/














































































































































































































































































































































































Автор: Гайдышев И.
Теги: компьютерные технологии информационные машины машины для обработки данных обработка данных
ISBN: 5-318-00220-X
Год: 2001




Текст
Игорь Гайдышев
АНАЛИЗ и ОБРАБОТКА ДАННЫХ Специальный справочник
Санкт-Петербург Москва • Харьков • Минск 2001
С^ППТЕР
Игорь Гайдышев
Анализ и обработка данных специальный справочник
Главный редактор Заведующий редакцией Руководитель проекта Литературный редактор Художник Корректоры
Верстка
Е. Строганова И. Корнеев А. Пасечник Е. Бочкарева Н. Биржаков И. Смирнова, И. Тимофеева А. Попов
ББК 32.973.233я22
УДК 681.3.01(03)
Гайдышев И.
Г14 Анализ и обработка данных: специальный справочник — СПб: Питер, 2001. — 752 с.: ил.
ISBN 5-318-00220-Х
Здесь вы найдете краткое описание большого количества алгоритмов анализа данных, с которыми приходилось работать авторам, а также известных математических методов, применяющихся в этих алгоритмах. Достаточно полно даны прокомментированные исходные тексты компьютерных программ, реализующих эти алгоритмы.
Книга может оказаться полезной в качестве справочника научным работникам, программистам, инженерам-исследователям, медикам, биологам и другим специалистам, профессионально имеющим дело с обработкой экспериментальной информации.
© И. Гайдышев, 2001
© Издательский дом «Питер», 2001
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Информация, содержащаяся в данной книге, получена из источников, рассматриваемых издательством как надежные. Тем не менее имея в виду возможные человеческие или технические ошибки, издательство не может гарантировать абсолютную точность и полноту приводимых сведений и не несет ответственность за возможные ошибки, связанные с использованием книги.
ISBN 5-318-00220-Х
ЗАО «Питер Бук», 196105, Санкт-Петербург, ул. Благодатная, д. 67.
Лицензия ИД № 01940 от 05.06.2000.
Налоговая льгота — общероссийский классификатор продукции ОК 005-93, том 2; 95 3000-книги и брошюры.
Подписано к печати 11.07.01. Формат 60 * 90/16. Усл. п. л. 47. Тираж 5000 экз. Заказ 2002.
Отпечатано с готовых диапозитивов в АООТ «Типография „Правда**».
191119, С.-Петербург. Социалистическая ул., 14.
Краткое содержание
Введение............................................15
От издательства.....................................21
Глава 1. Статистики эмпирического ряда..............22
Глава 2. Проверка гипотез...........................76
Глава 3. Дисперсионный анализ......................175
Глава 4. Теория распределений......................206
Глава 5. Корреляционный анализ.....................268
Глава 6. Методы снижения размерности...............316
Глава 7. Факторный анализ..........................324
Глава 8. Распознавание образов без обучения........356
Глава 9. Распознавание образов с обучением.........390
Глава 10. Многомерное шкалирование.................444
Глава 11. Методы теории информации.................450
Глава 12. Планирование эксперимента................463
Глава 13. Линейная алгебра.........................470
Глава 14. Методы теории множеств ..................562
Глава 15. Аппроксимация зависимостей...............579
Глава 16. Дифференциальное и интегральное исчисления.637
Глава 17. Прочие математические алгоритмы..........655
Глава 18. Реализация программы анализа данных......676
Заключение.........................................713
Литература.........................................721
Приложение. Заголовочный файл......................740
Алфавитный указатель...............................748
Содержание
Введение...........................................15
Предмет......................................... 15
Аудитория....................................... 17
Примеры......................................... 18
Благодарности................................... 19
От издательства....................................21
Глава 1. Статистики эмпирического ряда.............22
Классификация признаков по шкалам измерения......23
Описательная статистика..........................26
Среднее значение, математическое ожидание.....27
Медиана.......................................32
Мода..........................................35
Дисперсия, среднее квадратичное отклонение....36
Среднее отклонение............................42
Средняя разность Джини........................43
Асимметрия....................................44
Эксцесс.......................................45
Коэффициент вариации..........................47
Показатель точности опыта.....................48
Минимум, максимум и размах выборки............50
Моменты распределения.........................51
Вариационная статистика..........................53
Параметры классовых интервалов................54
Группировка...................................56
Функции эмпирического распределения...........61
Ранжирование.....................................67
Проверка случайности выборки из нормальной совокупности.......................72
Репрезентативность выборки .......................73
Дальнейшие исследования и программные ресурсы....74
Глава 2. Проверка гипотез .........................76
Общая методика...................................76
Сравнение методик................................80
Содержание
7
Односторонняя и двусторонняя гипотезы............81
Независимые и сопряженные выборки ...............82
Параметрические тесты............................83
f-критерий Стьюдента..........................83
Критерий Стьюдента для связанных выборок......85
Проблема Беренса—Фишера.......................87
F-критерий Фишера.............................91
G-критерий различий средних...................92
Параметрические множественные сравнения.......93
Непараметрические тесты..........................98
Критерии рандомизации ........................99
Критерии с2..................................122
Х-критерий Ван дер Вардена...................127
Критерий О Розенбаума........................129
Критерий серий Вальда—Вольфовица.............131
Критерий Колмогорова—Смирнова................134
Точный метод Фишера—Ирвина...................140
Критерий знаков..............................141
Критерий медианы.............................143
Непараметрические множественные сравнения.....147
Проверка типа распределения эмпирических данных..151
Простые и сложные гипотезы...................151
Простейшие методы............................151
Критерии согласия............................152
Критерии отклонения распределения от нормальности..............................170
Дальнейшие исследования и программные ресурсы....173
Глава 3. Дисперсионный анализ.................... 175
Однофакторный анализ............................175
Однофакторный дисперсионный анализ...........176
Ранговый однофакторный анализ Краскела—Уоллиса.............................178
Критерий Джонкхиера—Терпстра.................180
/Vf-критерий Бартлетта.......................182
G-критерий Кокрена...........................184
Критерий Шеффе...............................185
Критерий Дункана.............................189
Критерий Тьюки...............................189
Многофакторный анализ...........................190
8
Содержание
Двухфакторный дисперсионный анализ...........191
Ранговый критерий Фридмана...................194
Критерий Пэйджа..............................196
Q-критерий Кокрена...........................198
Критерий Шеффе для связанных выборок.........201
Дальнейшие исследования и программные ресурсы....205
Глава 4. Теория распределений ....................206
Общая методика..................................206
Функции распределения и обратные функции распределения................209
Одномерные распределения........................209
Непрерывные распределения ...................210
Дискретные распределения.....................248
Генерация одномерных распределений...........261
Многомерные распределения.......................263
Многомерное нормальное распределение.........263
Генерация многомерных распределений..........264
Теоретические и эмпирические распределения......265
Дальнейшие исследования и программные ресурсы....266
Глава 5. Корреляционный анализ....................268
Корреляция количественных признаков.............268
Коэффициент корреляционного отношения Пирсона............................269
Коэффициент корреляции Фехнера...............271
Ковариация...................................273
Корреляция порядковых признаков.................274
Показатель ранговой корреляции Спирмэна......275
Коэффициент ранговой корреляции Кендалла.....278
Корреляция номинальных признаков................281
Полихорический коэффициент сопряженности Чупрова........................282
Коэффициент Жаккара..........................284
Простой коэффициент встречаемости ...........285
Показатель подобия Рассела и Рао.............286
Коэффициент сопряженности Бравайса...........287
Коэффициент ассоциации Юла...................288
Хеммингово расстояние........................289
Содержание
9
Корреляция признаков, измеренных в различных шкалах...................290
Коэффициент Гауэра...........................290
Бисериальная корреляция в случае порядковых признаков................294
Бисериальная корреляция в случае номинальных признаков ..............300
Точечно-бисериальная корреляция..............302
Множественные корреляции........................304
Коэффициент множественной корреляции.........304
Канонический корреляционный анализ...........305
Коэффициент конкордации......................310
Критерии некоррелированности....................312
Коэффициент корреляции.......................312
Показатель ранговой корреляции...............312
Коэффициент ранговой корреляции..............313
Бисериальный коэффициент корреляции..........313
Точечно-бисериальный коэффициент корреляции...313
Коэффициент множественной корреляции.........314
Коэффициент конкордации......................314
Дальнейшие исследования и программные ресурсы....314
Глава 6. Методы снижения размерности .............316
Метод минимизации энтропии......................316
Преобразование Карунена—Лоэва...................320
Сжатие с помощью трехслойной нейронной сети.....322
Дальнейшие исследования.........................323
Глава 7. Факторный анализ.........................324
Метод главных факторов..........................327
Проблема общности............................334
Проблема факторов............................337
Измерение факторов...........................337
Метод максимума правдоподобия...................338
Центроидный метод...............................344
Проблема вращения...............................349
Критерии максимального числа факторов ..........352
Визуализация результатов факторного анализа.....354
Дальнейшие исследования и программные ресурсы....354
10
Содержание
Глава 8. Распознавание образов без обучения.....................................356
Меры различия и меры сходства..................356
Меры различия и информационная статистика...357
Меры сходства...............................359
Кластерный анализ..............................363
Метод ближней связи.........................364
Метод средней связи Кинга...................368
Метод Уорда.................................372
Метод k-средних Мак-Куина...................376
Метод корреляционных плеяд..................381
Вроцлавская таксономия......................383
Визуализация результатов кластерного анализа...386
Дальнейшие исследования и программные ресурсы...388
Глава 9. Распознавание образов с обучением......................................390
Выявление информативных параметров.............392
Метод Байеса...................................393
Линейный дискриминантный анализ Фишера.........396
Канонический дискриминантный анализ............404
Линейный дискриминантный анализ................417
Нейронная сеть прямого распространения.........425
Архитектура нейронной сети..................425
Обучение и распознавание....................430
Дальнейшие исследования и программные ресурсы...439
Глава 10. Многомерное шкалирование...............444
Метрический метод Торгерсона...................444
Дальнейшие исследования........................449
Глава 11. Методы теории информации...............450
Информация по Шеннону..........................450
Информация по Бриллюэну........................454
Избыточность...................................456
Разведочный информационный анализ...........456
Эквивокация.................................457
Организация системы............................457
Содержание
11
Дивергенция, информационные меры................458
Мера Кульбака................................458
Мера Махаланобиса............................460
Информационная статистика.......................461
Дальнейшие исследования.........................462
Глава 12. Планирование эксперимента...............463
Полный ортогональный план.......................463
Дробная реплика полного плана...................465
Дальнейшие исследования и программные ресурсы...469
Глава 13. Линейная алгебра........................470
Представление массивов..........................470
Векторные и матричные операции..................472
Векторные операции...........................472
Матричные операции...........................476
Единичная матрица............................486
Транспонированная матрица....................487
Векторные и матричные нормы .................488
Определитель матрицы.........................491
След матрицы.................................493
Обратная матрица.............................495
Псевдообратная матрица.......................500
Критерии положительной определенности и полуопределенности ........................502
Обусловленность матрицы......................506
Методы факторизации и приведения матриц.........509
Разложение Краута А = LU.....................509
Разложение Холецкого А = LLT.................513
Разложение по сингулярным числам.............515
Разложение А = QR, ортогонализация Грама—Шмидта . 520
Методы приведения к форме Хессенберга........526
Вычисление собственных значений и собственных векторов..........................534
Локализация собственных значений.............538
Стандартная проблема собственных значений....539
Обобщенная проблема собственных значений.....547
Линейные алгебраические уравнения...............549
Метод исключения Гаусса......................549
Итерационные методы .........................553
12
Содержание
Решение неопределенных систем................558
Дальнейшие исследования и программные ресурсы....560
Глава 14. Методы теории множеств..................562
Основные операции...............................562
Функции упорядочивания множеств.................564
Функции определения экстремума..................571
Метрики.........................................575
Метрика Минковского..........................576
Евклидова метрика............................576
Манхеттенское расстояние.....................577
Метрика доминирования, супремум-норма........578
Дальнейшие исследования.........................578
Глава 15. Аппроксимация зависимостей .............579
Математическое моделирование и регрессионный анализ..........................579
Общая методика..................................583
Полиномиальная аппроксимация....................585
Полином......................................585
Обращенный полином...........................588
Интерполяционный полином Лагранжа............591
Экспоненциально-степенная аппроксимация.........593
Экспоненциальная и показательная функции.....593
Степенная функция ...........................595
Гипербола....................................597
Экспоненциально-степенная функция............598
Логарифмическая функция.........................599
Гармонический анализ: тригонометрический многочлен Фурье..............601
Логистический анализ............................603
Функция Гомпертца...............................606
Нелинейная функция общего вида..................608
Симплексный метод Нелдера—Мида...............608
Метод сопряженных градиентов Флетчера—Ривса...614
Метод касательных Ньютона—Рафсона............618
Метод переменной метрики.....................621
Нейронная сеть прямого распространения..........626
Линейный множественный регрессионный анализ.....629
Дальнейшие исследования и программные ресурсы....635
Содержание
13
Глава 16. Дифференциальное и интегральное исчисления.........................637
Методы численного дифференцирования.............637
Первая производная...........................637
Матрица первых производных...................640
Матрица вторых производных...................646
Методы численного интегрирования................650
Формула прямоугольников......................651
Формула трапеций.............................651
Формула Симпсона.............................652
Ошибки разностных схем..........................653
Дальнейшие исследования.........................654
Глава 17. Прочие математические алгоритмы..........................655
Комбинаторика ..................................655
Число перестановок...........................655
Число сочетаний..............................656
Число благоприятных исходов..................657
Специальные функции.............................659
Г-функция Эйлера.............................659
В-функция Эйлера.............................664
Различные функции...............................665
Параметры вычислительной системы................673
Дальнейшие исследования.........................675
Глава 18. Реализация программы анализа данных ...................................676
Средства разработки приложений..................677
Выбор технологии программирования............677
Программные ресурсы..........................679
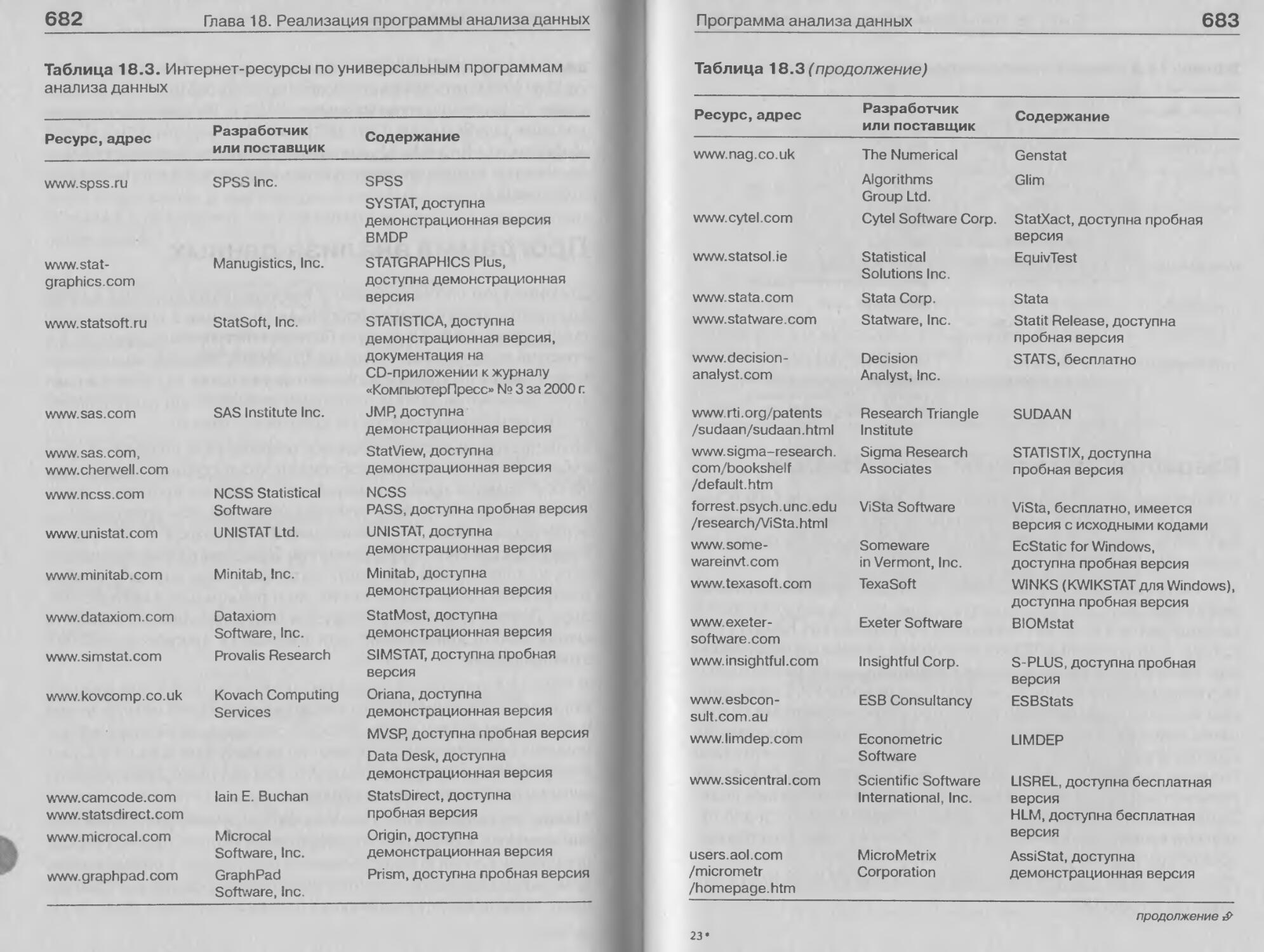
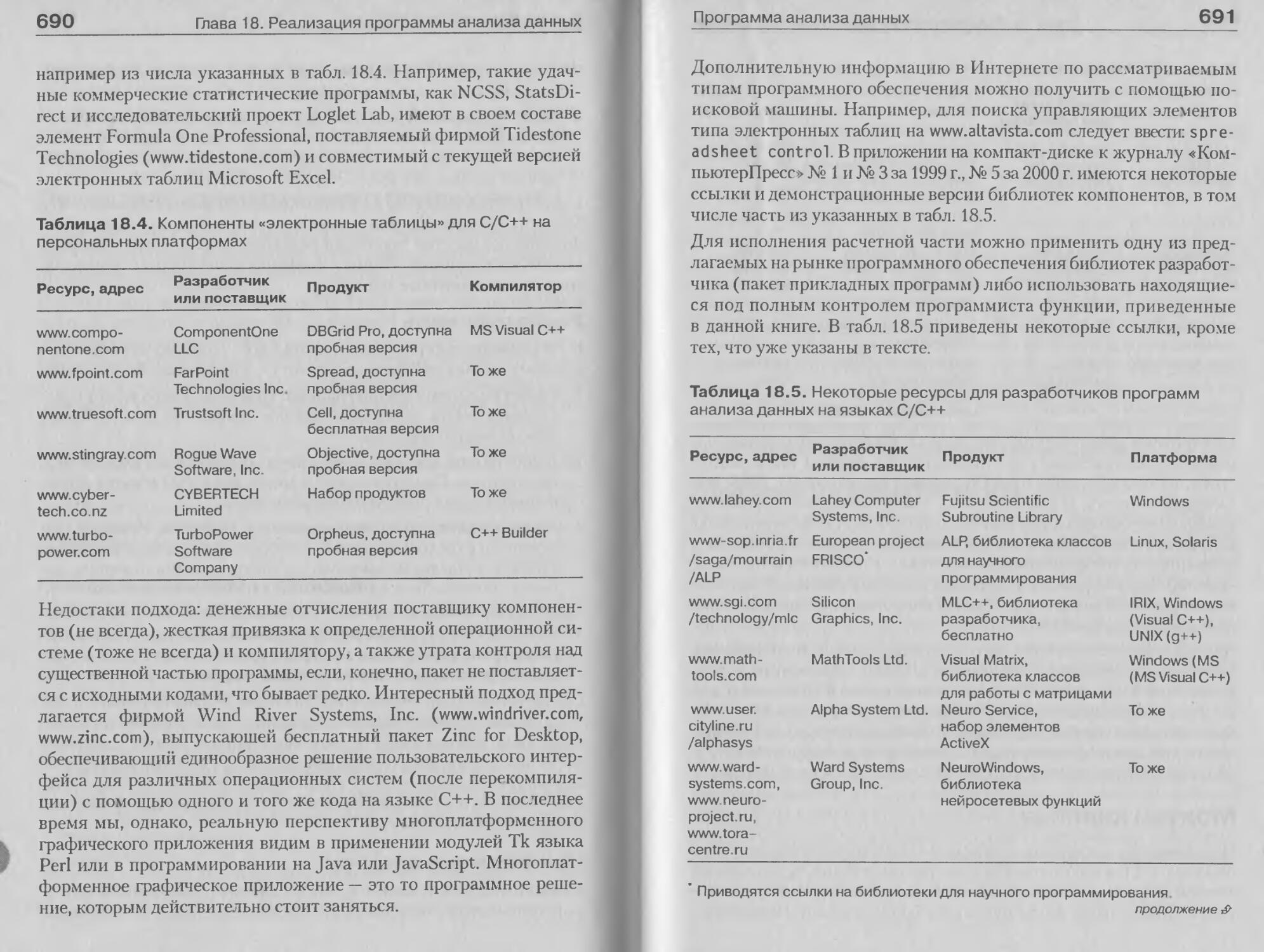
Программа анализа данных........................681
Разработка программы для MS-DOS..............684
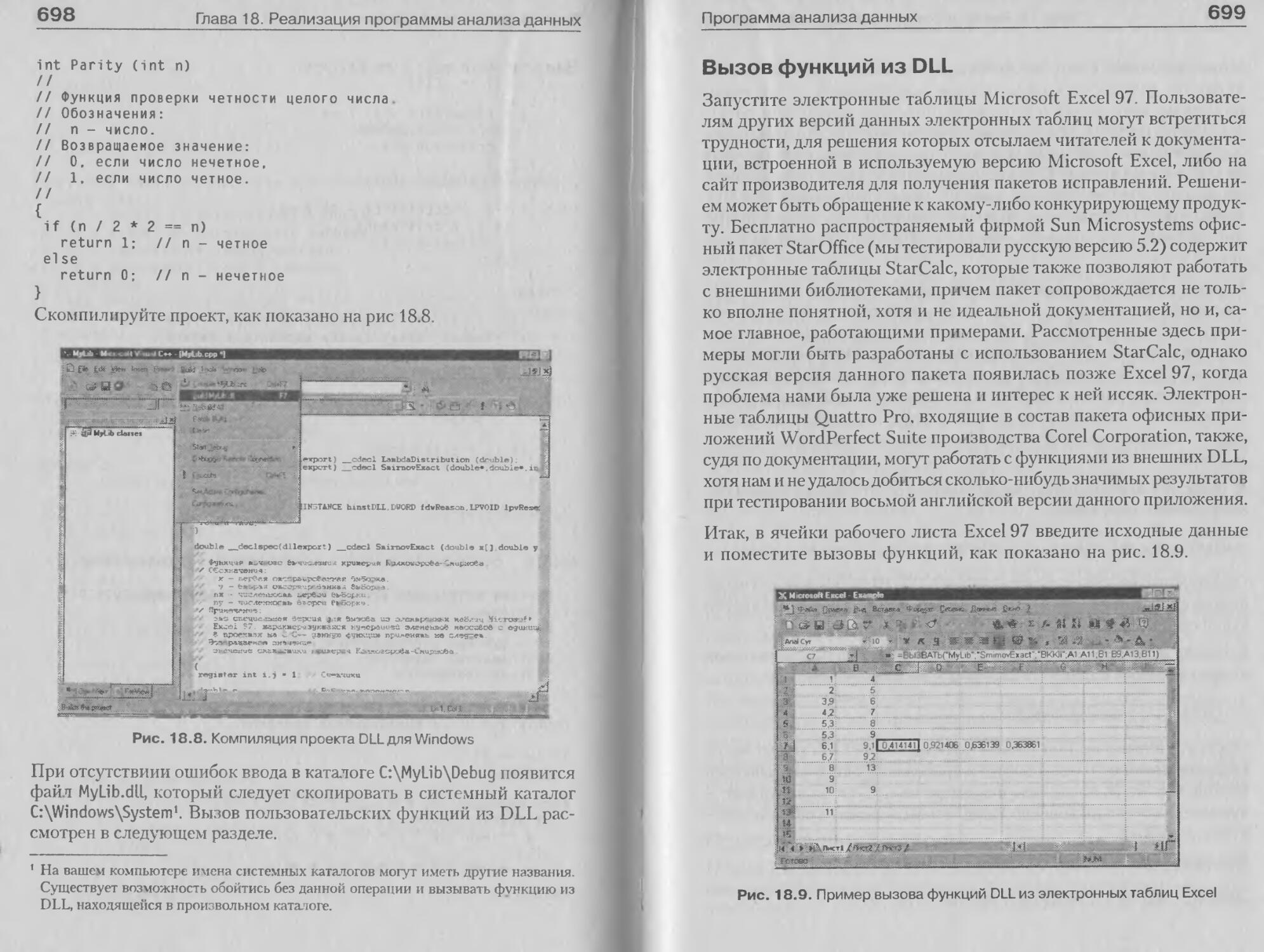
Пример консольного приложения для Windows....686
Проектирование оконного приложения...........688
Модули анализа...............................692
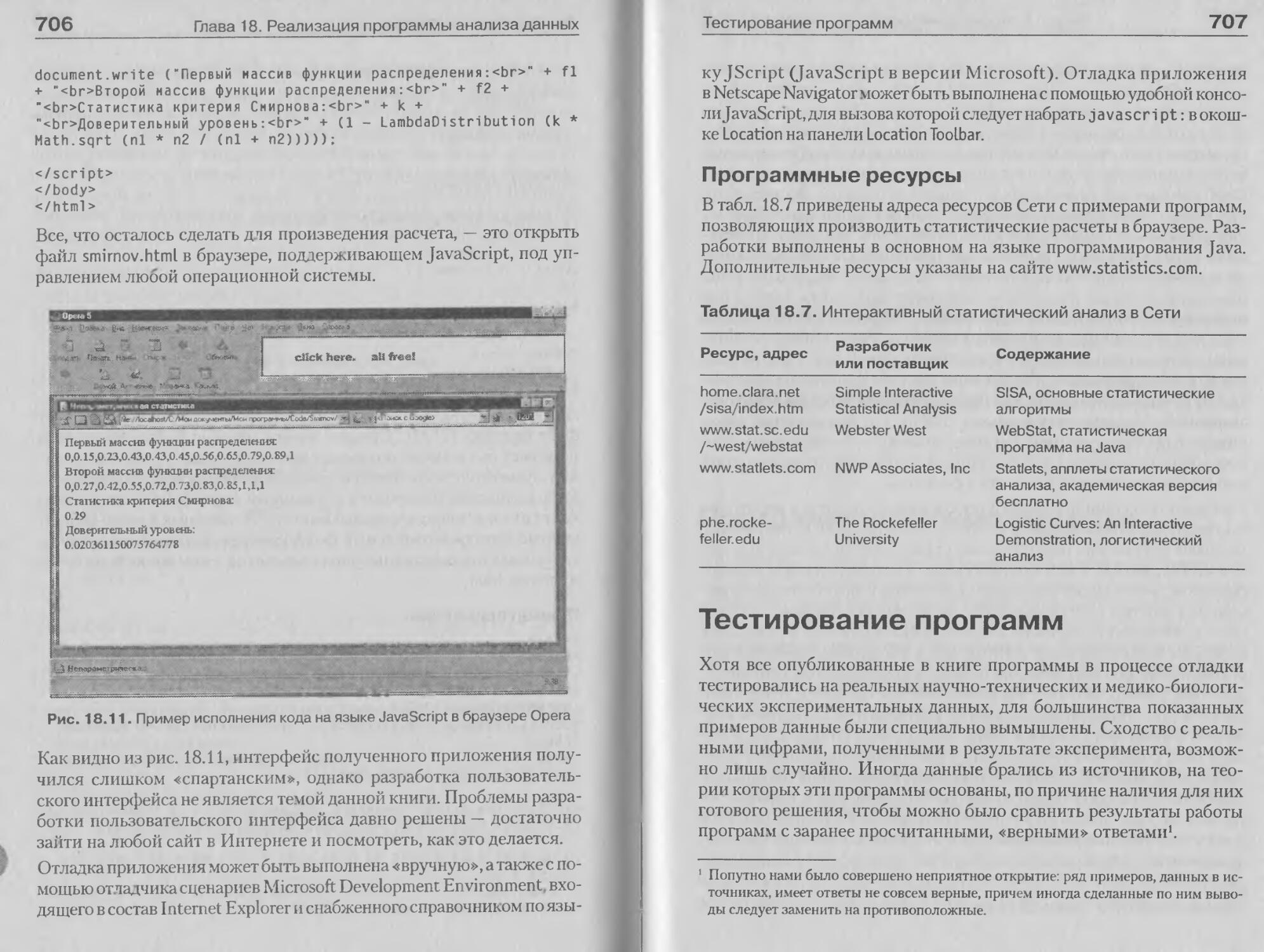
Статистический анализ в браузере.............702
Тестирование программ...........................707
14
Содержание
Программная совместимость.....................709
Дальнейшие исследования.......................711
Заключение .....................................713
Программы медико-биологической статистики.....716
Терминология..................................717
Полнота и воспроизводимость...................718
Структуризация и компактность.................719
Точная адресация..............................719
Литература .....................................721
Книги и публикации............................721
Электронные источники.........................736
Системные программы и средства разработки .736
Демонстрационные версии программ анализа данных на CD.......................737
Виртуальные ресурсы Сети ..................738
Приложение. Заголовочный файл...................740
Алфавитный указатель............................748
Введение
Предмет
Существует множество наименований рассматриваемого предмета. С возникновением новых методик анализа общепринятые определения уже не могут обобщенно его назвать, поэтому термин «анализ данных», понимаемый в широком смысле, оказывается наиболее уместным [111, с. 7]. Под методами анализа данных в настоящее время понимают совокупность как традиционных статистических приемов обработки информации, так и методов, развитых в последние годы и на вероятностных идеях не основанных [76, с. 6]. Однако в любом случае мы не занимаемся отвлеченными от практики мысленными построениями — нас интересует немедленный практический результат. По словам известного организатора науки, «данные науки всегда проверялись практикой, опытом. Наука, порвавшая связи с практикой, с опытом, — какая же это наука?... Наука потому и называется наукой, что она не признает фетишей, не боится поднять руку на отживающее, старое и чутко прислушивается к голосу опыта, практики»1.
Методы анализа данных применялись нами как при обработке результатов научно-технических экспериментов, так и в медико-биологических исследованиях. Статистические методы, рассмотренные в главах 1, 2 и 3 настоящего издания, применялись в основном при обработке медико-биологических данных. Это вызвано тем, что технические системы дают гораздо больше шансов для построения подробной и физически обоснованной математической модели по сравнению с медико-биологическими системами. Если какой-либо технический процесс показывает нестабильность в эксперименте, стараются локализовать причину этой нестабильности с максимально возможной точностью — неконтролируемые изменения обычно очень малы [24, с. 9]. Иначе обстоит дело с медико-биологическими системами. Полной воспроизводимости и стабильности при их экспериментальном исследовании добиться трудно. Интересующий исследователя исход опыта в таких задачах зависит от столь большого числа факторов, что применение методов исследования, принятых
Сталин И. В. Речь на первом всесоюзном совещании стахановцев, 17 ноября 1935 г. // Вопросы ленинизма,— М.: ОГИЗ, 1939.— 502 с.
16
Введение
в технических науках, себя не оправдывает [44, с. 13]. Статистические методы на сегодняшний день являются для таких систем почти единственным способом количественного описания явлений и объектов. Стремлением удовлетворить потребности обработки полярных по сути экспериментов объясняется номенклатура методов исследования и представленного программного обеспечения. В книге совершенно не рассмотрены методы непосредственного получения экспериментальных данных. Предполагается, что данные для математической обработки уже получены и искажены ошибками различных типов [133], [135, с. 388]. Таким образом, любые исходные данные для анализа представляют собой не какие-либо физические или иные характеристики изучаемого объекта или явления, а характеристики объекта или явления в совокупности с измерительным устройством. Далее мы не будем касаться этой проблемы, подробно изучаемой в курсе типа «Экспериментальные методы исследований» и в многочисленных источниках, сосредоточившись только на обработке уже полученных данных, кроме самих данных, возможно, требуя лишь незначительной дополнительной информации об объекте исследования.
Наша книга посвящена краткому описанию алгоритмов анализа данных, с которыми нам приходилось работать, а также известных математических методов, которые в этих алгоритмах применялись. Достаточно полно даны прокомментированные исходные тексты компьютерных программ, необходимых для проведения расчета. В главе 18 рассмотрено несколько стратегических подходов к составлению программ анализа данных.
После написания основного объема книги знакомство с [8] вызвало у нас удивление близостью подходов к решению проблемы и дополнительно убедило в необходимости подобного издания на русском языке. Однако в указанном источнике рассмотрен численный анализ и дана одна глава с примерами приложения этого анализа к статистике. У нас же упор сделан на прикладной анализ и получение практических результатов, а численные методы описаны в той мере, в которой это необходимо для проведения такого анализа. Влияние на идею нашей книги оказали также руководства и информационные материалы по зарубежным пакетам прикладных программ IMSL1, SSP2 [174], [175], отечественным пакетам [114], [156] и классический труд [189].
1 Поставляется Visual Numerics, Inc. (w3vw.vni.c0m)
2 Scientific Subroutine Package. Сейчас ESSL, разработка IBM Corp, (www.ibm.com)
Аудитория
17
Аудитория
Для чтения данной книги, практического применения описанных в ней алгоритмов и работы с программами требуются небольшие, но твердые познания в математике и программировании в объеме курса втуза. Возможно, адресуя книгу в числе других категорий читателей программистам и исследователям, мы слишком много внимания уделяем элементарным методам. Это вызвано тем, что курс теории вероятностей и математической статистики не дает практических навыков обработки реальных экспериментальных данных, поэтому наличия таких навыков у читателя мы не предполагаем, однако общая подготовка дает прочную платформу для изучения данных разделов самостоятельно. Книга может оказаться полезной в качестве Справочника научным работникам, программистам, инженерам-исследователям, медикам, биологам и другим специалистам, профессионально имеющим дело с обработкой экспериментальной информации. Представленный материал прост, но все-таки книга не «... для читателя, не имеющего ровно никаких познаний в даннОхМ вопросе»1.
Некоторые авторы полагают, что в недалеком будущем эффективность научного программирования на несколько порядков возрастет благодаря использованию отлаженных готовых компонентов [9], [10]. При этом почему-то не предполагается знание программистами предмета, с которым они собираются работать. Хорошо, когда программный продукт создается командой профессионалов, в состав которой наряду с программистами входят математики, менеджеры и т. д., но с другой стороны, мы становимся свидетелями того, что программирование вполне осваивают инженеры, медики, биологи, экономисты. Нам встречалось много предметных специалистов, для которых программирование стало если не второй специальностью, то по крайней мере хобби. Взгляд на анализ данных не со ставшей уже привычной в компьютерной литературе точки зрения пользователя готовых программных продуктов [78], [187], а, наоборот, изнутри, с точки зрения математика-программиста, поможет инженерам, медикам, экономистам разобраться с тем, что они могут на сегодняшний день получить от методик анализа данных, а программистам — понять, что от них требуется. К тому же упомянутые в начале абзаца безошибочные программные компонен
1 Восленский М. С. Номенклатура. Господствующий класс Советского Союза. - М.: Сов. Россия: Октябрь, 1991.— С. 394.
18
Введение
ты перед их эффективным применением кто-то должен сначала разработать. О командной и авторской разработке см. также [106, с. 279].
Примеры
Описания почти всех методов расчета проиллюстрированы примером вызова функции в составе законченной программы с диагностическими и информационными сообщениями на русском или английском языке или в составе фрагмента программы, если примеры вызовов методов сходного назначения уже даны в той же самой главе, поэтому сделать полезную программу для другого метода не составит труда вследствие сходного интерфейса программных реализаций этих методов. Для программ статистических обязательно даны или указаны вызовы методов, реализующих вычисление критического значения критериальной статистики или ее аппроксимации. Иногда пример программного решения не приводится, а дается описание алгоритма и ссылки на подробные источники — часто вербальное описание идеи метода много важнее страниц формул. Например, для базовой реализации метода ^-средних (глава 8) оказалось достаточно трех строчек текста в первоисточнике.
Ссылки даны и в исходных текстах составленных нами функций на языках программирования С, C++ и JavaScript, которые, как правило, имеют имена создателей реализованных в этих функциях методов расчета. Перефразируя Урсулу Ле Гуин1, вы получите полный контроль над каким-либо объектом, вещью, существом, только назвав его «подлинным именем». К тому же поиск алгоритмов и их авторов в глобальной компьютерной сети Интернет наиболее эффективен по именам разработчиков.
Словами Пример применения отмечено начало листинга с примером вызова функции. Это — некоторый фрагмент или полный текст тестовой программы, реализующий вызов метода и отображающий примерные диагностические сообщения.
Словами Исходные коды отмечено начало листинга исходного текста функции, реализующей описанный метод. Это тот текст, который должен быть обязательной составной частью вашей программы, реализующей нужный для ваших расчетов метод. Описание рабочих переменных в примерах, выделение необходимой памяти для
1 Миры Урсулы Ле Гуин. Волшебник земноморья. - Рига: Полярис, 1997. - 383 с.
Благодарности
19
массивов и классов и ее корректное возвращение системе, а также ввод и вывод данных, являются заботой и делом вкуса программиста, поэтому данному вопросу для экономии места внимания мы уделяем непозволительно мало.
Словами Исходные коды и пример применения обозначено начало листинга исходного текста законченной программы, возможно, за исключением некоторых стандартных методов. Для построения исполняемого модуля потребуется включение в проект всех вызываемых функций либо в виде исходного текста, либо в виде объектных пли библиотечных модулей, либо в виде динамических библиотек, в зависимости от аппаратно-программной платформы и от привычки программиста. Кроме реализации определенного метода, в расчетах обычно участвует несколько вспомогательных стандартных функций, применяющихся, кроме описываемого, и в других алгоритмах. Поэтому все универсальные «многоцелевые» функции помещены в общие разделы. Для удобства работы в конце книги дан алфавитный указатель функций, что позволяет быстро найти код необходимой процедуры для включения ее в проект.
Благодарности
Автор искренне благодарит:
• чл.-корр. РАМН, д. м. н. профессора В. И. Шевцова за оказанную всестороннюю поддержку,
• профессора Г. Голуб за предостережения, высказанные при обсуждении проблемы разложения матриц по сингулярным числам, критическую оценку предложенного метода и предоставленные печатные источники,
• д. м. н. К. С. Десятниченко за плодотворное творческое содружество, ряд ценных идей и внимание к новинкам в методах анализа данных,
• д. м. н. М. М. Щудло за формулировку основных потребностей в методиках математико-статистического анализа данных, полученных в экспериментальных и клинических медицинских исследованиях ортопедо-травматологического профиля,
• к. ф.-м. н. А. П. Кулаичева за пояснения к применению критериев согласия и введение в методики анализа сигналов,
• А. Е.-Х. Югай за полезные замечания, позволившие уточнить и расширить положения глав 1,2 и 3 книги и сделавшие ее понятнее
20
Введение
категориям читателей, для которых книга изначально не была предназначена, что дало нам возможность значительно расширить потенциальную аудиторию,
• Е. А. Помазова за помощь в работе над главой 18.
Особая благодарность В. А. Уткину за дружеские советы, внимательное чтение рукописи и рекомендации. Возможно, книга была бы гораздо лучше, если бы все рекомендации были нами приняты, поэтому ответственность за все ошибки и недочеты лежит только на авторе.
От издательства
Ваши замечания, предложения, вопросы отправляйте по адресу электронной почты comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
Подробную информацию о наших книгах вы найдете на web-сайте издательства http://www. piter.com.
Глава 1. Статистики эмпирического ряда
Статистикой называют функцию, зависящую лишь от результатов наблюдений, поэтому любой вычисленный по эмпирическим данным показатель можно называть статистикой [37, с. 102].
В описаниях методов приняты традиционные для статистической науки понятия эмпирического ряда, выборки или совокупности, обозначающие одну и ту же сущность. Выборкой называют [187, с. 38] последовательность независимых одинаково распределенных случайных величин. Элементы выборки называются вариантами. В исходных текстах программ приняты понятия вектора1 или массива, характерные для линейной алгебры и для программирования соответственно. Если исследуемая совокупность представляет собой многомерную выборку, иначе набор векторов показателей (признаков, переменных), говорят о многомерном анализе данных [78, с. 146].
Совокупности состоят из отдельных элементов (объектов), которые объединены общностью некоторых свойств (признаков, переменных). Количество элементов совокупности можно называть по-разному. Так, если речь идет о выборке, количество ее элементов может называться численностью, величиной или размером. Если речь идет о векторе (одномерном массиве), говорят о размере (длине) вектора или размерности массива. Однако в многомерном анализе под размерностью часто понимают число измерений (векторов) показателей [135, с. 514]. Математически строгое определение размерности дано в [183, с. 84]. Исходя из всего сказанного, мы будем использовать определение численности в приложении к выборке, определение размера или длины в приложении к вектору, а определение размерности будет использовано там, где говорится о многомерных сущностях (матрицы, многомерные выборки и т. д.). В программировании под размером массива понимают как количество элементов массива, так и размер массива в байтах, в зависимости от контекста.
В случаях, не оговоренных отдельно, под вектором всегда понимается вектор-столбец.
Классификация признаков по шкалам измерения
23
Чаще всего приходится работать с некоторой частью совокупности, являющейся выборкой из полной исходной совокупности. В связи с этим различают генеральную совокупность, включающую в себя все объекты данного рода, и выборочную совокупность. Под выборочной совокупностью понимается совокупность, специальным (случайным) образом отобранная из генеральной совокупности и отражающая основные статистические свойства последней.
Классификация признаков по шкалам измерения
Пользователю, начинающему работать с методами анализа данных, полезно ознакомиться с классификацией признаков по типам. В этом случае говорят о шкале измерения [78, с. 146], [172, с. 34, 67, 108], [191, с. 271]. В источниках приняты различные принципы классификации признаков по шкалам измерений. Классификация в зависимости от числа допустимых арифметических операций над признаками, измеренными в данных шкалах, включает [187, с. 285]: • Номинальные признаки (признаки с неупорядоченными состояниями, классификационные признаки), например: велосипед, мотоцикл, автомобиль. Номинальные признаки Moiyr быть оцифрованы — 0,1,2, однако смысла эти цифры, за исключением возможности различать признаки между собой, не имеют. Частным случаем номинальных признаков являются бинарные (качественные, дихотомические) признаки, представляющие собой номинальные признаки с двумя градациями, например: «нет» — 0, «да» — 1. Мы рекомендуем для бинарных признаков использовать оцифровку типа 0 и 1, а не какую-либо иную (например, -1 и +1), так как только эти две цифры предполагается использовать в методах анализа бинарных признаков, в том числе и в запрограммированных нами алгоритмах.
• Порядковые признаки (признаки с упорядоченными состояниями, ординальные признаки), например: отлично, хорошо, удовлетворительно, плохо. Порядок состояний имеет смысл, признаки могут быть осмысленно оцифрованы (в данном примере: 5, 4, 3, 2) и могут сравниваться между собой, однако расстояния между ними не определены. Как и предыдущие, подобного типа признаки часто используются в задачах диагностики, в том числе медицинской.
24
Глава 1. Статистики эмпирического ряда
• Количественные (численные, вариационные) признаки, иногда подразделяемые на интервальные и относительные, различающиеся положением нулевой отметки на шкале измерения. Например, год рождения — относительный количественный признак, а срок службы в рядах вооруженных сил — интервальный количественный признак. Если в первом примере определены только операции различения, сравнения и вычитания, то во втором к ним добавляются операции сложения и отношения. Численные признаки определяют измеряемые или исчислимые количества (величины) и являются истинными количественными, причем могут измеряться как непрерывные, так и целочисленные признаки.
Выяснить, к какой шкале принадлежит измеряемый в эксперименте признак, поможет табл. 1.1.
Таблица 1.1. Действия над признаками, измеренными в различных шкалах
Шкала измерения Допустимые действия Пример применения
Номинальная Различение Наличие или отсутствие симптома
Порядковая Различение, сравнение Школьная оценка
Количественная Различение, сравнение, сложение и/или вычитание, умножение и/или деление (отношение) Температура, масса, время, длина
В таблице речь идет о применении того или иного математического действия (операции) по отношению к полученному в эксперименте признаку. Само собой разумеется, что могут быть проделаны допустимые действия над разными признаками, принадлежащими одной шкале. Можно также представить себе действия, совершенные над признаками, измеренными в разных шкалах, но данное исследование не является сейчас предметом нашего рассмотрения — мы говорим о первичных параметрах, являющихся результатами измерений, а не математических вычислений (вычисления, впрочем, могут быть выполнены экспериментальной аппаратурой).
Шкалы могут приводиться одна к другой: количественная шкала — к порядковой или номинальной, порядковая шкала — к номинальной. Обратные операции считаются некорректными. Приведение од
Классификация признаков по шкалам измерения
25
ной шкалы к другой обычно называют понижением шкалы. Приведение признаков к шкале, отличной от тех, в которых первоначально признаки были измерены, необходимо при анализе групп признаков, измеренных в разных шкалах [187, с. 308].
Понижение шкалы ведет к потере некоторой части информации об изучаемых признаках. Описанная в одноименном разделе настоящей главы процедура присвоения рангов количественным признакам фактически означает приведение количественной шкалы к порядковой. Вообще, любой алгоритм классификации исходных данных по группам приводит их к порядковой или номинальной шкале, причем переменные могут и не выражаться в терминах какой-либо числовой переменной [91, с. 719]. В этом случае авторы говорят о качественных, категоризированных [там же], описательных [89, с. 23] или атрибутивных [ 111, с. 20] признаках, имея в виду либо совокупность номинальной и порядковой шкал, либо только порядковую шкалу. С подробной классификацией признаков по шкалам измерения можно ознакомиться на сайте «Высокие статистические технологии» (www.antorlov.nm.ru). См. также [184, с. 19].
Рассмотренная классификация признаков по шкалам измерений не исчерпывает всех мыслимых типов классификаций. Так, для применения статистических методов, оперирующих частотами распределений, более существенной может оказаться классификация по такому критерию, как непрерывность теоретической функции эмпирического распределения. Для других методов определяющим является решение вопроса о том, какому теоретическому типу распределения соответствует эмпирическое распределение либо, в более узком смысле, является ли распределение нормальным. Если же различать условия исследования того или иного явления, признаки могут подразделяться на факториальные признаки (причина) и результативные признаки (следствие) [89, с. 23].
«Успех применения любого метода зависит от того, насколько хорошо анализируемые данные соответствуют основным предположениям, принятым при разработке статистического метода» [186, с. 299]. Методы анализа, разработанные для определенного типа признаков, могут привести к совершенно неверным выводам при их применении к признакам другого типа, поэтому нужно быть особенно внимательным при выборе метода, адекватного анализируемым данным. Тип исходных данных определяет, какими методами эти данные могут быть обработаны. «Формулы ... нельзя применять слепо и автоматически, без рассмотрения вопроса об их пригодности
26
Глава 1. Статистики эмпирического ряда
в каждом данном случае» [24, с. 8]. Так, при оценке различий дихотомических выборок (например, числа осложнений при использовании различных методов лечения) можно использовать непараметрический критерий Z2 в специальной форме, можно применять точный метод Фишера (если число переменных равно двум), но ни в коем случае нельзя использовать ряд других методов проверки гипотез, предназначенных для порядковых и количественных признаков. Хотя при формальном применении методик расчета и компьютерных программ какие-то цифры получены будут, содержательно интерпретировать их будет нельзя. Некоторые из качественных фирменных программных продуктов анализа данных имеют в своем составе специальные компоненты — мастера, волшебники или навигаторы, — облегчающие пользователям выбор нужного метода расчета в зависимости от типа представленных для анализа данных.
Описательная статистика
Описательная статистика — это традиционный набор основных статистических показателей эмпирической выборки. Мы будем рассматривать выборочные (эмпирические) статистические характеристики, то есть характеристики, рассчитанные по выборке, в противоположность статистическим характеристикам генеральной совокупности.
Статистические выводы могут быть затруднены из-за неоднородности данных. Поэтому для исключения влияния некоторых факторов производится стандартизация коэффициентов. Популярное в отечественной медико-биологической литературе использование стандартных ошибок статистических показателей, строго говоря, правомерно только в том случае, когда распределение статистик стремится к нормальному распределению [92, с. 325]. Для распределений других типов формулы вычисления ошибок будут иными, а примеры некоторых из таких формул даны в [24, с. 40]. Практически это означает, что тест на нормальность распределения, или, в общем случае, контроль типа распределения, — это первое, что нужно сделать с экспериментальными данными, анализируемыми статистическими методами. Расчет ошибок статистических показателей, выполненный без контроля типа распределения, не является правомерным, но это повсеместно распространенная ошибка, снижающая качество выводов. Стандартизации медицинских показателей посвящен раздел [89, с. 57]. Полезно сравнить стандартизацию с часто
Описательная статистика
27
применяемой в технических науках (теория упругости, аэродинамика) процедурой обезразмеривания.
Для введения в рассматриваемые вопросы можно ознакомиться с одним из многочисленных источников, например [44], [54], [143], [173]. Описательная статистика в стандартных компьютерных программах рассмотрена в [17], [34], [131], [187]. Решение на языке программирования Бейсик дано в [184, с. 96].
Среднее значение, математическое ожидание
Из рассмотренных статистических показателей среднее значение, медиана и мода характеризуют центр статистического распределения, являясь мерами положения. Выборочное среднее значение, оно же математическое ожидание (expected value, expectation) [63, с. 31], арифметическое среднее (mean), средняя арифметическая простая [89, с. 78], — наиболее часто применяемая характеристика центра распределения случайной величины. Математическое ожидание можно рассматривать как центр тяжести распределения. Распространено обозначение среднего значения как а, если имеется в виду известное (истинное, а не вычисленное по эмпирической выборке) среднее совокупности. Эмпирическое (выборочное, вычисленное по эмпирической выборке) среднее (sample mean) чаще всего обозначают как х или Ц. В теоретических выкладках математическое ожидание обозначают через Е (в иностранных источниках) или через М (в источниках отечественных). При этом символы Е и Л/ можно рассматривать и практически применять как нелинейные операторы [135, с. 431], причем в формулах эти операторы могут действовать не только на скалярные случайные величины, но и на другие производные от них величины, например разности случайных величин, квадраты случайных величин и т. д. Поэтому математическое ожидание является более широким понятием, чем среднее значение. Среднее значение случайной величины, измеренной в количественной шкале, определяется выражениями [158, с. 85]:
для дискретной случайной величины так же, как
i=0
где х — значения, принимаемые случайной величиной с вероятностями р., для непрерывной случайной величины, распределенной в диапазоне ]-оо;+оо[,
28
Глава 1. Статистики эмпирического ряда
Д = J xf(x)(\x,
где f(x) — плотность распределения вероятностей случайной величины х.
Выборочное среднее значение и его ошибка вычисляются, соответственно, как [84, с. 39]
х-
где х, г = 1,2,..., п, — значения результатов наблюдений (значения вариант выборки),
п — численность выборки, сг— выборочное среднее квадратичное отклонение (см. ниже).
В случае, если исходные данные представлены в виде частот распределения случайной величины по интервалам, формулу вычисления среднего следует заменить на следующую [187, с. 46]:
где bit i =1,2,..., k, — середины интервалов (классовых интервалов, введенных в разделе «Вариационная статистика»),
vi, i =1,2,..., kt — эмпирические частоты, k — число классовых интервалов.
Свойства математического ожидания подробно рассмотрены [37, с. 50]. См. также [100, с. ИЗ], [155, с. 20]. Представлен пример вычисления и возможные ошибки проанализированы в [231, с. 387]. Решение на языке программирования JavaScript (без вычисления ошибки) приводится в [36, с. 158], упражнение на Fortran 77 см. в [162, с. 98], на языке Бейсик см. в [184, с. 42].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
^include <math.h>
#include "megastat.h"
void main (void)
Описательная статистика
29
int n = 14;
double a[] = {65.67.69.70,71,72.72,73,73,78.81,85.86.87}. sm. // Среднее mm; // Ошибка среднего
SampleMean (a.n.&sm.&mm);
cout « "Sample mean = " « sm « endl
« "Error = " « mm « endl:
void SampleMean (double *a,int n,double *sm.double *mm)
// Функция вычисляет параметры среднего значения эмпирического // ряда.
// Обозначения:
// а - исходная выборка.
// п - численность выборки.
// *sm - среднее,
// *mm - ошибка среднего.
// Возвращаемое значение:
// нет.
И {
*sm = VectorSum (a.n) I n;
*mm = sqrt (Cov (a.a.n) / n): }
Другие виды средних также находят применение в анализе данных [80, с. 76], [84, с. 17]. Средняя гармоническая величина (гармоническое среднее) определяется по формуле
Геометрическое среднее (среднее пропорциональное) определяется по формуле [135, с. 143]
Иногда применяется степенное среднее [там же, с. 558] /1А „
s«=\'rEx.“ - в>0>
30
Глава 1. Статистики эмпирического ряда
частными случаями которого являются другие виды средних, введенные выше и имеющие общее название — степенные средние. Степенные средние являются, в свою очередь, частными случаями взвешенных степенных средних, общая формула которых по аналогии с предыдущей формулой имеет вид [там же]
где i =1,2,..., п, — весовые коэффициенты.
Для рассмотренных средних величин имеет место неравенство [135, с.411]
h<g<х<s•
Общепринятая в медицинских и биологических работах запись М ±т означает среднее значение и ошибку среднего [24, с. 38], [117, с. 57]. Такая запись вполне информативна, характеризует как центр распределения, так и разброс данных, но она не позволяет судить, в каких интервалах следует ожидать появление случайной величины в опыте на заданном доверительном уровне — именно эти цифры часто интересуют исследователя, а также к каким ошибкам может привести замена параметра (например, истинного среднего) его оценкой, вычисленной по выборке [155, с. 32].
Поэтому будет лучше дополнительно вычислить границы доверительного интервала для среднего [1], [206, с. 94], включающие нижний и верхний пределы и означающие нахождение истинного среднего Д в интервале с вычисленными границами на выбранном стандартном доверительном уровне р (его следует задать из стандартной линейки, например: 0,90; 0,95; 0,99; 0,999). Доверительный интервал для истинного среднего Д в случае двусторонней гипотезы вычисляется по формуле [140, с. 127]
де х-Г
и-1,р / >
у/п
те tn_t р — значение обратной функции ^-распределения, р — стандартное значение доверительного уровня (доверительная вероятность, надежность оценки).
31
Описательная статистика
Формула дает доверительный интервал для неизвестного математического ожидания при неизвестной дисперсии в предположении нормальности распределения [37, с. 122].
Для односторонней гипотезы, в зависимости от ее формулировки, вместо левой или правой границы интервала в показанной формуле будет фигурировать -оо или +оо, а значение обратной функции t-распределения будет взято для одностороннего значения:
д2е
Х ^-Цр+1)/2 ^; +
Вычисление доверительного интервала среднего значения иллюстрирует показанный ниже пример. По поводу фактических параметров вызываемого из функции Confidencelnterval метода InverseTDistri-bution см. подробные пояснения в начале главы 4.
См. также [24, с. 39], [111, с. 108], [206, с. 94].
Исходные коды и пример применения
#include <fstream.h>
#include <math.h>
#include "megastat.h"
void main (void) {
int n = 9;
double m = s = P = d:
10.
2.
0.95.
// Среднее
// Среднее квадратичное отклонение
// Доверительный уровень
// Параметр доверительного интервала
d = Confidencelnterval (n.s.p.l);
cout « "One side:\n"
<< "Confidence interval 1 is [-infinity:" « (m + d)
<< "]\n"
« "Confidence interval 2 is [" « (m - d)
« ":+infinity]\n":
d = Confidencelnterval (n.s.p.2);
cout « "Two side:\n"
« "Confidence interval is [" « (m - d) « ":" « (m + d) « "]\n":
}
32
Глава 1. Статистики эмпирического ряда
double Confidencelnterval (int n.double s.double p.int Side) 11
II Функция вычисления доверительного интервала для среднего.
// Обозначения:
// п - численность выборки,
// s - выборочное среднее квадратичное отклонение.
// р - стандартный доверительный уровень,
// Side = 1 для односторонней гипотезы.
// =2 для двусторонней гипотезы.
// Возвращаемое значение:
// параметр доверительного интервала.
И
{
if (Side == 1)
return InverseTDistribution (n - l.p) * s / sqrt (n): el se
return InverseTDistribution (n - l,(p + 1) / 2)*s / sqrt (n); }
Выше мы рассмотрели вычисления для случайной величины, измеренной в количественной шкале. Теперь пусть М членов совокупности размером N обладают некоторым качественным признаком (значение 1), а остальные (Лг - М) этим признаком не обладают (значение 0). Показано [52, с. 124], что среднее значение такой совокупности совпадает с долей членов совокупности, обладающих признаком, то есть
д = М/N = р.
Медиана
Выборочная медиана (median) — числовая характеристика непрерывно распределенной случайной величины, определяемая условием, что случайная величина с вероятностью 0,5 принимает значения как большие, так и меньшие медианы. Медиана разделяет выборку на две равные по числу вариант части [84, с. 38]. В случае непрерывного распределения [158, с. 87] медианой называется значение т такое, что
J/(x)dr = J/(r)dr = |.
т
Для дискретного распределения медианой условились считать такое целое число т, что [там же]
Описательная статистика
33
m-l I tn 4
i=0 z i=0 z
Таким образом, выборочная медиана является решением уравнения
W= 1/2,
где Fn(x) — эмпирическая функция эмпирического распределения случайной величины1.
Для интервального вариационного ряда2 выборочная медиана определяется как варианта, имеющая порядковый номер (и + 1)/2 для нечетного п при нумерации с 1. Для четного п порядковый номер медианной варианты не определяется, а медиана равна среднему арифметическому двух средних вариант [135, с. 559], [187, с. 42]:
X(m),n = 2m + 1,
2L (w)J’ ’
где Х(т) — элементы вариационного ряда, п — численность вариационного ряда.
В [100, с. 180] имеется другое определение медианы для четного п. Там считается, что для четного п медиан две, и собственно медианой называется меньшая из двух. В [там же, с. 188] вводится понятие взвешенной медианы.
Ошибка медианы вычисляется как [50, с. 31]
Обсуждение см. [28, вып.2, с. 136], [84, с. 39], [89, с. 90], [229, с. 63]. Доверительные границы для медианы вычислены в [120, с. 46].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
^include <math.h>
#include "megastat.h"
1 Об эмпирических распределениях см. ниже.
2 Определение вариационного ряда см. ниже.
2-2002
34
Глава 1. Статистики эмпирического ряда
void main (void)
{
int n = 14: // Численность выборки
double a[] = // Исходная выборка
{65,67,69,70,71.72,72.73,73.78.81.85.86.87}.
m, // Медиана
rm: // Ошибка медианы
Median (а.n,&m.&rm):
cout « "Median = " « m « endl « "Error = " « rm « endl:
}
int Median (double *a.int n,double *m,double *rm)
//
// Функция вычисляет параметры медианы.
// Обозначения:
// а - исходная выборка.
// п - численность выборки.
// *т - медиана.
// *гт - ошибка медианы.
// Возвращаемое значение:
// 0 при нормальном окончании расчета,
// -1 при недостатке памяти.
//
{
int *inf; // Фиктивный параметр
double *data: // Ранжированный ряд
if ((data = new doublefn]) == 0) return -1;
ArrayloArray (a.data.n);
SortArrayllp (data,n,inf,0):
if (’.Parity (n))
* m = data[n / 2];
el se
* m = (data[n / 2 - 1] + data[n / 2]) / 2;
* rm = sqrt (Cov (a,a.n) * M PI / 2 / n):
delete [] data;
return 0;
}
Иначе медиана определяется как 50%-процентиль, так как она делит распределение пополам. Напомним, что 25%-процентиль
Описательная статистика
35
и 75%-процентиль отсекают от распределения по четверти соответственно слева и справа [52, с. 35].
Мода
Мода — числовая характеристика распределения случайной величины — точка максимума эмпирической функции распределения [84, с. 41]. Число классовых интервалов можно определить, например, по правилу Стержесса (правила и рекомендации по выбору числа классовых интервалов даны ниже). Разнесение частот по классам можно выполнить вручную или автоматически, используя предлагаемую нами функцию Allocate, после чего производятся вычисления, как показано в примере.
Обсуждение см. также в [89, с. 91].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include "megastat.h"
void main (void) {
int k = 7;
double b[] = {50.55.65,70.75.80.85}.
f[] = {67.71.78.85,90,86.83};
cout « "Mode = “ « Mode (b,f,k) « endl }
double Mode (double *b.double *f,int k)
//
// Функция вычисляет ноду.
// Обозначения:
// b - массив середин классовых интервалов.
// f - массив частот распределения,
// к - число классовых интервалов.
// Возвращаемое значение:
// значение моды.
//
{
int number; // Номер интервала максимальной частоты
MaximumOf (f,k.&number):
return b[numberj;
}
36
Глава 1. Статистики эмпирического ряда
Дисперсия, среднее квадратичное отклонение
Дисперсия (вариация, варианса, variance) характеризует степень отклонения вариант данной совокупности от среднего в абсолютных числах, иначе меру разброса (рассеяния) распределения относительно среднего значения [63, с. 31]. Дисперсия в разных источниках может обозначаться как ст2, Var(x), V. В теоретических исследованиях больше распространено обозначение D. При этом символ D можно рассматривать как нелинейный оператор, который может применяться как к случайным величинам, так и к их комбинациям и функциям случайных величин, в противоположность тому, что в данном разделе имеется в виду дисперсия среднего арифметического. Обобщение же понятия дисперсии на другие статистические показатели, например медиану, рассмотрены в [229, с. 50].
Для признака, измеренного в количественной шкале, дисперсия определяется формулами [158, с. 85]:
для дискретного случая
° =2JxiPi- Д > i=0
для непрерывного случая
<т2 = J x2f(x)dx-ii2.
Если среднее значение совокупности известно, оценка дисперсии совокупности вычисляется по формуле [32, с. 43]
п i=l
где а — известное среднее значение совокупности.
Хотя для больших выборок это несущественно, будет неверным пользоваться данной формулой, если оценка среднего значения совокупности производится также по выборке. Следуя [187, с. 149], обозначим:
£ — случайная величина,
хр х2,..., хп — ее реализации,
Описательная статистика
37
— дисперсия совокупности, х — среднее значение, вычисленное по выборке. Согласно определению и с учетом
9 1
М(х-а) =Dx = -D^ п
можно записать
=£(* -°)2=£[(*> -*)-(“ ~*)Т = i=l 1=1
= £(^-Л)2-2(а-х)£(х|-х)+и(а-х)2 1=1 1=1
В последнем выражении сумма во втором члене, очевидно, дает нуль, поэтому, перенеся первый член этого выражения в левую часть и сменив знак, получаем
£(х, - х)2 = nD£ -D£=(n-\)D%, 1=1
откуда непосредственно следует, что в случае оценки среднего значения по выборке в качестве оценки дисперсии совокупности берется величина, определяемая по формуле [187, с. 41]
rl~L 1=1
Подтверждение представленных выкладок см. также в [180, т.1, с. 106], [229, с. 52].
Ошибка дисперсии вычисляется как [111, с. 46] m F
Квадратичное отклонение (среднее квадратичное отклонение, стандартное отклонение, эмпирический стандарт или просто стандарт [155, с. 21], [204, с. 288], обозначается s или сг, корень квадратный из дисперсии) используют как меру качества статистических оценок и
38
Глава 1. Статистики эмпирического ряда
называют в этом случае квадратичной погрешностью (ошибкой, средней квадратичной ошибкой или просто квадратичной ошибкой) [24, с. 38], [135, с. 262]. Обычно обозначение ст используется там, где говорится о среднем квадратичном отклонении, вычисляемом по выборке (в этом случае некоторые авторы традиционно говорят о вычислении «сигмы»). Если по контексту под о2 понимается известная дисперсия генеральной совокупности, для того чтобы различить дисперсию генеральной совокупности и выборочную дисперсию, последнюю иногда обозначают как s2. Соответственно, выборочное среднее квадратичное отклонение будет обозначено как 5. Так сделано, например, при описании Г-критерия и Г-критерия.
Выборочное среднее квадратичное отклонение (standard deviation) и его ошибка вычисляются по формулам:
При этом выборочное среднее квадратичное отклонение иногда обозначают как <7n_j, чтобы отличить его от среднего квадратичного отклонения совокупности (standard deviation of the population), при известном среднем значении вычисляемого по формуле
CT=J|X(x.-fl)2 V п i=i
и обозначаемого как <ти. Далее под символом о всегда будем понимать сти_р так как мы работаем только с выборочными исходными данными и параметрами, вычисленными по выборке.
Применяются и другие формулы вычисления среднего квадратичного отклонения и дисперсии, полагаемые некоторыми авторами более удобными. Они базируются на том, что в показанных формулах сумма может быть после элементарных преобразований вычислена как [72, с. 29], [100, с. 115]
^}(х, -х)2 = Х(Х<2 -^х,х + х2) = х2 - 2х^х, + их2 = £х2 -ях2 i=i i=i i=i i=i i=i
Если исходные данные заданы в виде частот распределения, формула вычисления оценки дисперсии совокупности, основанная на использовании последнего преобразования, будет иметь вид [84, с. 30]
Описательная статистика
39
<r2 = ——-72-1
2"
k
n tr
где bp i = 1,2.k, — середины классовых интервалов,
v„ i=l,2,..., k, — частоты,
k — число классовых интервалов.
Формула находит практическое применение, в частности, при вычислении бисериальной корреляции для порядковых признаков, рассмотренной в разделе «Бисериальная корреляция в случае порядковых признаков» главы 5. Следует учесть, что расчет по данной формуле дает завышенное значение оценки дисперсии, для коррекции которого вводится поправка Шеппарда к величине дисперсии [24, с. 31]
s'2 = s 2-d2/12,
где d — так называемый интервал между группами (очевидно, при равных расстояниях между группами — то же самое, что величина классового интервала, рассчитываемая нами в разделе «Вариационная статистика» настоящей главы).
Иначе дисперсию можно вычислить через ковариацию, как показано в примере, рассмотренном в разделе «Ковариация» главы 5.
Обсуждение с практическими примерами дано в [37, с. 55], [50, с. 30], [111, с. 46]. Упражнение на Fortran 77 приводится в [162, с. 98], на языке Бейсик см. [184, с. 45]. О поправках Шеппарда см. примечания в разделе «Моменты распределения» данной главы. Пример построения дисперсионно-ковариационной матрицы многомерной выборки (матрицы дисперсий-ковариаций) представлен в разделе «Критерии положительной определенности и полуопределенности» главы 13.
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void)
{
int n = 14; // Численность выборки
double a[] = {65,67.69.70,71,72.72.73,73.78.81.85,86.87}, v2, // Дисперсия
40
Глава 1. Статистики эмпирического ряда
vm: // Ошибка дисперсии
Variance (a,n.&v2.&vm);
cout « "Variance = " « v2 « endl
« "Error = " « vm « endl:
}
void Variance (double *a.int n.double *v2,double *vm) //
// Функция вычисляет параметры дисперсии.
// Обозначения:
// а - исходная выборка.
// п - численность выборки.
// *v2 - дисперсия,
// *vm - ошибка дисперсии.
// Возвращаемое значение:
// нет.
//
{
*v2 = Cov (а.а.п);
*vm = *v2 * sqrt (2 / n);
}
Теперь настало время вычислить доверительный интервал для дисперсии, подобно тому, как мы это сделали для среднего значения. Доверительный интервал означает нахождение истинной дисперсии о2 в интервале с вычисленными границами на выбранном стандартном доверительном уровне р (его следует задать из стандартной линейки, например: 0,90; 0,95; 0,99; 0,999). Доверительный интервал для дисперсии о2 в случае двусторонней гипотезы вычисляется по формуле [111, с. 109], [140, с. 117]
а2е
(и-1)сг2 (п-1)а2
2 ’ 2
_Хи-1.(1+р)/2 Zn-l,l-(l+p)/2 _
где Хи-1,— значение обратной функции (^-распределения, р — стандартное значение доверительного уровня.
Для односторонней гипотезы, в зависимости от ее формулировки, вместо левой или правой границы интервала в показанной формуле будет фигурировать соответственно 0 или +«>, а значение обратной функции (^-распределения будет взято для одностороннего значения:
(У2е 0;
t.(K-l)a2 /л-1,1-р
(J2 G
(я-Do-2.
Описательная статистика
41
Вычисление доверительного интервала дисперсии иллюстрируется показанным ниже примером. По поводу фактических параметров вызываемого из функции Confidencelnterval метода InverseChiSqu-areDistribution см. пояснения в начале главы 4.
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void) {
int n = 20:
double d = 28, // Дисперсия
p = 0.95, // Доверительный уровень для двустронней // гипотезы
Low,High: // Параметр доверительного интервала
Confidencelnterval (n.d,p,l,&Low.&High);
cout « "One side:\n"
« "Confidence interval 1 is [0:" « Low « "]" « endl « "Confidence interval 2 is [" « High « ":+Infinity]" « endl:
Confidencelnterval (n,d,p,2.&Low,&High):
cout « "Two side:\n"
« "Confidence interval is [" « Low « « High «
« endl:
}
void Confidenceinterval (int n,double d.double p.int
Side.double *Low.double *High) //
// Функция вычисления доверительного интервала для дисперсии.
// Обозначения:
// п - численность выборки,
// d - выборочная дисперсия.
// р - стандартный доверительный уровень,
// Side = 1 для односторонней гипотезы,
// =2 для двусторонней гипотезы,
// *Low, *High - границы доверительного интервала.
// Возвращаемое значение:
// нет.
И
{
42
Глава 1. Статистики эмпирического ряда
if (Side == 1)
{
*Low= (n - 1) * d / InverseChiSquareDistribution (n - 1,1 - p):
*High = (n - 1) * d / InverseChiSquareDistribution (n - l,p):
}
el se
{
*Low = (n - 1) * d / InverseChiSquareDistribution (n - 1, (1 + p) / 2):
*High = (n - 1) * d / InverseChiSquareDistribution (n - 1,1 -(1 <- p) / 2);
}
}
Доверительная оценка для среднего квадратичного отклонения рассмотрена в [155, с. 33].
Мы рассмотрели вычисления для случайной величины, измеренной в количественной шкале. Для качественных признаков дисперсию или стандартное отклонение нельзя вычислить по формулам, предназначенным для количественных признаков. Показано [52, с. 125], что в этом случае стандартное отклонение зависит от доли и вычисляется как
а = А/р(1-р).
где вычисление доли р для качественного признака рассмотрено в конце раздела «Среднее значение, математическое ожидание» данной главы.
Среднее отклонение
Среднее отклонение является характеристикой рассеяния, обладающей тем преимуществом перед средним квадратичным отклонением, или размахом, что оно менее чувствительно к изменению формы распределения. Вычисление выборочного среднего отклонения производится по формуле [70, с. 39]
rf=-Zk-xl>
и “7
где все обозначения те же, что и ранее.
Рассматриваемая характеристика применяется довольно редко, поэтому функция, реализующая ее вычисление, нами не приводится. Эта функция может быть легко составлена в силу своей элементар-
Описательная статистика
43
нести, например, на основе функции Gini путем незначительной модификации ее кода.
Решение на языке программирования Бейсик дано в [184, с. 42].
Средняя разность Джини
Средняя разность, введенная Джини [92, с. 74] и применяемая весьма редко, характеризует разброс значений вариант друг относительно друга и не зависит от какого-либо центрального значения, например от среднего значения или медианы. Вычисление выборочной средней разности Джини производится по формуле [там же, с. 334]
где все обозначения те же, что и ранее.
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void) {
int n = 14: // Численность выборки
double a[] = {65,67.69.70.71.72.72,73.73.78.81.85.86,87}, g: // Средняя разность Джини
Gini (a.n.&g);
cout « "Gini = " « g « endl:
}
void Gini (double *a,int n,double *g) //
// Функция вычисляет параметры средней разности Джини
// Обозначения:
// а - исходная выборка,
// п - численность выборки.
// *д - средняя разность.
// Возвращаемое значение:
// нет.
//
44
Глава 1. Статистики эмпирического ряда
{
register int i.j; // Счетчики цикла
*g = 0;
for (i = 0; i < n: i++)
for (j = 0: j < n: j++)
*g += fabs (a[1] - a[j]);
* g /= n * (n - 1); }
Асимметрия
Асимметрией (выборочным коэффициентом скошенности, skewness) называют меру отклонения эмпирического распределения частот от симметричного распределения относительно максимальной ординаты [140, с. 11]. Отрицательный показатель асимметрии означает скошенность кривой распределения влево, положительный — вправо от теоретической симметричной кривой распределения. Для симметричного распределения асимметрия равна нулю. Асимметрия обычно вычисляется как основной момент (см. ниже) третьего порядка г3; приведем также и формулу вычисления ошибки [84, с. 55]:
А = г3, тА^ =
f 6
и + 3
Асимметрия находит применение в различных способах оценки отклонения распределения от нормальности.
Подробные рассуждения и вывод даны в [92, с. 124]. Обсуждение см. также [26, с. 27], [50, с. 30], [72], [89, с. 93].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void)
{
int n = 28; // Численность выборки
double a[] = {45.30.23,56.78,65.67.47,23,69,70.71.72,72,
73.73,78,81,85.86,87,90.93,96,70.73.60,56}. as, // Асимметрия
Описательная статистика
45
ma: // Ошибка асимметрии
Skewness (a.n.&as.&ma);
cout « "Skewness = " « as « endl « "Error = " « ma « endl;
}
void Skewness (double *a,int n,double *as.double *ma) //
// Функция вычисляет параметры асимметрии.
// Обозначения:
// а - исходная выборка,
// п - численность выборки,
// *as - асимметрия,
// *та - ошибка асимметрии.
// Возвращаемое значение:
// нет.
//
{
double xm: // Рабочая переменная
///////////////////////
// Среднее квадратичное
* as = sqrt (Cov (a.a.n)):
///////////////////////
// Параметры асимметрии
* as = Moment (3,a,0,&xm,n) / *as / *as / *as;
* ma = sqrt (6.0 / (n + 3));
}
Эксцесс
Степень отклонения эмпирической кривой распределения от теоретической кривой нормального распределения количественно выражается показателем эксцесса (выборочным коэффициентом островершинности, kurtosis) [140, с. 11]. Положительный эксцесс соответствует островершинной кривой эмпирического распределения (заостренной), отрицательный — туповершинной (пологой) по сравнению с нормальной кривой. Эксцесс и его ошибка вычисляются по формулам [84, с. 57]:
Е = г4 - 3, тЕ-2т -2./—^— , Е А Ъ+з
где г4 — основной момент четвертого порядка.
46
Глава 1. Статистики эмпирического ряда
Более точные, несмещенные оценки показателя эксцесса и его ошибки вычисляются, соответственно, как
г_ л2-1 (г 6 1
Е (п-2)(п-3)[(Г4 > я+1]’
24у?(п—I)2
Шг — ।-------------------- .
у (п - 3)(и - 2)(и+3)(и+5)
Эксцесс находит применение в различных способах оценки отклонения распределения от нормальности.
Обсуждение см. также в [26, с. 28], [50, с. 31], [72].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void)
{
int n - 28; // Численность выборки
double a[] - {45.30.23.56.78.65.67,47,23,69.70.71.72,72.
73.73,78.81.85.86.87.90.93.96.70,73.60.56}.
es. // Эксцесс
me; // Ошибка эксцесса
Kurtosis (a.n.&es.&me);
cout « "Kurtosis " « es « endl « "Error - " « me « endl;
}
void Kurtosis (double *a.int n,double *es.double *me)
//
// Функция вычисляет параметры эксцесса.
// Обозначения:
// а - исходная выборка,
// п - численность выборки,
// *es - эксцесс,
// *те - ошибка эксцесса.
// Возвращаемое значение:
// нет.
Описательная статистика
47
{
double xm; // Фиктивная переменная
/////////////////////
// Параметры эксцесса
*es = Moment (4,а,0,&xm,n) / Cov (a,a,n) - 3;
*me = 2.0 * sqrt (6.0 / (n + 3));
}
Коэффициент вариации
Коэффициент вариации представляет собой характеристику рассеяния распределения вероятностей случайной величины [135, с. 101]. В зависимости от применяемой формулы вычисления [там же] он показывает, какую долю или какой процент составляет среднее квадратичное отклонение от среднего значения. Коэффициент вариации имеет важное значение для установления степени выровпенности совокупности по тому или иному признаку. Он также применяется при проверке репрезентативности (достаточности объема) выборки. Коэффициент вариации и его ошибка вычисляются по формулам [111, с. 50]:
й = • 100%. тд = &J-0-jt.9:0001 1?Z X \ п
Коэффициент вариации может быть вычислен в абсолютных величинах [63, с. 31]. В этом случае используется обозначение Cv.
Обсуждение см. также в [26, с. 25], [84, с. 39], [70, с. 233, 245]. [89, с. 89], [155, с. 22].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h”
void main (void)
{
int n = 14; // Численность выборки
double a[] = {65.67.69,70,71.72.72.73.73.78.81.85.86,87}. cv, // Коэффициент вариации cm; // Ошибка коэффициента вариации
CoeffOfVariance (а.n.&cv.&cm);
48
Глава 1. Статистики эмпирического ряда
cout « "Coefficient of variance = " « cv « endl « "Error = " << cm « endl;
}
void CoeffOfVariance (double *a,int n,double *cv.double *cm) //
// Функция вычисляет параметры коэффициента вариации.
// Обозначения:
// а - исходная выборка.
// п - численность выборки.
// *cv - коэффициент вариации,
// *ст - ошибка коэффициента вариации.
// Возвращаемое значение:
// нет.
//
{
*cv = sqrt (Cov (a.a.n)) / VectorSum (a.n) * n * 100:
*cm = *cv * sqrt ((0.5 + 0.0001 * *cv * *cv) / n);
}
Доверительный интервал для коэффициента вариации можно вычислить по формуле [111, с. 109], используя принятые обозначения:
1 + к71+2См 1 - к/ +2С„
Показатель точности опыта
Показатель точности опыта [84, с. 37], иначе — показатель точности определения среднего значения [111, с. 105], выражает величину ошибки среднего значения в процентах от самого среднего. Точность считается удовлетворительной, если величина показателя не превышает 5%, а при значениях, больших 5%, рекомендуется увеличить число наблюдений или повторений. Иногда величину показателя точности можно уменьшить, если повысить точность измерений параметров объектов опыта. Показатель точности опыта и его ошибка вычисляются по формулам [там же]:
Р = ^-100%, X
тр=р.ц~ + р \2п
р Y юо
Описательная статистика
49
Очевидно, показатель точности определения среднего — это именно то, что имеют в виду исследователи, указывая в публикациях после М±т через запятую, к примеру, выражениеР< 0,05, называя его достоверностью, хотя это определение в данном случае не совсем верно.
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void) {
int n = 14; // Численность выборки
double a[] = {65.67.69.70.71,72.72.73.73,78.81,85.86,87}. cs. // Показатель точности ms: // Ошибка показателя точности
Sharp (a.n.&cs.&ms):
cout « "Sharp = " « cs « endl « "Error = " << ms « endl:
}
void Sharp (double *a,int n,double *cs.double *ms) //
// Функция вычисляет параметры показателя точности.
// Обозначения:
// а - исходная выборка, // п - численность выборки, // *cs - показатель точности.
// *ms - ошибка показателя точности.
// Возвращаемое значение:
// нет. //
{
double sm, // Среднее mm: // Ошибка среднего
И НН НИ Н Среднее SampleMean (a,n,&sm.&mm):
IIIIIIHIIHIIIIIIIH
Н Параметры точности
*cs = mm / sm * 100:
*ms = *cs * sqrt (0.5 / n + *cs * *cs / 10000): }
50 Глава 1. Статистики эмпирического ряда
Минимум, максимум и размах выборки
Минимальная xmin (minimum) и максимальная xmax (maximum) варианты выборки могут быть получены [100, с. 180] соответственно с помощью функций MinimumOf и MaximumOf.
Размах выборки (размах вариации, амплитуда ряда) — разность между максимумом и минимумом вариант выборки [92, с. 67] — дается формулой
— -Tnax ~ “^min*
Для вариационного ряда Xv..., X размах выборки W запишется как [135, с. 513]
Wn = Хп -X., Хп = тахХ,, X. = minX.. ” п 1 п l<k<n k 1 1<*<Л к
Функция распределения выборочного размаха рассмотрена в главе 4. Обсуждение см. также в [89, с. 29], [111, с. 45], [120, с. 27].
Для дискретных случайных величин, возникающих, например, при цифровом анализе графических изображений, размах определяется как [232, с. 103]
R = 1.
где — максимальное значение уровня, /zmin — минимальное значение уровня.
Так, например, для полутонового изображения, имеющего 256 уровней, от 0 до 255, максимальный размах может составить 256.
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include "megastat.h"
void main (void)
{
int n = 7; // Число вариант
double x[] = {23,35,27.29,28,25,30}:
cout « "Range = " « Range (x.n) « endl
}
double Range (double *x,int n)
//
Описательная статистика
51
// Функция вычисляет размах непрерывной случайной величины.
// Обозначения:
// х - исходная выборка,
// к - численность выборки.
// Возвращаемое значение:
// значение размаха.
И
{
return MaximumOf (x.n) - MinimumOf (x.n):
}
Для вычисления размаха дискретной случайной величины показанная функция может быть легко доработана. Функция распределения размаха выборки из нормальной совокупности рассмотрена в главе 4. Там же указана вся необходимая библиография.
Моменты распределения
Моментами распределения [84, с. 42] называют средние значения степеней отклонений вариант выборки:
• от среднего значения х, тогда моменты называются центральными и обозначаются Hk ,k = 1,2, 3, 4;
• произвольного числа С (например, медианы), тогда моменты называются условными и обозначаются mk, k = 1,2,3,4;
• нуля, тогда моменты называются начальными и обозначаются bk,k = 1,2, 3,4.
Условные и начальные моменты иначе называются нецентральными. Общие формулы определения моментов распределения даны в [ 155, с. 21 ], [ 158, с. 88]. Порядок момента равен степени k, в которую возводятся отклонения. На практике моменты порядка выше 4 используются редко.
Формулы вычисления оценок моментов по выборкам можно записать как [84, с. 43]
£(*,-*)* Yxi
1 1 1 «• 1
Если моменты вычисляются не по исходным данным, а по частотам распределения, под знаками суммы в показанных выше формулах необходимо добавить величины V,, а суммирование производить по числу классовых интервалов. Все остальные параметры — без изменений [там же, с. 43].
52
Глава 1. Статистики эмпирического ряда
Отметим, что а2 = <?2 — смещенная оценка дисперсии, Ьх = х — среднее арифметическое, а величины типа
г
s'
называются основными моментами порядка k. Основной момент порядка 3 является коэффициентом асимметрии, а основной момент порядка 4 нужен для вычисления эксцесса. Эксцесс и асимметрия рассмотрены в одноименных разделах настоящей главы.
При численности совокупности более 500 необходимо ввести поправки на длину интервала (поправки Шеппарда) [84, с. 45], [92, с. 72], [111] к начальным и центральным моментам. При этом должно соблюдаться условие близости распределения к симметричному [49, с. 83]. Обсуждение см. также в [33, с. 23]. Многомерные моменты распределения рассмотрены в [231, с. 97].
Исходные коды
double Moment (int index.double x[],int sw.double *xm,int n) //
// Функция вычисления момента распределения.
// Обозначения:
// index - порядок момента распределения.
// х - исходная выборка.
// sw - тип момента распределения:
// sw = 0 - вычисляется центральный момент.
//задавать *хт не нужно,
// sw = 1 - вычисляется условный момент, задать *хт = С,
// вычисляется начальный момент, задать *хт = 0.
// *хт - вычисляемое значение среднего (при sw = 0),
// п - численность выборки.
// Возвращаемое значение:
// значение момента распределения.
//
{
register int i,j; // Счетчики
double s = 0, // Начальное значение суммы
temp: // Вспомогательная величина
//////////////////////
// Вычисление среднего
if (sw == 0)
*xm = VectorSum (x.n) / n;
/////////////////////
// Вычисление момента
Вариационная статистика
53
for (i = 0; i < n; i++)
{
temp = x[t] - *xm:
for (j = 1; j < index; j++) temp *= x[i] - *xm;
s += temp;
}
return s / n; }
Вариационная статистика
Исчисление числовых и функциональных характеристик эмпирических распределений называется вариационной статистикой [ 135, с. 101 ]. Есть и другое определение данного термина. Так, часто используемый диссертантами по медико-биологической тематике термин «вариационная статистика» означает просто «статистика» [111, с. 7]. Слово «вариационный» в этом случае не имеет отношения к вариационным рядам, а является прилагательным от «варианта». По причине многочисленных трактовок и из-за того, что термин «вариационная статистика» стал штампом1, мы настоятельно не рекомендуем им пользоваться во втором смысле.
Варианты выборки могут быть отсортированы в порядке неубывания. По определению [135, с. 106], упорядоченный таким образом ряд называется вариационным и служит основой для построения методов вариационной статистики и эмпирических функций статистических распределений. Вариационный ряд может быть получен из исходной эмпирической выборки путем применения функции Sort Array Up.
Некоторые авторы [80, с. 83] выделяют три формы вариационных рядов:
• Ранжированный ряд — это собственно вариационный ряд, то есть ряд вариант, упорядоченный по неубыванию. Полученный таким образом ряд называют также порядковой статистикой [28, вып.2, с. 136], но этот термин крайне неудачен (имеется термин «порядковая шкала», означающий нечто совершенно иное) и в таком качестве нами применяться не будет. В смысле применяемой шкалы измерения вариационный (ранжированнный) ряд может быть получен как из порядковых, так и из количественных выборок.
Мифический «метод вариационной статистики».
54
Глава 1 Статистики эмпирического ряда
• Дискретный ряд.
• Интервальный ряд.
Два последних вариационных ряда представляют собой таблицы распределения количеств вариант по классам и различаются тем, что в первом случае количества относятся к определенным, возможно нечисловым, значениям признаков, а во втором случае — к интервалам изменения признака (классовым интервалам). Некоторые авторы в этом случае предпочитают говорить о группировке исходных данных [89, с. 19], и это очень хорошее определение, верно отражающее суть процесса. В упомянутом источнике дается подробное введение в проблему относительно медицинских данных, но выводы могут быть применены и к исходным данным любого другого происхождения.
Интервальные вариационные ряды могут дополнительно подразделяться на прерывные (в случае, когда величина варьирующего признака может принимать только целые значения) и непрерывные (в случае, когда варьирующий признак может принимать любые целые и дробные значения) [там же, с. 30].
Дискретный вариационный ряд, очевидно, возникает там, где анализируются некоторые качественные, но логически упорядоченные, а также порядковые признаки. Дискретный и интервальный вариационные ряды, иначе — просто ряды распределения [111, с. 26], используются нами там, где методы расчета оперируют эмпирическими частотами распределения признаков. Эти вариационные ряды служат основой для одного из методов построения функций эмпирических распределений.
Там, где говорится о вариационных рядах, если не оговорено иное, мы будем иметь в виду дискретный или интервальный вариационный ряд, в зависимости от контекста. Из смысла излагаемой методики всегда понятно, о каком ряде идет речь.
Параметры классовых интервалов
Для практического построения интервального вариационного ряда прежде всего необходимо определить число классов (групп, интервалов) k. Субъективным критерием правильности выбора числа классов является верная передача типа распределения эмпирических частот данной совокупности. Если выбрано слишком мало классов, можно потерять характерную картину эмпирического распределения. При слишком подробном делении на классы можно затуше
Вариационная статистика
55
вать реальную картину распределения частот случайными отклонениями. Авторы обычно выделяют несколько способов вычисления числа классов для выборок умеренных размеров. Так, способ экспертной оценки (эмпирическое правило) предлагает брать
k = 12 ±3
либо от 10 до 20 [135, с. 345]. Эмпирические правила даны в [72, с. 19], [106, с. 211], [111, с. 28], [206, с. 346]. Нами обычно применяется правило Стержесса (Стургеса) [84, с. 318]:
k = 3,321g?? + 1 = l,441n?2 + 1,
где п — численность совокупности.
Сводка основных рекомендаций по выбору числа интервалов группировки дана в [156, с. 31]. О правиле Стержесса см. также в [80, с. 85], [111, с. 28], [155, с. 35]. В некоторых источниках (например, [187, с. 295], [206, с. 346]) дается практическое правило, что если число наблюдений в классе окажется меньше четырех или пяти, следует объединять его с соседним классом. Следствием будут различные величины классовых интервалов. Это неудобно, но для некоторых методов, таких как критерий X , такой прием является необходимым. Проблемы объединения классовых интервалов подробно рассмотрены в [70, с. 23], [167, с. 604].
Исходные коды
1 nt Sturgess (int n) //
// Функция определения числа классовых интервалов
// по правилу Стержесса.
// Обозначения:
// п - численность выборки вариант.
// Возвращаемое значение:
// число классовых интервалов.
//
{
double s = п: // Возвращаемое значение
s = 1.44 * log (s) + 1: /////////////////////// // Эмпирическое правило if (s > 15)
s = 15:
return (int) floor (s); }
56
Глава 1. Статистики эмпирического ряда
Исходя из найденного числа классов определяются величины интервалов группировки, которые обычно берутся равными и рассчитываются по формуле [ 111, с. 28]
d = R / k,
где d — величина интервала группировки,
R — размах выборки,
k — число классов — определено выше.
Величину d называют также шириной классового интервала, просто классовым интервалом или длиной интервала группировки [205, с. 48]. Другая формула определения длины интервалов группировки, отличающаяся от показанной множителем 1,02, приводится в [156, с. 31], причем рассмотрение параметров классовых интервалов плавно перетекает в обсуждение группировки (разбиения выборки по интервалам, гистограммирования).
Если классовые интервалы выбираются различными, z-й классовый интервал
= xf - xf_p i = 1,2,..., k,
гдех, i = 0,1, 2,..., k, — границы классовых интервалов.
Напомним, что все изложенное здесь относилось к количественным признакам. Однако классификация объектов может быть проведена и по качественному признаку [135, с. 344] либо порядковому признаку. При этом, естественно, не имеют смысла понятия величины классового интервала, границ классового интервала и т. п.
Группировка
Под группировкой (классификацией, разнесением вариант по классам) понимается некоторое разбиение интервала, содержащего все п наблюдавшихся вариант хр..., х, на k интервалов, число которых определено нами в предыдущем разделе, с последующим разнесением вариант совокупности по интервалам [205, с. 45]. Для случая количественной шкалы измерения число наблюдений v., i = 1,..., k, попавших в г-й класс, означает количество наблюдений, удовлетворяющих неравенству
ti-di/2<x < ti + di/2,i = 1,2,...,^,
где t, i = 1,2,..., k, — середины классовых интервалов.
Вариационная статистика
57
Группировка для применяемых алгоритмов может производиться вручную с помощью показанной выше формулы. Автоматически группировка может быть выполнена с помощью функции Allocate. Особенностью функции является то, что она вычисляет классовые интервалы равной ширины. Кроме того, для компенсации ошибок округления функция применяет несколько иную формулу, чем показанная выше. Впрочем, эти особенности только помогают функции показывать стабильные результаты. Помимо численностей вариант, разнесенных по классам, функция выдает середины классовых интервалов. Для анализа иногда удобнее иметь границы классовых интервалов. Их несложно получить, если с помощью двух соседних значений середин классовых интервалов вычислить ширину классового интервала и отнять ее половину от значения середины первого интервала. Каждая последующая граница будет получена прибавлением ширины классового интервала.
Обсуждение см. в [111, с. 28]. Из широко распространенных в данное время программных продуктов с задачей группировки справляются электронные таблицы Microsoft Excel. Для этого надо выбрать в меню Сервис ► Пакет анализа ► Гистограмма (компонент Пакет анализа должен быть установлен) и следовать указаниям мастера, причем разбиение на классы может быть выполнено как вручную (явно задается так называемый интервал карманов, представляющих собой границы классов), так и автоматически. Отметим, что представленная нами функция Allocate автоматически вычисляет интервалы (выводятся середины интервалов), но также может быть легко трансформирована как на ручное задание границ классов, так и на задание начала первого класса и ширины классового интервала, в зависимости от пожеланий исследователей.
Как отмечено в предыдущем разделе, группировка может быть выполнена и по порядковым признакам. В этом случае понятия величины и границ классового интервала не имеют смысла, а упорядоченность признаков дает очевидное правило классификации.
Исходные коды
#include <fstream.h>
#include <iomanip.h>
#include "megastat.h"
void main (void) {
int k = 5, // Число классов
n: // Число вариант
58
Глава 1. Статистики эмпирического ряда
double х[] = // Массив вариант
{1,2,3,4,5,6,7,8,9.1,1.7,3,4,5,6,7,2,3,4,5,6,2},
*f, // То же по классам
*Ь, // середины классов
sum = 0: // Контрольное число
n = sizeof (х) / sizeof (х[0]);
f = new double [kJ;
b = new double [k];
Allocate (x,n,f,b,k);
cout « "Attempt to allocate sample of " « n « " members into " « k « " classes\n";
for (register int i = 0; i < k; sum += f[i++J)
cout « setw (10) « b[i] « setw (10) « f[i] « endl: cout « "Total allocated “ « sum « " membersXn";
delete [] f; delete [] b:
}
void Allocate (double datafj.int n.double f[],double b[],int k) //
// Функция разнесения вариант по классам.
// Обозначения:
// data - исходная выборка,
// п - численность выборки,
// f - вычисляемый массив вариант, разнесенных по классам.
// b - массив середин классов,
// к - число классов.
// Возвращаемое значение:
// нет.
//
{
register int i.j; // Счетчик цикла
double t,c; // Вспомогательная переменная
//////////////////
// Минимум выборки
t = MinimumOf (data.n):
t-t >0 ’ t * 0.99 : t * 1.01;
///////////////////
// Максимум выборки
с = MaximumOf (data.n);
C=C>O?C* 1.01 : c * 0.99;
////////////////////////////////
// Половина классового интервала
Вариационная статистика
59
с = (с — t) / к / 2;
////////////////////////////////////// // Массив середин классовых интервалов b[0] = t + с;
f[0] = 0;
for (1=1; 1 < k; 1++)
{
b[i] = b[i - 1] + с + с:
f[i] = 0;
}
////////////// // Группировка for (1=0; 1 < n; 1++) for (j = 0; j < k; j++) if (datafi] > b[j] - c && data[i] <= b[j] + c) {
f[j]++; break;
}
}
Функция Allocate предназначена для применения в методиках, которые предусматривают анализ одной выборки. При совместном разнесении по классам вариант двух эмпирических рядов с целью, например, сравнения эмпирических распределений двух совокупностей, было бы не совсем верным строить интервальный вариационный ряд отдельно для каждого эмпирического ряда. Если принято, что для сравниваемых вариационных рядов должны быть одинаковыми классовые интервалы1, для разнесения вариант по классам необходимо применять показанную ниже функцию AllocateCommon, в качестве формальных параметров которой нужно кроме самих эмпирических рядов задать также и число классов, которое должно быть вычислено или выбрано заранее с помощью одной из рассмотренных методик. Применение функции AllocateCommon гарантирует, что построенные интервальные вариационные ряды будут иметь одинаковые интервалы. Эмпирические выборки могут иметь разные численности, поэтому число классов можно выбрать по одному, например меньшему, из эмпирических рядов.
Исходные коды
void AllocateCommon (double х[],double у[],double fx[],double fy[],double b[],1nt nx.int ny.int k)
‘ Если принята иная точка зрения, можно применить функцию Allocate для каждой из сравниваемых совокупностей в отдельности.
60
Глава 1. Статистики эмпирического ряда
//
// Функция совместного разнесения вариант двух выборок по
// классам.
// Обозначения:
// х - первая выборка,
// у - вторая выборка,
// fx - разнесенные варианты первой выборки,
// fy - разнесенные варианты второй выборки,
// b - вычисленные середины классовых интервалов.
// пх - численность первой выборки,
// пу - численность второй выборки,
// к - заданное число классов.
// Возвращаемое значение:
// нет.
//
{
register int i.j; // Счетчик цикла
double с. // Величина классового
// интервала и рабочая переменная max = MaximumOf (x,nx), // Начальные значения минимума min = MinimumOf (x,nx); // и максимума
////////////////////////////////// // Вычисление минимума и максимума if ((с = MaximumOf (y.ny)) > max) max = с;
if ((с = MinimumOf (y.ny)) < min) min = c:
///////////////////////////////////////////////////////////// II Раздвигаем границы на It для компенсации ошибок округления max = max > 0 ? max * 0.99 : max * 1.01:
min = min > 0 ? min * 1.01 : min * 0.99;
//////////////////////////////// // Величина классового интервала с = (max - min) / k;
////////////////////////////////////// // Массив середин классовых интервалов b[0] = min + с / 2;
for (i = 1: i < k: i++)
b[i] = b[i - 1] + c:
//////////////
// Группировка
FillUp (fx.k.O):
FillUp (fy.k.O):
for (i = 0: i < nx; i++)
for (j = 0: j < k; j++)
if (b[j] - c / 2 <= x[i] && b[j] + c / 2 >= x[i])
Вариационная статистика
61
{
fx[j] += 1: break;
}
for (i = 0; i < ny; 1++) for (j = 0; j < k; j++) if (b[j] - c / 2 <= y[i] && b[j] + c / 2 >= y[i]) { fy[j] += 1: break;
} }
Функции эмпирического распределения
Теоретической функцией распределения случайной величиных называется функция действительного вещественного аргумента, задаваемая как [63, с. 24]
F(x) = P(t < х).
Эмпирической функцией распределения (функцией распределения выборки, выборочной функцией распределения) называют функцию F (х), определяющую для каждого значения х частотное распределение эмпирической выборки, то есть долю событий X < х [54, с. 191,120, с. 48]:
Г„(*) = «,/«.
где пх — число вариант, меньших, чем х, п — общее число вариант эмпирической выборки.
Величины пх называются накопленными (кумулятивными) абсолютными частотами [205, с. 46], а величины пх/п называются накопленными (кумулятивными) относительными частотами. Накопленная относительная частота иногда называется также интенсивностью и может выражаться в процентах [89, с. 51]. Соответственно, график F (х) называется полигоном накопленных частот [155, с. 35], [70, с. 29] и изображается в виде ступенек. В стандартных электронных таблицах нам не встречались графики подобного типа, поэтому наиболее близким по типу графиком можно считать гистограмму с нулевыми промежутками между колонками. Изображение данного графика в виде ломаной (а тем более кривой) линии не является верным, так как ломаная линия предполагает как наличие значений между точками излома, так и непрерывность функ
62
Глава 1. Статистики эмпирического ряда
ции в этих точках излома, что математически соответствует разрывам в производной функции. Ведь даже для больших значений п, во-первых, отсчет абсциссы практически будет производиться дискретно, а во-вторых, значение пх является целым. Поэтому на самом деле график Fn(x) представляет собой линию с разрывами на границах ступенек и параллельными оси абсцисс сегментами между ступеньками, пусть даже степенек будет много, что математически соответствует разрыву в самой функции на границах сегментов.
Свойства
Обсуждение свойств теоретической функции распределения дано в [70, с. 55], [135, с. 519, 654], [140, с. 9] (свойства относятся и к эмпирической функции распределения):
1. Р(хх) < F(x2) при Xj < х2
2. lim F(x) = 0,limF(x) = l.
Кроме того, теоретическая функция распределения непрерывна слева при каждом х.
Корень Xq уравнения
P(t X,) = F(X,) = q
называется выборочной квантилью (долевой точкой) порядка q функции распределения F(x) [101, с. 538], [140, с. И], [205, с. 63]. Поэтому, как было показано выше, квантиль X называется выборочной медианой. Квантили порядка У\, У2 и \ называются выборочными квартилями [там же, с. 64], 10%-, 20%-,..., 90%-квантили называются децилями, а 1%-, 2%-,..., 99%-квантили — процентилями [там же]. О долевых точках см. также [ 167, с. 404], о процентилях см. [52, с. 35], о квантилях и процентных точках см. [155, с. 15].
На практике различают дискретные и непрерывные распределения случайных величин [158, с. 83]. Говорят, что случайная величина X имеет дискретное распределение, если она может принимать лишь счетное (возможно, конечное) число различных значений х [63, с. 24]. Функцией распределения вероятностей при этом называют функцию
/(х) = Р(Х = х).
Для дискретной случайной величины имеют место свойства:
Вариационная статистика
63
1. P(X<r) = £Pj. i=0
2. P(r<X<s)= .
i=r+l
з. ip.=i.
»=0
Для непрерывной случайной величины существует неотрицательная функция /(х) — плотность вероятности (плотность распределения вероятностей [63, с. 25] пли просто плотность распределения), а рассмотренные выше свойства запишутся, соответственно, как:
1. P(X<x)=F(x)=
b
2. Р(а< X<b) =J f(t)dt=F(b)-F(d). a
3. =
Свойства дискретных случайных величин и распределений обсуждаются в [70, с. 67], [205, с. 86]. Свойства непрерывных случайных величин и распределений обсуждаются в [70, с. 70], [205, с. 83]. Нужно учитывать, что в практических вычислениях все функции распределения независимо от типа распределения являются рядами скалярных величин [101, с. 538].
Теоретическая плотность эмпирического распределения, соответствующая эмпирической плотности эмпирического распределения f(t), вычисленной по выборке, обозначается как F(t). Пример вычисления теоретической плотности эмпирического распределения дан в конце раздела «Теоретические и эмпирические распределения» главы 4.
Ниже показана сводная таблица, содержащая формулы для вычисления характеристик эмпирического распределения случайных величин (табл. 1.2). Формулы строки 2 прямо вытекают из введенных выше свойств 3 дискретной и непрерывной случайных величин, а именно: для дискретной случайной величины единице равна сумма вероятностей, для непрерывной же случайной величины
64
Глава 1. Статистики эмпирического ряда
единице равна площадь под кривой плотности распределения, поэтому для непрерывного распределения необходимо умножение знаменателя на размеры классовых интервалов, которые могут быть одинаковыми или различными (как показано в таблице) для разных классов. Обсуждение проблемы см. [205, с. 47] и, особенно, выделенное курсивом замечание [там же, с. 48]. О подборе типа теоретического распределения к представленным эмпирическим данным см. [98, с. 29].
Разнесенные по классам варианты эмпирического ряда называются абсолютными частотами распределения (групповыми частотами или просто частотами) [70, с. 54], [101, с. 537] либо численностями отдельных классов [135, с. 344]. Компоненты эмпирического ряда эмпирического распределения называются относительными частотами эмпирического распределения (частостями) [135, с. 344], [155, с. 7], [33, с. 44] и представляют собой в пределе вероятности наступления события [70, с. 54], так как близость частости случайного события к вероятности этого события позволяет по результатам наблюдения принимать частость в качестве статистической оценки (приближенного значения) вероятности [135, с. 628], [155, с. 7]. Поэтому выборочные эмпирические частоты распределения обозначаются некоторыми авторами через р(х). Предельные свойства подробно обсуждаются в [70, с. 55]. [205, с. 8] указывает, что слово «частота», если не оговорено иное, обычно означает относительную частоту, однако удобнее частотой называть абсолютную частоту распределения, а относительную частоту именовать частостью, что мы и намерены делать в дальнейшем. Не следует также путать введенные в начале текущего абзаца характеристики с рассмотренными выше накопленными (кумулятивными) абсолютными и относительными частотами.
График частот v, i = 1,2,..., k, изображается в виде гистограммы или многоугольника (полигона частот) с вершинами в точках, соответствующих срединным значениям интервалов и частотам [70, с. 28], [205, с. 47], а график/(х) изображается в виде гистограммы, на которую может накладываться график функции f'(x) в виде непрерывной кривой или отдельных точек, в зависимости от типа теоретического распределения. Мы не разделяем мнения источников, что график частот может быть построен в виде полигона, ибо соединение двух соседних точек графика отрезком прямой линии должно предполагать, что между этими точками существуют какие-то значения аргумента и функции, однако на самом деле это не так. Правильнее гистограмму непрерывного распределения изображать
Вариационная статистика
65
в виде столбиковой диаграммы (частота вычисляется как площадь), а гистограмму дискретного распределения — в виде точечного или линейчатого графика (частота есть точка на графике).
Подробное обсуждение дано в [44, с. 136]. Программные реализации методики построения диаграмм не слишком сложны. Методика построения гистограммы на примере гистограммы изображения, включая исходные тексты на языке С, представлена в [121, с. 321]. Основные понятия, включая нормализацию данных, рассмотрены в [230, с. 299], [185, с. 19]. См. также [106, с. 211].
Таблица 1.2. Эмпирические и теоретические характеристики распределений случайных величин
Ns ! Характеристика Распределение Дискретное Непрерывное
1 Частоты v i = 1,2,..., k Варианты эмпирического ряда разнесены по к классам. В каждый класс, таким образом, попало 1/, i =1,2,.... k вариант. Общее количество вариант совокупности i=l
2 Частости /(х) ft = nJ п, = nj(nd),i = 1,2 k i = 1,2, ...,Л
3 Функция плотности теоретического распределения f\x) Вычисляется по формуле частот теоретического распределения, выбранного на основании теоретических предположений
4 Эмпирическая функция эмпирического распределения F (х) ,*ч II 1М' III N5
5 Теоретическая функция эмпирического распределения F(x) F VP Вычисляется по формуле, Л ~ L Ji аналогичной предыдущей строке, где за величины г = 1,2,..., k V,, i = 1,2 k, берутся соответствующие величины теоретического ряда
Для некоторых методов анализа может потребоваться выполнение обратных вычислений. Так, чтобы получить теоретическую функцию дискретного распределения F' (х), необходимо по теоретиче-
3-2002
66
Глава 1. Статистики эмпирического ряда
ской плотности распределения путем использования обращенных формул строки 2 табл. 1.2 получить теоретический ряд частот распределения как
v, = nfv i =1,2,k.
Обсуждение см. в [180, т.1, с. 89].
Способы построения
Практически эмпирические функции эмпирического распределения (далее — функции распределения) могут быть построены двумя способами:
1 Способ построения функции распределения, исходя из частот распределения, основан на применении формулы строки 4 табл. 1.2. Задавшись некоторыми классовыми интервалами (чаще всего — равными), производят разнесение вариант исходной выборки по классам. Поделив попавшее в каждый класс число вариант на численность выборки, строится массив частостей, последовательное суммирование элементов которого дает искомый массив функции распределения. Таким образом, численность массива функции распределения равна числу классовых интервалов, а графически данный массив представлен в виде ступенчатого неубывающего графика, по оси абсцисс которого отложены середины классовых интервалов, причем в случае равных классовых интервалов отложены равномерно, а по оси ординат — значения элементов массива, находящиеся в интервале от 0 до 1. В стандартных электронных таблицах близким к данному типом графика является «Гистограмма». Способ применяется, если объем данных достаточно велик, чтобы построенная функция верно отражала характер распределения. Наиболее просто функция распределения данным способом вычисляется с помощью электронных таблиц Microsoft Excel путем выбора из меню программы: Сервис 4 Пакет анализа 4 Гистограмма 4 Интегральный процент, затем последнее отобразить в обычном числовом формате. Некоторые авторы дают минимально допустимую численность выборки для обоснованного применения данного способа, составляющую 100 и более вариант.
2. Способ построения функции распределения, исходя из исходной выборки, основан на непосредственном примении формулы определения функции распределения, данной в начале параграфа. Упорядочив исходную выборку по возрастанию, сразу присту-
Ранжирование
67
пают к построению массива функции распределения и графика. Выборку упорядочивают по возрастанию. Затем по оси абсцисс откладывают значения вариант, по оси ординат — числа, представляющие собой отношения номеров вариант упорядоченной выборки к численности выборки. Таким образом, численность построенного массива функции распределения равна численности исходной выборки, а графически данный массив также представлен в виде неубывающего ступенчатого графика, в отличие от предыдущего случая ординаты которого (при наличии совпадений ступеньки будут более высокими) расположены равномерно, а абсциссы соответствуют упорядоченной исходной выборке. В стандартных электронных таблицах близкого типа графика нам не встречалось. Способ может применяться для выборок практически любой численности, а для малых выборок является единственным способом получить функцию распределения для дальнейших расчетов, например для вычисления статистик типа Колмогорова—Смирнова.
Часто нужно получить две сопоставимые между собой функции распределения с целью их совместного анализа. Относительно второго способа трудности могут быть только в организации вычислительной процедуры — других проблем мы не видим. В первом же способе массивы функций распределения могут быть получены после совместного разнесения по классам вариант сравниваемых совокупностей1, например, с помощью функции AllocateCommon. Если функции распределения вычисляются с помощью электронных таблиц Microsoft Excel и функции распределения будут применяться для вычисления критерия Колмогорова—Смирнова, границы классов (Интервал карманов) нужно задать одинаковыми для сравниваемых выборок.
Ранжирование
С рассмотренными в предыдущем разделе процедурами построения вариационных рядов не следует путать процедуры присвоения рангов наблюдениям (ранжирования). Функции ранжирования находят широкое применение при реализации статистических методов проверки гипотез. Рангом наблюдения [187, с. 43] называют номер, который получит это наблюдение в совокупности всех данных после их упорядочивания по определенному правилу, например от меньшего к большему.
1 См. сноску в описании функции AllocateCommon.
з*
68
Глава 1. Статистики эмпирического ряда
При равенстве стоящих рядом вариант упорядоченной (отсортированной) выборки в зависимости от требований алгоритма вариантам выборки, как правило, присваиваются средние ранги, хотя эта операция вряд ли корректна — просто так условились. Дело в том, что ранги представляют собой величины, измеренные в порядковой шкале. Для количественных величин процедура ранжирования понижает исходную шкалу до порядковой (если исходные данные были измерены в порядковой шкале, понижения шкалы при ранжировании не происходит), а в порядковой шкале операции сложения и деления, применяемые при подсчете средней величины, не определены [187, с. 302].
Вычисление поправки на объединение рангов производится по формуле [37, с. 243]
g r=w-l). i=l
где£ — число групп совпадений, так называемых связок, — число совпадений в i-й связке.
Это очень важный параметр, применяемый в уточненном расчете статистических тестов. См. также [180, 124], [187, с. 123].
Исходные коды
double Rank (double х[].double xx[].int n) //
// Функция ранжирования.
// Обозначения:
// х - исходная выборка.
// хх - массив рангов.
// п - численность выборки.
// Замечание:
// Для получения верного результата выборка должна быть
// отсортирована по возрастанию, например функцией
// SortArrayUp.
// Возвращаемое значение:
// поправка на объединение рангов.
//
{
register int j: // Счетчик
int is. // Количество равных элементов
ii. // Рабочая переменная
i = 1; // Текущий ранг
doublе xi.
// Средний ранг равных элементов
Ранжирование
69
xj, // Сумма рангов равных элементов г = 0: // Поправка на объединение рангов
//////////////////////////////////////////////////// // Подсчет количества равных стоящих рядом элементов is = 1;
for (j = i - 1 ; j < n - 1: j++)
{
if (x[j + 1] == x[j]) i s++;
el se break:
}
/////////////////////////////////////////////
II Рядом стоит не менее двух равных элементов if (is > 1)
{ г += (is * is * is - is): ii = i - 1:
for (j = l.xj = 0: j <= is: j++) xj += (++ii):
xi = xj / is;
for (j = 1; j <= is : j++) xx[i++ - 1] = xi:
}
IIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIHI
II Равных стоящих рядом элементов на текущем шаге нет el se
xx[i - 1] = i++:
} while (i <= n):
return r;
}
Для вычисления коэффициента Кендалла процедура ранжирования имеет особенность, заключающуюся в том, что вычисление поправки на объединение рангов производится по формуле [151, с. 396]
1 *
r=|w-i).
где все обозначения те же, что и ранее.
70
Глава 1. Статистики эмпирического ряда
Исходные коды
double RankKendall (double х[],double xx[],int n) //
// Функция ранжирования для вычисления коэффициента Кендалла.
// Обозначения:
// х - исходная выборка.
// хх - массив рангов.
// п - численность выборки.
// Замечание:
// Для получения верного результата выборка должна быть
// отсортирована по возрастанию, например функцией
// SortArrayllp.
// Возвращаемое значение:
// поправка на объединение рангов.
//
{
register int j: // Счетчик
int is. // Количество равных элементов
ii. // Рабочая переменная
i = 1: // Текущий ранг
double xi. // Средний ранг равных элементов
xj. // Сумма рангов равных элементов
r = 0. // Поправка на объединение рангов
rs: // Рабочая переменная
do
{
/ / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / // Подсчет количества равных стоящих рядом элементов is = 1;
for (j=i-l:j<n-l; j++)
{
if (x[j + 1] == x[j])
is++;
el se
break:
}
/////////////////////////////////////////////
// Рядом стоит не менее двух равных элементов
if (is > 1)
{
rs = is * (is - 1):
r += rs:
ii » i - 1:
xj «= 0;
for (j = 1: j <= is: j++)
xj = xj + ++ii:
xi = xj / is:
for ( j = 1: j <= is : j++)
xx[i++ - 1] = xi:
}
Ранжирование
71
///////////////////////////////////////////////////// // Равных стоящих рядом элементов на текущем шаге нет el se
xx[i - 1] = 1++;
}
while (i <= n ):
return r / 2;
}
Для применения некоторых статистических процедур используется операция совместного ранжирования двух выборок. Функция, реализующая эту операцию, показана ниже. Вместо этой функции может быть применена связка функций: «слияние» (если выборки до выполнения вычислений уже не находятся в одном массиве) —> Sort Array Up -> Rank —» UnSort Array -> «разделение», — хотя такое решение менее эффективно. Недостатком функции RankCommon является то, что она не вычисляет поправку на объединение рангов.
Исходные коды
void RankCommon (double *х,double *у,double *хх,double *yy,int nx.int ny) //
// Функция совместного ранжирования двух выборок.
// Обозначения:
// х - первая выборка,
// у - вторая выборка.
// хх - массив рангов первой выборки,
// уу - массив рангов второй выборки.
// пх - численность первой выборки.
// пу - численность второй выборки.
// Замечание:
// Для получения верного результата выборки должны быть
// отсортированы
// по возрастанию и не содержать равных элементов, например
// обработаны
// функциями SortArrayUp и Compare.
// Возвращаемое значение:
// нет.
//
{
register int i.l, // Счетчики цикла
к = 0. // Счетчик элементов массива X
j = 0, // Счетчик элементов массива Y
is; // Вспомогательная переменная
/////////////////////////////// // Совместный перебор элементов for (i =1; i <= nx + ny; i++)
{
72
Глава 1. Статистики эмпирического ряда
//////////////////
// Ранг X < ранга Y
if (x[k] < y[j])
{
xx[k] = 1;
/////////////////////// // Последний элемент X? if (k < пх - 1)
k++ :
el se
{
//////////////////////// 11 Заполнение остатка YY is = i;
for (1 = j; 1 < ny; 1++) yy[l] = ++is;
return;
}
}
///////////////////
// Ранг Y < ранга X
el se
{
yy[j] = i:
/////////////////////// // Последний элемент Y?
if (j < ny - 1)
el se {
//////////////////////// // Заполнение остатка XX is = i ;
for (1 = k; 1 < пх; 1++) xx[l] = ++is;
return;
}
}
}
}
Проверка случайности выборки из нормальной совокупности
Для проверки, извлечена ли выборка случайно из нормальной генеральной совокупности либо, с другой точки зрения, независимы ли одинаково нормально распределенные случайные величины, мож
Репрезентативность выборки
73
но воспользоваться критерием Аббе. Статистика критерия подсчитывается по формуле [32, с. 62]
Дополнительную информацию о критерии Аббе см. в [37, с. 208], [156, с. 89], [161, с. 405]. Таблицы даны в [32,267], а доверительный уровень вычисляется функцией AbbeDistribution.
Исходные коды
double Abbe (double x[].int n)
//
// Функция вычисления критерия Аббе.
// Обозначения:
// х - исходная выборка.
// п - численность выборки.
// Возвращаемое значение:
// значение статистики критерия Аббе.
//
{
register int i: // Счетчик
double m. // Выборочное среднее
q = 0. // Вспомогательные величины
s = 0:
m = VectorSum (х. n) / n;
for (i = 0: i < n - 1; i++)
q += (x[i + 1] - x[i]) * (x[i + 1] - x[i]);
for (i = 0; i < n; i++)
s += (x[i] - m) * (x[i] - m):
return q / s / 2;
}
Репрезентативность выборки
Сделав определенные предположения о соотношении параметров выборки из генеральной совокупности и параметрах самой генеральной совокупности, можно на основании первых судить о вторых. Выбранная для исследования случайным образом из некоторой гене
74
Глава 1 Статистики эмпирического ряда
ральной совокупности группа величин называется репрезентативной, если она наилучшим образом представляет всю генеральную совокупность в смысле соответствия выборочных параметров параметрам генеральной совокупности.
Элементарные формулы определения численности репрезентативной выборки для различных случаев даны в [84, с. 67], [89, с. 125], [111, с. 309], а в [156, с. 13] приведен наиболее подробный анализ. См. также [157].
Так, если неизвестна численность генеральной совокупности, достаточный объем выборки оценивается по формуле
I ' J
где С — значение ^-распределения для оо степеней свободы,
< у — выборочное среднее квадратичное отклонение,
Д — заданная допустимая абсолютная погрешность определения среднего арифметического значения.
Отметим, что единицы измерения выборочного среднего квадратичного отклонения и допустимой абсолютной погрешности совпадают. При этом говорят, что данные параметры вводятся в именованных числах.
Дальнейшие исследования и программные ресурсы
• Восстановление пропущенных данных, базирующееся на итеративном подборе пропущенных значений [124, с. 35,147]. Данную проблему решает, например, пакет SOLAS разработки Statistical Solutions (www.statsol.ie).
• Исключение резко выделяющихся наблюдений по алгоритмам [32, с. 58], [70, с. 265], [111, с. 153], [120, с. 35], [140, с. 191], [155, с. 23].
• Сглаживание данных [146], [155, с. 62], [158, с. 35].
Многие из представленных в главе расчетов можно проделать с помощью стандартных электронных таблиц, таких как Microsoft Excel, входящих в комплект Microsoft Office, либо StarCalc из пакета Star Office производства Sun Microsystems. Это полезно для проверки в электронных таблицах правильности своих расчетов. Кроме того,
Дальнейшие исследования и программные ресурсы
75
можно воспользоваться одной из десятков коммерческих или бесплатных программ анализа данных, причем для расчета основных показателей достаточно самых простых программ, таких как NCSS Junior (NCSS Statistical Software, www.ncss.com) или NumLock Calculator (nlcalc.narod.ru, CD-приложение к «КомпьютерПресс», № 12 за 2000 г.).
В Интернете есть ряд подробных руководств по математической статистике, например интерактивное «Руководство InStat по выбору и интерпретации статистических тестов» (GraphPad Software, www.graphpad.com), руководство по математической статистике Electronic Statistics Textbook (StatSoft, www.statsoft.ru/home/textbook/ default.htm, CD-приложение к журналу «КомпьютерПресс», № 3 за 2000 г.), мультимедийный курс прикладной статистики ActiveStats (Longman Software Publishing, www.longman.net).
Глава 2. Проверка гипотез
Закономерности в экспериментальных данных можно обнаружить путем статистической проверки результатов многих опытов, принимая или отклоняя определенные гипотезы. Процедура статистической проверки начинается с формулировки нулевой гипотезы Но (например, «нет статистически значимого различия») и альтернативной (конкурирующей) гипотезы («имеет место статистически значимое различие»). Затем на основании выборок экспериментальных данных производится проверка нулевой гипотезы относительно альтернативной с помощью соответствующего теста (критерия). Результатом статистической проверки является вывод о том, в скольких случаях, например, на каждые 100 проведенных испытаний в предположении определенной модели отклонения от модели можно считать случайными. Таким образом, на заданном стандартном уровне значимости исследователь может остановиться на одной из гипотез. Выводы можно и не приводить к стандартному уровню значимости. При этом говорят, что вычисляется Р-значение.
Изложенные в данной главе методы проверки гипотез применяются для пары выборок. Для числа выборок, большего двух, применяется дисперсионный анализ, рассмотренный в главе 3.
Основы теории проверки гипотез наиболее полно изложены в [167, с. 480]. Основные положения кратко даны в [135, с. 561].
Общая методика
Мы рассматривали понятие доверительного интервала при вычислении среднего значения. Вообще, утверждение о том, что некоторая статистическая величина 0 лежит в доверительном интервале от tQ до означает, что равенство
Р(Го<0<^) = 1-а,
где (1 - а) — коэффициент доверия (confidence level), иногда обозначаемый также как р,
а — уровень значимости (significance level), справедливо в (1 - а) случаях [91, с. 141].
Общая методика
77
Для проверки гипотезы выборочное пространство W разделяется на две области: w и ( W - ю), называемые критической областью и областью принятия. При попадании выборочной точки в область w гипотеза отвергается, при попадании в (IV - w) принимается. Если известно распределение вероятностей наблюдений, соответствующее Но, можно определить w так, чтобы при выполнении Но вероятность отвергнуть эту гипотезу была равна заранее заданной величине — уровню значимости [91, с. 221]:
Р{хе щ|Я0} = о
Если выбор пространств w и, следовательно, ( W- w) достаточно широк, то решение о принятии или непринятии гипотезы Яо существенно зависит от того, против каких альтернативных гипотез Нх она проверяется.
Вместо уровня значимости в программных реализациях мы часто используем значение коэффициента доверия (доверительного уровня), который связан с уровнем значимости простой формулой [135, с.211]:
р - 1 -а,
где уровень значимости равен вероятности ошибочного отклонения верной нулевой гипотезы [167, с. 483] и соответствует ошибке I рода, или ошибке а-типа. Другое определение дано в [26, с. 59]. Вероятность ошибочного принятия ложной нулевой гипотезы соответствует ошибке II рода, или ошибке Д-типа [91, с. 223]. Естественно стремление исследователя минимизировать ошибку I рода, снижая уровень значимости, но тогда возрастает вероятность ошибки II рода. В связи с этим вводят понятие мощности критерия, определяемой как вероятность того, что критерий отклонит ложную нулевую гипотезу:
P{.re(W-w)|H,}= 1-/3, или Р{хе<а|Н,} = 1-^
Значение (1 - Д) называется мощностью критерия. На практике мощность критерия можно повысить, увеличив объем выборки, а из двух критериев следует пользоваться более мощным критерием, если для его применения имеется достаточно оснований.
Вместо прямого использования статистических таблиц или применения некоторых пороговых значений вероятности там, где это возможно, мы реализовали все применяемые нами статистические рас
78
Глава 2. Проверка гипотез
пределения программно, вычислив функции распределения точно (рекуррентные алгоритмы, прямое интегрирование с гарантированной точностью) или с помощью аппроксимации.
Общая методика выводов при проверке гипотез заключается в выборе уровня значимости, обычно 0,05, с последующим сравнением данного уровня значимости с уровнем значимости, полученным в результате вычисления критерия значимости. Отметим, что произвести точное вычисление уровня значимости позволяют лишь некоторые из методик. Обычно же уровень значимости находится по таблицам в зависимости от вычисленного значения статистики критерия либо нормальной или иной аппроксимации данной статистики. В последнем случае, естественно, пользуются таблицами нормального распределения либо, соответственно, распределения, использованного для аппроксимации (чаще всего t- или F-распределения). Существует несколько стандартных формулировок, принятых в любых, в том числе и в биомедицинских, исследованиях, поэтому приведем их для справки (здесь р — уровень значимости, это обозначение стандартно для рассматриваемой области науки) [ 106, с. 212], [180, т.1, с. 221]:
1. р > 0,05 — различия недостоверны, в случае недостоверных различий обычно ограничиваются уровнем значимости > 0,05, нулевая гипотеза об отсутствии различий может быть принята;
2. р < 0,05 — различия достоверны на уровне значимости 0,05;
3. р < 0,01 — различия достоверны на уровне значимости 0,01;
4. р < 0,005 — различия достоверны на уровне значимости 0,005;
5. р < 0,001 — различия достоверны на уровне значимости 0,001, причем данную формулировку можно применять и при р = 0.
В случаях 2,3,4 и 5 может быть принята альтернативная гипотеза о наличии различий на указанном уровне значимости. Для уровней значимости тестов нами обычно дается не табличное, а вычисленное «точное» значение. Такой подход применяется во многих коммерческих программных продуктах и называется вычислением Р-зна-чения [28, вып.1, с. 186], [37, с. 113], которое является решением так называемой обратной задачи: P-значение является величиной, получающейся в результате подстановки значения статистики критерия в ее функцию распределения. Фактически величина Р-значе-ния представляет собой вычисленный по опытным данным точный уровень значимости и иногда называется обратной вероятностью [231, с. 185]. Например, статистический вывод при этом может быть таким: средние двух выборок статистически различаются на уровне
Общая методика
79
значимости 0,012. В публикациях, однако, принято приводить ближайшее к вычисленному стандартное значение уровня значимости (или доверительного уровня): в данном примере стандартный уровень значимости (слово «стандартный» в публикациях обычно опускают) а = 0,05 как наименьшее стандартное значение, превышающее вычисленный уровень значимости. Очевидно, именно этот факт имеется в виду диссертантами по медико-биологической тематике, когда в своих работах они пишут: «различия достоверны при р < 0,05». Такая запись принята в литературе и вполне понятна, но запись «Р = 0,012» информативней.
Данная методика применима и при вычислениях так называемых критериев согласия, предназначенных для установления факта соответствия эмпирического распределения некоторому теоретическому, чаще всего нормальному, распределению. Разница в том, что если при вычислении критериев значимости желательным, если так можно выразиться, является установление различия между выборками (по меньшей мере р < 0,05), то при вычислении критерия согласия желательным для исследователя является доказательство отсутствия различий (то есть р > 0,05) между распределением эмпирической выборки и каким-либо теоретическим, чаще всего нормальным, распределением.
Для пересчета коэффициента доверия в соответствующий уровень значимости нужно применить формулу
а = 1 - р,
где р — коэффициент доверия.
Табл. 2.1 демонстрирует связь некоторых статистических характеристик, встречающихся в источниках.
Таблица 2.1. Разнообразие обозначений в статистических таблицах
Показатель Обозначение Единицы измерения Формула связи с коэффициентом доверия
Уровень значимости а Доли 1 -Р
Р-значение рили Р Доли 1 -Р
Коэффициент доверия рили Р Доли Р
Коэффициент доверия Р Проценты ЮОр
Q-процентная точка Q Проценты 100(1 -р)
80
Глава 2, Проверка гипотез
Уровень значимости иногда обозначают как р, Q или Fи иногда дают его в процентах. Всевозможные комбинации встречаются зачастую в пределах одного издания, например см. [195], [32], [92]. Интерпретация выводов дана при обсуждении примеров данной и следующей глав. Обсуждение см. также в [70, с. 239].
Сравнение методик
Нет необходимости помещать в публикуемую работу результаты, полученные при анализе одних и тех же данных разными, но предназначенными для одного и того же типа анализа методами (кроме работ, целью которых является сравнительный анализ методов), особенно если результаты совпадают. Однако попробовать сделать расчеты по разным методикам настоятельно рекомендуется. С целью экономии места в публикации и внимания читателя достаточно привести результаты расчета только одним методом.
Тем более неверно приводить результаты расчетов разными методами, если они значительно различаются. В последнем случае нужно еще раз проверить условия адекватности применяемых тестов природе данных, а для публикации выбрать единственный метод, который наиболее подходит для целей исследования и, кроме того, был успешно опробован ранее для аналогичных целей. Мы не предлагаем отбросить результаты, не удовлетворяющие исследователя. Напротив, мы предлагаем исследователю разобраться в причинах, по которым расчеты разными методами различаются настолько, что вынуждают исследователя отбрасывать плохие, с его точки зрения, результаты. Причины расхождения результатов применения однотипных методик анализа данных могут быть следующие:
• Допущены ошибки ввода данных.
• Все или некоторые из примененных методик не подходят для рассматриваемого типа данных. Тип исходных данных для расчета определяет методику для их обработки.
• При конструировании программ были допущены алгоритмические ошибки.
Исследователь, конечно же, может не учитывать эти рассуждения, однако это тот случай, когда почти невозможно проверить, были или нет выброшены «плохие» результаты — так или иначе придется положиться на честность исследователя.
О сравнении критериев см. [156, с. 137]. Замечания о выборе подходящего критерия даны в [231, с. 300].
Односторонняя и двусторонняя гипотезы
81
Односторонняя и двусторонняя гипотезы
Рассмотрим понятия односторонней (one sided) и двусторонней (two sided) гипотез [172, с. 15], [158, с. 142], которым соответствуют односторонний и двусторонний критерии значимости. Когда исследователь имеет достаточное количество данных, позволяющих предсказать в альтернативной гипотезе направление различий (например, доля желательных эффектов в опытной группе не просто отличается от контрольной, а превышает ее), используется односторонний критерий, в противном случае (опытная группа просто отличается от контрольной) используется двусторонний критерий.
Уровень значимости для двустороннего критерия в два раза превышает уровень значимости для одностороннего критерия. В табл. 2.2 представлены стандартные значения уровней значимости и коэффициентов доверия. То есть в определенном смысле его выводы «хуже». Слово «хуже» взято в кавычки, так как в зависимости от формулировки нулевой гипотезы и желательности выводов для исследователя (например, желательно не установить статистические различия, а, наоборот, показать отсутствие таких различий), «хуже» может означать «лучше».
Таблица 2.2. Стандартные значения уровней значимости и коэффициентов доверия
Уровень значимости (односторонний критерий) 0,001 0,005 0,01 0,05 0,1
Уровень значимости (двусторонний критерий) 0,002 0,010 0,02 0,10 0,2
Коэффициент доверия (односторонний критерий) 0,999 0,995 0,99 0,95 0,9
Коэффициент доверия (двусторонний критерий) 0,998 0,990 0,98 0,90 0,8
Для пересчета одностороннего значения уровня значимости в двустороннее значение можно воспользоваться простой формулой [187, с. 184]:
Двустороннее значение = 2 Одностороннее значение.
Для пересчета одностороннего значения коэффициента доверия в двустороннее значение нужно воспользоваться формулой:
82
Глава 2. Проверка гипотез
Двустороннее значение - 2 • Одностороннее значение - 1.
Обратный пересчет не вызовет затруднения:
Одностороннее значение = (Двустороннее значение + 1) / 2.
Обсуждению применения односторонних и двусторонних критери-2 ев посвящен раздел в [201, с. 39], где утверждается, что, даже если интересующее различие должно быть в одностороннем направлении, исследователь должен подстраховаться от неожиданных результатов, выполнив двусторонний тест. В том же источнике приводится ряд важных соображений о применении односторонних и двусторонних критериев в медицине. Мы не будем их здесь пересказывать. Отметим только, что в подавляющем большинстве исследований действительно применяется двусторонний критерий [там же, с. 41]. Подробное обсуждение проблемы в применении к медицинским данным дано также в [26, с. 74], [57, с. 88].
Независимые и сопряженные выборки
Данные, полученные в реальных экспериментах, могут быть представлены независимыми либо сопряженными выборками. Соответственно к этим выборкам применимы критерии значимости для независимых либо для сопряженных выборок.
Критерии для независимых выборок применяются, чтобы выявить статистическую значимость различий двух разных групп индивидуумов. Примерами независимых выборок могут служить:
• параметры двух групп пациентов, к которым применялись различные методики лечения с целью изучения значимости различий между методиками;
• параметры двух групп пациентов, к одной из которых (опытная группа) применялось воздействие методики, а к другой (контрольной) не применялось, с целью изучения значимости влияния данной методики на результат лечения.
Критерии, применяемые к выборкам с попарно сопряженными вариантами, называются парными критериями либо критериями для связанных или сопряженных выборок. Примеры сопряженных выборок:
• параметры одной и той же испытуемой группы до и после воздействия какого-либо фактора, например методики лечения;
Параметрические тесты
83
• параметры одного и того же объекта экспериментального исследования, но относящиеся к различным его частям, например состояния двух конечностей в процессе лечения, одна из которых подвергается лечебному воздействию, а другая нет.
Параметрические тесты
Критерии (тесты), при помощи которых могут быть сравнены статистические совокупности, разделяются на две группы: параметрические и непараметрические. Особенностью параметрических критериев является предположение о том, что распределение признака в генеральной совокупности подчиняется некоторому известному, в данном случае нормальному, закону. Нормальность эмпирического распределения выборки должна быть статистически доказана до применения любого параметрического теста с помощью одного из методов, рассмотренных в разделе «Критерии согласия» настоящей главы.
Параметрические критерии в большинстве случаев являются более мощными, чем их непараметрические аналоги. Если существуют предпосылки использования параметрических критериев, но используются непараметрические, увеличивается вероятность ошибки II рода, то есть вероятность принятия ложной нулевой гипотезы.
(-критерий Стьюдента
Пусть обе выборки извлечены из генеральных совокупностей, имеющих нормальные распределения с равными или неравными между собой известными или равными неизвестными дисперсиями. Нулевая гипотеза состоит в том, что средние совокупностей равны. Все наблюдения независимы (выборки не связаны попарно). Это означает, что сравниваться могут, например, две группы индивидуумов, одна из которых является опытной (к ней применялось воздействие какого-либо фактора), другая — контрольной (к ней воздействие фактора не применялось), но не одна и та же группа до и после воздействия фактора.
Критерий Стьюдента (t-критерий, two-group unpaired t-test) имеет множество применений. Внешне он прост в реализации, но, как это обычно бывает, за внешней простотой скрывается довольно много нюансов, учет которых представляет собой непростую задачу [52, с. 101].
84
Глава 2 Проверка гипотез
Отметим, что имеются данные о варианте f-критерия, связанном с рандомизацией, не требующем предположения нормальности [115, с. 236]. Интересный пример применения t-критерия при исследовании авторства литературных произведений рассмотрен в [204, с. 402].
Случай известных дисперсий
2 В случае равных известных дисперсий критерий вычисляется по фор-
муле [187, с. 176]
k.-^l
П Г
— + —
«2
где все обозначения соответствуют данным в главе 1. Статистика имеет стандартное нормальное распределение.
В случае неравных между собой известных дисперсий статистика вычисляется по формуле [там же, с. 177]
°2
«2
Статистика также имеет стандартное нормальное распределение.
Легко заметить, что вторая из приведенных формул при равных известных дисперсиях превращается в первую формулу. А так как критические значения вычисляются одинаково в обоих случаях, вычисления технически могут быть выполнены одной и той же функцией.
В [152, с. 5] дана иная форма критерия Стьюдента для случая известного отношения дисперсий, для вычисления критических значений использующая распределение Стьюдента. Решение на языке про-граммироваия Бейсик дано в [184, с. 166].
Как легко заметить, формулой критерия Стьюдента можно воспользоваться, не имея первичных данных для анализа в виде таблиц. Подобная проблема иногда возникает при попытке проверить правильность выводов публикации, автор которой не захотел или забыл привести исходные данные для расчета, однако показал в тексте публикации, в таблице или на графике среднюю, ошибку средней, а также указал численности выборок. Используя формулы вычисле
Параметрические тесты
85
ния параметров средней, данные в главе 1, можно легко получить все необходимые числа для расчета статистики критерия Стьюдента, связав, таким образом, статистическую значимость с ошибками средних [7].
Случай равных неизвестных дисперсий
В случае равных неизвестных дисперсий [24, с. 72]
Н Г’
s — + —
V1 «2
где оценка выборочной дисперсии s2 считается как [187, с. 177]
52_512(И1-1) + 522(я2-1) п\ + п2 ~~ 2
а оценки дисперсий $2 и считаются по соответствующим выборкам, или [135, с. 568]
s2_s2n1+s2n2 +/?2 -2
если при вычислении дисперсий деление производилось не на (й1 - 1) и (п2 - 1), а соответственно на и, и п2.
Статистика имеет распределение Стьюдента с числом степеней свободы (и, + п2 - 2). Доверительный уровень вычисляется функцией TDistribution.
Критерий Стьюдента для связанных выборок
Назначение критерия Стьюдента для связанных выборок (парного критерия Стьюдента, two-group paired t-test) аналогично f-критерию Стьюдента для независимых выборок, рассмотренному выше, однако все наблюдения связаны попарно, например относятся к одному и тому же индивидууму (группе индивидуумов) до воздействия определенного фактора и после воздействия этого фактора, с целью выявить наличие эффекта от воздействия этого фактора. Требова
86
Глава 2. Проверка гипотез
ние равенства дисперсий двух выборок при этом не ставится. В источниках критерий может называться одновыборочным критерием Стьюдента. Это название вызвано тем обстоятельством, что на самом деле, исходя из представленной ниже схемы расчета, анализируется действительно одна выборка, составленная из попарных разностей вариант исходных связанных выборок. В данном случае проверяется нулевая гипотеза о равенстве среднего значения полученной выборки известному значению, а именно — нулю.
Вычисления производятся по формуле [84, с.253]
я
t= Ы
я ( п \2
УJr ;
где п — численность каждой выборки,
8i - xi -yt, i = 1,2,..., п, — попарные разности вариант совокупностей, х, i = 1, 2,..., п, — варианты первой совокупности, yit i = 1, 2,..., п, — варианты второй совокупности.
Статистика имеет распределение Стьюдента с числом степеней свободы (п - 1). Доверительный уровень вычисляется функцией TDistribution.
Описание и примеры даны также в [158, с. 184], [52, с. 286]. Решение на языке программироваия Бейсик дано в [184, с. 170].
Исходные коды
double StudentPairedTest (double х[].double y[].int n) 11
II Функция возвращает значение парного критерия Стьюдента // Обозначения:
// х - первая сравниваемая выборка.
// у - вторая сравниваемая выборка.
// п - численность каждой выборки.
// Возвращаемое значение:
// значение парного критерия Стьюдента.
// -2 при ошибке в вычислениях.
И
{
double s2 = O.d.s = 0:
for (register int i
0; i < n; i++)
Параметрические тесты
87
d = y[i] - x[i]: s += d:
s2 += d * d:
If ((d = n * s2 - s * s) == 0) return -2:
el se
return fabs (s) / sqrt (d / (n - 1));
Проблема Беренса—Фишера
При анализе выборок из генеральных совокупностей с неизвестными дисперсиями, равенство которых не предполагается [63, с. 228], либо если отношение дисперсий неизвестно [152, с. 3], возникает так называемая проблема Беренса—Фишера (Behrens—Fisher problem). Рассмотрим два подхода, применяемых для решения проблемы [115, с. 257].
Критерий Уэлча
Вычисления производятся по формуле Уэлча (Велча) [37, с. 275]
1*1-*г|
Г~2 F
р_ + ^2_
УП1 П2
где оценки дисперсий $2 и $2 считаются по сравниваемым выборкам. Распределение статистики d критерия Уэлча близко к t-распреде-лению Стьюдента при числе степеней свободы, [там же, с. 277], [187, с. 177], [158, с. 169]
(s^+s2/^)2 (s2/n,)2 , (s2/?z2)2 пх -1 -1
Доверительный уровень вычисляется функцией TDistribution с указанным выше числом степеней свободы.
