а
Ъвфтвырьтт •
i Дана ат урана ' : v' Jj *
Большинство основных настроек формата графика доступно в диалоговом окне
Общая разметка (см. выше первую опцию контекстного меню).
420
Глава 10. Описательные статистики
feJfcL
[ MEASUR9 vt. MEASUR501ocr|MHMM уимии* ПД) 1*=х^5*;«% \
Ниже показаны основные соглашения по использованию мыши для настройки
графиков.
Вычисление описательных статистик
для группированных данных
Развитие сюжета далее довольно естественное. Вначале мы вычисляем
описательные статистики и корреляции для всего массива данных, затем для групп данных.
Оказывается, что зависимости в группах данных существенно отличаются от за-
Вычисление описательных статистик для группированных данных
421
висимостей в исходном массиве данных. Сравнивая полученные результаты,
приходим к мысли, что группировка — это действительно то, чем следует заниматься
на первых этапах дескриптивного анализа данных. Например, врач проводит
группировку пациентов по полу, возрасту, заболиваниям; экономист группирует
людей по уровню доходов; инженер по контролю качества группирует причины,
вызывающие смещение качества производимой продукции. Проводя группировку,
мы стараемся выделить группы однородных объектов (исходные реальные данные,
как правило, неоднородны) Вы можете воспользоваться методами кластерного
анализа для лучшего понимания структуры данных и разбиения их на одноролные
группы.
В системе STATISTICA вы можете вычислить разнообразные описательные
статистики (например, средние, стандартные отклонения) для данных, разбитых
на группы одной или несколькими группирующими переменными (например,
переменными Пол — Gender и Реклама — Ado). Мы рассмотрим, как это можно сделать.
Но если бы мы задали вопрос: как вообще провести группировку исходных
данных, то мы не могли бы на него ответить. Ответ лежит в предметной области
исследования. Итак, интуитивно вы ощущаете, что бы хотелось найти, далее,
используя систему STATISTICA, сравниваете различные способы группировки
(возможно, это займет довольно много времени) и находите нужный вариант.
Внутригрупповые описательные статистики вычисляются с помощью
процедуры Группировка и однофакторная ANOVA, доступной из стартовой панели
модуля Основные статистики и таблицы.
1ШШIIГШ1 ""I
j2i. Описательные статистики
| Корреляционные матрицы
ЕД t-критерии для
1B3) t-критерии для
швг
S3 •'••JK-
с выборок
£
Отмена
IffllllYil
(Таблицы частот
| Таблицы и заголовки
1а Вероятностный калькулятор
Dul Другие критерии значимости
1Й*
агж«*
После выбора процедуры Группировка и однофакторная ANOVA в стартовой
панели нажмите кнопку Переменные и выберите группирующие переменные
GENDER (МУЖЧИНА - MALE и ЖЕНЩИНА - FEMALE) и ADVERT.
В данном примере выбор группирующей переменной не представляет никакой
проблемы.
FmWllll..l.l|li..MllJ.i'IJ->.lliliii|inl.U.IJ,l|i
iG&yA Подробный анализ выбранных таблиц
422
Глава 10. Описательные статистики
анш
щ
шщшшшшш
ШШШ
3MEASUR1
UMEASUR2
J5MEASUR3
J6MEASUR4
7MEASUR5
J8MEASUR6
J9MEASUR7
10MEASUR8
11MEASUR9 21
12MEASUR10 22]
13MEASUR11 23
14MEASUR12 24
15MEASUR13 25
16MEASUR14
17MEASUR15
18MEASUR16
19MEASUR17
20MEASUR18
И Mt ASIJH1
4 MLASUH?
ЪMEASUR3
KMtASUfM
/ MIASUH5
HMIASUH6
9MtASUR7
IHMf ASIIMH
II MtAbUHy ?
_I?-MLASIJH10 ?;
13MEASUR11 ?
14MFASUR12 ?
15MEASUR13 У
16MLASUH14
17 MEASURE
1UHLASUH1B
19MEASUR1/
?nMFASIIR1R
VmiiiiAmmmmJ
' Отмен* i
; j See : lRtafcpo& H Нн»7~|| 8w | Поцроб. jj Ни», j
Грул
325
Щелкните по кнопке Коды для группирующих переменных и выберите коды для
группирующих переменных в диалоговом окне Коды для независимых факторов.
IWI.IllWI'H'l.l
;: :6ENi)Ellrjl 2
•;'-:.J^Bt;.[PEPsr
:'Г" *■■/."' ••* '•■
ЯИЕ5ЯИИИ
СОКЕ * '
"JiSL
Be*.
ИнФ. |
■HLJxj
ifv^CTf
* Отмене j !
ЙмИрат »всв|
Чтобы выбрать все коды переменной, можно либо ввести номера кодов в
соответствующем поле ввода, либо нажать кнопку Все, либо поставить * в
соответствующем поле ввода.
Щелкнув по кнопке Выбрать все в этом диалоговом окне, вы выберете все коды
для каждой переменной. Нажатие ОК без задания каких-либо значений
эквивалентно определению всех значений для всех переменных.
Нажмите ОК здесь и в диалоговом окне Внутригрупповые описательные
статистики и корреляции для того, чтобы открыть диалоговое окно Внутригрупповые
описательные статистики и корреляции — Результаты.
сательиые статистики и корреляции Результаты
ЗАВИСИМЫЕ 23 перемен MEASUR1 MEASUR2MEASUR3
MEASUR4 MEASUR5 MEASUR6
ГРУППИР 1 GENDER ( 2) MALE FEMALE
2A0VERT ( 2\ PEPSI COKE
•Ом
тяШшттЯ
I— r Статистики
!.Г
@ И*
Г Ото£р*ж«т1» дммиан им*** г
I* Ртобращдтъ лтшшшит мети впачении
Г &И4ММ
Г СТАНАОДН*» «TIUMMtHMI
Г* Дисперсии
Г Маяиана и квартили
; j.jOwwwjHi.J
^».-:
Апостериорные сравнения средни»
j &етегориэоаен1че гистогра»»<ы |
3 Категорией лице морм.а«р<мгм.графики I
Брд»<а-<ВорсеАт* (ОД) | ДД Графики ■
И ^тт | ВВ
\{ Переуоря*лт»гъ «хитром » табаиае [ Г-^1 Графики средни» и станл onmoiwiHifl |
Вычисление описательных статистик для группированных данных
423
Диалог Внутригрупповые описательные статистики и корреляции
предоставляет различные процедуры и настройки для внутригруппового анализа данных
(анализ данных внутри групп). Цель такого анализа — лучшее понимание
различий между группами.
Вы можете выбрать нужные статистики для того, чтобы отобразить их на
экране в Итоговой таблице средних или Подробных двухвходовых таблицах.
В этом примере выберите все пять возможных статистик (сделайте
соответствующие установки в группе опций Статистики).
ШШШШЖ
ЗАВИСШИЕ: 23 перемен.
HEASUR1 HEASUP2 KEA5UR3
HEASUR4 HEASUR5 HEASUR6
ГРУППИР.: 1-GE1IDER ( 2): HALE ГЕНАЬЕ
2-ADVERT ( 2): PEPSI COKE
ш
Г Отйрлмтья
ft йхобрщщюьш
Сгтчсгшн
< № Цист плбмттшЛ
Р» Стмтффшм отклонения
<*J
«5Г J
© О*
Г^^П
Дис1
J §8 КТТ0|Н№0ИИИ1Ы«ДИТР—«МЫ
1 И ь
Алосториооим* срштыщ с
д К ЛЯ М ОРИДЮХИ1Щ)И)
Ш Д«
1 И S»»i+±oec<*f[Om
tpa+жн ш9*нмалш*сг»иЛ
Ц Пврипорйциить чжтиам в уобтщш | Q3 Гречем
Затем щелкните по кнопке Подробные двухвходовые таблицы, чтобы увидеть
таблицу результатов.
М^ШШМШ
Палев И"^0 (Не* пропусков в завис перем )
J-IOIxj
GENDER KEAS0R1
ADVERT | Cpoqwua
PEPSI
COKE*
ЩА1Е
PEPSI
COKE
frf, fPOT4
Ж
285714
538462
066667
409091
428571
375000
900000
НЕАЗШЦ
MEASURl
С». ОШКА
13
15
22
14
8
50
176 0000
85 0000
91 0000
119 0000
76 0000
43 0000
295 0000
2 088011
2 331501
1 907379
2 648613
2 243428
3 420004
2 366863
KEASUR1
Диоптре.
35979
43590
63810
01515
03297
HEASUr-j
4 6428
4 4615
4 8000
4 4090
3 9285
5 2500
4 5400*
>Г1
В приведенной таблице результатов имеются описательные статистики для
выбранных переменных, разбитых на группы (прокрутите таблицу, чтобы увидеть
результаты для остальных переменных).
Изучим эту таблицу. В первом столбце показаны средние переменной Measur 1
для различных групп данных:
О для всех мужчин (MALE) среднее Measur 1 равно 6,29 (см. первую строку, мы
округлили приведенное в ней значение);
О для мужчин, выбравших PEPSI, среднее Measur 1 равно 6,54 (см. вторую строку);
О для мужчин, выбравших СОКЕ, среднее Measur 1 равно 6,07 (см. третью строку);
О для всех женщин (FEMALE) среднее Measur 1 равно 5,41 (см. четвертую строку);
424
Глава 10. Описательные статистики
О для женщин, выбравших PEPSI, среднее Measur 1 равно 5,43 (см. пятую строку);
О для женщин, выбравших СОКЕ, среднее Measur 1 равно 5,38 (см. пятую строку);
О среднее переменной Measur 1> вычисленное по всем наблюдениям, равно 5,9
(см. шестую строку).
Заметьте, если общее среднее, без учета группировки, равно 5,9, то среднее
в группах — уже другое.
Спрашивается, велико или мало отличие среднего в разных группах? В
анализе данных для ответа на вопрос имеется специальный критерий, известный как
t-критерий Стьюдента, который позволяет прояснить ситуацию. Этот критерий
подробно описан в отдельной главе.
Сейчас можно лишь сказать, что имеется слабое различие переменной Measurl
в группах MALES и FEMALES.
Как можно заметить, имеется слабое различие между группами PEPSI и СОКЕ
в пределах одного пола. Группы, получающиеся разделением по полу, кажутся
достаточно однородными. Максимальное отличие в средних имеет место
между группой MALES — PEPSI (среднее равно 6,54) и группой FEMALES — COKE
(среднее равно 5,38).
Внутригрупповые корреляции
Корреляции измеряют степень зависимости между переменными. Если данные
разбиты на однородные группы, то есть надежда, что зависимости станут более
отчетливыми. Именно за это и идет борьба.
Итак, если у вас имеется массив данных, то часто первое, с чего можно начать, —
это группировка данных. Очевидно, если у вас мало данных, то поле действий резко
сокращается. Рассматриваемая нами группировка достаточно проста и
проводится с помощью лишь двух группирующих переменных. Однако если вы, например,
изучаете зависимость суммарной покупки в супермаркете от дохода покупателей
или проводите сегментацию рынка, то вам придется достаточно поработать, чтобы
эффективным образом разбить данные на классы.
Итак, проведем группировку данных, рассмотрим зависимости внутри групп и
сравним с результатами для негруппированных наблюдений.
Если у вас имеется массив данных, то первое, с чего следует начать — провести
группировку данных, разбить их на более или менее однородные группы.
Нажмите кнопку Внутригрупповые корреляции и откройте диалоговое окно
Выберите группу или все группы, в котором можно выбрать группу (или Все группы)
для корреляционных матриц.
тмташштяж
ига!
6ЕН0СЙ ftOUERT
MALE PEPSI
HfllE COKE
FEMALE PEPSI
FEMALE COKE
Lter*,J
просмотреть
юн ют*
или Все
группы. <*и*
Внутригрупповые корреляции
425
В частности, нас интересует внутригрупповая корреляция между
переменными Measur 5 и Measur 9.
Ранее мы вычислили ее (г = - 0,47) для всех данных и увидели, что она
высокозначима (р<0,001).
В диалоговом окне Выберите группу или все группы дважды щелкните на
строке Все группы, чтобы получить следующие 4 корреляционные матрицы:
mnimi^'h! I'lifjii'^i/1
<£«вл Ядом 2ча £иалиэ &ДОика. Сервис: $кно ' 2
1-1б»|х|
Как можно заметить, корреляции в отдельных группах заметно отличаются друг
от друга, следовательно, отличаются зависимости в разных группах.
Следующий наш шаг состоит в представлении зависимости на графиках.
Внутригрупповые корреляции можно представить графически, используя
команду Категоризованные диаграммы рассеяния в диалоговом окне
Внутригрупповые описательные статистики и корреляции — Результаты.
Нажав эту кнопку, вы сможете выбрать переменные для графиков.
irrJI'^ViMi • ,1,111|'||1||1|ГЖ
[3 MEASUR 1
4-MEASUR2
J5-MEASUR3
J6MEASUR4
рснншаи
I8MEASUR6
9-MEASUR7
10MEASUR8
11 MEASUR9
12-MEASUR10
13 MEASUR 11
14MEASUR12
15-MEASUR13
16-MEASUR14
I17MEASUR15
18-MEASUR16
19MEASUR17
20-MEASUR18
21 MEASUR19
22-MEASUR20
3MEASUR1
4MEASUR2
K-MEASUR3
K-MEASUR4
7MEASUR5
I8MEASUR6
J9MEASUR7
10-MEASUR8
HizifM'i^i
12MEASUR10
13MEASUR11
14MEASUR12
15MEASUR13
16-MEASUR14
17MEASUR15
18-MEASUR16
19-MEASUR17
20-MEASUR18
|21 MEASUR19
22MEASUR20
'Ж-
■'*Н$\Ь&£?.
426
Глава 10. Описательные статистики
Выберем, например, переменную Measur 5 в первом списке и переменную
Measur 9 во втором списке.
Далее нажмите ОК, чтобы построить график.
Из графика отчетливо видна сильная зависимость между переменными Measur 5
и Measur 9 для группы СОКЕ — FEMALE. Эта группа состоит из женщин,
предпочитающих коку.
Для всех остальных групп зависимость не значима.
Итак, мы нашли группу, в которой отчетливо проявилась зависимость между
переменными Measur 5 и Measur 9.
Таким образом, с уверенностью можно сказать, что именно эта группа отвечает
за зависимость между Measur 5 и Measur 9.
Подобное клише анализа применимо и к другим исследованиям.
ГЪ График! MEASUR5v» MEASUR9
Ддясс...
HEA3VR5 v*. MEA3VR9
i '
Q £>. Q
HL-Ш
Р«гр«ссн*
95% яов«р.
ADVERT: PEPSI
ADVERT СОКЕ
Рассмотрим, например, корреляционную матрицу данных о продажах в
супермаркете. Фрагмент ее показан ниже:
*шш-
ОСНОВНЫЕ
СТАТИСТ
Перемен
КОНСЕРВЫ
КОРМА
КОФЕ
МАКАРОНЫ
МУКА
МОЛОКО
МОРОЖЕНС
МЯСО
ОВОЩИ
РЫБА
СОКИ
СПИРТНОЕ
Отмеченные корреляции
N-100
<ОНСЕР
ВЫ
46
1 00
-05
-01
ьо
03
40
-04
зо
21
24
-03
КОРМА
-07
-.05
1 00
-06
-05
22
26
12
03
34
08
08
-.03
•:"■."..'■
КОФЕ
-06
-01
-06
1 00
-13
-13
-06
12
06
07
18
05
.08
значимы не уровне р < 05000
МАКАРО
НЫ
47
65
-05
-13
1 00
22
39
-06
14
18
08
-07
49
::-■■'":-
МУКА
-06
03
22
-13
22
1 00
34
-01
19
-07
02
16
молоке
.41
49
26
-06
39
34
1 00
00
27
;л
24
40
ЮРОЖЕ
но
-02
-04
12
12
-06
-01
00
1 00
30
26
05
-12
-07
МЯСО
.22
3d
03
06
14
19
27
30
1 00
26
19
37
36
ОВОЩИ
19
21
34
07
18
-07
27
26
26
1 00
23
-13
10
РЫБА
16
24
08
18
08
02
:<1
05
19
23
100
02
31
СОКИ
13
-03
08
05
-07
24
-12
-13
02
1 00
11
■СЕ
ЗТИРТН
ОЕ
5 С
-03
08
43
16
4£
-07
"?Ь
10
;:i
11
1 00
Внутригрупповые корреляции
427
В этой матрице показаны корреляции между различными покупками.
Рассмотрим, например, первую строку. Она относится к кондитерским
изделиям.
В этой строке несколько корреляций значимы. На экране они выделяются
красным цветом. Рассмотрим максимальную из корреляций — корреляцию между
переменными Кондитерские изделия и Спиртное (г = 0,56).
Хотя корреляция большая, из диаграммы рассеяния видно, что никакой
зависимости между продажами спиртного и кондитерских изделий нет.
ПГраФмкБ КОНДИТЕРуж СПИРТНОЕ (Постро
КОНДИТЕР vs. СПИРТНОЕ
СПИРТНОЕ - 118.84 ♦ 2.1838 * КОНДИТЕР
Корреляция: г - .55538
1100
^0 20 60 100 140 180 220 260 300
КОНДИТЕР
Регрессия
95% довер.
Продолжая исследование, проведем группировку, разбив данные на дни недели.
Обратим внимание на внутригрупповые зависимости, в данном случае —
зависимости для каждого дня недели.
На диаграмме рассеяния зависимости для каждого дня недели имеют уже
более привлекательный вид:
4 КОНДИТЕРvt СПИРТНОЕ
КОНДИТЕР VI. СПИРТНОЕ
1100
800
500
200
100
•20 60 140 220 300 20 60 140 220 300 20 60 140 220 300
ДЕНЬ: ДЕНЬ: ДЕНЬ:
Сдц
Ш
20 60 140 220 300 -20 60 140 220 300 -20 60 140 220 300
ДЕНЬ: ДЕНЬ: ДЕНЬ:
500 ,
200
-100
-20 60 140 220 300
ДЕНЬ:
Век
Р«гр«ссия
95% Д01«р.
КОНДИТЕР
428
Глава 10. Описательные статистики
Очень полезны также графики взаимодействий:
вдшшшяи
График средних
350
Из этого графика отчетливо видно, что пик продаж спиртного в течение недели
приходится на пятницу, а средние продажи кондитерских изделий максимальны
в четверг и пятницу. Такого рода описательный анализ, совмещенный с
группировкой, является типичным первым шагом анализа данных.
11
Построение
и анализ таблиц
Вводный обзор
Одним из первых шагов анализа является табуляция данных. Табуляция данных
может быть очень изощренной, например, как в показанной выше таблице, где на
самом деле объединено несколько таблиц.
Мы начнем с самых простых таблиц. Приведенная ниже таблица называется
одномерной таблицей частот:
Цвет рубашки
Желтый
Черный
Цвет морской волны
Зеленый
Белый
Другие
Всего
5
3
1
1
7
10
27
В этой таблице табулирована переменная цвета рубашки у 27 встреченных
мужчин. Таблица называется одномерной, так как в ней табулирована только одна
переменная — цвет рубашки. Так как таблица показывает, насколько часто встреча-
430
Глава 11. Построение и анализ таблиц
ется тот или другой цвет, она называется также таблицей частот. Вы можете
видеть, насколько удобно табличное представление.
Табулируя, например, доход, можно проанализировать различные группы
населения по уровню дохода.
Наблюдаемые данные могут быть измерены в разнообразных шкалах
{интервальных, порядковых, номинальных), поэтому исследование зависимостей между
ними может быть затруднено (например, зависимости могут быть нелинейными,
данные — неоднородными и т. д.). Отсюда следует, что вначале разумно
сгруппировать данные, разбив на достаточно однородные группы (классы, категории —
в данном контексте эти слова рассматриваются как синонимы), интуитивно
ожидая, что зависимости в отдельных группах будут более отчетливыми.
Таким образом, возникают категоризованные переменные. Часто категоризо-
ванную переменную можно рассматривать как некоторую классификацию
исходной числовой переменной. Например, количество посетителей сайта в течение дня
можно отнести к определенным временным отрезкам, например к часам. Вы легко
можете построить соответствующую группировку.
Однако имеется много ситуаций, когда категоризованная переменная не
выражается в терминах какой-либо исходной числовой переменной, а определяется
самой природой данных. Например, на книжном рынке можно выделить
категории книг по Windows, Windows-приложениям (Word, Excel и др.), Интернету,
книги, посвященные языкам программирования, научным программам и т. д. В свою
очередь, пользователи могут быть разбиты на классы: начинающие пользователи,
продвинутые пользователи, профессионалы и т. д.
Пример категоризации данных. Рассмотрим файл данных о продажах.
Г£Д
ТЕКС
1
■
3
4
5
6
7
8
9
аиные: Contl sta 44л * 677н
,
штат
0 00
161 60
0 00
33 50
37 24
136 42
0 00
5077
0 00
15
<ОНДИТЕР
910
36 74
24 71
1420
38 25
26 10
33 00
104 50
0 00
16
СОНСЕРВЬ
71 19
0 00
000
000
000
000
0 00
62 82
34 65
17
«ЭНЦЕНТР
0 00
0 00
0 00
101 00
0 00
0 00
0 00
102 00
0 00
18
КОРМА
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
19
КОФЕ
65 52
0 00
0 00
63 95
0 00
0 00
0 00
0 00
134 40
20
vlAKAPOHb
0 00
0 00
000
0 00
0 00
0 00
0 00
0 00
0 00
21
МУКА
0 00
0 00
0 00
0 00
0 00
0 00
8 75
0 00
11 96
I
" 22
молоко 1
27 70
26 56
0 00
22 76
57 95
43 33
1381
0 00
27 70
Эти данные измерены в количественной шкале.
Предположим, что нас интересует только факт покупки данного товара. Тогда
количественная шкала явно избыточна. Перейдем к категориальным переменным.
Покажем, как это сделать в системе STATISTICA. Дважды щелкнем на имени
переменной КОЛБАСЫ. Это 14-я переменная в файле данных. Определим новую
переменную формулой: (vl4>0). Это уже категориальная переменная,
принимающая два значения: значение 0, если vl4<0 (то есть покупатель не купил товар),
и значение 1, если vl4>0 (покупатель купил товар).
Такие переменные называют также индикаторными, так как они являются
индикатором определенного события (в данном случае факта покупки).
Вводный обзор
431
ПТх11
Л^; [КОЛБАСЫ £о*ПД: [ЗээГ
Отмен*
Щщтнсгомб^ГЩ Две. ШФ$~Щ Q£] [g]
Тип;
Дета
Время
Научный
Денежный
Проценты
Представление:
■1,!,!,1,1,Ш».1,!,1,1,1
1.000 00. 1.000 00
1000 00.A000 00)
1.000 00 A.000 00)
1 flee парам, j
ГД|М^/СТйТМСТ.|
И Сре+икм I
Ддиииое имя (метка, связь или Формам с ^^^12у»^^*м^*уМ*^*Д Ь^
ы
Примеры Метка. 8«<к*о6 домоа *1931 Форму/** - v1 ♦ v2 •
; <Кж**\йе*Юг2с£*4с4 -(уЬОГАбЕ *v3
Построенная категориальная переменная разбивает покупателей на два класса:
покупатели, купившие продукт (значение переменной равно IX и покупатели, не
купившие продукт (значение переменной равно 0).
После того как мы записали формулу, значения переменной v14 будут
пересчитаны, и мы получим следующий столбец:
1 00
0 00
100
1 00
1 00
0 00
1 00
0 00
Подобную категоризацию можно выполнить для всего списка товаров. В итоге
получим файл данных, состоящий из значений 0 и 1.
Единица показывает, что данный покупатель (строка) купил данный товар
(столбец).
Заметим, что подобного рода таблицы, содержащие индикаторные переменные,
весьма часто появляются в медицинских исследованиях. В них строка — пациент,
переменные — симптомы болезни. Единица отмечает, что у данного пациента
присутствует данный симптом, 0 — симптом отсутствует.
Такого типа таблицы будут подробно рассмотрены также в главе Анализ
соответствий.
Теперь еще раз напомним идею категоризации, потому что эта идея является
ключевой.
Итак, идея состоит в том, чтобы разбить множество разнородных наблюдений на
однородные группы с помощью определенных признаков, отражающих существо
задачи, и провести дальнейшее исследование в каждой группе отдельно. Такие
группы гораздо проще анализировать, чем исходную корзину с разнородными данными.
Например, множество всех покупателей можно поделить на две группы —
купивших и не купивших мороженое, или на четыре группы — купивших
мороженое и купивших сыр, купивших мороженое и не купивших сыр, не купивших
мороженое и купивших сыр, не купивших мороженое и не купивших сыр и т. д.
432
Глава 11. Построение и анализ таблиц
..Bdrfr...*<r.;: :://Л''
ни
535 |
19
SSA
117
3 .
120
652
22
674
В STATISTICA таблицы строятся в модуле Основные статистики и таблицы.
Конкретный способ построения таблиц зависит от целей исследования.
Врач может табулировать частоты различных симптомов заболевания в
зависимости от возраста и пола пациентов, социолог имеет возможность построить
сводную таблицу результатов опроса и оценить связи между ответами мужчин и
женщин отдельно. В области образования можно табулировать число учащихся,
покинувших среднюю школу, в зависимости от возраста, пола и этнического
происхождения. Экономисту может понадобиться свести в таблицу количество
банкротств в зависимости от вида промышленности, региона и начального капитала,
а исследователю спроса классифицировать потребителей в зависимости от доходов.
Менеджеры, размещающие рекламу в Интернете, могут интересоваться частотой
посещения различных сайтов в отдельные дни недели.
Более серьезной задачей является установление цен на продукцию с целью
эффективного способа организации продаж: имеются разные категории
пользователей, например, учебные заведения, государственные организации, коммерческие
структуры и т. д. Покупательские возможности разных категорий различны,
поэтому разбиение на группы, когда вы имеете дело не со средним покупателем,
а с покупателем из определенной группы, выглядит совершенно естественно.
Далее в одной таблице можно табулировать значения двух переменных, тогда
возникают таблицы сопряженности. Пример такой таблицы, которую мог бы
поместить в свою записную книжку метрдотель ресторана, показан ниже:
Дни недели Количество посетителей ресторана «Табу» в 9 часов вечера
Мужчины Женщины Всего
Понедельник
Вторник
Среда
Четверг
Пятница
Суббота
Воскресенье
Всего
Вы видите, как естественно организована таблица: дни недели сопряжены с
количеством посетителей ресторана, отсюда и название таблицы — таблица
сопряженности: на пересечении строки дня недели и столбца показано количество
посетителей (мужчин и женщин) в выбранный день недели. В крайнем правом столбце
с литером ВСЕГО даются суммы значений по строкам таблицы. В последней
строке показаны суммы значений, подсчитанные по столбцам. Это так называемые
маргинальные частоты.
9
7
11
9
15
17
17
85
11
8
7
16
7
5
9
63
20
15
18
25
22
22
26
148
Вводный обзор
433
Удобство таблиц. Удобство таблиц очевидно. Метрдотелю достаточно
взглянуть на таблицу, чтобы представить, сколько было посетителей разного пола в
различные дни недели. Вместо того чтобы скользить глазами по длинному списку
посетителей, он просто бросает взгляд на таблицу. В нижней строке и правом столбце
количество посетителей просуммировано. Возможно, метрдотелю интересно знать,
сколько всего посетителей было в субботу, и ему вовсе не нужно суммировать
частоты в двух столбцах (мужчины и женщины), а достаточно посмотреть на
крайний столбец и строку Суббота.
В таблице табулированы значения двух переменных, поэтому она называется
двухвходовой. Если табулируется несколько переменных, то имеют дело с много -
входовыми (многомерными) таблицами (от английского термина multy-way) с
двумя или более факторами. Заметьте, что табулированные переменные на сленге
анализа данных называют также факторами.
Другой типичный пример таблицы сопряженности показан ниже:
Ш
ОСНОВНЫЕ
СТАТИСТ
GENDER
Пол и любимые программы TV
[(Итоговые маргинальные не отмечены)
■ -IDIxl
TV HH^HI Bcvc
t щШШШШЛ ппгтр
12 |
14
26
14 1
7
21 ,
26
21
47
В этой таблице табулированы переменные пол и программа телевидения.
Таблица построена из исходного файла данных, в котором отмечался выбор программ
ТВ респондентами разного пола.
Итак, представление данных в виде таблиц компактно, удобно и наглядно.
Вместо того чтобы иметь дело с файлом исходных данных, содержащим сотни и
тысячи наблюдений, вы имеете одну таблицу.
Для проверки факта зависимости между табулированными переменными
(например, Пол и ТВ) и оценки степени зависимости или, как иногда выражаются,
тесноты связи, разработаны специальные методы.
Анализ таблиц связан с определенным сленгом, который стоит запомнить.
Переменные, табулированные в таблице, называются также факторами. Значения
факторов называются уровнями. Например, переменная пол имеет два уровня —
мужчина и женщина, переменная ГУ также два уровня — 1 и 2. Конечно,
количеством уровней и числом табулируемых переменных можно управлять. Можно,
например, ввести дополнительные переменные — возраст, профессию и т. д.
В анализе таблиц также употребляется несколько архаичный термин вход
таблицы (от английского way) для обозначения табулированной переменной. Если
табулируются две переменные, то говорят о двухвходовой таблице (таблицы с
двумя входами), если табулируется три переменные — о трехвходовой таблице и т. д.
Несмотря на кажущуюся простоту идеи, техника работы с таблицами за много
лет развилась и стала чрезвычайно изощренной.
Альтернативные методы. Вначале таблицы строятся и анализируются в модуле
Основные статистики и таблицы. Однако имеются модули Логлинейный анализ и
Анализ соответствий, в которых также можно исследовать таблицы сопряженности.
Методы Логлинейного анализа (loglinear analysis) позволяют глубоко
исследовать сложные многомерные таблицы, возникающие, например, при проведении
массовых обследований.
434
Глава 11. Построение и анализ таблиц
Анализ соответствий (co?respondence analysis) — это разведочный метод анализа
двухвходовых и многовходовых таблиц, позволяющий визуализировать таблицы и
исследовать их структуру. Ясно, что гораздо проще анализировать таблицу
визуально, чем исследовать в численном виде. Этот разведочный метод анализа
применяется в разнообразных областях: в социологии, эконометрике, маркетинге, медицине
(см. например, Thomas Werani: Correspondence Analysis as a Means for Developing
City Marketing Strategies, 3rd International Conference on Recent Advances in
Retailing and Services Science, pp. 22—25, Juni 1996, Telfs-Buchen (Osterreich) Werani,
Thomas, werani@market.uni-linz.ac.at, http://www.market.uni-linz.ac.at).
Продвинутый метод исследования таблиц — анализ соответствий — будет
подробно описан в отдельной главе.
В данной главе рассмотрим классические методы анализа, реализованные в
модуле Основные статистики и таблицы. Обзор различных типов таблиц начнем
с наиболее простой таблицы — таблицы частот.
Таблицы частот
Частоты, или одновходовые таблицы, представляют собой простейший метод
анализа категориальных или искусственно категоризованных непрерывных переменных.
Часто их используют как одну из процедур разведочного анализа, чтобы
посмотреть, каким образом различные группы данных распределены в выборке. Например,
изучая зрительский интерес к разным видам спорта (возможно, для целей
рекламы), вы могли бы представить ответы респондентов в следующей таблице:
yUSUAU^A] 16 55 16 00000 55 0000
SOMETIMSI 26 81 26 00000 810000
NEVER I 19 100 19 00000 100 0000
.;^ОП<^вЙ^| 0 100 0 00000 100 0000
Таблица отображает число и кумулятивную {суммарную) долю респондентов,
характеризующих свой интерес к просмотру футбольных матчей в следующей
шкале: 1) Всегда интересуюсь — Alwaysinterested,!) Обычно интересуюсь — Usually
interested, 3) Иногда интересуюсь — Sometimes interested или 4) Никогда не
интересуюсь — Never interested.
Точно так же мы могли бы представить информацию о том, насколько часто
респондент использует в своей работе Интернет:
ОСНОВНЫЕ
СТАТИСТ
ВСЕГДА
ОБЫЧНО
ИНОГДА
ЕШЗВШЕИ
Пролущ.
13
14
38
35|
0
Куму п. j
частоте |
13
27
65
100
100
Процент |
13 00000
14 00000
38 00000
35 00000
0 00000
Кумул.
Процент
13 0000
27 0000
65 0000
100 0000
100 0000
STATISTIC А обеспечивает разнообразные возможности, позволяющие описать
различные категории наблюдений в таблице частот (например, используя «все
отличные между собой значения» переменных).
Таблицы частот
435
ЫИнЧШпП!1
Любая переменная из множества данных может быть проанализирована и
представлена в виде таблицы частот. Исследователь может также ввести определенные
коды для таблицы, задать интервалы и даже определить ряд логических условий,
позволяющих отнести наблюдение к определенной группе.
Практически каждый исследовательский проект начинается с построения
таблиц частот. Например, в социологических опросах таблицы частот могут
отображать количество мужчин и женщин, число респондентов из определенной
этнической группы и т. д. Ответы, измеренные в определенной шкале (например,
в шкале интерес к футболу), можно также свести в таблицу частот.
Ниже на графике показана табуляция частоты посещения магазина.
В медицинских исследованиях можно табулировать пациентов с определецны-
ми симптомами. В промышленности — частоту выхода из строя элементов,
приведших к авариям или отказам всего устройства при испытаниях на прочность
(например, для определения, какие детали телевизора действительно надежны после
эксплуатации в аварийном режиме и при большой температуре, а какие нет).
Обычно если в данных имеются категориальные переменные, то для них всегда
вычисляются таблицы частот для каждой переменной.
рдддддддддд
глота
2*3 pita ■ неделю
1 pas ■ н#д#лю
436
Глава 11. Построение и анализ таблиц
Таблицы сопряженности и таблицы флагов
и заголовков
Это более сложные таблицы, так как они содержат частоты нескольких
переменных. Процесс построения таблицы частот для одной переменной называется
табуляцией, для нескольких переменных — кросстабуляцией. На самом деле кросста-
буляция — это процесс объединения двух (или нескольких) таблиц частот так, что
каждая ячейка (клетка) в построенной таблице представляется единственной
комбинацией значений кросстабулированных переменных.
Таким образом, кросстабуляция позволяет совместить частоты появления
наблюдений на разных уровнях рассматриваемых факторов. Исследуя эти частоты,
можно определить зависимости между кросстабулированными переменными.
Идея проверки независимости табулированных переменных очень проста.
Рассмотрим двухвходовую таблицу сопряженности (v(zj), t<i<k,l<j< т}> в
которой табулированы значения двух переменных (X, Y).
Частоты v(i>j)/n являются оценками вероятностей p(ij).
При гипотезе независимости эти вероятности обладают свойством
мультипликативности:
p(i,j)=p(i)*p(j),
p(i) -p(l,i) +рB,г) + ... + p(myi)
pU)-p(iJ)+pQJ) + ~+p(bJ)
При наличии зависимости между табулированными переменными это
равенство нарушается.
Критерием проверки гипотезы независимости в таблицах сопряженности
является хи-квадрат Пирсона, который сравнивает наблюдаемые частоты в
реальной таблице с ожидаемыми, рассчитанными при условии независимости
табулированных переменных (см. далее).
Пример. Рассмотрим файл данных с информацией о прививках (см.
Вступительное эссе).
вщ
ТЕКСТ(
1. .,,...
г г
г.;..;.-
4
S-,\-
S •>
гГ^
»;Vi <
9 *■> V:
10 ,:■
IV:,::
!Г - ■
13
и ■■■
хь
16
1?
янщирЕша
■'■■'■+ ' "■'
ПРИ8ИВК*
до
нет
да
до
нет
до
до
нет
нет
до
до
до
нет
до
до
до
до
v"""'t •
БОЛЕЗНЬ
нет
до
нет
нет
до
нет
нет
нет
нет
до
нет
нет
нет
нет
до
нет
нет
Таблицы сопряженности и таблицы флагов и заголовков
437
Построим таблицу сопряженностей признаков ПРИВИВКА, БОЛЕЗНЬ.
NJIll.lf.ni'UiULniifll
Дмее~
Частоты выделенных ячеек> 10
(Итоговые маргинальные не отпечены)
БОЛЕЗНЬ
Вс*го
по стр.
5
11
16 !
1630
1033
2663
Посмотрим на хи-квадрат:
По результатам применения хи-квадрат критерия можно сделать вывод, что есть
серьезные основания для того, чтобы отвергнуть гипотезу о независимости признаков.
Общая схема рассуждений.
О Шаг 1. Проверьте гипотезу о независимости признаков.
О Шаг 2. Если гипотеза о независимости отвергается, используйте
специальные меры связи, например, статистику гамма, чтобы оценить степень
зависимости между табулированными переменными.
Обычно кросстабулируются номинальные переменные или переменные с
относительно небольшим числом значений.
Если вы хотите кросстабулировать непрерывные переменные (например,
доход), то вначале их следует категоризоватъ, разбив диапазон изменения на
небольшое число интервалов (например, низкий, средний, высокий).
Таблицы 2x2. Простейшая форма кросстабуляции — это таблица 2 х 2, в
которой значения двух переменных «пересечены» (сопряжены) и каждая
переменная принимает только два значения, то есть имеет два уровня (поэтому таблица и
называется 2 х 2). Рассмотрим поясняющий пример. Предположим, проводится
простое исследование, в котором мужчин и женщин спрашивают, какой напиток
они предпочитают (газированную воду марки А или газированную воду марки В);
файл данных показан ниже:
ПОЛ
ГАЗ. ВОДА
наблюдение 1
наблюдение 2
наблюдение 3
наблюдение 4
наблюдение 5
МУЖЧИНА
ЖЕНЩИНА
ЖЕНЩИНА
ЖЕНЩИНА
МУЖЧИНА
А
В
В
А
В
Результаты кросстабуляции выглядят следующим образом:
ГАЗ. ВОДА: А ГАЗ. ВОДА: В
ПОЛ: МУЖЧИНА
ПОЛ: ЖЕНЩИНА
20 D0%)
30 F0%)
50 E0%)
30 F0%)
20 D0%)
50 E0%)
50 E0%)
50 E0%)
100 A00%)
438
Глава 11. Построение и анализ таблиц
Каждая ячейка таблицы содержит единственную комбинацию значений двух
кросстабулированных переменных (в строке указана переменная ПОЛ, в столбце —
переменная ГАЗ. ВОДА). Каждая ячейка стоит на пересечении столбца и строки.
Числа в каждой ячейке на пересечении определенной строки и определенного
столбца показывают, сколько наблюдений соответствует данным значениям.
Посмотрите на таблицу. Таблица показывает, что женщины больше мужчин предпочитают
газированную воду марки Л, мужчины больше предпочитают марку В. Таким
образом, пол и предпочтение могут быть зависимыми (позже будет показано, как эту
зависимость измерить).
Маргинальные частоты. Значения, расположенные на краях таблицы, — это
просто одномерные таблицы частот для всех рассматриваемых переменных. Эти
значения важны, так как позволяют оценить распределение частот в отдельных
столбцах и строках. Например, 40% и 60% мужчин и женщин (соответственно),
выбравших марку А (см. первый столбец таблицы), не могли бы показать какой-
либо связи между переменными ПОЛ и ГАЗ. ВОДА — Soda, если бы маргинальные
частоты переменной ПОЛ были также 40% и 60%. В этом случае они просто
отражали бы разную долю мужчин и женщин, участвующих в опросе. Таким образом,
различия в распределении частот в строках (или столбцах) отдельных
переменных и в соответствующих маргинальных частотах дают информацию о
зависимости кросстабулированных переменных.
Проценты по столбцам, по строкам и кумулятивные проценты. Приведенный
пример показывает, что для оценки зависимости между кросстабулированными
переменными необходимо сравнивать маргинальные доли и индивидуальные доли
в столбцах и строках. Такие сравнения легче провести с использованием процентов.
Процедура Итоговые таблицы позволяет выдать кросстабулированные
частоты в таблице результатов вместе с числом наблюдений, попавших в ячейку,
процентами в столбцах и строках, а также суммарными процентами.
И^.и.|].1.М-1Ш,!1НШШ.И1.1Ш11Ш
ОСНОВНЫЕ
СТАТИСТ
GENDER
строк,*
F«»sle
сшрок.%
Все «рда
IUJ
ТаБ/t GENDERB) x S(
20 |
40 00*
30
60 00*/.
50
SODA
В
30
60 00У.
20
40 00'/.
50
)DAB)
Сьрок
Всего
50
щ
50 1
100 * 1
f
и
Можно построить итоговую объединенную таблицу, в которой каждая ячейка
содержит эти числа.
ветштщтт
■ ■iiH'H'iiii
ОСНОВНЫЕ
СТАТИСТ
GENDER
шш*шшш
сяод£ч•*
с»реж. *4
Все*© X
Female
СЖ04БЦ %
c»pqk.%
Всего %
Все tpyn
Вофсо К
hi i
■пшшам
2ЖшКшМШ1ААеШЛН^Н&Ш«а1
ТаБ/tGENDERB) x 50DAB)Т*
SODA
: А
20
4 0 00*
%Ш&й*;£Шт
30 |
60 00*
40 ООУ 60 00*
20 00* 30 00*
30 20
60 00* 40 00*
60 00* 40 00*
30 00* 20 00*
50 50
50 00* 50 00*
С*рох
Всево
50
50 00*
50 |
50 00* ■
100 i
►
Г
Таблицы сопряженности и таблицы флагов и заголовков
439
Графическое представление кросстабуляций. Отдельные строки и столбцы
таблицы удобно представить в виде графиков. Полезно также отобразить целую
таблицу на отдельном графике. Имеется несколько способов сделать это с
помощью процедуры Таблицы сопряженности. Таблицы с двумя входами можно
визуально представить ЗМ гистограммой.
ЗМ гистограмма для FOOTBALL и BASEBALL
Другой способ визуализации таблиц сопряженности — построение категори-
зованной гистограммы, в которой каждая переменная представлена
индивидуальными гистограммами, разбитыми на каждом уровне другой переменной (см. ниже).
Преимущество ЗМ гистограммы в том, что она позволяет представить на одном
графике таблицу полностью. Достоинство категоризованного графика
заключается в том, что он дает возможность точно оценить специфические частоты в каждой
ячейке.
FOOTBALL к BASEBALL ж BASKETBL
Категормэ гистограмма FOOTBALL x BASEBALL x BASKITBL
п
Щ
1
■I
ШшШ
BASEBALL
ALWAYS
KimmfMaa-
—, .—и a mi a n.
.~m.
ET^lmm
£ *". tt *
Ui>
BASEBAiL
USUALLY
_£23_
Щ.
яятМШ
J^CZL
Hi»
BASEBALL
SOMETMS
_CZL
. . ЕЕЯ
Щ
1
£4
BASEBALL
NEVER
440
Глава 11. Построение и анализ таблиц
Таблицы флагов и заголовков
Таблицы флагов и заголовков, или, кратко, таблицы заголовков, позволяют
отобразить несколько двумерных таблиц сопряженности в сжатом виде как одну
таблицу. Этот тип таблиц поясняется на примере файла, отражающего интерес к
спорту.
ronMVAffMPtf^
ОСНОВНЫЕ
СТЛТИСТ
FOOTBALL: "Watching football"
1 &ОДЛ&■■•?■ ■? ^АХчшчя i**t<Mreot#d : ;:
:; * .«о сжсмБцд •
USUALLY ,; Usueilr interested.
* »0 tawwdSuu
SOKETIMS: Sasetisea. interested
* * no е*ал&ю
METER : Never interested
■■:■■: >. no с»олБив
' ВСв»0 -.< • . ■.•"..:...,.;.. :;.
3 2-6x таблицы
ШШШМ
24|
85 71*
2 '
7 14^
2
7 1АУ.
0
0 00*
28"
BASEBALL
• ШАШ
8
47 06*
5
29 А1У
3
17 65*
1
5 88*
17
■■■■
■■■■■
BASEBALL
SOHETIHS
5
13 51*
у
18 92*
19
51 35*
6
16 22*
37
BASEBALL
HEVER
2
11 11*
2
11 11*
2
11 11*
12
66 67*
18
е*иеиег~П5П
"~ii
ШШЗШц
Bceto
йОС»р,
39
16
26
19 •
l0m
В данной таблице результатов представлены три двухвходовые таблицы, в
которых интерес к Футболу — Football сопряжен с интересом к Бейсболу — Baseball,
Теннису — Tennis и Боксу — Boxing. Таблица содержит информацию о процентах
по столбцам, поэтому суммы по строкам равны 100%. Например, число в левом
верхнем углу таблицы результатов (85,71) показывает, что 85,71 процентов всех
респондентов ответили, что им всегда интересно смотреть футбол и всегда
интересно смотреть бейсбол. Рассмотрите первый столбец приведенной таблицы. Вы
видите, например, что имеется 2 респондента, обычно интересующихся футболом
и всегда интересующихся бейсболом. Также 2 (других) респондента иногда
интересуются футболом и всегда интересуются бейсболом. Нет ни одного
респондента, которому был бы всегда интересен бейсбол и никогда не интересен футбол.
Аналогично интерпретируются другие столбцы. Если вы прокрутите таблицу
вправо, то увидите, что процент тех, кому всегда интересно смотреть футбол и всегда
интересно смотреть теннис, равен 38,46; для бокса этот процент составляет 70,0
(см. таблицы ниже).
M.J.ll.lJ.IAI.UI.I.|iil».J.m.l,HMU.I.UJI.!l
ОСНОВНЫЕ
СТЛТИСТ
FOOTBALL "Watching football"
■.■■% по столбцу
USUALLY : Usually interested
X nd ёпалбии
SOtfETIMS: Sometimes interested
% no саоысБцэ
SEVER : Never interested
X no сполбцд
Bcesa
3 2-6x таблицы
v воша,-
AIVAYS
«Ш№5
USUALLY
14 7
70 00* 70 00%
2 1
10 00* 10 00*
2 1
10.00* 10 00*
2 1
10 00* 10 00*
20
10
1
BOXIKG :
SOMETIKS
12
41 38*
8
27 59*
6
20 69*
3
10 34*
29
NEVER
6
14 63*
5
12 20*
17
41 46*
13
31 71*
41
ИИОзЩ
*"-: ::.Boetв •.'
no cnp
39
16
26
19
100
^T i:
П
Проценты в столбце (Всего по строке), показанные после каждого набора
переменных, всегда связаны с общим числом наблюдений. В диалоговом окне
Результаты кросстабуляции имеется множество процедур, позволяющих построить
таблицы заголовков в различных форматах. Например, можно одновременно ото-
Таблицы сопряженности и таблицы флагов и заголовков
441
бражать число наблюдений в ячейках, строках, столбцах и общие проценты в одной
и той же таблице.
&ЧПЧГШШПГГШ*ШТ^ПШ1ШГГ*ГТТЧТП
r^iiril'ITIIIfHill'TlJif-llllf-iliillill
'■\ ОСНОВНЫЕ
■i СТАТИСТ.
• FOOTBALL: "Watching football"
ь '•••'• ■■i-^ % »о столбцу
«а*« w -<*«-<**< -. :v ...... ,: ^^^w? строке
- у- -^л. ?х^-"? .>-i х ъ& «♦бди^е :
, ШШДГ: U«u*Uv iauwwwted
*Y*Z * л**::: . \: '.* »а с*олбия
' -^Ч :'}**,■;?'■ tf:4 -\."< •'• •/:'."-?:?Х ftQ СЯфОКО
.Гу,г,..;.^а ;>,,^-^;. АА*. /,& до а*&одэ •
:::90ЖШ«вг Sowttij^wi i*t***»t«4
~**. «Й&#&*>&>Ь *fciUMWMBhiSr
" :'' • •*>-}';<-,'ч"Й.': " ' ;.'<>- ' ' ^ 'U0< CWPOH©
• ущ^^шт'^^тш^мвяй^
уШШЪ$&Шмж /.int«r**t*l- •.:"••...
'•'" *.' " г?:---- * г'.- •. % * ш>. о»оибц^ ;
Щ ■■>.<■ . У"^--: :;;Ч- ;SfftO С*РОКв
ж :>*.р*щ$$>:^.:*-К. <*> **$л«чв :
^^•H^f:^;^^i^^.- iX j^p .щ^йли^в
liL— ----- - -----
Ttnt!ftiiwpmmmm
_^^^^^
3 2-6x таблицы
5
38 46*
12 82*
5.00*
4
30 77*
25 00*
4 00*
2
15.38*
7 69*
2 00*
2
15 38*
10 S3*
2 00*
13
13 00*
•<;.тшх&;::
tfSOUXY
5
35.71*
12 82*
5.00*
2
14 29*
12 50*
2 00*
5"
35.71*
19 23*
5 00*
2
14 29*
10 S3*
2.00*
14"
14 00*
^^^ —
^^—
otEHHTSv
SGHETIMS
31
30
12
21
50
... 8
34
50
13
13
26
^5
38
12
58*
77*
00*
8
05*
00*
00*
13
21*
00*
00*
5
16*
32*
00*
38
00*
KEVER
17
4 8 57*
43 59*
17 00*
2
5 71*
12 50*
2 00*
6
17.14*
23 08*
6 00*
10
28 57*
52 63*
10 00*
35"*
35 00*
1 ""ifVf
■ЬИ
• • •Всвао:';.'-.
по стр.
39
16
26
19
100
39
оо* •
16 :
00* - !
26*
оо* ::
9 , ,;|
оо* ;■; !
юо :
оо* 'Ш
мт
Многовходовые таблицы с контрольными переменными. Когда кросстабули-
руются только две переменные, результирующая таблица называется двухвходовой
(двумерной). Конечно, общую идею кросстабулирования можно обобщить на
большее число переменных. В примере с «газированной водой» добавим третью
переменную с информацией о штате, в котором проводилось исследование (Небраска
или Нью-Йорк).
ПОЛ ГАЗ. ВОДА
наблюдение 1 МУЖЧИНА
наблюдение 2 ЖЕНЩИНА
наблюдение 3 ЖЕНЩИНА
наблюдение 4 ЖЕНЩИНА
наблюдение 5 МУЖЧИНА
А
В
В
А
В
ШТАТ
НЕБРАСКА
НЬЮ-ЙОРК
НЕБРАСКА
НЕБРАСКА
НЬЮ-ЙОРК
Кросстабуляция этих трех переменных представлена в следующей таблице:
ШТАТ: НЬЮ-ЙОРК
ГАЗ. ВОДА ГАЗ. ВОД/
А
П: МУЖЧИНА 20
П: ЖЕНЩИНА 30
50
В
30
20
50
ШТАТ: НЕБРАСКА
i ГАЗ. ВОДА ГАЗ. ВОДА
А В
50 5 45
50 45 5
100 50 50
50
50
100
Теоретически любое число переменных может быть кросстабулировано в
одной многовходовой таблице. Однако на практике возникают сложности с
проверкой и «пониманием» таких таблиц, если они содержат более четырех
переменных.
442
Глава 11. Построение и анализ таблиц
Статистики таблиц сопряженности
Таблицы сопряженности позволяют исследовать зависимость между кросстабули-
рованными переменными. Следующая таблица отчетливо показывает очень
сильную зависимость между двумя переменными: переменная ВОЗРАСТ (ВЗРОСЛЫЙ
или РЕБЕНОК) и переменная предпочитаемый сорт ПЕЧЕНЬЕ (сорт А или сорт В).
ВОЗРАСТ: ВЗРОСЛЫЙ
ВОЗРАСТ: РЕБЕНОК
ПЕЧЕНЬЕ: А ПЕЧЕНЬЕ: В
50 0
0 50
50 50
50
50
100
Из этой таблицы видно, что все взрослые выбирают печенье Л, а все дети —
печенье В. В данном случае нет никаких оснований сомневаться в надежности этого факта.
Невозможно поверить, что данная структура частот носит случайный
характер. Мало кто усомнится, что между предпочтениями детей и взрослых имеется
отчетливое различие. Однако в реальной обстановке зависимости между
переменными значительно слабее, и поэтому возникает вопрос, как их измерить и оценить
надежность (статистическую значимость).
Далее обсуждаются общие меры зависимости между двумя группирующими
переменными.
Итак, вначале проверяется гипотеза: имеется ли зависимость между
представленными в таблице переменными?
Критерий хи-квадрат Пирсона. Хи-квадрат Пирсона — это наиболее простой
критерий проверки значимости зависимостей между группирующими
переменными. Критерий Пирсона основывается на том, что в двухвходовой таблице
ожидаемые частоты при гипотезе, что между переменными нет зависимости, можно
непосредственно вычислить.
Критерий хи-квадрат — это непараметрический критерий, его применение
никак не связано с распределением табулированных переменных.
Идея критерия очень проста.
Рассмотрим двумерную таблицу сопряженности {v(ij)}, г = 1, 2 ... г, j = 1,2 ... s,
состоящую из г строк и s столбцов.
Обозначим
п(г) = n(i,l) + ... n(i,s), г = 1,2 ... г
n(j) = лA J) + ... n(r,j), ./-1,2 ... г
п = ln(ij)
Итак, v(i) — сумма элементов в i-й строке, v(j) — сумма элементов в j-u столбце,
п — общее число наблюдений (сумма всех частот в таблице). v(i), v(j) называются
также маргинальными частотами, так как они располагаются по краям таблицы.
Рассмотрим какую-нибудь ячейку таблицы. Из частоты, стоящей в ячейке (это
наблюдаемая частота), вычтите ожидаемую частоту (она вычисляется
перемножением маргинальных частот и делением их на общее число наблюдений).
Полученную разность возведите в квадрат и разделите на ожидаемую частоту. Далее
проделайте то же самое со всеми ячейками и результаты сложите.
Таблицы сопряженности и таблицы флагов и заголовков
443
Это и есть знаменитая статистика хи-квадрат. Статистика хи-квадрат
замечательна тем, что при достаточно большом числе наблюдений ее распределение можно
приблизить распределением хи-квадрат и, значит, вычислить приближенный
р-уровень критерия.
Формально статистика хи-квадрат вычисляется по формуле:
Хи-квадрат = l[(n(ij) - n(f,;))**2]/n(f,;),
где суммирование производится по всем индексам i,j. v(ij) = v(i) * v(j)/n —
ожидаемая частота в ячейке i,j.
Большие значения хи-квадрат свидетельствуют против проверяемой гипотезы
о независимости признаков, табулированных в таблице.
Представьте, что опрошено 20 мужчин и 20 женщин относительно выбора
газированной воды (марка Л или марка В). Если между выбором и полом нет
зависимости, то естественно ожидать равного выбора марки А и марки В для каждого
пола.
Распределение хи-квадрат при проверке независимости можно
аппроксимировать хи-квадрат-распределением с числом степеней свободы (r-l)*(s-l). Однако
качество этой аппроксимации ухудшается, если число наблюдений в ячейках мало
(см. ниже).
Критерий хи-квадрат становится высокозначимым при отклонении реально
наблюдаемых частот в таблице от ожидаемых, иными словами, когда выбор мужчин
и женщин различен. Значение статистики хи-квадрат и ее уровень значимости
определяется общим числом наблюдений и количеством ячеек в таблице.
Иногда используют статистику хи-квадрат в форме максимального
правдоподобия:
МПхи-квадрат = 2 х Xn(ij) ln(n(f j)/n(iJ))
По существу, эти две статистики эквивалентны.
Имеется только единственное существенное ограничение использования
критерия хи-квадрат (кроме очевидного предположения о случайном выборе
наблюдений) — ожидаемые частоты должны быть не слишком малы (см. пример ниже).
Это ограничение возникает потому, что хи-квадрат сравнивает наблюдаемые
частоты и вероятности в каждой ячейке, и когда частоты в ячейках малы, например,
меньше 5 или даже 10, эти вероятности нельзя оценить с достаточной точностью
(см. например, Everitt B.S. A977) The analysis of contingency tables, London:
Chapman&Hall).
Замечание. Статистика хи-квадрат Пирсона позволяет строить также
критерии согласия и однородности (см. главу 4 Подгонка вероятностных распределений).
Поправка Йетса для таблиц 2x2. Для важного класса таблиц 2x2, содержащих
ячейки с малыми частотами, аппроксимация распределения статистики хи-квадрат
может быть улучшена понижением абсолютного значения разностей между
ожидаемыми и наблюдаемыми частотами на величину 0,5 перед возведением в квадрат
(поправка Йетса).
Поправка Йетса, делающая оценку более умеренной, применяется в случаях, когда
таблица содержит ячейки с малыми частотами. Принято считать, что наименьшая
Глава И. Построение и анализ таблиц
ожидаемая частота, позволяющая применять критерий хи-квадрат без поправок,
должна равняться 5. Из приведенной ниже таблицы видно, как могут отличаться
р-уровни критерия хи-квадрат без поправки и с поправкой Йетса. Исходная
таблица сопряженности имеет вид:
В таблице сопряжены два признака: покупка мороженого и орехов. Статистики
для этой таблицы сопряженности имеют вид:
М()РОЖЕНО(?| х OPf ХИ[?) |indc
ОСНОВНЫЕ
СТАТИСТ
Хи-каадрвт Пирсон»
МЛхи-квадрвт
кодлрвт Йетса
хи-кеешрат
Ст.ее.
2716230
1526840
3360730
Используя хи-квадрат без поправки Йетса, мы совершили бы грубую ошибку.
Точный критерий Фишера. Этот критерий применим только для таблиц 2x2.
Критерий основан на следующем рассуждении. Даны маргинальные частоты
в таблице. Предположим, что оба фактора в таблице независимы. Зададимся
вопросом: какова вероятность получения наблюдаемых в таблице частот исходя из
маргинальных? Эта вероятность вычисляется точно исходя из данных
маргинальных частот. Таким образом, критерий Фишера вычисляет точную
вероятность появления наблюдаемых частот при нулевой гипотезе. Вычисляются
односторонние и двусторонние вероятности.
Макнемара хи-квадрат. Этот критерий применяется, когда частоты в таблице
2x2 представляют зависимые выборки. Например, наблюдения одних и тех же
индивидуумов до и после эксперимента. Вы можете подсчитывать число студентов,
имеющих минимальные успехи по математике в начале и в конце семестра.
Вычисляются два значения хи-квадрата: A/D и В/С Л/О-хи-квадрат проверяет
гипотезу о том, что частоты в ячейках Л и D (верхняя левая, нижняя правая)
одинаковы. В/С- хи-квадрат проверяет гипотезу о равенстве частот в ячейках ВиС (верхняя
правая, нижняя левая).
Коэффициент фи. Фи-квадрат представляет собой меру зависимости между
двумя группирующими переменными в таблице 2x2. Его значения изменяются
от 0 (нет зависимости между факторами; хи-квадрат = 0,0) до 1 (абсолютная
зависимость между двумя факторами в таблице).
Тетрахорическая корреляция. Эта статистика вычисляется (и применяется)
только для таблиц сопряженности 2x2. Если таблица 2x2 может
рассматриваться как результат (искусственного) разбиения двух непрерывных переменных на
два класса, то коэффициент тетрахорической корреляции будет оценивать
зависимость между двумя этими переменными.
Таблицы сопряженности и таблицы флагов и заголовков
445
Коэффициент сопряженности С. Коэффициент сопряженности
представляет собой основанную на статистике хи-квадрат меру зависимости между двумя
группирующими переменными (предложенную Пирсоном). Преимущество этого
коэффициента перед обычным хи-квадрат состоит в том, что он легче
интерпретируется, так как диапазон его изменения от 0 до У (где 0 означает полную
независимость).
Недостаток заключается в том, что верхний предел «ограничен» размером
таблицы; С может достигать значения 1, только если число классов не ограничено.
Интерпретация мер сопряженности. Существенный недостаток мер
зависимости в трудности их интерпретации в обычных терминах вероятности или «доли
вариации», как в случае коэффициента корреляции г Пирсона.
Статистики, основанные на рангах
Во многих случаях классы, используемые в кросстабуляции, содержат
информацию о ранговом упорядочивании объектов; иными словами, имеются измерения
лишь в порядковой шкале. Предположим, вы опросили некоторое множество
респондентов для того, чтобы выяснить их отношение к некоторым видам спорта.
Затем представили измерения в 4-точечной шкале со следующими градациями:
1) всегда — always, 2) обычно — usually, 3) иногда — sometimes и 4) никогда — never
interested. Очевидно, что ответ иногда интересуюсь — sometimes interested
показывает меньший интерес, чем обычно интересуюсь — usually interested, обычно
интересуюсь — usually interested меньший интерес, чем всегда интересуюсь — always
interested, и т. д.
Для таких переменных имеются свои типы корреляции, позволяющие
численно выразить зависимости между ними (см. главу Непараметрическая
статистика).
Многомерные отклики и дихотомии
Переменные типа многомерных откликов или многомерных дихотомий
возникают в ситуациях, когда исследователя интересуют не только «простые» частоты
событий, но также некоторые (часто неструктурированные) качественные свойства
событий. Типичным примером является опрос общественного мнения, где
вопросы, по крайней мере частично, имеют так называемые «открытые концы» (не
подразумевая однозначного ответа), и респондент делает выбор из неограниченного
(или очень большого) списка ответов. Вопрос состоит в том, как разумным
способом закодировать ответы. Природу многомерных переменных (факторов) лучше
всего рассмотреть на примерах.
Многомерные отклики
Представьте, что в процессе большого исследования вы попросили пользователей
назвать три лучших, с их точки зрения, сайта. Обычный вопрос может выглядеть
следующим образом:
446
Глава 11. Построение и анализ таблиц
Напишите ниже три лучших сайта:
1: 2:_ 3:
Анкета содержит от 0 до 3 ответов. Очевидно, список может быть очень
большим. Ваша цель — свести результаты в таблицу, в которой, например, будет
подсчитан процент респондентов, предпочитающих определенный сайт.
Следующий шаг после получения анкет — занесение ответов в файл данных.
Предположим, в ответах упоминалось 50 различных сайтов. Вы могли бы,
конечно, создать 50 переменных — одну для каждого сайта, рассмотреть респондентов
как наблюдения (строки таблицы), ввести код 1 для респондента и переменной,
если он предпочитает данный сайт @, если нет); например:
Сайт 1 Сайт 2 Сайт 3
наблюдение 10 10
наблюдение 2 110
наблюдение 3 0 0 1
Такой метод кодирования откликов, то есть приписывания им конкретных
значений, очевидно, «расточителен». Заметим, что каждый респондент дает
максимум три ответа; однако для кодирования используется 50 переменных. (Если вы
интересуетесь только тремя сайтами, то такой метод кодирования будет успешным.
Чтобы табулировать предпочтения в выборе сайта, следует рассмотреть 3
переменные как одну многомерную дихотомию; см. ниже.)
Кодирование многомерных откликов. Более разумным является следующий
подход. Введите 3 переменные и определите схему кодирования для 50 сайтов. Затем
введите соответствующие коды (альфа-метки) для значений переменных и получите
таблицу вида:
набл. 1
набл. 2
набл.3
Ответ_1
сайт1
сайт 2
сайт 19
Ответ 2
сайт 17
сайт 21
сайт!
Ответ_3
сайт 13
сайт 77
сайт 4
Теперь, чтобы получить число респондентов, предпочитающих определенный
сайт, рассмотрите переменные Ответ 1 — Ответ 3 как переменную с
многомерным откликом. Само название переменной показывает, что она принимает
многомерные значения. Таблица значений такой переменной имеет вид:
N=500
Категория
сайт1
сайт 2
сайтЗ
сайт 4
Всего
ответов
Число
44
5
81
74
842
Процент
ответов
5,23
1
9,62
8,79
100,00
Процент
наблюдений
8,80
2,60
16,20
14,80
168,40
Таблицы сопряженности и таблицы флагов и заголовков
447
Интерпретация таблиц частот с многомерными откликами. Итак, общее
число респондентов в опросе п=500. Заметьте, что числа в первой колонке таблицы не
составляют в сумме 500, как можно было бы ожидать, а равны 842. Вы поймете,
почему это так, если вспомните, что каждый респондент может дать несколько
ответов, так как у него может быть несколько любимых сайтов. Число,
приведенное внизу в первом столбце (на границе таблицы), — это общее число ответов.
Каждый респондент может дать до трех ответов, поэтому общее число ответов
в действительности больше числа респондентов.
Вторые и третьи столбцы таблицы содержат проценты относительного числа
ответов (второй столбец) и респондентов (третий столбец). Таким образом, вход
8,80 в первой строке последнего столбца таблицы означает, что 8,8% всех
респондентов назвали сайт1 в числе лучших.
Как учитывать повторяющиеся ответы в одной и той же анкете? В отличие от
других популярных программ, строящих таблицы для многомерных откликов,
процедура Кросстабуляция в модуле Основные статистики и таблицы по умолчанию
игнорирует одинаковые отклики. Например, если респондент ответил: сайт 1,
сайт 1, сайт 1, то система STATISTICA учтет из его ответа сайт 1 только один
раз. Следовательно, этот респондент в таблице частот будет учтен только один раз
в группе сайт 1, иными словами, в эту группу будет добавлена единица, а не тройка.
Многомерные дихотомии
Предположим, вас интересуют только сайт Л, сайт В и сайт С. Как отмечалось,
одним из способов кодирования является следующий:
наблюдение 1
наблюдение 2
наблюдение 3
сайт А
1
сайт В
1
1
сайтС
1
Здесь каждая переменная используется для одного сайта. Код 1 будет введен
в таблицу всякий раз, когда соответствующий респондент указал ее в своем ответе.
Заметим, что каждая переменная является дихотомией, так как принимает только
два значения: «У» и «не 1» (можно ввести 1 и 0, на так обычно не делается, можно
просто рассматривать 0 как пустую ячейку или пропуск). Когда табулируются
такие значения, вы получите итоговую таблицу, очень похожую на ту, которая была
показана ранее для переменных с многомерными откликами; из нее вы можете
вычислить число и процент респондентов (и ответов) для каждого сайта. Таким
образом, вы компактно представили три переменные сайт А, сайт В, сайт С одной
переменной (Любимые сайты) — многомерной дихотомией. Заметьте, для
кодирования трех сайтов использовано 3 одномерные дихотомии, для кодирования десяти
напитков понадобится 10 одномерных дихотомий и т. д.
Кросстабуляция многомерных откликов
и дихотомий
Процедура Кросстабуляция модуля Основные статистики и таблицы позволяет
определить простые группирующие переменные (например, ПОЛ: МУЖЧИНА или
448
Глава 11. Построение и анализ таблиц
ЖЕНЩИНА), многомерные отклики и многомерные дихотомии. Все эти типы
переменных можно использовать в таблицах сопряженности. Например, вы можете
«сопрячь» многомерную дихотомию Сайт (закодированную, как описано выше)
с многомерным откликом Телевидение (со многими категориями, например,
ПРОГРАММА 1, ПРОГРАММА 2 и т. д.), а также с простой группирующей переменной
ПОЛ.
Как и в таблице частот для обычных переменных, в таблице частот для
многомерных переменных можно вычислить проценты и маргинальные суммы либо по
общему числу респондентов, либо по общему числу ответов (откликов).
Например, рассмотрим следующего респондента: *
ПОЛ
сайт 7
ЖЕНЩИНА 1
Этот
граммы
ставлен
ПОЛ
сайтЗ
1
сайт 9
ТВ ТВ
1 2
респондент ЖЕНЩИНА назвал своими любимыми сайт 7 и сайт 3 и про-
ТВ1 и ТВ2. В полной таблице сопряженности этот респондент будет пред-
следующими наборами:
Сайт
TBI
ТВ
ТВ2
Общее число ответов
ЖЕНЩИНА сайт 7 XX 2
сайтЗ X X 2
сайт 9
МУЖЧИНА сайт 7
сайтЗ
сайт 9
Данный респондент учитывается в таблице четыре раза. Дополнительно он
будет считаться дважды в столбце ЖЕНЩИНА -сайт 7 маргинальных частот, если этот
столбец запрошен для представления общего числа откликов. Если пользователь
запрашивает маргинальные суммы, вычисленные как общее число респондентов,
этот респондент будет учитываться только один раз.
Парная кросстабуляция переменных
с многомерными откликами
Лучше всего показать ее на простом примере. Предположим, проводится
обследование нынешних и бывших домовладений респондента. Вы попросили
респондента описать три последних дома, которыми он владел (включая тот, которым он
владеет в данный момент). Естественно, для некоторых из респондентов
нынешний дом является самым первым (если до этого они не приобретали дома в
частную собственность). Для каждого дома респондента запрашивается количество
квартир и число жильцов — членов семьи. Ниже показано, как ответ одного
респондента (скажем, наблюдение 112) может быть введен в файл данных:
№ набл Комнаты 12 3 Число жильцов 12 3
112
334
235
Средства построения таблиц системы STATISTICA
449
Респондент имел три дома: первый из трех комнат, второй также из трех
комнат, третий из четырех комнат. Количество членов семьи также росло: в первом
доме жили 2 человека, во втором — 3, в третьем — 5.
Допустим, вы хотите кросстабулировать число комнат с числом жильцов для
всех респондентов (например, чтобы понять, как количество комнат связано с
числом жильцов). Один из способов — создать три различные таблицы с двумя
входами, одну таблицу для одного дома. Вы можете также рассмотреть два фактора
в этом исследовании (Число комнат, Число жильцов) как переменные со многими
откликами. Однако очевидно, что нет никакого смысла в приведенном примере
с респондентом 112 учитывать значения 3 и 5 в ячейке Комнаты — Жильцы в
таблице сопряженности (которые вы могли бы учитывать, если бы рассматривали
два эти фактора как одинарные переменные с многомерными откликами). Другими
словами, вы хотите игнорировать комбинацию жильцов в третьем доме с числом
комнат в первом. Скорее всего, нужно рассматривать переменные попарно; вы
хотели бы рассмотреть число комнат в первом доме вместе с числом жильцов в первом
доме, число комнат во втором доме вместе с числом жильцов в нем и т. д. Именно
так и происходит, когда программа выполняет парную кросстабуляцию
многомерных переменных.
Иногда при создании сложных таблиц сопряженности с переменными типа
многомерных откликов и дихотомий возникает следующий вопрос (в ваших
вычислениях): какую «выбрать дорогу», или как точно будут учитываться наблюдения
в файле данных. Лучший способ проверить, как программа строит
соответствующую таблицу, — рассмотреть простой пример и увидеть, каким образом
учитывается каждое наблюдение (какой оно вносит вклад).
Средства построения таблиц
системы STATISTICA
Таблицы частот
|К Основные статистики и таблицы
JA Описательные статистики
Щ Корреляционные матрицы
7Ц (критерии для независимым выборок
(££] (-критерий для зависимым выборок
j££ Группировка и однофакториая AN OVA
\ Таблицы часто
] Таблицы и заголовки
JjJk Вероятностный калькулятор
Р£д Другие критерии значимости
В ft*
Отмена
р? Данные
SStt &ft
Данная процедура позволяет вычислить таблицы частот (и гистограммы). В этих
таблицах представляются частоты попадания значений переменной (наблюдений)
в разные классы (приводятся численные или численно-буквенные значения и их
метки). STATISTICA предлагает различные процедуры для определения катего-
450
Глава 11. Построение и анализ таблиц
рий (классов) в таблицах частот (например, целые интервалы, определенные коды
и т. д.). Пользователь может табулировать данные с помощью определенных
условий, заданных в виде логических выражений.
Категория 1
штщ
v0>10 and v7<3
Категория 2,
категория 1 i г
о*
(cl) Просмотреть перемешав
Iключ., если.
Открыть/Сохранить J
&
Охкрыть осе
£охр«иить все
Категория Д
Вкяюч . если ^ )| |0т1фьгтьЛ:оуа«<ить j
Категория!
В ключ.. если : »J|| Открыть/Сохранить ]
zl
Задайте группы для таблиц чест<д. введя
критерии категоризации Программе
проверяет выполнение критериев
последовательно, начиная с первого:
наблюдение приписывеется * той группе,
критерию которой он удовлетворяет
первым
Каждое маблювенив клАссиФииируется
только один раз, ее ли то же наблюдение
уаовлетеоряет критерию следующей
группы, оно не учитывается
Например, в показанном выше окне мы включили в категорию 1 только
наблюдения с номерами строго больше 10, для которых значения v7 строго меньше 3.
Таблицы частот для этой группы данных имеет вид:
ОСНОВНЫЕ
СТАТИСТ
Не выбраны
Кумул.
частоте
16
50
Процент
3? 00000
68 00000
Кумул
Процент
32 0000
100 0000
•г
Таблицы сопряженности и таблицы флагов
и заголовков
К Основные статистики и таблицы
£Щ Описательные статистики
ЩЦ Корреляционные матрицы
[fXf{ (критерий для независимых выборок
:(j~] (-критерий для эависимых выборок
jf§[ Группировка и одиофакториая AN OVA
j Таблицы частот
I Таблицы и заголовки
"иД Вероятностный калькулятор
02Л Другие критерии значимости
В ох
Отмена
& Д<
& &
Это процедуры позволяют кросстабулировать данные (таблицы с числом входов
до 6; многовходовые таблицы более высокого уровня можно строить, используя
условия выбора) и строить разнообразные таблицы сопряженности. Здесь также
доступно большое количество статистик (например, критериихи-квадрат, фи-квад-
рат, гамма и т. д.).
Средства построения таблиц системы STATISTICA
451
ьиямм
Днклиа: J Таблицы сопряженности
Миогоамодоаие таблицы сопряжем юсти
VI Задать таблицы |
Таблица флагов и заголовк!
VI Задть хеблицы
Число 2-9КОД. таблиц: нет
[в гоё
Отмена
ш U I А В.
(9 Исполъееедоъ только мель* колы • вьяЗреиньш м
Г Цспольмммтъ асе амбр и нале коды Qgg &од»:
Зааайг* таблицы
\ сопряженности; ал*
i таблицы Флаго» и
- заголовков выберите дм
i опиок*
Многомерные отклики и дихотомии
Модуль Основные статистики и таблицы имеет разнообразные возможности
построения итоговых таблиц для переменных с многомерными откликами, а также
для многомерных дихотомий. Обычно группирующие переменные или факторы
делят выборку на непересекающиеся (эксклюзивные) группы, например, группу
мужчин и женщин. Очевидно, достаточно только одной группирующей
переменной, чтобы закодировать пол субъекта. Однако в некоторых исследованиях
категории не исключают друг друга (пересекаются).
I 1МЧТ1
я
ш
Дмалив: I Таблицы для многомерных откликов JM
VI Дедать таблицы } Г" Д<»$ж*$) *4><>^с^«йул«в*!$).::
Отмена
]|в Ш
Тип многомерного Фактора
^
£<итик: П-g
|ST Считать только «метальные отклики
(итерировать повторяющиеся отклики)
VI Лчиним* *«*»#« *.>»■*<>««<?«>• I &**»*■ *■»**■»'*' »**:л>6 w.pvvHwsnt* ЗАМЕЧАНИЕ. Все значения. •
I '"' ' ' ———• no«f.M««fi которые не являются допоет
Г Удивить П Д построчно внутри каждого набора многом, диаотомии ^.TTiZ^ Z^J^Sl"^ **
Удалить ПД построчно внутри каждого набора многом, откликов ^^ счячт» (многом, дихотомии),
Г* Вклинить ПД как дололишвлыиж» категорию дли каждого Фактора игнорируются (не ресемвтрйваоте*
кехПД)
Например, в маркетинговых исследованиях респонденту можно задать вопрос
о трех самых любимых безалкогольных напитках. Предположим, 60 различных
напитков присутствует в ответах, которые можно закодировать тремя
группирующими переменными (первые три предпочтения). В этом случае категории, очевидно,
не являются взаимоисключающими. Действительно, человек может отметить три
различных напитка как предпочтительные. Следовательно, если наблюдение —
это субъект, то для трех различных группирующих переменных это наблюдение
является общим (не эксклюзивным). Такие группирующие переменные
называют переменными с многомерными откликами (многомерные дихотомии по
существу схожи с ними). Эти переменные легко анализировать в модуле Основные
статистики и таблицы.
452
Глава 11. Построение и анализ таблиц
Примеры
Пример 1. Таблицы частот
Пример основан на модельных данных опроса об использовании Интернета.
