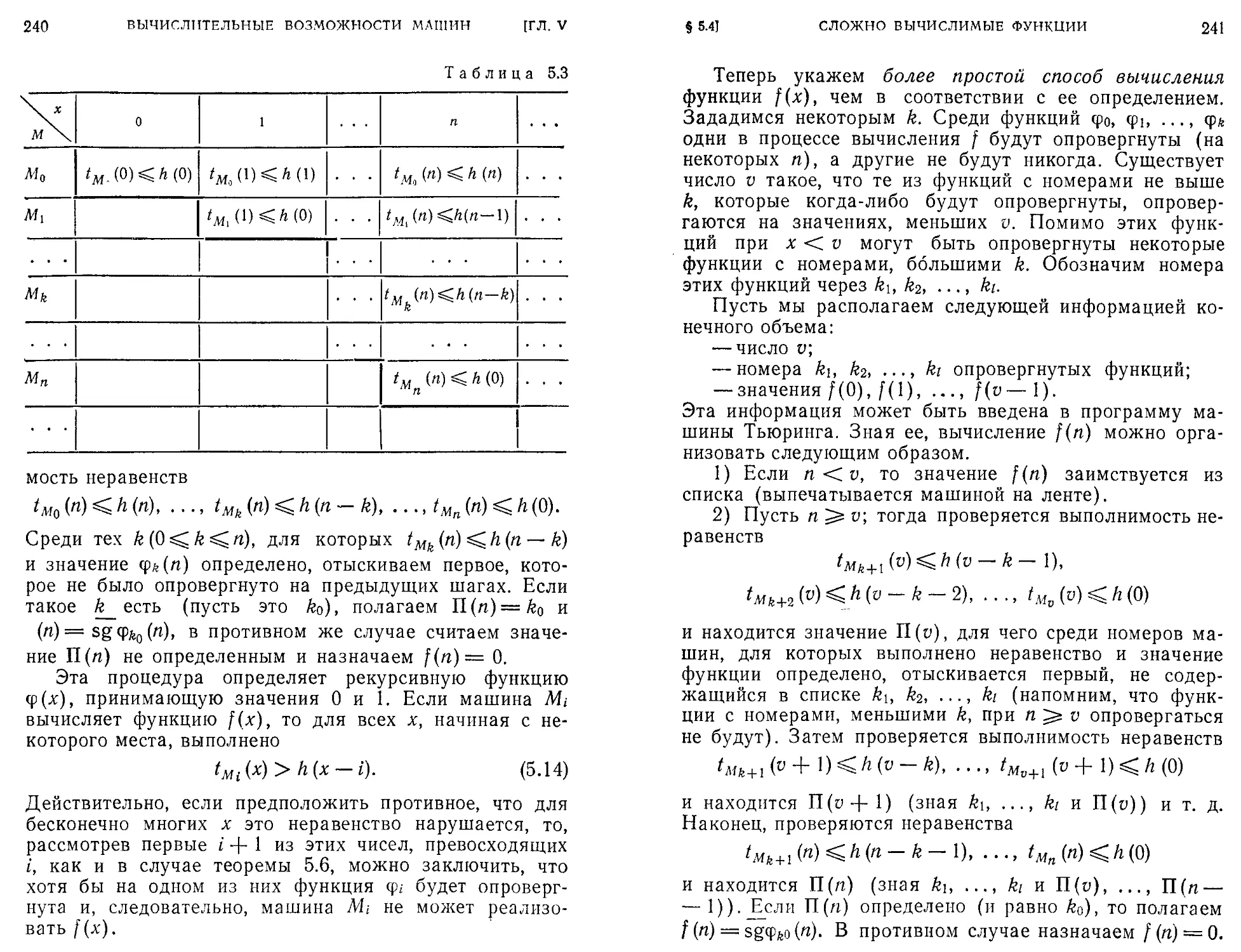
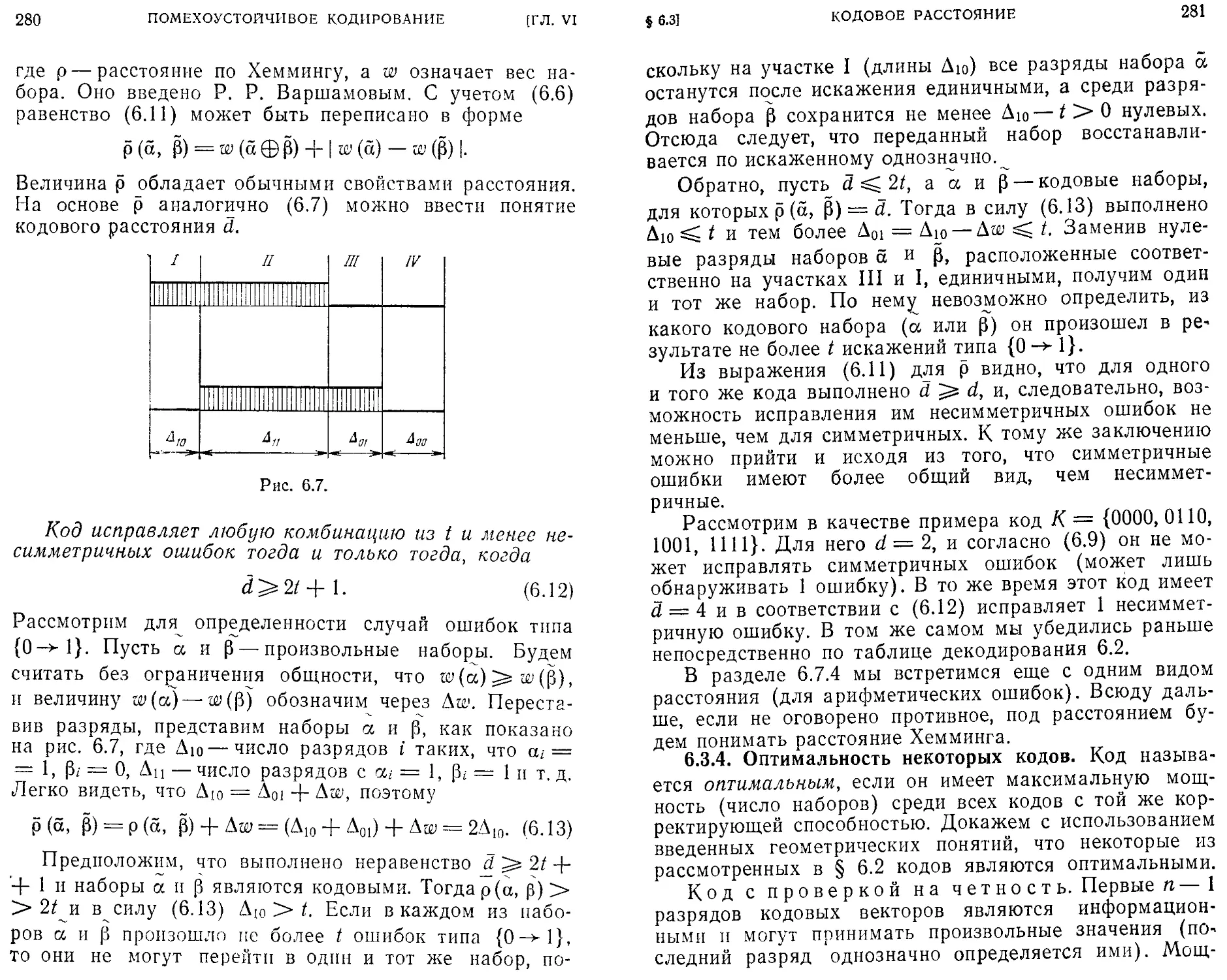
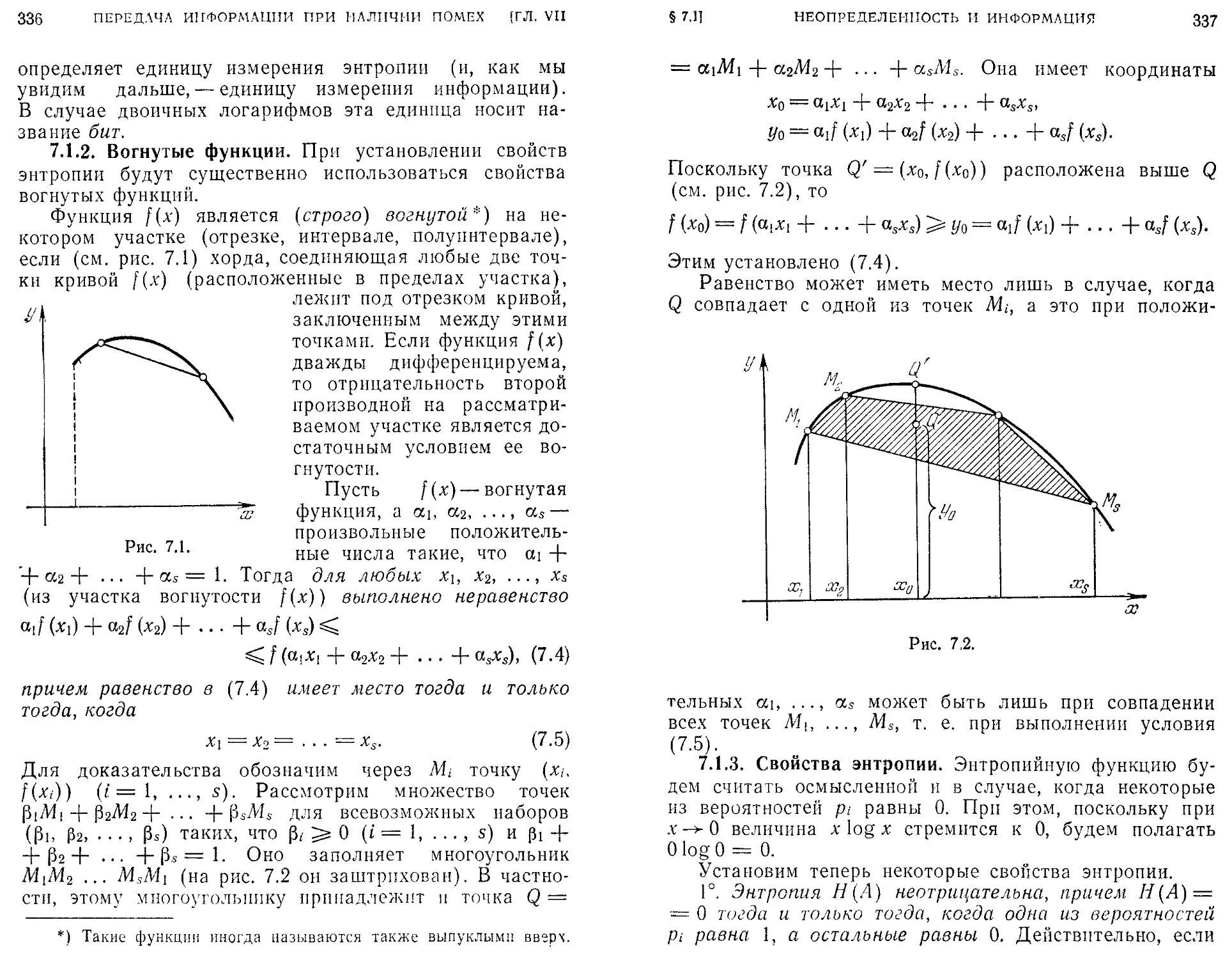
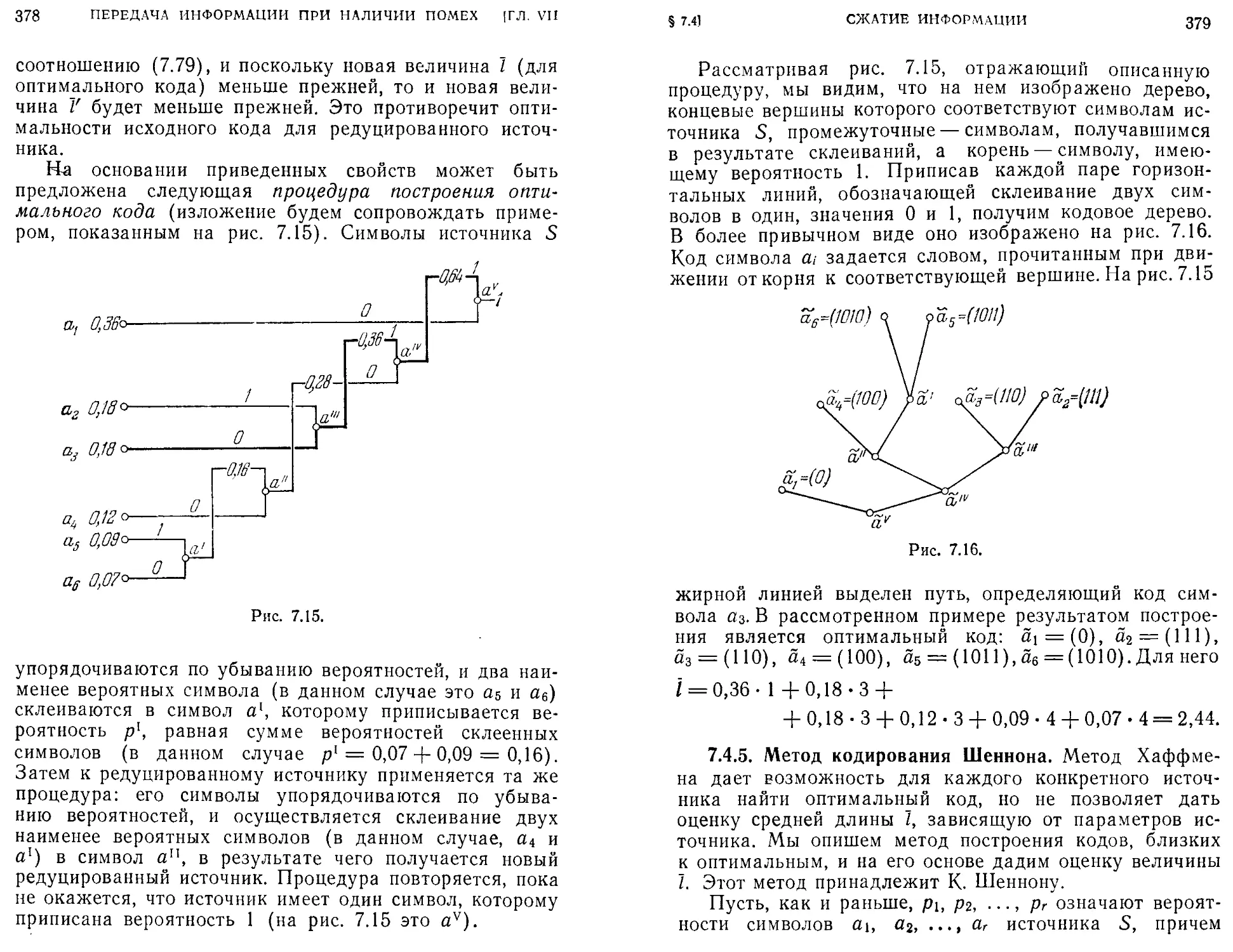
/



















































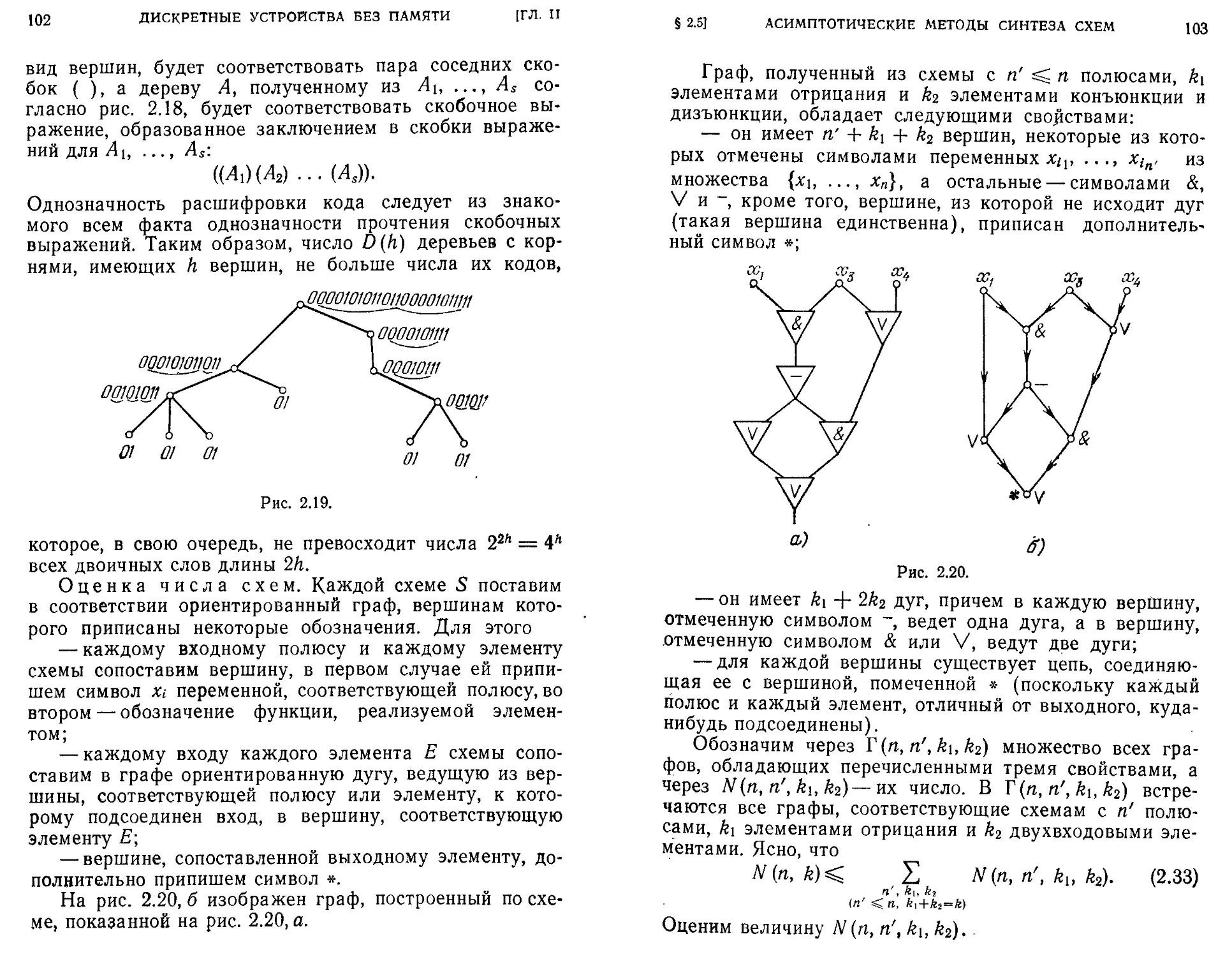

























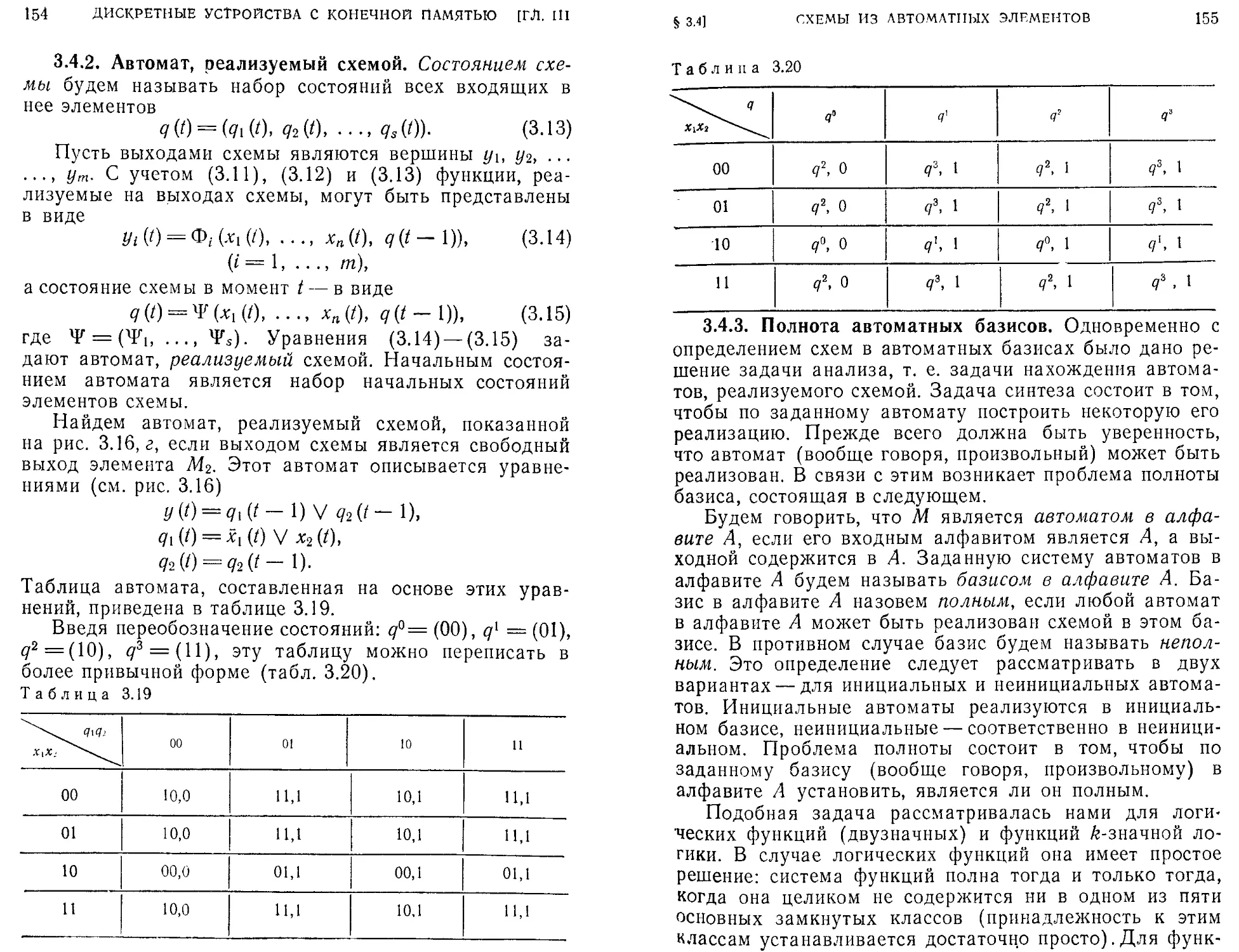







































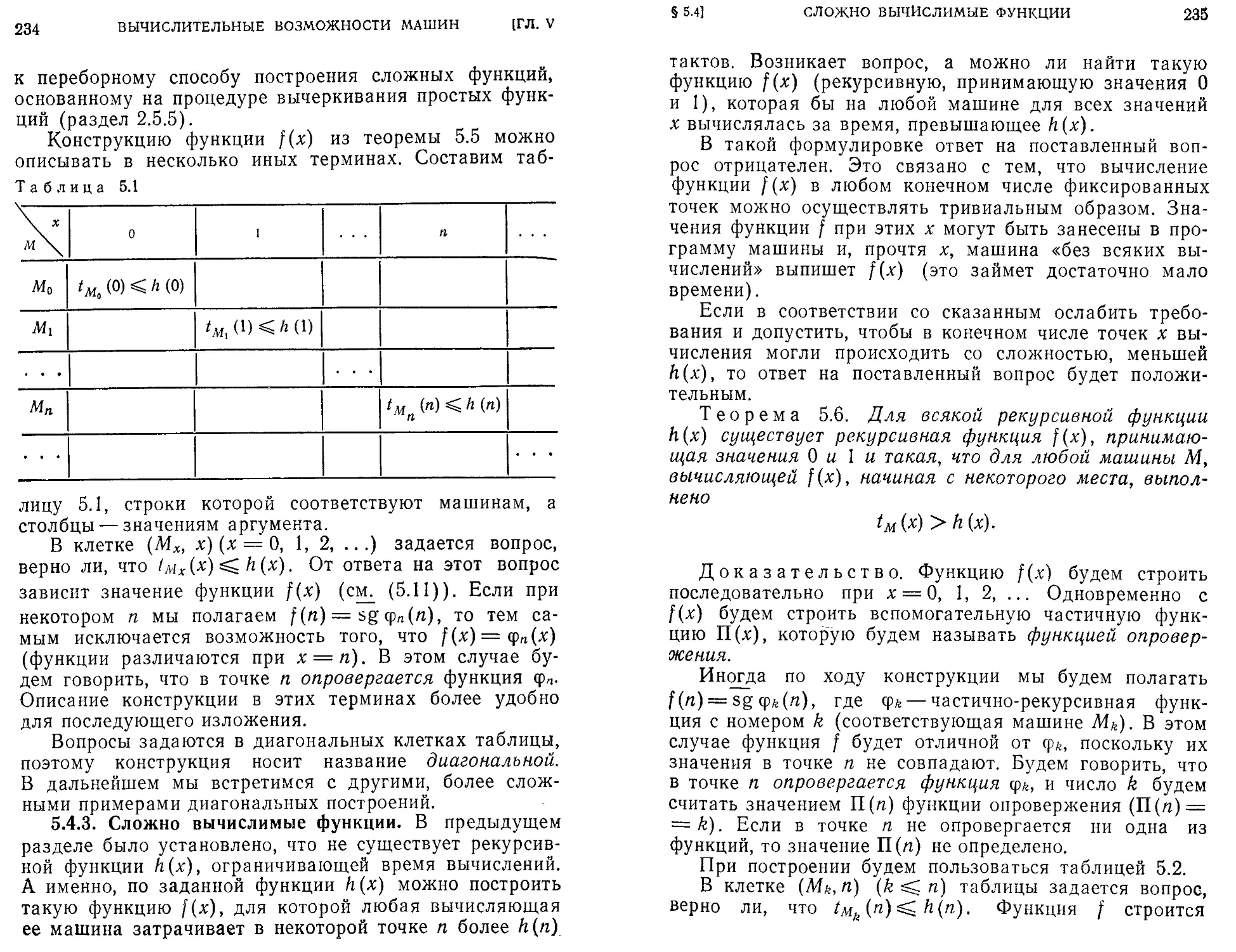
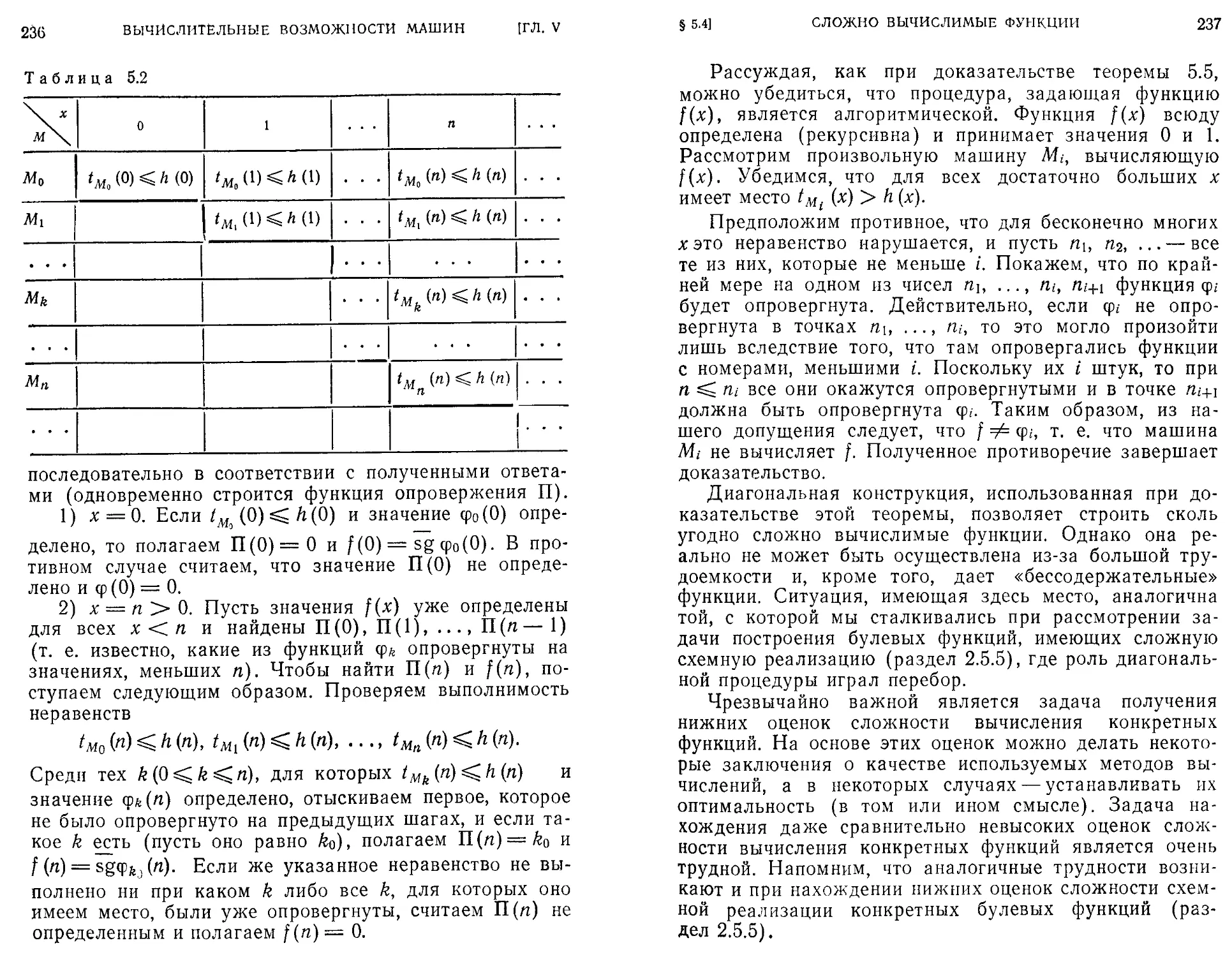


















































































Текст
Л. А. ШОЛОМОВ
ОСНОВЫ ТЕОРИИ
ДИСКРЕТНЫХ
ЛОГИЧЕСКИХ
И ВЫЧИСЛИТЕЛЬНЫХ
УСТРОЙСТВ
Под редакцией С. В. ЕМЕЛЬЯНОВА
Допущено Министерством
еысшего и среднего специального образования СССР
в качестве учебного пособия для студентов
высших технических учебных заведений
МОСКВА «НАУКА»
ГЛАВНАЯ РЕДАКЦИЯ
ФИЗИКО-МАТЕМАТИЧЕСКОЙ ЛИТЕРАТУРЫ
1980
32.815
Ш 78
УДК 519.95
Основы теории дискретных логических и вычислительных
устройств. Шеломов Л. А.. — М.: Наука. Главная редакция фи-
зико-математической литературы, 1980. — 400 с.
Книга содержит систематическое и вместе с тем доступное из-
ложение результатов по теории дискретных устройств.
Она состоит из трех частей, первая из которых посвящена
устройствам с конечной памятью, вторая — алгоритмам и идеали-
зированным моделям вычислительных машин, третья — надежным
хранению, передаче и переработке дискретной информации. Пред-
почтение отдается конструктивным методам, на основе которых
можно производить анализ, синтез и оптимизацию устройства.
Книга является учебным пособием для студентов кибернетиче-
ских специальностей втузов. Она будет полезной инженерам, имею-
щим дело с вычислительной техникой и устройствами управления,
а также может служить аспирантам и научным работникам для
первоначального ознакомления с предметом.
swl148' SO IS02000000
© Издательство <Наука>.
Главная редакция
физико-математической
литературы, 1980
ОГЛАВЛЕНИЕ
Предисловие редактора .................................... 5
Предисловие автора.........................................7
Введение....................................................9
ЧАСТЬ ПЕРВАЯ
Глава I. Логические функции................................25
§ 1.1. Задание логических функций.......................25
§ 1.2. Некоторые специальные представления логических
функций................................................32
§ 1.3. Полнота систем логических функций...............38
§ 1.4. Представление о функциях й-значной логики ... 46
Глава II. Дискретные устройства без памяти.................48
' § 2.1. Схемы из логических элементов................48
§ 2.2. Синтез схем на основе формул.................56
’ § 2.3. Минимизация логических функций...............65
§ 2.4. Синтез схем методом декомпозиции.................85
§ 2.5. Асимптотические методы синтеза схем..............93
Глава III. Дискретные устройства с конечной памятью . . .110
' § 3.1. Конечные автоматы..............................110
§ 3.2. Минимизация автоматов...........................119
§ 3.3. Схемы из логических элементов и задержек .... 135
§ 3.4. Схемы из автоматных .элементов-. ....... 150
ЧАСТЬ ВТОРАЯ
Глава IV. Модели алгоритмов...............................158
§ 4.1. Машины Тьюринга.............................. . 158
§ 4.2. Частично-рекурсивные функции . ........ 171
§ 4.3. Эквивалентность моделей алгоритмов..............182
§ 4.4. Универсальные машины и универсальные функции 193
§ 4.5. Некоторые общие теоремы теории алгоритмов . . . 203
Глава V. Вычислительные возможности машин.................210
§ 5.1. Алгоритмически неразрешимые проблемы. Метод сво-
димости ..............................................210
§ 5.2. Некоторые алгоритмически неразрешимые проблемы 213
§ 5.3. Неразрешимость проблемы полноты конечной систе-
мы автоматов..........................................222
§ 5.4. Сложно вычислимые функции.......................229
§ 5.5. Универсальные задачи перебора...................245
1*
4
ОГЛАВЛЕНИЕ
ЧАСТЬ ТРЕТЬЯ
Глава VI. Помехоустойчивое кодирование ...................264
§ 6.1. Общая схема передачи дискретной информации . . 264
§ 6.2. Равномерное кодирование........................268
§ 6.3. Кодовое расстояние и его связь с корректирующей
способностью . . ............................276
§ 6.4. Линейные коды..................................284
§ 6.5. Циклические коды.............................. 295
§ 6.6. Эффективное построение кодов с заданной корректи-
рующей способностью (БЧХ-коды) .......................307
§ 6.7. Другие типы искажений..........................323
§ 6.8. Самокорректирующиеся схемы................... 328
Глава VII. Передача дискретной информации при наличии по-
мех .....................................................333
§ 7.1. Неопределенность и информация..................333
§ 7.2. Характеристики системы передачи информации . . 351
§ 7.3. Теорема Шеннона о передаче при наличии помех . . 356
§ 7.4. Сжатие информации..............................369
Литература............................................... 389
Указатель обозначений ................................... 391
Предметный указатель......................................394
ПРЕДИСЛОВИЕ РЕДАКТОРА
В последнее время происходит интенсивное внедрение научных
методов, средств вычислительной техники и автоматических систем
специализированного назначения в сферу управления, организации
и планирования. Чтобы удовлетворить все возрастающую в связи
с этим потребность в специалистах, во многих вузах страны начата
подготовка студентов кибернетического профиля. Для них и студен-
тов других специальностей, соприкасающихся с вычислительной
техникой, автоматикой, телемеханикой, связью, в разных объемах
и под разными названиями читается курс (или совокупность кур-
сов) по теории дискретных устройств. Туда обычно включаются во-
просы из области математической логики, теории синтеза управляю-
щих систем и теории автоматов, теории алгоритмов и теории слож-
ности вычислений, теории информации и теории кодирования. Этот
перечень указывает на большой объем и разнообразие относяще-
гося сюда материала н на возникающие в связи с этим трудности
в формировании курса.
Образованный специалист, использующий вычислительную тех-
нику в своей повседневной деятельности, должен иметь правильное
представление о принципиальных возможностях вычислительных ма-
шин, о том, что представляет собой свойство универсальности и ка-
кие задачи могут решать универсальные машины, с помощью каких
средств эти задачи могут быть описаны. Он должен понимать, как
может быть формально уточнено интуитивное представление об ал-
горитме, и знать, что понятие алгоритма обладает большой сте-
пенью устойчивости (фактически не зависит от формализации).
Специалист-кибернетик должен представлять, какие особенности
вычислительных машин являются существенными с точки зрения
принципиальных возможностей машин, а какие служат для удоб-
ства или убыстрения вычислений, сколь сложными могут быть сами
вычисления и какие «сложностные эффекты» могут при этом иметь
место. Необходимо понимание того, что эти свойства являются об-
щими, не зависят от конкретной концепции машины и справедливы
как для простейших теоретических моделей, так и для современ-
ных ЦВМ и тех машин, которые появятся в будущем.
6
ПРЕДИСЛОВИЕ РЕДАКТОРА
С другой стороны, специалист-кибернетик должен иметь пред-
ставление о средствах, с помощью которых можно описывать функ-
ционирование специализированных дискретных устройств автомати-
ки, управления, регулирования и контроля, а также отдельных уз-
лов вычислительных машин, о том, как производится анализ, син-
тез и оптимизация этих устройств, как зависит их аппаратурная
сложность от исходных условий. В связи с усложнением систем
управления и вычислительной техники повышаются требования к
их надежности. Поэтому все большее значение приобретают спосо-
бы защиты информации от ошибок в процессе ее храпения, пере-
дачи и переработки.
Перечисленный круг вопросов послужил основой для отбора
материала и формирования курса. Предпочтение отдавалось фунда-
ментальным результатам и результатам, имеющим хорошую содер-
жательную интерпретацию и прикладную направленность. Изложе-
ние, как правило, ведется па базе простых моделей, что позволяет
легче выявить общие закономерности. Реальные модели дискретных
устройств, реальные языки, реальные информационные каналы
и т. д. рассматриваются в таких учебных дисциплинах, как «Циф-
ровые вычислительные машины», «Программирование на ЦВМ»,
«Автоматизация проектирования», «Автоматизированные системы
управления», которые обычно в том или ином объеме читаются
студентам кибернетических специальностей.
Учебного пособия (или совокупности пособий), охватывающего
в необходимом объеме теоретический материал, относящийся к
дискретным устройствам, и ориентированного на студентов высших
технических учебных заведении, в настоящее время не существует
(специальная литература по уровню изложения является трудно-
доступной). Данное пособие имеет своей целью выполнить этот
пробел. Оно является одним нз ряда руководств, разрабатываемых
на кафедре инженерной кибернетики Московского института стали
и сплавов и предназначенных для обеспечения учебной литературой
студентов кибернетического профиля.
Член-корреспондент АН СССР
С. В. Емельянов
ПРЕДИСЛОВИЕ АВТОРА
Книга предназначена в качестве учебного пособия
для студентов кибернетических специальностей высших
технических учебных заведений. В ней рассматриваются
принципиальные возможности дискретных устройств,
средства их описания, способы решения задач анализа
и синтеза, а также вопросы оптимизации и повышения
надежности.
Книга состоит из трех примерно равных по объему
частей. Первая часть посвящена дискретным устрой-
ствам с конечной памятью, вторая — алгоритмам и иде-
ализированным моделям вычислительных машин, третья
часть — надежным хранению, передаче и переработке
дискретной информации. Основой для книги послужил
материал трехсеместрового курса лекций, читающегося
в течение ряда лет в Московском институте стали и
сплавов для студентов, специализирующихся по кафед-
ре инженерной кибернетики. Каждая часть книги соот-
ветствует материалу одного семестра.
Решающее влияние на формирование курса оказала
методология С. В. Яблонского и О. Б. Лупанова.
Учитывая ориентацию книги, мы старались по воз-
можности избегать применения специального математи-
ческого аппарата (теория кодирования, например, изла-
гается без привлечения понятий группы и поля). Для
чтения заведомо достаточно сведений по математиче-
ском}' анализу, алгебре и теории вероятностей, давае-
мых обычными вузовскими курсами. Помимо этого пред-
полагается лишь знакомство с некоторыми понятиями,
относящимися к графам. Все основные результаты в
книге даются с доказательствами. При этом мы не всег-
да приводим наиболее короткие из известных доказа-
тельств, предпочитая доступность изложения краткости.
Имена авторов отдельных результатов, за редкими
исключениями, не упоминаются, а ссылки даются лишь
на дополнительный материал. Полный перечень исполь-
8 ПРЕДИСЛОВИЕ АВТОРА
зованной литературы приведен в конце книги. В каче-
стве основных источников при написании были взяты
[11, 15, 33, 22, 26].
Книга, как следует из ее названия, носит теорети-
ческий характер, в связи с чем алгоритмы анализа и
синтеза устройств изложены в ней на уровне основных
подходов и не доведены до деталей процедурного харак-
тера. Для студентов, специализирующихся в области
проектирования дискретных устройств, этого явно недо-
статочно, и им можно дополнительно рекомендовать
[27, 12].
Набор задач и упражнений для практических заня-
тий по курсу может быть заимствован из сборника [7].
Л. Шоломов
ВВЕДЕНИЕ
Дискретные устройства. При изучении устройств ос-
новное внимание будет уделяться вопросам обмена, пе-
реработки и запоминания информации. Поэтому рас-
смотрение будет вестись на уровне моделей, отражаю-
щих свойства, существенные лишь с этой точки зрения.
Вопросы конкретной физической и технической реализа-
ции затрагиваться не будут.
В устройстве могут быть выделены каналы, через
которые оно осуществляет обмен информацией с внеш-
ней средой. Информация поступает через входные ка-
налы (входные полюсы), перерабатывается устройством
в соответствии с его назначением и результат выдается
через выходные каналы (выходные полюсы). При этом
результат определяется не только текущими входными
воздействиями, но и текущим состоянием устройства, ко-
торое в процессе работы может меняться.
В большинстве своем устройства автоматики, управ-
ления и вычислительной техники являются дискрет-
ными. Они функционируют в дискретном времени и осу-
ществляют преобразование дискретной информации.
Дискретное время. Работа реальных устройств
осуществляется тактами. На каждом из них под влия-
нием входного воздействия протекает переходный про-
цесс, связанный с изменением внутреннего состояния и
выдачей выходной информации. Лишь после заверше-
ния этого процесса может быть подано входное воздей-
ствие, относящееся к следующему такту. В некоторых
устройствах тактность обеспечивается за счет введения
специального устройства — генератора синхронизирую-
щих импульсов. При этом такты длятся фиксированный
промежуток времени, величина которого определяется
временем протекания самого длительного переходного
процесса. В устройствах другого типа новый такт начи-
нается сразу после получения сигнала о завершении пе-
реходного процесса, относящегося к предыдущему так-
10
ВВЕДЕНИЕ
ту. При этом длительность тактов оказывается перемен-
ной. Это повышает быстродействие, но требует допол-
нительных аппаратурных затрат.
Можно ввести абстрактные моменты, времени t = 0,
1, 2, ..., нумерующие границы тактов (0 соответствует
началу работы устройства). При этом можно считать,
что процесс, относящийся к такту t (подача воздей-
ствия, изменение состояния, выдача выходного значе-
ния), протекает мгновенно в момент t. При такой идеа-
лизации процесс переработки информации описывается
адекватно.
Дискретная информация. Обычно входные и
выходные сигналы (воздействия), используемые в ди-
скретных устройствах, имеют несколько различимых
уровней*). Каждому уровню может быть сопоставлен
некоторый символ, который, в зависимости от содержа-
тельного смысла перерабатываемой информации, может
интерпретироваться как цифра, буква, признак и др.
Мы будем придерживаться единой терминологии и сим-
волы будем называть буквами, а совокупности симво-
лов— словами. В частности, словами являются и чис-
ла, записанные в некоторой позиционной системе счис-
ления (двоичной, десятичной и др.).
Таким образом, дискретные устройства осуществ-
ляют переработку информации, представленной в виде
слов. Такую информацию будем называть словарной.
Использование словарной информации фактически не
накладывает ограничений на область применения ди-
скретных устройств, ибо обычно непрерывная информа-
ция может быть с любой степенью точности аппрокси-
мирована дискретной, а дискретная — представлена в
виде словарной. Посредством слов может быть описана
информация, имеющая достаточно сложную логическую
структуру (многомерные массивы могут быть вытя-
нуты в линию, связи заданы с помощью ссылок и т. д.).
Внешние каналы устройства являются носителями
текущей информации. Информацию о данных, поступив-
ших ранее и необходимых для работы устройства, несут
внутренние состояния. Хранение информации обычно
*) Мы говорим об уровнях лишь в целях простоты. Сигналы
могут различаться также по частоте, номеру позиции (шины) и т. д.
ВВЕДЕНИЕ
11
осуществляется в специальных устройствах памяти. Па-
мять представляет собой совокупность ячеек, взаимо-
связь которых (огранизация памяти) может быть до-
статочно сложной. Состояние устройства определяется
состоянием памяти и настройкой некоторых эле-
ментов.
Наиболее часто используются дискретные устройст-
ва, у которых входные и выходные сигналы имеют два
различимых уровня, а ячейки памяти могут находиться
в двух различимых состояниях. Это связано с методами
физической реализации устройств, соображениями на-
дежности и удобством выполнения логических и ариф-
метических операций. Одному из уровней приписывает-
ся символ 0, другому — символ 1 и, таким образом,
устройство осуществляет переработку двоичной инфор-
мации (слов в алфавите {0, 1}). Отметим, что большая
значность алфавита может быть достигнута группиров-
кой символов; так, четыре двоичные цифры могут вос-
приниматься как одна шестнадцатеричная цифра, а
каждая из 32 букв русского алфавита (е и ё отождеств-
ляются) может быть задана посредством двоичного на-
бора длины 5.
В дальнейшем все рассмотрения будут вестись на
уровне словарной информации (как правило, двоичной),
и вопросы, связанные с аналого-цифровым преобразо-
ванием информации, квантованием и др., существенные
для реальных устройств, нас интересовать не будут.
Дискретные устройства, осуществляющие сложную
переработку информации, строятся из некоторых эле-
ментарных компонент — элементов. Элементы могут
представлять собой самостоятельные схемы электриче-
ской или другой природы. Мы будем абстрагироваться
от конкретной конструкции элемента и считать его объ-
ектом, имеющим входы и выходы и выполняющим не-
которую функцию. Он, например, может реализовывать
логическую операцию над входными переменными, за-
поминать информацию, поступающую на его входы, и
т. д. Элементы соединяются по определенным правилам,
и характером элементов и их соединений определяется
функционирование устройства в целом. Идеализирован-
ную модель устройства, отражающую лишь элементы
и их соединения, будем называть схемой.
12
ВВЕДЕНИЕ
В зависимости от преследуемой цели, дискретные
устройства могут рассматриваться с разной степенью
детализации. На макроуровне интересуются только
«входно-выходными» характеристиками, т. е. зависи-
мостью выходной информации от входной (и внутрен-
него состояния — содержимого памяти). На микроуров-
не рассмотрение ведется с учетом структуры устройства
(схемы). Возможны и промежуточные степени подроб-
ности — с точностью до блоков той или иной сложности
и логической природы.
Классификация. В зависимости от конструкции и
назначения дискретные устройства делятся на классы.
Одна из основных классификаций производится по объ-
ему памяти. Устройства описываются моделями
— без памяти;
— с конечной памятью;
— с бесконечной памятью.
В устройствах без памяти выходные значения опре-
деляются только текущими сигналами на входе. Функ-
ционирование такого устройства не зависит от внутрен-
него состояния, и можно считать, что оно имеет един-
ственное состояние. Устройства с конечной памятью об-
ладают конечным числом внутренних состояний. ’К это-
му типу относятся многие специализированные устрой-
ства автоматики, управления и регулирования, а также
отдельные узлы вычислительных машин. Модель уст-
ройства с конечной памятью носит название конечного
автомата. Автоматы, относящиеся к устройствам без
памяти, часто называют комбинационными.
Примером устройства без памяти (комбинационного
автомата) является параллельный сумматор, который
осуществляет сложение двух «-разрядных чисел. На его
входы поступают одновременно все цифры слагаемых,
а на выходе сразу реализуются все цифры суммы. В ка-
честве примера устройства с конечной памятью (конеч-
ного автомата) можно привести последовательной сум-
матор. Он имеет 2 входа, на каждый из которых после-
довательно, начиная с младшего, подаются разряды
слагаемых (по одному за такт). С выхода снимается
значение соответствующего разряда суммы. Последнее
определяется не только текущими разрядами слагае-
мых, но и переносом из предыдущего разряда, Значе-
ВВЕДЕНИЕ
13
ние переноса учитывается состоянием устройства. Па-
раллельный сумматор осуществляет сложение /г-разряд-
ных чисел гораздо быстрее, чем последовательный (за
1 такт вместо п), но он имеет более сложную схемную
реализацию.
Устройства с бесконечной памятью являются некото-
рой идеализацией. Такая идеализация удобна при опи-
сании работы вычислительных машин, ибо последние
имеют столь большое число состояний, что их практи-
чески невозможно задать перечислением. Модели с бес-
конечной памятью будем называть машинами. Отметим,
что обычно в этих моделях память в каждый момент
времени можно предполагать конечной, если допускать
возможность ее наращивания. Существенной особен-
ностью машин является то, что за одцн такт содержи-
мое памяти изменяется лишь в небольшой части (ло-
кально). В то время как для конечных автоматов опи-
сание функционирования обычно дается на уровне со-
стояний и конкретное заполнение памяти, соответствую-
щее состоянию, несущественно, работа машин описы-
вается уже на уровне содержимого памяти.
По способу функционирования дискретные устрой-
ства делятся на
— детерминированные;
— вероятностные.
В детерминированных устройствах поведение в каж-
дый момент времени однозначно определяется теку-
щими значениями входов и состоянием. При многократ-
ном воспроизведении одних и тех же условий такое
устройство всегда функционирует одинаково. В вероят-
ностных устройствах в каждой ситуации возможно не-
сколько вариантов поведения. Принятие того или иного
варианта зависит от некоторого механизма случайного
выбора. Функционирование такого устройства может
быть описано статистически.
Вероятностные устройства могут быть сведены к де-
терминированным, если механизм случайного выбора
«вынести за пределы устройства» и рассматривать де-
терминированные устройства со случайным входом. От-
метим, что на практике вместо случайных последователь-
ностей используются псевдослучайные (они порождают-
ся алгоритмически), и устройство функционирует как
14
ВВЕДЕНИЕ
детерминированное. В дальнейшем мы будем рассматри-
вать только детерминированные устройства.
По способу ввода входной информации дискретные
устройства подразделяются на
— автономные;
•— неавтономные.
Автономные устройства в процессе функционирова-
ния не приобретают внешней информации. Такой режим
является основным для вычислительных машин: началь-
ная информация помещается в память и машина до ос-
тановки работает без внешнего вмешательства. Неав-
тономные устройства в процессе функционирования по-
лучают информацию через внешние каналы. Одним из
главных режимов работы неавтономных устройств яв-
ляется работа в реальном масштабе времени. Так функ-
ционируют многие устройства контроля, регулирования
и управления: они получают информацию от датчиков и
выдают (с допустимым запаздыванием) управляющие
воздействия. В дальнейшем в качестве моделей вычис-
лительных машин рассматриваются автономные, а в
качестве моделей конечных автоматов — неавтономные,
работающие в реальном масштабе времени (при этом
считается, что выходные значения выдаются без запаз-
дывания, т. е. одновременно с поступлением входных).
Анализ. Задача анализа состоит в том, чтобы по
устройству, заданному в том или ином виде, найти осу-
ществляемое им преобразование (отображение) вход-
ной информации в выходную либо выяснить некоторые
свойства этого отображения.
Для устройств с конечной памятью (и, в частности,—
без памяти) задача анализа обычно рассматривается
для случая, когда устройство задано своей схемой. Тре-
буется по функциям элементов схемы и их соединениям
найти функцию всего устройства. Решение этой задачи
принципиальных трудностей не вызывает, поскольку
обычно одновременно с описанием правил, допустимых
при построении схем, приводится способ вычисления
функций, соответствующих применению каждого из пра-
вил, что позволяет найти выходную функцию всего
устройства.
В то время как для устройств с конечной памятью
всю информацию о реализуемой функции несет схема,
ВВЕДЕНИЕ
15
для устройств с бесконечной памятью (машин) вся ин-
формация содержится в программе. При этом либо
можно считать, что программа описывает специализи-
рованную машину для вычисления некоторой функции,
либо воспринимать ее как программу вычисления, кото-
рая реализуется в универсальной машине (принципи-
ального различия между этими подходами нет, ибо, за-
фиксировав программу, мы превращаем универсальную
машину в специализированную). Будем придерживаться
той точки зрения, что программа задает работу специа-
лизированной машины.
Задача анализа состоит в том, чтобы по программе
машины найти реализуемую функцию либо выяснить
некоторые ее свойства. Один из результатов, которые
будут установлены в дальнейшем, состоит в том, что в
общем случае по программе машины о свойствах соот-
ветствующей ей функции ничего сказать нельзя. Таким
образом, задача анализа машин не имеет решения даже
в очень слабых постановках. В этом проявляется суще-
ственное различие устройств с конечной и бесконечной
памятью.
Синтез. Задача синтеза состоит в том, чтобы по за-
данному «входно-выходному» преобразованию информа»
ции построить схему (в случае конечных автоматов)
либо написать программу (в случае машин), которая
бы реализовала это преобразование.
Исходные данные, на основе которых производится
синтез, предполагаются записанными на некотором фор-
мальном языке. Будем рассматривать случай, когда этот
язык является универсальным для заданного класса
устройств (для конечных автоматов или машин), т. е.
когда он позволяет представить условия работы, реа-
лизуемые любыми конечными автоматами, либо все
функции, вычислимые машинами. В случае машин та-
ким свойством обладают универсальные алгоритмиче-
ские языки (АЛГОЛ, ФОРТРАН и др.). При этом за-
дача синтеза фактически сводится к трансляции с алго-
ритмического языка на язык машины. Основная же
трудность состоит в разработке содержательных алго-
ритмов и их переводе на алгоритмический язык. Послед-
нее является задачей программирования.
16
ВВЕДЕНИЕ
Наибольший интерес для нас будет представлять за-
дача синтеза конечных автоматов. Синтез сложного ав-
томата обычно осуществляется в несколько этапов. На
этапе блочного синтеза производится разбиение автома-
та на отдельные блоки по функциональному признаку.
При этом определяются задачи блоков, их взаимодей-
ствие и обмен информацией между ними. Разбиение на
блоки осуществляется интуитивно с учетом функцио-
нального единства блока, типизации блока, удобства
контроля неисправностей и др.
Далее следует этап абстрактного синтеза, итогом ко-
торого является формализация условий работы отдель-
ных блоков и запись их на некотором специальном язы-
ке. Чем более широкие возможности предоставляет этот
язык заказчику с точки зрения простоты формулирова-
ния условий работы устройства, тем сложнее последую-
щий синтез, выполняемый проектировщиком (подобно
тому как увеличение выразительных возможностей алго-
ритмических языков приводит к усложнению транслято-
ров). Иногда этап абстрактного синтеза выполняется в
диалоге заказчика и проектировщика, в процессе кото-
рого заказчик уточняет условия работы устройства пу-
тем ответа на вопросы проектировщика (анкетный
язык). Проблематику, связанную с языками для описа-
ния работы устройств, мы рассматривать не будем. Бу-
дем предполагать, что условия работы задаются просто
путем перечисления всех допустимых ситуаций (их ко-
нечное число) и указания поведения устройства в каж-
дой из них. На практике обычно используются более
компактные способы представления этой информации.
На следующем этапе структурного синтеза осуществ-
ляется построение схемы, реализующей заданные усло-
вия работы. Набор типов элементов, из которых строят-
ся схемы, обычно предполагается заранее известным.
Он должен обладать свойством полноты (универсаль-
ности), т. е. должен предоставлять возможность реали-
зации произвольных условий работы, соответствующих
конечному автомату либо автомату без памяти. (Отме-
тим, что аналогичный смысл имеет свойство универ-
сальности вычислительных машин: набор операций, вы-
полняемых машиной, должен быть достаточным для
реализации любой функции, которая в принципе может
ВВЕДЕНИЕ
17
быть вычислена.) При выполнении этапа структурного
синтеза используются формальные логические методы.
Далее следует этап надежностного синтеза, на кото-
ром обеспечивается надежность функционирования схем
путем введения некоторой структурной избыточности.
Здесь предусматриваются средства для резервирования
отдельных участков схемы, для контроля работы схемы
и корректирования неисправностей.
На следующем этапе технического синтеза учиты-
ваются реальные ограничения на специфику элементов
и их соединений (коэффициент разветвления выхода
элемента, нагрузочная способность, задержка срабаты-
вания и др.). В схему вводятся дополнительные элемен-
ты, не несущие функциональной нагрузки, а осуществ-
ляющие размножение информации, усиление сигналов,
выравнивание задержек по цепям и др.
Приведенное деление на этапы является достаточно
условным. В реальной практике проектирования неко-
торые этапы могут отсутствовать, некоторые могут со-
вмещаться (например, этап структурного и надежност-
ного синтеза), может происходить возвращение к ка-
кому-либо этапу после выполнения остальных и т. д.
В настоящее время все более широкое распространение
находят системы автоматизации проектирования, вклю-
чающие в себя специальные средства математического
и технического обеспечения ЦВМ, ориентированные на
решение задач синтеза. Они позволяют существенно об-
легчить или даже полностью автоматизировать отдель-
ные этапы проектирования сложных автоматов.
Основное внимание мы будем уделять этапу струк-
турного синтеза и в дальнейшем под синтезом будем
понимать структурный синтез.
Оптимизация. С каждой схемой или программой
обычно связывается некоторая численная величина, ха-
рактеризующая ее сложность. Здесь термин «слож-
ность» понимается достаточно широко. В случае схем
это может быть число элементов схемы, ее «стоимость»,
задержка срабатывания, в случае программ — число
команд в программе, время, потребное для вычислений,
необходимый объем памяти. Задача синтеза в идеале
ставится как задача оптимального синтеза. Целью яв-
ляется нахождение схемной или программной реализа-
18
ВВЕДЕНИЕ
ции, имеющей минимальную сложность (в условленном
смысле).
Для конечных автоматов решение этой задачи в
принципе может быть получено посредством тривиаль-
ного переборного алгоритма, который сводится к про-
смотру всех схем рассматриваемого вида в порядке воз-
растания их сложности и проверке для каждой из них,
реализует ли она заданные условия работы. Первая из
встреченных схем, для которой ответ утвердителен, бу-
дет минимальной. Трудоемкость этого алгоритма тако-
ва, что его удается довести до конца (даже при ис-
пользовании ЦВМ) лишь в самых простейших случаях,
и, таким образом, для практически интересных задач
тривиальный алгоритм ничего не дает.
Некоторые задачи оптимального синтеза удается ре-
шить эффективно (с небольшой трудоемкостью). При-
мером может служить построение автомата с минималь-
ным числом состояний. Для большинства же задач эф-
фективных методов не найдено, а все известные спо-
собы «соизмеримы» по трудоемкости с тривиальным пе-
ребором. Имеются основания полагать (они обсуж-
даются в § 5.5), что простых способов решения этих
задач не существует.
Для того чтобы преодолеть указанное препятствие,
обычно ставятся и решаются более простые задачи.
Часто требуется лишь, чтобы построенные схемы были
«достаточно экономными» (практически хорошими).
В этом случае качество используемых алгоритмов про-
веряется статистически на некотором потоке задач.Дру-
гой подход (асимптотический) связан с построением
схем, которые для абсолютного большинства функций
от достаточно большого числа аргументов близки к ми-
нимальным. Он позволяет находить зависимость (асимп-
тотическую) сложности схем от некоторых параметров,
характеризующих условия работы.
Как уже отмечалось, тривиальный перебор не яв-
ляется эффективным средством решения задач. Однако
во многих случаях перебор может быть значительно
уменьшен за счет предварительного отсечения вариан-
тов. Существуют практические методы решения задач
оптимального синтеза, основанные на идее сокращения
перебора (один из них рассматривается в § 2.3). Приме-
введение
19
нение этих методов ограничивается задачами малой
размерности, ибо обычно с повышением размерности
трудоемкость становится чрезвычайно большой (и даже
«соизмеримой» с трудоемкостью тривиального пере-
бора) .
В случае вычислений на машинах задача оптималь-
ного синтеза без каких-либо ограничений на класс вы-
числимых функций вообще не может быть поставлена,
ибо, как мы увидим дальше, некоторые функции не
имеют наилучших вычислений ни в каком приемлемом
смысле. Этот результат справедлив фактически для лю-
бых моделей машин и любых характеристик сложности
вычислений. Имеются и другие факты, обнаруживаю-
щие большие трудности, возникающие в задачах по-
строения вычислительных программ с учетом характе-
ристик сложности. В связи со сказанным при решении
достаточно сложных задач требование оптимальности
обычно не выдвигается, а речь идет лишь о «эконом-
ных» вычислениях. Эти вопросы относятся уже к обла-
сти программирования и выходят за рамки наших рас-
смотрений.
Отметим еще, что достаточно широкое распростра-
нение имеют методы упрощения схем и программ, осно-
ванные на эквивалентных преобразованиях, т. е. на за-
мене отдельных их фрагментов более простыми и функ-
ционально эквивалентными фрагментами.
Надежность. В процессе хранения, передачи и пере-
работки на информацию действуют помехи, которые мо-
гут привести к ее искажению. В связи с увеличиваю-
щейся сложностью вычислительных и управляющих си-
стем задача обеспечения их надежной работы стано-
вится все более актуальной.
Повышение надежности может быть достигнуто за
счет технических средств: внедрения новых конструкций
и новой технологии, улучшающих характеристики эле-
ментов и узлов, применения специальных устройств
(усилителей, фильтров и пр.). Другую возможность
предоставляют средства контроля и диагностики не-
исправностей. При их использовании в устройство по-
дается специальная тестовая (проверочная) информа-
ция и на основе наблюдения за выходной информацией
делается заключение о наличии неисправностей и выяс-
20
ВВЕДЕНИЕ
няются места неисправных элементов и соединений. Эти
средства применяются для обнаружения систематиче-
ских нарушений, связанных с выходом из строя отдель-
ных элементов и соединений, их критическим состоя-
нием и др. Устранение обнаруженных неисправностей
требует внешнего вмешательства.
Наряду с этим информация должна быть защищена
от случайных сбоев, связанных с помехами в линиях
связей, колебаниями напряжения и питания в электри-
ческих цепях, нарушениями контактов из-за вибраций
и др., которые не носят систематического характера и
не требуют вмешательства для их устранения. Для
борьбы с этими явлениями используются специальные
способы кодирования информации, делающие ее поме-
хозащищенной, либо схемы, обладающие свойством ав-
томатического исправления ошибок определенного вида
(самокорректирующиеся схемы). Помехозащищенность
информации достигается за счет введения в нее некото-
рой избыточности (увеличения объема информации), а
свойство самокорректирования схем — за счет аппара-
турной избыточности. Простейшим примером является
использование кода с проверкой на четность для конт-
роля в ЦВМ ошибок при пересылках чисел и команд.
В разрядную сетку машины вводится дополнительный
разряд и к двоичному машинному слову дописывается
(помещается в дополнительный разряд) символ 1 или 0
так, чтобы число единиц было четным. При искажении
одного разряда число единиц становится нечетным, и в
этом случае выдается сигнал об ошибке.
Мы будем изучать лишь круг вопросов, связанных с
повышением надежности за счет помехоустойчивого ко-
дирования и самокорректирования, оставляя в стороне
вопросы применения технико-технологических средств и
средств диагностики.
Введение информационной избыточности увеличи-
вает объем памяти, необходимый для хранения инфор-
мации, замедляет ее передачу по линиям связи и т. д.,
а введение аппаратурной избыточности приводит к ус-
ложнению устройств. В связи с этим возникает задача
уменьшения избыточности при заданных свойствах по-
мехозащищенности. Помимо этого налагается условие,
чтобы кодирование и исправление ошибок осуществля-
ВВЕДЕНИЕ
21
лись с малыми затратами аппаратуры, времени и па-
мяти. Эти требования в некотором смысле противоре-
чивы, однако имеются конструкции, в которых их
удается удачно совместить.
Важной задачей является оценка минимально воз-
можной избыточности, при которой могут быть обеспе-
чены заданные свойства помехозащищенности. Эти
оценки обычно получаются из сопоставления «количе-
ства информации» (передаваемой или хранимой) и
«пропускной способности» среды, определяемой возмож-
ными ошибками и их вероятностными характеристика-
ми. При этом оценки обычно получаются неконструктив-
но, но они дают теоретически достижимую границу, к
которой надо стремиться при разработке конструктив-
ных методов.
Содержание книги. Выше был намечен круг вопро-
сов, связанных с дискретными устройствами, которые
мы предполагаем рассмотреть. Остановимся теперь бо-
лее подробно на содержании книги.
Она состоит из трех примерно равных по объему час-
тей. Первая часть (главы I—III) посвящена устройст-
вам с конечной памятью (конечным автоматом), вторая
часть (главы IV—V) — устройствам с бесконечной па-
мятью (идеализированным моделям вычислительных
машин) и алгоритмам, а третья часть (главы VI—VII) —
вопросам надежного хранения, передачи и переработки
дискретной информации.
