/










































































































































































































































































































































Автор: Тоу Д.
Теги: производство соды и поташа щелочи информационные машины машины для обработки данных базы данных издательство питер язык программирования sql
ISBN: 5-94723-959-0
Год: 2004




Текст
SQL Tuning
Dan Tow
O’REILLY®
Beijing • Cambridge • Farnham • Koln • Paris • Sebastopol Taipei • Tokyo
Настройка SQL
ДЛЯ ПРОФЕССИОНАЛОВ
Дэн Toy
Е^ППТЕР'
Москва Санкт-Петербург - Нижний Новгород Воронеж
Новосибирск - Ростов-на-Дону - Екатеринбург Самара
Киев Харьков Минск
2004
ББК 32.973.233-018
УДК 661.3.016
Т63
Toy Д.
Т 63 Настройка SQL. Для профессионалов. — СПб.: Питер, 2004. — 333 с.: ил.
ISBN 5-94723-959-0
В реальных приложениях, работающих с серверами баз данных, перед разработчиками
очень часто встает проблема улучшения производительности SQL-запросов. В этой книге
детально и на многочисленных примерах описывается метод, позволяющий кардинально
повысить скорость выполнения запросов к базам данных. Прочитав книгу, вы сможете не тратить
долгие часы на перебор различных вариантов кода, а максимально быстро найти оптимальный
способ построения запроса.
Метод настройки SQL-запросов не опирается на случайный или итеративный перебор
вариантов кода, а основан на четких и понятных правилах, которые достаточно просты для
понимания и основаны на принципах работы SQL-серверов.
Книга будет полезна разработчикам систем, взаимодействующих с базами данных, и всем
интересующимся аспектами работы SQL-серверов.
ББК 32.973.233-018
УДК 681.3.016
Праве на издание получены по соглашению с O'Reilly.
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме бвз письменного
разрешения владельцев авторских прав.
Информация, содержащаяся в данной книге, получена из источников, рассмвтриеаемых издательством как надежные. Твм не
мвнее, имея в виду возможные человечвскив или техническив ошибки, издательство не может гарантировать абсолютную
точность и полноту приводимых сведений и не несет ответственности за возможные ошибки, связанные с использоввнивм книги.
© 2004 O'Reilly & Associates, Inc.
ISBN 0596005733 (англ.) © Перевод на русский язык ЗАО Издательский дом «Питер», 2004
ISBN 5-94723-959-0 © Издание на русском языке, оформление ЗАО Издательский дом «Питер», 2004
Краткое содержание
Об авторе.........................................................И
Вступление.......................................................12
Предисловие......................................................14
От издательства..................................................20
1. Введение....................................................21
2. Основы доступа к данным.....................................29
3. Просмотр и интерпретация планов выполнения..................66
4. Управление планами выполнения...............................96
5. Диаграммное изображение простых запросов SQL...............131
6. Выбор наилучшего плана выполнения..........................157
7. Диаграммное изображение и настройка сложных SQL-запросов...201
8. Почему метод диаграмм работает.............................253
9. Особые случаи..............................................263
10. Решения сложных проблем.....................................276
Приложение А. Решения задач.....................................297
Приложение Б. Полный и непрерывный процесс......................310
Глоссарий.......................................................322
Алфавитный указатель............................................331
Содержание
7
Пути доступа для одной таблицы......................................43
Полное сканирование таблицы.......................................44
Индексный доступ к таблицам.......................................45
Выбор между полным сканированием таблицы и индексным доступом.....47
Вычисление селективности............................................50
Селективность фильтра.............................................50
Селективность условия на диапазоне индекса...................... 52
Селективность для строк таблицы, полученных при помощи индекса....56
Комбинирование индексов...........................................58
Соединения..........................................................59
Типы соединений...................................................59
Способы обработки соединений......................................61
3. Просмотр и интерпретация планов выполнения.......................... 66
Чтение планов выполнения в Oracle...................................67
Подготовка........................................................67
Процесс, лежащий в основе отображения планов выполнения...........67
Практический процесс отображения планов выполнения................69
Надежные планы выполнения.........................................70
Ненадежные планы выполнения.......................................75
Сложные планы выполнения..........................................76
Чтение планов выполнения в DB2......................................77
Подготовка...................................................... 78
Процесс, лежащий в основе отображения планов выполнения...........78
Практический процесс отображения планов выполнения................81
Надежные планы выполнения.........................................82
Ненадежные планы выполнения.......................................86
Сложные планы выполнения..........................................87
Чтение планов выполнения в SQL Server............................. 88
Отображение планов выполнения.....................................88
Как интерпретировать план.........................................90
Интерпретация плана выполнения....................................91
Интерпретация ненадежных планов выполнения........................93
Сложные планы выполнения..........................................93
4. Управление планами выполнения.......................................96
Универсальные техники управления планами............................96
Использование правильного индекса.................................97
Запрещение использования неправильных индексов.................. 100
Использование желаемого порядка соединения.......................101
Запрещение соединения в неправильном порядке.....................102
Выбор порядка выполнения для внешних запросов и подзапросов......103
Предоставление стоимостному оптимизатору хороших данных..........105
Обман стоимостного оптимизатора плохими данными................. 106
Управление планами в Oracle........................................107
Управление выбором оптимизатора в Oracle.........................109
Управление синтаксическими планами выполнения в Oracle...........112
Управление стоимостными планами выполнения в Oracle..............113
Управление планами в DB2.......................................... 120
Подготовка к оптимизации в DB2...................................121
Выбор уровня оптимизации.........................................122
Изменение запроса................................................123
Содержание
Об авторе...........................................................11
Вступление........................................................ 12
Предисловие....................................................... 14
Цели этой книги..................................................15
Аудитория этой книги.............................................15
Структура книги..................................................16
Условные обозначения.............................................17
Комментарии и вопросы............................................18
Благодарности....................................................19
От издательства................................................ 20
1. Введение.........................................................21
Зачем настраивать SQL?...........................................21
Кто должен настраивать SQL?......................................23
Чем может помочь эта книга.......................................25
Бонус............................................................26
«Внешние» решения................................................27
2. Основы доступа к данным..........................................29
Кэширование в базе данных........................................30
Таблицы..........................................................33
Последовательный рост.........................................34
Удаление самых старых данных..................................35
Удаление данных вне зависимости от возраста...................35
Полное удаление и рост с нуля.................................36
Индексы..........................................................36
Индексы в В-деревьях.............................................36
Стоимость индекса.............................................39
Редкие объекты базы данных.......................................40
Таблицы с индексной организацией..............................40
Однотабличные кластеры........................................41
Многотабличные кластеры.......................................42
Таблицы с разбиениями.........................................42
Растровые индексы.............................................43
8
Содержание
Управление планами в SQL Server.................................125
Подготовка к оптимизации в SQL Server.........................125
Изменение запроса.............................................126
Примеры подсказок.............................................127
Использование FORCEPLAN..................................... 130
5. Диаграммное изображение простых
запросов SQL................................................... 131
Зачем нужен новый метод?........................................131
Полные диаграммы запросов.................................... 133
Информация, отображаемая в диаграммах запросов................133
Что не входит в диаграммы запросов............................135
Когда диаграммы запросов помогают лучше всего.................137
Абстрактная демонстрация использования диаграмм запросов......138
Создание диаграмм запросов....................................139
Более сложный пример..........................................142
Сокращения....................................................147
Интерпретация диаграмм запросов.................................149
Упрощенные диаграммы запросов................................. 151
Упражнения..................................................... 153
6. Выбор наилучшего плана выполнения..............................157
Надежные планы выполнения.......................................157
Обычный эвристический порядок соединения........................159
Простые примеры.................................................160
Порядок 8-стороннего соединения...............................161
Окончательное решение для 8-стороннего соединения.............163
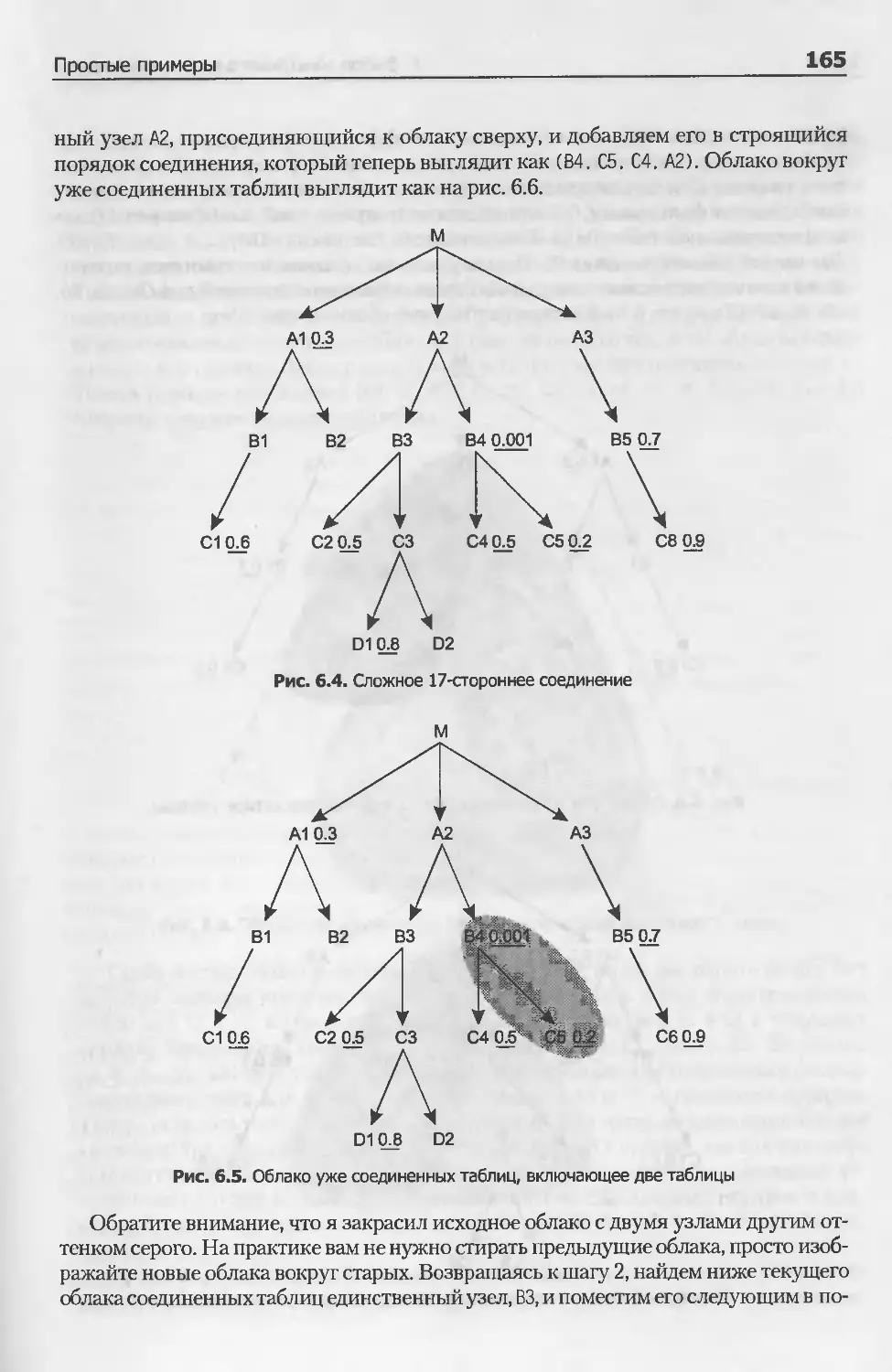
Сложное 17-стороннее соединение.............................. 164
Особый случай................................................. 168
Решение для Oracle............................................168
Решение специфичной проблемы для других серверов..............170
Сложный пример................................................ 171
Специальные правила для особых случаев........................175
Безопасные декартовы произведения.............................176
Детальные коэффициенты фильтрации, близкие к 1,0..............181
Коэффициенты соединения, меньшие 1,0......................... 182
Близкие коэффициенты фильтрации............................. 191
Случаи, когда нужно выбрать соединения хэшированием...........195
Упражнение....................................................199
7. Диаграммное изображение и настройка
сложных SQL-запросов...............................................201
Необычные диаграммы соединений..................................202
Графы циклических соединений..................................202
Несвязные диаграммы запросов..................................210
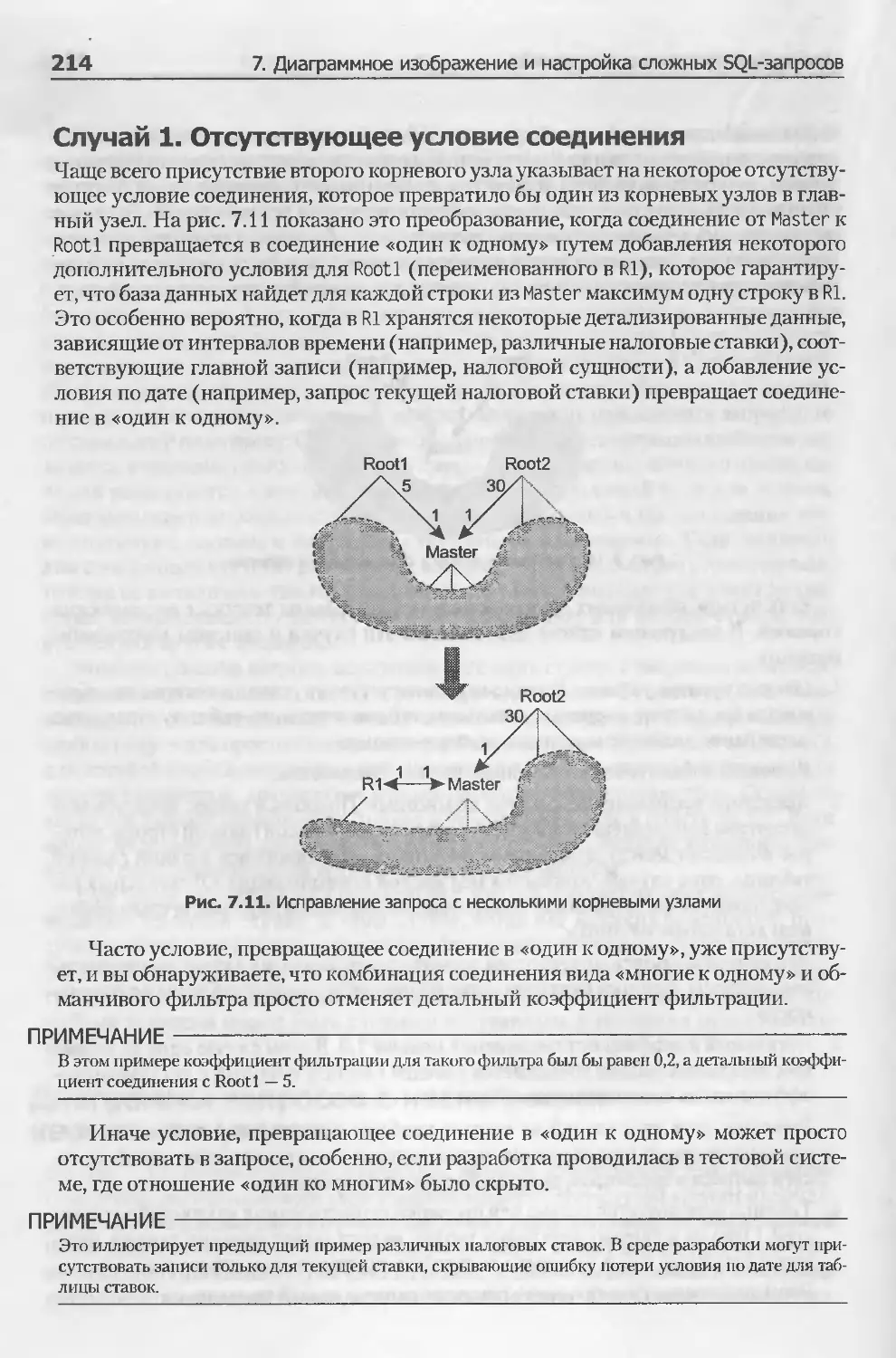
Диаграммы запросов с несколькими корневыми узлами.............212
Соединения без первичных ключей...............................217
Соединения вида «один к одному»...............................218
Внешние соединения............................................222
Содержание
9
Запросы с подзапросами...........................................228
Изображение запросов с подзапросами на диаграммах..............229
Настройка запросов с подзапросами..............................238
Запросы с представлениями........................................240
Диаграммное изображение запросов, использующих представления...241
Настройка запросов с представлениями...........................244
Запросы с операциями над множествами.............................250
Упражнение.......................................................251
8. Почему метод диаграмм работает................................ 253
Аргументы в пользу вложенных циклов..............................253
Выбор ведущей таблицы............................................255
Выбор следующей таблицы для соединения......................... 258
Объяснение различной стоимости считывания строки...............260
Объяснение преимуществ от поздних соединений...................260
Когда следует выбирать ранние соединения с узлами наверху......260
Резюме...........................................................262
9. Особые случаи...................................................263
Внешние соединения...............................................263
Шаги порядка оптимизации нормального внешнего соединения.......265
Пример....................................................... 266
Совмещенные соединения и фильтрующие индексы.....................268
Отсутствующие индексы.......................................... 271
Соединения, не прошедшие фильтрацию..............................273
Неразрешимые проблемы............................................273
10. Решения сложных проблем........................................276
Когда очень быстро — это еще недостаточно быстро.................276
Как избежать повторяющихся запросов при помощи кэширования.....277
Объединенные запросы...........................................279
Слияние повторяющихся запросов с предыдущим запросом...........279
Запросы, которые возвращают слишком много данных.................281
Объемные оперативные запросы...................................281
Объемные пакетные отчеты.......................................284
Агрегационные данные многих детальных записей..................290
Промежуточные процессы обрабатывают слишком много строк........291
Настроенные запросы, которые медленно возвращают несколько строк.293
Почему иногда запросы считывают много строк, а возвращают
лишь несколько..............................................293
Оптимизация запросов с распределенными фильтрами...............294
Приложение А. Решения задач....................................... 297
Решения для задач из главы 5.....................................297
Упражнение 1...................................................297
Упражнение 2...................................................298
Упражнение 3...................................................298
Упражнение 4...................................................299
Упражнение 5...................................................300
Упражнение 6...................................................300
10
Содержание
Решение для задачи из главы 6...............................301
Решение для задачи из главы 7...............................307
Приложение Б. Полный и непрерывный процесс....................310
Сокращение запроса до диаграммы запроса.....................310
Создание скелета запроса.................................310
Создание упрощенной диаграммы запроса....................312
Создание полной диаграммы запроса........................312
Решение диаграммы запроса...................................314
Проверка планов выполнения..................................315
Получение плана выполнения в Oracle......................315
Получение плана выполнения в DB2.........................316
Получение плана выполнения в SQL Server..................318
Изменение базы данных для получения лучшего плана...........319
Изменение SQL-кода для получения хорошего плана.............319
Изменение приложения........................................320
Взгляд в будущее............................................320
Глоссарий.....................................................322
Алфавитный указатель..........................................331
Об авторе
Дэн Toy (Dan Tow) — независимый консультант, работающий под лозунгом SingingSQL
(www.singingsql.com). Он начал работать над решением проблем производительно-
сти Oracle еще в 1989 году, когда пришел в Oracle Corporation. Большую часть
времени, проведенного в Oracle, Дэн занимался производительностью приложе-
ний, работающих с Oracle. В ходе этой работы он использовал множество возмож-
ностей для тестирования собственных методов настройки SQL-запросов. Методы
Toy применялись к огромному объему сложного SQL-кода, содержащегося в этих
приложениях. В 1998 году Дэн покинул Oracle и возглавил направление по реше-
нию проблем производительности в TenFold Corporation, где применил те же ме-
тоды для настройки кода, что и в Oracle, для DB2, SQL Server и Sybase.
В 2002 году Дэн открыл собственное дело — SingingSQL и предлагает различ-
ные услуги настройки баз данных, включая настройку SQL и систематический
анализ нагрузки, позволяющий понять, какой именно SQL-код требует настрой-
ки. Он ознакомил более 1000 человек со своим методом настройки SQL, прочитав
короткие лекции, и теперь предлагает углубленные курсы по данному материалу,
используя эту книгу как основное руководство.
Дэн живет в Пало-Альто, штат Калифорния, и вы можете связаться с ним по
адресу dantow@singingsqt.com.
Вступление
За годы моей деятельности разработчика и администратора баз данных единствен-
ной областью настройки, в которой я получил некоторый опыт и даже добился
определенного успеха, оказалась настройка отдельных SQL-запросов. Обладая по-
добным начальным опытом, я очень заинтересовался, когда Дэн Toy обратился ко
мне со своей идеей написать книгу о настройке SQL
Проблема с настройкой SQL, по крайней мере с моей точки зрения, заключает-
ся в том, что выявить плохо выполняющиеся SQL-запросы, требующие настрой-
ки, и определить план выполнения, использующийся в данный момент для этих
плохо работающих операторов, достаточно просто. Но затем всегда возникает за-
дача куда сложнее. Как найти наилучший план выполнения, который заставит этот
неприятный SQL-запрос выполняться быстрее? Давно прошло то время, когда я
тупо смотрел на долго выполняющийся запрос, проверял его плохо работающий
план выполнения и гадал, что же нужно сделать далее. Если уж на то пошло, поз-
волительно задать себе кардинальный вопрос: а можно ли было вообще что-ни-
будь улучшить? Возможно, план выполнения, работающий так плохо с точки зре-
ния пользователя, на самом деле был лучшим из возможных планов выполнения.
Возможно, я просто терял время, стараясь угадать лучший план.
Здесь я использовал слово «угадать», и именно это действие лежало в основе
всего того, что периодически делало настройку SQL-запросов бесполезным заня-
тием. Все скатывалось к тому, что я просто смотрел на запрос и пробовал угадать
лучший план. Конечно, я пытался использовать свой опыт, интуицию и знание
данных, получаемых при помощи запроса, я вспоминал подсказки и трюки, о кото-
рых читал в книгах и журнальных статьях, но в конце концов я снова озарялся
догадкой, пробовал новый план, опять о чем-то догадывался, пробовал следую-
щий план и так далее. Я останавливался, только когда происходило одно из двух
событий:
мне везло, и я угадывал план выполнения, достаточно хороший по сравнению
со старым планом, чтобы удовлетворить заказчика;
у меня заканчивались идеи.
Я всегда беспокоился, когда идеи заканчивались, так как не мог с уверенностью
сказать, был ли текущий план действительно оптимальным или я оказался слиш-
ком тупоголовым, чтобы интуитивно найти план выполнения, работающий луч-
ше, чем текущий план. Честно говоря, я всегда относился к себе слишком самокри-
Вступление
13
тично, считая личную несостоятельность причиной любой неудачной попытки
улучшить SQL-запрос.
Дэн не гадает. Напишите это жирным шрифтом и подчеркните. Он не выпол-
няет бесконечный цикл догадок, как это делал я, пробуя идею за идеей в надежде
зацепиться за улучшение. Вместо этого Дэн использует новейший математический
диаграммный метод для получения оптимального или близкого к оптимальному
плана выполнения для SQL-запроса. Затем он задействует план. И все. Никаких
догадок, никаких сомнений о том, возможно ли дальнейшее улучшение.
Сначала я скептически отнесся к подходу Дэна. Но чем дальше я читал его кни-
гу, тем яснее я начинал видеть логику, лежащую в основе его метода. Математика
не лжет, а опыт — это хороший показатель. У Дэна более чем десятилетний опыт
настройки, и я тоже добился высоких результатов, применяя метод, описанный
в его книге.
Любая попытка настройки SQL опирается на три типичных действия. Вам не-
обходимо знать, как идентифицировать плохо выполняющийся SQL-запрос. За-
тем нужно увидеть, какой план выполнения используется для этого оператора.
И, наконец, вам каким-то образом нужно придти к улучшенному плану. Я убеж-
ден, что метод Дэна представляет собой оптимальный способ выполнения столь
важного последнего, третьего действия, которое позволяет эффективно проводить
настройку SQL. Прочитайте эту книгу, примените его метод — и сэкономьте часы,
которые потратили бы на гадание, что сделать дальше.
Джонатан Генник (Jonathan Gennick),
автор, редактор, администратор баз данных Oracle
Посвящается Пар ее, Тайре и Эйбу за мечту о большем
и за жизнь, оказавшуюся лучше мечты.
Предисловие
Более 10 лет назад я понял, что значительным фактором, влияющим на произво-
дительность бизнес-приложений, является скорость выполнения их SQL-запро-
сов. Намного больше времени мне потребовалось, чтобы осознать, насколько ши-
рокие возможности улучшений обычно предоставляют SQL-серверы. SQL-код,
значительно влияющий на загрузку системы и производительность конечных
пользователей, обычно можно улучшить как минимум в два раза. Однако я нашел
совсем немного советов по настройке SQL-запросов. И, похоже, эта проблема со-
хранилась и до сегодняшнего дня.
Научные журналы описывают подробные методы, подходящие для автомати-
зированной оптимизации, но эти методы не адаптированы для ручной настройки.
Документация для профессионалов, насколько я мог видеть, неполна. Поставщи-
ки баз данных и независимые авторы хорошо описывают, как можно исследовать
путь, по которому извлекаются необходимые данные. Путь к данным обычно и
называется планом выполнения. Вооружившись планом выполнения, вы можете
понять, почему запрос выполняется за определенное время. С переменным успе-
хом в документации рассказывается, что можно сделать для изменения плана вы-
полнения, если вы подозреваете, что он не оптимальный. Но чего не хватает в ли-
тературе, так это подробного описания процесса осознания без бесконечных проб
и ошибок, какой же план выполнения вы хотите получить. Так как для выполне-
ния реальных запросов в бизнес-приложениях могут существовать миллиарды
различных путей выполнения, настройка практически бесполезна и безнадежна,
если у вас нет систематического метода выбора целевого плана. Эта проблема срод-
ни ситуации, когда вы теряетесь в незнакомом городе, не имея карты. Глаза и ноги —
это еще не все что нужно для того, чтобы найти требуемое место.
Отсутствие информации о выборе наилучшего плана выполнения, как оказыва-
ется, характерно для всех поставщиков баз данных. Таким образом, у книги по на-
стройке SQL, которая на 80 % не зависит от поставщика базы данных, появляется
чудесный шанс — ведь в 80 % содержания книги вы не встретитесь с неинтересными
подробностями просмотра и управления планами выполнения по методу, характер-
ному для определенного поставщика. Я написал эту книгу, чтобы воспользоваться
появившейся возможностью и познакомить вас с настройкой SQL, используя мощ-
ный, не зависящий от какого-то конкретно сервера баз данных подход.
Аудитория этой книги
15
Цели этой книги
Я написал эту книгу, чтобы вооружить вас методами правильного решения лю-
бых проблем, касающихся настройки SQL. Обычно для решения настройки SQL
применяется самое ограниченное, но тем не менее наиболее широко распростра-
ненное решение — какой-то набор изменений в структуре базы данных (например,
можно добавить новые индексы) или, чаще, в самом SQL-коде. Подобные измене-
ния позволяют медленному оператору SQL выполняться быстрее без изменения
его функциональности и перестройки приложения, которое использует этот зап-
рос. Это распространенное решение особенно привлекательно, так как оно явля-
ется достаточно простым и у него редко появляются неожиданные побочные эф-
фекты.
Иногда при анализе проблемы настройки SQL вы обнаруживаете симптомы,
которые указывают на небольшие функциональные ошибки, сопутствующие ошиб-
кам производительности. Метод анализа настройки, описанный мной, упрощает
идентификацию и описание этих мелких функциональных дефектов и помогает
вам находить решения, которые исправляют скрытые функциональные ошибки в
качестве побочного эффекта при анализе эффективности. Однако прежде всего
эта книга посвящена именно настройке SQL-запросов.
В редких случаях задачи настройки SQL нельзя решить за счет ускорения вы-
полнения одного запроса. Запрос может возвращать слишком много строк, или
выполняться слишком часто, чтобы достигнуть максимальной скорости, будь он
даже абсолютно оптимизированным. Для таких редких проблем я описываю сис-
тематические решения на уровне приложения, изменяющие модель применения
SQL-запроса, трансформируя ее к той конфигурации, для которой уже существу-
ет решение.
Аудитория этой книги
Я написал эту книгу для тех, кто уже знает SQL и кому хотя бы иногда требуется
найти способ заставить SQL выполняться быстрее. Обычно те же люди, которые
впервые пишут SQL-код программы, то есть разработчики приложения, выполня-
ют и большинство работы по настройке SQL. Конечно, я надеюсь, что эта книга
поможет разработчикам решить их проблемы настройки, особенно наиболее часто
встречающиеся типы проблем. Однако мой опыт специалиста по настройке гово-
рит, что настраивать SQL, написанный другими людьми, можно не менее эффек-
тивно. К счастью, в SQL предусмотрено четкое описание, какие строки приложе-
нию требуются в конкретный момент, и вам не обязательно иметь какие-либо
специфические знания о приложении, чтобы найти более быстрый способ получе-
ния нужных строк. Так как настройщику не требуется знание приложения, настра-
ивать SQL, написанный другими людьми, очень легко, и у специалиста есть шанс
научиться настраивать более эффективно, чем сможет не специалист, особенно при
возникновении сложных и запутанных проблем.
16
Предисловие
Структура книги
Преследуя собственные цели, вы можете читать книгу не по порядку и не обяза-
тельно от корки до корки. Описание ее структуры поможет вам решить, какие раз-
делы книги вы можете пропустить или бегло просмотреть, какие возьмете на за-
метку для редких консультаций, а какие необходимо тщательно изучить и в каком
порядке.
Глава 1. Введение
В этой главе рассказывается, почему необходимо настраивать SQL-запросы,
и перечислены описываемые в книге подходы к проблеме вместе с некоторыми
положительными побочными эффектами этих подходов. Это короткая и простая
глава, и я рекомендую вам прочитать ее в первую очередь.
Глава 2. Основы доступа к данным
Эта глава рассматривает способы обращения базы данных к отдельным табли-
цам путем полного сканирования таблиц и индексного считывания. Рассматрива-
ются способы соединения таблиц и предпосылки для выбора подходящего метода.
Если вы уже знакомы с основами выполнения запросов в базах данных, то можете
пропустить ее или лишь бегло ознакомиться с этой главой.
Глава 3. Просмотр и интерпретация планов выполнения
В этой главе объясняется, как читать и интерпретировать планы выполнения
в Oracle, Microsoft SQL Server и DB2. Если раньше вы уже занимались настрой-
кой SQL, то, вероятно, уже знакомы с решением этого вопроса на том сервере баз
данных, с которым обычно работаете. Материал этой главы разделен на несколько
частей, посвященных различным серверам баз данных, причем материал, общий
для нескольких серверов, повторяется, поэтому вы можете изучить только интере-
сующий вас раздел.
Глава 4. Управление планами выполнения
В этой главе вы узнаете, как проверять планы выполнения в Oracle, Microsoft
SQL Server и DB2. Обсуждение включает некоторые общие техники, которые мо-
гут обеспечить определенную степень контроля над планами выполнения в любой
реляционной базе данных. Если вы много занимались настройкой SQL, то долж-
ны знать, как управлять планами выполнения в интересующем вас сервере баз дан-
ных. Эта глава так же, как и предыдущая, разделена на части, посвященные раз-
ным серверам, и общая информация может повторяться в этих частях. Поэтому вы
можете читать только раздел, посвященный тому серверу баз данных, с которым
обычно работаете.
Глава 5. Диаграммное изображение простых запросов SQL
Эта глава закладывает основы для следующих глав книги, поэтому, не изучив
ее, читать оставшуюся часть книги бесполезно. В этой главе вы познакомитесь со
стенографическим изобразительным языком, который существенно проясняет сущ-
ность вопроса настройки SQL. Основы, изложенные в этой главе, делают оставшу-
юся часть книги намного понятнее, и при помощи изобразительного языка вы
изучите ее намного быстрее, чем без этого полезного инструмента. Внимательно
прочитайте эту главу и изучите предлагаемый язык до того, как читать последую-
щие главы. Для изучения языка вам потребуется терпение, но, поверьте, дело сто-
ит того1
Условные обозначения
17
Глава 6. Выбор наилучшего плана выполнения
Данная глава объясняет, как использовать диаграммы запросов, о которых вы
узнали ранее, для быстрой настройки 2-сторонних, 5-сторонних и даже 115-сто-
ронних соединений в SQL-запросах, не тратя силы на метод проб и ошибок. Это
чрезвычайно ценное умение, поэтому не сдавайтесь, пока полностью не поймете
этот материал.
Глава 7. Диаграммное изображение и настройка сложных SQL-запросов
Эта глава показывает, как настраивать сложные запросы (например, с исполь-
зованием подзапросов), не подходящие под стандартный шаблон простых п-сто-
ронних соединений. В качестве бонуса в этой главе также описан процесс диагно-
стики и решения логических ошибок в SQL, которые становятся очевидными, как
только вы научитесь строить и интерпретировать диаграммы запросов.
Глава 8. Почему метод диаграмм работает
Эта глава доказывает «правила большого пальца», которые обсуждались в пре-
дыдущих главах. Если вы не доверяете мне или считаете, что сможете лучше при-
менять методы, описанные в этой книге, когда поймете, почему же они работают,
то эта глава должна вам помочь. Если вы начнете терять терпение, изучая механи-
ческие приложения загадочных правил в первых главах, то можете сначала прочи-
тать эту главу.
Глава 9. Особые случаи
Здесь рассматривается дополнительный материал, к которому вы, вероят-
но, будете обращаться только в случае возникновения проблем, если решите не
читать эту книгу от корки до корки. Однако я рекомендую хотя бы просмотреть
эту главу, чтобы узнать, о чем она, и суметь распознать проблемы при встрече
с ними.
Глава 10. Решения сложных проблем
Эта глава объясняет, как справиться с «невозможными» проблемами. С запро-
сами, для которых не существует быстрого плана выполнения, позволяющего по-
лучить необходимые строки. Я настойчиво рекомендую изучить этот материал, но
оставляю его напоследок, так как пока вы не узнаете, как получить наилучший
план выполнения, вы не сможете распознать, какие проблемы (а их на удивление
мало) требуют применения «внешних» решений.
Приложение А. Решения задач
Решения для упражнений в конце глав 5,6 и 7.
Приложение Б. Полный и непрерывный процесс
Решение задачи настройки SQL диаграммным методом от начала до конца для
Oracle, DB2 и SQL Server. Если вы любите работать, имея перед глазами полные
и непрерывные примеры, то это приложение для вас.
Глоссарий
Определение ключевых терминов и выражений, которые используются в книге.
Условные обозначения
В книге используются следующие типографские обозначения:
Курсив
Используется для выделения технических терминов.
18
Предисловие
Шрифт постоянной ширины
Используется для адресов URL и имен файлов и каталогов, примеров SQL-
запросов, содержимого файлов, а также для полученных данных.
Также подобный шрифт используется для имен таблиц и столбцов — как в коде
SQL, так и при упоминании операторов SQL в тексте. Применяется для выделе-
ния псевдонимов и имен узлов, которые являются элементами диаграмм SQL и
теоретически соответствуют псевдонимам таблиц, даже в случаях, когда диаграм-
ма иллюстрирует абстрактную задачу настройки и для нее не приводится опреде-
ленного оператора SQL, соответствующего задаче. Так как псевдонимы обычно
составляются как акронимы на основе имен таблиц, например, СТ для столбца
Code_Translations, чаще всего они состоят только из прописных букв.
(С. 0. ОТ. 00. ODT. Р. S. А)
Список моноширинным шрифтом, состоящий из псевдонимов, имен узлов или
столбцов, заключенный в скобки. Я заимствовал это n-кратное обозначение из
математики для представления упорядоченного списка элементов. В одних
примерах эта условная запись обозначает порядок соединения узлов в диаграмме
соединения с использованием псевдонимов таблицы. В других примерах, напри-
мер (Code_Type, Code), это представление пары индексированных столбцов для
двухстолбцового индекса, где Code_Type — это первый столбец. В свою очередь,
Code_Translations(Code_Type, Code) представляет тот же индекс, но с указанием, что
он принадлежит таблице Code_Translations.
<Курсив постоянной ширины>
Текст, написанный курсивом постоянной ширины в треугольных скобках, опи-
сывает отсутствующие части шаблона оператора SQL, представляющего целый
класс операторов, которые вы должны восстановить самостоятельно. Например,
SomeAl las. Lead! ng_Indexed_Col ишп=<вь/ражение> представляет условие равенства веду-
щего столбца индекса и любого другого выражения.
ПРОПИСНЫЕ БУКВЫ
В SQL прописными буквами обозначаются ключевые слова, имена функций
и таблицы или представления, предопределенные поставщиком базы данных (на-
пример, PLAN TABLE в Oracle).
Обратите особое внимание на комментарии, выделенные следующим образом:
ПРИМЕЧАНИЕ -------------------------------------------------------------------
Общее замечание, совет или предположение. Например, иногда в примечаниях я описываю особенно-
сти, характерные для базы данных определенного поставщика, в середине какого-либо не зависящего
от поставщика обсуждения.
ВНИМАНИЕ ----------------------------------------------------------------
Так я обозначаю предостережения и возможные подвохи, относящиеся к текущему обсуждению.
Комментарии и вопросы
Мы, издательство O’Reilly, со всем тщани ем проверили и протестировали инфор-
мацию, представленную в этой книге, но вы можете заметить, что какие-либо функ-
ции изменились либо мы допустили ошибки. В таком случае, пожалуйста, сооб-
щите нам об этом по адресу:
Благодарности
19
O'Reilly & Associates, Inc.
1005 Gravenstein Highway North
Sebastopol, CA 95472
(800) 998-9938 (в CHIA и Канаде)
(707) 829-0515 (международный)
(707) 829-0104 (факс)
Также вы можете отправить сообщение по электронной почте. Чтобы добавить
свой адрес в наш список рассылки или заказать каталог, отправьте письмо по адресу:
info@oreilly.com
Если у вас есть технические вопросы или комментарии по этой книге, отправь-
те письмо по адресу:
bookquestions@oreilly.com
Для этой книги мы создали страницу в электронном каталоге, где вы найдете
примеры и список опечаток (ранее найденные ошибки и исправления). Адрес этой
страницы:
http://www.oreilly.com/catalog/sqltuning/
Подробную информацию об этой и остальных книгах вы найдете на web-узле
O'Reilly:
http://www.oreilly.com
Если вы хотите задать автору книги вопросы или обсудить эту книгу, настрой-
ку SQL или подобные темы, напишите ему по адресу dantow@singingsql.com. До-
машняя страница автора расположена по адресу http://www.singingsql.com.
Благодарности
Я в долгу перед моими родителями, Лоис и Филиппом, учеными, за тот пример,
которым они являлись для меня во всех аспектах жизни. Мой научный руководи-
тель Дейл Радд показал мне лучший пример полного видения вопроса, он никогда
не пропускал возможности решить основную проблему, не распыляясь на реше-
ние слишком узко определенных задач. Мой брат Брюс познакомил меня с реля-
ционными базами данных и всегда щедро делился своими знаниями.
Мой бывший менеджер Рой Кэмблин, работавший главным управляющим по
информации в Oracle, подтолкнул меня в верном направлении, показав простой на-
бор правил, лежащих в основе настройки SQL, о которых я раньше не Подозревал.
Вообще-то правила не столь уж просты, но, перефразируя Эйнштейна, они настоль-
ко просты, насколько они могут быть просты. Oracle предоставила мне свободу глубже
проработать эти правила, a TenFold Corporation дала возможность впервые увидеть,
как хорошо они работают в любых реляционных базах данных. TenFold Corporation
щедро предоставила мне доступ к тестовым базам данных для проверки характер-
ных функций серверов определенных производителей, которые я описываю в книге.
Я нахожусь в особенном долгу перед Джонатаном Генником, редактором этой
книги. Джонатан обеспечивал мне профессиональную помощь на всех этапах, об-
наруживая технические ошибки, исправляя организацию материала, когда это было
необходимо, и просто улучшая текст, отшлифовывая язык. Его превосходное, все-
гда терпимое отношение и прекрасные объяснения не только сделали эту книгу
намного лучше, но и подняли на новый уровень мое писательское мастерство.
20
Предисловие
Тай Джонсон, Дэвид Озен, Дэйв Хант, Алексей Чадович и Джеф Уолкер предо-
ставили щедрую и чрезвычайно ценную техническую помощь — спасибо вам! За
неоценимую помощь в проверке технической части книги я особо благодарю моих
технических редакторов, превосходных и опытных практиков Вираг Саксена и Ала-
на Болье. Все оставшиеся ошибки — исключительно мои, конечно же.
Так как книга — это нечто большее, чем просто слова на страницах, я благодарю
опытных сотрудников O'Reilly and Associates: Брайана Сойера, выпускающего
литературного редактора; Роберта Романо и Джессамин Рид, очень терпеливых
иллюстраторов; Элли Фолькхаузен, дизайнера обложки; Мелани Вонг, художни-
ка-декоратора; Джули Хоукс, которая занималась конвертированием файлов; Мэтта
Хатчинсона, корректора; Даррена Келли и Клэр Клотье, обеспечивающих конт-
роль качества; и Анжелу Ховард, составителя предметного указателя.
И, наконец, я нахожусь в долгу перед моей женой Парвой и моими детьми Тай-
рой и Эйбом за их бесконечное терпение и веру в меня и за то, что они стали луч-
шими причинами, почему я достиг всего, что умею.
От издательства
Ваши замечания, предложения и вопросы отправляйте по адресу электронной по-
чты comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
Подробную информацию о наших книгах вы найдете на веб-сайте издатель-
ства; http://www.piter.com.
1
Введение
Хорошее начало — половина дела.
Аристотель
Политика, кн. V, гл. 4
Эта книга предназначается читателям, которые уже знакомы с SQL-серверами
и имеют возможность настраивать SQL-сервер или базу данных с поддержкой SQL.
В книге содержится описание специфических методов настройки SQL-запросов
в таких системах управления базами данных, как Oracle, Microsoft SQL Server
и IBM DB2. Однако основная проблема настройки запросов заключается в опре-
делении оптимального пути к данным. Путь к данным называется планом выпол-
нения. Этот оптимальный путь практически не зависит от производителя базы дан-
ных, и большая часть этой книги посвящена методам решения этой проблемы, не
зависящим от производителя.
Наименее интересной и наиболее простой деталью задачи настройки SQL
являются специфичные для конкретного производителя методы просмотра и
управления планами выполнения. Эти детали SQL-настройки для Oracle, Mi-
crosoft SQL Server и IBM DB2 также обсуждаются в данной книге. Без обсуж-
дения этих деталей книга была бы неполной. Однако основной материал дан-
ной книги, посвященный не зависящим от производителя методам настройки
SQL, подходит и для других серверов баз данных (и для их новых версий). Сама
по себе книга довольно универсальна и не должна устаревать, как это обычно
бывает с книгами по компьютерной тематике. Заложенный в основу этой кни-
ги метод я использовал на протяжении 10 лет, с четырьмя серверами баз дан-
ных от различных производителей, и я рассчитываю, что он будет применим,
по крайней мере в течение еще 10 лет. В предоставляемой производителем до-
кументации (которая, как правило, располагается в Сети) вы всегда можете най-
ти описание относительно простых методов просмотра и управления планами
выполнения, которые подходят для конкретной версии сервера баз данных этого
поставщика.
Зачем настраивать SQL?
Начнем с основного вопроса: следует ли настраивать SQL-код в приложении
и следует ли заниматься этим вам лично? Если уж вы читаете эту книгу, можно
предположить, что вы ответили на эти вопросы положительно или, по крайней
мере, склоняетесь в эту сторону. Однако чтобы понять, насколько положительным
22
1. Введение
должен быть мой ответ на этот вопрос, мне понадобилось несколько лет. И в этой
главе я предлагаю свою точку зрения в качестве примера.
Попробуем описать ваше приложение с датацентрической точки зрения. При-
ложение предназначено для того, чтобы пользователи или, возможно, другие при-
ложения могли видеть данные, которые ваша организация хранит в реляционной
базе данных. Также, возможно, приложение должно получать эти данные в более
или менее обработанном виде и манипулировать ими. С выходными данными это
приложение выполняет такие действия, как сложение, умножение, подсчет, вы-
числение среднего значения, сортировка и форматирование. То есть все те опера-
ции, которые вы можете встретить в электронных таблицах. Оно не решает диффе-
ренциальных уравнений и вообще не выполняет каких-либо операций, требующих
больших вычислений с небольшим объемом входных данных. Количество работы,
выполняемой приложением после того, как оно извлечет данные из базы данных,
или до того, как оно поместит данные в базу данных, является умеренным по со-
временным компьютерным стандартам, так как объемы данных, извлекаемых из
базы, невелики, а также невелики объемы вычислений на единицу извлеченных из
базы данных.
ПРИМЕЧАНИЕ ----------------------------------------------------------------
Приложения, работающие в оперативном режиме, и приложения, производящие просматриваемые
людьми отчеты, должны формировать на выходе объемы данных, Которые человек способен перева-
рить. Эти объемы ничтожны по сравнению с объемами, которые способен обработать компьютер. Про-
межуточное программное обеспечение {middleware), перемещая данные из одной системы в другую без
человеческого вмешательства, способно обработать и большие объемы данных, но даже промежуточ-
ное программное обеспечение, как правило, выполняет некую агрегационную функцию, уменьшая объе-
мы данных до сравнительно умеренных.
Даже если большое количество конечных пользователей приводит к высоким
вычислительным нагрузкам за пределами базы данных, как правило, вы можете
бросить на борьбу с этой нагрузкой дополнительную аппаратуру, подключив к еди-
ной центральной базе данных столько серверов приложений, сколько необходимо.
Подобный подход повлечет определенные финансовые затраты, но я полагаю, что
поддерживающая, скажем, 50 000 конечных пользователей одновременно система
в свою очередь опирается на существенный бюджет.
С другой стороны, системе управления базой данных, работающей с коммер-
ческим приложением, часто приходится обработать миллионы строк таблиц из
базы данных только для того, чтобы вернуть несколько строк, удовлетворяющих
запросу приложения. Подобная неэффективность может иметь решающее зна-
чение в определении суммарной нагрузки на систему и производительности
системы. Более того: хотя вы легко можете увеличить количество прикладных
серверов, заставить несколько серверов баз данных работать с одним и тем же
непротиворечивым набором данных для одного и того же приложения, как пра-
вило, значительно труднее. По этой причине ограничения пропускной способно-
сти серверов баз данных имеют гораздо большее значение. Абсолютно необходи-
мо сделать так, чтобы ваша система удовлетворяла объемам ваших данных, а не
наоборот.
Если отвлечься от этих теоретических соображений, мой собственный 13-лет-
ний опыт настройки и исследования производительности заключается в том, что
система управления базой данных (точнее, та часть приложения, которая взаимо-
Кто долженнасграивать SQL?
23
действует с SQL-сервером) представляет собой лучшее место для попыток повы-
сить производительность и пропускную способность.
Изменения, связанные с повышением производительности SQL-запросов, как
правило, являются наиболее безопасными изменениями, которые вы можете про-
извести с приложением. При этом вероятность того, что приложение сломается
где-то еще, минимальна, так как принимаемые меры позволяют повысить как про-
изводительность, так и пропускную способность, а аппаратных затрат либо не бу-
дет вообще, либо они в худшем случае будут минимальны (в случае добавленных
индексов, для которых требуется дисковое пространство). Я надеюсь, что к концу
этой книги вы также убедитесь в том, что трудовые затраты на настройку SQL-
запросов минимальны, если использовать описанный в данной книге метод. Отно-
шение выигрыша к затратам настолько высоко, что во всех серьезных приложени-
ях для работы с базами данных SQL-код должен быть настроен на работу при
высоком уровне нагрузки.
ПРОИЗВОДИТЕЛЬНОСТЬ И ПРОПУСКНАЯ СПОСОБНОСТЬ-------------------------------------
Производительность и пропускная способность взаимосвязаны, но не идентичны. Например, в хоро-
шо сконфигурированной системе с несколькими (в среднем) простаивающими центральными про-
цессорами добавление центральных процессоров может повысить пропускную способность, но мало
повлияет на производительность, поскольку большинство программных процессов не могут исполь-
зовать более одного центрального процессора одновременно. Использование более быстрых процес-
соров позволяет повысить как пропускную способность, так и производительность приложения,
содержащего большие объемы вычислений, но, скорее всего, у вас и так уже имеется почти самый
быстрый центральный процессор, какой Только можно найти. Ускорение работы SQL во многом по-
добно получению более производительного центрального процессора, но без дополнительных затрат
на аппаратуру.
Недостаточно высокая производительность означает потерю продуктивности, так как конечные пользо-
ватели теряют время в ожидании завершения выполнения операции. Вы можете бороться с низкой
производительностью, наняв большее число конечных пользователей и компенсируя, таким образом,
низкую производительность каждого отдельного пользователя — не оставлять же работу невыполнен-
ной. В течение коротких периодов времени пользователи могут, к собственному неудовольствию, бо-
роться с низкой производительностью, отдавая работе большее количество времени.
Выбор средств для решения проблемы низкой пропускной способности ограничен. Можно устранить
узкие места (например, добавив центральных процессоров), если вы еще не достигли пределов воз-
можностей системы, либо настроить приложение, включая, конечно же, его часть, взаимодействую-
щую с SQL-сервером. Если вы не можете применить ни одного из этих способов, система не сможет
поддерживать желаемый уровень нагрузки. Данную проблему невозможно решить, использовав боль-
шее количество пользователей. Также не следует ожидать, что пользователи смирятся с низкой произ-
водительностью, причиной которой будет перегрузка системы. С центральными процессорами нельзя
договориться. Если для решения вашей задачи необходимо большее количество ресурсов, чем могут
предоставить центральные процессоры, их нельзя заставить работать более интенсивно. Если вы не
можете настроить систему или устранить лишнюю нагрузку на нее, это означает, что вам придется под-
гонять свой бизнес под систему, а такой результат является худшим из возможных и может означать
для вас потерю существенной доли ваших доходов.
Кто должен настраивать SQL?
Итак, вы убедились, что SQL настраивать стоит. Следует ли этим заниматься имен-
но вам и именно в вашей работающей системе? Скорее всего, вы приложили руку
к созданию, самое большее, лишь небольшого модуля работы с SQL-сервером
24
1. Введение
в вашей системе, поскольку большинство систем создаются большими группами
разработчиков. Вы можете даже — как и я в большинстве случаев из собственной
практики — иметь дело с приложением, для которого вы не написали ни одной
строчки на языке SQL, и даже не несете ответственности за устройство базы дан-
ных. На протяжении многих лет я полагал, что разработчики приложения, напи-
савшие SQL, всегда гораздо лучше меня разберутся в том, как исправить программу.
Тем не менее, поскольку на мне лежало бремя ответственности за производитель-
ность, я полагал, что лучшее, что я могу сделать, — это определить, которые опера-
торы SQL создают большую часть нагрузки и, соответственно, заслуживают усилий
по настройке. Затем (как я думал) моя задача заключалась в том, чтобы ворчливо
приставать к разработчикам с просьбами настроить созданные ими SQL-програм-
мы. Мне стыдно в этом признаваться, но я чудовищно заблуждался.
Оказывается, разработчики, настраивающие только собственные SQL-програм-
мы, находятся в крайне невыгодном положении, особенно если они не обучались
правильному, систематическому методу настройки (а литературы, посвященной
данной теме, всегда было мало). Довольно трудно написать реальное работающее
функциональное приложение, даже не ставя перед собой задачу получить высо-
кий уровень производительности. Время, отводимое среднему разработчику на
настройку SQL, коротко, а число самостоятельно созданных примеров, на кото-
рых разработчику приходится практиковаться, чтобы составить экспертную оцен-
ку, также невелико.
В данной книге описывается лучший из известных мне методов — метод, разра-
ботанный мною для удовлетворения собственных нужд в настройке SQL-запро-
сов на основании десятков приложений, написанных другими людьми. Однако если
вы действительно хотите стать первоклассным настройщиком SQL, этого метода
недостаточно. Вам также необходимо практиковаться. Практиковаться на множе-
стве SQL-программ, созданных другими разработчиками, работать с целыми SQL-
приложениями. Но как справиться со сложностью SQL-приложений во всей их
полноте, к тому же приложений, с которыми вы едва знакомы? Вот где SQL пре-
поднес мне большой сюрприз. Вам ие нужно понимать написанные другими людь-
ми программы на SQL, чтобы настраивать их!
Рассматривайте SQL как спецификацию — ясное и непротиворечивое описание
тою, какие строки из каких таблиц требуются для приложения в определенном
месте выполнения программы. SQL прост в понимании, потому что он был разра-
ботан для нерегулярного использования его обычными пользователями, не обла-
дающими подготовкой программиста. Он непротиворечив по необходимости; в про-
тивном случае система управления базой данных не могла бы его интерпретировать.
Вам не нужно знать, зачем приложению требуются те или иные строки или даже
какие именно данные в них содержатся. Просто обращайтесь с записями и табли-
цами как с абстрактными, даже математическими объектами. Все, что необходимо
знать, и все, что необходимо понять — это как быстрее добраться до этих строк.
А узнать это можно, исследуя задействованные в данной операции SQL-запросы,
таблицы и индексы при помощи простых обращений к базе данных, полностью
независимых от семантического содержимого данных. Затем вы можете изменить
SQL-запросы или базу данных (например, добавив необходимые индексы), при-
чем простым способом, почти с математической точностью гарантирующим, что
трансформированный результат вернет те же самые строки в том же самом поряд-
ке, но будет получать данные по лучшему, более быстрому пути.
Чем может помочь эта книга
25
Чем может помочь эта книга
Настройка SQL состоит из трех основных этапов. Необходимо:
1) понять, какой план выполнения (путь к данным, запрашиваемым вашим SQL-
оператором) у вас имеется;
2) изменить SQL или базу данных, чтобы получить выбранный план выполне-
ния;
3) выбрать оптимальный план выполнения.
Я намеренно привожу эти этапы вне логической последовательности, чтобы
отразить состояние большей части материала, посвященного данной теме. По-
чти все книги о настройке SQL в первую очередь посвящены первым двум эта-
пам, особенно второму. Описание третьего этапа, как правило, ограничивается
краткой дискуссией о том, в каких случаях индексированный доступ следует
предпочесть полному сканированию таблицы. Предполагаемый процесс настрой-
ки SQL (которому не хватает систематического подхода к третьему этапу) за-
ключается в повторе второго этапа и вылизывании SQL-выражения до тех пор,
пока вы не наткнетесь на достаточно быстрый план выполнения. Если же вам не
удастся найти такой план, процесс продолжается до тех пор, пока у вас не лопа-
ется терпение.
Вот достаточно хорошо работающая аналогия. Понимание первого этапа дает
вам чистое ветровое стекло; вы видите, где находитесь. Понимание второго шага
вкладывает вам в руки рулевое колесо; вы можете изменять направление движе-
ния. Понимание третьего шага дает вам карту с отметкой вашего текущего поло-
жения, а также того места, куда вы хотите попасть. Представьте себе, что вы нахо-
дитесь в чужом городе без дорожных знаков, без карты и пытаетесь как можно
быстрее найти отель, название которого не знаете. Представили? Теперь вы начи-
наете постигать задачу обучения настройке SQL Без систематического использо-
вания третьего этапа проблема настройки SQL оказывается даже хуже, чем наша
задача заблудившегося водителя. Обладая достаточным запасом времени, путе-
шественник может исследовать всю двухмерную сетку городских улиц, но состоя-
щая из 20 предложений операция соединения (JOIN) содержит около 20! (20 фак-
ториал, или 1х2хЗх4х... х!9х 20) возможных планов выполнения, то есть
необходимо исследовать 2 432 902 008 176 640 000 возможных вариантов. Даже ваш
компьютер не сможет перебрать все комбинации в данном пространстве поиска.
Для настройки вам необходим метод, которым вы можете воспользоваться вруч-
ную.
Учитывая вышесказанное, мы можем перевернуть традиционный процесс с ног
на голову и спланировать более поучительный процесс, на этот раз выраженный
в виде последовательности вопросов.
1. Какой план выполнения является наилучшим и как это узнать, не прибегая
к полному перебору всех вариантов?
2. Чем отличается текущий план выполнения от идеального плана выполнения,
если он от него вообще отличается?
3. Если различие между фактическим и идеальным планами выполнения имеет
значение, то как можно изменить определенную комбинацию SQL-запросов
26
1. Введение
и базу данных, чтобы подойти достаточно близко к идеальному плану выпол-
нения и получить требуемый уровень производительности?
4. Предоставляет ли новый план выполнения необходимый уровень производи-
тельности SQL-запросов?
В этой книге будут освещены все эти вопросы, но, безусловно, наиболее важ-
ные и наибольшие по объему разделы книги посвящены ответу на первый вопрос,
то есть нахождению наилучшего плана выполнения без использования метода проб
и ошибок. Кроме того, диапазон ответов на этот первый вопрос имеет решающее
влияние на обсуждение третьего вопроса. Например, поскольку я никогда не встре-
чался со случаем (и даже не могу представить его себе теоретически), когда иде-
альным планом выполнения в Oracle будет соединение с использованием сорти-
ровки слиянием, я не рассматриваю рекомендации Oracle о том, как ускорить этот
процесс. (Однако я объясняю, почему в Oracle вам следует предпочесть соедине-
ние хэшированием во всех случаях, когда соединение с использованием сортиров-
ки слиянием выглядит подходящим вариантом.)
Если посмотреть на проблему настройки SQL с этой новой точки зрения, то мы
получим неожиданное преимущество. Единственная действительно значительная
часть проблемы — решение, какой план выполнения является наилучшим — прак-
тически не зависит от нашего выбора реляционной базы данных. Наилучший план
выполнения всегда остается наилучшим планом выполнения, будем ли мы выпол-
нять оператор в Oracle, Microsoft SQL Server или DB2, поэтому знание этого факта
намного полезнее, чем все, что мы узнаем об особенностях базы данных опреде-
ленного поставщика. (Я даже смею утверждать, что наилучший план выполнения,
вероятнее всего, не сильно изменится в планируемых в ближайшем будущем вер-
сиях этих баз данных.)
Бонус
Метод, описанный в этой книге, упрощает запрос до абстрактного представления,
содержащего только информацию, важную для настройки.
ПРИМЕЧАНИЕ--------------------------------------------------------------
Я часто заменяю понятие запрос понятием SQL-onepcmop. Большинство проблем настройки относится
к запросам (например, запросом является оператор SELECT). Что же касается прочего, проблема обычно
заключается в подзапросе, вложенном в задачу обновления или вставки.
Это сродни упрощению сложной проблемы эквивалентности в высшей мате-
матике до простого абстрактного уравнения, которое решается автоматически, если,
конечно, вы знакомы с нужными разделами математики. Абстрактное представле-
ние задачи настройки SQL, диаграмма запроса, обычно принимает вид переверну-
того дерева с некими цифрами, как показано на рис. 1.1.
Как выясняется, SQL является настолько гибким языком, что на нем можно
создавать запросы, которые невозможно представить в виде обычного дерева, но,
с другой стороны, оказывается, что эти запросы просто бессмысленны с точки зре-
ния реальной работы. Таким образом, мы получаем еще одно неожиданное пре-
имущество. В ходе настройки SQL и создания абстрактных представлений запро-
«Внешние» решения
27
сов, помогающих вам в процессе, определенные проблемы с логикой запросов ста-
новятся очевидными, даже если у вас нет никаких предварительных сведений о
приложении. Разработчики обычно отлавливают такие проблемы еще до того, как
с SQL придется столкнуться вам, если только эти проблемы не запрятаны в даль-
них углах программы, которые не были тщательно протестированы (а так случает-
ся очень часто). Эти потайные проблемы — худшее, что может случиться с прило-
жением: например, на банковском счете могут неожиданно закончиться средства,
причем произойдет это намного позже первого запуска приложения, считающего-
ся идеальным, и необъяснимым способом, который трудно распознать и испра-
вить.
Рис. 1.1. Пример диаграммы запроса
ПРИМЕЧАНИЕ -------------------------------------------------------------------
Худшие из этих проблем никогда не будут обнаружены. Бизнес просто будет работать на основе невер-
ных результатов, выставления слишком больших или маленьких счетов, недоплаты, переплаты или
любых других просто ошибочных действий, которые никто не свяжет со вполне исправимыми ошибка-
ми приложения.
Иногда решение проблемы производительности требует решения логической
задачи. Даже если проблемы не зависят друг от друга (и вы можете улучшить про-
изводительность, не исправляя логические ошибки), вам может понадобиться вы-
полнить множество дополнительных действий, находя эти ошибки и убеждаясь,
что они исправлены. В этой книге такие логические ошибки рассматриваются об-
стоятельно, включая подробные описания, объясняющие, как найти каждую из
подобных ошибок и что с ними делать. При выполнении упражнений на диаграм-
мы SQL я даже рекомендую вам взять любую сложную написанную вручную SQL-
программу — просто чтобы найти эти незаметные логические ошибки, пусть даже
вы знаете, что программа прекрасно работает. В зависимости от используемого
инструмента некоторые продукты, автоматически генерирующие SQL-код, обыч-
но позволяют избегать большинства логических проблем.
«Внешние» решения
И, наконец, в этой книге рассматриваются «внешние» решения. Они подскажут,
что делать в случаях, когда вы не можете существенно улучшить производитель-
ность отдельного запроса, рассматривая его как спецификацию того, что требуется
28 1. Введение
приложению в конкретный момент. То есть именно тогда, когда вы настраиваете
единственный запрос, а не решаете проблему. Возникает целый класс задач, в ко-
торых вам действительно не нужно обращать внимание на то, что делает приложе-
ние и вы можете рассматривать его как абстрактный черный ящик, которому тре-
буется указанный набор строк из каких-то определенных таблиц. Даже здесь
существует несколько надежных «правил большого пальца» для корректировок
на уровне приложения, которые могут решить проблемы подобного типа. Скорее
всего, для решения этих проблем вам потребуется сотрудничать с разработчика-
ми, которые знают приложение в подробностях (предполагаем, что вы этого не
знаете), но, понимая правила, вы все же сможете предложить какие-либо возмож-
ные решения, даже не зная тонкостей приложения.
2
Основы доступа
к данным
Для решения алгебраической задачи вам необходимо четкое понимание арифме-
тических операций. Точно так же необходимо понимать, как база данных обраща-
ется к данным в отдельных таблицах и как она соединяет данные из нескольких
таблиц, чтобы научиться комбинировать эти операции для создания оптимально-
го плана выполнения. Эта книга фокусируется на методах доступа, имеющих наи-
большее значение для реально работающих запросов, но мы упомянем способы,
которые используются редко или вовсе не используются.
Вам может показаться, что название главы обманчиво. Некоторые из «основ»
доступа к данным достаточно сложны и загадочны, так как даже простейшая опе-
рация в базе данных может усложниться при детальном рассмотрении. Однако я
советую вам не терять оптимизма. Хотя я рассказываю много ужасающих подроб-
ностей для тех, кому это действительно интересно, и для редких случаев, когда это
может понадобиться, вы можете успешно справляться с задачей настройки, имея
лишь беглое представление об индексированном доступе и соединениях методом
вложенных циклов. Оптимизация запроса в целях ускорения его выполнения тре-
бует лишь базового понимания материала этой главы.
Я привожу в этой главе все подробности по двум причинам.
Некоторые читатели обнаружат, что дальнейший материал легче понять и за-
помнить, если в уме всегда появляется основательная, подробная картина при
упоминании определенных методов доступа к таблицам и соединения таблиц.
Например, такие читатели будут работать тяжело и непродуктивно, старатель-
но разбирая и запоминая «правила большого пальца», рассказывающие, поче-
му следует предпочесть соединения хэшированием, а не соединения методом
вложенных циклов, если они будут иметь весьма слабое представление об этих
методах. Нельзя их воспринимать лишь как какие-то процессы, происходящие
где-то в глубине. Если вы являетесь подобным вдумчивым читателем (как я),
эта глава, со всеми своими подробностями, поможет вам понять остальную книгу.
Людям, которые занимаются настройкой запросов, часто задают неловкие во-
просы, например: «Почему этот запрос, возвращая 200 строк, работает в 12 раз
дольше, чем другой, который возвращает 1000 строк?» Другой распростра-
ненный вопрос: «Не лучше ли было бы для ускорения выполнения запроса ис-
пользовать <Вставьте_самый_модный_тип_объектов_этого_года>?» Только
глубокое понимание основ, обсуждаемых в этой главе, поможет ответить на по-
добные вопросы.
30
2. Основы доступа к данным
Я немного забегу вперед. Многие особенности в этой главе упомянуты из-за
сложной природы Oracle. Я обнаружил, что максимально точные описания помо-
гают получать верные интуитивные догадки о правильных способах выполнения
запросов и настройки базы данных, так как вы можете держать в голове подроб-
ную, точную картину происходящего. Я мог бы выбрать и другую базу данных для
описания форматов таблиц, методов соединения и доступа к таблицам, но ни одно
решение не может угодить всем. Оказывается, в большинстве случаев различия
между серверами баз данных не влияют на настройку SQL. Лишь в редких случаях
имеет значение конкретная реализация определенного поставщика, и в таких слу-
чаях я подробно описываю различия.
Кэширование в базе данных
Во всех реляционных базах данных используются вариации одной общей схемы
кэширования для минимизации физического ввода-вывода, который включает дос-
туп к дисковому хранилищу, в пользу строго логического ввода-вывода, или досту-
па к данным только в памяти. (Любой доступ к данным является логическим вво-
дом-выводом. Ввод-вывод только в памяти — это строго логический ввод-вывод,
а ввод-вывод с диска является и физическим, и логическим.) Рисунок 2.1 иллюст-
рирует основы кэширования.
Рис. 2.1. Кэширование данных
Длинный растянутый по горизонтали серый прямоугольник (который был бы
действительно длинным, если бы включал 100 000 блоков, изъятых из середины)
представляет большой сегмент памяти, одновременно доступный всем сеансам базы
данных. Этот сегмент памяти, известный как буфер блоков кэша, состоит из одина-
ковых по размеру (обычно 2-16 Кбайт в зависимости от конфигурации базы дан-
ных) блоков данных, скопированных с диска. В этих блоках хранятся данные, не-
давно полученные из таблиц и индексов баз данных. Узкие серые прямоугольники
представляют отдельные блоки.
С небольшими изменениями кэш заполняется и поддерживается достаточно
простым способом. Каждый раз, когда базе данных необходимо обратиться к бло-
ку данных, еще не скопированному в кэш, она запрашивает операцию чтения с
диска (физический ввод-вывод) и помещает только что полученный блок в голову
буферного списка. Так как длина списка во время работы базы данных остается
Кэширование в базе данных
31
фиксированной, добавление блока со стороны головы приводит к тому, что блок
в хвосте списка удаляется (то есть более не является кэшированным).
ПРИМЕЧАНИЕ-----------------------------------------------------------------
На самом деле операции в кэше выполняются при помощи указателей в связном списке определен-
ного вида. Новый головной блок — это в действительности та же область памяти, что старый хвосто-
вой блок, в которую записаны новые данные, а указатели перемещены для изменения места блока
в списке.
Когда база данных обнаруживает, что нужный блок данных уже находится
в списке (что требует строго логического ввода-вывода), она перемещает этот блок
из текущего положения в голову списка. Так как блок, участвующий в логическом
вводе-выводе, всего лишь перемещается, а не добавляется в список, никакие блоки
из хвоста списка не выталкиваются. И снова база данных обрабатывает перемеще-
ние логического блока при помощи указателей; на физическом уровне данные в па-
мяти не копируются.
Так как при выполнении каждого логического ввода-вывода блоки перемеща-
ются обратно в сторону головы списка, в итоге кэш становится отсортированным:
последние по времени использования (most recently used, MRU) блоки находятся
ближе к голове, а блоки с наиболее давним использованием (least recently used,
LRU) — к концу списка. Обычно блоки, к которым обращение производится час-
то, называются горячими, а редко используемые блоки — холодными. Однако на-
сколько блок является горячим или холодным, зависит от того, имеете ли вы в
виду обращение при помощи логического или физического ввода-вывода. Наибо-
лее часто используемые блоки могут быть горячими с точки зрения логического
ввода-вывода, но, в то же время, с точки зрения физического ввода-вывода они
холодные, так как никогда не покидают кэша.
Блок, который удаляется из кэша в результате выполнения физического ввода-
вывода, — это блок с самым давним использованием в списке, или LRU-блок спис-
ка. По этой причине описываемый мной алгоритм кэширования часто называется
алгоритмом кэширования LRU, и этот подход к кэшированию часто используется
различными программистами не только в реляционных базах данных. Теория за-
ключается в том, что наиболее горячие данные постоянно находятся около головы
списка, и поэтому дольше живут в списке. Самые горячие данные могут вообще
никогда не покидать список. Хранение наиболее часто используемых данных в кэше
позволяет осуществлять быстрый доступ к данным, что, в свою очередь, ускоряет
выполнение запросов по сравнению со временем выполнения без применения кэша.
ПРИМЕЧАНИЕ ------------------------------------------------------------------
Когда сервер баз данных запрашивает выполнение физического ввода-вывода, это не обязательно при-
водит к тому, что физический диск передвигает считывающую головку к нужному сектору на диске.
Дисковые подсистемы и операционные системы выполняют собственное кэширование, и средняя ре-
зультирующая производительность действий, которые база данных воспринимает как физический ввод-
вывод, в среднем выше, чем обычно считают пользователи. Физический ввод-вывод намного дороже
логического ввода-вывода, поэтому промахи в кэше базы данных имеют значение, но не настолько боль-
шое, как вы можете подумать.
У схемы кэширования LRU есть несколько важных для настройки следствий.
Быстрее всего осуществляется доступ к MRU-блокам, так как они находятся
в кэше. Но ошибочным будет считать, что кэшированный доступ практически
32
2. Основы доступа к данным
ничего не стоит. Если вы подсчитаете полные затраты времени обработки для
логического ввода-вывода, то они будут в 30-200 раз меньше, чем для физиче-
ского ввода-вывода. Однако, это значение не настолько мало, чтобы полностью
игнорировать логический ввод-вывод, ведь кэширование так хорошо работает
потому, что логический ввод-вывод выполняется приблизительно в сто раз чаще,
чем физический. Даже если вы исключите все операции физического ввода-
вывода, производительность все же может серьезно страдать из-за затрат на
обработку процессором ненужных операций логического ввода-вывода. Если
же вы поработаете над сокращением количества операций логического ввода-
вывода, необходимость в физическом вводе-выводе в большинстве случаев от-
падет сама — конечно же, если у вас есть кэш разумного размера.
Если к блоку не обращаются операции логического ввода-вывода, то в обыч-
ной хорошо настроенной системе он перейдет из головы списка к хвосту и бу-
дет удален через несколько минут. Поэтому блок может быть самым горячим в
терминах физического ввода-вывода, если одна операция ввода-вывода совер-
шается для него каждые несколько минут. Если же обращения к этому блоку
производятся чаще, то блок становится хорошо кэшированным и требует мень-
ше физических операций ввода-вывода.
Строки таблицы и записи индекса, находящиеся в одном блоке с другими дан-
ными, к которым часто производятся обращения, получают преимущество от
своего соседства с горячими данными. Чем более эффективно вы организуете
горячие данные в таблицах и индексах, то есть чем ближе они будут находиться
друг к другу, тем более эффективным можно считать кэш.
Конечные пользователи получают преимущество, если другие пользователи
недавно обращались к горячим данным, так как кэш базы данных используется
совместно и большая часть требуемых данных (обычно 99 % или больше) воз-
вращается без выполнения операций физического ввода-вывода.
Для блоков, к которым производятся повторные обращения в пределах одного
запроса, потребуется немного операций физического ввода-вывода, даже если
эти блоки считаются холодными, так как ваш запрос сам сделает нужные дан-
ные горячими и, следовательно, кэшированными, для остальной части запроса.
Небольшие таблицы и индексы (таблицы, в которых меньше 10 000 строк, и ин-
дексы с менее чем 90 000 записей) обычно становятся идеально кэшированны-
ми. В реальной жизни нечасто возникает такая ситуация, что к небольшой таб-
лице или индексу обращаются очень редко, из-за чего они не могут стать хорошо
кэшированными. Однако следствием таких редких обращений становится то,
что низкая результирующая производительность не создаст большой пробле-
мы. Даже если запрос к небольшому объекту потребует физического ввода-вы-
вода, операций физического ввода-вывода будет выполнено немного, так как
первые несколько из них поместят весь объект в кэш на время, достаточное для
выполнения запроса. Для описания процесса, в ходе которого запрос к обычно
холодным блокам делает эти блоки горячими на время выполнения запроса,
я использую термин самокэширование. Самокэширование позволяет вам спо-
койно игнорировать потенциальные операции физического ввода-вывода для
небольших таблиц и индексов даже в таких редких случаях, когда небольшие
объекты являются холодными.
Таблицы
33
Даже большие индексы обычно становятся хорошо кэшированными, так как
индексы занимают намного меньше места, чем таблицы, а планы доступа, вклю-
чающие эти индексы, обычно работают на самых горячих областях индексов.
Только большие таблицы (таблицы с более чем 1 000 000 строк) обычно быва-
ют плохо кэшированными, если только вы систематически не обращаетесь к
горячему подмножеству таблицы. Минимизация количества различных бло-
ков, к которым производится обращение в больших таблицах, в целях умень-
шения излишнего физического ввода-вывода, действительно является важным
фактором для улучшения производительности.
Все остальные эквивалентные варианты (например, варианты, требующие оди-
накового количества операций логического ввода-вывода) относятся к случаю
использования самых горячих блоков. Часто встречается вариант, когда осу-
ществляется проход по индексу, так как блоки индекса и таблицы, к которым
производилось индексированное обращение, чаще становятся горячими, чем
случайные блоки таблицы.
Таблицы
Таблицы представляют собой основу реляционной базы данных. Реляционная те-
ория описывает таблицы как абстрактные объекты, не придавая значения порядку
составляющих их строк и столбцов. Однако таблицы также существуют в физи-
ческой форме на диске сервера баз данных, причем здесь порядок следования эле-
ментов уже ощутимо влияет на производительность. Если приложение запрашивает
байты, физически хранящиеся на диске или в кэше в памяти, серверные процессы
должны уметь обращаться к ним.
Физическое размещение строк таблиц влияет на производительность считыва-
ния этих строк, поэтому важно знать различные типы таблиц и понимать, как раз-
мещение зависит от типа. На рис. 2.2 показаны четыре различные физические таб-
лицы, иллюстрирующие основные схемы роста и старения таблицы, и показано,
как такие схемы влияют на расположение данных.
Таблицы занимают одну или несколько непрерывных областей дискового про-
странства (называемых в Oracle экстентами1), которые сервер может считывать с
минимальным количеством перемещений считывающей головки и максимальной
эффективностью. База данных объединяет строки таблицы в блоки, размер кото-
рых слишком мал, чтобы показать их здесь, — обычно 2-16 Кбайт. Размер этих
блоков остается неизменным в большинстве или всех базах данных (в зависимо-
сти от поставщика). Блоки — это элементы наименьшего размера, которые база
данных считывает с диска или из кэша, как мы уже увидели ранее. Когда в ранее
пустовавшие блоки экстента записываются данные, отметка заполнения — то есть
наивысшая точка таблицы, в которой база данных должна производить поиск —
1 Технически экстент является непрерывным согласно виртуальной дисковой адресации, которую
поддерживает любое программное обеспечение баз данных. На низшем уровне RAID или любая дру-
гая система расслоения/зеркального отображения дисков может преобразовывать эти непрерывные
виртуальные адреса в блоки на различных дисках, но при настройке SQL вы можете забыть об этих
тонкостях.
34
2. Основы доступа к данным
движется по направлению к верхушке экстента, по достижении которой выделя-
ется новый экстент1. Выше отметки заполнения находится пространство, зарезер-
вированное для записи будущих данных, причем база данных никогда не обраща-
ется к этому пространству при считывании данных. Отметка заполнения не
перемещается вниз, если только вы не перестраиваете или не усекаете таблицу.
Рисунок 2.2 иллюстрирует схемы роста таблицы, описанные в следующих разделах.
Обозначения:|
| | Экстент
Самые новые строки
Недавние,
но не новые строки
Самые старые строки
Отметка
заполнения таблицы
Последовательное Удаление
увеличение самых старых
Удаление Полное удаление.
данных рост с нуля
данных вне зависимости
от возраста
Рис. 2.2. Увеличение и старение физической таблицы
Последовательный рост
Последовательный рост, показанный на экстенте Т1 (рис. 2.2), — это наиболее рас-
пространенная схема среди таблиц транзакций, когда постоянно добавляются но-
вые строки, но практически никогда не удаляются старые. Ситуация, когда старые
строки остаются в таблице, давно уже не принося никакой пользы, очень часто
причиняет неудобства в работе. Однако приходится решать, какой вариант безо-
паснее. Удалять данные — это тяжелая (и небезопасная) работа, даже если не учи-
тывать усилия, потраченные на написание выполняющих это задание процедур.
Так или иначе, рассмотрение этого вопроса обычно оказывается в самом конце
списка приоритетов для возможностей продукта (да и кому это нужно в первом
выпуске продукта?), к большому удовольствию производителей жестких дисков.
В последовательно растущих таблицах полезность строк уменьшается по мере
их старения, поэтому более новые, удобно расположенные наверху таблицы стро-
ки, к которым чаще производятся обращения, легко кэшируются. Когда самые но-
вые строки являются самыми горячими, естественная кластеризация новых строк
позволяет оптимально использовать кэш, и даже в очень большой таблице коэф-
Это описание наиболее точно подходит для Oracle, однако различия в этой области между продукта-
ми разных поставщиков несущественны для настройки SQL.
Таблицы
35
фициент попадания в кэш (доля операций логического ввода-вывода, для которых
не требуется физический ввод-вывод) может быть очень хорошим, если вы исполь-
зуете индексный доступ, отсеивающий старые строки.
Запрос, который считывает все строки последовательно растущей таблицы (до
отметки уровня заполнения, конечно же), а затем удаляет практически все, за ис-
ключением нескольких самых новых строк, будет хорошо работать на новой ма-
ленькой таблице. Однако время обращения ко всей таблице растет линейно, если
предположить постоянный коэффициент роста таблицы, и вскоре становится вов-
се недопустимым. Путь доступа, включающий только новые строки, характеризу-
ется практически постоянной эффективностью, если таблица растет равномерно,
так как количество строк, созданных, например, в последнюю неделю, всегда прак-
тически постоянно.
Удаление самых старых данных
Схему удаления самых старых данных, показанную на рис. 2.2 для экстента Т2,
я называю схемой Уробороса в честь мифической змеи, поедающей собственный
хвост. В этой таблице самые старые строки периодически удаляются (все старые
строки, а не какой-то их поднабор), полностью освобождая ранее занимаемые бло-
ки для вставки новых строк. Отметка заполнения не двигается после достижения
таблицей максимального размера, так как предполагается, что вы удаляете строки
(однажды начав удаление) с той же скоростью, с которой вставляете новые. Голо-
ва змеи (где находятся новые строки) постоянно преследует хвост (где содержатся
старые строки), который убегает при каждом удалении. С точки зрения хранения
новых строк физически рядом эта схема имеет те же преимущества, что и схема
постоянного роста. Причем, поскольку рост таблицы останавливается, как только
начинается удаление, вероятность того, что вся таблица будет хорошо кэширова-
на, увеличивается. Помните, что это идеальный случай, который редко встречает-
ся в реальных ситуациях, так как сохранение нескольких старых строк или ско-
рость роста таблицы, превышающая скорость удаления строк, будет приводить к
основательному смешиванию старых и новых строк.
Удаление данных вне зависимости от возраста
Удаление данных независимо от их возраста, показанное для экстента ТЗ на рйс. 2.2,
отражает схему удаления строк, которая не зависит от их возраста. Добавление но-
вых данных в блоки разрешается сразу же, как только свободное пространство в них
превышает определенный порог (обычно 60 % в Oracle); они остаются доступными
для записи, пока свободное пространство в них не уменьшится до значения друго-
го порога (обычно 10 % свободного пространства в Oracle). Это происходит с бло-
ками, которые случайно разбросаны по таблице, поэтому новые строки вставля-
ются неравномерно, а кэширование со временем усложняется как из-за того, что
в среднем в блоках много свободного места, так и из-за того, что интересующие
нас строки могут находиться в любой части таблицы. Однако такая схема удале-
ния предполагает, что заинтересованность приложения в строках не зависит от их
возраста, поэтому кэширование такой таблицы затруднено и без того, что удале-
ние бессистемно разбрасывает новые строки.
36
2. Основы доступа к данным
Полное удаление и рост с нуля
Схема полного удаления и роста с нуля, показанная для экстента Т4 на рис. 2.2.,
отражает метод удаления всех данных для того, чтобы заполнение таблицы могло
начаться заново. На рис. 2.2 все содержимое таблицы было недавно удалено, и по-
казанные самые старые строки на самом деле не слишком устарели. Таблица будет
расти еще долго до того момента, как достигнет отметки заполнения. Эта схема
похожа на схему последовательного роста, показанную на Т1, но, так как таблица
уже достигала своего максимального значения и с тех пор не перестраивалась, от-
метка заполнения не опускалась. Поэтому при полном сканировании таблицы
выполняется столько же физических операций ввода-вывода, сколько и до удаления.
ПРИМЕЧАНИЕ ---------------------------------------------------------
Команда Oracle TRUNCATE, в противоположность DELETE, может опускать отметку заполнения. В любой
базе данных можно опустить отметку заполнения, удалив данные и перестроив таблицу.
Индексы
С функциональной точки зрения индексы не так фундаментальны, как таблицы.
Это всего лишь способ быстрого обращения к строкам таблицы. Индексы чрезвы-
чайно важны для получения высокой производительности, но фактически не яв-
ляются необходимыми.
Индексы в В-деревьях
Наиболее распространенный и важный тип индекса — это индекс в В-дереве, который
отражает структуру дерева, сбалансированную (В означает balanced) до опреде-
ленной глубины от корня до листовых блоков по каждой ветви. На рис. 2.3 показа-
но трехуровневое В-дерево, в виде которого можно представить индекс, указы-
вающий на 90 000-27 000 000 строк в таблице (это обычный диапазон размеров
для трехуровневых В-деревьев).
Листовые блоки:
(значение, идентификатор строки)...
Рис. 2.3. Индекс в трехуровневом В-дереве
Индексы в В-деревьях
37
Как оглавление в книге, индекс базы данных помогает ей быстро находить ссыл-
ки на некоторое значение или диапазон значений, которые требуется получить из
таблицы. Например, индексирование Last_Name в таблице Persons позволяет быст-
ро обращаться к списку строк таблицы, для которых Last_Name= ’SMITH' или где
Last_Name>='X' AND Last_Name<'Y'. Но, в противоположность оглавлению книги, ра-
бота с индексами базы данных практически не требует никаких усилий со стороны
приложения. База данных сама несет ответственность за прохождение индексов,
которые выбирает для использования, и поиск строк, необходимых запросу. При-
чем база данных обычно сама без подсказки выбирает подходящие индексы. Одна-
ко базы данных не всегда делают правильный выбор, и материал этой книги во
многом посвящен таким проблемам.
Для каждого индекса существует естественный порядок сортировки, обычно
по возрастанию в соответствии с типом индексированного столбца. Например,
число 11 лежит между 10 и 12, однако строка символов ' 1Г лежит между 'Г и ' 2 ’.
Часто индексы охватывают несколько столбцов, но вы можете считать, что для
таких индексов существует единственный ключ сортировки, составленный путем
конкатенации значений нескольких столбцов с соответствующим заполнением
пробелами, разрешающим сортировку второго столбца только после завершения
сортировки первого столбца.
Индексный доступ всегда начинается с единственного корневого блока, в кото-
ром записано до 300 интервалов индексных значений, соответствующих данным в
таблице. Если индекс составлен более чем для 300 строк (чаще всего фактическое
значение зависит от размеров блоков и столбцов), то эти диапазоны обычно содер-
жат указатели на блоки следующего уровня1. Индекс для таблицы, в которой мень-
ше 300 строк, обычно состоит только из корневого блока, содержащего указатели
прямо на индексированные строки в таблице. Такие указатели для каждой индек-
сированной строки принимают форму адреса блока и номера строки в блоке. В лю-
бом случае, независимо от того, насколько велика таблица, вы можете предполо-
жить, что корневой блок идеально кэширован, так как каждое использование
индекса обязательно начинается с этого блока.
ПРИМЕЧАНИЕ --------------------------------------------------------------
Адрес блока и номер с троки в блоке вместе называются идентификатором строки. Индексы указывают
на строки в таблицах при помощи идентификаторов строки.
Будем считать, что в таблице больше 300 индексированных строк. Тогда база
данных следует по указателю в корневом блоке и попадает в блок следующего уров-
ня, который охватывает начало диапазона значений, необходимых для вашего за-
проса. Если же в таблице больше 90 000 индексированных строк, то блок второго
уровня, в свою очередь, содержит поддиапазоны с указателями на блоки на следу-
ющем уровне. В конце концов (на первом не корневом уровне, если в таблице 300-
90 000 индексированных строк) база данных придет в листовой блок, в котором
содержатся точное значение, соответствующее началу требуемого диапазона (пред-
1 Я говорю об индексированных строках, противопоставляя их строкам таблицы, так как не всегда
индексы указывают на все строки таблицы. Например, индексы Oracle не содержат записей, указы-
вающих на строки со значением null во всех индексированных столбцах, поэтому индекс для столб-
ца, большинство значений в котором равны null, может быть весьма небольшим даже на очень большой
таблице, если лишь в нескольких строках для этого столбца значения ненулевые.
38
2. Основы доступа к данным
полагается, что запрошенный диапазон содержит хотя бы несколько строк), и иден-
тификатор строки для первой строки диапазона.
Если условие, которое управляет доступом к индексу, потенциально указывает
на диапазон, включающий несколько строк, база данных выполняет сканирование
диапазона индексов в листовых блоках. Сканирование диапазона индексов — это
операция считывания (обычно при помощи операций логического ввода-вывода
из кэша) последовательности индексов из необходимого количества листовых бло-
ков. Листовые блоки состоят из списка пар значение/идентификатор строки, от-
сортированного по индексированному значению. База данных сортирует записи с
одинаковыми значениями согласно порядку идентификаторов строк, отражая ес-
тественный порядок, в котором база данных хранит строки в физической таблице.
В конце каждого списка листового блока находится указатель на следующий лис-
товой блок, где отсортированный список продолжается. Если в таблице есть не-
сколько строк, удовлетворяющих условию для диапазона индекса, то база данных
следует по указателю от первой строки на следующую запись индекса в диапазоне
(в более чем 99 % случаев следующая запись индекса находится в том же листовом
блоке индекса) и так далее, пока не достигнет конца диапазона. Таким образом,
каждое считывание интервала отсортированных значений требует одного прохож-
дения вниз по дереву индекса и одного прохождения по отсортированным значе-
ниям в листовых блоках.
ПРИМЕЧАНИЕ-----------------------------------------------------------------
Обычно сканирование диапазона затрагивает только один листовой блок, так как в одном листовом
блоке хранится 300значений. Этого обычно достаточно для большинства операций сканирования сред-
него размера, чтобы не покинуть блок. Однако сканирование большого диапазона может потребовать
перехода по длинному списку листовых блоков.
Если в блоке индекса содержится приблизительно 300 записей, то на первом
некорневом уровне будет примерно 300 блоков. Это достаточно малое значение
для успешного кэширования, поэтому вы можете предполагать, что считывание
этих блоков индексов будет исключительно логическим, без выполнения опера-
ций физического ввода-вывода. На нижнем, листовом уровне индекса, если ин-
декс состоит из трех и более уровней, может быть гораздо больше трехсот листо-
вых блоков. Но если в базе данных используется действительно объемный индекс,
то на листовом уровне индекса находится порядка п/300 блоков, где п — количе-
ство индексированных строк, а база данных может эффективно кэшировать 1 000
или более блоков индекса.
Если индекс слишком велик, чтобы кэшировать его целиком, то при доступе
к такому индексу будет выполнено несколько операций физического ввода-выво-
да. Но помните, что индексы в общем случае охватывают только существенные
свойства, определяющие наиболее часто опрашиваемые части таблицы. Следова-
тельно, базе данных редко требуется кэширование всего огромного индекса — нуж-
но кэшировать только небольшой набор блоков индекса, указывающих на инте-
ресные строки. Поэтому даже большие индексы обычно характеризуются
прекрасными коэффициентами попадания в кэш. Следовательно, при сравнении
альтернативных планов выполнения можно игнорировать затраты на операции фи-
зического ввода-вывода для индексов. Если физический ввод-вывод вообще вы-
полняется, то физический ввод-вывод для таблиц будет практически всегда пере-
крывать стоимость физического ввода-вывода для индексов.
Индексы в В-деревьях
39
Стоимость индекса
Наличие нескольких индексов не может ухудшить производительность запроса,
если только вы не используете неверные индексы. Но у индексов, конечно, есть и
недостатки. При оптимизации неверные индексы выбираются намного чаще, чем
вы можете подумать, и вы удивитесь, узнав, сколько проблем с производительно-
стью запросов возникает всего лишь из-за добавления индексов в базу данных.
Даже если вы абсолютно уверены, что новый индекс никогда не займет место луч-
шего индекса в плане выполнения, добавляйте индексы осторожно и в меру.
В идеальном мире затраты на производительность, происходящие от добавле-
ния индексов, возникают только при добавлении, удалении и обновлении строк.
В спокойных таблицах стоимость индексов никогда не бывает проблемой, но в ак-
тивных, растущих таблицах стоимость индексов может быть весьма высока. Обычно
добавления в индекс проходят без проблем, особенно в СУБД Oracle, которая осо-
бенно элегантно обрабатывает блокировку блоков индексов для незавершенной
работы.
Удаления проходят сложнее, чем вставки, так как В-деревья при добавлении
строк и последующем их удалении ведут себя несимметрично. В индексе, в кото-
ром проводилось много удалений, в итоге образуется множество практически пус-
тых блоков, кэширование и считывание которых менее эффективно, чем для того
же индекса, указывающего на те же строки, если бы все эти удаления не были про-
изведены. Редкие, дорогостоящие перестроения индексов необходимы для восста-
новления полной эффективности индексов, испытавших большое количество уда-
лений.
Обновления — это самые дорогие операции с индексом. Если при обновлении
изменяется хотя бы один индексированный столбец, база данных рассматривает
его как вставку (нового значения) и удаление (старого значения). Такое дорогое
двусоставное обновление, не обязательное в таблицах, необходимо для индексов,
так как в действительности обновление значений индекса меняет местоположе-
ние строки в структуре индекса. К счастью, индексы по первичным ключам практи-
чески никогда не обновляются, если база данных разработана правильно, а обнов-
ления внешних ключей редки. Индексы, представляющие наибольшую опасность
для производительности операций обновления, — это индексы по столбцам, не
являющимся ключевыми, значение которых в реальных приложениях изменяется
со временем (например, по столбцам состояний для сущностей, часто меняющих
статус).
Некоторые индексы существуют по причинам, не зависящим от производитель-
ности, например для поддержки уникальности. Необходимость усиления уникаль-
ности обычно является хорошим оправданием уникального индекса, и в целом
уникальные индексы селективны, а потому безопасны и полезны. Однако неуни-
кальные индексы следует создавать с осторожностью. Они зависимы и потому,
однажды их создав, от них трудно избавиться, не рискуя производительностью, —
очень трудно доказать, что ни одному важному запросу не требуется данный ин-
декс. При решении проблем производительности я часто советую создать новые
индексы. И когда я делаю это, то практически всегда имею в виду по крайней мере
один специфический запрос, который выполняется достаточно часто, но не может
быть выполнен с необходимым быстродействием без нового индекса.
40
2. Основы доступа к данным
Редкие объекты базы данных
Простые таблицы и индексы в В-деревьях удовлетворяют практически всем нуж-
дам базы данных. Но вам нужно иметь хотя бы поверхностное представление о
менее распространенных типах объектов баз данных, на случай, если понадобится
привести доводы против безуспешных попыток решить проблемы при помощи
неверных и экзотических инструментов. В этом разделе рассматриваются наибо-
лее популярные специальные типы объектов.
Таблицы с индексной организацией
Таблицы с индексной организацией — это индексы, которые не указывают на таб-
лицы. Это характерная возможность Oracle, но их можно имитировать в любой
базе данных. Иногда база данных обнаруживает все столбцы, необходимые для
выполнения запроса, в индексе, и использует только индекс, даже не обращаясь к
соответствующей таблице. Если вы создали индекс, в котором содержатся все стол-
бцы таблицы, возможно, вы захотите вообще избавиться от таблицы. Таблицы с
индексной организацией работают в точности по этому сценарию, экономя про-
странство и снижая стоимость поддержки отдельной таблицы. Так как таблицы с
индексной организацией не указывают ни на какую реальную таблицу, то им не
нужно хранить идентификаторы строк. Поэтому в блок помещается больше строк,
чем в обычные индексы по тем же столбцам. Если какой-то индекс находится бук-
вально за порогом отметки, когда становится необходимым дополнительный уро-
вень индексов, замена комбинации индекс-таблица более компактной таблицей
с индексной организацией позволит устранить необходимость создания лишнего
уровня.
Рассмотрите возможность использования таблиц с индексной организацией
в следующих условиях.
Строки ненамного длиннее своих индексных ключей. Таблицы обычно хранят
данные более компактно и эффективно, чем индекс с теми же данными. Если
строки существенно длиннее своего ключа, считывание гораздо более компакт-
ного ключевого индекса, за которым следуют считывания из простой таблицы,
будет работать лучше, или, по крайней мере, так же хорошо, и гораздо гибче.
Вы практически всегда получаете строки через один индекс — возможно, при
помощи всего индекса или его части по первичному ключу. Можно создать обыч-
ные вторичные индексы по таблицам с индексной организацией, но при исполь-
зовании этих вторичных индексов цель создания такой таблицы не будет до-
стигнута.
Иногда вы считываете строки в больших диапазонах, основанных на порядке
сортировки индекса. Считывания больших диапазонов данных в индексе отно-
сительно эффективны в сравнении со считыванием тех же строк, разбросанных
случайным образом по обычной таблице. Но этот фактор в пользу таблиц с ин-
дексной организацией может конфликтовать с предыдущим фактором, так как
доступ при помощи первичного ключа обычно является уникальным, а не дос-
тупом к большому диапазону данных. В случае составных первичных ключей
вы иногда считываете диапазоны строк по частичным ключам, поэтому в ред-
Редкие объекты базы данных
41
ких случаях оба этих фактора будут говорить в пользу таблиц с индексной орга-
низацией.
Вы редко добавляете, удаляете и модифицируете строки. Обычные таблицы
лучше обрабатывают частое изменение данных, чем таблицы с индексной орга-
низацией. В приложениях оперативной обработки транзакций (Online Trans-
action Processing, OLTP) данные в больших таблицах изменяются часто; в про-
тивном случае они бы слишком разрослись. Это аргумент против больших
таблиц с индексной организацией в среде OLTP.
Если вам нравится идея таблиц с индексной организацией, но вы работаете не
в Oracle, то вы можете получить практически те же преимущества по времени счи-
тывания, построив обычные индексы со всеми столбцами, необходимыми для час-
то выполняемых запросов. Этой стратегии можно следовать и в Oracle, если вы
хотите для большей компактности оставить большие, но редко используемые столб-
цы за пределами индекса.
Самый большой недостаток добавления столбцов к обычным индексам возника-
ет, если эти индексы уже уникальны. Вы можете назвать ведущий поднабор столб-
цов в таблице с индексной организацией уникальным ключом, но обычные уникаль-
ные индексы соблюдают уникальность только на комбинации всех обрабатываемых
ими столбцов. Уникальные индексы обычно создаются и для увеличения произво-
дительности, и для внедрения уникальности по ключу. Однако если вы добавите
неключевые столбцы к обычному уникальному ключевому индексу, то пойдете про-
тив соответствующих требований к уникальности ключа. Эту проблему можно ре-
шить при помощи двух индексов. Один узкий индекс потребуется для соблюдения
уникальности ключа. Еще один широкий индекс нужен будет для обеспечения ис-
ключительно индексного доступа к столбцам таблицы. Однако базы данных чаще
всего не выбирают широкий индекс, если в узком уже содержатся все необходимые
для уникального считывания столбцы, поэтому вам может потребоваться приложить
дополнительные усилия, чтобы заставить базу использовать широкий индекс.
Однотабличные кластеры
Сами по себе однотабличные кластеры используются дольше, чем их близкие род-
ственники — таблицы с индексной организацией. Однотабличный кластер физи-
чески организует строки таблицы в определенном порядке в зависимости от како-
го-либо ключевого значения. Когда принцип отбора строк хорошо коррелирует
с использованным типом сортировки, такая организация доступа к данным улуч-
шает результативность за счет того, что горячие строки находятся рядом. Но су-
ществует устойчивая проблема, которая заключается в том, что трудно сохранять
таблицу отсортированной, если только строки не прибывают в нужном порядке.
(А если они прибывают уже отсортированными, то кластер не требуется, естествен-
ное упорядочение таблицы будет прекрасно работать.) Если же строки прибывают
неотсортированными, база данных должна оставлять пространство для размеще-
ния новых строк в подходящем месте, иначе придется периодически реорганизо-
вывать строки. Реорганизация дорога, а резервирование пространства приводит
к потере памяти и серьезно подрывает эффективность кэша. Резюмируя, могу ска-
зать, что мне никогда не требовались однотабличные кластеры для повышения
производительности, и я ожидаю, что вам они также будут не нужны.
42
2. Основы доступа к данным
Многотабличные кластеры
Как и однотабличные кластеры, многотабличные кластеры предварительно отсор-
тированы по какому-либо ключу. В случае многотабличных кластеров в одном
блоке находятся строки из нескольких таблиц, соединенные на основе этого клю-
ча, что делает операцию соединения таблиц исключительно быстрой. Если вы не
обращаетесь одновременно ко всем кластеризованным таблицам, то строки из дру-
гой таблицы в считываемом блоке только мешают, поэтому ключевым вопросом
является вопрос о том, как часто вы соединяете различные таблицы в запросах
приложений. Если у вас есть две или более постоянно соединенные таблицы, ко-
торые однозначно связаны друг с другом (то есть эти таблицы совместно исполь-
зуют уника льный ключ), многотабличные кластеры должны работать достаточно
хорошо. Но, в таком случае, зачем вообще разделять эти таблицы? Просто помес-
тите расширенное множество всех столбцов в одну таблицу. Чаще всего между
главной и детальной таблицей существует отношение «один ко многим», как, на-
пример, между таблицами Orders и Order_Detail. Здесь проблемой становится из-
менчивость отношений «один ко многим». В кластерном блоке вы должны пре-
дусмотреть возможность размещения множества деталей, но в то же время избежать
излишней траты пространства в случае, когда оказывается, что существует лишь
одна детальная строка (или не существует вообще ни одной). Как и с однотаблич-
ными кластерами, это приводит к проблеме компромисса между потерянным про-
странством и затратами на реорганизацию. И, как и однотабличные кластеры,
многотабличные кластеры мне никогда не требовались для улучшения произво-
дительности, и вам, вероятно, они также не пригодятся.
Таблицы с разбиениями
Таблицы с разбиениями — это еще одна особенность Oracle, возникшая из-за не-
обходимости поддерживать действительно огромные таблицы. Представьте, что у
вас есть система отслеживания сделок для крупного брокера. Вероятно, у вас есть
обширная история отдельных сделок, но вы редко интересуетесь сделками, кото-
рые произошли больше года назад. Вы хотите иметь эффективный и непрерывный
доступ к недавним сделкам, а также инструменты архивирования самых старых
сделок без нарушения целостности системы.
Таблицы с разбиениями выглядят как набор подтаблиц, или разбиений, кото-
рые можно поддерживать независимо друг от друга. Например, одно из разбиений
можно переключить в автономный режим, не нарушая доступа к остальным. Опе-
раторы запросов должны явно упоминать только имя таблицы с разбиениями, пред-
ставляющей весь набор. Разбиения организованы в соответствии с некоторым клас-
сифицирующим условием, которое определяет, какому разбиению принадлежат
какие строки. Это классифицирующее условие часто использует дату, например
Trade_Date в нашем примере, согласно которому каждое разбиение охватывает зна-
чительный диапазон времени, например месяц или год. Если условия запроса ис-
ключают некоторые разбиения, запрос может вовсе не обращаться к ним. Он мо-
жет быть выполнен, даже если эти разбиения находятся в полностью автономном
режиме. У таблиц с разбиением есть огромные преимущества в простоте управле-
ния, но за всю свою практику я ни разу не использовал их для решения исключи-
тельно проблем производительности. Я ожидаю, что они могут быть полезными
Пути доступа для одной таблицы
43
для отдельных очень больших таблиц, таких, как в примере с отслеживанием сде-
лок, в которых строки естественным образом удовлетворяют условиям разбиения,
например по дате. С точки зрения настройки SQL вы можете рассматривать таб-
лицы с разбиением как обычные большие таблицы.
Растровые индексы
Растровые индексы были созданы специально для решения особых задач органи-
зации информационных хранилищ. Главное достоинство растровых индексов за-
ключается в том, что они позволяют эффективно комбинировать несколько не очень
селективных условий, которым соответствуют различные индексы, для получе-
ния одного короткого списка строк, удовлетворяющего сразу всем условиям. Од-
нако один индекс, состоящий из нескольких столбцов, позволит совершить прак-
тически то же самое, но без недостатков, описанных в следующем абзаце, поэтому
я считаю, что растровые индексы редко оказываются полезными. Определенно,
для настройки запроса они мне никогда не требовались. Но я не очень много рабо-
тал с информационными хранилищами, поэтому вам растровые индексы вполне
могут понадобиться, если вы вплотную занимаетесь хранилищами данных.
Каждое значение растрового индекса указывает на некоторый объект, который
можно назвать списком битов со значениями «да» и «нет». Этот список, в свою
очередь, отображается на полный список строк таблицы, причем биты «да» ото-
бражаются на строки, в которых для индексированного столбца существует значе-
ние. На этих битовых строках и битовых строках других растровых индексов удоб-
но выполнять операции AND и OR, комбинируя условия для нескольких растровых
значений многих индексов. Существенным недостатком битовых строк является
дороговизна поддержки их синхронизации с часто меняющимся содержимым таб-
лиц, особенно если обновления производятся в середине таблицы. Растровые ин-
дексы хорошо работают для таблиц, содержимое которых только считывается
и очень редко меняется, но, с другой стороны, большие таблицы не разрастаются,
если не изменять их содержимое, а для небольших таблиц специальные индексы
эффективного доступа к данным не требуются. Наилучшее применение такого
индекса — это действительно информационное хранилище, для которого он и был
разработан. Например, база данных хранилища, доступная только для чтения в те-
чение дня и периодически, например по ночам или по выходным, проводящая об-
новление всех таблиц при помощи некоторой базы данных транзакций, табли-
цы в которой постоянно увеличиваются в размере.
Пути доступа для одной таблицы
Самый элементарный запрос запрашивает некоторое подмножество данных из
одной таблицы. Подобные запросы редко интересуют нас с точки зрения настрой-
ки, но даже самый сложный запрос, соединяющий множество таблиц, начинает с
одной ведущей таблицы. Вам необходимо выбрать путь доступа к ведущей табли-
це в многотабличном запросе так же, как для однотабличного запроса. Однотаб-
личный запрос всегда можно получить, разобрав многотабличный запрос на со-
ставляющие, удалив соединения, не ведущие в искомую таблицу, и условия для
44
2. Основы доступа к данным
них. Таким образом, каждая задача оптимизации запроса включает выбор опти-
мального однотабличного пути доступа к ведущей таблице. Реализации таблиц
и методов доступа к таблицам слегка различаются у разных поставщиков баз дан-
ных. Чтобы быть как можно более точным и конкретным, в этом разделе я буду
рассматривать доступ к таблицам в Oracle, поскольку различия между Oracle и про-
чими марками баз данных несущественны для настройки SQL.
Полное сканирование таблицы
Основной путь доступа к таблице — это полное сканирование таблицы, то есть чте-
ние таблицы полностью без использования индекса. На рис. 2.4 иллюстрируется
этот метод в приложении к типичной таблице в Oracle.
Рис. 2.4. Полное сканирование таблицы
Так как будет считана вся таблица, Oracle понимает, что следует выполнять
операции физического ввода-вывода частями, размер которых больше, чем блок —
в этом случае считываться будет по 64 Кбайт за раз. В результате выполняется
меньшее количество объемных физических считываний, что занимает меньше вре-
мени, чем множество небольших физических считываний тех же блоков. Не все
поставщики баз данных следуют этому методу, однако выясняется, что этим они
достигают немногого, так как дисковые подсистемы и операционные системы обыч-
но считывают сегменты большого размера, даже если база данных запрашивает
один блок. База данных может выдать много запросов на считывание небольших
объемов данных, но они преобразуются на низших системных уровнях в несколь-
ко запросов объемных операций считывания, а требование небольших запросов
удовлетворяется за счет кэша дисковой подсистемы. Данные считываются с пер-
вого блока до отметки заполнения, включая все встречающиеся пустые блоки.