Проводился опрос 100 человек относительно степени использования ими сети
Интернет. Каждый респондент получил список из семи разделов с просьбой определить
свой интерес: 1) Всегда интересуюсь — Always interested, 2) Обычно интересуюсь —
Usually interested, 3) Иногда интересуюсь — Sometimes interested и 4) Никогда не
интересуюсь — Never interested.
Ниже приведен файл InterneLsta.
iSCNESSfcQMPUTER
' -4 \
EDUCAT
5
HEALTH
SCIENCE
?
NEWS
U
Ы
i-L
•L.
!~
Ш
Ш
r±
Ш
n
ALWAYS ALWAYS ALWAYS NEVER SOMETIMS ALWAYS •
ALWAYS ALWAYS ALWAYS ALWAYS ALWAYS NEVER ALWAYS
ALWAYS SOMETIMS ALWAYS ALWAYS USUALLY USUALLY ALWAYS j
ALWAYS ALWAYS ALWAYS ALWAYS SOMETIMS ALWAYS ALWAYS j
ALWAYS ALWAYS ALWAYS ALWAYS NEVER ALWAYS ALWAYS j
ALWAYS ALWAYS ALWAYS SOMETIMS ALWAYS SOMETIMS ALWAYS
USUALLY; ALWAYS SOMETIMS; ALWAYS ALWAYS ALWAYS ALWAYS }
ALWAYS ALWAYS ALWAYS ALWAYS ALWAYS USUALLY ALWAYS |
SOMETIMS ALWAYS ALWAYS ALWAYS ALWAYS SOMETIMS ALWAYS :
NEVER ALWAYS USUALLY SOMETIMS ALWAYS ALWAYS ALWAYS j
NEVER ALWAYS SOMETIMS SOMETIMS SOMETIMS ALWAYS ALWAYS J
. ■ j?.n
Можно щелкнуть по кнопке Отображение числовых/текстовых значений та
панели инструментов таблицы исходных данных, чтобы переключиться в
численное представление значений переменных в таблице.
^cnfSurvey of INTERNET users
Z
r.:,
4
5
6
7
6
9
10
11
liL
J
«BUSENESS
1 3
3
XMPUTEF
A
EOUCAT
1 1 1 3
2 1 3 1
1^11
3 111
4 12 3
A 1
3
3
5
HEALTH
A
1
2
3
A
3
8
SCIENCE
3
A
2
1
1
3
1
2
3
1
1
исщ
?
NEWS
-J
г
Напомним, STATISTICA всегда обрабатывает данные в численном формате,
однако для удобства пользователя можно ввести текстовые значения и установить
взаимно однозначное соответствие между текстовыми и числовыми значениями
переменных. Это очень удобно для представления и ввода данных и
интерпретации результатов. Например, вместо того чтобы вводить значение ALWAYS,
можно вводить значение 1, вместо SOMETIMES — 3 и т. д.
Примеры
453
Таблицы частот
Из стартовой панели Основные статистики и таблицы выберите процедуру
Таблицы частот, чтобы открыть диалоговое окно Таблицы частот. В этом окне
щелкните по кнопке Переменные и выберите первые три переменные. Диалоговое окно
Таблицы частот появится на экране в следующем виде:
Шх
| 1$в1и»«ГММ«* ^^
mmmfSmmm*
Отт
V 1ДОмии*
iiiUlUiil ihiTnijUnu № i < Jjmil «.ДО 'ЛИНЦ f им i и ^
^^та>ШаШ^;^
2322ШЕ
Это диалоговое окно предлагает множество настроек, позволяющих изменять
вид и группировку в таблицах частот, а также проверять нормальность
распределения, в том числе и графическими способами. В этом примере используется
принятый по умолчанию метод группировки (в частности, Все различные значения, с
текстовыми значениями) и опции отображения {Кумулятивные частоты, Проценты
(относительные частоты), Кумулятивные проценты, 100% минус кумулятивные
проценты, Логит-преобразование, Пробит-преобразование), как показано в
диалоговом окне выше.
Как можно видеть, 19% респондентов отметили, что они всегда используют
Интернет для поиска информации по искусству, 33% — обычно его используют и т. д.
Всего 71% респондентов попали в категории всегда — always, обычно — usually,
иногда — sometimes и только 21% сказали никогда — never.
Большинство результатов в электронной таблице результатов понятно исходя
из здравого смысла. Разъясним, что такое логит и пробит значения. Это
специальные преобразования частот, которые часто используются на практике.
454
Глава 11. Построение и анализ таблиц
Логит — это преобразование вида: 1п(х/A-х)), где л: — относительная частота
(процент), наблюдаемая в ячейке.
Пробит переменной х — это стандартное нормализующее преобразование
переменной х. Пробит относительных частот — это обратное нормальное
преобразование, примененное к относительным частотам в ячейках. Итак, с помощью
пробит-преобразования из частот получаются величины, имеющие нормальное
распределение? Такое преобразование применяется в медицинских исследованиях
типа «доза — эффект».
Имея вероятностный калькулятор STATISTIC А, можно легко понять идею
этого преобразования (см. также главу Вероятностные распределения).
Посмотрите на таблицу результатов. Например, в первой строке таблицы
имеется частота 19 (относительная частота 0,19). Вычислим ее пробит.
Откройте вероятностный калькулятор. Выберите в списке распределений
нормальное распределение. Далее отметьте опцию Обратная функция распределения
и введите в полер относительную частоту 0,19. Нажмите кнопку Вычислить.
В поле Z вы увидите пробит введенной частоты, он равен 0,877896.
л
Лол
Логистическое
Парето
Релея
I (Стысмемтя)
[ВпЛбчяял
I? з>ксмр и*с«г«б \
£ j- 877896
р: J0 19
Сгдогк*.. |1
■г\
Точно такое же значение приведено в электронной таблице для
соответствующей частоты.
Построение гистограмм. Визуализируем таблицы, построив на их базе
гистограммы. Заметим, что можно без труда построить гистограммы всех выбранных
переменных, если вернуться обратно в диалоговое окно Таблицы частот и нажать
кнопку Гистограммы. Каскад гистограмм, по одной гистограмме для каждой
выбранной переменной, мгновенно появится на экране.
ItHUJ'HM.IH
■ -1рЫ
USUALLY SOMETIMS
Примеры
455
В системе STATISTICA можно распечатать (или сохранить в файле)
результаты анализа либо автоматически (когда содержимое каждой выводимой на экран
таблицы результатов одновременно направляется на принтер и/или в Окно
текста/вывода), либо вручную (когда пользователь сам выбирает, какую таблицу
результатов или часть какой таблицы результатов распечатать). Перед тем как
распечатать результаты анализа, программа попросит вас уточнить направление
вывода (то есть Текст, файл, Принтер, Нет и/или Окно) в окне Параметры
страницы/вывода (выберите установку Параметры страницы/вывода в выпадающем
меню Файл, настройку Принтер в выпадающем меню Сервис или дважды
щелкните на поле Вывод строки состояния).
Параметры страницы/вывода
(•" Хмхх/габл. реа./габд. да
Ш
^Сраеааш
} Принтер
Р=3 Текст »айя
ПОано
• Доля/Принтер I
j Заголовок выводе v • •• •■
:г
Г" Раамастить заголовки по венгру
? £? Датам!
| Автоотчвт -••' ~ . •-■•—
| Р Дет. дополнение содержания окна текста/вывода
| Г Авт. вывод из таблиц реаздьтатое м графиков
1 Г~ Авт. печать всея тебеид реаздьтатое {автоответ)
Р Авт. печать/выдача страхи* при каждом выводе
Г* Авт. выдача «аждояаатюанениоД страницы
F Печать твоЧаядмм а окна текста/вывода
В этом окне можно также определить дополнительную информацию для
печати вместе с таблицей результатов. Доступны следующие формы выводимого
отчета: Минимальный, Краткий, Средний или Полный.
Если в окне Параметры страницы/вывода была выбрана настройка Авт.
печать всех таблиц результатов (автоотчет), то дополнительная информация
(количество которой определяется установленным в этом же окне форматом
отчета), а также все результаты анализа будут автоматически выведены на принтер
или в файл (в зависимости от того, выбрана ли установка Окно в левой верхней
части этого диалогового окна). Этот режим печати полезен, если вы хотите
получить полную сводку всех результатов, выведенных на экран в процессе
анализа.
Графические процедуры. Практически все результаты могут быть отображены на
графиках с помощью графических процедур, доступных в данном окне. Прежде всего
щелкните по кнопке Диаграмма размаха для всех переменных, в появившемся
диалоговом окне выберите Средние/ст.оги./ст.откл. и затем нажмите ОК, чтобы построить
график.
456
Глава 11. Построение и анализ таблиц
(зшшшшЕшшшт
Диаграмма размаха
4.0
3.5
3.0
2.5
2.0
1.5
1.0
0.5
о
г • Ч
i \
о
AR
TS
BUSENESS
COMPUTER
IHHLsJSJLsJ
~Т" Мин макс
CD 25Ч-75Ч ;
о Медиана
Печать графиков в пакетном режиме. Если в диалоговом окне Параметры
страницы/вывода выбрана установка Автоматически печатать все графики,
STATISTICA автоматически направит создаваемые графики или на печать, или в
окно вывода (или сохранит в файле вывода, если выбрана Печать в файл в
диалоговом окне Печать графика).
Пример 2. Таблицы флагов и заголовков
Таблицы флагов и заголовков являются экономным способом представления
нескольких двухвходовых (двумерных) таблиц в одной. Работая с данными, нам
интересно узнать, имеют те же самые респонденты, которые проявили
наивысший интерес к бизнесу, также наивысший интерес к новостям в Интернета.
Описание анализа
Используемый файл данных InterneLsta описан в предыдущем примере. Из
стартовой панели Основные статистики и таблицы выберите процедуру Таблицы и
заголовки и откройте диалоговое окно Задайте таблицы.
]i V',"",! 'J&'»' ''>"•',"»' '. ' ,\\* " "и П
• V\£*' <$&?■$&':»'
Jfti|Hiy | Таблицы соприжаиности~jjj
Щ^^-*&пьу6т*»';
Число 2-ми*. TMlwtMf нт
CSttlfrt
Г в
*т«те*нчт
*;.,«a^f.L* 3«МЙГ#Т«ЛМИМ. >
а »*— ' *~ ' " •'* '~~jL\ —^^^/ ' оогрйяшноспкйт
«• исмюлмаоащ» тоамю щмма иодм.в ацмораиимш пидонаиинм ^ _ таблицы Флаго* и
ГИепо*и»»ат^ • лап^вакоав1и5м><гада*
^х_»^^.*^
Таблица флагов и заголовков по существу содержит несколько двумерных
таблиц, собранных вместе. Лучший способ понять эти таблицы — рассмотреть
конкретный пример. В диалоговом окне Задайте таблицы нажмите кнопку Задать
таблицы под заголовком Таблицы флагов и заголовков. Программа запросит ввод
переменных для таблицы.
Примеры
457
■■"■"■ "'■"■'■"■'"■■-"
1 AHTS
2BUSFNFSS
3C0MPUTER
44 DUCAT
5HEALTH
BSCItNff
7 NEWS
1 ARTS
2BUSENESS
3 COMPUTER
«E DUCAT
ft*
Отмен* ]
| Все [J rioftpotf. ]| Им*
Первый список, птрамлтшпг.
jl-G
J] Все J Подроб. || Ии+. j
Второй описок переменные
I' v-:|
Теперь диалоговое окно Задайте таблицы будет выглядеть следующим образом:
ее=ш
я
Диализ: j T аблицы сопряженности *|
Миогоежадовые таблицы сопряженности Таблице Флаге* и ««годом
VI Задать таблицы | I VI Задатыабяиды
Ь>| ГЬ.*о> *•*•$•> $>>*ву
■в ш
Отмене
Ju=*'t
чтя* гъ<>!Як&*\
Число 2-вмоа. таблиц: в
Число таблиц: нет
<• Использовать только долью коды • выбранных napOMeieiM*
С Использовать все выбранше коды Jgj-J &одьг. J
' *»«>«*«*«м
Задайтатаблииы
, сопряженности; дл*
i таблицы Флагов и
[ заголовков выберите два
, списка.
Нажмите ОК в этом диалоговом окне, чтобы открыть диалоговое окно
Результаты кросстабуляции.
Щ Результаты кросстабчляци
ill рссмотреть. итого!
Ч.Л*Ж№
ДД Подробные двуекодоеъм таблицы |
ВЯ Таблица ♦.легое м заголовков |
Р Ото£режлть длинные метки значений
Г* включить
Г" ft<--tfy-<iw<;iVi>iw>¥»'-ta<btfi У v vt&!i.iM*4* rat»
Статистики для двчвжодоеытс таблиц .•;
Г" Пирсона и М-П ки квадрат
' Г* Точный Фишера. Детсе, Макиемара B к 2)'
, Г* Фи Bк2 таблицы) и Крамере V м С
Г* Taj b и тау-с Кендалла
Г* £амма ■" • j
i Г* корреляция Спмрмена
Г" Сомщераб
Г Кор.#»ициоты неопределенности . j
Г W—■:■■:■.■'•-.-.■•:
i рс Выделить частоты >:
j Г Одидввюмв частоты
• Г" Остаточньде частоты
;Р Проценты от обжато
j Г Продеты по строк*
i Г* Проценты по столбце
"I
Ш WL
Отмена j
КаУеторщовыелле гистограммы
СЮГрделехи
*
ЗАМЕЧАНИЕ; Таблицы Флагов и заголовков
доступны, если выбраны два списка переменных
Чтобы вычислить «нимАоат ме*емма<**ого .
гоавдоподобия и проанализировать таблицы со
миогм.ц «модами, используйте модуль
Лог линейный «налив.
В этом диалоговом окне нажмите кнопку Таблица флагов и заголовков, чтобы
отобразить таблицу результатов.
Вы можете рассматривать построенную таблицу как объединение нескольких
двухвходовых таблиц. Например, в четырех начальных строках таблицы показаны
частоты двумерной таблицы ARTS — NEWS. Другой способ состоит в том, что
значения в четырех начальных строках и четырех начальных столбцах таблицы
рассматриваются как совместное распределение 100 респондентов в 4*4=16 ячейках,
созданных пересечением интереса к футболу с интересом к бейсболу. Теперь
рассмотрим различные способы представления результатов.
458
Глава 11. Построение и анализ таблиц
l II mMfmmm^mrmmmmmmmmmmmimmmwmt
Далее-
Фактор
^^^^^Н ARTS ALWAYS"
ARTS : USUALLY
ARTS SOMETlMS
ARTS :NEVER
ARTS :постр.
BUSENESS: ALWAYS
BUSENESS USUALLY
BUSENESS: SOMETlMS
BUSENESS NEVER
BUSENESS постр
COMPUTER ALWAYS
COMPUTER USUALLY
COMPUTER SOMETlMS
COMPUTER: NEVER ' -
COMPUTER: постр.
EDUCAT ALWAYS
EDUCAT : USUALLY
EDUCAT: SOMETtMS
EDUCAT : NEVER
Частоты выдел
(Маргинальные
1r |
10
5
9
39
24
8
5
2
39
14
7
К.
6
39
14
8
12
5
енных ямеек>10
суммы не отмечены)
NEWS
USUALLY
1
1
11
3
16
2
5
7
2
16
2
1
8
5
16
0
1
10
5
NEWS
SOMETlMS
2
3
5
26
2
3
10
2
26
2
1
6
17
26
2
5
10
9
NEWS
NEVE*
1
0
6
19
0
1
6
}>
19
2
1
3
l.j
19
2
2
8
7
■■ЕЖ
всего
постр
19
щ
14
38
29
100
28
17
37
18
100
20
ю
29
41
100
18
16
40
V
Частоты по строке. По умолчанию таблица флагов и заголовков отображает
частоты в строке. Таким образом, видно, например, что 15 (из 100) респондентов
всегда интересуются ARTS и всегда интересуются NEWS. Посмотрите на
четвертую строку таблицы, вы увидите, что из тех респондентов, которые никогда не
интересуется ARTS, 17 (9+3+5) интересуются NEWS: всегда — always (9), обычно —
usually C) или иногда — sometimes E).
Проценты. Снова вернемся в диалоговое окно Результаты кросстабуляции.
Диалоговое окно содержит настройки, позволяющие выразить результаты в
процентах. Проценты могут быть вычислены относительно общего числа наблюдений
в строке, относительно общего числа наблюдений в столбце или относительно
общего числа наблюдений.
Вы также можете включить в таблицу ожидаемые и/или остаточные частоты
(разность наблюдаемых и ожидаемых частот). Выберите настройку Проценты по
строке и снова нажмите кнопку Таблица флагов и заголовков.
После того как выбрана настройка Проценты по строке, станет доступна
настройка Отображать выбранные % в отдельных таблицах. Так как в одной
таблице может быть слишком много информации, выбор этой настройки помещает
проценты в отдельную таблицу результатов. Мы рассмотрим общую таблицу.
1.1.И1!Л1.Р.И111,ЧШ111Ц111М11.1.1Ш.Ш1Ш
Частоты выделенных ямеек> 10
[(Маргинальные суммы не отмечены)
■ JntxJ
NEWS
SOMETlMS
NEWS
NEVER
Всего
постр
строи %
USUALLY
строк %
SOMETtMS
строке
NEVER
строке;
Всего
IS I
7Z*i\
10
71 434
5
13 16%
9
31 03%
39
1
5 26%
1
7 1 4%
П
?rt %%
3
1 0 34%
16
2
10 53%
3
21 43%
'Ь
•г: 11 a.
5
1 7 24%
2b
1
5 26%
0
0 00%
6
15 79%
1:
*л •?•'<
19
19
14
38
29
Примеры
459
Из таблицы результатов следует, что из тех респондентов, которые всегда
интересуются — always interested ARTS (все респонденты в первой строке), 78,95%
также всегда интересуются — always interested NEWS.
Поэтому ARTS и NEWS тесно между собой связаны (в этих данных).
Так же можно найти темы, не связанные между собой.
Статистики
Рассмотрим некоторые из этих статистик, представленные в диалоговом окне
Результаты кросстабуляции. Наиболее употребляемая статистика — хи-квадрат.
Мерой зависимости между переменными подобно коэффициенту корреляции
г Пирсона является ранговая корреляция R Спирмена (см. главу
Непараметрическая статистика, где систематически описаны ранговые корреляции). Эта мера
предполагает, что значения переменных содержат, по крайней мере,
ранжированную информацию. Такое предположение разумно в данном примере, так как
ответы респондентов упорядочены по степени интереса.
Выберите опцию Корреляция Спирмена. Диалоговое окно Результаты
кросстабуляции примет следующий вид:
кросстабчляции
Просхотрть топтьт таблицы |
Ю Таблица флагов м
отдельный табл.
| р? Отображать д<
Г~ Включить пррпащадама данные
Г~ Отображать выбранные X а
: Статистики для длее иод.
. рТ Пирсона и М-Л
\ Г" Точный «Риешра. fterca.
' Г~ *>и 12*2 таблицы) и Крамера V
■ Г* Tajt-b и тау-с Кеидалла
\ Г" £амма
Р Коэффициенты неопределенности
Р? выделить частоты >: [То
! Г Ожидаемые частоты
I Г .Остаточные частоты , *\::-
' !ЯГ Проценты от общрго числа
\ Г* Проценты по строи©
| Г" Проценты по столбце
1 ЕЭ цк
Отмена
Катет оризоеениые гистограммы
| Графики вэаимодеЛстеий дли частот
Мекмемара B ж 2| ] *&
ЗМ гистограммы
иС
ЗАМЕЧАНИЕ: Таблицы Фмгоа и заголовков
дост/»<|>сес/ыае^р*н»дмспи(жап*рам«л««л
Чтобы вычислить жжаадрат максимального
правдоподобия и проенаяиеироеетъ таблицы со
многими входами, используйте модуль
Лог*
После того как выбраны статистики, нажмите кнопку Подробные двухвходовые
таблицы для того, чтобы выбрать таблицы для анализа.
На экране появится диалоговое окно Выбор таблиц для просмотра, в котором
приводится список всех двумерных таблиц:
(Выбор таблиц лля просмотра
Список возможных таблиц
•актор 1 Фактор 2
(все тавл.
JBUSENESS NEWS
COMPUTER HEWS
EDUCAT HEWS
HEALTH NEWS
SCIENCE NEWS
BBI
I UK I
j Отмена |
Выберите I
твблицыдл* j
просмотра
или выделит*
первую опцию.
что6ь»<аио«ггь
асе таблицы.
Можно воспользоваться параметром Все таблицы, чтобы построить каскад двух-
входовых таблиц.
460
Глава 11. Построение и анализ таблиц
В данном примере выберите таблицу ARTS — NEWS и нажмите ОК. Для
каждой выбранной таблицы будут построены две таблицы результатов.
Первая содержит наблюдаемые частоты и все остальные характеристики,
выбранные в поле Таблицы диалогового окна Результаты кросстабуляции (в
частности, Проценты от общего числа).
■ Jalxj
NEWS
SOMETIMS
NEWS
NEVER
Всего
по стр
Нлоетроке ;:-vV
USUAliV:Ueuel|yirt#ftet#d
Нло<*троке :.
SOMETIMS: Sometime* Interested
%noстроке •
NEVER Never interietted i
% no строке
Суммы по стпв
>■»}%;■.
10
71 43%
5
1316%
9
31 03е/.
39
m
5 26%
1
7 14%
11
:ь %'■<<■
з
10 34%
16
2
10 53%
3
21 43%
If.
С'Г,
5
1 7 24%
26
1
5 26%
0
0 00%
6
15 79%
К'
41 33%
19
19
14
38
29
100
•Г...
Вторая таблица содержит результаты хи-квадрат и корреляции Спирмена.
Значение статистики хи-квадрат для этой таблицы равно 44, что является
высокозначимым. ARTS и NEWS являются зависимыми. Степень зависимости
дает R Спирмена, равная 0,43.
В дополнение к этим методам вы можете построить графики, нажав кнопку
Графики взаимодействий для частот диалогового окна Результаты кросстабуляции
(из диалогового окна Результаты кросстабуляции), чтобы визуально исследовать
частоты в выбранных двумерных таблицах.
НИШЦШ»
моя AHTSxNtWS
График вмимод.:
ARTS X NEWS
/.
/
;
ALWAYS USUALLY SOMETIMS NEVER
NEWS
—>- ARTS
ALWAYS
-u- ARTS
USUALLY
• о• ARTS
SOMETIMS
-*- ARTS
NEVER
Примеры
461
Пример 3. Таблицы сопряженности
Для углубленного анализа результатов опроса (см. предыдущий пример)
рассмотрим некоторые таблицы более высокого порядка. В частности, определим процент
респондентов, являющихся «фанатами Интернета».
Иными словами, найдем число тех респондентов, которые всегда
интересуются — always interested ресурсами и arts, и news, и science в Интернете.
Задание анализа
В стартовой панели модуля Основные статистики и таблицы выберите
процедуру Таблицы и заголовки. Для определения таблицы нажмите на кнопку Задать
таблицы в разделе Многовходовые таблицы сопряженности диалогового окна
Задайте таблицы. Откроется стандартное окно выбора переменных.
ЕЕВШЕЕВ
ДиеАМГ | Таблицы сопряженности
Ииогммюцоа
»>1 •' :- -• Дадататабамц*
Ы 0,И*****»<************ ч* <>««#*< '.xS«ж*»*] >: Число
J,:'j-
табаня: мпг Г Ъэнткхм***
— . -.,„__ иои««г»< ••
(^ Иопоаьааеатьтоаша щлтм коды ■ ■iKtpMiiiniпартии»» :' } гм&ицмф/чгоаи
С Цепоаьаав*ть •©• ««браним, мам gff &о*ьс | Наембраим ^тУ****^*****
В открывшемся окне выбора переменных выберите группирующие
переменные (можно выбрать до шести списков группирующих переменных).
пяятт
IllliiiliVill'illi'i 'i lilliTig
|nonpo6jliHtH
1 ARTS
2BUSENESS I2BUSENESS
з computer HMIL'ILIIIlil
4EDUCAT
5 HEALTH
6 SCIENCE
74JEWS
4EDUCAT
5 HEALTH
6 SCIENCE
7 NEWS
1 ARTS
2BUSENESS
3 COMPUTER
4EDUCAT
5 HEALTH
6 SCIENCE
1подр»б|Ни»Л
ЕШ;
1 ARTS
2BUSENESS
3 COMPUTER
4E0UCAT
5HEALTH
6 SCIENCE
7NEWS
'F
Список!'
Поареб^Ин»!
1 ARTS
2BUSENESS
3 COMPUTER
4E0UCAT
5-HEALTH
6 SCIENCE
7 NEWS
1йшМвя<1
1^TS QDI
S3S3^^
• Cmtee*Cr...
Вы можете выбрать одну и более переменных в каждом из шести списков,
чтобы создать таблицы со многими входами. Теперь диалоговое окно Задайте
таблицы будет выглядеть следующим образом:
rfi'f'ilUf'illiB—Д^а^И
Днаана: | Таблицы сопряженности *1
: М|югоеиц*оаме табаним ахщтктыюспы . .< Табаиаа «дагоа и аагомм
■\ Ц Дадат» табаиты |
; i»t Дросмстрать нам едааип» тебяиаы 1
Число таблиц: 1
vl ' Задат*хабли*м
■аШвШВ
IB... JOB: 1
тт;: i 1 :'о»»м»:/^i
1 gSnl&il
Чмсао 2-ааац. табаиа; иат. . ;Г"фщ«»«*н»« J
;..;. ,л Э»да*ат*бл«*1 .
<• Иелоаымммпгь только |*лма коды • выбраним* переманим»
; С &сяол»аоа«гь аса ембранима коим QgQ &ojuc | На амбр ami
CWiWWftrMOCTkiAeA
таблицы♦лагови ч'-' :.'. ■■']
ааголоакоааыбаригадм i
описка.
462
Глава 11. Построение и анализ таблиц
Нажмите ОК в диалоговом окне Задайте таблицы, после этого откроется
диалоговое окно Результаты кросстабуляции.
проестабчляцим
QB Подробны» дочаущоаыа табйты
f* Отображать длинные МОТКИ ЭИаЧЛИИА |
Г Включить пропчщадоыа даииы»
Г" Ш <*%*«****> пм6$ш*т**: X ъ ы&<>т*ж*
Статистики для доуодоами таблиц
Г* ПирСОИв й М-Л НИ-КВАДраТ
Г Точный Фимюра, fterc«u Макнамарл B
Г Фи B*2 таблшы| ц Крамера V м С
Г* Таа*Ь и та** Каидалла
Г Евмма '
I Коррелящия Слирмлио
Г CoMMjepod
Г* Коа»»идиеиты неолрадядониости
| рТ выделить частоты >: [10
j Г* Одидав! но частоты
Г* Остаточные частоты
Г" Лродеиты от общего числа
Г" Лродеиты по стропа
Г* Ородвиты по croaoaj
Ш ОДС
Катагориаоааниыа гистогр впали
*2)!
ОД Грв+ики аааимодаистаий для частот i
Iflft ЗМ гистограммы
ЗАМЕЧАНИЕ: Таблицы Флагов и заголовков
доступны, если выбраны два списка перепетых.
Чтобы вычислит* ки-мивр*г максимального
правдоподобия и гроаналюировать таблицы со
многими входами, используйте модуль
Лог линейный анализ.
Это то же диалоговое окно, что и в примере с таблицами флагов и заголовков,
единственное отличие — неактивна кнопка Таблицы флагов и заголовков.
Выберите еще раз параметры таблицы (например, Проценты по строке,
Проценты от общего числа и т. д.) и статистики (например, Хи-квадрат, корреляции
и т. д.), нажав либо кнопку Просмотреть итоговые таблицы, либо кнопку
Подробные двухвходовые таблицы.
В любом случае на экране появится промежуточное диалоговое окно, в
котором можно выбрать таблицу из уже выбранных. Если использована команда Все
таблицы, то каскад таблиц результатов будет построен для каждой таблицы,
показанной в этом диалоговом окне.
Для Примера 3 процедура Подробные двухвходовые таблицы дает следующую
таблицу:
□ЕЕЯЕЕЯЕЗП
Далее..
Частоты выделенных ячеек> 10
[(Маргинальные ецммы не отмечены)
1.1PIX1
ARTS COMPUTER
шт/яшшшшшш
% построив
ALWAYS USUALLY
Ч по строк*.
ALWAYS SGME71MS
Ч по строк» .V-*•»%>-
ALWAYS NEVER ^ Т^'
ЧТО СТрОК*:?'" '•':.дЛ
вОИ« :.^} .;'"
Ч по строк» '*. ■
USUALLY ALWAYS :^v!\f
% по строк»- '■'- • •:• уг, >••
USUALLY USUALLY*:'■*
- % по строк» \
usually sometims .
вЖДдМЦГ*|М
10|
100 00%
2
100 00%
3
75 00%
0
0 00%
15
7895%
2
50 00%
А
80 00%
2
NEWS
USUALLY
NEWS
SOMETIMS
NEWS
NEVER
вс*го
111
0
0 00%
0
0 00%
1
25.00%
0
0.00%
1
526%
1
2500%
0
000%
0
0
0 00%
0
0 00%
0
0 00%
2
66 67%
2
10 53%
1
25 00%
1
20 00%
0
0
0 00%
0
000%
0
000% •
1 ;
3333% *
1 :
5.26%- !
0
000%
0 :
0 00%
0
10
50 00% !
2
20 00% .
4
13 79%
з .;
732%
19
4
20 00%
5
5000%
2 ~i\
>..n
Примеры
463
Как можно заметить, 10 респондентов из 100 сообщили, что они всегда
интересуются — always interested arts, news, computer.
Развитие этого примера очевидно. Например, в маркетинговых исследованиях
таким образом можно находить группы клиентов, которые всегда покупают
определенный набор продуктов.
«Работая руками», перебирая множество вариантов, вы добиваетесь четкого
представления данных и открываете нетривиальные связи.
Пример 4. Табулирование многомерных откликов
и дихотомий
Пример показывает, как обращаться с многомерными откликами и дихотомиями,
часто возникающими в массовых опросах, а также какие возможности для анализа
этих переменных имеются в модуле Основные статистики и таблицы. При
проведении массовых опросов имеется своя кухня, с некоторыми рецептами которой
мы сейчас познакомимся. Пример с результатами гипотетического опроса
находится в папке Примеры.
На основе рассматриваемых данных покажем, как табулируются следующие
типы переменных:
О простые группирующие переменные;
О переменные с многомерными откликами;
О многомерные дихотомии.
Термин многомерный отклик на сленге анализа данных означает многомерный
ответ, то есть ответ, содержащий в себе несколько ответов (а не один вариант ответа),
например, респонденту, возможно, нравится, несколько типов машин, а не одна
машина, или несколько фильмов, а не один из числа предложенных, несколько
развлекательных сайтов, а не один и т. д. Для того чтобы не заключать отвечающих в жесткие
рамки, при проведении опроса может допускаться несколько ответов. Число их
заранее оговаривается.
Дихотомия (от греческого 5i%OTO|iecD — разделять или рассекать на две части) —
это переменная, принимающая два значения, 0 или 1, а в текстовом виде — нет
или да. Соответственно многомерная дихотомия представляет собой набор нулей
и единиц.
Вначале расскажем, как строятся простые таблицы частот для описанных
переменных, затем построим и исследуем таблицы сопряженности для них.
Описание файла данных
Представьте, что проводится исследование покупательских предпочтений
молодых людей. Задаются следующие вопросы: 1) какую систему быстрого питания вы
предпочитаете; 2) какой тип автомобиля вы предпочитаете; 3) какой местный
ресторан вы посещали в течение последних двух недель. Дополнительно
записывается пол респондента. Эти ответы записаны в файл Fastfood.sta, переменные
которого описаны ниже.
464
Глава 11. Построение и анализ таблиц
Пол (простая группирующая переменная). Пол респондента записывается в
группирующую переменную Пол — Gender (Мужчина — Male, Женщина — Female).
Лучшая «быстрая» еда (многомерный отклик). Вопросник, используемый
в данном исследовании, предлагает респондентам выбрать любимое «быстрое»
блюдо (до трех блюд) из следующего списка:
1) Гамбургер — Hamburger
2) Сэндвич — Sandwiches
3) Цыпленок — Chicken
4) Пицца — Pizza
5) Мексиканские блюда — Mexican fast-food
6) Китайские блюда — Chinese fast-food
7) Еда из морепродуктов — Seafood
8) Другие национальные блюда — other ethnic or regionally popular fast-food
У каждого человека может быть несколько любимых блюд. Поэтому выбор
каждого респондента вводится в файл как переменная с многомерными значениями.
Например, первый пункт ответа записывается в столбец Еда J — Food J (первое
предпочтение), второй пункт (если он имеется) — в переменную EdaJ2 — Foodjl
и третий — в переменную Еда_3 — Food_3. Таким образом, в данном опросе мы
имеем одну переменную, принимающую три значения.
При анализе переменная Еда J — Food J может рассматриваться как простая
группирующая переменная. Далее можно задать вопрос: какое число
респондентов (или их доля) назвало определенный тип системы быстрого питания своим
любимым — favorite? Однако интерес может представлять также и то, сколько
респондентов выбрали определенную систему быстрого питания как одну из
любимых. Такой вопрос приводит нас к тому, чтобы рассматривать переменные Edajl —
Еда J} (Foodjl — Food_3) как одну переменную с многомерным откликом. Такие
переменные можно называть также многомерными.
Любимый автомобиль (переменная с многомерными откликами). В этом
опросе вас просят назвать три самых любимых типа автомашины (фактор денег,
стоимость машины, не учитывается, просто спрашивается о некотором идеальном
воображаемом автомобиле). Эти ответы (определенные марки и модели)
закодированы следующим образом:
1) Отечественный спортивный автомобиль — Domestic sports car
2) Отечественный седан (закрытый автомобиль) — Domestic sedan
3) Иностранная спортивная машина — Foreign sports car
4) Иностранный седан — Foreign sedan
Данная переменная рассматривается как переменная с многомерными
откликами подобно переменной любимая система быстрого питания — favorite fast-food.
Это означает, что ответы респондентов были введены как значения переменных
Машина J — Машина J3 (CarJ — CarJ3).
Например, если респондент называл тру любимых блюда Гамбургер — Hamburger,
Гамбургер — Hamburger и Гамбургер — Hamburger, тогда значение Гамбургер —
Примеры
465
Hamburger будет учитываться только один раз (в переменную Еда_1 — Food_1),
а соответствующие ячейки переменных EdaJ2 — Food_2wEda_3 — Food_3
рассматриваются как пустые.
Рестораны (многомерная дихотомия). Посетителей ресторана попросили
назвать, какие из четырех ресторанов они посещали за последние две недели.
Полученные данные были введены в файл так, что для каждого ресторана имелась своя
переменная. Всего использовано четыре переменные Хозяин_1 — Хозяин _4
(BurgerJ\ — Burger_4) для следующих ресторанов:
1) Бутерброд Мейстер — Burger Meister
2) Лучшие бутерброды у Билла — Bill's Best Burgers
3) Гамбургер «Блаженство» — Hamburger Heaven
4) Большой бутерброд — Bigger Burger
Если респондент сообщил, что в течение двух недель обедал в одном или
нескольких ресторанах, то в соответствующий столбец (столбцы) ставилась единица, если нет,
столбец оставался пустым. Таким образом, переменная представляет собой
многомерную дихотомию (со значениями Да или пропуск), которую желательно табулировать,
то есть указать число (или долю) респондентов, обедавших в каждом из четырех
ресторанов.
Заметьте, что можно было бы рассмотреть эту переменную как переменную
с многомерными откликами. Однако для этого нужно создать не менее четырех
переменных, например, Edajl — Edajt (Eatjl — Eat_4), и затем ввести названия
ресторанов, например, Бургер_1 — BurgerJl, Бургер_2 — BurgerJ2..., как значения
этих переменных в столбцы таблицы (аналогично переменным любимая машина —
favorite car и любимая система быстрого питания — favorite fast-food, см. выше).
Ниже представлены несколько первых наблюдений файла данных Fastfoodsta.
Ггд«
ТЕКСТ
h ■
% •••••
)ниме
Fast Го
IASIIIIIII) S
IA 11n ' ЛЖи
od and fast cars Survey of adolescent consumer preferences
■III
female!
MALE
MALE
MALE
FEMALE
PIZZA
SEAFOOO
PIZZA
SEAFOOO
HAMBURG*
$£28№
•::v:p54^:;.,::^
SEAFOOO
PIZZA
OTHER
MEXICAN
CHNESE
HAMBURGH
MEXICAN
SANDWICH
DOM.SEDN
FOR.SPRT
DOM.SEDN
DOM.SPRT
FOR.SPRT
DOM.SPRT
DOM.SPRT
DOM_SEDN
FOR.SPRT
DOM.SPRT
RHDl
*r
DOM_SPRT
FOR.SPRT
FOR.SEDN
FOR.SPRT |
DOM SEDN «*j
*F!
.ТЕКСТ
*■.-.
t
i3'
иные FAS
IrOUD SIA 1 lei - ?00m
Fast food and fast cars Survey of adolescent consumer preferences
<.;,'ei*oeu <■
•.••-•••10 •
piracl
4
aurtowji
YES YES
YES
YES
YES
YES YES
YES |
YES «rjj
Для того чтобы показать, каким образом каждый опрашиваемый респондент
введен в файл, посмотрите на первое наблюдение. Первый респондент —
женщина, поэтому в переменную Пол — Gender введено значение Же/ш^мня — Female.
Самое любимое быстро приготовленное блюдо — Пицца — Pizza (введено в перемен-
466
Глава 11. Построение и анализ таблиц
ную Еда_1 — Food_1), второе по предпочтению блюдо — Еда из морепродуктов —
Seafood (введено в переменную Еда_2 — Food_2), третий вид еды не указан,
поэтому в переменной Еда_3 — Food_3 стоит пропуск.
Далее этот респондент выбрал следующие три типа автомобилей: 1)
домашний седан — domestic sedan, 2) домашний спортивный автомобиль — domestic sports
car, 3) снова домашний спортивный автомобиль — domestic sports — переменные
Саг_1, Саг_2, Саг_3, — Car_1, Car_2, CarJ3 соответственно. Наконец, он ответил,
что последние две недели обедал в двух ресторанах Burger_1 (Burger Meister) и
Burger_3 (Hamburger Heaven), таким образом Да — Yes было записано в ячейках
соответствующих переменных, значения двух других переменных Burger остались
пустыми.
Всего было опрошено 200 респондентов.
Начнем с вычисления таблиц частот для простой группирующей переменной Пол —
Gender и переменных с многомерными откликами. Так как имеются пропущенные
значения во всех переменных Burger_1 — Burger_4, таблица для них будет определена
позже.
По умолчанию наблюдения со всеми пропусками в переменных Burger
исключаются из анализа, и частоты будут вычисляться лишь для респондентов,
посетивших, по крайней мере, один из четырех ресторанов. Другой способ обработки
пропусков состоит в том, чтобы сделать отметку в поле Включить ПД как
дополнительную категорию для каждого фактора.
Выберите Таблицы и заголовки в стартовой панели. В появившемся окне Задайте
таблицы выберите Таблицы для многомерных откликов в списке Анализ, при этом
откроется диалоговое окно Таблицы многомерных откликов. В этом окне можно определить
три типа группирующих переменных: простые группирующие переменные (Пол —
Gender в нашем примере), переменные с многомерными откликами (Еда_1 — Food_1
(Еда_3 — Food_3)wlиMaшuнa_1 — Саг_1(Машина_3 — Саг_3)) и многомерные
дихотомии (Burger_1 — 4).
I -tirl, 'I'lTlll
щ
В
J Таблицы для многомерных откликов *\
Ц Задет»таблицы [ Г" .&♦*****<»> «р>лм,*%««*»**
Отмена )lE> Щ\ \
Ими
Число
Тип многомерного фактора
О' N««>r<JH*': $.*»««* А***0*<S*W* $' М«»МУЬ^М*Л& WKfm*.
С4 М*•*<>;*«»<*!>*•»<»*•' nmw<t»&iH Ф Ми»* <>н*>^у«*$ vvx-vw
О Ъ*К'Я »t+i<;i^o** Я*<*«.»?«'>м*<** Ф Ыног км*'--р<'.'.хА *я << »v.t
£четчик: fl @ Jx Счетать только «мке;
'.'Г.Н;
И К*т*
зя *.#&*■
Ю*«*
вя*<**~
Ш8 *«*«•
Н.Г.
w r
■<}<■:
**:!
*<<S
(игнорировать повторяющиеся отклики)
Vl Дшнмй мткм фы.торсн J &**>* M*rfrм «**}**<*» **>*«?»ч*««**й ЗАМЕЧАНИЕ: 0св
:■ ■■'■ ,'. " ' **;**#<>** с п*с**
Г" Уладить ЛД построчно внутри каждого набора многом, дмяоп
которые не являются долусг.
кодами (многом откликов} млм не
_, м равны значению, резанному в
Г Ыдаемть ПД построчно внчтри каждого набора многом, откликов ^^ счетчик* (многом дихотомии).
Г~ Вкдцчить Л Д как дополнительнее категорию для каждого Фактора игнорируется (не оассметрмееются
кеьЛД}.
Примеры
467
Нажмите кнопку Задать таблицы для того, чтобы определить переменные
в диалоговом окне:
2F00D_1
3F00D_2
4F00D_3
5 CAR 1
6 CAR 2
7 CAR 3
8BURGER.1
9BURGER.2 i
10BURGER.3
11 BURGER.4
2F00D_1
3 FOOD_2
4 FOOD 1
5-CAR_1
6CAR.2
7CAR.3
8BURGER.1
9-BURGER.2
10BURGER_3
11 BURGER.4
I GENDER
2F00D.1
3F00D.2
4-F00D.3
5 CAR 1
6CAR~2
7CAR~3
8BURGER.1
9BURGER.2
10-BURGER.3
II BURGER.4
I GENDER
2F00D.1
3F00D.2
4F00D.3
5CAR.1
6CAR.2
7CAR.3
8-BURGER.1
9BURGER.2
10BURGER.3
II BURGER.4
Подро6,|инел| Подроб.1ин».| Подроб.1Ин+1 Подроб^Ии»! Подроб.|Ин«>.| Подроб.1Ин*>1
I GENDER
2F00D.1
3F00D.2
4F00D.3
5CAR.1
6CAR.2
7CAR.3
8BURGER.1
9BURGER.2
10 8URGER.3
II 8URGER.4
Отмене
Набор 1:
f
Набор 2:
E7—
Несер 3: Набор*
Р "I
йебор5:
Набор*
•Г
В окне можно выбрать до шести многомерных факторов (простых группирующих
переменных, многомерных откликов или дихотомий) для одной таблицы. В первой
колонке выберите только переменную Пол — Gender, программа автоматически
рассматривает единственную выбранную переменную как простую группирующую
(простая группирующая является частным случаем переменной с многомерными
откликами, для нее число откликов равно 1). Во второй колонке выберите переменные
Еда_1 — Еда_3 (Food_1 — Food_3)> в третьей — Машина_1 — Машина_3 (Саг_1 —
СагЗ). Сначала обратите внимание на простые таблицы частот для всех выбранных
факторов (таблица частот для BurgerJl — Burger_4 будет исследована позже). Нажмите
ОК, чтобы завершить выбор. Теперь в окне Таблицы многомерных откликов можно
видеть выбранные переменные.
bfQSSZSBBBjjBjjjjBjfjjBjBjjjejjjjjjjjjjjjjM^j
&»**из: | Таблицы для многомерных откликов ^rji»/^*: >'--::?j^' -'OrMeW^ ''j|E3 •••'•: Щ$ I '
Ц Задать таблицы j Г Дерна* кросстебЧри»!»* '. к» Д. ] «S» В. |
: Имя миогомерн. Чмсяо «^«♦tm^
♦актора парам. / •' :-^' 1тши<ттрПйП>+шпЫ>ш •
J;[GENDER 1 С М*>х-4жщтяът*о1н«** '# МногокаримЛ отклик QgQ (Совье
2|F00D_1 : Э :С М ног опершие диквтомид (? МногомарныА отклик Q$ Коим:
£JCAR_1 3 С Многомерная дихотомия (? Многомерны* отклик ОЙ Коды?
4 ] : 0- . С Мйог«»<#*&о**«fcxc»йий» ^M«w««ep«^^^i^ Q5Qk<*«m
: ^ j , Й . О Цшхьмефияя «*«*** <ихмя 'Л >feiiw*«»»pKw*«ry>«*!fc ОЙ Кяйы:
& ] 0 С Мияг-ом^иш* йкш*о«ш» й^: %j;(wrt»*«ip«trfa огяяав Q^jJ Keietx.
.,;,: f_Mi«e I R У Считатьтолькоедикалыеаеот»
f:t?$ ?-.'?■ :?':i?: *:;?i!>l^'!,0'w',e*,T|> яодторд«>еи«все от*
1 1*1 Длинные иткн>а*^^ У^'ЗлЯЕЧАНИБ^**
"".Г^" ",",! ,' ' ".;: :;' • «вжжвмсписке ••:/,•••%• .£у.«лв^.|«*»А»чюи
Г Уладить ПД построчно енутри каждого меборд многой, димотшеи! ^(^^^^
j Г Ыдалдо П Д гюстрочно внутри каждого наборе многом 01кдимш п^
нет
нет
нет
дики
1дижи|-'у-;';''
«иному а -
*а**от©н*4|
Термин фактор используется для общего обозначения всех типов переменных
(например, такая переменная, как любимая еда — food preference, в
действительности состоит из нескольких переменных). Мы употребляем термин многомерный
фактор и для простых переменных, и для переменных с многомерными
откликами, и для многомерных дихотомий. Заметим, что по умолчанию фактору присваи-
468
Глава 11. Построение и анализ таблиц
вается имя (как длинное, так и короткое) первой переменной в соответствующем
списке.
Определение факторов. Расположенная рядом с каждым фактором опция
позволяет определить его тип. Первая переменная Пол — Gender — это простая
группирующая переменная. Для второго и третьего факторов выберите опцию
Многомерный отклик.
Далее выберите коды для определения различных категорий. Выберите коды,
чтобы идентифицировать пол респондента Мужчина — Male и Женщина — Female
(переменная Пол — Gender), а также различные типы «быстрой» еды в переменных Еда_1 —
Еда_3 (Food_1 — Food_3) и различные типы автомобилей в Машина_1 — Машина_3
(Саг_1 — Саг_3).
Если вы не зададите коды явно (просто нажмете ОК), программа возьмет их
из первой переменной в каждом факторе. Данный способ обычно позволяет
определить все коды, однако может случиться так, что определенный код не
присутствует в первой переменной, а присутствует только во второй или в третьей.
В этом случае способ по умолчанию не применим, так как ряд значений окажутся
неучтенными.
Лучше задать все используемые коды точно. После нажатия одной из кнопок
Коды, расположенной рядом с каждым фактором, можно ввести коды для фактора.
III)I.IUI|I||JI|I.III,I,|I|..|IH—
■в£1ЮИ?:]1 2
' «TOOJifTl
iii'.iniiiii-.'1'iiiii.i'f
St»
J-jJ
ii
ШШШШ2±*1
■ * i!
Отмена j
Дыбретьосе| |
В данном примере не так интересно знать, все ли три выбранные машины были
определенного типа (в связи с чем чрезмерно увеличивается число идентичных
откликов). Интереснее определить число респондентов, предпочитающих,
например, домашнюю закрытую машину. Заметим, что переменные, составляющие
фактор Еда — Food, содержат только взаимно исключающие ответы
(непересекающиеся категории), так как респондентам не разрешалось давать идентичные
ответы (например, Гамбургер — Hamburgery Гамбургер — Hamburger и Гамбургер —
Hamburger). Их просили сделать выбор из восьми типов быстрой еды без
повторения. Поэтому для фактора Еда — Food данная опция не имеет значения.
Нажмите ОК в диалоговом окне Таблицы многомерных откликов, чтобы начать
анализ и открыть окно Результаты таблицы многомерных откликов.
Н.11ППГ1Г
щ
iii
Просмотреть
То&ашы частот
ППЩ1 ШаРЛО АОаепОАОееМТтабЛМНМ
Ш АФуМОАМкИГТЯбАИЯМ
& Отображать длинные метим wmeiwftj
Г Отображать аыбр* ш отлельмоД табл.
Q39 Срое»аш л»аимолебстаий частот |
р7 &ылажть частоты >: jl0 Ц
Г* Процент от общего числа
Г* Протащи по стропам
Г" Проценты по столбцам
гЧастотмУлрошакгы по
! С Н"с*9 отжата
j (а4- Числа, распомяоигоо . \ ;
ИВ Цтот зедеима таблицы J
ЗДСЧДНИС;
Дотлытелъиь»
граф»«и(гмстогр«*<ы,
m>gftm граошмиТА|
можно построить с
помошыо графических
опций непосрейстеенно
иэ таблицы рвэуътето»
Примеры
469
Вначале рассмотрим простой вывод Таблицы частот.
Введите в редактируемое поле Выделить частоты число 100 (что приведет
к тому, что все частоты больше 100 будут выделены в таблице результатов). Затем
нажмите кнопку Таблицы частот.
Таблица частот для переменной Пол — Gender интерпретируется обычным
образом, и на ней мы останавливаться не будем. Таблицы частот для других двух
факторов показаны ниже.
пгггштвшпрушщттттщтщттт
ОСНОВНЫЕ
СТАТИСТ
N-200
Группа
■пуй1:/шп^|ШЖМИ1И
. SANDWICH: Sandwiches
CHICKEN: Chicken
PIZZA : Pizza...,
MEXK>N: Mexican fast food
CHINESE: Chmes* test food
SEAFOOD: Seafood
OTHER : Other ethnic/regional
Сумме откликов
Ml
■WfTWTTW
liyiHIrTlii^
ММММШММВМШН
TTll
Еде З любимые системы быстрого питания ^j
(Переменная с многомерными откликами)
114 |
49
46
)'<*
42
45
46
42
522
Процент
откликов
Г.1 :А
9 39
8 81
U0 А А
8 05
8 62
8 31
8 05
100 00
Процент
наблюд
г. 7 ;"jf:
24 50
23 00
63 00 I
21 00
22 50
23 00
21 00
261 00 ^ |
■'
I
и^ггшттгжптттщтшттг^^
■ -Mfill'il ll<f4illi>i7i'i,lliTiiilJiiii'imm
ОСНОВНЫЕ
СТАТИСТ.
N-200
Гриппа
д^др^^1УНИЛ!таШте??1ТШИИИИ1
OOM_SEOM Oomediiceeden
FOR.SPPnr foreign $port$ car
FW.SEON Foreign seden
Сумма откликов
ы
тшшштяшшшшт
ЕЗлШШШШШшшшшшшшяшшшш
Машина Пюбимые типы машин
(Переменная с многомерными откли
к: J
76
I*'.'
64
420
1 Процент
I откликов
J '.'.A I'V
1810
15 24
100 00
■шииииииг-т-пг
—1
кем и)
Процент
наблюд.
^ 1>1
38 00
32 00
210 00
'
[..!
Всего в исследовании было опрошено 200 респондентов (число опрошенных
N=200 отображается в верхнем левом углу таблицы).
Столбец Частота показывает число респондентов, назвавших данный способ
питания как один из любимых. Напомним, что учитываются только уникальные ответы
(см. выше) и, таким образом, ответ каждого респондента может быть посчитан только
один раз в этом столбце. Отсюда вы можете прийти к заключению, что Пицца — Pizza
была самой популярной системой быстрого питания, указанной либо в первой, либо
во второй, либо в третьей позиции 138 респондентами, Гамбургер — Hambwger был
вторым по популярности A14). Все типы систем быстрого питания отметили только
40-50 респондентов.
Во втором столбце таблицы результатов вычислены относительные частоты,
соответствующие числам первого столбца. Можно сказать, например, что 26,44%
A00*138/522) всех указанных в ответах предпочтений составляет Пицца — Pizza.
В отличие от этой колонки третья колонка таблицы показывает проценты
респондентов, отметивших соответствующий тип еды как первый, второй или третий.
Пиццу — Pizza как лучшую систему быстрого питания выбрали 69% A00* 138/200)
всех респондентов.
Аналогично рассматривается таблица частот для фактора Машина — Саг.
Иностранные спортивные машины отмечены 157 респондентами на одной из трех по-
470
Глава 11. Построение и анализ таблиц
зиций (учитываются только различные ответы); отечественные спортивные
машины отмечены 123 респондентами. Вторая колонка показывает 37,38% ответов
для иностранных спортивных машин; эти числа не так легко
проинтерпретировать, так как подсчитывались только различные ответы (несколько одинаковых
ответов рассматривались как один). Таким образом, если респондент указал в
анкете три иностранные спортивные машины, то этот ответ учтен только один раз. Числа
в третьей колонке {Процент набл.) более информативны; из них, например, видно,
что 78,5% всех респондентов назвали иностранные спортивные машины в числе
трех самых любимых.
Возвратимся в диалоговое окно Таблицы многомерных откликов (нажмите
Отмена в окне Результаты), чтобы задать многомерную дихотомию в обследовании
посетителей ресторанов. Нажмите кнопку Задать таблицы, отмените
предыдущий выбор и выберите Burger_1 — Burger_4 как переменные первого множества.
вшпвие
НЕ
mmmmsmmm*.
шва
1 GENDER
2F00D_1
3F00D 2
4 FOOD 3
5 CAR 1
Б CAR 2
7 CAR 3
8BUHbtHI
9 BURGER 2
10-BURGIHJ
11 BURGFR <
I GENDER
2F00D_1
3 FOOD 2
4 FOOD 3
5 CAR 1
Б CAR 2
7 CAR 3
BBURGER_1
9 BURGER 2
10 BURGER 3
II BURGER 4
I GENDER
?F00D_1
3 FOOD 2
4FOOD_3
5 CAR 1
6CAR_2
7 CAR 3
BBURGER_
9 8URGER
10 BURGER
II BURGER
I GENDER
2F00D_1
3 FOOD 2
4FOOD_3
5 CAR 1
6CAR_2
7 CAR 3
BBURGER.I !
9 BURGER 2 I
10 BURGER 3
II BURGER 4
I GENDER
2F00D_1
3 FOOD 2
4 FOOD 3
5 CAR 1
GCAR_2
7 CAR 3
BBURGFR_1
9 8URGER 2
10BURGER 3
II BURGER 4
I GENDER
2F00D_1
3 FOOD 2
4 FOOD 3
5 CAR f
GCAR_2
7CAR.3
8BURGERJ
9 BURGER 2
10BURGER :
II BURGER
a*
Отмен*!
Ho»poe>H»:l Подро&|Ин».| Подроо^Ин».] По«роб>н».1 Подроб JKh+.| Подро&1ин#.|
Набор 1: Набор 2; Набор 3: Набор 4: Набор 5, Набор fc
Р
Г
Далее установите опцию Многомерная дихотомия рядом с первым фактором
в диалоговом окне Таблицы многомерных откликов. Как и ранее, можете
использовать опцию Длинные метки факторов для того, чтобы ввести подходящее имя
фактора. Например, можно назвать этот фактор Patron: Recently patronized restaurants —
Хозяин: Недавно посещенные рестораны.
™ЕВШШШШ
Диадйа: J Таблицы для многомерны! откликов 7J
Ц Да«*ть таблицы J f~ £J4>»** *.$*и^»абужнкия
Имя многомерн. Число
Фактора
J;|BURGER_1
U
мотки Факторов: ]
Тип многомерного ♦акторе
^ ^йогома^аяАШ1оУомш|| С Многомерный отклик
С Uuptхтщщю &шо*(т*к* & й*и«!Го*<кг*»<в »**,.«*»:
рТНЦ 1* Стпт»
* (игнорирош
В»яп» метки первой переменноА
I
езде
Lttl^ft!
::■, Г ,«:
м
QJ8 ¥:<>я,ы:
уЦз ¥.<»т
$8 *«***
8е8 &л«-**
828 ^«ь»
{$) К«А#*
Н<т;
Uf? .
«,г
*КГ: ,
«.т
ЗАМЕЧАНИЕ. 8се з
которые не яеялотса допусг
Г Удалить ПД построено внутри каждого набора многом, дмкотомми !^2?1Й!2!^ ?^????!1?У **
Г реяны эн«чонмо. ^еэепному е
Плавить ПД построчно внутри каждого набора многом- откликов поле счегмх» (многом дихотомии},
Г* Вкддомть ЛД как дополимтвльиуо категорию для каждого фактора игнорируется {не рассматриваются
Примеры
471
Вам также необходимо задать код, который использовался в факторе
многомерной дихотомии Patron для того, чтобы определить, обедал или нет респондент
в соответствующем ресторане в течение двух недель перед опросом. Задайте
нужный код в поле Счетчик ниже списка факторов. Так как код, равный 1 (числовой
эквивалент значения Да — Yes; см. Управление данными, глава 7), использовался
для того, чтобы определить, какой ресторан посещался респондентом, то можно
просто принять код, предложенный по умолчанию.
Напомним, каким образом многомерные дихотомии интерпретируются
программой. Переменные, из которых построен фактор, рассматриваются как его
уровни, затем подсчитывается число уровней со значениями, равными значению,
указанному в счетчике. Все значения, не равные этому значению, игнорируются. Вы
можете строить более «сложные» схемы кодирования (а не просто 1-0, как в этом
примере), задавая подходящие значения в поле Счетчик.
Например, можно использовать отдельный код (отличный от 1) для
обозначения ответа: «даже никогда не думал там обедать». Вы могли бы ввести код 2
в переменные Burger_1 — Burger_4 для обозначения таких резко отрицательных
ответов в отношении определенных ресторанов, задать этот код в поле Счетчик и
табулировать ответы. Таким образом, задавая различные значения для кодов
многомерной дихотомии, можно идентифицировать взаимоисключающие ответы.
Из диалогового окна Результаты снова выберите процедуру Таблицы частот.
Интерпретация чисел, представленных в этой таблице, аналогична таблицам для
многомерных откликов.
рЛЦ-и1Ц1|.Ц|||1Ц|||1Ц^||1|Ц1
ОСНОВНЫЕ
СТАТИСТ.
N«157
Группа
1 BURGERJ: Burger Meister
BURGER: Bill's Beet Burgers v■ '
BURGERS Hamburger Heeven
BURGERjt: Bigger Burger
Сумма откликов
ы
гиор ) (lasllood sta)
BURGERJ. Burger Meister
(Многомерная дихотомия; счетчик: 1
^^^^6^
68
61
59
248
.Процент
откликов
2419
2742
24.60
23 79
100 00
uracil
Процент
набпюд
3822
щ
43.31
38.85 |
3758
15796' И
л
Q
Всего 157 респондентов обедали в одном из четырех ресторанов (п = 157);
60 респондентов обедали в Burger Meister, 68 — в Bill's Best Burgers и т. д. Значения
во второй колонке (Процент откликов) выражают эти числа в процентах от
общего числа респондентов, обедавших хотя бы в одном ресторане (то есть от 157
респондентов).
Предполагается, что четыре (воображаемых) ресторана делят рынок быстрого
питания в городе и что 157 респондентов (из 200) в большей или меньшей степени
представляют мнение общего рынка. Поэтому значения во второй колонке
таблицы показывают долю рынка, которым владеет каждый ресторан.
Например, из всех мест (где подаются гамбургеры), которые посещались
респондентами в течение двух недель до опроса, Burger Meister посещали 24,19%, Bill's
Best Burger — 27,42% и т. д. Третья колонка (Процент набл.) содержит процент
респондентов, обедавших последние две недели в соответствующих ресторанах.
472
Глава 11. Построение и анализ таблиц
Напомним, что проценты вычислены для п = 157, то есть относительно числа
респондентов, обедавших, по крайней мере, в одном из четырех ресторанов. Поэтому
можно сказать, что 38,22% респондентов, обедавших в каком-то одном из четырех
ресторанов, где подают гамбургеры, обедали также в Burger Meister, 43,31% обедали в Bills Best
Burgerи т. д.
Заметим, что можно легко построить линейные графики или гистограммы
частот и процентов с помощью процедур меню Пользовательские графики.
\ш\жж\\
игеш
Таблица Частоты ( Идентичные отклики игнор ) (fastfood sta)
BURGERJ Burger Meister
(Многомерная дихотомия, счетчик 1)
70
68
66
64
62 h
60
58
шш?
ъш
Burger Meister Hamburger Heaven
Bi*s Best Burgers Bigger Burger
Покажем, как строить таблицы сопряженности для переменных с
многомерными откликами и многомерных дихотомий. Нажмите Отмена в диалоговом окне
Результаты для того, чтобы вернуться в диалоговое окно Таблицы многомерных
откликов. Прежде всего, посмотрим на таблицу сопряженности Пол — Gender и
Машина — Саг. Иными словами, исследуем интерес к различным типам машин у
Мужчин — Males и Женщин — Females. Нажмите кнопку Задать таблицы и в
открывшемся диалоговом окне выберите Пол — Gender как единственную
переменную в первом множестве, а переменные Машина_1 — Машина_3 (Саг_1 — Саг_3)
как переменные во втором множестве.
Выберите до 6 наборов i
.1.1.Ш.1!1>|||.Ч1.|1||.ии.|1|Л»1—
2-F00DJ
3-F00D_2
4F00D.3
5CARJ
6-CAR.2
7-CAR.3
8BURGERJ
9-BURGER_2
10-BURGER.3
11 BURGER 4
1 GENDER
2-F00DJ
3-F00D.2
4 FOOD 3
5CARJ
6 CAR 2
7CAR~3
8 BURGER,
9-BURGER.
10 BURGER
11 BURGER
1 GENDER
2-F00D 1
3-F00D~2
4-F00DI3
5-CAR 1
6-CAR.2
7-CAR 3
8BURGERJ
9 BURGER 2
10-BURGER.3
11-BURGER.4
I GENDER
2-F00DJ
3-F00D_2
4F00D.3
5CARJ
6-CAR.2
7-CAR_3
8BURGERJ
9BURGER_2
10-BURGER.3
II BURGER.4
I GENDER
2-F00DJ
3-F00D_2
4-FOOD.3
5CARJ
6-CAR_2
7-CAR_3
8-BURGERJ
9-BURGER_2
10 BURGER 3
II BURGER_4
I GENDER I
2F00DJ I
3F00D_2
4F00D.3
5CARJ
6-CAR_2
7CAR_3
8BURGERJ
9BURGER_2
10BURGER.3
II BURGER 4
Подроб.
Набор
<фн».| Подрой 1Ин».1 Подроб.1Ин».1 Пщ*Л.\Щ*Ф.\ Подроби[Ин».) Подроб ]Ии«х1
1: Набор2: Набор 3: Набор 4: Набор 5: Набор6:
- р~ 1 -г 1 1 ~
а*
Отмена:
Примеры
473
Нажмите OK и вернитесь в диалоговое окно Таблицы многомерных откликов.
Задайте далее коды для фактора Машина — Саг, чтобы идентифицировать четыре
различных типа автомобилей. Возможно, вы захотите изменить описание фактора,
тогда воспользуйтесь кнопкой Длинные метки факторов.
\mmn\mv\m
|У|х
&цштш: | Таблицы для многомерных откликов ^чр:'''.,.-
Ц Давать таблицы | Г &.*!>**» ^н»^г«^^^щ^
Отмена
й*
Имя многомерн. Число
Футора „врфм.
•: Тип мне* омар1ого,Шстор*
Г" В теменные
J; JGENDER
*[САгГ
С; Цнтылер***а яимт«Н*аL§г<Ф•< Многомерный отклик. Q£j Коды:
Г Многомерная дихотомии <? Многомерный отклик |Jg Коды:
С Мдоом«{Ж4и*£«хо1<мдо 9 Mtiefомкг{5»*<й Of>;*wr. [JJg Коды:
.О Ммдгамврмя* ди«1Яг<жи>»' ^MHi^tM^jpHb^ fl^yjjffc»; РД Коды.
нет
нет
«*t •
нет'
•I !&.!■*
•v.^#r:.vV:\,V3'*'
4 H*fлитьмл nuuipmwu«натрикаждогонеооремногом, от*
::'Г:|*л1гнг1ъ: ПД дед дополнит альнаю категорию для каждого <
ЭМ€ЧАНИЕ:Во«ем^«^йе-:
которыФ не яаляоте* дряаяг,.Д
кодами Imhotom. откликое) или *И
fC Щ^№пйп#ш WOT" каждого'iHtfope'iva^^ ЩвгтМпйЖ
„>r-•••-;—^_-MM -• . ->наю категориюдля каждого еедтора vrH0p>«e3Toa[нараоснатр>»иотсй
"■■■■ ;.. udnfo.''-\*.r:\'^;.''Z'.* i:-
Для этой таблицы отмените опцию Считать только уникальные отклики.
Напомним, что назначение этой опции — исключить одинаковые ответы
(одинаковые ответы одного и того же респондента на разные пункты считаются как один
ответ). В данном примере, напротив, вы можете захотеть включить такие ответы
в таблицу. Получившаяся таблица сопряженности будет показывать общее
число различных типов машин, определенных респондентом как первая, либо как
вторая, либо как третья, разбитых на классы значениями переменной Пол —
Gender. Нажмите ОК и откройте диалоговое окно Результаты таблицы
многомерных откликов.
Нажмите кнопку Просмотреть итоговые таблицы. В результате будет
построена следующая таблица:
ЕЛ
шт
ттттмт
тшш
Wfat<s
Частоты/проценты основываются на числе респондентов
[Многомерные идентичные отклики учтены
OOM^SEDN4
73
14
'"вУ"
FOFLSPRT
FOPLSEDN
217
54
271
61
10
71s
г.Строк.'
tcorb-
164
36
200
По умолчанию Быстрым статистическим графиком для этой таблицы является
ЗМ гистограмма. Нажмите правую кнопку мыши и выберите в меню опцию ЗМ
гистограмма.
474
Глава 11. Построение и анализ таблиц
ЫГМ'.НГГШШГИЩ^С
ШВШШшшШЗаМ
Т аблица Итоговая таблица для всех многомерны* откликов |la*tfood tie)
Частоты/проценты основываются на числе респондентов
Многомерные идентичные отклики учтены
*°{
7Z0
\во,
**>
&
&
to
• ^^^
^^щ
**" *^ Х^
О* **~ ^\
с^ ***' ^
с^ <**"
с^
Рассмотрев приведенную выше таблицу, можно прийти к выводу, что и
мужчины, и женщины отмечали спортивные машины чаще, чем седаны. Разницу в общем
числе машин, отмеченных мужчинами и женщинами, можно объяснить тем, что
число мужчин и женщин в выборке существенно различается (если вы
посмотрите на таблицу частот переменной Пол — Gender, то увидите, что в выборке
присутствует только 36 женщин).
Вместо ЗМ гистограммы можно использовать линейный график. Вернитесь в
диалоговое окно результатов и выберите опцию Графики взаимодействий частот.
\ШттЧШШМ1ЛУАЛ
Взаимодействия GENDER х CAR
Многомерные идентичные отклики учтены
-о- GENDER
MALE
•о- GENDER
D0M_SPRT D0M_SEDN F0R_SPRT FOR SEDN FEMALE
Здесь разница в предпочтении спортивных машин более отчетлива у мужчин,
чем у женщин (линия, соответствующая женщинам, более сглаженная, чем линия
мужчин).
Пример (анализ продаж)
Рассмотрим данные о продажах в магазине. Мы хотим провести разведочный
анализ этих данных и построить модель покупателя.
Примеры
475
Категоризируем исходные данные (способ категоризации количественных
переменных в системе STATISTICA описан выше), то есть будем работать с
данными вида:
ш
ТЕК С
76
79
80
81
82
83
64
85
86
k?
88
14
|.||;;|||.||,|,ц1,1М1,иш
день
Пнд
Пнд
Пнд
Пнд
Пнд
Пнд
Пнд
Пнд
Пнд
Пнд
Пнд
шш
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
о оо|
0 00
6//
м
3 1 4 1 5
колбасы 1<ондитеН<онсервь
0 00
0 00
0 00
0 00
0 00
1 00
1 00
000
0 00
100
000
0 00
100
0 00
1 00
0 00
0 00
1 00
0 00
0 00
0 00
1 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
6
КОФЕ
0 00
0 00
1 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
7
vWKAPOHb
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
нгао|
*
8
МУКА
0 00
*•*—
0 00
0 00
0 00
0 00 .
ооо •
0 00 :
0 00
0 00 :
1 00
0 00 * г
•Г;
В этом файле первая переменная — день недели, каждая оставшаяся
переменная принимает два значения: 0, если данный покупатель не купил данный товар, и 1,
если данный покупатель купил данный товар. Покупатели записаны в строках,
товары в столбцах.
Для данного покупателя 1 означает, что он купил соответствующий товар.
Мы хотели построить модель покупателя. Для этого нам нужно знать, как
распределены покупки и как они связаны между собой.
Работаем в модуле Основные статистики. Введите показанные данные в свой
файл или сгенерируйте нечто похожее, чтобы повторить действия.
Несколько тонких вопросов будут отмечены в ходе анализа и указаны
альтернативные способы исследования.
Распределение числа покупок. Вначале введем переменную (в наших данных
это будет переменная var24)> подсчитывающую общее число покупок, сделанных
покупателем (она равна сумме всех индикаторов покупок).
Тогда файл выглядит так:
о
ТЕКС
SS
5ТА 24л • 677н
17
ЛИРТНОЕ
18
ОРЕХИ
19
СЫРЫ
20
ТА6АК
21
ХЛЕВ
22
ЧАЙ
23
ЯЙЦО
138
199
200
201
ш
203
204
205
206
207
208
ы
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
1 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
1 00
0 00
1 00
1 00
1 00
0 00
0 00
1 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
0 00
ооо(
0 00
0 00
0 00
0 00
0 00
0 00
1 00
4 00
1 00
2 00
5 00J
2 00
2 00
1 00
2 00
3 00
3 00
Вначале посмотрим, как распределено число покупок.
Откройте процедуры описательной статистики.
\>Г
476
Глава 11. Построение и анализ таблиц
Корреляционные матрицы
JT| (критерий для независимых выборок
Jjjj (критерий для зависимых выборок
jJX Группировка и одно+акториая AN OVA
Таблицы частот
Таблицы и заголовки
%Д Вероятностный калькулятор
Wjk Другие критерии значимости
£*
LiJjBJL
Выберите все переменные, в которых записаны покупки различных продуктов,
и нажмите кнопку Подробные описательные статистики.
На экране появится таблица с описательными статистиками.
[ЗВЕШ
| БЕЗАЛК0ГЯЙЦ0
Пплрой^т» отсшг9йшы9 ттшггтн
Г Построаиов щшшштт ПД
Г* ОТОЖМИ?* ДОИНМЬИ NMetW
Г ОЯИМ
Г Крмгарм* Швпмро-Уммм W
Таблица с описательными статистиками имеет вид:
HiniUVJiflllLilL
ОООБмьЕ
СТАТИСТ
ВЕЗЛ/ГКОГ
КОЛБАСЫ
кондитер
КОНСЕРВЫ
КОФЕ
МАКАРОНЫ
МУКА
МОЛОКО
МОРОЖЕиС
. К1нвбл j
674
674
674
674
674
674
674
Ь74
Ь?<
ОЕОШИ
РЫБА
СОКИ
СПИРТНОЕ
ОРЕХИ
СЫРЫ
ТА6АК
ХЛЕБ
ЧАЙ
j ЯЙЦО
674
674
674
674
674
674
674
Ь74
Ь?<
674
^\
е?<з
$74
674
674
674
674
674
674
674
674
674
225519
474777
406012
115727
051929
048961
146384
436202
032541
078635
•ГС4ЭС
?'4*37
'?1?2'
137982
137982
117211
0ЮЭ86
178042
03П57
488131
059347
034125
Примеры
477
В этой таблице для нас прежде всего интересен второй столбец, в котором
показано, как часто покупались различные продукты. Но вначале построим
гистограмму числа покупок N.
Г|Графмк1 Гмстшрамма
Распределение числа покупок N
12 3 4 5
7 8 9 10 11 12 13 14 15 16 17 18 19
Из гистограммы видно, что наибольшее число покупателей делает от одной до
четырех покупок.
Редактор данных графика позволяет просмотреть данные графика в численном
виде. Нажмите кнопку Редактор данных графика, и вы увидите данные в
численном виде.
Итак, общее число покупателей равно 674. Из них 90 сделали одну покупку,
110 сделали 2 покупки, 110 сделали 3 покупки, 102 сделали 4 покупки и т. д.
^шшшшгшпшт
Наблюдение 1
Наблюдение 2
Наблюдение 3
Наблюдение 4
Наблюдение 5
Наблюдение 6
ШшШШ'ШШМШ
Наблюдение 0
Наблюдение В
Наблюдение 10
Наблюдение 1!
Наблюдение 12
Наблюдение 13
Наблюдение 14
Наблюдение 15
Наблюдение 1 б
Наблюдение 17
Наблюдение 18
Наблюдение 19
Наблюдение 20
и i
1И-1и1
Гистограмма (indcons STA 24
lii Столбм
X
000
1 00
2 00
3 00
4 00
5 00
600
7 00
8 00
9 00
10 00
11 00
12 00
13 00
14 00
15 00
16 00
17 00
18 00
диагр поХ
12 00
90 00
110 00
110 00
102 00
62 00
51 00
34 00
31 00
26 00
20 00
8 00
11 00
4 00
2 00
0 00
0 00
0 00
1 00
3
*>
*'
478
Глава 11. Построение и анализ таблиц
Случай одной покупки. Рассмотрим покупателей, сделавших только одну
покупку. Для этого введем условие выбора наблюдений.
Ulil.l,IJ!l..l!|l|.lll,ll!H.W—
б» flpUWM.^ ЬСМГ.
^ ИСКА.» «CMC
Зецоеоео* fcm* <
v24-1
1ИННИКПЕ]!
*- 1 OK 1
T]L. **, 1
1 0™»»"H
E3 Переменные] j
1 ; 1
Состоят*■■■■, Операторы» <> < > <„ >« NOT AND Ой g? Ощрыть | 1
; (• Bin 1 Пер««м%*;1м»1«ияиу1,у2.~ ]
; : . | Номер на&киоиик vO Ш &ифвимт*.<.
j (v7<1 OR v9»VE$') «id y4<>0
Группировка по дням недели. Рассмотрим, как распределены покупатели,
сделавшие одну покупку, по дням недели. Выберите переменную День и постройте
гистограмму.
Далее... }
i-ioixi
ДЕНЬ
ПКД
Bip Срд Ч1В Пш
Группа (различ. значения)
Из гистограммы следует, что наиболее часто единичные покупки делаются
в среду.
Какие продукты наиболее часто относятся к одиночным покупкам?
Найдем, какие продукты наиболее часто являются «одиночными». Выберем все
переменные из файла, кроме первой. Вычислим средние величины.
Из таблицы следует, что если покупатель сделал только одну покупку, то,
скорее всего, это было мясо, хлеб, овощи, кондитерские изделия или колбасы.
Вероятность сделать одиночную покупку из оставшейся части списка практически
нулевая.
Заметьте, что средние, приведенные во втором столбце таблицы с результатами
представляют собой оценки вероятностей покупки данного товара.
Таким образом, если покупатель пришел в магазин и решил сделать только одну
покупку, то с вероятностью 0,26 он купит мясо, с вероятностью 0,133 купит хлеб,
с вероятностью 0,11 купит овощи, с вероятностью 0,11 купит кондитерские
изделия, с вероятностью 0,9 купит колбасные изделия.
Примеры
479
Вероятность того, что покупатель сделает только 1 покупку, равна 90/677= 0,13
(см. таблицу с распределением N).
Сумма
^щщтттят
Да*ее~
БЕЗАЛКОГ
КОЛБАСЫ
КОНДИТЕР
КОНСЕРВЫ
КОФЕ
МАКАРОНЫ
МУКА
МОЛОКО
МОРОЖЕНС
КРУПЫ
Шееез^ш
ОВОЩИ
РЫБА
РЫБНАЯ К
СОКИ
СПИРТНОЕ
ОРЕХИ
СЫРЫ
ТАБАК
ХЛЕБ
ЧАЙ
ЯЙЦО
Nna6n
90
90
90
90
90
90
90
90
90
90
90
90
90
90
90
90
90
90
90
90
90
90
ОТ
044444
088889
111111
011111
033333
0 000000
0.000000
044444
011111
033333
255556 |
111111
033333
0 000000
0 000000
022222
0 000000
011111
033333
133333
022222
0 000000
400000
8 00000
10 00000
1.00000
3 00000
0 00000
000000
4 00000
1 00000
3 00000
23 00000
10 00000
3 00000
0 00000
0 00000
2 00000
0 00000
1 00000
3 00000
12 00000
2 00000
0 00000
►г
Модель покупателя, делающего одну покупку. С вероятностью 0,13
покупатель, пришедший в магазин, делает одну покупку. С вероятностью 0,26 он
покупает мясо, с вероятностью 0,133 — хлеб, с вероятностью 0,11 — овощи, с
вероятностью 0,11 — кондитерские изделия, с вероятностью 0,9 — колбасные изделия.