В главе I описывается аппарат логических функ-
ций, на базе которого в дальнейшем излагается мате-
риал, относящийся к устройствам с конечной памятью.
Важную роль здесь играют различные представления
логических функций, сказывающиеся полезными при
синтезе устройств. Дается решение задачи полноты, т. е.
выясняются условия, которым должен удовлетворять
набор логических элементов, чтобы схемами, построен-
ными из этих элементов, можно было реализовать лю-
бую логическую функцию.
Глава II посвящена дискретным устройствам без
памяти. Основное внимание уделено синтезу схем. Под
сложностью схемы понимается число входящих в нее
элементов. Поскольку эффективного (не основанного на
переборе) решения задачи синтеза минимальных схем
22
ВВЕДЕНИЕ
не известно, приводятся некоторые методы построения
«экономных» схем. В заключение главы описывается
асимптотический метод, позволяющий синтезировать
«почти наилучшие» схемы для «почти всех» функций.
На его основе выясняется, как растет сложность схем
с ростом числа входных полюсов.
В главе III изучаются устройства с конечной па-
мятью— конечные автоматы. Излагается эффективный
метод построения автомата, реализующего заданные
условия работы и имеющего минимальное число состоя-
ний. Дается решение задачи анализа и синтеза для слу-
чая, когда автоматы реализуются схемами из логиче-
ских элементов и простейших элементов памяти (задер-
жек). Далее рассматриваются схемы, в качестве элемен-
тов которых используются автоматы произвольного вида.
Задача анализа таких схем решается достаточно просто,
в то время как при синтезе (даже без требования оп-
тимальности) возникают серьезные трудности. Одна из
них состоит в том, что в принципе не существует спо-
соба, который бы по заданному набору автоматов уста-
навливал, является ли он полным (т. е. возможно ли с
его использованием схемно реализовать любой конеч-
ный автомат). Доказательство этого факта приводится
лишь в главе V, ибо оно требует некоторых сведений из
теории алгоритмов.
Глава IV посвящена моделям алгоритмов. Все из-
вестные модели алгоритмов эквивалентны в том смысле,
что классы функций, вычислимых в этих моделях, сов-
падают. Поэтому изложение можно вести на базе любой
из них. В качестве основной взята модель машины
Тьюринга, которая, с одной стороны, является очень
простой, а с другой — достаточно точно отражает содер-
жание вычислительного процесса. Фундаментальный
факт эквивалентности различных моделей алгоритмов
иллюстрируется на примере функций, вычислимых на
машинах Тьюринга, и функций, порождаемых с исполь-
зованием некоторых специальных операций алгоритми-
ческого типа (частично-рекурсивных функций). После-
дующая часть главы посвящена важному свойству уни-
версальности. Строится универсальная машина Тью-
ринга, которая при вводе соответствующей программы
может моделировать любую алгоритмическую процеду-
ВВЕДЕНИЕ
23
ру (тот же принцип используется в современных ЦВМ).
С применением свойства универсальности устанавли-
вается ряд общих результатов. Один из них утверж-
дает, что по программе, вообще говоря, ничего нельзя
сказать о реализуемой функции, и, таким образом, про-
ливается свет на природу многих трудностей, возникаю-
щих в области программирования, создания алгоритми-
ческих языков и др.
В главе V рассматриваются вычислительные воз-
можности машин. Устанавливается существование за-
дач, которые в принципе не могут быть решены алгорит-
мическими методами. Такой, в частности, является за-
дача полноты системы конечных автоматов, о которой
шла речь в главе III. Далее изучаются ограничения на
вычислимость, связанные с необходимым объемом вре-
мени и памяти. Доказывается, что некоторые задачи до-
пускают лишь очень сложное решение, и, таким обра-
зом, они практически недоступны (даже при использо-
вании самых мощных вычислительных средств). Уста-
навливается, что не всякая функция имеет наилучшее
вычисление (в каком-либо приемлемом смысле), и по-
этому вопрос об оптимальном вычислении может быть
поставлен не всегда. Многие дискретные задачи допу-
скают нахождение решения путем переборного процес-
са. В заключение главы рассматривается класс всех та-
ких задач. Показывается, что некоторые важные задачи
(в том числе ряд задач, связанных с оптимальным син-
тезом) являются самыми сложными в этом классе, и
поэтому трудно рассчитывать на то, что для них удастся
найти эффективный (достаточно простой) алгоритм ре-
шения.
Следующая глава VI посвящена эффективному
кодированию дискретной информации, делающему ее
помехозащищенной. Здесь изучаются свойства кодов,
обеспечивающие возможность обнаружения и исправ-
ления ошибок. Дается способ построения наилучших из
известных кодов (БЧХ-кодов), обладающих заданной
способностью исправления ошибок, малой избыточ-
ностью и допускающих достаточно простое кодирова-
ние и декодирование информации. На их основе опи-
сывается конструкция самкорректирующихся схем, ко-
торые для «почти всех» функций имеют «почти ту же»
24
ВВЕДЕНИЕ
сложность, что и минимальные схемы без требования
самокорректирования.
В главе VII рассматривается задача надежной
передачи и хранения дискретной информации в вероят-
ностной постановке (полученные результаты допускают
распространение и на переработку информации). Вво-
дятся количественные меры неопределенности и инфор-
мации, служащие базой для изложения дальнейшего
материала (они представляют и самостоятельный инте-
рес). Устанавливается основной результат, связываю-
щий избыточность, необходимую для надежной пере-
дачи (хранения) дискретной информации с некоторой
величиной (пропускной способностью), характеризую-
щей среду и определяемой типами возможных ошибок
и их вероятностными характеристиками. Помимо этого
рассматриваются вопросы оптимального «сжатия» ди-
скретной информации, обеспечивающего полную вос-
станавливаемость исходной информации.
Проблематика, связанная с дискретными устрой-
ствами, чрезвычайно широка, и поэтому многие важные
вопросы не нашли отражения в книге. Некоторые из
них, непосредственно примыкающие к излагаемому ма-
териалу, упоминаются в тексте и там же приводятся
соответствующие ссылки на литературу.
ЧАСТЬ ПЕРВАЯ
Глава I
ЛОГИЧЕСКИЕ ФУНКЦИИ
§ 1.1. Задание логических функций
1.1.1. Таблицы. Функция f(xit хп) называется
логической (или булевой), если она принимает значе-
ния 0 и 1 и ее аргументы также принимают значения О
и 1. Логическая функция от п аргументов может быть
задана таблицей, в которой перечислены всевозможные
наборы из 0 и 1 длины п и для каждого из них ука-
зано значение функции. Наборы обычно перечисляются
в порядке возрастания чисел, двоичными записями ко-
торых они являются. В таблице 1.1 приведен пример
логической функции от 3 аргументов.
Таблица 1.1
Х1 Х1 X,
f(Xi, Х2, Xi)
ООО
О О 1
О 1 О
О 1 1
1 о о
1 0 1
1 1 о
1 1 1
1
1
о
о
1
1
о
1
Таблицы для функций от п аргументов Xi, ..., хп
имеют 2Ч строк (по числу двоичных наборов длины п).
Различные таблицы отличаются лишь последним столб-
цом и, поскольку количество различных двоичных столб-
цов длины 2" составляет 22 , число функций от п аргу-
ментов %1, ..., Хп равно 22 . Заметим, что в это число
26
ЛОГИЧЕСКИЕ ФУНКЦИИ
[ГЛ. I
включены и функции, зависящие от некоторых из аргу-
ментов Xi, хп фиктивно*), т. е. функции, фактиче-
ски зависящие от меньшего числа аргументов. Вели-
чина 22 чрезвычайно быстро растет (так, 22 — 4, 22 —
= 16, 223 = 256, 22< > 6 • 104, 22’ > 4 • 109).
Приведем примеры функций, которые будут широко
использоваться в дальнейшем. При п — 1 имеются 4
Ими являются константы 0 и 1, значения которых не
зависят от значений аргумента, тождественная функция
х, повторяющая значение аргумента, и функция х, при-
нимающая значение, противоположное значению аргу-
мента. Функция х носит название отрицания или инвер-
сии. Заметим, что константы 0 и 1 фактически не зави-
сят от аргумента, и их иногда будем считать «функ-
циями от нуля аргументов».
Среди функций от 2 аргументов также выделим не-
которые функции (табл. 1.3). Они носят соответственно
Таблица 1.3
Х1 Х2 Х1 & х2 х; V X-J Х1 -> х-I X, ф Xi
0 0 0 0 1 0 1
0 1 0 1 1 1 0
1 0 0 1 0 1 0
1 1 1 1 1 0 1
названия конъюнкции, дизъюнкции, импликации, сум-
мы по модулю 2 (по mod 2) и эквивалентности. Как
*) Функция зависит от аргумента xi фиктивно, если на набо-
рах, различающихся лишь в 1-а позиции, она принимает равные
значения.
§ I.ll
ЗАДАНИЕ ЛОГИЧЕСКИХ ФУНКЦИИ
27
можно видеть из таблицы, конъюнкция равна 1 лишь
в случае, когда оба аргумента обращаются в 1, а дизъ-
юнкция равна 0 лишь на нулевом наборе. Конъюнкцию
принято также называть логическим умножением, а
дизъюнкцию — логическим сложением. Импликация об-
ращается в 0 только в случае, когда значение второго
аргумента меньше значения первого аргумента. Функ-
ция эквивалентности равна 1 при совпадении значений
обоих аргументов, а функция суммы по модулю 2 — при
несовпадении. Название последней из этих функций
объясняется тем, что она принимает значение 1 на на-
борах с нечетным числом единиц и значение 0 — на на-
борах с четным числом. Перечисленные функции от од-
ного и двух аргументов будем называть элементар-
ными.
1.1.2. Формулы. Наряду с табличным способом за-
дания логических функций применяются другие. Одним
из них является способ задания с помощью формул.
Пусть имеется некоторое множество & логических
функций. Множество $ будем называть базисом, а вхо-
дящие в него функции — базисными. По индукции опре-
делим понятие формулы (над :
— выражение f(%i.....х„), где f — базисная функ-
ция, есть формула;
— если fo(xi, ..., xm) — базисная функция, а выра-
жения Фь ..., Фт являются либо формулами, либо
символами переменных, то выражение /0(Фь ..., Ф«)
есть формула.
Все формулы, которые встречались в процессе по-
строения заданной формулы, будем называть ее под-
формулами. В качестве примера рассмотрим базис & =
= {g(xi,x2), Цх^ х2, х3)}, состоящий из двух функций.
Выражение h(g(xlt h(x2, х2, х2)), xi, h(xi, g(x2, х2), х,))
является формулой над Подформулами здесь будут
g(x2,x2), h(xi,g(x2,x2), Xi), h(x2,x2,x2), g(x,, h(x2, x2,
x2)) и вся формула.
Каждой формуле следующим образом сопостав-
ляется реализуемая ей логическая функция:
— формуле вида f(xi, ..., %п),где f — базисная функ-
ция, ставится в соответствие функция ..., х„);
— если формула имеет вид .... Фт), где
Ф< (i = 1, ..., m) является либо формулой, либо
28
ЛОГИЧЕСКИЕ ФУНКЦИИ
[ГЛ. I
символом переменной х/(1), то ей сопоставляется функция
/о(fi, ..., fm), где ft является соответственно либо функ-
цией, реализуемой подформулой Ф„ либо тождественной
функцией х/(().
Функция, реализуемая формулой, зависит от пере-
менных, которые участвовали в ее построении. В каче-
стве примера рассмотрим формулу (х2 -* %i)&(( (*2 ф
ф1)&х3)~х3). Она реализует некоторую функцию
f(xi, х2, х3). Пользуясь таблицами для элементарных
функций, можно вычислить ее значение на любом на-
боре (ai,«2, аз). Проделаем это для набора (0,1,0):
(1 -0) &(((!© 1)&0)~0) =
= (1 -► 0) & ((0 & 1) ~ 1) = о & (0 ~ 1) = 0 & 0 = 0.
Подобным образом можно убедиться, что функция
f(xt,x2, хз) задается таблицей 1.1.
1.1.3. Эквивалентные преобразования формул. Фор-
мулы Ф и Т будем называть эквивалентными и запи-
сывать Ф = если они реализуют равные функции,
т. е. на одинаковых наборах принимают одинаковые зна-
чения. Эквивалентность формул может быть установ-
лена путем нахождения табличного задания реализуе-
мых ими функций и сравнения этих таблиц (другой спо-
соб проверки эквивалентности будет изложен в следую-
щем параграфе). Очевидно, что замена в формуле неко-
торой подформулы на эквивалентную дает формулу,
эквивалентную исходной. На основании этого можно
осуществлять преобразования формул, не изменяющие
реализуемых функций.
Дальше в пределах параграфа будем рассматривать
формулы над базисом = {0, 1,х, &, V, ф, ~},
состоящим из всех элементарных функций.
По таблицам 1.2 и 1.3 легко проверить, что имеют
место эквивалентности
Xi -> х2 = Xi V х2, (1.1)
Х1фх2 = (Х] &х2) V (Х[ &х2), (1.2)
Xi ~ х2 = (х, & х2) V (хх & х2). (1.3)
С их использованием формулы над & могут быть заме-
нены эквивалентными формулами над более узким ба-
зисом {0, 1, х, &, У}.
§ I.1J
ЗАДАНИЕ ЛОГИЧЕСКИХ ФУНКЦИЙ
29
Приведем некоторые важные базиса {0, 1, х, &, V}: эквивалентности для
(Х] & х2) &х3 = хг& (х2 & х3), (xi V х2) V х3 = xi V (х2 V х3) Xi & Х2 = Х2 & Хь %! V Х2 = Х2 V Х[ х&х — х, х\/ X — X Xi & (х2 V х3) = (х, & х2) V (*1 & х3), Xi V (х2 & х3) = (Xi V х2) & (Xi V Х3) . 1 свойства ) ассоциативности, 1 свойства ) коммутативности, 1 свойства ) идемпотентности, 1 свойства ' дистрибутивности,
(xi & х2) = X] V х2, (Xi V х2) == х, & х2 1 законы де Моргана,
х = х
— закон двойного
отрицания.
Кроме того, справедливы следующие соотношения с
участием констант:
х&0 = 0, х&Л—х, х&х = 0,')
х V 1 — 1, х V 0 = х, х V х = I. J
Из свойства ассоциативности следует, что можно
рассматривать многоместную конъюнкцию xi&x2& ...
... &хп, которую будем обозначать также & х{. Фор-
мально она формулой не является, но может быть пре-
вращена в таковую расстановкой, скобок, причем рас-
положение скобок на реализуемую функцию влияния не
оказывает. Точно так же можно рассматривать много-
п
местную дизъюнкцию V xt = х\ V х2 V ... V хп. Выра-
/=»1
п п
жения & Xi и V Xi считаются осмысленными также при
/=1 /=1
п = 1 и п — 0. В случае п = 1 они означают хь Пустая
конъюнкция (при п = 0) полагается равной 1, пустая
дизъюнкция — равной 0. Законы де Моргана могут быть
30
ЛОГИЧЕСКИЕ ФУНКЦИИ
[ГЛ. I
обобщены для произвольного tv.
( & Xi) = V х,-, ( v Xi ) = & Xi. (1.4)
\< = 1 / Z = 1 \i = l / i=l
При n > 2 в этом можно убедиться, представив много-
местную функцию с помощью двуместных. При п — 3,
например, цепочка преобразований имеет вид
(Х1 & Х2 & Х3) = ((%1 & Х2) & х3) =
= (%1 & х2) v = (м V х2) V *3 = *1 V х2 V х3.
В случае п = 0 и п = 1 соотношения (1.4) выполняются
очевидным образом.
Соотношения (1.4) допускают дальнейшее обобще-
ние. Пусть функция f реализуется некоторой формулой
в базисе {О, 1,_, &, V}. Тогда формула, реализующая
ее отрицание f, может быть получена по следующему
правилу. Все функции & должны быть заменены на V,
функции V — на &, переменные Xi должны быть заме-
нены их отрицаниями, а константы 0 и 1 — противопо-
ложными константами 1 и 0. Это вытекает из законов
де Моргана, на основе которых отрицание над форму-
лой может быть последовательно пронесено вглубь фор-
мулы, пока оно не перейдет на переменные и константы.
Для пояснения этого рассмотрим пример. Пусть
функция / задается формулой
f = (Ui & х2) V х3) & (1 V (х3 & х2}}.
Последовательное применение законов де Моргана дает
f = ((xi & х2) V х3) & (1 V (х3 & х2)) =
= (Ui & х2) v Х3) V (1 V (х3 & х2)) =
= ((Xj & х2) & х3) V (Г& (х3 & х2)) =
= ((М V х2) & х3) V (0 & (х3 V х2))-
Тот же результат получается с использованием указан-
ного правила.
1.1.4. Упрощение формул. В дальнейшем с целью
сокращения записей условимся знак & иногда заменять
точкой или опускать и считать, что операция & связы-
§ 1.П
ЗАДАНИЕ ЛОГИЧЕСКИХ ФУНКЦИИ
31
вает сильнее других операций, т. е. что она выполняет-
ся раньше их (если скобки не предписывают другого
порядка). Так, вместо записи (xi&x2)->x3 будем при-
менять XjX2—>Хз.
Укажем некоторые полезные эквивалентности, кото-
рые могут быть использованы для упрощения формул:
Xi V XiX2 = Xi, )
? правила поглощения,
Xi (Xj V х2) = X] )
XiX2 V ххх2 = Xi — правило склеивания,
Х]Х2 V *1 — х2 V — правило вычеркивания.
Их доказательства проводятся на основе эквивалентно-
стей, приведенных раньше:
Xi V Х]Х2 — Xi • 1 V XjX2 = X] (1 V х2) = Xi • 1 = Xi,
Xi (Xi V Х2) == XiX] V Х]Х2 = Xi V Х[Х2 = А'1,
Х]Х2 V ххх2 *= Xi (х2 V х2) = X] • 1 = Xi,
Х]Х2 V хх = xix2 V (Xi V *ix2) = (xix2 V Xix2) V хх = х2 V х,.
При применении указанных правил вместо переменных
Xi и х2 могут подставляться любые формулы.
Применение правил проиллюстрируем на примере ра-
нее рассматривавшейся формулы Ф = (x2->Xi) ((х2 ф
ф 1)х3 ~ х3).
Используя соотношения (1.1) — (1.3), осуществим ее
перевод в базис {0, 1, х, &, V} с одновременным упро-
щением. Имеем
Ф1 = х2->Xi = х2 V Xi,
ф2 = х2 ф 1 = х2 • 1 V х2 • Т = х2,
Ф3 = Ф2х3 ~ х3 = х2х3 ~ х3 = (х2х3) х3 V (х2х3) х3 =
= (х2 V х3) х.з V х2х3 = х3 V х2х3 == х3 V х2,
Ф = Ф,Ф3 = (х2 V *1) (х з V х2) =
== (х2 V Л'1) (х2 V х3) = х2 V Х]Х3
(здесь мы воспользовались свойством дистрибутивно-
сти). Окончательно,
(х2 Xj) ((х2 ф 1) х3 ~ х3) = х2 V Х!Х3.
ЛОГИЧЕСКИЕ ФУНКЦИЙ
[ГЛ. I
§ 1.2. Некоторые специальные представления
логических функций
1.2.1. Разложение по переменным. Пусть х — логи-
ческая переменная. При ое{0, 1} введем обозначение
( х, если о = 1
= <
( х, если о = 0
Легко проверить, что ха — 1 тогда и только тогда, когда
х = о. Следовательно, конъюнкция х°1х°2 ... xakk равна 1
на единственном наборе значений аргументов х1 = о11
х2 = о2, ..., хк = oft.
Следующая теорема позволяет выразить функцию
f(xi, ..., хп) через функции от меньшего числа аргу-
ментов.
Теорема 1.1 (о разложении функций). Всякая ло-
гическая функция ..., хп) при любом k (1 k
п) может быть представлена в виде
f (Xj, • • ., Xfc, Xfc-f-1, . . ., Хп)
= V Ok, Xk+i.....х„), (1.5)
(°i...°а)
где дизъюнкция берется по всевозможным наборам
(01, ..., Ой) значений аргументов хц ..., Xk.
Доказательство. Убедимся, что для любого на-
бора (он, .... ап) значений аргументов левая и правая
части формулы принимают одинаковое значение. Рас-
смотрим правую часть. Поскольку af1 ... = 0 при (сть
.. •, сгА) #= («1» at) и «°1 ... akk = 1, то
V «;... ....ofe, а .... а„) =
(°!..
= < ...а“^(ар ..., ak, ak+l, .... a„) = f(«P , %).
Эта величина совпадает со значением левой части. Тео-
рема доказана.
Указанное представление функции задает разложе-
ние по переменным х1г ..., xk. Его частный случай при
§ 1.2] ПРЕДСТАВЛЕНИЯ ЛОГИЧЕСКИХ ФУНКЦИЙ
33
k = 1 имеет вид
f(xb х2) х„)=хф(^, х2, ..., х„) V xj (0, .х2..Хп)
и носит название формулы разложения по переменной.
Иногда будем использовать векторную запись фор-
мулы (1.5). Набор переменных хь ..., хь обозначим че-
рез х', а набор оставшихся переменных xft+!, ..., х,,—
через х". Для конъюнкции х®1 ... Xkk будем применять
обозначение Кв,(х'), где д' = (о;...о^). Тогда разло-
жение (1.5) может быть переписано в виде
f (х', х") = V Кв, (х') f (д', х") - V Кв, (х') fe, (х"), (1.6)
а' а'
где через fd, (х") обозначена функция f (д', х").
1.2.2. Совершенная дизъюнктивная нормальная фор-
ма. Воспользовавшись теоремой 1.1 при k — n, получаем
представление
f(xi......xn)== V •••>
(°1...М
которое для f(xi, ..., х.,)^0 может быть преобразо-
вано к виду
/ (хр .... х ) = V х11 ... х п.
(°!.....................а«)
(f (а...... а„)=1)
Это представление носит название совершенной дизъ-
юнктивной нормальной формы (с. д. н. ф.). С учетом со-
глашения, что пустая дизъюнкция равна 0, оно может
быть распространено и на функцию, тождественно рав-
ную нулю.
В качестве примера выпишем с. д. н. ф. для функции
f(xi,x2,x3), заданной таблицей 1.1:
f (хр х,, х,) = x?xW V х°х°х* V х!х°х“ V х'х^х’ V x.’xlxl =
I \ 4 * и/ 1 £ О 1*0 1*0 1*0 1*0
= Х1Х2Х3 V Х1Х2х3 V Х]Х2х3 V Х]Х2х3 V XiX2x3.
С.д. н. ф. обладает следующими свойствами:
1° является дизъюнкцией некоторых конъюнкций
Ki V К2 V ... V Ks;
2 А. Шеломов
34
ЛОГИЧЕСКИЕ ФУНКЦИИ
[ГЛ. I
2° каждая из конъюнкций Ki имеет вид
где п — число переменных функции;
3° все конъюнкции Ki (t = 1, s) различны.
Теорема 1.2. Представление логической функции,
обладающее свойствами 1°—3°, определено однозначно
и совпадает с с. д. н. ф. этой функции (однозначность по-
нимается с точностью до перестановки конъюнкций).
Доказательство. Пусть имеется представление
функции f(xi...хп), обладающее свойствами 1°—3°.
Запишем его в виде
’б,.....V » (1.7)
V4’ • *’ п)
где константа са а равна 1 или 0 в зависимости от
того, входит конъюнкция х°* ... х°« в представление или
нет. Подставив в обе части (1.7) произвольный набор
(он, ..., ап) значений аргументов, с учетом того, что
на этом наборе в 1 обращается единственная конъюнк-
а.
ция Xj1 ... хпп, приходим к равенству
Оно показывает, что коэффициенты с01,.,а однозначно
определяются функцией.
На основании этой теоремы можно указать еще один
способ установления эквивалентности формул. Форму-
лы приводятся к с. д. и. ф. и оказываются' эквивалент-
ными тогда и только тогда, когда их с. д. н. ф. совпа-
дают.
Способ приведения формул в базисе {0, 1,х, ~, &, V',
—>, ф, к с. д. н. ф. состоит в следующем. Вначале с
использованием представления операций ф, ~ через
операции ~, & и V осуществляется перевод в базис
{О, 1, х, ~, &, V}. Затем на основе законов де Моргана
формула преобразуется к виду, при котором отрицания
применяются лишь к элементарным переменным х,-. Да-
лее в результате раскрытия скобок с использованием
свойства дистрибутивности х(у V z) = ху V хг получает-
ся выражение вида дизъюнкции некоторых конъюнкций
§ 1.2] ПРЕДСТАВЛЕНИЯ ЛОГИЧЕСКИХ ФУНКЦИЙ
35
СГ/ со о
х 1 ... х, р. (1 считается конъюнкцией пустого множе-
Л ‘р
ства переменных). При этом можно предполагать, что
все переменные х^, ..., х. , входящие в состав одной
конъюнкции, различны, ибо конъюнкция, содержащая
переменную одновременно в формах х, и Xi, равна 0 и
может быть удалена, а если все вхождения перемен-
ной Xi в конъюнкцию одинаковы, то на основе равенства
= они могут быть заменены одним вхожде-
нием. Полученное представление отличается от с. д. н. ф.
лишь тем, что в нем конъюнкции могут иметь длину,
меньшую п (т. е. содержать не все переменные). Для
приведения к с. д. н. ф. каждая конъюнкция хг 1 ... х{ р
домножается на п — р скобок (XjVxj), соответствую-
щих переменным, не входящим в конъюнкцию (напом-
ним, что X/Vx/s 1). С использованием свойства ди-
стрибутивности осуществляется раскрытие скобок и из
множества полученных конъюнкций выбираются все
различные.
В качестве примера рассмотрим формулу (х2->
—>xi) ((х2ф 1)х3 ~ ха). Как мы видели, она эквивалент-
на формуле х2 V Х1Х3, которая может быть преобразо-
вана так:
Х2 (*I V Xj) (Х3 V Х3) V Х]Х3 (х2 V Х2) == Х1Х2Х3 V
V Х1Х2Хз V Х1Х2Х3 V XjX2X3 V Х]Х2Х3 V Х^гХз =
= XiX2X3 V X1X2X3 V *1Х2Хз V X1X2X3 V Х1Х2Х3,
Последнее выражение представляет собой с. д. н. ф.
функции, реализуемой формулой, и совпадает (с точ-
ностью до перестановки конъюнкций) с с. д. н. ф., выпи-
санной выше по таблице 1.1, задающей эту функцию.
1.2.3. Совершенная конъюнктивная нормальная фор-
ма. Всякая функция f(xi, ..., xn)^fe 1 может быть вы-
ражена также в виде конъюнкции некоторых дизъюнк-
ций x^V... Vx*". Для того чтобы получить это пред-
ставление, выпишем с. д. н. ф. функции 7(хь .... хп)^
sfe л-
.....,Д_>
(Н°1...CTn) = 1)
2*
36
ЛОГИЧЕСКИЕ ФУНКЦИИ
(ГЛ. I
Воспользовавшись правилом написания формулы для
отрицания функции и тем,что f = f, получаем
f (xi> • • • > хп) ~ & (%!1V ... V xnn) —
(°Р ап)
(Г(ар .... о„) = 1)
(°1
(f(ar
& I
ап)=°')
Это представление носит название совершенной конъ-
юнктивной нормальной формы (с. к. н. ф.). С учетом со-
глашения о том, что пустая конъюнкция равна 1, оно
распространяется на функцию f(xi, хп), тожде-
ственно равную 1.
Для с. к. н. ф. также имеет место теорема единствен-
ности, которая формулируется аналогично теореме для
с. д. н. ф. Она может быть доказана непосредственно
либона основе теоремы о с. д. н. ф., примененной к функ-
ции f.
В качестве упражнения выпишем с. к. н. ф. функции
f(xi, х2,хз), задаваемой таблицей 1.1,
f (Х], Х2, X3)=(X1VX2VX3)(X1V^VX3)(X1VX2VX3).
1.2.4. Полином Жегалкина. Еще одно важное пред-
ставление логических функций получается с использо-
ванием операций конъюнкции и суммирования по mod 2.
Отметим, что сумма по mod 2 обладает обычными
свойствами: Х1фх2 = х2фх] (коммутативность), xi ф
ф (х2 ф х3) = (xi ф х2) ф х3 (ассоциативность), хДхгф
ф х3) = XjX2 ф XjX3 (дистрибутивность). На основе свой-
ства ассоциативности можно рассматривать многомест-
п
ную операцию х{ = Х]фх2ф ... фхп. Значение этой
1=1
суммы равно 1 тогда и только тогда, когда в наборе зна-
чений переменных xi, х2, ..., хп имеется нечетное число
единиц. Заметим, что если в наборе значений перемен-
ных X], х2, ..., хп присутствует не более одной едини-
П п
цы, то X, совпадает с V Х[.
§ 1.21
ПРЕДСТАВЛЕНИЯ ЛОГИЧЕСКИХ ФУНКЦИИ
37
Рассмотрим теперь произвольную функцию f(xi, ...
хп) 0 и выразим ее посредством с. д. н. ф.:
КХ1........О = , V , Х°'
(°Р ••• ап)
хап
• • лп
На каждом наборе (он, ..., ап) в 1 обращается не бо-
лее одной из конъюнкций х°‘ ... х^, входящих в
с. д. н. ф. Поэтому внешняя дизъюнкция может быть за-
менена суммой по mod 2:
......О = 22 *1‘ •••<"•
(°Р • ап)
(Ц°1..ап)=Ч
Далее, поскольку х° = х = х © 1, х1 = х = х © 0, то ха =
= х®5. Подставив вместо хаА выражение х{®др по-
лучим
f(xb х„) = (Х1ф51) ... (х„фа„).
(’1...М
m.....М"1)
Обычным образом раскрыв скобки и приведя подобные
члены по правилу А © А = 0, придем к представлению
функции в виде полинома по mod 2:
где коэффициенты равны 0 или 1. Пустая конъ-
юнкция считается равной 1, так что коэффициент, со-
ответствующий пустому множеству индексов й, ..., й,
представляет собой свободный член полинома. Указан-
ное представление носит название полинома Жегалкина.
Для функции, тождественно равной нулю, в качестве
полинома берется 0.
Построим полином Жегалкина для функции, задан-
ной таблицей 1.1. Имеем
f (хь х2, х3) = (Х1 ф 1) (х2 ф 1) te ® 1) ©
© (*1 © 1) (х2© 1) Хз® х, (х2© 1) (х3® 1) ©
©Х1 (х2ф 1)х3®Х1Х2Х3.
Для преобразования этого выражения могут быть
использованы обычные приемы элементарной алгебры
38
ЛОГИЧЕСКИЕ ФУНКЦИИ
[ГЛ, I
(специфичным является лишь приведение подобных чле-
нов по правилу А®Л = 0). В частности, применяя
группировку членов и вынесение за скобки, получаем
f (xi, х2, х3) = (х2 ф 1) (х2 ф 1) (х3 © 1 ф х3) ф
(х2ф 1) (х3ф 1 фх3)фх1х2хз =
== (Х1 ф 1) (х2 ф 1) фХ1 (Х2 Ф 1) Фад*3 =
= (х2 ф 1) (Х1 ф 1 ф Х1) ф адхз .= Xjx2x3 ф х2 ф 1.
Теорема 1.3. Всякая логическая функция может
быть представлена в виде полинома Жегалкина един-
ственным образом.
Доказательство. Существование полинома для
любой функции было установлено, докажем единствен-
ность.
Подсчитаем количество полиномов от переменных
Xi, .... Хп. Число различных конъюнкций х{ ... х{ сов-
падает с числом подмножеств множества {1.....п} и
равно 2" (пустому подмножеству соответствует пустая
конъюнкция, равная 1). Полином задается множеством
конъюнкций, входящих в него с коэффициентом 1 (пу-
стому множеству конъюнкций соответствует полином,
равный 0). Число полиномов определяется числом этих
множеств и составляет 2 .
Всякой функции от п аргументов соответствует неко-
торый полином Жегалкина, и разным функциям отве-
чают разные полиномы. Поскольку число функций от п
аргументов совпадает с числом полиномов, то если бы
какая-либо функция имела несколько полиномов, для
некоторых функций полиномов не хватило бы. Теорема
доказана.
Представления, описанные в данном параграфе, иг-
рают важную роль и широко используются в различных
областях, связанных с конструированием дискретных
устройств.
§ 1.3. Полнота систем логических функций
1.3.1. Примеры полных систем. В § 1.1 было введено
понятие формулы над базисом & и функции, реализуе-
мой формулой. Если базис $ обладает тем свойством.
ПОЛНОТА СИСТЕМ ЛОГИЧЕСКИХ ФУНКЦИЙ
39
§ ТЗ]
что любая логическая функция может быть реализова-
на формулой над его будем называть полным, а в
противном случае — неполным.
Мы видели, что произвольная логическая функция,
тождественно не равная 0, представима в виде с. д.н. ф.,
являющейся формулой в базисе {&, V, Поскольку
тождественный нуль может быть реализован как х&х,
то базис {&, V,"} является полным.
Функция V выражается через & и отрицание
XiVx2 = Xj &*2-
Поэтому она может быть устранена и базис {&, также
оказывается полным. Аналогично, из соотношения
X] & х2 = Xi V х2
вытекает полнота базиса {V,-}.
Полным является и базис, состоящий из одной функ-
ции
Xi |x2 = Xj Vx2,
называемой штрихом Шеффера. Действительно, в этом
базисе могут быть выражены отрицание
х = xVх = х |х
и конъюкция
Xi & х2 = X] V х2 = (М I х2) = (xj | х2) I (х 11 х2),
после чего остается сослаться на полноту базиса {&, -}.
Аналогично можно доказать полноту базиса, состоящего
из одной функции .
Xj f Х2 = Х,$ х2,
носящей название стрелки Пирса.
Еще один пример полного базиса можно привести на
основе представления в виде полинома Жегалкина. Это
базис {&, ф, 0, 1}. Поскольку 0 = 1 ®1, то базис
{&, ®, 1} также полон. В то же время, как будет следо-
вать из дальнейшего, «близкий» к нему базис {&, ф, 0}
уже полным не является. Содержание данного парагра-
фа составляет выяснение условий, необходимых и до-
статочных для полноты базиса.
1.3.2. Замкнутые классы. Пусть имеются логические
функции g(yi, ..., у к) и fi, ..., fk. Будем считать, что
функции fi, ..., fk зависят от одних и тех же аргумен-
40
ЛОГИЧЕСКИЕ ФУНКЦИИ
[ГЛ. I
тов хь .... хп (этого можно достигнуть, добавив, при
необходимости, к аргументам некоторых из функций
фиктивные аргументы). Функцию
А (хь .. •, хп) = g (fi (xb ..., хп), . .., f k (хь .. ., х„))
(1.8)
будем называть суперпозицией функций g и fi, fk-
Рассмотрим некоторый класс А готических функций.
Класс А назовем замкнутым, если для всяких функций
g(y!t • , Уь) и ..., fk из А йк суперпозиция g(fi, ...
..., fk) содержится в А:' Приведем некоторые важные
примеры замкнутых классов.
Класс То сохранения нуля. Он содержит все
логические функции f(xb .... хп) такие, что f(0, ...
..., 0) = 0. Класс То включает, например, функции 0,
X, Xi & Х2, Xi V Х2, X] ф Х2, а фуНКЦИИ 1, X, X] —> Х2, X] ~ х2
ему не принадлежат. Для доказательства замкнутости
рассмотрим суперпозицию (1.8) функций g и fi, ..., fk
из То. Поскольку
h(0....O) = g(fi(0....0), .... fk(0, .... 0)) =
= g(0, ..., 0) = о,
то h содержится в Тй. -
Класс Ti сохранения единицы. Он состоит
из всех логических функций f(x\, ..., хп) таких, что
f(l....1) = 1. Класс Тг включает, например, функции
1, х, X! & хг, Xi V хг, Xi —> х2, X] ~ х2 и не содержит функ-
ций 0, х, Xi ф хг. Замкнутость класса Ti устанавливает-
ся аналогично замкнутости То.
Класс S самодвойственных функций.
Двойственной к логической функции f(xi..хп) назы-
вается функция
Г(хЬ .... x„)==f (хь ..., х„).
Легко видеть, что (/*)* = f. Если функция f задана фор-
мулой в базисе {0, 1, х, V}, то из приведенного в
§ 1.1 способа написания формулы для функции f выте-
кает следующее правило. Для того чтобы получить фор-
мулу, реализующую функцию f*, достаточно заменить
все операции V на &, все операции & на V, а все кон-
станты— противоположными константами. Отсюда, в
§ 1.3]
ПОЛНОТА СИСТЕМ ЛОГИЧЕСКИХ ФУИКЦИП
41
частности, следует, что функции х\ & х2 и Xi V х2 двой-
ственны друг другу, а каждая из функций х и х двой-
ственна себе.
Функцию f(x\, хп) назовем самодвойственной,
если
f(Xi, .... xn) = f*(xi, .хп).
Взяв отрицание от обеих частей и воспользовавшись оп-
ределением двойственности, получаем следующее свой-
ство самодвойственных функций:
f .......Xn) = f(xi....хп). (1.9)
Примером самодвойственной функции является xjx2 V
V Х[Х3 V х2х3. Действительно, согласно приведенному
выше правилу
(xix2VxiX3Vx2x3)‘ = (x1Vx2) (х[ Vx3) (x2Vx3) =
= (Xi V х2х3) (х2 V Х3) — Х]Х2 V Х[Х3 V х2х3.
Самодвойственность функции легко устанавливается
по ее таблице: столбец значений функции обладает тем
свойством, что значения, равностоящие от его середины,
Таблица 1.4
Х1 Х1 х3
х:х, V хзхз V Х2Х1
ООО
О 0 1
О 1 о
О 1 1
1 о о
1 0 1
1 1 о
1 1 1
о
о
о
1
о
1
1
1
противоположны (см. табл. 1.4, задающую функцию
Xjx2 V Xjx3 V х2х3).
Для доказательства замкнутости класса S само-
двойственных функций рассмотрим суперпозицию (1.8)
42
ЛОГИЧЕСКИЕ ФУНКЦИИ
[ГЛ. I
функций из S. С учетом (1.9) имеем
А*(хь ..х„) =
= h (хь . . ., Х„) = g (fl (xb ..., х„), ..., fk (Xj.x„)) =
= g(f\(Xi....X„), .... fk(Xi, xn)) =
= g(fi(xi, •••> Xn), fk(xi, ..., x„)) = A(xb ...,x„)
и, следовательно, h принадлежит S.
Класс M монотонных функций. Будем гово-
рить, что двоичный набор й = (аь ..., а„) предшествует
двоичному набору Р = (Pi, ..., Р«), и записывать
^р, если имеют место покомпонентные неравенства
«1 Рь • • •, «п р«. Легко видеть, что предшествова-
ние является отношением частичного порядка.
Логическую функцию f(x) = f(xi, ..., хп) будем на-
зывать монотонной, если для любых двух наборов й и
Р таких, что а^р, выполнено f(a)^f(P). Класс всех
монотонных функций обозначим через М. Он содержит,
в частности, функции 0, 1, х, xi&x2, Xi V х2, а функции
х, Xi ->-х2, Xi ф х2, Xj ~ х2 ему не принадлежат.
Рассмотрим суперпозицию (1.8) монотонных функ-
ций g и fb ..., fk. Пусть й и р — произвольные двоич-
ные наборы длины п такие, что й^р. Положим ц, =
= fi(a), Vi = f;(p) (i=l, ...,fe) и Й=(Ц1.......gft),
v=(vb ..., Vk). Из монотонности функций fi вытекает,
что ц/ vi и, следовательно, jl ^ v. С учетом этого и
монотонности функции g получаем
А(й) = ^(Ь(й), ..., fft(a)) = g(j!Xg(v) =
= g(fi(P), .... ffe(P)) = A(P).
Итак, h^M и замкнутость класса М установлена.
Достаточно простой метод распознавания монотон-
ности будет изложен в § 2.4.
Класс L линейных функций. Всякая логиче-
ская функция может быть единственным образом пред-
ставлена в виде полинома Жегалкина. Функции, для ко-
торых полином Жегалкина имеет степень не выше пер-
вой (т. е. содержит конъюнкции длины не более 1), на-
зываются линейными. Класс L всех линейных функций
содержит, в частности, функции 0, 1, х, х = х ф 1, X] ®
§ 1.3] ПОЛНОТА СИСТЕМ ЛОГИЧЕСКИХ ФУНКЦИЙ 43
фх2, X] ~ Х2 = X] ф Х2 ф 1, а функции X\&X2 = XiX2,
xi V х2 = %1Х2 Ф Х1 ф х2, х1-^-х2 = xix2 ф xi ф 1 ему не
принадлежат.
Всякая линейная функция может быть записана в
виде
....х„) = аофа1х1фа2Х2Ф ••• ®anxn,
где а, е {0, 1} (i = 0, 1, ..., п). Легко видеть, что коэф-
фициенты а, (( = 0,1, ..., п) связаны со значениями
функции следующим образом:
ao = f(O, 0, .... 0),
«! = f(0, 0, ..., 0)ф/(1, 0, .... 0),
а2 = /(0, 0, .... 0)фН0, 1...' 0),
a„ = f(O, 0, ..., 0)ф/(0, 0, ..., 1).
На основе этого может быть предложен следующий спо-
соб распознавания линейности. По приведенным форму-
лам нужно вычислить коэффициенты ао, аь ..., ап- Если
функция реализуется полиномом а0 ф щ.Г1 ф ... ф апхп,
то она линейна, а в противном случае — нелинейна.
Замкнутость класса линейных функций вытекает из
того, что суперпозиция полиномов не выше первой сте-
пени снова дает полином не выше первой степени.
Помимо приведенных 5 замкнутых классов сущест-
вуют и другие. Это следует, например, из того, что пе-
ресечение замкнутых классов снова образует замкнутый
класс. Но, как мы увидим дальше, классы То, Т\, S, М
и L играют решающую роль в вопросах полноты.
1.3.3. Критерий полноты. Докажем вначале некото-
рые вспомогательные утверждения.
1°. Из всякой несамодвойственной функции f(xlt ...
..., хп) путем подстановки функций х и х можно полу-
чить одну из констант. Действительно, из несамодвой-
ственности f следует, что существует набор (ab ..., аД
для которого f(ai, ..., an)=f(ai, ..., dn). Положим
g(x) = f(xa‘...xa«), тогда
g(0) = f(0\ ..., Oa«) = f(ab ..., a„) = f(ab ..., a„) =
= f(la‘.... l“n) = g(l).
и, следовательно, g(x) совпадает с одной из констант.
44
ЛОГИЧЕСКИЕ ФУНКЦИИ
[ГЛ. I
2°. Из всякой немонотонной функции ((хц, .... хп)
путем подстановки констант Oulu функции х можно
получить функцию х. Для немонотонной функции f най-
дутся наборы аир такие, что а^р и Да)> ДР). Об-
разуем функцию §(*)> подставив в Дхь ..., х„) на ме-
сто тех переменных, которым соответствуют одинаковые
разряды наборов аир, значения соответствующих раз-
рядов, а на место остальных переменных — функцию х.
С учетом условия а^Р заключаем, что
^(O) = f(a)>f(P) = g(l).
Последнее означает, что g'(0)= 1 и g-(l)= 0. Таким об-
разом, g'(x) совпадает с х.
3°. Из всякой нелинейной функции Дхь ..., хп) пу-
тем подстановки констант можно получить нелинейную
функцию двух аргументов. Для доказательства рассмот-
рим полином Жегалкина p(xi, ..., хп), реализующий
функцию f(xi, ..., хп). В силу нелинейности в нем най-
дется член, содержащий не менее двух множителей (без
ограничения общности можно считать, что среди мно-
жителей есть xi и х2). Путем вынесения за скобки пре-
образуем полином к виду
p(xt....xn) = xlx2pi(x3, ..., xn)©xip2(x3..х„)ф
ф Х2Рз (х3, xn)®Pi (х3, ..., х„).
Поскольку полином pi (хз, ..,, хп) имеет вид, отлич-
ный от 0, он реализует функцию, не являющуюся тож-
дественным нулем (в силу единственности полинома).
Поэтому найдется набор констант аз, • , ап, для ко-
торых pi(a3, ..., ап) = 1. Функция
(р(Х[, x2) = f(xi, х2, а3.а„) = х1х2-1ф
ф^1Рг(аз....«п)фх2р3(аз....а„)фр4(а3> • ••, а„) =
= Х1Х2фаХ]фРх2фу
является нелинейной.
Сформулируем и докажем основной результат.
Теорема 1.4 (о функциональной полноте). Базис
$ является полным тогда и только тогда, когда он це-
ликом не содержится ни в одном из пяти замкнутых
классов То, Ti, S, А4 и L.
§ 1.3]
ПОЛНОТА СИСТЕМ ЛОГИЧЕСКИХ ФУНКЦИИ
45
Доказательство. Если базис целиком при-
надлежит одному из перечисленных классов, то в силу
того, что классы замкнуты и содержат тождественные
функции Xi, формулами над & могут быть реализованы
лишь функции из данного класса. Но ни один из этих
классов не содержит всех логических функций. Следо-
вательно, базис $ неполон.
Докажем теперь, что базис 28, целиком не содержа-
щийся ни в одном из классов То, Т\, S, М, L, является
полным.
Установим вначале, что формулами над 22 могут
быть реализованы константы Он 1. В базисе 3? имеется
функция g, не сохраняющая 0, т. е. такая, что ^(О, 0, ...
..., 0) = 1. Вычислим ее значение на наборе из единиц.
а) Если окажется, что g(l, ..., 1) = 1, то функция
<р(х) = g(x, х) является константой 1 (ибо ср(О) =
= g(0 0)=1, <р(1)= g(l, ..., 1)= 1). Вторую
константу получим, взяв в Я функцию, не сохраняющую
1, и подставив вместо ее аргументов функцию 1 = ср(х).
б) Если g(l, ..., 1) = 0, то функция cp(x) = g(x, ...
х) совпадает с х (ибо ср(0) = g(0, ..., 0)= 1,
<р( 1) = g(l, ..., 1) = 0). С помощью х и содержащейся
в 2S несамодвойственной функции на основании вспомо-
гательного утверждения Г получим одну из констант.
Из нее с использованием х образуем вторую константу.
Тем самым возможность реализации констант уста-
новлена.
Имея константы, на основе вспомогательных утверж-
дений 2° и 3° из немонотонной функции получим х, а из
Нелинейной функции — нелинейную функцию двух ар-
гументов
ф(хь х2) = Х1Х2фах[фРх2фу-
Преобразуем последнюю:
Ф(хр х2) = (х1фР)(х2фа)ф(аЗфу) = хРх“ф(а₽фу).
Подставив вместо х, и х2 функции yf и z/“ (отрицание
у нас есть), получшм функцию yiy2, если сф ф у = 0, либо
функцию у\у2 ф 1 = у[ V у2, если оф фу == 1. Полнота
базиса & вытекает в первом случае из полноты системы
{&,“}, а во втором — из полноты штриха Шеффера.
46
ЛОГИЧЕСКИЕ ФУНКЦИИ
[ГЛ. 1
Отметим, что доказательство теоремы о полноте яв-
ляется конструктивным. Если заданы полный базис &
и некоторая логическая функция, то, исходя из ее пред-
ставления в виде с. д. н. ф. и промоделировав доказа-
тельство, можно построить формулу над Я, реализую-
щую эту функцию.
§ 1.4. Представление о функциях
&-значной логики
1.4.1. Задание функций. Для описания дискретных
устройств наряду с булевыми функциями применяются
такие, у которых аргументы и сами функции принимают
значения из некоторого множества, содержащего более
2 элементов. Если это множество содержит /г элементов,
то без ограничения общности можно считать, что его
элементами являются 0, 1, ..., k—1. Функция, прини-
мающая значения из множества {0, 1, .... k—1}, аргу-
менты которой также принимают значения из этого мно-
жества, называется функцией k-значной логики (буле-
вы функции часто называют функциями двузначной ло-
гики). Такая функция f(xb ..., хп) может быть задана
Таблица 1.5
XI хп-1 хп f (Х1>. . <xn-v xn)
0 . . 0 0 f(o,. . . ,0,0)
0 . . 0 1 f(o,. . .,0,1)
0 . . 0 k-\ НО,. . . 0Л-1)
0 . . 1 0 f(o,. . .,1,0)
k-\ . . . k-\ k— 1 f (fe-1,.
таблицей, где в некотором порядке перечислены все
fe-ичные наборы длины п (из элементов 0,1....k— 1)
и на каждом из них указано значение функции (см.
табл. 1.5).
Число &-ичных наборов длины п равно kn и на каж-
дом из них значение функции можно задать k спосо-
§ 1.4]
ФУНКЦИИ &-ЗНАЧНОЙ ЛОГИКИ
47
бами. Поэтому число функций &-значной логики, завися-
щих от аргументов хь ..., х„, составляет kkn.
Как и в двузначном случае, выделяется ряд элемен-
тарных функций. Приведем некоторые из них:
min(xb х2) —обобщение конъюнкции,
max(xb х2) — обобщение дизъюнкции,
Xi + х2 (mod k) — обобщение суммы по mod 2
(значение этой функции равно остатку от деления сум-
мы Xi + х2 на k),
х = х + 1 (mod k) — обобщение отрицания в смысле
«циклического сдвига» значений,
А/х = & — 1— х^ —обобщение отрицания в смысле
«зеркального отражения» значений.
Кроме того, к элементарным относятся следующие
функций одного аргумента:
k
( k- 1
^0 (х) । Q
при х = о,
при х#=о
(а = 0, 1, .... k- 1).
Аналогично двузначному случаю для произвольной
системы функций &-значной логики (базиса) & вводится
понятие формулы над & и с каждой формулой связы-
вается реализуемая ей функция. В частности, можно
рассматривать формулы в базисе, состоящем из элемен-
тарных функций.
Для функций min(xi,x2) и max(xbx2) также исполь-
зуются обозначения xi&x2 и хг V х2. В целях сокраще-
ния формул часто употребляются функции & и V от
произвольного числа аргументов:
п
& Х{ = Х]& ... &x„ = tnin(xb х„),
i=i
п
V xt = X] V ... V хп = max (хь ..., х,г).
i=i
Для функций &-значной логики имеет место представ-
ление, являющееся аналогом с.д. н.ф.:
f (^i > •••» хп)==
= V Jai(x{)& ... &Ja n(xn)&f (щ, ..., <jn). (1.10)
(а1.°п)
Его справедливость устанавливается прямой проверкой.
48
ДИСКРЕТНЫЕ УСТРОЙСТВА БЕЗ ПАМЯТИ
[ГЛ. II
1.4.2. Вопросы полноты. Базис Я называется полным,
если формулами над Я реализуются все функции
й-значиой логики. Из представления (1.10) следует, что
множество функций
{0, 1...k- 1, /0(х),
Л(х), ..., 7fe_i (х), min(xi, х2), max(xb х2)}
образует полную систему. При любом k 2 имеются
полные базисы из одной функции. Таким, в частности,
является базис, состоящий из функции Вебба:
Vk (xi, х2) = max (xb х2) + 1 (mod k)
(этот факт сообщаем без доказательства). При k — 2
функция Вебба совпадает со стрелкой Пирса, ибо
Л'1 t х2 — X] & х2 = (Х[ V х2)ф 1.
Приведем также без доказательства теорему о функ-
циональной полноте для й-значного случая.
Теорема 1.5 (А. В. Кузнецов). При любом k^2
можно построить такую конечную систему А2, ...
..., AS(k) замкнутых классов функций k-значной логики,
что базис & полон тогда и только тогда, когда он це-
ликом не содержится ни в одном из этих классов.
Определение замкнутого класса дается так же, как
и в двузначном случае. Отметим, что число s(k), уча-
ствующее в формулировке теоремы, быстро растет с
ростом k.
Доказательства фактов, приведенных в данном па-
раграфе, и некоторые дальнейшие результаты содержат-
ся в [11] (раздел 1).
Изложенный выше математический аппарат дает
удобные средства для описания дискретных устройств.
Глава II
ДИСКРЕТНЫЕ УСТРОЙСТВА БЕЗ ПАМЯТИ
§ 2.1. Схемы из логических элементов
2.1.1. Дискретные устройства без памяти. Будем рас-
сматривать устройства дискретного действия (рис. 2.1),
имеющие некоторое количество входов и выходов, обо-
§ 2.1J
СХЕМЫ ИЗ ЛОГИЧЕСКИХ ЭЛЕМЕНТОВ
4Э
значаемых соответственно через хг, ..., хп и у <, , ут-
Будем считать, что сигналы, поступающие на входы и
снимаемые с выходов устройства, имеют несколько раз-
личимых уровней*), которые будем обозначать посред-
ством символов некоторого конечного алфавита. Как
правило, будем рассматривать случай двух уровней, ко-
торым будем сопоставлять символы 0 и 1. Последова-
тельности сигналов поступают на входы в некоторые
дискретные моменты времени и вызывают на его выхо-
дах последовательности ответных сигналов. Отвлекаясь
от реальной шкалы времени (и пренебрегая задержкой
срабатывания устройства), будем считать, что сигналы
подаются на входы и снимаются с
выходов в некоторые условные мо- я?; х2 хп
менты t = 0, 1, 2, ... В общем слу- f ? " * Т
чае значения выходов зависят не —।‘1—
только от входных сигналов, подан-
ных в тот же момент, но и от сигна-
лов, поступивших ранее. Влияние
предшествующих сигналов учиты- ___________________
вается путем изменения внутренне- I I I
го состояния устройства. Таким об- У У У? • • • Ут'
разом, значения выходов опреде- рис
ляются значениями входов в тот же
момент и внутренним состоянием.
Число состояний характеризует «память» устрой-
ства. В частности, если устройство может находиться
лишь в одном фиксированном состоянии, то значения
его выходов не зависят от предыстории и однозначно
определяются значениями входов. Такое устройство па-
мятью не обладает.
Если входным и выходным алфавитами устройства
без памяти являются {0, 1}, то оно реализует на своих
выходах систему логических функций
£/i = fi (xi, хп),
Ут •••>
*) См. примечание на стр. 10.
50
ДИСКРЕТНЫЕ УСТРОЙСТВА БЕЗ ПАМЯТИ
[ГЛ. II
а при большей значности k алфавитов — систему функ-
ций й-значной логики.
Примером устройства без памяти может служить
«-разрядный двоичный сумматор параллельного действия.
Он имеет 2/1 входов хр ..., хп, х\, ..., х'п и п + 1 вы-
ходов у\ уп+\. При подаче на его входы двоичных
чисел (хп ... Xi) и (х' ... х£) на выходе выдается дво-
ичная запись их суммы (уп+\уп ... у\).
Для того чтобы описать работу сумматора с по-
мощью логических функций, воспользуемся обычным ал-
горитмом сложения «столбиком»:
Хп . . . Х2Х]
+ х'„ ... х'9х'
____п_____2 1
Уп+1Уп • • У2У1
Введем вспомогательные величины w, (1=1.........п),
указывающие значение переноса из i-го разряда в (i +
+ 1)-й. С их помощью разряды суммы выражаются сле-
дующим образом:
У^х.фх'фда^! (1 = 1............п+0 (2.1)
(при этом считается, что wo = 0, xrt+I = х'+1 = 0). Пере-
нос в (/’+1)-й разряд равен 1 тогда и только тогда,
когда среди величин х£, хг и не менее чем две рав-
ны 1. Это условие выражается логической формулой
(см. табл. 1.4)
wt = xtx'{ V x.wf_j V х£оь_Р (2.2)
Исходя из (2.1) и (2.2), может быть найдена и явная
зависимость разрядов суммы от разрядов слагаемых.
2.1.2. Схемы из логических элементов. В качестве
основного случая мы будем рассматривать устройства
без памяти, имеющие двоичные входы и выходы. Физи-
ческая реализация устройств обычно осуществляется
путем соединения некоторого набора элементарных ком-
понент. В качестве таких компонент мы будем рассмат-
ривать логические элементы. Если отвлечься от физиче-
ской природы элементов, то можно считать, что каждый
из них представляет собой объект с некоторым числом
входов (входы занумерованы) и одним выходом. На вы-
§ 2.1]
СХЕМЫ ИЗ ЛОГИЧЕСКИХ ЭЛЕМЕНТОВ
51
ходе элемента реализуется булева функция от его вхо-
дов. Элемент Е будем изображать схематически в виде,
показанном на рис. 2.2, а. Функцию, реализуемую эле-
ментом Е, будем обозначать
Пусть задан некоторый конечный набор элементов
<S = {Ei,E2, ..., Ek}. Этот набор будем называть ба-
зисом, а входящие в него элементы —
базисными. Из базисных элементов по / 2 и
определенным правилам строятся схемы II "I
(над «?)• Помимо элементов схемы со- ХЬ
держат входные полюсы, которые будем \/ °
изображать маленькими кружками сП
приписанной им переменной (рис. 2.2,6). $1
Дадим определение схемы по индук-
ции. (попутно определяется вспомога- Рис- 2-2,
тельное понятие вершины/схемы):
— совокупность полюсов, соответствующих различ-
ным переменным, есть схема, все полюсы являются ее
вершинами (рис. 2.3, а);
Рис. 2.3.
— результат присоединения к вершинам схемы всех
входов некоторого базисного элемента Е есть схема
(к одной вершине может присоединяться несколько
входов), вершинами новой схемы являются все вершины
исходной схемы и выход присоединенного элемента
(рис. 2.3,6).
Каждой вершине схемы может быть сопоставлена
функция следующим образом:
52
ДИСКРЕТНЫЕ УСТРОЙСТВА БЕЗ ПАМЯТИ
[ГЛ. II
— входному полюсу приписывается функция, равная
переменной, сопоставленной этому полюсу;
— если всем вершинам, к которым присоединены
входы элемента Е, уже приписаны функции, причем вер-
шине, к которой подсоединен i-й вход элемента Е, при-
писана функция fi, a <Pe(z/i.ys) является функцией
элемента Е, то выходу элемента Е приписывается функ-
ция CpE(fl, . . fs).
На рис. 2.4 представлен процесс последовательного
построения схемы с одновременным указанием функций,
приписанных ее вершинам (элементы обозначаются так
же, как и реализуемые ими функции).
В схеме выделяется некоторое количество вершин,
называемых выходами, и считается, что схема реали-
зует систему булевых функций, приписанных ее выхо-
дам. Базис S называется полным, если схемами над S
может быть реализована любая булева функция (и, сле-
довательно, любая система булевых функций).
Хотя понятия формулы и схемы различаются, усло-
вия полноты в обоих случаях формулируются одина-
ково. Действительно, если функция реализуется некото-
рой формулой над базисом, образованным функциями
элементов из <3*, то на основе этой формулы естествен-
ным образом может быть построена схема над S. Об-
ратно, по произвольной схеме над S в соответствии с
правилом приписывания функций вершинам могут быть
указаны формулы для функций всех вершин схемы и, в
частности, для ее выходов. Таким образом, условия пол-
ноты базиса <5 также задаются теоремой 1.4.
2.1.3. Задачи анализа и синтеза схем. В связи с вве-
денным понятием схемы возникают задачи анализа и
синтеза. Под анализом понимается нахождение функ-
ций, реализуемых заданной схемой, под синтезом — по-
строение схемы, реализующей заданную систему функ-
ций. Решение задачи анализа было указано выше (см.
пример на рис. 2.4). Если к схеме не предъявлять ника-
ких дополнительных требований, то задача синтеза мо-
жет быть решена просто. Достаточно, промоделировав
доказательство теоремы о полноте (базис <S считается
полным), найти формулы для всех функций, подлежа-
щих реализации, а затем по этим формулам построить
схему. Однако обычно ставится условие построения
§ 2.1]
СХЕМЫ ИЗ ЛОГИЧЕСКИХ ЭЛЕМЕНТОВ
53
Рис. 2.4.
54
ДИСКРЕТНЫЕ УСТРОЙСТВА ВЕЗ ПАМЯТИ
[ГЛ. й
схем, являющихся наиболее «простыми» (наиболее «де-
шевыми»), и это затрудняет решение задачи.
Под сложностью схемы S будем понимать число вхо-
дящих в нее элементов; эту величину будем обозначать
через L(S) (дальше мы встретимся и с некоторыми дру-
гими понятиями сложности схем). Сложностью системы
булевых функций F назовем минимальную из сложно-
стей схем, реализующих F, эту величину обозначим че-
рез L(F). Схему, на которой достигается значение L(F),
будем называть минимальной (таких схем может быть
несколько).
Существует тривиальный способ построения мини-
мальных схем, состоящий в следующем. Последователь-
но перебираются все схемы, состоящие лишь из полюсов
(состав полюсов определяется переменными, от которых
зависят функции системы F), затем перебираются все
схемы в заданном базисе, содержащие 1 элемент, со-
держащие 2 элемента и т. д. Для каждой из схем про-
веряется, реализует ли она при некоторой фиксации вы-
ходов заданную систему F. Первая из встреченных схем,
для которой ответ утвердителен, является минимальной.
Этот метод нахождения минимальной схемы очень тру-
доемок и в практически интересных случаях не может
быть реализован даже при использовании ЦВМ. Однако
существенно более простого способа до сих пор не най-
дено, и имеется гипотеза, что простых методов мини-
мального синтеза не существует. Некоторые соображе-
ния в пользу гипотезы приведены в § 5.5.
В связи со сказанным к алгоритмам синтеза обычно
предъявляют более слабые требования. Часто требует-
ся лишь, чтобы они давали «практически хорошие» схе-
мы. Качество таких алгоритмов проверяется статистиче-
ски на некотором потоке задач. При другом подходе
ищутся наилучшие схемы в некотором ограниченном
классе схем сравнительно простой структуры (этот под-
ход применим при достаточно малом числе аргументов).
Еще одна постановка (асимптотическая) связана с по-
строением схем, которые для абсолютного большинства
систем функций от большого числа аргументов близки
к наилучшим. Подробнее об этих подходах будет ска-
зано в следующих параграфах.
§ 2.1]
СХЕМЫ ИЗ ЛОГИЧЕСКИХ ЭЛЕМЕНТОВ
55
При реализации устройств одни базисы S могут ока-
заться более удобными, чем другие. Так, для построе-
ния двоичного сумматора, как мы видели, удобно ис-
пользовать функции Xi ф Х2 ф Х3 И X1%2 V Х1Х3 V х2*з-
Однако замена одного полного базиса другим может из-
менить сложность устройств не более чем в константу
раз (зависящую лишь от базисов). Это вытекает из
того, что функция каждого элемента одного базиса мо-
жет быть реализована некоторой схемой (блоком) в
другом базисе. Преобразование схемы из одного базиса
в другой может быть осуществлено путем замены каж-
дого элемента соответствующим блоком (при этом слож-
ность возрастает не более чем в константу раз, опреде-
ляемую максимальной из сложностей блоков). Из ска-
занного следует, в частности, что сложности минималь-
ных схем в разных базисах раз-
личаются не более чем в кон- .
станту раз. Ф-Л Ф-Л фА
В дальнейшем, как правило, \/ \/
будут рассматриваться схемы в I I Т
простейшем базисе So, состоя-
щем из двухвходовых элементов, Рис" 2-5,
реализующих функции & и V, и
одновходового элемента, реализующего отрицание
(рис. 2.5).
2.1.4. Устройства с недоопределенными условиями
работы. В реальном устройстве наборы значений пере-
менных соответствуют состояниям некоторых физиче-
ских величин. Часто эти значения бывают согласован-
ными, и поэтому в процессе функционирования устрой-
ства некоторые наборы никогда не встречаются. То, как
ведет себя устройство в этих случаях, оказывается не-
существенным. Работа таких устройств описывается
частичными булевыми функциями, т. е. двоичными функ-
циями, определенными не на всех двоичных наборах
заданной длины. Частичные функции могут возникнуть
и при синтезе всюду определенных устройств. Если, на-
пример, выходная функция устройства представлена в
виде fif2 и функция fi уже реализована, то значения
функции f2 на тех наборах, где f\ = 0, могут выбираться
произвольно.
56
ДИСКРЕТНЫЕ УСТРОЙСТВА ВЕЗ ПАМЯТИ
1ГЛ II
Частичная булева функция может быть задана таб-
лицей, в которой перечислены все наборы из области
ее определения и указаны значения функции на каждом
из них. Часто используется задание в виде двух таблиц,
в одной из которых перечислены наборы, на которых
функция равна 1, а в другой — наборы с нулевым значе-
нием функции.
Отметим, что частичные булевы функции, описываю-
щие работу устройств и заданные посредством таблиц,
обычно бывают слабо определенными, ибо иначе выпи-
сать таблицу функции от достаточно большого числа
аргументов не представляется возможным (например,
число двоичных наборов длины 20 превышает миллион).