В [24, с. 76] дана та же самая формула для определения числа степеней свободы, но в иной записи, и приведены формулы для вычисле
88
Глава 2. Проверка гипотез
ния доверительных границ для разности средних. Проблеме уделено большое внимание в [32, с. 49], [115, с. 258], [156, с. 91]. Гипотеза о равенстве средних нескольких (больше 2) выборок из нормальных генеральных совокупностей рассмотрена в [156, с. 93]. Многомерная проблема Беренса—Фишера рассмотрена в [15, с. 165].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void)
{
int nl = 53,
n2 = 20,
buf2:
double datal[] =
{165,164.158,168,162.166,167,154.165,164,172,167,164,157, 164,164.166,173.164.160,164.157,152,175.165,174.163.155. 163.162.178.166,165.163.168.161.164.173.161.161.160.164, 166.170.167.159,158,164.161,163.163,165,170}.
data2[] =
{182,183.168,174.165.174.163.168,179,185.171.174.180.175, 179.181,169,184.172,174},
buf.bufl:
if (!Welch (datal,data2,nl.n2.&buf,&buf2))
{
bufl = TDistribution (buf2,buf): cout « buf
« ", p = " « bufl
« ", n = " « buf2 « endl:
}
el se
cout « "Ошибка в вычисленияхХп":
}
int Welch (double *datal,double *data2,int nl.int n2,double *criterion.int *n)
11
II Функция сравнивает две выборки по критерию Стьюдента
// при неизвестных неравных дисперсиях (критерий Уэлча).
// Обозначения:
// datal - первая выборка.
// data2 - вторая выборка,
// nl - численность первой выборки.
// п2 - численность второй выборки.
// *criterion - критериальная статистика.
Параметрические тесты
89
// *п - число степеней свободы.
// Возвращаемое значение:
// 0 при нормальном окончании расчета,
// -2 при ошибке в вычислениях.
И
{
double dl,d2. // Дисперсии ml,m2, // Средние sl.s2; // Рабочие величины
dl = Moment (2,datal,0,&ml,nl); d2 = Moment (2,data2,0,&m2.n2):
if (! dl && !d2) return -2;
///////////////////////////// // Вспомогательные вычисления si = dl / nl;
s2 = d2 / n2;
////////////////////////////////////// // Вычисление критериальной статистики ♦criterion = fabs (ml - m2) * sqrt (si + s2);
////////////////////////////////////
// Вычисление числа степеней свободы
*n = (int) floor ((si + s2) * (si + s2) /
(si * si / (nl - 1) + s2 * s2 / (n2 - 1)));
return 0; }
Критерий Пагуровой
Приближенное решение проблемы Беренса—Фишера дано Пагуровой [152, с. 3], которая предположила, что распределение статистики критерия существенно зависит от отношения неизвестных дисперсий. Критерий редко применяется исследователями, очевидно, по причине недостатка информации о нем. Надеемся, данная публикация еще раз обратит внимание исследователей на данный метод анализа.
Вычисление критерия Пагуровой производится по формуле, аналогичной формуле Уэлча:
"2
однако критические значения статистики берутся иные.
90
Глава 2. Проверка гипотез
Числа степеней свободы при поиске критического значения следует положить равными (пг - 1) и (п2 - 1). Критические значения статистики критерия вычисляются функцией InversePagurovaDistri-bution, вызов которой показан в разделе «Распределение критерия Пагуровой» главы 4. При этом параметр, зависящий от отношения дисперсий, считается как
г-______*---
Пример применения аналогичен предыдущему случаю и здесь не приводится. Предлагаемый подход к решению проблемы разобран также в [115, с. 257].
Исходные коды
int Pagurova (double *datal,double *data2,int nl.int n2,double ♦criterion,double *c) //
// Функция сравнивает две выборки по критерию Стьюдента
// при неизвестных неравных дисперсиях (критерий Пагуровой).
// Обозначения:
// datal - первая выборка,
// data2 - вторая выборка,
// nl - численность первой выборки,
// п2 - численность второй выборки.
// *criterion - критериальная статистика.
// *с - параметр отношения дисперсий.
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -2 при ошибке в вычислениях. //
{
double dl,d2, // Дисперсии ml.m2, // Средние
sl,s2: // Рабочие величины
dl = Moment (2,datal.0,&ml.nl); d2 = Moment (2,data2.0.&m2.n2);
if (!dl && !d2)
return -2;
///////////////////////////// // Вспомогательные вычисления si = dl / nl;
s2 = d2 / n2;
Параметрические тесты
91
//////////////////////////////////////
// Вычисление критериальной статистики
♦criterion = tabs (ml - m2) * sqrt (si + s2):
///////////////////////////////////
// Вычисление параметра, зависящего
// от отношения дисперсий
*с = si / (si + s2):
return 0;
}
F-критерий Фишера
F-критерий Фишера применяют для сравнения дисперсий двух выборочных совокупностей. Критерий часто называют дисперсионным отношением [37, с. 259] или просто статистикой Фишера [187, с. 178]. Вычисление ведется по формуле [24, с. 75], предложенной Снедекором [111, с. 124]:
F = s2/s2>
где $2 — значение оценки большей дисперсии,
— значение оценки меньшей дисперсии.
Числа степеней свободы для поиска критического значения по таблице F-распределения следует взять равными - 1) и (п2 - 1). Доверительный уровень для односторонней гипотезы вычисляется функцией FDistribution. При вызове функции числа степеней свободы нужно взять равными численностям выборок. Вычитание единиц уже произведено в теле функции. Критическое значение статистики критерия для случая односторонней гипотезы может быть вычислено функцией InverseFDistribution. В случае двусторонней гипотезы при вызове функции следует доверительный уровень положить равным 1 - (1 - р) / 2.
Гипотеза о равенстве дисперсий сравниваемых совокупностей отвергается, если вычисленное значение статистики критерия превышает табличное на заданном доверительном уровне.
Описание критерия и примеры его применения см. в [158, с. 201], [140, с. 134], [101, с. 564], [180, т.1, с. 262]. Теоретическое обоснование дано в [115, с. 189]. Применение F-критерия при исследовании авторства литературных произведений упоминается в [204, с. 402].
92
Глава 2. Проверка гипотез
Исходные коды
int FTest (double *datal.doubl е *data2,double *criterion) //
// Функция сравнивает дисперсии двух выборок по F-критерию
// Фишера.
// Обозначения:
// datal - первая выборка.
// data2 - вторая выборка.
// п! - численность первой выборки.
// п2 - численность второй выборки,
// *criterion - критериальная статистика.
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -2 при ошибке в вычислениях.
И
{
double dl,d2, // Дисперсии
m; // Фиктивный параметр
dl= Moment (2.datal.0,&m.nl);
d2= Moment (2,data2.0.&m,n2):
if (!dl && !d2)
return -2;
♦criterion = d2 >= dl ? d2 / dl : dl / d2;
return 0;
}
G-критерий различий средних
G-критерий предназначен для сравнения средних двух нормально распределенных совокупностей равного объема. Вычисление статистики критерия производится как [151, с. 143]
2 ”(rx+rJ
п п
.»=1 1=1
где п — численность каждой выборки,
тх — размах первой выборки,
гу — размах второй выборки,
xit i - 1,2,..., п, — варианты первой выборки,
г/„ i = 1,2,..., п, — варианты второй выборки.
Доверительный уровень вычисляется функцией GTestDistribution.
Параметрические тесты
93
Исходные коды
double GTest (double х[].double у[],int n) //
// Функция возвращает значение G-критерия для проверки
// значимости различия между средними двух выборок равного // объема.
// Обозначения:
// х - первая сравниваемая выборка.
// у - вторая сравниваемая выборка.
// п - численность каждой выборки.
// Возвращаемое значение:
// значение G-критерия.
//
{
double w = MaximumOf (x.n) - MinimumOf (x.n) + MaximumOf (y.n) - MinimumOf (y.n);
if (!w) return 0;
el se
return fabs (VectorSum (x.n) - VectorSum (y.n)) / w * 2 / n; }
Параметрические множественные сравнения
Параметрические критерии могут быть использованы для множественного сравнения — иначе говоря, для сравнения двух групп выборок между собой. Каждая группа задается подобно тому, как задаются параметры массивов данных для рассмотренных ниже методов двухфакторного дисперсионного анализа.
Показано [52, с. 101], что при множественных сравнениях рассмотренные выше параметрические тесты применять нельзя. Для анализа используются их многомерные обобщения. Далее рассмотрены многомерные обобщения критерия Стьюдента. Реализации трех первых из рассмотренных критериев не показаны, так как они могут быть легко получены незначительной модернизацией одной из рассмотренных функций, например Welch или Pagurova.
Параметрические множественные сравнения подробно рассмотрены [16]. [Там же, с. 165] рассмотрена многомерная проблема Беренса-Фишера.
Критерий Стьюдента с поправками Бонферрони
Вычисление статистики критерия Стьюдента с поправками Бонферрони (Bonferroni) производится по формуле [52, с. 106]
94
Глава 2. Проверка гипотез
*л~*в| 2 2
°* А । ° В пв
где оА и <ув — равные ст известные внутригрупповые дисперсии, 2 пА и пв — численности групп.
В цитируемом источнике рассматривается случай т групп равной численности, для которого статистика имеет t-распределение с числом степеней свободы т(п - 1).
Критерий Ньюмена—Кейлса
Вычисление статистики критерия Ньюмена—Кейлса (Стьюдента— Ньюмена—Кейлса, Student—Newman—Keuls test) производится по формуле [52, с. 108]
~*в|
1 +J_
2 I пл пв
Критические значения для стандартных уровней значимости даны [там же, с. 110] в зависимости от числа степеней свободы, равного (N- т), где N — сумма численностей всех групп, а т — число групп.
Критерий Даннета
Имеется вариант рассмотренного выше критерия, предназначенный для сравнения нескольких групп выборок с контрольной. Предназначенный для этого критерий Даннета (Dunnett's test) вычисляется по формуле [там же, с. 116]
Критические значения для стандартных уровней значимости даны [там же, с. 114] в зависимости от числа степеней свободы, вычисляемого точно так же, как в предыдущем критерии.
Параметрические тесты
95
Критерий Т2
Критерий Т2 (критерий следа, критерий Хотеллинга, критерий Лоу-ли и Хотеллинга), для случая двух многомерных выборок предложенный Хоттелингом, применяется в задаче статистической проверки гипотезы о равенстве векторов средних двух многомерных совокупностей, когда ковариационные матрицы совокупностей, из которых отобраны выборки, равны между собой [70, с. 357]. Если искомая дисперсионно-ковариационная матрица совокупности неизвестна, она вычисляется через выборочные дисперсионно-ковариационные матрицы совокупностей по формуле [180, т.2, с. 216]
। 71^2 ~
где 5, и S2 — выборочные дисперсионно-ковариационные матрицы многомерных совокупностей.
Статистика критерия вычисляется по формуле [там же]
Т2 = - х2)' S-' (х, - х2) ,
П{ +П2
где и х2 — векторы средних двух многомерных совокупностей, — численность каждого ряда первой многомерной выборки,
п2 — численность каждого ряда второй многомерной выборки.
Можно заметить, что численности рядов, составляющих многомерные выборки, могут различаться, но в пределах одной выборки должны быть одинаковыми. Размерности же многомерных выборок всегда должны быть равными.
Доверительный уровень для рассмотренного случая двух многомерных совокупностей вычисляется функцией FDistribution, вызываемой с параметрами, указанными в примере. Случаи исследования более двух многомерных выборок представлены в [16, с. 57].
Описание и методику вычисления критерия см. также в [108], [139, с. 186]. [205, с. 527]. Связь с расстоянием Махаланобиса выведена в [190, с. 555]. Обобщения на случай более двух групп выборок подробно рассмотрены в [15, с. 152], [16, с. 50]. Близкий рассмотренному алгоритму критерий Уилкса представлен в [156, с. 102].
96
Глава 2 Проверка гипотез
Исходные коды
#include <fstream.h>
#include <iomanip.h>
#include "megastat.h"
void main (void)
{
int nl, // Численность каждого ряда первой выборки
п2, // Численность каждого ряда второй выборки
р = 4, // Размерность каждой выборки
Code: // Код ошибки
double yl[] = // Первая многомерная выборка
{53,56,47,57.47,67,37,53.48.43,58,32,60.60,54,53,4В,56,47,47,60.37,58,32.4, 3,3.8.9.12.8.11,26.15.12,6,12,1.7.10.26.15,3,8,12.1.11.6,12.13.
33,37,14.21,28,23,41.66.22.38,26.50.38.31.34.66,22,37,14.28,38.41.26.50,37.
2.4.4.1,2,1.1,5,2.3.1.1.1,2,2.5,2.4.4.2.1.1.1.1.4}. у2[] = // Вторая многомерная выборка
{55.61.61.55.51.59.60,65,54.47.42.42,60.70.54.65,54.61,60.65,55,54.65.54.59.
1.2.1.4.1.1.2.2.3,4.8.4.4.0.3.2.3.1,4.2.4.3.2.3.4.
41.35,32,34.42,37.28,33,42.48.48.51,35.30.34.33.42.32.35.33.34.34.33,42.39.
1.2.2.1.3,0.0.0.0,1.1,1.1,0.1,0.0.2.1.0.1.1.0.0.0}. х; // Статистика критерия
nl = sizeof (yl) / sizeof (yl[0]) / р:
n2 = sizeof (у2) / sizeof (у2[0]) / р:
if («(Code = Hotelling (у1.у2.п1,п2,р,&х)))
cout « "Test value is " « x « "\nP-value is "
« FDistribution (p.nl + n2 - p - 1.x I (nl + n2 - 2) / p * (nl + n2 - p - 1))
« endl:
else if (Code == -1)
cout « "Not allocated memoryXn":
el se
cout « "Run-time errorXn";
}
int Hotelling (double yl[],double y2[j,int kl.int k2,int
p.double *h)
//
// Функция вычисляет Т-квадрат критерий Хотеллинга.
// Обозначения:
// yl - первая многомерная выборка (ряды друг за другом),
// у2 - вторая многомерная выборка (ряды друг за другом).
// kl - численность каждого ряда первой выборки,
// к2 - численность каждого ряда второй выборки,
// р - размерность каждой выборки.
// *h - вычисляемое значение статистики.
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
Параметрические тесты
97
// -1 при недостатке памяти для рабочих массивов, // -2 при ошибке в вычислениях.
//
{
register int i.j; // Счетчик цикла
int Code, // Код ошибки
m,ml,m2, // Счетчик одномерного массива
p2 = p * p; // Рабочая величина
double *ysl. // Вектор средних первой выборки
// и массив разности средних
*ys2. // Вектор средних второй выборки
*s. // Ковариационная матрица
// и вспомогательный массив
*t. // Вспомогательный массив
*r; // Вспомогательный массив
If (!(ysl » new double[p])) return -1;
if (!(ys2 - new double[p]))
{
delete [] ysl;
return -1;
}
if (!(s = new double[p2]))
{
delete [] ysl; delete [] ys2;
return -1;
}
if (!(t = new double[p2]))
{
delete [] ysl; delete [] ys2; delete [] s:
return -1;
}
if (!(r = new double[p2]))
{
delete [] ysl: delete [] ys2; delete [] s; delete [] t; return -1;
}
///////////////////////////
// Параметры первой выборки
for (i » O.m - 0; i < p; ysl[1++] /= kl) for (j = 0,ysl[i] = 0; j < kl; j++)
ysl[i] +- yl[m++J;
MatrixTMultiplyMatrix (yl.yl,s.p.kl.p);
MatrixMultiplyMatrixT (ysl.ysl.r.p.l.p);
MatrixMultiplyNumber (r.p * p,-kl);
MatrixPlusMatrix (s.r,p2);
4-2002
98
Глава 2. Проверка гипотез
///////////////////////////
// Параметры второй выборки
for (1 = O.m = 0: 1 < р; ys2[i++] /= k2)
for (j = 0,ys2[i] = 0; j < k2; j++) ys2[i] += y2[m++]:
MatrixTMultiplyMatrix (y2,y2,t.p.k2.p):
MatrixMultiplyMatrixT (ys2.ys2,r,p,l.p);
MatrixMultiplyNumber (r.p * p,-k2);
MatrixPlusMatrix (t,r,p2);
/////////////////////////
// Ковариационная матрица
MatrixPlusMatrix (s,t,p2);
MatrixMultiplyNumber (s.p2,1.0 / (kl + k2 - 2)):
/////////////////////////////////// // Матрица, обратная ковариационной Code = InverseMatrix (s.t.p);
////////////////////////// // Массив разности средних for (i = 0; i < p: i++)
yslfi] -= ys2[i];
////////////////////////////////////// // Вычисление критериальной статистики MatrixTMultiplyMatrix (ysl,t,s,1.p,p); MatrixMultiplyMatrix (s,ysl,t,l,p,l);
*h = fabs (t[0] * kl * kl / (kl + k2)):
delete [] ysl; delete [] ys2; delete [] s; delete [] t; delete [] r:
return Code; }
Непараметрические тесты
Существует большое количество опытных данных, которые не показывают нормальности своего распределения, поэтому применение параметрических критериев не может быть обоснованным для данных рассматриваемого класса. Практически ценными явились методы, которые применимы в широком диапазоне условий. Слабая чувствительность к отклонениям от стандартных условий называется робастностью, а методы, применимые в широком диапазоне реальных условий, называют робастными [70, с. 314].
Непараметрические критерии не требуют предварительных предположений относительно вида исходного распределения и являются
Непараметрические тесты
99
более робастными, чем их параметрические аналоги, поэтому их называют также критериями значимости, независимыми от типа распределения. Естественно, непараметрические критерии применимы и для случая нормального распределения. Однако непараметрические критерии в большинстве случаев являются менее мощными, чем их параметрические аналоги. Если существуют предпосылки использования параметрических критериев, но используются непараметрические, увеличивается вероятность ошибки II рода, то есть вероятность принятия ложной нулевой гипотезы.
Изложение общих вопросов, связанных с рассматриваемой темой, дано в [14, с. 131], [57, с. 68], [58].
Критерии рандомизации
Ниже рассмотрено несколько критериев, объединенных общей идеей рандомизации компонент выборок или их рангов. При вычислении применяются комбинаторные алгоритмы (см. главу 17).
Критерий рандомизации компонент Фишера для независимых выборок
При анализе числовых результатов эксперимента исследователь часто сталкивается с проблемой невозможности расчета статистически значимых различий между выборками в силу очень малого размера выборок, вызванного условиями проведения опытов. Второй трудностью при анализе подобных данных является практическая невозможность установить вид распределения. В случае, если все же удается определить вид распределения, оно часто не является нормальным. Все это создает очевидные предпосылки для применения одного из непараметрических критериев, специально разработанных для малых выборок указанного типа. Критерий применяется для проверки нулевой гипотезы о том, отобраны ли две исследуемые выборки из генеральных совокупностей с одинаковыми средними [190, с. 468].
Методика теста базируется на идее перебора всех комбинаций наблюдаемых отметок. Пусть даны две выборки: х, i =1,2,..., пх, и у? 7=1,2,..., пу, где пх и пу — численности выборок. Сумма, меньшая из наблюдаемых, будет
4*
100
Глава 2. Проверка гипотез
Число благоприятных исходов вычисляется по формуле
Д i=l
"(Ц < S l,s, >5 '
где nt — оценка i-го исхода,
Ст — общее число исходов, Л
п = пх + пу — численность объединенной выборки,
т — численность выборки, соответствующей минимальной сумме
т
^=£zri=i,
здесь zfj = 1,..., т, — массив сочетаний из объединенной выборки. Одностороннее P-значение вычисляется по формуле
p=n/c;
и сравнивается с заданным уровнем значимости а. Например, проверяется нулевая гипотеза о равенстве средних двух выборок на уровне значимости 0,05. Предположим, вычислено р = 0,019048 < 0,05 или р = 0,988095 > 0,95, что вытекает из требования при оценке различий признавать значимыми как малые, так и большие величины статистики критерия [70, с. 337], [187, с. 110]. Нулевая гипотеза отклоняется и принимается альтернативная гипотеза о статистически значимом различии средних на уровне значимости менее 0,05.
Хотя критерий обычно применяют для анализа очень малых выборок, в [ 172, с. 110] даны минимальные значения выборок, позволяющие отклонить нулевую гипотезу (см. табл. 2.3).
Таблица 2.3. Минимально допустимые численности выборок для обоснованного применения критерия рандомизации компонент
Односторонний критерий Двусторонний критерий
Уровень значимости 0,01 0,05 0,01 0,05
Минимальная численность выборки 5 6 7 8
Обсуждение см. в [180, т.2, с. 135]. Для больших выборок время решения задачи может быть продолжительным, что вызвано значи
Непараметрические тесты
101
тельным объемом вычислений, поэтому при больших численностях выборок вместо описанного здесь критерия рекомендуется применять представленные ниже 1Г-критерий Вилкоксона [180, т. 2, с. 123], [37, с. 234] и критерий Ансари—Брэдли [70, с. 337] либо модифицированный критерий Вилкоксона [там же, с. 336], которые являются критериями ранговой рандомизации. Имеются варианты рассмотренного критерия, например критерий Фишера—Питмэна [190, с. 470], при алгоритмическом построении функции вычисления которого могут быть использованы фрагменты показанной ниже функции RandomCriterionlndependent. Представленная функция очень компактна вследствие применения рекурсии при вычислении благоприятных сочетаний.
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include "megastat.h"
void main (void)
{
int Code. // Код ошибки
nx = 6. // Численность первой
// выборки
ny = 3; // Численность второй
// выборки
double х[] = {1,0.73.2,0.51.0.39,0.67}.// Первый массив
у[] = {1.22,1.8.2.22}, // Второй массив
criterion; // Значение критерия
Code = RandomCriterionlndependent (x.y.nx.ny.&criterion);
if (’Code)
cout « "alpha = " « criterion « endl;
el se
cout « "Not enough memoryXn";
}
int RandomCriterionlndependent (double x[],double y[],int nx.int ny.double Criterion)
//
// Функция вычисляет значение критерия рандомизации для
// несвязанных выборок.
// Обозначения:
// х - первая выборка,
// у - вторая выборка,
// пх - численность первой выборки,
// пу - численность второй выборки.
// *criterion - вычисленное значение критерия.
102
Глава 2. Проверка гипотез
// Возвращаемое значение:
// 0 при нормальном окончании счета.
// -1 при недостатке памяти для размещения рабочих массивов. //
{
register int j.k; // Счетчик цикла
гэдьь int n, // Численность суммарного массива
' m. // Численность выборки сочетаний
Code: // Возвращаемый код ошибки
double nSUCCESS = 1, // Число благоприятных исходов
*dat, // Суммарный массив
sum, // Сумма вариант
sumx, // Сумма вариант массива х
sumy; // Сумма вариант массива у
///////////////////////////////// // Выбор массива с меньшей суммой sumx = VectorSum (x,nx);
sumy = VectorSum (y.ny);
if (sumx >= sumy)
{
m = ny; sum = sumy;
}
el se { m = nx; sum = sumx;
}
////////////////////////////////
11 Построение суммарного массива n = nx + ny;
if ((dat = new double[n]) == 0) return -1;
k = 0;
for (j = 0; j < nx; j++) dat[k++] = x[j];
for (j = 0; j < ny; j++) dat[k++] = y[j];
///////////////////////////////
// Вычисление значения критерия
if (’(Code = Combination (dat,n,m,sum,&nSUCCESS)))
♦criterion = nSUCCESS / (Factorial (n) / Factorial (nx) / Factorial (ny));
delete [] dat;
return Code;
}
Непараметрические тесты
103
Критерий рандомизации компонент для связанных выборок
Критерий рандомизации компонент для связанных выборок применяется для проверки нулевой гипотезы о равенстве средних двух связанных совокупностей, в качестве которых взяты параметры некоторой группы испытуемых объектов до и после воздействия какого-либо фактора, например параметры группы больных до применения некоторой методики лечения и после лечения с целью выявления статистически значимого эффекта от методики лечения.
Основным моментом в реализации критерия является перебор возможных исходов, построенных из разностных отметок. Пусть даны две выборки: xt и yit i = 1,2,..., и, где п — число пар экспериментальных значений. Тогда сумма массива разностных отметок будет
i=l
Определим значения разностных отметок:
>1
где aijt i = 1,..., 2n,j =1,2,..., и, — элементы матрицы возможных исходов.
Систематизацию перебора всех возможных исходов мы проведем в соответствии с ортогональным планом эксперимента первого порядка, методика построения которого изложена в разделе «Полный ортогональный план» главы 12. Размер полного ортогонального плана составляет 2п строк на п столбцов, причем j-й столбец размером 2п представляет собой чередующиеся с шагом 2 t величины +1 и -1, j = 1,2,..., и.
Число благоприятных исходов вычисляется по формуле
2я
ЛГ= Л./Г ~
»=1
0,^<5 l,s. >5
Одностороннее P-значение, вычисляемое по формуле
р = ЛГ/2и,
104
Глава 2. Проверка гипотез
сравнивается с заданным уровнем значимости а. Например, проверяется нулевая гипотеза о равенстве средних двух выборок на уровне значимости 0,05. Пусть вычислено р = 0,932022 < 0,95. Нулевая гипотеза об отсутствии статистически значимого различия средних принимается на уровне значимости более 0,05.
В нашей реализации ортогональный план не хранится в памяти компьютера во время вычислений — каждая очередная строка насчитывается при необходимости. При больших численностях сравниваемых выборок время расчета может стать неприемлемо большим для диалоговой системы, поэтому в этих случаях рекомендуется применять Г-критерий Вилкоксона, являющийся критерием ранговой рандомизации [172, с. 116].
Хотя критерий рандомизации применяют для анализа малых выборок, минимальные численности выборок не должны быть меньшими, чем указано в табл. 2.3. Обсуждение с примерами см. в [там же, с. 109,120], [190, с. 468].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void)
{
int n = 16; // Численность
// каждого массива
double x[] = {0.64.0.73.0.67.0.82.0.81.0.82.0.86.0.85,
// Первый массив
0.73.1.00.0.81.0.87.0.90.0.80.0.71.0.74}.
y[] = {0.77.0.77.0.77.0.83.0.83.0.77.0.84.0.90.
// Второй массив
0.91.0.93.0.90.0.78.0.88.0.89.0.72.0.73}, criterion; // Значение статистики
// критерия
if (IRandomCriterion (х.у,n.&criterion)) cout « "alpha = " « criterion « endl:
el se
cout « "Not enough memory\n";
}
int Randomcriterion (double x[],double y[].int n.double ♦criterion)
//
Непараметрические тесты
105
// Функция вычисляет значение критерия рандомизации для // связанных выборок.
// Обозначения:
// х - первая сравниваемая выборка,
// у - вторая сравниваемая выборка,
// п - численность каждой выборки.
// *criterion - вычисленное значение критерия.
// Возвращаемое значение:
// 0 при нормальном окончании счета.
// -1 при недостатке памяти //
{
register int i;
int *step.
*a;
long int j.
n2 = 2 « (n - 1):
double nl = 0,
*dat.
sum = 0.
suml;
для размещения рабочих массивов.
// Счетчик цикла
// Вектор шагов чередования
// Строка матрицы планирования
// Счетчик цикла
// Число возможных исходов
// Число благоприятных исходов
// Массив модулей разностей
// Пороговое значение
// Текущая сумма
if (!(dat = new double[n])) return -1:
if (!(step = new int[n]))
{
delete [] dat;
return -1;
}
if (!(a = new int[n]))
(
delete [] dat; delete [] step; return -1;
}
for (i = 0; i < n; i++)
{ dat[i] = x[i] - y[i];
sum += dat[i];
dat[i] = fabs (dat[i]): step[i] » TwoDegree (i); a[i] - -1;
}
///////////////////////////////// // Перечисление возможных исходов for (j = 0; j < n2; j++)
{
for (i = 0. suml = 0; i < n; i++)
106
Глава 2. Проверка гипотез
{
if (j / step[i] * step[i] == j) a[i] *= -1:
suml += dat[i] * a[i];
}
////////////////////// // Благоприятный исход if (suml >= sum) 2 nl++:
}
/////////////////////////////// // Вычисление значения критерия Criterion = nl / n2;
delete [] dat: delete [] step; delete [] a;
return 0;
}
l/U-критерий Вилкоксона
W-критерий Вилкоксона (критерий ранговых сумм Вилкоксона, двухвыборочный критерий Вилкоксона, статистика ранговой суммы Уилкоксона, Wilcoxon signed-rank test) применяется для сравнения двух независимых совокупностей одинаковой или разной численности по их центральной тенденции. Иначе говоря, по критерию Вилкоксона сравнивают центры двух эмпирических распределений, или эмпирические функции распределений [37, с. 233]. Этот критерий называется ранговым, так как он оперирует не численными значениями вариант, а их рангами, то есть местами в рядах, упорядоченных по возрастанию или убыванию вариант. Рассматриваемый критерий — один из самых популярных тестов среди исследователей-биологов и медиков и, исторически, один из первых критериев, основанных на рангах [187, с. 117]. Он является критерием ранговой рандомизации [190, с. 472] — процедура точного вычисления критерия Вилкоксона практически не отличается от вычисления критерия рандомизации компонент [37, с. 234], [180, т.2, с. 129] за исключением того, что манипуляции в алгоритме вычисления критерия Вилкоксона производятся не с самими вариантами выборок, а с их рангами.
Ранжирование сравниваемых выборок производят совместно. Данная процедура может быть организована различными способами, однако предпочтительным в смысле простоты реализации является объединение двух выборок, их сортировка, ранжирование и последующее разнесение рангов на места соответствующих им вариант
Непараметрические тесты
107
в обеих выборках. Если имеются совпадающие значения, совпавшим наблюдениям условились назначать средний ранг [37, с. 237]. Затем вычисление 1У-статистики критерия производится по формуле
ir = min|
I-1 1=1 J
где К., i = 1,..., nv— ранги выборки, имеющей наименьшую сумму рангов,
5., 2=1,..., п2 — ранги выборки, имеющей наибольшую сумму рангов. Если меньшая из сумм рангов меньше верхнего критического значения, различие между рядами достоверно на заданном стандартном доверительном уровне. Асимптотическая формула распределения статистики критерия дана в [32, с. 93]. Простая формула связи рассматриваемого критерия с СЛкритерием Манна—Уитни приведена в [151, с. 331], [120, с. 54], поэтому данный и следующий из описанных критериев в некоторых источниках носят наименование критериев Вилкоксона—Манна—Уитни. Как показано в главе 4, функция вычисления распределения {/-статистики Манна—Уитни может быть с успехом использована при вычислении точных значений распределения УУ-статистики критерия Вилкоксона.
Для практического вычисления критерия нами применяется другой подход [37, с. 236], [187, с. 120], основанный на том факте, что статистика
1У-Е[1У]
где£[1У] = + 1)/2 — математическое ожидание,
D[W] = 22^2^+ 1)/12 — дисперсия, которая при наличии совпадающих вариант корректируется, как показано в разделе «Непараметрические множественные сравнения» данной главы,
N= п{ + п2, распределена по стандартному нормальному закону. Если полученное значение статистики превышает 0,02, то в формулу вводится поправка на непрерывность: считается, что новое значение наименьшей суммы рангов равно W + 0,5 [37, с. 236]. Приведем простой пример. Пусть вычислено одностороннее Р-зна-чение, равное 0,033097. На уровне значимости < 0,05 принимается конкурирующая гипотеза о различии выборок.
108
Глава 2. Проверка гипотез
Методику вычисления критерия подробно приводят многие авторы. Мы рекомендуем [70, с. 326], [84, с. 264], [158]. Рассуждения с примером применения см. в [28, вып.2, с. 108], [156, с. 119]. Авторы [26, с. 132], [50, с. 141], [1111, с. ИЗ] описывают критерий Уайта, по технике вычислений совпадающий с представленным здесь критерием. Критерий Сэвиджа представлен [14, с. 132], критерий Кокса [14, с. 134]. Рассматривается обобщение критерия Вилкоксона на случай, когда анализируется более двух выборок [37, с. 239]. В этом случае критерий носит наименование Н-критерия Крускала (Крас-кела) и Уоллиса. Описана модификация критерия Вилкоксона, известная как критерий нормальных меток Фишера—Иэйтса—Терри—Гефдинга, отличающаяся от критерия Вилкоксона способом ранжирования [123, с. 193], а также критерий Фишера—Иэйтса [115, с. 265]. Все упомянутые варианты ранговых критериев могут быть получены из составленной нами функции путем незначительной модификации ее кода. В [70, с. 336] описан модифицированный критерий Вилкоксона, отличающийся по методике вычислений от W-критерия Вилкоксона только особым способом ранжирования. В сети Интернет по данной теме см. материалы, представленные на сайте «Высокие статистические технологии» (antorlov.nm.ru).
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void)
{
double x[] = // Первая выборка
{12.0072.12.0064.12.0054.12.0016.12.0077}, y[] = // Вторая выборка
{11.9853.11.9949.11.9985.12.0061}. criterion, // Значение статистики
// критерия t; // Параметр
// аппроксимации
int nx = sizeof (х) / sizeof (double). // Численность первой // выборки
ny = sizeof (у) / sizeof (double); // Численность второй // выборки
if (’WilcoxonTest (x.y.nx.ny.&criterion.&t))
Издание 1980 года.
Непараметрические тесты
109
cout « "Статистика критерия " « criterion
« "ХпАппроксимация " « t
« "\пР-значение " « (1.0 - NormalDistributionl (t)) « endl:
el se
cout « "Мало памятиХп":
}
int WilcoxonTest (double x[],double y[].int nx.int ny.double ♦criterion.double *t) // // Функция вычисляет значение W-критерия Вилкоксона // для односторонней гипотезы. // Обозначения: // х - первая сравниваемая выборка. // у - вторая сравниваемая выборка. // пх - численность первой выборки. // пу - численность второй выборки, // *criterion - вычисленное значение критерия, // *t - параметр нормальной аппроксимации. // Возвращаемое значение: // 0 при нормальном окончании счета. // -1 при недостатке памяти. // { register int i; // Счетчик
int *ix = 0, n = nx + ny. save; // Информация о перестановках // Общая численность // Буфер
double *xx.*yy, *xy. xn = 0,yn tt; = 0 // Массивы рангов // Рабочий массив . // Суммы рангов // Поправка на объединение рангов
if (1(ix = new int[n])) return -1:
if (!(xy = new double[n]))
{ delete [] ix: return -1:
}
if (!(xx = new double[n]))
{ delete [] ix: delete [] xy; return -1:
}
if (!(yy = new double[ny]))
{
delete [] ix: delete [] xy: delete [] xx: return -1:
}
110 Глава 2. Проверка гипотез
////////////////////////////
// Слияние исходных массивов
for (1=0; 1 < nx; 1++) ху[1] = х[1];
for (1 = 0; 1 < пу; 1++) ху[1 + пх] = у[1];
М//////////////////////////// +2 // Сортировка по возрастанию
SortArrayUp (ху,п,1х,1);
lllllllllllllll
// Ранжирование tt = Rank (xy,xx,n);
////////////////////////////////
// Восстановление порядка рангов UnSortArray (xx.xy,n,ix);
lllllllllllllll НШП III
II Вычисление суми рангов for (1=0: 1 < nx; 1++) xn += xy[i];
for (1=0; 1 < пу; 1++) yn += xy[1 + nx];
11IllllllIII III III III III Illlllllllllllll!Ill III
II Параметры выборки с наименьшей суммой рангов
if (хп <= уп)
*criterion = хп;
el se { ♦criterion = уп; save = пу;
пу = пх; nx = save;
}
////////////////////////////////////
// Параметр нормальной аппроксимации
*t = fabs ((*criterion) - 0.5 * nx * (n + 1)) /
sqrt (0.0833333333 * nx * ny * (n + 1 - tt / n / (n -1)));
//////////////////////////////////////
// Расчет с поправкой на непрерывность
if ((1.0 - NormalDistributionl (*t)) > 0.02)
*t = fabs ((*criterion + 0.5) - 0.5 * nx * (n + 1)) /
sqrt (0.0833333333 * nx * ny * (n + 1 - tt / n / (n - 1)));
delete [] ix; delete [] xy: delete [] xx; delete [] yy;
return 0;
}
Непараметрические тесты
111
(/-критерий Манна—Уитни
[/-критерий Манна—Уитни (Вилкоксона—Манна—Уитни) предназначен для проверки нулевой гипотезы о том, что совокупности распределены одинаково, или для проверки равенства других характеристик, например средних. Наблюдения должны быть независимыми (непарными). Вычисления производятся по формулам [158, с. 171]:
Ц = + + 1)/2-Яр
(/2 = + П2(П2 + 1)/2 - R2,
U = max (Ц,[/2),
где Rt и R2 — суммы рангов выборок,
и п2 — численности соответствующих выборок.
В другой записи статистика Манна—Уитни определяется эквивалентным выражением [120, с. 53]
м >1
где/гу =
и 7-1 2 п °»Х,(О^Х2О)
В [229, с. 35] по данной формуле вычисляется статистика Вилкоксона, причем заслуживают внимания также рассуждения о применении бутстреп-метода для вычисления статистики.
Имеются [151, с. 331] рекуррентные формулы точного вычисления критического значения (/-статистики, пригодные для составления подробных статистических таблиц, реализованные в главе 4. Практически значимость может вычисляться посредством нормальной аппроксимации критического значения критерия. Как показал опыт расчетов, это не ведет к большой погрешности даже при малых выборках (размером 6 и выше). При этом модифицированная статистика
U-E[U]
где £[[/] = nln2 /2 — математическое ожидание,
112
Глава 2. Проверка гипотез
Z>[L/] = пгп2 + 1 )/12 — дисперсия, которая в случае совпадений корректируется, как показано в последнем разделе параграфа,
N = пх + п2,
распределена по стандартному нормальному закону [57, с. 76], [158, с. 173], [174, с. 130].
Результаты вычислений с помощью описываемого критерия совпадают с результатами применения lV-критерия Вилкоксона. Методику вычисления критерия и примеры см. в [26, с. 134], [52, с. 327], [57, с. 72,76], [140, с. 228], [172, с. 79], [180, т. 2, с. 129], [190, с. 465]. Простая формула связи рассматриваемого критерия с W-критери-ем Вилкоксона приводится также в [28, вып. 2, с. 111], поэтому можно было бы вообще не рассматривать критерий Манна—Уитни отдельно, однако, во-первых, он традиционно применяется многими исследователями (в частности, физиологами), а во-вторых, на статистике 17-критерия Манна—Уитни основан многомерный тест Джонкхиера—Терпстра.
Исходные коды
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void)
{ double x[] = // Первая выборка
{12.0072,12.0064,12.0054,12.0016.12.0077}.
y[] = // Вторая выборка
{11.9853,11.9949.11.9985.12.0061}. criterion, // Значение статистики
// критерия
t; // Параметр аппроксимации
int nx = sizeof (х) / sizeof (double),// Численность первой
// выборки
ny = sizeof (у) / sizeof (double);// Численность второй
// выборки
if (IMannWhitneyTest (x.y.nx.ny.&criterion.&t)) cout « “Статистика критерия " « criterion
« "ХпАппроксимация " « t « "\пР-эначение “ « (1.0 - NormalDistributionl (t)) « endl;
else cout « "Мало памяти\п“;
}
Непараметрические тесты 113
\
int MannWhitneyTest (double х[],double y[].int nx.int ny.double ♦criterion.double *t)
// 1
// Функция вычисляет значение U-критерия Манна-Уитни.
// Обозначения:
// х - первая сравниваемая выборка,
// у - вторая сравниваемая выборка.
// пх - численность первой выборки.
// пу - численность второй выборки.
// *criterion - вычисленное значение критерия,
// *t - параметр нормальной аппроксимации.
// Возвращаемое значение:
// 0 при нормальном окончании счета.
// -1 при недостатке памяти.
//
{
int *ix, // Информация об отсортированном массиве
п - пх + пу; // Общая численность
register int i.j; // Счетчик
double buf. // Значение критерия U1
*s, // Объединенный массив
*хх. // Массив рангов
tt; // Поправка на объединение рангов
if (!(s = new double[n])) return -1;
if (!(ix = new int[n]))
{ delete [] s; return -1;
}
if (!(xx = new double[n])) Г
delete [] s; delete [] lx;
return -1;
}
///////////////////////////////////
// Построение объединенного массива
J = 0;
for (i = 0; i < nx; i++) s[j++] = x[i];
for (i = 0; i < ny; i++) s[j++] - y[i];
// Сортировка по возрастанию SortArrayUp (s,nx + ny.ix.l);
llllllllllllllllllll
11 Вычисление рангов
114
Глава 2. Проверка гипотез
tt = Rank (s.xx,n);
lllllllllllllllllllllllllllllllllllllllllllllllllll II Восстановление порядка рангов массива со знаками UnSortArray (xx,s,nx + ny.ix);
///////////////////////////////
// Вычисление значения критерия
but = nx * ny + пх * (пх + 1) / 2 - VectorSum (s,nx); ♦criterion - MaximumOf (buf.nx * ny - buf);
//////////////////////////////////// // Параметр нормальной аппроксимации *t = (*criterion - 0.5 * nx * ny) / sqrt (0.0833333333 * nx * ny * (n + 1 - tt / n / (n -1))):
delete [] xx; delete [] ix; delete [] s;
return 0;
}
T-критерий Вилкоксона для связанных выборок
Г-критерий Вилкоксона (одновыборочный критерий Вилкоксона, знаковый ранговый критерий Уилкоксона, критерий знаковых рангов Уилкоксона), в отличие от W-критерия Вилкоксона, применяется для сравнения выборок с попарно сопряженными вариантами. Критерием проверяется статистическая значимость нулевой гипотезы о том, что распределение случайных величин (эти случайные величины в рассматриваемом нами случае представляют собой разности случайных величин, соответствующих двум другим выборкам) симметрично относительно нуля [37, с. 241]. Например, критерием сравниваются выборки, представляющие собой параметры одной и той же совокупности до и после воздействия некоторого фактора с целью выявления эффекта от воздействия данного фактора. Другое название критерия — критерий Вилкоксона для сопряженных пар, Г-дельта-критерий, W-критерий Вилкоксона [1111, с. 115], [28, вып. 2, с. 123], [52, с. 338] либо просто критерий Вилкоксона.
Как и в предыдущем случае, методика точного вычисления критерия полностью совпадает с критерием рандомизации компонент для связанных выборок с тем исключением, что манипуляции производятся не с вариантами выборок, а с их рангами. Методика приближенных
Издание 1980 года.
Непараметрические тесты
115
вычислений похожа на процедуру вычисления W-критерия Вилкоксона, однако здесь мы оперируем абсолютными величинами разностей вариант. Массив разностей ранжируется. Затем рангам добавляются знаки разностей, и вычисляется наименьшая из сумм положительных W+ рангов, которая сравнивается с критическим значением. Функция WilcoxonTDistribution, вычисляющая уровень значимости нулевой гипотезы об отсутствии статистически значимых различий между выборками, может применяться для построения таблиц распределения критических значений критерия, в том числе в областях варьирования параметра, не затабулированных в литературных источниках.
Для практического вычисления критерия мы применяем подход [37, с. 243], [187, с. 127], учитывающий факт, что статистика
W+-E[W+]
где £[W+] = N(N+ 1)/4 — математическое ожидание,
£)[№+] = N (N + 1)(2N + 1)/24 — дисперсия, которая в случае совпадений рангов корректируется, как показано в разделе «Проблема совпадений в критериях Вилкоксона» данной главы,
N— численность каждого ряда,
распределена по стандартному нормальному закону.
Пример. Предположим, вычислено P-значение, равное 0,086476. Следовательно, различия можно признать значимыми на уровне значимости <0,1.
Методику вычисления дают [50, с. 139,151], [57, с. 71], [120, с. 55], [156, с. 115], [158, с. 188], [187, с. 126]. В [180, т.2, с. 124] дается более точная аппроксимация Имана и указаны полезные ссылки. Обсуждение см. в [115, с. 271], где также описан одновыборбчный аналог критерия Фишера—Иэйтса (ссылки в описании W-критерия Вилкоксона).
Исходные коды
#include <fstream.h>
#include <iomanip.h> include <math.h>
#include "megastat.h"
void main (void)
116
Глава 2 Проверка гипотез
double х[] = {1490,1300.1400.1410,1350,1000},// Первая // выборка
у[] = {1600.1850,1300.1500,1400.1010}, // Вторая выборка
criterion, // Статистика теста
t; // Значение
// аппроксимации
int n = sizeof (х) / sizeof (double); // Численность
// каждой выборки
if (!Wi1coxonSignedTest (x.y.n.&criterion.&t))
cout « "Статистика " « criterion « "ХпАппроксимация " « t
<< "\пР-значение " <<(1.0 - NormalDistributionI (t)) << endl; el se
cout « "Мало памяти для вычислений\п";
}
int WilcoxonSignedTest (double x[],double y[].int n,double ♦criterion,double *t) //
// Функция вычисляет значение парного Т-критерия Вилкоксона.
// Обозначения:
// х - первая сравниваемая выборка,
// у - вторая сравниваемая выборка,
// п - численность каждой выборки,
// *criterion - вычисленное значение критерия.
// *t - параметр нормальной аппроксимации.
// Возвращаемое значение:
// 0 при нормальном окончании счета.
// -1 при недостатке памяти,
// -2 при ошибке в вычислениях.
//
{
register int i.j; // Счетчик
int *ix; // Информация о сортировке
double *spx,*spy,// Копии исходных массивов
*хх. // Массив рангов
save; // Буфер, затем поправка на объединение рангов
if (!(spx » new double[n]))
return -1;
if (!(spy » new double[n]))
{
delete [] spx;
return -1;
}
///////////////////////////////////////
// Работаем с копиями исходных массивов
Непараметрические тесты
117
ArrayToArray (x.spx.n);
ArrayToArray (y.spy.n);
/ / / / / / / / / / / / / / / / / И /
// Массивы разностей
for (i = 0; i < n; i++)
{
save = spx [i];
spx[i] = fabs (spxfi] - spyfi]); // Разности без знаков spy[i] = save - spy[i]; // Разности co знаками
}
if (!(ix = new int[n]))
{
delete [] spx; delete [] spy;
return -1;
}
////////////////////////////
// Сортировка по возрастанию
SortArrayUp (spx.n.ix.l):
if (!(xx = new double[n]))
{
delete [] spx; delete [] spy: delete [] ix;
return -1;
}
lllllllllllllll
II Ранжирование
save = Rank (spx.xx.n);
///////////////////////////////////////////////////
// Восстановление порядка рангов массива со знаками UnSortArray (xx,spx.n,ix);
delete [] ix; delete [] xx;
///////////////////////////////////////
// Сумма рангов положительных разностей
for (i = 0, Criterion = 0; i < n; i++)
if (spy[i] >= 0)
(♦criterion) += spxfi]:
delete [] spx: delete [] spy;
*t = fabs ((*criterion) - 0.25 * n * (n + 1)) /
sqrt (0.0416666667 * n * (n + 1) * (2 * n + 1) -
0.0208333333 * save);
return 0;
}
118
Глава 2. Проверка гипотез
Критерий Ансари—Брэдли
Критерий Ансари—Брэдли относится, как и описанные выше критерии Вилкоксона и Манна—Уитни, к группе критериев ранговой рандомизации и предназначен для статистической проверки нулевой гипотезы о равенстве дисперсий двух совокупностей. Вычисления статистики критерия производятся по формулам [70, с. 337]:
4 ‘ 4
' 48и,(и-1) п2(п-2)(и +2)
если п — четное,
W =
f 48n,(n-l)
п2(п +1)(и +3)
, если п — нечетное,
где Rt, i -1,..., nv — ранги первой выборки,
— численность первой выборки,
п2 — численность второй выборки, п — общая численность двух выборок, причем процедура присвоения рангов отличается от аналогичной процедуры для рассмотренного ранее критерия Вилкоксона. Данная процедура подробно описана в [там же, с. 338] и может быть проиллюстрирована показанным исходным текстом программы. Распределение величин W при больших численностях выборок примерно совпадает со стандартным нормальным распределением. При этом выводы могут быть такими: предположим, вычислен доверительный уровень 0,968. Следовательно, наблюдается статистически значимое различие между выборками на доверительном уровне более 0,95 (ближайшее стандартное значение, не превышающее вычисленное) или уровне значимости менее 0,05.
Описанный критерий, в отличие от критериев Вилкоксона и Манна-Уитни, мало применяется отечественными исследователями, но популярен за рубежом. Метод включен во многие программные продукты анализа данных и пакеты прикладных программ. См. также [156, с. 125].
Исходные коды
#include <fstream.h>
#include <iomanip.h>
^include <math.h>
Непараметрические тесты
119
#include "megastat.h"
void main (void)
{
int nx = 10. // Численность первой выборки
ny = 12: // Численность второй выборки
double х[] = // Первая выборка
{3.6,3.91.3.75.4.03.3.96.3.4,3.67.3.72.4.01.3.64}. у{] = // Вторая выборка
{3.65,3.84.3.77,3.82.3.76.3.54.3.8,3.73,3.76.3.69.3.73,3.63}. w; // Статистика критерия
if (!(AnsariBradleyTest (х.у,nx,ny,&w)))
cout << "W = " « w « ". p = " << NormalDistribution (w)
<< endl:
el se
cout « "Мало памяти\п";
}
int AnsariBradleyTest (double xL],double y[].int nx.int ny,double *criterion)
//
// Функция вычисляет значение критерия Ансари-Брэдли.
// Обозначения:
// х - первая сравниваемая выборка.
// у - вторая сравниваемая выборка,
// пх - численность первой выборки.
// пу - численность второй выборки.
// *criterion - вычисленное значение критерия.
// Возвращаемое значение:
// 0 при нормальном окончании счета,
// -1 при недостатке памяти.
//
{ register int i.j; // Счетчик
int n = nx + ny, // Общая численность массивов
*ix, // Вспомогательный информационный массив
nn; // Рабочая переменная
double *г. // Общий массив, затем массив рангов
*s; // Рабочий массив
if ((г = new doubleLn]) == 0) return -1;
if ((s = new doubleLn]) == 0)
{ delete L] r; return -1:
}
if ((ix = new intLn]) =» 0)
120
Глава 2, Проверка гипотез
{ delete [] г: delete [] s: return -1:
}
///////////////////
II Слияние массивов
for (i = 0; i < nx; i++) r[i] = x[i]:
for (1 = nx. j = 0: i < n; i++, j++) rfi] = y[jl;
//////////////////////////// // Сортировка общего массива SortArrayUp (r.n.ix.l):
//////////////////////////////
// Ранжирование общего массива
if (Parity (n))
{ nn = n / 2; for (i = 0. j = nn; i < nn; i++) r[i] = j—;
} el se
{ nn = (n - 1) / 2; for (i = 0. j = nn; i <= nn; i++) r[i] = j—;
}
for (i = nn. j = 1; i < n; i++) r[i] = j++;
/////////////////////////////////////// II Восстановление оригинального порядка UnSortArray (r.s.n.ix);
///////////////////////////////
// Значение статистики критерия
if (Parity (n))
♦criterion = (VectorSum (s.nx) / nx - (n + 2) / 4) *
sqrt (48.0 * nx * (n - 1) / ny / (n - 2) / (n + 2));
el se
♦criterion = (VectorSum (s.nx) I nx - (n + 1) * (n + 1) / 4 /n)*
sqrt (48.0 * nx * (n - 1) / ny / (n + 1) / (n + 3));
delete □ r; delete [] s; delete [] ix;
return 0;
}
Непараметрические тесты
121
Проблема совпадений в критериях Вилкоксона
Рассмотрим две проблемы, возникающие при использовании критериев типа критерия Вилкоксона.
Первая проблема — равных рангов — не имеет места при точном вычислении статистик критериев, а возникает только при вычислении нормальной или иной аппроксимации критериев. При наличии совпадений в паре анализируемых выборок совпадающим наблюдениям приписывается средний ранг [37, с. 237], что удобнее всего сделать с помощью функции ранжирования Rank. При этом формулы для вычислений нормальных аппроксимаций статистик критериев остаются совершенно теми же, однако формулы для дисперсий, применяемых для их вычисления, корректируются.
Для W-критерия Вилкоксона соотношения для дисперсии запишутся как [37, с. 238]
у+1------£— ,
12 L N(N-i)
где Т— поправка на объединение рангов, определенная в разделе «Ранжирование» главы 1,
N = n{ + п2,
остальные обозначения те же, что и ранее.
Для 17-критерия Манна—Уитни модифицированные соотношения для дисперсии запишутся точно так же, как для W-критерия, [174, с. 130] с той лишь разницей, что вместо £)[ W] следует записать D[U]. Для Т-критерия Вилкоксона новая дисперсия будет считаться по формуле [187, с. 128]
N(N+1)(2N + 1) Т
1 J 24 48 ’
где N — численность каждого ряда, остальные обозначения те же, что и ранее.
В составленных программах совпадения учитываются. Легко заметить, что модифицированные соотношения при числе связок, равном нулю, обращаются в обычные соотношения. Следовательно, достаточно использовать только формулы для модифицированных соотношений, а в обычном случае поправка на объединение рангов просто полагается равной нулю.
122
Глава 2, Проверка гипотез
Другая проблема, возникающая только в алгоритме вычисления Г-критерия Вилкоксона,— наличие совпадений одновременно в двух анализируемых выборках, что приводит к нулевым разностям. В [37, с. 244], [84, с. 269] применяется прием вычеркивания равных сопряженных вариант из сравниваемых выборок. При этом соотве-ственно уменьшаются объемы выборок на количество выброшенных значений [187, с. 127]. Если будет принято решение воспользоваться этим алгоритмом, его удобнее и проще будет реализовать непосредственно перед вызовом функции вычисления статистики Г-критерия, не утяжеляя саму функцию данной процедурой. Функция может быть запрограммирована подобно методу Compare из главы 14, однако нужно учесть, что выбрасывать нужно только сопряженные пары, тогда как в методе Compare решается более общая задача.
Из сказанного уже понятно, что в настоящее время проблема совпадений не может считаться до конца решенной [37, с. 244], [187, с. 123].
Критерии^2
2
Критерий X имеет множество применений при проверке гипотез, в дисперсионном анализе и при использовании других методов анализа данных. Критерий предназначен для проверки нулевой гипотезы о том, что исследуемые случайные величины имеют одинаковое распределение. Рассмотрим применение критерия для признаков, измеренных (оба признака сразу) в количественной, порядковой или номинальной шкалах. Случаи, когда шкалы измерений сравниваемых выборок различны, будут рассмотрены позднее.
Критерий X* количественных и порядковых признаков
Вычисление статистики критерия X2 при сравнении эмпирических распределений равного объема производится по формуле [84, с. 270-283]
r2_^(Z~g.)2 Х Ь f^g,
где/, gt, i =1,2,..., п,— частоты распределений сравниваемых выборок, — численность каждого массива частот распределения.
Непараметрические тесты
123
При сравнении эмпирических распределений разного объема (численности массивов частот распределений должны совпадать) формула должна быть видоизменена:
У г _ 1 у (fin2 ~8jni) ( fi+gi ’
2
где nv п2 — численности сравниваемых выборок.
При = п2, вторая формула, как можно заметить, в точности соответствует первой, поэтому в программу заложена именно она. При этом размеры рядов в функцию не передаются — они вычисляются как суммы соответствующих вариационных рядов.
Для применения критерия ряды частот распределения должны иметь одинаковый объем и одинаковые классовые интервалы, что гарантируется при разнесении вариант по классам функцией А11о-cateCommon.
Необходимо обратить внимание, что критерий /2 оперирует не первичными данными, а распределениями вариант сравниваемых совокупностей по классам, поэтому должны соблюдаться минимальные требования о величинах анализируемых выборок. В случае, если число классов меньше 7, корректность вычислений будет под вопросом, хотя минимальная величина выборки равна 4. Данным критерием рекомендуется проводить сравнение рядов длиной не менее 40, по другим данным — не менее 20 [195, с. 128].
Доверительный уровень вычисляется функцией ChiSquareDistri-bution при числе степеней свободы (п - 1).
Многочисленные примеры применения критерия и обсуждение даны в [84, с. 273], [28, с. 35], [140, с. 119]. В [180, т.1, с. 365] анализируются сложности применения критерия по поводу объединения соседних классов с малой численностью.
Исходные коды
double ChiSquare (double fl[],double f2[],int n) //
// Функция вычисления значения критерия хи-квадрат Пирсона // для проверки нулевой гипотезы о том. что две независимые // случайные величины имеют одинаковое распределение.
// Обозначения:
// fl - массив частот распределения 1-го ряда.
// f2 - массив частот распределения 2-го ряда,
// п - численность каждого массива частот распределения.
// Возвращаемое значение:
124
Глава 2 Проверка гипотез
// значение критерия хи-квадрат. //
{
register int i; // Счетчик цикла
double chi = 0. // Возвращаемое значение
s, // Вспомогательная переменная
nl, // Число вариант 1-го ряда
п2; // Число вариант 2-го ряда.
nl = VectorSum (fl.n);
n2 = VectorSum (f2,n);
for (i = 0; i < n; i++)
if (fl[i] + f2[i] != 0)
{
s = fl[i] * n2 - f2[i] * nl;
chi += s * s / (flfi] + f2[i]): }
return chi / nl / n2: }
Критерий Z2 для номинальных признаков
2
Рассмотрим применение критерия X для анализа таблиц сопряженности признаков (критерий однородности X ) [24, с. 77]. Анализируются номинальные (при числе градаций, равном двум,— бинарные, или дихотомические) или приведенные к номинальной шкале данные, представленные в виде таблицы сопряженности признаков. По столбцам данной таблицы расположены градации анализируемых признаков, по строкам — анализируемые выборки. Каждый элемент таблицы представляет собой число, выражающее количество индивидуумов, которые имеют признак, соответствующий данной градации. Таким образом, схема вычислений позволяет количественно выразить степень зависимости между анализируемыми номинальными выборками. Вычисления статистики критерия производятся по формуле
где а , i = 1,2,..., r,j =1,2,..., с, — таблица сопряженности признаков, г — число столбцов таблицы (число выборок), с — число строк таблицы (число градаций признака),
Непараметрические тесты
125
eijt i = 1,2,r,j = 1, 2,..., с, — соответствующие а~ ожидаемые величины, вычисляемые как произведение i-ro столбца и J-й строки, деленное на сумму элементов всей таблицы сопряженности.
Число степеней свободы для вычисления P-значения статистики критерия X берется [89, с. 73] равным (г- 1)(с - 1).
Наименование функции, производящей вычисления статистики критерия, взято по имени ученых, изучивших вычисление критерия для случая с = 2 [24, с. 82]. Необходимое пояснение: исходные данные (таблица сопряженности) в показанную функцию вводятся по строкам. В качестве возможного варианта программного решения можно предложить определять суммы столбцов и строк заново при каждом вычислении ожидаемых частот. Это несколько увеличит время вычислений, но позволит отказаться от динамического выделения памяти для рабочих массивов.
Обсуждение дано в [70, с. 294], [101, с. 569], [140, с. 121], [172, с. 51], а в [26, с. 103] приводится подробный пример анализа четырехпольных (четырехклеточных) таблиц медицинских данных. В [26, с. 215] приводится обсуждение связи статистики X , вычисленной для четырехпольных таблиц, с коэффициентом сопряженности Бравайса (см. главу 5). Критерий X в описанной здесь форме применяется в схеме расчета критерия медианы для случая анализа более 2 выборок [ 172, с. 86]. Формула Брандта и Снедекора представлена в [24, с. 85].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void)
{
int r = 3, // Число столбцов
с » 3. // Число строк
Code; // Код ошибки
double а[] = {65,32,5.26.41.16.8.24,10}. // Таблица
//сопряженности х;
Code = BrandtSnedecor (a.r.c.&x);
cout « "Return code is “ « Code « endl;
if (!Code)
126
Глава 2. Проверка гипотез
cout « “Chi square value is " « x « endl;
cout « "p = " « ChiSquareDistribution C(r - 1) * (c - D.x) « endl;
}
el se
cout « "Not enough memory\n";
}
int BrandtSnedecor (double a[], int r. int c,double *x)
11
// Функция вычисляет хи - квадрат - критерий для таблицы
// сопряженности признаков.
// Обозначения:
//а - таблица сопряженности признаков, представлена по столбцам,
// г - число столбцов таблицы,
// с - число строк таблицы.
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -1 при недостатке памяти для вычислений.
//
register int i.j; // Счетчики цикла
int m = 0; // Индекс массива
double s = VectorSum (a,г * с), // Сумма элементов таблицы
е, // Рабочая переменная
*sr. // Суммы столбцов
*sc; // Суммы строк
*х = 0;
if ((sr = new doublefrj) == 0) return -1;
if ((sc = new doublefc]) == 0)
{ delete [] sr; return -1;
}
/////////////////////////////
// Вспомогательные вычисления
for (i = 0; i < r; i++)
for (j » 0. sr[i] e 0; j < c; j++) sr[i] += a[m++];
for (i = 0; i < c; i++)
for (j - 0, sc[i] « 0, m •• i: j < r; j++, m += c) sc[i] += a[m];
/////////////////////////////// // Вычисление значения критерия
Непараметрические тесты
127
for (i = 0. m = 0: i < г; i++)
for (j « 0: j < c; j++)
{
e = sr[i] * sc[j] / s:
*x += (a[m] - e) * (a[m++] - e) / e;
}
delete [] sr; delete [] sc;
return 0: }
Х-критерий Ван дер Вардена
Х-критерием Ван дер Вардена сравнивают ранжированные ряды вариант по их центральной тенденции. Критерий Ван дер Вардена является ранговым критерием [123, с. 194]. Критериальная статистика вычисляется по формуле
где ni — численность той выборки, в которой меньше вариант,
п2 — численность другой выборки,
х. — ранговые метки,
Т(.) — функция, обратная интегралу вероятности.
Ранжированные ряды не содержат равных вариант, то есть должны быть исключены из рассмотрения пары равных вариант, если таковые окажутся, в обоих сравниваемых рядах.
Критические значения Х-статистики критерия Ван дер Вардена вычисляются с помощью функции InverseXDistribution для заданного доверительного уровня.
Подробно методику вычисления критерия и примеры применения приводят [41, с. 346], [84, с. 266], [ 111, с. 128]. Обсуждение дано в [115, с. 268], [26, с. 135].
Исходные коды
int VanDerWaerdenTest (double х[].double y[].1nt nx.int
ny.double Criterion)
//
И Функция вычисляет значение критерия Ван дер Вардена.
И Обозначения:
И х - первая сравниваемая выборка.
128
Глава 2. Проверка гипотез
// у - вторая сравниваемая выборка,
// пх - численность первой выборки,
// пу - численность второй выборки.
// *criterion - вычисленное значение критерия.
// Возвращаемое значение:
// 0 при нормальном окончании счета,
// -1 при недостатке памяти,
// -2 при ошибке в вычислениях.
//
{
register int i; // Счетчик
int n,nxl,nyl,*ix e 0; // Вспомогательные переменные
double *spx.*spy, *xx,*yy;
if ((spx a new double[nx]) == 0) return -1:
if ((spy = new double[ny]) == 0)
{
delete [] spx;
return -1;
}
/////////////////////////////////////// // Работаем с копиями исходных массивов ArrayToArray (x.spx.nx);
ArrayToArray (y.spy.ny);
////////////////////////////
// Сортировка no возрастанию SortArrayUp (spx.nx.ix.O); SortArrayUp (spy.ny.ix.O);
//////////////////////////////////////////// // Сравнение и вычеркивание равных элементов Compare (spx.spy.nx.ny.&nxl.&nyl);
if ((nxl <= 0) || (nyl <= 0))
return -2;
if ((xx = new doubleEnxl]) == 0)
{
delete Г] spx; delete [] spy;
return -1;
}
if ((yy B new double[nyl]) -» 0)
{
delete [] spx: delete [] spy; delete [] xx;
return -1:
Непараметрические тесты
129
/ / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / // Совместное ранжирование массивов RankCommon (spx.spy.xx.yy.nxl.nyl);
delete [] spx; delete [] spy;
/////////////////////////////// // Вычисление значения критерия n = nx + ny + 1;
2
if (nx < ny)
for (i = O.*criterion = 0; i < nxl; i++)
♦criterion += InverseNormalDistribution (xx[i] / n): el se
for (i = 0,*criterion = 0; i < nyl; i++)
♦criterion += InverseNormalDistribution (yy[i] / n);
♦criterion = fabs (*criterion): delete [] xx; delete [] yy;
return 0; }
Критерий QРозенбаума
Критерий Q Розенбаума предназначен для проверки нулевой гипотезы о том, что совокупности распределены одинаково, или для проверки равенства других характеристик, например средних [151]. Вычисление статистики критерия производится по формуле [57, с. 75]
Q = + S2,
где 5, — количество результатов наблюдений первого ряда, больших максимума второго ряда,
$2 — количество результатов наблюдений второго ряда, меньших минимума первого ряда.
Решение о достоверности различий на выбранном доверительном уровне (0,95 или 0,99) принимается в случае, если вычисленное по выборкам значение критериальной статистики превышает критическое значение. Для применения представленной функции предварительное ранжирование выборок не является обязательным. Критерий нельзя применять при численности хотя бы одной из выборок менее 11. При численности хотя бы одной из выборок более 26 критические значения берутся, как указано в пояснениях к функции (^Distribution.
5 2002
130
Глава 2. Проверка гипотез
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include "megastat.h"
void main (void) {
int nl = 11, n2 = 12. Code, q:
double x[] = {95.100.105.105.110.110.115.115.120,130.135}, y[] = {75.80.80.85.90.95.100.100.105.110.115.115};
cout « "Value of Q = " « Rosenbaum (x.nl,y,n2) « endl;
QDistribution (nl,n2.0.95,&q);
cout « "Critical value of Q is " « q « “ for p = 0.95" « endl;
QDistribution (nl,n2,0.99.&q);
cout « "Critical value of Q is " « q « " for p = 0.99" « endl;
}
int Rosenbaum (double x[].int nl.double y[].int n2) //
// Фукнкция вычисляет значение критерия Q Розенбаума.
// Обозначения:
// х. у. - сравниваемые выборки,
// nl. п2 - размерности сравниваемых выборок.
// Возвращаемое значение:
// Значение критерия.
// {
register int i; // Счетчик цикла
int Retl = 0, // Число элементов первой выборки.
// больших максимума второй
Ret2 = 0; // Число элементов второй выборки.
// меньших минимума первой
double Махх = MaximumOf (x.nl).
Маху = MaximumOf (y,n2). Minx = MinimumOf (x,nl), Miny = MinimumOf (y.n2);
///////////////////// // Ведущий первый ряд if ( Махх > Маху)
Непараметрические тесты
131
{
for (i = 0; i < nl; i++) if (x[i] > Маху)
Retl++;
for (i = 0; i < n2; i++) if (y[i] < Minx)
Ret2++;
}
/////////////////////
// Ведущий второй ряд
el se
{
for (i = 0; i < n2; i++) if (y[i] > Maxx)
Retl++;
for (i = 0; i < nl; i++) if (x[i] < Miny)
Ret2++;
}
2
return Retl + Ret2;
}
Критерий серий Вальда—Вольфовица
Критерий серий Вальда—Вольфовица (Wald—Wolfowitz runs test) предназначен для проверки нулевой гипотезы о равенстве целого ряда параметров двух сравниваемых выборок, включая медианы и коэффициенты асимметрии. Критерий применяется в случае, если исследователя интересует, имеют ли место любые различия между генеральными совокупностями. Описание методики вычисления критерия дано в [172, с. 82], [84, с. 267]. Суть расчета заключается в объединении выборок с численностями и п2 в одну выборку численностью п = т\ + п2, сортировке объединенного массива по возрастанию или убыванию и подсчете числа серий элементов R, относящихся к первой и второй выборкам.
Для вычисления доверительного уровня применяется функция 1п-verseSerialDistribution. Дополнительно показан вызов функции Se-rialDistribution, демонстрирующий реальные критические границы статистики критерия, внутри которых принимается гипотеза об отсутствии различий. Так, в примере хорошо видно, что для статистики критерия, равной 24, вероятность различий между выборками равна 0,96 (в терминах уровня значимости можно записать р < 0,05). Это совпадает с результатами работы функции SerialDistribution, согласно которым статистика критерия выходит из области (14...23) принятия гипотезы об отсутствиии различий на стандартном дове
5*
132
Глава 2. Проверка гипотез
2
рительном уровне 0,95. Для реальных расчетов вызов функции Serial Distribution не является обязательным и может быть полезен для иллюстрации методики построения таблиц распределения критерия серий.
Для больших выборок (я, > 20 и/или п2 > 20) некоторые авторы [172, с. 84] используют z-преобразование:
jRJ2n!n^ + Л_05 V n J 2п1п2(2п1п2 -п)
]] п2(и-1)
Считается, что величина z распределена по стандартному нормальному закону. При необходимости читатель сам без труда составит функцию, реализующую данный алгоритм,— она достаточно проста. Мы не установили, вызвано ли это неточностью источника или какой-либо другой причиной, но данное решение не показывает стабильности в работе. В предлагаемом источником решении, по нашему мнению, совершенно нет необходимости — составленные нами функции точно работают при любых практически встречающихся значениях параметров.
Обсуждение см. в [120, с. 65], [156, с. 112].
Исходные коды и пример применения
#include <fstream.h>
#include <math.h>
#include "megastat.h"
void main (void)
{
int nl = 22, // Численность 1-й выборки
n2 = 17, // Численность 2-й выборки
pl, // Нижнее критическое значение
р2; // Верхнее критическое значение
double xl[] = // Варианты 1-й выборки
{49.35,26,59,35,58,14.29,17.11,37,22,39,8,50,67.54.19,29,93,109,95}.
х2[] = // Варианты 2-й выборки
{16,31,10.60.13.7,20.36,18,12,55.7,41.5.28,16.9}.
t; // Статистика критерия
if (’WaldWolfowitz (xl.nl,x2.n2,&t))
Непараметрические тесты
133
{
cout « "t = " « t « ". p = " « InverseSerialDistribution (nl.n2.t);
cout « "ХпКритические значения";
Seri al Distribution (nl.n2.0.95.&pl.&p2);
cout « "\np = 0.05 - 0.95. " « pl « " - " « p2:
SerialDistribution (nl.n2.0.99,&pl,&p2);
cout « "\np = 0.01 - 0.99. " « pl « " - " « p2;
SerialDistribution (nl.n2,0.999,&pl.&p2);
cout « "\np = 0.001 - 0.999. " « pl « " - " « p2 « "\n"; }
el se
cout « "Мало памятиХп";
}
int WaldWolfowitz (double datal[].int nl.double data2[].int n2.double *criterion) //
// Функция вычисления значения критерия серий Вальда-
// Вольфовица.
// Обозначения:
// datal - первая выборка.
// nl - численность первой выборки.
// data2 - вторая выборка.
// п2 - численность второй выборки,
// *criterion - вычисленное значение критерия.
// Возвращаемое значение:
// 0 при нормальном окончании счета.
// -1 при недостатке памяти для размещения рабочих массивов. //
{
char *b; // Массив условий
register int i.k = 0: // Счетчики
int n = nl + n2. // Размер суммарного массива
*ix; // Информация об оригинальных массивах
double *х; // Суммарный массив
if (!(х = new double[n])) return -1;
if (!(ix = new int[nJ))
{
delete [] x;
return -1;
}
if (!(b = new char[n]))
{
delete [] x; delete [] ix;
return -1;
}
134
Глава 2. Проверка гипотез
/////////////////////// // Объединение массивов for (1 = 0; 1 < nl: 1++) x[k++] = datal[i]:
for (1=0; 1 < n2; 1++) x[k++] = data2[1];
//////////////////////////// // Сортировка по возрастанию SortArrayUp (x.n.ix.l):
//////////////////////////////////////////////// // Значение 1 - первый массив, 2 - второй массив for (1=0: 1 < n; 1++)
b[i] = ix[i] < nl ? 1 : 2:
////////////////////////////////////////////// // Начальное значение накапливаемого параметра ♦criterion = 1.0;
////////////////////// // Подсчет числа серий for (1=1: 1 < п; 1++)
If (b[i - 1] != b[i])
♦criterion += 1:
delete [] x; delete [] lx:
return 0:
Критерий Колмогорова—Смирнова
По критерию Колмогорова-Смирнова (критерию Смирнова) сравнивают функции распределения двух эмпирических рядов. Проверяется нулевая гипотеза о том, являются ли одинаковыми непрерывные функции распределения генеральных совокупностей, из которых взяты выборки. Иначе, проверяется принадлежность двух выборок одной и той же генеральной совокупности при условии непрерывности ее функции распределения.
Статистика критерия имеет вид [32, с. 84], [190, с. 460]
Ч,.„ = SUP
где — максимальная разность между частостями рядов х и х, тип — численности вариационных рядов.
Непараметрические тесты
135
Возможен непосредственный расчет по данной формуле [57, с. 77], однако при этом нужно учесть, что функции распределения должны быть сопоставимы по оси абсцисс, что гарантируется, если они явились продуктом построения не по исходной выборке, а по частотам распределения с сопоставимыми классовыми интервалами. Данный способ особенно удобен при анализе больших выборок и подробно проиллюстрирован в [84, с. 284].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void)
{
double nl = 50. // Численность первой выборки n2 = 60: // Численность второй выборки
double к, // Значение статистики
п = 11, // Численность каждого массива функций
// распределения fl[] =
{0.00.0.15,0.23.0.43.0.43.0.45.0.56.0.65,0.79.0.89,1.00}. f2[] =
{0.00.0.27.0.42.0.55,0.72.0.73,0.83,0.85,1.00.1.00,1.00}: '
k = Smirnov (fl.f2.n):
cout « "Criterion = " « k « ". p = "
« (1 - LambdaDistribution (k * sqrt (nl * n2 / (nl + n2)))) « endl:
}
double Smirnov (double fl[],double f2[],int n)
//
// Функция вычисления критерия Смирнова.
// Обозначения:
// fl - массив функции распределения 1-й выборки,
// f2 - массив функции распределения 2-й выборки,
// п - численность каждого массива.
// Возвращаемое значение:
// значение критерия Колмогорова-Смирнова.
//
{
double s. // Рабочая переменная
criterion = 0: // Вычисленное значение статистики критерия
for (register int i = 0: i < n; i++)
136
Глава 2, Проверка гипотез
s = fabs (fl[i] - f2[i]); if (s > criterion) criterion = s;
return criterion;
}
В случае построения массивов функций распределения непосредственно по выборкам (без разнесения вариант по классовым интервалам) для двустороннего критерия вычисления производятся по формулам [32, с. 84]:
Dm ==max(lZ ,£) Y
т.п у т.п' т.п J'
(г А ( $-О
D* =тах-------F(x) =тах G(xs)----------,
т'п i<r<m\jn r/j 1<5<и 5' п J
Для одностороннего критерия
Dm,n=D^-
При данном способе построения массивов функций распределения они, в отличие от предыдущего случая, будут равномерны по оси ординат, чем и определяется вид формул.
Функция распределения статистики критерия
1 пт
т + п
при тп / (т + п) —> ©о сходится к функции распределения Колмогорова [140, с. 238]. P-значение вычисляется функцией LambdaDistri-bution, вызванной с указанным параметром.
Интересно, что при данном способе построения функций распределений в явном получении упомянутых функций вообще нет необходимости — мы используем свойство, что они равномерны по оси ординат, благодаря чему значение функции распределения в текущей точке вычисляется через номер варианты в исходной выборке. Данный подход подробно проиллюстрирован примерами и исходными текстами на алгоритмическом языке Фортран в [174, с. 107].
Непараметрические тесты
137
Составленная нами функция программно моделирует графический способ решения, описанный в [140, с. 238]. В представленном виде критерий очень похож на ранговые критерии, однако в [213, с. 163] показано, что это не совсем так.
Авторами [32, с. 84] вводятся поправки на дискретность распределения статистик и D~n. Обсуждение см. также в [84, с. 285], [120, с. 50], [135, с. 274].
Исходные коды и пример применения
#include <fstream.h>
#include <ioman‘ip.h>
#include <math.h>
#include "megastat.h"
void main (void)
{
double x[] = {1,2.3.9.4.2.5.3.5.3.6.1.6.7.8.9.10}. // Первая
// выборка у[] = {4.5.6.7.8.9.9.1.9.2.13}: // Вторая
// выборка
int nx = sizeof (x) / sizeof (x[0]), ny = sizeof (y) / sizeof (y[0]):
double k = SmirnovExact (x.y.nx.ny);
cout « "Criterion = " « k
« "\nnx = " << nx « "\nny = " « ny « "\np « "
« (1 - LambdaDistribution (k * sqrt ((double) nx * ny / (nx + ny))))
« endl:
}
double SmirnovExact (double x[].double y[].int nx.int ny)
//
// Функция точного вычисления критерия Колиогорова-Снирнова.
// Обозначения:
// х - первая отсортированная выборка.
// у - вторая отсортированная выборка.
// пх - численность первой выборки,
// пу - численность второй выборки.
// Возвращаемое значение:
// значение статистики критерия Колмогорова-Смирнова.
И
{
register int i.j = 0; // Счетчики
double s, // Рабочая переменная
138
Глава 2. Проверка гипотез
criterion = 0; // Статистика критерия
//////////////////////////////////////////////////
// Перебрать все варианты 2-й выборки относительно
// всех вариант 1-й выборки
for (i = 0: i < ny; i++)
///////////////////////////////////////////////////////////// // Текущая варианта 2-й выборки меньше или равна 1-й варианте // 1-й выборки if (y[i] <= х[0])
{
s - (double)i / ny;
if (s > criterion) criterion = s;
}
////////////////////////////////////////////////////////// // Текущая варианта 2-й выборки больше или равна последней // варианте 1-й выборки else if (y[i] >= x[nx - 1])
{
s = 1 - (double) i I ny;
if (s > criterion) criterion = s:
////////////////////////////////////////////////// // Дальше вычисления можно не проводить - максимум // уже был достигнут в процессе вычислений break;
}
//////////////////////////////////////////////////////
// Текущая варианта 2-й выборки в пределах 1-й выборки el se
{
//////////////////////////////////////////
// Уточним, между какими вариантами именно
for (; j < пх - 1; J++)
if (y[i1 >» x[j] && y[i] < x[j + 1]) {
s = fabs ((double)i / ny - (double)j I nx):
//////////////////////////////////////////////////////////
II Прервать цикл с сохранением достигнутого номера текущей // варианты 2-й выборки - так уменьшим объем вычислений break;
}
if (s > criterion) criterion = s;
}
Непараметрические тесты
139
/ / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / /
// Перебрать все варианты 1-й выборки относительно
// всех вариант 2-й выборки
for (i = 0. j = 0: i < nx: i++)
///////////////////////////////////////////////////////////// // Текущая варианта 1-й выборки меньше или равна 1-й варианте // 2-й выборки if (x[i] <= у[0])
{
s = (double)i / nx;
if (s > criterion) criterion = s:
}
//////////////////////////////////////////////////////////
// Текущая варианта 1-й выборки больше или равна последней
// варианте 2-й выборки
else if (x[i] >= y[ny - 1J)
{
s = 1 - (double) i / nx;
if (s > criterion) criterion = s;
//////////////////////////////////////////////////
// Дальше вычисления можно не проводить - максимум
// уже был достигнут в процессе вычислений break;
}
//////////////////////////////////////////////////////
// Текущая варианта 1-й выборки в пределах 2-й выборки el se
{
//////////////////////////////////////////
// Уточним, между какими вариантами именно
for (; j < ny - 1; j++)
if (x[i] >= y[j] && x[i] < y[j + 1]) {
s = fabs ((double)i / nx - (double)j I ny);
//////////////////////////////////////////////////////////
// Прервать цикл с сохранением достигнутого номера текущей
// варианты 1-й выборки - так уменьшим объем вычислений break;
}
if (s > criterion) criterion = s;
}
return criterion;
}
140
Глава 2. Проверка гипотез
Точный метод Фишера—Ирвина
Точный метод Фишера—Ирвина (критерий Фишера—Ирвина, точный метод Фишера) применяется для проверки нулевой гипотезы о том, отобраны ли две исследуемые бинарные (дихотомические) выборки из генеральных совокупностей с одинаковой частотой встречаемости изучаемого эффекта [201, с. 36]. Рассматриваемый метод предназначен для обработки так называемых четырехпольных (четырехклеточных) таблиц, или таблиц «2 х 2». В результате вычислений получается точное значение уровня значимости нулевой гипотезы. Вычисление производится по формуле [57, с. 80]
_(a + by.(c+dy(a + cy(b+dy nlalblcldl
где а — число наблюдений с эффектом А в первой выборке,
b — число наблюдений без эффекта А в первой выборке, с — число наблюдений с эффектом А во второй выборке, d — число наблюдений без эффекта А во второй выборке, n = a+ b + c + d.
Пример. Пусть вычислено значение а = 0,012 < 0,05. На уровне значимости < 0,05 (ближайшее стандартное значение) нулевая гипотеза отклоняется и принимается альтернативная гипотеза о различии средних.
Метод подробно исследован в [91, с. 736]. Там же даны примеры применения. Точный метод Фишера применяется в схеме описанного ниже критерия медианы для анализа различий медиан двух выборок.
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void) {
int a = 95, b = 10. c = 75. d = 20:
cout « Fisherlrwin (a.b.c.d) « endl: }
Непараметрические тесты
141
double Fisherlrwin (int a.int b.int c,int d) //
// Функция вычисления критерия значимости различий
// точным методом Фишера-Ирвина.
// Обозначения:
// а - число наблюдений с эффектом А в первой выборке.
// b - число наблюдений без эффекта А в первой выборке,
// с - число наблюдений с эффектом А во второй выборке.
// d - число наблюдений без эффекта А во второй выборке.
// Возвращаемое значение:
// уровень значимости различий между выборками по частоте
// эффекта А.
//
{
return exp (LogFactorial (а + b) + LogFactorial (с + d) + LogFactorial (a + c) + LogFactorial (b + d) -LogFactorial (a + b + c + d) - LogFactorial (a) -LogFactorial (b) - LogFactorial (c) - LogFactorial (d));
}
Критерий знаков
Критерий знаков (Sign test) предназначен для проверки гипотезы об однородности распределения совокупности, что эквивалентно проверке гипотезы о равенстве функций распределения Fx и FY [140, с. 217]. Критерий знаков часто используется при сравнении эффективности двух различных способов воздействия на п объектов и, таким образом, может применяться и для связанных выборок.
Статистика критерия вычисляется как число положительных разностей вариант сопряженных выборок [213, с. 17]:
1=1
s(X) =
1,Х>0,
0,Х<0,
гдехр 2=1,..., и, г/р 2=1,..., п — элементы выборок.
Критическое значение статистики критерия Zna вычисляется функцией Sign Distribution. Для односторонней конкурирующей гипотезы Fx > Fy или Fx < Fy вывод о статистически значимом различии на выбранном уровне значимости «делается в случае Z* </яаили Z* > п - Zna> соответственно. Для двусторонней конкурирующей ги
142
Глава 2. Проверка гипотез
потезы Fx * Fy на уровне значимости а/2 вывод о статистически значимом различии делается в случае Z* < ZnCf/2 или Z> п - Zna/2. Обсуждение различных аспектов применения критерия знаков см. также в [26, с. 135], [37, с. 226], [57, с. 70], [120, с. 47], [156, с. 113], [180, т.2, с. 120].
2 Исходные коды
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void)
Snt n; // Численность каждой выборки
double x[] = // Первая выборка
{11.14.13.11,18.22.14.14. 7.16, 9.20.24. 9.15.25. 4.13,12.10}.
y[] = // Вторая выборка
{18.10. 9. 1.12.20. 5. 8.14.15.
12. 8.19. 5. 6,20.14. 7. 8. 9}:
n = sizeof (x) / sizeof (x[0]);
cout « "n = " « n « ", s = " « SignTest (x.y.n)
« "\np = 0.01, k - " « (n - SignDistribution (n.O.OD)
« "\np = 0.05. k = " « (n - SignDistribution (n.0.05))
« endl:
}
double SignTest (double x[],double y[].1nt n)
//
// Функция критерия знаков.
// Обозначения:
// х - первая выборка,
// у - вторая выборка.
// п - численность каждой выборки.
// Возвращаемое значение:
// значение критерия знаков.
//
{
double s = 0: // Возвращаемое значение
for (register int i = 0: i < n; i++) if (x[i] > y[i])
s++:
return s:
}
Непараметрические тесты
143
Критерий медианы
Критерий медианы (медианный критерий) предназначен для проверки нулевой гипотезы о том, отобраны ли две исследуемые группы из генеральных совокупностей с одинаковыми медианами либо имеют ли совокупности одинаковое распределение. Этапы вычисления критерия для двух выборок численностями п1 и п2 [172, с. 75]: 1. Формирование таблицы сопряженности типа «2 х 2» по следующему правилу: в ячейку А заносится число отметок первой выборки, превышающих медиану выборки, полученной объедине-ниехМ двух исходных выборок; в ячейку В заносится число отметок второй выборки, превышающих медиану; в ячейки С и D заносится число отметок, не превышающих медиану, соответственно, первой и второй выборок;
2. В случае пх > 15 и/или п2 > 15 (некоторые источники указывают п{ + п2> 20, если число наблюдений в каждой клетке не менее 5) к полученной таблице применяется критерий Х\ в противном случае применяется точный метод Фишера. При использовании -.2
критерия X для вычисления доверительного уровня число степеней свободы берется равным 1.
В качестве альтернативы можно применять решение [180, т. 2, с. 126], где указано, что число наблюдений первой выборки, превосходящих медиану объединенной выборки, имеет гипергеометрическое распределение, а выводы могут быть сделаны так же, как в предыдущем разделе.
Функцией Median выдается значение доверительного уровня гипотезы о различиях медиан совокупностей. Например, программой выдано Р = 0,98. Поскольку наблюдаемое значение доверительного уровня превышает ближайшее стандартное значение 0,95, принимается гипотеза об имеющих место различиях медиан совокупностей на уровне значимости < 0,05.
Подробное обсуждение см. в [32, с. 77]. В [180, т. 2, с. 126] указаны особенности применения критерия, не рассмотренные в других источниках, но учтенные при составлении функции, реализующей описываемый метод анализа. Критерий может быть применен для исследования k > 2 выборок, как это описано в [ 158, с. 180] и [ 172, с. 86].
Исходные коды void main (void) {
int nl.nnl. // Численность 1-й выборки
144
Глава 2. Проверка гипотез
п2,пп2. // Численность 2-й выборки
ml; // Значение критерия
double xl[] = // 1-я выборка
{26,22.19.21.14.18,29,17,34}, х2[] = // 2-я выборка
{16,10.8,13,19.11.7.13.9.21}. р; // Р-значение
nl = sizeof (xl) / sizeof (double);
n2 = sizeof (х2) / sizeof (double):
if (IMedian (xl.nl.x2.n2.&ml.&p,&nnl.&nn2))
{
cout « "Ml = " « ml « "\nP = " « p
« "\nml = " « abs (ml - nnl / 2)
« "\nnl = " « nl « ". " « nnl « " corrected"
« "\nn2 = " « n2 « ", " « nn2 « " corrected"
« "\np = 0.001, k = " « MedianDistribution (nnl.nn2,0.001) « “\np =0.01, k = " « MedianDistribution (nnl.nn2,0.01) « "\np = 0.05, k = " « MedianDistribution (nnl,nn2,0.05) « endl;
}
el se cout « "Мало памятиХп";
}
int Median (double datal[],int nl,double data2[].int n2,int
*a,double *p,int *nnl,int *nn2)
//
// Функция критерия медианы.
// Обозначения:
// datal - первая выборка,
// nl - численность первой выборки,
// data2 - вторая выборка.
// п2 - численность второй выборки,
// *а - статистика критерия,
// *р - значимость различий,
// *nnl - скорректированная численность первой выборки,
// *пп2 - скорректированная численность второй выборки.
// Возвращаемое значение:
// 0 при нормальном окончании счета,
// -1 при недостатке памяти для размещения рабочих массивов. //
{
register int i.j = 0; // Счетчики
int n = nl + n2, // Численность суммарного массива
*ix, // Информация об оригинальном массиве
Непараметрические тесты
145
b = О.с = 0,d = 0; // Клетки В, С и D таблицы 2x2
double al.bl,cl.dl. // Ожидаемые частоты
a2,b2,c2,d2. // Вспомогательные величины
med, // Медиана суммарной выборки
*х. // Суммарный массив
*У; // Скорректированный суммарный массив
if (!(х = new double[n]))
return -1:
if (!(у = new double[n]))
{
delete [] x;
return -1;
}
if (!(ix = new int[n]))
{
delete [] x; delete [] y;
return -1;
}
///////////////////////
// Объединение массивов
for (i = 0; i < nl; i++) x[j++] = datal[i];
for (i = 0; i < n2; i++) x[j++] = data2[i] ;
///////////////////////////////////
// Сортировка объединенного массива
SortArrayUp (x.n.ix.l);
///////////////////////////////////////
// Расчет медианы объединенного массива
med = IParity (n) ? med = x[n / 2] : (x[n / 2 - 1] + x[n /
2]) / 2;
///////////////////////////////////////
// Восстановление оригинального порядка UnSortArray (x.y.n.ix);
delete [] x;
////////////////////////////////
// Корректировка для нечетного n
if (IParity (n))
{
//////////////////////////////////
// Вычеркивание медианной варианты
for (i = 0. j = 0; i < n; i++)
if (j != ix[n / 2]) y[j++l = y[il:
146
Глава 2. Проверка гипотез
/////III//////////////////И// // Уменьшение численности на 1
if (ix[n / 2] <= nl)
nl—:
el se
n2—;
n—:
}
*nnl = nl;
*nn2 = n2;
delete [] ix;
////////////////////////////
// Расчет клеток таблицы 2x2
for (i = 0, (*a) = 0; i < nl; i++)
if (y[iJ > med)
(*a)++;
el se
C++;
for (i = nl; i < n; i++)
if (y[il > med)
b++;
el se
d++:
delete [] y;
////////////////////////////////////////// // Критерий хи-квадрат для больших выборок if (nl > 15 || n2 > 15)
{
//////////////////////////
// Расчет ожидаемых частот
al = (*а + b) * (*а + с) / п;
Ы = (*а + b) * (b + d) / п;
cl = (с + d) * (*а + с) / п;
dl = (с + d) * (b + d) / п;
///////////////////////////// // Вспомогательные вычисления
а2 = fabs (al - (*a)) - 0
Ь2 = fabs (bl - b) - 0.5;
с2 = fabs (cl - c) - 0.5;
d2 = fabs (dl - d) - 0.5;
а2 *= a2;
Ь2 *= b2;
с2 *= с2;
d2 *= d2;
//////////////////////////////////////////// // Вычисление значимости критерия хи-квадрат
Непараметрические тесты
147
*р = 1 - ChiSquareDistribution (1,а2 / al + Ь2 / Ы + с2 / cl + d2 / dl):
}
/////////////////////////////////////////
// Точный метод Фишера для малых выборок el se
////////////////////////////
// Вычисление значимости ТМФ
*р = Fisherlrwin ((*а).b.c.d):
return 0: }
Непараметрические множественные сравнения
Непараметрические критерии могут быть использованы для множественного сравнения — иными словами, для сравнения двух групп выборок между собой. Каждая группа задается подобно тому, как задаются параметры массивов данных для рассмотренных ниже методов двухфакторного дисперсионного анализа.
Непараметрический критерий Ньюмена—Кейлса
Вычисления производятся по формуле [52, с. 351]
7_ |Дл-ДД| /п2/(и/ +1)
V 1Г~
где Ra и Rb — суммы рангов сравниваемых выборок, п — объем каждой выборки, I — интервал сравнения.
Критические значения для стандартных уровней значимости даны [52, с. 110] в зависимости от числа степеней свободы, равного ©о .
Непараметрический критерий Даннета
Имеется вариант рассмотренного выше критерия, предназначенный для сравнения нескольких групп выборок с контрольной,— критерий Даннета [52, с. 351], вычисляемый по формуле
148
Глава 2. Проверка гипотез
*кон ^А |
U2l(nl + i) ,
V б”
где / — число всех выборок, включая контрольную.
Критические значения для стандартных уровней значимости даны в [52, с. 114] в зависимости от числа степеней свободы, равного .
Критерий Данна
Вычисления производятся по формуле [52, с. 351]
|Уяд|
!#(#+!/1 ~
12 [п, пВ'
где /j и r — средние ранги двух сравниваемых выборок, пАипв — численности выборок,
N— общая численность сравниваемых выборок.
Критерий с успехом применяется для сравнения выборок как неравного, так и одинакового объемов, а также для сравнения с контрольной выборкой. В последнем случае составленную нами функцию потребуется незначительно модернизировать.
Различие считается статистически значимым на выбранном уровне значимости, если вычисленное значение статистики Q превышает критическое значение на этом уровне значимости. Критические значения для попарного сравнения в зависимости от числа сравниваемых выборок для стандартных уровней значимости даны в [52, с. 352] и вычисляются функцией DannDistribution95 для уровня значимости 0,05 и функцией DannDistribution99 для уровня значимости 0,01 так, как это показано в примере, а для сравнения с контрольной выборкой [52, с. 353] вычисляются функцией DannDistribution95c для уровня значимости 0,05 и функцией DannDistribution99c для уровня значимости 0,01.
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
Непараметрические тесты
149
#include "megastat.h"
void main (void)
{
register int i.j, // Счетчики цикла m » 0; // Счетчик
int n[] = {13,9.9}, // Численности выборок
k = 3: // Число выборок
double a[] = {2.04, 5.16, 6.11, 5.82, 5.41, 3.51, 3.18, 4.57. 4.83.
11.34, 3.79, 9.03, 7.21, 5.30, 7.28, 8.98, 6.59, 4.59, 5.17, 7.25, 3.47, 7.60, 10.36, 13.28, 11.81, 4.54, 11.04, 10.08, 14.47, 9.43, 13.41},
*c: // Массив критериальной статистики
с = new double[(k * k - k) /2];
if ('Dann (a,n,k,c))
{
for (i = 0; i < k - 1: i++)
for (j = i + 1; j < k; j++,m++)
cout « (i + 1) « « (j + 1) « " ” « c[m] «
endl:
cout « "Dann distribution 51 = " « DannDistribution95 (k) « endl
« "Dann distribution U - ’ « DannDistribution99 (k) « endl:
}
else
cout « "Мало памяти\п":
delete [] c:
}
int Dann (double data[],int n[],int k,double criterion[])
11
// Функция проводит множественные попарные сравнения по
// критерию Данна.
// Обозначения:
// data - массив к векторов данных (вектора друг за другом).
// п - массив длин к векторов.
// criterion - массив критериальной статистики длиной
// (к * к - к) / 2, заранее выделен.
// Возвращаемое значение:
// 0 при нормальном окончании расчета,
// -1 при недостатке памяти.
//
{
register int 1,j: // Счетчик цикла
int m, // Счетчик одномерного массива
150
Глава 2. Проверка гипотез
nn = VectorSum (n.k), // Общее число вариант
*inf; // Информация о перестановках
double *х, // Массив средних рангов
*у, // Рабочий массив
*t: // Массив сумм рангов
if ((t = new double[k]) == 0)
И return -1:
if ((x = new double[nn]) == 0) {
delete [] t:
return -1: }
if ((y = new doublefnn]) == 0) {
delete [] t; delete [] x;
return -1: }
if ((inf = new intfnn]) == 0) {
delete [] t; delete [] x; delete [] y;
return -1; }
////////////////////////////
// Вычисление массива рангов
SortArrayUp (data.nn,inf.1);
Rank (data.y.nn);
UnSortArray (y.x,nn,inf);
////////////////////////////
// Вычисление средних рангов
for (i =0, m = 0; i < k; i++) {
for (j = 0, t[i] = 0; j < n[i]: j++) t[i] += x[m++]:
t[i] /= n[i]; }
///////////////////////////////////////////
II Массив статистики для попарных сравнений
for (i =0, m = 0: i < k - 1; i++)
for (j = i + 1: j < k; j++)
criterion[m++] = fabs (t[i] - t[j]) / sqrt (nn * (nn + 1) / 12 * (1.0 I n[i] + 1.0 / n[j]));
delete [] t; delete [] x: delete [] y; delete [] inf;
return 0;
}
Проверка типа распределения эмпирических данных
151
Проверка типа распределения эмпирических данных
Проверка соответствия эмпирического распределения некоторому наперед заданному теоретическому может быть выполнена различными способами. Задача установления типа распределения не- •«<' избежно возникает при подготовке к применению методов проверки гипотез и дисперсионного анализа с целью выбора адекватной статистической модели.
Далее в настоящем разделе мы рассмотрим некоторые простейшие методы, затем критерии согласия, а также вычислим статистику d Гири. Нами описаны все перечисленные критерии, даны примеры их применения. Для больших выборок мы рекомендуем применять критерий согласия X , а для малых — критерий согласия IVШапиро-Уилка. Возможно, это вызвано разногласиями различных источников относительно применения критериев согласия Колмогорова и со2. В конце соответствующих разделов даны замечания для случая многомерных распределений.
Введение в исследование формы распределения см. в [28, вып. 2, с. 148]. См. также материалы и ссылки, представленные на сайте «Высокие статистические технологии» (antodov.nm.ru).
Простые и сложные гипотезы
Различаются простые гипотезы и сложные гипотезы [167, с. 482]. Согласно [92, с. 221], если распределение имеет I параметров и гипотеза утверждает, что k из них имеют заданные значения, то гипотеза будет:
• простой, если k = I,
• сложной, если k < /.
Разность (/ - k) называется числом степеней свободы гипотезы, a k будет числом ограничений, наложенных гипотезой.
Некоторые факты проверки сложных гипотез представлены в [ 156, с. 82].
Простейшие методы
В первом приближении соответствие эмпирического распределе-НИЯ теоретическому может быть оценено глазомерным методом. Для сравнения эмпирического распределения с некоторым теоре
152
Глава 2. Проверка гипотез
тическим распределением на график f(x) обычно накладывается кривая теоретического распределения f'(x). Данная процедура называется глазомерным методом установления типа эмпирического распределения и может быть использована для проверки нормальности. Другой простейший метод проверки нормальности — оценка по вычисленным коэффициентам асимметрии А и эксцесса Е. При этом [106, с. 213], [88, с. 59]:
• распределение считается симметричным, если |Л| < 0,1, сильно асимметричным при |Л| > 0,5;
• распределение считается близким к нормальному, если |£| < 0,1, значительно отклоняющимся от нормального при \Е\ > 0,5.
Описанный простейший метод проверки нормальности проиллюстрирован нами в примере, показанном в главе 4, где генерируется нормальное распределение, а затем для него рассчитываются рассматриваемые параметры.
Обратим внимание читателя на простой графический метод оценки соответствия распределения нормальному закону [57, с. 112]. В наиболее простом случае тип распределения, в том числе нормальность распределения, может быть принят в качестве допущения [70, с. 314]. Считается, что для нормального распределения это тем вернее, чем больше численность выборки. Численность выборки считается достаточно большой при п > 500, для других случаев п 100, но выборки численностью п < 30 почти всегда считаются малыми. Тем не менее вряд ли можно избежать статистической проверки нормальности распределения даже при больших выборках, постулировав нормальность ввиду большой численности. Так, для неоднородной выборки и при большой численности нормальность может отсутствовать. В то же время существуют (и рассматриваются нами) методы, позволяющие показать нормальность распределения для очень малых выборок.
Критерии согласия
В случае, если тип распределения некоторой случайной величины нам неизвестен, располагая случайной выборкой, мы можем захотеть проверить, совпадает ли функция распределения случайной величины с некоторой наперед заданной или вычисленной по выборке теоретической функцией распределения. При такой постановке говорят о проверке статистической гипотезы согласия [35, с. 171], [206, с. 336].
Проверка типа распределения эмпирических данных
153
Для проверки, совпадают ли два распределения — эмпирическое и теоретическое — с заданным уровнем значимости, применяют критерии согласия:
• критерий Колмогорова,
• критерий согласия а)2 Мизеса,
2
• критерий X в качестве критерия согласия.
В арсенале статистик имеются и другие критерии согласия, такие как J-критерий Ястремского [111, с. 145], критерий Бернштейна [167, с. 606]. О подборе типа теоретического распределения к представленным эмпирическим данным см. в [98, с. 29]. Критерии согласия для цензурированных (усеченных по той или иной причине) выборок рассмотрены в [ 14, с. 119].
Критерий Колмогорова
Критерий согласия Колмогорова (статистика Колмогорова-Смирнова или просто критерий Колмогорова) предназначен для сравнения функции эмпирического распределения с заданной функцией непрерывного теоретического распределения [140, с. 235]. Статистика критерия имеет вид
D„= sup |F„(x)-F(x)|,
-оо<Х<оо
где Dn — максимальная разность между частостями,
п — объем ряда частостей,
F„(x) ~ эмпирическая функция эмпирического распределения,
F(x) — теоретическая функция эмпирического распределения, х — интервальный вариационный ряд, построенный по исходной выборке.
В литературе даны примеры подхода к вычислению статистики критерия Колмогорова [44, с. 156], [84, с. 285], основанного на непосредственном применении формулы
Dn = max |F„ (х) - F(x)|.
Если построение функции распределения производится непосред-ственно по исходной выборке (см. способ 2, представленный в разделе «Вариационная статистика» главы 1, при этом численности исходной выборки и массива функции распределения совпадают), это позволяет при вычислении статистики в случае двусторонней гипотезы воспользоваться формулами:
154
Глава 2. Проверка гипотез
°»=тах(П<1);О<2)),
1<т<л ' '
D(i} = maxf—- F(x) 1 D{2) = maxf F( x) - ——-
а для односторонней гипотезы
Вид приведенных формул обусловлен тем, что эмпирическая функция распределения является ступенчатой. В точке разрыва функция скачком переходит от значения (тп - 1)/п к значению т/п. Наибольшая разность определяется в точке разрыва. Данное свойство позволяет вообще не передавать в программу эмпирическую функцию эмпирического распределения. Показанные формулы нельзя применять, если функция распределения строится по способу 1, поэтому нужно быть особенно внимательным при выборе метода. При построении функции распределения по способу 1 следует непосредственно применять формулу статистики рассматриваемого теста.
Распределение статистики Dn оказывается одним и тем же для всех непрерывных распределений. Функция распределения статистики критерия Dn4n при и —><» сходится к функции распределения Колмогорова [140, с. 236]. P-значение вычисляется с помощью функции LambdaDistribution.
2 Неприятной особенностью критерия по сравнению с критерием л является то, что упомянутое выше требование непрерывности теоретического распределения не позволяет применять критерий к любым распределениям [187, с. 324]. Кроме того, в рассматриваемой выше форме критерий применим только для случая простой гипотезы, т. е. для случая, когда параметры теоретического распределения не оцениваются по исходной выборке. Авторы обычно приводят пример для случая проверки согласия равномерному распределению, хотя есть хорошие примеры для анализа и других типов распределения: нормального, экспоненциального, Коши и равномерного, причем подробно проиллюстрированные исходными кодами на языке Фортран в [174, с. 103].
В показанном ниже примере помимо вызова функции вычисления критерия Колмогорова показан также вызов для следующей описанной нами функции, реализующей вычисление критерия согла
Проверка типа распределения эмпирических данных
155
сия X . Еще раз обратите внимание, что метод применим только в случае построения функции распределения вторым способом (см. главу 1) и для простой гипотезы. Пример расчета в случае построения функции распределения по первому способу представлен в [84, с. 284]. Его реализация не должна вызвать затруднений.
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
^include "megastat.h"
void main (void)
{
int n = 10: // Численность исходной выборки и массива функции
// распределения
double f[] = // Теоретическая функция эмпирического распределения {0.0834.0.1174.0.1794,0.3094.0.5424,0.6288.0.6606.0.6917,0.7410.0.9401}, к, // Значение критерия
а; // Уровень значимости
k = KolmogorovOneSided (f.n):
а = LambdaDistribution (к * sqrt (n)):
cout « "Kolmogorov criterionXnOne sidedXn к = " « к « endl
« - p = " « (i _ a) « endl:
к = KolmogorovTwoSided (f.n);
a = LambdaDistribution (k * sqrt (n));
cout « "Two sidedXn к = " « к « endl « " p = " « (1 - a / 2) « endl:
к = OmegaSquare (f,n);
a = OmegaSquareDistribution (k * n);
cout « "Omega-square criterionXnOne sidedXn к = " « к « endl « " p = " « (1 - a) « "XnTwo sidedXn к = " « к « "\n p = " « (1 - a / 2) « endl:
}
double KolmogorovOneSided (double f[].int n)
11
II Функция вычисления критерия согласия Колмогорова
// для односторонней гипотезы.
// Обозначения:
// f - массив теоретической функции эмпирического
II распределения,
II п - численность исходной выборки и массива распределения.
// Возвращаемое значение:
II значение критерия Колмогорова.
156
Глава 2. Проверка гипотез
//
{
double s, // Рабочая переменная
criterion = 0: // Вычисленное значение статистики критерия
for (register int i = 1: i <» n: i++) {
ah s = fabs ((double) i / n - f[i - 1]):
if (s > criterion) criterion = s:
}
return criterion:
}
double KolmogorovTwoSided (double f[],int n)
//
7/ Функция вычисления критерия согласия Колмогорова
// для двусторонней гипотезы.
// Обозначения:
// f - массив теоретической функции эмпирического
// распределения.
// п - численность исходной выборки и массива распределения.
// Возвращаемое значение:
// значение критерия Колмогорова.
//
{
double s. // Рабочая переменная
criterion = 0: // Вычисленное значение статистики критерия
for (register int i = 1; i <= n: i++)
{
s = fabs ((double) i / n - f[i - 1]):
if (s > criterion) criterion = s:
s = fabs (f[i - 1] - (double) (i - 1) / n):
if (s > criterion) criterion = s:
}
return criterion:
}
Если оценки всех или некоторых параметров неизвестного теоретического распределения все-таки делаются по эмпирической выборке, говорят о так называемой сложной гипотезе [187, с. 327]. При этом вводится модифицированная статистика Колмогорова
£>„= sup |f„(x)-f(x,e)|,
Проверка типа распределения эмпирических данных
157
практически вычисляемая по тем же формулам, что и показанные выше, но имеющая функцию распределения, отличную от функции распределения для простой гипотезы. Однако функция распределения уже не будет той же самой для всех непрерывных распределений. В цитируемом источнике даны пороговые значения модифицированной статистики для случаев проверки соответствия эмпирического распределения нормальному распределению и экспоненциальному распределению, указана необходимая библиография.
Дополнительно о критерии Колмогорова см. в [28, вып.2, с. 145], [70, с. 297], [120, с. 48], [135, с. 273], [156, с. 135], [158, с. 159]. Подробное обсуждение исследований Колмогорова дано в [167, с. 659]. Примеры выводов по результатам расчета даны в [187, с. 337].
Критерий со2 Мизеса
Критерий согласия со2 Мизеса (Крамера—Мизеса, Смирнова—Крамера—Мизеса) предназначен для сравнения функции эмпирического распределения с заданной непрерывной функцией теоретического распределения [167, с. 608]. Статистика критерия определяется формулой [32, с. 83], [187, с. 321]
где Fn(x) — эмпирическая функция распределения, F(x) — теоретическая функция распределения.
Свойства статистики критерия практически позволяют производить вычисления по формуле [там же]
2тл-П2 2л
1 "7
лю2 =----+ У F(x ) -
" 12л £1 т)
Функция распределения статистики критерия лщ2 при л -»«> сходится к функции flj(x) распределения ш2.
Все особенности и условия, включая понятие о сложной гипотезе, полностью аналогичны описанным в предыдущем разделе. Критические значения в случае простой гипотезы вычисляются посредством функции OmegaSquareDistribution. В [там же, с. 328] даны пороговые значения модифицированной статистики (5Я для сложной
158
Глава 2. Проверка гипотез
гипотезы при проверке нормальности и экспоненциальное™. Критические значения в случае сложной гипотезы для данных распределений могут быть вычислены по методике, аналогичной разобранной при описании функции KolmogorovDistribution.
Отметим, что подобно критерию Смирнова, основанному на статистике Колмогорова и предназначенному для оценки однородности двух выборок, имеется такой же «аналог» и для рассматриваемой статистики. Критерий однородности, основанный на статистике типа ft)2, описан в [32, с. 86]. Его предельное распределение сходится к функции а{(х) распределения со2. Теорема Смирнова изложена в [167, с. 609]. Примеры выводов по результатам расчета даны [187, с. 337]. См. также [156, с. 136].
Пример вызова показанной далее функции представлен в предыдущем разделе.
Исходные коды
double OmegaSquare (double f[].1nt n) //
// Функция вычисления критерия согласия омега-квадрат. // Обозначения:
// f - массив теоретической функции эмпирического
// распределения.
// п - длина массива распределения.
// Возвращаемое значение:
// значение критерия омега-квадрат.
//
{
double s = 0, а;
for (register int i = 1; i <= n: i++)
{
a = f[i - 1] - (double) (2 * 1 - 1) / 2 / n;
s += a * a:
return (s + (double) 1 / 12 / n) / n; }
Критерий X2
2
Критерий X в форме критерия согласия предназначен для сравнения эмпирической функции эмпирического распределения с соответствующей теоретической функцией эмпирического распределения и вычисляется по формуле [35, с. 174,173, с. 425,135, с. 622,111, с. 138]
Проверка типа распределения эмпирических данных
159
tt nPi
где vP i = 1,2,..., k, — количества (частоты) наблюдаемых случаев в k классах,
Pi ,i =1,2,..., k, — теоретические вероятности выбранного распределения, причем параметры теоретической функции эмпирического распределения рассчитываются по эмпирической выборке либо задаются, в зависимости от проверяемой гипотезы, k — число классов,
п — общее число наблюдений; для непрерывных распределений, например нормального, п нужно еще умножить на величину классового интервала d.
Число степеней свободы при вычислении критического значения или взятии табличного значения следует положить равным [ 111, с. 138] (k - г - 1), где г — число параметров теоретического закона распределения, вычисляемых по эмпирическим частотам распределения. Например, если все параметры теоретического закона вычисляются по интервальному вариационному ряду, то число степеней свободы берется равным [84, с. 274]: (k - 2) для биномиального распределения, (k - 3) для нормального распределения.
Возможно, что не все параметры теоретического закона распределения вычисляются по выборке или вообще все параметры закона распределения получены каким-то иным способом, например заданы, и в рассматриваемой форме критерий пригоден как для простой (критерий X Пирсона), так и для сложной (критерий X Фишера) гипотез [187, с. 324,329].
Необходимо особо отметить, что параметры теоретического закона распределения эмпирической выборки (например, среднее и дисперсия) должны быть получены из частот распределения построенного по выборке интервального вариационного ряда, а не из исходного эмпирического ряда вариант [там же, с. 329,331], хотя в литературе есть, очевидно, не совсем точные примеры вычисления параметров теоретического закона распределения по самой эмпирической выборке [84, с. 273].
Поясним общую схему практического применения критерия [206, с. 345]. Сначала строится эмпирическая функция распределения, а также определяются г оценок параметров, необходимых для построения теоретической функции распределения. Затем на основе вы
160
Глава 2. Проверка гипотез
численных оценок параметров вычисляется теоретическая функция эмпирического распределения, которая сравнивается с эмпирической функцией распределения посредством критерия. Тот факт, что параметры теоретической функции эмпирического распределения могут вычисляться по выборке либо задаваться, делает рассматриваемый критерий наиболее универсальным из рассмотренных нами критериев согласия.
2
Примеры применения критерия согласия X можно найти в [35, с. 174]. Проверка согласия с распределением Пуассона проиллюстрирована в [24, с. 99], [140, с. 119], с нормальным в [84, с. 273]. Общие вопросы рассмотрены в [44, с. 152], [70, с. 290], [173, с. 425], [229, с. 277]. Замечания о ненадежности применения рассматриваемого теста в качестве критерия согласия даны в [167, с. 606]. Решение на языке программироваия Бейсик дано в [ 184, с. 187].
Рассматриваемый критерий применяется нами также при построении описанного ниже критерия Саркади [32, с. 57], поэтому для изучения примера вызова функции ChiSquareEmpire можно воспользоваться примером вызова функции Sarkadi, реализующей вычисление критерия Саркади.
Исходные коды
double ChiSquareEmpire (double f[],double p[],int k,double n) //
// Функция вычисления значения критерия согласия хи-квадрат.
// Обозначения:
// f - массив наблюдаемых случаев в к классах.
// р - массив теоретических вероятностей,
// к - численность каждой выборки,
// п - величина выборки, для непрерывных распределений -
// величина выборки, умноженная на величину классового
// интервала.
// Возвращаемое значение:
// значение критерия хи-квадрат.
//
{
double chi = 0. // Возвращаемое значение
s: // Вспомогательная переменная
for (register int i if (p[i] != 0)
{
s = f[i] - n * chi += s * s /
= 0: i < k; i++)
p[i];
n / p[1J;
return chi;
}
Проверка типа распределения эмпирических данных
161
Критерий X для проверки соответствия исходных данных многомерному нормальному распределению описан в [63, с. 72,223]. Решение данного вопроса имеет исключительную важность в качестве основного этапа перед применением методов многомерной статистики (факторный, кластерный, дискриминантный анализ). В [115, с. 342] описано применение критерия для многомерного случая при простой гипотезе.
Критерий WШапиро—Уилка
Все рассмотренные выше методики проверки соответствия распределения эмпирической выборки наперед заданному теоретическому распределению могли применяться только для больших выборок. Однако в ряде опытов, особенно в экспериментальных и клинических медицинских исследованиях, часто возникает ситуация, когда численность выборки мала.
Специально для проверки нормальности распределения малых, численностью от 3 до 50 вариант, выборок Шапиро и Уилк разработали критерий W, основанный на регрессии порядковых статистик [91, с. 618]. Этот критерий при наличии ограниченного объема данных является более мощным для проверки гипотезы нормальности, чем применяемые обычно критерии согласия [123, с. 37].
Вычисления производятся по формулам [206, с. 337]:
W = />2/52,
52=Х(*. -г)2.й=Ев»-»1(^-.+1 ~xi\ i=l i=l
гдех, i = 1,2,..., п, — ранжированный ряд,
k = и/2, если п — четное,
k = (п - 1 )/2, если п — нечетное,
аи_,+Р i =1,2,..., k, п = 3,..., 50, — константы.
Схема вычисления, методика применения, примеры и интерпретация результатов расчета даны в [206, с. 337]. Например, вычисленное значение статистики критерия равно 0,943039. Это значение превышает критический уровень 0,938211, вычисленный функцией Critical W для вероятности 50% (в источнике даны таблицы для 1,2,5,10 и 50%). Следовательно, нет оснований предполагать, что представленные данные не подчиняются нормальному закону распределения.
6-2002
162
Глава 2. Проверка гипотез
В [206, с. 339] описан критерий WEQ для проверки допущения об экспоненциальном распределении. Авторы [28, вып.2, с. 153] описали статистику типа Шапиро—Уилка R2 и указали полезные ссылки.
Исходные коды и пример применения
finclude <fstream.h>
#include <iomanip.h>
#include "megastat.h"
void main (void)
{
int n = 10;
double x[] = {303,338,406,457.461,469,474,489.515.583}. alpha = 50;
cout « "Shapiro-Wilk = " « ShapiroWilk (x.n) « endl
« " n = ” « n « endl
« " Alpha = " « alpha « "X" « endl
« " Critical W = " « CriticalW (n,alpha) « endl;
}
double ShapiroWilk (double x[].int n) //
// Функция вычисления критерия W Шапиро-Уилка.
// Обозначения:
// х - отсортированная по возрастанию выборка,
// п - размер выборки.
// Возвращаемое значение:
// вычисленная величина критерия W.
// Примечание:
// функция определена только для п от 3 до 50. диагностика в
// случае
// выхода за эти пределы не выдается.
//
{
register int i.j.l = 0; // Счетчики цикла
int s = 0; // Начало отсчета массива коэффициентов
double d.b = 0, // Рабочие параметры
а[] = { // Полный ряд коэффициентов
0.7071.
0.6872.0.1677,
0.6646,0.2413,
0.6431.0.2806.0.0875.
0.6233,0.3031,0.1401,
0.6052,0.3164,0.1743,0.0561.
0.5888,0.3244,0.1976,0.0947,
0.5739,0.3291,0.2141.0.1224.0.0399,
Проверка типа распределения эмпирических даниых
163
0.5601,0.3315,0.2260.0.1429,0.0695.
0.5475.0.3325,0.2347.0.1586,0.0922.0.0303.
0.5359,0.3325,0.2412.0.1707,0.1099,0.0539,
0.5251,0.3318.0.2460.0.1802,0.1240,0.0727,0.0240, 0.5150,0.3306.0.2495.0.1878.0.1353,0.0880,0.0433, 0.5056,0.3290,0.2521,0.1939,0.1447,0.1005,0.0593,0.0196. 0.4968,0.3273,0.2540,0.1988.0.1524,0.1109,0.0725.0.0359, 0.4886.0.3253.0.2553.0.2027.0.1587.0.1197,0.0837,0.0496,0.0163, 0.4808.0.3232,0.2561.0.2059.0.1641.0.1271.0.0932,0.0612,0.0303, 0.4734.0.3211.0.2565,0.2085,0.1686.0.1334,0.1013,0.0711,0.0422.0.0140, 0.4643.0.3185,0.2578,0.2119.0.1736,0.1399,0.1092,0.0804,0.0530.0.0263, 0.4590,0.3156,0.2571.0.2131.0.1764,0.1443.0.1150,0.0878.0.0618,0.0368, 0.0122, 0.4542,0.3126.0.2563.0.2139.0.1787,0.1480.0.1201,0.0941.0.0696,0.0459, 0.0228, 0.4493,0.3098.0.2554.0.2145,0.1807,0.1512,0.1245.0.0997.0.0764.0.0539. 0.0321,0.0107, 0.4450.0.3069.0.2543,0.2148.0.1822,0.1539,0.1283,0.1046,0.0823.0.0610. 0.0403.0.02, 0.4407,0.3043,0.2533,0.2151.0.1836,0.1563,0.1316,0.1089,0.0876.0.0672. 0.0476.0.0284.0.0094.
0.4366.0.3018.0.2522.0.2152.0.1848,0.1584.0.1346.0.1128.0.0923,0.0728. 0.0540.0.0358.0.0178.
0.4328.0.2992.0.2510,0.2151.0.1857.0.1601.0.1372,0.1162,0.0965,0.0778.
0.0598.0.0424,0.0253.0.0084,
0.4291.0.2968.0.2499.0.2150.0.1864,0.1616.0.1395.0.1192.0.1002,0.0822, 0.0650,0.0483,0.0320,0.0159,
0.4254,0.2944,0.2487.0.2148,0.1870.0.1630.0.1415.0.1219.0.1036,0.0862. 0.0697,0.0537,0.0381,0.0227.0.0076,
0.4220,0.2921.0.2475.0.2145,0.1874,0.1641.0.1433,0.1243,0.1066,0.0899. 0.0739.0.0585,0.0435,0.0289.0.0144.
0.4188.0.2898.0.2463.0.2141,0.1878.0.1651.0.1449.0.1265.0.1093.0.0931. 0.0777.0.0629,0.0485,0.0344.0.0206.0.0068.
0.4156.0.2876,0.2451,0.2137,0.1880.0.1660.0.1463.0.1284.0.1118.0.0961. 0.0812.0.0669.0.0530,0.0395,0.0262.0.0131,
0.4127,0.2854,0.2439.0.2132,0.1882.0.1667.0.1475,0.1301,0.1140,0.0988. 0.0844,0.0706,0.0572,0.0441,0.0314.0.0187,0.0062, 0.4096,0.2834.0.2427.0.2127,0.1883,0.1673,0.1487.0.1317,0.1160.0.1013. 0.0873,0.0739.0.0610,0.0484,0.0361.0.0239,0.0119, 0.4068.0.2813,0.2415.0.2121.0.1883.0.1678,0.1496,0.1331,0.1179.0.1036. 0.0900,0.0770,0.0645,0.0523,0.0404,0.0287.0.0172,0.0057.
0.4040,0.2794,0.2403,0.2116,0.1883,0.1683,0.1505.0.1344.0.1196.0.1056, 0.0924,0.0798.0.0677.0.0559.0.0444.0.0331.0.0220,0.0110, 0.4015,0.2774.0.2391.0.2110.0.1881,0.1686,0.1513.0.1356,0.1211,0.1075. 0.0947.0.0824.0.0706.0.0592,0.0481.0.0372,0.0264.0.0158,0.0053, 0.3989.0.2755,0.2380,0.2104.0.1880,0.1689,0.1520.0.1366,0.1225.0.1092, 0.0967,0.0848.0.0733.0.0622,0.0515.0.0409,0.0305,0.0203.0.0101, 0.3964.0.2737,0.2368,0.2098,0.1878.0.1691.0.1526.0.1376,0.1237.0.1108. 0.0986.0.0870,0.0759.0.0651.0.0546.0.0444,0.0343.0.0244,0.0146.0.0049, 0.3940,0.2719.0.2357,0.2091,0.1876,0.1693,0.1531.0.1384,0.1249.0.1123. 0.1004,0.0891,0.0782,0.0677.0.0575,0.0476.0.0379.0.0283.0.0188.0.0094, 0.3917,0.2701,0.2345.0.2085,0.1874,0.1694,0.1535,0.1392,0.1259,0.1136.
б*
2
164
Глава 2. Проверка гипотез
0.1020,0.0909,0.0804,0.0701.0.0602.0.0506.0.0411.0.0318.0.0227.0.0136, 0.0045,
0.3894.0.2684,0.2334,0.2078.0.1871.0.1695.0.1539,0.1398.0.1269,0.1149. 0.1035,0.0927.0.0824,0.0724.0.0628.0.0534.0.0442,0.0352.0.0263.0.0175. 0.0087,
0.3872.0.2667,0.2323.0.2072.0.1868,0.1695.0.1542,0.1405.0.1278,0.1160, 0.1049,0.0943,0.0842,0.0745,0.0651.0.0560,0.0471,0.0383.0.0296,0.0211. 0.0126,0.0042.
0.3850,0.2651,0.2313.0.2065.0.1865,0.1695,0.1545.0.1410,0.1286.0.1170, 0.1062.0.0959,0.0860,0.0765,0.0673.0.0584.0.0497.0.0412,0.0328.0.0245, 0.0163.0.0081,
0.3830.0.2635,0.2302.0.2058.0.1862.0.1695,0.1548,0.1415.0.1293.0.1180. 0.1073,0.0972,0.0876,0.0783,0.0694.0.0607,0.0522.0.0439.0.0357,0.0277. 0.0197,0.0118,0.0039,
0.3808,0.2620,0.2291.0.2052.0.1859,0.1695,0.1550,0.1420,0.1300,0.1189, 0.1085.0.0986,0.0892.0.0801,0.0713,0.0628,0.0546.0.0465.0.0385,0.0307. 0.0229,0.0153,0.0076,
0.3789,0.2604,0.2281,0.2045,0.1855,0.1693.0.1551,0.1423,0.1306.0.1197, 0.1095,0.0998,0.0906,0.0817,0.0731,0.0648.0.0568,0.0489,0.0411,0.0335. 0.0259,0.0185.0.0111.0.0037,
0.3770.0.2589,0.2271.0.2038,0.1851.0.1692.0.1553,0.1427.0.1312.0.1205. 0.1105.0.1010.0.0919.0.0832.0.0748,0.0667,0.0588,0.0511.0.0436,0.0361. 0.0288.0.0215,0.0143,0.0071.
0.3751,0.2574,0.2260,0.2032.0.1847,0.1691,0.1554.0.1430,0.1317.0.1212. 0.1113,0.1020.0.0932.0.0846.0.0764.0.0685.0.0608,0.0532,0.0459.0.0386. 0.0314.0.0244,0.0174.0.0104,0.0035}:
//////////////////////////
// Определение знаменателя
d = VectorSum (x.n);
d = VectorSumSQ (x.n) - d * d / n:
//////////////////////////////////////////////////
// Вычисление начала отсчета массива коэффициентов
for (1 = 1: i < n - 2: 1++)
for (j = 0; j <= i / 2: j++)
s++:
////////////////////////
// Определение числителя
j = n - 1:
for (i = 0; 1 < n / 2; 1++)
b += a[s++] * (x[j—] - x[l++]):
return b * b / d:
}
Критерий Саркади
Для проверки нормальности распределения можно воспользоваться критерием Саркади [32, с. 57]. в основе которого лежит идея, за-
Проверка типа распределения эмпирических данных
165
ключаютцаяся в построении из исходной выборки £ выборки т], распределенной по стандартному нормальному закону, по формулам:
Сн---------~ =m>m+t •••>«-1-
П + у/п i=i \1П + 1
где тп — параметр, обычно равный п или 1.
Случайные величины £ подчиняются распределению Стьюдента с числом степеней свободы (п - j - 1) и вычисляются по формуле
J=1,2,..., и-2.
-----
n-j-ltt
Таким образом, если исходная выборка имела нормальное распределение, величины 8 имеют равномерное распределение на отрезке [0,1] и вычисляются по формуле
= ...«-2,
где 5V(.) — функция распределения Стьюдента с v степенями свободы.
Соответствие распределения величины 8 теоретическому равномерному распределению проверяется одним из критериев согласия. Мы выбрали для этого критерий X Пирсона [187, с. 324]. Критерий Саркади интересен тем, что тип распределения эмпирической выборки проверяется без оценки параметров распределения по выборке. Это позволяет применять в его схеме расчета хорошо исследованные критерии согласия для простой гипотезы. Теоретические вероятности равномерного распределения на интервале ]а,Д[, необходимые для проверки соответствия распределения величины 8 равномерному распределению, получены по формуле [63, с. 48]
fQ^aJb) = 1 / (b - а), а <х< b.
Интерпретация результатов расчета следующая. Предположим, вычислено р = 0,958 > 0,95 — распределение отличается от теоретического нормального распределения с коэффициентом дове-
166 Глава 2. Проверка гипотез
2
рия 0,95. Предположим, вычисленор = 0,258 < 0,95 — распределение не отличается от теоретического нормального распределения с коэффициентом доверия 0,95.
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <stdlib.h>
#include <math.h>
#include <megastat.h>
void main (void)
{
register int i; // Счетчик цикла
int п. т. Code; // Численность тестового массива
// Код ошибки
doublе у[200], // Тестовый массив вариант
с. // Статистика критерия
Р: // Доверительный уровень
n = sizeof (y) / sizeof (y[0]);
m = n - 1:
///////////////////////////////////////////
// Вычисление случайной величины, нормально
// распределенной с параметрами [0.1]
for (i = 0; i < n; i++)
{
y[i] = rand ():
y[i] /= RAND_MAX;
y[i] = InverseNormalDistribution (y[ij):
}
Code = Sarkadi (y.n.m.&c.&p):
if (’Code)
cout « "Chi Square = " « c « endl « "p = " « p « endl: else if (Code == -1)
cout « "Мало памятиХп";
el se
cout « "Ошибка в вычислениях\п":
}
int Sarkadi (double x[].int n.int m.double *c,double *p)
//
// Функция вычисления критерия Саркади для проверки
// нормальности
Проверка типа распределения эмпирических данных . 167
// распределения эмпирической выборки.
// Обозначения:
// х - анализируемая выборка,
// п - численность выборки.
// m - параметр, обычно (при нумерации с 0)
// *с - статистика хи-квадрат,
// *р - доверительный уровень.
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -1 при недостатке памяти для вычислений.
// -2 при ошибке в вычислениях.
//
register int j;
int k;
double si = VectorSum (x.n) / (n + sqrt (n)), s2 = 1 / (sqrt (n) + 1).
*h.*d.*b;
равный n - 1.
// Счетчик
// Число классов
// Параметр
// Параметр
// Рабочие
// массивы
2
if (!(h = new double[n - 1])) return -1;
if (!(d = new double[n - 2])) { delete [] h;
return -1;
}
/////////////////////////////////////////////
11 Выборка с нормальным распределением N[0,s]
for (j = 0: j < n - 1; j++)
h[j] - j < m - 1 ? x[j] - si - s2 * x[m] : x[j + 1] - si -s2 * x[m]:
for (j - 0; j < n - 2; j++)
{
for (k- j + 1. si = 0: k < n - 1; k++)
si += h[k] * h[k]:
if (!sl)
{
delete [] d: delete [] h:
return -2:
}
/////////////////////////////////////
// Выборка с распределением Стьюдента d[j] = h[j] / sqrt (si / (n - j)):
/////////////////////////////////////////////
II Выборка с равномерным распределением [0.1]
168
Глава 2. Проверка гипотез
d[j] = StudentDistribution (п - j.d[j]); }
k = Sturgess (n - 2):
if (!(b = new double[k]))
{ delete [] h; delete [] d:
- return -1;
}
////////////////////////////////////////////// // Получение эмпирических частот распределения Allocate (d.n - 2,h,b,k);
//////////////////////////////// // Величина классового интервала si - b[l] - b[0]:
///////////////////////////////////////////////////////////// // Теоретические вероятности равномерного распределения [0,1] for (j = 0; j < k: j++)
b[j] = 1;
/////////////////////////////////////// // Критерий согласия хи-квадрат Пирсона *с = ChiSquareEmpire (h,b,k,(n - 2) * si):
///////////////////////////////////////////// // Доверительный уровень для простой гипотезы *р = ChiSquareDistribution (к - 1,*с);
delete [] h; delete [] d; delete [] b;
return 0;
}
Метод размаха варьирования
Проверяется нулевая гипотеза об отличии эмпирического распределения от нормального распределения методом размаха варьирования [155, с. 28]. Исходными данными для расчета являются вычисленные нами в разделе «Описательная статистика» главы 1 размах выборки R и оценка среднего квадратичного отклонения s, а также численность выборки п. Решение об отличии эмпирического распределения от нормального на стандартном уровне значимости р принимается, если
L <R/s<H . пр ' njy
Проверка типа распределения эмпирических данных
169
где Ln<p — нижнее критическое значение, Нпр — верхнее критическое значение.
Нижнее и верхнее критические значения вычисляются функцией RangeOfVarDistribution, однако функция RangeOfVar, вычисляющая стандартный уровень значимости нулевой гипотезы, построена так, что в явном вызове функции RangeOfVarDistribution нет не-обходимости — все критические значения на стандартных уровнях ? значимости проверяются функцией RangeOfVar автоматически. Для уровня значимости 0,005 функцией не делается различия — р больше 0,005 или р меньше 0,005. Такую проверку несложно организовать путем небольшого усовершенствования функции, однако делать это нет необходимости. При проверке гипотезы об отсутствии нормального распределения, если можно так выразиться, желательным для исследователя обычно является опровержение нулевой гипотезы о том, что распределение не отличается от нормального, и уже на уровне значимости 0,05 с отстутствием нормальности приходится согласиться, поэтому более высокую значимость различий можно было бы вообще не проверять.
Рассмотрим пример. Пусть функцией вычислен стандартный уровень значимости 0,1. Следовательно, на уровне значимости >0,1 принимается нулевая гипотеза о том, что распределение значимо не отличается от нормального.
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include "megastat.h"
void main (void)
{
double г = 1.3, s = 0.391. n = 10.
P:
// Размах выборки
// Оценка среднего квадратичного отклонения
// Численность выборки
// Стандартный уровень значимости
if (’RangeOfVar (r.s.n.&p)) cout « "г = " « г « "\ns = " « "\np = " « p « endl:
el se
cout « "Domain error\n";
}
« s « "\nn = " « n
int RangeOfVar (double r.double s.double n.double *p) //
// Функция вычисляет критические значения статистики метода
170
Глава 2. Проверка гипотез
// размаха варьирования.
// Обозначения:
// г - размах выборки,
// s - оценка среднего квадратичного отклонения,
// п — численность выборки.
// *р - вычисленный стандартный уровень значимости (*р >).
// Возвращаемое значение:
// 0 при нормальном окончании расчета,
2 // -2 при ошибке в фактических параметрах.
“ //
{
register int i; // Счетчик
double low,high. // Интервалы
pp[] = {0.1.0.05,0.025,0.01,0.005}; // Стандартные
// уровни значимости
if (!s) return 2;
//////////////////////
// Размах варьирования г /= s;
/////////////////////
// Начальное значение
*Р - рр[4]:
/////////////////////////////////////////////
// Проверка на стандартных уровнях значимости
for (1=0: i < 5; 1++)
if (’RangeOfVarDistribution (n,pp[i],&1ow,&high)) {
if (low <= r && r <- high)
{
*p = ppCU:
return 0;
}
}
el se
return -2;
return 0;
}
Критерии отклонения распределения
от нормальности
Существует группа критериев, которые позволяют оценить откло-
нение ряда параметров распределения от нормального распределе
Проверка типа распределения эмпирических данных
171
ния [167, с. 626], но более точно, чем упрощенные методы, которые описаны в начале раздела. Данные критерии не рекомендуется называть критериями нормальности [91, с. 617], их лучше называть критериями эксцесса (статистики Ь2 и d) и критерием коэффициента асимметрии. Соответственно, не вводя в заблуждение потребителя результатов расчета, нужно формулировать и вывод по результату расчета, хотя вывод по результатам применения данных критериев, несомненно, более ценен, чем простое сделанное исследователем и не доказанное статистически предположение о нормальном характере распределения.
Применение критерия эксцесса и критерия коэффициента асимметрии для больших выборок рекомендуется [187, с. 336] для проверки отклонения от нормальности, например при решении вопроса о применении критерия Стьюдента, так как даже для выборок, несколько отличающихся от нормальных, результаты применения критерия Стьюдента будут близки к правильным, если эксцесс и коэффициент асимметрии у анализируемых выборок — такие же, как у нормальных.
Критерий эксцесса
Для проверки нормальности распределения достаточно больших, численностью более 50 вариант, выборок применяется статистика Ь2 [32, с. 56], вычисляемая по формуле
i=l
а в [там же, с. 259] приводятся таблицы распределения статистики. Название основано на том факте, что (Ь2 - 3) есть выборочный коэффициент эксцесса. Данный критерий не нашел широкого применения и упомянут здесь для полноты изложения.
См. также [155, с. 29], [180, т.1, с. 271], [187, с. 333].
Критерий Гири
Гири предложил заменить критерий Ь2 критерием d [161, с. 366], вычисление статистики которого производится по формуле [32, с. 56]
</ =—£|х,-х|.
Доверительный уровень вычисляется функцией GearyDistribution.
172
Глава 2. Проверка гипотез
Ввиду определенных теоретических и вычислительных сложностей применения критериев статистика Гири считается удобным способом проверки нормальности, если целью этой процедуры является только решение вопроса о возможности применения тех или иных параметрических тестов и методов дисперсионного анализа.
Исследования Гири (Джири) подробно изложены в [167, с. 630].
Исходные коды
double Geary (double х[],int n) //
// Функция вычисления статистики d Гири для проверки нормальности // распределения.
// Обозначения:
// х - исходная выборка,
// п - численность выборки.
// Возвращаемое значение:
// значение статистики Гири либо 0 при ошибке.
//
{
register int i; // Счетчик цикла
double m = VectorSum (x, n) / n, // Выборочное среднее sigma - 0, // Выборочная дисперсия
s = 0; // Рабочая переменная
for (i = 0: i < n: i++) sigma += (x[i] - m) * (x[i] - m);
sigma /= (n - 1):
for (i = 0: i < n: i++) s += fabs (x[i] - m);
if (sigma != 0)
return s / n / sqrt (sigma):
el se return 0;
}
Для многомерного случая критерий проверки сферичности нормального распределения описан в [190, с. 598].
Критерий коэффициента асимметрии
В [32, с. 56] дан еще один критерий оценки отклонения от нормальности, основанный на выборочном коэффициенте асимметрии. Вычисления производятся по формуле
Дальнейшие исследования и программные ресурсы
173
Программная реализация не сложнее предыдущей, а таблицы распределения статистики приводятся в [32, с. 258]. Критерий описан также в [28, вып. 2, с. 154], [155, с. 28], [187, с. 333]. В [180, т. 1, с. 271] представлена оценка в модификации Фишера. Для многомерного случая критерий проверки гипотезы о симметричности ^-мерного нормального распределения по k переменным рассмотрен в [190, с. 598]. Критерий Гупта, предназначенный для статистической проверки симметричности распределения относительно выборочной медианы, рассмотрен в [156, с. 117].
Критерий анализа процентилей
В [52, с. 35] предлагается критерий, позволяющий на основе процентилей разобраться, насколько эмпирическое распределение близко к нормальному. Так, если процентили эмпирического распределения не слишком отличаются:
2,5%-процентиль — от Д - 2ст,
16%-процентиль — от Д - а,
50%-процентиль — от Д,
84%-процентиль — от Д + а,
97,5%-процентиль — от Д + 2а, распределение близко к нормальному.
Данная процедура проверки может быть легко реализована с помощью разработанных нами и показанных выше функций и для экономии места не приводится.
Дальнейшие исследования и программные ресурсы
• Исследования по применению критериев согласия для различных типов теоретического распределения.
• Проверка соответствия типа распределения многомерных эмпирических данных многомернььм теоретическим типам распределения. Эта задача актуальна для многомерного нормального распределения, так как в ряде методов классификации и распознавания образов предполагается, что исходные данные имеют именно такой тип распределения.
174
Глава 2. Проверка гипотез
• Составление рекомендаций и программы-мастера, которые помогут пользователю выбрать метод исследования, адекватный представленным для анализа исходным экспериментальным данным: типом исходных данных определяется метод, предназначенный для их обработки. К тому же эта концепция хорошо укладывается в схему объектно-ориентированного проектирования.
Некоторые представленные в данной главе расчеты можно проделать с помощью стандартных электронных таблиц, например StarCalc из пакета Star Office производства Sun Microsystems. Для выполнения расчетов с помощью непараметрических тестов можно воспользоваться одной из десятков программ анализа данных, имеющихся на рынке программного обеспечения для научных исследований.
Глава 3.
Дисперсионный анализ
Дисперсионным анализом называют совокупность статистических методов, предназначенных для обработки данных экспериментов, целью которых являлось не установление каких-то свойств и параметров, а сравнение эффектов различных воздействий на каком-либо экспериментальном материале. Методы дисперсионного анализа используются для проверки гипотез о наличии связи между результативным признаком и исследуемыми факторами, а также для установления силы влияния факторов и их взаимодействий.
Для многих параметрических и непараметрических тестов существуют многомерные аналоги в дисперсионном анализе. Именно эти методы и следует использовать, когда число выборок больше двух. Авторы [158] отмечают, что в этом случае нельзя применять критерии, предназначенные для проверки статистических гипотез, то есть для сравнения групп выборок попарно, а затем делать какие-либо выводы относительно всей многомерной совокупности.
Подобно критериям проверки гипотез, методы дисперсионного анализа могут быть предназначены для нормально распределенных совокупностей (то есть будут многомерными аналогами параметрических тестов) и для выборок, свободных от предположения о типе распределения (то есть будут многомерными аналогами непараметрических тестов).
В дисперсионном анализе, как и в других областях анализа данных, сложилась определенная терминология [187, с. 191]. Фактором называют величину, определяющую свойства исследуемого объекта или системы [там же, с. 463], иначе — причину, влияющую на конечный результат [там же, с. 191]. Конкретную реализацию фактора называют уровнем фактора или способом обработки. Значение измеряемого признака называют откликом.
Однофакторный анализ
Данные для рассматриваемых далее методов однофакторного дисперсионного анализа представлены в виде таблиц, причем число столбцов (выборок) соответствует числу уровней фактора (уровней об
176
Глава 3. Дисперсионный анализ
работки), число строк равно числу наблюдений. При этом выборки могут иметь как однаковое число вариант (равные объемы), так и различное. В наших программных реализациях таблицы представлены в виде одномерных массивов, причем выборки расположены друг за другом. Задается также число столбцов (уровней фактора) и массив длин выборок (массив объемов выборок), причем длина упомянутого массива равна числу факторов.