В случае, когда каждый из набора 64-килобайтовых блоков уже находится в кэше,
кэширование позволяет базе данных избежать операции физического считывания
нескольких блоков. База данных считывает блоки небольших и средних по разме-
ру таблиц в кэш обычным образом, и они удаляются оттуда через несколько ми-
нут, если никакой другой запрос не обратится к ним. Кэширование небольших и
средних таблиц целиком часто бывает полезным, и такие таблицы остаются в кэше
надолго, если базе данных приходится часто сканировать их полностью.
Пути доступа для одной таблицы
45
Однако большие таблицы представляют собой опасность для стратегии кэши-
рования: редко бывает так, что в большой таблице происходят частые обращения
к блоку среднего размера. Если база данных последует обычной стратегии кэши-
рования, сканирование большой таблицы может удалить из кэша большинство не-
обходимых блоков (из индексов и других таблиц), что вызовет падение произво-
дительности большого количества прочих запросов. К счастью, обычно это не
представляет проблемы, так как блоки, полученные при полном сканировании
большой таблицы, отправляются в хвост кэша, где остаются ровно столько време-
ни, сколько необходимо, чтобы завершился текущий запрос, а затем их заменяет
следующая группа блоков, возвращенная тем же сканированием. (Такое поведе-
ние при полном сканировании больших таблиц — это одно из исключений техни-
ки кэширования LRU, которую я описывал ранее.)
Индексный доступ к таблицам
Самые важные затраты при полном сканировании таблицы приходятся на процес-
сор: это стоимость изучения каждого блока под отметкой заполнения и стоимость
изучения каждой строки в этих блоках.
Если только вы не считываете крохотную таблицу (а в этом случае любой ме-
тод доступа работает идеально) или большой фрагмент более объемной таблицы,
следует убедиться, что ваши запросы обращаются к требуемым строкам при помо-
щи индекса. На рис. 2.5 иллюстрируется индексный метод доступа к таблице.
Идентификатор
строки
Рис. 2.5. Индексный доступ к таблице
Сервер начинает поиск с некоторого индексированного значения, определяю-
щего начало диапазона тех индексированных значений, которые отвечают крите-
рию запроса. Начиная с корневого блока, сервер отыскивает диапазоны и поддиа-
пазоны, которые, если следовать вниз по дереву индекса, приводят к листовому
блоку или блокам, где хранятся индексированные значения, удовлетворяющие
критерию запроса. Сервер находит идентификаторы строк, соответствующие этим
значениям, и с их помощью переходит к определенным блокам таблицы и строкам
в этих блоках.
46
2. Основы доступа к данным
Давайте сравним методы индексного доступа и полного сканирования табли-
цы на определенном примере. На рис. 2.6 показаны два пути, ведущие к пяти стро-
кам, обозначенным черным цветом, в таблице, состоящей из 40 блоков. Обычно
в таких таблицах содержится приблизительно 3 200 строк.
Рис. 2.6. Индексный доступ и полное сканирование таблицы
Таблица в этом примере слишком мала, чтобы в ее индексе было более двух
уровней, поэтому сервер баз данных при поиске следует из корневого блока ин-
декса прямо в листовой блок. В этом листовом блоке хранится начало диапазона
из 5 строк, требуемого в запросе. Средний уровень, которого нет в индексах для
таблиц среднего размера, обозначен серым цветом. Сервер баз данных, вероятно,
найдет все пять записей индекса в одном листовом блоке, однако если нужный
диапазон начался близко к границе первого блока, может потребоваться прыжок
к следующему листовому блоку. Вооружившись пятью идентификаторами строк,
база данных переходит к блокам таблицы, в которых хранятся требуемые строки.
В нашем примере база данных выполняет две последовательные операции логи-
ческого ввода-вывода на одном блоке таблицы, так как строки оказались рядом, но
вторая операция логического ввода-вывода будет точно кэширована. (Этот при-
мер иллюстрирует преимущества, которые дает расположение интересующих нас
строк рядом в физической таблице.)
В случае полного сканирования таблицы, если до его начала блоки таблицы
еще не находятся в кэше, база данных выполняет пять считываний фрагментов
данных размером по 64 Кбайт, то есть считывает всю таблицу до отметки заполне-
ния. Затем сервер баз данных проходит через все 40 блоков и 3 200 строк, отметая
все, кроме пяти строк, удовлетворяющих условию запроса. Если у базы данных
нет кэша и вы заботитесь только о времени, которое занимает перемещение считы-
вающих головок диска при выполнении физического ввода-вывода, то вы насчи-
таете семь операций физического ввода-вывода для случая индексированного
доступа и пять операций для полного сканирования таблицы, и, следовательно,
выберете полное сканирование. Однако небольшая таблица и небольшой индекс,
как в этом случае, скорее всего, полностью кэшированы. Семь операций логиче-
ского ввода-вывода дешевле, чем 40 операций логического ввода-вывода, даже если
Пути доступа для одной таблицы
47
они нужны для полного сканирования таблицы. Кроме затрат на логический ввод-
вывод, индексированный план выполнения избегает затрат на работу процессора,
которая выполняется при просмотре более чем 3 000 ненужных строк.
Можно предположить, что оба плана будут выполняться достаточно быстро
и различия между ними не будут играть роли1, так как эффективность в не-
больших таблицах не настолько важна при однотабличном считывании. При
расширении этого примера до таблиц большого объема, вопросы станут намного
интереснее — придется считаться с проблемами, возникающими при смешении фи-
зического и логического ввода-вывода с трудностями уменьшения большого вре-
мени исполнения.
Выбор между полным сканированием таблицы
и индексным доступом
Поверхностный анализ зачастую заставляет сделать выбор в пользу полного ска-
нирования таблицы. Однако более тщательное рассмотрение потребует учесть не-
сколько соображений, которые могут сделать индексное считывание более при-
влекательным, чем может показаться с первого взгляда.
Индексные считывания практически всегда кэшируются.
Блоки таблицы, полученные при помощи индекса, обычно горячее и с большей
вероятностью будут кэшироваться, так как индексные считывания затрагива-
ют строки, которые вам (или другим пользователям) действительно нужны,
тогда как при полном сканировании все строки обрабатываются одинаково.
У одного блока вероятность попасть в кэш больше, чем у группы из нескольких
блоков, поэтому эффективный коэффициент попадания в кэш для таблицы
лучше при индексном считывании. Например, если в кэше находится половина
блоков таблицы, выбранная случайным образом, то коэффициент попадания в
кэш при чтении одного блока из этой таблицы равен 50 %, а вероятность на-
хождения в кэше всех восьми блоков при считывании нескольких блоков равна
всего лишь 0,58, то есть приблизительно 0,4 %. Чтобы достигнуть эффективно-
го коэффициента попадания в кэш не менее 50 % для считывания восьми бло-
ков, необходимо достигнуть коэффициента попадания в кэш, равного 91,7 %,
для отдельных блоков, кэшированных случайным образом.
На самом деле дисковые подсистемы обычно выполняют считывания отдель-
ных блоков как считывания нескольких блоков, преобразуя соседние операции
считывания отдельных блоков в операции виртуального ввода-вывода. Поэто-
му преимущество считывания нескольких блоков для полного сканирования
таблицы на самом деле оказывается меньше ожидаемого.
При индексном считывании изучается только небольшая часть каждого бло-
ка — строки, удовлетворяющие запросу. Эта операция производится вместо счи-
тывания всех строк в блоке, что экономит время процессора.
1 Я не пытаюсь зря потратить ваше время на незначительный пример. Различия будут иметь значение,
если расширить этот пример до весьма объемных таблиц и индексов, но такой пример невозможно
проиллюстрировать так же подробно, как на рис. 2.6. При помощи этого небольшого примера я зна-
комлю вас с общими принципами.
48
2. Основы доступа к данным
Обычно индексное считывание ведет себя лучше при увеличении таблицы, обес-
печивая стабильную производительность, тогда как полное сканирование таб-
лицы при увеличении ее размера выполняется все хуже и хуже, даже если на
таблице небольшого размера оно немного выигрывало.
Выбор индексного доступа или полного сканирования таблицы зависит от фраг-
мента таблицы, который будет считан однотабличным запросом. Оптимизатор базы
данных может сделать этот выбор за вас, но нет никакой гарантии, что этот выбор
всегда будет сделан правильно. Если SQL-запрос выполняется слишком медленно
и требует настройки, вам необходимо решить этот вопрос самостоятельно. Далее
перечислены основные диапазоны размеров сканируемых фрагментов таблиц, ко-
торые помогут выбрать соответствующую стратегию.
>20 % строк
Полное сканирование таблицы.
<0,5 % строк
Индексный доступ.
0,5%-20%
Необходимо рассмотреть дополнительные условия.
Если количество строк в необходимом фрагменте таблицы составляет от 0,5 %
до 20 % ее объема, то выбор стратегии затрудняется. Дополнительные условия
должны быть какими-то особенными, чтобы способствовать выбору индекса в слу-
чае, близком к 20 %. Также не следует выбирать полное сканирование таблицы,
если объем фрагмента ближе к 0,5 %, если нет условий, диктующих выбор именно
этой стратегии. Далее перечислены несколько факторов, относящихся к опреде-
ленным запросам, которые должны заставить вас выбрать индексный доступ для
фрагментов, чей объем приближается к 20 % от всего объема таблицы.
Таблица хорошо кластеризована по индексированному столбцу, что приводит
к самокэшированию в этом диапазоне. Несколько операций логического вво-
да-вывода будет выполнено на одних и тех же блоках, и последующие считыва-
ния этих блоков будут, вероятнее всего, происходить в кэше после того, как
первые операции поместят блоки туда.
Запрос обращается к строкам, которые достаточно горячи, обеспечивая лучшее
кэширование в индексированном диапазоне, чем будет выполнено при полном
сканировании таблицы.
Запрос считывает только одно значение, обращаясь к строкам по порядку в за-
висимости от их идентификаторов. Если у вас есть условия точного равенства
по полностью индексированному ключу, то, считывая идентификаторы строк
для этого единственного ключевого значения, сканирование индекса возвра-
щает их в отсортированном порядке. Если сервер баз данных требует физиче-
ского ввода-вывода, то в этом случае доступ выполняется практически анало-
гично полному сканированию таблицы, когда считывающая головка плавно
движется от начала до конца диапазона. Поскольку расположенные рядом стро-
ки считываются последовательно, чаще всего самокэширование успешно про-
исходит как в кэше сервера, так и в кэше дисковой подсистемы ввода-вывода,
которая выполняет опережающее считывание.
Пути доступа для одной таблицы
49
С другой стороны, если выполняется доступ к диапазону значений, например,
Reti rement_Date BETWEEN '2002/01/01‘ and '2003/01/01', то вы обнаружите целую
последовательность отсортированных списков идентификаторов строк для каж-
дой даты из диапазона. Движение считывающей головки диска будет менее
упорядоченным и, следовательно, менее эффективным. Самокэширование
в этом случае может вовсе не произойти, если время выполнения запроса пре-
вышает срок жизни блоков в кэше. Даже если вы введете условие равенства, то,
возможно, получите именно этот менее эффективный вариант в случае, когда
индекс состоит из нескольких столбцов. Например, Last_Name“' Smi th' — это в дей-
ствительности условие на диапазон для индекса (Last_Name. Fl rst_Name), так как
существует множество пар с различными значениями, удовлетворяющих это-
му условию для одного столбца.
Точные формулы, описывающие компромисс между производительностью пол-
ного сканирования таблицы и производительностью сканирования диапазона,
сложны и не очень полезны, так как вы сможете только попытаться определить
наугад необходимые входные данные (например, относительные коэффициенты
успешного попадания в кэш для блоков, к которым было произведено обращение
при сканировании диапазона и остальных блоков таблицы). Я понимаю, что все
это звучит излишне сложно и с этим неудобным диапазоном от 0,5 до 20 % трудно
работать, но на практике проблема обработки среднего диапазона становится не-
сложной.
Если таблица достаточно большая, и разница между полным сканированием
таблицы и индексным доступом к ней будет весьма существенна, лучше вы-
брать более жесткое условие и использовать индекс, В противном случае мо-
жет быть возвращено строк больше, чем требуется. Позже я подробно опишу,
почему несколько хорошо спроектированных запросов обязательно возвраща-
ют существенную часть (до 1 %) большой таблицы. Реальные приложения су-
ществуют в основном для того, чтобы предоставить конечным пользователям
удобный доступ к данным. Когда пользователи работают с данными в опера-
тивном режиме, им становится неудобно обрабатывать большие объемы дан-
ных. Они терпимо относятся к большим объемам данных в отчетах, но и отчет,
предоставляющий больше информации, чем пользователь может усвоить, яв-
ляется плохо проработанным. В Главе 10 мы подробно обсудим способы улуч-
шения запросов, возвращающих слишком много строк.
Если вы сомневаетесь, использовать ли полное сканирование таблицы или ин-
дексный доступ к ней, просто измерьте, сколько времени требует каждый из
вариантов. Метод проб и ошибок прекрасно работает, если на выбор у вас лишь
пара вариантов. Однако помните, что вариант, который вы протестируете пер-
вым, будет в невыгодном положении, если второй будет протестирован сразу
же после первого — второй вариант воспользуется блоками, кэшированными
во время проверки первого. Обычно я проверяю каждый из вариантов дважды,
с минимальным разрывом во времени, и учитываю второе время выполнения,
поскольку во второй раз кэширование было идеальным. Если время для обоих
вариантов различается несущественно, я повторяю эксперименты с разрывом
во времени 10 минут и более, чтобы измерить более реалистичные затраты на
физический ввод-вывод, и повторяю первый эксперимент через 10 минут пос-
ле второго, изучая его воспроизводимость.
50
2. Основы доступа к данным
Не гонитесь за небольшими улучшениями. Если производительность двух
вариантов практически одинакова, остановитесь на уже имеющемся плане
выполнения. Изменение одного оператора в целях улучшения производительно-
сти на несколько процентов не стоит затраченных усилий. При настройке сле-
дует добиваться улучшения времени выполнения в два и более раз. Такое улуч-
шение можно произвести на удивление часто, когда производительность запроса
настолько низка, что небольшие улучшения приводят к очень хорошему резуль-
тату.
Вычисление селективности
При настройке запросов лучше всего представлять себе однотабличные условия
как фильтры. Эти фильтры пропускают строки таблицы, которые требуются при-
ложению (то есть удовлетворяют условиям), одновременно отбрасывая ненужные
строки (не удовлетворяющие условиям). У приложения есть свои функциональ-
ные причины, по которым оно исключает ненужные строки из таблицы, но с точки
зрения производительности работа фильтра заключается в экономии усилий и
времени сервера баз данных. Смысл настройки заключается в том, чтобы избежать
любой работы со строками, с самого начала предназначенными на выброс.
В селективности заключается мощь фильтра как инструмента исключения
строк, выраженная в размере фрагмента таблицы, который фильтр пропускает даль-
ше. База данных может применять фильтры на трех этапах с переменным успехом
в деле минимизации стоимости запроса.
Определение условия для индексного диапазона.
Условия, которые определяют границы сканируемого диапазона индекса, не тре-
буют никакой работы на ненужных строках.
Указание строк таблицы, полученных из индекса.
Иногда условия не определяют границы индексного диапазона, но, тем не ме-
нее, их можно оценить в индексе до осуществления доступа к таблице. Эти усло-
вия требуют обращения к строкам, которые в конечном итоге исключаются из
результирующего набора, но происходит это в индексе, а не в таблице.
Указание строк, возвращенных после доступа к таблице.
Если условие требует получения столбцов, содержащихся в таблице, но не в ин-
дексе, сервер баз данных не может применить условие до тех пор, пока не счи-
тает строки таблицы. Фильтры, которые применяются к таблице, не имеют ни-
какого значения с точки зрения сокращения стоимости обращения к строкам
таблицы. Однако они сокращают себестоимость, так как исключенные строки
возвращать не требуется. Если фильтруемая таблица — не последняя и не един-
ственная, к которой идет обращение, любой фильтр также сокращает стоимость
соединений с другими таблицами позднее в плане выполнения.
Селективность фильтра
В этом разделе я расскажу, как подсчитать селективность условий, накладывае-
мых на таблицу. Начнем с нескольких определений:
Вычисление селективности
51
Селективность фильтра с единственным условием. Доля строк таблицы, удов-
летворяющая единственному условию на эту таблицу.
Селективность фильтра с несколькими условиями. Доля строк таблицы, удов-
летворяющая комбинации условий, которые относятся только к этой таблице.
Независимость фильтров. Предположение, обычно верное, что селективность
нескольких условий можно вычислять просто как произведение долей, характери-
зующих селективности с единственным условием. Например, условие на имя че-
ловека и условие на почтовый индекс человека логически независимы. Можно
предположить, что доля строк, в которых содержатся подходящие имя и почтовый
индекс, будет приблизительна равна произведению доли строк с подходящим име-
нем и доли строк с подходящим индексом. Например, если 1/100 строк содержит
желаемое имя и 1/500 строк — желаемый почтовый индекс, то селективность филь-
тра с несколькими условиями будет равна 1/100 х 1/500 = 1/50 000.
Избыточность фильтров. Противоположность к независимости фильтров. Ис-
тинность одного условия гарантирует истинность другого. Например, условие на
почтовый индекс с большой вероятностью гарантирует получение единственного
значения телефонного кода области, поэтому селективность обоих условий будет
не лучше селективности условия на почтовый индекс. Всегда можно проверить
избыточность полного или частичного фильтра, подсчитав селективность фильт-
ра с несколькими условиями с предположением независимости фильтров и по-
смотрев, равно ли это значение действительной селективности комбинации этих
условий.
Настраивая запрос и оценивая селективность фильтра, начните с вопроса, яв-
ляется ли запрос одиночным или же он представляет целую группу запросов. Во
втором случае задайтесь вопросом о распределении значений внутри группы. На-
пример, рассмотрим запрос1:
SELECT ... FROM Orders WHERE Unpa1d_Flag=’Y’;
Мы надеемся, что у этого запроса высокая селективность, так как условие бу-
дет выполняться для небольшой доли полной истории заказов. Если вы рассчиты-
ваете, что при выполнении запроса для Unpai d_Fl ад значения ' Y' будут найдены, то,
возможно, захотите индексировать этот столбец. Если же этот запрос является ча-
стью группы, которая так же часто выполняет поиск с не очень селективным усло-
вием Unpaid_Flag=’N', то лучше будет избежать индексирования. В этом примере
значение поля имеет особый смысл в запросе, оно управляет назначением запроса
в целом (найти счета, требующие отправки), поэтому вы можете рассчитывать на
то, что найдете в основном запросы по ' Y', которое является редким значением.
ПРИМЕЧАНИЕ-------------------------------------------------------------------
Да, раньше я обещал, что вам не нужно будет понимать приложение для настройки его SQL. Вы все-
гда сможете обратиться к разработчикам, если SQL приложения будет постоянно указывать на ред-
кое индексированное значение. Однако вы будете удивлены, когда поймете, насколько много вы
можете узнать о приложении, лишь немного подумав, что же составляет его смысл, и зная имена
таблиц и столбцов.
Обратите внимание, что в примерах список в операторе SELECT я обычно заменяю троеточием.
Оказывается, список выбираемых вами столбцов и выражений не имеет особого влияния на произ-
водительность запроса, которая в основном зависит от списка таблиц во фразе FROM и условий во
фразе WHERE.
52
2. Основы доступа к данным
Чтобы подсчитать селективность условия Unpaid_Flag-’Y', начните с выполне-
ния следующих двух запросов:
SELECT COUNT!*) FROM Orders WHERE Unpaid Flag-’Y’:
SELECT COUNT!*) FROM Orders:
Селективность условия равна результату первого оператора, поделенному на
результат второго.
Теперь рассмотрим запрос
SELECT ... FROM Order_Details WHERE OrderJD-:1d;
Конечные пользователи будут запрашивать детальную информацию о заказах,
разбросанных в таблице случайным образом. Это можно предположить даже с уче-
том того, что приложение заменяет параметр :id фактическим значением — ведь
приложению нет смысла всегда обращаться к одному и тому же заказу. Запрос по
любому идентификатору не может существовать сам по себе, он представляет це-
лое семейство запросов, которое следует рассматривать и настраивать как единое
целое. Конечные пользователи с одинаковой вероятностью могут обратиться к лю-
бому заказу, поэтому вычислять селективность фильтра следует так:
SELECT 1 / COUNT!DISTINCT OrderJD) FROM OrderJ)etai 1 s;
Чуть более сложный случай возникает, когда конечный пользователь может
обращаться к любому значению, но в действительности чаще обращается к каким-
то более популярным значениям, чем к другим, менее востребованным. Например,
если операторы ищут определенного покупателя путем выборки всех покупателей
с искомой фамилией, то они чаще будут задавать поиск по распространенным фа-
милиям, чем по редким, используя, например, такой запрос:
SELECT ... FROM Customers WHERE Last_Name - 'SMITH';
Если вы здесь подсчитаете различные имена так же, как ранее подсчитывались
идентификаторы запросов, то получите сверхоптимистичную селективность, ко-
торая предполагает, что вероятность поиска по LastJIame-’KMETEC такая же, как и
по LastJVame-1 SMITH'. Для каждой фамилии селективность равна n(i) / С, где nd) —
количество строк с i-й отличной от нуля фамилией, а С — общее количество строк
в таблице. Если бы вероятность выбора любой фамилии была одинакова, то мож-
но было бы просто подсчитать среднее n( 1) / С по всем фамилиям. Это среднее
значение было бы одинаково для всех различных фамилий. Однако вероятность
поиска фамилии в нашем сценарии равна nd) / С, где С — количество строк с
фамилиями, не равными null. Следовательно, нам требуется сумма селективно-
стей, умноженных на вероятность появления каждой селективности, то есть сум-
ма (п(1) / С) ? (п(1) / С) по всем фамилиям. Так как С — это также сумма
отдельных значений nd), можно подсчитать селективность фильтра на SQL сле-
дующим образом:
SELECT SUM(COUNT(LastName)*COUNT!Last Name))/
(SUM( COUNT! LastJiame) )*SUM(COUNT!*)))
FROM Customers GROUP BY Last_Name:
Селективность условия на диапазоне индекса
Селективность условия на диапазоне индекса — это доля строк таблицы, которую
база данных изучает в индексе во время его сканирования. Для каждого сканиро-
вания диапазона индекса должно существовать две крайних точки — точка начала
Вычисление селективности
53
и точка конца диапазона. Значением этих конечных точек может быть плюс или
минус бесконечность, что означает, что диапазон может быть не ограничен на лю-
бом из концов, хотя обычно не на обоих. Диапазон может исключать любую или
обе конечных точки в зависимости от природы граничного условия. Например,
условие на диапазон (Sal агу > 4000 AND Sal ary < 8000) исключает обе конечных точки
граничными условиями неравенства.
Существуют распространенные проблемы, не позволяющие базе данных найти
конкретные значения для начала и конца диапазона сканирования и эффективно
использовать индекс даже при очень селективном условии для индексированного
столбца. Очень тяжело и зачастую невозможно (в зависимости от функции) пре-
образовать условие для Некоторая_функция (Некоторый_столбец) в условие для одного
поля по простому индексу с ведущим столбцом Некоторый_столбеи. Обычно база дан-
ных даже не пытается сделать это.
ПРИМЕЧАНИЕ -------------------------------------------------------------------
Индексы, базирующиеся на функциях, которые поддерживает Oracle, — основное исключение из этого
правила. Они позволяют отдельно индексировать результат применения к столбцам таблицы некото-
рого выражения (например, UPPER(Last Name)), чтобы использовать индексированный доступ к ус-
ловиям по этому выражению, например, UPPER(Last_Name) LIKE 'SMITH?»'.
Таким образом, выражения, которые делают что-то большее, чем просто назы-
вают столбец, обычно не позволяют использовать индексированный доступ к диа-
пазонам, определенным для этого столбца, что зачастую делает создание индексов
для запросов, где используются такие выражения, бесполезным. Это палка о двух
концах: вам приходится переписывать некоторые запросы, чтобы использовать
желаемый индекс; но это и полезный инструмент, позволяющий переписать дру-
гие запросы, чтобы в базе данных не использовались ненужные индексы.
Простой пример функции, делающей невозможным использование индек-
са, — сравнение выражений различных типов, для которого база данных неяв-
но применяет функцию преобразования типов. Например, несовместимое по
типу условие CharacterColumn = 94303 на самом деле превращается в Oracle
в TO_NUMBER(CharacterColumn) = 94303. Чтобы разрешить эту проблему и использо-
вать индекс по символьному столбцу, выполните преобразование явно. Например:
Таблица 2.1. Соответствия преобразования
Исходное выражение Чем заменить
CharacterColumn=94303 CharacterColumn='94303'
CharacterColumn=TRUNC(SYSDATE) CharacterColumn=TO_CHAR(SYSDATE,’DD-MON-YYYY’)
ПРИМЕЧАНИЕ-------------------------------------------------------------------
При сравнении в Oracle символьного выражения со значением любого другого типа символьное выра-
жение неявно преобразуется в выражение другого типа, если только вы явно не преобразуете второе
значение. Это несколько необычно, так как числа и даты всегда можно безошибочно преобразовать
в строки символов, а символьные строки часто преобразуются в числа и даты с ошибками.
Даже при сравнении чисел преобразование типов может привести к трудно-
стям, если производитель базы данных поддерживает различные числовые типы,
например, целые и десятичные. Преобразование типов также препятствует эффек-
54
2. Основы доступа к данным
тивному индексированному соединению, если при этом внешний ключ одного типа
указывает на первичный ключ другого типа.
ВНИМАНИЕ ------------------------------------------------------------------
Чтобы избежать проблем с неявным преобразованием типов, мешающим применению индексов, ваша
база данных всегда должна использовать внешние ключи того же типа, что и первичные ключи, на ко-
торые они указывают.
При вычислении размера диапазона сканирования индекса можно применять
несколько правил.
Условия на ведущий столбец рассматриваемого индекса подходят для выясне-
ния начальной или конечной точки диапазона. Условия на остальные столбцы
того же индекса не подходят для выяснения начальной или конечной точки
диапазона, если только у вас нет точных условий равенства для всех упомяну-
тых столбцов этого индекса. Например, индекс по (Date_Column, 10 МигпЬег),если
применить его для условия Date_Colurnn >= T0_DATE('2003/01/0Г . 'YYYY/MM/DD'),
позволяет узнать диапазон сканирования, полностью определенный условием
даты. Дальнейшие условия на второй столбец, например, ID_Nurnber=137, не су-
жают диапазон сканирования. Чтобы сузить диапазон, основываясь на втором
условии, вам необходимо просмотреть длинный список диапазонов, по одному
для каждого возможного значения Date Col umn, удовлетворяющего первому ус-
ловию, но серверы баз данных не делают этого. Однако если вы поменяете мес-
тами столбцы в индексе, получив (ID_Number, Date_Column), то эти же два усло-
вия совместно определят крайние точки диапазона, и сканирование полученного
небольшого диапазона индекса будет выполнено быстрее.
ВНИМАНИЕ ---------------------------------------------------------------------
Так как условия запросов для дат (и, более того, для дат и времени, то есть дат, включающих временной
компонен т) обычно не являются условиями равенства, в многостолбцовых индексах ведущим не дол-
жен быть столбец с типом данных, относящимся к дате.
Сервер баз данных обычно решает, что Indexed Col IS NULL определяет слишком
большой диапазон значений, чтобы он мог быть полезным, и поэтому игнори-
рует такие условия при установлении конечных точек диапазона.
ПРИМЕЧАНИЕ-----------------------------------------------------------------
DB2 представляет собой исключение из этого правила. Oracle нс хранит ссылки на строки, в которых
для всех столбцов индекса присутствуют только значения null. Однако DB2 поддерживает такие ссыл-
ки и рассматривает значения null точно так же, как любые другие значения, с той же вероятностью
появления. Поэтому DB2 в состоянии работать с планом выполнения, использующим условие «равен
null», так как значения null, если они разрешены, встречаются намного чаще, чем отдельные ненулевые
значения.
База данных предполагает, что условие Indexed Col IS NOT NULL покрывает слиш-
ком большой диапазон данных, чтобы он был полезным, поэтому она не будет
использовать индекс для этого условия. В редких случаях присутствие любого
ненулевого значения настолько маловероятно, что предпочтительней становит-
ся сканирование диапазона индекса по всем возможным ненулевым значени-
ям. В таких случаях, если вы можете определить безопасную нижнюю или верх-
Вычисление селективности
55
нюю границу диапазона всех возможных значений, то сможете использовать
сканирование диапазона с условием, например, Positi ve_ID_Column > -1 or
Date_Column > TO_DATE( ’0001/01/0Г. 'YYYY/MM/DD’).
Условие Indexed Char Col LIKE 'АЮ' устанавливает начальную и конечную точки
допустимого диапазона для индекса, причем Indexed_Char_Col является ведущим
столбцом индекса. Схожим образом работает блок сравнения шаблонов в SQL,
где % является символом подстановки.
Условие lndexed_Char_Col LIKE 'ABCffiEF’ также задает начальную и конечную точки
допустимого диапазона, но в этом случае только часть 'АВСГ сужает диапазон
сканирования индекса.
Условие I ndexed_Number_Col umn LIKE' 123Я' не устанавливает начальную и конеч-
ную точки допустимого диапазона, так как сравнение LIKE имеет смысл толь-
ко для строк символов. В этом случае серверу для проверки условия необходи-
мо неявно преобразовать Indexed_Number_Column в строку символов, делая
невозможным применение любого индекса, для которого ведущим является
столбец I ndexed_Number_Co 1 umn. В терминах чисел это условие задает целую группу
диапазонов:
(Indexed_Number_Column >= 123 AND Indexed_Number_Column < 124) OR
(Indexed_Number_Column >= 1230 AND Indexed_Number_Column < 1240) OR
(Indexed_Number_Column >= 12300 AND Indexed_Number_Column < 12400) OR...
Условие Indexed_Char_Col LIKE ' &AEO' вообще не задает начальную и конечную
точки допустимого диапазона, так как стартовый символ подстановки указы-
вает, что этот шаблон может появиться в любом месте индекса.
Равенство (=), BETWEEN и большинство неравенств (<, <=, >, >=) для первых столб-
цов индексов устанавливают допустимые конечные точки диапазона индекса.
Неравенство вида «не равно», которое обычно выражается как 1= или <>, не
устанавливает диапазон индекса, так как база данных не считает такое условие
достаточно селективным, чтобы использовать для него индексный доступ. Если
исключенное значение покрывает практически все строки, а другие значения
встречаются редко, можно включить индексный доступ, заменив условие
Col umn !=' Domi nantValue' на Col umn IN (<список остальных, редко встречающихся зна-
чений^, хотя с изменением приложения с течением времени такой подход мо-
жет стать неудобным.
Использование групп условий, объединенных при помощи OR или в списке IN,
может привести к выполнению последовательности операций сканирования
диапазонов, но только если каждое из этих условий указывает на допустимый
диапазон. Например, IDColumn IN (123.124.125) преобразуется в три допустимых
условия равенства, для которых выполняется сканирование трех диапазонов.
Условие (Name= ’ Smj th' OR Name=' Jones ’) приводит к сканированию двух диапазо-
нов, однако (Name= ’ Smi th ’ OR Name' IS NULL) не разрешает использовать индекс (кроме
DB2), так как IS NULL не указывает на допустимый диапазон.
Если у вас есть условия, не определяющие ограниченный диапазон, по крайней
мере, по первому столбцу индекса, то единственный способ использовать индекс —
выполнить полное сканирование индекса, то есть сканирование всех записей ин-
декса во всех листовых блоках. Базы данных чаще всего не выбирают полное ска-
56
2. Основы доступа к данным
нирование индекса, так как оно достаточно дорого с точки зрения расходования
ресурсов и требует обращения к большой части таблицы. Поэтому себестоимость
полного сканирования индекса превосходит затраты на полное сканирование таб-
лицы. Вы можете выполнить полное сканирование таблицы принудительно (зача-
стую не подозревая об этом), добавив в запрос указание (подробнее об указаниях
мы поговорим позже) базе данных использовать индекс, даже если самостоятель-
но она бы решила индекс не применять. Чаще всего добавление указания является
ошибкой, безнадежной попыткой добиться чего-то лучшего, чем полное сканиро-
вание таблицы. Обычно это происходит, когда разработчик переоценивает индекс,
что приводит к получению худшего плана выполнения, чем тот план, который база
данных выбрала бы без посторонней помощи.
Даже в случаях, когда полное сканирование индекса лучше, чем полное скани-
рование таблицы, оно практически всегда хуже, чем третий вариант — использо-
вание другого, зачастую нового индекса или изменение условия для функции, что-
бы сузить диапазон сканирования.
Селективность для строк таблицы,
полученных при помощи индекса
Так как индексы — это компактные и обычно хорошо кэшированные объекты по
сравнению с таблицами, селективность сканирования диапазона индекса значит
меньше, чем эффективный доступ к таблице. Даже когда индекс и таблица идеаль-
но кэшированы, селективность для таблицы важнее, чем для индекса, так как вы
считываете около 300 строк индекса в листовом блоке одной операцией логиче-
ского ввода-вывода, но должны выполнять отдельную операцию логического вво-
да-вывода для каждой строки таблицы. Так мы приходим ко второй части оценки
полезности индекса: насколько сильно индекс может сузить доступ к таблице?
К счастью, производители баз данных достаточно умны, чтобы проверить все ус-
ловия как можно раньше в плане выполнения, еще до обращения к таблице, где это
позволяет сделать индекс. Это сокращает количество считываний данных из таб-
лицы, когда индекс содержит столбцы, необходимые для оценки условия, — даже
если база данных не может при помощи этого условия определить конечные точки
диапазона сканирования. Например, рассмотрим таблицу Persons с одним индек-
сом, включающим столбцы Area_Code. Phone_Number, Last_Name и Fi rst_Name. Возьмем
запрос к этой таблице с условиями:
WHERE Area_Code=916 AND UPPER(F1rst_Name)='IVA'
Только первое условие позволяет определить конечные точки диапазона ска-
нирования индекса. Второе условие, по четвертому индексированному столбцу,
не может сузить диапазон по трем причинам.
Для второго столбца индекса, Phone_Number, не указано условий равенства (по
большому счету, для него вообще нет условий).
Для третьего столбца индекса, Last Name, также не указаны условия равенства.
Условие для Flrst Name не в состоянии ограничить диапазон из-за функции
UPPER.
К счастью, ни одна из этих причин не запрещает базе данных проверить второе
условие до обращения к таблице. Так как в индексе есть столбец First Name, база
Вычисление селективности
57
данных может проверить условия для этого столбца при помощи данных из ин-
декса. В этом случае база данных использует условие Area_Code для определения
диапазона сканирования индекса. Затем она просматривает все записи индекса в
диапазоне и отметает записи, в которых имена не равны Iva. Вероятный результат
по этой селективной комбинации условий — одно или два считывания из табли-
цы.
Давайте изучим эту ситуацию подробнее и решим, стоит ли создавать для этой
комбинации условий лучший индекс. Как для Area_Code, так и для F1rst_Name мы
увидим несимметричное распределение. Чаще всего будут запрашиваться наибо-
лее распространенные коды областей и имена, поэтому используем стандартный
подход к несимметричным распределениям и найдем отдельные значения селек-
тивности:
SELECT SUM(COUNT(Area_Code)*COUNT(Area_Code))/
(SUM(COUNT(Area_Code))*SUM(COUNT!*)))
FROM Customers GROUP BY Area_Code:
SELECT SUM(COUNT(First_Name)*COUNT(F1rst_Name))/
(SUM(COUNT(F1rst_Name))*SUM(COUNT!*)))
FROM Customers GROUP BY First_Name:
Предположим, что при первом вычислении мы получим селективность, рав-
ную 0,0086, а при втором — 0,018. Далее предположим, что в нашей таблице
1 000 000 строк, а индекс указывает на 200 строк в каждом листовом блоке (мень-
ше, чем обычно, так как у нас необычно широкий ключ индекса). Условие на
Area_Code определяет количество сканируемых блоков индекса, поэтому сначала
найдем количество строк, на которые указывает условие. Наша формула выглядит
как 0,0086 х 1 000 000 = 8 600, то есть база данных сканирует 43 (8 600/20) листо-
вых блока. В запросах к одной таблице всегда можно пренебречь считыванием кор-
невого блока и средних блоков. Вероятнее всего, эти 43 листовых блока хорошо
кэшированы и для их считывания требуется около миллисекунды.
ПРИМЕЧАНИЕ------------------------------------------------------------------------------
Базы данных способны выполнять приблизительно 60 000 операций логического ввода-вывода на
обычных процессорах. Однако ваши оценки производительности могут заметно отличаться. В этой
книге я указываю такие числа, как 300 строк индекса в листовом блоке и 60 000 операций логическо-
го ввода-вывода, так как они достаточно точны и удобны для интуитивного понимания приоритетов
настройки. Среди множества производителей процессоров и серверов баз данных с разнообразными
размерами блоков и столбцов эти числа могут легко измениться в четыре раза и даже более, а произ-
водительность, без сомнения, существенно возрастет через какое-то время после выхода этой книги.
Интуитивное понимание и знание по крайней мере порядка изменения этих чисел все же помогут
вам, и, я надеюсь, вы считаете запоминание числа более легкой задачей, чем запоминание сложного
условного диапазона.
8 600 операций считывания из таблицы могут стать проблемой, но, к счастью,
у нас есть дополнительная селективность условия по столбцу Fi rst Name, которая
сокращает количество строк приблизительно до 155 (8 600 х 0,018). Для таблицы
будет выполнено приблизительно 155 операций логического ввода-вывода и не-
сколько операций физического ввода-вывода, так как коэффициент успешного
попадания в кэш для таблицы хуже, чем для более компактного индекса.
Селективность фильтра для нескольких столбцов, 0,0086 х 0,018 ~ 0,000155,
позволяет попасть в диапазон, подходящий для индексного доступа, хотя селек-
тивность только по первому столбцу находится в переходной зоне. Обратите вни-
58
2. Основы доступа к данным
мание, что даже если вы измените запрос или модель данных, чтобы добиться пол-
ной селективности в условиях диапазона индекса, стоимость снизится лишь ми-
нимально. Ненужными окажутся большинство из 43 операций считывания хоро-
шо кэшированных листовых блоков индекса, что ускорит запрос приблизительно
на миллисекунду. Никакого эффекта на 155 более дорогих операций считывания
блоков таблицы не будет. Можно изменить приложение, чтобы выполнялось чув-
ствительное к регистру сравнение имен, и создать новый индекс, включающий толь-
ко эти два столбца. Или же можно изменить таблицу, хранить имена в верхнем
регистре и индексировать этот новый столбец вместе со столбцом кода области.
Таким образом, хотя этот запрос и индекс не идеально подходят друг другу, ин-
декс вполне можно использовать. Добавление нового индекса и изменение запро-
са для получения небольшого потенциального преимущества во времени не стоят
усилий.
Комбинирование индексов
Случается, что база данных находит фильтры с условиями равенства, которые ука-
зывают на различные одностолбцовые индексы. Объединив операции сканирова-
ния диапазонов этих индексов, база данных может получить селективность много-
столбцового фильтра еще до того, как начнет обращение к таблице. Давайте еще
раз воспользуемся предыдущим примером запроса, который указывает код облас-
ти и имя покупателя, но заменим многостолбцовый индекс одностолбцовыми ин-
дексами по двум нужным нам столбцам. Далее заменим условие UPPER(Fi rst_Name)
на простое соответствие по столбцу, предполагая, что все значения хранятся в верх-
нем регистре. Типичные условия выглядят следующим образом:
WHERE Area_Code=415 AND First_Name='BRUCE'.
Теперь можно предположить, что в листовом блоке находится обычное коли-
чество строк — 300 или более, так как одностолбцовые индексы созданы по корот-
ким столбцам. Используя те же значения селективности фильтров по одному столб-
цу и предполагая, что в таблице содержится 1 000 000 строк, можно предсказать,
что условие для Area Code даст 8 600 (0,0086 х 1 000 000) строк, для чего потребует-
ся использовать 29 (8 600/300) листовых блоков индекса. Второе сканирование
диапазона индекса, для удовлетворения условия для F1rst_Name, даст 18 000
(0,018 х 1 000 000) строк, что требует использования 60 (18 000/300) листовых бло-
ков индекса. Так как оба условия являются условиями равенства, база данных на-
ходит два уже отсортированных списка идентификаторов строк и может легко объе-
динить их, отыскав те же 155 идентификаторов строк таблицы, как и в случае
с многостолбцовым индексом.
Описанная здесь операция, слияние списков идентификаторов строк, получен-
ных из двух индексов, называется операцией AND-EQUAL MERGE для индекса (сли-
яние по условиям равенства и условию И), и база данных может выполнять эту
операцию с любым количеством условий равенства для одностолбцовых индек-
сов. Стоимость доступа к таблице такая же, как при поиске строк по многостолб-
цовому индексу, но считать необходимо больше листовых блоков индекса — в дан-
ном случае 89 (29 + 60) вместо 43 в предыдущем примере.
Как вы можете видеть, стоимость операции AND-EQUAL MERGE больше, чем
применения многостолбцового индекса, но этот вариант может быть лучше, чем
Соединения
59
использование единственного одностолбцового индекса. Но такой случай, то есть
разумное предпочтение операции AND-EQUAL MERGE, очень редок. Практиче-
ски всегда наиболее селективное условие по одному столбцу само по себе явля-
ется прекрасным вариантом, и стоимость менее селективного сканирования диа-
пазона индекса превышает экономию на доступе к таблице, либо добавленная
стоимость операции AND-EQUAL MERGE оправдывает создание многостолбцо-
вого индекса. Если вы замечаете в плане выполнения операцию AND-EQUAL
MERGE, практически всегда следует либо запретить использование менее селек-
тивного индекса, либо создать и использовать многостолбцовый индекс. Новый
многостолбцовый индекс должен начинаться с наиболее селективного столбца,
в нашем случае это будет поле Area Code, и чаще всего должен использоваться вме-
сто любого одностолбцового индекса по этому столбцу.
Соединения
Однотабличные запросы быстро перестают казаться интересной задачей настрой-
ки. Возможных вариантов достаточно мало, что позволяет использовать даже ме-
тод проб и ошибок, который достаточно быстро приведет к появлению наилуч-
шего плана выполнения. Многотабличные запросы намного интереснее. Чтобы
настраивать многотабличные запросы, вам необходимо понимать различные типы
соединений и преимущества и недостатки разнообразных способов выполнения
соединения.
Типы соединений
Начнем с того, что попытаемся четко понять, что же означает многотабличный
запрос. Сначала рассмотрим, как базы данных понимают соединения — операции,
которые комбинируют строки из нескольких таблиц для получения требуемого
результата. Начнем с простейшего многотабличного запроса:
SELECT ... FROM Orders Order_Details;
Если фразы WHERE нет, то у базы данных также нет инструкций, как нужно
скомбинировать строки из этих двух больших таблиц, и она делает простейшую вещь:
возвращает все возможные комбинации строк из таблиц. Если у вас есть 1 000 000
заказов и 5 000 000 описаний заказов, то запрос вернет (если вы сможете дождаться)
5 000 000 000 000 строк! Это редко используемое и еще реже необходимое декартово
соединение. Результат этого запроса — все возможные комбинации элементов из двух
или более наборов — называется декартовым произведением. С точки зрения веде-
ния бизнеса вам совершенно неинтересно комбинировать данные из заказов и опи-
саний заказов, если они не имеют никакого отношения друг к другу. Если вы увиде-
ли в программе декартово соединение, практически всегда это ошибка.
ПРИМЕЧАНИЕ---------------------------------------------------------
Самое распространенное, но все так же очень редкое исключение из этого правила — это случай, когда
одна из таблиц возвращает единственную строку. В этом случае запрос на декартово соединение можно
рассматривать как более или менее разумную комбинацию результатов, полученных из запроса к од-
ной строке и присое; иненных для удобства к результатам логически независимого многострочного
запроса.
60
2. Основы доступа к данным
Внутренние соединения
Любому приложению обработки заказов обязательно понадобятся подробности,
относящиеся к определенным заказам, поэтому вы вряд ли увидите декартово со-
единение. Скорее условие соединения будет указывать базе данных, в каких отно-
шениях находятся таблицы:
SELECT ... FROM Orders 0. OrderJDetails D WHERE O.Order_ID=D.Order_IO;
Или, если записать в новом стиле:
SELECT .. FROM Orders 0
INNER JOIN Order_Details 0 ON O.Order_ID=D.Order_IO:
Логически такую операцию можно считать декартовым произведением с филь-
трованным результатом: «выдать все комбинации заказов и описаний, но удалить
те комбинации, для которых идентификаторы заказов не совпадают». Такое со-
единение называется внутренним соединением. Даже в худших случаях базы дан-
ных практически всегда находят лучший способ поиска требуемых строк, чем ме-
тод решения «в лоб», когда сначала вычисляется декартово произведение, а потом
из него удаляются составляющие, не отвечающие условиям запроса. И это замеча-
тельно, так как для получения многостороннего декартова произведения несколь-
ких больших таблиц может потребоваться несколько лет, а то и вечность. Большин-
ство соединений, например приведенное в примере, содержат условие равенства
внешнего ключа в какой-то подчиненной таблице и первичного (уникального)
ключа в главной таблице, но любое условие, в котором упоминают две или (реже)
больше таблиц, является условием соединения.
С процедурной точки зрения у базы данных есть несколько способов соеди-
нить таблицы в указанных запросах наилучшим образом.
Начать с главной таблицы и найти все соответствующие подчиненные данные.
Начать с детальной таблицы и найти соответствующие главные строки.
Получить оба набора строк независимо (но не при помощи декартова произве-
дения) и каким-либо образом соединить их, соблюдая соответствие между зна-
чениями соединенных столбцов.
Хотя результаты во всех случаях будут одинаковыми, производительность этих
способов может радикально различаться, поэтому в этой книге будет подробно
описан выбор наилучшего варианта.
Внешние соединения
Распространенная альтернатива внутреннему соединению — внешнее соединение.
Проще всего описать внешнее соединение в терминах выполнения. Для его полу-
чения следует начать со строк основной таблицы и найти, где это возможно, под-
ходящие строки из второй таблицы внешнего соединения. Если база данных не
может найти подходящую строку, требуется создать искусственную запись, состо-
ящую из значений nul 1, и присоединить ее к строке из ведущей таблицы. Напри-
мер, рассмотрим запрос Oracle в старом стиле:
SELECT .... D Department_Name FROM Employees E. Departments D
WHERE E.Oepartment_ID=D.Oepartment_ID(+);
В новом стиле записи в любой базе данных запрос будет выглядеть так:
SELECT .... D.Department_Name
FROM Employees E
Соединения
61
LEFT OUTER JOIN Departments 0
ON E.Department_ID-D.DepartmentalD:
Эти запросы возвращают информацию обо всех сотрудниках, в том числе ин-
формацию об отделах, где те работают. Однако если для сотрудника нет соответ-
ствующего отдела, запрос все же возвращает данные сотрудника, причем в резуль-
тирующих данных такие поля с ненайденными значениями, как D.Department_Name,
заполняются значениями null. С точки зрения настройки главным результатом
внешнего соединения является то, что оно запрещает путь выполнения, который
на основе данных из подчиненной таблицы пытается получить записи основной
таблицы. В нашем примере база данных не может начать с таблицы Departments и
искать соответствующие строки в таблице Employees, так как базе данных нужны
данные обо всех сотрудниках, а не только о тех, для которых указан отдел. Позже я
покажу, что это ограничение порядка соединения во внешних соединениях не все-
гда имеет большое значение, поскольку чаще всего нет необходимости проводить
соединение в запрещенном порядке.
Способы обработки соединений
Типы соединений определяют, какие результаты необходимы запросу, но не ука-
зывают, как база данных должна выполнять эти запросы. Во время настройки S QL-
запроса вы обычно просто знаете, какой именно результат запроса вы хотите полу-
чить, но вам необходимо также контролировать метод выполнения, чтобы добиться
хорошей производительности. Чтобы правильно выбрать метод выполнения, не-
обходимо понять, как они работают.
Соединения при помощи вложенных циклов
Самый простой способ эффективного выполнения соединения двух и более таб-
лиц — это соединение при помощи вложенных циклов, показанное на рис. 2.7.
Перввя твблица,
с которой производится
соединение
Вторая таблица,
с которой производится
соединение
Рис. 2.7. Соединения методом вложенных циклов
Выполнение запроса начинается с того, что можно считать однотабличным за-
просом к ведущей таблице (таблице, которую база данных считывает первой). При
этом используются только условия, относящиеся исключительно к этой таблице.
Считайте самый левый ящик с рукояткой на рис. 2.7 машиной для выполнения
62
2. Основы доступа к данным
этого однотабличного запроса. Он отделяет неинтересные строки (которые направ-
ляются в мусорное ведро в левом нижнем углу) от интересующих нас строк (удов-
летворяющих условиям однотабличного запроса) основной таблицы. Так как весь
запрос является соединением, база данных не останавливается на достигнутом. Она
передает результирующие строки из первого ящика в следующий. Задача второго
ящика — по одной принимать строки из первой коробки, находить соответствующие
строки в первой присоединяемой таблице, отбрасывать строки, не удовлетворяю-
щие условиям запроса для уже рассмотренных таблиц, и передавать подходящие
строки, для которых условия выполняются, дальше. Обычно база данных выпол-
няет этот шаг соединения методом вложенных циклов путем индексного поиска
по ключу соединения, который повторяется для каждой строки ведущей таблицы.
Если соединение является внутренним, база данных отбрасывает строки, для
которых на первом шаге не были найдены соответствия из присоединенной табли-
цы. Если же соединение внешнее, то база данных заполняет для таких строк места,
предназначенные для значений из присоединенной таблицы, значениями null, если
не может найти реальных существующих значений, сохраняя, таким образом, все
строки из первого шага. Этот процесс продолжается в остальных ящиках, точно
также присоединяя все остальные таблицы, пока запрос не будет завершен. В ре-
зультате мы получаем полностью соединенные данные, удовлетворяющие всем
условиям и соединениям запроса.
На внутреннем уровне база данных выполняет этот план выполнения как вло-
женную группу циклов — внешний считывает строки ведущей таблицы, следую-
щий находит соответствующие строки из первой присоединенной таблицы и так
далее — поэтому такой способ и называется соединениемметодом вложенных цик-
лов. В каждой точке процесс должен знать только то, где он в данный момент нахо-
дится, и содержимое единственной результирующей строки, которую он создает.
Поэтому для выполнения процесса требуется немного памяти и совсем не требу-
ется места на диске. Вот почему планы с вложенными циклами такие надежные.
Они могут создавать огромные результирующие наборы из больших таблиц, и при
этом не будет заканчиваться память или пространство на диске, хотя вам придется
ждать получения результатов довольно долго. Если вы выберете правильный по-
рядок соединения, вложенные циклы будут прекрасно работать в большинстве
важных для бизнеса запросов. Они демонстрируют лучшую производительность
среди всех методов соединения или же они настолько близки к наилучшей произ-
водительности, что дополнительное преимущество в виде надежности этого мето-
да заставляет выбрать именно его, игнорируя небольшие его недостатки.
ПРИМЕЧАНИЕ----------------------------------------------------------------
Говоря о надежности, я имею в виду исключительно метод соединения. Независимо от соединения,
запросу может потребоваться объемный отсортированный результирующий набор (например, если
присутствует фраза ORDER BY), для получения которого необходимо много памяти и дискового про-
странства.
Соединения хэшированием
Иногда база данных должна обратиться к соединяемым таблицам по отдельности,
а затем соединить соответствующие строки и отбросить ненужные. Можно сде-
лать это двумя способами: соединением хэшированием, которое рассматривается
Соединения
63
в этом разделе, и соединением с сортировкой слиянием, которому посвящен следу-
ющий раздел. На рис. 2.8 показано соединение хэшированием.
‘Обычно в памяти
Рис. 2.8. Соединение хэшированием
На рис. 2.8 оба верхних ящика с рукоятками работают как независимо оптими-
зированные однотабличные запросы. На основе статистики по таблице и индексу
стоимостной оптимизатор1 устанавливает, какая из двух независимых таблиц вер-
нет меньше строк после фильтрации. Он выбирает хэширование всего результата
запроса для этой таблицы. Другими словами, он выполняет некоторую рандоми-
зирующую математическую функцию на ключе соединения и использует резуль-
тат функции при выборе места для каждой строки в области хэширования. Иде-
альный алгоритм хэширования равномерно распределяет строки между некоторым
количеством областей хэширования, приблизительно равным количеству строк.
Так как области хэширования предназначены для небольшого результирую-
щего набора, можно надеяться, что все они разместятся в памяти, но, если необхо-
димо, база данных выделяет временное пространство на диске для размещения этих
областей. Затем она выполняет большой запрос (верхний правый ящик на рис. 2.8),
который возвращает ведущий набор строк. По мере того как каждая строка прохо-
дит этот шаг, база данных выполняет ту же функцию хэширования на ее ключе
соединения и использует полученный результат для перехода прямо в соответ-
ствующую область хэширования другого набора строк. Попав в подходящую об-
ласть хэширования, база данных производит поиск соответствующей строки в не-
большом списке в этой области.
Обратите внимания, что соответствие может быть и не найдено. Когда база дан-
ных находит соответствие (на рисунке это показано ящиком внизу в середине),
Синтаксический оптимизатор Oracle никогда не выберет слияние хэшированием, но стоимостной
оптимизатор часто делает это. Другие поставщики баз данных не используют синтаксические опти-
мизаторы.
64
2. Основы доступа к данным
она сразу же возвращает результат или отправляет его на следующее соединение,
если таковое существует. Если база данных не может найти соответствия, она от-
брасывает эту ведущую строку.
Для основного набора строк соединение хэшированием выглядит практически
идентично соединению методом вложенных циклов: в обоих случаях база данных
делает один проход по набору строк, во время которого должна хранить в памяти
только одну текущую строку. Но для меньшего предварительно хэшированного
набора такой вид соединения является менее надежным, если его размер оказыва-
ется неожиданно большим. Для большого предварительно хэшированного набора
может потребоваться дополнительное пространство на диске, работа будет мед-
ленной, и пространство может вовсе закончиться. Если вы абсолютно уверены, что
меньший набор строк всегда будет достаточно мал, чтобы поместиться в памяти,
то иногда можно предпочесть соединение хэшированием соединению методом вло-
женных циклов.
Соединения с сортировкой слиянием
При соединении с сортировкой слиянием, показанном на рис. 2.9, обе таблицы счи-
тываются независимо, но вместо того, чтобы находить соответствующие строки
хэшированием, оба набора строк предварительно сортируются по ключу соедине-
ния и затем объединяются. В самой простой реализации можно представить, что
наборы строк отсортированы и записаны рядом друг с другом. База данных попе-
ременно идет вниз по обоим спискам, проходя каждый список один раз, на каждом
шаге сравнивая верхние строки, отбрасывая те, которые находятся раньше (в по-
рядке сортировки), чем верхняя строка другого списка, и возвращая подходящие
друг другу строки. Если оба списка отсортированы, то процесс поиска соответ-
ствий проходит быстро, но предварительная сортировка дорога и ненадежна, если
только вы не можете гарантировать, что оба набора строк настолько малы, что мо-
гут целиком поместиться в памяти.
Рис. 2.9. Соединение с сортировкой слиянием
Соединения
65
Если сравнивать соединение с сортировкой слиянием и соединение методом
вложенных циклов, то у первого варианта практически те же потенциальные пре-
имущества, которые бывают у соединения хэшированием. Однако если сравнить
соединение с сортировкой слиянием и соединение хэшированием, то у второго
варианта будут серьезные преимущества. Он не помещает большие наборы строк
в память или на диск и практически не увеличивает стоимость. Таким образом,
если вам надо выбрать между соединением с сортировкой слиянием и соединени-
ем хэшированием, никогда не выбирайте соединение сортировкой слиянием.
Резюме
Резюмируя, можно сказать, что следует всегда выбирать вложенные циклы, чтобы
добиться производительности и надежности. Иногда можно получить дополни-
тельные преимущества, используя соединение хэшированием, когда независимый
доступ к двум таблицам существенно улучшает производительность, а риск сни-
жения надежности мал. Никогда не выбирайте соединение с сортировкой слияни-
ем, разве что для случая, когда больше подошло бы соединение хэшированием, но
реализовать его невозможно (например, как в случае синтаксического оптимиза-
тора Oracle). В следующих главах я буду считать соединение методом вложенных
циклов выбором по умолчанию. Правила, объясняющие, в каких случаях можно
получить преимущества, выбрав другие варианты, сложны, и в них используется
материал дальнейших глав. Главным назначением этого раздела было объяснить
операции, которые выполняются внутри базы данных и представляют собой осно-
ву для дальнейшего обсуждения.
3
Просмотр
и интерпретация
планов выполнения
В этой главе излагается основной материал, касающийся создания и чтения пла-
нов выполнения SQL-запросов. Он не является критичным, то есть вы не должны
обязательно читать эту главу, чтобы понять материал остальных глав книги. Все
производители серверов баз данных предлагают специальные инструменты созда-
ния и просмотра планов выполнения, зачастую обладающие удобным графическим
интерфейсом. Также существуют популярные утилиты сторонних производителей,
например ТО AD. Если у вас есть доступ к таким хорошо документированным ути-
литам и вы знаете, как с ними работать, то эту главу можно пропустить или быстро
просмотреть. Эта глава не предназначена для замены или дополнения специали-
зированных утилит или их документации. Нет, я описываю самые основные мето-
ды создания и чтения планов выполнения, методы, которые гарантированно дос-
тупны вам вне зависимости от того, какие утилиты есть в вашем арсенале. Эти
базовые методы особенно полезно знать, если вы работаете в разнотипных средах
разработки, где нельзя рассчитывать на постоянное и немедленное наличие спе-
циализированных инструментов. Если у вас уже есть более сложные методы и вы
умеете использовать их, то вам не потребуются мои методы (и, возможно, вы их не
захотите изучать). За время моей работы с разнообразными серверами баз данных
я никогда не беспокоился о наличии сложных инструментов. Я обнаружил, что
если знать, какой план выполнения тебе нужен и как его получить, для эффектив-
ной работы всегда хватит простых инструментов, интегрированных в базу данных.
Чтение плана выполнения — это лишь быстрая проверка, использует ли база дан-
ных действительно нужный разработчику план.
Если вы решили прочесть эту главу, то, вероятно, перейдете сразу же к разделу,
посвященному рассмотрению планов выполнения в том сервере баз данных, с ко-
торым работаете, если только вы не занимаетесь настройкой баз данных различ-
ных производителей. Все эти разделы независимы; кроме того, некоторый матери-
ал в них повторяется. Однако, читая эту главу, пожалуйста, помните, что планы
выполнения, с которыми вы встретитесь, не будут вам полезны, пока вы не изучи-
те главы с пятой по седьмую. В этих главах вы научитесь выбирать, какой именно
план выполнения вам нужен, а умение просматривать описание планов выполне-
ния не играет существенной роли, пока вы не сможете самостоятельно выбирать
правильные планы.
Чтение планов выполнения в Oracle
67
Чтение планов выполнения в Oracle
Oracle использует основанный на SQL подход к созданию и отображению планов
выполнения. При помощи SQL вы помещаете данные плана в таблицу, после чего
можете просмотреть их, используя обычный SQL-запрос. Поначалу этот процесс
может казаться неудобным, особенно если делать все вручную. SQL Server по за-
просу выводит описания планов выполнения на экран, но основанный на SQL под-
ход Oracle, то есть запись плана в таблицу, обладает большей гибкостью, если вы
хотите автоматизировать процесс одновременного анализа целых наборов планов
выполнения.
Подготовка
Oracle помещает данные плана выполнения в таблицу, которая обычно называет-
ся PLAN_TABLE. Если в схеме, которую вы используете для изучения планов выпол-
нения, еще нет PLAN TABLE, создайте такую таблицу. Можно создать соответствую-
щую текущим данным таблицу PLAN_TABLE при помощи сценария utlxplan.sql в
каталоге rdbms/admin в ORACLE_HOME. Если ORACLE_HOME вам недоступна, то вполне по-
дойдет PLAN_TABLE, созданная следующим сценарием:
CREATE TABLE PLANTABLE!
STATEMENT ID VARCHAR2I30).
TIMESTAMP DATE.
REMARKS VARCHAR2I80).
OPERATION VARCHAR2I30).
OPTIONS VARCHAR2I30).
OBJECT NODE VARCHAR2I128)
OBJECT_OWNER VARCHAR2I30).
OBJECT NAME VARCHAR2I30).
OBJECT INSTANCE NUMBERI3B).
OBJECT TYPE VARCHAR2I30).
OPTIMIZER VARCHAR2I255)
SEARCH COLUMNS NUMBERI38).
ID NUMBERI38).
PARENT ID NUMBERI38).
POSITION NUMBERC38).
COST NUMBER!38).
CARDINALITY NUMBER!38).
BYTES NUMBER(38).
OTHER TAG VARCHAR2(255)
OTHER LONG):
Процесс, лежащий в основе отображения
планов выполнения
Для создания и отображения планов выполнения в Oracle с минимальным вмеша-
тельством в работу других пользователей, которые также могут работать с табли-
цей плана, используется 4-шаговый процесс из утилиты SQL*Plus.
1. Удалите все строки из специальной таблицы Oracle для планов выполнения
PLAN TABLE в схеме, которую вы используете для создания планов выполнения.
Создать план выполнения для оператора SQL можно только под именем пользо-
вателя, у которого есть права выполнять операторы SQL. Таким образом, обыч-
68
3. Просмотр и интерпретация планов выполнения
но вы создаете планы выполнения, когда подключены к той же схеме, в которой
выполняется предназначенный для настройки SQL.
ВНИМАНИЕ -------------------------------------------------------------------
Иногда очень привлекательно выглядит идея создать пользователей и схемы базы данных специально
для проведения анализа и создания планов выполнения и назначить пользователям достаточно прав,
чтобы они могли исполнять настраиваемый SQL-код. Но такой подход следует применять с большой
осторожностью, поскольку специальные схемы будут работать из собственного пространства имен (и,
например, будут видеть различные варианты представлений). Когда вы подключаетесь как эти особые
пользователи, база данных может интерпретировать данный запрос иначе, не так, как в бизнес-прило-
жении, и потребует отдельного плана выполнения. * 2 3 4 5 6 7
2. Создайте записи плана выполнения в PLAN TABLE при помощи оператора SQL
EXPLAIN PLAN FOR Настраиваемый оператор>;.
3. Выведите на экран план выполнения при помощи подобного оператора:
SELECT LPADC ',2*(LEVEL-1))|(OPERATION)|' ’|(OPTIONS)Г
|| DECODE(OBJECT_INSTANCE. NULL. OBJECT_NAME.
TO_CHAR(OBJECT_INSTANCE)||'*’|| OBJECT_NAME) PLAN
FROM PLANJABLE
START WITH ID-0
CONNECT BY PRIOR ID - PARENTJD
ORDER BY ID;
4. Очистите результаты вашей работы при помощи ROLLBACK:.
Выполним эту последовательность действий и проанализируем план выполне-
ния для простого запроса:
SELECT Last_Name. F1rst_Name. Salary FROM Employees
WHERE ManagerJD-137
ORDER BY Last_Name. First_Name:
Далее вы видите реальное содержимое сеанса SQL*Plus для ручного определе-
ния плана выполнения нашего запроса:
SQL> delete from plan_table;
0 rows deleted.
SQL> EXPLAIN PLAN FOR SELECT Last_Name. First_Name. Salary FROM Employees
2 WHERE Manager JD=137
3 ORDER BY Last_Name. First_Name:
Explained.
SQL> SELECT LPADI' 1,2*(LEVEL-D)||OPERATION|Г ’ 1(OPTIONS]|’ ’||
2 DECODE(OBJECT_INSTANCE. NULL. OBJECT_NAME.
3 TO_CHAR(OBJECT_INSTANCE)||’*’|| OBJECT_NAME) PLAN
4 FROM PLANJABLE
5 START WITH 10=0
6 CONNECT BY PRIOR ID = PARENTJD
7 ORDER BY ID:
PLAN
SELECT STATEMENT
SORT ORDER BY
TABLE ACCESS BY INDEX ROWID 1*EMPLOYEES
Чтение планов выполнения в Oracle
69
INDEX RANGE SCAN EMPLOYEES_MANAGER_ID
4 rows selected.
SQL> rollback:
Rollback complete.
Здесь показан план выполнения, который находит диапазон индекса (по ин-
дексу Employees_Manager_ID), включающий данные о сотрудниках, подчиненных
менеджеру с идентификатором 137. Сканирование этого диапазона индекса (см.
последнюю строку выхода перед отчетом "4 rows selected") приводит к получе-
нию списка идентификаторов строк, указывающих на определенные строки
в определенных блоках таблицы Employees. Для каждого из этих идентификато-
ров строк Oracle выполняет операцию логического ввода-вывода и, если необхо-
димо, физического ввода-вывода в соответствующем блоке таблицы, где и нахо-
дит нужную указанную строку. После операций считывания из таблицы Oracle
сортирует строки в порядке возрастания по столбцам, указанным после выраже-
ния ORDER BY.
Практический процесс отображения
планов выполнения
Для новичка процесс отображения планов выполнения в Oracle выглядит неудоб-
ным, но вы можете автоматизировать основные шаги этого процесса, написав не-
большой и простой сценарий. Если вы работаете в Unix, создайте следующие файлы:
-- File called head.sql:
set pages!ze 999
set feedback off
DELETE FROM PLANJABLE WHERE STATEMENTJD = '<Your name>';
EXPLAIN PLAN SET STATEMENTJD = '<Your name>' FOR
-- File called tail.sql:
SELECT LPADC ',2*(LEVEL-1))||OPERAT'0N||' '|[OPTIONS)|' ’ ||
DECODE(OBJECT_INSTANCE. NULL. OBJECT_NAME.
TO_CHAR(OBJECT_INSTANCE)||'*'|| OBJECT_NAME) PLAN
FROM PLANJABLE
START WITH 10=0 AND STATEMENTJD = '<Your name>'
CONNECT BY PRIOR ID = PARENT ID AND STATEMENTJD = '<Your name>'
ORDER BY ID:
ROLLBACK:
-- File called ex.sql:
!cat head.sql tmp.sql tail.sql > tmp2.sql
spool tmp.out
0tmp2
spool off
После этого вы сможете последовательно обрабатывать планы выполнения. Со-
храните рассматриваемый SQL-код (вместе с завершающей символом точки с за-
пятой (;)) в файле tmp.sql в любом текстовом редакторе в одном окне. В другом
окне запустите сеанс SQL*Plus из каталога, в котором находятся файлы head.sql,
tail .sql, ex.sql и tmp.sql. Создавайте новые планы выполнения для текущей вер-
сии tmp. sql (после того, как сохраните этот файл!), вводя команду @ех в строке с при-
70
3. Просмотр и интерпретация планов выполнения
глашением SQL> в том окне, где выполняется сеанс утилиты SQL* Plus. Процесс
анализа и просмотра планов выполнения можно описать достаточно детально.
1. Поместите чистый SQL-код, анализ которого требуется произвести, в файл
tmp. sql в том же каталоге, где находятся ex. sql, head. sql и tai 1.sql.
2. В сеансе SQL*Plus, запущенном из того же каталога, в строке приглашения SQL>
выполните команду @ех.
3. Просмотрите план выполнения.
4. Настройте базу данных (например, изменив индекс) и рассматриваемый SQL-
код в tmp.sql (следуя методам, описанным в главе 4).
5. Сохраните файл tmp.sql и перейдите к шагу 2. Повторяйте действия, пока не
получите желаемый план выполнения, а затем сохраните правильный резуль-
тат где-либо для постоянного хранения.
Теперь для того, чтобы внести изменения и увидеть результаты, требуется по-
тратить лишь несколько секунд. Если вы хотите распечатать план выполнения или
просмотреть его в текстовом редакторе (особенно если он большой), то это тоже
можно сделать практически мгновенно, поскольку он хранится в файле tmp.out.
В других операционных системах, отличных от Unix, тоже можно попробовать
использовать подобные методы работы или же просто дописать содержимое фай-
ла head. sql в начало tmp. sql, содержимое tai 1. sql в конец tmp. sql и выполнить @tmp
в строке с приглашением SQL>. Этот вариант можно использовать во всех операци-
онных системах.
На практике оказывается, что половина всех изменений, которые вы внесете
при настройке плана выполнения, будет сделана в tmp. sql, а вторая половина —
в среде базы данных при помощи SQL*Plus. Причем это может быть создание и уда-
ление индексов, создание статистики по таблицам и индексам или изменение па-
раметров для оптимизации сеанса.
Надежные планы выполнения
При настройке SQL вы обычно хотите убедиться, что получаете простые планы
выполнения, которые выполняют вложенные циклы в правильном порядке соеди-
нения. Я называю такие планы выполнения надежными, так как они обычно хоро-
шо справляются с большими объемами данных. В этом примере возвращается
надежный план, упрощающий процесс, для следующего кода SQL, записанного
в tmp.sql:
-- File called tmp.sql
SELECT /*+ RULE */ E.FirstName. E.Last_Name. E.Salary.
LE.Description. M.First_Name. M.LastName. LM.Description
FROM Locations LE. Locations LM. Employees M. Employees E
WHERE E.Last_Name = :1
AND E.Manager_ID=M.Employee_ID
AND E.Location_ID=LE.Location_ID
AND M.Location_ID=LM.Location_ID
AND UPPER(LE.0escription)=:2:
Если в утилите SQL*Plus, запущенной из каталога, где находятся tmp.sql,
head. sql .tail, sql и ex. sql, выполнить команду @ex из строки с приглашением SQL>,
то мы получим следующий ответ с индексами только по первичным ключам и по
Emp1oyees(Last_Name):
Чтение планов выполнения в Oracle
71
SQL> @ех
PLAN
SELECT STATEMENT
NESTED LOOPS
NESTED ।OOPS
NESTED LOOPS
TABLE ACCESS BY INDEX ROWID 4*EMPL0YEES
INDEX RANGE SCAN EMPLOYEE_LAST_NAME
TABLE ACCESS BY INDEX ROWID 3*EMPL0YEES
INDEX UNIQUE SCAN EMPLOYEEPKEY
TABLE ACCESS BY INDEX ROWID 2*L0CATI0NS
INDEX UNIQUE SCAN LOCATIONPKEY
TABLE ACCESS BY INDEX ROWID 1*LOCATIONS
INDEX UNIQUE SCAN LOCATION_PKEY
SQL>
ПРИМЕЧАНИЕ --------------------------------------------------------------------------------
В предыдущем примере подсказка RULE использовалась исключительно для удобства. Это не означа-
ет, что вы должны предпочесть синтаксический оптимизатор RULE — это всего лишь удобный способ
получения воспроизводимого плана с вложенными циклами на пустых таблицах, что я и хотел проде-
монстрировать.
Как интерпретировать план
Для чтения полученного плана выполнения применяется определенная последо-
вательность операций.
Все соединения проводятся методом вложенных циклов и показаны как вло-
женная группа строк NESTED LOOPS. Если вы используете разные методы соеди-
нения, то первым будет выполнено самое внутреннее соединение (с самым боль-
шим отступом в записи), то есть последнее перечисленное. Порядок выполнения
соединений следует читать изнутри наружу или снизу вверх.
ПРИМЕЧАНИЕ ----------------------------------------------------------
Стандартный способ отображения планов выполнения в Oracle может несколько смутить начинающе-
го разработчика. Если бы вы собирались реализовать похожие вложенные циклы в виде собственной
процедуры, то первое соединение, показанное как цикл, находящийся максимально глубоко, было бы
на самом деле внешним циклом в реальной структуре вложенных циклов! Когда я писал первый черно-
вик главы 2 то по ошибке назвал выполняемое первым соединение с вложенными циклами циклом
с наибольшей глубиной, поскольку так привык к способу отображения планов выполнения в Oracle.
Конечно, альтернативный метод отображения мог бы быть полезен, если бы всем удалось к нему не-
медленно привыкнуть. К сожалению, множество инструментов и огромное количество практики и обу-
чения приучили разработчиков в Oracle использовать именно такую форму вывода результатов, поэтому
попытка изменить что-либо привела бы к неразберихе. Если вы новичок в этом деле, мужайтесь — ско-
ро и вы привыкнете.
Порядок доступа к таблицам. Дважды происходит обращение к таблице Empl oyees,
а затем дважды к таблице Locatl ons. В таком же порядке они перечислены в плане
выполнения. Когда сервер обращается к одним и тем же таблицам несколько
раз, псевдонимы для таблиц обязательны. Как можно видеть в примере в выра-
жении FROM, для таблицы Empl oyees есть два псевдонима — Е и М. Изучая индек-
72
3. Просмотр и интерпретация планов выполнения
сы, можно понять, что именно псевдоним Е, а не псевдоним М, представляет ве-
дущую таблицу, хотя оба псевдонима указывают на одну и ту же таблицу
Employees. Не настолько понятно, к какому из псевдонимов для Locations база
данных обращается первой. Здесь нам помогают номера перед именами таб-
лиц. Они указывают порядок перечисления псевдонимов в выражении FROM,
поэтому вы знаете, что первый псевдоним для Locations, LE, — это последний
псевдоним, к которому обращается план выполнения.
ПРИМЕЧАНИЕ ------------------------------------------------------------------------
Добавление номера перед именем таблицы — это единственное реальное изменение, которое я внес по
сравнению со стандартной формой, где разработчики Oracle просматривают планы выполнения. До-
бавление выражения TO_CHAR(OBJECT_INSTANCE) | Г*' в код SQL для просмотра плана позволяет избежать
двусмысленности. Номера помогают в случаях, когда одна таблица несколько раз появляется в выра-
жении FROM, но один из возможных порядков соединения псевдонимов важнее, чем другой.
Все четыре операции считывания из таблиц производятся через индекс, на что
указывает фраза TABLE ACCESS BY INDEX ROWID перед каждым именем таблицы. Ис-
пользуемый индекс и указание того, гарантируется ли его уникальность, мож-
но найти в записях с отступом под строкой с описанием доступа к каждой таб-
лице. Так, вы знаете, что к ведущей таблице Е доступ осуществляется путем
сканирования диапазона индекса EMPLOYEE_LAST_NAME (причем считывание хотя
бы потенциально затрагивает несколько строк за раз). Операции считывания
из остальных таблиц — это уникальные считывания через первичные ключи
таблиц. Так как все операции считывания, которые выполняются после обра-
ботки ведущей таблицы, относятся к уникальным соединениям, вы знаете, что
максимальное количество строк, которые запрос может считать из любой из
оставшихся таблиц, равно количеству строк, считанных из ведущей таблицы.
ВНИМАНИЕ ------------------------------------------------------------------------
Для этого примера я взял имена индексов, при помощи которых несложно понять, какой индексиро-
ванный столбец обеспечивает доступ к таблице, по чаще всего индексы имеют не такие понятные име-
на. Если вам не совсем понятно, какой столбец или столбцы составляют используемый индекс — не
гадайте! Одна из наиболее распространенных ловушек при настройке в Oracle — это неоправданное
предположение, что сканирование некоего диапазона индекса является сканированием именно желае-
мого диапазона индекса.
Когда вы видите уникальные операции сканирования индекса, то можете с уве-
ренностью сказать, что они обслуживают условия равенства по уникальному клю-
чу. Обычно существует только один столбец или комбинация столбцов, который
может охватить индекс, чтобы обеспечить уникальное сканирование. Сканирова-
ние диапазона индекса — это совсем другое дело. Если вы не знаете, какие индек-
сы существуют для таблицы и как называются индексы для каждой комбинации
столбцов, а также, если имена индексов не позволяют понять, какие столбцы обра-
батываются ими, всегда проверяйте индексы — на случай, если сканирование про-
водится не по тому диапазону индекса, который вы ожидаете. Вот простейший
сценарий проверки:
- - File called index.sql
column column_name format a40
set pages!ze 999
SELECT INDEXJWIE. COLUMNNAME
Чтение планов выполнения в Oracle
73
FROM USER_IND_COLUMNS
WHERE TABLE_NAME = UPPERC&&1')
ORDER BY INDEXJWIE, COLUMN_POSITION;
В утилите SQL* Plus, войдя в схему, содержащую таблицу, которую вы хотите
проверить, запустите в строке с приглашением SQL> команду @index <Имя_таблицы>.
В ответе утилиты будут по порядку перечислены многостолбцовые индексы, на-
чиная с первого столбца. Далее показан пример использования сценария:
SQL> @Index Locations
INDEX_NAME COLUMN_NAME
LOCATION_PKEY LOCATION JU
SQL>
Чтобы увидеть функциональные индексы и то, к чему они будут применяться
(обычно это блоки запроса, где есть условия для UPPER (< Столбец») или
LOWER(<Столбец>) или производится преобразование типа столбца), используйте
сценарий fl ndex. sql:
- - File called findex.sql
set long 40
set pagesIze 999
SELECT INDEXJWIE. COLUMN_EXPRESSION
FROM USER IND_EXPRESSIONS
WHERE TABLEJWIE = UPPER СМГ)
ORDER BY INDEXNAME. COLUMNPOSITION:
Интерпретация плана выполнения
Я объяснил, как узнать порядок соединения таблиц в запросе, методы их соедине-
ния и методы доступа к ним для получения надежного плана выполнения, пока-
занного ранее. Если вы объедините эти знания с основами, изложенными в главе 2,
то сможете понять, как Oracle обращается к данным. Чтобы проверить ваше пони-
мание, попробуйте изложить полный план выполнения по-русски, как набор ин-
струкций для базы данных. Сравните ваши результаты со следующим описани-
ем. Если возникло слишком много разногласий, попробуйте еще раз провести
анализ плана выполнения после того, как прочитаете еще несколько описаний дру-
гих планов, чтобы проверить, насколько улучшилось ваше понимание. Далее план
выполнения описан в повествовательной форме, как инструкции для базы дан-
ных.
1. Используя условие Е. I astJJame = : 1, перейти к индексу EMPLOYEE_LAST_NAME и най-
ти список идентификаторов строк, соответствующих сотрудникам с указанной
фамилией.
2. Для каждого из этих идентификаторов строк перейти к таблице Employees (Е)
и, используя ту часть идентификатора, где хранится адрес блока, считать один
блок (обычно логическое считывание, если необходимо — физическое) для каж-
дого идентификатора строки из предыдущего шага. Используя часть иденти-
фикатора, содержащую адрес строки, найти эту запись, на которую указывает
ее идентификатор, и считать из нее все необходимые данные (запрошенные для
псевдонима Е).
3. Для каждой такой строки, используя условие соединения Е. Manager_ID=M. Empl oyee lD,
перейти к индексу по первичному ключу EMPLOYEE PKEY и найти один подходя-
74
3. Просмотр и интерпретация планов выполнения
щий идентификатор строки, соответствующий записи сотрудника для менед-
жера того работника, чью запись вы уже считали ранее. Если соответствия не
найдено, отбросить результирующую строку, которая строится в данный мо-
мент.
4. Если же подходящая запись найдена, следует перейти к таблице Employees (М)
и, используя ту часть идентификатора строки, где хранится адрес блока, счи-
тать один блок (логическое считывание, если требуется — физическое), соот-
ветствующий идентификатору строки из предыдущего шага. Используя ту часть
идентификатора строки, где хранится адрес записи, найти ту строку, на кото-
рую указывает этот идентификатор, и считать из нее все необходимые данные
(запрошенные для псевдонима М). Присоединить подходящие данные к строке,
полученной при предыдущем считывании из таблицы, чтобы создать частич-
ную результирующую ст року.
5. Для каждой такой строки, используя условие соединения М. Locat 1 on_I D=LM. Loca -
tion_ID, перейти к индексу по первичному ключу LOCATION_PKEY и найти един-
ственный подходящий идентификатор строки, указывающий на запись о мес-
тоположении, соответствующую менеджеру сотрудника, запись которого вы уже
считали. Если соответствия не найдено, отбросить результирующую строку,
которая строится в данный момент.
6. Если искомое соответствие все же найдено, для подходящего идентификатора
строки перейти к таблице Locations (LM) и, используя ту часть идентификатора
строки, где хранится адрес блока, считать один блок (логическое считывание, если
требуется — физическое), соответствующий идентификатору строки из преды-
дущего шага. Используя ту часть идентификатора строки, где хранится ее адрес,
найти определенную строку, на которую указывает данный идентификатор, и счи-
тать из нее все необходимые данные (запрошенные для псевдонима LM). Присо-
единить подходящие данные к строке, полученной при предыдущих считывани-
ях из таблиц, чтобы создать частичную результирующую строку.
7. Для каждой подобной строки, используя условие соединения Е. Locati on_ID=LE.
Locati on_ID, перейти к индексу по первичному ключу LOCATION_PKEY и найти един-
ственный подходящий идентификатор строки, обозначающий запись о место-
положении для сотрудника, чью запись вы уже считали. Если соответствия не
найдено, отбросить результирующую строку, которая строится в данный мо-
мент.
8. В ином случае для подходящего идентификатора строки перейти к таблице
Locati ons (LE) и, используя ту часть идентификатора строки, где хранится адрес
блока, считать один блок (логическое считывание, если необходимо — физи-
ческое), соответствующий идентификатору строки из предыдущего шага. Ис-
пользуя ту часть идентификатора строки, где хранится адрес строки, найти оп-
ределенную строку, на которую указывает идентификатор строки, и считать из
нее все необходимые данные (запрошенные для псевдонима LE). Присоединить
подходящие данные к строке, полученной при предыдущих считываниях из
таблиц, чтобы завершить результирующую строку. Отбросить всю результи-
рующую строку, если она содержит данные, не удовлетворяющие условию
UPPER( LE. Descri pti on)=: 2. Иначе немедленно возвратить полностью построенную
результирующую строку.
Чтение планов выполнения в Oracle
75
ПРИМЕЧАНИЕ --------------------------------------------------------------------
В плане выполнения вы не найдете явного шага для последнего фильтра, который отбрасывает строки,
не удовлетворяющие условию для описания местоположения. Я называю этот фильтр фильтром *пос-
лесчитывания», так как он не является частью метода обращения к строке таблицы, а лишь использует-
ся для удаления некоторых строк уже после того, как те были считаны. Oracle не выполняет удаление
по подобным фильтрам явно в плане выполнения, но вы всегда можете рассчитывать, что Oracle сдела-
ет это при первой же возможности, как только получит данные, необходимые для оценки истинности
условий фильтров. Если в плане выполнения есть еще соединения после этого последнего соединения,
Oracle будет выполнять их только для строк, которые прошли фильтр послесчитывания, отбрасывая
остальные.
Ненадежные планы выполнения
Настраиваемые вами планы для SQL-запросов зачастую сначала будут ненадеж-
ными, внося свой вклад в проблему недостаточной производительности, которую
вам следует решить. В таких ненадежных планах выполнения используются мето-
ды соединения, отличные от вложенных циклов. От вас не требуется глубокого
понимания тех планов выполнения, которые нельзя считать оптимальными, нуж-
но только суметь увидеть, что это не те планы, которые вы хотите получить. Одна-
ко полезно иметь хотя бы общее представление о том, почему эти планы выполне-
ния такие медленные, и знать, насколько лучше будут ваши оптимальные планы.
Теперь я покажу, как выглядят альтернативные планы выполнения для запроса,
с которым мы работали в последних двух разделах. Если я удалю все индексы, син-
таксический оптимизатор создаст новый план выполнения:
PLAN
SELECT STATEMENT
MERGE JOIN
SORT JOIN
MERGE JOIN
SORT JOIN
MERGE JOIN
SORT JOIN
TABLE ACCESS FULL 4*EMPL0YEES
SORT JOIN
TABLE ACCESS FULL 3*EMPL0YEES
SORT JOIN
TABLE ACCESS FULL 2*L0CATI0NS
SORT JOIN
TABLE ACCESS FULL 1*LOCATIONS
Порядок соединения в этом плане такой же, но теперь база данных производит
соединения методом сортировки слиянием, и ищет строки в каждой таблице пу-
тем полного ее сканирования.
Соединения хэшированием более распространены в критичных к ресурсам пла-
нах выполнения, чем соединения слиянием, и иногда вы даже будете предпочи-
тать их соединениям методом вложенных циклов, поэтому далее я привожу пример
с соединением подобного типа. Обратите внимание, что в исходном SQL-запросе,
для которого был создан предыдущий план, сразу же за ключевым словом SELECT
есть выражение /*+ RULE */. Если я заменю выражение /*+ RULE */ выражением /
*+ORDERED USE_HASH(M LE LM) */ и изменю порядок в разделе FROM, то с пустыми таб-
76
3. Просмотр и интерпретация планов выполнения
лицами, без индексов и с полной статистикой стоимостный оптимизатор создаст
новый план выполнения:
PLAN
SELECT STATEMENT
HASH JOIN
HASH JOIN
HASH JOIN
TABLE ACCESS FULL 1*EMPLOYEES
TABLE ACCESS FULL 2*EMPL0YEES
TABLE ACCESS FULL 3*L0CATI0NS
TABLE ACCESS FULL 4*L0CATI0NS
Этот план выполнения идентичен предыдущему, но он заменяет соединения
слиянием соединениями хэшированием.
Сложные планы выполнения
Существуют и другие свойства планов выполнения, например, индикаторы, ука-
зывающие, какие из соединений являются внешними, перечисление шагов сорти-
ровки и операторов, обеспечивающих уникальность сортировки, которые удаля-
ют дублирующиеся значения. С ними вы будете встречаться часто, но их назначение
интуитивно понятно и они не столь важны для производительности. Однако есть
и важные для нас тонкости, с которыми вы также часто будете иметь дело. Они
относятся к подзапросам и составным планам выполнения. Я продемонстрирую
их в одном примере SQL-запроса:
SELECT /*+ RULE */ E.F1rst_Name Е Nickname. E.LastName
E.Phone_Number. L.Descript ion
FROM Employees E. Locations L
WHERE (E.Flrst_Name='Kathy' OR E.N1ckname='Kathy’)
AND E.Location_ID=L.Location_ID
AND EXISTS (SELECT null
FROM Wage_Payments P
WHERE P.Employee_ID=E.Employee_ID
AND P.Payment_Date > sysdate-31):
Создадим несколько индексов.
Employees(First_Name)
Employees(Nickname)
Locations(Location_ID)
Wage_Payments(Employee_IO)
Теперь мы получим соответствующий план выполнения:
PLAN
SELECT STATEMENT
CONCATENATION
FILTER
NESTED LOOPS
TABLE ACCESS BY INDEX ROWID 1*EMPLOYEES
INDEX RANGE SCAN EMPLOYEE_NICKNAME
TABLE ACCESS BY INDEX ROWID 2*L0CATI0NS
INDEX UNIQUE SCAN LOCATION_PKEY
TABLE ACCESS BY INDEX ROWID 3*WAGE_PAYMENTS
Чтение планов выполнения в DB2
77
INDEX RANGE SCAN WAGE_PAYMENT_EMPLOYEE_ID
FILTER
NESTED LOOPS
TABLE ACCESS BY INDEX ROWID 1*EMPLOYEES
INDEX RANGE SCAN EMPLOYEE_FIRST_NAME
TABLE ACCESS BY INDEX ROWID 2*L0CATI0NS
INDEX UNIQUE SCAN LOCATION_PKEY
Шаг CONCATENATION указывает, что оптимизатор реализовал запрос как неявный
оператор UNION для двух различных запросов (это существенно), один из которых
получает данные при помощи индекса Fl rst_Ndme, а второй — при помощи индекса
по полю Nickname. После выполнения внешнего запроса шаг FILTER реализует кор-
реляционное соединение по условию P.Employee_ID=E.Employee_ID, переходя при
помощи индекса по внешнему ключу из Wage_Payments в Employees. Шаг FILTER — это
в действительности то же самое, что и соединение со вложенными циклами, за ис-
ключением того, что он останавливается после появления первой подходящей
строки, если она существует. Обратите внимание, что второй шаг FILTER обращает-
ся к тому же корреляционному соединению с Wage_Payments, что и первый шаг
Wage_Payments. Это особенность сцепленного плана выполнения, который повторя-
ет во внешнем запросе шаги соединений, но не шаги корреляционного соедине-
ния.
Чтение планов выполнения в DB2
В DB2 применяется несколько подходов к созданию и отображению планов вы-
полнения. SQL-запрос используется для помещения данных в таблицу, после чего
данные можно просмотреть несколькими способами. Вот основные методы, кото-
рые компания IBM сама описывает в документации.
Visual Explain. Для Visual Explain требуется инсталляция этой утилиты на ра-
бочей станции клиента, и эта возможность доступна не на всех поддерживае-
мых платформах. Поэтому я никогда не использовал Visual Explain. Я предпо-
читаю работать с инструментом, который будет доступен всегда и везде.
Утилита db2exfmt. Эту утилиту можно запустить из командной строки в любой
среде, в том числе неграфической, поэтому вы всегда можете рассчитывать на
нее. Однако я обнаружил, что она сообщает мне гораздо больше, чем я хочу
знать, поэтому иногда работать становится слишком трудно и неудобно. На-
пример, она выдала отчет длиной 1216 строк по плану выполнения для просто-
го четырехстороннего соединения. Трудно использовать даже ту часть отчета,
которая представляет суть плана выполнения. Дерево плана выполнения ото-
бражается в символах ASCII с имитацией графического представления струк-
туры дерева, но для его просмотра, кроме случаев простейших планов выпол-
нения, требуется намного большая длина строки, чем человек может легко
воспринять.
Собственные запросы к таблицам с данными плана. Этот подход для меня яв-
ляется наилучшим, поэтому я подробно опишу его в данном разделе. Если вы
уже знаете, как находить ответы на основные вопросы о плане выполнения (то
есть порядок соединения, методы соединения и методы доступа к таблицам),
78
3. Просмотр и интерпретация планов выполнения
используя другие инструменты, возможно, вам не понадобится этот раздел, и вы
сможете прекрасно работать уже знакомыми вам методами.
Подготовка
DB2 помещает данные плана выполнения в семь таблиц.
EXPLAININSTANCE
EXPLAINSTREAM
EXPLAIN© BJ ЕСТ
EXPLAINARGUMENT
EXPLAINOPERATOR
EXPLAINPREDICATE
EXPLAINSTATEMENT
Чтобы создать эти таблицы, запустите сценарий EXPLAIN. DDL, расположенный
в подкаталоге ml sc каталога sqllib, будучи подключенным к схеме, в которой
вам потребуются эти таблицы. В каталоге ml sc подключитесь к серверу баз дан-
ных и активизируйте схему, принадлежащую пользователю, под именем кото-
рого вы будете создавать планы выполнения. В командной строке Unix выпол-
ните команду:
db2 -tf EXPLAIN.DDL
Таблицы плана DB2 содержат информацию об иерархии данных для каждого
плана выполнения; наверху иерархии находится EXPLAIN INSTANCE, в которой для
каждого плана выполнения существует отдельная строка. Когда вы удаляете стро-
ку из EXPLAIN INSTANCE, происходит каскадное удаление сведений об этом плане
выполнения из других таблиц. Обычно ваши планы выполнения хранятся в таб-
лицах в схеме, принадлежащей пользователю, под именем которого вы зарегист-
рированы. Например, вы подключились при помощи такой команды:
CONNECT ТО Server_Name USER UserJJame USING SomePassword;
В этом случае вы, вероятно, выбрали схему, содержащую данные приложения,
поэтому можете запускать запросы для получения этих данных:
SET SCHEMA Appl_Schema;
Однако последнее действие никак не повлияет на то, где создаваемые вами пла-
ны выполнения утратят силу Они все также хранятся в ЕХРЕАШтаблицах в схеме
User_Name.
Процесс, лежащий в основе отображения
планов выполнения
Для создания и отображения планов выполнения с минимальным вмешательством
в работу других пользователей, которые также могут использовать таблицу, хра-
нящую план выполнения, предназначен следующий 4-шаговый процесс в интер-
претаторе командной строки сервера DB2.
1. Удалите все строки из таблицы плана выполнения верхнего уровня
EXPLAIN_INSTANCE в схеме, которую вы используете для хранения планов выпол-
Чтение планов выполнения в DB2
79
нения (обычно это схема, принадлежащая пользователю, в качестве которого
вы зарегистрированы). Операция DELETE в таблице EXPLAIN_INSTANCE автомати-
чески выполняет каскадное удаление данных плана выполнения из остальных
шести таблиц.
2. Создайте записи плана выполнения при помощи оператора SQL EXPLAIN PLAN FOR
<Настраиваемый_оператор>.
3. Выведите план выполнения на экран любым из нескольких предусмотренных
в DB2 способов, описанных ранее под заголовком «Чтение планов выполнения
DB2».
4. Очистите результаты вашей работы при помощи ROLLBACK.
Я продемонстрирую этот процесс на плане выполнения для простого запроса:
SELECT Last_Name. F1rst_Name. Salary FROM Employees
WHERE Manager_ID-137
ORDER BY Last_Name. Flrst Name:
Далее вы видите реальное содержимое сеанса DB2 для ручного определения
плана выполнения нашего запроса с общими паролями и именами:
$ db2 +с -t
(с) Copyright IBM Corporation 1993.1997
Command Line Processor for DB2 SDK 5.2.0
You can issue database manager commands and SQL statements from the command
prompt. For example:
db2 => connect to sample
db2 => bind sample.bnd
For general help, type: ?.
For comand help, type: ? command, where command can be
the first few keywords of a database manager command. For example:
? CATALOG DATABASE for help on the CATALOG DATABASE command
? CATALOG for help on all of the CATALOG commands.
To exit db2 interactive mode, type QUIT at the command prompt. Outside
interactive mode, all commands must be prefixed with 'db2‘.
To list the current command option settings, type LIST COMMAND OPTIONS.
For more detailed help, refer to the Online Reference Manual.
db2 => CONNECT TO ServerName USER User_Name USING SomePassword;
Database Connection Information
Database server = DB2/SUN 5.2.0
SQL authorization ID = USER_NAME
Local database alias = SERVERJW1E
db2 => SET SCHEMA Appl_Schema;
DB20000I The SQL command completed successfully.
db2 => DELETE FROM USER_NAME.EXPLAINJNSTANCE;
DB20000I The SQL command completed successfully.
db2 => EXPLAIN PLAN FOR SELECT Last_Name. First_Name. Salary FROM Employees
db2 (cont.) => WHERE ManagerJD-137
db2 (cont ) => ORDER BY Last_Name. First_Name:
80
3. Просмотр и интерпретация планов выполнения
DB20000I The SQL command completed successfully.
db2 => SELECT 0 Operator_ID S2.Target_ID. 0.Operator_Type.
db2 (cont.) => S.Object_Name. CAST(O.Total_Cost AS INTEGER) Cost
db2 (cont.) => FROM USER_NAME.EXPLAIN_OPERATOR 0
db2 (cont.) => LEFT OUTER JOIN USER_NAME.EXPLAIN_STREAM S2
db2 (cont.) => ON 0.0perator_ID=S2.Source_ID
db2 (cont.) => LEFT OUTER JOIN USER_NAME.EXPLAIN_STREAM S
db2 (cont.) => ON O.Operator_ID = S.Target_ID
db2 (cont.) => AND O.Explain_Time = S.Explain_Time
db2 (cont.) => AND S.Object_Name IS NOT NULL
db2 (cont.) => ORDER BY O.Explain_T1me ASC. Operator_ID ASC;
OPERATORJD TARGETJD OPERATOR-TYPE OBJECT_NAME COST
1 - RETURN - 186
2 1 TBSCAN - 186
3 2 SORT - 186
4 3 FETCH EMPLOYEES 186
5 4 IXSCAN EMPMGRJD 25
5 record(s) selected.
db2 => ROLLBACK:
DB20000I The SQL command completed successfully.
db2 =>
Здесь показан план выполнения, который ищет диапазон индекса (в индексе
Emp_Mgr_ID), соответствующий сотрудникам, подчиненным менеджеру с иденти-
фикатором 137. Сканирование этого диапазона индекса приводит к получению
списка идентификаторов строк, которые указывают на определенные строки в
определенных блоках таблицы Employees. Для каждого такого идентификатора
строки DB2 выполняет операцию логического или, если необходимо, физиче-
ского ввода-вывода на соответствующем, блоке таблицы, где находит указанную
строку. После считывания из таблицы DB2 сортирует строки в возрастающем
порядке во временной таблице по столбцам, указанным в ORDER BY. Затем про-
изводится сканирование временной таблицы, содержащей отсортированный ре-
зультат.
Шаги для запроса в такой форме пронумерованы в столбце OPERATOR_ID. Этот
запрос позволяет выполнять проход древовидного плана по столбцу TARGET_ID.
TARGET_ID указывает на шаг, являющийся родительским для данной итерации. В на-
шем примере у каждого предка есть единственный потомок, но в общем случае
множество шагов, таких как шаги вложенных циклов, являются родительскими
для пары следующих шагов. При помощи TARGET_ID можно составить древовидную
структуру, соответствующую плану выполнения. Прочие способы отображения
планов выполнения в DB2 напрямую выводят ту же древовидную структуру, но ее
сложно будет увидеть на экране полностью.
Такой же тип древовидной структуры отображается при помощи отступов
в планах выполнения для предыдущего запроса, который я использовал для ил-
люстрации планов выполнения Oracle, но в них использовалась фраза CONNECT BY,
которой нет в DB2. SQL Server также использует отступы для отображения дре-
вовидной структуры плана выполнения, например в планах, показанных при по-
мощи SHOWPLAN_TEXT (см. далее).
Чтение планов выполнения в DB2
81
Практический процесс отображения
планов выполнения
Для новичка процесс отображения планов выполнения в DB2 выглядит достаточ-
но сложным, но вы можете автоматизировать основные шаги, написав небольшой
и простой сценарий. Если вы работаете в Unix, создайте следующие файлы:
-- File called head.sql
DELETE FROM User_Name.EXPLAIN_INSTANCE;
EXPLAIN PLAN FOR
-- File called tail.sql
SELECT 0.0perator_ID. S2.Target_ID. 0.0perator_Type.
S.Object_Name. CAST(O.Total_Cost AS INTEGER) Cost
FROM User Name.EXPLAIN_OPERATOR 0
LEFT OUTER JOIN User_Name.EXPLAIN_STREAM S2
ON 0.0perator_ID=S2.Source_I0
LEFT OUTER JOIN User_Name.EXPLAIN_STREAM S
ON 0.0perator_ID = S.Target ID
AND O.Explain_Time = S.Explain_Time
AND S.Object_Name IS NOT NULL
ORDER BY O.Explain_Time ASC. Operator_ID ASC;
ROLLBACK;
С помощью файлов head.sql и tail .sql процесс отображения планов выполне-
ния после того, как вы выбрали нужный план (см. главы 5-7), становится доста-
точно простым.
1. Поместите чистый SQL-код для анализа в файл tmp. sql, который находится в том
же каталоге, что и head.sql и tai 1.sql.
2. В сеансе DB2, запущенном из того же каталога, выполните команду quit:, что-
бы выйти в строку приглашения оболочки, затем выполните команду cat head. sql
tmp.sql tail.sql |db2+c+p-t.
3. Настройте базу данных (например, изменив индексы) и рассматриваемый SQL
код в файле tmp.sql (следуя методам, описанным в главе 4) и повторяйте пре-
дыдущий шаг в строке приглашения оболочки, пока не будет получен желае-
мый план выполнения. Затем запишите правильный результат где-либо для
постоянного хранения.
Редактируйте рассматриваемый SQL-код (вместе с завершающим символом
точки с запятой (;)) в файле tmp.sql в любом текстовом редакторе в одном окне.
В другом окне запустите сеанс DB2 из каталога, где находятся head.sql, tail .sql
и tmp. sql. Затем выйдите из обработчика командной строки DB2 командой qui t, но
останьтесь в строке приглашения оболочки. Создавайте и просматривайте новые
планы выполнения для текущей версии tmp. sql (после того, как сохраните файл!)
следующей командой:
cat head.sql tmp.sql tail.sql | db2 +c +p -t
Воспользуйтесь комбинацией клавиш для быстрого вызова, чтобы повторно
вызывать эту команду по мере необходимости. Теперь для того, чтобы внести из-
менения в SQL-запрос и увидеть результаты, потребуется лишь несколько секунд.
Если вы хотите распечатать план выполнения или просмотреть его в текстовом
редакторе, можно перенаправить вывод:
cat head.sql tmp.sql tail.sql | db2 +c +p -t > tmp.out
82
3. Просмотр и интерпретация планов выполнения
В других операционных системах, отличных от Unix, можно попробовать по-
добные фокусы или же просто дописать содержимое файла head. sql в начало tmp .sql,
содержимое tai 1. sql в конец tmp. sql и выполнить сценарий целиком. Это работает
во всех операционных системах. Вот пример выполнения этого процесса на том же
запросе, который я рассматривал ранее, начиная с команды qui t, чтобы выйти в стро-
ку приглашения оболочки:
db2 => quit:
DB20000I The QUIT command completed successfully.
$ cat head.sql tmp.sql tail.sql | db2 +c +p -t
DB20000I The SQL command completed successfully.
DB20000I The SQL command completed successfully.
OPERATORJD TARGETJD OPERATOR_TYPE OBJECT_NAME COST
1 - RETURN - 186
2 1 TBSCAN - 186
3 2 SORT - 1B6
4 3 FETCH EMPLOYEES 186
5 4 IXSCAN EMP_MGR_ID 25
5 record(s) selected.
DB20000I The SQL command completed successfully.
$
На практике оказывается, что половина всех изменений, которые вы внесете
при настройке плана выполнения, будет сделана в tmp.sql, а вторая половина —
в среде базы данных при помощи интерфейса командной строки db2. Это будет
создание и удаление индексов, создание статистики по таблицам и индексам или
изменение параметров для оптимизации сеанса.
Надежные планы выполнения
При настройке SQL вы обычно хотите убедиться, что получаете простые планы
выполнения, которые выполняют вложенные циклы в правильном порядке соеди-
нения. Я называю такие планы выполнения надежными, так как они обычно хоро-
шо справляются с большими объемами данных. В этом примере возвращается на-
дежный план, упрощающий процесс, для следующего кода SQL, записанного
в tmp.sql'.
-- File called tmp.sql
SELECT E.First_Name. E.Last_Name. E.Salary. LE.Description,
M.First_Name. M.Last_Name. LM.Description
FROM Employees E
INNER JOIN Locations LE ON E.Location_ID=LE.Location_ID
INNER JOIN Employees M ON E.Manager_ID=M.Employee_ID
INNER JOIN Locations LM ON M.Location_ID=LM.Location_ID
WHERE E.Last_Name = ?
AND UCASEILE.Description) = ? :
Чтобы продемонстрировать этот код на реальных данных, я поместил в табли-
цу Empl oyees 100 000 строк, причем для Last Name у меня есть 10 000 различных зна-
чений. В таблицу Locations я поместил 1 000 строк. После подключения к DB2 в
каталоге, где находятся файлы tmp.sql, head.sql и tai 1.sql, я вышел в командную
строку оболочки. Затем выполнил команду cat head. sql tmp. sql tai 1. sql | db2 +c +p -
Чтение планов выполнения в DB2
83
t и получил следующий выход с индексами только по первичным ключам
и Employees(Last_Name):
$ cat head.sql tmp.sql tail.sql | db2 +c +p -t
DB20000I The SQL command completed successfully
DB20000I The SQL command completed successfully.
OPERATORJD TARGETJD OPERATOR_TYPE OBJECT_NAME COST
1 - RETURN - 305
2 1 NLJOIN - 305
3 2 NLJOIN - 2B5
4 3 NLJOIN - 260
5 4 FETCH EMPLOYEES 80
6 5 IXSCAN EMP LAST NAME 50
7 4 FETCH LOCATIONS 50
8 7 IXSCAN LOCATION PKEY 25
9 3 FETCH EMPLOYEES 75
10 9 IXSCAN EMPLOYEEPKEY 50
И 2 FETCH LOCATIONS 50
12 11 IXSCAN LOCATION PKEY 25
12 record(s) selected.
DB20000I The SQL command completed successfully.
I
Интерпретация плана
План выполнения читается следующим образом.
Все соединения выполняются при помощи вложенных циклов и показаны как
набор строк, содержащих NLJOIN. Если вы используете различные методы со-
единения, то соединение, выполняемое первым, будет перечислено последним.
Порядок выполнения соединений следует читать снизу вверх.
Порядок доступа к таблицам — Employees, Locations, Employees, Locations. В том
же самом порядке они перечислены в плане выполнения. Когда SQL обращает-
ся к одним и тем же таблицам несколько раз, псевдонимы для таблиц обяза-
тельны. Как можно видеть в примере в разделе FROM, для таблицы Employees есть
два псевдонима — Е и М. Изучая индекс, можно понять, что именно псевдоним Е,
а не псевдоним М представляет ведущую таблицу, хотя оба псевдонима указы-
вают на одну и ту же таблицу Empl oyees. Не так очевидно, к какому из псевдони-
мов для Locations база данных обращается первой, но это должен быть LE, так
как только к нему можно обратиться вторым в порядке соединения.