Случай двух покупок. Рассмотрим покупателей, сделавших две покупки.
бора наблюдений
Изменить/добавить цсяовмя выбора;
(• Bjijmh., если: |
N-2
; С &скл., «сям: ]
3«£о*овок 1дяя +*&я*$спо*ыЛ выбор*):
О*
Отмена
ы
Ва<
Состояние
(• в&Л
| г вьуся
Операторы:* <><><» >«N0TAN0 0R (^ Открыть |
Переменные: имена или v1. v2... ''" '" "" '
Номер наблюдения vO (Щ) Сохранить . I
Примеры v1 » О OR v2 >« 0 '
{v7<l OR y*.VEST«nd v4<>0
Число таких покупателей равно 110.
Для этих покупателей N=2. Изменим условие выбора случаев.
Заметьте, в условии выбора наблюдений можно употреблять имя переменной,
что и было сделано в данном случае.
Вычислим описательные статистики при условии, что N=2.
480
Глава 11. Построение и анализ таблиц
ОСНОВНЫЕ
СТАТИСТ
Среднее
тяжгтШШШШШшШШ
КОЛБАСЫ ■:-.
КОНДИТЕР
КОНСЕРВЫ
КОФЕ
МАКАРОНЫ
МУКА
МОПОКО
МОРОЖЕНО
КРУПЫ
мясо
овощи
РЫБА
РЫБНАЯ JC
СОКИ
СПИРТНОЕ
ОРЕХИ
СЫРЫ
ТАБАК
ХПЕБ
ЧАЙ
ЯЙЦО
110 |
110
110
110
110
110
110
110
110
110
110
110
110
110
110
110
110
110
110
110
110
110
109091
.227273
227273
045455
009091
0 000000
036364
245455
009091
054545
200000
363636
118182
0 000000
0 000000
027273
0 000000
027273
018182
281818
0 000000
0 000000
НЕТ
>.Г-
Из этой таблицы видно, что если покупатель сделал две покупки, то наиболее
вероятно, что в эти покупки вошли овощи, хлеб, молоко, кондитерские изделия,
колбасы, мясо.
Поставим вопрос, какие пары покупок наиболее вероятны.
Ответ на этот вопрос можно получить с помощью простейших действий.
Всего переменных 22. Конечно, мы не будем перебирать все 22 х 21 = 462 пары
переменных и строить для них таблицы.
С помощью некоторых разумных приемов, например, рассмотрев корреляции
переменных, можно существенно сократить процедуру поиска.
За несколько минут можно найти наиболее вероятные пары покупок (см.
таблицы ниже).
1 -MMJ.l.M.Ul
ОСНОВНЫЕ
СТАТИСТ
ХЛЕБ
Пи-О
0-2:1
Всего
(f^BJPfWP
ОСНОВНЫЕ
СТАТИСТ
ОВОЩИ
QJ:0
1 G_21
тшшшпшшшшшшт
ни и
Частоты выделенных ячеек> 10
(Итоговые маргинальные не отмечены)
МОПОКО
QJ.;o_ j
w
2А
молоко
G 2:1
:о
7
83 27
*шштмщ^$щ$шшшяш
Частоты выделенных ячеек> 10
(Итоговые маргинальные не отме
РЫБА
GJ:0
hi
з:
Всего | 97
РЫБА
G_21
5
8
13
Всего
постр, |
79
31
110
HWDI
чены)
Всего I
по стр |
70
40
110
Примеры
481
IIUi|.liJ.HH.I.IJ.!.lU»H
Частоты выделенных ячеек> 10
(Итоговые маргинальные не отмечены)
ОВОЩИ
36
4
40
Всего
пастр.
104
б
110
шзшщ
ш
Падее~.
КОНДИТЕР
GJ:0
чн'жн.ш.ни.тш
Частоты выделенных ячеек> 10
(Итоговые маргинальные не отмечены)
ХПЕ6
Ъ8
21
79
27
Всего
по стр.
85
25
110
Полезными здесь являются гамма-статистики, массив которых сразу для всех
переменных можно вычислить с помощью непараметрических процедур (не
забудьте при вычислении поставить условие N - 2).
Р^ДЯШДГЖШИ
НЕПАРАМ
СТАТИСТ
Пары перем
ОВОЩИ & МОЛОКО
ОВОЩИ & МОРОЖЕНО
ОВОЩИ СКРИПЫ
овощи а мясо.
овощи & овощи
ПД попарно удалены
Чист*.:
—
. ..г
Р1«>о».> !
овощи
овощи
овощи
овощи
овощи
овощи.
дрывная^к :
* соки - • •'•
^СПИРТНОЕ ~ |
* ОРЕХИ ^ |
а сыры
Л ТАБАК ; ,; J
110
110
110
110
110
110
110
110
110
110
110
-.73099
-1 00000
58140
000000
52941
-1.00000
-1 00000
-1.00000
-4 63645
-1 12122
2 34306
0.00000
2.96682
-1 96008
-1 96008
-1.59297
000004
262193
019126
1 000000
.003009
049986
LL
049986
111166 ri
Просматривая таблицу и выбирая максимальные коэффициенты, можно
определить наиболее вероятные парные покупки.
Так же можно определить несовместимые пары.
Вероятность того, что покупатель сделает две покупки, равна 110/677в 0,16
(см. таблицу с распределением N).
В принципе, те же самые действия можно провести для остальных N, при этом
полезно использовать язык STATISTICA BASIC.
Однако очевидно, здесь мы сталкиваемся с довольно сложной переборной
задачей, поэтому наметим различные подходы к ее решению.
В частности, используем анализ соответствий и геометрическую
интерпретацию частот.
Здесь же рассмотрим, какие дополнительные возможности имеются в модуле
Основные статистики и таблицы.
482
Глава 11. Построение и анализ таблиц
Случай трех и четырех покупок. Воспользуемся процедурами группировки.
Не забудьте отменить условия выбора случаев, назначенные ранее.
^шшшшшшш/шытт
ЬЗД Описательные статистики
Щ$ Корреляционные матрицы
Щ! t критерий для независимых выборок
ЩЦ t-критерий для зависимых
выборок
ЕлЗ Группировка и однофакториая AN OVA
ggj Таблицы частот
%Щ Таблицы и заголовки
?<3k Вероятностный калькулятор
OQlk Другие критерии значимости
ЕЗ ' як
Отмена
& Данньм
tun И I & £
В диалоге Группировка и однофакториая ANOVA прежде всего выберите
переменные для анализа. Группирующие переменные — день и N Все остальные
переменные определите как зависимые.
шшмшшшц
в
щвщшэрв
БЕЗАЛКОГ
J3 КОЛБАСЫ
•КОНДИТЕР
КОНСЕРВЫ
КОФЕ
|7 МАКАРОНЫ
•МУКА
МОЛОКО
Поморожено
|11 -КРУПЫ
12 МЯСО
13 ОВОЩИ
14 РЫБА
15-РЫБНАЯ.К
16 СОКИ
17-СПИРТНОЕ
18 ОРЕХИ
19 СЫРЫ
20 ТАБАК
2БЕЗАЛК0Г
ЗКОЛБАСЫ
4КОНДИТЕР
ЪКОНСЕРВЫ
6К0ФЕ
'7 МАКАРОНЫ
8 МУКА
9 МОЛОКО
iW-MOPOXFHO
11 КРУПЫ
12 МЯСО
130В0ЩИ
14 РЫБА
15 РЫБНАЯ К
16 СОКИ
17СПИРТН0Е
180РЕХИ
19-СЫРЫ
70ТАБАК
м_
J_
dhL
>J
Все Ц Подроб. И Ии». И Вса 1 Пмроб || Ин», j
Грлпп.
' J2 23
Выберем коды для группирующих переменных, как показано ниже. Конечно,
можно было бы выбрать все коды для N, но мы ограничимся тремя и четырьмя
покупками как наиболее типичными.
Теперь окно выглядит следующим образом:
l^iHj4iirijiiHlfl|B1jM
Анализ: | Подробный анализ выбранных таблиц
Р53 Переменные |
Груплирумдиа: ДЕНЬМ
Зависимы»: 6ЕЗАЛКОГ ЯЙЦО
U9 &оды для гряппмрфомия паранччм*:} Выбраны
Г Построчное удаление ЛД
'£1
DE3
la as i:
I Отмена |
Нажмите ОК и проанализируйте результаты.
Примеры
483
зшшши^ш^^в^^^шяв
яввв
ЗАВИСИМЫЕ: 22 перемен.
БЕЗАЛКОГ КОЛБАСЫ КОНДИТЕР
КОНСЕРВЫ КОФЕ МАКАРОНЫ МУКА
ГРУППИР.: 1-ДЕНЬ
2-N
( 7): Пнд Втр Срл Чтв Птн
( 2): 3 4
j{fa*j,<*Д ijfitfДУI ^Wtfgg'
Дадробныв дчвлода
iтаблицы
Г Отображать*
0? Отоорадать джиаша ыатк» awwart :
Маргыиаааныа срадинв
~1 Статистики
1 :''Г'СвММЫ:''4 /'^
! : Г" Стандартны» отклонения .
ij Г Дмспаремм
| jgH Категориаоеанные днагртттл размада
Прежде всего, нажмите кнопку Итоговая таблица средних.
На экране появится таблица средних, вычисленная для каждой группы
данных. Всего имеются 14 групп: 7 дней недели, умноженные на 2 (мы задали два кода
переменной N — группа покупателей, сделавших три покупки, и группа
покупателей, сделавших четыре покупки).
НЕ
ДЕН
Пнд
Втр
Втр
Срл
Срд
Чтв
Чтв
Птн
Птн
Сбт
Сбт
Век
. Вс«
Ш1№Ш-111'1;
Далее.»
з N
G_2:4
GJ:3
QJA
GJ:3
G_24
GJ3
GJM
G 1:3
G_fc4 ...
GJ:3
GJA
GJ:3
GjM :
всегруппы
IMJ
N-212(HeTnpon
БЕЗАЛКОГ Я
083333 ™
0 000000
142857
294118
214286
100000
100000
055556
095238
333333
066667
166667
142857
166667
141509
уСКОВ В ЗОВ1
250000
750000
333333
294118
285714
500000
550000
500000
333333
466667
333333
611111
428571
833333
438679
-«с. перем)
кондитер
500000
375000
428571
294118
285714
450000
150000
388889
238095
533333
266667
444444
285714
166667
349057
КОНСЕР8Ы
083333
0 000000
0 000000
058824
0 000000
0 000000
'050000
0 000000
0 000000
0 000000
0 000000
055556
0 000000
0 000000
018868
КОФЕ
083333
0000000
0 000000
058824
0000000
050000
.050000
0 000000
0 000000
0 000000
066667
055556
0 000000
0000000
028302
ииыд1*1;
MAKAPOHfc j
i
0 00000C j
ooooooc |
04761? !
11764; 1
0 00000C ;
0 00000C ''
0S000C i
ooooooc |
OOOOOOC !
OOOOOOC j
0 00000C ;
0 00000C i
ooooooc I
ooooooc }
01886U<i
rd
Ориентироваться в этой таблице очень просто. Рассмотрим, например,
переменную КОЛБАСЫ.
Вы видите, что в понедельник покупатель, сделавший три покупки, с
вероятностью 0,25 покупает колбасу, а покупатель, сделавший четыре покупки, покупает ее
с вероятностью 0,75.
Рассмотрев вероятности по строке, можно видеть, что в понедельник
покупатель, сделавший три покупки (первая строка таблицы), скорее всего, купил хлеб,
кондитерские изделия или молоко.
484
Глава 11. Построение и анализ таблиц
^шшшшшшшщжяш
ОСНОВНЫЕ |N12 (Нет пропусков в завис перем)
СТАТИСТ
КОНСЕРВЫ
ДЕНЬ N
КОФЕ
МАКАРОНЫ
МУКА
083333
083333
0000000
083333
МОЛОКО
416667
шмш'Ш'щшлш
ОСНОВНЫЕ
СТАТИСТ
ДЕНЬ N
N-212 (Нет пропусков в завис, перем)
"С0КИ:Д;
СПИРТНОЕ
ОРЕХИ
СЫРЫ
ТАВАК
ХЛЕБ
0000000
0000000
0.00
083333
О 000000
500000
Связи между покупками. Рассмотрим таблицы сопряженности хлеб и колбаса
при числе покупок, равном 3.
Статистики критерия хи-квадрат показаны ниже.
ХМП.1Л к КОЛБАСЫ!?) (inticons st<i)
Д**ве,«-
Хи^аор*т Пирсона
МПхи*к»адр*т
ЬМтщфьтЯщтъь
:= Фцц»рй> рдносторонний
« хшусторонний
:Ст£в,
3 928571
3 960186
3182143
df-1
df-1
df-1
df-1
df-1
p-04747
p-04659
p-07445
p-03691
p-07382
p-08248
p-03689
a
Значение гамма-статистики 0,38 говорит о наличии неярко выраженной связи
между признаками.
После того как гипотеза о независимости отвергается с помощью критерия хи-
квадрат или точного критерия Фишера, необходимо измерить силу связи признаков.
Одной из таких мер принято считать гамма-статистику.
О Если модуль меры больше 0,8, то мы имеем сильную связь табулированных
переменных.
О Если модуль меры связи принимает значения от 0,3 до 0,8, то говорят о
неярко выраженной связи.
О Меньшие значения модуля меры связи свидетельствуют об отсутствии связи.
Как и во всех задачах, связанных с оценкой зависимости, здесь очень полезна
визуализация.
Рассмотрим при трех покупках степень связи между переменными: хлеб и. молоко.
Примеры
485
L Ulll.!.|.i|.l.lU.l|.i8M.l!l
НЖЫ1Ш1
ОСНОВНЫЕ
СТАТИСТ
Частоты выделенных ямеек> 10
ХПЕБ
GJ:1
Всего
■(v23>0)
;L.L:._:...--;..
^^^^^3^1
34
65
молоко
GJg:1
Всего
по стр.
:4
21
45
55
55
110
гт
:П
Из приведенной таблицы следует, что при трех покупках из 55 человек,
купивших хлеб, 21 купили молоко, 34 не купили молоко (вторая строка таблицы).
Из 55 человек, не купивших хлеб, 24 купили молоко, 31 не купили молоко.
С помощью критерия хи-квадрат проверим гипотезу о независимости
табулированных переменных.
Фишера, односторонний
двусторонний
Макнембрахй-хваа.ОМЭ)
Гамма
\Щ
1 557692
1 396552
-112474
df-1 L
df-1
df-1
df-1
df-1
p-56072 |
p-56061
p-69813
p-34918
p-69835
p-21201
p-23730
,*f!
Критерий хи-квадрат не позволяет отвергнуть гипотезу о независимости.
Как понимать это положение?
Рассмотрим внутренние ячейки таблицы с покупками хлеба и молока притрех
сделанных покупках.
Из таблицы получим следующие оценки вероятностей (при условии трех покупок!).
Вероятность того, что покупатель:
1) не купит ни молока, ни хлеба — 31/110 - 0,28;
2) не купит молоко, но купит хлеб — 24/110 - 0,22;
3) купит хлеб, не купит молоко — 34/110 в 0,31;
4) купит хлеб и молоко — 21/110 в 0,19.
Эти оценки получены из наблюдаемых частот.
Рассмотрим маргинальные частоты, эти частоты располагаются по краям
таблицы и при гипотезе независимости позволяют оценить ожидаемые частоты.
Имеем (см. таблицу):
О покупатель, пришедший в магазин и сделавший три покупки, с
вероятностью 65/110 - 0,59 не купит молоко, а с вероятностью 45/110 - 0,41 купит
молоко;
О покупатель, пришедший в магазин и сделавший три покупки, с
вероятностью 55/110 - 0,5 купит хлеб, с вероятностью 55/110 = 0,5 не купит хлеб.
Перемножая эти вероятности, получаем:
О 0,59 х 0,5 - 0,295 — вероятность того, что покупатель не купит ни молока,
ни хлеба;
486
Глава 11. Построение и анализ таблиц
О 0,59 х 0,5 = 0,295 — вероятность того, что покупатель не купит молоко, но
купит хлеб;
О 0,5 х 0,41 = 0,205 — вероятность того, что покупатель купит хлеб, но не купит
молоко;
О 0,5 х 0,41s 0,205 — вероятность того, что покупатель купит хлеб и купит молоко.
Можно видеть, что эти вероятности очень близки к вероятностям,
вычисленным ранее в 1-4.
Критерий хи-квадрат как раз и измеряет «расстояние» между этими частотами.
Итак, если покупатель делает три покупки, то покупка молока и покупка хлеба
независимы.
тшашштшшшшт
МОЛОКО МЯСО
т^т*ш^:г ■"
vCLt*.*JM -
-.всего
■А*?-0*1* ' • ;:-:-
всего
,/t С0Ш1ПФП ::;..-;: ■■■ :
шшшшшшшшшшшшшшшшпшш
Частоты выделенных *чеек> 10
(Итоговые маргинальные не отмечены)
22 17 39
15 11 ; 26
37 28 65
J4 7 31
8 [ 6 | 14
32 13 45
69 41 110
Заметим, что продвинутый анализ покупателей, сделавших даже три покупки,
связан с очевидными трудностями. В частности, не так просто найти группы
товаров, наиболее вероятно объединяющиеся в тройки.
Далее мы применим к данным о продажах разведочные методы анализа
соответствий (см. главу Анализ соответствий).
Г-критерий сравнения
средних в двух
группах данных
Анализ данных начинается с группировки и вычисления описательных статистик
в группах, например, вычисления средних и стандартных отклонений.
Если у вас имеется две группы данных, то естественно сравнить средние в этих
группах. Такого рода задачи во множестве возникают на практике, например, вы
можете захотеть сравнить средний доход двух групп людей: имеющих высшее
образование и не имеющих высшего образования.
В данной главе мы будем иметь дело с переменными, измеренными в
непрерывной шкале, такими переменными являются, например, доход или
артериальное давление. Переменные, измеренные в бедных шкалах, исследуются с помощью
специальных методов. В частности, категориальные переменные исследуются
с помощью таблиц сопряженности (см. главу Анализ и построение таблиц).
Переменные, измеренные в порядковых шкалах, исследуются методами
непараметрической статистики (см. главу Непараметрическая статистика).
Рассмотрим типичную задачу. Предположим, при производстве бетона вы
придумали добавлять в него некоторую новую компоненту и полагаете, что она
увеличит прочность бетона. Чтобы проверить свои предположения и доказать их
потребителю, вы взяли несколько образцов бетона с добавкой и несколько образцов без
добавки и измерили прочность каждого образца.
Таким образом, получили два столбца (две группы) цифр: прочность образцов
с добавкой и прочность образцов без добавки. Как разумно сравнить эти группы?
Очевидный подход состоит в том, чтобы сравнить описательные статистики,
например, средние двух групп. Конечно, можно было бы сравнивать медианы или
другие описательные статистики, но естественно начать со сравнения средних
значений. Итак, вы имеете два средних: среднее для первой группы и среднее для второй
группы.
Можно формально вычесть одно среднее из другого и по величине разности
сделать вывод о наличии эффекта. Однако целесообразно принять во внимание
разброс данных относительно средних, то есть вариацию (см. главу Элементарные
понятия). Очевидно, разумная процедура должна принимать во внимание
вариацию. Первое, что приходит в голову, — подходящим образом нормировать разность
средних двух выборок (групп данных), поделив ее, например, на стандартное
отклонение (корень квадратный из вариации).
Именно так и рассуждал В. Госсет — английский статистик, известный под
псевдонимом Стьюдент, придумавший t-критерий для сравнения средних двух
выборок.
12
488
Глава 12. Г-критерий сравнения средних в двух группах данных
Допустим, мы проверяем гипотезу о том, что добавка неэффективна (или как
говорят на сленге анализа данных: нет эффекта обработки), иными словами, средние
в двух группах равны. Этому положению соответствует альтернатива, согласно
которой имеется эффект — прочность бетона увеличивается при добавлении в него новой
компоненты.
Обратим внимание, альтернатива может быть выражена и по-другому,
например, средние не равны или средняя прочность образцов увеличилось (добавка
привела к увеличению прочности бетона).
Заметим далее, что возможны два варианта организации данных: вы можете
иметь дело с независимыми группами наблюдений или с зависимыми группами
наблюдений.
Если вы случайным образом разбили выборку на две части и сравниваете
показатели в первой и второй группе, то, скорее всего, вы имеете дело с независимыми
группами.
В STATISTICA t-критерий доступен в обоих вариантах организации данных.
NIIOIIHIflMfliri
ш
ш
ЩЛ4. Описательные статистики
В Корреляционные матрицы
1 ЮС!j t грин'рим и ля иг ганисимых выборок
О t-критерий для зависимых выборок
2S Группировка и однофакторная ANOVA
ЩТаблицы частот
ЩЦТаблицы и заголовки
ЪА Вероятностный калькулятор
DBA Другие критерии значимости
й*
Отмена
£? Данные
Естественным развитием сюжета сравнения средних является обобщение
t-критерия на три и более групп данных, что приводит к дисперсионному
анализу (в английской терминологии ANOVA — сокращение от Analysis of Variation —
Дисперсионный анализ), а также на многомерный отклик. Если мы имеем дело
с многомерным откликом, то используем методы MANOVA. Итак, методы
дисперсионного анализа позволяют разумным образом сравнить групповые средние, если
количество групп больше двух. Например, если вы хотите сравнить доход
жителей нескольких регионов, то можно использовать дисперсионный анализ. Если вы
исследуете два региона, то применяйте t-критерий.
Опишем один случай, не укладывающийся в общую схему. Представьте, вы
изучаете категориальную переменную, принимающую два значения, 0 и 1, и хотите
сравнить различие частот появления единиц в двух группах. Например, вы желаете
сравнить относительное число голосов, поданных за кандидата в двух
избирательных округах. Термин «относительное число» означает число голосов, поданных за
кандидата, деленное на общее число голосовавших. Статистический критерий для
сравнения частот (долей, пропорций...) реализован в модуле Основные статистики
и таблицы в диалоге Другие критерии значимости.
^критерий для независимых выборок
489
■Етштшшшшшшшшшшшшшшшшт
Различие между даумя коэффициентами корреляции
С Односторонним
jffixil
*1^
оо Id
N1:
ю
В N2:M0
; р: 1,000В
Вычислить
<• Двусторонним
Различие между двумя средними (нормальное распределение) -
г m г п г- m ^ ^ оооо
fil:
Ст.откл.
Вычислить
С 2: [£ 0 Ст.откл. |Т7
W 14НУС
i Г Среднее выборки 1 в сравнении со средним популяции 2
Различие между двумя пропорциями ■■-----■--
С Односторонний
& Двусторонний
иПрЦ
ПР.2|
50
N2:[
10
Г Односторонний
б» Двусторонний
Вычислит» |
Т-критерий для независимых выборок
Т-критерий является наиболее часто используемым методом, позволяющим
выявить различие между средними двух выборок. Еще раз напомним, переменные
должны быть измерены в достаточно богатой шкале, например количественной.
Конечно, применение t-критерия имеет некоторые ограничения, впрочем, очень
слабые.
Теоретически ^-критерий может применяться, даже если размер выборки очень
небольшой (например, 10; некоторые исследователи утверждают, что можно
исследовать и меньшие выборки) и если переменные нормально распределены (внутри
групп), а дисперсии наблюдений в группах не слишком различны. Известно, что
^-критерий устойчив к отклонениям от нормальности.
Предположение о нормальности можно проверить, исследуя распределение
(например, визуально с помощью гистограмм) или применяя критерий
нормальности. Следует заметить, что эффективно проверить гипотезу о нормальности
можно для достаточно большого объема данных (см. замечание Фишера о
проверке нормальности, цитированное нами в главе Элементарные понятия
анализа данных).
Более осторожно нужно подходить к различию дисперсий сравниваемых групп.
Равенство дисперсий в двух группах, а это одно из предположений ^-критерия,
можно проверить с помощью F-критерия (который включен в таблицу вывода
^-критерия в STATISTICA). Также можно воспользоваться более устойчивым
критерием Левена.
При сравнении средних, как и всегда в анализе данных, чрезвычайно полезны
визуальные методы. Например, на приведенной ниже категоризованной диаграмме
размаха видно существенное различие средних значений для мужчин и женщин.
На диаграмме точками показаны средние значения, а также стандартные
отклонения (прямоугольники) и стандартные ошибки (отрезки прямых линий),
вычисленные отдельно для мужчин и женщин.
490
Глава 12. Г-критерий сравнения средних в двух группах данных
и1111.1..|11Ш1П111И1!.1.1ЛЛ1Ш111.1Ш111111Ш1|1М
Диаграмма размаха по группам
8| . .
7 [ I <
6 t 1
* 3
2г
О1 ■ '
MALE FEMALE
GENDER
На графике заметно различие дисперсий в группах — высота прямоугольника
FEMALE больше высоты прямоугольника MALE.
Если условия применимости ^-критерия не выполнены, то можно оценить
различие между двумя группами данных с помощью подходящей непараметрической
альтернативы ^-критерию (см. главу Непараметрическая статистика, где
обсуждается вопрос применения альтернативных процедур,).
Р-уровень значимости ^-критерия равен вероятности ошибочно отвергнуть
гипотезу об отсутствии различия между средними выборок, когда она верна (то есть
когда средние в действительности равны).
Некоторые исследователи предлагают в случае, когда рассматриваются
отличия только в одном направлении (например, переменная Xбольше (меньше) в
первой группе, чем во второй), рассматривать одностороннее ^-распределение и
делить полученный для двухстороннего ^-критерия р-уровень пополам. Другие
предлагают всегда работать со стандартным двухсторонним ^-критерием.
Чтобы применить ^-критерий для независимых выборок, требуется, по крайней
мере, одна независимая (группирующая) переменная и одна зависимая переменная
(например, тестовое значение некоторого показателя, которое сравнивается в двух
группах).
Вначале с помощью значений группирующей переменной, например,
мужчина и женщина, если группирующей переменной является Пол, или Имеет
высшее образование и Не имеет высшего образования, если группирующей
переменной является Образование, данные разбиваются на две группы. Далее в каждой
группе вычисляется среднее значение зависимой переменной, например
артериальное давление или доход. Эти выборочные средние сравниваются между
собой.
Конечно, при применении ^-критерия, как и при применении любого другого
критерия в анализе данных, нужно сохранять здравый смысл. Применение t-кри-
терия мало оправданно, если значения двух переменных несопоставимы.
Например, если вы сравниваете среднее значение некоторого показателя в выборке
пациентов до и после лечения, но используете различные методы вычисления
ZE ±Ст откл.
I I tO ош
а Среднее
Формальное определение ^-критерия
491
количественного показателя или другие единицы во втором измерении, то
высокозначимые значения ^-критерия могут быть получены искусственно, за счет
изменения единиц измерения. Аналогично, не имеет смысла сравнивать доходы,
выраженные в рублях, при многократной девальвации или высокой инфляции.
В следующем разделе даются формулы вычисления статистики критерия Стью-
дента для проверки равенства средних двух выборок. Если вас интересует только
практическое применение, вы можете пропустить этот раздел.
Формальное определение t-критерия
Формально в случае двух групп (k = 2) статистика ^-критерия имеет вид:
/(я,+я2-2)= lV x 2V 2\
У I— + —
где х{ (и,) и Х2 (п2) — выборочные средние первой и второй выборки, У2 — оценка
дисперсии, составленная из оценок дисперсий для каждой группы данных:
У2 = 1—-[(п1 -1)У2(л,) + (и2 -1)*2(«2)];
и, + п2 - 2
sj (п) = —1— £ (х, - Xj (и)J, j = 1, 2.
Если гипотеза: «средние в двух группах равны» — верна, то статистика
Т{пх +п2 -2) имеет распределение Стьюдента с (л, +п2 -2) степенями свободы
(см. например, справочное издание Айвазян С. А., Енюков И. С, Мешалкин
Л. Д., Прикладная статистика., М.: Финансы и статистика, 1983. С. 395—397).
Большие по абсолютной величине значения статистики Т(и, + п2 - 2)
свидетельствуют против гипотезы о равенстве средних значений.
С помощью вероятностного калькулятора STATISTICA найдем 100ос/2%-ю
точку распределения Стьюдента с (и, + п2 - 2) степенями свободы.
Обозначим найденную точку через t(oc/2).
Если | Г(лг, + п2 - 2) | > t(oc/2), то гипотеза отвергается.
Заметим,чтобольшиеабсолютныезначениястатистикиСтьюдентаГ(п, +п2
-2)могут возникнуть как из-за значимого различия средних, так и из-за значимого различия
дисперсий сравниваемых групп.
Статистический критерий равенства или однородности дисперсии двух
нормальных выборок основан на статистике:
492
Глава 12. Г-критерий сравнения средних в двух группах данных
1 Л
7Zi(x2J-X2(n2)J
п2-\%
которая при гипотезе: «дисперсии в двух группах равны» имеет распределение
F(«,-l,«2-l).
Зададимся уровнем значимости а.
С помощью вероятностного калькулятора вычислим 100A — ос/2)%и 100(ос/2)%
точки распределения F{n{ -1, п2 -1).
Если F а (п\ -1, л2 -1) < Р(пх -1, п2 -1) < F„ (и, -1, п2 -1), то гипотеза об од-
2 2
породности дисперсии не отвергается.
Г-критерий для зависимых выборок
Степень различия между средними в двух группах зависит от внутригрупповой
вариации (дисперсии) переменных.
В зависимости от того, насколько различны эти значения для каждой группы,
«грубая разность» между групповыми средними показывает более сильную или
более слабую степень зависимости между независимой {группирующей) и
зависимой переменными.
Например, если при исследовании среднее значение WCC (число лейкоцитов)
равнялось 102 для мужчин и 104 для женщин, то разность только на величину 2
между внутригрупповыми средними будет чрезвычайно важной в том случае, если все
значения WCC мужчин лежат в интервале от 101 до 103, а все значения WCC
женщин — в интервале 103-105. Тогда можно довольно хорошо предсказать WCC
(значение зависимой переменной) исходя из пола субъекта (независимой переменной).
Однако если та же разность 2 получена из сильно разбросанных данных (например,
изменяющихся в пределах от 0 до 200), то разностью вполне можно пренебречь.
Таким образом, понятно, что уменьшение внутригрупповой вариации
увеличивает чувствительность критерия.
Г-критерий для зависимых выборок дает преимущество в том случае, когда
важный источник внутригрупповой вариации (или ошибки) может быть легко
определен и исключен из анализа. В частности, это относится к экспериментам, в
которых две сравниваемые группы наблюдений основываются на одной и той же
выборке наблюдений (субъектов), которые тестировались дважды (например,
пациенты до и после лечения).
В таких экспериментах значительная часть внутригрупповой изменчивости
(вариации) в обеих группах может быть объяснена индивидуальными
различиями субъектов. Заметим, что на самом деле такая ситуация не слишком отличается
от той, когда сравниваемые группы совершенно независимы (см. ^-критерий для
независимых выборок), где индивидуальные отличия также вносят вклад в дис-
, Пример 1 493
персию ошибки. Однако в случае независимых выборок вы ничего не сможете
поделать с этим, так как не сможете определить (или «удалить») часть вариации,
связанную с индивидуальными различиями субъектов. Если та же самая выборка
тестируется дважды, то можно легко исключить эту часть вариации.
Вместо исследования каждой группы отдельно и анализа исходных значений
можно рассматривать просто разности между двумя измерениями (например, «до теста»
и «после теста») для каждого субъекта. Вычитая первые значения из вторых (для
каждого субъекта) и анализируя затем только эти «чистые (парные) разности», вы
исключите ту часть вариации, которая является результатом различия в исходных
уровнях индивидуумов.
В сравнении с t-критерием для независимых выборок, такой подход дает всегда
«лучший» результат, так как критерий становится более чувствительным.
Теоретические предположения ^-критерия для независимых выборок также
применимы к критерию зависимых выборок. Это означает, что парные разности
должны быть нормально распределены. Если это не выполняется, то можно
воспользоваться одним из альтернативных непараметрических критериев (см. главу
Непараметрическая статистика).
В системе STATISTICA ^-критерий для зависимых выборок может быть
вычислен для списков переменных и просмотрен далее как матрица. Пропущенные
данные при этом обрабатываются либо попарным, либо построчным способом.
При этом возможно возникновение «чисто случайно» значимых результатов.
Если вы имеете много независимых экспериментов, то «чисто случайно» можете
найти один или несколько экспериментов, результаты которых значимы.
Как уже говорилось, сравнение средних в более чем двух группах проводится
с помощью дисперсионного анализа (английское сокращение — ANOVA).
Если имеется более двух «зависимых выборок» (например, до лечения, после
лечения-1 и после лечения-2), то можно использовать дисперсионный анализ с
повторными измерениями. Повторные измерения в дисперсионном анализе можно
рассматривать как обобщение ^-критерия для зависимых выборок, позволяющее
увеличить чувствительность анализа.
Например, дисперсионный анализ позволяет одновременно контролировать не
только базовый уровень зависимой переменной, но и другие факторы и включать
в план эксперимента более одной зависимой переменной.
Интересен следующий прием объединения результатов нескольких t-критери-
ев. Этот прием можно использовать также для объединения результатов других
критериев (см.: Справочник по прикладной статистике/Под редакцией Э. Ллойда
и У. Ледермана, т. 1. М.: Финансы и статистика, 1989. С. 274). Для нас этот пример
также интересен тем, что мы можем продемонстрировать новые возможности
STATISTICA.
Пример 1
Предположим, используя независимые эксперименты, вы получили уровни
значимости яA), аB) ... а(т). Предположим, эти уровни недостаточно убедительны.
Если уровни значимости неубедительны, то, возможно, имеет смысл объединить
данные и рассмотреть их как результат одного целого эксперимента.
494
Глава 12. Г-критерий сравнения средних в двух группах данных
При нулевой гипотезе уровни значимости, рассматриваемые как случайные
величины, имеют равномерное распределение.
Следовательно, величина
L = -2 х (Ln(a(l)) + Ln(aB)) + ... + Ln(a(m))
имеет хи-квадрат-распределение с числом степеней свободы 2т.
Например, если в испытаниях на прочность бетона были получены
недостаточно убедительные уровни 0,047, 0,054, 0,042, то уровень значимости объединенного
эксперимента равен 0,005547 и гипотеза о неэффективности добавки явно
отвергается.
Для того чтобы понять это, воспользуемся средствами системы STATISTICA.
Сначала вычислим величину I, например, задав формулу в электронной таблице.
Создайте файл и в первой строке введите запись:
А
УАЙ4
5
VAR5
б
VAR6
047
054
Переменная var7 содержит значение L, вычисленное по формуле.
JJmk JVAR7
IrTxli
Формат отобран ошм ~ - ~~-
. Тиф Представ!
— mm
JL
3
Дата
Время
Денежный
Проценты
ишаи
1.000 00000000000000;
1000 00000000000000; A
1.000 00000000000000: (
GD S3
1 ftcenapa»* }
J XtyxT.■ шлч. j
| Зиам/статист )
Дли*
|ИМЯ(мвТК«.
: |^ы^м«мм|):
- 2-(Log(v4J ♦ Loo4v5| ♦ Log(v€ft)
ы
Пример* Метке: ВаяяоА деод • 1991 Формулы • vl ♦ v2:
Ось: @E**teVfleie*2c£r4c4 «fv1>#AGE *v3
Затем откройте вероятностный калькулятор системы STATISTICA, выберите
в нем распределение хи-квадрат, введите число степеней свободы 6, а в поле хи-
квадрат введите величину 18,29.
Щ
вв
JF"WW»¥«»,
Э кспоиеициальиое
Экстрем, значении
F
П
П*
Лог нормальное
Логистическое
Парето
Ранее
I (Стыояемта)
ВеАбуаеа
Z (нормальное)
ч < ■$.$•#.£$'
Р? £жс*ф масштаб*
Пример 2
495
В результате в поле р мы получили 0,005547.
Таким образом, получен объединенный уровень значимости трех t-критериев
(сравните с результатами, приведенными в Справочнике по прикладной
статистике, под редакцией Э. Ллойда и У. Ледермана. Т. 1. М.: Финансы и статистика,
1989. С. 275). Это явно высокий уровень значимости, поэтому нулевая гипотеза
отвергается.
Пример 2
Здесь мы будем работать с файлом internet2000.sta. Можно также использовать файл
adstudyMa из папки Examples.
В файле internet2000.sta собраны результаты опроса нескольких пользователей
относительно их восприятия сайтов ENNUI и POURRITURE.
Такого рода данные несложно получить с помощью Интернета. Вы можете,
например, вывесить на сайт анкету, которая будет заполняться посетителями.
В этом модельном примере пользователи оценивали сайты в разных шкалах
(полнота, технологичность решения, информативность, дизайн и др.) В каждой из
шкал респонденты давали оценку сайту по десятибалльной шкале, от 0 до 9
баллов.
Интересен вопрос: различается ли восприятие сайтов мужчинами и женщинами?
Мужчины могут в некоторых шкалах давать более высокие или низкие оценки
по сравнению с женщинами.
Для решения этой задачи можно использовать ^-критерий для независимых
выборок. Группирующая переменная Пол разбивает данные на две группы. Выборки
мужчин и женщин будут сравнены относительно среднего их оценок по каждой
шкале. Вернитесь к стартовой панели Основные статистики и таблицы и
щелкните на процедуре t-критерий для независимых выборок, чтобы открыть диалоговое
окно Т-критерий для независимых выборок (групп).
ТЕКСТОВЫЕ
ЗНАЧЕНИЯ
*. Smith
Я. Ъгоут •'•
:€v Яауег
Ш. 9*at ;• Н
0. Young
S. В1г4
D. Fiytid
J, Oma•••••„
Я. Borrow
:Г» :«•**■•>*
С. CUttV
.'I;/-»**!,-: ••
0,.:В0**.Х..--:
Яг tteebtc*'
Эффективность рекламы на
• • 1
ЙОД
HALE
HALE
FEHALE
HALE
HALE
FEHALE
FEHALE
HALE
FEHALE
HALE
FEHALE
HALE
HALE
HALE
FEHALE
САЙТ
ENNUI
POURRITU
POURRITU
ENNUI
ENNUI
POURRITU
ENNUI
ENNUI
ENNUI
ENNUI
ENNUI
POURRITU
ENNUI
POURRITU
ENNUI
m
6
9
7
7
6
7
9
7
6
4
7
6
7
6
сайте
•ч
us
ЦК
1
7
8
9
1
0
4
9
8
6
6
3
2
2
2
nsKsm
6
i
2
6
0
3
2
2
2
6
3
3
4
7
■"■:■■ s--■■
KKXStl
7
HXASO
8 1
8 0
9 8
5 9
2 8
8 3
2 5
6
3 6
8 3
5 6
7 0
1 8
8 1
5 7
496
Глава 12. Г-критерий сравнения средних в двух группах данных
Хчфитормн =;••}• г
I Построчно уддрдто прояндомимо дойные
'1 Отоораздото ддиимыо миома лоромоиммш
Г* Ыфмгорм* о род*, ящминцмамопоромй
Г НиогоморнмА криторир Р<вта*лимгв ТЦ
Г |^итория Доооно (одиородС д*сворсиАГ : {
IT SpipMi и <Ьорсо*та (одиооод. дисперсно) :
BD
Диаграммы ртищ
• ИД ' • Ь«г»п
ормоооенимо гистограммы
Кетогормо. норм. оорооти. графики
[ Кцуогорма норн. гро+нки боэ тренде
Котогорио. диаграммы рассооиио
Щелкните по кнопке Переменные, чтобы открыть стандартное диалоговое окно
для выбора переменных. Здесь вы можете выбрать и независимые
(группирующие), и зависимые переменные.
Для нашего примера выберите переменную Пол как независимую переменную
и переменные от 3 до 25 (содержащие ответы) в качестве зависимых переменных.
ш
шшшшт
ВНЕ
меня!
12-САЙТ
3-MEASUR1
UMEASUR2
EMEASUR3
J6MEASUR4
7-MEASUR5
J8MEASUR6
J9MEASUR7
10MEASUR8
«J -^
11MEASUR9 21
12MEASUR10 22 j
13MEASUR11 23
14-MEASUR12 24
15MEASUR13 2Sl
16MEASUR14
17-MEASUR15
18MEASUR16
19MEASUR17
20MEASUR18
IMIAMIHI
4 MEASUftZ
SMIASIJM3
Б Ml AMIIU
/-MIA(JIJII5
H MLASUH6
4MFASIIR/
lOMTASIIRfl
11 MIASUMS ?
_1?MFASUR10 ?i
i:imiasiihii ?;
14MTASUR12 ?'
1bM(ASUH13 ?
16MLASUR14
1/MLASUH15
18MEASUR16
1SMFASUR17
?flMFASIIR18
J_
-±JLtL
J_
Отмой*
-il
1 Sco 1ГПодроо\ 11 Инол j] Boo j Подроб. | Ин». \
Грчлп.
Щелкните на кнопке OK в этом диалоговом окне, чтобы вернуться в диалоговое
окно Т-критерий для независимых выборок (групп), где отобразится ваш выбор.
|Щ Церемонные:
Грумирояндио: I
(СодлоягралпЫ^МАкЕ
Код ддо групп* £ |FEMALE
final t Хнфитормм | ■■
Огагии ;;;г;-: -.
j 1 ПОСТРОЧНО ОДООДТЬ Яр0Л*МДО1
! Г ОгОбрОДОП»ДЛ«1И»И НИМИ «
'■■ Г** 1"*риторми с роод< одеиками дисперсий .'•
j Г* Цногш iBPiMi mniropipl Р<отодошго Т2)
j Г" КригоркЙ Аеооно (oAHopoju дисперсия) :
\ Г~ Брооно и £орсоАта (одиород, дисперсий)
>:ПОЛ
MEASUR1-MCASUR23
Деаивм щелкните по соогоотствуошому
«ола. чтобы выбрать ковы и» описка
допустим** значений тремеиных
SSllldi
М*№?Ю*<
Котогорно. норм, oopoom граоюш
j Кдгегормэ. норм, графики боотроида
Котогорио. диаграммы рассеяния
Пример 2
497
Из диалогового окна Т-критерий для независимых выборок (групп) доступно
также много других процедур.
Щелкните на кнопке ОХ для вывода таблицы результатов.
If*11»Ч""ир
Дд*ее~
Перемен
*-.*шбта
i ■ KEASUR2
■:•■■ КЕА81Ш
: шага*
^-MEASBttta
: KEASPR5
Gl N1I И (icndei of 1Ы- tut»,.-
Группа1 MALE
Группа2 FEMALE
• 'гпшег
::.Wi
6 285714 5 409091
4 642857 4 409091
4 321429 3 909091
5 464286 5 590909
3 357143 4 727273
4 714286 5 000000
5 464286
3 821429
4 5714 29
3 636364
3.590909
3 636364
tsfM.ty IV 1
1 30945
.28152
52707
-.16547
-1 87198
-32910
2 73550
28554
1 07920
fe&^Ki*
48
48
48
48
48
48
48
48
48
.196615
.779520
.600572
.869267
067309
743511
0087Q3
776461
285892
Й'Й8&^:
28
28
28
28
28
28
1
28
28
P№IE3|
? ГШХЕ
22
-S-!
22 ' ■]
""'22 •.
22 • •
22 '
22 ']
22
22
22 '
fl
Самым быстрым способом изучения таблицы является просмотр пятого
столбца (содержащего р-уровни) и определение того, какие изр-значений меньше
установленного уровня значимости 0,05.
Для большинства зависимых переменных средние по двум группам
(МУЖЧИНЫ - MALES и ЖЕНЩИНЫ - FEMALES) очень близки.
Единственная переменная, для которой ^-критерий соответствует
установленному уровню значимости 0,05, — это Measur 7, для нее р-уровень равен 0,0087. Как
показывают столбцы, содержащие средние значения (см. две первые колонки), для
мужчин эта переменная принимает в среднем существенно большие значения —
в выбранной шкале измерений для мужчин она равна 5,46, а для женщин — 3,63.
При этом нельзя исключить вероятность того, что полученная разница на самом деле
отсутствует и получилась лишь в результате случайного совпадения (см. ниже), хотя
это выглядит маловероятным.
Графиком по умолчанию для этих таблиц результатов является диаграмма
размаха. Для построения этой диаграммы щелкните правой кнопкой мыши в любом
месте строки, соответствующей зависимой переменной (например, на среднем для
Measur 7).
В открывшемся контекстном меню выберите построение графика Диаграмма
размаха из подменю Быстрые статистические графики. Далее выберите опцию
Среднее/ст.ош./ст.откл. окна Диаграмма размаха и нажмите ОК для построения
графика.
Разность средних на графике выглядит более значительной и не может быть
объяснена только на основании изменчивости исходных данных.
Однако на графике заметно еще одно неожиданное отличие. Дисперсия для
группы женщин намного больше дисперсии для группы мужчин (посмотрите на
прямоугольники, которые изображают стандартные отклонения, равные корню
квадратному из вариации).
Если дисперсии в двух группах существенно отличаются, то нарушается одно
из требований для использования t-критерия, и разность средних должна
рассматриваться особенно внимательно.
Кроме того, дисперсия обычно коррелирована со средним значением, то есть
чем больше среднее, тем больше дисперсия.
498
Глава 12. 7"-критерий сравнения средних в двух группах данных
ШШШЕШЕШНИШ
8
7
6
5
I4
ш
* 3
2
п
Диаграмма размаха по группам
1 - 1
о
MALE
FEMALE
~Т~ id откл
□ id oui
о Среднее
GENDER
Однако в данном случае наблюдается нечто противоположное. В такой ситуации
опытный исследователь предположил бы, что распределение переменной Measur 7,
возможно, не является нормальным (для мужчин, женщин или для тех и других).
Поэтому рассмотрим критерий равенства дисперсий для того, чтобы проверить,
является ли наблюдаемое на графике отличие действительно заслуживающим
внимания.
Вернемся к таблице результатов и прокрутим ее вправо, увидим результаты
F-критерия. Значение F-критерия действительно соответствует указанному
уровню значимости 0,05, что означает существенную разность дисперсий переменной
Measur 7 в группах МУЖЧИНЫ - MALES и ЖЕНЩИНЫ - FEMALES.
Однако значимость наблюдаемой разности дисперсий близка к граничному
уровню значимости (еер-уровень равен 0,029).
1 '*£ 1 рчммыр
fl*ie*~
Перемен
ХЕДОШ1
&.Ю1ЯЯШ
KEAS0R3
HEASUIU
KEAS0K5
кшад»
KEASWtt
и-—
blNDEH ben
dei Ы the suhi<
Группа1 MALE
Труппа2 FEMALE
MALE
28
1 28
28
28
28
28
.??
28
28
W м«8л.
FEMALE
22
22
22
22
22
22
22
22
22
-cts [May lb.
- С* <э**Я
MALE
2 088011
2 971647
2 931989
2 987407
2 831232
3 125251
1 РЭ5497
2 708745
3 155578
азь|
С» олкл.
FEKAIE
2 648613
2.839502
2 486326
2 239453
2 186143
2 943920
? 8?0?b?
2 986622
2 887501
1 609058
1 095242
1 390620
1 779528
1 677234
1 126984
:: 44b5is
1 215694
1 194300
HfilG!
4>|
243145 ]
840625 .:
442073
179048
227482
787578
02*731 1
625190
683320 wy
Большинство исследователей посчитало бы один этот факт недостаточным для
признания недействительным t-критерия разности средних, дающего высокий
уровень значимости для этой разности (р = 0,0087).
Множественные сравнения
При проведении сравнений средних в трех и более группах можно использовать
процедуры множественных сравнений. Сам термин «множественные сравнения»
означает просто многократные сравнения.
Пример 2
499
Проблема состоит в следующем: мы имеем п > 2 независимых групп данных и
хотим разумным образом сравнить их средние. Предположим, мы применили
F-критерий и отклонили гипотезу: «средние всех групп равны». Наше
естественное желание — найти однородные группы, средние которых равны между собой.
Конечно, мы можем сравнить группы с помощью f-критерия и найти путем
многократных сравнений однородные группы. Но, оказывается, трудно вычислить
ошибку выполненной процедуры или, как говорят, составного критерия,
отправляясь от заданного уровня значимости каждого ^-критерия.
Тонкость состоит в том, что сравнивая с помощью f-критерия много групп, вы
чисто случайно можете обнаружить эффект. Представьте, что в 1000 клиник вы
провели испытание нового лекарства, сравнивая в каждой клинике группу
больных, принимающих препарат, с группой больных, принимающих плацебо.
Конечно, чисто случайно может найтись клиника, где вы найдете эффект. Однако с
высокой степенью вероятности это может быть арт-эффект.
Чтобы обезопасить себя от подобного рода случайностей, используются
специальные критерии для множественных или многократных сравнений.
В системе STATISTICA процедуры множественного сравнения реализованы в
модуле Основные статистики и таблицы в диалоге Апостериорные сравнения средних.
Описание процедур множественного сравнения можно найти, например, в книге:
Кендалл М. Дж. иСтьюарт А. Статистические выводы и связи. М.: Наука, 1973. С. 71—79.
Заметим, что самые общие методы сравнения нескольких групп реализованы
в модуле Общий дисперсионный анализ.
Однофакторный дисперсионный анализ можно провести в модуле Основные
статистики и таблицы.
ИИ
ж.
J*_J
Н*мии«с*4иы* 1*мсгорьф тп
' Отммм
В8 *г&**тяъ#*грфтжш+шхщт
»штор>ыи гит**, трщм hohji шттёц mi t **м**1 гумно» с и«абццисиро»»»<об
аявжаиностыо жамояци там»» о нстнъаошш ■ им наауий Кд»чпи т trw дистрсии и
500
Глава 12. Г-критерий сравнения средних в двух группах данных
Однофакторный дисперсионный анализ
и апостериорные сравнения средних
ЛЛ Описательные статистики
Ш Корреляционные матрицы
§]ЕВ t-критерий для независимых выборок
jOt-критерий для зависимых выборок
К№ Группировка и опипфпкторная ANOVA
ЩТаблмцы частот
И Таблицы и заголовки
1Л Вероятностный калькулятор
ШН Другие критерии значимости
" ***%< Л\&*Т'"
Ш^^цк
Отмена
>-."^<л v.; '
£5^ Данные J
Ш М
Итак, если вы хотите продвинуться в исследовании различий нескольких групп, то
дальнейший анализ следует вести в диалоге Группировка и однофакторный
дисперсионный анализ (ANOVA). Мы работаем с данными, которые находятся в
файле adstudy.sta (папка Examples).
Сделайте вслед за нами следующие установки.
Вначале стандартным образом выберите группирующие и зависимые
переменные в файле данных.
Затем выберите коды для группирующих переменных. С помощью этих кодов
наблюдения в файле разбиваются на несколько групп, сравнение которых мы
будем проводить.
MPWIMIIIIi.Lllli.JJ,il!l)IJll.lllJ].l|l|lll.lllllJi.llll|l
Диализ; | Подробный анализ выбранных таблиц «J [В " ЩИ» |
ЧЛТг <^<£* ><!*>
Ш Переменные | - >*■"
Груш1йру»тн^"
3aeHciiMtte:VMEASUR3hME^IBt^v,^^0 . ,,iw
СЕВ Коды для Н>у1^ру»щих деренеиных: | рмбраны
Г Построчное удаление ПД /' ■>&, 1/•"
Отмена
]
ЩВ.Я'!* В
*%*yf Взвешенные
\/' > f ишменты
-■ - гОГхево^ды •
в-1 С т
\
После того как выбраны переменные для анализа и определены коды
группирующих переменных, нажмите кнопку ОК и запустите вычислительную проце-
ДУРУ-
В появившемся окне вы можете всесторонне просмотреть результаты
анализа.
Пример 2
501
ЗАВИСИМЫЕ 7 перемен MEASUR3 MEASUR4 MEASUR5
MEASUR6 MEASUR7 MEASUR8
ГРУППИР 1 GENDER ( 2) MALE FEMALE
2-ADVERT ( 2) PEPSI COKE
riiill'iiil'ilili'ri
mm
ишшшишшшшшлЁМштм
ИгогоааяхвЬАёив.сяеймнх]
Щ Оопро<ныс двувходовыс таблицы I ]
Г Отображать длинные имей* переменных >
I** Отображать длинные испек значений
Статистики
: Г Уисло наваждений
• Г £уи»ш ,
Г Стандартные отклонения
•. Г Днсверснн
Г (радиана и квартили
Ш QK
Маргинальные средние 1 SB Категорнаованные диаграммы раемаха
, Дисперсионный «кал**
&атегориаоеаниые гистограммы
Апостериорные сравнения средних
Категориаоввиные норм.аервяти.грвфики [
fleeewa
Брауна^&орсанта @Д|
Прафик* взаимодействии
йнутрнгрупповые корреляции II Опции
1
Категориаоввиные диаграммы рассеяния
Переупорядочить факторы я таблице I £3 Графики средних и стана, отклонений |
Посмотрите внимательно на диалоговое окно. Результаты можно отобразить
в виде таблиц и графиков. Например, можно проверить значимость различий в
средних с помощью процедуры Дисперсионный анализ.
Щелкните на кнопке Дисперсионный анализ, и вы увидите результаты однофак-
торного дисперсионного анализа для каждой зависимой переменной.
вхжшштшшишшшя
Далее...
Перемен
MEAS0R1
MEAS0R2
MEAS0R3
XEASUR4
MEASURS
MEAS0R6
МЮШ
: HEAS0R9
HE4SUR9
Ш ,
Оянечеиь< эффекты, значимые на у ров р
Свм.кеа?
эффвх*
И 032
10 361
8 237
4 853
5€ ??Э
10 622
?2 04 3
6 075
10* 781
С» ев
эффвхж
3
3
3
3
3
3
3
Сркведо
эффект
3 6774
3 4536
2 7457
1 6178
•0 '>«*6
3 5406
1? 3*4«f.
2 0248
•34 S9*i7
Сдохве*
сжиВки
263 468
398 059
355 783
341 627
436 098
/S3 1/7
380 005
3S0 S39
< 05000
•Сж.ое.
ошибки
46
46
46
46
46
46
Аь
46
46
сягиБка
5 72756
8 65346
7 73441
7 42667
€15046
9 48039
5 50J75
8 26099
7 6<?'Ш
'■'■'■>■' '■■■
64206
39909
35500
21783
3 С0913
37347
3 1S S V S
24511
4S3444
ШШШТШГЦ]
Tji
ШЕИ!
59189
75428
78573
88353
g:<g:o
77252
0-^f I i
86438
007^4 ▼*
»Л1
Заметьте, что в таблице дисперсионного анализа мы имеем уже дело с F-критерием.
Как следует из результатов, для переменных Measur 5, Measur 7 и Measur 9
процедура однофакторного Дисперсионного анализа дала статистически значимые
результаты на уровне р<0,05.
Эти результаты показывают, что различие средних значимо. Итак, с помощью
F-критерия (этот критерий обобщает ^-критерий на число групп больше двух) мы
отвергаем гипотезу об однородности сравниваемых групп.
Возвратитесь в диалоговое окно результатов и нажмите кнопку
Апостериорные сравнения средних для того, чтобы оценить значимость различий между
средними конкретных групп. Прежде всего нужно выбрать зависимую переменную. В
данном примере выберем переменную Measur 7.
После того как вы нажмете ОК в окне выбора переменной, на экране появится
диалоговое окно Апостериорные сравнения средних.
502
Глава 12. 7"-критерий сравнения средних в двух группах данных
швт
- \Щ ДЙЗДЦЯВ t^fflf^gSyfflffUtffi aTCffiW$8.'.'-
БШ1
В этом окне можно выбрать несколько апостериорных критериев.
Выберем, например, Критерий наименьшей значимой разности (НЗР).
Критерий НЗР эквивалентен ^-критерию для независимых выборок,
основанному на ^сравниваемых группах.
^-критерий для независимых выборок показывает (проверьте на STATISTIC А!),
что имеется значимое различие между ответами МУЖЧИН — MALES и ответами
ЖЕНЩИН — FEMALES для переменной Measur 7:
рэтряишшрритостга
ОСНОВНЫЕ
статист
: GENDER ADVERT
-аши • •;, шэд •.;••: m •
КШ5 . СОКЕ Ш :
. ПЭШДГ PEPSI <3} .
а^шш^^!!!^^
(«■■■■■ШИИИИИИЯИИЯШИИИЯЯИИЯШИИИИИ
мШШШвШШШШШШШШШШШШШШШ
Отмечены разности, значимые на уровне
«л*ьлп$;---ШШжтЩ И-4.07И
420149 271547
420149 053365
271547 053365
042-27? | ОГНЬ 5 4 | 255767
—-та
"%nl
р< 05000 Тп
, ^;-:|4>,^;-
K-2>t7$0
042277
006554 |
255767
•■*
£|
Используя процедуру Группировка и однофакторнаяАЫОУА, мы видим (см.
таблицу результатов), что значимое различие средних имеется только для лиц,
выбравших СОКЕ.
Графическое представление результатов. Различия средних можно увидеть
на графиках, доступных в диалоговом окне Внутригрупповые описательные
статистики и корреляции — Результаты.
Например, для того чтобы сравнить распределения выбранных переменных
внутри групп, щелкните по кнопке Категоризованные диаграммы размаха и
выберите опцию Медиана/кварт./размах из диалогового окна Диаграмма размаха.
После того как вы нажмете OK, STATISTICA построит каскад диаграмм размаха.
гЦф
1 ' 1——1
!—i—'
1 | ° 1
PtPSi СОП
GCNOCR MALE
PtPSI СОИ
GfNDfR FFMALf.
Пример 2
503
Из графика видно, что между группой FEMALE — СОКЕ и группой MALE —
СОКЕ имеется явное различие.
Такого рода анализ с последовательно усложняющейся группировкой и
сравнением средних в получающихся группах, особенно часто применяемый в
массовых обследованиях, может быть с успехом выполнен в STAT1STICA.
Непараметрическая
статистика
Одним из факторов, ограничивающих применения критериев, основанных на
предположении нормальности, является объем выборки. До тех пор пока выборка
достаточно большая (например, 100 или больше наблюдений), можно считать, что
выборочное распределение нормально, даже если вы не уверены, что
распределение переменной в популяции является нормальным. Тем не менее, если выборка
мала, эти критерии следует использовать только при наличии уверенности, что
переменная действительно имеет нормальное распределение. Однако нет способа
проверить это предположение на малой выборке.
Использование критериев, основанных на предположении нормальности,
кроме того, ограничено шкалой измерений (см. главу Элементарные понятия анализа
данных). Такие статистические методы, как f-критерий, регрессия и т. д.,
предполагают, что исходные данные непрерывны. Однако имеются ситуации, когда данные,
скорее, просто ранжированы (измерены в порядковой шкале), чем измерены точно.
Типичный пример дают рейтинги сайтов в Интернете: первую позицию
занимает сайт с максимальным числом посетителей, вторую позицию занимает сайт с
максимальным числом посетителей среди оставшихся сайтов (среди сайтов, из которых
удален первый сайт) и т. д. Зная рейтинги, мы можем сказать, что число
посетителей одного сайта больше числа посетителей другого, но насколько больше, сказать
уже нельзя. Представьте, вы имеете 5 сайтов: А, В, С, D, Е, которые располагаются
на 5 первых местах. Пусть в текущем месяце мы имели следующую расстановку:
А, В, С, D, Е, а в предыдущем месяце: D, Е, А, В, С. Спрашивается, произошли
существенные изменения в рейтингах сайтов или нет? В данной ситуации,
очевидно, мы не можем использовать f-критерий, чтобы сравнить эти две группы данных,
и переходим в область специфических вероятностных вычислений (а любой
статистический критерий содержит в себе вероятностную калькуляцию!). Мы
рассуждаем примерно следующим образом: насколько велика вероятность того, что
отличие в двух расстановках сайтов вызвано чисто случайными причинами или
это отличие слишком велико и не может быть объяснено за счет чистой
случайности. В этих рассуждениях мы используем лишь ранги или перестановки сайтов
и никак не используем конкретный вид распределения числа посетителей на них.
Для анализа малых выборок и для данных, измеренных в бедных шкалах,
применяют непараметрические методы.
Краткий обзор непараметрических процедур
По существу, для каждого параметрического критерия имеется, по крайней мере,
одна непараметрическая альтернатива.
13
Краткий обзор непараметрических процедур
505
В общем, эти процедуры попадают в одну из следующих категорий:
О критерии различия для независимых выборок;
О критерии различия для зависимых выборок;
О оценка степени зависимости между переменными.
Вообще, подход к статистическим критериям в анализе данных должен быть
прагматическим и не отягощен лишними теоретическими рассуждениями. Имея
в своем распоряжении компьютер с системой STATISTICA, вы легко примените
к своим данным несколько критериев. Зная о некоторых подводных камнях
методов, вы путем экспериментирования выберете верное решение. Развитие сюжета
довольно естественно: если нужно сравнить значения двух переменных, то вы
используете t-критерий. Однако следует помнить, что он основан на предположении
нормальности и равенстве дисперсий в каждой группе. Освобождение от этих
предположений приводит к непараметрическим тестам, которые особенно полезны для
малых выборок.
Далее имеются две ситуации, связанные с исходными данными: зависимые и
независимые выборки, в которых применяется t-критерий для зависимых и
независимых выборок соответственно.
Развитие t-критерия приводит к дисперсионному анализу, который
используется, когда число сравниваемых групп больше двух. Соответствующее развитие
непараметрических процедур приводит к непараметрическому дисперсионному
анализу, правда, существенно более бедному, чем классический дисперсионный анализ.
Для оценки зависимости, или, выражаясь несколько высокопарно, степени
тесноты связи, вычисляют коэффициент корреляции Пирсона. Строго говоря, его
применение имеет ограничения, связанные, например, с типом шкалы, в которой
измерены данные, и нелинейностью зависимости, поэтому в качестве альтернативы
используются также непараметрические, или так называемые ранговые,
коэффициенты корреляции, применяемые, например, для ранжированных данных. Если
данные измерены в номинальной шкале, то их естественно представлять в таблицах
сопряженности, в которых используется критерий хи-квадрат Пирсона с различными
вариациями и поправками на точность.
Итак, по существу имеется всего несколько типов критериев и процедур,
которые нужно знать и уметь использовать в зависимости от специфики данных. Вам
нужно определить, какой критерий следует применять в конкретной ситуации.
Непараметрические методы наиболее приемлемы, когда объем выборок мал.
Если данных много (например, п >100), часто не имеет смысла использовать
непараметрическую статистику.
Если размер выборки очень мал (например, п - 10 или меньше), то уровни
значимости для тех непараметрических критериев, которые используют нормальное
приближение, можно рассматривать только как грубые оценки.
Различия между независимыми группами. Если имеются две выборки
(например, мужчины и женщины), которые нужно сравнить относительно некоторого
среднего значения, например, среднего давления или количества лейкоцитов в
крови, то можно использовать £-тест для независимых выборок.
Непараметрическими альтернативами этому тесту являются критерий серий
Валъда—Волъфовица, Манна—Уитни [/-тест и двухвыборочный критерий
Колмогорова—Смирнова.
506
Глава 13. Непараметрическая статистика
Различия между зависимыми группами. Если вы хотите сравнить две
переменные, относящиеся к одной и той же выборке, например, медицинские
показатели одних и тех же пациентов до и после приема лекарства, то обычно
используется t-критерий для зависимых выборок.
Альтернативными непараметрическими тестами являются критерий знаков и
критерий Вилкоксона.
Если рассматриваемые переменные категориальны, то подходящим является
хи-квадрат Макнемара.
Если рассматривается более двух переменных, относящихся к одной и той же
выборке, то обычно используется дисперсионный анализ (ANOVA) с повторными
измерениями.
Альтернативным непараметрическим методом является Ранговый
дисперсионный анализ Фридмана и Q-критерий Кохрена.
Исследование зависимости между порядковыми переменными.
Для того чтобы оценить зависимость между двумя переменными, обычно
вычисляют коэффициент корреляции Пирсона. Непараметрическими аналогами
коэффициента корреляции Пирсона являются коэффициенты ранговой корреляции
Спирмена R> статистика Кендалла и коэффициент Гамма (более подробно см.,
например, книгу Кендалл М. Дж., Ранговые корреляции, 1975).
Коэффициент ранговой корреляции {rank correlation coefficients) оценивает
величину зависимости между переменными, измеренными в порядковых шкалах,
то есть между порядковыми переменными.
Прозрачный способ построения парных коэффициентов корреляции из
обобщенного коэффициента корреляции предложил Daniels (Daniels H. E., 1948,
Biometrika, v. 35, p. 416-417), см. также заметку Е. В. Кулинской в Энциклопедии:
«Вероятность и математическая статистика», 1999. С. 537-538. Обобщенный
коэффициент корреляции определяется формулой:
УаЬ..
"Ш'
где а.. = а(Х{> XJ, b.. = b(Y.} Y) — некоторые функции пар наблюдений X и Y
соответственно, суммирование ведется по всем парам i, j.
Заметим, что при а.%. = X - X, b{ = Y - У. получаем обычный коэффициент
корреляции Пирсона. Если переменные ранжированы, то мы работаем с рангами.
Упорядочим значения X. по возрастанию, то есть построим вариационный ряд этих
величин. Номер величины X в этом ряде называется ее рангом и обозначается Я.
Затем упорядочим значения Y. в порядке возрастания. Номер величины Г..
в этом ряде называется ее рангом и обозначается 5..
Коэффициент ранговой корреляции Спирмена вычисляется как обобщенный
коэффициент парной корреляции с заменой наблюдений их рангами. Формально
для обобщенного коэффициента корреляции нужно положить а.. = R. - Rjt b.. = 5- 5..
Коэффициент Кендалла вычисляется, если в формуле для обобщенного
коэффициента положить а.. = 1 при R.< R.h a.. = -1 при R. > R.. Величины Ь..задаются
аналогичными соотношениями с заменой рангов R. на ранги 5. наблюдений У. Итак,
мы ясно видим, что идея всех корреляций возникает из одного и того же источника.
Если имеется более двух переменных, то используют коэффициент конкорда-
ции Кендалла. Например, он применяется ддядаенки согласованности мнений не-
Описание непараметрических процедур на примерах
507
зависимых экспертов (судей), например баллов, выставленных одному и тому же
участнику конкурса.
Если имеются две категориальные переменные, то для оценки степени
зависимости используют стандартные статистики и соответствующие критерии для
таблиц сопряженности: xw-квадрат, ^-коэффициент, точный критерий Фишера,
Нелегко дать простой и однозначный совет, касающийся использования этих
процедур. Каждая имеет свои достоинства и свои недостатки.
Например, двухвыборочный критерий Колмогорова—Смирнова чувствителен
не только к различию в положении двух распределений, но также и к форме
распределения. Фактически он чувствителен к любому отклонению от гипотезы
однородности, но не указывает, с каким именно отклонением мы имеем дело.
Критерий Вилкоксона предполагает, что можно ранжировать различия между
сравниваемыми наблюдениями. Если этого сделать нельзя, то используют
критерий знаков, который учитывает лишь знаки разностей сравниваемых величин.
В общем, если результат исследования является важным и наблюдений
немного (например, отвечает на вопрос — оказывает ли людям помощь
определенная очень дорогая и болезненная лекарственная терапия?), то всегда
целесообразно испытать непараметрические тесты. Возможно, результаты тестирования
(разными тестами) будут различны. В таком случае следует попытаться понять,
почему разные тесты дали разные результаты.
С другой стороны, непараметрические тесты имеют меньшую мощность, чем их
параметрические конкуренты, и если важно обнаружить даже слабые эффекты
(например, при выяснении, является ли данная пищевая добавка опасной для здоровья),
следует провести многократные испытания и особенно внимательно выбирать
статистику критерия.
Описание непараметрических процедур
на примерах
Стартовая панель модуля
Непараметрические статистики
Стартовая панель модуля имеет вид:
ршшшшшпшшшшш^шшшшшшшщ
1 10 Крит*рмА с«рм* В чшлл-Ъ ояьфомяы
|Ю U Ч»"*рмА Майи* Умтмм
|Е1 Д"yndоро«м**А крмтермА Колмогорова С мирном
]|$$ AM OVA Крмжем-Уоллмс* и мялиттшЛ тест
JO Kphtim* «who»
](£3 КрмтермА Вмякоксоиа -: .-v'; •:
IE23 AN0VA Фрияммм и коикордамю Кетвям
\ £&. Обычные ояистеяьиые статистики (медиеме. моде...) i gg* '«••!.':.'■."= Jfo В J
508
Глава 13. Непараметрическая статистика
Таблицы частот 2x2: статистики Xn/V/Фи-
квадрат, Макнемара, точный критерий
Фишера
Опция открывает диалоговое окно, в котором можно ввести частоты в таблицу
2x2 (состоящую из двух строк и двух столбцов) и вычислить различные
статистики, позволяющие оценить зависимость между двумя переменными,
принимающими только два значения.
Типичный пример таких таблиц — определение, например, числа мужчин и
женщин, предпочитающих рекламу ПЕПСИ или КОКИ, или числа заболевших и не
заболевших людей из числа сделавших и не сделавших прививки, и т. д.
Итак, одна переменная — ПОЛ, другая переменная — НАПИТОК. Первая
переменная имеет 2 уровня (принимает 2 значения) — мужчина, женщина. Вторая
переменная, НАПИТОК, также имеет 2 уровня, например, ПЕПСИ или КОКА.
Задача состоит в том, чтобы оценить зависимость между двумя
табулированными переменными.
Укажем на важное методологическое отличие использования слова связь
(зависимость) в повседневной жизни и в анализе данных (см. главу 33
фундаментального текста Кендалла и Стьюарта «Статистические выводы и связи»). Обычно
мы говорим, что два признака А и В связаны между собой, если они часто
встречаются вместе. В анализе данных дается строгое определение: если А встречается
относительно чаще с В, чем с не-В, то А и В связаны. Или, переходя на язык теории
вероятностей, Р( АХВ) должна быть больше Р( АХне-В). Оценкой вероятности
является частота.
В приведенной выше таблице пусть признак А — пол, признак В — напиток,
принимающий, например, два значения: пепси — не-пепси. Пусть а, Ь — частоты в
первой строке, с, d — частоты во второй строке. Если а/(а+с) - b/(b+d), то признаки
независимы. Формально имеем: 17/A7+27) - 0,39, 19/A9+29) - 0}396. Теперь
нам нужно понять, существенно или нет различие в частотах. Статистические
критерии, реализованные в этом диалоге, как раз и позволяют это сделать. В данном
случае различие, конечно, несущественно (или, как говорят в анализе данных,
незначимо). Следовательно, признаки независимы — пол не связан с выбором
напитка.
Опция 2x2 может быть использована как альтернатива корреляциям, если обе
рассматриваемые переменные являются категориальными.
Дополнительно к стандартному критерию хи-квадрат Пирсона и
скорректированному оси -квадрат (V-квадрат) вычисляются следующие статистики:
Таблицы частот 2x2: статистики Хи/У/Фи-квадрат, Макнемара
509
НЕПАРАМ
СТАТИСТ
Стола. 2
Процент от общего
Частоты.строка2 :..-.•
Процент от общего.
Сумме по столбцу
Процент от общего
Хи-квадрат (ст.св.И)
V-кеедрат (ст се.*1)
Поправка Йет се
Фи коэффициент
Фишере р> односторонний
двусторонний
Макнемера Хи-квадрат (/А/0)
Хи-калдрат (ЕУС)
ш
1? 1
18 478%
27
29 348%
44
47 826%
01
01
01
00009
2 63
107
19
20652%
29
31 522%
48
52 1 74%
р- 9259
р- 9263
р- 9038
р- 5483
р-1 0000
р- 1048
р-,3020
39 1 30°/
>.г
Классическая статистика хи-квадрат Пирсона замечательна тем, что ее
распределение приближается распределением хи-квадрат, для которого имеются подробные
таблицы. Процентные точки распределения хи-квадрат могут быть также
эффективно вычислены в системе STATISTICA с помощью вероятностного калькулятора.
Свойство критерия д^-квадрат (точность аппроксимации распределения
статистики распределением хи-квадрат) для таблиц 2 х 2 с малыми ожидаемыми
частотами может быть улучшено за счет уменьшения абсолютного значения
разностей между ожидаемыми и наблюдаемыми частотами на величину 0,5 перед
возведением в квадрат.
Это так называемая поправка Йетса на непрерывность для таблиц частот 2x2,
которая обычно применяется, когда ячейки содержат только малые частоты и
некоторые ожидаемые частоты становятся меньше 5 (или даже меньше 10).
Фи-коэффициент. Статистика фи-квадрат представляет собой меру связи
между номинальными или категориальными переменными, значения которых
нельзя упорядочить.
Пусть даны маргинальные или суммарные частоты в таблице 2x2.
Предположим, что оба фактора в таблице независимы. Зададимся вопросом: какова
вероятность получить наблюдаемые частоты, исходя из маргинальных? Замечательно,
что эта вероятность вычисляется точно, подсчетом всех возможных таблиц,
которые можно построить, основываясь на данных маргинальных частотах. Это и
делается в критерии Фишера. STATISTICA вычисляет р-уровни одностороннего и
двустороннего критерия Фишера.
Если сумма частот небольшая, то лучше использовать точный критерий
Фишера вместо критерия хи-квадрат.
Известны рекомендации Кокрена для таблиц 2x2: если сумма всех частот в
таблице меньше 20, то следует использовать точный критерий Фишера.
Если сумма частот больше 40, то можно применять критерий хи-квадрат с
поправкой на непрерывность.
Однако эти рекомендации не универсальны (см., например, Справочник по
прикладной статистике /Под. ред. Э. Ллойда и У. Ледермана. С. 375-376).
Рассмотрим следующий пример.
Пример. Исследуются 30 человек, совершивших преступления. У каждого из
преступников есть брат-близнец. Спрашивается, имеется ли связь между род-
510
Глава 13. Непараметрическая статистика
ственными отношениями и преступлением (см. Справочник по прикладной
статистике /Под. ред. Э. Ллойда и У. Ледермана. С. 376).
Данные приведены в таблице:
Оба брата Только один брат Сумма
преступники преступник
Однояйцевые близнецы
Разнояйцевые близнецы
Сумма
10
2
12
3
15
18
13
17
18
Проверяемая гипотеза состоит в том, что зависимости между родством и
преступностью нет. Альтернативная гипотеза заключается в следующем: чем теснее
родственные связи, тем более вероятно совместное участие в преступлении (то есть
между признаками имеется положительная связь). Заметьте — это односторонняя
альтернатива, так как нас интересует отклонение от гипотезы лишь в одну сторону
(вольно выражаясь, с сохранением знака больше).
Введем данные в систему STATISTICA.
После нажатия на кнопку ОК получим следующую электронную таблицу с
результатами:
частот строке 1
Процент or общего
Частоты» строка 2
npoutHt ot общего
Сунне по столбца
Процент от общего
Хи-к»адрвт<С1<а»«'1)
УЧсаодрат (ст,св «!)
Поправка Йетса
Фи ко;
Сгопб;1
двусторонний
Макиеиара Хи-квадрат QA/D)
ЕГ
frk-каадрат C/С)
10
33 333%
2
6 667%
12
40 000%
1303
1260
1046
43439
64
0 00
3
10 000%
15
50 000%
18
60 000%
р- 0003
р- 0004
р- 0012
р- 0005 |
р- 0005
р- 4237
р-1 0000
lino р
дн | i
строкам
13
43 333%
17
56 667%
30
;П
Значение статистики хи-квадрат равно 13,03.
Так как в данных имеются ячейки с малыми частотами B и 3), то для
улучшения точности критерия хи-квадрат используем поправку Йётса. Поскольку нас
интересует односторонняя альтернатива, мы делим уровень р = 0,0012 пополам и
получаем 0,0006.