Однофакторный дисперсионный анализ
При однофакторном дисперсионном анализе (дисперсионном анализе по одному признаку, ANOVA [28, вып. 2, с. 40]) предполагается, что результаты наблюдений для разных уровней представляют собой выборки из нормально распределенных генеральных совокупностей. Эти совокупности имеют свои средние и дисперсии, которые полагаются одинаковыми и не зависят от уровней. Задачей анализа является проверка нулевой гипотезы о равенстве средних рассматриваемых совокупностей. Вычисления критериальной статистики производятся по формуле1 [140, с. 135]
Л 2
* N-k £ л ' 7
“ bi k ~,
«=1 J=1
k
где W = — общая численность,
i=i
k — число выборок,
и, i =1,2,..., k, — численность i-й выборки,
xi = —^xij^ ~ 1,2,..., k > _ среднее i-й выборки,
ni j=i
1 *
= ~ общее среднее.
Сумма, стоящая в числителе формулы вычисления критериальной статистики, служит приближенной мерой вариации между анали
1 Мы несколько изменили запись формулы для удобства расчета.
Однофакторный анализ
177
зируемыми выборками, а сумма, стоящая в знаменателе, служит мерой вариации внутри выборок [28, с. 39].
Доверительный уровень вычисляется функцией FDistribution с параметрами (k - 1) и N.
Подробности методики применения однофакторного дисперсионного анализа и примеры применения даны в [26, с. 137], [89, с. 136], [123], [158, с. 174]. Ковариационный анализ подробно рассмотрен в [180, т. 1, с. 494].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void)
{
int n[] = {10.10.10,10}, // Численности выборок k = 4; // Число выборок
double a[] = {1,2,3,4.5,1.2.3.4,5.
2,3,4.5,6.2.3.4.5,6,
1.3.5,7.9.1.3.5.7.9.
2,3.2.3.2.3.2.3.2.3}.
с: // значение критерия
if (’OneWayAnalysis (a.n.k,&c)) cout « « el se cout «
с « enoi
FDistribution (k - 1,VectorSum (n.k).c) « endl;
"Мало памяти\п";
int OneWayAnalysis (double *data,int *n, int k.double *criterion) //
// Функция проводит однофакторный дисперсионный анализ.
// Обозначения:
// data - массив к векторов данных (вектора друг за другом).
// п - нассив длин к векторов.
// *criterion - критериальная статистика.
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -1 при недостатке памяти.
//
{
register int i.j; // Счетчик цикла
mt nn = VectorSum (n.k). // Общее число вариант
178
Глава 3. Дисперсионный анализ
m = 0; // Счетчик одномерного массива
double *x.*t. // Рабочий массив
s = 0, // Полная дисперсия
si = 0. // Сумма дисперсий выборок
ttt: // Вспомогательная переменная
if (Ct = new doublefk]) == 0)
return -1:
if ((x = new double[MaximumOf (n.k)]) == 0)
{
delete [] t:
return -1:
}
for (i = 0; i < k; i++)
{
for (j = 0; j < n[i); j++) x[j] = data[m++]:
t[i] = VectorSum (x,n[ij): s += VectorSumSQ (x.n[i]): si += t[i] * t[i] / n[i];
}
ttt = VectorSum (t.k): ttt *= ttt: s -= ttt / nn: si -= ttt / nn;
delete [] t: delete [] x:
♦criterion = si / (k - 1) / ((s - si) / (nn - k)):
return 0: }
Ранговый однофакторный анализ Краскела—Уоллиса
Критерий Краскела—Уоллиса (ранговый однофакторный анализ Краскела—Уоллиса, статистика Крускала—Уоллиса) является непараметрическим аналогом однофакторного дисперсионного анализа [52, с. 346] и предназначен для проверки нулевой гипотезы о равенстве эффектов воздействия (обработки) на выборки (количество выборок превышает две) с неизвестными, но равными средними. Нулевая гипотеза формулируется так: все совокупности одинаково распределены. Вычисление статистики критерия производится по формуле [111, с. 171]
Однофакторный анализ
179
гжЙ>!>'
где R., i = 1,2,..., k, — сумма рангов наблюдений z-й группы, k — число групп, k
N = ^nt — общая численность.
j=i
При больших n., i = l,2,k, распределение статистики Нимеет асимптотическое X -распределение с числом степеней свободы (k - 1). В этом случае доверительный уровень вычисляется функцией ChiSqu-areDistribution.
Обсуждение см. также в [28, вып. 2, с. 129], [120, с. 57], [156, с. 127], [158, с. 178], [187, с. 196], [218, с. 131].
Исходные коды
int KruskalWallis (double *data,int *n. int k,double *criterion)
//
// Функция проводит однофакторный дисперсионный анализ
// Краскела-Уоллиса.
// Обозначения:
// data - массив к векторов данных (вектора друг за другом).
// п - массив длин к векторов.
// *criterion - критериальная статистика.
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -1 при недостатке памяти.
//
{
register int i.j; // Счетчик
int kk, m. *ix; // Общее число наблюдений // Счетчик одномерного массива // Информация об оригинальном массиве
double s = O.sl. // Вспомогательная переменная
*y. // Массив рангов отсортированного массива
*x. // Массив рангов одного вектора
*r; // Копия исходного массива и массив рангов
kk = VectorSum (n.k);
if ((ix = new int[kk]) == 0) return -1;
if ((r = new double[kk]) == 0) {
delete [] ix;
180
Глава 3 Дисперсионный анализ
return -1:
}
if ((у - new double[kk]) == 0)
{
delete [] ix; delete [] r;
return -1;
}
if ((x = new double[MaximumOf (n.k)]) == 0)
{
delete [] ix; delete [] r; delete [] y;
return -1;
}
//////////////////////////
// Копия исходного массива
ArrayToArray (data.r.kk);
////////////////////////////
// Сортировка по возрастанию
SortArrayUp (r.kk.ix.l):
///////////////
// Ранжирование
Rank (r.y.kk);
//////////////////////////////////////////////
// Восстановление рангов оригинального массива UnSortArray (y.r.kk.ix);
for (i=0, m=0;i<k; i++)
{
for (j = 0; j < n[i]; j++) x[j] = r[m++J;
si = VectorSum (x.n[i]>;
s += si * si / n[i];
}
♦criterion = s * 12 / kk / (kk + 1) - 3 * (kk + 1);
delete [] ix; delete [] y; delete [] r; delete [] x;
return 0;
}
Критерий Джонкхиера—Терпстра
Критерий Джонкхиера—Терпстра представляет собой многомерное обобщение критерия Манна—Уитни и предназначен для проверки нулевой гипотезы о равенстве эффектов воздействия (обработки) на выборки с неизвестными, но равными средними. Вычисление критерия производится по формуле [187, с. 197]
Однофакторный анализ
181
*-i к
1=1 j=i+l
где Uijt i = 1, 2,k-l,j =2, 3,k, — статистика критерия Манна-Уитни для выборок с номерами i и у,
k — количество сравниваемых выборок, k > 2.
Для больших выборок [187, с. 198] доверительный уровень вычисляется функцией NormalDistribution, вызываемой с параметром нормальной аппроксимации, вычисленным функцией Jonckhe-ereTerpstra.
Обсуждение дано в [218, с. 136].
Исходные коды
int JonckheereTerpstra (double *data,int *n. int k.double Criterion, double *t)
//
// Функция вычисляет критерий Джонкхиера-Терлстра.
// Обозначения:
// data - массив к векторов данных (вектора друг за другом),
// п - массив длин к векторов.
// *criterion - критериальная статистика.
// *t - параметр нормальной аппроксимации.
// Возвращаемое значение:
// 0 при нормальном окончании расчета,
// -1 при недостатке памяти.
//
{
register int i.j.l.m; // Счетчик цикла
int nx, // Число вариант первого
// сравниваемого массива
nn = VectorSum (n.k), // Общее число вариант
ml.m2; // Счетчик одномерного массива
double *х,*у, // Рабочий массив
buf.bufl; // Рабочие переменные
if (!(х = new double[MaximumOf (n.k)])) return -1;
if (!(y = new double[MaximumOf (n.k)]))
{
delete [] x;
return -1;
}
for (i = 0,ml » O,*criterion » 0; i < k - 1; i++)
{
182
Глава 3 Дисперсионный анализ
for (j = 0; j < n[i]; j++) x[j] = data[ml++];
nx = n[i]:
for (m = i + 1. m2 = ml; m < k; m++)
{
for (1 = 0; 1 < n[m]; 1++)
y[l] = data[m2++];
MannWhitneyTest (x.y.nx.n[m].&buf);
♦criterion += buf;
}
}
delete [] x; delete [] y;
for (j = O.buf = O.bufl =0; j < k; j++) {
buf -= n[j] * n[j];
bufl -= n[j] * n[j] * (2 * n[j] + 3):
}
*t = (*criterion - 0.25 * (buf + nn * nn)) /
sqrt (0.01388889 * (bufl + nn * nn * (2 * nn + 3)));
return 0; }
М-критерий Бартлетта
M-критерий Бартлетта служит для проверки нулевой гипотезы о равенстве дисперсий нескольких генеральных совокупностей. Предполагается, что выборки извлечены из нормальных генеральных совокупностей. Вычисления производятся по формулам [140, с. 118]:
k
t = (N-A)lgS2-£(n,-l)lgS,2
с i=1
1 1 lv 1 1 I
с = 1н--->-----------,
k
где N = — общая численность,
i=l
k — число выборок, k > 2,
nif i =1,2,..., k, — численность z-й выборки,
Однофакторный анализ
183
s2 = — я,-1
— выборочная дисперсия i-й выборки,
X =—= .Л — среднееz-йвыборки.
' niM
При больших i = l,2,..., k, распределение статистики критерия имеет асимптотическое с2-распределение с числом степеней свободы (k - 1). В этом случае доверительный уровень вычисляется функцией ChiSquareDistribution.
Описание критерия дано также в [32, с. 47], [70, с. 271], [156, с. 96], [158, с. 203].
Исходные коды
int Bartlett (double *data,int *n, 1nt k,double *criterion)
//
// Функция вычисляет М-критерий Бартлетта для проверки
// равенства нескольких дисперсий.
// Обозначения:
// data - массив к векторов данных (вектора друг за другой), // п — массив длин к векторов.
// *criterion - критериальная статистика.
// Возвращаемое значение:
// 0 при нормальном окончании расчета,
// -1 при недостатке памяти.
//
{
register int i,j; // Счетчик цикла
int nn. // Общее число вариант
ш; // Счетчик одномерного массива
double *х, // Рабочий массив
s » 0. // Выборочная дисперсия
z, // Вспомогательная переменная
si = 0,
S2 = 0, с - 0;
if ((х » new double[MaximumOf (n.k)]) -- 0)
return -1:
nn - VectorSum (n.k);
for (i « o, m - 0; i < k; i++) {
for (j - 0; j < n[i]; j++) x[j] = data[m++];
184
Глава 3 Дисперсионный анализ
с += 1.0 / (n[ij - 1):
s = Moment (2,x.0,&z.n[iJ);
si += log (s) * (n[i] - 1):
s2 += s * (n[i] - 1);
}
c = (c - 1.0 / (nn - k)) / 3 / (k - 1) + 1:
s2 /= (nn - k);
♦criterion = (log (s2) * (nn - k) - si) / c:
delete [] x;
return 0;
G-критерий Кокрена
G-критерий Кокрена (статистика Кокрена) используется для проверки нулевой гипотезы о равенстве дисперсий k (k > 2) нормальных генеральных совокупностей по независимым выборкам с одинаковыми объемами. Вычисление статистики критерия производится по формуле [120, с. 26]
2 max ст lAz/, *
Критические значения для статистики G вычисляются с помощью функции CochraneGDistributionExact либо CochraneGDistribu-tionApprox. Применение последнего метода рекомендуется при &>2ии>10. Выводы по результатам расчета могут быть следующие. Так, допустим, при & = Зии=10 нами вычислено значение критериальной статистики G = 0,6112, что превышает критическое значение, при р = 0,95 равное 0,5983 (табличное «точное» значение составляет 0,6025 и отличается от приближенного примерно на 0,5%). Следовательно, на доверительном уровне 0,95 гипотеза о равенстве дисперсий должна быть отвергнута.
Методика рассмотрена также в [32, с. 46], [140, с. 155], [156, с. 95]. |
Исходные коды
int CochraneG (double *data,int k.int n,double *criterion) //
// Функция вычисляет G-критерий Кокрена для проверки равенства // нескольких дисперсий.
Однофакторный анализ
185
// Обозначения:
// data - массив к векторов данных (вектора друг за другом),
// п - длина каждого вектора,
// *criterion - критериальная статистика.
// Возвращаемое значение:
// 0 при нормальном окончании расчета,
// -1 при недостатке памяти.
//
register int i, J: // Счетчик цикла
int m: // Счетчик одномерного массива
double *х. // Рабочий массив
*s, // Массив выборочных дисперсий
z, // Вспомогательная переменная
ss = 0: // Сумма дисперсий
if (!(х = new doublefn])) return -1:
if (!(s = new doublefk]))
{ delete [] x; return -1:
}
for (i =0. m = 0; i < k: i++)
{
for (j = 0; j < n; j++) x[j] = data[m++];
s[i] = Moment (2,x.0.&z.n);
ss += s[i];
}
Criterion = MaximumOf (s,k) / ss;
delete [] x; delete [] s;
return 0; }
Критерий Шеффе
Дисперсионный анализ, выполненный с применением одного из рассмотренных выше критериев, может показать, что средние совокупностей различаются. Однако он не позволяет узнать, средние каких совокупностей действительно различаются между собой. Попарное сравнение выборок исследуемой группы выборок является ошибочным подходом, как это показано в [158, с. 182], поэтому Для решения проблемы применяется метод множественного срав
186
Глава 3. Дисперсионный анализ
нения Шеффе (критерий Шеффе, метод Шеффе). Критерий Шеф-фе предназначен для проверки так называемой гипотезы о линейном контрасте [140, с. 136]
i=l
Линейный контраст представляет собой линейную функцию от средних значений k независимых нормальных выборок с неизвестными, но равными дисперсиями, и известных постоянных, удовлетворяющих условию
1с. =0.
Вычисления статистики критерия при проверке нулевой гипотезы L = Lq производятся по формуле [там же]
ЕС.Л~А>
где N— общая численность,
k — число выборок,
i = 1,2,..., k, — численность z-й выборки,
М =
— средний квадратичный остаток,
г- =—У хй,г = 1,2,...,А, — среднее i-й выборки.
Нами дан пример применения критерия Шеффе для проверки серии гипотез о простых линейных контрастах вида
L = д, - Д, = 0, i = 1, 2,..., k - 1,7 = i + 1,k,
при этом вычисленное значение статистики критерия для сравнен ния с критическим значением следует взять по модулю.
Однофакторный анализ
187
Доверительный уровень вычисляется функцией FDistribution с параметрами (k - 1) и Лг.
Обсуждение и примеры применения даны в [28, вып. 2, с. 50], [111, с. 178], [120, с. 31], [156, с. 99], [158, с. 182]. В [37, с. 291] метод называется как 5-метод и дается его сравнение с критерием Тьюки.
Исходные коды и пример применения
#include ^include #include
#include
<fstream.h>
<iomanip.h>
<math.h>
"megastat.h
void main (void)
{
register int i.j.
m = 0:
// Счетчики цикла // Счетчик
int n[] = {10,10,10,10}. k = 4;
// Численности выборок
// Число выборок
double а[] = {1,2,3,4,5,1,2,3,4,5,
2,3.4,5.6,2,3,4.5,6,
1.3.5.7.9.1.3.5.7.9.
2,3.2.3.2.3.2.3.2.3}.
*с: // Массив критериальной статистики
с = new double[(k * k - k) / 2];
if (IScheffe (a.n.k.O)
for (i =0; i < k - 1; i++)
for (j = i + 1: j < k; j++,m++)
cout « (i + 1) « « (j + 1) « " "
« c[m] « ". p = "
« FDistribution (k - 1.VectorSum (n.k) - k.c[m]) « endl:
el se
cout « "Мало паняти\п":
delete [] c:
}
int Scheffe (double //
И Функция проводит
И независимых
II выборок в случае
II контрастах.
И Обозначения:
data[],int n[].int k,double criterion[]) множественные сравнения по Шеффе для проверки гипотез о простых линейных
188
Глава 3. Дисперсионный анализ
// data - массив к векторов данных (вектора друг за другом),
// п - массив длин к векторов.
// criterion - массив критериальной статистики длиной
// (к * к - к) / 2, заранее выделен.
// Возвращаемое значение:
// 0 при нормальном окончании расчета,
// -1 при недостатке памяти.
//
{
register int i.j: // Счетчик цикла
int m, // Счетчик одномерного массива
nn = VectorSum (n.k): // Общее число вариант
double *x,*t, // Рабочий массив
s = 0, // Полная дисперсия
si - 0, // Дисперсия между выборками,
// остаточная дисперсия
ttt; // Вспомогательная переменная
if ((t = new double[k]) == 0) return -1;
if ((x = new double[MaximumOf (n.k)J) == 0) {
delete [] t;
return -1;
}
for (i = 0, m = 0: i < k; i++) {
for (j = 0: j < n[i]: j++) x[j] = data[m++]:
t[i] = VectorSum (x,n[i]): s += VectorSumSQ (x,n[ij): si += t[i] * t[i] I n[i];
}
ttt = VectorSum (t.k):
ttt *= ttt:
s -= ttt / nn: si -= ttt / nn:
/////////////////////// // Остаточная дисперсия s -= si:
/////////////////
// Массив средних
for (i =0: i < k: i++) t[i] /= n[i]:
Однофакторный анализ
189
/ / / / / / / / / / / / / / / / / / / / / / / / / / / /
// Массив попарных сравнений
for (1 = 0. m = 0: i < к - 1; i++)
for (j = i + 1; j < k; j++)
criterion[m++] = (t[i] - t[j]) * (t[i] - t[j]) /
(k - 1) / s * (nn - k) / (1.0 / n[1] + 1.0 / n[j]);
delete [] t: delete [] x;
return 0: }
Критерий Дункана
Гипотезы о простых линейных контрастах могут быть проверены также с помощью критерия Дункана (метода Дункана), по технике вычислений практически совпадающего с критерием Шеффе в случае проверки гипотез о простых линейных контрастах. Критерий Дункана имеет аналогичные критерию Шеффе предпосылки для своего применения. Вычисления производятся по формуле [140, с. 157]
t= .‘°' М у с2 V
где все обозначения соответствуют предыдущему методу.
Для вычисления ^-значений критерия Дункана применяются таблицы распределения критерия Дункана [151, с. 106], реализованные функцией Duncan Distribution и построенные на основе таблиц стьюдентизированного размаха [там же, с. 145].
Обсуждение см. также в [120, с. 34].
Критерий Тьюки
Если независимые выборки имеют равные численности, гипотезы о простых линейных контрастах могут быть проверены также с помощью критерия Тьюки (метода Тьюки). Критерий Тьюки имеет аналогичные критерию Шеффе предпосылки для своего применения. Вычисления производятся по формуле [140, с. 164]
190
Глава 3. Дисперсионный анализ
где k — число выборок,
т — численность каждой выборки,
1 * 2
М - ~~ средний квадратичный остаток,
1 т
xL = 1,2,..., k, — среднее i-й выборки.
т i=\
Для вычисления p-значений критерия Тьюки применяются таблицы стьюдентизированного размаха [140, с. 164], [151, с. 144], выполненные нами в виде функции RangeStudent, показанной в главе 4.
Обсуждение см. также в [28, вып. 2, с. 48], [120, с. 31].
Многофакторный анализ
Результаты опытов никогда в точности не соответствуют степени влияния на них того или иного признака. Происходит это потому, что на результаты оказывают влияние и неучтенные в условиях эксперимента факторы. При включении в дисперсионный анализ двух и более факторов имеет место многофакторный дисперсионный анализ (MANOVA), различные методики которого рассмотрены ниже.
Данные для двухфакторного дисперсионного анализа, который мы далее рассматриваем, представлены в виде таблиц, причем число столбцов соответствует числу уровней первого фактора (уровней обработки), число строк равно числу уровней второго фактора (уровней обработки) [120, с. 225]. Как и на протяжении всей книги, в наших программных реализациях таблицы представлены в виде одномерных массивов. Задается также число столбцов (уровней первого факто-1 ра) и число строк (уровней второго фактора).
Обсуждение см. в [156, с. 105].
Многофакторный анализ
191
Двухфакторный дисперсионный анализ
Двухфакторный дисперсионный анализ, иначе называемый дисперсионным анализом по двум признакам, применяется для зависимых нормально распределенных выборок. Нулевая гипотеза состоит в утверждении о равенстве эффектов строк между собой и равенстве эффектов столбцов между собой. Вычисления производятся по формулам [158, с. 191]:
5
I — та' f — С0< row ’ со! ’
1 г т2
где =-^Т2--^- — дисперсия между столбцами, с i=i
Iе Т2
5СО1=-^Т2 ~~ ДиспеРсия между строками,
r f=i гс
7; = ,г = 1’ •••»г , ~ суммы строк,
Tj = , j = 1,2,...,с, — суммы столбцов,
1=1
г с
х„ — общая сумма,
i=l 7=1
;=1 >1
Т2
— остаточный средний квадрат, гс
с — число столбцов (выборок), г— число строк (параметров).
Если рассматриваемые данные не удовлетворяют предположениям статистической модели дисперсионного анализа по двум признакам, необходимо применять описанный ниже непараметрический критерий Фридмана.
Доверительный уровень вычисляется функцией FDistribution с параметрами (г — 1) и (г — 1)(с — 1) в случае исследования эффекта строк и (с - 1) и (г - 1)(с - 1) в случае исследования эффекта столбцов. Обсуждение более общей проблемы см. в [28, вып. 2, с. 41].
192
Глава 3. Дисперсионный анализ
Исходные коды и пример применения
finclude <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void) {
int n = 10. // Численность выборки
k = 4, // Число выборок
Code; // Код ошибки
double а[] - {1,2,3.4.5.1.2.3.4.5.
2.3.4.5.6.2.3.4.5.6.
1.3,5.7.9.1.3.5.7.9.
2.3.2.3.2.3.2.3.2.3}, г,с: // Критериальные статистики
if (!(Code = MultyFactor (a.n.k.&r.&c)))
cout « "Эффект строк: " « г
« ", р = " « FDistribution (n - l,(n - 1) * (k - l),r) « "ХпЭффект столбцов: " « с
« ", p = " « FDistribution (k - l,(n - 1) * (k - l),c) « endl;
else if (Code == -1)
cout « "Мало памятиХп";
el se cout « "Ошибка в вычисленияхХп";
}
int MultyFactor (double *data.int n, int k,double
*criterionR,double *criterionC) 11
// Функция проводит двухфакторный дисперсионный анализ.
// Обозначения:
// data - массив к векторов данных (вектора друг за другом),
// п - длина каждого вектора.
// *criterionR - критериальная статистика, эффект строк.
// *criterionC - критериальная статистика, эффект столбцов.
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -1 при недостатке памяти.
// -2 при ошибке в вычислениях.
//
{
register int i.j; // Счетчик цикла
int nn = n * k, // Общее число вариант
m; // Счетчик одномерного массива
double *x.*t.
// Рабочий массив
Многофакторный анализ
193
s = 0. // Полная дисперсия
sr = 0, // Дисперсия между строками
sc = 0. // Дисперсия между столбцами
ttt; // Вспомогательная переменная
if ((t = new double[MaximumOf (n.k)]) == 0) return -1;
if ((x = new double[MaximumOf (n.k)]) == 0) {
delete [] t:
return -1;
}
////////////////
// Эффекты строк
for (i =0. m = 0; i < k; i++)
{
for (j = 0: j < n; j++) x[j] = data[m++];
t[i] = VectorSum (x.n);
s += VectorSumSQ (x.n): sr += t[i] * t[i] / n;
}
ttt = VectorSum (t.k);
ttt *= ttt:
s -= ttt / nn: sr -= ttt / nn;
///////////////////
// Эффекты столбцов
for (i = 0: i < n; i++)
{
for (j = 0. m = i: j < k; j++)
{
x[j] = data[m]: m += n:
}
t[i] = VectorSum (x.k):
sc += t[i] * t[i] / k:
}
ttt = VectorSum (t,n);
ttt *= ttt:
sc -= ttt / nn:
delete [] t: delete [] x;
///////////////////////
И Остаточная дисперсия
s = (s - sr - sc) / (k - 1) / (n - 1):
7'2OO2
194
Глава 3 Дисперсионный анализ
if (s <= 0.000001) return -2:
sr /= к - 1: sc /= n - 1;
*criterionR = sr / s:
*criterionC = sc / s:
return 0; }
Ранговый критерий Фридмана
Если не выполнены предположения, позволяющие провести двух-1 факторный дисперсионный анализ, применяется свободный от типа распределения непараметрический критерий Фридмана. Ранговый двухфакторный анализ Фридмана (ранговый критерий Фридмана,] Кендалла и Смита) применяется для проверки нулевой гипотезы о том, что различные методы обработки или иных воздействий на изучаемый объект (процесс) дают одинаковые результаты [37, с. 244]. Таким образом, нулевая гипотеза состоит в отсутствии эффектов столч бцов (эффектов обработки).
Здесь предполагается, что данные расположены в виде прямоугольной матрицы, в которой п строк — блоков наблюдений параметров объектов — расположены в k столбцах, соответствующих видам обработки (видам воздействия на объекты). При этом каждый блок может быть результатом измерений параметров как на одном объек-| те, так и на группе объектов, например в виде среднего значения какого-либо параметра по всем объектам исследуемой группы при определенном виде воздействия на группу. Следующий блок, таким образом, будет средним значением другого параметра по всем объек-| там группы при том же виде воздействия. Отметим, что в зависимости от поставленной задачи матрица данных может быть транспонирована.
Вычисление статистики критерия производится по формуле [158, с. 196]
12 nk(k+l)
где k — число эффектов обработки (воздействий, уровней фактора), R., i =1,2,..., k, — сумма рангов г-го блока.
Многофакторный анализ
195
Доверительный уровень вычисляется функцией ChiSquareDistribu-tion при числе степеней свободы (k - 1).
Имеются разновидности приведенной формулы [123, с. 199], [187, с. 196], [218, с. 154], принципиально не отличающиеся от показанной нами. Хороший пример дан в [ 111, с. 170]. Обсуждение см. в [120, с. 59], [151, с. 407], [156, с. 129].
Исходные коды
int Friedman (double *data,int n, int k.double *criterion) //
// Функция проводит непараметрический дисперсионный анализ
И Фридмана по двум признакам для зависимых выборок.
// Обозначения:
// data - массив к векторов данных (вектора друг за другом), // п - длина каждого вектора.
// *criterion - критериальная статистика.
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -1 при недостатке памяти.
//
{
register int i, j; // Счетчик
int kk = n * k. // Общее число наблюдений
ml.m2. // Счетчик одномерного массива
*ix: // Информация об оригинальном массиве
double si = 0 ,s2 = 0. // Вспомогательная переменная
s.
*y. // Вспомогательный нассив
*x. // Массив рангов одного вектора
*r; // Массив рангов матрицы данных
if ((ix = new int[k]) = = 0)
return -1;
if ((г = new double[kk]) == 0)
{
delete [] ix:
return -1:
. }
if ((x = new double[k]) == 0)
{
delete [] ix; delete [] r;
return -1;
. }
if ((y = new double[k]) == 0)
{
delete [] x; delete [] ix: delete [] r: return -1:
}
7*
196
Глава 3. Дисперсионный анализ
for (1 = 0, m2 = 0: i < n; 1++)
{
/ / / / / / / / / / / / / / /
// Копия строки
for (j =0. ml = m2; j < k; j++. ml += n) y[j] = data[ml];
lllllllllllillllllllllllilll // Сортировка по возрастанию SortArrayUp (y.k.ix.l);
/////////////// II Ранжирование Rank (y.x.k);
////////////////////////////////////////////// // Восстановление рангов оригинального массива UnSortArray (x.y.k.ix);
///////////////////////////////////////
// Заполнение массива рангов по строкам for (j = 0, ml = m2++; j < k; j++, ml += n) r[ml] = у[j]:
}
for (i = 0, ml = 0; i < k; 1++)
{
for (j = 0; j < n; j++) x[j] = r[ml++J;
s = VectorSum (x. n);
si += s;
s2 += s * s;
}
♦criterion = (s2 - si * si / k) * 12 / kk / (k + 1);
delete [] ix; delete [] r; delete [] x; delete [] y:
return 0;
}
Критерий Пэйджа
Критерий Пэйджа (Z-критерий, дисперсионный анализ Пэйджа) предназначен для проверки нулевой гипотезы о равенстве эффектов воздействия (обработки) на выборки (количество выборок превышает две) с неизвестными, но равными средними. Нулевая гипотеза состоит в утверждении о равенстве эффектов строк между собой и равенстве эффектов столбцов между собой. Статистика критерия вычисляется по формуле [218, с. 163]
Многофакторный анализ
197
1 = ^7?,,
1=1
где k — число эффектов обработки (воздействий, уровней фактора), 7?., i = 1,2,k, — сумма рангов i-го блока.
Для больших выборок применяется нормальная аппроксимация критических значений статистики L. В этом случае доверительный уровень вычисляется функцией NormalDistribution, вызываемой с параметром нормальной аппроксимации, вычисленным функцией Page.
Описание критерия Пэйджа можно найти также в [187, с. 229], [123, с. 224].
Исходные коды
int Page (double *data,int n. int k,double *criterion, double *t) //
// Функция проводит дисперсионный анализ Пэйджа, основанный
// на ранговых суммах Фридмана.
// Обозначения:
// data - массив к векторов данных (вектора друг за другом),
// п - длина каждого вектора.
// *criterion - критериальная статистика,
// *t - параметр нормальной аппроксимации.
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -1 при недостатке памяти.
//
{
register int i.j; // Счетчик
int ml.m2. *ix; // Счетчик одномерного массива // Информация об оригинальном массиве
double *y. // Вспомогательный массив
*x. // Массив рангов одного вектора
*r; // Массив рангов матрицы данных
if ((ix - new int[k]) == 0) return -1;
if ((r = new double[n * k]) == 0) {
delete [] ix;
return -1;
}
if ((x = new double[k]) == 0)
{
delete [] ix; delete [] r;
198
Глава 3 Дисперсионный анализ
return -1;
}
if ((у = new double[k]) == 0)
{
delete [] x; delete [] ix; delete [] r;
return -1: }
for (i = 0, m2 = 0: i < n: i++) {
///////////////
// Копия строки for (j = 0. ml = m2: j < k: j++, ml += n) y[j] = data[ml];
SortArrayUp (y.k.ix.l):
Rank (y.x.k):
UnSortArray (x.y.k.ix):
/////////////////////////////////////// // Заполнение массива рангов по строкам for (j =0, ml = m2++: j < k: j++, ml += n) r[ml] = y[j];
}
for (i = 0. ml = 0, *criterion = 0: i < k: 1++) {
for (j = 0: j < n: j++) x[j] = r[ml++]:
♦criterion += VectorSum (x.n) * (k - i): }
*t = (*criterion - 0.25 * n * k * (k + 1) * (k + 1)) / sqrt (0.00694444 *n*(k*k*k-k)*(k*k*k-k) / (k - 1)):
delete [] ix: delete [] y: delete [] r: delete [] x:
return 0: }
Q-критерий Кокрена
Q-критерий Кокрена используется в случае, если группы однородных субъектов подвергаются более чем двум экспериментальным воздействиям, и их ответы (0 означает отрицательный ответ, 1 — положительный) носят двухвариантный (бинарный) характер. Каждая выборка представляет собой измерения одного условия по всем группам. Варианты выборки, таким образом, — это измерения в рассматриваемых группах по данному условию. Нулевая гипотеза со
Многофакторный анализ
199
стоит в том, что в генеральной совокупности доли всех экспериментальных условий равны. В альтернативной гипотезе утверждается, что доли условий в генеральной совокупности различны. Вычисления производятся по формуле [172, с. 61]
где Tj = = 2, — >с> ~ суммы столбцов,
»=1
TL = 1,2,rf — суммы строк, >=i
с — число столбцов (выборок),
г — число строк (параметров).
Доверительный уровень вычисляется функцией ChiSquareDistribu-tion при числе степеней свободы, равном (с - 1).
Обсуждение дано в [37, с. 246].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h”
void main (void)
{
int k = 4. // Число столбцов (выборок) n = 15; // Число строк (параметров)
double data[] = {0.0.О,0,1.0,1.1,0,0.1,1,0,1,1, 0,1,1,0,0,1,1,0.1,0.1,1,0,0.1. 0,0,0,0.1,0,0,0,1,0.0,1,0,0,1, 0.1.1,0,1.1,1.1.0.1.1,0,1,1,1}.
Ч:
if (ICochraneQ (data.n.k,&q))
cout « q « ". p = " « ChiSquareDistribution (k - l.q) « endl;
el se
200
Глава 3. Дисперсионный анализ
cout « "Мало памяти\п":
}
int CochraneQ (double *data.int n, int k,double *criterion) //
// Функция вычисляет Q-критерий Кокрена.
// Обозначения:
11 data - нассив k векторов данных (вектора друг за другом),
// п - длина каждого вектора.
// *criterion - критериальная статистика.
// Возвращаемое значение:
// 0 при нормальном окончании расчета,
// -1 при недостатке памяти.
//
{
register int i,j; // Счетчик цикла
int m = 0: // Счетчик одномерного массива
double *x,*t, H Рабочий массив
si = 0, H Сумма итоговых значений по столбцам
s2 = 0, // Сумма квадратов si по столбцам
s3 = 0, // Сумма итоговых значений по строкам
s4 = 0; // Сумма квадратов s3 по строкам
if ((х = new double[MaximumOf (n.k)J) == 0) return -1:
if ((t = new double[MaximumOf (n.k)J) == 0) {
delete [] x:
return -1;
}
for (i = 0; i < k; i++)
{
for (j = 0; j < n; j++) x[j] = data[m++];
t[i] = VectorSum (x,n);
si += t[i]:
s2 += t[i] * t[i);
}
for (i = 0; i < n: i++)
{
for (j = 0. m = i; j < k; j++)
{
x[j] = data[m]:
m += n:
}
t[i] = VectorSum (x,k);
s3 += t[i]:
s4 += t[i] * t[i];
Многофакторный анализ
201
★criterion = fabs ((k * s2 - si * si) * (k - 1) / (k * s3 -s4));
delete [] x: delete [] t:
return 0:
}
Критерий Шеффе для связанных выборок
Дисперсионный анализ по двум признакам (двухфакторный дисперсионный анализ) позволяет обнаружить существование эффектов столбцов (эффектов обработки) в таблице дисперсионного анализа Однако он не дает возможности точно указать столбцы, которые обладают нулевыми эффектами. Подход с попарными сравнениями всех выборок между собой будет неверным, как это показано в [ 158, с. 198]. Для решения проблемы применяется метод множественного сравнения Шеффе (критерий Шеффе) для связанных выборок. Вычисления производятся по формуле [там же]
(г \2
f=-L±!—L (г -1)^уС|2 с i=l
rc т2
где 5 = V у х2 - — — остаточный средний квадрат,
’ ГС т с
Т — общая сумма,
с — число столбцов (выборок),
г~ число строк (параметров),
остальные обозначения те же, что и при описании критерия Кокрена. Обратим внимание, что в показанной формуле с без индекса — это число строк (общепринятое обозначение для многофакторного дисперсионного анализа), а с„ i =1,2,..., г, — константы (общепринятое обозначение для проверки гипотез о линейных контрастах).
Доверительный уровень вычисляется функцией FDistribution с параметрами (г- 1) и (г - 1)(с - 1) в случае исследования эффекта строк и (с - 1) и (г- 1)(с - 1) в случае исследования эффекта столбцов.
202
Глава 3. Дисперсионный анализ
Нами дан пример применения критерия Шеффе для проверки серии гипотез о простых линейных контрастах между строками и столбцами вида [158, с. 199]
L = - Hj =0,i= 1,2,k - l,j = i + 1,k.
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void) {
register int i.j. // Счетчики цикла
m: // Счетчик
int n = 10, // Численность каждой выборки
k = 4, // Число выборок
nl.n2. // Рабочие переменнные
Code: // Код ошибки
double a[] = {1.2,3,4.5.1,2,3.4.5.
2.3.4.5.6.2.3.4.5.6.
1.3.5.7.9.1.3.5.7.9.
2.3.2.3.2.3.2.3,2.3}.
*r,*c: // Массивы критериальных статистик
г = new double[(n * n - n) /2]:
c = new double[(k * k - k) I 2];
if ('(Code = ScheffePair (a.n.k.r.c)))
{
nl - n - 1;
n2 = (k - 1) * nl:
cout « "Эффекты строк:\n": for (i=0, m=0:i<n-l: i++) for (j = i + 1; j < n; j++.m++)
cout « (i + 1) « « (j + 1) « " " « r[m]
<< ", p = " « FDistribution (nl.n2,r[mj) « endl:
nl = k - 1:
n2 = (n - 1) * nl:
cout « "Эффекты столбцов:\n";
for (i = 0. m = 0: i < k - 1: i++)
for (j=i+l:j<k: j++,m++)
cout « (i + 1) « « (j + 1) « " " « c[m]
« ". p = " « FDistribution (nl.n2,c[mj) « endl: }
Многофакторный анализ
203
else if (Code == -1)
cout « "Мало памятиХп";
el se
cout « "Ошибка в вычисленияхХп";
delete [] г; delete [] с:
}
int ScheffePair (double data[].int n, int k,double criterionR[].double criterionCf]) //
// Функция проводит множественные сравнения по Шеффе
// для зависимых выборок.
// Обозначения:
// data - массив к векторов данных (вектора друг за другом).
// п - длина каждого вектора.
// criterionR - массив длиной (п * п - п)/2. эффект строк.
// criterionC - массив длиной (к * к - к)/2. эффект столбцов.
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -1 при недостатке памяти.
// -2 при ошибке в вычислениях.
//
{
register int i.j; // Счетчик цикла
int nn m; = n * k. // Общее число вариант // Счетчик одномерного массива
double *x, // Рабочий массив
*t. // Рабочий массив, затем средние по строкам
*tl. // Рабочий массив, затем средние по столбцам
s = 0. // Полная дисперсия
sr = 0. // Дисперсия между строками
sc = 0. // Дисперсия между столбцами
ttt; // Вспомогательная переменная
if ((t = new double[k]) == 0) return -1;
if ((tl = new double[n]) == 0)
{ delete [] t; return -1;
}
if ((x = new double[MaximumOf (n.k)]) == 0) {
delete [] t; delete [] tl;
return -1;
}
//////////////// // Эффекты строк
204
Глава 3.
Дисперсионный
анализ
for (1 = 0. ш = 0: 1 < к; 1++) { for (j = 0; j < n: j++) x[j] = data[m++J;
t[i] = VectorSum (x.n): s += VectorSumSQ (x.n); sr += t[i] * t[i] / n;
}
ttt = VectorSum (t.k);
I ttt *» ttt; s -= ttt / nn; sr -= ttt / nn;
///////////////////
// Эффекты столбцов for (i = 0; i < n: 1++)
{
for (j = 0. m = i; j < k; j++. m += n) x[j] = data[m];
tl[i] = VectorSum (x.k); sc += tl[i] * tl[i] / k;
}
ttt = VectorSum (tl.n): ttt *= ttt; sc -= ttt / nn;
/////////////////////// // Остаточная дисперсия s = (s - sr - sc) / (k - 1) / (n - 1);
if (s < 0.000001) {
delete [] t; delete [] tl; delete [] x; return -2;
}
for (i = 0; 1 < к; 1++) t[i] /= n;
for (i = 0; i < n; 1++) tl[i] /= k;
for (i = 0, m = 0; i < n - 1; i++) for (j - i + 1; j < n; j++)
criterionR[m++] = (tl[1J - tl[jj) * (tl[i] - tl[jj) * к / (n - 1) / s / 2;
for (i =0, m=0: 1 < к - 1; i++)
for (j = i + 1: j < k; j++) criterionC[m++] = (t[i] - t[j]) * (t[i]
- 1)/ s / 2;
t[jj) * n
(k
дальнейшие исследования и программные ресурсы 205
delete [] t: delete [] tl; delete [] x;
return 0:
}
Дальнейшие исследования и программные ресурсы
• Расширение номенклатуры методик анализа данных методами 3 однофакторного и многофакторного дисперсионного анализа.
Представленные в главе расчеты можно проделать с помощью одной из десятков программ анализа данных, имеющихся на рынке программного обеспечения для научных исследований. По крайней мере, это полезно для проверки правильности расчета.
Глава 4. Теория распределений
В настоящей главе излагаются методы расчета теоретических распределений различных статистических показателей.
*Определенная сложность, с которой мы столкнулись при формиро-4 вании структуры настоящей книги, заключалась в том, что построе-
ние эмпирических распределений нам хотелось рассмотреть в главе 1, так как с эмпирическими частотами связана методика построения гистограммы — одной из основных характеристик выборки. В то же время эмпирические распределения невозможно рассмотреть, предварительно не введя определения плотности распределения, функции распределения, дискретных и непрерывных распределений, уровня значимости и коэффициента доверия. Поэтому понятия о функциях распределения мы ввели в разделе «Вариационная статистика» главы 1, где рассмотрели методику построения эмпирических распределений, а в конце настоящей главы рассмотрим пример вычисления теоретических частот эмпирических распределений. Основные понятия, касающиеся характеристик гипотез, были введены в главе 2.
Общая методика
При вычислении распределений используются:
• точное вычисление критических значений;
• прямое интегрирование формул распределения;
• разложение в бесконечный ряд и взятие конечного числа членов ряда;
• кусочная аппроксимация элементарными функциями;
• аппроксимация с помощью нейронной сети.
Точное вычисление с успехом применяется только при вычислении параметров дискретных распределений. При этом используется тот или иной рекуррентный алгоритм, что часто ведет к неоправданно! большому времени счета. Эта проблема затрудняет программную реа-| лизацию диалоговой статистической программной системы (не за-|
Общая методика
207
ставлять же пользователя ждать результата несколько минут!) и часто без потери точности выводов решается с помощью аппроксимации статистик критериев другими стандартными распределениями, как показано при описании соответствующих критериев.
Прямое интегрирование обычно производится по формуле трапеций либо с помощью формулы Симпсона, представленной в главе 16, хотя может быть применен и любой другой метод, например метод Монте-Карло [135, с. 386], [210, с. 26] или метод Гаусса [128, с. 219]. Наиболее полно вопросы расчета основных непрерывных статистических распределений — нормального распределения, Z2 3 -распределения и ^-распределения — с помощью рядов рассмотрены в [159]. Удобнее указать общий подход, чем проводить элементарные выкладки для частных случаев. Пусть требуется вычислить некоторую статистическую функцию распределения, в общем виде представленную формулой [159, с. 333]
Вычисление данного интеграла, который для перечисленных непрерывных статистических распределений не берется в квадратурах, упрощается благодаря следующим обстоятельствам:
1. Значение функции Р(°°) = 1, а следовательно, для симметричных относительно х = 0 распределений
P(x)=jf(t)dt = ± + jf(t)dt-— z о
2. Функция /(f) довольно быстро затухает при увеличении |ф поэтому, даже если не использовать свойство 1, левый предел, при котором Р(х) = 0 при заданной точности вычислений, можно указать довольно точно.
3. Функция/(£) непрерывна и дифференцируема бесконечное число раз, поэтому решение может быть получено разложением в ряд Тейлора или Маклорена. Это наиболее быстрое, в смысле времени работы программы, решение, если необходима гарантированная точность.
Предположим, что подынтегральная функция определена в некоторой окрестности t0 и имеет в этой точке производные всех порядков,
208
Глава 4. Теория распределений
согласно свойству 3. Тогда подынтегральная функция может быть представлена в виде бесконечного степенного ряда Тейлора [135, с. 578]:
и=0
п! о)
При t0 = 0 разложение функции принимает более простой вид и называется рядом Маклорена:
4
/«>=££»
t"
Подставив данное выражение в формулу вычисления определенного интеграла, после элементарных выкладок и взятия интеграла получим
п=0
/(л)(0) (п + 1)!
х”+1
Осталось вычислить для функции распределения производную порядка п в общем виде (если это возможно) и приступать к составлению достаточно простой программы [ 128, с. 149]. Количество удерживаемых членов разложения частичной суммы порядка п [135, с. 533] зависит как от требуемой точности, так и от интервала значений переменной. Случай разложения в ряд Маклорена функции т переменных представлен в [там же, с. 333], что необходимо, например, для вычисления функции F-распределения.
Кусочная аппроксимация при вычислении непрерывных статистических распределений, как правило, не обеспечивает точность, сопоставимую с точностью рассмотренного выше метода, однако при. достаточной для практического применения точности (до 2-3 знаков после десятичной запятой) сильно превосходит другие методы по скорости вычислений. Иногда аппроксимации делаются и при наличии точных формул, применение которых невыгодно из соображений высокой трудоемкости вычислений. В необходимых случаях аппроксимации были сделаны нами в электронных таблицах Microsoft Excel, а также с помощью функций, представленных в главе 15.
Аппроксимация с помощью нейронной сети выполняется с доста-| точной для практического применения точностью, обычно до 2-4 зна-j
функции распределения и обратные функции распределения 209
ков после десятичной запятой, и применяется либо при недоступности источников с опубликованными формулами распределений, либо если эти формулы крайне сложны.
Функции распределения и обратные функции распределения
По определению [211, с. 8], для функции распределения F, отображающей значение х в вероятность а, обратная функция G, отображающая а в х, называется обратной функцией распределения. Поэтому в показанных функциях (там, где речь идет о доверительном уровне или уровне значимости, а не о критических или пороговых значениях статистик) мы приняли, что функции, возвращающие значение статистики для заданного доверительного уровня или уровня значимости, называются обратными (inverse). Действительно, величины, вычисленные по формулам распределений, представляют собой вероятности, полученные в зависимости от значений статистик. Напротив, приводимые в сборниках статистических таблиц распределения представляют собой значения статистик, вычисленные в зависимости от вероятностей, то есть являются решениями обратных задач. Поэтому функции, возвращающие значение доверительного уровня или уровня значимости для заданного или вычисленного значения статистики, имеют то же наименование, за исключением слова Inverse. Для методов вычислений функций распределения, не предполагающих наличие методов вычисления обратной функции, слово Inverse не применяется.
Обратное распределение обычно вычисляется делением отрезка пополам. Возможно, это не лучшее решение в смысле скорости вычислений, но процесс сходится достаточно быстро, и для практических вычислений скорость приемлема. Для повышения скорости и точности вычислений возможно применение любого другого локального метода одномерной минимизации.
Одномерные распределения
Представленные ниже распределения подразделяются на непрерывные и дискретные, как показано в главе 1. Рассмотрены как основные стандартные типы распределений, так и вычисленные на их основе специфические распределения статистик различных тестов.
210 Глава 4. Теория распределений
Непрерывные распределения
В [32], [37, с. 136], [47], [63, с. 46], [72, с. 62], [134], [140, с. 126] можно найти структурированную информацию о взаимосвязи различных непрерывных теоретических распределений. На рис. 4.1 схематически показаны точные взаимоотношения между основными непрерывными одномерными распределениями. Эта информация поможет снизить объем кода программной реализации распределений различных типов: многие распределения могут быть запрограммированы с использованием кода уже составленных функций. Формулы здесь не приводятся, но при описании распределений в настоящей главе указаны подробные формулы и даны исходные коды функций для вычисления.
Рис. 4.1. Взаимоотношения между основными непрерывными одномерными распределениями
Примерно такая же схема представлена в [156, с. 39], причем в источнике отражены также связи непрерывных и дискретных типов распределений и несколько частных случаев.
Нормальное распределение и обратное к нему, нормальный интеграл
Функция плотности нормального распределения (- оо < д < оо, ст >0) имеет вид [158, с. 97]
р , — ОО < X < оо .
aVSF
В [84, с. 73] путем введения нормированного отклонения
Одномерные распределения
211
где а — обычно среднее арифметическое,
ст2 — дисперсия,
показанной выше формуле придан несколько иной вид. Этой формулой удобно пользоваться при расчете теоретических частот эмпирического распределения. К тому же таблицы обычно даются для функции [84, с. 73], называемой также плотностью вероятности стандартизованной (стандартной) нормальной случайной величины [151],
1
Функция плотности нормального распределения имеет краткое обозначение N(a, сг2). Стандартное нормальное распределение обозначается как 7V(0,l). Функция стандартного нормального распределения [140, с. 93]
1
и называется функцией Лапласа (вторым законом распределения Лапласа) [там же, с. 75], [135, с. 307] либо законом Гаусса (гауссовым распределением) в честь применения данного закона распределения для изучения ошибок наблюдений.
Для вычисления функции стандартного нормального распределения нами применяется аппроксимационная формула, данная в [161, с. 439]. Другие аппроксимации даны в [140, с. 95]. В [139, с. 280], помимо теоретических выкладок даны программы аппроксимаций на языке программирования Бейсик. Свойства стандартного нормального распределения рассмотрены в [33, с. 33], [37, с. 60], [63, с. 44], [187, с. 74]. В [128, с. 149] подробно проанализировано вычисление интеграла вероятностей
Р(х) = —== f e~^/2dy
путем разложения в ряд. Результатами обсуждения легко воспользоваться для вычисления функции распределения, вспомнив введенное в разделе «Общая методика» свойство 2, а именно разделив полученное по формуле число на 2, а затем прибавив к нему 0,5.
212
Глава 4. Теория распределений
Исходные коды
double NormalDistribution (double х)
//
// Вычисление функции стандартного нормального распределения.
// Обозначения:
// х - функция распределения.
// Возвращаемое значение:
// доверительный уровень.
//
^double с[] = {0,0.196854,0.115194.0.000344,0.019527};
return 1.0 - 0.5 / pow (1 + Horner (с,4,х),4);
}
В ситуциях, когда необходима повышенная точность (до 5-6 знаков после десятичной запятой), для вычисления функции стандартного нормального распределения мы используем прямое интегрирование. Наилучшую точность дает метод Симпсона, применяемый путем вызова функции Simpson без каких-либо модификаций последней. Нижний предел интегрирования и число узлов интегрирования подобраны эмпирически.
Исходные коды
double Normal Distribution! (double x)
//
// Вычисление функции стандартного нормального распределения.
// Обозначения:
// х - стандартизированная случайная величина.
// Возвращаемое значение:
// уровень значимости.
//
{
return Simpson (-15,х,lOO.NormalDensity) / sqrt (M_PI * 2);
}
double NormalDensity (double t)
//
// Функция вычисления плотности вероятности стандартизированной // случайной величины.
// Обозначения:
// х - стандартизированная случайная величина.
// Возвращаемое значение.
// значение плотности вероятности.
//
{
return 1.0 / exp (t * t / 2);
}
Результат работы следующей функции называется также нормальным интегралом [91, с. 412] и применяется в различных статиста-
Одномерные распределения
213
ческих алгоритмах. Аппроксимация производится по формулам, данным в [161, с. 440], [174, с. 154].
Исходные коды
double InverseNormalDistribution (double р)
//
// Функция вычисления обратной функции стандартного нормального // распределения.
// Обозначения:
// р - доверительный уровень.
// Возвращаемое значение:
// функция распределения.
//
{
int flag = 1: // Параметр для учета симметрии распределения
double t; // Рабочая переменная
if (р < 0.5)
р = 1 - р:
else if (р == 0.5)
return 0.0:
el se
flag = 0:
///////////////////
// Разложение в ряд
t = sqrt (- 2.0 * log (1.0 - p)):
t -= (2.515517 + 0.802853 * t + 0.010328 * t * t) /
(1.0 + 1.432788 * t + 0.189269 * t * t + 0.001308 * t *
t * t):
if ('flag) return t:
el se return -t;
}
Г-распределение, Z*- распределение и обратное к нему
Плотность Г-распределения (гамма-распределения) ( а > 0, Р > 0) определяется формулой [63, с. 47]
/(х)= Г(а)
——ха 'е Рх,х>0,
0,х<0.
214
Глава 4. Теория распределений
%2 -распределение (хи-квадрат распределение) является частным случаем Г-распределения [63, с. 47] с параметрами ct - n/2, Р = 1/2, поэтому плотность Z -распределения [187, с. 79]
/(*) =
1 2”/2Г(и/2)
x”/2"iex/2,x>0,
0,х<0.
2
Вычисление функции X -распределения производится по формуле [32, с. 16]
Fn(x)= 1-Рл(х),
где Р„(х, п) — интеграл вероятностей с2, вычисляемый по формуле [там же, с. 15, формула (1)]
Р (х) = - ------fyn/2~ie~y/2dy •
7 2"/2Г(и/2р/
Прямое вычисление по данной формуле реализует показанная ниже функция ChiSquarelntegral. Интегрирование производится по формуле трапеций, причем при п - 1 число интервалов интегрирования взято значительно большим, чем для других значений параметра, с целью получения приемлемой точности решения. Параметры быстродействия и точности, очевидно, могут быть значительно улучшены, если применять более совершенную формулу интегрирования либо интегрирование путем разложения в ряд [159, с. 335]. Данный подход обеспечивает заданную точность и требует от программиста только аккуратности.
Для больших выборок вычисляется аппроксимация обратного X -распределения [161, с. 442]. Если нужно вычислить Q-процентную точку X -распределения, весь код показанной далее функции ChiSquareDistribution следует заменить на
return ChiSquarelntegral (n.x) * 100.
В [174, с. 147] даны другие формулы вычисления, в которых используются асимптотические свойства оценок параметров, входящих в выражение функции распределения, а в [140, с. 116] обсуждаются различные аппроксимации. Подробности о приемах вычисления X -распределения см. в [37, с. 74], где также даны полезные аппроксимации. Авторы [211, с. 63] дают сводку связи X -распределения с дру-
Одномерные распределения
215
гимн типами распределений. Другой частный случай Г-распределе-ния — распределение Эрланга — проанализирован в [211, с. 79], [206, с. 111]
Исходные коды
double ChiSquareDistribution (double n.double x) //
// Вычисление функции хи-квадрат-распределения.
// Обозначения:
// n - число степеней свободы,
// х - функция распределения.
// Возвращаемое значение:
// доверительный уровень.
//
{ double buf;
if (х < 0.0001)
return 0:
buf = 1.0 - ChiSquarelntegral (n.x);
if (buf > 1.0)
return 1.0;
else
return buf;
}
double InverseChiSquareDistribution (double n.double p)
//
// Функция вычисления обратной функции
// хи-квадрат-распределения.
// Обозначения:
// п - число степеней свободы,
// р - доверительный уровень.
// Возвращаемое значение:
// функция распределения.
//
{
double с = 0.0000003, // Левая граница локализации
d, // Открытая правая граница локализации
у = с + 10.0, // Вспомогательная переменная cx.dx.
а[] = {0.0001,-0.020323,2.051022.-3.722753.13.242947, -18.82835.11.432256};
if (n == 1)
{
if (р <= 0.8)
return Horner (а.б.р):
if (р > 0.8 && р <= 0.9)
216
Глава 4. Теория распределений
return 10.64 * р - 6.87;
else if (р > 0.9 && р <= 0.95)
return 22.7 * р - 17.724;
else if (р > 0.95 && р <= 0.975)
return 47.32 * р - 41.113;
else if (р > 0.975 && р <= 0.99)
return 107.4 * р - 99.691;
else if (р > 0.99 && р <= 0.995)
return 248.8 * р - 239.677;
else if (р > 0.995 && р <= 0.999)
return 737.25 * р - 725.68475;
else if (р > 0.999)
return 2575.999993 * р - 2562.595993;
}
if (n < 120)
{
/////////////////////////////////////
// Поиск границ интервала локализации
сх = р - ChiSquareDistribution (п,с);
beg:
dx = сх * (р - ChiSquareDistribution (п.у));
if (!dx)
return у;
else if (dx > 0)
{
у += 1; // Шаг поиска goto beg;
}
el se
d = y;
//////////////////////////////////////////////////// // Уточнение корня в найденной интервале локализации // методом деления отрезка пополам do
{
сх = р - ChiSquareDistribution (п.с):
у = (с + d) / 2;
сх *= р - ChiSquareDistribution (п.у);
if (!сх)
return у;
else if (сх > 0)
с = у;
el se
d = у;
} while (fabs (с - d) > 0.0001);
return у;
}
el se
return InverseChiSquareDistributionBig (n.p);
}
Одномерные распределения
217
double InverseChiSquareDistributionBig (double n,double p) //
// Вычисление обратной функции хи-квадрат-распределения
// для больших выборок.
// Обозначения:
// п - число степеней свободы.
// р - доверительный уровень.
// Возвращаемое значение:
// функция распределения.
//
double t = InverseNormalDlstribution (р) + sqrt (2 * n - 1);
return t * t / 2:
}
double ChiSquarelntegral (double n.double x)
//
// Функция вычисления интеграла вероятностей хи-квадрат-
// распределения.
// Обозначения:
// п - число степеней свободы.
// х - параметр.
// Возвращаемое значение:
// доверительный уровень.
//
{
double s = 0.
У.
h = х / 1000.
п2 = п / 2.
c.d = 0:
if (n == 1) h /= 100;
for (у = h; у <= x; у += h)
{
c = d;
d = pow (y,n2 - 1) / exp (y / 2);
s +» c + d;
}
return 1.0 - s * h / pow (2.0.n2) / Gamma (n2) / 2:
В-распределение и обратное к нему
Плотность В-распределения (бета-распределения) (а > 0. Р > 0) задается как [63, с. 47]
218
Глава 4. Теория распределений
/(*)=
Г(«)Г(Д)
ха 1(1-х)р 1,0<х<1,
0,х<0,х>1.
Функция В-распределения определяется формулой [32, с. 27]
0
где В(д,6) — В-функция Эйлера, а = п2 / 2, Ь = п,/2.
Для больших выборок практическое вычисление производится по асимптотической формуле [32, с. 29, 31]. Обсуждение дано в [37. с. 135], [211, с. 75].
Исходные коды
double BetaDistribution (double nl.double n2.double x) //
// Вычисление функции В-распределения.
// Обозначения:
// nl и n2 - параметры распределения,
// х - функция распределения.
// Возвращаемое значение:
// доверительный уровень.
//
{
double s = 0.
to = 0.000000001. h = х / 200, а = n2 / 2.b = nl / 2.
c.d.y.t; // Рабочая переменная
if (nl <= 120 && n2 <= 120) {
////////////////////////////// // Прямое вычисление интеграла d = pow (t0.а - 1) * pow (1.0 - tO.b - 1); for (t = h; t <= x; t +- h)
{ c = d;
d = pow (t.a - 1) * pow (1.0 - t.b - 1):
s += h * (c + d) / 2: }
s /= Beta (a.b);
Одномерные распределения
219
//////////////////////////////////////////
// Компенсация небольших ошибок округления
if (s < 0)
return 0;
else if (s > 1)
return 1;
el se return s:
}
el se
{
////////////////////////////////////
// Аппроксимация для больших выборок do
{
t = х - InverseBetaDistributionBig (nl,n2,c);
у = (c + d) / 2;
t *= x - InverseBetaDistributionBig (nl.n2.y):
if (t == 0) return y;
else if (t > 0)
c = y;
el se
d = y:
} while (fabs (c - d) > 0.00000001): return y;
}
}
double InverseBetaDistribution (double nl, double n2, double p) //
// Функция вычисления обратной функции В-распределения.
// Обозначения:
// nl и п2 - параметры распределения.
// р - доверительный уровень.
// Возвращаемое значение:
// функция распределения.
//
{
double с = 0.000001, // Левая граница локализации
d = 1. // Правая граница локализации
у, // Середина интервала локализации
t: // Рабочая переменная
if (nl < 120 && n2 < 120)
{
do
{
t = р - BetaDistribution (nl.n2.c);
у = (с + d) / 2:
t *= р - BetaDistribution (nl,n2.y);
if (t == 0)
220
Глава 4. Теория распределений
return у;
else if (t > 0)
с = у;
el se
d = у;
} while (fabs (c - d) > 0.00000001);
return y;
}
el se
return InverseBetaDistributionBig (nl,n2,p);
}
double InverseBetaDistributionBig (double nl, double n2, double p) //
// Функция вычисления обратной функции В-распределения
// для больших выборок.
// Обозначения:
// nl и п2 - параметры распределения,
// р - доверительный уровень.
// Возвращаемое значение:
// функция распределения.
//
{
double а = п2 / 2,b » nl / 2. // Параметры распределения
t.c; // Рабочая переменная
t = 1 / (Ь * 2 + а - 1);
с ~ InverseChiSquareDistributionBig (п2,р);
return с * 2 / (2.0 /t+c-
((а * а - 1) * 2 + (а - 1) * с - с * с) * t / 6):
}
F-распределение и обратное к нему
Функция плотности F-распределения (т > 0, п > 0) имеет вид [158, с. 102]
Г(7п/2+и/2) xm/2-l
Г(т/2)Г(Я/2)[п] z т 1 +—х
I п 0,х<0.
,0<Х<оо,
где т — число степеней свободы числителя, п — число степеней свободы знаменателя.
Терминология и подробное обсуждение дано в [63, с. 50], [151, с. 63], [187, с. 81]. F-распределение (распределение дисперсионного отно
Одномерные распределения
221
шения) подробно рассмотрено в [211, с. 66]. Функция F-распреде-дения обычно выражается и вычисляется через функцию В-распре-деления [32, с. 33], [37, с. 136], [161, с. 444], а практически может быть вычислена с заданной точностью также путем разложения вряд [159, с. 335].
Исходные коды
double FDistribution (double nl, double n2, double x)
//
// Вычисление функции F-распределения.
// Обозначения:
// nl и n2 - параметры распределения.
// х - функция распределения.
// Возвращаемое значение:
// доверительный уровень.
//
{
return 1.0 - BetaDistribution (nl,n2.n2 / (n2 + nl * х));
}
double InverseFDistribution (double nl. double n2. double p) //
// Вычисление обратной функции F-распределения.
// Обозначения:
// nl и n2 - параметры распределения.
// р - доверительный уровень.
// Возвращаемое значение:
// функция распределения.
//
{
double х;
if (nl == 1)
{
х = InverseTDistribution (n2,p / 2 + 0.5); return x * x;
}
else if (n2 == 1)
{
x = InverseTDistribution (nl.l - p / 2); return 1/x/x;
}
el se
{
x = InverseBetaDistribution (nl,n2,l - p);
return n2 / nl * (1 - x) / x;
222
Глава 4. Теория распределений
{-распределение Стьюдента и обратное к нему
Плотность ^-распределения ( а > 0) вычисляется по формуле [63, с. 48]
Г((а + 1)/2)Г
л/шгГ(а/2)^ а
,-©о<Х<оо.
Функция ^-распределения определяется по формуле [32, с. 23], [174], [151, с. 27]
1 Г((и+1)/2) j- Л Г(и/2) £
и
2 х-(и+1)/2
- du •
п
При п -» оо распределение Стьюдента становится нормальным. Счи-1 тается, что нормальное приближение корректно уже при п > 30 [50, с. 51]. Обсуждение дано также в [187, с. 80]. В случае п = 1 £-распре-1 деление называют распределением Коши [63, с. 49], [70, с. 92]. Этот факт учитывается в показанной ниже функции. В [152, с. 46], [159, с. 336] приводятся достаточно простые формулы вычисления рассматриваемого распределения путем взятия конечного числа членов бесконечного для достижения любой заданной точности.
Исходные коды
double TDistribution (double n.double t) 11
// Вычисление функции t-распределения.
// Обозначения:
// n - число степеней свободы, // t - функция распределения. // Возвращаемое значение: // доверительный уровень. //
{ double s = 0, // Начальное значение интеграла
u, h = 0. // 04, // Текущая переменная Шаг интегрирования
c.d. // Значения на концах интервала
n2 = n n3 = - / 2. // n2 - 0.5: Вспомогательная величина
if (n == 1)
//////////////////////////////////////////// // Аппроксимация функцией распределения Коши return atan (t) / M_PI + 0.5:
Одномерные распределения
223
/ / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / /
// Прямое интегрирование по формуле трапеций
d = pow (t * t / n + 1,пЗ):
for (u = t - h: u >= -30; u -= h)
{
c = d;
d » pow (u * и / n + l,n3):
s += h * (c + d) / 2;
}
return s * Gamma (n2 + 0.5) / Gamma (n2) / sqrt (M_PI * n); }
С целью уменьшения времени счета для некоторых значений обратной функции 7-распределения там, где это допустимо из соображений точности, производится аппроксимация. См. [32, с. 25], Q рассматривается в [92, с. 554], Р = 2(1 - F) рассматривается в [151, с. 27].
Исходные коды
double InverseTDistribution (double n, double p) //
// Вычисление обратной функции t-распределения.
// Обозначения:
// n - число степеней свободы.
// р - доверительный уровень.
// Возвращаемое значение:
// функция распределения.
//
{
int m = = (int) n - 1: // Индекс элемента массива
double c = 0. // Левая граница локализации корня
d = 7. // Правая граница локализации корня
У. // Середина интервала локализации
ex, // Значения функции на конце интервала
/////////////////////////////////////////////////////////////// ///////
// Табличные значения для "трудных" в вычислительном смысле
// интервалов
t95[] = {2.9200.2.3534.2.1318.2.0150.1.9432.1.8946.
1.8595.1.8831.1.8125.1.7959.1.7823}.
t975[] = {4.3027.3.1824.2.7764.2.5706.2.4469.2.3646.
2.3060.2.2622.2.2281,2.2010.2.1788}.
t99[] = {6.9646.4.5407.3.7469,3.3649.3.1427.2.9980.
2.8965.2.8214.2.7638.2.7181.2.6810}.
t995[] = {9.9248.5.8409.4.6041.4.0321.3.7074.3.4995.
3.3554.3.2498,3.1693.3.1058.3.0545}.
t9975[] = {14.0890,7.4533.5.5976.4.7733.4.3168.4.0293.
3.8325.3.6897.3.5814.3.4966.3.4284}.
224
Глава 4. Теория распределений
t999[] » {22.3271.10.2145.7.1732,5.8934,5.2076,4.7853, 4.5008.4.2968.4.1437.4.0247.3.9296}.
t9995[] = {31.5991.12.9240.8.6103,6.8688.5.9588.5.4079.
5.0413.4.7809,4.5869.4.4370.4.3178}:
////////////////////////////////////////////
11 Аппроксимация функцией распределения Коши if (m == 0)
return tan (M_PI * (p - 0.5)):
if (m < 12 && p > 0.95)
{
////////////////////////////////////////////////
' // Сдвиг на 1, т.к. строка n = 1 не используется
I m—:
////////////////////////////////////////////
II Аппроксимация кусочно-линейными функциями if (0.95 < р && р < 0.975)
return (t975[m] - t95[m]) / 0.025 * (р - 0.95) + t95[m]:
else if (0.975 <= p && p < 0.99)
return (t99[m] - t975[m]) / 0.015 * (p - 0.975) + t975[m]: else if (0.99 <= p && p < 0.995)
return (t995[m] - t99[m]) / 0.005 * (p - 0.99) + t99[m];
else if (0.995 <= p && p < 0.9975)
return (t9975[mj - t995[m]) / 0.0025 * (p - 0.995) + t995[m]:
else if (0.9975 <= p && p < 0.999)
return (t999[m] - t9975[m]) / 0.0015 * (p - 0.9975) + t9975[m];
el se
return (t9995[m] - t999[m]) / 0.0005 * (p - 0.999) + t999[m];
}
///////////////////////////////////////
// Коррекция во избежание переполнения if (n > 250).
n = 250:
//////////////////////////////////////////////////
// Уточнение корня методом деления отрезка пополам do
{
сх = р - TDistribution (п.с):
у = (с + d) /2:
сх *= р - TDistribution (п,у);
if (!сх)
return у;
else if (сх > 0) с = у;
el se
Одномерные распределения
225
d = у:
} while (fabs (с - d) > 0.000001):
return у:
} 2
Существует так называемое Г-распределение Хотеллинга, которое представляет собой многомерное обобщение f-распределения Стьюдента [167, с. 710]. Плотность /^-распределения вычисляется по формуле [там же, с. 713]
/(*) =
где k — размерность многомерной выборки, q — число линейных условий.
Практически функция /^-распределения Хотеллинга вычисляется, да обычно и вводится на основе F-распределения [63, с. 203], [180, т. 2, с. 217], поэтому необходимости в составлении специальной функции нет. Подробное обсуждение дано в [15, с. 152], [70, с. 358].
Распределение G-критерия Кокрена
Распределение критических значений G-критерия Кокрена легко получается, если подробно расписать статистику критерия (см. главу 3) и учесть, что отношение дисперсий представляет собой F-статистику1. Полученная точная формула имеет простой вид [120, с. 26]
F 8kv'-a~(k-V) + F’
где k — число выборок,
v — размер каждой выборки,
а ~~ Уровень значимости,
значение обратной функции F-распределения для v и (k - 1) v степеней свободы и доверительного уровня (1 - a/k ). ----- --------
На данную методику нам указал В. А. Уткин.
Р-2ОО2
226
Глава 4. Теория распределений
Обсуждение см. в [ 156, с. 95]. Показанная выше формула в частном случае k = 2 представлена в [32, с. 48].
Распределение критических значений G-критерия Кокрена при k > 2 и v > 10 может быть также задано аппроксимационной формулой [там же]
&k,v,\-a
2х
v(26-l)-2+x +
(2-v)(2 + v+x)+2x2 ’ 6(v(2&-l)-2)
где х — значение обратной функции ^-распределения для v степеней свободы и доверительного уровня, равного (1 - a/k).
Таблицы для стандартных доверительных уровней даны в [там же,' с. 242], [120, с. 160], [140, с. 155].
В соответствии с этими формулами нами составлены функции CochraneGDistributionExact и CochraneGDistributionApprox. Инте-1 ресно, что аппроксимационная формула часто дает несколько более высокую точность вычислений, чем ее «точный» аналог. Это вызвано тем, что точность вычислений по «точной» формуле целиком зависит от точности вычисления обратной функции F-распределения, и повышение точности вычисления последней ведет к повышению точности всех функций, на ней основанных.
Исходные коды и пример применения
#include <fstream.h>
#include <math.h>
#include "megastat.h"
void main (void)
{
double k = 6, // Число выборок
n = 20: // Численность каждой выборки
double а = 0.01; // Уровень значимости
cout « "к = " « к « "\пп = " « п « "\па = " « а
« "\nG (approx.) = " « CochraneGDistributionApprox (k.n.a)
« "\nG (\"exact\") = " « CochraneGDistributionExact (k.n.a) « "\n":
}
double CochraneGDistributionExact (double k.double n.double a) //
Одномерные распределения
227
// Функция "точного" вычисления критического значения G-критерия // Кокрена в случае двусторонней гипотезы.
// Обозначения:
// к - число выборок.
// п - размер каждой выборки.
// а - уровень значимости.
// Возвращаемое значение:
// критическое значение G-критерия Кокрена.
//
{
double g = InverseFDistribution (n,(k - 1) * n.l - a / k):
// Рабочая переменная
return g / (k - 1 + g);
}
double CochraneGDistributionApprox (double k.double n.double a) //
// Функция вычисления критического значения G-критерия Кокрена // в случае двусторонней гипотезы.
// Обозначения:
// к - число выборок.
// п - размер каждой выборки.
// а - уровень значимости.
// Возвращаемое значение:
// критическое значение G-критерия Кокрена.
//
{
double x.g; // Рабочие переменные
/////////////////////////////////////////////////////////// // Аппроксимация обратной функцией хи-квадрат-распределения х = InverseChiSquareDistribution (n.l - а / k).
g = n * (2 * k - 1) - 2;
return x/(x+g+(4-n*n+(2-n)*x+2*x*x) /6 / g) * 2;
}
Распределение d-статистики Гири и обратное к нему
Вычисление критического значения d-статистики Гири производится нами с помощью аппроксимационных формул, полученных По табличным значениям [32, с. 56], с использованием программы Microsoft Excel. В пределах 11 < п < 1001 гарантируется точность относительно табличных значений 5%. Не рекомендуется использовать функцию InverseGearyDistribution при п < 11, так как дан-8‘
228
Глава 4. Теория распределений
ная область не табулирована в источнике. Впрочем, эта рекомендация перекрывается условиями применения критерия.
Исходные коды
double GearyDistribution (int n,double x)
//
// Вычисление функции распределения d-статистики Гири.
// Обозначения:
// п - число степеней свободы.
// х - функция распределения.
// Возвращаемое значение:
// доверительный уровень.
//
{
double с = 0.01, // Левая граница локализации
d = 1.0, // Правая граница локализации
у, // Середина интервала локализации
сх; // Рабочая переменная
do
{
сх = х - InverseGearyDistribution (п.с);
у = (с + d) / 2;
сх *= х - InverseGearyDistribution (п.у);
if (сх == 0)
return у;
else if (сх > 0)
с = у;
el se d = у;
} while (fabs (с - d) > 0.00000001);
return у;
}
double InverseGearyDistribution (int n, double p)
//
// Вычисление обратной функции распределения d-статистики Гири.
// Обозначения:
// п - число степеней свободы,
// р - доверительный уровень.
// Возвращаемое значение:
// функция распределения.
//
{
double a.b;
if (п <= 101)
{
if (0.95 < р)
{
а = 1.226575 * р - 0.183259;
b = -0.185425 * р + 0.139487;
Одномерные распределения
229
}
else if (0.9 <= р && р <= 0.95) {
а = 0.571320 *р+ 0.439233;
b = -0.091880 * р + 0.050619; }
else if (0.1 < р && р < 0.9)
{
а • 0.308114 * р + 0.676119;
b = -0.064391 * р + 0.025879; }
else if (0.05 <= р && р <= 0.1) {
а = 0.810620 * р + 0.625868;
Ь = -0.217080 * р + 0.041148;
}
el se
{
а = 1.813025 * р + 0.575748;
b = -0.528675 * р + 0.056728;
}
}
el se
{
if (0.95 < р)
{
а = 0.673075 * р + 0.243055;
b = -0.089525 * р + 0.072184;
}
else if (0.9 <= р && р <= 0.95) {
а = 0.370740 * р + 0.530273;
b = -0.054260 * р + 0.038682;
}
else if (0.1 < р && р < 0.9)
{
а = 0.153544 * р + 0.725750;
b = -0.024369 * р + 0.011780;
}
else if (0.05 <= р && р <= 0.1)
{
а = 0.335520 * р + 0.707552;
Ь = -0.058040 * р + 0.015147;
}
el se
{
а = 0.838325 * р + 0.682412;
b = -0.153100 * р + 0.019900;
return а
* exp (b * log (п));
230
Глава 4. Теория распределений
Распределение G-критерия и обратное к нему
Для п < 2, п > 20, а также для р < 0,95 и р > 0,9995 значение функции InverseGTestDistribution, реализующей аппроксимацию обратной функции распределения G-критерия [ 151, с. 143], не определено. Для 2 < п < 20 берутся табличные значения статистики, а вычисление при промежуточных значениях р производится путем линейной интерполяции табличных значений.
Исходные коды
double GTestDistribution (int n, double x) //
// Вычисление функции распределения G-критерия.
// Обозначения:
// n - число степеней свободы,
// х - функция распределения.
// Возвращаемое значение:
// доверительный уровень.
//
{
double с = 0.000001, // Левая граница локализации корня d = 26. // Правая граница локализации корня
у, // Середина интервала локализации
сх; // Рабочая переменная
do {
сх = х - InverseGTestDistribution (п.с);
у = (с + d) / 2:
сх *= х - InverseGTestDistribution (п.у);
if (сх == 0) break;
else if (сх > 0) с = у;
el se d = у;
} while (fabs (с - d) > 0.000001);
if (у < 0)
У = 0;
if (у > 1)
у = 1;
return у; }
double InverseGTestDistribution (int n, double p) //
// Вычисление обратной функции распределения G-критерия.
Одномерные распределения
231
// Обозначения:
// п - число степеней свободы,
// р - доверительный уровень.
// Возвращаемое значение:
// значение функции распределения.
//
S///////////////////////////////////
// Табличные значения для интервалов
double t95[]
{2.322.0.974,0.644,0.493,0.405.0.347,0.306,0.275.0.250,
0.233,0.214,0.201,0.189.0.179,0.170,0.162.0.155.0.149,0.143}. t975[] =
{3.427.1.272,0.813.0.613.0.499.0.426.0.373.0.334,0.304,
0.280.0.260,0.243,0.228.0.216.0.205.0.195.0.187,0.179,0.172}, t99[] =
{5.333,1.715,1.047,0.772.0.621,0.525,0.459,0.409,0.371,
0.340.0.315,0.294.0.276.0.261.0.247,0.236.0.225,0.216,0.207}, t995[] =
{7.916,2.093,1.237.0.896,0.714,0.600.0.521.0.464.0.419.
0.384,0.355,0.331.0.311,0.293.0.278,0.264,0.252.0.242.0.232}.
t999[] = {17.81, 3.27, 1.74. 1.21, 0.94, 0.77. 0.67.
0.59. 0.53, 0.48, 0.44, 0.41, 0.39, 0.36, 0.34, 0.33. 0.31, 0.30,0.29}.
t9995[] = {25.23, 4.18. 1.99, 1.35, 1.03, 0.85, 0.73. 0.64, 0.58, 0.52, 0.48, 0.45, 0.42, 0.39. 0.37, 0.35, 0.34, 0.32,0.31}:
/////////////////////////////////////
// Таблицы начинаются co строки n = 2
if (n < 2)
n = 2:
///////////////////////////////////////
// Таблицы заканчиваются строкой n = 20
if (n > 20)
n = 20:
n = 2:
////////////////////////////////////////////
// Аппроксимация кусочно-линейныни функциями
if (p < 0.975)
return (t975[n] - t95[n]) / 0.025 * (p - 0.95) + t95[n]:
else if (0.975 <= p && p < 0.99)
return (t99[n] - t975[n]) / 0.015 * (p - 0.975) + t975[n]:
else if (0.99 <= p && p < 0.995)
return (t995[n] - t99[n]) / 0.005 * (p - 0.99) + t99[n]:
else if (0.995 <= p && p < 0.9975)
return (t999[n] - t995[n]) / 0.004 * (p - 0.995) + t995[n]: el se
return (t9995[n] - t999[n]) / 0.0005 * (p - 0.999) +
232
Глава 4. Теория распределений
Процентиль критерия кУШапиро—Уилка
Значение критических значений критерия IV Шапиро—Уилка определено при численности выборки от 3 до 50 [206, с. 337,374]. Производится аппроксимация элементарными функциями. Параметры полиномиальной аппроксимации получены с помощью электронных таблиц Microsoft Excel. Дополнительно см. [123, с. 37].
Исходные коды
double CriticalW (int n.double alpha) //
// Функция вычисления процентили критерия W Шапиро-Уилка. // Обозначения:
// п - численность выборки.
// alpha - вероятность нормального распределения в %.
// Возвращаемое значение:
// процентиль.
//
{
double а = 0.000000003528 * n*n*n*n*n-
0.000000691142 * n*n*n*n +
0.000053501632 * n * n * n -
0.002083849650 * n * n +
0.043197037284 * n +
0.509166666826.
b =-0.000000002072 * n * n * n * n * n +
0.000000360047 * n * n * n * n -
0.000024632867 * n * n * n +
0.000840099068 * n * n —
0.014922836830 * n +
0.133766666669:
return а * pow (alpha.b); }
Распределение Х-статистики Ван дер Вардена
Точность настоящей реализации, вычисляющей значение функции распределения Аг-статистики Ван дер Вардена, обеспечивается, как правило, до 2-го знака в интервалах изменения параметров распре-1 деления: 0,95 < р < 0,999, 10 < (т + п) < 50, 0 < (п - т) < 4. Точность недостаточна для теоретических исследований и составления таблиц, но для практических расчетов функция вполне может быть использована. Нами применяется аппроксимация табличных значений элементарными функциями на основе таблиц, представлен! ных в [32, с. 95, 361].
Одномерные распределения
233
Исходные коды
double InverseXDistribution (double n,double m.double p) //
// Вычисление обратной функции распределения Х-статистики // Ван дер Вардена.
// Обозначения:
// пит- параметры распределения.
// р - доверительный уровень.
// Возвращаемое значение:
// критическое значение функции распределения.
//
{
double ЬО,Ы.Ь2,ЬЗ.сО.с1.с2, М = fabs (п - т).
N = п + т;
if (р <= 0.95) {
Ь0 = 1.250214:
bl = -0.098452;
Ь2 = 0.146892:
ЬЗ = 0.030469:
СО = -0.000849;
cl = -0.000034: с2 = -0.00000675:
}
else if (р > 0.95 && р <= 0 99) {
Ь0 = 1.341006:
Ы = -0.078017:
Ь2 = 0.1796:
ЬЗ = 0.020529;
сО = -0.001055:
С1 = -0.00005975;
с2 = 0.000003625:
}
el se { Ь0 = 1.342562; bl = -0.070649; Ь2 = 0.203976; ЬЗ = 0.01456; СО = -0.001244; cl = 0.0000255; с2 = -0.00001475:
}
return Ь0 * exp (bl * M) + b2 * exp (ЬЗ * M) * N +
, (cO + cl * M + c2 * M * M) * N * N:
234
Глава 4. Теория распределений
Распределение критерия Аббе и обратное к нему
Для и <4, а также для р < 0,95 и р > 0,999 значение функции InverseAbbeDistribution, реализующей распределение, обратное к распределению критических значений критерия Аббе, не определено. Для 4 < п < 60 берутся табличные значения статистики, вычисленные в [32, с. 267]. Для п > 60 производится аппроксимация по [161, с. 406].
Исходные коды
double AbbeDistribution (int n. double x) //
// Функция вычисления распределения статистики Аббе.
// Обозначения:
// п - число степеней свободы,
// х - функция распределения.
// Возвращаемое значение:
// доверительный уровень.
//
{ double c = 0.000001, // Левая граница локализации корня
d = 1. // Правая граница локализации корня
У. // Середина интервала локализации
ex: // Рабочая переменная
{
сх = х - InverseAbbeDistribution (п,с);
у = (с + d) / 2:
сх *= х - InverseAbbeDistribution (п.у):
if (сх == 0)
break:
else if (сх > 0)
с = у:
el se
d = у:
} while (fabs (с - d) > 0.000001):
if (у < 0) У = 0: if (у > 1) у = 1:
return у: }
double InverseAbbeDistribution (int n. double p) //
Одномерные распределения
235
// Функция вычисления обратной функции распределения статистики // Аббе.
// Обозначения:
// п - число степеней свободы.
// р - доверительный уровень.
// Возвращаемое значение:
// функция распределения.
//
S///////////////////////////////////
// Табличные значения для интервалов
double AbbeTable95[] = {
0.3902.0.4102.0.4451.0.4680.0.4912.0.5121.0.5311.0.5482.0.5638,0.5778, 0.5908.0.6027,0.6137,0.6237.0.6330.0.6417.0.6498.0.6574.0.6645,0.6713. 0.6776.0.6836,0.6893.0.6946.0.6996,0.7046.0.7091,0.7136.0.7177,0.7216. 0.7256,0.7292,0.7328.0.7363,0.7396.0.7429,0.7461,0.7491,0.7521,0.7550. 0.7576,0.7603.0.7628.0.7653.0.7676,0.7698.0.7718,0.7739.0.7759.0.7779. 0.7799,0.7817.0.7836.0.7853,0.7872.0.7891.0.7906},
AbbeTable99[] = {
0.3180,0.2690,0.2808.0.3070.0.3314.0.3544,0.3759.0.3957.0.4140,0.4309. 0.4466,0.4611.0.4746,0.4872,0.4989.0.5100.0.5203,0.5301.0.5393.0.5479, 0.5562.0.5639.0.5713.0.5784,0.5850.0.5915,0.5975.0.6034.0.6089,0.6141. 0.6193.0.6242,0.6290.0.6337.0.6381,0.6425.0.6467.0.6508.0.6548.0.6587. 0.6622.0.6659.0.6693,0.6727,0.6757.0.6787.0.6814,0.6842.0.6869,0.6896. 0.6924,0.6949.0.6974,0.6999,0.7024.0.7049.0.7071},
AbbeTablе999[] = {
0.2949.0.2080.0.1817,0.1848.0.2018.0.2210,0.2408.0.2598.0.2778.0.2949, 0.3112,0.3266,0.3413.0.3552.0.3684,0.3809,0.3926,0.4037.0.4142.0.4241, 0.4334.0.4423.0.4509.0.4591.0.4670,0.4748.0.4822.0.4895.0.4963,0.5027. 0.5090.0.5150.0.5208.0.5265.0.5319.0.5373.0.5425,0.5475.0.5524.0.5571. 0.5616.0.5660.0.5701.0.5743.0.5781.0.5817.0.5853,0.5887.0.5922.0.5955. 0.5989.0.6020.0.6051,0.6083.0.6114,0.6145.0.6174}.
a.b. // Коэффициенты аппроксимации прямой линией
criterion: // Возвращаемое значение статистики
if (п < 60)
{
а = р < 0.99 ? (AbbeTable99[n - 4] - AbbeTablе95[п - 4]) /0.04 : (AbbeTablе999[п - 4] - AbbeTablе99[п - 4]) / 0.009:
b = р < 0.99 ? AbbeTablе95[п - 4] - а * 0.95 :
AbbeTable99[n - 4] - а * 0.99:
return а * р + b:
}
el se
{
criterion = InverseNormalDistribution (1 - p);
criterion = criterion / sqrt ((criterion * criterion + 1) /
2 + n) + 1;
}
return criterion:
236
Глава 4. Теория распределений
Распределение критерия Пагуровой
Критическое значение статистики критерия зависит как от степеней свободы сравниваемых выборочных совокупностей Ц и и2 и доверительного уровня р, так и от параметра с, зависящего от отношения неизвестных дисперсий генеральных совокупностей (вычисляется вместе со статистикой критерия). Вычисления производятся по формулам [152, с. 4]:
n_. (0->Q2(l->7). , [в(1-в)+(20-1)(??-в)]??(1-г?) (0-77)27J
02 + H+v2.p 02(1-0)2 V-P (1-0)2 1
где — значения обратной функции Г-распределения.
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void) { // Численности выборок
int nl n2 = 18. = 18:
double c = 0.249. // Параметр, зависящий от отношения
// дисперсий
p = 0.995: // Доверительный уровень двухсторонней
// гипотезы
cout « InversePagurovaDistribution (nl - l,n2 - l,c,(p + 1) / 2) « endl:
}
double InversePagurovaDistribution (int nl.int n2, double
c,double p)
//
// Функция вычисления обратной функции распределения
// статистики критерия Пагуровой.
// Обозначения:
// nl - число степеней свободы.
// п2 - число степеней свободы.
Одномерные распределения
237
// с - параметр, зависящий от отношения дисперсий.
// р - доверительный уровень односторонней гипотезы.
// Возвращаемое значение:
// функция распределения.
//
double h.t. // Рабочие константы
ht.tl.hl: // Константы для уменьшения объема записи
h = с - 2 * с * (1 - с) * ((1 - с) / п2 - с / nl):
t = (double) nl / (nl + n2):
tl = 1 - t;
hl = 1 ~ h;
ht = h - t:
return ht * ht * hl / t / t * InverseTDistribution (n2.p) +
(t * tl + (2 * t - 1) * ht) * h * hl / t / t / tl / tl * InverseTDistribution (nl + n2.p) +
ht * ht * h / tl / tl * InverseTDistribution (nl.p):
}
Распределение критерия Данна
Критические значения статистики критерия Данна получены путем аппроксимации полиномом 6-й степени с помощью электронных таблиц Microsoft Excel табличных значений при стандартных уровнях значимости для попарного сравнения [52, с. 352] и для сравнения с контрольной группой [52, с. 353]. Критические значения зависят только от числа сравниваемых выборок k и табулированы для значений 2 < k < 25. Экстраполяцию для других значений k с помощью данных функций мы делать не рекомендуем.
Исходные коды
double DannDistribution95 (int k)
//
// Функция вычисления критического значения статистики критерия
Ч Данна для попарного сравнения при уровне значимости 0.05.
// Обозначения:
Ч к - число сравниваемых выборок.
Ч Возвращаемое значение:
Ч критическое значение статистики.
//
{
/////////////////////////////////////////////////
Ч Коэффициенты аппроксимации полиномом 6-й степени
double а[] = { 0.588190556232. 0.966244168207.-0.165163435034.
0.015897511430.-0.000842601438.
°-000022977149.-0.000000251503}:
238
Глава 4. Теория распределений
//////////////////// // Значение полинома return Horner (а.6,double (к)); }
double DannDistribut1on99 (int к) //
// Функция вычисления критического значения статистики критерия // Данна для попарного сравнения при уровне значимости 0.01. // Обозначения:
// к - число сравниваемых выборок.
// Возвращаемое значение:
// критическое значение статистики.
//
{
//////////////////////////III////////////////////
// Коэффициенты аппроксимации полиномом 6-й степени
double а[] = { 1.449135309643, 0.787940262178.-0.132133234787, 0.012609621752,-0.000664881283,
0.000018065176.-0.000000197198}:
//////////////////// // Значение полинома return Horner (а.6,double (k)); }
double DannDistribution95c (int k) //
// Функция вычисления критического значения статистики критерия // Данна для сравнения с контрольной группой при уровне // значимости 0.05.
// Обозначения:
// к - число сравниваемых выборок.
// Возвращаемое значение:
// критическое значение статистики.
// {
/////////////////////////////////////////////////
// Коэффициенты аппроксимации полиномом 6-й степени
double а[] = { 1.065120712080, 0.635501656065,-0.110820876210, 0.010771151900,-0.000574089821,
0.000015710820,-0.000000172389};
//////////////////// // Значение полинома return Horner (а,6,double (k)): }
double DannDistribution99c (int k) //
// Функция вычисления критического значения статистики критерия
Одномерные распределения
239
// Данна для сравнения с контрольной группой при уровне
// значимости 0.01.
// Обозначения:
// к - число сравниваемых выборок.
// Возвращаемое значение:
// критическое значение статистики.
//
S////////////////////////////////////////////////
// Коэффициенты аппроксимации полиномом 6-й степени
double а[] = { 1.842663470189. 0.518226356741.-0.089355861698, 0.008642394656.-0.000459257429.
0.000012542114.-0.000000137408};
////////////////////
// Значение полинома
return Horner (а.6.double (k));
}
Распределение выборочного размаха
Функция распределения выборочного размаха Р„(к’) для выборки численности п, или вероятность того, что размах выборки не превысит w [151, с. 138], определяется формулой [205, с. 276]
Рп (w)=п J [F(x+w) - F(x)]"-1 dF(x).
Если совокупность распределена нормально, то выражение F(.), входящее в представленную выше формулу, является функцией распределения стандартизованной случайной величины [151]
Р(х) = Г е r^dt-
Однако для практического вычисления функции распределения размаха дополнительно необходимо выразить величину dF(x), входящую в формулу его вычисления, через dx. Это нетрудно сделать, проведя небольшие выкладки. Так, можно записать
, dF(x) , dF(x) = —т-^-dx, dx
гДе производная F(x) по х — плотность распределения вероятности — ДДя стандартизованной нормальной случайной величины вычисляется по формуле [там же]
240
Глава 4. Теория распределений
dP(x) _ 1 g_x2/2 dx
Сделав все необходимые подстановки, получаем удобную для вычислений на компьютере формулу
Pn(w) = —^=l[P(x + w)-P(x)]n le ^dx,
где Р(.) вычисляется, как показано выше.
4 Функция вычисления выборочного размаха нормально распределенной случайной величины находит основное применение при вычислении стьюдентизированного размаха, представленного в разделе «Распределение стьюдентизированного размаха» данной главы. См. также [ 135, с. 543].
Исходные коды и пример применения
#include <fstream.h>
#include <math.h>
#include "megastat.h"
void main (void)
{
int n = 16:
double w = 23;
cout « "w = " « w « "\nn = " « n
« "\np = " « RangeNormal (w.n) << endl:
}
double RangeNormal (double w.int n)
//
// Вычисление функции распределения размаха выборки из
// нормальной совокупности.
// Обозначения:
// w - размах.
// п - численность выборки.
// Возвращаемое значение:
// вероятность того, что размах выборки не превысит w.
//
{
double s:
if (w > 8)
return 0.999999;
Одномерные распределения
241
s = RangeNormalIntegral (w.n) * n / SQRTMPI2;
if (s > 1)
return 1:
el se return s:
}
double RangeNormalIntegral (double w.int nl)
//
// Функция вычисления интеграла для определения функции
// распределения
// размаха выборки из нормальной совокупности.
// Обозначения:
// w - размах.
// nl - численность выборки.
// Возвращаемое значение:
// значение интеграла.
// Примечания:
// 1. Функция представляет собой специальную версию метода
Simpson.
// 2. Все константы вынесены за знак интеграла.
//
{
int п = = 200: // Число интервалов интегрирования
doublе а = -15.b = 15. // Пределы интегрирования
si = 0.S2 = 0. '/ Рабочая переменная
х1.х2. // Текущее значение переменной
h: // Удвоенный шаг интегрирования
h = 2 * (Ь - а) / п;
xl = а + h;
х2 = а + h / 2;
for (register int i = 1; i < n - 1; i += 2, xl += h. x2 += h) {
si += RangeNormalDensity (xl.w.nl);
s2 += RangeNormalDensity (x2.w,nl);
}
return h * (RangeNormalDensity (a.w.nl) + RangeNormalDensity (b.w.nl) +
si * 2 + (s2 + RangeNormalDensity (x2,w,nl)) * 4) / 6: }
double RangeNormalDensity (double x,double w.int n)
//
// Функция вычисления плотности распределения размаха
// выборки из нормальной совокупности.
// Обозначения:
// х - переменная интегрирования.
И w - размах.
242
Глава 4. Теория распределений
// п - численность выборки.
// Возвращаемое значение:
// значение плотности вероятности.
// {
double s = PowerOf (NormalDistributionl (х + w) -
NormalDistributionl (x),n - 1) * NormalDensIty (x);
//////////////////////////////// // Компенсация ошибок округления if (s < 0.000000000001)
return 0.000000000001;
el se return s;
}
Распределение стьюдентизированного размаха
Пусть из нормальной совокупности извлекается выборка численностью п и по данной выборке вычисляется выборочный размах w. Затем из той же нормальной совокупности или из другой нормальной совокупности с тем же стандартным отклонением извлекается выборка численностью/ (f— число «степеней свободы»), и по данной выборке вычисляется выборочное стандартное отклонение s. Тогда отношение w/s называется стьюдентизированным размахом (размахом Стьюдента), и его распределение на заданном уровне значимости зависит только от величин пи/. Вычисления производятся по формуле [151, с. 144]
Pn>f Г — < q 1 = J[г(//2) ]*2 -(//2)+1 f qx) dx ,
t5 J о
где Pn(.) — функция, определенная в предыдущем параграфе.
Функция RangeStudent представляет собой специальную версию метода Simpson, снабженную всеми необходимыми эмпирическими настройками, включая пороговые ограничения на величины параметров, что необходимо при вычислениях с конечной точностью во избежание ошибок типа переполнения и выхода за границы области определения. Для повышения точности вычислений в вызовах используются самые точные версии методов, что несколько замедляет работу функции. Это тот случай, когда обычный выбор программиста между высокой скоростью вычисления и приемлемой точностью сделан в пользу последней. Если численность выборки, использованной для вычисления дисперсии, равна 1, возникает чис
Одномерные распределения
243
ленная неустойчивость и/или потеря значимости, что заставило нас сделать кусочную аппроксимацию «трудных» участков элементарными функциями. Аппроксимация выполнена с помощью электронных таблиц Microsoft Excel и имеет точность, сопоставимую с точностью решения, полученного прямым интегрированием. Обсуждение проблемы и таблицы см. также в [205, с. 286], [140, с. 163], [120, с. 30].
Исходные коды и пример применения
#include <fstream.h>
#include <math.h>
#include "megastat.h"
void main (void)
{ int n = 60.
f = 1;
double q = 73.97;
cout « "q = " « q « "\nn = " « n « "\nf = " « f « "\np = " << RangeStudent (q.n.f) « endl;
}
double RangeStudent (double q.int nl.int f) //
// Функция вычисления вероятности стьюдентизированного размаха
// выборки из нормальной совокупности.
// Обозначения:
// q - стьюдентизированный размах.
// п - численность выборки для определения размаха.
// f - численность выборки для определения дисперсии.
// Возвращаемое значение:
// вероятность того, что размах выборки не превысит q.
//
{
int nl = 800; // Число интервалов интегрирования
double а = 0.000000000001. // Пределы интегрирования b = 40.000000000001, si = 0,s2 = 0. // Рабочая переменная
х1,х2, // Текущее значение переменной
h. // Удвоенный шаг интегрирования
с[] = // Пороговые значения
{8.929,13.44,16.36.18.49.20.15.21.51.22.64.23.62,24.48, 25.24,25.92,26.54.27.10,27.62,28.10,28.54,28.96,29.35,29.71}.
d[] = // Коэффициенты регрессии
{0.89326883,1.34139749,1.63270350,1.84506031,2.01134877,
244
Глава 4. Теория распределений
2.14668101.2.25920652.2.35710800.2.44305420.2.51938913, 2.58709453.2.64917496,2.70595180.2.75694765.2.80477208.
2.84883799.2.89057797,2.92956265.2.96534101};
/////////////////////////////////////////////////
II Аппроксимация для больших значений q при f = 1
if (f == 1)
{
if (n < 20)
{
///////////////////////////
// Аппроксимация гиперболой
if (q > c[n - 2])
return 1.0 - d[n - 2] / q;
}
el se
{
/////////////////////////////////
// Аппроксимация сложной функцией
if (q > 39.91)
return 1.0 - (2.3673883676 * log (loglO (n)) +
2.3285514134) / q;
}
}
h = 2 * (b - a) / nl;
xl = a + h;
x2 = a + h / 2:
for (register int i = 1; i < nl - 1; i += 2. xl += h. x2 += h)
{
si += RangeStudentDensity (xl.q.n.f);
s2 += RangeStudentDensity (x2,q,n.f);
}
return h * (RangeStudentDensity (a.q.n.f) +
RangeStudentDensity (b.q.n.f) +
2 * si + 4 * (s2 + RangeStudentDensity (x2,q.n.f))) / 6:
}
double RangeStudentDensity (double x.double q.int n.int f)
//
// Функция вычисления плотности вероятности
// стьюдентизированного размаха
// выборки из нормальной совокупности.
// Обозначения:
// х - переменная интегрирования.
// q - стьюдентизированный размах.
// п - численность выборки для определения размаха.
// f - численность выборки для определения дисперсии.
// Возвращаемое значение:
// значение плотности вероятности.
Одномерные распределения
245
{ double s, // Вспомогательные
// переменные fl = log (RangeNormal (q * x,n)), f2 = 0.5 * f;
/////////////////////////////////////////////////
// Логарифмирование формулы плотности вероятности
s = MLN2 + f2 * (log (f) - M_LN2 - x * x) + (f - 1) * log (x) -log (Gammal (f2)) + fl:
return exp (s): }
Распределение критерия Дункана
Функция распределения статистики критерия Дункана построена на основе таблиц стьюдентизированного размаха, как это показано в [151, с. 105].
Функция DuncanDistribution имеет низкое быстродействие, вызванное низким быстродействием вызываемого из нее метода RangeStudent, причем быстродействие резко снижается с повышением значений параметров распределения вследствие рекурсивной природы данной функции. Низкое быстродействие не позволяет рекомендовать использование функции в диалоговых программных системах, однако при пакетной обработке данных результаты работы вполне приемлемые. Повышения быстродействия можно добиться только оптимизацией вычисления стьюдентизированного размаха.
Обсуждение см. также в [140, с. 157].
Исходные коды и пример применения
#include <fstream.h>
#include <math.h>
#include "megastat.h"
void main (void) {
int n = 50.
f = 20:
double q = 5.394:
cout « "q = " « q « "\nn = " « n « "\nf = " « f « "\np = " « DuncanDistribution (q.n.f) « endl:
246
Глава 4. Теория распределений
double DuncanDistribution (double q,int n.int f) //
// Функция вычисления функции распределения статистики Дункана.
// Обозначения:
// q - значение статистики критерия Дункана.
// n.f - параметры распределения.
// Возвращаемое значение:
// p-значение статистики.
//
{
double s = RangeStudent (q,2,f). // Рабочие переменные si;
if (п == 2) return s;
si = DuncanDistribution (q.n - l.f):
if (s > si)
return s;
el se
return si:
}
Распределение размаха варьирования
Критические значения размаха варьирования вычислены по таблицам [155, с. 72] путем аппроксимации табличных значений с точностью, достаточной для практического применения. Особенностью функции является необходимость задания уровня значимости только из стандартной линейки: 0,005; 0,001; 0,025; 0,05; 0,1. Кроме того, численность выборки не может быть менее 3 и не может превышать 1000.
Исходные коды
int RangeOfVarDistribution (double n.double p.double
*low,double *high)
//
// Функция вычисляет критические значения статистики метода
// размаха варьирования.
// Обозначения:
// п - численность выборки.
// р - уровень значимости, выбранный из стандартной
// линейки.
// *low - нижнее критическое значение.
// *high - верхнее критическое значение.
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -2 при ошибке в фактических параметрах.
Одномерные распределения
247
if (n < 3 || n > 1000) return -2;
/////////////////////////////////////////////////////////////// //
// Аппроксимация квадратичным полиномом от логарифма
// численности выборки n = loglO (п);
if (р == 0.005)
{
*1OW = floor ((-0.019612414308 * п * п + 1.606721508300 * п +
0.885941911160) * 100) / 100; -Д
♦high = ceil ((-0.677416078497 * n * n + 4.679517241630 * n -0.070543440621) * 100) / 100;
return 0;
}
else if (p == 0.01) {
♦low = floor ((-0.032035793369 * n * n + 1.664968323848 * n + 0.886031984429) * 100) / 100;
♦high = ceil ((-0.626961819643 * n * n + 4.421692091895 * n + 0.067932224692) * 100) / 100;
return 0;
}
else if (p == 0.025)
{
♦low = floor ((-0.053784700844 * n * n + 1.765234519405 * n + 0.883987588228) * 100) / 100;
♦high = ceil ((-0.553993288546 * n * n + 4.056192960361 * n + 0.254892548764) * 100) I 100;
return 0;
}
else if (p == 0.05)
{
♦low = floor ((-0.073993702151 * n * n + 1.861130284455 * n + 0.882056162419) * 100) / 100;
♦high = ceil ((-0.492813571184 * n * n + 3.757754660084 * n +
0.397804472068) * 100) / 100;
return 0;
}
else if (p == 0.1) {
♦low = floor ((-0.101066702208 * n * n + 1.981145123894 * n + 0.880596808029) * 100) / 100;
♦high = ceil ((-0.422913738752 * n * n + 3 431109025149 * n + 0.542227716536) * 100) / 100;
return 0;
}
el se
return -2;
}
248
Глава 4. Теория распределений
Дискретные распределения
Подобно непрерывным распределениям, основные дискретные распределения также взаимосвязаны, что иногда позволяет просто вычислять одни распределения через другие, сокращая затраты ресурсов. Особенностью дискретных распределений являются целочисленные значения параметров распределений.
Биномиальное распределение, распределение критерия знаков
Функция биномиального распределения определяется формулой [63, с. 42]
i=0
При х = яир= 1/2 получается распределение критических значений критерия знаков [135, с. 95], [180, т. 2, с. 121]. P-значение критерия знаков выводится в результате подстановки данных параметр ров в показанную выше формулу. Следовательно, критическое значение вычисляется как наименьшее целое значение К, для которого выполняется соотношение [140, с. 218]
1 Л п\ — У-------->а>
где п — число степеней свободы, а — уровень значимости, взятый из стандартной линейки.
См. также обсуждение в [151, с. 362], [213, с. 17].
Исходные коды
int SignDistribution (int n.double p) //
11 Функция вычисления критического значения критерия знаков.
// Обозначения:
// п - численность выборки.
// р - уровень значимости.
// Возвращаемое значение:
// критическое значение критерия знаков.
И
{
int i = -1: // Возвращаемое значение
double s
0: // Рабочая переменная
Одномерные распределения
249
do
{
s += exp (LogFactorial (n) - LogFactorial (++i) -LogFactorial (n - i) - n * log (2));
} while (s <= p):
if (s == p)
return i:
el se
return (i - 1);
}
Гипергеометрическое распределение, распределение критерия медианы
Гипергеометрическое распределение определяется формулой [63, с. 44]
»=о
Для вычисления распределения критических значений критерия медианы следует взять х = Мt — число наблюдений первой выборки, превосходящих медиану объединенной совокупности, А = пх — численность первой выборки, В = п2 — численность второй выборки, п - и2)/2. Таким образом, критическое значение вычисля-
ется, как и в предыдущем разделе, как наименьшее целое значение К, для которого выполняется соотношение [180, т. 2, с. 126]
к
X i=o
П1+Л2
где п — число степеней свободы, а — уровень значимости, взятый из стандартной линейки. Подробное обсуждение см. в [32 ,с. 77].
Исходные коды
int MedianDistribution (int nl.int n2,double p) //
// Функция вычисления критического значения критерия медианы.
// Обозначения:
// nl - численность первой выборки,
// п2 - численность второй выборки,
// р - уровень значимости.
// Возвращаемое значение:
// критическое значение критерия медианы.
//
250
Глава 4. Теория распределений
{
int i = -1. // Возвращаемое значение
n = nl + п2: // Рабочая переменная
double s = 0; // Рабочая переменная
do
{
s += exp (LogFactorial (nl) - LogFactorial (++i) -LogFactorial (nl - i) + LogFactorial (n2) -LogFactorial (n / 2 - i) - LogFactorial ((n2 - nl) / 2
+ i) - LogFactorial (n) + LogFactorial (n / 2) * 2):
} while (s <= p);
return i;
}
Распределения типа Колмогорова—Смирнова
В параграфе приводятся формулы и функции, предназначенные для вычисления распределений типа Колмогорова—Смирнова. Основным типом рассматриваемого семейства распределений является Л-распределение. Вычисление его критического значения производится по точной формуле [140, с. 235]
К(А)=
0,Л<0.
Бесконечная последовательность быстро сходится, и для получения критического значения достаточно ограниченного числа ее членов. Мы взяли 31 член для улучшения точности при малых значениях Л, хотя для многих задач можно ограничиться значительно меньшим числом, например И.
Формулы вычисления предельного распределения Колмогорова-Смирнова с учетом асимптотических свойств, использующие меньшее число членов разложения, приведены в [174, с. 110].
Исходные коды
double LambdaDistribution (double у) //
// Функция вычисления распределения Колмогорова для простой // гипотезы.
// Обозначения:
// у - функция распределения.
// Возвращаемое значение:
Одномерные распределения
251
// уровень значимости.
//
{
double а = 0: // Возвращаемое значение
if (у <= 0)
return 0:
for (register int к = -15;
if (Parity (к))
a += exp (-2 * к * к * el se
a -= exp (-2 * к * к *
к <= 15: k++)
у * у);
у * У):
return а;
}
Как было отмечено при описании критерия согласия Колмогорова, статистика критерия для случая сложной гипотезы зависит от типа теоретического распределения и числа параметров распределения, вычисляемых по эмпирической выборке. Приближенная формула для рассматриваемого случая приводится в [156, с. 136].
Ниже показана аппроксимация для случая проверки нормальности, причем предполагается, что оба параметра нормального распределения вычисляются по выборке. На основе данных [ 187, с. 328] вычисление модифицированной статистики производится по формуле
P„(Vn-0,01 + 0,85/Vn).
Аппроксимация модифицированной статистики выполнена с помощью 4-слойной нейронной сети прямого распространения. Применение нейронных сетей в задачах аппроксимации зависимостей предложено в [144, ч. 1, с. 26]. В этом случае говорят, что нейронная сеть выполняет роль предиктора, в противоположность тому, что в главе 9 нейронная сеть выполняет роль классификатора — вместо заранее известного класса, которому принадлежит объект обучающей выборки, нейронной сети предъявляется известное действительное число.
Представленная методика может быть использована и для построения критических значений модифицированной статистики критерия Колмогорова в случае проверки экспоненциальности по табличным данным, а также для построения критических значений модифицированной статистики критерия а>п [187, с. 328] для проверки нормальности и экспоненциальности. Вычисление статистики
252
Глава 4. Теория распределений
показанной ниже функцией производится для сложной гипотезы для случая нормального распределения, причем оба параметра распределения вычисляются по выборке, а возвращаемые значения действительны в интервале входного параметра от 0,85 до 0,99, так как этот интервал был использован при обучении нейронной сети.
Исходные коды и пример применения
#include <fstream.h>
finclude <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void)
{
double p:
cout « "p = ": cin » p;
cout « endl « KolmogorovDistribution (p) « endl:
}
double KolmogorovDistribution (double p)
//
// Функция вычисления распределения модифицированной статистики // Колмогорова.
// Обозначения:
// р - доверительный уровень.
// Возвращаемое значение:
// функция распределения.
И
{
register int i.j.m, // Счетчик цикла
il » 0: // Счетчик
int al = 4, И Число слоев нейронной сети
ak[] = {1,7.7.!}. // Вектор размеров слоев
i2 = SpecialVectorSum (ak.al):// Счетчик
double dv[7],dvl[7], // Рабочие массивы
out. // Возвращаемое значение
y[] = // Синапсы и смещения
{-9.569977.1.623841.-4.617375.1.107604.1.117771.-0.292249. -0.551078.-6.084196.0.1032.-0.155393.-0.264672.-3.568227.
-1.115464,-0.294712.-0.781665.-1.383647,-1.057088.-1.003334, -0.939507.-0.89708,0.809497.1.08774.-0.635299,-0.077337.0.091707.
-0.388659.-0.057653.-0.149816.2.058079.-0.60375.0.051302,
-0.935535.-1.115495,-0.514461,0.187052,-0.395154.-0.152575.
-0.520102.0.266812,-1.05053.-0.031599.-0.295273.-4.469841.
Одномерные распределения
253
0.798921.0.701824.2.019915.2.008559.1.400117.-0.478454, 0.182765.-0.161796.-0.129722.0.036638,-0.157487.0.021738, 0.358042,7.893243.0.428812.3.903452.3.340814.
2.304325.-5.833338.-0.268809.9.752849.-7.516172, -0.007198.8.284651.-1.463197.-3.159512.4.268715, -1.869945,1.224727,-5.002196.-1.8682.2.439419, 3.024104,0.109497};
НИИПНИ И Вход сети dv[0] = р;
/////////////////////////////////// // Преобразование для скрытых слоев for (1 =0; i <al -2; i++)
{
///////////////////////////////////////////
11 Унножение матрицы синапсов на выход слоя
for (j = 0; j < ak[i + 1J; j++)
for (m = 0, dvl[j] = 0: m < ak[i]; m++) dvl[j] += y[il++] * dv[m];
////////////////////// // Нелинейные элементы for (j = 0; j < ak[i + 1]; j++) {
dv[j] = dvl[j] - y[i2++]: // Смещение
dv[j] /= (fabs (dv[j]) + 4.0); // Рациональный сигмоид }
}
И! I HI IИIИ
II Выход сети
for (j = 0, out =0; j < ak[al - 2]: j++) out += y[il++] * dv[j];
return out; }
Распределение co2
При n —» о© предельное распределение статистики па? вычисляется по формуле [32, с. 83]. Однако сложность формулы заставила нас аппроксимировать табличные значения [там же, с. 348] полиномом 6-й степени, как это сделано в показанной ниже функции. Как свидетельствует опыт расчетов, точность такой аппроксимации удовлетворительна для практического применения.
Исходные коды
double OmegaSquareDistribution (double x)
254
Глава 4, Теория распределений
//
// Функция вычисления распределения онега-квадрат для простой // гипотезы.
// Обозначения:
// х - функция распределения.
// Возвращаемое значение:
// уровень значимости.
//
{
double al[] = {0.0.889907.-165.141530.8917.211192.
-143399.597088.1009989.743591.-2699591.836609}, а2[] = {-0.204809.8.41686.-25.949245,42.970626.
-39.294718.18.621934.-3.563246}:
if (х <= 0.000001)
return 0;
else if (0.000001 < x && x <= 0.1)
return Horner (al,6.x);
else if (0.1 < x && x <= 1.49)
return Horner (a2,6,x):
el se
return 1:
}
Распределения Вилкоксона—Манна—Уитни
В расчетах критериев Вилкоксона (глава 2) применяется подход к вычислению статистик критериев, основанный на нормальной аппроксимации и хорошо работающий даже при небольших выборках. Некоторые авторы предлагают подход, основанный на использовании точных критических значений статистик критериев. Для решения задачи возможно применение показанных ниже рекуррентны х алгор и т -мов. Функции компактны, поэтому покажем их полностью. Они могут быть применены как в практических расчетах, так и для составления статистических таблиц, в том числе в интервалах, не за-табулированных в источниках.
Точное вычисление критических значений Т-статистики Вилкоксон на производится по рекуррентным формулам [151, с. 325]:
f(n,а) = f(n - 1,а) + f(n - 1,а - п),
f(n,O) = 1,
/(п,-Л) = 0,Л>0,
f(n,a) - f(n,n(n+ 1) / 2), а > п(п + 1)/2.
Одномерные распределения
255
Исходные коды
double WiIcoxonTDistribution (int n,double a) //
// Функция вычисления критического значения Т-статистики
// Вилкоксона.
// Обозначения:
// п - численность каждой из выборок.
// а - статистика критерия.
// Возвращаемое значение:
// Уровень значимости нулевой гипотезы.
//
{
return WTDistribution (п.а) / TwoDegree (п);
}
double WTDistribution (int n,double a)
//
// Вспомогательная функция для вычисления критического
// значения Т-статистики Вилкоксона.
// Обозначения:
// п - численность каждой из выборок.
// а - статистика критерия.
// Возвращаемое значение:
// результат рекурсии.
//
{
int nn = n * (n + 1) /2:
if (п < 0)
return 1:
if (а < 0)
return 0:
if (а == 0)
return 1:
if (a > nn)
return WTDistribution (n.nn):
el se
return WTDistribution (n - 1. a) + WTDistribution (n - 1, a -n): }
Точное вычисление критических значений /7-статистики Манна-
Уитни производится по рекуррентным формулам [151, с. 331]:
f(n,m,u) = f(n - 1,т,и - т) + f(n,m - l,w),
f(n,m-x) = 0, х > О,
/(К,772,0) = 1,
256
Глава 4. Теория распределений
/(h,0,w) = 1,
Исходные коды
double MannWhitneyDistribution (int n.int m.double u) //
// Функция вычисления критического значения U-статистики
// Манна-Уитни.
// Обозначения:
// п - численность первой из двух выборок.
// m - численность второй из двух выборок.
// и - сунна положительных разностей рангов, вычисленная
// по выборкам.
// Возвращаемое значение:
// критическое значение.
//
{
return UDistribution (n.m.u) *
exp (LogFactorial (m) + LogFactorial (n) - LogFactorial (m + n)):
}
double UDistribution (int n.int m,double u)
//
// Вспомогательная функция для вычисления критического значения // U-статистики Манна-Уитни.
// Обозначения:
// п - численность первой из двух выборок.
// m - численность второй из двух выборок,
// и - сумна положительных разностей рангов, вычисленная
// по выборкам.
// Возвращаемое значение:
// результат рекурсии.
//
{
if (п < 0)
return 0:
if (m < 0)
return 0;
if (u < 0)
return 0;
if (u == 0)
return 1:
if (m == 0)
return 1:
Одномерные распределения
257
Р(у = г)
return UDistribution (n - l.m.u - m) + UDistribution (n.m -l.u);
}
Благодаря простой связи статистики ^-критерия Вилкоксона со статистикой £/Манна— Уитни [187, с. 122]
W = I/+ и (и + 1)/2,
где п — численность второй из сравниваемых выборок, отпадает необходимость применять и точные таблицы распределения ^-критерия.
Распределение критерия серий и обратное к нему
Следуя [32, с. 91], обозначим через / общее число серий в данной последовательности. Случайная величина у принимает значения г = 2, 3, ...» 2т + 1 (при т < п) или г = 2, 3, ...» 2т (при т = п) с вероятностями
ork-i rk-i ,r = 2k,
1 n—1 m—i л—1 y._।
Cm т+и
Для расчетов с большими значениями численностей выборок функцию InverseSerialDistribution желательно модернизировать так, чтобы при вычислении не получались слишком большие промежуточные величины. Это можно сделать путем логарифмирования формул с последующим потенцированием. Логарифмирование позволит заменить произведение факториалов суммой их логарифмов. Вычисление логарифмов факториалов производится (для основания е) функцией LogFactorial. Попутно можно несколько снизить объем вычислений за счет упрощения формул.
Подробное обсуждение и таблицы см. также в [151, с. 373].
Исходные коды
void SerialDistribution (int m.int n,double p.int *low,int *high)
//
// Функция вычисляет критические значения критерия серий.
// Обозначения:
// m - численность элементов первой группы.
9—2002
258
Глава 4. Теория распределений
// п - численность элементов второй группы.
// р - доверительный уровень.
// *low - нижнее критическое значение.
// *high - верхнее критическое значение.
// Возвращаемое значение:
// нет.
И
{
int c.d. // Интервалы локализации корня
у: // Середина интервала локализации
double t: // Вспомогательная переменная
с » 2:
d » 150:
do
{
t = р - InverseSerialDistribution (т.п.с):
у = (с + d) / 2:
t *= р - InverseSerialDistribution (т.п.у);
if (t == 0) break;
else if (t > 0)
c = y:
else d = y:
} while (abs (c - d) > 1);
*low y:
c = 2:
d = 150:
p » 1 - p:
do
t = p - InverseSerialDistribution (m.n.c);
у = (c + d) / 2:
t *= p - InverseSerialDistribution (rn.n.y):
if (t =» 0) break;
else if (t > 0)
c = y:
el se d = y:
} while (abs (c - d) > 1);
if (y < *low)
{
*high » *low;
*low » y;
}
Одномерные распределения
259
el se
*high = у;
}
double InverseSerialDistribution (int m.int n.int u) //
// Функция вычисления уровня значиности критерия серий.
// Обозначения:
// го - численность элементов первой группы.
// п - численность элементов второй группы.
// и - значение критерия серий.
// Возвращаемое значение:
// уровень значимости.
//
{
int к; // Параметр суммирования
double s = 0; // Накапливаемое значение
for (register int j = 2; j <= u; j++)
{
if (Parity (j))
{
k = j / 2:
s += 2 * Combination (m - l.k - 1) * Combination (n - l.k - 1);
}
el se
{
k = (j + 1) / 2:
s += Combination (m - l.k) * Combination (n - l.k - 1) + Combination (m - l.k - 1) * Combination (n - l.k);
return s / Combination (m + n.m); }
Распределение критерия Q Розенбаума
Значение функции QDistribution определено только при И < пх < 26 и 11 < п2 < 26 для р = 0,95 и р = 0,99. Для других значений параметров действует правило [57, с. 75,151 ] равенства критического значения числу 8 для pQ = 0,95 и числу 10 для pQ = 0,99 при 26 < и, < 50 и/или 26 <п2 < 50, а также при \пх - и2| < 10, 50 < и, < 100 и/или 50 < п2 < 100, а также при \пх - и2| < 20, пх > 100 и/или п2 > 100, а также при 0,5 < и, / п2 < 2.
Исходные коды
int QDistribution (int nl.int n2,double p.int *q)
260
Глава 4. Теория распределений
//
// Функция вычисляет критическое значение критерия Q Розенбаума.
// Обозначения:
// nl. п2 - размерности сравниваемых выборок.
// р - доверительный уровень.
// *q - критическое значение статистики.
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -2 при ошибке в параметрах.
//
{
int а95[16][16] = {6.6.6.7.7.8.7.7.7.7.8.8.8.8.8.8.
6.6.6.7.7.7.7.7.7.7.7.8.8.8.8.8,
6.6.6.6.6.7.7.7.7.7.7.7.7.8.8.8.
7.7.6.6.6.7.7.7.7.7.7.7.7.8.8.8.
7.7.6.6.6,6.7.7.7.7.7.7.7.8.8.8,
8.7.7,7.6.6.7.7.7.7.7.7.7.8.8.8.
7.7.7.7.7.7.7.7.7.7.7.7.7.8.8.8.
7.7.7.7.7.7.7.7.7.7.7.7.7.8.8.8.
7.7.7.7,7.7.7.7.7,7.7.7.7,8,8.8.
7.7.7.7.7.7.7,7.7.7.7.7.7.8.7.8.
8.7,7,7,7.7.7,7.7.7.7,7.7.7.7,7,
8.7.7.7.7.7.7.7.7.7,7.7.7.7.7.7.
8.8.7.7.7.7.7.7.7.7.7.7.7.7.7.7.
8.8.8.8.8.8.8.8.8.8.7.7,7.7.7.7.
8.8.8.8.8.8,8.8.8.7.7.7.7.7.7,7.
8.8.8.8.8.8.8.8.8.8.7.7.7.7.7.7}.
а99[16][16] = { 9. 9, 9, 9. 9. 9.10.10,10.10.11.11.11.12.12.12. 9. 9. 9. 9. 9. 9. 9.10.10.10.10.11,11.11.11.12. 9. 9. 9. 9. 9, 9. 9, 9.10,10,10,10.10,11.11.11.
9, 9. 9. 9, 9, 9. 9. 9, 9.10.10,10,10.10.10.11.
9, 9. 9. 9. 9. 9. 9. 9. 9, 9. 9,10,10,10.10.10,
9. 9, 9. 9. 9, 9, 9. 9. 9. 9. 9. 9,10,10.10.10.
10, 9, 9. 9. 9. 9, 9, 9. 9. 9. 9. 9, 9,10.10,10,
10,10. 9. 9, 9, 9. 9. 9, 9, 9. 9. 9, 9, 9,10,10,
10,10,10, 9, 9, 9, 9, 9, 9. 9, 9, 9. 9, 9, 9.10, 10,10,10.10. 9, 9. 9, 9. 9, 9. 9. 9, 9. 9. 9. 9.
11.10.10.10. 9, 9, 9. 9, 9, 9. 9. 9, 9, 9. 9. 9,
11,11,10,10,10, 9, 9. 9, 9, 9. 9. 9. 9, 9. 9, 9,
11.11,10.10.10,10. 9. 9, 9. 9. 9. 9. 9. 9, 9. 9,
12,11,11.10,10.10.10. 9, 9 ,9, 9. 9. 9, 9, 9. 9,
12,11,11,10,10,10.10.10, 9. 9. 9. 9, 9. 9, 9. 9,
12,12,11.11,10,10,10,10,10, 9 ,9 .9, 9, 9 ,9. 9}:
if (nl < 11 || n2 < 11 || nl > 26 || n2 > 26 || (р != 0.95 && р != 0.99))
return -3;
if (р == 0.95)
*q = a95[nl - 11][п2 - И]; el se
Одномерные распределения
261
*q = a99[nl - 11][п2 - 11]:
return 0:
}
Генерация одномерных распределений
Для тестирования разработанных и запрограммированных алгоритмов важно уметь генерировать случайные выборки с заданным законом распределения. Методика этого процесса подробно описана в [ 140, с. 248] и сводится к генерации псевдослучайной выборки, имеющей равномерное распределение в интервале [0,1], а затем, путем применения требуемой обратной функции распределения, и псевдослучайной выборки с заданным законом распределения.
Псевдослучайные числа, имеющие равномерное распределение, наиболее просто генерируются с помощью стандартной функции rand, входящей в библиотеку, поставляемую с компилятором C/C++ [94, с. 251], [25, с. 595], хотя в многочисленных источниках встречается критика данной функции. Впрочем, ничто не мешает воспользоваться качественными алгоритмами, подробно рассмотренными в [156, с. 72], [184, с. 76].
Путем деления каждого псевдослучайного числа равномерной выборки на константу RAND_MAX получаем выборку с требуемым равномерным распределением.
В примере показана генерация выборки псевдослучайных чисел объема п, распределенной по стандартному нормальному закону. Генерация выборки, распределенной по закону N (д,с^), производится по выборке, распределенной по стандартному нормальному закону N (0,1), с помощью формулы [140, с. 255]
гд. = jU + о xit i = 1,2,..., п,
где д — заданное среднее,
— заданное среднее квадратичное отклонение, квадратный корень из дисперсии,
хь i = 1,2,..., п, — выборка, сгенерированная по закону N (0,1).
Другой алгоритм генерации случайной величины из нормально распределенной совокупности описан в [156, с. 77]. Основные пробле-мы рассмотрены в [104, с. 78], [211].
zoz
Глава 4. Теория распределений
Для контроля того, что получено именно то, что требовалось, мы проверили нормальность распределения с помощью простейших методов, представленных в главе 2.
Пример применения
#include <fstream.h>
#include <iomanip.h>
#include <stdlib.h>
#include <math.h>
#include "megastat.h"
void main (void) { register int i: // Счетчик цикла
int n. // Численность тестового массива
k; // Число классовых интервалов
double y[1000], // Тестовый массив вариант
*f. // Массив частот распределения
*b. // Массив середин классовых интервалов
m = 2.5. и Среднее
s = 1.1. H Среднее квадратичное
e.me: // Рабочие переменные
/////////////////////////////////////////////////// // Число вариант, классовых интервалов и память для // массива частот и середин классовых интервалов n = sizeof (у) / sizeof (у[0]);
k = Sturgess (п);
f = new doublе[к];
b = new double[k];
////////////////////////////////////////////
// Генерация случайной величины, равномерно // распределенной в интервале [0.1] for (i = 0: i < n; i++)
{
y[i] = rand ():
y[i] /= RANDMAX;
}
///////////////////////////////////////////
// Генерация случайной величины, нормально // распределенной с параметрами [0.1] for (i = 0: i < n; i++)
y[i] = InverseNormalDistribution (y[ij):
/////////////////////////////////////////// II Генерация случайной величины, нормально
Многомерные распределения
263
// распределенной с параметрами [m,s*s] for (1=0; 1 < n; i++)
y[i] = m + s * y[1J:
Allocate (y.n.f.b.k);
cout « "Середины классовых интервалов и частоты\п";
for (i = 0; i < k; i++)
cout « setw (10) « b[i] « "\t" « f[i] « endl;
///////////////////////////////////////////
// Контроль нормальности ; упрощенный методой
SampleMean (y.n.&e.&me); cout « "Среднее " « setw (10) << e « " +- " « me
« endl; Variance (у,n.&e.&me); cout « "Дисперсия " « setw (10) « e « " " « me
« endl; Kurtosis (y,n.&e.&me); cout « "Эксцесс " « setw (10) « e « " " « me
« endl;
Skewness (y,nt&e,&me);
cout « "Асимметрия " « setw (10) « e « " +- " « me « endl;
delete [] f; delete [] b;
}
Многомерные распределения
Нами не ставится цель подробно рассмотреть многомерные аналоги всех основных одномерных распределений (кроме нормального), поэтому укажем только их наименования и источники:
• нормальное распределение — многомерное нормальное распределение [63, с. 58];
• В-распределение — распределение Дирихле [там же, с. 57];
• Z2 -распределение — распределение Уишарта [там же, с. 65];
• t-распределение — многомерное t-распределение [там же, с. 67], в случае анализа многомерных совокупностей — ^-распределение Хотеллинга [167, с. 710].
Многомерное
нормальное распределение
В анализе данных находит применение многомерное нормальное (^компонентное гауссово) распределение. В случае ^-мерного
264
Глава 4. Теория распределений
нормального распределения плотность распределения совокупности определяется формулой [186, с. 312]
(2д)"'2|С|1/2е
где С — дисперсионно-ковариационная матрица, тп — вектор математического ожидания.
Дисперсионно-ковариационная матрица в случае многомерного распределения является параметром, аналогичным дисперсии в одномерном случае [206, с. 81]. Иногда многомерное распределение понимается в том смысле, что каждая переменная, составляющая многомерную совокупность, имеет нормальное распределение при фиксированных остальных переменных [97, с. 82], но это определение не совсем точное, так как авторы указанных источников имеют в виду маргинальное (то есть компонентное) распределение одной случайной величины, составляющей многомерное распределение [ 190, с. 176]. Они учитывают дисперсии, но не учитывают ковариации. Подробное обсуждение дано в [158, с. 105], [ У87, с. 76], [190, с. 177], [229, с. 140]. Датчик многомерных нормально распределенных случайных чисел представлен в [ 177, с. 78]. Двумерное нормальное распределение анализируется в [206, с. 97], где даны примеры его применения, и в [190, с. 173].
Генерация многомерных распределений
Рассмотрим генерацию многомерного распределения на примере многомерного нормального распределения. Получение многомерной нормальной выборки Y размера k х п по закону распределения где т — заданный вектор средних, С — заданная ковариационная матрица размера k х k, исходя из распределения Л/(0,1), немного сложнее, чем в одномерном случае. Здесь вычисление производится по формуле [140, с. 256]
У = Ц+LX,
где L — матрица размера k х k, вычисляемая из условия LLT = С. Последнее вычисление может быть легко выполнено, например, с помощью разложения Холецкого [189, с. 20], производимого функцией Choleski.
Теоретические и эмпирические распределения
265
Теоретические и эмпирические распределения
Теоретические вероятности эмпирических распределений необходимо уметь вычислять, например, для проверки соответствия эмпирического распределения какому-либо заданному типу распределения. В качестве примера мы рассмотрим вычисление теоретических вероятностей эмпирического распределения в предположении, что данный эмпирический ряд имеет нормальное распределение [84, с. 73], [70, с. 132].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void)
{
register int i;
double x[] = {60,65,70.75.80.85.90}. // Середины классов
f[7] . е[] = {2.30.34.62.74.8.4}. // Теоретические частоты // Численности // эмпирического ряда
m = 75, s = 6: // Выборочное среднее // Выборочное среднее // квадратичное // отклонение
int n = 7, // Численность // вариационного ряда
nn = VectorSum (e,n); // Объем эмпирического ряда
///////////////////////////////////////////////////
// Эмпирические частоты эмпирического распределения
// (для непрерывного распределения численности делятся
// на объем эмпирического ряда и величину классового интервала) for (i = 0:i < n; i++)
eCi] /= nn *(x[l] - x[0]):
//////////////////////////////////////////////////// // Теоретические частоты эмпирического распределения FrequencyNormal (x.f.n.m.s);
cout « "Середины классов, теоретические, эмпирические" «"частоты\п":
266
Глава 4. Теория распределений
for (i = 0:1 < n; i++)
cout « setw (10) « x[i]
« setw (10) « f[i]
« setw (10) « e[i] « endl:
}
void FrequencyNormal (double *x,double *f.int n,double m,double s) //
// Функция вычисляет теоретические частоты эмпирического
// распределения. Распределение нормальное.
// Обозначения:
// х - массив середин классовых интервалов.
// f - массив теоретических частот.
// п - численность каждой выборки.
// m - выборочное среднее арифметическое значение.
// s - выборочное среднее квадратичное значение.
// Возвращаемое значение:
// нет.
//
{
double t. // Нормированное отклонение
г = 1.0 / sqrt (М_Р1 * 2) / S: // Вспомогательная
// переменная
for (register int i = 0; i < n; i++)
{
t = (x[i] - m) / s:
f[i] = r / exp (t * t / 2);
}
}
В [206; 84] приводится большое количество практических примеров использования теоретических частот эмпирических распределений, в [161] дана сводка типов распределений с подробными формулами, в [ 111, с. 66] даны подробные примеры вычисления теоретических частот эмпирических распределений для различных законов распределения. Мы ограничились рассмотрением нормального распределения, но вычисление частот других типов распределений принципиально, по крайней мере с точки зрения программиста, не отличается от показанного.
Дальнейшие исследования и программные ресурсы
• Систематизация вычислений непрерывных распределений путем применения там, где это возможно, универсальных функций численного интегрирования.
дальнейшие исследования и программные ресурсы 267
• Повышение точности аппроксимационных решений, а также применение нейросетевых методов для аппроксимации одномерных и многомерных распределений.
• Вычисление плотности распределения вероятностей у = р (х) нормального, % , Стьюдента и других распределений Пирсона как аналитического или численного решения дифференциального уравнения [135, с. 457]
du х + а
-Z- —-----------у ,
dx b0 + Ь{х + Ь2х2
где a, b0, bitb2 — действительные числа, в зависимости от значений которых получается то или иное распределение.
Для расчета, помимо представленных в данной главе алгоритмов, можно применять фирменные статистические калькуляторы1, например Probability Calculator (NCSS Statistical Software, www.ncss.com), StatMate (GraphPad Software, Inc., www.graphpad.com), ESBPDF Analysis (ESB Consultancy, www.esbconsult.com.au) или StaTable (Cytel Software Corp., www.cytel.com). Проблема, однако, не решается так просто — перечисленные программы иногда дают различные значения для одних и тех же параметров.
1 Так называются программы, предназначенные для вычисления статистических распределений и заменяющие собой их таблицы.
Глава 5. Корреляционный анализ
В практических наблюдениях часто бывают случаи, когда зависимости не имеют функционального характера — равномерному изменению одного признака соответствует изменение величины другого признака в среднем. Такой вид соотношений называется корреляционной зависимостью, или корреляцией [там же, с. 151], [22, с. 676]. Корреляционным анализом называется совокупность методов обнаружения корреляционной зависимости между случайными величинами или признаками [135, с. 294]. В [91, с. 374] считается, что исследование взаимной зависимости приводит к теории корреляции, тогда как изучение зависимости ведет к теории регрессии. Выделяется также случай функциональной зависимости между величинами, измерения которых, возможно, подвержены ошибкам наблюдений или измерений [там же, с. 373]. При этом под функциональной связью понимается такой род соотношения между двумя признаками, когда любому значению одного признака всегда соответствует определенное одно и то же значение другого [89, с. 150]. Наличие статистической корреляционной зависимости не влечет зависимости причинной [89, с. 153]. Исследование причинной зависимости — не предмет статистики, и именно поэтому статистическое моделирование не является моделированием математическим. Ниже рассмотрены методы исследования корреляции для признаков, когда оба признака измерены в одной и той же шкале — количественной, порядковой, номинальной, — а также когда признаки измерены в различных шкалах (например, один признак — в дихотомической шкале, другой — в количественной).
Корреляция количественных признаков
В данном разделе рассмотрены методы исследования количественных признаков: коэффициент корреляционного отношения Пирсо-1 на, применяемый для измерения тесноты связи при прямолиней
Корреляция количественных признаков
269
ной корреляции [89, с. 154], и коэффициент корреляции Фехнера [111, с. 237]. Коэффициенты ранговой корреляции, которые исследуют корреляцию порядковых признаков (рангов), хотя и полученных из признаков количественных (путем применения операции присвоения рангов), помещены в раздел «Корреляция порядковых признаков» данной главу.
Полученные в результате применения линейных методов корреляционного анализа выводы могут подтвердить или опровергнуть гипотезу о существовании линейной зависимости между рядами, но не связи другого типа [44, с. 179]. Так, отсутствие линейной корреляционной связи не означает отсутствие связи вообще. Например, для рядов с зависимостью одного ряда от другого, близкой к квад-ратичной зависимости, линейная корреляция может быть мала или 5 вообще отсутствовать. Вывод в этом случае такой: чем ближе вычисленная величина корреляционного отношения к 0, тем слабее сила линейной связи между рядами, чем ближе вычисленная величина к значению +1 (полная положительная корреляция) или к значению -1 (полная отрицательная корреляция), тем сильнее сила линейной связи. Для измерения тесноты криволинейной связи применяется корреляционное отношение, нами в данной книге не рассматриваемое, поэтому мы отсылаем читателя к какому-нибудь хорошему источнику, например [89, с. 166].
Коэффициент корреляционного отношения Пирсона
Коэффициент корреляционного отношения Пирсона (коэффициент корреляции, выборочный коэффициент корреляции, коэффициент корреляции Бравайса—Пирсона) измеряет силу линейной корреляционной связи количественных признаков. Коэффициент корреляции вычисляется по известной формуле [140, с. 170]
1=1
1 i=l I i=l
где все обозначения стандартные.
Использование коэффициента корреляции в качестве меры связи оправдано лишь тогда, когда совместное распределение пары при
270
Глава 5. Корреляционный анализ
знаков нормально или приближенно нормально. Частой ошибкой в публикациях является игнорирование этого требования
Метод широко применяется для сравнительной оценки корреляции нескольких рядов между собой. Теоретическое обоснование методики и подробно разобранные примеры ее применения даны в [53, с. 106], [79, с. 19], [84, с. 144,413], [26, с. 192], [229, с. 67]. Вычислен ние коэффициента корреляции может быть выполнено также через ковариацию [ 18, с. 96,443], как и сделано в представленной функции.
Исходные коды
double Pearson (double х[],double y[],int n) //
// Функция вычисляет значение коэффициента корреляции Пирсона.
// Обозначения:
// х - первая сравниваемая выборка.
// у - вторая сравниваемая выборка.
// п - численность каждой выборки.
// Возвращаемое значение:
// значение коэффициента корреляции.
//
{
double s = Cov (x.x.n) * Cov (y.y.n);
if (!s)
return 0,-
el se
return Cov (x.y.n) / sqrt (s):
}
При исследовании многомерной совокупности случайных величин из коэффициентов корреляции, вычисленных попарно между случайными величинами, составляется квадратная симметрическая корреляционная матрица с единицами на главной диагонали [135, с. 296], которая служит основным элементом при построении многих алгоритмов многомерной статистики, например в факторном анализе. I Доверительный интервал выборочной оценки коэффициента корреляции р двумерной нормальной генеральной совокупности вычисляется как [140, с. 171]
ре tanh z(r)-
;tanh z(r) + ^«
J V/Г-з j
где n — объем выборки,
Mi+p)/2 — квантиль нормального распределения,
Корреляция количественных признаков
271
р — стандартное значение доверительного уровня, z(r) — 2-преобразование выборочного коэффициента корреляции г.
Исходные коды и пример применения
^-include <fstream.h>
^include <math.h>
^include "megastat.h"
void main (void)
Snt n = 50;
double г » 0.35, p « 0.95, Low,High;
Confidencelnterval (Arth (r).n.p.&Low.&High);
cout « "Confidence interval is [" « Low « « High «
"]\n";
}
void Confidencelnterval (double z.int n,double p,double
*Low,double *High)
//
// Функция вычисляет доверительный интервал коэффициента
// корреляции.
// Обозначения:
// z - преобразование Фишера,
// п - численность каждой выборки,
// р - доверительный уровень,
// *Low - нижняя граница доверительного интервала.
// *High - верхняя граница доверительного интервала.
// Возвращаемое значение:
// нет.
//
{
double b - InverseNormalDistribution ((1 + р) / 2) / sqrt (п - 3);
*Low = tanh (z - b);
*High » tanh (z + b);
СП
Коэффициент корреляции Фехнера
Кратко опишем коэффициент корреляции Фехнера (фехнеровский Коэффициент корреляции), хотя нам не кажется плодотворной Идея сводить количественную шкалу к номинальной, что фактически
272
Глава 5. Корреляционный анализ
Корреляция количественных признаков 273
происходит при вычислении данного коэффициента. В расчетах, однако, участвуют только количественные признаки (по ним вычисляются средние арифметические), поэтому метод представлен в разделе, посвященном количественным признакам. Вычисления призводятся по формуле [111, с. 237]
С-Н 'F~ С+н’
где С — число совпадений знаков отклонений вариант от соответствующих средних,
Н — число несовпадающих знаков.
Очевидно, вычисления можно упростить, учитывая, что Н = п - С, что и сделано в показанной ниже функции.
Случай применения коэффициента корреляции Фехнера рассмотрен на примере обработки результатов лингвистических исследований [204, с. 344].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void)
{
int n = 12:
double a[] = {3.10.3.17.3.76.3.61.3.27.3.61.
3.80.3.65.3.34.3.65.3.45.4.05}, b[] = {3.65.3.11.3.57.3.61.3.44,3.71.
3.61.3.98.3.36.3.89.3.45.3.79}:
cout « "Fechner value is " « Fechner (a.b.n) « endl: }
double Fechner (double a[], double b[].int n)
//
// Функция вычисляет коэффициент корреляции Фехнера.