Все четыре операции считывания из таблиц производятся при помощи индек-
са, на что указывает OPERATOR TYPE FETCH перед каждым именем таблицы. Ис-
пользуемые индексы указаны в записях OPERATOR—TYPE IXSCAN под записями о
доступе к каждой таблице. Так, вы знаете, что обращение к ведущей таблице Е
производится путем сканирования индекса EMP_LAST_NAME (причем считывание
хотя бы потенциально затрагивает несколько строк за раз). Все остальные опе-
рации доступа к таблицам — это уникальные считывания, так как в них исполь-
зуются условия уникальности для первичных ключей таблиц. Так как все опе-
рации считывания, которые выполняются после обработки ведущей таблицы,
относятся к уникальным соединениям, вы знаете, что максимальное количе-
84
3. Просмотр и интерпретация планов выполнения
ство строк, которые запрос может считать из любой таблицы, равно количеству
строк, считанных из ведущей таблицы.
ВНИМАНИЕ --------------------------------------------------------------------
Для этого примера я взял имена индексов, при помощи которых несложно понять, какой индексиро-
ванный столбец обеспечивает доступ к табл! 1цс, но чаще всего индексы имеют не такие понятные имена.
Если вам не совсем понятно, какой столбец пли столбцы составляют используемый индекс, не гадайте!
Одна из наиболее распространенных ловушек при настройке — это предположение, что сканирование
данного диапазона индекса является сканированием именно желаемого диапазона индекса.
Если вы еще не знаете, какие именно индексы созданы для таблицы, то вы не
знаете, как они называются для каждой комбинации столбцов, и названия индек-
сов могут не дать ответа на этот вопрос. Всегда проверяйте эту ситуацию в случае,
если сканирование диапазона индекса проводится не по тому диапазону, которого
вы ожидали. Самый простой сценарий для такой проверки выглядит следующим
образом:
-- File called inddb2.sql
SELECT IndName. Col Lanes
FROM SYSCAT.INDEXES
WHERE TabName = UCASE('EMPLOYEES');
В DB2, войдя в схему, содержащую таблицу, которую вам необходимо прове-
рить, отредактируйте сценарий, указав нужную таблицу, и выполните в строке
приглашения оболочки команду db2 -tf 1nddb2.sql. Будут по порядку перечисле-
ны многостолбцовые индексы начиная с первого столбца — в одной строке, разде-
ленные знаком +. Далее показан пример использования сценария:
$ db2 -tf inddbZ.sql
INDNAME
COLNAMES
EMP_MGR_ID
EMPLOYEE_PKEY
EMP_LOCATION_ID
EMP_DEPARTMENT_ID
EMP_HIRE_DATE
EMP_LAST_NAME
EMP_NICKNAME
EMP_FIRST_NAME
+MANAGER_ID
+EMPLOYEEJD
+LOCATIONJD
+DEPARTMENTJD
+HIRE_DATE
+LAST_NAME
+NICKNAME
+FIRST_NAME
8 record!s) selected.
Интерпретация плана выполнения
Я объяснил, как узнать порядок соединения таблиц, методы их соединения и спо-
собы доступа к ним для надежного плана выполнения, показанного ранее. Если вы
объедините эти знания с основами, изложенными в главе 2, то сможете понять, как
DB2 обращается к данным, от начала до конца. Чтобы проверить ваше понимание
материала, попробуйте изложить полный план выполнения по-русски, как набор
инструкций для базы данных. Сравните ваши результаты с моей версией. Если
возникло слишком много разногласий, попробуйте еще раз после того, как прочи-
таете еще несколько планов выполнения, чтобы проверить, насколько улучшилось
ваше понимание. Далее план выполнения описан в повествовательной форме, как
инструкции для базы данных.
Чтение планов выполнения в DB2
85
1. Используя условие Е. Last_Name=?, перейти к индексу EMP_LAST_NAME и найти список
идентификаторов строк, соответствующих сотрудникам с требуемой фамилией.
2. Для каждого из идентификаторов строки из предыдущего шага считать один блок
(логическое считывание, если требуется — физическое) из таблицы Empl oyees (Е),
используя ту часть идентификатора, где хранится адрес блока. Используя ту
часть идентификатора, где хранится адрес строки, найти определенную строку,
на которую он указывает, и считать из нее все необходимые данные (запрошен-
ные для псевдонима Е).
3. Для каждой такой строки, используя условие соединения Е Location_ID=LE. Lo-
cati on_ID, перейти к индексу по первичному ключу LOCATION_PKEY и найти един-
ственный подходящий идентификатор строки, соответствующий записи о мес-
тоположении для того сотрудника, чью запись вы уже получили ранее. Если
подходящей строки не найдено, отбросить результирующую строку, которая
строится в данный момент.
4. В ином случае для каждого подходящего идентификатора строки из предыду-
щего шага необходимо выполнить считывание одного блока (логическое счи-
тывание, если требуется — физическое) из таблицы Locations (LE), используя
ту часть идентификатора, где хранится адрес блока. Используя ту часть иден-
тификатора строки, где хранится адрес строки, найти определенную строку, на
которую указывает идентификатор, и считать из нее все необходимые данные
(запрошенные для псевдонима LE). Присоединить подходящие данные к входя-
щей строке, полученной при предыдущем считывании из таблицы, чтобы за-
вершить результирующую строку. Отбросить всю результирующую строку, если
она содержит данные, не отвечающие условию UCASE(LE.Description) = ?.
ПРИМЕЧАНИЕ --------------------------------------------------------------------
Обратите внимание, что в плане выполнения вы не найдете явного шага для последнего фильтра, кото-
рый отбрасывает строки, не удовлетворяющие условию для описания местоположения. Это тот же са-
мый фильтр «послесчитывания», так как он не является частью метода обращения к строке таблицы,
а лишь используется для удаления некоторых строк уже поле того, как те были считаны. DB2 не вы-
полняет удаление по подобным фильтрам явно, но вы всегда можете рассчитывать, что DB2 сделает это
при первой же возможности, как только получит данные, необходимые для оценки истинности усло-
вии фильтров. Так как в плане выполнения есть еще соединения после этого последнего соединения,
DB2 будет выполнять их только для строк, которые прошли фильтр, отбрасывая остальные.
Для всех возвращенных строк, объединяющих Е и LE, необходимо проделать еще
несколько шагов.
Используя условие соединения E.Manager_ID=M.Employee_ID, перейти к индексу
по первичному ключу EMPLOYEE РКЕУ и найти единственный подходящий иден-
тификатор строки, соответствующий записи сотрудника, для менеджера того
сотрудника, чью запись вы уже считали. Если подходящей строки не найдено,
отбросить результирующую строку, которая строится в данный момент.
Иначе для подходящего идентификатора строки из предыдущего шага считать
один блок (логические считывание, если требуется, физическое) из таблицы
Empl oyees (М), используя ту часть идентификатора, где хранится адрес блока.
Используя ту часть идентификатора строки, где хранится адрес строки, найти
определенную строку, на которую указывает идентификатор, и считать из нее
86
3. Просмотр и интерпретация планов выполнения
все необходимые данные (запрошенные для псевдонима М). Присоединить под-
ходящие данные к входной строке, полученной при предыдущих считываниях
из таблиц, чтобы создать частичную результирующую строку.
Для каждой такой строки, используя условие соединения М. Locatlon_ID=LM. Lo-
cation_ID, перейти к индексу по первичному ключу LOCATION_PKEY и найти един-
ственный подходящий идентификатор строки, соответствующий записи о мес-
тоположении для менеджера того сотрудника, чью запись вы уже считали. Если
подходящей строки не найдено, отбросить результирующую строку, которая
строится в данный момент.
В ином случае для подходящего идентификатора строки из предыдущего шага
считать один блок (логическое считывание, если требуется — физическое) из
таблицы Locations (LM), используя ту часть идентификатора, где хранится адрес
блока. Используя ту часть идентификатора, где хранится адрес строки, найти
определенную строку, на которую указывает идентификатор, и считать из нее
все необходимые данные (запрошенные для псевдонима LM). Присоединить
подходящие данные ко входной строке, полученной при предыдущих считыва-
ниях из таблиц, чтобы завершить результирующую строку. Немедленно вер-
нуть полностью построенную результирующую строку.
Ненадежные планы выполнения
В планах выполнения часто используются методы соединения, отличные от вло-
женных циклов, — особенно это касается «сырых» планов, которые вам потребу-
ется настроить. Далее я покажу вам пример, где одно из соединений выполняется
менее надежным методом сортировки слиянием. Если удалить все индексы, DB2
создаст новый план выполнения:
$ cat head.sql tmp.sql tail.sql | db2 +c +p -t
DB20000I The SQL command completed successfully.
DB20000I The SQL command completed successfully.
OPERATORJD TARGETJD OPERATORJYPE OBJECTJIAME COST
1 - RETURN - 21033
2 1 NLJOIN - 21033
3 2 NLJOIN - 20830
4 3 MSJOIN - 10517
5 4 TBSCAN - 204
6 5 SORT - 204
7 6 TBSCAN LOCATIONS 204
8 4 FILTER - 10313
9 8 TBSCAN - 10313
10 9 SORT - 10313
11 10 TBSCAN EMPLOYEES 10313
12 3 TBSCAN EMPLOYEES 10313
13 2 TBSCAN LOCATIONS 202
13 record(s) selected.
DB20000I The SQL command completed successfully.
$
Чтение планов выполнения в DB2
87
В шагах с значением идентификатора OPERATOR I D с 5 по 11 сервер DB2 сортиру-
ет результаты полного сканирования таблиц Locations и Employees (псевдонимы LE
и Е) по ключу соединения Location_ID, отбрасывая строки, не удовлетворяющие
фильтрующим условиям для этих таблиц. В шаге с 0PERAT0R_ID=4 DB2 выполняет
соединение сортировкой слиянием таблиц Е и LE. Интересно, что, видя такие хоро-
шие фильтры для обеих таблиц, она решает, что на этом шаге останется максимум
одна строка, и выбирает в качестве двух последних шагов вложенные циклы с пол-
ным сканированием таблиц для соединения псевдонимов М и LM. Вложенные цик-
лы с полным сканированием таблиц, как в данном случае, будут работать плохо,
если данные окажутся такими, что DB2 придется пройти цикл слишком много раз.
Стоимость соединения слиянием или хэшированием будет немного выше, чем у
вложенных циклов с одним полным сканированием таблицы, но такие соедине-
ния на больших объемах работают лучше.
Сложные планы выполнения
Существуют и другие возможности планов выполнения, например индикаторы,
указывающие, какие из соединений являются внешними, перечисление шагов сор-
тировки и операторов, обеспечивающих уникальность сортировки, которые уда-
ляют дубликаты. С ними вы будете встречаться часто, но назначение этих функ-
ций интуитивно понятно и они не столь важны для производительности. Однако
есть и важные для нас тонкости, с которыми вы также часто будете иметь дело.
Они относятся к подзапросам и составным планам выполнения. Я продемонстри-
рую их в одном примере:
SELECT E.First_Name. Е.Nickname. E.Last_Name,
E.Phone_Number, L.Description
FROM Employees E
INNER JOIN Locations L ON E.Location_ID=L.Location_ID
WHERE (E First_Name= ? OR E.Nickname= ?)
AND EXISTS (SELECT 1 FROM Wagejayments P
WHERE P.Employee_ID=E.Employee_ID
AND P.Payment_Date > CURRENT DATE - 31 DAYS);
Поместите в Wage_Payments 500 000 строк. Создайте следующие индексы.
Employees(First_Name)
Employees(Nickname)
Locat1ons(Location_ID)
Wage_Payments(Employee_ID)
Тогда вы получите следующий план выполнения:
$ cat head sql tmp.sql tail sql | db2 +c +p -t
DB20000I The SQL command completed successfully.
DB20000I The SQL command completed successfully.
OPERATORJD TARGETJO OPERATOR_TYPE OBJECT_NAME COST
1 - RETURN - 2014
2 1 MSJOIN - 2014
3 2 TBSCAN - 203
4 3 SORT - 203
5 4 TBSCAN LOCATIONS 202
88
3. Просмотр и интерпретация планов выполнения
6 2 FILTER - 1810
7 6 TBSCAN 1810
8 7 SORT - 1810
9 В NLJOIN - 1810
10 9 FETCH EMPLOYEES 422
11 10 RIDSCN 100
12 11 SORT - 50
13 12 IXSCAN EMP_FIRST_NAME 50
14 11 SORT - 50
15 14 IXSCAN EMP_NICKNAME 50
16 9 FETCH WAGE_PAYMENTS 134
17 16 IXSCAN WAGE_PYMNT_EMP_ID 50
17 record(s) selected.
$
Шаги со значениями идентификатора OPERATOR_ID с И до 15 обозначают сбор
объединения наборов идентификаторов строк по условиям для имени, объединен-
ным OR, для таблицы Е. Новый результирующий набор идентификаторов строк
передается в шаг с OPERATOR_ID=10 для получения набора сотрудников с выбранным
именем или прозвищем. Из этого списка DB2 выбирает выполнение вложенных
циклов (NLJOIN) по направлению к Wage_Payments. Циклы останавливаются, как толь-
ко появляется первое соответствие, так как это коррелированное соединение EXISTS.
Это соединение со вложенными циклами обозначено как 0PERAT0R_ID=9. Оно от-
брасывает все записи таблицы Employees, для которых подзапрос не находит соот-
ветствия в Wage_Payment. Так как DB2 считает, что на данный момент у нее все еще
есть длинный список записей Employees, она выбирает единственное считывание
таблицы Locations и соединение слиянием (MSJOIN) с записями Employees с сорти-
ровкой обоих наборов строк по ключам соединения.
Чтение планов выполнения в SQL Server
В Microsoft SQL Server применяется несколько подходов к созданию и отображе-
нию планов выполнения. При этом планы выполнения создаются и выводятся на
экран в графическом или текстовом виде, а не помещаются в таблицы, как это де-
лается в DB2 и Oracle.
ПРИМЕЧАНИЕ---------------------------------------------------
Если вы купили эту книгу, чтобы научиться настраивать Sybase Adaptive Server, мужайтесь. У этих
двух баз данных общее наследие, и практически все, что я расскажу о Microsoft SQL Server, можно
применить и к Sybase, кроме возможности графического отображения плана в SQL Server Query Analyzer,
которую Microsoft добавил после того, как эти две версии разделились.
Отображение планов выполнения
В SQL Server реализованы два подхода к отображению планов выполнения: гра-
фический, встроенный в SQL Server Query Analyzer, и текстовый, который под-
держивает сама база данных. На одном экране графического варианта не помеща-
ется полный план выполнения даже многотабличного запроса среднего размера.
Чтение планов выполнения в SQL Server
89
Поэтому я считаю, что при помощи графического отображения трудно ответить
на ключевые вопросы о длинных планах выполнения.
Каков порядок соединения?
Какой метод используется для каждого соединения?
Какой метод используется для доступа к каждой таблице?
При использовании текстового варианта отображения плана выполнения лег-
ко найти ответы на все три вопроса.
Графическое отображение планов выполнения
Чтобы увидеть графический вариант плана выполнения, нажмите на кнопку Display
Estimated Execution Plan в утилите SQL Server Query Analyzer. В окне, где вы обыч-
но видите результаты запроса, будет показана диаграмма, состоящая из стрелок,
соединяющих набор значков и обозначающих тип действия (вложенные циклы,
индексное считывание, табличный доступ и т. д.). Рядом с каждым значком есть
текст, но он обычно достаточно краток, поэтому не содержит ничего полезного.
Подведите к тексту курсор мыши, чтобы раскрыть окно, в котором будут приведе-
ны недостающие подробности. Кроме того, даже для простого четырехстороннего
соединения диаграмма не помещается на экран целиком, даже если раскрыть окно
Query Analyzer на полный экран. Мне графический подход кажется менее полез-
ным, чем текстовый, на котором можно прочитать все необходимое.
Текстовое отображение планов выполнения
В этом случае необходимо поместить запрос в окно Query в SQL Server Query
Analyzer после оператора SET SHOWPLAN_TEXT ON и нажать кнопку Execute Query.
SET SHOWPLAN_TEXT ON
GO
SELECT E.First_Name. E.Last_Name E.Salary. LE.Description.
M.First_Name. M.Last_Name. LM.Description
FROM Locations LE. Locations LM. Employees M. Employees E
WHERE E.Last_Name = 'Stevenson'
AND E.Manager_ID=M.Employee_ID
AND E.Location_ID=LE.Location_ID
AND M. Locati on_ID=LM. Locati on_ID
AND UPPER(LE.Description) = 'SAN FRANCISCO'
ПРИМЕЧАНИЕ -----------------------------------------------------------------------
Если вы работаете в Sybase, просто замените выражение SHOWPLAN_TEXT словом SHOWPLAN. Если вы хотите
получить более подробный план выполнения, в Microsoft SQL Server также можно использовать опе-
ратор SHOWPLAN ALL.
Если выполнить предыдущие команды на пустых таблицах, но иметь при этом
статистику, то в окне результатов появится следующий выход (несущественный
текст я заменил знаком многоточия и, чтобы выход помещался на страницу, доба-
вил выражение (wrapped line), указывая, что строка продолжается):
StmtText
SELECT Е.First_Name. E.Last_Name. Е.Salary. LE.Description.
M.First_Name. M.Last_Name. LM.Description
FROM Locations LE. locations LM. Employees M. Employees E
90
3. Просмотр и интерпретация планов выполнения
WHERE E.Last_Name = 'Stevenson'
AND E.Manager_ID=M.Employee_ID
AND E.Location_ID=LE.Location_ID
AND M.Location_ID=LM.Location_ID
ANO UPPERdE.Description) = 'SAN FRANCISCO'
(1 row(s) affected)
StmtText
(--Bookmark Lookup(B00KMARK:([Bmkl001]). OBJECT:([my_acct].[dbo].[Locations] AS [LM]))
|--Nested Loops!Inner Join)
| -Bookmark Lookup!.. (...[Employees] AS [M]))
| |--Nested Loops!Inner Join)
|--Filter(WHERE:(upper![LE].[Description])=
(wrapped line) 'SAN FRANCISCO'))
| | (--Bookmark Lookup!...(...[Locations] AS [LE]))
(--Nested Loops!Inner Join)
|--Bookmark Lookup!...(.. [Employees]
(wrapped line) AS [E]))
| | | (--Index Seek!...(...[Employees].
(wrapped line) [Emp_Last_Name] AS [E]). SEEK:([E].[Last_Name]='Stevenson')
(wrapped line) ORDERED)
| ( (--Index
(wrapped line) Seek!.. ( ..[Locations],[Location_PKey]
(wrapped line) AS [LE]). SEEK:([LE] [Location_ID]=[E].[Location_ID])
(wrapped line) ORDERED)
| (--Index Seek!...(...[Employees].[Employee_PKey]
(wrapped line) AS [M]), SEEK:([M],[Employee_ID]=[E].[Manager_ID]) ORDERED)
|--Index Seek!...(...[Locations].[Location_PKey]
(wrapped line) AS [LM]). SEEK:([LM].[Location_ID]=[M].[Location_ID])
(wrapped line) ORDERED)
(12 row(s) affected)
После первого выполнения анализа запроса две верхние строки, активизирую-
щие выражение SHOWPLAN_TEXT, более не требуются. Для всех следующих запросов
будут показаны только планы, пока вы не щелкнете по кнопке Query Analyzer
Execute Query, чтобы выполнить следующую команду:
SET SHOWPLAN_TEXT OFF
GO
Как интерпретировать план
План выполнения читается следующим образом.
Все соединения проводятся при помощи вложенных циклов, на что указывает груп-
па строк с выражением Nested Loopsdnner Join). Если вы используете различные
методы соединения, первым будет выполнено соединение, находящееся максималь-
но глубоко. Порядок выполнения соединений следует читать снизу вверх.
Порядок доступа к таблицам: Employees (Е), Locations (LE), Employees (М), Locations
(LM) — в выходе плана выполнения они перечислены в обратном порядке. Если
SQL-сервер обращается к одной таблице несколько раз, необходимо указывать
псевдонимы для этой таблицы. Так как в плане выполнения псевдонимы ука-
заны явно, нет никакой неопределенности относительно того, какой шаг вы-
полняется для какого псевдонима.
Чтение планов выполнения в SQL Server
91
Все четыре операции считывания из таблиц производятся при помощи индек-
са, на что указывает фраза Bookmark Lookup перед именами таблиц. Используе-
мые индексы указаны ниже в строках с таким же отступом, что и соответствую-
щие строки Bookmark Lookup. Так, вы видите, что к ведущей таблице Е доступ
осуществляется путем сканирования диапазона индекса EMPLOYEE_LAST_NAME (при-
чем считывание хотя бы потенциально затрагивает несколько строк за раз).
Доступ к остальным таблицам выполняется как уникальные считывания по
первичным ключам таблиц. Так как все операции считывания, которые выполня-
ются после обработки ведущей таблицы, относятся к уникальным соединениям,
вы знаете, что максимальное количество строк, которые запрос может считать из
любой таблицы, равно количеству строк, считанных из ведущей таблицы.
Когда вам встречается сканирование индекса, условие, следующее за именем
индекса, объясняет, диапазон какого размера будет охвачен сканированием. Если
необходимо узнать, какие еще индексы существуют для таблицы, то проще всего
использовать хранимую процедуру sp hel pi ndex. Результат выполнения такой ко-
манды выглядит следующим образом:
sphelpindex Employees
indexname index_description 1ndex keys
Employee Manager ID nonclustered located on PRIMARY Manager ID
Employee Last Name nonclustered located on PRIMARY Last Name
Employee Location ID nonclustered located on PRIMARY Location ID
Employee Department ID nonclustered located on PRIMARY Department ID
Employee Hire Date nonclustered located on PRIMARY Hire Date
Employee PKey nonclustered, unique located on PRIMARY Employee ID
Employee First Name nonclustered located on PRIMARY First Name
Empl oyeeNi ckname nonclustered located on PRIMARY Nickname
Если индекс охватывает несколько столбцов, они перечислены по порядку
в столбце indexkeys. Также получить полное описание таблицы с полным спис-
ком индексов таблицы можно при помощи sp_hel р.
Интерпретация плана выполнения
Я объяснил, как узнать порядок соединения, методы соединения и методы досту-
па к таблицам для надежного плана выполнения, показанного ранее. Если вы объе-
дините эти знания с основами, изложенными в главе 2, то сможете понять, как
SQL Server обращается к данным, от начала до конца. Чтобы проверить ваше по-
нимание, попробуйте изложить полный план выполнения на обычном языке, как
набор инструкций для базы данных. Сравните ваши результаты со следующим
изложением. Если возникло слишком много разногласий, попробуйте еще раз после
того, как прочитаете еще несколько планов выполнения, чтобы проверить, насколь-
ко углубилось понимание. Далее план выполнения описан в повествовательной
форме, как инструкции для базы данных.
1. Используя условие Е. Last Name = ’ Stevenson', перейти к индексу EMPLOYEELASTJWIE
и найти список идентификаторов строк, соответствующих сотрудникам с за-
прошенной фамилией.
2. Для каждого идентификатора строки из предыдущего шага считать один блок
(логическое считывание; если требуется, физическое) из таблицы Empl oyees (Е),
92
3. Просмотр и интерпретация планов выполнения
используя ту часть идентификатора, где хранится адрес блока. Используя ту
часть идентификатора, где хранится адрес строки, найти определенную строку,
на которую указывает идентификатор, и считать из нее все необходимые дан-
ные (запрошенные для псевдонима Е).
3. Для каждой такой строки, используя условие соединения Е.Location_ID4_E. Lo-
cati on_ID, перейти к индексу по первичному ключу LOCATION_PKEY и найти один
подходящий идентификатор строки, соответствующий записи о местоположе-
нии для сотрудника, чью запись вы уже считали Если подходящей строки не
найдено, отбросить результирующую строку, которая строится в данный мо-
мент.
4. В ином случае для подходящего идентификатора строки из предыдущего шага
считать один блок (логическое считывание; если необходимо, физическое) из
таблицы Locations (LE), используя ту часть идентификатора, где хранится адрес
блока. Используя идентификатор, хранящий адрес строки, найти определен-
ную строку, на которую указывает данный идентификатор, и считать из нее все
необходимые данные (запрошенные для псевдонима LE). Присоединить подхо-
дящие данные к входной строке, полученной при предыдущем считывании из
таблицы, чтобы построить частичную результирующую строку.
5. Для каждой такой строки отбросить всю результирующую строку, если ее дан-
ные не отвечают условию UPPER(LE.Description) = 'SAN FRANCISCO'.
6. Для каждой оставшейся строки, используя условие соединения Е. Manager_ ID=M.
Employee_ID, перейти к индексу по первичному ключу EMPLOYEE_PKEY и найти един-
ственный подходящий идентификатор строки, соответствующий записи сотруд-
ника, для менеджера того сотрудника, запись которого вы уже считали. Если
подходящей строки не найдено, отбросить результирующую строку, которая
строится в данный момент.
7. В ином случае для подходящего идентификатора строки из предыдущего шага
считать один блок (логическое считывание; если требуется, физическое) из таб-
лицы Empl oyees (М), используя ту часть идентификатора, где хранится адрес блока.
Используя ту часть идентификатора, где хранится адрес строки, найти опреде-
ленную строку, на которую указывает идентификатор, и считать из нее все не-
обходимые данные (запрошенные для псевдонима М). Присоединить подходя-
щие данные ко входной строке, полученной при предыдущих считываниях из
таблиц, чтобы создать частичную результирующую строку.
8. Для каждой такой строки, используя условие соединения М. Locati on_ID = LM Lo-
cation_ID, перейти к индексу по первичному ключу LDCATION_PKEY и найти един-
ственный подходящий идентификатор строки, соответствующий записи о мес-
тоположении для менеджера сотрудника, чью запись вы уже считали. Если
подходящей строки не найдено, отбросить результирующую строку, которая
строится в данный момент.
9. Иначе для подходящего идентификатора строки из предыдущего шага считать
один блок (логическое считывание; если требуется, физическое) из таблицы
Locations (LM), используя ту часть идентификатора, где хранится адрес блока.
Используя ту часть идентификатора, где хранится адрес строки, найти опреде-
ленную строку, па которую \ казы в идентификатор строки, и считать из нее
все необходимые данные (заирош. шые для псевдонима LM). Присоединить
Чтение планов выполнения в SQL Server
93
подходящие данные ко входной строке, полученной при предыдущих считыва-
ниях из таблиц, чтобы завершить и немедленно возвратить полностью постро-
енную результирующую строку.
Интерпретация ненадежных планов выполнения
В планах выполнения часто используются методы соединения, отличные от вло-
женных циклов, — особенно это касается «сырых» планов, которые вам потребу-
ется настроить. Далее я покажу вам пример, где вместо надежных соединений со
вложенными циклами выполняются соединения хэшированием. Если удалить все
индексы и добавить в конце запроса подсказку OPTION!HASH JOIN), SQL Server со-
здаст новый план выполнения:
StmtText
SELECT Е.First_Name. E.Last_Name. E.Salary. LE.Description.
M.First_Name. M Last_Name. LM.Description
FROM Locations LE. Locations LM. Employees M. Employees E
WHERE E.Last_Name = 'Stevenson'
AND E.ManagerID=M.Employee_ID
AND E.Location_ID=LE.Location_ID
AND M.Location_ID=LM.Location_ID
AND UPPER(LE.Description) - 'SAN FRANCISCO'
OPTIONCHASH JOIN)
(1 row(s) affected)
StmtText
| - Hash Matchdnner Join. ... ([LM], [Location_ID])=([M] ,[Location_IDJ)....)
|--Table Scan! ..(...[Locations] AS [LM]))
I--Hash Matchdnner Join.
(wrapped line) ...([М].[Employee_ID])=([E],[Manager_ID])....)
|--Table Scan(...(...[Employees] AS [M]))
I--Hash Matchdnner
(wrapped line) ...([E] [Location_ID])=([LE].[Location_ID])....)
|--Table Scan(. .( .[Employees] AS [E]).
(wrapped line) WHERE:([E].[Last_Name]='Stevenson'))
| —FlItertWHERE: (upper([LE].[Description])=
(wrapped line) 'SAN FRANCISCO'))
[--Table Scan(...(...[Locations] AS [LE]))
(8 row(s) affected)
Здесь любой доступ к таблице выполняется путем полного сканирования таб-
лицы. Запрос начинает выполняться на LE и отфильтровывает местоположения
с подходящим описанием. Следующая таблица, к которой производится доступ, —
это Е, из которой отфильтровываются сотрудники с подходящей фамилией. Полу-
ченные из этих двух таблиц строки хэшируются и соединяются. Затем результат
соединяется хэшированием с результатом полного сканирования М и, в итоге, с ре-
зультатом полного сканирования LM.
Сложные планы выполнения
Существуют и другие возможности планов выполнения, например индикаторы,
указывающие, какие из соединений являются внешними, перечисление шагов сор-
94
3. Просмотр и интерпретация планов выполнения
тировки и операторов, обеспечивающих уникальность сортировки, которые уда-
ляют дубликаты. С ними вы встречаетесь часто, но назначение этих функций ин-
туитивно понятно и они не столь важны для производительности. Однако есть и
важная для нас тонкость, с которой вы также часто будете иметь дело. Она отно-
сится к подзапросам. Я продемонстрирую ее в следующем примере:
SELECT E.First_Name, Е.Nickname. E.LastName.
E.Phone_Number. L.Description
FROM Employees E
INFER JOIN Locations L DN E.Location_ID=L.Location_ID
WHERE (E.First_Name= ? OR E.Nickname= ?)
AND EXISTS (SELECT 1 FROM Wage_Payments P
WHERE P.Employee_ID=E.Employee_ID
AND P.Payment_Date > CURRENT DATE - 31 DAYS):
Оставьте все таблицы пустыми. Создайте следующие индексы.
Employees(First_Name)
Employees(Nickname)
Locations!Location_ID)
Wage_Payments(Employee_ID)
Будет создан следующий план выполнения:
StmtText
SELECT E.First_Name, E.Nickname, E.Last_Name,
E.Phone_Number, L.Description
FROM Employees E. Locations L
WHERE (E.First_Name=‘Kathy' OR E.Nickname='Kathy')
AND E.Location_ID=L.Location_ID
AND EXISTS (SELECT null
FROM Wage_Payments P
WHERE P.Employee_ID=E.Employee_ID
AND P.Payment_Date > DATEADD(DAY.-31.GETDATE! )));
(1 row(s) affected)
StmtText
(--Nested Loops(Left Semi Join)
|-Filter(WHERE:([EJ.[FirstJame]='Kathy' OR [E].[Nickname]='Kathy'))
(--Bookmark Lookup([Employees] AS [E]))
(--Nested Loops(Inner Join)
(--Table Scan(...(...[Locations] AS EL]))
| - -Index Seek(...[Employees].[Employee Location lD]
(wrapped line) AS [E]), SEEK:([E].[Location_ID]=[L].[Location_ID]) ORDERED)
|--Filter(WHERE:([P].[Payment_Date]>dateadd(4. -31. getdate( ))))
(--Bookmark Lookup![Wage_Payments] AS [P]))
|--Index
(wrapped line) Seek(...(...[Wage_Payments].[Wage_Payment_Employee_ID]
(wrapped line) AS [P])_ SEEK;([P].[Employee_ID]=[E].[Employee_IDl) ORDERED)
(9 row(s) affected)
Этот план выполнения демонстрирует полное сканирование таблицы Locations
как ведущей таблицы, так как к ней производится первое обращение на самом глу-
боком уровне вложенности. Затем SQL Server выполняет вложенные циклы по
индексу по внешнему ключу Employee_Location_ID, чтобы присоединить Employees.
Чтение планов выполнения в SQL Server 95
После обработки таблицы Empl oyees SQL Server отбрасывает строки, не удовлетво-
ряющие условию для полей Fi rst_Name и Nickname. Далее выполняется специальное
соединение, называемое полусоединением, чтобы достигнуть коррелированного
подзапроса на присоединение подходящих записей из Employee lD с использовани-
ем индекса Wage_Payment_Empl oyee_ID. При помощи идентификаторов строк из этого
индекса производится обращение к Wage_Payments, после чего условие последнего
фильтра по Payment Date отбрасывает старые строки, не удовлетворяющие подза-
просу EXISTS. Соединение с коррелированным подзапросом EXISTS показано в са-
мом первом шаге, который описан как Left Semi Joi п. Этот результат не является
оптимальным планом выполнения для заполненных таблиц, но так как тестирова-
ние проводилось на пустых таблицах, я бы и не ожидал появления плана исполне-
ния, подходящего для больших объемов данных.
4
Управление планами
выполнения
В этой главе рассматриваются два способа настройки планов выполнения. Мы рас-
смотрим универсальные техники, которые работают в любых базах данных, и спо-
собы работы, подходящие для конкретных серверов баз данных. Индивидуальные
техники хорошо описаны в соответствующей документации, поэтому вы, возмож-
но, уже знакомы с ними. В общем случае для получения в точности желаемого
плана выполнения вам понадобятся оба варианта способов настройки. В этой гла-
ве предусмотрены отдельные разделы, посвященные техникам настройки, прису-
щим различным серверам баз данных, причем одинаковая информация в них может
повторяться. Поэтому вы можете пропустить разделы, которые вас не интересуют.
Для управления планами выполнения было придумано множество сложных
инструментов. Эта глава сосредоточена на простейших способах управления пла-
нами, с акцентом на получение планов таких типов, которые вам понадобятся для
оптимизации реального SQL. Я обнаружил, что если заранее знать, какой план
выполнения вы хотите получить, то процесс существенно упрощается и требует
лишь простейших инструментов.
Универсальные техники
управления планами
В этом разделе описано несколько независимых от используемого сервера баз дан-
ных техник управления планами выполнения. Эти методы удобно использовать
для следующих целей.
Использовать правильный индекс.
Запретить использование неподходящих индексов.
Использовать желаемый порядок соединения.
Запретить соединения в неправильном порядке;
Выбрать порядок выполнения внешних запросов и подзапросов.
Предоставить оптимизатору верные данные для анализа.
Нагрузить стоимостный оптимизатор плохими данными.
Эти способы часто являются хорошей альтернативой специальным методам для
достижения желаемых планов выполнения. Если у вас есть выбор, какую технику
Универсальные техники управления планами
97
применить, то специализированные методы обычно проще и понятней. Но суще-
ствуют проблемы, решаемые только универсальными техниками, которые предла-
гают решения, подходящие для SQL-запросов в базах данных самых различных
производителей.
Использование правильного индекса
Чтобы добиться эффективного использования индекса, вам необходимо разумное
селективное условие по ведущему (или единственному) столбцу индекса. Усло-
вие также должно быть выражено таким способом, который позволяет базе дан-
ных выделить достаточно узкий диапазон индексных значений. В идеальном слу-
чае условие принимает форму:
НекоторыйПсевдоним.Ведущий_индексированный_столбец - <Выражение>
В менее удачном случае сравнение выполняется с некоторым диапазоном зна-
чений при помощи операторов BETWEEN, LIKE, <, >, <= или >-. Сравнения по диапа-
зону значений потенциально позволяют использовать индекс, но диапазон индекса,
вероятнее всего, будет больше, и результирующий запрос будет работать медлен-
нее. Если диапазон индексированных значений слишком большой, оптимизатор
может сделать вывод, что индекс использовать не стоит, и выберет другой путь
доступа к данным. Если вы комбинируете условия равенства и поиска в диапазоне
для многостолбцовых индексов, следует предпочесть индексы, ведущими в кото-
рых являются столбцы, для которых указаны условия равенства. Столбцы, на ко-
торые наложены условия диапазона значений, должны находиться в конце индек-
са. Обратите внимание, что в левой части сравнения просто указано имя столбца,
без применения к нему функции и безо всяких выражений (например, сложения)
с использованием этого столбца. Использование функции, преобразования типов
или арифметического выражения для индексированного столбца в общем случае
приведет к невозможности использования индекса.
Преобразования типов — это особенно тонкий момент. Из-за них SQL-сервер
иногда отказывается от использования индекса. DB2 возвращает ошибку при по-
пытке сравнить два выражения несовместимых типов. SQL Server предпочитает
выполнить неявное преобразование той стороны сравнения, которая не приведет
к невозможности использования индекса. Oracle неявно преобразует выражения сим-
вольного типа в тот тип данных, который используется запросом, даже если это по-
влечет за собой отключение индекса. Например, рассмотрим такое выражение:
Р.Phone_Number=5551212
Если Phone_Number — столбец символьного типа, то на внутреннем уровне в Oracle
и SQL Server это выражение будет преобразовано по-разному.
В Oracle мы получим выражение TO_NUMBER(P. Phone_Number)=5551212
В SQLServer: P.Phone_Number=CAST(5551212 AS VARCHAR)
SQL Server сохраняет индексированный доступ к столбцу в результате произве-
денного преобразования. В Oracle неявное применение операции TO_NUMBER() сдела-
ет невозможным использование индекса точно так же, как если бы вы указали это
выражение явно. На самом деле разница лишь в том, что неявную форму приведения
типов обнаружить сложнее. Та же проблема может помешать использовать индексы
для соединений и для однотабличных условий. Например, возьмем соединение:
Р. Phone_Nurnber-C. Contact_Number
98
4. Управление планами выполнения
Если Contact_NurTiber принадлежит числовому типу, a Phone_Number — символь-
ному, то неявное преобразование в Oracle запрещает использовать вложенные
циклы по индексу для соединения С с Р. Соединение в обратном порядке пройдет
беспрепятственно. Выражение напротив упоминания индексированного столб-
ца может быть сколь угодно сложным. Но в нем не должны упоминаться столб-
цы с тем же псевдонимом, который указан для индексированного столбца. На-
пример:
P.Phone_Number=P.Area_Code| | '5551212'
База данных не может использовать с этим условием индекс по Р. Phone_Number,
так как она должна обратиться к псевдониму Р до того, как сможет оценить выра-
жение в правой части. Эта проблема яйца и курицы не позволяет обнаружить (с ис-
пользованием индекса) то подмножество таблицы, которое отвечает условию, пока
база данных не проверит таблицу полностью.
Есть еще один случай, когда SQL зачастую запрещает использовать индекс —
когда условия соединены оператором OR. Рассмотрим, например такой запрос:
SELECT ...
FROM Order_Details D.
WHERE ...
AND (D.Order_ID=:l or :1 IS NULL)
AND ...
В этом примере база данных может обратиться к Order_Detai 1 s при помощи ин-
декса по Order_ID, если параметр : 1 не равен nul 1. Но если параметр : 1 все же при-
нимает значение null, то никаких ограничений для Order_ID не остается и индекс
не используется. Так как во время разбора SQL и подготовки плана база данных не
может предсказать, какое именно значение будет у параметра : 1, она не увидит
никакой подходящей возможности использовать индекс. В этом случае хорошим
решением будет создание плана из двух частей, где каждая часть будет оптимизи-
рована для одного из возможных случаев:
SELECT ...
FROM Order_Details D.
WHERE ...
AND D.Drder_ID=:l
AND :1 IS NOT NULL
AND
UNION ALL
SELECT ...
FROM Order_Details D.
WHERE ..
AND :1 IS NULL
AND ...
Когда вы просматриваете план выполнения для этого запроса, вы видите, что ис-
пользуется индексированный доступ при помощи индекса по Order_Detai 1 s(Order_ID)
и доступ с полным сканированием таблицы к Order_Detai 1 s. Это может показаться
наихудшим решением, но вы защищены дополнительными условиями.
AND :1 IS NOT NULL
AND :1 IS NULL
В этих условиях нет никакого обращения к данным базы, поэтому она оценива-
ет условия перед тем, как начинает считывать данные для этой половины комби-
Универсальные техники управления планами
99
нированного оператора. Таким образом, на самом деле она никогда не выполняет
полное сканирование таблицы, если значение параметра : 1 не равно null, и никог-
да не выполняет индексированное считывание (и любую другую часть плана вы-
полнения для первой половины запроса), если значение параметра :1 равно null.
Так описывается метод разветвления плана выполнения в зависимости от усло-
вий по параметрам, которые определяют, какие данные будут использоваться для
выполнения запроса. Единственная хитрость: вы должны убедиться, что условия
по связанным переменным взаимно исключают друга, чтобы данные возвращались
только из одной ветви плана выполнения. Например, если у вас есть другой пара-
метр для определения Customer_Name, вы можете собрать запрос так:
SELECT ...
FROM Order_Details D. Customers C. ...
WHERE ...
AND D.OrderJD-:l
AND :1 IS NDT NULL
AND (C.Customer_Name=:2 DR :2 IS NULL)
AND
UNION ALL
SELECT ...
FROM Order_Details D. Customers C.
WHERE ...
AND :1 IS NULL
AND :2 IS NOT NULL
AND C.Customer_Name=:2
AND ...
UNION ALL
SELECT ...
FROM Order Details D. Customers C.
WHERE ...
AND :1 IS NULL
AND :2 IS NULL
AND ...
В итоге получается план из трех частей, в котором сервер баз данных выполня-
ет несколько операций.
1. Обращается к таблице Orders через индекс по Order_ID (первый вариант), когда
это возможно.
2. В ином случае обращается к таблице Customers при помощи индекса по полю
Customer_Name (второй вариант), если Order_ID не указан, но указано имя покупа-
теля.
3. Если оба предыдущих варианта не подходят, сервер просто получает все стро-
ки — вероятно, начиная с полного сканирования таблицы, если нет никаких се-
лективных условий.
В любом случае условия для связанных переменных во всех трех частях явля-
ются взаимоисключающими:
AND :1 IS NOT NULL
AND :1 IS NULL
AND :2 IS NOT NULL
AND :1 IS NULL
AND :2 IS NULL
100
4. Управление планами выполнения
Запрещение использования
неправильных индексов
Выражения для соединений обычно просты и выполняются на совместимых ти-
пах, например числовых идентификаторах. Условия для основной таблицы в дан-
ном случае также достаточно просты и позволяют использовать индекс. Более рас-
пространенная задача, чем принудительное использование правильного индекса
при обработке запроса, — это запрещение использования неправильного индекса.
Во многих запросах присутствует множество однотабличных условий, которые
разрешают использовать различные индексы, но вы хотите применить единствен-
ный из них, который позволит выполнить запрос максимально быстро. Условия
соединения обычно выражены так, чтобы разрешить соединения с использовани-
ем индекса в обоих направлениях, хотя лишь одно из возможных направлений со-
единения оказывается оптимальным. Иногда лучше полностью запретить исполь-
зовать индекс при соединении, чтобы реализовать соединение хэшированием или
сортировкой слиянием.
Чтобы запретить использование индекса, создайте простейшее из возможных
выражений при упоминании индексированного столбца. Например, вам нужно
предотвратить использование индекса по Status_Code для недостаточно селектив-
ного условия по закрытым заказам, так как с течением времени количество за-
крытых заказов будет все существенней превышать количество открытых зака-
зов:
O.Status_Code='CL'
Так как Status_Code — это столбец символьного типа, простейшим выражением,
запрещающим использование индекса без изменения результатов, будет простое
присоединение пустой строки к концу Status_Code.
В Oracle и DB2 мы можем использовать выражение O.Status_Code| |CL'
В SQL Server будет применяться выражение 0. Status_Code+ "=' CL'
Для столбцов числового типа можно прибавить 0, получив следующее усло-
вие:
0.Region_ID+0=137
Во всех базах данных есть функции определенного вида, значение которых при-
равнивается к первому аргументу, если он не равен nul 1, а в противном случае —
ко второму аргументу. В Oracle это функция NVLO. В SQL Server и DB2 это
COALESCE(). Если оба аргумента выражения оперируют данными одного и того же
поля, функция всегда возвращает один и тот же результат в виде самого столбца,
независимо от его типа. Таким образом, мы получаем простой способ отключения
использования индекса независимо от типа столбца.
Для Oracle зто будет выражение: NVL (O.Order_Date.O.Order_Date) = <3начение>
В DB2 и SQL Server для достижения той же цели придется использовать выра-
жение: COALESCE (0. Order_Date. 0.0rder_Date)=<3Ha4e/we>
Условие для соединения, запрещающее индексированный доступ к 0. Reg 1 on_ID
(но не к R. Regi on_ID) может выглядеть следующим образом:
О.Regi on_ID+0=R.Regi on_ID
Используя универсальный подход, то же соединение можно записать так:
NVL(0.Regi on_ID.О.Regi on_ID)=R.Regi on_ID
Универсальные техники управления планами
101
Использование желаемого порядка соединения
Кроме непредумышленного запрещения использования индексов, есть еще два
случая, когда бывает невозможно провести соединение в нужном порядке.
Использование внешних соединений.
Отсутствие избыточных условий соединения.
Внешние соединения
Рассмотрим запрос с внешним соединением в записи Oracle:
SELECT ...
FROM Employees E. Locations L
WHERE E.Locati on_ID=L.Location_ID(+)
или в новом варианте записи операторов:
SELECT ...
FROM Employees Е LEFT OUTER JOIN Locations L
ON E.Location_ID4_.Location_ID
Этот запрос получает записи сотрудников и соответствующие им записи об их
местоположении. Если для сотрудника не указано местоположение, то использу-
ется значение nul 1. Основываясь на этом запросе, легко понять, что он не может
эффективно работать, начиная с таблицы Locations и переходя к Employees, так как
требуются даже те сотрудники, для которых местоположение не указано. Пред-
ставьте случай, когда этот запрос является лишь шаблоном, к которому приложение
добавляет условия, зависящие от критерия поиска, заданного конечным пользова-
телем. Если пользователю требуются сотрудники с определенным местоположе-
нием, приложение может создать такой запрос:
SELECT ...
FROM Employees Е LEFT OUTER JOIN Locations L
ON E Location_ID=L.Location_ID
WHERE L.Descri pti on='Headquarters'
В случае внешнего соединения в порядке от Employees к Locations полю L.De-
scription будет присвоено значение null и условие для L.Description будет лож-
ным. Только внутреннее соединение вернет строки, которые отвечают ограниче-
ниям для L. Descri pti on, поэтому имеет смысл изменить порядок соединения на
противоположный, от Locations к Employees. Однако существование внешнего со-
единения часто не позволяет автоматическому оптимизатору выбрать обратный
порядок для внешнего соединения, поэтому это соединение необходимо явно сде-
лать внутренним, чтобы добиться нужного порядка:
SELECT ...
FROM Employees Е INNER JOIN Locations L
ON E.Location_ID=L.Location_ID WHERE L.Description='Headquarters'
Отсутствие избыточных условий соединения
Обычно в SQL-запросе между любым количеством таблиц количество соедине-
ний на единицу меньше количества таблиц. Например, между тремя таблицами
вы ожидаете увидеть два соединения. Иногда запрос позволяет использовать до-
полнительное, избыточное соединение. Например, если у вас есть таблица Addresses,
в которой хранятся все адреса, важные для компании, то между ней и таблицей
Locations может существовать отношение вида «один к нулю» или «один к одно-
102
4. Управление планами выполнения
му». В таблице Locations хранятся только местоположения, принадлежащие ком-
пании, и она связана с Addresses через одинаковые первичные ключи. В этом слу-
чае может иметь место такой запрос:
SELECT ...
FROM Employees Е. Locations L. Addresses A
WHERE E.Locati on_ID=L.Locati on_ID
AND E.Location_ID=A.Address_ID
AND A.ZIP_Code=95628
По свойству транзитивности (если a=b и b=c, то а=с) условие L. Locati on_ID=A.
Address_ID должно быть истинным для всех строк, которые вернет запрос. Однако
это условие не указано в запросе явно, и не все базы данных смогут вывести его и
подставить в запрос. В этом случае лучшим планом будет взять все адреса с дан-
ным почтовым индексом и сразу же соединить их с Locati ons, чтобы отбросить все
адреса кроме одного или двух, соответствующих адресам компании, а затем соеди-
нить с Employees. Так как этот порядок соединения требует отсутствующего усло-
вия соединения, позволяющего использовать индексированный путь от Addresses
к Locations, необходимо явно указать отсутствующее условие соединения:
FROM Employees Е, Locations L. Addresses A
WHERE E.Location_ID=L.Locati on_ID
AND E.Location_ID=A.Address_ID
AND L.Location_ID=A.Address_ID
AND A.ZIP_Code=95628
Так как вы не хотите использовать соединение от Addresses к Employees напря-
мую, можно также удалить, если необходимо, избыточное условие соединения
Е. Location_ID=A.Address_ID, запретив нежелательную операцию соединения.
Запрещение соединения в неправильном порядке
Задание соединений в желаемом порядке с применением описанных способов
предотвращения использования неправильных индексов также поможет запретить
проводить соединения в нежелательном порядке. Что следует делать, если вы хо-
тите, чтобы база данных создала некое соединение в определенном порядке не слиш-
ком рано в плане выполнения? Нельзя запрещать использовать индекс, поскольку
однажды он может понадобиться, просто не очень скоро. Рассмотрим два соедине-
ния, в которых вы хотите, чтобы запрос начал со считывания из Т1, затем соединил
результат с Т2, и затем с ТЗ:
... AND Tl.Key2_ID=T2.Key2_ID
AND Т1.Key3_ID=T3.Key3_ID ...
В данном случае требуется, чтобы вложенные циклы отработали на Т2 и ТЗ по
индексам в указанных ключах и к Т2 обращение проводилось до обращения ТЗ.
Чтобы отложить соединение на время, необходимо сделать так, чтобы оно зависе-
ло (или хотя бы казалось, что оно зависит) от данных соединения, выполненного
раньше. Вот как выглядит подходящее решение этой проблемы:
AND Tl.Key2_TD=T2 Key2_ID
AND Tl.Key3_ID+0*T2.Key2_ID=T3.Key3_ID ...
Мы знаем, что второй вариант логически эквивалентен первому. Однако база
данных находит в левой части второго соединения выражение, которое зависит от
Т1 и Т2 (не понимая, что значения из Т2 не могут изменить результат), поэтому она
не будет пытаться выполнить соединение с ТЗ до соединения с Т2.
Универсальные техники управления планами
103
Если необходимо, можно подобным образом связать все соединения, чтобы пол-
ностью контролировать порядок соединения. Для каждого соединения, следующего
за первым, добавьте к выражению соединения логически несущественный компо-
нент, который ссылается на один из столбцов, добавленных в предыдущем соедине-
нии. Например, если вы хотите, чтобы обращения к таблицам с Т1 по Т5 шли по по-
рядку, можно использовать следующий код. Обратите внимание, что в условии
соединения для таблицы ТЗ используется выражение 0*Т2. Кеу2_10, чтобы сначала было
выполнено соединение с Т2. Подобным образом в условии соединения для таблицы
Т4 используется 0*13. КеуЗ_10, чтобы сначала было выполнено соединение с ТЗ.
... AND Tl.Key2_ID=T2.Key2_ID
AND Tl.Key3_ID+0*T2.Key2_ID = T3.Key3_ID
AND Tl.Key4_ID+0*T3.Key3JD = T4.Key4_ID
AND Tl.Key4_ID+0*T4.Key4_ID = T5.Key5_ID ...
Я воспользуюсь этим методом на конкретном примере. Возьмем из главы 3 сле-
дующий SQL-код.
SELECT E.First_Name. E.Last_Name Е.Sal ary. LE.Description.
M.First_Name. M.Last_Name. LM.Description
FROM Locations LE. Locations LM. Employees M. Employees E
WHERE E.Last_Name = 'Johnson'
AND E.Manager_ID = M.Employee_ID
AND E.Location_ID = LE.Locat1on_ID
ANO M.Location_ID - LM.Location_ID
AND LE.Description = 'Dallas'
Предположим, что у нас есть план выполнения, который начинает с индекса по
фамилии сотрудников, но вы обнаружили, что соединение с местоположением
сотрудников (псевдоним LE), чтобы отбросить всех сотрудников, не находящихся
в Далласе (Dal 1 as), к сожалению, происходит в последнюю очередь, после осталь-
ных соединений (с М и LM). Необходимо присоединить LE сразу же после Е, чтобы
минимизировать количество строк, которое потребуется соединить с остальными
двумя таблицами. Если начать с Е, то сразу же выполнить соединение с LM невоз-
можно, поэтому если вы запретите соединение с М перед LE, то должны получить
желаемый порядок соединения. Как это сделать:
SELECT E.First_Name. E.Last_Name, Е.Salary. LE.Description.
M.First_Name. M.Last_Name. LM.Description
FROM Locations LE. Locations LM, Employees M. Employees E
WHERE E.Last_Name = 'Johnson'
AND E.Manager_ID + O*LE.Location_ID=M.Employee_ID
AND E.Location_ID = LE.Location_ID
AND M.Location_ID = LM.Location_ID
AND LE.Description = 'Dallas'
Смысл в том, что я сделал соединение с М зависящим от значения из LE. Выра-
жение O*LE. Location_ID заставляет оптимизатор выполнить соединение с LE до М.
Благодаря умножению на ноль добавленное выражение не влияет на результаты,
возвращенные запросом.
Выбор порядка выполнения для внешних
запросов и подзапросов
Большинство запросов с подзапросами могут логически начинаться с внешнего
запроса или подзапроса. В зависимости от селективности условия подзапроса лю-
104
4. Управление планами выполнения
бой вариант может быть лучшим. Обычно проблема выбора встает для запросов
с условиями EXISTS и IN. Всегда можно преобразовать условие EXISTS для коррели-
рованного подзапроса в эквивалентное условие IN для не коррелированного под-
запроса и наоборот. Например, такой запрос:
SELECT ...
FROM Departments D
WHERE EXISTS (SELECT NULL FROM Employees E
WHERE E.Department_ID=D.Department_ID)
можно преобразовать в следующий код:
SELECT ...
FROM Departments D
WHERE D.Department_ID IN (SELECT E.Department-ID FROM Employees E)
Первая форма подразумевает, что база данных начинает с внешнего запроса и пе-
реходит к подзапросу. Для каждой строки, возвращенной внешним запросом, база
данных выполняет соединение в подзапросе. Вторая форма подразумевает, что
выполнение начинается со списка различных отделов, в которых существуют со-
трудники, найденные подзапросом, и переходит от этого списка к соответствую-
щему списку отделов во внешнем запросе. Иногда база данных сама использует
подразумеваемый порядок соединения, хотя некоторые базы данных могут неяв-
но выполнять преобразование, если оптимизатор обнаружит, что альтернативный
порядок лучше. Чтобы сделать SQL-код более удобочитаемым и заставить его хо-
рошо работать вне зависимости от того, может ли ваша база данных преобразовы-
вать формы, используйте ту форму записи запроса, которая явно указывает жела-
емый порядок установки соединений. Чтобы этот порядок выполнялся, даже если
база данных может провести преобразование, используйте те же техники выбора
направления соединения, которые были описаны в разделе «Запрещение соедине-
ния в неправильном порядке». Так, условие EXISTS, которое заставляет внешний
запрос выполняться первым, будет выглядеть так:
SELECT ...
FROM Departments D
WHERE EXISTS (SELECT NULL FROM Employees E
WHERE E.Department_ID=D.Department_ID+O)
Для противоположного порядка условие IN, заставляющее использовать дру-
гой порядок, от подзапроса к внешнему запросу, будет выглядеть так:
SELECT ...
FROM Departments D
WHERE D.Department_ID IN (SELECT E.Department_ID+O FROM Employees E)
ПРИМЕЧАНИЕ-------------------------------------------------------------------------------
Второй порядок соединения чаще всего будет работать плохо, за исключением необычных случаев, когда
отделов больше, чем сотрудников!
У вас может быть несколько подзапросов, в которых база данных должна пере-
ходить от внешнего запроса к подзапросу (например, для подзапросов NOT EXISTS)
или же ей следует придерживаться стандартного порядка. Такой случай подразу-
мевает выбор порядка выполнения подзапросов. Также вы можете оказаться пе-
ред выбором — выполнять ли подзапросы после завершения внешнего запроса, при
первой же возможности выполнить корреляционное соединение, либо принять
некое промежуточное решение.
Универсальные техники управления планами
105
Первая тактика управления порядком выполнения подзапросов — просто пе-
речислить их по порядку во фразе WHERE (то есть верхний подзапрос будет выпол-
нен первым). Это один из редких случаев, когда порядок во фразе WHERE имеет смысл.
Иногда база данных выполняет подзапрос раньше, чем вам хотелось бы. Для
коррелированных соединений — соединений в подзапросах, которые связывают
подзапросы с внешними запросами, — работает та же тактика: просто откладывать
соединения (см. раздел «Запрещение соединения в неправильном порядке»). На-
пример, рассмотрим запрос:
SELECT ...
FROM Orders 0. Customers C. Regions R
WHERE O.Status_Code = 'DP'
AND O.Customer_IO = C.Customer_ID
AND C.Customer_Type_Code •= 'GOV'
AND C.RegionJD = R.Region_ID
AND EXISTS (SELECT NULL
FROM Order_Details OD
WHERE O.OrderJD = OD.Order lD
AND OD.Shipped_Flag = 'Y')
Для этого запроса вы можете обнаружить, что подзапрос выполняется сразу
же, как только достигается соединение с ведущей таблицей Orders. Однако вы хо-
тите, чтобы до того, как потратиться на выполнение подзапроса, было выполнено
соединение с Customers и отброшены неправительственные заказы. В таком случае
для того, чтобы отложить корреляционное соединение, потребуются следующие
изменения кода:
SELECT ...
FROM Orders 0. Customers C. Regions R
WHERE O.StatusCode = 'OP'
AND O.Customer_ID = C.Customer_ID
AND C.Customer_Type_Code = 'GDV
AND C.Region_ID = R.Region_ID
AND EXISTS (SELECT NULL
FROM Order_Details OD
WHERE O.DrderJD + 0*C.Customer_ID = OD.Order_ID
AND OD.Shipped_Flag = 'Y’l
Обратите внимание на добавление +0*С. Customer lD к разделу WHERE подзапроса.
Это гарантирует, что соединение с Customers будет выполнено первым, до выпол-
нения подзапроса.
Предоставление стоимостному
оптимизатору хороших данных
В любом стоимостном оптимизаторе (то есть для любого запроса, кроме запроса,
выполняющегося с синтаксическим оптимизатором Oracle, так как только в Oracle
есть такой) вторая по распространенности причина появления плохих планов вы-
полнения после отсутствующих индексов — это отсутствие статистики по табли-
цам, столбцам и индексам, участвующим в запросе. В целом стоимостные оптими-
заторы безо всякой помощи справляются с работой по поиску наилучшего плана,
если у них есть хорошая начальная информация. Однако когда какой-либо инфор-
мации не хватает, например, из-за того, что таблица или индекс были перестроены,
а статистика не сгенерирована заново, оптимизатор может сделать просто ужас-
ные предположения, которые приведут к серьезной потере производительности.
106
4. Управление планами выполнения
Если вы работаете в любой базе данных кроме Oracle или если вы используете
стоимостный оптимизатор Oracle (он более распространен, и Oracle рекомендует
использовать его) и не включаете синтаксический оптимизатор принудительно,
то первое решение, которое вам следует попробовать, если вы не можете получить
желаемый план выполнения, — заново сгенерировать статистику по всем табли-
цам и индексам, относящимся к запросу. Стандартной статистики обычно хватает
для получения разумных планов выполнения.
Стоимостные оптимизаторы обычно предполагают, что данные распределены
единообразно. Например, если статистика оптимизатора показывает таблицу с
1 000 000 строк и 50 000 различных значений для некоторого индексированного
внешнего ключа, база данных будет проводить оптимизацию, предполагая, что каж-
дое значение ключа будет встречаться в точности в 20 строках. Для большинства
индексированных столбцов, таких как внешние ключи, такое предположение о
единообразном распределении данных работает хорошо. Однако в некоторых столб-
цах распределение данных достаточно несимметрично, например если в них хра-
нится состояние, код или тип, или же внешние ключи для статуса или типа таблиц.
Например, рассмотрим такой запрос:
SELECT ... FROM Orders WHERE Status_Code = ’OP'
В 1 000 000-строчной таблице Orders может быть лишь три или четыре разных
значения Status_Code, но если ' 0Р' означает открытый заказ, еще не выполненный
или отмененный, то это условие становится намного более селективным, чем оп-
тимизатор мог бы предположить, основываясь только на количестве различных
значений. Если для этого столбца существует индекс, оптимизатор может никогда
не задействовать его, поскольку будет знать лишь о небольшом количестве раз-
личных индексированных значений. Однако в некоторых базах данных можно сге-
нерировать дополнительную статистику, которая позволит базе данных узнать не
только количество различных значений, но также их распределение. Генерация
подобной статистики является необходимым шагом, когда в таблице присутству-
ют такие асимметричные распределения данных.
Обман стоимостного оптимизатора
плохими данными
Последняя техника опасна, и я рекомендую использовать ее только в качестве пос-
леднего средства. Иногда вам нужно имитировать большую базу данных на не-
большой, тестовой базе данных. Если вы можете экстраполировать (или, лучше,
измерить в реальной базе данных) статистику скорости выполнения запросов для
большой базы данных, то сумеете вручную изменить таблицы словаря данных, в ко-
торых хранится статистика для оптимизатора, чтобы обмануть оптимизатор и за-
ставить его думать, что он работает с крупной базой данных. Статистика неболь-
шой базы данных будет убеждать сервер, что он работает с большими таблицами,
содержащими большое количество различных значений для многих индексов. Это
удобный способ проверки планов выполнения, которые будут применяться к про-
мышленным объемам данных, когда у вас есть лишь тестовая база данных с «игру-
шечными» объемами. Для таких игрушечных баз данных в подобном подходе нет
никакого риска. В промышленных базах данных оптимизатор иногда будет делать
лучший выбор именно на фальшивых данных; обычно, если данные преувеличи-
Управление планами в Oracle
107
вают селективность нужных индексов или преувеличивают размер таблицы, ког-
да полное сканирование таблицы нежелательно.
Попробуйте мысленно перевернуть логику оптимизатора. Спросите: «Что я
должен знать о таблицах и индексах этого запроса, чтобы посчитать альтернатив-
ный план (альтернативу, которую хотите получить вы, человеческий оптимиза-
тор) намного более привлекательным?» Если предоставить оптимизатору невер-
ную статистику, то нетрудно будет обмануть его и заставить сделать то, что нужно
вам, а не то, что он выбрал бы самостоятельно. Но в промышленных системах это
опасно по нескольким причинам.
Как только кто-либо заново сгенерирует статистику для таблиц или индексов,
оптимизатор вернется к обычному способу действия, если только статистика
не будет настроена вручную. Для предотвращения таких ситуаций вам придет-
ся строго следить за генерированием статистики.
Когда оптимизатор базы данных будет улучшен, например в следующей вер-
сии, невозможно будет применить эти улучшения на правильных данных.
Что самое важное, любой другой запрос к таблицам и индексам с фальшивой
статистикой будет считаться рискованным и потенциально может быть повреж-
ден. И все только из-за того, что статистика была сфальсифицирована, чтобы
помочь одному запросу.
Мне никогда не требовалось применять этот способ для получения адекватно-
го оптимизированного плана в Oracle, SQL Server или DB2, и я рекомендую вам
также избегать его.
Управление планами в Oracle
В текущее время Oracle предлагает два совершенно разных оптимизатора: синтак-
сический (rule-based optimizer, RBO) и стоимостный (cost-based optimizer, СВО),
с различными методами настройки.
RBO — это исходный автоматизированный оптимизатор Oracle, существовав-
ший еще в Oracle Version 6 и более ранних версиях. Под определением «синтакси-
ческий» Oracle подразумевает, что оптимизатор использует только фиксированные
свойства таблиц, индексов и SQL для определения оптимального плана выполне-
ния при помощи набора простых «правил большого пальца» (или эвристических),
встроенных в автоматизированный оптимизатор. RBO не учитывает сведения о
размерах таблиц и индексов или о распределении данных в этих объектах. Он ис-
пользует данные о фиксированных свойствах индексов — уникальны ли они, ка-
кие столбцы они охватывают, в каком порядке и насколько хорошо они соответ-
ствуют выглядящим наиболее селективными условиям фильтров и соединениям
в SQL. По мере того как таблицы растут и распределение данных изменяется,
RBO все также выдает один и тот же план, если только вы не изменяете индексы
(например, из уникальных делаете пеуникальные) или структуру таблиц (напри-
мер, из обычной таблицы делаете таблицу с разбиениями). Однако в будущем
(возможно, даже в Oracle Database 10g) Oracle прекратит поддерживать синтак-
сический оптимизатор и стоимостный оптимизатор станет вашим единственным
выбором.
108
4. Управление планами выполнения
Начиная с Oracle?, RBO стал еше более стабильным, чем раньше, так как Oracle
решила заморозить код RBO, за исключением редких и небольших изменений,
необходимых для получения функционально верных (в противоположность
обязательно оптимальным) результатов. Таким образом, план выполнения, явля-
ющийся правильным в RBO сегодня, скорее всего, останется верным, пока Oracle
полностью не прекратит поддержку RBO. Это привлекательно с точки зрения ста-
бильности, хотя оборотной стороной этой стабильности является то, что планы
выполнения также никогда не станут лучше.
Планы выполнения в RBO никогда не изменяются, подстраиваясь к изменени-
ям в распределении данных, и зачастую это становится важным аргументом в ре-
шении перейти к СВО. Однако мой опыт говорит о том, что изменения в распреде-
лении данных — это самый слабый из аргументов за СВО. Я занимаюсь этим
вопросом уже более 10 лет, и мне еще предстоит найти такой случай, в котором
было бы важно использовать различные планы выполнения для различных рас-
пределений реальных данных с одним и тем же SQL-запросом.
ПРИМЕЧАНИЕ --------------------------------------------------------------
Я видел много случаев, когда какой-либо план не являлся оптимальным для всех распределений ре-
альных данных, но во всех этих случаях существовал один надежный план, который был, по крайней
мере, практически оптимальным для любых данных.
Еще один аргумент в пользу СВО — то, что он может выдавать параллельные
планы выполнения, планы, которые могут заставить несколько процессоров одно-
временно обрабатывать один SQL-запрос. Я не считаю этот аргумент столь уж
серьезным, поскольку в реальной работе мне еще не встречался случай, когда для
достижения адекватной производительности оптимальному SQL-запросу с пра-
вильным дизайном базы данных требовалось параллельное выполнение. Можно
предположить, что такие запросы могут выполняться в хранилищах данных, с ко-
торыми я работал не слишком много. Однако практически во всех случаях, в кото-
рых, казалось бы, параллельные планы выполнения демонстрируют блистательную
скорость, на самом деле скрывается ошибка в дизайне базы данных, индексах или
дизайне приложения, последствия которой компенсируются аппаратной мощно-
стью. Само по себе это не так уж и страшно — дополнительная аппаратная мощ-
ность может обойтись дешевле, чем исправление приложения. Однако парал-
лельные планы обычно используются для больших пакетных процессов, которые
отнимают ресурсы у оперативных процессов, более важных для конечных пользо-
вателей. То есть параллельные планы выполнения часто крадут необходимые ре-
сурсы у других, более важных приложений.
Самые сильные аргументы против использования RBO.
Он станет недоступным в какой-либо очередной версии, возможно даже в Oracle
Database 10g, и вы никогда не сможете использовать более старую версию сервера.
СВО постоянно улучшается, в то время как RBO застрял на одном месте с теми
же старыми проблемами, какие у него были всегда.
У СВО есть огромное преимущество, позволяющее ему пользоваться соответ-
ствующей информацией для вычисления наилучшего плана.
RBO не может использовать преимущества функций, созданных после появле-
ния СВО в Oracle?, и в большинстве случаев RBO просто перебрасывает за-
Управление планами в Oracle
109
проси, содержащие новые типы объектов, такие как растровые индексы, СВО.
(Подробнее о том, какие функции не обрабатывает RBO, в следующем разделе,
«Управление выбором оптимизатора в Oracle».)
Но, с другой стороны, RBO выполняет свою работу на удивление хорошо. Его
эвристические функции прекрасно справляются с выбором наилучшего плана,
обладая лишь небольшим объемом информации. В главе 6 я опишу свойства пла-
на, который я называю надежным, плана, который хорошо работает на самых раз-
личных распределениях данных. RBO практически всегда выдает надежный план,
если есть все необходимые индексы и разработчик не запретил использование
индекса каким-либо из способов, рассмотренных ранее в этой главе. Имея пра-
вильные индексы, вы практически всегда можете получить наилучший план с
любым из оптимизаторов, дополнив его ручной настройкой. При автоматизи-
рованной настройке самое большое преимущество СВО — его изобретатель-
ность, которую он проявляет даже с не идеальным индексированием и не опти-
мальным SQL. Чаще всего он выдает, по крайней мере, адекватный план, даже
без ручной настройки. Когда возможно появление нескольких надежных пла-
нов, СВО с большей вероятностью найдет наилучший надежный план, a RBO
выберет один из них, не зная относительной стоимости, если только вы не на-
строите SQL вручную.
Управление выбором оптимизатора в Oracle
Невозможно одновременно оптимизировать запросы Oracle для синтаксического
и стоимостного оптимизаторов. Поэтому вы должны понимать, какими фактора-
ми руководствуется Oracle при выборе оптимизатора, и контролировать эти фак-
торы, заставляя выбрать нужный оптимизатор.
RBO не может обрабатывать объекты определенных типов и свойства объек-
тов, которые еще не существовали на момент, когда Oracle заморозила код RBO.
Однако вместо того, чтобы просто выдавать сообщение об ошибке, Oracle моди-
фицировала код RBO, чтобы оптимизатор умел распознавать недопустимые для
него случаи и передавать их СВО, Так, даже если вы думаете, что заставили систе-
му использовать синтаксическую оптимизацию, в следующих ситуациях абсолют-
но точно будет использоваться стоимостная оптимизация.
Существуют растровые индексы по любому столбцу таблицы, упомянутой
в SQL-запросе, даже если эти индексы охватывают столбцы, к которым запрос
не обращается.
В таблице, упомянутой в SQL-запросе, существуют индексы, базирующиеся
на функциях, и индексы, созданные по выражению, которое встречается в за-
просе.
SQL-запрос обращается к таблицам с разбиениями.
Существуют таблицы или индексы, предназначенные для параллельной обра-
ботки. Оптимизатор интерпретирует их как команду на поиск параллельных
планов выполнения, которые RBO не поддерживает. Как и растровые индексы,
индексы, настроенные со степенью параллелизма, предотвратят использование
RBO для таблицы, которая упоминается в SQL, даже если эти индексы охваты-
вают столбцы, к которым SQL не обращается.
110
4. Управление планами выполнения
НЕНАМЕРЕННОЕ ОТКЛЮЧЕНИЕ RBO -------------------------------------------------------------------
Я много раз встречал такой сценарий: у вас есть стабильное промышленное приложение, хорошо рабо-
тающее с RBO, и вдруг большие фрагменты приложения начинают работать со скоростью черепахи.
Тут же возникает паника и начинается проверка «методом тыка». После длительного расследования
выясняется, что прошлой ночью администратор базы данных (database administrator, DBA) случайно
удалил и создал заново некоторый большой индекс по центральной таблице, возможно, переместив его в
новую файловую систему, чтобы освободить больше места. Ваш DBA прозорливо решил, что это был
такой большой индекс, что создание его заново старым способом займет недопустимо много времени,
поэтому он создал его параллельно, используя подобную конструкцию:
CREATE INDEX Order_Ship_Date
ON Orders(Ship_Date)
PARALLEL 10,
Благодаря этому десять параллельных процессов занялись созданием индекса и существенно его ус-
корили, в то же время оставив время для обычной работы. Пока что все хорошо. Но о чем никто не
догадался, так это о том, что у индекса образовалось свойство, заставляющее Oracle использовать
стоимостную оптимизацию независимо от конфигурации базы данных и пытаться во всем SQL-коде,
в котором упоминается эта таблица, найти планы, использующие этот индекс в параллельных про-
цессах. Так как никто не ожидал, что к этому приложению будет применен СВО, то никто не создал
статистику по таблицам и индексам. Поэтому СВО работал без учета правильной статистики и нео-
жиданно выдал ужасные с точки зрения производительности планы для большей части SQL-кода.
использующего эту таблицу. Обнаружив причину, проблему можно решить такой командой:
ALTER INDEX Order_Ship_Date PARALLEL 1;
Поскольку этот оператор лишь настраивает значение в словаре данных, а не перестраивает индекс, он
выполняется практически мгновенно, моментально восстанавливая былую производительность при-
ложения. Индексы с подобной ошибкой можно найти, выполнив запрос:
SELECT Index_Name
FROM ALL.INDEXES
WHERE Deg гее 1=1;
Если таблицы и индексы, встречающиеся в вашем SQL-запросе, не запрещают
использовать RBO, Oracle делает выбор между RBO и СВО па основе следующих
аргументов в порядке использования.
1. Если после любого ключевого слова SELECT в SQL-запросе (даже в подзапросе
или определении представления) присутствует любая допустимая инструкция
кроме /*+ RULE */ или /*+ CHOOSE */, Oracle выбирает СВО.
2. Если после любого ключевого слова SELECT в SQL-запросе (даже в подзапросе
или определении представления) присутствует /*+ CHOOSE */ и для любой таб-
лицы или индекса, упоминающихся в запросе, не существует статистики, Oracle
выбирает СВО.
3. Если после любого ключевого слова SELECT в SQL (даже в подзапросе или опре-
делении представления) присутствует /*+ RULE */, Oracle выбирает RBO.
4. Если параметр сеанса optimizer_mode устанавливается на уровне сеанса (при
помощи ALTER SESSION SET OPTIMIZERJWE=<Baw_Bb/6op>:), Oracle выбирает RBO или
СВО согласно значению этого параметра уровня сеанса.
5. Если параметр optimizerjnode устанавливается для экземпляра базы данных
в файле init.ora, Oracle выбирает RBO или СВО согласно значению этого па-
раметра уровня экземпляра.
6. В ином случае Oracle выбирает оптимизатор согласно значению по умолчанию
параметра optlmizerjiiode, то есть CHOOSE.
Управление планами в Oracle
111
В трех последних шагах последовательности решений Oracle делает выбор на
основе значения параметра optlmlzerjriocle, которое устанавливаете вы или адми-
нистратор вашей базы данных. Допустимы четыре возможных значения парамет-
ра, которые влияют на выбор следующим образом.
RULE. Oracle использует синтаксическую оптимизацию.
ALL ROWS. Oracle использует стоимостную оптимизацию с целью минимизиро-
вать стоимость всего запроса. Этот режим по умолчанию стоимостной опти-
мизации иногда выдает ненадежные планы (планы, в которых используются
методы соединения, отличные от вложенных циклов) со всеми рисками, опи-
санными в главе 6. Однако оптимизатор выбирает эти планы только если счи-
тает, что они выполняются быстрее, чем наилучшие надежные планы.
FIRST_ROWS. Oracle использует стоимостную оптимизацию с целью минимизи-
ровать стоимость получения первых строк из запроса. На практике обычно
выбираются надежные планы со вложенными циклами, схожие с теми, кото-
рые выбирает синтаксический оптимизатор. Но в данном случае при постро-
ении планов учитывается больше информации о распределении данных и воз-
можной стоимости выполнения. Уровень оптимизации FI RST_ROWS создает тот
же эффект, что и подсказка OPTIMIZE FOR 1 ROW в DB2 и подсказка OPTION(FAST 1)
в SQL Server.
CHOOSE. Oracle использует стоимостную оптимизацию с той же целью что и в слу-
чае использования значения ALL_ROWS. Если же для таблиц или индексов, упо-
мянутых в запросе, нет статистики оптимизации, Oracle использует синтакси-
ческую оптимизацию.
СМЕШИВАНИЕ СТОИМОСТИ И ПРАВИЛ -----------------------------------------------
Значение CHOOSE предлагает возможность смешать стили оптимизации в экземпляре базы данных. На-
пример, можно использовать CHOOSE, если вы хотите использовать два различных приложения. В одном
из них SQL-код проверен и оптимален для синтаксической оптимизации, а для другого предпочти-
тельнее будет стоимостная оптимизация. Тогда вам не потребуется генерировать статистику для таб-
лиц, к которым обращается первое приложение, и его SQL-код будет оптимизироваться при помощи
RBO.
Хотя это звучит привлекательно, я не советую делать подобным образом. Есть шанс, что таблицы, кото-
рые используют два приложения, будут пересекаться, иначе, зачем бы вы помещали их в один экземп-
ляр базы данных? В этом случае вы получите SQL, оптимизированный наихудшим способом — при
помощи СВО, но с недостатками, проистекающими от отсутствия статистики по одной или несколь-
ким таблицам.
Даже если вы полностью разъединили наборы таблиц для двух приложений, высока вероятность того,
что кто-то когда-нибудь создаст статистику по некоторым таблицам, предназначенным для приложе-
ния, использующего RBO. И снова в результате вы получите организованные наихудшим способом
стоимостные планы для SQL, где перемешаны таблицы, для которых есть статистика, и для кото-
рых нет. Гораздо безопаснее использовать отдельные экземпляры и устанавливать значение параметра
optimizer mode=rule на уровне экземпляра для каждого приложения. Или же пусть одно из приложе-
ний явно установит параметр optimizer jnode при подключении к базе данных, перекрывая значение
optimizer_mode уровня экземпляра, которое применяется при выборе оптимизатора для другого прило-
жения.
Вот как быстро можно проверить значение параметра уровня экземпляра
optimizerjnode:
SELECT VALUE FROM V$PARAMETER WHERE NAME = 'optimizer-mode':
112
4. Управление планами выполнения
Если у вас есть план выполнения в PLANJABLE, можно быстро проверить, осно-
ван ли он на стоимости, выполнив следующий запрос:
SELECT POSITION FROM PLANJABLE WHERE ID-0:
Если план основан на стоимости, то будет возвращена стоимость всего плана
выполнения в произвольно выбранных единицах. Если стоимость не равна нулю,
то можно с уверенностью говорить, что данный план основан па стоимости.
Управление синтаксическими планами
выполнения в Oracle
Большинство методов управления синтаксическими планами выполнения — это
универсальные приемы управления планами, которые я рассмотрел в первых раз-
делах этой главы. Основной характерный для Oracle способ настройки, когда для
optimizerjnode выбрано значение по умолчанию, — синтаксическая оптимизация,
достаточно просто включить стоимостную оптимизацию, обычно указав необхо-
димый параметр. Например, можно использовать /*+ F1RST_ROWS */. Другими сло-
вами, вы всегда можете контролировать план при помощи подобных конструкций,
и эти управляющие параметры (за исключением /*+ RULE */) в SQL-операторе за-
ставляют Oracle использовать для этого оператора СВО.
Однако если вы не хотите использовать стоимостную оптимизацию, отказыва-
ясь от подсказок, остается еще одна техника для RBO. В разделе FROM перечислите
таблицы и их псевдонимы в порядке, в точности противоположном желаемому
порядку соединения. Обычно это оставляет достаточно свободы для контроля над
порядком соединения без использования способов, описанных ранее в разделе
«Запрещение соединения в неправильном порядке». В частности, допустимые уни-
кальные соединения по первичным ключам производятся в порядке, обратном
порядку в разделе FROM, без изменения условий соединения. Например, рассмот-
рим такой запрос:
SELECT /*+ RULE */ E.First_Name, E.Last_Name, E.Salary, LE.Description.
M.First_Name. M.Last_Name. LM.Description
FROM Locations LM. Employees M. Locations LE, Employees E
WHERE E.Last_Name - Johnson'
AND E.ManagerJD - M.EmployeeJD
AND E.LocationJD - LE.Location_ID
AND M.LocationJD - LM.LocatlonJD
AND LE.Description - 'Dallas';
В противоположность предыдущей версии этого запроса в главе 3, где был ис-
пользован неправильный порядок в разделе FROM, теперь мы получаем правильный
порядок соединения. В этом правильном плане выполнения Е соединяется с LE пе-
ред тем, как М соединяется с LM, что показано в описании плана:
SQL> @ех
PLAN
SELECT STATEMENT
NESTED LOOPS
NESTED LOOPS
NESTED LOOPS
TABLE ACCESS BY INDEX RDWID 4*EMPL0YEES
INDEX RANGE SCAN EMPLOYEE_LAST_NAME
Управление планами в Oracle
113
TABLE ACCESS BY INDEX ROWID 3*LOCATIONS
INDEX UNIQUE SCAN LOCATION PKEY
TABLE ACCESS BY INDEX ROWID 2*EMPLDYEES
INDEX UNIQUE SCAN EMPLOYEE PKEY
TABLE ACCESS BY INDEX ROWID 1*LOCATIONS
INDEX UNIQUE SCAN LOCATION_PKEY
Если RBO не может сделать выбор на основе условий и индексов, то он соеди-
няет таблицы справа палево во фразе FROM. Однако сам по себе этот метод оставля-
ет мало пространства для контроля, так как RBO выполняет собственные «прави-
ла большого пальца» перед тем, как выбрать порядок соединения во фразе FROM.
Например, если это возможно, RBO всегда выбирает уникальные индексные счи-
тывания и соединения перед сканированием диапазонов индекса.
Управление стоимостными планами выполнения
в Oracle
Настройка в СВО Oracle состоит из двух основных частей.
Предоставление оптимизатору хорошей статистики по таблицам и индексам,
чтобы он смог точно подсчитать стоимость всех вариантов. Это необходимый
этап подготовки к ручной настройке в СВО.
Добавление подсказок в запросы, которые СВО не может хорошо оптимизиро-
вать, даже имея полную статистику о таблицах и индексах, к которым обраща-
ется запрос.
Подготовка к использованию стоимостного оптимизатора
В очередной раз доказывая, что недостаток знания опасен, стоимостные оптими-
заторы часто выдают ужасные результаты, если им не предоставлена статистика
по всем таблицам и индексам, участвующим в запросе. Таким образом, вам обяза-
тельно нужно поддерживать достоверную статистику по таблицам и индексам и,
помимо этого, заново генерировать статистику в случае, если существенно изме-
няется объем таблицы или перестраиваются таблицы или индексы. Самый безо-
пасный способ — периодически заново генерировать статистику, используя для
этого отрезки времени, когда нагрузка невелика (например, это может быть ночь
или выходные). Для генерации и обновления статистики лучше всего использо-
вать пакет Oracle DBMS_STATS, подробное описание которого можно найти в
справочниках Огас1е8г Supplied PL/SQL Packages Reference и Oracle9z Supplied
PL/SQL Packages and Types Reference. Далее приведен простой пример использо-
вания пакета DBMS_STATS для создания статистики для полной схемы,
Appl_Prod, с выборкой 10 % данных в больших таблицах и каскадным переходом
для сбора статистики в индексах:
BEGIN
DBMS_STATS.GATHER_SCHEMA_STATS ('Appl_Prod1.10,
CASCADE -> TRUE);
END;
/
Часто в запросах встречаются условия для сильно асимметричных распределе-
ний, например условия по специальным типам, кодам или флагам в случае, когда
в этих столбцах присутствует лишь несколько различных значений. Обычно СВО
114
4. Управление планами выполнения
оценивает селективность условия, основываясь на предположении, что все нену-
левые значения поля одинаково селективны. Это предположение чаще всего хоро-
шо работает для внешних и первичных ключей, соединяющих сущности, но невер-
но для столбцов с постоянными специальными значениями, где одни значения
встречаются намного реже, чем другие.
Например, в таблице Orders может быть столбец Status_Code с тремя возможны-
ми значениями: ' CL' для закрытых (например, выполненных) заказов, 'СА' для от-
мененных заказов и 'ОР' для открытых заказов. Таким образом, большинство
заказов будет выполнено, если приложение проработало несколько месяцев. Зна-
чительная часть заказов будет в итоге отменена, поэтому это значение также будет
встречаться в большом списке заказов. Однако если бизнес идет хорошо и заказы
продолжают поступать, то количество открытых заказов будет оставаться умерен-
ным и стабильным, даже если данные будут накапливаться годами. Достаточно
скоро условие Status_Code='OP' станет достаточно селективным, чтобы оправдать
индексированный доступ, если, конечно, у вас есть индекс с таким ведущим стол-
бцом, и важно, чтобы оптимизатор мог понять этот факт. Будет совсем замечатель-
но, если ручная настройка оптимизатору не понадобится. Чтобы СВО мог понять,
когда столбец становится селективным, необходимо рассмотреть две причины.
В версиях до Огас1е9г Database в SQL-запросе должно быть указано определен-
ное селективное значение, а не параметр. Использовать параметры удобно, так
как SQL-код становится более абстрактным и его удобно разделять между про-
цессами. Однако необходимость явно указывать особенно селективные значе-
ния является исключением из этого правила. Если вы укажете Status_Code=:l
вместо Status_Code=' ОР' в версиях сервера до Огас1е9г, то во время разбора кода
СВО не сможет ничего узнать о селективности условия, поскольку еще неизвест-
но, будет ли параметру : 1 присвоено распространенное или редко встречающе-
еся значение Status_Code. К счастью, в таких случаях обычная причина выбора
параметров не имеет значения. Так как у этих специальных кодов есть особен-
ный, важный для бизнеса смысл, маловероятно, что когда-либо потребуется
заменить указанное селективное значение каким-нибудь другим.
ПРИМЕЧАНИЕ--------------------------------------------------------------------
В Oracle 9г впервые реализовано предварительное считывание параметра, то есть Oracle проверяет
первое значение, назначенное каждому параметру (когда запрос видит его первое упоминание в коде)
при выборе плана выполнения. Это устраняет необходимость указывать фиксированные значения вме-
сто параметров, когда все значения, которые потенциально могут быть присвоены им, имеют одинако-
вую селективность. Однако если параметр привязывает ся и к селективным, и, иногда, к неселективным
значениям, вам все же необходимо явно указывать значения в коде, чтобы для различных случаев по-
лучать разные планы выполнения.
Вы должны предоставить СВО специальную статистику, которая определяет,
насколько редко встречается нераспространенное значение кода, типа или со-
стояния, чтобы СВО мог знать, какие именно значения обладают высокой се-
лективностью.
Если вы запрашиваете специальную статистику по распределению, Oracle сор-
тирует строки по значению определенного столбца и размещает отсортированный
список в указанном количестве сегментов, в каждом из которых хранится одина-
ковое количество строк. Так как Oracle уже знает, что в диапазонах находится оди-
Управление планами в Oracle
115
наковое количество строк, серверу требуется найти только конечные точки диапа-
зонов значений для каждого сегмента. Ь нашем примере с 20 сегментами в первом
сегменте может храниться диапазон от ’ СА' до ' СА', а во втором — диапазон от ' СА'
до ' CL'. В следующих 17 сегментах может храниться наиболее часто встречающее-
ся значение — диапазон от ' CL' до ' CL . В последнем сегменте будет храниться ди-
апазон от ' CL' до ' 0Р', то есть диапазон, включающий самое редкое значение. Та-
ким образом, Oracle может сделать вывод, что селективность столбца равна 5-10 %
для значения ' СА ‘, 85-95 % для значения ’ CL' и 0-5 % для значения ' 0Р'. Так как
необходимо, чтобы оптимизатор точно знал, насколько селективно значение * 0Р',
стоит выбрать большее количество сегментов — возможно, максимальное, равное
254. (Oracle сжимает информацию в сегменте, когда рассматривается небольшое
количество значений, поэтому стоимость большого количества сегментов будет
небольшой.) Чтобы создать 254 сегмента для нашего примера, в схеме, владельцем
которой является Appl_Prod, выполните следующую команду:
BEGIN
DBMS_STATS.GATHER_TABLE_STATS (’AppQProd’. ’Orders’,
METHOD_DPT => 'FOR COLUMNS SIZE 254 Status_Code');
END;
/
После того как вы создадите статистику по основной таблице, сгенерируйте ги-
стограмму статистики, так как при создании статистики по таблице гистограмма
удаляется.
Общий синтаксис подсказок
В Oracle подсказки используются для ручного управления стоимостной оптими-
зацией. Синтаксически эти подсказки принимают форму комментариев, как, на-
пример, /*+ <Hint_String> */, стоящих сразу же за ключевым словом SELECT. Oracle
распознает, что это подсказка, а не комментарий, за счет знака + в начале и распо-
ложения подсказки — она обязана располагаться сразу же за словом SELECT. Но с точ-
ки зрения стандартного синтаксиса SQL подсказки все же являются комментари-
ями, так как они не мешают разбору SQL-выражения, если оно также должно
выполняться другими серверами баз данных.
ПРИМЕМ АН И Е------------------------------------------------------------------
Подсказки Oracle не помогают получить быстрые планы выполнения в других базах данных, отличных
от Oracle, и, к сожалению, в данный момент невозможно использовать настроенный вручную SQL-
запрос в разнообразных базах данных и во всех них проводить одинаковую ручную настройку.
Каждая подсказка влияет только на тот блок SELECT, в котором находится. По-
этому, чтобы контролировать порядок соединений и выбора индексов в подзапро-
се, поместите подсказку после ключевого слова SELECT, с которого начинается под-
запрос. Чтобы воздействовать на порядок соединений и выбор индексов во внешнем
запросе, поместите подсказку сразу же после SELECT во внешнем запросе.
Подходы к настройке с использованием подсказок
В настройке с применением подсказок есть два крайних случая.
Можно использовать минимум указаний для получения желаемого плана вы-
полнения или, по меньшей мере, плана, близкого к идеальному. Аргументы в
116
4. Управление планами выполнения
пользу этого подхода звучат так: у СВО есть больше информации, чем у вас,
и следует оставить ему свободу действий, позволить ему адаптироваться к из-
менениям в распределении данных и пользоваться преимуществами улучше-
ний в будущих версиях Oracle. Оставив СВО максимум свободы, вы увеличите
его способности хорошо оптимизировать запрос в будущем. Однако вы не мо-
жете знать, сколько указаний потребуется СВО, если он сразу же не сможет
получить наилучший план, пока не попробуете разные варианты, поэтому этот
подход обычно становится итерационным, с добавлением по одной подсказке
за раз, пока СВО не создаст хороший план.
Если вы не получили от СВ О желаемый план автоматически, то предполагаете,
что СВО сделал неверные предположения, которые распространяются на весь
код и портят все его вычисления. Следовательно, нужно оставить ему мини-
мальную свободу действий, явно и полностью указывая, какой именно план
вам нужен.
Если вы уверены в выбранном плане выполнения (а вы должны быть уверены,
если применили все методы, которые я опишу далее в этой книге), то не имеет
смысла полностью явно указывать план. Я пока что не сталкивался со случаем,
когда хорошо выбранный падежный план выполнения требуется изменить, чтобы
обработать данные с новым распределением или использовать новые возможно-
сти базы данных. С другой стороны, SQL, частично ограниченный набором под-
сказок, может выполняться неправильно, особенно если для некоторых таблиц или
индексов статистика утеряна. Когда СВО делает неправильный выбор, ошибка,
которая заставила сделать его этот выбор, вероятнее всего, портит весь план вы-
полнения. Например, рассмотрим запрос:
SELECT E.First_Name. E.Last_Name. Е.Salary. LE.Description,
M.First_Name. M.Last_Name. LM Description
FROM Locations LM, Employees M. Locations LE. Employees E
WHERE E.H1re_0ate > :1
AND E.Manager_ID-M.Employee_ID
AND E.Location_ID“LE.Location_ID
AND M.Location_ID-LM.Locat1on_ID
Во время разбора, когда работает оптимизатор, он не может знать, что парамет-
ру : 1, вероятно, будет назначено значение, соответствующее текущей неделе, по-
этому он делает благоприятное предположение о селективности этого условия в
Hi re_Date. Сделав такое предположение, он может не только запретить использо-
вание индекса по Hi re_Date (в зависимости от распределения данных), но также
посчитать, что запросу понадобятся практически все строки из всех соединенных
таблиц, и тогда СВО выберет полное сканирование таблиц с соединением хэширо-
ванием. Даже если вы заставите СВО использовать индекс по Hi re_Date, он все рав-
но будет считать, что ведущее условие неселективно, и придерживаться своего
неудачного выбора для других соединений и методов доступа к таблицам. В дей-
ствительности это не является ошибкой оптимизатора. Он не может знать того,
что знает разработчик приложения о вероятных значениях связанной переменной.
И, как следствие, если вам необходимо принимать в создании плана большее уча-
стие, чем просто указать ALL_ROWS или FIRST_ROWS, велика вероятность того, что ваша
помощь потребуется оптимизатору на всем протяжении его работы, чтобы испра-
вить некоторые неверные предположения.
Управление планами в Oracle
117
ПРИМЕЧАНИЕ ------------------------------------------------------------------
Подсказки ALL_R0WS и FIRST-ROWS представляют собой безопасный способ первичной оптимизации. Если
вы используете синтаксический оптимизатор, то вполне можете опробовать этот стоимостный подход,
указав подсказку еще до того, как начнете искать наилучший план выполнения. Если результат ока-
жется достаточно быстрым, то вы сможете сэкономить усилия. Если же вы уже используете стоимост-
ную оптимизацию в режиме ALL_ROWS, то попробуйте FIRST_ROWS и наоборот. Если вашу проблему может
решить подсказка opt irnzer_riode, значит, оптимизатор делает правильные предположения и ему мож-
но доверять.
Подсказки для доступа к таблицам
Далее перечислены основные подсказки, управляющие методами доступа к таб-
лицам.
INDEX(<Имя_псевдонима> <Имя_индекса>). Требует от Oracle, когда это возможно,
осуществлять доступ к псевдониму <Имя_псевдонима>, используя индекс с име-
нем <Имя_индекса>. Повторяйте эту подсказку для всех комбинаций индекса
и псевдонима, которые необходимо контролировать.
FULL (<Имя_псевдонима>). Рекомендует серверу, когда это возможно, осуществлять
доступ к псевдониму <Имя_псевдонима>, используя полное сканирование табли-
цы. Используйте эту подсказку для всех необходимых операций полного ска-
нирования таблицы.
1Н0ЕХ_0Е5С(<ймя_лсеедонима> <Иня_индекса>). Рекомендует Oracle, когда возмож-
но, осуществлять доступ к псевдониму <Имя_псевдонима>, используя индекс с
именем <Имя_индекса>, обращаясь к строкам в обратном порядке (обратном
по отношению к обычному порядку сортировки индекса). Повторяйте эту
подсказку для всех комбинаций индекса и псевдонима, которые необходи-
мо контролировать, хотя маловероятно, что это потребуется больше одного
раза в запросе.
Подсказки INDEX и FULL достаточно распространены, и их легко использовать.
Подсказка INDEX_DESC редко бывает полезной, но иногда она жизненно необходима.
Например, если вы хотите получить все сведения о сотруднике, нанятом в апреле
последним, можно использовать такой запрос:
SELECT *
FROM Employees Е
WHERE Hire_Date>=TO_DATE(’2003-04-0Г.'YYYY-MM-DD')
AND H1re_Date< TO_DATE(’2003-05-01 'YYYY-MM-DD')
ORDER BY HireJDate DESC
Сотрудник, нанятый последним, будет перечислен в начале набора строк, воз-
вращенных запросом. Чтобы избежать считывания всех данных для всех осталь-
ных сотрудников, нанятых в апреле, вы можете добавить в запрос условие AND
ROWNUM=1. Но иногда в таком случае вы получите нежелательный результат, так как
(в зависимости от данных) Oracle будет применять это условие до выполнения
сортировки по убыванию. Если Oracle проводит полное сканирование таблицы,
запрос вернет первого сотрудника, нанятого в апреле, которого найдет в таблице,
и, вероятно, это будет сотрудник, нанятый первым по времени. Если же Oracle ис-
пользует сканирование диапазона индекса по Hi re_Date, то начнет, как это проис-
ходит с диапазонами по умолчанию, с нижнего края диапазона индекса и вернет
первого сотрудника, нанятого в апреле. Однако подсказка INDEX DESC и индекс
118
4. Управление планами выполнения
Empl оуее_Н1 re_Date по столбцу Hi re_Date удачно решают эту проблему, возвращая
нужную строку при помощи всего лишь одной операции логического ввода-выво-
да для таблицы:
SELECT /*+ INDEX_DESC(E Employee_Hire_Date) */ *
FROM Employees E
WHERE H1re_Date>=TO_DATE('2003-04-01'.’YYYY-MM-DD’)
AND Hire_Date< TO_DATEC2003-05-01'.'YYYY-MM-DD’)
AND ROWNUM=1
Обратите внимание, что я удалил явное упоминание ORDER BY, так как он создает
ложное впечатление эффективности, и добавил условие для ROWNUM.
ВНИМАНИЕ --------------------------------------------------------------------------------
Предыдущий пример может произвести впечатление рискованного кода, который может разрушить
функциональность, например, если кто-либо удалит или переименует используемый код. Это действи-
тельно рискованно, и я рекомендую использовать такой подход, только если улучшение производи-
тельности существенно превышает стоимость риска получения неправильных результатов. Такой случай
характерен для синтаксиса SQL, разрешающего подобные запросы, возвращающие первые несколько
записей из набора, которые в полной мере используют преимущества наилучшего индексированного
пути. Используя текущий синтаксис, я еще не нашел решения, которое являлось бы одновременно оп-
тимальным и функционально безопасным.
Существует несколько других подсказок для доступа к таблицам, которые я не
привел в этом разделе, но я никогда не сталкивался со случаями, когда они были
бы полезны.
Подсказки для порядка выполнения запроса
Далее перечислены основные подсказки для управления порядком выполнения
соединений и подзапросов.
ORDERED. Рекомендует Oracle, когда возможно, соединять таблицы в том поряд-
ке, в каком они перечислены во фразе FROM.
ПРИМЕЧАНИЕ -----------------------------------------------------------
Эта подсказка, в отличие от остальных, обычно требует изменения тела SQL-запроса (или, по крайней
мере, раздела FROM) для получения желаемого плана, так как она относится к порядку выполнения FROM.
Обратите внимание, что желаемый порядок перечисления таблиц в разделе FROM будет в точности про-
тивоположным наилучшему порядку раздела FROM, который вы бы выбрали для синтаксической опти-
мизации. Это происходит потому, что RBO работает справа налево, в то время как подсказка заставляет
СВО выполнять FROM слева направо.
\_ЕЮЖ(<Имя_псевдонима>). Если подсказка ORDERED не указана, то выбирается ве-
дущая таблица, то есть первая таблица в порядке соединения. Хотя в данном
случае вы в меньшей степени контролируете порядок выполнения, чем с под-
сказкой ORDERED, вам зато не требуется изменять раздел FROM. Часто один лишь
выбор правильной ведущей таблицы — это все, что требуется для получения
производительности, близкой к оптимальной. Последующий порядок соедине-
ния значит меньше и, вероятнее всего, будет удачно выбран оптимизатором без
вашей помощи.
PUSH_SUBQ. Эта подсказка приказывает оптимизатору выполнять коррелирован-
ные подзапросы, как только это возможно — как только внешний запрос дос-
тигнет столбцов соединения, необходимых для оценки подзапросов. Обычно
Управление планами в Oracle
119
СВО в Oracle выполняет коррелированные подзапросы только после заверше-
ния всех соединений во внешнем запросе.
Подсказки ORDERED и LEADING часто встречаются и их легко использовать. Иногда
бывает полезной подсказка PUSH_SUBQ.
Когда дело доходит до подзапросов, Oracle предлагает управление на основе
подсказок только для двух крайних случаев — выполнение подзапросов как мож-
но раньше и как можно позже. Однако вы сможете полностью контролировать
момент выполнения подзапросов, если примените подсказку PUSH SUBQ вмес-
те с методами, позволяющими откладывать коррелированные соединения, описан-
ными ранее. Например, рассмотрим запрос:
SELECT ...
FROM Orders 0. Customers C. Regions R
WHERE O.Status_Code='OP'
AND O.Customer_ID=C.Customer_ID
AND C.Customer_Type_Code='GOV'
AND C.Region_ID=P.Region_ID
AND EXISTS (SELECT NULL
FROM OrderJDetails 0D
WHERE 0.Drder_ID+O*C.Customer_ID=DD.Order_ID
AND OD.Shipped_Flag='Y')
Без подсказки Oracle выполняет проверку EXISTS после соединения всех трех
таблиц во внешнем запросе. Смысл выражения 0.0rder_ID+0*C.Customer_ID заклю-
чается в том, чтобы отложить проверку EXISTS и выполнить ее только после присо-
единения С, но перед присоединением R. В случае, когда нет никаких подсказок,
все условия EXISTS автоматически откладываются, пока не будут выполнены все
соединения во внешнем запросе. Чтобы заставить условие EXISTS выполняться меж-
ду присоединением С и R, используйте и подсказку, и выражение, позволяющее
отложить коррелированное соединение:
SELECT /*+ PUSH_SUBO */ ...
FROM Orders 0. Customers C. Regions R
WHERE 0.Status Code= DP'
AND 0.Customer_[D”C.Customer_ID
AND C.Customer_Type_Code='GOV'
AND C.Region_ID=R.Region_ID
AND EXISTS (SELECT NULL
FROM OrderDetails 0D
WHERE 0.Order_ID+0*C.Customer_ID=0D.0rder_ID
AND DD.Shipped_Flag='Y')
Теперь подсказка PUSH_SUBQ заставляет Oracle выполнять условие EXISTS как
можно раньше, а выражение 0.0rder_ID+0*C.Customen_ID гарантирует, что этот мо-
мент нс наступит, пока не будет выполнено соединение с С.
Подсказки для методов соединения
Далее перечислены основные подсказки для управления методами соединения.
USE NL (<Список_псевдонимов>). Рекомендует Oracle соединять таблицы, перечис-
ленные в списке псевдонимов, используя вложенные циклы. Псевдонимы
в списке не должны разделяться запятыми, например, USE_NL(T1 Т2 ТЗ).
USE_HASH(<Список_псевдонимов>). Предлагает серверу соединять таблицы, перечис-
ленные в списке псевдонимов, используя хэширование. Псевдонимы в списке
не должны разделяться запятыми, например USE_HASH(T1 Т2 ТЗ).
120
4. Управление планами выполнения
Пример
Приведу пример подсказок, при помощи которых можно добиться полного кон-
троля над планом выполнения. Я принудительно выберу порядок соединения, ме-
тод доступа к каждой таблице и метод соединения для каждой таблицы. Рассмот-
рим ранее встречавшийся нам пример, настроенный для RB О и показанный в конце
раздела «Управление синтаксическими планами выполнения в Oracle». Чтобы
полностью контролировать план выполнения и при этом заменить первое соеди-
нение со вложенными циклами на соединение хэшированием, а местоположение
сотрудников считывать через индекс по Description, используйте такой запрос:
SELECT /*+ ORDERED USE_NL(M LM) USE_HASH(LE) INDEXCE Emp1oyee_Last_Name)
INDEXCLE Location_Description) INDEXCM Employee_Pkey)
INDEXCLM LocationPkey) */
E.First_Name. E.Last_Name. E.Sal ary, LE.Description.
M.First_Name. M.Last_Name. LM.Description
FROM Employees E. Locations LE. Employees M. Locations LM
WHERE E.Last_Name = 'Johnson'
AND E.Manager_ID = M.Employee_ID
AND E.Location_ID = LE.Location_ID
AND M.Location_ID = LM.LocatlonJD
AND LE.Description = 'Dallas'
Будет получен следующий план выполнения:
SQL> @ех
PLAN
SELECT STATEMENT
NESTED LOOPS
NESTED LOOPS
HASH JOIN
TABLE ACCESS BY INDEX ROWID 1*EMPLOYEES
INDEX RANGE SCAN EMPLOYEE_LAST_NAME
TABLE ACCESS BY INDEX ROWID 2*LDCATIDNS
INDEX RANGE SCAN LOCATION_DESCRIPTION
TABLE ACCESS BY INDEX ROWID 3*EMPLDYEES
INDEX UNIQUE SCAN EMPLOYEE PKEY
TABLE ACCESS BY INDEX ROWID 4*L0CATI0NS
INDEX UNIQUE SCAN LOCATIDN_PKEY
Управление планами в DB2
DB2 предлагает лишь несколько собственных инструментов управления планами
выполнения, поэтому для настройки в DB2 применяются косвенные методы. На-
стройка в DB2 выполняется за три основных шага.
1. Предоставить оптимизатору хорошую статистику по таблицам и индексам, что-
бы он мог точно подсчитать стоимость различных вариантов.
2. Выбрать уровень оптимизации, который DB2 будет применять к запросу.
3. Изменить запрос, чтобы запретить нежелательные планы выполнения, исполь-
зуя, в основном, методы, описанные ранее в разделе «Универсальные техники
управления планами».
Управление планами в DB2
121
Подготовка к оптимизации в DB2
В очередной раз доказывая, что недостаток знания опасен, стоимостные оптими-
заторы часто выдают ужасные результаты, если им не предоставлена статистика
по всем таблицам и индексам, участвующим в запросе. Таким образом, вам обяза-
тельно нужно поддерживать достоверную статистику по таблицам и индексам и,
помимо этого, заново генерировать статистику в случае, если объем таблицы су-
щественно изменяется или перестраиваются таблицы или индексы. Самый безо-
пасный способ — периодически заново генерировать статистику, используя для
этого отрезки времени, когда нагрузка невелика, например, это может быть ночь
или выходные. Из строки приглашения Unix отредактируйте файл runstats_schema. sql
и введите следующие команды, заменяя параметр <Имя_схемы> именем схемы, со-
держащей объекты, для которых вы хотите собрать статистику:
- - File called runstats_schema.sql
SELECT 'RUNSTATS ON TABLE <Имя_схемы>.‘ || TABNAME || 'AND INDEXES ALL;'
FROM SYSCAT.TABLES
WHERE TABSCHEMA = ' <Имя_схемы>';
Чтобы выполнить этот сценарий, зарегистрируйтесь в утилите db2, выйдите
в командную строку оболочки командой quit: и выполните две команды:
db2 +р -t < runstats_schema.sql > tmp_runstats.sql
grep RUNSTATS tmp_rwstats.sql | db2 +p -t > tmp_anal .out
Можно настроить расписание, чтобы эти две команды выполнялись автомати-
чески. Проверяйте содержимое файла tmp_anal. out на тот случай, если при прове-
дении анализа произойдет ошибка.