Точное значение одностороннего критерия Фишера равно 0,0005 (см.
таблицу). Оба эти результата высокозначимы, следовательно, мы отвергаем исходную
гипотезу об отсутствии зависимости между родством и преступлением в пользу
альтернативы: «между признаками имеется тесная положительная связь».
Таблицы частот 2x2: статистики Хи/У/Фи-квадрат, Макнемара
511
Заметьте, что сумма всех частот в таблице меньше 40, но оба критерия, точный
Фишера и хи-квадрат Йетса, дают почти одинаковые результаты.
Критерий хи-квадрам Макнемара. Этот критерий применяется, когда частоты
в таблице 2x2 получены по зависимым выборкам. Например, когда наблюдения
фиксируются до и после воздействия на одном и том же экспериментальном материале.
STATISTICA включает также модуль Логлинейный анализ, позволяющий
выполнить полный логлинейный анализ многовходовьрс таблиц сопряженности.
STATISTICA содержит программу на STATISTICA BASIC для вычисления
критерия Ментела—Хенцела (файл Manthaen.stb в каталоге STBASIC), позволяющего
сравнить две группы данных. Обратитесь к комментариям в программе Manthaen.stb
за дополнительной информацией.
Наблюдаемые частоты в сравнении
с ожидаемыми
Опция позволяет оценить согласие наблюдаемых частот с произвольным набором
ожидаемых частот.
С2ШШШЕЭШШЯЕЭШШМ
;7£=~ ;;• • ':
нцнюгп
iffl Ж 1
| Отмен* 1
SS«lfrftl
Процедура предлагает пользователю ввести две переменные: одна содержит
ожидаемые, другая — наблюдаемые частоты. Для проверки согласия наблюдаемых
и ожидаемых частот вычисляется критерий ягг-квадрат.
Следующий пример основан на данных (искусственных) об авариях на шоссе
(данные содержатся в файле Accident.sta). Данные записывались с интервалом,
равным месяцу, в 1983 и 1985 годах.
-~-~~- |Numtoei of accident* ovt «/
February
M«ch
***■
Mm
**e
Mr
Stcxwnb*
Gctob*
Kovcnbw
December
150
80
50
40
43
80
75
80
65
50
95
85 |
40 i
45 !
40
42 j
43 j
50 !
36 |
78 i
83*-:!
Допустим, что в 1984 году были потрачены значительные средства с тем, чтобы
улучшить безопасность движения на этом шоссе. Если затраченные средства ни к
чему не привели (нулевая гипотеза), то число несчастных случаев в 1985 году
могло бы прогнозироваться на том же уровне, что и в 1983-м (при условии, что общее
число машин на трассе и интенсивность движения не менялись). Таким образом,
данные за 1985 год рассматриваются здесь как ожидаемые значения, данные за
1983 год — как наблюдаемые.
512
Глава 13. Непараметрическая статистика
Задание анализа. После запуска модуля Непараметрические статистики и
распределения откройте файл Accidentia и выберите в стартовой панели опцию
Наблюдаемые в сравнении с ожидаемыми. В появившемся диалоговом окне
Наблюдаемые и ожидаемые частоты нажмите кнопку Переменные и выберите Y_1983 —
переменную с наблюдаемыми частотами и Y_1985 — переменную с ожидаемыми
частотами.
Г iirinii r mil ДЩДИашши
щшя^ЕШ!
ит т i>i
,\>.| ,_Ow*i«i. }•]
a'ulaal
После нажатия ОК таблица с результатами появится на экране.
^IM'IINii'H'HI'fW'-'lf
НЕПАРАМ.
СТАТИСТ.
Наблюд.
f>brueiy .. "■• -/■..:,;•••:.■ »:?■
March •"• •• • "• ■.■■/*?■■**''■.<?.
April- • :^;.\
;Ш*::*-Г.К... .-«Г***!*
лит'.:,; • ••..
" 4tfyW:? "ЛЪЩ-Ъ'^^-ЪХ ?
^;AM^u*l:^-.-:^;-^.^V; ••
. S»pte«jbAr .:<..,.:" . ••:,•!: : l,,.-.:-.'-.-"
; ОйбЬ^.^*1^^^^^^^'
• ЫШ$Ш$&&*}%№%/ &
•*0«rt*frife*^ Г: V- :-^--'\ ■-■ -•
-СуНМв:\: , ..••"■ ••••:• ".•■•" " '" • ■■• ••■
l£T j
ШРШШг,1ш^шт
хи-квадрат • 1
ЗАМЕЧАНИЕ
850000
800000
850000
400000
450000
400000
420000
430000
500000
36 0000
780000
830000
7070000
21 7010 ее-11
Неравные суг
1^::':ч-:вЖ&Д..: ••
| 125.0000
150.0000
80.0000
50 0000
400000
430000
800000
750000
80.0000
65 0000
500000
95.0000
9330000
р< оооооо *?!
чмы наблюдаемых и ожидаем^■ jj
•\nft*Ov^:
-40000
-70000
5.000
-10 000
5 000
-3 000
-38 000
-32 000
-30 000
-29 000
28 000
-12 000
-226.000
. <Н-ОГ2
/0
12 8000
326667
3125
2 0000
6250
2093
18 0500
136533 .
112500
129385
15 6800
15158
121 7010 *jj
►
G
Из таблицы ясно видно, что снижение числа аварий в 1985 году по сравнению
с 1983 годом высокозначимо.
Заметим, что в нижней части таблицы результатов показано общее число
аварий за каждый год (Сумма); разности между наблюдаемыми и ожидаемыми
значениями даны в третьем столбце, квадраты разностей, деленные на ожидаемые
значения (слагаемые :ш-квадрат), — в четвертом столбце.
Обратите внимание на число степеней свободы (ее) распределения хи-квадрат,
в этом примере оно равно 11.
Корреляции (Спирмена R, тау Кендалла, Гамма)
Опция позволяет вычислить три различные альтернативы коэффициенту
корреляции Пирсона: корреляцию Спирмена R, статистику may Кендалла и статистику
Гамма. После выбора опции на экране появится диалоговое окно, в котором
можно выбрать переменные и определенный тип корреляции для вычисления. Можно
вычислить одну непараметрическую корреляцию или матрицу
непараметрических корреляций.
Таблицы частот 2x2: статистики Хи/У/Фи-квадрат, Макнемара
513
?1 Подробим* отчет 21 .<* 'гч чадк* у
Следующий пример основывается на данных (файл Striving.sta),
представленных Siegel and Castellan A988) Nonparametric statistics for the behavioral sciences
Bnd ed.) New York: McGraw-Hill.
Двенадцать студентов ответили на вопрос анкеты, чтобы оценить связь между
двумя переменными: авторитарностью и борьбой за социальное положение.
Авторитарность (Adorno и др., 1950) — психологическая концепция, состоящая, грубо
говоря, в том, что властные люди имеют тенденцию считать, что власть должна
быть жесткой и ей следует подчиняться (иными словами, придерживаются
принципа: «закон и порядок»).
Данные показаны ниже.
Con*
L
^
4
Г
L
9
10
11
Ш
1ffiltii"fitiii
atcnbe
83
96
87
40
116
113
111
83
85
126
10b
117
■*1SJ
wmtimjIc
• 2
TRMNG
42
xl
46 ]
39
37
65
88
86.
56
62
92
54
81 *i
\ >rl
Цель исследования состояла в том, чтобы выяснить, зависимы, в
действительности, эти две переменные или нет.
Задание анализа. После запуска модуля Непараметрические статистики и
распределения откройте файл Accidentia и выберите в стартовой панели опцию
Корреляции (Спирмена, may Кендалла, Гамма). В появившемся диалоговом окне
нажмите кнопку Переменные и выберите Authorit как первую переменную, Striving —
как вторую переменную.
Модуль Непараметрические статистики и распределения вычисляет также
корреляционные матрицы. В этом примере выберите просто Спирмена R и Подробный отчет.
Ь ^.' Уг; ■■}; fCmcm 1: AUTHOlW *x {'■?%£$ чЬч. • Отмен. П
«* в7«УМ1%:
":':. 'Г^вт*"**."!.
<v '! l>qM^W.;-| Подробные ОТЧТ З^*^-" fr'^
514
Глава 13. Непараметрическая статистика
После нажатия ОК таблица с результатами появится на экране.
1 ""J-1-1"-"
ашт
32
Далее.»
ка
ГШ попарно удалены
■ JoJx|
Поры перем
Спирмена
R
шш
818182
ФЧ
4 500000
Р^Р°В
001143
\П
Вы видите, что корреляция между двумя шкалами высокозначима, и можно
сделать вывод, что индивидуумы, имеющие внутреннюю установку на авторитарность,
в свою очередь, стремятся к борьбе за свое положение в обществе (при условии, что
анкета адекватна данному исследованию), тем самым подтверждается концепция
Адорно.
Авторитаризм — внутренняя установка (ее трудно непосредственно измерить).
В отличие от этого борьба за положение в обществе и продвижение по
иерархической лестнице наблюдается отчетливо. Итак, между властностью и карьеризмом
имеется отчетливая зависимость.
Вы можете визуализировать найденную зависимость двумя способами. Либо
нажав кнопку Матричная диаграмма в диалоговом окне Непараметрические
корреляции (после того как выбрали переменные), либо щелкнув правой кнопкой
мыши на таблице результатов и выбрав опцию Диаграмма рассеяния/довер из меню
Быстрые статистические графики.
Параметрическая корреляция (г Пирсона) между шкалами (г = 0,77) показана
в заголовке графика (см. ниже). Интересно, что эта корреляция меньше ранговой
корреляции Спирмена (Спирмена R равно 0,82).
ГЙ7ра7
100
90
80
о 70
z
1Л
50
40
30
3
ml AUTHORIT vs STRIVING
AUTHORIT v$ STRIVING
STRIVING - -1 959 ♦ 66281 " AUTHORIT
С орреляция Пирсона t ■ 77452
о .' У
л' О / .
У
,""" У У •
уГ. Р
У
0 50 70 90 110 130
AUTHORIT
Шш!
S
1
^о^ Регрессия
H 95 \ довер
Если бы в этом примере мы располагали большим объемом данных, то могли
бы сделать вывод, что рассмотрение рангов (а не самих наблюдений) в
действительности улучшает оценку зависимости между переменными, так как
«подавляет» случайную изменчивость и уменьшает воздействия выбросов.
Статистики Кендалла тау и Гамма. Для сравнения вернитесь в окно
Непараметрические корреляции и выберите опцию Статистика may Кендалла, а также опцию
Гамма. Обе статистики, Кендалла may и Гамма, будут вычислены и окажутся равными 0,67.
Таблицы частот 2x2: статистики Хи/У/Фи-квадрат, Макнемара
515
L иГМИНЛ IHU....IJ
НЕПАРАМ
СТАТИСТ
ГЩ попврио уделены
■ -laixjl
и
Поры перем
гер°»
Как было сказано ранее, эти статистики тесно связаны между собой, но
отличаются от статистики Спирмена. Статистику Спирмена R можно представить себе
как вычисленную по рангам корреляцию Пирсона, то есть в терминах доли
изменения одной величины, связанной с изменением другой. Статистики Кендалла may
и Гамма скорее оценивают вероятности, точнее, разность между рероятностью того,
что наблюдаемые значения переменных имеют один и тот же порядок, и
вероятностью того, что порядок различный.
Матрицы двух списков. Опция вычисляет только корреляции между
переменными, заданными в первом списке, и переменными, заданными во втором списке.
Квадратная матрица. Опция вычисляет корреляции для одного списка
переменных (квадратная матрица). Заметим, если выбраны два списка переменных,
а затем выбрана эта опция, то списки будут «объединены» в один.
Матричная диаграмма
Нажмите кнопку, чтобы построить матричную диаграмму рассеяния для
выбранных переменных.
2 Корреляции ICAHS SIA 5ла22и)
Корреляции (CARS STA 5п'22и)
ACCELER
a__cjoQUc»_
BRAKING
J-
JL
MILAGE
JaQa.
ACCELER
BRAKING
.....J.
J.
MILAGE
a_OGB_a_
Этот график полезен тем, что он позволяет быстро оценить и сравнить
распределения выбранных переменных и форму зависимости между ними (например,
коэффициент ранговой корреляции R Спирмена может измерять нелинейную
монотонную зависимость между переменными).
516
Глава 13. Непараметрическая статистика
Критерий серий Вальда—Вольфовица
Критерий серий Вальда—Вольфовица представляет собой непараметрическую
альтернативу ^-критерию для независимых выборок. Данные имеют тот же вид,
что и в ^-критерии для независимых выборок. Файл должен содержать
группирующую (независимую) переменную, принимающую, по крайней мере, два
различных значения (кода), чтобы однозначно определить, к какой группе относится
каждое наблюдение в файле данных.
Программа открывает диалоговое окно выбора группирующей переменной и
списка зависимых переменных (переменных, по которым две группы
сравниваются между собой), а также кодов для группирующей переменной (опция Коды).
Критерий серий Вальда—Вольфовица устроен следующим образом.
Представьте, что вы хотите сравнить мужчин и женщин по некоторому признаку. Вы можете
упорядочить данные, например, по возрастанию, и найти те случаи, когда
субъекты одного и того же пола примыкают друг к другу в построенном вариационном
ряде (иными словами, образуют серию).
Если нет различия между мужчинами и женщинами, то число и длина «серий»,
относящиеся к одному и тому же полу, будут более или менее случайными. В про-
тивдом случае две группы (мужчины и женщины) отличаются друг от друга, то
есть не являются однородными.
Критерий предполагает, что рассматриваемые переменные являются
непрерывными и измерены, по крайней мере, в порядковой шкале.
Критерий серий Вальда—Вольфовица проверяет гипотезу о том, что две
независимые выборки извлечены из двух популяций, которые в чем-то существенно
различаются между собой, иными словами, различаются не только средними, но
также формой распределения. Нулевая гипотеза состоит в том, что обе выборки
извлечены из одной и той же популяции, то есть данные однородны.
U-критерий Манна—Уитни
Критерий Манна—Уитни представляет непараметрическую альтернативу
^-критерию для независимых выборок. Опция предполагает, что данные расположены
таким же образом, что и в ^-критерии для независимых выборок. В частности, файл
должен содержать группирующую переменную, имеющую, по крайней мере, два
разных кода для однозначной идентификации принадлежности каждого
наблюдения к определенной группе.
Критерий U Манна—Уитни предполагает, что рассматриваемые переменные
измерены, по крайней мере, в порядковой шкале (ранжированы). Заметим, что во
всех ранговых методах делаются поправки на совпадающие ранги.
Интерпретация теста, по существу, похожа на интерпретацию результатов
^-критерия для независимых выборок за исключением того, что {/-критерий
вычисляется как сумма индикаторов парного сравнения элементов первой
выборки с элементами второй выборки.
[/-критерий — наиболее мощная (чувствительная) непараметрическая
альтернатива ^-критерию для независимых выборок; фактически, в некоторых случаях
он имеет даже большую мощность, чем ^-критерий (см. например, Холлендер М.,
Критерий серий Вальда—Вольфовица
517
Вульф Д. А. A983), Непараметрические методы статистики, а также заметку
М. С. Никулина в Энциклопедии: «Вероятность и математическая статистика». С. 299).
Формально статистика Манна—Уитни вычисляется как:
U = W-l-m(m + l) = Z:XA>
где W— так называемая статистика Вилкоксона,
[1, еслиХ,<У]9
и [0 в противном случае.
Таким образом, статистика U считает общее число тех случаев, в которых
элементы второй группы, например мужчины, превосходят элементы первой группы,
например женщин.
Двухвыборочный критерий
Колмогорова—Смирнова
Критерий Колмогорова—Смирнова — это непараметрическая альтернатива
^-критерию для независимых выборок. Формально он основан на сравнении
эмпирических функций распределения двух выборок. Данные имеют такую же организацию,
как в ^-критерии для независимых выборок. Файл должен содержать кодовую
{независимую) переменную, имеющую, по крайней мере, два различных кода для
однозначного определения, к какой группе принадлежит каждое наблюдение.
Опция открывает диалоговое окно выбора кодовой переменной и списка
зависимых переменных (переменных, по которым две группы сравниваются между собой),
а также кодов, используемых в кодовой переменной для идентификации двух групп
(опция Коды).
Критерий Колмогорова—Смирнова проверяет гипотезу о том, что выборки
извлечены из одной и той же популяции, против альтернативной гипотезы, когда
выборки извлечены из разных популяций. Иными словами, проверяется гипотеза
однородности двух выборок.
Однако в отличие от параметрического ^-критерия для независимых выборок и
от {/-критерия Манна—Уитни (см. выше), который проверяет различие в
положении двух выборок, критерий Колмогорова—Смирнова также чувствителен к
различию общих форм распределений двух выборок (в частности, различия в
рассеянии, асимметрии и т. д.).
Пример. Критерий серий Вальда—Вольфовица,
Манна—Уитни U-критерий, двухвыборочный
критерий Колмогорова—Смирнова
Все эти критерии представляют собой альтернативы ^-критерию для независимых
выборок. Пример основан на исследовании агрессивности четырехлетних
мальчиков и девочек (Siegel, S. A956) Nonparametric statistics for the behavioral sciences
Bnd ed.) New York: McGraw-Hill). Данные содержатся в файле Aggressn.sta.
518
Глава 13. Непараметрическая статистика
ТВ
2
Э
4
5
»
7
в
9
10
Г?
ЕНДЗЕ
Aggression к
BOYSI
BOYS
BOYS
BOYS
BOYS
BOYS
BOYS
BOYS
BOYS
BOYS
I
■ЫВ1
xl!
ore of 12 b^:]
2
&GR£SSb
86
69 :
72 i
65
113 i
65
118 \
*b
141
104^:
Двенадцать мальчиков и двенадцать девочек наблюдались в течение
15-минутной игры; агрессивность каждого ребенка оценивалась в баллах (в терминах
частоты и степени проявления агрессивности) и суммировалась в один индекс
агрессивности, который вычислялся для каждого ребенка.
Задание анализа. После запуска модуля Непараметрические статистики
откройте электронную таблицу с данными (файл Aggressnsta), выберите опцию
Критерий серий Валъда—Волъфовица.
|jmU4liJ.njJJ14J,i.l4IJ4
ЕЩ
: <• \\цуфт*тр*тс*т сетлгмегмим С Подоим $
fymmmmtt*mc*m статистик*:
Таблицы 2 я 2: ки/У/фи. Макмемара. точный Фиаюра
Шх'0 Наблюдаемые частоты • сравнении с ожидаемыми
Щ Корреляции (Спирмеиа. тач Кеидалла, гамма)
,Ш1!1.Ц.|1|.ЦЛ|1|.|Ц||Щ1111,!1.|1!11|Щ
Выберите нужны*
иепарамвггричвокий
ьтсллпя
jYJ U критерий Маииа-Умтии
Ш% Двусвыборочный критерий Колмогорова Смирнова
jj*| ANOVA Краснела Uоллиса и медианный тест
[JJ22 Критерий знаков
B2) Критерий Вилкоксона
Ц22 ANOVA Фридмана и коикордавия Кеидалла
\ii'\ Q критерий Кокрена
&
JjA Обычные описательные статистики (медиана, мода. .)
.♦ft А
Далее нажмите (Ж
Нажмите кнопку Переменные и выберите переменную #ол — Gender как
группирующую и переменную Aggressn как зависимую.
11У^.Ц|1М1111,Д11
|2 AGGRESSN
1 GENDER
►ашниио
iMM'IIW'-l'NIi'llMNIIMfl*-
Ж
Г Все
"Г Подроб.
Неа—мснмад паре»и
;''
т
Инф.
И Bee
J Подрой. Jj
Э«и»сш«ла перемашд-иг
Р
ЙНЧ>. ]
Коды для однозначного отнесения каждого наблюдения к определенному полу
будут автоматически выбраны программой.
Критерий серий Вальда—Вольфовица
519
| Критерии серий Вальдл Вольфе
■ ш
Отмен*
Коды дм грумы £ [GIRLS
Дм*** щелкните ммшыо по
соответствующему поло, чтобы выбрать
коды м»спмск» допустимым »»ie»rt
ДЬетегарн
S^tflt&ll
Далее нажмите OK, чтобы выполнить анализ.
жтяшшатмшшттшшятятшшл
ПЯМРМ
______
r-liTiiUiVii шШШШШШШыт'М i in nyj—
Пяле* (Поперем
......М*Л "L.JTpyn1bBOYS Груп 2 2-GIRLS
Перен РКдвЯиЩ GIRLS
ПНЗяяЩ 12| 12
Ы I "
Среднее
BOYS
Среднее
OIRLB
80 7S000 26 66667
2
р-чрое.
-3 75681 000172
Zckopp
3 548Ю0
ввяял*г**т—г
__|
вжеШаШ.»}
Р-ЫРО».
000389
^
D
Как видно из таблицы результатов, различие между агрессивностью
мальчиков и девочек в этом исследовании высокозначимо.
Выполните то же самое исследование с помощью критерия Манна—Уитни.
($ Нерщиметршесшт статистики С Подгонке распределение
Цеяарамотричесдия статистиыг
еэ
Я*
Отмене
Таблицы 2 н 2: Hit/We*. Макиемара, точный Фиеюра
Qx'Q Наблюдаемые частоты в сравнении с ожидаемыми
Корреляции (Спирмема. твч Кеидалла. гамма)
щ{ Критерий серий Валмде-Воль+оеида
LvllllllHIJIiii.l U!Jlili.l!
ОДерите нужный
мвпарамвтричаокий
метод дм
IJTJ Дечхеыборочиый критерий Колмогорова-Смирнова
$$| AN OVA Крескела-Уоллиса и медианный тест
[22] Критерий знаков
[|*31 Критерий Вилкоксоиа
([♦jJJjANOVA Фридмана и коикордация Кеидалла
МИ 0 критерий Кохрена
£5 J*
в статистики (медиана, мода )
& ft
Нажмите кнопку Переменные и выберите переменную Яол — Gender как
группирующую и переменную Aggressn — как зависимую.
{2AGGRESSN
ii^!ixiijiaiiiiiiiiiuiiM!iiiiiiijjiiuMji!:jit!jiiiii»m
.1 GENOCR
>АШИ1ИЫ11Д
ЯШ!
QD
1 to g Педроб. | *н<Г""}| Все \ Педроб. f Ин». j
Коды для однозначного отнесения каждого наблюдения к определенному полу
будут автоматически выбраны программой.
520
Глава 13. Непараметрическая статиаика
швввштввтшввавш
НЕПАРАМ Поперем
СТАТИСТ |Грцп 1 1-BOYS Грцп 2 2-GIRLS
р*цро»
84 00000
6 000000
3810512
000139
скорр.
3812170
Р-ЦрО».
000138
Выберите опцию Двухвыборочный критерий Колмогорова—Смирнова.
Таблицы 2 i 2: хиЛ//е>м. Макиемара, точный Фишера
flxflj Наблпдаемые частоты в сравнении с ожидаемыми
Корреляции (Слирмеиа, тач Кендалла, гамма)
13 Критерий серий Вальда-Вольеювика
El U критерий Маииа-Ыитии
'.tiiiiiiiiiiii.iiiiiiiiiiiii.iiiirij.iii.ij.i.iii.ijii.i.ij.iu.i
Выберите нужный
«•параметрический
метод длл
исследование вашим
{»] ANOVA КраскелаЫоллиса и »
Д»3| Критерий знаков
(£2 Критерий Вилкоксона
223 AN OVA Фридмана и коикордация Кендалла
Q критерий Кокреиа
В
О л«
iM Обычные описательные статистики (медиана, мода...)
&а\
Нажмите кнопку Переменные и выберите переменную Пол — Gender как
группирующую и переменную Aggressn — как зависимую.
ПШЯПЗИвГ"
12 AGGRESSN
АЯЯ
. GENDER
1ММ*Ш1М*Р^^
JL
Во* Л Подроб. || И>н>. 11 Все
Г
Т
Коды для однозначного отнесения каждого наблюдения к определенному полу
будут автоматически выбраны программой.
tm*kmrp**mt Iboys
ИШ %/вГ9Г«ф»*Лй9тшЧт гистогрв>е<а|
: <*цг иш »у»цанд лв*о, чтобы еыбрат» '
■К0йы^с*нжа*ап¥стй*е*ам^^
с?й1аа|
Критерий серий Вальда—Вольфовица
521
Электронная мультимедийная таблица с результатами имеет вид:
эперем
1 1-BQYSrPLjn 2 2-GlRLS
ЕШЩ
.Макс поп.,
Разн.
833333
PUPO»
СраднФв
BOYS
Среднее
GIRLS
Ст:откп
80YS
Ст. откд
GIRtS
р< 001
80 75000
26 66667
31 82373
16.99911 г,1
.. .HI
Заметьте, что стандартные отклонения в обеих группах не равны (см. шестой и
седьмой столбец в таблице результатов) и мы не можем непосредственно
применить t-критерий.
График по умолчанию для этих тестов — диаграмма размаха. Вы можете
построить его двумя способами: нажав кнопку Диаграмма размаха в окне Критерий
знаков или щелкнув на таблице результатов правой кнопкой мыши и выбрав затем
опцию Диаграмма размаха в меню Быстрые статистические графики. Далее
программа попросит выбрать переменные. В этом примере выберите обе переменные.
Затем выберите тип графика в окне Диаграмма размаха: (см. ниже). Выберите
Медиана/кварт./размах и нажмите ОК.
С Ср«*иа»/ст.сш./ст от**,
С Сдави—/ет.от*иУ1.9в*(ст.оти,<.|
г \
Огытп |
Хку1т»иы>тмгь1н<сгри»аа1шцацаг0аг«црадмц»й
Ф*мш ■ыбрвссвЛмстр*. имы»« mam**
ом» м»ию Трафим*.
На диаграмме размаха для каждой переменной показаны: медиана,
квартальный размах B5%, 75% процентили), размах (минимум, максимум).
Диаграмма размаха по грушам
Парам-* AGGRESSN
160 г
140
120
100
Ъ> 80
to I
LU [
§60
40
20
0
-20 I
I I ° I
BOYS
GIRLS
_П М ии-макс
□ 25*75*
о Медиана
Из графика видно, что мальчики более агрессивны, чем девочки.
Для того чтобы увидеть распределение зависимой переменной, разбитой на
группы, нажмите кнопку Категоризованная гистограмма.
522
Глава 13. Непараметрическая статистика
mir/Hm^'^iviNiM1,1
Категормэоеаммдя гистограмма
Перем я AGGRESSN
40 60 80 100 120 140 160
GENDER BOYS
40 60 80 100 120 140 160
GENDER GIRLS
ANOVA Краскела—Уоллиса и медианный тест
Эти два теста являются непараметрическими альтернативами однофакторного
дисперсионного анализа. Мы применяем t-критерий, чтобы сравнить средние
значения двух переменных. Если переменных больше двух, то применяется
дисперсионный анализ. Английское сокращение дисперсионного анализа — ANOVA
(analysis of variation).
: <•" Н«дцн»—гричасимв омгмсгмк* С Подо*** Р
^^параметрические статист тклс
В
а*
Таблицы 2x2: хиЛгУ+и, Мак немара, точный Фишера
Щх'Ш Наблюдаемые частоты в сравнении с ожидаемыми
Корреляции (Спирмена, та) Кеидалла, гамма)
|TJ Критерий серий ВальдаВоль+оеида
|tj U критерий Манна-иитни
g'ij Двчхеыборочиый критерий Колмогорова-Смирнова
выбери** нужный
н*ларвматр**скмй
МвТОАДЯД
TWI
Д53 критерий знаков
B*2 Критерий Вилкоксона
(^ ANOVA Фридмана и коикордадия Кендалла
!НП Q критерий К охрена
О- Д«
jjk Обычные описательные статистики (медиана, мода. )
& а |
Критерий Краскела—Уоллиса основан на рангах (а не на исходных наблюдениях)
и предполагает, что рассматриваемая переменная непрерывна и измерена как
минимум в порядковой шкале. Критерий проверяет гипотезу: имеют ли сравниваемые
выборки одно и то же распределение или же распределения с одной и той же медианой.
Таким образом, интерпретация критерия схожа с интерпретацией параметрической
однофакторной ANOVA за исключением того, что этот критерий основан на рангах, а
не на средних значениях.
Медианный тест — это «грубая» версия критерия Краскела—Уоллиса. STA-
TISTICA просто подсчитывает число наблюдений каждой выборки, которые
попадают выше или ниже общей медианы выборок, и вычисляет затем значение
хи-квадрат для таблицы сопряженности 2 х k.
Критерий серий Вальда—Вольфовица
523
При нулевой гипотезе (все выборки извлечены из популяций с равными
медианами) ожидается, что примерно 50% всех наблюдений в каждой выборке
попадают выше (или ниже) общей медианы. Медианный тест особенно полезен, когда
шкала содержит искусственные границы, и многие наблюдения попадают в ту или
иную крайнюю точку (оказываются «вне шкалы»).
Пример основан на данных, представленных в книге Hays A981) Statistics
Crd ed.) New York: CBS College Publishing, которые содержатся в файле KruskaLsta.
Откройте файл данных.
Файл содержит результаты исследования маленьких детей, которые
случайным образом приписывались к одной из трех экспериментальных групп. Каждому
ребенку предлагалась серия парных тестов, например, давались два мяча: красный
и зеленый. Далее ребенка просили выбрать зеленый мяч, если он делал
правильный выбор, то получал вознаграждение.
TEilCwec» choice of receded л
Г? ...J
FORI
FORM
FORM
FORM
FORM
COLOR
COLOR
COLOR
COLOR
COLOR
ИИРИИГ
10
8
14
31
7
9
11
16 ч
В первой группе тестом была форма (группа 1-Форма — 1-Form), во второй —
цвет (группа 2-Цвет — 2-Color)y в третьей — размер (З-Размер — З-Size) предмета.
Зависимая переменная, показанная во втором столбце, — это число испытаний,
которые потребовались каждому ребенку, чтобы получить вознаграждение.
Задание анализа. После запуска модуля Непараметрические статистики и
распределения и выбора файла KruskaLsta выберите опцию ANOVA Краскела—Уолли-
са и медианный тест, чтобы открыть диалоговое окно Дисперсионный анализ Крас-
кела—Уоллиса и медианный тест.
Далее нажмите кнопку Переменные и выберите переменную Conditn как
независимую и переменную Perfrmnc — как зависимую.
штвшшшпшт
12 PERFRMNC
.1 CONDITN
тштмшттттшттп
№...
Г
Ht
h
8с«
11 П<мро& II Ии+.
имен гмромомнфя*
1Г£г
| Паяроб.
I2
т
Ии+.
З... ■■■':'•■!
Нажмите кнопку Коды и выберите все коды для независимой переменной
(нажмите кнопку Все).
524
Глава 13. Непараметрическая статистика
т.шииши.инишипиишиу.ишшии,
pORM ■ SIZE
I Отммм I
Диалоговое окно Дисперсионный анализ Краснела—Уоллиса и медианный тест
появится на экране:
Ж.
СОШИТ N ; - ^ - . • Г
■ "Г, :Л Л1:... • • ".'• •
Щ
JV4 "... Ди|*и1
Результаты. В диалоговом окне нажмите ОК для начала анализа. Результаты
ранговой ANOVA Краскела—Уоллиса будут показаны в первой таблице
результатов, результаты медианного теста — во второй.
НЕПАРАМ Независимая переменная CONDITN
СТАТИСТ [критерий К-Ы Н B. N 36) ИЗ 84438 р 0010
Завис: |1И|НГ:;\' %сао
шв
рент
12
12
12
139 0000
200 0000
3270000
!П
Вы видите, что критерий Краскела—Уоллиса высокозначим (р= 0,001). Таким
образом, характеристики различных экспериментальных групп значимо
отличаются друг от друга. Напомним, что процедура Краскела—Уоллиса, по существу,
является дисперсионным анализом, основанным на рангах. Суммы рангов (для
каждой группы) показаны в правом столбце таблицы результатов. Наибольшая
ранговая сумма (самое худшее выполнение теста) относится к Размеру — Size (это
тот параметр, который надо различить, чтобы получить вознаграждение).
Наименьшая ранговая сумма (лучшее выполнение) относится к Форме — Form.
Медианный критерий также значим, однако в меньшей степени (р = 0,0131).
Критерий серий Вальда—Вольфовица
525
В таблице результатов показано число детей в каждой группе, число попыток
которых меньше (или равно) общей медианы, и число наблюдений, лежащих выше
общей медианы.
И вновь оказывается, что наибольшее число испытуемых с числом попыток (до
получения вознаграждения) выше общей медианы относятся к группе Размер —
Size.
Больше всего испытуемых с числом попыток ниже медианы относятся к
группе Форма — Form.
Таким образом, медианный тест также подтверждает гипотезу, согласно
которой форма предмета наиболее легко различается детьми, тогда как размер
различается хуже всего.
Графическое представление результатов. График по умолчанию для этих
тестов — диаграмма размаха. Его можно построить двумя способами: нажав
кнопку Диаграмма размаха в окне Дисперсионный анализ Краснела—Уоллиса и
медианный тест или щелкнув на таблице результатов правой кнопкой мыши и
выбрав опцию Диаграмма размаха в меню Быстрые статистические графики.
Далее программа попросит выбрать переменные для графика. В этом примере
выберите обе переменные. Затем выберите тип статистики для графика в окне
Диаграмма размаха: (см. ниже). Выберите опцию Медиана/кварт./размах и
нажмите ОК.
На диаграмме размаха для каждой переменной показаны: медиана,
квартальный размах B5%, 75% процентили), размах (минимум, максимум).
жз
Отмена
С fip«m—/ст. о«./ст. от* «у
С CftMMe«/CT.oTiui>/1.9ncT.OTiui.)
; С Cp^uhWct.oo./I.SCct.owu
;■ Остальные тип» иастраимгмыи диаграмм раэмакан
; шатается и* шло Грен***. '.- ,
34
26
и 22
z
1
Е
10
Диаграмме размаха по группам
Перем-я: PERFRMNC
! •
о
о
1
О
FORM
COLOR
CONDITN
SIZE
Zll Мим-макс
О 25*75*
о Медиана
526
Глава 13. Непараметрическая статистика
Отчетливо видно, что выполнение теста в группе Форма — Form было лучше
любого другого; медиана числа испытаний при этом условии ниже, чем при любом
другом.
Для того чтобы увидеть распределение зависимой переменной, разбитой на
группы, нажмите кнопку Категоризованная гистограмма. Этот график снова
подтверждает, что в группе Форма — Form выполнение «лучше» (распределение слегка
скошено влево), чем при других условиях. Самое худшее выполнение, как
отчетливо видно из графиков, относится к группе Размер — Size.
Отсюда также можно заключить, что наиболее легко дети различают Форму —
Form.
Катвгориэоеамиая гистограмма
Перем-я PERFRMNC
шк
ттуушы
5 10 15 20 25 30 35 О
CONDITN FORM
5 10 15 20 25
CONDITN COLOR
ттжжшЩ-
10 15 20 25 30 35
CONDITN SIZE
Критерий знаков
Это непараметрическая альтернатива ^-критерию для зависимых выборок.
ЕШ
шн
BBS
(• Hapapti щтршвхкие статистики Г4 Подоим распределения
Цепареметрическне статистики:
JL_J
Таблицы 2x2: хн/V/em. Макиемера. точные Фишера
(jjxlj] Наб ломаемые частоты в сравнении с ожидаемыми
Корреляции (Спирмена. та* Кеидалла. гамма)
IjTJ Критерий серий ВальдаВольеюеида
ЦХ8 U критерий Маииа-Уитни
Щ Двчхаыборочиый критерий Колмогорова-Смирнова
gtj AN OVA Краске ла-Уол лиса и медианный тест
1^3 Критерий Вилкоксона
Ig«33 AN OVA Фридмана и конкордадия Кендалла
Q критерий Кокрена
%**щ
*ШЩ$Ш
-g^jt»
JJL Обычные описательные статистики (медиана, мода...)
Критерий применяется в ситуациях, когда исследователь проводит два
измерения (например, при разных условиях) одних и тех же субъектов и желает
установить наличие или отсутствие различия результатов.
Критерий серий Вальда—Вольфовица
527
Для применения этого критерия требуются очень слабые предположения
(например, однозначная определенность медианы для разности значений). Не нужно
никаких предположений о природе или форме распределения.
Критерий основан на интуитивно ясных соображениях. Подсчитаем количество
положительных разностей между значениями переменной (А) и значениями
переменной (В).
При нулевой гипотезе (отсутствие эффекта обработки) число положительных
разностей имеет биномиальное распределение со средним, равным половине объема
выборки (положительных разностей будет примерно столько же, сколько
отрицательных). Основываясь на биномиальном распределении, можно вычислить критические
значения. Для малых объемов выборки п (меньше 20) предпочтительнее
использовать значения, табулированные Siegel and Castellan A988) Nonparametric statistics for
the behavioral sciences Bnd ed.) New York: McGraw-Hill, чтобы оценить статистическую
значимость результатов.
Критерий Вилкоксона
Критерий Вилкоксона парных сравнений является непараметрической
альтернативой ^-критерию для зависимых выборок.
' <•" Недараматричвские статистики С Подгонка распределение'
ЦепараНетрические статистики:
|§Ш Таблицы 2 х 2: хи/У/е>и. Макиемара. точный Фишера
I ЩхЩ Наблюдаемые частоты в сравнении с ожидаемыми
ЩЦ Корреляции (Спирмена. тач Кендалла. гамма)
[ ШЦ Критерий серий Вальда-Вольч>оеица
| ||7| U критерий Манна-Уитни
| IHS Двчхвыборочный критерий Колмогорова-Смирнова
Щ4$ AN OVA Краскела-Уоллиса и медианный тест
1E5] КритвР** знаков
[^jANOVA Фридмана и коикордадия Кендалла
J \\\\\\ Q критерий Кохрена
\\JA О бычные описательные статистики (медиана, мода.)
После выбора опции на экране появится диалоговое окно, в котором можно
выбрать переменные из двух списков. Каждая переменная первого списка
сравнивается с каждой переменной второго списка. Это то же самое расположение
данных, что и в ^-критерии (зависимые выборки) в модуле Основные статистики и
таблицы.
Предполагается, что рассматриваемые переменные ранжированы. W —
статистика Вилкоксона равна сумме рангов элементов второй выборки в общем
вариационном ряду двух выборок. Итак, наблюдения двух групп объединяются, строится
общий вариационный ряд и вычисляется сумма рангов второй группы в
построенном ряде.
Требования к критерию Вилкоксона более строгие, чем к критерию знаков.
Однако если они удовлетворены, то критерий Вилкоксона имеет большую мощность,
чем критерий знаков.
В щс 1
) Ртуу... i
выберите нужный
мвларамвтрмческий
мвтоАдле
исследования евшим
Ценных.
£$ Денные
528
Глава 13. Непараметрическая статистика
ANOVA Фридмана и коэффициент конкордации,
или согласия, Кендалла
AN OVA Фридмана — это непараметрическая альтернатива однофакторному
дисперсионному анализу с повторными измерениями. Коэффициент конкордации
(согласия) Кендалла — аналог R Спирмена (непараметрический коэффициент
корреляции между двумя переменными), когда число переменных больше двух.
пяштшшяю 1МТА1ЮГ41 тшп
2.000
1.000
2.000
2.000
1Л00
3000
3000
злоо
4Л00
1Л00
SjOOO
6.000
SjOOO
1.000
4.000
3000
SjOOO
1.000
4.000
2000
6 000
6000
2000
4.000
4000
злоо
4000
4000
В следующем файле приведены рейтинги, выставленные пятью каталогам
программ независимыми экспертами. Экспертов просили учесть информативность
издания, привлекательность, качество рекламы.
Анализ преследовал следующие цели:
1. Определить, можно ли на основании оценок экспертов сделать вывод о
значимых различиях между каталогами. Этот вопрос может быть решен с
помощью рангового дисперсионного анализа (ANOVA) Фридмана.
2. Можно ли доверять экспертам? Иными словами, согласованы их оценки или
нет (зависимы или нет эксперты)? Если нет, то вы, очевидно, не можете
доверять их оценкам. Гипотезу о том, что эксперты согласованы в большей
степени, чем можно было бы ожидать из-за чисто случайных совпадений их
мнений, можно проверить с помощью коэффициента конкордации Кендалла.
Задание анализа. После запуска модуля Непараметрические статистики и
распределения и выбора файла cataloge.sta выберите опцию ANOVA Фридмана и кон-
кордация Кендалла.
I KAIAfllll i
4 КЛ1Л1НИ4
•• КЛ1ЛШП '.
Wto4*H«Mt*4MWr
'4^%ik:tf\
<У^>Ъ* v<g-$ ^ х»зд($ -^"H
fl«»*rl
4fr».
Критерий серий Вальда—Вольфовица
529
Теперь нажмите ОК, таблица с результатами появится на экране. Можно
отметить, что между каталогами имеются высокозначимые различия. Дополнительно
также видно, что эксперты, выставившие оценки, согласованы друг с другом — кон-
кордация Кендалла равна 0,57 (среднее ранговых корреляций равно 0,53).
График по умолчанию для этих таблиц результатов — диаграмма размаха. Его
можно построить двумя способами: нажав кнопку Диаграмма размаха в окне
Ранговый дисперсионный анализ Фридмана или щелкнув на таблице результатов правой
кнопкой мыши и выбрав опцию Диаграмма размаха в меню Быстрые
статистические графики. Далее программа попросит выбрать переменные для графика. В этом
примере выберите все 20 переменных. Затем выберите тип статистики для графика
в окне Диаграмма размаха: (см. ниже). Выберите опцию Медиана/кварт./размах и
нажмите ОК.
КАТАЛОП КАТАЛОГЭ КАТАЛОГ5 С=^ 26%-7S%
КАТАЛОГ2 КАТАЛ0Г4 ° М«ди*м*
Q-критерий Кохрена
Q-критерий Кохрена — это развитие критерия оси -квадрата Макнемара. Критерий
проверяет, значимо или нет различаются между собой несколько сравниваемых
переменных, принимающих значения 0-1. После выбора опции Q-критерий
Кохрена в стартовой панели программа предложит определить список переменных и коды,
идентифицирующие две категории или два уровня факторов.
Реализация критерия в системе STATISTIC А предполагает, что переменные
закодированы как единицы и нули, и коды, определенные пользователем, соответственно
преобразуются в эти значения (только для данного анализа, сам по себе файл не будет
изменен)
530
Глава 13. Непараметрическая статистика
В Переменные:) ВСЕ
Код 1 (перевод, m 0|: |0 Щ
Ко* 2 (переломе I* |1 Щ
ШШШШШШШШШ^!
-"\т Ш1 Г
| Отмена |
SS ill All:
Описательные статистики
Выбор этой опции позволяет вычислить разнообразные описательные
статистики: медиана, процентили, квартили, размах, квартальный размах, а также среднее,
гармоническое среднее, геометрическое среднее, стандартное отклонение,
асимметрия, эксцесс, дисперсия, гармоническое среднее, сумма.
Пользователь может также вычислить заданные процентили. Эти опции
дополняют опции основных статистик.
l-ieMMFMP^^^™
ЕД Деремемиые: J TIME
Границы для процеитмаея: Нмдрюя: |25
Ввр*ж*д: |75
5*0) Диаграмма размаха!
ННИПТх]
1_И._._Ш_1-
g | Отмена ]
£!;ы|да|
Дополнительно стандартные описательные статистики (минимум, максимум,
среднее, число наблюдений), а также описанные ниже статистики вычисляются
для каждой переменной.
ШОписат статистики (dodxon25 sta)
НЕПАРАМ
СТАТИСТ
IUJ
[ среднее
148 4550
N
| 20
^В деОписот. статистики (dodson25.sta)
НЕПАРАМ
СТАТИСТ
ы
Медиан;
геометр
среднее
136 7968
а
гармон.
среднее
1231392
медиана
1501000
ст.откл
5617363
мода
нет моды
дислерс.
3155 476
I
кол-во
мод
среднее
откл.
4538950
миним.
42 10000
JLi
v;
>г
HRDI
размах
216 7000
►
^j
г
Медиана разбивает выборку на две равные части. Пятьдесят процентов
наблюдений лежит ниже медианы, пятьдесят процентов — выше медианы. Если значение
медианы существенно отличается от среднего, то распределение скошено (более
подробно см. главу Элементарные понятия).
Мода
Мода — это максимально часто встречающееся значение в выборке. Частота
встречаемости также отображается. Если имеется несколько значений с максимальной
частотой, то распределение мультимодально. Если каждое значение встречается
Критерий серий Вальда—Вольфовица
531
лишь одни раз, программа делает запись: моды нет (см. электронную таблицу с
результатами).
Геометрическое среднее
Геометрическое среднее — это произведение всех значений переменной,
возведенное в степень 1/п (единица, деленная на число наблюдений). Геометрическое
среднее полезно, например, если шкала измерений нелинейная.
Пусть наблюдается переменная X, принимающая только положительные
значения. Тогда геометрическое среднее вычисляется как
G(X) = (f[Xi )"\
1=1
Гармоническое среднее
Пусть наблюдается переменная X, имеющая отличные от 0 значения. Тогда
гармоническое среднее вычисляется как
H(X) = l/(l/nJl/X,).
/=1
Гармоническое среднее меньше геометрического среднего, которое, в свою
очередь, меньше среднего арифметического.
Гармоническое среднее иногда используется для усреднения частот.
Дисперсия и стандартное отклонение
Выборочная дисперсия и стандартное отклонение — наиболее часто используемые
меры изменчивости (вариации) данных. Дисперсия вычисляется как сумма
квадратов отклонений значений переменной от выборочного среднего, деленная нап-1
(но не на п). Стандартное отклонение вычисляется как корень квадратный из
оценки дисперсии.
Размах
Размах переменной является показателем изменчивости, вычисляется как
максимум минус минимум.
Квартильный размах
Квартальный размах, по определению, равен: верхняя квартиль минус нижняя
квартиль G5% процентиль минус 25% процентиль). Так как 75% процентиль (верхняя
квартиль) — это значение, слева от которого находятся 75% наблюдений, а 25%
процентиль (нижняя квартиль) — это значение, слева от которого находится 25%
наблюдений, то квартильный размах представляет собой интервал вокруг медианы,
который содержит 50% наблюдений (значений переменной).
532
Глава 13. Непараметрическая статистика
Асимметрия
Асимметрия связана с третьим моментом и определяется формулой (см. также
главу 2):
-Е(Х,-ХK
е - п%
61 3 •
-Е(х,-хJ
Эксцесс
Эксцесс — это характеристика формы распределения, а именно мера остроты его
пика (относительно нормального распределения, эксцесс которого равен 0). Как
правило, распределения с более острым пиком, чем у нормального, имеют
положительный эксцесс; распределения, пик которых менее острый, чем пик
нормального распределения, имеют отрицательный эксцесс. Эксцесс связан с четвертым
моментом и определяется формулой (см. также главу 2):
1
Ь2 =
-£(Х,-ХL
_ п —
iJ(X,-XJ
-а
-3,
гдеХ = -УХ,..
Анализ
выживаемости
Введение в анализ выживаемости
Методы анализа выживаемости интенсивно применяются в медицине, биологии,
страховании и промышленности.
Одной из важных характеристик, описывающих течение болезни, является
продолжительность жизни пациентов с момента поступления в клинику или после
проведения операции.
В принципе, для описания средних времен жизни и сравнения новой методики
со старой можно использовать стандартные статистические методы.
Однако рассматриваемые данные имеют специфику, которую следует
учитывать. Дело в том, что в медицинской практике мы часто имеем дело с неполными
данными.
Это связано с тем, что трудно наблюдать все время жизни пациента после
операции, так как пациент мог быть выписан или переведен в другую клинику и связь
с ним была утеряна. При этом мы располагаем не полной информацией о времени
жизни пациента, а лишь частичной.
Естественное желание исследователя использовать все данные, то есть
анализировать как полные времена жизни, так и неполные, и не терять с трудом
собранную информацию.
Для этого и предназначены методы анализа выживаемости, которые
позволяют изучать неполные, или цензурированные, данные.
Наблюдения, которые содержат неполную информацию, называются
неполными, или цензурированными (например, «пациент А был жив по крайней мере
4 месяца после того, как был переведен в другую клинику и контакт с ним был
потерян»). Это пример цензурированного наблюдения: информация о том, что
пациент был жив 4 месяца, важна и может быть использована для построения
оценок.
Наблюдения от момента операции до летального исхода называются полными.
Итак, в анализе выживаемости различают полные (по-английски complete) и
неполные, или цензурированные, наблюдения (по-английски censored).
Конечно, можно было использовать только полные времена жизни, но тогда мы
имели бы в своем распоряжении очень мало наблюдений и соответственно неточные
оценки.
Использование, наряду с полными наблюдениями, неполных, или цензуриро-
ванных, наблюдений является главной особенностью методов анализа
выживаемости.
14
534
Глава 14. Анализ выживаемости
Таблицы времен жизни
Прежде всего, постараемся оценить вероятность того, что пациент прожил
больше t дней после операции. Это важный показатель, называемый функцией
выживания.
Наиболее естественный способ описания функции выживаемости состоит в
построении Таблиц времен жизни.
Это один из старейших приемов анализа данных о выживаемости и
традиционно используется, например, в страховании, где такие таблицы называются
таблицами дожития.
I ш'н-ш'шшш
и*1-1 ■'■"■'•|J|J|J!
\[£^_ Метол множительных оценок. Капяанд-Меиера
JTJ Сравнение двух выборок
IjfJJj Сравнение нескольких выборок
|Л._ Регрессионные модели
В ц* 1
| Отмена }
0 Данные!
S£ujdft|
Организация данных
Исходный файл данных имеет вид:
HEART STA 11п'Б5н
Heart transplant data from Crowley and Hu. stratified
ДИ iamiiarvI
>AYlYEARJ
6
MAY 2
AUGUST 31
AUGUST 22
EPTEMBR 9
OCTOBER 5
OCTOBER 26
NOVEMBER 22
NOVEMBER 20
pEBRUARY 15
FEBRUARY 8
MARCH 29
APRIL 13
JULY 16
MAY 22
AUGUST 16
3EPTEMBR 3
MONTHS |DAY|YEAFC2
^ENSOREDAGE
9
ANT!
10
IMISMA
11
HOSPITAL
68 JANUARY 21
68 MAY 5
68 MAY 17
68 OCTOBER 7
68 JANUARY 14
68 DECEMBER 8
68 JULY 7
68 AUGUST 29
68 DECEMBER 13
69 rEBRUARY 25
69 NOVEMBER 29
69 MAY 7
69 APRIL 13
69 NOVEMBER 29
69 APRIL 1
69 AUGUST 17
69 DECEMBER 18
68:ENSORED 54
68:ENSORED 40
70 COMPLETE 51
68 COMPLETE A?
69:ENSORED AS
68 COMPLETE
72COMPLETE
69 COMPLETE
68:ENSORED
69 COMPLETE
71 COMPLETE
69 COMPLETE
71 COMPLETE
69 COMPLETE
74:ENSORED
69:ensored
71 complete
1 11
1 66
1.32
61
36
1 89
87
1 12
2 05
2 76
1 13
1 38
96
1 62
1 06
A7
1 58
HILLVIEW j
HILLVIEW |
HILLVIEW j
ST_AND ;
ST_AND
ST_AND !
BINER :
BINER »
HILLVIEW ;
HILLVIEW '
BINER '
HILLVIEW '
ST_AND t
ST.AMD '
ST_AND ;
BINER |
BINERrj
4
Организация файла следующая.
Пациенты располагаются в строках. В столбцах записаны даты операции и
даты завершения пребывания в больнице. Например, из первой строки видно,
что пациенту была сделана операция 6 января 1968 (первые три клетки),
выписался 21 января 1968 года (вторая тройка клеток). Далее связь с ним была
утеряна, таким образом, это неполное наблюдение (значение переменной
номер 7 — censored).
Восьмая переменная A GE содержит возраст пациентов.
Переменные 9, 10 содержат специальную медицинскую информацию об
особенностях операции.
Введение в анализ выживаемости
535
Значение переменной 11 — название госпиталя, где сделана операция.
Ниже показана таблица жизни для этого файла данных.
АНАЛИЗ
ВЫЖИВ
Интервал
Инт. N2
Иит.ЫЗ
Инт. N4
Инт. N5
Инт N6
Hht.N?
Инт. N8
Инт. N9
Инг. N10
Инт. N11
Hht.NU
111 .
J"J'I J'L'!"ll,'.Mlf
Логарифм правдоподобия
Средня*
точка
80 682
242 045
403 409
564 773
726136
887 500
1048 864
1210227
1371 591
1532 955
1694 318
1
Интервал
ширина
161 3636
161 3636
161 3636
161 3636
161 3636
161 3636
161 3636
161 3636
161 3636
1613636
161 3636
68 6809
Число
в начал*
65
32
24
20
15
13
9
6
5
3
1
1
Число
14
4
4
4
1
3
1
1
1
2
0
1
Число
иэучави.
58 00000
30 00000
22 00000
18 00000
14 50000
11.50000
8 50000
5 50000
4 50000
2 00000
1 00000
.50000
Число
умерших
19
4
0
1
1
1
2
0
1
0
0
0
■HLi£l£j
Доля
уперших ■■■■
327586
133333
022727
055556
068966
086957
235294
090909
222222
250000
500000
1 000000 »
...!.Г
Конечно, подобную таблицу жизни можно рассматривать как «расширенную»
таблицу частот. Однако обычная таблица частот строится по полным
наблюдениям. В таблице жизни учтены как полные, так и неполные наблюдения.
Идея таблиц жизни, или дожития, в терминологии страхования, проста. Нам
нужно вычислить простейшие статистики, чтобы описать время выживания
пациентов.
Для этого временная ось разбивается на некоторое число интервалов. В
приведенной выше таблице это число равно 12. В системе STATISTICA количество
интервалов на временной оси пользователь может выбрать по своему
усмотрению.
Для каждого интервала вычисляется число объектов, которые в начале
рассматриваемого интервала были «живы» (см. соответствующий столбец в электронной
таблице — переменная ЧИСЛО В НАЧАЛЕ), и число объектов, которые «умерли»
в данном интервале (переменная ЧИСЛО УМЕРШИХ).
Также вычисляется число цензурированных или изъятых из наблюдения
объектов на каждом интервале — переменная ЧИСЛО ИЗЪЯТЫХ (в таблицах жизни
употребляют термин изъятые — withdrawn для цензурированных наблюдений,
в данном примере это выписанные больные). Вычисляются доли этих объектов.
Для понимания таблиц полезно помнить, что на данном временном интервале
наблюдение может быть либо цензурировано (больной выписан или переведен
в другую клинику), либо наблюдается фатальный исход.
Рассмотрим более формально переменные в электронной таблице жизни.
Число в начале
Это число объектов, которые были «живы» в начале рассматриваемого
временного интервала.
Число изъятых
Это число цензурированных на данном интервале объектов (объектов, изъятых из
наблюдения). Эти объекты имеют метку цензурированые {censored).
536
Глава 14. Анализ выживаемости
Число изучаемых
Это число объектов, которые были «живы» в начале рассматриваемого
временного интервала, минус половина от числа изъятых.
Число умерших
Это число объектов, умерших на данном интервале. Умершие или отказавшие
объекты обычно имеют метку complete.
Доля умерших
Эта отношение числа объектов, умерших в соответствующем интервале, к числу
объектов, изучаемых на этом интервале.
Прокрутим электронную таблицу вправо и рассмотрим оставшиеся
переменные таблицы.
P^lFnWWW
АНАЛИЗ
ВЫЖИВ
Интервал
Имт N2
Имг.Ю *
Инт.Ж
Инг. N5
Инт N5
Инт.Ы?
Имт.Ыв
Иит.Ы9
Инг N10
Инт.ЫИ
Икг.Ми
W
рмярмяи
Логарифм правдоподобия:
;.::.-.Л)яй.^.-
: выжиеш
672414
866667
977273
944444
931035
913043
764706
909091
777778
750000
500000
0 000000
9МЖИ8Ш/
1 000000
672414
582759
569514
537874
500780
457234
349649
317863
247227
185420
092710
■68 6809
:':' ПЛОТ;
ввролти.
002030
000556
000082
000196
000230
000270
000667
000197
.000438
000383
000575
: Ийтанс.
отказов
002428
000885
000142
.000354
.000443
000563
001653
000590
001549
001771
004131
Стдош.
кумвыяс
0 000000
061626
067780
068779
071868
075883
080819
090803
093012
095468
104196
106345
Стдош.
плоттер
000382
000264
000115
.000192
000224
000261
000429
000270
000407
000492
000659
■шшгПпТ
/.-.СТАОШ,-Г;:';
ИнтОткез
000546
000442
i
■ i
\
000201 {
000354 1
000442 1
000563 !
001158 \
000834 :
001537 ;
002478 ■
005509 i
- *i
»
n
Доля выживших
Эта доля равна единице минус доля умерших.
Кумулятивная доля выживших объектов, или функция выживания
Это — оценка функции выживания, то есть вероятность того, что пациент
переживет данный интервал. Она равна произведению долей выживших объектов
по всем предыдущим интервалам. Если посмотреть на столбец КУМ.ДОЛЯ
ВЫЖИВП1. приведенной выше таблицы, то можно увидеть, например, что
0,582759 = 0,672414 х 0,866667, 0,569514 = 0,582759 х 0,977273 и т. д.
Плотность вероятности
Это плотность вероятности смерти на данном интервале, когда из функции
выживания на данном интервале вычитается функция выживания на следующем
интервале и делится на длину интервала, показанную во втором столбце таблицы.
Например, A - 0,672414)/161,3636 = 0,00203.
На графике оценки плотности видно, что вероятность смерти в первые 160 дней
после операции максимальна. Далее она резко падает.
Большие вероятности смерти расположены также в интервалах от 161 до 322,
от 968 до 1129 и др.
Введение в анализ выживаемости
537
Оценю* плотное ти вероятности
322.73 645.45 968.18 1290.9 1613.6 1936.4
161.36 484.09 806.82 1129.5 1452.3 1775.0 2097.7
Начамтермла
Ш2 НаОлюд.
Вес1
Вес 2
ВесЗ
Функция риска
Это также одна из важных характеристик, описывающих течение болезни. Функция
мгновенного риска является важной прогностической характеристикой,
описывающей течение болезни. В анализе выживаемости риск имеет точное определение.
Формально функция риска равна вероятности того, что пациент умрет в
данном интервале, при условии, что в начале интервала был он жив.
Ь11'Д|,Л111ШП11111||1ШМ11'И1|1
Оцепе!»»* риск после операции
0.005 г
Наблюд.
Вес1
Вес 2
ВесЗ
График функции риска достаточно наглядно показывает, что в первые дни риск
смерти очень велик, затем он падает и спустя некоторое время вновь начинает
возрастать. Заметим, что именно функция риска используется для прогностических целей.
Позвольте сделать отступление. Одним из лейтмотивов нашей книги является
непредвзятость и критическое отношение к полученным результатам. Такая
критичность особенно важна в медицине. Мы доверяем результатам, полученным
с помощью компьютера, однако всесторонне их проверяем.
Итак, нас интересует функция риска, однако реально мы получаем лишь
оценку риска. Поэтому важна точность полученных оценок. Из простых соображений
следует, что мы не доверяем оценкам с большой погрешностью. Например, мы не
будем доверять оценкам, погрешность которых имеет тот же порядок, что и сами
оценки. Поэтому внимательно просмотрите построенную таблицу и выбросите из
нее плохие оценки (оценки с большой погрешностью). Это чрезвычайно важный
принцип анализа данных!
538
Глава 14. Анализ выживаемости
Известно, что для получения надежных оценок параметров и ошибок в
таблицах жизни требуется как минимум 30 наблюдений.
1- "■'■"""■'"!
АНАЛИЗ
ВЫЖИВ
Интервал
Инт. N1
Инт. N2
Инт. N3
Инт. N4
Инт. N5
Инт. N6
Инт. N7
Инт. N8
цщуцщцц
Инт. N10
Инт. N11
Инг. N12
ш
тшшшшш
Погарифм правдоподобия
ППОТ ::
•вро»гн.
002030
000556
000082
000196
000230
000270
000667
000197
000438
000383
000575
Интвмс
ОТКвЭО»
002428
000885
000142
000354
000443
.000563
001653
000590
.001549
001771
004131
-68 6809
0 000000
061626
067780
068779
071868
075883
080819
090803
| 093012 |
095468
104196
106345
Стдош
плот.мр
000382
000264
000115
000192
000224
000261
000429
000270
000407
000492
000659
Стдош.
ИитОткаэ
000546
000442
000201
000354
000442
000563
001158
000834
001537
002478
005509
Медиана
ожервм
809 707
1036 422
1028 682
882 446
757 222
638 229
532 677
502 532
368 831
268 939
80 682
■ИНоМ
Стдош. |
243 2836
311 6103
141 9141
153 3263
161 3412
168 6732
204 7241
129 7479
130 4015
1521351
161 3636
-
. 1>
Взгляните на таблицу. Заметьте, в ней наряду с оценками приведены
стандартные ошибки полученных оценок.
Медиана ожидаемого времени жизни
По определению, медиана равна моменту времени, в котором функция
выживания становится равной Vi. Например, из первой строчки таблицы вы видите, что
пациент с вероятностью 1Л будет жить 809 дней после операции.
Если пациент пережил первый временной интервал A61 день после операции), то
с вероятностью !4 он проживет еще 1036 дней (см. вторую строчку таблицы) и т. д.
В общем случае таблица времен жизни дает хорошее представление о
распределении отказов или смертей, если наблюдений достаточно много.
Однако для прогноза часто необходимо знать форму функции выживания. Для
этой цели используются различные семейства распределений.
Наиболее важны следующие семейства распределений: экспоненциальное, Вей-
булла и распределение Гомперца.
Эти распределения имеют неизвестные параметры, которые программа
оценивает. Процедура оценивания параметров основана на методе наименьших
квадратов. Для проведения оценивания применима модель линейной
регрессии, поскольку все перечисленные семейства распределений могут быть «сведены
к линейным» (относительно параметров) с помрщью подходящих преобразований.
Такие преобразования приводят иногда к тому, что дисперсия остатков зависит
от интервалов (то есть дисперсия различна на разных интервалах). Чтобы учесть
это, в алгоритмах подгонки дополнительно используются оценки взвешенных
наименьших квадратов двух типов.
Оценки Каплана—Мейера
Напомним, что одна из задач анализа выживаемости состоит в том, чтобы оценить
функцию выживания S(t), то есть вероятность того, что пациент проживет больше
t дней после операции. Формально S(t) e Р{х > t}, где х — случайная величина,
Оценки Каплана—Мейера
539
описывающая время жизни после операции. Заметьте, что функция выживания
является убывающей функцией, равной 1 при £=0, и обращающейся в 0 при
больших значениях L
Если все наблюдения являются полными, то оценка S(t) строится легко: мы
просто подсчитываем количество пациентов, проживших t дней после операции, и делим
их на общее число пациентов. Наличие неполных наблюдений усложняет ситуацию.
Оказывается, что для цензурированных наблюдений функцию выживания
можно оценить непосредственно, не используя таблицу времен жизни. Такой метод
впервые предложили Каплан и Мейер в 1958 году.
I Wil'II^HIIIIHIIIIf'lHIIITI'I'I'.l.
ijj§ Таблицы и распределения времен жизни ЕЕ1
nit
I..U.I.I4.Hl.lJ.II!IIH.IIIJII.!IAI.I,|llH..IJ.U.Il:fi:
Щ§ Сравнение двух выборок
ftjj Сравнение нескольких выборок
[/^ Регрессионные модели
Отмене
£? Данные
[uj£>a[
Представьте, что вы имеете файл, в котором записаны в хронологическом
порядке отдельные события. Тогда имеет место следующая оценка функции выживания:
S(t) = Yl[(n-j)/(n-j+iy^]
В этом выражении S(t) — оценка функции выживания, п — общее число
событий (объем выборки), j — порядковый (хронологически) номер отдельного
события, S(j) равно У, если j-e событие означает отказ (смерть), и 8(j) равно 0, если
j-e событие означает потерю наблюдения (индикатор цензурирования), Я
означает произведение по всем наблюдениям j, завершившимся к моменту L
Данная оценка функции выживания состоит из произведения нескольких
сомножителей, поэтому она также называется множительной оценкой.
Рассмотрим тот же файл данных, что и для таблиц времен жизни. Оценка
Каплана—Мейера функции выживания, построенная по этим данным, показана в
следующей таблице:
N№111
АНАЛИЗ
ВЫЖИВ.
Номер
чт-штушт
(Замечание: цензурированные наблюдения отмечены -
1-lDlxJI
Набл.
Г~''3Г"''~
16+
65+
2*
10
46+
64*
Н
9+
42
58+
49
69*
12
26+
hi I
Времена I
оооо |
1.000
1.000
3.000
10.000
12.000
13.000
15.000
23.000
25.000
26.000
29.000
30.000
39.000
44.000
Кумул.
Времен»
Станд.
Ошибка
.983607
.966042
.948152
.929919
.016259
.023622
.029183
.033842
>г!
540
Глава 14. Анализ выживаемости
Из таблицы видно, например, что вероятность того, что пациент проживет
больше 25 дней, равна 0,966, вероятность того, что пациент проживет больше 39 дней,
равна 0,9299 и т. д.
В первом столбце таблицы показаны номера наблюдений, для которых в
данный момент времени произошло некоторое событие, знак + означает, что пациент
цензурирован (был выписан).
Прокрутите электронную таблицу с результатами вниз по временной оси:
АНАЛИЗ
ВЫЖИВ.
Номер
Набл.
64+
61*
60+
47+
37+
43+
44+
3
41+
13
36+
17
34+
32+
27
11
2А+
^вшшшшвшшшшшшшшшшшшшшшшшьш
Замечание: цензурирование наблюдения отмечены ♦
Времена
389.000
439.000
466.000
499.000
661.000
689.000
692.000
624.000
660.000
730.000
816.000
836.000
838.000
876.000
994.000
1024.000
1106.000
Времена
.619290
.482198
.442016
.392902
.343789
;",>•' Спид.", г';,-
Ошибка
-
-
i
I
I
-
~
-
.074004 J
-
.077468 !
-
.080766
.!
-*
.086422
.087734
* ?!
Обратите внимание на ошибки оценок. Стандартная ошибка функция
выживания достаточно мала (сравните с ошибками для таблиц времен жизни).
Ниже показан график функции выживания.
Отметим, что для удобства интерпретации на графике полные наблюдения
помечены точками, неполные наблюдения отмечены крестиками.
Преимущество метода Каплана—Мейера (по сравнению с методом таблиц
жизни) состоит в том, что оценки не зависят от разбиения времен жизни на интервалы.
Таким образом, нам не нужно разбивать временную ось на интервалы. Оценки
Каплана—Мейера строятся в STATISTICA одним щелчком мыши.
Сравнение выживаемости в группах
541
Сравнение выживаемости в группах
Интересно сравнить времена жизни пациентов в различных группах, например,
в группах мужчины и женщины. В STATISTIC А имеются специальные процедуры
для сравнения выживаемости в группах.
Если количество групп — две, то используется диалог Сравнение двух выборок.
BE
штшщшшшшяш
\г^_ Мета« множительных оценок Кеплеие-МеАера
MlllllfllHII
Г
к
нескольких
llu-
Если количество групп больше двух, то используется диалог Сравнение
нескольких выборок.
Wli irrifl ['ШЫШШМшШ
I Т аблиды и распределения времен жизни сд '-: ДИ
[[/£_ Метод множительным оценок Каплаие-М онере
|3 Сравнение двф выборок
Для сравнения выживаемости в группах имеется несколько критериев:
вариант известного непараметрического критерия Вилкоксона, предложенный для
неполных наблюдений Геханом и Пето, а также F-критерий Кокса и
логарифмический ранговый критерий.
Большинство этих критериев приводят соответствующие z-значения
(нормального приближения), которые могут быть использованы для статистической
проверки различий между группами.
Однако критерии дают надежные результаты лишь при достаточно больших
объемах выборок. При малых объемах выборок эти критерии не столь надежны.
В любом случае всегда полезны визуальные методы.
ИЕППГЕ
НИИ,"!!"'llilMSEES
Кумулятивная доля выживших (по Каплану-Мейеру)
о Завершен ♦ Ценэурир
1.0 J
3 0.9j
<о |
* 0. 8 Ь
■ °'7
§> 0.6 t
« I
2 0.5
(О
8 0-4
£ ° 3
0.2 *■
:.ч ... d. t . i-
О- :
i ... ° . "•" . . ;.
&~ +
0 400 800 1200 1600 2000
200 600 1000 1400 1800
Время
HILLVIEW
ST_AND
BINER
542
Глава 14. Анализ выживаемости
Эти графики позволяют увидеть различие между группами.
Кроме этого STATISTICA содержит программу на STATISTICA BASIC (файл
Manthaen.stb), вычисляющую критерий Ментела-Хенцела для сравнения двух
групп данных (см. Lee E. Т. A992) Statistical methods for survival data analysis).
Этот критерий может быть полезен во многих клинических и
эпидемиологических работах для того, чтобы контролировать эффект смешивающих
переменных.
Критерий основан на анализе таблиц 2x2 (например, Группировка 1/2 и
Выживаемость) , стратифицированных или расслоенных с помощью категориальной
переменной (смешанной переменной; например, Положением). Критерий
позволяет проверить, являются две переменные в таблицах 2x2, например, переменные
Группировка и Выживаемость, зависимыми или нет.
Не существует твердо установленных рекомендаций по применению
определенных критериев.
Известно, что F-критерий Кокса обычно мощнее, чем критерий Вилкоксона—
Гехана, если:
О данных мало (объем группы п меньше 50);
О выборки извлекаются из экспоненциального распределения или
распределения Вейбулла;
О нет цензурированных наблюдений.
В работе Lee, Desu, and Gehan A975) A Monte-Carlo study of the power of some
two-sample tests, Biometrika, 62, p. 425-532, критерий Гехана сравнивался с
некоторыми другими критериями. Показано, например, что критерий Кокса—Ментела
и логарифмический ранговый критерий являются более мощными, если выборки
имеют определенное распределение, например, экспоненциальное или Вейбулла.
При этих условиях между критерием Кокса—Ментела и логарифмическим
ранговым критерием почти нет различия.
В работе Ли (Lee E. Т. A980) Statistical methods for survival data analysis. Belmont,
CA: Lifitime Learning) обсуждается мощность различных критериев более
детально. Если вас затрудняет выбор определенного критерия, рекомендуем обратиться
к этим работам.
Если сравниваются две или более группы, важно проверить доли
цензурированных наблюдений в каждой. В частности, в медицинских исследованиях степень
цензурирования может зависеть, например, от различий в методике лечения:
пациенты, которым стало много лучше или стало хуже, с большой вероятностью
теряются из наблюдения. Различие в степени цензурирования может привести
к смещению в статистических выводах.
Это очень важный момент. Чтобы подогнать результат, недобросовестный
исследователь может искусственно исключить из исследования тяжелых больных.
Поэтому при проведении сравнения различных методик нужно
руководствоваться здравым смыслом. Ясно, что если в одной группе доля цензурированных
наблюдений существенно больше, чем в другой, нужно принять естественные меры
предосторожности, по крайней мере, точно указать проблему.
Регрессионные модели в анализе выживаемости
543
Регрессионные модели в анализе
выживаемости
В предыдущих разделах мы кратко обсуждали задачу оценивания функции
выживания на основе реальных данных.
Более трудной задачей является оценка функции мгновенного риска, которая
представляет собой вероятность летального исхода в малый промежуток времени
при условии, что в начале исследуемого промежутка пациент был жив. Это
важная характеристика прогноза развития болезни.
Непосредственная оценка функции мгновенного риска может потребовать
большого количества наблюдений, поэтому применяются специальные модели, одна
из которых — это модель Кокса пропорциональных рисков, или, на языке теории
надежности, пропорциональных интенсивностей.
Большая проблема медицинских и биологических исследований состоит в
выяснении того, являются ли некоторые переменные связанными с наблюдаемыми
временами жизни. Если зависимость есть, то ее нужно оценить численно.
I «11-14IIfизШ^Д^^И^1Ш
jifffi Таблицы и распределения времен жизни ЕЕ5 QK |
\\idL Иет°* миожительнык оценок Каллана-Мейера | (Ь-цицд 1 I
!(Ш) Сравнение двух выборок .
|1*$ Сравнение нескольких выборок ,!^,n,ffi?mltl??-J 1
ШВВПв^Н ss*J ©jy
Существуют две главные причины, по которым в таких исследованиях нельзя
непосредственно использовать классическую регрессию. Во-первых, времена жизни
обычно не являются простыми линейными функциями от соответствующих' ре-
грессоров, поэтому анализ методами множественной регрессии может привести к
ошибочным выводам, например, не позволит обнаружить важных регрессоров.
Во-вторых, вновь возникает проблема неполных наблюдений, так как некоторые
наблюдения могут быть незавершенными.
Анализ выживаемости предлагает пять общих регрессионных моделей для
неполных данных:
1) модель пропорциональных интенсивностей Кокса (Сох A972) Regression
models and life tables, Journal of the Royal Statistical Sociaty, 34, p. 187-220);
2) модель Кокса с зависящими от времени ковариатами;
3) экспоненциальную регрессионную модель (см. книги Prentice A973)
Exponential survivals with censoring and explanatory variables, Biometrika, 60,
p. 279-288);
4) нормальную линейную регрессионную модель (см., например, Wolynetz
A979) Maximum likelihood estimation in a linear model from confined and
censored normal data, Applied Statistics, 28, p. 185-206);
5) логнормальную линейную регрессионную модель (являющуюся
модификацией нормальной модели).
Для каждой из этих моделей STATISTICA позволяет вычислить оценки
максимального правдоподобия (Maximum likelihood estimations).
544
Глава 14. Анализ выживаемости
Модель Кокса
Модель пропорциональных интенсивностей, или пропорциональных рисков,
Кокса — наиболее общая регрессионная модель, в которой предполагается, что
функция интенсивности имеет вид: h(t) - h0(t) y(zv...,zm). Множитель h0(t) называется
базовой функцией интенсивности.
Модель может быть параметризована, например, в виде:
h[(t),(zv z2,..., zj] - hQ(t) x exp(bi x zx +...+ bm x zm)
Заметьте, в правой части стоит произведение двух функций, причем каждая из
них зависит от своего множества переменных.
Функция интенсивности h0(t) может рассматриваться как функция
интенсивности при равенстве нулю всех ковариат. Она не зависит от переменных z (называемых
ковариатами). Второй сомножитель зависит от переменных z, которые, возможно,
зависят от t.
Приведем пример такой модели.
Пусть изучается воздействие некоторого препарата на состояние больного,
a z — категориальная переменная со значениями 1 для больных, принимавших
новое лекарство, и 0 — для больных, не принимавших это лекарство. Тогда функцию
риска можно записать в виде:
h(t,z) - h0(t) x exp{b{xz+b2x [z x log(£)-100]}
Обратите внимание, что функция интенсивности в момент t (левая часть
формулы) есть функция: 1) функции интенсивности hQt 2) ковариаты z и 3) z,
умноженной на логарифм времени.
Умножение ковариаты z на логарифм времени позволяет учесть, например,
фактор времени при приеме нового лекарства.
Константа 100 в этом примере использована просто как нормировка, так как
среднее логарифма времени жизни для этого множества данных равно 100.
Зная оценки параметров Ц,Ь2 и функцию интенсивности h0, можно оценить
функцию мгновенного риска через время t после операции.
Самое замечательное, что такие модели позволяют учитывать интуицию
медицинских исследователей. Построение и оценка адекватности модели в
конкретных исследованиях — отдельная нетривиальная задача.
Другой пример, h(t,s,x)- риск коронарной смерти для пациента возраста t лет
при условии, что в возрасте s его систолическое артериальное давление было х (см.
Meshalkin L. D., Kagan А. В. A972) A contribution to the discussion upon the paper
«Regression models and life tables» by D. R. Cox, J. R. Statist. Soc. Ser. B, № 2).
Итак, функция мгновенного риска в модели Кокса представлена в виде
произведения двух сомножителей, один из которых характеризует объект, другой —
базовую функцию мгновенного риска.