// Обозначения:
// а, b - двунерная выборка,
// п - число наблюдений.
// Возвращаемое значение:
// Значение коэффициента корреляции Фехнера.
И
{
register int i; // Счетчики цикла
double ха = VectorSum (a.n) I n, // Среднее первого ряда xb = VectorSum (b.n) / n, // Среднее второго ряда с = 0: // Число совпадений знаков
for (i = 0: i < n; i++)
if (SignNull (a[i] - xa) == SignNull (b[i] - xb)) C++:
return 2.0 * c / n - 1:
}
Ковариация
5
Второй смешанный момент называется ковариацией. Данный показатель мало похож на коэффициент, характеризующий корреляцию, так как он не является безразмерным. Его значение не ограничено сверху числом 1. В данной книге этот показатель приводится для полноты изложения. Ковариация между двумя выборками случайных величин практически вычисляется как показано в [205, с. 78]:
1 ”
Соу(Х,У) =—Х(х, -х)(& -у),
1 i=l
где х„ yt, i =1,2,..., п, — компоненты векторов X и Y, п — численности выборок X и К
Ковариация выборки с самой собой будет называться дисперсией (см. главу 1). Данный факт иногда применяется при вычислении дисперсии.
Исходные коды и пример применения
double Cov (double х[].double уЕ].int n) //
// Функция вычисляет значение ковариации.
// Обозначения:
// х - первая сравниваемая выборка.
// у - вторая сравниваемая выборка,
// п - численность каждой выборки.
// Возвращаемое значение:
// значение ковариации.
И
{
register int i: // Счетчик цикла
double xm, // Среднее значение х
274
Глава 5 Корреляционный анализ
ут, s = 0:
// Среднее значение у
// Вспомогательная переменная
xm » VectorSum (х.п) / п;
ут « VectorSum (у.п) / п;
for (i = 0: i < n: 1++)
s += (x[i] - xm) * (y[i] - ym);
return s / (n - 1);
Если X есть р-мерный вектор, его удобно представить в виде матрицы, состоящей из р столбцов длиной п элементов. Матрицей дисперсий-ковариаций такой многомерной совокупности будет
5 [63, с. 32]
Var(Xt) Cov(XpX2) ... Cov(XpXp)
Cov(X2,Xj) Var(X2) ... Cov(X2,Xp)
Cov^.X,) Cov(Xp,X2) ... Var(X )
Вычисление дисперсионно-ковариационной матрицы по данной формуле легко реализуемо, но не очень эффективно. Поэтому практически дисперсионно-ковариационную матрицу лучше вычислять, используя матричную запись [180, т. 2, с.’208]
где х — вектор средних длиной п.
Пример рассматриваемого подхода показан в главе 2 при составлении функции Hotelling. Ковариация применяется также в корреляционном, факторном, кластерном и других методах анализа данных. Обсуждение см. в [18, с. 96,443].
Корреляция порядковых признаков
В данном разделе рассмотрены методы исследования корреляции признаков, измеренных в порядковой шкале либо приведенных к порядковой шкале.
Корреляция порядковых признаков
275
Показатель ранговой корреляции Спирмэна
Показатель ранговой корреляции Спирмэна (показатель корреляции рангов Спирмэна, коэффициент корреляции рангов [111, с. 238], коэффициент корреляции Спирмэна [120, с. 61], коэффициент ранговой корреляции р, Spearman rank correlation) применяется в случае, если изучается линейная связь между рядами, представленными в количественной или порядковой шкале [187, с. 298]. Практически при анализе количественных признаков применять показатель Спирмэна вместо коэффициента корреляционного отношения Пирсона не следует, так как при его вычислении происходит понижение ко-личественной шкалы до порядковой. Поэтому наиболее широ- 5 кое применение показатель Спирмэна нашел при анализе корреляции порядковых признаков. Расчет ведется по формуле [84, с. 135, 151, с. 400,41]
Ps ~ 1
6(5р+Вх + Ву) п3-п
1=1
где rit s„ i =1,2,..., п, — массивы рангов,
п — число пар вариант исследуемых рядов,
В*, Ву — поправки на объединение рангов в соответствующих рядах, вычисляемые по формуле
здесь т — число групп объединенных рангов в ряду,
i =1,2,..., т, — число рангов в г-й группе.
В [91, с. 638], [135, с. 295], [52, с. 261], [26, с. 224], [151, с. 400] для вычисления показателя Спирмэна, где он назван ранговым коэффициентом корреляции, и в [89, с. 173], где в числе прочих наименований фигурирует ранговый коэффициент, не используются поправки на объединение рангов. Тот же подход принят в [101, с. 570]. Вывод формулы для расчета показателя ранговой корреляции непосредственно из формулы коэффициента корреляционного отношения Пирсона дан в [28, вып.2, с. 133], [70, с. 340].
Исходные коды и пример применения
#lnclude <fstream.h>
276
Глава 5. Корреляционный анализ
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void)
{ int Code.
n = 13:
double x[] = {52.53.63,72.56.34.33.44.53.64,64,54.67}. y[] = {64.66,57,62,61,63.71,70,65,70.72,68.60}, ro:
Code » Spearman (x.y.n.&ro);
if (!Code)
cout « "Ro « " << ro « endl:
else (Code == -1)
cout « "Мало памяти\п":
int Spearman (double x[],double y[],int n.double *criterion) //
// Функция вычисляет значение показателя ранговой корреляции // Спириэна.
// Обозначения:
// х - первая сравниваемая выборка.
// у - вторая сравниваемая выборка,
// п - численность каждой выборки.
// *criterion - вычисленное значение показателя.
// Возвращаемое значение:
// 0 при нормальном окончании счета.
// -1 при недостатке памяти,
// -2 при невозможности рассчитать достоверность.
//
{
register int i; // Счетчик
int *ix,*iy; // Вспомогательные переменные
double *spx,*spy, // Копии исходных массивов
*хх,*уу, // Массивы рангов
bx.by, // Поправки на объединение рангов
s = 0:
if ((spx = new double[n]) == 0)
return -1:
if ((spy = new double[n]) == 0)
{
delete [] spx:
return -1:
}
Корреляция порядковых признаков
if ((xx = new double[n]) == 0)
delete [] spx: delete [] spy: return -1:
}
if ((yy = new doublefn]) == 0) {
delete [] spx: delete [] spy: delete [] xx: return -1:
}
if ((ix = new int[n]) e= 0) {
delete [] spx: delete [] spy; delete [] xx: delete [] yy: return -1;
}
if ((iy = new int[n]) == 0)
delete [] spx: delete [] spy: delete [] xx; delete [] yy: delete [] ix:
return -1: }
/////////////////////////////////////// // Работаем с копиями исходных массивов ArrayToArray (x.spx.n): ArrayToArray (y.spy.n);
//////////////////////////// // Сортировка по возрастанию SortArrayUp (spx.n,ix.1): SortArrayUp (spy,n,iy.1):
bx s Rank (spx.xx.n) / 12: by = Rank (spy.yy.n) / 12;
////////////////////////// // Ранги исходных массивов UnSortArray (xx.spx.n.ix): UnSortArray (yy.spy,n,iy):
delete [] xx: delete [] yy: delete [] ix: delete [] iy;
//////////////////////////////////////////// // Сумма квадратов попарных разностей рангов for (i = 0: i < n; i++)
s +- (spx[i] - spy[i]) * (spx[ij - spy[i]):
delete [] spx: delete [] spy:
Criterion = 1 - 6 * (s + bx + by) / n / (n * n - 1);
return 0; }
278
Глава 5. Корреляционный анализ
Коэффициент ранговой корреляции Кендалла
Коэффициент ранговой корреляции т Кендалла (коэффициент корреляции рангов, ранговый коэффициент корреляции, коэффициент корреляции Кендэла [120, с. 63], Kendall rank correlation) предназначен для вычисления силы корреляционной связи между двумя рядами при тех же условиях, что и рассмотренный выше показатель Спирмэна. Коэффициент Кендалла считается более строгой оценкой по сравнению с показателем ранговой корреляции Спирмэна.
Все основные положения и замечания, данные при описании показателя Спирмэна, справедливы и в отношении коэффициента Кендалла. Расчет ведется по формуле [41], [32, с. 97], [84, с. 138], [151, с. 396]
т = 5г., ST = £ £ sgn(r? - s,) t
к 2 dl 2 ’)
где r„ st, i =1,2,..., n, — массивы рангов анализируемых рядов, п — число пар вариант исследуемых рядов,
B# Ву — поправки на объединение рангов в соответствующих рядах, вычисляемые по формуле [180, т. 2, с. 140]
здесь т — число групп объединенных рангов в ряду, nt, i =1,2,..., ттг, — число рангов в i-й группе.
Поправки на объединение рангов, как можно заметить, вычисляются иначе, чем это сделано для других алгоритмов (например, для вычисления показателя Спирмэна и критерия Вилкоксона—Манна—Уитни), поэтому для вычисления поправок для коэффициента Кендалла применяется особая процедура ранжирования. Как и в предыдущем случае, некоторые авторы [32, с. 97] не используют поправки на объединение рангов. Проблема совпадающих рангов, возникающая в ранговых методах, обсуждается в [70, с. 346].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
Корреляция порядковых признаков
279
#include <math.h>
#include "megastat.h"
void main (void)
{
int Code, n = 13;
double x[] = {1.2,3.5,3.5,5,6,7.8.5.8.5,10,11.12.13}. y[] = {10.12,1.3.5,13,11,5.6,7.8,3.5.9,2}, tau;
Code = Kendall (x.y,n.&tau);
if (’.Code)
cout << "Tau = " << tau << endl;
el se
cout « "Мало паияти\п";
}
int Kendall (double x[],double y[],int n,double *criterion) //
// Функция вычисляет значение коэффициента ранговой корреляции // Кендалла.
// Обозначения:
// х - первая сравниваемая выборка.
// у - вторая сравниваемая выборка.
// п — численность каждой выборки.
// *criterion - вычисленное значение коэффициента,
// *t - его достоверность.
// Возвращаемое значение:
// 0 при нормальном окончании счета,
// -1 при недостатке памяти.
//
{
register int i.j; // Счетчики
int *ix.*iy; // Вспомогательные переменные
double *spx,*spy. // Копии исходных массивов
*xx.*yy. // Массивы рангов
bx.by. // Поправки на объединение рангов
s - 0;
if ((spx - new double[n]) == 0) return -1:
if ((spy = new double[n]) == 0) {
delete [] spx;
return -1;
}
280
Глава 5. Корреляционный анализ
if ((хх - new doublefn]) =e 0) {
delete [] spx; delete [] spy: return -1;
}
if ((yy = new double[n]) == 0) {
delete [] spx: delete [] spy: delete [] xx;
return -1;
}
if ((ix = new intfn]) == 0) {
delete [] spx: delete [] spy: delete [] xx; delete [] yy; return -1;
}
if ((iy e new int[n]) == 0)
{
delete [] spx; delete [] spy: delete [] xx: delete [] yy; delete [] ix:
return -1; }
/////////////////////////////////////// // Работаем с копиями исходных массивов ArrayToArray (x.spx.n);
ArrayToArray (y.spy.n);
/////////////////////////
// Сортировка по убыванию SortArrayDown (spx.n,ix,1): SortArrayDown (spy,n,iy,1):
///////////////// // Массивы рангов bx « Rank (spx.xx,n); by « Rank (spy.yy,n);
////////////////////////// // Ранги исходных массивов UnSortArray (xx,spx,n,ix); UnSortArray (yy.spy.n.iy);
/////////////////////////////////////////////////////// // Совместная сортировка по возрастанию первого массива SortArrayCommon (spx,spy,n);
delete [] ix; delete [] spx; delete [] iy: delete [] yy; delete [] xx;
for (i = 0; i < n - 1; i++) for (j = i + 1; j < n; j++) if (spy[i] < spyEJJ)
Корреляция номинальных признаков
281
S++;
else if (spy[i] > spy[j]) s—:
delete [] spy:
★criterion = s / sqrt ((n * (n - 1) / 2 - bx) * (n * (n - 1) / 2 - by)):
return 0: }
Корреляция номинальных признаков
В данном разделе представлены методы исследования корреляции признаков, измеренных в номинальной шкале либо приведенных к номинальной шкале.
Ниже показан полихорический коэффициент сопряженности Чупрова, предназначенный для исследования корреляции в таблицах сопряженности, которые могут быть построены как из номинальных, так и из порядковых признаков. В последнем случае, однако, происходит понижение порядковой шкалы до номинальной, поэтому для исследований корреляции порядковых признаков лучше применять методы, представленные в разделе «Корреляция порядковых признаков» данной главы. Рассмотрены также показатели подобия (Жаккарда, Сокала и Миченера, Рассела и Рао, Бравайса, Юла), предназначенные для оценки связи между дихотомическими признаками. Данные показатели находят широкое применение в кластерном анализе, где они именуются также мерами сходства типа корреляции.
Из непредставленных нами упомянем коэффициент корреляции (р [174, с. 164] и тетрахорический коэффициент корреляции [там же, с. 170]. В составленных функциях построение таблицы ассоциативности для мер типа корреляции можно было бы для удобства производить до вызова самих функций, как это сделано при вычислении коэффициента сопряженности Чупрова, а функциям оставить только роль вычисления показателей по готовой таблице ассоциативности. Более того, можно легко составить общую функцию, производящую вычисление как таблицы ассоциативности размера 2x2, так и таблицы сопряженности любого размера.
282
Глава 5. Корреляционный анализ
Таблица 2x2 (при ислледовании показателей подобия называемая таблицей ассоциативности) строится по тому же принципу, что и таблица сопряженности для номинальных признаков, рассмотренная в разделе «Точный метод Фишера—Ирвина» из. главы 2 (О указывает на отсутствие переменной, 1 — на наличие). Например, в ячейку а записано число пар элементов массивов 1 и 2, одновременно имеющих признак, равный 1, в ячейку с записано число пар элементов массивов 1 и 2, в которых значение элемента массива 1 равно 1, а значение элемента массива 2 равно 0 и т. д. Впрочем, при вычислении представленных ниже показателей путаница между b и с не ведет к каким-либо непрятностям. Таблица сопряженности типа гхс строится аналогично таблице 2 х 2 с учетом того, что признаки могут варьироваться на большем числе градаций.
Полихорический коэффициент сопряженности Чупрова
Полихорический коэффициент сопряженности Чупрова предназначен для исследования корреляции в таблице сопряженности типа гхс. Вычисления производятся по формуле [84, с. 162]
г_у у Л*| V(r-l)(c-l) ££ т.
i =1,2,..., c,j =1,2,..., г, — элементы таблицы сопряженности, n„ i =1,2,..., с, — суммы строк таблицы сопряженности, туг,, j =1,2,..., г, — суммы столбцов таблицы сопряженности, с — число столбцов таблицы сопряженности, г — число строк таблицы сопряженности.
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
iinclude "megastat.h"
void main (void) {
register int i.j;
int r » 3,
Корреляция номинальных признаков
283
с = 3 Code;
double а[] = {2.12,14.27,74,47,9.25,4}, t;
Code = Chuprov (a,r,c,&t);
cout << "Return code is " « Code << endl;
if (ICode)
cout « "Chuprov value is ” « t « endl;
el se
cout « "Not enough memoryXn";
}
int Chuprov (double a[], int r, int c.double *t) //
// Функция вычисляет полихорический коэффициент сопряженности // Чупрова.
// Обозначения:
// а - таблица сопряженности.
// г - число строк таблицы,
// с - число столбцов таблицы.
// *t - коэффициент сопряженности.
// Возвращаемое значение:
// 0 при нормальном окончании расчета,
// -1 при недостатке памяти для вычислений.
//
{
register int i.j; // Счетчики цикла
int m = 0; // Индекс массива
double е. // Рабочая переменная
*sr. // Суммы столбцов
*sc; // Суммы строк
*t = 0;
if ((sr = new doublefr]) == 0) return -1;
if ((sc = new double[c]) == 0) {
delete [] sr;
return -1;
}
/////////////////////////////
// Вспомогательные вычисления
for (i = 0; i < r; i++)
for (j = 0. sr[i] = 0; j < c; j++)
284
Глава 5. Корреляционный анализ
sr[i] += a[m++]:
for (i = 0: i < с; i++)
for (j « 0, sc[i] - 0. m - 1; j < r: j++, m += c) sc[i] += a[m]:
/////////////////////////////////// // Вычисление значения коэффициента for (1 = 0: i < с: i++)
{
for (j « 0, m = i, e e 0: j < c: j++. m += r) e +e a[m] * a[m] / sr[j]:
*t += e / sc[i ]; }
delete [] sr; delete [] sc;
*t = (*t - 1) / sqrt ((r - 1) * (c - D);
return 0;
}
Коэффициент Жаккара
Показатель подобия Жаккара (коэффициент Жаккара) вычисляется по формуле [148, с 161]
J = а / (а + b + с),
где а,Ь,с — значения в клетках таблицы 2x2.
Коэффициент Жаккара обсуждается также в [154, с. 141].
Исходные коды
double Jaccard (double х[],double yfl.int n) //
// Функция вычисляет показатель подобия Жаккара.
// Обозначения:
// х - первая сравниваемая выборка.
// у - вторая сравниваемая выборка, // п — численность каждой выборки.
// Возвращаемое значение:
// значение метрики.
//
{
register int i; H Счетчик цикла
double s. // Знаменаталь формулы
pll = O.plO = 0. // Клетки а и с таблицы "2x2
pOl = O.pOO = 0; // Клетки b и d таблицы "2x2
Корреляция номинальных признаков
285
//////////////////////////////////////
// Построение таблицы ассоциативности
for (i=0: i < n: i++)
if (x[i] == 1 && y[i] == 1)
pll += 1:
else if (x[i] == 1 && y[i] == 0)
plO += 1:
else if (x[i] == 0 && y[i] == 1)
pOl += 1:
el se
pOO += 1:
////////////////////////////////////////////
// Вычисление и контроль знаменателя формулы
s = pll + plO + pOl:
if (!s) с
return 0;
el se
return pll / s:
}
Простой коэффициент встречаемости
Показатель подобия Сокала и Миченера (простой коэффициент встречаемости) вычисляется по формуле [148, с 161]
J = (а + d) / (а + b + с + d),
где a, b,cyd — значения в клетках таблицы 2x2.
Коэффициент обсуждается также в [154, с. 141].
Исходные коды
double Sokal (double х[].double y[],int n) //
// Функция вычисляет показатель подобия Сокала и Миченера.
// Обозначения:
// х - первая сравниваемая выборка.
// у - вторая сравниваемая выборка.
// п - численность каждой выборки.
// Возвращаемое значение:
// значение метрики.
//
{
register int i; // Счетчик цикла
double s,
pll = O.plO = 0,
pOl = O.pOO = 0:
for (i - 0: i < n: i++)
286
Глава 5. Корреляционный анализ
if (x[i] == 1 && уЕ1] == 1) pll += 1;
else if (x[i] == 1 && y[i] == 0)
plO += 1;
else if (x[ij == 0 && y[i] == 1)
pOl += 1:
el se
pOO += 1;
s = pll + plO + pOl + pOO:
if (s == 0)
return 0;
el se
return (pll + pOO) / s:
5 >
Показатель подобия Рассела и Рао
Показатель подобия Рассела и Рао вычисляется по формуле [154, с. 141]
J = a/(a+b + c + d),
где a, b,c,d - значения в клетках таблицы 2x2.
Исходные коды
double Rao (double х[].double уЕ].int n) //
// Функция вычисляет показатель подобия Рассела и Рао. // Обозначения:
// х - первая сравниваемая выборка.
// у - вторая сравниваемая выборка.
// п - численность каждой выборки.
// Возвращаемое значение:
// значение метрики.
//
{
register int i; // Счетчик цикла
double s,
pll = O.plO » 0.
pOl = O.pOO = 0:
for (i = 0; i < n:
if (x[i] == 1 &&
pll += 1:
else if (x[i] == plO += 1;
i++)
y[i] == 1)
1 && y[i] == 0)
Корреляция номинальных признаков
287
else if (x[i] == 0 && y[i] -= 1)
pOl += 1:
el se
pOO += 1;
s - pll + plO + pOl + pOO;
if (s == 0) return 0;
el se
return pll / s;
}
Коэффициент сопряженности Бравайса
Специальная форма коэффициента корреляции — коэффициент со- 5 пряженности Бравайса ((^коэффициент Пирсона [191, с. 275]) — рассчитывается по формуле [26, с. 215]
_________ad-he__________ у](а + b)(a + c)(d + Z>)(J + с) ’
где a, b,c,d — значения в клетках таблицы 2x2.
Обсуждение дано также в [89, с. 174]. В [154, с. 143] рассматриваемый коэффициент назван показателем подобия Чупрова — у каждой нации есть свои изобретатели автомобиля, радио и самолета.
Исходные коды
double Bravais (double х[],double y[].int n) //
// Функция вычисляет коэффициент сопряженности Бравайса.
// Обозначения:
// х - первая сравниваемая выборка,
// у - вторая сравниваемая выборка,
// п - численность каждой выборки.
// Возвращаемое значение:
// значение метрики.
//
{
register int i: // Счетчик цикла
double s,
pll = O.plO = 0,
pOl = O.pOO = 0;
for (i = 0: i < n; i++)
if (x[i] « 1 && y[i] == 1)
288
Глава 5 Корреляционный анализ
pll += 1:
else if (x[i] == 1 && y[i] == 0)
plO += 1;
else if (x[i] == 0 && y[i] == 1)
pOl += 1;
el se
pOO += 1;
s = (pll + plO) * (pll + pOl) * (plO + pOO) * (pOl + pOO);
if (s == 0)
return 0;
el se
return (pll * pOO - plO * pOl) / sqrt (s); }
Коэффициент ассоциации Юла
Ориентировочную оценку корреляционной связи в случае исследования таблиц сопряженности 2x2 может дать коэффициент ассоциации Юла. Вычисления производятся по формуле [91, с. 723]
ad-bc ad + bc
где обозначения те же, что и ранее.
Обсуждение см. в [26, с. 218], [154, с. 143].
Исходные коды
double Yule (double х[].double y[],int n) //
// Функция вычисляет коэффициент ассоциации Юла.
// Обозначения:
// х - первая сравниваемая выборка,
// у - вторая сравниваемая выборка,
// п - численность каждой выборки.
// Возвращаемое значение:
// значение метрики.
//
{
register int i: // Счетчик цикла
double s.
pll = O.plO = 0.
pOl = O.pOO = 0;
for (i = 0; i < n;
if (x[i] == 1 &&
i++)
y[i] 1)
Корреляция номинальных признаков
289
pH += 1:
else if (x[i] == 1 && y[i] == 0)
plO += 1:
else if (x[i] == 0 && y[i] == 1)
pOl += 1;
el se
pOO += 1;
s = pll * pOO + plO * pOl:
if (s == 0)
return 0;
el se
return (pll * pOO - plO * pOl) / s;
}
Юл предложил коэффициент коллигации [91, с. 723], не имеющий 5 преимуществ перед показанным выше коэффициентом ассоциации:
ad - \lbc ^ad + yfbc
Хеммингово расстояние
Хеммингово расстояние (метрика Хемминга) менее других показателей похоже на коэффициент, характеризующий корреляцию, так как оно не является безразмерным, подобно ковариации. Его значение не ограничено сверху числом 1. Этот показатель приводится в данной книге для полноты изложения. Алгоритм вычисления хеммингова расстояния может быть представлен простой формулой [81, с. 67]:
Н = а + d,
где a,d — значения в клетках таблицы 2x2.
Локальная взвешенная метрика Хемминга (Хэмминга) представлена в [78, с. 194].
Исходные коды
double Hemming (double х[],double у[].int n) //
// Функция вычисляет хеммингово расстояние.
// Обозначения:
// х - первая сравниваемая выборка,
// у - вторая сравниваемая выборка,
10- 2002
290
Глава 5. Корреляционный анализ
// п - численность каждой выборки.
// Возвращаемое значение:
// значение метрики.
//
{
double s = 0: // Возвращаемое значение
for (register int i = 0; i < n; i++)
s += x[i] == y[i] ? 1 : 0;
return s;
}
Корреляция признаков, измеренных в различных шкалах
Настоящий раздел посвящен корреляции признаков, измеренных в различных шкалах. Рассмотрен коэффициент Гауэра, а также бисериальная корреляция, позволяющая исследовать корреляцию в некоторых частных случаях. Проблема исследования корреляции в таблицах данных, полученных измерением параметров, относящихся к различным шкалам, довольно часто возникает в практике, особенно в медико-биологических исследованиях.
Коэффициент Гауэра
Коэффициент Гауэра допускает одновременное использование признаков, измеренных в шкалах: количественной, порядковой и дихотомической. Вычисление элемента матрицы сходства, построенной на основе коэффициента Гауэра, производится по формуле [148, с. 163]:
s. =-Ad_, i = 1,2,..., nJ =1,2,..., п,
ix ы
где Sijk, i = 1, 2,..., nJ = 1, 2,..., n, k = 1, 2, ...,p, — вклад признака в сходство объектов,
Wyk, i = 1,2,..., n,j = 1,2,..., n, k = 1,2, ...,p, — весовая переменная признака, p — число признаков, характеризующих объект, п — число объектов.
Корреляция признаков, измеренных в различных шкалах
291
При этом:
• для дихотомических признаков алгоритм подсчета вклада признака и взятия весовых переменных совпадает с коэффициентом Жаккара;
• для порядковых признаков алгоритм вычисления вклада признака совпадает с хемминговым расстоянием, если последнее мысленно обобщить на порядковые переменные, а весовые переменные берутся равными 1 для каждого участвующего в расчете порядкового признака;
• для количественных признаков
$tjk 1
где xik и xjk — значения k-й переменной для объектов i nj, Rk — размах k-ro признака, вычисленный по всем объектам, а весовые переменные берутся аналогично случаю порядковых признаков.
Пример использования коэффициента Гауэра для анализа медицинских данных рассмотрен в [13].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void)
{ register int i.j;
int n = 4.
k = 10.
inf[] = {2.2.2.2.2.2.2.2.0.1},
m = 0, Code:
// Счетчики цикла
// Число объектов
// Число параметров
// Информация о типах
// параметров
// Счетчик элементов матрицы
// Код ошибки
double х[] = {1.0.0.1.0.0,0.0. 69.1, // Массив данных
1.1.0.1.0.0.0.0.167.2.
1,1.0.1,1.0.1.1.179.3.
1.0.0.0.1.1.1.1.158,3}, а[16]; // Матрица сходства
10*
292
Глава 5 Корреляционный анализ
Code = Gower (х,п.к,inf.а):
if (ICode)
{
cout « "Likeness matrixXn":
for (i = 0; i < n; i++) {
for (j = 0: j < n; j++, m++) cout « setw (12) « a[m];
cout << endl;
}
}
else if (Code == -1)
cout << "Not enough memoryXn":
el se
cout « "Cannot build Gower likeness matrixXn";
}
int Gower (double x[].int n.int k.int inf[],double a[]) //
// Функция вычисляет матрицу сходства с применением коэффициента // Гауэра.
// Обозначения:
// х - массив исходных данных (к векторов по п элементов // друг за другом), // п - число объектов.
// к - число признаков,
// inf - массив с информацией о шкале измерения каждого
// признака:
// =0 для количественной.
// =1 для порядковой,
// = 2 для дихотомической.
// а - вычисленная матрица сходства размером п х п.
// Возвращаемое значение:
// 0 при нормальном окончании расчета,
// -1 при недостатке памяти для вычислений,
// -2 при ошибке в вычислениях.
//
{
register int i. j. 1; // Счетчик цикла
int mr = 0,my, // Счетчики первого сравниваемого массива
mz. // Счетчик второго сравниваемого массива
ma = O.mt; // Счетчики верхнегоинижнего треугольников
double *r. // Вектор размахов
S,w; // Рабочие переменные, затем числитель
// и знаменатель
// элемента матрицы сходства
if (!(г = new double[k])) return -1;
Корреляция признаков, измеренных в различных шкалах
293
////////////////////////////////
// Формирование вектора размахов for (1=0: 1 < k; 1++)
{
for (j = О, ma = 1, w = x[i], s = x[ij; j < n; j++, ma += k) { if (x[ma] > w)
w = x[ma]:
if (x[ma] < s) s = x[ma]:
}
r[i] = w - s;
if (!inf[i] && !r[i])
5
delete [] г; ^КЯ
return -2;
}
}
////////////////////////////////
// Формирование матрицы сходства
for (j = 0; j < n - 1; j++, mr += k)
{
ma = j * n + j + 1:
mt = j * n + j + n:
mz = j * к + k:
for (1 = j + 1, s = 0. w = 0: 1 < n: 1++, mt+=n)
{
for (i =0. my = mr; i < к; 1++, mz++, my++)
///////////////////////////////
// Для количественных признаков if (!inf[ij)
{
s += 1.0 - fabs (x[mz] - x[my]) / r[i]; w++;
}
///////////////////////////
// Для порядковых признаков
else if (inf[i] == 1) {
if (x[mz] == xfmyj) { s++: w++:
} }
294
Глава 5. Корреляционный анализ
/ / / / / / / / / / / / / / / / / / / / / / / / / / / / / / /
// Для дихотомических признаков el se
{
if (x[mz] =з 1 && x[my] == 1)
{
s++: w++: }
else if C(x[mz] == 1 && x[my] == 0) || (x[mz] == 0 && x[my] == D)
w++:
}
if C!w)
{
delete [] r;
return -2;
}
a[ma] = s / w;
a[mt] = a[ma++J:
}
}
/////////////////////////////
// Диагональ матрицы сходства
for (i = 0; i < n: i++)
a[i * (n + 1)] = 1:
delete [] r:
return 0:
}
Бисериальная корреляция в случае порядковых признаков
Бисериальный коэффициент предназначен для исследования корреляции в таблицах типа 2 х qy являющихся дихотомиями по некоторому качественному (номинальному) признаку и классификациями по номинальному [84, с. 166] либо порядковому [91, с. 411] признаку, который классифицируется по q классам и может быть упорядоченным либо неупорядоченным. В источниках указано на существенность предположения о двумерной нормальности исходного распределения, без указания, однако, на то, как это предположение может быть проверено. Бисериальная корреляция обсужда-| ется в [111, с. 249].
Корреляция признаков, измеренных в различных шкалах
295
Бисериальный коэффициент корреляции
формулы для расчета бисериального коэффициента корреляции г в случае классификации по порядковому признаку даны в [84, с. 166]. По [91, с. 414],
х.-хп. 1 Г =_!---1_,
\ п h
где — среднее по строке 1,
- — общее среднее по всей таблице,
sx — выборочное среднее квадратичное отклонение,
— численность строки 1, 5
п — общая численность всех выборок, zk — ордината плотности нормального распределения в точке k, где k суть решение уравнения
i-ед
Ошибка бисериального коэффициента корреляции определяется по формуле [84, с. 167]
Обсуждение и порядок вычислений см. также в [174, с. 163].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
include "megastat.h"
void main (void) {
register int i.j;
int c e 6;
double x[] = {16.17.18.20.25.33}, a[] = {583.666.525.383.214.40.563.980,868.814.439.81}.
r;
if (‘Biserial (x.a.c.&r))
296
Глава 5. Корреляционный анализ
cout « "Biserial value is ” « г « endl: el se
cout « "Not enough memoryXn";
}
int Biserial (double x[J.double a[], int c,double *t) //
// Функция вычисляет бисериальную корреляцию для порядковых // признаков.
// Обозначения:
// х - середины классовых интервалов.
// а - таблица сопряженности,
// с - число столбцов таблицы,
// *t - бисериальная корреляция.
// Возвращаемое значение:
// 0 при нормальной окончании расчета,
// -1 при недостатке памяти для вычислений. //
{
register int i: // Счетчик цикла
double *е, // Рабочий массив
nl = VectorSum (а,с). // Численность 1-й строки
п = VectorSum (а,с * 2), // Общая численность xl, // Среднее 1-й строки
хх = 0. // Вспомогательная величина
sx = 0: // Общая дисперсия
if ((е = new double[c]) == 0) return -1:
/////////////////////////////
// Вспомогательные вычисления
for (i = 0: i < с: i++)
e[i] = x[i] * a[i]:
xl = VectorSum (e.c) / nl:
for (i = 0: i < c: i++)
{
e[i] += x[i] * a[c + i]:
sx += (a[c + i] + a[i]) * x[i] * x[i];
xx += (a[c + i] + a[i]) * x[i]:
}
sx = sqrt ((sx - xx * xx / n) / (n - D):
*t = fabs (InverseNormalDistribution (nl / n))
*t = 0.39894 / exp (*t * *t / 2):
///////////////////////////////
// Вычисление оценки корреляции
*t = (xl - VectorSum (e.c) / n) / sx * nl / n / *t:
Корреляция признаков, измеренных в различных шкалах 297
delete [] е:
return 0;
}
Бисериальный коэффициент по таблице Келли—Вуда
В [84, с. 168] рассматривается бисериальный коэффициент корреляции по таблице Келли—Вуда, обозначаемый так же, как и предыдущий из рассмотренных коэффициентов, и вычисляемый по формуле
I*!-*;!/*?
где р = njn — доля частот в строке, определяемой из условия р > q, q —р — доля частот в другой строке,
С — ордината в точке границы классов частот первой и второй строк, определяемая по таблице Келли—Вуда, остальные обозначения те же, что и раньше.
Как оказалось, таблица Келли—Вуда [84, с. 397] вполне удовлетворительно для практических расчетов аппроксимируется полиномами 6-го порядка. Мы даем вычисленные коэффициенты аппроксимации в теле функции, а для проверки эта аппроксимация может быть выполнена с помощью электронных таблиц Microsoft Excel.
При п < 100 коэффициент должен быть скорректирован по формуле [84, с. 169]
rk=rt 1+11о,25+^-Г1-^
1+^+0,25г2
где х — абсцисса в точке границы классов частот первой и второй строк в долях среднего квадратичного отклонения, определяемая по таблице Келли—Вуда, остальные обозначения те же.
Ошибка бисериального коэффициента корреляции находится по формуле [84, с. 170]
298
Глава 5. Корреляционный анализ
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void)
{
register int i.j;
int c = 7. Code;
k double x[] = {3.4.5.6.7.8.9}.
a[] = {0.0.0.2,5.2.0.1.4.7.21.16.3.1}.
r;
Code = KellyWood (x.a.c.&r);
if (!Code)
cout « "Biserial value is " « r << endl; el se
cout « "Not enough memoryXn";
}
int KellyWood (double x[],double a[], int c.double *t) //
// Функция вычисляет бисериальную корреляцию
// по таблице Келли-Вуда.
// Обозначения:
// х - середины классовых интервалов,
// а - таблица сопряженности,
// с - число столбцов таблицы.
// *t - бисериальная корреляция.
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -1 при недостатке памяти для вычислений. //
{
register int i; // Счетчик цикла
double ах[] = {328.4743129110. // Коэффициенты аппроксимации
-2900.5961519408,10552.8860824811, -20273.7171729728.21714.7515916749.
-12298.6906330287.2879.4131874144}.
ау[} = {-6.5578492838.60.1135820561.
-216.6989288679.417.1468658186.
-450.8952582758.258.2764594071.-61.3800505623}.
*е. // Рабочий массив
nl = VectorSum (а,с), // Численность 1-й строки
Корреляция признаков, измеренных в различных шкалах 299
п = VectorSum (а.с * 2),// Общая численность
xl. // Среднее 1-й строки
х2. // Среднее 2-й строки
хх = 0, // Вспомогательная переменная
sx = 0, // Общая дисперсия
р, // Доля 1-й строки
q, // Доля 2-й строки
z.xz; // ПараметрыпотаблицеКелли-Вуда
if ((е = new doublefc]) == 0) return -1:
///////////////////////////// // Вспомогательные вычисления for (i = 0: i < с: i++) e[i] = x[i] * a[i];
xl = VectorSum (e.c) / nl;
for (i =0; 1 < c: i++)
{
e[i] = x[i] * a[c + i]:
sx += (a[c + i] + a[i]) * x[i] * x[i];
xx += (a[c + i] + a[i]) * x[i]:
}
x2 = VectorSum (e.c) / (n - nl);
sx - sqrt ((sx - xx * xx / n) / (n - 1));
delete [] e;
p = nl / n; if (p < 0.5) { q = p: p = i - q;
}
el se
q = 1 - p;
xz - Horner (ax,6,p);
z - Horner (ay.6,p);
/////////////////////////////// // Вычисление оценки корреляции *t = fabs (xl - x2) * p * q / z / sx;
//////////////////////////////////////
11 Коэффициент с поправкой для малых n if (n <= 100)
*t *= (1 + (0.25 +p*q/2/z/z-(l-p*xz/z)* (1 + q * xz / z) + *t * *t / 4) / n);
return 0;
}
300
Глава 5 Корреляционный анализ
Бисериальная корреляция в случае номинальных признаков
Вычисление выборочной оценки бисериального коэффициента корреляции в случае классификации по номинальному признаку производится по формуле [91, с. 412]
где п — общая численность таблицы,
и, — численность таблицы в сечении г, г =1,2,..., q,
m J st — оценка в сечении г, i =1,2,..., q, получаемая по таблице нормального интеграла от относительной частоты первого из двух качественных признаков,
ту / sy — оценка, получаемая по таблице нормального интеграла от относительной частоты первого качественного признака по всей таблице.
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void)
{
register int i.j;
int c = 6, Code;
double a[] = {50.88.155.379.18.63,43.62.110.300.14.144}.
r;
Code = Biserial (a.c.&r);
cout « "Return code is " « Code « endl;
if (iCode)
Корреляция признаков, измеренных в различных шкалах
301
cout « "Biserial value is " « г « endl: e! se
\cout « "Not enough memory\n";
} |
int’ Biserial (double a[], int c,double *t)
// I
// Функция вычисляет бисериальную корреляцию для // номинальных признаков.
// Обозначения:
// а - таблица сопряженности,
// с - число столбцов таблицы,
// *t - бисериальная корреляция.
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -1 при недостатке памяти для вычислений.
//
{
register int i; // Счетчик цикла
double е, // Рабочая переменная
*х. // Относительные частоты
*п. // Суммы столбцов
s = VectorSum (а,с * 2): // Общая сумма таблицы
if ((х = new double[c]) == 0) return -1;
if ((n = new double[c]) == 0)
{
delete [] x:
return -1:
}
/////////////////
// Суммы столбцов
for (i = 0: i < c: i++) n[i] = a[i] + a[c + ij;
//////////////////////// // Относительные частоты for (i = 0; i < c; i++) x[i] = a[i] / n[i]:
////////////////////////////////////////////////
// Оценки отношений средних к среднеквадратичным for (i = 0; i < с; i++)
x[i] « InverseNormalDistribution (x[ij):
e = InverseNormalDistribution (VectorSum (a,c) / s);
///////////////////////////// // Вспомогательные вычисления for (i « 0, *t = 0: i < c: i++)
302
Глава 5. Корреляционный анал!
*t += n[i] * x[i] * x[i]:
*t /= s:
///////////////////////////////// // Оценка коэффициента корреляции *t = sqrt ((*t - e * e) / (*t + 1)):
delete [] x; delete [] n:
return 0; }
Точечно-бисериальная корреляция
В случае, если одна переменная дихотомизирована, а другая измерена в количественной шкале, вычисляется точечно-бисериальный коэффициент корреляции (точечный двухсерийный коэффициент корреляции) [174, с. 168] по формуле
где х ~ среднее вариант количественной выборки, соответствующих событиям верхнего уровня (уровня 1) дихотомической выборки, х — среднее количественной выборки,
sx — среднее квадратичное количественной выборки,
пр — число событий в верхней группе (с уровнем 1),
nq — число событий в нижней группе (с уровнем 0).
В составленной нами функции предполагается, что дихотомическая переменная может принимать только значения 1 (верхний уровень) и 0 (нижний уровень).
Точечно-бисериальная корреляция является специальным случаем корреляционного отношения Пирсона [там же] и подробно обсуждается в [91, с. 416].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#inclide "megastat.h"
void main (void)
корреляция признаков, измеренных в различных шкалах
303
{
egister int i.j; // Счетчики
ht п = 7, // Число пар
] Code; // Код ошибки
фиЫе a[] = {0.0,1.1,0,1,1}. // Дихотомическая выборка
x[] = {1,2,4.5.1.4,6}. // Количественная выборка
r; // Коэффициент корреляции
Code = Point (a.x.n.&r);
if (’Code)
cout « “Point biserial value is H « r « endl;
else
cout « "Error\n";
}
int Point (double a[],double x[],int n,double *t) //
// Функция вычисляет точечно-бисериальную корреляцию.
// Обозначения:
// а - дихотомический массив,
// х - непрерывный массив,
// п - численность каждой выборки.
// *t - точечно-бисериальная корреляция.
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -2 при ошибке в вычислениях.
//
{ register int i, // Счетчик цикла
пр = 0; // Число событий в верхней группе
double s = 0; // Рабочая переменная
5
///////////////////////////////////////////////// // Получение дополнительной информации о массивах for (i = 0; i < n; i++)
if (a[ij)
{
np++;
s += x[i];
}
///////////////////////////////////////////////// // Если равно нулю число событий нижней группы if (пр == п)
return -2;
/////////////////////////////////////////// // Значение точечно-бисериальной корреляции
304
Глава 5. Корреляционный анали;
*t = (s / пр - VectorSum (x.n) / п) / sqrt (Cov (х.х.п) / пр (п - пр));
return 0:
}
Множественные корреляции
Предположим, что некоторая величина зависит не от одного, как рассмотрено выше, а от ряда внешних факторов. В этом случае говорят о множественной корреляции [231, с. 351].
Методы данного раздела применимы для признаков, измеренных в количественной шкале (коэффициент множественной корреляции и канонический корреляционный анализ), и для ранжированных количественных или порядковых признаков (коэффициент конкордации).
Коэффициент множественной корреляции
Оценка тесноты связи между переменными в случае множественной регрессии вводится коэффициентом множественной корреляции R, квадрат которого определяется формулой [22, с. 691]
где Yi — значения переменной, взятые из корреляционной таблицы, yi — то же, вычисленное по регрессионной формуле, остальные обозначения стандартные.
Отметим, что величина достоверности аппроксимации Я2, выводимая программой Microsoft Graph, не то же самое, что коэффициент множественной корреляции, и вычисляется по другой формуле, данной в справочной системе упомянутой программы.
Мы не приводим функции вычисления коэффициента множественной корреляции в силу достаточной элементарности алгоритма.
В [135, с. 296] вводится множественный коэффициент корреляции, отличающийся от описанного здесь коэффициента множественной корреляции. Множественный коэффициент корреляции служит
Множественные корреляции 305
мерой линейной корреляции между Хх и совокупностью остальных величин Х2,..., Хп и вычисляется как обычный коэффициент корре-л^хии между Xi и множественной регрессией по Х2,...,Хп.
Частный случай вычисления коэффициента множественной корреляции рассмотрен в [89, с. 169], множественная детерминация (квадрат коэффициента множественной корреляции) изучена в [140, с. 137]. Обсуждение см. в [120, с. 38], [139, с. 35].
Канонический корреляционный анализ
Представление математических объектов называется каноническим, если две различные записи соответствуют двум различным объектам. Иначе говоря, если каждому объекту одного множества соответствует один и только один элемент другого множества, и данное соответствие взаимно однозначно, представление называется каноническим. О представлении объектов в математике см. [74, с. 85]. Канонический корреляционный анализ выполняется между двумя совокупностями (группами) выборок и предназначен для определения линейной функции от первых р компонент и линейной функции от остальных q компонент так, чтобы коэффициент корреляции между этими линейными функциями принял наибольшее возможное значение [190, с. 585]. Численности групп (количество выборок в первой и второй группах, р и q) могут различаться, однако необходимым требованием является равное количество вариант во всех выборках, составляющих обе группы. Матрица взаимной корреляции R двух групп выборок имеет вид
где — матрица взаимной корреляции р переменных 1-й группы, размер р х р,
R22 — матрица взаимной корреляции q переменных 2-й группы, размер q х q,
R[2— матрица взаимной корреляции переменных 1-й и 2-й групп, размер р х q.
Решение сводится к обобщенной проблеме собственных значений
где Л — вектор q собственных значений.
306
Глава 5. Корреляционный анал^
Так называемые канонические корреляции представляют собой квадратные корни из собственных значений. Представленной далее функцией выводятся: значения критерия X (массив длиной И) и соответствующие степени свободы (массив длиной q), а также коэффициенты правой (массив размером q х q) и левой (массив размером q^p) сторон.
Методику канонического корреляционного анализа см. в [174, с. 69], [139, с. 194], [108, с. 214]. Практический пример дан в [78, с. 179].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
5 #include <math.h>
#include "megastat.h"
void main (void)
{
register int i.j: // Счетчики
int Code. // Код ошибки
ml = O.m2 = 0. // Счетчики элементов массивов
p = 4, // Число рядов первой группы
q = 3, // Число рядов второй группы
п = 23: // Число вариант
double datl[] = // Первая группа выборок
{191.195.181.183.176.208.189.197.188.192.179.183,174.190.188.
163,195.196.181.175.192.174.176,
155,149,148,153,144.157.150,159,152,150,158,147,150,159.151,
137,155,153,145.140.154.143.139.
65. 70, 71, 82. 67, 81, 75, 90, 76, 78. 99. 65, 71, 91. 98.
59. 85. 80. 77. 70. 69, 79, 70,
19. 20, 19, 18, 18, 22, 21. 20. 19. 20. 18. 18, 19. 19. 20.
18. 20, 21. 20. 19, 20, 20. 20}.
dat2[] = // Вторая группа выборок
{179.201.185.188.171.192.190.189,197.187.186.174.185.195.187.
161.183,173.182.165.185.178.176.
145.152,149,149.142.152.149,152,159.151.148.147.152.157.158,
130,158.148.146.137,152.147.143,
70. 69, 75, 86, 71. 77. 72. 82, 84. 72. 89. 70, 65, 99. 87.
63. 81. 74. 70. 81. 63. 73. 69}.
* z, // Канонические корреляции
* s, // Коэффициенты правой стороны
* г, // Коэффициенты левой стороны
* х. // Значения критерия хи-квадрат
Множественные корреляции
307
*t; // Степени свободы
Z = new double[q];
S = new double[q * q]
г = new double[q * p]
X = new double[q];
t = new doubleEq]:
if (!(Code = CanonicalCorrelationAnalysis (datl,dat2.p.q.n,z.s.r.x.t)))
for (i - 0; i < q: i++) {
cout « "r = " « z[i] « " chi square = " « x[i] « " nu - " « t[i]
« - p = - « chiSquareDistribution (t[i].x[i])
« "ХпКоэффициенты левой стороныХп";
for (j = 0; j < p; j++,ml++)
cout << r[ml] « " ";
cout « "ХпКоэффициенты правой стороныХп";
for (j - 0; j < q: J++,m2++)
cout « s[m2] « " cout « endl;
}
else if (Code == -1)
cout << "Мало памятиХп":
el se
cout « "Потеря значимости при вычисленииХп";
delete [] z; delete [] s; delete [] r; delete [] x; delete [] t; }
int CanonicalCorrelationAnalysis (double yl[],double y2[],int p.int q.int n,double 1[],double t[],double rE],double xi[],double u[]) //
// Функция выполняет канонический корреляционный анализ между
// двумя группами выборок.
// Обозначения:
// yl - массив - первая группа - размером п х р.
// у2 - массив - вторая группа - размером п х q,
// р - число рядов в первой группе.
// q - число рядов во второй группе.
// п - число вариант в ряду группы,
// 1 - вектор вычисляемых канонических корреляций длиной q.
// t - массив вычисляемых коэффициентов правой стороны длиной
// q х q.
// г - массив вычисляемых коэффициентов левой стороны длиной
// q х р.
// xi - массив значений критерия хи-квадрат длиной q,
// и - массив степеней свободы для критерия хи-квадрат длиной q.
// Возвращаемое значение:
308
Глава 5. Корреляционный анализ
// 0 при нормальном окончании расчета,
// -1 при недостатке памяти для рабочих массивов,
// -2 при ошибке в вычислениях.
//
{
register int i.j.il; // Счетчик цикла
int ml,m2.m3; // Вспомогательные переменные
double *a,*rll, // Вспомогательный массив
save; // Вспомогательная переменная
if ((rll = new double[n]) == 0) return -1;
if ((a = new doublefn]) == 0) {
delete [] rll;
return -1;
}
/////////////////////////////////////////////
// Матрица взаимных корреляций между группами
for (i = 0. ml = 0; i < p; i++)
{
for (il =0; il < n; il++) rll[il] = yl[ml++j;
for (j = 0, m2=0, m3 = i; j < q: j++. m3 += p) {
for (il = 0; il < n; il++) a[il] = y2[m2++J;
r[m3] e Pearson (rll.a.n);
}
}
delete [] rll; delete [] a;
//////////////////////////////////////////////
// Матрица взаимных корреляций в первой группе
if ((rll = new double[Maximum0f (p.q) * MaximumOf (p.q)]) == 0) return -1;
if (LikenessForCorrelation (yl.rll.n.p.0) ! = 0) {
delete [] rll;
return -1;
}
if (! (a = new double[Maximum0f (p.q) * MaximumOf (p.q)])) {
delete [] rll;
return -1;
}
Множественные корреляции
309
if ((m2 = InverseMatrlx (rll.a.p)) != 0) {
delete [] rll; delete [] a;
return m2;
}
/////////////////////////////////////////////// // Матрица взаимных корреляций во второй группе if (LikenessForCorrelation (y2.t.n,q.O) != 0)
{
delete [] rll; delete [] a;
return -1;
}
MatrixMultiplyMatrix (a.r.rll.p.p.q);
MatrixTMultiplyMatrix (r.rll,a.q.p.q):
if ((m2 = Eigen (a,t.q.O.000001,&ml)) 1= 0) {
delete [] rll; delete [] a;
return m2;
}
///////////////////////////////////////////////// // Упорядочивание собственных значений и векторов for (i = 0; i < q; i++)
{
1Ei] - a[i * (q + 1)];
if (l[i] <= 0 && l[i] >= 1)
return -2;
el se
1[i] = sqrt (l[i]): }
delete [] a;
for (i = 0; i < q; i++)
{
m2 = i;
save = 1[i];
for (j = i + 1; j < q; j++)
if (save < 1EjJ)
{
m2 = j;
save = 1[j];
}
Col Interchange (l.l.i,m2):
Col Interchange (t,q,i,m2); }
310
Глава 5. Корреляционный анализ
for (1=0: i < q: i++)
{
for (j » 1, save = 1: j < q: j++)
save *= (1.0 - 1[j]):
xi[i] - -(n - (p + q + 1) / 2) * log (save):
u[i] = (p - 1) * (q - 1):
}
/////////////////////////////////////////
// Вычисление коэффициентов левой стороны MatrixMultiplyMatrix (rll.t.r.p.q.q);
for (i = 0: i < p: i++)
for (j = 0, ml = i: j < q; j++, ml += p) r[ml] /= l[j]:
delete [] rll:
return 0;
}
Коэффициент конкордации
Коэффициент конкордации предназначен для исследования, хорошо ли согласуются друг с другом k ранжировок выборки из п членов. Такая задача, например, возникает при решении вопроса о том, насколько хорошо согласуются друг с другом ранжировки массива данных размера пу проведенные k экспертами. Вычисления производятся по формуле [70, с. 342]
где xtJ, i = 1,2,..., nJ =1,2,..., k, — массив ранговых оценок,
п — размер каждого массива, k — число массивов.
Исследование ранговой корреляции с помощью коэффициента конкордации рассмотрено в [32, с. 97].
Исходные коды и пример применения
tfinclude <fstream.h>
#include <iomanip.h>
finclude <math.h>
Множественные корреляции
311
^include "megastat.h"
void main (void)
{
int n = 12, // Численность каждой выборки k = 6: // Число выборок
double х[] = // Массив выборок
{11. 4. 3, 6. 1, 5. 7, 8.10. 2.12. 9.
8, 7. 4. 5. 3. 2, 6. 9,12, 1.11.10.
9, 8. 5. 6. 1, 7. 2.11.12. 3.10. 4.
11. 3. 2. 8. 1. 4, 5.10, 9, 6,12. 7,
8. 7, 1. 9. 4. 6, 2.11.12. 3.10, 5.
9. 6. 4.11, 3, 7. 1. 5.10. 2.12. 8}
w; // Значение коэффициента конкордации
w = Concord (x.n.k);
cout « "W = " « w « ". p = "
« FDistribution (n - l.(n -
/ (1.0 - w))
« endl;
}
1) * (k - 1) / 2,(k - 1) * w
double Concord (double x[].int n.int k) //
// Функция вычисляет значение коэффициента конкордации. // Обозначения:
// х - массив выборок (выборки друг за другом),
// п - численность каждой выборки.
// к - число выборок.
// Возвращаемое значение:
// значение коэффициента конкордации.
//
{
register int i.j; // Счетчики цикла
int 1: // Счетчик массива
double г = k * (n + 1) / 2, // Среднее значение
s, // Сумма по столбцам
si = 0; // Рабочая переменная
for (i = 0; i < n: i++) {
for (j = 0,s = 0.1 = i: j < k: j++. 1 += n)
s += x[l J;
si +» (s - r) * (s - r);
}
return si * 12 / к / к / n / (n * n - 1): }
312
Глава 5. Корреляционный анализ
Критерии некоррелированности
Рассмотрим применение коэффициентов корреляции для проверки независимости признаков (некоррелированности, значимости связи) [187, с. 301]. Гипотеза о независимости признаков отвергается на выбранном уровне значимости, если вычисленное по опытным данным значение коэффициента корреляции превосходит (по модулю) критическое. Практические вычисления, однако, производятся несколько иначе.
Коэффициент корреляции
Коэффициент корреляции может применяться для проверки гипотезы значимости связи следующим образом. В случае нормального распределения исходных данных величина выборочного коэффициента корреляции считается значимо отличной от нуля, если выполняется неравенство [135, с. 295]
р2 >[l+(n-2)/t’]-',
где ta — критическое значение ^-распределения с (п - 2) степенями свободы.
Обсуждение дано в [140, с. 167], где немного в иной записи приводится та же самая формула.
Статистика у/ц-1 р имеет г-распределение [ 101, с. 568] с плотностью
Для больших выборок статистика ^п-\р распределена приближена но по стандартному нормальному закону N(fi, 1) [там же, с. 569].
Показатель ранговой корреляции
В качестве критериев некоррелированности могут применяться и другие коэффициенты корреляции, например показатель ранговойI
Критерии некоррелированности
313
корреляции Спирмэна. При этом вычисление производится по формуле [158, с. 211]
где критические значения статистики tp для стандартных уровней значимости даны в [там же, с. 212], [52, с. 264], а для больших выборок (п > 50) распределены по Стьюденту [там же, с. 265] с числом степеней свободы (п - 2).
В [ 187, с. 302] указано, что для больших выборок статистика yjn-\.ps распределена приближенно по стандартному нормальному закону Х(0,1). Обсуждение см. также в [151, с. 400]. Пример применения показателя ранговой корреляции в качестве критерия независимости признаков рассмотрен в [28, вып. 2, с. 134].
Коэффициент ранговой корреляции
Для коэффициента ранговой корреляции Кендалла в случае больших выборок статистика
19п(п +1)
V2(2w + 5)T
распределена приближенно по стандартному нормальному закону [там же].
Бисериальный коэффициент корреляции
Ошибка бисериального коэффициента корреляции [84, с. 167] имеет ^-распределение с числом степеней свободы (и - 2).
Точечно-бисериальный коэффициент корреляции
Точечно-бисериальный коэффициент корреляции может приме-пяться для проверки гипотезы значимости связи следующим образом. Величина выборочного точечно-бисериального коэффициента Корреляции считается отличной от нуля на уровне значимости а, если выполняется неравенство [174, с. 168]
314
Глава 5. Корреляционный анализ
п-2
1-гД
*ta’
где ta — критическое значение t-распределения с (и - 2) степенями свободы.
Коэффициент множественной корреляции
Пусть имеется случайная выборка объема п из (р + 1)-мерного нормального распределения. Коэффициент множественной корреляции отличается от нуля на уровне значимости «, если выполняется неравенство [120, с. 39]
I
yv + pF
где F — значение обратной функции F-распределения для числа степеней свободы р и (п - р - 1) и доверительного уровня (1 - а).
Коэффициент конкордации
Величина (k-X)-—--1 — Vv
имеет F-распределение с числом степеней
свободы (п - 1) и ((п - 1)(& - 1) - 2). Высокий уровень выдаваемого функцией FDistribution значения свидетельствует о высокой
степени согласования между ранжировками.
Пример применения методики дан выше при описании коэффициента конкордации.
Дальнейшие исследования и программные ресурсы
• Построение доверительных интервалов для показателя Спирмэна и коэффициента Кендалла.
• Более подробное изучение связи признаков, измеренных в различных шкалах в [187, с. 308], [196], [197].
• Исследование частной корреляции в [24, с. 191].
Дальнейшие исследования и программные ресурсы
315
Для расчета с помощью представленных в главе алгоритмов можно применить не только программы, составленные нами, но и множество имеющихся на рынке программного обеспечения программ. Помимо стандартных электронных таблиц, корреляционный анализ стандартно с той или иной степенью полноты входит в большинство универсальных программ анализа данных.
Глава 6. Методы снижения размерности
Изложенные в главах 8 и 9 методы распознавания образов имеют дело с основными элементами анализа как с объектами распознавания (классификаций), в оцифрованном виде представленными своими параметрами. В настоящей главе мы рассмотрим некоторые методы снижения размерности, позволяющие обоснованно сократить длину вектора параметров до приемлемых величин.
Следует отличать методы снижения размерности от методов сжа-6 тия информации, например архивирования, предназначенных для максимального уменьшения объема образов при их хранении и транспортировании по сетям передачи данных. Методы снижения размерности призваны найти компромисс между максимальным уменьшением объема, занимаемого информацией об образе, и сохранением его способности быть идентифицированным (узнанным) и классифицированным, причем само сжатие (снижение размерности) производится, прежде всего, с целью облегчения решения указанных двух вычислительных задач. Например, в задаче идентификации личности по отпечатку пальца на основе графического образа отпечатка может формироваться последовательность длиной до 2500 бит [186, с. 46], хотя исходное изображение имеет гораздо больший объем.
Проблеме снижения размерности вектора параметров распознаваемых образов посвящена глава книги [там же, с. 261], причем авторы рассматривают ряд методов выбора признаков:
• метод минимизации энтропии,
• разложение по системе ортогональных функций, представленное разложением в ряд Фурье и разложением Карунена—Лоэва,
• другие методы.
Метод минимизации энтропии
Метод предложен в [186, с. 281], где показано, что снижения размерности пространства параметров можно добиться, используя линейное преобразование
Метод минимизации энтропии
317
У = Ах,
где х — исходный вектор параметров объекта, размерность вектора равна и,
у — новый вектор меньшей размерности тп < и, А — матрица преобразования.
Матрица А составлена из т ортонормированных собственных векторов, соответствующих наименьшим собственным значениЯхМ ковариационной матрицы С, построенной на основе некоторой совокупности обучающих образов — объектов, принадлежащих исследуемому пространству. Предполагается, что при последующей классификации объектов ковариационные матрицы выделенных классов будут равными. Метод выводится из условия минимизации энтропии (меры неопределенности) и по технике вычислений, а также по ограничениям применения сильно напоминает линейный дискриминантный анализ Фишера.
Применяемый нами для вычисления собственных значений и собственных векторов метод Якоби годится только для векторов параметров умеренных размерностей, что вызвано прежде всего не численной неустойчивостью или большим временем вычислений, а возможной потерей точности наименьших собственных значений. Поэтому в случае больших размерностей вектора параметров следует применять более пригодный для большой задачи метод решения проблемы собственных значений, а лучше обратиться к методу снижения размерности путем использования преобразования Карунена—Лоэва (см. раздел «Преобразование Карунена—Лоэва» данной главы).
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void) ( register int i.j; // Счетчики
int n = 4. // Число объектов
P = 3. // Число параметров до сжатия
s = 2, H Число параметров после сжатия
Code. // Код ошибки
m; // Рабочая переменная
double e[] = // Значения параметров объектов
318
Глава 6. Методы снижения размерности
{О,1,1,1. // Параметр 1
0,0,0,1. // Параметр 2
0.0,1.0}, // Параметр 3
*а: // Матрица преобразования
а = new double [р * р]:
Code = Той (е.п.р,s,а):
if C'Code)
cout « "Matrix in transposal view:\n";
for (i =0. m = 0: i < p; i++)
{
for (j = 0: j < s: j++. m++)
cout « setw (10) « a[m]:
cout « endl:
}
}
el se cout « "Error code is " « Code « endl:
delete [] a: }
int Tou (double e[].int n.int p.int s.double a[])
11
II Функция вычисляет матрицу преобразования для сжатия образов // методом минимизации энтропии.
// Обозначения:
// е - матрица размером п х р значений параметров объектов // (параметр 1 для всех объектов, затем параметр 2 для // всех объектов и т.д.).
// п - число объектов,
// р - число параметров до сжатия, // s - число параметров после сжатия.
// а - искомая матрица преобразования, размером s х р.
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -1 при недостатке памяти для вычислений.
// -2 при ошибке в вычислениях.
И { register int i.j.k: // Счетчики цикла
int m = 0,ml = 0,m2. // Счетчики
Code = 0: // Код ошибки
double *с. // Ковариационная матрица
*Ь. // Полная матрица преобразования
*х,*у, // Рабочие массивы
buf: // Рабочая переменная
if ((с = new double [р * р]) == 0)
Метод минимизации энтропии
319
return -1;
if ((х = new double [MaximumOf(n.p)]) == 0) {
delete [] c: return -1;
}
if ((У = new double [n]) == 0) {
delete [] c: delete [] x;
return -1;
}
if ((b = new double [p * pj) == 0) {
delete [] c; delete [] x; delete [] y: return -1:
}
/////////////////////////
// Ковариационная матрица for (i = 0: i < p: 1++)
{
for (к = 0; к < n; k++) x[k] = e[ml++];
for (j = 0. m2 = 0: j < p: j++) {
for (к = 0; к < n; k++) y[k] = e[m2++];
///////////////////////////////////// // Деление и умножение для приведения // функции Cov к авторскому варианту c[m++] = Cov (x.y.n) / n * (п - 1);
} }
/////////////////////////////////
// Собственные значения и вектора
Code = Jacobi (с.р.0.000001.&m2.b);
if (!Code)
{
//////////////////////////////////////
// Упорядочивание собственных векторов
// в порядке возрастания собственных значений for (i = 0: i < р; i++)
x[i] = c[i * (p + 1)1:
for (i =0; i < p; i++) {
m2 = i;
buf = x[i]:
for (j = i + 1; j < p; j++) if (buf >= x[j])
320
Глава 6. Методы снижения размерности
{
m2 = j:
buf = х[j];
}
Col Interchange (x,1,1.m2);
Col Interchange (b.p.i,m2); }
///////////////////////////////////
// Выводимая матрица преобразования for (1 = 0. ml = 0; 1 < s; i++)
for (j = 0. m « 1; j < p; j++. m += s) a[m] = b[ml++J;
}
delete [] c; delete [] x; delete [] y; delete [] b;
return Code;
6 }
Преобразование Карунена—Лоэва
Рассмотрим разложение действительной прямоугольной матрицы А размером тп строк на п столбцов, тп > п, по сингулярным числам (подробнее см. раздел «Разложение по сингулярным числам» главы 13). Пусть U — матрица размером тп х и, сформированная из п ортонормированных собственных векторов, соответствующих наибольшим из тп собственных значений матрицы ААТ. Оставим в матрице U только 5 собственных векторов, соответствующих наибольч шим сингулярным числам, s < п. Получим матрицу Us размером тп х s. Теперь сформируем вектор-столбец у размером s такой, что
y=U]x,
где UJ — часть матрицы U, в которой оставлено только $ столбцов, соответствующих наибольшим собственным векторам, х — вектор-столбец длиной тп.
Последнее выражение называют преобразованием Карунена—Лоэва [www-ccrma.stanford.edu/~bosse/proj7node29.html] либо дискретным разложением Карунена—Лоэва [186, с. 297]. Иногда его сравнивают с анализом главных компонент или более широко — с факторным анализом [42, с. 254], рассмотренным в одноименной главе данной книги, однако от факторного анализа преобразование Карунена— Лоэва отличается тем, что в результате его применения не происхо! дит выявления связи между объектами или параметрами.
Преобразование Карунена—Лоэва
321
В нашем случае т — это число параметров, п — число объектов, которые можно было бы назвать обучающими данными, составляющими матрицу А1. Идея метода состоит в том, что вместо использования для распознавания векторов х размером т применяются вектора у размером s < т. Это значительно сокращает требуемый объем вычислений. Матрица Us, применяемая для преобразования, вычисляется только один раз на основании набора исходных данных — матрицы А, после чего вектора х преобразуются и дают на выходе вектора у. Параметры, составляющие вектора г/, не могут применяться для иных целей, кроме целей распознавания, так как фактически представляют собой суперпозиции параметров (именно поэтому рассматриваемый метод называется как преобразованием, так и разложением Карунена—Лоэва — разложением по ортогональным функциям), составляющих векторах, и самостоятельного смысла не имеют. Вычисление матрицы преобразований на основе g некоторой «обучающей» выборки позволило некоторым авторам отнести преобразование Карунена—Лоэва к методам распознавания образов с обучением, однако это не так. Преобразование Карунена— Лоэва является методом сжатия информации.
Укажем примеры применения преобразования Карунена—Лоэва для сжатия распознаваемых образов в различных областях: распознавание транспортных средств [202, с. 216], сжатие акустических сигналов [Bosse Lincoln, «Ап Experimental High Fidelity Perceptual Audio Coder», Project in MUS420 Win97, www-ccrma.stanford.edu/~bosse/ proj/proj.html, Центр компьютерных исследований в музыке и акустике Стэнфордского университета], распознавание трехмерных изображений [S.Golman, A.Zhdanov, «3D object recognition using Karhunen-Loeve expansion», Lab report, www.cs.technion.ac.il/ labs/isl/projects_done/object_recognition/main.html, Лаборатория интеллектуальных систем Израильского технологического института Technion].
Для решения задачи нами применяется функция MatrixMulti-plyMatrix, а для вычисления матрицы преобразования — функция SingularValueDecomposition, реализующая разложение по сингулярным числам и гарантирующая ортонормированность полученных собственных векторов. Пример применения не приводится — решение строится аналогично методу, рассмотреннному в разделе «Метод минимизации энтропии» данной главы.
1 В [ 186, с. 297] в качестве ААТ применяется корреляционная матрица, и задача естественно сводится к выделению ее наибольших собственных значений.
112002
322
Глава 6.
Методы
снижения размерности
Сжатие с помощью трехслойной нейронной сети
Авторами [214] предложен алгоритм сжатия с помощью трехслойной нейронной сети, у которой число элементов входного и выход-
ного слоев одинаково, причем вектор входа в точности равен векто-
ру выхода, а число элементов скрытого слоя значительно меньше, как показано на рис. 6.1. На элементах скрытого слоя возникает пред-
ставление каждого вектора данных, которое намного короче длины оригинала. Сжатый (с помощью слоев 1 и 2) образ может подвергаться экономичной передаче по локальным и глобальным компьютерным сетям. Сжатый образ может быть подвергнут и распоз
наванию, однако новые параметры, составляющие вектор, как
в предыдущих случаях, никакого смысла сами по себе не несут. Вос-
становление образа производится с
помощью второй части
сети
(слои 2 и 3). Единственное отличие от обычной процедуры решения состоит в том, что перед подачей на вход некоторого образа ог
должен быть нормализован (как и в случае распознавания образов),
а после выхода денормализован с использованием сохраненных коэффициентов.
Рис. 6.1. Архитектура нейронной сети для сжатия образов
Дальнейшие исследования
323
Процедуру вычисления коэффициентов нормализации входных данных выполняет функция NormalizeMatrix. Нормализацию и денормализацию можно сделать функцией MatrixMultiplyMatrix.
Для обучения нейронной сети рассмотренной архитектуры может применяться алгоритм, приведенный в главе 9.
Дальнейшие исследования
• Фрактальное сжатие образов. Материалы по алгоритмам сжатия данных, включая фрактальное сжатие изображений, представлены на сайте www.rasip.fer.hr/research/compress/algorithms/index.htmL
• Лингвистический анализ изображений, см. также [83].
6
и*
Глава 7. Факторный анализ
Основным объектом исследования методами факторного анализа является корреляционная матрица, построенная с использованием коэффициента корреляционного отношения Пирсона (для количественных признаков). Предлагается также использование других коэффициентов типа корреляции, предназначенных для порядковых, качественных и смешанных признаков, но опыта в этой области пока недостаточно. Некоторые авторы [126], [135, с. 606] предлагают использовать для факторного анализа дисперсионноковариационную матрицу. Основным требованием к построенной 7 матрице является ее положительная полуопределенность. Напомним, что эрмитова матрица называется положительно полуопреде-ленной, если все ее главные миноры неотрицательны. Из данного свойства как раз и следует неотрицательность всех собственных значений. Более подробно положительная полуопеределенность рассмотрена в главе 13.
Методами факторного анализа решаются три основных вида задач:
• отыскание скрытых, но предполагаемых закономерностей, которые определяются воздействием внутренних или внешних причин на изучаемый процесс;
• выявление и изучение статистической связи признаков с факторами или главными компонентами;
• сжатие информации путем описания процесса при помощи общих факторов или главных компонент, число которых меньше количества первоначально взятых признаков (параметров), однако с той или иной степенью точности обеспечивающих воспроизведение корреляционной матрицы.
Следует пояснить, что в факторном анализе понимается под сжатием информации. Дело в том, что корреляционная матрица получа-1 ется путем обработки исходного массива данных. Предполагается,] что та же самая корреляционная матрица может быть получена с использованием тех же объектов, но описанных меньшим числом параметров. Таким образом, якобы присходит уменьшение размерности задачи, хотя на самом деле это не так. Это не сжатие инфор-
Глава 7. Факторный анализ
325
мации в общепринятом смысле — восстановить исходные данные по корреляционной матрице нельзя.
Коэффициенты корреляции, составляющие корреляционную матрицу, по умолчанию вычисляются между параметрами (признаками, тестами), а не между объектами (индивидуумами, лицами), поэтому размерность корреляционной матрицы равна числу параметров. Это так называемая техника R. Однако может быть, например, изучена корреляция между объектами (точнее, их состояниями, описываемыми векторами параметров). Эта методика называется техникой Q. Проведение факторного анализа техникой Q1 обосновано тем, что состояния объектов могут иметь общую побудительную причину (причины), которая (которые) как раз и может быть выявлена с помощью факторного анализа. Существует также техника Р, предполагающая анализ исследований, выполненных на одном и том же индивидууме в различные промежутки времени («объекты» — один и тот же индивидуум в различные промежутки времени), причем изучаются корреляции между состояниями индивидуума. Аналог техники Q для последнего случая составляет предмет исследования техники О.
Применение техники R (Р) или техники Q (О) или выбор техники R (Q) или Р(О) могут быть осуществлены программистом с помощью одних и тех же алгоритмов в пределах одной программы путем простых манипуляций с исходными данными.
Мы рассмотрим три метода факторного анализа: метод главных факторов (если корреляционная матрица не редуцируется — он же метод главных компонент), метод максимального правдоподобия, а также центроидный метод. Иначе метод главных компонент называют просто компонентным анализом. В основе всех методов факторного анализа лежит предположение, что изучаемая зависимость носит линейный характер, хотя высказываются мнения о том, что использование такого предположения ничем не обосновано [147]. Основное требование к исходным данным — это то, что они должны подчиняться многомерному нормальному распределению [126, с. 19]. По крайней мере, должно быть сделано допущение о многомерном нормальном распределении совокупности, однако в [там же, с. 139] высказывается предположение, что из рассмотренных методов факторного анализа центроидный метод весьма устойчив к колебаниям распределения.
Авторы [ 148, с. 179] относят обратный факторный анализ, или факторизацию Q-типа, к методам кластерного анализа.
326
Глава 7. Факторный анализ
Редуцированием корреляционной матрицы называется процесс за-( мены единиц на главной диагонали корреляционной матрицы некоторыми величинами, называемыми общностями. По определению [208], общность — сумма квадратов факторных нагрузок. По [147] общность данной переменной — та часть ее дисперсии, которая обусловлена общими факторами. Это вытекает из предположения, что полная дисперсия складывается из общей дисперсии, обусловленной общими для всех переменных факторами, а также специфичной дисперсии, обусловленной факторами, специфичными только для данной переменной, и дисперсии, обусловленной ошибкой. Мы рассматриваем только методы, оперирующие общностями, не превышающими единицу.
Получение матрицы факторного отображения в принципе является целью факторного анализа. Ее строки представляют собой координаты концов векторов, соответствующих т переменным в г-мерном факторном пространстве. Близость концов этих векторов дает пред-4 7 ставление о взаимной зависимости переменных. Каждый вектор в сжатой, концентрированной форме несет информацию о процессе. Близость этих векторов дает представление о взаимной зависимости переменных. Дополнительно, если число выделенных факторои больше единицы, обычно производится вращение матрицы факторного отображения с целью получения так называемой простой структуры. Мы применяем программу вращения популярным методом VARIMAX [174, с. 90,255], который используется и в других разделах анализа данных.
Для наглядности результаты можно изобразить графически, что, однако, проблематично для трех и более выделенных факторов. Поэтому обычно дают изображение r-мерного факторного простран! ства в двумерных срезах.
В процессе решения задачи факторного анализа нужно быть готовым к тому, что иногда решение получить не удается1. Это вызвано] сложностью решаемой проблемы собственных значений корреляционной матрицы. Например, корреляционная матрица может оказаться вырожденной, что может быть вызвано совпадением или полной линейной корреляцией параметров. Для матриц высокого порядка может произойти потеря значимости в процессе вычислений. Поэтому теоретически нельзя исключить ситуацию, когда методы факторного анализа, к сожалению, окажутся неприменимы, по
1 Замечание данного абзаца в большей степени относится к методу максимума правдоподобия, в схеме которого фигурирует матрица, обратная корреляционной.
Метод главных факторов
327
крайней мере до тех пор, пока исходные данные не удастся «исправить». Исправлены данные могут быть следующим образом. Выявите линейно зависимые параметры с помощью, например, метода корреляционных плеяд (возможно применение и других методов) и оставьте в исходных данных только один из группы линейно зависимых параметров.
Применяемый для определения собственных значений метод Якоби дает решение и в случае вырожденности корреляционной матрицы. При этом часть собственных значений, равная разности порядка матрицы и ее ранга, будет нулевой в вычислительном смысле, что делает метод главных факторов более устойчивым к «нехорошим» данным, чем метод максимума правдоподобия. Однако метод главных факторов уступает методу максимума правдоподобия в том, что он не позволяет получить точной оценки общности и добиться таким образом полной воспроизводимости корреляционной матрицы.
Метод главных факторов
Рассмотрим подробнее метод главных компонент — вариант метода главных факторов, а затем сам метод главных факторов.
Основная модель метода главных компонент записывается в матричном виде следующим образом:
Z = AP,
где Z — матрица стандартизованных исходных данных,
А — факторное отображение,
Р — матрица значений факторов.
Матрица Z имеет размер т х и, матрица А имеет размер т х г, матрица Р имеет размер г х и, где
т — количество переменных (векторов данных),
п — количество индивидуумов (элементов одного вектора), г — количество выделенных факторов.
Как видно из приведенного выше выражения, модель компонентного анализа содержит только общие для имеющихся векторов факторы.
Матрица стандартизованных исходных данных определяется из матрицы исходных данных Y (ее размер т х и) по формуле
328
Глава 7. Факторный анализ
г_ _ % У?, i _ j, 2.mJ = jt 2,.... п, I
где у1} — элемент матрицы исходных данных,
— среднее значение,
s — стандартное отклонение.
Для вычисления корреляционной матрицы — основного элемента факторного анализа — имеет место простое соотношение
—ZZ’=R, п-1
где R — корреляционная матрица; она имеет размер т х т, ' — символ транспонирования.
7 На главной диагонали матрицы R стоят значения, равные 1. Эти значения называются общностями и обозначаются как №, являясь мерой полной дисперсии переменной. Для метода главных факторов, рассматриваемого ниже, общности отличны от 1 и вычисляются определенным образом.
Неизвестными являются матрицы Л и Р. Матрица Л может быть найдена из основной теоремы факторного анализа
R = ACA\
где С — корреляционная матрица, отражающая связь между факторами.
Если С = I, то говорят об ортогональных факторах, если С * I, говорят о косоугольных факторах. Здесь I — единичная матрица.
Для матрицы С справедливо соотношение
—РР'=С-п-1
Нами рассматривается только случай ортогональных факторов, для которых
R = ЛЛ'.
Модель классического факторного анализа содержит ряд общих фак-| торов и по одному характерному фактору на каждую переменную.
Метод главных факторов
329
Первая из приведенных в разделе формул является основной моделью факторного анализа для метода главных компонент. Число главных компонент всегда меньше либо равно числу переменных.
Для метода главных факторов основная модель записывается в виде
Z = FP+,
где F — полная факторная матрица,
Р+ — матрица значений факторов, включая значения характерных факторов.
Матрица Z имеет размер тпхп, матрица F имеет размер тп х (г + ти), матрица Р* имеет размер (г + тп) х п. Матрица F может быть представлена в виде суммы двух матриц
F = А + U,
где Л — матрица нагрузок общих факторов, U — матрица нагрузок характерных факторов.
Очевидно, что матрицы А и U имеют размерность матрицы F. Матрица А (а именно ее часть размером тп х г, остальная же ее часть размером тп х тп является нулевой) понимается как матрица факторного отображения.
Полная дисперсия переменной складывается из общности h*, значение которой меньше либо равно 1 и означает часть полной дисперсии переменной, приходящейся на главные факторы, и характерности, обозначаемой как «,2, приходящейся на характерные факторы. Следовательно,
ц2=1-^-
Часть (размером тп х г) матрицы U является нулевой, остальная ее часть (размером тп х тп) представляет собой диагональную матрицу с квадратными корнями из характерностей на главной диагонали, которые уже вычислены из общностей. Таким образом, может быть определена матрица [/, а следовательно, и матрица F, если известна матрица А.
Используя введенную выше основную теорему для случая ортогональных факторов, можно записать
R = FF'.
330
Глава 7. Факторный анализ
Развернув выражение, получим:
R = Rh + U2,
где R — корреляционная матрица с единицами на главной диагонали, Rh — корреляционная матрица с общностями на главной диагонали, определяемая выражением
Rh = AA',
U2 означает UU'.
Исходные коды и пример применения
#include <fstream.h>
#include <iomaniр.h>
#include <math.h>
#include "megastat.h"
void main (void)
{
char *ReduceName[] = {"нет редукции (главные компоненты)\п“, "способ наибольшей корреляцииХп", "коэффициент множественной корреляцииХп". "средние коэффициенты корреляцииХп ", "метод триадХп"}:
register int i.j.il; // Счетчики
int Code, Commonality = 4, n = 17. k = 12. m. Factor = 4; // Код ошибки // Код оценки общности // Число объектов // Число параметров // Вычисленное количество факторов // Заданное пользователем число факторов
double z[] = { // Исходные данные
9.1.9.2.6.6.6.5.8.6,4.7.7.9,4.9.4.0.5.1.4.0.5.3,6.0.8.5.4.2.8.0.10.9, 33.29.29,27,27.17,23,27.32,21,27,24.20,30.21.26,24, 0.44.1.54.0.82.0.63.0.78,0.15,0.42,0.43,0.7.0.51,0.3,0.43,0.41.1,0.5,1.1.1.2. 23.58.43.36.34.19.23.26.54.51,24.34,34.40.57.50.45.
0.48.0.96.0.59.0.51,0.62.0.5,0.4,0.63,0.58,0.43,0.4.0.47.0.37,0.9.0.37,0.85.1.1, 25,36.31,29,27.63.21,38,46,40,38,37.31,34,42.41,41,
0.03,0.08,0.06,0.05,0.07,0.024,0.05,0.05.0.02,0.03,0.02,0.04,0.04.0.1,0.053,0.1,0.05, 2.3,3,3,3,3.3,3,2,3.2,3,3,4.6,5.2.
1.55.1.2.3.4,3.8.1.6,7.0.1.4,1.0,1.05,2.3,3.5.6.0,1.1,0.98,1.6.2.3,5.9, 0.78.0.62,1.08,1.92,0.61,1.6.1.0.1.44.1.44.4.8,2.0.4.4.1.28.0.96,0.68,0.72.1.04, 9.2.7.4.12.12.6.6.72,16.0.15.6.11.2,8.4,9.4.9.6,8.8.9.2.11.6.10,13.6.11.2, 80.90.81.78.88.88,82.78.127.87.83.80,95.81.89.81.63}.
Метод главных факторов
331
*datal, *data2, *t. *s. buf: // Корреляционная матрица // Редуцированная корреляционная матрица // Матрица факторного отображения // Дисперсии // Рабочая переменная
datal = new double [k * к]:
data2 = new double [k * к]:
t = new double [k * k]: s = new double EkJ:
////////////////////////////////////
// Вычисление корреляционной матрицы
if (!LikenessForCorrelation (z.datal.n.k.O))
{
cout « "Корреляционная матрица\п";
for (i = O.il = 0; i < k: i++) { for (j = 0: j < k: j++.il++) cout << setw (10) « datalfil]: cout « endl:
}
//////////////////////////////////
// Редукция корреляционной матрицы
if (!(Code = Reduction (datal,data2,k,Commonality))) {
cout << "Метод оценки общности: " « ReduceName[Communality]:
if (Commonality != 0) {
cout << "Оценки общности:\n";
for (i = O.il = 0; i < k; i++,il += k + 1)
cout « (i + 1) « " = " « data2[il] « endl: }
///////////////////
// Факторный анализ
if (!(Code = PrincipalFactor (data2,k.t.&m)))
{
cout « "Число выделенных факторов " « m « endl:
/////////////////////////////////////////////////// // Коррекция числа факторов по желанию пользователя if (0 < Factor && Factor < m)
{
m = Factor:
cout « "Заданное число факторов " « m « endl: }
//////////////////////////////////////// // Оценка выделенной факторами дисперсии
332
Глава 7. Факторный анализ
PercentOfVariance (data2.k.t.s.m): cout « "Выделенные дисперсии:\n"; for (i = O.buf =0: i < m; i++) {
buf += s[i] ; cout « setw (3) « (i + 1) « " = "
« setw (8) « s[i] « "X. всего = " « buf « "X\n"l }
///////////////////////////////// // Матрица факторного отображения cout « "Матрица факторного отображенияХп": for (i = 0; i < k; i++)
for (j = 0.11 = i; j < m; j++,il += k) cout « setw (14) << t[il];
cout « endl; }
////////////////////
□к // Варимакс-вращение
7 if (m > 2)
F {
cout « "Повернутая матрица факторного " « "отображенияХп";
if (IVarimax (t.k.m)) { for (i = 0; i < k; i++) {
for (j = O.il = i; j < m: j++.il += k) cout « setw (14) « t[il];
cout « endl; }
} el se cout « "Мало памятиХп";
} } else if (Code == -1) cout << "Мало памятиХп"; el se
cout « "Ошибка при вычисленииХп";
}
else if (Code == -1) cout « "Мало памятиХп";
el se
cout « "Ошибка при редукцииХп";
} el se cout « "Мало памятиХп";
delete [] datal; delete [] data2; delete [] t; delete [] s; }
Метод главных факторов
333
int PrincipalFactor (double z[],int k.double r[],int *m) //
// Функция производит факторный анализ методом главных факторов. // Обозначения:
// z - корреляционная матрица,
// к - порядок корреляционной матрицы,
// г - матрица факторного отображения размером не менее к * к.
// *т - число факторов.
// Возвращаемое значение:
// 0 при нормальном окончании счета,
// -1 при недостатке памяти для рабочих массивов.
// -2 при ошибке в вычислениях.
//
{
register int i.j: // Счетчики
int ml,m2,Code; // Вспомогательная переменная
double *zl, // Рабочая копия корреляционной матрицы
save; // Буфер
*m = 0:
if ((zl = new double[k * k]) == 0) return -1;
///////////////////////////////////////
// Рабочая копия корреляционной матрицы ArrayToArray (z.zl.k * k);
////////////////////////////
// Решение проблемы факторов
if ((Code = Jacobi (zl.k.O.000001,&ml,r)) != 0)
{
delete [] zl;
return Code:
}
/////////////////////////////////////////////////
// Упорядочивание собственных значений и векторов
for (i = 1; i < k: i++)
zl[i] = zl[i * (k + 1)]; // Первый столбец -// собственные значения
for (i =0; i < k: i++) {
Code = i:
save = zl[i];
for (j = i +1: j < k: j++) if (save < zl[jj)
{
Code = j: save = zl[j]; }
334
Глава 7. Факторный анализ
Col Interchange (zl.1,1.Code);
Col Interchange (r.k,i.Code);
}
/////////////////////////////
// Отбор собственных значений
for (i = 0, ml = 0: i < k; 1++)
if (zl[i] < 0) break;
el se
{
(*m)++:
//////////////////////////////////////////// // Вычисление матрицы факторного отображения save = sqrt Czl[i]);
for (j = 0: j < k: j++. ml++) r[ml] *= save:
}
delete [] zl:
return 0:
}
Проблема общности
Для метода главных факторов имеет место проблема общности, то-есть на главной диагонали корреляционной матрицы, в отличие от метода главных компонент, необходимо проставить значения общностей, чтобы получить корреляционную матрицу Rh. Процесс оценки общностей в методе главных факторов называется редукцией корреляционной матрицы. Без редукции, то есть с единицами на главной диагонали корреляционной матрицы, мы получаем широко известный компонентный анализ (метод главных компонент). Были опробованы четыре способа оценки общностей:
• способ наибольшей корреляции;
• коэффициент множественной корреляции, при этом общности вычисляются с помощью выражения
где в знаменателе стоит диагональный элемент матрицы, обратной к матрице^. Этот метод, однако, осложняется тем фактом, что, как показывает наш опыт расчетов, полученная в результате редукции]
Метод главных факторов
335
корреляционная матрица обычно не является матрицей Грама. Замена же диагональных членов оценками общностей считается допустимой, только если сохраняются свойства матрицы Грама;
• средние по столбцу корреляционной матрицы коэффициенты корреляции;
• метод триад.
Пример применения
int Reduction (double z[], double r[],int k.int Mode) //
// Функция производит редукцию корреляционной матрицы.
// Обозначения:
// z - корреляционная матрица,
// г - редуцированная корреляционная матрица,
// к - размерность корреляционной матрицы,
// Mode - метод вычисления общностей:
// = 0 - анализ главных компонент,
// = 1 - способ наибольшей корреляции,
// = 2 - коэффициент множественной корреляции,
// = 3 - средние коэффициенты корреляции,
// = 4 - метод триад.
И Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -1 при недостатке памяти,
// -2 при ошибке в параметрах, например к >= 3 для метода триад.
//
{
register int i.j; // Счетчики
int m,ml,kl,k2; // Счетчики одномерного массива
double *t, // Вспомогательный массив
s.sl,s2; // Вспомогательные переменные
if (Ct = new doublefk * k]) == 0) return -1;
///////////////////////////////
// Копия корреляционной матрицы
ArrayToArray (z.r.k * k):
////////////////////////
// Определение общностей
switch (Mode)
{
case 0:
//////////////////////////////////////////
// Нет редукции - анализ главных компонент break;
336
Глава 7. Факторный анализ
case 1:
///////////////////////////////
// Способ наибольшей корреляции
for (i = 0, m = 0, ml = 0: i < k; 1++) {
for (j = 0; j < к; j++, m++)
t[j] = i == j ? 0 : fabs (z[mj);
r[ml] = MaximumOf (t,k);
ml += к + 1;
}
break;
case 2:
///////////////////////////////////////
// Коэффициент множественной корреляции
if (InverseMatrix (r.t.k) == 0)
for (i = 0, m = 0; i < k; i++,m+= к + 1)
if (t [m] != 0 || t[m] != 1) r[m] = 1 - 1 / t[m];
break;
case 3:
//////////////////////////////////
11 Средние коэффициенты корреляции
for (i = 0, m = 0. ml = 0; i < k; i++,ml += k + 1) {
for (j = 0. r[ml] =0; j < k; j++, m++) r[ml] += i == j ? 0 : fabs (z[m]);
r[ml] /= k - 1;
}
break;
default:
//////////////
// Метод триад
if (k < 3)
{
delete [] t;
return -2;
}
for (i = 0, m = 0. ml = 0; i < k; i++,ml += k + 1) {
//////////////////////////////////
// Поиск двух наксинумов в столбце
for (j = 0; j < k; j++) t[j] = fabs (z[m++J);
t[i] = 0;
si = MaximumOf (t,k.&kl);
t[kl] = 0;
s2 = MaximumOf (t,k,&k2);
///////////////////////////////////////////// // Корреляция между максимальными параметрами s = fabs (z[kl + k2 * k]);
Метод главных факторов
337
if (s != 0) r[ml] = si * s2 / S;
}
}
delete [] t:
return 0:
}
Проблема факторов
Матрица факторного отображения определяется для компонентного анализа или для метода главных факторов методом множителей Лагранжа (максимизация функции, связанная с дополнительными условиями) из решения проблемы собственных значений матрицы R или Rh. Для простоты записи значок h далее опускаем, имея в виду R или Rh в зависимости от применяемой разновидности метода факторного анализа.
Факторы пропорциональны собственным векторам матрицы R. Стандартная проблема собственных значений матрицы R записывается в виде:
(Я-Л/) = 0,
где Л/, I = 1,2,..., т — Z-e собственное значение матрицы R,
ар I =1, 2, .... т — соответствующий Z-му собственному значению собственный вектор,
I — номер собственного значения.
Задача упрощается тем, что матрица R является действительной и симметрической, поэтому для решения проблемы собственных значений применимы эффективные устойчивые алгоритмы.
Измерение факторов
Оценка значений факторов (так называемое измерение факторов) не является необходимой для интерпретации результатов процедурой. Остановимся на ней для полноты изложения.
Способ измерения главных компонент основан на применении основной модели факторного анализа:
Z = АР.
338
Глава 7. Факторный анализ
Умножив обе части равенства на А', а затем на (А'А)", получим
Р = A+Z,
где А+ — матрица, определяемая по формуле
А+ =(А'А)~А'.
Способ измерения главных факторов основан на иных теоретических предпосылках — множественном регрессионном анализе — и нами не рассматривается.
Анализу главных компонент уделено внимание в [ 183, с. 260]. С методикой применения метода главных компонент и метода главных факторов в рамках стандартных пакетов программ можно ознакомиться по [78, с. 162].
Метод максимума правдоподобия
В методе максимума правдоподобия (максимального правдоподобия) оценка общностей до непосредственного применения алгоритма факторного анализа не производится. Общности находятся в результате вычислений из условия полной воспроизводимости корреляционной матрицы. В этом заключается основное преимущество метода максимума правдоподобия перед методом главных факторов. Соответственно, бессмысленно применение различных критериев выделения значащих факторов, описанных в ряде источников и якобы основанных на сопоставлении оценки воспроизведенной корреляционной матрицы и исходной корреляционной матрицы. При любом количестве выделенных факторов корреляционная матрица воспроизводится полностью, с точностью до ошибки вычислений.
Программой выдаются оценки общностей, вычисленные из условия полной воспроизводимости корреляционной матрицы. Если задать число факторов равным числу параметров, то оценки общности будут совпадать с общностями нередуцированной корреляционной матрицы, то есть будут равны единице. Максимальное число удерживаемых факторов можно приблизительно установить из анализа процента дисперсии, выдаваемой программой для каждого фактора. Основной недостаток метода — неустойчивость к «нехорошим» данным, например к данным, содержащим совпадающие или линейно зависимые вектора. С точки зрения многомерной статистики
Метод максимума правдоподобия
339
(в широком смысле) проблема заключается в том, что в данном случае, даже если исходные данные показывают многомерное нормальное распределение, оно будет вырожденным [63, с. 60]. С точки зрения факторного анализа (в узком смысле) будет вырожденной матрица характерностей. Вряд ли можно избежать численной неустойчивости в данном случае. Если же это произошло, воспользуйтесь методом главных факторов либо одним из способов выделения и последующего исключения из рассмотрения линейно зависимых параметров.
Описание метода и примеры применения см. в [208, с. 237], [209].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void)
{
register int i.j.il: // Счетчики
int Code, // Код ошибки
n = 17, H Число объектов
k = 12, H Число параметров
m. // Вычисленное количество факторов
Factor = 4: // Заданное пользователем число факторов
double z[] = { // Исходные данные
9.1,9.2.6.6.6.5.8.6.4.7,7.9.4.9,4.0.5.1.4.0.5.3.6.0.8.5.4.2.8.0,10.9, 33,29,29.27.27,17.23,27,32,21.27.24,20,30,21,26,24,
0.44,1.54.0.82,0.63,0.78.0.15.0.42,0.43.0.7,0.51,0.3.0.43.0.41,1.0.5.1.1,1.2. 23.58.43.36,34.19.23.26,54.51.24.34,34.40,57.50.45.
0.48,0.96.0.59.0.51,0.62,0.5,0.4,0.63.0.58.0.43,0.4,0.47,0.37.0.9,0.37,0.85,1.1, 25.36.31.29.27.63,21,38.46,40.38,37.31,34.42,41.41.
0.03.0.08.0.06,0.05,0.07.0.024.0.05.0.05.0.02.0.03.0.02,0.04,0.04,0.1.0.053,0.1,0.05.
2.3.3.3,3,3.3,3,2,3,2.3,3,4,6,5.2.
1.55,1.2,3.4.3.8,1.6,7.0.1.4.1.0,1.05.2.3.3.5.6.0.1.1.0.98.1.6,2.3.5.9, 0.78.0.62,1.08.1.92.0.61.1.6.1.0.1.44.1.44,4.8.2.0,4.4.1.28.0.96,0.68,0.72.1.04. 9.2.7.4,12.12.6.6.72.16.0.15.6,11.2.8.4.9.4.9.6,8.8.9.2,11.6.10,13.6.11.2. 80.90,81.78.88.88,82.78.127.87,83,80.95,81,89,81.63},
*datal, // Корреляционная матрица, затем
// редуцированная корреляционная матрица
*t. // Матрица факторного отображения
*s, // Дисперсии
buf: // Рабочая переменная
datal = new double [k * k];
340
Глава 7. Факторный анализ
t = new double [k * k];
s = new double [k];
////////////////////////////////////
11 Вычисление корреляционной натрицы
if (ILikenessForCorrelation (z.datal.n.k.O))
{
cout « "Корреляционная натрица\п";
for (1=0,11=0; 1 < k; 1++)
{
for (j = 0; j < k; j++,il++) cout « setw (10) « datal[il];
cout « endl;
}
if (KCode = MaximumLikelihood (datal.k.t.s.Factor,&m)))
{
///////////////////////
II Вычисленные общности cout « "Оценки общности:\n"; for (1=0: 1 < k; 1++ ) cout « (1 + 1) « " = " « s[i] « endl;
//////////////////////////////////////// // Редуцированная корреляционная натрица for (1 = 0.11 = 0; 1 < k: 1++.11 += k + 1) datal[il] = s[1]:
//////////////////////////////////////// // Оценка выделенной факторами дисперсии PercentOfVariance (datal.k.t.s.m): cout << "Выделенные дисперсии:\n";
for (1 = 0. buf =0; 1 < m; 1++ )
{
buf += s[1];
cout « setw (3) « (1 + 1) « " = " « setw (8) « s[i] « "X, всего = " « buf « "X\n";
}
/////////////////////////////////
// Матрица факторного отображения
cout « "Матрица факторного отбраженияХп";
for (1=0; 1 < k; 1++)
{
for (j = 0,11 = 1; j < m; J++.11 += k) cout « setw (14) « t[il];
cout « endl;
}
////////////////////
// Варимакс-вращение
if (m > 2)
Метод максимума правдоподобия
341
{
if (’Varimax (t.k.m)) {
cout « "Повернутая матрица факторного "
« "отбраженияХп":
for (i =0: 1 < k; i++) {
for (j = 0,11 = i; j < m: j++, il += k) cout « setw (14) « t[il];
cout « endl:
} } el se
cout « "Мало панятиХп":
}
}
else if (Code == -1)
cout « "Мало панятиХп":
el se
cout « "Ошибка в вычисленияхХп":
}
el se
cout « "Мало панятиХп":
delete [] datal: delete [] t: delete [] s: }
int MaximumLikelihood (double z[],int k.double r[],double b[J.int mz,int *ms) //
// Функция производит факторный анализ нетодон наксинуна
// правдоподобия.
// Обозначения:
// z - нередуцированная корреляционная натрица, // к - разнер корреляционной патрицы.
// г - натрица факторного отображения разнерон не ненее к * к,
// b - вычисленный вектор общностей.
// mz - заданное число факторов.
// *ms - вычисленное число факторов.
// Принечание:
// если заданное число факторов велико, оно корректируется.
// Возвращаеное значение:
// 0 при норнальнон окончании счета,
// -1 при недостатке памяти для рабочих массивов,
// -2 при ошибке в вычислениях.
И
{
register int i: // Счетчик цикла
int m. // Число факторов
Code, // Код ошибки
ml: // Счетчик одномерного массива
342
Глава 7. Факторный анализ
double *a,*am, // Факторная матрица
*d,*dm, // Матрица характерностей и обратная ей
*t. // Вспомогательная матрица
buf; // Сумма для проверки сходимости
/////////////////////////////////
// Вычисление m главных компонент
if ((Code = Principal Factor (z,k,r.&m)) ’= 0) return Code;
if ((a = new doublefk * k]) == 0) return -1;
if ((am = new double[k * kJ) == 0)
{ delete [] a; return -1;
}
if ((d = new double[k * kJ) == 0)
{ delete [] a; delete [] am; return -1;
}
if ((dm = new double[k * k]) == 0)
{
delete [] a; delete [] d; delete [] am;
return -1;
}
if ((t = new double[k * k]) == 0)
{
delete [] a; delete [] d; delete [] dm; delete [] am; return -1;
}
///////////////////////////////
// Корректировка числа факторов
if (mz < m && mz > 0)
{
// Заданное количество факторов
*ms = mz; m = mz;
}
el se
// Вычисленное количество факторов
*ms = m;
FillUp (b,k.l);
//////////////////////////////////////////////
// Начало итераций - матрица главных компонент ArrayToArray (r.am.k * m);
do
Метод максимума правдоподобия
343
{
/////////////////////////////////////////
// Матрица А для следующего шага итераций
// Здесь а - матрица A(i - 1/2), как альтернативу
// можно применить функцию ArrayToArray
for (i = 0: i < k * m: i++) a[i] = am[i];
//////////////////////////////// // Определение матрицы общностей MatrixMultiplyMatrixT (a.a.d.k.m.k);
for (i = 0, ml = 0; i < k; i++, ml += k + 1) {
//////////////////////////////
// Вектор общностей для вывода b[i] = d[ml]:
/////////////////////////// // Матрица характерностей D d[ml] = 1 - d[ml];
}
//////////////////////////////////////////////////
// Определение обратной матрицы характерностей DM
if ((Code = InverseMatrix (d.dm.k)) ! = 0) {
delete [] d; delete [] t: delete [] dm: delete [] am;
delete [] a: return Code: }
/////////////////////////////////
// Определение матрицы J(i - 1/2)
// Здесь d - матрица J(i - 1/2)
MatrixTMultiplyMatrix (a,dm,t,m,k,k);
MatrixMultipiyMatrix (t.a,d,m,k,m):
///////////////////////////////////////////////////////// // Вращение матрицы J(i - 1/2) - определение матрицы J(i) // Здесь t - матрица вращения Q
// d - матрица J(i)
if ((Code = Jacobi (d.m.O.000001,&ml,t)) != 0) {
delete [] d; delete [] t; delete [] dm: delete [] am: delete [] a:
return Code;
}
///////////////////////////////////// // Определение факторной матрицы A(i)
344
Глава 7. Факторный анализ
MatrixMultiplyMatrix (a.t.r.k.m.m);
////////////////////////////////////
// Определение обратной матрицы J(1)
// Здесь t - обратная матрица J(i)
if ((Code = InverseMatrix (d.t.m)) != 0)
{
delete [] d; delete [] t; delete [] dm; delete [] am;
delete [] a:
return Code;
}
/////////////////////////////////
// Определение матрицы A(i + 1/2)
// Здесь am - матрица A(i + 1/2)
MatrixMultiplyMatrix (z.dm.am.k.k.k);
for (i = 0, ml = 0; i < k; i++, ml += k + 1)
am[ml] -= 1:
MatrixMultiplyMatrix (am.r.d.k.k.m);
MatrixMultiplyMatrix (d,t.am.k.m,m);
////////////////////////////
// Условие окончания расчета
for (i = 0, buf =0; i < k * m; i++)
buf += fabs (am[il - a[i]);
} while (buf < 0.001);
delete [] d; delete [] t; delete [] dm; delete [] am;
delete [] a;
return 0;
}
Центроидный метод
Браверманом [цит. по 208, с. 194] показано, что в методах главных факторов и главных компонент максимизируется квадратичный критерий. В центроидном методе (методе центра тяжести) максими! зируется модульный критерий. С точки зрения смысловой интерпретации эти критерии эквивалентны. Поэтому утверждения некоторых авторов о том, что центроидный метод является приближенным (очевидно, имеется в виду степень приближения к истине, ибо приближенными в математическом смысле являются все рассмотренные нами методы факторного анализа), что центроидный метод име j ет лишь историческое значение и т. п., не являются оправданными. Описание идеи метода и примеры применения даны в [208, с. 188],
Центроидный метод
345
[126, с. 38], [147, с. 67], причем в [126, с. 139] высказывается предположение об устойчивости центроидного метода (как непараметрического) к колебаниям распределения.
Схемы расчета, данные различными авторами, идентичны во всем, кроме так называемой операции отражения. Так, отражению (см. исходные коды) подвергаются переменные, имеющие наибольшее число отрицательных значений, или только одна из таких переменных [126, с. 43], либо первой одна из переменных, имеющая наибольшее число минусов [208, с. 196], а затем следующая переменная с наибольшим числом минусов и т. д., либо первой — переменная с номером столбца, имеющего максимальную отрицательную сумму [147, с. 76], затем все остальные переменные с отрицательными суммами столбца. Мы просчитали тестовые примеры, приведенные разными авторами, и оказалось, что результаты расчетов нашей программой практически совпадают с результатами, приводимыми авторами, причем мы использовали методику, предложенную в [126, с. 43].
Далее остановимся на методах определения требуемого числа выделяемых факторов. Тэрстоун [147, с. 82] дает формулу определения минимального числа переменных п, необходимых для однозначного определения т факторов. Из формулы Тэрстоуна следует, что
2п +1 - х/втГ+Т т =--------------
В [126, с. 44] приводится правило, ограничивающее число факторов (в тех же обозначениях):
(п + т) < (п - т)2.
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include '‘megastat.h"
void main (void)
{
register int i.j; // Счетчики цикла
int n = 6.
P = 3. m.
Code:
// Размерность корреляционной матрицы
// Число выделяемых факторов
// Счетчик одномерного массива
// Код ошибки
346
Глава 7. Факторный анализ
double а[] = // Исходная корреляционная матрица
{1.000,0.299,0.400.0.297.0.116,0.232.
0.299,1.000.0.568.0.534,0.432.0.154.
0.400,0.568.1.000.0.487.0.436.0.071.
0.297.0.534.0.487.1.000.0.545.0.092.
0.116.0.432.0.436.0.545.1.000.0.016.
0.232.0.154.0.071.0.092.0.016.1.000}.
*с. // Матрица факторного отбражения
s: // Рабочая переменная
с = new double[n * р];
cout « "Original correlation matrix\n";
for (i = 0, m = 0; 1 < n; i++)
{
for (j = 0; j < n: j++. m++) cout « setw (10) « a[m]:
cout « endl;
}
Code = Thurstone (a.n.c.p);
cout « "Return code is " « Code « endl:
if (!Code)
{
cout « "Factor loading matrix\n";
for (i = 0. m = 0; 1 < p; i++)
{
for (j « 0; j < n: j++. m++)
cout « setw (10) « c[m]:
cout « endl:
}
cout « "Variances\n";
for (i = 0. m = 0; i < n; i++)
{
for (j = 0. m = i. s = 0; j < p; j++. m += n) s += c[m] * c[mj;
cout « setw (10) « s:
}
cout « endl:
}
delete [] c:
}
int Thurstone (double a[],int n.double c[],int p)
II
II Функция выполняет факторный анализ центроиднын методом.
// Обозначения:
// а - корреляционная матрица,
// п - порядок корреляционной матрицы.
// с - матрица факторного отображения размером не менее п х р.
Центроидный метод
347
// р - заданное число факторов.
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -1 при недостатке памяти для вычислений.
И
register int i.j.k: // Счетчики цикла
int m, mg = 0. *sign. 1. Code = 0; // Рабочий индекс // Счетчик матрицы факторного отбражения // Массив информации о перемене знаков // Счетчик отрицательных знаков столбца
И Возвращаемое значение
double *r. И Редуцированнная корреляционная матрица
*rl. И Матрица остаточных корреляций
*b. И Массив сумм элементов столбцов
s: // Итоговая сумма
if ((г = new doublefn * nJ) == 0) return -1;
if ((rl = new doublefn * nJ) == 0) {
delete [] r:
return -1:
}
if ((b = new doublefn]) == 0)
{
delete [] r: delete [] rl: return -1;
}
if ((sign = new int[n]) == 0)
{
delete [] r; delete [] rl: delete [] b: return -1;
}
//////////////////////////////////// // Начальные значения массива знаков FillUp (sign.n.l);
//////////////////////////////////////// // Копия исходной корреляционной матрицы ArrayToArray (a.rl.n * п);
//////////////////////////
// Цикл выделения факторов
for (к = 0: к < р: к++)
{
///////////////////////////////////////// // Редукция матрицы остаточных корреляций if (Reduction (rl.r.n.l) != 0)
348
Глава 7. Факторный анализ
{
Code = -1;
break;
}
////////////////////////////////////
// Суммы столбцов матрицы корреляций
for (1 = 0, ш = 0; 1 < п; 1++)
for (j = 0, b[i] = 0; j < n; j++) b[i] += r[m++];
s = sqrt (VectorSum (b.n));
for (1=0; 1 < n; 1++)
{
/////////////////////////////// // Нагрузки на текущий центроид b[i] /= s * sign[i];
/////////////////////////////////////////////// // Заполнение матрицы факторного отображения c[mg++] = b[i];
}
////////////////////////////////
// Матрица остаточных корреляций
for (1 = 0, m = 0; 1 < п; 1++)
for (j = 0; j < n; j++) r[m++] -= b[i] * b[j];
llllllllllllllllllllllllllllllllllllllllllllll
II Анализ знаков матрицы остаточных корреляций
FillUp (sign.n.0);
for (1=0; 1 < n; 1++)
for (j = 1, m = 1 * n + 1: j < n; j++)
if (Sign (r[m++]) == -1) sign[j]++;
for (1=0; 1 < n; 1++)
sign[i] = sign[i] >= n / 2 ? -1 : 1;
/////////////////////////////////////
// Перемена знаков матрицы остаточных корреляций
for (1=0, m = 0; 1 < n; 1++)
for (j = 0; j < n; j++, m++)
rl[m] = (sign[i] == -1 && sign[j] != -1) ||
(sign[j] == -1 && signal J != -1) ? -r[m] : r[m]; }
delete [] r: delete [] rl; delete [] b: delete [] sign;
return Code;
}
Проблема вращения
349
Проблема вращения
Оси координат, соответствующие выделенным факторам, ортогональны, и их направления устанавливаются последовательно, по максимуму оставшейся дисперсии. Но полученные таким образом координатные оси большей частью содержательно не интерпретируются. Поэтому получают более предпочтительное положение системы координат путем вращения этой системы вокруг ее начала. Пространственная конфигурация векторов в результате применения этой процедуры остается неизменной. Целью вращения является нахождение одной из возможных систем координат для получения так называемой простой факторной структуры. Мы применяем популярный метод вращения VARIMAX [174, с. 90,255]. Применяемая в схеме метода операция нормализации обсуждается в разделе «Нейронная сеть прямого распространения» главы 9. Обратная операция называется денормализацией.
Подробное обсуждение проблемы см. в [ПО, с. 184], [126, с. 68], (
[208, с. 326].
Исходные коды
int Varimax (double г[].int k.int m) //
// Функция производит варинакс-вращение матрицы факторного // отображения.
// Обозначения:
// г - матрица факторного отображения размером к * т.
// к - размерность корреляционной матрицы, к > 2.
// m - число факторов.
// Возвращаемое значение:
// 0 при нормальном окончании счета.
// -1 при недостатке памяти для рабочих массивов.
//
{
register int i.j.JI: // Счетчики цикла
int ml.m2,m3.m4: // Счетчик одномерного массива
double *x. // Вращаемая пара векторов
*y. // Повернутая пара векторов
*h. // Суммарная нагрузка
u, V. // Вспомогательные переменные
A.B.C.D. vc = O.vcl, // Величина для проверки окончания процедуры
num. // Числитель и знаменатель
cs[4]: И Матрица вращения
if ((h = new double[k])
0)
350
Глава 7. Факторный анализ
return -1;
//////////////////////////////////
// Нормализация факторных нагрузок
for (1 = 0; i < k: 1++)
for (j = 0. h[i] = 0, ml = i; j < m; j++, ml += k) h[i] += r[ml] * r[ml];
h[1] = sqrt (h[ij);
}
for (i = 0,ml = 0; i < m: i++)
for (j = 0; j < k; j++) r[ml++] /= h[jj;
If C(x = new double[k * 2]) == 0)
{ delete [] h; return -1:
}
if ((y = new double[k * 2]) == 0) {
delete [] x;
return -1;
}
do {
vcl = vc;
////////////////
// Цикл вращения
for (1 =0; i < m - 1; 1++) {
for (j = i + l,m3 = j * k,m4 = m3; j < m; j++) {
III III ШН
II Вектор x
for (jl = 0,ml = i * k,m2 = ml: jl < k; jl++) xC jl] = r[ml++];
///////////
// Вектор у
for (jl = k: jl < k + k; jl++) x[jl] = r[m3++]:
///////////////////////////////////// // Вычисление вспомогательных величин for (jl = 0.A = 0.B = 0.C = 0.D = 0; jl < k: jl++)
{
u = x[jl] * x[jl] - x[jl + k] * x[jl + k]:
v = 2 * x[jl] * x[jl + k]:
Проблема вращения
351
А += и;
В += v:
C+=u*u-v*v;
D += и * v;
}
//////////////////////////////////////
// Тангенс учетверенного угла вращения
num = 2 * (D - А * В / к):
и = num / (С - (А * А - В * В) / к):
/////////////////////////////////////////// // Выбор угла из условия наксинума критерия if (и > 0 && num < 0)
и = atan (и) - M PI;
else if (и < 0 && num > 0)
и = atan (и) + MPI;
el se
и = atan (и);
и /= 4;
////////////////////////////
// Если вращение имеет смысл
if (fabs (u) >= 0.000001)
{
//////////////////////////////
// Вычисление матрицы вращения
cs[0] = cos (и):
cs[1] = sin (и);
cs[2] = -cs[l]:
cs[3] = cs[0];
///////////////////////// // Вращение пары векторов MatrixMultiplyMatrix (x.cs,y.k,2,2):
//////////////////////
// Вектор x - на место
for (jl =0: jl < k: jl++)
r[m2++] = y[jl]:
//////////////////////
// Вектор у - на место
for (jl = k; jl < k + k: jl++) r[m4++] = y[jl];
}
}
}
///////////////////////////////////////////
II Проверка сходимости по варимакс-критерию
352
Глава 7. Факторный анализ
for (1 = 0,vc = O.ml =0: i < m: i++)
{
for (j = 0,u = 0,v =0; j < k; j++,ml++) {
A = r[ml] * r[ml];
u += A * A:
v += A:
}
vc += k * U - v * v;
}
} while (fabs (vcl - vc) > 0.000001):
delete [] x; delete [] y:
////////////////////////////////////
// Денорнализация факторных нагрузок
for (1 = O.ml =0: i < m: 1++)
for (j = 0: j < k; j++)
r[ml++] *= h[j];
delete [] h:
return 0:
}
Критерии максимального числа факторов
Существует несколько критериев оценки максимального числа удерживаемых факторов. Критерии, основанные на анализе определителей (детерминантов) исходной и воспроизведенной корреляционной матриц, не показывают стабильности. Критерии, основанные на величине собственных значений корреляционной матрицы, в конечном счете приводят к анализу процента дисперсии, выделенной факторами. Все общие факторы, число которых равно числу параметров, выделяют 100% дисперсии. Если сумма процентов дисперсии превышает величину 100%, то это означает: при вычислении собственных значений корреляционной матрицы были получены отрицательные собственные значения и, как следствие, комплексные! собственные вектора, что может означать некорректную редукцию исходной корреляционной матрицы.
Таким образом, максимальное число удерживаемых факторов можно приблизительно установить из анализа процента дисперсии, выдаваемой программой для каждого фактора (можно было бы выдать
Критерии максимального числа факторов
353
и собственные значения, как это делается в каноническом дискриминантном анализе). Резюмируя сказанное выше, мы рекомендуем такой порядок действий: сначала пользователь проводит «разведочный» факторный анализ без указания максимального числа факторов, затем по величине дисперсий приблизительно оценивает число факторов, задает их или поручает сделать это программе и проводит повторный анализ, используя его результаты как окончательные. Обсуждение см. в [95, с. 35, 208].
Исходные коды
void PercentOfVariance (double z[],int k.double r[],double s[],int ms)
II
II Функция вычисляет процент дисперсии, выделенной факторами.
// Обозначения:
// z - корреляционная матрица.
// к - размерность корреляционной матрицы,
// г - матрица факторного отображения.
// s - вектор процентов дисперсии.
// ms - число факторов.
// Примечание:
И функция применяется после успешного завершения факторного // анализа, поэтому ошибка типа нулевой суммарной дисперсии // не отслеживается.
// Возвращаемое значение:
// нет.
//
{
register int i.j: // Счетчики
int m; // Счетчик одномерного массива
double sd = 0; // Суммарная дисперсия
for (i = 0. m = 0; i < k: i++)
{
sd += z[m]:
m += k + 1:
)
for (i = 0. m = 0: i < ms; i++)
{
for (j = 0. s[i] = 0; j < k; j++. m++) s[i] +» r[m] * r[m];
s[i] /= sd / 100;
12-2002
354
Глава 7. Факторный анализ
Визуализация результатов факторного анализа
Пусть в эксперименте получены некоторые опытные данные, представляющие собой измерения трех параметров, обозначенных цифрами 1, 2 и 3. В результате проведенных расчетов были выделены два фактора (две главные компоненты), обозначенные буквами А и В
Рис. 7.1. Изученные параметры 1,2 и 3 в пространстве главных компонент, которым соответствуют фактор А и фактор В
Из рис. 7.1 видно, что вектора данных четко распадаются на две груп-пы: одну группу, включающую в себя параметр 1 и параметр 2, и другую группу, включающую в себя параметр 3. Таким образом, по результатам расчета можно выдвинуть гипотезы:
• Параметр 1 и параметр 2 имеют сильную взаимную линейную корреляцию.
• Параметр 3 слабо зависит от параметров 1 и 2 в рассматриваемых сериях эксперимента.
Практический вывод: в эксперименте достаточно измерять не три параметра, а только два: параметр 1 (или 2) и параметр 3. Это послужит снижению стоимости эксперимента практически без потери точности выводов.
Дальнейшие исследования и программные ресурсы
• Нелинейный факторный анализ.
В табл. 7.1 приводятся адреса некоторых программных ресурсов по факторному анализу.
дальнейшие исследования и программные ресурсы 355
Таблица 7.1 Ресурсы по программным продуктам анализа данных. Факторный анализ
ресурс, адрес Разработчик или поставщик Содержание
www.bmstu.ru /facult/iu/iu4 /rus/stat/book5 www.simstat.com www.exetersoft ware.com Институт вычислительного моделирования СО РАН Provalis Research Exeter Software FAMaster, восстановление пропущенных данных с помощью методов факторного анализа, бесплатная версия EASY FACTOR ANALYSIS, анализ главных факторов и главных компонент NTSYSpc, программа многомерного анализа данных, включая факторный анализ
7
12*
Глава 8. Распознавание образов без обучения
Эпиграфом данной главы мог бы быть известный афоризм «Не в совокупности ищи единства, но более — в единении разделения»». Для определенности условимся: вынесенное в название главы положение следует понимать в том смысле, что программная система на основании определенных выделенных самой системой критериев производит классификацию предъявляемых ей образов. При этом возможно задание некоторых наборов параметров, но разделение объектов по классам на основе этих наборов будет выполнено автоматически.
Классическими методами распознавания образов без обучения являются методы кластерного анализа (кластер-анализа). В после-8 днее время для решения задачи распознавания образов без обучения применяются также и нейронные сети, однако этот интересный раздел мы оставим пока за рамками нашего рассмотрения.
Номера, получаемые в результате расчета кластеров, смыслового значения не имеют. Эти номера нужны только для того, чтобы отличить один кластер от другого, поэтому при использовании результатов кластерного анализа в других методах, например в распознавании образов с обучением, порядок следования кластеров может быть любым удобным для исследователя.
Все рассмотренные далее методы могут быть использованы как для классификации объектов, так и для классификации признаков [79, с. 104]. Общие понятия классификации рассмотрены в [40, с. 129]. Основные понятия распознавания образов и ссылки на ряд исследовательских программ применительно к изображениям даны в [61].
Меры различия и меры сходства
Виды используемых в кластерном анализе мер сходства и различия перекликаются с философской дилеммой: «ищите сходство» или
Прутков К. Плоды раздумья. Мысли и афоризмы: Сочинения. — М.: Правдам 1986. - С. 100.
Меры различия и меры сходства
357
«ищите различие». Меры сходства для кластерного анализа могут быть следующих видов:
• Мера сходства типа расстояния (функции расстояния), называемая также мерой различия. В этом случае объекты считаются тем более похожими, чем меньше расстояние между ними, поэтому некоторые авторы называют меры сходства типа расстояния мерами различия.
• Мера сходства типа корреляции, называемая связью, является мерой, определяющей похожесть объектов. В этом случае объекты считаются тем более похожими, чем больше связь между ними. Меры могут быть легко приведены к предыдущему типу, как показано ниже.
• Информационная статистика.
Рассмотренными ниже мерами могут оперировать различные методы кластерного анализа, но программные реализации этих методов, в зависимости от меры сходства или меры различия, различны.
Меры различия и информационная статистика
Показанная ниже функция служит для построения матрицы мер сходства типа расстояния.
Исходные коды
int Likeness (double data[],double z[],double s[],int n.int k.int Mode) //
// Функция строит матрицу мер сходства типа расстояния.
// Обозначения:
// data - массив исходных данных об объектах (к векторов
// друг за другом).
// z — вычисленный массив мер сходства размером п х п.
// s - заранее вычисленная обратная дисперсионно-ковариационная
// матрица (только для вычисления расстояния Махаланобиса).
// п - число классифицируемых объектов.
//к число параметров, описывающих каждый объект.
// Mode - вариант меры сходства:
// = 0 - евклидово расстояние.
// = 1 - манхеттенское расстояние.
// = 2 - расстояние Махаланобиса,
// = 3 - супремум-норма.
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
358
Глава 8. Распознавание образов без обучения
// -1 при недостатке памяти.
И
{
register int i,j,l: // Счетчики
int m.ml.m2: // Счетчик одномерного массива
double *datl,*dat2; // Копии векторов данных
if ((datl = new double[k]) == 0) return -1;
if ((dat2 = new double[k]) == 0) {
delete [] datl;
return -1;
}
//////////////////////////////
// Построение матрицы сходства for (i = 0. m2 = 0: i < n; i++) for (j = 0: j < n: j++) {
//////////////////////////////////////////////////// // Копия делается в текущем цикле для восстановления // после разрушения datl функцией Mahalanobis for (1 = 0, m = i; 1 < k; 1++, m += n) datl[l] = data[m];
for (1 = 0, ml = j; 1 < k; 1++. ml += n) dat2[l] = data[ml];
switch (Mode) { case 0:
z[m2++] = Euclid (datl,dat2.k);
break:
case 1:
z[m2++] = CityBlock (datl,dat2.k): break: case 2:
z[m2++] = Mahalanobis (datl.dat2,s,k);
break:
default: z[m2++] = Sup (datl,dat2.k): }
}
delete [] datl; delete [] dat2:
return 0;
}
Меры различия и меры сходства
359
Используемые при этом метрики — евклидово расстояние, манхет-тенское расстояние, сюпремум-норма — описаны в главе 14. В главе 11 рассматривается расстояние Махалонобиса.
Перечисленные меры сходства выбраны нами не случайно. Они отражают все многообразие подходов к решению проблемы. Первая метрика используется традиционно, вторая метрика является наиболее известным представителем класса метрик Минковского. Расстояние Махаланобиса, по определению метрикой не являющееся, связано с помощью дисперсионно-ковариационной матрицы с корреляциями переменных (параметров), и широко применяется как в кластерном, так и в других методах анализа данных. Другие метрики, такие как метрика Брея—Кертиса, Канберровская метрика и т. д., подробно исследованы в [ 191, с. 278] и могут быть легко запрограммированы по образцу показанных нами функций.
Меры сходства используются нами для методов:
• ближней связи (этот метод имеет вариант и для мер сходства);
• средней связи Кинга;
• Уорда;
• ^-средних Мак-Куина.
Меры сходства
Показанная ниже функция применяется для построения матрицы мер сходства (связей) типа корреляции. Функция не оптимальна. Как мы уже указывали при описании мер сходства в разделе «Корреляция номинальных признаков» главы 5, для исследования корреляции в таблицах сопряженности (последние 6 мер сходства) логичнее выделить из тела функций построение самих таблиц сопряженности, поручив это отдельной функции. Это улучшило бы структуризацию программы. О сокращении времени расчета в общем говорить не приходится, так как кластеризация производится с использованием только одной избранной исследователем меры сходства. В этом случае функция построения матрицы мер сходства уже не будет столь универсальной, как показанная ниже. Уменьшение объема программы, достигнутое выделением блока построения таблицы сопряженности из функций расчета мер сходства, с лихвой компенсируется необходимостью построения отдельной функции вычисления матрицы сходства для случая исследования номинальных переменных. В любом случае выбор остается за программистом.
360
Глава 8. Распознавание образов без обучения
Матрица мер сходства типа корреляции может быть построена с помощью показанной ниже функции LikenessForCorrelation с использованием обозначенных параметром Mode мер сходства, за исключением коэффициента Гауэра. Матрица мер сходства в случае применения коэффициента Гауэра строится функцией Gower. Впрочем, пользователь может и сам легко составить функцию построения матрицы мер сходства путем модификации той же функции LikenessForCorrelation в результате ее упрощения либо добавления новых, введенных им мер.
Исходные коды
int LikenessForCorrelation (double data[].double z[].int n.int k.int Mode) //
// Функция строит матрицу мер сходства типа корреляции.
// Обозначения:
// data - массив исходных данных (к векторов друг за другом).
// z - корреляционная или ковариационная матрица размером к * к.
// п - длина каждого из к векторов.
// Mode - вариант меры сходства:
// = 0 - коэффициент Пирсона.
// = 1 - дисперсия-ковариация.
// = 2 - показатель Спирмэна.
// = 3 - коэффициент Кендалла.
// = 4 - хеммингово расстояние.
// = 5 - показатель подобия Жаккарда.
// = 6 - простой коэффициент встречаемости.
// = 7 - показатель подобия Рассела и Рао.
// = 8 - показатель подобия Юла.
// = 9 - коэффициент сопряженности Бравайса
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -1 при недостатке памяти.
//
{
register int i.j.l; // Счетчики цикла
int m,ml.m2; // Счетчик одномерного массива
double criterion.t. // Вспомогательные величины *datl.*dat2; // Копии векторов данных
if ((datl = new double[n]) == 0) return -1:
if ((dat2 = new double[n]) == 0) {
delete [] datl;
return -1;
}
Меры различия и меры сходства
361
I
//////////////////////////////
// Построение матрицы сходства
for (i = 0, m = 0, m2 = 0: i < к; 1++) { for (1=0; 1 < п; 1++)
datl[l] = data[m++];
for (j = 0, ml = 0; j < к; j++) {
for (1 = 0: 1 < n; 1++) dat2[l] = data[ml++]; switch (Mode)
{
case 0:
criterion = Pearson (datl,dat2,n):
break:
case 1:
criterion = Cov (datl,dat2,n); break;
case 2:
if (Spearman (datl,dat2,n.&criterion,&t) == -1) {
delete [] datl: delete [] dat2;
return -1; }
break;
case 3:
if (Kendall (datl,dat2,n.&criterion,&t) == -1) {
delete [] datl; delete [] dat2;
return -1; }
break:
case 4:
criterion = Hemming (datl,dat2,k) / k; break;
case 5:
criterion = Jaccard (datl,dat2,k): break;
case 6:
criterion = Sokal (datl.dat2,k): break: case 7:
criterion = Rao (datl.dat2,k): break;
case 8:
criterion = Yule (datl,dat2.k): break: default:
criterion = Bravais (datl,dat2.k): }
z[m2++] = criterion:
362
Глава 8. Распознавание образов без обучения
}
delete [] datl; delete [] dat2;
return 0:
}
Связями могут быть: коэффициент корреляции, коэффициенты ассоциативности (ассоциации) и т. д. Из этих связей для количе-) ственных признаков предназначены: коэффициент корреляционного отношения Пирсона, дисперсия-ковариация. Для порядковых признаков предназначены: показатель ранговой корреляции Спирмэна, коэффициент ранговой корреляции Кендалла. Отметим, что данные показатели с помощью простого преобразования могут быть приведены к мерам сходства типа расстояния соответственно с помощью формул [82, с. 92]
dij =1-ps, dij = 1-т.
В этом случае они будут называться расстоянием Спирмэна и расстоянием Кендалла. Мы не применяем данное преобразование, однако оно может быть легко запрограммировано подобно формулам предыдущего раздела.
Для дихотомических признаков и признаков, размещенных в таблицах сопряженности, предназначены: хеммингово расстояние, показатель Жаккарда, простой коэффициент встречаемости, показатель Рассела и Рао, коэффициент ассоциации Юла, коэффициент сопряженности Бравайса. Как и в предыдущем случае, рассмотренные показатели подобия можно преобразовать (кроме хеммингова расстояния), отняв вычисленное значение от единицы. В этом случае рассмотренные меры называют расстояниями [82, с. 93].
Для смешанных признаков предназначен коэффициент Гауэра, представленный в разделе «Корреляция признаков, измеренных в различных шкалах» главы 5. Перечисленные меры сходства используют методы:
• ближней связи (этот метод имеет вариант и для мер различия);
• корреляционных плеяд;
• максимального корреляционного пути.
По умолчанию в последних двух методах обычно классифицируют] ся параметры (в первом классифицируются объекты), что обусловлено их традиционной авторской реализацией и назначением, однако путем простого транспонирования матрицы исходных данных
Кластерный анализ
363
и перемены местами чисел строк и столбцов можно легко изменить тип классификации на противоположный.
В комбинации с различными метриками, связями и мерами сходства других типов перечисленные алгоритмы дают большое число вариантов решения задачи классификации без обучения. Результаты классификации разными методами, как правило, принципиально не различаются, и выбор того или иного метода является делом вкуса исследователя и традиции школы.
Кластерный анализ
Методами кластерного анализа решается задача разбиения (классификации, кластеризации) множества объектов таким образом, чтобы все объекты, принадлежащие одному кластеру (классу, группе) были более похожи друг на друга, чем на объекты других кластеров. В отечественной литературе синонимом термина «кластерный анализ» является термин «таксономия». В иностранной литературе под таксономией традиционно понимается классификация видов животных и растений [186, с. 103].
Здесь рассматриваются следующие методы кластерного анализа:
• Иерархические методы:
о метод ближней связи,
о метод средней связи Кинга,
о метод Уорда.
• Итеративные методы группировки:
о метод ^-средних Мак-Куина.
• Алгоритмы типа разрезания графа:
о метод корреляционных плеяд Терентьева, о вроцлавская таксономия.
Как уже указывалось, классифицируемы могут быть как параметры, так и объекты, поэтому по ходу изложения там, где идет речь о классификации объектов, вполне можно говорить о классификации параметров, и наоборот.
Существует специальная общая формула пересчета расстояния между классами Ланса и Уильямса [78, с. 155], [130, с. 69]:
dk(ij) = aidkt + ajdkj + bdij + c | dk - dkj |,
364
Глава 8. Распознавание образов без обучения
где ah cij, b, с — параметры, определяющие способ расчета расстояния между кластерами.
В зависимости от значения параметров, входящих в эту формулу, могут быть получены:
я, = dj = 1/2, b = 0, с = - 1/2 — метод ближней связи,
di = dj= 1/2, b = 0, с = 1/2 — метод дальней связи и т. д., см. [79, с. 39]. В [130, с. 69] и [82, с. 120] дана еще более общая, чем показанная выше, формула Жамбю, позволяющая получить разнообразные варианты кластеризации. В [130, с. 48] дана подробная классификация алгоритмов кластерного анализа, описаны десятки процедур и мер сходства и различия, а также приведена исчерпывающая библиография. Нами выбраны лишь несколько характерных процедур.
Метод ближней связи
Этот метод является самым простым для понимания из иерархических агломеративных методов кластерного анализа. Метод начи-_ нает процесс классификации с поиска и объединения двух наиболее похожих объектов в матрице сходства. На следующем этапе находятся два очередных наиболее похожих объекта, и процедура повторяется до полного исчерпания матрицы сходства.
В процессе кластеризации методом ближней связи явно прослеживается образование цепочек объектов. Таким образом, для выделения кластеров после окончания процесса кластеризации требуется задаться некоторым пороговым уровнем сходства, на котором выделяется число кластеров, большее единицы. Процедура не всегда обнаруживает такое свойство, как образование одного большого кластера на последнем этапе кластеризации, и часто заканчивается явным разделением всех предъявленных объектов на кластеры.
После проведения классификации рекомендуется визуализировать результаты кластеризации путем построения дендрограммы (ден-дограммы) [79, с. 72]. Для большого числа объектов такая визуализация является единственным способом получить представление об общей конфигурации объектов.
Пример применения
if (’NearLink (data.ns.ph.pl,t))
for (i = 0; i < ns; i++)
cout « (ph[i] + 1) « " - H « (pl[i] + 1) « " Link = « t[i] « endl;
el se
cout « "Мало панятиХп";
Кластерный анализ
365
3 показанной далее функции, производящей кластерный анализ, используется мера сходства типа корреляции (чем больше мера, тем сильнее связь между объектами).
Исходные коды
int NearLink (double a[],int n.int ph[].int pl[],double s[J) //
// Функция производит кластерный анализ методом ближней связи.
// Обозначения:
// а - матрица связи,
// п - число объектов, подлежащих классификации,
// ph.pl - на выходе - массивы номеров длиной п каждый,
// содержащие информацию о группировке объектов,
// s - на выходе - массив длиной п - уровни объединения
// пар [ph.pl].
// Возвращаемое значение:
// 0 при нормальном окончании расчета,
// -1 при недостатке памяти.
// { register int i.j; // Счетчик цикла
int k = 0, // Счетчик пар номеров
ш; // Счетчик одномерного массива
double buf, // Рабочая переменная
*t; // Копия исходной матрицы связи
if ((t = new double[n * n]) == 0) return -1:
ArrayToArray (a.t.n * n);
do { buf = MaximumOf (t.n * n);
for (i = 0, m = 0; i < n; i++)
for (j = 0: j < n: j++, m++) if (t[m] == buf)
{
///////////////////////
// Запомнить соединение ph[k] = 1;
pl Ek] = j: s[k++] = buf;
//////////////// // Убрать строку FillUpCol (t.n.i.O);
366
Глава 8. Распознавание образов без обучения
////////////////////////////// // Убрать симметричный элемент t[j * п + 1] = 0:
}
} while (к < п);
delete [] t;
return 0:
}
В показанной далее функции, производящей кластерный анализ, в отличие от предыдущего случая, используется мера сходства типа расстояния (чем меньше мера, тем сильнее связь между объектами).
Исходные коды
int Near (double data[].int n.int k.int Mode.int ph[].int pl[],double s[]) //
// Функция производит кластерный анализ методом ближней связи.
// Обозначения:
// data - матрица исходных данных размером п * к
// (к векторов длиной п друг за другом).
// п - число объектов, подлежащих классификации.
// к - число параметров,
// Mode - вариант меры сходства, см. пояснения к функции
// построения матрицы сходства.
// ph.pl - на выходе - массивы номеров длиной п каждый,
// содержащие информацию о группировке объектов.
// s - на выходе - массив длиной п - уровни объединения
// пар [ph.pl].
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -1 при недостатке памяти.
И
{
register int i.j: // Счетчик цикла
int kl = 0. // Счетчик пар номеров
Code. // Код ошибки
т; // Счетчик одномерного массива
double buf.bufl. // Рабочая переменная
*t, // Матрица, обратная дисперсионно-
//ковариационной
*z; // Матрица сходства
if ((z = new double[MaximumOf (k.n) * MaximumOf (k.n)]) == 0)
return -1:
if ((t = new double[k * k]) == 0)
Кластерный анализ
367
{
delete [] z;
return -1;
}
////////////////////////////////////////////////// // Построение обратной дисперсионно-ковариационной // матрицы для вычисления расстояния Махаланобиса if (Mode == 2)
{
///////////////////////////////////////////////// // Построение дисперсионно-ковариационной матрицы Code = LikenessForCorrelation (data,z.n,k.1);
if (Code != 0) { delete [] t: delete [] z: return Code;
}
//////////////////////////////////////////////// // Матрица, обратная дисперсионно-ковариационной Code = InverseMatrlx (z.t.k);
if (Code != 0)
{
delete [] t; delete [] z;
return Code;
}
}
if ((Code = Likeness (data.z.t.n.k,Mode)) != 0)
{
delete [] t; delete [] z;
return Code;
}
delete [] t;
//////////////////
// Сдвиг максимума
bufl = MaximumOf (z.n * n) + 1;
///////////////////////////////////
// Фактическое исключение диагонали
for (i = 0, m = 0; i < n; i++. m+= n+ 1) z[m] = bufl;
do
{
buf = MinimumOf (z.n * n);
368
Глава 8 Распознавание образов без обучения
for (i=0. m=0;i<n; i++)
for (j = 0: j < n; j++, m++)
1f (z[m] == buf)
{
///////////////////////
// Запомнить соединение phEklJ = i; pl[kl] = j; s[kl++] = buf;
//////////////// // Убрать строку FillUpCol (z.n.i.bufl);
////////////////////////////// 11 Убрать симметричный элемент z[j * n + i] = bufl:
}
} while (kl < n);
delete [] z;
8 return 0;
}
Метод средней связи Кинга
Метод средней связи подобен методу ближней связи. Разница в том, что на каком-либо этапе ранее объединенные в один кластер! объекты считаются одним объектом с усредненными по кластеру параметрами [96, с. 131], [148, с. 172].
В процессе кластеризации методом средней связи явно прослеживается образование цепочек объектов. Таким образом, для выделения кластеров после окончания процесса кластеризации требуется задаться некоторым пороговым уровнем сходства, на котором выделяется число кластеров, большее 1. Как и предыдущий описанный нами метод, данная процедура не всегда обнаруживает такое свойство, как образование одного большого кластера на последнем этапе кластеризации. Кластеризация часто заканчивается явным раз-| делением объектов на кластеры.
После проведения классификации рекомендуется визуализировать результаты кластеризации путем построения дендрограммы, как это показано ниже. Для большого числа объектов такая визуализация является единственным способом получить представление об общей конфигурации пространства объектов.
Кластерный анализ
369
Пример применения
if (KCode = King (z, n. ns. Likeness, ph, pl ,p))) for (i = 0: i < n - 1: i++)
{
for (j = 0; j < n - i; j++)
cout « (j + 1) « "
cout « "ХпОбъединены объекты: "
« (ph[i] + 1) « « (pl[i] + 1)
« " Link = ” « p[i] « endl
« "ХпСделана перенумерация, исключен номер " « (pl И ] + 1) « endl:
}
else if (Code == -1)
cout « "Мало памятиХп":
el se
cout « "Потеря значимости при вычисленииХп":
По поводу алгоритма показанной далее функции поясним, что на каждом (г + 1)-м шаге кластер, объединивший объекты (кластеры) на шаге г, имеет номер меньшего из сравниваемых номеров объектов, остальные объекты перенумеровываются, и количество объектов уменьшается, таким образом, на 1.
Исходные коды
int King (double data[],int n.int k.int Mode.int ph[].int pl[],double s[])
11
II Функция производит кластерный анализ методом средней связи // Кинга.
// Обозначения:
// data - матрица исходных данных размером п * к
// (к векторов длиной п друг за другом),
// п - число объектов, подлежащих классификации.
// к - число параметров,
// Mode - вариант меры сходства, см. примечания к функции
// LikenessForCorrelation.
// ph.pl - на выходе - массивы номеров длиной (п-1) каждый.
// содержащие информацию о группировке объектов.
// s - уровень объединения пар [ph.pl].
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -1 при недостатке памяти.
// -2 при потере значимости.
И
{
register int i.j, // Счетчик цикла
1; // Счетчик кластеров
int m.ml.
// Счетчик одномерного массива
370
Глава 8. Распознавание образов без обучения
г. // Число объектов на текущей шаге
Code = 0; // Возвращаемый код ошибки
double *z,*dat, // Рабочая матрица
*t: // Матрица, обратная дисперсионно-
// ковариационной
if ((t = new double[k * k]) == 0) return -1;
////////////////////////////////////////////////// // Построение обратной дисперсионно-ковариационной // матрицы для вычисления расстояния Махаланобиса if (Mode == 2)
{
/////////////////////////////////////////////
// Здесь z временно используется для хранения
// дисперсионно-ковариационной матрицы
if ((z = new double[k * kJ) == 0)
{
delete [] t:
return -1;
}
///////////////////////////////////////////////// 11 Построение дисперсионно-ковариационной матрицы Code = LikenessForCorrelation (data.z.n.k.l);
if (Code != 0) { delete [] t: delete [] z: return Code:
}
////////////////////////////////////////////////
// Матрица, обратная дисперсионно-ковариационной Code = InverseMatrix (z.t.k):
/////////////////////////////////////// // Теперь память для массива z свободна delete [] z:
if (Code != 0)
{
delete [] t:
return Code: }
}
if ((dat = new double[n * k]) == 0)
{
delete [] t:
Кластерный анализ
371
return -1;
}
/////////////////////////////////
// Копия исходного массива данных
ArrayToArray (data.dat,п * к):
////////////////
// Основной ЦИКЛ
for (1 = 0. г = n: 1 < п - 1; 1++, г—)
{
if ((z = new double[r * г]) == 0)
{
delete [] t: delete [] dat:
return -1;
}
//////////////////////////////
11 Построение матрицы сходства
if ((Code = Likeness (dat,z,t,r,k,Mode)) != 0)
{
delete [] t: delete [] z: delete [] dat: return Code;
}
/////////////////////////////////////////////
// Поиск двух наиболее похожих объектов путем
// анализа нижнего треугольника матрицы сходства
for (i = 0: i < г: i++)
for (j 1 + 1, m = i * г + i + 1: j < r; j++. m++) if (m == 1 || z[m] < s[l])
{
ph[l] = i: // Номер первого элемента пары объектов pl [1] = j: // Номер второго элемента лары объектов s[l] = z[m]; // Расстояние между объектами кластера
}
////////////////////////////////////////////////////
// Теперь массив z используется для хранения массива
// данных, полученного на предыдущем шаге
delete [] z:
if ((z = new double[r * k]) == 0)
{
delete [] t; delete [] dat;
return -1;
}
///////////////////////////////// // Копия исходного массива данных ArrayToArray (dat.z.r * k);
372
Глава 8. Распознавание образов без обучения
////////////////////////////////////////
// Уменьшенный на 1 строку массив данных delete [] dat;
dat = new double[(r - 1) * k];
////////////////////////////////////////////
// Центр тяжести нового кластера на месте ph[l] for (j = 0, ml = ph[l], m = pl[l]; j < k;
j++, ml += r, m += r) z[ml] = (z[ml] + z[m]) / 2;
/////////////////////////////////////////
// Сдвинуть строки на место pl[l] и далее
for (1 = pl[1]: i < г - 1; 1++)
for (j = 0, m = 1; j < k; j++, m += r) z[m] = z[m + 1];
/////////////////////////////
// Копия уменьшенного массива
for (i = 0; i < r - 1; i++)
for (j = 0. m = i. ml = i; j < k;
j++, m += r - 1. ml += r)
dat[m] = z[ml];
8
/////////////////////////////////////////////////// // Теперь массив z свободен и будет использован для // хранения матрицы сходства delete [] z;
}
delete [] t; delete [] dat:
return Code;
}
Метод Уорда
Данный метод напоминает метод средней связи Кинга. Особенность состоит в том, что основанием для помещения объекта в кластер является не близость двух объектов в каком-либо смысле, в зависимости от меры сходства, а минимум дисперсии внутри кластера при помещении в него текущего классифицируемого объекта [79, с. 30], [148, с. 174].