Часто в запросах встречаются условия для сильно асимметричных распределе-
ний, например, условия по специальным типам, кодам или флагам, когда в этих
столбцах присутствует лишь несколько различных значений. Обычно СВО оце-
нивает селективность условия, основываясь на предположении, что все ненуле-
вые значения столбца одинаково селективны. Это предположение чаще всего хо-
рошо работает для внешних и первичных ключей, соединяющих сущности, но
неверно для столбцов с постоянными специальными значениями, где одни значе-
ния встречаются намного реже, чем другие.
Например, в таблице Orders может быть столбец Status_Code с тремя возможны-
ми значениями: 'CL' для закрытых (например, выполненных) заказов, 'СА' для от-
мененных заказов и ' ОР' для открытых заказов. Таким образом, большинство зака-
зов будет выполнено. Поэтому, если приложение проработало несколько месяцев,
вы ожидаете, что ' CL' встречается в большой и постоянно увеличивающейся части
заказов. Значительная часть заказов будет в итоге отменена, поэтому значение ' СА'
также будет встречаться в большом списке заказов. Однако если бизнес идет хоро-
шо и заказы продолжают поступать, то количество открытых заказов будет оста-
ваться умеренным и стабильным, даже если данные будут накапливаться годами.
Достаточно скоро условие Status_Code=' ОР' станет достаточно селективным, чтобы
оправдать индексированный доступ, если, конечно, у вас есть индекс с таким веду-
щим столбцом. Важно, чтобы оптимизатор мог понять этот факт, причем лучше
всего, если для этого не потребуется ручная настройка. Чтобы СВО мог понять,
когда столбец становится селективным, необходимо выполнение двух условий.
В SQL должно быть указано определенное селективное значение, а не пара-
метр. Использовать параметры удобно, так как SQL-код становится более аб-
122
4. Управление планами выполнения
страктным и его можно разделять между процессами. Однако необходимость
явно указывать особенно селективные значения — исключение из этого прави-
ла. Если вы укажете Status_Code=? вместо Status_Code=‘OP', то во время разбора
кода СВО не сможет узнать о селективности условия, поскольку еще неизвест-
но, будет ли параметру ? присвоено распространенное или редко встречающее-
ся значение Status_Code. К счастью, в таких случаях обычная причина исполь-
зования параметров не имеет значения. Так как у этих специальных кодов есть
особенный, важный для бизнеса смысл, маловероятно, что когда-либо потребу-
ется заменить указанное селективное значение каким-нибудь другим.
Вы должны предоставить СВО специальную статистику, которая определяет,
насколько редко встречается нераспространенное значение кода, типа или со-
стояния, чтобы СВО мог знать, какие именно значения обладают высокой се-
лективностью.
Если вы запрашиваете специальную статистику по распределению, DB2 также
сохраняет ее. Например, чтобы создать статистику по распределению данных, имея
индекс с именем Order_Stts_Code и схему, владельцем которой является Appl Prod,
используйте следующую команду:
RUNSTATS ON TABLE ApplProd.Orders
WITH DISTRIBUTION FOR INDEX ApplProd.Order_Stts_Code:
Всегда, когда у вас есть столбец с асимметричным распределением и индекс,
который вы хотите использовать с высокоселективным условием для этого столб-
ца, обязательно создавайте статистику по распределению, как показано здесь.
Выбор уровня оптимизации
DB2 предлагает несколько уровней оптимизации. Уровень оптимизации — это, гру-
бо говоря, потолок, определяющий, насколько умным пытается быть оптимизатор
при рассмотрении набора возможных планов выполнения. На уровне оптимиза-
ции О DB2 выбирает план с наименьшей стоимостью в пределах поднабора пла-
нов, которые он рассматривает на уровне 1. На уровне 1 он рассматривает только
поднабор планов, относящихся к уровню 2 и так далее. Считается, что на самом
высоком уровне оптимизации мы должны всегда получать наилучший план, так
как в этом случае выбирается план с наименьшей стоимостью среди самого широ-
кого диапазона вариантов. Однако планы, полученные на высочайших уровнях
оптимизации, обычно являются менее надежными. В противоположность расче-
там оптимизатора, эти менее надежные планы часто выполняются дольше, чем
наилучший надежный план, который можно получить при оптимизации нижнего
уровня. Высокие уровни оптимизации также требуют больше времени на разбор,
так как оптимизатору необходимо изучать дополнительные степени свободы. В иде-
альном случае каждый оператор разбирается на самом низком уровне среди тех, на
которых можно найти наилучший план выполнения для данного запроса.
В DB2 предусмотрено семь уровней оптимизации: 0,1,2,3,5,7 и 91. Обычно по
умолчанию устанавливается уровень 5, хотя администратор базы данных может
переопределить это значение. Мне никогда не требовался уровень оптимизации
Уровни 4,6 и 8 недоступны — возможно, по каким-либо историческим причинам, хотя я никогда не
встречал упоминания об этом в документации.
Управление планами в DB2
123
выше 5; уровни 7 и 9 предназначены скорее для экзотических преобразований за-
просов, необходимость в которых возникает редко. Однако я часто получал отлич-
ные результаты на низшем уровне оптимизации, уровне 0, в то время как уровень
5 выдавал плохой план. Перед выполнением запроса (или проверкой плана вы-
полнения) установите уровень 0 при помощи следующего оператора SQL:
SET CURRENT QUERY OPTIMIZATION 0:
Когда вы захотите вернуться к уровню 5 для других запросов, используйте тот
же синтаксис, заменив 0 на 5. Если вы получили плохой план на уровне 5, я реко-
мендую попробовать уровень 0 после проверки статистики по используемым таб-
лицам и индексам. На уровне 0 часто получается именно надежный план, который
лучше всего работает для реальных приложений.
Изменение запроса
В основном при ручной настройке в DB2 применяются изменения в SQL, описан-
ные ранее в разделе «Универсальные техники управления планами». Однако одна
техника заслуживает отдельного упоминания, поскольку ее использование в DB2
намного эффективнее, чем в Oracle или SQL Server. DB2 хранит записи индекса
даже для значений null индексированных столбцов и обрабатывает null так же, как
и любое другое индексированное значение.
Если в DB2 не хватает специальной статистики по распределению (см. «Подго-
товка к оптимизации в DB2»), она считает, что селективность условия Индексиро-
ванный_столбец IS NULL в точности равна селективности Индексированный_столбец =
198487573 или для любого другого не равного null значения. Поэтому старые вер-
сии DB2 часто работают на выглядящем селективным условии IS NULL по индекси-
рованным столбцам. Иногда все получается прекрасно. Но по моему опыту, селек-
тивность условия IS NULL очень редко приближается к селективности среднего не
равного нулю значения, и индексированный доступ по условиям IS NULL - это прак-
тически всегда ошибка.
Таким образом, если в запросе DB2 вы находите условие IS NULL для индексиро-
ванного столбца, нужно предотвратить использование индекса. Простейшее экви-
валентное условие, запрещающее использовать индекс, — это COALESCE (Indexed_Col umn,
Indexed_Column) IS NULL. Этот вариант полностью эквивалентен исходному условию
Indexed_Col umn IS NULL, но функция COALESCE() не позволяет использовать индекс.
Кроме способов настройки, подходящих для любой базы данных, есть три по-
лезные методики, специфичные для DB2, которые я опишу в следующих разделах.
Установка внутренних соединений на первое место
в разделе FROM
Эта техника заключается в простом перечислении внутренних соединений на первых
местах в разделе FROM. Он никогда не повредит запросу, и в старых версиях DB2
при помощи такой техники я получал существенно улучшенные планы выполнения.
Предотвращение одновременного разбора слишком
большого количества внешних соединений
В старых версиях DB2 разбор запросов, содержащих более 12 внешних соедине-
ний, может занять минуты, и даже после может быть выдана ошибка. К счастью,
124
4. Управление планами выполнения
для этой проблемы существует решение — в SQL нужно использовать шаблон, при-
веденный ниже. В решении используется синтаксис вложенных таблиц DB2. В раз-
деле FROM внешнего запроса содержится другой запрос, который с точки зрения
внешнего запроса обрабатывается как одна таблица:
SELECT ...
FROM (SELECT ...
FROM (SELECT ... FROM <все внутренние соединения и
десять внешних соединений?
WHERE <условия. относящиеся к максимально вложенной
таблице >) Т1
LEFT OUTER JOIN <внешние соединения с 11-го
по 20-е>
WHERE <усповия. если таковые существуют, относящиеся
к этой вложенной таблице, находящейся на самом внешнем уровне?) Т2
LEFT OUTER JOIN <остальные внешние соединения (максимум 10)?
WHERE <условия. если таковые существуют, относящиеся к внешнему запросу?
Этот шаблон подходит для запроса с 21-30 таблицами с внешними соединени-
ями. Если внешними соединениями соединяются 11-20 таблиц, вам понадобится
только одна вложенная таблица. Если таблиц больше 30, то потребуется больший
уровень вложенности. Для такого синтаксиса DB2 эффективно создает вложен-
ные представления «на лету», как определено запросами внутри круглых скобок в
разделах FROM. Для успешной обработки внешних соединений DB2 обрабатывает
все небольшие запросы независимо, уходя от проблемы слишком большого коли-
чества внешних соединений в одном запросе.
ПРИМЕЧАНИЕ ------------------------------------------------------------------------------
На предыдущем месте работы, в TenFold, мы обнаружили, насколько полезна эта техника, расширили
продукт EnterpriseTenFold, чтобы при необходимости он автоматически генерировал этот исключи-
тельно сложный SQL-код. Вероятно, это не самое простое решение для кода, написанного вручную, но
все равно этот метод вполне может быть единственным эффективно работающим решением для случая
с медленным или слишком сложным разбором множества внешних соединений в DB2.
Как принудить DB2 оптимизировать стоимость
считывания первых строк
Обычно DB2 подсчитывает стоимость выполнения всего запроса и выбирает план,
который должен выполняться быстрее от начала до конца. Однако, особенно для
оперативных запросов, важнее всего получить только первые несколько строк, и вы
предпочитаете оптимизацию в целях скорейшего получения первых строк.
Чтобы быстро считать первые строки, обычно при помощи вложенных цик-
лов, нужно добавить фразу OPTIMIZE FOR <n> ROWS (или OPTIMIZE FOR 1 ROW), где <n> —
это количество строк, которые вы хотите получить быстрее, из большого набора
строк, который теоретически вернет запрос. Этот оператор находится в самом
конце запроса и сообщает DB2, что необходимо оптимизировать стоимость воз-
вращения только первых <п> строк, не обращая внимания на стоимость выполне-
ния оставшейся части запроса. Если вы точно знаете, сколько строк хотите полу-
чить, и доверяете оптимизатору выбор наилучшего плана, то можете выбрать <п>,
исходя из этих начальных условий. Если вы хотите заставить надежный план со
вложенными циклами начать выполняться как можно скорее, используйте
OPTIMIZE FOR 1 ROW.
Управление планами в SQL Server
125
На практике этот метод обычно приводит к использованию соединений со вло-
женными циклами, так как в этом случае для начала соединения не требуется счи-
тывать наборы строк полностью. Однако явно указанное выражение ORDER BY мо-
жет свести на нет любую попытку быстро получить первые строки. Она обычно
требует сортировки, которая выполняется после завершения запроса, откладывая
возвращение первой строки независимо от плана выполнения. Если вы хотите ис-
пользовать соединения с вложенными циклами, применяя эту технику, то можно
удалить условие сортировки и произвести сортировку в приложении. Подсказка
OPTIMIZE FOR 1 ROW эквивалентна подсказке FIRST_ROWS в Oracle и подсказке OPTION(FAST
1) в SQL Server.
В DB2 мало методов, которые помогают использовать точно выбранные планы
выполнения, в противоположность огромному количеству подробностей, которые
DB2 предлагает для уже существующего плана выполнения, объясняя, почему был
выбран именно он. Но я должен признаться, что доступные техники в сочетании с
хорошим оптимизатором DB2 на моей практике проявляли себя замечательным
образом.
Управление планами в SQL Server
Процесс настройки в SQL Server состоит из трех основных шагов.
1. Предоставление оптимизатору хорошей статистики по таблицам и индексам,
чтобы он мог точно подсчитать стоимость различных вариантов.
2. Изменение запроса, чтобы запретить нежелательные планы выполнения, ис-
пользуя, в основном, методы, характерные для SQL Server.
3. Если необходимо, принудительный выбор простого плана выполнения при по-
мощи инструкции FORCEPLAN.
Подготовка к оптимизации в SQL Server
В очередной раз доказывая, что недостаток знания опасен, стоимостные оптими-
заторы часто выдают плохие результаты, если им не предоставлена статистика
по всем таблицам и индексам, участвующим в запросе. Таким образом, вам обя-
зательно нужно поддерживать достоверную статистику по таблицам и индексам,
и помимо этого, заново генерировать статистику в случае, если объем таблицы
существенно изменяется или перестраиваются таблицы или индексы. Самый бе-
зопасный способ — периодически заново генерировать статистику, используя для
этого отрезки времени, когда нагрузка невелика, например, зто может быть ночь
или выходные. В Query Analyzer выполните следующую команду, затем скопи-
руйте и вставьте полученные команды UPDATE STATISTICS в окно запроса и снова
выполните их:
-- file called updateal 1.sql
-- update your whole database
SELECT 'UPDATE STATISTICS '. name
FROM sysobjects
WHERE type = 'U'
126
4. Управление планами выполнения
Часто в запросах встречаются условия для сильно асимметричных распределе-
ний, например условия по специальным типам, кодам или флагам в случае, когда в
этих столбцах присутствует лишь несколько различных значений. SQL Server ав-
томатически создает статистику по распределению значений индексированных
столбцов, позволяя автоматически устанавливать значения селективности, даже
если индексированные столбцы характеризуются асимметричным распределени-
ем значений.
Иногда бывает полезно помочь SQL Server определить селективность условия
с асимметричным распределением, даже если это распределение относится к не
индексированному столбцу. В таком случае вам необходимо особым образом за-
просить данные из этого столбца. Например, чтобы получить статистическую груп-
пу с именем Efl ад по не индексированному столбцу Exempt_Fl ад таблицы Empl oyees,
выполните:
CREATE STATISTICS EFlag on Employees(Exempt_Flад)
В качестве примера случая асимметричного распределения возьмем табли-
цу Orders, в поле Status Code которой может быть три значения: ’CL' для закры-
тых (например, выполненных) заказов, 'СА‘ для отмененных заказов и 'ОР' для
открытых заказов. Таким образом, большинство заказов будет выполнено, то
есть если приложение проработало несколько месяцев, количество значений
’ CL' стабильно растет. Значительная часть заказов будет в итоге отменена, по-
этому значение ' СА ’ в итоге также будет встречаться в большом списке заказов.
Однако если бизнес идет хорошо и заказы продолжают поступать, то количе-
ство открытых заказов будет оставаться умеренным и стабильным, даже если
данные будут накапливаться годами. Скоро условие Status_Code='OP' станет
достаточно селективным, чтобы предпочесть соединение соответствующих таб-
лиц, даже если столбец Status_Code не индексирован, и важно, чтобы оптимиза-
тор мог понять этот факт, лучше — без ручной настройки. Для этого в SQL в
условии нужно явно указать необходимое значение, а не использовать общую
хранимую процедуру, которая просто выдает константу после разбора, во вре-
мя выполнения.
Изменение запроса
Чаще всего следует настраивать SQL Server, используя подсказки. Подсказки обыч-
но указываются в разделе FROM, где воздействуют на доступ к определенной табли-
це, или в операторе SQL Server OPTION () в самом конце запроса. Далее перечислены
наиболее распространенные подсказки.
WITH (INDEX (<Имя_индекса>')'). Эта подсказка должна находиться сразу же за псев-
донимом таблицы в разделе FROM. Она заставляет SQL Server использовать для
доступа к этому псевдониму таблицы указанный индекс. Поддерживается так-
же старый синтаксис, 1№\=<Имя_индекса>, но в будущем от него могут отказаться,
поэтому я не рекомендую использовать его. Еще более устаревшим и опасным
является пока что поддерживаемый метод указания внутреннего идентифика-
тора объекта, соответствующего желаемому индексу. Указание индекса при
помощи идентификатора очень ненадежно, поскольку индекс получит новый
идентификатор, если кто-нибудь удалит и заново создаст его или если прило-
жение будет перенесено в новую базу данных SQL Server.
Управление планами в SQL Server
127
WITH (I NDEX (0)). Эта подсказка должна находиться сразу же за псевдонимом таб-
лицы в разделе FROM. Она заставляет SQL Server обращаться к этому псевдони-
му таблицы при помощи полного сканирования.
WITH (NOLOCK). Эта подсказка должна находиться сразу же за псевдонимом таб-
лицы в разделе FROM. Она заставляет SQL Server считывать данные из таблицы
с указанным псевдонимом, не применяя блокировок или каких-либо других мер
для обеспечения непротиворечивости. Блокировки считывания в SQL Server
могут создать «узкое место», если их применять во время активного обновле-
ния таблицы. Эта подсказка предотвращает появление такой проблемы, воз-
можно, за счет стоимости непротиворечивого представления данных на какой-
то конкретный момент времени.
LOOP и HASH. Две этих подсказки могут находиться сразу же перед ключевым сло-
вом JOIN в разделе FROM. Они принуждают SQL Server выполнить указанное со-
единение указанным методом. Для того чтобы применять эти подсказки, не-
обходимо использовать синтаксис соединения в новом стиле, с ключевым словом
JOIN в разделе FROM. Если указана хотя бы одна подсказка этого типа, то все со-
единения будут выполнены в том же порядке, в каком псевдонимы перечис-
лены в FROM.
OPTION!LOOP JOIN). Эта подсказка находится в конце запроса и приказывает вы-
полнять все соединения методом вложенных циклов.
OPTION(FORCE ORDER). Эта подсказка находится в конце запроса и приказывает
выполнять все соединения в том порядке, в котором в разделе FROM перечисле-
ны псевдонимы таблиц.
OPTION!FAST 1). Эта подсказка просто принуждает SQL Server попытаться вы-
дать первые строки как можно быстрее, что обычно приводит к выбору плана
выполнения с вложенными циклами. Она работает почти как подсказка OPTION (LOOP
JOIN), хотя теоретически SQL Server может понять, что никакой план выполне-
ния не сможет быстро вернуть первые строки, если в запросе явно присутству-
ет ORDER BY, сводящий на нет эффект OPTION (FAST 1). Подсказка OPTION (FAST 1) эк-
вивалентна подсказке FIRST_ROWS в Oracle и подсказке OPTIMIZE FOR 1 ROW в DB2.
Подсказки вполне можно комбинировать. Например, в одну фразу WITH можно
вставить несколько подсказок, разделяя их запятыми: WITH (I NDEX (Empl oyee_Fi rst_Name).
NOLOCK). Несколько подсказок во фразе OPTION также разделяются запятыми, на-
пример, OPTION (LOOP JOIN. FORCE ORDER). Вместе эти подсказки обеспечивают полный
контроль над порядком соединения, методами соединения и методами доступа к
таблицам.
Примеры подсказок
Я продемонстрирую настройку с подсказками на паре запросов. Если вы выбрали
надежный план только со вложенными циклами, который начинает с фамилии со-
трудника и переходит к другим таблицам в оптимальном порядке, используя для
обращения к каждой из них первичные ключи, подсказки в этом запросе обеспечат
желаемый план:
SELECT E.First_Name, E.Last_Name. Е.Salary. LE.Description.
M.First_Name. M.Last_Name. LM.Description
128
4. Управление планами выполнения
FROM Employees Е WITH (INDEX(Employee_Last_Name))
INNER JOIN Locations LE WITH (INDEX!Location_PKey))
ON E.Location_ID-LE.Location ID
INNER JOIN Employees M WITH (INDEX(Employee_PKey))
ON E.Managen ID-M.Employee ID
INNER JOIN Locations LM WITH (INDEX(Location_PKey))
ON M.Location_ID-LM.Location_ID
WHERE E.Last_Name - 'Johnson'
AND LE.Descript!on-'Dallas'
OPTION(LOOP JOIN, FORCE ORDER)
SET SHOWPLAN_TEXT ON (as described in Chapter 3) generates the following results when you
run this query from SQL Server Query Analyzer:
StmtText
|--Bookmark Lookup!...(...[Locations] AS [LM]))
|--Nested Loops(Inner Join)
--Bookmark Lookup!...(...[Employees] AS [M]))
|--Nested Loops(Inner Join)
--Fi1 ter(WHERE:([LE].[Descri pti on]-'Dallas'))
(--Bookmark Lookup(...(...[Locations] AS [LE]))
(--Nested Loopsdnner Join)
|--Bookmark Lookup(...(...[Employees]
(wrapped line) AS [E]))
| | | (--Index Seek(...(...
(wrapped line) [Employees].[Employee_Last_Name]
(wrapped line) AS [E]). SEEK:([E].[Last_Name]-'Johnson') ORDERED)
| | | -Index
(wrapped line) Seek(...(...[Locations],[Location_PKey]
(wrapped line) AS [LE]), SEEK:([LE].[Location_ID]-[E].[Location_ID])
(wrapped line) ORDERED)
| |--Index Seek(...(...[Employees].[Employee_PKey]
(wrapped line) AS [M]). SEEK:([M].[Employee_ID]-[E].[Manager_ID]) ORDERED)
|--Index Seek(..(.. [Locations].[Location_PKey]
(wrapped line) AS [LM]). SEEK:([LM].[Location_ID]=[M].[Location_ID])
(wrapped line) ORDERED)
(12 row(s) affected)
Если вы не хотите использовать только вложенные циклы, вам могут потребо-
ваться подсказки HASH и LOOP, как показано в следующем варианте последнего за-
проса:
SELECT E.First_Name. E.Last_Name. Е.Salary. LE.Description.
M.F1rst_Name. M.Last_Name, LM.Description
FROM Employees E ~ WITH (INDEX(Employee_Last_Name))
INNER HASH JOIN Locations LE WITH (INDEX(Location_Description))
ON E.Location_ID=LE.Location_ID
INNER LOOP JOIN Employees M WITH (INDEX(Employee_PKey))
ON E.Manager_ID-M.Employee_ID
INNER LOOP JOIN |_ocations LM WITH (INDEX(Location_PKey))
ON M.Location_ID-LM.Location_ID
WHERE E.Last_Name = 'Johnson'
AND LE.Description-'Dallas'
Предыдущий запрос обеспечивает следующий план выполнения, включенный
при помощи SET SHOWPLAN_TEXT ON:
StmtText
(--Bookmark Lookup(...(...[Locations] AS [LM]))
(--Nested Loopsdnner Join)
Управление планами в SQL Server
129
|--Bookmark LookupC. (...[Employees] AS [M]))
|--Nested Loopsdnner Join)
j |--Hash Matchdnner Join...
(wrapped line) ([E].[Location_ID])-([LE].[Location_ID])...)
| | |--Bookmark Lookup(...(...[Employees] AS [E]))
|--Index
(wrapped line) Seek(...(...[Employees].[Employee_Last_Name]
(wrapped line) AS [E]). SEEK:([E].[Last_Name]-'Johnson’) ORDERED)
| j |--Bookmark LookupC. (...[Locations] AS [LE]))
j | |--Index
(wrapped line) Seek( ..(...[Locations].[Location_Description]
(wrapped line) AS [LE]). SEEK:([LE].[Description]-'Dallas') ORDERED)
| |--Index Seek(...(...[Employees].[Employee_PKey]
(wrapped line) AS [M]). SEEK:([М].[Employee_ID]-[E].[Manager_ID]j ORDERED)
|--Index Seek(...(...[Locations].[Location_PKey]
(wrapped line) AS [LM]). SEEK:([LM].[Location_ID]-[M].[Location_ID])
(wrapped line) ORDERED)
(11 row(s) affected)
В настройке с подсказками есть два основных критических случая, как, напри-
мер, здесь.
Можно использовать как можно меньше указаний для получения желаемого
плана выполнения, или, по меньшей мере, плана, близкого к идеальному. Аргу-
менты в пользу этого подхода звучат так, что у SQL Server есть больше инфор-
мации, чем у вас, и следует оставить ему свободу действий, позволить ему
адаптироваться к изменениям в распределении данных и пользоваться пре-
имуществами улучшений в будущих версиях SQL Server. Оставив СВО макси-
мум свободы, вы максимизируете его способности хорошо оптимизировать в
будущем. Однако вы не можете знать, сколько указаний потребуется SQL Server,
если он сразу же не сможет получить наилучший план, пока не попробуете раз-
ные варианты, поэтому этот подход обычно становится итерационным, с до-
бавлением по одной подсказке за раз, пока SQL Server не создаст хороший план.
Если вы не получили от SQL Server желаемый план автоматически, то предпо-
лагаете, что база данных сделала неверные предположения, которые распрост-
раняются на весь код и портят все ее вычисления. Следовательно, нужно оста-
вить ей минимальную свободу действий, явно и полностью указывая, какой
именно план вам нужен.
Если вы уверены в выбранном плане выполнения (а вы должны быть уверены,
если применили все методы, которые я опишу далее в этой книге), то не имеет
смысла полностью явно указывать план. Я пока что не сталкивался со случаем,
когда хорошо выбранный надежный план выполнения требуется изменить, чтобы
обработать данные с новым распределением или использовать новые возможнос-
ти базы данных. С другой стороны, SQL, частично ограниченный набором подска-
зок, может выполняться неправильно, особенно если для некоторых таблиц или
индексов статистика утеряна. Когда SQL Server делает неправильный выбор, то
ошибка, которая заставила сделать его этот выбор, вероятнее всего портит весь
план выполнения. Однако подсказка OPTION (FAST 1) — это инструкция, которая
может оказаться полезной, даже если у SQL Server уже есть прекрасная информа-
ция. Она всего лишь указывает, что время получения первой строки намного важ-
нее времени получения последней строки.
130
4. Управление планами выполнения
Использование FORCEPLAN
Параметр FORCEPLAN иллюстрирует старый метод настройки в Microsoft SQL Server
и Sybase. Он требует отдельного оператора SQL:
SET FORCEPLAN ON
Этот параметр действует на весь SQL-код, который выполняется в текущем
соединении, пока вы не выполните оператор:
SET FORCEPLAN OFF
Когда значение параметра FORCEPLAN равно ON, база данных выполняет только
простейшую оптимизацию SQL. Обычно она использует планы выполнения с вло-
женными циклами, которые работают при помощи индексов и соединяют табли-
цы в том же порядке, в каком они перечислены в разделе I ROM. Если вы хотите по-
лучить план именно такого типа, то SET FORCEPLAN будет идеальным вариантом,
поскольку не только включает нужный план, но и экономит время разбора, кото-
рое в противном случае было бы потрачено на выбор из большого диапазона пла-
нов, особенно для соединений множества таблиц. Это, образно говоря, «обоюдоту-
пой» меч, поэтому применяйте его только когда знаете, что в разделе FROM указан
правильный порядок соединения, и хотите использовать вложенные циклы.
5
Диаграммное
изображение
простых запросов SQL
Для превращения искусства настройки SQL в науку необходим общий язык, об-
щая парадигма для описания и решения проблем настройки SQL. Эта книга — пер-
вое печатное издание, которое может научить вас методу, исправно служившему
мне и тем, кому я его объяснил. Я называю этот метод методом диаграммного изоб-
ражения запросов.
Как и любой новый инструмент, метод диаграммного изображения запросов
требует некоторых авансовых инвестиций и затрат времени от будущего пользо-
вателя. Но мастерство владения этим инструментом обеспечивает гигантские воз-
награждения, поэтому я прошу вас быть терпеливыми — трудно будет лишь в са-
мом начале. Скоро вы найдете ответы, которые не дал бы вам ни один другой
инструмент, причем приложить придется лишь немного усилий. А в конце изуче-
ния мой метод станет вам настолько привычным, что, как и в случае с любым дру-
гим хорошим инструментом, вы не будете замечать, что используете его.
Зачем нужен новый метод?
Поскольку я прошу вас быть терпеливыми, начну с рассмотрения того, зачем нам
нужен этот новый инструмент. Почему бы не использовать то, что вы уже знаете,
например информацию SQL-сервера, для решения проблем производительности?
Самая большая проблема с использованием SQL-сервера для настройки — то, что
он предлагает одновременно слишком много и недостаточно информации для ре-
шения задачи настройки. Информация SQL-сервера существует для функциональ-
ного описания, какие столбцы и строки нужны приложению из каких таблиц, по
каким условиям их нужно соединять, и в каком порядке возвращать. Однако боль-
шая часть этой информации совершенно не относится к настройке запроса. С дру-
гой стороны, информация, относящаяся и даже жизненно необходимая для настрой-
ки — о распределении данных в таблицах— полностью отсутствует. У SQL много
общего со старыми проблемами эквивалентности, печально известными еще из
математики начальной школы, разве что SQL-сервер с большей вероятностью про-
пускает необходимую информацию. Какую задачу, из двух приведенных ниже, вам
будет легче решить?
132
5. Диаграммное изображение простых запросов SQL
Для отдыха на природе Джонни приготовил по восемь лепешек, три сосиски,
одной полоске бекона и два яйца для себя и своих друзей Джима, Мэри и Сью.
Каждая девочка отдала одну треть своих сосисок, 25 % лепешек и половину яиц
мальчикам. Джим уронил лепешку и две сосиски, и их украл енот. У Джонни
аллергия на кленовый сироп, а у Мэри на половине лепешек была клубника, но
все остальные поливали лепешки кленовым сиропом. Сколько лепешек с кле-
новым сиропом съел каждый ребенок?
(8+(0.25 х 8) -1) + (0.75 х 8/2) + (0.75 х 8) - ?
Естественно, вторую задачу решать проще.
Диаграмма запроса — это скелетный синтез основных элементов настройки
«проблемы эквивалентности» SQL и ключевых распределений данных, необходи-
мых для поиска оптимального плана исполнения. Благодаря скелетному синтезу
вы отбрасываете отвлекающие, ненужные детали и сосредотачиваетесь на ядре
проблемы. В результате получается намного более компактный язык, который
можно использовать для реальных задач и упражнений. Проблемы, которые на
языке SQL описывались бы страницами кода (а в реальных проблемах, когда па-
тентованный код нельзя легально просмотреть, потребовались бы дни для изуче-
ния поведения запроса), превращаются в простые, абстрактные диаграммы, зани-
мающие половину страницы. Ваш темп изучения чрезвычайно ускорится с этим
инструментом, частично благодаря тому, что сходство между проблемами настрой-
ки и функционально отличающимися запросами станет очевидным. Вы увидите
шаблоны и сходства, которые никогда бы не заметили на уровне SQL-кода, и буде-
те многократно использовать свои решения с минимальными усилиями.
Ни один известный мне инструмент не создаст для вас ничего подобного диаг-
рамме запроса, так же, как ни один инструмент не превращает математическую
проблему эквивалентности в простую арифметику. Поэтому вашим первым ша-
гом в настройке SQL будет перевод проблемы SQL в проблему диаграммы запро-
са. Так же, как преобразование задач эквивалентности в арифметическое выраже-
ние является самым трудным шагом, вы, вероятнее всего, будете считать перевод
проблем настройки SQL в диаграммы запросов самым сложным (или хотя бы са-
мым долгим) шагом в настройке SQL, по крайней мере, в первое время. Однако
обнадеживает то, что, хотя человеческие языки развивались бессистемно по мере
эволюции общения между сложными человеческими разумами, SQL был создан
как структура для общения с компьютерами. Проблемы эквивалентности настройки
SQL составляют гораздо меньшую сферу интересов, чем проблемы эквивалентно-
сти натуральных языков. По мере тренировки процесс перевода SQL в диаграмму
запросов становится все быстрее и проще, иногда вы даже сможете даже быстро
выполнить этот перевод в уме. Как только вы сделаете диаграмму запросов и полу-
чите хотя бы начальное понимание метода диаграммного изображения запросов,
то будете считать большинство проблем настройки тривиальными.
Дополнительным и совершенно незапланированным преимуществом оказыва-
ется то, что диаграммы запросов оказываются ценным средством в поиске целых
классов незаметных логических ошибок приложения, которые трудно обнаружить
при тестировании, так как они возникают в достаточно редких и трудных случаях.
В главе 7 я буду подробно обсуждать, как использовать эти диаграммы для поиска
и исправления таких логических проблем.
Полные диаграммы запросов
133
В следующих разделах я опишу два стиля диаграмм запросов — полные и упро-
щенные. Полные диаграммы включают все данные, которые потенциально могут
относиться к проблеме настройки. Упрощенные диаграммы более качественные и
не содержат данных, которые обычно не требуются. Я начну с описания полных
диаграмм, так как понять упрощенные диаграммы, рассматривая их как полные
диаграммы, из которых удалили подробности, легче, чем полные диаграммы как
упрощенные с добавленными деталями.
Полные диаграммы запросов
В примере 5.1 показан простой запрос, иллюстрирующий все значимые элементы
диаграммы запроса.
Пример 5.1. Простой запрос с одним соединением
SELECT D.Department_Name. E.Last_Name. E.First_Name
FROM Employees E. Departments D
WHERE E.Department_Id=D.Department_Id
AND E.Exempt_Flag='Y'
AND D.US_Based_Flag=’Y':
Этот запрос переводится в диаграмму запроса, показанную на рис. 5.1.
EOJ
20
▼0.98
DO5
Рис. 5.1. Полная диаграмма запроса для простого запроса
Сначала я опишу значение каждого элемента диаграммы, а затем объясню, как
создать диаграмму, используя в качестве стартовой точки SQL-код.
Информация, отображаемая в диаграммах
запросов
В математических терминах то, что вы видите на рис. 5.1, является направленным
графом. Это набор узлов и связей, причем связей часто обозначаются стрелками,
указывающие направление. Узлы на этой диаграмме представлены буквами Е и 0.
Рядом с узлами и обоими концами каждой связи есть числа, которые указывают
дополнительные свойства узлов и связей. В терминах запроса вы можете интер-
претировать эти элементы диаграммы следующим образом.
Узлы
Узлы представляют таблицы или псевдонимы таблиц в разделе FROM — в нашем
случае это псевдонимы Е и D. Вы можете сокращать названия таблиц или псевдо-
нимов, как вам удобно, если только это не вызовет двусмысленности или недопо-
нимания.
134
5. Диаграммное изображение простых запросов SQL
Связи
Связи представляют соединения между таблицами, а направленная связь обозна-
чает, что соединение гарантированно получит уникальные значения в той табли-
це, на которую указывает связь. В данном случае Department_ID — первичный (уни-
кальный) ключ в таблице Departments, поэтому у связи есть стрелка на конце,
указывающем на узел D. Так как Department_ID не уникален в таблице Employees, на
другом конце связи стрелки нет. Следуя моим обозначениям, всегда рисуйте свя-
зи, состоящие из одной стрелки, так, чтобы стрелка указывала вниз. Если вы все-
гда будете рисовать стрелки, направленные вниз, то вам будет намного проще чи-
тать планы, где главные таблицы всегда будут расположены под детальными
таблицами. В главах 6 и 7 я опишу «правила большого пальца» для поиска опти-
мальных планов исполнения при помощи диаграмм запроса. Так как эти правила
обрабатывают соединения с главными таблицами иначе, нежели соединения с де-
тальными таблицами, в них, чтобы удобно различать эти два типа, специально упо-
минаются соединения вниз и соединения вверх.
Хотя вы можете догадаться, что Department_ID — это первичный ключ для De-
partments, SQL не объявляет явно, какая сторона соединения является первичным
ключом, а какая — внешним. Необходимо проверить индексы или объявленные
ключи, чтобы удостовериться, что Department_ID гарантированно уникален в таб-
лице Departments.
Подчеркнутые числа
Подчеркнутые числа рядом с узлами обозначают долю строк каждой таблицы,
удовлетворяющих условиям фильтрации для этой таблицы. Здесь под услови-
ями понимаются не условия соединения, а условия, относящиеся только к кон-
кретной таблице на диаграмме SQL. На рис. 5.1 10 % строк таблицы Employees
удовлетворяют условию Exempt_Fl ag=' Y', и 50 % строк таблицы Depa rtments удов-
летворяют условию US_Based_Fl ад=' У'. Я называю эти доли коэффициентами
фильтрации.
Часто для одной или нескольких таблиц вообще не указаны условия фильтра-
ции. В этом случае для коэффициента фильтрации (R) я использую значение 1,0,
так как 100 % строк удовлетворяют (несуществующим) условиям фильтрации для
этой таблицы. Также в подобных случаях я обычно вообще не указываю коэффи-
циент фильтрации на диаграмме. Отсутствие этого числа обозначает R = 1,0 для
данной таблицы. Коэффициент фильтрации не может быть больше 1,0. Зачастую
можно приблизительно угадать значение коэффициентов фильтрации, зная, что
представляют таблицы и столбцы. Если вам доступны распределения реальных
данных, вы можете найти точные значения коэффициентов фильтрации, просто
получив и проанализировав эти данные. Рассматривайте каждую фильтрованную
таблицу с операторами фильтрации, относящимися только к этой таблице, как
однотабличный запрос, и ищите селективность условий фильтров так, как я рас-
сказывал в главе 2 в разделе «Вычисление селективности».
Во время фазы разработки приложения вы не можете всегда точно знать, каких
коэффициентов фильтрации следует ожидать во время работы приложения на ре-
альных объемах данных. В этом случае производите оценку, основываясь на зна-
нии работающего приложения, а не на крохотных искусственных объемах данных
в тестовых базах данных.
Полные диаграммы запросов
135
Неподчеркнутые числа
Неподчеркнутые числа рядом с обоими концами связи представляют среднее ко-
личество строк, найденных в таблице на этом конце соединения для соответству-
ющей строки на другом конце соединения. Я называю их коэффициентами соедине-
ния. Коэффициент соединения в начале соединения — это детальный коэффициент
соединения, а на конце соединения (со стрелкой) — главный коэффициент соедине-
ния.
Главные коэффициенты соединения всегда меньше или равны 1,0, так как уни-
кальный ключ гарантирует обнаружение нескольких главных строк для одной де-
тальной. Часто встречается случай, когда в детальной таблице внешний ключ обя-
зателен и ссылочная целостность данных идеальна (что гарантирует существование
подходящей главной строки), тогда главный коэффициент соединения равен в точ-
ности 1,0.
Детальные коэффициенты соединения могут быть равны любому неотрицатель-
ному числу. Они могут быть меньше 1,0, так как некоторые отношения главной и
детальной таблиц разрешают существование нуля, одной или многих детальных
строк, причем чаще всего встречается случай «один к нулю». В этом примере обра-
тите внимание, что для средней строки Empl oyees есть соответствующая строка (с
которой она связана) в Departments в 98 % случаев, тогда как средняя строка
Departments соответствует (связывается с) 20 строкам Employees. Хотя вы можете
приблизительно угадать коэффициенты соединения, зная, что собой представля-
ют таблицы, старайтесь, когда это возможно, получать эти значения из полных,
реальных распределений данных. Так же, как и с коэффициентами фильтрации,
вам может потребоваться вычисление коэффициентов соединения во время фазы
разработки приложения.
Что не входит в диаграммы запросов
Понимать, что не входит в диаграммы запросов, так же важно, как знать, что они
включают. В следующих разделах описаны несколько элементов, которые в диа-
граммы не входят, и дано этому объяснение.
Списки выбора
Диаграммы запросов полностью исключают любые упоминания списков столб-
цов и выражений, которые выбирает запрос (то есть все, что находится между SELECT
и FROM). Производительность запроса практически полностью определяется тем,
какие строки выбираются из базы данных, и каким образом вы их получаете. Что
вы делаете с этими строками, какие столбцы возвращаются, и какие выражения вы
подсчитываете — это практически несущественно для производительности. Глав-
ное, но редкое исключение из этого правила — когда вы изредка выбираете так
мало столбцов из таблицы, что база данных может выполнить запрос, используя
только данные из индекса, совершенно не обращаясь к основной таблице. Иногда
доступ только к индексу может существенно сэкономить ресурсы, но он мало вли-
яет на решения, которые вы принимаете относительно оставшейся части плана
исполнения. Решать, нужно ли попробовать только индексный доступ, следует в
последний момент процесса настройки и только если наилучший план без приме-
нения этой стратегии оказывается слишком медленным.
136
5. Диаграммное изображение простых запросов SQL
Сортировка и соединение
В диаграмме отсутствуют любые указания на сортировку (ORDER BY), группировку
(GROUP BY) и фильтрацию после группировки (HAVING). Эти операции практически
никогда не имеют большого значения для производительности запроса. Шаг сор-
тировки, который они обычно включают, может влиять на скорость выполнения,
но для изменения его стоимости мало что можно сделать, и эта стоимость обычно
не так велика по сравнению с производительностью плохо выполняющегося за-
проса.
Имена таблиц
В диаграммах запроса имена таблиц обычно заменяются псевдонимами. Если у вас
есть необходимая статистика по таблицам, большинство остальных подробностей
незначительны для проблемы настройки. Например, не имеет значения, из какой
таблицы запрос считывает данные или какие сущности хранятся в таблицах. В кон-
це концов, вы должны уметь преобразовывать результат обратно в действия в ис-
ходном SQL и в базе данных (такие действия, как создание нового индекса, напри-
мер). Однако когда вы решаете абстрактную проблему настройки, то чем более
абстрактными будут названия узлов, тем лучше. Аналогично, когда ваша цель —
правильно добавить последовательность чисел, то нет разницы, работаете ли вы с
элементами инвентарного списка или пациентами больницы. Чем более абстракт-
но вы рассматриваете проблему, тем яснее она становится, и тем четче вы видите
аналогии с похожими проблемами, встречавшимися ранее, которые, возможно,
работали с другими сущностями.
Подробные условия соединения
Детали условий соединения теряются, когда вы представляете соединения как
простые стрелки с парой чисел, полученных откуда-то за пределами SQL. Если вы
знаете статистику соединения, то подробности (например, столбцы соединения
и как они между собой связаны) не играют роли.
Абсолютные размеры таблиц
(в противоположность относительным)
Диаграмма не указывает размеры таблиц. Однако вы можете сделать предполо-
жение о размерах таблиц, исходя из детального коэффициента соединения, ко-
торый находится у верхнего конца связи. Имея диаграмму запроса, вам необхо-
димо знать общие размеры таблиц, чтобы установить, сколько будет возвращено
строк, и сколько времени займет выполнение запроса. Но оказывается, что эта
информация не нужна для выяснения относительного времени выполнения раз-
личных вариантов, и, следовательно, для поиска лучшего. Это полезный резуль-
тат, поскольку зачастую необходимо добиться хорошего выполнения запроса не
только на единственном экземпляре базы данных, но на целом диапазоне экзем-
пляров для множества покупателей. Для различных покупателей могут суще-
ствовать таблицы различных абсолютных размеров, но относительные размеры
обычно изменяются несущественно, а коэффициенты соединения и фильтрации
и того меньше. В действительности они изменяются настолько мало, что разли-
чия можно игнорировать.
Полные диаграммы запросов
137
ПРИМЕЧАНИЕ --------------------------------------------------------------------
Исходя из собственного опыта, я могу сказать: предположение о том, что одним из основных преиму-
ществ стоимостных оптимизаторов является их способность выдавать для различных статистик по таб-
лицам и индексам различные планы исполнения для одного и того же SQL-кода, является мифом. Эта
теоретическая возможность часто используется в качестве аргумента против ручной настройки SQL при-
ложения, так как результат может (теоретически) навредить такому же количеству покупателей, какому
он может помочь, что сводит на нет все преимущества оптимизации. С другой стороны, мне пока еще
предстоит найти запрос, для которого не существует плана исполнения, прекрасно работающего на лю-
бых распределениях данных. (Эти планы не являются оптимальными для всех распределений, но они
достаточно близки к оптимальным, чтобы различия не имели значения.) В результате выясняется, что
осторожная ручная настройка SQL продукта не обязательно должна повредить одному покупателю, что-
бы помочь другому.
Подробности условий фильтрации
Подробности условий фильтрации теряются, когда вы абстрагируете их до обык-
новенных чисел. Можно выбрать оптимальный путь к данным, ничего не зная о
том, как, или по каким столбцам база данных исключает строки из результата вы-
полнения запроса. Вам необходимо только знать, насколько эффективен в число-
вом отношении каждый фильтр для достижения поставленных целей исключения
строк. Как только вы обнаружите этот абстрактный оптимальный план, вам потре-
буется вернуться к подробным условиям фильтрации, чтобы понять, что нужно
изменить. Можно изменить индексы для достижения оптимального пути, или из-
менить SQL-код, чтобы заставить базу данных использовать уже существующие
индексы, но, в любом случае, этот финальный шаг прост, если вы уже знаете, каков
оптимальный абстрактный план.
Когда диаграммы запросов помогают лучше всего
Так же, как некоторые проблемы эквивалентности слишком просты, чтобы требо-
вать абстракции (например: «У Джонни было пять яблок, он съел два, сколько яб-
лок осталось?»), некоторые запросы, подобные запросу в примере 5.1., настолько
просты, что абстрактное и формальное представление проблемы может и не потре-
боваться. Если бы все запросы были двусторонними соединениями, вы бы прекрас-
но справлялись без диаграмм запросов. Но в реальных приложениях соединения
шести и больше таблиц, и даже соединения 20 и более таблиц встречаются не на-
столько редко, как вы могли бы предположить. Особенно часто подобные многосто-
ронние соединения встречаются среди запросов, которые вам все же придется на-
страивать, так как эти более сложные запросы с большей вероятностью требуют
ручной настройки. (Мой персональный рекорд — 115-стороннее соединение, а на-
стройка соединений более чем 40 таблиц — обыкновенная рутинная работа.) Чем
более полно нормализована ваша база данных и чем сложнее пользовательский ин-
терфейс, тем вероятнее, что вам придется работать с многосторонними соединения-
ми. Это миф, что современные базы данных не могут обрабатывать 20-сторонние
соединения. Хотя это правда, что базы данных (некоторые в большей степени, чем
другие) с гораздо большей вероятностью требуют ручной настройки для получения
пристойной производительности таких сложных запросов, чем для простых.
Кроме очевидных преимуществ избавления от несущественных деталей и кон-
центрации внимания на абстрактной сути, диаграммы запросов часто дают еще
138
5. Диаграммное изображение простых запросов SQL
одно, более тонкое преимущество. С диаграммами становится гораздо проще гене-
рировать практические задачи! В этой главе каждую задачу я начинаю с реального
SQL-кода, но я не могу использовать примеры из приложений, защищенных пра-
вами собственности, которые я настраивал. Поэтому для получения хороших при-
меров я придумываю базу данных приложения и реальные сценарии действий, для
которых могут быть созданы SQL-запросы. После того как я подробно продемон-
стрирую процесс сокращения оператора SQL до диаграммы запроса, в оставшейся
части книги задачи будут поставлены при помощи диаграмм. Схожим образом боль-
шинство трудов по математике концентрируются на абстрактной математике, а не
на проблемах эквивалентности. Абстракция позволяет получать компактные за-
дачи и добиваться эффективного обучения. Абстракция спасает меня от головной
боли изобретения сотен реалистичных проблем эквивалентности, относящихся к
математическим концепциям, которым я хочу научить читателей. Вас может не
беспокоить, сколько сил и времени сэкономил я, но абстракция экономит и ваше
время. Чтобы лучше изучить настройку SQL, одно из лучших упражнений, кото-
рые вам стоит выполнять, — это придумывать задачи по настройке SQL и решать
их. Если вы начнете с реалистичного SQL-кода, то обнаружите, что это медленный
и болезненный процесс, но если вы придумаете задачи, выраженные при помощи
диаграмм запросов, то сможете щелкать их сотнями как орехи.
Абстрактная демонстрация использования
диаграмм запросов
Я безо всякого доказательства объявил, что диаграммы запросов включают все дан-
ные, необходимые для ответа на самые важные вопросы о настройке. Чтобы не ис-
пытывать ваше терпение и доверчивость, я продемонстрирую, как использовать ди-
аграмму запроса на рис. 5.1 для подробной настройки соответствующего запроса,
особенно для поиска лучшего порядка соединения. Оказывается, лучший путь до-
ступа, или план исполнения, для большинства многотабличных запросов включает
индексированный доступ к первой, ведущей таблице, за которым следуют вложенные
циклы обращений к остальным таблицам, и эти циклы используют индексы по соот-
ветствующим ключам соединения в некотором оптимальном порядке соединения.
ПРИМЕЧАНИЕ ----------------------------------------------------------
Для небольших главных таблиц можно слегка улучшить производительность, заменив для них соеди-
нения методом вложенных циклов соединениями хэшированием, но улучшения в этом случае мини-
мальны и не стоят вероятного риска по отношению к надежности, который всегда присутствует при
использовании хэширования.
Однако для многосторонних соединений количество возможных порядков со-
единения может достигать миллионов и миллиардов. Поэтому самый важный ре-
зультат, которого мы должны добиться, — это быстрый способ поиска наилучшего
порядка соединения.
Перед тем как я продемонстрирую сложный процесс оптимизации порядка со-
единения для многостороннего соединения с использованием диаграммы запроса,
давайте просто посмотрим, что диаграмма на рис. 5.1 говорит нам о сравнительной
стоимости обоих порядков для двустороннего соединения, возможных в предло-
женном SQL-запросе. С удивительно высокой точностью стоимость только индек-
Полные диаграммы запросов
139
сированного доступа со вложенными циклами пропорциональна количеству строк,
которые получает база данных, поэтому стоимость запроса я буду рассчитывать на
основе количества считанных строк. Если начать с подчиненного узла Е, то будет
невозможно узнать абсолютную стоимость (если не сделать предположения о ко-
личестве строк для этой таблицы). Но этого значения нет на диаграмме, поэтому
возьмем некоторое значение С и рассмотрим последствия строго формально.
1. Используя индекс на фильтре для Е, база данных должна начать с получения
0,1 х С строк из ведущей таблицы Е.
2. Следуя вложенным циклам по направлению к главной таблице D, главный коэф-
фициент соединения показывает, что база данных получит 0,1 х С х 0,98 строк из D.
3. Складывая результаты шагов 1 и 2, получим общее количество строк из обеих
таблиц: (0,1 х С) + (0,1 х С х 0,98).
4. Вынесем за скобки С и 0,1 из обоих выражений. Общее количество строк, полу-
ченных базой данных, равно С х (0,1 х (1 + 0,98)) или 0,198 х С.
Начиная с противоположного конца соединения, также выразим стоимость че-
рез С, но зададим через С размер D. Зная размер D, выраженный через С, сто-
имость запроса в терминах С вычислим следующим образом.
1. Для каждой строки из D база данных находит приблизительно 20 строк в Е, что
показывает детальный коэффициент соединения. Однако только 98 % строк в Е
в принципе подходят к строкам из D, поэтому общее количество строк С долж-
но быть в 20/0,98 больше, чем количество строк, полученных из D. Следова-
тельно, количество строк, полученных из D, равно С х 0,98/20.
2. Используя индекс для получения только отфильтрованных строк из D, мы по-
лучим половину строк из ведущей таблицы, или С х 0,5 х 0,98/20.
3. При выполнении соединения с Е база данных получает в 20 раз больше строк из
этой таблицы, то есть 20 х С х 0,5 х 0,98/20 или С х 0,5 х 0,98.
4. Складывая количества строк из двух таблиц и вынося за скобки общие множи-
тели, получим общую стоимость: С х (0,5 х 0,98 х ((1 / 20) +1)) или 0,5145 х С.
В действительности абсолютная стоимость нас не интересует. Нам важна отно-
сительная, поэтому наилучший план можно выбрать исходя из того, что, каково
бы ни было С, 0,198 х С всегда будет меньше 0,5145 х С. В диаграмме запроса есть
вся информация, которую вам необходимо знать: что план, начинающийся с Е и
присоединяющий D, будет намного быстрее (приблизительно в 2,6 раз), чем план,
начинающийся с D и присоединяющий Е. Если вы найдете другие, близкие значе-
ния, то стоит подумать о том, что оценка стоимости на основе количества строк
была не очень верна, но об этом я расскажу позже. Самое главное, что следует за-
помнить, так это то, что диаграмма запроса отвечает на основные вопросы, относя-
щиеся к оптимизации запроса. Вам просто необходим эффективный способ ис-
пользования диаграмм запросов для понимания и настройки сложных запросов.
Создание диаграмм запросов
Теперь, когда вы знаете, что означает диаграмма запроса, нужно познакомиться
с методом создания диаграммы на основе оператора SQL, включая шаги, которые
не требовались для показанного выше запроса, но которые вам понадобятся позже.
140
5. Диаграммное изображение простых запросов SQL
1. Начните с произвольно выбранного псевдонима таблицы из раздела FROM и по-
местите его в середину пустой страницы. Эту таблицу я буду называть цен-
тральной таблицей, подразумевая, что она будет текущей точкой, начиная с ко-
торой мы будет добавлять дальнейшие элементы в диаграмму запроса. Для
нашего примера в качестве начальной точки я выберу псевдоним Е, просто по-
тому что он первым встречается в запросе.
2. Найдите условия соединения, соответствующие единственному значению пер-
вичного ключа центральной таблицы. Для каждого такого соединения нари-
суйте стрелку, указывающую вниз, на центральную таблицу, пометив начало
стрелки псевдонимом на противоположной стороне соединения. (Обычно вы
найдете максимум одно соединение с таблицей сверху, по причинам, которые я
объясню позже.) Если связь представляет внешнее соединение, добавьте посе-
редине связи острие стрелки, направленное на дополнительную таблицу.
В нашем примере соединения с первичным ключом таблицы Empl oyees, предпо-
ложительно Employee_ID, нет. Если вы хотите убедиться, что Department_ID — это
достаточно хорошее имя для первичного ключа Empl oyees, то можете проверить
объявленные ключи и уникальные индексы таблицы. Если вы подозреваете,
что соединение на самом деле может быть уникальным, но разработчик базы
данных не объявил и не включил уникальность при помощи объявленного ключа
или индекса, то можете проверить уникальность при помощи SELECT COUNT!*).
COUNT(DISTINCT Department_ID) FROM Empl oyees:. Однако вы, наверное, будете удив-
лены, насколько редко возникают какие-либо сомнения насчет того, с какой
стороны соединение является уникальным, так как очень часто помогают на-
звания столбцов и таблиц. Так что обычно вы можете работать, используя соб-
ственные догадки, и проверяя их, только если полученный результат будет ра-
ботать хуже, чем вы ожидали или хуже, чем требуется.
3. Найдите условия соединения, идущие от внешнего ключа центральной табли-
цы к первичному ключу другой таблицы, и нарисуйте для таких соединений
стрелки, указывающие вниз от центральной таблицы. У нижнего конца каждой
стрелки напишите псевдонимы таблиц, с которыми проводится соединение.
Если связь представляет внешнее соединение, в центре связи добавьте острие
стрелки, указывающее на дополнительную таблицу.
4. Сместите фокус на другой, пока что не рассмотренный узел в диаграмме и по-
вторяйте шаги 2 и 3, пока не соберете узлы, представляющие все псевдонимы в
разделе FROM, и стрелки, представляющие все соединения. (Например, я пред-
ставляю многоэлементное соединение как одну стрелку от составного внешне-
го ключа к составному первичному ключу.) Обычно вниз на узел будет указы-
вать только одна стрелка, поэтому вы будете искать новые указывающие вниз
соединения из узлов, уже находящихся на нижнем конце соединения (со стрел-
кой). Так получается перевернутая древовидная структура, ниспадающая из
одной детальной таблицы наверху.
5. Заполнив все узлы и связи, впишите числа для коэффициентов фильтрации
и коэффициентов соединения, основываясь, если возможно, на статистике по
таблицам для промышленного приложения. Если у вас нет промышленных дан-
ных, то постарайтесь угадать как можно точнее. Нет необходимости добавлять
коэффициенты соединения рядом со связями, представляющими внешние со-
Полные диаграммы запросов
141
единения. Практически всегда для дополнительной таблицы внешнего соеди-
нения (на стороне со знаком (+) соединения, в старой записи Oracle, или в но-
вом стиле — сразу за ключевыми словами LEFT OUTER) условия фильтрации не
указаны, поэтому коэффициент фильтрации равен 1,0, что обозначается про-
сто фактом отсутствия числа на диаграмме.
6. Нарисуйте звездочку рядом с коэффициентом фильтрации для всех фильтров,
которые гарантированно возвращают максимум одну строку. Это не функция,
высчитанная на основе коэффициента и количества возвращенных строк из
таблицы, так как условие может в среднем возвращать одну строку, но не обя-
зательно она будет возвращать только одну строку. Чтобы гарантировать, что
максимальное количество возвращенных строк будет равно единице, необхо-
димо иметь уникальный индекс или понятные ограничения приложения, даю-
щие реальную гарантию.
ОБЕСПЕЧЕНИЕ УНИКАЛЬНОСТИ ----------------------------------------------------
Иногда условие фильтрации настолько близко к гарантированному уникальному соответствию, что
хочется считать его уникальным. Обычно это можно делать без опаски, но я обнаружил, что полезно
сначала попытаться сделать уникальность полной, добавив несколько отсутствующих условий или
исправив дизайн базы данных. Например, у вас может быть фильтр Order_ID=: 1 для таблицы Orders,
и первичный ключ для Orders, состоящий из столбцов Order.IO и Company_ID, причем у Company_I0 един-
ственное, доминирующее значение встречается в 99,9 % случаев. Наиболее вероятная причина, почему
разработчик не указал никаких условий для Company_ID, — он просто забыл, что иногда этот столбец
принимает значение, не равное доминантному, и что Order_ID отдельно не всегда указывает на уникаль-
ный заказ. Я обнаружил, что, когда условия фильтрации близки к уникальным, то практически всегда
разработчик хотел сделать их уникальными, и следует добавить отсутствующее условие или условия,
чтобы добиться запланированной функциональности.
Схожие комментарии можно сделать для почти уникальных соединений. Когда условия соединения
подразумевают соединение вида «много к практически всегда одному», высока вероятность, что струк-
туру запроса или базы данных следует изменить, чтобы гарантировать идеальное соединение вида «много
к одному».
Если у вас есть настоящие данные, использующиеся для работы приложения,
то они являются идеальным источником коэффициентов фильтрации и соедине-
ния. Для примера 5.1, чтобы точно определить зти коэффициенты, нужно выпол-
нить следующие запросы (от Q1 до Q5):
QI: SELECT COUNT(*) Al FROM Employees
WHERE Exempt_Flag- Y';
Al: 1000
02: SELECT COUNT(*) A2 FROM Employees;
A2: 10000
03: SELECT COUNT(*) A3 FROM Departments
WHERE US_Based_Flag='Y':
A3: 245
04: SELECT COUNT(*) A4 FROM Departments;
A4: 490
05: SEI ECT COUNT(*) A5 FROM Employees E. Departments D
WHERE E.Department_ID=D.Department_ID;
A5: 9800
142
5. Диаграммное изображение простых запросов SQL
Значения с А1 до А5 — это результаты, возвращенные запросами, поэтому вы-
полните следующие математические действия.
Чтобы найти коэффициент фильтрации для узла Е, найдите значение А1/А2.
Чтобы найти коэффициент фильтрации для узла D, найдите значение АЗ/А4.
Чтобы найти детальный коэффициент соединения, найдите значение А5/А4, то
есть количество возвращенных строк неотфильтрованного соединения разде-
лите на количество строк, возвращенных из главной таблицы.
Чтобы найти главный коэффициент соединения, найдите значение А5/А2, то есть
количество возвращенных строк неотфильтрованного соединения разделите на
количество строк, возвращенных из детальной таблицы.
Например, в результате выполнения запросов Q1-Q5 получены значения 1 000,
10 000, 245, 490 и 9 800, соответственно. Получаются в точности коэффициенты
фильтрации и соединения на рис. 5.1, и, если вы умножите все результаты выпол-
нения запросов на одну и ту же константу, то получите те же коэффициенты.
Более сложный пример
Теперь я проиллюстрирую процесс диаграммного изображения для достаточно
большого запроса. Я нарисую диаграмму для запроса в примере 5.2, в котором вы
видите внешние соединения в старом стиле Oracle (если вы чувствуете себя уве-
ренно, попробуйте нарисовать для этого запроса диаграмму самостоятельно).
Пример 5.2. Более сложный запрос с соединениями восьми таблиц
SELECT С.Phone_Number. С.Honorific. C.First_Name. C.Last_Name,
С.Suffix. C.AddressID A.AddressID. A.Street_Address_Linel,
A.Street_Address_Line2. A.City_Name. A.State_Abbreviation.
A. ZIP_Code. DD.Deferred_Shipment_Date. 00. Itern Count,
COT.Text. 0T.Text, P.Product_Description, S.Shipment_Date
FROM Orders 0. Order_Details 0D. Products P. Customers C. Shipments S.
Addresses A. Code_Translations OCT. Code_Translations 0T
WHERE UPPER(C.Last_Name) LIKE :Last_Name||'Г
AND UPPERIC.FirstJlame) LIKE :First_Name| |'Г
AND 0D.0rder_ID = 0.0rder_ID
AND O.CustomerlD = C.CustomerlD
AND OD.Product_ID = P.Product_ID(+)
AND OD.Shipment_ID = S.Shipment_ID(+)
AND S.Address_ID = A.Address_ID(+)
AND O.Status_Code = 0T.Code
AND DT Code Дуре = ORDER_STATUS'
AND 0D Status_Code = ODT Code
AND ODT.CodeJype = 'ORDER_DETAIL_STATUS'
AND 0.0rder_Date > :Now - 366
DRDER BV C.Customer_ID. O.Drder_ID DESC. S.Shipment_ID. DD.Order_Detail_ID;
Как и раньше, следует игнорировать все части запроса кроме секций FROM и WHERE.
У всех таблиц интуитивно понятные имена первичных ключей кроме Code_Transl ati ons,
первичный ключ которой состоит из двух частей: (Code_Type. Code).
Обратите внимание, что, когда вы находите однотабличное условие равенства
по части первичного ключа, как в запросе по Code_Translations, следует считать
это условие частью условия соединения, а не фильтрации. Если вы обрабатывае-
те однотабличное условие как часть соединения, то обычно рассматриваете фи-
Полные диаграммы запросов
143
зическую таблицу с двумя или несколькими логическими подтаблицами. Я на-
зываю их таблицами «с яблоками и апельсинами». Чаще всего это физические
таблицы, в которых хранятся в чем-то разные, но связанные между собой типы
сущностей. Для оптимизации запроса на этих подтаблицах вас должна интересо-
вать статистика по отдельной подтаблице, к которой обращается запрос. Поэто-
му выполните все запросы для статистики по таблице, добавив условие, указы-
вающее интересующую вас подтаблицу, и не забудьте запрос для общего
количества строк (SELECT COUNT(*) FROM <Таблицд>), который превращается в дан-
ном примере в запрос количества подходящих строк (SELECT COUNT(*) FROM
Code_Translations WHERE Code_Type='ORDER_STATUS').
Если вы в качестве упражнения хотите завершить скелет диаграммы запроса
самостоятельно, выполните перечисленные ранее шаги по созданию диаграммы
запроса вплоть до шага 4, и перейдите к рис. 5.4, чтобы посмотреть, все ли получи-
лось правильно.
Изображение соединений к первой
центральной таблице
Для выполнения первого шага поместите псевдоним 0 в центр диаграммы. Для
шага 2 найдите все соединения с первичным ключом таблицы 0,0. Order_I D. Вы дол-
жны найти соединение от 0D, которое представлено на рис. 5.2 как указывающая
вниз стрелка от 0D к 0. Чтобы не забыть, что вы уже изобразили это соединение,
вычеркните его из запроса.
OD
▼
О
Рис. 5.2. Начало диаграммы для примера 5.2
Изображение соединений от первой
центральной таблицы
Переходя к шагу 3, найдите все внешние соединения (не к Order_ID, а к внешним
ключам) с Orders и добавьте их на диаграмму как стрелки, указывающие вниз от
0 к С и к ОТ, так как эти соединения используют первичные ключи Customers
и Code_Transl ations. Теперь диаграмма выглядит как на рис. 5.3.
OD
Рис. 5.3. Результат шага 3 для второй диаграммы
144
5. Диаграммное изображение простых запросов SQL
Смена центральной таблицы и повторение
На данный момент обработаны все соединения, которые исходят из таблицы с псев-
донимом 0. Чтобы не забыть, какая часть работы уже завершена, перечеркните 0 во
фразе FROM, и вычеркните соединения, уже изображенные на диаграмме связями.
Шаг 4 указывает, что вам необходимо повторить шаги 2 и 3 с новой центральной
таблицей, но в нем не говорится, как выбрать новую таблицу. Если вы будете по-
очередно выбирать центральной каждую таблицу на диаграмме, то завершите ди-
аграмму правильно независимо от порядка, но можно сэкономить время, приме-
нив пару правил.
Сначала пытайтесь завершить верхние части диаграммы. Поскольку вы пока
не пробовали выбирать верхний узел 0D в качестве центрального, начните с него.
Используйте еще не нанесенные на диаграмму соединения для поиска новой
центральной таблицы, для которой завершена еще не вся работа. Проверка спис-
ка еще не вычеркнутых соединений даст нам следующий список потенциаль-
ных кандидатов: OD, Р, S, А и ODT. Однако из всего этого списка только 0D находит-
ся на диаграмме, поэтому это единственный узел, который можно выбрать
центральным и расширить диаграмму. Если вы смогли заметить, что с таблица-
ми С и ОТ больше не будет соединений, то следует вычеркнуть их из фразы FROM
как не требующих дальнейшей обработки.
Выполняя эти правила, вы завершите диаграмму быстрее. Если на любом шаге
вы обнаруживаете, что диаграмма слишком плотно скомпонована, то можете пере-
рисовать ее, чтобы свободнее расположить элементы. Пространственная органи-
зация узлов используется только для удобства, она не несет никакого особого смыс-
ла. Например, я нарисовал С слева от ОТ, но вы можете поменять их местами, если
это поможет вам лучше разместить элементы диаграммы.
ПРИМЕЧАНИЕ-----------------------------------------------------------
Иллюстраторы издательства хорошо поработали, чтобы мои диаграммы выглядели привлекатель-
но, но вам не обязательно так трудиться. В большинстве случаев никто, кроме вас, больше не уви-
дит диаграммы, а вам они будут понятны, даже если вы не будете слишком заботиться об их внешнем
виде.
Итак, вы не нашли соединений с первичным ключом Order_Details (то есть
к OD.Order_Detai 1_ID), поэтому все связи с 0D указывают вниз на Р, S и ODT, которые
связаны с 0D при помощи своих первичных ключей. Так как S и Р являются допол-
нительными таблицами во внешних соединениях, посередине этих связей добавь-
те указывающие вниз острия стрелок. Вычеркните соединения от 0D, которые пред-
ставлены этими тремя связями. Теперь осталось только одно соединение — внешнее
соединение от S к первичному ключу А. Поэтому следует в последний раз выбрать
новую центральную таблицу, на этот раз S, и добавить одну последнюю стрелку,
указывающую вниз на А, с острием стрелки посередине, обозначающим это внеш-
нее соединение. Вычеркните последнее соединение. Выбирать новую центральную
таблицу не нужно, так как все соединения и псевдонимы уже на диаграмме.
ПРИМЕЧАНИЕ-----------------------------------------------------------------------
Следует удостовериться, что не осталось «осиротевших» псевдонимов, то есть таких псевдонимов, для
которых нет условий соединения, привязывающих их к оставшейся части диаграммы. Это иногда про-
исходит, особенно если запрос использует декартово соединение.
Полные диаграммы запросов
145
На этой стадии, если вы выполняли правильно все действия, соединения на
вашей диаграмме должны соответствовать рис. 5.4, хотя конкретное расположе-
ние псевдонимов может отличаться от приведенного на рисунке. Я называю это
скелетом запроса или скелетом соединений. После того, как вы создали скелет,
вам нужно только вписать числа, представляющие распределения нужных дан-
ных в базе данных, как описано в пятом шаге процесса диаграммного изображения
запроса.
Рис. 5.4. Скелет запроса
Вычисление коэффициентов фильтрации и соединения
У нас нет условий фильтрации для дополнительных таблиц внешних соедине-
ний, поэтому для этих таблиц и соединения нам не нужна статистика. Также
вспомните, что обманчивые условия фильтрации ОТ. Code_Type - 1 ORDER_STATUS'
и ODT. Code_Type - ' ORDER_DETAIL_STATUS' не осуществляют фильтрацию в чистом виде,
а относятся к соединениям с соответствующими таблицами, так как являются ча-
стью ключей соединения для доступа к этим таблицам. Таким образом, у нас оста-
ются только условия фильтрации по имени покупателя и дате заказа. Если вы хо-
тите попрактиковаться в методе поиска коэффициентов соединения и фильтрации
для диаграммы запроса, то перед тем, как читать дальше, попробуйте написать зап-
росы для получения нужных чисел и формулы вычисления коэффициентов.
Селективность условий по именам и фамилиям зависит от длины соответствую-
щих шаблонов. Подсчитайте селективность, предполагая, что параметры Last_Name
и . Fl rst_Name обычно привязываются к первым трем буквам каждого имени, и что
пользователи производят поиск по распространенным трехбуквенным строкам
(а это действительно так для реальных имен) пропорционально намного чаще, чем
по редко встречающимся. Так как это пример для Oracle, используйте выражение
Oracle SUBSTR(Char_Col .1,3) для возвращения первых трех символов значений из
каждого из этих символьных столбцов.
Вспомните, что для таблицы «с яблоками и апельсинами» Code_Transl at ions вам
нужно собрать статистику только по определенным типам, как если бы каждый
тип хранился в собственной отдельной физической таблице. Другими словами, если
ваш запрос использует коды состояния заказа в некоторых условиях соединения,
то следует запросить из Code_Тcans 1 ati ons не общее количество строк в этой табли-
це, а количество строк для состояния заказа. Оказывается, только строки таблицы
для типов, участвующих в запросе, значительно влияют на стоимость запроса. Воз-
можно, вам придется опрашивать одну таблицу дважды, но для различных подна-
боров этой таблицы. Пример 5.3 опрашивает CodeTransl at ions один раз, чтобы под-
146
5. Диаграммное изображение простых запросов SQL
считать коды состояния заказа, и еще раз, чтобы подсчитать коды состояния дета-
лей заказа. Запросы в примере 5.3 получают все данные, необходимые для вычис-
ления коэффициентов соединения и фильтрации.
Пример 5.3. Запросы статистики для настройки запроса
01: SELECT SUM(COUNT(*)*COUNT(*))/(SUM(COUNT(*))*SUM(COUNT(*))) Al
GROUP BY UPPER(SUBSTR(First_Name. 1. 3)). UPPER(SUBSTR(Last_Name. 1. 3));
Al: 0.0002
02: SELECT COUNT!*) A2 FROM Customers:
A2: 5000000
03: SELECT COUNT!*) A3 FROM Orders
WHERE Order Date > SYSDATE - 366:
A3: 1200000
04. SELECT COUNT!*) A4 FROM Orders;
A4: 4000000
Q5 SELECT COUNT!*) A5 FROM Orders 0. Customers C
WHERE O.Customer_IO = C.Customer_ID:
A5: 4000000
06. SELECT COUNT!*) A6 FROM OrderJtetails-
A6: 12000000
07: SELECT COUNT!*) A7 FROM Orders 0. 0rder_Deta11s OD
WHERE OD OrderJD = 0. Order JD:
A7: 12000000
Q8: SELECT COUNT!*) A8 FROM Code_Translations
WHERE Codejype = 'ORDER_STATUS':
A8: 4
09: SELECT COUNT!*) A9 FROM Orders 0. Codejranslations ОТ
WHERE 0. Status Code - ОТ Code
AND Code Type = ’ORDER-STATUS':
A9: 4000000
Q10: SELECT COUNT!*) AID FROM Code Translations
WHERE Codejype = 'ORDER DETAIL STATUS':
A10: 3
Oil: SELECT COUNT!*) All FROM 0rder_Deta11s DD. Codejranslations ODT
WHERE OD.Status_Code = ODT.Code
AND Codejype = 'ORDER_DETAIL_STATUS':
All: 12000000
Начиная с коэффициентов фильтрации, получите средневзвешенный коэффи-
циент фильтрации для условия по имени и фамилии покупателей (таблица Customers)
напрямую из А1. Результат этого запроса равен 0,0002. Найдите коэффициент филь-
трации для Orders как АЗ/А4, что в итоге дает 0,3. Так как для других псевдонимов
фильтров нет, коэффициенты фильтрации для них равны 1,0, которые не нужно
указывать на диаграмме запроса для соответствующих узлов.
Найдите детальные коэффициенты соединения и поместите их у верхнего кон-
ца всех стрелок для внутренних соединений. Для этого разделите количество строк,
Полные диаграммы запросов
147
полученных при соединении двух таблиц, на количество строк в нижней таблице
(главной таблице в этом отношении). Коэффициенты для соединений от 0D к О
и ODT равны 3 (А7/А4) и 4 000 000 (А11/А10), соответственно.
ПРИМЕЧАНИЕ-----------------------------------------------------------------
Чтобы коэффициенты соединения поместились на диаграмму, я сокращу миллионы до m и тысячи до
к, поэтому последний результат будет выглядеть как 4m.
Коэффициенты для соединений от 0 к С и ОТ равны 0,8 (А5/А2) и 1 000 000 (или
Im, А9 / АВ), соответственно.
Найдите главные коэффициенты соединения для нижних концов всех стрелок,
обозначающих внутренние соединения, разделив количество строк, полученных
при соединении, на количество строк в верхней таблице. Если у вас есть обяза-
тельные внешние ключи и обеспечена целостность ссылочных данных (внешние
ключи всегда указывают на существующие значения первичного ключа), то глав-
ные коэффициенты соединения всегда в точности равны 1,0, что верно для всех
случаев в нашем примере: А7/А6, А11/А6, А5/А4 и А9/А4.
Проверьте, есть ли уникальные условия фильтрации, которые нужно пометить
звездочкой (шаг 6). В нашем примере таких условий нет.
Затем запишите все числа на диаграмме запроса, как показано на рис. 5.5.
Рис. 5.5. Полная диаграмма запроса для второго примера
Сокращения
Хотя полный процесс заполнения подробной, полной диаграммы запроса для мно-
гостороннего соединения выглядит и является трудоемким, вы можете использо-
вать несколько упрощенных способов, которые обычно сокращают процесс до не-
скольких минут и даже меньше.
Узнать, какие столбцы являются первичными ключами, обычно можно исходя
из их имен.
Обычно можно игнорировать коэффициенты для внешних соединений и уча-
ствующих в них дополнительных таблиц. Часто внешние соединения можно
вообще не заносить на диаграмму, по крайней мере, на предварительный вари-
ант, который показывает, каким потенциалом для улучшения обладает запрос.
Главный коэффициент соединения (у соединения, обозначающего первичный
ключ) практически всегда равен 1,0, если только внешний ключ не является
дополнительным. Если у вас нет причины подозревать, что значение внешнего
148
5. Диаграммное изображение простых запросов SQL
ключа часто равно null или он >’асто указывает на более не существующие зна-
чения первичного ключа, просто игнорируйте его, подразумевая значение 1,0
В некоторых базах данных реализованы ограничения, которые строго гаранти-
руют целостность ссылочных данных. Даже без таких ограничений хорошо по-
строенные приложения поддерживают ссылочную целостность или хотя бы
практически полную целостность в своих таблицах. Если вы гарантируете или
хотя бы предполагаете ссылочную целое тность, то можете предположить, что
не равные null внешние ключи всегда указывают на допустимые первичные
ключи. В этом случае для поиска фактора соединения не нужно выполнять (от-
носительно медленный) запрос количества строк в присоединенной таблице.
Вместо этого вам нужно знать лишь процент строк с не равным null внешним
ключом и количество строк в двух таблицах. Чтобы подсчитать их, выполните
подобный SQL-код:
SELECT COUNT(*) D. COUNT(,<Столбец_внешнего_ключа>'> F FROM <Детальная_таблица>:
SELECT COUNTC*) M FROM <Главная_таблица>;
Пусть первое количество строк, полученное первым запросом, равно D. Второе
количество строк, полученное тем же запросом, равно F. Количество строк, по-
лученное вторым запросом, равно М. Тогда главный коэффициент соединения
равен F/D, а детальный коэффициент соединения — F М.
Коэффициенты соединения редко имеют непредсказуемое и необычное значе-
ние. Обычно можно угадать их. Детальный коэффициент соединения наиболь-
ший смысл имеет в редко встречающемся случае, когда он намного меньше 1,0
и он указывает насколько близок детальный фактор соединения к 1,0. Обычно
можно угадать достаточно близко, по крайней мере, попасть в правильную ок-
рестность.
Обоснованные догадки для факторов соединения иногда являются наилучши-
ми! Даже если текущие данные демонстрируют удивительную статистику для
определенного отношения главной и детальной таблиц, возможно, вы не захо-
тите зависеть от этой статистики во время ручной настройки запроса, посколь-
ку она может со временем изменяться или не подходить к другим экземплярам
базы данных, в которых будет использоваться тот же SQL. (Последнее особен-
но верно, если вы настраиваете совместно используемый программный продукт.)
При настройке нескольких запросов из одного приложения повторно исполь-
зуйте данные о коэффициентах соединения, если обрабатываете одни и те же
соединения.
Коэффициенты фильтрации имеют самое главное значение, но обычно варьи-
руются в пределах нескольких порядков, и, если разница между коэффициен-
тами фильтрации очень большая, будет достаточно, если вы угадаете порядок
их величины. Для успешной настройки с любыми коэффициентами вам прак-
тически никогда не потребуется точность большая, чем до первой отличной от
нуля цифры (первой значащей цифры, если вы помните термины из математи-
ки старших классов). Например, 0,043 округляется до 0,04 с одной значащей
цифрой, а 472 до 500.
Так же, как и для коэффициентов соединения, информированная догадка для
коэффициентов фильтрации иногда работает лучше всего. В этом случае вы,
вероятно, получите результат, хорошо работающий для различных покупате-
Интерпретация диаграмм запросов
149
лей длительное время. Слишком большая зависимость от измеренных значе-
ний может привести к оптимизации, теряющей надежность на разных экземп-
лярах приложений или со временем.
Главное значение диаграммного изображения — это воздействие на ваше пони-
мание проблемы настройки. С опытом вы сможете находить наилучший план в го-
лове, вообще не рисуя диаграммы на бумаге.
Интерпретация диаграмм запросов
Перед тем как приступить к дальнейшему изучению метода, потратьте немного
времени просто на то, чтобы понять содержимое диаграммы запроса. Попробуйте
научиться видеть больше, чем просто странную абстрактную картинку. Имея не-
сколько «правил большого пальца», интерпретировать диаграмму запроса доста-
точно просто. Возможно, вы уже знакомы с диаграммами отношений между сущ-
ностями. Существует полезное и понятное отображение диаграмм отношений
между сущностями и скелетов диаграмм запросов. На рис. 5.6 показан скелет за-
проса для примера 5.1 и соответствующая часть диаграммы отношений между сущ-
ностями.
Рис. 5.6. Скелет запроса по сравнению с диаграммой отношений между сущностями
Диаграмма отношений между сущностями отображает дизайн базы данных,
который не зависит от запроса. Следовательно, скелет запроса, который олицетво-
ряет то же отношение «много к одному» (где стрелка показывает на «одного») так-
же исходит из дизайна базы данных, а не из запроса. Скелет запроса просто указы-
вает, какой поднабор строения базы данных важен в данный момент, поэтому вы
концентрируете внимание только на этом поднаборе, закодированном в скелете
запроса. Если одна и та же таблица появляется под различными псевдонимами,
диаграмма запроса в каком-то смысле расширяет диаграмму отношений между
сущностями, показывая несколько соединений с одной таблицей, как если бы это
были соединения с клонами этой таблицы. Это упрощает проблему настройки не-
скольких соединений.
При помощи коэффициентов соединения в скелете запроса вы кодируете ко-
личественные характеристики фактических данных, используя их вместо каче-
ственных характеристик «много» (many) на диаграмме отношений между сущнос-
тями. Например, для отношений «многие к одному» вы указываете количество этих
«многих» детальным коэффициентом соединения; и когда встречаете отношения
«многие к нулю или одному», при помощи главного коэффициента соединения
указываете, как часто встречается нулевое значение. Это характеристики самих
данных, а не дизайна базы данных, и они не зависят от запроса. Эти коэффициен-
150
5. Диаграммное изображение простых запросов SQL
ты соединения могут изменяться в различных экземплярах баз данных, которые
используют одно приложение с различными данными, но внутри одного экземп-
ляра коэффициенты соединения фиксированы для всех запросов, выполняющих
одинаковые соединения.
ПРИМЕЧАНИЕ------------------------------------------------------------
К счастью, оптимальный план обычно не зависит от коэффициентов соединения, что практически все-
гда позволяет вам успешно настраивать запрос для всех покупателей приложения одновременно.
Только добавляя коэффициенты фильтрации, вы действительно учитываете
данные, характерные для некоего конкретного запроса (в сочетании с информаци-
ей о распределении данных), так как условия фильтрации зависят от запроса, а не
от данных. Данные лишь показывают относительные размеры всех поднаборов всех
таблиц, необходимых запросу.
В диаграммах для правильно написанных запросов (как я покажу далее) прак-
тически всегда на вершине дерева находится одна детальная таблица, от которой
стрелки указывают вниз на главные таблицы (или таблицы соответствия), из ко-
торых могут исходить другие стрелки, обозначающие связи между таблицами. Если
вам попадается такая нормальная форма диаграммы запроса, то запрос интерпре-
тируется достаточно просто.
Подобный запрос является вопросом о сущностях, соответствующих верхней
детальной таблице, с одним или несколькими соединениями с главными таблица-
ми внизу, предназначенными для дальнейшего поиска данных об этих сущностях,
хранящихся в других таблицах для правильной нормализации.
Например, запрос, соединяющий Employees и Departments — это на самом деле
вопрос о сотрудниках, для ответа на который база данных должна обратиться к таб-
лице Departments и получить информацию о сотрудниках, например, Department_Name,
которую вы храните в таблице Departments для правильной нормализации.
ПРИМЕЧАНИЕ---------------------------------------------------------------------
Да, я знаю, что для разработчика базы данных Department_Name — это свойство отдела а не сотрудника,
но я говорю о вопросе бизнеса, а не формальной базе данных. В нормальной деловой семантике вы
думаете о названии отдела (и других свойствах Departments) как о свойстве сотрудников, наследуемом
из Departments.
Вопросы о бизнес-сущностях, достаточно важных для того, чтобы иметь отдель-
ные таблицы, естественны в бизнес-приложениях, и зачастую требуют нескольких
уровней соединения для поиска детальных данных, хранящихся в главных табли-
цах. Вопросы о странных, неестественных комбинациях сущностей также неесте-
ственны для бизнеса, и при изучении диаграмм запросов, не соответствующих нор-
мальной форме, вы обнаруживаете, что они возвращают именно бесполезные
результаты, результаты, в которых приложение обычно не нуждается.
Далее перечислены правила для диаграмм запросов, соответствующих нормаль-
ной форме хранения данных. Запросы, стоящие за этими нормальными диаграм-
мами, можно интерпретировать как важные вопросы об одном наборе сущностей,
соответствующих верхней таблице.
Запросу соответствует одно дерево.
У дерева один корень — ровно одна таблица без соединений с ее первичным
ключом. У всех остальных узлов, кроме корня, есть единственная указываю-
Упрощенные диаграммы запросов
151
щая вниз, на них, стрелка, связывающая их с детальным узлом наверху, но лю-
бой узел может находиться на верхнем конце любого количества указывающих
вниз стрелок.
Для всех соединений есть указывающие вниз стрелки.
Внешние соединения не фильтруются, стрелки для них направлены вниз, вне-
шние соединения могут быть только под внешними соединениями.
Вопрос, на который отвечает запрос, — это обычно вопрос о сущности, пред-
ставленной в корневом узле дерева (или об агрегациях этой сущности).
Прочие таблицы просто предоставляют справочные и детализированные дан-
ные, хранящиеся в них для нормализации.
Упрощенные диаграммы запросов
Вы увидите, что множество подробностей, присутствующих на полных диаграм-
мах запросов, не обязательны, разве что для самых редких проблем. Когда вы кон-
центрируетесь на необходимых элементах, то вам нужен только скелет диаграммы
и приблизительные коэффициенты фильтрации. Изредка требуются коэффици-
енты соединений, но обычно только когда любой из детальных коэффициентов
соединения меньше 1,5 или главный коэффициент соединения меньше 0,9. Если
только у вас нет причины подозревать, что вы встретились именно с этими редки-
ми значениями для отношения главной и детальной таблиц, можете даже не бес-
покоиться о вычислении этих значений. Это, в свою очередь, значит, что меньшее
количество данных требует создания более простых диаграмм соединения. Вам не
потребуется узнавать количество строк для таблиц без фильтров. На практике в
многосторонних соединениях обычно есть фильтры только для 3-5 таблиц, по-
этому даже самый сложный запрос легко изобразить на диаграмме, не используя
множество запросов для сбора статистики.
Отбросив ненужные детали, которые я только что перечислил, вы можете упро-
стить рис. 5.5 до рис. 5.7.
Рис. 5.7. Упрощенная диаграмма запроса для рис. 5.5
Обратите внимание, что детальный коэффициент соединения от С к 0 на рис. 5.5
меньше 1,5, поэтому я продолжаю указывать его даже на упрощенной диаграмме
на рис. 5.7.
152
5. Диаграммное изображение простых запросов SQL
Когда дело доходит до фильтров, даже приблизительные значения обычно не
нужны, если вы знаете, какой фильтр лучше и если другие конкурирующие филь-
тры не относятся к тому же родительскому детальному узлу. В нашем случае мож-
но обозначить наилучший фильтр заглавной буквой F и малые фильтры — строч-
ной буквой f. Рисунок 5.7 упрощается до рис. 5.8.
CF ОТ
Рис. 5.8. Полностью упрощенная диаграмма запроса для рис. 5.7
Обратите внимание, что детальный коэффициент соединения от С к 0 меньше
1,5, поэтому я продолжаю указывать его даже на полностью упрощенной диаграм-
ме на рис. 5.8.
Хотя я удалил коэффициенты фильтрации с рис. 5.8, следует продолжать рисо-
вать символ звездочки рядом с любыми уникальными фильтрами (фильтрами, га-
рантированно возвращающими не более одной строки). Также следует указывать
фактические значения фильтрации для малых фильтров, относящихся к одному и
тому же родительскому детальному узлу. Например, если у вас есть малые фильт-
ры в узлах В и С на рис 5.9, укажите для них реальные коэффициенты фильтрации,
как показано на рисунке, поскольку у них есть общий родительский детальный
узел А.
Рис 5.9. Полностью упрощенная диаграмма запроса с коэффициентами фильтрации
для общего предка
На практике вы обычно можете начать с упрощенной диаграммы запроса и за-
тем по необходимости добавлять детали. Если план исполнения (о том, как его
найти, я расскажу в главе 6), найденный из этой упрощенной задачи, выполняется
настолько быстро, что дальнейшие улучшения бессмысленны, то работу можно
считать законченной. Вы можете удивиться, узнав, как часто это случается. На-
пример, пакетный запрос, который выполняется за несколько секунд несколько
Упражнения
153
раз в день, достаточно быстр, чтобы его дальнейшее улучшение не требовалось.
Схожим образом не нужно продолжать настройку любого оперативного запроса,
который выполняется за 100 миллисекунд и который конечные пользователи со-
вместно выполняют меньше 1000 раз в день. Если после первого раунда настройки
вы считаете, что дальнейшая работа будет стоить приложенных усилий, то можете
быстро проверить, осуществима ли дальнейшая настройка, посмотрев, не пропус-
тили ли вы важные коэффициенты соединения. Самый быстрый способ сделать
это — спросить, действительно ли единственный наилучший фильтр ответствен за
практически все уменьшения количества возвращенных строк по сравнению с пол-
ностью не отфильтрованным запросом к самой детализированной таблице. Пред-
полагая, что диаграмма соединения выглядит как перевернутое дерево, можно
ожидать, что весь запрос, без фильтров, вернет то же количество строк, что и самая
детализированная таблица в корне дерева соединения (то есть наверху).
В случае с фильтрами вы ожидаете, что каждый фильтр сокращает количество
строк, возвращенных из самой детализированной таблицы (в корне дерева соеди-
нения) на коэффициент фильтрации. Если произведение наилучшего коэффици-
ента фильтрации на количество строк самой детализированной таблицы прибли-
зительно равно количеству строк, которое возвращает весь запрос, то можете быть
уверены, что не пропустили важных фильтров, и упрощенной диаграммы хватит.
С другой стороны, если произведение количества строк самой детализированной
таблицы на наилучший фильтр (или то, что вы считали наилучшим фильтром)
намного превосходит количество строк, которое возвращает запрос, то, возможно,
вы пропустили важную причину сокращения количества строк и необходимо со-
брать больше статистики. Если произведение всех коэффициентов фильтрации
(подсчитанное или угаданное), умноженное на количество строк самой детализи-
рованной таблицы, даже близко не дает количества строк, возвращенного всем зап-
росом, следует подозревать, что вам нужно больше информации. В частности, у вас
могут быть скрытые фильтры соединений, коэффициенты соединений для кото-
рых неожиданно оказываются намного меньшими 1,0. Поиск таких фильтров и
использование их для получения лучшего плана может обеспечить большую даль-
нейшую прибыль.
Упражнения
1. Создайте диаграмму для следующего запроса:
SELECT ...
FROM Customers С. ZIP_Codes Z. ZIPJDemographlcs D. Regions R
WHERE C.ZIP_Code - Z.ZIP_Code
ANO Z.Demographic_ID - O.DemographicJD
AND Z.Region_ID - R.Region_ID
AND C.Activejlag - 'Y'
AND C.Profiled Flag - 'N'
AND R.Name - 'SOUTHWEST'
AND D.Name IN ('YUPPIE', 'OLDMONEY');
Сделайте обычные предположения об именах первичных ключей, кроме пер-
вичного ключа ZIP_Codes, который является таблицей ZIP_Codes. Обратите вни-
мание, что столбцы Name в REGIONS и ZIPJDemographlcs имеют уникальные индек-
154
5. Диаграммное изображение простых запросов SQL
сы. В таблице Customers 5 000 000 строк, в таблице Zi p_Codes 250 000 строк, в таб-
лице ZIP Demographi cs 20 строк, и в таблице Regi ons 5 строк. Предполагается, что
внешние ключи никогда не равны nul 1 и всегда указывают на допустимые пер-
вичные ключи. Следующий запрос возвращает 2 000 000 строк:
SELECT COUNT!*) FROM Customers C WHERE Active_Flag = 'Y' AND Profiledjlag = ' N':
2. Создайте диаграмму для следующего запроса:
SELECT ...
FROM Regions R. Zip_Codes Z. Customers C. Customer_Mailings CM.
Mailings M. Catalogs Cat. Brands В
WHERE R.Region_ID(+) = Z.Reg1on_ID
AND Z.ZIP_Code(+) = C.ZIP_Code
AND C.Customer_ID = CM.Customer_ID
AND CM.Mailing_ID = M.MalllngID
AND M.Catalog_ID = Cat.Catalog_ID
AND Cat.Brand_ID = B.Brand_ID
AND B.Name = 'OhSoGreen'
AND M.Mailing_Date >= SYSDATE-365
GROUP BY... ORDER BY ...
Начните с тех же предположений и статистики, что и в упражнении 1. В табли-
це Customer_Mailings находится 30 000 000 строк. В таблице Mailings — 40 000
строк. В Catalogs 200 строк. В Brands 12 строк и есть альтернативный уникаль-
ный ключ по Name. Следующий запрос возвращает 16 000 строк:
SELECT COUNT!*) FROM Mailings M WHERE Mailing_Date >= SYSDATE-365;
3. Создайте диаграмму для следующего запроса:
SELECT ...
FROM Code_Translat1ons SPCT. Code_Translations TRCT. Code_Translations CTCT.
Products P. Product_L1nes PL. Inventory_Values IV. Brands B.
Product_Locations Loc. Warehouses W. Regions R.
Inventory_Taxing_Entities ITx. Inventory_Tax_Rates ITxR. Consignees C
WHERE W.Region_ID = R.RegionlD
ANO Loc.Warehouse_ID = W Warehouse_ID
AND W.Inventory_Tax1ng_Entity_ID = ITx.Inventory_Taxing_Entity_ID
AND ITx.Inventory_Taxing_Entity_IO = ITxR.Inventory_Tax1ng_Entity_ID
AND ITxR.Effective_Start_Date <= SYSDATE
AND ITxR.Effect!ve_End_Date > SYSDATE
AND ITxR.Rate > 0
AND P.Product_ID = Loc.Product_ID
AND LOC.Quantity > 0
AND P.Product_L1ne_ID = PL.Product_L1ne_ID(+)
AND P.ProductID = IV.Product_ID
AND P.Taxable_Inventory_Flag = 'Y'
AND P.Cons1gnee_ID = C.Consignee_ID(+)
AND P.Strateg1c_Product_Code = SPCT.Code
ANO SPCT.Code_.Type = 'STRATEGIC_PRODUCT'
AND P.Turnover_Rate_Code = TRCT Code
AND TRCT.Code_Type = 'TURNOVER_RATE'
AND P Consignment Type_Code = CTCT.CODE
AND CTCT. Codejype = ’CONSIGNMENT_TYPE’
AND IV.Effect1ve_Start_Date <= SYSDATE
AND IV.Effect!ve_End_Date > SYSDATE
AND IV.Unit_Value > 0
AND P.Brand_ID = B.Brand_ID
AND B.Name = ’2Much$'
AND ITX.Tax_Day_Of_Year = 'DEC31'
GROUP BY.. DRDERBY...
Упражнения
155
Начните с тех же предположений и статистики, что и в упражнениях 1 и 2, за
исключением того, что значение поля W. Inventory_Taxi ng_Enti ty_ID указывает на
допустимую налоговую сущность, только в тех случаях, когда она не равна nul 1,
то есть в 5 % случаев. Количества строк для таблиц следующие:
Products = В.500
Product_L1nes = 120
Inventory_Values = 34000
Brands = 12
Product_Locations = 176000
Warehouses = 80
Regions = 5
Inventory_Taxing_Entit1es = 4
Inventory_Tax_Rates = 7
Consignees = 14
В таблице Code_Tnans! ati ons существует первичный ключ из двух частей: Code_Type,
Code.
В Inventory_Val ues и Inventory_Tax_Rates есть зависящий от времени первичный
ключ, состоящий из идентификатора и эффективного диапазона времени, так,
что любая данная дата попадает в единственный диапазон даты для любого зна-
чения ключевого ID. В частности, условия соединения с каждой из этих таблиц
гарантированно уникальны, что обеспечивается условиями Effect! ve Start Date
и Ef fecti ve_End_Date, являющимися частью соединений, а не отдельными филь-
трами. К сожалению, удобного способа гарантировать уникальность при помощи
индекса нет, это условие создается приложением. Следующие запросы возвра-
щают количества строк, указанные в строках, следующих за каждым запросом:
01: SELECT COUNT!*) Al FROM Inventory_Taxing_Entit1es ITx
W.IERE ITx.Tax_Day_Of_Year = 'DEC31'
Al: 2
02: SELECT COUNT!*) A2 FROM Inventory_Values IV
WHERE IV.Un1t_Value>0
AND IV. Effect! veStartDate <= SYSDATE
AND IV.Effective End Date > SYSDATE
A2: 7400
03: SELECT COUNT!*) A3 FROM Products P
WHERE P.Taxable_Inventory_Flag = ' Y'
A3: 8300
Q4: SELECT COUNT!*) A4 FROM Product Locations Loc
WHERE Loc.Quantity > 0
A4: 123000
05: SELECT COUNT!*) A5 FROM Inventory_Tax_Rates ITxR
WHERE ITxR.RATE > 0
AND ITxR.Effect)ve_Start_Date <= SYSDATE
AND ITxR.Effective_End_Date > SYSDATE
A5: 4
06: SELECT COUNT!*) A6 FROM Inventory_Values IV
WHERE IV.Effect!ve_Start_Date <= SYSDATE
AND IV.Ef :ct1ve_End_Date > SYSDATE
A6: 8500
07: SELECT COUNT!*) A7 FROM INVENTORY_TAX_RATES ITxR
156
5. Диаграммное изображение простых запросов SQL
WHERE ITxR.Effect)ve_Start_Date <- SYSDATE
AND ITxR.Effect)ve_End_Date > SYSDATE
A7: 4
QB: SELECT COUNT(*) A8 FROM Codejranslations SPCT
WHERE Codejype - 'STRATEGIC-PRODUCT'
AB: 3
Q9: SELECT COUNT!*) A9 FROM Codejranslations TRCT
WHERE Codejype - TURNOVER_RATE'
A9: 2
Q10: SELECT COUNT!*) AID FROM CTCT
WHERE Codejype - ' CONSIGNMENTjYPE'
AID: 3
4. Полностью упростите диаграмму запроса из упражнения 1. Попробуйте начать
с запросов и статистики по запросам, а не с полных диаграмм запросов. Затем
сравните полученные результаты с результатами, полученными, если начать
с полных диаграмм запросов, чем вы уже занимались.
5. Полностью упростите диаграмму запроса из упражнения 2, выполняя инструк-
ции из упражнения 4.
6. Полностью упростите диаграмму запроса из упражнения 3, выполняя инструк-
ции из упражнения 4.
6
Выбор наилучшего
плана выполнения
Если упрощение проблемы эквивалентности до абстрактной математики — это
обычно самая сложная часть решения задачи, то создание диаграммы запроса
сложнее, чем поиск наилучшего плана выполнения на этой диаграмме. Теперь,
когда вы научились справляться со сложной частью перевода запроса в диаграм-
му, я продемонстрирую вам легкий способ. Вот несколько вопросов, на которые
вам нужно ответить, чтобы полностью описать оптимальный план выполнения
для запроса.
Каким образом идет обращение к каждой таблице в плане выполнения — путем
полного сканирования таблицы, с использованием одного или нескольких ин-
дексов, и если применяются индексы, то какие именно?
Как соединяются таблицы в плане выполнения?
В каком порядке соединяются таблицы в плане выполнения?
Из этих трех вопросов основным и самым сложным является вопрос о по-
рядке соединения. Если вы начнете с поиска оптимального порядка соедине-
ния, который стоит отдельно от остальных вопросов, то обнаружите, что ответы
на оставшиеся два вопроса очевидны. В худших случаях вам может понадо-
биться выполнить несколько экспериментов для ответа на эти два вопроса, но
для каждой таблицы таких экспериментов будет максимум один или два. Если
у вас нет систематического пути ответа на вопрос о порядке соединения, то вам
потребуется провести миллиарды экспериментов для того, чтобы найти наи-
лучший план.
Надежные планы выполнения
Некоторое подмножество всех возможных планов выполнения можно описать как
надежные. Хотя такие планы могут быть не всегда близки к оптимальным, в реаль-
ных запросах они все же практически оптимальны и обладают хорошими характе-
ристиками, такими, как предсказуемость и низкая вероятность появления ошибок
во время выполнения. Ненадежное соединение может полностью выйти из строя с
ошибкой «недостаточно доступного пространства», если для соединения хэширо-
ванием или сортировкой слиянием потребуется больше места на диске, чем до-
ступно. Надежные планы хорошо работают на широком диапазоне возможных рас-
158 6. Выбор наилучшего плана выполнения
пределений данных или просто в другом экземпляре базы данных, обрабатывае-
мом тем же приложением. Надежные планы также терпимы к неточностям и ошиб-
кам; с надежным планом небольшая ошибка в вычисленной селективности фильт-
ра может привести к не оптимальному, но не к чудовищному плану. Когда вы
используете надежные планы выполнения, то практически всегда можете решить
проблему настройки SQL раз и навсегда, вместо того чтобы повторно решать ее
каждый раз, когда со временем или на другом наборе покупателей вам встречают-
ся другие распределения данных.
ПРИМЕЧАНИЕ ------------------------------------------------------------------
Неточности и ошибки неизбежны при решении проблемы оптимизации. Например, даже имея пре-
красную информацию на время разбора (когда база данных создает план выполнения), условие напо-
добие Last_Name = :LName обладает неточной селективностью, зависящей от реального значения, которое
во время выполнения будет привязано к параметру : LName. Неизбежность появления неточностей и
ошибок делает надежность планов выполнения особенно важной.
Надежные планы выполнения обычно обладают несколькими свойствами.
Их стоимость выполнения пропорциональна количеству возвращенных
строк.
Им практически не требуется пространство в памяти для сортировки или хэши-
рования.
Они не требуют изменений по мере увеличения размеров таблиц.
Они не очень чувствительны к распределениям и хорошо работают для множе-
ства экземпляров, использующих одно и то же приложение, или в любом эк-
земпляре с часто изменяющимися данными.
Они особенно хороши, когда оказывается, что запрос возвращает меньше строк,
чем вы ожидали (когда фильтры более селективны, чем кажется).
ПРИМЕЧАНИЕ --------------------------------------------------------------
В каком-то смысле надежный план выполнения всегда оптимистичен. Он предполагает, что вы разра-
ботали приложение для обработки сравнительно небольшого количества строк, даже когда непонятно,
как именно запрос умудряется уменьшить набор строк до такого малого количества.
Требование надежности описывается несколькими условиями.
Обращаться к первой таблице через селективный индекс.
Следуя по связям на диаграмме запроса, обращаться к каждой последующей
таблице при помощи вложенного цикла через индекс полного ключа соедине-
ния, который указывает на таблицу, уже считанную базой данных.
ПРИМЕЧАНИЕ --------------------------------------------------------------
Вложенные циклы, реализующиеся через ключи соединения, обычно определяются количеством строк,
удовлетворяющих условиям запроса. Из-за этого им не требуется дополнительное пространство в па-
мяти, необходимое для выполнения соединений хэшированием или сортировкой слиянием, которые
могут чрезмерно расходовать память. Такой расход может даже привести к ошибкам нехватки про-
странства, если кэшированные наборы строк оказываются больше, чем вы ожидали.
Переходить вниз к первичным ключам перед тем, как переходить вверх к не-
уникальным внешним ключам.
Обычный эвристический порядок соединения
159
ПРИМЕЧАНИЕ--------------------------------------------------------------------
Переходя вниз перед тем, как переходить наверх, вы избегаете ситуации, когда слишком большое коли-
чество строк будет получено раньше, чем вы предполагали. Подобные снтуацин возникают, когда в де-
тальных таблицах для каждой строки оказывается больше данных, чем вы ожидали.
Если вы используете только надежные планы, то правила надежности сами от-
вечают на первые два вопроса поиска наилучшего плана выполнения, оставляя
открытым только вопрос о порядке соединения. Обычно возникает только два ва-
рианта.
Обращение к каждой таблице будет проходить через единственный индекс Это
будет индекс по полному условию фильтрации для первой таблицы и индекс
по ключу соединения для всех остальных таблиц.
Все таблицы будут соединяться при помощи вложенных циклов.
Позже я объясню, в каких случаях можно безопасно и выгодно ослабить требо-
вания надежности для соединений со вложенными циклами, но сейчас я хочу скон-
центрироваться только на оставшемся вопросе для надежных планов — порядке
соединения. Позже я расскажу, что делать, когда идеальный план выполнения
нельзя получить, обычно из-за отсутствия индексов. Но сейчас мы предполагаем,
что ищем действительно оптимальный надежный план, не ограниченный отсут-
ствующими индексами.
Обычный эвристический порядок
соединения
Эвристика для поиска наилучшего надежного плана выполнения, включая поря-
док соединения, выглядит следующим образом.
1. Сначала обработать таблицу с наилучшим (ближайшим к нулю) коэффициен-
том фильтрации.
2. При помощи вложенных циклов — проходя через полные, уникальные индек-
сы по первичным ключам — пройти как можно дальше, сначала обработав наи-
лучший (ближайший к нулю) из оставшихся фильтров.
3. Только тогда, когда это действительно необходимо, проследовать по вложен-
ным циклам вверх по связям диаграммы (против направления стрелки) через
полные, неуникальные индексы по внешним ключам.
Сейчас эти шаги могут быть еще не очень понятны. Не беспокойтесь. Далее
в этой главе я подробно объясню каждый шаг. Эвристические методы обычно лег-
че продемонстрировать, чем объяснить.
Если ведущая таблица оказалась на несколько уровней ниже верхней детальной
таблицы (корневой таблицы, поскольку она находится в корне дерева), то вам потре-
буется возвращаться к шагу 2 после каждого перемещения вверх по дереву в шаге 3.
Я описываю некоторые тонкости для редких специальных случаев, но в целом по-
иск оптимального плана очень прост, если у вас уже есть диаграмма запроса.
Настроив тысячи запросов из реальных приложений, включающих десятки
тысяч подзапросов, я могу с уверенностью заявить, что эти правила сложны ровно
160
6. Выбор наилучшего плана выполнения
настолько, насколько это необходимо и достаточно. Любое существенное упроще-
ние этих правил приведет к пропуску больших и распространенных классов плохо
настроенных запросов, а усложнение позволит добиться заметного улучшения толь-
ко для относительно редких классов запросов.
ПРИМЕЧАНИЕ--------------------------------------------------------------
Позже в этой книге я рассмотрю эти редкие случаи и объясню, что с ними делать, но сначала надо как
можно глубже уяснить базовые принципы.