Предикторы определяются постановкой задачи, например, пол пациента,
возраст, наличие определенных сопутствующих заболеваний или прием нового
лекарства. Выбор предикторов определяется интуицией исследователя. Врач
может попытаться предсказать на основе определенного набора предикторов степень
риска на ближайшие несколько дней. Имея прогноз, он может изменить
методику лечения.
Регрессионные модели в анализе выживаемости
545
Займемся некоторой математической кухней. Модель Кокса можно
линеаризовать, поделив обе части соотношения на h0(t) и взяв натуральный логарифм от
обеих частей:
\og{h[(t)Xz...)]/h0(t)} = b{xz{ +...+ bmx zm
Таким образом, мы получили линейную модель.
Итак, еще раз отметим, в основе модели Кокса лежат два предположения. Во-
первых, зависимость между функцией интенсивности и логлинейной функцией
ковариат является мультипликативной. Это предположение называется
гипотезой пропорциональности. Реально оно означает, что для двух заданных
наблюдений с различными значениями независимых переменных отношение их функций
интенсивности не зависит от времени (чтобы ослабить это предположение,
используются ковариаты, зависящие от времени; см. ниже). Второе предположение
состоит в логлинейной зависимости функции интенсивности и регрессоров.
Предположение пропорциональности рисков часто подвергается сомнению.
Например, рассмотрим гипотетическое исследование, в котором ковариатой
является категориальная переменная, а именно индикатор того, подвергнут пациент
хирургической операции или нет. Пусть пациент 1 подвергнут операции, в то время
как пациент 2 — нет.
Согласно предположению пропорциональности, отношение функций интенсив-
ностей для обоих пациентов не зависит от времени и означает, что риск для
прооперированного пациента постоянно более высокий (или более низкий), чем риск
пациента, не подвергнутого операции (при условии, что оба дожили до
рассматриваемого момента).
Реалистичней другая модель, когда сразу после операции риск
прооперированного пациента выше, но при благоприятном исходе операции с течением времени
убывает и становится меньше риска не оперированного пациента. В этом случае
используются регрессоры, зависящие от времени.
Можно привести много других примеров, где предположение о
пропорциональности неприемлемо. Так, при изучении физического здоровья возраст является
одним из факторов выживаемости после хирургической операции. Ясно, что
возраст — более важный предиктор для риска сразу после операции, чем по
прошествии некоторого времени после операции (например, вслед за первыми
признаками выздоровления).
В случае категориальных ковариат, например, учитывающих, был или не был
пациент подвергнут хирургической операции, рекомендуется обратиться к
стратифицированному анализу выживаемости, в котором, исходя из априорных
знаний, исследователь разбивает пациентов на однородные по фактору риска группы.
Можно провести подгонку модели пропорциональных интенсивностей отдельно
для каждой группы наблюдений. Таким образом, можно явно представить
функцию интенсивности для каждой группы. Иногда предположение
пропорциональности не выполняется. В таком случае можно явно определить ковариаты как
функции времени.
В главе Подгонка вероятностных распределений показано, как с помощью
критерия хи-квадрат проверяется выполнимость предположений модели Кокса в
системе STATISTICS
Заметим, что арифметические выражения, которые определяют ковариаты, не
должны содержать ссылок на длительности жизни. Однако допускается, чтобы
546
Глава 14. Анализ выживаемости
некоторые ковариаты были функциями двух или большего числа других ковариат.
Это, например, удобно в моделях многофакторных экспериментов. Для каждого
фактора можно создать переменную в файле данных, чтобы установить желаемые
контрасты. Логика и выбор априорных значений коэффициентов контрастов те
же, что и в дисперсионном анализе. Если специфицируются ковариаты для
регрессионной модели пропорциональных интенсивностей, то можно также
определить взаимодействия факторов.
Например, предположим, что фактор А имеет 2 уровня. Всем субъектам,
отнесенным к первому уровню этого фактора, мы приписываем -1 как значение
соответствующей переменной (переменной Л) в файле данных. Аналогично всем
субъектам, отнесенным ко второму уровню, приписываем значение +1. Второй
фактор, также с двумя уровнями, будет закодирован тем же способом (переменная В).
После того как переменные АиВ определены как ковариаты, выражение А *В есть
третья ковариата для проверки взаимодействия между этими двумя факторами.
Для задания зависящих от времени ковариат можно использовать тот же самый
синтаксис, который используется в формулах электронной таблицы.
В некоторых случаях есть основание предполагать, что влияние одной или
нескольких ковариат на функцию интенсивности не является непрерывным по
времени. Например, риск для пациента после операции может зависеть от времени,
прошедшего после операции в течение первых двух дней, и, во вторую очередь, от
некоторых других факторов. В таком случае можно использовать некоторые
логические операции, которые также поддерживаются при вводе формул электронных
таблиц.
Например, можно определить зависящую от времени ковариату с помощью
следующего выражения:
Agex(T_<2)
Логическое выражение Т< 2 равно 0 (ложь), если после операции прошло
больше 2 дней, и равно 1 (истина), если меньше. Таким образом, здесь явно учтен
эффект первых двух послеоперационных дней.
Экспоненциальная регрессия
Эта модель записывается в виде:
S(z) = ехр(а + bt х z, + Ь2 х z2 + ... + bm x zm)
S(z) обозначает время жизни, а — неизвестная константа, Ь. — параметры регрессии.
Вновь можно использовать критерий согласия хи-квадрат, чтобы оценить
адекватность модели.
Статистика хи-квадрат может быть вычислена как функция логарифма
правдоподобия для модели со всеми оцененными параметрами (Z,,) и логарифма
правдоподобия модели, в которой все ковариаты обращаются в О (L0).
Если значение хи-квадрат значимо, отвергаем нулевую гипотезу и принимаем,
что независимые переменные значимо влияют на время жизни.
Один из способов проверить адекватность экспоненциальной модели —
построить остатки времен жизни и сравнить их со значениями стандартных
экспоненциальных порядковых статистик.
Регрессионные модели в анализе выживаемости
547
Осиаяки и сшлид экспоненциальная
порядковая сьаашсмика
Если предположение о том, что данные имеют экспоненциальное
распределение, справедливо, то все точки на графике хорошо ложатся на прямую линию.
Нормальная и логнормальная регрессия
В этой модели предполагается, что времена жизни (или их логарифмы) имеют
нормальное распределение. Модель совпадает с обычной моделью множественной
регрессии и может быть записана следующим образом:
t = а + Ь. х гх + Ь0х 29 + ... + Ъя х zm,
112 2 mm'
где t — время жизни.
Если принимается модель логнормальной регрессии, то t заменяется In t.
Модель нормальной регрессии особенно полезна, поскольку часто данные можно
преобразовать в приблизительно нормальные с помощью подходящего преобразования.
Таким образом, в некотором смысле это наиболее общая параметрическая
модель (в противоположность модели пропорциональных интенсивностей Кокса,
которая является непараметрической).
Для всех регрессионных моделей в системе STATISTICA доступен
стратифицированный анализ, который открывается в окне Результаты.
ШШУЖШ
Модель: Норн, регресиия
Перенеи.
зависите: число дней, вычисленное по датам
независимые: AGE
Индикатор цензурирования:CENSORED
Стратфкцировам.анализ по перен.: HOSPITAL К групп: 3
Общее число допустимых наблюдений: 65
неиенэур.: 29 ( 44.624) ценэуриров.: 36 ( 55.384)
Лог-правдоподобие окончат.решения:-240.825
Лог-правдоподобие кулев. нодели (бета«0): -243.015
Хи-квадрат (нулевая нодель-оконч.решение):14.38085 ее» 1 р« .0001
Од«нки
В Гр*Ж>* Н9бтол*
Wtt^^^tWM • • 1Ж
■□
548
Глава 14. Анализ выживаемости
Цель стратифицированного анализа — проверить гипотезу о том, что одна и та
же регрессионная кривая подходит для разных групп данных. Итак, стандартным
образом мы разбиваем данные на несколько однородных групп.
Затем строятся регрессионные модели отдельно для каждой группы. Сумма
логарифмов правдоподобия для разных моделей представляет собой логарифм
правдоподобия модели с разными коэффициентами регрессии (и свободными
членами, если требуется) в разных группах.
Далее ко всем данным обычным образом подгоняется регрессионная модель,
не учитывая разбиение на группы, и вычисляется общий логарифм
правдоподобия. По разности двух логарифмов правдоподобия проверяется значимость
различия между группами.
В стратифицированном анализе на основе априорных соображений
исследователь разбивает объекты на однородные группы риска, которые называются
стратами, и проводит регрессионный анализ внутри каждой группы (см., например,
книгу Кокрен У. A976) «Методы выборочного исследования», где всесторонне
обсуждаются методы построения групп). Во многих ситуациях риск-группы
заранее известны, технически их можно получить, введя группирующие
переменные.
Для модели пропорциональных интенсивностей Кокса система STATISTICA
предлагает опцию подгонки к стратифицированным данным модели с общими
коэффициентами для разных групп, но с разными базовыми функциями
интенсивности. В результате наблюдения в отдельной группе удовлетворяют
предположению пропорциональности, но это предположение не обязательно выполняется для
наблюдений объединенных групп.
STATISTICA позволяет исследовать модель Кокса с ковариатами,
зависящими от времени, а также сравнить модель с зависимыми от времени ковариатами и
постоянными ковариатами.
Подробное введение в анализ выживаемости можно найти, например, в работах
Bain A978), Barlow and Proschan A975) — русский перевод: Барлоу Р., Прошан Ф.
Статистическая теория надежности и испытаний на безотказность. М.: Наука, 1984,
Сох and Oakes A984) — русский перевод: Кокс Д. Р., Дукс Д. Анализ данных типа
времени жизни. М.: Финансы и статистика, 1988, Elandt-Johnson and Johnson A980),
Gross and Clark A975), Lawless A982), Lee A980, 1992), Miller A981), and Nelson
A982). Инженерные приложения этой техники обсуждены у Hahn and Shapiro
A967) — русский перевод: Хан Г., Шапиро С. Статистические модели в
инженерных задачах. М.: Мир, 1969.
На этом мы закончим общий обзор методов анализа выживаемости и перейдем
к их реализации в системе STATISTICA, а также к примерам.
Обзор системы
Модуль Анализ выживаемости системы STATISTICA предназначен для анализа
цензурированных или неполных данных о выживаемости и отказах.
Модуль содержит процедуры для описания времен жизни и оценивания
функций выживания, интенсивности и плотности вероятности, для подгонки тео-
Обзор системы
549
ретических распределений выживаемости к данным и для сравнения выживаемости
в двух и более выборках. Модуль Анализ выживаемости содержит также
регрессионные процедуры для подгонки объясняющих моделей к цензурированным
данным (модель пропорциональных интенсивностей Кокса, в том числе с
зависящими от времени ковариатами, экспоненциальная регрессия, нормальная и
логнормальная регрессия).
Все процедуры в модуле Анализ выживаемости автоматически преобразуют
данные в числовой формат. Таким образом, чтобы получить интересующие данные,
пользователь может записать даты начала и даты окончания наблюдений,
связанные с отказами или цензурированием (потерями объектов).
Таблицы времен жизни могут быть построены по исходным данным. Однако
можно анализировать и готовые таблицы времен жизни.
Для всех регрессионных моделей доступны оценки максимального
правдоподобия. При вычислении этих оценок для моделей пропорциональных
интенсивностей и экспоненциальной регрессионной модели используется процедура
безусловной максимизации. Для нормальной и логнормальной регрессионных моделей
оценки параметров проводятся с помощью £Л/-алгоритма. Этот алгоритм был
впервые предложен в работе Dempster, Laird, and Rubin A977) Maximum likelihood from
incomplete data via the EM algorithm, Journal of the Royal Statistical Sociaty, 39,
p. 1-38, и обсуждается в книге Сох and Oakes A984) Analysis of survival data, New
York: Chapman&Hall.
Общая значимость регрессионной модели может быть оценена с помощью
критерия хи-квадрат, вычисляемого на основе логарифмов правдоподобия для
подогнанной и нулевой моделей.
Для оценки адекватности подогнанной модели предоставляется большой
выбор графических опций. В случае моделей пропорциональных интенсивностей
пользователь может построить функции выживания для различных значений
независимых переменных. Для экспоненциальной регрессионной модели есть
возможность построения графиков зависимости остатков и экспоненциальной
порядковой статистики, остатков и предсказанных с помощью регрессионного уравнения
времен жизни, остатков и логарифмов наблюдаемых времен жизни. Для
нормальной и логнормальной линейной регрессионной модели пользователь может
воспроизвести на экране график зависимости наблюдаемых и подогнанных времен
жизни, подогнанных времен жизни и остатков подгонки, а также нормальный
вероятностный график остатков.
Альтернативные процедуры
Альтернативные процедуры возможны для нецензурированных данных.
Если данные о продолжительности жизни (безотказной работы) нецензу-
рированы, то применимо большинство непараметрических статистик. Для
нецензурированных данных можно также использовать нелинейное оценивание, чтобы
подогнать определенную регрессионную модель (включая пробит, логит и
экспоненциальную модели) к данным.
Если продолжительность жизни или безотказной работы описывается
бинарной переменной, то могут быть применены логит или пробит регрессионные
модели.
550
Глава 14. Анализ выживаемости
Другой общий метод сравнения выживаемости в различных группах
реализуется с помощью таблиц частот. Если времена жизни, или наработки до момента
отказа, распределены по нескольким временным интервалам, может быть
использована общая логлинейная модель.
Пример 1. Таблицы времен жизн(|
В этом примере мы рассчитаем таблицу времен жизни, оценим функцию
выживания, плотность вероятности и функцию интенсивности для различных временных
интервалов, а также найдем теоретическое распределение, наилучшим образом
согласующееся с данными. Данные основаны на работе Crowley, J., & Ни, М., A977)
Covariance analysis of heart transplant survival data, Journal of the American Statistical
Association, 72, p. 27-36.
Задание параметров анализа
В модуле Анализ выживаемости откройте файл Heart.sta. г
I-WMIWIHIIIMIW
штттшшмттшш
\\j^_ Мета« множительных оценок Каллаиа-
IjjTjj Сравнение двух выборок
jf*| Сравнение нескольких выборок
|/\ Регрессионные модели
Далее выберите Таблицы и распределения времен жизни из стартовой панели
Анализ выживаемости и времен отказов.
Врвмоиа mjtaiB» A) mi даты B май 6£ наг
. :. Иидмкатор мигрирования: нет
.,, &щ turn гимчфадемжф н^я«р««иА JO
- Построить таодиды исходи ив:
<? Нисаа интервалов:
12
: С Размера виг* (вмрмиы ииторвааов}. |1. И ;• '
р7 Исдрввит» имтврвааы и* содержащие откааовУсмвртвА **Ц,».15Р *)
Можно анализировать как исходный файл данных, так и сгруппированные
данные. В данном случае мы анализируем исходные данные.
Нажмите кнопку Переменные и выберите шесть переменных в первом списке.
Первые три переменные — дата начала (например, дата операции), оставшиеся
три переменные — дата наступления события.
Программа интерпретирует первую и четвертую переменные как месяцы,
вторую и пятую — как дни, а третью и шестую — как год.
Пример 1. Таблицы времен жизни
551
Заметим, что можно сразу ввести времена жизни (одна переменная в файле
данных или даты в другом формате — две переменные).
МШУЩ!
171*11
1 MUNTH.1
?OAY I
} YEAR J
4MUNIH_2
'* DAY_2
liYIAR 2
17 CENSORED
W-AGE
IS ANTIGEN
^0 MISMATCH
11 HOSPITAL
1 MONTH_1
|2-OAY_1
3 YEAR 1
4MONTH_2
BDAY_2
|6 YEAR 2
JL
| Qtmpw j
yifn:Mii«
«AGE
}9 ANTIGEN
10 MISMATCH
111 HOSPITAL
! <p«n.>Hinin p L a«m B мм 8fc Икнкжгойми
ПТ"
F
Далее необходимо определить переменную Censored как индикатор
цензурирования во втором списке.
Диалоговое окно Таблицы и распределения времен жизни будет теперь выглядеть
так:
%жт*ытйЯ*т**. [ Исжодиые данные <J
Sjgj
J pTWHC
•им m мм A«rw 12 мяи в* MONTHS-VtAR^2
Hwtwn» мицр1фоч»»мс CtHSORED
liMJiM
ДМ выббрв КОДОВ И»
[COMPLETE епием допустима»
У Недра—m> *итщ*шшю ewymmm вттмюв/смортЫ» !У*1® "|
Поскольку были использованы коды по умолчанию для индикатора
цензурирования @ -полное, 1 — неполное), STATISTICA автоматически отображает Код
для завершенных наблюдений и Код для неполных или цензурированных наблюдений.
Дополнительно можно определить для таблицы времен жизни число
интервалов или ширину интервалов.
Процедура подгонки теоретического распределения к данным невозможна при
наличии интервалов, не содержащих ни смертей (отказов), ни изъятых
наблюдений.
Если вы хотите сделать подгонку, установите флажок Исправить интервалы,
не содержащие смертей/отказов.
Если таблица времен жизни используется только в описательных целях и не
предполагается подгонка распределения, то корректировку интервалов делать не
нужно.
Оставив опции по умолчанию, нажмите ОК. После того как все наблюдения
обработаны, откроется диалоговое окно Результаты для таблиц и распределений
времен жизни.
552
Глава 14. Анализ выживаемости
Нажмите на кнопку Таблица времен жизни, чтобы отобразить на экране полную
таблицу результатов времен жизни.
т
ШШШШШНШШШУШ
Перемен.: число дней, вычисленное по датами
Индикатор цензурирования:CEN30P£P
Обжее число допустинкх наблюдений : 65
иеиеивур. : 29 ( 44,624) цеивур.
36 ( 55,384
'7':'ii^i%t:yi^\:
llftjfy^tJ ЛииЫмки интенсивность <jj
?. Равней ,»»шм<н цнт«»си»юстн J ЕЗ ГрМ>»* »<и«щии интанси—кюи
Я ■ 0**iim щутат вммтажмсттн | В ГрМнк »»ищин 1ыжчеааиостн
ИГ Ощйм! пдшгиостк —poirmoT»» } В График мротиостной длотности [
РЭПШШШ
ПИИИМ М
ВРЕМЕНА
выжив
;Инжврбал
Hnrnv H2 '
m**v m
ЖилГМ
tottb HS
,***;Н6
/И**< КТ
»1Ш&М?
Ика? Н9
1i«*V WO
Их* МП
Мха- H12
аНЗЬмё^^шмм^аЗ
■ЯМММШЯМ
Лоаарифм пребдоподови* : «68.6809
ppij
65 14 ; 58.0000]
32 4"i 30.0000
24 4 22.0000
20 4 ; 18.0000
15 1 : 14.5000
13 3 11.5000
" '9 1 8.5000
6 1 ! 5.5000
5 1 4.5000
3 2 v 2.0000
1 0 . 1.0000
1 i"' .5000
ii
1:ЖФШш?0
.00203 .00243
.00056 .00089
.00008 .00014
.00020 .00035
.00023 .00044
.00027 .00056
'.00067 .00165
.00020 .00059
.00044 .00155
.00038 .00177
.00057 .00413
41...
Кен ♦«*«>
0.00000
.06163
.06778
.06878
.07187
.07588
.08082
.09080
.09301
.09547
.10420
.10635
TiTi
■■ПпТ
€*9-о*.
ВррПлоак
.00038
.00026
.00012
.00019
.00022
.00026
.00043
.00027
.00041
.00049
.00066
1" ">-
5
н
1
1
i
i
1
!
1
•f
На рисунке показана часть полной таблицы жизни.
Можно подгонять к данным основные семейства распределений, используя
обычный метод наименьших квадратов или две модификации метода взвешенных
наименьших квадратов.
Чтобы выбрать наиболее подходящее семейство распределений, сначала
рассмотрим модель с экспоненциальным распределением (выбрав позицию
Экспоненциальная в поле Модель).
Оценка согласия проводится с помощью критерия хи-квадарт.
Нажмите кнопку Оценки параметров, чтобы посмотреть оценки для данного
семейства распределений, а также значение критерия хи-квадрат.
РЯШШШ
■ fllHlililiHi
■ ВРЕМЕНА
; выжив
Memo?
MfflllW
шшшш'ппштшшршштшшшш
ШШшЖШШшШШЕМШЕШВШШШ
Замечание Веса 1-1 . 2-1 W. 3-НA)
.00132 1 .00000
"*•• в»сt | ; 00050 .ооооо
>fcW' -JA .00126 .00000
!lp«ftfloo.
•H(I)
Хи«Хв»А.
.00059 -79.712 22.0622
.00014
.00022
-86.778
-79.547
36.1937
21.7332
«'ОГО*'.-■"■
10
10
10
НЕЛ&Ш1
"/;;• р- -■■ |
.01481 1
.00008 1
.01655 1
Пример 1. Таблицы времен жизни
553
Если критерий значим, делается заключение, что подогнанное распределение
значимо расходится с наблюдаемыми данными. Поэтому мы отвергаем это
семейство распределений и говорим, что оно не согласуется с данными.
Из таблицы результатов следует, что ни один метод подгонки не дает
экспоненциального распределения удовлетворительного согласия. Тот же результат
хорошо виден на графиках.
Нажмите кнопку График функции выживания. На приведенных ниже графиках
ни одна из экспонент также не аппроксимирует наблюдаемую функцию
выживания удовлетворительно. Видно, что оцененная функция выживания сильно
отклоняется от аппроксимирующих функций выживания.
Г11р*Фмк/ МНК Пце
ИНК Оценки функции выживаемости
Модель:Экспокекц
Замечание Веса: 1-1.. 2-1 /V. 3-N(I)«H(I)
0.0
0.0000 322.73 645.45 968.18 1290.9 1613.6 1936.4
161.36 484.09 806.82 1129.5 1452.3 1775.0 2097.7
Нач интервала
НаБлюд
Вес 1
Вес 2
Вес 3
Можно просмотреть оценки параметров для различных семейств
распределений. Вначале выберите соответствующее семейство из поля списка Модель,
а затем нажмите кнопку Оценки параметров. Если проанализировать все эти
семейства, можно сделать вывод, что только для семейства Вейбулла (см. главу
Вероятностные распределения) нет значимого отличия от наблюдаемых значений
при оценивании параметров по минимуму суммы взвешенных квадратов.
|'£* Оценки параметром. Модель Вейбчлл.1 (he.ul st<i)
ВРЕМЕН*
ВЫЖИВ
Мемод
Оценив
ШШШКШ
ВвС ,2,
Вес *•.:«
Замечание Веса 1-1.. 2-1./V. 3-N(I)
Лямбда
Дисперс,
Лямбда
?-.CtagV«wr, :
Лямбда
Гамма !
.00031 .00000 .00057 1.142171
.01600 .00032 .01795 .64432
. 05110 .00522 : .07223 .42768|
•НA)
31.3240|
13.5076
7.7570
iU Hi!
с* оо
9
9
9
№D
.' р
.00026
.14101
.55881
Л
*i
Tf
Ниже показаны графики функции выживания из семейства Вейбулла,
подогнанные тремя разными способами.
554
Глава 14. Анализ выживаемости
hii'fll|iiiiliiin.nii,lii"i;;!ii
МНК Оценки функции быжибаеноски
Модель ВейБулла
Замечание Веса 1-1 . 2-1 /V. 3-НA)»НA)
0.0000 322.73 645.45 968.18 1290.9 1613,6 1936.4
161.36 484.09 806.82 1129.5 1452.3 1775.0 2097.7
Нач интервала
НаБлюд
Вес 1
Вес 2
Вес 3
Для третьего набора параметров (соответствующего Weight 3) имеется
удовлетворительное согласие с данными. Хи-квадрат — критерий для этой ситуации —
не дает значимого отклонения (р=0,56). Следовательно, мечено сделать вывод, что
распределение Вейбулла с этим набором параметров удовлетворительно
описывает наблюдаемые времена жизни. I
В заключение заметим, что модуль Анализ выживаемости STATISTIC А
позволяет анализировать также табулированные данные (для этого нужно выбрать
опцию Таблица времен жизни в поле списка Входные данные).
ЩШ
шиш
IB ШУ|
Otwh* |
fclHTJ>TRt
... Число щтпщрнриш тшшш пшбтьлтшЛ; NO_CNSRI>
" Ч*ст or***» tompuft): NO.DIEO
З/icm ншЛмщптттт тртич ытщттт: J523 {§} i
Файл с табулированными данными должен содержать 3 переменные со
следующей информацией:
1) нижняя граница временных интервалов;
2) число цензурированных или неполных наблюдений;
3) число отказов (число умерших в каждом временном интервале).
После выбора Таблиц времен жизни откроется диалоговое окно Таблицы и
распределения времен жизни, в котором можно выбрать эти переменные.
Пример 2. Регрессионная модель Кокса
Файл данных Heartsta содержит дополнительные переменные: возраст пациента
во время трансплантации (переменная Возраст — Age) и медицинские
характеристики: мера антигенной несовместимости (переменная Антиген — Antigen) и мера
тканевой несовместимости (переменная Несовместимость — Mismatch).
Пример 2. Регрессионная модель Кокса
555
Представляет интерес зависимость между переменными Возраст — Age,
Антиген — Antigen и Несовместимость — Mismatch и временами жизни. Наиболее
общей регрессионной моделью, не накладывающей ограничения на форму функции
выживания, является модель пропорциональных интенсивностей
Кокса.,Рассмотрим, как можно оценить коэффициенты регрессии для этих трех независимых
переменных для того, чтобы предсказать времена жизни с помощью модели
пропорциональных интенсивностей Кокса.
Задание параметров анализа
Нажмите опцию Регрессионные модели на Стартовой панели, чтобы открыть
диалоговое окно Регрессионные модели для цензурированных данных.
Чтобы выбрать переменные для анализа, нажмите кнопку Переменные и
задайте все времена жизни и цензурирующую переменную, как это было сделано ранее.
Необходимо также выбрать независимые переменные или регрессоры
(Возраст — Aget Антиген — Antigen, Несовместимость — Mismatch).
Группирующую переменную в данном примере мы не отмечаем.
ШМШ1
1 MUNTH_1
?OAY 1
3YEAR 1
4 MONTH 2
bDAY 2
В YE ЛИ 2
7 CENSORED
8 AGE
9 ANTIGEN
10 MISMATCH
11 HOSPITAL
1ТГх11
II MONTH 1
2-OAY 1
3YEAR 1
|4MONTH 2
5-DAY 2
J-YEAR 2
17 CENSORED
i U AGE
! 9 ANTIGEN
i 10 MISMATCH
1 MONTH 1
2 DAY 1
3 YEAR 1
4 MONTH 2
5 DAY 2
6YEAR_2
8 AGE
9 ANTIGEN
10 MISMATCH
11-HOSPITAL
8p«m.«m9Mn{1,2.6|: Н
1 MONTH 1
2 DAY 1 "
3 YEAR 1
4 MONTH 2
5 DAY 2 "
6-YEAR 2
7 CENSORED
8 AGE
9 ANTIGEN
10 MISMATCH
11-HOSPITAL
'ГЙН
I 0tm«m)J
Uimiiiiii J
[ПцфобЛ Ик+П |По<|роб|! Ин». J .
ГрфМДич) ООЯ9.|Г
Теперь выберите коды для цензурирующей переменной. С помощью этих кодов
STATISTICA разобьет данные на 2 группы: полные и неполные. По умолчанию
STATISTIC А использует следующий код: 0 = завершенное наблюдение, 1 = цензури-
рованное.
Если вы используете другой код, дважды щелкните по полю ввода Коды
завершенного наблюдения и Коды цензурированного наблюдения и выберите коды из списка.
Им* CENSORED
ПД: -9ЭЭЗ
Формат U0
Отм
1. CENSORED
Дмтды щелкните не значении.
чтобы выбрать значение мвыйт >
556
Глава 14. Анализ выживаемости
Диалоговое окно Регрессионные методы для цензурированных данных появится
на экране:
шшштттттмшштшшшт
Цм*ЛЬ.к j Perрессмониая монет» Кокса *|
И Цер»и»шм>1> модем [mrmi чист групоируниея, осей она есть)
Отмена
i {1J ыт даты B шш б* M0NTH_1-YEAR_2
:AfiE-MISMATCH ;
Цинт9грршщ*фщщмт1 CENSORED,
(COMPLETE
CENSORED
B8-s XtoUfamtpymj-J \wt
Для »ыбор« кодов иэ списка
: допдо*4м**и»«им* дважды
,. щелкните на соответст» пол»
Оценивание параметров
Выберите в списке Модель позицию Регрессионная модель Кокса. Нажмите ОК и
откройте диалоговое окно Оценивание регрессионной модели.
Модель: Регрессионная модель Кокса
Перемен.
зависимые: число дней, вычисленное по датам
независимые: AGE ANTIGEN HISNATCH
Индикатор цензурирования:CENSORED
Мм&яеа^ййкоф; шсео ДОерадмДт
••'••• К^шгдрмЙ смдмеости!.7
50
Loooi
Отмена
дм тем параметров
UfteMiiiit QpWiMieMHMM деииыг. I Замена средним т|
Это диалоговое окно позволяет задать параметры процедуры оценивания.
Процедура оценивания максимизирует логарифм правдоподобия
регрессионной модели с помощью метода Ньютона—Рафсона.
Алгоритм оценивание параметров является итеративным и начинается с
некоторых начальных значений параметров (кнопка Начальные значения). Далее
программа делает несколько итераций, последовательно приближаясь к оценкам
неизвестных параметров. Разность между текущими оценками и оценками, полученными на
предыдущем шаге, называется невязкой. Если невязка удовлетворяет критерию
сходимости (см. поле Критерий сходимости), то процесс приближения завершается.
Максимальное число итераций и критерий сходимости указываются в
соответствующих полях.
Значения, предлагаемые программой по умолчанию, обычно приемлемы,
поэтому просто нажмите ОК и начните процедуру оценивания.
Пример 2. Регрессионная модель Кокса
557
oiB=cas^^^H
Модель: Регрессионна* модель Кокса
Перепек.
зависите: число дней, вычисленное по детая
меэависюше: АСЕ ANTIGEN MISMATCH
Итерация
• 1t
• 11
• 12
« 13
♦ 1*
■• : 1&/Ф
• 16
i
. Лродеео«
Индикатор цензурирования:CENSORED
ЛогПравдоподобие Параметры
-87,867 ,1М6Э7 -,64851
-•7,867 ,168876 -.04865
-•7,867 ,188986 -,8*872
-•7,867 ,189«li -.84875
-•7,867 ,18V 874 *,6W77
'<•'* *в7,М7 ,лР':,1»ввК^««*17*^
-•7.867 .109896 -.84878
•••" <.4.~.w.A..*....~v. ..«.,.. ~.
hhhbhQTx]
1.В6172
1.66276
1,»6327
1,86353
.Я«МШ„
Н9шпл-К*'.-.
1.86376
^-^нм-оо^ж ■•^t;> уЩ^Ш ШИ 1 0™"* |1|
*|>М||.*«*|..У.Ч|||.ы.|.|*|м,
.' .< • I
С помощью этого диалогового окна можно наглядно проследить, как
происходит процесс оценивания. В столбцах Параметры показаны оценки параметров на
каждом шаге.
После того как критерий сходимости будет выполнен, процедура оценивания
останавливается.
Обычно процедура поиска быстро сходится, если приближения за заданное
число итераций неудовлетворительны, программа запросит дополнительно некоторое
количество итераций. Вы можете изменить начальные значения, используя,
например, оценки параметров, полученные на предыдущем экспериментальном материале.
В данном примере наилучшие оценки параметров найдены, итеративная
процедура сходится, поэтому предлагается нажать ОК, чтобы перейти в диалоговое
окно Результаты регрессии.
пшшушж
Модель: Регрессионная модель Кокса
Перемен.
зависимые: число дней, вычисленное по датам
независимые: АСЕ ANTIGEN MISMATCH
Индикатор цензурирования:CENSORED
Общее число допустимых наблюдении: 65
кецеиэур.: 29 ( 44,62%) иенэуриров.: Эб ( 55,
Лог-правдоподобие окончат.решения:-87,8674
Лог-правдоподобие нулев. модели (бета>0): -99,0270
Хи-квадрат (нулевая модель-оконч.решение):22,31933 ее- 3 р>
JEssBu^sssaa^
От*»— \
&ЩМ*т&т#**ФшЬ ******
>ЩУ Ту**+л
Щ Ср—>»«• * crwminmm утыююнт \' Effi Тр»»мк ». i
558
Глава 14. Анализ выживаемости
Результаты
Это диалоговое окно позволяет просмотреть результаты. Значение статистики
критерия хи-квадрат для данной модели высокозначимо, поэхрму можно заключить,
что, по крайней мере, некоторые независимые переменныегзначимо
действительно связаны с выживаемостью.
Нажмите кнопку Оценки параметров, чтобы увидеть оценки параметров и их
стандартные ошибки.
пгшяшшштштштшшттшшшштттшшшшшттш
ВРЕМЕНА
ВЫЖИВ
N•65
Цензурир перем CENSORED
Хи2 - 22.3193 ее - 3 р - .00006
■•"•,' БвЙ*•■■:'•::'■■■
■в^вв^ЮШ 109096
AMTIGEH
MISMATCH
-.048782
1,063761
0#й5к* : ИВЗЯЕвЯ Бе»а
.033293 | 3.276836 | 1.115269
.471644 -.103431 .952388
.394599 2.695804 2.897246
Сяамис**
Вельда
10.73766
.01070
7.26736
ИЕШЕ0
Р .
.001051 1!
.917622 1
.007026 ||
Стандартные ошибки вычисляются как часть процедуры* оценивания и по своей
природе являются асимптотическими. Они вычисляются на основе частных
производных второго порядка от логарифма функции правдоподобия. Это означает, что
t-значения тоже должны рассматриваться только как приближенные. Обычно любая
оценка параметра (регрессионной модели), которая по крайней мере в два раза
превосходит свою стандартную ошибку (t>2,0\ может рассматриваться как
статистически значимая (на уровне р<0,05).
Электронная таблица с результатами также содержит статистику критерия
Вальда для каждого коэффициента (см. книгу Рао С. Р. «Линейные
статистические методы и их применения»). Из приведенной таблицы следует, что возраст
пациента и тканевая несовместимость — наиболее важные предикторы для функции
мгновенного риска.
Итак, значимые переменные в модели — AGE и MISMATCH. Рассмотрим
графики функции выживания как функции независимых переменных. Пусть все
независимые переменные равны своим средним значениям, тогда график функции
выживания имеет вид (нажмите кнопку График выживаемости для средних):
П0ШШЕ
тшштттшттт
Функция выживания для средних
неззвмеммых переменных
400 600 800 1000 1200 1400 1600 1800 2000
Времена жизни
Пример 2. Регрессионная модель Кокса
559
Средние значения независимых переменных и стандартные ошибки можно
посмотреть в таблице:
Ш Средние м стандартные отклонения (heart sta)
нгаЕЭ
ВРЕМЕНА
ВЫЖИВ
1 AGE ]
ANTIGEN
MISMATCH
!Чдней
Среднее
45 6769
2615
1 1646
382 6769
Стоткл.
| 9.1858
АА23
6233
4632327
Минимум
19 00000
000000
000000
0 00000
Максимум J
64 000
1 000
3 050
1775 000
Зададим определенные значения предикторов. Мы имеем значимые переменные:
AGE — возраст и MISMATCH — тканевая несовместимость. Увеличим возраст
больного до 55 лет.
Значения независимой переменной
AGE
ANTIGEN | 261538 S j
MISMATCH |1646
Q* \
Отмена
Oj&mee
Применить]
График функции выживания изменится и будет иметь вид:
(Г1График5: Функция выживаемости дяя заданных
Функция выживания
значений независимых переменных
ННЕЗ
200 400 600 800 1000 1200 1400 1600 1800 2000
Времена жизни
В заключение заметим, что с помощью кнопки Редактор данных графика мож
но представить функцию выживания в численном виде:
560
Глава 14. Анализ выживаемости
М!Ш!Ш¥Ш1ШМ1ШЯШтПШ.
Функция выживания для заданных
значении независимых переменных
ШЪптм
НИаНШ
39 00
44.00
46.00
4700
48 00
5000
50.00
51 00
51.00
5400
6000
63.00
|...„ v; .._
втый гр %фи*
w.v.,,
0 84
084
0.80
0.77
077
0.77
0.68
068
0.60
0.56
052
0.48
^.ш^..,,..:..:...,
ii
Таким образом проводится регрессионный анализ в модуле Анализ
выживаемости.
Анализ
соответствий
Данная глава продолжает тему главы Построение и анализ таблиц. Мы
рекомендуем просмотреть ее, а затем приступить к чтению данного текста и упражнениям
на STATISTICS
Анализ соответствий (по-английски correspondence analysis) — это разведочный
метод анализа, позволяющий визуально и численно исследовать структуру таблиц
сопряженности большой размерности.
В настоящее время анализ соответствий интенсивно применяется в
разнообразных областях, в частности в социологии, экономике, маркетинге, медицине,
управлении городами (см., например, Thomas Werani, Correspondence Analysis as a
Means for Developing City Marketing Strategies, 3rd International Conference on
Recent Advances in Retailing and Services Science, p. 22-25, Juni 1996, Telfs-Buchen
(Osterreich) Werani, Thomas).
Известны применения метода в археологии, анализе текстов, где важно
исследовать структуры данных (см. Greenacre, M. J., 1993, Correspondence Analysis in
Practice, London: Academic Press).
В качестве дополнительных примеров приведем:
О Исследование социальных групп населения в различных регионах со
статьями расхода по каждой группе.
О Исследования результатов голосования в ООН по принципиальным
вопросам A — за, 0 — против, 0,5 — воздержался, например, в 1967 году
исследовалось 127 стран по 13 важным вопросам) показывают, что по первому
фактору страны отчетливо разделяются на две группы: одна с центром США,
другая с центром СССР (двухполюсная модель мира). Другие факторы
могут интерпретироваться как изоляционизм, неучастие в голосовании и т. д.
О Исследование импорта автомобилей (марка машины — строка таблицы,
страна-производитель — столбец).
О Исследование таблиц, используемых в палеонтологии, когда по выборке
разрозненных частей скелетов животных делаются попытки их
классифицировать (отнести к одному из возможных типов: зебра, лошадь и т. д.).
О Исследование текстов. Известен следующий экзотический пример: журнал
New-Yorker попросил лингвистов установить анонимного автора
скандальной книги об одной президентской кампании. Экспертам были
предложены тексты 15 возможных авторов и текст анонимного издания. Тексты
представлялись строками таблицы. В строке i отмечалась частота данного
15
562
Глава 15. Анализ соответствий
слова/ Таким образом получалась таблица сопряженности. Методом
анализа соответствий был определен наиболее вероятный автор
скандального текста.
Применение анализа соответствий в медицине связано с исследованием
структуры сложных таблиц, содержащих индикаторные переменные, показывающие
наличие или отсутствие у пациента данного симптома. Подобного рода таблицы
имеют большую размерность, и исследование их структуры представляет
нетривиальную задачу.
Задачи визуализации сложных объектов могут быть также исследованы, по
крайней мере, к ним можно найти подход, с помощью анализа соответствий.
Изображение — это многомерная таблица, и задача состоит в том, чтобы найти
плоскость, позволяющую максимально точно воспроизвести исходное изображение.
Математическое основание метода. Анализ соответствия опирается на
статистику хи-квадрат. Можно сказать, что это новая интерпретация статистики хи-квад-
рат Пирсона.
Метод во многом похож на факторный анализ, однако в отличие от него, здесь
исследуются таблицы сопряженности, а критерием качества воспроизведения
многомерной таблицы в пространстве меньшей размерности является значение
статистики хи-квадрат. Неформально можно говорить об анализе соответствий как
о факторном анализе категориальных данных и рассматривать его также как
метод сокращения размерности.
Итак, строки или столбцы исходной таблицы представляются точками
пространства, между которыми вычисляется расстояние хи-квадрат (аналогично
тому, как вычисляется статистика хи-квадрат для сравнения наблюдаемых и
ожидаемых частот).
Далее требуется найти пространство небольшой размерности, как правило,
двумерное, в котором вычисленные расстояния минимально искажаются, и в этом
смысле максимально точно воспроизвести структуру исходной таблицы с
сохранением связей между признаками (если вы имеете представление о методах
многомерного шкалирования, то почувствуете знакомую мелодию).
Итак, мы исходим из обычной таблицы сопряженности, то есть таблицы, в
которой сопряжены несколько признаков (подробнее о таблицах сопряженности см.
главу Построение и анализ таблиц).
Допустим, что имеются данные о пристрастии к курению сотрудников
некоторой компании. Подобные данные имеются в файле Smoking.sta, входящем в
стандартный комплект примеров системы STATISTICA.
В этой таблице признак курение сопряжен с признаком должность:
Группа сотрудников
1 A) Старшие менеджеры
1 B) Младшие менеджеры
1 C) Старшие сотрудники
1 D) Младшие сотрудники
1 E)Секретари
1 Всего по столбцу
A)
Некурящие
4
4
25
18
10
61
B)
Слабо
курящие
2
3
10
24
6
45
C)
Средне
курящие
3
7
12
33
7
62
D)
Сильно
курящие
2
4
4
13
2
25
Всего по
строке
11
18
51
88
25
193 |
Анализ соответствий
563
Это простая двухвходовая таблица сопряженности. Вначале рассмотрим
строки.
Можно считать, что 4 первых числа каждой строки таблицы (маргинальные
частоты, то есть последний столбец не учитывается) являются координатами строки
в 4-мерном пространстве, а значит, формально можно вычислить расстояния хи-
квадрат между этими точками (строками таблицы).
При данных маргинальных частотах можно отобразить эти точки в
пространстве размерности 3 (число степеней свободы равно 3).
Очевидно, что чем меньше расстояние, тем больше сходство между группами, и
наоборот — чем больше расстояние, тем больше различие.
Теперь предположим, что можно найти пространство меньшей размерности,
например, размерности 2, длр представления точек-строк, которое сохраняет всю или,
точнее, почти всю информацию о различиях между строками.
Возможно, такой подход неэффективен для таблиц небольшой размерности, как
приведенная выше, однако полезен для больших таблиц, возникающих, например,
в маркетинговых исследованиях.
Например, если записаны предпочтения 100 респондентов при выборе 15
сортов пива, то в результате применения анализа соответствий можно представить
15 сортов (точек) на плоскости (см. далее анализ продаж). Анализируя
расположение точек, вы увидите закономерности при выборе пива, которые будут
полезны при проведении маркетинговой кампании.
В анализе соответствий используется определенный сленг.
Масса. Наблюдения в таблице нормируются: вычисляются относительные
частоты для таблицы, сумма всех элементов таблицы становится равной 1 (каждый
элемент делится на общее .число наблюдений, в данном примере на 193).
Создается аналог двумерной плотности распределения. Полученная стандартизованная
таблица показывает, как распределена масса по ячейкам таблицы или по точкам
пространства. На сленге анализа соответствий суммы по строкам и столбцам
в матрице относительных частот называются массой строки и столбца
соответственно.
Инерция. Инерция определяется как значение хи-квадрат Пирсона для двух-
входовой таблицы, деленный на общее количество наблюдений. В данном
примере: общая инерция =х2/193 = 16,442.
Инерция и профили строк и столбцов. Если строки и столбцы таблицы
полностью независимы (между ними нет связи — например, курение не зависит от
должности), то элементы таблицы могут быть воспроизведены при помощи сумм по
строкам и столбцам или, в терминологии анализа соответствий, при помощи
профилей строк и столбцов (с использованием маргинальных частот; см. главу
Построение и анализ таблиц с описанием критерия хи-квадрат Пирсона и точный
критерий Фишера).
В соответствии с известной формулой вычисления хи-квадрат для двухвходо-
вых таблиц ожидаемые частоты таблицы, в которой столбцы и строки независимы,
вычисляются перемножением соответствующих профилей столбцов и строк с
делением полученного результата на общую сумму.
Любое отклонение от ожидаемых величин (при гипотезе о полной
независимости переменных по строкам и столбцам) будет давать вклад в статистику
хи-квадрат.
564
Глава 15. Анализ соответствий
Анализ соответствий можно рассматривать как разложение статистики хи-квад-
рат на компоненты с целью определения пространства наименьшей размерности,
позволяющего представить отклонения от ожидаемых величин (см. таблицу ниже).
Здесь показаны таблицы с ожидаемыми частотами, рассчитанными при
гипотезе независимости признаков, и наблюдаемыми частотами, а также таблица
вкладов ячеек в хи-квадрат:
у■ \\\ in нш' умттптттт
АНАЛИЗ
СООТВЕТ
Таблице вводе (Стр* Столб) 5x4
|Общая инерция» 08519 Хи2 «16 442 сс-12 р« 17190
СЛА60
СРЕДНЕ-
СИЛЬНО
мл менеджеры
ст.сотруднмки •' ■■■> < *..
мп.сотруанмкм
секретари
Всего
3 47668 |
5 68912
16.11917
27 81347
7 90155
61 00000
овт
Всего
2 56477
4 19689
11.89119
2051813
582902
45 00000
3 53368
5 78238
16 38342
2826943
8 03109
62 00000
1 4С487
2 33161
6 60622
11 39896
3 23834
25 00000
11 0000
18 0000
51 0000
88 0000
25 0000
193 0000
АНАЛИЗ
СООТВЕТ
Таблица ввода (Стр.х Столб) 5 х 4
Общая инерция» 08519 Хи2 -16 442 сс-12 р- 17190
СЛАБО
СРЕДНЕ
СИЛЬНО
-56477
-1 19689
-1 89119
3 48187
17098
-53368
1 21762
-4 38342
4 73057
-1 03109
57513
1 66839
-2 60622
1 60104
-1 23834
209845
Например, из таблицы видно, что число некурящих младших сотрудников
примерно на 10 меньше, чем можно было бы ожидать при гипотезе независимости.
Число некурящих старших собрудников, наоборот, на 9 больше, чем можно было
бы ожидать при гипотезе независимости, и т. д. Однако хотелось бы иметь общую
картину.
Цель анализа соответствий состоит в том, чтобы суммировать эти отклонения
от ожидаемых частот не в абсолютных, а в относительных единицах.
iMHUUIJ'
АНАЛИЗ
СООТВЕТ
ст.меиеджеры
|Таблица ввода (Стр х Столб) 5 х 4
Общая инерция- 08519 Хи2 «16 442 сс-12 р* 17190
мл.ненеджеры
1ГТ51
078770
501505
4.892877
3 462503
557292
9492948
СРЕДНЕ
124363
341336
300778
СИЛЬНО
всего
590862
005016
1 362354
080600
256398
П72794
791607
132378
2 433777
232143
1 193828
1 028178
224873
473542
3152565
51588
2 29307
7 39463
5 06985
1 16823
1644164
Анализ строк и столбцов. Вместо строк таблицы можно рассматривать также
столбцы и представить их точками в пространстве меньшей размерности, которое
максимально точно воспроизводит сходство (и расстояния) между
относительными частотами для столбцов таблицы. Можно одновременно отобразить на одном
графике столбцы и строки, представляющие всю информацию, содержащуюся
в двухвходовой таблице. И этот вариант — самый интересный, так как позволяет
провести содержательный анализ результатов.
Анализ соответствий
565
Результаты. Результаты анализа соответствий обычно представляются в виде
графиков, как было показано выше, а также в виде таблиц типа:
Число
измерений
1
2
| 3
Процент
инерции
87,75587
11,75865
0,48547
Кумулятивный
процент
87,7559
99,5145
100,0000
Хи-квадрат
14,42851
1,93332
0,07982
Посмотрите на эту таблицу. Как вы помните, цель анализа — найти
пространство меньшей размерности, восстанавливающее таблицу, при этом критерием
качества является нормированный хи-квадрат, или инерция. Можно заметить, что
если в рассматриваемом примере использовать одномерное пространство, то есть
одну ось, можно объяснить 87,76% инерции таблицы.
ПГрАфин1 STG 1M rpa*Mi
яя измерения 1
чинили.'и
Координаты строк (размерность 1)
Таблица ввода (Стр х Столб ) 5 х 4
Стандартизация Профили столбцов
Соб знач 07476 (87 756 % инерции ) Вклад в хи-квадрат 14 429
1 5
10
05
I 00
О)
I -05
7
" -10
-1 5
-2 0
п м«м«д*«р
оотаудиики
ст м«н«4*«р
стсотрудники
Коорд-ты строк
Две размерности позволяют объяснить 99,51% инерции.
Координаты строк и столбцов. Рассмотрим получившиеся координаты в
двумерном пространстве.
Имя строки
1 Старшие менеджеры
1 Младшие менеджеры
1 Старшие сотрудники
1 Младшие сотрудники
1 Секретари
Измерение 1
-0,065768
0,258958
-0,380595
0,232952
-0,201089
Измерение 2
0,193737 1
0,243305 |
0,010660 |
-0,057744 |
-0,078911 |
Можно изобразить это на двумерной диаграмме.
566
Глава 15. Анализ соответствий
1.Ш. IU»Jli..l UH.U.IM.Ji
2М грмфпж юордиют erpoi. и9««р«ии1 1x2
Т шЪптцш moaj (Стр х Стопб Mх4
Ctjm*jpth»jhh« Профили CTpoi и столбце»
030
0.25
0.20
О 15
О 10 \
0 06
0 00
0 06
•010
•О 1в
•05
Иммраии* 1. Соб тшч 07470 (87 70 * инерции )
Очевидным преимуществом двумерного пространства является то, что строки,
отображаемые в виде близких точек, близки друг к другу и по относительным
частотам.
Рассматривая положение точек по первой оси, можно заметить, что Ст.
сотрудники и Секретари относительно близки по координатам. Если же обратить
внимание на строки таблицы относительных частот (частоты стандартизованы так,
что их сумма по каждой строке равна 100%), то сходство данных двух групп по
категориям интенсивности курения становится очевидным.
Проценты по строке:
Группа сотрудников
1 A) Старшие менеджеры
1 B) Младшие менеджеры
1 C) Старшие сотрудники
1 D) Младшие сотрудники
| E) Секретари
Категории курящих |
A)
Некурящие
36,36
22,22
49,02
20,45
40,00
B)
Слабо
курящие
18,18
16,67
19,61
27,27
24,00
C)
Средне
курящие
27,27
38,89
23,53
37,50
28,00
D)
Сильно
курящие
18,18
22,22
7,84
14,77
8,00
Всего по
строке
100,00
100,00
100,00
100,00
100,00 |
Окончательной целью анализа соответствий является интерпретация векторов
в полученном пространстве более низкой размерности. Одним из способов,
который может помочь в интерпретации полученных результатов, является
представление на диаграмме столбцов. В следующей таблице показаны координаты
столбцов:
Категории курящих
1 Некурящие
1 Слабо курящие
1 Средне курящие
1 Сильно курящие
Измерение 1
-0,393308
0,099456
0,196321
0,293776
Измерение 2
0,030492 |
-0,141064 |
-0,007359 |
0,197766 |
Можно сказать, что первая ось дает градацию интенсивности курения.
Следовательно, большую степень сходства между Старшими менеджерами и Секре-
Анализ соответствий
567
тарями можно объяснить наличием в данных группах большого количества
Некурящих.
Метрика координатной системы. В ряде случаев термин расстояние
использовался для обозначения различий между строками и столбцами матрицы
относительных частот, которые, в свою очередь, представлялись в пространстве меньшей
размерности в результате использования методов анализа соответствий.
В действительности расстояния, представленные в виде координат в
пространстве соответствующей размерности, — это не просто евклидовы расстояния,
вычисленные по относительным частотам столбцов и строк, а некоторые взвешенные
расстояния.
Процедура подбора весов устроена таким образом, чтобы в пространстве более
низкой размерности метрикой являлась метрика хи-квадрат, учитывая, что
сравниваются точки-строки и выбирается стандартизация профилей строк или
стандартизация профилей строк и столбцов или же сравниваются точки-столбцы и
выбирается стандартизация профилей столбцов или стандартизация профилей
строк и столбцов.
Оценка качества решения. Имеются специальные статистики, помогающие
оценить качество полученного решения. Все или большинство точек должны быть
правильно представлены, то есть расстояния между ними в результате
применения процедуры анализа соответствий не должны искажаться. В следующей
таблице показаны результаты вычисления статистик по имеющимся координатам строк,
основанные только на одномерном решении в предыдущем примере (то есть
только одно измерение использовалось для восстановления профилей строк
матрицы относительных частот).
Координаты и вклад в инерцию строки:
[ Группа
сотрудников
1 Старшие
менеджеры
1 Младшие
менеджеры
1 Старшие
сотрудники
Младшие
сотрудники
Секретари
Координаты
измер. 1
-0,065768
0,258958
-0,380595
0,232952
-0,201089
Масса
0,056995
0,093264
0,264249
0,455959
0,129534
Качество
0,092232
0,526400
0,999033
0,941934
0,865346
Относит,
инерция
0,031376
0,139467
0,449750
0,308354
0,071053
Инерция
измер. 1
0,003298
0,083659
0,512006
0,330974
0,070064
Косинус**2 1
измер. 1
0,092232
0,526400
0,999033
0,941934
0,865346 |
Координаты. Первый столбец таблицы результатов содержит координаты,
интерпретация которых, как уже отмечалось, зависит от стандартизации. Размерность
выбирается пользователем (в данном примере мы выбрали одномерное
пространство), и координаты отображаются для каждого измерения (то есть отображается
по одному столбцу координат на каждую ось).
Масса. Масса содержит суммы всех элементов для каждой строки матрицы
относительных частот (то есть для матрицы, где каждый элемент содержит
соответствующую массу, как уже упоминалось выше).
Если в качестве метода стандартизации выбрана опция Профили строк или
опция Профили строк и столбцов, которая установлена по умолчанию, то координа-
568
Глава 15. Анализ соответствий
ты строк вычисляются по матрице профилей строк. Другими словами,
координаты вычисляются на основе матрицы условных вероятностей, представленной
в столбце Масса.
Качество. Столбец Качество содержит информацию о качестве представления
соответствующей точки-строки в координатной системе, определяемой выбранной
размерностью. В рассматриваемой таблице было выбрано только одно измерение,
поэтому числа в столбце Качество являются качеством представления результатов
в одномерном пространстве. Видно, что качество для старших менеджеров очень
низкое, но высокое для старших и младших сотрудников и секретарей.
Отметим еще раз, что в вычислительном плане целью анализа соответствий
является представление расстояний между точками в пространстве более низкой
размерности.
Если используется максимальная размерность (равная минимуму числа строк
и столбцов минус один), можно воспроизвести все расстояния в точности.
Качество точки определяется как отношение квадрата расстояния от данной
точки до начала координат, в пространстве выбранной размерности, к квадрату
расстояния до начала координат, определенному в пространстве максимальной
размерности (в качестве метрики в этом случае выбрана метрика хи-квадрат, как
уже упоминалось ранее). В факторном анализе имеется аналогичное понятие
общность.
Качество, вычисляемое системой STATISTIC А, не зависит от выбранного
метода стандартизации и всегда использует стандартизацию, установленную по
умолчанию (то есть метрикой расстояния является хи-квадрат, и мера качества может
интерпретироваться как доля хи-квадрат, определяемая соответствующей строкой
в пространстве соответствующей размерности).
Низкое качество означает, что имеющееся число измерений недостаточно
хорошо представляет соответствующую строку (столбец).
Относительная инерция. Качество точки (см. выше) представляет отношение
вклада данной точки в общую инерцию (Хи-квадрат), что может объяснять
выбранную размерность.
Качество не отвечает на вопрос, насколько в действительности и в каких
размерах соответствующая точка вносит вклад в инерцию (величину хи-квадрат).
Относительная инерция представляет долю общей инерции, принадлежащую
данной точке, и не зависит от выбранной пользователем размерности. Отметим,
что какое-либо частное решение может достаточно хорошо представлять точку
(высокое качество), но та же точка может вносить очень малый вклад в общую
инерцию (то есть точка-строка, элементами которой являются относительные
частоты, имеет сходство с некоторой строкой, элементы которой представляют
собой среднее по всем строкам).
Относительная инерция для каждой размерности. Данный столбец содержит
относительный вклад соответствующей точки-строки в величину инерции,
обусловленный соответствующей размерностью. В отчете данная величина приводится
для каждой точки (строки или столбца) и для каждого измерения.
Косинус**2 (качество, или квадратичные корреляции с каждой
размерностью). Данный столбец содержит качество для каждой точки, обусловленное
соответствующей размерностью. Если просуммировать построчно элементы столбцов
косинус**2 для каждой размерности, то в результате получим столбец величин Ка-
Анализ соответствий
569
чество, о которых уже упоминалось выше (так как в рассматриваемом примере была
выбрана размерность 1, то столбец Косинус 2 совпадает со столбцом Качество). Эта
величина может интерпретироваться как «корреляция» между соответствующей
точкой и соответствующей размерностью. Термин Косинус**2 возник по причине
того, что данная величина является квадратом косинуса угла, образованного данной
точкой и соответствующей осью.
Дополнительные точки. Помощь в интерпретации результатов может оказать
включение дополнительных точек-строк или столбцов, которые на
первоначальном этапе не участвовали в анализе. Имеется возможность для включения как
дополнительных точек-строк, так и дополнительных точек-столбцов. Можно
также отображать дополнительные точки вместе с исходными на одной диаграмме.
Например, рассмотрим следующие результаты:
1 Группа сотрудников
1 Старшие менеджеры
1 Младшие менеджеры
1 Старшие сотрудники
1 Младшие сотрудники
1 Секретари
1 Национальное среднее
Измерение 1
-0,065768
0,258958
-0,380595
0,232952
-0,201089
-0,258368
Измерение 2
0,193737
0,243305
0,010660
-0,057744
-0,078911
-0,117648 1
Данная таблица отображает координаты (для двух размерностей),
вычисленные для частотной таблицы, состоящей из классификации степени пристрастия
к курению среди сотрудников различных должностей.
Строка Национальное среднее содержит координаты дополнительной точки,
которая является средним уровнем (в процентах), подсчитанным по различным
национальностям курящих. В данном примере это чисто модельные данные.
Если вы построите двумерную диаграмму групп сотрудников и Национального
среднего, то сразу убедитесь в том, что данная дополнительная точка и группа
Секретари очень близки друг к другу и расположены по одну сторону
горизонтальной оси координат с категорией Некурящие (точкой-столбцом). Другими словами,
выборка, представленная в исходной частотной таблице, содержит больше
курящих, чем Национальное среднее.
Хотя такое же заключение можно сделать, взглянув на исходную таблицу
сопряженности, в таблицах больших размеров подобные выводы, конечно, не столь
очевидны.
Качество представления дополнительных точек. Еще одним интересным
результатом, касающимся дополнительных точек, является интерпретация качества,
представления при заданной размерности.
Еще раз отметим, что целью анализа соответствий является представление
расстояний между координатами строк или столбцов в пространстве более низкой
размерности. Зная, как решается данная задача, необходимо ответить на вопрос,
является ли адекватным (в смысле расстояний до точек в исходном пространстве)
представление дополнительной точки в пространстве выбранной размерности.
Ниже представлены статистики для исходных точек и для дополнительной точки
Национальное среднее применительно к задаче в двумерном пространстве.
570
Глава 15. Анализ соответствий
1 Косинус**2
Группа сотрудников
1 Старшие менеджеры
1 Младшие менеджеры
1 Старшие сотрудники
1 Младшие сотрудники
1 Секретари
| Национальное среднее
Качество
0,892568
0,991082
0,999817
0,999810
0,998603
0,761324
Измерение 1
0,092232
0,526400
0,999033 '
0,941934
0,865346
0,630578 ,
Измерение 2
0,800336
0,464682
0,000784
0,057876
0,133257
0,130746 |
Напомним, что качество точек-строк или столбцов определено как отношение
квадрата расстояния от точки до начала координат в пространстве сниженной
размерности к квадрату расстояния от точки до начала координат в исходном
пространстве (в качестве метрики, как уже отмечалось, выбирается расстояние хи-
квадрат).
В определенном смысле качество является величиной, объясняющей долю
квадрата расстояния до центра тяжести исходного облака точек.
Дополнительная точка-строка Национальное среднее имеет качество, равное
0,76. Это означает, что данная точка достаточно хорошо представлена в
двумерном пространстве. Статистика Косинус**2 — это качество представления
соответствующей точки-строки, обусловленное выбором Пространства заданной
размерности (если просуммировать построчно элементы столбцов Косинус 2 для
каждого измерения, то в результате мы придем к величине Качество, полученной
ранее).
Графический анализ результатов. Это самая важная часть анализа. По
существу, вы можете забыть о формальных критериях качества, однако
руководствоваться некоторыми простыми правилами, позволяющими понимать графики.
Итак, на графике представляются точки-строки и точки-столбцы. Хорошим
тоном является представление и тех и других точек (мы ведь анализируем связи
строк и столбцов таблицы!).
Обычно горизонтальная ось соответствует максимальной инерции. Около стрелки
показан процент общей инерции, объясняемый данным собственным значением.
Часто указывают также соответствующие собственные значения, взятые из
таблицы результатов. Пересечение двух осей — это центр тяжести наблюдаемых точек,
соответствующий средним профилям. Если точки принадлежат одному и тому же
типу, то есть являются либо строками, либо столбцами, то чем меньше расстояние
между ними, тем теснее связь. Для того чтобы установить связь между точками
разного типа (между строками и столбцами), следует рассмотреть углы между ними с
вершиной в центре тяжести.
Общее правило визуальной оценки степени зависимости заключается в
следующем.
О Рассмотрим 2 произвольные точки разного типа (строки и столбцы
таблицы).
О Соединим их отрезками прямых с центром тяжести (точка с
координатами 0,0).
О Если образовавшийся угол острый, то строка и столбец положительно кор-
релированы.
Пример 1 (анализ курильщиков)
571
О Если образовавшийся угол тупой, то корреляция между переменными
отрицательная.
О Если угол прямой, корреляция отсутствует.
Рассмотрим анализ конкретных данных в системе STATISTICA.
Пример 1 (анализ курильщиков)
Шаг 1. Запустите модуль Анализ соответствий.
В стартовой панели модуля имеются 2 вида анализа: Анализ соответствий и
Многомерный анализ соответствий.
Выберите Анализ соответствий. Многомерный анализ соответствий будет
рассмотрен в следующем примере.
Шаг 2. Откройте файл данных smokingsta папки Examples.
вмй : определение таблицы
Метод
;(• Амдли» соотмтстемА (АС)
: Входные данные ~ у--
'; С Иоюдные данные {требуется гдбудядия}.
:| С Д«стеты с груишруошш»! переметили
Часхоты без грушмруоеца перепет мш
С Многомерный анализ соответствий (МАО
Вы можете табулировать
переменную с помощь»
кодов или задать таблицу
<«cwr с кооируошими
в
3
Отмена |
»ттттттттяА* .
I Г» Частоты бед п>у1пмр»оеца перелета*» j w* с «*ип»эшими ^ • • ..;.
:Щ»в»1адо/вк»ыогс>еделтъмаяри^ Берта для М^ пввем»аамм>Ния*бе$ни4 ™/Денные*
''" :"'™ ^'~' *:"•**-*•*■-"■■•-* :•'•-—г ; ■;.. ' • • "^.:. ?^, "ЗАМБМАН!^: 2сл*аЙ;
в
л QepeMciame с *естотеми
ВСЕ
ездоке; Ofciiidtpano бЬдоо :
..- ^ одной *1ВрвменЮ^й.
-.* бмав!промавая§нч^--Г;
. енаяиэмногоежжпвой-
таблицы' •••.-. JVS.
В файле содержатся данные о распространении курения среди сотрудников
фирмы.
щ Данные SMOKING STA 4п ■ !
ЧИСЛОВЫЕ
€п>жж*жж*т----:-?
Simple со
HETJ
рЩ1Щи1Щ\ 41
ст. сотрудники
мл.сотрудники
секретари
25
18
10
rrespondence
СЛАВО
г
3
10
24
б
Н13ЁП
analysis exi
СРЕДНЕ
сильно 1
3 2{
7 4 i
12 4
33 13
7 2!
Файл уже представляет собой таблицу сопряженности, поэтому табуляция не
требуется. Выберите вид анализа — Частоты без группирующей переменной.
Шаг 3. Нажмите кнопку Переменные с частотами и выберите переменные для
анализа.
В данном примере выберите все переменные.
572
Глава 15. Анализ соответствий
2СЛАБ0
ICI'IJIHE
Отмене
J Выбрать ocoj
П.,
рог
Ддвроб |
И»*
Шаг 4. Нажмите ОК и запустите вычислительную процедуру. На экране появится
окно с результатами.
юшшшшшшшт
FTxl
Число переменных (столбцов в таблице):
Число маблжшеиии (строк в таблице):
Соб. знач.: .0748 .0100 .0004
Общий хи-квадрат*16.4416 сс-12 р-,1719
1 '«уи'жу;^
" *****
Н»станм^1^о>ш<мц<| иаггрмщм || *Ц Проспим строк.. ';
sou
^gii^^j
IGO ,'fryft* im r> jE3 &| G£ эн
Ш cH^Wx'lB^ji^Ml
СтеН**рТИ«*AИЯ
w»H,.? ч!'-^:
i^k{>^t®^ll)n«ib"
Ш Cm. «i т*Л* 1ЕЗ 2ИI C£ 9И ]
Не&доеемы* частоты
Проценты по строке
* l1fio«wru no столокj
Прокеитм от общего -
НооЖ мжцс одреномыо |
•• Вклад Pw«iMpOT
Сг ендерти*, отклонения I
Г" Градик только выбрей, измерений
Г* Сократить метки до Р~й>
Г Одинаковые ХЛ7£) оси
Дне построенет ЭМ <>ютограмм исяо/1ьдуйг§ быстры! „ <v * *
Дополнительные точкн-столокы и точки-строки - -- -:,:
^ • * б«до еключены • таблицы
Ц Добелить точки-столо'кы
нвт результатов и графики.
Шаг 5. Рассмотрим результаты с помощью опций данного окна.
Обычно сначала рассматриваются графики, для чего имеется группа кнопок
График координат.
Графики доступны для строк и столбцов, а также для строк и столбцов
одновременно.
Размерность максимального простарнства задается в опции Размерность.
Наиболее интересна размерность 2. Заметьте, что на графике, особенно если
имеется множество данных, метки могут накладываться друг на друга, поэтому
может быть полезной опция Сократить метки.
Нажмите третью кнопку 2Mb диалоговом окне. На экране появится график:
Пример 1 (анализ курильщиков)
573
ItII1 IMI'mH ",м^|, ||
2М график координат строк и столбцов
0.30
0.25
0.20
0.15
0.10
0.05
0.00
-0.05
-0.10
-0.15
-0.20
с I.менеджер
НЕТ
СТ.СОДОДНМКИ
секретари
мшменеджер
+
СИЛЬНО
Центр тяжести
СРЕДНЕ
мл.сотрудники
СЛАБО
-0.2 -0.1 0.0 0.1
Измерение 1; 87.76 %
Коорд.стр.
Коорд.сш.
Заметьте, что на графике представлены оба фактора: группа сотрудников —
строки и интенсивность курения — столбцы.
Соедините отрезком прямой категорию СТАРШИЕ СОТРУДНИКИ, а также
категорию НЕТ с центром тяжести.
Образовавшийся угол будет острым, что на языке анализа соответствий
говорят о наличии положительной корреляции между этими признаками
(просмотрите исходную таблицу, чтобы убедиться в этом).
Координаты строк и столбцов можно посмотреть и в численном виде с
помощью кнопки Координаты строк и столбцов.
НЕЗЕС
;"чамс'в.~;:|
Таблице вводе(СтрхСтолб) 5x4
Стандартизация Профили строк и столбцов
Столбец l^^^^g
Имя I^^^^Q
СЛАБО
СРЕДНЕ
СИПЬНО
1«Ц[ —^.
^Ш Координ.
1Ц измер.1
1| -393308
2 099456
3 196321
4 293776
Координ.
мзмвр.2
030492
-141064
-007359
197766
Масса
316062
233161
321244
129534
Качество
999995
984016
983228
994552
■■LJulJ
Относит,
инерции
577372
082860
148025
191743 -1
»
Г
Используя кнопку Собственные значения, можно увидеть разложение
статистики хи-квадрат по собственным значениям.
Опция График только выбранных измерений позволяет просмотреть
координаты точек по выбранным осям.
574
Глава 15. Анализ соответствий
Группа опций Просмотр таблиц в правой части окна позволяет просмотреть
исходную и ожидаемую таблицу сопряженности, разности между частотами и
другие параметры, вычисленные при гипотезе независимости табулированных
признаков (см. главу Построение и анализ таблиц, критерий хи-квадрат).
Таблицы большой размерности лучше всего исследовать постепенно, вводя по
мере надобности дополнительные переменные. Для этого предусмотрены опции:
Добавить точки-строки, Добавить точки-столбцы.
Пример 2 (анализ продаж)
В главе Анализ и построение таблиц был рассмотрен пример, связанный с
анализом продаж. Применим к данным анализ соответствий.
Ранее отмечалось, что вопрос, какие именно покупки произвел покупатель при
условии, что куплено 3 товара, является сложным. •
Действительно, всего мы имеем 21 продукт. Чтобы просмотреть все таблицы
сопряженности, требуется выполнить 21x20x19 = 7980 действий. Число действий
катастрофически возрастает при увеличении товаров и количества признаков.
Применим анализ соответствий. Откроем файл данных с индикаторными
переменными, отмечающими купленный продукт.
БЕЗАЛКОЛ
КОЛБАСЫ
2
1
L.
7_
!_
11
11
I
0 00
0 00
0 00
1 00
1 00
0 00
0 00
1 00
0 00
0 00
0 00
0 00
1 00
ооо£
1 00
1 00
1 00
000
100
0 00
100
1 00
1 00
1 00
Too)
1 00
1 00
1 00
1 00
1 00
0 00
1 00
0 00
koHCEPBb
1 00
0 00
| 0 00
0 00
0 00
0 00
0 00
100
100
0 00
0 00
КОФЕ
1 00
0 00
0 00
1 00
0 00
0 00
000
0 00
100
0 00
0 00
7
vlAKAPOHb
000
0 00
0 00
0 00
000
000
000
0 00
0.00
0 00
0 00
МЯЕ31
11
8
МУКА
0 00
0 00
0 00
0 00 1
0 00 !
0 00
100
0 00
100
0 00
0 00
н
В стартовой панели модуля выберем Многомерный анализ соответствий.
I 1Ш1|1!!1|.Щ|. LIJ.!..UJI.|l,H.lllJ.IJ,U.HJHWW^a—^ШТП
I (АС) О МногонариыЛ мммма соответствий (MAC)
Входные *
С Яастотмс
С Чжлогы бе* грутирукниж
, Вм*юж«г*табулировать I Ез ifl&
переменило с помошыо
коде» ил< эеаетъ таблицу
частот с коаодошимй
Отмен*
* частоты ос» групираюшии пвр w частот с *св>*<уюшим* ^ |
UW**>» должны определять матрицу Берге для MAC) лереме1»»*ии1или6о»инк1. 1С? Дичма |
Деремеиные {«fterrop+i ш тебаме.» Сорта) 13 S13141719 21
&о*ыааягрдпомр»юаив>поре<1гн«11|1м [выбраны
E3 Доподиитеаьиые стоабцы Ь
*J 17 19 21
& в|
Зададим условие выбора наблюдений.
Пример 2 (анализ продаж)
575
ЕЕН
Зц_илооои. Цкм ТоАлй у. пеший омборо)*
ы
S
Состояние • Операторы:- <><><• >»N0TAND0R £* Ощрыть
<• BKfl Переменные: имена или v1.v2... ~*~«—-————
: -Не»«рHfpVwwHtwrDO -• ill
fv7<1 OR v9«VES1 end v4o$
Это условие позволяет выбрать покупателей, сделавших ровно 3 покупки.
Поскольку мы имеем дело с нетабулированными данными, выберем вид
анализа Исходные данные (требуется табуляция).
Для удобства дальнейшего графического представления выберем небольшое
количество переменных. Выберем также дополнительные переменные (см. окно
ниже). >
iiii,ijjujjj;uiM
[3 КОЛБАСЫ
}э молоко
12 МЯСО
13 ОВОЩИ
14 РЫБА
I/-СПИРТНОЕ
19 СЫРЫ
?1 ХПГК
жп
JhMOHa_ J
IftMoptbocj
Dpmpod.
рвг
Запустим вычислительную процедуру.
\*шттттттшттттят
Число анализируемых столбцов в таблице: 10
Переменные и число категории:
КОЛБАСЫB) МОЛОКОB) МЯСО С) 0В0КИB) РЫБАB)
спиртное (г) сыры I г \ хш: <:)
(Дополнительные факторы выделены выше)
Соб. знач.: .2953 .2265 .1949 .1805 .1028
Обшии хи-кваярат-604.045 сс-81 р-0.000
(Хи-квадрат (ее, р) истинно только при использовании двувход. таблицы)
Координаты столбцов*
BU lf;O(M*T90HNM9 ЗИо^вИМР!
Раэмоомость
——— в» Радмарност»: |2
15 ' ''"• ■" 3f*w»r-Лотт}
В Ностатчггм^жмчмо матрицу |
Греецаш коараммапг''.:''' ..~^*...:«~..*. ~-~.-|Просмртртаба<
Г" Гоаац* тоаьио выбрившие ни юдениЛ *; ЯШ Набавщ.
!« 1
Отмена
Дачат»
АО!»
Г., -~-т=55|
Г Сократить метам до р Ц
Г* Оанцмоамв ХЛТрП ми
устоты
■ ffl Проааиш ро строи»
: Д| Промокли по столбца | Щ
Ш Орощлтыотоощог» \Ш Сучытттиа. отачХиним
ц ■' inriijii|iliiiiiimi и . i|i ш nj'im iji> i>< iiii»i
flilll I HiyiMiHi Hi riii-WfMTlMA.IilTliita.li/lia A MIHUi i*
Дмпостро§ии«ЭМгмсгогр»<мц
статистически* графики, оост^нм»и»т*$йицреэ5*лктвп».
В появившемся окне Результаты многомерного анализа соответствий
просмотрим результаты.
576
Глава 15. Анализ соответствий
С помощью кнопки 2М выводитм двуыерншй график переменных.
На этом графике дополнительные переменные отмечены красными точками,
что удобно для визуального анализа.
Заметьте, что каждая переменная имеет признак 1, если товар куплен, и
признак 0, если товар не куплен.
Рассмотрим график. Выберем, например, близкие пары признаков — МЯСО:1
и ОВОЩИ:1, СЫРЫ:1 и КОЛБАСЫ.1 — и присоединим к ним переменную ХЛЕБ.
1.6
1.4
1.2
1.0
0.8
0.6
0.4
0.2
0.0
-0.4
Я .6
ал
1.0
2М график столбцов
КОЛБАСЫ.О
МЯСО:1
ОВОЩИ:1
{близкие товары при з-х покупках!
СПИРТНОЕ :+1
МОЛОКО:0
1.2 1.0 -0.8 -0.6 -0.4 -0.2 0.0 0.2 0.4
Измерение 1; 29.53 4
0.6 0.8 1.0 1.2 1.4
Коорд.стл.
Доп.столб.
В итоге получим следующее:
Д*«ее~
мясо овощи
GJ.-0 QJ:0
QJ 0 CUM
Всего
алл сия
Частоты выделенных *чеек> 10
(Итоговые маргинальные не отмечены)
ХЛЕБ
СЦ:0
17
М
31
1С
1С
24
55
29
10
39
11
16
55
вСвГО
по. стр.
46
24
70
23
17
40
110
нжзяЕЕшап
Деле*.*»
ХЛЕБ СЫРЫ
• CLT*: OJM
J&2L
0.2:1 ОЛЯ
Частоты выделенных ямеек> 10
|(Итоговые маргинальные не отмечены)
КОЛБАСЫ
QJ.0
всего
по стр.
36
4
40
29
1
30
70
13
2
15
СО
25
40
49
6
55
49
6
55
110
Аналогичные исследования можно провести и для других данных, когда отсут
ствуют какие-либо априорные гипотезы о зависимостях в данных.
Примеры анализа
данных в системе
STATISTICA
В этой главе мы рассмотрим несколько примеров анализа данных с помощью
системы STATISTICA. Первый пример относится к области маркетинга (мы
показываем возможности модуля Множественная регрессия)у три следующие
примера — к промышленным приложениям (мы показываем возможности модулей
Планирование эксперимента и Карты контроля качества), пятый пример
иллюстрирует возможности STATISTICA по наложению результатов анализа на
географические карты.