В процессе кластеризации методом Уорда явно прослеживается образование цепочек объектов. Таким образом, для выделения кластеров после окончания процесса кластеризации требуется задаться некоторым пороговым уровнем сходства, на котором выделяется число кластеров, большее 1. Процедура не всегда обнаруживает такое
Кластерный анализ
373
свойство, как образование одного большого кластера на последнем этапе кластеризации. Кластеризация часто заканчивается явным разделением объектов на кластеры.
После проведения классификации рекомендуется визуализировать результаты кластеризации путем построения дендрограммы. Для большого числа объектов такая визуализация является единственным способом получить представление об общей конфигурации объектов.
Пример применения аналогичен предыдущему. Относительно алгоритма поясним, что на каждом (i + 1)-м шаге кластер, объединивший объекты (кластеры) на шаге i, имеет номер меньшего из сравниваемых номеров объектов, остальные объекты перенумеровываются, и количество объектов уменьшается, таким образом, на 1.
Исходные коды
int Ward (double data[],int n,int k.int ph[],int pl[],double s[])
//
// Функция производит кластерный анализ методой Уорда.
// Обозначения:
// data - матрица исходных данных размером п * к
// (к векторов длиной п друг за другом),
// п - число объектов, подлежащих классификации.
// к - число параметров.
// ph.pl - на выходе - массивы номеров каждый длиной (п-1),
// содержащие информацию о группировке объектов,
// s - уровень объединения пар [ph.pl].
// Возвращаемое значение:
// 0 при нормальном окончании расчета,
// -1 при недостатке памяти,
// -2 при потере значимости.
//
{
register int i,j.ll, H Счетчик цикла
1; // Счетчик кластеров
int m.ml,m2. // Счетчик одномерного массива
r, H Число объектов на текущем шаге
Code = 0, H Код ошибки
*inf: H Количество элементов в кластерах
double *z,*dat. // Рабочая матрица
*datl,*dat2; H Копии векторов данных
if ((dat = new double[n * k]) == 0) return -1;
if ((inf = new int[n]) == 0)
374
Глава 8. Распознавание образов без обучения
{
delete [] dat: return -1;
}
if ((datl = new double[n]) == 0)
{
delete [] dat: delete [] inf: return -1:
}
if ((dat2 = new double[n]) == 0)
{
delete [] datl: delete [] inf: delete [] datl: return -1;
}
////////////////////////////////////////////
// На первом шаге - по 1 элементу в кластере
FillUp (inf.n.l):
///////////////////////////////// // Копия исходного массива данных ArrayToArray (data,dat.n * k);
8 ////////////////
// Основной цикл
for (1=0. г = n: 1 < n - 1: 1++. г—)
{
if ((z = new double[r * r]) == 0) {
delete [] dat; delete [] inf: delete [] datl;
delete [] dat2:
return -1: }
//////////////////////////////////////////// // Построение внутригрупповых сумм квадратов for (i = 0, m2 = 0; i < r; i++)
{
for (11=0, m = i; 11 < k; 11++. m += r) datl[ll] = dat[m]:
for (j = 0: j < r: j++) {
for (11 = 0, ml = j: 11 < k; 11++, ml += r) dat2[ll] = dat[ml]:
z[m2++] = Euclid (datl.dat2.k) * inf[i] * inf[j] / (inf[i] + inffj]);
}
}
///////////////////////////////////////////// // Поиск двух наиболее похожих объектов путем // анализа нижнего треугольника матрицы сходства
Кластерный анализ
375
for (1=0: 1 < г: 1++)
for (j « 1 + 1, и - 1 * г + i + 1; j < г; j++. m++) If (m == 1 || z[m] < s[l])
{
ph[l] =1; // Номер первого элемента пары
// объектов
pl[l] = j: // Номер второго элемента пары
// объектов
s[l] = z[m]: // Расстояние между объектами
// кластера
}
//////////////////////////////////////////////////// // Теперь массив z используется для хранения массива // данных, полученного на предыдущем шаге delete [] z:
if ((z = new double[r * k]) == 0)
{
delete [] dat; delete [] inf; delete [] datl;
delete [] dat2;
return -1;
}
///////////////////////////////// // Копия исходного массива данных ArrayToArray (dat.z.r * k);
//////////////////////////////////////// // Уменьшенный на 1 строку массив данных delete [] dat:
dat = new double[(r - 1) * k]:
////////////////////////////////////////////
// Центр тяжести нового кластера на месте ph[l] for (j = 0, ml = ph[l]. m = pl[1]: j < k;
j++, ml += r. m += r)
z[ml] = (z[ml] + z[m]) / 2:
//////////////////////////////////// // Добавился элемент в кластер ph[l] inf[ph[l]J += 1:
///////////////////////////////////////// // Сдвинуть строки на место р1[1] и далее for (1 = pl[1]: 1 < г - 1: 1++)
{
inf[i] = inf[i + 1]:
for (j = 0, m = 1: j < k; j++. m += r) z[m] = z[m + 1];
}
///////////////////////////// // Копия уменьшенного массива
376
Глава 8. Распознавание образов без обучения
for (1=0: 1<г-1: 1++)
for (j = 0. m = 1, ml = 1: j < к: j++, m += r - 1, ml += r) dat[m] = z[ml]:
/////////////////////////////////////////////////// II Теперь массив z свободен и будет использован для // хранения матрицы сходства delete [] z;
}
delete [] dat: delete [] inf; delete [] datl: delete [] dat2;
return Code:
}
Метод к-средних Мак-Куина
Теоретическое обоснование метода ^-средних (k внутригрупповых средних) сравнительно просто, логично и может быть найдено во многих источниках. Принцип классификации сводится к некоторому, 8 возможно, случайному, исходному разбиению множества объектов на заданное число кластеров (классов, групп, популяций), последующему отнесению остальных объектов к ближайшим кластерам, пересчету новых «центров тяжести» кластеров и продолжению описанной процедуры, пока не будет получено некоторое оптимальное разбиение [186, с. 109]. Кластеризация обычно продолжается, пока новые «центры тяжести» кластеров не перестанут отличаться от старых «центров тяжести». Особенностью метода является то, что выделенные в результате расчетов кластеры не будут пересекаться — гарантируется, что каждый классифицированный объект будет отнесен только к одному кластеру. Отметим, что в цитируемом источнике рассматривается в качестве меры сходства евклидово расстояние. В показанной же ниже функции применяется мера сходства, выбираемая из целого набора различных мер.
В визуализации результатов кластеризации методом ^-средних, по нашему мнению, совершенно нет необходимости, хотя может оказаться наглядным и красивым изображение пространственных эллипсоидов (только для размерности не более 3, для большей же размерности используются двумерные срезы пространства), содержащих классифицированные объекты.
С описанием методики расчета можно ознакомиться в [207, с. 119], [96, с. 131], [148, с. 176]. Дополнительная информация о методе и его многочисленных, по-разному называемых вариантах содержится
Кластерный анализ
377
в массе источников, часть из которых указана в списке литературы. Авторство метода установить сейчас не представляется возможным, поэтому мы привели один из вариантов наименования. По крайней мере, если Мак-Куин и не был автором метода, название было предложено им [130, с. 60]. Дополнительно укажем на изобретенный Боллом и Холлом алгоритм ISODATA [217, с. 348], который в принципе аналогичен изложенному алгоритму, но отягощен набором вспомогательных эвристических процедур [186, с. 112], [79, с. 33].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void) {
register int i. j: // Счетчики цикла
int n = 20. // Число объектов
k = 2, // Число параметров
m = 2. // Заданное число кластеров
Mode = 0. // Код меры сходства
Counter, // Число проделанных итераций
*inf. // Массив принадлежности объектов кластерам
Code. // Код ошибки
1: // Счетчик одномерного массива
double data[] = {0,1. .0.1.2.1.2,3.6.7.8.6.7,8.9,7,8.9.8,9,
0,0. ,1.1,1.2,2,2.6,6,6.7.7.7.7,8,8.8.9.9},
*c. // Центры тяжести кластеров
Quality: // Функционал качества классификации
inf = new int[n]:
c = new double[m * k];
Code = McQueen (data.n.k.m,Mode,inf.c.&Quality.&Counter);
if (!Code)
{
cout « "Objects" « endl
« ---------" « endl:
for (i = 0; i < n: i++)
cout « "Object " « (i + 1) « " -> Class "
« (inf[i] + 1) « endl:
cout « "\nClusters" « endl « "---------------" « endl:
378
Глава 8. Распознавание образов без обучения
for (1=0: i < m; i++) {
cout « "Cluster " « (i + 1) « endl;
for (j = 0, 1 = i; j < k; j++. 1 += k)
cout « setw (10) « c[l] « endl;
cout « endl: }
cout « "Quality is ” « Quality « endl
« "Iteration number is " « Counter « endl;
}
delete [] inf; delete [] c;
}
int McQueen (double data[].int n.int k.int m.int Mode.int inf[],double c[],double *sum.int *Counter) //
// Функция производит кластерный анализ
// методом k-средних Мак-Куина.
// Обозначения:
// data - матрица исходных данных размером п * к (к п-мерных
// векторов друг за другом).
// п - число объектов, подлежащих классификации.
// к - число параметров,
// m - заданное число кластеров,
// Mode - вариант керы сходства:
// = 0 - евклидово расстояние,
// = 1 - манхеттенское расстояние.
// = 2 - расстояние Махаланобиса.
// = 3 - супремум-норна.
// inf - на выходе - массив номеров длиной п, содержащий
// информацию о принадлежности объектов к кластерам,
// с - массив центров тяжести кластеров размером ш * к
// (к m-нерных векторов друг за другом),
// *sum - функция качества классификации,
// *Counter - счетчик итераций.
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -1 при недостатке памяти.
// -2 при потере значимости.
//
{
register int i.j.l; // Счетчик
int ml,m2.m3, // Счетчик одномерного массива
Count, // Счетчик элементов кластера
Code = 0; // Код ошибки
double *z.
// Расширенная матрица сходства
Кластерный анализ
379
*dat. // Расширенная матрица данных
*t. // // Матрица, обратная дисперсионноковариационной
Cri t; // Функция качества на предыдущем шаге
//////////////////////////////////////////////////
// Построение обратной дисперсионно-ковариационной
// матрицы для вычисления расстояния Махаланобиса
if (Mode == 2)
{
////////////////////////////////////////////////////
II Для экономии памяти массив t фактически определен
// при Mode = 2. в остальных случаях - фиктивный массив if ((t = new double[k * k]) — 0)
return -1:
/////////////////////////////////////////////
// Здесь z временно используется для хранения
// дисперсионно-ковариационной матрицы
if ((z = new double[k * k]) == 0)
{
delete [] t;
return -1;
}
///////////////////////////////////////////////// // Построение дисперсионно-ковариационной матрицы Code = LikenessForCorrelation (data.z.n.k,1);
if (Code != 0) {
delete [] t; delete [] z; return Code:
}
for (i =0: i < k * k; i++) z[i] = fabs (z[i]);
//////////////////////////////////////////////// // Матрица, обратная дисперсионно-ковариационной Code = InverseMatrix (z.t.k):
/////////////////////////////////////// // Теперь память для массива z свободна delete [] z;
if (Code != 0)
{
delete [] t: return Code;
}
}
э j oV о io) WKHaodX хсяЛахэхааюоэ и±эояэо1гц изо олэ ш\ччн(1к1гХяи1Г -нэпсЬп ‘икк1эояэо1Ш олошюнэээес! ‘ЫгнигиП al/ия а 0933 чхиаихэйзди онжого иипвяифиззию! iqiaiairAead ончтгвХЕид таолв! Etfoxaiv 41X9 1/. ‘э ‘ZSI ] ^ка1ш XHHHOiiHKifaddon Voiajv H3isd9O£H 1ЛЧ9 wiaasaiHsdsj^
tfeairu xiRHHOHtiBLfaddox tfoiai/y
{
:эроэ ujn^sj
U [J э}Э1эр :гвр [] э}э[эр :z [] э}Э|эр
:[++гш]}ер = [++1ш]э
(++Р :ш > С :и + (ш + и) * l = ?ш ‘о = С) joj (++l :>| > l :q = тш *о = l) jo^ аос1э1эвим И1ээжк1 udiHah // ///////////////////////////
:(1НЗ =i шп$¥ I I 0 == ++(jaiunog*)) а[^м {
:(Егш]егвр - [тш]явр) sqBj =+ iuns¥
([LJJul == C) jl
(++?ш ‘++L *u > i :u¥ l = giu *o = L) JOj (++IUT++C ‘ш > C :u + (ш + u) l = уш ‘Q = C) joj
(++L :>| > L 1Q = mns¥ '0 = L) JOJ иипвмифиээван валээнвн ииПмнЛф эинэаэиыяд // ////////////////////////////////////////////
{
’.qunoo =/ Eiwliep
(0 =i lunoo) JL
иснэЛи эн daiOBi/M иаэз // /////////////////////////
{
:++}ипоэ
:E?w]eVP =+ Етш^вр
}
(EllJUL == Г) J!-
(++гш *++l
:u > L :u ¥ l = ?ш ‘0 = ЕМгер 'о = гипоэ ‘о = L) Joj p daiDBi/H 0 Х1яннэно1им0 'оолмэядо dogiig // ///////////////////////////////////////// } (++1ш *++p :ш > p :u + (ш + u) ¥ l = тш *o = p) joj (++l :>| > l :q = l) joj BOdaiDBUH И1ээжк1 oodiHah хкаон эинэиэиыяд // lllllllllllllllllllllllllllllllllllllllllllll
= P = EHJUL
(Eiuijz > Е?шК) jl
L8£
ЕИИВНВ MI4Hd910BLf>|
(U + ш =+
?ш '++С :ш > С :о = [lJjul ‘и + ш + тш = ?ш *i = f) J0J
(++1Ш ‘++l :и > l :(и + ш) ¥ и = уш *Q = l) joj aodai3BUX илээжкл инес11нэП и инвлхаядо ЛНжэн кинио1ээрс1 //
оле - валзИохэ ntindieH ионнэс1итэвс1 (aohgi/олз ш иии) // Modi3 ш эиниаиэои oih 'лмвф 101 ьэлэЛЕяиоиэи •HedaiDBUN ои // аолмэядо bHH939H£Bd 19Htf9dU ВН ВЭЛЭНОХЭ HtlMdlBH EHLfBHV // /////////////////////////////////////////////////////////
{ :эрод ujn}9j цвр □ 949[эр :z [] 94.э[эр U [] эзэ[эр } (0 =i ((арон^'ш + iTVz'W) ssaua^Lq = эрод)) jl ВЗЛЭНОХЭ HhMdABH HOHH0dMffl3Bd 9HH90dA30U // //////////////////////////////////////////
:iuns¥ = }Ljg } op
:q = uins* :q = J^^unog^
:[++гш]в*вр = [++1Ш]1вр
(++C :ш > С :и ¥ l = гш *и + (ш + и) * l = 1ш ‘q = С) joj
(++l > l :о = !•) Joj
инвлхэядо ш и ина da и з иниЬсиейриаоз хи нанясод // 8Od9A3BUM ИЛЭ9ЖИЛ HdAH9tl - M0dA3 Ш Э1ЯНЯ1/ВЛЭ0 // ///////////////////////////////////////////////
8
-[++?Ш]в^вр = [++тш]1вр (++С :и > С :(ш + u) ¥ l = уш 'о = С) joj
(++l > l :о = '0 = !-) JOj
XHHHBtf yahMdABH ионИохэи э лавнвиаоз // хнннви iqhwdABH noHHadumaBd xodAa и aiaadau // ////////////////////////////////////////////
{
:[- илцэз
:z [] э^ЭЕэр ii [] 949L9p }
(0 == (И * (Ш + U)]9L4noP мои = Э-вр)) JL {
ujn}9j
[] Э1э[эр }
(0 == ([(Ш + и) (ш + и)]э[С|пор май = z)) jl
:у- ujniaj
(0 == ([Tlotqnop мэи = г)) Ji-
as la
винэкЛдо сэд aocedgo эинеаен£оиэвс| g eaeqj
08С
382
Глава 8. Распознавание образов без обучения
шагом 0,1), на которых объединяются параметры или объекты, подлежащие классификации, поэтому метод напоминает метод ближней связи, но с фиксированными уровнями объединения. Графически результаты классификации изображают в виде окружностей — срезов (плеяд) упомянутого выше корреляционного цилиндра. На окружностях отмечают классифицируемые объекты. Связи между классифицированными объектами указывают путем соединения хордами точек окружности, соответствующих объектам.
С описанием методики и интерпретацией результатов расчета можно ознакомиться по [28, с. 179-181,186]. В [130, с. 44] показано, что метод корреляционных плеяд явился основой многочисленных пороговых алгоритмов.
Пример применения
if (’Rings (data.ns.ph.pl.pi))
for (i = 0; i < 10: i++)
{
buf = 0.1 * i;
bufl = ((double) pi[i] / pi[OJ):
cout « "r = ” « buf « " E = " « bufl « endl:
for (j = 0: j < pi[i]: j++)
cout « ph[j] « « pl[j] « " " cout « endl:
}
el se
cout « "Мало панятиХп":
Исходные коды
int Rings (double dat[],int k.int ph[],int plO.int pi[]) //
// Функция строит корреляционные кольца методом корреляционных // плеяд Терентьева.
// Обозначения:
II dat - матрица сходства.
// к - размерность матрицы dat,
// ph - массив 1-го элемента колец в соответствии с pi.
// pl - массив 2-го элемента колец в соответствии с pi,
// pi - вектор количеств элементов в каждом кольце.
// Примечание:
// массивы ph и pl должны иметь размер не менее
// 5k(k - 1), нассив pi - не менее 10.
// Возвращаемое значение:
// 0 при нормальном окончании расчета,
// -1 при недостатке памяти.
//
{
register int i.j.l: // Счетчики цикла
int ix[l]. // Фиктивный массив
Кластерный анализ
383
m.ml = 0,m2: // Счетчик одномерного массива
double *z. // Копия корреляционной матрицы
р[] = // Уровни корреляционных колец
{.О,.1,.2,.3,.4,.5,.6,.7,.8,.9}:
if ((z = new double[k * k]) == 0)
return -1:
////////////////////////
// Все коэффициенты >= 0
for (i =0: i < k * k: i++)
z[i] = fabs (dat[1J);
//////////////////////
// Цикл по числу колец
for (1 = 0: 1 < 10; 1++)
{
//////////////////////////////////////
// Выбор элементов для текущего кольца for (i = 0. m = 1, pi Cl 1 = 0; i < k - 1; i++)
{
////////////////////////////////////////// // Корреляционная матрица симметрическая -// анализ только нижней половины
for (j = i + 1, m2 = m; j < k: J++) {
if (z[m2++] >= p[l]) {
ph[ml] = i + 1;
pl[ml++] = j + 1;
pi[l] += 1: } }
m += k + 1:
delete [] z:
return 0;
}
Вроцлавская таксономия
Результатом работы программы, использующей метод максимального корреляционного пути, являются пары чисел, указывающие порядок «соединения» подлежащих классификации параметров или объектов, наиболее близких попарно. Получающийся кратчайший незамкнутый путь можно отобразить графически в виде оптимального дерева (дендрита), как это описано в следующем разделе.
384
Глава 8. Распознавание образов без обучений
Как и в представленных ранее алгоритмах, классифицируемы могут быть параметры либо объекты. Метод похож на метод ближней! связи, однако относится к алгоритмам типа разрезания графа и напоминает методы вроцлавской таксономии [130, с. 52, 64]. Если в качестве меры сходства применяется коэффициент корреляции,, получается метод максимального корреляционного пути [28, с. 181]. Пример применения аналогичен представленному в разделе «Метод ближней связи» данной главы.
Исходные коды
int MaximumPath (double dat[],int k.int pl[].int p2[],double p3[]) //
// Функция строит дендрит методом максимального
// корреляционного пути.
// Обозначения:
// dat - матрица сходства.
//к - размерность квадратной матрицы z.
// pl. р2, рЗ - соответственно первый и второй элемент пары, // а также коэффициент корреляции между этими элементами.
// Длина каждого из этих массивов равна к-1.
8 // Возвращаемое значение:
// -1 при недостатке памяти.
// 0 при нормальном окончании расчета.
//
{
register int i.j.l; // Счетчики
int *ix. // Информационный массив
row.col,
m,ml,m2; // Счетчик одномерного массива
double max = 0.
*z.*datl: // Рабочий массив
if ((z = new double[k * k]) == 0) return -1;
if ((datl = new double[kj) == 0)
{
delete [] z;
return -1:
}
if ((ix = new int[k]) == 0)
{
delete [] z; delete [] datl:
return -1;
}
////////////////////////
// Все коэффициенты >= 0
Кластерный анализ
385
for (1=0: 1 < к * к: 1++) zЕ1] = fabs (dat[1]):
/////////////////////
// Обнулить диагональ
for (1=0, m = 0; 1 < к: 1++)
{
z[m] = 0;
m += к + 1:
}
/ / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / // Инициализация процесса построения дендрита col = 1: row = 0: max = z[k]:
for (1 = 2, m=k+k; 1 <k: 1++)
{
for (j = 0. ml = m: j < 1: j++, ml++)
if (z[ml] > max)
{
col = 1:
row = j;
max = z[ml];
} m += k;
}
for (1 =0, m = row * k: 1 < к; 1++)
{
1x[1] = row:
z[m++] = 0:
}
//////////////////////////
// Первая копия строки row
for (1 = 0, m = row: 1 < к: 1++)
{
datlfi] = z[m]:
m += k:
}
//////////////////////
// Построение дендрита
for (1 = 0: 1 < к - 1; 1++)
{
pl[l] = row + 1:
p2[l] = col + 1:
p3[l] = max;
//////////////////////////////////////////// // Исключение столбца корреляционной матрицы 13-2002
386
Глава 8. Распознавание образов без обучения
for (1 = 0, m = col * к; i < к; i++) z[m++] = 0:
////////////////////////////// // Построение следующей строки for (i = 0, m = col; i < к; i++) { if (1 != col) { if (z[m] > datl[i]) { datl[i] = z[m];
ix[i ] = col;
}
}
el se
datl[i] = 0;
m += k;
}
//////////////////////////////////////// // Поиск максимального элемента в строке for (i = 0, max =0: i < k; i++) if (datl[i] >= max) { max = datl[i];
col = i;
}
row = ix[col];
}
delete [] z; delete [] datl; delete [] ix;
return 0;
}
Визуализация результатов кластерного анализа
Хотя от графического представления данных во многих методах можно отказаться, иерархические методы кластерного анализа становятся более наглядными, если результаты расчета представить в виде специального графика, называемогодендрограммой (дендограммой). Рассмотрим пример, поясняющий построение дендрограммы [130, с. 53], [79, с. 72] по результатам расчета, а также выделение заданного числа кластеров по построенной дендрограмме
Визуализация результатов кластерного анализа
387
в иерархических методах кластерного анализа (из рассмотренных нами это методы ближней связи, Уорда и средней связи Кинга).
Предположим, после применения одного из иерархических методов получены результаты классификации в виде величин связи для пар объектов. Идея построения дендрограммы очевидна — пары объектов соединяются в соответствии с уровнем связи, отложенным по оси ординат (рис. 8.1).
70- -------------
60- ---—
5°- Д-i
40- -------
э°- JL
2°- [-L
ю- L
1 2 3 4 5 6 7 8
Рис. 8.1. Дендрограмма иерархического метода
Например, задав число кластеров, равное 3, мы смотрим, на каком уровне связи число пересечений горизонтальной линии, соответствующей уровню связи, и вертикальных линий, соответствующих объектам, равно трем. Находим, что такому уровню соответствует связь 60 и ниже. Разматывая деревья объединения объектов от точки пересечения горизонтали «чуть меньше 60» вплоть до уровня связи, равного нулю, находим все объекты, соответствующие кластерам 1, 2 и 3 (нумерация кластеров произвольна). Принадлежность объектов кластерам указана в третьей колонке последней таблицы. Эти результаты могут использоваться непосредственно, а также в качестве входной информации для методов распознавания образов с обучением.
Результаты расчета в некоторых методах, например в методах вроцлавской таксономии, изображаются в виде графа (дендрита). Расположение на плоскости точек — изображений параметров или объектов — и соединяющих их отрезков — связей — произвольно, а уровни связи отражают максимальное значение из всех связей Данного параметра с другими параметрами (рис. 8.2).
13*
388
Глава 8 Распознавание образов без обучения
Рис. 8.2. Пример графа метода максимального корреляционного пути
Анализируя полученный граф, можно делать выводы о взаимосвязи тех или иных параметров и групп параметров, например о том, что все параметры условно распадаются на две группы: группе 1 принадлежат параметры 1,2 и 5, а группе 2 — параметры 3,4,6,7 и 8 (нумерация групп не несет какого-либо смысла).
В [79, с. 76], [130, с. 124] показано, что и дендрограмма, и дендрит — визуальное отображение одной и той же сущности. По графу легко может быть построена дендрограмма, верно и обратное. Лучшее введение в методы визуализации результатов кластерного анализа дано в [82, с. 57].
Дальнейшие исследования и программные ресурсы
• Кластеризация данных с помощью самоорганизующихся карт Кохонена [194, 178] и другие нейросетевые решения задачи распознавания без обучения.
В табл. 8.1 приводятся адреса некоторых ресурсов по распознаванию без обучения. Ресурсы по нейронным сетям представлены в конце главы 9.
Таблица 8.1. Ресурсы по программным продуктам анализа данных. Распознавание без обучения
Ресурс, адрес Разработчик или поставщик Содержание
www.exetersoftware.com Exeter Software NTSYSpc, программа многомерного анализа данных, включая кластерный анализ
Дальнейшие исследования и программные ресурсы
389
Таблица 8.1 (продолжение)
ресурс, адрес Разработчик или поставщик Содержание
www.cemi.rssi.ru Центральный экономике- КЛАССМАСТЕР,
/ruswin/activities математический институт классификация,
/models.htm Hawww.tvp.ru РАН демонстрационная версия
www.datacenter.ru Фирма «Дата-Центр» STARC, программа распознавания образов
www clustan.com Clustan Ltd. Clustan Package, пакет кластерного анализа для UNIX Clustan/PC, пакет кластерного анализа для UNIX на персональных компьютерах ClustanGraphics, пакет кластерного анализа для Windows
Глава 9. Распознавание образов с обучением
Методы распознавания образов с обучением (с учителем) предназ-1 начены для отнесения неклассифицированных объектов (явлений, ситуаций, процессов) к заранее описанным кластерам (классам, обучающим группам). В этом случае программа (или устройство) распознавания называется классификатором [144, ч. 1, с. 88]. Если устройство распознавания выдает ответ в виде действительного числа или вектора действительных чисел, оно называется соответственно предиктором или локализатором [там же].
Из вероятностных методов распознавания наиболее известен метод, основанный на формуле Байеса, приспособленный для ручного счета. Современные методы распознавания для расчета без применения компьютеров уже совершенно непригодны, и их полноценная реализация стала возможной только после получения доступа широкой научной общественности к вычислительной технике.
Дискриминантный анализ представляет собой надежный линейный (линейным он является потому, что модель метода линейна относительно дискриминантных функций и напоминает множественную линейную регрессию) метод распознавания данных с обучением. Пользователь должен задать некоторое число объектов, указав их принадлежность к так называемым обучающим группам (классам! кластерам, популяциям). Применению методов распознавания обязательно должны предшествовать исследования методами классе фикации без обучения (кластерного анализа или эмпирической классификации, когда, например, врач на основании своего опыта выполняет отнесение того или иного пациента к определенному клас! су — диагнозу). Принадлежность объектов обучающим группам может быть установлена также методами многомерного шкалирования. Кластеры могут пересекаться, особенно если обучение производит! ся на основании эмпирической классификации. Когда не удается установить точную принадлежность объекта к некоторым стандартным описанным группам, рекомендуется образовать из таких объек! тов новые кластеры.
Методы дискриминантного анализа, как и все методы распознавай ния (классификации) с обучением, вырабатывают некоторые реша
[лава 9. Распознавание образов с обучением
391
ющие правила, позволяющие отнести предлагаемые объекты, а заодно и объекты, содержащиеся в обучающих группах (именно так оценивают качество классификации), к заданным выше классам, решающие правила могут быть получены:
1. В виде вероятности диагноза при заданном комплексе симптомов, как предполагает метод Байеса.
2. В виде простых классифицирующих функций, как это сделано в линейном дискриминантном анализе Фишера.
3. В виде дискриминантных функций, как это сделано в каноническом дискриминантном анализе.
4. В виде некоторых характеристик (групповая ковариационная матрица, групповой вектор средних и определитель ковариационной матрицы), как это сделано в линейном дискриминантном анализе.
5. В виде настроенных весов синапсов и смещений нейронов, как это сделано в случае обучаемой нейронной сети.
Для первых трех методов последующее отнесение новых объектов на основании полученных правил возможно «вручную», для четвертого из рассмотренных методов решение «вручную» возможно лишь теоретически, поэтому в результатах расчетов, которые пользователь, возможно, захочет поместить в свой научный отчет, нет необходимости приводить все полученные характеристики обучающих кластеров (читатель, не обладающий программным инструментарием, подобным вашему, все равно не сможет проверить ход вычислений), хотя представленными ниже функциями они и выводятся.
Методы распознавания образов с обучением используют в качестве обучающих выборок объекты, заранее классифицированные тем или иным способом. Качество процедуры дискриминации определяется вероятностью правильной классификации [69, с. 339]. Очень хорошие результаты для распознавания образов с обучением дает предварительное применение метода ближней связи, а применение метода 6-средних для предварительного отнесения объектов классам дает практически 100% качество распознавания для любого метода дискриминантного анализа. Это обусловлено тем, что из рассмотренных нами методов распознавания без обучения только метод 6-средних на основе выбранной метрики гарантированно строит непересекающиеся кластеры.
Общие понятия классификации рассмотрены в [40, с. 129].
О)
392
Глава 9. Распознавание образов с обучением
Выявление информативных параметров
Под информативностью параметров обычно понимается их способность описывать объект классификации с точностью, достаточной для обеспечения самой классификации [85]. Распознаванию образов с обучением должно предшествовать применение методов дисперсионного [16, с. 13], корреляционного, факторного анализа либо иного метода с целью выявления информативных параметров и классификации без обучения для определения обучающих групп. Так, для решения задачи в линейной постановке могут быть применены методы множественного регрессионного анализа [67, с. 77], [215, с. 53].
Возможны ситуации, когда либо параметров недостаточно для верной, с точки зрения исследователя, классификации, либо имеются «лишние» параметры, наличие которых для верной классификации не является обязательным, но сделает результаты вычислений громоздкими и трудно интерпретируемыми. Параметров, по которым должны классифицироваться объекты, должно быть достаточно для правильной классификации. Возможно, особенно когда обучение производится на основании эмпирической классификации, что объекты из обучающих групп в процессе распознавания (после обучения) будут отнесены не к тем кластерам, куда их поместил исследователь. В этом случае необходимо провести дополнительное исследование, в гом числе относительно необходимости и достаточное ги гех параметров, по которым производится отнесение объектов к классам, для их верной классификации. Вполне вероятно, что существует еще ряд параметров, необходимых для правильной классификации.
Пример: исследователь производит дискриминантный анализ с целью диагностики некоторого заболевания по результатам нескольд ких анализов. В этом случае исследователю полезно спросить себя, может ли он сам, без компьютера, однозначно диагностировать дан-^ ное заболевание по результатам этих же анализов без привлечения другой информации? В случае отрицательного ответа мы уточним вопрос: «Чего же тогда вы хотите от компьютера?»
Желательно также установить, нет ли «лишних» параметров, введение которых не является обязательным, что может быть установлено методами дисперсионного, корреляционного и факторного анализа, а также методами многомерного шкалирования.
Метод Байеса
393
Обсуждение см. в [136]. Понятие информативности, по нашему мнению, тесно связано с понятием чувствительности исследуемой системы к параметрам [169, 171]. В свою очередь, серьезное исследование реальной системы не может не привлекать методов математического моделирования — математическая статистика окажет здесь помощь разве что на этапе подготовки и представления экспериментальных данных, необходимых для осмысления природы явления.
Метод Байеса
Байесовский метод является вероятностным методом распознавания образов. Метод позволяет учитывать признаки различной физической природы благодаря использованию единообразных и безразмерных характеристик признаков — частот встречаемости (вероятностей) признаков при различных состояниях [164, с. 606]. Основой метода является диагностическая матрица, пример которой показан в табл. 9.1. В матрице даны вероятности двух диагнозов для трех признаков, первый из которых имеет 4 разряда, второй — три, третий — два [57, с. 143]. Эта же матрица использована и в примере расчета.
Таблица 9.1. Диагностическая матрица для многоразрядных признаков
D Ki к3 P(D)
D, р(Кц) Р(К12) Р(К1: 0,01 0,04 0,59 ,) Р(К„) Р(К2|) Р(К22) Р(К23) Р(К3|) Р(К32) 0,36 0,11 0,16 0,73 0,40 0,60 0,01
о2 0,47 0,40 0,13 0,00 0,28 0,57 0,14 0,10 0,90 0,99
Вычисление вероятности диагноза производится по формуле [164, с. 607]
P(Pj|r)=_P(W£|£L, £P(Ps)P(r|Os)
где К(КЪ — ряд v многоразрядных признаков, К — его реализация,
394
Глава 9. Распознавание образов с обучением
P(Dt\K*) — вероятность диагноза D,, если комплекс признаков К получил реализацию X*,
Р(Х’|Д) — вероятность появления комплекса признаков у объектов с диагнозом Dit
P(D,) — вероятность диагноза Dif определяемая по статистическим данным (априорная вероятность диагноза), i — номер диагноза.
Если комплекс признаков содержит v признаков,
р(к' Щ)=Р(к; |Ц)Р(К; IW-Ж\кх2.Х-Х).
В настоящее время значительное распространение имеет формула Байеса для независимых признаков [57, с. 146], так как в большинстве практических задач можно принимать условие независимости признаков даже при наличии существенных корреляционных связей [164, с. 607]. Поэтому имеем [там же]
ЖЩ)=ПЖЩ).
Г=1
Обсуждение см. в [180, т.2, с. 143], пример практического использования дан в [144, ч.2, с. 62].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>.h>
#include "megastat.h"
void main (void)
{ int nd = 2. // Число диагнозов
nk = 3, // Число признаков
dl = 0. // Рассматриваемый диагноз
x[] = {4.3.2}, // Массив разрядов признаков
t[] = {3.3.0}; // Шаблон комплекса симптомов
double tablet] = // Диагностическая таблица
{0.01,0.04,0.59.0.36.0.11.0.16.0.73,0.40.0.60, 0.47.0.40.0.13.0.00.0.28,0.57.0.14.0.10.0.90}.
p[] = {0.01,0.99}; // Априорные вероятности диагнозов
cout « "Diagnosis probability is "
« Bayes (table,nd,dl.nk.x.t.p) « endl;
}
Метод Байеса
395
double Bayes (double *k,int d.int s.int n.int *x.lnt *t,double *p) //
// Функция выполняет последовательную процедуру распознавания // методом Байеса по комплексу независимых признаков.
// Обозначения:
// к - диагностическая таблица размером d х VectorSum (х.п).
// данные расположены по строкам,
// d - число диагнозов,
// s - рассматриваемый диагноз (нумерация с 0), // п - число многоразрядных признаков.
// х - массив разрядов признаков длиной п,
// t - шаблон комплекса симптомов длиной п (нумерация с 1), // р - вектор априорных вероятностей диагнозов.
// Возвращаемое значение:
// вероятность диагноза для заданного комплекса признаков. //
{
register int i.j; // Счетчик цикла
int m, // Индекс элемента
1=0, // Число анализируемых признаков
11 = VectorSum (х,п); // Общее число разрядов
double r.b.bl; // Рабочая переменная
//////////////////////////////////////// // Подсчет числа анализируемых признаков for (i = 0; i < n; i++) if (t[ij)
1++:
////////////////////////////////////// // Вычисление числителя формулы Байеса г = p[s];
m = s * 11;
for (j = 0; j < 1; m += x[j], j++) r *= k[m + t[j] - 1];
////////////////////////////////////////
// Вычисление знаменателя формулы Байеса
for (i = 0, b = 0; i < d; i++)
{
Ы = p[i];
m = i * 11;
for (j = 0; j < 1; m += x[j], j++) bl *= k[m + t[j] - 1];
b += bl;
}
return r / b;
}
396
Глава 9. Распознавание образов с обучением
Линейный дискриминантный анализ Фишера
Метод линейного дискриминантного анализа (линейная дискриминация Фишера, дискриминаторный анализ) предложен Фишером [167, с. 732], который предположил, что классификация должна проводиться с помощью линейной комбинации дискриминантных (различающих) переменных. Основанием отнесения объекта к кластеру (классу, популяции) является наибольшее значение так называемой простой классифицирующей функции hk для k-ro класса, являющейся линейной комбинацией дискриминантных переменных [97, с. ИЗ]:
Л, = Ь, 0 + bkX, R R0 Л «1 I ’
1=1
где р — число дискриминантных переменных,
bh — коэффициент для i-й переменной k-ro класса, определяемый как
здесь п — общее число наблюдений по всем классам,
— элементы матрицы, обратной к матрице IV — матрице разброса внутри классов (внутригрупповая матрица сумм попарных произведений), вычисляемой по формуле
я "k
*=lm=l
где g — число классов,
nk — число наблюдений в &-м классе,
Xiktn ~~ значение i-й дискриминантной переменной (величина i-й переменной 7п-го наблюдения k-ro класса),
X — среднее i-й переменной &-го класса.
В основе метода лежат два предположения:
1. Популяции, среди которых производится дискриминация, подчиняются многомерному нормальному распределению [97. с. 82].
Линейный дискриминантный анализ Фишера
397
2. Популяции, среди которых производится дискриминация, имеют статистически неразличимые ковариационные матрицы.
Последнее предположение, очевидно, упрощает вычислительную процедуру для конечного пользователя (программа усложняется), однако при искусственном объявлении ковариационных матриц статистически неразличимыми могут оказаться отброшенными наиболее важные индивидуальные черты, имеющие большое значение для хорошей дискриминации.
Программой, которая показана ниже, помимо координат центров тяжести кластеров, коэффициентов простых классифицирующих функций и таблицы принадлежности объектов кластерам выводятся также вероятности принадлежности объектов кластерам. После вычисления классифицирующих функций отнесение новых объектов к кластерам может производиться и без применения компьютера. Это является некоторым достоинством метода. Процент правильно классифицированных объектов обучающих выборок называется качеством распознавания (классификации, дискриминации) и вычисляется программой.
Введенное выше предположение 2 позволяет получить решение и в случае, когда количество обучающих выборок в кластере оказывается меньшим количества дискриминантных функций — то есть при тех условиях, когда линейный дискриминантный анализ не работает.
Результаты линейного дискриминантного анализа Фишера совпадают в смысле качества классификации с результатами более сложного в реализации канонического дискриминантного анализа, что наблюдалось во всех сделанных нами расчетах. Авторы некоторых работ приводят результаты и того, и другого метода для подтверждения правильности своих вычислений [198]. Примеры применения подробно разобраны в [73, с. 129], [174, с. 80, 242], [78]. По технике вычислений метод выбора признаков при помощи минимизации энтропии, предназначенный для снижения размерности вектора параметров распознаваемых объектов и предлагаемый [186, с. 281], в точности повторяет алгоритм линейного дискриминантного анализа Фишера и основан на тех же самых исходных предположениях.
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
^include "megastat.h"
398
Глава 9. Распознавание образов с обучением
void main (void) {
register int i.j.m; // Счетчики
int n. // Число объектов
k = 3. // Число параметров
c = 6, H Число классов
Code, H Код ошибки
*PP. H Номера классов
pl[] = {10,7,7,10.7.8}, // Количества объектов по классам
ph[] = // Номера объектов в соответствии с р1[]
{1.2.3,4.5,6,7,8,9,10, 11,12.13.14,15,16.17.
18.19.20,21,22,23.24.
25,26.27.28.29,30,31,32.33,34.
35.36,37.38.39.40,41.
42,43.44.45.46.47.48,49}:
double data[] = // Значения параметров
{
/////////////
// Параметр 1
131.2.163.3.457.0,370.0.227.8,169.4.110.3,293.8,200.3,161.8.
307.4.208.6.288.4.256.3.360.8.214.4.380.2.
208.6,186.8,216.2.230.0,192.6,204.4,220.2.
251.3.260.4,240.6.196.8,236.6.242.4.208.2,180.6,224.8,230.0.
198.0.189.0.252.6.194.0.221.7,216.8.208.4,
167.7.213.0,180.2,176.6,190.0.170.4,186.6,198.8.
I ННИННИ
Н Параметр 2
33.3,35.0.24.6,18.0.15.5.28.8.47.5.19.5,23.0,38.2,
66.6,16.6.59.1,24.5,100.0.15.6,45.8.
12.0,24.2,10.4,11.1,11.8.12.6.9.8.
9.3.8.4,10.2,12.4.11.0.8.6,14.4,16.2.12.0.8.8.
6.7.7.8.8.4,10.8,7.3.7.1.8.3.
24.4.26.8,30.2.22.6,28.4.25.5,26.6.25.8.
НН III НИН
Н Параметр 3
60.0.60.0.94.1.79.4,91.2.85.0.78.0,110.5.136.7,129.2.
90.3,66.5,95.5,50.0,102.4.72.0.166.4,
72.9,68.4.80.2.74.4,70.5.74.2.70.0,
143.4.150.5.136.8.98.6.102.6,124.0.102.0.96.0.120.0,116.6.
107.0.128.0.139.0,98.8.120.0,96.6,110.8.
45.7,62.5.83.0.62.5,70.2,53.9.42.0.72.8},
*s,*p, v:
п = VectorSum (pl,с);
s = new doublе[п];
Линейный дискриминантный анализ Фишера
399
р = new double[c * (k + 1)];
рр = new int[n]:
if (!(Code = FisherDiscriminantAnalysis (data.n.k.pl.c,ph,p,&v)))
{
///////////////////////////////////////////
// Вывести V-статистику Рао и ее значимость cout « "V-статистика Рао: " « v « ". р = "
« ChiSquareDistribution (k * (с - l),v) « endl:
///////////////////////////////////////////////
// Вывести коэффициенты дискриминантных функций
cout « "Простые классиф. функции: константа, козффициентыХп": for (i = 0, m = 0; i < с; i++)
{
cout « "Кластер " « (i + 1) « ":
for (j = 0; j <= k; j++, m++) cout « p[m] « "
cout « endl:
}
/////////////////////////
// Классификация объектов
cout « "Принадлежность объектов кластерам\п":
if (FDAClass (data.n.k.c.p.s.pp) != 0) cout « "Мало панятиХп":
el se { for (i = 0: i < n; i++)
cout « (i + 1) « " --> " « pp[i] « " p = " « s[i] « endl; cout « "Качество классификации (Я) " « Quality
(pl.c.ph.pp) « endl:
}
}
else if (Code == -1)
cout « "Мало памятиХп";
el se
cout « "Потеря значимости при вычисленииХп";
delete [] рр: delete [] р; delete [] s;
int FisherDiscriminantAnalysis (double z[],int n.int k.int Hl.int g.int h[],double p[],double *v) //
// Функция производит линейный дискриминантный анализ по
// Фишеру (без отнесения объектов к кластерам).
// Обозначения:
// z - матрица исходных данных размером п * к (к п-мерных // векторов друг за другом),
// п - общее число объектов, включает в себя и обучающие // выборки.
400
Глава 9. Распознавание образов с обучением
// к - число параметров,
// 1 - массив длиной g размеров к-мерных выборок (числа
// объектов) в каждом из обучающих кластеров,
// g - число обучающих групп, оно же число дискриминантных
// функций,
// h - вектор, содержащий номера объектов, составляющих
// обучающие классы.
// номера расположены в соответствии с 1 друг за другом.
// р - массив длиной g * (k + 1) коэффициентов g
// дискриминантных (простых классифицирующих) функций,
// расположенных друг за другом, начиная со свободного члена.
// *v - V-статистика Рао.
// Замечание.
// Предполагается, что каждый элемент массива h не меньше 1 и
// не превышает п. Это обязательно нужно проверить до вызова
// функции.
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -1 при недостатке памяти.
// -2 при потере значимости.
И
{
register int i.j.il; // Счетчики цикла
int ml.m2.m3.ni4.m5. Code: // // Счетчик одномерного массива Код ошибки
double *х. // Матрица групповых средних
*t.*d. // Рабочий массив
*s. // Текущая групповая дисперсионная
// матрица
buf: // Рабочая переменная
if ((d = new double[k * kJ) == 0) return -1;
if (Cs = new double[k * kJ) == 0) {
delete [] d;
return -1;
}
if ((x = new double[k * g]) == 0) {
delete [] s: delete [] d;
return -1:
}
//////////////////////////////////////////////////////// // Начальные значения объединенной дисперсионной матрицы FillUp (d.k * k.O):
//////////////////////////////////////////////// // Построение объединенной дисперсионной матрицы
Линейный дискриминантный анализ Фишера
401
// и матрицы групповых средних
for (1 = 0, m3 = 0. m5 = 0: 1 < g: i++)
{
////////////////////////////////////
// Групповая матрица исходных данных
if ((t = new doublet][i] * kJ) == 0) {
delete [] s; delete [] d; delete [] x;
return -1:
}
for (11 = 0, ml = 0. m4 = 0; il < k; 11++. m4 += n)
for (j = 0, m2 = m3: j < l[i]: j++) t[ml++] = z[h[m2++] + m4 - 1]:
m3 += l[i];
////////////////////////////
// Матрица групповых средних
for (11 =0. m2 = 0; 11 < k; 11++) {
for (j = 0, x[m5] = 0: j < l[i]; j++) x[m5] += t[m2++]:
x[m5++] /= 1[1J:
}
////////////////////////////////////////////////
// Групповая дисперсионно-ковариационная матрица
if (LikenessForCorrelation (t. s. 1 [1].k,1) != 0) {
delete [] s: delete [] d; delete [] x; delete [] t: return -1;
}
//////////////////////////////////////////
// Групповая матрица взаимных произведений отклонений от // средних
MatrixMultiplyNumber (s.k * k.l[i] - 1);
/////////////////////////////////////////////
// Объединенная матрица взаимных произведений
// отклонений от средних MatrixPlusMatrix (d.s.k * k);
delete [] t;
}
delete [] s:
///////////////////////////////////////////////////
// Объединенная дисперсионно-ковариационная матрица MatrixMultiplyNumber (d.k * k.1.0 / (m3 - g)):
//////////////////////////////////////////////// // Матрица, обратная дисперсионно-ковариационной
402
Глава 9. Распознавание образов с обучением
If ((t = new double[k * к]) == 0) { delete [] d; delete [] x: return -1:
}
if ((Code = InverseMatrix (d.t.k)) ! = 0) {
delete [] d; delete [] x; delete [] t; return Code:
}
delete [] d:
///////////////////////
// Вектор общих средних
if ((d = new doublefk]) == 0) {
delete [] x; delete [] t: return -1:
}
for (j = 0: j < k: j++)
for (il = 0. m2 = j, d[j] =0: il < g: il++, m2 += k) d[j] += 1[i1] * x[m2]:
d[j] /= m3:
9 }
////////////////////////////////////////////////
// Вычисление обобщенной статистики Махаланобиса for (i = 0. *v = 0: i < k: i++) for (j = 0: j < k: j++)
{
for (il = 0. buf =0: il < g; il++)
buf += 1[il] * (x[i + il * k] - d[i]) * (x[j + il * k] - d[j]):
*v += buf * t[i + j * k]: }
//////////////////////////////////////////////////////////// // Вычисление коэффициентов простых классифицирующих функций for (il = 0, ml=0: il < g: il++)
{
for (j = 0, p[ml] =0: j < k: j++)
for (i = 0: i < k; i++)
p[ml] += t[j + i * k] * x[j + il * k] * x[i + il * k]:
p[ml++] /= (-2):
for (i = 0: i < k: i++, ml++)
for (j = 0, p[ml] =0; j < k; j++) p[ml] += t[i + j * k] * x[j + il * kJ:
}
Линейный дискриминантный анализ Фишера
403
delete [] d: delete [] х; delete [] t;
return 0;
}
int FDAClass (double z[],int n.int k.int g.double u[].double ptl.int d[J) //
// Функция производит классификацию объектов по данным
// линейного дискриминантного анализа Фишера.
// Обозначения:
// z - матрица исходных данных размером п * к (к п-нерных
// векторов друг за другом),
// п - число объектов,
// к - число параметров,
// g - число обучающих кластеров, оно же число дискриминантных // функций,
// и - массив длиной g * (k + 1) коэффициентов g
// дискриминантных (простых классифицирующих) функций,
// расположенных друг за другом, начиная со свободного члена.
// р - вектор длиной п вероятностей принадлежности объектов
// группам,
// d - вектор длиной п номеров кластеров, которым принадлежат // объекты.
// Возвращаемое значение:
// 0 при нормальном окончании расчета,
// -1 при недостатке памяти.
//
{
register int i.j,count: // Счетчики цикла
int buf, // Номер максимального элемента
m.ml: // Счетчик одномерного массива
double bufl, // Рабочая переменная
*s; // Рабочий массив
9
if ((s = new double[g]) == 0) return -1;
for (count = 0: count < n; count++) {
///////////////////////////////////
II Цикл по дискриминантным функциям for (j = 0. ml = 0: j < g; j++)
for (i = 0, m = count.s[j] = u[ml++J: i < k; i++,m += n)
s[j] += u[ml++] * z[m]:
////////////////////////////////////////
// Расчет вероятности наибольшей функции и принадлежности // объекта группе
404
Глава 9. Распознавание образов с обучением
bufl = MaximumOf (s.g.&buf):
d[count] = buf + 1;
for (i = 0, p[count] =0; i < g; i++)
pfcount] += exp (s[1] - bufl);
p[count] = 1.0 / p[count];
}
delete [] s;
return 0;
}
double Quality (int l[],int g.int h[],int d[J)
//
// Функция вычисляет качество классификации.
// Обозначения:
// 1 - массив длиной g числа объектов в каждом из кластеров.
// g - число кластеров.
// h - вектор, содержащий номера объектов, составляющих
// обучающие кластеры, номера расположены в соответствии
// с 1 друг за другом; задан до классификации.
// d - вектор номеров кластеров, которым принадлежат
// объекты; вычислен по итогам классификации.
// Возвращаемое значение:
// процент верно отнесенных объектов обучающих кластеров.
//
{
register int i.j; // Счетчик цикла
int m = 0; // Счетчик одномерного массива
double Ret = 0; // Возвращаемое значение
for (i = 0; i < g; i++)
for (j = 0: j < l[i]; j++, m++)
if (d[h[m] - 1] == i + 1)
Ret += 1;
return Ret / m * 100:
}
Канонический дискриминантный анализ
Канонический дискриминантный анализ основан на определении так называемых дискриминантных функций, количество которых меньше либо равно числу параметров объектов [97, с. 88]:
Канонический дискриминантный анализ
405
А,=Ц,+2ЛХ*т’ i=l
где fkm ~ значение канонической дискриминантной функции для ттг-го объекта k-ro класса,
щ — коэффициенты, определяемые по формуле
i=l
где XL — среднее i-й переменной по всем классам,
Vj, i =1,2,..., р, — коэффициенты, вычисляемые как компоненты собственных векторов решения обобщенной проблемы собственных значений:
Bv = AWv,
здесь В — межгрупповая сумма квадратов отклонений,
V— собственный вектор, остальные обозначения те же, что и в предыдущем разделе. Матрица В определяется как
В= T-W,
где Т— матрица сумм квадратов и попарных произведений, элементы которой вычисляются как [97, с. 90]
s nk
k=im=\
Вычисления по приведенным формулам отнюдь не очевидны, поэтому для анализа тщательно отлаженной логики работы алгоритма можно воспользоваться подробно прокомментированными исходными текстами приведенной ниже функции CanonicalDiscri-minant Analysis.
Помимо координат центров тяжести кластеров, коэффициентов дискриминантных функций и принадлежности объектов кластерам программа выводит также координаты объектов в пространстве дискриминантных функций.
406
Глава 9. Распознавание образов с обучением
Отнесение новых, неклассифицированных объектов к заданным клас-1 терам производится после вычисления дискриминантных функций на основе евклидовой метрики. После вычисления дискриминантных функций отнесение новых объектов к кластерам может производиться и без применения компьютера. Это является достоинством метода, потому что, например, разработанная и обученная экспертная система может поставляться конечному пользователю без поставки обучающих, да и вообще без вычислительных модулей.
Результаты распознавания методом канонического дискриминантного анализа совпадают с результатами линейного дискриминант-1 него анализа Фишера, однако математически решение более сложно, что, впрочем, несущественно для компьютера и его пользователя, а является проблемой только программиста.
Качество классификации методом канонического дискриминантного анализа в нашей программе может быть оценено одним из трех способов, а именно:
• относительным процентным содержанием (рекомендуется) [97, с. 106],
• канонической корреляцией [там же]
• Л-статистикой Уилкса [там же, с. 109]
Л
где k — число уже вычисленных функций,
g — число групп.
Примеры применения и подробное обсуждение алгоритма см. также в [190, с. 571], [73, с. 133], [198]. Другая формула Л-статистики Уилкса дана в [67, с. 96], где также приводится формула вычисления соответствующей F-статистики.
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
Канонический дискриминантный анализ
407
void main (void)
register int i,j.i2,m.ml; // Счетчики
int n, // k = 3. H c = 6. // Code. // Codel = 2. // Disc = 3. // // *pp. // pl □ = {10.7.7,10,7.8}. // Число объектов Число параметров Число классов Код ошибки Код значимости Число выводимых дискриминантных функций Номера классов Количества объектов по классам
ph[J = // Номера объектов в соответствии с р![]
{1,2.3,4,5,6,7,8,9.10,
11.12.13,14.15,16.17.
18,19.20.21.22,23,24,
25.26.27.28,29.30.31,32.33.34.
35.36.37.38,39.40.41.
42.43.44.45.46,47.48.49}:
double data[] = // Значения параметров
{
/////////////
// Параметр 1
131.2.163.3,457.0.370.0.227.8.169.4.110.3.293.8.200.3.161.8,
307.4.208.6.288.4.256.3.360.8.214.4.380.2.
208.6.186.8,216.2.230.0.192.6,204.4.220.2,
251.3,260.4.240.6.196.8.236.6,242.4.208.2.180.6,224.8,230.0.
198.0,189.0.252.6.194.0.221.7.216.8,208.4.
167.7,213.0.180.2,176.6,190.0,170.4,186.6.198.8.
/////////////
// Параметр 2
33.3,35.0,24.6.18.0.15.5,28.8.47.5.19.5.23.0.38.2.
66.6,16.6,59.1,24.5.100.0,15.6,45.8.
12.0,24.2.10.4,11.1,11.8.12.6.9.8.
9.3,8.4.10.2,12.4,11.0.8.6,14.4,16.2.12.0,8.8.
6.7,7.8.8.4.10.8.7.3.7.1.8.3,
24.4.26.8,30.2.22.6,28.4.25.5.26.6.25.8.
/////////////
// Параметр 3
60.0,60.0,94.1,79.4.91.2.85.0.78.0,110.5,136.7,129.2,
90.3.66.5,95.5,50.0,102.4,72.0,166.4.
72.9.68.4.80.2,74.4.70.5.74.2,70.0,
143.4.150.5.136.8.98.6.102.6.124.0,102.0,96.0.120.0,116.6, 107.0,128.0,139.0.98.8.120.0.96.6.110.8.
45.7.62.5,83.0.62.5.70.2.53.9.42.0.72.8},
*s. // Общая корреляционная матрица
*t, // Внутригрупповая корреляционная матрица
408
Глава 9. Распознавание образов с обучением
9
* р, // Коэффициенты канонических функций
* г, // Массив центроидов
* и. // Вектор собственных значений
V , // Рабочая переменная
vv; // Сумма собственных значений
n = VectorSum (pl,с);
s = new double[k * k];
p = new double[k * (k + 1)];
pp = new int[n]:
u = new double[k];
t = new double[k * kJ:
r = new double[k * c]:
if (’(Code = CanonicalDiscriminantAnalysis
(data.n.k.s.t.r.pl.c.ph.p.u)))
{
vv = VectorSum (u.k):
//////////////////////
// Проверка значимости
for (i = 0: i < k: i++)
cout « "Собственное значение " « (i + 1) « ” « u[i]j
if (ICodel)
//////////////////////////////////////
// Относительное процентное содержание
cout « " = " « u[i] / vv * 100 « "Я
else if (Codel == 1)
//////////////////////////
// Каноническая корреляция
cout « " r* = " « CanonicalCorrelation (u[i] .0.000001): el se
{
////////////////////
// Статистика Уилкса
v = Wilks (u.k.i.0.000001):
cout « " Wilks = " « v « " Chi-square = " « ApproximationWilks (v.vv.k.c):
}
cout « endl;
}
cout « "Общая корреляционная матрица\п";
for (i = 0, m = 0; i < k; i++)
{
for (j = 0: j < k: j++, m++)
cout « setw(12) « s[m] « "
cout « endl:
cout « "Внутригрупповая корреляционная матрица\п";
Канонический дискриминантный анализ
409
for (i = 0, m = 0; i < k; i++)
{
for (j = 0; j < k; j++. m++)
cout « setw(12) « t[m] « "
cout « endl:
}
cout « "Канонические функции: константа, коэффициентыХп": for (i = 0, m = 0; i < k; i++)
(
cout « "Функция " « (i + 1) « ": ":
for (j = 0: j < k + 1; j++, m++)
cout « p[m] « "
cout « endl;
)
////////////////////////////////////
// Проверить число выводимых функций
if (Disc <= 0 || Disc > k)
Disc = k:
else
cout « "Число функций скорректировано^":
////////////////////////////////////////
// Вывести центроиды обучающих кластеров
cout « "Координаты центров кластеровХп";
for (i = 0. m = 0: i < с: i++)
{
cout « "Кластер " « (i + 1) « ": ":
for (j = 0. m = i * k: j < Disc: j++, m++)
cout « setw(12) « r[m] « " ":
cout « endl:
}
///////////////////////////////////////////////
// Рассчитать принадлежность объектов кластерам
if (ICDAClass (data,n.k.Di sc,г.с,p,pp))
{
cout « "Координаты и принадлежность объектовХп":
for (i = 0; i < n: i++)
{
cout « (i + 1) « ": :
for (j = 0, ml = 0: j < Disc:j++)
{
v = p[ml++]:
for (i2 = 0,m = i;i2 < k;i2++,m += n)
v += p[ml++] * datafm];
cout « setw(10) « v « " ":
}
cout « " --> " « pp[i] « endl:
}
cout « "Качество классификации (Я) "
<< Quality (pl.c.ph.pp) « endl;
}
410
Глава 9. Распознавание образов с обучением
el se
cout « "Мало панятиХп":
}
else if (Code == -1)
cout « "Мало панятиХп";
el se
cout « "Потеря значиности при вычисленииХп";
delete [] р; delete [] s; delete [] u;
delete [] r; delete [] t; delete [] pp:
}
int CanonicalDiscriminantAnalysis (double z[],int n.int
k,double r[], double w[],double c[],int l[],int g.int
h[],double p[],double u[])
//
// Функция производит канонический дискрининантный анализ
// (без отнесения объектов к кластеран).
// Обозначения:
// z — натрица исходных данных разнерон п * к (к п-нерных
// векторов друг за другой),
// п - общее число объектов, включает в себя и обучающие
// выборки,
// к - число паранетров, оно же число канонических функций,
// г - общая корреляционная натрица,
// w - внутригрупповая корреляционная натрица.
// с - нассив центроидов обучающих кластеров разнерон к * д, // 1 - нассив длиной g разнеров к-нерных выборок
// (числа объектов) в каждой из обучающих кластеров,
// g - число обучающих групп.
// h - вектор, содержащий нонера объектов, составляющих
// обучающие классы,
// нонера расположены в соответствии с 1 друг за другой, // р - нассив длиной (k + 1) * к коэффициентов и канонических // дискрининантных функций, расположенных друг за другой, // начиная со свободного члена,
// и - вектор длиной к собственных значений.
// Занечание.
// Предполагается, что каждый зленент нассива h не меньше 1 и // не превышает п.
// Возвращаеное значение:
// 0 при нормальной окончании расчета,
// -1 при недостатке памяти,
// -2 при потере значимости.
//
{
register int i.j.il; // Счетчики цикла
int ml,m2.ni4,m5, // Счетчик одномерного массива
m3, // Общее число обучающих выборок (объектов)
Code; // Рабочая переменная
Канонический дискриминантный анализ
411
double *t,*d. // Рабочий массив
*х. // Вектор общих средних
buf: // Рабочая переменная
if ((d = new doublefk * kJ) == 0)
return -1;
/////////////////////
// Начальные значения
FillUp (d.k * k.0):
for (i =0. m3 = 0. m5 = 0; i < g; i++)
{
////////////////////////////////////
// Групповая матрица исходных данных
if C(t = new double[l[i] * kJ) == 0)
{
delete [] d: return -1;
}
for (il = 0, ml=0, m4=0; il < k: 11++. m4 += n)
for (j = 0, m2 = m3: j < 1[i]: j++) t[ml++] = z[h[m2++] + m4 - 1]:
m3 += l[i]:
/////////////////////////////////////
// Массив средних обучающих кластеров
for (j = 0. ml = 0: j < k: j++, m5++)
{
for (il = 0. c[m5] =0: il < l[i]: il++) c[m5] += t[ml++]:
c[m5] /= l[i];
}
////////////////////////////////////////////////////// // Внутригрупповая дисперсионно-ковариационная натрица if (LikenessForCorrelation (t,p.lti],k,l) != 0)
{ delete [] d: delete [] t: return -1:
}
//////////////////////////////////////////
// Групповая матрица взаимных произведений
// отклонений от средних
MatrixMultiplyNumber (p.k * k,l[i] - 1):
//////////////////////////////////////////////// // Внутригрупповая натрица взаимных произведений // отклонений от средних
412
Глава 9. Распознавание образов с обучением
MatrixPlusMatrix (d,p,k * к): delete [] t;
}
/////////////////////////////////////////
// Внутригрупповая корреляционная матрица
for (i = 0. ml = 0. m2 =0: i < к; 1++, m2 += к + 1) for (j = 0. m4 = 0; j < к: j++, ml++, m4 += к + 1) w[ml] = d[ml] / sqrt (d[m2J * d[m4]);
///////////////////////////
// Общая матрица наблюдений
if (Ct = new double[m3 * k]) == 0)
{
delete [] d:
return -1:
}
for (j = 0; j < m3: j++)
for (i = 0, ml = j. m2 = h[j] - 1: i < k;
i++, ml += m3, m2 += n)
t[ml] = z[m2];
///////////////////////
// Вектор общих средних
if (Cx = new double[k]) == 0)
{
delete [] d; delete [] t:
return -1;
}
for (j = 0: j < k: j++)
{
for (i = 0. ml = j, x[j] =0: i < g: i++, ml += k) x[j] += c[ml]:
x[j] /= g:
}
////////////////////////////////////////////
// Общая дисперсионно-ковариационная матрица
if (LikenessForCorrelation (t,p,m3,k,l) == -1)
{
delete [] d; delete [] t; delete [] x:
return -1:
}
///////////////////////////////
// Общая корреляционная матрица
if (LikenessForCorrelation (t.r.m3,k,0) == -1)
{
delete [] d; delete [] t; delete [] x;
return -1;
}
Канонический дискриминантный анализ
413
/ / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / // Общая матрица взаимных произведений отклонений от средних MatrixMultiplyNumber (p.k * k,m3 - 1):
///////////////////////////////////////////////// // Межгрупповая матрица сумм квадратов и попарных // произведений
MatrixMinusMatrix (p,d,k * k):
//////////////////////////////////////// // Решение проблемы собственных значений if (Eigen (p.d.k.O.000001,&ml) 1= 0)
{
delete [] d: delete [] t: delete [] x; return Code:
}
///////////////////////////////////////////// // Сортировка собственных значений и векторов for (i = 0; i < k: i++)
u[i] = p[i * (k + 1)]:
for (i = 0: i < k; i++)
{
Code = i:
buf = u[i]:
for (j = i + 1: j < k: j++) if (buf < u[j])
{
Code = j;
buf = u[j];
}
Col Interchange (u.l.i.Code):
Col Interchange (d,k,i.Code):
}
9
ihiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiii // Вычисление коэффициентов канонических функций ArrayToArray (d,t,k * k);
MatrixMultiplyNumber (t.k * k.sqrt (m3 - g));
for (i = 0, m2 = 0. m4 = 0; i < k; i++, m4 += k + 1)
for (j = 0, ml = i * (k + 1) + 1, p[m4] =0: j < k: j++. m2++)
{
p[ml++] = t[m2]:
p[m4] -= t[m2] * x[j];
}
delete [] x; delete [] t; delete [] d;
////////////////////
// Массив центроидов
414
Глава 9. Распознавание образов с обучением
if ((t = new doublefk * g]) == 0)
return -1;
ArrayToArray (c.t.k * g);
for (i = 0, ml = 0; i < g: i++)
{
for (j = 0, m4 = 0; j < k; j++, ml++)
{
c[ml] = p[m4++J;
for (11 = 0. m2 = 1 * k: il < k: il++) c[ml] += p[m4++] * t[m2++J;
}
}
delete [] t:
return 0:
}
int CDAClass (double z[],int n.int k.int y.double cfj.int g.double u[],int d[]) //
H // // H // // // // H // П H // // H //
Функция производит классификацию объектов по данным
канонического дискриминантного анализа.
Обозначения:
z - матрица исходных данных размером п * к (к п-мерных векторов друг за другом).
п - число объектов,
к - число параметров.
у - число дискриминантных функций. <= к,
с - массив длиной g * к координат центроидов обучающих кластеров в пространстве дискриминантных функций.
g - число обучающих кластеров,
и - массив длиной k * (k + 1) коэффициентов к дискриминантных функций.
расположенных друг за другом.
начиная
со свободного
члена
d - вектор длиной п номеров кластеров, которым принадлежат
объекты.
И Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -1 при недостатке памяти.
//
{
register int i.j.count: // Счетчики цикла
int m.ml.m2;
// Счетчик одномерного массива
double r.rl. // Расстояние между объектом
H и кластером
*sl. и Координаты объекта
*s2; H Координаты центра кластера
if ((si = new doublefy]) == 0)
Канонический дискриминантный анализ
415
return -1:
if ((s2 = new double[y]) == 0)
{
delete [] si:
return -1;
}
/////////////////////////////////////////
// Расчет принадлежности объекта кластеру for (1=0; i < n; i++)
{
/////////////////////
// Координаты объекта
for (j = 0, ml = 0: j < у: j++) {
sl[j] = u[ml++J;
for (count = O.m = 1; count < k: count++.m += n) slC+= u[ml++] * z[m];
}
/////////////////////////////
// Координаты центра кластера
for (j = 0, m2 = 0; j < y; j++) s2[j] = c[m2++J;
/////////////////////////////////////
// Пропустить дискриминантные функции,
// соответствующие отброшенным собственным значениям for (j = у: j < k; j++)
m2++;
///////////////////// // Начальные значения г = Euclid (sl,s2,y); d[i] = 1;
//////////////////////////////////
// Проверка всех центров кластеров
for (j = 1; j < g; j++) {
for (count = 0; count < y; count++) s2[count] = c[m2++];
for (count = y; count < k; count++) m2++:
rl = Euclid (si.s2,y):
if (rl < r) { r = rl; d[i] = j + 1:
}
}
}
416
Глава 9 Распознавание образов с обучением
delete [] si: delete [] s2;
return 0: }
double CanonicalCorrelation (double 1.double eps) 11
II Функция вычисляет каноническую корреляцию.
// Обозначения:
// 1 - собственное значение,
// eps - предел значимости собственного значения.
// Возвращаемое значение:
// значение канонической корреляции. //
{
if (1 < eps) return 0.0;
el se return sqrt (1 / (1 + 1));
}
double Wilks (double l[].int g.int k.double eps) 11
II Функция вычисляет статистику Уилкса. // Обозначения:
// 1 - вектор собственных значений длиной д.
// к - число вычисленных дискриминантных функций, // eps - предел значимости собственного значения. // Замечание.
// Во избежание неверного результата вычислений перед
// вызовом функции нужно убедиться, что к не превышает див // пределах заданной точности все собственные значения // неотрицательны.
// Возвращаемое значение:
// значение статистики Уилкса. //
{
register int i; // Счетчик цикла
double Buf, // Вспомогательная величина
Ret = 1; // Возвращаемое значение
for (i = k; i < g: i++) {
Buf = l[i] < eps ? 0 : l[i];
Ret *= (1.0 / (Buf + D);
}
return Ret; }
double ApproximationWi1ks (double w.int n.int p.int g)
ринейный дискриминантный анализ 417
// функция вычисляет хи-квадрат- аппроксимацию статистики Уилкса.
// Обозначения:
ц w - значение статистики Уилкса,
ц п - общее число наблюдений в обучающих кластерах,
// р - максимальное число дискриминантных функций
// (число дискриминантных переменных),
// g - число обучающих кластеров.
// Возвращаемое значение:
// значение хи-квадрат - аппроксимации статистики Уилкса.
//
^return log (w) * (0.5 * (р + g) - n + 1):
)
Линейный дискриминантный анализ
Недостатком метода линейной дискриминации Фишера является предположение о равенстве ковариационных матриц рассматриваемых выборок, вследствие чего могут оказаться отброшенными важные индивидуальные черты, имеющие большое значение для хоро- g шей дискриминации. В методе линейного дискриминантного анализа, напротив, ковариационные матрицы для различных классов априори считаются различными (если это не так, метод также может быть с успехом применен), что ведет к такому возрастанию трудоемкости вычислений для конечного пользователя, котором решение без компьютера становится практически нереализуемым (если для отнесения объектов используются простые классифицирующие функции или дискриминантные функции и вычисления еще можно провести «вручную», то в рассматриваемом нами методе вычисления «вручную» для отнесения объектов провести практически невозможно за реальный промежуток времени).
Отказ от предположения о статистической неразличимости ковариационных матриц (лежащего в основе линейной дискриминации Фишера) для обучающих кластеров не позволяет получить решение в случае, когда количество обучающих выборок в кластере оказывается меньше количества дискриминантных функций. В этом случае программа выдаст сообщение о потере значимости при вычислении, а пользователю придется применить линейный дискриминантный анализ Фишера или канонический дискриминантный анализ.
14-2002
418
Глава 9. Распознавание образов с обучение»
В рассматриваемом методе основанием отнесения объекта к классу! является наибольшее значение для данного объекта функции плотности нормального распределения среди всех классов. Программой помимо координат центров тяжести классов и таблицы принадлежности объектов классам выводятся также вероятности принадлежу ности объектов классам. Дополнительно выводятся ковариационные матрицы для каждого кластера и корни квадратные из определителей этих ковариационных матриц. Именно эти параметры применяются для конструирования решающих правил об отнесении объекта к тому или иному кластеру.
Отсутствие простых решающих правил было некоторым препятствием для широкого применения этого мощного метода в период, предшествовавший распространению персональных компьютеров. Метод использовался фактически редко, но здесь введен нами как серьезная альтернатива линейному дискриминантному анализу Фишера. В наших расчетах метод линейного дискриминантного анализа показал в целом примерно на 5% более высокое качество распознавания по сравнению с линейной дискриминацией Фишера и каноническим дискриминантным анализом. Последние два метода в наших тестах показали одинаковые результаты, уступая только обучаемой нейронной сети.
Схему вычисления см. в [192, с. 116]. Там же дано сравнительное описание методов дискриминантного анализа и введен метод коалиций, представляющий собой комбинацию линейной дискриминации Фишера и линейного дискриминантного анализа (в зависимости от значимости различий выборочных оценок ковариационных матриц популяций).
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void)
{ register int i.j.il.m.ml;
int n.
k = 3.
c = 6, Code, *PP.
// Счетчики
// Число объектов
// Число параметров
// Число классов
// Код ошибки
// Номера классов
^инейный дискриминантный анализ
419
р![] = {10,7,7,10,7,8},// Количества объектов по классам ph[] = // Номера объектов в соответствии с р1[]
{1,2,3,4.5.6.7,8.9,10.
11.12.13.14.15.16,17,
18,19,20,21,22.23,24,
25.26.27,28.29.30.31.32,33,34,
35,36.37,38.39.40.41.
42,43.44.45.46.47.48.49}:
double data[] = // Значения параметров
^/////////////
// Параметр 1
131.2.163.3.457.0.370.0,227.8.169.4,110.3.293.8.200.3,161.8.
307.4.208.6.288.4.256.3.360.8.214.4.380.2,
208.6,186.8.216.2.230.0,192.6.204.4.220.2,
251.3,260.4,240.6.196.8.236.6,242.4.208.2,180.6.224.8.230.0, 198.0,189.0,252.6,194.0.221.7.216.8.208.4.
167.7.213.0.180.2,176.6.190.0.170.4.186.6.198.8.
/////////////
// Параметр 2
33.3.35.0.24.6,18.0.15.5.28.8.47.5.19.5.23.0.38.2.
66.6.16.6,59.1.24.5.100.0.15.6,45.8.
12.0.24.2.10.4.11.1.11.8.12.6.9.8.
9.3.8.4.10.2.12.4.11.0.8.6.14.4.16.2.12.0,8.8,
6.7.7.8.8.4,10.8.7.3.7.1.8.3.
24.4,26.8.30.2,22.6,28.4.25.5,26.6,25.8,
/////////////
// Параметр 3
60.0.60.0.94.1.79.4.91.2.85.0.78.0.110.5.136.7.129.2.
90.3.66.5,95.5.50.0.102.4.72.0,166,4.
72.9.68.4.80.2.74.4.70.5.74.2.70.0,
143.4.150.5.136.8.98.6,102.6,124.0.102.0,96.0.120.0.116.6.
107.0.128.0.139.0.98.8.120.0,96.6.110.8.
45.7.62.5.83.0.62.5.70.2.53.9.42.0,72.8}.
*p.*t,*r.*s, v:
п = VectorSum (pl.с):
р = new double[c * k * k];
pp = new int[n]:
s = new double[n];
t = new double[c * k];
r = new double[c];
if (!(Code = LinearDiscriminantAnalysis
(data,n.k,pl.c.ph.p.t.r)))
{
//////////////////////////////////
II Вывести параметры дискриминации
14
420
Глава 9 Распознавание образов с обучением
for (i =0, m=0, ml = 0; 1 < с; i++) {
///////////////////////// // Вывести номер кластера cout « "Кластер " « (i + 1) « ":\n";
/////////////////////////
// Вывести вектор средних cout « "Вектор средних:\п": for (j = 0; j < k; j++. ml++) cout « setw (12) « t[ml];
/////////////////////////////////
// Вывести ковариационную матрицу cout « "ХпКовариационная матрицами": for (j = 0; j < k; j++) { for (il = 0: il < k; il++. m++) cout « setw (12) « p[m] « " ": cout « endl:
} I
cout « "ХпКорень квадратный из определителя = " « r[i] « endl:
}
/////////////////////////
// Классификация объектов
cout « "Принадлежность объектов кластерамХп";
if (’(Code = LDAClass (data.n.k.c.p.t.r.s.pp)))
{
for (i = 0; i < n; i++)
cout « (i + 1) « " --> " « pp[i] « " p = " « s[i] « endl;
cout « "Качество классификации (Я) " « Qua!ity (pl.k.ph.pp) « endl;
}
else if (Code == -1)
cout « "Мало памятиХп";
el se
cout « "Потеря значимости при вычисленииХп";
}
else if (Code == -1)
cout « "Мало памятиХп":
else
cout « "Потеря значимости при вычисленииХп";
delete [] рр; delete [] t; delete [] r; delete [] p; delete [] s: }
int LinearDiscriminantAnalysis (double z[].int n.int k.int l[],int g.int h[],double p[],double x[],double v[])
Линейный дискриминантный анализ
421
ц функция производит линейный дискриминантный анализ ц (без отнесения объектов к кластерам).
I/ Обозначения :
ц z - матрица исходных данных размером п * к (к п-мерных ц векторов друг за другом).
ц п - общее число объектов, включает в себя и обучающие
// выборки.
ц к - число параметров.
// 1 - массив длиной g размеров к-мерных выборок (числа
// объектов) в каждом из обучающих кластеров.
// g - число обучающих групп.
// h - вектор, содержащий номера объектов, составляющих
// обучающие классы.
// номера расположены в соответствии с 1 друг за другом.
// р - массив длиной g * к * к g ковариационных матриц.
// расположеннных друг за другом.
// х - массив длиной g * к средних.
// v - массив длиной g корней квадратных из
// определителей ковариационных матриц.
// Замечание.
// Предполагается, что каждый элемент массива h не меньше 1 и // не превышает п. Это обязательно нужно проверить до вызова // функции.
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -1 при недостатке памяти,
// -2 при потере значимости.
//
{
9
register int i.j.il: // Счетчики цикла
int ml.m2.m3.m4. H Счетчик одномерного массива
m5 = 0. // Счетчик массива ковариационных
// матриц
m6 = 0: // Счетчик массива средних
double *t. // Групповая матрица исходных данных
*s: и Групповая дисперсионная матрица
if ((s = new double[k 1 return -1: " k]) । == 0)
/ / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / /
// Построение дисперсионной матрицы
for (1 = 0. m3 = 0; 1 < g; i++)
{
if ((t = new double[l[il * kJ) == 0)
{
delete [] s;
return -1;
}
422 Глава 9. Распознавание образов с обучением
for (il =0. ml = 0, m4 =0; il < к; il++, m4 += n) for (j = 0, m2 = m3: j < l[i]; j++)
t[ml++] = z[h[m2++] + m4 - 1]: m3 += 1[i]:
////////////////////////////
// Матрица групповых средних
for (il = 0, m2=0: il < k; il++) {
for (j = 0, x[m6] = 0; j < l[i]: j++) x[m6] += t[m2++J;
x[m6++] /= 1[i]: }
////////////////////////////////////////////////
// Групповая дисперсионно-ковариационная натрица
if (LikenessForCorrelation (t,s,1[i],k,1) != 0) {
delete [] s: delete [] t: return -1;
}
for (il = 0. ml = 0: il < k: il++)
for (j = 0: j < k: j++) p[m5++] = s[ml++J:
v[i] = Krauth (s.k):
delete [] t:
//////////////////////
// Проверка значимости
if (v[ij <= 0.000001) {
delete [] s:
return -2: }
v[i] = sqrt (v[ij):
}
delete [] s:
return 0:
}
int LDAClass (double z[],int n.int k.int g.double u[J.double x[J.double v[],double p[].int d[J)
//
// Функция производит классификацию объектов по результатам // линейного дискриминантного анализа.
Линейный дискриминантный анализ
423
// Обозначения:
// z - натрица исходных данных разнерон п * к (к п-нерных
// векторов друг за другой),
// п - число объектов,
// к - число паранетров,
// g - число обучающих кластеров,
// и - нассив длиной g * к * к ковариационных натриц (д натриц
// разнерон
// к * к каждая, расположеннных друг за другой),
// х - нассив длиной g * к средних,
// v - нассив длиной g корней квадратных из определителей
// ковариационных натриц.
// р - вектор длиной п вероятностей принадлежности объектов
// группан,
// d - вектор длиной п нонеров кластеров, который
// принадлежат объекты.
// Возвращаемое значение:
// 0 при норнальнон окончании расчета.
// -1 при недостатке паняти,
// -2 при ошибке в вычислениях.
//
{
register int i,j,count; // Счетчики цикла
int Code, // Код ошибки
buf, // Нонер наксинального эленента
ml, // Счетчик средних
m2; H Счетчик ковариационной натрицы
double bufl, И Рабочая перененная
*s. // Рабочий нассив
*zl. // Вектор координат объекта
*ul, // Групповая ковариационная натрица
*u2, // Матрица, обратная к
// ковариационной
*xl; // Рабочий нассив
if ((s = new double[g]) == 0) return -1:
if ((zl = new double[k]) == 0)
{
delete [] s;
return -1:
}
if ((ul = new doublefk * kJ) == 0) {
delete [] s; delete [] zl;
return -1;
}
if ((u2 = new double[k * kJ) == 0)
424
Глава 9 Распознавание образов с обучением
{
delete [] s: delete [] zl; delete [] ul:
return -1:
}
if ((xl= new double[k]) == 0)
{
delete [] s; delete [] zl: delete [] ul: delete [] u2: return -1:
}
for (count = 0: count < n: count++)
{
/////////////////////
// Координаты объекта
for (i = 0, j = count; i < k; i++. j += n) zl[i] = z[j]:
///////////////////////////////////////
// Расчет массива плотностей для объекта
for (i = 0. ml = 0, m2 = 0: i < g: i++)
{
/////////////////////////
// Ковариационная матрица
for (j = 0; j < k * k; j++)
ul[j] = u[ml++]:
/////////////////////////////////////
// Матрица, обратная к ковариационной
if ((Code = InverseMatrix (ul,u2.k)) != 0)
{
delete [] s: delete [] zl: delete [] ul:
delete [] u2: delete [] xl:
return Code: }
/////////////////
// Вектор средних
for (j = 0: j < k: j++)
xl[j] = zl[j] - x[m2++J;
MatrixMultipiyMatrix (u2,xl,ul,k,k,l);
MatrixTMultipiyMatrix (xl.ul.u2,1,k.1):
s[i] = exp (- 0.5 * u2[0J) I v[1];
}
/////////////////////////////////////////////////// // Расчет вероятности принадлежности объекта группе bufl = MaximumOf (s,g,&buf):
d[count] = buf + 1:
pEcount] = bufl / VectorSum (s.g):
}
Нейронная сеть прямого распространения
425
delete [] s; delete [] zl; delete [] ul; delete [] u2; delete [] xl:
return 0;
}
Нейронная сеть прямого распространения
Так называемые нейронные сети прямого распространения (feedforward neural networks) применяются нами здесь для тех же целей, что и описанные выше методы дискриминантного анализа. Иногда нейронные сети называют перцептронами (персептронами).
Архитектура нейронной сети
При описании такого объекта, как нейронная сеть, принято использовать терминологию, заимствованную из наук о мозге [31]. Для математических изысканий в области искусственных нейронных сетей необязательно изучать строение и механизмы, протекающие в биологических нейронных сетях, однако знакомство с ними, Q по крайней мере в объеме упомянутого источника, не только может помочь оптимизировать вычислительный процесс и послужить источником новых идей, но и значительно расширит кругозор. Нейронные сети пока еще далеки от того, о чем можно сказать: «Она — живая!»1, но гораздо ближе, чем другие описанные в настоящей книге объекты. Интересно ознакомиться с трудами, посвященными исследованию биологических нейронных сетей и математическому моделированию происходящих в них процессов [27], [226], [21, с. 163].
Можно допустить, что математическая нейронная сеть моделирует биологическую с информационной точки зрения. Можно даже допустить, что мы рассматриваем информационную модель биологической нейронной сети. Поэтому, если проводить аналогию с биологической нейронной сетью, объекты математической нейронной сети моделируют:
• Нейроны — отдельные нервные клетки. Один нейрон соединяется с несколькими определенными -нейронами. Как и нейроны живой сети, нейроны модели дифференцированы в зависимости от выполняемой ими функции.
1 Херберт Ф. Бог — Император Дюны. — Ангарск: Амбер, Лтд., 1994.— С. 166.
426
Глава 9. Распознавание образов с обучением
• Рецептивные нейроны биологической нейронной сети моделируются входным слоем математической нейронной сети. В математической модели эти нейроны отличаются от нейронов скрытых слоев.
• Двигательные нейроны биологической нейронной сети моделируются выходным слоем математической нейронной сети. В математической модели эти нейроны также отличаются от нейронов скрытых слоев.
• Синапсы — специфические точки на поверхности нейронов. В этих точках посредством медиаторов происходит процесс передачи информации, называемый синаптической передачей информации. В структурной модели связи между нейронами следовало бы назвать аксонами и дендритами, но, как отмечено выше, мы работаем с информационной моделью биологической нейронной сети. Поэтому синапсы (информационные связи) математической нейронной сети моделируют информационные связи между реальными нейронами.
Рис. 9.1. Архитектура нейронной сети для представленного примера
Нейронная сеть прямого распространения
427
рис. 9.1 для примера показана архитектура нейронной сети прямого распространения, содержащая входной слой (4 нейрона), один скрытый слой (7 нейронов) и один выходной слой (3 нейрона). Размер входа сети равен 4, размер выхода, очевидно, равен 3.
Входной слой нейронной сети
Согласно [194], во входном слое может производиться так называемая нормализация входа, то есть операция преобразования вектора входа сети х, i =1,2,..., т, для каждого из т обучающих объектов, а также для каждого распознаваемого объекта, по формуле
sj.>=^zixi’J=i’2.”1>
i=l
где — число нейронов входного слоя, размер входа, z, — вектор коэффициентов нормализации,
Xi - элемент вектора входа для одного распознаваемого объекта. Нормализация (от франц, normalisation — упорядочение) — придание однородности — часто применяется в программировании для -преобразования массива исходных данных с целью уменьшения слож- О
ности некоторых вычислительных проблем [232, с. 299]. Вектор Z коэффициентов нормализации вычисляется на этапе обучения сети. Каждый элемент вектора нормализации, размер которого равен размерности входа сети, представляет собой величину, обратную евклидовой норме, вычисляемую по формуле
Zf = - *—,i = 1,2,...,
Im 7
№
V >1
где J = 1, 2,..., m, — элемент матрицы обучающих объектов.
Показанная далее функция нормализации применяется при подготовке входных данных для обучаемой нейронной сети на этапе распознавания. Коэффициенты нормализации расчитываются на основе обучающих данных.
Исходные коды
void NormalizeMatrix (double* у, int n.int m.double* sc) //
// Функция нормализации матрицы.
428
Глава 9. Распознавание образов с обучением
// Обозначения:
// у - нормализуемый массив - п векторов по m вариант.
// п - число объектов.
// m - число параметров.
// sc - вычисляемый массив коэффициентов нормализации длиной го.
// Возвращаемое значение:
// нет.
//
{
register int i.j. // Счетчик цикла
ii = 0. // Счетчик одномерного массива jj = 0;
for (i = 0: i < m: i++)
{
///////////////////////////////////////
II Вычисление коэффициента нормализации
for (j = O.sc[i] = 0.0: j < n; j++)
sc[i] += y[ii] * y[ii++J:
sc[i] = sc[i] == 0.0 ? 1.0 : 1.0 I sqrt (sc[ij);
///////////////////////
// Нормализация вектора
for (j = 0: j < n; j++) y[jj++l *= sc[i];
}
}
Другой подход к нормализации представлен в [144, ч. 1, с. 42]. Это технически простая процедура, поэтому за более подробной информацией мы отсылаем читателя к указанному источнику.
Скрытые слои нейронной сети
Выход 5>Лу-го нейрона скрытого &-го слоя, k = 2, 3,..., У - 1, где N— общее число слоев, определяется как функция состояния от взвешенной суммы его входов [194]:
s..
j*
,7 -1,2,..., п*
где nk_{ — число нейронов предыдущего, (k - 1)-го слоя, nk — число нейронов текущего &-го слоя, обычно выбираемое эмпирически,
— элемент матрицы весовых коэффициентов между /г-м и (k - 1)-м слоями,
/(.) — активационная функция.
Нейронная сеть прямого распространения
429
Иногда из состава нейрона выделяют сумматор [55, с. 14], то есть линейный элемент, связанный с каждым нейроном и суммирующий поступающие к нему по синаптическим связям сигналы от других нейронов. Сумматор производит операцию суммирования, как показано в приведенной выше формуле в скобках, а нейрон при такой постановке вопроса является только нелинейным элементом. Тогда в нашей модели нейроны, как нелинейные элементы, являются принадлежностью только скрытых слоев нейронной сети. Чем неудобно предложенное разделение для нас — только тем, что придется скорректировать введенные в начале раздела представления о моделировании нейронной сетью процессов, происходящих в реальной нейронной сети.
Активационная функция нейрона
В качестве передаточной (так называемой активационной) функции нейрона в ранних исследованиях использовался пороговый элемент [166], [138], [55, с. 9]
0,х<а,
1,х>а, 9
где а — порог (порог срабатывания).
Позднее было доказано, что такой подход оказался не вполне правомерен, ибо «элементы памяти ... следует рассматривать как непрерывнозначные элементы» [102, с. 209], и относительный неуспех первых опытов был вызван именно этим [57, с. 128], [138]. Считается, что вид нелинейности не так важен, как факт ее существования вообще [56], однако вид нелинейности оказывает влияние на численную устойчивость процесса обучения сети. Исследователями был предложен ряд нелинейных активационных функций, наиболее известной из которых является экспоненциальный сигмоид [3]:
/(х) = —-—, 4 7 l + e-ttJ
где а — параметр, имеющий величину от 1 до 4.
Мы выбрали активационную формулу типа рационального сигмоида [55, с. 9], физиологически обоснованную для спектра переходной функции модели реального, живого нейрона [64, с. 68]:
430
Глава 9. Распознавание образов с обучением
г, х Х-Ь
fM~\x-U(+a’ !
где b — смещение нейрона, настраиваемое одновременно с весами, а — параметр, в наших опытах имевший величину от 2 до 4.
В последнюю формулу в качестве слагаемого может входить параметр спонтанной активности [55, с. 22]. Существуют и другие активационные функции [там же, с. 9,194].
Выходной слой нейронной сети
Выход sjn j-ro нейрона выходного слоя определяется как взвешенная сумма его входов:
s. = s .,i = 1,2,..., п jfl 7 < Я-1.И ’ Л >
«=1
где nkA — число нейронов слоя, предшествующего выходному,
nN — число нейронов выходного слоя,
9 wn-ifl ~ элемент матрицы весовых коэффициентов между выходным " и предшествующим ему слоями.
В случае, если принято решение выделять из состава нейрона сумматор [55, с 14], выходной слой нейронной сети в нашей модели состоит только из сумматоров, а не из нейронов.
Обучение и распознавание
После подачи на вход обученной нейронной сети некоторого входного набора параметров мы получим на выходе сети определенный выходной набор параметров. При этом говорят, что сеть решает задачу распознавания образов. Для верного распознавания нужно обучить сеть, предъявляя ей наборы входных параметров и правильные наборы выходных параметров. Набор и значения выходных параметров устанавливаются путем экспертной оценки, одним из методов кластерного анализа либо с использованием нейронных сетей типа ассоциативной памяти.
Задача обучения нейронной сети, которой предшествует выбор архитектуры сети (число слоев и количество нейронов в слоях), состоит в получении весовых коэффициентов, смещений и, возможно, каких-то дополнительных параметров сети. Качество обучения
Нейронная сеть прямого распространения
431
оценивается путем подачи на вход обученной сети поочередно параметров всех обучающих объектов. Мерой качества обучения считают процент правильно классифицированных обучающих объектов либо процент правильно классифицированных объектов, принадлежность которых классам известна, но при обучении сети они не использовались. Второй подход предпочтителен, если объем исходных данных достаточно велик, чтобы они могли быть разбиты на две части — обучающую и тестовую.
Задачу обучения сети стандартно решаем путем минимизации квадратичного функционала, построенного на разностях значений заданных и вычисленных выходов сети, применяя метод переменной метрики [146, с. 361] или метод сопряженных градиентов Флетчера—Ривса [там же, с. 314]. Квазиньютоновские методы вообще очень хорошо зарекомендовали себя при обучении нейронных сетей [55, с. 108], [144, ч. 2, с. 30], что подтверждается и нашими расчетами.
Ниже рассмотрены два примера использования нейронной сети для решения задачи классификации образов с обучением. В первом примере входом сети является вектор некоторых физиологических или иных характеристик пациента, выходом — вектор условных номеров диагноза, причем размерность выхода сети равна числу диагнозов. О принадлежности объекта классу свидетельствует равенство единице компоненты вектора выхода, соответствующего данному диагнозу. Во втором примере вход сети такой же, как и в первом примере, однако выходом сети, размер которого равен единице, является непосредственно номер диагноза.
Нейронные сети находят широкое применение в различных областях деятельности. Как это обычно бывает, новые технологии в первую очередь применяются в финансируемых правительствами и корпорациями антигуманистических и деструктивных мероприятиях — «Большой брат видит тебя»1. Нейронные сети широко применяются также для решения задач медицинской диагностики [144, ч. 1, с. 30], в бортовых системах летательных аппаратов [там же, ч. 2, с. 62], для распознавания визуальных образов, для прогнозирования на финансовых рынках [30], [109], [181].
О перцептроне см. [186, с. 178], [191], [202, с. 159]. Журнал «Открытые системы» (www.osp.ru) посвятил нейронным сетям два тематических выпуска: № 4 за 1997 г. [66] и № 4 за 1998 г., журнал «Компьютерра» (www.computerra.ru) — № 4 за 2000 г. В [21, с. 204]
' Оруэлл Дж. 1984: Роман; Скотный двор: Сказка. — Пермь: Издательство «КАПИК», 1992.-304 с.
432
Глава 9. Распознавание образов с обучением
дан достаточно полный для своего времени список литературы по моделированию биологических нейронных сетей. Успешное применение нейросетевых методов распознавания в медицинских исследованиях упоминается в [85]. См. также [207].
В [55, с. 152] рассмотрены уровни отчуждения нейронной сети. По классификации источника, в наших исследованиях используется нулевой уровень отчуждения, когда нейронная сеть существует на универсальном компьютере (см. пример ниже), а также третий уровень отчуждения, когда заказчику поставляется нейронная сеть без возможностей дообучения (см. пример аппроксимации зависимо-) сти с помощью нейронной сети в главе 15).
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <stdlib.h>
#include <math.h>
#include "megastat.h"
int *ak, // Вектор размеров слоев
ко. // Число обучающих объектов
is. // Число синапсов
al; // Число слоев
double *in.*out. // Вход и выход сети
*du,*dul.*dv.*dvl; // Рабочие массивы
void main (void)
{
register int i.j:
// Счетчики цикла
int s.sl. // Счетчики элементов массива
Max = 500, // Заданное максимальное число итераций,
// затем - затраченное число итераций. // затем - заданный номер диагноза
Maxi. // Вычисленный номер диагноза
ni = 3. // Размер входа (число параметров)
ml. // Число синапсов скрытых слоев
по = 6, // Размер выхода (число диагнозов)
ah[] = {10.7,7.10,7,8}.// Количества объектов по классам
kl [] = // Номера объектов в классах
{1.2.3.4.5.6.7.8,9.10,
11,12,13,14,15.16,17,
18,19,20.21.22,23,24, 25,26.27.28,29.30,31.32.33.34.
35,36,37,38.39.40.41.
42,43,44,45,46,47,48,49};
double *у.
// Синапсы и смещения
Нейронная сеть прямого распространения
433
Qual я 0. Temp, ine[] - {
// Качество распознавания
// Рабочая переменная
// Обучающий массив
/ / / / / / / / / / / / /
// Параметр 1
131.2,163.3.457.0,370.0.227.8,169.4,110.3,293.8,200.3.161.8,
307.4.208.6.288.4,256.3.360.8.214.4.380.2.
208.6.186.8.216.2,230.0,192.6.204.4.220.2,
251.3.260.4,240.6,196.8.236.6,242.4,208.2.180.6,224.8,230.0.
198.0,189.0,252.6,194.0,221.7.216.8.208.4.
167.7,213.0,180.2,176.6.190.0,170.4,186.6.198.8.
IIIIIIIIIIIII
II Параметр 2
33.3,35.0.24.6,18.0.15.5,28.8.47.5,19.5.23.0,38.2,
66.6,16.6,59.1,24.5,100.0,15.6,45.8,
12.0,24.2,10.4.11.1,11.8,12.6,9.8,
9.3.8.4,10.2,12.4.11.0,8.6.14.4.16.2.12.0,8.8,
6.7.7.8,8.4,10.8,7.3,7.1.8.3,
24.4.26.8,30.2,22.6,28.4.25.5,26.6,25.8,
IIIIIIIIIIIII
II Параметр 3
60.0,60.0,94.1,79.4.91.2,85.0,78.0.110.5,136.7.129.2,
90.3.66.5,95.5,50.0,102.4,72.0.166.4.
72.9,68.4,80.2.74.4.70.5.74.2,70.0,
143.4,150.5,136.8,98.6.102.6.124.0,102.0,96.0,120.0,116.6.
107.0.128.0,139.0,98.8,120.0.96.6,110.8,
45.7.62.5.83.0,62.5.70.2.53.9.42.0.72.8};
///////////////////////// // Рабочие параметры сети al = 3;
ак - new int[al]:
ак[0] = 3;
ак[1] = 6;
ак[2] = 6;
// //
//
Размер входного слоя
Размер скрытого слоя (слоев)
Размер выходного слоя
is я SpecialVectorSum (ak.al);
ml = VectorSum (ak.al) - ak[0] - ak[al - 1]; ко = VectorSum (ah.no);
у - new double[is + ml];
in = new double[ni * ко]:
out - new double[no * ко];
du = new double[ni];
dul s new double[no];
dv - new double[MaximumOf (ak.al)];
dvl - new double[MaximumOf (ak.al)];
434
Глава 9 Распознавание образов с обучением
/ / / / / / / / / / / / / / / / / / / / / // Нормализация входа NormalizeMatrix (ine.ko.ni,du); Matrix! (ine,in.ko.ni);
///////////////////////////////////// // Инициализация заданными значениями FillUp (out.no * ko.O);
for (1 = O.s = 0: i < no; i++)
for (j = 0; j < ah[i]; j++) out[(kl[s++] - 1) * no + 1] = 1:
////////////////////////////////////// // Инициализация случайными значениями for (1=0; 1 < is + ml; 1++) y[i] = rand ();
Temp = AbsMaximumOf (y.is + ml);
for (i =0; i < is + ml; i++)
y[i] = y[i] / Temp - 0.5:
////////////////
// Обучение сети
cout « " Размер входа: " « ni « "\n Размер выхода: " « no « "\n Число слоев: " « al « "ХпЧисло синапсов: " « is « "ХпЧисло нейронов: " « (ml + ak[0] + ak[al - 1]) « "ХпЧисло объектов: " « ко « "Хп Код ошибки: " « BFGS (y.is +
ml.0.0001,&Max,0.OOOl.RGradient,FeedforwardError); cout « "ХпЧисло итераций: " « Max;
///////////////////////////////
// Решение задачи распознавания
Cout « "ХпОбъект: диагноз заданный. вычисленныйХп":
for (j = O.s = 0,si = 0; j < ko; j++)
{
for (i = 0; i < no; 1++) dul[i] = out[s++];
MaximumOf (dul,no.&Max);
for (i = 0; i < ni; i++) du[i] = in[sl++]: Feedforward (y.du,dul): MaximumOf (dul,no.&Maxl);
cout « (j + 1) « ": " « (Max + 1) « ". " « (Maxi + 1) « endl;
if (Max == Maxi) Qual++;
}
Нейронная сеть прямого распространения
435
cout « "Качество распознавания " « (Qual /ко * 100) « "Х\п"; delete [] du; delete [] dv; delete [] dul; delete [] y;
delete [] dvl; delete [] in; delete [] out; delete [] ak; }
double FeedforwardError (double* y.int m) //
// Функция вычисляет функционал ошибки feedforward нейронной сети. // Обозначения:
// у - нассив синапсов и снещений длиной го.
// Принечание:
// параметр ш введен для общности, в расчетах не применяется, // используется ряд глобальных параметров и массивов.
// Возвращаемое значение:
// значение функционала ошибки. //
{ register int i.j, // Счетчик цикла i0 = 0, // Счетчик входов il = 0; // Счетчик выходов
double Ret = 0; // Возвращаемое значение
/////////////////////////////////// // Цикл по числу обучающих объектов for (j = 0: j < ко; j++)
{
//////////////////////////////////
// Значения входа сети для объекта
for (i = 0; i < ak[0]; i++) du[i] = in[i0++];
///////////////////////////////// // Расчет выхода сети для объекта Feedforward (у,du,dul);
////////////////////////////
// Сравнение расчета и опыта
for (i = 0; i < ak[al - 1]; i++) Ret += (dul[i] - out[il]) * (dul[i] - out[il++]);
}
return Ret: }
void Feedforward (double* y.double* in.double* out) //
// Функция вычисляет выход feedforward нейронной сети для одного // объекта. Функция описывает архитектуру нейронной сети.
// Обозначения:
// у - массив синапсов и смещений.
436
Глава 9. Распознавание образов с обучением
// in - заданный вектор входов сети, // out - вычисляеный вектор выходов сети.
// Занечание:
// перед вызовом функции нормализация входа обязательна.
// используется ряд глобальных параметров и массивов.
// Возвращаемое значение:
// нет.
//
{ register int i.j.rn, // Счетчик цикла
il = 0. // Счетчик
i2 = is; // Счетчик смещений
////////////
// Вход сети
for (j = 0; j < ak[0]: j++) dv[j] = in[j]:
///////////////////////////////////
// Преобразование для скрытых слоев
for (i = 0; i < al - 2; i++)
{
///////////////////////////////////////////
// Умножение матрицы синапсов на выход слоя
for (j = 0; j < ak[i + 1]; j++)
for (m = 0. dvl[j] = 0: m < ak[i]; m++) dvlCJJ += y[il++] * dv[m];
////////////////////// // Нелинейные элементы for (j = 0; j < ak[i + 1]; j++) {
dv[j] = dvl[j] - y[i2++]; // Смещение
dv[j] /= (fabs (dv[j]) + 4.0); // Рациональный сигмоид }
}
/////////////
// Выход сети
for (i = 0; i < ak[al - 1]; i++)
for (j = 0, out[i] =0; j < ak[al - 2]; j++) out[i] += y[il++] * dv[j];
}
Второй представленный нами пример отличается от первого только функцией main. Все остальные функции — те же самые, что и для первого примера, и поэтому не показаны.
Пример применения
#include <fstream.h>
#include <iomanip.h>
Нейронная сеть прямого распространения
437
^include <stdlib.h>
^include <math.h>
^include "megastat.h"
int *ак. // Вектор размеров слоев
ко. // Число обучающих объектов
is. // Число синапсов
al; // Число слоев
double *in,*out, // Вход и выход сети
*du,*dul,*dv,*dvl; // Рабочие массивы
void main (void) { register int i.j: //
Счетчики цикла
int s, // Счетчики элементов массива
Max = 1000, // // Заданное максимальное число итераций
ni = 3, // Размер входа (число параметров)
ml: // Число синапсов скрытых слоев
double *y. // Синапсы и смещения
Qual = 0, // Качество распознавания
Temp. // Рабочая переменная
ine[] = { // Обучающий массив
/////////////
// Параметр 1
131.2,163.3,457.0,370.0.227.8,169.4,110.3,293.8,200.3,161.8,
307.4.208.6.288.4.256.3.360.8.214.4,380.2.
208.6.186.8.216.2.230.0.192.6.204.4.220.2.
251.3.260.4.240.6.196.8,236.6.242.4,208.2.180.6.224.8.230.0.
198.0.189.0.252.6.194.0,221.7,216.8.208.4.
167.7.213.0.180.2.176.6.190.0.170.4.186.6.198.8,
/////////////
// Параметр 2
33.3.35.0.24.6.18.0.15.5.28.8.47.5.19.5.23.0,38.2,
24.4,26.8.30.2.22.6.28.4,25.5,26.6.25.8.
66.6.16.6.59.1.24.5.100.0.15.6.45.8.
12.0.24.2,10.4.11.1,11.8.12.6.9.8.
9.3.8.4,10.2,12.4.11.0.8.6.14.4.16.2,12.0.8.8,
6.7,7.8,8.4,10.8.7.3.7.1.8.3,
24.4.26.8,30.2,22.6.28.4.25.5.26.6,25.8.
I ННИИНН
Н Параметр 3
60.0,60.0,94.1,79.4.91.2.85.0,78.0,110.5,136.7,129.2.
90.3,66.5,95.5,50.0.102.4.72.0.166.4,
72.9.68.4.80.2.74.4,70.5.74.2.70.0.
143.4,150.5,136.8.98.6,102.6,124.0.102.0.96.0.120.0.116.6.
438
Глава 9. Распознавание образов с обучением
107.0.128.0,139.0.98.8,120.0.96.6.110.8,
45.7,62.5,83.0.62.5,70.2,53.9.42.0,72.8},
ке[] = // Номера объектов в классах
{1.1.1.1.1.1.1.1.1.1.
2.2.2.2.2.2.2.
3.3,3.3.3.3.3.
4,4,4.4.4.4.4. 4,4.4.
5,5.5.5.5.5,5.
6,6.6,6.6.6.6. 6}:
/////////////////////////
// Рабочие параметры сети al = 3;
ak = new int[a1];
ak[0] = ni; // Размер входного слоя
ak[l] = 6; // Размер скрытого слоя
ak[2] = 1: // Размер выходного слоя
ко = sizeof (ке) / sizeof (ке[0]):
is = SpecialVectorSum (ak.al);
ml = VectorSum (ak.al) - ak[0] - ak[al - 1];
у = new doublets + ml]; in = new double[ni * ко]; out = new double[ko]: du = new double[ni];
dul = new double[l];
dv = new doubleCMaximumOf (ak.al)]; dvl = new doubleCMaximumOf (ak.al)];
///////////////////// // Нормализация входа NormalizeMatrix (ine.ko.ni,du); MatrixT (ine.in.ko.ni);
///////////////////////////////////// // Инициализация заданными значениями ArrayToArray (ke.out.ko);
////////////////////////////////////// // Инициализация случайными значениями for (i = 0: i < is + ml; i++)
yCi] = rand ();
Temp = AbsMaximumOf (y.is + ml);
for (i = 0; i < is + ml; i++) yCi] = yCi] / Temp - 0.5;
////////////////
// Обучение сети
дальнейшие исследования и программные ресурсы
439
cout « ” Размер входа: " « ni
« "\п Число слоев: " « al
<< "ХпЧисло синапсов: " « is
« "ХпЧисло нейронов: " << (ml + ак[0] + akfal - 1])
« "ХпЧисло объектов: " « ко
« "\п Код ошибки: " « BFGS (у.is +
ml,0.000001,&Мах.О.000001.RGradient,FeedforwardError);
cout « "ХпЧисло итераций: “ « Max;
///////////////////////////////
// Решение задачи распознавания
cout « "ХпОбъект: диагноз заданный, вычисленныйХп”;
for (j = 0,s = 0: j < ko; j++)
{
for (i = 0: i < ni; i++)
dufi] = in[s++];
Feedforward (y.du.dul);
Temp = SmartRound (dulfO]);
cout « (j + 1) « " « outfj] « ". " « Temp «
endl ;
if (outfj] == Temp) Qual++;
}
cout « "Качество распознавания " « (Qual /ко * 100) « "t\n":
delete [] du; delete [] dv; delete [] dul; delete [] y;
delete [] dvl; delete [] in; delete [] out; delete [] ak;
}
Дальнейшие исследования и программные ресурсы
• Исследование методик определения информативности параметров.
• Совершенствование алгоритмов нейросетевого распознавания и их программной реализации.
В табл. 9.2 и 9.3 представлены некоторые ресурсы по программному обеспечению, предназначенному для распознавания образов с обучением. Развитие нейросетевых технологий привело к тому, что подавляющее большинство современных программ распознавания с обучением основано на нейронных сетях.
440
Глава 9. Распознавание образов с обучением
Таблица 9.2. Программные ресурсы по распознаванию образов с обучением
Ресурс, адрес Разработчик или поставщик Содержание
www.tvp.ru Центральный экономикоматематический институт РАН КЛАССМАСТЕР, классификация, доступна демонстрационная версия
www. datacenter, ru Фирма «Дата-Центр» STARC, программа распознавания образов
www.aeat.co.uk/pes /ancctoolkit.htm АЕА Technology Neural Network Tool Suite, нейросетевой пакет программ
www. biocomp systems.com BioComp Systems, Inc. NeuroGenetic Optimizer, нейросетевой пакет для моделирования и оптимизации, доступна демонстрационная версия
9 www.calsci.com, www.tora-centre.ru California Scientific Software BrainMaker, BrainMakerPro и NetMaker для Windows и Macintosh, подготовка данных и решение задач прогнозирования с помощью нейронных сетей
www.gensym.com Gensym Corporation NeurON-Line, программа для проектирования нейронных сетей
www. ward-systems.com, www.neuro-project.ru Ward Systems Group, Inc.' NeuroShell, комплекс программ прогнозирования и распознавания образов посредством нейронных сетей, доступны демонстрационные версии
www.nd.com NeuroDimension Inc. NeuroSolution, моделирование нейронных сетей, доступна пробная версия
www.spss.com, www.spss.ru SPSS Inc. Neural Connection, моделирование нейронных сетей
www.neural- ware.com Aspen Technology, Inc. NeuralWorks, моделирование нейронных сетей
www. neuroproject.ru. /nb_2001 .htm РосБизнес- Консалтинг Neuro Builder, нейросетевая программа прогнозирования
" Партнер российской компании «НейроПроект».
Дальнейшие исследования и программные ресурсы
441
Таблица 9.2 (продолжение)
ресурс, адрес Разработчик или поставщик Содержание
www.bmstu.ru /facult/iu/iu4/rus /stat/book4 Институт вычислительного моделирования СО РАН NeuroPro, программа для производства знаний с помощью нейронных сетей, бесплатная версия
www.neural-bench.ru Neural Bench Development Neural Bench для Windows, программа моделирования нейронных сетей, доступна демонстрационная версия
www. orc. ru/~stasson /synax.zip С. Короткий SYNAX, моделирование нейронных сетей, бесплатная версия
ftp://ftp.kiarchive.ru /pub/windows/demo /iterator.zip Московский государственный технический университет NeuroIterator, программа программа нейронных сетей, бесплатная версия
pu.samson.spb.su /Education/Faculties / Psyhology/nps/ Санкт- Петербургский государственный университет Neuro Psychological System, нейросетевая исследовательская программа, доступна демонстрационная версия S j
www. StatSoft, com. au, www.statsoft.ru StatSoft, Inc. STATISTICA Neural Networks, моделирование нейронных сетей
www.partek.com Partek, Inc. Partek Data Analysis & Modelling Software, нейронные сети, дискриминантный анализ и другие методы, доступна пробная версия
Таблица 9.3. Информационные ресурсы по распознаванию образов с обучением
Ресурс, адрес Разработчик или поставщик Содержание
www.spss.com, www.tvp.ru SPSS, Inc. Neural Book II, интерактивное введение в нейронные сети
www.shef.ac.uk University of Sheffield, Книга «Введение
/psychology/gurney Department в нейронные сети»
/notes/contents.html of Psychology в формате Post Script
продолжение &
442
Глава 9. Распознавание образов с обучением
Таблица 9.3 (продолжение)
Ресурс, адрес Разработчик или поставщик Содержание
canopus.lpi.msk.su /neurolab Физический институт им. П. Н. Лебедева Цикл лекций «Нейрокомпьютинг и его применения в экономике и бизнесе» в формате Post Script и ссылки на программные ресурсы по нейронным сетям
www. neu roproject. ru Компания «НейроПроект» Интерактивный учебник «Аналитические технологии 1 для прогнозирования и анализа данных» и другие материалы по нейронным сетям и генетическим алгоритмам
www. bmstu. ru/f acult /iu/iu4/rus/stat /book2/ann.htm «НейроКомп» Монография «Нейроинформатика» в формате HTML
9 www.nd.com NeuroDimension Inc. «Neural Systems: Fundamentals Through Simultions», электронная книга по основам нейронных сетей
www.cis.hut.fi Helsinki University of Technology, Neural Networks Research Centre Материалы по нейронным сетям, программное обеспечение, ссылки
www.neuralbench.ru Neural Bench Development Тоже
www.neurok.ru ООО «НейрОК» Материалы по нейронным сетям
neural.chg.ru Научный центр в Черноголовке Тоже
www.kcl.ac.uk /neuronet N EuroNet Тоже
www.user.cityline.ru /-neurnews /neurnews.html A. Vlasov То же
www.neuropower.de Alexander Kuck Материалы по искусственному интеллекту
дальнейшие исследования и программные ресурсы 443
Таблица 9.3 (продолжение)
ресурс, адрес Разработчик или поставщик Содержание
aimtelligence.com Al Information Bank Материалы по искусственному интеллекту
xfactor.wpi.edu Worcester Polytechnic Institute Материалы и проекты по распознаванию образов
Глава 10. Многомерное шкалирование
Подобно методам факторного анализа, методы многомерного шкалирования используются для поиска структуры объектов (по терминологии многомерного шкалирования — стимулов) в многомерном пространстве. Подобно методам кластерного анализа, с помощью методов многомерного шкалирования изучаются группировки объектов в многомерном пространстве.
Доступное введение в методики многомерного шкалирования дано в [16], [76], [103], [180, с. 256].
Метрический метод Торгерсона
В программной реализации метод Торгерсона полностью совпадает с техникой Q факторного анализа методом главных компонент. Напомним, что под техникой Q подразумевается анализ объектов, а не 0 параметров, их описывающих. Однако в многомерном шкалировании в качестве матрицы мер связи (или различий) используется не корреляционная либо ковариационная матрица, как в факторном анализе, а так называемая матрица скалярных произведений, построенная на основе матрицы различий с использованием евклидовой метрики. Соответственно и интерпретация результатов расчета иная. Так, полученные координатные оси (оси шкальных значений), в отличие от факторного анализа, почти всегда могут быть содержательно интерпретированы. Кроме того, результаты анализа могут быть использованы для классификации объектов. Основным результатом расчета является матрица шкальных значений — координат стимулов в пространстве шкал.
Количество осей шкальных значений может быть задано пользователем исходя из анализа выдаваемых программой собственных значений (также их процентного содержания) матрицы скалярных произведений. Описаны и другие методы выбора количества осей [76]. Осей должно быть достаточно для содержательной интерпретации, однако на практике часто ограничиваются двумя или тремя осями. В наших расчетах, как правило, происходило следую-1
Метрический метод Торгерсона
445
щее: из величины собственных значений было сразу ясно, сколько собственных значений нужно оставить, так как отброшенные значения были очень малыми величинами, по модулю порядка 1О'10. Если число осей шкальных значений (размерность пространства) больше двух, дополнительно производится объективное вращение решения методом VARIMAX подобно тому, как это сделано в факторном анализе. Процедура вращения часто улучшает интерпретируемость решения, однако может и не повлечь за собой получения осмысленного результата.
Результаты анализа рекомендуется изобразить графически, а для размерности пространства более двух или трех графики должны быть представлены двумерными срезами пространства.
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void) {
register int i.j: // Счетчики цикла
int n = 6, // Число стимулов
m = 2. // Число осей
r. // Число ненулевых собственных значений
1 : // Индекс массива
double d[] = // Матрица различий
{0.00,0.71.1.41.1.73.2.00.2.00.
0.71.0.00.1.41.1.73.2.00.2.00.
1.41.1.41,0.00.1.00.1.41.1.41.
1.73.1.73.1.00.0.00.1.00.1.00.
2.00.2.00.1.41.1.00.0.00.0.71.
2.00.2.00.1.41.1.00.0.71.0.00}
р[3б], // Матрица скалярных произведений
t[36]. // Матрица координат (полная)
s[6]. // Вектор ( собственных значений
buf: И Рабочая переменная
SealarMatrix (d.p.n);
cout « "Матрица скалярных произведенийХп”: for (i = 0; i < n; i++)
{
for (j = 0,1 = 1; j < n: j++,l += n)
cout « setw (13) « p[lj;
446
Глава 10. Многомерное шкалирование
cout « endl: }
if (Torgerson (p.n.t.s.&r) == -1) cout « "Мало панятиХп":
else
{
cout « "Собственные значенияХп":
buf = VectorSum (s,n);
for (1=0: i < n; i++)
cout « setw (13) « s[i] « " = " « (s[i] * 100 / buf) « ” t\n”;
cout « "Матрица координат стинуловХп”; for (1=0; i < n; i++)
{
for (j = 0,1 = i; j < m; j++.l += n) cout « setw (13) « t[l];
cout « endl: }
if (m > 2) {
cout « "ХпВаринакс-вращениеХп”;
if (Varimax (t.n.m) == -1) cout « "Мало панятиХп":
el se {
cout « "Матрица координат стинуловХп":
for (i = 0: i < n; i++) {
for (j = 0,1 = i; j < m; j++, 1 += n)
cout « setw (13) « t[l]: cout « endl:
}
}
}
}
}
int Torgerson (double z[],int k.double r[],double s[].int *m) //
// Функция производит нногонерное шкалирование нетрическин
// нетодон Торгерсона.
// Обозначения:
// z - натрица скалярных произведений,
// к - порядок натрицы скалярных произведений,
// г - натрица координат разнерон не ненее к * к,
// s - вектор собственных значений,
// *т - число ненулевых собственных значений.
// Возвращаеное значение:
Метрический метод Торгерсона
447
// 0 при нормальном окончании счета.
// -1 при недостатке памяти для рабочих массивов.
// -2 при ошибке в вычислениях.
//
register int i.j; // Счетчики
int ml.m2,Code; // Вспомогательная переменная
double *zl. // Рабочая копия матрицы скалярных
// произведений
save; // Буфер
*m = 0;
if ((zl = new double[k * kJ) == 0) return -1;
ArrayToArray (z.zl.k * k):
////////////////////////////
// Решение проблемы факторов
if ((Code = Jacobi (zl.k.O.000001,&ml.r)) != 0)
{
delete [] zl;
return Code;
}
/////////////////////////////////////////////////
// Упорядочивание собственных значений и векторов for (i = 1; i < k; i++)
zl[i] = zl[i * (k ♦ 1)]; // Первый столбец -// собственные значения
for (i = 0; i < k; i++)
{
Code = i;
save = zl [ i ];
for (j = i + 1; j < k; j++) if (save < zl[j])
{
Code = j;
save = zl[j]; }
Col Interchange (zl.1.i.Code);
Col Interchange (r. k. i.Code);
}
////////////////////////////////////////////////
// Сохранение упорядоченных собственных значений ArrayToArray (zl.s.k):
10
448
Глава 10. Многомерное шкалирование
/////////////////////////////
// Отбор собственных значений
for (i - 0, ml в 0; i < k; 1++)
if (zl[i] < 0)
break:
el se
{
(*m)++:
///////////////////////////////
// Вычисление матрицы координат
save - sqrt (zl[i]):
for (j - 0; j < k; j++, ml++) r[ml] *- save:
}
delete [] zl:
return 0:
}
void ScalarMatrix (double a[],double b[],int n) //
// Функция вычисления матрицы скалярных произведений // для многомерного шкалирования.
// Обозначения:
// а - матрица различий,
// b - матрица скалярных произведений,
// п - порядок матриц а и Ь.
// Возвращаемое значение:
// нет.
//
{
register int i.j.k; // Счетчики
int m » O.ml; // Индекс текущего элемента
double dit.dtj.dtt: // Вспомогательные величины
/////////////////////////////
// Вспомогательные вычисления
for (k - 0, dtt » 0; k < n * n; k++)
dtt += a[k] * a[k]:
dtt = dtt /n / n:
////////////////////////////////////////////
11 Построение матрицы скалярных произведений
for (i - 0: i < n; i++)
for (j = 0: j < n; j++)
{
for (k e O.dit e O.ml e i: k < n; k++. ml +e n) dit += a[ml] * a[ml];
дальнейшие исследования
449
for (к = O.dtj = O.ml = j * n; к < n: k++) dtj += a[ml] * a[ml++]:
b[m] = - (a[m] * a[m++] - dit / n - dtj / n + dtt) / 2;
}
}
Дальнейшие исследования
Неметрические методы многомерного шкалирования [180, т. 2, с. 266].
10
15—2002
Глава 11. Методы I теории информации
Методы теории информации применяются нами как в качестве самостоятельных методов анализа данных, так и при построении рассматриваемых в книге других алгоритмов анализа данных. Например, методы теории информации могут применяться для определения таксономической ценности признаков [65, с. 118—130] и при анализе изображений [232, с. 99]. Основания, предпосылки практического применения информационного анализа и библиография подробно изложены в [ 119]. Кроме того, из-за тесной взаимосвязи методов анализа данных теория информации иногда рассматривается в курсах теории вероятностей [44] или математической статистики [108]. Рекомендуется также ознакомиться с находящейся по адресу www.cs.toronto.edu/~mackay/itprnn книгой «Теория информации, выводы и алгоритмы обучения», изданной Кембриджским университетом.
Информация по Шеннону
В теории информации в качестве меры количества информации, возможности выбора (количества разнообразия) и неопределенности [222, с. 261] применяется величина
1=1
где р,— вероятность появления дискретного события z, i =1, 2,..., п, величиныpit i = 1,2,..., п, образуют множество вероятностей, для практических вычислений вероятности допустимо заменить частотами распределений,
а — основание логарифма — единица, выбранная для оценки вели-i чины энтропии, обычно равная 2 или числу е.
При вычислении условились считать, что [140, с. 241], [135, с. 654]
О • log^O = 0.
Информация по Шеннону
451
Величина Я называется энтропией дискретного множества вероятностей (энтропией дискретной случайной величины, средней собственной информацией) и иногда обозначается как I, чтобы отличить ее от энтропии непрерывного распределения. Энтропия представляет собой количественную меру степени неопределенности исхода случайного опыта, зависящую не от индивидуальных свойств результатов опыта, а от соответствующих вероятностей [140, с. 242]. В дискретном случае энтропия равна нулю, когда одна из вероятностей равна 1, а остальные нулю.
Энтропия непрерывного распределения [222, с. 296] с функцией плотности распределения р(х) определяется как
Н = ~$ P(x)logap(x)dxt
однако в такой форме определение энтропии в наших расчетах пока не применяется.
Если в качестве основания логарифма а выбрано число 2, энтропия вычисляется в битах, если число е — в нитах. Если энтропия вычислена в нитах, для вычисления энтропии в битах нужно разделить значение в нитах на 1п2. Это утверждение вытекает из известной формулы замены основания логарифмов [101, с. 34], [219, с. 6]:
log С= logtC ,а>о,а * 1. log;, °
Программная реализация с примером применения показана ниже сразу для всех информационных показателей. Исходные данные для вычисления энтропии системы представляют собой дискретный или интервальный вариационный ряд, то есть таблицу распределения количеств вариант по классам.
Некоторые авторы энтропию называют количеством информации [211, с. 15] или двоичной энтропией [100, с. 105].
Исходные коды и пример применения
#include <fstream.h>
^include <iomanip.h>
#1nclude <math.h>
include "megastat.h"
void main (void)
11
15*
452
Глава 11. Методы теории информации
{
int п: // Число классов
double f[] = // Дискретный вариационный ряд
{115,67,55,191.396,513,396,51.8,4,1}.
nn. // Число вариант
hh. // Энтропия
hmax. // Максимальная энтропия
h. // Относительная энтропия
г. // Избыточность
о; // Организация
////////////////////
// Параметры выборки
n = sizeof(f) / sizeof(f[0]);
nn = VectorSum (f,n):
///////////////////////////
// Получение массива частот
MatrixMultiplyNumber (f.n.l / nn);
hh = Entropie (f.n):
hmax = MaxEntropie (n);
h = RelEntropie (hmax.hh);
r = Surplus (hmax.hh);
о = Organization (hmax.hh);
cout « "Число классов " « n « endl
« "Число вариант " « nn « endl
« "Энтропия " « hh « endl
« "Макс, энтропия " « hmax « endl
« "Oth. энтропия “ « h « endl
« "Избыточность. X " « r « endl
« "Организация " « о « endl;
}
double Entropie (double f[],int n)
//
// Функция вычисления неопределенности (энтропии) системы // для дискретных процессов по Шеннону.
// Обозначения:
// f - дискретный вариационный ряд,
// п - число классов.
// Возвращаемое значение:
// вычисленное значение энтропии (в битах). //
{
register int i; // Счетчик цикла
double h = 0; // Энтропия в нитах
Информация по Шеннону
453
for (1 = 0: i < n; 1++) if (f ! = 0)
h += f[i] * log
return - h * ML0G2E:
}
Максимальное разнообразие системы вычисляется по формуле
Хартли [28, с. 53], [ 119, с. 48]
Н max — 10g2?2.
Таким образом, справедлива формула [там же]
0<Н<Нтах
Максимум энтропии соответствует наибольшей неопределенности или равенству вероятностей всех возможностей. Опыт имеет наибольшую энтропию при k равновероятных исходах с вероятностями \/k. Степень неопределенности опыта тем больше, чем больше число k его исходов.
Исходные коды
double MaxEntropie (int n) //
// Функция вычисления максимальной неопределенности (энтропии) // системы
// для дискретных процессов по Шеннону.
// Обозначения:
// п - число разрядов позиций кода.
// Возвращаемое значение:
// вычисленное значение энтропии (в битах).
//
{ return log (n) * ML0G2E;
)
Энтропия графического изображения зависит от количества уровней, а при одинаковом числе уровней — от закона распределения [232, с. 100]. Равномерный закон распределения соответствует полной хаотичности. В этом случае энтропия достигает максимума, который зависит только от количества уровней:
Wn.ax = 10g#max-Ami„+ О.
где (.) — размах дискретной случайной величины.
Для сравнения систем, различающихся по количеству элементов кода, сопоставление энтропий не будет корректным. Для решения задачи
454
Глава 11. Методы теории информаций
применяется относительная энтропия (коэффициент сжатия информации), определяемая как [119, с. 50]
Относительная энтропия определяет относительную степень информационной загруженности системы по отношению к возможной максимальной нагрузке [там же]. Кроме того, относительная энтропия, как и рассмотренная ниже избыточность, может характеризовать степень близости закона распределения к равномерному.
Исходные коды
double RelEntropie (double hmax,double h) //
// Функция вычисления относительной энтропии системы.
// Обозначения:
// hmax - максимальная энтропия,
// h - текущая энтропия.
// Возвращаемое значение:
// вычисленное значение организации.
//
{
return h / hmax;
}
Свойства и применения энтропии в анализе данных описаны в [222, с. 261], [140, с. 241], [88, с. 29], [84, с. 59]. Подробные примеры рассмотрены в [119]. В [204, с. 381] представлены интересные примеры использования энтропии в лингвистических исследованиях и вводятся понятия информационной эстетики, основанной на энтропии по Шеннону, и информационной психологии.
Информация по Бриллюэну
Информация по Бриллюэну, в отличие от информации по Шеннону, основана на величине 1пи!. Считается, что в большинстве случаев различия не существенны [191, с. 279].
Логарифмы факториалов находят и другое, помимо информационного анализа, применение в анализе данных и затабулированы [32, с. 103]. Вычисление логарифма факториала призвано уменьшить вероятность переполнения при реализации ряда алгоритмов. Мы приводим два варианта: первый — с вычислением «в лоб», а также второй, более экономичный — с применением немного преобразо
Информация по Бриллюэну
455
ванной формулы Стирлинга [84, с. 343]. Обратите внимание — функции не отслеживают ошибку п < 0, поэтому программист должен быть уверен в этом до вызова функций.
Исходные коды и пример применения
^include <fstream.h>
^include <iomanip.h>
^include <math.h>
#include "megastat.h"
void main (void)
{
cout « LogFactorial (1500) « endl;
cout « Stirling (1500) « endl;
}
double LogFactorial (int n)
//
// Функция вычисляет логарифм факториала.
// Обозначения:
// п - заданное число. > 0.
// Возвращаемое значение:
// значение логарифма факториала.
int i; // Счетчик
double Ret = log (1.0); // Возвращаемое значение
for (i = 1; i <= n; i++)
Ret += log ((double) i);
return Ret;
}
double Stirling (int n)
//
// Функция вычисляет логарифм факториала.
// Обозначения:
// п - заданное число. > 0.
// Возвращаемое значение:
// значение логарифма факториала.
//
{ double m = (double) n;
return ((n + 0.5) * logic (m) + loglO (sqrt (M_PI * 2))) / ML0G10E - m;
456
Глава 11. Методы теории информации
Избыточность
Избыточность показывает, какая доля или процент передаваемой информации является избыточной. Она дает соотношение между полным количеством информации, шумом и сохранившейся упорядоченностью системы [119, с. 51]. Избыточность (в источниках обозначается также как R) вычисляется по формуле [там же, с. 50]
^ = 1-я/ятах.
Избыточность характеризует степень близости закона распределения к равномерному и может быть выражена в долях, как в показанной формуле, либо в процентах. Например, для полутонового изображения с 256 уровнями энтропия не может превышать 8, а избыточность при равномерном законе распределения равна нулю.
Исходные коды
double Surplus (double hmax,double h) //
// Функция вычисления избыточности системы.
// Обозначения:
// hmax - максимальная энтропия.
// h - текущая энтропия.
// Возвращаемое значение:
// вычисленное значение избыточности (в процентах).
//
{
return (1 - h / hmax) * 100:
}
Разведочный информационный анализ
Понятие избыточности может применяться в разведочном информационном анализе. При моделировании важно точно обосновать возможность применения тех или иных методов анализа и адекватность модели. В первом приближении проверку адекватности можно выполнить путем вычисления информационных показателей. В [88, с. 31,88] приводятся примеры применения избыточности для выбора типа модели, с помощью которой можно адекватно описать изучаемую систему. В [119, с. 52] даны рекомендации, изложенные в табл. 11.1.
Организация системы
457
Таблица 11.1. Выбор адекватной модели
Величина избыточности, % Характеристика системы Тип модели
о-ю Вероятностная (статистическая) Вероятностная
10-30 Вероятностно-детерминированная Дифференциальные уравнения
зо-юо Детерминированная Дифференциальные или
интегральные уравнения
Обсуждение видов моделей см. также в [57, с. 30]. Мы сознательно опустили в данном разделе термин «математическая модель», так как вернемся к нему в начале главы 15.
Эквивокация
Разность избыточности в норме и при патологии приводит к понятию ненадежности (эквивокации) передачи информации, что дает количественную характеристику структурной перестройки исследуемого объекта (системы) [119, с. 52]. Вычисление эквивокации производится по формуле [там же]
Н — Н
D — R — R — 1 1 попт> >
norm pal тт
1 max
где Rnorm — избыточность в норме,
Rpa[ ~ избыточность в патологиии,
Hpai — энтропия в патологии,
Нпопп — энтропия в норме.
Пример применения дан в [там же, с. 57].
Организация системы
Под организацией системы понимают реализованную в ней неопределенность [88, с. 30], [119, с. 50]. Абсолютная организация системы вычисляется по формуле
При организации, равной максимальной энтропии, система становится детерминированной, полностью стабильной.
458
Глава 11 Методы теории информации
Исходные коды
double Organization (double hmax,double h) //
// Функция вычисления абсолютной организации системы.
// Обозначения:
// hmax - наксинальная энтропия,
// h - текущая энтропия.
// Возвращаемое значение:
// вычисленное значение организации (в битах).
//
{
return hmax - h:
Дивергенция, информационные меры
Для различных ковариационных матриц в случае произвольного распределения дивергенция, оценивающая расхождение между pacnpe-i делениями, выражается формулой [186, с. 312]
Js=(х)-
Иначе дивергенция называется полной средней информационной мерой различия двух классов или, более коротко, средней различа] ющей информацией.
Практически дивергенция может быть вычислена по формуле [там же, с 313]
Л4fr[(c--СЖ -c")]v[(cr‘+c;')h-^)(^’
где С„ Cj — дисперсионно-ковариационные матрицы совокупностей i и у,
mt, mj — вектора средних совокупностей i nj.
Мера Кульбака
Иначе дивергенция называется мерой Кульбака (информационной мерой Кульбака, расстоянием Кульбака, мерой Калбэка) [160, с. 66]. В практических исследованиях мера Кульбака применяется для изу
дивергенция, информационные меры
459
чения расхождения между двумя эмпирическими распределениями. Значение меры, равное нулю, означает отсутствие различий. Мера Кульбака вычисляется по формуле [108, с. 6]
y[Z ...g.kg”2Z, «1+«2Щ”1 «2 J
где обозначения те же, что и в описании критерия с2.
Алгоритм вычисления меры Кульбака оперирует частотами эмпирических распределений сравниваемых совокупностей, поэтому должны соблюдаться минимальные требования к величинам анализируемых выборок. В случае, если число классов меньше 7, корректность вычислений будет под вопросом, хотя минимально допустимая величина выборки равна 4. Данным методом рекомендуется проводить сравнение рядов длиной не менее 40 каждый.
Методика применения меры Кульбака для задач медицинской диагностики представлена в [57, с. 116]. Приводимая в источнике формула отличается от данной выше наличием множителя 0,5 перед скобками и множителя 10 перед логарифмом, именно на этой формуле основана показанная ниже функция.
Исходные коды
double Kullback (double fl[],double f2[],int n) //
// Функция вычисления меры Кульбака.
// Обозначения:
// fl - массив частот распределения 1-го ряда,
// f2 - массив частот распределения 2-го ряда,
// п - численность каждого массива.
// Возвращаемое значение:
// значение меры Кульбака.
//
{
register int i; // Счетчик цикла
double nl = VectorSum (fl.n), // Объем ряда 1
n2 = VectorSum (f2,n), // Объем ряда 2
hl = 3,h, // Вспомогательная величина
sign, // Знак диагностического
// коэффициента
j = 0; // Мера Кульбака
///////////////////////////////////////// // Частости и диагностический коэффициент for (i = 0; i < n: i++)
460
Глава 11. Методы теории информации
{
if (!fl[i] || !f2[i])
{
sign = fl[i] ? 1 : -1:
h = hl * sign;
hl += 3:
}
el se
h = 10 * loglO (fl[i] / f2 [i] / nl * n2);
j += 0.5 * h * (fl[i] / nl - f2[i] / n2):
}
return J;
Мера Махаланобиса
Мера Махаланобиса (расстояние Махаланобиса, обобщенное евклидово расстояние, обобщенное расстояние), находящая широкое применение в кластерном анализе, может быть выведена из дивергенции [186, с. 311]. Мера Махаланобиса является дивергенцией в предположении, что ковариационные матрицы классов равны [там же, с. 313]:
G = С} = S,
а совокупности подчиняются многомерному нормальному распре-11 делению [там же, с. 312]. Последние требования накладывают определенные ограничения на применение рассматриваемой меры различия, что часто не принимается во внимание исследователями1, но должно учитываться в практических расчетах. Заметим, при рассмотрении метрики Минковского и произведенных от нее мер никакие требования на вид статистического распределения исходных данных не накладывались.
После должных преобразований получим, что мера Махаланобиса вычисляется как [148, с. 158]
dg = (X-^yxl(X-Xj),
где Е — общая внутригрупповая дисперсионно-ковариационная матрица.
См. также [108, с. 204].
1 Ситуация напоминает проблемы, с которыми сталкивается исследователь при использовании Z-критерия, необоснованно полагая его весьма простым в использовании.
Информационная статистика
461
Исходные коды
double Mahalanobis (double datl[].double dat2[].double s[].int k) //
// Функция вычисления неры Махаланобиса.
// Обозначения:
// datl - первый из сравниваемых векторов данных.
// dat2 - второй из сравниваемых векторов данных,
// s - заранее вычисленная дисперсионно-ковариационная матрица, // к - длина каждого вектора данных и порядок матрицы s.
// Примечание: массивы datl и dat2 разрушаются.
// Возвращаемое значение:
// значение неры Махаланобиса.
//
{
register int i.j; // Счетчики циклов
int m; // Счетчик одномерного массива
double г = 0; // Расстояние Махаланобиса
for (i =0; i < k; i++)
da11[i] -= dat2[i];
for (i=0, m=0:i<k: i++)
for (j = 0. dat2[i] =0; j < k; j++) dat2[i] += datl[j] * s[m++];
for (i = 0; i < k; i++)
r += dat2[i] * datl[i]:
return r;
}
Информационная статистика
Подробное описание применения информационной статистики в методах кластерного анализа дано в [191, с. 279]. Так, информационное содержание группы из п элементов, описываемых s бинарными (в этом случае, очевидно, s = 2) признаками или номинальными признаками с несколькими состояниями (s > 2), определяется как
Z = snln/2-^^ailna/ + (n-aj)ln(/?-ai)J >
где cl, i=l,2,..., s, — число элементов, обладающих признаком г, так что
462
Глава 11. Методы теории информации
Xя, =«
1=1
Если информационное содержание групп А и В обозначено, соот-| ветственно, через 1А и 1В, и группы объединены в группу С с информационным содержанием 1С, информационный выигрыш определяется формулой
= ?с~ (J.а + h )
В указанном источнике даны также соображения, иногда скептические, относительно применения информационной статистики для порядковых и непрерывных признаков, а также предложен порядок действий в случае отсутствующих значений.
Мы не приводим исходных текстов. Программная реализация не вызовет затруднения у читателя. Об информационном расстоянии см. [82, с. 105].
Дальнейшие исследования
Применение методов теории информации в различных алгоритмах анализа данных. Например, вывод информационного критерия гомогенности выборки дан в [127].
Глава 12.
Планирование эксперимента
Планирование эксперимента применяется в тех областях деятельности, будь это натурные эксперименты или организация вычислительного процесса, где необходимо, как минимум, систематизировать порядок проведения некоторых действий и, как максимум, оптимизировать этот порядок.
Методы планирования эксперимента в нашем исследовании применяются при построении и оптимизации алгоритмов других методов расчета, значительно увеличивая их эффективность (например, численное дифференцирование) или оказывая неоценимую помощь в смысле стройности построения алгоритмов (например, критерии рандомизации).
Полный ортогональный план
Ортогональный план первого порядка для п факторов представляет собой матрицу, составленную из знаков «+» и «-». Для определенности в составленных нами функциях используются числа +1 и -1. Так, для трех факторов полный ортогональный план имеет вид
+1 +1 +1
-1 +1 +1
+1 -1 +1
-1 -1 +1
+1 +1 -1
1 +1 1
+1 -1 -1
-1 -1 -1
Посмотрим, как строится такой план [99] Знаки чередуются с шагом, кратным степени двойки. Первому столбцу соответствует шаг 2°, второму 21, третьему 22и т. д. Число строк плана для п факторов (п столбцов) составляет 2".
464
Глава 12 Планирование эксперимента
Ортогональный план является весьма интересным объектом. Отметим два его основных свойства:
1. Сумма элементов любого столбца равна нулю.
2. Сумма почленных произведений любых двух столбцов (скалярное произведение векторов-столбцов) равна нулю.
Полный план применяется нами при реализации критерия рандомизации для связанных выборок, однако от показанной ниже функции фрагмент метода RandomCriterionIndependent, ответственный за построение полного плана, отличается тем, что с целью экономии памяти план строится не по столбцам, а по строкам. При этом из построенного плана одномоментно хранится только текущая строка.
Исходные коды
void FullOrtoPlan (signed char а[]. int ni) //
// Функция построения полной матрицы планирования
// (ортогонального плана эксперимента) первого порядка.