Нужно знать одну тонкость, которая появляется, когда в шагах 2 и 3 упомина-
ются очередные связи вверх или вниз, обозначающие соединения. Таблицы, уже
обработанные в плане, объединяются в один виртуальный узел, чтобы упростить
выбор следующего шага плана. Наверное, будет проще отображать уже обработан-
ные таблицы как объединение узлов в виде облака. Для оставшейся части плана
совершенно неважно, как организованы уже обработанные таблицы или в каком
порядке к ним обращались. Ответ на вопрос «Какая таблица идет следующей?»
совершенно не зависит от порядка или метода, которые вы использовали при со-
единении предыдущих таблиц. Таблицы, находящиеся в объединении, определя-
ют его границы и важны для плана, но как они туда попали — это, грубо говоря,
уже история, которая не относится к очередному решению.
Когда вы составляете план выполнения, то можете обнаружить, что выбрали
ведущей только что присоединенную таблицу. Это, конечно, ошибка. Если табли-
цы присоединяются к любому члену набора уже соединенных таблиц, то они со-
вершенно одинаково могут присоединяться снизу или сверху облака. По мере про-
хождения шагов процесса можно даже рисовать расширяющиеся таблицы облака
уже обработанных таблиц, чтобы четко видеть, какие таблицы лежат за его преде-
лами. Отношения оставшихся таблиц с облаком четко указывают — присоединя-
ются ли они к нему сверху или снизу, или даже вообще не присоединяются напря-
мую, потому что перед этим необходимо обработать присоединение других таблиц.
Позже в этой главе я подробнее рассмотрю этот вопрос.
Простые примеры
Ничто не иллюстрирует метод лучше, чем примеры, поэтому я приведу пример,
используя диаграммы запроса, построенные в главе 5, начиная с простейшего слу-
чая, двустороннего соединения, показанного на рис. 6.1.
EOJ
20
▼ 0.98
□ 0^5
Рис. 6.1. Простое двустороннее соединение
Применяя первый шаг метода, сначала спросим себя, какой узел предлагает
наилучший (наименьший) эффективный коэффициент фильтрации. Это будет узел
Е, так как коэффициент фильтрации для Е, равный 0,1, меньше коэффициента D,
Простые примеры
161
равного 0,5. Начиная с этого узла, выполним шаг 2 и обнаружим, что наилучшим
(и единственным) узлом внизу будет узел D, поэтому перейдем к нему. Больше
таблиц нет — следовательно, мы получили полный порядок соединения. Выпол-
няя правила для надежного плана выполнения, к Е мы будет обращаться при помо-
щи индекса по его фильтру, Exempt_Fl ад. Затем по вложенным циклам через индекс
по первичному ключу DepartmentalD для Departments мы перейдем к соответствую-
щим отделам. Применив грубую силу, в главе 5 я уже продемонстрировал, что этот
план является наилучшим — по крайней мере, в терминах минимизации количе-
ства полученных строк.
ПРИМЕЧАНИЕ -------------------------------------------------------------------
Правила для надежных планов и оптимальных надежных планов не учитывают, какие индексы у вас уже
есть. Помните, что в этой главе рассматривается вопрос о том, какой план вам нужен, и этот вопрос не дол-
жен быть ограничен отсутствием необходимых индексов. Позже я рассмотрю случаи, когда можно доволь-
ствоваться неоптимальными планами, если какие-то индексы отсутствуют. Но вы должны сначала найти
идеальные планы, а затем оценивать ситуацию и решать, идти ли на компромисс.
Порядок 8-стороннего соединения
Пока что все идет неплохо, но двусторонние соединения слишком просты, чтобы
изучать новый метод, поэтому перейдем к следующему примеру, 8-стороннему
соединению. Теоретически для восьми таблиц можно придумать 8! порядков со-
единения (то есть 40 320 вариантов) — достаточно для того, чтобы воспользовать-
ся систематическим методом. Рисунок 6.2 повторяет задачу из главы 5.
Рис. 6.2. Типичное 8-стороннее соединение
Воспользовавшись эвристическим методом, оптимальный порядок соединения
для запроса, изображенного на диаграмме на рис. 6.2, можно определить следую-
щим образом.
1. Найдем таблицу с наименьшим коэффициентом фильтрации. В этом случае это
С с коэффициентом 0,0002, поэтому С становится ведущей таблицей.
2. Из С невозможно перейти вниз к какой-либо таблице через индекс по первич-
ному ключу. Поэтому следует перейти по диаграмме вверх.
3. Единственный путь из С ведет к 0, поэтому таблица 0 присоединяется второй.
4. После обработки 0 мы обнаруживаем, что теперь можно перейти вниз к ОТ. Ког-
да возможно, всегда выбирайте путь вниз, и переходите вверх, только в случае,
когда путей вниз не осталось. Таблица ОТ присоединяется третьей.
162
6. Выбор наилучшего плана выполнения
5. Ниже ОТ нет никаких таблиц, поэтому мы возвращаемся к 0 и переходим вверх
к таблице 0D, которая присоединяется четвертой.
6. Все оставшиеся соединения ведут вниз и не фильтруются, поэтому соединения
с S, Р и ODT можно выполнять в любом порядке.
7. Соединение с А можно выполнить в любой момент, но только после соединения
с S, которое открывает путь к таблице А.
ПРИМЕЧАНИЕ---------------------------------------------------------------
Я покажу, что при рассмотрении коэффициентов соединения вы всегда будете помещать ведущие вниз
внутренние соединения перед внешними. Это происходит потому, что у внутренних соединений есть,
по крайней мере, возможность отбрасывать строки, даже в таких случаях, как этот, когда статистика
показывает, что соединение никак не повлияет на текущее количество строк.
Таким образом, мы обнаружили, что оптимальный порядок соединения можно
описать как С; 0; ОТ; OD; S, Р и ODT в любом порядке, а также А в любой момент после S.
То есть допустимыми являются 12 одинаково хороших порядков соединения из
40 320 возможных. Изматывающий поиск всех возможных порядков соединения
подтверждает, что эти 12 одинаково хороши. Их лучше всего использовать для
минимизации количества полученных строк в надежных планах выполнения.
Диаграмма запроса может показаться вам слишком простой, чтобы представ-
лять реальную проблему, но я обнаружил, что это совсем не так. В большинстве
запросов даже с большим количеством соединений всего лишь один или два филь-
тра и один из коэффициентов фильтрации обычно очевидно лучше, чем осталь-
ные.
В большинстве случаев переход к наилучшему фильтру, за которым следуют
соединения вниз, а затем соединения вверх и, возможно, обработка одного или двух
незначительных фильтров по пути (лучше раньше, чем позже) — это все, что нуж-
но для поиска отличного плана выполнения. Этот план практически всегда явля-
ется наилучшим или так близок к наилучшему, что различия не играют большой
роли. В этом случае мы получаем упрощенные диаграммы запросов. Полностью
упрощенная диаграмма запроса, показанная на рис. 6.3, где наилучший фильтр
обозначен заглавной буквой F, а второй — строчной буквой f, позволяет получить
тот же результат, имея лишь качественную информацию о фильтре.
Рис. 6.3. Полностью упрощенная диаграмма запроса для того же 8-стороннего соединения
Я вернусь к этому примеру позже и покажу, что этот результат можно немного
улучшить, ослабив требования для полностью надежного плана выполнения и ис-
Простые примеры
163
пользуя соединение хэшированием, но сейчас я хочу сфокусироваться на том, что-
бы научить вас мастерству оптимизации для наилучшего надежного плана. Мы
уже нашли 12 наилучших порядков соединения, и мне необходим один из них для
дальнейшего рассмотрения и завершения решения этой задачи. Я выбираю поря-
док соединения (С. 0. ОТ. OD. ODT. Р. S. А).
Окончательное решение для 8-стороннего
соединения
Чтобы закончить решение нашей задачи, нужно применить правила для надеж-
ных планов и получить желаемый порядок соединения в надежном плане. Надеж-
ный план применяет вложенные циклы по индексам, начиная с фильтрующего
индекса для ведущей таблицы и затем следуя по индексам для ключей соедине-
ния. Далее наилучший план расписан в деталях (исходный запрос и условия филь-
трации вы можете найти в главе 5).
1. Перейти к таблице Customers, используя индекс по (Last_Name F irst_Name), ка-
ким-либо образом модифицировав запрос, чтобы этот индекс был доступным
и полностью пригодным
2. Соединить, применяя вложенные циклы, с таблицей Orders, используя индекс
по внешнему ключу Customer_ID.
3. Соединить, применяя вложенные циклы, с Code_Transl at 1 ons (ОТ), используя его
индекс по первичному ключу (Code_Type. Code).
4. Соединить, применяя вложенные циклы, с Order_Detai 1 s, используя индекс по
внешнему ключу Order_ID.
5. Соединить, применяя вложенные циклы, с Code_Translations (ODT), используя
его индекс по первичному ключу (Code_Type, Code).
6. Внешнее соединение с применением вложенных циклов с Products, используя
его индекс по первичному ключу Product_ID.
7. Внешнее соединение с применением вложенных циклов с Shi pments, используя
его индекс по первичному ключу Shipment_ID.
8. Внешнее соединение с применением вложенных циклов с Addresses, используя
его индекс по первичному ключу Address_ID.
9. Если необходимо, сортировка полученных результатов.
Любой план выполнения, не следующий этому порядку соединения, не исполь-
зующий вложенные циклы или не использующий указанные индексы, не будет
оптимальным надежным планом. Правильный выбор ведущей таблицы и индек-
са — это ключевая проблема в 90 % случаев, и этот пример не будет исключением.
Первое препятствие при получении правильного плана — это проблема получе-
ния доступа к правильному ведущему фильтрующему индексу на первом шаге.
В Oracle можно использовать функциональный индекс по значениям столбцов
Last_Name и First_Name в верхнем регистре, чтобы при переходе к индексу не было
сложных выражений. В других базах данных вы можете увидеть, что имена всегда
хранятся (или должны храниться) в верхнем регистре, или вы можете денормали-
зовать структуру новыми индексированными столбцами, которые повторяют имена
в верхнем регистре, или же изменить приложение так, чтобы поиск зависел от регис-
164
6. Выбор наилучшего плана выполнения
тра. Есть несколько путей решения данной специфичной проблемы, но вам придется
правильно выбрать ведущую таблицу, чъ |бы хотя бы обнаружить такую проблему.
Теперь, когда вы можете правильно выбрать и обратиться к ведущей таблице,
все ли проблемы решены? Практически всегда у вас есть индексы по необходи-
мым первичным ключам, но хорошо разработанная база данных не гарантирует
(или не должна гарантировать), что у каждого внешнего ключа также есть индекс,
поэтому следующая вероятная задача — убедиться, что существуют индексы по
внешним ключам Orders(Customer_ID) и Order_Details(Order_ID). Они позволяют
использовать необходимые для надежного плана, начинающегося с Customers, со-
единения вверх методом вложенных циклов.
Другая возможная проблема заключается в том, что оптимизаторы для одной
или нескольких таблиц могут выбрать метод соединения, отличный от вложенных
циклов, и вам понадобится использовать подсказки или другие техники запреще-
ния всех методов соединения, кроме вложенных циклов. Если сервер будет ис-
пользовать этот сценарий, оптимизаторы, вероятно, также выберут другой метод
доступа к таблицам, которые не соединяются вложенными циклами, получая все
соединяемые строки за раз.
ПРИМЕЧАНИЕ---------------------------------------------------------------------
Далее я покажу, что соединения сортировкой слиянием или хэшированием для такой небольшой таб-
лицы как Code_Translations будут прекрасно работать, даже немного быстрее и без потери надежности,
так как эти таблицы не должны сильно разрастаться.
В этом простом случае, если используются только указанные фильтры, поря-
док соединения может быть наименьшей из проблем, если вы правильно выберете
ведущую таблицу и создадите все необходимые индексы по внешним ключам.
Сложное 17-стороннее соединение
На рис. 6.4 я намеренно привожу сложный пример, чтобы полностью продемонст-
рировать используемый метод. Я отбросил коэффициенты соединений, превратив
рис. 6.4 в частично упрощенную диаграмму запроса, так как они не влияют на пра-
вила, которые я сформулировал. Решение этой задачи я объясню очень подробно,
но, возможно, вы захотите сначала попытаться решить ее самостоятельно, чтобы
проверить, какие части метода вы уже полностью понимаете.
Для шага 1 быстро находим, что у В4 наилучший коэффициент фильтрации,
равный 0,001, поэтому выбираем эту таблицу ведущей. Такой селективный фильтр
лучше использовать вместе с индексом, поэтому в реальной задаче, если бы это
был достаточно важный запрос, можно было бы создать новый индекс, чтобы ис-
пользовать его для обработки В4. Но сейчас мы будем заниматься только порядком
соединения. Шаг 2 говорит, что далее следует проверить присоединенные снизу
узлы С4 и С5, отдавая предпочтение соединению с узлами с лучшей фильтрацией.
Коэффициент фильтрации для С5 равен 0,2, а для С4 — 0,5, поэтому далее мы будем
проводить соединение с С5. На данный момент порядок соединения (В4, С5), и об-
лако вокруг уже соединенных таблиц выглядит как на рис. 6.5.
Если к С5 снизу были бы присоединены один или несколько узлов, теперь их
следовало бы сравнить с С4, но так как внизу узлов нет, шаг 2 предлагает нам един-
ственный выбор — С4. Расширив границы облака, чтобы захватить С4, мы видим,
что под ним больше нет узлов, поэтому переходим к шагу 3, находим единствен-
Простые примеры
165
ный узел А2, присоединяющийся к облаку сверху, и добавляем его в строящийся
порядок соединения, который теперь выглядит как (В4, С5. С4. А2). Облако вокруг
уже соединенных таблиц выглядит как на рис. 6.6.
Рис. 6.4. Сложное 17-стороннее соединение
Рис. 6.5. Облако уже соединенных таблиц, включающее две таблицы
Обратите внимание, что я закрасил исходное облако с двумя узлами другим от-
тенком серого. На практике вам не нужно стирать предыдущие облака, просто изоб-
ражайте новые облака вокруг старых. Возвращаясь к шагу 2, найдем ниже текущего
облака соединенных таблиц единственный узел, ВЗ, и поместим его следующим в по-
166
6. Выбор наилучшего плана выполнения
рядок соединения, не обращая внимания на коэффициент фильтрации, который мог
бы быть указан. Расширьте границы облака, включив ВЗ. Теперь шаг 2 надо выпол-
нить на узлах С2 и СЗ. Следующим в порядке соединения выбираем С2, так как его
коэффициент фильтрации, 0,5, лучше, чем подразумеваемый коэффициент 1,0 для
не фильтрованной таблицы СЗ. Теперь порядок соединения (В4, С5. С4, А2. ВЗ. С2).
Расширьте облако, включив С2. Новых узлов под облаком не появилось, поэтому
шаг 2 выполняется только для узла СЗ. Теперь порядок соединения будет (В4. С5. С4.
А2, ВЗ. С2. СЗ), и рис. 6.7 иллюстрирует текущее облако соединения.
Рис. 6.6. Облако уже соединенных таблиц, включающее четыре таблицы
Рис. 6.7. Облако уже соединенных таблиц, включающее семь таблиц
Простые примеры
167
Теперь для шага 2 у нас есть два новых узла под облаком соединения, D1 и D2,
причем коэффициент фильтрации у D1 лучше. Так как к этим узлам никакие дру-
гие узлы снизу не присоединены, присоединим их последовательно в зависимости
от коэффициентов фильтрации и перейдем к шагу 3, имея порядок соединения
(В4. С5, С4, А2, ВЗ, С2, СЗ. DI, D2). Вся ветвь ниже А2 обработана и осталась только
связь вверх к М (это главная таблица запроса), поэтому мы переходим к этому узлу.
Так как мы достигли главной таблицы в корне дерева соединения, для оставшейся
части задачи шаг 3 нам не понадобится. Применяйте шаг 2, пока не вставите в по-
рядок соединения остальные таблицы. Сразу же под М (и под всем облаком) нахо-
дятся А1 и АЗ, причем фильтр есть только у А1, поэтому присоединяем таблицу А1.
Теперь порядок соединения (В4. С5. С4. А2 ВЗ, С2. СЗ. DI. D2. М. А1), а на рис. 6.8
показано текущее облако соединения.
Рис. 6.8. Облако уже соединенных таблиц, включающее одиннадцать таблиц
Сразу же под облаком находятся узлы Bl, В2 и АЗ, но ни для одного из них нет
фильтра, поэтому проверим фильтры следующего шага. Такие фильтры можно
найти для С1 и В5, но фильтр С1 лучше, поэтому добавляем В1 и С1 к текущему
порядку соединения. Теперь порядок соединения (В4. С5. С4. А2. ВЗ, С2. СЗ, D1.
D2. М. Al, Bl. С1). Все так же у нас нет лучшего выбора, чем оставшийся фильтр
следующего шага для В5, поэтому присоединяем АЗ и В5 в указанном порядке.
Теперь осталось только два узла, В2 и Сб, и оба можно сразу же присоединить, так
как они напрямую присоединены к облаку. Выберем Сб первым, так как его коэф-
фициент фильтрации равен 0,9, и это значение лучше, чем подразумеваемый ко-
эффициент 1,0 для не фильтрованного соединения с В2. Полный порядок соеди-
нения будет следующим — (В4. С5, С4. А2. ВЗ. С2, СЗ. DI, D2. М. Al. Bl. С1. АЗ. В5.
Сб. В2).
Кроме порядка соединения правила указывают, что база данных должна об-
ращаться к таблице В4 через индекс для его условий фильтрации, а ко всем ос-
168
6. Выбор наилучшего плана выполнения
тальным таблицам база данных должна обращаться при помощи вложенных
циклов по индексам по их ключам соединения. Эти индексные ключи соедине-
ния — первичные ключи для соединений вниз с С5, С4, ВЗ, С2, СЗ, DI, D2, Al, Bl, С1,
АЗ, В5, С6 и В2 и внешние ключи для А2 (указывающий на В4) и М (указывающий на
А2). Все вместе, это полностью описывает единственный оптимальный план из 17!,
то есть 355 687 428 096 000 возможных порядков соединения и всех возможных
методов соединения и индексов. Однако этот пример все же имеет два слабых
места.
В реальных запросах редко бывает так много фильтрованных узлов, поэтому
маловероятно, что для соединения такого количества таблиц будет лишь один
оптимальный порядок. Чаще всего вы будете находить целый набор одинаково
хороших порядков соединения, как я продемонстрировал в предыдущем при-
мере.
Последняя часть порядка соединения не сильно влияет на время выполнения,
если первая часть порядка составлена правильно и все таблицы обрабатывают-
ся через их ключи соединения. В этом примере, как только база данных достиг-
нет узла М, и, возможно, А1 по правильному пути, путь к оставшимся таблицам
повлияет на время выполнения лишь незначительно. В большинстве запросов
даже меньшая доля таблиц действительно важна для порядка соединения, по-
этому вы получите прекрасный план, лишь правильно выбрав ведущую табли-
цу и выполняя для остальных таблиц вложенные циклы по ключам соединения
в любом порядке, допустимом в дереве.
ПРИМЕЧАНИЕ----------------------------------------------------------------
Если вам все равно нужно изменить запрос и есть шанс получить правильный порядок соединения
полностью, сделайте это. Однако если у вас уже есть правильный план для начала порядка соединения,
улучшения могут не стоить беспокойства и работы по изменению запроса только для того, чтобы ис-
править порядок соединения.
Особый случай
Обычно выполнение шагов процесса настройки без отклонений показывает себя
превосходно, но проблема, показанная на рис. 6.4, может заставить применить пос-
ледний трюк, особенно подходящий для Oracle.
ПРИМЕЧАНИЕ-----------------------------------------------------
В этом разделе сначала описан особенно эффективный трюк, который иногда срабатывает в Oracle.
Однако если вам нужно что-то подобное для других серверов баз данных, потерпите — в конце раздела
я опишу менее эффективный вариант этого фокуса для других баз данных.
Решение для Oracle
Вернитесь к рис. 6.4 и представьте, что все таблицы кроме М относительно невели-
ки и хорошо кэшированы, а М — очень большая и поэтому плохо кэширована, и до-
ступ к ней существенно дороже, чем к остальным таблицам. Кроме того, М — это
особенная таблица комбинаций, выражающая отношение «многие ко многим» меж-
Особый случай
169
ду Al и А2. Примером такой таблицы комбинаций может быть таблица, содержа-
щая сочетания актер-фильм для базы данных об истории кинематографа, связы-
вающая таблицы Movies и Actors, отношения между которыми принадлежат виду
«многие ко многим». В такой таблице комбинаций естественно использовать пер-
вичный ключ, состоящий из двух частей, то есть из идентификаторов связанных
таблиц — в нашем случае Movi e_ID и Actor_ID. Как это часто бывает, у таблицы ком-
бинаций есть индекс по комбинации внешних ключей, указывающих на таблицы
А2 и А1. Для нашего примера предположим, что порядок ключей в индексе таков:
сначала внешний ключ, указывающий на А2, затем внешний ключ, указывающий
на А1.
Рассмотрим стоимость доступа к каждой таблице в том плане, который я соста-
вил ранее, считая его решением для рис. 6.4. Можно найти низкую стоимость дос-
тупа для таблиц под М, затем намного большую стоимость доступа к М, так как вы
получаете существенно больше строк из этой таблицы, чем из предыдущих, и до-
ступ к этим строкам требует операций физического ввода-вывода. После обработ-
ки М база данных присоединяет такое же количество строк из А1 (так как для М нет
фильтра), но стоимость каждой такой строки гораздо меньше, поскольку они пол-
ностью кэшированы. Затем фильтр в А1 сбрасывает количество строк обратно до
небольшого количества для оставшихся в плане таблиц. Таким образом, стоимость
практически полностью определяется стоимостью доступа к М, поэтому полезно
было бы снизить именно эту составляющую.
Как это случается в подобных необычных случаях, вы находите возможность
обойти внешний ключ в М, указывающий на А2, и перейти к указывающему на А1
внешнему ключу, который хранится в том же многостолбцовом индексе в М, даже
не обращаясь к таблице М. Позже базе данных потребуется считать строки из самой
таблицы М, чтобы получить внешний ключ, указывающий на АЗ и, возможно, счи-
тать столбцы из списка SELECT запроса. Однако вы можете отложить обращение к
этой таблице до того момента, как база данных пройдет фильтрованные таблицы
А1 и С1. Таким образом, базе данных потребуется получить только 18 % тех строк из
М (0,3 х 0,6, учитывая коэффициенты фильтрации 0,3 для А1 и 0,6 для С1), которые
потребовалось бы считать, если бы база данных перешла к таблице М сразу же пос-
ле обращения к индексу для М. Это существенно снижает стоимость запроса, так
как стоимость считывания строк из таблицы М преобладает в данном специфиче-
ском случае.
Ни в одной базе данных разъединение считываний из индекса и считываний из
таблицы не дается легко. Считывание из таблицы обычно автоматически следует
сразу же за считыванием из индекса, даже если это не оптимально. Но Oracle по-
зволяет выполнить фокус, решающий эту проблему, так как в SQL в Oracle можно
явно указывать идентификаторы строк. В данном случае наилучший порядок со-
единения - (В4. С5, С4. А2. ВЗ. С2. СЗ. DI. D2. MI. Al. Bl. С1, ИГ. АЗ. В5. 06. В2).Здесь
MI — это индекс по M(FkeyToA2, FkeyToAl), который в порядке соединения находится
на исходном месте М. МТ — это таблица М, доступ к которой производится по плану
позже через ROWID из MI. МТ вставлена в порядок соединения после обработки филь-
тров для А1 и 01. Трюк заключается в том, чтобы обратиться к таблице М дважды
в разделе FROM, один раз только для доступа к индексу и один раз для прямого
соединения по ROWID, как показано далее. Имя индекса M(FkeyToA2.FkeyToAl) — это
M_DoubleKeyInd:
170
6. Выбор наилучшего плана выполнения
Select /*+ ORDERED INDEXCMI MJtoubleKeyInd) */ MT.Coll. MT.C012
FROM B4. C5. 04. A2. B3. 02. 03. DI D2.
M MI. Al. Bl. Cl. M MT. A3. B5. C6. B2
WHERE ...
AND A2.Pkey=MI.FKeyToA2
AND Al.Pkey=MI.FKeyToAl
AND MI.R0WID=MT.ROWID
AND...
Для подобного необычного случая два соединения с М действительно дешевле
одного! Обратите внимание на две подсказки в этом варианте запроса.
Выражение ORDERED указывает, что таблицы должны соединяться в том поряд-
ке, в каком перечислены в разделе FROM.
Выражение INDEX (MI M_DoubleKeyInd) гарантирует использование правильного
индекса в той точке порядка соединения, где вам требуется только доступ к ин-
дексу ML
Для правильного выполнения оставшейся части плана могут потребоваться
другие подсказки. Также обратите внимание на необычное соединение «иденти-
фикатор строки с идентификатором строки» между MI и МТ, и что единственные
ссылки на MI есть только в разделе FROM и в условиях раздела WHERE. Для этих ссы-
лок требуются только данные (два внешних ключа и идентификатор строки), хра-
нящиеся в индексе. Это очень важно — Oracle не переходит к таблице М сразу же
после того, как считывает индекс по первичному ключу М только потому, что MI
обращается только к индексированным столбцам и идентификаторам строки, ко-
торые также хранятся в индексе. Все столбцы в операторе SELECT и везде в усло-
виях раздела WHERE (например, соединение с АЗ, которое не показано) получе-
ны из МТ. Поэтому оптимизатор считает, что все столбцы, необходимые для MI, уже
находятся в индексе. Он считает это соединение исключительно индексным. Пря-
мое соединение с МТ по ROWID выполняется позже в порядке соединения, и все стол-
бцы таблицы М выбираются из МТ.
Однако только что описанный мной метод используется очень редко по несколь-
ким причинам.
Комбинированные индексы из двух необходимых вам внешних ключей в пра-
вильном порядке встречаются редко.
Обычно корневая детальная таблица не увеличивает стоимость настолько, в от-
носительных и абсолютных единицах, чтобы оправдать старания.
Выгоды редко оправдывают создание нового многостолбцового индекса, если
он еще не существует.
Решение специфичной проблемы
для других серверов
Если в разделе WHERE вы не можете указывать напрямую идентификаторы строк,
может ли этот трюк сработать в той же форме? Единственная часть настройки,
которая зависит от идентификаторов строк, — это соединение между MI и МТ Эти
псевдонимы таблиц также можно соединить по полному первичному ключу. Стой-
Сложный пример
171
мость первого соединения с MI не изменится, а более позднее соединение с МТ потре-
бует получения той же записи индекса, которую вы уже получили при выполнении
только индексного соединения с MI для оставшихся строк. Это не так эффективно,
но обратите внимание, что дополнительные обращения к индексу обязательно бу-
дут кэшированы, так как план выполнения только что обращался к тем же записям
индекса, поэтому добавится только стоимость дополнительного логического вво-
да-вывода. Так как база данных выбрасывает большинство строк еще до того, как
достигнет МТ, эта дополнительная операция логического ввода-вывода стоит го-
раздо меньше, чем экономится на доступе к самой таблице.
Сложный пример
Теперь я продемонстрирую пример с менее очевидным порядком соединения, ко-
торый потребует больше внимания ко всему облаку соединения. Вы обнаружите,
что в случаях, подобных тому, который я описываю в этом разделе, порядок следо-
вания очередных таблиц для достижения наилучшего соединения может быть раз-
бросан по всей диаграмме запроса. Рассмотрим задачу на рис. 6.9. Перед тем как
читать дальше, попытайтесь решить ее самостоятельно.
Рис. 6.9. Другая задача с тем же скелетом соединения
Это довольно распространенный случай, когда наилучший фильтр накладыва-
ется на корневую детальную таблицу.
ПРИМЕЧАНИЕ----------------------------------------------------------------
Наилучший фильтр часто находится рядом с корневой детальной таблицей, потому что в центре
запроса находятся сущности именно этой таблицы. Главный фильтр чаще относится непосредствен-
но к свойствам этих сущностей, а не к некоторому унаследованному свойству в присоединенных
таблицах.
172
6. Выбор наилучшего плана выполнения
Так как обработка начнется с корневой детальной таблицы, шаг 3 никогда
не будет выполняться. У вас нет узлов выше начальной точки. Облако соеди-
ненных таблиц, таким образом, будет расти сверху вниз, но помните, что следу-
ющий лучший узел может находиться в любом месте около границы облака, не
обязательно рядом с последней присоединенной таблицей. Перед тем как про-
должать чтение, попытайтесь найти наилучший порядок соединения самостоя-
тельно.
Первые допустимые узлы — это Al, А2 и АЗ, а лучший коэффициент фильтрации
относится к А1, поэтому вторым в порядок соединения мы помещаем узел А1. Пос-
ле расширения облака на А1 в список допустимых узлов добавляются узлы В1 и В2,
причем А2 и АЗ также остаются допустимыми. Среди этих четырех узлов у АЗ наи-
лучший коэффициент фильтрации, поэтому его мы присоединяем следующим.
Итак, на данный момент порядок соединения (М. А1. АЗ), а облако соединения выг-
лядит как на рис. 6.10.
Рис. 6.10. Облако соединения после обработки первых трех таблиц
Список допустимых узлов, присоединенных к облаку, теперь выглядит как
В1, В2, А2 и В5. Среди них у В1 наилучший коэффициент фильтрации, поэтому мы
присоединяем его следующим и расширяем облако, одновременно добавляя в
список допустимых узлов С1. Теперь можно выбирать из узлов В2, А2, В5 и С1. Сре-
ди них наилучшим является С1, поэтому мы присоединяем его и расширяем об-
лако. От С1 вниз не ведут никакие связи, поэтому мы выбираем следующий наи-
лучший узел из текущего списка. Это А2, поэтому к списку допустимых узлов
добавляются ВЗ и В4, и он теперь выглядит как В2, В5, ВЗ и В4. На данный момент
порядок соединения (М, А1. АЗ. Bl. Cl. А2), а облако соединения выглядит как на
рис. 6.11.
Среди допустимых узлов наилучший коэффициент фильтрации на данный
момент у В4, поэтому мы присоединяем его. (Было бы удобнее присоединить его
Сложный пример
173
раньше, но это невозможно, пока база данных не достигнет А2.) После присоедине-
ния В4 в список допустимых попадают узлы С4 и С5, и теперь этот список включает
В2, В5, ВЗ, С4 и С5. Из них лучшим является С5, поэтому присоединяем его. Теперь
порядок соединения (М. А1. АЗ. В1, С1. А2. В4, С5), а облако соединения выглядит
как на рис. 6.12.
Рис. 6.11. Облако соединения после обработки первых шести таблиц
Рис. 6.12. Облако соединения после обработки первых восьми таблиц
174
6. Выбор наилучшего плана выполнения
Теперь допустимые узлы сразу под облаком соединения — это В2, ВЗ, В5 и С4, и луч-
шим кандидатом на присоединение среди них является В5. Он добавляет в список
допустимых узел С6, а следующим наилучшим узлом становится С4, который в спи-
сок допустимых не добавляет никаких узлов. Очередной наилучший узел — это С6,
но он также не пополняет список допустимых узлов, поэтому выбирать можно толь-
ко из В2 и ВЗ. Ни для одного из них нет фильтра, поэтому мы проверяем фильтры
следующего шага и обнаруживаем, что ВЗ позволяет перейти к фильтру для С2, по-
этому следующим мы присоединяем ВЗ. Сейчас порядок соединения — (М. А1. АЗ. В1.
С1. А2, В4. С5. В5. С4. С6. ВЗ), а облако соединения выглядит как на рис. 6.13.
D1 0.8 D2 0.9
Рис. 6.13. Облако соединения после обработки первых двенадцати таблиц
Теперь выбирать можно из В2, С2 и СЗ, причем только у С2 есть фильтр, поэто-
му присоединяем ее следующим. Ниже него больше нет узлов, поэтому допус-
тимыми остаются узлы В2 и СЗ, а схема разрешения конфликтов говорит нам,
что после СЗ на следующем шаге появляются фильтры для D1 и D2, поэтому мы
присоединяем СЗ. Теперь порядок соединения — (М. А1. АЗ. В1. С1. А2, В4. С5. В5.
С4, С6, ВЗ. С2. СЗ). Допустимые узлы внизу — это В2, D1 и D2. На данной точке
процесса это все оставшиеся узлы, под которыми мы не найдем очередных кан-
дидатов на присоединение. Просто отсортируем оставшиеся узлы по коэффи-
циенту фильтрации и завершим порядок соединения — (М. А1. АЗ. Bl, Cl, А2.
В4. С5. В5. С4. С6, ВЗ. С2. СЗ. DI. D2. В2). В реальных запросах такая ситуация,
в которой требуется лишь отсортировать напрямую присоединенные к облаку
узлы, возникает несколько раньше. В достаточно распространенном особом
случае, когда есть одна детальная таблица, от которой отходят только прямые
соединения с поиском в главных таблицах (обычно это таблицы размерности) —
такое соединение относится к типу «звезда» — главные узлы нужно сортиро-
вать в самом начале.
Сложный пример
175
Получив оптимальный порядок соединения, завершите описание плана
выполнения, потребовав доступ к ведущей таблице М из индекса для условий
фильтрации для этой таблицы. Затем присоедините остальные таблицы мето-
дом вложенных циклов с использованием индексов по первичным ключам этих
таблиц.
ПРИМЕЧАНИЕ----------------------------------------------------------------
Случай, когда начинать приходится с корневого узла дерева соединения, достаточно прост. Обычно вы
можете рассчитывать на существование нужных индексов по первичным ключам, необходимых базе
данных для выполнения соединений исключительно по направлению вниз.
Специальные правила для особых случаев
Пока что эвристические правила могут хорошо обработать большинство случаев
и практически всегда выдать отличный, надежный план. Однако за разумными
объяснениями этих правил кроется несколько предположений, которые не все-
гда истинны. На удивление часто, даже когда эти предположения ложны, они
достаточно верны, чтобы получить близкий к оптимальному план. Далее я пере-
числяю эти предположения и рассматриваю более сложные правила для обра-
ботки редких случаев, когда отклонения от предположений имеют существенное
значение.
Промежуточные результаты запроса в форме декартова произведения приво-
дят к плохой производительности. Если вы не будете следовать по связям во
время разработки порядка соединения, то в результате получите декартово про-
изведение первого набора строк и набора строк, полученного из следующего по
порядку узла. Иногда это безопасно, но даже когда такой результат быстрее,
чем порядок соединения по связям, он опасен и плохо работает при увеличе-
нии размеров таблиц.
Значения детальных коэффициентов соединения велики, намного больше 1,0.
Так как главные коэффициенты соединения (вниз по дереву соединения) ни-
когда не превышают 1,0, будет гораздо безопаснее, если вы произведете как
можно больше соединений вниз перед переходом к соединениям в верхнем на-
правлении, даже если во втором случае вы получаете доступ к большему коли-
честву фильтров. Обычно фильтры для узлов, расположенных в верхней части
дерева, отбрасывают не больше строк, чем база данных выбирает, переходя к
более детальной таблице. Даже когда детальные коэффициенты соединения
невелики, сама природа соединения «один ко многим», обеспечивает вероят-
ность того, что эти значения могут существенно возрасти в будущем или на
других машинах, где выполняется то же самое приложение. Поэтому для боль-
шого коэффициента детализированного соединения лучше выбирать надежный
SQL-код, кроме тех случаев, когда вы полностью уверены, что локальная, теку-
щая статистика не изменится со временем и будет одинакова для различных
наборов данных.
Таблица в корневом узле дерева соединения намного больше остальных
таблиц, которые служат для нее главными таблицами или таблицами соот-
ветствия. Это предположение вытекает из предыдущего Так как у больших
176
6. Выбор наилучшего плана выполнения
таблиц коэффициенты попадания в кэш хуже, и так как сервер баз данных
считывает из большой таблицы намного больше строк, чем из большинства
или даже всех остальных таблиц вместе взятых, то главная цель настройки
запроса — минимизировать количество строк, считанное из этой корневой
детальной таблицы.
Главные коэффициенты соединения равны 1,0 или достаточно близки к этому
значению, чтобы разница не играла роли. Это относится к распространенному
случаю, когда не равные нулевому значению внешние ключи детальных таблиц
обладают превосходной целостностью ссылочных данных.
Когда таблицы достаточно велики, чтобы эффективность имела большое зна-
чение, то существует один коэффициент фильтрации, намного меньший всех
остальных. Редко встречаются две таблицы с практически одинаковым коэф-
фициентом фильтрации. Если таблицы велики, а результат выполнения запро-
са относительно мал, как обычно бывает с полезными результатами запросов,
то произведение всех коэффициентов фильтрации должно быть небольшим.
Гораздо проще получить этот небольшой результат при помощи одного селек-
тивного фильтра, иногда в сочетании с несколькими достаточно не селектив-
ными фильтрами, чем при помощи большого количества схожих полуселек-
тивных фильтров. Поиск разумных (в терминах ведения бизнеса) объяснений
большому количеству полуселективных фильтров оказывается неблагодарным
делом, и я мог бы сосчитать количество раз, когда встречался с подобными слу-
чаями за 10 лет настройки SQL, по пальцам одной руки. Имея один фильтр,
обладающий намного большей селективностью, чем остальные, гарантировать
считывание минимального количества строк из самой важной корневой деталь-
ной таблицы можно, если начать выполнение запроса с таблицы с наилучшим
фильтром.
Количество строк, возвращаемых запросом, даже перед возможным объедине-
нием таблиц будет достаточно мало, чтобы даже для крохотных главных таб-
лиц у вас было мало или вообще никаких мотивов заменить вложенные циклы
через ключи соединения независимыми считываниями из таблиц с последую-
щими соединениями хэшированием. Обратите внимание, что это предположе-
ние разваливается, если вы выполняете соединения намного большего количе-
ства строк, чем запрос в итоге возвращает. Однако эвристика разработана так,
чтобы гарантировать, что у вас практически никогда не будет намного больше
строк в любой промежуточной точке плана запроса, чем база данных возвраща-
ет из полного запроса.
В следующих разделах добавлены правила для обработки редких специальных
случаев, которые противоречат этим предположениям.
Безопасные декартовы произведения
Рассмотрим запрос, диаграмма для которого показана на рис. 6.14. Выполняя
обычные правила (и выбирая первым самый левый узел, просто для удобства),
мы переходим к фильтру для Т1 и присоединяем Т1 к М, используя индекс по
внешнему ключу, указывающему на Т1. Затем мы переходим к Т2, используя
индекс по первичному ключу, и в конце отбрасываем строки, не проходящие
Сложный пример
177
через фильтр для Т2. Если предположить, что в Т1 100 строк, то, на основании
коэффициентов соединения, в М должно быть 100 000 строк, и в Т2 — также 100
строк.
м
л.
Т1 0X1 Т2 0X1
Рис. 6.14. Запрос с потенциально хорошим планом выполнения с декартовым произведением
Описанный план затронет 1 строку в Т1,1000 строк в М (1 % от общего количе-
ства) и 1000 строк в Т2 (в среднем каждая строка из Т2 нужна 10 раз) перед тем,
как отбросить из результата все строки, оставив лишь 10. Если аппроксимиро-
вать стоимость запроса как количество полученных из таблиц строк, то она со-
ставит 2001. Однако если пойти против правил, то можно получить план, кото-
рый не следует связям, обозначающим соединения. Можно выполнить вложенные
циклы между Т1 и Т2, используя соответствующие фильтрующие индексы. По-
скольку между Т1 и Т2 нет соединения, в результате мы получим декартово про-
изведение всех строк, удовлетворяющих условию фильтрации для Т1 и всех
строк, удовлетворяющих условию фильтрации для Т2. Для данных размеров таб-
лиц результирующий план выполнения считает лишь по одной строке из Т1 и Т2.
Выполнив декартово соединение Т1 и Т2, база данных сможет использовать ин-
декс по внешнему ключу, которые указывает на Т1, чтобы перейти к М и считать
из нее 1000 строк. Затем база данных отбросит 990 строк, не удовлетворяющих
условию соединения для М и Т2.
ПРИМЕЧАНИЕ -----------------------------------------------------------------
Если вы не используете условие соединения на каждом шаге запроса, одно из соединений становится
отложенным, то есть можно сказать, что оно никогда не используется для улучшения производитель-
ности запроса. Затем база данных отбрасывает строки, которые не удовлетворяют условию отложенно-
го соединения, эффективно используя это соединение как фильтр после того, как считает строки из
обеих таблиц, участвующих в соединении.
С использованием декартова произведения стоимость плана составит лишь 1002,
если за функцию стоимости принять количество считанных строк.
Что же произойдет, если размеры таблиц удвоятся? Стоимость исходного пла-
на, следующего связям для соединений, удвоится, составив 4002, что пропор-
ционально количеству возвращенных запросом строк, которое также удваивается.
Это нормально для надежных планов, стоимость которых пропорциональна ко-
личеству возвращенных строк. Однако план с декартовым произведением рез-
ко ухудшается: база данных считает 2 строки из Т1, затем для каждой из этих
строк считает по 2 строки из Т2 (всего 4 строки), и затем, с декартовым произве-
дением, состоящим из 4 строк, считает 4000 строк из М. Стоимость запроса, 4006,
теперь практически равна стоимости обычного плана. Еще раз удвоив размеры
таблиц, мы получим, что стоимость стандартного плана становится равной 8004,
а плана с декартовым произведением — 16 020. Это демонстрирует ненадеж-
ность большинства планов выполнения с декартовым произведением, которые
178
6. Выбор наилучшего плана выполнения
плохо работают на быстро растущих таблицах. Даже если размеры таблиц не
увеличиваются, планы с декартовым произведением ведут себя менее предска-
зуемо, чем обычные планы, поскольку коэффициенты фильтрации обычно пред-
ставляют собой среднее значение среди всех возможных значений. Фильтр, про-
пускающий в среднем лишь одну строку, может иногда пропустить 5 или 10
строк, в зависимости от значений параметра. Если селективность фильтра для
стандартного надежного плана меньше среднего, стоимость возрастает пропор-
ционально количеству строк, которое вернет запрос. Если план с декартовым
произведением применять с такими же непостоянными фильтрами, его сто-
имость может возрасти как квадрат изменения объема отфильтрованных дан-
ных или даже хуже.
Но иногда можно использовать декартовы произведения без опасений за ухуд-
шение производительности, получая неожиданные преимущества. Вполне
безопасно можно создавать декартовы произведения любого количества набо-
ров, возвращающих гарантированно одну строку, получая недорогой, одностроч-
ный результат. Можно даже комбинировать однострочный набор с многостроч-
ным, и результат будет не хуже, чем если бы вы считали этот многострочный набор
из ведущей таблицы отдельно. Основное преимущество надежных планов — тща-
тельное исключение планов выполнения, которые сочетают несколько многостроч-
ных наборов. Вспомните, что в главе 5 правила требовали поместить звездочку
рядом с уникальными условиями фильтрации (условиями, гарантированно про-
пускающими максимум одну строку). С тех пор я не использовал эти звездочки,
но сейчас они снова выходят на сцену.
Рассмотрим рис. 6.15. Обратите внимание, что на нем есть два уникальных
фильтра, для В2 и СЗ. Начиная с единственной строки из СЗ, которой соответству-
ет уникальное условие фильтрации, вы можете быть уверены, что из D1 и D2 будет
присоединено по одной строке через их первичные ключи (см. указывающие вниз
стрелки к D1 и D2). Изолируйте эту ветвь, считая ее отдельным однострочным
запросом. Теперь получите единственную строку из В2, которая удовлетворяет
уникальному условию фильтрации, и объедините два независимых запроса де-
картовым произведением, чтобы получить комбинированный набор из одной
строки.
Поместив эти односгрочные запросы на первое место, вы получите начальный
порядок соединения (СЗ. DI. D2. В2) (или (В2. СЗ. DI. D2), без разницы). Если вы
будете считать первые запросы, выдающие однострочный результат, независимой
операцией, то обнаружите, что для таблиц А1 и ВЗ получатся новые условия филь-
трации, так как до того, как выполнить оставшуюся часть запроса, вы уже будете
знать значения внешних ключей, указывающих на В2 и СЗ. Измененный запрос те-
перь выглядит как на рис. 6.16, на котором уже выполненные однострочные запро-
сы помещены в серое облако, обозначающее границы уже считанного фрагмента
запроса.
Указывающие вверх стрелки обозначают, что начальное условие фильтрации
для А1 комбинируется с новым условием фильтрации по внешнему ключу, указы-
вающему на В2, что дает общую селективность 0,06. Не фильтрованный ранее узел
ВЗ получает из условия по внешнему ключу, указывающему на СЗ, коэффициент
фильтрации 0,01.
Сложный пример
179
Рис. 6.15. Запрос с уникальными условиями фильтрации
Рис. 6.16. Запрос с уникальными условиями фильтрации, с заранее считанными ветвями
однострочных операций
ВНИМАНИЕ -----------------------------------------------------------------------
Обычно можно предположить, что любая данная часть строк главной таблицы будет соединяться с прак-
тически такой же по размерам частью строк детальной таблицы. Для таблиц транзакций, таких, как
Orders и Order_Details, это хорошее предположение. Однако небольшие таблицы часто предназначены
для хранения типов или состояний, а в таблицах транзакций типы и состояния распределены неравно-
мерно. Например, с 5-строчной таблицей состояний (которой может быть В2) какое-то состояние мо-
жет соответствовать большинству строк транзакций или же всего нескольким. В подобных случаях,
когда главная таблица содержит асимметричные значения, необходимо исследовать фактическое асим-
метричное распределение.
180
6. Выбор наилучшего плана выполнения
Теперь оставшуюся часть запроса за пределами облака можно оптимизиро-
вать как отдельную, следуя стандартным правилам. Оказывается, что АЗ — это
наилучшая ведущая таблица с лучшим коэффициентом фильтрации. (Неважно,
что АЗ не соединяется напрямую с В2 или СЗ, так как декартово произведение с
однострочным набором безопасно.) Отсюда переходим к В5 и Сб, затем наверх к М.
Так как А1 получила добавленную селективность от унаследованного фильтра по
внешнему ключу, указывающему на В2, ее коэффициент фильтрации лучше, чем
у А2, поэтому далее присоединяем А1. На данный момент порядок соединения —
(СЗ. DI, D2. В2, АЗ. В5, Сб. М А1), а запрос с облаком соединения выглядит как на
рис. 6.17.
Так как мы заранее считали В2, следующие допустимые узлы — В1 и А2, и у А2
лучший коэффициент фильтрации. Это позволяет добавить в список допусти-
мых узлы ВЗ и В4, и оказывается, что унаследованный фильтр для ВЗ делает его
лучшим выбором для очередного соединения. Завершая порядок соединения,
следуя обычным правилам, добавляем В4, Сб, В1, С4, С2 и С1 в указанном порядке.
Полный порядок соединения — (СЗ. DI. D2. В2, АЗ. В5, Сб, М. Al, А2, ВЗ, В4. С5, В1,
С4. С2, С1).
Рис. 6.17. Запрос с уникальными условиями фильтрации, с заранее полученными
ветвями однострочных операций и облаком соединения вокруг считанных
следующими пяти узлов
Даже если у вас есть только одно уникальное условие фильтрования, выпол-
ните этот процесс предварительного считывания одной строки из узла или вет-
ви, передавая коэффициент фильтрации наверх к детальной таблице и оптими-
зируя оставшуюся часть диаграммы так, как если бы она существовала отдельно.
Когда уникальное условие относится к какой-либо таблице транзакций, а не к
таблице, хранящей типы или состояния, оно обычно характеризуется наилуч-
шим коэффициентом фильтрации в запросе. В этом случае результирующий по-
Сложный пример
181
рядок соединения будет таким же, какой вы бы выбрали, если бы не знали, что
условие фильтрации уникально. Однако когда наилучший фильтр не уникаль-
ный, лучший порядок соединения может «прыгать» по скелету соединения, то
есть вторая таблица может считываться не через ключ соединения, указываю-
щий на первую таблицу.
Детальные коэффициенты фильтрации,
близкие к 1,0
Рассматривайте соединения вверх как соединения вниз, когда коэффициент филь-
трации близок к 1,0 и когда это позволяет получить доступ к полезным фильтрам
(с меньшими коэффициентами фильтрации) как можно раньше в плане выполне-
ния. Если сомневаетесь в разумности подобного подхода, попробуйте оба вариан-
та. На рис. 6.18 показан случай, когда два из существующих соединений вверх не
хуже, чем существующие соединения вниз. Перед тем, как прочитать решение,
попробуйте решить задачу самостоятельно.
Как обычно, начните с наилучшего фильтра, соответствующего В4, и исполь-
зуйте индекс. Затем переходите к остальным таблицам через вложенные циклы по
индексам по ключам соединения. В отличие от предыдущих случаев, до того как
рассмотреть соединения вверх с коэффициентами соединения, равными 1,0, не
нужно выполнять все соединения вниз.
Рис. 6.18. Случай с детальными коэффициентами соединения, равными 1,0
ПРИМЕЧАНИЕ ---------------------------------------------------------------
Очевидно, здесь есть соединения вида «один ко многим», очень близкие к «один к одному» Также
существуют соединения «один к нулю» и «один ко многим», где случаи «один к нулю» аннулируют
увеличение количества строк после выполнения соединений «один ко многим». В любом случае, с точ-
ки зрения оптимизации, это практически то же самое, что соединения «один к одному».
182
6. Выбор наилучшего плана выполнения
Как обычно, найдите фильтры в соседних узлах. Две первые лучшие возможно-
сти — это С5, а затем С4. Затем у вас есть только одна возможность — выполнить
соединение вверх к нефильтрованному узлу А2, которое вы бы выполнили следую-
щим, даже если детальный коэффициента соединения был бы велик. Получается,
что небольшой коэффициент соединения с А2 не играет роли. На данный момент
порядок соединения (В4. С5. С4. А2).
Из облака вокруг этих узлов найдите соседние узлы ВЗ (вниз) и М (вверх). Так
как детальный коэффициент соединения с М равен 1,0, то, если прочие факторы
говорят в пользу М, не нужно выбирать соединение вниз. Ни у одного из узлов нет
фильтра, поэтому посмотрите на фильтры для узлов, соседних с рассматриваемы-
ми узлами. Лучший коэффициент фильтрации рядом с М равен 0,3 (для А1), а луч-
ший коэффициент фильтрации рядом с ВЗ равен 0,5 (для С2), поэтому мы выбира-
ем присоединение М, а затем А]. Сейчас порядок соединения (В4. С5. С4. А2, М, А1).
Теперь, когда база данных пришла к корневому узлу, все соединения будут вести
вниз, поэтому можно применять обычные правила оптимизации, выбирая из при-
мыкающих к облаку узлов и для решения спорных вопросов рассматривая узлы,
соседние с данными. Полный оптимальный порядок соединения (В4, С5. С4, А2. М.
А1, ВЗ. С2. Bl. С1. АЗ. В5, С6. СЗ. DI. (D2. В2)).
ПРИМЕЧАНИЕ--------------------------------------------------------------
Запись (D2, В2) в конце порядка соединения указывает, что порядок двух последних узлов не играет
роли.
Обратите внимание, что даже в этом особом случае, предназначенном для де-
монстрации исключения из предыдущих правил, мы получаем лишь небольшое
улучшение благодаря более раннему доступу к А1, чем позволила бы простая эври-
стика, так как это улучшение встречается в порядке соединения достаточно по-
здно.
Коэффициенты соединения, меньшие 1,0
Если детальный или главный коэффициент соединения меньше 1,0, то это соеди-
нение фактически в среднем принадлежит к виду «[некоторое число] к [меньше,
чем 1,0]». Может ли сторона «меньше, чем 1,0» этого соединения принадлежать
виду «ко многим» — для проблемы оптимизации несущественно, если вы увере-
ны, что текущее среднее количество связанных данных не должно сильно изме-
ниться для других экземпляров баз данных. Если соединение вниз с обычным глав-
ным коэффициентом соединения, равным 1,0, предпочтительней, чем соединение
вверх вида «ко многим», то соединение в любом направлении с коэффициентом,
меньшим 1,0, является более предпочтительным. Эти коэффициенты соединения,
меньшие 1,0, в каком-то смысле являются скрытыми фильтрами, которые при вы-
полнении соединения отбрасывают строки так же эффективно, как и явные одно-
узловые фильтры, и поэтому влияют на оптимальный порядок соединения так же,
как фильтры.
Правила для коэффициентов соединения, меньших 1,0
Чтобы учесть эффект небольших коэффициентов соединения при выборе опти-
мального порядка соединения, вам потребуются три правила.
Сложный пример
183
При выборе ведущего узла все узлы на фильтрованной стороне соединения на-
следуют дополнительные преимущества скрытого фильтра соединения. Напри-
мер, если меньший 1,0 коэффициент соединения — это J, а коэффициент филь-
трации узла равен R, при выборе наилучшего узла берите значение J ? R. При
сравнении узлов на одной стороне фильтра соединения это не будет иметь ни-
какого эффекта, но у узлов на фильтрованной стороне соединения будет пре-
имущество перед узлами на стороне, не имеющей фильтра.
Выбирая следующий узел в последовательности, считайте все соединения с ко-
эффициентом соединения} (меньшим 1,0) соединениями вниз. При сравнении
узлов используйте эффективный коэффициент фильтрации} х R, где R — это
коэффициент фильтрации одного узла, обращение к которому идет через это
фильтрующее соединение.
Однако для главных коэффициентов соединения, меньших 1,0, рассмотрите,
не будет ли лучше сделать скрытый фильтр явным фильтром вида «внешний
ключ не равен null». Превращение «не null» фильтра в явный позволяет де-
тальной таблице, находящейся прямо над фильтрующим главным соедине-
нием, также наследовать селективность} х R во время выбора ведущей табли-
цы и порядка соединения сверху. Подробнее об этом правиле — в следующих
разделах.
Детальные коэффициенты соединения, меньшие 1,0
Значение небольших коэффициентов соединения оказывается различным в за-
висимости от того, является ли коэффициент главным или детальным, меньшим
1,0. Детальный коэффициент соединения, меньший 1,0, означает, что когда от-
сутствие деталей определенного типа вообще более вероятно, чем наличие несколь-
ких, вероятность появления нескольких деталей все же существует. Например, у вас
может быть таблица Employees, связанная с таблицей Loans для отслеживания зай-
мов, которые компания делает нескольким менеджерам верхнего звена в каче-
стве вознаграждения. Дизайн базы данных должен разрешать нескольким сотруд-
никам иметь несколько займов, но у гораздо большего количества сотрудников
вообще не будет займов от компании, поэтому детальный коэффициент соедине-
ния будет близок к 0. Для обеспечения ссылочной целостности столбец Empl oyee_ID
таблицы Loans должен указывать на реального сотрудника. Это его единственное
предназначение, и все займы в этой таблице будут относиться только к сотруд-
никам. Однако нет никакой необходимости, чтобы Empl oyee_ID соответствовал ка-
кому-либо займу. Столбец Employee_ID таблицы Employees существует (как и лю-
бой первичный ключ) только для того, чтобы указывать на собственную строку,
а не на строки в другой таблице, поэтому не удивительно, что соединение не мо-
жет найти соответствия по направлению вверх, от первичного ключа ко внеш-
нему.
Так как обработка детальных коэффициентов соединения, меньших 1,0, оказы-
вается делом простым, хотя и редко встречающимся, я проиллюстрирую этот слу-
чай. Проработаем пример из предыдущего абзаца, чтобы попытаться сделать новые
правила более убедительными. Начнем с запроса, который присоединяет Lmp1 oyees
к Loans, и добавим соединение с Departments с фильтром, который отбрасывает по-
184
6. Выбор наилучшего плана выполнения
ловину отделов. Результат показан на рис. 6.19, где каждый узел обозначен первой
буквой имени соответствующей таблицы.
LT0
0.01
▼ 1
Е
100
▼1
DO5
Рис. 6.19. Простой пример с фильтрующим соединением
ПРИМЕЧАНИЕ ----------------------------------------------------------------
Обратите внимание, что на рис. 6.19 для L указан коэффициент фильтрации 1,0, что означает, что для L
нет фильтра. Обычно такие коэффициенты не указываются. Однако я включил в диаграмму коэффи-
циент фильтрации для L, чтобы объяснить, что число 0,01 в верхней части связи с L — это детальный
коэффициент соединения для связи от Е к L, а не коэффициент фильтрации для L.
Предположим, что у нас есть 1000 сотрудников, 10 отделов и 10 займов для 8 из
этих сотрудников. Пусть единственный фильтр отбрасывает половину отделов. Де-
тальный коэффициент фильтрации для Loans должен быть равен 0,01, так как по-
сле соединения 1000 сотрудников с таблицей Loans мы найдем только 10 займов.
Исходные правила требуют, чтобы мы начали с единственной фильтрованной таб-
лицы, Departments, считали 5 строк, соединили с половиной сотрудников (еще 500
строк), и затем соединили с приблизительно половиной займов (для приблизи-
тельно 4 сотрудников в выбранной половине отделов). Таким образом, база дан-
ных считает 5 займов, выполнив 496 безуспешных операций сканирования диа-
пазонов индекса Employee lD для Loans, используя идентификаторы Employee_ID
сотрудников без займов.
С другой стороны, если таблица Loans унаследует преимущество фильтрующе-
го соединения, то вы бы начали с Loans, считали из нее все 10 строк, а затем нашли
бы 10 соответствующих строк в Employees (8 различных строк с повторениями).
Наконец, 10 раз выполнили бы соединение с Departments, причем база данных от-
бросила бы в среднем половину строк. Хотя обычная цель оптимизации — мини-
мизировать количество строк, считанных из основной таблицы, этот пример де-
монстрирует, что минимизация количества операций считывания из таблицы на
верхнем конце сильно фильтрующего детального соединения гораздо менее важ-
на, чем минимизация количества строк из намного большей таблицы на нижнем
конце.
Насколько хорошим должен быть фильтр для Empl oyees, чтобы снизить количе-
ство строк, считанных из этой таблицы, до количества строк во втором плане?
Фильтр должен быть в точности таким, как коэффициент фильтрующего соедине-
ния, 0,01. Предположим, что он даже лучше — 0,005, и пропускает только 5 со-
трудников (скажем, это фильтр по Last_Name). В этом случае какую таблицу сле-
дует присоединить следующей? Опять-таки исходные правила привели бы нас
Сложный пример
185
к Departments, потому что она находится ниже и потому что у нее лучше коэффици-
ент фильтрации. Однако обратите внимание, что для 5 сотрудников база данных
считает в среднем только 0,05 займов, поэтому гораздо лучше сначала соединить с
таблицей Loans, а затем с Departments.
ПРИМЕЧАНИЕ----------------------------------------------------------------------
В действительности конечный пользователь, скорее всего, выберет фамилию одного из сотрудников,
получившего заем, сделав эти фильтры более зависимыми, чем обычно. Но даже в этом случае займов
будет всего один или два, что сократит соединение с Departments до считывания всего одной или двух
строк вместо пяти.
Оптимизация детальных коэффициентов соединения,
меньших 1,0, по формальным правилам
На рис. 6.20 показан еще один пример с детальным коэффициентом соединения,
меньшим 1,0. Перед тем как продолжать чтение, попробуйте найти порядок соеди-
нения самостоятельно.
М0.03
А
А10.01 А2
▼ ▼
B1QJJ В20.05
Рис. 6.20. Пример с детальным коэффициентом соединения, меньшим 1,0
Сначала изучим влияние коэффициента соединения на выбор ведущей табли-
цы. На рис. 6.21 я показал корректировки коэффициентов фильтрации с точки зре-
ния правильного выбора ведущей таблицы. После того как эти изменения будут
внесены, эффективный фильтр для М, равный 0,003, станет лучшим, поэтому начи-
наем цепочку соединений с таблицы М. На этой точке нужно вернуть исходные
коэффициенты фильтрации, чтобы выбрать дальнейший порядок соединения, так
как, если начать с любого узла (М, А2 или В2) на детальной стороне соединения,
коэффициент соединения не будет более играть роли. В более сложном запросе
может показаться, что подсчитать все эти эффективные значения фильтров для
множества узлов на одной стороне фильтрующего соединения очень сложно. На
практике необходимо просто найти наилучшие коэффициенты фильтрации на каж-
дой стороне (0,01 для А1 и 0,03 для М в данном случае) и сделать единственную
корректировку для наилучшего коэффициента фильтрации на стороне соедине-
ния с фильтром.
ПРИМЕЧАНИЕ-------------------------------------------------------------
Если у коэффициента соединения сохраняется постоянный эффект на протяжении всей оптимизации
запроса, вы просто можете внести этот эффект в коэффициенты фильтрации. Но если эффект изменя-
ется во время процесса оптимизации, лучше записывать эти числа отдельно.
186
6. Выбор наилучшего плана выполнения
При выборе дальнейшего порядка соединения сравните исходные коэффици-
енты фильтрации для А1 и А2 и выберите А1. Сравнив В1 и А2, выберите В1. Порядок
соединения на данный момент — (М. Al. В1). Оставшаяся часть порядка соедине-
ния полностью ограничена скелетом соединения, и полный порядок выглядит как
(М. А1, В1. А2. В2).
М JxR=0.1x0.03=0.003
А10.01
А2 JxR=0.1x1=0.1
В10 8
В2 JxR=0.1x0.05=0.005
Рис. 6.21. Эффективные фильтры для выбора ведущей таблицы
Рисунок 6.22 приводит к точно такому же результату. Не имеет значения, что в
этот раз наименьший начальный коэффициент фильтрации не связан напрямую с
фильтрующим соединением. Все узлы на фильтрованной стороне соединения по-
лучают преимущество фильтра соединения при выборе ведущей таблицы, а все
фильтры на другой стороне соединения — нет. Ни у А1, ни у А2 нет фильтров, иду-
щих от М, поэтому выберите первым узел А1, так как фильтр следующего шага для
В1 лучше. Порядок соединения будет таким же, как в предыдущем примере.
М0.03
В10.01 В2 0.05
Рис. 6.22. Еще один пример с детальным коэффициентом соединения, меньшим 1,0
На рис. 6.23 узлы М и В2 получают одинаковое преимущество от фильтрующего
соединения, поэтому просто сравните исходные коэффициенты фильтрации и
выберите В2. Начиная с этой точки, порядок соединения будет полностью ограни-
чен скелетом соединения — (В2, А2. М. Al. В1).
На рис. 6.24 снова сравниваются только фильтрованные узлы на одной стороне
фильтрующего соединения, но заметили ли вы влияние на последующий порядок
соединения?
Преимущество фильтрующего соединения появляется, только если вы выпол-
ните соединение в этом направлении. Так как вы начинаете с А2, соединение этого
узла с М проводится обычным соединением вида «один ко многим», которое следу-
ет отложить на как можно более поздний срок. Таким образом, следует выполнить
Сложный пример
187
соединение вниз с В2 перед тем, как соединять вверх с М, даже несмотря на то, что
у М лучше коэффициент фильтрации. Следовательно, порядок соединения (А2. В2,
М. Al, В1).
М0.03
А1 А2
▼ ▼
В1 В20.01
Рис. 6.23. В этом примере сравниваются фильтры только на одной стороне
фильтрующего соединения
МО.З
А1 А20.02
▼ ▼
В1 B20J
Рис. 6.24. В этом примере также сравниваются фильтры только на одной стороне
фильтрующего соединения
Перед тем как продолжить чтение, попробуйте построить порядок соединения
для рис. 6.25 самостоятельно.
МО.З
А1 0.02 А2Ф5
▼ ▼
В1О1 В2
Рис. 6.25. Последний пример с детальным коэффициентом соединения, большим 1,0
Обратите внимание, что в данном случае корректировка коэффициентов филь-
трации при выборе ведущей таблицы не играет роли в в ыборе фильтрованной сто-
роны соединения. Все равно фильтр для А1 остается наилучшим. Тогда с чего же
начать? Теперь на сцену выходит фильтрующее соединение. Это соединение, име-
ющее вид «один ко многим», в действительности обычно превращается в «один к
нулю». Поэтому, хотя на диаграмме оно выполняется снизу вверх, вам следует
188
6, Выбор наилучшего плана выполнения
предпочесть его обыкновенному соединению вниз с обычным коэффициентом
соединения (для удобства не показанным), равным 1,0. При выборе следующей
таблицы эффективный фильтр для М равен R ? J (0,3 ? 0,1 = 0,03), и он лучше, чем
фильтр для В1, поэтому следующее соединение должно быть с М. Однако при срав-
нении А2 и В1 нужно сравнивать простые, не скорректированные коэффициенты
фильтрации, поскольку вы, в каком-то смысле, уже израсходовали преимущество
фильтрующего соединения на М. Таким образом, полный порядок соединения (А1.
М. В1. А2. В2).
Главные коэффициенты соединения, меньшие 1,0
У главных коэффициентов соединений, меньших 1,0, есть два возможных объяс-
нения.
Отношение с главной таблицей не применяется (или неизвестно) в некоторых
случаях, когда внешний ключ для главной таблицы равен null.
Отношение с главной таблицей в некоторых случаях повреждено, когда не рав-
ное null значение внешнего ключа указывает на недопустимую запись из основ-
ной таблицы. Так как единственная допустимая цель внешнего ключа — одно-
значно указывать на соответствующую главную запись, не равные null значения
этого ключа, не связанные с главной таблицей, являются нарушением ссылоч-
ной целостности. Эти сбои ссылочной целостности неизбежны в нашем неиде-
альном мире, но идеальный ответ на такие ситуации — исправить их, или удалив
детальные записи, которые стали лишними после того, как приложение удалило
главные записи. Также можно исправить внешний ключ, заставив его указывать
на допустимую главную запись или приравняв null. Ошибкой было бы исправ-
лять SQL-код, чтобы он мог работать в обход испорченного отношения, которое
вскоре должно быть исправлено. Поэтому в случае сбоев ссылочной целостно-
сти, вам следует игнорировать главные коэффициенты соединения, меньшие 1,0.
Первый случай встречается часто, и вполне допустим в некоторых таблицах.
Например, если компания в предыдущем примере с таблицей Loans — это банк, то
он может потребовать, чтобы в этой таблице хранились все займы, которые дает
банк, а не только займы, сделанные для его сотрудников. В такой таблице Loans
допустимое реальное значение поля Employee_ID будет встречаться редко, и прак-
тически всегда будет равным null. Однако в этом случае базе данных не нужно
производить соединение, чтобы использовать этот ценный скрытый фильтр со-
единения, отбрасывающий строки. Если база данных уже достигла таблицы Loans,
лучше сделать фильтр явным, указав в запросе условие, например, Employee_ID IS
NOT NULL. Таким образом, ядро выполнения отбросит не входящие в соединение стро-
ки, как только перейдет к таблице Loans. Можно сделать так, чтобы следующее со-
единение использовало другой фильтр ближе к началу плана выполнения, не ожи-
дая соединения с Empl oyees.
ПРИМЕЧАНИЕ ---------------------------------------------------------
Можно ожидать, что программное обеспечения базы данных самостоятельно умеет понимать, что внут-
реннее соединение подразумевает условие «не null» для внешнего ключа, который может принимать
значение null. Базы данных могут автоматически применять это предполагаемое условие при первой
же возможности, но я никогда не видел, чтобы они это делали.
Сложный пример
189
В следующих примерах предположите, что главный коэффициент соединения,
меньший 1,0, возникает только из-за иногда равных null внешних ключей, а не из-
за сбоев в ссылочной целостности. Выберите ведущую таблицу, выполняя прави-
ла в этом разделе. Если ведущая таблица соединяется с дополнительной главной
таблицей сверху, явно укажите условие «не null» в запросе и поместите селектив-
ность этого условия в коэффициент фильтрации детального узла. Рассмотрим ди-
аграмму SQL на рис. 6.26.
Рис. 6.26. Запрос с фильтрующим главным соединением
Сначала посмотрим: влияет ли главный коэффициент фильтрации на выбор ве-
дущей таблицы? Обе стороны соединения от А1 к В1 получают преимущество от это-
го скрытого фильтра соединения, и у А1 лучше начальный коэффициент фильтра-
ции. Узлы, присоединенные к В1 снизу, также получили бы преимущество, но под В1
нет узлов. Ни у одного другого узла нет конкурирующего коэффициента фильтра-
ции, поэтому начнем с А1, как если бы скрытого фильтра не было. Чтобы получить
максимальное преимущество от такого начала, явно укажите условие «не null» для
внешнего ключа А1, который указывает на В1, добавив следующий оператор:
Al.ForeignKeyToBl IS NOT NULL
Это явное добавление оператора в SQL-код позволяет базе данных выполнить
первое соединение с другой таблицей, используя только долю, равную 0,01 х 0,1 =
= 0,001 строк из А1. Если в фильтре ведущего индекса участвует столбец
Forei gnKeyToBl, база данных может вообще не считывать ненужные строки из А1.
Что же присоединять дальше? Так как база данных уже использовала скрытый
фильтр (теперь не скрытый) в явном условии Al .ForeignKeyToBl IS NOT NULL, то этот
фильтр «сгорел», поэтому сравнивайте Bl с В2, как если бы фильтрующего соеди-
нения вообще не было.
ПРИМЕЧАНИЕ------------------------------------------------------------------------
В действительности после применения условия «не null» фильтрующего соединения больше не суще-
ствует. Строки, с которых база данных начинает до выполнения этих соединений, успешно присоеди-
няются к В1, поскольку строки с внешними ключами, равными null, уже отброшены.
Сравнивая В1 и В2 по их простым коэффициентам фильтрации, сначала выбе-
рите В2, получив в итоге порядок соединения (Al В2. В1. М. А2. ВЗ).
Теперь рассмотрите диаграмму на рис. 6.27 и попробуйте обработать ее само-
стоятельно перед тем, как читать дальше.
И снова фильтрующее соединение не оказывает никакого влияния на выбор
ведущей таблицы, так как коэффициент фильтрации для М намного лучше даже
190
6. Выбор наилучшего плана выполнения
откорректированных коэффициентов фильтрации для А1 и В1. Что присоединять
дальше? Если вы проводите соединение с не фильтрованной стороны фильтрую-
щего главного соединения, сделайте скрытый фильтр явным, указав условие «не
null» для Forel gnKeyToBl. Когда вы превращаете этот фильтр в явный, то у соедине-
ния оставшихся строк эффективный коэффициент соединения становится равным
всего лишь 1,0, как у большинства главных соединений. Исправленная диаграмма
SQL показана на рис. 6.28.
Рис. 6.27. Еще один запрос с фильтрующим главным соединением
Рис. 6.28. Исправление диаграммы, для установки явного фильтра главного соединения
Теперь становится понятно, что у А1 фильтр лучше, чем у А2, поэтому сначала
присоединяем А1. После обработки А1 база данных может выбрать для следующе-
го соединения также В1 или В2. Сравнивая их с А2, мы опять находим вариант
лучше А2. Присоединяем В2, поскольку уже использовали преимущество фильт-
рующего соединения для В1. Полный оптимальный порядок в таком случае (М.
А1. В2. А2. В1. ВЗ).
Теперь рассмотрите более сложную задачу на рис. 6.29 и попытайтесь решить
ее самостоятельно перед тем, как продолжать чтение.
Рассматривая в первую очередь наилучший эффективный фильтр, скорректи-
руйте коэффициент фильтрации для А1 и коэффициенты фильтрации ниже фильт-
рующего главного соединения. Теперь для С1 эффективный фильтр равен 0,1 х 0,02 -
= 0,002. Можно было бы сделать этот фильтр явным для А1, как в предыдущих
примерах, указав условие «не null» для внешнего ключа, указывающего на В2, но
это не смогло бы добавить А1 достаточно селективности, чтобы сделать его лучше
С1. Прочие варианты — это не прошедшие корректировку коэффициенты для дру-
гих узлов. Лучший из них — 0,005 для М. Этот коэффициент не настолько хорош,
как эффективный ведущий фильтр для С2, поэтому ведущей таблицей выбираем
Сложный пример
191
С2. Теперь фильтрующее главное соединение уже не имеет значения, поскольку
база данных не будет выполнять соединения в этом направлении, и полный поря-
док соединения становится (Cl. В2. Al, Bl. М. А2. ВЗ).
М 0.005
V
В1О5 В20.04 ВЗ
▼
С1 0.02
Рис. 6.29. Еще один запрос с фильтрующим главным соединением
Как бы изменилась ситуация, если бы коэффициент фильтрации для А1 равнял-
ся 0,01? Превращая подразумеваемое условие «не null» для Forei gnKeyToB2 в явное в
SQL-коде, как в предыдущих примерах, можно было бы сделать селективность филь-
тра с несколькими условиями равной 0,1 х 0,01 = 0,001, лучше, чем эффективный
коэффициент фильтрации для 01. Так, А1 стала бы ведущей таблицей. После того
как фильтр соединения «сгорел», можно выбирать порядок соединения на основе
простых коэффициентов фильтрации. Этот порядок: (Al. В2. Cl. Bl. М. А2. ВЗ).
Близкие коэффициенты фильтрации
Иногда вам встречаются коэффициенты фильтрации, достаточно близкие по зна-
чению, чтобы можно было ослабить эвристические правила и воспользоваться
преимуществами вторичных соображений о порядке соединения. Может показать-
ся, что такой случай должен быть важным и часто встречаться, но на самом деле он
редко играет существенную роль по нескольким причинам.
Когда таблицы достаточно велики, реальному приложению требуется долго
обрабатывать фильтр, чтобы вернуть набор строк разумного размера (не слиш-
ком большой), особенно если запрос обслуживает оперативную транзакцию.
Пользователи не считают длинные списки строк в отчетах хорошей идеей. Из
этого следует, что произведение всех фильтров — это небольшое число, если
запрос включает хотя бы одну большую таблицу.
В полезных запросах редко бывает много фильтров, обычно их от одного до трех.
Среди нескольких фильтров (но когда произведение всех фильтров невелико),
по крайней мере, один фильтр должен быть небольшим и селективным. На-
много проще добиться надежной и существенной селективности одним селек-
тивным фильтром (возможно, в сочетании с несколькими фильтрами средней
селективности), чем при помощи целой группы практически одинаково селек-
тивных фильтров.
192
6. Выбор наилучшего плана выполнения
Если один фильтр намного селективней остальных, выбор ведущей таблицы
становится очень простым.
Иногда вы начинаете сомневаться, выбирая между слабо селективными коэф-
фициентами фильтрации для таблиц, находящихся в конце плана выполнения.
Но порядок соединения в конце плана обычно играет лишь небольшую роль,
если вы начинаете с правильной таблицы и используете надежный план, соот-
ветствующий скелету соединения.
Мой опыт настройки запросов подтверждает, что редко приходится рассматри-
вать вторичные соображения. Мне приходилось делать это меньше, чем раз в год,
за несколько лет интенсивной настройки.
Так или иначе, если вы дочитали до этого места, то вам, вероятно, интересно
знать, когда нужно хотя бы рассмотреть возможность ослабления простых правил,
поэтому вот несколько усовершенствованных правил, которые иногда бывают по-
лезны в трудных ситуациях.
Сначала обрабатывайте небольшие таблицы. После того, как вы выбрали ве-
дущую таблицу, реальное соотношение преимуществ и стоимости соединения
со следующей главной таблицей равно (1 - R)/C, где R — коэффициент филь-
трации, а С — стоимость считывания одной строки из этой таблицы через пер-
вичный ключ. Небольшие таблицы лучше кэшированы и у них обычно меньше
уровней индекса, что уменьшает С и улучшает соотношение преимуществ
и стоимости для маленьких таблиц.
ПРИМЕЧАНИЕ ----------------------------------------------------------------
На полной диаграмме соединений небольшие таблицы находятся на нижнем конце одного или несколь-
ких (вплоть до корня) соединений с большими детальными коэффициентами соединения. Также обычно
вы уже знаете или можете угадать по именам таблиц, какие из них имеют небольшой размер.
Выбирайте обработку таблиц, позволяющих перейти к другим таблицам с еще
более хорошими коэффициентами фильтрации как можно раньше в плане вы-
полнения. Общая цель — отбросить как можно больше строк как можно рань-
ше в плане выполнения. Хорошие (низкие) коэффициенты фильтрации позво-
ляют достигнуть этого на каждом шаге, но вам может понадобиться заглянуть
немного вперед и проверить следующие фильтры, чтобы заметить полное пре-
имущество скорейшей обработки узла.
При сравнении узлов при выборе ведущей таблицы сравнивайте абсолютные
значения коэффициентов фильтрации напрямую. Значения 0,01 и 0,001 не близ-
ки, а различаются на порядок. Близкие значения для ведущего фильтра прак-
тически никогда не встречаются, кроме случаев, когда приложение опрашивает
небольшие таблицы либо без фильтров, либо только с фильтрами средней се-
лективности. В случае запросов, которые обращаются только к небольшим таб-
лицам, редко бывает необходимо настраивать запрос. Автоматическая оптими-
зация легко выдает быстрый план.
ПРИМЕЧАНИЕ -------------------------------------------------------------
Вероятно, мне следует сказать, что сомнения в близких значениях ведущего фильтра возникают регу-
лярно, но только в запросах для небольших таблиц, которые вам не нужно настраивать! Автоматиче-
ским оптимизаторам часто приходится заниматься их настройкой, но вам это не нужно.
Сложный пример
193
При сравнении узлов во время выбора более поздних соединений рассматри-
вайте значения 1 - R, где R — это коэффициент фильтрации каждого узла. В этом
контексте значения 0,1 и 0,0001 близки. Хотя они различаются в 1000 раз, зна-
чения 1 - R отличаются лишь на 10 %, и соотношение преимущества и стоимо-
сти (см. первое правило в этом списке) будет говорить в пользу менее селек-
тивного фильтра, если соответствующий узел намного меньше.
ПРИМЕЧАНИЕ----------------------------------------------------------------
Если у вас есть коэффициент фильтрации 0,0001, то вы, вероятно, уже используете этот узел в качестве
ведущей таблицы, кроме редкого случая, когда в этом запросе у вас есть два независимых, сверхселек-
тивных условия.
На рис. 6.30 показан первый пример с близкими значениями, который может
заставить вас пойти против простых исходных эвристических правил. Попробуй-
те решить проблему самостоятельно перед тем, как читать дальше.
▼
С1 0.4
Рис. 6.30. Случай, когда нужно рассмотреть исключения из простых правил
При выборе ведущего узла не стоит идти против правил. Коэффициент фильт-
рации для М намного лучше с точки зрения выбора ведущей таблицы. Затем возни-
кает проблема выбора между А1 и А2, и в обычном случае вы предпочтете более
низкий коэффициент фильтрации для А2. Посмотрев на детальные коэффициенты
соединения от А1 к М и от А2 к М, вы видите, что из А1 и А2 возвращается одинаковое
количество строк, поэтому нет причин делать выбор на основе размера. Однако
если вы посмотрите на узлы ниже этих, то увидите, что А1 обеспечивает доступ к
двум узлам, которые выглядят еще лучше, чем А2. Нужно попытаться вставить их в
план как можно раньше, поэтому вы слегка выиграете, если выберете А1 первым.
После того как А1 стала второй таблицей в порядке соединения, выбор третьей оче-
виден: В2 намного меньше и лучше фильтруется, чем А2.
ПРИМЕЧАНИЕ--------------------------------------------------------------
Если бы под А1 не было узла, очевидно говорящего в пользу присоединения его перед А2, то узлы под
А1 никак не влияли бы на выбор между А1 и А2!
Таким образом, порядок соединения — (М. Al. В2). Выбор следующей табли-
цы менее очевиден. Коэффициент фильтрации у С1 немного хуже, чем у А2, но
194
6. Выбор наилучшего плана выполнения
первая таблица намного меньше, в 300 х 2000 раз, поэтому стоимость одной ее
строки определенно достаточно низка, чтобы поместить эту таблицу перед А2.
Теперь порядок соединения (М. А1. В2, С1), а следующие допустимые узлы — это
В1 и А2. Для этих узлов значения (1 - R) равны, соответственно, 0,5 и 0,7, и В1
вдвое меньше А2, что делает ожидаемую стоимость строки из В1 немного меньше.
Если бы В1 находилась на грани необходимости добавления нового уровня в ее
индекс по первичному ключу, у А2, вероятно, был бы дополнительный индекс-
ный уровень, и тогда В1 была бы лучшим выбором. Так как каждый уровень уве-
личивает объем приблизительно в 300 раз, маловероятно, что индекс будет на-
столько близок к границе, что различие в размерах в 2 раза сыграет существенную
роль. То есть маловероятно, что небольшое различие в размерах может значить
достаточно много, чтобы отвергнуть простые правила, основанные на коэффи-
циенте фильтрации. Даже если В1 будет лучше, чем А2, в данной точке плана вы-
полнения это не сыграет большой роли — строки всех четырех уже соединенных
таблиц эффективно фильтровались. Так, стоимость последних соединений таб-
лиц будет минимальна, независимо от выбора, по сравнению со стоимостью пре-
дыдущих соединений. Таким образом, выберите полный порядок соединения —
(М, А1. В2. С1. А2. В1. ВЗ).
Теперь рассмотрим задачу на рис. 6.31. Попытайтесь решить ее самостоя-
тельно.
С10.1
Рис. 6.31. Еще один случай, когда нужно рассмотреть исключения из простых правил
Этот случай выглядит практически так же, как и предыдущий, но фильтр для М
не настолько хорош, а фильтры в ветви А1 в целом лучше. Фильтр для М в два раза
лучше фильтра следующей наилучшей таблицы, С1, но у С1 другие преимущества —
существенно меньший размер (в 2000 х 300 х 10, или 6 000 000 раз), и она близка к
другим фильтрам, обеспечивая чистый дополнительный фильтр 0,2 х 0,4 х 0,5 = 0,04.
Если скомбинировать все фильтры в ветви А1, то вы найдете, что чистый коэффи-
циент фильтрации равен 0,04 х 0,1 = 0,004 — более чем в 10 раз лучше, чем тот же
коэффициент фильтрации для М.
Смысл выбора ведущей таблицы с наименьшим коэффициентом фильтрации
состоит в том, чтобы не считывать строк больше, чем крохотная часть самой боль-
шой таблицы (обычно корневой), так как стоимость считывания строк из самой
Сложный пример
195
большой таблицы обычно и определяет стоимость запроса. Однако здесь вы види-
те, что база данных считает всего лишь 8 % строк из М, если начнет с ветви А1, вме-
сто того, чтобы начать непосредственно с фильтрации М. Поэтому С1 — это лучшая
ведущая таблица. Отсюда, следуя обычным правилам, вы найдете полный поря-
док соединения как (Cl. В2. Al. Bl. М. А2. ВЗ).
Все эти исключения из правил выглядят запутанными и сложными, я знаю, но
не позволяйте им сбить вас с пути или разочаровать! Я добавляю исключения, чтобы
полностью изложить теорию и описать некоторые редкие особые случаи, и вы встре-
титесь с ними максимум несколько раз в жизни. Вы практически всегда будете
прекрасно работать, намного лучше, чем остальные, если будете применять про-
стые правила, перечисленные в начале главы. В редких случаях вы можете обнару-
жить, что результат недостаточно хорош, и тогда, если ставки достаточно высоки,
можете рассмотреть вопрос о применении этих исключений.
Случаи, когда нужно выбрать соединения
хэшированием
Когда хорошо оптимизированный запрос возвращает умеренное количество строк,
практически невозможно при помощи соединения хэшированием добиться суще-
ственного улучшения по сравнению с вложенными циклами. Однако в редких слу-
чаях большой запрос может получить заметные преимущества от соединений хэши-
рованием, особенно от соединений с небольшими и хорошо фильтрованными
таблицами.
Если вы начинаете с таблицы, отфильтрованной лучше остальных в запросе, любое
соединение вверх, от главной к детальной таблице, унаследует селективность веду-
щего фильтра и всех остальных фильтров, которые встретятся к этому моменту в
порядке соединения. Например, рассмотрим рис. 6.32. Следуя обычным правилам,
начните с А1 с коэффициентом фильтрации 0,001, и выполните два соединения вниз,
используя остальные фильтры, равные 0,3 и 0,5, для В1 и В2, соответственно. Следу-
ющее соединение с детальной таблицей, М, обычно происходит через индекс по внеш-
нему ключу, который указывает на А1, причем доля нужных строк составит 0,00015
(0,001 х 0,3 х 0,5). Если детальная таблица достаточно большая, чтобы иметь значе-
ние для работы приложения, а запрос не возвращает большого количества строк, эта
стратегия практически гарантирует, что вложенные циклы по внешним ключам по
направлению к детальным таблицам будут наилучшим выбором. Другие методы
соединения, например соединение хэшированием, которое обращается к детальной
таблице независимо, через собственный фильтр, считают большую долю строк той
же таблицы, так как лучший вариант (с вложенными циклами) начинает работу с
лучшего коэффициента фильтрации в запросе.
ПРИМЕЧАНИЕ----------------------------------------------------------
Единственный редкий случай, в котором соединение с детальной таблицей при помощи хэширования
хотя бы немного оправдывает себя, возникает, когда кумулятивное произведение фильтров (произве-
дение уже обработанных коэффициентов фильтрации) перед детальным соединением лежит в том ди-
апазоне, в котором вы могли бы предпочесть полное сканирование детальной таблицы. Этот случай
обычно подразумевает или плохо отфильтрованный запрос, возвращающий больше строк, чем нужно,
если только таблицы не настолько малы, что оптимизация не играет роли, или редкий запрос с множе-
ством плохих фильтров в различных ветвях под детальной таблицей.
196
6. Выбор наилучшего плана выполнения
Рис. 6.32. Иллюстрация запроса, требующего соединений хэшированием
С другой стороны, когда вы выполняете соединение вниз по направлению
к главной таблице, то это может быть соединение с намного меньшей таблицей,
и стоимость получения строк через первичный ключ может быть больше, чем
стоимость независимого считывания таблицы для соединения хэшированием. Из
статистики на рис. 6.32 можно узнать, что в А1 в 3000 раз больше строк, чем в В1.
Даже отбросив 999 строк из 1000 из А1, база данных выполнит соединение с каж-
дой строкой из В1 в среднем три раза. Предположим, что в А1 3 000 000 строк, а в
В1 1000 строк. После уменьшения А1 до 3000 строк с использованием ведущего
фильтра база данных выполнит соединения со строками таблицы В1 3 000 раз.
Если база данных будет считывать В1 через ее собственный фильтр, ей понадо-
бится считать лишь 300 (0,3 х 1000) строк, по приблизительно 1/10 стоимости.
Так как запрос получает более 20 % строк из В1, база данных обнаружит даже
меньшую стоимость, просто выполнив полное сканирование таблицы В1 и отфиль-
тровав результат перед выполнением соединения хэшированием. Таким обра-
зом, не изменяя оставшуюся часть стоимости, выбор соединения хэшированием
с В1 практически полностью устранит стоимость считывания из таблицы В1 по
сравнению со стандартным надежным планом, который считывает В1 через вло-
женные циклы.
Когда вы встречаете большие детальные коэффициенты соединения, соедине-
ния хэшированием с главными таблицами могут оказаться быстрее. Но насколько
велико улучшение? В этом примере частичное улучшение для одной таблицы было
достаточно большим, более 90 %, но абсолютное улучшение не столь значительно,
приблизительно 9000 операций логического ввода-вывода (6000 в двухуровневом
ключевом индексе и 3000 в таблице), что займет приблизительно 150 миллисе-
кунд. Вы не найдете никаких операций физического ввода вывода для таблицы и
индекса такого размера. С другой стороны, этот запрос считает приблизительно
2 250 строк (3000 х 0,3 х 0,5 х 5) из 15 000 000-строчной таблицы М, выполнив 3600
операций логического ввода-вывода.
ПРИМЕЧАНИЕ-----------------------------------------------------------------
Вложенные циклы выполняют 450 (3000 х 0,3 х 0,5) сканирований диапазонов для индекса по внешне-
му ключу, указывающему на М, и для этого требуется 350 (450 х 3) операций логического ввода-выво-
да в трехуровневом индексе. Затем последуют 2250 операций логического ввода-вывода для таблицы,
чтобы считать 2250 строк из М. Так, общее количество операций логического ввода-вывода будет рав-
но 3600 (1350 + 2250).
Сложный пример
197
Эти 3600 операций логического ввода-вывода, особенно 2250 для искомой таб-
лицы, потребуют сотен операций физического ввода-вывода для такой большой,
трудно кэшируемой таблицы. Если на одну операцию физического ввода-вывода
потребуется 5-10 миллисекунд, то считывание из М займет секунды. Это пример
типичного случая, когда соединения хэшированием выполняются лучше. В таких
случаях улучшение обеспечивается обычно только в операциях логического вво-
да-вывода для самых маленьких таблиц, и это улучшение очень невелико по срав-
нению со стоимостью оставшейся части запроса.
Две эмпирические формулы помогут вам выбрать лучший метод соедине-
ния:
H = CxR
L=CxDxFxN
Переменные в этих формулах определяются следующим образом.
Н — количество операций логического ввода-вывода, необходимых для неза-
висимого считывания главной таблицы при выполнении соединения хэширо-
ванием.
С — количество строк, возвращенных из главной таблицы.
R — коэффициент фильтрации главной таблицы. Предполагайте, что база дан-
ных считывает таблицу независимо, при помощи сканирования диапазона ин-
декса по этому фильтру.
L — количество операций логического ввода-вывода, необходимых для считы-
вания из главной таблицы при помощи вложенных циклов по ее первичному
ключу.
D — детальный коэффициент соединения для связи, которая ведет вверх от глав-
ной таблицы, и обычно указывает, насколько эта таблица меньше детальной
таблицы наверху.
F — произведение всех коэффициентов фильтрации, включая ведущий коэф-
фициент, обработанный до этих соединений.
N — количество операций логического ввода-вывода, необходимых для считы-
вания одной строки через индекс по первичному ключу.
Так как первичные ключи до 300 строк обычно помещаются в корневой блок,
то N = 2 (1 для корневого блока индекса и 1 для таблицы), если С меньше 300.
N - 3, если С находится между 300 и 90 000. N -4, если С между 90 000 и 27 000 000.
Так как обычно вы будете начинать с наилучшего коэффициента фильтрации, то
F < R, даже если план не обнаружит дополнительных фильтров после фильтра для
ведущей таблицы.
Н меньше L, что говорит в пользу соединения хэшированием для стоимости
логического ввода-вывода, когда R < С х F х N. F < R, когда вы начинаете с узла
с наилучшим коэффициентом фильтрации. N невелико, как показано, так как В-
деревья на каждом уровне сильно разветвляются. Таким образом, чтобы выбрать
соединение хэшированием, либо F по абсолютному значению должно быть близко
к R, либо D велико, превращая это соединение в соединение с намного меньшей по
размеру главной таблицей. Те же вычисления иногда будут демонстрировать эконо-
198
6. Выбор наилучшего плана выполнения
мию логического ввода-вывода при соединении с большой главной таблицей, но
будьте осторожны. Если главная таблица слишком велика, чтобы хорошо кэширо-
ваться, в игру вступает физический ввод-вывод, что приводит к стремлению зап-
ретить соединение хэшированием по двум причинам.
Так как строки таблиц намного хуже кэшированы, чем блоки индекса, преиму-
щество стоимости соединения хэшированием (если оно присутствует), когда
стоимость физического ввода-вывода сильно доминирует, сравнимо с количе-
ством строк таблицы, что ставит вопрос, верно ли, что R < D х F. Поскольку
ввод-вывод для индекса намного лучше кэширован, чем ввод-вывод для табли-
цы, стоимость, определяемая физическим вводом-выводом, для считывания ин-
дексных блоков уменьшается в N раз. Без множителя N соединения хэширова-
нием выглядят не настолько привлекательно.
Если С х R велико, при соединении хэшированием может понадобиться запи-
сать предварительно хэшированные строки на диск и затем снова считать, что
делает соединение хэшированием намного дороже и потенциально может при-
вести к ошибкам недостатка дискового пространства во время выполнения зап-
роса. Это риск надежности упомянутых вложенных циклов.
В целом, сложно найти реальные запросы, для которых экономия, полученная
на соединениях хэшированием, по сравнению с наилучшим надежным планом бу-
дет оправдывать приложенные усилия. Практически единичные случаи большой
экономии на соединениях хэшированием возникают, когда запрос начинается с
плохого ведущего фильтра и обращается к большим таблицам, что неизбежно оз-
начает, что весь запрос вернет неразумно большой набор строк.
Однако это не подразумевает, что соединения хэшированием — ошибка. Сто-
имостные оптимизаторы ищут небольшие улучшения с таким же усердием, как и
действительно существенные, и они успешно справляются с поиском случаев, в ко-
торых соединения хэшированием немного помогают. Хотя я практически никогда
не ухожу с обычного пути, чтобы насильно включить соединение хэшированием,
но я и не пытаюсь исправить выбор оптимизатора, если он выбирает такое соеди-
нение для небольшой таблицы (а он часто так делает), не портя при этом порядок
соединения и выбор индексов. Если вы сомневаетесь, то всегда можете поставить
эксперимент. Но сначала найдите наилучший надежный план с вложенными цик-
лами.
ПРИМЕЧАНИЕ----------------------------------------------------------------
Если вы начали не с наилучшего порядка соединения, замена соединений с вложенными циклами со-
единениями хэшированием может привести к большой экономии, потому что в этом случае первые
таблицы не гарантируют использования для них лучших фильтров (то есть они не гарантируют, что
F < R). Плохо оптимизированные порядки соединения могут выполнять поиск в соединении слишком
много раз. Если вы обнаружите, что запрос демонстрирует огромное улучшение с соединением хэши-
рованием, следует заподозрить, что для него выбран очень плохой порядок соединения, или же он не
обращается к присоединяемой таблице через индекс по полному ключу соединения.
Затем замените вложенные циклы для главной таблицы оптимизированным
однотабличным путем доступа и соединением хэшированием в этой же точке
порядка соединения. Это изменение не повлияет на стоимость обращения к
другим таблицам, но отделит этот вариант от других возможных вариантов оп-
Сложный пример
199
тимизации. Выберите, какой вариант быстрее, помня, что тексты нужно выпол-
нять повторно или запускать их через большие промежутки времени, чтобы
избежать необъективности, происходящей от кэширования во время первого
теста.
Первый пример в разделе «Порядок 8-стороннего соединения» с диаграммой
на рис. 6.2 хорошо иллюстрирует минимальное улучшение производительности,
полученное благодаря соединениям хешированием. Обратите внимание, что де-
тальные коэффициенты соединения над узлами ОТ и ODT — это значения, равные
нескольким миллионам, что указывает, что это соединения с крошечным набором
строк таблицы Code_T rans 1 at 1 ons. Так как каждый набор допустимых строк для дан-
ных значений Code_Type достаточно мал, вам потребуется меньше операций логи-
ческого ввода-вывода для того, чтобы за один раз считать весь набор строк через
индекс по столбцу Code_Type. Поэтому выполните соединение хешированием вмес-
то того, чтобы обращаться к каждой строке (вероятно, несколько раз) через вло-
женные циклы каждый раз, когда она потребуется. Оба варианта дешевы и займут
лишь небольшую часть времени выполнения, так как количество возвращаемых
запросом строк невелико, а физический индекс и блоки таблицы Code_Transl atт ons
будут полностью кэшированы.
Упражнение
Следующее упражнение содержит в себе все рассмотренные проблемы. В нем боль-
ше фильтров и исключений, чем вы, вероятно, увидите за всю свою жизнь. Диа-
грамма запроса на рис. 6.33 намного сложней и запутанней, чем я когда-либо встре-
чал в реальных задачах настройки.
С10.1
С2 С30.2 С4 С5
D10.7 D20.7 D3 0.4
Рис. 6.33. Нереально сложная задача
Если вы сможете справиться с этой задачей, то решите и любую диаграмму за-
проса, которую встретите в реальной работе, поэтому попытайтесь! Если с первого
раза у вас не получится, вернитесь к этой задаче и попытайтесь решить ее еще раз,
200
6. Выбор наилучшего плана выполнения
попрактиковавшись на других проблемах. Найдите наилучший порядок соедине-
ния. Найдите лучший метод соединения для всех связей, предполагая, что в таб-
лице А1 30 000 000 строк и полагая, что полное сканирование таблицы предпочти-
тельней для любой таблицы, из которой будет считано минимум 5 % строк. Найдите
набор необходимых индексов по первичным ключам, набор необходимых индек-
сов по внешним ключам и все остальные индексы, которые могут потребоваться.
Найдите все изменения в SQL-коде, которые могут понадобиться для того, чтобы
суметь использовать скрытые фильтры как можно раньше. Сделайте обычные пред-
положения о ссылочной целостности.
Диаграммное
изображение
и настройка сложных
SQL-запросов
Вы уже знаете, как создать диаграмму и настроить запросы к реальным таблицам,
когда диаграмма отвечает нескольким требованиям к обычному бизнес-запросу.
Запрос отображается на одно дерево.
У дерева есть один корневой узел, то есть одна таблица без соединений с ис-
пользованием ее первичного ключа. У всех остальных узлов, кроме корневого,
есть по одной указывающей вниз, на них, стрелке, связывающей их с деталь-
ным узлом наверху. Любой узел может находиться на верхнем конце любого
количества указывающих вниз стрелок.
Для всех соединений есть указывающие вниз стрелки (соединения уникальны
на одном конце).
Внешние соединения не фильтруются, указывают вниз; под внешними соеди-
нениями могут быть только внешние соединения.
Вопрос, на который отвечает запрос, это обычно вопрос о сущности, представ-
ленной в корневом узле дерева или об агрегациях этой сущности.
В прочих таблицах хранятся справочные данные, размещенные в этих табли-
цах в целях нормализации.
Я называю запросы, отвечающие этим критериям, простыми запросами, хотя
в них может содержаться любое количество соединений, и для их оптимизации
может понадобиться применить какие-либо трюки, особенно в особых случаях при
выборе между коэффициентами фильтрации, или когда присутствуют скрытые
фильтры соединений.
Запросы не всегда соответствуют этой стандартной простой форме. В таких
случаях я называю запросы сложными. Как я продемонстрирую в этой главе, не-
которые сложные запросы являются следствием ошибок в дизайне базы данных
или приложения. Также причиной появления сложных запросов могут быть
ошибки реализации. Зачастую ошибки такого типа действительно приводят к
появлению неправильных запросов. В этой главе вы узнаете об аномалиях, с ко-
торыми можете встретиться в диаграммах запросов и которые явно извещают
202
7. Диаграммное изображение и настройка сложных SQL-запросов
вас об ошибке в запросе или дизайне. Также вы узнаете, как исправить эти де-
фекты функциональности или дизайна, иногда одновременно в качестве побоч-
ного эффекта улучшая производительность. Обычно исправления позволяют
перевести запрос в простую форму или, по крайней мере, в форму, достаточно
близкую к простой, чтобы можно было применить методы, описанные ранее в этой
книге.
Некоторые сложные запросы выходят за пределы любых форм, где использу-
ются подзапросы, представления или операции над множествами, например UNION
и UNION ALL, диаграммное изображение которых я описывал. Обычно такие слож-
ные запросы полностью функциональны и распространены, поэтому вам потребу-
ется способ создавать для них диаграммы и оптимизировать, для чего нужно рас-
ширить предыдущие методы для простых запросов.
Необычные диаграммы соединений
Если в вашем запросе содержатся только простые таблицы (не представления),
нет подзапросов и операций над множествами, таких, как UNION, всегда можно
создать определенную диаграмму запроса, применив методы из главы 5. Но
иногда диаграмма обладает необычными характеристиками, которые не подхо-
дят ни к одному шаблону древовидных соединений, которые я описывал ранее.
Я по очереди опишу такие отклонения и объясню, как справиться с каждым из
них.
Для иллюстрации необычных ситуаций я буду приводить частичные диаграм-
мы запросов, в которых те части диаграммы, которые не существенны для обсуж-
даемого вопроса, будут закрыты серыми облаками. Это привлечет внимание к наи-
более важной части запроса и сделает пример более обобщенным. В качестве еще
одного соглашения я буду рисовать связи с частями скелета соединения, скрыты-
ми за облаками, серым цветом, если они не существенны для текущего обсужде-
ния. Количество серых связей и даже их существование не имеют значения в этих
примерах, они просто иллюстрируют потенциальное существование дополнитель-
ных соединений в реальных случаях. Иногда к скрытым частям скелета запроса
будут вести связи, окрашенные черным. Существование черных связей важно для
обсуждения, но скрытая часть скелета запроса — нет.
Графы циклических соединений
Как следует обрабатывать скелеты соединений, которые невозможно отобразить
на простое дерево, в которых связи в какой-то части скелета замыкаются в цикл?
Такая диаграмма может встретиться вам в нескольких случаях. В следующих раз-
делах я рассмотрю четыре случая с различными решениями.
ПРИМЕЧАНИЕ--------------------------------------------------------
Теория графов — это область математики, которая описывает абстрактные сущности, называемые гра-
фами, состоящие из связей и узлов. Используемые в этой книге диаграммы также являются графами.
В теории графов в циклическом графе есть связи, которые формируют замкнутый цикл. В следующих
примерах, до рис. 7.8, обратите внимание, что на диаграмме есть реальные или подразумеваемые цик-
лы, превращающие эти графы в циклические.
Необычные диаграммы соединений
203
Случай 1. Две главные таблицы с отношением
«один к одному» совместно используют одну
и ту же детальную таблицу
На рис. 7.1 показан первый случай, когда единственный внешний ключ соединяет-
ся с первичными ключами двух различных главных таблиц.
Рис. 7.1. Первый случай циклических диаграмм запросов
SQL-код для этого случая может выглядеть следующим образом:
SELECT ...
FROM ...Tl. ... Т2. ... ТЗ. ...
WHERE ... Tl.FKeyl = Т2.РКеу2
AND Tl.FKeyl = ТЗ РКеуЗ
AND Т2.РКеу2 = ТЗ.РКеуЗ ...
Здесь я назвал единственный внешний ключ таблицы Т1, который указывает на
обе таблицы, FKeyl, а первичные ключи Т2 и ТЗ — РКеу2 и РКеуЗ, соответственно. Если
все эти три соединения явно прописаны в SQL, то циклические связи очевидны, но
обратите внимание, что одна из этих связей могла бы быть пропущена в запросе и от-
сутствующее условие соединения подразумевалось бы по условию транзитивности
(если а = Ь и Ь = с, то а = с). Если бы одно из соединений было пропущено, то для того
же запроса вы бы создали диаграмму в одной из трех форм, показанных на рис. 7.2.
Рис. 7.2. Тот же циклический запрос, на котором одно из условий соединения пропущено
Обратите внимание, что в вариантах этого запроса А и В догадаться о суще-
ствовании отсутствующей стрелки можно на основе того факта, что у связи между
Т2 и ТЗ острие стрелки есть на обоих концах, а стрелка на обоих концах подразуме-
вает соединение «один к одному». Вариант С, с другой стороны, выглядит как са-
мое простое дерево соединения, и вы бы ни за что не догадались, что в нем присут-
ствует циклическое соединение, если бы не заметили, что Т1 использует один и тот
же внешний ключ для соединения с Т2 и с ТЗ.
204
7. Диаграммное изображение и настройка сложных SQL-запросов
Когда у вас есть таблицы с отношениями «один к одному», то цикл ические со-
единения, как на рис. 7.1, встречаются часто. Это не функциональная проблема,
хотя дальше я перечислю вопросы, которые следует рассмотреть, когда встречает-
ся соединение такого типа. Вместо того чтобы рассматривать их как проблему, эти
соединения можно считать удачной возможностью для оптимизации запроса. Если
вы уже обработали Т1, то полезно иметь выбор — обращаться далее к Т2 или ТЗ, так
как у какой-то из них может быть лучший коэффициент фильтрации, или же она
может предоставить доступ к хорошим фильтрам ниже по дереву. Если вы в по-
рядке соединения обрабатываете Т2 или ТЗ до Т1, то возможность провести соеди-
нение вида «один к одному» с противоположной таблицей (от Т2 к ТЗ или от ТЗ
к Т2) также полезна. Это позволяет вам использовать любой фильтр, который мо-
жет быть у второй таблицы, до соединения с Т1. Без горизонтальной связи вы мог-
ли бы соединять Т2 с ТЗ и наоборот только через Т1 — вероятно, с более высокой
стоимостью.
Некоторые оптимизаторы написаны достаточно хитро, чтобы использовать
транзитивность для восстановления отсутствующего условия соединения, даже
если оно пропущено, и пользоваться преимуществами дополнительных степеней
свободы, предоставляемых порядком соединения. Однако если вы заметили, что
два соединения по закону транзитивности подразумевают третье, для надежности
лучше сделать все три соединения явными. По крайней мере, в вашем операторе
SQL следует сделать явными все соединения, которые требуются для найденного
вами оптимального плана.
Существует особый случай, когда таблицы с отношением «один к одному», обо-
значенные как Т2 и ТЗ, являются одной и той же таблицей. В этом случае каждая
строка из Т1 соединяется с одной и той же строкой из Г2 дважды. Это абсолютно
неэффективно. Очевидный случай, когда одно имя таблицы дважды повторяется
в разделе FROM и ему назначаются псевдонимы Т2 и ТЗ, маловероятен, исключитель-
но потому, что он слишком очевиден, чтобы остаться незамеченным. Однако со-
единение с одной таблицей дважды может произойти незаметно, и быть пропу-
щенным разработчиком при просмотре кода. Например, это может случиться, если
синоним или простое представление скрывают сущность основной таблицы, по
меньшей мере, за одним псевдонимом в запросе. В любом случае лучше всего изба-
виться от лишней ссылки на таблицу в запросе и перенести в оставшийся псевдо-
ним все ссылки на столбцы и дальнейшие соединения вниз.