Доопределением частичной булевой функции / назы-
вается всякая (всюду определенная) булева функция,
совпадающая с f там, где значения f заданы. Доопреде-
лением системы F — {fi, ..., fm} частичных булевых
функций называется система, полученная заменой каж-
дой функции ft (z=l, ..., т) некоторым ее доопреде-
лением. Считается, что схема реализует систему F, если
она реализует какое-либо ее доопределение. Для систем
частичных функций также ставится задача построения
схем наименьшей сложности. На этот случай переносит-
ся все сказанное о трудности построения минимальных
схем и об ослаблении требований к методам синтеза.
В заключение отметим, что дальше мы будем зани-
маться реализацией отдельных функций (а не систем из
нескольких функций). Некоторые из описанных методов
распространяются на случай систем.
§ 2.2. Синтез схем на основе формул
2.2.1. Схемы без ветвлений. Можно выделить класс
схем, которые адекватно описываются формулами. Адек-
ватность понимается в том смысле, что между всеми
элементами Е схемы и всеми функциональными симво-
лами фе, входящими в соответствующую формулу, мож-
но установить взаимно однозначное соответствие. В ре-
зультате синтез схем такого вида с малым числом эле-
ментов сводится к построению формул с малым числом
функциональных символов. Возможность применения
аналитических методов для решения последней задачи
§ 2.2]
СИНТЕЗ СХЕМ ПЛ ОСНОВЕ ФОРМУЛ
57
создает определенные удобства, поэтому на практике
наиболее часто используются методы, связанные с по-
строением формул.
Формулами описываются так называемые схемы без
ветвлений, т. е. схемы, в которых выход каждого эле-
мента используется не более одного раза (к нему под-
соединено не более одного входа не более чем одного
элемента схемы). В качестве примера рассмотрим схе-
му без ветвлений, показанную на рис. 2.6, а. Она описы-
вается формулой
ФдДфд.^Р О’ Ф£,(*2> О’ О’
в которой каждому элементу схемы соответствует ровно
один функциональный символ. В то же время схема,
изображенная на рис. 2.6, б, имеет ветвление и описы-
вается формулой
Фд2(фд,(хР О> Фе,(*р О’ О’
где элементу схемы соответствуют два функциональ-
ных символа. Схема, представленная на рис. 2.6, в, опи-
сывается формулой
Ф£,(Ф/?2(Фд,(*р О’ Фд.(хр ОУ Фд/фд^и О’ЧеХх1’ ОУ)-
Отсюда видно, что число вхождений в формулу симво-
лов, соответствующих одному элементу схемы, может
быстро расти с ростом количества ветвлений.
58
ДИСКРЕТНЫЕ УСТРОЙСТВА БЕЗ ПАМЯТИ
[ГЛ. II
2.2.2. Связь сложности схем и сложности формул
в базисе {&, V, ~}. Будем рассматривать схемы без
ветвлений в базисе So — {&, V, -} (см. рис. 2.5). При
изучении таких схем удобно считать, что в них наряду
с полюсами, соответствующими переменным xi, ..., хп,
могут присутствовать полюсы, соответствующие инвер-
сиям xi, ...., хп (рис. 2.7, а). Если бы полюсы с отри-
цаниями переменных не допускались, то (см. рис. 2.7, б)
понадобилось бы еще не более п дополнительных инвер-
торов (элементов отрицания). Под сложностью схемы S
(рис. 2.7, а) будем понимать число входящих в нее эле-
ментов. Эту величину будем обозначать через L' (S)
Рис. 2.7.
(в отличие от величины L(S), относящейся к схемам,
где полюсов с инверсиями переменных нет).
Рассмотрим произвольную формулу в базисе {&, V,-}.
Применением законов де Моргана можно добиться
того, чтобы отрицания относились лишь к элементар-
ным переменным. Поскольку при использовании зако-
нов де Моргана общее количество операций & и V не
изменяется, такое преобразование сохраняет суммарное
число символов & и V в формуле. Схема, построенная
по преобразованной формуле, содержит лишь элементы
& и V, и ее сложность не превосходит сложности схе-
мы, соответствующей исходной формуле. В качестве
примера рассмотрим формулу Xj V (х2х3 V х2х3). С по-
мощью законов де Моргана она преобразуется к виду
xi V (х2х3) (х2х3) = xi V (х2 V х3) (х2 V х3).
§ 2.2]
СИНТЕЗ СХЕМ НА ОСНОВЕ ФОРМУЛ
59
Схемы, соответствующие исходной и преобразованной
формулам, показаны соответственно на рис. 2.8, а и 2.8, б.
На основе сказанного будем рассматривать форму-
лы, в которых отрицания применяются лишь к элемен-
тарным переменным. Для таких формул Ф имеется
простая зависимость между числом /(Ф) вхождений
переменных в формулу и сложностью L'(S®) построен-
ной по ней схемы So :
Г(5ф) = /(Ф)-1. (2.3)
Доказательство этого равенства проведем индукцией по
числу т символов операций & и V в формуле Ф.
Пусть т = 0. Тогда формула Ф имеет вид х°. При
этом I (Ф) = 1, Z/(So) = 0 (элементов не требуется, зна-
чение xf снимается с полюса), и равенство (2.3) оказы-
вается выполненным.
Предположим теперь, что соотношение (2.3) спра-
ведливо для всех формул, содержащих менее т (т 1)
вхождений символов & и V. Рассмотрим произвольную
формулу Фет вхождениями. Выделив в ней послед-
нюю операцию, представим формулу в виде Ф = Ф] о ф^
60
ДИСКРЕТНЫЕ УСТРОЙСТВА БЕЗ ПАМЯТИ
[ГЛ. II
где через ° обозначена одна из операций & и V. Фор-
мула Ф реализуется схемой, показанной на рис. 2.9. Ее
сложность с учетом сделанного предположения состав-
ляет
L' (Зф) = L' (Зф,) -J- L,' (Зф2) 1 =
= (/(Ф1)-1) + (/(Ф2)-1) + 1=/(Ф1) + /(Ф2)-1.
Замечая, что /(Ф)= /(Ф1) + /(Ф2), получаем требуемое
равенство (1.13).
Таким образом, синтез минимальных схем без вет-
влений в базисе <^о — {&, V, сводится к построению
формул, содержащих ми-
нимальное число вхож-
дений символов перемен-
ных. А если имеется не-
которая формула, то вся-
кое ее эквивалентное пре-
образование, приводящее
к уменьшению числа
вхождений переменных,
уменьшает сложность со-
ответствующей схемы.
Напомним некоторые из
доказанных в § 1.1 эквивалентностей, которые могут
быть использованы для упрощения формул. Ниже они
помещены в левом столбце, в правом выписаны двой-
ственные им преобразования формул:
Ф| V Ф]Ф2 — Фц
Ф)Ф2 V Ф]Ф2 = Ф1,
Ф|Ф2 V Ф^З ==:
= Ф, (Ф2 V Фз),
V Ф1Ф2 = Ф1 V Ф2,
Ф, (Ф( V Ф2) = Ф1,
(Ф1 V Ф2) (Ф[ V ф2) = Ф1,
(Фх V Ф2) (Ф1 V Фз) =
= Ф; V Ф2Ф3
Ф| (Ф] V Ф2)= Ф1Ф2.
2.2.3. Метод синтеза схем. Опишем теперь метод син-
теза схем без ветвлений (точнее, метод построения фор-
мул) в базисе {&, V,для частичных булевых функ-
ций. Он основан на формуле разложения частичной
(булевой) функции по переменной. Пусть частичная
функция f(xi, ..., хп) задана таблицей, в которой пере-
§ 2.2]
СИНТЕЗ СХЕМ ИА ОСНОВЕ ФОРМУЛ
61
числены наборы, на которых она определена, и указаны
ее значения на этих наборах (табл. 2.1).
Таблица 2.1
Х1 Х2 Хз Ха f
0 0 0 1 0
0 1 0 0 1
0 1 1 0 1
1 0 0 0 0
1 0 1 0 1
1 1 0 0 0
1 1 1 1 1 1 0 1 0 1
Обозначим через f(0, х2, ..., xn)=fo(x2, ..., хп)
частичную функцию, таблица которой образуется сле-
дующим образом. В таблице для f берутся все наборы,
первый разряд которых равен 0, и этот разряд отбрасы-
вается. Полученным укороченным наборам приписы-
ваются значения функции f на наборах, из которых они
образованы. Аналогично определяется функция f(l,X2,...
Xn) = fi(x2...хп). В таблицах 2.2 и 2.3 представ-
Таблица 2.2
Х2 Хз X* fo
0 0 1 0
1 0 0 1
1 1 0 1
Таблица 2.3
ООО
О 1 о
1 о о
1 1 о
1 1 1
о
1
о
о
1
62
ДИСКРЕТНЫЕ УСТРОЙСТВА БЕЗ ПАМЯТИ
[ГЛ. II
лены соответственно функции /о(х2, Хз, х4) и fi (х2, хз, х4),
полученные из функции f, задаваемой табл. 2.1.
Обозначив неопределенное значение символом *, рас-
пространим операции конъюнкции и дизъюнкции на
случай, когда одним из элементов, к которым приме-
няется операция, является неопределенный:
0V* = *, 1 V* = l, 0&* = 0, 1&* = *. (2.4)
Легко видеть, что при замене » любым из символов 0 и
1 равенства сохраняются. С учетом соглашений (2.4)
частичная функция f может быть представлена в виде
f(xi, х2, ..., хп) = xji (х2, xn)VxJo(x2, х„).
В этом можно убедиться, сравнив значения левой и пра-
вой частей на произвольном наборе (oi, .... ап). Если
функции fi и fo заменить их произвольными доопреде-
лениями, то формула разложения даст некоторое дооп-
ределение функции f.
Пусть теперь требуется реализовать заданную час-
тичную функцию f(xi,x2, . . . ,хп) формулой. Будем рас-
сматривать нетривиальный случай, когда функция f не
может быть доопределена до константы 0 или 1 (отсю-
да, в частности, следует, что функция f задана более
чем на одном наборе). В таблице f найдется столбец,
соответствующий некоторой переменной х«, который со-
держит как нули, так и единицы. Разложим f по пере-
менной Xi', f (Х1...Хп) = Xififxi, ..., Xi-1, Xi, Х/+1, ...
. .., Xn)VXifo(Xi...Xi-1, Xi, Xi+1, ..., Xn).
Если какая-либо из функций fa (о = 0, 1) может
быть доопределена до константы, то полагаем ее равной
константе. В этом случае разложение упрощается: при
fa — 0 оно имеет вид
f(xi....= > xi-i> xi+i’ ХЛ
а при f0 — 1
f(xp .... xn) = x?Vf}(xt, .... xf_r x.+ 1, ..., x„)
(здесь мы воспользовались равенством xf\/x^fd=xf V fs).
Если обе функции fa и fe могут быть заменены констан-
тами Z и ц (А,#= ц,ибо f не доопределима до константы),
то функция f может быть доопределена до х, либо до
§ 2.2]
СИНТЕЗ СХЕМ НА ОСНОВЕ ФОРМУЛ
63
xi. Например, при А — 1 и р — О
/(.Гр .... x„) = xf • 1 Vx°-0 = x?.
Заметим, что в этом случае столбец таблицы, соответ-
ствующий переменной xi, при о = 1 совпадает со столб-
цом значений функции /, а при о = 0 получается из него
инверсией, т. е. заменой нулей единицами и единиц ну-
лями.
Далее к каждой из функций fa (ст = 0, 1), если она
не доопределена до константы, применяем ту же про-
цедуру. В результате разложения fa по переменной х/
получаем пару функций fai и fao, при возможности заме-
няем одну или обе функции константами, выписываем
соответствующее разложение и т. д. Поскольку функция
fa определена на меньшем числе наборов, чем f, функ-
ция fax — на меньшем числе наборов, чем fa, и т. д., а
функция, заданная на одном наборе, доопределима до
константы, то через конечное число шагов не останется
функций, отличных от констант. На основе полученных
разложений конструируется формула для f.
В качестве примера построим формулу для функции
f(xi,x2,x3,x4), заданной таблицей 2.1. Разложим ее по
переменной Хь
/(ХЬ Х2, Х3, Х4) = Xifi (х2, Хз, Х4) V Xif0(x2, Х3, х4).
Функции f0 и fi задаются таблицами 2.2 и 2.3 и не до-
определимы до констант. Рассмотрим функцию fo
(табл. 2.2). Столбец ее значений совпадает со столбцом
х2, поэтому можно положить
/о (Х2, Хз, х4) = х2
(заметим, что можно было бы взять f0 (х2, Хз, х4) = х4).
Перейдем к функции fi. Разложим ее, например, по пе-
ременной х3. Функции fio(%2, х4) и /ц(х2, х4) задаются
таблицами 2.4 и 2.5.
Таблиц а 2.4 Т а б л и ц а 2.5 Т а б л и ц а 2.6 Т а б л и ц а 2.7
х2 fio хг X, Ai х. filo Xi fill
0 0 1 0 0 0 0 0 1 0 1 1 1 0 0 1 1 0 1 0 1
64
ДИСКРЕТНЫЕ УСТРОЙСТВА БЕЗ ПАМЯТИ
[ГЛ. II
Доопределив /10 нулем, получаем представление
fl Хз> Х4) = Xsfn(X2, Х4).
Функцию ffa(x2, Х4) разлагаем по х2- Возникающие при
этом функции /цо(х4) и f\u(Xi) задаются таблицами2.6
и 2.7.
С учетом того, что функция /по(%4) доопределима до
1, а /и; (х4) = х4, получаем представление
/п (х2, Xi) = x2 V Xi.
Объединяя найденные выражения, приходим к формуле
для /:
/ = %1Х3 (х2 V х4) V Х[Х2. (2.5)
Схема, построенная на основе этой формулы, содержит
5 элементов & и V. Заметим, что сложность формул за-
висит от порядка, в котором производилось разложе-
ние по переменным. Так, начав с х2, можно было бы
получить более простую формулу
/ = х2х3 V х2 (xi V х4). (2.6)
2.2.4. Оценка сложности схем. Покажем, что если
функция /(xi, .... хп), не доопределимая до константы,
задана на N наборах (ясно, что N^2), то число букв
/(Ф) в формуле Ф, построенной для реализации / опи-
санным методом, удовлетворяет неравенству
/(Ф)<4^-2. (2.7)
Доказательство будем вести индукцией по N.
Базис индукции. Пусть N = 2. Столбец значений
гот Г1!
функции / имеет вид j I или I I и совпадает со
столбцом, соответствующим переменной xi, по которой
производится разложение, либо с его инверсией. Таким
образом, Ф = х? и I(Ф) = 1. При N = 2 величина у N—2
равна 1 и совпадает с /(Ф).
Индуктивный шаг. Пусть функция определена,
на N > 2 наборах и для всех меньших значений N'
(N' 2) доказываемое неравенство имеет место. Произ-
ведем разложение по переменной Xi и, в зависимости от
5 ал).
МИНИМИЗАЦИЯ ЛОГИЧЕСКИХ ФУНКЦИЙ
65
того, имеются ли среди функций fa (о = 0, 1) доопреде-
лимые до констант или нет, рассмотрим 2 случая.
а) Пусть ровно одна функция fa доопределима до
константы, например, до 1. Тогда разложение имеет вид
f = x4'Vfe, где функция fa задана не более чем на
N—1 наборах. Обозначим через Ф и Фа формулы для
f и fa. С учетом предположения индукции получаем
Цф)=1+/(фв)<14-|(#-1)-2<|лГ~2.
Если обе функции fa(a = О, 1) доопределимы до кон-
стант, то f совпадает с х, либо с xi, и неравенство (2.7)
выполнено очевидным образом.
б) Пусть теперь функции fo и fi не доопределимы до
констант и заданы соответственно на Nq и Ni наборах
(Nq + Ni = N). Разложение имеет вид
f = V xtft. (2.8)
Обозначим через Ф и Фо (о = 0,1) формулы для f и
fa. С учетом предположения индукции из (2.8) полу-
чаем
/(Ф)==2 + /(Фо) + /(Ф1)<2 + (-|-^о-2) + (4^1-2) =
= {(JVo + M)-2 = |^-2.
Тем самым оценка (2.7) доказана. Из нее и из соотно-
шения (2.3) следует, что приведенный метод синтеза
позволяет реализовать функции, заданные на N набо-
рах, схемами без ветвлений, содержащими не более
g
— 3 элементов & и 'V. Если учитывать и инвер-
торы, то к этой оценке нужно добавить величину, не
превосходящую числа переменных п.
§ 2.3. Минимизация логических функций
2.3.1. Постановка задачи. В предыдущем параграфе
была установлена зависимость между сложностью схем
без ветвлений в базисе {&, V,_) и числом вхождений
символов переменных в формулы, которые описывают
схемы. На ее основе синтез минимальных схем без вет-
3 Л, А. Шолохов
66
ДИСКРЕТНЫЕ УСТРОЙСТВА БЕЗ ПАМЯТИ
[ГЛ. и
влений сводится к построению формул с минимальным
числом вхождений символов переменных. В данное вре-
мя не известно приемлемого (не использующего пере-
бора формул) метода решения последней задачи, по-
этому мы ограничимся формулами некоторого специ-
ального вида. Ниже описывается метод построения фор-
мул, минимальных в этом классе.
Дизъюнктивной нормальной формой (д.н. ф.) назы-
вается формула, имеющая вид дизъюнкции некоторых
конъюнкций
O = K,VK2V ... УКг, Кг = х°^2 ... х°‘р
(1=1, 2, .... s).
Всякая логическая функция f(xi....х„) может быть
реализована некоторой д. н. ф. (например, с. д. н. ф.,
если f Ф 0). Минимальной дизъюнктивной нормальной
формой (м. д. н. ф.) функции f называется д. н. ф., содер-
жащая минимально возможное число вхождений симво-
лов переменных среди всех д. н. ф., реализующих f. За-
дача построения м.д. н. ф. носит название задачи мини-
мизации. Иногда ставится аналогичная ей задача
построения д. н. ф., содержащей минимально возможное
число конъюнкций (такая д. н. ф. называется кратчай-
шей). Эта постановка возникает в случае, когда при
построении схем без ветвлений допускается использова-
ние элементов конъюнкции и дизъюнкции от произволь-
ного числа входов, а сложность схем измеряется (как и
раньше) числом элементов.
Те же самые задачи возникают и для частичных бу-
левых функций. При этом, как обычно, под реализацией
функции формулой понимается реализация ее произ-
вольного доопределения.
2.3.2. Строение м.д.н.ф. Описание начнем со случая
всюду определенных функций.
Пусть имеется логическая функция f(xi, ..., хп). Ло-
гическая функция g(x\, .... хп) называется импликан-
том функции f(xi, ..., хп), если для всякого набора
(О1, ..., о„) значений аргументов выполнено неравен-
ство f(pi, ..., оп)^ g(oh .... оп). Это условие может
быть эквивалентно переписано в виде
f(xh ..., xn)g(x{..x„) = g(xb .... хп).
$ 2.3] МИНИМИЗАЦИЯ ЛОГИЧЕСКИХ ФУНКЦИИ
67
Импликант называется простым, если он представляет
собой конъюнкцию переменных (возможно, с отрица-
ниями) и любая конъюнкция, полученная из него в ре-
зультате вычеркивания каких-либо переменных, импли-
кантом не является. Легко видеть, что для выяснения
того, является ли импликант, имеющий вид конъюнк-
ции, простым, достаточно исследовать наличие импли-
кантов среди конъюнкций, полученных из него вычер-
киванием ровно одной переменной (а не их произволь-
ного числа).
К качестве примера рассмотрим функцию /(xi,X2,
Хз, Х4) = XI V Х2 (х3*4 V Х[Х3). Функция gi = Х1 V *2*3*4
является импликантом, ибо
fgl — (*1 V *2*3*4 V *1*2*3) (*1 V *2*3*4) = *1 V *2*3*4
(мы воспользовались соотношением (А\/В)А=А).
Поскольку gi не есть конъюнкция, импликант gi не про-
стой. Конъюнкция g2 == *2*3*4 также является импли-
кантом. Если из нее вычеркнуть переменную х2, полу-
ченная конъюнкция g3 = *2*4 снова будет импликантом,
ибо
fg3 = (*1 V *2 (*3*4 V *1*3» *2*4 =
= *1X2*4 V *2*3*4 V *1*2*3*4 = *2*4 (*1 V *3 V *1*з) = *2*4»
Отсюда следует, что импликант g2 не является про-
стым. Легко проверить, что конъюнкции х2 и *4, полу-
ченные из gs = *2*4 вычеркиванием одной переменной,
импликантами не будут. Поэтому х2*4 представляет со-
бой простой импликант.
Сформулируем теорему о строении м. д. н. ф.
Теорема 2.1. М.д.н.ф. функции, отличной от кон-
станты 0 и 1, является дизъюнкцией некоторых простых
импликантов.
Доказательство. Рассмотрим произвольную
м. д. н. ф. функции f:
f = K2V ... V Ks. (2.9)
Предположим, что некоторая конъюнкция из этого пред-
ставления, пусть Ki, не является простым импликантом
и из нее путем вычеркивания переменной можно образо-
вать импликант К'. Покажем, что в этом случае функция
... VK, (2.10)
3»
68
ДИСКРЕТНЫЕ УСТРОЙСТВА БЕЗ ПАМЯТИ
[ГЛ. II
совпадает с f. Для этого достаточно убедиться, что f и
f' обращаются в 1 на одних и тех же наборах.
Рассмотрим произвольный набор (щ........о-(1). По-
скольку при укорачивании конъюнкции область ее еди-
ничных значений не уменьшается, то на этом наборе
выполнено неравенство К’ К\ и, следовательно,
f = K'V(K2V ... VT<s)>KiV(K2V ... V/Q = f.
Отсюда вытекает, что если .. .,о„)=1, то и
Г(oi, • • •, о«)= 1.
Обратно, пусть f'(oj, ..., <тп) = 1. Это означает, что
на наборе (од, ..., оп) либо К', либо К2 V ... V Ks об-
ращается в 1 (то и другое возможно одновременно).
Равенство f(oi.....ап) = 1 в первом случае следует
из того, что К! является импликантом, а во втором —
из представления (2.9).
Тем самым установлено, что = /. Это приводит к
противоречию, ибо представление (2.10) имеет на одно
вхождение переменной меньше, чем м.д. н. ф. (2.9). Тео-
рема доказана.
Кратчайшие д. н. ф. могут состоять и не из простых
импликантов. Так, например, для функции xi V х2д. н. ф.
Xi V *1*2 является кратчайшей (так же, как и xiVx2),
хотя конъюнкция Х[Х2 не есть простой импликант. Од-
нако всякая конъюнкция в кратчайшей д. н. ф. может
быть заменена простым импликантом, образованным из
нее вычеркиванием "екоторых переменных. Как следует
из доказательства теоремы, такая замена не приводит
к изменению функции. В то же время она не увеличи-
вает числа конъюнкций. Таким образом, при построении
кратчайших д. н. ф. можно считать, что они образованы
из простых импликантов.
2.3.3. Геометрическая интерпретация. Множество
всех двоичных наборов (щ, ..., о.п) будем рассматри-
вать как множество вершин «-мерного единичного куба
(на рис. 2.10 приведен трехмерный куб). Тогда всякая
функция f(xi, .... хп) может быть описана множеством
вершин куба, на которых она принимает значение 1.
Рис. 2.10 соответствует функции f(xi, х2, хз), обращаю-
щейся в 1 на наборах (0, 0, 0), (0, 0, 1), (1, 0, 0), (1, 0, 1)
и (1, 1, 1) (она задается табл. 1.1).
Функция g(xi, ..., хп) является импликантом для
§ 2.3]
МИНИМИЗАЦИЯ ЛОГИЧЕСКИХ ФУНКЦИЙ
69
/(хь .... хп), если соответствующее ей множество вер-
шин куба содержится в .множестве вершин для f. Всякая
& ;. а,
конъюнкция х^1 ... задает подкуб, представляю-
щий собой множество вершин (xi......хп), для кото-
рых х/1=о(-1, ..., Xik — oik, а значения остальных п — k
компонент могут быть выбраны произвольно. Подкуб,
соответствующий конъюнкции длины k, содержит 2re~*
вершин. В частности, подкуб для конъюнкции длины п
вырождается в вершину. На рис. 2.10 заштрихован под-
куб, соответствующий конъюнкции х2 (он представляет
собой грань х2 = 0). Простой
импликант определяет под-
куб, все вершины которого
принадлежат множеству еди-
ничных вершин функции, и та-
кой, что он не содержится ни
в каком большем подкубе, об-
ладающем этим свойством.
Такие подкубы будем назы-
вать максимальными. Всякая
д. н. ф. задает некоторое по-
крытие множества единичных
вершин функции подкубами,
соответствующими ее конъ-
юнкциям.
На этом языке теорема 2.1 становится очевидной.
Она означает, что в покрытии, соответствующем м. д. н. ф.,
используются только максимальные подкубы (макси-
мальные подкубы покрывают большее число вершин в
сравнении с содержащимися в них немаксимальными
подкубами и имеют «меньшую стоимость», ибо’ задают-
ся конъюнкциями меньшей длины). Из рассмотрения
рис. 2.10 видно, что изображенная на нем функция имеет
единственную м.д. н. ф. x2VxiX3, соответствующую по-
крытию подкубами, один из которых представляет со-
бой грань х2 = 0, а другой — ребро Xi = 1, хз = 1. В об-
щем случае функция может иметь несколько м. д. н. ф.
Кратчайшей д. н. ф. соответствует покрытие наименьшим
числом подкубов. Ясно, что при построении такого по-
крытия можно использовать лишь максимальные под-
кубы.
70
ДИСКРЕТНЫЕ УСТРОЙСТВА БЕЗ ПАМЯТИ
[ГЛ. и
Первым этапом в нахождении м.д. н. ф. (и кратчай-
шей д. н. ф.) является построение системы всех простых
импликантов.
2.3.4. Построение простых импликантов. Рассмотрим
некоторый импликант функции f(xi, хп), являющий-
ся конъюнкцией. Для удобства будем считать, что в
него входят первые р переменных, т. е. что импликант
имеет вид х^'х^2 • • • хРр. На всех наборах (oi...<тР,
тр+1, ..., тп) (при разных Тр+ь ..., тп) импликант
х?‘ ... Хр₽ равен 1. Поэтому функция f на этих наборах
также обращается в 1 и в ее с. д. н. ф. присутствуют все-
возможные конъюнкции вида х’1 ... x^px*^ ... ххпп.
Осуществив склеивания по переменной х„:
4* • • • V х"‘ ... х°рххрр+‘ ... х^'х„ =
=<* ••• <Р*М •••
из них можно получить всевозможные конъюнкции вида
х°' ••• хрРхрр-и‘ хп-~1‘- Затем, произведя склеивания
по переменной xn_j, придем к всевозможным конъюнк-
циям хР' ... xPxJp++* ... х^22 и т. Д-, пока не получим
х°‘ ... хрр. Таким образом, всякий импликант, имею-
щий вид конъюнкции, можно получить из конъюнкций
с. д. н. ф. последовательным применением операции
склеивания. Легко видеть, что верно и обратное: всякая
конъюнкция, полученная таким образом, является им-
пликантом [. Отсюда можно сделать вывод, что все
импликанты, имеющие вид конъюнкций, и только они,
могут быть образованы в результате последовательного
склеивания конъюнкций из с. д. н. ф.
Рассмотрим пример. Пусть в с. д. н.ф. функции
f(Xi, Х2, ХЗ, х4) ВХОДЯТ КОНЪЮНКЦИИ Х1Х2Х3Х4, Х]Х2Х3Х4,
Х1Х2Х3Х4, Х1Х2ХзХ4. Произведем последовательные склеи-
вания по х4 и по х2:
(xlx2x3xi V Х1Х2Х3Х4) V (Х1Х2ХзХ4 V Х]Х2хзх4) =
— Х{Х2Х3 V XjX2X3 = х,х3,
в результате чего получим импликант xjx3. Конъюнкции
§2.3] МИНИМИЗАЦИЯ ЛОГИЧЕСКИХ ФУНКЦИИ
71
удобно задавать наборами длины п из символов 0,1 и —.
Если переменная Xi входит в конъюнкцию в форме х\1,
то в этом наборе на i-м месте записывается а,-, а если
xt отсутствует, то на z-м месте проставляется —. Конъ-
юнкции %1Хз, например, соответствует набор 1 — 0 —.
С использованием такого представления конъюнкций
рассмотренный выше пример получения лцхз из с. д. н. ф.
может быть описан следующим образом:
Xi Хг Хг Xi
1 0 0 0 |
1 0 0 1 ) 1
1 1 0 0 1
1 1 0 1 J
0 0- )
>1-0-
1 о- )
На основе сказанного приведем алгоритм построе-
ния всех импликантов, имеющих вид конъюнкции. Из-
ложение будем сопровождать примером. Пусть функция
f (xi, Х2, х3, Ха) задана таблицей 2.8.
Таблица 2.8
xi х, хз xt
f
0 о 0 о
0 0 0 1
0 0 10
0 0 11
0 10 0
0 10 1
0 110
0 111
10 0 0
10 0 1
10 10
10 11
110 0
110 1
1110
1111
1
1
о
1
1
о
1
о
1
1
о
1
1
1
о
о
Выпишем в полосе I таблицы 2.9 все наборы, на
которых функция f обращается в 1. Для осуществления
алгоритма их удобно выписывать разбитыми на группы
72
ДИСКРЕТНЫЕ УСТРОЙСТВА БЕЗ ПАМЯТИ
[ГЛ. II
Таблица 2.9
-00-
- - о о
-0-1
1 - 0 -
III
в соответствии с числом единичных компонент в набо-
рах. Поскольку склеиваются лишь наборы, отличаю-
щиеся в одной компоненте, то для того чтобы произ-
вести все склеивания по одной переменной, достаточно
просмотреть всевозможные пары наборов, входящих в
соседние группы.
Результаты склеиваний наборов из полосы I поме-
стим в полосе II. Наборы из полосы I, которые участво-
вали в склеиваниях, пометим значком 4-. В полосе II
наборы уже автоматически разбиваются на группы по
числу единиц (при склеивании наборов полосы I из
групп с i—1 единицами и с i единицами получается
набор полосы II с i—1 единицами). К образованным
наборам снова применяем операцию склеивания (склеи-
ваются пары наборов, которые содержат прочерк на
одинаковых местах и различаются одной компонентой).
При этом нужно опять просмотреть все пары наборов
из соседних групп. Наборы, к которым применена опе-
рация, помечаем значком +. Результаты склеивания
(соответствующие конъюнкциям длины 2) заносим в по-
лосу III таблицы. В полосе III снова пытаемся осущест-
вить склеивания, однако этого сделать не удается. На
этом процедура завершается.
В полученной таблице содержатся все импликанты
функции f, имеющие вид конъюнкции. Простыми будут
§ 2.3]
МИНИМИЗАЦИЯ ЛОГИЧЕСКИХ ФУНКЦИИ
73
те из них, которые не помечены значком + (из них
нельзя вычеркнуть ни одной переменной, иначе приме-
нима операция склеивания). В рассмотренном примере
ПРОСТЫМИ ИМПЛИКЭНТаМИ ЯВЛЯЮТСЯ КОНЪЮНКЦИИ Х]Х2^4,
Хз-^4, *2*4, Х1*з, которые соответствуют наборам
01 — 0, — 00 ----00, — 0 — 1, 1 — 0 —.
2.3.5. М.д.н.ф. монотонных функций. Следующий этап
после нахождения всех простых импликантов состоит
в формировании м.д.н.ф. В некоторых случаях необхо-
димость в этом этапе отпадает. В частности, это имеет
место для монотонных функций.
Теорема 2.2. М. д. н. ф. монотонной функции, от-
личной от тождественной константы (0 и 1), является
дизъюнкцией всех ее простых импликантов.
Доказательство. Убедимся вначале, что простые
импликанты монотонной функции f не содержат отри-
цаний переменных. Предположим противное, что имеется
простои импликант хц .. . xij ... xiyp, содержащий отри-
цание некоторой переменной хг/. На всех таких на-
борах, что xtl = сть ..., xlf = 0, ..., х1р = ар, этот
импликант равен 1 и по определению импликанта f = 1.
Из монотонности f вытекает, что она обращается в 1
и на всех наборах, у которых xZ1 = ct1; ..., xtj—l,...
°1 °i
..., х. = ст0. Это означает, что х, ... х, ... х, р
1р „ > 7 7
также является импликантом. К паре конъюнкций
<7. а а, о
хц ... xif ... хгр и хц ... Xi) ... xip применима опе-
рация склеивания, приводящая к удалению перемен-
а. а
нои х^. Поэтому импликант Хц ...х^ ... xjp не может
быть простым.
Докажем теперь утверждение теоремы. Рассмотрим
произвольный простой импликант g — x^ ... xip. Обра-
зуем набор 5, положив xtl = ... =xip = l, а остальные
переменные — равными 0. На наборе ст импликант g
обращается в 1, поэтому и /(ст) = 1. Любой другой
простой импликант xSl ... на наборе ст равен 0.
5 противном случае все переменные х^,..., х^ должны
74
ДИСКРЕТНЫЕ УСТРОЙСТВА БЕЗ ПАМЯТИ
[ГЛ. и
содержаться среди xi{, xip и импликант х{[ ... х1р
не будет простым (вычеркиванием из него можно обра-
зовать х1{ ... Х]^. Таким образом, на наборе б дизъюнк-
ция всех простых импликантов, отличных от g, равна О
и, поскольку И<*)— 1, простой импликант g необходимо
включить в м. д. н. ф. Теорема доказана.
Приведем некоторые следствия.
1. Из процесса доказательства следует, что функция
(тождественно не равная 0 и 1) является монотонной
тогда и только тогда, когда она может быть представ-
лена формулой в базисе {&, V}. Действительно, если
функция монотонна, то ее м.д. н. ф. не содержит отри-
цаний переменных и является формулой в базисе {&, V).
Обратно, поскольку функции Х1 & х2 и Xj V х2 монотон-
ны, их суперпозиция, задаваемая произвольной форму-
лой в базисе {&, V}, также монотонна (класс монотон-
ных функций замкнут).
2. Если функция f представлена в виде д. н. ф., конъ-
юнкции которой не содержат отрицаний переменных, и
ни одна из этих конъюнкций не поглощает другую (не
может быть получена из другой вычеркиванием пере-
менных), то это представление совпадает с м.д. н. ф.
Действительно, любая конъюнкция Ki, входящая в пред-
ставление, является импликантом. Если из Ki вычерк-
нуть некоторую переменную, то полученная конъюнкция
K'i импликантом не будет (положив все переменные,
входящие в K'i, равными 1, а остальные — равными О,
получим набор, на котором K'i—1, а f — О). Таким об-
разом, все конъюнкции, содержащиеся в рассматривае-
мом представлении, являются простыми импликантами.
По предыдущему следствию функция f монотонна и в
силу теоремы 2.2 это представление совпадает с
м.д. н. ф.
3. На том свойстве, что простые импликанты моно-
тонной функции не содержат отрицаний переменных,
может быть основан способ распознавания монотонно-
сти.
2.3.6. Формирование м.д.н.ф. Перейдем к описанию
метода построения м.д. н. ф. из простых импликантов
для произвольной функции f. Обозначим через Ai,
J 2.3] МИНИМИЗАЦИЯ ЛОГИЧЕСКИХ ФУНКЦИЙ 78
А2, ...» As все простые импликанты функции f. Будем
говорить, что импликанты Atl, Al2, ..., Ait образуют по-
крытие функции f, если
Л, V Xi2V ... V At~f.
I Л I
В частности, все простые импликанты функции f, а так*
же импликанты, входящие в некоторую ее м. д. н. ф.,
образуют покрытия. Покрытие назовем неизбыточным,
если при удалении из него произвольного импликанта
оно перестает быть покрытием. Так, множество импли-
кантов, входящих в м.д. н. ф. или в кратчайшую д. н. ф.,
образует неизбыточное покрытие. Ниже будет указан
способ нахождения всех неизбыточных покрытий. Из
них затем могут быть выбраны покрытия, которым со-
ответствуют м. д. н. ф.
Будем говорить, что конъюнкция К покрывает набор
а, если на наборе а она обращается в 1. Заметим, что
в этом случае представляющий набор конъюнкции по-
лучается из а заменой некоторых компонент прочер-
ками. Так, например, конъюнкция Х1Хз, задаваемая на-
бором 1 — 0 —, покрывает наборы 1000, 1001, 1100 и
1101. Ясно, что множество импликантов образует покры-
тие функции f тогда и только тогда, когда для каж-
дого набора а такого, что f(a)=l, в этом множестве
содержится импликант, покрывающий а. Построим по
функции f импликантную таблицу. Ее строки соответ-
ствуют единичным наборам функции f, а столбцы —
простым импликантам. В пересечении строки а и столб-
ца Ai проставляется *, если импликант Ai покрывает
набор а (в противном случае клетка оставляется пу-
стой). Множество импликантовобразует покрытие функ-
ции f, если столбцы, соответствующие импликантам
этого множества, содержат * в каждой строке.
В качестве примера рассмотрим функцию f(xi,X2, Хз,
Х4), задаваемую таблицей 2.8. Как мы видели (см.
табл. 2.9), ее простыми импликантами являются конъ-
юнкции Ai = Х1Х2х4, Аг — х2Хз, А3 = Х3Х4, А4 = х2х4 и
Аб = Х1Хз. Импликантная таблица функции f приведена
в таблице 2.10.
С импликантом At будем связывать логическую пере-
менную а/ (принимающую значения 0 и 1). Каждому
множеству импликантов приписывается набор значений
76 дискретные устройства БЕЗ ПАМЯТИ [ГЛ и
Таблица 2.10
л( Лд х-> х. Л? Х?.Хз А Х3 Л'< А X? Ха Ла Х1 Хз
0000 « »
0001 » *
ООН *
0100 * •
оно *
1000 * * •
1001 • * *
1011 *
1100 «
1101 •
переменных аг. если импликант At входит в множество,
то а, = 1, если нет, то а< = 0. Рассмотрим строку таб-
лицы покрытий, соответствующую некоторому набору
а. Пусть в этой строке символы * находятся в столбцах
А^, Ai2, ..., А{ . Строка а будет покрытой тогда и
только тогда, когда в множество включен хотя бы один
из импликантов Atl, А1г, ..., А/д, т. е. когда дизъюнкция
V ati V ... V aig равна 1. Составим такую дизъ-
юнкцию для каждой строки импликантной таблицы и
возьмем их произведение по всем строкам. Полученную
функцию обозначим через F. В частности, функция, со-
ответствующая таблице 2.10, имеет вид
F = (а2 V а3) (а2 V а4) а4 V а3) di (а2 V а3 V а5) &
& (а2 V а4 V а5) «4 («з V а5) а5.
Множество импликантов образует покрытие тогда и
§ 2.31 МИНИМИЗАЦИЯ ЛОГИЧЕСКИХ ФУНКЦИИ 77
только тогда, когда набор значений переменных ai, со-
ответствующий этому покрытию, обращает функцию F
в единицу, ибо равенство F = 1 имеет место тогда и
только тогда, когда все скобки равны 1, т. е. когда все
строки покрыты.
Преобразуем формулу, задающую функцию F. Вна-
чале с использованием правила поглощения (Ф1V;
УФ2)Ф| =Ф1 удалим более длинные скобки (т. е. та-
кие, что из них вычеркиванием некоторых членов можно
получить другие скобки). Затем на основе свойства
дистрибутивности раскроем все скобки, в результате
чего получим выражение вида дизъюнкции конъюнкций.
И, наконец, пользуясь правилом поглощения Ф! У(
у Ф1Ф2 = Ф], удалим более длинные конъюнкции (т. е.
такие, что из них вычеркиванием некоторых переменных
можно получить другие конъюнкции). В результате при-
дем к представлению
V ata{ ...а,, (2.11)
(<Р <2. lp)^> Р
в котором отсутствуют поглощения конъюнкций (дизъ-
юнкция берется по некоторому множеству I наборов
(Л, i2, .... г’р)). По следствию 1 к теореме 2.2 функция
F является монотонной, а по следствию 2 представление
(2.11) совпадает с м.д.н.ф. и является дизъюнкцией
всех простых импликантов. Отсюда вытекает, что функ-
ция F имеет единственное представление вида (2.11).
Осуществим указанные преобразования примени-
тельно к функции F из рассматриваемого примера. Вы-
черкивание более длинных скобок дает выражение
F — (а2 V аз)а^ащ^. Раскрывая скобки, получаем пред-
ставление вида (2.11)
F = aia2a4a5 V aia3a4a5. (2.12)
Теорема 2.3. Всякой конъюнкции a{ai...ai,
входящей в представление (2.11) функции F, соответствует
неизбыточное покрытие {Л([, Al2.Aip] функции f и, на-
оборот, всякому неизбыточному покрытию {Allt А,2,.... Ai }
соответствует конъюнкция ailai2 ... az представления
(2.Н).
Доказательство. Рассмотрим произвольную
конъюнкцию aixai2 ... aip из представления (2.11).
78
ДИСКРЕТНЫЙ УСТРОЙСТВА БЕЗ ПАМЯТИ
(ГЛ. II
Согласно сказанному выше она является простым импли-
кантом функции F. Полагая aZ1 = a(-2— ... = aip=l,
а остальные переменные равными 0, получаем F = 1.
Отсюда заключаем, что множество {Alt, Ai2, .... Atp]
образует покрытие. Предположим, что оно избыточно и
при удалении из него А{ , например, снова получается
покрытие. Тогда на наборе а(1 = ... =0/ , = 1» —О
ip-i) функция F обращается в 1. В силу
монотонности она равна 1 и на всяком другом наборе,
гдеа([== ... =а{ =1. Поэтому конъюнкция ait... a/p_j
является импликантом, а это противоречит тому, что
импликант а/j...a/ простой. Таким образом, покрытие
{Ai{, ..., неизбыточно.
Обратно, пусть имеется неизбыточное покрытие
{Л(1, ..., At j. Полагая atl — ... —aip~ 1, а остальные
переменные равными 0, получаем F—1 (поскольку
{Лц, ..., А 1р] — покрытие). В силу монотонности F
обращается в 1 на всех наборах, где — ... = aip = 1.
Поэтому ait ... aip является импликантом. Если бы он
не был простым и в нем можно было вычеркнуть, на-
пример, aip, то на наборе ац= ... — а(р_( = 1, а, = 0
(IФ г'], ..., ip_j) функция F равнялась бы 1 и множество
(тЦ, ..., Atp_^ образовывало бы покрытие. Это проти-
воречит неизбыточности покрытия .... Л/р).
Теорема доказана.
Таким образом, представление (2.11) задает все не-
избыточные покрытия функции f. Из них могут быть вы-
браны покрытия, соответствующие м.д. и. ф.
Продолжим рассмотрение примера. Представление
(2.12) показывает, что имеются 2 неизбыточных покры-
тия: {41, А2, А4, Д5} и {Ai, Аз, А4, Л5}. Им соответствуют
д. н. ф., содержащие по 9 вхождений символов перемен-
ных, поэтому каждая из них является минимальной. Та-
ким образом, [ имеет две м. д. н. ф.:
f = А; V А2 V А4 V А5 — xix2x4 V х2х3 V х2х4 V од,
f = At V А3 V А4 V А5 — Х[Х2х4 V х3х4 V х2х4 V Xii3.
§ 2.3] МИНИМИЗАЦИЯ ЛОГИЧЕСКИХ ФУНКЦИЙ 79
Построение кратчайших д. н. ф. осуществляется тем
же способом. Им соответствуют неизбыточные покрытия
наименьшей мощности и, следовательно, конъюнкции
представления (2.11) наименьшей длины.
Изложенный способ построения м.д. н. ф. хорошо ил-
люстрирует подход к отысканию оптимальных решений,
основанный на сокращении перебора. Тривиальный спо-
соб нахождения м.д. н. ф. связан с просмотром всех
д. н. ф. в порядке возрастания их сложности вплоть до
д. н. ф., реализующей исходную функцию f. Теорема 2.1
позволила существенно сократить поиск, ограничившись
д. н. ф., составленными только из простых импликантов
функции f. Дальнейшее уменьшение вариантов осуществ-
лено за счет выделения тех из них, которые соответ-
ствуют неизбыточным покрытиям. В результате их пол-
ного просмотра находится минимальное решение.
С ростом числа аргументов число неизбыточных по-
крытий для абсолютного большинства функций растет
чрезвычайно быстро ([И], раздел 3), поэтому описан-
ный метод минимизации применим лишь к функциям от
небольшого числа аргументов.
При большом числе аргументов наиболее трудоем-
ким является этап, связанный с отысканием наилучшего
покрытия (система простых импликантов находится
сравнительно просто). Для осуществления этого этапа
обычно используются приближенные методы, не гаран-
тирующие минимальности построенной д. н. ф. Один из
них состоит в следующем. Если в импликантной таб-
лице имеются строки, содержащие по одному символу *
(см. строки ООН, 0110, 1011 и 1101 табл. 2.10), то по-
крывающие их импликанты (в данном случае Да, А\,
Л5) входят в любую д. н. ф. Они включаются в покрытие
и соответствующие им столбцы, и покрываемые ими
строки вычеркиваются из таблицы. Дальнейший выбор
импликантов осуществляется с использованием следую-
щей пошаговой процедуры. В новой таблице берется
столбец с наибольшим числом символов * (если таких
столбцов несколько, то любой из них). Этот столбец
и строки, в которых он содержит *, из таблицы вычер-
киваются, а соответствующий импликант включается в
покрытие. К полученной таблице применяется та же
операция и т. д.. пока все строки не окажутся
во
ДИСКРЕТНЫЕ УСТРОЙСТВА ВЕЗ ПАМЯТИ
[ГЛ. II
вычеркнутыми, т. е. все единичные наборы функции не
окажутся покрытыми. Изложенный метод, несмотря на
его простоту, дает практически хорошие результаты.
Тот же способ применяется и для приближенного
решения задачи отыскания кратчайшей д. н. ф.
2.3.7. Минимизация частичных функций. Понятие
простого импликанта обобщается на случай частичных
функций следующим образом. Конъюнкция К назы-
вается простым импликантом частичной функции f, если
— она покрывает хотя бы один набор а, на котором
f (а)= 1;
— не покрывает ни одного набора а, такого что
/(«)= 0;
— любая конъюнкция, полученная из нее вычерки-
ванием переменных, покрывает некоторый набор а, на
котором f(a) — 0.
Если воспользоваться геометрической интерпрета-
цией, задав функцию f на множестве вершин «-мерного
единичного куба, то простым импликантам будут соот-
ветствовать максимальные подкубы, обладающие тем
свойством, что они покрывают некоторые единичные
вершины функции f и не покрывают никаких ее нулевых
вершин. Отсюда видно, что всякая м. д. н. ф. частичной
функции является дизъюнкцией простых импликантов и
что в качестве кратчайших д. н. ф. можно рассматривать
лишь такие, которые состоят из простых импликантов.
Для построения системы всех простых импликантов
удобно пользоваться заданием частичной функции f
в виде таблиц Л и То, в первой из которых перечислены
единичные наборы функции f, а во второй — нулевые.
Для функции, заданной посредством таблицы 2.1, эти
таблицы соответственно приведены ниже.
Таблица 2.11
Таблица 2.12
X, X, Хз X,
Xi Хг Хз х<
0 10 0
0 110
10 10
1111
0 0 0 1
10 0 0
110 0
1110
I 2.3]
МИНИМИЗАЦИЯ ЛОГИЧЕСКИХ ФУНКПИП
81
Метод построения всех простых импликантов проил-
люстрирован таблицей 2.13.
Таблица 2.13
0 10 0+ =
0 110+ i
10 10+ i
1111+ i
0-00 +
0 1-0 +
0 10-h
0-10 +
Oil--h
-010 +
10 1-h
-111 +
1-11 +
11-1 +
II
0--0
0 1 - -
0 - 1 -
-01-
- - 1 1
-1-1
1--1
III
В полосе I помещены все наборы таблицы Т\. В по-
лосе II содержатся всевозможные наборы, образован-
ные из наборов полосы I заменой одного разряда про-
черком и обладающие тем свойством, что они не покры-
вают никаких наборов таблицы То (не совпадают сними
в невычеркнутых разрядах). Они могут быть найдены
просмотром всех наборов из полосы I и проверкой воз-
можности вычеркивания в каждом из них каждого из
символов. Наборы полосы I, покрываемые наборами по-
лосы II, помечаются значком В полосе III находятся
все наборы, полученные из наборов полосы II заменой
одного разряда прочерком и не покрывающие наборов
таблицы То. Покрытые ими наборы полосы II помечают-
ся значком Из наборов полосы III уже не удается
образовать наборов с 3 прочерками, не покрывающих
наборов из таблицы То. На этом процедура завершает-
ся. Все непомеченные наборы таблицы 2.13 соответ-
ствуют простым импликантам. В данном случае это
41 = Х]Х4, А2 = Х\Х2, Аз = Х\Хз, А4 = х2х3, As = Х3Х4,
4в = х2Х4, Ai = Х1Х4.
Далее, как и в случае всюду определенных функций,
строится импликантная таблица, с использованием
функции F находятся все неизбыточные покрытия и из
них выбирается то, которое соответствует м. д. н. ф. или
кратчайшей д. н. ф.
82
ДИСКРЕТНЫЕ УСТРОЙСТВА БЕЗ ПАМЯТИ
[ГЛ. И
Таблица 2.14
А, Лг А, А, А, ’ Лв А,
0100 • *
оно * * *
1010 *
1111 * * •
Импликантная таблица для данного примера приве-
дена в таблице 2.14. Образуем функцию
F = (at V а2) (ai V а2 V а3) at (а5 V а6 V а7).
Вычеркивая (aiV а2У а3) и раскрывая скобки, полу-
чаем 6 различных конъюнкций длины 3. Каждой из них
соответствует неизбыточное покрытие, приводящее к
д. н. ф. с 6 вхождениями символов переменных. Все эти
д. н. ф. являются минимальными. Примером м. д. н. ф.
может служить
f — V ^4 V И5 = Х[Х$ V ^2^3 V АГ3Х4.
На практике построение д. н. ф. обычно является про-
межуточным этапом, после чего осуществляется упро-
щение формулы путем группировки и вынесения за
скобки. В данном случае группировка приводит к фор-
муле Х1Х4 V х3(х2 V х^, содержащей 5 символов пере-
менных (ср. с реализациями (2.5) и (2.6), полученными
в § 2.2).
Как и в случае всюду определенных функций, для
частичных функций от большого числа аргументов наи-
более трудоемким является этап, связанный с отыска-
нием наилучшего покрытия. Нахождение приближен-
ного решения может быть осуществлено с использова-
нием пошаговой процедуры, описанной выше для всюду
определенных функций.
2.3.8. Сложность м.д.н.ф. Рассмотрим вопрос о том,
сколь сложными могут быть м.д.н.ф. функций от п
аргументов (под сложностью д. н. ф. будем понимать
число входящих в нее символов переменных),
§ 2.3) МИНИМИЗАЦИЯ ЛОГИЧЕСКИХ ФУНКЦИЙ 83
Рассмотрим линейную функцию
4*(Х1, х2...Х„) = Х1©Х2ф ... фх„.
На соседних наборах (различающихся в одной компо-
ненте) она принимает разные значения. Поэтому ника-
кие два единичных набора этой функции не склеи-
ваются, и ее м.д.н.ф. совпадает с с. д. н. ф. Функция
ln(xi, ..., хп) принимает 2"-1 единичных значений (на
всех наборах длины п с нечетным числом единиц), и
каждому из них в с. д. н. ф. соответствует конъюнкция
длины п. Поэтому с. д. н. ф. (а следовательно, и
м.д.н.ф.) этой функции содержит п-2п~1 символов пе-
ременных.
Покажем, что м.д.н.ф. любой функции f(xt....хп)
от п аргументов не сложнее, чем у /п(хь ..., хп). Рас-
смотрим все единичные наборы функции f. Отбрасыва-
нием последней компоненты образуем из них укорочен-
ные наборы длины п—1. Каждому укороченному на-
бору (oi....оп-1) следующим образом сопоставим
конъюнкцию. Если функция f имеет единственный еди-
ничный набор (ai, ..., On-i, Оп), совпадающий с укоро-
ченным в первых п— 1 компонентах, то в качестве конъ-
юнкции возьмем х°' ... хап±11х°пп, а если таких единичных
наборов два, то возьмем х®1 ... Дизъюнкции всех
полученных конъюнкций совпадает с f, ибо каждый еди-
ничный набор (oi, ..., вп), не имеющий соседнего по
последней компоненте, реализуется индивидуально конъ-
юнкцией х°> ... х°п> а всякая пара соседних наборов
(сп, ..., Оп-ь 0) и (tri.Од-i, 1) — укороченной конъ-
юнкцией х°1 ... хап1_-['- Число конъюнкций в полученной
д.н. ф. совпадает с числом укороченных наборов и не
превосходит 2"-1 (общего числа наборов длины п— 1).
Поэтому сложность этой д. н. ф. (а следовательно, и
м.д.н.ф.) не выше п.2"-1. Из процесса доказательства
нетрудно заключить, что м. д. н. ф. максимальной слож-
ности п-2"-1 имеют лишь две линейные функции от п
аргументов:
Z„(xb хп) = Х1ф ... фх„
84
ДИСКРЕТНЫЕ УСТРОЙСТВА БЕЗ ПАМЯТИ
[ГЛ. II
И
(хь . . ., Х„) = XI ф ... ф хп ф 1,
и что кратчайшая д. н. ф. содержит не более 2"-1 конъ-
юнкций, причем максимальное значение 2"-1 опять до-
стигается лишь на линейных функциях.
Результат минимизации дает формулы, сложность
которых не превышает п-2"-1, причем эта оценка дости-
гается. Для сравнения напомним, что метод, описанный
в предыдущем параграфе, гарантирует для всюду опре-
деленных функций формулы, сложность которых не
больше -|- 2” = 3 • 2га~1 (см. (2.7)).
В заключение отметим, что наряду с представле-
ниями функций в виде д. н. ф. рассматриваются пред-
ставления
f = D. & D. &. ... &D , D, = х°1' V х,1* V ... V ха,1р
1 z s 1 *1 *2 1р
(/ = 1, ..., s),
называемые конъюнктивными нормальными формами
(к. н. ф). Применительно к ним возникают задачи по-
строения минимальных к. н. ф. (м.к. н. ф.), содержащих
наименьшее число вхождений символов переменных, и
кратчайших к. н. ф., состоящих из наименьшего числа
дизъюнкций. Эти задачи легко сводятся к уже рассмот-
ренным. Для того чтобы найти м. к. н. ф. функции f,
можно перейти к двойственной функции /*, построить
для нее м. д. н. ф. и взять двойственную к ней к. н. ф.
Она будет минимальной, ибо если бы для f существо-
вала к. н. ф. меньшей сложности, то двойственная к ней
д. и. ф. реализовала бы f* с меньшей сложностью, чем
м. д. н. ф. Аналогично, задача построения кратчайшей
к. н. ф. сводится к задаче нахождения кратчайшей д. н. ф.
двойственной функции.
Поскольку двойственной к линейной функции снова
является линейная функция (либо она сама, либо ее
отрицание), то наибольшую сложность имеют м. к. н. ф.
линейных функций. Они содержат п-2"-1 символов пе-
ременных. Кратчайшая к. н. ф. линейных функций со-
стоит из 2"-1 дизъюнкций, и эта величина также яв-
ляется максимально возможной.
$ 2.41
СИНТЕЗ СХЕМ МЕТОДОМ ДЕКОМПОЗИЦИИ
85
§ 2.4. Синтез схем методом декомпозиции
2.4.1. Декомпозиция функций. В предыдущих параг-
рафах рассматривалось построение схем без ветвлений.
Они адекватно описываются формулами, и это создает
определенные удобства. Однако использование ветвле-
ний позволяет, как правило, значительно уменьшить
сложность схем. Ниже описывается подход, на основе
которого можно строить схемы с ветвлениями.
Пусть в схеме для функции f(x)=f(xi, хп) вы-
ход элемента Е подается на входы нескольких элемен-
тов (рис. 2.11, а), и на нем реализуется функция /г(х'),
где х' — некоторое подмножество множества х. Удалим
из схемы элемент Е и введем новый полюс у, к которому
подсоединим освободившиеся входы (рис. 2.11, б). Функ-
цию, реализуемую на выходе полученной схемы, обо-
значим через g(x", у) (она зависит от некоторого под-
множества х" множества переменных х и от у). Если на
полюс у подать й(х'), то будет реализована функция
f (х), поэтому /(х) = g (х", h(x')).
Указанное представление получено на основе схемы,
однако обычно требуется обратное. Нужно найти де-
композицию (разложение)
f(x) = g(x", h(x')), (2.13)
а затем с ее использованием построить схему. Всякая
функция может быть тривиально представлена в форме
(2.13), если взять в качестве х' или х" множество всех
переменных х. При практическом синтезе схем исполь-
зуются декомпозиции, являющиеся в некотором смысле
86
ДИСКРЕТНЫЕ УСТРОЙСТВА ВЕЗ ПАМЯТИ
[ГЛ. И
«хорошими». Наиболее распространенным является ус-
ловие, чтобы множества х' и х" не пересекались. Деком-
позиции, удовлетворяющие этому требованию, назы-
ваются разделительными. Простейшим случаем разде-
лительной декомпозиции является формула разложения
по переменной (1.5). В ней множество х' включает
одну переменную, а х" — все оставшиеся. Ослабление
требования разделительное™ состоит в том, чтобы пере-
сечение множеств х' и х" было «малым».
Каждая из функций g и h, входящих в разложение
(2.13), может, в свою очередь, быть представлена с ис-
пользованием некоторых других функций и т. д., в ре-
зультате чего может быть получена «многоступенчатая»
декомпозиция.
2.4.2. Условие существования декомпозиций задан-
ного вида. Рассмотрим произвольную частичную булеву
функцию f(x) = f(xi, ..., хп). Пусть х' и х"— некото-
рые подмножества ее переменных, дающие в объедине-
нии х. Выясним условия, при которых существуют функ-
ции h(x') и g(x", у) такие, что имеет место разложение
(2.13) (более точно это означает, что в таком виде пред-
ставимо некоторое доопределение функции f(x)).
Обозначим через й пересечение множеств х' и х", а
через v и w соответственно множества переменных из
х! и из х", не вошедших в это пересечение. С учетом
введенных обозначений представление (2.13) может
быть переписано в виде
f(u, v, w) = g(u, w, h(u, v)),
где множества й, v и w попарно не пересекаются.
Пусть мощности множеств й, v и w равны соответ-
ственно р, q и г (р q + г = п). Рассмотрим некоторый
двоичный набор а длины р. Обозначим через fa (б, w)
частичную булеву функцию f(a, v, w), полученную из f
в результате приписывания переменным множествам й
значений из набора а. Функцию /а(б, w) будем зада-
вать таблицей Ts (б, w) с 2q столбцами и 2Г строками
(рис. 2.12). Ее столбцы соответствуют двоичным набо-
рам Р длины q, а строки — двоичным наборам у длины
г. В пересечении столбца р и строки у помещается зна-
чение fa (fl, у), если последнее определено. В противном
§ 2.4]
СИНТЕЗ СХЕМ МЕТОДОМ ДЕКОМПОЗИЦИИ
87
случае клетка оставляется пустой. Функция f(u,v,w)
однозначно задается совокупностью всех 2Р таблиц
Ta(v, w) (значение f (ст, ₽, у) содержится в пересечении
столбца р и строки у таблицы Та (у, &)). Доопределени-
ем таблицы Та(и, й))будем называть всякую таблицу, ко-
торая может быть получена из нее в результате записи
в каждой пустой клетке символа 0 или 1.
Следующая теорема дает ответ на вопрос, в каком
случае функция f(x)=f(U, v, w) представима в виде
g(u,w, h(U, и)) при заданных й, v и w.
Рис. 2.12.
Теорема 2.4. Частичная функция f(u,v,w) пред-
ставима в виде
f(fi, v, w) = g(U, w, h(tl, и)) (2.14)
при некоторых g и h тогда и только тогда, когда для
каждого а таблица Т«(5, w) допускает доопределение,
содержащее столбцы не более двух различных типов.
Доказательство. 1. Убедимся, что если некото-
рое доопределение функции f(u,v, w) представимо в
виде (2.14), то каждая из таблиц Та(и, wj допускает
доопределение, содержащее столбцы не более двух
типов.
Пусть
/ (й, v, — w, h(fi, v))
88
ДИСКРЕТНЫЕ УСТРОЙСТВА БЕЗ ПАМЯТИ
[ГЛ. И
является доопределением частичной функции f(u,v,w).
Тогда при каждом а таблица Ta(v, w), соответствующая
функции
f.(v, w) = f(a, v, w)~g(a, w, h(a, v))=g&(w, /ia(6)),
доопределяет таблицу Ta(v, w). Рассмотрим столбцы
таблицы Ta(v, w), соответствующие всем наборам р,
для которых /га(Р) = О, и в каждом из них возьмем
клетку, отнесенную одному и тому же набору у. В ней
записано значение
ga(Y> Ae(P)) = ge(Y» 0),
не зависящее от р. Следовательно, все столбцы, соот-
ветствующие наборам р с нулевым значением /ie(P), сов-
падают. Аналогично можно убедиться в совпадении
столбцов для всех наборов р с единичным значением
ha (Р). Это означает, что таблица T&(v, w) (являющаяся
доопределением для Т& (б, w)) имеет столбцы не более
двух типов.
2. Обратно, пусть при каждом а существует доопре-
деление fa(6, таблицы Га (б, ®), содержащее столбцы
не более двух типов. Обозначим через /г(а> (б) булеву
функцию, которая равна единице (нулю), если набору б
соответствует столбец первого (второго) типа. Обозна-
чим также через <р(а) (ш) булеву функцию, значения кото-
рой определяются столбцом первого типа (<р(а) (у) яв-
ляется значением, записанным в клетке столбца, соот-
ветствующей набору у), а через ф(а)(й>) — булеву функ-
цию, определяемую столбцом второго типа. Тогда
функция fa (б, w), задаваемая таблицей Та(б, й)), удо-
влетворяет соотношениям
г - _ ( <₽(a)M если /г(а)(Р)=1,
“ ’ { ф(а) (w), если /г(а) (Р) = 0,
и, следовательно, может быть представлена в виде
f. (б, w) = hw (б) <р(а) (й)) V hm (б) ф(а) (й>) =
= £!а,(й), /г(а)(б)), (2.15)
где gw (й>, у) = z/<p(3) (й>) V ytyw (w).
§2.4]
СИНТЕЗ СХЕМ МЕТОДОМ ДЕКОМПОЗИЦИИ
89
Введем функции
g(u, w, у) = V Ka(fi)gw(®> У)> (2.16)
б
h(u, 5)= V Ka<u)ha,(v) (2.17)
б
(напомним, что Кв.(й) означает конъюнкцию перемен-
ных множества й, взятых с показателями из набора а)
и положим
f (й, v, w) = g(H, w, h(fi, о)). (2.18)
Из (2.16) и (2.17) следует, что
g(a, w, y) = gl5->(&, у),
h(a, v) — h!a} (о).
Поэтому
/(a, v, w) = g(a, w, й(а, v)) = gw(w, /г(а>(и)),
и f(a, v, w) при каждом а совпадает с функцией fa(v, w),
задаваемой таблицей Ta(v, w) (см. (2.15)) и являющейся
доопределением fa(v, w). Таким образом, функция f,
введенная равенством (2.18), доопределяет f, а это озна-
чает, что исходная функция f представима в виде (2.14).
Теорема доказана.
Заметим, что в случае разделительной декомпозиции
множество й пусто и роль функций fa в теореме играет
сама функция f.
Для не всюду определенных таблиц большого раз-
мера проверка впрямую возможности доопределения до
таблиц с двумя типами столбцов оказывается затруд-
нительной. Другой более простой способ проверки осно-
ван на том факте, что для всюду определенных таблиц
следующие два свойства эквивалентны,-.
а) таблица содержит столбцы не более двух различ-
ных типов;
б) существует такая строка, что всякая строка таб-
лицы либо совпадает с ней, либо получается ее инвер-
сией (заменой единиц нулями и нулей единицами), либо
является чисто нулевой, либо чисто единичной.
90
ДИСКРЕТНЫЕ УСТРОЙСТВА БЕЗ ПАМЯТИ
(ГЛ. II
Действительно, если выполнено свойство а) и таб-
лица состоит из столбцов двух типов, то все строки,
содержащие в» обоих столбцах 0, являются нулевыми, а
содержащие в обоих столбцах 1—единичными. Все
строки, имеющие в первом столбце 1 п во втором 0, сов-
падают между собой, а строки, имеющие в первом
Рис. 2.13. Рис. 2.14.
столбце 0 и во втором 1, являются их инверсиями. Об-
ратно, если выполнено свойство б), то все столбцы, со-
держащие в «эталонной» строке 1, совпадают между со-
бой. То же самое относится и к столбцам, содержащим
в этой строке 0.
При выяснении вопроса о существовании доопреде-
ления таблицы, обладающего свойством б), строки, не
содержащие одного из символов 0 или 1, могут игнори-
роваться, ибо допускают доопределение до строк из
одинаковых символов. Возможность доопределения ос-
тальных строк таблицы до некоторой строки или ее ин-
версии проверяется просто.