Еще раз отметим, что современная STATISTICA — это средство разработки
приложений в конкретных областях (бизнесе, медицине, промышленности и др.).
Библиотека STATISTICA содержит более 10 000 тщательно отлаженных и
проверенных на практике процедур анализа данных. Развитие системы естественно приводит
к созданию средств разработки собственного интерфейса и использования
библиотеки STATISTICA для создания оригинальных модулей, включающих, наряду
с процедурами STATISTICA, алгоритмы разработчика. Все эти процедуры
объединяются общим интерфейсом, средствами управления данными и графикой
STATISTICS
Именно в создании средств для разработки приложений мы видим будущее
систем анализа данных.
Пример 1
Пример основан на реальных данных, описывающих рынок пива в Греции (см.
статью Kioulofas К. Е. «An Application of Multiple Regression Analysis to the Greek Beer
Market» в журнале «Journal of Operational Research Society», Vol. 36, № 8, p. 689-
696,1985).
Известно, что этот рынок поделен между 5 фирмами, обозначенными далее А,
В, С, D и Е. До 1981 года на рынке присутствовали фирмы А, В и С, в 1981 году на
рынок пришли фирмы D и Е. Но уже в 1983 году фирма D не выдержала
конкуренции, а у фирмы А возникли финансовые проблемы.
Фирма/год
А
В
С
D
Е
1980
27,6
28,6
43,8
-
-
1981
21,3
22,0
33,8
14,7
8,2
1982
21,3
22,0
33,8
14,7
8,2
16
578
Глава 16. Примеры анализа данных в системе STATISTICA
В следующей таблице представлены объемы продаж в отрасли и доля каждой
фирмы
Фирма/ Год
В целом
А
В
С
D
Е
1980
Знач. %
7 646,287 100,0
1926,300 25,2
2 347,987 30,7
3 372,000 44,1
-
-
1981
Знач. %
10 458,140 100,0
1571,417 15,0
3 073,511 29,4
4 381,000 41,9
596,755 5,7
835,457 8,0
1982
Знач. %
13 475,974 100,0
1595,742 11,8
3 660,954 27,3
5 677,000 42,1
1042,278 7,7
1500,000 11,1
1980 г. 1981 г.
Можно заметить, что после появления фирм D и Е произошло резкое
снижение доли фирмы А. Две новые фирмы D и Е по-разному освоили рынок. Фирма D
имела большие производительные способности, чем фирма Е, но заметно отстала
по объемам продаж. Этот пример интересен тем, что показывает соотношение
затрат на рекламу и производство.
Будем считать, что основным показателем эффективности рекламы является
объем продаж фирмы. В этой таблице представлены расходы на рекламу каждой
фирмы и ее доля в рекламе.
Фирма/ Год 1980 1981 1982
Знач. % Знач. % Знач. %
В целом 44,596 100,0 136,273 100,0 187,997 100,0
А
В
С
D
Е
12,667
13,897
18,050
-
-
28,4
31,2
40,4
-
-
6,747
38,174
39,581
21,340
30,421
5,0
28,0
29,0
15,7
22,3
22,298
43,079
65,114
20,687
36,519
11,9
22,9
34,6
11,0
19,6
Понятно, что вхождение в отрасль фирм D и Е потребовало больше расходов на
рекламу (в процентном отношении к объему продаж). Это отчетливо видно из
следующей таблицы:
Примеры анализа данных в системе STATISTICA
579
Фирма/год
А
В
С
D
Е
1980
0,7
0,6
0,5
-
-
1981
0,4
1,2
0,9
3,6
3,6
198:
1,4
1,2
1,1
2,0
2,5
1980 г. 1981 г.
Заметим, фирма D в 1982 году резко снизила расходы на рекламу, что,
возможно, стало причиной потери рынка.
Предполагается, что для рекламы используются следующие средства массовой
информации: телевидение, газеты, журналы и радио.
Эффективность рекламы в каждом случае различна, и возникает вопрос о
количественных зависимостях между объемом продаж и расходами на рекламу в
каждом из средств массовой информации. Обычно доля телевидения составляет 70-
90%, и поэтому в таблице, представляющей распределение расходов на рекламу
между средствами массовой информации, все СМИ, кроме телевидения,
объединены в одну группу «другие».
На реальный объем продаж пива влияют также такие факторы, как
температура воздуха, число туристов и индекс потребительских цен (инфляция).
В предлагаемой модели теоретическая зависимость основывается на
предположении, что объем продаж за период t (далее это месяцы) является функцией
объема продаж за прошлый период расходов на рекламу в периоды t и t-1,
количества туристов, значений температуры и индекса розничных цен.
st = ь0+ед_, + b2At + М-, + ъАт( + b5wt + b6pt,
где
St — объем продаж (в драхмах);5
At — ассигнования на рекламу;
Tt — число туристов в месяц t;
Wt — средняя температура воздуха;
Pt — индекс розничных цен.
580
Глава 16. Примеры анализа данных в системе STATISTICA
Итак, мы построили модель зависимости, но коэффициенты этой модели
неизвестны. Эти коэффициенты оцениваются из исходных данных в модуле
Множественная регрессия.
Оценка коэффициентов по методу наименьших квадратов выявила
статистическую незначимость переменных Wt и Pt> и они были исключены из дальнейшего
анализа.
В результате получилось уравнение, содержащее меньшее число переменных:
Sl=b0+blS„+b2Al+bA_l+bAT, (*).
Оценим коэффициенты этого уравнения, используя реальные данные.
Для анализа использовались данные о месячных продажах за 2 года. Число
наблюдений равнялось 24. Результаты регрессии приведены в таблице:
тг
0,52
0,22
0,25
0Д9
0,73
R2
0,801
0,881
0,893
0,703
0,317
0,600
н
1,56
1,95
1,14
-0,21
0,21
-0,68
С. о. Р.
132Д1
35,82
43,28
55,09
37,75
41,76
Фирмы
Отрасль
А
В
С
D
Е
■«
0,56
0,29
0,49
0,45
0,59
0,60
АГ
11,81
Л93
3,85
од
2,6
Значения коэффициента детерминации R2, близкие к единице, говорят о
хорошем приближении линии регрессии к наблюдаемым данным и о возможности
построения качественного прогноза.
Низкое значение коэффициента детерминации R2 для фирмы D объясняется
низкой эффективностью рекламной кампании и трудностями на
административном уровне. Можно сделать вывод, что модель плохо применима к фирме D.
Статистики Дарбина—Уотсона свидетельствуют об отсутствии
автокорреляции остатков при 5%-м уровне значимости, так как все ее значения по модулю
меньше 1,96.
Все значения регрессионных коэффициентов значимы при уровне
значимости 0,5, за исключением коэффициентов при At для фирм В, D и Е.
Одним из возможных объяснений этого факта является то, что показатели
этих фирм зависят от рекламной деятельности за прошлый период времени, то
есть от Ам.
Это подтверждается тем, что для этих фирм коэффициенты при At1 значимы
на уровне 95%. Более того, можно заметить, что показатели всех фирм, кроме
фирмы Е, имеют положительную корреляцию с числом туристов.
Незначительную корреляцию между туризмом и объемами продаж фирмы Е можно
объяснить недавним появлением этой фирмы. Объемы продаж всех фирм также
находятся под влиянием объемов продаж в прошлом периоде, 5М, возможно, благодаря
эффекту «привычки» потребителей к торговым маркам. Значимость этого
параметра с распределенным лагом также наводит на мысль о некоторых обучающих
эффектах.
Продажи фирмы А имеют значительную положительную корреляцию с ее
расходами на рекламу за период t, что отличает ее от других фирм. Окончательно вза-
Примеры анализа данных в системе STATISTICA
581
имосвязь между рыночными продажами и совокупными расходами на рекламу
положительна и значима при уровне 5%.
Представленные выше результаты регрессии образуют основу оценки
эффективности совокупных расходов на рекламу.
Покажем, как строятся такие модели в системе STATISTICA. Для этих целей
обычно используется модуль Множественная регрессия.
В этом модуле собраны методы, позволяющие оценить зависимость одной
переменной от нескольких других переменных.
Переменная, для которой строится зависимость, называется зависимой
(по-английски dependent variable). Эта переменная входит в левую часть уравнения,
описывающего зависимость (см. уравнение (*)). Переменные, от которых мы хотим
построить зависимость, называются независимыми переменными (по-английски
independent variables), или предикторами (от английского predict — предсказывать).
Эта переменная входит в правую часть уравнения, описывающего зависимость.
Сам термин множественная регрессия (по-английски multiple regression) означает,
что модель может содержать несколько предикторов, позволяющих предсказывать
зависимую переменную.
Итак, общая идея состоит в том, чтобы по значениям предикторов
предсказывать значения зависимой переменной, например, по значениям продаж и расходам
на рекламу в текущем и предыдущем месяце предсказывать продажи в следующем
месяце.
Конечно, количество предикторов можно увеличить, например, ввести объем
продаж у конкурентов или какие-то другие, имеющие смысл и доступные
наблюдению переменные. Однако здесь имеется тонкость — предикторы могут
оказаться зависимыми между собой.
Переменные, которые следует включить в модель, определяет специалист в
предметной области. Затем нужно выполнить следующие действия.
Шаг 1. Запустите модуль Множественная регрессия.
Шаг 2. Введите исходные данные в файл системы STATISTICA. Назовите его,
например, ВеегМа.
582
Глава 16. Примеры анализа данных в системе STATISTICA
7
а
9
10
и
п
13
14
1Б
16
17
16
19
20
21
22
23
24
щ
зал
зкшшаш
■ г....
'« •
У -J 4 ь
У1,24
шз;
ВЬ4с
86'
■••''»?*f
Щ j 11
• \;;-
. 11:23
о 4
lfflflfffflKH
1
16 9
11758 5
118672
9577 6
10898 4
9638 6
92039
9231 1
7334 5
7467 0
7839 6
9787.0
9600 3
71999
9547 7
101875
9661 2
9189 2
I
2
SI
88621
8646 9
117585
118672
9577 6
10898 4
9638 6
9203 9
9231 1
7334 5
7467 0
78396
9787 0
9600 3
7199 9
95477
101875
9661 2
' К
1 :is
*few*
', ЛО 0
_> 2ju ь
: jj4 i.
• JJ2 <:
: 4 зу 2
6 ?b 2
.•?:. Ari....I
Ш^
1404 ••'
igMmi
.,3 :,
A
4160
327 7
1606
4031
269 7
280 5
3351
169 3
206 0
2161
322 2
285 5
79 2
333 6
2931
238 5
255 4
383 6
•ч A -
. A1
2128
4160
327 7
160 6
4031
269 7
280 5
3351
169 3
206 0
2161
3222
285 5
79 2
333 6
2931
238 5
255 4
S
т
1741 5
2060 0
1777 8
13789
1253 3
794 0
1384 4
1392 5
2484 3
2777 5
3301 9
3635 9
34159
2606 8
2508 0
2834 1
2481 8
14744
, Г-,
а
•)
20
-Ь
гь
J 2
18
1 1]
•!■■>
2 101
4 ' 103
1 1U*
7 и:
j и j
Ь 114
7 ib
Ь 11»
7 12:
W
22 8
187
155
11 7
56
65
81
103
97
22 4
20 6
26 8
27 8
183
120
97
51
28
21
^pj
<• j
- i
4
■ -iOixfl
•7.::....
p
1141
1160 j
116 6
1226 |
1195 |
130 6
1250 I
1242 |
1307
131 6 '
133 4
1391 i
1423 ]
139 9
144 5
1439
148 0 j
1493
Г1,
Шаг З. Определите переменные в модели. Задайте S в качестве зависимой
переменной и S1...P — в качестве независимых переменных, или предикторов. После
этого стартовая панель модуля будет выглядеть так:
&ййл »М««:| Исходные данные J*j
Уодмим* ГЩ.| Пострлчипя ^|
Тшден*с«им;|(:1а«в<нпнаи ^J
fx Провести ihmm* mi уйциатяв |и* поцычжыЛ] ' • *£
Г По&Ч*»»Т» ОЛИСДОМЫ** СДОИЛИ**. Ыфр. К*Т|Н«М* •;
Г* Пл1*.ти<** &,paforH,*Jn&4ati?' '" *
Г" М*\$#< 4Г»Ь $**--*$( *H>*»TWS 4МЛ4И&Ф ОЛ**»*.»*»
Звцй?» »ц» гщи»#» »»и? д<ю dmmt* асстояыяуьнм* мацми '
HHHHlInl
IB ' Ш \ j
1 n™»* I
%fUl&fil
•<*
^ .. , :s ,.|
Примеры анализа данных в системе STATISTICA
583
Шаг 4. Нажмите кнопку ОК. Появится диалоговое окно результатов, в котором
отображаются итоги стандартной процедуры.
Измените процедуру на Пошаговую с включением. Для этого нажмите на
кнопку Отмена и в появившемся диалоговом окне Определение модели выберите в поле
Процедура опцию Пошаговая с включением. В этой процедуре система начинает
построение модели с одного предиктора, затем, используя F-критерий, в модель
включается еще один предиктор и т. д. На каждом шаге вычисляется коэффициент
множественной корреляции. Квадрат коэффициента множественной корреляции,
коэффициент детерминации, свидетельствует о качестве построенной модели.
Нажмите кнопку ОК.
Ж
В а*
ОтмжяД
13
СреЛошмЛ члш: | Добавить в модель Н
1о«р«тюс?ь: | 00010 g рР<аиг»РД «ngJw нмп»
• В5 Просмотр*!» ooHCf <ь»ца стотжтики
В появившемся окне Пошаговая множественная регрессия снова нажмите (Ж.
blM'J.MIHi.
;ест»е«н«* оегоессяя
».rja:4*tmn
'.[.«г: ■'* У-мсг»«гиг>: .'Л.?»':
::ЕЛ1 ::£ = «:!
■■;■<;/*.■'■ j'|'s«s<^^^'
Г»ДИmi
Теперь перед вами диалоговое окно результатов, полученных с помощью
пошаговой процедуры с включением. Следует отметить, что в нем указаны
стандартизованные коэффициенты регрессии.
Заметим, если вы предполагаете, что в модели должно присутствовать неболь
шов число предикторов, то естественно использовать пошаговый метод с
включением предикторов. Если вы предполагаете, что в модели должно присутствовать
большое число предикторов, то естественно использовать метод с исключением.
584
Глава 16. Примеры анализа данных в системе STATISTICA
Р
i л in и urn, т—т
Сол/нь?aiH множ роцюссии (Ui.ti
:Ja«»iwpcM S Мможосгп R J£jP#**o37 f UH
\\7 m»ft3030? cc 4.19
Число нлСп 7Л скоррокт N? A4 /?0049 p 00<
С|<11Ш.'ф1Н11Я «>A1и0к.'1 <н»онки 3I2.980046W
свовчлон '\'2)У ?.nms? с г ошибка н;и <т t( 14}
123
:> 44*: р '. оо?/
ТНИ
Шаг 5. Нажмите кнопку Итоговая таблица регрессии. Появится таблица
результатов с подробными статистиками.
В столбце БЕТА показаны стандартизованные коэффициенты регрессии, а в
столбце В — нестандартизованные коэффициенты. Все коэффициенты в таблице
значимы, так как р-значения для каждого из них меньше заданной величины 0,05.
lll^llllll'l.lllllllMliyji'llllfllMllflJwl
97794837 R2- 95638302 Скорр R2-
19)04 15 р< 0000 С» ow оценки
94720 :
312 98;
Щ±
mm
Щ^ощ,
шж
ШШ±
1 02954
66535
30767:
29160
-3211 3931.414-3.4478 00270!
05484 15 3 812 18 7733 00000<
05609 7 05611 8627 .000001
05983 5 099 5 1424 00006:
05965 4 2 869 4 8887 00010:
Шаг 6. В окне результатов нажмите кнопку Анализ остатков,
гзвшшвзшшшшшшшшшшшшшшшшшшшшт
пщ
•:*чу; «м<п« -f.w .?-■)> г» «.хну» "••< <:)* ♦.
*?
itmmtMtt'n
r^*fr^ftrl&t
штш
m гтшущ пир ч hi » цн
)|м 1МММ«айи*и Ml •■
ait- lGft««»»»
]Ж&!££^^
JS=
4*un»w «ем*** Ц
Шаг 7. В диалоговом окне Анализ остатков нажмите кнопку Статистика
Дарвина—Уотсона. Эта статистика позволяет исследовать зависимость между
остатками. Формально остатки представляют собой разность: наблюдаемые значения
зависимой переменной минус оцененные с помощью модели значения зависимой
переменной.
Примеры анализа данных в системе STATISTICA
585
Зачем проверять зависимость остатков? Идея проста: если остатки существенно
коррелированны (зависимы), то модель неадекватна (нарушено важное
предположение о независимости ошибок в регрессионной модели).
Рассмотрим более подробно статистику Дарбина—Уотсона. Мы уделяем этой
статистике так много внимания, потому что статистика Дарбина—Уотсона
является стандартом для проверки некоторых видов зависимости остатков и с ней нужно
научиться работать.
Статистика Дарбина—Уотсона используется для проверки гипотезы о том, что
остатки построенной регрессионной модели некоррелированы (корреляции равны
нулю), против альтернативы: остатки связаны авторегрессионной зависимостью вида:
е,-**,.,+5, С).
где d. — независимые случайные величины, имеющие нормальное распределение
с параметрами @, s), i = 1... п.
Формально статистика Дарбина—Уотсона вычисляется следующим образом:
d = ±(e-ej/±ef
/=2 / ;=1
Иными словами, сумма квадратов первых разностей остатков нормируется
суммой квадратов остатков. Проведя вычисления, вы легко выразите статистику
Дарбина—Уотсона через коэффициент корреляции: d = 2A — р).
Критические точки статистики Дарбина—Уотсона табулированы (см.,
например, Драйпер Н., Смит Г. Прикладной регрессионный анализ. М.: Финансы и
статистика, т. 1. с. 211, см. также таблицу, показанную ниже).
^^Критические точки DL_k и DU_k Дарб-Уотсона (уровень 0 05. число предикторов_к) ^j
ТЕКСТ
ш
16
17
18
19
20
21
22
23
24
25
26
27
26
29
30 ;
Критическ
__-
WSBL
1.080|
1.100
1.130
1.160
1.180
1.200
1.220
1.240
1.260
1.270
1.290
1.300
1.320
1.330
1.340
1.350
Ав ТОЧКИ
2
OU_t
1.360
1.370
1.380
1.390
1.400
1.410
1.420
1.430
1.440
1.450
1.450
1.460
1.470
1.480
1.480
1.490
DL_k и DU_k Дарб-Уотсона (уровень 0 05. число предикторов_к)
3
OL.2
.950
.980
1.020
1.050
1.080
1.100
1.130
1.150
1.170
1.190
1.210
1.220
1.240
1.260
1.270
1.280
4
1.540
1.540
1.540
1.530
1.530
1.540
1.540
1.540
1.540
1.550
1.550
1.550
1.560
1.560
1.560
1.570
S
OUT
.820
.860
.900
.930
.970
1.000
1.030
1.050
1.080
1.100
1.120
1.140
1.160
1.180
1.200
1.210
6
DU.J
1.750
1.730
1.710
1.690
1.680
1.680
1.670
1.660
1.660
1.660
1.660
1.650
1.650
,1.650
1.650
1.650
7 :.
OL.4
.690
.740
.780
.820
.860
.900
.930
.960
.990
1.010
1.040
1.060
1.080
1.100
1.120
1.140
.. : •: w
DIL4
1.970
1.930
1.900
1.870
1.850
1.830
1.810
1.800
1.790
1.780
1.770
1.760
1.760
1.750
1.740
1.740
.560
.620
.670
.710
.750
.790
.830
.860
.900
.930
.950
.980
1.010
1.030
1.050
1.070
10
OUL5
2.210
-|
-J
2.150
2.100 I
2.060
2.020
1.990 <
1.960
1.940
1.920
1.900
1.890
1.880
1.860
1.850 j
1.840 |
1.830
*i
586
Глава 16. Примеры анализа данных в системе STATISTICA
31
зг
33
34
35
36
3?
за
39
40
45
50
S5
50
66
70
75
86
т
9S 5
100
ки,
1.360
1.370
1.380
1.390
1.400
1.410
1.420
1.430
1.430
1.440
1.480
1.500
1.530
1.550
1.570
1.580
1.600
1.620
1.630
1.640
1.650
1.500
1.500
1.510
1.510
1.520
1.520
1.530
1.540
1.540
1.540
1.570
1.590
1.600
1.620
1.630
1.640
1.650
1.670
1.680
1.690
1.690
1.300
1.310
1.320
1.330
1.340
1.350
1.360
1.370
1.380
1.390
1.430
1.460
1.490
1.510
1.540
1.550
1.570
1.600
1.610
1.620
1.630
1.570
1.570
1.580
1.580
1.580
1.590
1.590
1.590
1.600
1.600
1.620
1.630
1.640
1.650
1.660
1.670
1.680
1.700
1.700
1.710
1.720
1.230
1.240
1.260
1.270
1.280
1.290
1.310
1.320
1.330
1.340
1.380
1.420
1.450
1.480
1.500
1.520
1.540
1.570
1.590
1.600
1.610
1.650
1.650
1.650
1.650
1.650
1.650
1.660
1.660
1.660
1.660
1.670
1.670
1.680
1.690
1.700
1.700
1.710
1.720
1.730
1.730
1.740
1.160
1.180
1.190
1.210
1.220
1.240
1.250
1.260
1.270
1.290
1.340
1.380
1.410
1.440
1.470
1.490
1.510
1.550
1.570
1.580
1.590
1.740
1.730
1.730
1.730
1.730
1.730
1.720
1.720
1.720
1.720
1.720
1.720
1.720
1.730
1.730
1.740
1.740
1.750
1.750
1.750
1.760
1.090
1.110
1.130
1.150
1.160
1.180
1.190
1.210
1.220
1.230
1.290
1.340
1.380
1.410
1.440
1.460
1.490
1.520
1.540
1.560
1.570
1.830
1.820
1.810
1.810
1.800
1.800
1.800
1.790
1.790
1.790
1.780
1.770
1.770.
1.770
1.770
1.770
1.770
1.770
1.780
1.780
1.780
(шгшЕЕввашг
2,4
2,0
1,6
1,2
0,8
0,4
Верхние и нижние кршическме значения ci км ДарбинаУспсона
в зависимости oi числа наблюдений (альфа - 0.05)
"V
*-*
*-*
^ >■ *• ■* * * * * * -а * • * ■* * ■ i"■ :
:*■■*■
15 17 19 21 23 25 27 29 31 33 35 37 39 45 55 65 75 85 95
16 18 20 22 24 26 28 30 32 34 36 38 40 50 60 70 80 90 100
■ -Ш1х|
DL_1
DU_1
DL_2
DU_2
DL_3
DU_3
DL_4
DU_4
DL_5
DU_5
В таблице приведены два критических значения статистики Дарбина—Уотсо-
на: DL_k и DU_k — нижнее и верхнее, зависящие как от числа наблюдений, по
которым оцениваются параметры, так и от числа предикторов к, которые включены
в модель.
На графике видно, как меняются значения DL_k и DU_k в зависимости от
числа наблюдений (к = 1, 2,3,4, 5).
Число наблюдений, для которого рассчитаны критические значения, указано
в заголовках строк приведенной таблицы.
Примеры анализа данных в системе STATISTICA
587
Итак, вы находите строку с нужным числом наблюдений и два смежных
столбца с нужным числом предикторов. На пересечении строки и столбцов
располагаются нижние и верхние критические точки статистики Дарбина—Уотсона.
Если нужно проверить гипотезу: «остатки независимы, то есть р = 0», против
общей альтернативы р * 0, поступают следующим образом. Вычисляют значение
статистики Дарбина—Уотсона d. Для данного числа наблюдений и числа
предикторов находят критические точки DL_k и DU_k в таблице, составленной для
определенного уровня а. В приведенной таблице уровень а = 0,05.
Если d < DL_k или 4 — d < DL_k, то гипотеза о независимости остатков
отвергается на уровне 2а. Если d > DU_k и 4 — d > DU_k, то гипотеза о независимости
остатков не отвергается на уровне 2а.
Если нужно проверить гипотезу: «остатки независимы, р = 0», против
альтернативы р > 0, то есть остатки положительно автокоррелированы, поступают
следующим образом. Вычисляют значение статистики Дарбина—Уотсона d. Находят по
таблице критические точки DL_k и DU_k, вычисленные для определенного
уровня а. Заметьте, в приведенной таблице а = 0,05.
Если d < DL_k, то гипотеза о независимости остатков отвергается на уровне а
в пользу альтернативы.
Если d > DU_k, то гипотеза о независимости не отвергается на уровне а.
Случай DL_k < d < DU_k является сомнительным (см. рисунок).
ПГРАФИК1 STG ЛинеАныАгра
■ -1П1Х1
Применение критерия Дарбина Уотсона.
Гипотеза: "остатки независимы"
альтернатива: "остатки пополажпельно коррелированы"
2,4
2,0
1,6
1.2 \
0,4
"V
В этой области гипотеза
о независимости остатков
не отвергается
• ::::::::.:£Пт-гщрю1
**#>"*
В этой области гипотеза
о независимости остатков
отвергается
15 17 19 21 23 25 27 29 31 33 35 37 39 45 55 65 75 85 95
16 18 20 22 24 26 28 30 32 34 36 38 40 50 60 70 80 90 100
DL_1
DU_1
DL_2
DU_2
DL_3
DU_3
DL_4
DU_4
DL_5
DU 5
Если нужно проверить гипотезу: «остатки независимы, р = 0», против
альтернативы: р < 0, то есть остатки отрицательно автокоррелированы, то вместо d следует
рассмотреть значение 4 — d и повторить рассуждения предыдущего абзаца,
которые использовались для проверки гипотезы «остатки независимы, р = 0», против
альтернативы р > 0.
После того как мы познакомились со статистикой Дарбина—Уотсона,
продолжим работу в модуле Множественная регрессия.
Шаг 8. Нажмите кнопку Предсказанные и наблюдаемые.
588
Глава 16. Примеры анализа данных в системе STATISTICA
I.II.U..|l|ll.l.lJ.IJt.Ll.l!l!l!!Jl|!l.!.Mll,I.IJl.l.llXI.I.M
Предсказанные и набпюааемые значения
Зависимая перемен S
13500
12500k
11500 |
10500
9500
8500
7500
65ogt2l
^500
8500 9500 10500 11500 12500 13500
Предсказанные
Шаг 9. Вернитесь в окно Результаты множественной регрессии и нажмите
кнопку Предсказать зависимую переменную. Далее в полях Л1 wS1 укажите значения
текущего месяца, а в полях Г и А — значения на следующий месяц.
г ~ д ежи
3
А1
St
т
{9661
11500
|400
-Ah*
] Применить]
Нажмите кнопку ОК. Появится таблица результатов предсказания.
На рисунке выделена ячейка, содержащая прогнозируемый объем продаж на
следующий месяц.
i ЛШ\АШ
МНОЖЕСТВ
РЕГРЕС
Переи
А1
SI
.-.■*■ --т
.;>■■ ; а
СВ.члвх
lii|.H!P.UJii..lU.l.JlllH
Переменная S
,- хми»-
Значение
15 25167 383 000
66330 9661 000
50829 1500 000
4 24928 400 000
^^■ТТпГх!
IHbHEHf
5841 39 *
6408 10 \
762 44 i
1699 71 i
-3211 29 .:
1 11500 35 |
11171 42 ;
11829 28 i
Пример 2
Этот пример относится к промышленной статистике (см. Cornell J. A. A990). How
to Apply Response Surface Methodology, vol. 8 in Basic References in Quality Control-
Statistical Techniques, edited by S. S. Shapiro and E. Mykytka. Milwaukee: American
Society for Quality Control).
Любая машина или станок, используемые на производстве, позволяют
операторам производить настройки, чтобы воздействовать на качество производимого
продукта. Изменяя настройки, инженер стремится добиться максимального
эффекта, а также выяснить, какие факторы играют наиболее важную роль в
улучшении качества продукции.
Примеры анализа данных в системе STATISTICA
589
В системе STATISTICA имеется мощный модуль планирования
экспериментов, позволяющий эффективно планировать и анализировать эксперименты.
?шя\к р| факторные пг
Р, 2-i уровиеаые отсеивающие планы (Плакетта-Бермаиа) Г
Pt Максимально несмешанные 2""(к-р) --—
Отмена
Аналн» псу»»* *ттсря*
0, Планы Э"(кр) и планы БоксаБеикема ниарар»1<аСм|алож»»»а1
ЯР» Смешанные *-ш м Jmu уровневыв планы *>ш»ьмУпдмум> ат^кла -v
l£3?i Центральные композиционные планы, поверх, отклика q HtfUlfcH n/mwmtfiO
Латинские м греко-латинские квадраты
хб), Робастные планы Тагучм (ортогональные масси
Ь^ Планы для смесея
-)
|[£>j Планы для повержиостея и смесея с ограничен»
I[dJO- и А- (Т-) оптимальные планы
аов>лйш4И¥41йм| Фнмуая*
Д»С1МЦ!1101»»лЛе11»Й1«а, "
Ж i 1& ft
Задача состояла в том, чтобы исследовать факторы, влияющие на качество
производимых пластиковых дисков.
Известно, что наибольшее влияние на качество оказывают следующие два
фактора:
1) материал, характеризующийся отношением наполнителя к эпоксидной
резине,
2) расположение диска в форме.
В качестве зависимой переменной рассматривалась плотность полученного
диска.
Сначала использовался дробный факторный план 22 для того, чтобы
определить адекватность модели первого порядка. В этой модели оба фактора
комбинировались друг с другом на верхних и нижних значениях (всего имеется 4
комбинации). Но оказалось, что модель оказалась адекватной лишь для некоторой области
значений факторов и неадекватной для всей значений факторов. На самом деле
зависимость между факторами и откликом была нелинейной. Поэтому было
решено использовать центральный композиционный план и применить модель
второго порядка.
Построение плана
Центральный композиционный план может состоять из куба и звезды. Куб
соответствует полному факторному плану — точки эксперимента располагаются в
вершинах куба (фактически это факторный план 22).
Звезда содержит дополнительное множество точек, расположенных на
одинаковых расстояниях от центра куба на отрезках, исходящих из центра и
проходящих через каждую сторону куба.
В данном исследовании применялся ротатабельный план, в котором дисперсия
отклика является постоянной во всех точках, одинаково удаленных от центра
плана.
Пусть фактор А — это характеристика материала, из которого изготовлен диск,
более точно, так называемое композиционное отношение (disk composition ratio),
фактор В — положение диска в форме (position of disk in mold). Зависимая
переменная, или отклик эксперимента, — плотность диска {Thickness).
590
Глава 16. Примеры анализа данных в системе STATISTICA
Запустите модуль Планирование эксперимента.
На стартовой панели выберите Центральные композиционные планы,
поверхности отклика и нажмите кнопку ОК.
В появившемся диалоговом окне выберите опцию Построение плана, а в поле
Факторы/блоки/опыты — строку 2/1/10. Нажмите кнопку ОК.
Появится диалоговое окно План эксперимента для поверхности отклика.
Нажмите на кнопку Имена факторов, значения и заполните таблицу в диалоговом
окне Итоги для переменных так, как показано на рисунке.
ШШВЩ
Далее»
шшт
пин
Чтобы изменить метки факторов и их уровней и т п
[сделайте необходимые изменения и нажмите Далее
1-lOlxJ
8 B)
Их
1ВЯЯЩ
I ratio |
Вижк
:*еащ».->
Центр
Центр
Верхи. '
знамение
.750000
750000
Минимум
Минимум
825000
843750
Центр тч
Центр тч
■;«fff<«
900000 Максиму
937500 Максима. *t;
jE5
Нажмите кнопку Далее и выберите опции для настройки отображения плана
так, как показано на следующем рисунке. Сделайте точно все показанные
настройки, чтобы получить нужный результат!
IJJll!LIIJJiJ.JlJ!llJi.lJJJJ.ll!lJJl|.iJI,l.UIIIJ!.I.Hll!J.|J.!U.I.L И!Ш|.,.Ш11
ИТОГИ СТАНДАРТНОГО ПЛАНА:2**B) кубич. и эвеэд. точки (центр, гояп. план)
Число факторов: 2
Число блоков: 1
Число опытов: 10 пс-4 пз-4 пО-2
Альфа для ротатабельи.: 1.4142 Альфа для ортогональн.: 1.0781
Прасмотр/Праека/Сохренеиие • ■ ■■
Ш Просмотр/Праака/Сокраиемие
Обоз*, фаюгары
Г номерами
Г £укеая* '*
': № цмеиами '
Добавить к лиану
VI Ыие*а.факгарАВ.ацаяенк*~»)| j
fi*
Поря да* onwroe Отобразить
J <? стандартный , ^ Г чисад (tl.Ualpha)
: | ^ 1^У*1ей#1ы* <"* из займи \ > (? цнм^мамс *
|| С*у&*«*«о:% |пьг?н/| [| ij'O тежстоеие значен** <4
Отмена
8 окна
пенные дов*аиОДУ
пуста додвф* f»aa?<ie»4 |
цектр» тон» (и***
Характеристика иавиа- ** **■%—*'.-&^*^J
<? аддо* для ротата$ель*остн % * ? л ^>. «^«г***»
С 4льф» А« •втвсонвэьностн
Г неитрмрощмйые аае$д>ше"
i iiftiiiniOmiwiiSw iimnimii wiiinmi» wimWimini» m wnjlinwliifii 1 > frrfiifonitoHiMif;
Просмотрите план. Для этого нажмите Просмотр/Правка/Сохранение.
900000
900000
718934
931088
62S000
82S000
825000
825000
шиетив
I 750000
937500
750000
937500
843750
843750
711167
976333
843750
843750
ШЭ
1
i
i
1
i
\
■\
1
Примеры анализа данных в системе STATISTICA
591
Задание имени и сохранение
экспериментального плана
Выберите Сохранить как файл данных..:, появится соответствующее диалоговое
окно. Задайте имя плана disk.sta и нажмите кнопку ОК.
шваишяв
HliUllil
Имя файла:
IdiskJsta
ULi
Папки:
cleUQexample*
OK
N* W.SIA
В STAT
fe examples
DDEMO
Отмене
3^
Network...
J
1нп файлов:* Диски:
[файлы данных f*.sta) ^1 (He:
. Евиочая книг*: -::\ '
Вернитесь в диалоговое окно План эксперимента для поверхности отклика.
Нажмите кнопку Печать итогов. В зависимости от настроек вывода в
диалоговом окне Параметры страницы/вывода результаты плана будут распечатаны на
принтере или выведены в отчет.
В построенной таблице показан порядок сбора экспериментальных данных.
Данные, полученные в результате эксперимента, занесены в таблицу.
Номер Block Ratio
Mold
Thickness
1
2
3
4
5
6
7
8
9
10
1
1
1
1
1
1
1
1
1
1
0,75
0,9
0,75
0,9
0,718934
0,931066
0,825
0,825
0,825
0,825
0,5
0,5
1
1
0,75
0,75
0,396447
1,103553
0,75
0,75
7,3
7
7,1
8
7,6
7,4
7,4
7,9
8,2
8,3
Анализ экспериментальных данных
Проведем анализ полученных данных.
В диалоговом окне План эксперимента для поверхности отклика нажмите
кнопку Отмена. Вы возвратитесь к диалогу Центральные композиционные
планы.
592
Глава 16. Примеры анализа данных в системе STATISTICA
И1ШН5/2/44 8/5/82 <^ «
L&2/10 5/5/47
№1/16 БЛ/46
13/2/16 6/2/46
13/3/17 6/3/47
.ИЛ/26 7/1/80
Н4/2/26 7/2/80
14/3/27 7/5/83
=15/1/27 7/9/87
E/2/28 8/1/82
ф/1/44 8/2/82
&*vit*
5SM
4/j/ia
>/1/?4
|с>/^/эо
7/1/40
Г/4П
JO/1/M
W/'.-l
•ЛЧЛ'< <C?Ja.-' i& '}i'%to? < $ '" %•& - 1
4 >•'«'■ *•" s>n4"
Выберите опцию Анализ результатов. Нажмите кнопку Переменные. Задайте
thick в качестве зависимой переменной, ratio и mold в качестве независимых
переменных и block в качестве блоковой переменной.
В поле Для перекодирования использовать оставьте принятое по умолчанию
положение уровни факторов из файла данных. Теперь нажмите ОК.
На экране появится следующее окно системы STATISTICA:
|.'.'Ка'>.^'М."!'..?''.!,^А!!.1-"-'"И'.-!..'у.. '■ Гл
щщ?;
}^фы^ща^ I ток _
ИТОГ* ПЛАНА:
Число факторов (кезавкскгасх переяеюшх): 2
Общее число опитоi (набл., экспериментов): 10
Число отдельных опитоi (набл., эксперии.): 9
Число блоков: 1
Число реплик: 0-1
*!^:'<ш**шг~*т»тт*+*'тт*ч1Ъу-■■■■■■■■■■ У ••: <*&t* я}4 '•:.:." ••.;•• Л *——» щ J
• Н*ИвММТЪ*ВрХШ(в, ММЖМЛв 1 Щ .:• ЗДОДШМЦИЯ Эфф«1СГО»
,imU,,»,Win-,,\..,W,p,\f,,^ynn .у,,;.....,,!,.,. I.,
I M";."l,!lii:i»i':!-],::iil. <!**>)'»■№ u^'fay >'Ч^>?ЯГ =■ I:-11 •"'* !;0г.УЦьст^м^Н:^^$^11^^
;■■!■",' ;iw*rtft<wii*ij»;tw^ftwi<^J№jf-ifci4**''ii'*!iwi vfo iW""'
г эффекты «i'irikU^-OMi^ пи*;>!С:г* «■* ш ? ^,,
3 I U» ПоВерж* la! ГПвА^м|МЧ|;гЧ*е«1^Ч»ДА:
gljj:>i( ,,;,•■„ >■ ГтГУу^^У Кмвур*•#*] {**.Осгагоч,суп., к*.
flPJg(^*^H*tf j950
Адьфв ^Atitimt): | обо
&»mjM»«Ktt%i4 ******
nMli^^a^ »™^ ll ■ K|N«W *И4*вН1«> (*»*.* *•<* .4 j j С ЧМГТМ WilH6«
П^АР»^ ^%Ц^ Wpe»», |J <л .J^,,,. ,,■ 7, _ , *ш Щ([^т ,7, ,|1,^^^^Л^■:,^■^■^■^V^^^■ =••••■:
„ними, ■■■■■ ii^i^^uy.1.» ^i»;;!;.!!;,^^ ..1,1.;^...»1,1|..1^» ..j.. ■ ......|... »^;c'^Tjr^^^"->:.-,^j^:Vr^^ "^ v>\-~:-T""^T.3-":-^ v ^.' T^.*: ~~-'':.:-~ v^~ "^ ~ ^ "г: "^Т^.- :>-^: - - ^v:..- vr.. •,-.•:•.
Jl|l|ll|l ,•" jllillll^ll^Ml'.l >ily I|l I III' I III II I
Прежде всего оцените адекватность модели второго порядка.
Для оценки адекватности воспользуйтесь таблицей дисперсионного анализа
и графиками. На панели Включить в модель выберите опцию гл. лин./кв. эфф. и
2-взаимодействия, а на панели Член ошибки ДА — Остаточная сумма квадратов.
Нажмите на кнопку Дисперсионный анализ.
Примеры анализа данных в системе STATISTICA
593
ваш
ПЛЛНИР
ЭКСПЕРИМ
: Фактор
RATIO
т»ад>
HOLD
■':■-.::< It.- no
■ 0w« .:;;::;■:,
■:. <*••*.. c*
¥XIY^:
(Q): •
?*v„:iiprf
ЩШ'Ш
2 факторе
ЗП THICK
144S34
6501"?
025033
.560179
360000
204754
1'876000
1 блока
**$
i
" i'.
4 '•
9 ":
шшшшшшшш
.0 on . Остаточн СК-
*{&№?■*
Ъ'^ЦШ:
144534 2 82356
35С17Э ' Н 60877
025033 48904
SС01?9 [ 11 33416
360000 7 03282
051189
0511885
V':.v •».:•/•.
168187
±1
0151 f-1-
522887
028132
056866
-1:
m
Из этой таблицы следует, что статистически значимые эффекты (уровень
р<0,05) имеют два квадратичных члена: ratio (Q) и mold (Q).
Для того чтобы определить, насколько модель хорошо описывает
экспериментальные данные, будем использовать тест lack-of-fit (потери согласия).
Вернитесь к диалоговому окну результатов анализа, выберите Чистую ошибку
для Члена ошибки ДА и снова нажмите кнопку Дисперсионный анализ. Система
добавит в таблицу значения потери согласия и чистой ошибки.
* ЯЧ0Я8 Спор /Ь443 (disk ш\л\
Вследствие того, что р-значение использованного дополнительного теста
больше 0,05, модель второго порядка представляется адекватной для описания отклика.
Установите снова Член ошибки ДА в положение Остаточная сумма квадратов.
Теперь рассмотрим вероятностный график.
Для этого нажмите на кнопку Нормальный график.
Из рисунка видно, что квадратичные члены с меткой Q находятся в стороне от
линии нормального распределения, что указывает на статистическую значимость
их влияния на отклик.
Вероятное? графи»; Пер THICK. R-ki = 89086.Скор 75443
2 фактора, 1 блока . 10 on . Остаточн СК= 0511885
М01ГЧО)
♦
RATIOCO)
C2)MOUXU
+
(URATIOCU
1lno2L
•
95
85
75 I
65 ]
55 i
<5 i
35
15 I
•3-2-10 1 2
Стандартизированные эффекты A-эначения)
■ • »заимодейст + • Гпавные и другие эффекты
594
Глава 16. Примеры анализа данных в системе STATISTICA
Рассмотрим также карту Парето. Нажмите на кнопку Парето эффектов.
Шва
шшштттшжп
т
Диаграмма Парето для стандартиз эффектов; Перемен : THICK
2 фактора, 1 блока, 10 on, Остаточн СК= 0511885
р=05
RATIO(O)
MOLD(O)
1.0 1.5 2 0 2.5 3 0
Оценка эффекта (абсолютное значение)
Итак, квадратичные члены модели дают значимые эффекты. Соответствующие
им колонки пересекают вертикальную линию, которая представляет 95%-ю
доверительную вероятность.
Определим теперь область значений факторов, в которой плотность
пластиковых дисков является максимальной. Для этого лучше всего использовать график
поверхности отклика. Нажмите на кнопку Поверхность.
■1 4 281
■14 681
■1 5 081
U 5 481
CD 5 881
□ б 281
iB 6 681
■1 7 081
■1 7.481
■1 7 881
■■ выше
Подогнанная поверхность, Перемен THICK
2 фактора, 1 блока , 10 оп , Остаточн СК= 0511885
Эта поверхность имеет экстремум, равный примерно 0,9. Для более детального
рассмотрения области максимума целесообразно рассмотреть контурный график
(цветная квадратная кнопка рядом с кнопкой Поверхность). На графике показаны
линии уровня поверхности. Это весьма удобно для исследования поверхности.
Примеры анализа данных в системе STATISTICA 595
ЯЯИ1.П|1111111.1111!1ПИ1.1Ш11|У111!111Л.тУ.ШПУ1И11111^1ЯГЫ
Подогнанная поверхность, Перемен THICK
2 фактора. 1 блока. 10 on. ОстаточнСК= 0511885
•ыше 0 70 0.74 0 78 0 82 0.86 0.90 0 94 0 98
RATIO
Посмотрите на цветовые метки, расположенные слева от графика. Эти метки,
показывающие интенсивность цветов, позволят легко сориентироваться и понять,
что максимальная плотность достигается при изменении параметров в
центральном эллипсе, положение главных осей которого легко оценить графически.
Например, максимально прочные диски будут получены при значениях
композиционного соотношения, изменяющихся от 0,78 до 0,86, и значениях mold,
изменяющихся от 0,6 до 0,9. Более строго — все значения независимых
переменных, попадающие в центральный эллипс, приводят к наивысшему качеству
пластиковых дисков.
Пример 3
В этом эксперименте изучается ракетное топливо, которое представляет собой
комбинацию окислителя, горючего и связывающего вещества. Интересующим нас
свойством топлива является его эластичность. Цель состоит в том, чтобы найти
пропорции, для которых эластичность достигает величины 3 000. Задача такова — по
результатам эксперимента найти математическую формулу, позволяющую связать
эластичность с компонентами топлива.
Пример основан на данных, описанных в книге: Kurotori I. S. A966). Experiments
with Mixtures of Components Having Lower Bounds, Industrial Quality Control, 22,
p. 592-596.
Начнем с построения плана эксперимента.
Запустите модуль Планирование эксперимента.
596
Глава 16. Примеры анализа данных в системе STATISTICA
В данном случае выберите Планы для смесей, потому что компоненты,
выраженные в долях, в сумме должны равняться 1. Нажмите кнопку ОК.
В появившемся диалоговом окне выберите опцию Построение плана, далее
укажите Симплекс-центроидный плац, введите 3 в поле Число факторов и выделите
опцию Дополнить внутренними тттами.
Г*
. .... , Змайга t$tqMflwt
stI* ■j'<«P'«rf< и нижний
10
мет* итл могут быг»
эамиы е сл*х*ощ#м
диалоговом окнч.
Дл* н*«с«а«иил точек
пяеная<1Я областей со
сяржиыми orpa»M<wtw
м* воспользуйтесь
«тиией Центроиды*
еаршмныяля
ограничен*** областей.
Нажмите кнопку ОК. Появится диалоговое окно План эксперимента для
смеси.
ш
Щ£
Ш
Ш1
ЕЩ
ИТОГИ СТАНДАРТНОГО ПЛАНА: 3 факт, симплекс-центрошшыи план
Число факторов: 3
Число опытов: 10 (Число внутренних точек:
Прос*«агрЛ1рев«ауСелфет1аа1 •
&К
Факторов, значения.<.
Обоам. вдам-врм-- гЛоралок. опмтое *-*;■?Опираешь ~~^_^" ~~~-.; 1 1
<5 цонирми , ^! ^ чсримртиа*. v] j<S Ew^JMWWWS. 1P«.V^J i: Замвчани* Итоги.
:^Г Душам» ' j] С'cflytaaiajft ' ' j :С Эна*. дактороа {верх/ниж/ ' аыаодиммввокне.
... .... ,..,.... ч-..,1 s.-. **".' \.ЛЪ„ , А ,. А
; ОТНОСИТСЯ!
: применяемому по
'■ умолчание план»
Добавит» к план* •--•••-'•••• '■;*«
[(Г gj полные рвплмш E § претив дтоаааы (аааис. парам.) £Ь п
Нажмите на кнопку Имена факторов, значения и заполните появившуюся
таблицу следующим образом.
сагввввввар!
■ •IfllH'lifciliifl
Да*ее„,
Факиор
В B)
С C)
06*ве> •
Ц1
чмп
SEE
Задай
ряду
ЩШ&ШЩШШШШШКШ
же имена, верхние и нижни
укажите обшее значение с*
ввЯЯВ^^нннвВ
binder |
oxidizer
fuel
1.
е значения
ecu (сумму
Нижм
значение
200000
400000
200000
факторов:
и нажми*
в последнем
в Далее
Верхи, .
..значение
400000
600000
400000
-ll
"\-
!
Нажмите кнопку Далее. Полученный план можно просмотреть, нажав на кнопку
Просмотр/Правка/Сохранение, предварительно определив опции, как показано на рисунке
ниже.
Примеры анализа данных в системе STATISTICA
597
I J.lli|4IJ.!Jlll.iUi.AI.I.JWP!
ИТОГИ СТАНДАРТНОГО ПЛАНА: 3 флг.т. скнплег.с-центроидкый план
Число факторов: 3
Число опитов: 10 (Число внутренних точек:
Просмогр/Пр«в««/С<мр«и«мм«
SB9 Щюемет»/П|мим(*/См|миаии«
VI Икона +актороо. доиеммя...
О*
- Обоон. факторы , Порядок опытов
ОтобрОвМГЬ Ur. шп I
<? вдидегим* :С Сг«н%в«м»нмя (О,JL.-J * Замен»*»: Итоги.
Г едгмАный (• |3н»ч. ^«кторо» {еерх/ниж' выводимые вокне.
Ш- 7" ~. .
;Чме«о ^МН1Г
относятся к
применяемому п>
умолчание паем»».
а
1 постыв столбцы (маме порем.)
Q Пуют» 1
Сохраните план. Для этого выберите из меню Файл — Сохранить как файл
данных; появится соответствующее диалоговое окно. Задайте имя плана rocket.sta
и нажмите кнопку ОК.
Ш
имя
НОСКЕ TIS ТА
,:1«:П.М<;.51Л
« i Г> f A
AUrsW.NT STA
Л:>ЛГ'Ш4Г> МЛ
AiK.nWY VTA
лг;«нгг>':»ц :>тл
AU.tHfiY.SVA
j Файлы данных (*.tla) ^1
. £обочая кнмга; |
Диски:
План построен. Это позволяет организовать сбор данных.
Предположим, что вы организовали эксперимент согласно построенному
плану и для разных значений компонент измерили эластичность ракетного топлива.
После того как данные собраны, задача состоит в том, чтобы провести анализ и
найти зависимость между эластичностью и компонентами ракетного топлива.
Откройте файл данных rocketsta и добавьте переменную elastic, содержащую
данные для 10 откликов, полученных экспериментальным путем.
ROCKET БТАБл' 10н
2
3
4
5
Г
7
8
9
10
1|
2
3
4
5
6
7
8
9
10
г
BLOCK-
1
1
1
1
1
1
1
1
1
1
3
BINDER
400000
200000
200000
300000
300000
200000
266667
333333
233333
233333
v , А ■ s
ОХОДЕЯ
400000
600000
400000
500000
400000
500000
466667
.433333
533333
433333
S *
200000
200000
400000
200000
300000
300000
266667
233333
233333
333333
6 f
ELASTIC I
2350;
2450'
2650,
2400 J
2750*
2950'
3000
2690
2770'
2980>
598
Глава 16. Примеры анализа данных в системе STATISTICA
Введите данные. В диалоговом окне Планирование экспериментов для смесей
выберите Анализ результатов.
Нажмите кнопку Переменные. Задайте elastic в качестве зависимой
переменной, binder, oxidizer к fuel — в качестве независимых переменных.
нжовягсяЫ
Ч*ни*иве *«.)/:
^шш&йтйЩ *■*>
'*жм<г# {Лилии*?
^ W|spi^.<p^onp«iJ»m». постой^
_ Ьи-»»<|>гем»см;лрм импорт» дан»й>»
"" <> 1%#*#$17^ - ♦• ■' "* ***** rerpedttMirbt* ксдоегцроек* *той величины; д<я
• '/'w'S-* ^у*^* >1ЛГФ <С/*^А ttvv*»»* бш»е подробной ннфврнации нажмите и» 7
В поле Перекодировать факторы оставьте принятое по умолчанию положение
Автоматически определяемые мин./макс. значения. Теперь нажмите ОК.
Появится диалоговое окно Анализ эксперимента для смеси.
На панели Модель выберите Специальная кубическая.
ЕЕ
шшшшмшш
ИТОГИ ПЛАНА: 3 факторный план для сп
Число факторов (компонент): 3
Общая сумма всех компонент: 1.00000
Общее число опытов (набл., экспериментов):
10
Число отдельных опытов (набл.
Число реплик: 0
эксперт.): 10
ELASTIC jJ1^^^1tt»Wte''.-| -:. V:Msfi жркшт*** •; :S Дсгдажм j
^.•^^^^./..л«:•^^>:Ф^^».^ч^.:•:../:■?'Ч'ЧЙ?*,?,''?",Г?,,'TT?*,'??,,^ < .л >• •' *. ."':•..'."■ .>..■*.'} "■""• ,. m it.
<^л.>ДГЛМ,« „л
Щ}?*$и&ш*1тт »а*торор
Отм*и«
ffl ^р1цм^;Ш1йЦ|1Жо»<п<и»»1т' I ■' Qqi^r flpoafciux <mmn«+
Nx Крат*©;
[• ОцЙИКН ||С>0>|и'.<<И|КН!>И^ . ЦшД j^KWjt>.
lie in *
W»i&
(? Сгимдовьиа* « j6*t.
*анмрп*икмн. t#fimi
Я. Право- jtMMiol
C^witWa :'--j fx" Контрмин* о&истм
ffiПове»иост»| /^ &owr»j> \ ЦЩ Прщсцмь щ набл.
Смстогр. осгвткое
i I Вер. rp*«A осгвтми»
Нажмите на кнопку Дисперсионный анализ. Появятся две таблицы. В одной из
них приведена сводка проведенного анализа, а в другой — результаты
дисперсионного анализа для специальной кубической модели.
Примеры анализа данных в системе STATISTICA
599
план для см . общее змач см -1 . 10 on
подгонка моделей Возрастающей сложности
ЕШШ
farth',
jm&sL
ьщъ*
2
3
1
9
89600 00
*9ЭС9 8:
36644 92
57321 11
336690 0
36960.5
315 ь
7
4
3
48098 57
9240 13
105 20
1 8628
it: 6I26
346 3201
22457: \
U217S
00033i 1
Л..^П
Значимые модели выделены красным цветом.
Из таблицы видно, что статистически значимые эффекты наблюдаются в квад-
ратической и специальной кубической моделей (р-значения меньше 0,05).
Качество регрессионной модели оценивается с помощью коэффициента
детерминации R-квадрат.
Так как у специальной кубической модели среднеквадратичная ошибка
меньше, а значения коэффициента детерминации R-квадратов больше, чем у квадрати-
ческой модели, мы будем использовать специальную кубическую модель.
Нажмите кнопку Оценки псевдокомпонент. Программа отобразит статистики,
рассчитанные для специальной кубической модели.
ПЛЛНИР 13 -факт, план для сн . общее змач
ЭКСПЕРИМ ЗП: ELASTIC; Остаточм СК-105.2047
жМ
жш±ж
**&.. ~**Х
(ВHХПI2Е»й
...(С>ШЬ-.;^:/>--
АВ ■•>. <-■■■> ъ/
АС •
ВС
ABC' „•
23Ы 163 1
244S 709
2*52 981
-6 256
1008 28«
1597 3B0
6141 182
Мшт
ш
•А
э
ч
49
49
49
32?
9153
9153
915 3
9115
9115
9115
о?об
237
24ь
26?
-
20
32
18
1250
6604
5 6 4 ь
1253
2015
004 2
6633
000000
000000
000000
908179
000265
000067
0003 36
231*i
2414
2621
-165
849
14 38
509 3
608
154
426
097
448
5 39
996
2362
24V 7
2681
152
1167
1756
71P3
718
264
Sir;.
585
129
?21
3*8
J£j
Как следует из полученных результатов, все члены специальной кубической
модели имеют значимые эффекты (р < 0,05), кроме одного члена АВ.
Таблица дисперсионного анализа показывает весьма неплохие результаты для
подобранной специальной кубической модели (р-значение гораздо меньше 0,05).
||-41|.||||^.|.!||М'111<Д1'1-Ш|1'|ЩИ«-ЦИМИИ
ШМНИР.
ЭКСПЕРИМ
Источник
1 Модель
■:Овщья:от&<г-*:<---
ОБщ«М5 UCnp/ЗК. :
Ш_ .•':„_^
3 -факт план для см
ШШШ7Щ с*^'.с*,;.
СЛС,5?4 4 | $
315.6 3
515890 0 9
; общее змач. см ■1
"£d/*:k*v
85929 Оь 816.77Э4
105 20
57321 11
:?//Лг, 'i,-
■■;•;•:••:•. : '
рШез!
. 10 on.
Р .
oooi»;
д|
5
v i
■ ■ .у
L,
Чтобы проиллюстрировать данные результаты, рассмотрим графики.
Нажмите на кнопку Поверхность.
На графике поверхности отклика хорошо виден максимум эластичности
топлива. Заметьте, что зависимость эластичности от компонент смеси носит
нелинейный характер.
Для точного определения оптимальных долей рассмотрим контурный график.
Он вызывается кнопкой Контур.
600
Глава 16. Примеры анализа данных в системе STATISTICA
|Г|График2Ь: Подогнанная поверхность; Перемен ELASTIC
Подогнанная поверкность. Перемен ELASTIC
ЗП ELASTIC. R-кв = 9994.Скор 9982
Модель Спец кубич
■■ 2414 904
■■ 2478.645
Ш 2542 387
СИ 2606 13
□ 2669.87
ПЗ 2733 61
ШШ 2797 353
■■ 2861.094
■■ 2924 836
■■ 2988.58
■■ выше
£1§ Графмк.29 Подогнанная поверхность; Перемен.: ELASTIC
Подогнанная поверхность, Перемен ELASTIC
ЗП ELASTIC. R-kb = 9994,Скор 9982
Модель Спец кубич
FUEL
■■ 2380
■■ 2460
Ш 2540
СО 2620
CZD2700
СИ 2780
ЕШ 2860
■■ 2940
■■ 3020
■■ 3100
■■ выше
BINDER
OXIDIZER
На графике визуально легко определить, при каких значениях FUEL, BINDER,
OXIDIZER достигается нужная эластичность.
Эластичность 3000 лежит вблизи доли связующего вещества 0,25, доли
окислителя 0,45 и доли горючего 0,25. Более точные значения пропорций компонентов
следующие: связывающее вещество — 0,26667; окислитель — 0,46667 и горючее —
0,26667.
Можно выбрать некоторые пропорции компонент, которые дают значения
эластичности, близкие к 3000. Например, набор компонент @,25; 0,5; 0,25) дает
эластичность 2927,7, набор @,25; 0,45; 0,3) — эластичность 3 042,9.
Примеры анализа данных в системе STATISTICA
601
На значения компонент могут быть наложены дополнительные ограничения,
например, можно максимизировать эластичность для значений окислителя или
связывающего вещества, лежащих в определенных пределах.
Для нахождения таких решений опции STATISTICA оказываются незаменимыми.
Чтобы оценить эластичность по любому набору компонент, воспользуйтесь
кнопкой Предсказать зависимую переменную. Задайте значения факторов,
например, как показано ниже.
<llll.!.!.il!UU!.i|!ffWHH
BINDER
OXIDIZER
FUEL
И
и
и
1
i
2
1 в™*"* I;
Нажмите кнопку ОК.
«о* Пер ELASTIC; R i
. 99939Хкор 99816
ШШИР
Фактор
ЗП ELASTIC. Осталочн СК-105 2047
Ко?**
<B)onmmi
(С)ГОЬ *.v*
АВ ♦ . <
к :. <
:,BCs;"-'-'^'. .
ЛВС
Првфек**'.
-95 * floev.
♦95.К ДсЛ,
-9S* Пр«.
,:+.»у-*.чга* 1
2351
2445
2652
-6
1008
1597
6141
163 |
709
981
256
289
380
182
500000
500000
000000
250000
000000
000000
000000
и
1175
1222
о
-1
о
о
с
2396 872
2365 566
2428 178
2351 644
2442 100
582
854
000
564
000
000
000
КРПООИ, ■
300000
500000
200000
j£
На экране появится таблица прогнозируемых значений эластичности. В
нижней части таблицы показывается значение Предсказ. - 2 396,872 предсказанной
эластичности для исходных компонент. Также приводятся верхние и нижние
границы 95%-го доверительного интервала и границы для прогноза. Измените
значения компонент топлива, например, BINDER - 0,27, OXIDIZER - 0,43,
FUEL - 0,3.
602
Глава 16. Примеры анализа данных в системе STATISTICA
Для этих компонент будут получены следующее значения эластичности.
ПЛЛНИР
ЭКСПЕРИМ
Факжо]
Е I AS Tit Н ив - 999 ЗУ. (пор 99В1Г>ЙН*1ЁЭ:
ЗП: ELASTIC; Ос»а»очн СК-105.2047
:::.О0бА$о
Энам ...
Исходные
коптом
35000
15000
50000
.05250
.17500
07500
02625
822 91
366 86
1326 49
-.33
176.45 ?
119 80
161.21
2973 39 Г
2952 31 ;
2994.46 !
2934.53 1
301224 }
\.,^,^.„^Л,^.:^
27000
43000
30000
. 1
г\
Пример 4
Этот пример иллюстрирует возможности системы STATISTICA для
промышленных приложений, связанных с контролем качества. Мы рассматриваем
химическое производство, но вы легко можете представить и другую область
применения, например, пищевую промышленность или металлургическую
промышленность.
Пример основан на данных, взятых из книги Montgomery D. С, Runger G. С.
A994). Applied Statistics and Probability for Engineers (N. Y.: Wiley & Sons).
Предположим, необходимо контролировать концентрацию некоторого
вещества на выходе химического процесса. Вы наблюдаете процесс в реальном времени
в течение 20 часов и снимаете с датчиков нужную характеристику каждый час.
Считается, что процесс выходит из-под контроля, если концентрация превысит
допустимый уровень и выходит за верхнюю контрольную границу.
Рассмотрим данные, представленные в таблице.
1
102
11
101
2
95
12
99
3
98
13
101
4
98
14
98
5
102
15
97
6
99
16
97
7
99
17
100
8
98
18
101
9
100
19
97
10
98
20
101
Особенностью процессов, протекающих в реальном времени, является то, что
в них не является естественным группировать измерения, так как, производя
группировку, вы с запаздыванием реагируете на ухудшение качества. Группируя
данные, вы добиваетесь более точных оценок параметров процесса, однако плата за
точность — запаздывание в управлении. Поэтому воспользуемся контрольными
картами для индивидуальных наблюдений. Назовем контролируемый параметр
concent.
Шаг 1. Введите исходные данные в файл системы STATISTICA, например, с
именем Chemipro.
Примеры анализа данных в системе STATISTICA
603
га
ч
1
Г
з-
■**
■в;
f-
7-:
*>.
*•:•
10
11
It
13
14
Щ
18
17
18
19
»
пятМитгаятяпвям
ШкшШШёШкШг
■НИН
^■ИК^Н^
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
Шж;-;
: ;■■*■,
Т|
ЩЮЕКГ^
•: ••••■•' •'.'
102
■ i
95 j
98
98
102
99
*э ;
98;
100
98 ']
юг
99
101
98 J
97 j
97 .'j
100 :j
101 j
97. ,.]
101 jM
: *:fl
Шаг 2. Запустите модуль Интерактивный контроль качества.
шштшттштттт
ЯДЯИР
Зедоъиое*ю1
КЖ11;
W^f^v? JS !1-1 ■'■'■'■!'!'!' 'U ''•!•'! I'' <" -Уv|
gX- и R/S карта для непрерывных переменных
^ Скользящее среднее и R/S
Л11.1и.Ц1||1Ш!>1.1.П1.Ш!1ШШ.11.1М1. МИ И —
L»/j Контрольная карта по альтернативному признаку
|0 Карта Парето
прМТОЛЙОСт*Х*Ло^^ I
контроля, «нале повтцШ^тЦг^^ "?
эксперимента} доступ* до >£^Ц£Я»Щ <jj> ft
'T^^-^?^^
Шаг 3. На стартовой панели выберите Отдельные наблюдения и скользящий
размах и нажмите кнопку ОК.
В появившемся диалоговом окне выберите concent в качестве переменной с
измерениями.
Задание переменных дли X
мттщ
тяшшщшшт
с ищу eiHiw^CaNCEN<^1; $}" Ш^:> Ж "]
ц «*»^.^; U^M*S5T|
|Пр»м4^А#АотвмййТА но?кно1»ддг» поздние! ^$*Hvfr4 gg ц] АФ|'
Шаг 4. Постройте контрольную карту скользящих размахов для
последовательности наблюдений.
604
Глава 16. Примеры анализа данных в системе STATISTICA
ЫГИ'Щ'П.РЛп!1!!,,1,
Гистограмма наблюдений
108
X Сред 99 0500 (99 0ХЮ) Сигма 2 09896 B 09696) п 1
рг
а^х&з
д: 7f.з 1;
Гистограмма размахов
12 4 в в 10 12 <4 10 18 20
СкользЛ Сред 2 36842 (Г 36547) Сигма 1 78937 (< 75937) п 1
70 га
00 И
20 Ь.^>ЙШ
оо М3
2 308421
О 000000
10 18 20
Карт*»)КйСтъ| Пвчвгь) Опций) Наборы]
Eg **MR,
! Е)а ЕЗма
Одис«гг>
^др^г^'-х4-
VI Негадр. X
ЩГйсг.МВ
г./
Кр^сцжА
l" гПригядюст» процесса
I 00 "£мстогр. | ДВ Иту
]Жс|^р«ГрАвт9
1 ^ CfcpfcTfc
Шаг 5. Известно, что для всех производственных процессов возникает
необходимость установить пределы характеристик изделия, в рамках которых
произведенная продукция удовлетворяет своему предназначению.
Вообще говоря, существует два «врага» качества продукции:
1) отклонения от значений плановых спецификаций изделия и
2) слишком высокая изменчивость реальных характеристик изделий
относительно значений плановых спецификаций, что говорит о
несбалансированности процесса.
Вы видите, что на Х-карте скользящих средних все точки попадают внутрь
контрольных границ.
Примеры анализа данных в системе STATISTICA
605
На контрольной карте скользящих размахов (MR-карте) все точки также
находятся внутри контрольных границ. Размахи служат оценкой изменчивости
характеристик, поэтому можно сказать, что концентрация вещества подчиняется
требованиям статистического контроля по уровню средних и изменчивости.
Продолжение анализа. Следует иметь в виду, что карты для индивидуальных
или отдельных наблюдений не способны отражать малые изменения среднего
уровня концентрации, которые, однако, могут играть существенную роль в реальном
производственном процессе.
Поэтому для анализа данных воспользуемся также контрольными картами
накопленных сумм.
Шаг 6. Выявление малых изменений средних значений.
Запустите модуль Карты контроля качества.
fcbyjX- и R карте для непрерывных переменных
hi* Х- и S карте для непрерывных переменных
Ejjjj^X- и S2 карта для непрерывных переменных
[~7\ С карта по альтернативному признаку
(v^j U карта по альтернативному признаку
|[Т] Np карта по альтернативному признаку
ЕР1Р карта по альтернативному признаку
(~3 Многомерная карта Т2 Хотеллинга
fi*
^ужн»--^!
£? Данные
ц 1 & в
h'H'ir'ifl'l
[уу^ МА карта для непрерывных переменных
карта для непрерывных переменных
£\] Регрессионная контрольная карта
[^ПКартаПарето
Друие процедуры '.'
■ fрасчет нет ауссоес***
индакоод пригонносги,
I процесса, <манм :
выборочного контосд*,
анфлиэ flOftOPBii *0CtH
;ллдии>о«еии# ••,.._
ЭКОлврммвиГе}
. наждое* а *одояк:",
'Лланиромнив
амларимвнт*^;
Шаг 7. На стартовой панели выберите CUSUM карта для непрерывных
переменных и нажмите кнопку ОК.
Заметьте, термин CUSUM происходит от сокращения кумулятивные, или
накопленные, суммы.
Шаг 8. В появившемся диалоговом окне выберите concent в качестве
переменной с измерениями.
ШШШШт
для CUSUM карп
; Денные:j Исходные данные
jflQ Переменные:] '" ••"
Д-«в \
йрлтиь
рТ Постоянны* ооЧем выборок; |1 Щ^ "^", S&ul&fcl
выверит* переменило о **мар*«ым>« и перемену с твитяфикаторамм выборок
{кодам*!, вместо кодов можно задать постоянный 04ы^аы6оро*$»ям подробно
СМ. Электронное РУКОВОДСТВО (Д/И 1вДИМ НвЖМИТ#?ИЙМг*1}\
Тип анализируемых данных: исходные данные.
Нажмите кнопку ОК. На экране появится CUSUM-карта.
606
Глава 16. Примеры анализа данных в системе STATISTICA
На карте изображена также так называемая V-маска, имеющая следующий
смысл.
Запомните: если в наблюдаемом процессе имеется значимое смещение
среднего значения, то точки выходят за пределы V-маски.
В системе STATISTICA V-маска строится автоматически, и вам не нужно
думать о ее определении. В нашем случае точки не выходят за пределы маски,
поэтому можно сделать заключение о том, что исследованный химический процесс
удовлетворяет требованиям контроля качества.
Из приведенного графика следует, что все точки данных попадают внутрь
контрольного интервала.
Шаг 9. Опции STATISTICA позволяют всесторонне исследовать результаты и
управлять процессом, находя незначительные сдвиги в значениях (см. опцию
Обнаружить сдвиг больше чем...).
V-^.Ijiwj;
Ы • :у**>-
Vj 06и«р»»»т> сд»мг 6&*я» ч
Ш
.- Лосззмип* илрт§ v
ОпИС*т««ьиыв статистики
S
Примеры анализа данных в системе STATISTICA
607
Например, нажмите на кнопку Описательные статистики на панели. Вы
увидите следующую таблицу с результатами.
«CONCENT CUSUM карт,
КОНТРОЛЬ С» кар»а Сред »о же
К/1ЧЕСТВ/1 [альфа - 05000 бе»а -
Выборка
крВмРяии
1
2
3
4
5
6 ■
7
0
Э
10
11
12
13
14
15
16
17
18
19
20
Ж
2
-1
-2
-3
-1
-1
2
1
-1
-1
00000 |
95000
10000
15000
20000
25000
30000
35000
40000
45000
50000
45000
40000
35000
30000
75000
80000
85000
10000
95000
00000
ср*д*-
93 ОЬОО Сигма 1 90438
Сигма яа «е
05000 оБнаруж сдб
1 0000» Сигма
Сколъз
Разках
■ЗКП
—
102 0000
95 0000
98 0000
98 0000
102 0000
99 0000
99 0000
98 0000
100 0000
98 0000
101 0000
99 0000
101 0000
98 0000
97 0000
97 0000
100 0000
101 0000
97 0000
101 0000
0
7
3
0
4
3
0
1
2
2
3
2
2
3
1
0
3
1
4
4
__
000000 ]
000000 ]
000000 ]
000000 ]
000000
000000 ]
000000
000000 ]
000000
000000 ]
000000 ]
000000 ]
000000
000000
000000
000000
000000
000000
000000
000000
- -24
-23
-22
-21
-20
-19
-18
-17
-17
-16
-15
-14
-13
-12
-11
-10
L -9
L -8
L -7
L -6
L -5
6589
7064
7539
8014
8489
8964
9440
9915
0390
0865
1340
1815
2290
2765
3240
3715
4191
4666
5141
5616
6091
24
23
22
21
20
19
18
17
17
16
15
14
13
12
11
10
9
8
7
6
5
65889 \
70640
75391
80142
84893 «
89644
94395 \
99146 \
03897 '\
08648 •
13399 :
18150
22901
27652
32404
37155
41906
46657
51408
56159
60910 »£■
ш
:П
Шаг 10. Можно продолжить анализ, например, просмотреть Гистограммы
средних. Для этого нажмите кнопку Гистограммы средних. Далее задайте желаемые
значения контрольных пределов и числа категорий и нажмите кнопку ОК.
Г$Графмк2 Гистограмма средних, перем CONCENT
Гистограмма ср«дииж. гмр«м.: CONCENT
у-полпа1(* М 09.1 «ИМ? 20" 1
Пример 5
На этом примере мы покажем, как наложить результаты анализа на
географическую карту. Мы намеренно берем грубую реализацию карты и очень простые
данные, чтобы показать принципиальную возможность метода.
Представьте, что имеется файл данных о заболеваниях определенного вида и
травматизме для каждого региона России (данные носят чисто модельный
характер, не отражают реальной ситуации и необходимы лишь для иллюстрации
возможностей).
608
Глава 16. Примеры анализа данных в системе STATISTICA
|1ИЛв1д|
пилит
JllTll(№iM3
ЦНЛияайски!
здЕодкеЛтраЗИлтиН
I
Амурская
Архангел
4 |Лс»рахаи
Ee/ieopog
Брянская
Владимир
Волгогра
936
525
716
41
366
157
830
23
245
612
829
293
431
775
846
579
.110
Координаты границ регионов задаются в отдельном файле данных.
STATISTICA отображает карту России следующим образом:
ETJ Г рафик lb Kepi а Российский Федерации Н1*]ЕЗ
Карт* Poccicdcaoft ▼•■«?*!
Конечно, эту карту можно улучшать, делать более точными границы регионов,
увеличивать и т. д. Мы намеренно берем самую грубую реализацию.
На карте цвета задаются случайным образом.
Наложим данные о заболеваемости на эту карту. Выберем опцию
Шкалирование карты в диалоговом окне выбора слайда. Показанные далее диалоговые окна
не являются частью какого-либо модуля STATISTICA, они легко создаются с
помощью языка STATISTICA BASIC.
(Рандомизация карты
iMHf.i'iiiiHHiTi'iimfiiiPi
ВыАтм из лрогра
Далее выберем переменную, с помощью значений которой мы хотим провести
раскраску карты, выберем, например, Заболевание. Идея проста: мы хотим
добиться того, чтобы регионы с большей интенсивностью заболевания были окрашены
более интенсивным цветом.
Примеры анализа данных в системе STATISTICA
609
Пожалуйста, выберите колонки в таб
►*Ц№1|№Я1
3 ТРАВ МАТ И
йК
Отмена
£ыбр«ть все}
Какую переменную анализировать?
Подрой
W
Цн*
Следующее меню предлагает выбрать способ отображения карты. Линейное
разбиение позволяет задать число интервалов или категорий (цветов), на которые
будут разбиты все регионы.
H'rH^'iMHi'-H-l-l-iM-l-H М1"кГ|Ч'||Ш ^
{Стандартный способ
lil!l!M'l!MJ,HMHJ!l!
OK
]
Непрерывная шкала
Разбиение вручную
Отмен»
Зададим, например, число интервалов, равное 4.
LI-'iH,, -iMII^'illl-l,1.MJ'liir M
Количество интервалов » ]4Щ
ОК
Отмена
Последний шаг — выбор общего цвета (раскраска карты производится путем
тональной градации выбранного цвета в зависимости от уровня заболевания):
выберите цвет
Синий
Голубой
Жёлтый
Фиолетовый
Бронзовый
Другой
В результате мы получили карту, раскрашенную в 4 цвета. Все регионы
разбиты на группы по значению показателя Заболевание. Самый темный цвет
соответствует группе (региону), в котором наблюдаются самые большие значения
показателя Заболевание.
610
Глава 16. Примеры анализа данных в системе STATISTICA
|1»т;пи,гт1Ш-н1|1и|-|1Л1||и-1'аа
28
24
«г 20
о 12
2 8
Ч 4
т 0
iiiiiiiiiii
iiiiiiiiiii
<-263
, -" * -.
1Ч|1И1|||
ишччп
I263.503) I503.743)
ЗАБОЛЕВАНИЕ
pii'liiiiii'
4*111 ■ 1 * I • ■'
> 743
Изменим число градаций цвета, возьмем 10 и наложим на карту графики
STATISTICA, тогда можно получить, например, следующую карту.
ГС Г рафик 35: Карта Российской Федерации НЕёНЗ!
Карта Poci
мом §едера
наб)
cptjHtt: 530.79
joetp .-954:464.1
joetp.95%: 597 5
сумма: 41402.00
минимум:23
максимум: 984 •?
размах. 961 х
дисперс: 87539.9 ^
ст. откл.: 295.87
ст. ошиб.: 33 50
асимм«т . -0.129
эксцесс: -1.36
S d *0 «D^arf^r-tDr-CDO
*: <о *: *3<Ъоосс,__х
о * о оо^ахчэчэчэчэг
»so»s * х =* о u ? ? ? ? <=
ьаа?<ос»хоооох
^ йв в US О £ 4) 4) 4) 4) «О
СО С ^
»- =п=г
РЕГИОН
Теперь регионы разбиты на 10 групп по степени заболеваемости.
Конечно, такой анализ может быть гораздо изощреннее: на карте можно
отобразить корреляции, зависимости между различными параметрами, например,
между использованием мобильной связи и Интернета в различных регионах, можно
рассмотреть карту отдельного региона и т. д.