Случай 2. В главной и детальной таблицах хранятся
копии внешнего ключа, которые указывают на один
и тот же первичный ключ третьей таблицы
На рис. 7.3 показан второй из основных случаев циклических соединений. Здесь
идентичные внешние ключи в Т1 и Т2 указывают на одно и то же значение первич-
ного ключа в ТЗ.
В этом случае SQL-код выглядит следующим образом:
SELECT ...
FROM ...Tl. ... Т2. ... ТЗ. ...
WHERE ... Tl.FKeyl = Т2.РКеу2
AND Tl.FKey2 = ТЗ.РКеуЗ
AND T2.FKey2 = ТЗ.РКеуЗ ...
Необычные диаграммы соединений
205
Рис. 7.3. Циклическое соединение, подразумевающее денормализацию
В этом операторе SQL я назвал внешние ключи, указывающие из Т1 на Т2 и ТЗ,
FKeyl и FKey2 соответственно. По закону транзитивности значение столбца внешнего
ключа Т2. FKey2 равно значению Т1. FKey, так как оба ключа соединяются с ТЗ. РКеуЗ.
Первичные ключи Т2 и ТЗ называются РКеу2 и РКеуЗ, соответственно. Самое вероят-
ное объяснение того, что Т1 и Т2 соединяются с одной таблицей, ТЗ, по ее полному
первичному ключу заключается в том, что Т1 и Т2 содержат избыточные внешние
ключи, указывающие на эту таблицу. В этом сценарии в столбце FKey2 детальной
таблицы Т1 содержатся денормализованные данные из ее главной таблицы Т2. Эти
данные всегда равны значению FKey2 в соответ ствующей главной строке таблицы Т2.
ПРИМЕЧАНИЕ ----------------------------------------------------------------
Предполагается, что значения FKey2 совпадают, но обычно это не так, потому что денормализованные
данные чаще всего не синхронизированы.
В главе 10 перечислены аргументы за и против денормализации в подобных
случаях. Вкратце, если денормализация оправдывает себя, возможно, что допол-
нительная связь на диаграмме запроса предоставит вам доступ к лучшему плану
исполнения. Однако более вероятно, что денормализация — это ошибка, стоимость
и риск которой превосходят преимущества. Отказ от денормализации означает
удаление внешнего ключа FKey2 в Т1, таким образом устраняя связь от Т1 к ТЗ и пре-
вращая диаграмму запроса в дерево.
Случай 3. Двухузловой фильтр (не уникальный на обоих
концах) уже связан при помощи обычных соединений
На рис. 7.4 показан третий основной случай циклических соединений. На этот раз
у нас есть обычные указывающие вниз стрелки от Т1 к Т2 и ГЗ, но такж > присутству-
ет третье, необычное условие соединения между 12 и ТЗ, которое не задействует
первичного ключа ни одной из двух таблиц.
ПРИМЕЧАНИЕ ---------------------------------------------------------
Так как ни один из первичных ключей не используется в соединении между Т2 и ТЗ, у связи между
ними нет стрелки ни на одном конце.
SQL-код для рис. 7.4 выглядит следующим образом:
SELECT ...
FROM ...Tl. ... Т2. ... ТЗ....
WHERE ... Tl.FKeyl - T2.PKey2
ANO Tl.FKey2 - ТЗ.РКеуЗ
AND Т2.Со12<Каким-то_образом_срав1,ивается_с>ТЗ.Со13 ...
206
7. Диаграммное изображение и настройка сложных SQL-запросов
Рис. 7.4. Циклическое соединение с двухузловым фильтром
Например, если Т1—это псевдоним таблицы Orders, которая соединяется с Customers,
Т2, и Salespersons, ТЗ, то это может означать, что запросу требуются заказы, покупате-
ли и ответственные продавцы в которых связаны с разными регионами:
SELECT ...
FROM Orders Tl. Customers T2. Salespersons T3
WHERE Tl.Customer_ID = T2.Customer_ID
AND Tl.Salesperson_ID = T3.Salesperson_ID
AND T2.Region_ID! = T3.Region_ID
Здесь условие T2. Regi on_ID! = ТЗ. Regi on_ID — это, строго говоря, соединение, но
лучше рассматривать его как условие фильтрации, которому строки из двух раз-
личных таблиц требуются еще до того, как его можно применить. Если вы проиг-
норируете эту необычную связь между Т2 и ТЗ, то обращение к Т1 будет проходить
до применения двухузлового фильтра по Region_ID. Единственные порядки соеди-
нения, которые избегают непосредственного выполнения необычного соединения
между Т2 и ТЗ, это:
(Tl. Т2. ТЗ)
(Т1. ТЗ. Т2)
(Т2. Т1. ТЗ)
(ТЗ. Tl. Т2)
Любой другой порядок (например, (Т2. ТЗ. Т1)), после обработки второй табли-
цы создал бы ужасающее сочетание строк гида «многие ко многим», практически
декартово произведение строк из Т2 и ТЗ. Все перечисленные ранее порядки соеди-
нения обрабатывают Т1 первой или второй, перед тем, как обработать обе таблицы
Т2 и ТЗ. Таким образом, эти порядки соединения выполняют только два обычных
соединения «многие к одному» между детальной таблицей Т1 и ее главными таб-
лицами Т2 и ТЗ.
Необычный двухузловой фильтр не ведет себя как обычный фильтр, когда вы
достигаете первой из двух фильтрованных таблиц. Но потом, когда вы обрабаты-
ваете вторую таблицу, работает как обычный фильтр, отбрасывая некоторую часть
строк. С этой точки зрения обработка такого случая проста: считать, что фильтр не
существует (или недостижим напрямую), пока не будет произведено соединение с
одной из фильтрованных таблиц. Однако как только с любым из концов двухузло-
вого фильтра будет выполнено соединение, противоположный узел неожиданно
получит лучший коэффициент фильтрации и станет лучшим выбором для следу-
ющего присоединения.
На рис. 7.5 показан специфический пример с двухузловым фильтром, в кото-
ром доля строк из обычных соединений от Т1 к Т2 и ТЗ, удовлетворяющих условию
Необычные диаграммы соединений
207
дополнительного двухузлового фильтра, равна 0,2. В этом случае сначала выби-
райте порядок соединения независимо от существования этого фильтра, следуя
только по обычным связям. Однако как только произойдет соединение с Т2 или ТЗ,
коэффициент фильтрации противоположной таблицы (0,1 для Т2 и 0,5 для ТЗ) ста-
нет равен исходному, умноженному на 0,2, превращаясь в привлекательный выбор
для будущих соединений.
Т1 0.01
▼
Т5 ф4
Рис. 7.5. Двухузловой фильтр с явным двухузловым коэффициентом фильтрации
Следуйте обычной процедуре, чтобы настроить диаграмму на рис. 7.5, игнори-
руя двухузловой фильтр между Т2 и ТЗ, пока не достигнете одной из этих таблиц.
Ведущая таблица — Т1, за ней Т4 — таблица под Т1 с наилучшим обычным фильт-
ром. Далее у ТЗ лучший обычный фильтр с коэффициентом фильтрации 0,5, по-
этому она помещается в порядок соединения следующей. Теперь необходимо выб-
рать между Т2 и Т5, но для Т2 активирован двухузловой фильтр, поскольку ТЗ уже
обработана, что дает ей более эффективный коэффициент фильтрации (0,2), чем у
Т5, поэтому присоединяем Т2 следующей. Итоговый лучший порядок соединения
(Т1. Т4. ТЗ. Т2. Т5).
ПРИМЕЧАНИЕ ------------------------------------------------------------------
Соединение с Т2 в предыдущем примере — это обычное соединение, которое выполняется методом вло-
женных циклов от внешнего ключа, указывающего вниз из Т1, к индексу по первичному ключу Т2.
Избегайте вложенных циклов для таблицы, с которой связан двухузловой фильтр. Возвращаясь обрат-
но к SQL-коду перед рис. 7.5, можно заметить, что гораздо выгоднее обратиться к таблице Customers
методом вложенных циклов, выполняя соединение Tl.Customer_ID = T2.Customer_ID, чем условия
двухузлового фильтра Т2.Region_ID! = T3.Region_ID.
Случай 4. Составное соединение от двух внешних
ключей к составному первичному ключу
разложено на две таблицы
Наконец, на рис. 7.6 представлен четвертый из основных случаев циклических со-
единений. Здесь присутствуют два необычных соединения с ТЗ, и ни в одном из
них не используются ни полный первичный ключ этой таблицы, ни первичные
ключи таблиц на противоположных концах соединений. Если такие случаи, когда
не удается произвести соединение с полным первичным ключом хотя бы на одной
стороне соединения, это ошибки, то случай 4 — это случай, когда две ошибки ком-
пенсируют друг друга.
208
7. Диаграммное изображение и настройка сложных SQL-запросов
Рис. 7.6. Циклическое соединение с двумя необычными соединениями
В ситуации, показанной на рис. 7.6, SQL обычно выглядит следующим образом:
SELECT ...
FROM ...Tl. ... Т2. ... ТЗ. ...
WHERE ... Tl.FKeyl - T2.PKey2
AND Tl.FKey2 - T3.PKeyColumnl
AND T2.FKey3 - T3.PkeyColumn2 ...
Такой код обычно появляется, когда первичный ключ ТЗ состоит из двух час-
тей, а состоящий из двух частей внешний ключ каким-либо образом распределен
по двум таблицам, составляющим отношение главной и детальной таблиц.
Конкретный пример прояснит этот случай. Рассмотрим таблицы словаря дан-
ных: Tables, Indexes, Tab! e_Col umns и Index_Col umns. Для Tabl e_Col umns можно выбрать
состоящий из двух частей первичный ключ как (Table_ID, Column_Number), где
Col umn_Number обозначает место, которое столбец таблицы занимает в естественном
порядке столбцов таблицы. Единица для первого столбца, двойка — для второго и
так далее. Внешний ключ для таблицы Tables в таблице Indexes состоит из столбца
TableJD. У таблицы Index_Columns первичный ключ (Index_ID. Column_Number) тоже
состоит из двух частей. Значение Column_Number в Index_Columns имеет то же значе-
ние, что и Column_Number в Table_Columns — место, которое столбец занимает в
естественном порядке столбцов таблицы (но не его место в индексе, которое обо-
значается как Index_Position). Если бы вы знали имя индекса и хотели бы узнать
список имен столбцов, которые составляют индекс, в порядке, указанном
Index_Position, то написали бы такой запрос:
SELECT TC.Column_Name
FROM Indexes Ind. Index_Columns IC. Table_Columns TC
WHERE Ind.Index_Name - 'EMPLDYEESJd'
AND Ind.Index ID - IC.Index ID
AND Ind.TableJD = TC.TableJO
AND IC.Column_Number - TC.Column_Number
ORDER BY IC.Index_Position ASC
ПРИМЕЧАНИЕ ------------------------------------------------------------------------------
Перед тем. как читать дальше, в качестве упражнения попробуйте создать диаграмму для скелета этого
запроса самостоятельно.
Если коэффициент фильтрации условия по Index_Name равен 0,0002, то диаграмма
запроса без коэффициентов соединения выглядит как на рис. 7.7.
Здесь две ошибки (то есть два соединения, на концах которых нет полных пер-
вичных ключей) компенсируют друг друга, если рассматривать соединения с ТС
Необычные диаграммы соединений
209
совместно, так как вместе они используют полный первичный ключ этой таблицы.
Можно трансформировать диаграмму этого редкого случая, как на рис. 7.8.
Рис. 7.7. Конкретный пример для четвертого типа циклических соединений
Рис 7.8. Комбинирование составных соединений от внешних ключей,
распределенных по двум таблицам
Если вы выполните правило большого пальца, которое заставляет проводить
соединение от полных первичных ключей (или к ним), то наилучший порядок со-
единения для рис. 7.7 станет очевидным. Начните с фильтра для Ind и перейдите
по связи вверх к IC. Только после этого, получив обе части первичного ключа для
ТС, можно выполнять соединение с ТС. На самом деле это лучший план исполнения
для этого примера. Правило большого пальца в таких случаях — следовать по этим
необычным связям к составному первичному ключу после того, как база данных
обработает все узлы наверху, необходимые для использования полного первично-
го ключа.
Резюме по циклическим соединениям
В следующем списке суммируются способы обработки каждого из четырех типов
циклических соединений.
1. Две главные таблицы с отношениями «один к одному» разделяют одну и ту же
детальную таблицу.
В этом случае есть возможность настройки и увеличения количества степеней
свободы в порядке соединения, но необходимо рассмотреть дополнительные
варианты обработки соединений «один к одному», перечисленные далее в этой
главе.
2. В главной и детальной таблицах хранятся копии внешнего ключа, который ука-
зывает на один и тот же первичный ключ третьей таблицы
В этом случае у вас также есть возможность увеличить количество степеней
свободны в порядке соединения, но он подразумевает денормализацию, кото-
рая обычно не оправдывает себя. Если у вас есть выбор, лучше избавиться от
210
7. Диаграммное изображение и настройка сложных SQL-запросов
денормализации, если только преимущества, полученные для этого или како-
го-либо другого запроса, не оправдывают денормализацию. В главе 10 вы узна-
ете, как оценить преимущества и недостатки денормализации.
ПРИМЕЧАНИЕ -----------------------------------------------------------------
В книге я рекомендую действия в идеальном случае, предполагающие, что у вас есть полный контроль
над приложением, дизайном базы данных и SQL-кодом. Я также попытался дать пример компромиссных
решений, которые можно применить, если у вас есть лишь ограниченный контроль. Когда вы видите нео-
правданную денормализацию в уже созданной и выпущенной базе данных, которой не владеете и на ко-
торую не можете повлиять, то наилучший компромисс — ничего не делать.
3. Двухузловой фильтр (не уникальный на обоих концах) уже сцеплен при помо-
щи обычных соединений
В этом необычном случае считайте, что никакого фильтра нет, пока не обработаете
один из узлов. Затем при поиске оставшейся части порядка соединения обрабаты-
вайте второй узел, как если бы у него был лучший коэффициент фильтрации.
4. Составное соединение от двух внешних ключей к составному первичному клю-
чу разложено на две таблицы. Выполняйте соединение по первичному ключу
только когда пола чите обе части ключа.
Эти способы обработки позволяют справиться со всеми возможными случая-
ми циклических соединений.
Несвязные диаграммы запросов
На рис. 7.9 показано два случая несвязных диаграмм запросов. Это запросы, ко-
торые не объединяют все таблицы в одну связную структуру. В каждом из этих
случаев вы видите два независимых запроса; для каждого из них существует от-
дельная диаграмма, которую можно оптимизировать независимо от другого за-
проса.
Случай А
Рис. 7.9.11есвязные диаграммы запросов
Случай Б
Т1 Т2
В случае А я демонстрирую запрос, состоящий из двух выглядящих независи-
мыми запросов, в каждом из которых есть соединения. В случае Ь я демонстрирую
немного другой обычный запрос, одна из таблиц которого (таблица Т2) не связана
с деревом соединения (то есть не связана ни с какой другой таблицей). Оба случая
соответствуют двум независимым запросам, которые выполняются внутри одно-
го. Что же происходит, когда вы сочетаете независимые, несвязные запросы в одном
запросе? Когда две таблицы сочетаются в одном запросе без условий соединения,
база данных возвращает декартово произведение — все возможные комбинации
строк первой таблицы со строками второй таблицы. В случае несвязных диаграмм
запросов считайте результаты запросов, представленных каждым независимым
Необычные диаграммы соединений
211
скелетом запроса (или изолированным узлэм), отдельной виртуальной таблицей.
С этой точки зрения база данных возвратит все комбинации строк из двух незави-
симых запросов. То есть вы получите декартово произведение.
Столкнувшись с декартовым произведением, например с показанным на рис. 7.9,
необходимо исследовать причину его возникновения. Узнав причину, вы можете
решить, какие действия предпринимать в зависимости от того, с каким из четырех
случаев несвязных запросов встретились.
В запросе отсутствует соединение между не связанными частями. В этом слу-
чае необходимо просто добавить отсутствующее соединение.
Запрос объединяет два независимых запроса, каждый из которых возвращает
несколько строк. Здесь избежать появления декартова произведения можно,
выполнив независимые запросы по отдельности.
Один из независимых запросов возвращает одну строку. Рассмотрите вариант
разделения запросов, чтобы сохранить производительность базы данных, осо-
бенно если второй независимый запрос возвращает много строк. Сначала вы-
полните однострочный запрос.
Оба независимых запроса возвращают по одной строке. В этом случае просто
оставьте запрос несвязным, если только он не ставит вас в тупик или его не
сложно обрабатывать.
Перед тем как превращать несвязный запрос в два разных запроса, посмотрите,
не забыл ли случайно разработчик одно из соединений. На ранней стадии цикла
разработки самая распространенная причина появления несвязных диаграмм за-
просов заключается в том, что разработчики просто забывают некоторые операто-
ры соединения, которые связывают разъединенные поддеревья. В таком случае
нужно просто добавить отсутствующее условие соединения, после чего у вас боль-
ше не будет несвязного дерева. Если у одной из таблиц в дереве есть внешний ключ,
указывающий на первичный ключ корневого узла второго дерева, то практически
точно это соединение было по невнимательности забыто.
Если каждый из независимых запросов возвращает несколько строк, то коли-
чество комбинаций превзойдет количество строк, которые вы бы получили, вы-
полнив два запроса независимо. Однако набор комбинаций двух результатов со-
держит не больше информации, чем вы бы получили при раздельном выполнении
запросов, поэтому работа по созданию избыточных данных — это всего лишь поте-
ря времени, по крайней мере, с точки зрения получения сырых данных. Поэтому,
возможно, лучше выполнить два запроса по отдельности.
Иногда есть причины, хоть как-то оправдывающие создание комбинаций декарто-
ва произведения с точки зрения удобства программирования. Но всегда есть обход-
ные пути, позволяющие избежать лишних данных, если их стоимость не оправданна.
ПРИМЕЧАНИЕ-----------------------------------------------------------------
Если бы вы беспокоились только о физическом вводе-выводе, то декартово произведение было бы до-
пустимо, так как излишние считывания данных из повторяющегося запроса практически всегда пол-
ностью кэшированы после первого считывания. В действительности некоторые разработчики даже
защищают подобные долго выполняющиеся примеры запросов, оправдывая их низкой стоимостью физи-
ческого ввода-вывода. Подобные запросы — отличный способ нагрузить процессор и создать чудовищ-
ное количество операций логического ввода-вывода, если вам когда-либо понадобится это, — например,
для нагрузочных испытаний или других лабораторных исследований, но им нет места в бизнес-прило-
жениях.
212
7. Диаграммное изображение и настройка сложных SQL-запросов
Если один из независимых запросов гарантированно возвращает единствен-
ную строку, то декартово произведение будет, по крайней мере, безопасным и
гарантированно вернет не больше строк, чем второй независимый запрос. Одна-
ко при комбинировании запросов потенциально существует и небольшая сто-
имость работы при получении данных через сетевое соединение с сервером, так
как список выбора комбинированного запроса может возвращать данные из не-
большого запроса несколько раз по одному для каждой строки, возвращаемой
большим запросом. А это требует пересылки большего количества байт, чем при
использовании разъединенных запросов. Эти затраты пропускной способности
определенным образом противопоставляются экономии времени ожидания сети.
Комбинированный запрос экономит повторные обращения к базе данных по сети,
поэтому выбор зависит от деталей запроса. Если вы не разъедините запросы, то
оптимальный план прост. Сначала необходимо выполнить оптимальный план для
запроса, возвращающего одну строку. Затем, при помощи вложенного цикла, ко-
торый выполняется всего один раз, выполнить оптимальный план для запроса,
возвращающего несколько строк. Этот комбинированный план исполнения сто-
ит столько же, сколько и выполнение двух запросов независимо. Если же вместо
этого вы выполните план для запроса, возвращающего несколько строк, первым,
то план со вложенным циклами потребует повторного выполнения плана для за-
проса, возвращающего одну строку, — по одному разу для каждой строки, воз-
вращенной другим запросом.
Комбинирование запроса, возвращающего одну строку, с запросом, возвраща-
ющим несколько записей, иногда и удобно, и оправданно. Существует специаль-
ный случай, соответствующий правой части рис. 7.9, когда запрос, возвращающий
одну строку — это просто считывание одной строки из изолированной таблицы Т2,
для которой вообще нет соединений. Декартово произведение иногда полезно для
выбора параметров, хранящихся в однострочной таблице параметров. Особенно
когда эти данные упоминаются только в разделе WHERE, а не в списке SELECT. Если
запрос не возвращает данные из таблицы параметров, то дешевле выполнить пра-
вильно скомбинированный запрос, чем отдельные запросы.
Еще более редкий случай гарантирует, что оба изолированных запроса воз-
вращают по одной строке. В этом случае, когда нет никаких опасностей, при-
сутствующих в ютальных случаях, комбинирование запросов будет абсолютно
безопасным с точки зрения производительности. Однако с точки зрения про-
граммирования и поддержки программного обеспечения комбинирование по-
добных запросов может быть слишком запутанным, а экономия будет неболь-
шая.
Диаграммы запросов с несколькими
корневыми узлами
На рис. 7.10 показан пример диаграммы запроса, нарушающей предположение
о наличии одного корневого узла у дерева запроса. Этот случай сродни предыду-
щему случаю (несвязные диаграммы запросов). Здесь для каждой строки таблицы
Master, удовлетворяющей условию запроса, запрос вернет все комбинации соот-
ветствующих детальных строк из Rootl и Root2. С данными детальными коэффици-
ентами соединения можно ожидать, что все комбинации 5 детализированных строк
Необычные диаграммы соединений
213
из Root 1 и 30 строк из таблицы Root2 дадут 150 комбинированных строк для каждой
соответствующей строки из Master. Эти 150 строк содержат не больше исходных
данных, что 5 строк из Rootl и 30 строк из Root2 вместе, поэтому будет быстрее
считать 5 и 30 строк по отдельности, избежав декартова произведения. Тогда как
несвязные диаграммы запросов генерируют одно большое декартово произве-
дение, несколько корневых узлов приводят к появлению целых наборов неболь-
ших декартовых произведений, по одному для каждой соответствующей глав-
ной строки.
Рис. 7.10. Диаграмма запроса с несколькими корнями
Есть четыре возможных случая появления диаграммы запроса с несколькими
корнями. В следующем списке перечислены эти случаи и описаны подходящие
решения.
1. Отсутствующее условие. В этом запросе отсутствует условие, которое преобра-
зовало бы одну из корневых детальных таблиц в главную таблицу, превратив
соединение «один ко многим» в «один к одному».
Решение: добавить отсутствующее условие соединения.
2. Декартово произведение «многие ко многим». Подобный запрос представляет
декартово произведение «многие ко многим» для каждой главной строки, кото-
рое возникает между детальными таблицами, относящимися к одной главной
таблице. Этот случай скрывается под маской превышающих 1,0 детальных ко-
эффициентов фильтрации от одной главной таблицы к двум различным корне-
вым детальным таблицам.
Решение: избавьтесь от декартова произведения, разделив запрос на независи-
мые запросы, которые считывают две корневые детальные таблицы по отдель-
ности.
3. Детальный коэффициент соединения меньше 1,0. В этом случае одна из корне-
вых детальных таблиц соединяется с общей главной таблицей с детальным ко-
эффициентом соединения, меньшим 1,0.
Решение: хотя этот случай не создает проблем для производительности, рас-
смотрите вариант разъединения частей запроса или превращения одной из ча-
стей запроса в подзапрос, по функциональным причинам.
4. Таблица используется только для проверки существования каких-либо сущно-
стей. Одна из корневых детальных таблиц не поставляет никаких данных, нуж-
ных в списке SELECT, и включена только для проверки существования.
Решение: превратите проверку существования в явный подзапрос.
214
7. Диаграммное изображение и настройка сложных SQL-запросов
Случай 1. Отсутствующее условие соединения
Чаще всего присутствие второго корневого узла указывает на некоторое отсутству-
ющее условие соединения, которое превратило Ьы один из корневых узлов в глав-
ный узел. На рис. 7.11 показано это преобразование, когда соединение от Master к
Rootl превращается в соединение «один к одному» путем добавления некоторого
дополнительного условия для Rootl (переименованного в R1), которое гарантиру-
ет, что база данных найдет для каждой строки из Master максимум одну строку в R1.
Это особенно вероятно, когда в R1 хранятся некоторые детализированные данные,
зависящие от интервалов времени (например, различные налоговые ставки), соот-
ветствующие главной записи (например, налоговой сущности), а добавление ус-
ловия по дате (например, запрос текущей налоговой ставки) превращает соедине-
ние в «один к одному».
Rootl Root2
Рис. 7.11. Исправление запроса с несколькими корневыми узлами
Часто условие, превращающее соединение в «один к одному», уже присутству-
ет, и вы обнаруживаете, что комбинация соединения вида «многие к одному» и об-
манчивого фильтра просто отменяет детальный коэффициент фильтрации.
ПРИМЕЧАНИЕ -----------------------------------------------------------------
В этом примере коэффициент фильтрации для такого фильтра был бы равен 0,2, а детальный коэффи-
циент соединения с Rootl — 5.
Иначе условие, превращающее соединение в «один к одному» может просто
отсутствовать в запросе, особенно, если разработка проводилась в тестовой систе-
ме, где отношение «один ко многим» было скрыто.
ПРИМЕЧАНИЕ ----------------------------------------------------------------
Это иллюстрирует предыдущий пример различных налоговых ставок. В среде разработки могут при-
сутствовать записи только для текущей ставки, скрывающие ошибку потери условия по дате для таб-
лицы ставок.
Необычные диаграммы соединений
215
Потеряно ли условие, которое превращает соединение в «один к одному», или
просто не очевидно, что оно связано с соединением, но вы должны включить это
условие и распознать его как часть соединения, а не как независимое условие филь-
трации. Такое отсутствующее условие соединения особенно вероятно, когда вы
обнаруживаете, что внешний ключ для одной из корневых таблиц, указывающий
вниз на общую главную таблицу, также является частью составного первичного
ключа этой корневой таблицы.
Случай 2. Разбивка декартова произведения
на несколько запросов
На рис. 7.12 показано другое решение задачи с диаграммой запроса с несколькими
корневыми узлами. Это решение сродни явному выполнению отдельных запросов
на несвязной диаграмме запроса. Оно заключается в том, чтобы разбить декартово
произведение и заменить его двумя отдельными наборами. В этом примере мы за-
меняем запрос, который вернул бы по 150 строк для каждой строки из Master, на
два запроса, которые совместно вернут по 35 строк для каждой строки из Master.
Если вы видите отношение «один ко многим» главной таблицы с двумя различны-
ми корневыми детальными таблицами, то можете получить в точности те же дан-
ные, считав намного меньше строк раздельными запросами, как показано на рисун-
ке. Поскольку результаты примут немного другую форму, вам также потребуется
изменить логику приложения, чтобы обработать данные в новой форме.
Рис. 7.12. Исправление декартова произведения за счет отдельных запросов
Случай 3. Отношения с корневыми детальными
таблицами не более чем «один к одному»
На рис. 7.13 показан случай диаграммы с несколькими корнями, когда производи-
тельность исходного запроса не представляет проблемы. Так как детальный коэф-
фициент соединения Master с Rootl равен 0,5, декартово произведение не приводит
к резкому увеличению количества строк в декартовом произведении, когда вы ком-
216
7. Диаграммное изображение и настройка сложных SQL-запросов
бинируете подходящие записи из Rootl и Root2 для средней подходящей записи из
Master. Можно считать соединение с Rootl соединением вниз и даже отдавать ему
предпочтение, как если бы оно улучшало в 0,5 раз коэффициент фильтрации для
фильтрующего соединения, следуя правилам из главы 6 для специальных случаев
(в данном случае для детальных коэффициентов фильтрации, меньших 1,0).
Рис. 7.13. Декартово произведение с небольшим детальным коэффициентом соединения
Хотя этот запрос не является проблемой для настройки, он все же может быть
неверным. Соединение вида «один к нулю» или «один ко многим» от Master к Rootl,
очевидно, обычно превращается в «один к нулю» или «один к одному», обеспечи-
вая безопасное декартово произведение. Но так как соединение в редких случаях
все же может превращаться в «один ко многим», необходимо учитывать, что ре-
зультат может возвратить декартово произведение с повторениями для данной
строки из Root2. Поскольку такой случай редок, вероятнее всего, запрос в действи-
тельности разрабатывался и тестировался, чтобы возвращать результаты, однознач-
но отображающиеся на строки из Root2 («один к одному»), а приложение во всех
прочих, редких случаях может вовсе не работать.
ВНИМАНИЕ ------------------------------------------------------------------
Чем менее вероятна ситуация «один ко многим», тем более вероятно, что этот случай упущен в дизайне
приложения.
Например, если приложение изменит данные Root2 после считывания их из таб-
лицы этим запросом и попытается отправить изменения обратно в базу данных, то
ему необходимо будет решить, какую копию повторяющейся строки Root2 следует
отправить. Должно ли приложение предупреждать конечного пользователя, что
произошла попытка отправить противоречивые копии? Если приложение собира-
ет данные Root2 при помощи запроса, избегает ли оно добавления данных из повто-
ряющихся строк Root2?
Случай 4. Преобразование проверки существования
в явный подзапрос
Одно из решений функциональной задачи на рис. 7.13 уже показано на рис. 7.12.
Один запрос просто разбивался на два подзапроса. Другое решение, которое часто
бывает лучшим, позволяет изолировать ветвь с Rootl в подзапросе, обычно с усло-
вием EXISTS. Это решение особенно хорошо работает, если исходный запрос не вы-
бирает столбцы из Rootl (или из любых таблиц, присоединенных ниже при помо-
щи скрытых серых связей на рис. 7.13). В этом относительно часто встречающемся
специфическом случае вас в действительности интересует только, существует ли
Необычные диаграммы соединений
217
подходящая строка в таблице Rootl и удовлетворяет ли она некоторым фильтрую-
щим условиям, а не содержимое этой строки или количество совпадений строк,
если таковые есть. Позже в этой главе вы узнаете, как создавать диаграммы и на-
страивать запросы с подобными подзапросами.
Соединения без первичных ключей
Я использую связи без стрелок на концах для обозначения соединений, на обеих
сторонах которых не задействуются первичные ключи. В целом они представляют
необычные соединения вида «многие ко многим», хотя в некоторых случаях они
превращаются в «многие к нулю» или «многие к одному». Если они никогда не
бывают вида «многие ко многим», то вы просто не заметили условие уникально-
сти и должны добавить стрелку на уникальном конце соединения. Если хотя бы
иногда эти соединения бывают вида «многие ко многим», то у вас появляются все
те же проблемы (и, следовательно, те же решения), как и для диаграмм запросов с
несколькими корневыми узлами. На рис. 7.14 показано соединение вида «многие
ко многим» между Т1 и Т2, где детальный коэффициент соединения на обоих кон-
цах больше 1,0. Главные коэффициенты соединения присутствуют только на уни-
кальном конце связи, обозначенном стрелкой, поэтому у этой связи два детальных
коэффициента соединения.
Рис. 7.14. Соединение вида «многие ко многим»
Этот случай встречается намного чаще, чем предыдущие примеры необычных
диаграмм соединений. Хотя в нем есть все те же возможные источники проблем (и
решения), как и в случае нескольких корневых узлов, подавляющее большинство
соединений вида «многие ко многим» появляется просто из-за отсутствующих ус-
ловий соединения. Начните с проверки, не нужно ли условия фильтрации в запро-
се считать частью соединения, потому что они завершают спецификацию полного
первичного ключа для одной из сторон соединения. Пример 5.2 в главе 5 — это
’акой случай, в котором условие ОТ. Code_Type - ' ORDER_STATUS' требуется тля завер-
шения уникального соединения с псевдонимом ОТ. Если бы я рассматривал это
условие как простое фильтрующее условие для псевдонима ОТ, то соединение с ОТ
превратилось бы в соединение вида «многие ко многим». Даже если вы не находи-
те отсутствующую часть соединения среди фильтрующих условий запроса, всегда
следует подозревать, что она по ошибке не была указана в запросе.
Такой случай отсутствующего условия соединения особенно часто встречает-
ся, когда дизайн базы данных разрешает существование нескольких типов сущ-
ностей или разбиений в пределах таблицы, а разработчик забывает ограничить разби-
ение или тип в запросе. Например, в предыдущем примере с таблицей Code_T га ns 1 at 1 ons
для каждого Code_Type существовали различные типы сущностей преобразования
(translation), и если бы условие для Code_Type не было указано, то соединение с
Code_Translat1ons превратилось бы в соединение вида «многие ко многим». Зачас-
218
7. Диаграммное изображение и настройка сложных SQL-запросов
тую тестирование не позволяет обнаружить эту ошибку на ранней стадии, посколь-
ку даже если база данных разрешает различные типы или разбиения, в тестовой
среде может присутствовать лишь один тип или разбиение, а разработчики могут
принимать это положение дел как должное. Даже когда в реальных данных при-
сутствуют различные типы или разбиения, то другая, более селективная часть ключа
сама по себе обычно может быть уникальной. Это одновременно и удача, и пробле-
ма. Хотя большие неприятности из-за отсутствия условия соединения предотвра-
щаются, проблему становится труднее распознать и исправить, а это ведет к лож-
ному чувству, что приложение правильно. Поиск и исправление отсутствующего
условия соединения может лишь слегка улучшить производительность, делая со-
единения более селективным, но также может стать огромной помощью, если ис-
правлена будет действительно фатальная скрытая ошибка.
По аналогии с диаграммами запросов с несколькими корневыми узлами реше-
ния для соединений вида «многие ко многим» соответствуют решениям различ-
ных диаграмм с несколькими корневыми узлами.
Соединения вида «один к одному»
Вы, вероятно, слышали шутку о старике, который жаловался, что ему в детстве
приходилось ходить в школу по пять километров в гору туда и обратно. В каком-
то смысле соединения вида «один к одному» переворачивают эту картинку с ног
на голову. Для эвристических правил, подсказывающих, какую таблицу присое-
динять следующей, соединения «один к одному» оказываются «под гору» в обе
стороны! Как таковые, эти соединения не представляют никакой проблемы для
настройки, и это наименее хлопотливые из всех необычных ситуаций, возможных
на диаграммах запросов. Однако такие соединения иногда указывают на возмож-
ности улучшения дизайна базы данных, если вы находитесь на той стадии разра-
ботки, когда дизайн еще не зафиксирован. Также полезно иметь стандартный спо-
соб представления соединений вида «один к одному» на диаграмме запроса, поэтому
я опишу различные способы.
Соединение вида «один к одному»
с таблицей-подмножеством
На рис. 7.15 показано типичное соединение вида «один к одному», встроенное
в большой запрос. В то время как у соединения вида «многие ко многим» на обоих
концах детальные коэффициенты соединения, у соединения вида «один к одно-
му» это главные коэффициенты соединения. Главные коэффициенты соединения
в этом примере показывают, что соединение между Т1 и Т2 в действительности бы-
вает только «один к нулю» или «один к одному»; случай «один к нулю» возникает
для 30 % строк из Т1.
Рис. 7.15. Типичное соединение вида «один к одному»
Необычные диаграммы соединений
219
Так как это внутреннее соединение, случаи соединения «один к нулю» между Т1
и Т2 представляют собой скрытый фильтр соединения, который следует обрабатывать,
как описано в конце главы 6. Также обратите внимание, что это может быть случай
скрытого циклического соединения, что часто случается, когда главная таблица одно-
значно («один к одному») соединяется с другой таблицей. Если над Т1 есть детальная
таблица, что подразумевается окрашенной в серый цвет связью вверх, и если эта де-
тальная таблица соединяется с Т1 по тому же уникальному ключу, что и с Т2, то по
закону транзитивности у вас есть подразумеваемое соединение от детальной таблицы
к Т2. На рис. 7.16 подразумеваемая связь показана серым. О том, как обрабатывать
циклические соединения, рассказывалось несколько раньше в этой главе.
Рис. 7.16. Подразумеваемая связь, создающая циклическое соединение
Есть у вас циклическое соединение или нет, вы всегда можете улучшить ди-
зайн базы данных. Случай на рис. 7.16 подразумевает набор сущностей, однознач-
но отображающихся на Т1, и поднабор тех же сущностей, однозначно отображаю-
щихся на Т2, причем таблица Т2 построена из первичного ключа Т1 и столбцов,
которые употребляются только для этого поднабора. В этом случае совершенно
нет жесткой необходимости в двух таблицах. Попробуйте просто добавить допол-
нительные столбцы к Т1 и присвоить им значение null для членов большого набо-
ра, которые не входят в поднабор. Иногда есть и другие причины, почему для удоб-
ства в подобных ситуациях разработчик предпочитает иметь две таблицы. Однако
с точки зрения настройки комбинирование этих соразмерных таблиц практически
всегда полезно, поэтому хотя бы подумайте об их использовании, если у вас есть
возможность влиять на дизайн базы данных.
Точные соединения «один к одному»
На рис. 7 17 показан случай, требующий обязательного соединения двух таблиц
в одну, когда это возможно. Здесь главные коэффициенты фильтрации равны в точ-
ности 1,0, и между таблицами существует точное отношение «один к одному». Та-
ким образом, обе таблицы отображаются на один и тот же набор сущностей, и со-
единение — это всего лишь ненужные затраты по сравнению с использованием
комбинированной таблицы.
Рис. 7.17. Точное соединение вида «один к одному»
220
7. Диаграммное изображение и настройка сложных SQL-запросов
Единственная ситуация, когда с точки зрения производительности нужно раз-
делить эти таблицы? — когда запросам практически всегда нужны лишь данные из
одной из таблиц, и редко требуется выполнять соединение. Самый распространен-
ный пример такого случая — данные одной из таблиц требуются намного реже,
чем из другой. В этом случае, особенно если каждая строка редко требуемых дан-
ных занимает много места, вы можете обнаружить, что компактность часто опра-
шиваемой таблицы, увеличивающая коэффициент успешного попадания в кэш,
будет едва оправдывать стоимость редко выполняемого соединения. Даже с точки
зрения функциональности или разработки, вероятно, что затраты на кодирование
добавления и удаления строк одновременно для обеих таблиц, и, иногда, обновле-
ния обеих таблиц, будут велики. Возможно, вы предпочтете поддерживать одну
комбинированную таблицу. Обычно, если вы видите точное соединение вида «один
к одному», оно появилось в результате некоторой жесткой функциональности,
требующей новых столбцов для уже имеющихся сущностей, и некоторых вообра-
жаемых или реальных ограничений разработки, не позволяющих изменять исход-
ную таблицу. Когда возможно, лучше решать проблему путем устранения этого
ограничения.
Соединение вида «один к одному»
с намного меньшим набором данных
На другом конце спектра находится случай, показанный на рис. 7.18, — соедине-
ние вида «один к нулю» или «один к одному», котороепрактически всегда работа-
ет как «один к нулю». Этот случай идеально оправдывает разделение таблиц. Для
крошечного поднабора сущностей, представленного таблицей Т2, могут существо-
вать другие требования оптимизации, отличные от требований для расширенного
набора, представленного таблицей Т1. Вероятно, Т1 обычно опрашивается без со-
единения с Т2, и в этих случаях исключение ненужных столбцов Т2 и поддержка
только тех индексов, которые имеют смысл для общих сущностей, полезны. Здесь
скрытый фильтр соединения, представленный низким главным коэффициентом
соединения на стороне Т2 соединения отлично работает. Он настолько хорош, что
вы даже можете начать выполнение запроса с не фильтрующегося полного скани-
рования таблицы Т2 и все так же найти наилучший путь к остальным данным. Если
вы объедините эти таблицы в одну, то добиться подобного плана исполнения бу-
дет трудно, разве что за счет создания индексов, бесполезных для всех остальных
случаев.
Рис. 7.18. Соединение вида «один к нулю» или «один ко многим» между сильно
различающимися по размеру таблицами
Здесь главная задача — не забыть учесть скрытый фильтр соединения от Т1 к Т2,
либо начиная запрос с Т2, либо обрабатывая ее как можно скорее, чтобы как можно
раньше использовать скрытый фильтр.
Необычные диаграммы соединений
221
Соединения вида «один к одному» со скрытыми
фильтрами соединения в обоих направлениях
На рис. 7.19 показан редкий случай соединения вида «(ноль или один) к (нулю или
одному)», которое фильтруется в обоих направлениях. Если соединения вида «один
к одному» — это движение под гору в обоих направлениях, то эти соединения — спуск
круто под гору в обоих направлениях. Если только данные не повреждены (напри-
мер, в одной из таблиц какие-либо данные отсутствуют), то этот редкий случай, ве-
роятно, подразумевает, что существует или должна существовать еще и третья таб-
лица, представляющая расширенный набор этих перекрывающихся наборов. Если
вы найдете или создадите такую таблицу, то те же аргументы, что и ранее, будут
говорить в пользу комбинирования ее с одной или обеими таблицами поднаборов.
Рис. 7.19. Соединение вида «(ноль или один) к (нулю или одному)»
Соглашения для изображения соединений вида
«один к одному»
Полезно иметь определенные договоренности о едином изображении диаграмм
запросов. Такие соглашения помогают развивать интуицию, единообразно пред-
ставляя ключевую информацию. Односторонние стрелки всегда указывают вниз.
На рис. 7.20 показано два альтернативных варианта, хорошо подходящих для со-
единений вида «один к одному», лежащих под корневой детальной таблицей. В пер-
вом варианте особенно подчеркивается двухсторонняя стрелка, узлы на концах
которой размещены на одном уровне. Во втором варианте подчеркивается обыч-
ное направление ссылок — вниз от корневой детальной таблицы. Любой из вари-
антов хорош, если вы помните, что соединения вида «один к одному» в каком-то
смысле с обеих сторон указывают вниз.
Рис. 7.20. Диаграммное изображение соединений вида «один к одному»,
лежащих под корневой детальной таблицей
Для этого случая, когда обе таблицы, участвующие в соединении, находятся
под корнем, помните, что если равноправные таблицы используют общий первич-
222
7. Диаграммное изображение и настройка сложных SQL-запросов
ный ключ, то связь сверху с Т1 по закону транзитивности точно так же может отно-
ситься и к Т2, если только она не ведет к некоторому альтернативному уникально-
му ключу по Т1, который в Т2 не используется. Это неявный случай циклического
соединения, показанный в варианте Б на рис. 7.2.
На рис. 7.21 показаны альтернативные диаграммы соединений вида «один к одно-
му» двух корневых детальных таблиц (такие таблицы находятся сверху, и с ними
нет соединений), когда хотя бы одно из направлений соединения характеризуется
главным коэффициентом соединения, меньшим 1,0. И снова вы можете подчерк-
нуть характер соединения либо горизонтальным расположением, либо указать,
какая из таблиц больше (и какое из направлений соединения «круче под гору»),
поместив узел с большим главным коэффициентом соединения выше. Узел с боль-
шим главным коэффициентом соединения представляет таблицу, большая часть
строк которой участвует в этом соединении вида «(ноль или один) к (нулю или
одному)».
Рис. 7.21. Альтернативные способы диаграммного изображения для корневых детальных
таблиц с отношением «(ноль или один) к (нулю или одному)»
Рисунок 7.22 иллюстрирует случай, схожий с рис. 7.21, но с узлами с точным
соотношением «один к одному», обозначающими таблицы, которые всегда соеди-
няются успешно. И снова вы можете подчеркнуть эквивалентность направлений
соединения, расположив узлы рядом по горизонтали. Или же выберите направле-
ние, которое позволит изобразить дерево более сбалансированным, чтобы оно луч-
ше помещалось на страницу, поместив узел с более длинными ветвями выше. В этом
случае выбор значит мало, если вы помните, что оба направления ведут «под гору»,
независимо от того, как расположены на диаграмме.
Рис. 7.22. Альтернативные способы диаграммного изображения корневых детальных таблиц
с точным отношением «один к одному»
Внешние соединения
Практически всегда смысл и назначение внешнего соединения — предотвраще-
ние потери нужной информации из таблицы, находящейся в начале соедине-
Необычные диаграммы соединений
223
ния, независимо от содержимого присоединяемой внешне таблицы. Необыч-
ные внешние соединения, которые я опишу ь следующих разделах, подразуме-
вают некоторые противоречия самой причине использования внешнего соеди-
нения.
Фильтрованные внешние соединения
Рассмотрим рис. 7.23, где внешнее соединение производится с таблицей с филь-
трующим условием. Do внешнем случае, то есть случае, когда для строки Т1 нет
подходящей строки из Т2, база данных назначает в результирующей строке каж-
дому столбцу Т2 значение null, Таким образом, кроме Т2. Некоторый_столбец IS NULL,
практически любое фильтрующее условие для Т2 приведет к исключению ре-
зультирующей строки, которая создается во внешнем случае внешнего соеди-
нения.
Рис. 7.23. Внешнее соединение с фильтрованным узлом
Даже такие условия, как T2.Unpaid_Flag != ' Y' или NOTT2.Unpaid_Flag = 'Y', кото-
рые, как вы ожидаете, должны быть истинными во внешнем случае, на самом деле
истинными не являются.
ВНИМАНИЕ ----------------------------------------------------------------------
Когда дело доходит до условий в разделе WHERE, базы данных интерпретируют значения null не интуи-
тивным образом. Если вы считаете, что mill по отношению к столбцу таблицы обозначает «неизвест-
но», а не «не применимо», то, возможно, сможете попять, как базы данных обрабатывают значения null
в условиях. Кроме вопросов о том, равно ли значение в столбце null, практически любой вопрос, кото-
рый вы можете задать о неизвестном значении, вернет отвг «неизвестно», что, на самом деле, и есть
истинностное значение для большинства условий по null. С точки зрения отбрасывания строк для зап-
роса, база данных обрабатывает истинностное значение «неизвестно» как FALSE, отбрасывая строки с
неизвестными истинностными значениями во фразе WHERE И хотя NOT FALSE = TRUE, вы обнаружите,
что NOT «неизвестно» = «неизвестно»!
Так как большинство фильтров для внешней таблицы отбрасывают внешние
случаи внешних соединений, и предназначение внешних соединений состоит в
сохранении таких случаев, вам необходимо обращать особое внимание на любые
фильтры для внешних таблиц. Существует несколько сценариев, и вам следует
потратить достаточно времени, чтобы определить, какой применим для конкрет-
ного случая.
Фильтр достаточно редкий, например Некоторый_столбец IS NULL, и может вер-
нуть значение TRUE для полей, равных null, принудительно вставленных во внеш-
нем случае, и поэтому фильтр функционально верен.
224
7. Диаграммное изображение и настройка сложных SQL-запросов
Разработчик не планировал отбрасывать внешнее соединение, и фильтрующее
условие необходимо удалить.
Фильтрующее условие предназначено для отбрасывания внешнего соединения,
и соединение с таким же успехом может быть внутренним. В этом случае нет
никакого функционального различия между запросом с соединением, выражен-
ным как внешнее или внутреннее соединение. Однако, сделав его формально
внутренним соединением, вы дадите базе данных больше степеней свободы для
создания планов исполнения, которые могут выполнять соединение в любом
направлении. Когда наилучший фильтр находится на той же стороне соедине-
ния, где и ранее присоединяемая внешне таблица, дополнительные степени сво-
боды могут позволить выбрать лучший план исполнения. С другой стороны,
превращение соединения во внутреннее может заставить оптимизатор сделать
ошибку, которой он бы избежал с внешним соединением. Внешние соедине-
ния — это один из способов ограничения порядка соединения, когда вы созна-
тельно хотите сделать это, даже если вам совсем не требуется сохранять вне-
шний случай.
Фильтрующее условие добавлено намеренно, но оно должно быть частью со-
единения! Если фильтрующее условие сделать частью соединения, то запрос к
базе данных будет звучать как «Для каждой строки детальной таблицы найти
подходящую строку из этой таблицы, удовлетворяющую фильтру, если тако-
вая существует; иначе, поставить в соответствие псевдостроку, состоящую из
значений null».
УСЛОВИЯ ВНЕШНЕГО СОЕДИНЕНИЯ ДЛЯ ОДНОЙ ТАБЛИЦЫ -----------------------------------------
В старом стиле записи Oracle превращение фильтрующего условия в часть соединения производится за
счет добавления (+). Например, двусоставное внешнее соединение с таблицей Code_T cans 1 at ions, кото-
рое использовалось в предыдущих примерах, выглядело бы так:
WHERE . ..
AND 0.0rder_Type_Code - OTypeTrans.Code(+)
AND OTypeTrans.Type(+) - 'ORDER_TYPE'
В новом стиле записи соединений ANSI, единственном разрешенном в DB2 для записи внешних
соединений, фильтрующее условие переходит в раздел FROM, чтобы стать явным условием соедине-
ния:
FROM ... Orders 0 ...
LEFT OUTER JOIN Code_Translations OTypeTrans
ON 0.0rder_Type_Code > OTypeTrans.Code
AND OTypeTrans.Type - ’ORDER_TYPE'
В первоначальной записи внешних соединений в SQL Server база данных просто предполагает, что
фильтрующее условие является частью соединения:
WHERE ...
AND 0.0rder_Type_Code *= OTypeTrans.Code
AND OTypeTrans.Type = ‘ORDER_TYPE’
Обратите внимание, что это делает рассмотренную проблему невозможной для внешних соединений в
SQL Server в старом стиле; база данных автоматически делает фильтр частью соединения. Также обра-
тите внимание, что в редких случаях, когда фильтр действительно является фильтром, для получения
желаемого результата вам необходимо либо преобразовать запись в новый стиль, либо превратить со-
единение в эквивалентный запрос NOT EXISTS, о чем я расскажу позже.
Необычные диаграммы соединений
225
Рассмотрим первый сценарий подробнее. Возьмем запрос следующего вида:
SELECT ...
FROM Employees Е
LEFT OUTER JOIN Departments 0
ON E.DepartmentJD - D.DepartmentJD
WHERE D.Dept_Manager_ID IS NULL
Что же на самом деле запрос хочет получить от базы данных? Семантически
он запрашивает два различных набора строк. Один набор содержит данные обо
всех сотрудниках, для которых не указан отдел, а второй отыскивает всех сотруд-
ников, для которых указан отдел, не имеющий начальника. Существует вероят-
ность, что приложение действительно хочет одновременно получить два таких
разных набора, но более вероятно, что разработчик не заметил, что у такого про-
стого запроса настолько сложный результат, и ему не нужен один из этих набо-
ров строк.
Рассмотрим слегка отличающийся пример:
SELECT ... FROM Employees Е
LEFT OUTER JOIN Departments D
ON E.DepartmentJD - D.Department ID
WHERE D.DepartmentJD IS NULL
С первого взгляда кажется, что это неестественный запрос, потому что первич-
ный ключ (Department JD) таблицы Departments не может быть равен null. Даже если
бы null было допустимым значением первичного ключа, подобное соединение с
другой таблицей никогда бы не было успешным для такого ключевого значения
(так как условное выражение NULL = NULL возвращает истинностное значение «не-
известно»), Однако, так как это внешнее соединение, существует разумная интер-
претация этого запроса — «Найти всех сотрудников, для которых не существует
соответствующих отделов». Во внешнем случае этих внешних соединений все стол-
бцы Departments, включая даже обязательно не равные null столбцы, получат значе-
ние null, поэтому условие D. Department JD IS NULL будет истинно только во внешнем
случае. Есть и более распространенный и простой для восприятия способ записи
этого запроса:
SELECT ..
FROM Employees Е
WHERE NOT EXISTS (SELECT *
FROM Departments D
WHERE E.DepartmentJD = D.DepartmentJD)
Хотя форма NOT EXISTS запросов такого рода более естественна и ее проще чи-
тать и понимать, в настройке SQL есть место и для другой формы (для лучшего
понимания ее рекомендуется хорошо комментировать). Преимущество выраже-
ния условия NOT EXISTS в виде внешнего соединения, за которым следует Первич-
ный_ключ IS NULL, заключается в том, что такая форма позволяет более точно контро-
лировать, когда именно в плане исполнения будет выполнено соединение, и когда
будет использована селективность этого условия. Обычно условия NOT EXISTS оце-
ниваются после всех обычных соединений, по крайней мере, в Oracle. Это один из
примеров, когда фильтр (не являющийся частью внешнего соединения) на присо-
единяемой внешне таблице действительно может быть предумышленным и вер-
ным.
226
7. Диаграммное изображение и настройка сложных SQL-запросов
ПРИМЕЧАНИЕ---------------------------------------------------------------------—---------
В старой записи внешних соединений в SQL Server комбинация внешнего соединения и условия «рав-
но null» не работает. Например, преобразуя предыдущий пример в запись SQL Server, вы могли бы
попробовать такой запрос:
SELECT ...
FROM Employees Е. Departments D
WHERE E.Department_ID *= D.Department_ID
AND D Department_ID IS NULL
Но результат был бы совсем не тот, которого вы ожидаете! Вспомните, что SQL Server интерпретирует
все фильтрующие условия для присоединяемой внешне таблицы как часть соединения. SQL Server
попытается провести соединение со строками Departments, для которых существуют равные null пер-
вичные ключи (например, значения D. Department_ID, равные null). Даже если бы такие строки сущест-
вовали, нарушая правильный дизайн базы данных, они бы никогда не могли быть успешно присоединены
к таблице Empl oyees, так как соединение по условию равенства не может быть успешно выполнено для
ключевых значений, равных null. Вместо этого запрос не отфильтрует никакие строки, а вернет всех
сотрудников, причем все соединения будут внешними.
Внешние соединения, ведущие
к внутренним соединениям
Рассмотрим рис. 7.24, на котором внешнее соединение ведет к внутреннему соеди-
нению.
▼
ТЗ
Рис. 7.24. Внешнее соединение ведет к внутреннему соединению
В старом стиле Oracle SQL подобное соединение записывается так:
SELECT ...
FROM Tablel Tl. Table2 T2 ТаЫеЗ ТЗ
WHERE Tl.FKey2 = T2.PKey2( ) •
AND T2.FKey3 = ТЗ.РКеуЗ
Во внешнем случае первого соединения база данных сгенерирует псевдостроку
из Т2, причем значение всех столбцов, в том числе Т2. FKey3 будет равно null. Одна-
ко равный null внешний ключ никогда не может быть успешно присоединен к дру-
гой таблице, поэтому строка, представляющая внешний случай соединения, будет
отброшена при попытке выполнить внутреннее соединение с ТЗ. Таким образом,
внешнее соединение, ведущее к внутреннему соединению, дает в точности тот же
результат, который вы бы получили, если бы оба соединения были внутренними.
Но его стоимость выше, так как база данных отбрасывает стоки, которые не удов-
летворяют соединению, позже в плане исполнения. Это всегда будет ошибкой. Если
разработчик требует сохранить подобное соединение, замените внешнее соедине-
ние, ведущее к внутреннему, внешним соединением, ведущим к другому внешне-
му соединению. В противном случае используйте два внутренних соединения.
Необычные диаграммы соединений
227
Внешние соединения, указывающие
на детальную таблицу
Рассмотрим рис. 7.25, где указатель стрелки посередине связи обозначает внешнее
соединение, указывающее на детальную таблицу.
Рис. 7.25. Внешнее соединение по направлению к детальной таблице
В новом стиле записи ANSI это может быть запрос следующего вида:
SELECT ...
FROM Departments D
LEFT OUTER JOIN Employees E
ON D.Department_ID - E.Department_ID
Или в старой записи Oracle:
SELECT ...
FROM Departments D. Employees E
WHERE D.Department_ID = E.Department_ID(+)
В старой записи SQL Server:
SELECT ...
FROM Departments D. Employees E
WHERE D.DepartmentJD *= E.Department_ID
В любом случае, что же семантически означает этот запрос? Его можно пред-
ставить как обращение: «Перечисли мне всех сотрудников, для которых указаны
отделы (внутренний случай), а также данные об их отделах, и еще присовокупи
данные об отделах, в которых нет сотрудников (внешний случай)». Во внутреннем
случае результат сопоставляет каждую строку с детальной сущностью (сотрудник,
принадлежащий какому-то отделу), а во внешнем случае результат отображает
каждую строку на главную сущность (отдел, не принадлежащий ни одному сотруд-
нику). Маловероятно, что такая нелепая смесь сущностей будет полезна и необхо-
дима в одном запросе, поэтому подобные запросы, в которых внешние соединения
ведут к детальным таблицам, редко бывают верны. Самый распространенный слу-
чай такой ошибки — это соединение с детальной таблицей, которая обычно пред-
лагает ноль или одну детальную строку для каждой главной, и лишь изредка это
соединение предлагает несколько детальных строк для главной таблицы. Иногда
разработчики упускают из виду последствия этого редкого случая «многие к одно-
му», а во время тестирования ошибка может и не всплыть.
Внешние соединения с детальной таблицей с фильтром
На рис. 7.26 показано внешнее соединение с детальной таблицей, для которой так-
же существует фильтрующее условие. Иногда две ошибки компенсируют друг дру-
га. Внешнее соединение с детальной таблицей, имеющей фильтр, может представ-
228
7. Диаграммное изображение и настройка сложных SQL-запросов
лять собой двойную ошибку и иметь все недостатки, описанные в последних двух
подразделах. Иногда фильтр компенсирует эффект проблемного внешнего соеди-
нения, функционально превращая его во внутреннее. В таких случаях следует из-
бегать удаления фильтра, если только вы не превращаете одновременно внешнее
соединение во внутреннее.
Т10.3
Т2
Рис. 7.26. Внешнее соединение с фильтрованной детальной таблицей
Наиболее интересный случай, который может проиллюстрировать рис. 7.26, —
когда фильтр имеет смысл только в контексте внешнего соединения. Это случай,
когда фильтрующее условие для Т1 истинно только во внешнем случае — напри-
мер, Tl.Fkey_ID IS NULL. (Здесь Tl.Fkey_ID — это внешний ключ, указывающий на
Т2. РКеу_Ю в показанном на диаграмме соединении.) Как и в предыдущем примере
условия IS NULL для значения ключа соединения (тогда это был первичный ключ),
этот случай эквивалентен подзапросу NOT EXISTS. Так же, как и в том примере, это
необычное выражение условия NOT EXISTS иногда обеспечивает дополнительную
степень контроля над местом в плане исполнения, когда база данных выполняет
соединение и отбрасывает строки, не удовлетворяющие условию. Так как все стро-
ки, присоединенные во внутреннем случае, отбрасываются условием IS NULL, мы
избегаем обычной проблемы внешних соединений с детальными таблицами — сме-
шивания различных сущностей в строках, полученных во внутреннем и внешнем
случаях соединения. Опять две ошибки компенсируют друг друга!
Запросы с подзапросами
Практически все реальные запросы с подзапросами включают особый вид усло-
вий для строк во внешнем, главном запросе; они должны соответствовать или не
соответствовать подходящим строкам в связанном запросе. Например, если вам
нужны данные об отделах, в которых есть сотрудники, вы можете использовать
такой запрос:
SELECT ...
FROM Departments D
WHERE EXISTS (SELECT NULL
FROM Employees E
WHERE E.Department_ID - D.Department_ID)
Или же вы можете запросить данные об отделах, в которых нет сотрудников:
SELECT ... FROM Departments D
WHERE NDT EXISTS (SELECT NULL
FROM Employees E
WHERE E.Department_ID - D.Department_ID)
Запросы с подзапросами
229
Соединение Е. DepartmentalD = D. Department_ID в каждом из этих запросов — это
корреляционное соединение, которое ставит в соответствие друг другу строки во
внешнем запросе и подзапросе. У запроса EXISTS есть альтернативная эквивалент-
ная форма:
SELECT ...
FROM Departments D
WHE.iE D.Department_ID IN (SELECT E.Department_ID FROM Employees E)
Так как функционально эти формы эквивалентны, а диаграмма должна быть
непредвзятой по отношению к обеим формам, то диаграммы для них выглядят оди-
наково. Только после оценки диаграммы следует делать выбор, какая из форм луч-
ше решает проблему настройки и выражает лучший путь к данным.
Изображение запросов с подзапросами
на диаграммах
Игнорируя соединение, которое связывает внешний запрос с подзапросом, вы все-
гда можете создать отдельные, независимые диаграммы запросов для каждого из
двух запросов. Единственный открытый вопрос — как следует представлять отно-
шение между этими двумя диаграммами, которое объединяет их в одну. Как объяс-
няет форма EXISTS предыдущего запроса, внешний запрос связан с подзапросом
при помощи корреляционного соединения. У этого соединения есть особое свой-
ство — для каждой строки внешнего запроса база данных прекращает поиск соот-
ветствующих строк, считает условие EXISTS удовлетворенным и передает строку
внешнего запроса на следующий этап плана исполнения, как только найдет первое
соответствие для данного соединения. Когда она находит соответствие для корре-
лированного подзапроса NOT EXISTS, то прекращает работу, считая условие NOT EXISTS
не удовлетворенным, и немедленно отбрасывает строку из внешнего запроса, не
выполняя с ней более никаких действий. Такое поведение подразумевает, что ди-
аграмма запроса должна отвечать на четыре особых вопроса о корреляционном
соединении. Эти вопросы неприменимы к обычным соединениям.
Это обычное соединение? (Нет, это корреляционное соединение с подзапро-
сом.)
Какая сторона соединения является подзапросом, а какая — внешним запро-
сом?
Его можно выразить как запрос EXISTS или как запрос NOT EXISTS?
Как скоро в плане исполнения следует выполнять подзапрос?
Работая с подзапросами и рассматривая эти вопросы, помните, что вам все так
же нужно передать на диаграмме свойства, характерные для любых соединений —
какой конец соединения относится к главной таблице и каковы коэффициенты
соединения.
Диаграммное изображение подзапросов EXISTS
На рис. 7.27 я показал условные обозначения, которые использую для диаграмм-
ного изображения запроса с подзапросом типа EXISTS (который может быть выра-
жен в виде эквивалентного подзапроса IN). Этот рисунок относится к предыдуще-
му подзапросу EXISTS:
230
7. Диаграммное изображение и настройка сложных SQL-запросов
SELECT ... FROM Departments D
WHERE EXISTS (SELECT NULL
FROM Employees E
WHERE E.Department_ID = D.Department_ID)
E
20,0.8
mE20
▼ 0.98
D
Рис. 7.27. Простой запрос с подзапросом
Для корреляционного соединения (также называемого полусоединением при-
менительно к подзапросам типа EXISTS) Departments с Employees диаграмма начина-
ется с той же статистики соединения, которая приведена для рис. 5.1.
Полусоединение, связывающее внутренний запрос с внешним, — это связь с ука-
зателем на том конце (или обоих концах), который указывает на первичный ключ.
Как и для любого соединения, на обоих концах полусоединения указаны коэффи-
циенты, представляющие те же статистические свойства, которые у этого соедине-
ния были бы в обычном запросе. Посередине связи я рисую стрелку, указываю-
щую от коррелированного узла во внешнем запросе на коррелированный узел в
подзапросе. Рядом с центральным указателем стрелки я рисую букву Е, чтобы по-
казать, что это полусоединение для подзапроса EXISTS или IN.
В этом случае часть диаграммы, представляющая подзапрос, — это один узел,
то есть у подзапроса нет собственных соединений. В более редких случаях вне-
шний запрос тоже отображается как единственный узел, представляющий внешний
запрос без собственных соединений. Синтаксис намеренно не ограничивается, раз-
решая такие ситуации, как несколько подзапросов, связанных с внешним запро-
сом, подзапросы с собственным сложным скелетом соединения и даже подзапро-
сы, указывающие на еще более глубоко вложенные собственные подзапросы.
Связи, представляющей полусоединение, требуется до двух новых чисел, чтобы
передать свойства подзапроса, упрощающие выбор наилучшего плана. На рис. 7.27
показаны оба дополнительных значения, которые иногда требуются при выборе
оптимального плана обработки подзапроса.
Первое значение, рядом с буквой Е (20 на рис. 7.27) — это корреляционный
коэффициент предпочтения. Корреляционный коэффициент предпочтения равен
отношению I/Е. Е — это установленное или измеренное время выполнения наи-
лучшего плана в случае, когда он выполняется от внешнего запроса к подзапросу
(следуя логике EXISTS). I — это установленное или измеренное время выполнения
наилучшего плана, когда он выполняется от внутреннего запроса к внешнему зап-
росу (следуя логике IN). Вы всегда можете вычислить этот коэффициент, замерив
время выполнения обеих форм запроса. Обычно это не представляет большой про-
блемы, если только вам не усложняет жизнь комбинация многих подзапросов.
Скоро я объясню несколько правил большого пальца для измерения соотношения
I/Е более или менее точно, но даже грубая оценка подходит для выбора плана,
когда, как это часто бывает, значение либо намного меньше 1,0, либо намного больше
1,0. Когда корреляционный коэффициент предпочтения больше 1,0, выбирайте
Запросы с подзапросами
231
коррелированный подзапрос с условием EXISTS и план, который начинает с внеш-
него запроса и идет к подзапросу.
Другое новое значение — это уточненный коэффициент фильтрации подзапро-
са (0,8 на рис. 7.27), который записывается рядом с детальным коэффициентом
соединения. Это установленное значение, которое помогает выбрать лучшее место
в порядке соединения для проверки условия подзапроса. Он используется только
в запросах, начинающихся с внешнего запроса, поэтому исключайте его из связи
полусоединения (с корреляционным коэффициентом предпочтения, меньшим 1,0),
которое превращаете в ведущий запрос в плане.
ПРИМЕЧАНИЕ --------------------------------------------------------------
Если у вас несколько полусоединений с корреляционным коэффициентом предпочтения, меньшим 1,0,
то начинать следует с подзапроса с наименьшим коэффициентом, и вам все так же понадобятся уточ-
ненные коэффициенты фильтрации для остальных подзапросов.
Перед тем как объяснить процесс вычисления корреляционных коэффициен-
тов предпочтения и уточненных коэффициентов фильтрации подзапросов, давай-
те выясним, когда они нам нужны. На рис. 7.28 показана частичная диаграмма за-
проса для подзапроса типа EXISTS, в котором корневая детальная таблица подзапроса
находится на конце полу соединения, указывающем на первичный ключ.
Рис. 7.28. Полусоединение с первичным ключом
Здесь полусоединение функционально ничем не отличается от обычного со-
единения, так как запрос никогда не найдет более одного соответствия в таблице М
для данной строки из внешнего запроса.
ПРИМЕЧАНИЕ------------------------------------------------------------------
Я предполагаю, что все поддерево под вершиной М соответствует нормальной форме (то есть все связи
указывают вниз на первичные ключи), а полный подзапрос однозначно отображается на строки из кор-
невой детальной таблицы М поддерева.
Так как функционально полусоединение ничем не отличается от обычного со-
единения, вы можете добиться более высокой степени свободы в плане исполне-
ния, явно исключив условие EXISTS и соединив подзапрос с внешним запросом.
Например, рассмотрим такой запрос:
SELECT <Столбцы только из внешнего запроса>
FROM Order_Details OD. Products P. Shipments S.
Addresses A. Code_Translations ODT
WHERE OD.Product_ID = P.Product_ID
AND P.Unit_Cost > 100
AND OD.Shipment_ID = S.Shipment_ID
AND S.Address_ID = A.Address_ID(+)
232
7. Диаграммное изображение и настройка сложных SQL-запросов
AND DD.Status_Code = ODT.Code
AND ODT. Codejype = 'Order_Detail_Status'
AND S.Sh1pment_Date > :now - 1
AND EXISTS (SELECT null
FROM Orders 0. Customers C. Code_Translations DT.
Customerjypes CT
WHERE C. CustomerJype_iD - CT.Customer_Type_ID
AND CT.Text - 'Government'
AND OD.Order_ID - O.Drder_ID
AND D Customer_ID C.Customer_ID
AND O.Status_Code • ОТ.Code
AND O.Completed_Flag - 'N'
AND ОТ.Codejype - 'ORDER_STATUS'
AND ОТ.Text I- 'Canceled'!
ORDER BY <Столбцы только из внешнего запроса>
Используя новые условные обозначения для полусоединений, этот запрос мож-
но изобразить в виде диаграммы на рис. 7.29.
Рис. 7.29. Сложный пример полусоединения с корреляционной связью с первичным ключом
корневой детальной таблицы подзапроса
Если вы просто перепишете этот запрос, переместив соединения и условия для
таблиц подзапроса во внешний запрос, то получите функционально идентичный
запрос, так как полусоединение проводится с первичным ключом и подзапрос од-
нозначно отображается на свою корневую детальную таблицу:
SELECT <Столбцы только из исходного внешнего запроса>
FROM Order_Deta1ls OD. Products P. Shipments S,
Addresses A Codejranslations ODT.
Orders 0, Customers C, Codejranslations 0T, Customerjypes CT
WHERE OD.ProductJd - P.Product Id
AND P Un1t_Cost > 100
AND OD.ShipmentJd - S.ShlpmentJd
AND S.AddressJd - A.Address_Id?+)
AND OD.Status_Code - ODT.Code
AND DDT.Codejype - '0rder_Deta1l_Status'
AND S.Sh1pment_Date > :now - 1
AND C.CustomerJypeJd - CT. CustomerJypeJd
AND CT.Text - 'Government'
AND OD.OrderJd - 0.OrderJd
Запросы с подзапросами
233
AND O.Customer_Id = C.Customer_Id
AND O.Status_Code = ОТ.Code
AND D.Completedjnag = 'N'
AND OT.CodeJype = ’DRDER_STATUS’
AND ОТ.Text != ’Canceled’
ORDER BY Столбцы только из исходного внешнего запроса>
Я специально записал эту версию с отступами, чтобы переход от предыдущей
версии был очевиден. Диаграмма запроса также практически идентична, что вид-
но на рис, 7.30.
Рис. 7.30. Тот же запрос, преобразованный, чтобы слить подзапрос с внешним запросом
У этой новой формы есть существенные дополнительные степени свободы, по-
зволяющие провести соединение с фильтрованным узлом Р после соединения с
хорошо фильтрованным узлом 0, но до соединения с практически не отфильтро-
ванным узлом ОТ. В исходной форме базе данных пришлось бы полностью обрабо-
тать всю ветвь подзапроса перед тем, как перейти к соединениям со следующими
узлами внешнего запроса. Так как присоединение подзапроса в подобных случаях
может только помочь и при этом получается диаграмма запроса, которую вы уже
умеете оптимизировать, далее в этой главе я буду предполагать, что вы присоеди-
няете подзапросы такого типа к внешним запросам. Я буду рассматривать только
диаграммное изображение и оптимизацию других типов запросов.
Теоретически можно применять этот же трюк со слиянием подзапросов типа
EXISTS, когда стрелка полусоединения указывает на детальный конец соединения,
но это сложно и менее вероятно, что он поможет улучшить производительность
запроса. Рассмотрим предыдущий запрос к отделам с условием EXISTS для Empl oyees:
SELECT ...
FROM Departments D
WHERE EXISTS (SELECT NULL
FROM Employees E
WHERE E.Department_ID = D.DepartmentID)
Следующие проблемы возникают при попытке использовать такой же трюк
в данном случае.
Исходный запрос возвращает максимум одну строку на каждую строку из глав-
ной таблицы для каждого отдела. Чтобы получить такой же результат от преоб-
разованного запроса с обычным соединением с детальной таблицей ( Empl oyees ),
234
7, Диаграммное изображение и настройка сложных SQL-запросов
вам необходимо включить в список SELECT уникальный ключ главной таблицы
и выполнить операцию DISTINCT на полученных строках запроса. Эти шаги от-
брасывают дубликаты, которые получаются, когда для одной главной записи
есть несколько подходящих детальных.
Когда для главной строки есть несколько подходящих детальных, то, зачастую,
поиск всех соответствий обходится дороже, чем остановка полусоединения пос-
ле того, как найдено первое соответствие.
Таким образом, редко возникает необходимость преобразовывать полусоеди-
нения в обычные соединения, когда стрелка полусоединения указывает вверх, разве
что в тех случаях, когда детальный коэффициент соединения для полусоединения
близок к 1,0 или даже меньше.
Чтобы завершить диаграмму для подзапроса типа EXISTS, вам нужны лишь пра-
вила вычисления корреляционного коэффициента предпочтения и уточненного
коэффициента фильтрации подзапроса. Чтобы найти корреляционный коэффи-
циент предпочтения, выполните следующие действия.
1. Пусть D — детальный коэффициент соединения для полусоединения, а М —
главный коэффициент соединения. Пусть S — лучший (наименьший) коэффи-
циент фильтрации среди всех узлов в подзапросе, a R — лучший (наименьший)
коэффициент фильтрации среди всех узлов во внешнем запросе.
2. Если D х S < М х R, то корреляционный коэффициент предпочтения равен
(D х S)/(M х R).
3. Иначе, если S > R, то корреляционный коэффициент предпочтения равен S/R.
4. Иначе, пусть Е — измеренное время выполнения наилучшего плана исполне-
ния, который начинает с внешнего запроса и переходит к подзапросу (следуя
логике EXISTS). Пусть I— измеренное время выполнения наилучшего плана,
который начинает с внутреннего запроса и переходит к внешнему (следуя ло-
гике IN). Пусть корреляционный коэффициент предпочтения равен I/Е. Если
вы смогли оценить корреляционный коэффициент предпочтения при помощи
шага 2 или 3, то на основе этих значений можете уверенно выбрать направле-
ние обработки подзапроса, не измеряя реальное время выполнения.
ПРИМЕЧАНИЕ -------------------------------------------------------------
Значение, вычисленное на шаге 2 или 3, может не совпадать с точным временем выполнения, которое вы
можете получить измерением. Однако оценка достаточно точна, если она умеренна и избегает значений,
которые могут привести к неверному выбору ведущего запроса между внешним запросом и подзапро-
сом. Правила на шаге 2 и 3 специально предназначены для случаев, когда такая надежная, умеренная
оценка вполне применима.
Если на шаге 2 или 3 вы не смогли получить правильную оценку, то безопаснее
и проще всего использовать значение, полученное при реальном измерении. В та-
ком редком случае поиск безопасного вычисленного значения будет намного слож-
нее, и результат не оправдает усилий.
После того как вы нашли корреляционный коэффициент предпочтения, про-
верьте, нужен ли вам уточненный коэффициент фильтрации подзапроса, и если
необходимо, найдите его, выполнив следующие действия.
1. Если корреляционный коэффициент предпочтения меньше 1,0 и меньше всех
остальных корреляционных коэффициентов предпочтения (для случая, когда
Запросы с подзапросами
235
у вас несколько подзапросов), остановитесь. В этом случае коэффициент пред-
почтения подзапроса вам не понадобится, так как он нужен для принятия ре-
шения, только когда вы начинаете с внешнего запроса, но это не тот случай.
2. Если подзапрос — это однотабличный запрос без фильтрующего условия, только
с условием корреляционного соединения, измерьте q (количество строк, воз-
вращенное внешним запросом, если убрать условие подзапроса) и t (количе-
ство строк, возвращенное полным запросом, включая подзапрос). Уточненный
коэффициент фильтрации подзапроса равен t/q. В этом случае условие EXISTS
достаточно легко проверяется. База данных просто ищет первое совпадение в ин-
дексе соединения.
3. Иначе, для полусоединения, пусть D — это детальный коэффициент соедине-
ния. Пусть s — коэффициент фильтрации корреляционного узла (то есть узла,
присоединенного к связи полусоединения) на детальном конце, то есть конце,
принадлежащем подзапросу.
4. Если D <1, то уточненный коэффициент фильтрации подзапроса равен s х D.
5. Иначе, если s х D < 1, то уточненный коэффициент фильтрации подзапроса
равен (D - 1 + (s х D))/D.
6. Иначе, пусть уточненный коэффициент фильтрации подзапроса равен 0,99. Даже
очень плохо фильтрующее условие EXISTS позволит в действительности избежать
увеличения количества строк и обеспечит лучшую стоимость фильтрации на еди-
ницу измерения, чем соединение вниз совсем без фильтра. Это последнее прави-
ло относится к случаям «лучше, чем ничего» (правда, ненамного лучше).
ПРИМЕЧАНИЕ----------------------------------------------------------------
Как прочие правила в этой книге, эти правила вычисления корреляционного коэффициента подзапро-
са и уточненного коэффициента фильтрации подзапроса являются эвристическими. Так как точные
числа редко необходимы для выбора правильного плана исполнения, эти тщательно спроектирован-
ные, надежные эвристические правила позволяют принять правильное решение по крайней мере в 90 %
случаев, и практически никогда не выдают очень плохих решений. Как и во многих других частях кни-
ги, точное вычисление коэффициентов для сложного запроса находится далеко за пределами возмож-
ностей ручных методов настройки.
Проверьте, как вы понимаете правила, вычислив корреляционный коэффици-
ент предпочтения и уточненный коэффициент фильтрации для рис. 7.31, в кото-
ром не хватает этих двух чисел.
Рис. 7.31. Сложный запрос, в котором отсутствуют нужные значения для полусоединения
236
7. Диаграммное изображение и настройка сложных SQL-запросов
Проверьте свой ответ, прочитав следующее объяснение. Вычислим корреляци-
онный коэффициент предпочтения.
1. Пусть D = 2 и М = 1 (что подразумевает отсутствие этого числа на диаграмме).
Пусть S = 0,015 (наилучший коэффициент фильтрации среди всех в подзапро-
се, принадлежащий таблице S3, которая находится на два уровня ниже корне-
вой детальной таблицы D подзапроса). Пусть теперь R = 0,01, то есть равно
значению наилучшего фильтра среди всех узлов дерева под корневой деталь-
ной таблицей М внешнего запроса, включая этот узел.
2. Найдем D х S = 0,03 и М х R = 0,01; следовательно, D х S > М х R. Перейдем
к шагу 3.
3. Так как S > R, то корреляционный коэффициент предпочтения равен S/R, то
есть 1,5.
Чтобы найти уточненный коэффициент фильтрации подзапроса, сделайте сле-
дующее.
1. Обратите внимание, что корреляционный коэффициент предпочтения больше
1, поэтому необходимо перейти к шагу 2.
2. Обратите внимание, что подзапрос включает несколько таблиц и содержит
фильтры, поэтому необходимо перейти к шагу 3.
3. Найдем D = 2, и найдем коэффициент фильтрации для узла D, s = 0,1.
4. Так как D > 1, необходимо перейти к шагу 5.
5. Вычислим s х D = 0,2, что меньше 1, поэтому уточненный коэффициент фильт-
рации вычисляется как (D - 1 + (s х D))/D = (2 - 1 + (0,1 х 2))/2 = 0,6.
В следующем разделе, посвященном оптимизации подзапросов EXISTS, я про-
иллюстрирую оптимизацию полной диаграммы, показанной на рис. 7.32.
Диаграммное изображение подзапросов NOT EXISTS
Условия подзапроса, которые можно выразить при помощи NOT EXISTS или NOT IN,
проще, чем подзапросы типа EXISTS, в одном отношении — невозможно перейти от
подзапроса наружу к внешнему запросу. Это устраняет необходимость в корреля-
ционном коэффициенте предпочтения. Буква Е, указывающая условие подзапро-
са типа EXISTS, заменяется на букву N, чтобы обозначить условие подзапроса типа
NOT EXISTS, а корреляционное соединение теперь называется антисоединением, а не
полусоединением, так как оно предназначено для поиска случая, когда для соеди-
нения со строками из подзапроса не находится соответствия.
Оказывается, практически всегда условия подзапроса типа NOT EXISTS лучше
выражать при помощи NOT EXISTS, а не при помощи NOT IN. Рассмотрим следующий
шаблон для подзапроса NOT IN:
SELECT ..
FROM ... Outer_Anti_Joined_Table Outer
WHERE...
AND Outer.Some_Key NDT IN (SELECT Inner.Some_Key
FROM ... Subquery_Ant1_Jo1ned_Table Inner WHERE
<Условия и соединения для таблиц подзапроса^
Можно и нужно перефразировать этот шаблон в эквивалентную форму NOT
EXISTS: х
Запросы с подзапросами
237
SELECT ...
FROM . 0uter_Ant1_Joined_Table Outer
WHERE...
AND Outer.Sorne_Key IS NOT NULL
AND NOT EXISTS (SELECT null
FROM ... Subquery_Anti_Joined_Table Inner WHERE
«Условия и соединения для таблиц подзапроса»
AND Outer.Some_Key - Inner.Some_Key)
ПРИМЕЧАНИЕ --------------------------------------------------------------------------------
Чтобы преобразовать NOT IN в NOT EXISTS без изменения функциональности, необходимо добавить
условие NOT nul 1 для ключа корреляционного соединения во внешней таблице. Причиной служит
то, что условие NOT IN эквивалентно набору условий «не равно», соединенных условием ИЛИ, но
база данных не считает выражение NULL 1 - <Некоторое_значение> истинным, поэтому форма NOT
IN отбрасывает все строки из внешнего запроса с равными null ключами корреляционного соедине-
ния. Этот факт малоизвестен, поэтому, вероятно, действительным намерением разработчика такого
запроса является включение в результат запроса строк, которые форма NOT IN незаметно исключает.
При преобразовании форм у вас появляется отличная возможность найти и исправить эту вероят-
ную ошибку.
Условия подзапросов типа EXISTS и NOT EXISTS прекращают поиск соответствий
сразу же после того, как находят первое соответствие, если таковое существует.
Условия подзапроса NOT EXISTS потенциально полезнее, если применять их рано в
плане исполнения, так как, когда они быстро останавливаются с найденным соот-
ветствием, то отбрасывают соответствующую строку, а не сохраняют ее, что делает
следующие шаги плана быстрее. Напротив, чтобы отбросить строку с условием
EXISTS, база данных должна проверить все потенциально подходящие строки и ис-
ключить их — это более дорогая операция, если в полусоединении для каждой глав-
ной строки существует много детальных записей. Помните следующие правила
для сравнения условий EXISTS и NOT EXISTS, указывающих на детальные таблицы от
главной таблицы во внешнем запросе:
Проверка неселективного условия EXISTS недорога (так как соответствие нахо-
дится просто, обычно в первой же проверенной строке полусоединения), но
отбрасывает немного строк из внешнего запроса. Чем больше строк вернет под-
запрос, тем дешевле и менее селективна проверка условия EXISTS. Если же усло-
вие EXISTS селективно, то его проверка, вероятнее всего, дороже, так как при
этом должно исключаться соответствие для каждой детальной строки.
Проверка селективного условия NOT EXISTS недорога (так как соответствие на-
ходится просто, обычно в первой же проверенной строке полусоединения) и
отбрасывает много строк из внешнего запроса. Чем больше строк вернет под-
запрос, тем дешевле и селективнее проверка условия NOT EXISTS. С другой сто-
роны, проверка неселективных условий NOT EXISTS также дорога, так как для
каждой детальной строки необходимо подтверждение, что соответствия не су-
ществует.
Так как преобразование условий подзапроса NOT EXISTS в эквивалентные про-
стые запросы без подзапросов и дорого, и не слишком полезно, лучше использо-
вать подзапросы NOT EXISTS на обоих концах антисоединения: там, где находится
главная таблица, и там, где детальная. Очень редко возникает необходимость по-
иска альтернативных способов выражения условия NOT EXISTS.
238
7. Диаграммное изображение и настройка сложных SQL-запросов
Поскольку проверка селективных условий NOT EXISTS недорога, оказывается,
вычислить уточненный коэффициент фильтрации подзапроса легко.
1. Измерьте q (количество строк, возвращенных внешним запросом, если удалить
условие подзапроса NOT EXISTS) и t (количество строк, возвращенное полным
запросом, включая подзапрос). Пусть С — количество таблиц в разделе FROM
подзапроса (обычно для условий NOT EXISTS это число равно единице).
2. Пусть уточненный коэффициент фильтрации подзапроса равен (С - 1 + (t/q))/C.
Настройка запросов с подзапросами
Как и для простых запросов, оптимизация сложных запросов с подзапросами вы-
полняется просто, если у вас есть правильная диаграмма запроса. Далее перечис-
лены шаги оптимизации сложных запросов, включая подзапросы, на основе пол-
ной диаграммы запроса.
1. Преобразуйте все условия NOT IN в эквивалентные условия NOT EXISTS следуя
описанному ранее шаблону.
2. Если корреляционное соединение — это соединение типа EXISTS, и подзапрос на-
ходится на главном конце этого соединения (то есть указатель стрелки посереди-
не связи указывает вниз), преобразуйте сложный запрос в простой, как описано
ранее, и настройте его, следуя обычным правилам для простых запросов.
3. Иначе, если корреляционное соединение — это соединение типа EXISTS, найди-
те наименьший корреляционный коэффициент предпочтения среди всех под-
запросов типа EXISTS (если их больше одного). Если значение этого коэффици-
ента меньше 1,0, преобразуйте это условие подзапроса в эквивалентное условие
IN и выразите все остальные условия подзапросов типа EXISTS, явно применяя
условие EXISTS. Оптимизируйте некоррелированный подзапрос IN, как если бы
это был отдельный запрос; это начало плана исполнения всего запроса. После
обработки некоррелированного подзапроса база данных выполнит операцию
сортировки, чтобы выбросить повторяющиеся ключи коррелированного соеди-
нения из списка, созданного подзапросом. Следующее соединение после обра-
ботки этого первого подзапроса выполняется с коррелированным ключом во
внешнем запросе, следуя индексу по этому ключу соединения, который должен
быть индексирован. Начиная с этой точки, обрабатывайте внешний запрос, как
если бы ведущий подзапрос не существовал, а первым узлом была бы ведущая
таблица внешнего запроса.
4. Если все корреляционные коэффициенты предпочтения больше или равны 1,0
или если в запросе есть только условия подзапросов типа NOT EXISTS, выберите
ведущую таблицу из внешнего запроса, как если бы в нем не было условий под-
запроса, следуя обычным правилам для простых запросов.
5. Когда вы достигнете узлов внешнего запроса, которые включают полусоедине-
ния или антисоединения с еще не выполненными подзапросами, обрабатывай-
те каждый подзапрос, как если бы это был один находящийся ниже узел (даже
если корреляционное соединение на самом деле вверх). Выбирайте точки вы-
полнения оставшихся подзапросов, как если бы у этих виртуальных узлов был
коэффициент фильтрации, равный уточненному коэффициенту фильтрации
подзапроса.
Запросы с подзапросами
239
ПРИМЕЧАНИЕ---------------------------------------------------------------------
Так как коррелированные подзапросы останавливаются, как только находят первую подходящую строку,
если такая существует, то они избегают риска увеличения строк и могут лишь уменьшить текущее ко-
личество строк. Однако поскольку им часто приходится изучать много строк для того, чтобы выпол-
нить фильтрацию, правильное значение уточненного коэффициента фильтрации подзапроса зачастую
делает этот виртуальный узел эквивалентным практически не фильтрованному узлу в отношении пре-
имуществ к затратам.
6. Как только, выполнив шаг 5, вы помещаете коррелированное соединение в по-
рядок соединения, сразу же выполняйте весь данный коррелированный под-
запрос, оптимизируя план исполнения этого подзапроса, считая корреляцион-
ный узел ведущим узлом этого независимого запроса. Закончив обработку этого
подзапроса, возвращайтесь к внешнему запросу и продолжайте оптимизиро-
вать дальнейший порядок соединения.
В качестве примера возьмем рис. 7.32, представляющий собой рис. 7.31 с ука-
занными корреляционным коэффициентом предпочтения и уточненным коэффи-
циентом фильтрации подзапроса.
Рис. 7.32. Задача на оптимизацию сложного запроса с подзапросом
Так как коррелированное соединение относится к типу EXISTS, шаг 1 не при-
меняется. Так как указатель стрелки посередине полу соединения указывает вверх,
шаг 2 не применяется. Самый маленький (и единственный) корреляционный ко-
эффициент предпочтения равен 1,5 (рядом с Е), поэтому шаг 3 не применяется.
Выполняя шаг 4, находим, что наилучший ведущий узел во внешнем запросе —
это М. Выполняя шаг 5, выбираем между соединениями вниз с А1 и А2 с коэффи-
циентами фильтрации 0,2 и 0,7, соответственно, и виртуальным соединением вниз
с виртуальным узлом, представляющим полный подзапрос, с виртуальным ко-
эффициентом фильтрации 0,6. А1 — лучший из этих трех кандидатов, имеюший
лучший коэффициент фильтрации, поэтому присоединяем его следующим. Так
как от А1 нет соединений вниз, следующим лучшим выбором в порядке соедине-
ния считаем подзапрос (опять применяя шаг 5), поэтому выполняем полусоедине-
ние с 0.
Выполняя шаг 6, уже начав обработку подзапроса, необходимо закончить его,
начиная с D как с ведущего узла. Следуя правилам для простых запросов, далее
присоединяем S1, S3, S2 и S4 в указанном порядке. Возвращаясь к внешнему запро-
су и применяя обычные правила для простых запросов, находим оставшийся по-
240
7. Диаграммное изображение и настройка сложных SQL-запросов
рядок соединения как А2, Bl, В2. Полный оптимальный порядок соединения, вклю-
чая полусоединение — (М. Al. D. S1. S3. S2. S4, А2. Bl, В2).
ПОЧЕМУ НЕОБХОДИМО ТАК БЕСПОКОИТЬСЯ О ПОДЗАПРОСАХ?------------------------------
Правила для подзапросов достаточно сложны, чтобы обескуражить, поэтому я хотел бы сделать призна-
ние, могущее укрепить ваш боевой дух. Вот уже более 10 лет я успешно настраиваю SQL с подзапросами,
не используя формальные правила, а лишь прислушиваясь к собственной интуиции и применяя общее
правило выбора точки начала от подзапроса или от внешнего запроса, основываясь на том. у кого из них
более селективные условия. Обычно я не забочусь о том, когда именно будут выполнены подзапросы,
кроме случаев, когда с них начинается выполнение всего запроса, так как этим трудно управлять, а улуч-
шения по сравнению с выбором автоматических оптимизаторов минимальны.
Время от времени (хотя не так часто, как вы можете подумать) я встречаюсь с граничными случаями, когда
имеет смысл попробовать разные альтернативные варианты и выбрать самый быстрый. Мой способ может
прекрасно подойти и вам. Если вы не доверяете интуиции или хотите иметь твердую основу, включающую
мой опыт, то формальные правила будут вам полезны. Формальные правила, приведенные в этом разделе,
которые я сформулировал специально для этой книги, предназначены для обработки всего диапазона ре-
альных запросов с разумным компромиссом между математической безупречностью и удобством. Только
объемные вычисления «в лоб* могут справиться с задачей такой сложности без применения метода проб и
ошибок, но эти правила предлагают использовать некоторую автоматическую интуицию, которая так же
хороша, а может быть, даже лучше моего «ленивого» подхода.
Запросы с представлениями
Используя представления, можно сделать так, чтобы чрезвычайно сложный за-
прос выглядел как простая таблица с точки зрения человека, который пишет запрос
с использованием представления. Когда множество запросов совместно использу-
ют большое количество базового SQL-кода, то общие представления многократ-
ного использования могут стать мощным механизмом для упрощения кода прило-
жения. К сожалению, простое сокрытие действий от разработчика приложения не
уменьшает сложность этих действий, предназначенных для получения фактиче-
ских данных. С другой стороны, сокрытие сложности от разработчика с большой
вероятностью усложнит проблему настройки, которую оптимизатору придется
преодолеть в поиске быстрого плана исполнения. В этом разделе я упоминаю два
типа запросов, значимых для проблемы настройки.
1. Запросы, определяющие представления.
Это запросы, лежащие в основе представлений (то есть запросы, которые при-
меняются для создания представлений при помощи CREATE VIEW <Имя_представле-
ния> AS <3апрос_определяющий_представление>).
2. Запросы, использующие представления.
Это запросы, которые вы настраиваете, и которые база данных фактически вы-
полняет. В этих запросах представления упоминаются во фразе FROM (напри-
мер, SELECT ... FROM Viewl VI. View2 V2,... WHERE ...).
При настройке SQL представления обычно добавляют сложности в трех отно-
шениях.
Необходимо преобразовывать запросы, использующие представления, в экви-
валентные запросы к реальным таблицам, чтобы создавать и оптимизировать
диаграммы соединений.
Запросы с представлениями
241
Запросы к представлениям обычно содержат ненужные или излишние узлы
в скелете запроса. Каждое представление с собой приносит и весь определяю-
щий представление запрос, вместе с поддеревом, включающим все определяю-
щие представление узлы и соединения. Использование представления подра-
зумевает и использование полного поддерева. Однако разработчику, который
применяет представление, часто требуется лишь несколько столбцов представ-
ления, и он мог бы пропустить некоторые узлы и соединения в запросе, опре-
деляющем представление, при создании эквивалентного запроса к простым
таблицам. Когда приложению требуются все узлы представления, запрос, ис-
пользующий представление, все же может излишне часто обращаться к этим
узлам, присоединяя те же строки тех же основных таблиц в различных скры-
тых контекстах. Я приведу такой пример в разделе «Излишние считывания
в запросах, использующих представления».
Иногда использующие представления запросы невозможно выразить просто
как эквивалентные запросы к простым таблицам. Обычно случаи, когда исполь-
зующий представления запрос возвращает разные результаты из запроса к про-
стой таблице, скрыты и редко возникают. Однако правильные результаты в этих
скрытых случаях — это не те результаты, которые получает использующий пред-
ставления запрос! Если запрос, использующий представления, нельзя легко
разложить в эквивалентный простой запрос к таблицам, производительность
чаще всего страдает, а скрытые случаи, определяющие поведение, относящееся
именно к представлениям, содержат ошибки. Тем не менее, улучшение про-
изводительности с практически эквивалентным простым запросом к таблицам
не должно приводить даже к небольшим изменениям функциональности, и вам
нужно быть очень осторожными, чтобы не внести ошибку. (Чаще всего вы бу-
дете исправлять ошибки, а не добавлять новые, но новые ошибки будут более
заметны!) Этот случай я проиллюстрирую в разделе «Внешние соединения
с представлениями».
ВНИМАНИЕ ---------------------------------------------------------------------------
Меня часто просят настроить или установить производительность запроса, определяющего представ-
ление, не предоставляя мне список всех запросов, использующих данное представление. Также меня
просят настроить запросы, использующие представления, не показывая запрос, определяющий пред-
ставление. Обе эти просьбы невыполнимы. Дело в том, что ни одни определяющий представление зап-
рос, чуть более сложный, чем SELECT <Список_простых_столбцов> FROM <Одна_таблииа> не может прекрасно
выполняться во всех возможных запросах, использующих представление. И ни один использующий
представление запрос не будет хорошо выполняться, если в запросе, определяющем представление, не
используется эффективный путь к необходимым данным.
Для данного представления вам необходимо знать и настроить все запросы, использующие представле-
ние, чтобы быть уверенным, что определяющий представление запрос абсолютно правильный в соответ-
ствующем контексте. Вам необходимо знать запрос, определяющий представление, для всех используемых
представлений, чтобы быть уверенным, что использующий представления запрос верен.
Диаграммное изображение запросов,
использующих представления
Диаграммное изображение использующих представления запросов относительно
просто, хотя иногда может быть утомительно.
242
7. Диаграммное изображение и настройка сложных SQL-запросов
1. Создайте диаграмму для всех определяющих представление запросов, как если
бы это были отдельные запросы. Все диаграммы запросов, определяющих пред-
ставление, должны быть нормальными, в том смысле, что у них должна быть
одна корневая детальная таблица и указывающие только вниз соединения «мно-
гие к одному» от этого верхнего узла, соответствующие структуре дерева. Если
определяющий представление запрос не отображается на нормальный скелет
запроса, то запросы, использующие это представление, будут, вероятно, рабо-
тать плохо и возвращать неправильные результаты. Считайте первичный ключ
корневой детальной таблицы запроса, определяющего представление, вирту-
альным первичным ключом всего представления.
2. Создайте диаграмму запроса, использующего представление, считая, что все
представления — это всего лишь простые таблицы. У соединения с представле-
нием должна быть стрелка на конце, соответствующем представлению (и вам
следует помещать представление на нижний конец связи), только если соеди-
нение производится с виртуальным первичным ключом представления. Сим-
волически укажите условия фильтрации для представления в запросе, исполь-
зующем представление, в виде буквы F, не задумываясь пока что о вычислении
коэффициента фильтрации. Обведите пунктирной окружностью каждый узел.
3. Разверните диаграмму запроса, использующего представления, созданную на
шаге 2, заменив все узлы, соответствующие представлениям, полной диаграммой
запроса, определяющего представление, из шага 1. Затем обведите пунктирной
линией поддерево запроса, определяющего представление. Любое соединение
сверху будет присоединяться к определяющему представление поддереву как
его корневой детальный узел. Соединения, отходящие от представления вниз,
могут начинаться от любого узла представления, в зависимости от того, какая
из таблиц запроса, определяющего представление, содержит внешний ключ
(в определяющем представление списке SELECT) соединения. Любое условие
фильтрации для представления становится фильтрующим условием соответ-
ствующего узла запроса, определяющего представление, в зависимости от того,
на столбец какого узла действует зто условие. Найдите фактический коэффи-
циент фильтрации для всех подобных условий обычным способом (дополняя
символ F на начальной диаграмме запроса). Если необходимо, комбинируйте
коэффициенты фильтрации из определяющих представление и использующих
представление запросов, если эти запросы накладывают различные фильтры
на одни и те же узлы.
Возможно, эти правила покажутся вам абстрактными и сложными, но пример
должен прояснить процесс.
Возьмем два определения представлений:
CREATE VIEW Shipment^ AS
SELECT A.Address_ID Sh1pmcnt_Address_ID. A.Street_Addr_Linel
Shipment_Street_Address_Linel. A.Street_Addr_L1ne2
Shipment_Street_Address_L1ne2. A.C1ty_Name Shipment CityName.
A.State_Abbrev1ation Shipment_State. A.ZIP_Code Shipment_ZIP.
S.Sh1pment_Date. S.Shipment_ID
FROM Shipments S. Addresses A
WHERE S.Address_ID = A.Address_ID
CREATE VIEW Recent_Order_V AS
Запросы с представлениями
243
SELECT 0.0rder_ID. О Order_Date. O.Customer_ID.
C.Phone_Number Customer_Ma1n_Phone, C.F1rst_Name Customer_First_Name.
C.Last_Name Customer_Last_Name,
C.Address_ID Customer_Address_ID. ОТ.Text Order_Status
FROM Orders 0. Customers C, Code_Trans1ations ОТ
WHERE O.CustomerlD = C.Customer_ID
AND O.Status_Code = ОТ.Code
AND DT.CodeJype = 'ORDER_STATUS'
AND D.Drder_Date > SYSDATE - 366
Шаг 1 требует создания диаграмм для обоих определяющих представления зап-
росов, как показано на рис. 7.33. Для создания этих диаграмм мы воспользовались
методом, описанным в главе 5, и использовали ту же статистику для коэффициен-
тов фильтрации и соединения, что и для соответствующего примера, показанного
на рис. 5.5.
Запрос, определяющий
представление,
Shipment_V
Запрос, определяющий
представление,
Order_V
Рис. 7.33. Диаграммы запросов для определяющих представления запросов
Вот как выглядит запрос, использующий представление:
SELECT 0V.Customer_Ma1n_Phone. С.Honorific. 0V.Customer_F1rst_Name.
OV.Customer_Last_Name. C.Suffix. OV.Customer_Address_ID.
SV.Shi pment_Address_ID. SV.Shi pment_Street_Address_Linet.
SV.Sh1pment_Street_Address_Li ne2. SV.Shi pment_C1ty_Name.
SV.Shipment_State. SV.Shipment_Z1p, DD.Deferred_Shipment_Date.
OD.Item_Count, ODT.Text. P.Product_Descr1ption. SV Shipment_Date
FROM Recent_Order_V DV. Order_Details DD, Products P. Shipment_V SV.
Code_Translations ODT. Customers C
WHERE UPPER(OV.CustomerJ_ast_Name) LIKE :last_name||T
AND UPPER(OV.Customer_First_Name) LIKE :f1rst_name||’%'
AND OD.Order_ID = DV.Order_ID
AND OV.Customer_ID = C Customer_ID
AND DD.Product_ID = P.Product_ID(+)
AND OD.Shipment_ID = SV.Shipment_ID(+)
AND DD.Status_Code = ODT.Code
AND ODT.CocteType = 'ORDER_DETAIL_STATUS'
ORDER BY OV.Customer_ID. DV.Grder_ID Desc. SV.Shipment_ID, 0D.0rder_Detai1_ID
Переходя к шагу 2, создадим начальную диаграмму запроса так, как если бы
представления были простыми таблицами, как показано на рис. 7.34.
Заменим все узлы представлений на рис. 7.34 диаграммами запросов, опреде-
ляющих представления, с рис. 7.33. А скелеты этих запросов обведем пунктирной
кривой, чтобы обозначить границы представлений. Присоединим скелеты опреде-
ляющих представления запросов к оставшейся части полной диаграммы запроса к
подходящим узлам, в зависимости от того, какая таблица из определения пред-
ставления содержит ключ соединения. Обычно любые соединения с представле-
нием сверху связаны с корневой детальной таблицей определяющего представле-
244
7. Диаграммное изображение и настройка сложных SQL-запросов
ние запроса. Однако узлы, представляющие главные таблицы, находящиеся под
представлением (например, узел С на рис. 7.34), могут быть присоединены к любо-
му узлу скелета определения представления, в зависимости от того, какая таблица
содержит внешний ключ, указывающий на этот главный узел. Добавим явные чис-
ловые коэффициенты фильтрации ко всем узлам в скелете запроса, имеющим филь-
тры — как в запросе, определяющем представление, так и в запросе, использую-
щем его. На рис. 7.34 коэффициент фильтрации 0,3 рядом с узлом 0 появляется
благодаря фильтру в определяющем представление запросе, а коэффициент филь-
трации 0,0002 рядом с узлом С — благодаря условиям на имя и фамилию покупате-
лей в использующем представление запросе.
Рис. 7.34. Нерасширенная диаграмма запроса, использующего представление
Результат должен выглядеть как на рис. 7.35. Там я добавил звездочку к левому
узлу С, чтобы указать на различие между узлами, имеющими одинаковые имена.
И снова я использовал ту же статистику для фильтра по имени покупателя, что
и в схожем примере на рис. 5.5, чтобы получить коэффициент фильтрации 0,0002
рядом с С внутри правого скелета представления.
OD
Рис. 7.35. Расширенная диаграмма запроса, использующего представление
Итак, мы завершили диаграмму, которая потребуется для перехода к фактиче-
ской настройке запроса, использующего представления, для чего необходимо оп-
ределить, нужно ли для получения оптимального плана изменить определяющий
представление или использующий представление запрос.
Настройка запросов с представлениями
Обычно оптимальный план исполнения для запроса, использующего представле-
ния — это план, который бы вы составили для соответствующей диаграммы запро-
са к простым таблицам. Однако вам придется решить четыре проблемы.
Запросы с представлениями
245
Некоторые соединения со сложными представлениями трудно представить как
простые соединения с простыми таблицами. В частности, внешние соединения
с представлениями, в которых есть соединения в запросах, определяющих пред-
ставления, сложно выражать, используя простые соединения. Эта проблема
касается нашего примера, поэтому я рассмотрю ее подробнее в следующем раз-
деле «Внешние соединения с представлениями».
Некоторые представления используют в точности те же строки той же табли-
цы, что и другая таблица в запросе, использующем представления, что создает
излишнюю работу для базы данных, которую вам придется устранить. Это про-
исходит с узлами С* и С на рис. 7.35, поэтому данная проблема будет рассматри-
ваться позднее.
Преимущество представлений с точки зрения упрощения разработки заключа-
ется в том, что они скрывают сложность запросов, но это преимущество также
позволяет незаметно создавать в коде избыточные соединения, которые были
бы очевидны и потребовали бы большей работы по кодированию, если бы раз-
работчики использовали только простые таблицы.
Узлы внутри определяющих представления запросов и соединения с ними час-
то оказываются ненужными для получения результата, необходимого в исполь-
зующем представления запросе.
Использование представлений ограничивает ваши возможности управления
планом исполнения. Если вы измените определяющий представление запрос,
чтобы улучшить план исполнения запроса, использующего представление, то
можете ненамеренно ухудшить производительность других запросов, исполь-
зующих то же самое представление. Вы всегда можете создать новое представ-
ление, исключительно для удобства использования одного запроса, но это про-
тиворечит преимуществу представлений, которое заключается в совместном
использовании кода. В целом, подсказки SQL и прочие изменения в запросе,
использующем представления, не могут улучшить контроль над тем, как база
данных обращается к таблицам в запросе, определяющем представление. Иногда
для получения необходимого плана вам приходится исключать использование
представлений.
Внешние соединения с представлениями
Возвращаясь к предыдущему примеру, рассмотрим, что же означает наличие внеш-
него соединения с представлением Shipment_V, которое само по себе является внут-
ренним соединением между таблицами Shipments и Addresses. Так как база данных
должна считать, что существует реальная таблица с точно теми строками, которые
найдет представление, соединение обнаруживает внутреннее соединение для зна-
чений Shipment_ID, которые присутствуют в Shipments и указывают на поставки, поле
Address_ID для которых успешно соединяется с таблицей Addresses. Если база данных
не может провести успешное соединение одновременно и с Shi pments, и с Addresses,
то соединение с представлением становится полностью внешним (с обеими табли-
цами), даже если первое соединение с Shipments могло пройти успешно. При поис-
ке плана со вложенными циклами база данных не может знать, будет ли для внеш-
него соединения найден внутренний случай, пока не проведет успешное соединение
с обеими таблицами в запросе, определяющем представление.