2.4.3. Синтез схем. Метод построения схем на основе
представления (2.13) носит название метода декомпо-
зиции. При синтезе этим методом последовательно про-
сматриваются пары подмножеств (х',х"), обладающие
заданными свойствами (например, пепересекающиеся
§ 2.4]
СИНТЕЗ СХЕМ МЕТОДОМ ДЕКОМПОЗИЦИИ
91
либо пересекающиеся по «малым» подмножествам), и
для каждой из них проверяются условия теоремы 2.4.
После того как такая пара (%', х") найдется, методом,
использованным при доказательстве теоремы 2.4, могут
быть построены функции g и h, участвующие в разло-
жении (2.13). В результате задача сведется к реализа-
ции функций g и h, а общая схема будет иметь вид, по-
казанный на рис. 2.13. Затем та же процедура может
быть применена к функциям g и Л, и, если их удастся
разложить, схема приобретет вид, приведенный на
рис. 2.14. Продолжая этот процесс, можно получить не-
которую «многоступенчатую» схему из блоков. Каждый
блок соответствует определенной булевой функции. Эти
функции являются в некотором смысле «более про-
стыми», чем исходная. Их реализация может быть осу-
ществлена любым из известных методов (например,
описанным в § 2.2).
В качестве примера рассмотрим применение метода
декомпозиции к функции f(xi, х2, х3, х4), заданной таб-
лицей 2.1. Будем искать разделительные декомпозиции.
Проверим, имеется ли разложение вида f = g(xi,x2,
h(x3, Х4)). Для этого составим таблицу 2.15.
Таблица 2.15
Первая и вторая строки таблицы содержат элемен-
ты лишь одного вида. Поэтому достаточно проверить,
могут ли третья и четвертая строки быть доопределены
одинаковым образом либо до взаимно инверсных строк.
Очевидно, что этого сделать нельзя, и, следовательно,
декомпозиции искомого вида не существует. Применяя
те же рассуждения к столбцам таблицы 2.15, убеждаем-
92
ДИСКРЕТНЫЕ УСТРОЙСТВА ВЕЗ ПАМЯТИ
[ГЛ. II
ся, что функция не обладает и декомпозицией вида
g(x3, х4, 1г (Х[, х2)).
Таблица 2.16
Х1 Хз 0 0 0 1 1 0 1 1 Хк
0 0 0 0 1 1
0 1 1 1 1 1
1 0 © 0 ф 0
1 1 1 0> i
Попытаемся теперь найти декомпозицию в форме
f = g\x\, х3, h[xi, х2)). Рассматривая таблицу 2.16, где
значения функции f обозначены
жирным шрифтом, видим, что вто-
рая и третья строки могут быть до-
определены до единичной и нуле-
вой, а первая и четвертая — до
имно инверсных строк.
Полученное доопределение
*лицы содержит столбцы двух
пов. Столбцам первого типа
ответствует функция ф(хь х3) —
= xjx3 V Х{Хз = Хз, столбцам второ-
го типа — функция ф(хь х3) ==
=X]X3VxiX3=Xt. Функция /г(х2, х4)
равна 0 на единственном наборе
(1,0), указывающем положение
столбца второго типа, поэтому
h (х2, х4) = х2 V х4. Функция f выра-
жается согласно (2.15):
ж,
х, Хп
&з
О
Рис. 2.15.
вза-
таб-
ти-
со-
f (хь х2, х3, х4) = <р (хь х3) h (х2, х4) V ф (хь хз) h (х2, х4) =
= х3/г (х2, х4) V xi h (х2, х4).
Схема, построенная в соответствии с этим представле-
нием, изображена на рис. 2.15. Заметим, что при лю-
бом задании функции ф(Х1,х3) на наборе (0,1) таблица
§ 2.5] АСИМПТОТИЧЕСКИЕ МЕТОДЫ СИНТЕЗА СХЕМ 93
будет содержать столбцы двух типов. Таким образом,
функция ф(хьхз) может считаться частичной, а это
приведет к тому, что и функция g(x\,Xz, у) будет ча-
стичной (она не определена на наборе (0,1, 1)). Следо-
вательно, в результате декомпозиции частичных функ-
ций снова могут возникнуть частичные функции.
Теорема 2.4 допускает следующее обобщение. Если
каждая из таблиц Та может быть доопределена до таб-
лицы, содержащей не более t типов столбцов, то функ-
ция f представима в виде
f(x) = g(x", hdx'), ..., hs(x'))> (2.19)
где s не превосходит ближайшего целого числа, не
меньшего log2t. Доказательство этого факта и конструк-
ция функций g, hi, ..., hs легко могут быть получены
на основе доказательства теоремы 2.4. Представление
(2.19) значительно расширяет область применения ме-
тода декомпозиции. Отметим, что формула разложения
по k переменным (1.6) является частным случаем та-
кого представления.
§ 2.5. Асимптотические методы синтеза схем
2.5.1. Основные понятия. Как уже говорилось, извест-
ные методы построения наилучших схем связаны с пере-
бором и являются чрезвычайно трудоемкими. В данном
параграфе излагается существенно более простой метод,
который строит «почти наилучшие схемы» для «почти
всех» функций. Для произвольного числа е > 0 доля тех
функций от п аргументов, для которых схемы, синтези-
рованные этим методом, отличаются от наилучших бо-
лее чем в 1 + е раз, стремится к 0 с ростом п.
Будем рассматривать схемы в базисе {&, V, -}. Под
сложностью L(S) схемы S будем понимать число всех
входящих в нее элементов. (Если не учитывать элемен-
тов отрицания, подсоединенных к полюсам схемы
(рис. 2.7), как это делалось для схем без ветвлений,
окончательный результат не изменится.) Как и раньше,
Минимальную из сложностей схем, реализующих [, бу-
дем называть сложностью функции f и обозначать L(f).
Введем числовую функцию Ё(п), равную максимальной
Из сложностей функций f (всюду определенных) от п
94
ДИСКРЕТНЫЕ УСТРОЙСТВА БЕЗ ПАМЯТИ
[ГЛ. и
аргументов. Функция А(п) впервые была введена и ис-
следовалась (для схем другого вида) К. Э. Шенноном
и носит название функции Шеннона.
Мы будем изучать асимптотическое поведение функ-
ции L(n) при п—>оо. В связи с этим напомним ряд упо-
требительных понятий и обозначений. Будем говорить,
что числовые функции а(п) и Р(п) асимптотически рав-
ны, и записывать этот факт в виде а(п)~ Р(м), если
lim-^7^- = l. Если lim-^7^| = 0, будем использовать
обозначение а(п) = о(Р(п)) и говорить, что функция
а(п) существенно меньше, чем р(п). Легко видеть, что
соотношение а(п) ~ р(м) эквивалентно тому, что а(п) —
— р(п) + о(Р(п)). Таким образом, асимптотическое ра-
венство означает равенство с точностью до малых чле-
нов. Аналогично можно ввести понятие асимптотиче-
ского неравенства. Будем говорить, что функция а(п)
асимптотически не больше, чем р(м), и записывать
а(п) << Р(п), если а (и) Р(п)-(-о(Р(п)). Заметим, что
из асимптотического неравенства а(п)^р(п) еще не
следует обычное неравенство а (п) Р(п) (например,
можно записать 2" -ф п2 2п, хотя соотношение 2" -ф
-ф п2 2" неверно), в то время как из обычного нера-
венства асимптотическое следует. Соотношение а(п) ~
~ р(и) эквивалентно тому, что одновременно выпол-
нено а(п) р(п) и Р(п) а(п).
Величина функции Шеннона L(n) позволяет 'соста-
вить представление о том, сколь сложными могут быть
наилучшие схемы для функций от п аргументов. Асимп-
тотически точное значение функции Цп) найдено
О. Б. Лупановым. Оценка величины L(n) сверху полу-
чена им конструктивно, путем указания соответствую-
щего метода синтеза. Асимптотически совпадающая с
ней нижняя оценка установлена на основе одного об-
щего приема, предложенного К. Э. Шенноном. Этот
прием позволяет также доказать, что схемы, построен-
ные по методу Лупанова, являются «почти наилучшими»
для «почти всех» функций.
2.5.2. Метод синтеза Лупанова. Рассмотрим произ-
вольную булеву функцию f(xi, хп) от п аргумен-
тов. Возьмем некоторое натуральное число k, не превос-
5 2.5]
АСИМПТОТИЧЕСКИЕ МЕТОДЫ СИНТЕЗА СХЕМ
95
ходящее п, и разложим f по первым п — k аргументам
/(Х1.......х„) =
= . V Х11 • • ' (ffl...°п-к’ Xn-k+l........Хп)~
(01...ап-к)
= S-(a V a ft)*'' (Xn-ft+P Хп)- (2-20)
Зададимся натуральным числом s (l^s:C2ft) и
разобьем столбец длины 2к значений функции
^(хл-а+1....хп) на КУСКИ длины s (последний кусок
имеет длину s'<s). Куски занумеруем
1,2, .... р, где р определяется из условия
2й 2* . .
— <т + 1-
числами
(2.21)
Обозначим через /3 ;xn) (Z=l, р) бу-
леву функцию, которая в z-м куске совпадает с
f3(xn_k+1.....хй), а вне его равна 0 (рис. 2.16). Ясно,
что
р
fa{Xn-k + l’ Хп) ~ У Ja, i(.Xn-k+l> Хп)>
96
ДИСКРЕТНЫЕ устройства без памяти
[ГЛ. II
а потому разложение (2.20) приобретает вид
f (-^Ь • • •» Хп) =
= а . Х1' Xn-'kky fs.i(Xn-k+l.........Хл)"
3=(а1...an-k) ‘"1
С использованием полученного представления построим
схему для /.
Рис. 2.17.
Схема состоит из блоков (рис. 2.17):
а) Блок А реализует все конъюнкции х°‘ ... х’*7*
от первых п — k переменных. Для этого вначале реали-
зуются отрицания переменных Xi, хп-ь (на это идет
п — k элементов отрицания), затем с помощью двухвхо-
довых элементов & строятся конъюнкции х°> ... xAn-k
длины п — k. Всего таких конъюнкций 2п~к и на реали-
зацию каждой из них затрачивается п — k — 1 элемен-
§ 2.51 АСИМПТОТИЧЕСКИЕ МЕТОДЫ СИНТЕЗА СХЕМ
97
тов &. Поэтому общая сложность блока А удовлетво-
ряет оценке
£(Л)<п-Н2л"‘(п-4-1)<(п-4) 2п-\
Ь) Блок В реализует все конъюнкции . хапп
последних k переменных. Аналогично предыдущему,
L (В)< k • 2*.
с) Блок С реализует все функции fg t. Каждая из
них характеризуется номером i куска, в котором она
может принимать единичные значения (р вариантов),
и заполнением этого куска длины не больше s (на бо-
лее 2s вариантов). Поэтому число различных функций
fg t не превосходит р • 2s. Каждая из функций fg z рав-
на 1 не более чем на s наборах и ее с. д. н. ф. является
дизъюнкцией самое большее s конъюнкций, которые
уже реализованы в блоке В. Таким образом, в блоке С
на одну функцию f s> t достаточно затратить s — 1 < $
элементов, и общая сложность блока С составляет
T(C)<sp-2s.
р
d) В блоке D реализуются все функции fg = V fg t.
На одну функцию fg затрачивается р — 1 < р элемен-
тов V (функции fg f уже реализованы). Число различ-
ных функций fg не превосходит числа 2п~к наборов б
длины п — k, поэтому
L(D)<р • 2п~к.
е) В блоке Е реализуются все произведения
& fs- Для этого требуется 2n~k элемен-
тов & (по числу наборов б), и, следовательно,
L(E)^2n~k.
f) Блок F реализует внешнюю дизъюнкцию по 5.
Для построения дизъюнкции длины 2"~А требуется
— 1 < 2п~к двухвходовых элементов V, поэтому
L (F) < 2п~к.
4 Л. А. Шеломов
98
ДИСКРЕТНЫЕ УСТРОЙСТВА БЕЗ ПАМЯТИ
[ГЛ. И
Суммируя оценки пунктов а)—f), окончательно по-
лучаем
L(f)^L(A) + L(B) + L(C) + L(D) + L(E) + L(F)^
<(n - k)2n~k + k • 2k + sp • 2s + p • 2n-ft + 2 • 2n~k. (2.22)
Эта оценка справедлива при любых k и s. Параметры
k и $ нужно выбрать так, чтобы величина правой части
в (2.22) была по возможности малой. Некоторый анализ
полученного выражения (на котором мы останавливать-
ся не будем) показывает, что асимптотически наилуч-
ший результат может быть получен при следующем
выборе параметров:
k = [3 log га], s = [n — 5 log n] (2.23)
(здесь и дальше под logx понимается logzx, а через
[х] обозначено наибольшее целое число, не превосходя-
щее х). Из (2.23) следует, что числа k и s удовлетворяют
неравенствам
3 logn — 1 < k 3 logn, (2.24)
п — 5 logn — 1 < п — 5 logn. (2.25)
Оценим величину — с учетом (2.24) и (2.25):
2к 231О8'г-1 п3 п2
s п 2п 2
Следовательно, -у->оо, и в силу (2.21)
2ft
(2.26)
(2.27)
Из (2.26) и (2.27) вытекает, что п = о(р), поэтому
(п - k) 2n~k + 2 • 2n~k = о (p2n~k).
С учетом этого и (2.27) из (2.22) получаем оценку
L(f)^ k • 2k + sp • 2s + p • 2n~k k • 2k +
(2.28)
§ 2.51 АСИМПТОТИЧЕСКИЕ МЕТОДЫ СИНТЕЗА СХЕМ
99
Из неравенств (2.24)
s ~ п. Поэтому
и (2.25) видно, что k ~31ogn и
2" 2П
S п
k • 2к = о (s2fe) = о (2fe+s),
и оценка (2.28) приобретает вид
(2.29)
Используя (2.24) и (2.25), оценим величину 2k+s:
nk+s n3 log п+п—5 log п______ 2п _ ( 2п \
2 2 ~~ п2~ ° \п Г
Отсюда и из (2.29) получаем окончательный результат:
' п
Таким образом, метод Лупанова позволяет реализо-
вать любую функцию f от п аргументов со сложностью,
2П
асимптотически не превосходящей—. Взяв в качестве
f самую сложную функцию от п аргументов, получаем
верхнюю оценку функции Шеннона:
(2.30)
2.5.3. Мощностной метод нахождения нижних оценок.
Для доказательства верхней оценки L(f)^.A доста-
точно для функции f указать схему, сложность которой
не превосходит А, в то время как для установления
нижней оценки L(f)^B необходимо доказать, что
проще, чем В, функция f реализована быть не может.
Аналогичное различие имеется и между верхней и ниж-
ней оценками функции Шеннона. В частности, оценка
L(n)^B(n) означает, что никакой метод синтеза не
может для всех функций от п аргументов дать схемы
более простые, чем В(п). Общий прием, с использова-
нием которого можно получить нижнюю оценку для
L(n), был предложен К. Шенноном. Он основан на том
соображении, что схем малой сложности мало и их не
хватает для реализации всех функций от п аргументов,
4*
100
ДИСКРЕТНЫЕ УСТРОЙСТВА БЕЗ ПАМЯТИ
[ГЛ. II
в связи с чем существуют функции, требующие схем
большей сложности.
Обозначим через N{n,k) число различных схем (в ба-
зисе {&, V, “}), имеющих не более п входных полюсов,
соответствующих некоторым переменным из множества
{xi, ..., хп}, один выход и не более k элементов. Схемы
считаются различными, если их нельзя изобразить так,
чтобы они полностью совпали. Кроме того, будем рас-
сматривать лишь схемы, у которых каждый полюс и
выход каждого элемента, не являющийся выходом схе-
мы, присоединены к входам некоторых элементов (иначе
полюс или элемент можно из схемы удалить). Получе-
ние нижней оценки основано на следующем утвержде-
нии.
Лемма о нижней оценке. Если для некоторой
функции k(n) при п~* оо выполнено
N (n, k (п))
22« U-
(2.31)
то, начиная с некоторого п, имеет место оценка
L(ri)> k (п),
причем доля тех функций f(xi, ..., хп), для которых
L(f) s~Zk(n), стремится к 0 с ростом п.
Доказательство. Каждая функция f(xi.......хп)
такая, что L(f)^ k(n), реализуется некоторой схемой,
содержащей не более п полюсов и не более k(n) эле-
ментов, причем разные функции требуют разных схем.
Поэтому число таких функций f не превосходит У(п,
k(п)), и в силу условия (2.31) их доля среди всех 22"
функций от п аргументов стремится к 0 с ростом п. Тем
самым вторая часть утверждения леммы доказана.
Из (2.31) следует, что, начиная с некоторого п, вы-
W(п, k (п)) 1 „ „
полнено ---------<—, т. е. при этих п по крайней
мере половина всех функций имеет сложность выше k(n},
а потому L(n)> k(n). Лемма доказана.
Таким образом, задача свелась к оценке величины
АГ(п,/г) и к подбору по возможности большей функции
k(n), удовлетворяющей условию леммы.
Указанный прием применим к схемам других видов
(при этом величина N(n, k) относится к схемам соот-
АСИМПТОТИЧЕСКИЕ МЕТОДЫ СИНТЕЗА СХЕМ
101
можно опреде-
§ 2.5]
ветствующего вида), к реализации функций из специ-
альных классов (при этом вместо общего числа 22"
функций от п аргументов фигурирует число функций
от п аргументов из рассматриваемого класса), к реали-
зации устройств с памятью и др. Методы получения оце-
нок, основанные на этом приеме, носят название мощ-
ностных.
2.5.4. Подсчет числа схем. Оценка числа де-
ревьев. Нам понадобится оценка числа деревьев с кор-
нями. Дерево представляет со-
бой связный граф (неориенти-
рованный) без циклов, а дерево
с корнем — это дерево, в кото-
ром отмечена одна вершина (ко-
рень). Обозначим через D(h)
число различных деревьев с кор-
нями, имеющих h вершин. Пока-
жем, что
£>(/?)< 4ft. (2.32)
Легко видеть, что дерево с ь
лить индуктивно следующим обра
— вершина есть дерево с корнем, корнем является
эта вершина;
— если Л1, ..., As (s> 1) деревья с корнями, то ре-
зультат присоединения к каждому из корней ребра и
отождествления свободных концов этих ребер (рис. 2.18)
есть дерево с корнем; корнем является вёршина, обра-
зованная в результате отождествления.
Каждому дереву А с корнем в соответствии с его
индуктивным определением сопоставим код k(A) из
нулей и единиц. Для этого вершине сопоставим код 01.
Если дерево А образовано из А1г ..., As в соответствии
с рис. 2.18, то его кодом будем считать слово
k(A) = Qk(Ai) ... k(As) 1.
Легко видеть, что длина кода для дерева с h верши-
нами имеет длину 2h. Процесс последовательного при-
писывания кодов проиллюстрирован на рис. 2.19.
По коду k(A) дерево с корнем А восстанавливается
однозначно. Действительно, заменив 0 в коде дерева ле-
вой скобкой, а 1 правой скобкой, мы преобразуем код
в скобочное выражение. При этом деревьям, имеющим
102
ДИСКРЕТНЫЕ УСТРОЙСТВА БЕЗ ПАМЯТИ
[ГЛ. II
вид вершин, будет соответствовать пара соседних ско-
бок ( ), а дереву А, полученному из Ai, As со-
гласно рис. 2.18, будет соответствовать скобочное вы-
ражение, образованное заключением в скобки выраже-
ний для ..., Ast
((А)(Л2) ... Ш).
Однозначность расшифровки кода следует из знако-
мого всем факта однозначности прочтения скобочных
выражений. Таким образом, число D(h) деревьев с кор-
нями, имеющих h вершин, не больше числа их кодов,
которое, в свою очередь, не превосходит числа 22А = 4А
всех двоичных слов длины 2/г.
Оценка числа схем. Каждой схеме S поставим
в соответствии ориентированный граф, вершинам кото-
рого приписаны некоторые обозначения. Для этого
— каждому входному полюсу и каждому элементу
схемы сопоставим вершину, в первом случае ей припи-
шем символ Xt переменной, соответствующей полюсу, во
втором — обозначение функции, реализуемой элемен-
том;
— каждому входу каждого элемента Е схемы сопо-
ставим в графе ориентированную дугу, ведущую из вер-
шины, соответствующей полюсу или элементу, к кото-
рому подсоединен вход, в вершину, соответствующую
элементу Е;
— вершине, сопоставленной выходному элементу, до-
полнительно припишем символ *.
На рис. 2.20, б изображен граф, построенный по схе-
ме, показанной на рис. 2.20, а.
§ 2.5]
АСИМПТОТИЧЕСКИЕ МЕТОДЫ СИНТЕЗА СХЕМ
103
Граф, полученный из схемы с п' п полюсами, ki
элементами отрицания и /гг элементами конъюнкции и
дизъюнкции, обладает следующими свойствами:
— он имеет п' + k\ + k2 вершин, некоторые из кото-
рых отмечены символами переменных Хц, ..., х1п, из
множества {%i, ..., хп}, а остальные — символами &,
V и ", кроме того, вершине, из которой не исходит дуг
(такая вершина единственна), приписан дополнитель-
ный символ *;
Рис. 2.20.
— он имеет ki + 2k2 дуг, причем в каждую вершину,
отмеченную символом ведет одна дуга, а в вершину,
отмеченную символом & или V, ведут две дуги;
— для каждой вершины существует цепь, соединяю-
щая ее с вершиной, помеченной * (поскольку каждый
полюс и каждый элемент, отличный от выходного, куда-
нибудь подсоединены).
Обозначим через Г (п, п', ki, k2) множество всех гра-
фов, обладающих перечисленными тремя свойствами, а
через N (п, п', k\, k2)—их число. В Г(п, п', k\, k2) встре-
чаются все графы, соответствующие схемам с п' полю-
сами, ki элементами отрицания и k2 двухвходовыми эле-
ментами. Ясно, что
N (п, k)^. У. N(п, п', ki, k2). (2.33)
fl', k\, ki
(n' < n, k}+ki^k)
Оценим величину N(n, n', k\, ki).
104
ДИСКРЕТНЫЕ УСТРОЙСТВА БЕЗ ПАМЯТИ
[ГЛ. И
В каждом графе из множества Г(п, п', ki, #2) можно
выделить дерево с корнем в вершине *, содержащее все
вершины графа (одно из деревьев, построенных по
графу, изображенному на рис. 2.20, б, показано на
рис. 2.21,а). Исходя из сказанного, каждый граф из
Г(п, п', k\, &2) может быть построен следующим обра-
зом (изложение будем сопровождать примером построе-
ния графа, показанного на рис. 2.20, б).
Рис. 2.21.
1. Выбирается дерево с корнем, содержащее п' +
+ &1 + &2 вершин (рис. 2.21, а); согласно (2.32) это
можно сделать 4n +fe,+fe!^4n+fei+fe’ способами.
2. Корню приписывается символ * и дуги ориенти-
руются по направлению к корню (рис. 2.21,6); это де-
лается однозначно.
3. Из множества {xi, ..., хп} выбираются п' пере-
менных xiv х(п,; для этого имеется С" 2* воз-
можностей.
4. Одна из вершин отмечается символом xt, дру-
гая — символом xt и т. д........ некоторая п'-я — сим-
волом х1п, (рис. 2.21,в); для выбора каждой из вершин
имеется не более п' 4- k\ + k2 возможностей, поэтому
вариантов выбора всех вершин не больше (n' + ^i +
Wn'^(» + ^i+^)n.
5. Среди ki + k2 вершин, не отмеченных символами
переменных, выбираются и отмечаются символом ~ ki
вершин; это можно сделать C^+k^ 2kl+>h способами.
Остальные k2 вершин отмечаются одним из символов &
и V; для этого имеется 2кг возможностей. (Граф, по-
§ 2.5]
АСИМПТОТИЧЕСКИЕ МЕТОДЫ СИНТЕЗА СХЕМ
105
строенный после данного шага, изображен на
рис. 2.21, г.)
6. Выделенное дерево содержит п' + k\ +-&2 — 1 дуг
(на одну меньше числа вершин), а всего в графе долж-
но быть ki + 2^2 дуг. Для недостающих kx + 2&2—(п' +
+ k\ + fe2— 1) = fe2 — п' + 1 дуг известны вершины, к ко-
торым они должны быть направлены (поскольку в каж-
дую вершину, помеченную & или V, должны входить
две дуги, а в вершину, помеченную одна дуга). Вто-
рые концы каждой из этих дуг можно выбрать не более
чем n' + &i + &2 способами; а всего вариантов выбора
не больше (п' + kx + &2)Аг-п +1 (п + kx + k2)k\ После
этого шага граф полностью построен (в данном случае
он совпадает с изображенным на рис. 2.20,6).
Величина N (п, п', kx, k2) не превосходит произведе-
ния оценок из пунктов 1—6:
N (п, п', kx, k2)^.
< 4«+^+^2«(rt + kx 4. 62)n2*,+*!2*’(n + + k2)k,=
= 84+fe,+*!2*! (n + kx + k2)n+k2 <
< (16 (n + kx + k2))n+k'+kl = (16 (n + k))n+k.
При суммировании в (2.33) по п', kx и k2 для вычисле-
ния W(n, k) индекс п' может принимать не более п зна-
чений (от 1 до п), а каждый из индексов kx и k2 —
не более (&+ 1) значений (от 0 до k). Поэтому
N(n, k)^n(k + l)2(16(n + k))n+k.
Отсюда, поскольку п 1, окончательно получаем
У(п, £)<(16(п + £))п+а+3. (2.34)
2.5.5. Нижняя оценка сложности схем. Теперь мы
имеем возможность применить лемму о нижней оценке.
С ее использованием докажем, что при всех достаточно
больших п
on
b(«)>v (2.35)
и доля тех функций f(xx, ..., х„), для которых
стРемится к 0 с ростом п.
106
ДИСКРЕТНЫЕ УСТРОЙСТВА ВЕЗ ПАМЯТИ
[ГЛ. II
Для этого достаточно проверить выполнимость уело-
2п
вия (2.31) при k (п) = — или, что эквивалентно, условия
log М [п, — 2п-> — оо. (2.36)
Используя оценку (2.34), получаем цепочку соотноше-
ний
<(л + £+3)(4+108 (»+О-2“<
<(»+т+3)(4 + 1»8^)~2" =
= (» + '7г+ 3) (^ + 5 —• logn) —• 2* =
-2 п + 5 + п2 — n log п + 8п — 31ogn + 15 =
= --^(1 -о(1)).
Последняя величина стремится к —оо, и условие (2.31)
оказывается выполненным.
Сопоставляя оценки (2.30) и (2.35), получаем сле-
дующее утверждение.
Теорема 2.5 (О. Б. Лупанов). Имеет место асимп-
тотическое равенство
(2.37)
причем доля тех функций f(xIt хп), для которых
2"
Т (/) ^ —, стремится к 0 с ростом п.
Таким образом, почти все функции являются асимп-
тотически самыми сложными, и метод Лупанова строит
для почти всех функций почти наилучшие (асимптоти-
чески наилучшие) схемы.
Мощностные методы дают возможность получать вы-
сокие нижние оценки. Однако они неэффективны в том
смысле, что не позволяют указывать конкретные слож-
ные функции подобно тому, как это было сделано, на-
пример, в разделе 2.3.8 при рассмотрении д. н. ф. На-
§ 2.5]
АСИМПТОТИЧЕСКИЕ МЕТОДЫ СИНТЕЗА СХЕМ
107
хождение конкретной функции от п аргументов, слож-
ность которой превосходит заданную величину /(п)
(t(n) < L(n)), в принципе может быть осуществлено с
использованием переборной процедуры, в процессе ко-
торой просматриваются все схемы в порядке возраста-
ния сложности и из списка функций от п аргументов вы-
черкиваются те, которые реализуются этими схемами.
После того как окажутся перебранными все схемы со
сложностью не выше t(n), любая из невычеркнутых
функций f будет иметь сложность L(f)>t(n). Более
простой процедуры построения сложных функций не из-
вестно, и имеются основания полагать, что эта задача
не допускает простого решения [39].
Чрезвычайно важной является проблема получения
нижних оценок сложности конкретных функций. Имея
такие оценки, можно делать заключение о том, насколь-
ко построенные схемы близки к наилучшим, а в неко-
торых случаях — доказывать минимальность схем. За-
дача нахождения нижних оценок для конкретных функ-
ций оказывается очень трудной. К настоящему времени
для схем из функциональных элементов удается полу-
чать лишь оценки вида
L (f (xi, ..., хп)) > схп — с2, (2.38)
где Сц Сг—положительные константы (см., например,
[29]). Наивысшая из найденных оценок для схем без
ветвлений имеет вид [35]
L(f(xh хп))^п2. (2.39)
На основе оценок (2.38) и (2.39) была доказана мини-
мальность ряда схем.
2.5.6. Некоторые дальнейшие результаты. Теорема
2.5 допускает обобщение на случай систем булевых
функций [19]. Обозначим через 9~т, п множество всех
систем из т функций от п аргументов, а через L(m, п) —
функцию Шеннона для класса т, п, равную макси-
мальной из сложностей L(F) систем F&.9~m,n. Тогда,
если т = т(ц) достаточно мало в сравнении с общим
числом функций от п аргументов (удовлетворяет соот-
ношению log/п = о (log 22")), то выполнено асимптоти-
ческое равенство
(2.40)
108
ДИСКРЕТНЫЕ УСТРОЙСТВА БЕЗ ПАМЯТИ
[ГЛ. II
причем почти все системы из STm, п имеют сложность,
асимптотически равную величине L(m, п).
Этот результат и теорема 2.5 относятся к произволь-
ным системам и функциям. Функции (и системы), ис-
пользуемые на практике, не являются произвольными.
Обычно они обладают какими-либо особенностями (на-
пример, обращаются в 1 на малом числе наборов, до-
пускают специальные виды декомпозиции и др.), что
уменьшает сложность их схемной реализации. В связи
с этим представляет интерес задача разработки методов
синтеза для функций (и систем) из специальных клас-
сов. Общий подход к решению этой задачи был развит
О. Б. Лупановым [19]. Этот подход путем некоторой
перекодировки сводит реализацию функций из задан-
ного класса к реализации произвольных функций от
меньшего числа аргументов. С его использованием уда-
лось построить методы асимптотически наилучшего син-
теза фактически для всех известных классов функций
и систем, представляющих интерес с точки зрения схем-
ной реализации. Одним из примеров является реализа-
ция частичных булевых функций от п аргументов, за-
данных на W наборах. Было показано [37], что в широ-
ком диапазоне значений У = У(п) сложность схемной
реализации частичных функций асимптотически не пре-
восходит __
причем почти все такие функции имеют
сложность,
большую j (ср. с верхней оценкой (2.7)
для схем без ветвлений).
Исходя из оценок сложности функций из отдельных
классов, можно делать выводы о том, каким образом те
или иные качественные свойства функций (монотон-
ность, симметрия и др.) влияют на сложность схем и
как зависит сложность от различных числовых парамет-
ров функций (число наборов, на которых они опреде-
лены, число единичных значений и др.). Основанные на
этом соображения находят применение при практиче-
ском синтезе схем.
До сих пор речь шла лишь о схемах в базисе {&, V,
а под сложностью схемы понималось число элемен-
тов. Однако все приведенные выше асимптотические ре-
§2.51
АСИМПТОТИЧЕСКИЕ МЕТОДЫ СИНТЕЗА СХЕМ
109
зультаты допускают обобщение на случай произволь-
ного базиса. Будем рассматривать схемы в конечном
базисе 8 = {£i, ..., Ek} и будем считать, что каждому
элементу Ei приписан вес (стоимость) р, > 0. Слож-
ностью L®(S) схемы S в базисе 8 будем называть сум-
му весов входящих в нее элементов, а сложностью
системы F — минимальную из сложностей схем, реали-
зующих F. На этой основе можно ввести функции
Шеннона Б? (п) и L? (т, п) для базиса 8.
Пусть элемент Ei (i — 1, ..., k) реализует булеву
функцию, существенно зависящую от v, аргументов.
Приведенным весом элемента Ei назовем величину
Pi
(значение р, вычисляется лишь в случае vt 2, при
Vi = 1 оно не определено), а приведенным весом базиса
<8 — величину
р, = min р,.
• Ег <=«(«, >2)
Все асимптотические результаты, относящиеся к базису
{&, V,-}, могут быть переформулированы для произ-
вольного базиса с тем отличием, что величину оценки
необходимо домножить на рг [19]. Так, например, тео-
рема 2.5 приобретает вид
2”
(°) ~ Р? ~ ’
причем доля тех функций f .... хп), для которых
2п
— , стремится к 0 с ростом п.
Отметим, что для рассматривавшегося выше основ-
ного случая, когда базисом является {&, V, *}, а слож-
ность схем измеряется числом элементов (т. е. веса всех
элементов считаются равными 1), приведенный вес ба-
зиса равен 1.
по
ДИСКРЕТНЫЕ УСТРОЙСТВА С КОНЕЧНОЙ ПАМЯТЬЮ [ГЛ. Ill
Глава III
ДИСКРЕТНЫЕ УСТРОЙСТВА
С КОНЕЧНОЙ ПАМЯТЬЮ
§ 3.1. Конечные автоматы
3.1.1. Основная модель. До сих пор рассматривались
дискретные устройства без памяти. В них значения вы-
ходов однозначно определяются сигналами, поданными
на вход в тот же момент. В более общем случае выходы
дискретных устройств могут зависеть и от внутренних
состояний устройств. Посредством внутренних состоя-
ний может быть учтена необходимая информация о сиг-
налах, поступивших на входы раньше. Если число этих
состояний конечно, то будем говорить об устройствах с
конечной памятью.
Примером такого устройства является двоичный сум-
матор последовательного действия. Он имеет 2 входа
и 1 выход. На входы в моменты времени t= 1,2, ...
последовательно поступают двоичные разряды слагае-
мых (начиная с младшего разряда), а с выхода сни-
маются значения соответствующих двоичных разрядов
суммы. Каждый разряд суммы определяется разрядами
слагаемых, относящимися к той же позиции, и тем,
имеется ли перенос из предыдущего разряда. По-
этому последовательный сумматор имеет 2 состояния,
одно из которых соответствует наличию переноса, а вто-
рое — отсутствию.
Моделью дискретного устройства с конечной па-
мятью является конечный автомат. Он имеет п входов
xi, ..., хп, на каждый из которых могут подаваться
символы конечного алфавита A, m выходов у\, ..., ут,
каждый из которых может принимать значения из ко-
нечного алфавита В, и конечное множество Q = {t/o,
7i, ..., qr-1} внутренних состояний.
Конечный автомат функционирует в дискретные мо-
менты времени t = 0, 1, 2, ... Если обозначить через
yj(t) и q(t) значения входа xi, выхода у, и состоя-
ния q в момент t, то работа автомата описывается урав-
§ 3.1]
КОНЕЧНЫЕ АВТОМАТЫ
111
нениями
^/(/) = Ф/(%!(/), .... xn(t), q(t - 1)), (/=1.т), |
q(t)==4 ..., xn(t), q(t—l)), )
(3.1)
которые называются каноническими. Функции Ф/ и Т,
присутствующие в этих уравнениях, называются соот-
ветственно функцией j-го выхода и функцией переходов.
Для того чтобы задать поведение автомата, нужно до-
полнительно указать его начальное состояние <?(0).
Зная q(0) и входные воздействия в 1-й момент времени,
можно, пользуясь каноническими уравнениями, опре-
делить значения выходов и состояние в 1-й момент, по
q(i) и входным воздействиям во 2-й момент можно оп-
ределить значения выходов и состояние во 2-й момент
и т. д. Существуют два типа автоматов — инициальные
и неинициальные. В инициальных автоматах начальное
состояние фиксировано (т. е. они всегда начинают функ-
ционировать из одного и того же состояния). В неини-
циальных автоматах в качестве начального состояния
может быть взято любое. Выбор начального состояния
определяет его поведение в последующие моменты.
Рассмотрим в качестве примера двоичный сумматор
последовательного действия. Входы сумматора обозна-
чим через хи/, а выход — через у. Состояния, соответ-
ствующие наличию и отсутствию переноса, обозначим
символами 1 и 0. Тогда на основании (2.1) и (2.2) ка-
нонические уравнения последовательного сумматора мо-
гут быть записаны в виде
y(t) = x(t)®x'(f)®q(t — 1),
q (0 = х (/) х' (0 V x(t)q(t — 1) V x'(t)q(t — 1).
Последовательный сумматор всегда начинает функцио-
нировать из состояния (?(0) = 0, соответствующего от-
сутствию переноса, поэтому ему отвечает инициальный
автомат.
Введенная модель конечного автомата допускает
упрощение. Обозначим через А алфавит А X А X • •
... Х^4 (п, раз). Его символами являются всевозмож-
ные наборы а = (а(1), ..., а(гг>), гле a(i) *= А. Анало-
гично, положим В — ВХ ВХ ••• X В (т раз). Автомат
112
ДИСКРЕТНЫЕ УСТРОЙСТВА С КОНЕЧНОЙ ПАМЯТЬЮ [ГЛ. III
с п входами и т выходами можно рассматривать, как
автомат с 1 входом х и 1 выходом у. Подача на входы
xi, .... хп символов а(1), ..., а(Г1) алфавита А при этом
интерпретируется как подача на вход х символа а е А,
а появление на выходах yi, ..., ут символов &(1>, ...
..., алфавита В интерпретируется как появление
на выходе у символа Б е В. Таким образом, изучение
автоматов с произвольным числом входов и выходов
сводится к изучению автоматов с 1 входом и 1 выхо-
дом. Заметим, что при схемной реализации автоматов
(см. §§ 3.3—3.4) каждый из п входов и т выходов
должен реально присутствовать в схеме. В связи с этим
понадобится и обратная операция, сводящая автомат
с 1 входом и 1 выходом к автомату с несколькими вхо-
дами и выходами (чаще всего двоичными).
В качестве основной модели будем рассматривать
автомат с 1 входом х и 1 выходом у. Он описывается
каноническими уравнениями
£(0==Ф(х(0, q(t- 1)),
= qlt-Vj).
Входные сигналы принимают значения из конечного ал-
фавита А, выходные—из конечного алфавита В, состоя-
ния являются символами конечного алфавита Q. Авто-
маты этого вида носят название автоматов Мили.
3.1.2. Способы задания автоматов. Для решения раз-
ных задач, связанных с анализом, синтезом и упроще-
нием устройств, оказываются удобными различные спо-
собы задания автоматов.
Опишем два из них, являющиеся наиболее распро-
страненными. Эти способы относятся к неинициальным
автоматам (для инициальных должно быть дополни-
тельно указано начальное состояние).
Таблица. Функции Т и Ф задаются таблицей,
строки которой соответствуют буквам входного алфави-
та, а столбцы — состояниям. В пересечении строки а,
и столбца qi помещаются состояние Чг(а/, qi), в которое
переходит автомат из qi под действием входного сиг-
нала а/, и значение Ф(а/, qi), которое при этом появ-
ляется на выходе. В таблице 3.1 приведен пример ав-
томата с алфавитами А ={0,1,2}, В = {0,1} и Q —
= {Vo> ?2, ?з}.
§ 3.1]
КОНЕЧНЫЕ АВТОМАТЫ
113
Диаграмма,
скости кружками.
Состояния qi изображаются на пло-
Из кружка qi проводится стрелка в
Рис. 3.1.
qu, если автомат, находящийся в состоянии qt, при по-
даче некоторого входного символа может быть переве-
ден в состояние qu. Пусть а^, а^, ..af — все входные
воздействия, переводящие qt в qu, a b^, b^, .... —
сигналы на выходе, соответствующие этим переходам.
Тогда стрелке, ведущей из qi в qu, приписывается выра-
жение^, &0[) V (а!г, bvJ V ... V (a/s, b^. На рис. 3.1
дана диаграмма автомата, заданного таблицей 3.1.
Диаграммы обладают большей наглядностью, чем
таблицы. Так, например, из приведенной диаграммы
видно, что состояние q2 является тупиковым (оказав-
шись в нем, автомат навсегда остается в этом
Таблица 3.1
q X <7» <7i <71
0 <71. 1 1 <72, о <7ь 0
1 <7о, 1 <7о- 0 <72. 0 <7о, 1
2 <7о, 0 <7ъ 1 <72, 1 <7з, 0
114
ДИСКРЕТНЫЕ УСТРОЙСТВА С КОНЕЧНОЙ ПАМЯТЬЮ [ГЛ. Ш
состоянии), a q3 является невозвратным состоянием
(выйдя из q3, автомат туда не возвращается). Заметить
подобные свойства по таблице более сложно.
Таблица 3.2
X xf Qi <7>
0 0 <7о, 0 <7о, 1
0 1 <7о, 1 <7ь 0
1 0 <7о, 1 <7ь 0
1 1 <7i, 0 <71, 1
Для иллюстрации приведем таблицу и диаграмму
двоичного сумматора последовательного действия. Если
обозначить через qo и qi состояния, соответствующие
отсутствию и наличию переноса, то, как нетрудно ви-
деть, сумматор описывается таблицей 3.2. Его диаграм-
ма приведена на рис. 3.2.
Рис. 3.2.
3.1.3. Другие модели конечного автомата. Автомат
Мили не является единственной моделью дискретного
устройства с конечной памятью. Почти столь же широ-
кое распространение получила и другая модель — авто-
мат Мура. В нем значение выхода однозначно опреде-
ляется состоянием в тот же момент. Канонические урав-
нения автомата Мура имеют вид
q(f) = y‘¥ g(/-l)),
у (0 = (<?(/)).
Подставив во второе уравнение из первого значение
§3.1) КОНЕЧНЫЕ АВТОМАТЫ 115
</(/) и положив Ф —A(W), можно преобразовать второе
уравнение к виду:
</(/) = А (х (/), q (t - 1))) = Ф (х (/), q (t - 1)).
Таким образом, автомат Мура можно рассматривать
как частный случай автомата Мили при функции вы-
хода специального вида Ф = Х(ЧГ). Оказывается, что и
автоматы Мили в некотором смысле сводятся к автома-
там Мура. Чтобы сформулировать этот факт более
точно, дадим ряд определений.
Два инициальных автомата будем называть экви-
валентными, если любую одну и ту же входную после-
довательность х(1)х(2) ... они перерабатывают в одну
и ту же выходную последовательность 1/(1)#(2) ... (для
инициальных автоматов выходная последовательность
однозначно определяется входной). Неинициальные ав-
томаты М и М' будем называть эквивалентными, если
для любого состояния q автомата М найдется состоя-
ние q' автомата М' такое, что если в качестве началь-
ных состояний автоматов М и М' взять соответственно
q и q', то одинаковые входные последовательности они
будут перерабатывать в одинаковые выходные последо-
вательности, и наоборот, для любого состояния q' ав-
томата М' найдется состояние q автомата М такое, что
q и q' обладают указанным выше свойством. Другими
словами, эквивалентность инициальных автоматов оз-
начает, что они осуществляют одинаковую переработку
информации, а эквивалентность неинициальных — что
этого всегда можно добиться путем подходящей на-
стройки.
Отметим, что эквивалентные автоматы имеют оди-
наковые входные алфавиты и одинаковые выходные, но
могут иметь разные алфавиты состояний.
Покажем, что для всякого автомата Мили сущест-
вует эквивалентный ему автомат Мура (причем это
справедливо как для инициальных, так и для неиници-
альных автоматов).
Рассмотрим вначале случай неинициальных автома-
тов. Пусть входным и выходным алфавитами автомата
Мили М являются А = {а0, ai, ..., a*-i} и В = {Ьо,
bi, ..., bi-\}, а алфавитом состояний — Q~ {qo, qi,
qr-i}. Каждой паре (qi,bj) сопоставим состояние
116
ДИСКРЕТНЫЕ УСТРОЙСТВА С КОНЕЧНОЙ ПАМЯТЬЮ [ГЛ. III
qt/ автомата Мура М'. Функции Т' и V автомата М'
зададим следующим образом. Для всех i положим
(Яц) — Ь/.
Функцию Ч*1' определим на основе функций Ф и W ав-
томата М. Если
(as, qt) = qu,
Ф (as> ?,) = bv,
то при всех j положим
'E'fe, qij) — qUv
Легко видеть, что автомат М' моделирует работу авто-
мата М в следующем смысле. Если М запущен в со-
стоянии <7Z_, а М' — в состоянии q.^ при некотором jo,
то на каждом такте состояние qtj автомата М' соответ-
ствует состоянию q, и значению выхода bj автомата М.
При этом на выходе автомата М' появляется значение
h'(qii) — bj, совпадающее с выходным значением для
автомата М. Это указывает на эквивалентность неини-
циальных автоматов М и М'.
Если автомат Мили М является инициальным, то
вначале, считая его неинициальным, нужно указанным
способом построить автомат М.', а затем в качестве на-
чального состояния взять любое состояние qt jt соответ-
ствующее начальному состоянию qt автомата М.
Таким образом, модели Мили и Мура обладают рав-
ными функциональными возможностями в том смысле,
что всякое преобразование дискретной информации, осу-
ществимое в одной из них, осуществимо и в другой.
Описанные модели автоматов соответствуют так на-
зываемым синхронным дискретным устройствам. По-
следние характеризуются тем, что в них имеется спе-
циальное устройство — генератор синхронизирующих
импульсов, определяющее моменты времени, в которые
происходит изменение состояний. Соседние моменты
обычно оказываются при этом разделенными равными
временными промежутками.
Другой разновидностью дискретных устройств яв-
ляются асинхронные устройства. В них моменты пере-
ходов из одного состояния в другое заранее не опреде-
лены. При подаче входного воздействия устройство про-
КОНЕЧНЫЕ АВТОМАТЫ
117
§ 3.1]
ходит через некоторую последовательность состояний
(неустойчивых) и останавливается в устойчивом состоя-
нии. После этого можно подавать следующее входное
воздействие. Устойчивое состояние характеризуется тем,
что при повторной подаче на входы того же воздействия
состояние не изменяется. Значение выхода устройства
обычно определяется устойчивым состоянием.
Если не учитывать переходный процесс и принимать
во внимание лишь устойчивые состояния, то можно вве-
сти абстрактное время t = 0, 1, 2....... определяемое
моментами т0, -гд, то, ... переходов в устойчивые состоя-
ния под действием входной последовательности. При
этом моделью асинхронного дискретного устройства бу-
дет автомат Мура, функция переходов которого удов-
летворяет условию
Ф(х, Т(х, g)) = T(x, q)
при любых х и q. Последнее означает, что состояние,
полученное при повторной подаче одного и того же
входного воздействия, совпадает с состоянием, в кото-
рое переходит автомат после однократной подачи этого
воздействия.
Наиболее общей из рассмотренных моделей являет-
ся модель Мили, все остальные можно считать ее част-
ными случаями. Всюду дальше мы будем ограничивать-
ся рассмотрением автоматов Мили.
3.1.4. Частичные автоматы. При реальной работе ди-
скретного устройства некоторые ситуации (х, q) могут
никогда не встречаться, и поведение устройства в этих
ситуациях оказывается несущественным. В ряде случаев
несущественным может оказаться только выходной сиг-
нал либо только следующее состояние. Моделью ди-
скретного устройства с конечной памятью, имеющего
недоопределенные условия работы, является частичный
конечный автомат. Для него значения Ф(х, q) и ЧДх, q)
заданы не на всех возможных парах (х, q). Доопреде-
лением частичного автомата называется всюду опреде-
ленный автомат, для которого функции выхода и пере-
хода совпадают с соответствующими функциями час-
тичного автомата везде, где последние определены.
Частичный автомат может бать задан таблицей,
которая отличается от таблицы всюду определенного
118
ДИСКРЕТНЫЕ УСТРОЙСТВА С КОНЕЧНОЙ ПАМЯТЬЮ [ГЛ. III
Таблица 3.3
х 4' Qi <72
0 <7ь 1 <?2. 1 дг, - <7ь 0
1 — —, 0 дг, 0 —
2 <7о> 0 q0, - дг, 1 —, 0
автомата тем, что в клетках вместо некоторых пар или
отдельных элементов пар могут проставляться прочер-
ки, указывающие на то, что соответствующие значения
не определены. В таблице 3.3 приведен пример таблич-
ного задания частичного автомата.
(2,0)
Рис. 3.3.
Одним из доопределений этого автомата является
автомат, представленный в таблице 3.1. Частичные ав-
томаты могут также задаваться диаграммами, которые
строятся аналогично описанным ранее. Помимо стрелок,
имеющих начало и конец, в диаграммах могут присут-
ствовать стрелки, не оканчивающиеся вершинами. Они
соответствуют случаю, когда следующее состояние не
определено. На рис. 3.3 изображена диаграмма частич-
ного автомата, рассмотренного выше (ср. с диаграммой
на рис. 3.1, относящейся к доопределению этого ав-
томата).
Пусть частичный автомат находится в некотором со-
стоянии q и на его вход подается последовательность
§3.2] МИНИМИЗАЦИЯ АВТОМАТОВ Ц9
Х1Х2 ... Хр. После подачи очередного входного символа
автомат изменяет свое состояние. Если на некотором
шаге окажется, что следующее состояние не определено,
то дальше детерминированность поведения автомата на-
рушается: нельзя указать его следующих состояний. Это
можно допустить лишь в случае, когда неопределенное
состояние возникает на последнем шаге (после подачи
хР), ибо дальнейшее поведение автомата нас не инте-
ресует. В связи с этим дадим следующее определение.
Входную последовательность Х[Хг ... хр будем называть
применимой к состоянию q, если определены состояния
q\ = Ч^Х], q), 92 = 4f(x2,9i), ..., ?p-i =4f(xp-i, qp-2).
Для рассмотреннего выше частичного автомата
(табл. 3.3) входная последовательность 012 применима
к состоянию q\, но не применима к qo (после второго
такта возникает неопределенное состояние). Укорочен-
ная последовательность 01 применима и к q$.
Пару (q, х), где х— входная последовательность (ко-
нечная), применимая к состоянию q, будем называть
допустимой. Множество всех допустимых пар составляет
область определения частичного автомата. Область оп-
ределения может оказаться как конечной, так и беско-
нечной. Заметим, что для допустимых пар (q, х) при по-
даче в состоянии q входной последовательности х
выходная последовательность может содержать произ-
вольное число неопределенных символов: наличие неоп-
ределенного символа на выходе содержательно означает
несущественность выходного значения в данной ситуа-
ции и не сказывается на поведении автомата в после-
дующие моменты.
§ 3.2. Минимизация автоматов
3.2.1. Постановка задачи. Автоматы являются моде-
лями устройств для переработки дискретной информа-
ции. Входной и выходной алфавиты автоматов опреде-
ляются перерабатываемой информацией, в то время как
на внутренний алфавит Q обычно никаких условий не
накладывается. Нужное преобразование информации
может быть осуществлено автоматами с разным числом
состояний. Поэтому возникает задача построения авто-
мата, для которого это число минимально.
120
ДИСКРЕТНЫЕ УСТРОЙСТВА С КОНЕЧНОЙ ПАМЯТЬЮ [ГЛ. III
Начнем со случая всюду определенных автоматов.
Автоматы, одинаково перерабатывающие информацию,
мы называли эквивалентными. Переформулируем поня-
тие эквивалентности в более удобных для дальнейшего
терминах. Состояния q автомата М и q' автомата М'
будем называть эквивалентными, если оба автомата,
получив одну и ту же (любую) входную последователь-
ность в состояниях q и q' соответственно, перерабаты-
вают ее в одинаковую выходную последовательность.
Если М и М' означают один и тот же автомат, то полу-
чаем определение эквивалентности состояний для од-
ного автомата. Автоматы М и М' будем называть экви-
валентными, если для каждого состояния автомата М
существует эквивалентное состояние автомата М' и на-
оборот. Легко видеть, что это понятие эквивалентности
совпадает с введенным ранее (для неинициальных ав-
томатов). Автомат, эквивалентный заданному и имею-
щий наименьшее возможное число состояний, назовем
минимальным. Задачу построения минимального автома-
та будем называть задачей минимизации автомата.
На частичные автоматы понятие эквивалентности
распространить не удается. Это связано с тем, что вы-
ходные последовательности частичного автомата могут
допускать доопределения, приводящие к неэквивалент-
ным автоматам. Однако для частичных автоматов мо-
жет быть введен некоторый аналог понятия эквивалент-
ности.
Пусть v и w являются последовательностями одина-
ковой длины, составленными из символов некоторого
алфавита и неопределенного символа. Будем говорить,
что последовательность v покрывает w, если некоторые
неопределенные символы последовательности w можно
заменить так, что получится и. (Так, например, после-
довательность 2—102—10 покрывает 2— —02— —0.)
Будем говорить, что состояние q' частичного автомата
М' покрывает состояние q частичного автомата М, если
любая входная последовательность х, применимая к
состоянию q автомата М, применима к состоянию q' ав-
томата М' и соответствующая выходная последователь-
ность автомата М' покрывает выходную последователь-
ность автомата М. Если для каждого состояния q
автомата М найдется покрывающее его состояние q' ав-
§ 3.2]
МИНИМИЗАЦИЯ АВТОМАТОВ
121
томата М', будем говорить, что автомат М' покрывает
М. Автомат, покрывающий М и имеющий наименьшее
число состояний из всех автоматов, удовлетворяющих
этому условию, будем называть минимальным (для М).
Задача минимизации частичного автомата состоит в
нахождении автомата, минимального в указанном
смысле.
3.2.2. Нахождение эквивалентных состояний. Рас-
смотрим множество Q всех состояний некоторого (всюду
определенного) автомата М. Отношение эквивалентно-
сти состояний обладает обычными свойствами эквива-
лентности (рефлексивностью, симметрией, транзитив-
ностью). Поэтому согласно известному результату мно-
жество Q разбивается на классы эквивалентности.
(Построение минимального автомата будет осуществ-
ляться в два этапа. Вначале будет находиться разбие-
ние состояний на классы эквивалентности, а затем на
его основе — строиться минимальный автомат.
Разбиение состояний на классы экви-
валентности. Опишем вначале метод нахождения
всех пар qtqi эквивалентных состояний. Изложение бу-
дет сопровождать примером автомата, заданного табли-
цей 3.4.
Таблица 3.4
X X. Qi Q» <7«
0 Ча, 1 ?2, 0 Ча, 1 Ча, 1 <7в, о 4s, 0
1 ?б, о ?2, 0 92, 0 Чз, 0 <7в, 0 4s, 0
2 <71, о <?6, 1 Чз, 0 Чз, 0 4s, 1 42, 1
Составим треугольную таблицу, клетки которой со-
ответствуют всем различным неупорядоченным парам
состояний qtqj (i #= /), и заполним ее следующим обра-
зом. Если для состояний qt и qs существует входной
символ х, приводящий к разным значениям выхода, то
соответствующую клетку таблицы перечеркнем крестом.
В нашем примере так нужно поступить с клеткой, со-
поставленной, например, паре QiQz, ибо при х — О
122
ДИСКРЕТНЫЕ УСТРОЙСТВА С КОНЕЧНОЙ ПАМЯТЬЮ [ГЛ. III
автомат в состояниях q\ и 72 выдает 1 и 0 соответственно.
Если же при каждом к выход автомата в состояниях qi
и q, принимает одинаковые значения, то в клетке запи-
шем все пары состояний qvqw (и #= да), отличные от qiqj,
в которые автомат может перейти из qi и qt при подаче
одного и того же входного символа. Так, например, в
клетке для пары q^qt, следует записать пару 7275, возни-
кающую при х — 2, ибо х = 0 приводит к исходной паре
7576, а х = 1 — к паре q^qe одинаковых состояний. Рас-
сматриваемому примеру соответствует треугольная таб’
лица 3.5.
Таблица 3.5
Далее в таблице следует зачеркнуть клетки, в кото-
рых присутствуют пары, соответствующие вычеркнутым
клеткам. В данном случае необходимо зачеркнуть клет-
ку для пары 7174 (ибо в ней содержится 7з7б) и клетку
для пары 7374 (в ней содержится 7273). После этого
таблица приобретет вид, показанный в таблице 3.6.
Затем снова необходимо зачеркнуть все клетки, ко-
торые содержат пары, соответствующие вычеркнутым
клеткам, и т. д., пока не образуется таблица, в которой
ни одной клетки вычеркнуть нельзя. В данном примере
этим свойством обладает таблица 3.6.
Невычеркнутые клетки результирующей таблицы со-
ответствуют всем парам эквивалентных состояний. Дей-
ствительно, если состояния q' и q" неэквивалентны, то
МИНИМИЗАЦИЯ АВТОМАТОВ
123
§ 3.2]
Таблица 3.6
найдется входная последовательность х = xix2 ... хр,
на которой автомат, запущенный в состояниях q' и q",
выдает разные выходные последовательности. Можно
считать, что значения выходов различаются лишь на
шаге р (после подачи хр), иначе последовательность х
можно укоротить (до первого различия выходов). Пусть
автомат при подаче х, начав функционировать из со-
стояния q', проходит последовательность состояний
q\, Яг • • • а из состояния q" — последовательность
g", q", ..., q". В состояниях q'p_x и q''_x подача хр
приводит к разным значениям выхода, поэтому пара
?р_17р_1 будет вычеркнута в треугольной таблице на
первом шаге. Поскольку сигнал xp-i превращает пару
q'p-^p-2 в Яр-^р-Р то на следующем шаге пара q'p_2q"_2
также окажется вычеркнутой, и т. д. Не позже чем че-
рез р шагов исходная пара q'q" будет вычеркнута. Если
же состояния q' и q" эквивалентны, то всякой входной
последовательности будут соответствовать одинаковые
выходные последовательности и не найдется пары со-
стояний, исходя из которой цепочка вычеркиваний при-
ведет к q'q".
На основе таблицы 3.6 выпишем все эквивалентные
пары: 717з, q^q-, q%qe и q^qe- Класс эквивалентности об-
разуется состояниями, которые попарно эквивалентны.
124
ДИСКРЕТНЫЕ УСТРОЙСТВА С КОНЕЧНОЙ ПАМЯТЬЮ [ГЛ. III
В данном случае получаем классы {<?i, 7з} и {72, qs, q&}.
Каждое состояние, не вошедшее ни в один из этих клас-
сов, эквивалентно лишь себе и само образует класс эк-
вивалентности. Добавив эти классы, получаем требуе-
мое разбиение. В рассматриваемом примере к классам
{71,73} и {72,75,7б} необходимо добавить {74}.
3.2.3. Построение минимального автомата (случай
всюду определенных условий). Пусть имеется некоторое
разбиение всех состояний автомата М на множества Qi,
Q2, ..., Qs. Разбиение назовем замкнутым, если для
любого множества Qo и любого входного сигнала х мно-
жество всех состояний, в которые под действием х пе-
реходят состояния из Qv, целиком содержится в неко-
тором множестве Qw, зависящем от v и х.
Разбиение множества состояний на классы эквива-
лентности является замкнутым. Действительно, если со-
стояния qi и 7/ эквивалентны и при подаче х они пере-
ходят в состояния 7/' и 7;', то последние также эквива-
лентны. Если бы это было не так и существовала
входная последовательность xt ... хр, дающая в примене-
нии к состояниям 7;' и 7/' разные выходные последова-
тельности, то последовательность xxi ... хр, применен-
ная к qi и 7/, также приводила бы к разным выходным
последовательностям, что противоречит эквивалентно-
сти 7, и 7/. Таким образом, состояния из одного класса
эквивалентности при подаче одинакового входного воз-
действия снова попадают в один класс эквивалентности,
что и указывает на замкнутость разбиения.
Имея разбиение множества состояний Q автомата М
на классы эквивалентности Qi, Q2, ..., Qs, построим но-
вый автомат М'. Для этого каждому классу Qo сопо-
ставим состояние q'v (v = 1, .. ., s), а в качестве вход-
ного и выходного алфавитов автомата М' возьмем соот-
ветствующие алфавиты автомата М. Чтобы назначить
переход в автомате М' из состояния 7' под действием
х, рассмотрим соответствующий класс эквивалентности
Qv. Согласно свойству замкнутости входной сигнал х
переводит все состояния из Qv в некоторый класс экви-
валентности Qw. Им определяется следующее состоя-
ние q'w. По свойству эквивалентности состояний подача
входного воздействия х в каждом состоянии из Qv при-
§ 3.2]
МИНИМИЗАЦИЯ АВТОМАТОВ
125
водит к одинаковому значению выхода. Оно прини-
мается в качестве выходного значения, соответствую-
щего переходу в автомате М' из q'v под действием х.
Автомат М', построенный указанным способом по
автомату М, заданному таблицей 3.4, с учетом разбие-
ния на классы эквивалентности {71,73}, {72, 7б, 7б}, {74}
представлен в таблице 3.7.
Таблица 3.7
/ / /
х ’1 "з
0 <7з- 1 <4 0 <4 1
1 ?2> 0 <?2> 0 41, о
2 <71> 0 ?2> 1 41, 0
Теорема 3.1. Всякий минимальный автомат с точ-
ностью до переобозначения состояний совпадает с ав-
томатом М', построенным выше.
Доказательство теоремы разобьем на несколь-
ко утверждений.
Г. Автомат М' эквивалентен автомату М.
Согласно определению эквивалентности автоматов
достаточно установить, что для каждого состояния qt
автомата М найдется эквивалентное состояние q'u ав-
томата М' и наоборот. Эквивалентным состоянию qi яв-
ляется состояние 7', соответствующее классу Qo, содер-
жащему 7<, и, наоборот, в качестве эквивалентного со-
стоянию 7' может быть взято любое состояние из Qv.
Действительно, пусть автоматы М и М' установлены в
состояниях qt е Qv и 7' соответственно и на их входы
подается произвольная последовательность Xi.r2 ... хр.
По построению М' после приложения воздействия xi оба
автомата выдадут одинаковый выходной символ и пе-
рейдут в состояния 7у и q'w такие, что q, е Qw. Подача
Л'2 снова приведет к одинаковым выходным символам
и переведет автоматы в состояния qk и 7' такие, что
126
ДИСКРЕТНЫЕ УСТРОЙСТВА С КОНЕЧНОЙ ПАМЯТЬЮ [ГЛ. Ill
qk е Qz, и т. д. Продолжив эти рассмотрения, можно
убедиться в полном совпадении выходных последова-
тельностей.
2°. Автомат М' является минимальным.
Предположим противное, что существует автомат
М", эквивалентный М и имеющий меньшее число со-
стояний, чем М'. Для каждого состояния q'( автомата
М’ имеется эквивалентное состояние q" автомата М".
Следовательно, некоторому состоянию q" эквивалентны
по крайней мере два состояния q\ и q'l2. Но тогда состоя-
ния q't и q't эквивалентны, а потому эквивалентны со-
стояния автомата М из множеств Qlt и Q;,. Это противо-
речит тому, что Q/, и Qi2 являются различивши классами
эквивалентности.
3°. Любой минимальный автомат с точностью до пе-
реобозначения состояний совпадает с М'.
Рассмотрим произвольный минимальный автомат
М". Автоматы М' и М" имеют одинаковое число состоя-
ний и для каждого состояния автомата М' существует
единственное эквивалентное ему состояние автомата М".
Упорядочим состояния автомата М" в соответствии с
упорядочением состояний автомата М' так, чтобы при
всех i состояние q" было эквивалентно q'(. Рассмотрим
переходы из состояний q't и q” при некотором i под
действием входного сигнала х. Поскольку эти состояния
эквивалентны, в обоих случаях будет выдан одинаковый
выходной сигнал. Если автомат М' перейдет в состояние
q'jt то М" должен оказаться в состоянии q". В против-
ном случае (если следующим состоянием автомата М"
будет q'/' (k =/= /)) в силу неэквивалентности q^ и найдет-
ся входная последовательность х\ ... хр, подача кото-
рой в состояниях q'j и q'£ приводит к неодинаковым вы-
ходным последовательностям. Тогда последовательности
хх\ ... хр, примененной к состояниям q'{ и q", также
будут соответствовать разные выходные последователь-
ности, что противоречит эквивалентности q't и q''. Из
сказанного следует, что автоматы М' и М" совпадают
с точностью до обозначения состояний.
§ 3.2]
МИНИМИЗАЦИЯ АВТОМАТОВ
127
Теорема доказана. Из нее, в частности, вытекает, что
автомат, представленный таблицей 3.7, является мини-
мальным для автомата М (табл. 3.4).
3.2.4. Совместимые состояния частичных автоматов.
Последовательности v и w, составленные из символов
некоторого алфавита и неопределенного символа, будем
называть совместимыми, если существует общая для них
покрывающая последовательность. Другими словами,
если в некоторой позиции последовательностей v и w
расположены значащие символы, то эти символы обя-
заны совпасть (примером совместимых последователь-
ностей являются 2—01 012 и —10 10——). Со-
стояния qt и 7/ частичного автомата М будем называть
совместимыми, если всякой входной последовательности,
одновременно применимой к состояниям qt и qt, отве-
чают совместимые выходные последовательности. Неко-
торое множество состояний частичного автомата обра-
зует группу совместимости, если все входящие в него
состояния попарно совместимы. Группа совместимости
называется максимальной, если при добавлении к ней
любого состояния она перестает быть группой совмести-
мости. Совокупность некоторых групп совместимости
представляет собой группировку, если всякое состояние
автомата входит хотя бы в одну из них. Группировка,
составленная из всех максимальных групп совместимо-
сти, называется максимальной.