// Обозначения:
// а - матрица планирования, при обращении к функции под нее
// должна быть выделена память в количестве
// ((2 в степени ni) х ni ячеек);
// ni - задаваемое число факторов.
//
{
long int n. // Число вариантов
i. j.k; // Счетчики
int step. // Шаг чередования
1=0; // Глобальный счетчик элементов
n = TwoDegree (ni);
///////////////////
// Построение плана
for (i = 1: i <= ni; i++)
{
step = TwoDegree (i - 1);
for (k - 1; k <= n / TwoDegree (i); k++)
{
for (j = 1; j <= step; j++)
a[l++] = 1;
for (j = 1; j <= step: j++) a[l++] = -1;
}
)
}
Разработка компактных функций, представленных в данной главе, делает ненужным применение громоздких таблиц типа [69, с. 242].
Дробная реплика полного плана
465
Дробная реплика полного плана
Для многих задач нет необходимости в вычислении полного плана. Урезанный особым образом план называется дробной репликой полного плана. При этом в качестве основы построения дробной реплики для г факторов используется такой минимальный полный план для п факторов, что выполняется неравенство
п + С$ >г,
где п столбцов соответствуют полному плану для п факторов,
С2п столбцов (число сочетаний из п по 2) описывают так называемые эффекты взаимодействия п первых столбцов между собой. Это означает, что столбцы перемножаются попарно по следующей схеме (показана схема вычисления дробной реплики для 9 факторов):
Столбец
1 2 3 4 5=1X2 6=1X3 7=1X4 8 = 2X3 9 = 2 X 4
В качестве примера из полного плана для 4 факторов нами строится реплика для 7 факторов. Это означает, что в ряде задач для 7 факторов может применяться дробная реплика размером 7 х 24 = 112 элементов вместо полного плана размером 7 х 27 = 896 элементов, причем без потери каких-либо существенных особенностей. Обратите внимание, что динамическая память для матрицы, в которой хранится план, резервируется только после того, как будут подсчитаны оптимальные размеры плана.
Дробные реплики факторных планов применяются нами в задаче построения матрицы первых частных производных системы функций по вектору (якобиана системы), способствуя тем большему увеличению эффективности вычислений, чем больше размеры самой системы. Пример практического применения дробной реплики факторного плана дан в [4].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include "megastat.h"
void main (void)
466
Глава 12. Планирование эксперимента
{
int i.j.m.n = 7,nopt,nful;
double *a;
OptimalPlan (n.&nful,&nopt);
a = new doublefn * nopt];
OrtoPlan (a.n.nful.nopt);
cout « "n = " « n « endl
« "nful = " « nful « endl
« "nopt = " « nopt « endl « "Matrix A\n“;
for (i - O.m = 0; i < n; i++) {
for (j = 0; j < nopt; j++.m++) cout « setw (4) « a[m];
cout « endl;
}
delete [] a; }
int OrtoPlan (double a[], int ni, int ir. int n) //
// Функция построения полной или усеченной (дробной реплики)
// матрицы планирования (ортогонального плана эксперимента) // первого порядка. План хранится в виде вектора.
// соответствующего матрице размером [ni.n].
// Обозначения:
//а - матрица планирования, при обращении к функции под нее // должна быть выделена память (ni * п ячеек), // ni - задаваемое число факторов.
// ir - заданное (не более ni) или вычисленное программой
// OptimalPlan число факторов плана полного факторного // эксперимента, из которого должна быть получена натрица а. // п - заданное (не более 2 в степени ni) или вычисленное
// программой OptimalPlan минимально необходимое // количество опытов.
// Возвращаемое значение:
// 0 при нормальном окончании счета.
// -1 при недостатке памяти для рабочих массивов. //
{
register int i.j.k; // Счетчики
int step, // Шаг чередования
1=0, // Глобальный счетчик элементов
ml.m2; // Счетчики цикла
Дробная реплика полного плана
467
/////////////////////////////////////////////// // Построение плана без эффектов взаимодействия for (i = 0: i < ir; i++)
{
if (!i) step = 1;
el se
step = 2 « (i - 1);
for (k = 1; k <= n / (2 « i) ; k++) {
for (j = 1; j <= step; j++) a[l++] = 1;
for (j = 1: j <= step; j++) a[l++] = -1;
} }
///////////////////////////////////// // Построение эффектов взаимодействия i = 0;
k = ni * n;
while (1 < k)
{
for (j = i + 1; j < ir; j++)
{ ml = i * n; m2 = j * n; for (k = 0; k < n; k++) a[l++] = a[ml++] * a[m2++];
} i++:
}
return 0;
}
int OrtoPlan (int a[], int ni. int ir, int n) //
// Функция построения полной или усеченной (дробной реплики)
// матрицы планирования (ортогонального плана эксперимента)
// первого порядка. План хранится в виде вектора,
// соответствующего матрице размером [ni,n].
// Обозначения:
//а - матрица планирования, при обращении к функции под нее // должна быть выделена память (ni * п ячеек), // ni - задаваемое число факторов,
// ir - заданное (не более ni) или вычисленное программой
// OptimalPlan число факторов плана полного факторного
// эксперимента, из которого должна быть получена матрица а.
// п - заданное (не более 2 в степени ni) или вычисленное
468
Глава 12, Планирование эксперимента
// програнной OptimalPlan минимально необходимое
// количество опытов.
// Возвращаемое значение:
// 0 при нормальном окончании счета,
// -1 при недостатке памяти для рабочих массивов.
//
{
register int i.j.k: // Счетчики
int step, // Шаг чередования
1=0. // Глобальный счетчик элементов
ml,m2: // Счетчики цикла
///////////////////////////////////////////////
// Построение плана без эффектов взаимодействия
for (i = 0; i < ir: i++)
{
if (!i)
step = 1:
el se
step = 2 « (i - 1):
for (k = 1: k <= n / (2 « i) ; k++) {
for (j = 1: j <= step: j++)
a[l++] = 1:
for (j = 1: j <= step: j++) a[l++] = -1:
}
}
/////////////////////////////////////
// Построение эффектов взаимодействия
i = 0:
k = ni * n:
while (1 < k)
{
for (j = i + 1: j < ir: j++)
{
ml = i * n;
m2 = j * n;
for (k = 0: k < n: k++)
a[l++] = a[ml++] * a[m2++]:
}
i++:
}
return 0:
}
Для заданного числа факторов ортогональная матрица планирования должна быть получена усечением полного плана, построенного
Дальнейшие исследования и программные ресурсы
469
для большего числа факторов. Также должно быть вычислено минимально необходимое количество опытов. Эти данные являются входными для функции OrtoPlan, строящей ортогональный план. Таким образом вычисляются оптимальные размеры ортогонального плана эксперимента.
Исходные коды и пример применения
void OptimalPlan (int ni, int *ir, int *n) //
// Функция определения оптимальных размеров матрицы планирования // (ортогонального плана эксперимента) первого порядка или
// дробной реплики полного ортогонального плана эксперимента.
// Обозначения:
// ni - задаваемое число факторов,
// ir - предлагаемое программой число факторов полного
// факторного эксперимента,
// п - вычисленное программой минимально необходимое
// количество опытов.
//
{
for (register int i = 1; i < ni: i++)
if (ni <= i + i * (i - 1) / 2) break;
*i r = i ;
*n = 2 « (i - 1);
Дальнейшие исследования и программные ресурсы 12
Применение методов планирования эксперимета для оптимизации вычислительных процессов и реальных экспериментов [4], [69], [142], [200]. См. также программу Design-Expert и другие материалы, представленные на сайте Stat-Ease Inc. (www.statease.com).
Глава 13. Линейная алгебра
В данной главе представлены алгоритмы линейной алгебры, которые могут применяться в представленных методах анализа данных. Набор методов может показаться недостаточно полным, однако это не так. Реализуя тот или иной расчетный метод, мы попутно программировали и все его компоненты, используемые также и в других методах, поэтому в результате сложилась определенная связная самодостаточная структура. Элементы этой структуры могут быть использованы при построении других расчетных методов, не вошедших в данное издание.
Разработчик всегда может использовать некоторую стандартную математическую библиотеку. Однако ряд соображений может застаЧ вить его отказаться от этого шага, используя в качестве альтернативы свою собственную библиотеку либо решения, приведенные в настоящей главе. Во-первых, известные нам стандартные матема! тические и статистические библиотеки в настоящее время с исходными текстами обычно не поставляются. Во-вторых, подробный анализ опубликованных исходных текстов, например одной из известных библиотек научных программ [ 12], [ 175], указывает не только на недостаточную эффективность ряда процедур, но и в некоторых случаях на явные, возможно, введенные намеренно, ошибки. В-третьих, многие поставщики требуют отчислений при распространении приложений. Полагаем, что сказанного достаточно — всегда лучше иметь полный контроль над проектом и зависеть только от собственных решений.
В настоящей главе рассмотрены алгоритмы линейной алгебры, то есть численные методы, посвященные двум задачам — решению линейных алгебраических уравнений и определению собственных значений и собственных векторов матриц [135, с. 312], — а также вспомогательные процедуры, способствующие решению этих двух задач.
Представление массивов
Сначала посмотрим, как передаются двумерные массивы через формальные параметры подпрограмм (функций). Предположим, в основ
Представление массивов
471
ной программе имеется массив А размером тп = 5 строк на п = 4 столбцам. При его передаче в системах программирования на алгоритмическом языке Фортран проблем не возникает, если передается весь массив. Однако что будет, если передается часть массива размером тпх = 4 строк на пх = 3 столбцам? Всего при вызове, например, CALL FUNCI (A.M.N.M1.N1) должны были бы передаться 12 элементов массива из 20: Иц, 1221’1^31’ ^4i»^i2’ ^22’ ^32’ ^42» ^13’^23» ^33’ ^43 (напомним, что в С и C++ нумерация элементов массива начинается только с нуля, в Фортран — произвольно). Однако на самом деле будут переданы совсем другие 12 элементов. Лц, ^21» ^зь ^4ь ^51» ^12» ^22» ^32> ^42’ ^52’ а1з» ^23" Это связано с тем, что в памяти компьютера массивы любых размерностей хранятся в виде одномерных. Используя только одномерные массивы на самом деле, мы не только смогли получить неплохую эффективность алгоритмов, но также принципиально избавились от проблем с передачей формальных параметров как в Фортран, так и в С. К тому же стандартно в С многомерные массивы через формальные параметры не передаются [230, с. И] (на самом деле двумерные массивы в С можно легко передать через формальные параметры, поместив двумерный массив в структуру и передав в подпрограмму указатель на структуру [38, с. 127]). При использовании предложенного механизма нужно только иметь в виду несколько моментов:
• Двумерные массивы расположены по столбцам — сначала меняется первый индекс. Мы приняли это соглашение для определенности, так как в Фортран двумерные массивы расположены именно так [38, с. 126]. В С наоборот —двумерные массивы располагаются по строкам [там же].
• Матрицы данных, представленные одномерными массивами, при последовательных вводе и выводе будут показаны в транспонированном виде.
Перебор элементов, обусловленный требованиями алгоритмов, сводится к перебору индексов, причем предпочтительным, из соображений скорости вычислений, является не прямое вычисление индекса, стоящего на пересечении строки i и столбца) элемента матрицы с п строками по очевидному правилу (нумерация с нуля)
indexfa^) = i + jn,
а накапливание индексов с использованием только операций сложения, вычитания, инкремента и декремента. Такой подход является более трудоемким в программировании и менее наглядным, но он компактен и дает существенный выигрыш, экономя вычислитель
472 Глава 13. Линейная алгебра
ные ресурсы. Например, при разработке функции Jacobi мы приме-нили первый способ, а при составлении функции Gauss — второй.
Векторные и матричные операции
В раздел включено большое число необходимых алгоритмов матричных вычислений. От их качественного исполнения во многом зависит не только эффективность, но и сама работоспособность других алгоритмов.
Напомним, что матрицей называется [101, с. 347] прямоугольная таблица чисел (скаляров) размером п строк на т столбцов. При этом матрица размером п х 1 называется столбцом (вектор-столбцом), а матрица размером 1 х т называется строкой (вектор-строкой). При т = п матрица называется квадратной, а квадратная матрица вида
Ч 0
Л= 0 А, ... .
к........>
где на диагонали находятся квадратные матрицы, называется блочной (клеточной). Специальные типы матриц описаны в соответствующих разделах, посвященных вычислению, приведению матриц от одного вида к другому, а также производимым над ними операциям. Подробное обсуждение матриц и их свойств дано во многих источниках, например в [100, с. 670].
В разделах «Векторные операции» и «Матричные операции» содержатся простые алгоритмы, которые дают значительное сокращение кода программ и положительно сказываются на их надежности и эффективности.
Векторные операции
При записи алгоритмов, в частности методов оптимизации, нами применяется запись вида [55, с. 109]
S = (а,Ь),
где 5 — скалярное произведение векторов,
а — первый вектор,
b — второй вектор.
Векторные и матричные операции
473
Скалярное произведение векторов вычисляется как сумма произведений компонент перемножаемых векторов, поэтому длины векторов должны совпадать. Вычисление по приведенной формуле производится непосредственно в алгоритмах, поэтому отдельная функция, реализующая данное вычисление, нами не приводится, а при необходимости ее будет нетрудно составить.
функция, вычисляющая сумму элементов вектора, применяется во многих алгоритмах анализа данных и способствует, как и все матричные методы, значительному сокращению кода программ и, как следствие, улучшению их удобочитаемости. Сумма элементов вектора х вычисляется как [100, с. 49]
Язык C++ предлагает три пути решения этой задачи для разных типов параметров: различные функции с разными именами, шаблон, перегрузка имени. Мы выбрали последний вариант.
Исходные коды
int VectorSum (int x[].int n)
//
// Функция вычисления сунны эленентов целого пассива
// Обозначения:
// х - пассив.
// п - длина пассива.
// Возвращаеное значение:
// сунна эленентов пассива.
//
{
register int i;
int s = 0:
for (i =0; i < n; i++)
s += x[i];
return s;
}
double VectorSum (double x[],int n)
//
// Функция вычисления сунны эленентов нассива.
// Обозначения:
// х - пассив.
// п - длина нассива.
// Возвращаеное значение:
474
Глава 13. Линейная алгебра
// сунна эленентов нассива. //
{ register int i:
double s = 0;
for (i = 0: i < n; i++) s += x[i];
return s: }
Следующая функция носит вспомогательный характер и вычисляет сумму квадратов элементов вектора по формуле [128, с. 248]
1=1
Функция применяется в ряде алгоритмов, в том числе для вычисления евклидовой нормы вектора.
Исходные коды
double VectorSumSQ (double х[].int n) //
// Функция вычисления сунны квадратов эленентов нассива.
// Обозначения: // х - нассив, // п - длина нассива.
// Возвращаеное значение:
// сунна эленентов нассива. //
{
register int i:
double s = 0;
for (i =0; i < n; i++) s += x[i] * x[i]:
return s: }
Следующая функция также носит вспомогательный характер и вычисляет сумму попарных произведений элементов вектора вида
Векторные и матричные операции
475
Исходные коды
int SpecialVectorSum (int x[],int n)
//
// Функция вычисления суммы попарных произведений
// элементов нассива.
// Обозначения:
// х - массив.
// п - длина массива.
// Возвращаемое значение:
// сумма попарных произведений элементов массива.
// ( int s = 0:
for (register int i = 0: i < n - 1; i++)
s += x[i] * x[i + 1];
return s;
}
Еще одна широко применяемая нами функция копирует один вектор в другой, сокращая запись алгоритмов.
Исходные коды
void ArrayToArray (double х[].double y[],int n) //
// Функция копирования массива в массив.
// Обозначения:
// х - массив - источник.
// у - массив - приемник,
// п - количество копируемых элементов.
// Возвращаемое значение:
// нет.
//
{
for (register int i = 0; i < n: i++) y[i] = x[i]:
}
Далее мы решили указать на один из алгоритмов, который может оказаться полезен при анализе данных, однако без приведения кода функции, реализующей данный алгоритм. Приведем формулу для вычисления критерия Грама линейной зависимости векторов. Вектора х, г =1,2,..., ти, называются линейно зависимыми, если существуют такие не равные одновременно нулю числа cf, i = 1,2,..., т, что
т
£<w=°-
1=1
476
Глава 13. Линейная алгебра
Для того чтобы векторах, i = 1,2,тп, были линейно независимыми, необходимо и достаточно, чтобы был равен нулю [48, с. 212] определитель Грама, составленный из этих векторов,
(*Л) (х,х2) ... (х,хт) (*Л) (х2х2) ... (х2хи)
(Vl) Cv2) - (X„XJ
где (xrv;), i,j =1,2,..., m, — скалярные произведения векторов, введенные выше.
Матричные операции
В данный раздел включены процедуры манипулирования матрицами: алгоритмы их перемножения, умножения на число и другие. Большое число вариантов вызвано стремлением получить максимальную эффективность при счете. Пусть, например, нужно умножить некоторую матрицу на транспонированную матрицу. Для решения задачи можно сначала транспонировать матрицу, а затем умножить на нее первую матрицу, однако такое решение неэффективно. Оказывается, используя манипуляции с индексами элементов матриц, задачу можно решить, не применяя операцию транспонирования. Решения такого типа более эффективны, хотя и вынуждают иметь отдельную функцию на каждую часто используемую связку матричных операций. Основополагающее введение в теорию матриц дано в [48].
Показанные ниже функции поэлементного сложения матриц (массивов любой допустимой размерности) отличаются способом сохранения результата — в специально отведенном массиве либо в первом слагаемом.
В нашей реализации, когда массивы независимо от их размерности располагаются в виде одномерного массива, не имеет значения, что складывается: два вектора, два двумерных массива (прямоугольная или квадратная матрицы) и т. д. Главное, чтобы массивы имели равные размеры. Это замечание относится ко всем показанным далее методам, связанным со сложением и вычитанием матриц.
Вычисления ведутся по формуле [101, с. 348]
С = А + В,
Векторные и матричные операции
477
где А — первое слагаемое,
— второе слагаемое, С — суммарный массив. Обсуждение см. также в [100, с. 673].
Исходные коды
void MatrixPlusMatrix (double а[],double b[], int n)
//
// Функция суммирует поэлементно два нассива.
// Обозначения:
// а - первое слагаемое.
// b - второе слагаемое.
// п - размер каждого нассива.
// Примечание.
// Результат сохраняется в первом массиве.
// Возвращаемое значение:
// нет.
//
{ register int i;
for (i = 0: i < n: i++) a[iJ <-= b[i]:
}
void MatrixPlusMatrix (double a[],double b[],double c[].int n) //
// Функция суммирует поэлементно два нассива.
// Обозначения:
// а - первое слагаемое,
// b - второе слагаемое.
// с - сунна.
// п - размер каждого массива.
// Возвращаемое значение:
// нет.
//
{ register int i;
for (i = 0: i < n; i++) c[i] = a[i] + b[i];
}
Показанные ниже две функции аналогичны приведенным выше, но производят операцию вычитания:
С = А - В,
где А — уменьшаемое, В — вычитаемое,
478
Глава 13. Линейная алгебра
С — разность.
Функции также различаются только способом хранения результата.
Исходные коды
void MatrixMinusMatrix (double а[].double b[],int n) //
// Функция вычитает поэлементно из одного нассива другой.
// Обозначения:
// а - уменьшаемое.
// b - вычитаемое.
// п - размер каждого массива.
// Примечание.
// Результат сохраняется в первом массиве.
// Возвращаемое значение:
// нет.
//
{
register int i;
for (i = 0; i < n; i++)
a[i] -= b[i]:
}
void MatrixMinusMatrix (double a[],double b[J.double c[].int n) //
// Функция вычитает поэлементно из одного массива другой.
// Обозначения:
// а - уменьшаемое.
// b - вычитаемое.
// с - разность.
// п - размер каждого массива.
// Возвращаемое значение:
// нет.
//
{
register int i:
for (i = 0: i < n: i++) c[i] = a[i] - b[i];
}
Операцию, выполняемую следующей процедурой, можно записать для результирующей квадратной матрицы как
С = А + diag (В),
где А — первое слагаемое,
diag (В) — второе слагаемое — диагональная матрица, С — сумма.
векторные и матричные операции 479
результат записывается в первом слагаемом. Второе слагаемое хранится в виде вектора, соответствующего диагонали.
^сходные коды
void MatrixPlusDiag (double a[],double b[].int n)
//
// функция прибавляет к квадратной матрице диагональную матрицу.
// Обозначения:
// а - первое слагаемое размера п * п.
// b — второе слагаемое размера п.
// Примечание.
// Результат сохраняется в первом массиве.
// Возвращаемое значение:
// нет.
//
register int i:
int m = 0:
for (i = 0: i < n: i++. m += n + 1) a[m] += b[i];
}
Операцию, выполняемую следующей функцией, можно записать для результирующей квадратной матрицы как
С = А - diag (В),
где А — уменьшаемое,
diag (В) — вычитаемое — диагональная матрица,
С — разность.
Результат записывается в уменьшаемом. Вычитаемое хранится в виде вектора, соответствующего диагонали.
Исходные коды
void MatrixMinusDiag (double а[].double b[].int n)
//
// Функция вычитает из квадратной матрицы диагональную матрицу.
// Обозначения:
// а - уменьшаемое размера п * п.
// b - вычитаемое размера п.
// Примечание.
// Результат сохраняется в первом массиве.
// Возвращаемое значение:
// нет.
//
{
register int i:
480
Глава 13. Линейная алгебра
int m = 0:
for (i = 0: i < n: i++. m += n + 1) a[m] -= b[i];
}
Умножение матрицы или вектора на число (скаляр) производится поэлементно [101, с. 348]:
С = п . Д
причем результат записывается на место умножаемой на скаляр матрицы.
Обсуждение и пример применения см. в [183, с. 18].
Исходные коды
void MatrixMultiplyNumber (double x[],int n.double number) //
// Функция умножения матрицы поэлементно на число.
// Обозначения:
// х - первый сомножитель - матрица.
// number - второй сомножитель - скаляр.
// п - число элементов матрицы.
// Возвращаемое значение:
// нет.
//
{
register int i:
for (i = 0; i < n: i++) x[i] *= number:
}
void RowMultiplyNumber (double a[],int n.int m.int k.double Number) //
// Функция умножения строки матрицы на число.
// Обозначения:
// а - исходная матрица.
// п - число строк матрицы.
// m - число столбцов матрицы,
// к - номер умножаемой строки.
// Number - число.
// Возвращаемое значение:
// нет.
//
{
register int i; // Счетчик цикла
for (i = 0: i < m; i++. k += n) a[k] *= Number:
}
Векторные и матричные операции
481
void ColMultiplyNumber (double a[].int n.int k,double Number) //
// Функция умножения столбца матрицы на число.
// Обозначения:
// а - исходная матрица.
// п - число строк матрицы.
// к - номер умножаемого столбца,
// Number - число.
// Возвращаемое значение:
// нет.
//
register int i: // Счетчик цикла
int m = k * n; // Счетчик
for (i = 0: i < n; i++) a[m++] *= Number;
}
Следующие функции реализуют различные операции умножения. Функции весьма эффективны, так как в них реализуются не совсем очевидные, но очень быстрые способы манипуляции с индексами.
Показанная далее функция перемножает две прямоугольные матрицы. Для наглядности формула дана в поэлементной записи [101, с. 348]:
тп
Су=^а1,Ьц,г = 1,2, n;j = 1,2, ы
где а — первый сомножитель,
b — второй сомножитель,
с — произведение,
п — число строк в первом сомножителе,
тп — число столбцов в первом сомножителе и строк во втором,
I — число столбцов во втором сомножителе.
Подробное обсуждение, иллюстрированное примерами применения, дано в [183, с. 24]. Алгоритмы перемножения матриц на псевдокоде даны в [100, с. 289, 513], на языке программирования Perl рассмотрены в [104, с. 84].
Исходные коды
void MatrixMultiplyMatrix (double a[],double b[],double r[].int n.int m.int 1)
//
16-2002
482
Глава 13. Линейная алгебра
// Функция перемножения натриц.
// Обозначения:
// а - первый сомножитель, n х т,
// b - второй сомножитель, m х 1.
// г - произведение, n х 1,
// п - число строк в матрице а.
// m - число столбцов в матрице а и строк в матрице Ь.
// 1 - число столбцов в матрице Ь.
// Возвращаемое значение:
// нет.
//
{ regi ster int i. // Счетчик цикла по столбцам b
j. // Счетчик цикла по столбцам а
k; // Счетчик цикла по строкам b
int ia. // Счетчик элементов матрицы а
ib. // Счетчик элементов матрицы b
ir = -1. // Счетчик эленентов матрицы г
ik = -m - - 1; // Индекс । перед первым элементом столбца b
/ / / / / / / / / / / / / / / / / / / / / / / / / / / / / / // Цикл по столбцам матрицы b for (к = 0: к < 1; к++)
/ / / / / / / / / / / / / / / / / / / / / / / / / / / /
// Цикл по строкам матрицы а for (j = 0. ik += m; j < n: j++)
/////////////////////////////
// Цикл по столбцам матрицы a
for (i =0. ia = j. ib = ik, r[++ir] =0: i < m; i++, ia += n) r[ir] += a[ia] * b[++ibj:
}
Следующая функция умножает транспонированную прямоугольную] матрицу на другую матрицу (в поэлементной записи):
т
Сц = Yak,bb,i=t 2,и;; = 1,2.1,
ы
где а — первый сомножитель,
b — второй сомножитель,
с — произведение,
п — число столбцов в первом сомножителе,
т — число строк в первом сомножителе и строк во втором, I — число столбцов во втором сомножителе.
Векторные и матричные операции
483
Исходные коды
void MatrixTMultiplyMatrix (double a[],double b[],double r[],int n,int m,int 1)
//
// Функция умножения транспонированной матрицы на матрицу.
// Обозначения:
// а - первый сомножитель, ш х п,
// b - второй сомножитель, m х 1.
// г - результат, n х 1,
// п - число столбцов в матрице а,
// ш - число строк в матрице а и строк в матрице Ь.
// 1 - число столбцов в матрице Ь.
// Возвращаемое значение:
// нет.
//
register int i, // Счетчик цикла по столбцам b // Счетчик цикла по столбцам а
J. k:
// Счетчик цикла по строкам b
int ia, ib, ir = -1. bs = -m - 1; // Счетчик // Счетчик // Счетчик // Первый элементов матрицы а элементов матрицы b элементов матрицы г элемент текущего столбца b
///////////////////////////// // Цикл по столбцам матрицы b for (к = 0: k < 1; к++)
/////////////////////////////
// Цикл по столбцам матрицы а
for (j =0, ia = -1. bs += m; j < n; j++) //////////////////////////// // Цикл по строкам матрицы a
for (i = 0, r[++ir] =0. ib = bs: i < m; 1++) r[ir] += a[++ia] * b[++ib]:
}
Следующая функция перемножает квадратную матрицу и вектор по формуле [101, с. 348], [183, с. 19]
t = А • w,
где А — матрица — первый сомножитель, и — вектор — второй сомножитель, t — вектор — произведение,
п — размерность матрицы и длины векторов.
Исходные коды
void MatrixMultiplyVector (double* a.double* u.double* t.int n)
16»
484
Глава 13. Линейная алгебра
//
// Функция умножения матрицы на вектор.
// Обозначения:
// а - матрица размером п * п (хранится по столбцам),
// и - вектор-столбец длиной п,
// t - результирующий вектор-столбец длиной п.
// Возвращаемое значение:
// нет.
//
{
register int i,j.k;
for (i = 0; i < n: i++)
for (j = 0, t[i] = 0, k = i; j < n; j++. k += n) t[i] += a[k] * u[j];
}
Следующая функция умножает прямоугольную матрицу на транспонированную матрицу (в поэлементной записи):
т
Су = = 1.2,.... п; j = 1,2,.... /,
k=l
где а — первый сомножитель,
b — второй сомножитель,
с — произведение,
п — число строк в первом сомножителе,
т — число столбцов в первом сомножителе и столбцов во втором, I / — число строк во втором сомножителе.
Исходные коды
void MatrixMultiplyMatrixT (double a[],double b[],double
r[],int n.int m,int 1)
//
// Функция умножения матрицы на транспонированную матрицу.
// Обозначения:
// а - первый сомножитель, n х т,
// b - второй сомножитель, 1 х ш,
// г - результат. n х 1,
// п - число строк в матрице а,
// m - число столбцов в матрице а и столбцов в матрице Ь,
// 1 - число строк в матрице Ь.
// Возвращаемое значение:
// нет.
//
register int i, // Счетчик цикла по столбцам ,Ь
Векторные и матричные операции
485
j. k: // Счетчик цикла по столбцам а // Счетчик цикла по строкам b
int ia. // Счетчик элементов матрицы а
ib. // Счетчик элементов матрицы b
ir = -1. // Счетчик элементов матрицы г
ik = -1-1: // Первый элемент текущей строки b
////////////////////////////
// Цикл по строкам матрицы Ь
for (к = 0; к < 1: к++)
////////////////////////////
// Цикл по строкам матрицы а
for (j = 0. ik++; j < n; j++)
/////////////////////////////
// Цикл по столбцам матрицы a
for (i =0. ia = j - n. ib = ik. r[++ir] = 0: i < m; i++) {
ia += n:
ib += 1:
r[ir] += a[ia] * b[ib]:
}
}
Две следующие вспомогательные функции служат для перестановки соответственно столбцов и строк прямоугольной матрицы. Эта операция экономит место при записи алгоритмов.
Исходные коды
void Col Interchange (double a[].int n.int k.int 1)
//
// Функция перестановки столбцов матрицы.
// Обозначения:
//а исходная матрица.
// п число строк матрицы,
// к.1 - номера переставляемых столбцов (нумерация с нуля).
// Примечание:
// результат записывается на место исходной матрицы.
// Возвращаемое значение:
// нет.
//
{
register int i: // Счетчик цикла
int ml.m2; // Счетчики одномерного массива
double save: // Вспомогательная переменная
for (i = 0. ml = k * n. m2 = 1 * n; i < n: i++)
486
Глава 13. Линейная алгебра
{
save = a[ml];
a[ml++] = a[m2];
a[m2++] = save:
} }
void Rowinterchange (double a[].int n.int m.int k.int 1)
//
// Функция перестановки строк матрицы.
// Обозначения:
//а - исходная матрица.
// п число строк матрицы.
// m число столбцов матрицы.
// к.1 - номера переставляемых строк (нумерация с нуля).
// Примечание:
// результат записывается на место исходной матрицы.
// Возвращаемое значение:
// нет.
//
{
register int i: // Счетчик цикла
double save: // Вспомогательная переменная
for (i = 0; i < m: i++, k += n. 1 += n)
{
save = a[k]:
a[k] = a[l]:
a[l] = save:
}
}
Единичная матрица
Единичной матрицей называется квадратная матрица, имеющая единицы на главной диагонали и нули во всех остальных позициях. Уилкинсон [ 188, с. 19] определяет единичную матрицу как квадрат-, ную матрицу, все элементы которой положены равными символу Кронекера 8у, так что
Sij> = 0 при г: j и Sij; = 1 при i = j.
Единичная матрица применяется в ряде алгоритмов, в том числе как начальное значение в итерационных алгоритмах и в ряде процедур линейной алгебры там, где требуется отслеживать трансформации исходных матриц, с тем чтобы впоследствии, при необходимости, можно было бы восстановить их оригинальное состояние (например, метод Гивенса).
Обсуждение см. в [183, с. 29].
Векторные и матричные операции
487
Исходные коды и пример применения
^include <fstream.h>
^include <iomanip.h>
#include "megastat.h"
void main (void) г
{ register int i.j; // Счетчики цикла
int n = 10. // Размерность квадратной матрицы
m = 0; // Счетчик
double a[100J; // Тестовый массив
Matrixllnit (a.n);
cout « "Единичная матрица порядка ” « n « endl; for (1=0; 1 < n; i++)
{
for (j = 0; j < n; j++)
cout « setw (5) « a[m++J;
cout « endl;
}
}
void Matrixllnit (double *e,int n)
//
// Обозначения:
// e - на выходе - единичная матрица.
// n - размерность матрицы.
//
{
register int i.j: // Счетчики цикла
int k = 0. // Рабочие переменные
m = 0;
for (i = 0; i < n; i++, e[m] =1. m += n + 1)
for (j = 0; j < n; j++)
e[k++] = 0;
}
Транспонированная матрица
Транспонированной называется матрица, полученная из данной прямоугольной матрицы путем замены ее строк соответствующими столбцами [135, с. 586]. Подробное обсуждение и свойства транспонированной матрицы см. также в [183, с. 131].
488
Глава 13. Линейная алгебра
Отметим, что практически в матричных вычислениях показанная функция не находит широкого применения, так как с целью повышения эффективности вычислений реализация операции транспонирования там, где это требуется, производится непосредственно в схеме алгоритма.
Исходные коды
void MatrixT (double х[],double уС].int n.int k) //
// Функция транспонирования матрицы.
// Обозначения:
// х - исходная матрица из к векторов по п элементов друг за // другом.
// у - транспонированнная матрица из п векторов по к элементов.
// Возвращаемое значение:
// нет.
//
{
register int i.j; // Счетчик циклов
int mml.mm2; // Счетчики элементов массивов
for (i = 0. mm2 = 0; i < k; i++)
for (j = 0. mml = i; j < n: j++. mml += k) y[mml] = x[mm2++J;
}
Векторные и матричные нормы
Показанная далее функция вычисляет евклидову норму вектора [188, с. 64], [100, с. 675]. Эта норма называется также евклидовой длиной вектора. Вычисления производятся по формуле [183, с. 101]
Исходные коды
double EuclidNormaVector (double* a.int n) //
// Функция вычисления евклидовой нормы вектора.
// Обозначения:
// а - исходный вектор длиной п.
// Возвращаемое значение:
// значение норны.
//
{
return sqrt (VectorSumSQ (a.n));
}
Векторные и матричные операции
489
Евклидова (шуровская) норма матрицы находит широкое применение и вычисляется по формуле
114
у 1=1 >=1
Показанные ниже функции вычисляют евклидову норму матрицы, причем вторая из функций производит вычисление без учета диагональных членов матрицы, что бывает необходимо при построении некоторых алгоритмов.
Исходные коды
double EuclidNorma (double a[],int n)
//
// Функция вычисления евклидовой нормы матрицы.
// Обозначения:
// а - исходная матрица.
// п - порядок матрицы.
// Возвращаемое значение:
// значение норны.
//
{
return sqrt (VectorSumSQ (a.n * n));
}
double EuclidNormaWithoutDiag (double a[].int n)
//
// Функция вычисления евклидовой нормы матрицы без учета
// диагональных элементов.
// Обозначения:
// а - исходная матрица.
// п - порядок матрицы.
// Возвращаемое значение:
// значение нормы.
//
{
register int i.j:
int m = 0:
double s = 0:
for (i = 0: i < n: i++)
for (j = 0: j < n: j++, m++) if (i '= j)
s += a[m] * a[m];
return sqrt (s):
}
490
Глава 13. Линейная алгебра
double EuclidNormaTri (double a[],int n)
//
// Функция вычисления евклидовой нормы матрицы без учета
// верхнего треугольника.
// Обозначения:
// а - исходная матрица,
// п - порядок матрицы.
// Возвращаеное значение:
// значение норны.
И
{
register int i.j:
int m;
double s = 0:
for (i = 1: i < n; i++)
for (j=i,m=(i-l) * n + i: j < n: j++,m++) s += a[m] * a[m];
return sqrt (s):
}
Бесконечная норма матрицы вычисляется по формуле [188, с. 65]
HL=maxhl'
Рассматриваемая норма применяется, в частности, для определения радиуса локализации всех собственных значений матрицы (спектра собственных значений) как более простая, но менее точная альтернатива кругам Гершгорина.
Исходные коды
double InfiniteNorma (double a[],int n) //
// Функция вычисления бесконечной норны матрицы.
// Обозначения:
// а - исходная матрица,
// п - порядок матрицы.
// Возвращаеное значение:
// значение норны.
//
{
register int i.j:
int m;
double s = 0,sl:
Векторные и матричные операции
491
for (1 » 0. m » 0; 1 < n; 1++)
{
for (j = 0, si = 0; j < n; j++. m++) si += fabs (a[m]);
if (si > s)
s = si;
}
return s;
}
В [51, c. 44] даны формулы норм прямоугольной матрицы размером 772X72:
— максимум суммы модулей элементов в столбце,
||Л||2 = ^Лтах [ЛтЛ] — квадратный корень из максимального собственного значения матрицы АТА, эту квадратичную норму иногда называют спектральной нормой матрицы [183, с. 344],
= тах 1<|<т
— максимум суммы модулей элементов в строке,
V i=i j=i
— норма Фробениуса.
Перечисленные четыре нормы могут быть легко запрограммированы путем незначительного изменения приведенных выше функций вычисления норм квадратных матриц.
Определитель матрицы
Определителем (детерминантом) матрицы называется [135, с. 432] многочлен от элементов квадратной матрицы А порядка п, каждый член которого является произведением п элементов, взятых по одному из каждого столбца и каждой строки, и снабжен определенным знаком: плюсом, если перестановка четна, и минусом, если перестановка нечетна. Число п называется порядком определителя. Определитель является одной из важнейших характеристик квадратной матрицы, обусловливающей ее поведение в различных алгоритмах. По определению, детерминант может быть разложен по элементам любого столбца (строки):
492
Глава 13, Линейная алгебра
det у! = ^ajkAjk,k = 1,2,п ,
где k — номер столбца (строки),
Ajk = (-iy+kMjk — алгебраическое дополнение элемента aJk,
Mjk — минор элемента ajk, то есть определитель порядка (п - 1).
Минор получается при вычеркивании из исходной матрицыj-й строки и k-ro столбца. При j = k миноры называются главными.
Подробное обсужение вопросов, связанных с вычислением и применением определителя, см. в [183, с. 182], [100, с. 676]. В частности, применение определителя обычно иллюстрируется его использованием для решения систем линейных алгебраических уравнений по правилу Крамера [там же, с. 201].
Формула показанного разложения называется рекурсивным определением детерминанта, а показанная функция det является непосредственной реализацией этого определения.
Исходные коды
double Det (double а[]. int n)
//
// Функция вычисления определителя
// Обозначения:
// а - заданная матрица.
// п - порядок матрицы.
// Примечание:
// функция не проверяет результат динамического выделения памяти.
// Возвращаемое значение:
// значение определителя.
И
{
register int i.j.k; // Счетчики цикла
int m.ml. // Счетчик одномерного массива
sign = 1: H Знак алгебраического дополнения
double s = 0. // Возвращаемое значение
*al: // Минор
////////////////////////
// Для матрицы размера 1
if (n == 1)
return а[0];
el se
{
///////////////////////////////////
// Рекурсия для матрицы размера > 1
Векторные и матричные операции
493
al = new double[(n - 1) * (n - 1)];
for (i = 0; i < n; i++)
{
///////////////////
// Получение нинора
for (j=l, m=0,ml=n; j < n; j++) for (k = 0; k < n; k++. ml++)
if (k ! = i)
al[m++] = a[ml]:
////////////////////////// // Вычисление определителя sign *= -1,-
s += a[i] * sign * Det (al.n - 1);
}
delete [] al;
}
return s;
}
Эффективность рассмотренной функции для матриц даже небольших порядков крайне низка. Поэтому для решения практических задач предлагается воспользоваться функцией одного из типов факторизации матриц, побочным продуктом которой является вычисленное значение определителя, а данная функция может служить разве что учебным примером рекурсии.
Свойства определителей описаны в ряде источников, например [135, с. 433], [189, с. 92]. Укажем несколько полезных свойств определителя [101, с. 350]:
1. det(AB) = det(TM) = det(H)det(B) для двух квадратных матриц. 2. det(/l) = det(Xt)det(X2)... для блочной (клеточной) матрицы.
След матрицы
След квадратной матрицы А порядка п — это сумма ее диагональных элементов [135, с. 546]:
i=l
Иначе след матрицы — это сумма всех ее собственных значений:
1=1
494
Глава 13. Линейная алгебра
Обозначения trA (ТгА) и SpA являются эквивалентными, их происхождение вызвано английскими и, соответственно, немецкими источниками.
Укажем несколько свойств следа матрицы [101, с. 350]:
• tr(A + В) = tr(A) + tr(B)y
• tr(aA) = atr(A),
• tr(AB) = tr(BA),
• tr(AB - BA) = 0,
• а также для блочной (клеточной) матрицы
Гг(А) = Гг(А1) + Гг(А2) + ....
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include "megastat.h"
void main (void) {
int n = 5, i.j = 0: // // Порядок Счетчики матрицы
double a[] = { 2, 1, -1.-3. 9. // Исходная матрица
b = 1. 7. 2.10. 7. 8. 1. 2. *b. s = 0: new doublefn * n] 13.-2. 8. -1.13. 1. 3. 4. 4. 0. 4. 3}. // // Рабочий Рабочая массив переменная
cout « "Trace as sum of diagonal members is " « Trace (an) « endl;
Jacobi (a.n,0.000001,&i,b);
for (i =0; i < n; i++, j += n + 1)
s += a[j]:
cout « "Trace as sum of eigen values is " « s « endl:
delete [] b; }
double Trace (double* a, int n)
Векторные и матричные операции
495
// Функция вычисления следа квадратной матрицы, // Обозначения:
// а - квадратная матрица.
// п - порядок матрицы.
// Возвращаемое значение:
// значение следа матрицы.
//
register int i.j = 0:
double s = 0;
for (i = 0; i < n; i++, j += n + 1) s += a[j]:
return s;
}
Обратная матрица
Пусть исходная квадратная матрица Л имеет отличный от нуля определитель (детерминант, его определение и вычисление см. в разделе «Определитель матрицы»). Тогда существует матрица/Г1 (или просто Л") такая, что
А/Г1 = А'А = 1,
где I — единичная матрица, то есть матрица, имеющая единицы на главной диагонали и нули на месте остальных элементов.
Матрица Л-1 называется матрицей, обратной данной матрице Л.
Критерий обратимости матрицы дает ее определитель: если он равен нулю, матрица вырождекна, если не равен, то матрица обратима [183, с. 182].
Широко применяется итерационный метод обращения матриц [112, с. 123], основанный на формуле
Х + 1 = Х(2/-ЛХ),
где Хг — приближение обратной матрицы Л на r-й итерации, I — единичная матрица.
В качестве начального приближения можно взять единичную матрицу.
Для примера приведем наиболее простой способ вычисления обратной матрицы, вытекающий из определения. Внимательно посмотрев на формулу
496
Глава 13. Линейная алгебра
АА~' = I,
замечаем в ней матричную систему линейных уравнений, то есть такую систему, у которой вектор свободных членов обобщен до матрицы, единичной в данном случае, а вектор неизвестных обобщен до матрицы, которой как раз и является искомая обратная матрица [100, с. 701]. Таким образом, код функции вычисления обратной матрицы полностью базируется на каком-либо коде решения системы линейных алгебраических уравнений, например на методе Гаусса [203, с. 94], [212, с. 365]. Пример вычисления обратной матрицы показан ниже, совместно с примером итерационного уточнения обратной матрицы. Подробное обсуждение метода Гаусса—Жордана дано в [ 183, с. 45], а также в [135, с. 425]. Вопросы обратимости рассмотрены в [100, с. 675].
Исходные коды
int InverseMatrix (double а[],double t[],1nt k) 11
// Функция вычисления обратной матрицы.
// Обозначения:
// а - исходная матрица,
// t - обратная матрица,
// к - порядок матрицы.
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -1 при недостатке памяти.
// -2 при ошибке в вычислениях.
//
{
int Code: // Возвращаемый код ошибки
double *al: // Копия исходной матрицы
if ((al = new double[k * k]) == 0)
return -1;
ArrayToArray (a.al.k * k);
MatrixUnit (t.k);
Code = Gauss (t,al,k,k,O.000001);
delete [] al:
return Code:
}
Ввиду того что показанная выше функция может давать неприемлемую ошибку при обращении матрицы большого порядка, авторы
Векторные и матричные операции 497
[203, с. 95] рекомендуют уточнение обратной матрицы с помощью итерационного метода, например метода Ньютона. Функцию Newton можно применять только для уточнения вычисленной тем или иным способом обратной матрицы, но никак не для определения самой обратной матрицы, задавшись некоторыми произвольными начальными значениями, так как интервалы сходимости метода очень узки.
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include "megastat.h"
void main (void)
{
int i,j.l. Max = 100. n = 4; // Счетчики // Максимальное число итераций // Порядок матрицы
double a[] = {2. 1. -1.-3. 1,-7. 13.-2, 2, 5. -1.13, 7. 8. 3. 4.}. // Исходная матрица
*x, *c; // Обратная матрица // Рабочий массив
x = new doubletn * n]; c = new double[n * n];
cout « "ORIGINAL MATRIX\n";
for (i = 0.1 = 0; i < n; i++)
{
for (j = 0; j < n; J++.1++) cout « setw (14) « a[l];
cout « endl;
}
cout « "RETURN CODE = " « InverseMatrix (a.x.n) « endl;
cout « "INVERSE MATRIX\n";
for (i = 0,1 =0; i < n; i++)
{
for (j = 0; j < n; J++.1++) cout « setw (14) « x[l];
cout « endl;
}
cout « "TEST\n":
MatrixMultiplyMatrix (x.a.c.n.n.n);
for (i = 0.1 = 0; i < n; i++)
498
Глава 13. Линейная алгебра
{
for (j = 0: j < n; J++.1++) cout « setw (14) « c[l]: cout « endl;
}
cout « "APPLAY 50* ERROR\n";
for (i = 0.1 = 0; i < n; i++)
{
for (j = 0: j < n; J++.1++) {
x[l] *= 1.5;
cout « setw (14) « x[l];
}
cout « endl;
}
cout « “TEST\n";
MatrixMultiplyMatrix (x.a.c.n.n.n): for (i = 0.1 = 0; i < n; i++)
{
for (j = 0; j < n; J++.1++) cout « setw (14) « c[l];
cout « endl;
}
cout « "RETURN CODE = "
« Newton (a.x.n.&Max.0.000001) « endl;
cout « "ITERATION NUMBER = " « Max « endl;
cout « "INVERSE MATRIXXn";
for (i = 0.1 =0; i < n; i++) {
for (j = 0; j < n; J++.1++) cout « setw (14) « x[l];
cout « endl;
}
cout « "TEST\n";
MatrixMultiplyMatrix (x.a.c.n.n.n);
for (i = 0.1 - 0; i < n; i++)
{
for (j = 0; j < n; J++.1++) cout « setw (14) « c[l];
cout « endl;
}
delete [] x; delete [] c;
}
int Newton (double a[],double x[].int n.int *max.double eps)
Векторные и матричные операции
499
// Функция уточнения обратной матрицы методом Ньютона.
// Обозначения:
// а - исходная матрица.
// х - на входе - подлежащая уточнению обратная матрица,
// вычисленная заранее, на выходе - уточненная обратная // матрица.
// п — порядок матриц а и х,
// *тах - на входе - максимальное заданное число итераций,
// на выходе - реально затраченное число итераций,
// eps - заданная погрешность.
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -1 при недостатке памяти для вычислений,
// -2 при ошибке в вычислениях.
И
{
register int i,j: // Счетчик
int Code = 0, // Возвращаемое значение
Iter = О. // Счетчик итераций
к, // Счетчик одномерного массива
n2 = п * п: // Общее число элементов матрицы
double *xl.*x2, // Рабочий массив
Norma: // Параметр для контроля точности
if (Cxi = new double[n2J) == 0) return -1:
if ((x2 = new double[n2]) == 0) {
delete [] x2:
return -1:
}
do
{
MatrixMultiplyMatrix (a.x.xl.n.n.n):
for (i = 0, k = 0: i < n; i++)
for (j = 0: j < n: j++, k++)
xl[k] = i == j ? 1.0 - xl[k] : 0.0 - xl[k];
Norma = EuclidNorma (xl.n);
MatrixMultiplyMatrix (x,xl,x2,n.n.n):
MatrixPlusMatrix (x,x2,n2):
if (++Iter > *max)
{
Code = -2: break:
}
} while (Norma > eps):
*max = Iter:
500
Глава 13. Линейная алгебра
delete [] xl: delete [] х2:
return Code; }
Псевдообратная матрица
Для действительной прямоугольной матрицы А размера т х п вводится понятие псевдообратной матрицы А+, то есть такой матрицы размера пхт, что
АА*А = А; А'АА* - А*; (АА*)Т = АА*; И*А)Т = А*А.
Процедура вычисления псевдообратной матрицы основана на функции разложения прямоугольной матрицы по сингулярным числам [2], [188, с. 129], алгоритм которой требует выполнения условия т х п. Отметим, что для квадратной матрицы вычисление псевдообратной матрицы гораздо проще [76, с. 32]:
А+= (А'А-')А'.
Обсуждение для случая квадратных матриц см. в [100, с. 708].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void)
{
int i,j,1, // Счетчики
m = 8, // Число строк матрицы
n = 5; // Число столбцов матрицы
double а[] = {22,14, -1,-3, 9, 9, 2, 4, // Исходная матрица 10, 7, 13,-2, 8. 1,-6. 5, 2,10, -1,13, 1,-7, 6. 0.
3, 0,-11,-2.-2. 5, 5,-2, 7. 8, 3, 4, 4,-1, 1. 2}. *ар, // Псевдообратная
// матрица
*с; // Рабочий массив
ар = new double[n * m]: с = new double[m * m];
cout « "ORIGINAL MATRIX\n":
Векторные и матричные операции
501
for (1 = 0.1 =0: 1 < п: 1++)
{
for (j = 0: j < m: J++.1++) cout « setw (7) « a[l]: cout « endl;
}
cout « "RETURN CODE = " « PseudoInverseMatrix (a.ap.m.n) « endl;
cout « "CALCULATED PSEUDOINVERSE MATRIX\n";
for (i =0,1 =0: 1 < m; i++)
{
for (j = 0; j < n: J++.1++) cout « setw (10) « ap[l]: cout « endl;
}
MatrixMultipiyMatrix (a.ap.c.m.n.m): MatrixMultipiyMatrix (c,a,ap,m,m,n);
cout « “CHECK RESULT - MUST BE EQUIVALENT TO ORIGINAL MATRIX\n": for (i = 0,1 =0; i < n; i++)
{
for (j = 0: j < m; J++.1++)
if (fabs (ap[lj) < 0.000000001) // Нуль в пределах точности cout « setw (7) « 0:
el se
cout « setw (7) « ap[l]: cout « endl;
}
delete [] ap: delete [] c:
}
int PseudoInverseMatrix (double a[],double apfj.int m.int n) //
// Функция вычисления псевдообратной матрицы.
// Обозначения:
// а - исходная матрица m х п, не разрушается,
// ар - псевдообратная матрица n х т.
// т - число строк матрицы а,
// п - число столбцов матрицы а.
// Возвращаемое значение:
// 0 при нормальном окончании расчета,
// -1 при недостатке памяти для вычислений,
// -2 при потере значимости или ошибке в вычислениях.
//
{
register int i: // Стетчик цикла
int Code = 0:
// Возвращаемое значение
502
Глава 13. Линейная алгебра
double *u.*v.*s. // Матрицы разложения по сингулярным числам *г: // Рабочий массив, можно не выделять, если
// разрушать исходную матрицу
if ((u = new double[m * mJ) == 0)
return -1:
if ((v = new double[n * nJ) == 0)
{
delete [] u:
return -1;
}
if ((s = new double[n * nJ) == 0)
{
delete [] u: delete [] v;
return -1:
}
if ((r = new double[n * n]) == 0)
{
delete [] u: delete [] v: delete [] s;
return -1;
}
if ((Code = SingularValueDecomposition (a.m.n.u.s.v)) != 0) return Code:
for (i = 0; i < n * n: i += n + 1)
if (s[i] != 0)
s[i] = 1.0 / s[i]:
MatrixMultiplyMatrix (v.s.r.n.n.n):
MatrixMultiplyMatrixT (r.u.ap.n.n.m);
delete [] u: delete [] v; delete [] s: delete [] r;
return Code: }
Критерии положительной определенности и полуопределенности
Представляет интерес матрица специального вида, получившая название матрицы Грама, особенностью которой является симметричность и положительная полуопределенность [208, с. 46]. Напомним, что положительно полуопределенной называется матрица, если и только если все ее главные миноры больше либо равны нулю. Положительно определенной матрица будет, соответственно, если все ее главные миноры строго больше нуля [135, с. 472]. Из положительной полуопределенности прямо следует неотрицательность всех собственных значений матрицы, а этот факт имеет решающее значе
Векторные и матричные операции 503
ние, в частности, в факторном анализе, чем сначала и было вызвано наше внимание к проблеме. Так, например, матрицей Грама должна быть редуцированная корреляционная матрица — если это оказывается не так, считается, что редукция выполнена некорректно.
См. также [16, с. 21].
Исходные коды и пример применения
^include <fstream.h>
#include <iomanip.h>
#include "megastat.h"
void main (void) {
register int i.j.l; // Счетчики
int n = 5. // Численность каждой выборки
k = 4, // Число выборок
m = O.ml. // Счетчики элементов выборок
m2 = 0; // Счетчик элементов дисперсионно-
// ковариационной
// матрицы
double a[] = {1.2.3.1.2. // Исходные данные
2.4.3.3.1.
1.3.2.6.6.
2.3.2.4.1}.
d[16]. // Дисперсионно-ковариационная матрица
x[5].y[5]; // Рабочие массивы
///////////////////////////////////////////////// // Построение дисперсионно-ковариационной матрицы for (i = 0: i < k; i++)
{
for (1 = 0: 1 < n; 1++) x[l] = a[m++]:
for (j = 0,ml = 0; j < k: j++) {
for (1 = 0; 1 < n; 1++) y[l] = a[ml++];
d[m2++] = Cov (x.y.n);
}
}
cout « Gram (d.k) « endl;
}
504
Глава 13. Линейная алгебра
int Gram (double а[]. int n)
11
// Функция проверки, является ли заданная натрица матрицей
// Грама (симметрической и положительно полуопределенной).
// Обозначения:
// а - заданная матрица,
// п - порядок матрицы.
// Возвращаемое значение:
// 0 - матрица является матрицей Грама.
// -1 - недостаточно памяти для вычислений.
// -2 - матрица не является матрицей Грама.
//
{
register int i.j.k: // Счетчики цикла
int m,ml,m2; // Счетчик одномерного массива
double *al: // Главный минор
//////////////////////////
// Проверка симметричности
for (i = 0; i < n: i++)
for (j = 0; j < n; j++)
if (a[i + j * n] != a[j + i * nJ) return -2;
/////////////////////////////
// Память для главных миноров
if ((al = new double[n * nJ) == 0)
return -1;
////////////////////////////////////////////
// Проверка положительной полуопределенности
for (i = 0: i < n: i++)
{
/////////////////////////////
// Вычисление главного минора
for (j = i, m = 0, ml = i * (n + 1): j < n; j++,ml += n) for (k = i. m2 = ml: k < n; k++)
al[m++] = a[m2++J;
if (Krauth (al.n - i) < 0)
{
delete [] al:
return -2:
}
}
delete [] al:
return 0;
}
Векторные и матричные операции
505
Проверка на положительную определенность может производиться в ряде алгоритмов, например с целью выяснения их сходимости. Представленный пример демонстрирует проверку, является ли матрицей Грама дисперсионно-ковариационная матрица, построенная для факторного анализа.
Следующая функция определяет, является ли матрица положительно определенной [208, с. 46]. Пример вызова аналогичен предыдущему случаю и поэтому не приводится.
Исходные коды
int PlusDef (double* a. int n)
//
// Функция проверки положительной определенности матрицы.
// Обозначения:
// а - заданная матрица.
// п - порядок матрицы.
// Возвращаемое значение:
// 0 - натрица является положительно определенной,
// -1 - недостаточно памяти для вычислений,
// -2 - матрица не является положительно определенной.
//
{
register int i.j.k; // Счетчики цикла
int m,ml,m2; // Счетчик одномерного массива
double *al: // Главный минор
if ((al = new double[n * nJ) == 0)
return -1:
////////////////////////////////////////
// Проверка положительной определенности for (i = 0; i < n; i++)
{
/////////////////////////////
// Вычисление главного минора
for (j = i, m = 0, ml = i * (n + 1): j < n; j++,ml += n) for (k = i, m2 = ml: k < n; k++)
al[m++] = a[m2++];
if (Krauth (al.n - i) <= 0.0)
{
delete [] al:
return -2;
}
}
delete [] al:
return 0:
}
506
Глава 13. Линейная алгебра
13
Дополнительно о положительной определенности, отрицательной определенности и знаконеопределенности матрицы см. [51, с. 41], [101, с. 360], [100, с. 677]. Строгое определение положительной определенности и критерии положительной определенности и полуопределенности представлены в [183, с. 286, 295].
Обусловленность матрицы
Число обусловленности системы уравнений характеризует чувствительность решения задачи к погрешности входных данных и определяется по формуле [135, с. 426]
г(Л)= ||Л|| |А1||.п(Л) = И1ИЧ I
Другое обозначение числа обусловленности cond(/l) [51, с. 45,462]. Для симметрической матрицы число обусловленности может быть вычислено как отношение максимального и минимального собственных значений [там же, с. 430,113, с. 8]:
v(X) = iwL , Anin
ибо для симметрической матрицы [183, с. 328]
Л max = || А ||,Л min = 1/ || А 1 ||. /|Т1ах — ||А||, /min = 1 / ||А-1||-
В примере, показанном ниже, с целью иллюстрации мы применяем для вычислений и тот, и другой способы. Результаты, как и следовало ожидать, совпадают.
В случае решения системы линейных уравнений число обусловленности матрицы системы оказывается полезной величиной при оценке того, насколько чувствительным будет решение системы как к неточностям в данных, так и к влиянию арифметики конечной точности [77, с. 74]. Число обусловленности может принимать значения v(/l) > 1 [71, с. 117], причем чем эта величина больше, тем более чувствительна система к возмущениям. Это означает, что небольшое возмущение в матрице системы или в элементах столбца свободных членов приведет к существенному изменению решения системы.
Посмотрим, как применяется число обусловленности матрицы при выяснении, заслуживает ли доверия решение системы на данной
Векторные и матричные операции
507
вычислительной машине. Считается [188], [77, с. 75], что решение вполне надежно, если
vH)<4=’
где е — «машинный эпсилон» (см. пояснения к функции GetMin-Мах).
Например, для операционной системы Windows NT эта информация позволяет исследователю быть уверенным в правильности решения систем уравнений с матрицами, имеющими числа обусловленности, заключенные в интервале 1 < г(Л) < 108.
Ниже показан пример и исходные коды функции вычисления числа обусловленности матрицы.
См. также [139, с. 110].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include "megastat.h"
void main (void)
{
i nt i. // Счетчик
n = 4, // Порядок матрицы
it. // Вспомогательная величина
Ret: // Возвращаемое значение
double a[] = // Исходная матрица
{22.3034,18.4384. 7.6082.13.7463, 18.4384.15.2666. 6.2848.11.3694.
7.6082, 6.2848, 2.5964, 4.6881, 13.7463,11.3694, 4.6881. 8.4735.}.
Ь[16]. // Массив собственных векторов
Мах. // Максимальное собственное значение
Min, // Минимальное собственное значение
Cnumber; // Число обусловленности матрицы
/////////////////////////////////////// // Вычисление числа обусловленности как // произведения норм исходной и обратной матриц Ret = ConditionNumber (а,n,&Cnumber);
cout « "RETURN CODE = " « Ret << endl;
if (!Ret)
508
Глава 13. Линейная алгебра
cout « "CONDITION NUMBER = " « Cnumber « endl;
/////////////////////////////////////////////////
// Вычисление числа обусловленности как отношения // максимального и минимального собственных значений // по [51. с. 430] Ret = Jacobi (а,n.О.000001,&it,b);
cout « "RETURN CODE = " « Ret « endl;
if (’Ret)
{
Max = a[0];
Min = a[0]:
for (i = O.it = 0; i < n; i++. it += n + 1)
{
if (Max < a[it]) Max = a[i t];
if (Min > a[it]) Min = a[it];
}
}
cout « "Maximal eigen value is " « Max « endl
« "Minimal eigen value is " « Min « endl;
if (Min)
cout « "CONDITION NUMBER = " « (Max I Min) « endl;
}
int ConditionNumber (double *a,int n,double *number) //
// Функция определений числа обусловленности матрицы.
// Обозначения:
// а - исходная матрица.
// п - порядок матрицы.
// number - число обусловленности, для вырожденной матрицы
// не выводится.
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -1 при недостатке памяти.
// -2 - матрица вырожденна.
//
{
int Ret = 0; // Возвращаемое значение
double *t; // Обратная матрица
if ((t = new double[n * nJ) == 0) return -1;
if (’(Ret = InverseMatrix (a.t.n)))
*number = EuclidNorma (a.n) * EuclidNorma (t.n);
Методы факторизации и приведения матриц
509
delete [] t;
return Ret:
}
Методы факторизации и приведения матриц
Методы факторизации (разложения) и приведения матриц к специальному виду широко применяются в большом числе алгоритмов, часто фактически являясь их основой и принципиально упрощая постановку задачи. Далее, эти методы дают возможность привести решение той или иной вновь возникшей задачи к решению уже известной проблемы. Кроме того, побочные результаты факторизации могут использоваться для решения других важных задач, например для вычисления определителя матрицы.
Разложение Краута А = LU
Неособую матрицу А можно представить в виде произведения двух матриц [189, с. 92]:
А = LU,
где L — нижняя треугольная матрица, U — верхняя треугольная матрица.
Разложение не единственно. Если его записать как
LU = (LDyjy'U),
где (D'U) есть верхняя треугольная матрица с единичной диагона-лью, мы получим разложение Краута. В результате вычислений, кроме самого разложения, мы получаем значение определителя исходной матрицы. Эта потребность в основном и инициировала составление нами показанной ниже функции. Приводятся два варианта функции Krauth. Различие между ними объясняется в комментариях к исходному коду. В отличие от оригинала выбор ведущего элемента не производится, поэтому в перестановке строк и сохранении вектора перестановок нет необходимости. Для практических вычислений, конечно же, выбор ведущего элемента производить желательно (это не усложнит решение).
510
Гл а ва 13. Линейная алгебра
В [203, с. 41], [175, с. 89] дан пример применения рассматриваемого разложения в задаче решения системы линейных уравнений:
Ах = Ь.
Вычислив матрицы LhU, сводим задачу к двум элементарно решаемым системам с треугольными матрицами
Ly = buUx = у.
Первая из двух последних формул называется прямым исключением, а вторая — обратной подстановкой, что полностью соответствует вычислительной схеме метода Гаусса. Если вы решите использовать показанный код для решения систем линейных уравнений, мы рекомендуем, как было сказано выше, несколько модернизировать его с целью выбора ведущего элемента. Эквивалентность метода исключения и рассматриваемого типа разложения подробно обсуждается также в [183, с. 30]. По утверждению [там же, с. 156], рассмотренное разложение представляет собой просто удобную запись метода исключения Гаусса, что подтвержается также в [100, с. 693].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include "megastat.h"
void main (void) {
int n = 12;
double a[] = {11.889, 0.193, -9.575, 7.984, 2.994, 1.472,
-5.790, 0.890, -2.847, -3.004, -1.099, -3.107.
0.193. 11.123. -3.923. -2.196. -5.180, -5.604.
0.177, -3.006, 3.151, -1.664, 5.785, 1.145.
-9.575. -3.923, 29.291,-14.083, -6.282, -0.737,
12.461,-10.994. 5.822. 0.731. -0.578. -2.132,
7.984, -2.196,-14.083, 12.868, 9.817, 2.902,
-8.717, 2.912, -3.012, -2.473. -5.602, -0.399,
2.994, -5.180. -6.282, 9.817, 14.546, 1.944,
-4.536, 1.503, -2.757, -2.943, -7.844, -1.262,
1.472, -5.604, -0.737. 2.902, 1.944. 5.999,
-3.546. 0.046, -2.193, 2.952, -2.590. -0.644,
-5.790, 0.177, 12.461, -8.717, -4.536, -3.546,
9.863, -2.959, 1.112, -0.520, 1.040, 1.414,
0.890, -3.006,-10.994, 2.912. 1.503, 0.046.
-2.959, 18.387, -6.193, -2.069, -1.154. 2.635.
Методы факторизации и приведения матриц
511
-2.847. 3.151. 5.822. -3.012. -2.757, -2.193,
1.112. -6.193. 6.308, 0.325, 1.273. -0.988,
-3.004, -1.664. 0.731, -2.473, -2.943, 2.952.
-0.520. -2.069, 0.325, 6.084. 3.141, -0.560,
-1.099. 5.785, -0.578, -5.602. -7.844, -2.590.
1.040, -1.154, 1.273, 3.141, 10.186, -2.558,
-3.107, 1.145, -2.132, -0.399, -1.262, -0.644.
1.414, 2.635, -0.988, -0.560 -2.558, 6.456}
cout « "DETERMINANT = " « Krauth (a.n) « endl: }
double Krauth (double a[].int n)
//
// Функция разложения действительной матрицы по алгоритму
// Краута с вычислением значения определителя.
// Обозначения:
// а - исходная матрица, разрушается, на выходе - комбинация
// нижней треугольной матрицы (в оригинале L) и верхней
// треугольной матрицы (в оригинале U)
// с подразумеваемой единичной диагональю,
// п - порядок матрицы а.
// Примечание.
// Этот вариант функции Krauth не требует для своей реализации // дополнительной памяти, вынуждая, однако, разрушить исходную // матрицу.
// Возвращаемое значение:
// значение определителя исходной матрицы при нормальном
// окончании счета,
// 0 при вырожденности матрицы.
//
{
register int i.k.r: // Счетчики
int rr = 0: // Индекс диагонального элемента
double Det = 1, // Возвращаемое значение определителя
buf: // Вспомогательная величина
for (r = 0: r < n; r++, , гг += п + 1)
{
/////////////////////////////////
// Вычисление элементов матрицы L
for (i = г: i < n: i++)
{
for (k - 0, buf =0: k < r: k++)
buf += a[i + k * n] * a[k + r * n]:
a[i + r * n] -= buf: }
512
Глава 13 Линейная алгебра
/ / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / /
// Вычисление элементов матрицы II
for (i » г + 1; 1 < n; 1++)
{ for (к = 0. buf =0: к < г; к++) buf += а[г + к * п] * а[к + i * nJ;
/////////////////////////
// Проверка на значимость
if Ca[rr] < 0.000001) return 0:
el se a[r + 1 * n] = (a[r + i * n] - buf) / a[rr]:
}
///////////////////////////////////
// Вычисление значения определителя Det *= a[rr];
}
return Det;
}
double Krauth (double a[J.double ![].double u[].int n)
//
// Функция разложения действительной матрицы по алгоритму
// Краута с вычислением значения определителя.
// Обозначения:
// а - исходная матрица, не разрушается.
// 1 - вычисленная нижняя треугольная матрица.
// и - вычисленная верхняя треугольная матрица с единичной // диагональю.
// п - порядок каждой из матриц.
// Возвращаемое значение:
// значение определителя исходной матрицы при нормальном // окончании счета,
// 0 при вырожденности матрицы.
//
{
register int i.k.r; // Счетчики
int rr = 0; // Индекс диагонального элемента
double Det = 1. // Возвращаемое значение определителя
buf; // Вспомогательная величина
/ / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / // Присвоение начальных значений FillUp (l.n * n.0);
MatrixUnit (u.n);
for (r = 0; r < n; r++, rr += n + 1)
Методы факторизации и приведения матриц
513
{
/////////////////////////////////
// Вычисление элементов матрицы L
for (i = г: i < n: 1++) {
for (к = 0, buf = 0: к < г; к++) buf += l[i + к * n] * u[k + г * nJ;
1[1 + г * n] = a[i + г * n] - buf; }
/////////////////////////////////
// Вычисление элементов матрицы U
for (i = r + 1; i < n; i++)
{
for (k = 0» buf =0; к < r; k++) buf += l[r + к * n] * u[k + 1 * n];
///////////////////////// // Проверка на значимость if (l[rr] < 0.000001) return 0;
el se
u[r + i * n] = (a[r + i * n] - buf) / 1[rr]; }
///////////////////////////////////
// Вычисление значения определителя
Det *= 1[rr];
}
return Det;
}
Разложение Холецкого Д = LLT
Разложение Холецкого (схема Холецкого, схема квадратного корня) основано на теореме Холецкого, а именно: если А — симметрическая положительно определенная матрица, то существует действительная невырожденная нижняя треугольная матрица L такая, что
А = ££т.
Этот эффективный вид разложения может применяться в ряде процедур линейной алгебры [189, с. 20], [139, с. 86], например при решении задачи приведения обобщенной проблемы собственных значений к стандартной проблеме собственных значений и для решения систем линейных уравнений. Разложение может быть успешно ис-17-2002
514
Глава 13. Линейная алгебра
пользовано для вычисления определителя [135, с. 262], [175, с. 171] и в задаче генерации многомерного нормального распределения [140, с. 256].
Рассматриваемое разложение получается из разложения [51, с. 55] А = LDLr,
где L — нижняя треугольная матрица с единичной диагональю, D — диагональная матрица с положительными диагональными элементами, как
А = LDi/2D1/2LT = LLt
что с точностью до обозначений совпадает с показанной выше формулой.
Различные аспекты схемы Холецкого и ее применения рассмотрены в [139].
Исходные коды
int Choleski (double а[].double b[],int n)
//
// Функция действительного треугольного разложения
// положительно определенной симметрической матрицы по схеме
// Холецкого.
// Обозначения:
// а - исходная матрица, в которой правильным может быть
// только нижний треугольник,
// b - полученная нижняя треугольная матрица.
// п - порядок каждой из матриц.
// Возвращаемое значение:
// 0 при нормальном окончании счета.
// -2 нельзя получить действительное треугольное разложение
// (исходная матрица вырожденна).
//
{
register int i.j.k: // Счетчики цикла
int ii,jj.ij.is.js,ik.jk.kk = - n - 1: // Индексы
double s; // Рабочая переменная
////////////////////////////////////////////
// Обнуление верхнего треугольника матрицы b
for (i = 1, jj = 0; i < n: i++)
{
jj += n:
for (j = 1, ij = jj: j <= i: j++) b[ij++] = 0;
}
Методы факторизации и приведения матриц 515
for (1 =0. ii = kk, is = kk; 1 < n; 1++) {
//////////////////////////////////////
// Получение внедиагональных элементов
for (j = 0. js = kk, ij = ++is, jj = kk; j <= 1 - 1: j++) {
ij += n:
s = a[ij];
for (k =0. ik = is. jk = ++js: k <= j - 1; k++) {
ik += n;
jk += n;
s -= b[ik] * b[jk];
}
jj += n + 1;
if (!b[jj]) return -2;
el se b[ij] = s / b[jj];
}
/////////////////////////////////// // Получение диагональных элементов ii -= kk;
s = a[ii];
for (k = 0. ik = is; k <= i - 1; k++)
{
ik += n;
s -= b[ik] * b[ik];
}
if (s < 0) return -2;
el se b[ii] = sqrt(s);
}
return 0;
}
Разложение по сингулярным числам
Рассмотрим разложение действительной прямоугольной матрицы А размером т строк на п столбцов, сформированной из п вектор-столбцов размером т, причем т > и, вида
A = U
Ут,
0
7
где U — матрица размером т х т, сформированная из т ортонормиро-ванных собственных векторов, соответствующих собственным значениям матрицы ААТ, if U = 1т,
17*
516
Глава 13. Линейная алгебра
13
V — матрица размером п х п, состоящая из п ортонормированных собственных векторов матрицы АТА,
VTV= Wr=In
X — диагональная матрица, диагональные элементы которой представляют собой так называемые сингулярные числа — квадратные корни из неотрицательных собственных значений матрицы АТА, О — прямоугольная нулевая матрица размером (т - п) строк на п столбцов.
В другой записи (которая подразумевается в показанной ниже функции)
А = UnXVr,
где Un — матрица размером т х п, сформированная из п ортонормированных собственных векторов, соответствующих п наибольшим из т (что означает необходимость сортировки массивов собственных значений и собственных векторов) собственным значениям матрицы ААТ,
UrU = уту = уу1 = /п.
Рассмотренное разложение называется разложением по сингулярным числам [ 189, с. 125]. Известно множество приемов решения этой задачи. Мы производим вычисления в следующем порядке. Сначала находим собственные числа и собственные вектора матрицы АТА методом Якоби или каким-либо другим методом. Метод Якоби отличается хорошей численной устойчивостью и дает в результате ортонормированную систему собственных векторов. Упорядочив собственные числа и, в соответствии с ними, собственные вектора, вычисляем матрицу сингулярных чисел X •
По формуле U = /ЦХУ1*) *, полученной путем несложных выкладок из показанной выше формулы, находим матрицу U.
Предлагаемый подход к решению задачи разложения матрицы по сингулярным числам впечатляет своей простотой, но, возможно, не так эффективен, как приведенные в источниках алгоритмы, однако, когда вы будете разрабатывать свою весьма эффективную функцию (мы в этом не сомневаемся!), хорошо иметь как запасное решение функцию работающую. Предложенный алгоритм может применяться во многих приложениях, правда вследствие его применил могут быть утрачены наименьшие из сингулярных значений. Поэтому
Методы факторизации и приведения матриц
517
в применении к другим задачам, нежели решаемые нами — а нас интересовали наибольшие собственные значения, — может понадобиться другой алгоритм, например [189, с. 125], более подробно изложенный в [2].
Дополнительно к печатным источникам, перечисленным выше, а также [77, с. 85], [183, с. 164], рекомендуем посмотреть источники в Интернете, находящиеся по адресам xfactor.wpi.edu/works/dchan/ msthesis/chapter2_6.html и www.cs.ut.ee /~toomas_l/linalg/lin2/ nodel4.html, а также провести поиск, например, с помощью поисковой машины Altavista по ключевым словам «singular value decomposition».
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
^include <math.h>
#include "megastat.h"
void main (void)
{
int i. j.l. // Счетчики
m = 6. // Число строк матрицы
n = 4: // Число столбцов матрицы
double а[] = { 2. 1. -1,-3, 9,15, // Исходная матрица
1. 7. 13,-2, 8. 1, 2,10. -1,13, 1, 7.
7, 8. 3. 4. 4,-1,},
* и, // Левая матрица
* v, // Правая матрица
* s, // Матрица сингулярных чисел
*с; // Рабочий массив
u = new double[m * n]; s = new double[n * n];
v = new double[n * n]; c = new doublefm * m]:
cout « "ORIGINAL MATRIXXn";
for (i = 0,1 =0: i < n: i++)
{
for (j = 0: J < m: J++.1++)
cout « setw (14) « a[l]: cout « endl:
}
cout « "RETURN CODE = "
« SingularValueDecomposition
(a,m,n,u,s.v) « endl;
518
Глава 13. Линейная алгебра
MatrixMultipiyMatrix (u.s.c.m.n.n):
MatrixMultipiyMatrixT (c.v.a.m.n.n);
cout « "CALCULATED MATRIX. MUST BE EQUIVALENT TO ORIGINAL\n"; for (i = 0,1 = 0: i < n: i++)
{
for (j = 0: j < m; j++,l++) cout « setw (14) « a[l]:
cout « endl;
}
cout « "TEST ORTHOGONAL MATRIX V. DONE\n":
MatrixMultipiyMatrixT (v.v.c.n.n.n):
for (i = 0,1 =0: i < n: i++)
{
for (j = 0; j < n; J++.1++)
cout « setw (14) « c[l]:
cout « endl:
}
cout « "TEST ORTHOGONAL MATRIX U. D0NE\n”;
MatrixTMultipiyMatrix (u,u,c,n,m,n);
for (i = 0,1 =0; i < n; i++)
{
for (j = 0: j < n: j++,l++) cout « setw (14) « c[lj;
cout « endl;
}
delete [] u; delete [] s; delete [] v: delete [] c; }
int SingularValueDecomposition (double a[],int m.int n.double u[],double s[],double v[]) //
// Функция разложения матрицы по сингулярным числам.
// Обозначения:
// а - исходная матрица ш х п, не разрушается,
// m - число строк матрицы а,
// п - число столбцов матрицы а,
// и - левая матрица ортогональных преобразований ш х п.
// s - матрица сингулярных чисел п х п,
// v - правая матрица ортогональных преобразований п х п.
// Возвращаемое значение:
// 0 при нормальном окончании расчета,
// -1 при недостатке памяти для вычислений,
// -2 при потере значимости или ошибке в вычислениях. И
{
register int i.j: // Счетчик
int k. // Рабочая переменная
Code = 0; // Возвращаемое значение
Методы факторизации и приведения матриц
519
double save, // Рабочая переменная
*c,*t; // Рабочий массив
if ((с = new doublefn * n]) == 0) return -1;
if ((t » new doublefn * n]) == 0)
{
delete [] c;
return -1;
}
/////////////////////////////////////////////
// Вычисление собственных значений и векторов MatrixTMultipiyMatrix (a.a.s.n.m.n);
if ((Code = Jacobi (s.n.O.000001.&k,v)) != 0) return Code;
///////////////////////////////////////////////// // Упорядочивание собственных значений и векторов for (i = 1, k = n + 1; i < n; i++, k += n + 1)
s[i] = s[k]:
for (1=0; i < n; i++)
{
k = i ;
save = s[i];
for (j = i + 1; j < n; j++) if (save < s[j])
{
k = j;
save = s[j];
}
Col Interchange (s.l.i.k);
Col Interchange (v.n.i.k);
}
////////////////////////////
// Матрица сингулярных чисел
for (i =1. k = n + 1: i < n; i++, k+=n+l)
{
s[k] = s[i];
s[1] = 0;
}
for (i=0;i<n*n;i+=n+l) s[i] = sqrt (s[i]);
////////////////
// Левая матрица
MatrixMultipiyMatrixT (s.v.c.n.n.n);
InverseMatrix (c.t.n);
MatrixMultipiyMatrix (a.t.u.m.n.n);
delete [] c: delete [] t;
return Code;
}
520
Глава 13. Линейная алгебра
Разложение A = QR, ортогонализация Грама—Шмидта
В некоторых способах разложения матрицы по сингулярным числам [www.cs.ut.ee/~toomas_l/LinaLg/lin2/nodel4.htmll, [184, с. 340] применяется QR-разложение [там же, с. 154] с помощью процесса ортогонализации Грама—Шмидта [там же, с. 157,338], [ 101, с. 431], [107, с. 125]. QR-разложен не исходной матрицы Л вида
Л = QR,
где Q — ортогональная матрица,
R — верхняя треугольная матрица, эквивалентно построению ортонормированной системы векторов в гильбертовом пространстве, порождающей то же самое линейное многообразие, что и заданная система. Процесс Грама—Шмидта может быть истолкован как разложение невырожденной квадратной матрицы в произведение ортогональной матрицы и верхней треугольной матрицы с положительными диагональными элементами [135, с. 438]. Решение ведем по рекуррентным формулам [101, с. 402] (в обозначениях источника)
Г. II *-<
где и — ортонормированная система векторов,
е — заданная система векторов, п — число вектров.
Нетрудно видеть, что вычисленные таким образом векторы и представляют собой столбцы ортогональной матрицы Q. Вывод верхней треугольной матрицы R производим, как показано в [183, с. 156].
Представленная ниже функция QRDecomposition является вариантом приведенной следом за ней функции GramSchmidt и отличается от нее только возможностью вывода матрицы Qu слегка оптимизированным кодом.
Исходные коды и пример применения
#include <fstream.h>
#include <1 onianip. h>
#include <math.h>
#include ‘‘megastat.h"
Методы факторизации и приведения матриц
521
void main (void) {
int i.j. 1. // Счетчики
n = 4. // Число строк исходной матрицы
m = 3; // Число столбцов исходной матрицы
double а[] = {1.1.0.1. // Исходная матрица
1.0.1.1.
0.1.1.1}.
*q,*r; // Матрицы QR-разложения
q = new double[n * m]; г = new double[m * m];
cout « "A-martix\n" « "------------\n":
for (i = 0,1 = 0: i < m; i++) {
for (j = 0; j < n: j++.l++) cout « setw (14) « a[l];
cout « endl;
}
if (’QRDecomposition (a.q.r.n.m)) {
cout « "Q-martix\n" « "-----------\n";
for (i = 0,1 = 0; i < m: i++) {
for (j = 0: j < n; J++.1++) cout « setw (14) « q[l];
cout « endl;
}
cout « "R-martix\n" « "-----------\n”;
for (i = 0.1 =0; i < m; i++) {
for (j = 0; j < m; J++.1++) cout « setw (14) << r[l];
cout « endl: }
cout « "Q * R must be A\n" « "-------------------\n";
MatrixMultiplyMatrix (q.r.a.n.m.m);
for (i = 0,1 = 0: i < m; i++) {
for (j = 0: j < n; J++.1++)
cout « setw (14) « a[l]; cout « endl;
}
cout « "Q(transposed) * Q must be I\n" « ------------------------------------\n";
MatrixTMultiplyMatrix (q.q.a.m.n.m); for (i = 0.1 =0: i < m; i++)
522
Глава 13. Линейная алгебра
{
for (j = 0; j < m; j++.l++)
cout « setw (14) « a[l];
cout « endl:
}
}
el se
cout « "ErrorXn”:
}
int QRDecomposition (double a[J.double q[],double r[].int n.int m) //
// Функция QR-разложения матрицы общего вида.
// Обозначения:
// а - исходная натрица. не разрушается,
// q - ортогональная матрица.
// г - верхняя треугольная матрица,
// п - число строк исходной матрицы.
// m - число столбцов исходной матрицы.
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -1 при недостатке памяти для вычислений.
// -2 при ошибке в вычислениях.
//
{
register int i.j.k: // Счетчики
int Code = 0. H Возвращаемое значение
1. H Счетчик элементов матрицы а
11.12. H Счетчик элементов системы
13. H Счетчик элементов матрицы q
14; И Счетчик элементов матрицы г
double *v. H Рабочий нассив
s: H Рабочая переменная
if (!(s = EuclidNormaVector (a.n))) return -2:
if (!(v = new double[n]))
return -1:
lllllllllllllllllllllllllll // Первый столбец матрицы q for (13 = 0; 13 < n; 13++)
q[13] = a[13] / s;
lllllllllllllllllllllllllll II Первый столбец матрицы г r[0] = s:
for (14 =1: 14 < m: 14++)
r[14] = 0:
Методы факторизации и приведения матриц
523
///////////////////////
// Рекуррентный процесс
for (i = 1: i < m; 1++)
{
for (j=0.1=i*n;j<n: j++) v[j] = a[l++];
for (k = 0,1 = 0,11 = 0; k < 1: k++)
{
for (j = 0,s = 0,12 = i * n; j < n: j++)
s += q[l++] * a[12++]: for (j = 0: j < n; j++) v[J] -= s * q[ll++]: r[14++] = s:
}
if (!(s = EuclIdNormaVector (v.n)))
{
Code = -2;
break;
}
for (j = 0: j < n: j++)
q[13++] = v[j] / s;
r[14++] = s;
for (j = i + 1: j < m: j++) r[14++] = 0:
}
delete [] v;
return Code:
}
Если верхнюю треугольную матрицу R выводить не нужно, вместо рассмотренной функции лучше воспользоваться функцией Gram-Schmidt, показанной ниже, реализующей процесс ортогонализации Грама—Шмидта. По утверждению [183, с. 156], разложение А = QR представляет собой просто удобную запись алгоритма процесса Грама—Шмидта.
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void)
{
int i, j, 1, // Счетчики
524
Глава 13. Линейная алгебра
п = 4. // Размер вектора
m = 3; // Число векторов
double е[] = {12. 1. -1, 3. // Исходная система 10. 7, 1.-2.
9. 8. 3. 4.},
и[12],с[9];
cout « "ORIGINAL SYSTEM\n"; for (1 = 0.1 =0; i < Ш; i++) { for (j = 0; j < n; J++.1++) cout « setw (14) « e[l]: cout « endl;
} cout « "NON ORTHONORMAL SYSTEMXn"; MatrixTMultiplyMatrix (e.e.c.m.n.m); for (i = 0,1 =0: i < m; i++)
{
for (j = 0; j < m: J++.1++) cout « setw (14) « c[l]; cout « endl;
}
cout « "RETURN CODE = " « GramSchmidt (e.u.m.n) « endl;
cout « "CALCULATED SYSTEMVn"; for (i = 0.1 =0; i < m; i++) { for (j = 0; j < n; J++.1++) cout « setw (14) « u[l]; cout « endl;
}
cout « "ORTHONORMAL SYSTEMXn";
MatrixTMultiplyMatrix (u.u.c.m.n.m); for (i =0,1 =0; i < m; i++) { for (j = 0; j < m: j++,l++) cout « setw (14) « c[lj;
cout « endl: }
}
int GramSchmidt (double e[],double u[],int m.int n) //
// Функция ортогонализации системы векторов //(процесс ортогонализации Грана-Шмидта). // Обозначения:
// е - исходная система векторов, не разрушается, // и - ортонормированная система векторов,
Методы факторизации и приведения матриц
525
// m - число векторов,
// n - размер каждого вектора. // Возвращаеное значение: // 0 при нормальном окончании расчета, // -1 при недостатке памяти для вычислений. // -2 при ошибке в вычислениях. // { register int i.j.k; // Счетчики
int Code e 0, 1.11,12.13 = 0; И И Возвращаемое значение Счетчик элементов системы
double *v, s; И И Рабочий массив Рабочая переменная
if ((v = new double[n]) == 0) return -1:
///////////////////////// // Инициализация процесса ArrayToArray (e.v.n);
s = EuclidNormaVector (v.n); if (s == 0)
{
delete [] v;
return -2;
} for (i = 0: i < n: i++) u[13++] = v[i] / s:
///////////////////////
II Рекуррентный процесс for (i = 1: i < m: i++) {
for (j = 0,1 = i * n; j < n; j++) v[j] = e[l++]:
for (k = 0,1 = 0,11 = 0: k < i; k++) {
for (j = 0, s = 0,12 = i * n: j < n; j++) s += u[l++] * e[12++]:
for (j = 0; j < n; j++) v[j] -= s * u[ll++];
}
s = EuclidNormaVector (v,n);
if (s == 0) {
Code = -2;
break;
}
526
Глава 13 Линейная алгебра
for (j = 0; j < n: j++) u[13++] = v[j] i s;
}
delete [] v;
return Code;
}
Метод может применяться для решения системы алгебраических уравнений [135, с. 438].
Методы приведения к форме Хессенберга
Показанная далее функция реализует приведение произвольной квадратной матрицы к верхней почти треугольной форме Хессенберга (верхней форме Хессенберга), то есть такой квадратной матрице, у которой каждый элемент
а. = 0 для всех г > j + 2.
Если окажется, что исходная матрица симметрическая, та же функция осуществляет приведение исходной матрицы к трехдиагональной форме, то есть такой квадратной матрице, у которой каждый элемент
atj = 0 для всех [/ - г| > 1.
Трехдиагональная матрица по определению одновременно является как верхней, так и нижней матрицей Хессенберга.
Важность эффективного получения матрицы Хессенберга обусловлена тем, что для этой формы построены многие алгоритмы линейной алгебры. В алгебрической форме соотношения между матрицами выглядят следующим образом:
Н = Т’АТ,
где Н — матрица Хессенберга,
А — исходная матрица,
Т— матрица преобразования.
Метод Гивенса
Для преобразования исходной матрицы к верхней форме Хессенберга мы обычно применяем метод Гивенса [188, с. 311], [139, с. 125].
Методы факторизации и приведения матриц
527
Собственные значения исходной матрицы и формы Хессеберга будут совпадать. Однако собственные вектора преобразование не сохраняет. Соотношения между собственными векторами исходной матрицы и матрицы Хессенберга запишутся как
ХЛ =
Тх
где хА — собственный вектор исходной матрицы, хн — собственный вектор матрицы Хессенберга.
Для того чтобы практически восстановить собственные вектора исходной матрицы, мы можем вычислить матрицу вращения, введя единичную матрицу и одновременно проделав с ней те же манипуляции, что и с исходной матрицей. Обратите внимание, что в данной функции исходная матрица разрушается, поэтому, если предполагается работа с матрицей в исходной форме и далее, ее копию нужно сохранить в каком-либо массиве.
Исходные коды
void Givens (double a[],int n.double t[].int ich) //
// Функция приведения действительной матрицы к верхней почти // треугольной форме Хессенберга либо, как частный случай, к // трехдиагональной форме, если исходная матрица является // симметрической, методом Гивенса (вращений).
// Обозначения:
// а - исходная матрица, на выходе - матрица Хессенберга.
// п - порядок матриц а и t.
// t - на выходе - матрица вращения.
// ich - параметр, равный 1. если нужно выводить матрицу t.
// и равный 0. если не нужно выводить матрицу t. в
// последнем случае резервировать память для массива
/ t не обязательно.
// Возвращаемое значение:
// нет.
//
{
register int i.j; // Счетчики
int itl.iul. // Вспомогательные индексы
ir. // Индекс основного шага
it = - n. // Текущий индекс a(ir+l.ir)
iu. // Начальный индекс a(i,ir) при i=ir+l
im. // Текущий индекс a(j,i) при j=l
ik = - 1; // Текущий индекс a(j,ir+l) при j=l
double x.save, // Буферы
ct.st; // Косинус и синус угла вращения
528
Глава 13. Линейная алгебра
/////////////////////////////////////////////////// // Получение единичной матрицы - начальных значений // матрицы вращения, если нужно if (ich)
MatrixUnit (t.n);
//////////////////////
// Основной шаг метода
for (ir - 1; ir <= n - 2; ir++)
{
it += n + 1;
iu = it;
ik += n;
im = ik + n;
for (i = ir + 1; i < n; i++)
{
iu++;
x = sqrt (a[it] * a[it] + a[iu] * a[iu]);
if (x)
{
ct = a[it] / x;
st = a[iu] / x;
////////////////////////////////////////
// Умножение слева на матрицу вращения в // плоскости (ir+l,i) itl = it;
iul = iu;
for (j = ir; j < n; j++)
{
itl += n;
iul += n;
save = a[itl] * ct + a[iul] * st;
a[iul] = -a[itl] * st + a[iul] * ct;
a[it1] = save:
}
/////////////////////////////////////////
// Умножение справа на матрицу вращения в // плоскости (ir+l,i) itl = ik;
for (j = 0; j < n; j++)
{
save = a[++itl] * ct + a[++im] * st; a[im] = -a[itl] * st + a[im] * ct; a[itl] = save;
////////////////////////////////////////// // Сохранение матрицы вращения, если нужно if (ich)
{
save = t[itl] * ct + t[im] * st:
Методы факторизации и приведения матриц
529
t[im] = -t[itl] * st + t[1m] * ct: t[itl] = save:
}
}
}
a[it] = x:
a[iu] = 0;
}
}
}
Метод действительных устойчивых преобразований подобия
Несмотря на привлекательность метода Гивенса, это не самый эффективный алгоритм. Ниже показана функция Hessenberg, реализующая метод действительных устойчивых преобразований подобия, предложенный, по-видимому, Уилкинсоном [188, с. 318]. Нами не выводится матрица преобразования для метода действительных устойчивых преобразований подобия, однако это можно сделать по аналогии с функцией Givens.
Исходные коды
void Hessenberg (double* a.int n) //
// Функция приведения действительной матрицы к верхней
// форме Хессенберга методом действительных устойчивых // преобразований подобия.
// Обозначения:
// а - на входе - квадратная матрица общего вида,
// на выходе - матрица Хессенберга.
// п - порядок матрицы а.
// Возвращаемое значение:
// нет.
//
{
register int i.j:
int k = 0.
m = n + n.ii,isl,is2, i r, is:
double x,
У:
for (ir = 1; ir < n - 1:
{
//////////////////
// Ведущий элемент
// Счетчики цикла
// Рабочая переменная
// Индексы
// Номер текущей строки
// Номер ведущего столбца
// Ведущий элемент
// Параметр преобразования
i г++)
530 Глава 13 Линейная алгебра
for (i - ir.is - ir.x = 0: i < n; i++) if (fabs (a[k + 1]) > fabs (x))
{
x e a[k + i]; is “ i:
}
if (x !- 0)
S//////////////////////////////////////// // Перестановка строк и столбцов is и ir if (is != ir) {
Rowinterchange (a.n.n.is.ir);
Col Interchange (a.n.is.ir); }
///////////////////////
// Преобразование строк
for (i = ir + 1; i < n: i++) {
у = a[k + i] / x:
for (j = O.isl = i,is2 = ir; j < n; j++,isl += n,is2 +» n)
a[isl] -= у * a[is2]; }
//////////////////////////
// Преобразование столбцов
for (i = ir + l.ii « 0 ; i < n; i++,ii++) {
y-a[m+n*ii]/x;
for (j » O.isl - i * n.is2 = ir * n; j < n; j++) a[isl++] -= у * a[is2++];
} }
k += n;
m += n + 1;
}
}
Метод Хаусхолдера
Очень эффективна процедура построения трехдиагональной матрицы, основанная на ортогональных преобразованиях Хаусхолдера [189, с. 190]. Основные соотношения:
Т= UAV,
где Т — трехдиагональная матрица, А — исходная матрица,
Методы факторизации и приведения матриц
531
U — левая матрица ортогональных преобразований, V — правая матрица ортогональных преобразований. Собственные значения исходной матрицы и трехдиагональной матрицы будут совпадать, однако собственные вектора преобразование не сохраняет. Соотношение между собственными векторами исходной матрицы и трехдиагональной матрицы запишется как
ХА ~ Vх Т>
где хА — собственный вектор исходной матрицы, хт — собственный вектор трехдиагональной матрицы.
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include "megastat.h"
void main (void) {
int i, j,1. // Счетчики
n s 5: // Порядок матрицы
double a[] = {10, 1, 2, 3, 4, // Исходная матрица
1 , 9.-1, 2,-3,
2 .-1, 7. 3,-5.
3 , 2, 3.12.-1,
4 .-3,-5,-1,15}, tl[25],t2[25], // Ортогональная матрица
a0[25]; // Рабочий массив
cout « "Оригинальная матрицаХп";
ArrayToArray (a,a0,n * n): for (i = 0,1 = 0; i < n; i++) {
for (j = 0; j < n; J++.1++) cout « setw (14) « a0[l];
cout « endl: }
cout « "Возвращаемое значение = " « Householder (a.n.tl,t2) « endl;
cout « "Трехдиагональная матрицаХп"; for (i = 0.1 = 0; i < n; i++)
{
for (j = 0; j < n; J++.1++) cout « setw (14) « a[l];
532
Глава 13 Линейная алгебра
cout « endl; }
cout « "Ортогональная матрица левая\п"; for (1 = 0,1 =0: i < n; 1++)
{
for (j = 0: j < n; j++,1++) cout « setw (14) « tl[l];
cout « endl: }
cout « "Ортогональная матрица праваяХп";
for (i = 0,1 =0: i < n: i++) {
for (j = 0; j < n; J++.1++)
cout « setw (14) « t2[l]: cout « endl:
}
cout « "Проверка - должна быть трехдиагональная матрицаХп";
MatrixMultiplyMatrix (tl.aO.a.n.n.n);
MatrixMultiplyMatrix (a,t2,a0,n,n,n): for (i = 0,1 = 0; i < n; 1++)
{
for (j = 0: j < n; J++.1++) cout « setw (14) << a0[l]:
cout « endl;
}
}
int Householder (double a[],int n,double tl[],double t2[]) //
// Функция приведения действительной симметрической матрицы к
// трехдиагональной форме методом ортогональных преобразований // Хаусхолдера.
// Обозначения:
// а - исходная натрица, на выходе - натрица Хессенберга,
// п - порядок натриц а и t,
// tl - левая натрица ортогональных преобразований (Р).
// t2 - правая натрица ортогональных преобразований (Q).
// Замечания:
// 1. Метод сохраняет собственные значения исходной матрицы,
// но не сохраняет собственные вектора.
// 2. В алгебраической форме соотношения между матрицами
// выглядят следующим образом:
// Т = Р * А * Q, Ха = Q * Xt,
// где Т - трехдиагональная матрица.
// А - исходная матрица,
// Р - левая натрица ортогональных преобразований.
// Q - правая натрица ортогональных преобразований.
// Ха - собственный вектор исходной матрицы,
// Xt - собственный вектор трехдиагональной матрицы.
// Возвращаемое значение:
Методы факторизации и приведения матриц
533
// 0 при нормальной окончании расчета.
// -1 при недостатке памяти для вычислений.
// -2 при потере значимости. //
{ register int i.j.l; // Счетчики
int Code = 0. // Возвращаемое значение
k2: // Рабочие переменные
double *u.*p,*q,s.k;
if C(u = new double[nj) == 0) return -1:
if C(p = new doublefn * nJ) == 0) {
delete [] u: return -1:
}
if ((q = new double[n * n]) == 0) {
delete [] u: delete [] p; return -1;
}
for (1 = n - 1; 1 > 1: 1 — ) {
/////////////////////////////////////// // Вычисление параметров преобразования for (j = 0. s = 0. k2 = 1: j < 1: j++, k2 += n) s += a[k2] * a[k2];
if (s <- 0.000001) {
Code = -2; break:
} s = sqrt (s):
for (j = 0. k2 = 1; j < 1 - 1; j++.k2 += n) u[j] = a[k2]:
u[l - 1] = a[k2] - SignNull (a[k2]) * s;
for (j = 1: j < n: j++) u[j] = 0:
s = VectorSumSQ (u.n) / 2;
MatrixMultiplyVector (a.u.p.n): for (j = 0. k=0: j < n; j++) { p[j] /= s: k +« u[j] * p[j]:
}
534
Глава 13. Линейная алгебра
к /= s * 2;
for (j = 0; j < n; j++) qCJ] = p[j] - к * u[j];
//////////////////////////////////////// // Формирование трехдиагональной матрицы for (j = O.k2 = 0; j < n; j++)
for (i = 0; i < n: i++)
a[k2++] -= u[j] * q[i] + q[j] * u[i];
///////////////////////,//////////////////////////// // Формирование матрицы ортогональных преобразований for (i = 0.k2 =0; i < n; i++)
for (j = 0; j < n; j++)
p[k2++] = i == j ? 1 - u[i] * u[j] / s : 0 -u[i] * u[j] / s;
if (1 == n - 1)
{
//////////////////////////////////////// // Матрицы преобразований на первом шаге ArrayToArray (p.tl.n * n):
ArrayToArray (p,t2,n * n):
}
el se
{
///////////////////////////////////// II Накопленные матрицы преобразований MatrixMultiplyMatrix (p.tl.q.n.n.n): ArrayToArray (q,tl,n * n):
MatrixMultiplyMatrix (t2.p.q,n,n,n): ArrayToArray (q,t2,n * n);
}
}
delete [] u: delete [] p: delete [] q:
return Code:
}
Последнее замечание, касающееся приведения матриц к форме Хес-сенберга и трехдиагональной форме, заключается в том, что эта операция не единственна, хотя все свойства сохраняются.
Вычисление собственных значений и собственных векторов
Собственными значениями квадратной матрицы А порядка п [189] называются такие значения Л , при которых система п уравнений
Вычисление собственных значений и собственных векторов 535
Axi = \xi, i = 1,2,..п,
где Д , i = 1,2,.... п, — собственные значения,
х,, i =1,2,п, — собственные вектора, соответствующие Л,, имеет нетривиальное решение.
Собственным вектором матрицы А называют ненулевой вектор х, удовлетворяющий показанной выше системе [135, с. 551].
Собственные значения находят очень широкое применение в различных методиках аг миза данных. К проблеме собственных значений сводится большое число алгоритмов факторного и кластерного анализа, многомерного шкалирования и других методов, имеющих отношение к распознаванию образов.
Легко заметить, что собственный вектор, умноженный на число, также будет собственным вектором [183, с. 334]. Система собственных векторов, вычисленная различными методами, может быть ор-тонормированной или нет. Таким образом, собственные вектора, определяемые различными методами, могут быть различными, что, однако, не влияет на выводы, сделанные по результатам применения методов анализа данных, на основе изучения собственных векторов системы. В ходе применения упомянутых и других методов анализа, использующих собственные значения и собственные вектора, надо также учитывать, что собственные вектора, соответствующие совпадающим собственным значениям, в общем случае различны, поэтому учитываться должны все собственные значения, отвечающие избранному критерию для их удержания.
Один из методов определения собственных значений состоит в раскрытии определителя [112, с. 95]
|Л-Л/|=0.
Это характеристическое уравнение матрицы А [183, с. 213]. Хотя разработаны эффективные приемы решения уравнений такого типа, в расчетах этот метод применяется только в учебных целях. Показанная ниже функция PolynomCoeff вычисляет коэффицинты характеристического полинома матрицы в форме Хессенберга.
Исходные коды
int PolynomCoeff (double h[],int n.double b[J) //
// Функция вычисления коэффициентов характеристического полинома
536
Глава 13. Линейная алгебра
// действительной матрицы в верхней почти треугольной форме
// Хессенберга либо, как частный случай, в форме
// трехдиагональной матрицы.
// Обозначения:
// h - матрица Хессенберга.
// п - порядок матрицы h.
// b - полученный вектор длиной (n + 1) коэффициентов
// характеристического полинома, расположенных начиная
// с коэффициента при младшей степени
// переменной.
// Возвращаемое значение:
// 0 при нормальном окончании счета,
// -1 при недостатке памяти для вычислений.
//
{
register int i.is.l, // Счетчики
ir: // Номер основного шага вычислений
int ij. // Начальный индекс для произведения
il. // Начало первой строки рабочего нассива
in. // Рабочий индекс для суммирования
ik = 0, // Начало ir-й строки рабочего массива
kl. // Текущий индекс для суммирования
j, // Текущий индекс для произведения
im. // Рабочий индекс для сдвига
кп = 0, // Начальные индексы для суммирования
km = 0:
double *s.
sr.
sig,
sigl = -1:
// Рабочий массив
// Буфер
// В формуле: (-1)
// Знак последнего
в степени (1г-1) слагаемого
//////////////////////////////////////////////////////////// // Рабочий нассив - нижняя треугольная натрица коэффициентов // - хранится в виде вектора по строкам без последней строки if ((s = new double[n * (n + 1) / 2]) == 0)
return -1:
s[0] - 1:
for (i = 1; i < n * (n + 1) / 2; i++)
s[i] = 0;
for (i = 0: i <= n; i++)
b[i] = 0:
for (ir = 1: ir <= n; ir++)
{
lllllllllllllll
II Суммирование
il » 0;
ik +» ir:
ij = 1:
kl = km:
Вычисление собственных значений и собственных векторов 537
sigl - -sigl:
sig = sigl:
for (is = 0; is <= ir - 1: is++)
{
if (is != ir - 1)
{
sr = 1:
J = ij:
for (1 = is + 2; 1 <= ir; 1++)
{
sr *= h[j];
j += n + 1:
}
sr *= h[kl] * sig;
sig = -sig;
}
el se
sr = h[kn];
kl++;
in = ik;
for (i = 0; i <= is; i++)
{
if (ir != n)
s[in] = s[in] + sr * s[ilj:
el se
b[i] = b[i] + sr * s[ilj;
i n++; + ’
ij += n + 1;
}
kn += n + 1;
km += n;
////////
// Сдвиг
in = ik; // Далее in - индекс для сдвига
im = in - ir;
for (i = 0; i <= ir - 1; i++)
{
if (ir != n)
s[in + 1] = s[in + 1] - s[im];
el se
b[i + 1] = b[i + 1] - s[im];
in++;
im++;
}
}
delete [] s;
return 0;
}
538
Глава 13. Линейная алгебра
Напомним, что матрица (А - II) называется резольвентой, множество всех собственных значений матрицы называется спектром собственных значений [101, с. 354], а число р(Л) = тах|Л^ [Л]| называют спектральным радиусом матрицы Л [51, с. 41].
Укажем несколько интересных свойств собственных значений произведения матриц [188, с. 63]:
1. Собственные значения матрицы АВ и матрицы В А, где А и В — квадратные матрицы, одинаковы.
2. Собственные значения матрицы АВ и матрицы В А, где А и В — прямоугольные матрицы размером п х тп и тп х п соответственно, одинаковы, за исключением того, что произведение большего порядка имеет \п - тп\ нулевых собственных значений.
Для практического вычисления собственных значений и собственных векторов широкое применение находят различные итеративные схемы [112, с. 96]. Чаще всего нами используется описанный ниже достаточно надежный метод Якоби [189, с. 182], [112, с. 105], вполне подходящий для матриц умеренных порядков, возникающих в решаемых нами задачах [47].
Локализация собственных значений
Интервалы локализации любого собственного значения действительной матрицы (границы спектра собственных значений) могут быть получены путем вычисления с»-нормы матрицы (функция InfiniteNorma) или так называемых кругов Гершгорина [183, с. 351], [48, с. 415], [188, с. 78], основаннных на теореме: каждое собственное значение матрицы А лежит в одном из кругов Clf С2,С„, где круг С, имеет центром диагональный элемент а„, а его радиус равен сумме абсолютных значений оставшихся элементов строки:
VEI4 I
>1.
>*«
Исходные коды
void Gerschgorin (double a[],int n.double *xmin,double *xmax) //
// Функция определяет границы интервала локализации любого // собственного значения действительной матрицы, используя // теорему Гершгорина (круги Гершгорина).
Вычисление собственных значений и собственных векторов 539
// Обозначения:
//а - действительная матрица,
// п - порядок матрицы.
// *xmin - левая граница интервала.
// *хтах - правая граница интервала.
// Возвращаемое значение:
// нет.
//
{
register int i.j; // Счетчики столбцов и строк
int m = 0; // Счетчик элементов матрицы
double Sum. // Сумма модулей элементов столбца
Middle; // Середина текущего интервала
/////////////////////
// Начальные значения
*xmi п = а[0];
*хтах = а[0]:
////////////////////
// Цикл по столбцам
for (i = 0; i < n; i++)
{
for (j = 0, Sum =0; j < n; j++. m++) if (i == j)
//////////////////////////////////////////// II Диагональный элемент - середина интервала Middle = a[m];
el se
////////////////////////////////// // Сумма внедиагональных элементов Sum += fabs (a[m]);
if (Middle - Sum < *xmin)
*xmin = Middle - Sum;
if (Middle + Sum > *xmax)
*xmax = Middle + Sum;
} }
Стандартная проблема собственных значений
Проблема собственных значений [189, часть II] для действительной симметрической матрицы умеренных размеров обычно решается методом Якоби (вращения) либо с помощью QT^-алгоритма [183, с. 340], причем предпочтительнее первый метод , если исследователя интересует прежде всего точное определение наибольших
540
Глава 13 Линейная алгебра
собственных значений, второй метод — если исследователя интересуют наименьшие собственные значения. Для произвольной действительной матрицы проблема собственных значений решается с помощью (ЛК-алгоритма или одного из его вариантов [183, с. 340].
Метод Якоби
Метод Якоби производит диагонализацию исходной матрицы [189, с. 182]:
D = VTAV,
где D — диагональная матрица с неупорядоченными собственными значениями на главной диагонали,
V — ортогональная матрица, столбцы которой суть расположенные в соответствии с собственными значениями ортонормированные собственные вектора матрицы А,
А — исходная симметрическая матрица.
Как уже указано во вводной части к данной главе, вычисление индексов в составленной нами функции далеко от оптимального, хотя и очень наглядно. У вас есть шанс значительно улучшить данную функцию путем ее модернизации.
Для сравнения в примере показан также вызов следующей из представленных функций FrancisKublanovskaya, реализующей (^-алгоритм. Обратите внимание, что сравниваться алгоритмы могут только при вычислении собственных значений действительных симметрических матриц, так как метод Якоби предназначен только для матриц такого типа. Другие примеры применения метода Якоби можно найти во многих разделах данной книги, например в главах «Факторный анализ» и «Распознавание образов с обучением».
Критерий останова итерационного процесса взят нами по рекомендации [112, с. 107] в виде евклидовой нормы предельной матрицы D без главной диагонали, однако может быть принят и любой другой критерий останова — этот вопрос не принципиален.
В отличие от результатов QT^-алгоритма, собственные значения (и собственные вектора), вычисленные методом Якоби, в общем случае по величине не упорядочены, поэтому, как показано в примерах, в реальных задачах производится упорядочивание собственных значений по величине и в соответствии с этим переставляются собственные векторы.
Вычисление собственных значений и собственных векторов 541
Исходные коды и пример применения
^include <fstream.h>
^include <iomanip.h>
^include <math.h>
^include "megastat.hH
void main (void) {
int m = i.j.l . 6. s: // Счетчики // Размер матрицы
// Счетчик итераций
double a[] = { 5, 1.-2, 0.-2. 1. 6.-3. 2. 0. -2.-3. 8.-5.-6. 0. 2.-5. 5. 1. -2. 0.-6, 1. 6. 5. 6. 0.-2.-3. *q.*b; q = new double[m * m]; b = new double[m * m]; cout « "Original matrix\n": for (i = 0.1 = 0; i < m; i++) 5. // 6. 0. -2. -3. 8}. // Исходная матрица Вспомогательный массив
{
for (j = 0: j < m: J++.1++) cout « setw (14) « a[l];
cout « endl;
}
ArrayToArray (a.q.m * m);
Jacobi (q,m,0.000001.&s,b): cout « "New matrix (Jacobi)\n"; for (i = 0,1 =0: i < m: i++)
{
for (j = 0: j < m: J++.1++) cout « setw (14) « q[lj;
cout « endl:
}
cout « "Iteration number is " «
s « endl:
FrancisKublanovskaya (a.m.0.000001,&s): cout « "New matrix (QR-iteration)\n"; for (i = 0.1 = 0; i < m; i++)
{
for (j = 0; j < m; J++.1++) cout « setw (14) « a[l];
cout « endl:
}
542
Глава 13. Линейная алгебра
cout « "Iteration number is " « s « endl;
delete [] q; delete [] b;
}
int Jacobi (double a[],int n.double eps,int *it,double b[])
11
II Функция вычисления собственных значений и соответствующих // собственных векторов действительной синнетричной матрицы
II методом Якоби.
// Обозначения;
//а - симметричная действительная матрица, разрушается,
// на выходе на главной диагонали - собственные значения,
// п - порядок матрицы а,
// eps - малая величина для проверки значимости.
// *it - счетчик итераций,
// b - массив собственных векторов, соответствующих вычисленным
// собственным значениям, расположенных по столбцам.
// Примечание:
// Проверка вырожденности матрицы системы не производится -// для вырожденной матрицы получатся нулевые в пределах точности // вычислений собственные значения. Для проверки вырожденности // используйте функцию Krauth.
// Возвращаемое значение:
// 0 при нормальном окончании расчета,
// -1 при недостатке памяти для рабочих массивов.
// -2 при ошибке в вычислениях.
//
{
register int i.j; H Счетчики цикла
int p.q. H Координаты наибольшего внедиагонального
H элемента
ml; H Индекс одномерного массива
13 double max. H Модуль наибольшего внедиагонального элемента
t. H Параметр угла вращения
s,s2,c,c2. H Синус и косинус угла вращения и их квадраты
*rl,*r2; H Рабочие массивы
////////////////////
// Для размерности 1
if (п == 1)
{
if (а[0] == 0) return -2;
el se
а[0] = 1.0 / a[OJ;
b[0] = 1;
*it = 1;
return 0;
}
Вычисление собственных значений и собственных векторов 543
/////////////////////
// Начальные значения
MatrixUnit Cb.n):
*it = 0:
if ((rl = new double[n * n]) «» 0) return -1;
if (Cr2 = new double[n * n]) e= 0)
{ delete [] rl: return -1;
}
do
{
//////////////////////////////////////////////
// Поиск наибольшего внедиагонального эленента
for (i » 0: i < n: i++)
for (j = i + 1, ml - i * n + i + 1: j < n: j++, ml++) {
t = fabs (a[ml]):
if (ml « 1 || t > max)
{
P - i;
q = j; max = t;
} }
/////////////////////////////////
// Вычисление параметров вращения
t = a[p * (n + 1)] == a[q * (n + D] ? M_PI / 4 * SignO (a[n * q + p]) :
atan (a[q * n + p] / (a[p * n + p] - a[q * n + q]) * 2)
/ 2:
s = sin (t): |
c = cos (t):
s2 - s * s: c2 » c * c:
////////////////////////////
// Вращение исходной матрицы ArrayToArray (a.rl.n * n):
for (i = 0: i < n; i++)
if (i !- p && i != q) {
rl[p * n + i] » a[p * n + i] * c + a[q * n + i] * s;
rl[i * n + p] = rl[p * n + i]:
rl[q * n + i] = - a[p * n + i] * s + a[q * n + i] * c:
rl[i * n + q] « rl[q * n + i];
}
544
Глава 13. Линейная алгебра
rl[p * n + р] = а[р * п + р] * с2 + 2 * a[q * п + р] * с * s +
a[q * n + q] * s2:
rl[q * n + q] = a[p *n+p]*s2-2* a[q *n+p]*c*s+ a[q * n + q] * c2;
rl[q * n + p] = (a[q * n + q] - a[p * n + p]) * c * s + a[q
* n + p] * (c2 - s2);
rl[p * n + q] = rl[q * n + p]:
(*it)++;
ArrayToArray (rl.a.n * n);
////////////////////////////////// // Сохранение собственных векторов MatrixUnIt (rl.n):
rl[p * n + p] = c:
rl[q * n + q] = c;
rl[q * n + p] = s;
rl[p * n + q] = - s;
MatrixMultipiyMatrixT (b, rl.r2,n.n,n): ArrayToArray (r2.b.n * n);
/////////////////////////////////////////// // Условие окончания итерационного процесса
} while (EuclidNormaWithoutDiag (a.n) > eps);
delete [] rl; delete [] r2;
return 0;
}
QR-алгоритм
Для вычисления собственных значений действительной матрицы применяется предложенный Франсисом и Кублановской [189, с. 203] (ZR-алгоритм, основанный на рассмотренном выше методе (^-разложения. Рекуррентные формулы простейшего варианта QT^-алго-^ ритма без сдвига имеют вид [183, с. 340]
= 0Л>
A+t _ RkQk>
где Qk и Rk — матрицы (?7?-разложения исходной матрицы на k-й итерации.
Вычисление собственных значений и собственных векторов 545
При продолжении итерационного процесса последовательность Ak сходится к треугольной матрице с собственными значениями исходной матрицы на диагонали. В [189, с. 203] утверждается, что при наличии р кратных собственных значений предельная матрица Ak не сходится к треугольной, а содержит диагональные блоки кратности р, однако показанный выше пример демонстрирует, что это не совсем так.
Критерий останова итерационного процесса взят нами аналогично представленному выше методу Якоби за исключением того, что вычисляется евклидова норма матрицы не только без главной диагонали, но и без верхнего треугольника.
В отличие от метода Якоби, собственные значения, вычисленные с помощью QR- алгоритма, упорядочены по величине от большего к меньшему.
Исходные коды
int FrancisKublanovskaya (double a[].int n.double eps,int *it) //
// Функция вычисления собственных значений действительной матрицы // с помощью QR-алгоритма без сдвига.
// Обозначения:
// а - действительная матрица, разрушается, на выходе
// на главной диагонали - собственные значения.
// п - порядок матрицы а,
// eps - малая величина для проверки значимости,
// *it - счетчик итераций.
// Возвращаемое значение:
// 0 при нормальном окончании расчета,
// -1 при недостатке памяти для рабочих массивов.
// -2 при ошибке в вычислениях.
//
{
double *q,*r; // Матрицы QR-разложения
////////////////////
// Для размерности 1
if (n == 1)
{
if (а[0] == 0) return -2;
el se
а[0] = 1.0 / а[0];
*it = 1;
return 0;
}
/////////////////////
// Начальное значение
18-2002
546
Глава 13 Линейная алгебра
*it = 0;
if (!(q = new double[n * n])) return -1:
if C!(r = new double[n * n])) {
delete [] q:
return -1;
}
{
////////////////
// QR-разложение
QRDecomposition (a.q.r.n.n):
///////////////////////////
// Перестановка и умножение
MatrixMultiplyMatrix (r.q.a.n.n.n):
(*it)++;
/////////////////////////////////////////// // Условие окончания итерационного процесса
} while (EuclidNormaTri (a,n) > eps):
delete [] q; delete [] r:
return 0: }
В [183, c. 340], [189, c. 204] представлены различные варианты QR-алгоритма, призванные повысить точность вычислений и улучшить их сходимость и скорость, хотя уже в рассмотренном выше простейшем варианте на некоторых задачах скорость работы алгоритма (по числу итераций) может значительно превосходить скорость работы метода Якоби (ради справедливости отметим, что метод Якоби одновременно дает и собственные вектора). Помимо введения сдвига, в качестве меры, значительно увеличивающей скорость алгоритма, предлагается искать собственные значения исходной матрицы, предварительно приведенной к форме Хессенберга (либо трехдиагональной, если исходная матрица является симметрической) Сказанное, однако, относится скорее не к представленной выше функции FrancisKublanovskaya, а к вызываемому из нее методу QRDecomposition. Поэтому для практического применения метода следовало бы запастись специальной версией последней функции, учитывающей свойства почти треугольной или трехдиагональной матрицы. Дальнейший резерв повышения быстродействия таится
Вычисление собственных значений и собственных векторов 547
в создании специальной версии функции перемножения матриц, учитывающей, что первый сомножитель представляет собой верхнюю треугольную матрицу. Лучше даже не составлять специальную функцию, а реализовать вычисление непосредственно в теле функции FrancisKublanovskaya. Указанные доработки достаточно тривиальны и могут быть легко сделаны при необходимости.
Собственные вектора после применения Q/^-алгоритма определяются с помощью обратного степенного метода, как это описано в [ 183, с. 341]. Мы этого здесь не делаем, а только указываем источник, так как (^-алгоритм вообще представлен нами только для сравнения с методом Якоби, для контроля правильности решения и для полноты картины. В представленных в данной книге методиках алгоритм нами не применяется.
Обобщенная проблема собственных значений
Обобщенная проблема собственных значений [101, с. 384], то есть определение нетривиальных решений уравнения
Аг = Л Вх,
где А — симметрическая матрица,
В — симметрическая положительно определенная матрица,
А — собственное значение,
х — собственный вектор, соответствующий Л ,
путем замены переменных, используя разложение по Холецкому, приводится к стандартной проблеме [ 189, с. 267]. Эту задачу решает показанная ниже функция.
Напомним, что положительная определенность матрицы В может быть до выполнения решения проверена функцией PlusDef.
Исходные коды
int Eigen (double а[],double b[],int n.double eps.int *it) //
// Функция решения обобщенной проблемы собственных значений // для системы специального вида.
// Обозначения:
// а - симметрическая действительная матрица, разрушается, на // выходе на главной диагонали - собственные значения.
// b - симметрическая действительная положительно
// определенная матрица, разрушается, на выходе -
548
Глава 13. Линейная алгебра
// нассив собственных векторов, соответствующих вычисленный // собственным значениям, расположенных по столбцам.
// п - порядок матриц а и Ь.
// eps - малая величина для проверки значимости.
// *it - счетчик итераций.
// Возвращаемое значение:
// 0 при нормальном окончании счета.
// -1 при недостатке памяти для рабочих массивов.
// -2 при ошибке в вычислениях.
//
{
int Code.Codel; II Вспомогательная переменная
double *l,*li; // Рабочие массивы
if ((1 = new double[n * nJ) == 0)
return -1;
////////////////////////////////////
// Разложение матрицы b no Холецкому
if ((Code = Choleski (b.l.n)) != 0)
{
delete [] 1;
return Code;
}
///////////////////////////////////////
// Сохранить копию 1 для восстановления
// собственных векторов
ArrayToArray (l.b.n * п);
//////////////////////////////
// Вычисление обратной матрицы
if ((li = new double[n * nJ) == 0)
{
delete [] 1;
return -1;
}
if ((Code = InverseMatrix (l.li.n)) != 0)
{
delete [] 1; delete [] li:
return Code;
}
/////////////////////////////////////////
// Приведение системы к стандартному виду
MatrixMultiplyMatrix (li.a.l.n.n.n);
MatrixMultipiyMatrixT (l.li.a.n.n.n);
delete [] 1;
/////////////////////////////////////
// Матрица системы для восстановления
Линейные алгебраические уравнения
549
// собственных векторов
MatrixT (b.li.n.n);
///////////////////////////////
// Решение стандартной проблемы
if ((Code = Jacobi (a.n.eps.&Codel.b)) != 0)
{
delete [] li;
return Code;
}
*it = Codel;
//////////////////////////////////////
// Восстановление собственных векторов
Code = Gauss (b.1i,n,n.eps):
delete [] li;
return Code;
}
Линейные алгебраические уравнения
Методы решения систем линейных алгебраических уравнений представлены здесь двумя функциями, отражающими два различных подхода к решению проблемы.
Метод исключения Гаусса
Первая из показанных функций реализует метод исключения Гаусса [212, с. 360]. Функция представляет собой несколько более общую процедуру по сравнению с обычной системой линейных уравнений [188, с. 188]. Так, система линейных алгебраических уравнений в матричной записи выглядит как
Ах = Ь,
где А — матрица системы,
х — вектор подлежащих определению неизвестных,
Ъ — столбец свободных членов.
Часто возникает необходимость (см., например, задачу вычисления обратной матрицы) решить так называемую матричную систему линейных уравнений [175, с. 82]:
550
Глава 13. Линейная алгебра
АХ = В,
когда гс и b обобщаются до матриц, Хи В соответственно. Фактически последняя формула включает в себя несколько систем линейных уравнений, объединенных общей матрицей системы уравнений А, но имеющих различные столбцы свободных членов, составляющие матрицу В. В этом случае эффективнее решать систему с помощью одной общей функции. Естественно, и обычные системы с помощью показанной ниже функции решаются превосходно. В последнем случае число столбцов матрицы В следует положить равным единице. Единице будет равно и число столбцов решения. Представление матриц X и В или, соответственно, векторов х и b единоообразно — они всегда являются одномерными массивами.
Обсуждение и пример применения метода исключения с выбором ведущего элемента см. также в [183, с. 13].
Исходные коды
int Gauss (double b[],double a[].int row,int column,double eps) //
// Функция решения матричной системы линейных алгебраических // уравнений методом Гаусса с выбором ведущего элемента.
// Обозначения:
// b - матрица или вектор свободных членов.
// разрушается, на выходе - соответственно
// матрица или вектор решения.
// а - матрица системы размерности row, разрушается.
// row - размерность системы - число строк матриц а и b и
// столбцов матрицы а,
// column - число столбцов матрицы Ь,
// eps - малая величина для проверки значимости.
// Возвращаемое значение:
// 0 при нормальном окончании счета,
// -2 при потере значимости.
//
{
int i,j.k, // Счетчики
js,ji.ij.
im,mi,mj.
is, / / Номер начала поиска ведущего элемента
ik. // Номер ведущей строки
in, // Номер строки ведущего элемента
jn; // Номер столбца ведущего элемента
double guide. // Абсолютная величина ведущего элемента
save: // Буфер
/ / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / // Прямая процедура - преобразование системы
Линейные алгебраические уравнения
551
for (к =0, ik = -row; к < row; к++)
{
Ik += row;
is = ik + к;
//////////////////////////
// Выбор ведущего элемента
for (1 = к. ij = is. in = к, jn - к. guide = a[isj;
i < row; i++)
for (j = k, im = ij++; j < row; j++)
{
if (fabs (a[imj) > fabs (guide))
{
guide = a[im];
i n = i;
jn = j:
}
im += row:
}
/////////////////////////
// Проверка на значимость
if (fabs (guide) < eps) return -2;
/////////////////////
// Перестановка строк
for (i = k. im = is. ij = ik + in; i < row; i++)
{
save = a[ij];
a[ij] = a[im]:
a[im] = save / guide;
ij += row;
im += row;
}
for (i =0. ij = in, im = k; i < column; i++)
{
save = b[ij];
b[ij] = b[im];
b[im] = save / guide;
ij += row;
im += row;
}
////////////////////////
// Перестановка столбцов
for (i =0, im = ik - 1, ij = row * jn - 1; i < row; i++) {
save = a[++ij];
a[ij] = a[++im];
a[im] = save;
}
552
Глава 13. Линейная алгебра
/ / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / //1 / / / //1 /
// Преобразование оставшейся части нассива
ji - к + 1;
for (i = ji. im = is. mi = is + row: i < row: i++) {
for (j = ji. mj = mi, ij = ++im + row, save = a[imj; j < row: j++)
{
a[ij] = a[ij] - a[mj] * save:
mj += row: ij += row:
}
for (j = 0. ij = i, mj = k; j < column; j++)
{
b[ij] = b[ij] - b[mj] * save:
ij += row: mj += row:
}
}
//////////////////////////////////////////////////////// // Сохранение номеров эленентов столбцов матрицы решения // в первом столбце матрицы системы if (к == 0)
for (i =0: i < row: i++)
a[i] = (double) i: // Начальный порядок номеров
save = a[jnj: // Фиксация порядка перестановки
a[jn] = a[k]:
a[k] = save:
}
/////////////////////////////////////////
// Обратная процедура - раскрытие системы
for (i = row - 1. im = row * row - 1: i > 0: i—)
for (js = 0. —im, in = i - 1, mi =0; js < column; js++) {
for (j = row - 1, ij = im. save =0; j >= i: j—) {
save += b[j + mi] * a[ij];
ij -= row;
}
ji = in + mi;
brji] = b[ji] - save;
mi += row;
}
/////////////////////////////////
// Восстановление порядка решения
for (i =0. j = 0; i < row; i++)
{
in = (int) (a[jj);
if (in == j)
Линейные алгебраические уравнения
553
J++: // Элемент вектора решения на своем месте
el se { for (js =0. ij = in, ji = j; js < column; js++) { save = b[i j]: b[ij] = b[jij: b[ji] = save: ij += row: ji += row;
}
save = a[in]: a[in] = a[j]: a[j] = save: }
}
return 0: }
Недостатком метода Гаусса является тот факт, что при решении происходит накопление ошибки, вследствие чего для больших систем метод почти не применяется. Другие неитерационные методы упомянуты в [135, с. 430].
Итерационные методы
Для решения больших систем могут применяться итерационные методы1. Разработано большое количество итерационных процедур как для систем общего вида, так и для различных специальных случаев. Запрограммированный нами и показанный ниже метод простой итерации является наиболее элементарным, но тем не менее достаточно мощным среди методов семейства.
До начала итерационной процедуры система преобразуется к виду, представленному в [101, с. 663], но ни в коем случае не к приведенному в [86, с. 67], чтобы диагональные коэффициенты матрицы системы были положительными и возможно большими. Для этого мы используем перестановки уравнений, что не отражается на порядке элементов в векторе решений. Если вы захотите модернизировать функцию так, чтобы можно было использовать еще и перестановки столбцов, порядок элементов в векторе решения изменится в соответствии с проведенными перестановками. Для восстановления исходного порядка потребуется только ввести некоторый информационный массив, заполненный номерами от 0 до (п - 1), где п — по-
’ Итерационные методы иногда применяются для уточнения решения, полученного методом Гаусса.
554
Глава 13. Линейная алгебра
рядок системы, в котором по ходу решения следует производить перестановки в соответствии с перестановками столбцов. После проведения решения с помощью этого массива путем обратной перестановки можно будет легко восстановить оригинальный порядок элементов. Этим простым, наглядным и эффективным способом мы пользуемся и в некоторых других алгоритмах.
Итак, начиная с произвольных (например, нулевых) значений неизвестных х, вычисляются последовательные приближения по формуле простой итерации
xi+‘=х1 - — f -ъ, |
an V k=\ J
где i = 1,2,..., n — номер уравнения, j — номер итерации.
Коэффициент перед скобками может быть выбран и иным [23, с. 335]. Часто от выбора коэффициента зависит, будет ли процесс сходиться вообще. В любом случае итерации заканчиваются при достижении максимально заданного числа итераций, что считается аварийным завершением процесса. Процесс может сходиться достаточно медленно, однако сходимость в принципе гарантирует только положительная определенность матрицы системы. Дополнительные способы релаксации и сверхрелаксации даны в [101, с. 664]. Нормальное окончание итерационного процесса будет при выполнении для каждого уравнения системы следующего условия:
|х/+1 -х/|<е,
где Е — наперед заданная ошибка вычисления истинного решения исходной системы уравнений, остальные обозначения те же, что и раньше.
Кроме релаксации ошибки вычисления, благодаря своей схеме вычислений, метод простой итерации допускает параллельное решение одной задачи на нескольких компьютерах [86, с. 66] или на реализованных в пределах одной многопроцессорной системы виртуальных машинах. Это весьма нетривиальная задача: с целью согласования вычислительных процессов требуется предпринимать специальные меры для обмена результатами итерации (нескольких итераций) между машинами.
Линейные алгебраические уравнения
555
Модификация приведенной выше формулы до
*/+‘ =Х‘~7г(-bi У aii I А=1 k=i J
где обозначения аналогичны предыдущей формуле, дает метод Зей-деля (Гаусса—Зейделя) [183, с. 345], реализация которого в рамках электронных таблиц приводится в [149, с. 375]. Функция, реализующая схему метода Зейделя, может быть путем незначительной модификации получена из показанной нами функции.
В [183, с. 344] представлен метод Якоби итерационного решения системы линейных алгебраических уравнений, не имеющий преимуществ по сравнению с методом простой итерации. В [там же, с. 346] описано обобщение метода Гаусса—Зейделя, известное как метод последовательной верхней релаксации, а также дано подробное обсуждение проблем построения и реализации итерационных схем решения систем линейных алгебраических уравнений.
Исходные коды и пример применения
#include <fstream.h>
#include <math.h>
#include "megastat.h"
void main (void)
{
int i. // Счетчик
n = 3. // Порядок системы
Maxlter = 100: // Максимальное число итераций
double а[] = { 1.-3, 1, // Матрица системы
8, 1, 5,
2, 5, 7}.
Ь[] = { 1. 2. 0}, // Столбец свободных членов х[] = { 0, 0, 0}: // Начальные значения
cout « "Return code = "
« Simpleiteration (a,b.x.n.O.000001,&MaxIter): cout « "\nMaximum of iteration = " « Maxlter « endl:
for (i = 0: i < n: i++) cout « x[i] « endl:
}
int Simplelteration (double a[].double b[],double x[],int n,double Eps.int *Max)
//
556
Глава 13. Линейная алгебра
// Функция решения системы линейных уравнений методом
// простой итерации.
// Обозначения:
// а - матрица системы, разрушается,
// элементы расположены по столбцам.
// b - вектор свободных членов, разрушается,
// х - на входе - начальные приближения решения,
// на выходе - вектор решения,
// л - размерность системы.
// Eps - малая величина для проверки значимости,
// *Мах - на входе - максимально допустимое число итераций,
// на выходе - реально затраченное число итераций.
// Возвращаемое значение:
// 0 при нормальном окончании счета,
// -1 при недостатке памяти для вычислений.
// -2 при достижении максимально допустимого числа итераций.
// -3 при равенстве нулю одного из диагональных элементов
// матрицы системы уравнений.
//
{
register int i.j: // Счетчики цикла
int Iter = 0. // Счетчик итераций
Code = 0, // Возвращаемое значение
End, // Индикатор окончания процесса
i 1, // Номер переставляемой строки
m; // Номер диагонального элемента
double *xl. // Рабочий массив
Maximum, // Рабочие переменные
Probe. Sign; // Знак диагонального элемента
/////////////////////////
// Преобразование системы
for (i = 0: i < n - 1: i++)
{
m = i * n + i:
i 1 = i;
Maximum = fabs (a[mj);
Sign = a[m] >= 0 ? 1 : -1;
///////////////////////////////////////////// // Поиск максимального диагонального элемента for (j = i + 1: j < n; j++)
{
Probe = fabs (a[++m]);
if (Maximum < Probe)
{
il = j:
Maximum = Probe;
Sign = a[m] >= 0 ? 1 : -1:
}
}
Линейные алгебраические уравнения
557
///////////////////////////////
// Нулевой диагональный элемент
if (Maximum == 0)
return -3:
/////////////////////////////////////
II Положительный диагональный элемент if (Sign == -1)
{
RowMultiplyNumber (a.n.n.il.Sign): b[il] *= Sign;
}
/////////////////////////
// Перестановка уравнений
if (i ! = il)
{
Rowinterchange (a.n.n.i,il);
Rowinterchange (b.n.l.i,il); }
}
if ((xl = new double(nj) == 0)
return -1;
do
{
////////////////////////
// Основной шаг решения
for (i =0; i < n; i++)
{
xl[i] = 0;
for (j = 0,m = i; j < n; j++. m += n) xl[i] += a[m] * x[j]:
xl[i] = x[i] - (xl[i] - b[i]) / a[i * n + i]; }
//////////////////////////////////////
// Проверка допустимого числа итераций if (++Iter > *Max)
{
Code = -2;
break:
}
////////////////////
// Контроль точности
for (i = O.End = 0; i < n; i++)
if (fabs (xl[i] - x[i]) > Eps) {
End = 1;
break:
}
558
Глава 13. Линейная алгебра
ArrayToArray (xl.x.n);
} while (End == 1):
delete [] xl;
*Max = Iter - 1:
return Code;
}
Решение неопределенных систем
Если в системе число линейно независимых уравнений меньше количества неизвестных, возникает неопределенная (недоопределенная) система линейных уравнений порядка тп [183, с. 68], [100, с. 689]
Ах - Ь,
в которой ранг п матрицы системы А меньше порядка системы [ 189, с. 130], [135, с. 403]. Существует бесчисленное множество решений рассматриваемой системы, однако из них можно выделить одно решение, наложив на систему некоторые дополнительные условия. Можно найти решение, обладающее минимальной евклидовой нормой
||6 - Лх||2 = min.
Размерность матрицы А суть пхтп, причем п < т, как уже было отмечено выше.
Сначала нужно так преобразовать запись системы, чтобы тп и п поменять местами, то есть создать предпосылки для поиска псевдооб-ратной к Ат матрицы. После элементарных выкладок с применением свойств псевдообратной матрицы (см. пояснения к функции PseudoInverseMatrix) получаем формулу для нахождения решения, обладающего минимальной нормой, в виде
гт=6т(Лт)+.
Разработанная нами функция очень компактна. Для решения задачи последовательно применяются функции MatrixT, PseudoInverseMatrix и MatrixTMultiplyMatrix.
По поводу решения переопределенных систем, когда число уравнений превышает число неизвестных [100, с. 689], см. раздел «Линейный множественный регрессионный анализ» главы 15.
Линейные алгебраические уравнения
559
Исходные коды и пример применения
#include <fstream.h>
^include <iomanip.h>
^include <math.h>
#include "megastat.h"
void main (void) {
Г- •O II II •«- С E c •r- // Счетчики // Число неизвестных
// Число уравнений
double a[] = { 2, 4, 1,-3, // Исходная матрица системы
1, 7. 3,-2, // размером m х п
2, 2, 0, 3.
7, 8, 3,-4,
2. 3. 1. 4}.
*t. // Копия исходного массива
b[] ={1.2, 3, 5, 0}; // Столбец свободных членов.
// последний элемент - фиктивный
t = new double[m * n];
ArrayToArray (a,t,m * n):
cout « "ORIGINAL DATAXn";
for (i = 0; i < m; i++)
{
cout « i «
for (j = 0, 1 = i; j < n; j++,l += m) cout << setw (4) « t[l];
cout « " b = " « setw (4) « b[i];
cout « endl;
}
cout « ’RETURN CODE = " « Solves (t.b.n.m) « endl
« "SOLUTION " « endl;
for (j = 0; j < n; j++)
cout « setw (10) « b[j]; cout « endl:
cout « "CHECK RESULTSXn";
for (i = 0; i < m; i++)
{
for (j = 0, t[i] = 0, 1 = t[i] += a[l] * b[j];
cout « t[i] « endl;
}
}
j < n; J++.1 += m)
560
Глава 13. Линейная алгебра
int Solves (double а[].double b[].int n.int m) //
// Функция решения неопределенной системы линейных уравнений. // Обозначения:
// а - исходная матрица системы размером m х п, разрушается. // b - столбец свободных членов длиной п, на выходе - решение // на входе используется только m <= п ячеек.
// п - порядок системы (число неизвестных).
// m - ранг матрицы системы <= п.
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -1 при недостатке памяти для вычислений.
// -2 при потере значимости или ошибке в вычислениях. //
{
int Code = 0: // Возвращаемое значение
double *t; // Рабочий массив
int i.j.1;
if ((t = new double[m * nJ) == 0) return -1;
MatrixT (a.t.m.n):
if ('(Code = PseudoInverseMatrix (t.a.n.m))) {
MatrixTMultiplyMatrix (b.a.t.l.m.n);
ArrayToArray (t.b.n);
} delete [] t:
return Code: }
Дальнейшие исследования и программные ресурсы
• Разработка программного обеспечения, реализующего более устойчивые, чем представленные налги, вычислительные схемы.
• Разработка версии программы разложения по сингулярным числам, основанной на (^-разложении. См. также [И].
В табл. 13.1 представлены наименования важнейших математических программных продуктов для распространенных платформ.
Дальнейшие исследования и программные ресурсы
561
Таблица 13.1. Интернет-ресурсы по математическим программным продуктам
Ресурс, адрес Разработчик или поставщик Содержание
www.mathsoft.com, www.softline.ru MathSoft, Inc. Mathcad, модульный математический пакет, доступна демонстрационная версия
store.wolfram.com, www.softline.ru Wolfram Research, Inc. Matematica, модульная* система для технических вычислений
www.mathworks.com The MathWorks, Inc. MATLAB, модульная” система для вычислений и визуализации
www.maplesoft.com, www.softline.ru Waterloo Maple Maple V, система компьютерной математики, доступна демонстрационная версия
* Поставляются компоненты Mathematics Application Library: Experimantal Data Analyst, Fuzzy Logic, Wavelet Explorer и другие [www.softline.ru].
* * Поставляются компоненты Matlab Toolboxes: C/C++ Math Library, Excel Link, Fuzzy Logic, NAG Foundation, Neural Network, Optimization, Partial Differential Equation, Statistics, Wavelet и другие. Кроме MathWorks, специализированные пакеты для MATLAB поставляет большое число независимых поставщиков [там же].
Специфические математические пакеты в виде надстроек (add-ins) для Microsoft Excel, которые могут оказаться полезными при конструировании алгоритмов анализа данных, поставляют Octavian Micro Development, Inc. (www.octavian.com/excel.html), MathTools Ltd. (www.mathtools/matrixl.html), Delisoft Ltd. (www.delisoft.fi), Ward Systems Group, Inc.
Глава 14. Методы теории множеств
Множеством называют любую совокупность объектов (предметов) [135, с. 382]. Составляющие множество объекты называют элементами множества, а тот факт, что объект х есть элемент множества А, записывают как [там же, с. 380]
хе А
Теория множеств изучает общие свойства множеств [там же]. Нами рассматриваются только те разделы теории множеств, которые оказались полезными при построении алгоритмов анализа данных, представленных в книге. Информация по теории множеств, приведенная в данной главе, составляет лишь небольшую часть теории.
Основные операции
Если каждый элемент множества А является в то же время элементом множества В, то множество/! называют подмножеством множества В и записывают это как [там же]
Л с В или Во А.
Если А — подмножество В, не равное всему В, А называют собственным подмножеством В [45, с. 6]. Пустое множество 0 не содержит ни одного элемента и является подмножеством любого множества. Рассмотрим основные операции, определенные для множеств.
Пересечение (логическое произведение) множеств — общее множество тех элементов, которые содержатся во всех данных множествах [там же, с. 454], [224, с. 289]. Для двух множеств это
С = А п В или С = А ♦ В
Объединение (логическая сумма) множеств — совокупность тех элементов, которые принадлежат хотя бы одному множеству совокупности [ 135, с. 427], [224, с. 288]. Для двух множеств это запишется как
Основные операции
563
С = АиВ или С = А + В.
Разность множеств А и В — множество С тех элементов множества А, которые не входят одновременно в множество В [ 135, с. 516], [224, с. 289]. Для двух множеств это запишется как
С = А \ В или С = А - В.
Если А — подмножество В, то есть A IB, то разность множеств А и В является пустым множеством.