246
7. Диаграммное изображение и настройка сложных SQL-запросов
К сожалению, это все слишком сложно, чтобы такой случай мог быть обработан
автоматически сгенерированным кодом, поэтому ваша база данных может просто
сдаться и отказаться искать план с вложенными циклами. Вместо этого сервер базы
данных понимает, что не так уж важно, насколько сложна лежащая в основе запро-
са логика. Эта логика функционально не сможет сделать никакой ошибки, если,
просто получит все строки из запроса, определяющего представление, и обработа-
ет результат как реальную таблицу. Для внешнего соединения с представлением
база данных обычно выполняет соединение методом сортировки слиянием или
соединение хэшированием с временно созданной таблицей. Это достаточно безо-
пасно в плане функциональности, но обычно становится кошмаром для произво-
дительности, кроме тех случаев, когда сам по себе запрос, определяющий пред-
ставление, достаточно быстр.
ВНИМАНИЕ -----------------------------------------------------------------------
В качестве основного правила для улучшения производительности избегайте внешних соединений
с любыми представлениями, более сложными, чем SELECT <Список_прость1Х_столбцов> FROM <0дна_
таблицам
Схожие проблемы возникают для всех типов соединений с представлениями,
в которых в определяющем представление запросе присутствуют UNION или GROUP
BY. Однако соединения, исходящие от подобных представлений, когда в них есть
таблица, которую можно выбрать ведущей таблицей запроса, обычно работают
прекрасно.
Снова рассмотрим использующий представление запрос из предыдущего под-
раздела. Если вы поместите определяющий представление запрос для Shi pment V в
запрос, использующий представления, чтобы разрешить проблему производитель-
ности с внешним соединением, то, вероятно, получите такой результат:
SELECT OV.Customer_Main_Phone. С.Honorific. OV.Customer_First_Name.
OV Customer Last^Name. C.Suffix. OV.Customer_Address_ID.
A.Address_ID Shi pment_Address_ID.
A.Street_Addr_Linel Sh1pment_Street_Address_Linel.
A.Street_Addr_Line2 Shipment_Street_Address_L1ne2.
A.CityJtaine Shipment_C1ty_Name. A.State_Abbreviation Shipment_State.
A.ZIP_Code Shipment ZIP, OD.Deferred_Ship_Date. DD.Item_Count.
DDT.Text. P.Prod_Descr1ption. S.Shipment_Date
FROM Recent_Drder_V OV. Drder_Details 00. Products P. Shipments S,
Addresses A. Code_Translations OCT. Customers C
WHERE UPPER(OV.Customer_Last_Name) LIKE :last_name||T
AND UPPER(0V.Customer_F1rst_Name) LIKE :f1rst_name||T
AND OD.Order_ID = 0V Order_ID
AND OV.CustomerlD = C.CustomerlD
AND OD.ProductID = P.Product_ID(+)
AND OD.Shipment_ID = S.Shipment_ID(+)
AND S.Address_ID = A.Address_ID(+)
AND OD.Status_Code = ODT.Code
AND ODT.CodeJype = ’ORDER_DETAIL_STATUS’
ORDER BY OV.Customer_ID. OV.Order_ID Desc. S.Shipment_ID. 0D.0rder_Deta11_ID
К сожалению, этот код не позволяет получить тот же результат, что и исходный
запрос, из-за специфики внешнего соединения с представлением. В частности,
исходный запрос возвращает значение Shi pment Date, равное null, если полное пред-
ставление, включая соединение с Addresses, не может успешно соединиться
с Order Details. Таким образом, если для перевозки (shipment) не указано допус-
Запросы с представлениями
247
тимого, не равного null значения Address_ID, исходный запрос возвращает null для
Shi pment_Date, несмотря на то, что соединение с Shi pments само по себе допустимо.
Скорее всего, такое поведение — это совсем не то, что требовалось разработчи-
ку, и в нем нет функциональной необходимости, поэтому новая форма будет, ско-
рее всего, работать прекрасно, даже лучше, чем исходная, в этом редком случае.
Однако любое изменение функциональности, сделанное для улучшения произво-
дительности, опасно. Следовательно, перед тем как вносить изменения, например,
проводить описанное слияние запроса, определяющего представление, с главным
оператором SQL, удостоверьтесь, что новое поведение запроса будет правильным
для редких случаев, и предупредите разработчиков, что изменение может привес-
ти к тому, что тестирование вернет другие результаты. Маловероятно, что вам дей-
ствительно понадобится именно исходное поведение запроса. Но если вы просто
хотите проявить осторожность, не выясняя, было ли исходное поведение правиль-
ным для редкого случая, то можете прекрасно эмулировать функциональность
исходного запроса таким кодом:
SELECT OV.Customer_Main_Phone. C.Honorific. OV.Customer_First_Name.
OV.Customer_Last_Name. C. Suf fix DV.Customer_Address_ID.
A.Address_ID Shi pment_Address_ID,
A.Street_Addr_Li nel Shipment_Street_Address_L1nel.
A.Street_Addr_L1ne2 Shi pment_Street_Address_Li ne2.
A.City_Name Shipment_City_Name, A.StateAbbreviation Shipment-State.
A.ZIP_Code ShipmentZIP. DD.Deferred_Ship_Date, OD.Item_Count.
DDT.Text. P.Prod_Descr1ption,
DECODE(A.AddressJD. NULL. TO_DATE(NULL).
S.Shipment_Date) Shipment-Date
FROM Recent_Drder_V OV. Drder Details DD. Products P. Shipments S.
Addresses A, Code_Translat1ons ODT, Customers C
WHERE UPPER(DV.Customer_Last_Name) LIKE :last_name||X
AND UPPER(OV.Customer_F1rst_Name) LIKE :first_name||X
AND DD.OrderlD = DV.Order_ID
AND OV.Customer_ID = C.Customer_ID
AND OD.Product_ID = P.Product_ID(+)
AND OO.Shipment_ID = S.Shipment_ID(+)
AND S.AddressID = A.Address_ID(+)
AND OD.Status_Code = ODT.Code
AND ODT.Codejype = 'ORDER_DETAIL_STATUS'
ORDER BY DV Customer_ID, OV.Order_ID Desc.
DECODE(A.Address_ID. NULL. TO_NUMBER(NULL). S.ShipmentJD).
OD.Order_Detail_ID
В этом запросе есть два изменения, которые заставляют запрос возвращать ре-
зультаты, как если бы соединение с Shipments выдавало внешний случай независи-
мо от того, возникает ли внешний случай в соединении с Addresses. Без представ-
ления запрос будет обрабатывать соединение с Shi pments независимо от соединения
с Addresses. Однако выражение DECODE в конце списка SELECT и в середине списка
ORDER BY заставляет внутренний случай первого соединения эмулировать внешний
случай соединения (создавая null вместо Shipment_Date и Shipment ID), независимо
от того, будет ли при соединении с Addresses найден внешний случай.
Иногда у вас будут действительно хорошие причины использовать представле-
ние вместо простых таблиц. Наиболее распространенная причина — необходимость
обойти ограничения в автоматически сгенерированном SQL-коде. Функциональ-
но вам может понадобиться какой-то сложный синтаксис SQL, который генератор
SQL обработать не может. Распространенный обход — скрыть эту сложность в оп-
248
7. Диаграммное изображение и настройка сложных SQL-запросов
ределяющем представление запросе, который вы создадите вручную, и заставить
генератор SQL считать представление простой таблицей, скрывая от него все слож-
ности. В таких случаях у вас может не получиться избежать представлений, как,
например, я предполагал в предыдущих решениях. Тогда альтернативный подход —
расширить использование представления, скрывая больше SQL в определении
представления. Например, так как предыдущая задача включала внешнее соеди-
нение с представлением, то вы могли бы решить ее, заключив внешнее соединение
в запрос, определяющий представление. Тогда вместо Shipment_V вы бы использо-
вали OrderDetai 1_V и следующий определяющий представление запрос:
CREATE VIEW Order_Detail_V AS
SELECT A.Address_ID Shipment_Address_ID.
A.Street_Addr_Li nel Shi pment_Street_Address_Linel.
A.Street_Addr_Line2 Shipment_Street_Address_Line2.
A.City_Name Shipment_City_Name. A.State_Abbreviation Shipment_State.
A.ZIP^Code Shipment_ZIP. S.Shipment_Date. S.ShipmentlD.
OD.Deferred_Shi p_Date. OD.Item_Count. DD.Order lD,
OD.Order_Detail_ID. OD.Product_ID. OD.Status_Code
FROM Shipments S. Addresses A. Order_Details OD
WHERE OD.Shipment_ID = S.Shipment_ID(+)
AND S.Address_ID = A.Address_ID(+)
Тогда запрос, использующий расширенное представление, становится таким:
SELECT OV.Customer_Main_Phone. С.Honorific. DV.Customer_First_Name.
DV.Customer_Last_Name. C.Suffix. OV.Customer_Address_ID.
ODV Shipment_Address_ID. ODV.Shipment_Street_Address_Linel.
ODV.Shi pment_Street_Address_Li ne2. ODV.Shi pment_Ci ty_Name.
OOV.ShipmentState. ODV.Shipment_Zip. ODV.Deferred_Ship_Date,
ODV.Item_Count. ODT.Text. P.Prod_Description. ODV.Shipment_Date
FROM Recent_Order_V OV. Order_Detail_V ODV Products P.
Code_Translations ODT. Customers C
WHERE UPPER(OV.Customer_Last_Name) LIKE :last_name||X
AND UPPER(DV.Customer_First_Name) LIKE :first_name||T
AND ODV.Order_ID = OV.OrderlD
AND DV.Customer_ID = C.Customer_ID
AND ODV.Product_ID - P.Product_ID(+)
AND ODV.Status_Code - ODT.Code
AND ODT.Code_Type - 'ORDER_DETAIL_STATUS'
ORDER BY OV.Customer_ID. OV.Order_ID Desc. ODV.Shipment_ID. ODV.Order_Detail_ID
Излишние считывания в запросах,
использующих представления
Теперь рассмотрим случай соединений с узлами, помеченными С* и С на рис. 7.35.
Эти узлы представляют одну и ту же таблицу с одинаковыми операторами соеди-
нения, поэтому любой план исполнения, включающий оба узла, избыточен, он счи-
тывает одни и те же строки таблицы и, вероятно, записи индекса, дважды. Второе,
ненужное считывание в любом случае не должно требовать физического ввода-
вывода, так как первое считывание, выполненное менее чем миллисекунду назад,
должно поместить блок таблицы или индекса в голову совместно используемого
кэша. Если план исполнения сильно фильтруется перед тем, как обратиться ко
второму, избыточному узлу, то дополнительными операциями логического ввода-
вывода можно пренебречь. Но для больших запросов или запросов, в которых боль-
шинство строк фильтруются только после подобных ненужных считываний, сто-
имость излишних операций логического ввода-вывода существенна.
Запросы с представлениями
249
Если разработчик первоначально создал запрос к простым таблицам, вероят-
ность появления ошибки такого типа весьма мала. Чтобы включить ненужное со-
единение, ему пришлось бы сойти со своего пути создания запроса, и избыточ-
ность была бы очевидна при просмотре кода. С представлениями, однако, эти
ошибки легко допустить, причем они будут хорошо спрятаны.
Как избавиться от лишнего соединения с таблицей Customers? У вас есть три
варианта.
Добавить новые требуемые столбцы в список SELECT запроса, определяющего
представление, и использовать их вместо ссылок на столбцы лишней таблицы
в запросе, использующем представления. Это безопасно для других запросов,
которым нужно то же представление, так как изменения включают только до-
бавление столбцов, но не модификацию диаграммы определяющего представ-
ление запроса.
Исключить лишнее соединение из запроса, определяющего представление, и ис-
пользовать только столбцы из узла простой таблицы в запросе, использующем
представления. Однако это опасно, если существуют другие использующие
представления запросы, которым могут понадобиться исключенные столбцы
представления.
Устранить представление из запроса, использующего представления, заменив
его эквивалентными не избыточными соединениями с простыми таблицами.
Ненужные узлы и соединения
Рассмотрим соединение с узлом ОТ в последнем запросе, использующем представ-
ления. Кажется, что исходный определяющий представление запрос включает это
соединение в целях поддержки запросов, относящихся к состоянию заказов. Но на
самом деле этот запрос даже не упоминает состояние заказа, поэтому у вас может
возникнуть вопрос, нужен ли этот узел. Если вы не заметили этот бесполезный
узел, то могли бы распознать его, заметив в плане исполнения соединение с индек-
сом г ) первичному ключу этой таблицы, но без считываний из самой таблицы.
Такие только индексные считывания индексов по первичным ключам обычно ука-
зывают на ненужные соединения.
Безопасное исключение таких ненужных соединений будет достаточно непро-
стым делом, потому что иногда у них есть функциональные побочные эффекты.
Так как это внутреннее соединение, то, по крайней мере, вероятно, что, даже без
фильтра для этого узла, само соединение отбрасывает строки, которые запрос не
должен возвращать. Это может быть сделано за счет отбрасывания строк, где
Orders .Status_Code IS NULL или где Status_Code указывает не недопустимые коды со-
стояния, для которых не существует соответствия в таблице Code_Translations.
Последнее маловероятно или должно быть исправлено во время восстан< >вления
ссылочной целостности. Однако равные null внешние ключи встречаются часто,
и если значение столбца может быть null, вам следует задуматься о добавлении
явного условия Status_Code IS NOT NULL перед тем, как убирать соединение, чтобы
эмулировать неявную фильтрующую функцию внутреннего соединения. Более ве-
роятно, что разработчик, применяющий представление, даже не подумал о неяв-
ной фильтрующей функции представления, и неявный фильтр — это нежелатель-
ная случайность. Таким образом, перед тем, как имитировать прежнее поведение
250
7. Диаграммное изображение и настройка сложных SQL-запросов
в запросе, обращающемся только к базовой таблице без ненужного соединения,
проверьте, было ли предыдущее поведение правильным. Если ваши изменения не-
заметно изменят работу запроса, даже в лучшую сторону, предупредите тестеров,
что результаты тестирования могут измениться в этом случае.
Запросы с операциями над множествами
Иногда вам приходится настраивать составные запросы, в которых используются
операции над множествами, такие, как UNION, UNION ALL, INTERSECT и EXCEPT для ком-
бинирования результатов двух или более простых запросов. Расширение метода
настройки с диаграммами SQL на эти составные запросы выполняется просто: со-
здавайте диаграмму и настраивайте все части независимо, как если бы они были
отдельными запросами. Если отдельные части работают быстро, то и комбиниро-
вание результатов при помощи групповых операций работает хорошо.
ПРИМЕЧАНИЕ --------------------------------------------------
EXCEPT — это ключевое слово, описанное в стандарте ANSI SQL для операций над множествами, пред-
назначенное для поиска различий между двумя наборами. DB2 и SQL Server следуют стандарту, под-
держивая оператор EXCEPT. Однако в Oracle для выполнения той же операции используется MINUS,
вероятно, потому, что Oracle поддерживала ее еще до введения стандарта.
Однако некоторые операции над множествами заслуживают дополнительного
внимания. Операция UNION, кроме комбинирования частей, также должна сортиро-
вать их и отсеивать дубликаты. Последний шаг часто не нужен, особенно, если эти
части разработаны так, чтобы с самого начала избегать повторений. В Oracle опе-
рацию UNION можно заменить операцией UNION ALL, если вы обнаруживаете, что на-
личие дубликатов либо невозможно, либо их не нужно удалять. В базах данных,
которые не поддерживают UNION ALL, можно пропустить шаг, посвященный устра-
нению дубликатов, заменив один запрос UNION двумя или более простыми запроса-
ми, комбинируя результаты на уровне приложения, а не в базе данных.
Операцию INTERSECT обычно можно с успехом заменять подзапросом типа EXISTS,
который ищет подходящую строку, которую выдала бы вторая часть. Например,
если у вас есть две таблицы Employees, вы можете провести поиск совместно ис-
пользуемых записей сотрудников при помощи:
SELECT EmployeeJD FROM Employees!
INTERSECT
SELECT Employee_ID FROM Employees2
Запрос INTERSECT всегда можно заменить следующей конструкцией:
SELECT DISTINCT EmployeeJD
FROM Employees! El
WHERE EXISTS (SELECT null
FROM Employees2 E2
WHERE El.EmployeeJD - E2.EmployeeJD)
Используя методы, описанные в разделе «Запросы с подзапросами», вы бы мог-
ли определить, нужно ли подзапрос типа EXISTS выразить в форме EXISTS или IN
или следует преобразовать его в простое соединение. Обратите внимание, что ус-
ловия корреляционного соединения сильно разрастаются, если в списке SELECT
Упражнение
251
содержится много элементов. Также обратите внимание, что INTERSECT будет ста-
вить в соответствие спискам столбцов значения null, что корреляционное соеди-
нение делать не будет, если только вы не укажете условия соединения специально
для этой цели. Например, если для положительного внешнего ключа Manager_ID
разрешено значение null (а значение Employee_ID не может быть null), то в Oracle
вместо запроса
SELECT Employee_ID. Manager_ID FROM Employees!
INTERSECT
SELECT Employee_ID. Manager_ID FROM Employees2
можно использовать эквивалентный запрос:
SELECT DISTINCT Employee lD. ManagerJD
FROM Employees! El
WHERE EXISTS (SELECT null
FROM Employees2 E2
WHERE El.EmployeeJD = E2.Employee_ID
AND NVL(El.Manager_ID.-l) = NVL(E2.Manager_ID.-D)
Выражение NVL(..., -1) в условии второго корреляционного соединения преоб-
разовывает значения null в столбцах, где оно допустимо, чтобы, когда значению
null сопоставляется также null, соединение было успешно проведено.
Операцию EXCEPT (или MINUS) обычно можно с успехом заменять подзапросом
типа NOT EXISTS. Для поиска записей сотрудников в первой таблице, но не во вто-
рой, вы могли бы воспользоваться таким запросом:
SELECT Employee_ID FROM Employees!
MINUS
SELECT Employee_ID FROM Employees2
Но его всегда можно заменить иным запросом:
SELECT DISTINCT EmployeeJD
FROM Employees! El
WHERE NOT EXISTS (SELECT null
FROM Employees2 E2
WHERE El.Employee_ID = E2.Employee_ID)
И тогда запрос можно обрабатывать, используя методы, описанные ранее в раз-
деле «Запросы с подзапросами».
Упражнение
Далее представлен невообразимо сложный запрос, предназначенный для глубо-
кой проверки вашего понимания настройки запросов с подзапросами. На рис. 7.36
показана более сложная и запутанная диаграмма запроса, чем любая, с которой
вы встретитесь за целый год интенсивной настройки SQL. Если вы сможете спра-
виться с такой диаграммой, то решите и любой сценарий с подзапросами, кото-
рый встретится вам в реальной жизни, поэтому попытайтесь выполнить упраж-
нение.
ПРИМЕЧАНИЕ------------------------------------------------------------------------
Если вам не удастся справиться с задачей с первого раза, вернитесь к ней и попытайтесь еще раз после
дополнительной практики и повторного изучения материала.
252
7. Диаграммное изображение и настройка сложных SQL-запросов
Рис. 7.36. Сложная задача с несколькими подзапросами
Найдите отсутствующие коэффициенты для корреляционных соединений.
Предполагайте, что t - 5 (количество строк, возвращенное всем запросом, вклю-
чая подзапрос NOT EXISTS), a q - 50 (количество строк, возвращенное запросом, если
из него убрать условие NOT EXISTS). Найдите лучший порядок соединения, включая
все таблицы в подзапросах и во внешнем запросе.
Почему метод
диаграмм работает
В главах с 5 по 7 рассказывалось, как настраивать SQL-код при помощи диаграмм,
но я не рассказывал, почему этот метод позволяет получить хорошо настроенный
SQL-запрос. Обладая безграничной верой и хорошей памятью, вы, вероятно, обо-
шлись бы без знания, как именно работает метод. Однако даже если вы слепо вери-
те в этот метод, все равно, вероятно, иногда вам придется объяснять причину изме-
нений в SQL-запросе. Кроме того, этот метод достаточно сложен, и понимание,
почему он действительно работает, поможет вам запомнить подробности лучше,
чем если вы просто попытаетесь зазубрить их.
Аргументы в пользу вложенных циклов
На протяжении всей книги я утверждаю, что соединения методом вложенных цик-
лов по ключам соединения обеспечивают более надежные планы выполнения, чем
соединения хэшированием или сортировкой слиянием. Давайте посмотрим, поче-
му это именно так. Рассмотрим диаграмму запроса с двумя таблицами, показан-
ную на рис. 8.1.
A Fa
Jd>1
Jm=1
▼
В Fb
Рис 8.1. Тестовый запрос с двумя таблицами
Хотя с первого взгляда зто незаметно, но с большой вероятностью об этом за-
просе можно сказать очень многое, если вы уже знаете, что это функционально
полезный бизнес-запрос, поступивший к вам для настройки.
Верхняя таблица в диаграмме велика или же ожидается ее большое увеличе-
ние. Так как Jd, детальный коэффициент соединения, больше 1,0, нижняя таб-
лица меньше верхней в несколько раз, причем число, равное отношению между
ними, может быть средним или большим. Чаще всего встречаются запросы, счи-
254
8. Почему метод диаграмм работает
тывающие данные только из небольших таблиц, но они редко становятся воп-
росом настройки — когда все таблицы малы, встроенный оптимизатор выдает
быстрые планы выполнения без посторонней помощи.
Большие таблицы с течением времени со значительной вероятностью еще за-
метнее увеличиваются в размерах. Обычно они становятся такими большими
благодаря постоянному росту, и их увеличение редко останавливается или
замедляется.
Запрос должен возвращать умеренное количество строк, небольшую часть строк
детальной таблицы. Запросы действительно могут возвращать большие набо-
ры строк, но подобные наборы редко бывают полезны в реальных приложени-
ях, так как конечные пользователи не могут эффективно обрабатывать боль-
шие объемы данных одновременно. Интерактивные запросы для реального
приложения обычно должны возвращать не более 100 строк, и даже пакетные
запросы не должны возвращать более чем несколько тысяч записей.
Хотя таблицы растут со временем, неумение конечных пользователей перева-
ривать слишком много данных не меняется. Это часто означает, что условия
запроса должны указывать на все время уменьшающуюся часть строк таблицы.
Обычно это достигается при помощи некоторых условий, которые указывают в
основном на новые данные, так как те представляют больший интерес с точки
зрения бизнеса. Хотя в таблице может храниться все время увеличивающаяся
история деловых данных, объем набора новых данных будет расти намного мед-
ленней или же вовсе не увеличиваться.
Количество строк, которое вернет запрос, равно Са х Fa х Fb, где Са — это коли-
чество строк, возвращенное иэ таблицы А.
Эти утверждения ведут к заключению, что произведение двух коэффициентов
фильтрации (Fa х Fb) должно быть небольшим, и со временем уменьшаться. Таким
образом, по крайней мере, одно из значений Fa или Fb также должно быть неболь-
шим. На практике это практически всегда достигается за счет того, что один из ко-
эффициентов фильтрации намного меньше другого. Меньшим коэффициентом филь-
трации обычно является именно тот коэффициент, который со временем монотонно
уменьшается. В целом, наименьший из этих коэффициентов фильтрации оправды-
вает индексный доступ при выборе между ним и полным сканированием таблицы.
Если лучший (наименьший) коэффициент фильтрации — это Fb и он доста-
точно мал, чтобы оправдать индексный доступ к таблице В, то вложенные циклы
от В в общем случае будут указывать на такую же часть (Fb) строк таблицы А.
Данное количество главных записей будет указывать на такую же долю детализи-
рованных строк. Эта доля также будет достаточно небольшой, чтобы оправдать
индексный доступ (в данном случае через внешний ключ) к таблице А, причем его
стоимость будет меньше, чем у полного сканирования таблицы. Так как по нашим
предположениям Fb < Fa, вложенные циклы будут минимизировать количество
затронутых строк и уменьшать количество операций физического и логического
ввода-вывода для таблицы А в сравнении с планом выполнения, который начинает
выполняться непосредственно с индекса для фильтрации таблицы А. И соедине-
ние хэшированием, и соединение методом сортировки слиянием с таблицей А потре-
буют более дорогого полного сканирования таблицы или сканирования диапазона
индекса по менее селективному фильтру. Так как блоки индекса для соединения
Выбор ведущей таблицы
255
кэшируются лучше, чем большая таблица А, то их считывание по сравнению с бло-
ками таблицы будет достаточно недорогим. Таким образом, если лучший коэффи-
циент фильтрации — это Fb, то вложенные циклы минимизируют стоимость счи-
тывания данных из таблицы А.
Когда лучший фильтр принадлежит детальной таблице (в этом случае табли-
це А), то, если Jd = 1, в силе остаются те же аргументы. Если Jd > 1, то большие
значения Jd благоприятствуют выбору соединений хэшированием. Однако, если
Jd не очень велико, этот фактор обычно не может превзойти преимущества обра-
щения к каждой таблице через самый селективный фильтр. Когда значение Jd
достаточно велико, это подразумевает, что главная таблица В намного меньше
детальной таблицы А, и, следовательно, будет намного лучше кэширована. А зна-
чит, стоимость обращения к ней будет меньше вне зависимости от метода соеди-
нения. Я подробно описывал этот вариант в разделе «Случаи, когда нужно выб-
рать соединения хэшированием» главы 6, поэтому не буду повторяться. Смысл в
том, что даже в случаях, когда соединения хэшированием максимально улучша-
ют стоимость данного соединения, они обычно уменьшают только сравнительно
небольшую составляющую стоимости запроса — стоимость обращения к намно-
го меньшей, хорошо кэшированной главной таблице. Чтобы достигнуть даже этого
небольшого преимущества, базе данных приходится помещать присоединяемый
набор строк в память или, что еще хуже, временно хранить хэшированный набор
на диске.
Выбор ведущей таблицы
Самый важный выбор, которые вы делаете при сборе плана выполнения, — это
выбор ведущей таблицы. Редко можно найти хороший план выполнения, если на-
чать не с единственного лучшего варианта. Правильный выбор ведущей таблицы
обычно гарантирует в худшем случае весьма хороший план, даже если после веду-
щей таблицы выбирать порядок соединения случайным образом. Я утверждал, что
правило выбора лучшей ведущей таблицы является очень простым. Нужно начи-
нать составление диаграммы с таблицы с самым маленьким коэффициентом филь-
трации. Далее я приведу аргументы в пользу того, что это простое правило работает
практически всегда, и это действительно единственно возможное правило, кото-
рое одновременно и просто и верно.
Проблема для всех оптимизаторов, человеческих или нет, заключается в спосо-
бе выбора лучшей ведущей таблицы без перебора всех возможных порядков со-
единения или хотя бы значительной доли возможных порядков соединения. Лю-
бой быстрый метод выбора ведущей таблицы должен зависеть от некоей локальной
информации, которая не отражает всей сложности полного запроса. Чтобы проде-
монстрировать объяснение этого простого правила — начинать с таблицы с наи-
меньшим коэффициентом фильтрации — я буду рассматривать задачу с намерен-
но спрятанными подробностями, чтобы не отвлекаться на сложность всего запроса.
Возьмем частично скрытую диаграмму на рис. 8.2.
Что может сказать такая диаграмма с отсутствующими связями? Даже без свя-
зей и коэффициентов соединения вы можете уверенно сделать несколько заклю-
чений.
256
8. Почему метод диаграмм работает
М — это корневая детальная таблица, вероятно, самая большая и хуже всех кэ-
шированная во всем запросе. Пусть количество строк этой таблицы равно С.
Al, А2 и АЗ — это главные таблицы, которые присоединяются непосредственно к М.
Все прочие таблицы — это также главные таблицы, и, вероятно, присоединяют-
ся к М не напрямую, а через промежуточные соединения.
Рис. 8.2. Частично скрытая диаграмма запроса
Даже имея такую скудную информацию, вы можете вычислить ключевое свой-
ство стоимости считывания данных из самой большой и хуже всех кэшированной
корневой детальной таблицы М.
Количество строк, считанных из корневой детальной таблицы, будет не больше
количества строк этой таблицы (С), умноженного на коэффициент фильтрации
ведущей таблицы.
Например, если фильтр, принадлежащий таблице В4,—это единственный фильтр,
которым вы можете воспользоваться до соединения с М, то, начав с В4 и используя
вложенные циклы, вы можете гарантировать, что считаете только одну тысячную
строк М. Рисунок 8.3 иллюстрирует этот случай.
Конечно, если В4 соединяется напрямую с другими узлами с фильтрами до того,
как произойдет соединение с М, можно получить еще более хороший результат.
Однако если вы выбираете соединения методом вложенных циклов, то сразу же
можете утверждать, что верхняя граница стоимости считывания данных из корне-
вой детальной таблицы равна С х Fd, где Fd — это коэффициент фильтрации вы-
бранной ведущей таблицы. Это объясняет правило выбора ведущей таблицы, которое
требует, чтобы ведущим был выбран узел с наименьшим коэффициентом фильт-
рации. Чтобы еще раз убедиться в справедливости правила, на рис. 8.4 связи, ука-
занные на рис. 8.3, реорганизованы, чтобы новая диаграмма максимизировала пре-
имущество варианта, альтернативного выбору ведущей таблицей таблицы В4.
Теперь если вы начнете с А1 или любого узла под ней, то сможете использовать все
фильтры кроме фильтра для В4 до того, как обработаете М. В результате из М будет счи-
тано количество строк, равное С х 0,0045 (С х 0,3 х 0,7 х 0,6 х 0,5 х 0,5 х 0,2 х 0,9 х 0,8),
Выбор ведущей таблицы
257
что более чем в четыре раза хуже, чем стоимость при выборе ведущей таблицей В4.
Кроме того, с плохим первым фильтром стоимость доступа к другим таблицам в
начале порядка соединения также будет высока, если только размер всех этих таб-
лиц не окажется небольшим.
Рис. 8.3. Диаграмма запроса, на которой указаны возможные связи
Рис. 8.4. Диаграмма запроса, измененная, чтобы минимизировать недостатки
выбора ведущей таблицей А1
Вы можете спросить, был ли этот пример предназначен для того, чтобы пока-
зать лучший ведущий фильтр в еще более привлекательном свете, но на самом
деле это не так. В большинстве реальных запросов начать с наименьшего коэффи-
циента фильтрации еще более выгодно! В запросах обычно намного меньше филь-
тров, которые можно скомбинировать, и эти фильтры сильнее распределены по
различным ветвям под корневой детальной таблицей, чем в этом примере. Если
258
8. Почему метод диаграмм работает
у вас есть два одинаково хороших фильтра, то вы можете привести убедительные
аргументы в пользу выбора ведущей таблицы с немного худшим фильтром, когда
рядом с ней находится много узлов с также хорошими фильтрами, как, например,
на рис. 8.5.
Рис. 8.5. Диаграмма запроса с конкурирующими ведущими узлами
В этом сложном случае ВЗ, вероятно, была бы лучшим ведущим узлом, чем В4,
так как ВЗ может воспользоваться помощью от соседних узлов перед тем, как вы
проведете соединение с М. Это может выглядеть правдоподобно, и я не сомневаюсь,
что такой случай может произойти, но, основываясь на своем опыте, могу сказать,
что это все же редкость. Я не встречался с подобным случаем за 10 лет работы по
настройке SQL, в основном потому, что чрезвычайно трудно встретить два очень
селективных фильтра с практически одинаковой величиной селективности в од-
ном запросе. Намного вероятнее, что селективность запроса обеспечивается од-
ним очень селективным условием.
Выбор следующей таблицы для соединения
После того как вы выбрали ведущую таблицу, остальные решения в ходе создания
надежного плана выполнения принадлежат к серии вопросов «Что дальше?». Ког-
да вы задаете этот вопрос, это означает, что у вас есть одно облако уже соединен-
ных узлов, которые вы выбрали раньше в порядке соединения, и набор узлов, при-
соединенных к облаку, один из которых можно присоединить следующим. Если
диаграмма запроса имеет обычную структуру дерева, максимум один узел будет
находиться над текущим облаком, и любое количество узлов может «свисать» из
него. На рис. 8.6 показан типичный случай.
Рассмотрим вопрос «Что дальше?» в этой точке в порядке соединения. База
данных получила некоторое количество строк, которое я обозначу какК Соедине-
ния с таблицами ниже текущего облака соединения умножат текущее количество
строк на какой-то коэффициент: коэффициент фильтрации, умноженный на глав-
Выбор следующей таблицы для соединения
259
ный коэффициент соединения. Пусть F = R х М, где R — коэффициент фильтра-
ции, а М — главный коэффициент соединения (равный 1,0, если не указано другое
число). Чем больше коэффициент сокращения количества строк, равный 1 - F,
тем ниже стоимость будущих соединений, поэтому узлы с большими значениями
1 - F важны для оптимизации оставшейся части запроса, и их следует присоеди-
нить как можно раньше. У сокращения количества строк тоже есть определенная
стоимость, основанная на стоимости каждой строки, участвующей в соединении,
которую я обозначу С. Отношение преимуществ к стоимости рассматриваемого
соединения вниз равно (1 - F)/C. Если полагать, что считывание каждой строки
из всех таблиц, находящихся ниже уже соединенных узлов, стоит одинаково, то
выбор узла снизу с максимальным значением (1 - F)/C эквивалентен выбору узла
с минимальным F.
f пиюоисдатагчые';
- узлы
Т
A 0J
2
Рис. 8.6. Типичная точка выбора во время оптимизации порядка соединения
Как же тогда можно улучшить оптимизацию? Существует три возможности
улучшения, которые перечислены в разделе «Специальные правила для специаль-
ных случаев» главы 6.
1. Неу всех узлов снизу одинаковая стоимость считывания строки соединения,
поэтому в действительности параметр С отличается у разных узлов.
2. Полная выгода соединения иногда появляется не сразу, а после соединения
с другими узлами, находящимися еще ниже, доступ к которым открылся через
промежуточное соединение.
3. Иногда узел сверху обеспечивает лучшее отношение преимуществ к стоимос-
ти, даже если еще остались необработанные узлы внизу.
Я по очереди рассмотрю эти возможности для улучшения, чтобы показать, как
они влияют на специальные правила, которые иногда перекрывают простейшие
правила большого пальца.
260
8. Почему метод диаграмм работает
Объяснение различной стоимости
считывания строки
Чаще всего узлы в нижней части диаграммы меньше, чем самая большая таблица,
уже обработанная в плане выполнения. Поэтому чаще всего они лучше кэширова-
ны и маловероятно, что для них существуют более глубокие индексы, чем для са-
мой большой уже обработанной таблицы, поэтому их воздействие на общую сто-
имость обычно минимально. Даже когда стоимость считывания данных из узлов
внизу значительно варьируется, стоимость предположения, что она одинакова для
всех узлов, обычно минимальна по сравнению с общей стоимостью запроса. Как
бы то ни было, вероятность значительных различий стоимости оправдывает ис-
ключение, уже упомянутое в главе 6: «В трудных случаях сначала обрабатывайте
небольшие таблицы. После того, как вы выбрали ведущую таблицу, реальное соот-
ношение преимуществ и стоимости соединения со следующей главной таблицей
равно (1 - F)/C. Небольшие таблицы лучше кэшированы и у них обычно меньше
уровней индекса, что уменьшает С и улучшает соотношение преимуществ и сто-
имости для маленьких таблиц».
Объяснение преимуществ от поздних соединений
Иногда, особенно когда узлы вообще не фильтруются, наибольшее преимуще-
ство соединения заключается в том, что оно обеспечивает доступ к узлам, нахо-
дящимся на уровень ниже, но имеющим хороший фильтр. Это причина еще од-
ного исключения, описанного в главе 6: «В трудном случае выбирайте обработку
таблиц, открывающих доступ к другим таблицам с лучшими коэффициентами
фильтрации, как можно раньше в плане выполнения. Общая цель — отбросить
максимальное количество строк как можно раньше в плане выполнения. Хоро-
шие (небольшие) коэффициенты фильтрации достигают этой цели на каждом
шаге, но вам следует смотреть немного дальше и проверять следующие фильтры,
чтобы воспользоваться полным преимуществом скорейшего перехода к данному
узлу».
Полное объяснение этих распределенных эффектов, которые обеспечиваются
фильтрами, разбросанными по разным узлам, лежит за пределами этой книги и
любого метода оптимизации, предназначенного для ручного применения. К счас-
тью, эти ограничения минимальны. Я не встречал такого случая, когда требова-
лось бы настолько глубокое объяснение. Практически всегда предыдущее грубое
правило обеспечивает оптимальное решение или решение, настолько близкое к
оптимальному, чтобы различия не играли роли. Иногда стоит применить метод
проб и ошибок, если вам попался граничный случай. Редкое обращение к этому
методу намного проще и гораздо точнее, чем самые сложные вычисления.
Когда следует выбирать ранние соединения
с узлами наверху
Потенциально узлы из верхней части диаграммы могут обеспечить самое эффек-
тивное соотношение преимуществ и стоимости. Для этих узлов можно подсчитать
F = R х D, где R — коэффициент фильтрации узла, как и раньше, a D — детальный
коэффициент соединения. Однако в противоположность главному коэффициенту
Выбор следующей таблицы для соединения
261
соединения, который должен быть меньше или равен 1,0, детальный коэффициент
соединения может быть любым положительным числом, и обычно он больше 1,0.
Когда он велик, то F обычно больше 1,0, а отношение преимуществ к стоимости,
(1 - F)/C, меньше нуля, что делает соединение вверх менее привлекательным, чем
даже совершенно не фильтрованное соединение вниз (для которого 1 - F равно 0).
Когда F больше 1,0, выбор очевиден. Следует отложить соединение вверх, пока все
соединения вниз не будут обработаны. Даже когда детальный коэффициент филь-
трации (D) настолько мал, что F меньше 1,0, раннее соединение вверх не всегда
может быть оправданным. Детальный коэффициент фильтрации может быть на-
много больше для других пользователей, которые будут работать с тем же прило-
жением. Этот же коэффициент может стать больше для того же пользователя в
иных условиях. Раннее соединение вверх, выгодное для конкретного пользовате-
ля в данный момент, может позже или на других узлах принести больше вреда, чем
пользы. Соединения вверх ненадежны по отношению к изменениям в распределе-
нии данных.
Большие детальные коэффициенты соединения обладают еще одним скрытым
эффектом. Они указывают на большие таблицы, из которых базе данных потребу-
ется считать несколько строк для каждой присоединяемой строки, что умножает
С, по меньшей мере, на детальный коэффициент соединения. Если таблицы в верх-
ней части диаграммы достаточно большие, то у них будет также больше значение
С (по сравнению с соединениями вниз) благодаря плохому кэшированию и более
глубоким индексам. Все эти причины обычно делают С достаточно большим, что-
бы соотношение преимуществ и стоимости для соединения вверх было непривле-
кательным, даже с очень низкими коэффициентами фильтрации детальных таб-
лиц.
На рис. 8.6 доля строк (F) для А равна 0,2 (0,1 х 2), столько же, сколько и для
лучшего узла снизу — ВЗ. Но стоимость (С) будет минимум в два раза выше, чем
для любого узла снизу, так как база данных должна считать две строки из А для
каждой строки из уже соединенных узлов, стоящей в начале соединения. Задав
Cd (стоимость каждой строки детальной таблицы) равной 2 ? Сш (стоимость со-
единения с каждой строкой главной таблицы в худшем случае), мы получим (1-
- 0,2)/(2 х Сш) = (1 - Fe)/Cm, где Fe — коэффициент фильтрации, который был
бы у худшего соединения вниз, если бы отношение преимуществ к стоимости
для него равнялось соединению вверх с А. Находя Fe, получаем 1 - Fe = 0,8/2,
или Fe = 0,6. Основываясь на этом расчете, вы точно выберете соединения с ВЗ, В4
и В2 до соединения с А. Даже соединение с В5, вероятно, было бы лучше провести
перед соединением с А, так как В5 должна быть лучше кэширована и иметь менее
глубокий индекс, чем А. Соединение с В1 можно безопасно отложить до выполне-
ния соединения с А, если вы уверены, что коэффициент F для А никогда не пре-
высит 1,0, и для узлов ниже В1 нет дополнительных фильтров. К моменту, когда
вы достигнете точки, в которой соединение вверх должно быть выполнено до
соединения вниз, это практически не имеет значения, так как после применения
предыдущих фильтров осталось уже так мало строк, что экономия по сравнению
со стоимостью оставшейся части запроса минимальна. Можно сделать вывод, что
вероятность необходимости хотя бы рассмотреть ранние выполнения соедине-
ний вверх, если детальный коэффициент для них равен 2 или больше, чрезвы-
чайно мала.
262
8. Почему метод диаграмм работает
Однако детальные коэффициенты соединения иногда бывают точно меньше 1,0,
что приводит к простейшему исключению из правила, что не следует выполнять
соединения вверх слишком рано.
Выбирая следующий узел в последовательности, обрабатывайте все соедине-
ния с коэффициентом соединения D, меньшим 1,0, как соединения вниз. И при
сравнении узлов считайте D х R эффективным коэффициентом фильтрации узла,
где R — это коэффициент фильтрации одного узла.
Случаи, когда детальные коэффициенты соединения близки к 1,0, но не мень-
ше этого числа, более двусмысленны. В этом случае обрабатывайте соединения
вверх как соединения вниз, когда коэффициент фильтрации близок к 1,0 и когда
это позволяет перейти к полезным фильтрам (с низкими коэффициентами фильт-
рации) как можно раньше в плане выполнения. Если вы сомневаетесь, то попро-
буйте оба варианта.
Ключевая проблема в последнем случае состоит в том, уверены ли вы, что де-
тальный коэффициент соединения близок к 1,0. Если он может увеличиться, луч-
ше вставить соединение вверх ближе к концу плана выполнения, следуя простей-
шему эвристическому правилу, которое рекомендует откладывать соединения
вверх, пока не будут обработаны все соединения вниз. Серьезные исключения из
этого правила встречаются на удивление редко.
Резюме
Без анализа «в лоб» огромных чисел, относящихся к планам выполнения, идеаль-
ная оптимизация запросов со многими таблицами лежит за пределами сегодняш-
него состояния дел. Даже если будут сделаны определенные шаги вперед, идеаль-
ная оптимизация, вероятно, останется за пределами возможностей ручных методов
настройки. Если вы решили зарабатывать на жизнь настройкой SQL-запросов, то
без работы вы не останетесь. Проблема настройки SQL достаточно сложна, чтобы
не удивляться такому положению дел. Но что действительно удивительно — так
это тот факт, что, сосредоточившись на надежных планах выполнения и несколь-
ких достаточно простых правилах, вы можете подойти вплотную к идеальной оп-
тимизации для подавляющего большинства запросов. Локальная информация об
узлах на диаграмме соединений, в частности, информация о коэффициентах филь-
трации, оказывается вполне достаточной для выбора эффективного и надежного
плана, не принимая во внимание его полную комбинаторную сложность.
Особые случаи
В этой главе рассматривается набор иногда возникающих особенных случаев.
В главах 6 и 7 перечислены обычные решения для стандартных типов задачи
«Какой план выполнения мне нужен?». Здесь я дополню рассмотренные ре-
шения, чтобы помочь вам лучше справиться с несколькими нетипичными слу-
чаями.
Внешние соединения
В каком-то смысле этот раздел принадлежит главе 6 или 7, так как во многих
приложениях внешние соединения встречаются так же часто, как и внутрен-
ние. Действительно, в этих главах уже обсуждались некоторые проблемы, ка-
сающиеся внешних соединений. Однако некоторые вопросы о внешних соеди-
нениях логически исключаются из проблемы настройки SQL-запроса, а ответы
на эти вопросы более понятны, если вы уже знакомы с аргументами, приведен-
ными в главе 8. Таким образом, здесь я завершу обсуждение внешних соедине-
ний.
Внешние соединения печально известны благодаря своей способности ухуд-
шать производительность, но они совершенно не обязаны превращаться в про-
блему, если обращаться с ними правильно. В большинстве случаев проблемы про-
изводительности с внешними соединениями являются лишь мифами, основанными
либо на непонимании, либо на проблемах, которые были решены давным-давно.
Если их правильно реализовать, то внешние соединения становятся настолько
же эффективными, как и внутренние соединения. Более того, в задачах ручной
настройки их в действительности проще обрабатывать, чем внутренние соедине-
ния.
Я уже рассматривал несколько специальных вопросов относительно внешних
соединений в главе 7 в соответствующих разделах.
Фильтрованные внешние соединения.
Внешние соединения, ведущие к внутренним соединениям.
Внешние соединения, указывающие на детальную таблицу.
Внешние соединения с представлениями.
Все эти случаи требуют особых средств решения, описанных в главе 7. Здесь
я расширяю правила, данные в главе 7, чтобы суметь еще лучше оптимизировать
264
9. Особые случаи
простейший и наиболее часто встречающийся случай — простые, неотфильтро-
ванные внешние соединения вниз с таблицами, являющимися либо листовыми
узлами диаграммы запроса, либо узлами, ведущими к другим внешним соеди-
нениям. На рис. 9.1 проиллюстрирован такой случай с 16 внешними соедине-
ниями.
ОПРАВДАНИЕ ИСПОЛЬЗОВАНИЯ ВНЕШНИХ СОЕДИНЕНИЙ -----------------------------------
Я часто слышу обсуждения внешних соединений в таком стиле: «Оправдай превращение этого
соединения во внешнее соединение, докажи, что затраты на внешнее соединение здесь необходи-
мы».
Так как я не вижу никаких затрат в правильно реализованных внешних соединениях, то задаю проти-
воположный вопрос: «Зачем использовать внутреннее соединение, если внешний случай внешнего со-
единения может быть полезен?»
В частности, если па диаграмме запроса я нахожу неотфильтрованные листовые узлы, то подозреваю,
что соединение должно быть внешним. Целые ветви деревьев соединения часто должны быть свя-
заны внешними соединениями с остальной диаграммой запроса, если в этих ветвях отсутствуют
фильтры. Как я уже упоминал в главе 7, фильтрованные узлы обычно исключают внешний случай
внешнего соединения. Явно делая эти фактически внутренние соединения внутренними, вы уве-
личиваете количество степеней свободы в порядке соединения, что позволяет оптимизатору по-
лучить лучший план выполнения. Внутренние соединения с узлами без фильтров также могут
выполнять скрытую фильтрующую роль, если главный коэффициент соединения с этими узлами
хотя бы немного меньше 1,0. Если такой фильтрующий эффект функционально необходим, то
внутреннее соединение необходимо. Однако намного более вероятно, что такой фильтрующий
эффект — последняя вещь, о которой думал разработчик во время написания SQL. Скорее всего
фильтрующий эффект внутреннего соединения с узлом без фильтров — это нежелательная слу-
чайность.
Даже если внешний ключ не может быть равен null, и соединение выдает внешний случай только
при сбое ссылочной целостности, спросите себя: было бы лучше показать строки с ошибками в
ссылочной целостности или же спрятать их? Ошибка в ссылочной целостности — это всегда про-
блема, вне зависимости от того, видите вы ее или нет. Поэтому я призываю использовать внешние
соединения, чтобы суметь продемонстрировать такой сбой конечному пользователю и представить
разработчикам или администраторам баз данных шанс узнать о дефекте — а это первый шаг к его
исправлению.
Рис. 9.1. Запрос с 16 неотфильтрованными внешними соединениями
Внешние соединения
265
Я называют эти нефильтрованные внешние соединения вниз с простыми таб-
лицами нормальными внешними соединениями. У нормальных внешних соедине-
ний есть особое полезное с точки зрения оптимизации свойство: количество строк,
оставшееся после выполнения нормального внешнего соединения, равно количе-
ству строк перед выполнением этого соединения.
Это свойство делает рассмотрение нормального внешнего соединения особен-
но простым — нормальные внешние соединения никак не влияют на текущее ко-
личество строк (количество строк, считанное в любой точке порядка соедине-
ния). Таким образом, они несущественны для оптимизации оставшейся части
запроса. Главная причина, почему следует выполнять соединения вниз перед со-
единениями вверх, уже не играет роли. Нормальные внешние соединения, в от-
личие от внутренних соединений, не могут сократить количество строк, которое
передается в дальнейшие, более дорогие соединения вверх. Так как они не влия-
ют на оставшуюся часть задачи оптимизации, то вам следует просто выбрать точку
в порядке соединения, где стоимость нормального внешнего соединения сама по
себе минимальна. Это точка, в которой текущее количество строк минимально,
но после того, как присоединяемая внешне таблица становится доступна в дере-
ве соединения.
Шаги порядка оптимизации нормального
внешнего соединения
Свойства нормальных внешних соединений приводят нас к новому набору шагов,
подходящих для оптимизации запросов с такими соединениями.
1. Изолируйте часть диаграммы соединения, в которой нет нормальных внешних
соединений. Назовем ее внутренней диаграммой запроса.
2. Оптимизируйте внутреннюю диаграмму запроса, не учитывая нормальные вне-
шние соединения.
3. Разделите узлы, присоединяемые внешне в нормальных внешних соединени-
ях, на поднаборы согласно тому, на каком уровне они прикреплены к внут-
ренней диаграмме запроса. Назовем поднабор, прикрепленный к ведущей таб-
лице или под ней, s_0. Набор, к которому можно перейти только через одно
соединение вверх от ведущей таблицы, — s_l. Набор, к которому можно пе-
рейти только через два соединения вверх от ведущей таблицы, — s_2, и так
далее.
4. Подсчитайте относительное текущее количество строк для каждой точки в по-
рядке соединения перед следующим соединением вверх и для конечной точки
порядка соединения.
ПРИМЕЧАНИЕ ----------------------------------------------------------
Под относительным текущим количеством строк я подразумеваю, что вы можете выбрать любое на-
чальное значение количества строк, просто для удобства подсчетов, если после этой точки все вычис-
ления будут непротиворечивы.
Назовем относительное текущее количество строк перед первым соединением
вверх г_0; относительное текущее количество строк перед вторым соединени-
266
9. Особые случаи
ем вверх г_1; и так далее. Назовем конечное относительное количество строк
r_j, где j — количество соединений вверх от ведущей таблицы к корневой де-
тальной таблице.
5. Среди всех поднаборов s_n найдите минимальное значение r_m (так, чтобы
m > п) и присоедините все узлы в этом поднаборе сверху вниз в точке порядка
соединения, где относительное количество строк равно этому минимальному
значению. Присоедините последний поднабор, прикрепленный внизу к корне-
вой детальной таблице, в конце порядка соединения после всех внутренних
соединений, так как это единственный допустимый минимум для этого под-
набора.
Пример
Эти шаги требуют более глубокого рассмотрения. Чтобы применить шаги 1 и 2
к рис. 9.1, рассмотрим рис. 9.2.
Рис. 9.2. Внутренняя диаграмма запроса для предыдущего запроса
Первоначальное сложное 22-стороннее соединение мы сократили до 6-сторон-
него соединения, показанного на внутренней диаграмме запроса черным цветом.
Это простая задача оптимизации, для которой легко находится лучший порядок
внутренних соединений (СЗ. D1, ВЗ. Al, М. АЗ).
Теперь перейдем к шагу 3. Ведущая таблица — это СЗ, поэтому поднабор s О
содержит все нормальные присоединяемые внешне таблицы, доступные через
соединения вниз от СЗ. Это набор {02. 03}. Первое соединение вверх — это со-
единение с ВЗ, поэтому s_l состоит из {С2, С4} — набора узлов (исключая узлы
из поднабора s 0), достижимых через соединения вниз от ВЗ. Второе соедине-
ние вверх проводится с А1, поэтому s_2 выглядит как {В1. В2. С1}. Последнее
соединение вверх — это соединение с М, поэтому в s_3 содержатся все осталь-
ные нормальные присоединяемые внешне таблицы: {А2. В4. В5. С5. С6, D4, D5.
06. 07}. На рис. 9.3 показано, как присоединяемые внешне таблицы разделены
на поднаборы.
Внешние соединения
267
Теперь перейдем к шагу 4. Так как нам нужны только сравнительные (или от-
носительные) текущие количества строк, пусть начальное количество строк в СЗ
будет любым числом, на основе которого можно будет выбрать удобное круглое
значение г_0, например, 10. Начиная с этого значения, найдем список значений
для г_п.
г_0:10 — выбрано произвольно, лишь для упрощения подсчетов.
г_1: 6 (г_0 х 3 х 0,2) — числа 3 и 0,2 — это детальный коэффициент соедине-
ния для соединения с ВЗ и произведение всех коэффициентов фильтрации, со-
бранных до следующего соединения вверх. Также нужно было бы скорректи-
ровать количества строк в зависимости от главных коэффициентов соединения,
меньших 1,0, если бы такие существовали, но в нашем примере только обычные
главные коэффициенты соединения, равные 1,0. Так как под ВЗ нет фильтро-
ванных узлов, которые обрабатываются после соединения с ВЗ, единственный
значимый фильтр — это фильтр для ВЗ, коэффициент фильтрации которого ра-
вен 0,2.
Рис. 9.3. Поднаборы присоединяемых внешне таблиц для предыдущего запроса
г_2: 120 (г_1 х 50 х 0,4) — числа 50 и 0,4 это детальный коэффициент соеди-
нения для соединения с А1 и произведение всех коэффициентов фильтрации,
собранных до следующего соединения вверх. Так как ниже А1 нет фильтро-
ванных узлов, которые обрабатываются после соединения с А1, единственный
значимый фильтр — это фильтр для А1, коэффициент фильтрации которого
равен 0,4.
г_3:36 (г_2 х 2 х 0,15) — числа 2 и 0,15 являются детальными коэффициентами
соединения для связи с М и произведением всех оставшихся коэффициентов филь-
трации. Так как после соединения с М обрабатывается один фильтрованный узел
АЗ, то произведением всех оставшихся коэффициентов фильтрации является про-
изведение коэффициента фильтрации для М (0,5) и коэффициента фильтрации
для АЗ (0,3): 0,5x0,3 = 0,15.
268
9. Особые случаи
Наконец, выполним шаг 5. Минимальным из всех относительных значений ко-
личества строк является г_1, поэтому наборы s_0 и s_l, которые можно соединять
до того, как запрос обработает А1, должны быть присоединены в этой точке поряд-
ка соединения перед соединением с А1. Следующее минимальное значение — это
г_3, поэтому поднаборы s_2 и s_3 нужно присоединить в конце порядка соедине-
ния. Единственное дополнительное ограничение — поднаборы должны присоеди-
няться сверху вниз, чтобы таблицы внизу обрабатывались, следуя дереву соедине-
ния. Например, С1 нельзя присоединить до соединения с В2; a D7 — до соединения с
В5 и Сб. Так как я пометил главные таблицы по уровням, D ниже С, С ниже В, а В ниже
А, вы можете составить соединения сверху вниз, просто отсортировав каждый на-
бор в алфавитном порядке. Например, полный порядок соединения, отвечающий
всем требованиям, будет выглядеть как (СЗ. 01. ВЗ. {D2. D3}, {С2. С4}, Al, М. АЗ. {В1.
В2. С1}, {А2. В4, В5. С5. Сб. 04 , 05 , 06 , 07}). Фигурные скобки в данном случае обо-
значают поднаборы.
Совмещенные соединения
и фильтрующие индексы
Метод, который я рассматривал до сих пор, позволяет найти лучший порядок со-
единения для надежного плана выполнения, который предполагает, что вы може-
те эффективно получать строки из ведущей таблицы и у вас есть все необходимые
индексы по ключам соединения. Иногда можно улучшить даже этот формально
лучший план выполнения, если добавить индекс, комбинирующий ключ соедине-
ния по одному или нескольким столбцам фильтрации. Задача на рис. 9.4 иллюст-
рирует случай, когда возникает такая возможность.
OD 0.005
О 0.001 S 0.3
Рис. 9.4. Простое трехстороннее соединение
Стандартный надежный план, построенный на основе эвристических правил
из главы 6, начинает с 0 и при помощи вложенных циклов переходит к индексу по
внешнему ключу 0D, который указывает на 0. После перехода к таблице 0D база
данных отбрасывает 99,5 % строк, так как они не проходят через очень селектив-
ный фильтр для 00. Затем база данных переходит к S по индексу по ее первичному
ключу и отбрасывает 70 % оставшихся строк, считав таблицу S, так как они не от-
вечают условиям фильтра для S. В целом это неплохой план выполнения, и он мо-
жет быть достаточно быстрым, если количество строк в 00 мало, а требования к про-
изводительности невысоки.
Однако оказывается, что можно добиться лучших результатов, если создать
индексы, идеально подходящие для этого запроса. Чтобы сделать задачу более кон-
кретной, предположим, что рис. 9.4 иллюстрирует следующий запрос:
Совмещенные соединения и фильтрующие индексы
269
SELECT ... FROM Shipments S. Order_Details OD. Orders 0
WHERE 0 Order_JD = OD.Order_ID
AND OD.Shipment_ID = S.Shipment_ID
AND O.Customer_ID = :1
AND OD.Product_ID = :2
AND S.Shipment_Date > :3
Предполагая, что у нас приблизительно 1000 покупателей, 200 продуктов,
а дата, обозначенная параметром 3, указывает точку, находящуюся приблизи-
тельно в 30 % от конца периода регистрации поставок, мы получим коэффици-
енты фильтрации, указанные на диаграмме. Чтобы еще более конкретизиро-
вать задачу, предположим, что количество строк в Order_Detai 1 s равно 10 000 000.
Согласно имеющемуся детальному коэффициенту соединения Orders с Order_Detai 1 s,
количество строк в Orders должно быть 200 000, то есть ожидается считывание
200 строк из Orders, которые соединятся с 10 000 строкам из Order_Detai 1 s. Пос-
ле отбрасывания записей Order_Detai 1 s с неподходящими значениями Product_ID,
текущее количество строк станет равным 50. Эти строки соединятся с 50 стро-
ками из Shipments, и после того, как старые поставки будут отброшены, останет-
ся 15 строк.
Что же в плане выполнения составляет большую часть стоимости? Определен-
но затраты на Orders и Shi pments и их индексы минимальны, так как из этих таблиц
считывается немного строк. Для считывания из индекса Order_Details(Order_ID)
потребуется сканирование 200 диапазонов индекса, каждый из которых покрыва-
ет 50 строк. Каждое сканирование диапазона потребует прохождения по дереву
индекса глубиной в три уровня и, вероятно, затронет один листовой блок для каж-
дого сканирования, что потребует примерно три операции логического ввода-вы-
вода. В целом это потребует приблизительно 600 достаточно хорошо кэширован-
ных операций логического ввода-вывода для индекса. Только для самой таблицы
Order_Detai 1 s потребуется 10 000 операций логического ввода-вывода, и эта табли-
ца достаточно велика, чтобы многие операции также потребовали физического
ввода-вывода. Как же можно улучшить ситуацию?
Фокус заключается в том, чтобы использовать условие фильтрации для
Order_Details еще до обработки этой таблицы, вместе с индексом. Если вы заме-
ните индекс по Order_Detai 1 s (Order_ID) новым индексом по Order_Detai 1 s (Order_ID.
Product_ID), то сканирование 200 диапазонов индекса по 50 строк каждый пре-
вратятся в сканирование 200 диапазонов индекса, размером в среднем с полови-
ну строки.
ПРИМЕЧАНИЕ-----------------------------------------------------------------------------
Противоположный порядок столбцов в этом индексе для данного запроса также подходит. При этом
произойдет даже лучшее самокэширование, так как необходимые записи индекса будут собраны вмес-
те в одном Product ID.
С этим новым индексом вам придется считать только 50 действительно необ-
ходимых строк из Order_Details, а это 200-кратная экономия на физическом и ло-
гическом вводе-выводе для данной таблицы. Так как Order_Detai 1 s — это единствен-
ный объект запроса, требующий существенных объемов ввода-вывода, то описанное
мной нововведение позволит достигнуть 50-кратного увеличения производитель-
ности всего запроса, предполагая намного лучшее кэширование других, неболь-
ших объектов.
270
9. Особые случаи
Но почему же я тянул до главы 9 с описанием такой значительной возможно-
сти оптимизации? Практически везде в этой книге я ставил целью поиск лучшего
плана выполнения, независимо от того, какие индексы есть в базе данных на теку-
щий момент. Однако позади этой идеальной картинки просвечивает реальность:
многие индексы, предназначенные для оптимизации отдельных, редко используе-
мых запросов, будут стоить больше, чем смогут оказать помощи. Хотя индекс, ох-
ватывающий внешний ключ и условие фильтрации, ускорит запрос в нашем при-
мере, он замедлит любую вставку и удаление, а также многие обновления, если
они будут затрагивать индексированные столбцы. Эффект, который оказывает один
новый индекс на любую данную операцию вставки, минимален. Однако, если
распространить его на все вставки и добавить эффект множества других поль-
зовательских индексов, то увеличение количества индексов легко может принести
больше вреда, чем пользы.
Рассмотрим еще один способ оптимизации того же запроса. Узел S, как и 0D,
обрабатывается через ключ соединения, и для него есть фильтрующее условие. Что,
если создать индекс по Shipments(Shipment_ID, Shipment_Date), чтобы избежать не-
нужных считываний из таблицы Shipments? Количество считываний из этой таб-
лицы сократится на 70 %, но это всего лишь экономия 35 операций логического
ввода-вывода и, возможно, одной или двух операций физического ввода-вывода,
что, вероятно, будет недостаточно для получения заметного эффекта. В реальных
запросах такие минимальные улучшения с пользовательскими индексами, комби-
нирующими ключи соединения и условия фильтрации, встречаются намного чаще,
чем возможности для существенных улучшений.
ПРИМЕЧАНИЕ --------------------------------------------------------------------
Я специально придумал этот пример, чтобы максимизировать улучшения, предлагаемые первой на-
стройкой индекса. Такие существенные улучшения производительности всего запроса, полученные
благодаря комбинированию столбцов соединения и фильтрации в одном индексе, достаточно редки в
реальной жизни.
Если вы замечаете, что отсутствует индекс по некоторому внешнему ключу,
необходимому для получения надежного плана с лучшим порядком соединения,
справедливо полагать, что тот же индекс по внешнему ключу будет полезен для
всего семейства запросов. Однако комбинирование внешних ключей и условий
фильтрации с гораздо большей вероятностью будет уникально для определенных
запросов, а дополнительные преимущества добавленных столбцов фильтрации
обычно невелики, даже в пределах одного запроса.
Рассмотрите частоту выполнения настраиваемого вами запроса и то, насколь-
ко существенна возможность настройки. Если общая экономия времени выполне-
ния всего приложения не менее одного часа в день, то не сомневайтесь, что следует
добавить пользовательский индекс, который может положительно влиять только
на этот запрос. Если экономия на времени выполнения меньше этого порога, про-
верьте, влияет ли экономия на оперативную производительность или только на
пакетную загрузку, и решите, принесет пользовательский индекс больше вреда или
пользы. Случаи, в которых индекс с большей вероятностью принесет пользу, по-
хожи на мой последний пример и характеризуются рядом признаков.
В запросах с небольшим количеством узлов время выполнения больше всего
расходуется на доступ к единственной таблице.
Отсутствующие индексы
271
Самая важная таблица для времени выполнения — это обычно корневая деталь-
ная таблица, и ее значительность приблизительно пропорциональна детально-
му коэффициенту соединения с этой таблицей от ведущей таблицы.
Если детальный коэффициент соединения велик, а коэффициент фильтрации
наоборот, небольшой (но не настолько, чтобы стать ведущим фильтром), то эко-
номия за счет комбинированного индекса по ключу и фильтру для корневой
детальной таблицы максимальна.
Если вы обнаруживаете существенную возможность сэкономить на запросе,
который сильно нагружает сервер базы данных, то комбинированные индексы по
ключу и фильтру становятся ценным инструментом; но используйте этот инстру-
мент осторожно.
Отсутствующие индексы
Подход, который рассматривается в этой книге, заключается в поиске оптималь-
ных надежных планов, при условии, что все условия фильтрации ведущей табли-
цы и все необходимые ключи соединения были уже индексированы. Поэтому если
вы обнаруживаете, что этим оптимальным планам необходим индекс, которого пока
не существует, его необходимо создать и сгенерировать для него статистику, что-
бы оптимизатору стала известна его селективность. Если вы настраиваете только
самый важный SQL-запрос, который существенно влияет (или будет влиять в бу-
дущем) на загрузку и конечную производительность реальной системы, то любой
индекс, который вы создадите, применив этот метод, с большой вероятностью оп-
равдает себя.
К сожалению, часто вам приходится настраивать SQL-запрос, не имея пред-
ставления о его значительности в общей производительности и загрузке, особенно
в самом начале процесса разработки, когда вам предоставлены лишь крошечные
объемы данных для проведения тестов и вы не знаете, каким образом будущие ко-
нечные пользователи будут работать с приложением.
Чтобы оценить, насколько важным оператор SQL будет для общей загрузки
и производительности сервера, задайте себе следующие вопросы.
Он используется в оперативном режиме или только в пакетной обработке дан-
ных? Ожидание в течение нескольких минут при выполнении пакета обычно
не представляет проблемы, так как конечные пользователи метут продолжать
свою работу, ожидая распечатки или электронного отчета. Оперативные зада-
чи должны выполняться менее чем за секунду, если их часто запускает боль-
шое количество конечных пользователей.
Как много конечных пользователей будут страдать от задержки в работе при-
ложения, если SQL будет выполняться долго?
Как часто конечные пользователи встречаются с задержками в работе прило-
жения за неделю?
Существует ли альтернативный способ, при помощи которого конечный пользо-
ватель может выполнить ту же задачу, не используя новый индекс? Например,
конечные пользователи, осуществляющие поиск данных о сотрудниках, метут
272
9. Особые случаи
проводить его по номерам социального страхования или именам, и им необяза-
тельно иметь индексный доступ к обоим столбцам, если они могут выбирать,
что именно использовать в основе поиска, и по каким данным проводить поиск.
Некоторые проблемы производительности лучше решать, обучая конечных
пользователей следовать по уже существующим быстрым путям доступа к дан-
ным.
Сравните время выполнения лучшего плана выполнения с текущими индек-
сами со временем лучшего плана с идеальными индексами. Насколько мед-
леннее работает лучший, но слегка ограниченный план, для которого не тре-
буются вовсе или требуется лишь несколько новых индексов? Неидеальный
индекс по ведущей таблице или даже полное сканирование таблицы может
работать практически так же быстро, как и идеальный индекс, особенно, если
ведущая таблица — не самая дорогая часть запроса. Отсутствующий индекс
по ключу соединения может привести к плану, который начинается с узла,
занимающего второе место по фильтрации, или даже еще более плохого веду-
щего узла, причем у альтернативного узла есть доступ ко всему дереву соеди-
нения через текущие индексы. Насколько хуже такой вариант? Единственный
способ узнать — попробовать выполнить запрос обоими способами. В каче-
стве еще одного варианта попробуйте использовать соединения хэшировани-
ем там, где индексы по ключу соединения отсутствуют, и проверьте, настоль-
ко ли велико улучшение, чтобы устранить необходимость введения новых
индексов.
Измерьте еженедельную потерю производительности для оперативных задер-
жек как длину каждой задержки, умноженную на частоту запуска задачи одним
конечным пользователем и на количество конечных пользователей. Если в сумме
задержка для одной недели равна нескольким дням, то это означает и серьезную
потерю денег. Если в сумме задержка за одну неделю составляет пару минут, то это
меньше, чем вы бы сэкономили, купив еще одну кофеварку, чтобы сократить ко-
личество действий сотрудников во время перерыва на кофе. Не стоит отвлекаться
на такие мелочи!
Также рассмотрите и основные внешние эффекты. Например, оперативные
задержки для приложения поддержки покупателей, работающего в реальном вре-
мени, могут привести к тому, что покупатели займутся поисками другого постав-
щика приложений, а ущерб от этой проблемы просто неоценим! Пакетные задер-
жки, приводящие к взысканиям за пропущенные конечные сроки, тоже могут
принести огромные расходы. Если задержки работы SQL-запроса слишком до-
роги, а улучшения за счет добавления нового индекса существенны, не сомне-
вайтесь, что индекс лучше добавить. В противном случае, взвесьте все за и про-
тив.
ВНИМАНИЕ ------------------------------------------------------------------
Гораздо проще добавить индексы, чем избавиться от них! Если индекс используется в реальной работе
какое-то время, то риск падения производительности от его удаления сильно возрастает. Кроме того,
невозможно заранее гарантировать, что удаление индекса будет безопасно. После того, как индекс вве-
ден в работу, первоначальное его обоснование быстро забывается, а новый код может стать зависимым
от индекса, даже если никто об этом догадываться не будет. Время сказать «нет» плохому индексу на-
ступает еще до того, как он становится реальной частью промышленного окружения, от которого зави-
сит конечный пользователь.
Неразрешимые проблемы
273
Соединения, не прошедшие фильтрацию
Пока что метод в общем случае предполагает, что вы настраиваете запросы к боль-
шим таблицам, так как они преобладают среди SQL-кода, требующего настройки.
Для таких запросов, особенно когда это оперативные запросы, вы всегда можете
рассчитывать на наличие, по меньшей мере, одного селективного фильтра, откры-
вающего доступ к привлекательной ведущей таблице. Иногда, особенно для боль-
ших пакетных запросов и оперативных запросов к небольшим таблицам, вам при-
дется настраивать не отфильтрованные соединения с целыми таблицами безо
всяких ограничений. Например, рассмотрим рис. 9.5.
Как же оптимизировать такой запрос, если невозможно руководствоваться се-
лективностью фильтров? Для планов с вложенными циклами едва ли играет роль
выбранный порядок соединения, если, конечно, вы придерживаетесь дерева со-
единения. Однако для этих запросов лучше всего подходят соединения хэширо-
ванием, или, если их нельзя применить, то соединения методом сортировки сли-
янием. Предполагая, что можно выполнять соединения хэшированием, база
данных должна считать все три таблицы методом полного сканирования и хэши-
ровать меньшие таблицы, А1 и А2, по возможности кэшируя результат в памяти.
Затем при последнем проходе через самую большую таблицу, М, каждая хэширо-
ванная строка быстро сопоставляется с подходящими хэшированными в памяти
строками таблиц А1 и А2. Стоимость запроса в идеальном случае приблизительно
равна стоимости трех полных сканирований таблиц. База данных просто не мо-
жет отработать лучше, даже теоретически, если предполагать, что требуются все
строки из всех трех таблиц. Чаще всего стоимостные оптимизаторы хорошо справ-
ляются с задачей поиска оптимальных планов для таких запросов без ручной
помощи.
А1 А2
Рис. 9.5. Неотфильтрованное трехстороннее соединение
Если либо таблица А1, либо А2 слишком велика, чтобы кэшировать ее в памяти,
рассмотрите вариант более надежного плана с вложенными циклами, который на-
чинает работу с таблицы М, и проверьте, насколько медленнее он окажется. Индек-
сный поиск по одной строке за раз, вероятно, будет намного медленнее, но, в конце
концов, завершится успешно. А у соединений хэшированием все же есть риск, что
временное пространство на диске закончится, если А1 или А2 слишком велики для
хранения в памяти.
Неразрешимые проблемы
Пока что я описывал стратегии решения задач, которые я называю строгими зада-
чами настройки SQL. Это задачи, в которых текст медленного запроса определяет
274
9. Особыеслучаи
постановку всей задачи, и в которых вы можете настраивать запрос вне контекста,
не рассматривая остальных частей приложения. Следующая узко определенная
постановка задачи производительности иллюстрирует границы проблемы, кото-
рую я решал до сих пор.
Улучшить данный оператор SQL, чтобы вернуть в точности тот же набор
строк, который он возвращает сейчас (то есть без изменения оставшейся части
приложения) быстрее, чем за некоторое предопределенное целевое время вы-
полнения.
Предполагая, что предопределенное целевое время выполнения задано рацио-
нально, согласно реальным требованиям бизнеса, можно перечислить четыре при-
чины, по которым данная задача может быть неразрешима.
Запрос выполняется так часто, что целевое время выполнения должно быть
очень небольшим. Это относится, в частности, к запросам, которые запускают-
ся приложением сотни раз или даже больше, чтобы выполнить единственный
оперативный запрос конечного пользователя.
Запрос должен возвратить слишком много записей таблиц (учитывая количе-
ство таблиц), чтобы хотя бы иметь возможность достигнуть цели, даже с пре-
восходным кэшированием в базе данных.
Запрос должен агрегировать слишком много строк таблиц (учитывая количе-
ство таблиц), чтобы хотя бы иметь возможность достигнуть цели, даже с пре-
восходным кэшированием в базе данных.
Размещение данных не предполагает потенциального плана выполнения, по-
зволяющего избежать большого текущего количества строк в некоторой точке
плана выполнения, даже если итоговое количество возвращенных строк неве-
лико.
В этом разделе я опишу, как распознать каждый из этих типов проблемы. В гла-
ве 10 я рассмотрю решение этих «неразрешимых» задач, выходя за рамки, очер-
ченные слишком узкой формулировкой задачи.
Первый тип проблемы очевиден — цель находится слишком глубоко, чтобы
конечный пользователь задумывался над этим. Это объясняется тем, что данное
действие конечного пользователя или пакетный процесс требует выполнять зап-
рос сотни или даже миллионы раз, чтобы выполнить то, что для конечного пользо-
вателя выглядит как одна задача.
Проблемы второго и третьего типа легко распознать на диаграмме запроса. При-
мер такой проблемы представлен на рис. 9.5: у запроса, который считывает хотя бы
одну большую таблицу, фильтров нет совсем или есть только пара плохо селек-
тивных фильтров. Если в запросе не используется агрегация (нет фразы GROUP BY,
например), то это второй тип проблемы. Когда вы тестируете лучший из возмож-
ных план с вложенными циклами, убрав все шаги, предназначенные для сортиров-
ки строк, то обнаруживаете, что запрос возвращает строки с большой скоростью,
но строк настолько много, что он выполняется бесконечно. Третий тип проблемы,
в котором участвует GROUP BY или другая агрегация, выглядит так же, как второй, но
с добавлением агрегации.
Четвертый тип проблемы наиболее тонкий. На диаграмме запроса, по меньшей
мере, с одной большой таблицей есть несколько фильтров со средней степенью
Неразрешимые проблемы
275
селективности, разбросанных по диаграмме, часто содержащей подзапросы. При-
чем все может быть организовано таким способом, что большие фрагменты одной
или нескольких объемных таблиц приходится считывать до того, как становится
возможным воспользоваться достаточным количеством фильтров, чтобы сокра-
тить количество строк до приемлемого. Возможно, этот случай выглядит распро-
страненным, но на самом деле он встречается достаточно редко. Я сталкиваюсь
с возможностью его возникновения в среднем менее раза в год.
W Решения сложных
проблем
Сейчас компьютеры достаточно быстры, чтобы не превращаться в «узкое место»
в бизнес-процессе. Если же они все-таки начинают создавать проблемы, то реше-
ния всегда существуют. Однако решения не всегда принимают форму ответов на
вопрос «Как же мне заставить этот запрос возвратить те же строки быстрее?». Пока
что изложение материала концентрировалось на ответе только на этот вопрос,
и в главе 9 описывались некоторые обстоятельства, когда удовлетворительные от-
веты на этот вопрос не существуют. Настоящая глава выводит проблему произ-
водительности за эти рамки и предлагает некоторые решения редких проблем,
связанных с производительностью запроса, которые невозможно решить путем про-
стой настройки данного оператора.
Когда очень быстро — это еще
недостаточно быстро
Оперативные шаги бизнес-процесса, которые выполняются менее чем за секун-
ду, вряд ли существенно замедлят работу конечного пользователя, запускающе-
го процесс. Даже шаги, требующие больше секунды на выполнение, часто могут
быть настроены так, чтобы работа конечного пользователя не страдала, если эти
части процесса выполняются автономно или являются частью пакетных процес-
сов. Единственный случай в бизнес-процессе, когда запросам необходимо вы-
полняться очень быстро, например менее чем за половину секунды, возникает,
когда единственный шаг бизнес-процесса выполняется очень часто. Некоторые
приложения повторяют запрос сотни раз для выполнения одного оперативного
события, или даже миллионы раз для завершения пакетного процесса. В таком
случае запрос должен выполняться за несколько миллисекунд или меньше, что-
бы отвечать требованиям конечного пользователя. Но большинство запросов все
же не достигают этой скорости выполнения, даже после идеальной настройки.
Когда вы встречаетесь с этой проблемой, настоящий вопрос заключается в том,
нужно ли вам так много запросов, а не в том, как сократить время выполнения
каждого запроса. Вот три основных решения для случаев, когда требуется повто-
рять запросы.
Когда очень быстро — это еще недостаточно быстро
277
Кэшируйте в памяти все, что однажды может потребоваться повторяющему-
ся запросу, и затем по необходимости извлекайте данные из кэша приложе-
ния.
Объедините повторяющиеся запросы в единственный новый запрос.
Слейте повторяющиеся запросы в соединения, которые добавляются к един-
ственному запросу, который уже выполняется приложением.
Перед тем как я рассмотрю эти три решения, возьмем типичный повторяющий-
ся запрос, который получает ценовую историю для данного продукта:
SELECT Product_Priсе FROM Pnce List
WHERE Product_ID = :1
AND Effect!ve_Date <= :today
ORDER BY Effect1ve_Date DESC;
Чтобы найти лучшее решение для такого повторяющегося запроса, вам нужно
ответить на несколько вопросов.
Сколько раз подряд приложению необходимо запустить запрос, чтобы выпол-
нить задачу?
Откуда параметры : 1 и : today, на основе которых выполняется запрос, получа-
ют свои значения?
Сколько строк нужно будет предварительно считать и кэшировать, чтобы все
данные, которые могут понадобиться приложению, могли быть получены из
кэша? Насколько часто этот кэш будет использоваться в будущем?
Каков диапазон количества строк и среднее количество строк, возвращаемое
запросом? Какую часть этих строк приложение в действительности исполь-
зует?
В нескольких следующих разделах я опишу три возможных решения и покажу,
как при помощи ответов на перечисленные вопросы придти к одному из возмож-
ных решений.
Как избежать повторяющихся запросов
при помощи кэширования
Если набор возможных значений Product_ID невелик по сравнению с тем, сколько
раз выполняется запрос в нашем примере, то зто именно тот случай, когда нужно
кэшировать весь набор. Например, у нас может быть 10 различных значений
Product_ID, а запрос повторяется 1000 раз. В этом случае имеет смысл предвари-
тельно кэшировать результаты для всего набора и считывать их из кэша, вместо
того, чтобы повторно выполнять запросы к базе данных. Например, вы могли бы
использовать такой запрос:
SELECT Product_Price FROM Price_List
WHERE Effective_Date <- ;today
ORDER BY ProductJD ASC. Effective_Date DESC:
Полученные результаты могут храниться в кэше — например, в структуре па-
мяти приложения, использующей сегменты хэширования, или в бинарном дере-
ве, которое обеспечивает быстрый (за миллисекунды) доступ к результатам для
определенного значения Product ID. Так как количество отдельных операций счи-
278
10. Решения сложных проблем
тывания в первом варианте превышает количество значений Product ID, второй
вариант предлагает два преимущества в терминах стоимости доступа к базе дан-
ных.
База данных считывает меньше строк, используя меньше операций логическо-
го ввода-вывода. В первоначальном варианте база данных считывает каждую
строку в среднем более одного раза, так как в среднем каждое значение Product ID
встречается больше одного раза. Эти считывания также были, вероятно, менее
эффективными в терминах логического ввода-вывода для каждой строки, так
как, скорее всего, они выполнялись путем индексного считывания, а для каж-
дой такой операции требовалось несколько операций логического ввода-выво-
да. Вариант с предварительным кэшированием, напротив, использует полное
сканирование таблицы, при котором одна операция логического ввода-вывода
позволяет считать несколько строк.
База данных получает данные при помощи одного запроса, вероятно, совершив
одно обращение по сети. Даже с повторным выполнением предварительно ра-
зобранного запроса подход с повторяющимся запросом требует, по меньшей
мере, одного обращения к базе данных для каждого повторения, с существен-
ными накладными расходами.
КЭШИРОВАНИЕ В ПРИЛОЖЕНИИ И КЭШИРОВАНИЕ В БАЗЕ ДАННЫХ --------------------------
База данных кэширует часто используемые блоки базы данных в собственной совместно используемой
памяти, так зачем же создавать еще один кэш приложения, в котором будут храниться данные, кото-
рые, вероятно, уже кэшированы в базе данных? Определенно не для того, чтобы сократить количество
операций физического ввода-вывода; оба подхода к кэшированию прекрасно справляются с этой зада-
чей. И все же у кэша приложения есть свои преимущества.
Прежде всего при доступе к нему приложение не генерирует сетевой трафик. Он максимально близок
к самому приложению.
Также кэш можно настроить особым образом, чтобы получать в точности те данные, которые чаще все-
го требуются приложению, и при этом минимально использовать время центрального процессора, не
создавая лишней нагрузки, за которую приходится расплачиваться ядру базы данных, — например,
блокировок и проблем непротиворечивости считывания данных.
Цена, которую приходится платить за быстрый кэш приложения, — это увеличенная сложность прило-
жения. Несколько простых статических кэшей для повторно считываемых наборов строк достаточно
легко поддерживать, но если вы увлечетесь, то воссоздадите функциональность программного обеспе-
чения базы данных в собственном приложении. В экстремальном случае окажется, что вы используете
Oracle, SQL Server или DB2 как простой файловый сервер, хоть и со звучным именем, а ваше приложе-
ние будет ответственно за всю работу, которую обычно делает база данных, имея за спиной на порядок
меньше разработок, чем в этих базах данных.
В нашем примере повторяющийся запрос, вероятно, возвращает несколько
строк для каждого значения Product ! D, но также возможно, что для приложения
важна только строка с самым большим значением Effect! ve Date (первая в по-
рядке сортировки). Идеальный алгоритм кэширования учитывал бы это и про-
сто отбрасывал остальные строки, экономя память и прочие расходы на наполне-
ние кэша.
Таким образом, даже если такой кэш используется один раз, чтобы выпол-
нить единственную задачу одного конечного пользователя, он может стоить
меньше, чем повторяющиеся запросы, которые он делает ненужными. А если
Когда очень быстро — это еще недостаточно быстро
279
тот же кэш используется и для будущих задач того же конечного пользователя,
выгода увеличивается, оправдывая даже использование кэша, заполнение ко-
торого вышло дороже, чем выполнение повторяющихся запросов для одной за-
дачи. Если кэш хранится в совместно используемой памяти, доступной несколь-
ким конечным пользователям, то, предполагая, что его содержимое полезно
целому сообществу конечных пользователей, преимущества кэша еще более
возрастают.
Объединенные запросы
Слепой запрос, считывающий все строки, которые потенциально может затронуть
повторяющийся запрос, может быть слишком дорогим, и результирующий набор
может оказаться слишком большим, чтобы его кэшировать. Однако это не препят-
ствует тому, чтобы приложение объединяло несколько запросов в один запрос в
той или другой форме. В нашем примере каждьш проход по циклу приносит оче-
редное значение Product_ID, на базе которого выполняется исходный повторяющий-
ся запрос. Можно выполнять циклы и без запросов, а просто создать список иден-
тификаторов, чтобы использовать их в одном объединенном запросе. Например,
запрос может принимать такие формы:
SELECT Product_Price FROM Price_List
WHERE Product_ID in (<дпинный список ID>)
AND Effect!ve_Date <= :today
ORDER BY Product_ID ASC. Effective_Date DESC:
или
SELECT Product_Price FROM Pr1ce_L1st
WHERE ProductID in ^подзапрос, возвращающий длинный список ID>t
AND Effect:vejjate <= :today
ORDER BY Product_ID ASC. Effect;!ve_Date DESC:
Здесь мы все также получаем преимущества устранения перегрузки из-за обра-
ботки нескольких запросов, и обрабатываем случай, когда кэширование набора всех
возможных результатов запроса не срабатывает. В результате выполнения этих
запросов повторное использование строк происходит намного реже. В целом этот
подход с применением объединенных запросов решает широкий класс проблем
производительности повторяющихся запросов.
Слияние повторяющихся запросов
с предыдущим запросом
Обычно источником значений параметров в повторяющихся запросах является
предыдущий запрос. В нашем примере значение параметра : today скорее всего по-
ступает из часов или календаря, но значение параметра : 1 практически наверняка
берется из предыдущего запроса, который вернул длинный список значений Product ! D.
Самая вероятная причина появления повторяющегося запроса заключается в том,
что мы пытаемся получить текущую (с самым недавним значением Effect! ve_Date)
цену продукта для каждой строки, возвращенной предыдущим запросом, для чего
используем первую строку среди тех, которые этот запрос возвращает при каждом
280
10. Решения сложных проблем
выполнении. Так как цель запроса — найти подходящую строку с ценой для каж-
дой строки предыдущего запроса, функционально он похож на соединение, но да-
леко не так эффективен.
Техника решения таких проблем заключается в попытке превратить запро-
сы в реальные соединения. Когда эти повторяющиеся запросы — это простые
запросы по первичному ключу, возвращающие одну строку, то преобразование
в соединение очевидно. В таких случаях, как этот пример, решение сложнее.
Запрос возвратил ценовую историю, отсортированную по Effect! ve_Date, что-
бы поместить текущую эффективную цену в начале списка. Эта запись о теку-
щей эффективной цене на самом деле единственная запись, которая нужна
пользователю. Чтобы объединить этот повторяющийся запрос с другим запро-
сом, возвращающим список Product_ID, вам нужно найти способ, как присоеди-
нить первую строку, возвращенную отсортированным запросом, не считывая
остальные.
Есть несколько подходов, позволяющих решить задачу с таким требованием,
и я опишу два из них. Каждый подход начинается с создания нового столбца,
Current_Pr1 ce_Fl ag, значение которого равно ' Y' тогда и только тогда, когда данная
цена является действующей на данный момент.
Если строки никогда не создаются с будущими значениями Effect! ve_Date, со-
здайте триггер, который устанавливает значение флага Current_Pri ce_Fl ад равным
' N' для уже устаревших цен и создает новые цены со значением Current_Pri ce_Fl ag
равным 'Y .
Если иногда создаются записи для будущих значений цены, каждую ночь запус-
кайте пакетный процесс, который ищет будущие записи эффективных цен, толь-
ко что ставших текущими, и обновляет эти записи, присваивая Current_Pri ce_Fl ag
значение ' Y , одновременно изменяя значение поля Current_Pri ce_Fl ag для толь-
ко что устаревших цен на ' N'. Этот ночной пакетный процесс будет, вероятно,
дополнять обновления при помощи триггера новых записей цен, бывших теку-
щими на время создания.
С таким правильно созданным столбцом Current_Pri ce_Fl ag соединение выпол-
нить просто. Если первоначальный запрос выглядел так:
SELECT ... 00.ProductJD. ...
FROM ... Order_Details OD. ...
WHERE ...
то новый запрос, включающий соединение, будет таким:
SELECT ... OD.ProductJD....PL.Product_Price
FROM ... OrderJ)etai Is OD.Price List PL
WHERE ...
AND OD. Product JD-PL ProductJD
AND PL.Current_Price_Flag-'Y'
He всегда процедурный код можно заменить соединением так же легко, как
в последнем примере. Однако в SQL поддерживаются мощные логические выра-
жения, такие, как CASE, которые позволяют практически любую процедурную фун-
кцию поиска данных преобразовать в некоторый набор соединений, комбиниро-
ванных со сложными (часто вложенными) выражениями SQL.
Запросы, которые возвращают слишком много данных
281
Запросы, которые возвращают
слишком много данных
Существует четыре основные ситуации, когда запросы затрагивают слишком мно-
го строк, что приводит к долгому выполнению запроса в целом, даже если сто-
имость возврата одной строки мала настолько, насколько это возможно. •
Оперативные запросы, возвращающие сотни или более строк. Эти запросы все-
гда избыточны с точки зрения конечных пользователей; такие огромные набо-
ры неудобны или их просто невозможно использовать в оперативном режиме.
Наиболее вероятная реакция конечного пользователя на такой результат —
повторить запрос с измененными и улучшенными условиями, чтобы попытаться
сократить результат до некоторого разумного размера.
Пакетные отчеты, возвращающие десятки тысяч или более строк. Эти запросы
всегда избыточны с точки зрения конечных пользователей. Такие огромные
наборы данных неудобно читать, даже в отчете. Набор данных, возвращаемых
действительно большим, хорошо упорядоченным отчетом не обязательно бу-
дет прочитан от начала до конца, но если целью было просто обеспечить способ
поиска выбранных фактов, то почему бы не использовать для этой цели хоро-
шо разработанную оперативную транзакцию? Хорошо разработанное прило-
жение в реляционной базе данных — это гораздо лучший способ поиска нуж-
ных фактов, чем вывод огромного отчета.
Агрегации. Запросы иногда агрегируют (то есть суммируют) большие наборы
строк, выдавая результаты достаточно малого размера, чтобы конечные пользо-
ватели могли их обработать.
Промежуточная обработка. Пакетные процессы иногда функционируют как
промежуточное программное обеспечение, перемещающее данные внутри од-
ной системы или между различными системами, но не отправляя их конечным
пользователям. Так как конечные пользователи не являются частью процесса,
а компьютеры обладают достаточным терпением, чтобы обрабатывать большие
объемы данных, этим пакетным процессам иногда действительно необходимо
управлять объемами данных, слишком большими для человеческого восприя-
тия.
Давайте изучим способы устранения избыточного считывания для каждого из
этих случаев.
Объемные оперативные запросы
Если рассматривать продолжительный период времени, то объемные оператив-
ные запросы обычно сами заботятся о себе. Каждый раз, когда конечные пользова-
тели намеренно или случайно запускают запрос с недостаточно селективным кри-
терием фильтрации, они получают неудовлетворительный ответ в форме долгого
ожидания и слишком большого результата, чтобы его можно было просмотреть в
оперативном режиме. В этом результате слишком много «плевел» (ненужных дан-
ных) перемешано с «зернами» (данными, которые пользователю действительно
282
10. Решения сложныхпроблем
необходимы), чтобы его было удобно использовать. Со временем конечные пользо-
ватели узнают, какие критерии запроса будут с большей вероятностью возвращать
«убийственно» большие результирующие наборы и учатся, как избегать исполь-
зования этих критериев. Обучение конечных пользователей может помочь этому
процессу изучения запросов, но проблема в каком-то смысле решается самостоя-
тельно, даже без формальных усилий.
К сожалению, за короткий период времени может возникнуть два ключевых
момента, когда такой тип автоматического изменения поведения не предотвраща-
ет серьезной проблемы.
Тестовое использование. Конечные пользователи и разработчики обычно тес-
тируют оперативные формы в случаях, когда допустимыми могут быть любые
значения. В действительности конечный пользователь знает имя, или хотя бы
большую часть имени, перед тем, как начинает его поиск, и он знает, что нужно
ввести хотя бы часть его, чтобы в поисках нужного имени не пришлось про-
сматривать список, состоящий из тысячи записей. Однако в тестовом сценарии
проверяющий будет удовлетворен, запросив произвольное имя (такой запрос
называется слепым запросом) и выбрав для удобства запись «Aaron, Abigail» из
начала огромного алфавитного списка.
Слепые запросы чаще всего используются, когда конечные пользователи про-
сто проверяют тестовую систему еще до ввода ее в промышленную эксплуата-
цию, чем когда у них уже есть реальная работа. Слепые запросы могут обнару-
житься даже в поспешно скомпилированных автоматических тестах оценки
производительности, ужасающе искажая контрольные результаты. К сожале-
нию, именно во время такого тестирования вы, вероятно, будете искать и про-
блемы производительности, поэтому эти слепые запросы искажают видение
проблемы и оставляют плохое первое впечатление о производительности при-
ложения.
Процесс обучения конечных пользователей. Новые пользователи еще не зна-
ют, что необходимо избегать слепых и слишком неселективных (то есть полу-
слепых) запросов даже в промышленном использовании. Когда они выполняют
такие долгие запросы, то формируют плохое и дорогостоящее первое впечатле-
ние о производительности приложения. На ранней стадии промышленного ис-
пользования и даже позже, при большой текучести кадров, загрузка системы от
таких ошибок может быть высокой и вредить всем, даже конечным пользовате-
лям, избегающим подобных ошибок.
Слепые и полуслепые запросы в наиболее часто используемых транзакциях
стоят того, чтобы предотвратить их появление на уровне приложения. Когда
возможно, приложение должно просто отказываться выполнять потенциально
объемный запрос, в котором нет хотя бы одного точно селективного условия
поиска, указанного перед началом выполнения запроса. Требуется немного до-
полнительных усилий, чтобы заранее обнаружить, какие селективные крите-
рии поиска будут доступны конечным пользователям при реальной работе при-
ложения. Эти селективные критерии поиска будут соответствовать списку
столбцов таблицы, на основе которых должны выполняться эффективные зап-
росы. Однако вы должны задать себе вопрос, есть ли у вас индексные пути от
Запросы, которые возвращают слишком много данных
283
этих столбцов к другим данным? В ином случае вы придете к настройке запро-
сов с индексами, которые бесполезны для всех остальных случаев, и никогда не
будут применяться в действительности. Когда конечные пользователи хотят
выполнить запрос без разумных критериев поиска, лучше немедленно возвра-
тить сообщение об ошибке, предлагающее указать более селективный крите-
рий поиска, чем затормозить работу пользователей долгими и бесполезными
запросами.
Иногда невозможно заранее угадать, насколько селективным будет поиск, если
не выполнить его. Селективность часто зависит от конкретных данных приложе-
ния. Например, с большой вероятностью приложение вернет больше соответствий
для фамилии «Smith», чем для «Kmetec», но вы совершенно не хотите жестко ко-
дировать список частот, с которыми встречаются различные имена, в приложении.
В таких случаях вам нужен способ убедиться, что список слишком длинный, при
этом не тратясь на считывание полного списка. Решение состоит из нескольких
шагов.
1. Определите максимальную длину списка, который можно возвратить без ошиб-
ки. Чтобы нам было удобнее рассуждать, предположим, что максимальная дли-
на равна 500.
2. В обращении к базе данных запросите на одну строку больше, чем выбранная
максимальная длина (501 строка для нашего примера).
3. Заранее примите меры, чтобы план выполнения запроса был надежным и воз-
вращал строки, используя вложенные циклы, чтобы до того, как вернуть пер-
вую партию, состоящую из 501 строки, не было необходимости предваритель-
но хэшировать, сортировать или иным способом хранить весь набор строк.
4. Сделайте так, чтобы запрос возвращал данные не проводя сортировку, чтобы
базе данных не нужно было считывать все строки перед тем, как вернуть пер-
вые результаты.
5. Отсортируйте результаты, как необходимо, на уровне приложения, если резуль-
тат не вызвал ошибку, перейдя за установленный порог (501 строка для нашего
примера).
6. Отмените запрос и возвратите сообщение об ошибке с просьбой указать более
селективный критерий поиска, если количество строк достигло максимального
значения (501 строка для нашего примера).
На моем прежнем месте работы в качестве настройщика производительности,
в TenFold Corporation, эта техника оказалась так полезна, что мы внедрили ее в
платформу приложения EnterpriseTenFold, добавив возможность изменять мак-
симальное количество строк.
Итак, предотвращайте объемные оперативные запросы при помощи трехсто-
роннего подхода.
Обучайте конечных пользователей, чтобы они указывали достаточно узкие кри-
терии поиска, и не получали слишком много данных.
Возвращайте сообщения об ошибках, когда конечные пользователи пытаются
выполнить явно неселективные запросы, особенно слепые запросы, основан-
ные на больших корневых детальных таблицах.
284
10. Решения сложных проблем
Запускайте потенциально объемные запросы так, чтобы получать первые стро-
ки быстро, и возвращайте сообщение об ошибке, как только количество возвра-
щенных строк перейдет выбранный порог.
Объемные пакетные отчеты
Медленные действия приложений так неприятны для пользователей, что они не
остаются неисправленными. Испытавшие их на себе конечные пользователи либо
меняют свое поведение, либо достаточно громко жалуются, чтобы проблема была
вскоре решена. Пакетная загрузка может нести скрытую опасность, так как за-
частую проблемы с пакетной производительностью остаются незамеченными,
создавая огромную нагрузку и понижая пропускную способность системы, но
никак не проявляя себя в явном виде. Когда общая загрузка слишком высока,
замедляются все составляющие приложения, но пакетные процессы, потребляю-
щие слишком много системных ресурсов, могут все также работать достаточно
хорошо, чтобы оставаться незамеченными, особенно если это низкоприоритет-
ные процессы, завершения которых никто не ждет с нетерпением. Периодиче-
ские пакетные процессы с автоматическим расписанием особенно опасны. Они
могут запускаться намного чаще, чем это необходимо, и никто этого не заметит.
Может отпасть необходимость использовать их так же часто, как и раньше, или
они могут стать вовсе ненужными, но все так же выполняться, незаметно ухуд-
шая работу системы.
В целом есть несколько вопросов относительно больших пакетных отчетов, от-
ветив на которые, можно выбрать решение проблемы производительности.
Какова причина создания отчета?
Как инициируется создание отчета?
Почему производительность отчета стала проблемой?
Информацию какого типа читатель извлекает из отчета?
Ответы на все эти вопросы влияют на получение лучшего ответа на последний
вопрос — как повысить производительность отчета?
Причины создания больших отчетов
Если предполагать, что никто никогда не будет читать огромный прикладной от-
чет от корки до корки, то зачем приложениям вообще запросы, создающие ог-
ромные отчеты? Существуют общие причины создания запросов для больших
отчетов и стратегии повышения производительности для каждой из этих ситуа-
ций.
У отчета множество читателей, каждый из которых заинтересован в разных
поднаборах данных.
Никто не читает отчет от корки до корки, но любая данная часть отчета мо-
жет быть интересна, по меньшей мере, одному из читателей. Цели, которые
преследуют такие отчеты, лучше достигать при помощи нескольких неболь-
ших отчетов. Если необходимо, они могут выполняться параллельно, поэто-
му системе становится проще считать все необходимые данные быстрее.
Также каждый отчет может выполняться настолько часто, как это нужно
Запросы, которые возвращают слишком много данных
285
только его читателям, не заставляя всех пользователей читать общие дан-
ные.
Все подробности отчета, вероятно, интересуют пользователей на тот момент,
когда отчет был запрошен, но конечные пользователи прочитают только неболь-
шую часть отчета; на основе ее возникнут вопросы, на которые этим пользова-
телям необходимо будет найти ответ.
Необходимость отвечать на подобные вопросы по мере их возникновения на-
много лучше обслуживается оперативными прикладными запросами к базе дан-
ных. Структура огромного однородного отчета никогда не сможет предложить
настолько же удобный путь к данным, как хорошо построенное приложение.
Если вы используете отчеты для быстрого доступа к данным вместо конкрет-
ных запросов, то упускаете все преимущества, которые предлагает реляцион-
ная база данных. Так как специальные оперативные запросы на месте целого
огромного отчета затронут только небольшой поднабор данных, необходимых
пользователю, оперативное решение потребует намного меньше операций ло-
гического и физического ввода-вывода.
Используется только поднабор данных запроса.
В этом случае решение очевидно и чрезвычайно выгодно. Просто исключи-
те из запроса и отчета те строки, которые никогда не используются. Там, где
отчет выводит меньше строк, чем возвращает запрос, добавьте фильтры, что-
бы пропустить только необходимые отчету строки. Если вы сокращаете сам
отчет, добавьте фильтры в запросы, обслуживающие сокращенный отчет,
и настройте запросы так, чтобы они никогда не затрагивали ненужные дан-
ные. Особый случай, когда требуется лишь поднабор данных, возникает,
когда конечный пользователь запрашивает только суммарную информацию
(то есть агрегации) из отчета, содержащего и детали, и агрегатные данные.
В этом случае исключите детали и из отчета, и из запросов к базе данных,
и обратитесь к разделу «Агрегация множества деталей» за дальнейшими ре-
шениями.
Отчет необходим только по правовым причинам, а не потому, что кто-либо ког-
да-либо прочтет его.
Такое оправдание существования отчета вызывает несколько вопросов. Дей-
ствительно ли правовые нормы все так же требуют его создания, или же требо-
вания давно упразднены, а вы выдаете отчет лишь по привычке? Действитель-
но ли он нужен так часто, как вы его создаете? Если огромные отчеты создаются
изредка, то маловероятно, что они превратятся в проблему производительно-
сти или пропускной способности, поэтому крайне необходимо выдавать их как
можно реже, если не можете совсем избавиться от отчетов. Действительно ли
закон требует данных в форме этого отчета, или же будет достаточно предос-
тавлять доступ к данным в иной форме? Часто требования к сохранению дан-
ных не указывают, в какой форме они должны храниться. Сама база данных
или ее резервные копии могут вполне удовлетворять требованиям без приклад-
ных отчетов. Если отчет необходим только по правовым причинам, то его, веро-
ятно, можно выполнять в свободные часы, когда нагрузка не представляет про-
блемы.
286
10. Решения сложных проблем
ПРИМЕЧАНИЕ-------------------------------------------------------------
Однажды из третьих рук до меня дошла история об отчете, выдаваемом по правовым причинам, ко-
торый с самого начала работал неправильно: он заполнял множество страниц содержимым систем-
ной памяти при каждом запуске. Так как никто на самом деле не использовал этот отчет, то никто
и не заметил, что он не работал. Однако все бумажные версии системной памяти были старательно
сохранены, а работник архива исправно ставил галочку в форме, указывающей, что формальное тре-
бование создать и сохранить отчет в архиве было выполнено. При перестройке системы, наконец,
было обнаружено, что отчет был неисправен, и его удалили. Команда, занимавшаяся перестройкой,
сделала вывод, что на самом деле отчет никогда не был нужен. Однако даже когда человеку, ответ-
ственному за выставление галочки на старой форме о создании и архивировании отчета, сказали о том,
что отчет никогда не работал и не создавался, он потребовал, чтобы отчет вернули на место в старой,
неисправной форме.
Способы запуска отчетов
Специальные запросы.
Когда отчет запускается специально вручную, высоки шансы, что инициатор
запуска знает о действительной необходимости получения хотя бы части этого
отчета. Также вполне вероятно, что его волнует, сколько времени придется
ждать, пока отчет будет создан, и большое время выполнения отчета может при-
нести бизнесу убытки. Когда отчет нужен пользователю как можно скорее, ему
должен быть назначен высокий приоритет. Возможно даже, придется разбить
его на параллельные процессы, которым, чтобы уложиться в поставленный срок,
придется занять большую часть системных ресурсов. В противном случае по-
лезно убедиться, что запросы не выполняются параллельно, таким образом, не
снижая производительность процесса с высоким приоритетом. Кроме того, вы-
полнение отчетов с низким приоритетом должно быть автоматически отложе-
но до периода функционирования системы с низкой загрузкой. Этого обычно
достаточно, чтобы исключить любое воздействие этих отчетов на производи-
тельность.
Автоматические запросы.
Большая часть пакетной нагрузки на бизнес-системы создается автомати-
чески в форме отчетов, для которых давным-давно было создано расписа-
ние запусков, и они выполняются автоматически каждые день, неделю, или
через какой-то другой определенный период времени. Эти периодические
пакетные процессы особенно коварны в плане создания нагрузки, так как о
них так легко забыть или проигнорировать. Большинство заказчиков отче-
тов получают намного больше материалов, чем они когда-либо могут прочи-
тать, даже если считать только материалы, созданные людьми, и не учитывать
ужасающие автоматические отчеты с обширными наборами неинтересных
чисел. Так или иначе, большинство людей, занятых в бизнесе, чувствуют себя
несколько неудобно из-за невозможности прочитать и проанализировать
огромное количество информации, поступающей на их адрес. Таким обра-
зом, вместо того, чтобы жаловаться, что они никогда не читают какой-то
страшный отчет, получаемый ежедневно или еженедельно, и доказывать, что
это лишь напрасная трата ресурсов, они продолжают смиренно молчать о
своей постыдной неспособности совершить невозможное. (Я знаю, я тоже
Запросы, которые возвращают слишком много данных
287
так поступал. А вы?) Если вы хотите сократить частоту, с которой выдаются
огромные отчеты, или удалить их совсем, не ждите, что адресаты отчета по-
жалуются, что они им не нужны!
Один из способов избавиться от отчетов — задать наводящий вопрос: «Мы по-
дозреваем, что отчет больше не требуется, а как вы думаете?» Другая стратегия
предлагает заявить: «Мы собираемся удалить этот отчет, который, по нашему
мнению, больше не нужен, если только кто-либо из вас не сообщит, что ему
этот отчет требуется. Если же вам нужен этот отчет, то хотите ли вы получать
его с той же частотой, или можно выдавать его несколько реже?» Моя любимая
стратегия — удалить из списка получателей отчета всех кроме себя и посмот-
реть, будет ли кто-нибудь жаловаться. Если кто-либо проявит себя, отправить
ему копию и сохранить отчет, добавив этого человека обратно в список адреса-
тов. Если же никто не пожалуется, то я просто удаляю запланированный отчет
через безопасный промежуток времени. Конечно, я бы не рекомендовал делать
это, не имея соответствующих полномочий. Для отчетов, получаемых по требо-
ванию, вы можете добиться тех же результатов, сделав файл недоступным и
подождав жалоб.
Почему производительность пакетных запросов
может стать проблемой
Если долго выполняющаяся пакетная задача не создает перегрузки системы или
каким-либо другим образом не приносит убытки, не беспокойтесь о ней. В против-
ном случае есть несколько причин, по которым нужно рассмотреть производитель-
ность процесса, с разными решениями для каждой причины.
Конечные пользователи ожидают получения результата.