Совместимые состояния частичного автомата играют
роль эквивалентных состояний. Заменить термин «со-
вместимость» на «эквивалентность» нельзя, ибо свойство
совместимости, вообще говоря, нетранзитивно: два со-
стояния, совместимые с третьим, могут оказаться несо-
вместимыми друг с другом. Максимальной группировке
в случае всюду определенных автоматов соответствует
разбиение на классы эквивалентности. Для частичных
автоматов вместо разбиения приходится говорить о груп-
пировке потому, что различные группы совместимости
могут пересекаться.
Первым этапом в построении минимального авто-
мата является нахождение максимальной группировки.
3.2.5. Нахождение максимальной группировки. Она
формируется на основе пар совместимых состояний. Для
выявления всех пар совместимых состояний может быть
128
ДИСКРЕТНЫЕ УСТРОЙСТВА С КОНЕЧНОЙ ПАМЯТЬЮ [ГЛ. III
использован метод, применявшийся раньше для пар эк-
вивалентных состояний. Он заключается в составлении
треугольной таблицы, клетки которой соответствуют па-
рам несовпадающих состояний, и в последовательном
вычеркивании клеток. На первом шаге вычеркиваются
клетки, относящиеся к парам состояний, для которых
существует входной сигнал х, приводящий к разным
значениям выхода, а в остальные клетки заносятся
возможные пары qvqw (v =^= w) следующих состояний,
отличные от исходной пары cjicjj. Далее вычеркиваются
все клетки, содержащие вычеркнутые пары, и т. д., пока
Таблица 3.8
X X. <7з <?6
0 <?2, - <7з, 0 <74, - <75, 1 — —
1 <7з, 0 <75, 0 <7б, — <7з, 0 <7е, 0 —, 1
2 — — <?3, — — — <74, -
3 <74, - — — <71, - — <72, —
§ 3.2]
МИНИМИЗАЦИЯ АВТОМАТОВ
129
это возможно. Невычеркнутые клетки результирующей
таблицы соответствуют всем парам совместимых состоя-
ний (доказательство этого факта аналогично доказатель-
ству для случая эквивалентности).
В качестве примера рассмотрим частичный автомат,
заданный таблицей 3.8. Соответствующими ему тре-
угольными таблицами — исходной и результирующей —
являются таблицы 3.9 и 3.10.
Таблица 3.10
Из таблицы 3.10 заключаем, что всеми парами со-
вместимых состояний будут q\q5, q^, q3q5, q3q6 и q4q5.
Рассмотрение этих пар показывает, что отношение со-
вместимости нетранзитивно.
Построение максимальной группировки производится
с использованием результирующей треугольной таб-
лицы. На основе просмотра столбцов этой таблицы сле-
ва направо последовательно образуются некоторые си-
стемы множеств. В качестве исходной берется система,
состоящая из единственного множества — множества
всех состояний. Предположим, что после рассмотрения
i—1 столбцов построена система множеств Qi, Q2, ...
..., Qp. При переходе к столбцу i выделяются все со-
стояния, несовместимые с qi (им соответствуют зачерк-
нутые клетки столбца). Если множество Q, одновремен-
но не содержит qi и несовместимых с ним состояний, оно
не изменяется. В противном случае из него образуются
два множества: одно — путем удаления состояния qi,
другое—путем удаления всех состояний, несовмести-
5 Л. А- Шоломов
130
ДИСКРЕТНЫЕ УСТРОЙСТВА С КОНЕЧНОЙ ПАМЯТЬЮ [ГЛ. Ill
мых с qt. Проделав это для всех Q/ и устранив немакси-
мальные множества (содержащиеся в других), получим
систему, которая является результатом шага i. Сово-
купность множеств, образованная после просмотра по-
следнего столбца матрицы, является максимальной груп-
пировкой. Это вытекает из легко проверяемых фактов,
что каждое из полученных множеств является совмести-
мой группой состояний и что никакая совместимая груп-
па (в частности, максимальная) в течение процедуры не
дробится, входя в некоторые множества целиком.
Построение максимальной группировки иллюстри-
руется таблицей 3.11, где приведены системы множеств,
Таблица 3.11
шага Система множеств
0 {?!, <72, <?з, Щ, <75, <7б1,
1 2 3 4 5 {<7г> <7з> 74, <7з, <7б1, {<7ь <7з}, {<7з, 7s, 7е}> {7г1, {71, 7з}, {7з, 74, 7s, 7б1, {72}, {71, 7s}, {7з, 7s, 7сЬ {7з, 74, 7s!, {72}, {71, 7sl, {7з, 7б1, {7з, 74, 7s}> {72b {7ь 7s}-
являющиеся результатами последовательных шагов (ос-
новой для построения служит таблица 3.10).
Для пояснения рассмотрим шаг 5. Из последнего
столбца таблицы 3.10 заключаем, что состояние qz не
совместимо с q6l Множество {q$, qz, <7g} из строки 4, од-
новременно содержащее состояния qz и qz, расщепляем
на {73,75} и {73, 7б}. Остальные множества из строки 4
оставляем неизменными. Удалив множество {73,75}, по-
глощаемое множеством {73, 74, 75}, приходим к системе,
помещенной в строке 5. Она является максимальной
группировкой.
3.2.6. О построении минимального частичного авто-
мата. Пусть имеется некоторая группировка Q2, . •.
..., Qs состояний частичного автомата. Группировку на-
зовем замкнутой, если для любого множества Qa и лю-
бого входного сигнала х множество всех состояний, в
которые под действием х переходят состояния из Qv, це-
§ 3.2]
МИНИМИЗАЦИЯ АВТОМАТОВ
13!
ликом содержится в некотором множестве Qw, завися-
щем от v и х. Отметим, что при этом учитываются лишь
те состояния из Qo, для которых следующее состояние
определено.
Имея замкнутую группировку Q1; Q2, Qs состоя-
ний частичного автомата М (на группы совместимости),
можно построить покрывающий его автомат М' анало-
гично тому, как это делалось для всюду определенных
автоматов на основе классов эквивалентности. С этой
целью каждой группе совместимости Qn (v = 1, ..., s)
необходимо сопоставить в автомате М' состояние
q'v Состояние q'w, в которое переходит q'v под дейст-
вием входного сигнала х, определяется группой Qw, со-
держащей все состояния, в которые входной сигнал х
переводит состояния из Qv (если таких групп Qw не-
сколько, то можно взять любую из них). Поскольку Qv
образует группу совместимости, то подача входного воз-
действия х приводит в каждом состоянии из Qo либо к
неопределенному символу на выходе, либо к символу,
общему для всей группы Qv. Этот символ и принимает-
ся в качестве выходного значения, соответствующего
переходу в автомате М' из состояния q'v под действием
х. Если же в каждом состоянии из Qv при подаче х воз-
никает лишь неопределенный символ, то значение вы-
хода автомата М' может быть назначено произвольно
либо может считаться неопределенным.
Автомат М' покрывает М, ибо всякое состояние qi
покрывается любым состоянием q'v таким, что qi е Q
Действительно, пусть автоматы М и М' установлены в
состояниях и и на их входы подается последова-
тельность XiX2 ••• хр, применимая к состоянию q\. Тог-
да, если при подаче Xi значение выхода автомата М оп-
ределено, то это же значение будет принимать и выход
автомата М' и при этом автоматы перейдут в состояния
qt и q'w такие, что q, е Qw. Те же рассуждения могут
быть продолжены для состояний qjt q'w и входного сиг-
нала х2, и т. д. Таким образом, последовательность
Xi%2 ... хр окажется применимой к состоянию q'v, а
соответствующая выходная последовательность — совме-
стимой с выходной последовательностью автомата М.
132
ДИСКРЕТНЫЕ УСТРОЙСТВА С КОНЕЧНОЙ ПАМЯТЬЮ [ГЛ. III
Всякий автомат М', покрывающий М, может быть
получен указанным способом при подходящем выборе
замкнутой группировки. Действительно, рассмотрим про-
извольный автомат М', который покрывает М. Каждому
его состоянию q'v сопоставим множество Qv всех покры-
ваемых им состояний автомата М. Множество Qv яв-
ляется группой совместимости, поскольку для любых
состояний qt, q, eQ8 и любой применимой к ним вход-
ной последовательности х выходные последовательности
совместимы (они покрываются выходной последова-
тельностью автомата М', возникающей при подаче х
в состоянии <?'). Совокупность всех групп Qo образует
группировку.
Осталось установить ее замкнутость. Рассмотрим
произвольное состояние qi е Qo и входной сигнал х. Со-
стояние 7/, в которое переходит qt под действием х (если
оно определено), покрывается состоянием q'w, в которое
сигнал х переводит q'v. В противном случае найдется
входная последовательность х — xj ... хр, применимая
к q, и q' и приводящая к выходным последовательно-
стям у и у' таким, что у' не покрывает у. Тем же свой-
ством будут обладать выходные последовательности, от-
вечающие последовательности xxi ... хр, поданной в
состояниях qt и q'v. Это противоречит тому, что q'v покры-
вает qi. Тем самым установлено, что все состояния из
Qo под действием х переходят в множество Qw. Это
означает, что группировка замкнута.
Из сказанного следует, что построение покрываю-
щего автомата сводится к нахождению замкнутой груп-
пировки, а построение минимального автомата — к по-
строению замкнутой группировки, содержащей мини-
мально возможное число групп совместимости.
Последняя задача может быть решена перебором.
Всякая группа совместимости содержится в некоторой
максимальной группе и, следовательно, является под-
множеством некоторого множества, входящего в состав
максимальной группировки. Перебирая все такие под-
множества и составляя из них группировки, можно
найти минимальную замкнутую группировку. Ясно, что
этот способ решения не эффективен. Однако эффектив-
§ 3.2]
МИНИМИЗАЦИЯ АВТОМАТОВ
133
ного способа минимизации частичных автоматов не из-
вестно, и имеется предположение, что его не существует.
Основания для такого предположения будут рассмот-
рены в § 5.5.
3.2.7. О приближенном решении задачи минимиза-
ции. В связи со сказанным актуальной является задача
отыскания приближенного решения, т. е. задача по-
строения автомата, «близкого к минимальному». О сте-
пени близости иногда можно судить на основе оценок.
Простейшее соображение, позволяющее получать ниж-
нюю оценку числа состояний, состоит в следующем. Если
фо — некоторое множество состояний автомата М, ника-
кая пара из которых не совместима, то число состояний
минимального автомата не меньше мощности множе-
ства Qo. Это следует из того, что никакие два состояния
из Qo не могут быть покрыты одним состоянием.
Верхней оценкой числа состояний минимального ав-
томата является число множеств в максимальной груп-
пировке. Это вытекает из того, что максимальная груп-
пировка является замкнутой, и, следовательно, на ее
основе можно построить покрывающий автомат. Для до-
казательства замкнутости рассмотрим произвольную
максимальную группу совместимости Qv. Если состоя-
ния qi и q, принадлежат Qv и при подаче х следующие
состояния q{’ и qy определены, то qp и q^ совме-
стимы. В противном случае существует входная после-
довательность %1 ... хр, применимая к q^ и qpr и приво-
дящая к несовместимым выходным последовательно-
стям. Но тогда, применив последовательность xxi ... хр
к состояниям qi и qp можно заключить, что они также
не совместимы. Таким образом, все состояния, возни-
кающие из состояний множества Qv при подаче х, со-
вместимы и, следовательно, содержатся в некоторой
максимальной группе совместимости Qw.
Вернемся к рассмотрению примера. Как мы видели,
максимальной группировкой является {<?з, <?б}, {<?з. <?4,
7s}, {72}, {7i. 7s}- Поэтому минимальный автомат содер-
жит не более четырех состояний. В то же время состоя-
ния множества Qo — {qi, q<z, qi, qe} попарно не совме-
стимы, а поэтому минимальный автомат содержит не
менее четырех состояний. Из сказанного следует, что
покрывающий автомат, построенный на базе максималь-
134
ДИСКРЕТНЫЕ УСТРОЙСТВА С КОНЕЧНОЙ ПАМЯТЬЮ [ГЛ. III
ной группировки, в данном случае является минималь-
ным. Если сопоставить множествам максимальной груп-
пировки в порядке их перечисления состояния q'v q'v q3,
q't автомата M', то его таблица будет иметь следую"
щий вид (табл. 3.12).
Таблица 3.12
X / f ч f Чл
0 ч,, - ч'2, 1 q\, 0 Чу -
1 0 0 ч'\, 0
2 ч{> - — —
3 / ?2- ~ ч'ь - / Чу ~
Отметим, что состояние q3 исходного автомата Л4
покрывается состояниями и <?' и в процессе работы
автомата М' роль q3 играет то q'v то q'r При подаче
символа 1 в состояниях q\ и q'2 выход автомата М' при-
нимает разные значения. Поэтому выход автомата М,
соответствующий переходу из состояния q3 под дей-
ствием х—1, в разных ситуациях доопределяется по-
разному. Если такую возможность запрещать, это мо-
жет привести к увеличению необходимого числа со-
стояний.
Задача минимизации частичных автоматов приводит
к следующей ситуации. Нахождение минимального авто-
мата может быть осуществлено последовательным про-
смотром всех автоматов в порядке возрастания числа их
состояний. Перебора устранить не удалось, однако его
удалось сместить в заключительную часть алгоритма,
где он применяется к нахождению замкнутой группиров-
ки, содержащей наименьшее число множеств. Подобная
ситуация имела место и в задаче построения м. д. н. ф.,
где перебор использовался на заключительном этапе для
§ 3.3]
СХЕМЫ ИЗ ЭЛЕМЕНТОВ И ЗАДЕРЖЕК
135
отыскания наилучшего покрытия импликантной табли-
цы. Указанные сведения позволяют сократить объем
перебора по сравнению с тривиальным. Существенным
является и то, что перебираются объекты более простой
природы, чем исходные, и перебор легче машинизиро-
вать. Кроме того, облегчается нахождение практически
хороших приближенных решений.
§ 3.3. Схемы из логических элементов и задержек
3.3.1. Правила построения схем. Автоматная модель
отражает поведение дискретных устройств с памятью
на макроуровне (состояние — вход — выход).
Реальные устройства обычно строятся по оп- ж
ределенным правилам из некоторых элемен- |
тарных компонент. Моделями устройств на
микроуровне, учитывающими характер и взаи- &
модействие этих компонент, являются схемы.
В предыдущей главе рассматривались схе-
мы из логических элементов. Значения выхо- У
дов таких схем однозначно определяются
сигналами, поданными на входы, и поэтому ис’ ' ’
они могут быть использованы лишь для
реализации устройств без памяти. Для того чтобы обес-
печить возможность запоминания информации, в схемах
должны присутствовать элементы, обладающие памятью,
т. е. имеющие по меньшей мере два внутренних состоя-
ния. Простейшим из них является элемент задержки. Он
имеет 1 вход и 1 выход (рис. 3.4) и описывается кано-
ническими уравнениями
7(/)^х(0, |
г/(/) = 7(/-1). J
Из уравнений заключаем, что y(t + 1) = q(t) = x(t), и,
таким образом, этот элемент осуществляет задержку
на 1 такт: сигнал, поданный на вход в момент t, появ-
.ляется на выходе в следующий момент.
В данном параграфе мы будем рассматривать схемы,
построенные из логических элементов и элементов за-
держки *).
*) Схемы с памятью (такого типа и более общего) в лите-
раторе часто называют логическими сетями [15].
136
ДИСКРЕТНЫЕ УСТРОЙСТВА С КОНЕЧНОЙ ПАМЯТЬЮ [ГЛ. Ill
Пусть имеется некоторое конечное множество, со-
стоящее из логических элементов и элемента задержки.
Это множество будем называть базисом, а входящие в
него элементы — базисными. Схемы строятся по опре-
деленным правилам из полюсов и элементов. Дадим
индуктивное определение схемы (попутно определяется
вспомогательное понятие вершины схемы):
— совокупность полюсов, соответствующих некото-
рым переменным (рис. 3.5, а), есть схема; все полюсы
являются ее вершинами;
Рис. 3.5.
— результат присоединения к вершинам схемы всех
входов некоторого базисного элемента (рис. 3.5,б, в)
есть схема; вершинами новой схемы являются все вер-
шины исходной схемы и выход присоединенного эле-
мента, а полюсами — все полюсы исходной схемы;
— результат присоединения выхода задержки к не-
которому полюсу xi (рис. 3.5, г) есть схема; ее верши-
нами являются все вершины исходной схемы, за исклю-
чением xt, а полюсами — все полюсы исходной схемы,
кроме xi.
Операция, соответствующая рис. 3.5, г, называется
введением обратной связи. Требование, чтобы при обра-
зовании обратной связи присутствовал элемент задерж-
ки, позволяет избежать противоречия в работе уст-
ройств, связанного с тем, что в один и тот же момент
времени на некотором входе могут оказаться разные
сигналы. Простейший случай такой ситуации показан
§ 3.3]
СХЕМЫ ИЗ ЭЛЕМЕНТОВ И ЗАДЕРЖЕК
137
на рис. 3.6, а. Если на входе инвертора имеется сигнал
а, то сигнал 6, снимаемый с его выхода, поступает на
вход одновременно с а (считается, что элемент сраба-
тывает мгновенно). В схеме, представленной на
рис. 3.6,6, противоречия не происходит, ибо, благодаря
элементу задержки, значение выхода инвертора посту-
пает на его вход только на следующем такте.
В соответствии с построением схемы каждой ее вер-
шине может быть сопоставлена функция, указывающая
значение, приписанное этой вершине в момент t, а каж-
дой задержке 3, дополнительно — функция, указываю-
щая ее состояние ду(/) в момент
t. Приписывание функций осуще-
ствляется следующим образом:
— полюсу Xt приписывается
функция Xi(t), значения которой
являются значениями перемен-
ной xt, в моменты /=0, 1,2, ...;
— если всем вершинам, к ко-
торым присоединены входы логи-
ческого элемента Е (рис. 3.5,6),
уже приписаны функции, причем
вершине, к которой подсоединен
i-й вход элемента Е, приписана
функция а . . ,Ук) есть функция элемента Е,
то его выходу приписывается функция фв(М0, •••
.... ЫО);
— если элемент задержки 3, присоединен к вершине
(рис. 3.5, в), которой приписана функция f(t), то в соот-
ветствии с (3.2) в качестве функции <?/(/), указывающей
состояние задержки, берется f(t), а выходу задержки
приписывается функция Qj(t— 1);
— если обратная связь образована отождествлением
выхода задержки 3/ и полюса (рис. 3.5,г), то в функ-
циях, приписанных вершинам и состояниям задержек,
функция Xi(t) всюду, где она появляется, заменяется
на 1).
На рис. 3.7 представлен процесс последовательного
построения схемы с одновременным указанием функций,
приписанных вершинам и состояниям задержек.
В схеме выделяется некоторое количество вершин,
которые объявляются выходами схемы.
138
ДИСКРЕТНЫЕ УСТРОЙСТВА С. КОНЕЧНОЙ ПАМЯТЬЮ [ГЛ. III
3.3.2. Автомат, реализуемый схемой. Пусть всеми
полюсами схемы являются х\, х2, . , хп, а всеми за-
держками— 31, 32, 3s. Из процесса приписывания
функций вершинам видно, что они зависят от значений
Рис. 3.7.
xt(t) переменных в момент t и состояний <?/(/—1) за-
держек в предыдущий момент. То же самое относится к
функциям, выражающим состояния задержек в момент
t. Пусть
г/г(/) = Фг(х1(/).xn(t), 71 (/-1), .... qs(t-V)) (3.3)
является функцией, приписанной вершине yi, а
q, (t) = (xi (/), ..., x„ (/), 7, (Z - 1), ..., 7s (/-D) (3.4)
— функцией, приписанной состоянию задержки 3/.
§ 3.3]
СХЕМЫ ИЗ ЭЛЕМЕНТОВ И ЗАДЕРЖЕК
139
Назовем состоянием схемы набор состояний всех
входящих в нее задержек 3/ (/ = 1.........s):
7(/) = (71(/); 72(/)...7s(/)). (3.5)
Пусть выходами схемы являются вершины z/i, у%, ...
..., ym. С учетом (3.3) и (3.5) функции, сопоставленные
выходам, можно записать в виде
г/,(/) = Ф/ (х, (/), ..., х„(/), q(t — 1)), i = 1, .... т,
а из (3.4) и (3.5) следует, что состояние схемы в мо-
мент t задается равенством
q (/) = (^1 (хЛ/), .... х„(7), ?(/-!)).
^(xi (/), ..., х„ (/), q (t — 1)) = Y (%! (О.xn (/), q (/ — 1)),
где 4f=(4fi, .... Ys). В результате получаем, что схе-
ме с полюсами xi, ..., хп и выделенными выходами
у\, ..., ут соответствует автомат Мили с канониче-
скими уравнениями
У) (/) = Ф/ (xi (/).....хп (t), q(t— 1)), '
/= 1, ..., т,
7(/) = Y(x1(7), ..., х„(7), q(t-l)).
(3.6)
Будем говорить, что схема реализует этот автомат. На-
чальное состояние автомата определяется состояниями
задержек в момент t = 0:
<7(0) = (7i(0), ..., 7s(0)).
Если начальные состояния задержек фиксированы, при-
ходим к инициальному автомату. В противном случае
получаем неинициальный автомат.
3.3.3. Задача анализа схем. Она состоит в том, что-
бы по заданной схеме найти реализуемый ей автомат.
Эта задача фактически уже была решена выше. Однако
существует более простой способ, основанный на ана-
лизе схем из логических элементов.
Всякая схема из логических элементов и задержек,
построенная правильно, обладает следующими двумя
свойствами:
140
ДИСКРЕТНЫЕ УСТРОЙСТВА С КОНЕЧНОЙ ПАМЯТЬЮ [ГЛ. III
1) каждый вход всякого элемента подсоединен либо
к полюсу, либо к выходу некоторого элемента;
2) в любой циклической цепочке элементов (рис. 3.8)
присутствует по крайней мере 1 элемент задержки.
Действительно, схема, состоящая лишь из полюсов,
обладает свойствами 1) и 2), а операции присоединения
к схеме новых элементов (рис. 3.5, б, в) и введения об-
ратной связи через задержку (рис. 3.5, г) этих свойств
не нарушают. Верно и обратное, если выполнены свой-
ства 1) и 2), то рассматриваемое «соединение элемен-
тов» представляет собой правильно построенную схему.
Для того чтобы в этом убедиться, устраним все задерж-
ки и введем дополнительные полюсы на месте
выходов задержек в соответствии с рис. 3.9.
Из свойства 2) следует, что при этом исчез-
нут все циклические цепочки элементов, а в
силу свойства 1) получится схема из логиче-
ских элементов в смысле § 2.1. Таким образом,
построение исходной схемы может быть осу-
ществлено в следующем порядке. Вначале с
использованием первых двух правил построе-
ния схем (которые совпадают с правилами
из § 2.1) может быть образована схема из ло-
гических элементов. Затем на основе второго
правила могут быть добавлены элементы за-
Рис. 3.8. держки (в соответствующие места) и по
третьему правилу введены обратные связи.
Операция устранения задержек лежит в основе ме-
тода анализа схем.
Пусть имеется схема, содержащая s элементов за-
держки (рис. 3.10,а). Удалим из нее задержки и введем
дополнительные полюсы z't (j — 1, .. ., s) и дополни-
тельные выходы Zj (j = 1, ..., s), как показано на
рис. 3.10,6. В результате схема с п входами и m выхо-
дами преобразуется в схему из логических элементов с
п + s входами и m + s выходами. Она реализует неко-
торую систему логических функций
yt = ф,-(л- •••> хп> z'i.О (г’=1> •••’
2/=1Г/(Х1.....ХП’ (/=1,
§ 3.3]
СХЕМЫ ИЗ ЭЛЕМЕНТОВ И ЗАДЕРЖЕК
141
Применительно к заданному моменту времени t эти ра-
венства дают
= .... xn(t), z[(t), z's{t))
(i = 1......tn),
Zi (t) = ч;. (x, (/).xn (/), Z\ (/), .... < (0) (3>7)
В схеме (рис. 3.10, а) полюсам z'- соответствуют выходы
задержек 3/ и, как следует из канонических уравнений
а,) б)
Рис. 3.9.
задержки, в момент t на них появляется значение
qi(t—1). Выходам г/ схемы соответствуют входы за-
держек 3j и согласно каноническим уравнениям задерж-
ки Zj{t) = qj(t). Подставив в равенства (3.7) значения
142
ДИСКРЕТНЫЕ УСТРОЙСТВА С КОНЕЧНОЙ ПАМЯТЬЮ [ГЛ. III
Рис. 3.11.
qi(t— 1) вместо z't (/) и qj(t) вместо Zi(t), получаем
уравнения, описывающие автомат, реализуемый исход-
ной схемой:
У( (О = Ф/ Ui (/), .... хп (/), q} (t — 1), . . ., qs (t — 1)),
(i = 1, .. ., m),
7/ (0 = V; (x, (/), .... xn (0, 7, (/ - 1), ..., qs (t - 1)),
(/=1.......................s).
Эти уравнения также будем называть каноническими.
От них с учетом того, что полное состояние автомата
есть 9(/) = (9j(Z), ..., qs(t)), можно пе-
рейти к каноническим уравнениям в фор-
ме (3.6).
В качестве примера рассмотрим схе-
му, представленную на рис. 3.7, ж. Пусть
ее выходом у является выход элемента
&. Устранив задержки 31 и 32, перейдем
к схеме, показанной на рис. 3.11 (здесь
п дальше вместо г' и zt используют-
ся более удобные обозначения q^ и q^.
Полученная схема реализует функции
У = 72 = 7i (*i v
71 =*!•
Поэтому канонические уравнения автомата будут иметь
вид
У (0 = qi(t — 1) Ui (0 V <72 (^ — 1))>
71 (0 = *1 (0>
<7г(/) = 7i — 1) fri (0 V q2{t — 1)).
От записи функций посредством формул перейдем к таб-
личному представлению (табл. 3.13) .
Теперь можно построить таблицу автомата, строки
и столбцы которой соответствуют входным символам
х(0 и состояниям <?(/—1) = (7i(/—1), q2(t — 1)), а в
клетках помещены последующие состояния q(t) = (qi(t),
q2(t)) и значения выхода y(t) (табл. 3.14).
Переобозначив состояния <7°==(00), 71 =(01), q2 =
= (Ю), q3 = (11), приходим к таблице автомата в более
привычной форме (табл. 3.15).
§ 3.3]
СХЕМЫ ИЗ ЭЛЕМЕНТОВ И ЗАДЕРЖЕК
143
Таблица 3.13
X, (t) <?i (i —1) q, (t-1) У It) <71 (f> <7 г (Г)
0 0 0 0 1 0
0 0 1 0 1 0
0 1 0 0 1 0
0 1 1 1 1 1
1 0 0 0 0 0
1 0 1 0 0 0
1 1 0 1 0 1
1 1 1 1 0 I
Таблица 3.14
<7 X 0 0 0 1 1 0 1 1
0 10,0 10,0 10,0 11,1
1 00,0 00,0 01,1 01,1
по заданному конечному автомату с двоичными входами
и выходами построить реализующую его схему из логи-
ческих элементов и задержек. Набор логических эле-
ментов предполагается полным (§ 1.3).
Пусть требуется реализовать автомат с п входами,
т выходами и р состояниями. Возьмем произвольное
целое число s, удовлетворяющее условию 2s Тэ р (на-
пример, наименьшее из таких чисел). Каким-либо
образом сопоставим каждому состоянию q автомата дво-
144
ДИСКРЕТНЫЕ УСТРОЙСТВА С КОНЕЧНОЙ ПАМЯТЬЮ [ГЛ. III
ичный набор («/I, qs) так, чтобы разным состояниям
соответствовали разные наборы (это можно сделать в
силу условия 2s р). Набор, соответствующий значе-
нию q(t), обозначим через (qi(t).......). Заменив
состояния автомата в момент t соответствующими на-
борами, представим канонические уравнения автомата
в виде
Pi (0 = Ф< (*i (0.....(t), qt (t — 1), . . ., qs (t — 1)), '
(Z = 1, . .., m),
(<71(0, .. ., <7s(/)) =
= ^(x,(/)......xn(t), q^t-V), qs(t — V)).
(3.8)
Последнее уравнение, расписанное покомпонентно, дает
$ уравнений
qt (/) = (%i (/), . .., хп (/), <71 (/ — 1), .... qs (t - 1)),
(7=1, .... s).
Поскольку каждая из величин принимает два значения,
функции Ф< и Чт/ будут булевыми (возможно, частич-
ными). На основе полученных канонических уравнений
синтезируем схему с s элементами задержки. Для этого
вначале построим схему из логических элементов, реа-
лизующую систему булевых функций
У{ = ф1(х1.....хп> У'1.....<Л) (z=1......т~)>
•••> •••> .....................s)
(рис. 3.12, а). Это можно сделать в силу полноты на-
бора логических элементов. Затем в схему введем об-
ратные связи через элементы задержки в соответствии
с рис. 3.12,6. Полученная схема реализует заданный
автомат, ибо если провести ее анализ описанным выше
методом, то придем к каноническим уравнениям (3.8).
Очевидно, что приведенный метод синтеза применим
и к частичным автоматам.
Если рассматривается инициальный базис (фикси-
ровано начальное состояние q0 задержки) и нужно реа-
лизовать инициальный автомат, то можно использовать
§ 3.3]
СХЕМЫ ИЗ ЭЛЕМЕНТОВ II ЗАДЕРЖЕК
145
описанный выше метод синтеза со следующим уточне-
нием. При установлении соответствия между состояния-
ми автомата и двоичными наборами длины s началь-
ному состоянию автомата необходимо сопоставить
набор (<7о, <7о, • • •, <7о) (в остальном соответствие произ-
вольно).
Рис. 3.12.
Для пояснения алгоритма синтеза рассмотрим при-
мер. Пусть требуется построить схему в базисе {&, V,
~,3} для автомата с 1 входом, 2 выходами и 3 состоя-
ниями, заданного таблицей 3.16, в клетках которой по-
мещено следующее состояние и значения выходов z/j
И 1/2-
Возьмем s = 2, являющееся наименьшим целым чис-
лом, удовлетворяющим условию 2s 3, и установим со-
ответствие между состояниями автомата и некоторыми
146
ДИСКРЕТНЫЕ УСТРОЙСТВА С КОНЕЧНОЙ ПАМЯТЬЮ [ГЛ. III
двоичными наборами длины 2: <?° = (00), q} = (01),
q2 — (10). Заменим в таблице 3.16 значения q соответ-
ствующими наборами (<71,(72), в результате чего придем
к таблице 3.17. Наборы (00), (01) и (10), нумерующие
Таблица 3.17
X. / / ^1^2 X X. 0 0 0 1 1 0
0 00,00 00,10 10,01
1 00,00 01,01 01,11
столбцы таблицы, относятся к состояниям в момент
t—1, и соответствующие переменные снабжены штри-
хами. В клетках таблицы помещены четверки q\qхуя,
относящиеся к моменту t.
Таблица 3.17 задает систему булевых функций, ко-
торая в более привычной форме приведена в таб-
лице 3.18.
Таблица 3.18
X / 41 / 41 «2 У\ У-2
0 0 0 0 0 0 0
0 0 1 0 0 1 0
0 1 0 1 0 0 1
1 0 0 0 0 0 0
1 0 1 0 1 0 1
1 1 0 0 1 1 1
Эти функции являются частичными. Они не заданы
на наборах (ОН) и (111), ибо пара (11) не соответ-
ствует никакому состоянию. Реализация функций может
быть осуществлена на основе любого из методов, опи-
санных в главе II.
§ 3.3]
СХЕМЫ ИЗ ЭЛЕМЕНТОВ И ЗАДЕРЖЕК
147
Поступим, например, следующим образом. Методом
из § 2.3 найдем м. д. и. ф. этих функций:
<71 = xq\,
q2 = xq\ V xq2,
Уi = *q-2 V xq't,
У2 = y'i v X(/'-
Реализуем простые импликанты xq't, xq', xq', xq'2, встре-
чающиеся в этих выражениях, а затем, образовав соот-
Рис. 3.13.
ветствующие дизъюнкции, получим требуемые реализа-
ции функций. Схема, построенная этим способом, изо-
бражена на рис. 3.13, а, а схема, реализующая задан-
ный автомат, получается из нее введением обратных
связей через задержки 5] и 32 (рис. 3.13, б).
Тем самым описан способ реализации произвольных
автоматов. Обычно ставится задача построения «про-
стых» реализаций (например, содержащих по возмож-
ности малое число элементов). Синтез схем с задерж-
ками, как мы видели, осуществляется в два этапа. На
первом из них, носящем название этапа кодирования
состояний, выбирается число s задержек и устанавли-
148
ДИСКРЕТНЫЕ УСТРОЙСТВА С КОНЕЧНОЙ ПАМЯТЬЮ [ГЛ. Ш
вается соответствие между состояниями автомата и
двоичными наборами длины s (состояниями задержек).
На втором этапе осуществляется синтез схемы, из кото-
рой в результате добавления s задержек получается
требуемая реализация. После того как произведено ко-
дирование состояний, однозначно определяется система
логических функций и для ее экономной реализации мо-
гут быть использованы все описанные раньше методы
синтеза схем (т. е. на втором этапе не возникает новых
задач). Этап кодирования состояний оказывает сущест-
венное влияние на сложность схем. Кроме того, здесь
решаются некоторые задачи, связанные с надежностью
функционирования схем. Вопросы кодирования состоя-
ний с учетом сложности окончательных схем в настоя-
щее время развиты недостаточно, поэтому на этапе ко-
дирования состояний останавливаться не будем.
3.3.5. Асимптотическая оценка сложности схем. Для
простоты будем рассматривать схемы в базисе {&, V,
3}. Под сложностью L(S) схемы S будем понимать
число входящих в нее элементов. Минимальную из
сложностей схем, реализующих автомат М, будем назы-
вать сложностью автомата М и обозначать £(Л1). Пусть
L(n,m,p) означает максимальную из сложностей авто-
матов с п двоичными входами, m двоичными выходами
и р состояниями. Функцию L(n,m,p) будем называть
функцией Шеннона.
Асимптотическая оценка функции L(n,m,p) может
быть получена на основе асимптотической оценки функ-
ции Шеннона для схем в базисе {&, V,-} (§ 2.5). Для
простоты рассмотрим случай, когда р является степенью
двух, т. е. р = 2С Закодируем состояния автомата на-
борами длины s. В результате канонические уравнения
автомата запишутся в виде системы m + s логических
функций от п + s аргументов. Согласно (2.40) эта си-
стема может быть реализована схемой, содержащей
л (m + S) 2n+s
асимптотически не более ;—р ; . on+sv элементов, при
log ((m + s) 2 т )
условии, что log(m + s) = o(2n+s). Последнее, как не-
трудно видеть, эквивалентно условию log m = o(2”+s)
или, что то же самое, logm — о{р-2п).
Для того чтобы преобразовать построенную схему
в схему, реализующую заданный автомат, достаточно
§ 3.3]
СХЕМЫ ИЗ ЭЛЕМЕНТОВ И ЗАДЕРЖЕК
149
добавить s элементов задержки. Легко видеть, что ве-
личина s существенно меньше сложности уже построен-
ной схемы и ею можно пренебречь. Таким образом,
сложность реализации автомата асимптотически не пре-
(т 2n+s
восходит —--------—-~тд-. Подставив вместо s вели-
log ((/и + s) 2re+i)
чину log р, получаем оценку функции Шеннона:
L (п> т> р} . (3 9)
' > г/log ((m + log р) р • 2п) ' '
Условие, что р является степенью двух, несущественно,
и от него можно избавиться небольшим усложнением
конструкции (на этом останавливаться не будем).
Полученная оценка может быть несколько упрощена.
Представим знаменатель в виде log(m + logp) ф-
+ log р 4- п. Для произвольных а и b (а,Ь^1) имеет
место а -ф b 2аЬ, поэтому в силу монотонности лога-
рифма выполнены неравенства
log а log (а -ф b) log a -ф log b -ф 1.
Воспользовавшись ими при а = т, b = log р, получаем
log т -ф log р -ф п log (m -ф log р) -ф log р -ф п
log т -ф log log р -ф 1 -ф log р -ф п.
Крайние части этих неравенств асимптотически равны,
поэтому
log (т -ф log р) + log р -ф п ~ log т -ф log р -ф п.
Заменив в (3.9) знаменатель асимптотически равной
ему величиной log т -ф log р -ф п, приходим к оценке
L {п, т, р) Р-j- = ±1+ А) Р; 2",. (3.10)
' log т 4- log р + п log(mp-2) - ’
С помощью мощностных соображений можно дока-
зать, что при log р = о(т-2п) эта оценка асимптоти-
•чески неулучшаема и что почти все автоматы с парамет-
рами (п,т,р) имеют сложность, асимптотически совпа-
дающую с правой частью (3.10). Для получения асимп-
тотически точной оценки в случае, когда это условие не
выполнено, нужно использовать некоторый специальный
способ кодирования состояний [15].
Г>0
ДИСКРЕТНЫЕ УСТРОЙСТВА С КОНЕЧНОЙ ПАМЯТЬЮ [ГЛ. III
Приведенные результаты допускают обобщение на
случай, когда конечный базис состоит из произвольной
полной системы логических элементов и элемента за-
держки и всем элементам приписаны положительные ве-
са. В этом случае асимптотическая оценка домножается
на приведенный вес р (§ 2.5) логической части базиса.
§ 3.4. Схемы из автоматных элементов
3.4.1. Правила построения схем. В предыдущем па-
раграфе изучались схемы из логических элементов и за-
держек. Задержка представляет собой автомат с кано-
ническими уравнениями (3.2). Логический элемент Е
тоже можно рассматривать как автомат с единствен-
ным внутренним состоянием q0. На его выходе в каж-
дый момент t реализуется функция <р£ от значений его
входов хь ..., xk в тот же момент. Канонические урав-
нения соответствующего автомата имеют вид
q (О = <7о,
1/(0 = <PeUi(О. • • •> х*(0).
В данном параграфе мы будем рассматривать схемы
общего вида, построенные из автоматных элементов.
Пусть задан некоторый конечный набор автоматов
Л = {Л4Ь Л!2, ..., ЛК}. Этот набор будем называть ба-
зисом, а входящие в него автоматы — базисными. Каж-
дый базисный автомат имеет некоторое число входов и
некоторое число выходов. В частности, могут использо-
ваться и автоматы без входов (автономные), для кото-
рых выходы и состояния в момент t зависят лишь от со-
стояний в момент I — 1.
Входные алфавиты всех базисных автоматов будем
предполагать одинаковыми (обозначим этот общий ал-
фавит через Л) и будем считать, что выходные алфа-
виты базисных автоматов содержатся в А. Это требова-
ние необходимо для того, чтобы к выходам автоматов
можно было подсоединять входы других автоматов. Все
автоматы из Л одновременно являются инициальными
либо неинициальными. В зависимости от этого будем
говорить об инициальном либо неинициальном базисе.
Из базисных автоматов, которые дальше будем на-
зывать также элементами, по определенным правилам
§ 3.4]
СХЕМЫ ИЗ АВТОМАТНЫХ ЭЛЕМЕНТОВ
151
строятся схемы. Помимо элементов они содержат по-
люсы, каждому из которых соответствует некоторая пе-
ременная принимающая значения из алфавита А.
Как и раньше, полюсы и выходы элементов схемы бу-
дем называть общим термином вершины.
Пусть полюсами схемы S являются xi, ..., хп и она
содержит элементы А4(1), ..., ЛЕЧ Каждому элементу
сопоставим функцию Ч*/, указывающую его состоя-
ние qj(t) в момент t в зависимости от входных значе-
Рис. 3.14.
ний xi(t), .... xn(f) и состояний элементов схемы в мо-
мент t — 1:
9/(0 = ^/(х1(0, ..., х„(/), </,(/-1), .... <?,(/-1)), (3.11)
а каждой вершине yi— функцию Ф/, указывающую зна-
чение, приписанное этой вершине в момент t\
yt (/) = Ф, (х, (/), . . ., хп (t), q{ (t - 1), . . ., qs (/ - 1)). (3.12)
Ниже дается индуктивное определение схемы и одно-
временно указывается способ приписывания функций
и Ф„
— Совокупность полюсов, которым соответствуют
различные переменные х,-, есть схема (рис. 3.14,а). По-
люсу xi приписывается в момент t значение, совпадаю-
щее со значением х,(/) переменной х>.
— Результат присоединения к вершинам схемы S
всех входов некоторого элемента М есть схема
(рис. 3.14,6). Ее полюсами являются полюсы исход-
ной схемы. Если автомат М имеет с входов ги, d выхо-
152
дискретные устройства с КОНЕЧНОЙ ПАМЯТЬЮ [ГЛ. III
дов wv, задается каноническими уравнениями
(0 = Фл1,0 (Z! О'), • • Zc(t), qM(t— 1)) (о=1, .... d),
и его входы zu присоединены к вершинам уи, которым
приписаны функции fu(t), то вершине wu приписывается
функция
Фм,ИЛ(О> fc(t), qM(t—\)),
а состояние автомата М задается функцией
4^0), qM(t~i)).
Если М является автоматом
его присоединения к схеме S
Рис. 3.15.
без входов, то результат
дает схему, являющуюся
«объединением» схемы S
и автомата М (рис.
3.14,в). В этом случае
значения выходов и со-
стояние автомата М в мо-
мент t задаются его
каноническими уравне-
ниями.
— Если Xi является
полюсом, у, — вершиной
схемы и функция
приписанная вершине yh не зависит существенно от
х,(1) (т. е. произвольное изменение xi(t) не оказывает
влияния на величину у;(/) в тот же момент), то резуль-
тат присоединения вершины у, к полюсу х, есть схема
(рис. 3.14,г). Ее полюсами являются все полюсы исход-
ной схемы, за исключением хг. Функции, приписанные
вершинам и состояниям элементов схемы, полученной
в результате такого преобразования, образуются из
прежних подстановкой всюду вместо х;(/) функции
приписанной вершине у,.
Последняя из рассмотренных операций (рис. 3.14, г)
называется введением обратной связи. Требование неза-
висимости функции fj(t) от величины х,(/) введено,
чтобы избежать противоречия в работе схемы (иначе
бы функция у;(/) зависела от хг(/), а хг(/) от yi(t)).
Правило введения обратной связи через задержку, при-
менявшееся в предыдущем параграфе, удовлетворяет
требованию независимости, ибо выходу задержки 3/
§ 3.4]
СХЕМЫ ИЗ АВТОМАТНЫХ ЭЛЕМЕНТОВ
153
приписывается функция qi(t— 1), не зависящая от вхо-
дов схемы в момент /.
В качестве примера рассмотрим базис, состоящий из
автоматов АТ и М2, показанных на рис. 3.15. Пусть
входным и выходным алфавитами обоих автоматов яв-
ляется алфавит {0, 1} и каждый из автоматов имеет
по 2 состояния. Обозначим одно из них символом О,
второе — символом 1. Тогда канонические уравнения
автоматов могут быть записаны с помощью булевых
cc,(t) xfi) x,(t)
О о о"
а)
xz х3
о 9
М,
x3(t)qz(t-1)
'г
qfi-Dq/t-1)vx3(ty\ tq (f-J)yqM J
el
в)
Рис. 3.16.
функций. Пусть автомат М1 имеет канонические урав-
нения
w (/) = <?(/ — 1),
<7(0 = 2^/) V М),
а автомат М2— уравнения
Wi (/)==Z! (fyq(t — 1) V z2(0,
(/) = Zi О') V q{t — 1),
q (f) ~ z2 (t)q(t — 1).
На рис. 3.16 представлен процесс последовательного
построения схемы с одновременным указанием функций,
приписанных вершинам и состояниям элементов.
В схеме выделяется некоторое количество вершин,
которые объявляются ее выходами.
154
ДИСКРЕТНЫЕ УСТРОЙСТВА С КОНЕЧНОЙ ПАМЯТЬЮ [ГЛ. Ill
3.4.2. Автомат, реализуемый схемой. Состоянием схе-
мы будем называть набор состояний всех входящих в
нее элементов
q = (О...............(3.13)
Пусть выходами схемы являются вершины у\, у2, ...
..., ym. С учетом (3.11), (3.12) и (3.13) функции, реа-
лизуемые на выходах схемы, могут быть представлены
в виде
Vi (t) = Ф; (х, (/).х„(/), q{t - 1)), (3.14)
(i = 1, .. ., m),
а состояние схемы в момент t — в виде
< /(/) = Т(х1(/), .... %„(/)> q(t - 1)), (3.15)
где 4r = (4ri, ..., Ts). Уравнения (3.14) —(3.15) за-
дают автомат, реализуемый схемой. Начальным состоя-
нием автомата является набор начальных состояний
элементов схемы.
Найдем автомат, реализуемый схемой, показанной
на рис. 3.16,г, если выходом схемы является свободный
выход элемента М2. Этот автомат описывается уравне-
ниями (см. рис. 3.16)
t/(0 = <7i(/ — 1) V q2<,t— 1),
< 71 (/) = х{ (/) V х2 (/),
< 72(О = <72(/ — 1).
Таблица автомата, составленная на основе этих урав-
нений, приведена в таблице 3.19.
Введя переобозначение состояний: q°= (00), ql = (01),
q2 =(10), q3 = (11), эту таблицу можно переписать в
более привычной форме (табл. 3.20).
Таблица 3.19
XiX. 00 01 10 11
00 10,0 11,1 10,1 11,1
01 10,0 11,1 10,1 11,1
10 00,0 01,1 00,1 01,1
11 10,0 11,1 10,1 11,1
§ 3.4]
СХЕМЫ ИЗ АВТОМАТНЫХ ЭЛЕМЕНТОВ
155
Таблица 3.20
ч° ч'3
00 q2, о q3, 1 q2, 1 q3, 1
01 q2, 0 <73, 1 q2, 1 q3, 1
10 о ?’> 1 q°, 1 ql, i
11 q2, 0 д3, 1 q2> 1 q3 , 1
3.4.3. Полнота автоматных базисов. Одновременно с
определением схем в автоматных базисах было дано ре-
шение задачи анализа, т. е. задачи нахождения автома-
тов, реализуемого схемой. Задача синтеза состоит в том,
чтобы по заданному автомату построить некоторую его
реализацию. Прежде всего должна быть уверенность,
что автомат (вообще говоря, произвольный) может быть
реализован. В связи с этим возникает проблема полноты
базиса, состоящая в следующем.
Будем говорить, что М является автоматом в алфа-
вите А, если его входным алфавитом является А, а вы-
ходной содержится в А. Заданную систему автоматов в
алфавите А будем называть базисом в алфавите А. Ба-
зис в алфавите А назовем полным, если любой автомат
в алфавите А может быть реализован схемой в этом ба-
зисе. В противном случае базис будем называть непол-
ным. Это определение следует рассматривать в двух
вариантах — для инициальных и неинициальных автома-
тов. Инициальные автоматы реализуются в инициаль-
ном базисе, неинициальные — соответственно в неиници-
альном. Проблема полноты состоит в том, чтобы по
заданному базису (вообще говоря, произвольному) в
алфавите А установить, является ли он полным.
Подобная задача рассматривалась нами для логи-
ческих функций (двузначных) и функций й-значной ло-
гики. В случае логических функций она имеет простое
решение: система функций полна тогда и только тогда,
когда она целиком не содержится ни в одном из пяти
основных замкнутых классов (принадлежность к этим
классам устанавливается достаточно просто).Для функ-
156
ДИСКРЕТНЫЕ УСТРОЙСТВА С КОНЕЧНОЙ ПАМЯТЬЮ [ГЛ. III
ций й-значной логики задача полноты может быть ре-
шена на основе теоремы 1.5, однако трудоемкость про-
цедуры проверки полноты быстро возрастает с ростом
k (быстро растет число замкнутых классов, участвую-
щих в формулировке теоремы). В случае автоматных
базисов ситуация становится принципиально иной. Ока-
зывается, что не существует способа (алгоритма), поз-
воляющего по произвольной системе автоматов устанав-
ливать, является ли она полной. Или, как говорят в
этом случае, задача является алгоритмически неразре-
шимой. Относящиеся сюда понятия будут точно опреде-
лены в следующей главе, а доказательство этого факта
будет дано в главе V после выработки соответствующей
техники. Сейчас же приведем лишь его формулировку.
Теорема 3.2 (М. И. Кратко). Для любого конеч-
ного алфавита А, содержащего не менее двух букв, за-
дача распознавания по произвольной системе автома-
тов в алфавите А, является ли она полной, алгоритми-
чески неразрешима. Этот факт справедлив как для ини-
циальных автоматов, так и для неинициальных.
3.4.4. Вопросы синтеза схем в автоматных базисах.
Если автоматный базис является полным, то задача
синтеза схем в этом базисе может быть в принципе ре-
шена следующим образом. Для того чтобы реализовать
заданный автомат, можно последовательно перебирать
все схемы в базисе Л, которые не содержат элементов,
содержат 1 элемент, содержат 2 элемента и т. д. (со-
став полюсов схемы определяется входами автомата).
Для каждой из схем можно проверить, реализует ли
она заданный автомат (при некоторой фиксации выхо-
дов). В силу полноты базиса Л в результате такой про-
цедуры будет найдена нужная реализация. Более того,
она будет минимальной по числу содержащихся в схе-
ме элементов.
Указанная переборная процедура, хотя и дает прин-
ципиальное решение задачи синтеза, из-за своей трудо-
емкости на практике реализована быть не может. Если
ставить задачу отыскания какой-нибудь (не обязатель-
но минимальной) реализации, то в этой процедуре обыч-
но нет необходимости. Как правило, доказательство пол-
ноты базиса проводится конструктивно и в самом дока-
зательстве содержится эффективный способ построения
§ 3.4]
СХЕМЫ ИЗ АВТОМАТНЫХ ЭЛЕМЕНТОВ
157
реализации произвольного автомата. Примером может
служить рассматривавшийся в предыдущем параграфе
базис, состоящий из произвольной логически полной си-
стемы элементов и задержки. Тот же способ реализации
может быть применен и для автоматов в fe-зиачном ал-
фавите, если базис состоит из элементов, реализующих
полную систему fe-значных функций, и элемента за-
держки. Отличие при синтезе будет состоять лишь в
том, что канонические уравнения (3.8) будут записы-
ваться с помощью функций fe-значной логики и схема
на рис. 3.12, а будет реализовать систему функций k-
значной логики (она может быть построена из элемен-
тов базиса).
Отсюда вытекает, что такой базис будет полным в
fe-значном алфавите А. Полным, в частности, будет и ба-
зис, состоящий из задержки и элемента, реализующего
полную функцию fe-значной логики, например, функцию
Вебба Vk(x, у} (§ 1.4). Этот факт будет использован в
дальнейшем при доказательстве теоремы 3.2.
Результат об алгоритмической неразрешимости про-
блемы полноты указывает на большую трудность за-
дачи синтеза схем в автоматных базисах в сравнении
с задачей синтеза логических схем. Приведем еще один
факт, свидетельствующий о том же. Рассмотрим задачу
синтеза в асимптотической постановке. Пусть имеется
полный базис Ж, состоящий из конечного числа автома-
тов М; в алфавите А. Каждому автомату Mt <= Ж при-
писан положительный вес (стоимость) pi > 0. Под
сложностью Lm(S) схемы S в базисе Ж будем понимать
сумму весов всех входящих в нее элементов. Слож-
ностью Lm(M) автомата М назовем минимальную из
сложностей схем, реализующих М. Введем функцию
Шеннона Ьм(п, т, р), указывающую максимальную из
сложностей автоматов в алфавите А, имеющих п вхо-
дов, т выходов и р состояний. В то время как для схем
из логических элементов удалось получить асимптоти-
чески точную оценку функции Шеннона для произволь-
ного базиса & (§ 2.5), в случае схем из автоматных эле-
ментов дело обстоит по-другому: задача выяснения по
произвольному полному базису Ж асимптотического по-
ведения функции Шеннона LM(n, т, р) является алгорит-
мически неразрешимой [25].
ЧАСТЬ ВТОРАЯ
Глава IV
МОДЕЛИ АЛГОРИТМОВ
§ 4.1. Машины Тьюринга
4.1.1. Тезис Чёрча. До сих пор мы рассматривали мо-
дели дискретных устройств с конечной памятью. С по-
мощью таких моделей могут быть описаны различные
специализированные устройства автоматики и отдель-
ные узлы вычислительных машин. Сами же вычисли-
тельные машины удобно считать устройствами с беско-
нечной памятью, либо устройствами, память которых в
каждый момент конечна, но в процессе работы может
неограниченно наращиваться. Ниже производится изу-
чение таких устройств.
Понятие (вычислительной) машины тесно связано с
понятием вычислительной процедуры, или алгоритма.
Интуитивно под алгоритмом понимается процесс после-
довательного построения (вычисления) величин, проте-
кающий в дискретном времени так, что в каждый сле-
дующий момент времени система величин получается по
определенному закону из системы величин, имевшихся
в предыдущий момент.
Перечислим несколько общих черт, характерных для
алгоритмического процесса.
1) Элементарность шагов алгоритма: решение за-
дачи распадается на ряд шагов, каждый из которых яв-
ляется достаточно простым.
2) Детерминированность: после выполнения очеред-
ного шага однозначно определено, что делать на сле-
дующем шаге.
3) Массовость: алгоритм пригоден для решения всех
задач из заданного класса.
§ 4.1]
МАШИНЫ ТЬЮРИНГА
159
Несмотря на нестрогость, интуитивное представление
об алгоритме является настолько отчетливым, что прак-
тически не возникает разногласий относительно того, яв-
ляется ли алгоритмическим тот или иной процесс. Од-
нако ситуация оказывается принципиально иной, когда
имеют дело с задачами, решение которых не известно и
относительно которых имеется предположение, что они
по сути своей не могут быть решены алгоритмическими
методами. Доказать алгоритмическую неразрешимость
задач на основе интуитивного представления об алго-
ритме невозможно. В середине 30-х годов были пред-
приняты попытки формализовать это понятие и были
предложены различные модели алгоритмов. Впослед-
ствии было установлено, что эти (и другие) модели эк-
вивалентны в том смысле, что классы решаемых ими за-
дач совпадают. Это дает основания для предположения
о том, что класс задач, решаемых в любой из этих фор-
мальных моделей, и есть класс всех задач, которые мо-
гут быть решены «интуитивно алгоритмическими» ме-
тодами. Явно эта гипотеза впервые (в несколько ином
виде) была высказана А. Чёрчем и носит название те-
зиса Чёрча. Сейчас она является общепризнанной. Фор-
мальное определение понятия алгоритма создало пред-
посылки для разработки теории алгоритмов. Прогресс
вычислительной техники стимулировал ее дальнейшее
развитие.
4.1.2. Машина Тьюринга. Как уже говорилось, раз-
личные формальные модели алгоритмов эквивалентны с
точки зрения класса решаемых задач. Поэтому теорию
алгоритмов можно излагать на базе любой из них.
В Качестве основной мы примем модель машины Тью-
ринга.
Машина Тьюринга состоит из бесконечной в обе сто-
роны ленты, разбитой на ячейки, и рабочей головки
(рис. 4.1). Машина работает в дискретные моменты
времени t — 0, 1, 2, ... В каждый момент во всякой
ячейке ленты записана одна буква из некоторого конеч-
ного алфавита А = {ао, «1...a*-i}, называемого внеш-
ним алфавитом машины, а головка находится в одном
из конечного числа внутренних состояний Q = {qo, q\, ...
..., qr-\}. Условимся считать, что символ а0 является
«пустым» (он будет обозначаться также Л). Наличие
160
МОДЕЛИ АЛГОРИТМОВ
[ГЛ. IV
символа Л в некоторой ячейке содержательно означает,
что в ней ничего не записано.
В каждый момент времени рабочая головка обозре-
вает одну ячейку ленты и, в зависимости от того, что
там записано, и от своего внутреннего состояния *) она
заменяет символ в обозреваемой ячейке новым (воз-
можно, прежним), переходит в новое состояние (воз-
можно, в прежнее) и сдвигается на одну ячейку (вправо
или влево) либо остается на месте.
Рис. 4.1.
Работа машины задается системой команд вида
qtat-> qt'Ui'S, (4.1)
где Se {П, Л, Н}. Если головка в состоянии q, читает
символ at, то в следующий момент времени она запи-
сывает в эту ячейку вместо а,- символ а/, переходит в
состояние qj> и, в зависимости от того, совпадает ли S
с П, Л или Н, головка сдвигается на одну ячейку впра-
во, влево или остается на месте. Среди состояний ма-
шины выделено одно, называемое заключительным
(впредь мы будем считать, что это qo). Если после не-
которого шага головка оказывается в состоянии qQ, то
машина прекращает свою работу (останавливается).
Будем предполагать, что для каждой пары qjai (q, е
eQ\ {<7о}, at е Д) имеется ровно одна команда с левой
частью qitti, так что всего имеется (г— 1) /г команд. Со-
вокупность этих команд будем называть программой
машины.
Работа машины состоит в изменении ее конфигура-
ций. В понятие конфигурации (в рассматриваемый мо-
мент) входит распределение букв по ячейкам ленты, со-
стояние головки и обозреваемая ячейка. Конфигурацию
*) Состояния головки иногда будем называть также состоя-
ниями машины.
§ 4.1]
МАШИНЫ ТЬЮРИНГА
161
в момент t будем обозначать Kt. В случае, если конфи-
гурация Kt не является заключительной (т. е. машина
не находится в заключительном состоянии), она в соот-
ветствии с очередной выполняемой командой переходит
в конфигурацию /ф-м- Всякая начальная конфигурация
Ко порождает последовательность конфигураций Ко, Ki,
К2, , Kt, ... В случае, когда эта последовательность
обрывается (некоторой заключительной конфигура-
цией), будем говорить, что машина применима к кон-
фигурации Ко (в противном случае — неприменима).
Если нужно решить некоторую задачу на машине
Тьюринга, исходным данным задачи определенным об-
разом сопоставляется начальная конфигурация Ко, а от-
вет задачи определяется заключительной конфигура-
цией, в которую машина переводит Ко (точные опреде-
ления будут даны дальше).
4.1.3. Машины Тьюринга и конечные автоматы. Су-
ществует тесная связь между моделями машины Тью-
ринга и конечного автомата. Машину Тьюринга можно
представить как сочетание ленты и некоторого устрой-
ства управления. Последнее представляет собой конеч-
ный автомат. Состояние 7/ головки можно рассматри-
вать как внутреннее состояние автомата, а считываемый
символ at — как входное воздействие. Функции пере-
хода и выходов автомата определяются программой ма-
шины. Если управляющее устройство находится в со-
стоянии qj и воспринимает символ at, то в соответствии
с командой (4.1) оно переходит в новое состояние qp
и выдает выходные символы ад и S. Первый из них за-
писывается в обозреваемую ячейку, а второй управля-
ет сдвигом головки.
С другой стороны, конечные автоматы можно рас-
сматривать как машины Тьюринга частного вида. Пове-
дение всякого конечного автомата допускает описание
посредством системы команд вида
qx->q'y, (4.2)
где q — состояние автомата, х— входной символ, q' -—
новое состояние, у — выходной символ. Пусть автомат
запущен в некотором начальном состоянии q{ и на его
вход в течение заданного промежутка времени подана
последовательность Х1Х2 ... х?. Рассмотрим машину
162
МОДЕЛИ АЛГОРИТМОВ
[гл. iv
Тьюринга, программа которой получается в результате
дописывания к каждой команде (4.2) символа П, т. е. со-
стоит из команд вида qx-^q'yU. Запустим эту машину
в конфигурации, показанной на рис. 4.2. Головка ма-
шины, перемещаясь направо в соответствии с програм-
мой, будет последовательно считывать символы Xi, Х2,...
и перерабатывать их в выходные символы у\, у2, ...
тем же образом, что и автомат. Потребуем, чтобы после
того, как головка наткнется на пустой символ А (сой-
дет со слова Xi ... Хг), она переходила в заключитель-
ное состояние и сохраняла в ячейке пустой символ.
Тогда после остановки машины на ленте будет содер-
жаться выходная последовательность автомата yi... ут.
Л ос1 •. . Д7Г Л
б
Рис. 4.2.
Таким образом, конечный автомат может интерпрети-
роваться как машина Тьюринга, у которой головка
сдвигается в одном направлении.
4.1.4. Вычисление функций на машинах Тьюринга.
Обычно мы будем иметь дело со случаем, когда в на-
чальной конфигурации на ленте имеется лишь конечное
число непустых символов. При этом и все последующие
конфигурации будут обладать тем же свойством. Актив-
ной зоной данной конфигурации будем называть мини-
мальную связную часть ленты, содержащую обозревае-
мую ячейку и все ячейки, в которых записаны непустые
буквы. В конфигурациях, представленных на рис. 4.3, а,
б, активные зоны заштрихованы.
Пусть активная зона имеет некоторую длину р, в ней
записано слово а(1) ... а<р> и головка обозревает букву
а(0 этого слова в некотором состоянии q. Такую конфи-
гурацию будем задавать словом длины р + 1:
а(1) ... . а(р),
в котором состояние головки указывается перед обозре-
ваемым символом. В частности, конфигурациям, изобра-
женным на рис. 4.3, а, б, соответствуют слова l^OAAO
5 4.1]
МАШИНЫ ТЬЮРИНГА
163
и (/гЛЛААПЛО. В последующем мы не будем различать
конфигурации и связанные с ними слова.
Пусть нужно решить некоторую задачу. Исходные
данные задачи и ее ответ могут быть закодированы не-
которым «естественным» образом словами некоторого
алфавита. (Так, например, граф может быть представ-
лен в виде слова в алфавите {0, 1,*}, составленного из
приписанных друг к другу строк матрицы инциденций,
разделенных знаком *.) В результате задача сводится
к вычислению функции f, отображающей слова в сло-
ва. Такие функции будем называть словарными. Мы бу-
дем рассматривать частичные словарные функции f (Р),
Рис. 4.3.
т. е. такие, значения которых определены не на всех
словах Р (в данном алфавите). В дальнейшем, не ого-
варивая особо, под словарной функцией будем подра-
зумевать частичную словарную функцию.
Опишем теперь, в каком смысле мы будем понимать
вычисление на машине Тьюринга словарной функции
f(P). В машине выделено некоторое состояние, назы-
ваемое начальным (впредь будем считать, что это qi).
В начальной конфигурации па ленте записано слово Р
н головка в состоянии обозревает самый левый сим-
вол этого слова. Если значение f(P) определено, то
после некоторого конечного числа шагов машина долж-
на перейти в заключительную конфигурацию, в которой
записано слово f(P) и головка (в состоянии <?0) нахо-
дится у его левого символа (т. е. конфигурация qiP
должна быть переведена в qof(P)). В противном слу-
чае машина должна работать бесконечно.
164
МОДЕЛИ АЛГОРИТМОВ
(ГЛ. IV
При определении понятия вычисления на машине
Тьюринга мы допустили некоторый произвол, условив-
шись о способе ввода и вывода данных. Может пока-
заться, что это влияет на класс решаемых задач. Однако
неформальные рассуждения, основанные на тезисе
Чёрча, показывают, что возможность решения той или
иной задачи не зависит от способа ввода и вывода дан-
ных (при условии, что способ является «алгоритмиче-
ским») . Это связано с тем, что всякое «алгоритмиче-
ское» преобразование данных может быть выполнено
на машине Тьюринга.
Рассмотрим пример решения задачи на машине
Тьюринга. Пусть требуется перевести унарную запись
числа п 1 (изображается в виде п палочек) в двоич-
ную запись. Другими словами, нужно построить машину
Тьюринга М, которая конфигурацию <71 11 ... | ,при лю-
п
бом п 1 преобразовывала бы в конфигурацию
(/осгюг ••• Пр, где ощг ... Пр— двоичная запись числа п,
начинающаяся с 1.
Построение машины М может быть выполнено, на-
пример, следующим образом. В качестве входного ал-
фавита машины М берется {А, |,0, 1}. Работа машины
осуществляется циклами. К началу цикла г (1^г^
еС п— 1) машина находится в конфигурации
<7210... 11
дв. запись г п — г
В течение цикла г стирается одна палочка и к числу
г в двоичной записи прибавляется 1. Цикл г осуществ-
ляется в несколько этапов:
— головка проходит направо до конца записи (непу-
стой), используя команды
q21 -><721П,
720 -> </20П,
<?21 -! п;
— «нащупывает» правый конец и оказывается у по-
следней палочки в состоянии q^.
qz Л —> 7з Л Л; (4.3)
§ 4.11
МАШИНЫ ТЬЮРИНГА
165
— стирает последнюю палочку и запоминает состоя-
нием 74 необходимость прибавления единицы
7з |->74 Л Л;
— проходит сквозь палочки налево вплоть до цифр
О и 1
I * I -П;
— прибавляет 1, для чего в соответствии с алгорит-
мом двоичного сложения
а) перемещаясь в состоянии 74 справа налево, го-
ловка заменяет все символы 1, расположенные в конце
двоичной записи (до первого 0), символом 0:
741 -» 74ОЛ;
б) первый из встреченных нулей (если они есть) за-
меняется на 1 и головка изменяет состояние на 75:
740->751Л;
в) в состоянии 75 голвка проходит налево сквозь все
цифры
foO -> 750Л,
fol fol Л;
г) встретив пустой символ, головка перемещается в
состоянии 72 к первой цифре
75А->72ЛП;
д) если двоичная запись сплошь состоит из единиц,
то после осуществления пункта а) головка встречает
пустой символ, заменяет его на 1 и останавливается в
состоянии 72:
74Л-^721Н.