Отметим, что в различных источниках, в том числе в цитированных нами, могут применяться и другие обозначения и определения основных операций с множествами. Рассмотренные в [224, с. 289] операции применяются во многих методах анализа данных и обычно реализованы непосредственно в функциях, производящих этот анализ. Построение универсальных функций, производящих данные вычисления, не составит труда и здесь не иллюстрируется. Примеры реализации некоторых из рассмотренных операций на языке программирования Perl даны в [104, с. 129]. Свойства операций над множествами обсуждаются в [100, с. 79].
Некоторые методы, в частности ранговые критерии, по своей схеме вычислений требуют более сложных манипуляций с исходными массивами данных, которые в данном случае могут рассматриваться как множества. Например, для вычеркивания равных элементов из обеих сравниваемых выборок мы построили показанную ниже функцию сравнения Compare. Фактически для двух исходных множеств Ct и С2 функция строит такие два множества В{ и В2, корректируя при этом размеры выборок за счет вычитания из данных множеств множества А (естественно, сначала определяя множество А), что
B, = C,\A,
В2=С2\А,
где А — подмножество, общее для множеств С\ и С2.
Показанная функция осуществляет операцию, часто применяемую при конструировании статистических алгоритмов, в частности рассмотренных в главе 2. Конечно, выполняемая операция, как и рассмотренные далее, могла быть сформулирована и без привлечения понятий теории множеств, но пример оказался удобным для иллюстрации.
564
Глава 14. Методы теории множеств
Исходные коды
void Compare (double х[],double y[].int nx.int ny.int *nxl.int *nyl) //
// Функция сравнения двух множеств.
// Обозначения:
// х - первое множество,
// у - второе множество,
// пх - число элементов первого множества,
// пу - число элементов второго множества.
// *пх1 - скорректированное число элементов первого множества,
// *nyl - скорректированное число элементов второго множества.
// Возвращаемое значение: // нет.
//
{
register int i.j.k; // Счетчики
/////////////////////////////////////////////////////////
// Сравнение множеств и вычеркивание одинаковых элементов
for (i = 0; i < nx: i++)
for (j = 0; j < ny: j++) if (x[i] == y[j])
{
nx—:
ny—;
for (k = i: k < nx: k++)
x[k] = x[k + 1]:
for (k = j; k < ny: k++)
y[k] = y[k + 1]: }
*nxl = nx;
*nyl = ny;
}
i Функции упорядочивания множеств
Рассмотренные функции предназначены для упорядочивания множества (сортировки) либо в порядке возрастания, либо в порядке убывания, в зависимости от требований расчетной схемы применяемого метода анализа. В статистике функции сортировки применяются для построения вариационного ряда — расположения последовательности случайных величин в неубывающем порядке. Функции сортировки различного назначения составляют целое семейство.
В качестве основного алгоритма сортировки во всех функциях нами применяется сортировка методом отбора [224, с. 26], называемого
Функции упорядочивания множеств
565
также методом линейной обменной сортировки [162, с. 86]. Несмотря на простоту, этот метод достаточно быстрый и вполне годится для задач малой и умеренной размерности, то есть в тех условиях, когда более изощренные методы сортировки не успевают показать свою эффективность подобно тому, как пешеход на несколько метров успевает обогнать автомобиль при одновременном старте по зеленому сигналу светофора, хотя и безнадежно проигрывает автомобилю в дальнейшем.
Более совершенные алгоритмы сортировки вместе с исходными кодами на языке программирования C++ даны в [162], на языке С, например алгоритм Хоора, см. в [94, с. 89], а числовая сортировка на языке Perl рассмотрена в [104, с. 137]. См. также [94, с. 117], [184, с. 25]. В [100, с. 19], [138], [151], [168] подробно рассматриваются различные как простые, так и изощренные, в том числе вероятностные алгоритмы сортировки, и приводятся примеры на псевдокоде, который может быть легко записан на каком-либо языке программирования. Решение на языке Fortran 77 представлено в [ 162, с. 87].
Исходные коды
void SortArrayUp (double x[].int n.int ix[].int k) //
// Функция сортировки массива вещественных чисел в порядке
// возрастания.
// Обозначения:
// х - сортируемый массив.
// п - его размер,
// ix - сохраненная информация об оригинальном массиве.
// к - переключатель вида работы:
// к=0 - не сохранять информацию о перестановках элементов.
// к=1 - сохранять.
// Возвращаемое значение:
// нет.
//
{
register int i;
int j.ia.ii;
double a:
////////////////////////////
// Инициализация, если нужно
if (к == 1)
for (i = 0: i < n; i++)
ix[i] = i;
/////////////////////////////////////////// // Сортировка массива в порядке возрастания
566
Глава 14. Методы теории множеств
for (i = 0; i < n; 1++)
{
1 а = i:
а = x[ia]:
for (j = 1 + 1; j < n; j++) if (a > x[j])
{
ia = j;
a = x[j];
}
a = x[i]:
x[i] = x[ia]: x[ia] = a;
///////////////////////////////////////////// // Сохранение исходной информации, если нужно if (к == 1)
{
ii = ix[i]:
ix[i] = ix[ia]: ix[ia] = ii:
}
}
}
void SortArrayUp (int x[],int n.int ix[].int k) //
// Функция сортировки массива целых чисел в порядке возрастания. // Обозначения:
// х - сортируемый массив.
// п - его размер.
// ix - сохраненная информация об оригинальном массиве.
// к - переключатель вида работы:
// к=0 - не сохранять информацию.
// к=1 - сохранять.
// Возвращаемое значение:
// нет.
//
{
register int i;
int a.j.ia.ii:
////////////////////////////
// Инициализация, если нужно
if (к == 1)
for (i = 0: i < n; i++)
ix[i] = 1:
/////////////////////////////////////////// // Сортировка массива в порядке возрастания for (i = 0: i < n; i++)
функции упорядочивания множеств
567
{
ia = i:
а = х[iа]:
for (j = 1 + 1: j < п: j++)
if (a > x[j])
{
ia = j:
a = x[j]:
}
a = x[i] ;
x[i] = x[ia]:
x[ia] = a;
///////////////////////////////////////////// // Сохранение исходной информации, если нужно if (k == 1)
{
i i = i x [ i ]:
ix[i] = ix[ia]:
i x [ 1 a ] = i 1:
}
}
}
void SortArrayDown (double x[],int n.int ix[],int k)
//
// Функция сортировки массива вещественных чисел в порядке // убывания.
// Обозначения:
// х - сортируемый массив.
// п - его размер,
// ix - сохраненная информация об оригинальном массиве.
// к - переключатель вида работы:
// к=0 - не сохранять информацию,
// к=1 - сохранять.
// Возвращаеное значение:
// нет.
//
{
register int i;
int j.ia.ii;
double a;
////////////////////////////
// Инициализация, если нужно
if (к == 1)
for (i = 0; i < n; i++) ix[i] = i;
//////////////////////////////////////// // Сортировка нассива в порядке убывания
568
Глава 14. Методы теории множеств
for (1=0; 1 < n; 1++)
{
ia = i:
а = х[1а];
for (j = 1 + 1; j < n; j++)
if (а <= х[j])
{
ia = j;
a = x[j];
}
a = x[i];
x[i] = x[ia];
x[ia] = a:
///////////////////////////////////////////// // Сохранение исходной информации, если нужно if (к == 1)
{
ii = ix[i];
ix[i] = 1x[ia];
ix[i a] = i i;
}
}
}
void SortArrayDown (int x[].int n.int ix[].int k)
//
// Функция сортировки массива целых чисел в порядке убывания. // Обозначения:
// х - сортируемый массив.
// п - его размер.
// 1х - сохраненная информация об оригинальном массиве.
// к - переключатель вида работы:
// к=0 - не сохранять информацию.
// к=1 - сохранять.
// Возвращаемое значение:
// нет.
//
{
register int i;
int a.j.ia.ii;
////////////////////////////
// Инициализация, если нужно
if (к == 1)
for (i = 0; i < n; 1++) ix[i] = i:
//////////////////////////////////////// // Сортировка массива в порядке убывания for (i = 0; 1 < п; i++)
функции упорядочивания множеств
569
{
1 а = i;
а = х[1 а];
for (j = i + 1; j < n; j++) if (a <= x[j])
{
ia = j:
a = x[j];
}
a = x[i]:
x[i] = x[ia]: x[ia] = a;
lllltllllllllllllllllllllllllllllllllllllllll // Сохранение исходной информации, если нужно if (k == 1)
{
ii = ix[i]:
ix[i] = ix[ia]: ixfia] = ii;
}
}
}
Следующая функция предназначена для сортировки двух массивов таким образом, чтобы первый массив был упорядоченным. Сопряженный массив при этом получает порядок в соответствии с первым массивом. Функция применяется, в частности, при вычислении ранговых коэффициентов корреляции [187, с. 300].
Исходные коды
void SortArrayCommon (double х[].double у[]. int n) //
// Функция совместной сортировки массивов чисел.
// Обозначения:
// х - сортируемый массив.
// у - сопряженный массив,
// п - размер каждого массива.
// Возвращаемое значение:
// нет.
//
{
register int i.j.ia; // Счетчики
double а; // Рабочая переменная
/////////////////////////////////// // Сортировка в порядке возрастания for (i = 0: i < n; i++)
{
ia = i;
a = x[ia];
570
Глава 14. Методы теории множеств
for (j = i + 1; j < n; j++) if (a >= x[j]) { ia = j: a = x[j];
}
a = x[i];
x[i] = x[iaj: x[ia] s a: a = y[i]: y[i] = y[ia]; y[ia] = a;
}
}
Важное значение в реализации ряда статистических методов имеет восстановление порядка элементов оригинального массива в таком виде, какой эти элементы имели до сортировки. Это очень просто сделать, если в функциях сортировки предусмотреть, чтобы исходный порядок вариант был сохранен в некотором информационном массиве. Показанная далее функция восстанавливает порядок оригинального массива на основании информации о перестановках, сохраненных функциями сортировки. Применение данной функции эффективно в некоторых алгоритмах проверки гипотез. Например, ее применение к построенному по исходным данным массиву рангов, а не к исходному массиву, позволяет очень просто и очевидно восстановить оригинальный порядок в массиве рангов.
Исходные коды
14
void UnSortArray (double х[].double y[],int n.int ix[J) //
// Функция восстановления порядка эленентов
// отсортированного массива чисел
// в соответствии с информацией об оригинальном массиве.
// Обозначения:
// х - отсортированный массив,
// у - восстановленный массив,
// п - численность каждой выборки,
// ix - массив порядковых номеров эленентов оригинального
// нассива.
// Возвращаеное значение:
// нет.
//
{
for (register int i = 0 : i < n: i++) y[ix[i]] = x[ij:
}
Функции определения экстремума
571
Функция перемены порядка элементов на обратный оказывается полезной в некоторых алгоритмах. В [94, с. 67] приводится несколько алгоритмов решения данной задачи, которые показывают, насколько разнообразными могут быть подходы к решению не слишком сложной задачи. Один из алгоритмов [94, с. 67] реализован в показанной ниже функции. Пример на языке программирования Perl дан в [104, с. 132], на Java — в [75, с. 20]. См. также [185, с. 75].
Исходные коды
void Reverse (double afj.int n)
//
// Функция перемены порядка элементов в массиве на обратный.
// Обозначения:
// а - преобразуемый нассив.
// п - численность выборки.
// Возвращаемое значение:
// нет.
//
{
register int i,j. // Счетчики
int n2 = n / 2: // Вспомогательная константа
double Temp; // Вспомогательная переменная
for (i = 0; i < n2: i++)
{
Temp = a[i]:
j = n - i + 1:
a[i] = a[jj:
a[j] = Temp:
}
}
Функции определения экстремума
Для вычисления минимальной и максимальной из двух величин применяют функции или макроопределения — это дело вкуса программиста. Показанные далее функции применяются нами в большом количестве алгоритмов. Решения на языке программирования JavaScript даны в [36, с. 158].
Исходные коды
double MinimumOf (double х, double у) //
// Функция вычисления минимума.
572
Глава 14. Методы теории множеств
// Обозначения:
// х и у - сравниваемые величины.
// Возвращаемое значение:
// минимальная величина из двух представленных.
//
{
if (х <= у) return х:
el se
return у;
}
double MaximumOf (double x. double y)
//
// Функция вычисления максимума.
// Обозначения:
// х и у - сравниваемые величины.
// Возвращаемое значение:
// максимальная величина из двух представленных.
//
{
if (х >= у)
return х:
el se return у;
}
int MinimumOf (int x. int y)
//
// Функция вычисления минимума.
// Обозначения:
// х и у - сравниваемые величины.
// Возвращаемое значение:
// минимальная величина из двух представленных.
//
{
if (х <= у)
return х:
el se return у:
}
int MaximumOf (int x. int y)
//
// Функция вычисления максимума.
// Обозначения:
// х и у - сравниваемые величины.
// Возвращаемое значение:
// максимальная величина из двух представленных //
{
if (х >- у)
Функции определения экстремума
573
return х: el se
return у;
}
Если речь идет о массиве, можно отсортировать массив, затем в качестве минимального взять первый элемент, а в качестве максимального — последний элемент массива. Однако при этом мы будем вынуждены разрушить оригинальную структуру массива либо работать с его копией. Все это сказывается на увеличении времени расчета или на занимаемой памяти. Функции показанного ниже семейства сохраняют исходную выборку и не требуют для своей работы дополнительной памяти [100, с. 130]. Оценка эффективности алгоритмов поиска минимума и максимума неупорядоченого массива дана в [там же, с. 181].
Исходные коды
double MaximumOf (double data[].1nt n) //
// Функция поиска максимального элемента массива..
// Обозначения:
// data - исходная выборка длиной п.
// Возвращаемое значение:
// величина максимального элемента массива.
//
{
register int i; // Счетчик
double RetValue = datafOJ: // Возвращаемое значение
for (i = 1; i < n; i++) if (datafi] > RetValue)
RetValue = datafi];
return RetValue;
}
double MaximumOf (double data[].int n.int *k) //
// Функция поиска минимального элемента массива.
// Обозначения:
// data - исходная выборка длиной п.
// к - номер максимального элемента.
// Возвращаемое значение:
// величина максимального элемента массива.
//
{
register int i; // Счетчик
double RetValue - datafOJ; // Возвращаемое значение
574
Глава 14. Методы теории множеств
*к = 0;
for (1=1: 1 < n; 1++)
if (data[i] > RetValue)
{ RetValue = data[i]; *k = i:
}
return RetValue; }
int MaximumOf (int data[],int n) //
// Функция вычисления максимальной величины элемента массива // Обозначения:
// data - исходная выборка длиной п.
// Возвращаемое значение:
// величина максимального элемента массива. // { register int i; // Счетчик
int Ret = data[0]: // Возвращаемое значение
for (i = 1: 1 < n; i++)
if (data[i] > Ret) Ret = data[i];
return Ret: }
double MinimumOf (double data[].1nt n) //
// Функция вычисления минимальной величины элемента массива. // Обозначения:
// data - исходная выборка длиной п.
// Возвращаемое значение:
// величина минимального элемента массива. // {
register int i: // Счетчик
double RetValue = data[0]: // Возвращаемое значение
for (i = 1; i < n: i++)
if (data[i] < RetValue) RetValue = data[i]:
return RetValue; }
Метрики
575
double MinimumOf (double data[].int n.int *k) //
// Функция вычисления иинииальной величины элемента массива.
// Обозначения:
// data - исходная выборка длиной п.
// к - номер минимального элемента.
// Возвращаемое значение:
// величина минимального элемента массива
//
{
register int i; // Счетчик
double RetValue = data[0]; // Возвращаемое значение
*k = 0:
for (i = 1; 1 < n; i++)
if (data[i] < RetValue) {
RetValue = data[i];
*k = i;
}
return RetValue;
}
int MinimumOf (int data[].int n)
//
// Функция вычисления минимальной величины элемента массива.
// Обозначения:
// data - исходная выборка длиной п.
// Возвращаемое значение:
// величина минимального элемента массива.
//
{
register int i; // Счетчик
int RetValue = data[0]; // Возвращаемое значение
for (i = 1; i < n; i++)
if (data[i] < RetValue) RetValue = data[i] ;
return RetValue;
}
Метрики
Мера сходства между элементами множеств (типа расстояния) называется метрикой, если она удовлетворяет определенным условиям:
576
Глава 14 Методы теории множеств
симметрии, неравенству треугольника, различимости нетождественных объектов и неразличимости тождественных объектов [135, с. 364].
Метрика Минковского
Наиболее общей мерой является метрика Минковского [148, с. 158]
Исходные коды
double Minkovski (double х[],double y[],int n,int r) //
// Функция вычисляет метрику Минковского.
// Обозначения:
// х - первая сравниваемая выборка.
// у - вторая сравниваемая выборка.
// п - численность каждой выборки.
// г - порядок метрики.
// Возвращаемое значение:
// значение метрики.
//
{
register int i: /7 Счетчик цикла
double s = 0; // Возвращаемое значение
for (i = 0: i < n: i++)
s += pow (fabs (x[i] - y[i]).r):
return pow (s, 1.0 / r);
}
Евклидова метрика
Если в метрике Минковского положить г = 2, мы получим стандартное евклидово расстояние (евклидову метрику) [76, с. 87]
Обсуждение евклидовой метрики и сопутствующих проблем см. также в [148, с. 157], [81, с. 66].
Метрики
577
Исходные коды
double Euclid (double х[].double y[].1nt n) //
// Функция вычисляет евклидово расстояние.
// Обозначения:
// х - первая сравниваемая выборка,
// у - вторая сравниваемая выборка.
// п - численность каждой выборки.
// Возвращаемое значение:
// значение метрики.
//
{
register int i;
double s = 0:
for (i = 0: i < n; i++)
s += (x[ij - y[i]) * (x[i] - y[i]):
return sqrt (s):
}
Манхеттенское расстояние
При г = 1 метрика Минковского дает манхеттенское расстояние (метрику города, city block, Manhattan distance) [76, с. 87]
ы
Обсуждение см. также в [100, с. 189], [148, с. 158].
Исходные коды
double CityBlock (double х[].double y[].int n) //
// Функция вычисляет манхеттенское расстояние.
// Обозначения:
// х - первая сравниваемая выборка.
// у - вторая сравниваемая выборка.
// п - численность каждой выборки.
// Возвращаемое значение:
// значение метрики.
//
{
register int i;
double s = 0:
for (i = 0: i < n; i++)
19-2002
578
Глава 14. Методы теории множеств
s += fabs (x[i] - y[i]):
return s: }
Метрика доминирования, супремум-норма
При г —> °° метрика Минковского дает метрику доминирования [76, с. 87]
d4 = -хл| k = 2> •••’ ”>
что совпадает с супремум-нормой (oo-нормой) [79, с. 17]
d =sup{|x -х |}, k = 1, 2,..., n.
ij ik jk
Исходные коды
double Sup (double x[],double y[],int n) //
// Функция вычисляет супремум-норму (метрику доминирования). // Обозначения:
// х - первая сравниваемая выборка.
// у - вторая сравниваемая выборка.
// п - численность каждой выборки.
// Возвращаемое значение:
// значение метрики.
//
{
register int i:
double s = O.buf;
for (i = 0; i < n; i++)
{
buf = fabs (x[i] - у[i]);
if (buf > s)
s = buf;
}
return s: }
Дальнейшие исследования
Составление программ, реализующих усовершенствованные алгоритмы быстрой сортировки.
Глава 15.
Аппроксимация зависимостей
По определению [135, с. 76] аппроксимацией называется замена одних математических объектов другими, в том или ином смысле близкими к исходным. Из определения видно, насколько широко понятие аппроксимации. В настоящей главе мы будем рассматривать аппроксимацию в более узком смысле. Разные разделы математики и статистики (регрессионный анализ, гармонический анализ, логистический анализ) объединены в этой главе по соображениям их вычислительной близости — вычисление (подбор) неизвестных параметров алгебраических уравнений. Толкование термина «аппроксимация» в данной главе будет применяться нами только в смысле «приближение» [135, с. 487], в том числе как приближение одних функций другими [там же], причем аналитическое выражение для аппроксимируемой функции может быть известно (примеры см. в главе 4) или неизвестно. При этом в первом случае целью построения аппроксимирующих функций является упрощение формулировки вычислительной задачи и сокращение времени счета.
Некоторые из рассмотренных ниже методов аппроксимации, такие как полиномиальная, логарифмическая, экспоненциальная и другие, включены в стандартную поставку пакета Microsoft Office и описаны в его справочной системе.
Математическое моделирование и регрессионный анализ
Регрессионным анализом называют раздел математической статистики, объединяющий практические методы исследования регрессионной зависимости между величинами по статистическим данным [135, с. 522], то есть зависимости среднего значения случайной величины от некоторой другой величины или от группы величин. В отличие от функциональной зависимости, при регрессионной связи одному и тому же значению независимой переменной могут со
19*
580
Глава 15. Аппроксимация зависимостей
ответствовать различные значения зависимой переменной в статистическом смысле.
Основное отличие функциональной зависимости от регрессии заключается в том, что поиск функциональной зависимости является методом математического моделирования и направлен на поиск причинной зависимости в отличие от методов корреляционного и регрессионного анализа, направленных на поиск зависимости стохастической [205, с. 23]. В качестве образного примера сказанного в источнике цитируется Б. Шоу: «Легко доказать, что ношение цилиндров и употребление зонтиков увеличивает грудную клетку, продлевает жизнь и дает известный иммунитет к болезням. Действительно, по статистическим данным оказывается, что богатые люди, пользующиеся этими предметами, выше, здоровее и живут дольше, чем те люди, которые никогда не помышляют о приобретении таких вещей. Не требуется большой проницательности, чтобы видеть, что эта разница в действительности создается не цилиндрами и зонтиками, а тем богатством и питанием, о которых они свидетельствуют, и что золотые часы или членство в клубе на Пэл-Мэл имеют такие же превосходные свойства».
«... Случайность существует объективно и не зависит от того, знаем ли мы причины явления или не знаем.»1 Статистика как метод исследования не интересуется причинами явления, а математической моделирование как раз пытается исследовать эти причины. Математическим моделированием называется [135, с. 343] приближенное описание какого-либо класса явлений внешнего мира2 (физического, экономического, социального и т. д.), выраженное с помощыд математической символики, а также процесс изучения явления с помощью математических моделей. Математическое моделирование включает в себя следующие этапы:
1. Формулировка законов, связывающих основные объекты модели, на основе изучения явлений и проникновения в их взаимосвязи. При этом уровень проникновения в глубину изучаемых явлений может быть различным. Данный этап — основной в определении того, является ли математическим моделированием
1 Розенталь М. М. Марксистский диалектический метод. — М.: Гос. изд-во полит, литературы, 1952.— С. 74.
2 Словосочетание «внешний мир» может вызвать возражения. По отношению к чему «внешний»? Видимо, по отношению к исследователю. Так как смоделирован может быть и внутренний мир исследователя, спорный термин без всякого ущерба может быть опущен.
Математическое моделирование и регрессионный анализ
581
последовательность некоторых совершаемых исследователем действий.
2. Составление уравнений модели, возможно, с точностью до некоторой совокупности неизвестных на этапе составления модели параметров и начальных условий. Исследование и математическое решение задачи, к которой приводит математическая модель (так называемое решение прямой задачи). Важным моментом является попытка сведения уравнений модели к задаче, решение которой известно, так как часто различные явления могут быть описаны уравнениями одинаковой структуры.
3. Сопоставление результатов расчета математической модели с данными изучаемого явления, полученными в результате наблюдения за этим явлением (то есть в результате физического эксперимента). При наличии в структуре модели параметров, неизвестных на этапе составления модели или вообще недоступных для прямого измерения, производится идентификация модели на основе экспериментальных данных (т. н. решение обратной задачи).
4. Исследование изучаемого явления с помощью математической модели. Уточнение модели на основе новых данных об изучаемом явлении.
Имеется и другое, более широкое понимание математического моделирования [57, с. 10], однако мы не будем пользоваться таким определением как неточным и не отражающим действительного положения вещей.
Из рассмотренных нами в данной книге разделов анализа данных к математическому моделированию можно отнести аппроксимацию зависимостей, и то только в том случае, если методы аппроксимации используются для идентификации (подбора коэффициентов) уже составленной математической модели. Математическое моделирование является очень перспективным инструментом исследования, широкое применение которого сдерживается только неумением большинства исследователей, в особенности по медикобиологической тематике, формулировать свои идеи на языке математики. Без сомнения, еще большее распространение методы математического моделирования получат в будущем, когда будут открыты основные физические законы, хотя затянувшийся кризис в физике и направленность усилий большинства ученых не на разгадку тайн природы, а на успех личной карьеры не позволяют надеяться, что это произойдет скоро.
15
582
Глава 15. Аппроксимация зависимостей
Подробно проанализировав сущность этапов математического моделирования, мы вынуждены констатировать, что все статистические методы, рассмотренные в настоящей книге в числе других методов анализа данных (включая факторный и дискриминантный анализ), математическим моделированием не являются, как этого ни хотелось бы некоторым исследователям — любителям терминологических игр, из-за отсутствия основного первого этапа.
Относительно того, являются ли математическим моделированием различные нейросетевые методы, вопрос остается открытым. Не исключено, что не являются из-за постулируемого в теории нейронных сетей, подобно математической статистике, отсутствия глубокого изучения внутренних взаимосвязей изучаемого явления. Здесь необходимо коснуться уровня детализации изучаемого явления. Так, при составлении уравнений автоколебаний опоры шасси при посадке самолета (явление шимми) упругость последнего может быть учтена в математической модели путем введения некоторой достаточно несложной системы балок с грузиками на пружинках. Такая простая схема упругого летательного аппарата, естественно, совершенно неприемлема при исследовании аэродинамического нагружения конструкции летательного аппарата — там применяется тоже несложная, но совершенно иная модель. Совсем другая по уровню сложности модель применяется при анализе прочности конструкции летательного аппарата. Если нейронная сеть моделирует некоторый физический объект, не являющийся биологической нейронной сетью, то такая модель, видимо, не может называться математической. Однако если искусственная (программная пли аппаратная) нейронная сеть моделирует биологическую нейронную сеть с той или иной степенью детализации, отнесение такой модели к классу математических моделей сомнения не вызывает.
Регрессионный анализ, в отличие от методов математического моделирования, не занимается исследованием внутренних взаимосвязей изучаемого явления. Для него материалом исследования являются числовые материалы, полученные в опыте, существенные для описания внешних проявлений наблюдаемого явления. Следовательно, коэффициенты регрессии, построенной по результатам обработки, могут не быть (хотя могут и быть) содержательно интерпретированы — важно только внешнее сходство изменения наблюдаемых параметров реального явления и параметров регрессионного уравнения. Дополнительно по результатам анализа могут быть вычислены доверительные интервалы коэффициентов регрессии, что обычно не делается в функциональной (математической) модели.
Общая методика
583
Таким образом, регрессионный анализ является методом математической статистики, а поиск функциональной зависимости — методом математического моделирования. Рассмотренные в настоящей главе методы аппроксимации являются инструментами и регрессионного анализа, и математического моделирования в смысле поиска функциональной зависимости, если вид аппроксимирующей функции не установлен из теоретических соображений (не исключен, впрочем, случай, когда построенная аппроксимирующая кривая подтолкнет исследователя к пониманию внутренних взаимосвязей изучаемого явления).
При рассмотрении регрессии величины у относительно одной или большего количества величин х первую обычно называют зависимой переменной, а вторые — независимыми [91, с. 461]. Авторы упомянутой публикации считают эту терминологию неудачной, так как величины х не являются независимыми в вероятностном смысле. По крайней мере в настоящей главе величины х не считаются даже случайными, и изложенное непосредственно к регрессионному анализу отнести нельзя. Мы не рассматриваем распределения и другие статистические характеристики оценок, в том числе не вычисляем их доверительных интервалов, хотя по технике вычислений результаты исследований могут быть применены в ряде методик регрессионного анализа. Правильнее назвать изложенное аппроксимацией зависимостей [149, с. 270], имея в виду установление функциональных зависимостей, структура которых известна или предполагается известной из предварительных теоретических исследований. В конце концов, структура функциональной зависимости может просто подбираться исследователем методом простого перебора до получения наилучшего варианта. При этом, однако, для того чтобы построенное уравнение могло считаться функциональной (математической) моделью, исследователю придется содержательно интерпретировать коэффициенты и взаимосвязи модели. Введенные в настоящем разделе методы мы применяем также в методах распознавания образов, в частности при оптимизации (обучении) нейронной сети.
Общая методика
«Теоретическая кривая никогда не проходит в точности через все точки, полученные в результате измерений» [204, с. 282]. Методы аппроксимации обычно основаны на двух подходах: минимизация суммы квадратов отклонений либо минимизация суммы модулей
584
Глава 15. Аппроксимация зависимостей
отклонений [128, с. 329]. В последнем случае неизбежны определенные трудности, подробно проанализированные в [165]. Практические решения, основанные на минимаксном критерии и иллюстрируемые кодами на алгоритмическом языке Бейсик, даны в [146, с. 98]. Мы применяем методы аппроксимации, основанные на минимизации квадратичного функционала, поэтому сначала кратко рассмотрим теоретические основы построения зависимости с использованием метода наименьших квадратов [212, с. 232].
Пусть F(a) — функционал, записанный в виде
Л 2
Ла) = Х(г>(«'О-’г,)’
i=l
где Zj(a, t) — значение, рассчитанное по формуле
z = ^zk(a,t) при t = t„ i = 1, 2,..., М ы
где а — вектор параметров, подлежащих определению, г — число параметров,
т — число функций, введенное для общности,
N — число пар экспериментальных значений, t — независимая переменная, называемая также аргументом функции либо просто аргументом (ось на графике, соответствующая аргументу, называется абсциссой, в противоположность ей ось, соответствующая функции, называется ординатой),
Л, — экспериментальное значение, соответствующее значению абсциссы tif 1=1,2,..., N.
Минимизация функционала F(a)
F(a) —> min
приводит к системе г алгебраических уравнений:
^> = 0.7= 1,2....г,
<4
где в левой части уравнения находятся частные производные функционала F(a) по параметрам а.
Полиномиальная аппроксимация
585
Решив полученную линейную или нелинейную систему алгебраических уравнений, мы получим искомый r-мерный вектор параметров а. Линейная система может быть решена одним из стандартных методов, например методом Гаусса с выбором ведущего элемента. Некоторые простые нелинейные системы путем замены переменных также удается решить сравнительно просто [149, с. 288].
Отметим одну особенность, на которую часто не обращают внимания исследователи. Нужно точно указывать границы (интервалы изменения аргумента) применимости полученной формулы. Так, некоторые авторы ради упрощения постановки задачи пользуются полиномиальной моделью. Например, предлагается формула, полученная интерполированием полиномом временной зависимости числа посещений поликлиники, без указания интервалов аргумента, в которых действительна эта модель. При экстраполировании [135, с. 643] полученной зависимости даже на небольшой промежуток времени получаются совершенно странные числа типа «минус 10 обращений в поликлинику». При этом полученная формула предлагается для прогнозирования заболеваемости, а это при серьезном отношении к данному исследованию может нанести большой социальный и экономический ущерб. Помимо ошибки представления данных (не указаны интервалы экстраполирования), в данном случае, очевидно, неверно выбрана и математическая модель.
Полиномиальная аппроксимация
Полином
Пусть модель представлена в виде полинома:
м
z(t)=£a/.
7-0
где М — степень полинома, нумерация от 0 здесь более удобна, что дает возможность одинаково обозначить номер коэффициента и показатель степени аргумента:
М - 0 соответствует прямой, параллельной оси абсцисс, при этом ордината не зависит от абсциссы,
А/ = 1 соответствует прямой, не параллельной оси абсцисс,
М = 2 определяет параболу и т. д.,
586
Глава 15. Аппроксимация зависимостей
а — коэффициенты полинома, при введенной нумерации нулевой коэффициент находится при нулевой степени аргумента, первый коэффициент — при первой степени аргумента и т. д.
Вычислив частные производные функционала F(a) по параметрам а, получаем систему (М + 1) линейных алгебраических уравнений относительно параметров а [146, с. 58]:
М N N
Z(a,X^‘) = £^‘^ = °’1’2.....М-
j=0 i=l 1=1
Пример практического использования полиномиальной модели рассмотрен в [78, с. 45]. Иначе полиномиальная модель называется степенной регрессией в [149, с. 283]. Частный случай с примером на алгоритмическом языке Бейсик рассмотрен в [184, с. 175]. См. также [88, с. 68].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void)
{ register int i.j:
int Low = 0,
Degree = 3, n, Code:
// Счетчики
// Минимальная степень полинома
// Степень полинома
// Число пар значений
// Код ошибки
double arg[] = {5.15.30.45.50}.//
data[] = {37.34,33.29.20}.//
*coeff. //
buf. //
err = 0: //
Массив абсцисс
Массив ординат
Массив коэффициентов
Рабочая переменная
Ошибка
n = sizeof (data) / sizeof (data[0]):
coeff = new double [Degree - Low + 1]:
if (’(Code = Polynomial (data.arg.Low,Degree,n,coeff)))
{
cout « "y =":
for (j = 0: j <= Degree - Low: j++)
cout «“+("« coeff[j] « ”) * x ** " « (j + Low);
Полиномиальная аппроксимация
587
cout « endl « "Аргумент, опыт, расчетХп";
for (J = 0: j < n; j++)
{
for (1 = 0, buf = 0: i <= Degree - Low; 1++) buf += coeff[i] * pow (arg[j],i + Low);
cout « arg[J] « ",\t" « data[j] « ",\t" « buf « endl; err += (data[j] - buf) * (data[j] - buf);
}
cout « "Квадратичный функционал = " « err « endl;
}
else if (Code == -1)
cout « "Мало панятиХп";
el se
cout « "Ошибка при построении полинонаХп";
delete [] coeff:
}
int Polynomial (double y[],double x[],int u.int m.int n,double c[]) 11
II Функция построения полиномиальной модели.
// Обозначения:
// у - массив функции длиной п,
// х - массив аргумента длиной п,
// и - степень минимального члена,
// m - степень полинома,
// с - вычисленный вектор коэффициентов длиной m - u + 1.
// Возвращаемое значение:
// 0 при нормальном окончании счета.
// -1 при недостатке памяти,
// -2 при потере значимости.
// Примечание: m <= п.
//
{
register int i.j.k.l; // Счетчики
int Code = 0. // Код ошибки
mu = m - u + 1; // Вспомогательная величина
double *z, // Массив левых частей
*b; // Массив правых частей
if ((z = new double[mu * mu]) == 0) return -1:
if ((b = new double[mu]) == 0)
{ delete [] z; return -1;
}
//////////////////////////////////////////////////////
// Присвоение нулевых значений накапливаемым элементам
588
Глава 15. Аппроксимация зависимостей
FillUp (z,mu * mu,0):
FillUp (b,mu,0);
////////////////////////////////////////
// Построение системы линейных уравнений
for (k = u; k <= m; k++)
{
for (i = 0; i < n: i++)
{
for (j = u. 1 = k - u; j <= m; j++) {
z[1] += pow (x[i], j + k);
1 += m - u + 1; }
b[k - u] += y[i] * pow (x[i],k);
}
}
/////////////////////////////////////
// Решение системы линейных уравнений
if (’(Code = Gauss (b.z,mu.1,0.000001)))
ArrayToArray (b.c.mu);
delete [] z: delete [] b:
return Code:
}
Обращенный полином
Далее представлена функция вычисления параметров обращенной полиномиальной модели
г(о=-лД-’
У=0
где все обозначения те же, что и в предыдущем случае.
Обращенная парабола рассмотрена в [84, с. 203].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void)
Полиномиальная аппроксимация
589
{
register int i.j;
int Low = 0. Degree = 1, n = 5. Code: // Минимальная степень // Степень полинома // Число пар значений // Код ошибки
double data[] = {-3,10.4.5.1}, // Массив ординат
arg[] = {3,-2.1.4,-1}, // Массив абсцисс
coeff[2]. // Массив коэффициентов
buf. // Рабочая переменная
err; // Ошибка
if (’(Code = InversePolynomial (data,arg,Low,Degree.n.coeff))) {
cout « "y = x / (";
for (j = 0; j <= Degree - Low; j++)
cout « " + (" « coeff[j] « ”) * x ** " « (j + Low); cout « ")\n” « "Аргумент, опыт, расчет\п”; for (j = 0. err =0; j < n; j++)
{
for (i = 0, buf = 0; i <= Degree - Low; i++) buf += coeff[i] * pow (arg[j],i + Low);
buf = arg[j] / buf;
cout « arg[j] « ",\t" « data[j] « ",\t" « buf « endl; err += (datafj] - buf) * (data[j] - buf);
} cout « "Ошибка “ « err « endl;
}
else if (Code == -1)
cout « "Мало памятиХп";
el se
cout « "Ошибка при построении полиномаХп"; }
int Inversepolynomial (double y[],double x[],int u.int m.int n,double c[]) //
// Функция построения обращенной полиномиальной модели.
// Обозначения:
// у - массив функции длиной п.
// х - массив аргумента длиной п,
// и - степень минимального члена,
// m - степень полинома.
// с - вычисленный вектор коэффициентов длиной m - u + 1.
// Возвращаемое значение:
// 0 при нормальном окончании счета.
// -1 при недостатке памяти.
// -2 при ошибке в вычислениях.
// Примечание: m <= п.
//
590
Глава 15. Аппроксимация зависимостей
{
register int i.j.k.l: // Счетчики
int Code = 0, // Код ошибки
mu = m - u + 1: // Вспомогательная величина
double *уу, // Копия массива функции
*z, // Массив левых частей
*Ь: // Массив правых частей
if ((уу = new double[n]) == 0) return -1;
///////////////////////////////////////////////////// // Преобразование массива функции к стандартному виду for (i = 0; i < n: i++)
if Cy[i] != 0)
yy[i] = x[i] / y[i]:
el se
{
delete [] yy:
return -2:
}
if ((z = new double[mu * mu]) == 0) {
delete [] yy:
return -1;
}
if ((b = new double[mu]) == 0)
{
delete [] yy: delete [] z:
return -1:
}
////////////////////////////////////////////////////// // Присвоение нулевых значений накапливаемым элементам FillUp (z.mu * mu.O):
FillUp (b.mu.O):
//////////////////////////////////////// // Построение системы линейных уравнений for (k = u; k <= m: k++)
{
for (i = 0: i < n: i++)
{
for (j=u, l=k-u:j<=m; j++) {
z[l] += pow (x[i],j + k):
1 += m - u + 1:
}
Полиномиальная аппроксимация
591
b[k - u] += yy[i] * pow (x[i],k): }
}
/////////////////////////////////////
// Решение системы линейных уравнений
if (!(Code = Gauss (b.z.mu.1,0.000001))) ArrayToArray (b.c.mu);
delete [] yy: delete [] z; delete [] b:
return Code;
}
Рассмотренные полиномиальная и обращенная полиномиальная модели применяются довольно часто. Однако представленные нами функции, в отличие от включенных во многие стандартные пакеты анализа данных, дополнительно обладают двумя полезными особенностями:
1. Они не ограничены по максимальной степени полинома. Трудности, возникающие при использовании полиномов высокого порядка, проанализированы в [146, с. 60].
2. Имеется возможность задавать интервал степеней членов полинома путем ввода величины минимальной степени, начиная от нуля, и степени полинома, например с 3 по 7 — при этом степени от 0 до 2 будут проигнорированы. Эта возможность дает большую гибкость при решении задачи. Нужно обратить внимание, что в самих функциях не проверяется условие, что степень полинома должна превышать минимальную степень. Во избежание проблем это должен сделать программист до вызова функций.
Существует много форм представления полиномов, аппроксимирующих данную экспериментальную зависимость. В узком смысле задача восстановления функции по ее известным значениям в заданных точках называется задачей интерполирования [135, с. 240]. Поясним только, что приведенные там функции определяют численные значения полиномов, но не позволяют получить значения коэффициентов полиномов, необходимые для представления интерполяционных полиномов в общем виде (в виде формул). Для решения данной задачи можно использовать методы, описанные нами в настоящем разделе.
Интерполяционный полином Лагранжа
Интерполяционный полином Лагранжа в общем виде записывается как [146, с. И]
592
Глава 15. Аппроксимация зависимостей
П<х-х*> N k=\ ---------------
i=l
**/
где АГ — число точек.
Ввведенный таким образом полином совпадает с функцией в Латочках, однако в промежуточных точках это не так, причем повышение степени полинома не всегда улучшает точность аппроксимации [146, с. 13].
Показанная ниже функция вычисляет значение полинома в заданной точке, однако не позволяет получить коэффициенты полинома для его представления в общем виде (в виде формулы).
Интерполяционная формула Лагранжа рассмотрена также в [135, с. 305], [101, с. 589]. Интерполяционная формула Ньютона описана в [146, с. 29], [135, с. 420], [101, с. 590].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include "megastat.h"
void main (void) {
double x[] = {5,15.30}, // Массив абсцисс
y[] = {37.5.34.2,33}, // Массив ординат
t; // Абсцисса
for (t = 0; t <= 30: t += 5)
cout « "t = " « t « " p = " « Lagrange (t,x,y,3) « endl: }
double Lagrange (double t,double x[],double y[],int n) //
// Функция интерполяции с помощью полинома Лагранжа.
// Обозначения:
// t - абсцисса,
// х - массив абсцисс.
// у - массив ординат,
// п - размер каждого массива = (степень полинома - 1).
// Возвращаемое значение:
// значение интерполяционного полинома в точке t. //
Экспоненциально-степенная аппроксимация
593
{
register int j,k; // Счетчики
double Ret = 0. // Возвращаемое значение
sl.s2: // Вспомогательные переменные
for (j = 0; j < n; j++)
{
for (k = O.sl = l,s2 = 1: k < n: k++) if (j != k)
{
si *= t - x[kj:
s2 *= x[j] - x[kj:
}
Ret += y[j] * si / s2;
}
return Ret;
}
Экспоненциально-степенная аппроксимация
Для рассмотренных в настоящем разделе экспоненциально-степенных типов аппроксимирующей зависимости решение путем логарифмирования может быть сведено к решению одного уравнения или системы линейных алгебраических уравнений.
Экспоненциальная и показательная функции
Аппроксимируются экспериментальные данные теоретической зависимостью [179, с. 36]
У = ш?,
называемой экспонециальной функцией.
Зависимость вида
у=<?
вообще называется показательной функцией [46, с. 390]. Легко видеть, что используемый нами вид функции является частным случаем последней, умноженной на масштабный коэффициент.
594
Глава 15. Аппроксимация зависимостей
Исходные коды
int Exponent!alFunction (double y[],double x[],int n,double *a) //
// Функция аппроксимации эмпирической зависимости
// экспоненциальной функцией.
// Обозначения:
// у - значения эмпирической функции.
// х - значения аргумента.
// п - число пар значений функция-аргумент.
// а - коэффициент функции у = а * ехр (х).
// Возвращаемое значение:
// 0 при нормальном окончании расчета,
// -2 при ошибке в вычислениях.
//
{
register int i: // Счетчик цикла
for (i = 0. *а =» 0: i < n; i++)
if (y[il <= 0)
return -2;
el se
*a += log (y[ij):
a * exp ((a - VectorSum (x.n)) / n);
return 0:
}
В [37, c. 362] и в справочной системе Microsoft Office экспоненциальной названа зависимость вида
у = сеЬх,
для которой задача определения неизвестных параметров сводится к системе двух нелинейных уравнений либо путем логарифмирования к двум линейным уравнениям. Легко заметить, что от предыдущей зависимости данная зависимость отличается только масштабом, поэтому путем замены переменной задача может быть просто сведена к предыдущей. В [84, с. 223] эта же зависимость называется показательной функцией. Задача решается показанной ниже функцией.
Исходные коды
int ExponentFunction (double у[].double x[],int n,double
*a.double *b)
//
// Функция аппроксимации эмпирической зависимости показательной // функцией.
// Обозначения:
// у - значения эмпирической функции.
Экспоненциально-степенная аппроксимация
595
// х - значения аргумента,
// п - число пар значений функция-аргумент,
// а.Ь - коэффициенты функции у = а * ехр (Ь * х).
// Возвращаемое значение:
// 0 при нормальном окончании расчета,
// -2 при ошибке в вычислениях.
//
{
register int i; // Счетчик цикла
double m.ml,sl,s2:
for (i =0, ml = 0; i < n: i++)
if <y[i] <= 0) return -2;
el se
ml += log (y[1J):
ml /= n;
if ((m = VectorSum (x.n)) == 0) return -2;
for (i = 0, si = 0; i < n: i++)
si += x[i] * log (y[ij):
si /= m:
si -= ml:
for (i = 0, s2 = 0: i < n; i++)
s2 += x[i] * x[i]:
s2 /= m:
m /= n;
s2 -= m:
if (s2 == 0)
return -2:
si /= s2:
*b = si:
*a = exp (ml - si * m):
return 0:
}
Степенная функция
Аппроксимируются экспериментальные данные теоретической зависимостью [84, с. 218], [187, с. 417]
у = ахь,
596 Глава 15. Аппроксимация зависимостей
называемой степенной функцией. В зависимости от значений показателя степени b виды степенных функций могут быть весьма разнообразны [46, с. 387].
Исходные коды
int PowerFunction (double у[],double x[],int n.double *a.double *b) //
// Функция аппроксимации эмпирической зависимости степенной // функцией.
// Обозначения:
// у - значения эмпирической функции.
// х - значения аргумента,
// п - число пар значений функция-аргумент,
// а.Ь - коэффициенты функции у = а * х ** Ь.
// Возвращаемое значение:
// 0 при нормальном окончании расчета,
// -2 при ошибке в вычислениях.
//
{
register int i; // Счетчик цикла
double t[4], // Матрица системы уравнений
г[2]; // Вектор свободных членов
t[0] = п:
for (i = 0,t[l] = 0,t[3] = 0: i < n; i++)
if (x[i] <= 0)
return -2;
el se
{
t[l] += log (x[i]);
t[3] += log (x[ij) * log (x[ij);
}
t[2] = t[l] ;
for (i = 0,r[0] = 0,r[l] =0: i < n; i++)
if (y[i] <= 0)
return -2;
el se
{
r[0] += log (y[i]);
r[l] += log (x[i]) * log (y[ij):
}
if (Gauss (r.t,2.1.0.000001) != 0)
return -2:
a = exp (r[0]):
Экспоненциально-степенная аппроксимация
597
*Ь = г[1]:
return 0:
}
Гипербола
Аппроксимируются экспериментальные данные теоретической зависимостью [179, с. 35]
у = а / х + Ь,
называемой гиперболой.
Гипербола может считаться частным случаем степенной функции [46, с. 387].
Исходные коды
int HyperFunction (double у[].double х[],int n,double *a.double *b)
II
// Функция аппроксимации эмпирической зависимости гиперболой.
// Обозначения:
// у - значения эмпирической функции.
// х — значения аргумента.
// п - число пар значений функция-аргумент.
// а.Ь - коэффициенты функции у = а / х + Ь.
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -2 при ошибке в вычислениях.
//
{
register int i; // Счетчик цикла
double t[4]. // Матрица системы уравнений
г[2]; // Вектор свободных членов
for (i = 0.t[0] = O.t[l] = 0.r[0] = O.r[l] = 0: i < n: i++) if (x[i] == 0)
return -2;
el se
{
t[0] += 1 / x[i];
t[l] += 1 / x[i] I x[i];
r[0] += y[i];
r[l] += y[i] / x[i];
}
t[2] = n;
t[3] = t[0];
if (Gauss (r.t.2.1.0.000001) != 0)
598
Глава 15. Аппроксимация зависимостей
return -2;
*а = г[0] ;
*Ь = г[1]:
return 0:
}
Экспоненциально-степенная функция
Аппроксимируются экспериментальные данные теоретической зависимостью [179, с. 71]
у =
называемой экспонециально-степенной функцией.
Исходные коды
int ExpPowerFunction (double у[],double x[],int n.double
*a.double *b)
11
II Функция аппроксимации эмпирической зависимости
// экспонециально-степенной функцией.
// Обозначения:
// у - значения эмпирической функции.
// х - значения аргумента,
// п - число пар значений функция-аргумент.
// а.Ь - коэффициенты функции у = exp (а * х) * х ** b
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -2 при ошибке в вычислениях.
//
{
register int i; // Счетчик цикла
double t[4]. // Матрица системы уравнений
г[2]. // Вектор свободных членов
bx.by;
for (i = 0,t[0] = 0.t[l] = 0,t[3] = 0,r[0] = 0.r[l] = 0: i < n; i++)
{
if (x[i] < 0 || y[i] < 0) return -2:
bx = log (x[i]); by = log (y[i]):
r[0] += x[i] * by;
r[l] += bx * by;
Логарифмическая функция
599
t[0] += x[i] * x[i];
t[l] += x[i] * bx;
t[3] += bx * bx;
}
t[2] = t[l]:
if (Gauss (r.t.2.1,0.000001) ’= 0)
return -2;
*a = r[0];
*b = r[l];
return 0;
}
Логарифмическая функция
Аппроксимируются экспериментальные данные теоретической зависимостью вида
у = a +bx + d 1п(х),
называемой логарифмической функцией [84, с. 240]. В [187, с. 357] логарифмической называется зависимость
в справочной системе Microsoft Office логарифмической называется зависимость
у = b + с 1п(х),
хотя правильнее было бы следовать классическому определению логарифмической функции [46, с. 390]
У = l°go(x),
где а — постоянное положительное число — основание логарифма, что отличается от предпоследней функции сдвигом, масштабом и основанием логарифма, которое может быть легко изменено по известной формуле преобразования логарифмов.
Нами используется более общая формула, по сути, не совсем точно названная логарифмической функцией. Вид зависимости при этом обусловлен требованиями практики.
600
Глава 15. Аппроксимация зависимостей
Исходные коды
int LogarithmFunction (double у[].double x[],int n,double *a,double *b,double *d) 11
II Функция аппроксимации эмпирической зависимости
// логарифмической функцией.
// Обозначения:
// у - значения эмпирической функции,
// х - значения аргумента.
// п - число пар значений функция-аргумент,
// a.b.d - коэффициенты функции y=a+b*x+d*ln (х)
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -2 при ошибке в вычислениях.
//
{
register int i; // Счетчик цикла
double t[9]. // Матрица системы уравнений
г[3], // Вектор свободных членов
buf: // Вспомогательная переменная
t[0] = 1:
for (i = 0,t[l] = 0,t[2] = 0,t[4] = 0.t[5] = 0,t[8] = О, r[0] = 0.r[l] = 0,r[2] = 0: i < n: i++)
if Cx[i] <= 0)
return -2;
el se { buf = log (x[i]): t[l] += x[i]:
t[2] += buf:
t[4] += x[i] * x[i];
t[5] += x[i] * buf:
t[8] += buf * buf;
r[0] += y[i]:
r[l] += x[i] * y[il:
r[2] += y[i] * buf:
}
t[3] = t[l]:
t[6] = t[2]:
t[7] = t[5J;
if (Gauss (r.t,3,1,0.000001) != 0)
return -2;
*a = r[0]:
*b = r[l]: *d = r[2J:
return 0;
Гармонический анализ: тригонометрический многочлен Фурье 601
Гармонический анализ: тригонометрический многочлен Фурье
Процесс аппроксимации опытной зависимости тригономерическим многочленом называется гармоническим анализом. Вид зависимости дан в [135, с. 619]. В зависимость входят определенные интегралы. Если вычислить интегралы по формуле трапеций, практические расчеты можно будет вести по приближенным формулам Бесселя [146, с. 88, 86]:
> ч “2л кос г-у . 2jtkx
У, (х) = aQ + Yak cos—- + £bk sin —-,
Ы 1 k=l 1
n k=0
z>0=o,
2Л 2л km
4, = ~ 2Л cos----, m = 1,2 r,
п Ы) n
. 2^ . 2nkm
Ь,=-2&sin--------’m=!'2- 'r-
n k=0 n
rneyk, k=Q, 1,..., n, — ординаты опытной зависимости в точках х = —, k п
Т— период наблюдения опытной зависимости,
п — количество равных частей, на которые разделен период,
г — количество гармоник, г<п /2.
Подробное обсуждение см. в [212, с. 78,282], [101, с. 687], [39, с. 558], [183, с. 160].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
void main (void)
{ register int j.k;
int m = 21,
// Число опытных точек
602
Глава 15. Аппроксимация зависимостей
п = 8: // Число членов ряда, нумерация с 1
double у[] =
// Экспериментальные значения
{5.95,6.35.5.80.5.50,5.75.5.85.5.90,6.10,7.10,7.65.
6.95.6.80.7.10,7.40,7.00,6.45.6.00,5.75,5.47.5.25.5.35}.
e = 0, s, T = 0.336, t. *a,*b: // Квадрат ошибки // Вспомогательная величина // Период наблюдения
// Текущая // Массивы переменная коэффициентов ряда
cout « "PERIOD = " << т << endl
« "NUMBER = " « п << endl
« "POINTS = " « m « endl:
a = new double [n + И:
b = new double [n + 1J;
Fourier (y.m.n.a.l Ь):
cout « "FULL ROW RATIOXn":
for (j = 0; j <= n; j++)
cout « "a[" « j « "] = " « setw (10) « a[j]
« "b[" « j « "] = " << setw (10) « b[j] « endl:
cout « "ROW RATIO = " « n « endl:
for (k = 0: k < m; k++)
{
III НИ III I
II Аргумент t = k * T / m;
///////////////////////////////
// Расчетное значение в точке t
for (j = 0, s = 0, j <= n: j++)
s += a[j] * cos (M_PI * j * 2 * t / T) + b[j] * sin (M_PI * j * 2 * t / T):
cout « "Point " « k « setw (10) « t « setw (10) « y[k] « setw (10) « s;
////////////////////////////// // Отклонение опыта от расчета s -= y[k];
cout « setw (10) « s « endl:
///////////////////////////// 11 Накопленный квадрат ошибки e += s * s:
}
Логистический анализ
603
cout « "ERROR = " « е « endl; t
delete [] a: delete [] b;
}
void Fourier (double y[],int m.int n,double a[],double b[]) //
// Функция вычисления коэффициентов гармонического ряда.
//у - массив опытных значений длиной m аппроксимируемой функции, // m - количество опытных значений, // п - количество удерживаемых гармоник, n < m / 2, //а - вектор коэффициентов перед cos длиной n + 1. нумерация // с нуля,
// b - вектор коэффициентов перед sin длиной n + 1, нумерация // с нуля.
// Возвращаемое значение:
// нет.
//
{
register int j.k; // Счетчики
а[0] = VectorSum (y.m) / m;
b[0] = 0:
for (j - 1: j <= n: j++)
{
for (k = 0. a[j] = 0. b[j] = 0; k < m; k++)
{
a[j] += y[k] * cos (M_PI * j * 2 * k / m);
b[j] += y[k] * sin (M_PI * j * 2 * k / m);
}
a[j] = a[j] * 2 / m:
b[j] = b[j] * 2 / m;
}
Логистический анализ
Процесс построения и исследования логистической зависимости называется логистическим анализом и является методом математического моделирования в смысле, введенном нами в начале данной главы. Логистическая кривая иначе называется законом роста [84, с. 344]. ибо подобная зависимость каких-либо параметров живых организмов, например увеличения массы или численности особей, от времени присуща всем известным формам и уровням жизни. Результаты могут быть использованы при рассмотрении аналогичных процессов в технических и социальных науках [205, с. 562]. Обрат
604
Глава 15. Аппроксимация зависимостей
ный процесс происходит по обратной логистической кривой (см. пример применения), причем схема расчета одинакова для обоих случаев. Следуя [205, с. 562], пусть х означает время или величину растущего объекта, влияющего на размер у наблюдаемого явления. Тогда скорость роста может быть охарактеризована дифференциальным уравнением
ах
В частном случае введенная зависимость может иметь вид
^=f(y)gM-ах
Не повторяя выкладки [там же], введя зависимость у от х, а в качестве g(x) взяв функцию специального вида [там же, с. 563], можно получить различные примеры кривых роста, например [179, с. 35]
С
где С — предельная величина,
а и b — параметры, определяющие характер кривой.
В литературе описана также логистическая кривая, вычисляемая по аналитическому уравнению Ферхюльста [111, с. 295]:
,=_А^+с.
* И-КГ’"
где Af — предельная величина,
С — базисная величина признака.
Логистическому анализу посвящены многочисленные исследования и пакеты прикладных программ, например LogXact, Loglet Lab. Дополнительные материалы, кроме упомянутого подробного исследования [205, с. 562], по логистическому анализу даны в [ 187, с. 357]. Множественный логистический анализ описан в [6, с. 2143]. Полезные ссылки даны на сайте phe.rockefeUer.edu.
Казалось бы, расчет с помощью одного из методов нелинейной оптимизации (см. раздел «Нелинейная функция общего вида» настоящей главы) провести выгоднее, чем специально составлять пока
Логистический анализ
605
занную ниже функцию. Однако это не так. Дело в том, что упомянутые методы оптимизации осуществляют минимизацию функционала невязки за счет подбора всех параметров, входящих в показанную выше зависимость, что в данном случае неприемлемо, так как нижняя и верхняя асимптоты зависимости должны занимать фиксированное положение у = 0 и у = С соответственно.
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include ’megastat.h"
void main (void) {
i nt i, n = 9;
double x[] = {7.0.6.0.5.0,4.0,3.0. // 2.0.1.0.0.5,0.1}.
y[] = {0.1.0.64,6.0,36.52.0.//
71.4.80.3.85.0.86.0}, h. //
c.a.b, //
Error = 0: //
Массив аргумента
Массив опытных данных
Расчетные данные в точке Коэффициенты кривой Функционал ошибки
if (!LogisticFunction (y.x.n.&c.&a.&b)) {
cout « "c = “ « c « endl
« "a = - « a « ent]]
« "b = ” « b « endl:
for (i = 0; i < n: i++)
{
h = c / (1.0 + exp (a + b * x[i]));
cout « setw (10) « x[i] « ”\t"
« setw (10) « y[i] « "\t" « setw (10) << h « endl:
Error += (y[i] - h) * (y[i] - h);
}
cout « "Error = " « Error « endl: } el se
cout « "Ошибка при построении зависиности\п": }
int LogisticFunction (double y[],double x[],int n,double
*c,double *a,double *b) //
// Функция аппроксимации эмпирической зависимости логистической // кривой (законом роста).
606
Глава 15. Аппроксимация зависимостей
// Обозначения:
// у - значения энпирической функции.
// х - значения аргумента.
// п - число пар значений функция-аргумент.
// с.а.Ь - коэффициенты функции у = с / (1 + exp (а + b * х))
// Возвращаемое значение:
// 0 при нормальном окончании расчета.
// -2 при ошибке в вычислениях.
//
{
register int i: // Счетчик цикла
double t[4], // Матрица системы уравнений
г[2]. // Вектор свободных членов
buf:
* с = MaximumOf (у.л);
for (i = 0,t[0] = O.t[l] = O.t[3] = 0.r[0] = O.r[l] = 0; i < n: i++)
{
if (y[il == 0) return -2;
buf = MaximumOf (y.n) I y[i] - 1:
if (x[i] != 0 && buf > 0) {
buf = log (buf):
r[0] += buf:
r[l] += x[i] * buf:
t[0] += 1:
t[l] += x[i]:
t[3] += x[i] * x[i]: }
}
t[2] = t[l]:
if (Gauss (r.t.2.1,0.000001) != 0) return -2:
* a = r[0]:
* b = r[l];
return 0:
}
Функция Гомпертца
Экспериментальные данные аппроксимируются теоретической зависимостью [179, с. 71]
Функция Гомпертца
607
ln(z/) - k - аех,
называемой функцией Гомпертца. В книге [187, с. 357] функцией Гомпертца названа зависимость
lg(z/) = « “ br, 0 < г< 1.
Исходные коды
int GompertzFunction (double у[],double x[],int n.double
*k.double *a) //
// Функция аппроксимации эмпирической зависимости функцией // Гомпертца.
// Обозначения:
// у - значения эмпирической функции.
// х - значения аргумента.
// п - число пар значений функция-аргумент,
// к.а - коэффициенты функции log (у) » к - а * ехр (-х).
// Возвращаемое значение:
// 0 при нормальном окончании расчета,
// -2 при ошибке в вычислениях.
//
{
register int i: // Счетчик цикла
double t[4]. // Матрица системы уравнений
г[2]: // Вектор свободных членов
t[0] = п;
for (i = O.t[l] = 0,t[4] = 0,r[0] » O,r[l] = 0: i < n: i++) if (y[i] <“ 0)
return -2;
el se {
t[l] += 1 / exp (x[i]);
t[4] _= 1 / exp (2 * x[i]);
r[0] += log (y[i]):
r[l] += log (y[i]) / exp (x[ij)
}
t[3] = -t[2]:
if (Gauss (r.t.2,1.0.000001) != 0) return -2:
*k = r[OJ:
*a = r[l]:
return 0;
}
608
Глава 15. Аппроксимация зависимостей
Нелинейная функция общего вида
При построении показанных ниже функций мы предусмотрели возможность ввода программистом или пользователем вида оптимизируемой функции и функции вычисления градиента для методов, в которых применяется градиент, поэтому необходимо ввести следующий фрагмент в заголовочных файлах:
////////////////////////////////////////////////// // User defined functions for optimization methods typedef double (*userFuncRight) (double*,int);
typedef void (*userFuncGrad)
(double*,double*.int.double.userFuncRight);
Интерфейс пользовательских функций должен в точности соответствовать прототипам. Мы не рекомендуем чрезмерно утяжелять список формальных параметров введением новых переменных.
Нами рассмотрены несколько методов: симплексный метод Нелдера—Мида представляет методы нулевого порядка, метод сопряженных градиентов Флетчера—Ривса представляет семейство методов первого порядка, метод Ньютона—Рафсона и квазиньютоновский метод переменной метрики относятся к методам второго порядка (порядок метода определяется порядком производных, участвующих в расчете). Обсуждение см. в [90], [146], [177].
Симплексный метод Нелдера—Мида
Сначала приведем законченный пример применения модифицированного симплексного метода Нелдера—Мида. Подробное описание метода дано в [146, с. 286]. В схеме метода участвуют четыре эмпирических коэффициента: отражения, растяжения, сжатия и редукции, оптимальные значения которых даны в примере вызова функции. При задании начальных значений координат вершин регулярного симплекса применяется еще одна эмпирическая величина — расстояние между вершинами. В примере при задании начальных значений используется слагаемое 0,5.
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
double Right (double*.int);
Нелинейная функция общего вида
609
double ta[ll]. // Массив аргумента
z[ll]; // Массив функции
int Global = 0; // Счетчик вызовов функции
void main (void) {
int i ,m = 4.Max = 500;
double y[] = {1.5,2,1,2}, // Начальные приближения параметров k[] = {2,3.0.7,3}; // Истинные значения для контроля
/////////////////////////////////////
// "Опытные" данные для аппроксимации for (i =0; i <11; i++)
{
ta[i} = 0.5 * i;
z[i] = k[0] / (1.0 + k[l] * ta[i]) +
exp (- k[2] * ta[i]) * cos (k[3] * ta[i]); }
cout « "RETURN CODE: "
« NelderMead (y.m,0.005,&Max.l,0.5.2.0.5,Right) « endl; cout << "ITERATION: " « Max « endl « "Coefficients\n";
//////////////////////////////////////////////
// Сравнение истинных и вычисленных параметров for (i = 0; i < m; i++)
cout « setw (10) « y[i] « setw (5) « k[i] « endl;
//////////////////////////////////////////////// // Контроль числа вызовов минимизируемой функции cout « "Calls = " « Global « endl;
//////////////////////////////////////////
// Сравнение истинных и вычисленных данных
cout « "CheckingXn":
for (i = 0; i < 11; i++)
cout « setw (4) « ta[i] « setw (12) « z[i] « setw (12) «'(y[0] / (1.0 + y[l] * ta[i]) + cos (y[3] * ta[i]) /
exp (y[2] * ta[i])) « endl;
}
int NelderMead (double* y.int k,double Eps,int *Max, double 11,double bl,double cl,double dl,userFuncRight Right) //
// Функция минимизации функции многих переменных модифицированным // симплексным методом Нелдера-Мида.
// Обозначения:
// у - на входе - начальные приближения искомых параметров, // на выходе - вектор решения длиной к.
// Eps - константа прерывания вычислений,
2O-2OO2
610
Глава 15. Аппроксимация зависимостей
// *Мах - на входе - максимально допустимое число итераций.
И на выходе - реально затраченное число итераций,
и 11 - коэффициент отражения.
и ы - коэффициент сжатия.
и С1 - коэффициент растяжения,
и dl - коэффициент редукции.
и Right - определяемая । пользователем подлежащая минимизации
и функция.
// Возвращаемое значение:
// 0 при нормальном окончании расчетов,
// -1 при недостатке памяти для рабочих массивов,
// -2 при достижении максимально допустимого числа итераций.
//
{
register int i.j;// Счетчик цикла
int Ret = -2, И Возвращаемое значение
kl = k + 1, H Рабочая константа
Iter = 0, u Счетчик итераций
1 mi n, и Вершина максимального значения функции
Imax, и Вершина минимального значения функции
m; и Счетчик одномерного массива
double *d, *f, fO. *s.*sJ fOl. r; // Регулярный симплекс // Значения функции в вершинах симплекса // Значение функции в центре тяжести симплекса L, // Рабочие массивы // Рабочая переменная // Значение целевой функции и рабочая переменная
if (Cd = new double[k * kl]) == 0)
return -1: if ((f = new double[kl]) == 0)
{ delete [] d;
return -1; } if CCs = new { delete [] double[k]) == 0)
d: delete [] f;
return -1; } if ((si = new double[k]) == 0)
delete [] d; delete [] f; delete [] s;
return -1; }
/////////////////////////////// // Начальные значения симплекса for (i = 0, ш = 0: i < k; i++) d[m++] = y[i];
Нелинейная функция общего вида
611
for (i = 0: i < k: 1++) for (j = 0: j < к: j++) d[m++] = j == j ? y[j] + 0.5 : y[j];
////////////////////////////////////////
// Значения функции в вершинах симплекса
for (j = 0, m = 0; j <= k: j++)
{
for (i = 0; i < k: i++) y[i] = d[m++];
f[j] = Right (y.k):
}
///////////////////////////////
// Для сокращения времени счета
Eps *= kl * Eps:
while (Iter++ < *Max)
{
//////////////////////////////////////
// Координаты центра тяжести симплекса
for (j = 0; j < k: j++)
{
for (i = O.y[j] = 0,m = j; i <= k: i++, m += k) y[j] += d[m]:
y[j] /= kl:
}
//////////////////////////////////////////////
// Значение функции в центре тяжести симплекса f0 = Right (y.k);
///////////////////////////
// Значение целевой функции
for (i = 0,г = 0; i <- k: 1++)
г += (f[i] - f0) * (f[i] - fO):
///////////////////////////////
// Нормальное окончание расчета
if (г <= Eps)
{
Ret = 0: break;
}
///////////////////////////////
// Поиск вершины с максимальным // значением функции MaximumOf (f.kl.&lmax);
////////////////////////////////////// // Координаты центра тяжести симплекса
20»
612
Глава 15. Аппроксимация зависимостей
// без точки масимального значения функции
for (j = 0; j < k: j++)
for (i = 0.y[j] = O.m = j: i <= k; i++. m += k)
if (i != Imax)
y[j] += d[m];
y[j] /= k;
}
////////////
// Отражение
for (i = 0, j = Imax * k: i < k; i++) s[i] = y[i] + 11 * (y[i] - d[j++]);
if ((fOl = Right (s.k)) < f[lmax])
{
/////////////
// Растяжение
for (i = 0. j = Imax * k; i < k; i++)
sl[i] = y[i] + cl * (d[j++] - y[i]);
if ((fO = Right (s.k)) < fOl)
{
for (i = 0. j = Imax * k; i < k; i++)
d[j++] = sl[i];
f[lmax] = fO: // Корректируем значение в вершине }
el se
{
for (i = 0. j = Imax * k; i < k: i++)
d[j++] = s[i]:
f[lmax] = fOl; // Корректируем значение в вершине }
}
el se
{
IИIH III
II Сжатие
for (i = 0; i < k; i++)
s[i] = y[i] + bl * (s[i] - y[i]):
if ((fOl - Right (s.k)) < f[lmax])
{
for (i = 0. j = Imax * k; i < k; i++)
d[j++] = s[i];
f[lmax] = fOl; // Корректируем значение в вершине } el se
{
//////////////////////////////
// Поиск вершины с минимальным
// значением функции
Нелинейная функция общего вида
613
MinimumOf (f,kl,&lmin);'
for (i = 0. j = Imin * k; i < k: i++) s[i] = d[j++]:
/////////////////////
// Редукция симплекса
for (i = 0, m = 0: i <= k; i++)
for (j = 0: j < k; j++)
d[m] = s[j] + dl * (d[m++] - s[j]):
////////////////////////////////////////
// Значения функции в вершинах симплекса
// после редукции
for (j = 0. m = 0; j <= k; j++)
{
for (i =0; i < k; i++)
y[i] = d[m++]:
f[j] = Right (y.k);
}
}
}
}
*Max = Iter;
delete [] d; delete [] f; delete [] s: delete [] si:
return Ret:
}
double Right (double *s,int m)
//
// Пример функции вычисления квадратичного функционала, // построенного по экспериментальным и теоретическим данным. //
{
int i: // Счетчик
double Ret = 0, // Возвращаемое значение х: // Рабочая переменная
for (i = 0; i < 11; i++)
{
x « z[i] - s[0] I (1.0 + s[l] * ta[i])
- exp (- s[2] * ta[i]) * cos (s[3] * ta[i]): Ret +» x * x;
}
Global++: // Переменная для контроля числа итераций
return Ret;
}
614
Глава 15 Аппроксимация зависимостей
Метод сопряженных градиентов Флетчера—Ривса
Решение ведется по формуле [146, с. 315]
где i — номер итерации,
а. — параметр шага итераций, pt — градиент на текущем шаге итераций, вычисляемый как
р0 =vf(fim,p. ^Ro^-P.p^-
Параметры длины шага а, итераций выбираются из условия
/(0(,) - а{р) = min - а,р,),
где поиск оптимальной величины шага ведется методом квадратичной интерполяции по формуле [146, с. 341]
а =1+1
' 2+4/«-2/«+/<»>’
где/0 j соответствуют значениям минимизируемой функции в точ-
ках « = О, Я, 1:
Л<,,=/(0<,)). I
Параметр длины шага итераций Д вычисляется по формуле
(V/ (0(О), V/(0<,-,)) - 7/(0о)) )
А =
(V/(0(i’,))1V/(0(W)))
Исходные коды и пример применения
#include <fstream.h>
Нелинейная функция общего вида
615
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
double Right (double*,int):
double ta[11], // Массив аргумента
z[U]: // Массив функции
int Global = 0; // Счетчик вызовов функции
void main (void) {
int i,m = 4,Max = 100;
double y[] = {2.3,2.5,0.9.3.5}, // Начальные приближения параметров
k[] = {2.0.3.0.0.7,3.0}; // Истинные значения для контроля
lllllllllllllllllllllllllll
II Данные для аппроксимации for (i = 0; i < 11; i++)
{
ta[i] = 0.5 * i:
z[i] = k[0] I (1.0 + k[l] * ta[i]) +
exp (- k[2] * ta[i]) * cos (k[3] * ta[i]) ; }
cout « "XnRETURN CODE: " « ConjugateGradient
(y.m.0.00001.&Max,0.00001,GradC,Right) « endl;
cout « "ITERATION: " « Max « endl « "CoefficientsXn";
//////////////////////////////////////////////
// Сравнение истинных и вычисленных параметров for (i - 0; i < m; i++)
cout « setw (10) « y[i] « setw (5) « k[i] « endl;
////////////////////////////////////////////////
// Контроль числа вызовов минимизируемой функции cout « "Calls = " « Global « endl;
//////////////////////////////////////////
// Сравнение истинных и вычисленных данных
cout « "CheckingXn";
for (i = 0; i < 11; i++)
cout « setw (4) « ta[i] « setw (12) « z[i] « setw (12) « (y[0] / (1.0 + y[l] * ta[i]) + cos (y[3] * ta[1]) / exp (y[2] * ta[i])) « endl;
}
616 Глава 15. Аппроксимация зависимостей
int ConjugateGradient (double* у,int m.double Eps,int
*Max,double Step.userFuncGrad Grad,userFuncRight Right) 11
// Функция минимизации функции многих переменных методом
// сопряженных градиентов Флетчера-Ривса.
// Обозначения:
// у - на входе - вектор начальных приближений длиной ш,
// на выходе - вектор решения,
// Eps - константа прерывания вычислений
// (квадрат евклидовой нормы приращения),
// *Мах - на входе - максимально допустимое число итераций,
// на выходе - реально затраченное число итераций,
// Step - шаг покачивания при вычислении градиента.
// Grad - определяемая пользователем функция вычисления // градиента.
// могут использоваться функции семейства GradX,
// Right - определяемая пользователем подлежащая минимизации // функция.
// Возвращаемое значение:
// 0 при нормальном окончании расчетов.
// -1 при недостатке памяти для рабочих массивов.
// -2 при достижении максимально допустимого числа итераций. //
{
register int i; // Счетчик цикла
int Ret » -2. // Возвращаемое значение
Iter = 0: // Счетчик итераций
double *h. // Вектор градиента на предыдущей итерации
*g. // Вектор градиента на текущей итерации
a ,b. // Параметры длины шага итераций и рабочие
// переменные
r: И Рабочая переменная
if ((g = new double[m]) == 0) return -1:
if ((h = new double[mj) == 0)
{
delete [] g: return -1;
}
/////////////////////////////// // Градиент для первой итерации Grad (у.g.m.Step.Right):
while (Iter++ < *Max)
{
//////////////////////
// Длина шага итераций
Нелинейная функция общего вида
617
г - Right (y.m):
for (1 =0; 1 < m; i++) h[i] = y[i] - 0.5 * g[i]:
a = Right (h.m);
for (i =0: 1 < m; i++) h[i] = y[i] - g[i];
b = Right (h.m);
a = 0.5 + 0.25 * (r - b) / (r - 2 * a + b):
/////////////////////////////////
// Приближение вектора параметров
for (i = 0; i < m: i++) y[i] -= a * g[i]:
//////////////////////////////// // Градиент для текущей итерации Grad (у.h.m.Step.Right);
////////////////////////////////////////// // Длина шага итераций и параметр останова for (1 = 0. Ь - 0, г = 0: i < m: i++)
{ b += h[i] * (g[ij - h[ij): г += g[i] * g[i]:
} b /= r;
////////////////////////
// Приближение градиента
for (i • 0. r = 0: i < m; i++)
{ g[i] = h[i] - b * g[i]: r +- g[i] * g[i]:
}
///////////////////////////////
// Нормальное окончание расчета
if (г <= Eps)
{
Ret = 0; break: } }
*Max » Iter:
delete [] g: delete [] h;
return Ret:
}
618
Глава 15. Аппроксимация зависимостей
Метод касательных Ньютона—Рафсона
Наиболее простым в реализации является метод Ньютона (метод касательных, Ньютона—Рафсона) [146, с. 325]. Главным достоинством метода является очень высокая скорость сходимости, а основным недостатком — очень узкие интервалы, в которых должны лежать начальные приближения параметров для достижения сходимости. Вычисления производятся по формуле
0(i + ° = 0(o-[V2/(0(,>)]1V/(0(,)),
где f(0) — минимизируемая функция, в данном случае представляющая собой квадратичный функционал невязок, построенный на экспериментальных и модельных значениях некоторой функции.
Различные модификации метода Ньютона рассмотрены в цитируемом источнике. Матрицу Гессе и векор градиента мы получаем численно. Для простоты шаг покачивания принят одинаковым и для матрицы Гессе, и для градиента, причем одинаковый для всех параметров. Это в принципе не совсем правильно, и пользователь при необходимости может без труда внести необходимые изменения в исходные коды.
Обсуждение см. в [114, с. 39], [149, с. 362], [158, с. 29]. Применение метода для решения одной частной задачи на алгоритмическом языке Fortran 77 представлено в [162, с. 72].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
double Right (double*,int);
double ta[ll], // Массив аргумента
z[ll]; // Массив функции
int Global = 0; // Счетчик вызовов функции
void main (void)
{
int i,m = 4,Max = 50;
double y[] = {2.5.2.7,0.9,3.3}, // Начальные приближения // параметров
Нелинейная функция общего вида
619
к[] = {2.О,3.0.0.7.3.0}: // Истинные значения для контроля
///////////////////////////
// Данные для аппроксимации
for (i = 0: i < 11: i++)
(
ta[i] - 0.5 * i:
z[i] = k[0] / (1.0 + k[l] * ta[i]) +
exp (- k[2] * ta[1J) * cos (k[3J * ta[i]) :
}
cout « "XnRETURN CODE: "
« Newton (y.m.O.00001,&Max.0.00001,HesseC,GradC,Right) « endl:
cout « "ITERATION: " « Max « endl << "CoefficientsXn":
//////////////////////////////////////////////
// Сравнение истинных и вычисленных параметров
for (i = 0; i < m: i++)
cout « setw (10) « y[i] « setw (5) « k[i] « endl:
////////////////////////////////////////////////
// Контроль числа вызовов минимизируемой функции
cout « "Calls e " « Global « endl:
//////////////////////////////////////////
// Сравнение истинных и вычисленных данных
cout « "CheckingXn";
for (1 = 0: i < 11: i++)
cout « setw (4) « ta[i] « setw (12) « z[i] « setw (12) « (y[0] / (1.0 + y[l] * ta[i]) + cos (y[3] * ta[ij) / exp (y[2J * ta[i])) « endl;
}
int Newton (double* y.int m.double Eps,int *Max.double
Step.userFuncHesse Hesse,userFuncGrad Grad,userFuncRight Right) 11
// Функция минимизации функции многих переменных методом Ньютона // Обозначения:
// у - на входе - вектор начальных приближений длиной т,
// на выходе - вектор решения.
// Eps - константа прерывания вычислений
// (квадрат евклидовой нормы приращения),
// *Мах - на входе - максимально допустимое число итераций,
// на выходе - реально затраченное число итераций,
// Step - шаг покачивания при вычислении матрицы Гессе и
// градиента,
// Hesse - определяемая пользователем функция вычисления матрицы
// Гессе, могут использоваться функции семейства HesseX,
// Grad - определяемая пользователем функция вычисления градиента, // могут использоваться функции семейства GradX.
// Right - определяемая пользователем подлежащая минимизации // функция.
620
Глава 15. Аппроксимация зависимостей
// Возвращаеное значение: // 0 при нормальной окончании расчетов.
// -1 при Hef И -2 при дос // юстатке паняти для рабочих нассивов,
:тижении наксинально допустимого числа итераций
{ register int
i.j; // Счетчик цикла
int Ret = -2. // Возвращаеное значение
Iter = 0; // Счетчик итераций
double *h. // Матрица Гессе, далее вектор приращений
*a. // Обратная матрица Гессе
*g. И Вектор градиента
r; И Рабочая переменная
if ((g = new double[m]) == 0)
return -1;
if ((h = new double[m * m]) == 0)
{
delete [] g;
return -1;
} •
if ((a = new double[m * m]) == 0)
{
delete [] g; delete [] h;
return -1;
}
while (Iter++ < *Мах) {
ИИ IИ НИ
И Градиент
Grad (у,g.m,Step,Right);
И И И И И И И И И Матрица Гессе Hesse (у,h.m,Step,Right);
И И И И И И И И И И И И И
И Обращение матрицы Гессе
if ((Ret = InverseMatrix (h.a.m)) != 0) break;
MatrixMultiplyMatrix (a.g.h.m.m.l);
ИИИИИИИИИИИИИИИИИИИИИИИ1 И Квадрат норны приращения и новое приближение for (i = 0,г = 0; i < m; i++)
{
г += h[i] * h[i];
y[i] — h[i];
}
Нелинейная функция общего вида
621
///////////////////////////////
// Нормальное окончание расчета
if (г <= Eps)
{
Ret = 0; break; } }
*Мах = Iter;
delete [] g; delete [] a; delete [] h;
return Ret;
}
double Right (double *s,int m)
//
// Пример функции вычисления квадратичного функционала.
// построенного по экспериментальным и теоретическим данным.
// {
int i; // Счетчик
double Ret = 0, // Возвращаемое значение х; // Рабочая переменная
for (i = 0; i < 11; i++)
{
x = z[i] - s[0] / (1.0 + sCl] * taCi])
- exp (- s[2] * taCi]) * cos (s[3] * ta[1]);
Ret += x * x;
}
Global++; // Переменная для контроля
return Ret;
}
Метод переменной метрики
Показанная далее функция реализует относящийся к классу квази-ньютоновских один из наиболее эффективных методов нелинейного оценивания параметров — метод переменной метрики. В [77, с. 253] дана общая формула рекуррентного соотношения рассматриваемого метода. Мы применяем один из вариантов метода, называемый также методом Бройдена—Флетчера—Голдфарба—Шанно (Вгоу-den—Fletcher—Goldfarb—Schanno, BFGS) [там же, с. 240]. Автор [146, с. 361] называет формулу описываемого метода формулой Дэ-
622
Глава 15. Аппроксимация зависимостей
видона—Флетчера—Пауэлла (Davidon—Fletcher—Powell). На самом деле формула Дэвидона—Флетчера—Пауэлла представлена в [77, с. 244].
Следуя [146, с. 362] и в основном сохраняя принятые в этом источнике обозначения, очередное приближение искомого вектора О решения нелинейной системы можно найти как
0('+i) = + pidt,
где i — номер итерации,
pi — параметр шага итераций,
di — направление антиградиента, вычисляемое как
4 = -Д V/(0<o),
здесь Д — симметрическая положительно определенная матрица, аппроксимирующая матрицу, обратную к матрице Гессе системы [vW»)]’1.
/(0) — минимизируемая функция, в данном случае она представляет собой квадратичный функционал невязок, построенный на выходе экспериментальных и модельных значений некоторой функции.
Параметр Р1 определяется из условия минимума функции
<P(P)=f(6(i> + Pd),
минимизация которой производится методом квадратичной интерполяции [146, с. 341].
Следующее приближение матрицы Л,+1 вычисляется по формуле
Л -Л + Г-Г‘
Д+1 _ Г Т л
r^gi g{Atgi
где г, = 0<i+t> - p(i) — разность приближений,
gi = V/(0(’+,)) - V/(0(О) — разность градиентов.
Начальные значения входящих в формулы переменных берутся как go = v Ао = I, а 0(О) задано.
Нелинейная функция общего вида
623
Вычисления прекращаются, если евклидова норма градиента становится меньше некоторого заранее заданного малого положительного числа Е.
Конечно, в практической реализации нет необходимости в перемножении векторов и матриц, входящих в расчетные формулы. При таком подходе функция работала бы неприемлемо медленно. Здесь как раз тот случай, когда приходится идти на получение микроскопических выигрышей, оборачивающихся существенной экономией времени расчета, ибо функция применялась нами для обучения нейронной сети, где имеют место сотни переменных и сотни итераций, поэтому высокая скорость вычислений являлась главным критерием качества программы. Все вычисления, например аппроксимация матрицы, обратной к матрице Гессе, производятся в двух двойных циклах. Проверку обусловленности матрицы А не производим, как это требуется в [146, с. 363], — неустойчивости схемы вычислений по этой причине в своих расчетах мы не наблюдали. Если необходимо, положительную определенность матрицы А можно проверять на каждом шаге с помощью функции PlusDef, а в случае нарушения этого условия положить Л = /и продолжать процесс. Ознакомиться с примером вызова функции можно по исходным текстам, приведенным в разделе «Нейронная сеть прямого распространения» главы 9.
Функция компактна, но для своей работы резервирует достаточно много памяти, однако то, что считалось пороком 10 лет назад, сегодня при многократно возросшей мощи вычислительных систем не является таким уж большим недостатком.
Обсуждение см. также в [114, с. 136], [150, с. 242].
Исходные коды
int BFGS (double* у.int m.double Eps.int *Max.double Step. userFuncGrad Grad,userFuncRight Right)
11
II Функция минимизации функции многих переменных методом
// переменной метрики с аппроксимацией обращенной матрицы Гессе // по формуле Бройдена-Флетчера-Голдфарба-Шанно.
// Обозначения:
// у - на входе - вектор начальных приближений длиной ш, // на выходе - вектор решения,
// Eps - константа прерывания вычислений (квадрат евклидовой // нормы).
// *Мах - на входе - максимально допустимое число итераций. // на выходе - реально затраченное число итераций.
624
Глава 15. Аппроксимация зависимостей
// Step - шаг покачивания при вычислении градиента, // Grad - определяемая пользователей функция вычисления // градиента,могут использоваться функции семейства GradX, // Right - определяемая пользователем подлежащая минимизации
// функция.
// Возвращаемое значение: // 0 при нормальном окончании расчетов. // -1 при недостатке памяти для рабочих массивов. // -2 при достижении максимально допустимого числа итераций. // { register int i.j, // Счетчик цикла 1: // Счетчик одномерного массива
int Ret = -2, Iter = 0: // // Возвращаемое значение Счетчик итераций
double *a, *d. *g. *s. *z. Г1.Г2; H // и H H H H Аппроксимация обращенной матрицы Гессе Направление поиска минимума Вектор градиента Вектор градиента на текущем шаге, затем разность градиентов Рабочий массив Рабочая переменная
if ((g = new double[m]) == 0) return -1;
if ((s = new double[m]) == 0)
{ delete [] g: return -1:
}
if ((a = new double[m * m]) == 0)
{ delete [] g; delete [] s; return -1;
}
if ((z = new double[m]) == 0)
{
delete [] g; delete [] s: delete [] a; return -1;
}
if ((d = new double[m]) == 0)
{
delete [] g; delete [] s; delete [] a: delete [] z: return -1:
}
///////////////////////////////////////////
// Вычисление градиента для первой итерации
Grad (у,g,m,Step,Right):
Нелинейная функция общего вида 625
//////////////////////////////////////////////
// Начальное значение обращенной матрицы Гессе MatrixUnit (а.ш);
while (Iter++ < *Мах)
{
////////////////////////////////////////
// Вычисление оптимального шага итераций
// методом квадратичной интерполяции
for (i = 0,1 =0; i < m; i++) {
for (j = 0,d[i] = 0; j < m; j++) d[i] += a[l++] * g[j]:
z[i] = y[i] - 0.5 * d[i];
s[i] = y[i] - d[i];
}
rl = Right (y.m);
r2 - Right (s.m);
rl = (r2 - rl) I (rl - Right (z.m) * 2.0 + r2) / 4 - 0.5;
////////////////////////
// Следующее приближение
for (i = 0; i < m; i++) {
d[i] *= rl:
У[1] += d[i];
}
///////////////////////
// Вычисление градиента Grad (у,s.m,Step.Right);
/////////////////////////////////////////
// Разность градиентов и ее квадрат нормы
for (i = O.rl =0; i < m; i++) {
s[i] -= g[il:
rl += s[i] * s[i]; }
///////////////////////////////
// Нормальное окончание расчета
if (rl <= Eps) {
Ret = 0; break: }
///////////////////////////////////////// // Аппроксимация обращенной матрицы Гессе for (i = 0,1 = 0,rl = O.r2 = 0; i < m; i++)
626
Глава 15 Аппроксимация зависимостей
{
for (j = 0,z[i] =0; j < m; j++) z[i] += a[l++] * s[JJ:
rl += d[i] * s[i];
r2 += z[i] * s[i];
g[i] += s[ij:
}
for (1 = 0,1 = 0: i < m: 1++)
for (j = 0; j < m; j++)
a[l++] += d[i] * d[j] I rl - z[i] * z[j] I r2;
}
*Max = Iter:
delete [] g: delete [] s: delete [] a; delete [] z: delete [] d:
return Ret:
Нейронная сеть прямого распространения
Для аппроксимации зависимостей (в том числе временных) с успехом может применяться нейронная сеть прямого распространения в качестве предиктора [144, ч. 1, с. 26 — аппроксимация полиномами Чебышева]. Мы приводим законченный пример применения с теми же исходными данными, что и использованные при иллюстрации описанного выше модифицированного симплексного метода Нелдера—Мида.
Функция Feedforward, вычисляющая выход сети, и функция Feedforward Error, вычисляющая ошибку сети, не показаны, так как они являются теми же самыми, что и использованные в главе 9, хотя и могут быть несколько упрощены благодаря тому, что в рассматриваемом случае размерности входа и выхода сети равны единице. Тем не менее вход и выход сети не следует делать скалярами из соображений сохранения стандартных вызовов применяемых методов.
По сравнению со случаем применения нейронной сети в качестве классификатора, в показанном ниже примере не производится нормализация входа. Далее, выход сети в данном случае является непрерывной, а не «дискретной» величиной, и задача распознавания, решаемая после обучения сети, заменяется задачей аппрокси
Нейронная сеть прямого распространения
627
мации, которая в вычислительном смысле менее трудоемка, чем задача распознавания, благодаря меньшей размерности системы.
Пример практического применения рассмотренной методики дан при описании функции KolmogorovDistribution, представляющей собой модифицированную функцию Feedforward, предназначенную для решения задачи распознавания на основе параметров нейронной сети, вычисленных на этапе обучения. Пример показывает, в каком виде могут передаваться заказчику материалы расчета. В данном случае исходными данными для построения функции распознавания явились: вектор размеров слоев сети, число слоев сети и массив синапсов и смещений.
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <stdlib.h>
#include <math.h>
#include “megastat.h"
int *ak, ко, is. al : double *in,*out. *du,*dul,*dv.*dvl; // Вектор размеров слоев // Число пар значений абсцисса-ордината // Число синапсов // Число слоев // Вход и выход сети
// Рабочие массивы
void main (void) { register int i.j; и Счетчики цикла
int Max = 500. И Заданное максимальное число итераций
ni = 1. и Размер входа
ml. и Число синапсов скрытых слоев
no = 1; И Размер выхода
double *y. // Синапсы и смещения
Temp. И Рабочая переменная
Qual = 0: и Квадратичный функционал качества
///////////////////////// // Рабочие параметры сети al = 3;
ak = new int[al];
ak[0] = ni: ak[l] = 8:
// Размер входного слоя // Размер скрытого слоя
628
Глава 15 Аппроксимация зависимостей
ак[2] = по; // Размер выходного слоя
ко = И:
is = SpecialVectorSum (ak.al):
ml = VectorSum (ak.al) - ak[0] - ak[al - 1]:
у = new doublets + ml];
in = new double[ko];
out = new double[ko]:
du = new double[l];
dul = new double[l];
dv = new double[MaximumOf (ak.al)];
dvl = new doublefMaximumOf (ak.al)]:
//////////////////////////////////////
// "Опытные" данные для аппроксимации.
// можно ввести произвольные числовые значения:
// in - массив абсцисс ("аргумента”) длиной ко.
// out - массив ординат ("функции") длиной ко.
for (i = 0; i < ко: i++)
{
in[i] = 0.5 * i;
out[i] = 2 / (1.0 + 3 * in[i]) + exp (- 0.7 * in[i]) * cos (3 * in[i]):
}
//////////////////////////////////////
// Инициализация случайными значениями
for (i =0; i < is + ml: i++)
y[i] = rand ():
Temp = AbsMaximumOf (y.is + ml):
for (i = 0: i < is + ml: i++)
y[i] = y[i] I Temp - 0.5;
////////////////
// Обучение сети
cout « " Число слоев: " « al
« "ХпЧисло синапсов: ” « is
« "ХпЧисло нейронов: " « (ml + ak[0] + ak[al - 1])
« "Хп Число точек: " « ко
« "Хп Код ошибки: " « BFGS
(y.is +
ml.0.000001,&Мах.0.000001.RGradlent.FeedforwardError):
cout « "ХпЧисло итераций: " « Max « endl:
///////////////////////////////
// Решение задачи аппроксимации
cout << "Вход, выход заданный, выход вычисленныйХп":
for (j = 0: j < ко: j++)
Линейный множественный регрессионный анализ
629
{
du[0] = in[jj;
Feedforward (у,du,dul);
cout « setw (6) « in[j] « setw (12) « out[j] « setw (12) « dul[0] « endl;
Qual += (out[j] - dulEOJ) * (out[jj - dul[0]);
}
cout « "Квадратичный функционал качества ” « Qual « endl;
delete [] du; delete [] dv; delete [] dul; delete [] y; delete [] dvl; delete [] in; delete [] out; delete [] ak;
}
Линейный множественный регрессионный анализ
В ходе нетривиального эксперимента абсолютно точные измерения параметров, как правило, невозможны. Чтобы уменьшить влияние ошибок, производится большое число измерений. Каждое измерение дает нам уравнение с известной из теоретических соображений структурой с точностью до коэффициентов, подлежащих определению. При числе измерений большем, чем число параметров, мы приходим к необходимости решения системы, число уравнений которой превышает число неизвестных параметров. Если систему удается решить, в общем случае полученный вектор решения системы уравнений не будет точно удовлетворять ни одному уравнению системы, однако в каком-то смысле будет наилучшим [60], [88, с. 72].
При обработке данных иногда возникает вопрос о влиянии того или иного параметра на результат эксперимента, причем этот результат может быть выражен, в частности, в виде экспертной оценки. На подобный вопрос экспериментатор вынужден отвечать на начальном этапе исследований в случае, когда об изучаемом объекте имеется лишь незначительное количество информации и не совсем ясно, какими параметрами при изучении объекта можно пренебречь, а измерение каких обязательно. Важность решения вопроса возрастает и оттого, что увеличение числа измеряемых параметров приводит к удорожанию и усложнению эксперимента, и выбор оптимального числа параметров позволяет при равных затратах увеличить качество эксперимента. Для решения задачи в первом приближении положим зависимость результата эксперимента от параметров линейной (то есть примем линейную модель) и сформулируем задачу математически следующим образом. Требуется решить систему линейных уравнений:
630
Глава 15. Аппроксимация зависимостей
т
У ах. ~b,i = 1,2,.... п, j ‘
J=i
где ау — элемент матрицы экспериментальных данных,
Xj — элемент подлежащего определению вектора весовых коэффициентов,
Ь, — элемент вектора оценок результатов эксперимента,
т — количество измеряемых в эксперименте параметров, п — количество опытов.
При т = п система в случае, если матрица системы невырожденна, имеет одно решение, поиск которого не вызывает трудностей и может быть осуществлен методом Гаусса или одним из итерационных методов. При т > п система имеет бесчисленное множество решений (в этом случае можно выделить одно решение, например обладающее минимальной нормой, — см. пояснения к функции Solves, исходные коды опубликованы в настоящем издании). При т < п система является несовместной и может быть решена приближенно. В формуле знак == применен вместо знака равенства, чтобы подчеркнуть неточность определения результата эксперимента.
Введем вектор ошибок eit i = 1,2,..., п. Тогда исходную систему можно переписать:
У а х. + е. = b ,i =
У } 1 i ’ 1 *
/=1
Точное решение системы при т < п в общем случае получить не удается, поэтому обычно применяют один из двух методов: либо метод, основанный на критерии минимакса, для чего минимизируют максимальную ошибку из i =1,2,..., п, либо метод наименьших квадратов [33, с. 146], в котором минимизируют сумму квадратов ошибок eit i = 1,2,...,и. Воспользуемся методом наименьших квадратов. Составим квадратичный функционал
п п т %
1(Х1,Х2,-Л) = ^='Ё Ь,-^Х! •
«=1 i=l |_ >1
Потребуем минимума функционала I = I(xlt хъ..., хт) по элементам вектора х?у = 1,...,тя:
Линейный множественный регрессионный анализ
631
1(х1,х2.....=1................т.
Требование означает равенство нулю всех частных производных функционала I по элементам х7, j = 1, т, что приводит к системе линейных алгебраических уравнений, решив которые мы найдем неизвестных у = 1,..., пг.
5 3
—=0,k =1
..., тп.
Распишем подробнее. Подставив выражение для функционала, после элементарных преобразований получим:
£ х>=tAa*-k=i’••••m-
;=i L «=1 J i=i
Это выражение является системой тп уравнений для тп неизвестных. Выражение в квадратных скобках представляет собой запись в общем виде элемента матрицы системы уравнений, а правая часть формулы — элемента столбца свободных членов.
Лучшие результаты в смысле более точного описания реального объекта исследований часто можно получить, если использовать уравнения со свободным членом:
777
ro+EV/+ei=z,i''=1......”
>1
Тогда остальные уравнения примут, соответственно, вид
2
тп
/(хоЛ<л2,...,^)=Е<=Х ь.-x0~Ya«xi
4xo,xt>x2..xm)-+min ,j = 0....m,
--= 0, £ = О,тп, dxt
632
Глава 15. Аппроксимация зависимостей
Последнее выражение является системой (т + 1) уравнений для (т + 1) неизвестных. Практически, однако, в применении последней формулы нет необходимости. При расчете достаточно ввести дополнительный (т + 1)-й параметр, которому будет соответствовать число 1 в каждом векторе данных.
Частные случаи множественной линейной регрессии рассмотрены в [60], [88, с. 72], [1 И, с. 258, 266]. Применение теоремы Маркова к расчету наилучших оценок параметров множественной линейной регрессии [167, с. 294] дает те же результаты, что и полученные выше на основе метода наименьших квадратов. Обсуждение проблемы см. также в [67, с. 77], [139], [155, с. 49], [189, с. ИЗ]. Подробный пример расчета дан в [78, с. 47]. Полезные источники упомянуты в [187, с. 249]. Оценка силы корреляционной связи между переменными в случае множественной регрессии рассмотрена в [22, с. 691] и дается коэффициентом множественной корреляции, формула вычисления которого приводится нами в одноименном разделе в главы 5. Выбор наилучшего подмножества регрессионных переменных изучен в [215, с. 53]. Частный случай рассмотрен в [184, с. 184].
Исходные коды
int LinearRegression (double t[],double z[],double data[],int m.int n)
II
II Функция построения множественной линейной регрессионной // модели.
// Обозначения:
Hi - матрица системы размером m х п.
// t - вектор свободных членов длиной го,
// data - вектор вычисленных коэффициентов длиной ш,
// п - число опытов,
// m - число параметров.
// Возвращаемое значение:
II 0 - при нормальном окончании счета, // -1 при недостатке памяти.
// -2 при потере значимости.
// Примечание: ш <= п.
И
Линейный множественный регрессионный анализ
633
{
register int i, j,к.mm,mml,mm2: // Счетчики
int Code = 0: // Код ошибки
double *zz, // Массив левых частей
*bb: // Массив правых частей
if ((zz = new double[m * m]) »» 0) return -1;
if ((bb = new doublefm]) — 0)
{
delete [] zz;
return -1;
}
////////////////////////////////////////////////////// II Присвоение нулевых значений накапливаеиын элементам FillUp (zz,m * m.0);
FillUp (bb,m,0):
////////////////////////////////////////
// Построение системы линейных уравнений
for (k = 0, mm2 =0; k < m: k++)
{
for (i = 0. mm “ k; i < n; i++)
{
bb[k] += t[i] * z[mm]: mm += m;
}
for (j = 0; j < m; j++)
{
for (i = 0, mml = j, mm - k; i < n; i++) {
zz[mm2] +- zfmml] * z[mmj;
mm += m: mml += m;
}
mm2++;
}
}
/////////////////////////////////////
// Решение системы линейных уравнений
if (’(Code = Gauss (bb,zz,m,1.0.000001)))
for (i = 0: i < m; i++) datafi] = bb[i];
delete [] zz: delete [] bb:
634
Глава 15. Аппроксимация зависимостей
if (ICode)
return 0;
el se
return -2:
}
int LinearRegressionO (double data[].doubl e z[],double t[].1nt numbers.int m)
II
II Функция построения множественной линейной регрессионной
// модели со свободным членом.
// Обозначения:
11т. - матрица системы размером numbers х т.
// data - вектор свободных членов длиной т,
// t - вектор решения длиной m + 1,
// m - число опытов.
// numbers - число параметров.
// Возвращаемое значение:
// 0 при нормальной окончании счета.
// -1 при недостатке памяти.
// -2 при потере значимости.
// Примечание: m <= п.
И
{
register int i,count.mml.mm2; // Счетчики
int Code =0; // Код ошибки
double *zz; // Массив левых частей
if ((zz = new double[(numbers + 1) * mJ) == 0)
return -1;
////////////////////////////////////////
// Преобразовать матрицу исходных данных
for (i = 0. mml =0: i < m; i++, mml += numbers + 1)
zz[mml] = 1; // Единичный вектор - свободный член
for (i = 0; i < numbers; i++)
for (count = 0, mml = i + 1. mm2 = i; count < m; count++) {
zz[mml] = z[mm2];
mml += numbers + 1;
mm2 += numbers;
}
Code = LinearRegression (data.zz.t,numbers + l.m);
delete [] zz;
if (ICode)
Дальнейшие исследования и программные ресурсы
635
return 0:
el se
return -2:
}
Представленная множественная линейная модель может быть обобщена на случай учета взаимодействия факторов. В этом случае модель становится нелинейной. Существуют различные, довольно сложные, формулы расчета коэффициентов такой модели для частных случаев [ 123], однако вряд ли эти усилия могут быть оправданы — ведь задача сравнительно просто решается одним из методов аппроксимации зависимости нелинейной функцией общего вида.
Дальнейшие исследования и программные ресурсы
• Повышение точности аппроксимационных решений.
• Генетические алгоритмы.
• Проверка гипотетических значений коэффициентов регрессии [140], [130]. Вычисление доверительных зон для линий регрессии [155, с. 46]. См. также [132], [134], [188].
В табл. 15.1 представлены некоторые ресурсы Интернета по регрессионному анализу. Для полноты даны некоторые материалы по анализу временных рядов [93]. Ссылки на ресурсы по нейронным сетям см. в главе 9.
Таблица 15.1. Интернет-ресурсы по программным продуктам анализа данных. Регрессионный анализ и анализ временных рядов
Ресурс, адрес Разработчик или поставщик Содержание
www.pro-invest.com Про-инвест Консалтинг Forecast Expert, прогнозирование и анализ временных рядов, доступна демонстрационная версия
statsoft.msu.ru НПО «Информатика и компьютеры» SIGN, анализ регрессионных и факторных моделей знаковыми методами, доступна демонстрационная версия
phe.rockefeller.edu The Rockefeller University Loglet Lab, логистическая регрессия
продолжение &
636
Глава 15. Аппроксимация зависимостей
Таблица 15.1 (продолжение)
Ресурс, адрес Разработчик или поставщик Содержание
www.cemi.rssi.ru Центральный МЕЗОЗАВР, анализ
/ruswin/activities ЭКОНОМИКС- временных рядов, доступна
models.htm, www.tvp.ru математический институт РАН демонстрационная версия
www bsu.unibel.by Белорусский государственный университет Динстат, анализ временных рядов
www.cytel.com Cytel Software Corp LogXact, логистическая регрессия, доступна пробная версия
www.simstat.com Provalis Research ITALASSI, построение и анализ регрессии, бесплатно LOGISTIC, логистическая регрессия, бесплатно
www.estima.com Estima RATS, регрессионный анализ временных рядов для различных версий Windows: WinRATS, WinRATS Plus и WinRATS-32
Глава 16.
Дифференциальное и интегральное исчисления
Методы численного дифференцирования
Первая производная
Как известно [219, с. 39], производной называется предел отношения приращения функции к приращению аргумента, когда последнее стремится к нулю:
lim /<уо+Дх)-Ж) .
° ДГ-»О Дг
Производная широко используется в различных методах анализа данных, причем от эффективности вычисления производной зависит эффективность, а часто и сама возможность реализации применяемых методов анализа.
Производные могут вычисляться аналитически или численно. Аналитически вычислять более или менее сложные производные невыгодно. Для решения проблемы есть ряд пакетов прикладных программ [74], позволяющих вычислять производные с помощью компьютера в аналитической форме. Тем не менее процедура дифференцирования является утомительной для исследователя и потому содержит много возможностей для внесения ошибок. В рассмотренных нами алгоритмах принят подход, предусматривающий численное определение производных.
Конечно-разностные схемы численного определения производных построены на идее применения такого малого приращения аргумента (покачивания), что вычисление дает достаточную для практического применения точность. Формула метода правых разностей имеет вид [51, с. 75,454]
638
Глава 16. Дифференциальное и интегральное исчисления
h
а метод центральных разностей может быть записан как [51, с. 75,454]
Ж)«
/(х0 + Л)-/(х0-/?) 2Л
где в обоих случаях h — конечно-разностный интервал (шаг покачивания).
Выбор h обычно производится эмпирически. Например, можно, вычислив производную при некотором значении А, уменьшить h вдвое. Если при вычислении с новым шагом значение производной будет отличаться от предыдущего незначительно в пределах заданной точности, вычисления можно проводить с начальным шагом, в противном случае алгоритм уменьшения (дробления) длины шага покачивания следует повторить.
Мы предлагаем три функции вычисления вектора первых производных функции (градиента функции); в формульной записи градиент функции /(0), где 0— вектор параметров, обозначается как grad /(0) или N/(0). Во всех функциях вычисление производных производится численно конечно-разностным методом.
Трудности численного дифференцирования описаны в [158, с. 61]. Там же дано несколько не описанных здесь практически применяемых методов.
Исходные коды
void GradR (double* у,double* д.int m,double s.userFuncRight Right)
//
// Функция вычисления вектора градиента методой правых
// разностей.
// Обозначения:
// у - вектор переменных длиной т.
// g - вектор градиента длиной ш.
// s - шаг покачивания.
// Right - определяемая пользователем функция.
// Замечание:
// функция обеспечивает максимальное быстродействие среди
// функций семейства.
// Возвращаемое значение:
// нет.
И
Методы численного дифференцирования
639
{
for (register int i = 0: i < m; i++) {
y[i] += s:
g[i] = Right (y.m);
y[i] -= s;
g[i] = (g[i] - Right (y.m)) I s;
}
}
void GradL (double* y.double* g,int m,double s.userFuncRight Ri ght)
//
// Функция вычисления вектора градиента методой левых разностей. // Обозначения:
// у - вектор переменных длиной го,
// g - вектор градиента длиной т.
// s - шаг покачивания.
// Right - определяемая пользователем функция.
// Замечание:
// функция обеспечивает максимальное быстродействие среди
// функций семейства наряду с GradR.
// Возвращаемое значение:
// нет.
//
{
for (register int i = 0: i < m; i++)
{
y[i] -= s:
g[i] = Right (y.m);
y[i] += s;
g[i] = (g[i] - Right (y.m)) / s;
}
}
void Grade (double* y.double* g.int m.double s.userFuncRight Right) //
// Функция вычисления вектора градиента методом центральных
// разностей.
// Обозначения:
// у - вектор переменных длиной т.
// g - вектор градиента длиной т.
// s - шаг покачивания.
// Right - определяемая пользователем функция.
// Замечание:
// функция обеспечивает наивысшую точность среди функций
// семейства при относительно низком быстродействии.
// Возвращаемое значение:
// нет.
//
640
Глава 16. Дифференциальное и интегральное исчисления
for (register int i = 0: i < m; i++)
{
y[i] += s:
g[i] e Right (y.m);
y[i] -= (s + s):
g[i] = Cg[i] - Right (y.m)) / s / 2; y[i] += s;
}
Матрица первых производных
Для ряда алгоритмов требуется вычислить производные системы функций по вектору (элементам вектора) параметров. В этом случае можно использовать рассмотренные выше конечно-разностные алгоритмы для каждой производной каждой функции по каждому элементу вектора, однако сейчас мы покажем, как путем несложных рассуждений количество вычислений можно сократить в несколько раз, в зависимости от размерности системы, причем эффект тем заметнее, чем больше размерность системы. Рассмотрим более эффективный метод [99], построенный на основе теории планирования эксперимента и с учетом чувствительности системы [141], [168], [169], [170], [171].
Обозначим:
а[г х 1 ] — вектор параметров,
*
г — число параметров,
<5a[rx 1] — вектор покачиваний параметров,
Act[rx М] — матрица покачиваний параметров,
М — число покачиваний параметров,
z[m х 1] — вектор дифференцируемых функций, т — число дифференцируемых функций,
W\m х г] — матрица частных производных функций по параметрам. Записью «х 1» мы особо подчеркиваем, что имеется в виду вектор-столбец.
Необходимость введения числа покачиваний обусловлена следующим. В стандартном методе центральных разностей вычисление функции производится дважды: при покачивании параметра в сторону уменьшения и в сторону увеличения значения аргумента. Как было показано выше, при достаточно малом покачивании производная равна отношению приращения функции к приращению аргумента.
Методы численного дифференцирования
641
Число покачиваний, таким образом, равно удвоенному числу параметров дифференцирования (2г). Однако оказывается, что благодаря линейной постановке задачи число покачиваний реально можно значительно снизить.
Итак, в линейной постановке
z(a + 8а,t) = z(a,t) + W(t)8a.
Осуществим М> г покачиваний 8а:
z(a + 8со,t) = z(a,t) + W(t)8a, i -1,2,.... M.
Второе слагаемое представляет собой вектор приращений функции Az.
Получаем тп х М уравнений для тп х г неизвестных, то есть приходим к задаче решения М систем линейных алгебраических уравнений — матричной системе линейных уравнений (системе, у которой столбец свободных членов заменен более общей формой — матрицей, и соответственно вектор решения заменен матрицей решения, совпадающей по размерности с матрицей свободных членов), вопрос о вырожденности которых не имеет отличий от известной постановки. В матричной форме
Az ~ WAa,
zfa+8a\t) Zi(a+8a2,t) ... zx(a+8aM,t) z2(a+8a\t) z2(a + 8a2,t) ... z2(a+3aM,t)
zm(a+8a',t) zm(a+8a2,f) ... zm(a+8aM,t)
Aa = [5a1 8a?... <5aw] и, как ясно из обозначений, состоит из вектор-столбцов.
Преобразуем правую часть уравнения:
X - К' '5ап 5а12 . .. 8aiM
W21 - К ^^21 5а?2 .. 8а2М
л. ^2 • <5аг1 5аг2 . .. 8агМ
21-2002
642
Глава 16. Дифференциальное и интегральное исчисления
tW^ tW4Sa,2 - tW45ajM
J j j
= tW2JSaj> tW2,S»J2 -• tW2^
j J j
tW^ tW^,2 - tW^
. i i i -
Пусть |5ал| = |<5а>2| = ... = |<5а>Л1| = j =1,2.г.
Тогда W^Sa^W^a^Wfy,
где |<5ot| — абсолютная величина покачиванияj-го параметра, ajk — знак k-ro покачивания/го параметра,
W / ту -Wy~ /(Say
где; = 1, 2,г.
Для вектора приращений функции справедливо равенство:
Az = W/b
где матрица Л = ||а ||, i =1,2,г;; = 1, 2,М, составлена из знаков покачиваний параметров.
Рассмотрим случай, когда матрица А является ортогональным планом первого порядка либо дробной репликой от него. Домножив справа обе части предыдущего выражения на обратную к А матрицу, то есть на А', и учтя, что для ортогонального плана эксперимента (ортогональной матрицы) транспонированная Ат и обратная А' матрицы совпадают, в результате имеем
W =—AzAT.
М
Резюмируя сказанное, сформулируем порядок экономичного определения матрицы частных производных следующим образом:
1. Вычисление дробной реплики матрицы планирования А.
2. Цикл: определение матрицы приращений функций Az.
Методы численного дифференцирования
643
3. Определение столбца матрицы покачиваний Да (на самом деле хранится только текущий столбец матрицы покачиваний).
4. Вычисление столбца матрицы Az как отклика системы функций на вектор покачиваний.
5. Определение вспомогательной матрицы W через матрицы Az и А.
6. Определение матрицы частных производных VVфункций по параметрам.
Последний нерешенный вопрос в проблеме численного определения матрицы частных производных — как выбрать абсолютную величину покачивания параметра? С учетом машинной арифметики можно предложить следующий способ [90]:
|<5az| = у]10е max{typaj},
где Е — наименьшее положительное число, воспринимаемое моделью компьютера, на котором производится расчет, может быть автоматически быстро вычислено с помощью функции GetMinMax, typ ajJ = 1» 2,.... г, — характерный размер а..
Ниже показан пример вычисления якобиана системы 7-го порядка. При использовании метода центральных разностей нам пришлось бы 7 х 7 х 2 = 98 раз обратиться к функции, вычисляющей отклик системы уравнений. За счет только особой организации вычислительного процесса по рассмотренной выше схеме число обращений к функции будет уменьшено до 16 при той же точности.
Несколько замечаний по практической организации вычислительного процесса:
1. Вычисляйте применяемую матрицу планирования или каждую матрицу планирования для каждой матрицы частных производных, если эти матрицы должны быть различны, только один раз перед вызовом функции построения якобиана или матрицы частных производных по параметрам, с целью сокращения времени расчета.
2. При определении производных системы по идентифицируемым параметрам и начальным условиям частные производные вычисляются аналогично вычислению якобиана, только матрица производных в общем случае уже может не быть квадратной. Следовательно, нужно указать соответствующие случаю размерности при вызове нужных методов, не забыв выделить достаточно памяти.
21*
644
Глава 16. Дифференциальное и интегральное исчисления
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.il>
#include <math.h>
#include "megastat.h"
void II serFunc (doubl e. double*. int.double*);
void main (void)
{
int i.j.n = 7,m = 0;
double x = 0.h[7].y[7],dy[49];
for (i = 0: i < n; i++)
{
y[i] = 1:
h[i] = 0.01; // Шаг покачивания
}
cout << "Return Code " << Derive (x.y.n.dy.h.llserFunc) << endl;
for (i = 0; i < n; i++)
{
for (j = 0; j < n; j++,m++)
cout << setw (10) << dy[mj;
cout << endl;
}
}
int Derive (double x.double* y.int n.double* dy.double*
h. userFuncMany fff)
//
// Функция вычисления якобиана
// Обозначения:
// х - независимая переменная,
// у - вектор обобщенных координат длиной п,
// dy - матрица производных по координатам размером п х п,
// fff - имя функции вычисления вектора выходных величин (функций).
// h - вектор покачиваний координат (амплитуд отклонений
// при численном дифференцировании) длиной п.
// Возвращаемое значение:
// 0 при нормальном окончании счета.
// -1 при недостатке памяти для рабочих массивов.
//
{
register int i.j: // Счетчик цикла
int nful. // Размер полного плана
Методы численного дифференцирования
645
nopt. m.k = 0; // // Размер дробной реплики Вспомогательные переменные
double *yin. H Массив входов системы
*yout; H Массив выходов системы
a. И План эксперимента в
И транспонированном виде
*dd: И Массив откликов системы
////////////////////////////////// // Определение оптимального плана OptimalPlan (n.&nful,&nopt);
if ((a = new double[n * nopt]) == 0) return -1;
if ((dd = new double[n * nopt]) == 0)
return -1:
if ((yin = new double[n]) == 0)
{
delete [] a; delete [] dd;
return -1;
}
if ((yout = new double[n]) == 0)
{
delete [] a; delete [] dd; delete [] yin;
return -1;
}
///////////////////////////////////
// Вычисление дробной реплики плана
if (OrtoPlan (a,n,nful.nopt) == -1) {
delete [] a; delete [] yout; delete [] yin; return -1;
}
////////////////////////////////////////
// Вычисление матрицы приращений функций for (i = 0: i < nopt; i++)
{
for (j = 0. m = i; j < n; j++.m += nopt) yin[j] = y[j] + h[j] * a[m];
fff (x.yin.n,yout);
for (j = 0; j < n; j++) dd[k++] = yout[j];
}
MatrixMultiplyMatrix (dd.a.dy.n.nopt.n);
MatrixMultiplyNumber (dy.n * n.1.0 / nopt);
for (i = O.m =0; i < n; i++)
646
Глава 16. Дифференциальное и интегральное исчисления
for (j = 0; j < n; j++) dy[m++] /= fabs (h[i]);
delete [] a: delete [] yout; delete [] yin; delete [] dd;
return 0:
}
void UserFunc (double x,double* yi.int n.double* yo)
//
// Это пример функции для тестирования программы
//
{
for (register int i = 0; i < п; i++) yo[i] = yi[i] * yi[ij;
}
Матрица вторых производных
В ряде методов, в частности в методах безусловной оптимизации, применяется симметричная матрица порядка п вторых частных производных функции от п параметров х„ вида
, i = 1,..., n;j = 1,..., п
dxfix,
называемая матрицей Гессе (в ряде источников — гессианом, однако гессианом принято называть определить матрицы Гессе) функции f(x) и обозначаемая через N2/(x) [51, с. 71, 454].
Матрицу Гессе можно получить численно с помощью правых разностей и центральных разностей [там же, с. 76] соответственно по формулам:
dxidx/ hh]
/(*; + fy*, +^>-/7, -fy*,++fyx, -hj)+f(x, -h^-h) дх.дх^ ih)ij
где в обоих случаях h — конечно-разностный интервал — принят различным для величин xt и хр хотя в практических вычислениях, как в цитируемом источнике, без потери общности часто может
Методы численного дифференцирования
647
быть принят одинаковым. Именно так сделано в показанных ниже функциях, которые при необходимости могут быть легко доработаны.
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include "megastat.h"
double Right (double*,int):
void main (void)
{
int i.j, // Счетчики цикла
m = 4, // Порядок матрицы Гессе
k = 0: // Счетчик элементов массива
double у[] = {1,2,1,2}, // Значения переменных h[16]: // Матрица Гессе
HesseR (у.h.m.0.0001.Right);
cout « "HESSE MATRIX BY RIGHT IS\n":
for (i = 0: i < m; i++)
{
for (j = 0: j < m: j++,k++)
cout « setw (14) << h[k]:
cout « endl:
}
HesseC (y.h.m,0.0001.Right):
cout « "HESSE MATRIX BY CENTRAL IS\n":
for (i = 0,k = 0: i < m; i++)
{
for (j - 0; j < m; j++,k++) cout << setw (14) « h[k];
cout « endl:
}
}
void HesseC (double* y,double* h.int m,double s,userFuncRight Right) 11
// Функция вычисления матрицы Гессе методом центральных разностей.
648
Глава 16. Дифференциальное и интегральное исчисления
// Обозначения: // у - вектор переменных длиной m. // h - матрица вторых производных порядка т. // s - шаг покачивания (общий для всех переменных) // Right - определяемая пользователем функция. // Возвращаемое значение: // нет. // { register int i.j: // Счетчики цикла
int k.kl = -m.k2.k3 = m; // Счетчики элементов массива
double s2 = s * 2: // Удвоенный шаг покачивания
/ / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / // Верхний треугольник матрицы Гессе for (1=0: 1 < m: i++)
for (j = 0, k = i * m: j <= 1: j++.k++) {
h[k] = 0:
y[i] += s;
y[j] += s:
h[k] += Right (y.m):
y[i] -= s2:
h[k] -= Right (y.m);
y[i] += s2:
y[j] -= s2;
h[k] -= Right (y.m);
y[i] -= s2:
h[k] = (h[k] + Right (y.m)) / 4 / s / s:
y[i] += s: y[j] += s:
}
///////////////////////////////////
// Нижний треугольник матрицы Гессе
for (i = 1: i < m; i++,k3 += m + 1)
for (j = i. kl += m + 1. k2 = kl. k = k3; j < m: j++. k += m)
h[k2++] = h[k]:
void HesseR (double* y.double* h.int m.double s.userFuncRight Right)
Методы численного дифференцирования
649
//
// Функция вычисления матрицы Гессе методом правых разностей.
// Обозначения:
// у - вектор переменных длиной т,
// h - матрица вторых производных порядка т.
// s - шаг покачивания (общий для всех переменных).
// Right - определяемая пользователем функция.
// Возвращаемое значение:
// нет.
//
{
register int i.j; // Счетчики цикла
int k.kl = -m,k2,k3 = m; // Счетчики элементов массива
////////////////////////////////////
// Верхний треугольник матрицы Гессе
for (i = 0; i < m; i++)
for (j = 0, k = i * m; j <= i; j++,k++)
{
h[k] = Right (y.m);
y[i] += s;
h[k] -= Right (y.m);
y[j] += s;
h[k] += Right (y.m);
y[i] -= s;
h[k] = (h[k] - Right (y.m)) / s / s;
y[j] -= s;
}
///////////////////////////////////
// Нижний треугольник матрицы Гессе
for (i = 1; i < m; i++.k3 += m + 1)
for (j = i. kl += m + 1. k2 = kl. k = k3; j < m; j++. k
+= m)
h[k2++] = h[k];
}
double Right (double* y.int m)
//
// Простой пример для проверки работы функции
И
{
return у[0] * у[0] * у[0] * у[1] * у[1] * у[1] *
У[2] * у[2] * у[2] * у[3] * у[3] * у[3];
}
650
Глава 16. Дифференциальное и интегральное исчисления
Методы численного интегрирования
Задача вычисления определенного интеграла, то есть выражения вида
ь ]f(x)dx, а
часто возникает в анализе данных. Числа а и b называются соответственно нижним и верхним пределами интегрирования, а отрезок \а,Ь\ называется участком интегрирования. Функция f(x) называется подынтегральной функцией.
Если подынтегральная функция непрерывна на участке интегрирования и один предел или оба сразу положены равными ©о, а также если подынтегральная функция имеет один или несколько разрывов на участке интегрирования, интеграл называется несобственным [149, с. 335]. Несобственный интеграл сходится (существует), если существует предел интеграла в рассматриваемых случаях [135, с. 232], в противном случае говорят, что несобственный интеграл расходится (не существует).
Несобственные интегралы часто возникают, например, при вычислении теоретических функций распределения. С уменьшением или увеличением, в зависимости от типа распределения, пределов интегрирования эти функции уменьшаются очень быстро, поэтому практически вычисления можно производить по тем же алгоритмам, что и для обычных определенных интегралов, только соответствующая бесконечному нижнему или верхнему пределу величина подбирается, соответственно, достаточно малой или достаточно большой для того, чтобы точность вычислений была приемлемой. Методы преобразований формул подынтегральных функций для упрощения вычисления несобственных интегралов подробно описаны в [149, с. 335].
В [114, с. 91-93] даны формулы численного интегрирования, реализованные в виде программ на Fortran, а в [149, с. 336] — с помощью электронных таблиц Microsoft Excel. В [158, с. 50], [101, с. 601] дополнительно описаны формула Уэддла (Уэддля) и несколько других методов. Практически определенные интегралы вычисляются с помощью квадратурной формулы Ньютона—Котеса [212, с. 164], различные варианты которой показаны далее.
Методы численного интегрирования
651
Формула прямоугольников
В наиболее простом случае из формулы Ньютона—Котеса получаются формулы прямоугольников [59, с. 378]
£ п-1 п
J /(х)<& = Л£/(х,) = /?£/(*,), а i=0 i=l
где h = (b - а)/п — шаг интегрирования,
п — заданное число участков разбиения квадратурной суммы,
х} = а + jh,j = 0, 1, 2,..., п.
Пример практического использования метода представлен в [149, с. 333].
Формула трапеций
Если берутся два узла формулы, имеет место широко применяемая формула трапеций (правило трапеций) [158, с. 45]
a L 2 i=l
Улучшенная формула трапеций, известная как метод Ромберга, описана в [там же, с. 334]. Пример практического использования метода в электронных таблицах представлен в [149, с. 333]. Пример вызова функции, реализующей формулу трапеций, показан в разделе «Формула Симпсона» данной главы. Обсуждение см. в [114, с. 92], [59, с. 414], [101, с. 601], [128, с. 205], [135, с. 587].
Исходные коды
double Trapezium (double a.double b.int n.userFunc Func) //
// Функция вычисления определенного интеграла
// по формуле трапеций.
// Обозначения:
// а и b - пределы интегрирования.
// п - число интервалов интегрирования.
// Func - определяемая пользователем функция подынтегрального // выражения.
// Возвращаемое значение:
// вычисленное значение интеграла.
И
652
Глава 16. Дифференциальное и интегральное исчисления
{ double s = (Func (а) + Func (b)) h = (b - а) / n, x = a + h;
I 2, // Рабочая переменная // Шаг интегрирования // Текущее значение // переменной
for (register int i = 0: i < n - 1: i++. x += h) s += Func (x);
return s * h; }
Формула Симпсона
Если берутся три узла формулы Ньютона—Котеса, получается формула парабол, называемая также формулой Симпсона [158, с. 47] или правилом Симпсона [149, с. 334],
b h
J /(x)A=-/(a)+/(6)+2[/(x2)+/(x4)... +/fr3>- +/(xn-i)}
где п — четное.
Обсуждение см. в [114, с. 92], [59, с. 384], [135, с. 543], [101, с. 601], [128, с. 217].
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
double UserFunc (double);
void main (void)
{
cout « "SIMPSON IS " « Simpson (1,2,100.UserFunc) « endl ;
« "TRAPEZIUM IS " « Trapezium (1.2.1000,UserFunc)
« endl;
« "SHARP IS " « (UserFunc (2) - UserFunc (1)) « endl;
}
double UserFunc (double x)
//
// Это пример подынтегральной функции exp (х)
//
Ошибки разностных схем
653
{ return exp (х);
}
double Simpson (double a.double b.int n,userFunc Func) 11
// Функция вычисления определенного интеграла
// по формуле Симпсона.
// Обозначения:
// а и b - пределы интегрирования,
// п - число интервалов интегрирования,
// Func - определяемая пользователем функция подынтегрального // выражения.
// Возвращаемое значение:
// вычисленное значение интеграла.
//
{
double si = 0,s2 = 0, // Рабочая переменная
х1,х2, // Текущее значение переменной
h; // Удвоенный шаг интегрирования
//////////////////////////////////
// Проверка и коррекция четности п
if (’Parity (n)) n++:
h = 2 * (b - a) / n;
xl=a+h;
x2 = a + h / 2;
for (register int i = 1; i < n - 1; i += 2. xl += h, x2 += h) {
si += Func (xl);
s2 += Func (x2);
}
return h * (Func (a) + Func (b) + 2 * si + 4 * (s2 + Func (x2))) I 6;
}
Ошибки разностных схем
Разностные формулы характеризуются ошибками двух типов: ошибками отбрасывания и ошибками округления [149, с. 327]. Ошибки отбрасывания принято характеризовать порядком ошибки О (hn). Все разностные схемы вычисления первых и вторых производных, построенные на правых или левых разностях, имеют ошибку 0(h). Схемы, построенные на центральных разностях, имеют ошибку
654
Глава 16. Дифференциальное и интегральное исчисления
0(А2). Однако было бы неверно думать, что чем меньше шаг А, тем меньше ошибка. Одновременно с уменьшением ошибки отбрасывания при уменьшении шага h увеличивается ошибка округления, вызванная тем, что компьютер хранит в своей памяти числа с фиксированным количеством знаков. Поэтому суммарная ошибка достигает минимума при некотором оптимальном значении шага [128, с. 215].
Дальнейшие исследования
Совершенствование реализаций алгоритмов численного дифференцирования и интегрирования.
Глава 17. Прочие математические алгоритмы
В настоящей главе описаны применяемые нами математические алгоритмы и реализующие их функции, не вошедшие ни в одну из предыдущих глав. Выделение каждой группы алгоритмов в самостоятельную главу нерационально по причине их малочисленности, что, однако, не умаляет важности рассмотренных методов и эффективной организации процедур, их реализующих.
Комбинаторика
Методы комбинаторного анализа (комбинаторики) используются при вычислении различных статистических сущностей, а также применяются для конструирования вычислительных схем алгоритмов. Общие вопросы применения комбинаторики в статистическом анализе данных рассмотрены в [70, с. 20]. Полезные решения опубликованы в [223].
Число перестановок
Число перестановок из п элементов равно факториалу п. Показанная далее функция является прямой реализацией определения факториала [ 135, с. 606]:
п! = П&,и >0-ы
Условились считать, что 0! = 1 [101, с. 34]. Алгоритм рекурсивного определения факториала приводится в [45, с. 70]. Обсуждение см. в [100, с., с. 102].
Исходные коды
double Factorial (int n)
И
656
Глава 17. Прочие математические алгоритмы
// Функция возвращает значение факториала п. И
{
register int i; II Счетчик
double Ret = 1: // Возвращаеное значение
for (i = 1; i <= n: i++)
Ret *= i:
return Ret:
}
Для больших значений n вычисление факториала может быть произведено по асимптотической формуле Стирлинга [135, с. 566], [43, с. 183], уже при п = 10 дающей ошибку менее 1%:
Анализ ошибки показанной формулы дан в [100, с. 44].
Если вычисление числа перестановок не представляет трудности, то определение самих перестановок представляет собой нетривиальную, хотя и давно решенную задачу. В наших исследованиях не требовалось определение перестановок, поэтому приведем только ссылки. Рекурсивный генератор перестановок на языке С представлен в [193, с. 265], на языке Perl — в [104,с. 147]. Алгоритм вычисления одной перестановки, не основанный на рекурсии, описан в [там же, с. 148].
Число сочетаний
Число сочетаний из п элементов по тп элементам, обозначаемое так
же как
, может быть вычислено прямо по определению [219, с. 10]
Ст^ П\ т\(п-т)\
Условились считать, что С™ = 0 при п<т [149, с. 322]. Для практических вычислений при небольших значениях параметров удобно применять рекуррентную формулу:
Комбинаторика
657
Q=i.
Q=.”7?.t1Q-|,5 = l,2.m,
s
реализация которой на C/C++ достаточно элементарна.
При больших значениях п и тп возможны вычислительные проблемы переполнения. Вычисление по рекуррентной формуле изящно, однако возможны проблемы со стеком и, опять же, время счета будет велико. Есть универсальный прием для решения задач такого типа (когда некоторое большое число делится на другое большое число): формула сначала логарифмируется, затем основание использованного логарифма возводится в полученную степень. Однако такой способ не должен применяться в методах, где необходимы точные значения при вычислениях (целочисленные вычисления). Обсуждение см. в [100, с. 103].
Исходные коды
double Combination (int m.int n)
11
II Функция возвращает число сочетаний из m по n
11
{
return exp (LogFactorial (m) - LogFactorial (n) - LogFactorial (m - n)):
}
Число благоприятных исходов
При вычислении критерия рандомизации для независимых выборок требуется определить число благоприятных исходов. Данное вычисление реализуется с помощью показанной ниже функции. При вычислении применяется одна дополнительная рекурсивная функция CombinationAdd, которая также может пригодиться при решении других задач, например при вычислении перманента матрицы [135, с. 277].
Исходные коды
int Combination (double dat[],int n.int m.double sum.double *nSUCCESS)
II
II Функция определения числа благоприятных исходов.
// Обозначения:
// dat - массив переменных длиной п.
658
Глава 17. Прочие математические алгоритмы
// m - численность выборки сочетаний,
// sum - заданное критическое значение.
// *nSUCCESS - число благоприятных исходов.
// Возвращаемое значение:
// 0 при нормальном окончании расчета,
// -1 при недостатке памяти для рабочего массива.
//
{
register int j: i nt *i: // Счетчик цикла // Массив счетчиков
double *ext, S[l] - {1}; // Массив сочетаний // Рабочая переменная // (для упрощения манипуляций задана // в виде массива)
if (Hext = new double[m])) return -1;
if (Hi = new int[m]))
{
delete [] ext:
return -1:
}
if (m == 1)
{
*nSUCCESS = 1:
for (j = 0: j < n: j++) if (dat[j] <= sum)
s[0] += 1:
}
el se
CombinationAdd (dat,n.m.ext,sum,i,s.O):
*nSUCCESS = s[0]:
delete [] ext: delete [] i;
return 0;
}
void CombinationAdd (double dat[],int n.int m,double ext[],double sum, int i[],double s[],int k) //
// Вспомогательная функция для определения числа благоприятных // исходов.
// Обозначения:
// dat - массив переменных длиной п,
// m - численность выборки сочетаний,
// ext - нассив сочетаний,
// sum - заданное критическое значение.
Специальные функции
659
// i - массив счетчиков,
// s[0] - число благоприятных исходов,
// к - параметр управления рекурсией.
// Возвращаемое значение:
// нет.
И
{
int count = !k ? - 1 : i[k - 1]: // Рабочая переменная
for (i[k] = count + 1: i[k] <n-m+k+l; i[k] += 1)
{
//////////////////////////
// Набор массива сочетаний
ext[k] = dat[i[k]];
if (k == m - 1)
{
//////////////////////
// Благоприятный исход
if (VectorSum (ext.m) <= sum) s[0] += 1;
}
el se
//////////////////////////////////////////////// // Продолжение процесса набора массива сочетаний CombinationAdd (dat,n,m.ext.sum,i.s,k + 1);
}
}
Специальные функции
В данном разделе приводятся различные способы вычисления двух специальных функций, называемых эйлеровыми интегралами [135, с. 642] и применяемых в представленных методах анализа данных.
Г-функция Эйлера
Г-функция (гамма-функция) действительного аргумента определяется формулой [135, с. 137]
1=0
Пример применения показанных нами функций вычисления Г-функ-ции дан при описании последнего из представленных алгоритмов семейства.
660
Глава 17. Прочие математические алгоритмы
Исходные коды
double GammaE (double х)
11
II Функция возвращает значение Г-функции Эйлера положительного // действительного аргумента
И
{
double п = 10000.
s = х * log (n) - log (х):
for (double 1=1: 1 <= n; 1++)
s += log (i) - log (x + i):
return exp (s):
}
Г-функция также может определяться формулой [135, с. 137, 642], [206, с. 103], [32, с. 103], [101, с. 633]
Г(р) = Jxp~le~xdr • о
В показанных далее функциях в некоторых ветвях алгоритмов производится полиномиальная аппроксимация. Для уменьшения объема записи и некоторого повышения скорости вычислений этот код можно улучшить путем вызова функции Ногпег, что несложно сделать, только нужно будет свести коэффициенты полинома в один массив. Вычисление производится прямым определением значения интеграла по формуле трапеций и частично аппроксимацией.
Исходные коды
double GammaS (double р)
11
II Функция возвращает значение Г-функции Эйлера положительного // действительного аргумента.
И
{
double s = 0.0,
х,
а = 0.000000001.
Ь;
////////////////////////////////////
// Аппроксимация полиномом 4-й степени
if (р <= 1.0)
return 0.83818860 *р*р*р*р- 4.53889793 * р * р * р + 9.69529949 * р * р - 9.71633752 * р + 4.72177274;
if (р <- 6.0)
Специальные функции
661
{
///////////////////////////////////////
// Интегрирование в интервале от 1 до б
b = pow (а.р - 1) / ехр (а):
for (х = а; х <= 2.0 + а; х += 0.001)
{
а = Ь;
b = pow (х.р - 1) / ехр (х);
s += 0.0005 * (Ь + а);
}
for (х = 2.1 + а: х < 15.0; х += 0.1)
{
а = Ь;
b = pow (х.р - 1) / ехр (х);
s += 0.05 * (Ь + а);
}
return s;
}
el se
/////////////////////////////////////
11 Аппроксимация по формуле Стирлинга
return sqrt (6.2831853 / p) * pow (p.p) *
exp (0.0833333 / p - 0.00277777 / p / p / p - p);
}
Для сокращения времени счета вычисления производятся иначе, чем в показанных выше функциях, а именно путем аппроксимации табличных значений. Для больших значений аргумента следующая функция эффективнее всех остальных представленных алгоритмов. Вычисление производится с помощью аппроксимационных формул, полученных по «точным» значениям с использованием программы Microsoft Excel.
Исходные коды
double Gamma (double р) //
// Функция возвращает значение Г-функции Эйлера положительного // действительного аргумента.
//
{
////////////////////////////////////
// Аппроксимация полиномом 4-й степени
if (р <= 1.5)
return 0.83818860 *р*р*р*р- 4.53889793 * р * р * р + 9.69529949 * р * р - 9.71633752 * р + 4.72177274;
if (р <= 3.0)
return 0.10313867 *р*р*р*р- 0.76558711 * р * р * р + 2.53052150 * р * р - 3.81093902 * р + 2.97423187;
if (р <= 4.5)
return 1.05613222 *р*р*р*р- 13.78206423 * р * р * р
662
Глава 17. Прочие математические алгоритмы
+ 69.64262748 * р * р - 158.44821978 * р + 137.18896270:
if (р <= 6.0)
return 17.88486850 *р*р*р*р- 346.24448872 * р * р * р + 2540.77068329 * р * р - 8345.27844238 * р +
10333.60119629:
el se
/////////////////////////////////////
// Аппроксимация по формуле Стирлинга
return sqrt (M_PI * 2 / р) * pow (p.p) *
exp (0.0833333 / p - 0.00277777 / p / p / p - p): }
В [174, c. 308] даны асимптотические формулы вычисления логарифма Г-функции, полученные путем разложения исходной функции в ряд и удержания конечного числа его членов. Для больших значений аргумента (действительной части аргумента) Г-функция может быть приближенно очень экономично вычислена по асимптотической формуле Стирлинга [135, с. 566]. В [114, с. 158] приведен рекуррентный алгоритм вычисления Г-функции, причем ядром соотношения является аппроксимационная формула, а [92, с. 119], [ 101, с. 637] дают более точное выражение для формулы Стирлинга, что позволяет вычислять Г-функцию и ее логарифм с любой заданной точностью:
т-/ \ -х х"? L 1 1 3/1
Г(х) = е х 2 ] 1 +---+---------------------------т...
v 7 1 12х 288х2 51840х3 2488320*4
1 ч Г 1, п 1 1 1
logr(x)= х-- logx-x + -log2rc + ——ттт-^4-
12 1 2 12х ЗоОх 1260х
1 1
1680х7 +1188х9 " ’
Во многих практических вычислениях, однако, нет необходимости примененять столь громоздкие выкладки. Так, Г-функция обладает свойством [63, с. 46]
Г(а) = (а- 1)Г(а- 1), а> 1.
Поскольку Г(1) = 1, для всех натуральных (то есть целых положительных) чисел п
Т(п) = (п- 1)!,
Специальные функции
663
г-
а так как Г - = у/л , для полуцелых значении аргумента значение
г -I2,
куррентной формулы. Пример вычисления значений Г-функции для целых и полуцелых значений аргумента приводится нами в сравнении с «точным» значением.
Обсуждение см. также в [149, с. 336].
может быть также легко вычислено из показанной выше ре-
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void)
{
for (double n - 0.5: n <« 6: n +- 0.5)
cout « "n = " « n « endl « "gamma (exact) = " « Gammal (n) « ". gamma (approximate) = " « Gamma (n) « endl:
}
double Gammal (double n)
//
// Функция вычисляет ганиа-функцию целого или полуцелого
// аргумента.
// Обозначения:
// п - аргумент.
// Возвращаемое значение:
// значение гамма-функции.
//
{
double а. // Вспомогательная величина, затем шаг
seed; // Возвращаемое значение
////////////////////////////////
// Выбор между целым и полуцелым
if (!modf (n.&a))
{
seed = 1:
a = 2:
}
el se
{
seed = sqrt (M_PI):
a = 1.5:
}
664
Глава 17. Прочие математические алгоритмы
/////////////////////////////
// Рекурсия по подсчету ганна-функции for (: а <= п; а++)
seed *= (а - 1);
return seed;
}
В-функция Эйлера
В-функция Эйлера (бета-функция) определяется по формуле [135, с. 94]
В(«, b) = | У2 1 (1 - х)ь' dx • о
Исходные коды
double Betas (double a. double b)
11
II Функция возвращает значение В-функции Эйлера. // {
double s = 0.0.
х = 1.0. // Верхний предел
// интегрирования
t.tO = 0.000000001.
h = х / 200. // Шаг интегрирования
c.d;
d = pow (tO.а - 1) * pow (1.0 - tO.b - 1): for (t = h; t <= x: t += h)
{
C = d;
d = pow (t.a - 1) * pow (1.0 - t.b - 1):
s += h * (c + d) / 2;
}
return s;
)
В-функция выражается через Г-функцию [там же] как
B(«,Z>) =
Г(Д)Г(6) Г(а + Ь)
В представленной функции может быть применен любой из рассмотренных выше алгоритмов вычисления Г-функции с учетом всех указанных в комментариях к этим алгоритмам ограничений.
Различные функции
665
Исходные коды
double Beta (double a, double b)
11
II Функция возвращает значение В-функции Эйлера.
//
{
return Gamma (а) * Gamma (b) / Gamma (a + b):
}
Обсуждение см. также в [101, с. 638].