Когда процесс требует, чтобы конечный пользователь запросил создание отче-
та, а следующая важная задача, которую пользователь может выполнить, тре-
бует вывода этого отчета, то время создания отчета является узким местом. Рас-
параллеливание процесса создания отчета может стать одним из возможных
решений, позволяя нескольким процессорам одновременно решать поставлен-
ную задачу. Также можно добиться этого на уровне сервера базы данных при
помощи параллельных планов выполнения (которые за время моей работы
никогда не оказывались полезными) или на уровне приложения, породив не-
сколько прикладных процессов, одновременно решающих задачу, и в конце
объединив результаты. Однако намного чаще решение заключается в удалении
всего отчета или отдельных его частей. Это самый правильный способ, так как
подобный процесс, представляющий собой узкое место в работе, редко требует,
чтобы пользователь обработал огромный объем данных; есть лишь небольшая
вероятность, что хотя бы несколько строчек отчета действительно нужны ко-
нечному пользователю.
Отчет не успевает выполняться за установленный период.
Многим периодически выполняющимся процессам для работы отведено спе-
циальное временное окно, обычно в середине ночи или во время выходных.
В оставшейся части главы описаны стратегии сокращения времени выпол-
нения, позволяющие уложиться в данное временное окно. Однако чаще все-
288
10. Решения сложных проблем
го самым простым решением оказывается ослабление временных ограниче-
ний. Если вы сделаете шаг назад и изучите основные требования бизнеса, то
границы временных окон окажутся более гибкими, чем это может показать-
ся с первого взгляда. Обычно период, предназначенный для одного процес-
са, располагается внутри другого периода большего размера, предназначен-
ного для целого набора процессов. Размер большого периода может оказаться
меньше, чем необходимо. Даже если это не так, практически всегда можно
реорганизовать процессы в пределах этого набора, чтобы выделить доста-
точно времени любому данному процессу, если остальные процессы разум-
но настроены.
Отчет перегружает систему.
Время выполнения отчета само по себе может не представлять проблемы, так
как отчет никому не нужен мгновенно. Просто убедитесь, что отчет во время
выполнения захватывает лишь небольшие объемы ресурсов, которых всегда не
хватает. Избегайте запуска параллельных процессов, ускоряющих отчет с низ-
ким приоритетом за счет более приоритетной работы. Практически всегда можно
найти способ, как отложить такие низкоприоритетные процессы на часы без-
действия, когда системных ресурсов хватает, и когда воздействие на произво-
дительность других процессов достаточно мало.
Типы информации в получаемых отчетах
Каждый запрос определяется (или должен определяться) одним или несколькими
требованиями бизнеса. Если отчет никогда не влияет на поведение его получате-
лей, то это всего лишь бесполезная трата ресурсов. В идеальном мире отчет просто
сказал бы: «Сделай следующее ...» и был бы так хорошо разработан, что вы могли
бы слепо последовать советам. Так как рекомендуемые действия не нужно было
бы подробно описывать, длинные отчеты просто не существовали бы. В реальном
мире отчет помогает какому-то человеку прийти к тому же заключению, опираясь
на информацию в отчете. Однако все же вероятно, что если отчет намного длиннее
описания предлагаемого решения, то он не настолько хорошо отфильтровывает
данные, как следовало бы. Поняв, как сократить объем данных до разумного пре-
дела, вы не только сделаете запросы быстрее, но также сможете создать намного
более полезный отчет.
Рассмотрим различные способы того, каким именно образом пользователь мо-
жет использовать длинный отчет, предполагая, что тысячи строк чисел не могут
сами по себе повлиять на принятие бизнес-решения.
Пользователя интересуют только итоги, средние показатели и прочие агрега-
ции, а строки с деталями ему неинтересны.
В этом случае удалите детальные строки и выдавайте только агрегации. Рас-
смотрите стратегии, как лучше настроить итоговые запросы, в следующем раз-
деле, «Агрегация множества деталей».
В действительности пользователя интересуют только агрегации, или хотя бы
приближенные значения, но они отсутствуют в отчете.
Бедному менеджеру приходится просматривать детальные записи, чтобы на глаз
определить средние значения или их суммы. Это напрасная трата человечес-
Запросы, которые возвращают слишком много данных
289
ких усилий и ненадежный способ вычислений. Если адресаты обнаруживают,
что им приходится заниматься арифметикой «на глаз», это явный знак, что от-
чет плохо спроектирован, и что он должен напрямую выдавать агрегированные
значения.
Пользователю нужны исключения.
Большая часть строк отчета бесполезна, но менеджер изучает отчет в поисках
особых случаев, требующих неких действий. В голове менеджера есть крите-
рии условий, требующих каких-либо действий, или хотя бы глубокого изуче-
ния. Ответ в этом случае очевиден. Определите критерии исключений и выда-
вайте в отчете только эти исключения. Если критерии исключения слишком
запутаны, по крайней мере, определите, что точно не является исключением,
и отбрасывайте эти случаи. В результате вы абсолютно точно получите более
быстрый и намного более полезный отчет.
Важны только лучшие (или худшие) п записей (п — хорошее круглое число).
Это действительно особый случай среди исключений, но здесь действитель-
но сложно определить критерий исключения без первоначального изучения
всех деталей из отсортированного списка. Смысл обработки такого случая —
понять, что ничего волшебного в хорошем круглом п нет. Вероятно, так же
удобно будет выдать отсортированный список записей, отвечающих неко-
торому предварительно заданному критерию исключения. Например, вы
хотите наградить 10 лучших продавцов. Однако действительно ли вы хоти-
те наградить десятого среди них, если он продал меньше, чем средний про-
давец за прошедший год? С другой стороны, захотели бы вы обойти один-
надцатого в списке лучших, если он продал меньше, чем десятый, на 15
долларов? Смысл в том, что, по сравнению со списком 10 лучших, по край-
ней мере, так же полезно выдать отсортированный список исключений —
например, тех продавцов, которые превысили порог в половину миллиона
долларов за квартал. Определив хороший критерий исключения, который
может меняться по мере развития бизнеса, вы можете сэкономить работу
сервера базы данных по поиску всех строк и выполнения полной сортиров-
ки, когда практически все данные не исключительны, и даже не имеют реаль-
ного шанса достичь верхушки списка. Также вы можете получить дополни-
тельную информацию — например, как близко одиннадцатый в списке был
к десятому, и сколько продавцов превысили порог по сравнению с после-
дним прочитанным вами отчетом.
Пользователя интересует поднабор данных.
Просто отбросьте лишнюю часть набора данных.
Решения
Для любого достаточно большого отчета хотя бы один из предыдущих наборов
вопросов должен привести к решению проблемы производительности. Иногда ком-
бинация вопросов приводит к составному решению или подкрепляет набор при-
чин, почему выбрано одно решение. Итак, вот перечень методов, при помощи ко-
торых вы сможете решить проблемы производительности.
290
10. Решения сложных проблем
Исключите из данных отчета ненужные блоки данных. Удостоверьтесь, что эти
ненужные данные не только не выводятся в отчете, но и не запрашиваются из
базы данных. Есть несколько приемлемых решений.
□ Удалите детали, оставив только агрегированные данные, и перейдите к сле-
дующему разделу, чтобы узнать, как можно быстрее выдать отчет.
□ Выдавайте в отчете только исключения, удаляя ненужные строки.
□ Замените отчет с первыми нескольким!I строками на отсортированный спи-
сок исключений.
Замените большие отчеты несколькими небольшими отчетами, каждый из ко-
торых отвечает требованиям только подмножества адресатов.
Исключите большие отчеты в пользу оперативной функциональности, которая
помогает конечным пользователям находить нужную информацию, как только
она им потребуется, вместо того, чтобы искать ее в отчете.
Исключите отчеты, создаваемые согласно требованиям резервного хранения
информации, вместо этого открыв доступ к тем же данным напрямую на серве-
ре или в резервных копиях таблиц.
Распараллельте обработку отчетов с высоким приоритетом, которые нужно
получить срочно.
Обеспечьте последовательную обработку отчетов с низким приоритетом и пе-
редвиньте обработку на свободные часы. Также стоит уменьшить частоту вы-
дачи отчетов. Нередко самая правильная частота выдачи низкоприоритетных
отчетов — никогда.
Реорганизуйте нагрузку по обработке отчетов в установленных временных пе-
риодах, чтобы ослабить нагрузку на систему во время этих периодов.
Агрегационные данные многих
детальных записей
Никогда не следует показывать конечному пользователю миллион строк данных,
ни в оперативном режиме, ни в отчете. Однако конечный пользователь может
задать резонный вопрос о каких-либо агрегированных данных миллионов или
более записей. Например, попросив показать общий доход за последний квар-
тал, где для вычисления дохода суммируется миллион или более записей с дета-
лями заказов. К сожалению, базе данных ничуть не легче считывать миллион
строк в целях вычисления агрегированных данных или в целях выдачи деталь-
ного отчета. В результате эти большие вычисления часто становятся итоговой
причиной сложных проблем производительности. Это прекрасные, разумные с
функциональной точки зрения запросы, которые всегда дороги в выполнении,
даже с превосходной настройкой. Такие проблемы часто требуют двустороннего
подхода.
Изучите запрос так, как если бы это был запрос на получение множества де-
тальных данных, используя методы из предыдущих разделов, и примените ме-
тоды для улучшения производительности больших запросов.
Запросы, которые возвращают слишком много данных
291
Также стоит рассмотреть возможность исключения из запроса детализирован-
ных данных, не подходящих для агрегирования. Например, при суммировании
деталей заказов при подсчете дохода вы можете также обнаружить другие под-
робности о заказах, например, бесплатные рекламные материалы, ничего не сто-
ящие покупателю. Они не влияют на агрегированные данные, поэтому разра-
ботчик мог просто избавить себя от беспокойства исключения их из запроса.
Но если вы явно исключите их, то запросу придется обработать меньшее коли-
чество строк, не изменяя результата.
Когда необходимо, заранее агрегируйте данные на стороне сервера, и выдавай-
те отчет об итогах, не затрагивая подробности.
Это самая оправданная форма получения избыточных данных, хранящихся
в базе. Например, можно вычислить остаток на счете, исходя из суммы всех
транзакций, проведенных с этим счетом и хранящихся в истории. Однако сум-
ма остатка на счетах требуется так часто, что гораздо больший смысл имеет
хранение непосредственно текущего баланса и строгая синхронизация его с
суммой всех прошедших транзакций. Основная сложность, ошибки и избы-
точность в приложениях происходят от требований подобной синхронизации.
Сегодня при тщательной разработке большинство из этих требований можно
выполнить при помощи триггеров базы данных, которые автоматически умень-
шают или увеличивают текущие суммы и вычисления при каждом добавле-
нии, обновлении или удалении детальной записи. С таким основанным на
триггерах подходом интерфейсной части приложения вовсе не нужно забо-
титься о требованиях синхронизации, и множество различных причин изме-
нения детализированных данных могут быть учтены в итоговых данных при
помощи одного триггера, работающего в фоновом режиме. Это гарантирует,
причем намного лучше, чем может код приложения, чистую и строгую синх-
ронизацию избыточных данных.
Промежуточные процессы обрабатывают
слишком много строк
Когда собранные данные должны быть переданы некоей системе, а не человеку,
часто имеет смысл использование больших объемов данных. Тем не менее, техни-
ки сокращения объемов данных для промежуточных приложений очень похожи
на методы сокращения объемов получаемых данных в отчетах. Просто в этом слу-
чае получателем будет не человек, а машина. Далее перечислены основные методы
сокращения объемов отчетов.
Исключите ненужные поднаборы передаваемых данных. Удостоверьтесь, что
эти ненужные наборы не только не передаются, но даже не запрашиваются из
базы данных. Обратите внимание на особые случаи.
□ Исключите детализированные данные и используйте агрегированные дан-
ные. Стоит рассмотреть предыдущий раздел, чтобы узнать, как быстро по-
лучить агрегированные данные.
□ Передавайте только исключения, удаляя ненужные строки.
292
10. Решения сложных проблем
Распараллельте обработку высокоприоритетных системных интерфейсов, ко-
торым необходимо быстро переместить данные.
Обеспечьте последовательную обработку низкоприоритетных системных ин-
терфейсов и отложите ее на свободные часы, одновременно сократив частоту.
Нередко самая правильная частота выдачи низкоприоритетных отчетов — ни-
когда.
Реорганизуйте нагрузку по передаче данных во временных окнах, чтобы осла-
бить ограничения окон.
Кроме этих уже знакомых вам методов есть и еще несколько способов, хорошо
работающих именно с промежуточным программным обеспечением.
Передавайте только измененные данные, но не те данные, которые не измени-
лись со времени последнего запуска отчета.
Это на данный момент самая мощная техника сокращения объемов данных
промежуточного программного обеспечения, так как изменения данных за-
трагивают намного меньшие объемы, по сравнению со сбором всех данных
для отчета сразу. Однако промежуточное программное обеспечение часто
использует более медленный путь доступа ко всем данным, так как поддер-
живать синхронизацию данных при помощи отслеживания изменений слож-
нее, чем при помощи получения полного набора данных. Так же как и для
предварительного агрегирования данных, самые безопасные стратегии рас-
пространения только измененных данных зависят от хорошо разработанных
триггеров. С триггерами любое изменение данных по любой причине авто-
матически заставит триггер сработать и зарегистрировать необходимые из-
менения.
Удалите интерфейс.
Если приложения совместно используют один и тот же экземпляр базы дан-
ных, то часто можно удалять интерфейсы к серверу, позволяя приложениям
считывать данные непосредственно друг у друга, вместо того, чтобы копиро-
вать данные из одного приложения в другое.
Передвиньте разделительную линию между приложениями.
Например, вы работаете с двумя комбинированными приложениями, одно из
которых ответственно за поступление заказов (Order Entry), а другое за вы-
полнение заказов (Order Fulfillment) и счета к получению (Accounts Recei-
vable). Интерфейс между Order Entry и Order Fulfillment, вероятно, будет пе-
редавать практически совпадающие данные. Если вы реорганизуете системы,
чтобы скомбинировать Order Entry и Order Fulfillment, то получите намного
более тонкий интерфейс с перемещением меньших объемов данных в Accounts
Receivable.
Сделайте интерфейс быстрее.
Если вы перемещаете большие объемы данных между приложениями, хотя бы
организуйте работу так, чтобы большие объемы можно было перемещать быст-
ро. Самый быстрый интерфейс просто перемещает данные между таблицами в
экземпляре базы данных. Чуть более медленный интерфейс перемещает дан-
ные между экземплярами сервера баз данных на одном компьютере. Следую-
Настроенные запросы, которые медленно возвращают несколько строк
293
щий, еще более медленный интерфейс перемещает данные по локальной сети
между экземплярами сервера баз данных на разных машинах. Самый медлен-
ный вариант интерфейса перемещает данные по глобальной сети с низкой про-
пускной способностью на большие расстояния, может быть даже между конти-
нентами.
Настроенные запросы, которые медленно
возвращают несколько строк
Изредка полностью настроенный запрос, возвращающий несколько строк, даже
без вычисления агрегированных значений, выполняется ужасающе медленно.
Так как настроенные запросы начинают выполняться с лучшего фильтра, это
подразумевает, что такому запросу приходится считывать множество строк в не-
которой точке плана выполнения перед тем, как более поздние фильтры сокра-
щают количество строк до умеренного. Правила большого пальца, которые
описаны в этой книге, разработаны для того, чтобы сделать такой случай ма-
ловероятным. За годы моей работы такое в среднем случалось один-два раза
в год.
Почему иногда запросы считывают много строк,
а возвращают лишь несколько
Запросы, возвращающие небольшое количество строк, которые выполняются мед-
ленно даже после их настройки, могут иметь важные фильтры, все из которых не-
возможно использовать до того, как по мере выполнения запроса будет достигну-
та, по меньшей мере, одна большая таблица. Возьмем, например, рис. 10.1. Если в
корневой детальной таблице М находится 50 000 000 строк, то детальные коэффи-
циенты соединения показывают, что в А1 и А2 по 10 000 000 строк, а в В1 и В2 по
100 000 строк. Надежные и основанные на индексном доступе планы выполнения
с порядком соединения (Bl. Al. М. А2. В2) и (В2. А2. М, Al. В1) симметричны и оди-
наково привлекательны. Для определенности будем рассматривать только первый
порядок соединения. В этом плане мы получаем 100 строк из В1,10 000 строк из А1
и 50 000 строк из М, А2 и В2 перед тем, как отбросить все, кроме 50 строк, удовлетво-
ряющих условию фильтрации для В2.
В10.001 В2 0.001
Рис. 10.1. Медленный запрос, возвращающий несколько строк
294
10. Решения сложных проблем
Если вы ослабите требование надежности, то сможете предварительно счи-
тать 100 строк, удовлетворяющих фильтру для 62 и соединить их с ранее считан-
ными строками путем хэширования. Можно даже предварительно соединить эти
100 строк с А2 при помощи вложенных циклов и выполнить соединение хэширо-
ванием между строками, полученными при помощи метода вложенных циклов
из (Bl. Al, М) и строками, считанными методом вложенных циклов, которые со-
единяют комбинацию (В2. А2). Это позволит сократить количество строк, кото-
рое нужно считать из А2, до 10 000, и сохранить количество строк из В2 равным
100. Однако ни одна из этих стратегий не устраняет необходимости считать 50 000
строк из самой большой и хуже всех кэшированной таблицы М, и это определен-
но потребует больше времени, чем вам бы хотелось для запроса, возвращающего
всего 50 строк.
Корень этой проблемы лежит в диаграмме соединения, на которой селек-
тивные фильтры распределены по двум или более ветвям под некоторой
большой таблицей. В результате к конечному уровню фильтрации (общий ко-
эффициент фильтрации, равный произведению отдельных коэффициентов
фильтрации) невозможно даже приблизиться, пока база данных не достигнет
самой большой таблицы. Высокоселективная комбинация фильтров использу-
ется слишком поздно в плане выполнения, чтобы избежать ненужных считы-
ваний.
Оптимизация запросов
с распределенными фильтрами
Чтобы оптимально использовать распределенные фильтры, вам необходимо ка-
ким-то образом сблизить их на диаграмме запроса, лучше всего — в одной таблице.
Еще раз обратимся к рис. 10.1. Предположим, что оба фильтра для В1 и В2 пред-
ставляют собой условие равенства для некоторого столбца таблицы, соответству-
ющей данному фильтру. Нормализованный дизайн базы данных предполагает
размещение фильтрованного столбца из В1 там, где он есть, так как он кодирует
свойство, которое вам нужно указать только один раз для каждой сущности В1.
Более того, это свойство, о котором вы не можете узнать исходя из сущностей лю-
бой главной таблицы, которая соединяется методом «один ко многим» с В1. Если
вы поместите этот столбец в А1, то это уже будет денормализация, определенная
как свойство, о котором можно узнать исходя из соответствующей главной сущно-
сти А1, хранящейся в В1. Такая денормализация потребует, чтобы в таблице А1
хранились избыточные данные, так как все 100 (в среднем) сущностей А1, которые
соединяются с любой данной строкой 61, должны иметь одинаковое значение в
этом наследованном столбце. Однако в принципе все свойства сущностей главной
таблицы являются наследованными свойствами детальных сущностей, соответству-
ющих этим сущностям главной таблицы.
ПРИМЕЧАНИЕ ----------------------------------------------------
Форма денормализации, которую я описываю, — не единственная существующая форма денормализа-
ции. Написаны целые книги, посвященные нормализации баз данных, но эта простейшая форма денор-
мализации — единственная, подходящая для нашего обсуждения.
Настроенные запросы, которые медленно возвращают несколько строк
295
Например, если Customer_ID — это свойство Orders, то это также наследован-
ное свойство Order Details, соответствующих этим заказам. С денормализаци-
ей вы всегда можете протолкнуть свойства вверх по дереву соединения к узлам,
находящимся над узлами, владеющими этими свойствами в нормализованном
варианте. Такое наследование фильтрующих свойств не должно останавли-
ваться на первом уровне. Например, Customer_Name, нормализованное свойство
Customers, можно наследовать на два уровня вверх, через Orders, передав его
в Order_Details.
Эта возможность проталкивать столбцы фильтрации вверх по дереву соедине
ния на любую высоту подсказывает нам итоговое решение проблем производи-
тельности с распределенными фильтрами. Чтобы избежать проблем, вызванных
распределенными фильтрами, продолжайте перемещать вверх самые селективные
фильтрующие условия, пока они не соединятся в одном узле, который унаследует
комбинированный фильтр, селективность которого равна произведению селектив-
ностей исходных фильтров. В экстремальном случае все фильтры поднимаются
на максимальную высоту в корневой детальный узел, и запрос считывает лишь
несколько строк из этой таблицы, которые в итоге вернет, и соединяет их вниз с
таким же количеством строк из находящихся ниже главных таблиц. В задаче, по-
казанной на рис. 10.1, таблица М получает два денормализованных столбца, из В1 и
В2 соответственно. Комбинированный фильтр для этих двух столбцов обладает се-
лективностью 0,000001 (0,001 х 0,001), или одна строка из 1 000 000, как показано
на рис. 10.2. Оптимальный план выполнения для этой диаграммы запроса считы-
вает 50 строк из М и выполняет вложенные циклы через индексы по первичным
ключам, получая по 50 строк из всех остальных таблиц, Al, А2, В1 и В2. Это очень
быстрый план.
В1&004 В2-0.(О1
Рис. 10.2 Перемещение фильтров к верхним таблицам с использованием денормализации
Возможно, вам покажется странным, что я упоминаю эту эффективную техни-
ку комбинирования фильтров так поздно в книге. Многие публикации предпола-
гают, что денормализация является повсеместной необходимостью, но я с этим
совершенно не согласен. В большинстве приложений, которые я настраивал, для
настройки мне не потребовалось добавить ни одного элемента денормализации,
а ведь именно настройка является единственной значимой причиной денормали-
зации. Если вы будете следовать техникам, описанным в этой книге, то необходи-
мость использовать денормализацию у вас также будет появляться крайне редко,
только если вы столкнетесь со специфичным важным запросом, который другими
способами ускорить невозможно.
296
10. Решения сложных проблем
ПРИМЕЧАНИЕ -------------------------------------------------------------------
Многие запросы можно ускорить при помощи денормализации, но не в этом дело. Дело в том, что даже
без денормализации практически любой запрос можно сделать достаточно быстрым, применив пра-
вильную настройку. Улучшение в несколько миллисекунд не оправдывает стоимости денормализации.
Большинство случаев, когда в целях улучшения производительности применяется денормализация,
обеспечивают ненамного больше, чем крошечное улучшение, по сравнению с лучшей оптимизацией,
возможной без денормализации.
Если денормализация выполнена идеально, с тщательно проработанными триг-
герами базы данных, которые автоматически поддерживают точную синхрониза-
цию денормализованных данных, то функционально она может быть безопасна.
Однако ее нельзя назвать бесплатной — она требует дискового пространства и за-
медляет добавление, обновление и удаление данных, которые должны задейство-
вать триггеры, отвечающие за синхронизацию данных. Столкнувшись с неизбеж-
ными затратами на денормализацию, я рекомендую применять ее только если вы
встречаетесь со специфичным высокоприоритетным оператором SQL, который
невозможно сделать достаточно быстрым другими способами. Но это действительно
очень редкий случай.
Приложение А.
Решения задач
В этом приложении содержатся решения для задач из глав с 5 по 7.
Решения для задач из главы 5
Далее приведены решения для упражнений из главы 5.
Упражнение 1
На рис. А.1 показано решение для упражнения 1.
00.4
Рис. А.1. Решение для упражнения 1
У решения этой задачи есть определенная тонкость. Тонкость этого упражне-
ния заключается в том, что для поиска коэффициентов фильтрации узлов R и D
запросы вообще не нужны (кроме общего количества строк для таблиц). Коэффи-
циенты можно вычислить исходя из точного соответствия уникальных индекси-
рованных имен для каждого из этих узлов, однозначного соответствия для R и спис-
ка IN для D. Чтобы найти коэффициенты фильтрации, нужно только подсчитать
1/R и 2/D, где D и R это количество строк в соответствующих таблицах. Вы не
забыли добавить звездочку (*) к коэффициенту фильтрации для R, чтобы указать,
что это уникальное условие? Оказывается, это важно для оптимизации некоторых
запросов. Можно было бы добавить звездочку для условия, налагаемого на табли-
цу D, если бы ему сопоставлялось одно имя вместо списка имен.
Есть и еще одно допущение, позволяющее получить хороший план выполне-
ния. Если предположить, что внешние ключи не равны null и ссылочная целост-
298
Приложение А. Решения задач
пость идеальна, то количество строк, возвращаемых соединениями, будет в точно-
сти равно количеству строк в таблицах с детализированными данными. Таким об-
разом, детальные коэффициенты соединения равны просто d/m, где d — количе-
ство строк в верхней детальной таблице, ат — количество строк в нижней главной
таблице. Главные коэффициенты соединения с теми же предположениями равны
в точности 1,0, и их указывать не требуется.
Упражнение 2
На рис. А.2 показано решение для упражнения 2.
Рис. А.2. Решение для упражнения 2
В этой задаче вам нужны те же сокращения при поиске коэффициентов соеди-
нения и коэффициента фильтрации для В, что и для упражнения 1. Вы не забыли
добавить * для уникального фильтра для В? Не забыли указать направление вне-
шних соединений с Z и R при помощи указателей стрелки посередине соответству-
ющих связей?
Упражнение 3
На рис. А.З показано решение для упражнения 3.
В этой задаче для поиска коэффициентов соединения и коэффициента фильт-
рации для В вам понадобятся те же предположения, что и для упражнения 1. Не
забудьте добавить * для уникального фильтра, накладываемого на таблицу В. Так-
же не забудьте указать направление внешних соединений с С и PL при помощи ука-
зателей стрелки посередине соответствующих связей.
Соединения с ITxR и IV от Их и Р соответственно являются соединениями типа
«один к одному», которые обозначаются при помощи стрелок на обоих концах свя-
зи. Коэффициенты фильтрации на обоих концах этих соединений вида «один к
одному» равны в точности 1,0. Это особый класс таблиц с детализированными дан-
ными, часто встречающийся в реальных приложениях. Детализированные данные,
зависят от времени, и в этих таблицах существует по одной строке для каждой
подходящей главной строки, соответствующей любой эффективной дате. Напри-
мер, несмотря на то, что у вас может быть несколько налоговых ставок для некоей
налоговой сущности, на данный момент действующей будет только одна из них,
Решения для задач из главы 5
299
поэтому диапазоны даты, определяемые Effectii'e_Start_Date и Effect!ve_End_Date,
не перекрывают друг друга. Даже хотя комбинации идентификаторов (ID) и усло-
вий на диапазон даты не составляют условий равенства для полного уникального
ключа, описываемая ими допустимая дата гарантирует, что соединение уникаль-
но, если оно включает условия на диапазон даты.
ITxR 1.0
Рис. А.З. Решение для упражнения 3
Так как вы считаете диапазон даты, определяемый Effect! ve_Start_Date и
Effective_End_Date, частью соединения в запросе, не принимайте это условие за
фильтр. Считайте действующей в условиях диаграммы запроса только ту подтаб-
лицу, которая отвечает условию, налагаемому на диапазон даты. Так, количество
строк в Р и IV будет одинаково и равно 8 500, и также будут равны 4 количества
строк в ITx и ItxR. Это подтверждает, что данные соединения принадлежат типу
«один к одному» и коэффициенты соединения, равные 1,0, на обоих концах свя-
зей.
Как и для примера на рис. 5.4, вы должны использовать количества строк толь-
ко в подтаблицах для соединений с SPCT, TRCT и CTCT, так как Code_Tcans 1 at! ons — это
одна из тех таблиц с яблоками и апельсинами, которая в определенный момент
соединяется только с некоей конкретной подтаблицей.
ПРИМЕЧАНИЕ ---------------------------------------------------------------
Я ослабил собственное правило насчет указания только одной значащей цифры для коэффициен-
тов соединения и фильтрации. В основном я сделал это для того, чтобы показать вам, что ваши
вычисления верны; вы не просто случайно выбрали правильное число по каким-то неверным при-
чинам.
Упражнение 4
На рис. А.4 показано решение для упражнения 4, которое на самом деле является
упрощенным решением для упражнения 1.
Так как эта за? ача включает только большие детальные коэффициенты соеди-
нения и главные коэффициенты соединения, равные 1,0, вы просто добавляете за-
главную букву F к наиболее сильно фильтрованному узлу и строчную букву f
300
Приложение А. Решения задач
к остальным фильтрованным узлам, добавляя звездочку к уникальному фильтру
для узла R.
Рис. А.4. Решение для упражнения 4
Упражнение 5
На рис. А.5 показано решение для упражнения 5, являющееся упрощенным реше-
нием для упражнения 2.
СМ
R ВР
Рис. А.5. Решение для упражнения 5
Так как эта задача включает только большие детальные коэффициенты соеди-
нения и главные коэффициенты соединения, равные 1,0, вы просто добавляете за-
главную букву F к наиболее сильно фильтрованному узлу и строчную букву f к
другому фильтрованному узлу, добавляя звездочку к уникальному фильтру для
узла В.
Упражнение 6
На рис. А.6 показано решение для упражнения 6, являющееся упрощенным реше-
нием для упражнения 3.
Так как эта задача включает только большие детальные коэффициенты соеди-
нения, их можно не указывать на диаграмме. Однако обратите внимание, что она
включает один главный коэффициент соединения, намного меньший 1,0, в соеди-
нении вниз с таблицей 1Тх, поэтому его необходимо все же указать. Иначе нужно
Решение для задачи из главы 6
301
просто добавить заглавную F к наиболее сильно фильтрованному узлу и строчную
f к остальным фильтрованным узлам, добавляя звездочку к уникальному фильтру
для узла В.
ITXR_f
Рис. А.6. Решение для упражнения 6
Решение для задачи из главы 6
Эта глава содержит только одну, исключительно сложную задачу. В этом разделе
дано подробное пошаговое решение задачи.
На рис А.7 показано, как скорректировать эффективные фильтры, чтобы учесть
коэффициенты соединения, меньшие 1,0, появляющиеся на рис. 6.33 в трех местах.
Рис. А.7. Эффективные фильтры, учитывающие коэффициенты соединения,
для выбора ведущей таблицы
Корректируйте эффективные фильтры одновременно с обеих сторон, начиная
с главных коэффициентов соединения, так как эти фильтры можно перемещать
302
Приложение А. Решения задач
вверх при помощи явных условий IS NOT NULL для внешних ключей. Таким образом
корректируются фильтры для таблиц Bl, Cl, 02 и 01, после чего нужно зачеркнуть
главные коэффициенты соединения, чтоб показать, что они уже учтены. Обратите
внимание на детальный коэффициент соединения, равный 0,02, между М и А1, при
помощи которого можно достигнуть еще более существенной корректировки всех
фильтров, находящихся ниже М в ветви А2.
ПРИМЕЧАНИЕ------------------------------------------------------------------
Если бы существовали и другие ветви, то коэффициенты для них тоже были бы скорректированы. Кор-
ректировка не влияет только на ветвь А1. присоединенную через фильтрующее соединение.
Обратите внимание, что эффективные коэффициенты соединения для С2 и D1
корректируются дважды, так как на них влияют два фильтрующих соединения.
Просмотрев все полученные числа, мы видим, что лучший эффективный фильтр,
равный 0,004 (0,2 х 0,02), принадлежит СЗ, поэтому она становится ведущей табли-
цей.
После того как ведущая таблица выбрана, вам нужно провести несколько но-
вых корректировок, чтобы учесть два небольших главных коэффициента соедине-
ния перед тем, как выбирать порядок соединения. Обратите внимание, что вам
больше не нужно учитывать детальный коэффициент соединения, так как база
данных начинает обработку с той стороны соединения, где строки при помощи
этого соединения не отбрасываются. Это происходит всегда, когда вы выбираете
ведущую таблицу с эффективным фильтром, скорректированным с учетом деталь-
ного коэффициента соединения. В каком-то смысле вы используете фильтр в са-
мом начале, начиная с небольших таблиц, которые указывают только на поднабор
строк главной таблицы (в данном случае А1) на противоположной стороне соеди-
нения.
Лучше использовать преимущества скрытых фильтров соединения, указы-
вающих на С1 и D1 как можно раньше в плане исполнения. Следовательно, сто-
ит сделать явными фильтры вида «не равен null» по внешним ключам (в В1 и
С2), указывающим на эти фильтрующие соединения, как показано на рис. А.8.
Если сделать эти фильтры явными, сами соединения больше не будут выпол-
нять фильтрующую функцию, поэтому нужно вычеркнуть эти коэффициенты
соединения.
Начиная с СЗ, соединение можно выполнить только с ВЗ, поэтому ставим это
соединение следующим в создаваемом порядке выполнения запроса. Теперь мож-
но соединить с С2, С4 и С5 (вниз) или с А2 (вверх). В обычной ситуации вы выбрали
бы только какое-то из соединений с таблицами из нижней части диаграммы. Но
следует обратить внимание, что детальный коэффициент соединения с А2 равен
1,0, поэтому это соединение можно выполнять достаточно рано в порядке выпол-
нения запроса. На самом деле, оказывается, что у него лучший эффективный фильтр
среди всех возможных соединений, поэтому выполняем соединение с А2. Теперь в
список допустимых узлов попадает узел М, но детальный коэффициент соедине-
ния с М слишком большой, поэтому используем это соединение как можно позже.
Теперь единственный допустимый узел внизу, имеющий фильтр — это С2, благо-
даря ставшему теперь явным условию «не null» по внешнему ключу, указывающе-
му на D1, следовательно, следующим присоединяем узел С2. Теперь порядок соеди-
нения — (СЗ, ВЗ. А2, С2).
Решение для задачи из главы 6
303
Рис. А.8. Корректировка по превращению условия типа «не равен null» по внешним ключам
в явные, чтобы оптимизировать остаток порядка соединения
Соединение с С2 добавляет D1 и D2 в список допустимых узлов, находящихся
ниже уже соединенных таблиц, и это единственные допустимые таблицы в этом
направлении, имеющие фильтры, поэтому выберем одну из них. Коэффициенты
фильтрации равны, следовательно, предстоит рассмотреть иные характеристики.
Можно заметить, что D2 должна быть меньше, так как приписанный ей детальный
коэффициент намного больше. Таким образом, следуя правилу выбора меньшей
таблицы, присоединяем D2 перед D1. Теперь порядок соединения — (СЗ. ВЗ. А2. С2.
D2. D1).
Выбирая между С4 и С5, мы также сталкиваемся с одинаковыми коэффициента-
ми фильтрации, равными 1,0, поэтому решаем проблему при помощи правила бли-
зости фильтров, которое благоприятствует узлу С4, так как он открывает доступ к
фильтру для D3. После обработки С4 переходим к D3, чтобы использовать его фильтр,
и, наконец, присоединяем не фильтрованный узел С5. Теперь порядок соединения —
(СЗ. ВЗ. А2. С2. D2. DI. С4, D3. С5).
В данной ситуации у нас нет выбора, какой узел присоединять следующим, сле-
дует просто выбрать соединение вверх с М. После обработки М у нас опять не остает-
ся выбора, так как А1 — это единственный присоединенный к нему узел. После это-
го можно будет выбирать, присоединить далее В1 или В2. Их коэффициенты
фильтрации практически равны с точки зрения поздних соединений, а детальные
коэффициенты соединения одинаковы, следовательно, таблицы должны быть од-
ного размера, поэтому этот фактор не поможет выбору. Также из рассмотрения
можно выкинуть близость других фильтров, так как фильтр для С1 не лучше филь-
тра для В1. Поэтому необходимо выбрать следующее соединение с В1. Теперь поря-
док соединения — (СЗ. ВЗ. А2. С2. D2. DI. С4. D3. С5. М. Al. В1). На данный момент
можно использовать оба оставшихся узла — В2 и С1. У В2 лучший фильтр, и комби-
нация главного и детального коэффициентов фильтрации для таблицы С1 показы-
вает, что она должна быть в 10 раз меньше таблицы В1. В свою очередь, В1 такого же
размера, как и В2, поэтому В2 и С1 на порядок различаются в размере, вероятно,
достаточно для применения правила выбора меньшей таблицы. Следовательно,
304
Приложение А. Решения задач
выбираем С1. Таким образом, сначала присоединяем С1, а полный порядок соеди-
нения выглядит как (СЗ, ВЗ. А2, С2. D2, DI. С4, D3, С5, М, Al. Bl. Cl. В2).
ПРИМЕЧАНИЕ -------------------------------------------------------------
На самом деле последние несколько соединений слабо влияют на стоимость запроса, так как количе-
ство строк к этому моменту становится весьма небольшим.
Чтобы достичь корневой детальной таблицы из СЗ, используя надежный план
со вложенными циклами, базе данных потребуются индексы по внешним ключам
(от М к А2, от А2 к ВЗ и от ВЗ к СЗ) для М, А2 и ВЗ. Вероятно, вам не потребуется индекс
для СЗ, так как 20 % фильтр для этой таблицы недостаточно селективен, чтобы
предпочесть индексный доступ полному сканированию таблицы. Чтобы обеспе-
чить надежный план, для всех остальных таблиц требуются индексы по их первич-
ным ключам.
Чтобы сделать скрытые фильтры соединений с С1 и D1 явными и использовать
их как можно раньше в плане исполнения, добавьте в запрос условия С2.FkeyToDl
IS NOT NULL AND Bl. FkeyToCl IS NOT NULL.
Теперь ослабьте требования надежного плана и подумайте, какие соединения
должны проводиться методом хэширования и какой путь доступа нужно исполь-
зовать для таблиц, соединяемых хэшированием. Вспомните, что в таблице А1
30 000 000 строк. Исходя из детальных коэффициентов соединения, в В1 и В2 дол-
жно быть в 300 раз меньше строк. То есть в обеих таблицах находится по 100 000
записей. Исходя из комбинации главного коэффициента соединения и детального
коэффициента соединения, в С1 в десять раз меньше строк, чем в В1, — 10 000. Пе-
реходя вверх от А1 к М, видим, что в М в 0,02 раза меньше строк, чем в А1, — 600 000.
Спускаясь вниз от М и используя детальные коэффициенты соединения, вычис-
лим, что в А2 и ВЗ по 60 000 строк, в С2 30 000 строк, в СЗ 10 000 строк, в С4 20 000
строк и в С5 12 000 строк. Учитывая главный и детальный коэффициенты соедине-
ния от С2 к D1, вычислим, что в D16 000 (30 000 х 0,4/2) строк. Исходя из детальных
коэффициентов соединения, найдем, что в D2 150 строк, а в D3 2 000 строк.
Любая часть плана, в которой из таблицы считывается больше строк, чем база
данных считала бы, используя фильтры для этой таблицы, означает, что доступ к
этой таблице следует осуществлять через фильтрующий индекс и использовать
соединение хэшированием в этой точке исходного плана выполнения. В любой
части плана, где считывается хотя бы 5 % строк таблицы, лучше использовать пол-
ное сканирование этой таблицы с соединением хэшированием. Когда любой из
видов доступа путем соединения хэшированием предпочтительней вложенных
циклов (то есть соединение хэширование с индексным считыванием фильтра или
с полным сканированием таблицы), выберите полное сканирование таблицы, если
фильтр пропускает хотя бы 5 % строк таблицы.
ПРИМЕЧАНИЕ----------------------------------------------------------------
Как обсуждалось в главе 2, фактически порог для индексного доступа может находиться в любой точке
между 0,5 и 20 %, но в этом упражнении граничным значением считается 5 %, чтобы сделать задачу
конкретнее.
Итак, в таблице А.1 показаны размеры таблиц и граничные значения для выбо-
ра полного сканирования таблицы, отсортированные в порядке соединения.
Решение для задачи из главы 6
305
Таблица А.1. Размеры таблиц и пороги для выбора полного сканирования таблицы
для решения упражнения из главы 6
Таблица Количество строк Граничное значение для выбора полного
сканирования таблицы
СЗ 10 000 500
ВЗ 60 000 3 000
А2 60 000 3 000
С2 30 000 1500
D2 150 8
D1 6 000 300
С4 20 000 1000
D3 2 000 100
С5 12 000 600
М 600 000 30 000
А1 30 000 000 1 500 000
В1 100 000 5 000
С1 10 000 500
В2 100 000 5 000
Теперь, узнав количество строк на каждом шаге запроса, мы обнаруживаем, что
после полного сканирования таблицы СЗ фильтр для СЗ сокращает количество строк
до 2000. Соединение вверх методом вложенных циклов с В1 затрагивает 12 000 строк
из этой таблицы, так как детальный коэффициент фильтрации равен 6. Для ВЗ нет
фильтра, поэтому следующее соединение вида «один к одному» (в среднем) с А2
также затрагивает 12 000 строк, после чего фильтр для А2 оставляет лишь 30 %
(3600 строк) для следующего соединения с С2. Имея главный коэффициент соеди-
нения, равный 1.0, вложенные циклы затронут 3600 строк из С2. Фильтры для С2
(включая ставший явным фильтр «не равен null» по внешнему ключу к D1) сокра-
щают количество строк до 1440 перед соединением с D2. Вложенные циклы для D2
считывают 1440 строк из этой таблицы, после чего фильтр оставляет 1008 строк.
Вложенные циклы для 01 считывают 1008 строк из этой таблицы (так как на дан-
ный момент у всех строк есть не равные null внешние ключи, указывающие на 01),
после чего фильтр оставляет 706 строк (я округляю это значение, что буду делать
и в дальнейшем).
Вложенные циклы для С4 считывают 706 строк из этой таблицы, и они не филь-
труются, оставляя количество строк равным 706. Вложенные циклы для D3 считы-
вают 706 строк из этой таблицы, после чего фильтр оставляет 282. Вложенные цик-
лы для С5 считывают 282 строки из этой таблицы, и они не фильтруются, оставляя
количество строк равным 282. С детальным коэффициентом соединения равным
10, соединение вверх с М считывает 2820 строк из этой таблицы, после чего фильтр
оставляет только 1410. С не указанным главным коэффициентом соединения рав-
ным 1,0, вложенные циклы считывают 1410 строк из самой большой таблицы, А1,
и после этого фильтр оставляет 564 строки. Вложенные циклы для В1 считывают
564 строки из этой таблицы, после чего фильтры (включая ставшее явным усло-
вие «внешний ключ не равен null» по ключу В1, указывающему на С1) оставляют
28. Вложенные циклы для С1 считывают 28 строк из этой таблицы (так как на дан-
ный момент во всех строках есть внешние ключи, не равные null, которые указыва-
306
Приложение А. Решения задач
ют на С1), после чего фильтр оставляет 3 записи. Вложенные циклы для В2 считы-
вают 3 строки из этой таблицы, после чего итоговый фильтр оставляет 0 или 1 стро-
ку в качестве результата.
Если вы сравните эти количества строк, считываемых вложенными циклами,
с пороговыми значениями для выбора полного сканирования таблицы, то увиди-
те, что соединения хэшированием с полным сканированием таблицы сокращают
стоимость для нескольких таблиц. Так как ни один из фильтров в этом запросе не
был достаточно селективным, чтобы предпочесть индексный доступ к одной таб-
лице полному сканированию таблицы (считая граничным значением 5 %), то сле-
дует выбрать соединения хэшированием с наборами строк, считанными при помо-
щи полного сканирования таблиц, если вы решите, что соединения хэшированием
вообще стоит использовать для данного запроса. Этот пример демонстрирует нео-
бычно привлекательный случай для использования соединений хэшированием.
Более распространенные примеры, с запросами к большим таблицам, имеющим,
по меньшей мере, один селективный фильтр, демонстрируют несколько более мел-
кие улучшения при использовании соединений хэшированием только с самыми
маленькими таблицами.
В таблице А.2 перечислены количества строк, вычисленные для лучшего на-
дежного плана, а также граничные значения, при достижении которых соедине-
ния хэшированием с полным сканированием таблицы работают быстрее. В пра-
вом столбце, «Метод/соединение», перечислены оптимальные методы доступа к
таблицам и соединения для каждой таблицы в левом столбце.
Таблица А.2. Лучшие методы доступа и соединения для данного примера
Таблица Количество строк Граничное значение для выбора полного сканирования таблицы Строки, считанные надежным планом Метод/соединение
СЗ 10 000 500 2 000 Полное сканирование/ведущее
ВЗ 60 000 3 000 12 000 Полное сканирование/хэширование
А2 60 000 3 000 12 000 Полное сканирование/хэширование
С2 30 000 1500 3 600 Полное сканирование/хэширование
D2 150 8 1440 Полное сканирование/хэширование
D1 6 000 300 1008 Полное сканирование/хэширование
С4 20 000 1000 706 Индексный/вложенные циклы
D3 2 000 100 706 Полное сканирование/хэширование
С5 12 000 600 282 Индексный/вложенные циклы
М 600 000 30 000 2 820 Индексный/вложенные циклы
А1 30 000 000 1 500 000 1410 Индексный/вложенные циклы
В1 100 000 5 000 564 Индексный/вложенные циклы
С1 10 000 500 28 Индексный/вложенные циклы
В2 100 000 5 000 3 Индексный/вложенные циклы
Обратите внимание, что замена соединений методом вложенных циклов на
соединения хэшированием, как показано в таблице, устраняет необходимость
Решение для задачи из главы 7
307
(по крайней мере, в этом запросе) использовать индексы по внешним ключам для
ВЗ и А2 и индексы по первичным ключам для С2, D2, D1 и D3.
Решение для задачи из главы 7
Глава 7 включает одну достаточно сложную задачу, позволяющую использовать
большинство правил для подзапросов. В этом разделе вы найдете детальное поша-
говое решение этой задачи. На рис. А.9 показаны отсутствующие коэффициенты
для трех полусоединений и антисоединения.
Рис. А.9. Диаграмма с рис. 7.36 с указанными отсутствующими коэффициентами подзапросов
Я начну с объяснения вычислений отсутствующих коэффициентов, показан-
ных на рис. А.9. Чтобы найти корреляционный коэффициент предпочтения для
полусоединения с D1, просто выполните правила, перечисленные в главе 7, в разде-
ле «Диаграммное изображение подзапросов EXISTS». На первом шаге мы нахо-
дим, что детальный коэффициент соединения для D1, исходя из рис. 7.36, равен
D = 0,8. Это редкий случай соединения «многие к одному», когда одной главной
строке соответствует в среднем менее одной детализированной строки. Предполо-
жим, что М = 1. Это обычное значение главного коэффициента соединения для
случая, когда он явно не показан на диаграмме. Лучший коэффициент фильтра-
ции среди узлов в этом подзапросе (01, S1 и S2) равен 0,3 для D1, поэтому S = 0,3.
Лучший коэффициент фильтрации срезу узлов внешнего запроса (М, Al, А2, В1 и В2)
равен 0,2 для А1, поэтому R = 0,2. На втором шаге правила находим D х S = 0,24, а
М х R = 0,2, поэтому D х S > М х R. Следовательно, нужно перейти к шагу 3. Мы
находим, что S > R, поэтому корреляционный коэффициент предпочтения равен
S/R = 1,5; записываем его рядом с указателем полусоединения Е от М к D1.
Чтобы найти корреляционный коэффициент предпочтения для полусоедине-
ния с D2, повторяем процесс. На первом шаге находим детальный коэффициент
соединения на рис. 7.36 (D = 10). Предполагаем, что М = 1, обычный главный ко-
эффициент соединения, когда он явно не указан на диаграмме. Лучший коэффи-
циент фильтрации между 02 и S3 равен 0,0005 для S3, поэтому S = 0,0005. Лучший
308
Приложение А. Решения задач
коэффициент фильтрации среди узлов внешнего запроса, как и раньше, равен R = 0,2.
На втором шаге правил находим D х S = 0,005, а М х R - 0,2, поэтому D х S < М х R.
Следовательно, вычисления завершаются на шаге 2, и корреляционный коэффи-
циент предпочтения равен (D х S)/(M х R) = 0,025; записываем его рядом с указа-
телем полусоединения Е от М к D2.
Чтобы найти корреляционный коэффициент предпочтения для полусоедине-
ния с D4, повторим процесс. На первом шаге находим детальный коэффициент со-
единения на рис. 7.36 (D - 2). Предполагаем, что М - 1, обычный главный коэф-
фициент соединения, когда он явно не указан на диаграмме. Лучший коэффициент
фильтрации среди D4, S4, S5, S6 и S7 равен 0,001 для 04, поэтому S - 0,001. Лучший
коэффициент фильтрации среди узлов внешнего запроса, как и раньше, равен R = 0,2.
На втором шаге находим D х S = 0,002, а М х R = 0,2, поэтому D х S < М х R. Сле-
довательно, вычисления завершаются на шаге 2, и корреляционный коэффи-
циент предпочтения равен (D х S)/(M х R) = 0,01; записываем его рядом с указа-
телем полусоединения Е от М к D4.
Теперь перейдем к следующему набору правил, чтобы найти уточненные коэф-
фициенты фильтрации подзапросов. Шаг 1 указывает, что нам не нужен уточнен-
ный коэффициент фильтрации для D4, так как его корреляционный коэффициент
предпочтения меньше 1,0 и меньше всех остальных коэффициентов предпочте-
ния. Перейдем к шагу 2 для D1 (корреляционный коэффициент предпочтения ко-
торого больше 1,0) и D2 (коэффициент предпочтения которого больше того же ко-
эффициента для D4). В подзапросах под узлами D1 и D2 есть фильтры, поэтому для
каждого из них перейдем к шагу 3. Для D1 найдем D = 0,8 и s - 0,3, то есть значение
s равно самому коэффициенту фильтрации для D1. На шаге 4 заметим, что D < 1,
поэтому уточненный коэффициент фильтрации подзапроса равен s х D = 0,24, и мы
записываем его рядом с числом 0,8 у верхнего конца полусоединения с D1.
На шаге 3 для D2 находим, что D = 10 и s = 0,5, то есть значение s равно самому
коэффициенту фильтрации для D2. На шаге 4 замечаем, что D > 1, поэтому перехо-
дим к шагу 5. Обратите внимание, что s х D = 5, что больше 1,0, поэтому переходим
к шагу 6. Пусть уточненный коэффициент фильтрации подзапроса равен 0,99, и за-
пишем это число рядом с числом 10 у верхнего конца полусоединения с D2.
Теперь единственный отсутствующий коэффициент — это уточненный коэф-
фициент фильтрации подзапроса для антисоединения с D3. Следуя правилам для
антисоединений, на шаге 1 находим, что t = 5 и q = 50 для рассматриваемого опера-
тора. На шаге 2 замечаем, что в этом подзапросе есть лишь один узел (как это часто
бывает с условиями NOT EXISTS), поэтому С - 1, и вычисляем (С - 1 + (t/q))/C -
- (1 - 1 + (5/50))/1 - 0,1.
Теперь обратимся к правилам настройки подзапросов, имея полную диаграм-
му запроса. Согласно шагу 1, убедимся, что антисоединение с 03 выражено как кор-
релированный подзапрос NOT EXISTS, а не как некоррелированный подзапрос NOT IN.
Шаг 2 не применяется, так как у нас нет полусоединений (с условиями EXISTS),
у которых указатели стрелки посередине связи указывают вниз. Выполняя шаг 3,
найдем наименьший корреляционный коэффициент предпочтения — 0,01 для по-
лусоединения с D4, поэтому следует выразить это условие как некоррелированный
подзапрос IN и убедиться, что остальные условия типа EXISTS выражены как явные
условия EXISTS для коррелированных подзапросов. Оптимизируя подзапрос под
D4, как если бы это был отдельный запрос, находим, следуя правилам для простых
Решение для задачи из главы 7
309
запросов, что начальный порядок соединения — (D4. S4.S6.S5, S7). Начиная с это-
го момента, база данных должна выполнить операцию уникальной сортировки по
внешнему ключу D4, указывающему на М в этом полусоединении. Вложенные цик-
лы перейдут к М по индексу по первичному ключу М. Оптимизируйте запрос, начи-
ная с М, как если бы условия подзапроса для D4 не существовали.
Шаг 4 не применяется, так как мы начали с подзапроса с условием IN. Шаг 5
следует выполнить, так как в узле М мы находим остальные три соединения с под-
запросами. Полусоединение с D1 ведет себя как узел снизу с коэффициентом филь-
трации 0,24 — немного хуже, чем А1, но лучше, чем А2. Полусоединение с D2 ведет
себя как узел внизу с коэффициентом фильтрации 0,99, чуть лучше, чем соедине-
ние вниз с не фильтрованным узлом, но не так хорошо, как соединение с А1 или А2.
Антисоединение с D3 выглядит лучше всех остальных, как и многие селективные
антисоединения, так как ведет себя как узел внизу с коэффициентом фильтрации
0,1 — лучше, чем у остальных.
Таким образом, далее выполняем условие NOT EXISTS для D3 и находим новый
порядок соединения (04 S4, S6. S5, S7. М. 03). Так как подзапрос с D3 состоит из
одной таблицы, возвращаемся во внешний запрос и находим следующий лучший
среди находящихся внизу узлов — узел А1. Это позволяет выполнить соединение с
В1, но В1 менее привлекателен, чем еще один возможный вариант, D1, уточненный
коэффициент фильтрации подзапроса которого равен 0,24, поэтому далее присое-
диняем D1. Начав обработку этого подзапроса, необходимо закончить его, следуя
обычным правилам оптимизации простого подзапроса, и начиная с D1 как с веду-
щего узла.
Теперь допустимыми становятся узлы А2, В1 и D2, которые лучше всего при-
соединять именно в этом порядке, о чем говорят их коэффициенты фильтрации
или (для D2) уточненный коэффициент фильтрации подзапроса. После соедине-
ния с А2 появляется новый допустимый узел, В2, но его коэффициент фильтрации
равен 1,0, и он не так привлекателен, как остальные. Таким образом, присоединя-
ем А2, В1 и D2 в указанном порядке, получая порядок соединения (D4 S4.S6.S5.S7,
М, D3. Al. DI, SI, S2. А2, Bl, D2). Достигнув D2, необходимо завершить этот подзап-
рос, выполнив соединение с S3. После этого остается присоединить только узел В2
и получить полный порядок соединения как (D4, S4, S6. S5, S7, М, D3, Al, DI, SI. S2.
А2. Bl, D2. S3, В2).
Приложение Б. Полный
и непрерывный процесс
На протяжении всей книги я приводил примеры, иллюстрирующие каждый шаг
процесса в деталях, но пока что не описал ни одного процесса полностью, от на-
чала до конца. Если вы предпочитаете рассматривать процессы в полном виде и
работать, основываясь на таких примерах, то это приложение предназначено для
вас.
Пример в этом приложении описывает достаточно сложный запрос, чтобы про-
иллюстрировать основные вопросы, постоянно возникающие в ходе работы, и в то
же время содержит несколько ошибок, требующих исправления. Представьте, что
следующий запрос был предложен для приложения, разработанного для работы
под Oracle, DB2 и SQL Server, а вас попросили вынести решение относительно его
оптимальности в этих базах данных и, если необходимо, предложить изменения:
SELECT C.Phone_Number. С.Honorific. C.FirstJIame. C.LastJIame. C.Suffix.
C.Address_ID. A.Address_ID. A.Street_Addr_Linel. A.Street_Addr Line2
A.City_Name. A.State_Abbreviation. A.ZIP Code. OD.Deferred_Sh,p_Date.
OD. ItemCount. P. ProdJlescri pti on. S. Shi pment_Date
FROM Orders 0. Order_Details 00. Products P. Customers C. Shipments S.
Addresses A
WHERE 00.OrderJD = 0.OrderJD
AND 0 CustomerJD = C.Customer ID
AND 0D.ProductJD = P.ProductJD
AND 0D.Shipment ID = S.ShipmentJD
AND S.AddressJD = A.AddressJD
AND 0.PhoneJlumber = 6505551212
AND O.BusinessJJnitJD = 10
ORDER BY C CustomerJD. O.OrderJD Desc. S.ShipmentJD. OD.Order_Detail_ID:
Сокращение запроса до диаграммы запроса
Первый шаг процесса — создать диаграмму запроса. Начните со скелета запроса
и затем добавляйте детали, чтобы завершить диаграмму. Следующие несколько
подразделов посвящены процессу создания диаграммы для запроса в примере.
Создание скелета запроса
В начальной точке поместите любой псевдоним в центр диаграммы. Чтобы было
удобнее рисовать, я начну с узла 0. Нарисуйте стрелки вниз от этого узла ко всем
Сокращение запроса до диаграммы запроса
311
узлам, с которыми 0 соединяется через их первичные ключи (они называются так
же, как и таблицы, но «s» на конце заменена на «_1С»), Нарисуйте указывающие
вниз ведущие к 0 стрелки от всех псевдонимов, участвующих в соединениях с 0 по
первичному ключу таблицы Orders, Order_ID. Начало скелета запроса должно вы-
глядеть как на рис. Б.1.
OD
▼
О
▼
С
Рис. Б.1. Начало скелета запроса
Теперь сместим фокус внимания на 00. Найдите соединения от этого узла и до-
бавьте соответствующие связи на скелет соединений. Результат должен выглядеть
как на рис. Б.2.
OD
▼
С
Рис. Б.2. Промежуточное состояние скелета запроса
Найдите условия соединения, еще не указанные на диаграмме. Единственное
оставшееся условие — S.Address_ID = A.Address_ID, поэтому нужно добавить связь
для этого соединения, чтобы завершить скелет запроса, как показано на рис. Б.З.
OD
S Р О
▼ ▼
А С
Рис. Б.З. Полный скелет запроса
312
Приложение Б. Полный и непрерывный процесс
Создание упрощенной диаграммы запроса
Чтобы создать упрощенную диаграмму запроса, найдите самый селективный фильтр
и обозначьте его подчеркнутой буквой F рядом с фильтрованным узлом. Условие
по телефонному номеру покупателя практически однозначно будет самым селек-
тивным фильтром. Добавьте строчную подчеркнутую букву f для единственного
оставшегося фильтра, намного менее селективного условия по Busi nessJJni t_ID для
Orders. Результат, показанный на рис. Б.4, — это упрощенная диаграмма запроса.
OD
S Р Of
Рис. Б.4. Упрощенная диаграмма запроса
Создание полной диаграммы запроса
Упрощенной диаграммы запроса достаточно для настройки этого запроса. Однако
чтобы было понятнее, я покажу, как создать полную диаграмму запроса со всеми
подробностями. Используйте следующие запросы для сбора статистики, необхо-
димой для полной диаграммы запроса. Результаты, которые я использую в приме-
ре, перечислены под каждым запросом. В качестве упражнения вы можете вычис-
лить коэффициенты фильтрации и соединения самостоятельно.
QI: SELECT SUM(COUNT(Phone_Number)*COUNT(Phone_Number))/
(SUM(COUNT(Phone_Number))*SUM(COUNTC*))) Al
FROM Customers
GROUP BY Phone Number;
Al: 0.000003
02: SELECT COUNT(*) A2 FROM Customers;
A2: 500 000
03: SELECT SUM(COUNT(Business_Unit ID)*COUNT(Business UnitJD))/
(SUM(COUNT(Business_Un7t_IO))*SUM(COUNT(*)')) A3
FROM Orders
GROUP BY Bus1ness_Un1t ID;
A3: 0.2
Q4: SELECT COUNT!*) A4 FROM Orders:
A4: 400 000
05: SELECT COUNT!*) A5
FROM Orders 0. Customers C
WHERE O.Customer_ID - C.Customer_I0;
A5: 400 000
06: SELECT COUNT!*) A6 FROM Order_Details:
Сокращение запроса до диаграммы запроса
313
А6: 1 200 000
Q7: SELECT COUNT!*) А7
FROM Orders 0. Order_Details 0D
WHERE DD.Order_ID = O.Order_ID;
A7: 1 2000 000
08: SELECT COUNT!*) A8 FROM Shipments:
A8: 540 000
09: SELECT COUNT!*) A9
FROM Shipments S. Order_Details OD
WHERE OD.Shipment_ID = S.Shipment_ID;
A9: 1 080 000
Q10: SELECT COUNT!*) A10 FROM Products;
A10. 12 000
QU: SELECT COUNT!*) All
FROM Products P. OrderJDetal1s OD
WHERE OD.Product_ID = P.Product_ID:
АП : 1 200 000
012: SELECT COUNT!*) A12 FROM Addresses.
A12: 135 000
013: SELECT COUNT!*) A13
FROM Addresses A, Shipments S
WHERE S.AddressJD = A.Address ID:
A13: 540 000
ПРИМЕЧАНИЕ----------------------------------------------------------------------------------
Я уменьшил размеры таблиц в этом примере, чтобы предоставить удобные сценарии генерации данных
для проверки планов выполнения, которые для этих таблиц создадут стоимостные оптимизаторы. Са-
мые большие таблицы в этом примере будут, вероятно, приблизительно в 10 раз меньше, чем в реаль-
ных условиях.
Начиная с коэффициентов фильтрации, найдите средневзвешенный коэффи-
циент фильтрации для условия по Customers Phone Number непосредственно как А1,
то есть результат запроса Q1 (0,000003). Точно так же найдите коэффициент филь-
трации для Orders, из Q3, который для АЗ возвращает результат 0,2.
Так как у остальных четырех псевдонимов фильтров нет, коэффициенты филь-
трации для них равны 1,0 и их значение не нужно указывать на диаграмме запроса
для этих узлов.
Для каждого соединения найдите детальный коэффициент соединения и запи-
шите его у верхнего конца каждой стрелки, обозначающей соединение. Для этого
разделите количество строк, возвращаемое при соединении двух таблиц, на коли-
чество строк в нижней таблице (главной для этого отношения главной и деталь-
ной таблиц). Коэффициенты для верхних концов соединения от 0D к S, 0 и Р равны
2 (А9/А8), 3 (А7/А4) и 100 (А11/А10), соответственно. Коэффициент для верхнего конца
соединения от S к А равен 4 (А13/А12). Коэффициент для верхнего конца соедине-
ния от 0 к С равен 0,8 (А5/А2).
Найдите главные коэффициенты соединения и поместите их у нижнего конца
каждой стрелки, обозначающей соединение. Для этого разделите количество строк,
314
Приложение Б. Полный и непрерывный процесс
возвращаемое соединением двух таблиц, на количество строк в каждой верхней
таблице (детальной для этого отношения главной и детальной таблиц). Коэффи-
циент для нижнего конца соединения от 0D к S равен 0,9 (А9/А6). Все прочие глав-
ные коэффициенты соединения оказываются равными 1,0, поэтому на диаграмме
их указывать не нужно.
Добавьте коэффициенты фильтрации и коэффициенты соединения к скелету
запроса (см. рис. Б.З), чтобы создать полную диаграмму запроса, показанную на
рис. Б.5.
А С 0.000003
Рис. Б.5. Полная диаграмма запроса
Решение диаграммы запроса
После того как вы упростили содержащий различные детали запрос до абстракт-
ной диаграммы соединения, то прошли уже 80 % пути поиска лучшего плана вы-
полнения, так же, как проблемы эквивалентности в математике обычно становят-
ся тривиальными, если преобразовать их в символьную форму. Однако вам еще
предстоит решить символьную задачу. Используя методы из главы 6, решите зада-
чу, абстрактно изображенную на рис. Б.5.
1. Выберите лучшую ведущую таблицу. Лучший (наиболее близкий к 0) коэффи-
циент фильтрации принадлежит С, поэтому ведущей выберите таблицу С.
2. От С вниз не ведут никакие соединения, поэтому надо выбрать единственное
соединение вверх с 0, поместив 0 второй в порядок соединения.
ПРИМЕЧАНИЕ —-----------------------------------------------------
Даже если бы существовали соединения вниз от С, вы бы все равно выбрали соединение с 0, так как
детальный коэффициент соединения с 0 меньше 1,0, и у 0 собственный хороший фильтр.
3. У 0 нет необработанных соединений вниз, поэтому выберите единственное со-
единение вверх с 00, поместив 00 третьей в порядок соединения.
4. Начиная с 00, мы обнаруживаем два необработанных соединения вниз: с S и с Р.
Для оставшихся узлов нет простых фильтров, но существует скрытый фильтр
соединения в соединении с S, так как главный коэффициент соединения для
него меньше 1,0. Таким образом, следует присоединить S, помещая ее четвер-
той в порядок соединения.
Проверка планов выполнения
315
ПРИМЕЧАНИЕ---------------------------------------------------------------------
Если бы существовал фильтр для узла Р, то вы бы сделали неявный фильтр OD.Shipment_ID IS NOT NULL
явным. Тогда вы могли бы использовать этот фильтр перед соединением с S и перейти к фильтру для Р
после того, как получите преимущества фильтра NOT NULL, не платя дополнительную цену за соедине-
ние с S перед Р.
5. Оставшиеся узлы, А и Р, не фильтруются, и достижимы при помощи соединений
от уже обработанных таблиц. Их главные коэффициенты соединения равны 1,0,
поэтому нет разницы, в каком порядке присоединять их. Просто для упорядоче-
ния произвольно выберите А пятой в порядке соединения, а Р присоедините пос-
ледней. Таким образом, оптимальный порядок соединения — (С. 0. OD, S. А. Р).
6. Получив порядок соединения, укажите полный план выполнения, следуя пра-
вилам для надежных планов выполнения, в оптимальном порядке соединения.
1) Перейти к первой таблице Customers через индекс по столбцу фильтрации,
Phone_Number. Если это необходимо, следует изменить запрос, чтобы сделать
этот индекс доступным и полезным.
2) Методом вложенных циклов присоединить Orders через индекс по внешне-
му ключу Customer_ID.
3) Методом вложенных циклов присоединить Order_Details через индекс по
внешнему ключу Order_ID.
4) Методом вложенных циклов присоединить Shi pments через индекс по пер-
вичному ключу Shipment_ID.
5) Методом вложенных циклов присоединить Addresses через индекс по пер-
вичному ключу Address_ID.
6) Методом вложенных циклов присоединить Products через индекс по первич-
ному ключу Product_ID.
Второй шаг процесса настройки завершен. Далее необходимо проверить, какой
план выполнения фактически применяется во всех трех базах данных, так как этот
пример иллюстрирует SQL, предназначенный для выполнения во всех этих базах
данных.
Проверка планов выполнения
Для этого примера предположим, что разработка базы проводится в Oracle, а за-
тем она тестируется, чтобы проверить, что тот же SQL-код правильно работает и в
DB2, и в SQL Server. Вы узнали об этом SQL-коде, так как в Oracle он выполнялся
медленнее, чем ожидалось, поэтому уже подозреваете, что он выдает плохой план
выполнения, по крайней мере, в этом сервере баз данных. Вам будет необходимо
проверить планы выполнения и в других базах данных, которые еще не были про-
тестированы.
Получение плана выполнения в Oracle
Поместите SQL в файл с именем tmp. sql и запустите сценарий ex. sql, как описано
в главе 3. Вы получите следующий результат:
316
Приложение Б. Полный и непрерывный процесс
PLAN
SELECT STATEMENT
SORT ORDER BY
NESTED LOOPS
NESTED LOOPS
NESTED LOOPS
NESTED LOOPS
NESTED LOOPS
TABLE ACCESS FULL ^CUSTOMERS
TABLE ACCESS BY INDEX ROWID 1*ORDERS
INDEX RANGE SCAN ORDERCUSTOMERID
TABLE ACCESS BY INDEX ROWID 2*0RDER_DETAILS
INDEX RANGE SCAN ORDER_DETAIL_ORDER_ID
TABLE ACCESS BY INDEX ROWID 5*SHIPMENTS
INDEX UNIQUE SCAN SHIPMENT_PKEY
TABLE ACCESS BY INDEX ROWID 6*ADDRESSES
INDEX UNIQUE SCAN ADDRESS PKEY
TABLE ACCESS BY INDEX ROWID 3*PR0DUCTS
INDEX UNIQUE SCAN PRODUCT PKEY
Вы замечаете, что настройки базы данных заставляют использовать синтакси-
ческий оптимизатор, поэтому вы переключаетесь на стоимостный оптимизатор,
проверяете, что статистика для всех таблиц и индексов собрана, и еще раз прове-
ряете план, получая новый результат:
PLAN
SELECT STATEMENT
SORT ORDER BY
HASH JOIN
TABLE ACCESS FULL 3*PRODUCTS
HASH JOIN
HASH JOIN
HASH JOIN
HASH JOIN
TABLE ACCESS FULL ^CUSTOMERS
TABLE ACCESS FULL 1*ORDERS
TABLE ACCESS FULL 2*0RDER_DETAILS
TABLE ACCESS FULL 5*SHIPMENTS
TABLE ACCESS FULL 6*ADDRESSES
Оба плана выполнения далеки от оптимального. И план, полученный с синтак-
сической оптимизацией, и план со стоимостной оптимизацией начинают работу с
полного сканирования больших таблиц. База данных должна обращаться к веду-
щей таблице через очень селективный индекс, поэтому улучшение данного плана
выполнения действительно необходимо и возможно.
Получение плана выполнения в DB2
Поместите SQL-код в файл tmp. sql и запустите следующую команду согласно про-
цессу, описанному в главе 3:
cat head.sql tmp.sql tail.sql | db2 +c +p -t
Результатом будет ошибка; DB2 сообщает, что видит несовместимые типы
столбцов в условии по Phone_Number. Оказывается, столбец Phone_Number принадле-
жит типу VARCHAR, который не совместим с числовым типом константы 6505551212.
Проверка планов выполнения
317
В отличие от Oracle, DB2 не выполняет неявное преобразование столбцов сим-
вольного типа в числовые, когда SQL сравнивает несовместимые типы данные.
Это именно такой случай, так как преобразование может деактивировать индекс
по PhoneJIumber, если таковой существует. Вполне вероятно, что именно этот факт
вызвал плохую производительность запроса в основной среде разработки Oracle.
Ошибку можно исправить самым очевидным способом, поместив константу,
обозначающую телефонный номер, в кавычки, чтобы преобразовать ее в символь-
ный тип.
SELECT C.Phone_Number. С.Honorific, C.FirstJlame. C.Last_Name, C.Suffix.
C.AddressJD. A.AddressJD, A. Street. AddrjTnel. A.Street_Addr_Line2,
A.C1ty_Name. A.State_Abbreviat1on, A.ZIPJode, OD.Deferred_Sh1p_Date,
OD.Item Count. P.Prod_Descript1on, S.Sh1pment_Date
FROM Orders 0, Order_Details OD. Products P, Customers C. Shipments S,
Addresses A
WHERE 0D.0rder_ID - O.Order_ID
AND O.CustomerJD - C.CustomerJD
AND OD.Product_ID - P. Product JD
AND OD.Shipment_ID - S.Shipment_ID
AND S.AddressJD - A.AddressJD
AND C.Phone_Number - ’6505551212'
AND D.BusinessJJnitJD - 10
ORDER BY C.CustomerJD. D.OrderJD Desc. S.ShipmentJD. OD.OrderJJetailJD:
Сохранив новый вариант SQL-запроса в файле tmp.sql, следует снова получить
информацию о плане выполнения:
$ cat head.sql tmp.sql tail.sql | db2 +c +p ,-t
DB20000I The SOL command completed successfully.
DB20000I The SOL command completed successfully.
OPERATORJD TARGETJD OPERATORJYPE DBJECT_NAME CDST
1 - RETURN - 260
2 1 NLJOIN - 260
3 2 NLJOIN - 235
4 3 NLJOIN - 210
5 4 TBSCAN - 1B5
6 5 SORT - 185
7 6 NLJOIN - 185
В 7 NLJOIN - 135
9 8 FETCH CUSTOMERS 75
10 9 IXSCAN OUST PH NUMBER 50
11 8 FETCH ORDERS 70
12 11 IXSCAN ORDER CUST ID 50
13 7 FETCH ORDER DETAILS 75
14 13 IXSCAN ORDER DTL ORD ID 50
15 4 FETCH PRODUCTS 50
16 15 IXSCAN PRODUCT.PKEY 25
17 3 FETCH SHIPMENTS 75
18 17 IXSCAN SHIPMENT PKEY 50
19 2 FETCH ADDRESSES 75
20 19 IXSCAN ADDRESS PKEY 50
20 record(s) selected.
DB20000I The SOL command completed successfully.
$
318
Приложение Б. Полный и непрерывный процесс
Это похоже на план выполнения, который вы выбрали, анализируя SQL-код
сверху вниз. Но есть небольшая проблема — таблица Products обрабатывается до
Shipments. Впрочем, это практически никак не будет влиять на время выполнения
запроса. Так как несовместимость типов, затрагивающая Phone_Number, может по-
требовать исправления в SQL Server и Oracle, вам нужно немедленно опробовать
модифицированный вариант в других базах данных.
Получение плана выполнения в SQL Server
Подозревая, что уже получили решение проблемы производительности этого
запроса, вы запускаете SQL Server Query Analyzer и используете showplan_text,
чтобы посмотреть краткое представление плана выполнения оператора, в кото-
ром несовместимость типов была исправлена при помощи С.Phone_Number =
‘6505551212'. Щелчок по кнопке Execute-Query в Query Analyzer выдает следую-
щий результат:
StmtText
|--Bookmark Lookup(...(...[Products] AS [P]))
|-Nested Loops(Inner Join)
(--Bookmark Lookup!...(...[Addresses] AS [A]))
I (--Nested Loops!Inner Join)
| |—SortfORDER BY: ([0]. [CustomerJD] ASC. (wrapped line) [0]. [OrderJD] DESC.
(wrapped line) [OD].[Shipment_ID] ASC. [OD].[Order_Detail_ID] ASC))
| | (--Bookmark Lookup!...(...[Shipments] AS [S]))
I | (--Nested Loops!Inner Join)
I | (--Bookmark
(wrapped line) Lookup! ..(...[Order_Details] AS [OD]))
| | | (--Nested Loopsdnner Join)
| | | |-Filter(WHERE:([O].[Business_Unit_ID] =
10))
|| || (--Bookmark
(wrapped line) Lookup!...(...[Orders] AS [0]))
|| || (--Nested
(wrapped line) Loopsdnner Join)
|| || |--Bookmark
(wrapped line) Lookupd. ( .
(wrapped line) [Customers] AS [C]))
II II I |-Index
(wrapped line) Seek(...(...
(wrapped line) [Customers] [Customer_Phone_Number]
(wrapped line) AS [C]). SEEK([C].[Phone_Number] = ’6505551212’) ORDERED)
II II (-Index
(wrapped line) Seek(...(...
(wrapped line) [Orders]. [OrderJustomerJD] AS [0]).
(wrapped line) SEEK:([0].[CustomerJD] = [C].[Customer_ID]) ORDERED)
| | | |--Index Seek!...(...
(wrapped line) [Order_Details].[Order_Detail_Order_ID]
(wrapped line) AS [0D]). SEEK:([00].[OrderJD] = [0].[OrderJD]) ORDERED)
| | |--Index
(wrapped line) Seek (...(...[Shipments].[Shipment_PKey]
(wrapped line) AS [S]). SEEK:([S].[ShipmentJD] = [OD].[Shipment_ID]) (wrapped line)
ORDERED)
( |--Index Seek(...(...[Addresses].[Address_PKey]
(wrapped line) AS [A]). SEEK:([A],[AddressJD] = [S].[AddressJD]) ORDERED)
Изменение SQL-кода для получения хорошего плана
319
| - -Index Seek(...(...[Products].[Product_PKey]
(wrapped line) AS [P]). SEEK:([P].[Product_ID] = [OD].[Product_ID]) ORDERED)
(19 row(s) affected)
Хорошие новости! С исправленным SQL-кодом вы получаете оптимальный
план. Просто из любопытства можно проверить план выполнения для исходного
SQL-кода и получить тот же самый результат! Очевидно, SQL Server выполняет
преобразование данных для константы, не запрещая использование индекса.
Изменение базы данных для получения
лучшего плана
Предыдущие результаты в DB2 и SQL Server уже продемонстрировали, что в ди-
зайне базы данных есть все необходимые индексы, чтобы использовать желаемый
план выполнения. Но в Oracle могут отсутствовать индексы, которые существуют
в других базах данных. Таким образом, вы можете пропустить этот шаг. Однако
если бы вы еще не знали, что индексы существуют, то проверили бы, есть ли ин-
дексы по Customers(Phone_Number), Orders(Customer_ID) и Order_Details(Order_ID), ис-
пользуя методы, описанные в главе 3. Обычно можно принять как должное, что
необходимые индексы по первичным ключам уже существуют. Проверяйте отсут-
ствующие индексы по первичному ключу, только когда наиболее вероятная при-
чина неправильного плана выполнения не объясняет проблему и заставляет про-
верить, нет ли каких-нибудь иных источников проблем.
Изменение SQL-кода для получения
хорошего плана
Можно предположить, что хороший план в Oracle можно получить после исправ-
ления несовместимости типов на этой платформе. Как-никак, другие базы данных
сумели избежать преобразования типа индексированного столбца и выдали хоро-
ший план. Поэтому стоит испытать новый план в Oracle, но с исправленным срав-
нением С. Phone_Number =' 6505551212 ’, чтобы избежать неявного преобразования типов
данных. Используйте исходные настройки для синтаксической оптимизации, что-
бы проверить план выполнения:
PLAN
SELECT STATEMENT
SORT ORDER BY
NESTED LOOPS
NESTED LOOPS
NESTED LOOPS
NESTED LOOPS
NESTED LOOPS
TABLE ACCESS BY INDEX ROWID ^CUSTOMERS
INDEX RANGE SCAN CUSTOMER_PHONE_NUMBER
TABLE ACCESS BY INDEX ROWID BORDERS
320
Приложение Б. Полный и непрерывный процесс
INDEX RANGE SCAN ORDER CUSTOMER ID
TABLE ACCESS BY INDEX ROWID 2*0RDERJ)ETAILS
INDEX RANGE SCAN ORDER_DETAIL_ORDER_ID
TABLE ACCESS BY INDEX RDWID 5*SHIPMENTS
INDEX UNIQUE SCAN SHIPMENT PKEY
TABLE ACCESS BY INDEX RDWID 3*PR0DUCTS
INDEX UNIQUE SCAN PRODUCT PKEY
TABLE ACCESS BY INDEX ROWID 6*ADDRESSES
INDEX UNIQUE SCAN ADDRESS_PKEY
Это именно 'гот план, который нам нужен. Предполагая, что приложение вско-
ре перейдет на стоимостную оптимизацию, можно проверить стоимостный план
выполнения, и он окажется точно таким же.
Теперь оба оптимизатора Oracle возвращают оптимальный план — значит,
работа закончена! Чтобы убедиться в этом, можно выполнить SQL-запрос со зна-
чением параметра sqlplus равным timing on. Оказывается, Oracle возвращает ре-
зультат всего за 40 миллисекунд, по сравнению о предыдущим показателем произ-
водительности 2,4 секунды для исходного синтаксического плана выполнения и
8,7 секунды для исходного стоимостного плана выполнения.
Изменение приложения
Как это чаще всего бывает, единственное необходимое изменение приложения
в этом примере — это небольшзя модификация самого SQL-кода. Это всегда са-
мый хороший результат, так как это наименее рискованное изменение, которое
проще всего производить. Запрос вернет всего несколько строк, так как лучший
фильтр сам по себе очень селективный. Если бы запрос возвращал слишком много
строк или если бы он выполнялся чрезвычайно часто, просто чтобы выполнить
одну задачу приложения, то вы бы исследовали изменения, которые необходимо
внести в приложение, чтобы сузить запрос или выполнять его реже.
Взгляд в будущее
Большинство запросов так же просты в настройке, если вы уже овладели методом,
описанным в этой книге. Обычно отсутствующий индекс или некоторая триви-
альная проблема в SQL — это единственная вещь, которая мешает оптимизатору
выдать оптимальный план выполнения, выбранный вами, или план, настолько
близкий к оптимальному, чтобы различия не имели значения. Редко приходится
применять специальные техники, описанные в конце главы бив главе 7.
ПРИМЕЧАНИЕ-------------------------------------------------------------------
Однако когда вам нужны методы для особых случаев, это значит, что они вам действительно нужны!
Главное значение этого метода — он позволяет вам быстро получить единствен-
ный ответ, в котором вы можете быть полностью уверены, не беспокоясь, что, воз-
можно, длинный путь проб и ошибок дал бы вам что-нибудь лучшее. Когда при
помощи этого метода вы получите очень быстрый запрос, у вас останется мало
Взгляд в будущее 321
возражений. Когда метод приводит к более медленному результату, чем вам хоте-
лось бы (обычно это случается с запросами, возвращающими тысячи строк), то вы
должны помнить, что этот не самый быстрый результат на самом деле лучший,
который вы можете получить, не выходя за рамки настройки SQL. Внешние реше-
ния для таких медленных запросов обычно оказываются неудобными. Очень важно
знать и быть полностью уверенным в том, когда эти неудобные решения дейст-
вительно становятся необходимы. Вы должны доверять этому чувству без бес-
конечных тщетных попыток настроить исходный SQL методом проб и ошибок и
иметь твердые аргументы, чтобы, если необходимо, доказать свою правоту в более
сложных ситуациях.
Глоссарий
Агрегация
Резюмирование деталей в небольшом количестве суммарных информационных
точек (обычно суммы, количества и средние), чаще всего с использованием
GROUP BY.
Антисоединение
Корреляционное соединение, примененное к подзапросу типа NOT EXISTS.
Блок
Наименьшая единица физического хранилища или хранилища кэша в базе дан-
ных. Размер блока обычно равен нескольким килобайтам; они могут содержать
менее чем сотню строк и, максимум, до нескольких сотен строк.
Буфер блоков кэша
Кэш, который хранит недавно использованные блоки таблицы и индекса в совме-
стно используемой памяти для упрощения логического ввода-вывода, устраняя
необходимость физического ввода-вывода кэшированных блоков. SQL-код любого
пользователя может считывать блоки в буфер блоков кэша и SQL любого пользо-
вателя автоматически пользуется преимуществами этих кэшированных блоков.
См. кэширование LRU.
Ввод-вывод
Ввод-вывод. Обычно обозначает физический ввод-вывод, но также может относить-
ся к логическому вводу-выводу.
Ведущая таблица
Таблица, которая обрабатывается первой во время выполнения базой данных зап-
роса. База данных должна найти путь к ведущей таблице, не зависящий от нали-
чия данных из любой другой таблицы.
Внешнее соединение
Операция, которая комбинирует строки из двух источников данных, обычно таб-
лиц. Внешнее соединение возвращает строки, удовлетворяющие либо внутренне-
му случаю внешнего соединения, либо внешнему случаю внешнего соединения.
Строки, которые удовлетворяют внутреннему случаю внешнего соединения, иден-
тичны результату, который вернула бы база данных, если заменить внешнее со-
единение на внутреннее. Во внешнем случае внешнего соединения база данных не
находит подходящей строки в присоединяемой таблице, а, когда в SQL упомина-
ется присоединяемая таблица, возвращает строку, в которой к строке из таблицы,
стоящей в начале соединения, присоединяются искусственные столбцы, содержа-
щие только значения null.
Глоссарий
323
Внешний ключ
Значение кортежа хранящихся в таблице строк, которое соответствует уникаль-
ному ключу в строке какой-то другой таблицы, что определяется соответствием
первичному ключу.
Внутреннее соединение
Операция, сопоставляющая строки из двух источников данных, обычно таблиц,
которая возвращает комбинации, удовлетворяющие одному или нескольким ус-
ловиям соединения, относящимся к источникам данных. Строки возвращаются
только в комбинациях. Любая строка из источника, для которой не находится со-
ответствия в присоединяемой таблице, отбрасывается.
Главная таблица
Таблица, в которой находится максимум одна подходящая строка для каждой стро-
ки из другой таблицы (обычно детальной таблицы), которая присоединяется к
ней. Таблица может быть главной по отношению к одной таблице, и детальной по
отношению к другой, поэтому термин «главная таблица» описывает положение
таблицы в отношении с другой таблицей в данном соединении.
Главный коэффициент соединения
Коэффициент соединения на уникальном конце соединения. См. коэффициент
соединения.
Горячий
Блок базы данных называется горячим, когда к нему часто производится доступ.
Блок может быть горячим в контексте определенного типа ввода-вывода. Напри-
мер, блок, являющийся горячим по отношению к логическому вводу-выводу мо-
жет быть так хорошо кэширован, что относительно физического ввода-вывода бу-
дет холодным.
Декартово произведение
Набор всех возможных комбинаций строк из двух или более наборов строк. Декар-
тово произведение получается, когда в SQL присутствует декартово соединение.
Декартово соединение
Соединение между двумя таблицами или двумя комбинациями таблиц, при кото-
ром в SQL не указаны никакие условия или комбинации условий, которые связы-
вают соединяемые таблицы друг с другом.
Денормализация
Хранение денормализованных данных в одной или нескольких таблицах.
Денормализованные данные
Избыточные, повторяющие другие данные, уже хранящиеся в базе данных. На-
пример, хранение Customer_ID в Order_Lines, было бы денормализацией данных,
если бы соединение от Order_Lines к Orders использовало те же значения
CustomerJD, но хранящиеся в виде столбца Orders.
Детальная таблица
Таблица, где потенциально находится более одной подходящей строки для любой
данной строки из другой таблицы (обычно главной таблицы), которая соединяет-
ся с ней. Таблица может быть главной для одной таблицы и детальной для другой,
поэтому термин «детальная таблица» описывает положение таблицы в отноше-
нии с другой таблицей в определенном соединении.
324
Глоссарий
Детальный коэффициент соединения
Коэффициент соединения на не уникальном конце соединения. См. кт'Ьфициент
соединения.
Диаграмма запроса
Диаграмма в форме узлов и связей с указанными числовыми значениями, такими,
как коэффициенты фильтрации и коэффициенты соединения. Диаграмма запроса
кратко передает математические основы проблемы настройки запроса. В главе 5
рассказывается, как создать диаграмму запроса для запроса SQL, а в главе 7 добав-
ляется несколько улучшенных техник для сложных запросов.
Запрос, использующий представление
Любой запрос, в котором упоминается представление базы данных.
Запрос, определяющий представление
Запрос, который определяет представление базы данных — результат, который вы
получите, выполнив SELECT * FROM <Имя_представления>.
Идентификатор строки
Внутренний адрес физической строки таблицы, состоящий из адреса блока, ука-
зывающего на блок таблицы, который содержит строку, и адреса строки внугри
блока. При помощи идентификатора строки можно перейти прямо к строке.
Избыточность фильтров
Отношение между фильтрами, когда истинность одного условия гарантирует ис-
тинность другого (в противоположность независимости фильтров). Например, ус-
ловие на почтовый индекс с большой вероятностью гарантирует единственное зна-
чение для телефонного кода региона, поэтому селективность условий по обоим
значениям будет не лучше, чем селективность только почтовому индексу. Вы всегда
можете проверить, присутствует ли полная или частичная избыточность фильтров,
вычислив селективность фильтра с несколькими условиями, считая их независимы-
ми, и посмотрев, равна ли она действительной селективности комбинации условий.
Индекс
Структура базы данных, помогающая базе данных эффективно обращаться исклю-
чительно к требуемому поднабору строк таблицы, не считывая таблицу целиком.
См. индекс в В-дереве (пока что самый распространенный тип).
Индекс в В-дереве
Сбалансированная, разветвленная, отсортированная структура, которая позволя-
ет базе данных быстро находить строку или набор строк, соответствующий усло-
виям индексированного столбца или столбцов.
Количество строк
Количество строк в наборе строк.
Корневая детальная таблица
Таблица на диаграмме запроса, которая соединяется с другими таблицами только
через внешние ключи, находясь на детальном конце всех соединений, в которых
принимает участие. Большинство диаграмм запросов принимают форму дерева,
вершиной которого является одна корневая детальная таблица. Строки, возвра-
щенные из такого запроса, однозначно отображаются на строки, которые запрос
возвращает из корневой детальной таблицы. Корневая детальная таблица обычно
самая большая в запросе.
Глоссарий
325
Корневая детальная таблица подзапроса
Корневая детальная таблица диаграммы запроса для подзапроса, если изолиро-
вать его от внешнего запроса.
Корневой блок
Первый блок, который считывается при сканировании диапазона индекса или уни-
кальном сканировании индекса в В-дереве. Корневой блок содержит указатели на
субдиапазоны, которые охватывают блоки индекса уровнем ниже, когда индекс не
помещается в один блок. Иногда (обычно когда индекс состоит менее чем из 300
строк) весь индекс помещается в корневой блок. Корневые блоки полезных ин-
дексов практически всегда постоянно находятся в кэше, так как к ним слишком
часто обращаются операции логического ввода-вывода, чтобы они могли оказать-
ся в хвосте кэша LRU.
Корреляционные соединения
Соединения в подзапросах, которые устанавливают соотношение между строками
подзапроса и значениями из внешнего запроса.
Корреляционный коэффициент предпочтения
Коэффициент, полученный как частное от деления времени выполнения формы
IN (которая начинает от подзапроса и переходит к внешнему запросу) запроса с
подзапросом типа EXISTS на время выполнения формы EXISTS (которая выполня-
ется от внешнего запроса к подзапросу) того же запроса. Если корреляционный
коэффициент предпочтения больше 1,0, то это означает, что лучший план испол-
нения начинается с внешнего запроса и переходит к подзапросу, так как этот аль-
тернативный вариант выполняется быстрее.
Кортеж
Упорядоченная группировка фиксированного числа значений, например, зна-
чений или выражений столбцов. Например, первичный ключ из двух столбцов
состоит из двузначных кортежей, соответствующих уникальным строкам таб-
лицы.
Коэффициент соединения
Для соединения между таблицами А и В коэффициент соединения на стороне таб-
лицы А — это количество строк, возвращаемое при соединении А с В, деленное на
количество строк в В. Если А — это детальная таблица для главной таблицы В, то
коэффициент соединения на стороне А (детальный коэффициент соединения) оп-
ределяет, как много дета тьных строк содержит А для отношения вида «многие к
нулю» или «многие к одному» с В. На стороне В того же соединения главный коэф-
фициент соединения определяет, «как часто наступает случай «одного»» на конце
с отношением «ноль к одному» того же отношения вида «многие к нулю» или «мно-
гие к одному».
Коэффициент успешного попадания в кэш
Доля операций логического ввода-вывода, которые избегают физического ввода-
вывода.
Коэффициент фильтрации
Доля строк таблицы, для которой набор фильтрующих условий по одной этой таб-
лице истинен. Математически это количество строк таблицы, удовлетворяющее
условию фильтра, деленное на общее количество строк в таблице.
326
Глоссарий
Кэширование LRU
Обычная форма кэширования, которую база данных применяет для хранения
в совместно используемом кэше. При кэшировании LRU база данных заменяет кэ-
шированные блоки с наиболее давним использованием (в хвосте кэшированного
списка блоков), если ей необходимо считать новый блок с диска в кэш. Следова-
тельно, операции логического ввода-вывода в кэше перемещают блоки в голову
списка, где находятся недавно использованные блоки. Иногда базы данных обра-
батывают ввод-вывод для объемного полного сканирования таблиц особым спосо-
бом, оставляя блоки, полученные при полном сканировании таблиц, в хвосте кэша
LRU, чтобы не вытолкнуть из кэша наиболее полезные блоки.
Листовой блок
Блок индекса нижнего уровня, к которому база данных обращается через корневой
блок или промежуточный блок. Листовые блоки не указывают на блоки индекса
более низкого уровня. Они указывают на блоки таблицы, которые содержат ин-
дексированные строки. Листовой блок содержит кортежи значений индексиро-
ванных столбцов и идентификаторы строк, которые указывают на строки, содер-
жащие эти значения столбцов.
Логический ввод-вывод
Любое считывание или запись блоков базы данных из совместно используемого
кэша или в него во время выполнения SQL-кода, даже если сначала базе данных
необходимо считать блок с диска, чтобы поместить его в совместно используемый
кэш.
Набор строк
Любой набор строк: строки таблицы или результирующие строки после выполне-
ния всего или части запроса. Во время выполнения запроса база данных строит
наборы строк для возврата по мере соединения опрашиваемых таблиц, по пути
отбрасывая строки, когда во внутреннем соединении не находится соответствия
или когда строки из соединяемых таблиц не удовлетворяют условиям запроса.
В итоге запрос возвращает строки, удовлетворяющие всем условиям запроса.
Надежный план исполнения
План исполнения, который эффективно достигает ведущей таблицы, обычно при
помощи индексного считывания, и который достигает остальных таблиц при по-
мощи вложенных циклов по индексам по ключам соединения.
Независимость фильтров
Предположение, обычно истинное, что селективность нескольких условий можно
вычислить как простое произведение отдельных коэффициентов фильтрации. На-
пример, условия по имени человека и его почтовому индексу логически независи-
мы. Вы можете предположить, что доля строк, в которых содержатся правильное
имя и правильный почтовый индекс, будет приблизительно равна произведению
доли строк с правильным именем и доли с правильным почтовым индексом. На-
пример, если 1/100 строк содержат нужное имя и 1/500 строк содержат нужный
почтовый индекс, тогда селективность фильтра с несколькими условиями будет
равна 1/50 000 (1/100 х 1/500).
Нормализованные данные
Полностью неизбыточные данные (данные, в которых нет денормализованных
данных). См. денормализованные данные.
Глоссарий
327
Отметка заполнения
Адрес блока в таблице, указывающий самый высокий блок, в котором когда-либо
хранились строки таблицы с момента ее создания или последнего усечения. Полное
сканирование таблицы должно начинаться с начала таблицы и продолжаться до от-
метки заполнения, включая каждый блок в экстентах таблицы между этими двумя
точками, даже если большинство этих блоков было очищено во время удаления.
Первичный ключ
Значение или кортеж, хранящийся в строке базы данных, который уникальным
образом идентифицирует строку в таблице. Внешние ключи указывают на первич-
ные ключи. В отношении вида «один к одному» первичный ключ также может слу-
жить внешним ключом.
План исполнения
Путь, по которому будет идти база данных, чтобы получить данные, требуемые
запросу. План исполнения состоит в основном из методов доступа к каждой упо-
мянутой в запросе таблице, порядка соединения, начиная с ведущей таблицы, и ме-
тодов соединения для каждой таблицы, присоединяемой после ведущей.
Подзапрос типа EXISTS
Подзапрос, связанный с внешним запросом условием EXISTS или условием IN, ко-
торое можно преобразовать в условие EXISTS.
Подзапрос типа NOT EXISTS
Подзапрос, связанный с внешним запросом условием NOT EXISTS или условием NOT
IN, которое можно преобразовать в условие NOT EXISTS.
Полное сканирование индекса
Операция считывания всех записей индекса во всех листовых блоках.
Полное сканирование таблицы
Операция считывания напрямую всей таблицы, без предварительного получения
идентификаторов строк из индекса.
Полусоединение
Корреляционное соединение, которое применяется к подзапросу типа EXISTS.
Промежуточное программное обеспечение
Программное обеспечение, которое перемещает данные внутри системы или меж-
ду системами, не отправляя их конечным пользователям. Так как конечные пользо-
ватели не являются частью схемы, а компьютеры обладают огромным терпением
для обработки больших объемов данных, эти пакетные процессы иногда обосно-
ванно обрабатывают объемы данных, слишком большие для восприятия человека.
Промежуточный блок
Блок индекса, в который база данных попадает из корневого блока или промежу-
точного блока более высокого уровня. Промежуточный блок, в свою очередь, ука-
зывает на листовые блоки или промежуточные блоки более низкого уровня, кото-
рые содержат записи нужного диапазона. См. корневой блок и листовой блок.
Простой запрос
Запрос, который отвечает следующим условиям.
1) Запрос отображается на одно дерево.
2) У дерева в точности один корень (одна таблица без соединений с ее первичным
ключом). У всех узлов, отличных от корневого, есть одна указывающая вниз, на
328
Глоссарий
них, стрелка, которая связывает их с детальным узлом наверху, но любой узел
может находиться на верхнем конце любого количества указывающих вниз стре-
лок.
3) Для всех соединений существуют указывающие вниз стрелки (соединения уни-
кальны на одном конце).
4) Внешние соединения не фильтруются, указывают вниз; под внешними соедине-
ниями могут быть только внешние соединения.
5) Вопрос, на который отвечает запрос, — это обычно вопрос о сущности, пред-
ставленной верхним (корневым) узлом дерева или об агрегациях этой сущности.
6) Прочие таблицы лишь предоставляют ссылочные данные, которые хранятся
в этих таблицах в целях нормализации.
Распределенные фильтры
Фильтрующие условия, разбросанные по нескольким таблицам, которые совмест-
но обладают большей селективностью, чем фильтрующие условия для любой из
таблиц по отдельности.
Самокэширование
Большинство запросов обнаруживают большую часть необходимых блоков в кэше,
куда те были помещены предыдущими запросами, обычно в предыдущих сеансах.
Самокэширование происходит, когда запрос повторно выполняет операции логичес-
кого ввода-вывода для одних и тех же блоков базы данных, которые, возможно, еще
не были кэшированы до начала выполнения запроса. Первая операция ввода-выво-
да для каждого из этих блоков может быть физической, но тенденция запросов по-
вторно использовать те же блоки обеспечивает самокэширование, когда сам запрос
гарантирует, что кэш наполнится блоками, которые еще будут нужны этому запро-
су. Эффективность самокэширования зависит от того, насколько хорошо кластери-
зованы опрашиваемые строки (то есть насколько близко друг к другу они находятся
в физических таблицах или индексах). Самокэширование особенно эффективно для
блоков индекса, особенно если эти блоки находятся на высших уровнях индекса.
Селективность фильтра с несколькими условиями
Доля строк таблицы, удовлетворяющих комбинации условий, относящихся толь-
ко к этой таблице.
Селективность фильтра с одним условием
Доля строк таблицы, удовлетворяющих единственному условию для этой таблицы.
Сканирование диапазона индекса
Операция считывания (обычно при помощи логического ввода-вывода из кэша)
диапазона индекса (набора, который может включать указатели на несколько строк),
который затрагивает столько листовых блоков, сколько необходимо.
Скелет запроса
То же, что и скелет соединения, часть диаграммы запроса, которая показывает, как
таблицы соединяются, но не включает коэффициенты фильтрации или соединения.
Скелет соединения
То же, что и скелет запроса, — часть диаграммы запроса, которая показывает, как
соединяются таблицы, но не включает коэффициенты фильтрации и соединения.
Сложный запрос
Многотабличный запрос, не являющийся простым запросом. См. простой запрос.
Глоссарий
329
Соединение
Операция сопоставления строк из двух источников данных, обычно таблиц. См.
внутреннее соединение и внешнее соединение.
Соединение «многие к одному»
Соединение от детальной таблицы к главной таблице.
Соединение методом вложенных циклов
Метод соединения, который использует каждую строку из уже полученного ре-
зультата запроса, чтобы перейти к присоединяемой таблице, обычно через индекс
по ключу соединения.
Соединение методом сортировки слиянием
Метод соединения, когда два соединяемых набора строк один раз независимо счи-
тываются, сортируются, а затем происходит управляемое слияние, в ходе которого
сопоставляются наборы строк, отсортированные по ключам соединения.
Соединение хэшированием
Метод соединения, когда два соединяемых набора строк один раз считываются
независимо и ставятся в соответствие друг другу согласно выходу рандомизирую-
щей функции хэширования, примененной к столбцам соединения. Меньший на-
бор строк (или, по крайней мере, набор строк, который база данных считает мень-
шим) обычно предварительно сортируется в сегменты хэширования в памяти.
Затем база данных налету вычисляет значение функции хэширования, одновре-
менно считывая больший набор строк, и сопоставляет строки из большого набора
строк хэшированным строкам в памяти из меньшего набора.
Ссылочная целостность
Свойство внешнего ключа, которое заключается в том, что в каждой строке табли-
цы есть значение внешнего ключа, указывающее на подходящий первичный ключ в
строке соответствующей главной таблицы. Если для внешних ключей не соблюда-
ется ссылочная целостность, то обычно можно сделать вывод о дефекте в прило-
жении или дизайне базы данных, так как внешние ключи становятся бессмыслен-
ными, если не указывают на существующие первичные ключи.
Таблицы с яблоками и апельсинами
Таблицы, содержащие в чем-то различающиеся, но родственные типы сущностей,
в пределах одной физической таблицы.
Условие соединения
Условие в фразе WHERE, для оценки которого как истинного или ложного требуют-
ся значения из двух (или, редко, многих) таблиц. Условия в фразе WHERE, не являю-
щиеся фильтрующими условиями, являются условиями соединения. Условия со-
единения обычно обеспечивают эффективный путь к другим таблицам, если вы
уже считали строки из лучшей из возможных ведущих таблиц.
Уточненный коэффициент фильтрации подзапроса
Вычисленное значение, которое помогает выбрать лучшую точку в порядке соеди-
нения, чтобы проверить условие подзапроса.
Физический ввод-вывод
Поднабор (обычно небольшой) операций логического ввода-вывода, для которого
необходимый блок не был найден в кэше, что приводит к необходимости произве-
сти физическое считывание или запись. Хотя представления базы данных могут
330
Глоссарий
обращаться к диску при помощи физического ввода-вывода, операционная систе-
ма и дисковая подсистема обычно поддерживают собственные кэши и быстро вы-
полняют вызовы обращения к диску, не применяя настоящий физический ввод-
вывод, для которого необходимо медленное физическое считывание с диска.
Фильтр послесчитывания
Фильтрующее условие, которое можно оценить как истинное или ложное только
после того, как база данных считает строку таблицы в данном плане исполнения.
Индекс, использующийся для доступа к таблице, не содержит данных, необходи-
мых для оценки истинности фильтрующих условий послесчитывания, поэтому
базе данных приходится сначала считывать строку таблицы, чтобы найти столб-
цы, упоминающиеся в фильтре послесчитывания.
Фильтр соединения
Коэффициент соединения со значением, меньшим 1,0, благодаря которому во вре-
мя выполнения соединения количество строк сокращается. Фильтры соединения
могут быть только у внутренних соединений.
Фильтрующее условие
Условие во фразе WHERE, которое можно оценить как истинное или ложное, имея
данные только из одной таблицы. Используется для того, чтобы сократить запрос
до поднабора строк из этой таблицы. Селективные фильтрующие условия — это
ключ к эффективным планам исполнения.
Холодный
Блок базы данных называется холодным, если к нему редко обращаются. Блок мо-
жет быть холодным в контексте определенного типа ввода-вывода. Например, го-
рячий блок по отношению к логическому вводу-выводу может быть настолько хо-
рошо кэширован, что по отношению к физическому вводу-выводу он будет
холодным.
Центральная таблица
Таблица, являющаяся текущей точкой, начиная с которой следует добавлять оче-
редные таблицы в диаграмму запросов при ее построении. Когда в диаграмме за-
проса вокруг текущей центральной таблицы не остается отсутствующих элемен-
тов, необходимо выбрать новую центральную таблицу.
Центральный процессор, CPU
Центральный процессор. Составляющая часть компьютера, в которой выполня-
ются находящиеся в памяти программные команды. Операции в процессоре вы-
полняются быстро по сравнению с физическим вводом-выводом в базу данных и из
нее, но, тем не менее, базы данных могут занимать ресурсы процессора на длитель-
ные периоды времени (эти интервалы называются временем процессора), чтобы
обслужить неэффективные запросы к хорошо кэшированным данным. Для опера-
ций логического ввода-вывода требуется время процессора, тогда как физический
ввод-вывод потребляет время в дисковой подсистеме.
Циклический граф соединения
Диаграмма запроса, на которой связи формируют замкнутый цикл.
Алфавитный указатель
0 Online Transaction Processing, 41 К Коэффициент
A попадания в кэш, 35 соединения, 135
Агрегация, 281 Алгоритм кэширования LRU, 31 фильтрации, 134
Б Блок, 33 Буфер блоков кэша, 30 Л Логический ввод-вывод, 30 м
В Метод
Ведущая таблица, 61 Внешнее соединение, 60 Внутреннее соединение, 60 вложенных циклов, 62 диаграммного изображения запросов, 131 Многотабличный кластер, 42
Г О
Главный коэффициент соединения, 135 Граф, 202 Однотабличный кластер, 41 Отметка заполнения, 33
д Декартово произведение, 177 Детальный коэффициент соединения, 135 Диаграмма запроса, 132 п план выполнения, 21 Полное сканирование таблицы, 44 Последовательный рост, 34 Предварительное считывание
И параметра, 114 Промежуточное программное
Индекс, 37 в В-дереве, 36 обеспечение, 22 Простой запрос, 201
332
Алфавитныйуказатель
Р
Растровый индекс, 43
С
Самокэширование, 32
Связь, 134
Селективность
условия, 52
фильтра, 51
Синтаксический оптимизатор, 107
Сканирование диапазона
индексов, 38
Скелет запроса, 143,145
Сложный запрос, 201
Соединение, 59
с сортировкой слиянием, 64
хэшированием, 62
Стоимостный оптимизатор, 107
Стоимость индекса, 39
т
Таблицы
с индексной организацией, 40
с разбиениями, 42
Теория графов, 202
У
Узел, 133
Уровень оптимизации, 122
Ф
Физический ввод-вывод, 30
э
Экстент, 33
Toy Дэн
Настройка SQL. Для профессионалов
Перевели с английского А. Леонтьев, Е. Шикарева
Главный редактор
Заведующий редакцией
Руководитель проекта
Литературный редактор
Иллюстрации
Художник
Верстка
Корректоры
Е. Строганова
И. Корнеев
А. Крузенштерн
И. Шапошников
Л. Родионова
Н. Биржакоь
А. Келле-Пелле
А. Моносов, И. Смирнова
Лицензия ИД № 05784 от 07,09.01.
Подписано в печать29.06.fr1 Формат70X100/16. Усл. п. л. 27,09.
Тираж4000 экз. Заказ№ 2883.
ООО «Питер Принт». 196105, Санкт-Петербург, ул. Благодатная, д. 67в.
Налоговая льгота — общероссийский классификатор продукции ОК 005-93, том 2; 953005 — литература учебная.
Отпечатано с готовых диапозитивов в ФГУП «Печатный двор» им. А. М. Горького
Министерства РФ по делам печати, телерадиовещания и средств массовых коммуникаций.
197110, Санкт-Петербург, Чкаловский пр., 15.