Нейронные
сети
Идея нейронных сетей возникла в результате попыток смоделировать поведение
живых существ, воспринимающих воздействия внешней среды и обучающихся на
собственном опыте. Такого рода идеи на стыке различных областей знания
характерны для науки современного времени.
Наша цель состоит в том, чтобы кратко описать идею нейронных сетей и
научить читателя экспериментировать с нейронными сетями в системе STATISTIC А.
Более подробная информация о нейронных сетях доступна в текстах Уссермен Ф.
Нейрокомпьютерная техника, М.: Мир, 1992, Lippman R. P. An introduction to
computing with neural nets, IEEE ASSP Magazine. Apr. 1987, p. 4-22, и др.
Ключевым является понятие нейронов — специальных нервных клеток,
способных воспринимать, преобразовывать и распространять сигналы.
Начнем со следующей модели нейрона. Хотя эта модель очень простая, она
работает. Итак, нейрон имеет несколько каналов ввода информации — дендриты, и
один канал вывода информации — аксон. Аксоны нейрона соединяются с дендри-
тами других нейронов с помощью синапсов. При возбуждении нейрон посылает
сигнал по своему аксону. Через синапсы сигнал передается другим нейронам,
которые, в свою очередь, могут возбуждаться или, наоборот, оказываться в
состоянии торможения.
Заметьте, биологические образы естественны при описании процесса обучения,
создавая контекст для математических рассуждений.
Нейрон возбуждается, когда суммарный уровень сигналов, пришедших в него,
превышает определенный уровень (порог возбуждения или активации).
Интенсивность сигнала, получаемого нейроном, зависит от активности синапсов.
Итак, запомним следующее.
О Нейрон получает сигналы через несколько входных каналов. Каждый
сигнал проходит через соединение — синапс, имеющее определенную
интенсивность, или вес, который соответствует синаптической активности нейрона.
О Текущее состояние нейрона определяется формулой:
N
Щ = ^™(ij)x(j) + и<1*,0) A),
Tjxex(j),j = 1,2...N — входные сигналы. Коэффициенты w(i,j) называются
весами синаптических связей, положительное значения которых
соответствуют возбуждающим синапсам, отрицательные значения - тормозящим
синапсам. Если w(i,j) = 0, то говорят, что связь между нейроном i и нейроном
j отсутствует. Величина w(i,0) называется пороговым значением.
7
612
Глава 17. Нейронные сети
О Полученный нейроном сигнал преобразуется с помощью функции
активации или передаточной функции/в выходной сигнал
У,-=/(«,-) B)
Это одна из первых моделей нейрона предложена МакКаллоком и Питсом в
1943 году.
Заметим также, что имеется стохастическая модель нейрона, в которой
выходной сигнал является случайной величиной, принимающей пару значений, которые
соответствуют торможению или возбуждению.
С математической точки зрения в модели нейрона мы имеем нелинейное
преобразование вектора xA)jcB)..jc(N) в выходной сигнал уг
Функция активации или передаточная функция/ в формуле B) — это
некоторая нелинейная функция, моделирующая процесс передачи возбуждения.
Простейшие пример такой функции — индикаторная или скачкообразная
функция, определяемая равенствами:/(м,)=1, если u>=0,f(u)=1y если и<0.
Если выбрать функцию/вида
/(") = ТТ^г
где Ь>0, то получится так называемый сигмоидальный нейрон и т. д.
Объединенные между собой нейроны образуют сеть, с математической точки
зрения задающую сложное многомерное преобразование, собранное из
простейших преобразований. Замечательно, что с помощью таких простейших
преобразований можно приближать очень сложные многомерные функции, следовательно,
оценивать сложные зависимости (заметим, замечательная теорема Колмогорова
является математическим основанием нейронных сетей).
STATISTIC А позволяет задавать различные передаточные функции, например,
линейную, логистическую и др. (эти функции можно выбрать в диалоговом окне
Network Editor, доступном из меню File).
Q3| I'«" £t*tttic» Bun Qpt
yatabfet ►
Cfttet ►
£opy Orf-C
QetaSeL.
Network Set..
Pie/Port Ptoctwv
Выходы нейронов соединяются с входами других нейронов, таким образом,
сигнал от одного нейрона передается другим нейронам (нейрон информирует о
своем состоянии другие нейроны). Конечно, с математической точки зрения мы
имеем преобразование исходных значений X на входе сети в значения Y на выходе.
На биологическом языке входы и выходы соответствуют сенсорным и
двигательным нервам. Кроме входных и выходных нейронов в сети могут присутствовать
еще промежуточные (скрытые) слои нейронов. Простейшие сети имеют структуру
Нейронные сети
613
прямой передачи сигнала: сигналы проходят от входов через скрытые элементы и
в конце концов поступают на выходные элементы (см. рисунки).
■.№l.ll".lll.!IUJIIifH
trror function J Sum-squared jj]
.[-&**• I wan r~m
Connection» Shown | Current lay» jj
praif
ISERIES SI lS£BtES_G-1 lSERl€$.fr1
Рис. 1. Окно Редактор Сети системы STATISTICA с набором передаточных функций
Network Illustration (Series_g... НццЕЗ
Network Illustration;
Щ
Рис. 2. Двухслойная сеть, имеющая 12 входов, 1 выход и 6 элементов на промежуточном слое
Network Illustration (Serres.g... МИОЕЗ
Network Illustration1
Ш\
Рис. 3. Трехслойная сеть, имеющая 12 входов и 1 выход
614
Глава 17. Нейронные сети
Итак, каждый нейрон как элемент сети описывается своим набором
параметров (см. формулы 1,2).
Входной слой служит для ввода значений входных переменных, выходной
слой — для вывода результатов. Скрытые выходные нейроны соединены со всеми
элементами предыдущего слоя. Последовательность слоев и их соединений
называется архитектурой сети.
При работе сети на входные элементы подаются значения входных
переменных (входной сигнал), затем возбуждаются нейроны первого промежуточного слоя,
далее — второго промежуточного слоя, в итоге преобразованный сигнал поступает
на выходной слой.
Преобразование сигнала проводится следующим образом.
Последовательно для каждого нейрона в сети вычисляется значение
активации, берется взвешенная сумма выходов элементов предыдущего слоя и
вычитается пороговое значение. Затем значения активации преобразуются с помощью
передаточной функции, и в результате получается выход нейрона, поступающий
на вход нейронов, с которыми он соединен.
Обучение сети
Обычно нейронные сети используют в задачах классификации, прогнозирования
и построения нелинейных зависимостей (нелинейная регрессия).
Но для этого сеть нужно обучить. Замечательный факт состоит в том, что
нейронную сеть действительно можно обучить!
Теорема Колмогорова — это высший уровень абстракции, рассмотрение
нейронов — самый низкий или глубокий. Объединяя эти два уровня, мы пытаемся по
существу понять, как организовано мышление, когда состоящий из простейших
нейронов человеческий мозг постигает глубочайшие закономерности. Процесс
получения знания моделируется с помощью нейронных сетей.
Мы знаем, что знания получаются последовательно, иными словами они не
даются в законченном виде, а достигаются с помощью обучения, этот принцип
использован в нейронных сетях. Итак, мы построили модель нейрона и нейронной
сети, теперь нужно предложить модель обучения.
Как мы уже отмечали, формально соотношения A), B) задают простое
преобразование величин с различными функциями f. Пусть мы имеем сложное
преобразование F исходного набора данных (который поступает на вход сети) в выходной
набор (который наблюдается на выходе сети).
Возникает вопрос: как реализовать преобразование F с помощью нейронной
сети. На математическом языке мы должны приблизить неизвестную сложную
функцию простейшими преобразованиями, задаваемыми уравнениями A), B).
Теорема Колмогорова утверждает в принципе, что такая сеть существует, но не
говорит, как именно ее настроить. Мы используем общий подход, связанный с
обучением, то есть последовательным получением знаний, наказанием за неправильный
ответ и поощрением за правильный ответ.
Вначале мы определяем архитектуру сети, то есть устанавливаем количество
нейронов и связи между ними, выбираем конкретную синаптическую функцию,
моделирующую процесс передачи возбуждения.
Разобьем данные на две части, обучающие и контрольные, на сленге
нейронных сетей — обучающую и контрольную выборку.
Нейронные сети
615
Общая идея состоит в следующем: вначале на вход сети подается обучающая
выборка с известными результатами, величины X и наблюдаются отклики Y=F(X).
Меняя веса w(i,j) и значения порога активации для каждого нейрона мы
настраиваем сеть, иными словами, находим как можно более точное приближение
функции F.
Далее на тестовой выборке экзаменуем простроенную сеть или сети, если их
несколько (в общем случае мы получаем ансамбль сетей). Например, в задаче
классификации мы можем потребовать, чтобы сеть правильно классифицировала не
менее 90% наблюдений. В задаче прогнозирования мы можем стремиться к тому,
чтобы точность прогноза на определенное количество шагов вперед была не ниже
заданной. Если сеть прошла экзамен, мы можем использовать ее для анализа
данных, построить прогноз или провести классификацию.
Очевидно, невозможно умозрительно организовать данный процесс в силу его
трудоемкости и сложного преобразования данных, только компьютерные
технологии позволяют эффективно сделать это.
Конечно, в данном процессе имеется определенный произвол связанный,
например, с выбором обучающей выборки и риском применения сети на реальных данных,
но тот же произвол возникает при применении любых математических методов на
практике, именно потому, что эти методы имеют дело с сырыми данными
(действительностью), а не с возвышенными числами, с которыми они призваны оперировать.
В замечательной модели нейронных мы имеем синтез различных методов,
которые могут «ожить» только с помощью компьютерных технологий.
Рассмотрим идею обучения на простой и ясной модели Розенблатта
однослойного персептрона. Анализируя алгоритм, вы можете заметить, что он основан на
древнем как мир принципе кнута и пряника. Если сеть правильно
классифицирует сигнал, она получает пряник, в противном случае кнут.
Модель Розенблатта
(однослойный персептрон — single layer perceptron)
Как видно из названия, в этой модели число слоев равно 1, поэтому исключим
второй индекс и рассмотрим только веса w(i)> 1 < г <N(cm. формулы A), B)).
Конечно, заранее эти веса не известны, и их нужно найти с помощью разумной
процедуры.
На вход сети подается сигнал (xl, х2 ... xN). Пусть входной сигнал может
принадлежать либо классу А, либо классу Б. Предположим, для простоты, что мы
анализируем двумерный сигнал, иными словами, число N= 2.
Обучение однослойного персептрона
Шаг 0. Начальные установки: веса wl(l), w2(l) и порог Т задаются случайным
образом.
Будем обозначать t шаг обучения. Вначале t = 0.
Шаг 1. Положим t = t+\. Предъявим сети входной сигнал из обучающей
выборки: (xl(t),x2(t)).
Определим d(t) - 1, если входной сигнал принадлежит классу А, и d(t) = -1,
если входной сигнал принадлежит классу Б.
Шаг 2. Вычислим состояние нейрона в момент времени t (просто суммируем
входные сигналы с весами и вычитаем порог Г): s(t) = wl(t)x xl(t) + w2(t) X x2(t) — Т.
616
Глава 17. Нейронные сети
Шаг 3. Вычислим выходной сигнал нейрона y(t) в момент t (заметьте,
используется скачкообразная функция): y(t) = sign(s(£))
Шаг 4. С учетом результата обучения вычислим новые веса нейрона по
формулам: wi(t) = wl(t-i) + rX (y(t) - d(t))y w2(t) = w2(t-\) + r(y(t) - d@), г- шаг
обучения.
Шаг 5. Если шаг обучения г меньше объема обучающей выборки I, то
переходим к шагу 1.
В противном случае обучение заканчивается.
Таким образом, получается обученный персептрон, который может решать
простые задачи классификации. Если вы захотите доказать, что это действительно
обученный персептрон, то вам следует воспользоваться методами теории
вероятности или проверить это утверждение экспериментально, например с помощью
статистического моделирования.
Многослойный персептрон
Обобщение однослойного персептрона приводит к многослойному персептрону
(см. рис. 2 и 3).
В многослойном персептроне каждый элемент сети строит взвешенную сумму
своих входов с поправкой в виде слагаемого, а затем пропускает вычисленное
значение через передаточную функцию. Таким образом, по общим правилам
получается выходное значение персептрона.
Нейроны организованы в послойную структуру с прямой передачей сигнала.
Веса и пороговые значения являются свободными параметрами модели, которые
оцениваются в процессе обучения.
Многослойный персептрон может моделировать функцию практически любой
степени сложности.
Имея в своем распоряжении STATISTICA, вы можете всесторонне
экспериментировать с моделями, переходя от простых моделей к более сложным.
Конечно, с математической точки зрения, нейронная сеть осуществляет
преобразование одного сигнала в другой. Фокус состоит в том, что это преобразование
подчиняется рекурсивным правилам и может быть реализовано технически.
Общий взгляд
Сделаем шаг в сторону и посмотрим на нейронные сети с общих позиций. Как мы
говорили (см. главу 2), одной из основных задач анализа данных является оценка
зависимости между переменными, например, между переменной X и
переменной Y. Наблюдая различные значения переменной X и соответствующие значения
переменной У, мы хотим оценить зависимость Y = F(X).
В частном случае мы хотим оценить линейную зависимость F(X) = а*Х + Ь,
где а, Ъ неизвестные константы, или полиномиальную зависимость, когда ^пред-
ставляет собой полином некоторой степени. Можно также разложить функцию F
в ряд Фурье и, используя комбинации синусов и косинусов или других базисных
функций, последовательно приближать функцию F. В различных разделах
анализа используются различные методы решения этой задачи.
В нейронных сетях мы собираем функцию F из простейших нейронов,
комбинируя их разнообразным образом друг с другом. Получая на вход набор X, с
помощью простейших функций мы преобразуем X в Y, ожидая при этом, что собранная
сеть приближает искомую функцию F. Конечно, такая игра может показаться бес-
Нейронные сети
617
смысленной, но знаменитая теорема Колмогорова, о которой часто не
подозревают практики, утверждает, что такие упражнения вполне оправданы, — действуя
подобным образом можно в принципе собрать из простейшихнейронов сколь
угодно сложную функцию F. Теорема Колмогорова утверждает также, что достаточно
иметь не более двух скрытых слоев нейронов в сети для восстановления зависимости.
Заметьте, явный вид собранной функции нам не интересен, для нас важно в
принципе знать, что она близка к искомой.
Как проверить, насколько собранная функция близка той, которую мы ищем?
Одним из естественных подходов к решению этой задачи является следующий:
данные разбиваются на две части, по одной из которых строится оценка функции,
собранной из нейронов, на второй части данных проверяется, насколько построенная
функция близка искомой (такая процедура называется кросс-проверкой, см. также
раздел Обучение сети). Конечно, подобное решение нематематично (действительно,
оно зависит, например, от того, как именно произведено разделение данных на
обучающую и тестовую выборку) и не может удовлетворить любителей строгости, однако
оказывается вполне приемлемым во многих прикладных задачах. Заметим, что
программа SNN предлагает различные способы проверки качества построенной сети.
Теперь можно приступить к экспериментированию с нейронными сетями в
системе STATISTICS
Обратим внимание, что в модуле Нейронные сети системы STATISTICA
имеется Советнику подсказывающий выбор архитектуры сети (см. описанный ниже
пример классификации с помощью нейронных сетей).
Покажем, как построить многослойный персептрон в системе STATISTICA.
Построение многослойного персептрона в системе
STATISTICA
Шаг 1. Запустите модуль Нейронные сети.
Шаг 2. Откройте, например, файл series_g.sta из папки Examples. Используйте
меню File-Open. Файл содержит данные о месячных авиаперевозках пассажиров.
Если вы хотите создать свой набор данных в модуле Нейронные сети,
поступите следующим образом:
О Войдите в диалоговое окно Создать набор данных — Create Data Set с
помощью команды Набор данных — Data Set... из меню Файл—Новый — File—New.
ВЗ £А Iran Statistics fiun Qptiore &nd
Рис. 4. Создание файла данных
О Введите нужные значения для количества входных — Inputs и выходных —
Outputs переменных в наборе данных. Введите, например, 17 и 7.
О Нажмите кнопку Создать — Create.
618
Глава 17. Нейронные сети
Заметьте, что имена входных переменных имеют черный цвет, имя выходных
переменных — голубой цвет; входы от выходов отделяются темной вертикальной
линией.
1 Create Data Set
Inputs |17
Щ
Outputs |7
fl
ПЕЗ!
Cieate I
Ck»e |
Рис. 5. Определение числа входных и выходных наблюдений
В данном примере, однако, мы не будем создавать нового файла, а будем
работать с имеющимся файлом series_g.sta.
Шаг 3. После того как файл данных series_g.sta открыт, перейдем к созданию
сети.
Для этого в меню File выберите команды: New—Network — Новая Сеть (см. рис. 6).
Шаг 4. Вначале создадим структуру сети. В появившемся диалоговом окне
сделайте установки, как показано на рис. 7.
В поле Туре — Тип выберите тип сети: Многослойный персептрон.
Задайте параметр Временное окно — Steps равным 12. Мы выбрали эту
установку, так как в ряде имеется сезонная составляющая с лагом 12.
Установите параметр Горизонт — Lookahead равным 1.
jdpene Data Set Fie
Рис. 6. Рабочее окно модуля Нейронные сети
Нейронные сети
619
Jypt | MuMayei Perception »j
TroeSenet
Slept Lookaheed
Inpui* Г" § Qutput* fi § HoLeyer* F~||
Cjeate ]
МП
il
ol
Convert
Minmax
Hinmax
«LI л
RFwW
Layer 1
Layer 2
Layer Э
Units
iLL
1
Рис. 7. Диалоговое окно построения сети
Данные содержат значения одной переменной. Для нейронной сети эта
переменная будет служить одновременно входной и выходной (в разные моменты
времени). Для того чтобы определить переменную как входную/выходную, нужно
выделить ее щелчком на заголовке таблицы, а затем в появившемся меню выбрать
пункт Input/Output.
Обратите внимание на установку в окне No Layers — Число слоев.
Мы выбрали сеть, содержащую 3 слоя. В таблице ниже для слоя 2 показано:
Layer 2 — Слой 2:1.
В вашем распоряжении имеются две кнопки Advise — Советовать и Create —
Создать.
Нажмите кнопку Advise — Советовать.
Заметьте, что после нажатия кнопки Advise — Советовать значение в поле No
Layers — Число слоев изменится и станет равным 6.
Система советует выбрать 6 элементов на промежуточном слое. Вы можете
воспользоваться советом или построить персептрон со своей структурой.
Например, вы можете щелкнуть мышью на поле Layer2 и ввести любое значение
для числа нейронов на слое 2. Гибкий интерфейс позволяет вам задавать
архитектуру сети.
Шаг 5. Нажмите кнопку Create — Создать. На экране появится следующая сеть:
Рис. 8. Трехслойный персептрон с 7 элементами на 2-м слое
620
Глава 17. Нейронные сети
Таким образом, можно создать персептрон с нужным количеством слоев и
числом элементов на каждом слое.
В окне Редактор сети STATISTIC А можно послойно просмотреть и
отредактировать сеть, выбирать передаточную функцию для каждого слоя, а также пост-
синаптический потенциал или значение активации нейрона.
Итак, создана архитектуру сети. Мы продолжим рассмотрение этого примера,
но вначале дадим необходимые теоретические сведения.
Обучение многослойного персептрона
После того как структура многослойного персептрона определена, его нужно
обучить, то есть найти значения весов и порогов сети, являющиеся свободными
(неизвестными) параметрами. Их нужно определить, чтобы сеть решала поставленную
задачу. Представьте, вы случайным образом выбрали значения этих параметров, —
вряд ли такая сеть будет для вас полезной. Трудно угадать нужные значения
параметров, однако имеется процесс, называемый обучением, который позволяет
последовательно находить эти параметры, приближаясь к лучшей сети.
Процесс обучения представляет собой подгонку модели, которая реализуется
сетью, к обучающим данным, например, с известным ответом. Ошибка для
конкретной сети определяется путем прогона всех имеющихся наблюдений и сравнения
реально выдаваемых выходных значений сети с целевыми (правильными)
значениями. Грубо говоря, мы обучаем сеть, продвигаясь в сторону уменьшения ошибок.
В качестве функции ошибки, например, можно взять среднеквадратичную
ошибку, вычисляемую следующим образом: ошибки выходных элементов для всех
наблюдений возводятся в квадрат и затем суммируются.
В модуле Нейронные сети выдается так называемая среднеквадратичная
ошибка: описанная выше величина нормируется на число наблюдений и переменных,
после чего из нее извлекается квадратный корень.
Это достаточно разумная мера ошибки, усредненная по всему обучающему
множеству и по всем выходным элементам. Конечно, эта мера ошибки естественна в
нелинейной регрессии, но вряд ли она полезна в задачах классификации, где
критерием качества может являться доля правильно классифицированных наблюдений.
Заметим, что разнообразные функции ошибок можно выбрать в окне Редактор Сети.
Итак, после того как мы задали архитектуру сети, нам нужно найти параметры,
минимизирующие ошибку или максимизирующие качество работы сети.
В линейных моделях можно определить параметры, дающие абсолютный
минимум ошибки.
С нелинейными моделями дело обстоит гораздо сложнее. Настраивая сеть с
целью минимизации ошибки, нельзя быть уверенным, что алгоритм обучения
достиг глобального минимума, иными словами, утверждать, что нельзя добиться
лучшего результата.
Поверхность ошибок
Для контроля обучения сети полезна поверхность ошибок, к описанию которой
мы сейчас переходим.
Каждому из весов и порогов сети (то есть свободных параметров модели; их
общее число мы обозначим через N) соответствует одно измерение в многомерном
пространстве. (W+l^-мерное измерение соответствует ошибке сети.
Нейронные сети
621
Для данного набора весов соответствующую ошибку сети можно изобразить
точкой в (N+l)-MepnoM пространстве. В итоге все такие точки образуют
некоторую поверхность — поверхность ошибок.
Цель обучения нейронной сети состоит в том, чтобы найти самую низкую
точку этой поверхности. В случае линейной модели с суммой квадратов в качестве
функции ошибок поверхность ошибок представляет собой параболоид, и
минимум находится легко.
В общем случае поверхность ошибок имеет сложную структуру, в частности,
может иметь локальные минимумы (точки, самые низкие в некоторой своей
окрестности, но лежащие выше глобального минимума), седловые точки и т. д.
Обучение нейронной сети заключается в исследовании поверхности ошибок.
Отталкиваясь от некоторой начальной конфигурации весов и порогов, алгоритм
обучения производит поиск глобального минимума.
Как правило, для этого вычисляется градиент в данной точке, а затем эта
информация используется для продвижения вниз по склону на поверхности. В
конце концов, алгоритм приводит к некоторой нижней точке (ниже спуститься нельзя),
которая, однако, может оказаться лишь точкой локального минимума. Очевидно,
следует использовать различные начальные приближения.
STATISTICA предлагает следующие методы обучения многослойного персеп-
трона:
ВЕЯ £*****£$ В"" flptions &indow ]Jdp
ШШШШШШт s«*p>°P«o«m.. I
Conjugate Gradients...
Line* JJuasbNevyiOf\ >
f* *"< lever^g-MequardL.
[■о. !"'' Quick Propagation..
fi>e*«-Bar-De*a...
Pfr«ipal£omponentt . j
&uxikary ► 1
Рис. 9. Алгоритмы обучения многослойного персептрона
Для обучения многослойных персептронов в пакете Neural Networks
реализовано пять различных алгоритмов: алгоритм обратного распространения, быстрые
методы второго порядка — методы сопряженных градиентов и Левенберга—Маркара,
а также методы быстрого распространения и Дельта-дельта с чертой (вариация метода
обратного распространения). Все эти методы являются итеративными, то есть
последовательно приближаются к минимуму, начиная с некоторого начального значения.
Выбор алгоритма обучения
В большинстве случаев вначале следует испытать метод сопряженных
градиентов — в этом случае обучение происходит достаточно быстро (иногда на порядок
быстрее, чем, например, методом обратного распространения).
Последний метод следует предпочесть в случае, когда в очень сложной задаче
требуется быстро найти удовлетворительное решение или когда данных очень
много (порядка десятков тысяч наблюдений).
Метод Левенберга—Маркара для некоторых типов задач может оказаться
эффективнее метода сопряженных градиентов, но его можно использовать только
622
Глава 17. Нейронные сети
в сетях с одним выходом, квадратичной функцией ошибок и не очень большим
числом весов. Фактически область его применения ограничивается небольшими
по объему задачами нелинейной регрессии.
Итеративное обучение. Итеративный алгоритм обучения последовательно
проходит ряд так называемых эпох — Epochs, на каждой из которых на вход сети
подается наблюдение за наблюдением — весь набор обучающих данных, вычисляются
ошибки и по ним подправляются веса сети.
Известно, что итеративные алгоритмы подвержены нежелательному явлению
переобучения (когда сеть хорошо учится выдавать те же выходные значения, что и
в обучающем множестве, но оказывается не способна обобщить закономерность
на новые данные). Поэтому качество работы сети следует проверять на каждой
эпохе с помощью специального проверочного множества (для этого нужно выбрать
опцию Кросс-проверка — Cross verification в диалоговом окне обучения).
Контроль обучения
За ходом обучения можно следить в окне График ошибки обучения — Training Error
Graph (оно открывается из меню Статистики — Statistics), где на графике
отображается среднеквадратичная ошибка на обучающем множестве на данной эпохе.
Если выбрана опция Кросс-проверка — Verification, выводится также
среднеквадратичная ошибка на проверочном множестве.
С помощью расположенных под графиком элементов управления можно
менять масштаб изображения, а если график целиком не помещается в окне, под ним
появляются линейки прокрутки.
Рис. 10. График ошибок обучения
Если требуется сопоставить результаты различных этапов обучения, нажмите
кнопку Переустановить — Reinitialize в окне обучения, а затем еще раз нажмите
кнопку Обучить — Train (повторное нажатие кнопки Обучить — Train без
Переустановки — Reinitialize просто продолжит обучение сети с того места, где оно было
прервано).
Чтобы облегчить сравнение результатов, имеется возможность перед нажатием
кнопки Обучить — Train задать для графика Метку — Label: тогда очередная линия
будет рисоваться новым цветом, а информация о ней будет добавлена в легенду в
правой части окна. По окончании обучения график можно переслать в STATISTICA
(кнопка О).
На графике обучения можно легко заметить эффект переобучения. Вначале
ошибка обучения и проверочная ошибка убывают. При возникновении эффекта переобуче-
Нейронные сети
623
ния ошибка обучения продолжает убывать, а ошибка проверки растет. Рост
проверочной ошибки сигнализирует о начале переобучения. Если наблюдается переобучение,
то обучение следует прервать, нажав кнопку Стоп — Stop в окне обучения или нажав
клавишу ESCAPE.
Можно также задать автоматическую остановку программы ST Neural Networks с
помощью условий остановки, которые задаются в окне Условия остановки — Stopping
Conditions (доступ к которому происходит через меню Обучение-дополнительные — Train-
Auxiliary).
■И1...ЛИ.Л.Л1И
£pod» foo~|!
Target Enor
Tiaining |0
Venfic«bon |°
Minimum improvement
1ммг* |5
У«Лс*юп fo
Window |0 (fj
шшим
Рис. 11. Задание условий остановки обучения
Кроме максимального числа эпох, отводимого на обучение, можно потребовать,
чтобы обучение прекращалось при достижении определенного уровня ошибки или
когда ошибка перестает уменьшаться на определенную величину (остановка по
невязке).
Борьба с переобучением
Самое лучшее средство борьбы с переобучением — задать нулевой уровень
минимального улучшения. Однако поскольку при обучении присутствует шум, обычно
не рекомендуется прекращать обучение лишь потому, что на очередной эпохе
ошибка ухудшилась. Поэтому в диалоге Stopping Conditions — Условия остановки
имеется специальное Окно — Window, в котором задается число эпох, на протяжении
которых должно наблюдаться ухудшение, и только после этого обучение будет
остановлено. Обычно в этом окне устанавливают значение 5.
Сохранение лучшей сети
Вы можете восстановить наилучшую конфигурацию сети из всех, полученных в
процессе обучения, с помощью опции Лучшая сеть — Best Network... (меню
Обучение-дополнительные — Train-Auxiliary).
Если опция Сохранить лучшую — Retain Best включена, программа Neural
Networks автоматически сохраняет наилучшую из сетей, полученную в ходе обучения.
Если включена опция Учитывать все прогоны обучения — Span training runs, то
это делается и для прогонов обучения различных сетей.
Таким образом, программа Neural Networks автоматически хранит наилучший
результат всех экспериментов.
624
Глава 17. Нейронные сети
К Retain Best Netwcxk
[X Bet*nJM ;
f* Span beting runt
UnJtPenaftyl0
Netwodcenort
Tracing A02096
Verification Д
ПЕГ
Restore j
£*c«d j
Oote 1
Рис. 12. Опция: лучшая сеть
Можно также установить Штраф за элемент — Unit Penalty с тем, чтобы при
сравнении штрафовать сети с большим числом элементов (наилучшая сеть
обычно представляет собой компромисс между качеством работы и размером).
Наилучшая сеть
Для того чтобы вызвать наилучшую сеть, нажмите кнопку Восстановить — Restore.
Такая возможность, как правило, очень помогает, однако ясно, что она отрицательно
сказывается на эффективности (программа Neural Networks должна копировать и
сохранять сеть каждый раз, когда достигается улучшение), поэтому в некоторых
случаях имеет смысл отключить эту опцию.
Рис. 13. Ошибки обучения
Ошибки сети (во время и по результатам обучения) можно наблюдать также в окне
Ошибки наблюдений — Case Errors (доступ — через меню Статистики — Statistics).
Здесь выводится диаграмма ошибок для отдельных наблюдений. Установив опцию
Пересчитывать по ходу — Real-time Update, можно следить за изменением ошибок от
эпохи к эпохе.
Обратное распространение
Перед применением алгоритма обратного распространения необходимо задать
значения ряда управляющих параметров.
Наиболее важными параметрами являются скорость обучения, инерция и
перемешивание наблюдений в процессе обучения.
Скорость обучения — Learning rate задает величину шага при изменении весов:
в случае недостаточной скорости алгоритм медленно сходится, а при слишком
большой алгоритм неустойчив. К сожалению, величина наилучшей скорости зависит
Пре/постпроцессирование
625
от конкретной задачи; для быстрого и грубого обучения подойдут значения от ОД
до 0,6; для достижения точной сходимости требуются гораздо меньшие значения
(например, 0,01 или даже 0,001, если эпох много тысяч).
Momentum |03 ; [51 ■• jogWeghtt )
go*e I3 S*0P И
f* $bU«eCam "=--y ; • 0p>e I
У РоцувнЙсаЬоп V |
Рис. 14. Опции алгоритма обратное распространение
Иногда полезно уменьшить скорость обучения. В программе Neural Networks
можно задать начальное и конечное значения скорости, и по мере обучения
производится интерполяция между ними. Начальная скорость задается в левом поле,
конечная —в правом.
Инерция — Momentum помогает алгоритму, когда он застревает в низинах и
локальных минимумах. Этот коэффициент может иметь значения в интервале от нуля до
единицы.
Реально «правильное» значение можно найти только опытным путем, и для
этого в STATISTIC А имеются все возможности.
Перемешивание наблюдений
Перемешивать порядок наблюдения обычно рекомендуется, когда для решения
задачи используется метод обратного распространения, поскольку этот способ
уменьшает вероятность того, что алгоритм застрянет в локальном минимуме, а
также уменьшает эффект переобучения. Чтобы воспользоваться такой возможностью,
установите опцию Перемешивать наблюдения — Shuffle Cases.
При работе с нейросетями следует помнить о важном моменте — процессиро-
вании, или преобразовании, данных.
Пре/постпроцессирование
Передаточная функция для каждого элемента сети обычно выбирается так, чтобы
ее входной аргумент мог принимать произвольные значения, а выходные
значения лежали бы в строго ограниченном диапазоне. При этом возможен эффект
насыщения, когда элемент сети оказывается чувствительным лишь к входным
значениям, лежащим в некоторой ограниченной области.
На этом рис. 15 представлена логистическая функция.
Логистическая функция является гладкой, ее производная легко вычисляется,
что существенно для алгоритмов минимизации на этапе обучения сети (в этом
также кроется причина того, что ступенчатая функция для этой цели практически не
используется). Если применяется логистическая функция для вычисления вы-
626
Глава 17. Нейронные сети
ходного сигнала (см. формулу A)), то выходное значение всегда лежит в
интервале @,1), а область чувствительности для входов чуть шире интервала (-2;+2).
;i i\m шин тугттмАпмттвяи мщ
LOGISTIC FUNCTION
•/" ; ' '
/ ;
■■/'■ \
/i I
У ■ \
'■4 2 0 2 4
Рис. 15. Логистическая функция
Чтобы согласовать вход-выход при решении задач методами нейронных сетей,
требуются этапы предварительной обработки (Bishop, A995) Neural Networks with
Pattern recognition, Oxford: University Press). Эти преобразования включают,
в частности, шкалирование и преобразование категориальных переменных в
числовую форму.
Шкалирование
Числовые значения должны быть приведены в масштаб, подходящий для сети.
В пакете Нейронные сети STреализованы алгоритмы минимакса и
среднего/стандартного отклонения, которые автоматически находят масштабирующие
параметры для преобразования числовых значений в нужный диапазон.
В некоторых случаях более подходящим может оказаться нелинейное
шкалирование (например, если заранее известно, что переменная имеет
экспоненциальное распределение, есть смысл взять ее логарифм). Можно шкалировать
переменную с помощью средств преобразования данных в STATISTICA, а затем работать
с ней в модуле Нейронные сети ST.
Номинальные переменные
Номинальные, или категориальные, переменные преобразовываются в числовую
форму (например, Муж = 0, Жен = 1). Для кодирования многомерных
номинальных переменных используется так называемый метод 1-H3-N, так как при наивном
способе кодирования, например Собака = 0, Овца = 1, Кошка = 2, может
возникнуть ложное упорядочивание значений категориальной переменной: Овца окажется
чем-то средним между Собакой и Кошкой.
В методе 1-H3-N одна номинальная переменная представляется несколькими
числовыми переменными. Количество числовых переменных равно числу
возможных значений номинальной переменной; при этом всякий раз ровно одна из N
переменных принимает ненулевое значение (например, Собака = {1,0,0}, Овца - {0,1,0},
Кошка = {0,0,1}). Заметим, что этот метод кодирования требует большого количества
числовых переменных, если номинальная переменная принимает много значений.
08
00
04
02
Диалог в модуле Нейронные сети STATISTICA
627
Оценка качества работы сети
После того как сеть обучена, стоит проверить, насколько хорошо она работает. Для
этого доступны несколько показателей.
Среднеквадратичная ошибка, которая выдается в окне График ошибки
обучения — Training Error Graph, представляет лишь грубую меру производительности.
Более полезные характеристики выводятся в окнах Статистики классификации —
Classification Statistics к Статистики регрессии — Regression Statistics (доступ к
обоим происходит через меню Статистики — Statistics).
Окно Статистики классификации — Classification Statistics применяется для
номинальных выходных переменных. Здесь выдаются сведения о том, сколько
наблюдений каждого класса (классы соответствуют номинальным значениям) из
файла данных было классифицировано правильно, сколько неправильно и сколько
не классифицировано, а также приводятся подробности об ошибках классификации.
Обучив сеть, нужно просто открыть это окно и нажать в нем кнопку Запуск —Run.
Статистики выдаются раздельно для обучающего, проверочного и тестового
множеств {внимание: чтобы увидеть тестовые статистики, нужно прокрутить таблицу
вправо). В верхней части таблицы приводятся суммарные статистики (общее число
наблюдений в каждом классе, сколько из лих классифицировано правильно,
неправильно и не классифицировано), а в нижней части — кросс-результаты классификации
(сколько наблюдений из данного столбца было отнесено к данной строке).
Окно Статистики регрессии — Regression Statistics действует в случае
числовых выходных переменных. В нем суммируется точность регрессионных оценок.
Наиболее важной статистикой является S. D. ratio — отношение стандартного
отклонения ошибки прогноза к стандартному отклонению исходных данных.
Если бы у нас вообще не было входных данных, то лучшее, что мы могли бы
взять в качестве прогноза для выходной переменной, — это ее выборочное
среднее, а ошибка такого прогноза была бы равна стандартному отклонению выборки.
Если нейронная сеть работает результативно, мы вправе ожидать, что ее
средняя ошибка на имеющихся наблюдениях будет близка к нулю, а стандартное
отклонение этой ошибки будет меньше стандартного отклонения выборочных
значений (иначе сеть давала бы результат не лучше, чем простое угадывание).
Таким образом, если S. D. ratio значительно меньше единицы, то сеть эффективна.
Величина, равная единице минус S. D. ratio, является долей объясненной
дисперсии модели.
Перейдем к работе с нейронными сетями в системе
STATISTICA
Для того чтобы понять, как решаются задачи прогнозирования с помощью нейро-
сетей, мы будем использовать файл series__g.sta, для задач классификации
используем файл irissta.
Диалог в модуле Нейронные сети STATISTICA
Мы продолжаем работать с файлом Series_g.sta. Это классический файл данных,
обычно используемый для тестирования методов прогнозирования (см., например, книгу
Бокс Дж., Дженкинс Г. Д. Анализ временных рядов и прогнозирование. М.: Мир, 1974).
628
Глава 17. Нейронные сети
Шаг 1. Откройте файл данных Series\g.sta из папки Examples.
Данные содержат значения одной переменной: месячные перевозки пассажиров. Как
мы уже заметили, для нейронной сети эта переменная будет служить входной/выходной
(так как мы прогнозируем будущие значения ряда на основе предыдущих значений).
ЕДШЗЕЕ—
• todkft;: ■ :•") £3 Examples
~ЭМ й!
[ГП osadki
|f") Patients
ЩРке
|Й Pistons
[£]Piston$2
[Г1 Plssim
Li
Q. Jpnevmon
0 Poverty
|i""j pnvivkal
[l] processes
[["^Pfocmix
(ГП Program
[HPfcrfein
[|*"| pulse
[f J puenoise
О Radios
□ Rats
(ГП Reading
I
П<е$<
П Retail
[i"'J Screws
ияйЯ^ЦЯ
[i""]Shoftfun
□ $.te999
±1
Яедатг |Sene$_g
Fletoljype: JSTATISTICA data hie (" sta) 3
Qpen
Cancel
Рис. 16. Выбор файла
Поэтому задайте тип переменной как входная/выходная.
input
Qutput
tonote
toput/Шр*
Order Ascending
Ofdei Descending
£elinjtion,..
Cut
Copy
Paste
Clear
Рис. 17. Задание типа переменной
Для этого выделите переменную в открытом файле данных (щелчком на
заголовке столбца). Затем нажмите правую кнопку мыши и выберите из
появившегося контекстного меню пункт Входная/выходная — Input/Output. Имя переменной
высветится зеленым цветом.
Шаг 2. С помощью мыши выберите команду Сеть — Network... из меню Файл-
Новый — File—New.
STATISTICA Neuial Netwofks - Senes_g
I £d< Jiain $»abdics Run Qfiiom ^ndow
fipwv.
£lo$e
£ave
Network Set ►
E**
пгевша г
InteUgent РюЫет Solver. j~~
BataSet.. Щ
-ЩГ-
3IES 'л |
И2Л
118 —
£j Cased144
Рис. 18. Построение сети
Диалог в модуле Нейронные сети STATISTICA
629
На экране появится диалоговое окно Создать сеть — Create Network.
Jype | MuMayer Perception jj
T«r*Seriet
РгвУРоа Rtoc«ttine
Jnpult [i § flutputt
EMM
dote
Щ U9lV*t F~@
IConvert
Mim»ax
Hiniaax
U 11
тыщ
U»»1
JLyef2
by*3
Рис. 19. Задание параметров персептрона
В поле Туре — тип выберите тип сети Многослойный персептрон — Multilayer
Perceptron и сделайте следующие установки:
Входы — Inputs = 1, Выходы — Outputs = 1.
Задайте число слоев равным трем, No Layers = 3. Выберите трехслойный
персептрон. Задайте параметр Временное окно — Steps равным 12 (данные
представляют собой ежемесячные авиаперевозки с присутствующей в них сезонной
составляющей), а параметр Горизонт — Lookahead — равным 1. После этого нажмите
кнопки Совет — Advise и Создать — Create. На экране появится схема
трехслойного персептрона. Этот персептрон имеет 12 входов.
Рис. 20. Трехслойный персептрон
Шаг 3. Обучение сети. Структура сети определена. Теперь ее нужнотэбучить.
В файле данных выберите 66 обучающих — Training и 66 контрольных —
Verification наблюдений. Всего в файле содержится 144 наблюдения. Первые 12
резервируются для построения прогноза на первом шаге.
630
Глава 17. Нейронные сети
мттт
£fc, ДО !*•« $Ufebo< Дш fiptaro Window q«p
: аштмг^амадн mm
Но! Ыы
шшшшзде
У^Ы» >Г|Г—В; ^ F6— gfsG ^
Рис. 21. Из файла данных выбрано 66 обучающих и 66 контрольных наблюдений
Далее воспользуйтесь опцией Shuffle — Перемешать.
Заметьте, во временном ряде наблюдения упорядочены во времени, поэтому
при перемешивании нельзя пользоваться функцией Сгруппировать множества —
Group Sets.
¥* '•-vV''"'
fcalrte.
Ivp*
IP-"!
Pje/Port Proceisng...
{jctacxk.
^ГЭ IienandVenTy
Tia«\,y*ity jndTesi
£1
Arid into V«MNe
Рис. 22. Выбор функции Shuffle — Перемешивание позволяет случайным образом перемешать
наблюдения в процедуре обучения
Опция перемешивания позволяет распределить обучающие и контрольные
наблюдения в файле данных. Для обучения сети воспользуемся методом
сопряженных градиентов.
. STATISTICA Nemal Netwwkt "Sm
Jjjte I* РГГТЙ $t«hf«M fiur> QpliQr* ДОч&я» ЦЫр
ir**
¥«wbim
Leverbei a-M a»<jj* dt.
2wcfc Рюрадамоп..
Pnrxapal£ompon*n»i...
"ft _ *?;■ 4и***У...
Рис. 23. Выбор метода сопряженных градиентов для обучения сети
Г : Conjugato'GiadienttPM(Mnfl?WBi3
ь*. № Ш
Ф Got» ietrfic«»ion
i^%$- ■■"■;■
i '■■■;. „ , v .
I» |
Stop j
ОЬм |
Рис. 24. Окно минимизации методом сопряженных градиентов
Диалог в модуле Нейронные сети STATISTICA
631
Обратите внимание на кнопку Переустановить — Reinitialize: она позволяет
случайным образом выбрать новые начальные значения свободных параметров сети
и провести обучения, исходя из этих установок.
Опция Кросс-проверка — Cross verification позволяет провести обучение с кросс-
проверкой (проверять сеть на контрольном множестве на каждой эпохе обучения).
Шаг 4. Проекция временного ряда.
Проекция ряда строится следующим образом:
О сеть обрабатывает начальный набор значений (первые 12 наблюдений) и
выдает прогноз;
О первое наблюдение из исходного набора отбрасывается, вместо него
ставится прогноз, полученный на первом шаге;
О по новому набору входных значений строится следующий прогноз и т. д.
Процесс проектирования можно продолжать неограниченно.
Для построения проекции откройте окно Проекция временного ряда — Time Series
Projection командой Проекция временного ряда — Time Series Projection... меню Запуск —
Run.
шъ\жж
Qne-оИ...
&с1*«югчи
Re«pon»e Surface,,
£Ы« Diagiam.
Рис. 25. Открытие окна Проекция временного ряда
В модуле Нейронные сети можно построить проекцию временного ряда с
некоторого наблюдения текущего набора (см. опции окна). Выбирая опции окна, можно
получить разнообразные проекции и прогноз ряда с помощью построенной и
обученной сети.
13. i^ F~§
Рис. 26. Проекция временного ряда на 44 наблюдения
632
Глава 17. Нейронные сети
Чтобы оценить качество работы сети, откройте окно Статистики регрессии
Regression Statistics и нажмите кнопку Запуск — Run.
фШ*
ж**
vmm
Date Mean
Data SO.
Error MeeiV
EwocSO
AbtE Mean
S.O. Ratio
Correlation
Tr. SERIES |ve. SERIES
200.6818 №.ЪАК$
47.42838 Ь::.--Г-^4
-0.007445 -4Л.1Ъ-П-\
11.12794 2i.22.0Sh
8.46584 4-1.-10607
0.2346262 0.3290319
0.9720871 0.9551597
Рис. 27. Описательные статистики позволяют оценить качество прогноза
Шаг 5. Для того чтобы построить прогноз на 1 шаг с помощью обученной сети,
выберите команду меню Run — Single Case...
ШШШШШШ
&at*$et.
Ojie-ofrV
X*1* Series»;.
Besporoe Graph...
Besporoe Surface».
Cjutfet Diagram. :
Рис. 28. Выбор команды Run Single Case
На экране появится диалоговое окно Run Single Case. В поле Case No введите
номер наблюдения, для которого нужно построить прогноз, и нажмите кнопку Run.
£a*eNo
Енот 1164
Ryn
ЯШИ
InpU .
SERIES u-1 IsEftiES G 1 |sER:ES Ь-1 !
417 39i 41?
«JJ JJ
OUflUfc Shown [Variables jJ
laifbiin
Output.
Target
Error
SERIESJ3 |
347.866
Рис. 29. Прогноз на один шаг вперед, построенный с помощью обученной сети
В строке Output появится прогноз ряда на один шаг вперед. В строке Target
стоит знак ?, так как в исходном файле всего 144 наблюдения.
Диалог в модуле Нейронные сети STATISTICA
633
Классификация
Для решения задачи классификации воспользуемся файлом данных Iris.sta и
Мастером решения задач.
Это классические данные Фишера, для классификации которых применяется
дискриминантный анализ, дающий оптимальное линейное решающее правило.
Заметим, что альтернативным вариантом исследования являются деревья
классификации.
Мы используем эти данные только в иллюстративных целях: на простых и
ясных примерах можно познакомиться с возможностями нейронных сетей по
классификации данных.
■WHIffff.lJffl"J,U,ii'J.lH:MI!J,!l,l,l'A!,'JJ,l
SetecUhe Bali: or Advanced Vernon
Thebaic version make*« many deceioro as роздЫ* automatical (or you
T he advanced version atows >юу to cuelomee the detign procen.
Vereon
^ Batic(nvftl^dldeciwomeuioma6c^wntfipo»«bte}
<~ Advanced
Caned
ffie^Tf
Рис. 30. Мастер решения задач (начало диалога)
Шаг 1. Откройте файл Iris.sta. Первые 4 переменные — это параметры цветков
ириса. Категориальная переменная IRISTYPE обозначает тип ириса. Измеряя
параметры цветка, нужно отнести его к одному из трех типов (Setosa, Versicol, Virginic).
Мастер решения задач последовательно открывает диалоговые окна, в
которых просит сделать несложный выбор.
Шаг 2. Одно окно уже открыто — это Problem Type — Тип задачи. Укажите тип
задачи и нажмите кнопку Next.
Intelligent Problem Solver - Problem Type
Ptea$* «peciry Whether 0w » a Time Serie* or Standard problem In a Standard
prob^thecA»eiritl^datatetaretrea(ed*trtieper>JenLATimeS«wj
problem h one *here >ou with to predtot the value of * variable ba$edona
ProbJemTjpe , • • _ ^
<• :&nr&d'(ie^Kc^
*** Tin» Sena* (preoW late» value* from ea*« one*}
Cancel I < Back fje*» >
Рис. 31. Выберите стандартный тип
Шаг 3. В следующем окне выберите зависимую переменную.
634
Глава 17. Нейронные сети
,у*ш^1т,ут,ыщт
tf you vvtth to Mha mufcipfe otfpU у*«Ы«, pm* the Muktyt button fated
MuH*..
C«x*l < fiack | (Hg^>
fx":«
Рис. 32. Выберите переменную iristype как выходную (зависимую) переменную
Выходная переменная — номинальная, она принимает три значения: Setosa,
Versicol, Virginic. Нажмите кнопку Next.
Шаг 4. В следующем диалоговом окне выберите входные (независимые)
переменные.
пгшгшпип
SEBS&
Stiictifto i"(ni ffidiQififlwitliMMitoi ipi thi доЫмь YoU c*w specify #ЙЫк
ih*t9w IPS. feMt &• мйи$яуи$|Ым1 м pottibto input* and Mlectttoeiojt
1* $M№H^*4ft«0ttoW>rt
Cm* <fi«k Qtaol .**»
Рис. 33. Выберите входные переменные (параметры цветка)
Нажмите кнопку Next. Мастер решения разобьет выборку на обучающую
(черный цвет значений), контрольную (синий цвет) и тестовую выборку (красный
цвет). Также автоматически будет произведено перемешивание наблюдений.
Шаг 5. На экране появится окно Duration of Design Process.— Длительность поиска.
•IKiKlWt f* b»0#dtoeftl how doMitd lh> {ЫдояниЦ be» oi spocfy th$--;
A fry iwhtirrn m»<fc^»t)PSWdkcoy*rb<«qtna>woA<. ..-Vp
^ M«dMn|Cor>dyoU^*e^
' /^:>ТМ^М^«йН«м^л^«рвс1МЬеЫЬв$ «xpired)
Caned
<B*ck J ["SjTJ
Рис. 34. В окне Длительность поиска можно задать длительность поиска
(быстрый, средний, полный, ограниченный по времени)
Заключительные комментарии
635
Шаг 6. Далее на экране появится окно Saving Networks — Сохранение сетей.
В этом окне можно задать способы сохранения сетей, например, максимальное
число сохраняемых сетей, сохранить сети с лучшим качеством решения и т. д.
the IPS eieenmenit **h тепу networks, end may atore * number of the bett
be done I*» network »et» already ful ос пеаф Jul
М«чти« number o«netv«rk« savedI0 gj
Selection of network* to be aaved
Г K«epnebNort(ti^trwbet(per4oriMnc« $$
<V Beience pertownence ega**l fype *nd оап%Шку (memtein dwerefci
Action f ihe nework tec it too ful to odd the niw nehwkt
f Ipcreeje »he nrtwo*. «et tee
r Replace e*wf*^ nrtw»k» I r»ew network» we better {marten dr*«tt>|
Cancel I <geek I JJerf> I Г
Рис. 35. В этом окне можно задать способы сохранения сетей
Затем откроется окно, в котором указаны опции представления результатов.
1 ЫеЯюел* РгсЫея» Sorver • Re*** Shown - ***^
Select гы tow» of '«**• k> be d*pieyed ar t« *e пе»чю* it creeled
J* Qetaeheet of «nub tor each case
P* Qverel «штагу siatitbct
Г Sem^MyAnaMMorBeflNetMQrk , Г
ПО
'•:-
•H
cwcrt|' a**i *,.*.{ rganfr
Рис. 36. В этом окне выбираются опции представления результатов
Шаг 7. Нажмите кнопку Finish. STATISTICA произведет вычисления и
представит результаты в следующем виде таблицы.
В этой таблице показаны 10 лучших сетей, найденных советником. В столбце
Туре — Тип указан тип сетей: RBF — радиальные базисные функции, Linear —
линейные, MLP — многослойный персептрон. Далее в таблице результатов идут
столбцы: ошибка, входы, скрытые. В столбце Perfomance — Качество указаны доли
правильно классифицированных цветков каждой сетью.
ршщМ\ in mi iiiiii I—inn
1в£м*1гШ« fiuwntrwhw* F I fcetelihown j8«e
Lr*>wt*M$ofe
(bfartt/Detolet
MMbtoewlbtw
Ik oomptoNty ftm
U10 network» tc
b the eearch now
DAntopovedr*
pAnknprovedn»
ТвСГ~""'" f
to
11
ta
13
14
15
IUe 1
ИМИ
НЙ V:
03
04
m: -:;-:
OS '''У.'
w
p
k»
m:
T«e.., km».. Ilrwtt,-
РВГ 0.Э63ПЭ9
Linear 0.3509866
Linear 0.2963068
Linear 0.2952465
RBF 0.2301922
RBF 0.1880883
HLP 0.15Э5256
HLP 0.01849
HLP 0.0002072
HLP 7.261e-0S
~3 Qa*»»-!
LfeddM - ireiOTunct
4 1 0.7837838
1 - 0.6486486
3 - 0.8378378
4 - 0.8918919
4 2 0.972973
4 4 0.9459459
1 2 0.9459459
4 6 1
4 8 1
71
* ■ -УЛ.?'
Рис. 37. В результаты работы советника найдено 10 сетей
636
Глава 17. Нейронные сети
Заключительные комментарии
Указанная в таблице на рис. 37 сеть радиальной базисной функции (RBF) имеет
промежуточный слой из радиальных элементов, каждый из которых воспроизводит
гауссову поверхность отклика. Сети RBF иногда имеют некоторое преимущество
перед сетями MLP. Во-первых, они моделируют любую нелинейную функцию с
помощью только одного промежуточного слоя. Во-вторых, параметры линейной
комбинации в выходном слое можно оптимизировать с использованием известных
методов линейного программирования. В задачах классификации выходной элемент
должен выдавать большой сигнал, если данное наблюдение принадлежит к
интересующему нас классу, и слабый — в противоположной ситуации. Имеется и
более тонкий способ интерпретации уровней выходного сигнала сети —
вероятностный. В этом случае сеть выдает несколько большую информацию, чем просто
«да/нет»: она сообщает, с какой вероятностью наблюдение принадлежит данному
классу. В модуле Нейронные сети имеются методы, позволяющие интерпретировать
выходной сигнал сети как вероятность, в результате чего сеть, по существу, учится
моделировать плотность вероятности распределения для наблюдений из данного
класса.
Линейная модель представляет собой сеть без промежуточных слоев, которая
в выходном слое содержит только линейные элементы (то есть элементы с
линейной функцией активации). Линейная модель обычно записывается с
помощью матрицы N х Nn вектора смещения размера N Веса соответствуют
элементам матрицы, а пороги — компонентам вектора смещения. Сеть умножает вектор
входов на матрицу весов, а затем к полученному вектору прибавляет вектор
смещения. Можно создать линейную сеть и обучить ее с помощью стандартного
алгоритма оптимизации, основанного на псевдообратных матрицах. Тот же
алгоритм реализован в модуле Множественная регрессия системы STATISTICA. Это
самый простой тип сетей. Линейная сеть позволяет сравнить качество
построенных сетей. Может оказаться так, что задача успешно решается не только с
помощью сложных нейронных сетей, но и простыми линейными методами. Заметим,
что в модуле Нейронные сети реализованы также другие типы нейронных сетей,
например, сети Кохонена, вероятностные сети, обобщенно-регрессионные
нейронные сети (GRNN), предназначенные для решения задач регрессии, однако
описание этих сетей выходит за рамки данной главы.
Рассмотрим подробнее столбцы таблицы на рис. 37.
Тип — Туре. В этом столбце указан тип нейронной сети. В большинстве
случаев это многослойные персептроны (MLP), радиальные базисные функции (RBF)
или линейные сети.
Ошибка — Error. Здесь указана ошибка сети, полученная на контрольном
подмножестве, которая вычисляется по всем контрольным наблюдениям. Чем
меньше значение ошибки, тем лучше качество сети.
Входы — Inputs. В этом столбце указано число входных переменных,
используемых нейронной сетью. Заметим, что лучше использоэать сеть с меньшим
числом входных переменных, если это не ухудшает существенно ее качество по
сравнению с сетями, использующими большее количество переменных на входе.
Заключительные комментарии
637
Скрытые — Hidden. Здесь указано число скрытых элементов сети. Заметьте,
линейные сети не имеют скрытых элементов, поэтому для них в этом столбце
указан пропуск.
Качество — Performance. В этом столбце показано качество сети, которое
определяется по контрольному подмножеству. Для задач классификации
качество — это доля правильно классифицированных наблюдений. Очевидно,
предпочтительнее использовать сети с лучшими показателями качества. Однако
заметим, что в задачах классификации меньшее значение ошибки не всегда
соответствует лучшему качеству. Иногда сеть может улучшить ошибку на
некотором множестве уже правильно классифицированных наблюдений за счет
неправильной классификации дополнительного наблюдения. В результате может
оказаться, что такой вариант имеет меньшую ошибку и одновременно худшее
качество по сравнению с другим вариантом сети.
Лучшая сеть отмечена * (в данном примере это сеть с номером 10, см. рис. 37).
Заметьте, что в набор сетей включены и некоторые сети с плохим качеством
(см. например, сеть с номером 2, которая правильно классифицирует лишь 65%
наблюдений). На примере таких сетей можно понять, какой результат дают простые
модели.
Сети низкого качества легко удалить из набора. Чтобы сделать это, выделите
сеть, щелкнув на ней мышью, а затем нажмите правую кнопку мыши и выберите из
появившегося меню команду Удалить — Delete. Выделенная сеть будет удалена.
Можно сделать выделенную нейронную сеть активной с помощью команды
всплывающего меню Выбрать — Select.
Если набор нейронных сетей заполнен, программа STNeural Networks должна
определить, какие из имеющихся сетей заменять вновь создаваемыми. Нажмите кнопку
Опции — Options... в диалоговом окне Редактор набора сетей — Network Set Editor.
: Netwoik Sel Options
Numbe^ndworktinsei ^0>e
Cure*. ,17 :<
Maximum Щ gj " A"^ >•••.'-.J-':
Action when « netwotk it added to a ful tet '
Ас** j Keep D,verse jj j* ^ U|e| ^
Transfer current network to *et .
Ш
i*<;
fieplace
Metworktatepiec^f^ M
Select best network (lowest error) in set
gest
Рис. 38. Настройка параметров набора сетей
638
Глава 17. Нейронные сети
На экране появится диалоговое окно Параметры набора сетей — Network Set
Options.
В этом окне задается максимальное количество сетей в наборе. По умолчанию
максимальный размер составляет 30 нейронных сетей.
Если вы хотите, чтобы программа сообщала вам об удалении сети, включите
режим Вначале сообщать пользователю — Inform User First
Кроме того, взглянув на окно (рис. 38), мы видим, что при попытке добавить сеть
в уже полный набор программа по умолчанию будет использовать режим Сохранять
разнообразие — Keep Diverse... В этом случае решение о том, заменить ли новой сетью
какую-либо из существующих, будет принято с учетом необходимости сохранить в
наборе разнообразные соотношения между качеством и сложностью сетей (при этом
всегда сохраняется лучшая сеть каждого типа, независимо от ее сложности).
Установив нужные значения параметров набора сетей, нажмите кнопку
Закрыть — Close.
Если вы не хотите удалять некоторую сеть из списка, заблокируйте ее
командой Блокировать — Lock из выпадающего меню правой кнопки мыши.
Заблокированные сети выделяются голубым цветом и никогда не удаляются, независимо от
их качества. Чтобы разблокировать сеть, используйте команду Разблокировать —
Unlock.
Иногда требуется изменить порядок сетей в списке, например, сгруппировать
их по типам или рассортировать по величине ошибки или качеству. Чтобы
осуществить это, щелкните правой кнопкой мыши на названии столбца и выберите из
выпадающего меню команду Сортировать по возрастанию — Sort Ascending или
Сортировать по убыванию — Sort Descending.
Для исследования важности входных переменных обученной сети полезен
анализ чувствительности.
Представьте, вы имеете обученную сеть и вам нужно знать, как изменится
качество работы сети, если некоторые входные переменные будут удалены. Чтобы
ответить на этот вопрос, выберите команду Чувствительность — Sensitivity... из
выпадающего меню Статистики — Statistics.
Рис. 39. Выбор анализа чувствительности
Заключительные комментарии
639
В появившемся окне Анализ чувствительности нажмите кнопку Обновить
Update.
■ SentuivrtyAnalysirMlf'AJH^
Prune rputc w4h tow tarotrvity ratio
IhtesnoW F5T§ frune |
HE3E3
'ДШХ
ш<ыюя
[flank
Error
Rato
iRank ■•■"■
lEftof .
[Ratb;
swiDTH Ipcength MotH^-
3 2 II
0.1422066 0.3271987 0.4642051
2.110493 4.855968 6.889285
3 2 1
0.164695? 0.33:6603 0.4509132
i.328125 2.692615 3.6362::
$Sv-"--:"'4--':*
Рис. 40. Диалоговое окно Анализ чувствительности
Программа построит таблицу, в которой будет показана чувствительность сети
по отношению к каждой переменной. Посмотрите на таблицу (рис. 40).
В таблице приводятся три показателя: Ранг — Rank, Ошибка — Error и
Отношение —Ratio. Показатели чувствительности даются отдельно для обучающего
(первые три строки) и контрольного набора наблюдений. Столбцы таблицы — это
переменные исходного файла данных.
Вначале рассмотрим строку Error. Для каждой переменной значение Error
показывает, каким будет качество сети, если данную переменную исключить из числа
входных переменных. Очевидно, более важным для классификации переменным
отвечают большие значения ошибок.
Отношение — Ratio представляет собой отношение между значением в строке
Ошибка — Error и основной ошибкой (Baseline Error). Baseline Error вычисляется
для сети со всеми входными переменными. Если Отношение — Ratio меньше
единицы, то исключение данной переменной улучшает качество работы сети.
В строке Ранг — Rank переменные просто ранжированы в порядке убывания
ошибки.
Упражнение. Исследуйте данные об ирисах и найдите параметры цветов,
наиболее важные для классификации. Сравните результаты, полученные с
помощью нейронных сетей, с результатами классических методов классификации.
Заметим, что для экспериментирования с набором входных переменных в
SNN имеются Алгоритмы отбора входных переменных — Feature Selection Algorithms,
чтобы проверять различные комбинации входных переменных и строить так
называемые вероятностные сети, используемые для поиска лучшего набора
входных переменных.
640
Глава 17. Нейронные сети
Stepping Condi^oot..
Sebright*,,
Wwgend fieguiewrfioa;
Рис. 41. Выбор алгоритма отбора входных переменных нейронной сети
Эти алгоритмы, включающие в себя пошаговое включение, пошаговое
исключение входных переменных и так называемый генетический алгоритм отбора входных
переменных, иногда позволяют найти варианты, пропущенные процедурой Intelligent
Problem Solver.
Упражнение. Постройте с помощью нейронных сетей прогноз продаж бензина
(см. данные в приложении 1) и сравните с результатами классических методов
прогнозирования.
Л Q Язык STATISTICA
I О VISUAL BASIC (SVB)
В этой главе мы кратко опишем возможности языка STATISTICA VISUAL BASIC
(SVB), доступного в новой версии STATISTICA.
Этот язык открывает огромные возможности для пользователей из самых
различных областей, предоставляя намного больше возможностей, чем просто
«вспомогательный язык программирования», который используется для создания
пользовательских приложений.
STATISTICA Visual Basic (SVB) использует огромные преимущества
объектно-ориентированной структуры системы STATISTICA и позволяет получить
доступ практически ко всем функциям пакета. Сложные процедуры анализа и
графический вывод результатов можно записать как макрос или сценарий анализа для
дальнейшего многократного использования и редактирования. Макросы
представляют собой самостоятельные блоки, которые легко встраиваются в другие приложения.
STATISTICA Visual Basic добавляет богатый арсенал из более чем 10,000
новых статистических и аналитических функций к стандартному синтаксису
Microsoft Visual Basic и является, таким образом, одним из самых функционально
богатых средств прикладного программирования.
Пользователь может представлять макрос как сценарий действий, который
затем может быть многократно «проигран» в STATISTICA. При этом не нужно
повторять эти действия, а достаточно нажать одну лишь кнопку, выведенную на
панель управления.
Мы еще раз подчеркнем, что SVB предназначен для самого широкого круга
пользователей, а не для узких программистов. Именно с помощью SVB
пользователи из различных областей могут создать собственный модуль анализа данных.
Структура языка STATISTICA Visual Basic
STATISTICA Visual Basic состоит из двух основных компонент:
1. общая среда программирования Visual Basic, содержащая визуальные средства
создания пользовательского интерфейса, включая собственные диалоговые окна
пользователя;
2. библиотека STATISTICA, содержащая тысячи функций, обеспечивающих доступ
практически ко всем аналитическим и графическим процедурам STATISTICA..
Среда программирования Visual Basic удовлетворяет стандартным
соглашениям Microsoft Visual Basic. Небольшие отличия имеются в основном между
способами создания диалоговых окон и появились они для того, чтобы предоставить
642
Глава 18. Язык STATISTICS VISUAL BASIC (SVB)
пользователю большую гибкость в разработке собственного интерфейса при
написании сложных программ анализа данных.
Библиотека STATISTIC А (более 10 000 аналитических и графических
процедур) открыта для использования не только в Visual Basic, но и в других языках
программирования, например C/C++, Java или Delphi.
Запись макросов
Существуют три основные категории макросов, которые могут быть созданы при
работе в STATISTICA 6.0:
О макросы анализа, используемые в одном модуле;
О мастер-макросы (объединение нескольких макросов анализа в один макрос или
сценарий выполнения нескольких видов анализа);
О клавиатурные макросы, полезные, например, для атоматизации ddjlf.
Когда вы создаете макрос анализа (используя команду Options — Create Macro —
Параметры — Создать макрос), точная последовательность действий сохраняется
в виде программы на STATISTICA Visual Basic. Эта программа может быть в
дальнейшем запущена с целью воспроизведения данного анализа.
Рассмотрим макросы и приведем примеры их записи. Мы рекомендуем вслед
за нами повторить описанные нами действия, а также самостоятельно
поэкспериментировать с системой, чтобы убедиться, как легко записываются макросы
в STATISTICA. Надеемся, что макросы или сценарии анализа станут привычным
для вас способом работы в STATISTICA.
Мы начнем с самого простого макроса STATISTICA, который относится к
одному модулю или анализу STATISTICA. Ключевым является слово событие.
Событие - это операция, которая совершается пользователем при работе с
системой, например, нажатие кнопки мыши, клавиши клавиатуры, изменение
значений переменных, открытие таблицы данных или рабочей книги, — это события.
В STATISTICA могут отслеживаться также некоторые события, которые
происходят во внешних приложениях. Они также могут быть обработаны и
перепрограммированы. Данные возможности расширяют возможности STATISTICA по
созданию пользовательских программ.
Обработка событий - мощное средство, встроенное в STATISTICA, которое
позволяет программировать сложные задачи.
Макрос анализа
Обычно анализ данных включает определенную последовательность действий:
выбор анализа, открытие файла данных, выбор переменных, задание условий выбора
наблюдений, выбор весов, выбор аналитической процедуры, установка
параметров, просмотр результатов и т. д.
Заметим, что термин «анализ» в STATISTICA означает определенную задачу,
выбранную в меню Statistics или Graphs. Задача может быть как простой, например
Запись макросов
643
построение диаграммы рассеяния из меню Graphs — Графика, так и достаточно
сложной, например пошаговая множественная регрессия, включающая
разнообразные опции просмотра результатов и графики.
Запись макроса анализа
Следующий пример показывает создание макроса анализа для простого типа анализа:
О Запустите STATISTICA.
О Откройте файл heartsta. Это знакомый нам файл, содержащий данные об
операциях на сердце (см. главу 14).
D«« Heart (llv by 6bc)
Heart transplant data from Crowley and Hu. stratified
1
щ
4]
~.
Щ
Щ
Щ
Щ
it
"Щ
13
Ц
Щ
.16
•17
Й
[JANUARY [~
,ialx{
MONTH 1
7
OAYJ
3
YEAftJ;
MAY
AUGUST
AUGUST
SEPTEMBR
OCTOBER
OCTOBER
NOVEMBER
NOVEMBER
FEBRUARY
FEBRUARY
MARCH
APRIL
JULY
MAY
AUGUST
SEPTEMBR
CCOTCMOO
6
2
31
22
9
5
26
22
20
15
8
29
13
16
22
16
3
4
JANUARY
MAY
MAY
OCTOBER
JANUARY
DECEMBER
JULY
AUGUST
DECEMBER
FEBRUARY
NOVEMBER
MAY
APRIL
NOVEMBER
APRIL
AUGUST
DECEMBER
W$L
21
5
17
7
14
6
7
29
13
25
29
7
13
29
1
17
18
CO МГЛ/СМОСО
68 CENSORED
68 CENSORED
70 COMPLETE
68 COMPLETE
69 CENSORED
68 COMPLETE
72 COMPLETE
69 COMPLETE
68 CENSORED
69 COMPLETE
71 COMPLETE
69 COMPLETE
71 COMPLETE
69 COMPLETE
74 CENSORED
69 CENSORED
71 COMPLETE
CO ГПМО! CTC
^ i)WT«3E».*S$MAfCH; HOSPiTAfc
1.11 HILLV1EW
1.66 HILLV1EW
1.32 HILLV1EW
0.61 ST AND
0.36 STRAND
1.89 ST_AND
0.87 BINER
1.12 BINER
2.05 HILLV1EW
2.76 HILLVIEW
1.13 BINER
1.38 HILLVIEW
0.96 ST AND
1.62 ST~AND
1.06 ST~AND
0.47 BINER
1.58 BINER
о со uit i \лс\а/
Выберите команду Basic Statistics/Tables — Основные статистики/Таблицы из
меню Statistics.
В стартовой панели модуля Basic Statistics and Tables — Основные статистики
и таблицы выберите опцию Descriptive Statistics — Описательные статистики
и нажмите кнопку ОК.
В диалоговом окне Descriptive Statistics — Описательные статистики
щелкните на кнопке Variables — Переменные и выберите для анализа переменную Age —
Возраст из открытого файла данных.
Далее нажмите кнопку Summary: Descriptive statistics — Подробные
описательные статистики, чъобы вывести на экран таблицу результатов, содержащую
описательные статистики.
Когда таблица результатов появится на экране, диалоговое окно анализа
сворачивается на панели Analysis — Анализ.
Нажмите кнопку Descriptive Statistics — Описательные статистики на панели
Analysis — Анализу чтобы развернув диалоговое окно анализа.
Затем выберите вкладку Normality — Нормальность и нажмите кнопку
Histograms — Гистограммы; для переменной Age — Возраст пациента будет
построена следующая гистограмма:
644
Глава 18. Язык STATISTICA VISUAL BASIC (SVB)
Histogram AGE Age of patient in years
K-S d=.14188, p«.15 , Lilliefors р«,01
— Expected Normal
10
У'ШШЫМ&
10
И Detcrpdvc Slarbtict (HftartJ
30 40 50
X <= Category Boundary
I H»toyarftACE:Afleofp*ientif>y»*t |
70
Код программы на STATISTICA Visual Basic, который соответствует
проведенному анализу, можно посмотреть в окне редактора STATISTICA Visual Basic Editor
двумя способами.
Если диалоговое окно текущего анализа свернуто, нажмите правую кнопку
мыши на свернутом окне анализа на панели Analysis — Анализ и выберите команду
Create Macro — Создать макрос.
Чз'Йвшю*^
,OH*R
j^Detoripdvt St
д' flow**', -fr ..;o\
гчггл '•—
Если диалоговое окно анализа развернуто, воспользуйтесь кнопкой [gl-tfafem
и выберите из появившегося меню команду Create Macro — Создать макрос.
И Descnptn
щв^тш
Quck | AdVar»^ ^ pk**| Optica
[TUlxj
■"'.■ Н Summey
• <" Integef intaivals |c«tegaiiesi
it-
• (***r &0)t« fit ethw
A*y4st*fit4teri№onf .
to мпкичд <Utt.
CtoteAneb»*
Запись макросов
645
После этого запись завершается и появляется диалоговое окно New Macro
Новый макрос.
[New Macro ^:™Ш1ШШ
H&tm
JMyMacrcj
£escnpfon:
[Macro recorded 10Л 2/2002
Scripting language:
| STAT IS TICA Visual Basic
Г" f«w •■.'&№&: '■■:■ bt df??»-.'.'d ;0r-v'..-<- Г.v.-.iV:.
P Array indices stall a» one (Option Basel)
Г Include STATISTICA BASIC Library
£'.-
-1
d
JU2U:
1 0K 1 1
Cancel I
О В поле Name введите текст и назовите вновь созданный макрос My Macro.
О Нажмите кнопку (Ж, чтобы открыть новый макрос в автономном окне.
■ МуМасго*
Object (Genetal)
~В
Ртос ](declaia(ions)
^JSJiU
Т?
Main
Pi ж newanalysis Ai Analysis
bet newanalysis - Analysis (scBasicStatistics. ActlveDataSet)
>\ t h newanalysis . E'ia leg
Statistics » scBasDescriptives
End Vith
newanalysis Run
Vi1";. newanalysis Dialog
Vsrisbies » "8"
FairvisePeletlonOtMD s Ti u-e
PisplavLongVariableNames * Folce
ExtendedPrecisionCalculations ж False
PlotMedianQuartlleRange ж Folse
PlotMeanSEAndSD - l->isc
PlotHeanSL'196Ti»esSD - Tr-m
PlotMeanSE196Ti»esSE - False
UserDefmedPercentlies - False
ValidN - True
d
J
О Чтобы запустить макрос, нажмите клавишу F5 или кнопку > Дня Macro —
Выполнить макрос на панели Макрос.
О Нажмите клавишу F5 или кнопку ^ и вы увидите, что STATISTICA
повторит ваши действия и построит приведенную выше гистограмму возраста
пациентов.
Заметьте, что имеется различие между автономными макросами и
глобальными макросами.
Автономные макросы перед выполнением должны быть предварительно
открыты в системе, в то время как глобальные макросы становятся частью STATISTICA.
646
Глава 18. Язык STATISTICS VISUAL BASIC (SVB)
Для того чтобы создать глобальный макрос, воспользуйтесь командой Save
As Global Macro, доступной из меню File — Файл.
В появившемся на экране окне нажмите кнопку Сохранить.
:;;.: Q«*<] £а) STATISTIC* 6_eng ^J <" Й CJ* H* : ' . |
Впоследствии глобальный макрос будет загружен автоматически при
очередном запуске системы STATISTICA.
По умолчанию глобальные макросы доступны через диалог Macro Manager —
Менеджер макросов (вызываемый командой Macros — Макросы из меню Tools —
Macro — Сервис — Макрос).
Глобальные макросы расположены по умолчанию в директории, где
расположены файлы запуска STATISTICA. Если вы выбираете команду Save as Global Macro
из меню File — Файл, то STATISTICA предложит сохранить глобальный макрос
именно в этой директории.
Создание графика
Приведем еще один пример, когда запись данного макроса полезна.
Предположим, вы проводите разведочный анализ данных, используя
множественную регрессию. В некоторый момент своего исследования, пользуясь
командой Scatterplots — Диаграммы рассеяния в меню Graphs — Графика, вы создаете
диаграмму рассеяния, которая, на ваш взгляд, заслуживает внимания.
Чтобы сохранить последовательность операций выполненных при построении
данной диаграммы, вы выбираете Create Macro — Создашь макрос из быстрого меню
(которое можно вызвать нажатием правой кнопкой мыши на кнопке анализа) и
записываете всю последовательность действий, которую сделали при построении
данной диаграммы (с помощью команд Graphs — Scatterplots — Графика — Диаграммы
рассеяния).
Записанный макрос отражает все необходимые настройки и не содержит
информации по проведению многомерного регрессионного анализа или о других
графиках, которые вы строили и которые не представляют интерес.
Запись макросов
647
3$NewRec1 tim ScaMerpJot (OilAnalysis sta 13v'20c)
'_j NewRecl stw
i-j \_J Cluster Analysis @4Analy$i$ sta)
:-i \j) Jor^ng (treecluttemg) resufcs dalog
@ Tree Diagram lor Variables
3 'i$ Prrxapal Components and Classrfcation I
Ct; 'j Advanced PCA factor analysis rest*
jjfji Protection of the variables on the
Q Factor coordinates of the variabl.
: -t) 'ij Muttple Regression (Ottnab>sis sta)
:) 'ij Regression resufcs dialog
Summary Statistics, DV Alumnui
Regression Summary lor Depenc;
i-) 'ii Regression residuals oWog
@ Normal Probabkty Plot of Residu}
■2 '_j Base Statistics/Tables @(Analysis sta) |
!♦• Cj Descnptrve statistics dialog
[r, *j 20 Scatierplots | ^g QwuWiW
? Ogiom •**""■
Qutput Manage».