Тем самым цикл завершен. Осталось назначить
команды для входа машины в цикл и выхода из цикла.
Переход к циклу осуществляется с использованием
единственной команды
*71 |->-721Н.
Выход из цикла происходит следующим образом.
Если после выполнения команды (4.3) головка в со-
стоянии 7з считывает не палочку, а цифру (все палочки
166
МОДЕЛИ АЛГОРИТМОВ
[ГЛ. IV
стерты), то она проходит налево сквозь цифры
<7з^ —► <730Л,
<731 -><7з1Л
и останавливается у первого непустого символа
<7з А-><70 А П.
Проиллюстрируем работу машины М на примере,
когда в начальной конфигурации на ленте записаны
3 палочки:
gJH —(вход в цикл 1)->^211|-> 1<72||-> 1
1) | ?2 Л-> 11 <?з |-> 1 1-> 11->
-><74Л0| — (переход к циклу 2)-><7210|г> 1<72О|->
-> 10</2|-> 101</2Л —> Ю<7з|-> 1<740-><7511 ->
-> </5 Л 11 — (переход к циклу 3)-><7211 -> 1<?21 ->
-> 11<72Л-> 1<731 — (выход из цикла 3)-><7311->
-><73Л 11 -><7о11.
Заметим, что в приведенном списке команд машины
М присутствуют лишь команды для тех пар qa, кото-
рые встречаются в процессе работы машины. Остальные
команды несущественны и могут быть взяты произ-
вольно.
Условимся теперь о способе вычисления на маши-
нах числовых функций. Будем рассматривать лишь
функции, которые принимают натуральные значения
(0,1,2, ...) и аргументы которых также принимают на-
туральные значения. Функции, вообще говоря, будем
считать частичными, т. е. заданными не на всех набо-
рах натуральных значений аргументов.
При вычислении на машине мы будем пользоваться
записью числа п (п ~ 0, 1, 2, ...) в виде п -ф I пало-
чек (чтобы запись нуля была непустой). Из разобран-
ного выше примера построения программы видно, что
такое представление числа п может быть переведено
машиной в двоичное, обратный переход также возмо-
жен. Будем говорить, что машина Тьюринга вычис-
ляет функцию f(xi,x2, ..., хп), если конфигурацию
<7111 ... [ * | [ ... | * ... * 11 ... | она переводит в заклю-
х1 Ы
МАШИНЫ ТЬЮРИНГА
167
§ 4.1]
чительную конфигурацию q0 11 ... | в случае, когда зна-
f (х1'?Г7Х)+1
чение f(Х[, .... хп) определено, и работает бесконечно
в противном случае.
Отметим, что задача вычисления словарных функ-
ций может быть сведена к задаче вычисления числовых
функций, если все слова в заданном алфавите перену-
меровать каким-либо «естественным» способом (напри-
мер, в словарном порядке). В дальнейшем основное
внимание будет уделяться числовым функциям.
4.1.5. Некоторые приемы программирования на маши-
нах Тьюринга. Непосредственное построение машин Тью-
ринга для решения даже сравнительно простых задач
является довольно трудоемким делом. Ниже будут опи-
саны некоторые приемы, облегчающие этот процесс, Бу-
дут изложены способы сочетания нескольких машин в
более сложные машины. Это позволит свести програм-
мирование исходной задачи к программированию более
простых подзадач. Нас будет интересовать, в основном,
сам факт существования тех или иных машин, поэтому
детали, связанные с написанием конкретных программ,
как правило, приводиться не будут. Машина Тьюринга
Задается своей программой, и мы не будем различать
машин и их программ. Наряду с терминами «суперпо-
зиция машин», «композиция машин» и др. будем упо-
треблять термины «суперпозиция программ», «компози-
ция программ» и др.
I. Суперпозиция программ. Пусть имеются
машины Тьюринга Afi и М2, которые соответственно
вычисляют словарные функции ft (Р) и f2(P) в одном и
том же алфавите. Тогда можно построить машину М,
вычисляющую суперпозицию /2(/i(P)). Значение супер-
позиции f2(f [ (Р)) считается определенным тогда и
только тогда, когда определены ft (Р) и значение функ-
ции f2 на слове Программа машины М может
быть получена следующим образом. Состояния машины
М2 переобозначаются так, чтобы все они, за исключе-
нием начального, были отличны от состояний машины
Мц а начальное совпадало с заключительным состоя-
нием машины All. Программы приписываются друг к
ДРугу и начальным состоянием машины М объявляется
168
МОДЕЛИ АЛГОРИТМОВ
|ГЛ. IV
начальное состояние Mh а заключительным состоя-
нием — заключительное состояние машины М2.
Пусть на ленте машины М записано слово Р и она
запущена в начальном состоянии. Поскольку это состоя-
ние является начальным для Mi, то вначале машина М
работает как М\ и вычисляет fi(P). После этого го-
ловка находится в заключительном состоянии машины
Mi и обозревает крайний левый символ слова
Заключительное состояние машины /Mi является на-
чальным для М2, поэтому далее М работает как М2 и
вычисляет f2(fi (Р)) • После чего машина М останавли-
вается, ибо она имеет то же самое заключительное со-
стояние, что и М2. Если fi (Р) или значение f2 на аргу-
менте fi(P) не определены, то, очевидно, машина М
будет работать бесконечно. Машину М будем называть
суперпозицией машин Alj и М2 и обозначать Л12°М1.
Схематично работу машины М будем изображать сле-
дующим образом:
II. Композиция программ. Пусть машины
Тьюринга М\ и М2 вычисляют соответственно словарные
функции fi(P) и f2(P)- Тогда можно построить машину
М, которая выполняет работу обеих машин. Слово Р
она перерабатывает в слово fi (Р)« f2(P), где •» — сим-
вол, не встречающийся в алфавите машин Mi и М2.
При этом, если хотя бы одно из значений fi(P) и f2(P)
не определено, М на слове Р работает бесконечно. Ма-
шину М будем называть композицией машин Alj и М2
и обозначать Mi *М2.
При построении машины М используется прием,
который является довольно распространенным. Иногда
удобно считать, что машина имеет «двухэтажную» лен-
ту. Это означает, что в качестве символов внешнего
. (ь\ п
алфавита используются пары I I' Переработка ин-
формации на каждом этаже ленты может осуществ-
ляться «независимо». Если, например, мы хотим, чтобы
на нижнем этаже выполнялась команда qa q'a'S не-
зависимо от записи па верхнем этаже, то в программу
§ 4.1]
МАШИНЫ ТЬЮРИНГА
169
л ( Ь\
машины должны быть введены команды </1 ->
\ a J
,^5для всех Ь, принадлежащих алфавиту верх-
него этажа.
Машина М строится с использованием двухэтажной
ленты. Каждой букве а алфавита машины Mi пли М2
Л с
ставится в соответствие двухэтажная буква I I. Сло-
во Р записывается в нижнем этаже. После запуска ма-
шины оно переписывается также во второй этаж (для
/ Л \
этого каждая непустая буква I 1 заменяется на
/ а \
I). Далее машина работает на нижнем этаже как
\а J
Mi до тех пор, пока не вычислит fi(P). После чего,
работая на верхнем этаже как М2, вычисляет там fz(P).
Затем к слову fi (Р) на нижнем этаже она добавляет *
и побуквенно дописывает слово /ДР), находящееся на
втором этаже (переписанные буквы слова /2(Р) на вто-
ром этаже стираются). Более подробно на реализации
этой идеи мы останавливаться не будем.
С использованием трехэтажной ленты можно по-
строить композицию ЛК * М2« М2 трех машин, вычис-
ляющую значения fi (Р)» f2(P) * fa (Р), и т. д.
III. Ветвление прогр а м м. Пусть имеются ма-
шины Тьюринга М\ и М2, которые вычисляют словарные
функции /ДР) и /ДР) в одном и том же алфавите, и
пусть буквы и и л («истина» и «ложь») не входят в
этот алфавит. Требуется построить машину М, которая
слово а •» Р, где (7^{и,л}, переводит в /ДР), если
ч = и, ив если а = л. Машину М будем обозна-
чать Mi У_М2 п изображать в виде
170
МОДЕЛИ АЛГОРИТМОВ
[ГЛ. IV
Машина М может быть сконструирована следующим
образом. Обозначим через q^ и q'^ начальные состоя-
ния машин All и М2 (считаем, что все состояния машин
Mi и М2 обозначены разными буквами). Программы
машин Mi и М2 допишем друг к другу, введем новое
начальное состояние <?i и дополнительные команды
qtu -> q^ А П,
qf> * -> q^ А П,
qyA -> q<? А П,
q^} « -> q^ А П.
Кроме того, заключительные состояния qff! и qff> ма-
шин Mi и М2 обозначим одной буквой qo и состояние
qo будем считать заключительным для машины М.
Пусть на ленте записано слово и*Р и машина М
запущена в начальном состоянии qx. Тогда головка
сотрет символ и, переместится в состоянии q^' к сим-
волу *, сотрет его и переместится в том же состоянии
к первой букве слова Р. Поскольку состояние q\n яв-
ляется начальным для Mi, дальше машина будет ра-
ботать как Mi и вычислит значение fi(P). Случай <т = л
рассматривается аналогично.
IV. Осуществление цикла. При программиро-
вании задач часто процесс вычисления разбивают на
циклы. После осуществления каждого цикла проверяют
выполнимость некоторого условия. В случае утверди-
тельного ответа выдается результат, в противном слу-
чае цикл повторяется. Более точно, пусть имеются неко-
торое свойство Ф слов и словарные функции fi и f2.
Проверяется, обладает ли исходное слово Р свойством
Ф, и если обладает — выдается ответ fi(P). В против-
ном случае вычисляется слово Р'— f2(P) и проверяется,
обладает ли Р' свойством Ф. Если обладает, то вы-
дается ответ fi(P'), если нет — вычисляется Р"—
= fsfP'), И т. д.
Указанная процедура может быть реализована на
машинах Тьюринга. Пусть свойство Ф проверяется ма-
шиной Мф, а функции ft и f2 вычисляются машинами
Mj и Мя. Обозначим через Мо машину, которая всякое
§ 4.2]
ЧАСТИЧНО РЕКУРСИВНЫЕ ФУНКЦИИ
171
входное слово Р оставляет без изменения. Машина М,
осуществляющая цикл, может быть построена следую-
щим образом. Вначале к слову Р применяется машина
Мф*Л4о, которая переводит его в о*Р, где а »= и, если
Р обладает свойством Ф, и о = л в противном случае.
Затем запускается машина Afi_VM2 (заключительное
состояние машины Л1ф»Л40 объявляется начальным для
AfiJVAh)- При этом, в отличие от описания из преды-
дущего пункта III, заключительные состояния qfi и
qff> машин Mi и М2 не объединяются в одно состоя-
ние qo, считаются разными. Состояние q^ объявляет-
ся заключительйым состоянием машины М, a q^ отож-
дествляется с начальным состоянием. В результате,
если машина М\У_ М2 работала как Mlt то полученное
значение является выходным, если же она работала как
М2, то полученное значение снова подается на вход
машины М. Схематично работу машины М можно
представить следующим образом:
Приведенные способы сочетания машин существен-
но облегчают процесс программирования. Они позво-
ляют разбивать задачу на подзадачи, а затем устраи-
вать последовательное соединение программ для от-
дельных подзадач (суперпозицию), параллельное со-
единение (композицию), использовать связки, «если Ф,
делай fi, иначе f2», «пока Ф, повторяй fi, иначе f2». Та-
ким образом, язык тьюрингова программирования мо-
жет быть сделан достаточно богатым. Это служит до-
полнительным доводом в пользу тезиса, что всякий
интуитивно алгоритмический процесс может быть реа-
лизован на машине Тьюринга.
§ 4.2. Частично-рекурсивные функции
4.2.1. Основные операции. Как уже говорилось, было
предложено несколько моделей вычислительных про-
цедур (алгоритмов). С каждой из них связано понятие
172
МОДЕЛИ АЛГОРИТМОВ
[ГЛ. IV
«вычислимой функции». Понятие функции, вычислимой
на машине Тьюринга (вычислимой по Тьюрингу), было
рассмотрено выше. Сейчас будет описан еще один
класс вычислимых функций. Он порождается из не-
скольких простейших функций с использованием ряда
операций.
Операция суперпозиции. Пусть заданы п-
местная частичная функция g и частичные функции f\,
f2, ..., fn- Будем считать, что функции fi, f2, ..., fn за-
висят от одних и тех же аргументов xh х2, ..., х.п
(этого можно достигнуть, добавив при необходимости
к аргументам некоторых из функций дополнительные
фиктивные аргументы). Суперпозицией функций g и
fi, , fn назовем частичную функцию
/г(%1, ..., xm) — g (f I (xb хш), fn(X[, ..., хт)),
значение которой на наборе (хь ..., хт) задается ука-
занной формулой, если определены значения Z] =
= fi(xb ..., хт), ..., Zn — fn(xi, ..., хту и значение
g(zb ..., zn). В противном случае величина h(xlt ...
..., хт) считается неопределенной.
Пусть, например, fi(x,y) = x — y, f2(x, z) = х2 + z
g(x, y) = -~. Мы рассматриваем функции от натураль-
ного аргумента, принимающие натуральные значения,
поэтому значения указанных функций будем считать
определенными лишь в случае, когда они целые и не-
отрицательные. Суперпозиция функций g и fi, f2 запи-
сывается в виде
h(x, у, z) = ~xi~A.Vz
Л "р <
Вычисление некоторых из значений функции h проил’
люстрировано таблицей 4.1.
Таблица 4.1
X У Z fl—X — у h — x‘ + z к л=77
1 2 5 6 —
4 1 0 3 16 —
2 2 1 0 5 0
J 4.2]
ЧАСТИЧНО-РЕКУРСИВНЫЕ ФУНКЦИИ
173
Операция рекурсии*). Рассмотрение начнем
с частного случая. Пусть функция f(x) задана усло-
виями
Г / (0) = «,
. П(х+1) = Нг, ИО).
Эти уравнения позволяют последовательно находить
значения f(Q)=a, f(l)=/i(O,f(O)), f (2) = /i(l,
f (3) = h (2, , ... и, следовательно, полностью за-
дают функцию f.
В качестве примера рассмотрим функцию, опреде-
ляемую соотношениями
С 7(0) = 1,
1 f(x+ 1) = (х+ l)f(x).
Для нее f(0)=l, f (1) = 1 -f (0) = 1, f(2) = 2-f(l) =
= 2-1=2, f(3) = 3-Д2) = 3-2 - - 6 и т. д. Легко ви-
деть, что f(x) = х!
Аналогичный способ можно применять и для зада-
ния функций от более чем одного аргумента. Функция
от двух аргументов может быть задана условиями
( / (х, 0) = g(x),
I f(x, у+ 1) = /г(х, у, f(x, у)).
Здесь первый аргумент является параметром, а рекур-
сия ведется по второму аргументу. Так, например,
функция f (х, у) — ху определяется соотношениями
Г f (х, 0) = 1
I f(x, у+ l) = xf(x, у).
Это следует из того, что х° = 1, ху+1 = х-ху.
Перейдем к рассмотрению общего случая. Пусть при
имеются «-местная частичная функция g(xb ...
.х„) и (п + 2)-местная частичная функция /i(xi, ...
.хп, у, г). Будем говорить, что функция f(xs, ...
Хп, у) возникает из g и h применением операции
рекурсии, если для всех натуральных значений хц ...
• • •, хп, у имеет место
Г f (*i...хп, 0) = g(x„ . .., хп),
( f(xt, ..., Хп, у + 1) = /г(х1, . .., хп, у, f(x{.х„, у)).
*) Часто ее называют операцией примитивной рекурсии.
174
МОДЕЛИ АЛГОРИТМОВ
[ГЛ. IV
Величина f(xi, хп, усчитается определенной
тогда и только тогда, когда определены [(х1г ..., хп, у)
и h(xi....хп, y,z) при z —f(xb хп,у). Таким об-
разом, если значение f(xit ..., хп, уо) не определено, то
то же самое справедливо и для значенийf(xi, ..., хп,у)
при всех у > z/o. Очевидно, что применение операции
рекурсии к всюду определенным функциям g и h дает
всюду определенную функцию f.
Операция минимизации. Пусть имеется п-
местная частичная функция g(xi, ..., xn-i,y). Фикси-
руем некоторый набор (xi, ..., хп) и рассмотрим урав-
нение относительна у:
g(Xi....Хп-l, у) = хп.
Будем решать это уравнение, последовательно вычисляя
g(xb ..., Хп-1, 0), g(xb ..., Хп—1, 1), g(XU ..., Хп—1,
2), ... Наименьшее у, для которого окажется g(xi, ...
.... Xn-i, у) = хп, обозначим через gi/(g(xb ..., xn-i,
у) = Хп). Считается, что это значение не определено,
если в процессе последовательного вычисления встрети-
лось некоторое go, при котором g{x\.....xn-i, уо) не
определено (в частности, это может быть при go = O),
а при всех меньших у уравнение не выполняется, либо
если g(xb .... Xn-i, у) определено при всех у, но от-
лично от хп. Значение y.,,(g(xi....xn-i,y) = xn) яв-
ляется функцией переменных xi......хп. Будем гово-
рить, что функция
f(xi, ..., xn) = nl/(g(xi, ..., xn-i, у) = хп)
получена из g операцией минимизации.
В качестве примера рассмотрим функцию
f (xi, х2) ~Ру(У ~ Xi = х2).
При X; = 0 минимальным из значений у = 0,1,2, ...,
удовлетворяющих уравнению у — Xi = х2, является х2.
Если же xi 1, то в процессе отыскания минимального
решения перебором у = 0, 1, 2, ... мы наткнемся на
неопределенное значение уже при у = 0 (ибо 0 — xi <
•< 0). Таким образом,
Х2 ПрИ X! — 0,
не определено в остальных случаях.
f (хь х2) =
5 4.2]
ЧАСТИЧНО-РЕКУРСИВНЫЕ ФУНКЦИИ
175
Типичной ситуацией применения операции миними-
зации является построение обратных функций. Исполь-
зуя, например, функции х + у, ху, х2 и т. д., можно по-
лучить обратные им функции:
х — у = ц2 (х + z = у},
-^ = p2(xy = z),
д/x = цй(у2 = х) и т. д.
Функции х — у, ~ и Vх являются частичными. Следо-
вательно, операция минимизации даже в применении
к всюду определенным функциям может давать частич-
ные функции.
4.2.2. Частично-рекурсивные функции. С помощью
описанных операций мы будем из некоторых исходных
функций строить более сложные функции. В качестве
исходных функций будем использовать следующие:
— функция нуль 0(х), тождественно равная 0;
— функция следования s(x) — х + 1, указывающая
по х следующее за ним число;
— функции выбора аргумента Im(xi.......xn)~xm,
Смысл функций 0(х) и s(x) ясен. Функция In
по набору длины п выдает число, стоящее на m-м ме-
сте. Так, например, /|(0, 1, 2, 1, 4) = 2. С помощью функ-
ций Im может быть осуществлено формальное введе-
ние фиктивных аргументов, о котором шла речь при
описании операции суперпозиции. Двуместную функцию
f (х2, х3) можно записать, например, в виде четырех-
местной функции
f (/2 (Х1, х2, Хз, х4), 7з (Хь х2, Хз, х4)) = h (хь х2, х3, х4).
Дадим теперь основное определение. Функцию
f(xi, ..., Хп) назовем частично-рекурсивной, если она
может быть получена из исходных функций 0(х), s(x),
lm{x\, ..., хп) применением конечного числа операций
суперпозиции, рекурсии и минимизации. Всюду опреде-
ленные частично-рекурсивные функции будем называть
рекурсивными *).
*) Часто их называют общерекурсивными.
176
МОДЕЛИ АЛГОРИТМОВ
[ГЛ. IV
Введя специальные обозначения для операций су-
перпозиции, рекурсии и минимизации, можно представ-
ление частично-рекурсивной функции через исходные
функции и основные операции записать в виде некото-
рой строчки, содержащей символы аргументов, исход-
ных функций и операций. Такую запись будем называть
рекурсивной схемой (явный вид рекурсивных схем нам
не понадобится, поэтому подробнее на этом останав-
ливаться не будем). По рекурсивной схеме может быть
вычислена задаваемая ей функция, т. е. может быть
найдено ее значение на любом наборе, где она опреде-
лена.
4.2.3. Примеры рекурсивных функций. Покажем, что
многие функции, применяемые в арифметике и анализе
(точнее, аналоги этих функций для натуральных чисел),
являются рекурсивными. Рекурсивность всех этих функ-
ций будет использоваться нами в дальнейшем.
1°. Все константы являются рекурсивными функ-
циями. Действительно, 0 = 0(х), l=s(0(x)), 2 =
= s (s(0(x))) и т. д.
2°. Сложение ху является рекурсивной функ-
цией. Оно задается схемой
( х + 0 = х = (х, у),
t X + {у + 1) = (х + у) + 1 = S (х + у).
Здесь g (х) = (х, у), h (х, у, z) = s (z).
3°. Умножение х-у является рекурсивной функ-
цией. Оно задается схемой
Г х . 0 = 0 = 0(х),
( X • (у + 1 ) = X • у + X.
Здесь g(x)=0(x), h(x, у, z) = х -ф z (сложение рекур-
сивно) .
4°. Показательно-степенная функция ху
является рекурсивной. Она задается схемой
Г х° = 1 = s (0 (х)),
( ху+* = х x’J.
Здесь g(х) = s(0(х)), h(x, у, z) ~ x-z (умножение ре-
курсивно).
§ 4.2]
ЧАСТИЧНО-РЕКУРСИВНЫЕ ФУНКЦИИ
177
5°. Функции сигнум и антисигнум. В обыч-
ном анализе используется функция sign(x) (знак х),
которая равна 0 при х = 0 и равна —1 и +1 соответ-
ственно для отрицательных и положительных х. По-
скольку отрицательных чисел мы не рассматриваем, бу-
дем использовать аналог этой функции
, ч (0, если х = 0,
sg (х) = < . ..
( 1, если х > 0,
которую будем называть сигнум. Будет применяться
также отрицание этой функции — антисигнум.
— ч fl, если х = 0,
Sg W = <
( 0, если х > 0.
Обе эти функции являются рекурсивными и могут быть
заданы схемами
( sg(O) = O,
I sg (х + 1) = 1;
fsg (0) = 1,
Isg(x4-1) = 0.
6°. Усеченная разность х—у. Обычная раз-
ность х — у является частичной функцией. Вместо нее
будем рассматривать всюду определенную функцию
х — у =
х — у, если х у,
0, в противном случае,
называемую усеченной разностью. Функция х—1 за-
дается схемой
<0—1=0,
1 (х + 1) — 1 — х
и, следовательно, является рекурсивной. С ее исполь-
зованием рекурсивная схема для усеченной разности
записывается в виде
х — 0 = х,
х {у + 1) = (х — у) — 1.
178
МОДЕЛИ АЛГОРИТМОВ
[ГЛ. TV
Действительно, если х^у+1, то х —(у4-1) = х —
— у— 1 и (х — у) — l-х — у — 1. Если же х < у + 1,
то х у, а потому х —(у 4-1)= 0 и (х = у)—1 =
= 0=1 = 0.
7°. Функция модуль разности |х — у\ может
быть записана в виде
I х — у | = (х — у) 4- (У — х),
а потому является рекурсивной.
На основе рекурсивности функции |х — у\ можно
видоизменить определение операции минимизации и
вместо
f(xt, x„) = Hff(g(xh ..., xn-i, у) = хп) (4.4)
рассматривать операцию
f(xb .... х„) = цу(h(Xi..хп, у) = 0). (4.5)
Действительно, если функция f(xi, ..., хп) получена в
соответствии с (4.4), то она может быть эквивалентно
задана равенством (4.5) при /г(хь ..., хп, у) = |g(xi, ...
..., хп-1, у) — хп\ (если g частично-рекурсивна, то и /г
частично-рекурсивна). И обратно, всякая функция, оп-
ределенная равенством (4.5), может быть получена из
функции цД/Цхь ..., Xn,y) = xn+i) подстановкой кон-
станты 0 вместо х„+1, а подстановка констант не выво-
дит за пределы класса частично-рекурсивных функций.
8°. Целая часть от делениях на у. Функция
деления — является частичной. Вместо нее будем рас-
У
сматривать всюду определенную функцию -у , которая
L у J
в области определения функции — совпадает с ней.
Функцию [-у] при у Ф 0 положим равной частному
от деления х на у, а при у = 0 будем считать равной х.
Докажем ее рекурсивность.
Ясно, что при у 0 величина — равна наимень-
L У J
шему z, при котором у (z 4- 1) > х. Последнее условие
эквивалентно тому, что у (г 4- 1) х -ф 1 и, следова-
§ 4.2]
ЧАСТИЧНО-РЕКУРСИВНЫЕ ФУНКЦИИ
179
тельно,
У =/= О,
(х+ 1)-^-f/(Z
то значение
--1)=0. Таким образом, если
х 1
— определяется выражением
- У J
рг((х + 1) — y(.z + 1) = 0). Чтобы учесть значение у — 0
Г х 1
и получить при этом — = х, введем дополнительный
L У J
сомножитель х --- z. В результате
[-Я = Н2 ((-г - Z) ((х + 1) - у (z + 1)) = 0).
L */ -I
Если у Ф 0, то найдется z х, при котором (x-f-l) —
— i/(z+1)=0 (сомножитель х-z мешать не будет).
Наименьшее из таких чисел и будет значением функции.
Если же г/= 0, то величина (х-{-1) -y(z + 1) всегда
отлична от 0 и при z — х уравнение обратится в 0 из-за
сомножителя х —z.
9°. О с т а т о к от деления х на у. Эту функцию будем
обозначать ост (х, у). При у 0 значение ост (х, у)
определяется обычным способом, а при у = 0 положим
ост (х, у) = х. Рекурсивность этой функции следует из
легко проверяемого соотношения
ост (х, у) = х — у[у].
10°. Функция делимости. Эта функция, обо-
значаемая дел(х, у) равна 1, если х делится на у, и
равна 0 в противном случае. Ясно, что
, . ( 1, если ост(х, w) = 0,
дел (х, у) = < л '
(. 0, если ост(х, у)=£0.
Поэтому
дел (х, у) = sg (ост (х, у)),
что и свидетельствует о рекурсивности этой функции.
11°. Двоичная степень х. Эта функция, обо-
значаемая ст2(х), равна максимальному показателю, с
которым входит 2 в число х. То есть, если х = 2'(2s +
;+ 1), то ст2(х)=Л Из определения следует, что
ст2 (х) = (дел (х, 2/+1) = 0).
Функция 2(+' рекурсивна (получается из ху подста-
новкой х = 2, у = t -j- 1) , а потому и ст2(х) рекурсивна.
180
МОДЕЛИ АЛГОРИТМОВ
[ГЛ. IV
12°. Функция, отличная от 0 в конечном
числе точек, является рекурсивной. Действительно,
если f(x) отлична от 0 в точках xi, х2, , хк и прини-
мает там значения у\, у?, уь, то она может быть
представлена в виде
ZW = r/iSg|x —XiH-Z/2Sg|x —Х2|+ ... +//*sg|x —х*|,
4.2.4. Нумерация наборов. В теории алгоритмов часто
используется прием, сводящий функции от нескольких
аргументов к функциям от одного аргумента. С этой
целью наборы значений аргументов нумеруются нату-
ральными числами так, что по номеру сам набор нахо-
дится однозначно. При этом требуется, чтобы нумерую-
щая функция и функции, выдающие по номеру набора
его компоненты, были рекурсивными.
Пусть имеется некоторая взаимно однозначная нуме-
рация пар, и пусть номер пары (х, у) задается функцией
р(х,у), а левый и правый элементы пары с номером п
определяются функциями /(га) и г (га). Функции р, I и
г будем называть нумерационными.
Очевидно, что они удовлетворяют соотношениям
р (I (га), г (га)) = га,
I (Р (х, у)) = х,
г(р(х, у)) ~ у-
С помощью нумерации пар легко получить нумера-
цию троек натуральных чисел, четверок и т. д. Они мо-
гут быть заданы функциями
р3(х, У, z) = p(p(x, у), z),
р* (х, у, z, и) = р {р (р (х, у), г), и) и т. д.
По номеру набора его компоненты определяются одно-
значно. Так, например, если га — р3(х, у, г) = р(р(х, у),
2), то z = г(га), р(х, у) — I(га), х = /(/(га)), у = г(/(га)).
Если функции р, I и г рекурсивны, го п построенные на
их основе нумерационные функции для троек, четверок
и т. д. будут рекурсивными. Таким образом, задача сво-
дится к нумерации пар.
Опишем одну из возможных нумераций. Номер
пары (х, у) будем задавать функцией
р(х, у) = 2х(2у+1)-1.
§ 4,2)
ЧАСТИЧНО-РЕКУРСИВНЫЕ ФУНКЦИИ
181
Эта функция рекурсивна, ибо в силу того, что при лю-
бых х и у выполнено 2Л' (2у + 1) Тй 1, она может быть
записана в виде 2 х ( 2у1) --1, а все функции, входя-
щие в это выражение, рекурсивны. По номеру п =
= 2х(2у4~1)—1 пары (х,у) левый элемент х находит-
ся однозначно
х = ст2(/г 4- 1). (4.6)
Из соотношений
о,, । 1 _ п + 1 __ п + 1
У "Т 1 2х 2СТг('г + 1
следует, что
|__1___п + 1
У * 2 2CT2(rt4-l)4"l ’
а потому
[п 4- 1 ”1
2<:тлП+ !)+ 1 I * ( *• /
Правые части выражений (4.6) и (4.7) представляют
собой функции /(п) и г (л). Эти функции рекурсивны,
ибо являются суперпозициями рекурсивных функций.
Таким образом, построенная нумерация пар обладает
нужными свойствами.
Приведем пример использования нумерационных
функций. Покажем, что функция f(x,y), отличная от О
на конечном числе пар, является рекурсивной. Пусть)
на наборах (х2,у2), ..., (хь, уц) принимает со-
ответственно значения Z\, г2, ..., Zk, а на остальных
равна 0. Положим ti\ = р (%i, у\), м2 — р (х2, *Л>), ...
..., па = p(Xk. уи) и рассмотрим функцию g’(ra), кото-
рая отлична от 0 лишь в точках п\, п2, ..., па и прини-
мает там значения Z\, z2, ..., Zk. Как мы видели
раньше, эта функция рекурсивна. Функция f(x,y) мо-
жет быть записана в виде
f (х, у) = g{p (х, г/))
и поэтому также является рекурсивной. Используя ну-
мерацию троек, четверок и т. д., можно доказать ана-
логичный результат для функций от трех, четырех и
Т. д. аргументов.
4.2.5. Совместная рекурсия. В дальнейшем нам пона-
добится некоторое обобщение операции рекурсии —
182
МОДЕЛИ АЛГОРИТМОВ
[ГЛ. IV
совместная рекурсия. В схеме совместной рекурсии од-
новременно участвуют несколько функций. В случае
двух функций /i(xi, хп, у) и f2(xi, хп,у) схема
имеет следующий вид (через х обозначен набор (хь ...
.... хп)):
fl (х, 0) = gt (х),
f2(x, 0) = g2(x),
ft (х, У + 1) = Л, (х, у, ft (х, у), f2 (х, у)),
. ?2(х, у + 1)=± /г2 (х, у, fl (х, у), f2 (х, у)).
Докажем, что если функции gt, g2, hi и h2 частично-
рекурсивны, то такими же будут и функции ft и f2. Вве-
дем функцию
и(х, y) = p(fi(x, у), f2(x, у)),
где р— нумерационная функция. Тогда
ft (х, у) = 1(и (х, у)), f2 (х, у) = г(и (х, у)),
откуда
и (х, 0) = р (fi (х, 0), f2 (х, 0)) = р (gi (х), g2 (X)),
U(x,y+\) = p (/11 (х, у, I (и (х, у)), г (и (х, у))),
h2 (х, у, I (и (х, у)), г (и (х, у)))).
Таким образом, и(х,у) получается по схеме обыч-
ной рекурсии из частично-рекурсивных функций
g(x) = p(gt (х), g2(x)),
h (х, у, z) = p (hi (х, у, I (z), г (z)), h2 (х, у, I (z), г (z))),
а потому является частично-рекурсивной. Такими же бу-
дут и функции fi (х, у)= 1(и (х, у)) и f2 (х, у) — г (и (х, у)).
Аналогично с использованием нумерации троек, четверок
и т. д. можно доказать допустимость совместной рекур-
сии трех функций, четырех и т. д.
§ 4.3. Эквивалентность моделей алгоритмов
4.3.1. Введение. Как уже говорилось, имеются раз-
личные формальные модели вычислительных процедур
(алгоритмов). С каждой из них связано понятие вычис-
лимой функции. На основе изученных нами моделей
$ 4.3]
ЭКВИВАЛЕНТНОСТЬ МОДЕЛЕЙ АЛГОРИТМОВ
183
опишем некоторые общие черты, присущие всем фор-
мализациям.
1°. Вычислимая функция задается конечным набо-
ром инструкций — программой (программа машины
Тьюринга, рекурсивная схема).
2°. Имеется конечный набор правил, с помощью ко-
торого производятся вычисления значений функции по
программе.
3°. Указывается единый способ представления вход-
ной и выходной информации (значений аргументов и
функции).
Понятие вычислимой функции оказывается устойчи-
вым в том смысле, что модели, удовлетворяющие усло-
виям 1° — 3°, фактически определяют один и тот же
класс функций (в некоторых более ограниченных мо-
делях реализуется часть этого класса). Указанный факт
подтверждается рассмотрением всех известных моделей
и некоторыми теоретическими исследованиями в этой
области. Тот же класс функций вычисляется и на ЦВМ
(при неограниченном ресурсе памяти и времени). Ус-
тойчивость понятия вычислимой функции служит основ-
ным доводом в пользу тезиса Чёрча.
Ниже факт эквивалентности различных понятий вы-
числимой функции иллюстрируется на примере функ-
ций, вычислимых по Тьюрингу, и частично-рекурсивных
функций.
4.3.2. Вычисление частично-рекурсивных функций на
машинах Тьюринга. Частично-рекурсивные функции
строятся ИЗ функций 0(x), s(x) и/т(Х1, ..., хп) с по-
мощью операций суперпозиции, рекурсии и минимиза-
ции. Поэтому достаточно доказать выполнимость на ма-
шине Тьюринга каждой из этих операций, применяемых
к вычислимым функциям, И ВЫЧИСЛИМОСТЬ ИСХОДНЫХ
функций.
Реализация операции суперпозиции.
Пусть
Л (Х[, . . ., Хт) = g (fl (Xi, . ., хт), . . ., fn (Х\, ..., хт))
и функции g, fi, ..., fn вычисляются машинами Mg,
Mi, ..., Мп. Тогда функция h(xi, ..., хт) может быть
вычислена машиной Afgo(Mi* ... *Мп) в соответствии
во следующей схемой (слово из х -J-I палочек, изрбра-
184
МОДЕЛИ АЛГОРИТМОВ
[ГЛ. IV
жающее число х, обозначается через х):
Л'!*...*Хт -» Л(х1; ..хш)*.. .*f„(xb ..хт)->
g (f 1 (*b • • • > %т)> • • • » fп (-^b • • •, Ят)).
мй
Реализация операции рекурсии. Для про-
стоты опишем лишь реализацию схемы
Г f(0) = «,
I f (х + l) = g(x, f (х))
(схема более общего вида реализуется аналогично).
Вычисление осуществляется циклами. После цикла
i (;'х) на ленте-записана тройка чисел ху * х2 «• х3 =
= х—i* i » f(t). Поскольку f(i + 1) = g(i, ((/)), то по
прошествии цикла г-J-1 либо слово xj-»X2»x3 должно
быть преобразовано в Xj — 1 «- х2 + 1 •» g(x2, х3), если
i < х (т. е. Xi > 0), либо должно быть выдано f(x) =
= х3, если i — х (т. е. Xi = 0).
При осуществлении цикла используются программы
следующих машин:
— машина В по слову xi <:• х2 •» х3 выдает символ и,
если xi = 0, и символ л в противном случае;
— машина 2Ио оставляет всякое слово без изменения;
— машина М\ по слову xi»x2®x3 выдает xi — 1
(стирает «х2»х3, а в xi стирает 1 палочку);
— машина М2 по слову Xi * х2 х3 выдает х2 1 (сти-
рает xi * и *х3, а к х2 приписывает палочку);
— машина Мз по слову xi « x2-;:-x3 выдает х3 (стирает
Xi « х2 *);
— машина Mt по слову xi«x2«x3 выдает g(x2, х3)
(стирает X] * и вычисляет g{x2, х3)).
Кроме того, для входа в цикл применяется машина
А, которая слово х перерабатывает в х«0*а (дописы-
вает постоянное слово »0«-а). С учетом сказанного
схема вычисления функции f(x) имеет следующий вид:
§ 4.3]
ЭКВИВАЛЕНТНОСТЬ МОДЕЛЕЙ АЛГОРИТМОВ
185
Реализация операции минимизации.
Опишем реализацию операции минимизации простей-
шего вида
f W = (g (х, у) = 0)
(в общем случае делается то же самое). Вычисление
значения Цх) осуществляется циклами. После цикла i
на ленте содержится запись х * i (если вычисление еще
не закончено). В течение цикла г+ 1 вычисляется
g-(x, г) и проверяется, выполнено ли равенство g(x,i) =
= 0. Если выполнено, то выдается значение i, если нет,
то слово х •» i преобразуется в х «• i + 1.
При осуществлении цикла используются программы
следующих машин:
— машина В по слову xi * х2 » х3 выдает и, если
X] = 0, и л в противном случае;
— машина Мо оставляет слово без изменения;
— машина Alj по хр •» х2 вычисляет g(xi, х2);
— машина М2 переводит слово xi*x2*x3 в х2*х3;
— машина А13 по слову х « i выдает г;
— машина. АД переводит слово x*i в х « I -)- 1.
Кроме того, для входа в цикл применяется машина
А, преобразующая слово х в х*0. С учетом сказанного
схема вычисления ,f(x) имеет следующий вид:
Реализация исходных функций. Исходными
функциями ЯВЛЯЮТСЯ 0(х), s(x) и ..., х„). Функ-
ции 0(х) и s(x) реализуются тривиальным образом: в
первом случае в слове х (состоящем из х + 1 палочки)
стираются все палочки, за исключением одной, во вто-
ром— к слову дописывается 1 палочка. При реализации
машиной функции /m(xj, . . ., х„) в записи || . .. | * || . . .
• •. | * ... * ||... | должна быть оставлена лишь m-я груп-
па палочек. Для того чтобы «сосчитать» до заданного
т, нужна конечная память, и это может сделать машина
Тьюринга с подходящим числом состояний.
186
МОДЕЛИ АЛГОРИТМОВ
[ГЛ. IV
Тем самым установлено, что исходные функции вы-
числимы (по Тьюрингу) и что если некоторая функция
получена из вычислимых применением операции супер-
позиции, рекурсии или минимизации, то она также вы-
числима. Отсюда следует, что все частично-рекурсив-
ные функции могут быть вычислены на машинах Тью-
ринга.
4.3.3. Арифметизация машин Тьюринга. Нашей
дальнейшей целью является доказательство того факта,
что всякая функция, вычислимая по Тьюрингу, частич-
но-рекурсивна. При этом будет использован прием, ши-
роко применяемый в теории алгоритмов и математиче-
ской логике и называемый арифметизацией. Суть его
Рис. 4.4.
состоит в том, что нечисловые объекты нумеруются на-
туральными числами и преобразования объектов сво-
дятся к арифметическим операциям над их номерами.
Пусть имеется машина Тьюринга с внешним и внут-
ренним алфавитами А={йо, Пь •••> «4-1} и Q = {q0,
qu ..., qr-ij. Будем предполагать, что в алфавит А вхо-
дит символ | (это нужно для представления чисел) и
что а0 = A, ai = |. Кроме того, как и прежде, будем
считать, что состояния qo и qi являются соответственно
заключительным и начальным. Букве ai (t = О, 1, ...
..., k—1) сопоставим число i и впредь эти буквы и
числа различать не будем.
Рассмотрим произвольную конфигурацию (рис. 4.4).
Запись на ленте будем представлять тройкой чисел <и, т,
00
п>, где а = а, — обозреваемый символ, т—^Ьф1—
1=0
число, &-ичной записью*) которого является слово, рас-
положенное слева от обозреваемой ячейки (младшим
*) Частными видами А-ичных записей являются широко при-
меняемые двоичная, восьмеричная и десятичная записи чисел.
$ 4.3]
ЭКВИВАЛЕНТНОСТЬ МОДЕЛЕЙ АЛГОРИТМОВ
187
считается разряд, ближайший к ячейке), п= —
число, fe-ичной записью которого является слово, распо-
ложенное справа от обозреваемой ячейки (младшим
считается разряд, ближайший к ячейке). Несмотря на
то, что в записи чисел т и п участвует бесконечное чис-
ло членов, только конечное число из них отлично от О
(напомним, что мы рассматриваем лишь конфигурации
с конечной активной зоной). Таким образом, числа т и
п конечны. По т и п слова, находящиеся слева и спра-
ва от обозреваемой ячейки, восстанавливаются одно-
значно (всякое число представляется fe-ичной записью
Рис. 4.5.
единственным образом). Конфигурацию машины будем
задавать четверкой чисел (/, а, т, п}, где / — номер со-
стояния, а а, т и п соответствуют записи на ленте. Этой
четверкой конфигурация определяется однозначно.
Посмотрим, как преобразуется четверка при выпол-
нении команды. Пусть вначале команда имеет вид
После ее выполнения конфигурация, изображенная на
рис. 4.4, перейдет в конфигурацию, показанную на
рис. 4.5.
Новые значения чисел а, т и п обозначим через а',
т', п'. Легко видеть, что приписывание к А-ичной записи
числа т цифры ац преобразует его в mk + а?,
младший разряд со числа п совпадает с ост(п, k), а
число, полученное из п отбрасыванием младшего раз-
ряда, равно [у-]- Таким образом,
а' = ост (n, k),
т' — mk + ац,
188
МОДЕЛИ АЛГОРИТМОВ
(ГЛ. IV
и четверка {j, а, т, п) преобразуется в (/', ост (п, k), mk +
Для команды qtai-> qi'a^R, осуществляющей сдвиг
влево, получаем аналогичные выражения
а/ = ост(щ, k),
п' — nk-\- av.
Если команда имеет вид q/ai-^- qj-ai-H, то после ее вы-
полнения числа тип сохраняются, а а, заменяется на
а?, т. е.
a' = ai’,
т' - т,
п' = п.
Введем функцию S(j, а/), характеризующую сдвиг
головки при Для этого рассмотрим выполнении при / = 1, . команду команды Г— 1, с левой ai ~ 0, частью 1, qi ai- li — 1
<7/аг -> qrat'S (4.8)
и положим ' 0, если s = n,
S (/, аг) = 1, если 5 = Л,
- 2, если S = H.
На остальных парах функцию S(j,ai) доопределим рав-
ной нулю. Аналогично определим функции (см. (4.8))
' если j е {1, ..., г — 1},
Q(j, аг) = < а; е {0, — 1},
О в противном случае,
аг, если /е{1, г— 1},
= \ <= {0, 1, ..., k — 1},
О в противном случае.
ЭКВИВАЛЕНТНОСТЬ МОДЕЛЕЙ АЛГОРИТМОВ
189
§ 4.3]
Функции Q и А соответственно указывают номер
нового состояния и символ, записываемый на ленте.
Каждая из функций 5, Q и А отлична от 0 на конечном
числе пар и по доказанному ранее все они рекурсивны.
Используя эти функции, элементы новых четверок мож-
но записать в виде
/' = Q (/, а),
а' = ост (п, k) sg S (/, а) +
+ ост(т, k) sg | S (/, a) — 1 |+ A (j, a)sg \ S (j, a) — 2 I,
m' = (mk + A (j, a)) sg S (/, a) + [-p] sg | S (./, a) — 1 | +
+ tn sgj S(j, a) —2J,
n'= [t] sg S + (nk + A fl)) sg I 5 (/’> — +
+ nsg]S(j, a) — 2|.
Действительно, если, например, команда с левой
частью 7/а предписывает сдвиг влево, то S(j,a)=l.
Следовательно,
sgS(7, a) = 0, sg | S(j, а) — 1 |= 1, sg | S(j, а) — 2 |== О,
а потому
j' = Q(j,a), а' = ост(т, k), tn = п' — nk + A(j,a).
Это совпадает с формулами преобразования четверок
для случая сдвига влево (Л(/, я) означает новый сим-
вол яц). Аналогично рассматриваются другие случаи
сдвигов. Выписанные функции
а' = a' ( j, а, т, п),
т' = т' (j, а, т, п),
п' — п' (j, а, т, п)
являются суперпозициями рекурсивных функций, а по-
тому сами рекурсивны.
Обозначим через функцию, указы-
вающую номер состояния, в которое перейдет машина
из начальной конфигурации, описываемой четверкой
190
МОДЕЛИ АЛГОРИТМОВ
(ГЛ. IV
(/, а, т, ri), через t тактов. Аналогично введем функ-
ции
A (t, j, а, т, ri), М (t, j, а, т, ri), N (t, j, а, т, ri),
которые указывают остальные 3 элемента четверки че-
рез t тактов. Чтобы найти, например, значение 1,
/, а, т,п), можно вначале найти элементы четверки че-
рез t тактов, а затем применить преобразование а', со-
ответствующее осуществлению еще одного такта. То же
самое относится к функциям Q, fit, R. Начальными ус-
ловиями для функций <5, А, М, Я являются /’, а, т, п.
Таким образом, указанные функции удовлетворяют со-
отношениям:
Q (0, /, а, т, ri) = /,
А (0, j, a, т, ri) = а,
М (0, /, а, т, п) = т,
N (0, /, а, т, ri) = n,
Q (t -f- 1, /, a, m,ri) = Q (Q (t, j, a, m, n), A (t, j, a, tn, ri)),
A (t + 1. /> a, tn, ri) = a (Q (t, j, a, tn, n), A (t, j, a, tn, ti),
M (t, j, a, tn, ri), N (t, j, a, m, n)),
M (t -f- 1, j, a, m, ri) = m' (Q (t, j, a, tn, ri), A (t, j, a, tn, ri),
M(t, j, a, m, ri), N (t, j, a, tn, n)),
N (t -f- 1> /> a> m> tt) — n' (Q (^> /> a> m> n)> (^, /’> n)>
M (t, j, a, m, n), N (t, j, a, tn, ri)).
Это схема совместной рекурсии функций 5, A, X?, N.
Поскольку функции Q, а', т' и п' рекурсивны, то рекур-
сивными будут и функции Q, А, М, N.
Тем самым нам удалось описать работу машины
Тьюринга с помощью рекурсивных функций. Они позво-
ляют по исходной конфигурации и числу t найти конфи-
гурацию, в которой окажется машина через t тактов.
4.3.4. Частичная рекурсивность функций, вычисли-
мых на машинах Тьюринга. Для простоты будем рас-
сматривать функции одного аргумента. Пусть функция
$ 4.3]
ЭКВИВАЛЕНТНОСТЬ МОДЕЛЕЙ АЛГОРИТМОВ
191
f(x) вычисляется некоторой машиной Тьюринга. Про-
изведем арифметизацию этой машины описанным выше
способом.
При вычислении значения f(x) начальная конфигу-
рация машины имеет вид, показанный на рис. 4.6.
Ей соответствует четверка <1,1,0, п(х)>, где п(х) —
число, fe-ичной записью которого является И ... 1. Ясно,
X
Ьх — 1
что п(х) = 1 +fe-H2+.. .+fex~1= — • Поскольку
hx__1
k > 1 и деление fe _ 1-- осуществляется нацело, то
п« = [-Т^г]-
Функция п(х) является рекурсивной.
Обозначим через q(t,x) состояние, в котором ока-
зывается машина после t тактов, начав работу в кон-
ге+7
Рис. 4.6.
фигурации, приведенной на рис. 4.6. Используя функ-
цию <5, полученную в результате арифметизации, мож-
но записать
q(t, x) = Q(7, 1, 1, 0, n(x)).
Аналогично введем функции a(t, х), m(t,x), n(t,x), за-
дающие остальные элементы четверки через t тактов.
Они получаются из функций А, ft подстановкой j ~ 1,
а — 1, т = 0, п — п(х). Функции q(/, х), a(t, х), m(t,
х), n(t, х) являются суперпозициями рекурсивных функ-
ций, а потому сами рекурсивны.
Остановка машины происходит в момент, когда она
переходит в заключительное состояние q0, поэтому мо-
мент остановки /о(х) может быть найден из условия
io(x) = Pt(q^> х) = 0). (4.9)
192
МОДЕЛИ АЛГОРИТМОВ
(ГЛ. IV
Если значение f(x) не определено, то машина не
останавливается, ее состояние всегда отлично от q0 и
выражение (4.9) дает для t0(x) неопределенное значе-
ние. Функция to(x) является частично-рекурсивной, ибо
получается из рекурсивной функции q(t,x) применением
операции минимизации.
Зная момент останова to(x), можно найти четверку,
соответствующую заключительной конфигурации
<7о (х) = <7 (/0 (х), х),
а0 (х) = a (t0 (х), х),
m0(x) = m(/0(x), х),
По (х) = л (<0 (х), х).
Из этих выражений видно, что функции qo(x), ао(х)’,
т0(х) и п0(х) являются частично-рекурсивными.
f(&)+1
Рис. 4.7.
Если значение f(x) определено, то заключительной
является конфигурация, показанная на рис. 4.7. Для нее
По(х) = 1 + k + ... + fefW-1 = [ n-k
откуда
f (x) = щ(| «о (x) — [ ] | = °) •
(4.10)
Если f(x) не определено, то не определены /0(х) и
лС|(х) =/г(/о(х), х) и выражение (4.10) также дает не-
определенное значение. Формула (4.10) показывает, что
функция f(x) является частично-рекурсивной.
В результате доказано, что класс функций, вычисли-
мых на машинах Тьюринга, совпадает с классом час-
тично-рекурсивных функций.
§ 4.4] УНИВЕРСАЛЬНЫЕ МАШИНЫ И ФУНКЦИИ
193
§ 4.4. Универсальные машины и универсальные функции
4.4.1. Шифры машин. Работа машины Тьюринга не
зависит от обозначения состояний и символов на ленте.
Важно лишь, что разным объектам соответствуют раз-
личные символы и что можно различать, соответствует
ли данный символ букве внешнего алфавита, состоянию
или сдвигу. В связи с этим мы зафиксируем счетные
множества символов {а0) fli, , а,, ...} и {q0, q\, ...
ив дальнейшем будем считать, что внешние
алфавиты и алфавиты внутренних состояний всех ма-
шин Тьюринга заимствуются из этих множеств. Напом-
ним, что для каждой конкретной машины эти алфавиты
конечны, но они могут быть сколь угодно большими.
Будем считать, что буква а0 принадлежит внешним ал-
фавитам всех машин и интерпретируется в них одина-
ково как пустой символ А, а буквы q0 и q\ содержатся
в алфавитах внутренних состояний всех машин и всегда
означают заключительное и начальное состояния.
Опишем теперь некоторый единый способ представ-
ления информации о машинах и их работе посредством
двоичных слов специального вида. Каждому символу
d е {П, Л, Н, я0, • • •, а/, • • •, qo, • • •, q>, • • •} сопоста-
вим его шифр Ш (d) в соответствии с таблицей 4.2.
Таблица 4.2
Тип символа Символ Шифр Число нулей в шифре
Обозначение сдвига п 10 1
л 100 2
н 1000 3
Буква внешнего алфа- Gq 10 000 4
вита 01 1 000 000 6
ai 10 0 2Z + 4
Буква алфавита состоя- <7о 100 000 5
иий <71 10 000 000 7
<И 10 .’..’ 0 2/ + 5
194
МОДЕЛИ АЛГОРИТМОВ
[ГЛ. IV
Команде R машины, имеющей вид
qa -> q'a'S,
сопоставим шифр
Ш (R) = Ш (q) Ш (а) Ш (q') Ш(а') Ш (S),
образованный приписыванием друг к другу шифров
символов, входящих в команду. Пусть внешним и внут-
ренним алфавитами машины М являются {ао, <21, •••
..., flfe-i} и {<7о, <7ь ..., Qr-i}. Упорядочим лексикогра-
фически пары qtai (/ = 1, ..., г— 1, i = 0, 1, .... k —
-I):
qia0, q{a{, ..., qxa.k-\, ..., 7r-i°o, qr-iab .... qr-iak-i
и в соответствии с этим упорядочим команды машины
с левыми частями q^ac.
Ri, R2, ..., R(r-qk-
Машине М сопоставим шифр
Ш(М) = Ш (Rd Ш (Rd ...Ш (R(r-ы).
Ясно, что по шифру команды и шифру машины сами
команда и машина (программа машины) восстанавли-
ваются однозначно.
Каждой конфигурации
К = a(l). . ,a(i~l)q(,)a(O.. ,а№
сопоставим шифр
Ш (R) = ш (Ф'О... Ш (а<‘~!’) Ш (q('d Ш (а^) ...Ш (<№),
образованный приписыванием друг к другу шифров со-
ставляющих ее символов. По шифру конфигурации од-
нозначно находится, какой из входящих в него шифров
соответствует состоянию (он имеет нечетное число ну-
лей). Заключительное состояние qo кодируется для всех
машин одинаково, и поэтому по шифру конфигурации
всегда может быть установлено, является ли она за-
ключительной.
4.4.2. Конструкция универсальной машины. Если
имеется программа некоторой машины Тьюринга М и
конфигурация К = а(!) ... ... п(р) этой ма-
шины, то можно воспроизвести процесс переработки
§ 4.4) УНИВЕРСАЛЬНЫЕ МАШИНЫ И ФУНКЦИИ 195
машиной М конфигурации К. Для этого нужно оты-
скать в программе команду с левой частью и в
соответствии с ней изменить К, затем то же самое про-
делать с полученной конфигурацией К' и т. д., пока не
придем к заключительной конфигурации (в противном
случае процесс будет бесконечен). Указанная процеду-
ра носит регулярный («механический») характер, и ее
можно осуществить с помощью подходящей машины
Тьюринга.
Прежде чем описать конструкцию этой машины, за-
метим следующее. Эта машина (как и всякая другая)
должна иметь конечные внешний и внутренний алфа-
виты. С другой стороны, она должна моделировать ра-
боту любой машины Тьюринга и, в частности, такой, у
которой мощности внешнего и внутреннего алфавитов
больше, чем у нее самой. Поэтому информация о моде-
лируемой машине (программа, начальная конфигура-
ция) должна записываться на ленту универсальной ма-
шины в закодированном виде (с использованием ко-
нечного алфавита). Для этой цели мы будем применять
описанные выше шифры машин и шифры конфигураций.
Если К является конфигурацией машины М и М
применима к К, то через М(К) будем обозначать соот-
ветствующую заключительную конфигурацию. Машина
Тьюринга U называется универсальной, если для любой
пары М. и К (где К — конфигурация машины М) запись
на ленте она перерабатывает в запись
Ш(М(К)) (т. е. конфигурацию Ш(К) перево-
дит в q0III(М(К))), если Л4 применима к К, и работает
бесконечно в противном случае.
Нашей ближайшей целью является построение уни-
версальной машины. При этом, как и раньше, детали
построения приводиться не будут, но будет видно, что
указанное построение может быть осуществлено.
При описании конструкции машины мы будем упо-
треблять выражение «в записи на ленте выделяется (от-
мечается) подслово». Под этим будет подразумеваться,
что указанное подслово побуквенно переводится в неко-
торый другой алфавит. Например, выделение подслова
а2й1 в записи (цеьсцам может быть осуществлено за-
меной соответствующих букв буквами со штрихами:
оюхгщщг. Мы будем употреблять также выражение
7*
196
МОДЕЛИ АЛГОРИТМОВ
(ГЛ. IV
«пометки в записи стираются», подразумевая этим пере-
вод отмеченных букв в прежний алфавит. Так, стирание
пометок в записи превращает ее в а^га^^г-
Иногда нужно будет выделять различные подслова раз-
ным способом. В этом случае будет осуществляться их
перевод в разные алфавиты.
Опишем теперь конструкцию универсальной маши-
ны U. Она имеет двухэтажную ленту. В начальной си-
туации на нижнем этаже содержится запись Ш(М)*
а верхний этаж оставляется пустым. Работа
машины протекает следующим образом.
— В шифре машины М, записанном на нижнем эта-
же, выделяются шифры Ш(д)Ш (а) левых частей всех
команд. Для этого, начиная слева, первые две группы
вида 10 ... 0 выделяются, затем 3 пропускаются, 2 вы-
деляются, 3 пропускаются и т. д.: пока головка не на-
ткнется на разделительный символ *.
— В шифре конфигурации Ш(К) находится группа
10 ... 0, соответствующая состоянию (она содержит не-
четное число нулей). Эта группа и следующая за ней
выделяются. Выделенная пара групп ЦЦсро)
определяет состояние q'J> головки и обозреваемый сим-
вол а(г).
— После этого в шифре машины должна быть най-
дена команда с левой частью q^ а(е>. Для этого путем
побуквенного сравнения выделенной части
Ш (q^) Ш(а'‘1) шифра конфигурации с каждой из выде-
ленных частей LU(q)III(a) шифра машины среди них
находится такая, которая совпадает с Ш(q(I">) Ш(а(б).
Следующие за ней 3 группы вида 10 ... 0 соответствуют
правой части команды, которую необходимо выполнить
в конфигурации К. Пусть эта тройка групп имеет вид
Ш(q(u})Ш(а(и')Ш(8). Пара Д/(<7<“>)Д/(а(0)) выделяется
некоторым специальным образом, а сдвиг S «запоми-
нается» состоянием машины.
— Теперь нужно заменить Ш(К) шифром новой кон-
фигурации, полученной из К в результате выполнения
команды. Это делается за 2 этапа. Вначале в Ш(К)
выделенное слово Ш(а‘‘>'} заменяется словом
Ш (g(u)) Ш(а^), выделенным специальным образом в
ЦЦМ), а затем, в зависимости от того, совпадает ли S
с П, Л или Н (информацию об этом несет состояние
УНИВЕРСАЛЬНЫЕ МАШИНЫ И ФУНКЦИИ
197
§ 4.41
машины U), группа 10 ... 0, соответствующая состоя-
нию 7(и), либо переставляется с соседней группой (спра-
ва или слева), либо остается на месте. Эти этапы осу-
ществляются следующим образом. Левая часть записи
на ленте, предшествующая выделенному слову
Ш (q{i)) Ш в шифре конфигурации, переписывается
с нижнего этажа на верхний, затем к ней на верхнем
этаже дописывается слово Ш(qw) Ш(а^), выделенное
специальным образом, н переписывается с нижнего
этажа запись, следующая за словом Ш(q(n)Ш(с№) (со-
держимое нижнего этажа стирается). Перестановка
групп 10 ... 0, соответствующих состоянию qw и со-
седнему символу, осуществляется при обратном пере-
писывании содержимого верхнего этажа на нижний
(запись на верхнем этаже стирается). Все пометки сти-
раются.
— Далее машина выполняет некоторые «контроль-
ные» операции. После осуществления действий, описан-
ных в предыдущем пункте, может оказаться, что в шиф-
ре новой конфигурации крайняя левая группа 10 ... 0
является шифром пустого символа либо правая крайняя
группа является шифром пустого символа и ей не пред-
шествует шифр состояния. Это означает, что соответ-
ствующая ячейка машины М не является активной и
шифр пустого символа должен быть устранен из шифра
конфигурации. Машина U стирает этот шифр пустого
символа. Если он был крайним слева, то в результате
стирания образуется пустое пространство между <:• и
шифром конфигурации. Машина U в этом случае сдви-
гает шифр конфигурации влево к разделительному сим-
волу. Может оказаться также, что в шифре новой кон-
фигурации крайним справа является шифр состояния.
Это означает, что в данной конфигурации головка ма-
шины обозревает пустой символ. В этом случае машина
U дописывает справа к шифру конфигурации шифр пу-
стого символа.
Затем машина U проверяет, является ли конфигура-
ция заключительной. Если является, то запись Ш(М)*
стирается и головка останавливается у крайнего слева
непустого символа. В противном случае процесс повто-
ряется.
198
МОДЕЛИ АЛГОРИТМОВ
[ГЛ. IV
Тем самым работа универсальной машины U опи-
сана. По этому описанию принципиально нетрудно со-
ставить программу машины.
Универсальная машина Тьюринга способна решать
любую алгоритмическую задачу. Для того, чтобы она
решала конкретную задачу, в ее память должна быть
введена соответствующая программа (шифр
Тот же принцип используется в современных универ-
сальных ЦВМ.
4.4.3. Нумерация машин. Шифр Ш(М) машины М
представляет собой слово из нулей и единиц, поэтому
его можно рассматривать как двоичную запись нату-
рального числа. Поскольку шифры начинаются с 1, раз-
ным шифрам соответствуют разные числа. Упорядочим
машины Тьюринга по возрастанию чисел, изображаемых
их шифрами, и занумеруем их: Мо, Mi, ..., Мп, ...
Номер машины М в этом упорядочении будем обозна-
чать пм. Указанное упорядочение является эффектив-
ным в том смысле, что существует машина Тьюринга,
которая по п выдает Ш(Мп), и существует машина, ко-
торая, наоборот, по Ш(М) выдает Пм-
Действительно, нетрудно перечислить признаки, ко-
торые отличают шифры машин от других двоичных слов
(шифры разбиваются на пятерки групп вида 10 ... 0,
первая группа каждой пятерки имеет нечетное число
нулей, не меньше 7, и т. д.). Существует машина Тью-
ринга, которая может проверить выполнимость каж-
дого из условий и на основе этого установить, является
ли заданное слово шифром некоторой машины.
Машина, которая по числу п выдает шифр машины
Мп, устроена следующим образом. Она имеет двухэтаж-
ную ленту. В начальной ситуации на нижнем этаже
записано число п в виде п + 1 палочек, а верхний этаж
является пустым. В процессе работы на верхнем этаже
последовательно порождаются двоичные наборы в по-
рядке изображаемых ими натуральных чисел: 1, 10, 11,
100, 101 ... Для каждого набора проверяется, является
ли он шифром машины и если является, то в нижнем
этаже стирается одна палочка и указанный процесс
продолжается. В момент, когда стирается последняя па-
лочка, на верхнем этаже находится шифр машины Мп.
§ 4.4] УНИВЕРСАЛЬНЫЕ МАШИНЫ И ФУНКЦИИ ]99
Машина, которая по шифру Ш (Л1) выдает номер пм,
устроена аналогично.
Каждой машине Тьюринга М сопоставим функцию
фм(х). Значение срм(а) определяется следующим обра-
зом. Машина М запускается в конфигурации 7il|...|
а + 1
(считается, что символ | присутствует в алфавитах
всех машин). Если она остановится в конфигурации
</о 11. .. | при некотором Ь, то полагаем фм (а)=Ь. В про-
''~ь+7'
тивном случае значение фм(а) считаем неопределен-
ным. В отличие от введенного ранее понятия вычисле-
ния функции машиной, здесь значение считается неоп-
ределенным не только в случае, когда машина работает
бесконечно, но и тогда, когда заключительная конфигу-
рация отличается от 11.. .|. Нетрудно видоизменить
конструкцию машины М так, чтобы новая машина М'
не останавливалась в заключительной конфигурации,
отличной от <7о 11 • • -|, а работала в этом случае беско-
нечно. Машина М' вычисляет функцию фм(х) в преж-
нем смысле, поэтому функция фм(х) является частично-
рекурсивной.
Обозначим через фп(х) функцию, соответствующую
машине Мп. В результате получим некоторую нумера-
цию всех одноместных частично-рекурсивных функций:
Фо(х), Ф1(х), . •ф„(х), ...,
ибо всякая частично-рекурсивная функция вычисляется
некоторой машиной. Более того, каждая частично-ре-
курсивная функция f (х) встречается в этом списке беско-
нечное число раз, поскольку она может быть вычислена
многими способами (например, в соответствии с выра-
жениями f(x)4-0, f(х) + 0 + 0, ...), а всякому вычисле-
нию соответствует своя машина.
4.4.4. Универсальная частично-рекурсивная функция.
Пусть имеется некоторый класс F функций от k аргу-
ментов. Функцию U(ti, xq, ..., Xk) от k + 1 аргументов
будем называть универсальной для класса F, если вы-
полнены два условия:
1) при любом фиксированном п функция f(xi, ...