Различные функции
Различные функции, предназначенные для выполнения простых вспомогательных операций с числами, применяются практически во всех разделах анализа данных. Эти функции полезны для построения других методов расчета, так как по крайней мере экономят место при записи, как показанные далее функции специального заполнения массивов.
Исходные коды
void FillUpDiag (double a[].1nt n.double p) //
// Функция заполняет диагональ квадратной матрицы
// заданным значением.
// Обозначения:
// а - натрица.
// п - размерность матрицы,
// р - заполнитель.
// Возвращаемое значение:
// нет.
//
{
for (register int i = 0: i < n * n: i += n + 1) a[i] = p:
}
void FillUpCol (double a[],int n.int c.double p)
//
// Функция заполняет столбец матрицы заданным значением.
// Обозначения:
// а - натрица.
// п - число строк матрицы а.
// с - номер заполняемого столбца (нумерация от 0),
// р - заполнитель.
// Возвращаемое значение:
// нет.
И
666
Глава 17. Прочие математические алгоритмы
{
int 1: // Счетчик одномерного массива
for (register int i = 0, 1 = с * n: i < n; i++) a[l++] = p;
}
void FillUpRow (double a[],1nt n.int m.int c,double p)
//
// Функция заполняет строку матрицы заданным значением.
// Обозначения:
// а - матрица.
// п - число строк матрицы а,
// m - число столбцов матрицы а.
// с - номер заполняемой строки (нумерация от 0).
// р - заполнитель.
// Возвращаемое значение:
// нет.
//
{
int 1: // Счетчик одномерного массива
for (register int i = 0. 1 = с; i < m: i++, 1 += n) a[l] = p;
}
void FillUp (double a[],int n.double p)
//
// Функция заполняет массив заданным значением.
// Обозначения:
// а - массив длиной п.
// р - заполнитель.
// Возвращаемое значение:
// нет.
//
{
for (register int i = 0: i < n; i++)
a[i] = p:
}
void FillUp (int a[].int n.int p)
//
// Функция заполняет массив целых заданным значением.
// Обозначения:
// а - массив длиной п.
// р - заполнитель.
// Возвращаемое значение:
// нет.
//
{
for (register int i = 0: i < n: i++) a[i] = p;
}
Различные функции
667
Рассмотренная далее функция применяется для округления числа до целых значений в соответствии с общепринятыми правилами [22, с. 759]. Случай является частным по отношению к изложенному в указанном источнике правилу дополнения, которое гласит, что число округляется путем отбрасывания одной или нескольких цифр справа, причем если первая из отбрасываемых цифр 5, 6, 7, 8 или 9, то предшествующую цифру следует увеличить на единицу. Функция предназначена для компенсации ошибок округления при различных вычислениях, например при подсчете числа сочетаний с параметрами высоких порядков в комбинаторике.
Обсуждение и ссылки на ресурсы Интернета по данной проблеме приводятся в [36, с. 173].
Исходные коды и пример применения
#include <fstream.h>
#1nclude <iomanip.h>
#include <math.h>
#include "megastat.h"
void main (void) {
cout « "Round of " « 2.4 « " is " « SmartRound (2.4)
« "\nRound of " « 2.6 « " is " « SmartRound (2.6) « endl;
}
double SmartRound (double x)
//
// Функция округления числа до целых значений.
// Возвращаемое значение:
// округленное значение числа.
//
{
double у = floor (х);
if (х - у < 0.5)
return у;
el se
return у + 1:
}
Функция проверки четности числа обычно служит для принятия решения об использовании той или иной ветви алгоритма.
Исходные коды int Parity (int n)
668
Глава 17. Прочие математические алгоритмы
//
// Функция проверки четности целого числа.
// Обозначения:
// п - число.
// Возвращаеное значение:
И 0. если число нечетное
и 1. если число четное.
и г
i f (n / 2 < t 2 == п)
return 1; // п - четное
el se
return 0: // n - нечетное
}
Приводится два варианта функции определения знака числа в зависимости от отношения к нулю, что требуется различными алгоритмами.
Исходные коды
double Sign (double k)
//
// Функция вычисления знака вещественного числа.
// Обозначения:
// к - число.
// Возвращаемое значение:
// 0. если число равно нулю.
// единица со знаком числа в ином случае
//
{
if (к > 0)
return 1;
else if (к < 0)
return -1:
el se return 0;
}
int Sign (int k)
//
// Функция вычисления знака целого числа.
// Обозначения:
// к - число.
// Возвращаеное значение:
// 0. если число равно нулю.
// единица со знаком числа в ином случае.
//
{
if (к > 0)
return 1;
else if (к < 0)
Различные функции
669
return -1:
el se
return 0:
}
double SignNull (double k)
//
// Функция вычисления знака вещественного числа.
// Обозначения:
// к - число.
// Примечание:
// 0 считается положительным числом.
// Возвращаемое значение:
// единица со знаком числа.
//
{
if (к >= 0)
return 1;
el se
return -1;
}
Представленная далее функция подсчитывает число отрицательных значений в массиве.
Исходные коды
int NumberOfMinus (double x[],int k)
//
// Функция подсчета отрицательных значений в массиве.
// Обозначения:
// х - массив чисел,
// к - численность выборки.
// Возвращаемое значение:
// количество отрицательных значений в массиве.
//
{
int Ret = 0; // Возвращаеное значение
for (register int i = 0: i < k: i++)
if (SignNull (x[ij) < 0)
Ret++:
return Ret:
}
Следующая функция производит простую операцию перемены местами значений двух чисел. Помимо пратического использования подобные простые алгоритмы часто применяются также в учебных целях. Решение на языке Fortran 77 см. в [162, с. 32].
670
Глава 17. Прочие математические алгоритмы
Исходные коды
void Numberlnterchange (int *а. int *b) //
// Функция перемены местами значений двух чисел.
// Обозначения:
// *а и *Ь - исходные числа.
// Возвращаемое значение:
// нет.
//
{
int с;
с = *Ь;
*Ь = *а:
*а = с:
}
Функция возведения произвольного числа в целую степень намного увеличивает диапазон применимости функции pow, обычно входящей в стандартные поставки различных систем программирования. Полезной особенностью данной функции является то, что она может возводить в степень и отрицательное основание, чего стандартная функция не делает, так как по сути она представляет собой комбинацию взятия экспоненты и логарифмирования, а логарифм отрицательного числа не определен.
Исходные коды
double PowerOf (double x,int n)
//
// Функция возведения произвольного числа в целую степень.
// Обозначения:
// х - основание степени.
// п - показатель степени.
// Возвращаемое значение:
// степень числа.
//
{
double s = 1; // Возвращаемое значение
for (register int i = 0; i < n: i++)
s *= x;
return s;
}
Функция возведения числа 2 в целую степень заменяет собой битовую операцию типа 2 «, причем в данной функции, в отличие от указанной операции языка С или C++, корректно работает возведение в нулевую степень.
Различные функции
671
Исходные коды
int TwoDegree (int n)
//
// Функция возвращает значение 2 в степени п.
// Обозначения:
// п - показатель степени.
// Возвращаемое значение:
// степень числа 2.
//
{
int Ret = 1; // Возвращаемое значение
for (register int i = 1; i <= n: i++)
Ret *= 2;
return Ret:
}
Быстрое вычисление значения полинома (многочлена) в данной точке может быть произведено по схеме Горнера (правилу Горнера). Метод основан на применении формулы [100, с. 716]
Л(*о) “ а0 + Х0^а2 ••• + Хо(ап-/))—)•
Подробное обсуждение схемы алгоритма см. также в [114, с. 16], [128, с. 104], [129, с. 19], [159, с. 17]. Решение на языке Fortran 77 дано в [162, с. 88].
Исходные коды
double Horner (double a[],int n,double x) //
// Функция быстрого вычисления полинома по схеме Горнера.
// Обозначения:
// а - заданный вектор коэффициентов полинома, расположенных // в порядке возрастания степени одночленов, длиной (n + 1), // п - степень полинома,
// х - заданная переменная.
// Возвращаемое значение:
// значение полинома.
//
{
double г = 0; // Возвращаемое значение
for (register int i = n: i >= 0; i—) r = r * x + a [ i ]:
return r;
}
672
Глава 17. Прочие математические алгоритмы
/-преобразование Фишера [140, с. 170], или гиперболический арктангенс действительной переменной, вычисляется по формуле [135, с. 423]
Arth(x) = ПРИ W < 1-
Исходные коды
double Arth (double г)
//
// Функция вычисления арктангеса гиперболического
// действительной переменной.
// Обозначения:
// г - переменная.
// Примечание:
// (нодуль г) < 1. случай (нодуль г) >= 1 не проверяется
// Возвращаемое значение:
// значение арктангенса гиперболического.
//
{
return log ((1.0 + г) / (1.0 - г)) / 2;
}
В стандартной поставке средств разработчика часто отсутствуют некоторые необходимые функции. Показанный далее фрагмент служит иллюстрацией того, как может быть расширена стандартная библиотека. Функция вычисляет арккотангенс путем разложения в бесконечный ряд и удержания стольких членов ряда, чтобы, с одной стороны, обеспечить достаточную точность, а с другой — не потерять быстродействия. Вычисления производятся по формулам [219, с. 96]
7Г “ Г2”+1
агсс^) = Г2(-1Г1^й
ДЛЯ И < 1,
arcctg(x) = —1—- Длях> 1,
^П + 1)Х
“ 1
arcctg(x) = л + £(-1)" ———для х < -1.
В источнике даны и другие примеры разложений.
Параметры вычислительной системы
673
Исходные коды
double Arcctg (double х) //
// Функция вычисляет значение функции арккотангенса. // Обозначения: // х - аргумент.
// Возвращаемое значение:
// значение функции арккотангенса в радианах.
//
{
double s; // Возвращаемое значение
if (fabs (х) <= 1)
return М PI / 2 - х + 0.333333333333 * pow (х.З) - 0.2 * pow (x.5) + 0.142857142857 * pow (x.7) - 0.111111111111 * pow (x,9);
s = 1.0 / x - 0.333333333333 / pow (x.3) + 0.2 / pow (x.5) -0.142857142857 / pow (x.7) + 0.111111111111 / pow (x.9);
if (x < -1)
return M_PI + s;
el se
return s;
}
Параметры вычислительной системы
Типы данных, используемые в С и C++, являются машинно-зависимыми [153, с. 112]. Надо отличать диапазон представления переменной, например, типа double, от минимальной и максимальной величины переменной. Если в стандарте ANSI C++ максимальная величина типа double равна 1Е+37, в MS-DOS указанная величина будет 1.7Е+308. Однако это совсем не значит, что ваша DOS-программа сможет различить, к примеру, величины 1,7 • 1О40 и (1,7 • 1О40 + 1). Важно также знать, насколько малой будет величина, не отличимая системой от нуля. В обоих случаях проблема состоит в том, сколько позиций в системе отводится под мантиссу.
Машинную точность принято [77, с. 26], [139, с. 291] характеризовать наименьшим положительным числом е («машинным эпсилоном») таким, что
1 +Е> 1.
22-2002
674
Глава 17. Прочие математические алгоритмы
Рассуждая аналогично, максимальным числом, которое может различить данная модель компьютера (операционная система), будет такое наибольшее число т, что
т * т + 1.
Показанный ниже пример является одним из вариантов выяснения размера минимального и максимального чисел, воспринимаемых вычислительной системой. Этот вопрос важно решить до применения конечно-разностных и иных вычислительных, в частности итерационных, методов, когда нужно иметь информацию о возможностях системы по получению требуемой точности. Для практических целей заданная точность обычно назначается гораздо меньшей, чем точность, обеспечиваемая операционной системой. Так, для решения систем линейных или дифференциальных уравнений точность обычно задается примерно 0,000001. Обсуждение см. также в [149, с. 16]. Ошибки подробно рассмотрены в [128]. См. также [ 184, с. 48]. Максимальный порядок чисел в системе особенно важно учитывать при использовании некоторых криптографических алгоритмов.
Исходные коды и пример применения
#include <fstream.h>
#include <iomanip.h>
#include "megastat.h“
void main (void) {
double Min.Max:
GetMinMax (&Min.&Max);
cout « "Minimum in operating system is E-" « Min « endl « "Maximum in operating system is E+" « Max « endl:
}
void GetMinMax (double *xmin.double *xmax)
II
II Функция вычисления минимального и максимального
// чисел типа double, распознаваемых операционной системой.
// Обозначения-
// *xmin - порядок минимального числа (добавить минус к порядку).
// *хтах - порядок максимального числа (можно добавить плюс).
// Возвращаемое значение:
// нет.
И
{
*xmin = 0:
Дальнейшие исследования
675
*хшах = 0;
for (double t - 1; 1 + t > 1; t /= 10) (*xmin)++;
for (t = 1: t != t + 1: t *= 10) (*xmax)++;
}
Дальнейшие исследования
Разработка и реализация алгоритмов, применение которых обусловлено требованиями новых методик анализа данных, а также совершенствование уже реализованных методов.
22*
Глава 18. Реализация программы анализа данных
Программа анализа данных может быть реализована несколькими способами:
• Составление законченного приложения, для работы которого требуется только компьютер с установленным системным программным обеспечением. Внешний вид программы зависит от возможностей операционной системы и опыта и привычки программиста. Минимальная программа с использованием приведенных в данной книге исходных текстов расчетных функций может быть построена для MS-DOS или в виде консольного приложения Windows NT. При этом большинство функций может быть использовано вместе с примерами их применения, также показанными в книге, без какой-либо модернизации. Однако, если предполагается сделать действительно удобную, полезную для пользователей программу, придется заняться графическим интерфейсом, а также обеспечить импорт данных из распространенных электронных таблиц и баз данных.
• Исполнение программы в виде надстройки (add-in) к популярной программе электронных таблиц или персональной системе управления базами данных либо поставка функций в составе динамически подключаемых библиотек (DLL) для Windows. Для запуска такой программы нужно иметь на компьютере базовую программу, под управлением которой предполагается работа приложения, а поставляемая надстройка призвана увеличить функциональность базовой программы.
• Программа может быть построена также в виде апплета или сценария. Апплет обычно загружается через Интернет, либо может использоваться его локальная копия. Выполнение программы производится под управлением стандартного браузера (броузера, browser) независимо от типа используемой аппаратно-программной платформы.
Средства разработки приложений
677
Средства разработки приложений
На выбор или отказ от выбора продукта могут оказать определяющее влияние различия этических и эстетических убеждений разработчика и заказчика. Выбор платформы и компилятора, основного рабочего инструмента, — дело вкуса и привычки программиста. Не последнюю роль могут сыграть требования заказчика и его финансовые возможности. Возможно, у программиста не будет выбора, какой технологией пользоваться при решении задачи, — мы немного познакомились с методикой набора программистов для работы за рубежом, в частности для решения пресловутой Проблемы-2000. Однако в противном случае следующий раздел поможет сделать выбор.
Выбор технологии программирования
Предметом нашего интереса на протяжении последних лет является так называемое научное программирование. Вычислительная математика опирается на методы, предложенные 1000 и более лет назад, в той же мере, что и на разработанные в последние 10 лет. Вычислительные компьютерные программы и заложенные в них алгоритмические идеи, созданные и развитые в 60-х годах XX века, применяются до сих пор. Это позволяет надеяться, что научная программа имеет срок жизни, значительно превышающий срок жизни других категорий программ.
В жанре научного программирования чаще всего применялись различные диалекты алгоритмических языков Фортран (Fortran — от FORmula TRANslation), разработанного фирмой International Business Machines в 1956 г. (стандарт ANSI 1966 г. и 1978 г.), Алгол (Algol — от ALGOrithmic Language), появившегося в 1958 г., либо Бейсик (BASIC — от Beginnerr's All-purpose Symbolic Instruction Code), разработанного в 1964 г. сотрудниками Дармутского колледжа. Программы на Фортран обладают хорошей переносимостью благодаря реализации на различных типах ЭВМ и хорошей скоростью выполнения. Фортран и ныне не утратил привлекательности, особенно в свете возможностей программирования на нескольких языках одновременно, в пределах одного разрабатываемого проекта.
Язык программирования С был разработан Д. Ритчи в 1972 г. (стандарт ANSI 1988 г.). Язык C++ разработан Б. Страуструпом из AT&T Bell Laboratories в 1984 г. С повсеместным распространением Интернета создаются новые языки и технологии программи
678
Глава 18. Реализация программы анализа данных
рования. С 1986 г. сообщество программистов развивает универсал ь-ный язык Perl (Practical Extraction and Reporting Language). Фирма Sun Microsystems, Inc. в 1990 г. разработала технологию Java, а в конце 1995 г. фирма Netscape Communication Corp, создала JavaScript. Можно выделить следующие критерии выбора языка программирования:
1. Стандартизация либо повсеместное распространение (стандарт де-факто) языка, наличие его реализаций на большинстве или на всех программно-аппаратных платформах.
2. Фирменная поддержка применяемой в разработке системы программирования, подкрепленная устойчивостью и авторитетом ее производителя, и в то же время наличие свободно распространяемых версий систем программирования на данном языке.
3. Компактность и эстетическая привлекательность языковых конструкций и проектных решений.
Считаем, что по этим показателям в текущий момент времени выбор языков C/C++ наиболее оправдан. Реализации компиляторов таковы, что расчетная программа, написанная для одной операционной системы, скорее всего, без больших переделок пойдет и на другой. Благодаря поддержке крупнейших фирм-разработчиков, с одной стороны, а с другой стороны, благодаря наличию бесплатно распространяемых версий, накрывается практически весь диапазон требований и финансовых возможностей потребителей. Основными коммерческими версиями систем программирования на языках C/C++ для персональных компьютерных систем на платформе Microsoft Windows являются: Microsoft Visual C++ (www.micro-soft.com), начавший свое развитие [ 199, с. 18] от разработанного фирмой Lattice Inc. и благополучно здравствующего до сих пор компилятора Lattice С (www.lattice.com), а также Borland C++ и C++ Builder, ныне принадлежащие Inprise Corp, (www.inprise.com), начавшие свое развитие от разработанного фирмой Borland International компилятора Turbo С.
Говоря об эстетике языковых конструкций C/C++, можно привести аналогию с давно замеченным авиастроителями фактом, что хорошо летает только красивый самолет. Правда, чтобы написать хорошую программу на С, программисту надо думать на С.
Утверждается [224, с. 367], что переход Kjava (и, добавим, к JavaScript, Perl и другим языкам, в числе своих прародителей имеющим язык С), если возникнет необходимость, легче совершить от C++, чем от какого-либо другого языка, и это на самом деле так. Предлагаемые
Средства разработки приложений
679
в нашей книге программы могут быть переписаны на Java, JavaScript или Perl гораздо быстрее, чем с языка программирования, по синтаксису сильно отличного от C/C++, что мы намерены продемонст-ровать.
В табл. 18.1 приводится сравнительная стоимость некоторых конфигураций средств разработки. Цены даны по каталогу SoftLine direct (www.softline.ru) для стандартных версий. В случае использования каких-либо визуальных средств быстрой разработки приложений цена сильно увеличится. Например, стоимость True DBGrid может добавить 475 USD к общей сумме.
Таблица 18.1. Сравнительная стоимость некоторых конфигураций средств разработки
Операционная система Средства разработки Пользовательские средства Сумма, USD
Название Цена, USD Название Цена, USD Название Цена, USD
MS Windows 155 Visual C++ 109 MS Excel 97 346 610
Тоже 155 Тоже 109 Sun StarCalc или не требуется — 264
Тоже 155 Perl или JavaScript — Браузер или не требуется — 155
MS-DOS 56 Turbo C++ 81 Не требуется — 137
Linux 0 С, Perl или JavaScript — Sun StarCalc, браузер или не требуется — 0
Программные ресурсы
Далее приведем некоторые ссылки на фирмы, поставляющие визуальные средства быстрой разработки и библиотеки классов для систем программирования на C/C++. Также упомянем библиотеки, которые написаны не на С, и компиляторы не C/C++, которые тем не менее могут применяться в программах и с программами на C/C++. Например, компилятор Intel Fortran1 выполнен как допол-
Компиляторы Fortran поставляют: Salford Software Ltd.; Microway, Inc.; Silicon Graphics, Inc.; Sun Microsystems, Inc.; Microsoft Corp.; Sybase, Inc.; Compaq Computer Corp, и др.
680
Глава 18. Реализация программы анализа данных
нительный модуль (plug-in) к Microsoft Visual C++ (www.micro-soft.com). Обратные примеры — компиляторы С входят в комплект поставки Lahey/Fujitsu Fortran (www.Lahey.com) и Absoft Corporation Pro Fortran (www.absoft.com). В последней колонке табл. 18.2 указаны поддерживаемые операционные системы, а для средств разработки — также и компиляторы. Большинство разработчиков снабжают свои средства разработки различными библиотеками (или поставляют их отдельно), облегчающими построение законченных приложений.
Таблица 18.2. Программные ресурсы по системам программирования на языках C/C++
Ресурс, адрес Разработчик или поставщик Продукт Платформа
www.gnu.org /software/gcc /gcc.html Free Software Foundation, Inc. GNU C (GCC) Windows, UNIX, Linux, OS/2
www.powersoft.com Sybase, Inc. Watcom C/C++ Windows, OS/2, Netware
www. microway. com Microway, Inc. NDP C/C++ Windows, OS/2, UNIX
www.salford.co.uk Salford Software Ltd Salford C++ Windows, MS-DOS
www.sas.com /software/sas_c /crosplat.html SAS Institute Inc SAS/C C, C++ Windows, UNIX
developer.intel.com /vtune/icl Intel Corp. Intel C/C++ Compiler Windows
www.kai.com Kuck & Associates, Inc. KAI C++ UNIX
www.sun.com Sun Microsystems, Inc. Forte C, C++ Solaris
www.sgi.com Silicon Graphics, Inc. ProDev C++ IRIX
Системы разработки приложений поставляют также Sybase, Silicon Graphics, Absoft Corporation, Visual Numerics, (www.vni.com/products/ imsl/imslc.html), Metrowerks (www.metrowerks.com), Santa Cruz Operation (www.sco.com).
Системы программирования на C/C++ подробно описаны во многих источниках. Из классики по языку С см. [25], [94], [185], [199],
Программа анализа данных
681
а по C++ [183], [227], [122]. На CD-приложении к «КомпьютерПресс» № 12 за 1998 г. есть небольшая подборка ресурсов Интернета по средствам программирования на языках C/C++. По языку программирования JavaScript см. [36], [62], а по Perl — [104]. [216], [220]. Добавим, что Java и JavaScript поддерживаются большинством современных браузеров, причем некоторые имеют средства отладки приложений.
Программа анализа данных
Достоинством рассматриваемого подхода является то, что в итоге получается действительно настоящая программа в общепринятом смысле этого слова. Она может быть зарегистрирована, продана, поставлена пользователю во вполне осязаемом виде вне зависимости от того, какие программы пользователь уже имеет на своем компьютере. Для анализа данных пользователю достаточно только приобрести операционную систему и программу анализа.
Недостатком является сложность разработки и поддержки, усугубленная возможными проблемами коллективной разработки. Хотя и имеются примеры разработки подобных программ одним человеком, это является скорее исключением, чем правилом. Совершенно очевидно, что данные разработки находятся па пределе возможностей одного программиста. При этом разработчики должны не только уметь построить интерфейс, чем, впрочем, и ограничиваются большинство из них, но и разбираться в методах анализа. Другим недостатком является платформенная зависимость составленного приложения, хотя намечается прогресс в решении этой проблемы.
В табл. 18.3 приводятся адреса ресурсов Сети, чтобы программист мог посмотреть примеры того, как должна выглядеть его программа и сколько она должна стоить. Высокая стоимость зарубежных и большинства отечественных программ по анализу данных дает пользователям основание предполагать, что они получают действительно качественные программные продукты.
Многие поставщики предлагают пробные и демонстрационные версии программ, как правило, отличающиеся тем, что пробная версия представляет собой полнофункциональный продукт с ограниченным сроком использования, а демонстрационная версия скорее напоминает электронную презентацию.
23-2002
682
Глава 18. Реализация программы анализа данных
Таблица 18.3. Интернет-ресурсы по универсальным программам анализа данных
Ресурс, адрес Разработчик или поставщик Содержание
www.spss.ru SPSS Inc. SPSS SYSTAT, доступна демонстрационная версия BMDP
www. statgraphics.сот Manugistics, Inc. STATGRAPHICS Plus, доступна демонстрационная версия
www.statsoft.ru StatSoft, Inc. STATISTICA, доступна демонстрационная версия, документация на CD-приложении к журналу «КомпьютерПресс» Ng 3 за 2000 г.
www.sas.com www.sas.com, www.cherwell.com SAS Institute Inc. JMP, доступна демонстрационная версия StatView, доступна демонстрационная версия
www.ncss.com NCSS Statistical Software NCSS PASS, доступна пробная версия
www.unistat.com UNISTAT Ltd. UNISTAT, доступна демонстрационная версия
www.minitab.com Minitab, Inc. Minitab, доступна демонстрационная версия
www.dataxiom.com Dataxiom Software, Inc. StatMost, доступна демонстрационная версия
www.simstat.com Provalis Research SIMSTAT, доступна пробная версия
www. kovcom р. со. uk Kovach Computing Services Ghana, доступна демонстрационная версия MVSP, доступна пробная версия Data Desk, доступна демонстрационная версия
www.camcode.com www.statsdirect.com lain E. Buchan StatsDirect, доступна пробная версия
www.microcal.com Microcal Software, Inc. Origin, доступна демонстрационная версия
www.graphpad.com Graph Pad Software, Inc. Prism, доступна пробная версия
Программа анализа данных
683
Таблица 18.3 (продолжение)
Ресурс, адрес Разработчик или поставщик Содержание
www.nag.co.uk The Numerical Genstat
Algorithms Group Ltd. Glim
www.cytel.com Cytel Software Corp. StatXact, доступна пробная версия
www.statsol.ie Statistical Solutions Inc. EquivTest
www.stata.com Stata Corp. Stata
www.statware.com Statware, Inc. Statit Release, доступна пробная версия
www.decision- Decision STATS, бесплатно
analyst.com Analyst, Inc.
www.rti.org/patents Research Triangle SUDAAN
/sudaan/sudaan.html Institute
www. sigma-research. Sigma Research STATISTIX, доступна
com/bookshelf /default.htm Associates пробная версия
forrest.psych.unc.edu ViSta Software ViSta, бесплатно, имеется
/research/ViSta.html версия с исходными кодами
www.some- Someware Ecstatic for Windows,
wareinvt.com in Vermont, Inc. доступна пробная версия
www.texasoft.com TexaSoft WINKS (KWIKSTAT для Windows), доступна пробная версия
www. exe tersoftware, com Exeter Software BIOMstat
www.insightful.com Insightful Corp. S-PLUS, доступна пробная версия
www.esbcon-sult.com.au ESB Consultancy ESBStats
www.limdep.com Econometric Software LIMDEP
www.ssicentral.com Scientific Software LISREL, доступна бесплатная
International, Inc. версия HLM, доступна бесплатная версия
users.aol.com MicroMetrix AssiStat, доступна
/micrometr /homepage.htm Corporation демонстрационная версия
продолжение &
23
684
Глава 18. Реализация программы анализа данных
Таблица 18.3 f продолжение)
Ресурс, адрес Разработчик или поставщик Содержание
www. abtech. com MarketMiner Inc. Prophet
statsoft.msu.ru НПО «Информатика и компьютеры» STADIA, доступна демонстрационная версия
www.bsu.unibel.by Белорусский государственный университет Стан Ростан
www.ultersys.ru АЛЬТЕР СИСТЕМЫ (Ulter Systems, Inc.) Pulsar, доступна демонстрационная версия
www.softsite.ru Центр интеллектуальных систем (ЦИС)«Метод» Stat-Media
www.megaputer.ru Мегапьютер Интеллидженс PolyAnalyst, доступна демонстрационная версия, также на CD-приложении к «КомпьютерПресс» № 12 за 1999 г.
Разработка программы для MS-DOS
Для создания приложения в операционной системе MS-DOS мы обычно применяем одну из доступных и хорошо документированных, в том числе на русском языке, систем программирования, такую как Borland C++ 3.1.
С точки зрения разработчика вычислительных программ основной недостаток MS-DOS заключается в том, что ни одна отдельная единица данных не может превышать 65 536 байт (64 Кбайт) [193, с. 139]. В 16-разрядной Windows (Win 16) отдельный объект данных также не должен превышать 64 Кбайт [153, с. 376]. Это означает, что массив типа double будет содержать не более 8192 элементов. Для методов, оперирующих, например, корреляционными матрицами, максимальный порядок матрицы составит в таком случае 90. Данные ограничения не позволяют разрабатывать действительно большие программы, хотя для многих практических задач таких размеров данных будет достаточно. Стандартные функции выделения памяти не отслеживают ошибку выделения памяти для отдельной единицы данных свыше 64 Кбайт — это является обязанностью программиста.
Для создания простейшего приложения откройте новый проект, как показано на рис. 18.1.
Программа анализа данных
685
Рис. 18.1. Создание проекта для MS-DOS
Добавьте к проекту файл, как показано на рис. 18.2, и наберите в нем исходный текст программы.
Рис. 18.2. Этап разработки программы для MS-DOS
Скомпилируйте проект, как показано на рис. 18.3.
Рис. 18.3. Компиляция приложения для MS-DOS
686
Глава 18. Реализация программы анализа данных
Повторяйте последний этап, пока не удастся исправить все ошибки. Запустите программу на выполнение. При работе в операционной системе MS-DOS программу можно запустить на выполнение непосредственно из системы программирования, однако делать этого не следует, так как сбой программы обычно ведет к сбою системы программирования и потере всех несохраненных данных. При работе в операционной системе Windows 95/98 и более поздних версиях запускать вновь созданную программу MS-DOS на выполнение лучше не из интегрированной системы, а в отдельном окне MS-DOS — чаще всего это безопасная процедура и для операционной системы, и для системы программирования.
По программированию в системе Borland C++ см. [19], [25], [145], [193].
Пример консольного приложения для Windows
С точки зрения разработчика вычислительных программ главным преимуществом 32-разрядной операционной системы является снятие ограничения на максимальный объем отдельной единицы данных в 64Кбайт [105, с. 160]. Доступная для выделения память ограничена только ее физическим (виртуальным) объемом.
Для создания приложения в 32-разрядной операционной системе семейства Windows (95/98/NT) мы применяем одну из вполне доступных, благодаря наличию специальных версий и гибкой ценовой политике производителя, и хорошо документированных систем программирования Microsoft Visual C++ (в примере показана версия 5.0). Создайте новый проект типа Win32 Console Application, как показано на рис. 18.4.
Fib- P«i«ds | ВфаФиаагум* |:
Гансом Awwead
Д ^DevSturioAddoWized
|| rglSARExtermon Wizard
: Уу. Макете
: ^MFCActr^ConhoWizard
: «5MFCA«>Weaid(<D
< 0MFCA₽oWeard(e><e)
Ti l Йу Proper
,МЛ» >
J
*
/v Qeara new «зЛадс»
tWryy ....
r 2 “
Г CK~| Cared ।
Рис. 18.4. Создание проекта для Windows
Программа анализа данных
687
Добавьте к проекту файл, как показано на рис. 18.5, и введите исходный текст программы.
jJkyApd
JwjApp "
IcAMjAr»
Рис. 18.5. Разработка программы для Windows
|£ gtlAdive Serve Pag*
<-< Bitmap He
О OC*+ eadeFfe
U ЭСтогЯ»
? \ js HTML Page Н Jljwfie ij ;>ac« He ji> ^Resouce Sopt
Resource Template IfiTatHe
Скомпилируйте проект, как показано на рис. 18.6.
а
MjApp Mictotoft Vnual С«* [МуАрр срр ’1
МП
LJ
z ' РаБсчзя пере-немкая Зачисленное значение сханискики кримерия
*)e6ugg«harnUe<ane •...
.32.^
Рис. 18.6. Компиляция приложения для Windows
688
Глава 18, Реализация программы анализа данных
Повторяйте последний этап, пока не удастся исправить все ошибки. Запустите программу на выполнение.
По программированию в системе Microsoft Visual C++ см. [29], [105], [153], а также десятки отечественных и переводных более новых источников, в избытке имеющихся в книжных магазинах.
Проектирование оконного приложения
В рассмотренных нами типах приложений отсутствует весьма важная, с точки зрения потребителя, часть, определяющая полезность программы, а именно — пользовательский интерфейс.
В рамках операционной системы MS-DOS разработка интерфейса проводилась нами с применением мощных и хорошо документированных библиотек: Turbo Vision фирмы Borland [12], [145] либо Object Professional фирмы TurboPower Software, причем по последнему пакету литература на русском языке нам не встречалась, что с избытком компенсировалось наличием великолепной документации в двух томах. Для доступа к базам данных мог применяться Paradox Engine фирмы Borland, также прекрасно документированный. Хотя программы для MS-DOS пишутся и сейчас, создание коммерческого программного продукта для этой операционной системы считается в настоящее время бесперспективным, поэтому далее мы кратко рассмотрим средства разработки оконных приложений для Windows.
Пользовательский интерфейс
Анализ образцов рассматриваемого типа программного обеспечения показывает, что современная программа анализа данных представляет собой электронные таблицы, возможно, с ограниченными по сравнению с обычными электронными таблицами средствами манипуляций данными, но с изощренными методами расчетов по этим данным.
Большинство программ состоит из следующих компонентов:
1. Система меню и диалоговых окон для манипуляции исходными данными на уровне файлов и для выбора метода расчета.
2. Модуль электронных таблиц — для ввода, импорта* данных и манипуляций* 2 над ними на уровне строк, столбцов, групп ячеек и 'отдельных ячеек.
’ Возможность импорта или конвертирования может быть реализована отдельным модулем.
2 Должна быть предоставлена возможность транспонирования матрицы данных.
Программа анализа данных
689
3. Модуль текстового редактора или браузера — для вывода текстовых результатов расчета на экран и принтер.
4. Модуль графопостроителя — для вывода графических результатов расчета на экран и принтер. О типах применяемых в прикладном статистическом анализе графиков и правилах их построения см. в [70, с. 26], [89, с. 36], [205, с. 43], [228, с. 57].
Современные системы программирования имеют возможности быстрого построения минимального приложения, которым обычно является простой текстовый редактор. К сожалению, для построения электронных таблиц и графопостроителя необходимо затратить существенные усилия.
Расчетная часть
С точки зрения программиста-практика все методы мотуг относиться к одному из следующих типов расчета, с учетом шкалы измерения: 1. Расчет по одному вектору данных. При этом вектор может представлять собой первичные данные (эмпирическую выборку) либо вариационный ряд.
2. Расчет по паре векторов, размер которых может быть равным либо различаться. При этом вектора могут представлять собой первичные данные либо вариационные ряды.
3. Расчет по двум или более многомерным выборкам. При этом размерности (число измерений) выборок должны быть равными, а размеры отдельных векторов, составляющих многомерную выборку, должны быть одинаковыми в пределах одной многомерной выборки.
4. Расчет по двум группам векторов равной длины, причем численности групп (количества векторов в группах) могут быть равными или различаться, но длины всех векторов равны.
Соответственно проектируются диалоговые панели выбора переменных для анализа. Обратите внимание, что здесь нами не затронуты такие важные свойства исходных данных, как их сопряженность или независимость, тип гипотезы и т. д. В хорошей программе эти вопросы должен решать специальный модуль — мастер, ведущий пользователя от исходных данных к решению и помогающий сделать правильный выбор.
Программные ресурсы
Считается, что в настоящее время неразумно разрабатывать интерфейсные модули самостоятельно, если можно приобрести готовые,
690
Глава 18. Реализация программы анализа данных
например из числа указанных в табл. 18.4. Например, такие удачные коммерческие статистические программы, как NCSS, StatsDi-rect и исследовательский проект Loglet Lab, имеют в своем составе элемент Formula One Professional, поставляемый фирмой Tidestone Technologies (www.tidestone.com) и совместимый с текущей версией электронных таблиц Microsoft Excel.
Таблица 18.4. Компоненты «электронные таблицы» для C/C++ на персональных платформах
Ресурс, адрес Разработчик или поставщик Продукт Компилятор
www.compo-nentone.com ComponentOne LLC DBGrid Pro, доступна пробная версия MS Visual C++
www.fpoint.com FarPoint Technologies Inc. Spread, доступна пробная версия То же
www.truesoft.com Trustsoft Inc. Cell, доступна бесплатная версия Тоже
www.stingray.com Rogue Wave Software, Inc. Objective, доступна пробная версия Тоже
www.cyber-tech.co.nz CYBERTECH Limited Набор продуктов Тоже
www.turbo-power.com TurboPower Software Company Orpheus, доступна пробная версия C++ Builder
Недостаки подхода: денежные отчисления поставщику компонентов (не всегда), жесткая привязка к определенной операционной системе (тоже не всегда) и компилятору, а также утрата контроля над существенной частью программы, если, конечно, пакет не поставляется с исходными кодами, что бывает редко. Интересный подход предлагается фирмой Wind River Systems, Inc. (www.windriver.com, www.zinc.com), выпускающей бесплатный пакет Zinc for Desktop, обеспечивающий единообразное решение пользовательского интерфейса для различных операционных систем (после перекомпиляции) с помощью одного и того же кода на языке C++. В последнее время мы, однако, реальную перспективу многоплатформенного графического приложения видим в применении модулей Тк языка Perl или в программировании на Java или JavaScript. Многоплатформенное графическое приложение — это то программное решение, которым действительно стоит заняться.
Программа анализа данных
691
Дополнительную информацию в Интернете по рассматриваемым типам программного обеспечения можно получить с помощью поисковой машины. Например, для поиска управляющих элементов типа электронных таблиц на www.aLtavista.com следует ввести: spreadsheet control. В приложении на компакт-диске к журналу «КомпьютерПресс» № 1 и № 3 за 1999 г., № 5 за 2000 г. имеются некоторые ссылки и демонстрационные версии библиотек компонентов, в том числе часть из указанных в табл. 18.5.
Для исполнения расчетной части можно применить одну из предлагаемых на рынке программного обеспечения библиотек разработчика (пакет прикладных программ) либо использовать находящиеся под полным контролем программиста функции, приведенные в данной книге. В табл. 18.5 приведены некоторые ссылки, кроме тех, что уже указаны в тексте.
Таблица 18.5. Некоторые ресурсы для разработчиков программ анализа данных на языках C/C++
Ресурс, адрес Разработчик или поставщик Продукт Платформа
www.lahey.com Lahey Computer Systems, Inc. Fujitsu Scientific Subroutine Library Windows
www-sop.inria.fr /saga/mourrain /ALP European project FRISCO* ALP, библиотека классов для научного программирования Linux, Solaris
www.sgi.com Silicon MLC++, библиотека IRIX, Windows
/technology/mlc Graphics, Inc. разработчика, бесплатно (Visual C++), UNIX (g++)
www. math-tools.com MathTools Ltd. Visual Matrix, библиотека классов для работы с матрицами Windows (MS (MS Visual C++)
www. user. cityline.ru /alphasys Alpha System Ltd. Neuro Service, набор элементов ActiveX To же
www.ward-systems.com, www neuroproject, ru, www.tora-centre.ru Ward Systems Group, Inc. NeuroWindows, библиотека нейросетевых функций Тоже
* Приводятся ссылки на библиотеки для научного программирования
продолжение &
692
Глава 18. Реализация программы анализа данных
Таблица 18.5 (продолжение)
Ресурс, адрес Разработчик или поставщик Продукт Платформа
www.aasdt.com Applied Analytic Библиотеки Windows (C++
/statistics www.hav.com Systems, Inc. hav. Software статистического анализа havBpNet++, havFmNet++, библиотеки классов для конструирования нейронных сетей Builder)
www. hyper- HyperLogic OWL Neural Network MS-DOS,
logic.com Corporation Library, библиотека для разработки нейронных сетей Windows
www.delisoft.fi Delisoft Ltd. 1пС++, математическая библиотека PC, UNIX
www.khoral.com KHORAL Research, Inc. Khoros Pro 2000 SDK, библиотека для моделирования и визуализации данных Windows, Linux и др.
Библиотеки разработчика для других языков программирования поставляют Society for Industrial and Applied Mathematics (www.netlib.org/lapack), Intel Corporation (www.intel.ru), FMS, Inc. (www.fmsinc.com), MathWorks, Inc. (www.mathworks.com/products/ compilerlibrary), IBM Corp, (www.ibm.com), OPTEX Ltd. (www.ccas.ru/ pma/sector.htm). Подборка материалов по программной реализации нейронных сетей на C++ представлена С. Коротким (www.orc.ru/ -stasson/menu.html), а для владеющих японским языком может оказаться полезной библиотека Toshiba Corporation Enfant / Kodomo (www2.toshiba.co.jp/enfant).
Для пакетов, реализующих методы анализа данных, поставляемых в исходных текстах или с входными текстами, очень важным моментом является хороший стиль программирования. К сожалению, для многих, даже весьма совершенных пакетов это не всегда так, и изучение исходных текстов, записанных в ужасном стиле, без комментариев или, еще хуже, с тривиальными комментариями, затруднительно — более простой задачей может оказаться создание программ заново.
Модули анализа
Пользовательская функция на языке С может компилироваться в обычную DLL и вызываться из электронных таблиц, персональной системы управления базами данных или иной программы, работающей с динамически подключаемыми библиотеками. Подобными
Программа анализа данных
693
возможностями обладают многие современные программы анализа данных, например Microcal Origin Professional и MathSoft Mathcad Professional, и электронные таблицы, например Microsoft Excel [149, с. 462] и StarCalc из пакета StarOffice. Отметим, что для системы MATLAB (см. главу 13) некоторые поставщики предлагают средства интеграции с системами программирования на C++. Например, это фирмы MathTools Ltd. (www.mathtools.coni) и KHORAL Research, Inc. (www.khoral.com).
Основные выгоды данного подхода в том, что программист избавляется от необходимости создавать некое подобие электронных таблиц и вдобавок получает мощные средства манипулирования данными, включая их импорт и экспорт, гарантированную совместимость с прошлыми и будущими версиями распространенных коммерческих программных продуктов на уровне файлов данных, а также богатые графические возможности основных программ. Еще одним плюсом рассматриваемого типа программ является то, что пользователям не приходится заново изучать возможности основного программного продукта, что для многих является критерием, определяющим выбор программы анализа данных.
Особенности разработки DLL
Основным моментом, который нужно учесть при вызове функций С из электронных таблиц (пример показан для Microsoft Excel 97), является различие в порядке нумерации элементов массива в С и в электронных таблицах (мы проверили только Microsoft Excel 97, для других программ это может оказаться не так). В C/C++ элементы массива всегда нумеруются с нуля. В Microsoft Excel, как и по умолчанию в Microsoft Fortran 77 (порядок нумерации в Fortran можно выбрать любой) [38], [126], элементы массива нумеруются с единицы. Поэтому для вызова из электронных таблиц Microsoft Excel нужно составить специальные версии разработанных на С функций, в которых применяется правило нумерации массива электронных таблиц Microsoft Excel. Никакого переопределения индексов при вызове не происходит — мы это проверили. Для решения проблемы, работая на С, мы просто считаем, что элементы массива нумеруются с единицы, перестраивая в соответствии с этим предположением касающуюся массивов логику программы1. Естественно, в проектах на С и C++ эти специальные версии функций при
1 Перестраиваются явные операции с индексами. Нумерация элементов массивов сохраняется.
694
Глава 18. Реализация программы анализа данных
менять уже будет нельзя без риска получить ошибку1. Ниже показан вызов такой функции. Для примера мы выбрали функцию SmirnovTwoSided, подробно рассмотренную в главе 2. Показан также пример функции LambdaDistribution, вызов которой не отличается от стандартного, так как в ней не используются массивы.
Все функции DLL, которые вызываются вне проекта, описаны как extern "Си decl spec(dl 1 export)2 cdecl.«Внутренние»функции, предназначенные для использования только внутри текущего проекта (в показанном примере это функция Parity), в таком описании не нуждаются. Данные модификаторы означают:
1. extern "С" —описанная функция разработана на языке С, ее имя нельзя использовать как имя C++, например перегружать [153, с. 449], так как функция C++ распознается не только по имени, но и по типу и количеству параметров [там же, с. 91]. В данном случае модификатор, по всей видимости3, необходим,так как требуется обычная (не расширенная) версия DLL, а других простых средств сообщить используемому нами компилятору, что требуется обычная DLL (построенная из функций С, но не C++), в Microsoft Visual C++ мы не обнаружили.
2. decl spec (dl 1 export) — описанная функция экспортируется из DLL. Использование данного модификатора делает ненужным применение файла определения модуля (расширение .def) с целью описания имен экспортируемых из DLL функций.
3. cdecl для функций на языке С (для C++ действие данного
модификатора иное) означает, что используемые в программе идентификаторы при компиляции сохраняют свое написание (различие заглавных и строчных букв) [там же, с. 121].
Как показал опыт, явное применение модификатора__pascal, ре-
комендуемое некоторыми авторами [там же, с. 837], в данном случае не требуется.
Запустите компилятор Microsof Visual C++ для Windows. Мы использовали 5-ю версию данной системы программирования под управлением операционной системы Microsoft Windows 98 со всеми известными нам на момент написания книги пакетами обновлений. Для других версий Microsoft Visual C++, других операционных систем, а также для других систем программирования все сказанное в
1 Лучшим решением может быть составление специальных интерфейсных функций.
2 Перед данным и следующим модификатором ставится два подчерка.
3 Мы можем ошибаться, но данный подход, в отличие от ряда источников, например [Орвис], безусловно работает
Программа анализа данных
695
настоящем разделе может отличаться от действительной ситуации, и для получения точной информации будет необходимо обратиться к документации, поставляемой в комплекте с применяемым вами компилятором. Подробное обсуждение проблемы см. в [105, с. 370]. Для примера создайте новый проект Win32 Dynamic-Link Library под названием Му Lib, как показано на рис. 18.7.
Ftes fitted? | j MjttoDajureri»
Рис. 18.7. Создание проекта DLL для Windows
I : .jjA'LCOMAppWrzard js ^'SvbtudoAddn Wizard ' Й SAP Exterwon Weed Й^^МакеЯе
MFC ActiveX ContioWeard J^MFCAppMzardM j 0MFC AppWizard(exe) : Л U«y Project
<]'*'Г13гАрйсайоп
~ .in?2 rede Apcfcation
4]wW2 Static Uxarji
Добавьте к проекту файл MyLib.cpp и введите в него показанный ниже исходный текст со специальными версиями функций SmirnovTwoSided и LambdaDistribution. Наличие функции DllMain обязательно. Еще одна содержащаяся в проекте функция Parity рассмотрена ранее и дается только для полноты изложения. В примере не используется входящий во все ранее рассмотренные проекты заголовочный файл megastat.h. Вместо этого явно указаны прототипы всех используемых функций.
Исходные коды
#include <windows.h>
#include <math.h>
extern "C" {
double __declspec(dllexport) _cdecl. LambdaDistribution (double):
double __declspec(dllexport) __cdecl SmirnovExact
(double*.double*.int,int);
}
int Parity (int):
BOOL WINAPI DllMain («INSTANCE hinstDLL.DWORD fdwReason,LPVOID IpvReserved)
696
Глава 18 Реализация программы анализа данных
{ return TRUE:
}
double___declspecfdl1 export)____cdecl SmirnovExact (double
x[],double y[].int nx.int ny) //
// Функция точного вычисления критерия Колмогорова-Смирнова.
// Обозначения:
// х - первая отсортированная выборка.
// у - вторая отсортированная выборка,
// пх - численность первой выборки,
// пу - численность второй выборки.
// Примечание:
// это специальная версия для вызова из электронных таблиц
// Microsoft Excel 97, характеризующаяся нумерацией элементов
// массивов с единицы, в проектах на C/C++ данную функцию
// применять не следует.
// Возвращаемое значение:
// значение статистики критерия Колмогорова-Смирнова.
//
{
register int i.j = 1; // Счетчики
double s. // Рабочая переменная
criterion = 0: // Статистика критерия
for (i = 1: i <= ny; i++) if (y[i] <= x[l])
{
s = (double)Ci - 1) / ny: if (s > criterion) criterion = s:
}
else if (y[i] >= x[nx])
{
s = 1 - (double) (i - 1) / ny:
if (s > criterion) criterion = s: break:
} el se
{
for (: j <= nx: j++)
if (y[i] >= x[j] && y[i] < x[j + 1]) {
s = fabs ((double)(i - 1) / ny - (double)(j - 1) / nx): break:
}
if (s > criterion) criterion = s:
}
Программа анализа данных
697
for (1 = 1, j = 1: 1 <= nx; i++) if (x[i] <= y[l])
{
s = (double)(i - 1) / nx;
if (s > criterion) criterion = s;
} else if (x[i] >= y[ny])
{
s = 1 - (double) (i - 1) / nx;
if (s > criterion) criterion = s;
break:
}
el se
{
//////////////////////////////////////////
// Уточним, между какими вариантами именно
for (; j < ny; j++)
if (x[i] >= y[j] && x[i] < y[j + 1])
s = fabs ((double)(i - 1) / nx - (double)(j - 1) / ny); break:
}
if (s > criterion) criterion = s;
} return criterion;
}
double___declspec(dllexport) _cdecl LambdaDistribution(double y)
//
// Функция вычисления распределения Колмогорова для простой // гипотезы.
// Обозначения:
// у - функция распределения.
// Возвращаемое значение:
// уровень значимости.
//
{
double а = 0; // Возвращаемое значение
if (у <= 0) return 0;
for (register int k = -15; k <= 15; k++) if (Parity (k) == 1)
a += exp (-2 *k*k*y*y);
el se
a -= exp (-2 *k*k*y*y);
return a; }
698
Глава 18. Реализация программы анализа данных
int Parity (int n)
//
// Функция проверки четности целого числа.
// Обозначения:
// п - число.
// Возвращаемое значение:
// 0, если число нечетное,
// 1. если число четное.
//
{
if (п / 2 * 2 == п)
return 1; // п - четное
el se
return 0: // n - нечетное
}
Скомпилируйте проект, как показано на рис 18.8.
;Й Р» tdi 13**1 (т**-- / T^irl Ь*Л'
' са?ЙО Г.......
и Mjrbb clas<es~
preset
fwkMt
t»s*
•’.Мигеле
export) __cdecl LaabdaDistribution (dr-uble); $
expert) __cdecl SmirnovExact (double».double», inf'
I IH3TAHCE hinstDLL.DOORD (dvReason.LPVOID IpvRese:
double _declspec(dllexpcrt) __cdecl SmirnovExact (double x(J double у
♦'JHhuup а^чаозс Ьччскшс; критерия Еилхспзрсва- Сяиркова ССсхначеиия:
x - первая oacopaupcfewex оя^срха.
Рис. 18.8. Компиляция проекта DLL для Windows
чиилеииосяа иервии tb-ocpr.u
численность ваорсч» Гиборкч.
Прииечанч'Ч:
сиечиаиьноя версия ij.-Я выэова из o.'Caa(zuoasx наё.тиц Hicros-Excei ?7. хараг.аеризукваяся нуаераиией эленешев насеивав ? проег.азх ыа С С— gamfgxi сукхци» применять не слетаеа.
При отсутствиии ошибок ввода в каталоге C:\MyLib\Debug появится файл MyLib.dll, который следует скопировать в системный каталог C:\Windows\System1. Вызов пользовательских функций из DLL рассмотрен в следующем разделе.
На вашем компьютере имена системных каталогов могут иметь другие названия. Существует возможность обойтись без данной операции и вызывать функцию из DLL, находящейся в произвольном каталоге.
Программа анализа данных
699
Вызов функций из DLL
Запустите электронные таблицы Microsoft Excel 97. Пользователям других версий данных электронных таблиц могут встретиться трудности, для решения которых отсылаем читателей к документации, встроенной в используемую версию Microsoft Excel, либо на сайт производителя для получения пакетов исправлений. Решением может быть обращение к какому-либо конкурирующему продукту. Бесплатно распространяемый фирмой Sun Microsystems офисный пакет StarOffice (мы тестировали русскую версию 5.2) содержит электронные таблицы StarCalc, которые также позволяют работать с внешними библиотеками, причем пакет сопровождается не только вполне понятной, хотя и не идеальной документацией, но и, самое главное, работающими примерами. Рассмотренные здесь примеры могли быть разработаны с использованием StarCalc, однако русская версия данного пакета появилась позже Excel 97, когда проблема нами была уже решена и интерес к ней иссяк. Электронные таблицы Quattro Pro, входящие в состав пакета офисных приложений WordPerfect Suite производства Corel Corporation, также, судя по документации, могут работать с функциями из внешних DLL, хотя нам и не удалось добиться сколько-нибудь значимых результатов при тестировании восьмой английской версии данного приложения.
Итак, в ячейки рабочего листа Excel 97 введите исходные данные и поместите вызовы функций, как показано на рис. 18.9.
Рис. 18.9. Пример вызова функций DLL из электронных таблиц Excel
700 Глава 18. Реализация программы анализа данных
Нами применен один из многих возможных способов вызова внешних функций из DLL, причем использованы те же самые исходные данные, что и в примере применения функции Smir-novTwoSided на C/C++ (глава 2), чтобы можно было проконтролировать правильность вычислений, произведенных программой на C/C++ и функцией С, вызванной из DLL В связи с изложенными выше особенностями составления функций для вызова из DLL такой прием двойного контроля за правильностью работы функций настоятельно рекомендуется с целью избежания ошибок в расчетах.
Первый из сравниваемых массивов занимает ячейки с Al по АН (обозначается как ALA11 — всего 11 элементов, численность выборки записана в ячейке А13). Второй из сравниваемых массивов занимает ячейки с Bl по В9 (обозначается как BLB9 — всего 9 элементов, численность выборки записана в ячейке ВИ). Размеры массивов, записанные в ячейках А13 и В11, требуется явно передать в вызываемую функцию, так как сейчас у нас нет иной возможности узнать из вызываемой функции фактический размер полученных массивов.
В ячейке С7 производится вызов функции SmirnovExact, строка вызова которой имеет вид
=ВЫЗВАТЬ(“MyLib":"SmirnovExact";"BKKII":Al:All;Bl:B9;A13;В11)
Отметим, что вместо ссылок на ячейки А13 и Bl 1 в показанном выше вызове функции ВЫЗВАТЬ можно было явно указать численности выборок, а именно ввести числа 11 и 9.
С целью получения критического значения теста, пригодного для вызова функции LambdaDistribution, в ячейку D7 записано
=С7*К0РЕНЬ(А13*В11/(А13+В11))
Обратите внимание, при вызове функции КОРЕНЬ (извлечение квадратного корня) необходимости приведения к типу с плавающей точкой, как это было сделано в примере на C/C++, не возникает — приведение будет выполнено Excel автоматически, и результат получится верный.
В ячейке Е7 вызывается функция LambdaDistribution
=ВЫЗВАТЬ("MyLib":“LambdaDistribution";"ВВ":D7)
Программа анализа данных
701
Для расчета P-значения в ячейке F8 производится простая операция
=1-Е7
Поясним формат параметров функции ВЫЗВАТЬ на примере вызова функции SmirnovExact. Первым параметром является имя файла DLL (без расширения), содержащегося в системном каталоге Windows, а именно "MyLib". Вторым параметром является имя вызываемой функции, содержащейся в DLL, а именно "SmirnovExact". Третьим параметром является строка "ВКК1Г, первый символ которой в Microsoft Excel означает тип, возвращаемый вызываемой из DLL функцией SmirnovExact. В данном случае "В" означает передаваемое по значению 8-байтовое число с плавающей точкой, соответствующее типу double в C/C++. Следующие символы означают типы формальных параметров функции, вызываемой из DLL. Тип "К" в Microsoft Excel означает массив, что соответствует указателю double* в C/C++. Тип "I" в Microsoft Excel означает передаваемое по значению 2-байтовое целое со знаком, что соответствует типу short и int в Microsoft Visual C++ [153, с. 113].
Рассмотренные типы параметров рекомендуется вводить с особой аккуратностью, так как ошибка (например, ввод типа "Е" вместо типа "В") может привести к краху если не операционной системы, то Microsoft Excel наверняка. Другие типы ошибок при вызове функций из DLL, например ошибочное задание интервала ячеек, обычно безопасны для системы, так как легко локализуются Excel с выдачей соответствующей диагностики. Другие типы параметров, которые могут понадобиться при вызове из Microsoft Excel функций, разработанных вами на языке С или другом языке высокого уровня (например, на Fortran), подробно описаны во встроенной справочной системе Microsoft Excel и в поставляемом фирмой Microsoft за отдельную плату пакете документации Microsoft Excel 97 Developer’s Kit. входящем в комплект MSDN. Поможет и изучение источников, которые посвящены приемам программирования на нескольких языках одновременно в пределах одной решаемой задачи. Последнее замечание касается в основном языка Fortran, так как, по всей видимости, возможность вызова из Microsoft Excel функций внешних DLL была ориентирована прежде всего на пего.
Программные ресурсы
Некоторые примеры дополнительных программных модулей анализа данных для электронных таблиц Microsoft Excel показаны в табл. 18.6.
702 Глава 18. Реализация программы анализа данных
Таблица 18.6. Дополнительные модули анализа для электронных таблиц Microsoft Excel
Ресурс, адрес Разработчик или поставщик Содержание
www.baran-systems.com BaRaN Systems Ltd. SQC, статистический анализ для Windows и Macintosh
www.analyse- it. com Analyse-it Software Ltd Analyse-it Statistical Add-in to Excel, доступна пробная версия
www.nag.co.uk The Numerical Algorithms Group Ltd. NAG Statistical Add-ins
market@soglasie.ru, www.microsoft.ru /offext/b.asp Росэкспертиза ОЛИМП: СтатЭксперт, доступна демонстрационная версия
www.neurok.ru ООО «НейрСЖ» Excel Neural Package
www. analycorp. com/c/ AnalyCorp. INSIGHTxIa, моделирование и прогнозирование
www.wardsystems.com, Ward Systems NeuroShell Easy Fire,
www.neuroproject.ru Group, Inc. нейронные сети
www.kovcomp.co.uk Kovach Computing Services XLSTAT, доступна демонстрационная версия
www.man.deakin. Deakin University XLStatistics, статистические
edu.au/rodneyc Warrmanbool рабочие книги и шаблоны
www.j-walk.com/ss JWalk & Associates Power Utility Pack, доступна пробная версия
www.promland.com Promised Land Technologies Inc Braincel, моделирование нейронных сетей, доступна демонстрационная версия
www.nd.com NeuroDimension Inc. NeuroSolution for Excel, доступна пробная версия
canopus.lpi.msk.su Физический институт Excel Neural Package,
/neurolab им. П. Н. Лебедева бесплатно
Для программ, отличных от MS Excel, дополнительные модули анализа поставляют FMS, Inc. (www.fmsinc.com), John Galt Solutions, Inc. (www.forecastx.com), Alpha System Ltd. (www.user.cityline.ru/ -alphasys). Последние две компании поставляют продукты и для MS Excel.
Статистический анализ в браузере
Анализ данных в браузере привлекателен по нескольким причинам. Если предыдущие подходы требовали более или менее значительных финансовых вложений в легально приобретенные средства раз
Программа анализа данных
703
работки, то данный подход гораздо более дешев, а в зависимости от принятой стратегии иногда влечет нулевые затраты на средства разработки приложений. Так, анализ в окне браузера может быть реализован с помощью апплетов, разработанных на одном из предназначенных для этого языков программирования, например на Java, бесплатные версии которого можно загрузить из Интернета (Borland JBuilder Foundation Edition, www.borland.com, также CD-приложение к «КомпьютерПресс», № 12, 2000 г.) либо получить как приложение (Microsoft Visual J++ Publisher Edition) к книге [75], а также на JavaScript или другом языке сценариев.
Приложение на языке сценариев
Мы продемонстрируем простой подход, для реализации которого на компьютере требуется только наличие любой операционной системы и любого браузера с поддержкой языка программирования JavaScript версии не ниже 1.1. Эта версия поддерживается подавляющим числом браузеров.
Введите показанный ниже исходный текст программы на языке JavaScript с помощью текстового редактора (рис. 18.10) (в нашем примере это программа Блокнот, но данную процедуру можно проделать и из командной строки MS-DOS: сору con [имя файла] Enter [исходный текст] Ctrl-Z). Предполагается, что файл имеет имя smirnov.js. Данный файл является простым текстовым файлом (в данном случае в кодировке Windows-1251), поэтому при использовании тестового процессора следует сохранять его просто как текст, но не как текст DOS (иначе кириллица будет исковеркана) и тем более не как документ текстового процессора.
Function Sairnov (F1.F2)
// Функция вычисления критерия Смирнова.
// Обозначения: // F1 - массив Функции распределения 1-го ряда, // F2 - массив Функции распределения 2-го ряда.
// Возвранаемое значение:
// значение критерия Колмогорова-Смирнова.
И < var s. // Рабочая переменная
RetUalue “ Я; // Возвращаемое значение
for (oar i - 0; i < F1.length; !*•) <
s - Math.abs <F1[i] - F2[i]> IF (s > RetUalue)
RetUalue - s;
return RetUalue;
Рис. 18.10. Пример ввода исходных кодов на языке JavaScript
704
Глава 18. Реализация программы анализа данных
Сравнив исходные коды на C++ и JavaScript, мы видим, насколько просто может быть произведена конверсия между данными языками программирования. «... Язык Java очень похож на интерпретатор языка С или C++» , однако еще больше на интепретатор C/C++ похож JavaScript. К тому же JavaScript имеет массу новых достоинств и менее отягощен недостатками C++. Единственная причина, по которой можно отказаться от предлагаемой технологии — снижение быстродействия программы по сравнению с программой компилируемой.
Исходные коды function Smirnov (fl,f2) // // Функция вычисления критерия Смирнова. // Обозначения:
// fl - нассив функции распределения 1-го ряда.
// f2 - нассив функции распределения 2-го ряда. // Возвращаеное значение: // значение критерия Колногорова-Снирнова.
// { var s, // Рабочая перененная
RetValue = 0; // Возвращаеное значение
for (var i = 0; i < fl.length; i++) {
s = Math.abs (fl[i] - f2[i])
if (s > RetValue) RetValue = s;
}
return RetValue; }
function LambdaDistribution (y)
//
// Функция вычисления распределения Колногорова для простой
// гипотезы.
// Возвращаеное значение:
// функция распределения Колногорова.
//
{
var RetValue = 0; // Возвращаеное значение
if (у <= 0) return 0;
for (var k » -15; k <= 15; k++)
if (Parity (k))
Программа анализа данных
705
RetValue += Math.exp (-2 *у*у*к*к); el se
RetValue -= Math.exp (-2 *y*y*k*k);
return RetValue: }
function Parity (n)
//
// Функция проверки четности числа n.
// Возвращаеное значение:
// 0 - п нечетное,
// 1 - п четное.
//
{
if (Math.round (n / 2) * 2 == n) return 1:
else
return 0:
}
Далее с помощью текстового или специального редактора наберите файл на языке HTML. Предполагается, что имя файла smirnov.html, но может быть любое другое, не противоречащее требованиям используемой операционной системы. Тело файла smirnov.js могло бы быть полностью включено в показанный ниже файл между тегами <scr i pt> и </scr i pt>, однако вынести отлаженные и часто используемые методы в отдельный файл удобнее. В примере предполагается местонахождение файла smirnov.js в том же каталоге, что и smirnov.html.
Пример применения
<html>
<head>
<titlе>Непаранетрическая статистика</41tle>
<meta http-equi v=,,Content-Type" content="text/html; charset=windows-1251">
<script 1anguage=”JavaScriptl.1" src="smirnov.js"></script> </head>
<body>
<script 1 anguage="JavaScript1.1">
var fl = new Array
(0.00,0.15.0.23,0.43.0.43.0.45.0.56,0.65,0.79.0.89.1.00),
f2 = new Array
(0.00,0.27,0.42,0.55,0.72,0.73.0.83,0.85,1.00,1.00.1.00), nl = 50, n2 = 60, k = Smirnov (fl.f2);
706
Глава 18. Реализация программы анализа данных
document.write ("Первый массив функции распределения:<br>" + fl + "<Ьг>Второй массив функции распределения:<br>" + f2 + "<Ьг>Статистика критерия Смирнова:<Ьг>" + к + "<Ьг>Доверительный уровень:<br>" + (1 - LambdaDistribution (к * Math.sqrt (nl * n2 / (nl + п2)))));
</script>
</body>
</html>
Все, что осталось сделать для произведения расчета, — это открыть файл smirnov.html в браузере, поддерживающем JavaScript, под управлением любой операционной системы.
6
/Мои д<жу>1енгы/Мс4. просрам
dick here, all free!
Первый массив функции распределения:
0,0.15,0.23,0.43,0.43,0.45,0.56,0.65,0.79,0.89,1
Второй массив функции распределения:
0,0.27,0.42,0.55,0.72,0.73,0.83,0.85,1,1,1
Статистика критерия Смирнова:
0.29
Доверительный уровень:
0.020361150075764778
f
ГД Неяараметричесжа,;
Рис. 18.11. Пример исполнения кода на языке JavaScript в браузере Opera
Как видно из рис. 18.11, интерфейс полученного приложения получился слишком «спартанским», однако разработка пользовательского интерфейса не является темой данной книги. Проблемы разработки пользовательского интерфейса давно решены — достаточно зайти на любой сайт в Интернете и посмотреть, как это делается.
Отладка приложения может быть выполнена «вручную», а также с помощью отладчика сценариев Microsoft Development Environment, входящего в состав Internet Explorer и снабженного справочником по язы-
Тестирование программ
707
KyJScript (JavaScript в версии Microsoft). Отладка приложения в Netscape Navigator может быть выполнена с помощью удобной консоли JavaScript, для вызова которой следует набрать javascript:B окошке Location на панели Location Toolbar.
Программные ресурсы
В табл. 18.7 приведены адреса ресурсов Сети с примерами программ, позволяющих производить статистические расчеты в браузере. Разработки выполнены в основном на языке программирования Java. Дополнительные ресурсы указаны на сайте www.statistics.com.
Таблица 18.7. Интерактивный статистический анализ в Сети
Ресурс, адрес Разработчик или поставщик Содержание
home.clara.net Simple Interactive SISA, основные статистические
/sisa/index.htm Statistical Analysis алгоритмы
www.stat.sc.edu /-west/webstat Webster West WebStat, статистическая программа на Java
www.statlets.com NWP Associates, Inc Statlets, апплеты статистического анализа, академическая версия бесплатно
phe.rocke- The Rockefeller Logistic Curves: An Interactive
feller, edu University Demonstration, логистический анализ
Тестирование программ
Хотя все опубликованные в книге программы в процессе отладки тестировались на реальных научно-технических и медико-биологических экспериментальных данных, для большинства показанных примеров данные были специально вымышлены. Сходство с реальными цифрами, полученными в результате эксперимента, возможно лишь случайно. Иногда данные брались из источников, на теории которых эти программы основаны, по причине наличия для них готового решения, чтобы можно было сравнить результаты работы программ с заранее просчитанными, «верными» ответами1.
Попутно нами было совершено неприятное открытие: ряд примеров, данных в источниках, имеет ответы не совсем верные, причем иногда сделанные по ним выводы следует заменить на противоположные.
708
Глава 18. Реализация программы анализа данных
Наличие примеров в данной книге, по нашему мнению, вовсе не является обязательным. Согласно [212, с. 15], «если придется разрабатывать план и писать программу без каких-либо числовых примеров, то чем скорее мы усвоим это и научимся обходиться без примеров, тем лучше». При постановке задачи и последущих разработке и/или применении программ анализа данных многие допускают принципиальную ошибку, начиная процедуру анализа даже не с методики получения экспериментальных данных, а с объяснения физического смысла явления. Это неверно. Изучение физического смысла явления — задача не анализа данных, а начального этапа математического моделирования. При анализе данных наша работа начинается с уже готового числового материала, причем нас интересует, каков тип данных по шкале измерения и относятся ли эти данные к одному или к разным индивидуумам. Интерпретация выводов примеров не должна отвлекать читателя от сущности описанных методов анализа. Следующий важный довод в пользу отказа в примерах от реальных пли принадлежащих кому-то на правах авторской собственности данных — это то, что разработчику алгоритмов и программ не приходится дополнительно обременять себя просьбами разрешения у собственника данных на их публикацию или необоснованно включать его в соавторы.
При использовании некоторого программного продукта необходимо убедиться в правильности расчетов на специально подобранных тестовых задачах или найти аналоги применения используемых методов. Так, многие пакеты прикладных программ анализа данных сопровождаются многочисленными примерами практического применения данных программ (примеры поставляются как в составе пакета, так и в составе руководства пользователя, а также находятся на сайтах производителей в Интернете). Например, перед тем как рекомендовать нашим пользователям стандартные расчетные методы в электронных таблицах Microsoft Excel, мы сделали контрольные расчеты для проверки правильности статистических тестов и убедились в правильности последних. Хотя авторы [206, с. 42] призывают «быть цензором себе, но не другим», errare humanum est1. Следовательно, не нужно безоговорочно доверять ни одной программе, тем более что любой разработчик вычислительных программ оставляет за собой право на ошибку, что в равной степени относится и к бесплатным, и к коммерческим программным продуктам. Производители программ обычно полностью гарантируют только каче-
Человеку свойственно ошибаться (лат.).
Программная совместимость
709
ство их носителей — дискет и компакт-дисков, хотя и это бывает проблемой.
Ошибки в программных продуктах обычно относятся не к плохому программированию, хотя некоторые протестированные нами пробные версии коммерческих и бесплатных программ не совсем корректно работали. По утверждению [146, с. 4], «... опубликованные программы часто содержат преднамеренно внесенные в них ошибки, защищающие программы от несанкционированного использования». Добавим, что причиной внесения ошибок может быть и злой умысел. Так, например, немалая часть ключевых программ [175], несмотря на заверения переводчиков в их подробной численной проверке, совершенно нерабочая, хотя в теоретических обоснованиях алгоритмов грубых ошибок нет — очевидно, при внесении ошибок не предполагалось хотя бы минимальных знаний программирования у читателей. Особенностью ошибок рассматриваемого типа является то, что они хорошо видны квалифицированному программисту. Более серьезной проблемой являются ошибки методологические [187, с. 507], локализовать которые специалисту в методах анализа данных трудно, а неспециалисту невозможно. См. также [87]
Программная совместимость
В процессе разработки и тестирования программ могут встретиться случаи, когда средства разработки или среды выполнения программ немного, но различаются между собой. Например, тщательно отлаженные в среде разработки фирмы Borland (Inprise) методы C/C++ могут давать ошибку при компиляции в интегрированной среде Microsoft. У нас сложилось впечатление, что компилятор Microsoft более строг к ошибкам программиста, вызванным отклонением от стандартов. Что касается совместимости браузеров, то данный вопрос подробно рассмотрен в [36, с. 345], однако и здесь возможны неточности. Так, показанный выше полный исходный тест приложения на JavaScript на самом деле в JavaScript версии 1.0 исполняться не может, хотя использует только синтаксис и методы, описанные в JavaScript версии 1.0 [там же, с. 361].
Все разработанные нами функции написаны на языке С, но с расширениями C++. Предусмотрена возможность быстрой трансформации наших функций в чистые функции С. Для этого прежде всего нужно заменить операторы new и del ete их функциональными эк-
710
Глава 18. Реализация программы анализа данных
Бивалентами из библиотек С mal 1 ос (или cal 1 ос) и free [176 с. 27], а также, возможно, сделать замену комментариев в стиле C++ на комментарии в стиле С, как это показано в примерах. Также нельзя будет одновременно использовать различные функции с одинаковыми именами. Проиллюстрируем сказанное на примере. Итак, тест на C++ [153, с. 263]:
Пример применения
#include <fstream.h>
#include <iomanip.h>
void main (void)
{
double *c;
////////////////////////////////////////////////////////////// lllllllllllllll
// Проверить результат выделения памяти для массива из 10 чисел // двойной точности
if (!(с = new double [10]))
cout « "Error! Insufficient memory to allocate arrayXn": return:
}
///////////////////////////////
// Освободить занимаемую память delete [] с:
}
Эквивалентный тест на С [там же]:
Пример применения
#include <alloc.h>
#include <stdio.h>
void main (void)
{
double *c:
/* Проверить результат выделения памяти для массива из 10 чисел двойной точности */
if ((с = (double *) malloc (10 * sizeof (double))) == NULL)
printf ("Oops! Not enough memory to allocate arrayXn"); return;
}
/* Освободить занимаемую память */
free (с):
}
Дальнейшие исследования
711
Обратите внимание на форму оператора del ete в примере на C++ (освобождение памяти, выделенной под массив, производится оператором delete [], ане просто del ete — компилятор данную ошибку пропустит), а также на то, что освобождение выделенной памяти производится только после ее успешного выделения. Для аварийного выхода из программ в обоих случаях мы применили операторы return. Можно было применить и любое другое решение (например, функцию ex i t или переход на конец программы в операторе if - е 1 s е). В случае неуспешного выделения памяти оператором new и функцией ma 11 ос возвращается нулевой указатель. Применение оператора de 1 е t е к нулевому указателю безопасно [ 182, с. 289], поэтому не является ошибкой освобождение памяти оператором d е 1 е t е в случае неуспешного ее выделения, как это сделано в [ 153, с. 263]. Мы делаем немного иначе — память освобождается только в случае ее успешного выделения, так как показанные примеры считаться будут быстрее. Если в простых программах выигрыш времени минимален, то в сложных случаях добиться более быстрого исполнения было бы неплохо.
Ошибки при работе с памятью очень опасны, так как сбой программы может быть и не получен гарантированно во время тестирования. В результате данная ошибка доставит большие непрятности пользователю. Так, применение оператора del ete к указателю, не являющемуся результатом выполнения оператора new (не путать с рассмотренным выше неуспешным завершением вызова оператора new), ведет к «последствиям ужасным» [227, с. 71]: в наших «опытах» с помощью данной ошибки удавалось привести систему в такое состояние, что способность компьютера вновь включаться была достигнута только после того, как шнур питания был на короткое время вынут из электророзетки. Интересно, что применение сочетания клавиш Ctrl-Alt-Delete, клавиши Reset и выключение тумблера на системном блоке компьютера успеха не имели.
Другие расширения языка C++ (кроме перегрузки имен функций) мы не применяли, пользуясь только потоковым вводом (с i п ») и выводом (cout «), которые в процессе перевода программ па язык С нужно заменить эквивалента ы ми функциями языка Cscanfuprintf.
Обсуждение трудностей, с которыми может встретиться программист при переводе программ с С на C++ и обратно, см. в [122, т. 2, с. 313]. Примеры применения функций malloc, calloc и free см. также в [25, с. 514, 546, 579].
Дальнейшие исследования
• Исследование возможности передачи массивов назад в электронные таблицы через формальные параметры при вызове функции
712
Глава 18, Реализация программы анализа данных
из DLL. Это необходимо при вычислении ряда статистических тестов и при реализации многомерных методов анализа данных.
• Разработка полнофункциональной мультиплатформенной программы по одному из разделов статистики, например непараметрическим методам проверки гипотез, на языке JavaScript или Perl.
• Составление электронного путеводителя по ресурсам Сети, связанным с анализом данных и научным программированием.
Заключение
В заключение остановимся на некоторых особенностях применения математической статистики в медико-биологических исследованиях и обратим внимание на несколько простых, но важных средств, позволяющих добиться более эффективного представления результатов исследований.
На современном этапе развития средств вычислительной техники компьютер представляет собой не замену человеческого интеллекта, а лишь его усилитель. «Сегодня это действительно слишком просто: вы можете подойти к компьютеру и практически без знания того, что вы делаете, создавать разумное и бессмыслицу с поистине изумительной быстротой» [139, с. 294]. Введение настоящей главы показалось нам своевременным в ответ на многочисленные вопросы коллег, а также из-за встречающегося не совсем верного оформления материалов публикаций, связанных с математической обработкой результатов научных изысканий в различных областях знаний. Это вызвано тремя обстоятельствами:
1. К мощной компьютерной технике получили вполне свободный доступ лица — профессионалы в своей предметной области, но не имеющие специального компьютерного или математического образования [149, с. 8].
2. Стало своеобразной модой наряду с другими методиками научного поиска обращаться также и к математическим методам описания и анализа данных экспериментальных исследований.
3. Методы анализа данных на современном этапе их развития при грамотном применении действительно способны дать такое описание.
С распространением мощных персональных компьютеров стало возможно реализовать методы расчета, которые раньше считались очень трудоемкими в вычислениях, хотя любой достаточно сложный расчет можно проделать и вручную. Так, реализация системы распознавания образов без применения вычислительной техники подробно описана в литературе1, однако это возможно только при
1 Солженицын А. И. В круге первом. - М : ИНКОМ НВ, 1991 - 352 с. (Кн. I), 320 с. (Кн. II).
714
Заключение
крайней дешевизне квалифицированной рабочей силы1. Возможно, у тоталитарного государства больше возможностей для концентрации усилий на перспективных научных направлениях, но насилие общества над личностью не может компенсироваться прогрессом науки на благо этого общества.
При использовании методов математико-статистического анализа в задачах обработки данных медицинских исследований нужно учесть ряд особенностей [26, с. 9]:
1. Наличие параметров, не поддающихся прямому количественному измерению.
2. Чрезвычайная сложность связей.
3. Наличие нечетко выраженных понятий.
4. Измерение параметров объекта исследования в различных шкалах.
Добавим особую ответственность, которая возложена на врача при решении вопроса о постановке верного диагноза и принятии адекватных мер воздействия на исследуемый объект. Вообще говоря, ответственность за принимаемое решение у инженера-исследователя, от правильности которого могут зависеть десятки и сотни жизней, зачастую более высокая, чем у врача, от решения которого зависит жизнь одного пациента. Просто обратное воздействие успеха или неудачи решения на инженера более опосредованно. Однако вряд ли можно представить себе случай, когда при принятии важного решения можно ограничиться только лишь результатом статистического исследования. Мы немного затрагивали данный вопрос в главе 8, когда по результатам какого-либо теста пытаются поставить диагноз, даже не взглянув на больного. Это является проблемой не математической и не статистической: нам встречался случай, когда на сделанное нами предупреждение о неадекватности применяемого теста анализируемым данным в ответ выдвигался аргумент, что исследователя это не интересует, главное для него — наличие в публикации ссылки на программу анализа данных, и если расчет сделан неверно, то это проблема разработчика программы, а не пользователя.
В отечественных медицинских кругах до сих пор не завершены дискуссии о том, нужны ли математико-статистические методы вообще. Поэтому состояние статистического анализа данных в отечествен
1 Солженицын А. И. Архипелаг ГУЛАГ. - М.: ИНКОМ НВ, 1991. - 432 с. (Т. 1). 432 с. (Т. 2), 354 с. (Т. 3).
Заключение
715
ных медико-биологических исследованиях, как показано в [116], [117], [118], производит тяжелое впечатление. Математическая статистика до сих пор не входит в арсенал основных методов исследований крупнейших медицинских научных центров России, однако обойтись без нее для описания и анализа экспериментальных и клинических данных уже нельзя, о чем свидетельствуют косвенные упоминания практически во всех разделах исследований [221].
Математическая статистика часто становится средством придания наукообразия публикации. Приходится признать, что мотивация многих исследователей далека от желания приближения к истине: место любознательности1 занимает желание сделать диссертацию2 как самоцель. Были случаи, когда к нам обращались за консультацией по поводу применения того или иного математического метода обработки экспериментальных данных. И в этом нет ничего странного, если бы иногда вопрос не формулировался примерно так: «Мы три года проводили опыты. Нельзя ли теперь из этого что-нибудь посчитать cmamucmunecKii?^. Грамотное планирование эксперимента до его постановки могло бы не только увеличить его эффективность, но и сохранило бы жизнь десяткам живых существ.
«Нет необходимости, чтобы специалист-медик был вместе с тем специалистом по физике или ботанике и наоборот», и спорить с автором данного тезиса было бы трудно3. Из беседы с авторитетным в своем кругу ученым, профессором, мы выяснили, что под нормальным распределением он понимает (и учит своих студентов!) контрольную группу. Да, именно так: нормальное распределение — это контрольная группа, потому что там все в норме. Не приходится удивляться, что на научной конференции молодой ученый-физио-лог на вопрос: «Какой параметр имеется в виду в Вашей записи М± т после знака±, не ошибка ли это средней?» — отвечает: «Нет, не ошибка, здесь все правильно». Есть радикальное решение проблемы. За рубежом уже длительное время существуют фирмы, специализирующиеся на консультациях по применению статистических методов для исследователей, например Stat Ex (www.statex.qc.ca). Возникают такие структуры и в России, например Центр прикладной статистики STAT-POINT (www.doktor.ru). Только профессионал в области статистических методов сможет выбрать адекватные методы
1 Шульман С. Инопланетяне над Россией. - М.: Профиздат, 1990.— С. 191.
2 Смирнов Г. Заметки редактора //Техника-молодежи.— № 7.— 1999.— С. 38.
3 Сталин И. В, Отчетный доклад на XVII съезде партии о работе ЦК ВКП(б) // Вопросы ленинизма.— М.: ОГИЗ, 1939.— С. 598.
716
Заключение
статистического анализа и помочь ученому, диссертанту провести математическую обработку научно-клинического или иного материала. «Многие вещи нам непонятны не потому, что наши понятия слабы; но потому, что сии вещи не входят в круг наших понятий»1. Общие требования представления данных для публикации рассмотрены в [ 1]. Ознакомиться с рекомендациями по составлению отчетов об исследованиях, использующих тот или иной специальный математический метод анализа экспериментальных данных, можно по [57, с. 86], [147, с. 170] — факторный анализ, [148, с. 209] — кластерный анализ. Дополнительные материалы по рассматриваемым ниже проблемам даны в [139], [195].
Программы медико-биологической статистики
В случае применения в исследованиях аппаратно-программного обеспечения в настоящее время считается обязательным дать название и общие характеристики диагностической аппаратуры, а также наименование программного обеспечения и номер его версии [1].
Программное обеспечение, применяемое в медицинских учреждениях Российской Федерации с целями, связанными с диагностикой и выбором тактики лечения и самим лечением пациентов, согласно Указу Президента Российской Федерации №161 от 18 февраля 1995 года и Приказу Министра здравоохранения и медицинской промышленности Российской Федерации № 85 от 4 апреля 1995 года «О сертификации программных средств и баз данных в системе Мин-здравмедпрома России», должно в обязательном порядке пройти сертификационные испытания и иметь Сертификат программного продукта, подтверждающий его безопасность для здоровья пациентов. Аналогичные правила действуют и в ряде других государств. Опубликованное в настоящем издании программное обеспечение не предполагалось сертифицировать для специального применения, а следовательно, сертификата Минздрава оно не имеет и не может быть применено для указанных целей. Справедливости ради отметим, что ни один из известных нам универсальных фирменных пакетов анализа биомедицинских данных не имеет упомянутого сер
Прутков К. Плоды раздумья. Мысли и афоризмы: Сочинения. - М.: Правда, 1986.— С. 98.
Терминология
717
тификата. Подобные сертификаты имеет только небольшое число программных средств, предназначенных для решения специальных задач [198].
В табл. А представлены некоторые ресурсы Интернета по анализу биомедицинских данных, причем некоторые фирмы, например Cytel Software Corp. (www.cyteL.com), выпускают целые наборы узкоспециализированных программ анализа данных.
Таблица А. Программные ресурсы по анализу биомедицинских данных
Ресурс, адрес Разработчик или поставщик Содержание
www.graphpad.com доступна GraphPad Software, Inc. InStat, анализ экспериментальных и клинических научных данных, пробная версия
www.medcalc.be /index.html Frank Schoonjans MedCalc, статистика для биомедицинских исследований, доступна пробная версия
ic.net/~biomware /index.html BioMedware Stat!, кластерный анализ медицинских данных
www.longman.net Pearson Education Ltd. Arcus QuickStat Biomedical, доступна пробная версия
www. spacestat, com Luc Anselin SpaceStat, статистический анализ медицинских данных, доступна демонстрационная версия
www.sghms.ac.uk Medical School, Clinstat, учебная программа по
/phs/staff/jmb /jmb.htm University of London математической статистике в медицине, бесплатно
pu.samson.spbsu Санкт- Материалы по моделированию
/education/faculties Петербургский функций организма с помощью
/psyhology/nps/ государственный университет нейронных сетей
Терминология
Как и в любой другой области, начиная с написания собственных имен и заканчивая наименованиями методик, терминология вызывает большое количество споров при обсуждении методик анализа данных, иногда переходящих в личные конфликты среди исследователей. Не приходится надеяться, что терминология когда-либо станет единой. Например, в отечественных источниках дисперсию все
718
Заключение
чаще называют вариацией, но однофакторный дисперсионный анализ пока не решаются называть ANOVA, тем более что в.иностран-ных источниках этот метод тоже не всегда так называют.
Замечено, что в терминологические игры пускаются те, кому больше нечего сказать. Вряд ли возникнет претензия к автору, если названия методик и собственные имена он дасг по тому или иному цитируемому источнику. Есть ли разница, если автор скажет «мера Кульбака» или «мера Калбэка», если методика применена верно и имеется ссылка? Однако общая рекомендация остается актуальной в любом случае: в работах, использующих анализ данных, следует избегать использования терминов, специфических для анализа данных и статистики, в общеупотребительном, иногда даже в «бытовом» смысле [ 1 ]. Например, это: вероятность, многофакторый анализ, полезность, моделирование, нормальное распределение, норма и т. д.
Полнота и воспроизводимость
Общим правилом изложения материалов научных публикаций, а особенно результатов математической обработки экспериментальных данных, является полнота. Читатели должны иметь возможность изучить исходные данные, проверить результаты и проконтролировать расчеты. Это следствие непременного условия воспроизводимости результатов эксперимента, в том числе и эксперимента вычислительного. Необходимо приводить все первичные данные эксперимента, применяемые в вычислениях. «Воспроизводимость и есть критерий честности экспериментов» [125]. Полной воспроизводимости в некоторых типах экспериментов добиться практически невозможно, однако мы настаиваем на предоставлении в публикации всех исходных данных, использованных в расчетах, и говорим о необходимости полной воспроизводимости вычислительного эксперимента, который следом за автором может быть проделан читателем, ибо «... восприятия должны допускать возможность проверки всеми людьми, производящими наблюдения, то есть знание должно носить межличностный, интерсубъективный характер» [204, с. 283]. Сокрытию существенных деталей разработки, чтобы не дать пользователю полной информации, мы пытаемся противопоставить генерацию идей с такой скоростью, чтобы другие не успевали их осваивать: «... радость и гордость Ауле — в творчестве и в сотворенной вещи, а не в обладании и господстве; и потому он дарит, а не копит, и свободен от забот, все время переходя от уже сделанного к но
Структуризация и компактность
719
вой работе»1. Впрочем, «гений мыслит и создает. Человек обыкновенный приводит в исполнение. Дурак пользуется и не благодарит»2.
Структуризация и компактность
В связи с возрастанием объема и сложности полученных результатов научных исследований возрастают требования к представлению результатов исследований в максимально компактной форме. Исследователи уже давно стали ясно ощущать, что по мере возрастания размерности задачи все более теряется обозримость результатов [79, с. 6]. Именно этим вызвана растущая популярность научно-практических изданий, публикующих выжимки из результатов наиболее важных исследований [137, с. 67]. Ограниченная пропускная способность информационных каналов — это проблема техническая, однако в качестве информационного канала можно рассматривать и тракты человеческого восприятия. Если для технических систем найдены или будут найдены приемлемые решения увеличения пропускной способности информационных каналов и экстенсивное развитие пока еще приводит к успеху, то относительно информационных каналов человека этого сказать уже нельзя. Средством увеличения количества информации, которую может воспринять мозг человека, считается структурированное представление информации, что в конечном счете улучшает компактность ее представления. Средства компактного представления информации, обеспечивающего ее адекватное восприятие, представлены в [228].
Рассмотренные принципы должны применяться не только в смысле переработки огромных массивов информации, но и относительно каждой отдельно взятой небольшой работы, статьи, отчета. Небольшое исследование станет частью большого интеллектуального багажа научного сообщества в целом. Интересный подход к проблеме, причем не только и не столько в области программирования, обсуждается в [40].
Точная адресация
Нет никакого смысла в описании тонкостей интерпретации результатов математико-статистических расчетов, если печатная работа или
1 Толкин Дж. Р. Р. Сильмариллион: Сборник. - М.: ООО «Издательство АСТ»; СПб.: Terra Fantastica, 2000.— С. 14.
2 Прутков К. Некоторые материалы для биографии К. П. Пруткова: Сочинения. -М.: Правда, 1986.— С. 345.
720
Заключение
программа написана или составлена для обычного пользователя, не математика. Разработчики фирменных программных продуктов обращают на это внимание и точно адресуют поставляемые программы анализа данных определенной категории исследователей. Лучше попытаться объяснить результаты в терминах, понятных читателю или пользователю. Проблема в том, что автор должен представлять себе некий обобщенный портрет своего читателя или пользователя. Пренебрежение этим очевидным правилом приводит к тому, что некоторые работы и программы не находят своего читателя и пользователя в той мере, в какой бы хотелось их авторам. Возможно, причина в том, что автору бывает трудно отделить математикостатистическую часть работы от специальной, например медико-биологической, хотя надо дать возможность читателю без потери общности пропустить, если он в этом нетвердо разбирается, слишком сложные для него математические выкладки, перейдя прямо к выводам и не потеряв при этом нити повествования. Трудно сказать, какой аудитории адресован источник, если хитрое смешение хороших математических выкладок со столь же хорошей медицинской терминологией не позволяет полностью понять рассматриваемый автором предмет ни математикам, ни медикам. Иногда создается впечатление, что авторам важен только факт публикации работы, но совершенно неинтересен как резонанс, вызываемый публикацией, так и применение результатов исследований в дальнейшей практике.
Каждому исследователю, особенно медику, биологу и другим специалистам, имеющим дело со сложными системами, настоятельно рекомендуется ознакомиться с материалами [116]—[118], а специалистам-медикам для первоначального знакомства нужно изучить источники, составленные специально для них и сопровождаемые большим числом практических решений: [24], [52], [57]—[89], [111], [ 195]. К примерам из области медицины обращаются авторы других пособий: [201], [228]. Обсуждение см. также в [26, с. 251] и в дополнительной главе [208, с. 391].
Литература
Книги и публикации
1. Bailar J. С., Mosteller F. Guidelines for Statistical Reporting in Articles for Medical Journals. Amplifications and Explanations // Annals of Internal Medicine, 15 February 1988,108 : 266—273. (www.acponline.org/journals/resource/guidelines.htm)
2. Golub G., Kahan W. Calculating the singular values and pseudo-inverse of a matrix //J. SIAM Numer. Anal. Ser. B, Vol. 2, No. 2, 1965, pp. 205-223.
3. Kasumova M. K. A Backpropagation Neural Network Applied to Image Segmentation and Recognition // Pattern Recognition and Image Analysis, Vol. 2, No. 4,1992, pp. 438—440.
4. Kraber S. A Case to Test Your Metal // Stat—Teaser, December, 1999, p. 1,3.
5. Mehta C. R., Patel N. R. Exact inference for categorical data // BAE040—A. A.—10—Maj. (www.cytel.com)
6. Mehta C. R., Patel N. R. Exact logistic regression: theory and examples // Statistics in medicine, Vol. 14,1995, pp. 2143—2160. (www.cytel.com)
7. Motulsky H. The link between error bars and statistical significance // GraphPad Insight, Autumn, 2000, p. 4.
8. Numerical Recipes in C: The Art of Scientific Computing / W. H., Press, S. A. Teukolsky, W. T. Vetterling et al., New York: Cambridge University Press, 1992. (www.nr.com)
9. Numerical Recipes in Fortran 77: The Art of Scientific Computing / W. H. Press, S. A. Teukolsky, W. T. Vetterling et al., New York: Cambridge University Press, 1992. (www.nr.com)
10. Rice J. R. Будущее систем программного обеспечения для научных исследований // Computer—weekly (Computer—week Moskow), № 10,1998, c. 25—26. (www.infoart.ru/it/press/cwm/ 10_98/sistem.htm)
11. Small R. D. Интеллектуальный анализ данных: мифы и факты // Computer—weekly (Computer—week Moskow), № 22—23,1997, c. 38—39. (www.infoart.ru/it/press/cwm/22_97/data.htm)
24-2002
722
Литература
12. Stewart D. E. A new algorithm for the SVD of a long product of matrices and the stability of products // Electronic Transactions on Numerical Analysis. Vol. 5, pp. 29—47, June 1997. (www.ras.ru/EMIS/journals/ETNA/index.html)
13. System/360 Scientific Subroutine Package (360—CM—03X). Programmer’s Manual (H20—0205—3). — IBM, Technical Publications Department, N.Y., 1970.
14. Turbo Vision для C++. — Киев: Крещатик, 1992. — 256 с.
15. Амиянц В. Ю., Верес А. А., Уткин В. А. Изучение роли тренирующих нагрузок с позиций кластерного и факторного анализа у больных ишемической болезнью сердца, перенесших аортокоронарное шунтирование // Сб. научных трудов IV Всероссийского симпозиума «Математическое моделирование и компьютерные технологии». Т. 3 «Информационные технологии», «Компьютерная медицина». — Кисловодск, 2000. — С. 67—79.
16. Андерсон Т. Введение в многомерный статистический анализ. — М.: Гос. изд-во физико-математической литературы, 1963. - 500 с.
17. Афанасьев Д., Афанасьев В. Описательная статистика в SPSS // КомпьютерПресс. — 1999. № 5. — CD.
18. Афифи А., Эйзен С. Статистический анализ: Подход с использованием ЭВМ. — М.: Мир, 1982. — 488 с.
19. Бабэ Б. Просто и ясно о Borland C++. — М.: БИНОМ, 1994.
20. Базара М., Шетти К. Нелинейное программирование. Теория и алгоритмы. — М.: Мир, 1982. — 583 с.
21. Балантер Б. И., Ханин М. А., Чернавский Д. С. Введение в математическое моделирование патологических процессов. — М.: Медицина, 1980. — 264 с.
22. Батунер Л. М., Позин М. Е. Математические методы в химической технике. — Л.: Химия, 1968. — 824 с.
23. Бахвалов Н. С. Численные методы. — М.: Наука, 1973.
24. Бейли Н. Статистические методы в биологии. — М.: Мир, 1963. - 272 с.
25. Белецкий Я. Энциклопедия языка Си. — М.: Мир, 1992.
26. Бессмертный Б. С. Математическая статистика в клинической, профилактической и экспериментальной медицине. — М.: Медицина, 1967. — 304 с.
Книги и публикации
72;
27. Бехтерева Н. Слово в нейронных ансамблях // Наука и жизн] - 1977. - № 10. - С. 90-94.
28. Бикел П., Доксам К. Математическая статистика. — М.: Финаи сы и статистика, 1983. — 278 с. (Вып.1), 254 с. (Вып.2).
29. Биллиг В. А., Мусикаев И. X. Visual C++ 4. Книга для пре граммистов. — М.: Русская редакция, 1996. — 352 с.
30. Блинов С. BrainMaker — прогнозирование на финансовы рынках // Открытые системы. — 1998. -№ 4. - (Электронна версия на www.osp.ru/os/1998/04/06.htm)
31. Блум Ф., Лейзерзон А., Хофстедтер Л. Мозг, разум, поведе ние. — М.: Мир, 1988. — 248 с.
32. Большев Л. Н., Смирнов Н. В. Таблицы математической ста тистики. — М.: Наука, 1983. — 416 с.
33. Борель Эм., Дельтейль Р., Юрон Р. Вероятности, ошиб ки. — М.: Статистика, 1972. — 176 с.
34. Боровиков В. П. Русская версия системы STATISTICA // Ком пьютерПресс. — 1999. — № 5.
35. Бородин А. Н. Элементарный курс теории вероятностей и ма тематической статистики. — СПб: Лань, 1999. — 224 с.
36. Бранденбау Дж. JavaScript: сборник рецептов для профессио налов. — СПб: Издательство «Питер», 2000. — 416 с.
37. Браунли К. А. Статистическая теория и методология в науке г технике. — М.: Наука, 1977. — 408 с.
38. Брич 3. С., Капилевич Д. В., Клецкова Н. А. Фортран 77 дл$ ПЭВМ ЕС. — М.: Финансы и статистика, 1991. — 288 с.
39. Бронштейн И. Н., Семендяев К. А. Справочник по математи ке.-М., 1967.-608 с.
40. Буч Г. Объектно-ориентированное проектирование с примерами применения. — М.: Конкорд, 1992. — 519 с. (Есть более поздний перевод на русский язык второго издания книги.)
41. Ван дер Варден Б. Л. Математическая статистика. — М.: Издательство иностранной литературы, 1960. — 436 с.
42. Ватанабе С. Разложение Карунена—Лоэва и факторный анализ Теория и приложения // Автоматический анализ сложных изображений. — М.: Мир, 1969. — С. 239—253.
43. Введение в криптографию / Под общ. ред. В. В. Ященко. - М.: МЦНМО: «ЧеРо», 1999. - 272 с.
24*
724
Литература
44. Вентцель Е. С. Теория вероятностей. — М.: Высш, шк., 1999. — 576 с.
45. Верещагин Н. Л., Шень А. Лекции по математической логике и теории алгоритмов. Часть 1. Начала теории множеств. - М.: МЦНМО, 1999. - 128 с.
46. Выгодский М. Я. Справочник по элементарной математике. — М.: Гос. изд. технико-теоретической лит., 1954. — 412 с.
47. Гайдышев И. П., Кобазева О. М., Уткин В. А. Оптимизация выбора алгоритмов линейной алгебры под задачи многомерной статистики с позиций практического подхода программиста // Тезисы докладов II региональной конференции «Информационные технологии в обществе. Различные аспекты информатизации», 24—25 апреля 2000 г. Курган, С. 25—27.
48. Гантмахер Ф. Р. Теория матриц. — М.: Наука, 1966. (Есть более позднее переиздание)
49. Гатаулин А. М. Методическое пособие по математической статистике. Раздел I. — М.: Московская сельскохозяйственная академия им. К. А. Тимирязева, 1968.
50. Гатаулин А. М. Методическое пособие по математической статистике. Раздел II. Выборки и проверка статистических гипотез. — М.: Московская сельскохозяйственная академия им. К. А.Тимирязева, 1970.
51. Гилл Ф., Мюррей У., Райт М. Практическая оптимизация. — М.: Мир, 1985. — 509 с.
52. Гланц С. Медико-биологическая статистика. — М.: Практика, 1999.-449 с.
53. Гласс Дж., Стэнли Дж. Статистические методы в педагогике и психологии. — М.: Прогресс, 1976.
54. Гмурман В. С. Теория вероятностей и математическая статистика. — М.: Высш, шк., 1972. — 368 с.
55. Горбань А. Н. Обучение нейронных сетей. — М.: СП ПараГраф, 1990.- 160 с.
56. Горбань А. Н. Функции многих переменных и нейронные сети // Соросовский образовательный журнал. —1998. — № 12. — С. 105-112.
57. Гублер Е. В. Вычислительные методы анализа и распознавания патологических процессов. — Л.: Медицина, 1978. — 296 с.
58. Гублер Е. В., Генкин А. А. Применение непараметрических критериев статистики в медико-биологических исследованиях. — Л.: Медицина, 1973.
Книги и публикации
725
59. Гусак А. А. Справочное пособие к решению задач: математический анализ и дифференциальные уравнения. — Мн.: Тетра-Системс, 1998. — 416 с.
60. Гутер, Овчинский. Основы теории вероятностей. — М.: Просвещение, 1967. — 159 с.
61. Дадашев Т. Поиск видеоданных в сети // Компьютерра. — 1998. — № 12.-С. 42-45.
62. Дарнелл Р. JavaScript: справочник. — СПб: Питер., — 192 с.
63. Де Гроот М. Оптимальные статистические решения. — М.: Мир, 1974.
64. Дейч С. Модели нервной системы. — М.: Мир, 1970. — 326 с.
65. Дерябин В. Е. Критерий для определения таксономической ценности признака // Биометрический анализ в биологии. — М.: Издательство Московского университета, 1982. — С. 118-130.
66. Джейн А. К., Мао Ж., Моиуддин К. М. Введение в искусственные нейронные сети // Открытые системы, 1997 № 4. (www.osp.ru/ os/1997/04/source/16.html)
67. Дженнрич Р. И. Пошаговая регрессия // Статистические методы для ЭВМ / Под ред. К. Энслейна, Э. Рэлстона, Г. С. Уилфа. - М.: Наука, 1986. - С. 77-94.
68. Дженнрич Р. И. Пошаговый дискриминантный анализ // Статистические методы для ЭВМ / Под ред. К. Энслейна, Э. Рэлстона, Г. С. Уилфа. — М.: Наука, 1986. — С. 94—113.
69. Джонсон Н., Лион Ф. Статистика и планирование эксперимента в технике и науке. Методы планирования эксперимента. — М.: Мир, 1981. — 518 с.
70. Джонсон Н., Лион Ф. Статистика и планирование эксперимента в технике и науке. Методы обработки данных. — М.: Мир, 1980.-612 с.
71. Дикусар В. В. Некоторые численные методы решения линейных алгебраических уравнений // Соросовский образовательный журнал. — 1998. — № 9. — С. 111—120.
72. Доерфель К. Статистика в аналитической химии. — М.: Мир, 1969. - 247 с.
73. Дуда Р„ Харт П. Распознавание образов и анализ сцен. — М.: Мир, 1976. — 512 с.
726
Литература
74. Дэвенпорт Дж., Сирэ И., Турнье Э. Компьютерная алгебра. Системы и алгоритмы алгебраических вычислений. — М.: Мир, 1991.-352 с.
75. Дэвис С. Р. Программирование на Microsoft Visual Java++. — М.: Издательский отдел «Русская редакция» ТОО «Channel Trading Ltd.», 1997. — 376 с.
76. Дэйвисон М. Многомерное шкалирование. Методы наглядного представления данных. — М.: Финансы и статистика, 1988. — 348 с.
77. Дэннис Дж., мл., Шнабель Р. Численные методы безусловной оптимизации и решения нелинейных уравнений. — М.: Мир, 1999.-440 с.
78. Дюк В. Обработка данных на ПК в примерах. — СПб.: Питер, 1997. - 240 с.
79. Дюран Б., Оделл П. Кластерный анализ. — М.: Финансы и статистика, 1977. — 176 с.
80. Елисеева И. И., Юзбашев М. М. Общая теория статистики. — М.: Финансы и статистика, 1995. — 368 с. (В 1998 году выпущено переиздание)
81. Енюков И. С. Методы, алгоритмы, программы многомерного статистического анализа: пакет ППСА. — М.: Финансы и статистика, 1986. — 232 с.
82. Ерохин В., Харисов В. Нейропакет в корпоративной системе поддержки принятия решений // Computer—weekly (Computer— week Moskow). — 1998. — № 43. — C. 20. (www.infoart.ru/it/press/ cwm/43_98/neiro.htm)
83. Завалишин H. В., Мучник И. Б. Модели зрительного восприятия и алгоритмы анализа изображений. — М.: Наука, 1974. — 344 с.
84. Зайцев Г. Н. Математическая статистика в экспериментальной ботанике. — М.: Наука, 1984. — 424 с.
85. Информативность лабораторных исследований*! в травматологии и ортопедии / К. С. Десятниченко, Л. С. Кузнецова, И. П. Гайдышев и др. Современные методы диагностики. Тезисы докладов. — Барнаул, 1999. — С. 202—203.
86. Информатика: Энциклопедический словарь для начинающих / Сост. Д. А. Поспелов. — М.: Педагогика-Пресс, 1994. — 352 с.
Книги и публикации
727
87. Йыуду К. Если компьютер обманывает // Техника для всех. — 1996.-№4.-С. 48-49.
88. Кадыров X. К., Антомонов Ю. Г. Синтез математических моделей биологических и медицинских систем. — Киев: Наукова думка, 1974.
89. Каминский Л. С. Обработка клинических и лабораторных данных. — Л.: Медгиз, 1959. — 196 с.
90. Катковник В. Я. Непараметрическая идентификация и сглаживание данных. Метод локальной аппроксимации. — М.: Мир, 1985.
91. Кендалл М. Дж., Стьюарт А. Статистические выводы и связи. — М.: Наука, 1973. — 899 с.
92. Кендалл М. Дж., Стьюарт А. Теория распределений. — М.: Наука, 1966. — 588 с.
93. Кендэл М. Временные ряды. — М.: Финансы и статистика, 1981.
94. Керниган Б., Ритчи Д. Язык программирования Си. — М.: Финансы и статистика, 1992. (lib.ru/CTOTORAernigan.txt)
95. Ким Дж. О., Мюллер Ч. У. Факторный анализ: статистические методы и практические вопросы // Факторный, дискриминантный и кластерный анализ / Дж. О. Ким, Ч. У. Мюллер, У. Р. Клекка и др. — М.: Финансы и статистика, 1989. — 215 с.
96. Классификация и кластер. — М.: Мир, 1980. — 392 с.
97. Клекка У. Р. Дискриминантный анализ // Факторный, дискриминантный и кластерный анализ / Дж. О. Ким, Ч. У. Мюллер, У. Р. Клекка и др. — М.: Финансы и статистика, 1989. — 215 с.
98. Кориков А. М. Математические методы планирования эксперимента. — Томск: ТГУ, 1973.
99. Кормен Т., Лейзерсон Ч., Ривест Р. Алгоритмы: построение и анализ. — М.: МЦНМО, 2000. — 960 с.
100. Корн Г, Корн Т. Справочник по математике для научных работников и инженеров. — М.: Наука, 1973.
101. Кохонен Т. Ассоциативная память. — М.: Мир, 1980.
102. Краскэл Дж. Б. Многомерное шкалирование и другие методы поиска структуры // Статистические методы для ЭВМ / Под ред. К. Энслейна, Э. Рэлстона, Г. С. Уилфа. — М.: Наука, 1986. — С. 301-347.
728
Литература
103. Кречетов Н. Продукты для интеллектуального анализа данных // Computer—weekly (Computer—week Moskow). — 1997. — № 14-15.-C. 32-39; 1997.-№ 16.-C. 17-19. (www.infoart.ru/ it/press/cwm/14_97/data.htm, www.infoart.ru/it/press/cwm/ 16 97/ data.htm)
104. Кристиансен T., Торкингтон H. Perl: библиотека программиста. — СПб: Издательство «Питер», 2000. — 736 с.
105. Круглински Д. Дж. Основы Visual C++. — М.: Издательский отдел «Русская редакция» ТОО «Channel Trading Ltd.», 1997. — 696 с.
106. Кулаичев А. П. Компьютерный контроль процессов и анализ сигналов. — М.: Информатика и компьютеры, 1999. — 330 с.
107. Куликовский Л. Ф., Мотов В. В. Теоретические основы информационных процессов. — М.: Высш, шк., 1987. — 248 с.
108. Кульбак С. Теория информации и статистика. — М.: Наука, 1967.
109. Курочкин С. В. Нейронные сети: просто о сложном // Банковские технологии, 1997, № 9. (www.tvp.ru/progrfr.htm)
110. Кэттел Р. Б., Ханна Д. К. Принципы и процедуры однозначного поворота в факторном анализе // Статистические методы для ЭВМ / Под ред. К. Энслейна, Э. Рэлстона, Г. С. Уилфа. — М.: Наука, 1986. - С. 184-218.
111. Лакин Г. Ф. Биометрия. — М.: Высш, шк., 1990. — 352 с.
112. Ланс Дж. Н. Численные методы для быстродействующих вычислительных машин. — М.: Изд-во ин. лит., 1962.
113. Ларичев О. И., Горвиц Г. Г. Методы поиска локального экстремума овражных функций. — М.: Наука, 1990. — 95 с.
114. Левин М. Г. Программное обеспечение для решения задач численного анализа на СМ ЭВМ. — Кишинев: Штиинца, 1991.
115. Леман Э. Проверка статистических гипотез. — М.: Наука, 1979. — 408 с.
116. Леонов В. П. Применение статистики в статьях и диссертациях по медицине и биологии. Часть II. История биометрии и ее применения в России // Международный журнал медицинской практики, 1999 № 4. (mediasphera.aha.ru/mjmp/99/4/ r4-99con.htm)
117. Леонов В. П., Ижевский П. В. Об использовании прикладной статистики при подготовке диссертационных работ по медицинским и биологическим специальностям // Бюллетень Го
Книги и публикации
729
сударственного высшего аттестационного комитета Российской Федерации. — 1997. — № 5. — С. 56—61.
118. Леонов В. П., Ижевский П. В. Применение статистики в статьях и диссертациях по медицине и биологии. Часть I. Описание методов статистического анализа в статьях и диссертациях // Международный журнал медицинской практики. — 1998. — № 4. (mediasphera.aha.ru/mjmp/98/4/r4—98con.htm)
119. Леонтюк А. С., Леонтюк Л. А., Сыкало А. И. Информационный анализ в морфологических исследованиях. — Мн.: Наука и техника, 1981. — 160 с.
120. Ликеш И., Ляга Й. Основные таблицы математической статистики. — М.: Финансы и статистика, 1985. — 356 с.
121. Линдли К. Практическая обработка изображений на языке Си. — М.: Мир, 1996. — 512 с.
122. Липпман С. Б. C++ для начинающих. — М.: Унитех; Рязань: Гэлион, 1993. — Том 1. — 304 с. Том 2. — 345 с.
123. Лисенков А. Н. Математические методы планирования многофакторных медико-биологических экспериментов. — М.: Медицина, 1979. — 344 с.
124. Литтл Р. Дж. А., Рубин Д. Б. Статистический анализ данных с пропусками. — М.: Финансы и статистика, 1990.
125. Логинов В. С., Дорошенко С. И. Мошенничество в науке // Химия и жизнь. — 1992. — № 3. — С. 22—25. (www.doktor.ru/ doctor/biometr/lib/obman.htm)
126. Лоули Д., Максвелл А. Факторный анализ как статистический метод. — М.: Мир, 1967. — 144 с.
127. Лыхмус К. Н. Информационный критерий гомогенности выборки // Биометрический анализ в биологии. — М.: Издательство Московского университета, 1982. — С. 51—57.
128. Мак-Кракен Д., Дорн У. Численные методы и программирование на ФОРТРАНе. — М.: Мир, 1977.
129. Малоземов В. Н., Певный А. Б. Рекуррентные вычисления. — Л.: Издательство Ленинградского университета, 1976. — 56 с.
130. Мандель И. Д. Кластерный анализ. — М.: Финансы и статистика, 1988. — 176 с.
131. Манзон Б. Statistica 5.1: программа для начинающих и профессионалов // Мир ПК. — 1998. — № 3. — (www.osp.ru/pcworld/ 1998/03/4 l.htm)
730
Литература
132. Математика в социологии: моделирование и обработка информации / Под. ред. А. Г. Аганбегяна и Ф. М. Бородкина. — М.: Мир, 1977. - 550 с.
133. Математическая энциклопедия. ТТ. 1—5. — М.: Советская энциклопедия, 1982.
134. Математические моделирование / Под ред. Дж. Эндрюса и Р. Мак-Доуна. — М.: Мир, 1979.
135. Математический энциклопедический словарь. — М.: Большая Российская энциклопедия, 1995. — 848 с.
136. Маттсон Р. Л., Дамман Дж. Е. Метод определения и кодирования подклассов в задачах распознавания образов // Автоматический анализ сложных изображений. — М.: Мир, 1969. — С. 239-253.
137. Мешалкин Л. Д. От Потсдамской декларации до шкалы надежности знаний // Компьютерные технологии в медицине. — 1998.-М 1.-С. 65-68.
138. Минский М., Пейперт С. Перцептроны. — М.: Мир, 1971.
139. Мэйндоналд Дж. Вычислительные алгоритмы в прикладной статистике. — М.: Финансы и статистика, 1988. — 350 с.
140. Мюллер П., Нойман П., Шторм Р. Таблицы по математической статистике. — М.: Финансы и статистика, 1982. — 278 с.
141. Налимов В. В. Теория эксперимента. — М.: Наука, 1971.
142. Налимов В. В., Голикова Т. И. Логические основания планирования эксперимента. — М.: Металлургия, 1980.
143. Нейман Ю. Вводный курс теории вероятностей и математической статистики. — М.: Наука, 1968. — 448 с.
144. Нейропрограммы. Учебное пособие // Л. В. Гилева, С. Е. Гилев, А. Н. Горбань и др. — Красноярск: КГТУ, 1994. — 137 с. (4.1), 123 с. (Ч. 2).
145. Неформальное введение в C++ и Turbo Vision. — СПб: Галерея «Петрополь», 1992. — 384 с.
146. Носач В. В. Решение задач аппроксимации с помощью персональных компьютеров. — М.: МИКАП, 1994. — 382 с.
147. Окунь Я. Факторный анализ. — М.: Статистика, 1974. — 200 с.
148. Олдендерфер М. С., Блэшфилд Р. К. Кластерный анализ / Факторный, дискриминантный и кластерный анализ /
Книги и публикации
731
Дж. О. Ким, Ч. У. Мюллер, У. Р. Клекка и др. — М.: Финансы и статистика, 1989. — 215 с.
149. Орвис В. Дж. Excel для ученых, инженеров и студентов. — Киев: Юниор, 1999. — 528 с.
150. Ортега Дж., Рейнболдт В. Итерационные методы решения нелинейных систем уравнений со многими неизвестными. — М.: Мир, 1975.
151. Оуэн Д. Б. Сборник статистических таблиц. — М.: Выч. центр АН СССР, 1966. — 586 с. (Есть более позднее исправленное издание)
152. Пагурова В. И. Критерий сравнения средних значений по двум нормальным выборкам. — М.: ВЦ АН СССР, 1968. — 58 с.
153. Паппас К., Мюррэй У. Visual C++. Руководство для профессионалов. — Спб: BHV — Санкт-Петербург, 1996.
154. Парницкий Г. Основы статистической информатики. — М.: Финансы и статистика, 1981. — 199 с.
155. Педусаар X. Дайте мнепалец...//Техникадля всех, 1996, № 3, С. 79.
156. Петров А. П. Статистическая обработка результатов экспериментальных исследований: Учебное пособие. — Курган: Изд-во Курганского гос. ун-та, 1998. — 85 с.
157. Плохинский Н. А. Достаточная численность выборки // Биометрический анализ в биологии. — М.: Издательство Московского университета. — 1982. — С. 152—157.
158. Плохинский Н. А. Основные вопросы современной биометрии // Биометрический анализ в биологии. — М.: Издательство Московского университета. — 1982. — С. 7—11.
159. Поллард Дж. Справочник по вычислительным методам статистики. — М.: Финансы и статистика, 1982. — 344 с.
160. Прикладная статистика: Классификация и снижение размерности. Справ, изд. / С. А. Айвазян, В. М. Бухштабер, И. С. Енюков, Л. Д. Мешалкин. — М.: Финансы и статистика, 1989. — 608 с.
161. Прикладная статистика: Основы моделирования и первичная обработка данных. Справ, изд. / С. А. Айвазян, И. С. Енюков, Л. Д. Мешалкин. — М.: Финансы и статистика, 1983. — 471 с.
162. Прохоров А. Биометрия на службе безопасности // КомпьютерПресс. — 2000. — № 3. — С. 68—73.
163. Райс Дж. Матричные вычисления и математическое обеспечение. — М.: Мир, 1984.
732
Литература
164. Расчет на прочность деталей машин: Справочник / И. А. Биргер, Б. Ф. Шорр, Г. Б. Иосилевич. — 4-е изд., перераб. и доп. — М.: Машиностроение, 1993. — 640 с.
165. Ремез Е. Я. Основы численных методов чебышевского приближения. — Киев: Наукова Думка, 1962.
166. Розенблатт Ф. Принципы нейродинамики. Перцептроны и теория механизмов мозга. — М.: Мир, 1965.
167. Романовский В. И. Математическая статистика. Кн. 2. Оперативные методы математической статистики. — Ташкент: Изд-во Академии наук УзССР, 1963.
168. Рубан А. И. Идентификация и чувствительность сложных систем. — Томск: ТГУ, 1982.
169. Рубан А. И. Идентификация нелинейных динамических объектов на основе алгоритма чувствительности. — Томск: ТГУ, 1975.
170. Рубан А. И., Гусев В. П. Подход к идентификации нелинейных динамических объектов // Оптимизация управления сложными технологическими процессами. — Томск: ТГУ, 1980.
171. Рубан А. И., Ткаченко О. С., Уташев К. Т. Алгоритм чувствительности в задаче оптимизации амортизационных характеристик стоек шасси // Проблемы автоматизации в прочностном эксперименте. — М.: ЦНТИ «Волна», 1986.
172. Рунион Р. Справочник по непараметрической статистике. — М.: Финансы и статистика, 1982. — 198 с.
173. Сборник задач по теории вероятностей, математической статистике и теории случайных функций / Под ред. А. А. Свешникова. — М.: Наука, 1970. — 656 с.
174. Сборник научных программ на Фортране. Вып. 1. Статистика. - М„ 1974.-316 с.
175. Сборник научных программ на Фортране. Вып. 2. Матричная алгебра и линейная алгебра. — М., 1974. — 222 с.
176. Сван Т. Форматы файлов Windows. — М.: БИНОМ, 1995. — 288 с.
177. Себер Дж. Линейный регрессионный анализ. — М.: Мир, 1980.
178. Симахин В. А., Кашинцев А. В. Кластеризация медицинских данных с помощью нейросетей // Тезисы докладов II региональной конференции «Информационные технологии в обществе. Различные аспекты информатизации», 24—25 апреля 2000 г., Курган. С. 11-16.
Книги и публикации
733
179. Славин М. Б. Методы системного анализа в медицинских исследованиях. — М.: Медицина, 1989. — 302 с.
pBg/Сталин И. В. Речь на первом всесоюзном совещании стахановцев, 17 ноября 1935 г. // Вопр. ленинизма. — М.: О ГИЗ. — 1939. - С. 502.
181. Степанов В. С. Фондовый рынок и нейросети // Мир ПК. 1998, № 12. (www.osp.ru/pcworld/1998/12/40.htm)
182. Сторожилова О. Только детектор лжи? //Техника—молодежи. 2000, №3, С. 51.
183. Страуструп Б. Язык программирования Си++. — М.: Радио и связь, 1991. (lib.ru/cpphb/cpptut.txt, также «Введение в язык C++», www.citforum.ru/programming/cpp/aglav.shtml)
184. Стренг Г. Линейная алгебра и ее применения. — М.: Мир, 1980.-454 с.
185. Тондо К., Гимпел С. Язык Си. Книга ответов. — М.: Финансы и статистика, 1994.
186. Ту Дж., Гонсалес Р. Принципы распознавания образов. — М.: Мир, 1978.
187. Тюрин Ю. Н., Макаров А. А. Статистический анализ данных на компьютере. — М.: ИНФРА—М, 1999. — 528 с.
188. Уилкинсон Дж. X., Алгебраическая проблема собственных значений. — М.: Наука, 1970.
189. Уилкинсон, Райнш. Справочник алгоритмов на языке АЛГОЛ. Линейная алгебра. — М.: Машиностроение, 1976. — 389 с.
190. Уилкс С. Математическая статистика. — М.: Наука, 1967. — 632 с.
191. Уиллиамс У. Т., Ланс Дж. Н. Методы иерархической классификации // Статистические методы для ЭВМ / Под ред. К. Эн-слейна, Э. Рэлстона, Г. С. Уилфа, М., Наука, 1986, с. 269—301.
192. Уилф Г. С. Метод коалиций в статистическом дискриминантном анализе // Статистические методы для ЭВМ / Под ред. К Энс-лейна, Э. Рэлстона, Г. С. Уилфа. — М.: Наука, 1986. — С. 113—134.
193. Уинер Р. Язык Турбо Си. — М.: Мир, 1991.
194. Уоссермен Ф. Нейрокомпьютерная техника — М.: Мир, 1992. (www.neuropower.de/rus/books/index.html или www.sihf.spb.ru/ lib/anno2.htm)
195. Урбах В. Ю. Статистический анализ в биологических и медицинских исследованиях. — М.: Медицина, 1975. — 295 с.
734
Литература
196. Уткин В. А. Вычисление действительных значений вектора атрибутивных переменных, зависимых от переменных, принадлежащих интервальной шкале // Материалы II Международной научно-технической конференции «Новые информационные технологии и системы». 1996. Ч. I. С. 98—100.
197. Уткин В. А., Амиянц В. Ю. О возможности оцифровки атрибутивных переменных, зависимых от переменных, принадлежащих интервальной шкале // Тезисы докладов региональной конференции «Применение информационных технологий в научных исследованиях и обучении». Курган, 1999. С. 18—20.
198. Уткин В. А., Скляр Е. И. Классификация и диагностика с участием и без участия врача // Материалы XXVI научно-практической конференции врачей Курганской области. Курган, 1993. С. 28-35.
199. Уэйт М., Прата С., Мартин Д. Язык Си. Руководство для начинающих. — М.: Мир, 1988.
200. Финни Д. Введение в теорию планирования экспериментов. — М.: Наука, 1970.
201. Флейс Дж. Статистические методы для изучения таблиц долей и пропорций. — М.: Финансы и статистика, 1989. — 319 с.
202. Фор А. Восприятие и распознавание образов. — М.: Машиностроение, 1989. — 272 с.
203. Форсайт Дж., Молер К. Численное решение систем линейных алгебраических уравнений. — М.: Мир, 1969.
204. Фукс В. По всем правилам искусства. Точные методы в исследованиях литературы, музыки и изобразительного искусства // А. Моль , В. Фукс , М. Касслер. Искусство и ЭВМ. — М.: Мир, 1975. - 556 с.
205. Хальд А. Математическая статистика с техническими приложениями. — М.: Изд. иностр, лит., 1956. — 664 с.
206. Хан Г., Шапиро С. Статистические модели в инженерных задачах. — М.: Мир, 1969.
207. Хант Э. Искусственный интеллект. — М.: Мир, 1978. — 558 с.
208. Харман Г. Современный факторный анализ. — М.: Статистика, 1972.-486 с.
209. Харман Г. Дж. Метод минимальных остатков в факторном анализе // Статистические методы для ЭВМ / Под ред. К. Энслейна, Э. Рэлстона, Г. С. Уилфа. — М.: Наука, 1986. — С. 169—183.
Книги и публикации
735
210. Хартли Г. О. Решение статистических задач о распределении методом Монте-Карло // Статистические методы для ЭВМ / Под ред. К. Энслейна, Э. Рэлстона, Г. С. Уилфа. — М.: Наука, 1986.-С. 26-50.
211. Хастингс Н., Пикок Дж. Справочник по статистическим распределениям. — М.: Статистика, 1980. — 95 с.
212. Хемминг Р. В. Численные методы для научных работников и инженеров. — М.: Наука, 1972. — 400 с.
213. Хеслоп Б., Бадник Л. HTML с самого начала. — СПб: Питер, 1997.-416 с.
214. Хехт—Нильсен Р. Нейрокомпьютинг: история, состояние, перспективы // Открытые системы, 1998, № 4. (www.osp.ru/os/ 1998/04/03.htm)
215. Хокинг Р.Р. Выбор наилучшего помножества регрессионных переменных // Статистические методы для ЭВМ / Под ред. К. Энслейна, Э. Рэлстона, Г. С. Уилфа. — М.: Наука, 1986. - С. 53-77.
216. Холзнер С. Perl: специальный справочник. — СПб: Питер, 2000.-496 с.
217. Холл Д.Д., Ханна Д.К. ISODATA: метод анализа сходств и различий в сложных реальных данных // Статистические методы для ЭВМ / Под ред. К. Энслейна, Э. Рэлстона, Г. С. Уилфа. — М.: Наука, 1986. - С. 348-372.
218. Холлендер М., Вулф Д. Непараметрические методы статистики. — М.: Финансы и статистика, 1983. — 518 с.
219. Цыпкин А. Г., Цыпкин Г. Г. Математические формулы. Алгебра. Геометрия. Математический анализ: Справочник. — М.: Наука, 1985.- 128 с.
220. Шварц Р. Л., Кристиансен Т. Изучаем Perl. Программирование в среде UNIX. — Киев: BHV—Киев, 2000. — 352 с.
221. Шевцов В. И. Медико-биологические научные исследования и их значение для практического здравохранения // Гармония и здоровье. Обозрение за 1996 г. — Курган: Центр «Гармония и здоровье», 1997.
222. Шеннон К. Работы по теории информации и кибернетике. — М.: Изд. иностранной лит., 1963.
223. Шень А. Программирование: теоремы и задачи. — М.: МЦНМО, 1995. — 264 с. (ftp://ftp.mccme.ru/pub/users/shen/progbook)
, .. --— и- 1 "" ' "
736
Литература
224. Шилдт Г. Теория и практика C++. — СПб: BHV — Санкт-Петербург, 1996. — 416 с.
225. Шмидт В. М. Математические методы в ботанике: Учеб, пособие. Л.: Изд. Ленинградского университета, 1984. — 288 с.
226. Эйди Р. Мембраны — кладовые информации // Наука и жизнь. — 1977.-№ 10. - С. 94-96.
227. Эллис М., Страуструп Б. Справочное руководство по языку программирования C++ с комментариями. — М.: Мир, 1992. (lib.ru/cpphb/cppref.txt, www.citforum.ru/programming/cpp_ref/ index.shtml)
228. Язык «Си» для профессионалов / По материалам книги Г. Шилдта. - М.: И.В.К.-Софт, 1992. - 319 с.
229. Яноши Л. Теория и практика обработки результатов измерений. — М.: Мир, 1968. — 462 с.
( 230. Яншин В. В., Калинин Г. А. Обработка изображений на языке Си для IBM PC: Алгоритмы и программы. — М.: Мир, 1994.
Электронные источники
В последнее время часть литературных источников распространяется в электронном виде. Прежде всего, это документация к компьютерным программам, особенно к системам разработки приложений. По этой причине здесь же мы указываем наименования использованных нами данных средств — почти все коммерческие программные продукты были снабжены фирменной документацией, которую мы активно использовали. Виртуальные ресурсы, ссылки на которые мы даем, имеют только одно неудобство по сравнению с печатными источниками — они могут прекратить свое существование или сменить владельца к моменту, когда эта книга выйдет из печати.
Системные программы и средства разработки
Применялась печатная и электронная документация к следующим программам:
1. Borland C++ & Application Frameworks 3.1. — BoraInd International, Inc.
Электронные источники 737
2. Collie HTML 4.1. — Collie Software.
3. Collie Perl Shell 1.0. — Collie Software.
4. Java 2 SDK, Standard Edition. Version 1.2.2. — Sun Microsystems, Inc.
5. Microsoft Developer Network (MSDN) Library July 1998. — Microsoft Corp.
6. Microsoft Developer Network (MSDN) Library — Visual Studio 97, Special Edition. — Microsoft Corp.
7. Microsoft Internet Explorer 3.02 (pyc.), 4.0 (pyc.), 5.0 (pyc.), 5.5. — Microsoft Corp.
8. Microsoft Office 97 Professional SR-2 (pyc.). — Microsoft Corp.
9. Microsoft Office 2000 Professional SR-1 (pyc.). — Microsoft Corp.
10. Microsoft Visual C++ 5.0 Enterprise Edition. — Microsoft Corp.
11. Microsoft Visual C++ 6.0 Standard Edition. — Microsoft Corp.
12. Microsoft Windows 95 OEM Release 2 (pyc.). — Microsoft Corp.
13. Microsoft Windows 98 (pyc.). — Microsoft Corp.
14. Microsoft Windows 98 Second Edition (pyc.). — Microsoft Corp.
15. Microsoft Windows Millenium Edition (pyc.). — Microsoft Corp.
16. Microsoft Windows NT 4.0 Workstation SP3 (pyc.). — Microsoft Corp.
17. Netscape 6. — Netscape Communications.
18. Netscape Communicator 4.75. — Netscape Communications.
19. Opera 5.01,5.02 (pyc.). — Opera Software AS.
20. Perl 5.004 02 for Win32.
21. StarOffice 5.2 (pyc.). — Sun Microsystems, Inc.
22. TurboPower Object Professional C++ 1.02. — TurboPower Software.
23. Сибкон Коммуникатор 4.7. — Netscape Communications.
Демонстрационные версии программ анализа данных на CD
1. Minitab DEMO. Release 12. — Minitab Inc.
2. Origin 5.0 Demo. — Microcal Software, Inc.
738
Литература
3. Origin 6.0 Demo Version. — Microcal Software, Inc.
4. StatView for Windows Demo / Demo CD. February 1999. — Cherwell Scientific.
5. StatXact 4 for Windows. LogXact 2.30—day Trial CD. Full Versions. — CYTEL Software Corp.
Виртуальные ресурсы Сети
Трудно охватить в небольшом обзоре все доступные материалы. Это и не нужно делать — есть поисковые машины. Проведите поиск в Rambler (www.rambler.ru) по ключевому слову «фракталы» — вы получите множество русскоязычных ссылок, которые, в свою очередь, дают ссылки на многочисленные ресурсы по фракталам в русском и всемирном Интернете. Введите в Altavista (www.altavista.com) ключевые слова: neural nets, neural networks, information theory, statistical sofware или mathematical statistics — у Вас будет такое количество ценной информации, которое физически невозможно было получить, когда не было Сети. Помимо поисковых возможностей, в большинстве машин существуют тематические каталоги ссылок на программные ресурсы, позволяющие наиболее коротким путем выйти на необходимые ресурсы Сети. Есть и специальные сайты — каталоги [Федоров, КомпьютерПресс. — 1999. — № 2. — С. 36—52]. Например, информацию по статистическим ресурсам Сети, используя каталоги, можно получить на Yahoo (www.yahoo.com) по цепочке Science ► Mathematics ►Statistics ► Software, где далее даны ссылки на сайты разработчиков и поставщиков, а также на бесплатные, исследовательские и учебные ресурсы по программному обеспечению прикладной статистики.
Начинать исследование виртуальных ресурсов по статистическому анализу данных лучше с сайтов www.statistics.com и www.statistics.org, которые содержат исчерпывающее количество ссылок. См. также сайты ЗАО «Компания СофтЛайн» (www.softline.ru), ТВП (www.tvp.ru), EuroStat Limited (www.eurostat.com), Assessment Systems Corporation (www.assess.com), Cherwell Scientific Publishing Ltd. (www.cherwell.com), Statistical Solutions Inc. (www.statsol.ie), Kovach Computing Services (www.kovcomp.co.uk). cti statistics (www.stats.gla.ac.uk/cti/links_stats/index.html), ESB Consultancy (www.esbconsult.com.au), Томского госуниверситета (www.math. tsu.ru/russian/indexl.html). Российские фирмы — производители программных продуктов могут быть найдены с помощью средств поисковой машины yandex.ru или справочника «Желтые страницы России», находящегося по адресу www.pages.ru.
Электронные источники
739
В этом списке даны некоторые программные ресурсы, которые мы применяли, кроме их ценности как источников свежей информации, еще и потому, что многие темы пока недостаточно освещены в отечественной литературе. Печатная литература по распознаванию образов, в том числе по методам сжатия изображений, нейронным сетям, фракталам, вейвлетам и многим другим современным прикладным проблемам, изданная за рубежом, оказалась практически недоступной российским, да и многим зарубежным разработчикам и пользователям из-за очень высоких цен на нее.
Источники в сети, помимо текста в различных кодировках, обычно публикуются в следующих форматах:
• Adobe Acrobat (расширение имени файла pdf). Для просмотра и выводы на принтер файлов в формате pdf применяется программа Acrobat Reader фирмы Adobe Systems Inc. (www.adobe.com/ prodindex/acrobat/readstep.html).
• Post Script (расширение имени файла ps). Формат Post Script просматривается на экране и выводится на печать с помощью программы GSview (www.cs.wisc.edu/~ghost/index.html, об авторах и авторских правах на GSview и ее компоненты см. документацию, прилагаемую к названной программе). Эта же программа может читать и распечатывать файлы pdf, поэтому для работы с обоими форматами достаточно программы GSview. В последнем случае, однако, может понадобиться заплатка, находящаяся по адресу www.ozemail.com.au/~geoffk/pdfencrypt
• DVI (расширение имени файла dvi). Формат просматривается на экране и выводится на печать с помощью программы DVI driver (www—ikl.fzk.de/lava/dviinst.html, об авторских правах на программу см. документацию, прилагаемую к программе).
• HTML (расширение имени файла обычно htm или html). Формат HTML читается специальной программой-броузером типа Microsoft Internet Explorer или Netscape Navigator.
• Microsoft Word (расширение имени файла doc). Документы Word, а также файлы в формате rtf, могут быть просмотрены и распечатаны с помощью программы Word Viewer производства Microsoft Corp, (www.microsoft.com).
Алфавитный указатель
А
Abbe, 73
AbbeDistribution, 234
Allocate, 58
AllocateCommon, 59
AnsariBradleyTest, 119
ApproximationWilks, 416
Arcctg, 673
ArrayToArray, 475
Arth, 672
В
Bartlett, 183
Bayes, 395
Beta, 665
BetaDistribution, 218
BetaS, 664
BFGS, 623
Biserial, 296, 301
BrandtSnedecor, 126
Bravais, 287
c
CanonicalCorrelation, 416
CanonicalCorrelationAnalysis, 307
Canonical Discriminant Analysis, 410
CDAClass, 414
ChiSquare, 123
ChiSquareDistribution, 215
ChiSquareEmpire, 160
ChiSquarelntegral, 217
Choleski, 514
Chuprov, 283
CityBlock, 577
CochraneG, 184
CochraneGDistributionApprox, 227
CochraneGDistributionExact, 226
CochraneQ, 200
CoeffOfVariance, 48
Col Interchange, 485
ColMultiplyNumber, 481
Combination, 657
Combination, 657
CombinationAdd, 658
Compare, 564
Concord, 311
ConditionNumber, 508
Confidencelnterval, 32, 41, 271
ConjugateGradient, 616
Cov, 273
CriticalW, 232
D
Dann, 149
DannDistribution95,237
DannDistribution95c, 238
DannDistribution99, 238
DannDistribution99c, 238
Derive, 644
Det, 492
DuncanDistribution, 246
E
Eigen, 547
Entropie, 452
Euclid, 577
EuclidNorma, 489
EuclidNormaTri, 490
EuclidNormaVector, 488
EuclidNormaWithoutDiag, 489
ExponentFunction, 594
ExponentialFunction, 594
ExpPowerFunction, 598
F
FDAClass, 403
FDistribution, 221
Fechner, 272
Feedforward, 435
FeedforwardError, 435
Алфавитный указатель
74S
FillUp, 666 Fill Up, 666 FillUpCol, 665 FillUpDiag, 665 FillUpRow, 666 FisherDiscriminantAnalysis, 399 Fisherlrwin, 141 Fourier, 603 FrancisKublanovskaya, 545 FrequencyNormal. 266 Friedman, 195 FTest, 92 FullOrtoPlan, 464 InverseBetaDistribution, 219 InverseChiSquareDistribution, 215 InverseChiSquareDistributionBig, 217 InverseFDistribution, 221 InverseGearyDistribution, 228 InverseGTestDistribution, 230 InverseMatrix, 496 InverseNormalDistribution, 213 InversePagurovaDistribution, 236 InversePolynomial, 589 InverseSerialDistribution, 259 InverseTDistribution, 223 InverseXDistribution, 233
G J
Gamma, 661 GammaE, 660 Gammal, 663 GammaS, 660 Gauss, 550 Geary, 172 Geary Distribution, 228 Gerschgorin, 538 GetMinMax, 674 Gini, 43 Givens, 527 GompertzFunction, 607 Gower, 292 GradC, 639 GradL, 639 GradR, 638 Gram, 504 GramSchmidt, 524 GTest, 93 GTestDistribution, 230 Jaccard, 284 Jacobi, 542 JonckheereTerpstra, 181 К Kelly Wood, 298 Kendall, 279 King, 369 Kolmogorov Distribution, 252 KolmogorovOneSided, 155 KolmogorovTwoSided, 156 Krauth, 511, 512 KruskalWallis, 179 Kullback, 459 Kurtosis, 46 L Lagrange, 592 LambdaDistribution, 250, 697, 704
H LDAClass, 422 LinearDiscriminantAnalysis, 420
Hemming, 289 HesseC, 647 Hessenberg, 529 HesseR, 648 Horner, 671 Hotelling, 96 Householder, 532 HyperFunction, 597 LinearRegression, 632 LinearRegressionO, 634 Logarithm Function, 600 LogFactorial, 455 LogisticFunction, 605 M Mahalanobis, 461
1 MannWhitneyDistribution, 256 MannWhitneyTest, 113
InfiniteNorma, 490 InverseAbbeDistribution, 234 MatrixMinusDiag, 479 MatrixMinusMatrix, 478
750
Алфавитный указатель
MatrixMultiplyMatrix, 481
MatrixMultiplyMatrixT, 484
MatrixMultiplyNumber, 480
MatnxMuItiplyVector, 483
MatrixPlusDiag, 479
MatrixPlusMatrix, 477
MatrixT, 488
MatrixTMultiplyMatrix, 483
MatrixUnit, 487
MaxEntropie, 453
MaximumLikelihood, 341
MaximumOf, 572, 573, 574
MaximumPath, 384
McQueen, 378
Median, 34, 144
MedianDistribution, 249
MinimumOf, 575
MinimumOf, 571, 572, 574, 575
Minkovski, 576
Mode, 35
Moment, 52
MultyFactor, 192
N
Near, 366
NearLink, 365
NelderMead. 609
Newton, 498, 619
NormalDensity, 212
Normal Distribution, 212
Normal Distribution!, 212
NormalizeMatrix, 427
Numberinterchange, 670
NumberOfMinus, 669
о
OmegaSquare, 158
OmegaSquareDistribution, 253
OneWay Analysis, 177
OptimalPlan, 469
Organization, 458
OrtoPlan, 467
OrtoPlan, 466
p
Page, 197
Pagurova, 90
Parity, 698, 705
Parity, 667
Pearson, 270
PercentOfVariance, 353
PlusDef, 505
Point, 303
PolynomCoeff, 535
Polynomial, 587
PowerOf, 670
Principal Factor, 333
PseudoInverseMatrix, 501
Q
QDistribution, 259
QRDecomposition, 522
Quality, 404
R
RandomCriterion, 104
RandomCriterionlndependent, 101
Range, 50
RangeNormal, 240
RangeNormalDensity, 241
RangeNormal Integral, 241
RangeOfVar, 169
RangeOfVarDistribution, 246
RangeStudent, 243
RangeStudentDensity, 244
Rank, 68
RankCommon, 71
RankKendall, 70
Rao, 286
Reduction, 335
RelEntropie, 454
Reverse, 571
Rings, 382
Rosenbaum, 130
Rowinterchange, 486
RowMultiplyNumber, 480
s
SampleMean, 29
Sarkadi, 166
ScalarMatrix, 448
Scheffe, 187
ScheffePair, 203
SerialDistribution, 257
ShapiroWilk, 162
Sharp, 49
Sign, 668
Sign Distribution, 248
Алфавитный указатель
751
SignNull, 669
SignTest, 142
Simplelteration, 555
Simpson, 653
SingularValueDecomposition, 518
Skewness, 45
SmartRound, 667
Smirnov, 135, 704
SinirnovExact, 137, 696
Sokal, 285
Solves, 560
SortArrayCommon, 569
SortArrayDown, 567, 568
SortArrayUp, 565, 566
Spearman, 276
SpecialVectorSum, 475
Stirling, 455
StudentPairedTest, 86
Sturgess, 55
Sup, 578
Surplus, 456
T
TDistribution, 222
Thurstone, 346
Torgerson, 446
Tou,318
Trace, 494
Trapezium, 651
TwoDegree, 671
u
UDistribution, 256
UnSortArray, 570
V
VanDerWaerdenTest, 127
Variance, 40
Varimax, 349
VectorSum, 473
VectorSumSQ, 474
w
WaldWolfowitz, 133
Ward, 373
Welch, 88
WilcoxonTDistribution, 255
WilcoxonTest, 109
Wilks, 416
WTDistribution, 255
Y
Yule, 288