8o«tttrplot(OHAn«lysiSJU 13V 20 c)
Aluminum • 0.5271*0 0104%.5J0e38E-e*x*2
E
э
I
3
iL
y^*>>-
Щ2Р ScaUwptota
Qui»
о i о-
200 400 000 800
1000 1200
и*руГф^ 13
$V*S'(>%■■■ '<
: 0*&*Ыж^Ы?&**:'
Данный макрос содержит информацию о настройках и условиях выбора для
построения только интересующего вас типа графика (Scatterplots — Диаграммы
рассеяния). Записанный макрос может выглядеть следующим образом:
с
Li
\хшшшшшшшяяшшшшшвшяявяшяш
И*** j(Geneial) Zl Pfccr|(decleiation«)
Option, P<>:7c...l.
Sub Main
Dim nevanalysis As Analysis
Set nevanalysis ■ Analysis (sc2dScatterplots.Act
With nevanalysis Dialog
Variables • | 11 | "
GraphType ■ scRegularPlot
FitType » scFitLogarithmс
Ellipse ■ scEllipseOff
EllipseCoefficient ■ 0 950000
RegressionBands • scRegresslonBandOf£
RegresslonBandsLevel » 0.950000
DisplayCorrelationAndP » False
DisplayRegressionEquation » False
DisplayRSquare » False
GraphStyle » 2
DocimentStyle » 1
End With
Set Properties » nevanalysis Dialog
With Properties CategoryOne
EnableCategory ■ False
End With
Set Properties ■ Nothing
U
г ■ . ■ 1кш$%$:';^< '' '
^^^ИГЛйГ*1
d I
ij
iveDataSet) 1
A
ji"
Как видно из рисунка, запись началась в текущем анализе. Создается объект
для диаграммы рассеяния.
При запуске макроса будет создан нужный вам график. Таким образом, вы
можете записать макрос, чтобы затем включить его в окончательный отчет или
повторно запускать для разведочного анализа других данных.
648
Глава 18. Язык STATISTICS VISUAL BASIC (SVB)
Мастер-макрос
При записи простого макроса анализа мы работали только в одном модуле
STATISTICA, однако при проведении сложных исследований возникает
необходимость переключаться в различные модули системы. Здесь полезен Мастер-макрос.
В отличие от простого макроса, с помощью Мастер-макроса вы можете
записать сценарий исследования, который включает несколько видов анализа,
например, анализ главных компонент и множественную регрессию, множественную
регрессию и анализ временных рядов, различные методы классификации, например,
деревья классификации и дискриминантный анализ и т. д.
Итак, Мастер-макрос представляет собой сценарий исследования, включающий
в себя несколько видов анализа и модулей STATISTICA.
В отличие от простого макроса анализа, вы можете в любой момент начать
запись Мастер-макроса или приостановить ее.
Таким образом, управляя моментом начала записи и моментом окончания, вы
записываете в единый макрос только те этапы исследования, которые
необходимы, поскольку в Мастер-макрос попадут лишь действия, которые совершены
между началом записи и ее окончанием.
Данная возможность придает системе большую гибкость и позволяет
связывать различные виды анализа.
Для создания Мастер-макроса STATISTICA выполните следующие действия.
О Выберите команду Recording Log of Analyses (Master Macro) — Записать
журнал анализа (Мастер-макрос) из меню Tools — Macro — Сервис — Макрос.
П55?
Заметим, после старта записи Мастер-макроса на экране появляется панель
инструментов Record — Запись.
О Начните проведение анализа.
О Чтобы приостановить запись, нажмите на кнопку остановки записи ■ на
панели инструментов Record — Запись.
Среда программирования
649
После нажатия кнопки остановки ■ весь код, записанный с помощью
синтаксиса Visual Basic (отражающий все виды анализа, выполненные во время сессии),
будет перенесен в окно редактирования Visual Basic.
О Мастер-макрос может быть в дальнейшем отредактирован, сохранен или
запущен на исполнение, с целью точного повторения записанной
последовательности действий.
Замечание: если вы одновременно выполняете несколько видов анализа,
например, Basic Statistics — Основные статистики и Multiple Regression —
Множественная регрессия, то эти действия будут записаны одно за другим. В результате,
когда вы воспроизведете Мастер-макрос, то вначале получите таблицу
результатов Basic Statistics — Основные статистики, затем таблицу результатов Multiple
Regression — Множественной регрессии. Далее могут быть выведены гистограммы,
построенные в модуле Basic Statistics — Основные статистики, предсказанные
значения зависимой переменной, построенные в модуле Multiple Regression —
Множественная регрессия и т. д.
Итак, следует запомнить:
основная цель мастер-макроса заключается в том, чтобы сохранять всю
последовательность действий при проведении сложного исследования данных,
включающего несколько видов анализа.
Когда вы запускаете этот макрос «как есть», будет повторена вся
последовательность анализа.
Клавиатурные макросы
Если вы выбираете команду Start Recording Keyboard Macro — Записать
клавиатурный макрос в меню Сервис — Макрос — Tools — Macro, то STATISTICA
записывает последовательность нажатия клавиш, которую вы производите.
По окончании записи в редакторе STA TISTICA Visual Basic Editor открывается окно
с простой программой, содержащей единственную команду SendKeys с символами,
которые перечисляют все нажатия клавиш во время рабочей сессии в STATISTICA.
Заметим, что в данном типе макроса запоминается лишь последовательность
нажатия клавиш, а не команды, которые выбираются при этом. Несмотря на
простоту, данный макрос также оказывается полезным, например, для автоматизации
ввода данных.
Среда программирования
Итак, мы показали, как можно записать последовательность действий в STATISTICA.
Вы проводите анализ данных в STATISTICA, программа записывает код сценария,
имея код, можно многократно повторять его.
Очевидно, можно непосредственно записать код сценария на языке SVB и
заставить программу выполнить его.
Писать такой код довольно легко, язык SVB предназначен для самого
широкого круга пользователей.
Вначале вы можете писать программы по образцу или просто скопировать
какой-либо пример, чтобы затем модифицировать его.
650
Глава 18. Язык STATISTICS VISUAL BASIC (SVB)
Далее вы легко научитесь писать полезные для себя небольшие программы. Если
вам понравится написание простых программ, вы сможете перейти к более
сложным. Поэкспериментируйте с языком, вы быстро освоите его. Наши примеры
также помогут вам в этом.
Наше популярное изложение основано, главным образом, на текстах программ
и комментариях к ним. Так же как при изучении иностранных языков вы
стараетесь совместить чтение текста с правилами грамматики, так и при изучении языка
программирования изучение программ следует совместить с основными
правилами и соглашениями языка. Мы настоятельно рекомендуем вам
экспериментировать с STATISTICA, писать собственные программы и модифицировать
известные. Лейтмотивом нашей книги является слово «эксперимент», нельзя научиться
анализировать данные, не экспериментируя всесторонне с программой.
Представьте, вы врач, проводящий обследование пациентов. Вы получаете
таблицу результатов обследования, в которой по строкам записаны имена пациентов,
в столбцах признаки (возраст, пол), характеристики обследования, например
параметры крови, результаты ультразвукового обследования и т. д.
Заметьте, таких переменных может быть достаточно много, также может быть
большое количество пациентов, которые прошли обследование, поэтому вам
трудно обозреть полученные результаты.
Получив таблицу, вы хотели бы визуально представить полученные
результаты, например, выделить определенным цветом группу пациентов, которые не
укладываются в норму, или выделить группы пациентов, которые близки друг к
другу по ряду параметров, и т. д. В выборе способа выделения ваша фантазия ничем не
ограничивается. Конечно, каждый модуль системы STATISTICA предлагает
специальные средства визуализации результатов анализа, однако вам хотелось бы
получить нечто свое.
Здесь наступает творческий момент, связанный с использованием SVB, многие
исследователи из самых различных областей, не имеющие представления о
тонкостях программирования (и не обязанные их иметь!), могут получить очень
эффективные результаты. Среда визуального программирования создана именно для
решения таких задач, а действия, которые нужно провести, просты и понятны
каждому.
Конечно, наше описание не является полным, для всестороннего знакомства
следует использовать руководство по стандартному Visual Basic.
В следующем разделе приводятся некоторые грамматические правила языка.
Вообще представление о программе как о тексте, написанном с помощью
определенных правил, поможет вам продвинуться © изучении SVB.
Основные соглашения
STATISTICA Visual Basic
О Основная программа: как минимум, в каждой программе имеется процедура
Main, которая декларирована как Sub Main в начале программы.
О Процедура завершается оператором End Sub. Между Sub Main и End Sub
пишется текст программы.
Основные соглашения STAHSTTCA Visual Basic
651
О Комментарии: любая строчка, которая начинается с апострофа, считается
комментарием.
О Комментарии не исполняются программой, однако очень удобны для ее
понимания.
О Разбиение длинной команды на несколько строк: вы можете разбить одну
команду на несколько строк, каждая из которых должна начинаться символом
подчеркивания (символом «_»; который, в свою очередь, должен отстоять
от предыдущего текста как минимум на один пробел).
О Справочник по ключевым словам SVB: в любой момент вы можете высветить
текст и нажать клавишу F1, чтобы вывести на экран общую справку по
синтаксису SVB для данной конкретной команды и просмотреть пример ее
использования.
О Для того чтобы записать код программы на SVB, нужно выполнить
следующие действия.
Вначале выберите команду File New — Файл Создать.
Далее в диалоге Create New Document — Создать новый документ выберите Macro
(SVB) — Макрос (SVB) и создайте макрос, например с именем Example 1. Далее
нажмите ОК.
Cieate New Document
f ^{Example 1 ' ' f 'jj)teibtjl*L§-Щ
*Ш
^''Sk'' "i%^''**'4''^~-
ЗГ
$cfewtaW0fc
| STATISTICA Visual Base
P Fo»w variable* to be d*fio«dpDp6»€)<ploi[)
l? Aujp^birrftfi at or* (OpBon Saw I) •
^,QK A^
] ^ЪшЫ |
На экране появится следующее окно.
Ш Гмал*р1е1
Qbj** ((General)
Я Sub Mam
JEnsLSi\b..__ _....
»l Prcc | (declaration*)
-—з
3
J
652
Глава 18. Язык STATISTICA VISUAL BASIC (SVB)
В появившемся окне напишите текст программы. Нажмите клавишу F5 или
кнопку у и пошлите код на исполнение.
Типы данных, массивы, функции
Следующая простая программа вычисляющая корень квадратный из суммы
квадратов, иллюстрирует, как объявляются и используются переменные и массивы в
SVB. Она также показывает, как следует объявлять подпрограммы (или функции)
и каким образом передавать в них аргументы.
Текст программы:
Sub Main
Dim x A То 10) As Double
Dim Sum As Double. ResText As String
Dim i As Integer
For i =1 To 10
x(i)=i
Next i
Sum=ComputeSumOfSqrs ( LBound (x),
UBound(x).
x)
ResText="The sum of the square root of values from " + _
Str(LBouncKx)) + _
" to " + _
Str(UBouncKx)) + _
" is " + _
Str(Sum)
MsgBox ResText
End Sub
Function ComputeSumOfSqrs (iFrom As Integer.
iTo As Integer,
x() As Double) As Double
Dim i As Integer
ComputeSumOfSqrs=0
For i= iFrom To iTo
ComputeSumOfSqrs=ComputeSumOfSqrs+x(iГ2
Next i
End Function
Просмотрите программу, заметьте, что для явного объявления переменных
используется оператор Dim, который имеет следующий синтаксис:
Dim Имя_переменной [As Тип_данных]
Например, вы видите, что строка Dim i As Integer объявляет переменную,
принимающую целые значения, Dim x A То 10) As Double объявляет вещественный
массив, Dim Sum As Double, ResText As String объявляет вещественную
переменную и строковую.
Числа. Типы данных Double, Integer и Long наиболее часто используются
в вычислениях.
Переменные, объявленные как Double, могут хранить вещественные числа
в интервале от +1.7Е ± 308 (приблизительно 15 знаков точности); переменные,
Основные соглашения STATISTICA Visual Basic
653
объявленные как Integer, содержат целые числа в интервале от -32,768 до 32,767,
и, наконец, переменные типа Long содержат целые числа в интервале от -2,147,483,648
до 2,147,483,647.
Просмотрите программу и найдите, где используются эти типы данных.
Строки. Для операций со строками произвольной длины используется, как вы
уже видели, тип данных String.
Логический тип. Переменная типа Boolean (логическая переменная)
принимает два значения: True A) и False @).
Приведем некоторые другие типы: Currency (денежная величина) Date (дата/
время), Object (объект), Variant.
Тип данных Object служит для хранения объектов. Заметим, язык SVB
работает с объектами анализа, например для того, чтобы запустить анализ, относящийся
к модулю Basic Statistics — Основные статистики, нужно создать объект анализа с
константой в конструкторе scBasicStatistics и (необязательно) имя файла
данных (путь к файлу, содержащему входную таблицу). После создания объекта
анализа, например, Basic Statistics — Основные статистики, фактически в коде
программы вы по шагам задаете параметры, обычно задаваемые в диалоговых окнах,
при проведении соответствующего анализа в STATISTICA.
Если вы хотите связать объект с переменной, используйте команду Set Variable
= Object.
Тип данных Variant устанавливает тип данных в зависимости от содержимого
и может меняться в ходе выполнения программы. Переменные, декларированные
как Variant, могут быть пустыми, принимать численные значения, иметь денежный
формат, значения дат, содержать строки, быть объектом или кодом ошибки,
указателем null или массивом. При использовании SVB для включения статистических
модулей (функций) в пользовательскую программу тип Variant оказывается
полезным, например, когда приходится иметь дело со списком переменных.
Переменная может быть определена как строковая (то есть. Variables="My VarName"),
численная (то есть .Variables=2) или массив (.Variables=VarArray).
Заметим, что переменная, явно не описанная, по умолчанию имеет тип Variant.
Этот тип иногда называют также хамелеоном, потому что он принимает
значения в зависимости от выполнения программы.
Массивы. Приведенный пример также иллюстрирует применение массивов в
Visual Basic. Массив — это набор элементов определенного типа, каждый из
которых имеет свой порядковый номер (индекс). Для объявления массива также
используется оператор Dim с указанием в круглых скобках максимального
порядкового номера либо с указанием верхней и нижней границы.
По умолчанию массивы имеют нулевой элемент; это означает, что массив,
объявленный как Dim xE), на самом деле содержит шесть элементов: первый элемент
х@), потом хA) и шестой элемент — хE). Вы также можете декларировать
массивы с точными границами; объявление Dim x(l to 5) говорит о том, что массив будет
иметь только пять элементов, и к первому элементу можно обратиться как хA).
Вы также можете поместить в начало программы команду Option Base 1,
которая по умолчанию декларирует все массивы как массивы с первым элементом,
имеющим номер 1.
654
Глава 18. Язык STATISTICS VISUAL BASIC (SVB)
Например, Dim x A To 10) As Double объявляет массив с номерами 1, 2 ... 10.
Для того чтобы определить нижнюю и верхнюю границу массива,
используются функции Lbound (Массив, Размерность), Ubound (Массив,Размерность).
Эти функции помогают определить фактические размеры массива.
Посмотрите на приведенную в начале раздела программу, и вы поймете, как используются
эти функции.
Естественным образом задаются многомерные массивы, верхние границы
которых разделяются запятыми, например,
Dim xy A.10) As Double
Этот двумерный массив ху содержит 22 значения Bx11 = 22).
Коллекции и массивы. Во многих случаях работа с коллекциями более удобна,
чем работа с массивами. В STATISTICA Visual Basic все таблицы результатов и
графики из анализа сохраняются по умолчанию как коллекции, которые
допускают редактирование, сохранение и делают дальнейшую обработку данных очень
удобной.
Циклы. Для многократного выполнения одного или нескольких операторов
применяются циклы. В разбираемой нами программе применяется цикл вида:
For Счетчик = Начальное_значение То Конечное_значение [Step Шаг]
Операторы
Next Счетчик
Действие этого оператора легко понять. Рассмотрим только цикл вида:
For Счетчик = Начальное_значение То Конечное_значение
Операторы
Next Счетчик
В приведенной программе вы легко найдете цикл:
For i =1 То 10
x(i)-i
Next i
Счетчиком в нашем случае является переменная i, объявленная как Integer
(см. программу). В начале цикла значение счетчика принимает начальное
значение (в нашем случае 1), выполняются все операторы.
Значение счетчика увеличивается на 1. Если это значение становится равным
или превышает Конечное_значение, цикл завершается.
Если значение счетчика меньше величины Конечное_значение, цикл
повторяется. Значение счетчика вновь увеличивается на 1 и т. д.
Если число проходов зависит от некоторого условия, то применяется
конструкция цикла типа: Do... Loop.
Приведем еще один пример цикла:
For j=l To NumberCriterionVars
VariableCateg(j.CountCatComb) = r(j).Text
VarCategCode(j.CountCatComb) = r(j)
Next j
'Этот цикл перебирает значения категориальных переменных, задавая
'текстовые и численные значения кодов.
Основные соглашения STATISTICA Visual Basic
655
Операторы управления порядком
выполнения команд
Хотя эти операторы не встретились нам в программе, кратко их опишем. Наиболее
часто используется оператор If... Then.
Однострочный синтаксис этого оператора имеет вид:
If Условие Then Оператор [Else Оператор]
Заметьте, в квадратных скобках как всегда мы записываем необязательную часть
оператора.
Часто этот оператор записывают в несколько строк (блочный синтаксис), при
этом в последней строке следует написать End If, например:
If Ret-0 Then
VariablesSpeci fi cati ons=False
Else
Van' abl esSpeci f i cati ons=True
End If
'Этот оператор выполняет проверку значения Ret.
'В случае если Ret=0. то присваиваем VariablesSpecifications значение
'False, иначе значение True.
Приведем еще один пример:
If CurrentDataSet.MissingData(vr,VarCodeNumber(j)) Then
GoTo NextCase
Else
Set r(j) - CurrentDataSet.Cells (vr.VarCodeNumber(j))
End If
Приведем еще несколько фрагментов программ, позволяющих
почувствовать SVB.
Фрагмент 1:
'Создаем рабочую книгу, в которую будут включены таблицы результатов
'и графики.
Set ResultsWorkbook = Application.Workbooks.New
'Начинаем анализ для всех возможных комбинаций
'категорий переменных.
For i - 1 То NumberOfCategCombns
'Объявляем модуль Statistica для использования в
'данном анализе и определяем набор данных, с которым
'будет связан анализ.
Dim newanalysis As Analysis
Set newanalysis = Analysis (scMultipleRegression, CurrentDataSet)
'Добавляем папки в рабочую книгу и задаем для них имена: папки
'будут содержать результаты для каждой комбинации категорий.
Set Folder=ResultsWorkbook.InsertFolder(
ResultsWorkbook.Root. scWorkbookLastChild)
Folder.Name=""
Folder.Name= FolderTitle + FolderCaseName(i)
656
Глава 18. Язык STATISTICA VISUAL BASIC (SVB)
Фрагмент 2:
'Объявляем переменные типа String.
Dim ListlTitle As String
Dim List2Title As String
Dim List3Title As String
Dim List4Title As String
'Объявляем переменные типам Long.
Dim VarCodeNumberO As Long
Dim Nvars As Long
Dim Ncases As Long
'Объявляем переменную типа String.
Dim NumberAnalysisVarLists As String
'Объявляем переменную типа Long.
Dim NumberCriterionVars As Long
'Объявляем переменную типа String.
Dim AdditionalCaseSelectCondO As String
'Объявляем переменную типа Workbook.
Public ResultsWorkbook As Workbook
'Объявляем переменную типа String.
Dim FolderCaseNameO As String
'Объявляем переменную типа Workbookltem.
Public Folder As Workbookltem
'Объявляем переменную типа Spreadsheet.
Public CurrentDataSet As Spreadsheet
Фрагмент 3:
'Определяем число переменных для анализа.
NumberAnalysisVarLists = "
'Задаем заголовки списков переменных для анализа.
ListlTitle = "Dependent variables"
List2Title = "Independent variables"
'Задаем заголовок папки.
FolderTitle = "Multiple Regression Analysis"
'Задаем таблицу результатов, в которой будут находиться результаты.
Dim ResSpreadsheet As Spreadsheet
'Задаем результирующий график.
Dim Resgraph As Graph
'Объявляем переменную типа Long.
Dim MaxNoCriterionVars As Long
Глобальные переменные, передача аргументов
по значению и по ссылке
Оператор ByRef. В разбираемой нами программе используется функция Compute-
SumOfSqrs.
По умолчанию переменные передаются в процедуры и функции по ссылке. Это
позволяет процедурам и функциям изменять переданную переменную.
Таким образом, если в процедуре или функции необходимо изменять
определенное значение, передавайте его по ссылке (то есть используйте режим по умолча-
Основные соглашения STATISTICA Visual Basic
657
нию или в явном виде в заголовке функции декларируйте аргументы как
передаваемые по ссылке с помощью оператора ByRef). Когда переменная передается в
процедуру или функцию по ссылке, то передается сама переменная (если
говорить более точно, то в процедуру передается не сама переменная, а ее адрес, отсюда
и название «по ссылке»). Если внутри процедуры ее значение изменяется, эти
изменения сохраняются и после завершения процедуры. Таким образом, в то место,
откуда была вызвана процедура, возвращается уже измененная переменная.
'Место вызова процедуры.
ComputeX x. yl.y2
'Описание процедуры.
Sub ComputeX(ByRef x As Double. ByVal yl As Double.
ByVal y2 As Double)
' or: Sub ComputeX(x As Double. ByVal yl As Double.
ByVal y2 As Double)
x-yl+y2
End Sub
Оператор ByVal. Переменные также могут быть переданы в процедуру или
функцию по значению. Это означает, что в процедуру передается не сама переменная,
а лишь ее копия. С практической точки зрения это выражается в том, что если
внутри процедуры значение копии меняется, это никак не изменяет переменную
(ее значение в том блоке, откуда вызвали процедуру, остается без изменения);
таким образом, аргументы, передаваемые по значению, используются только как
входные переменные.
Приведем пример:
'Место вызова функции.
х - ComputeX(yl.y2)
'Описание функции.
Function ComputeX(ByVal yl As Double. ByVal y2 As Double) As Double
ComputeX-yl+y2
End Function
Глобальные переменные. Вы можете декларировать некоторые переменные вне
процедур и функций. В таком случае они имеют характер «глобальных» и
доступны во всех подпрограммах и функциях соответствующей SVB-программы.
'Задание глобальных переменных.
Dim х as double, yl as double. y2 as double
Sub Main
'Место вызова процедуры.
ComputeX
End Sub
658
Глава 18. Язык STATISTICA VISUAL BASIC (SVB)
'Описание процедуры. Обратите внимание на то. что при использовании
'глобальных переменных описание их в процедурах или в функциях не
'требуется.
Sub ComputeX
x=yl+y2
End Sub
Передача массивов. Кроме отдельных значений, процедуры и функции Visual
Basic могут быть вызваны с аргументами, которые являются массивами. Массивы
всегда передаются по ссылке.
'Описание массива.
Dim xyC) As Double
'Место вызова процедуры для массива ху.
ComputeX ху
'Описание процедуры.
Sub ComputeX (xy() As Double)
хуA) =хуB)+хуC)
End Sub
Приведем еще несколько примеров программ.
Примеры программ с комментариями
Sub Main
' Замечание: файл exp.sta может находиться в другом месте.
' В зависимости от места расположения вашей установочной директории.
' Также вы можете создать этот код при помощи Мастер-макрос.
' по умолчанию последовательность анализов будет объявлена как
' newanalysisl. newanalysis2. а таблицы данных будут объявлены
' как SI. S2. и т.д.
Set newanalysis = Analysis (scBasicStatisties.
"j:\STATISTICA\Examples\Datasets\exp.sta")
newanalysis.Dialog.Statistics - scBasDescriptives
newanalysis.Run
newanalysis.Dialog.Variables - -8"
' Замечание: следующая строка отображает наипростейший путь
' визуализации проведенного анализа.
newanalysis.Dialog.Summary.Visible = True
End Sub
Пример: формирование коллекции таблиц
данных
Выберите команду File New — Файл Создать.
В диалоге Create New Document — Создать новый документ выберите диалог
Macro (SVB) Program — Макросы и создайте макрос.
Примеры программ с комментариями
659
Затем введите код:
Sub Main
' Замечание: файл exp.sta может находиться в другом месте.
' В зависимости от места расположения вашей установочной директории.
Set newanalysis = Analysis (scBasicStatisties.
"j:\STATISTICA\Examples\Datasets\exp.sta")
newanalysis.Dialog.Statistics - scBasFrequencies
newanalysis.Run
newanalysis.Dialog.Variables = -8"
Set s=newanalysis.Dialog.Summary
s.Visible-False
MsgBox "Number of Spreadsheets: " + s.Count
s.Item(s.Count).Visible=True
End Sub
Создание таблицы данных и заполнение
ее случайными числами
Следующая программа создает новую таблицу результатов и заполняет ее
случайными значениями. Первый столбец заполняется равномерно распределенными
случайными числами. Второй столбец — нормально распределенными
случайными числами.
Option Base l
Sub Main
Dim n As Long.i As Long
n=1000
' Создаем новую таблицу результатов.
Dim s As New Spreadsheet
' Задаем размеры таблицы: n - число наблюдений. 2 - число переменных.
s.SetSize(n.2)
1 Заполняем таблицу случайными числами.
For i-1 To n
s.Value(i.l)-Rndd)
s.Value(i.2)=RndNormal(l)
Next i
' Устанавливаем имена переменных.
s.VariableName(l)="Uniform"
s.VariableNameB)="Normal"
s.Visible=True
End Sub
Вывод индикатора состояния
Иногда в процессе длительных вычислений желательно отображать индикатор
состояния, который показывает процент выполненных операций. Индикатор
состояния отображается в STATISTICA во время вычислений на больших объемах
данных. Приведем пример кода, реализующего индикатор состояния в программе,
генерирующей нормально распределенные случайные числа:
660
Глава 18. Язык STATISTICA VISUAL BASIC (SVB)
Option Base 1
Sub Main
Dim n As Long.i As Long
n-1000
1 Создаем новую таблицу результатов.
Dim s As New Spreadsheet
1 Задаем размеры таблицы: n - число наблюдений, 2 - число переменных. s.SetS1ze(n.2)
1 Устанавливаем индикатор состояния.
Dim pb As ProgressBar
Set pb - AddProgressBar("Generating random numbers". 1. n)
For 1-1 To n
1 Обновляем индикатор состояния.
pb.CurrentCounter - i
' Заполняем таблицу случайными числами.
s.ValueCi.l)-Rnd(l)
s. Valued. 2)-RndNormal(l)
Next 1
' Закрываем индикатор состояния.
Set pb - Nothing
' Сохраняем имена переменных.
s. Van'ableName(l)-"Uni form"
s.VariableNameB)-"Normal"
s.Visible-True
End Sub
Построение гистограммы с подгонкой
нормального распределения
Следующий пример иллюстрирует построение гистограмм для выборки,
сгенерированной ранее.
Option Base l
Sub Main
Dim n As Long
n-1000
Dim s As New Spreadsheet
1 Заполняем таблицу s случайными числами.
ComputeRandomNumbers s. n
1 Строим гистограмму для s.
CreateHistograms s
End Sub
1 Описание процедуры заполнения таблицы s случайными числами.
Sub ComputeRandomNumbers (s As Spreadsheet, n As Long)
Dim i As Long
ReDim x(n.2) As Double
s.SetSize(n.2)
For i-1 To n
x(i.l)-Rndd)
x(i.2)-RndNormal(l)
Next i
Примеры программ с комментариями
661
s.Data=x
s. Van' ableName(l)="Uni form"
s.VariableNameB)-"Normal"
End Sub
' Описание процедуры построения гистограммы.
Sub CreateHistograms (s As Spreadsheet)
' Задание и описание вида анализа.
Dim newanalysis As Analysis
Set newanalysis - Analysis (sc2dHistograms. s)
' Описание параметров гистограммы.
With newanalysis.Dialog
.Variables - 2 | "
.GraphType - scHistgoramRegularPlot
End With
' Активация гистограммы (построение гистограммы).
newanalysis.Dialog.Graphs.Visible - True
End Sub
Отметим, что в программе вызываются две процедуры: подготовка данных и
построение гистограммы.
Гистограмма строится с использованием встроенных процедур STATISTICA.
Раскраска таблицы
Option Base l
'Данный макрос выделяет ячейки рабочей таблицы
'шрифтом Arlal Black с наклоном, размером 12 и цветом B55.12.255).
'где ix.y.z)- координаты цвета в (красном.зеленом.синем) тонах.
'Предполагается, что таблица содержит в ячейках числа, отличные от 0.
Sub Main
662
Глава 18. Язык STATISTICA VISUAL BASIC (SVB)
'Выбираем активную таблицу
Set s = ActiveSpreadsheet
'Цикл по переменным таблицы
For j=l To s.NumberOfVariables
'Цикл по наблюдениям таблицы
For i=l To s.NumberOfCases-1
'Условия выбора ячейки, которую мы хотим отметить
If s.Valued.j)/s.Value(i+l.j)>l Then
'Задание названия шрифта в данной ячейке
s.Cells(i.j).Font.Name = "Arial Black"
'Задание размера шрифта в данной ячейке
s.Cells(i.j).Font.Size = 12
'Задание наклона шрифта в данной ячейке
s.Cells(i.j).Font.Italic - True
'Задание цвета шрифта в данной ячейке
s.Cells(i.j).Font.Color = RGBB55.12.255)
End If
Next i
Next j
End Sub
Создание пользовательских диалогов
Нажмите левую верхнюю кнопку User Dialog, на экране появится окно User Dialog
Editor, Это редактор пользовательских диалоговых окон, который позволяет вам
визуально создавать необходимые диалоговые окна.
• UserDialog Editor
*:* л Чав:\ Ч а»
rjoHA
lB»gir, 6i^ iT««KAg ШШ'ШШюзТЛ
ITju
ш
ш
щ
1ШШ^^Ш^
Например, работая только мышью, вы мгновенно создадите окно.
Последовательность ваших действий очень проста: с помощью мыши вы
выбираете кнопку в левой части и перетаскиваете ее в нужное место справа в
создаваемом диалоговом окне. Итак, из типовых заготовок вы последовательно собираете
нужное вам окно.
Просмотр объектов и функций
663
< User Dialog Iditor
df|X» R^ft 4% ^qh н It,
га "' '
AY
Ш|
11
щ\
;яош
Мой анализ дажых
щшш
♦ '. . ♦ ... . >l'»4ir'llfl4l'>">i|i> 1-Е »
7 :—ri:: * > :••; л|ТжсгТТТ §• ♦ ♦• ♦■
Двойной щелчок левой мышью на кнопке позволяет редактировать свойства
кнопки, вносить текст, менять положение и т.д.
Height JIT
Caption [Анализ текстов
field |Pu$hButton2
Qofivnent 1
F Quoted
Просмотр объектов и функций
Нажав на клавиатуре кнопку F2 или кнопку Object Browser, вы откроете окно, в
котором можете просмотреть доступные вам объекты.
'•'(STATISTICA
jflfftTtt
1& InputDescnpto»
USlKeyt
Ш1*и*
19 LineCaseProffes
|#LneP1ot2D
US Macro
HI
..d^LLlBJ
d
J
_J^
M*Ae*ofU>feiy*
fcpName
Bfi1 Option
tf Parent
tfPath
Bfi1 Property
rfRange
fifi1 Reports
(propeW"aiub А$алш
I rettorty
{ Member d$IAjailCAU«*x , . .
I Return* the SteUJb а
ДО.ДО&еах
r$«ioeteti»tk^«ndpfobeb«yfurceom.
d
J
zj
'
664
Глава 18. Язык STATISTICA VISUAL BASIC (SVB)
В левом списке выбираются классы объектов, в правом прокручиваются
элементы выбранного класса. В нижней части окна приводится краткое описание
выбранного объекта (см. рисунок).
Кнопка/п позволяет просмотреть доступные в SVB функции, например,
выбрав, в левом окне тип Distributions - Распределения вы можете просмотреть
функции распределения, плотности и обратные функции распределения.
[CrittflWy
«$ Constant
4( Conversion
4fc Data Type
«4 DDE
«$ Declaration
#£ Dialog Function
^OMutkyv
«$ Error Handing
*F*>
4t Flow Control
«gMeth
4t Matrix
zi
■:'Х^У^
•a
р&щШтМ
I
Заметьте, имена обратных функций распределения начинаются с буквы V,
имена интегральных функций распределения начинаются с I, плотности
распределения записываются непосредственно.
Например, Normal обозначает плотность нормального распределения, INormal
кумулятивную или интегральную функцию распределения (интеграл от
плотности), VNormal обратную кумулятивную функцию распределения. Эти функции
подробно описаны в главе 3.
Вы можете, например, использовать обратные функции распределения для того,
чтобы преобразовать равномерно распределенную случайную величину в
переменную, имеющую данное распределение F.
Более точно, пусть переменная X имеет равномерное распределение на отрезке
[О, 1]. Тогда переменная VF(X) имеет распределение /. Например, переменная
VNormal(Xf0,1) будет иметь стандартное нормальное распределение со средним О
и дисперсией 1. Переменная VPareto(X,2) будет иметь распределение Парето с
параметром 2 и т. д.
Этот прием удобен, если вы хотите сгенерировать случайную величину,
имеющую заданное распределение, исходя из равномерно распределенной переменной.
В SVB доступно огромное количество функций, например, вы можете выполнить
разнообразные действия с матрицами. Выберите в разделе Category пункт Matrix.
Прокрутив правый список, вы увидите набор доступных матричных функций,
например, декомпозицию Холецкого, вычисление собственных значений,
собственных векторов, вычисление обратных матриц, обобщенных псевдообратных,
выметания и т. д. Таким образом, вам не нужно программировать эти методы, а следует
воспользоваться ими в своей программе.
Просмотр объектов и функций
665
а Function Browser - Macro I
4ЫЛ,,, .
fcUtogoiy
|«£DDE jj
|«$ Declaration
|«2£ Dialog Function
L$ D «tributes *
L$ Error Handing
kFte
4t Flow Control -^
L$Math
|«$M*m jj
Ittro
^Lowe$$
^MatrrxAdd
^MatrixAINonZero
■-Л MatrrxAnyNonZero
.%пиятаишиыиил/ятт1
■Л M atr rxCombirr jH oriz
•Л MatrixConibineVert
^MatrixCopy
Л MatrrxCorreiatioro
|M«tri)rChol#$kyOeccnipoeftJOri
tfrtbcCltotesW^^ 4« 4ЭД>*, fly**
ШДО<ОД^4*{ЭД*)
I Performe a Cholesky Decomposition on the upper diagonal of Matrix and
iDlacMlnMatrteResult
a]
-J
t]
.':-d
—J
^j
В заключение приведем список библиотек и модулей SVB на английском и
русском языках.
Список библиотек и модулей STATISTICA Visual Basic
Модуль
Библиотека
Константа
ANOVA*
Basic Statistics
Canonical Analysis
Classification Trees
Cluster Analysis
Correspondence Analysis
Discriminant Analysis
Distribution Fitting1
Experimental Design (DOE)
Factor Analysis
General CHAID Models
General Classification and Regression Trees
General Discriminant Analysis Models
Generalized Additive Models
Generalized Linear/Nonlinear Models
General Linear Models
General Partial Least Squares Models
General Regression Models
Log-Linear Analysis
Multidimensional Scaling
Multiple Regression
Nonlinear Estimation
Nonparametrics
Principal Componentsand Classification Analysis*
Process Analysis Techniques
Quality Control
Reliability/Item Analysis
STAMANOVA
STABasicStatistics
STACanonical
STAQuickTrees
STACIuster
STACorrespondence
STADiscriminant
STANonparametrics
STAExperimental
STAFactor
STAGCHAID
STAGTrees
STAGDA
STAGAM
SJAGLZ
STAGLM
STAPLS
STAGRM
STALogLinear
STAMultidimensional
STARegression
STANonlinear
STANonparametrics
STAFactor
STAProcessAnalysis
STAQuality
STAReliability
scMANOVA
scBasicStatistics
scCanonicalAnalysis
scClassificationTrees
scClusterAnalysis
scCorrespondenceAnalysis
scDiscriminantAnalysis
scDistributions
scDesignOfExperiments
scFactor Analysis
scGCHAID
scGTrees
scGDA
scGAM
scGLZ
scGLM
scPLS
scGSR
scLoglinearAnalysis
scMultidimensionalScaling
scMultipleRegression
scNonlinearEstimation
scNonparametrics
scAdvancedPCA
scProcessAnalysis
scQualityControl
scReliabilityandltemAnalysis
666
Глава 18. Язык STATISTICA VISUAL BASIC (SVB)
Модуль
Библиотека
Константа
Survival Analysis
Time Series
Variance Components
Дисперсионный анализ*
Основные статистики
Канонический анализ
Деревья классификации
Кластерный анализ
Анализ соответствий
Дискриминантный анализ
Подгонка распределений1
Планирование эксперимента
Факторный анализ
Общие модели хи-квадрат
Общие модели деревьев
классификации/регрессии
Общие модели дискриминантного анализа
Обобщенные аддитивные модели
Обобщенные линейные/нелинейные модели
Общие линейные модели
Общие модели частных наименьших квадратов
Общие регрессионные модели
Логлинейный анализ
Многомерное шкалирование
Множественная регрессия
Нелинейное оценивание
Непараметрические методы
Анализ главных компонент и классификация*
Анализ процессов
Контроль качества
Надежность и позиционный анализ
Анализ выживаемости
Временные ряды
Компоненты дисперсии
STASurvival
STATimeSeries
STAVarianceComponents
STAMANOVA
STABasicStatistics
STACanonical
STAQuickTrees
STACIuster
STACorrespondence
STADiscriminant
STANonparametrics
STAExperimental
STAFactor
STAGCHAID
STAGTrees
STAGDA
STAGAM
STAGLZ
STAGLM
STAPLS
STAGRM
STALogLinear
STAMultidimensional
STARegression
STANonlinear
STANonparametrics
STAFactor
STAProcessAnalysis
STAQuality
STAReliability
STASurvival
STATimeSeries
STAVarianceComponents
scSurvivalAnalysis
scTimeSeries
scVarianceComponents
scMANOVA
scBasicStatistics
scCanonicalAnalysis
scClassificationTrees
scClusterAnalysis
scCorrespondenceAnalysis
scDischminantAnalysis
scDistributions
scDesignOfExperiments
scFactor Analysis
scGCHAID
scGTrees
scGDA
scGAM
scGLZ
scGLM
scPLS
scGSR
scLoglinearAnalysis
scMultidimensionalScaling
scMuIti pie Regression
scNonlinearEstimation
scNonparametrics
scAdvancedPCA
scProcessAnalysis
scQualityControl
scReliabilityandltemAnalysis
scSurvivalAnalysis
scTimeSeries
scVarianceComponents
* Функции доступа к ANOVA — Дисперсионному анализу содержатся в библиотеке General Linear
Models — Общие линейные модели.
f Функции и процедуры модуля Distribution Fitting — Подгонка распределений являются частью
библиотеки Nonparametrics — Непараметрическая статистика.
* Методы Principal Components — Главные компоненты и Classification Analysis — Классификация
собраны в библиотеке Factor Analysis — Факторный анализ.
Замечание 1: Список модулей и процедур STATISTICA, доступных в Visual
Basic, постоянно расширяется. Советуем регулярно отслеживать информацию на
сайте StatSoft, Inc. (www.statsoft.com).
Замечание 2: Процедуры, реализующие все команды меню Graphs — Графика,
полностью содержатся в справочной библиотеке STATISTICA. В диалоге Object
Browser — Просмотр объектов вы можете просмотреть соответствующие
константы, которые передаются в конструктор объекта — анализа (графика) и
инициализируют его.
Приложение 1
Розничные продажи бензина в США (источник: www.economagic.com
в разделе Census Bureau: Retail Sales by Kind of Business).
Переменные: Т - месяц/год, V - объем продаж.
т
Янв-1967
Фев-1967
Map-1967
Апр-1967
Май-1967
Июн-1967
Июл-1967
Авг-1967
Сен-1967
Окт-1967
Ноя-1967
Дек-1967
Янв-1968
Фев-1968
Map-1968
Апр-1968
Май-1968
Июн-1968
Июл-1968
Авг-1968
Сен-1968
Окт-1968
Ноя-1968
Дек-1968
Янв-1969
Фев-1969
Map-1969
Апр-1969
Май-1969
Июн-1969
Июл-1969
Авг-1969
Сен-1969
Окт-1969
Ноя-1969
Дек-1969
Янв-1970
Фев-1970
Map-1970
Апр-1970
Май-1970
Июн-1970
Июл-1970
Авг-1970
Сен-1970
Окт-1970
Ноя-1970
Дек-1970
V
1697
1599
1765
1803
1891
1986
2009
1969
1893
1900
1914
1936
1858
1799
1966
2013
2106
2165
2220
2232
2051
2105
2102
2133
2051
1896
2126
2151
2277
2283
2331
2323
2173
2242
2179
2269
2220
2053
2287
2347
2484
2541
2625
2482
2366
2506
2458
2534
Т
Янв-1971
Фев-1971
Map-1971
Апр-1971
Май-1971
Июн-1971
Июл-1971
Авг-1971
Сен-1971
Окт-1971
Ноя-1971
Дек-1971
Янв-1972
Фев-1972
Map-1972
Апр-1972
Май-1972
Июн-1972
Июл-1972
Авг-1972
Сен-1972
Окт-1972
Ноя-1972
Дек-1972
Янв-1973
Фев-1973
Map-1973
Апр-1973
Май-1973
Июн-1973
Июл-1973
Авг-1973
Сен-1973
Окт-1973
Ноя-1973
Дек-1973
Янв-1974
Фев-1974
Map-1974
Апр-197^
Май-1974
Июн-1974
Июл-1974
Авг-1974
Сен-1974
Окт-1974
Ноя-1974
Дек-1974
V
2332
2164
2404
2446
2551
2635
2766
2763
2607
2646
2633
2673
2529
2401
2641
2612
2775
2817
2934
2943
2782
2871
2853
2914
2771
2648
2970
3009
3160
3226
3314
3246
3046
3203
3221
3128
3005
2898
3325
3427
3674
3815
3987
4034
3700
3831
3675
3683
Т
Янв-1975
Фев-1975
Мар-1975
Апр-1975
Май-1975
Июн-1975
Июл-1975
Авг-1975
Сен-1975
Окт-1975
Ноя-1975
Дек-1975
Янв-1976
Фев-1976
Map-1976
Апр-1976
Май-1976
Июн-1976
Июл-1976
Авг-1976
Сен-1976
Окт-1976
Ноя-1976
Дек-1976
Янв-1977
Фев-1977
Map-1977
Апр-1977
Май-1977
Июн-1977
Июл-1977
Авг-1977
Сен-1977
Окт-1977
Ноя-1977
Дек-1977
Янв-1978
Фев-1978
Map-1978
Апр-1978
Май-1978
Июн-1978
Июл-1978
Авг-1978
Сен-1978
Окт-1978
Ноя-1978
Дек-1978
V
3546
3305
3708
3756
4026
4065
4410
4448
4078
4145
3966
4150
3974
3781
4113
4193
4287
4446
4714
4602
4353
4494
4438
4642
4339
4053
4555
4749
4828
4862
5101
5011
4736
4806
4699
4899
4525
4306
4802
4790
5059
5163
5196
5307
5122
5202
5144
5273
Т
Янв-1979
Фев-1979
Map-1979
Апр-1979
Май-1979
Июн-1979
Июл-1979
Авг-1979
Сен-1979
Окт-1979
Ноя-1979
Дек-1979
Янв-1980
Фев-1980
Map-1980
Апр-1980
Май-1980
Июн-1980
Июл-1980
Авг-1980
Сен-1980
Окт-1980
Ноя-1980
Дек-1980
Янв-1981
Фев-1981
Map-1981
Апр-1981
Май-1981
Июн-1981
Июл-1981
Авг-1981
Сен-1981
Окт-1981
Ноя-1981
Дек-1981
Янв-1982
Фев-1982
Map-1982
Апр-1982
Май-1982
Июн-1982
Июл-1982
Авг-1982
Сен-1982
Окт-1982
Ноя-1982
Дек-1982
V
5026
4873
5460
5590
6055
6282
6366
6834
6531
6822
6777
6905
6800
6818
7401
7580
7964
8205
8456
8425
7946
8215
7936
8347
8062
7643
8419
8538
8784
9046
9219
8989
8665
8762
8341
8604
8102
7416
7850
7735
7969
8365
8758
8508
8110
8297
8081
8249
668 Приложение 1
т
Янв-1983
Фев-1983
Map-1983
Апр-1983
Май-1983
Июн-1983
Июл-1983
Авг-1983
Сен-1983
Окт-1983
Ноя-1983
Дек-1983
Янв-1984
Фев-1984
Map-1984
Апр-1984
Май-1984
Июн-1984
Июл-1984
Авг-1984
Сен-1984
Окт-1984
Ноя-1984
Дек-1984
Янв-1985
Фйв-1985
Map-1985
Апр-1985
Май-1985
Июн-1985
Июл-1985
Авг-1985
Сен-1985
Окт-1985
Ноя-1985
Дек-1985
Янв-1986
Фев-1986
Map-1986
Апр-1986
Май-1986
Июн-1986
Июл-1986
Авг-1986
Сен-1986
Окт-1986
Ноя-1986
Дек-1986
Янв-1999
Фев-1999
Мар-1999
Апр-1999
Май-1999
Июн-1999
Июл-1999
Авг-1999
Сен-1999
Окт-1999
Ноя-1999
Дек-1999
V
7717
7092
7835
8124
8704
8992
9388
9417
8929
8953
8704
9072
8497
8108
8763
8812
9341
9411
9357
9358
8908
9179
8954
8877
8620
7796
8793
9265
9794
9814
10189
10169
9522
9879
9528
9972
9407
8368
8468
8229
8846
8875
8812
8482
8191
8356
7919
8140
12624
11924
13700
14633
15185
15289
16325
16622
15938
16339
15657
16737
Т
Янв-1987
Фев-1987
Map-1987
Апр-1987
Май-1987
Июн-1987
Июл-1987
Авг-1987
Сен-1987
Окт-1987
Ноя-1987
Дек-1987
Янв-1988
Фев-1988
Map-1988
Апр-1988
Май-1988
Июн-1988
Июл-1988
Авг-1988
Сен-1988
Окт-1988
Ноя-1988
Дек-1988
Янв-1989
Фев-1989
Map-1989
Апр-1989
Май-1989
Июн-1989
Июл-1989
Авг-1989
Сен-1989
Окт-1989
Ноя-1989
Дек-1989
Янв-1990
Фев-1990
Map-1990
Апр-1990
Май-1990
Июн-1990
Июл-1990
Авг-1990
Сен-1990
Окт-1990
Ноя-1990
Дек-1990
Янв-2000
Фев-2000
Мар-2000
Апр-2000
Май-2000
Июн-2000
Июл-2000
Авг-2000
Сен-2000
Окт-2000
Ноя-2000
Дек-2000
Янв-2001
V
7761
7481
8278
8639
8936
9144
9490
9446
8928
9092
8672
8902
8408
8119
8830
8957
9415
9484
9689
10006
9359
9532
9179
9363
8840
8505
9590
10195
11058
11044
11147
10967
10268
10572
10221
10475
10120
9434
10497
10537
11210
11442
11548
12739
12406
13242
12952
12377
15272
15971
18313
17259
18619
19649
19561
19387
18901
18856
17856
17647
16941
Т
Янв-1991
Фев-1991
Map-1991
Апр-1991
Май-1991
Июн-1991
Июл-1991
Авг-1991
Сен-1991
Окт-1991
Ноя-1991
Дек-1991
Янв-1992
Фев-1992
Map-1992
Апр-1992
Май-1992
Июн-1992
Июл-1992
Авг-1992
Сен-1992
Окт-1992
Ноя-1992
Дек-1992
Янв-1993
Фев-1993
Map-1993
Апр-1993
Май-1993
Июн-1993
Июл-1993
Авг-1993
Сен-1993
Окт-1993
Ноя-1993
Дек-1993
Янв-1994
Фев-1994
Map-1994
Апр-1994
Май-1994
Июн-1994
Июл-1994
Авг-1994
Сен-1994
Окт-1994
Ноя-1994
Дек-1994
V
11297
10064
10883
11052
11960
11846
12091
12406
11350
11678
11360
11308
10508
10071
10725
10885
11836
11874
12225
12218
11569
12002
11418
11619
10839
10498
11476
11684
12346
12291
12638
12418
11679
12237
11806
11785
10966
10652
11800
11842
12491
12835
13207
13710
12854
12983
12647
12880
Т
Янв-1995
Фев-1995
Мар-1995
Апр-1995
Май-1995
Июн-1995
Июл-1995
Авг-1995
Сен-1995
Окт-1995
Ноя-1995
Дек-1995
Янв-1996
Фев-1996
Map-1996
Апр-1996
Май-1996
Июн-1996
Июл-1996
Авг-1996
Сен-1996
Окт-1996
Ноя-1996
Дек-1996
Янв-1997
Фев-1997
Map-1997
Апр-1997
Май-1997
Июн-1997
Июл-1997
Авг-1997
Сен-1997
Окт-1997
Ноя-1997
Дек-1997
Янв-1998
Фев-1998
Map-1998
Апр-1998
Май-1998
Июн-1998
Июл-1998
Авг-1998
Сен-1998
Окт-1998
Ноя-1998
Дек-1998
V
11981
11443
12790
12701
13937
14210
14013
14186
13213
13190
12650
12931
12456
12203
13518
13998
15258
14840
14839
15034
13885
14488
14007
14224
13732
12863
14240
14163
14912
14786
15077
15348
14547
14827
13685
13901
12945
11982
13088
13394
14366
14412
14820
14393
13505
13947
12943
13404
Приложение 2
Прогнозирование месячных розничных продаж на бензоколонках
США с помощью мастера решения задач STATISTICA Neural Networks
(версия 4.0).
Ниже приведены последовательные диалоговые окна, которые возникают в SNN
при построении прогноза данных о продажах бензина, приведенных в
приложении 1. Данные имеются также на диске.
кзш
Рис. 1. Открытие файла данных retain.
Переменная varl — исходный ряд месячных продаж, переменная var2 — первые разности
Рис. 2. Файл данных и рабочее окно SNN
Рис. 3. Вызов мастера решения задач — Intelligent Problem Solver
pf» send
Lj Презентации
fa Bank
He lection»
0PfW
&еы
670
Приложение 2
: ...r;o^(mik»altteOwto<iakii>>^%Wwft|io»<b>{/; .
Рис. 4. Выбор в мастере решения задач режима Advanced
тшшшашшвшвшшшшшщ
***! <g«*l E>1 >- 1
Рис. 5. Выбор в мастере решения задач типа задачи — Problem Type. Решаемая задача —
прогнозирование временного ряда — predict later values from earlier ones
Рис. 6. Задание периода ряда (анализируемый ряд имеет период 12).
Если период неизвестен или ряд непериодичный, то в поле Period ставится 1
Рис. 7. Выбор «выходной» или прогнозируемой переменной
Приложение 2
671
■
' tai tfitlPS imtfffn litecMtt 1|мЫ<| if jqhHihMi cn4 vtfpirt м wnl*.
Рис. 8. В этом окне выбираются входные (независимые) переменные.
Переменная varl — исходный ряд. Переменная var2 — ряд первых разностей.
На первом этапе в качестве единственной независимой переменной выбираем varl
Yrti кцр ipitijf (wtm>w It» IfTt #jwtf MMjbrtfc fruifafl пол К» №>ii> • "*
Рис. 9. Задание обучающего, контрольного и тестового множества
швшшшшшашшш
Рис. 10. Выбираются типы сетей, среди которых организован поиск
int/irtiff I .* *&>—
Рис. И. Количество нейронов в скрытом слое (трехслойный персептрон)
672
Приложение 2
Рис. 12. Способы поиска сети (по полноте и времени)
Рис. 13. Количество сохраняемых сетей
Рис. 14. Форма отчета
Рис. 15. Окно сообщений. Процесс поиска:
30 секунд работы, найдено 2 конфигурации сети, способных решить задачу
Приложение 2
673
явшрвш
Рис. 16. Окно сообщений спустя 3 минуты
i и т т ■тяшшшшшшшшшшшштвт
ш
Щф
шл
ж
HIP 581.1412 1 1 0.1Э74195^|
HIP 580.7396 1 20 0.1407334 :'
HIP 572. 4562 1 ЗОЛ391212" '
HLP 535.3925 1 4 0.1300702 *:•
HLP 461.9709 1 13 0.112509^
ЕЗСЗЗГЛЗСШЗ
Рис. 17. Список найденных сетей в порядке убывания ошибки — error
Рис. 18. Статистики лучшей сети
Рис. 19. Архитектура сети
674
Приложение 2
Рис. 20. Процедура квазиньютоновского дообучения
(кнопка Q — Run Quasi Newton Training — на панели инструментов)
шэщ
шщшшшшшшшшшшшршшшшшш
w
Ш
1й;:*+ХШн1?кШШ*&
i,uu ; i mm
_Тгет
Veriy
4Z1
Рис. 21. График ошибки обучения
ш
Рис. 22. Восстановление наилучшей сети
|fflpUp
TtRW StMM QOJNttOft
К^'^;\^^^?:на-^;^,^^^^аж^»^..^-:, .**". '* ч,'*>
Рис. 23. Построение прогноза на 50 шагов, начиная с наблюдения 200
Приложение 2
675
(Г)I рафик 1 Линейный график
22000
Продажи автозаправочных станций США
18000
14000
10000
6000
2000
Рис. 24. Исходный временной ряд месячных продаж бензина
Линейный график (RETAIL1 STA 4v*265c)
22000 ,
4000
PoTxl
ПРОГНОЗ
исходный
Рис. 25. Сравнение исходного ряда и прогноза на 1 шаг
676
Приложение 2
Рис. 26. Прогноз «тестового» множества на 2 года B4 точки)
Комментарий. Для повышения качества прогноза рекомендуется добавить еще
одну переменную — var2 (см. рис. 8). Тогда прогноз будет строиться исходя из двух
рядов: исходного ряда varl и ряда первых разностей var2. Заметьте, для построения
прогноза можно использовать также другие дополнительные переменные (предикторы ).
о- РЕАЛЬН
о ПР0ГН0Э1
Рис. 27. Новый прогноз и реальные данные из тестового множества
21000
10000
17000
16000
1Э000
11000
7
ж J
9t
i /
9s>\
V* /
ч
в/ .4
| Ч0
\ /S х
-»- ПРОГНОЗ
-о Р|АЛЬН
** ПР0ГМ0Э1
Рис. 28. Сравнение прогнозов
Приложение 3
Словарь терминов пакета SNN (версия 4.0)
Add
Add Cases
Add Variables
Advanced Intellegent Problem Solver
Advise
Accept
Action
Activation
Activation Function
Add Cases
All Layers
Append Network
Apply
Area Under Curve
Assigned Cases
Automatic Network Design
Automatic Network Designer
Automatic update on Exit
Auxiliary
Back Propagation
Backwards Stepwise
Baseline Errors
Basic
Basic Intellegent Problem Solver
Best
Best Network Retention
Candidate Network Types
Cases (Train, Verify, Test)
Case Errors
City-Block Error
Class Labeling
Class Labeling of Radial Units
Добавить
Добавить наблюдения
Добавить переменные
Расширенный мастер решения задач
Совет
Принять
Действие
Активация
Функция активации
Добавить наблюдения
Все слои
Присоединить сеть
Применить
Площадь под кривой
Связанные наблюдения
Автоматическое построение сети
Автоматический конструктор сети
Автоматически обновлять при выходе
Дополнительно
Обратное распространение
Пошаговое исключение
Исходные ошибки
Основной
Основной мастер решения задач
Лучшая
Сохранение лучшей сети
Типы сетей, среди которых
производится поиск (сети-кандидаты)
Наблюдения (обучающие,
контрольные, тестовые)
Ошибки наблюдений
Ошибка «городских кварталов»
Разметка классов
Присвоение меток классов
радиальным элементам
678
Приложение 3 #
Classes
Classification
Classification Output Type
Classification Statistics
Classification Confidence Threshold
Classification Statistics Datasheet
Cluster Diagram
Clustering Networks
Commit Network to Network Set
Complexity
Confidence
Confidence limits
Conjugate Gradient Descent
Convert
Create Data Set
Create Network
Cross Verification
Crossover Rate
Current Layer
Data Management
Data Set
Data Set Datasheet
Data Set Editor
Data Set Shuffle
Default
Definition
Delimiter
Delta-Bar-Delta
Details
Detail Shown
Deviation
Dimenionality Reduction
Direct
Discard
Division
Division of Cases
Duration of Design Process
Dynamic Link Library
Edit Case Names
Editing Pre/Post Processing
Enlarge Set
Entropy
Epochs
Epsilon
Error
Классы
Классификация
Форма результата классификации
Статистики классификации
Доверительный порог классификации
Таблица статистик классификации
Диаграмма кластеров
Сети для кластеризации
Поместить сеть в набор сетей
Сложность
Доверие
Доверительные границы
Спуск по сопряженным градиентам
Преобразование
Создать набор данных
Создать сеть
Кросс-проверка
Скорость скрещивания
Текущий слой
Управление данными
Набор данных
Таблица данных
Редактор данных
Перемешать данные
По умолчанию
Определение
Разделитель
Дельта-дельта с чертой
Подробности
Степень подробности
Отклонение
Понижение размерности
Прямой
Отвергнуть
Деление
Разбиение наблюдений
Длительность поиска
Динамически подключаемая
библиотека
Редактировать имена наблюдений
Редактирование параметров
пре/пост-процессирования
Увеличить набор
Энтропия
Эпохи
Эпсилон
Ошибка
Приложение 3
679
Error function
Error Mean
Explicit Deviation Assignment
Exponential distribution
Feature Selection
Hidden
Hidden Units
Generalized Regression
Generalized Regression Training
Generation
Genetic Algorithm Input Selection
GRNN
Group Sets
Ignore
Inform User First
Initialization Algorithms
Input Variable
Input Feature Selection
Input/Output Variable
Inputs Datasheet
Intelligent Problem Solver
Intelligent Problem Solver Message
10 Settings
Isotropic
Isotropic Deviation Assignment
Iterations
Jog Weights
Keep Diverse
K-Means
K-Means Center Assignment
K-Nearest Neighbor Deviation
Kohonen Network
Kohonen Training
Layer
Layers Datasheet
Layers Shown
Learned Vector Quantization Training
Learning rate Levenberg—Marquardt
Linear
Linear Network
Lock
Logistic
Lookahead
Loss Coefficient
Loss Matrix
Функция ошибки
Среднее ошибки
Явное задание отклонений
Экспоненциальное распределение
Отбор признаков
Скрытый
Скрытые элементы
Обобщенная регрессия
Обучение обобщенной регрессии
Поколение
Генетический алгоритм отбора
входных данных
Обобщенно-регрессионные сети
Сгруппировать множества
Не учитывать
Сначала сообщать пользователю
Алгоритмы инициализации
Входная переменная
Отбор входных признаков
Входная/выходная переменная
Таблица входных значений
Мастер решения задач
Сообщения мастера решения задач
Параметры ввода/вывода
Изотропный
Изотропный выбор отклонений
Число итераций
Встряхнуть веса
Сохранять разнообразие
К-средних
Выбор центров по К-средним
Отклонение по К-ближайшим соседям
Сеть Кохонена
Обучение Кохонена
Слой
Таблица слоев
Показываемые слои
Квантование обучающего вектора
Скорость обучения Левенберга—
Маркара
Линейный
Линейная сеть
Блокировать
Логистическая
Горизонт
Коэффициент потерь
Матрица потерь
680
Приложение 3
Main
Mask
Max/SD
Mean/SD
Median
Medium
Merge
Method
MicroScroll
Min/Mean
Minimax
Minimum Improvement
Min Proportion
Missing Value
Momentum
Move Cases
Multilayer Perceptron (MLP)
Mutation Rate
Name
Name and Nominals
Nearest Neighbor
Neighborhood
Network Advisor
Network (Append)...
Network Illustration
Network Set
Network Set Editor
Network Set Options
Network to Replace
Network Wizard
Networks for Classification
Neuro-Genetic Input
Selection Algorithm
No Layers
Noise
Nominal Variables
Nonlinear
Normal Distribution
Normalization
One-off Input Datasheet
One-of-N
Open Data Set
Open Network
Optimum Threshold
Главное
Маска
Максимальное/(стандартное
отклонение)
СреднееДстандартное отклонение)
Медиана
Средняя (длительность поиска)
Объединить
Метод
Микропрокрутка
Минимум/среднее
Минимаксное
Минимальное улучшение
Минимальная доля
Пропущенное значение
Инерция
Переместить наблюдения
Многослойный персептрон
Скорость мутаций
Имя
Имя и номинальные
Ближайший сосед
Окрестность
Наставник
Сеть (добавить)
Схема сети
Набор сетей
Редактор набора сетей
Параметры набора сетей
Заменяемая сеть
Мастер создания сети
Сети для задач классификации
Нейрогенетический алгоритм
отбора входных данных
Число слоев
Шум
Номинальные (категориальные)
переменные
Нелинейный
Нормальное распределение
Нормировка
Таблица задания одного входного
вектора
Один-из-N
Открыть набор данных
Открыть сеть
Оптимальный порог
Приложение 3
681
Options
Output Type
Output Variable
Outputs Datasheet
Outputs Shown
Partially or unusually
defined text values
Penalty
Performance
Plot
PNN
Population
Popup Class Selector
Predict
Prediction
Pre/Post Processing
Pre/Post Processing Datasheet
Pre/Post Processing Editor
Pre/Post Processing Editor's Datasheet
Principal Components
Principal Components Analysis
Prior probabilities
Probabilistic
Probabilistic Training
Problem Type
Producing a Reduced Data Set
Prune
Pseudo-Inverse
PSP-function
Quick Propagation
Radial Basis Function (RBF)
Radial Sampling
Rank
Range
Range selection
Ratio
Real number fields
Real-time update
Receiver Operating
Characteristic (ROC)
Redundancy of variables
Regression
Regression Statistics
Regularization
Reinitialize
Опции
Тип выхода
Выходная переменная
Таблица выходных значений
Показывать при выводе
Частично или нестандартно
заданные текстовые значения
Штраф
Качество
График
Вероятностная нейронная сеть
Популяция
Контекстный выбор класса
Прогнозировать, предсказывать
Прогноз
Пре/постпроцессирование
Таблица пре/постпроцессирования
Редактор пре/постпроцессирования
Таблица редактора
пре/постпроцессирования
Главные компоненты
Анализ главных компонент
Априорные вероятности
Вероятность
Вероятностное обучение
Тип задачи
Формирование уменьшенного набора
данных
Удалить
Псевдообратный
Постсинаптическая функция
Быстрое распространение
Радиальные базисные функции
Радиальная выборка
Ранг
Диапазон, размах
Выделение диапазона ячеек
Отношение
Поля для вещественных чисел
Пересчитывать по ходу
Операционная характеристика
Избыточность переменных
Регрессия, зависимость
Статистики регрессии
Регуляризация
Переустановить, инициализировать
682
Приложение 3
Reject
Replace
Replace Oldest
Replace Worst
Response Graph
Response Surface
Restore
Retain Best Network
RMS (Root Mean Squared) error
Run
Run All Cases
Run Data Set
Run One-off Case
Run Single Case
Run/Activations
S.D. (Standard Deviation) Ratio
Sample
Subsample
Save as Type
Scale
Select
Sensitivity Ananlysis
Set Case Types
Set Variable Types
Set Weights
Shift
Shuffle
Shuffle Cases
Single Case
Single output networks
Smoothing
Smoothing Constant
Sort Ascending
Sort Descending
Standard (each case is independent)
Statistics
Step
Stopping Conditions
Sum-squared error function
Target Error
Test
Text Import Wizard
Threshold
Thorough
Time Series
Отвергнуть
Заменить
Заменить самую первую
Заменить худшую
График отклика
Поверхность отклика
Восстановить
Восстановить лучшую сеть
Среднеквадратичная ошибка
Запуск
Прогнать все наблюдения
Прогнать набор данных
Прогнать отдельное наблюдение
Прогнать одно наблюдение
Запуск/активации
Отношение стандартных отклонений
Выборка
Подвыборка
Тип сохраняемого файла
Масштаб
Выбрать
Анализ чувствительности
Задать типы наблюдений
Задать типы переменных
Задать веса
Сдвиг, смещение
Перемешать
Перемешать наблюдения
Одно наблюдение
Сети с одним выходом
Сглаживание
Константа сглаживания
Сортировать по возрастанию
Сортировать по убыванию
Стандартная (наблюдения независимы)
Статистики
Шаг
Условия остановки
Функция ошибки как сумма
квадратов разностей между выходами сети и
целевыми значениями
Целевая ошибка
Тестовое (множество)
Мастер импорта текста
Порог
Полный (режим поиска)
§|^щшюйряд
Приложение 3
683
Time Series Period
Time Series
(predict later values from earlier ones)
Time Series Projection
Topological Classes
Topological Map
Total
Train
Train RMS (Root Mean
Squared) Error
Training Error
Training Error Graph
Training Graph
Training Set
Train-Multilayer Perceptrons
Two-State Conversion
Type
Type of Network
Unit Length
Unit Names
Unit Penalty
Unit Number
Unknown
Unlock
Update
Value
Variable Definition
Variable type in Data Files
Variant
Verbose
Verification Error
Verification Standard Deviation Ratio
Verification Set
Verify
Weigend Weight Regularization
Weights Distribution
Win Frequencies Datasheet
Период временного ряда
Временной ряд (прогноз следующих
значений по предыдущим)
Проекция временного ряда
Топологические классы
Топологическая карта
Всего
Обучить, обучающее множество
Среднеквадратичная ошибка обучения
Ошибка обучения
График ошибки обучения
График обучения
Обучающее множество
Обучение многослойного персептрона
Преобразование в два значения
Тип
Тип сети
Единичная длина
Имена элементов
Штраф за элемент
Номер элемента
Неизвестно
Разблокировать
Пересчитать, обновить
Значение
Определение переменной
Тип переменных в файлах данных
Вариант
Подробно
Контрольная ошибка
Контрольное отношение стандартных
отклонений
Контрольное множество
Контрольное (множество)
Регуляризация весов по Вигенду
Распределение весов
Таблица частот выигрышей
Функции активации, реализованные в SNN
Все эти функции доступны в окне Network Editor, вызываемом из меню Edit
Network... или с помощью кнопки ННна панели инструментов.
684
Приложение 3
Линейная. Уровень активации нейрона передается на выход в неизменном виде.
Эта функция используется в сетях различных типов, в том числе линейных, а
также в выходных слоях сетей радиальных базисных функций.
Логистическая. Ее график имеет форму S-образной кривой, выходные
значения лежат в интервале @,1). Этот тип функций активации нейронов используется
в сетях наиболее часто.
Гиперболическая. Функция гиперболического тангенса (tanh). Ее график
также имеет вид S-образной кривой, выходные значения лежат в интервале (-1,+1).
Эта "функция часто дает лучшие результаты, чем логистическая из-за свойства
симметрии.
Экспоненциальная с отрицательным показателем. Экспоненциальная
функция с аргументом со знаком минус.
Софтмакс. Экспоненциальные функции с нормировкой. При использовании
этой функции сумма всех активаций в слое становится равной 1. Применяется
в многослойных персептронах для задач классификации, так что выходные
значения сети можно интерпретировать как вероятности, задающие принадлежность
к классу.
Квадратный корень. Функция квадратного корня.
Синус. Может быть полезна для распознавания радиально распределенных
данных. По умолчанию не используется.
Кусочно-линейная. Кусочно-линейный вариант S-образной функции.
Ступенчатая (кусочно-постоянная). Дает на выходе значения 0, если аргумент
отрицательный, и 1, если аргумент неотрицательный. Может использоваться при
моделировании простых сетей, например персептронов.
Ниже приведены точные формулы функций активации.
Функции активации
Название Формула Значения
(-оо,+оо)
@,+1)
(-1|+1)
Линейная х
1
Логистическая " :
\ + е
Гиперболическая —:
ех + е'-
Приложение 3
685
Название Формула Значения
(О, +оо)
@,+1)
[О, +оо)
[-1,+1]
[0,+1]
Функции ошибок, доступные в SNN
Функции ошибок — Error functions выбираются в том же окне Network Editor, что
и функции активации.
Квадратичная. Ошибка полагается равной сумме квадратов разностей между
целевыми и фактическими выходными значениями каждого выходного элемента.
При обучении сетей такая функция ошибок является стандартной, часто
применяется для задач регрессии (построения нелинейных зависимостей).
Городских кварталов. Ошибка равна сумме абсолютных значений разностей
между целевыми и фактическими выходными значениями каждого выходного
элемента.
Эта функция менее чувствительна к выбросам, чем среднеквадратичная
функция ошибок.
Кросс-энтропия (простая и множественная). Ошибка этого типа
вычисляется как сумма произведений целевых значений на логарифмы ошибок по всем
выходным элементам. Имеется два варианта функции: для сетей с одним выходом
(двумя классами) и для сетей с несколькими выходами.
Эта функция ошибок специально предназначена для задач классификации. Ее
применение может улучшить результаты классификации сети, особенно если
в выходном слое сети используются логистическая (случай одного выхода) или
софтмакс (несколько выходов) функции активации.
Кохонена. Вычисление ошибки по Кохонену предполагает, что второй слой
сети состоит из радиальных элементов, представляющих центры кластеров.
Ошибка вычисляется как расстояние от входного набора данных до ближайшего из этих
центров.
Функция ошибок Кохонена предназначена для использования только в сетях
Кохонена.
Экспоненциальная
Софтмакс
е~х
ех
i
Квадратный корень 7х
Синус sin(x)
.
Кусочно-линейная
-1 х<-\
х -\<х<+\
+1 *>+1
Ступенчатая
' 0 *<0
+1 *>0
686
Приложение 3
PSP-функции
Эти функции также доступны в диалоговом окне Network Editor.
В пакете STATISTICA Neural Networks используются два основных типа PSP-
функций.
Линейная. Линейные PSP-элементы берут взвешенную сумму своих входов и
сдвигают на пороговое значение {Threshold), см. нижнюю часть диалогового окна,
приведенного выше.
Такие элементы стремятся осуществить классификацию, разбивая
пространство входов на классы с помощью системы гиперплоскостей.
Радиальная. Радиальные PSP-элементы вычисляют квадрат расстояния
между двумя точками в N-мерном пространстве (где N — число входов),
соответствующими входному вектору и вектору весов данного элемента.
Такие элементы стремятся осуществить классификацию, измеряя расстояния
от входных наборов до эталонных точек в пространстве входов (координаты этих
эталонных точек хранятся в весах элементов).
Линейные PSP-элементы используются в многослойных персептронах и
линейных сетях, а также в последних слоях сетей на радиальных базисных
функциях, вероятностных и регрессионных сетей.
Радиальные элементы используются во втором слое сетей Кохонена,
радиальных базисных функций, вероятностных и регрессионных сетей и не используются
ни в каких других слоях сетей стандартной архитектуры.
В пакете SNN имеется еще один тип PSP-функций, предназначенный только
для регрессионных сетей.
Деление. Эта функция ожидает, что один из входных весов равен +1, другой -1,
все остальные — нулю. Значение, которое выдает функция, равно частному от
деления входа, соответствующего +1, на вход, соответствующий -1.
Алфавитный указатель
А
Анализ выживаемости
Модель Кокса, 544
Оценка Каплана-Мейера, 538
регрессионные модели, 552
согласие, 552
составная таблица времен жизни, 554
Сравнение выживаемости в группах, 541
Функция риска, 537
Анализ мощности, 141—144
Анализ соответствий, 561
Асимметрия, 109
Анализ таблиц времен жизни, 550
Б
Броуновское движение, 148,149
в
Вероятностный калькулятор STATISTICA, 454
Внутригрупповая вариация, 492
г
Гамма распределение, 155
Гистограмма, 210—212
Графики
для таблиц результатов, 418
Группировка
итоговая таблица средних, 423
пример, 421
Группирующая переменная, 464
д
Дисперсия, 106
Дисперсионный анализ, однофакторный,
421,501
3
Зависимость, 112—113
Зависимые переменные, 496
Значимость, 128
к
Корреляции
выделение значимых корреляций, 416
корреляция Пирсона, 414
Корреляции (продолжение)
ложные, 120
множественные, 118—119
ранговые, 117
частные, 117,118
частные корреляции с точки зрения
линейной регрессии, 119
Контроль качества, 32-38,602-607
Кохонена ошибка, 685
Коэффициент сопряженности, 445
Критерий Стюдента (t-критерий), 480-481
Критерий Фишера, 507
Критерий хи-квадрат
Макнемара хи-квадрат, 444
Пирсона хи-квадрат, 442
поправка Йетса, 443
Кросстабуляция
графическое представление, 439
2 на 2 таблицы, 437
Кросстабуляция данных, 432,436,442
Кросстабуляция многомерных откликов
и дихотомий, 472
л
Логистическая, 684
Логлинейный анализ
кросстабуляция данных, 432
м
Медиана, 108
Мода, 109
Макнемара хи-квадрат, 444
Маргинальные частоты, 438
Меры сопряженности, 445
Многовходовые таблицы с контрольными
переменными, 441
Многомерные дихотомии, 445,466
задание многомерной дихотомии, 470
кросстабуляция многомерных дихотомий, 447
определение факторов, 468
парная кросстабуляция, 448
переменные, 465
пример, 463
Многомерные отклики, 447,466
кодирование многомерных переменных, 446
кросстабуляции многомерных откликов, 447
определение факторов, 468
688
Алфавитный указатель
Многомерные отклики (продолжение)
парная кросстабуляция, 448
переменные, 445
пример, 463
таблицы частот, 468
н
Независимые переменные, 496
Нейронные сети
математическая модель нейрона, 611, 612
многослойный персептрон, 616
принципы обучения, 614
поверхность ошибки, 620
примеры
классификация, 633,634
погнозирование, 627-632
Непараметрические критерии, 504—507
Номинальные переменные, 110,111
о
Однофакторный дисперсионный анализ
апостериорные сравнения
средних, 501
пример, 421
Оценка объема выборки, 137,141
п
Переменная
категориальная, 110,111
порядковая, 111
Планирование эксперимента, 32—34,504—602
Прогнозирование, 17—20
Переменная с многомерными откликами, 464
Поправка Йетса, 443
Порог, 686
Построение графиков для таблиц
результатов, 418
р
Распределение
Арксинуса, 165—166
Бета, 171-182
Биномиальное, 160—165
Вейбулла, 173-177
Гамма, 155—157
Геометрическое, 170
Гипергеометрическое, 170-171
Коши, 181
Лапласа, 154—155
Логнормальное, 157—158
Логистическое, 178
Максвелла, 180-181
Нормальное, 147—151
Отрицательное Биномиальное, 166— 167
Парето, 177-178
Полиномиальное (мультиминальное), 171
Пуассона, 167-170
равномерное, 151—152
Релея, 172
Распределение (продолжение)
Стьюдента (t-распределение), 182—183
Фишера (F-распределение), 183—184
хи-квадрат, 159—160
Хотеллинга, 179-180
Экспоненциальное, 152-153
Экстремальных значений, 172
Эрланга, 153-154
Разность между средними
(t-критерий), 495
Распределения
подгонка, 550
Регрессия, 23,24,577-583
С
Согласие, 552
Среднее, 107
Стандартное отклонение, 108
Статистика Дарбина-Уотсона, 584
Стьюдента t-критерий
t-критерий для зависимых
выборок, 492
t-критерий для независимых выборок, 489
графики, 497
матрицы t-критериев, 493
разности между средними, 495
результаты, 497
т
Таблицы 2 на 2, 437
Таблицы времен жизни, анализ, 554
Таблицы времен жизни
в страховании, 550
Таблицы сопряженности, 461
Таблицы флагов и заголовков, 440,456
Таблицы частот, 434,452
ф
Функция риска, 535
Фукнция выживаемости, 30-31
Фи-квадрат, 444
х
хи-квадрат критерий согласия, 192-193,
хи-квадрат критерий независимости признаков
в таблицах сопряженности, 440—442
ч
Частоты
преобразования
логит, 452
пробит, 452
маргинальные, 438
э
Эксцесс, 109
множественная, 685
простая, 685