• • •, Xk) — U (п, Xi.Xk) содержится в F;
200
МОДЕЛИ АЛГОРИТМОВ
[ГЛ. IV
2) для любой функции f(xj, ..., Xk)^F найдется
значение п, при котором f(xb ..., Xk) — Щп, Xi, ...
.xk).
Теорема 4.1. Существует частично-рекурсивная
функция U(п,х), универсальная для класса всех одно-
местных частично-рекурсивных функций.
Доказательство. Положим U(n, х) = фп(х),где
срп — функция, соответствующая машине Мп. Докажем
вначале, что функция U(n, х) является частично-рекур-
сивной. Достаточно установить, что она может быть
вычислена на машине Тьюринга.
Для построения машины, вычисляющей U (п, х), бу-
дут использоваться программы следующих машин:
— машина А по слову ||.. ,| * ||.. .| находит Ш(М^)
а + 1 Ь 4-1
(она стирает *||...| и далее действует, как было опи-
сано в разделе 4.4.3.);
— машина В по слову ||.. .|* ||.. .| выдает слово
и “Ь 1 Ъ 4- 1
Ш (qi) Ш (\). . .Ш (\)‘,
Ь 4- 1
— машина С по слову, имеющему вид
Ш (qa) Ш (\). . .Ш (\)
6 + 1
при некотором Ь, выдает ||...|, а в остальных случаях
работает бесконечно;
— универсальная машина U.
Функция U (п, х) вычисляется машиной С ° (U ° (А *
*В)), как это видно из следующей схемы, где через Кх
обозначена конфигурация 7о|1---1:
х +1
1Ь_1 * ITJ 7^ HI (Мп) * Ш (Кх)
Ш(Мп(Кх))—>Ч>п(х) = и(п,х).
(Если фл х)=Ь, то Мп (Кх) — <7о11. • -1> а потому
УНИВЕРСАЛЬНЫЕ МАШИНЫ И ФУНКЦИИ
201
§ 4.4J
Ш (Мп (О = Ш (7о) Ш (])... Ш(\) и С выдает 11... |.
6+1 \+7-/
В противном случае машина С не останавливается.)
Частичная рекурсивность функции Щп, х) доказана.
Убедимся теперь, что она является универсальной для
класса одноместных частично-рекурсивных функций.
1) При любом фиксированном п функция f(x) =
= U(n,x) является частично-рекурсивной, поскольку
получается из частично-рекурсивной функции U под-
становкой константы вместо первого аргумента.
2) Рассмотрим произвольную одноместную частич-
но-рекурсивную функцию f(x). Она может быть вычис-
лена некоторой машиной Af^. Тогда по определению
f (х) = ср„0 (х) = U (по, х).
Теорема доказана.
Следствие. При любом k 1 существует частич-
но-рекурсивная функция Uk(n, Xi,..., Xk), универсаль-
ная для класса всех ^-местных частично-рекурсивных
функций.
Доказательство этого факта при k 5s 2 осуществ-
ляется с использованием нумерационных функций. Для
простоты рассмотрим случай k — 2.
Введем функцию
U2 (п, xt, х2) = U(п, р (xi, х2)),
где Щп, х) — построенная выше универсальная функ-
ция, а р — нумерационная функция. Покажем, что она
удовлетворяет требуемым условиям. Функция
U2(n, хь х2) является частично-рекурсивной, поскольку об-
разуется суперпозицией частично-рекурсивных функций
U и р. При любом фиксированном п функция f(xt,x2) =
— U2(n,xt,x2) частично-рекурсивна, так как получается
из U2 подстановкой константы. Осталось установить,
что любая частично-рекурсивная функция f(хг, х2) мо-
жет быть получена из U2 некоторой фиксацией первого
аргумента.
Действительно, образуем из f(x\,x2) функцию
g (т) = f (/ (m), г (m)),
202
МОДЕЛИ АЛГОРИТМОВ
[ГЛ. IV
где I и г — нумерационные функции. Она частично-ре-
курсивна, а потому найдется и0, при котором
g (m) = U (п0, т).
Положив т — p(xi,Xi), получаем
f (х{, Х2) = g(p (хь х2)) = U (ц0, р (хь х2)) = U2 (п0, Xi, х2),
что и требовалось.
Универсальные функции играют важную роль в тео-
рии алгоритмов. В связи с этим возникает вопрос, су-
ществует ли универсальная рекурсивная функция.
Теорема 4.2. Ни при каком k 1 не существует
рекурсивной функции Ok(n,x\, ..., Xk), универсальной
для класса всех k-местных рекурсивных функций.
Доказательство. Предположим противное, что
такая функция Ok(n, хь ..., х*) существует. Образуем
из нее рекурсивную функцию
g (Х[, ..., xk) = 0k (xb Xb X2.....Xk) + 1.
В силу универсальности найдется п0, при котором
Ok(n0, Х{....Xk) = g(Xi, .... Xk) =
= U'1 (xb хь х2, ..., Xk) -Т 1.
Так как рекурсивные функции всюду определены, это
тождество справедливо при всех значениях хь ..., хк-
Положив xi = ... = Xk — па, приходим к противоре-
чию
Uk (по, п0, .. ., По) = Uk (По, По.п0) 4- 1 •
Теорема доказана.
Универсальная частично-рекурсивная функция
Uk(n, xi, ..., Xk) порождает некоторое упорядочение (ну-
мерацию) всех 6-местных частично-рекурсивных функ-
ций
Фо(хь ... Хй), ф, (xi, ..., xk), ..., <р„(хь ..., xk), .
где через фп(хь ..., х*) обозначена функция, получен-
ная из универсальной в результате подстановки вме-
сто первого аргумента значения п. Всякая 6-местная
частично-рекурсивная функция встречается в этом спи-
ске бесконечное число раз.
§ 4.5]
НЕКОТОРЫЕ ТЕОРЕМЫ ТЕОРИИ АЛГОРИТМОВ
203
§ 4.5. Некоторые общие теоремы теории алгоритмов
4.5.1. Пример применения универсальной функции.
В данном параграфе с использованием универсальных
функций доказывается ряд важных теорем. Проиллю-
стрируем вначале применение универсальной функции
для доказательства одного факта.
На практике часто имеют дело со случаем, когда
значения функции считаются неопределенными из-за
того, что они не интересуют вычислителя. Доопределив
эти значения некоторым образом (например, нулем),
мы получим "всюду определенную функцию, которую
можно использовать вместо исходной частичной. Так
мы поступали, например, заменяя частичные функции
х — у и у всюду определенными функциями х — у
Г х "I ..
и [~J* Могло возникнуть предположение, что так
можно сделать всегда. Доказываемый ниже результат
показывает, что это не так. Существуют частичные вы-
числимые функции, любое доопределение которых де-
лает их невычислимыми. Этот факт является одним из
доводов в пользу необходимости рассмотрения в теории
алгоритмов частичных функций.
Теорема 4.3. Существует частично-рекурсивная
функция v(x), которая не может быть доопределена до
рекурсивной. В качестве и (х) можно взять функцию,
принимающую значения 0 u 1.
Доказательство. Рассмотрим функцию
v (х) = sg U (х, х),
где U — универсальная функция. Она получается супер-
позицией частично-рекурсивных функций, а потому и
сама является таковой. Предположим, что у(х) может
быть доопределена до рекурсивной функции т’о(х). По-
следняя является и частично-рекурсивной и, следова-
тельно, найдется п, при котором ц0(х)= U (п, х). Функ-
ция у0 рекурсивна, а потому определена при всех х.
В частности, при х = п получаем, что значение у0(п) =
= U(п, п) определено, вследствие чего определено и
sg U(n, п) = v (п). Значение и0(п) должно совпасть с
204
МОДЕЛИ АЛГОРИТМОВ
[ГЛ. IV
v(n), откуда
sg U (п, n) — v (n) = v0 (п) = U (п, п).
Но последнее равенство не может иметь места (если
Щп, n)=£Q, то sg U(п, п) = 0, а если U(n,n) = 0, то
sg U (п, п)У= 0), а потому допущение о том, что функция
v(x) может быть доопределена до рекурсивной, являет-
ся неверным.
4.5.2. Теорема о неподвижной точке. В различных
разделах математики важную роль играют теоремы б
неподвижных точках. Такая теорема занимает видное
место и в теории алгоритмов.
Для ее доказательства нам понадобится следующий
результат, устанавливающий связь между номерами
двуместных частично-рекурсивных функций и номерами
одноместных функций, полученных из них фиксацией
первого аргумента.
Теорема 4.4 (итерационная). Существует рекур-
сивная функция а от 2 аргументов, такая что
U2 (п, xlt х2) = U (а (п, Х[), х2). (4.11)
Заметим, что равенство (4.11) может быть перепи-
сано в виде
фп(Х1, Х2) = фо(п,-с,)(х2)>
и, таким образом, теорема утверждает, что для того,
чтобы вычислить значение фл(Х1,х2), можно вначале
найти a(n,xi), а затем вычислить значение одноместной
функции фа (л, X,) на числе х2.
Доказательство. По определению
U2 (п, xt, х2) = U (п, р (хь х2)) = ф„ (р (xi, х2)).
Рассмотрим следующие машины Тьюринга:
— машина (х = 0,1,2, ...) дописывает спереди
к произвольному слову Q фиксированное слово 11... |*;
х + 1
— машина Мр вычисляет нумерационную функцию
р(х,у) (функция р рекурсивна и, следовательно, мо-
жет быть вычислена на машине).
Обозначим через a(n, xi) номер машины, являющей-
ся суперпозицией Мп ° (Мр ° M(Xl)). Если применить маши-
ну Ма (п, xi) к числу х2, то вычисления будут протекать
НЕКОТОРЫЕ ТЕОРЕМЫ ТЕОРИИ АЛГОРИТМОВ
205
§ 4.5]
по схеме:
х2 —* *1 * х2--> р (хь х2)--> ср„ (р (хь х2У) =
М '*' МР мп
— U2 (п, хь х2).
Отсюда следует, что
U (а (п, Xi), х2) — сра („, Х1) (х2) = U2 (п, xt, х2).
Осталось установить, что функция а является рекур-
сивной. Здесь и часто в дальнейшем мы будем пользо-
ваться неформальными доказательствами, основанными
на тезисе Чёрча. Будем считать, что если некоторая
функция вычислима в интуитивном смысле, то она мо-
жет быть вычислена на машине Тьюринга и, следова-
тельно, является частично-рекурсивной. Построение со-
ответствующих машин Тьюринга в принципе может быть
осуществлено, но это связано с громоздкими рассмот-
рениями.
По числу %! машина Af(X1> легко может быть по-
строена. Машина Мр вычисляет конкретную функцию
(нумерационную) и ее программа может быть явно
выписана. Суперпозиция Мр ° М<х,) образуется объедине-
нием программ для Мр и М(Х1> и отождествлением за-
ключительного состояния машины М[х,) с начальным
состоянием машины МР. По числу п может быть най-
дена машина Мп (см. раздел 4.4.3 о нумерации ма-
шин), а затем может быть образована суперпозиция ма-
шин Мп и Мр о AfU1). По полученной машине может быть
установлен ее номер а(п, М).
Все этапы, возникающие в процессе вычисления а (п,
%1), являются алгоритмическими, поэтому функция
а(п, %1) частично-рекурсивна. Легко видеть, что она оп-
ределена при любых п и и, следовательно, является
рекурсивной.
Теорема доказана.
Теперь сформулируем и докажем принадлежащую
С. К. Клини теорему о неподвижной точке.
Теорема 4.5 (о неподвижной точке). Для всякой
частично-рекурсивной функции h(x) найдется число а,
называемое неподвижной точкой отображения h, такое,
что
Фл (а) (х) = Ф0(х).
206
МОДЕЛИ АЛГОРИТМОВ
[ГЛ. IV
Доказательство. Рассмотрим вспомогательную
частично-рекурсивную функцию
f (у, x) = U(h (а (у, у)), х),
где U — универсальная частично-рекурсивная функция,
а а — функция из итерационной теоремы. В силу уни-
версальности функции U2 найдется п, при котором
f (у, x) = U(h (а (у, у)), х) = V2 (п, у, х).
Используя итерационную теорему, отсюда получаем
U (h (а (у, у)), x) = U(a (п, у), х).
При у = п имеем
U (h (а (п, п)), х) = U (а (п, п), х).
Функция а является рекурсивной; следовательно, зна-
чение а(п,п) определено. Обозначив его через а, из
предыдущего равенства получаем
U (h (a), x) = U (а, х)
или, что то же самое,
(а) (х) = Фа (*)•
4.5.3. Теорема Райса. Она является одной из наибо-
лее общих теорем теории алгоритмов и проливает свет
па природу многих трудностей, возникающих в прак-
тике программирования, создания алгоритмических
языков и т. д. Доказательство этой теоремы опирается
на теорему о неподвижной точке.
Вначале дадим ряд определений. Пусть имеется не-
которое множество А натуральных чисел. Характери-
стической функцией множества А будем называть функ-
цию
, ч (1, если х е А,
Ха(х)=< , .
(0, если х ф А.
Множество А назовем рекурсивным, если его характе-
ристическая функция рекурсивна.
Теорема 4.6 (М.. Райс). Пусть F — некоторое не-
пустое семейство одноместных частично-рекурсивных
функций, не совпадающее с совокупностью всех одно-
§ 4.5] НЕКОТОРЫЕ ТЕОРЕМЫ ТЕОРИИ АЛГОРИТМОВ 207
местных частично-рекурсивных функций. Тогда множе-
ство Nf всех номеров функций, входящих в F, нерекур-
сивно.
Доказательство. Предположим противное, что
множество Nf рекурсивно, т. е. рекурсивна его харак-
теристическая функция Тогда рекурсивным бу-
дет и дополнение У у? множества NF, поскольку его ха-
рактеристическая функция может быть выражена сле-
дующим образом:
W = 1 — Xnf W-
По условию в F и вне F функции есть, поэтому множе-
ства Nf и Nf непусты. Выберем некоторые числа а е NF
и b е N'f и определим функцию
. , (а, если х е NF,
(b, если х е Nf.
Функция g(x) рекурсивна, поскольку она может быть
представлена в виде
g(x) = a%N,p (х) + bxNp(x).
По теореме о неподвижной точке найдется п, при ко-
тором фг(„)(х)= ф«(х). Какому из множеств Nf и Nf
принадлежит п?
1) Предположим, что n^NF. Тогда по определе-
нию Nf выполнено <р« е F, и поскольку сре(п) совпадает
с фп, то и фг(П) е F. С другой стороны, из п е Nf сле-
дует, что g(n)=b, т. е. g(n)<= Nf и фг(п) фр. В ре-
зультате приходим к противоречию.
2) Предположим теперь, что ns.Nf. Тогда <р,г ф F
и фг(Я) ф F (поскольку Ф§(п) = фп). С другой стороны, из
n^Np следует, что g(n) = а^ NF, а потому ф^еР.
Также получаем противоречие.
Таким образом, п не содержится ни в одном из мно-
жеств Nf и Nf, чего не может быть, ибо их объедине-
ние дает множество всех натуральных чисел. Указанное
противоречие возникло из предположения о рекурсивно-
сти множества Nf. Теорема доказана.
208
МОДЕЛИ АЛГОРИТМОВ
[ГЛ. IV
Дадим более содержательную формулировку этой
теоремы. Пусть Q — некоторое свойство одноместных
частично-рекурсивных функций. Свойство Q назовем
нетривиальным, если есть функции, обладающие свой-
ством Q, и функции, не обладающие этим свой-
ством.
Все обычно рассматриваемые свойства функций яв-
ляются нетривиальными. Примерами нетривиальных
свойств являются следующие: функция тождественно
равна 0, функция нигде не определена, функция являет-
ся рекурсивной, функция монотонна, функция взаимно
однозначна, функция определена при х = 0 и т. д. Ча-
стично-рекурсивные функции обычно задаются програм-
мами их вычисления. Возникает вопрос, можно ли по
программе узнать, обладает ли соответствующая функ-
ция заданным нетривиальным свойством (более точно,
существует ли алгоритм такого распознавания). В при-
нятой нами формализации будем считать, что функции
задаются программами вычисляющих их машин Тью-
ринга.
Согласно тезису Чёрча задача является алгоритми-
чески разрешимой тогда и только тогда, когда сущест-
вует некоторая машина Тьюринга Af°, которая решает
эту задачу. Пусть требуется узнать, обладает ли функ-
ция ф.м(х), реализуемая машиной М, свойством Q. На
ленту машины М° должна быть записана информация
о программе машины Af. Эту информацию будем зада-
вать в виде шифра Ш(М). Результатом работы машины
Мо должен быть ответ «да» или «нет», в зависимости
от того, обладает функция <рм(х) свойством Q или нет.
Первому случаю условимся сопоставлять символ 1,вто-
рому— символ 0. Подытоживая сказанное, дадим сле-
дующее определение. Машина Тьюринга А4° распознает
свойство Q одноместных частично-рекурсивных фуню
ций, если конфигурацию она перерабатывает
в фо1, если функция <рм(х) обладает свойством Q, и в
<7оО в противном случае.
Теорема 4.7. Каково бы ни было нетривиальное
свойство Q одноместных частично-рекурсивных функ-
ций, задача распознавания этого свойства алгоритми-
чески неразрешима, т. е. не существует машины М°,
которая решает эту задачу в указанном выше смысле.
§ 4.5]
НЕКОТОРЫЕ ТЕОРЕМЫ ТЕОРИИ АЛГОРИТМОВ
209
Доказательство. Покажем, что из существова-
ния машины М°, распознающей свойство Q, следует ре-
курсивность множества номеров семейства Fq функций,
обладающих свойством Q.
При наличии распознающей машины Af° вычисление
характеристической функции %vF (п) может быть осу-
Q
ществлено следующим образом. Вначале запись числа
п переводится в шифр Ш (Мп) машины с номером п, за-
тем применяется распознающая машина М°, которая
выдает 1, если функция фи (х) = Ф„(х)
И-
ством Q, и 0 — в противном случае. В
чение XnFq
(п) вычисляется в алфавите
преобразуется в |, а 1 —в JJ.
Из вычислимости функции %N (х)
Q
обладает свой-
результате зна-
{0, 1}. Затем 0
следует ее ре-
курсивность. Но в силу нетривиальности свойства Q се-
мейство Fq непусто и отлично от совокупности всех
одноместных частично-рекурсивных функций, поэтому
по теореме Райса функция
Fq
(х) не может быть рекур-
сивной. Полученное противоречие доказывает теорему.
Аналогичные результаты могут быть установлены
и для всех других «естественных» языков (программ),
на которых выразимы все частично-рекурсивные функ-
ции (рекурсивные схемы, алгоритмические языки и др.).
Отсюда следует неразрешимость многих задач, связан-
ных с программированием. Например, если имеется не-
которая программа (составленная кем-то другим), то по
ней, вообще говоря, ничего нельзя сказать о функции,
реализуемой программой. По двум программам нельзя
установить, реализуют ли они одну и ту же функцию,
а это приводит к неразрешимости многих задач, связан-
ных с эквивалентными преобразованиями и минимиза-
цией программ. В любом алгоритмическом языке, какие
бы правила синтаксиса там ни применялись, всегда бу-
дут иметься «бессмысленные» программы, задающие
функции, не определенные ни в одной из точек (эти
программы нельзя обнаружить). Теорема Райса позво-
ляет доказывать алгоритмическую неразрешимость мно-
гих задач, связанных с вычислениями на машинах,
210
ВЫЧИСЛИТЕЛЬНЫЕ ВОЗМОЖНОСТИ МАШИН
[ГЛ. V
Глава V
ВЫЧИСЛИТЕЛЬНЫЕ ВОЗМОЖНОСТИ МАШИН
§ 5.1. Алгоритмически неразрешимые проблемы.
Метод сводимости
5.1.1. Алгоритмическая неразрешимость. Основным
стимулом, приведшим к выработке понятия алгоритма
и созданию теории алгоритмов, явилась потребность до-
казательства неразрешимости многих проблем, возник-
ших в различных областях математики. После развития
соответствующей техники доказательств было установ-
лено, что многие важные задачи, встречающиеся в ки-
бернетике, также являются неразрешимыми. Специалист
по кибернетике, решая ту или иную задачу, всегда дол-
жен считаться с возможностью того, что она может ока-
заться неразрешимой. Поэтому он должен иметь пред-
ставление о технике доказательства неразрешимости.
В предыдущем параграфе мы встретились с одной
алгоритмически неразрешимой проблемой. Она относит-
ся к распознаванию нетривиальных свойств частично-
рекурсивных функций по программам реализующих их
машин. Однако эта проблема связана с вычислениями
на машинах, а потому она является «внутренней» для
теории алгоритмов.
Ниже мы докажем алгоритмическую неразрешимость
некоторых «внешних» задач. В качестве основной за-
дачи, на которой иллюстрируется техника доказатель-
ства неразрешимости, взята задача распознавания пол-
ноты конечной системы автоматов (она была сформу-
лирована в разделе 3.4.3).
В теории алгоритмов рассматриваются так называе-
мые массовые проблемы (задачи). Массовая проблема
представляет собой бесконечную совокупность отдель-
ных (индивидуальных) задач. Так, например, индиви-
дуальной задачей является следующая: обладает ли
свойством Q функция, вычисляемая заданной машиной
М. Совокупность всех таких задач (для всех Af) состав-
ляет массовую проблему распознавания свойства Q.
Массовую проблему Z, состоящую из индивидуальных
задач Zi, будем обозначать через Z={zt}. Мы будем
§5.1] АЛГОРИТМИЧЕСКИ НЕРАЗРЕШИМЫЕ ПРОБЛЕМЫ 211
рассматривать лишь массовые проблемы, в которых все
индивидуальные задачи имеют двузначный ответ («да»
или «нет»), В частности, таковы проблемы, рассматри-
вавшиеся ранее; обладает ли свойством Q функция
фм(х), является ли полным автоматный базис М и др.
Согласно тезису Чёрча массовая проблема Z яв-
ляется алгоритмически разрешимой, если существует
машина Тьюринга Af°, решающая данную проблему.
Под этим подразумевается следующее. Индивидуаль-
ные задачи Zt кодируются каким-либо «естественным
образом» в виде слов А (так, например, кодом машины
может считаться ее шифр). Машина М° запускается в
конфигурации q\Pi и должна остановиться в конфигу-
рации gol или 700, в зависимости 'от того, какое реше-
ние («да» или «нет») имеет задача Zi.
Может показаться, что понятие разрешимости зави-
сит от способа ввода данных о задаче zi в машину (в ча-
стности, от ее кодирования) и от вывода ответа. Однако
неформальные рассуждения, основанные на тезисе Чёр-
ча, показывают, что это не так при условии, что спо-
собы ввода и вывода являются «алгоритмическими».
Всякое «алгоритмическое» преобразование информации
может быть выполнено машиной Тьюринга, и переход
от решения на основе одного представления информа-
ции к решению на основе другого представления мо-
жет быть осуществлен с использованием суперпозиции
подходящих машин.
5.1.2. Метод сводимости. Основной метод, применяе-
мый при доказательстве алгоритмической неразрешимо-
сти, основан на следующем соображении. Пусть имеют-
ся массовые проблемы Z~ {zi} и Z' = {zj}, и пусть су-
ществует некоторый! алгоритмический способ построе-
ния по всякой задаче zt^.Z задачи г/eZ'такой, что Zj
имеет положительный ответ («да») тогда и только тог-
да, когда положителен ответ на задачу г, (в этом слу-
чае говорят, что проблема Z сводится к Z'). Тогда, если
проблема Z неразрешима, то неразрешимой является и
Z'. Действительно, в противном случае можно по всякой
задаче Zt^Z построить задачу г, е Z и, решив ее (про-
блема Z' разрешима), получить решение задачи Zt (про-
блема Z также была бы разрешимой).
212
ВЫЧИСЛИТЕЛЬНЫЕ ВОЗМОЖНОСТИ МАШИН
[ГЛ. V
Пусть требуется доказать алгоритмическую неразре-
шимость проблемы Z. Тогда вначале непосредственно
доказывается неразрешимость некоторой «простой» про-
блемы Z°, а затем строится цепочка проблем Z1, Z2, ...
..., Zq такая, что Z0 сводится к Z1, Z1 к Z2, Z’ к Z.
Если этот план удается реализовать, то отсюда следует
неразрешимость проблемы Z. Описанный метод носит
название метода сводимости.
5.1.3. Проблема самоприменимости. В качестве ис-
ходной проблемы, на основе которой методом сводимо-
сти будет доказываться неразрешимость других проб-
лем, будем использовать так называемую проблему са-
моприменимости, которая состоит в следующем.
Будем рассматривать машины Тьюринга, во внеш-
нем алфавите которых присутствуют символы 0 и 1 (на-
ряду с другими). Пусть на ленту машины М записан
ее шифр и машина запущена в начальном со-
стоянии 71 (головка обозревает крайний левый непустой
символ). Если после некоторого конечного числа шагов
машина М придет в заключительное состояние, то та-
кую машину будем называть самоприменимой, а в про-
тивном случае — несамоприменимой. Существуют само-
применимые и несамоприменимые машины. Самоприме-
нимой является, например, машина, у которой в правую
часть всех команд входит заключительное состояние, а
несамоприменимой — машина, у которой состояние qo не
встречается среди правых частей команд. Проблема са-
моприменимости состоит в том, чтобы по всякой машине
М (или, что то же самое,— по ее шифру Ш(М)) уста-
новить, является ли она самоприменимой или нет.
Будем говорить, что машина Тьюринга Af° решает
проблему самоприменимости, если для любой машины
М конфигурацию q\IH(М) она переводит в 701, если М
самоприменима, и в qoO — если несамоприменима.
Теорема 5.1. Проблема самоприменимости алго-
ритмически неразрешима, т. е. не существует машины
Тьюринга Af°, которая решает эту проблему в указан-
ном выше смысле.
Доказательство. Предположим противное, что
машина М°, решающая проблему самоприменимости,
существует. Построим по ней новую машину М'. Для
этого состояние qo сделаем незаключительным, введем
§ 5.2] НЕКОТОРЫЕ НЕРАЗРЕШИМЫЕ ПРОБЛЕМЫ 213
новое заключительное состояние 9о и добавим к про-
грамме машины М° две новые команды
7о1^7о1Н> (5.1)
доО-><7оОН. (5.2)
Машина М' применима к шифрам несамопримени-
мых машин и не применима к шифрам самоприменимых
машин. Действительно, если некоторая машина Af неса-
моприменима, то вначале ЛГ, работая как М°, перейдет
в конфигурацию qoO, а затем в соответствии с коман-
дой (5.2) остановится. Если же М самоприменима, то
М' перейдет в конфигурацию и эта конфигурация
будет повторяться бесконечно в соответствии с (5.1).
Сама машина М' является либо самоприменимой,
либо несамоприменимой. В первом случае она приме-
нима к собственному шифру, т. е. к шифру самоприме-
нимой машины, что невозможно по построению М'. Во
втором случае она не применима к собственному шиф-
ру, т. е. к шифру несамоприменимой машины, что так-
же невозможно. Указанное противоречие возникло из
допущения существования машины Af°, решающей про-
блему самоприменимости.
Теорема доказана.
На основе проблемы самоприменимости с использо-
ванием метода сводимости может быть доказана нераз-
решимость ряда других проблем, относящихся к маши-
нам Тьюринга. Одной из них является проблема оста-
нова. Она состоит в том, чтобы по машине М и слову
Р узнать, применима ли машина М к слову Р (т. е. ос-
танавливается ли она, будучи запущенной в конфигура-
ции qiP). Если бы эта проблема была разрешимой, то,
взяв в качестве слова Р шифр машины П1(М), можно
было бы установить, применима ли машина М к соб-
ственному шифру, и тем самым решить проблему само-
применимости.
§ 5.2. Некоторые алгоритмически
неразрешимые проблемы
5.2.1. Проблема выводимости в системе подстановок.
До сих пор мы доказывали лишь неразрешимость не-
которых массовых проблем, связанных с машинами
214
ВЫЧИСЛИТЕЛЬНЫЕ ВОЗМОЖНОСТИ МАШИН
[ГЛ. V
Тьюринга. В данном параграфе мы установим нераз-
решимость некоторых «внешних» проблем. Выбор имен-
но этих проблем связан с тем, что они позволят нам
доказать теорему 3.2 о неразрешимости проблемы пол-
ноты автоматных базисов.
Начнем с рассмотрения проблемы выводимости в
системе подстановок.
Система подстановок задается конечным алфавитом
А и базисными подстановками
Pi^Qi (Z=l,
где Pi и Qi — фиксированные слова в алфавите А. Под-
становка Pt-^-Qi применима к любому слову R =
= R1P1R2, где Ri и R2 — произвольные слова в алфа-
вите А (возможно, пустые), и переводит его в слово
R'= RlQiR2. В этом случае будем записывать R-+R'.
Слово Q выводимо из слова Р, если существует цепоч-
ка слов ..., такая, что = Р, R(m> =
= Q и при i = 1, .... m — 1 выполнено /?<')_>
Рассмотрим пример. Пусть А= {а,Ь,с) и подста-
новки имеют вид
аа -> с,
сс -> Ьа,
ас—>а.
Тогда слово aabaacac может быть преобразовано,
например, следующим образом:
aabaacac —> aabccac -> aabcca -> aabbaa -> cbbaa.
Таким образом, слово cbbaa выводимо из aabaacac.
Пусть заданы система подстановок П и слово Ro
(здесь и далее считается, что подстановки и слова —
в одном и том же алфавите А). Проблема выводимости
в системе подстановок П из слова Ro состоит в том, что-
бы по произвольному слову Р установить, выводимо ли
оно из Ro с применением подстановок из П.
В некоторых случаях эта проблема допускает про-
стое решение. Так, например, если А = {а, Ь} и система
П состоит из подстановок а -> b и Ь->а, то слово Р
выводимо из Ro тогда и только тогда, когда оно имеет
ту же длину, что и Ro. Однако, как показывает следую-
§5.2] НЕКОТОРЫЕ НЕРАЗРЕШИМЫЕ ПРОБЛЕМЫ 215
щая теорема, проблема выводимости может оказаться
и неразрешимой.
Теорема 5.2. Существуют система подстановок П
и слово Ro такие, что проблема выводимости из слова
Ro в системе П алгоритмически неразрешима.
Доказательство этой теоремы будет проводиться на
основе неразрешимости проблемы самоприменимости.
В связи с этим нам понадобится способ моделирования
машин Тьюринга системами подстановок.
5.2.2. Моделирование машин Тьюринга системами
подстановок. Пусть имеется машина М с внешним и
внутренним алфавитами {«о, Яь , a*-i} и {q0, qi, ...
..., <T-i}. Возьмем некоторую новую букву а и каждой
конфигурации
К = а(1> ... , а(р)
поставим в соответствие слово
RK = аа(1) ... а<1'- !)^(Л а(0 ... с№а.
Слова, сопоставленные указанным способом конфигу-
рациям, будем называть машинными. Нашей целью яв-
ляется описание такой системы подстановок П,м, что ма-
шинное слово Rk' выводимо в этой системе из машин-
ного слова Rk тогда и только тогда, когда конфигура-
ция К может быть переведена машиной в К'.
В качестве алфавита системы подстановок Пм возь-
мем А — {«о, «1, ..., ak-i, qo, qi, •qr-i, а}. Каждой
команде машины М сопоставим некоторое множество
подстановок. Объединение всех таких множеств (для
всех команд) и даст систему Пм. Пусть, например,
команда имеет вид
qa->q'a'H. (5.3)
При ее выполнении происходит преобразование конфи-
гурации, показанное на рис. 5.1.
Рассмотрим, как при этом изменяются машинные
слова.
—Если обозреваемая ячейка не является концом
конфигурации (точнее, активной зоны конфигурации),
то машинное слово преобразуется следующим образом:
а ... bqad ... а —> а ... ba'q'd ... а.
216
ВЫЧИСЛИТЕЛЬНЫЕ ВОЗМОЖНОСТИ МАШИН
|ГЛ. V
Это преобразование может быть осуществлено приме-
нением подстановки
bqad—> ba'q'd (b,d^a).
— Пусть обозреваемая ячейка является левым кон-
происходит следующее преобразование машинного слова:
aqad ... а-> aa'q'd ... а, если а' Л,
aqad ... a-^-aq'd ... а, если а = К.
Оно описывается подстановкой
aqad —> aa'q'd,
если а' =И= Л, а в противном случае — подстановкой
aqad -> aq'd.
— Пусть обозреваемая ячейка является правым кон-
цом конфигурации, но не является левым. Тогда машин-
ное слово преобразуется следующим образом:
а ... bqaa -> а ... ba'q'Na.
Это равносильно выполнению подстановки
bqaa -> ba'q'Na.
—Пусть обозреваемая ячейка одновременно являет-
ся левым и правым концом конфигурации (т. е. являет-
ся единственной активной ячейкой). Тогда происходит
следующее преобразование машинного слова:
aqaa -> аа'q'Ka, если а' Л,
aqaa -> aq'Aa, если а' = Л.
Подстановка имеет тот же вид, что и само преобразо-
вание.
5 5.2] НЕКОТОРЫЕ НЕРАЗРЕШИМЫЕ ПРОБЛЕМЫ
217
Система подстановок, соответствующая команде
(5.3), полностью указана. Аналогично могут быть вы-
писаны подстановки, соответствующие командам, при
выполнении которых происходит сдвиг головки влево,
либо головка остается на месте.
Левые части всех подстановок имеют вид bqad. Из
построения системы Пм видно, что если имеется неза-
ключительная конфигурация К, то к машинному слову
Rk применима ровно одна подстановка системы Пм
(в слове R& имеется единственный символ q, а потому
однозначно находится четверка bqad, которой опреде-
ляется единственная подстановка). Эта подстановка пе-
реводит слово Rk в машинное слово RK’, соответствую-
щее конфигурации К', в которую машина Af переводит
К за 1 такт. Если конфигурация К является заключи-
тельной, то к слову Rk не применима ни одна из под-
становок системы Пм. Отсюда следует, что одно машин-
ное слово выводимо из другого в системе Пм тогда и
только тогда, когда первая из соответствующих кон-
фигураций может быть переведена машиной во
вторую.
5.2.3. Доказательство теоремы 5.2. 1) При доказа-
тельстве будет использована машина Тьюринга АР, ко-
торая для любой машины М конфигурацию q\UJ(M)
переводит в <?оО, если М самоприменима, и не останав-
ливается, если М несамоприменима. Машина Af° рабо-
тает следующим образом. Вначале запись Ш(М) пере-
водится в Ш (Af)* Ш (qd) Ш (Ш (М)), Затем М° работает
как универсальная машина Lz. Машина Id переходит в
заключительную конфигурацию тогда и только тогда,
когда машина М применима к конфигурации qddl(M'),
т. е. является самоприменимой. Если V оказывается в
заключительной конфигурации, то при последующей ра-
боте машины М° запись на ленте (она занимает связ-
ный кусок ленты) стирается, после чего записывается О
и машина останавливается. Если М несамоприменима,
то универсальная машина U на записи Ш (М)*Ш (qi)X
X Ш(Ш (Af)) работает бесконечно, а потому бесконечно
работает и Af°.
2) Покажем теперь, что существуют системы под-
становок П' и слово Ro в некотором алфавите А такие,
что проблема распознавания по любому слову Р в
218
ВЫЧИСЛИТЕЛЬНЫЕ ВОЗМОЖНОСТИ МАШИН
[ГЛ. V
алфавите А, выводимо ли из него /?0> является алгорит-
мически неразрешимой.
Возьмем машину М°, описанную в пункте 1), и по-
строим по ней систему подстановок ПЛ|». В качестве II'
возьмем Па в качестве Ло — слово а<7оОа. Пред-
положим, что проблема распознавания по любому сло-
ву в алфавите {«0, яь , ак-1, qo, q\, ..., qr-\, а}, вы-
водимо ли из него Ro, является алгоритмически разре-
шимой. Тогда проблема самоприменимости может быть
решена следующим образом. По шифру Ш(/И) произ-
вольной машины М выписывается слово aqtlll (М)а и
выясняется, выводимо ли из него в системе Пи= слово
Ro = aqoOa. Если выводимо, то М° переводит конфигу-
рацию в </оО, что свидетельствует о самопри-
менимости машины Л1. Если же Ro не выводимо из
aqiII/(M)a, то машина М несамоприменима (на ее
шифре М° работает бесконечно). Из неразрешимости
проблемы самоприменимости следует отсутствие алго-
ритма, решающего по любому слову Р, выводимо ли из
него в системе П' = Пи, слово Rq.
3) Завершим доказательство теоремы. По системе
подстановок IT образуем систему П, заменив каждую
подстановку Pi-+Qi из 1Т на обратную Qi-+Pi. Легко
видеть, что слово R выводимо из S в системе П' тогда
и только тогда, когда в системе П слово S выводимо из
R. Отсюда следует, что множество всех слов, выводи-
мых из Ro в системе П, совпадает с множеством всех
слов, из которых в системе П' выводимо Ro. Согласно
доказанному в пункте 2) проблема распознавания по
произвольному слову Р, содержится ли оно в этом мно-
жестве, алгоритмически неразрешима. Поэтому слово
Ro и система подстановок П удовлетворяют условиям
теоремы.
5.2.4. Проблема выводимости в системе продукций.
Система продукций задается конечным алфавитом А
и базисными продукциями
P{R-+RQi (г = 1, ..../),
где Pi и Qt — фиксированные слова в алфавите А. Под
R понимается произвольное (возможно пустое) слово
в алфавите А. Пусть некоторое слово Р начинается
словом Pi. Произвести над Р продукцию P-.R—^RQi —
НЕКОТОРЫЕ НЕРАЗРЕШИМЫЕ ПРОБЛЕМЫ
219
§ 5.2]
это значит вычеркнуть из Р начальное подслово Pi, а
затем к оставшемуся слову приписать справа Q,. Если
слово Р' получено из Р применением продукции, то бу-
дем записывать Р —> Р'. Будем говорить, что слово Q
выводимо из слова Р, если существует цепочка слов
..., такая, что R,v> = Р, R‘-m'1 — Q и при
i = 1....т— 1 выполнено
Рассмотрим пример. Пусть А = {а, Ь, с} и базис-
ные продукции имеют вид
aR —> Raa,
bR->Rc.
Тогда слово abba может быть преобразовано следую-
щим образом:
abba —> bbaaa —> baaac —> ааасс —> aaccaa.
Таким образом, слово аассаа выводимо из слова abba.
Пусть заданы система продукций л и слово Ro (всю-
ду считается, что продукции и слова в одном и том же
алфавите Л). Проблема выводимости в системе продук-
ций л из слова Ro состоит в следующем. Требуется по
произвольному слову Р установить, выводимо ли оно
из Ro с применением продукций из л. В некоторых слу-
чаях эта проблема допускает простое решение. Так, на-
пример, если А = {а, £>} и система л состоит из продук-
ций aR-+Ra, aR-+Rb, bR—^Ra и bR-+Rb, то слово Р
выводимо из Ro тогда и только тогда, когда оно имеет
ту же длину, что и Ro. Следующая теорема показывает,
что проблема выводимости в системе продукций может
оказаться и неразрешимой.
Теорема 5.3. Существуют система продукций л и
слово Ro такие, что проблема выводимости из слова Ro
в системе л алгоритмически неразрешима.
В следующем разделе будет описан способ модели-
рования системы подстановок системой продукций.
А именно, по системе подстановок П в алфавите А бу-
дет построена система продукций л в некотором расши-
рении А' алфавита А такая, что если Р и Q — слова
в алфавите А, то Q выводимо из Р в системе П тогда
и только тогда, когда Q выводимо из Р в системе л.
Из этого факта легко вытекает утверждение тео-
ремы. Действительно, рассмотрим систему подстановок
220
ВЫЧИСЛИТЕЛЬНЫЕ ВОЗМОЖНОСТИ МАШИН
[ГЛ. V
П и слово Ro с неразрешимой проблемой выводимости
(теорема 5.2) и промоделируем П системой продукций
л. Полученная система л и слово Ro удовлетворяют ус-
ловиям теоремы. В противном случае, если бы имелся
алгоритм, решающий по словам в расширенном алфа-
вите А', выводимы ли они из слова Ro в системе л, то,
применяя этот алгоритм к словам Р в алфавите А,
можно было бы устанавливать, выводимы ли они из Ro
в системе П.
5.2.5. Моделирование систем подстановок системами
продукций. Пусть задана система подстановок П:
Pi-*Qi (*=1,2 ..., О,
в алфавите А = {сц, ар}. Образуем систему про-
дукций л в алфавите А! = {а1; ..., ар, а\, ..., а'р} со сле-
дующими базисными продукциями:
PiR-^RQ'i (5.4)
где Q't — слово, полученное из Q; заменой каждой бук-
вы а/ на а/,
ajR^-Ra'i (j=l, ..., р), (5.5)
a'jR ->Rctj (j — 1, ..., p). (5.6)
Рассмотрим 2 слова P и Q в алфавите А.
а) Покажем, что если Q выводимо из Р в системе
подстановок П, то Q выводимо из Р и в системе про-
дукций л. Для этого достаточно рассмотреть случай
применения одной подстановки. Пусть подстановка
применяется к слову RiPtRo (и переводит его
в RiQiRzj. То же преобразование слов может быть осу-
ществлено в системе продукций л следующим образом.
Вначале последовательным перекидыванием букв под-
слова R\ в конец слова с заменой их штрихованными
буквами (см. продукции типа (5.5)) слово RiPtRo пре-
образуется BPiR2R'i- Затем применением продукции
RQ'i из него получаем слово R2R\Q'i. Далее производим пе-
рекидывание букв слова Ro в конец с заменой их
штрихованными буквами и в результате приходим кслову
RiQ'iRi- После чего, используя продукции типа (5.6),
осуществляем последовательное перекидывание букв из
начала слова в конец со снятием штрихов. По оконча-
нии этой процедуры получаем требуемое слово RiQiRo.
§ 5.2] НЕКОТОРЫЕ НЕРАЗРЕШИМЫЕ ПРОБЛЕМЫ 221
б) Покажем теперь, что если слово Q выводимо из
Р в системе продукций л, то Q выводимо из Р в си-
стеме подстановок П. Пусть цепочка слов
/?'», /?("», Rd) = P, R^=Q (5.7)
соответствует выводу Q из Р в системе л. Рассмотрим
более подробно, как осуществляется этот вывод.
До тех пор, пока левыми буквами слов /?(2), ...
являются нештрихованные, могут применяться лишь
продукции типа (5.4) или типа (5.5). При этом полу-
чаемые слова имеют вид VW', где через V обозначено
слово в алфавите А = {ai, ..., ар}, а через W'— слово
в алфавите {«(, ..., ар}. Так будет продолжаться, пока
слово не окажется полностью составленным из штрихо-
ванных букв. На следующих шагах могут использовать-
ся лишь продукции типа (5.6), и получаемые слова бу-
дут иметь вид V'W. После того как слово V окажется
пустым, т. е. образуется слово в алфавите А, снова мо-
гут применяться лишь продукции типов (5.4) и (5.5),
и т. д. Отсюда следует, что всякое слово цепочки (5.7)
имеет вид VW' или V'W (некоторые из слов V, W', V',
W могут быть пустыми).
Слову R, имеющему вид VW' или V'W, сопоставим
слово R = WV в алфавите А. Вместо цепочки (5.7) рас-
смотрим соответствующую цепочку
Я<», Я(2>....................(5.8)
Если слово получено из /?(/) применением продук-
ции (5.4), то Rd) = PiSW' (при некоторых S и W'), а
R(l+d = SW'Q'i. В этом случае Rd) = WP;S, Rd+d =
= WQiS и слово Rd+d получается из Rd) применением
подстановки системы П. Если же слово Rd+d образо-
вано из Rd) продукцией типа (5.5) или типа (5.6), то,
как нетрудно проверить, Rd+d = Rd). Таким образом,
каждое слово цепочки (5.8) либо совпадает с предыду-
щим, либо получается из него применением подстановки
системы П. Отсюда, в частности, следует, что вы-
водимо из Rd) в системе П. Поскольку Rd) = Р nRd") ~
= Q являются словами в алфавите А, то /?(1) — /?(') =
= Р и R<~m) = Rd") — Q. Это означает, что Q выводимо
из Р в системе П.
222
ВЫЧИСЛИТЕЛЬНЫЕ ВОЗМОЖНОСТИ МАШИН
[ГЛ. V
Тем самым необходимое моделирование систем под-
становок системами продукций получено. Отсюда, как
мы видели, вытекает утверждение теоремы 5.3.
§ 5.3. Неразрешимость проблемы полноты
конечной системы автоматов
5.3.1. Проблема полноты. Напомним, в чем она зак-
лючается (см. § 3.4). Рассматриваются схемы в ав-
томатных базисах. Базис Л состоит из конечного числа
автоматов, каждый из которых имеет некоторое количе-
ство входов и некоторое количество выходов (могут
использоваться и автоматы без входов). Все базисные
автоматы имеют одинаковый входной алфавит А, а их
выходные алфавиты содержатся в А. Схемы строятся
исходя из полюсов с использованием двух операций.
Одна из них состоит в присоединении к схеме базисного
автомата, а вторая — во введении обратной связи. При
этом обратная связь может быть образована путем
подсоединения вершины у/ ко входу х,- лишь в случае,
когда каноническое уравнение t)j(t) не зависит суще-
ственно ОТ
Каждая схема реализует некоторый автомат в ал-
фавите А. Если схемами в базисе Л могут быть реали-
зованы все автоматы в алфавите А, базис называется
полным, в противном случае — неполным. Проблема
полноты состоит в том, чтобы по заданному автомат-
ному базису выяснить, является ли он полным. Как уже
говорилось, имеет место следующий результат, принад-
лежащий М. И. Кратко.
Теорема 3.2. Проблема полноты конечной систе-
мы автоматов алгоритмически неразрешима.
Эта теорема, справедливая для любого алфавита А,
содержащего не менее двух букв, будет доказана нами
для некоторого достаточно большого алфавита. Кроме
того, будет рассматриваться лишь случай инициальных
автоматов, в то время как результат справедлив и для
неинициальных автоматов.
Доказательство основано на возможности моделиро-
вания автоматами систем продукций.
5.3.2. Моделирование автоматами систем продукций.
Рассмотрим проблему выводимости в системе продук-
§ 5.3]
ПРОБЛЕМА ПОЛНОТЫ ДЛЯ АВТОМАТОВ
223
ций л из некоторого слова Ro- Пусть алфавитом систе-
мы л является Ао — {fli, .... аг}, а продукции имеют
вид
(Р/) RQi (« = 1, ...» Z).
Введем новые буквы а, р и у и положим А = Ао U {«,
р, у}. Будем рассматривать автоматы в алфавите А.
Поскольку автоматы осуществляют переработку бес-
конечных входных последовательностей в бесконечные
выходные последовательности, нам придется иметь дело
и со словами бесконечной длины, которые будем назы-
вать сверхсловами. Кодом (конечного) слова R в алфа-
вите Ао будем называть всякое сверхслово avRa°°, v 1
ос
Рис. 5.2.
(через обозначено а ... aRaa . . .). Сверхслово
V
вида Рр00, где Р — слово в алфавите А, будем называть
fi-сверхсловом. Если Q — произвольное слово, то через
Q(i) будем обозначать его t'-ю букву, а через |Q| — дли-
ну (число букв).
При моделировании будут использоваться следую-
щие автоматы.
Автомат Во без входов с 1 выходом. Он реали-
зует постоянное сверхслово aRoa°°, где Ro — слово, вы-
водимость из которого в системе продукций л рассмат-
ривается. Начав работать, автомат Во сперва выдает
символ а, затем буквы слова Ro, после чего зацикли-
вается и вырабатывает постоянный символ а. Его диаг-
рамма приведена на рис. 5.2 (стрелкам приписаны зна-
чения выхода, вход отсутствует).
Автомат В, (;'= 1, ..., /) с 1 выходом и 1 вхо-
дом соответствует продукции (щ) системы л. По коду
слова PiR (при произвольном R в алфавите Ао) он вы-
дает код слова RQi, а в остальных случаях — р-сверх-
224
ВЫЧИСЛИТЕЛЬНЫЕ ВОЗМОЖНОСТИ МАШИН
[Гл. v
слово. Переработка слова avPiRa,x осуществляется ав-
томатом следующим образом. При подаче на вход сим-
волов а автомат остается в начальном состоянии qo и
его выход принимает значение а. При дальнейшем по-
ступлении на вход символов слова Pi автомат проходит
последовательность из |Р,| состояний, каждый раз
выдавая на выходе а. После этого автомат оказывается
в состоянии q, в котором он остается, пока на вход по-
ступают символы алфавита Ао, дублируя на выходе бук-
вы, получаемые на входе. В течение этого периода он
воспроизводит на выходе слово R, подаваемое на вход
вслед за словом Pt. При последующем поступлении сим-
волов а автомат вначале проходит последовательность
из | Q.-| состояний и выдает на выходе слово Qi, а за-
тем зацикливается и на каждом последующем такте
его выход принимает значение а.
§ 5.31
ПРОБЛЕМА ПОЛНОТЫ ДЛЯ АВТОМАТОВ
225
Таким образом, автомат Bi перерабатывает сверх-
слово
avP;/?a°° в av+lP‘l RQ^a0-
Для того чтобы при подаче последовательности, от-
личной от кода слова PiR, автомат Bi реализовывал на
выходе p-сверхслово, он снабжается тупиковым состоя-
нием <7*. Как только на вход автомата посту-
пает «непредвиденный» символ, автомат пе-
реходит в тупиковое состояние и на всех по-
следующих тактах выдает постоянный сим-
вол р. Диаграмма автомата В, приведена на
рис. 5.3. Обозначения некоторых состояний
не указаны. Стрелка соответствует
переходам при всех значениях входа, за иск-
лючением указанных отдельно. При переходе
по стрелке => выход принимает значе-
ние р.
Из конструкции автоматов видно, что если
имеется цепочка автоматов, показанная на
рис. 5.4, то на ее выходе реализуется код вы-
водимого слова (если применение последова-
тельности продукций ptv pi2, pik к сло-
“Г
i
Рис. 5.4.
ву Ro дает вывод) либо ^-сверхслово.
5.3.3. Сведение к задаче выводимости в системе
продукций. Построим теперь множество базисов, для
которых решение проблемы распознавания полноты
дает решение проблемы выводимости в системе продук-
ций. С этой целью опишем конструкцию еще некоторых
автоматов.
С каждым словом R в алфавите Ло будем связы-
вать автомат Br с 1 входом и 1 выходом, который
сверхслово avRa,x перерабатывает в ах, а сверхслова
другого вида — в |3-сверхслова. Автомат Br строится
аналогично автомату Bi.
Автомат V имеет 2 входа и 1 выход. Он реали-
зует функцию Вебба V(хц хг) в алфавите А (эта функ-
ция является полной, § 1.4). Автомат V имеет 1 состоя-
ние и описывается каноническими уравнениями
q (О = <7о>
У (0 = V («1 *2 (0)-
226
ВЫЧИСЛИТЕЛЬНЫЕ ВОЗМОЖНОСТИ МАШИН
[гл. v
Автомат 3 с 1 входом и 1 выходом реализует за-
держку. Он описывается каноническими уравнениями
q(t) = x (/),
У® = q(t —
Автомат Н с 2 входами и 1 выходом (аналог
конъюнкции). Он имеет 1 состояние и при поступлении
на левый вход сигнала а повторяет на выходе значение
правого входа, а при поступлении сигнала, отличного
от а, выдает р (рис. 5.5).
Рис. 5.5.
2 3
Рис. 5.6.
Автомат Vr устроен, как показано на рис. 5.6.
Если на вход 1 поступает код слова R, то он работает
как V, а в противном случае выдает р-сверхслово.
Автомат 3R устроен аналогично (рис. 5.7). Если
на вход 1 поступает код слова R, то 3R работает как 3,
в противном случае он выдает р-сверхслово.
С каждым словом R в алфавите До будем связывать
инициальный базис
J(R = {BQ, Bh .... Bh V R, 3R}.
Покажем, что базис J6R полон тогда и только тогда,
когда слово R выводимо из Ro в системе продукций л.
1. Пусть слово R выводимо из Rn в результате по-
следовательного применения продукций pi{, pt2, ..., pt
Тогда цепочка из автоматов Во,В^, Bt2, Вf выдает
код слова R и автоматы V и 3 могут быть построены из
автоматов базиса MR в соответствии с рис. 5.8, а, б.
§ 5.3]
ПРОБЛЕМА ПОЛНОТЫ ДЛЯ АВТОМАТОВ
227
Имея автоматы V и 3, можно реализовать любой
автомат в алфавите А (§ 3.4); поэтому базис Яр по-
лон.
2. Пусть теперь слово R не выводимо из Ro. Пред-
положим, что базис Яр полон. Тогда в нем может быть
реализован автомат, выдающий константу у (т. е. сверх-
слово у00). Рассмотрим произвольную схему, реализую-
щую этот автомат.
Идя в этой схеме от выходного элемента к предыду-
щим по самому левому входу, выделим максимально
возможную цепочку ав-
Рис. 5.7. Рис. 5.8.
б) цепочка завершается автоматом без входов;
в) происходит возвращение по петле обратной связи
к одному из автоматов, входящих в построенную часть
цепочки.
Рассмотрим указанные случаи по отдельности.
а) Этот случай не может иметь места, поскольку
при подаче на вход х сигнала р на выходе также полу-
чим р (из конструкции автоматов видно, что сигнал р
по левому входу проходит сквозь все автоматы). Но по
условию при любом входном наборе на выходе должен
появляться сигнал у.
228
ВЫЧИСЛИТЕЛЬНЫЕ ВОЗМОЖНОСТИ МАШИН
[ГЛ. V
б) Верхним автоматом является Во (только он не
имеет входа). Идя от этого автомата по цепочке вниз,
находим первый из автоматов, имеющих не менее 2 вхо-
дов (пусть, для определенности, Vr). Такой автомат
найдется, ибо на выходах автоматов Bi, i — 0, 1, ..., /,
не может появиться у. Полученная цепочка имеет вид,
показанный на рис. 5.10.
По свойству автоматов В,- на выходе каждого из ав-
томатов Во, В; ..., Bik реализуется либо код выводи-
Рис. 5.9. Рис. 5.10.
мого слова, либо p-сверхслово. Поскольку слово R не-
выводимо, на вход элемента Vr не подается код слова
R, а потому Vr выдает p-сверхслово. Сигналы р прохо-
дят сквозь оставшуюся часть цепочки и на выходе схе-
мы реализуется p-сверхслово (а не у°°). Таким образом,
случай б) также не может иметь места.
в) Рассмотрим некоторый момент времени t. Обо-
значим через q и б соответственно состояние схемы и
значение выхода g в момент t. Значение б отлично от р,
ибо в противном случае на выходе схемы присутство-
вал бы сигнал р (а не у). Если разомкнуть обратную
связь ge и подать в состоянии q на вход е значение б,
§ 5.41 СЛОЖНО ВЫЧИСЛИМЫЕ ФУНКЦИИ 229
то на выходе также появится 6. Если же в состоянии q
на вход е подать р, то на выходе g будет р. Таким об-
разом, в состоянии q значение выхода g существенно
зависит от сигнала на входе е. Согласно правилам по-
строения схем в этом случае обратную связь ge образо-
вывать нельзя. Случай в) не может иметь места.
В результате доказано, что если R не выводимо, то
базис MR неполон (в нем не реализуема константа у).
Завершим теперь доказательство теоремы. Возьмем
в качестве л и Ro систему продукций и слово с нераз-
решимой проблемой выводимости. На их основе по-
строим систему базисов Mr. Если бы проблема пол-
ноты автоматных базисов в алфавите А была алгорит-
мически разрешимой, то можно было бы, построив по
произвольному слову R в алфавите А базис Mr и ре-
шив для него проблему полноты, установить, выводимо
ли R из Ro в системе л. Из несуществования алгоритма
распознавания выводимости следует неразрешимость
проблемы полноты.
На основе доказательства можно сделать вывод, что
неразрешимой является и более простая проблема: по
произвольному базису в алфавите А установить, реали-
зуется ли в нем заданная константа.
§ 5.4. Сложно вычислимые функции
5.4.1. Характеристики сложности вычислений. До
сих пор мы интересовались лишь принципиальной воз-
можностью алгоритмического решения задач, не обра-
щая внимания на ресурсы времени, памяти и др. Од-
нако (как мы увидим дальше) существуют задачи, ко-
торые, хотя и могут быть решены на машине, требуют
столь большого объема вычислений, что их решение
практически недоступно. Таким образом, принципиаль-
ная возможность алгоритмического решения еще не оз-
начает, что оно реально может быть получено. Ниже
рассматривается круг вопросов, связанных со слож-
ностью решения задач.
Как мы знаем, различные модели алгоритмов и ма-
шин при достаточно широких предположениях дают
один и тот же класс вычислимых функций. Поэтому
вопросы вычислимости можно изучать на базе
230
ВЫЧИСЛИТЕЛЬНЫЕ ВОЗМОЖНОСТИ МАШИН
[ГЛ. V
произвольной модели. В то же время выбор той или иной
модели машины может оказать существенное влияние на
сложность вычислений. Однако имеется ряд фактов,
которые справедливы, по существу, для любых моделей
машин и характеристик сложности вычислений. Мы бу-
дем изучать только такие факты, и в этом случае во-
просы выбора модели снова становятся непринципи-
альными.
В качестве модели вычислительного устройства, как
и раньше, будем рассматривать машину Тьюринга, а в
качестве характеристик сложности вычислений — необ-
ходимое время (число тактов) и память (размер лен-
ты). В конце параграфа будет приведено обобщение по-
лученных результатов на произвольные машины и про-
извольные характеристики сложности.
Пусть машина Тьюринга М вычисляет функцию /(х).
Введем функцию /м(х), равную числу тактов машины М
при вычислении f(x), если значение f(x) определено.
В случае, когда f(x) не определено, величину /м(х) так-
же будем считать неопределенной. Функцию йи(х) назо-
вем временной сложностью. Активной зоной при ра-
боте машины М на числе х называется множество всех
ячеек ленты, которые были активными в процессе вы-
числения значения f(x), т. е. входили в активные зоны
конфигураций (раздел 4.1.4). Определим функцию
вм(х), равную длине активной зоны при работе ма-
шины М на числе х, если f(x) определено. В противном
случае значение Sm(x) будем считать неопределенным.
Функцию Sm(x) назовем ленточной сложностью. Анало-
гичные характеристики /.и(Р) и Зм(Р) можно ввести и
для случая вычисления машиной М словарной функции
На-
следующая теорема показывает, что если имеется
верхняя оценка одной из характеристик сложности вы-
числения, то можно найти верхнюю оценку другой ха-
рактеристики.
Теорема 5.4. Пусть внешний и внутренний алфа-
виты машины М содержат соответственно k и г букв.
Тогда имеют место следующие оценки:
Ям (х) О + 1 + С W> (5-9)
tM(x)<rs№ (5.10)
§ 5.41
СЛОЖНО ВЫЧИСЛИМЫЕ ФУНКЦИИ
231
Доказательство. 1. В начальной ситуации на
ленте записано число х, т. е. занята х + 1 ячейка. На
каждом шаге активной становится не более одной но-
вой ячейки, поэтому
(Х) X + 1 + /д! (х).
2. Подсчитаем число различных конфигураций
K = aw ... ... a{s,) (s'^s)
с активной зоной, не большей s. Имеется ks ^ks ва-
риантов записи на ленте, г возможностей выбора со-
стояния, s' s вариантов выбора положения головки
и s возможностей для длины s' конфигурации К. Таким
образом, число рассматриваемых конфигураций не пре-
восходит rs2ks.
Если в процессе работы встретятся 2 одинаковые
конфигурации, то машина зациклится:
К(и), /С<и+1> ... /(<“>, ... , /С°>, /(<“>,
Поэтому, если машина в процессе вычисления исполь-
зует зону Sm(x), то число ее шагов оценивается числом
различных конфигураций с зоной не выше s.u(x):
tM W < rs2M (х) kSM<x}-
Теорема доказана.
Отметим, что в случае вычисления словарной функ-
ции f(P) оценки (5.9) и (5.10) принимают вид
PI +/м(П
tM(P)^rs2M(P) ks"m-
5.4.2. О верхней границе сложности вычислений.
Рассмотрим вопрос, сколь сложными могут быть вы-
числения. Подобная задача исследовалась нами в § 2.5
применительно к схемной реализации булевых функций.
Там было установлено, что сложность функций от п
аргументов ограничена величиной, асимптотически рав-
ной 2п/п.
Для случая вычислений на машинах задача ставит-
ся следующим образом. Существует ли такая всюду оп-
ределенная вычислимая (т. е. рекурсивная) функция
й(х), что для любой вычислимой функции f(x) имеется
232
ВЫЧИСЛИТЕЛЬНЫЕ ВОЗМОЖНОСТИ МАШИН
[ГЛ. V
машина М, вычисляющая ее за время /м(х)^й(х)
(в другой постановке — с памятью s,m(x) й(х)) там,
где значения f(x) определены?
Если не накладывать дополнительных ограничений
на величины значений f(x), то ответ будет отрицатель-
ным. Можно взять функцию f(x) столь быстрорастущей,
что на выписывание ответа понадобится более /г(х) так-
тов (более /г(х) ячеек). Чтобы предотвратить такую
возможность, будем рассматривать лишь функции f(x),
принимающие 2 значения (Он 1).
Из рассмотрения также следует исключить и частич-
ные функции. Если бы для всех вычислимых функций,
принимающих значения 0 и 1 (в том числе и частич-
ных), существовала функция /г(х) с указанным свой-
ством, то любую частично-рекурсивную функцию со зна-
чениями 0 и 1 можно было бы доопределить до рекур-
сивной (что противоречит теореме 4.3). Для того чтобы
осуществить такое доопределение, нужно при вычисле-
нии значения f (х) на соответствующей машине отсчитать
h(x) тактов, и если к этому времени значение функции
выдано не будет, то оно является неопределенным и
можно положить f(x)=O. Эта процедура является ал-
горитмической и дает всюду определенную вычислимую
функцию, доопределяющую f(x).
Исходя из сказанного, задачу о существовании верх-
ней границы h(x) сложности вычислений будем рас-
сматривать применительно к рекурсивным функциям
f(x), принимающим значения 0 и 1. Следующая теорема
показывает, что и в этом случае рекурсивной верхней
границы h (х) не существует.
Теорема 5.5. Для всякой рекурсивной функции
h(x) найдется рекурсивная функция f(x), принимающая
значения 0 и 1 и такая, что для любой машины М, вы-
числяющей f(x), имеется некоторое значение х = п,при
котором
tM (п) > h (п).
Доказательство. Рассмотрим функцию
j sg<px(x), если tMx (х) «С h (х)
f W — | и значение срх (х) определено, (5.11)
[ 0 в противном случае
§ 5.4]
СЛОЖНО ВЫЧИСЛИМЫЕ ФУНКЦИИ
233
(здесь срх — функция с номером х, она соответствует ма-
шине Мх с номером х). Функция f(x) может быть вы-
числена следующим образом. Вначале находится зна-
чение рекурсивной функции h в точке х. Затем машина
Mr запускается на числе х и считаются такты работы
этой машины.
Если в течение h(x) тактов машина остановится, то
проверяется, имеет ли ее заключительная конфигурация
вид
<7о1|...| (5.12)
у+1
при некотором у. Для этого нужно знать активную зону
заключительной конфигурации. Активная зона может
состоять из нескольких частей, разделенных произволь-
ным числом пустых символов. Для выявления всей ак-
тивной зоны можно использовать специальные пометки,
которые в процессе работы машины отмечают концы
активной зоны. Если заключительная конфигурация
имеет вид (5.12), то полагаем f(x)—sgy. В противном
случае величина срДх) не определена, и значение f(x)
считаем равным 0.
Если машина Мх при работе на числе х не остано-
вится в течение h(x) тактов, то величину f(x) также
считаем равной 0.
Из приведенного описания видно, что все этапы, воз-
никающие в процессе вычисления f(x), являются алго-
ритмическими, поэтому функция f(x) вычислима. Рас-
смотрим произвольную машину Тьюринга М, вычисляю-
щую Цх). Пусть она имеет номер п; тогда
М") > h(n).
Действительно, если бы это было не так и машина
М = Мп на числе п работала менее /г(п) тактов, то
(поскольку функция f = (рп всюду определена) соглас-
но (5.11) __ _________
f (re) = sg<pn (n) = sg <pM (n).
Отсюда следует, что f (п)¥= срм(н), а это противоречит
тому, что f вычисляется машиной М. Теорема доказана.
Отметим, что метод, использованный при доказа-
тельстве теоремы 5.5, в некотором отношении близок
234
ВЫЧИСЛИТЕЛЬНЫЕ ВОЗМОЖНОСТИ МАШИН
[ГЛ. V
к переборному способу построения сложных функций,
основанному на процедуре вычеркивания простых функ-
ций (раздел 2.5.5).
Конструкцию функции f(x) из теоремы 5.5 можно
описывать в несколько иных терминах. Составим таб-
Таблица 5.1
\ х м \ 0 1 п
Мо tM> (0) К h (0)
Mi
Мп (мп («) < h («)
. . . . . .
лицу 5.1, строки которой соответствуют машинам, а
столбцы — значениям аргумента.
В клетке (ЛК, х) (х = 0, 1, 2, ...) задается вопрос,
верно ли, что (мх (х) h (х). От ответа на этот вопрос
зависит значение функции /(х) (слц (5.11)). Если при
некотором п мы полагаем f (n) = sg cpn(n), то тем са-
мым исключается возможность того, что f (х) = <prt(x)
(функции различаются при х = п). В этом случае бу-
дем говорить, что в точке п опровергается функция <рп.
Описание конструкции в этих терминах более удобно
для последующего изложения.
Вопросы задаются в диагональных клетках таблицы,
поэтому конструкция носит название диагональной.
В дальнейшем мы встретимся с другими, более слож-
ными примерами диагональных построений.
5.4.3. Сложно вычислимые функции. В предыдущем
разделе было установлено, что не существует рекурсив-
ной функции h(x), ограничивающей время вычислений.
А именно, по заданной функции h(x) можно построить
такую функцию /(х), для которой любая вычисляющая
ее машина затрачивает в некоторой точке п более h(n)
§5.4]
СЛОЖНО ВЫЧИСЛИМЫЕ ФУНКЦИИ
235
тактов. Возникает вопрос, а можно ли найти такую
функцию f(x) (рекурсивную, принимающую значения О
и 1), которая бы на любой машине для всех значений
х вычислялась за время, превышающее h(x).
В такой формулировке ответ на поставленный воп-
рос отрицателен. Это связано с тем, что вычисление
функции f(x) в любом конечном числе фиксированных
точек можно осуществлять тривиальным образом. Зна-
чения функции f при этих х могут быть занесены в про-
грамму машины и, прочтя х, машина «без всяких вы-
числений» выпишет f(x) (это займет достаточно мало
времени).
Если в соответствии со сказанным ослабить требо-
вания и допустить, чтобы в конечном числе точек х вы-
числения могли происходить со сложностью, меньшей
h(x), то ответ на поставленный вопрос будет положи-
тельным.
Теорема 5.6. Для всякой рекурсивной функции
h(x) существует рекурсивная функция f(x), принимаю-
щая значения 0 и 1 и такая, что для любой машины М,
вычисляющей f(x), начиная с некоторого места, выпол-
нено
tM (х) > h (х).
Доказательство. Функцию f(х) будем строить
последовательно при х = 0, 1, 2, ... Одновременно с
f(x) будем строить вспомогательную частичную функ-
цию П(х), которую будем называть функцией опровер-
жения.
Иногда по ходу конструкции мы будем полагать
f (n) = sg ср*(«), где ср* — частично-рекурсивная функ-
ция с номером k (соответствующая машине Mk). В этом
случае функция f будет отличной от ср*, поскольку их
значения в точке п не совпадают. Будем говорить, что
в точке п опровергается функция ср*, и число k будем
считать значением П(га) функции опровержения (П(п) =
= k). Если в точке п не опровергается ни одна из
функций, то значение П(л) не определено.
При построении будем пользоваться таблицей 5.2.
В клетке (А4*, п) (k п) таблицы задается вопрос,
верно ли, что tMk (п) h(n). Функция f строится
236
ВЫЧИСЛИТЕЛЬНЫЕ ВОЗМОЖНОСТИ МАШИН
[ГЛ. V
Таблица 5.2
х м\ 0 1 п
ма tM, (0)<Л(0) . . . tMg W h (”)
All tMl (1)<А(1) (n) < h (п) . . .
• . . . . . . . . . . .
Mk tMk м < h (") . . .
. . . . . . , . » . . .
Мп (м < h п
. . .
последовательно в соответствии с полученными ответа-
ми (одновременно строится функция опровержения П).
1) х — 0. Если tM (0) h (0) и значение сро(О) опре-
делено, то полагаем П(0)=0 и f (0) = sg сро(О). В про-
тивном случае считаем, что значение П(0) не опреде-
лено и ср (0) = 0.
2) х = п > 0. Пусть значения f(x) уже определены
для всех х<п и найдены П(0), П(1), П(п—1)
(т. е. известно, какие из функций ср* опровергнуты на
значениях, меньших п). Чтобы найти П(га) и f(n), по-
ступаем следующим образом. Проверяем выполнимость
неравенств
(п) < h (п), tMl (п) ^h(n), ..., tMn (п) < h (n).
Среди тех k(Q^.k^ri), для которых tMk («) < h («) и
значение ср*(п) определено, отыскиваем первое, которое
не было опровергнуто на предыдущих шагах, и если та-
кое k есть (пусть оно равно ко), полагаем П(п)==/г0 и
f (n) = sg<pfej (п). Если же указанное неравенство не вы-
полнено ни при каком k либо все k, для которых оно
имеем место, были уже опровергнуты, считаем П(н) не
определенным и полагаем f(ra)= 0.
СЛОЖНО ВЫЧИСЛИМЫЕ ФУНКЦИИ
237
§ 5.4]
Рассуждая, как при доказательстве теоремы 5.5,
можно убедиться, что процедура, задающая функцию
f(x), является алгоритмической. Функция f(x) всюду
определена (рекурсивна) и принимает значения 0 и 1.
Рассмотрим произвольную машину Mi, вычисляющую
f(x). Убедимся, что для всех достаточно больших х
имеет место tMi (х) > h (х).
Предположим противное, что для бесконечно многих
хэто неравенство нарушается, и пусть п\, «2, ... — все
те из них, которые не меньше I. Покажем, что по край-
ней мере на одном из чисел гаь ..., т, Пщ функция <р,-
будет опровергнута. Действительно, если ср, не опро-
вергнута в точках п\, ..., щ, то это могло произойти
лишь вследствие того, что там опровергались функции
с номерами, меньшими I. Поскольку их i штук, то при
п ni все они окажутся опровергнутыми и в точке ni+\
должна быть опровергнута ерь Таким образом, из на-
шего допущения следует, что f =£= ср/, т. е. что машина
Mi не вычисляет f. Полученное противоречие завершает
доказательство.
Диагональная конструкция, использованная при до-
казательстве этой теоремы, позволяет строить сколь
угодно сложно вычислимые функции. Однако она ре-
ально не может быть осуществлена из-за большой тру-
доемкости и, кроме того, дает «бессодержательные»
функции. Ситуация, имеющая здесь место, аналогична
той, с которой мы сталкивались при рассмотрении за-
дачи построения булевых функций, имеющих сложную
схемную реализацию (раздел 2.5.5), где роль диагональ-
ной процедуры играл перебор.
Чрезвычайно важной является задача получения
нижних оценок сложности вычисления конкретных
функций. На основе этих оценок можно делать некото-
рые заключения о качестве используемых методов вы-
числений, а в некоторых случаях — устанавливать их
оптимальность (в том или ином смысле). Задача на-
хождения даже сравнительно невысоких оценок слож-
ности вычисления конкретных функций является очень
трудной. Напомним, что аналогичные трудности возни-
кают и при нахождении нижних оценок сложности схем-
ной реализации конкретных булевых функций (раз-
дел 2.5.5).
238
ВЫЧИСЛИТЕЛЬНЫЕ ВОЗМОЖНОСТИ МАШИН
[ГЛ. V
5.4.4. О наилучших вычислениях. При изучении ди-
скретных устройств с конечной памятью основной зада-
чей, с которой мы сталкивались, была задача мини-
мального синтеза (схем с минимальным числом эле-
ментов, автоматов с минимальным числом состояний
и др.). При рассмотрении машин аналогичным образом
возникает задача о наилучшем (в том или ином смысле)
вычислении. Однако, если в случае схем, автоматов и
др. вопрос о существовании минимального объекта не
возникал (в конечном множестве объектов всегда су-
ществует минимальный), то в случае вычислений этот
вопрос требует специального исследования.
Можно рассматривать различные ослабления задачи
о наилучшем вычислении и ставить вопрос об отыска-
нии асимптотически наилучшего вычисления или вычис-
ления, наилучшего по порядку (отличающегося по
сложности от наилучшего не более чем в константу
раз), наилучшего с точностью до полиномиального пре-
образования оценок и др. Как будет видно из дальней-
шего, даже в таком ослабленном смысле наилучшего
вычисления гарантировать нельзя.
Мы покажем, что существуют функции, любое вы-
числение которых можно существенно убыстрить. Бо-
лее точно, по любой рекурсивной функции г(х) можно
построить функцию f (х), обладающую тем свойством,
что если она может быть вычислена за время t(x), то
она допускает вычисление и за время /'(х), где /(х)>
> /•(?(%)). Если взять, например, г(х) = 2х, то функции
t(x) и t'(x) будут удовлетворять соотношению
t' (х) < log/ (х).
Убыстренное вычисление снова допускает убыстрение,
в результате чего получаем неравенства
t" (х) < log t' (х) < log log t (x)
ит. д.
Отметим, что выше мы допускали некоторую неточ-
ность, говоря об убыстрении вычислений при всех х. На
самом деле (как мы видели при предварительном об-
суждении теоремы 5.6) вычисления можно запрограм-
мировать так, чтобы для заданного конечного множе-
ства точек фактически обходиться «без вычислений».
§ 5.4]
СЛОЖНО ВЫЧИСЛИМЫЕ ФУНКЦИИ
239
Поэтому можно говорить лишь об убыстрении всюду, за
исключением конечного числа точек.
Приведем теперь формулировку теоремы, принадле-
жащей М. Блюму.
Теорема 5.7 (об убыстрении). Для любой рекур-
сивной функции г(х) найдется рекурсивная функция
f(x), принимающая значения 0 и 1 и такая, что, какова
бы ни была машина Mt, вычисляющая f (х), найдется
машина Мр вычисляющая f(x) так, что для всех х, на-
чиная с некоторого,
tMi U) > г (tMj (х)).
Дадим подробный эскиз доказательства. Бу-
дем считать функцию г(х) монотонной, иначе вместо
г(х) можно использовать монотонную функцию
r°(x) —maxr(z).
Возьмем «быстрорастущую» рекурсивную функцию
h(x), удовлетворяющую неравенству
х— 1
h (х) > г (х £ h (и)) (5.13)
и=1
(на самом деле понадобится более сильное условие, но
мы будем отбрасывать детали, несущественные для
идеи доказательства; в заключение мы на них укажем).
По /г(х) построим рекурсивную функцию f(x), прини-
мающую значения 0 и 1 (одновременно будем строить
функцию опровержения П(х)). Для этого воспользуем-
ся таблицей 5.3.
Будем последовательно определять значения П(х) и
/(*)•
1) х = 0. Если tM (0)^й(0) и значение <ро(О)
определено, то полагаем П(0) = 0 и f (0) = sg <ро(О)
(т. е. в нуле опровергается фо) Если же tMo (0)>/г(0),
то считаем, что значение П(0) не определено, и назна-
чаем /(0) = 0.
2) х — п > 0. Пусть уже найдены значения /(0),
f(l), ..., f(n— 1) и П(0), П(1), ..., П(п—1) (т. е.
известно, какие из функций cpfe опровергнуты при х <
<; п). Чтобы найти f(n) и П(п), проверяем выполни-
240
ВЫЧИСЛИТЕЛЬНЫЕ ВОЗМОЖНОСТИ МАШИН
[ГЛ. V
Таблица 5.3
X. X М X 0 1 п
м0 tM. (0) < h (0) /Мо(1)<Л(1) tMa (я) < h (я)
Ml (1) (0) С.4, (я)<Л(я—1)
Mk tм (n)<h(n—k}
Мп tM iYln
. . .
мость неравенств
*м0 («) < h («), • • • - tMk («X h (п — k), ..., tMn (п) < h (0).
Среди тех k(O^k^ri), для которых tMk (п) h (п — k)
и значение <р*(/г) определено, отыскиваем первое, кото-
рое не было опровергнуто на предыдущих шагах. Если
такое k_ есть (пусть это ko), полагаем П(/г) = 60 и
(n) = sgcp^Q (п), в противном же случае считаем значе-
ние П(/г) не определенным и назначаем f(n)= 0.
Эта процедура определяет рекурсивную функцию
<р(х), принимающую значения 0 и 1. Если машина Mi
вычисляет функцию [(х), то для всех х, начиная с не-
которого места, выполнено
(mi (*) >h(x — г).
(5.14)
Действительно, если предположить противное, что для
бесконечно многих х это неравенство нарушается, то,
рассмотрев первые i + 1 из этих чисел, превосходящих
I, как и в случае теоремы 5.6, можно заключить, что
хотя бы на одном из них функция ср/ будет опроверг-
нута и, следовательно, машина Mi не может реализо-
вать /(%).
§ 5.41
СЛОЖНО ВЫЧИСЛИМЫЕ ФУНКЦИИ
241
Теперь укажем более простой способ вычисления
функции f(x), чем в соответствии с ее определением.
Зададимся некоторым k. Среди функций фо, Фь ..., Ф*
одни в процессе вычисления f будут опровергнуты (на
некоторых п), а другие не будут никогда. Существует
число v такое, что те из функций с номерами не выше
k, которые когда-либо будут опровергнуты, опровер-
гаются на значениях, меньших v. Помимо этих функ-
ций при х < v могут быть опровергнуты некоторые
функции с номерами, большими k. Обозначим номера
этих функций через ki, ., ki.
Пусть мы располагаем следующей информацией ко-
нечного объема:
— число V,
— номера k\, fe, ki опровергнутых функций;
— значения f(0), f(l), ..., —1).
Эта информация может быть введена в программу ма-
шины Тьюринга. Зная ее, вычисление f(ri) можно орга-
низовать следующим образом.
1) Если п <_ v, то значение f(n) заимствуется из
списка (выпечатывается машиной на ленте).
2) Пусть п о; тогда проверяется выполнимость не-
равенств
- 1),
tMk+2 <h(v-k — 2)........tMv (v) < h (0)
и находится значение П(г), для чего среди номеров ма-
шин, для которых выполнено неравенство и значение
функции определено, отыскивается первый, не содер-
жащийся в списке ki, k2, .ki (напомним, что функ-
ции с номерами, меньшими k, при п v опровергаться
не будут). Затем проверяется выполнимость неравенств
Gift+i(f + V)^h(v-k)........./Мо+1 (г+ 1)</г(0)
и находится П(и + 1) (зная k\, ..., ki и П(г)) и т. д.
Наконец, проверяются неравенства
tMk+i (n)^h(n — k — 1)...tMn (/г) < h (0)
и находится П(/г) (зная k\, ..., ki и П(ц), ..., П(/г —
— 1)). Дели П(/г) определено (и равно k0), то полагаем
f(n) — sg(fko(n). В противном случае назначаем f(n) = O.
242
ВЫЧИСЛИТЕЛЬНЫЕ ВОЗМОЖНОСТИ МАШИН
[ГЛ. V
На рис. 5.11 приведено схематичное изображение
таблицы, в соответствии с которой происходит вычисле-
ние f(n). При старом способе вычисления вопросы за-
даются во всей заштрихованной зоне, при новом —
в зоне с мелкой штриховкой. Отметим, что «наиболее
сложные» вопросы задаются в
верхней части таблицы (ответ на
них связан с «прокручиванием»
машины в течение большого чис-
ла тактов). За счет того, что
функция h является достаточно
быстрорастущей, отбрасывание
вопросов из верхней части табли-
цы существенно снижает слож-
ность вычислений.
Приведем некоторые прики-
дочные расчеты. При вычислении
значения f(n) в соответствии с
Рис. 5.11.
сокращенным методом машины M*+i, .... Мп «прокру-
чиваются» в течение суммарного числа тактов, равного
(h(v - k - \) + h(v - k - 2) + ... +й(0)) +
+ (h (v - k) + h (v - k - 1) + ... + /i(0)) + ...
...+ (h(n—k — 1) + A (« — Z? — 2) + ... +/i(0))<
n—k—1 rt—fe—1
<(n — v+1) У, /1(х)<(«-/г) У, h(x).
x=0 x=0
При указанном способе вычислений k является сво-
бодным параметром; положим его равным i (напомним,
что i — номер рассматриваемой машины, реализующей
f). Обозначим через М/ машину, осуществляющую вы-
числение f в соответствии с сокращенной процедурой
при k — i. Число шагов машины М/ будем считать «при-
мерно равным» суммарному числу тактов, уходящему
на «прокручивание» машин. Это, с учетом неравенства,
полученного выше, приводит к следующей «приблизи-
тельной» оценке:
n-i-l
/ («х («- о У
• х=0
§ 5Л]
СЛОЖНО ВЫЧИСЛИМЫЕ ФУНКЦИИ
243
Отсюда, с учетом монотонности г и /г и в силу соотноше-
ний (5.13) и (5.14), получаем
n—i—1
г (hij («)) < г ((/г — г) h (х)) < h (п — i) < tMi (п),
что и требовалось.
При доказательстве мы не учитывали многих де-
талей, связанных с осуществлением указанной сокра-
щенной процедуры на машине М/. В частности, не учи-
тывались шаги, связанные с выписыванием информации
о v, k\.....kt, f(0), ..., f(v— 1) на ленту (эта ин-
формация содержится в программе), с вычислением
значений /г(0), /г(1)...h(n — i—1), с нахождением
П(х) (о х п) (поиск неопровергнутых значений,
запись на ленту и др.). Но наиболее существенное ог-
рубление оценки числа шагов произошло за счет того,
что «прокручивание» машин M*+i, ..., Мп осуществ-
ляется машиной Mi, имеющей фиксированный алфавит,
и происходит с растяжением во времени подобно тому,
как это делается в универсальной машине (раздел
4.4.2). Все эти обстоятельства должны быть учтены
(и могут быть учтены) в неравенстве (5.13) при стро-
гом доказательстве_теоремы.
Приведенный результат не снимает вопроса об оты-
скании вычислений, наилучших в том или ином смысле.
По-видимому, абсолютное большинство функций, воз-
никающих из содержательных задач, допускает такие
вычисления. Теорема заставляет проявлять осторож-
ность в этом вопросе, ибо приходится считаться с той
возможностью, что вычисления, наилучшего в нужном
смысле, может и не быть.
5.4.5. Общий подход. Выше было установлено не-
сколько теорем, относящихся к времени вычисления на
машинах Тьюринга. Эти результаты допускают распро-
странение и на ленточную сложность «м(х). Для доказа-
тельства можно применить варианты тех же диаго-
нальных конструкций (с заменой 6и(х) на «м(х)). Усло-
вие 8м(п) <5 h(n), возникающее по ходу конструкций,
может быть проверено алгоритмически. Если машина
использует зону, не превосходящую h(n), и останавли-
вается, то в силу оценки (5.10) остановка происходит
244
ВЫЧИСЛИТЕЛЬНЫЕ ВОЗМОЖНОСТИ МАШИН
[ГЛ. V
не позже, чем через rh2 (п) k1^ тактов, и для проверки
условия Sm (п) h (м) достаточно наблюдать за работой
машины М в течение этого времени. В остальном дока-
зательства проводятся так же, как для временной слож-
ности (несущественные отличия имеются лишь в теоре-
ме об убыстрении).
Для последующих обобщений вместо 1м(х) и Sm(x)
более удобно использовать обозначения 6(х) и s,(x),
где I—номер машины М. Пусть Ф,(х) означает одну
из функций ti(x) и Si(x). Функция ФДх) обладает сле-
дующими свойствами:
1° она вычислима (т. е. частично-рекурсивна);
2° она определена при тех и только тех х, при кото-
рых определена функция <рг(х), соответствующая ма-
шине Мг,
3° для любых натуральных г, х и h неравенство
Фг (х) h
может быть проверено алгоритмически (в случае вре-
менной сложности — путем подсчета шагов работы ма-
шины Mi на числе х, в случае ленточной сложности —
с использованием неравенства (5.10)).
Содержательный анализ показывает, что любые «ра-
зумные» характеристики сложности должны обладать
перечисленными свойствами. Эти свойства и были вы-
браны М. Блюмом в качестве определяющих при вве-
дении им общего понятия характеристики сложности
вычислений.
Для каждой модели машины (алгоритма) можно
задать некоторую «естественную» нумерацию машин
(алгоритмов)
Мо, Мь Л?2, ..., (5.15)
и она порождает нумерацию всех одноместных частич-
но-рекурсивных функций
ФО, Ф1, Ф2, ... (5-16)
(одну из них, основанную на упорядочении машин
Тьюринга, мы рассматривали, еще одну можно полу-
чить, например, на базе упорядочения рекурсивных
схем). Пусть
Ф0(х), Ф1(х), Ф2(х), ...
§ 5.5]
УНИВЕРСАЛЬНЫЕ ЗАДАЧИ ПЕРЕБОРА
245
— некоторая совокупность функций, связанная с ну-
мерацией (5.16). Будем считать, что эта совокупность
определяет характеристику сложности вычислений, если
для нее выполнены свойства Г—3°.
Легко видеть, что свойства Г—3° позволяют реали-
зовывать диагональные конструкции применительно к
функциям Ф,(х). С их использованием теоремы 5.5—
5.7 могут быть распространены на произвольные харак-
теристики сложности.
Для двух различных характеристик сложности мож-
но доказать аналог теоремы 5.4 о том, что верхняя
оценка одной характеристики позволяет получить верх-
нюю оценку для другой.
Таким образом, все результаты, установленные выше
для конкретных характеристик би (х) и $м(х), приобре-
тают универсальное значение. Они оказываются спра-
ведливыми для всех «разумных» концепций машин и ха-
рактеристик сложности вычислений. В частности, можно
утверждать, что при любом выборе характеристик су-
ществуют сколь угодно сложно вычислимые функции и
что невозможно так определить понятие наилучшего
(в каком-либо смысле) вычисления, чтобы им обладали
все функции.
Подробное изложение результатов, приведенных в
данном разделе, можно найти в [33].
§ 5.5. Универсальные задачи перебора
5.5.1. Введение. Большинство дискретных задач,
встречающихся на практике, допускает нахождение ре-
шения путем некоторого переборного процесса. Так,
например, эквивалентность двух логических формул, за-
висящих от п аргументов, может быть установлена в
результате просмотра всех двоичных наборов длины п
и сравнения значений формул на каждом из них, оты-
скание минимальной схемы для заданной булевой функ-
ции может быть осуществлено посредством перебора
всех схем в порядке возрастания их сложности вплоть
до схемы, реализующей заданную функцию, и т. д. За-
дачи, для которых решение может быть найдено путем
перебора, будем называть задачами переборного типа
(более точные определения будут даны дальше).
246
ВЫЧИСЛИТЕЛЬНЫЕ ВОЗМОЖНОСТИ МАШИН
[гл. v
Число шагов переборной процедуры растет чрезвы-
чайно быстро (экспоненциально) с ростом размерности
задач, поэтому переборный способ решения практиче-
ски неосуществим уже при сравнительно небольших
размерностях (даже при использовании современных
ЦВМ). Для некоторых задач перебор удается устранить
и найти эффективные методы решения (построение эк-
вивалентного всюду определенного автомата с мини-
мальным числом состояний, раздел 3.2.3; минимизация
монотонной функции, раздел 2.3.5). Для других задач
все известные способы решения оказываются эквива-
лентными по трудоемкости перебору и фактически реа-
лизованы быть не могут (построение минимальной схе-
мы, раздел 2.1.3).
В данном параграфе описывается подход, позволяю-
щий для некоторых конкретных задач сделать заклю-
чение о том, что они являются в определенном смысле
самыми сложными в классе всех переборных задач.
Оказалось, что таково, в частности, большинство извест-
ных задач, для которых не удалось найти способов
решения, отличных от переборного. Суть подхода со-
стоит в том, что к некоторым конкретным задачам
удается свести любую задачу переборного типа (такие
конкретные задачи называются универсальными). Ре-
шение универсальной задачи фактически дает решение
любой переборной задачи, поэтому она не проще (в не-
котором смысле) любой из переборных задач.
Свойство универсальности является качественной
характеристикой задачи и не дает количественной оцен-
ки сложности ее решения. Однако, если бы удалось ус-
тановить «высокую» нижнюю оценку времени решения
хоть для какой-нибудь задачи переборного типа (даже
искусственно построенной), то на ее основе можно было
бы получить «высокую» нижнюю оценку для любой пе-
реборной задачи, универсальность которой удалось до-
казать. Вопрос о действительной сложности перебор-
ных задач пока остается открытым. Диагональные про-
цедуры, используемые для построения сколь угодно
сложно вычислимых функций (раздел 5.4.3), не уда-
лось применить к построению сложных задач перебор-
ного типа.
§ 5.5]
УНИВЕРСАЛЬНЫЕ ЗАДАЧИ ПЕРЕБОРА
247
Если бы некоторая универсальная задача допускала
эффективное (простое) решение, то и любая перебор-
ная задача могла бы быть решена эффективно. Это в
свете имеющегося практического опыта представляется
маловероятным. Поэтому универсальные задачи счи-
таются ттщнорешаемыми.
5.5.2. Эффективные вычисления. До сих пор мы
употребляли выражения «эффективное решение зада-
чи», «эффективная процедура» и т. д., понимая их со-
держательно. В данном разделе мы укажем точный
смысл, в каком следует понимать слово «эффективный».
Будем рассматривать решение массовых задач Z =
= {г} на машинах Тьюринга. Исходные данные задач
будем представлять каким-либо «естественным» обра-
зом в виде слов Р в конечном алфавите А (зависящем
от Z). Способ такого представления для каждой за-
дачи Z будем считать фиксированным. Размерностью
l(z) индивидуальной задачи zeZ будем называть дли-
ну слова Р, кодирующего ее исходные данные. В каче-
стве примера рассмотрим задачу Z построения по буле-
вой функции минимальной схемы. Исходными данными
индивидуальной задачи z е Z является булева функции
f от некоторого числа п аргументов. Она может быть
задана словом длины 2" в алфавите {0, 1}, которое со-
впадает со столбцом значений функции при табличном
задании. Размерность /(г) задачи z равна при таком
представлении 2".
Дальше задачу z будем отождествлять со словом Р,
кодирующим ее исходные данные. Будем считать, что
задача Z решается эффективно (или просто), если су-
ществует такой полином Q(x), что время решения (чис-
ло тактов машины) для каждой задачи zeZ ограни-
чено сверху величиной Q(/(z)). Приведем некоторые
доводы в пользу такого понятия эффективности.
1. Оно соответствует реальной вычислительной прак-
тике, ибо все практически используемые алгоритмы
имеют полиномиальную (степенную) оценку времени
вычисления.
2. Оно фактически не зависит от вида вычислитель-
ной машины, поскольку переход от одной модели ма-
шины к другой обычно связан не более чем с полино-
миальным изменением времени вычислений. Это делает
248
ВЫЧИСЛИТЕЛЬНЫЕ ВОЗМОЖНОСТИ МАШИН
!ГЛ. V
полученные ниже результаты независимыми от конкрет-
ной концепции машины.
3. Оно фактически не зависит от способа представ-
ления исходных данных задачи. Одна и та же содержа-
тельная задача может быть представлена многими спо-
собами. Так, например, задание графа можно получить
на основе его матрицы инциденций либо матрицы смеж-
ности, либо списка пар, соответствующих его дугам, и
т. д. Однако обычно все «естественные» представления
отличаются друг от друга по длине не более чем поли-
номиально, и то, какое из них используется, фактически
оказывается несущественным. Это делает полученные
ниже результаты независимыми от конкретного пред-
ставления задачи.
Переборная процедура требует экспоненциального
времени, и поэтому является неэффективной в указан-
ном смысле. Далее наряду с термином «эффективное
вычисление» мы будем употреблять выражение «вычис-
ление с полиномиальной сложностью».
5.5.3. Метод сводимости. Используемый дальше под-
ход является модификацией метода сводимости, опи-
санного в разделе 5.1.2, и в общих чертах состоит в сле-
дующем.
Предположим, что массовая задача Z = {z} может
быть «просто» сведена к массовой задаче Z' = {г}, т. е.
по произвольной индивидуальной задаче z е Z может
быть с помощью «простых» вычислений построена ин-
дивидуальная задача z'^Z', решение которой дает ре-
шение задачи г. В этом случае можно сделать заключе-
ние, что если массовая задача Z «достаточно сложна»,
то такой же является и задача Z'. Действительно, если
бы задача Z' допускала «простое» решение, то по про-
извольной задаче z е Z можно было бы построить за-
дачу z’ е Z’ и, решив ее, получить «простое» решение
задачи г. Поэтому можно считать, что задача Z' в неко-
тором смысле не проще, чем Z. Если удается доказать,
что к некоторой переборной задаче Z0 может быть све-
дена («просто») любая из переборных задач, то это
означает, что Z0 не проще любой задачи переборного
типа.
Под «простыми» вычислениями будем понимать вы-
числения с полиномиальной сложностью. Как и раньше
§ 5.5]
УНИВЕРСАЛЬНЫЕ ЗАДАЧИ ПЕРЕБОРА
249
(в § 5.1), будем рассматривать лишь задачи, имеющие
двузначный ответ («да» или «нет»).
Будем говорить, что массовая задача Z = {г} поли-
номиально сводится к массовой задаче Z'= {z'}, если
существует словарная функция F, которая по произ-
вольной индивидуальной задаче строит задачу
F(z) = г' е Z' такую, что г' имеет положительный ответ
(«да») тогда и только тогда, когда положителен ответ
задачи г, причем время вычисления (на машине Тью-
ринга) слова F(z) ограничено для любой задачи zeZ
величиной Q(/(z)), где Q(x)—’Некоторый полином (за-
висящий от Z и Z’, но не от индивидуальных задач z
и г').
Рассмотрим в качестве примера задачу построения
кратчайшей д. н. ф., т. е. д. и. ф., содержащей наимень-
шее число конъюнкций (раздел 2.3.1). Как мы видели
(раздел 2.3.6), решение этой задачи сводится к нахож-
дению минимального покрытия множества единичных
значений функции системой подмножеств, задаваемых
столбцами импликантной таблицы. Нетрудно видеть не-
посредственно, что построение импликантной таблицы
по таблице функции от п аргументов может быть осу-
ществлено за время (число тактов), ограниченное не-
которым полиномом от размера 2" исходных данных.
Задачи нахождения кратчайшей д. н. ф. и отыскания ми-
нимального покрытия имеют недвузначный ответ. Для
того чтобы можно было применить понятие сводимости,
указанные задачи нужно несколько видоизменить. Бу-
дем рассматривать задачу выяснения по булевой функ-
ции f и числу k, может ли она быть реализована по-
средством д. н. ф., содержащей не более k конъюнкций.
Эта задача полиномиально сводится к задаче установ-
ления по заданному множеству и системе его подмно-
жеств, имеет ли оно покрытие, состоящее из не более
k подмножеств.
В определении полиномиальной сводимости тре-
буется, чтобы функция F была вычислимой за поли-
номиальное время. Отсюда на основании теоремы 5.4
следует, что и необходимая память (размер ленты) ог-
раничена некоторым полиномом от размерности. Это,
в частности, означает, что размерность /(г') растет в
сравнении с /(г) не более чем полиномиально. Отметим
250
ВЫЧИСЛИТЕЛЬНЫЕ ВОЗМОЖНОСТИ МАШИН
[ГЛ. V
также, что обычно все «естественные» представления
одной и той же задачи полиномиально сводимы друг к
другу, так что можно исходить фактически из любого
представления.
5.5.4. Примеры переборных задач. Прежде чем дать
определение переборной задачи, рассмотрим несколько
типичных примеров таких задач.
Задача 1 (об изоморфизме графов). По
графам G; и G2 требуется узнать, являются ли они изо-
морфными, т. е. существует ли такая перенумерация
вершин графа G2, при которой он совпадает с Gi. Вся-
кий граф G может быть представлен словом G в алфа-
вите {0,1,*}, составленным из последовательно выпи-
санных строк его матрицы смежности*), разделенных
знаком ». Пара графов (Gi, G2) может быть задана сло-
вом G!**G2. При таком представлении задача выяс-
нения изоморфизма графов с п вершинами имеет раз-
мерность 2п2 + 2п.
Задача 2 (о тождественной истинности
формул). По логической формуле в базисе {&, V,
0, 1} требуется определить, является ли она тожде-
ственно истинной. Если в формуле все выражения Ф
заменить на 1 Ф, то она будет представлять собой слово,
составленное из букв &, V, | ,), (, 0, 1 и символов пере-
менных Xi (i= 1, 2, ...). Для того чтобы алфавит стал
конечным, вместо х, будем использовать запись x(5(i)),
где 5(0 — слово из 0 и 1, являющееся двоичной записью
числа i (например, Хб заменим на х (ПО)). Если исход-
ное слово содержит N символов, то можно считать, что
номера i переменных не превосходят N, а потому слово,
соответствующее преобразованной формуле, будет иметь
длину, не большую 2V(]log АД+3) (через ]х[ обозна-
чено ближайшее к х целое число, не меньшее х). Раз-
мерность задачи будем считать равной этой оценке.
Задача 3 (о сложности д. н. ф.). По булевой
функции f и числу k требуется выяснить, может ли f
быть реализована д. н. ф., сложность которой (число
*) Напомним, что матрица смежности имеет размерность
п X п, где п — число вершин графа. В клетке (i, J) матрицы содер-
жится символ 1 либо 0 в зависимости от того, соединены верши-
ны I и / графа ребром или нет.
УНИВЕРСАЛЬНЫЕ ЗАДАЧИ ПЕРЕБОРА
251
§ 5.5]
букв) не превосходит k. Можно считать, что для функ-
ций f от п аргументов величина k не превосходит п2п~1
(это верхняя оценка сложности м.д.н.ф., раздел 2.3.8).
Исходные данные будем задавать в виде слова /«• 5(&),
где f — набор длины 2" значений функции f, a(k) —
двоичная запись числа k длины ]log(«2n-1)[=n—l-]-
-j-]l°gn|. Размерность этой задачи составляет 2" +
4- п + ]16gn[.
5.5.5. Определение переборной задачи. Все перечис-
ленные массовые задачи могут быть сформулированы
следующим образом: по заданному объекту z выяснить,
существует ли объект у такой, что выполнено некоторое
свойство R(z,у). Действительно, в задаче 1 объектом г
является пара графов (Gb G2), объектом у — подста-
/1 2 ... п \
новка I . . . I, задающая перенумерацию вер-
\ И 12 • • • 1п /
шин графа G2, а свойство R(z,y) означает, что графы
Gi hG2, соответствующие объекту г, прн перенумерации
вершин у совпадают. Задача 2 сводится к выяснению
того, существует ли набор значений переменных, на ко-
тором функция равна 0. Объектом z является формула,
объектом у — набор значений переменных, свойство
R(z. у) состоит в том, что на наборе у формула z равна
0. В задаче 3 объектом z служит пара (f, k), объектом
у — д. н. ф., а свойство R (г, у) означает, что сложность
д. н. ф. у не превосходит k и у реализует z.
Во всех приведенных примерах размерность объекта
у (т. е. длина некоторого его «естественного» представ-
ления) не превосходит значения полинома от размерно-
сти исходного объекта г. Действительно, в задаче 1
/1 2 ... п\
подстановка у==1 . . -I может быть задана
\ ^2 • • • '
СЛОВОМ б (й)* a(l2)* ... •» 5(й) длины n]logn[-|-n—1,
которая не превосходит размерности 2п2 -|- 2п объекта z.
В задаче 2 набор у имеет длину «, не большую длины
формулы. В задаче 3 сложность д. н. ф. у ограничена
величиной k п2п-'1 и у может быть задан словом в ко-
нечном алфавите, содержащим не более п22п символов.
Эта величина ограничена значением полинома Q(x) =
— х2 от размерности 2"-ф n-f-]logn[-f-l исходного объ-
екта г.
252
ВЫЧИСЛИТЕЛЬНЫЕ ВОЗМОЖНОСТИ МАШИН
[ГЛ. V
Кроме того, можно видеть, что во всех разобранных
примерах время (число тактов) проверки свойства
R(z, у) на подходящей машине Тьюринга ограничено
некоторым полиномом от суммы размерностей /(£) +
+ /(?/), т. е. свойство R(z,y) проверяется «просто». Со-
держательное рассмотрение переборных задач показы-
вает, что эта ситуация является типичной.
На основании сказанного дадим следующее опреде-
ление. Массовая задача Z называется переборной, если
она может быть сформулирована в следующем виде: по
заданному z выяснить, существует ли у, размерность
которого 1(у) не превосходит некоторого полинома от
/(г) и такой, что выполнено свойство R(z,y), проверяе-
мое на подходящей машине Тьюринга за время, огра-
ниченное некоторым полиномом от l(z) + 1(у).
Решение такой задачи может быть найдено перебо-
ром объектов у (при заданном г) до тех пор, пока свой-
ство R(z, у) не окажется выполненным. Каждый укруп-
ненный шаг этой процедуры (проверка свойства R(z, у))
достаточно прост, а число укрупненных шагов растет
экспоненциально с ростом размерности у. Отметим, что
среди переборных задач встречаются и заведомо про-
стые. Примером может служить задача «узнать, являет-
ся ли число z четным», которая может быть сформули-
рована как задача выяснения по г, существует ли такое
целое у, что =2. Нас же будут интересовать в неко-
тором смысле наиболее сложные переборные задачи —
универсальные.
Переборная задача Z° называется универсальной,
если к ней полиномиально сводится любая переборная
задача*). Для того чтобы доказать универсальность
некоторой задачи Z°, строится цепочка переборных за-
дач Z1, Z2, ..., Zq, каждая из которых полиномиально
сводится к предыдущей и такая, что задача Z1 является
универсальной, a Z’ совпадает с Z°. Универсальность за-
дачи Z1 доказывается непосредственно.
5.5.6. Задача выполнимости к. н. ф. В качестве на-
чальной задачи, на основе которой будет установлена
*) Универсальные задачи перебора в литературе часто назы-
ваются /VP-полными [16, 13].
§ 5.5]
УНИВЕРСАЛЬНЫЕ ЗАДАЧИ ПЕРЕБОРА
253
универсальность других, будет взята так называемая
задача выполнимости к. н. ф. Она состоит в том, чтобы
по заданной к. н. ф. узнать, обращается ли реализуемая
ей функция в 1 хотя бы на одном наборе (или она тож-
дественно равна 0). К. н. ф. будет задавать словами в
конечном алфавите способом, описанным при формули-
ровке задачи 2.
Теорема 5.8. Задача выполнимости к. н. ф. являет-
ся универсальной задачей перебора.
Доказательство этой теоремы осуществляется путем
описания работы машин Тьюринга с помощью формул,
имеющих вид к. н. ф.
Рассмотрим произвольную переборную задачу Z =
— {г}. Найдется машина Тьюринга М, которая рас-
познает соответствующее свойство R(z, у) за время, ог-
раниченное полиномом от суммы размерностей l(z)-\-
+ 1(у). Поскольку 1(у) также не превосходит значения
некоторого полинома от /(г), то время распознавания
свойства R(z,y) зависит от /(г) не более чем полино-
миально. То же самое относится и к необходимому раз-
меру ленты. Обозначим через Р(х) такой полином, что
время вычисления и размер ленты ограничены величи-
ной Р(/(г)).
Положим /г = /(г) и Т==Р(/г). Занумеруем все
ячейки ленты машины слева направо числами ..., —2,
— 1, 0, 1, 2, взяв начало отсчета 0 произвольно. Ус-
ловимся, что в начальной ситуации исходные данные за-
дачи z помещаются в ячейках с номерами 1, ..., п.
В этом случае вычисление R(z, у) происходит при лю-
бом у (допустимом) в зоне, расположенной между
ячейками —Т и Т, и завершается не более чем за Т
тактов.
Как обычно, будем считать, что машина М, начав
работу в конфигурации q\z*y, останавливается в кон-
фигурации <7о1, если свойство R(z, у) выполнено, и в
конфигурации q0G в противном случае. В дальнейшем
будет удобно полагать, что, оказавшись в состоянии qo,
машина не останавливается, а работает бесконечно, не
изменяя конфигурации (этого можно добиться введе-
нием дополнительных команд qoa->qoaH для всех а).
Таким образом, в момент времени Т машина М будет
находиться в состоянии qo.
254
ВЫЧИСЛИТЕЛЬНЫЕ ВОЗМОЖНОСТИ МАШИН
[ГЛ. V
Приступим к построению к. н. ф. Ф, которая будет
выполнимой тогда и только тогда, когда найдется до-
пустимое у (при заданном г) такое, что R(z, г/)=1
(т. е. когда задача z имеет положительный ответ). Фор-
мулу Ф составим в виде конъюнкции ряда высказыва-
ний, относящихся к работе машины М при вычислении
/?(г, у):
<b = B&C&.D&E&.F&.G. (5.17)
Высказывания В, С и D означают, что машина работает
правильно: в каждый момент времени головка обозре-
вает ровно одну ячейку ленты (высказывание В), в
каждой ячейке записан ровно один символ (высказыва-
ние С) и машина находится ровно в одном состоянии
(высказывание D). Следующее высказывание Е утверж-
дает, что машина начинает работу в начальной конфи-
гурации q\z*y, высказывание F— что она работает в
соответствии с программой, а высказывание G — что
заключительная конфигурация имеет вид <?о1 -
В записи формул будут присутствовать переменные
трех типов. Пусть внешним и внутренним алфавитами
машины М являются
А = {аа, щ....и Q = {<7o, <71, ..
Введем булевы переменные uls t, v!t и ws —
— 1, 0 < / < г — 1, — Т 0 «С t Т), где
ulst = 1 тогда и только тогда, когда на шаге t ячейка
s содержит символ аг,
и' = 1 тогда и только тогда, когда на шаге t машина
находится в состоянии <?/;
ws, t = 1 тогда и только тогда, когда на шаге t го-
ловка обозревает ячейку s.
С помощью этих переменных запишем ряд высказы-
ваний.
Пусть высказывание Bt означает, что на такте t
(0 t Т) головка обозревает ровно одну ячейку
ленты. Построим формулу, которая принимает значение
1 тогда и только тогда, когда Bt истинно. Тот факт, что
на шаге t обозревается некоторая ячейка (заключенная
между —Т и Г), выражается следующей формулой:
V ws t, а то, что одновременно обозревается не
$ S.SJ
УНИВЕРСАЛЬНЫЕ ЗАДАЧИ ПЕРЕБОРА
255
более одной ячейки, — формулой & (ws, t V wa, t).
-T<s<«7<r
Поэтому
v M- (5-18)
С использованием выражений для Bt можно записать
высказывание В, утверждающее, что на каждом шаге
t (0 t Т) обозревается ровно одна ячейка ленты:
В — & Bt.
Os^t^T
Высказывание Cs, t о том, что на шаге t в ячейке
s записан ровно 1 символ, представляется формулой
“4U<U-,
Утверждение С, означающее, что в каждый момент t
(О <5 t Т) во всякой ячейке s (—Т s Т) нахо-
дится ровно 1 символ, задается конъюнкцией
С — & & Cs t.
—Т<s<T
Формула для высказывания D о том, что на каждом
шаге t (О Т) машина находится ровно в одном
состоянии, имеет вид
D — & Dt,
<т
где Dt означает аналогичное утверждение, отнесенное
к шагу t, и представляется выражением (ср. с (5.18))
В начальной ситуации (при t = 0) головка обозре-
вает ячейку 1 в состоянии qt, в первых п ячейках запи-
саны символы слова z = z(l) ... z(n), за ними идет
разделительный знак «, после чего записано допустимое
слово у (остальные ячейки пусты). Высказывание Е ут-
верждает, что начальная конфигурация имеет указан-
ный вид (при выполнении В, С, D). Тот факт, что при
t = 0 головка в состоянии q\ обозревает ячейку 1, ячей-
ки —Т, —1, 0 пусты, а в ячейках 1, ..., п 1 со-
держится слово z*, выражается формулой
0 (-7 |j <0 ^°) С < m “"’Ч “С*•0
256
ВЫЧИСЛИТЕЛЬНЫЕ ВОЗМОЖНОСТИ МАШИН
[ГЛ. V
(здесь в целях упрощения вместо записи uls t упо-
требляется т. е. вместо номера i символа исполь-
зуется сам символ).
Обозначим через А' (Л'£.4\{А}) алфавит, в кото-
ром представляются допустимые слова у. Для про-
стоты будем считать, что допустимыми являются все
слова у в алфавите А' такие, что 1 К.У)^ Т— п— 1-
Пусть £2 — высказывание, означающее, что, начиная с
ячейки п -ф 2, записано некоторое слово в алфавите А',
а затем сплошь идут пустые ячейки. Оно может быть
представлено формулой
£2=Г & С V & («^oVu^+i о)Ъ
Ln+2<s<rkae4'U{A} ' /J + ’ ° U+2<s<T-l4 s'0
где член в квадратных скобках обеспечивает запись во
всех ячейках s (п -ф 2 s Т) символов алфавита А'
или пустого символа, сомножитель й^+2>0 указывает на
то, что в ячейке п -ф 2 находится непустой символ, а
часть формулы, заключенная в фигурные скобки, вы-
ражает тот факт, что все символы алфавита А' пред-
шествуют пустым (если ячейка s пуста, то и s + 1 пу-
ста). Высказывание Е есть конъюнкция Е\ и Е2.
Пусть программа машины состоит из команд
Обозначим через т(/, i) сдвиг головки при выполнении
команды с левой частью
т (/, г) =
— 1, если Sjt = Л,
О, если 5/г = Н,
1, если Sji = П.
Введем высказывание Fls\ i, утверждающее, что если
в момент t в ячейке s записан символ а,, а машина на-
ходится в состоянии <7/, то при наличии в s головки
конфигурация меняется в соответствии с программой
машины, а при отсутствии головки запись в s сохра-
няется прежней. Из определения F ‘j следует, что
Fs, t = (иИ tWs, t i>UVi+lWs+r (/. n. t + 1) &
&(< +
S 5,51
УНИВЕРСАЛЬНЫЕ ЗАДАЧИ ПЕРЕБОРА
257
Воспользовавшись эквивалентностью d-+e = dVe и
вторым дистрибутивным законом (раздел 1.1.3), преоб-
разуем это выражение следующим образом:
Pls, 1 = (^ У % t V Ws, t V v<tf{ Z)ufH\>s+T f)> /+1) &
V®s, г V< j+i) =
= (yit wSi t V «) (vi V < ( V ws> t V «£%'>) &
& (»/ V Hlst V wSt t V ®5+T (,. 0> /+1) tVwstV uls> <+1).
Высказывание F, задаваемое формулой
F = & & & & F‘- f
-r<s<r 0</<Г 0</<r-l
утверждает, что работа машины протекает в соответ-
ствии с программой.
Пусть высказывание G означает, что на шаге Т ма-
шина окажется в конфигурации г/ol- Оно задается фор-
мулой
0=IU«U «-v < -v =!. -))]&
где выражение в квадратных скобках означает, что в
момент Т на ленте записаны символы А и 1, причем 1
содержится не более чем в одной ячейке, сомножитель
v? указывает на то, что машина находится в состоянии
<7о, а выражение в фигурных скобках обеспечивает на-
личие в обозреваемой ячейке символа 1.
Из приведенных выражений видно, что формула Ф,
задаваемая равенством (5.17), является к. н. ф. Она ут-
верждает, что найдется такое допустимое у, что ма-
шина М, начав работу в конфигурации q\z*y, перейдет
в конфигурацию </о1-
Если задача z имеет положительный ответ, то для
некоторого допустимого у выполнено R(z, у) = 1. В этом
случае, назначив значения переменных t, v!t и ws, t
на основе работы машины над начальной конфигура-
цией q\z* у, получим набор, на котором Ф = 1. Обрат-
но, если существует набор, обращающий Ф в 1, то зна-
чения переменных u{s 0 (О i & — 1, п 4- 2 Т)
258
ВЫЧИСЛИТЕЛЬНЫЕ ВОЗМОЖНОСТИ МАШИН
[ГЛ. V
в этом наборе определяют слово у такое, что ма-
шина переводит q\z*y в </о1 (и задача z решается
положительно). Тем самым задача Z сведена к задаче
выполнимости к. н. ф.
Непосредственный подсчет показывает, что длина N
формулы Ф ограничена некоторым полиномом от п =
~l(z). При записи формулы Ф в виде слова в конеч-
ном алфавите ее длина возрастает примерно в log N раз
и остается полиномиально ограниченной. Из рассмот-
рения формулы Ф видно, что от индивидуальной задачи
z зависит лишь сомножитель Mi/o’Mf,® • • в выра-
жении для Е и величины п — l(z) и Т = Р (п). В ос-
тальном формула Ф определяется машиной М (т. е.
массовой задачей Z) и от конкретного z не зависит. От-
сюда нетрудно заключить, что сведение осуществимо за
полиномиальное время. Тем самым теорема доказана.
Нашей конечной целью будет установление универ-
сальности одной задачи, связанной с минимизацией час-
тичных булевых функций. В связи с этим будет рассмот-
рена цепочка промежуточных задач, позволяющая осу-
ществить сведение к ней задачи выполнимости к. н. ф.
Мы не будем останавливаться на способе кодирования
объектов, встречающихся в этих задачах (графов, мно-
жеств, таблиц и др.); можно воспользоваться их любым
«естественным» представлением. Из приведенных кон-
струкций будет видно, что сведение может быть осу-
ществлено с полиномиальной сложностью.
5.5.7. Задача о полном подграфе. Она состоит в том,
чтобы по заданному (неориентированному) графу G и
числу k выяснить, имеется ли в G полный подграф с k
вершинами. (Напомним, что граф называется полным,
если любые две его вершины соединены ребром.) По-
кажем, что к этой задаче сводится задача выполнимости
к. н. ф.
Рассмотрим произвольную к. н. ф. Ф. Обозначим че-
рез k число входящих в нее сомножителей (дизъюнк-
ций). Построим по Ф граф G следующим образом.
Каждому вхождению переменной в формулу сопоставим
вершину графа и присвоим ей обозначение (х°, i), где
(ое{0, 1}) — рассматриваемое вхождение, a i — но-
мер сомножителя (дизъюнкции), в котором оно содер-
жится. Вершины (ха, i) и (ут, j) соединим ребром тогда
§ 5.51
УНИВЕРСАЛЬНЫЕ ЗАДАЧИ ПЕРЕБОРА
259
и только тогда, когда i =# / и х° не является отрицанием
ух (т. е. х У= у или о = т).
В качестве примера рассмотрим к. н. ф.
Ф = (xj V х2 V х3) (xi V х3) (х2 V х3).
Вершинами графа G являются (х1; 1), (х2> 1), (х3, 1),
(хь2), (х3, 2), (х2, 3), (х3, 3), а сам граф изображен на
рис. 5.12.
Предположим, что к. и. ф. Ф выполнима и 5 — набор,
на котором Ф(5)— 1. В каждом сомножителе формулы
Ф найдется хотя бы одно вхождение, принимающее зна-
чение 1. Произвольно выберем по одному такому вхож-
дению и рассмотрим со-
ответствующее множест-
во вершин графа G (его
мощность равна k — по
числу сомножителей).
Покажем, что любые две
из этих вершин соедине-
ны ребром. Действитель-
но, ребро между верши-
нами (х°, i) и (у\ j) мо-
жет отсутствовать лишь
в случае i = j либо ух —
= хв. Но i =#= /, посколь-
ку вхождения берутся из
разных скобок, а ух У=хг, ибо одно и то же значение пе-
ременной х (определяемое соответствующей компонен-
той набора 5) не может одновременно обратить в 1 вхо-
ждения х° и Xs. Таким образом, из выполнимости Ф сле-
дует наличие в G полного /г-вершинного подграфа.
В приведенном примере Ф(1, 0, 0) = 1. Если вы-
брать в первой скобке вхождение Xi, а во второй и
третьей — вхождения х3, получим полный подграф, вы-
деленный на рис. 5.12 жирной линией.
Обратно, пусть G содержит полный подграф с k
вершинами (х°‘, /Q, ...,(ха>, Положим х^ = о<7
(<7=1, ..., k) (при этом будет xf‘7=l), значения осталь-
ных переменных (если они есть) назначим произвольно.
Противоречия при таком задании не возникнет, ибо
если х° и хх соединены ребром, то о — т. По построению
260 ВЫЧИСЛИТЕЛЬНЫЕ ВОЗМОЖНОСТИ МАШИН (ГЛ. V
графа G вершинам /0 соответствуют вхождения
из разных сомножителей и, поскольку число вершин
равно k, каждый сомножитель имеет вхождение, обра-
щающее его в 1. При этом формула Ф также окажется
равной 1.
Рассмотрим в качестве примера полный подграф, вы-
деленный на рис. 5.12. Ему соответствуют значения
П = 1, х3 = 0. Взяв х2 произвольно, получим набор, об-
ращающий Ф в 1.
Построенное сведение доказывает, что задача о пол-
ных подграфах является универсальной.
5.5.8. Задача о вершинном
^2 покрытии. Некоторое множество
3 вершин образует вершинное по-
7-----крытие графа G, если для любо-
/ / го ребра найдется инцидентная
JlXC. / ему вершина из этого множества.
Задача состоит в том, чтобы по
/ / у8 графу G и числу k узнать, имеет
\ / / / ли граф вершинное покрытие
\ / \/ мощности k.
*5 Задача о полном подграфе
может быть сведена к задаче о
Рис. 5.13. вершинном покрытии следую-
щим образом. Пусть требуется
решить задачу о ^-вершинном полном подграфе графа
G (с п вершинами). Построим граф G', являющийся до-
полнением G до полного графа. Так, например, если в
графе, изображенном на рис. 5.12, переобозначить вер-
шины (xi, 1)= 1, (х2, 1)=2, (х3, 1) —3, (xi,2) = 4,
(х3, 2) = 5, (х2,3) = 6, (х3,3) = 7, то граф G' будет
иметь вид, показанный на рис. 5.13.
Пусть А — некоторое множество вершин. Полный
граф с множеством вершин А является подграфом G
тогда и только тогда, когда дополнение А' множества А
образует вершинное покрытие графа G' (на рис. 5.13
показано вершинное покрытие, соответствующее пол-
ному подграфу, выделенному на рис. 5.12). Действи-
тельно, пусть полный граф с множеством вершин А со-
держится в О. Тогда, если бы оба конца некоторого
ребра v графа G' содержались в А, то по определению
§ 5.5]
УНИВЕРСАЛЬНЫЕ ЗАДАЧИ ПЕРЕБОРА
261
полного графа ребро v должно было бы принадлежать
G (а не G'). Обратно, если Д' образует вершинное по-
крытие графа G', то всякое ребро, оба конца которого
находятся в Д, не может принадлежать G' и содержит-
ся в G (т. е. в G имеется полный подграф с множест-
вом вершин Д).
Таким образом, задача о й-вершинном полном под-
графе сводится к задаче о вершинном покрытии мощно-
сти k'— п — k. Отсюда вытекает универсальность за-
дачи о вершинном покрытии.
5.5.9. Задача о сложности д. н. ф. частичной функ-
ции. Она состоит в том, чтобы по частичной булевой
функции f и числу k установить, может ли f быть реа-
лизована д. и. ф., содержащей не более k букв.
Построим сведение к этой задаче задачи о вершин-
ном покрытии. Пусть требуется решить задачу вершин-
ного покрытия графа G. Обозначим через М его мат-
рицу инциденций. Столбцы матрицы А'1 соответствуют
вершинам 1, ..., п, а строки — ребрам ..., vm. В пе-
ресечении строки Vj и столбца i находится 1, если ребро
Vj инцидентно вершине i, и 0 в противном случае.
Построим частичную булевую функцию f следующим
образом. К матрице М добавим нулевую строку 0. По-
ложим /(0) = 0 и f(vj)=l (/=1, ..., tn), где через
Vj обозначена строка матрицы М, соответствующая реб-
ру Vj. Если для ребер графа G, представленного на
рис. 5.13, ввести обозначения щ—(1, 2), у2 = (1,3),
и3 = (1,4), щ = (2, 3), 05 = (2,6), t>6 = (3, 5),ц7 = (3,7),
Us —(4, 5), и9 = (6, 7), то соответствующая частичная
функция f будет задаваться таблицей 5.4 (матрица ин-
циденций графа G обведена в ней пунктиром).
Покажем, что функция f может быть реализована
посредством д. н. ф. сложности не выше k тогда и толь-
ко тогда, когда в G имеется вершинное покрытие мощ-
ности k. Предположим, что множество {и, i2, .... й}
является вершинным покрытием. Тогда функция f реа-
лизуется д. н. ф. xi{ V Xi2 V ... V xik, содержащей k
букв. Действительно, на наборе 0 эта дизъюнкция обра-
щается в 0. Всякое ребро V/ (j = 1, ..., т) инцидент-
но некоторой вершине ip вершинного покрытия, по-
этому компонента ф набора б/ равна 1. Таким образом,
262
ВЫЧИСЛИТЕЛЬНЫЕ ВОЗМОЖНОСТИ МАШИН
[ГЛ. V
Таблица 5.4
Xt X2 Хз Xi Хз Хв X7 f
0 0 0 0 0 0 0 0 0
V1 1 1 0 0 0 0 0 1
V2 1 0 1 0 0 0 0 1
V3 1 0 0 1 0 0 0 1
V4 0 1 1 0 0 0 0 1
VS 0 1 0 0 0 1 0 1
Ив 0 0 1 0 1 0 0 1
v7 0 0 1 0 0 0 1 1
Vs 0 0 0 1 1 0 0 1
vs 0 0 0 0 0 1 1 1
на наборе б/ переменная xtp принимает значение 1 и
дизъюнкция обращается в 1. В рассматриваемом при-
мере вершинному покрытию, выделенному на рис. 5.13,
соответствует реализация
f = х2 V х3 V х4 V х6.
Обратно, пусть f реализуется некоторой д. н. ф., со-
держащей не более k вхождений переменных. Рассмот-
рим в этой д.н.ф. произвольную конъюнкцию К. =л71/1 • • •
... x^q. Поскольку f (б) = 0, то в ней найдется перемен-
ная Xj, входящая с показателем = Заменим
в д. н. ф. конъюнкцию К на х/. Проделав это со
всеми конъюнкциями, получим дизъюнкцию не более k
переменных, которая реализует f. Это следует из того,
что при укорачивании конъюнкций значения функции не
убывают, а на нулевом наборе дизъюнкция равна 0.
Множество вершин jt, соответствующих переменным Xjt,
входящим в состав дизъюнкции, образует вершинное
покрытие графа О (всякое ребро о/ инцидентно вер-
шине, соответствующей той переменной Х](, которая на
наборе Vi обращается в 1). Если мощность этого по-
крытия меньше k, то произвольным образом дополним
его так, чтобы оно содержало k вершин.
§ 5.5] УНИВЕРСАЛЬНЫЕ ЗАДАЧИ ПЕРЕБОРА 2бЗ
Полученное сведение задачи о вершинном покрытии
к задаче о сложности д. н. ф. доказывает универсаль-
ность последней.
Тем же способом может быть установлена универ-
сальность задачи о сложности схем для частичных функ-
ций. Задача о минимизации частичных автоматов также
является универсальной [43].
Мы видим, что многие важные задачи, возникающие
при синтезе и оптимизации дискретных устройств, ока-
зываются универсальными и, следовательно, в некото-
ром смысле самыми сложными среди задач перебор-
ного типа. Это проливает свет на природу тех трудно-
стей, которые возникают при попытках нахождения эф-
фективного решения этих задач.
ЧАСТЬ ТРЕТЬЯ
Глава VI
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
§ 6.1. Общая схема передачи дискретной информации
6.1.1. Схема передачи информации. В предыдущих
главах рассматривались устройства для переработки
дискретной информации. При этом предполагалось, что
информация поступает на входы (или в память) уст-
ройства без искажений и ее переработка осуществляет-
ся в точном соответствии с назначением и конструк-
цией устройства. Однако в процессе хранения, передачи
и переработки информации могут возникнуть ошибки,
и для того чтобы уменьшить или исключить их влия-
ние, нужно уметь представлять информацию в таком
виде, чтобы она была устойчивой к определенным иска-
жениям. Последующие главы посвящены изучению этой
проблематики.
Согласно сложившейся традиции мы будем употреб-
лять выражение «передача информации по каналу».
Однако его следует трактовать более широко, относя
сюда и хранение информации. Под «каналом» можно
понимать любой источник погрешностей. Он может быть
связан со средой, в которой осуществляется передача
информации, либо со средой, где она хранится. Полу-
ченные результаты допускают распространение и на
«вычислительные» каналы, т. е. на переработку инфор-
мации [5].
Передаваемую (хранимую, перерабатываемую) ин-
формацию будем называть сообщением. Мы не будем
рассматривать вопросов, связанных с представлением
реальной (физической) информации в дискретном виде
и в большинстве случаев будем считать, что сообщение
является последовательностью из символов 0 и 1.
§ 6.1] ОБЩАЯ СХЕМА ПЕРЕДАЧИ ИНФОРМАЦИИ 265
Если использовать простейшую схему передачи от
источника информации к адресату, показанную на
рис. 6.1, то к адресату будет поступать искаженное со-
общение. Поэтому обычно применяют более сложную
схему (рис. 6.2). Перед входом в канал ставится коди-
рующее устройство — кодер, которое путем введения в
сообщение некоторой избыточности (удлинения сообще-
ния) дает возможность впоследствии обнаруживать и
Рис. 6.1.
исправлять ошибки определенного вида, происходящие
в канале. Само исправление осуществляется декодером,
помещаемым на выходе канала. Из декодера сообще-
ние поступает к адресату.
Эта схема передачи реализуется следующим обра-
зом. Передаваемое сообщение d = a1c'2c'3 ... разбивает-
ся определенным образом на куски а = a(I>d(2> ...
Рис. 6.2.
(обычно все куски имеют одинаковую длину). В ко-
дере каждому а(г) сопоставляется некоторый двоичный
набор р(/>, который затем посимвольно передается по
каналу. На выходе канала из-за происшедших ошибок
принимается, вообще говоря, другой набор у(,). Он по-
ступает в декодер, где преобразуется в некоторый дво-
ичный набор 6(,). Адресат получает сообщение 6 =
= 6<1)&<2) ... Цель состоит в том, чтобы переданное и
принятое сообщения а и 6 «мало» отличались друг ог
друга в некотором условленном смысле.
Сообщения, порождаемые источником информации,
обычно обладают некоторыми закономерностями (на-
пример, одни символы или сочетания символов
266
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
[ГЛ. VI
встречаются в них чаще, чем другие). Эти закономерно-
сти могут быть использованы для сжатия сообщений
путем кодирования их более короткими последователь-
ностями (произвольного вида). С учетом этого рассмот-
ренная схема передачи приобретает вид, показанный на
рис. 6.3. Кодер для источника производит сжатие сооб-
щений. Затем к сжатым сообщениям применяется пре-
дыдущая схема помехоустойчивой передачи (кодер для
канала — канал — декодер для канала). После чего де-
кодер для источника осуществляется преобразование,
обратное сжатию.
В описанной схеме сжатие информации и ее поме-
хоустойчивое кодирование производятся по отдельности.
Койердля
канала
Канал
Рис. 6.3.
Оказывается, что при таком разделении функций, отно-
сящихся к источнику и каналу, во многих случаях
удается достичь почти наилучших (асимптотически наи-
лучших) характеристик передачи (см. раздел 7.4.8).
6.1.2. Описание основных задач. Имеются две основ-
ные постановки задач, связанных с исправлением оши-
бок,— детерминированная и вероятностная.
При детерминированной постановке требуется обес-
печить исправление в сообщении определенного количе-
ства ошибок заданного вида. Характер ошибок опреде-
ляется каналом. Опишем некоторые возможные виды
ошибок.
Симметричная ошибка (типа {0—>-1, 1->-0}) состоит
в замене некоторого символа противоположным. Этот
вид ошибок рассматривается наиболее часто. При не-
симметричной ошибке типа {1->0} происходит замена
1 на 0 (но не наоборот). Если наличию сигнала (фи-
зического) соответствует 1, а отсутствию — 0, то такие
ошибки происходят в результате размыканий (обрывов)
в канале, ибо при размыкании сигнал может лишь ис-
чезнуть. Аналогично можно рассматривать несиммет-
§ 6.1]
ОБЩАЯ СХЕМА ПЕРЕДАЧИ ИНФОРМАЦИИ
267
ричные ошибки типа {О-* 1}. Они происходят в резуль-
тате замыканий в канале. Ошибка стирания (типа
{О -> х, 1 х}) возникает в случае, когда сигнал, пред-
ставляющий символ 0 или 1, искажается в канале так,
что его нельзя интерпретировать ни как 0, ни как 1.
В результате стирания значащий символ заменяется не-
определенным, который обозначается через х. Дальше
встретятся и другие типы ошибок (пачки, арифметиче-
ские) ; их описание будет дано в соответствующих ме-
стах.
В качестве основной задачи в детерминированной
постановке будет рассматриваться следующая: по-
строить кодирование, обеспечивающее возможность ис-
правления в словах длины п всех симметричных ошибок
при условии, что их количество не превосходит задан-
ной величины t. При этом налагаются дополнительные
требования, чтобы удлинение сообщений при кодиро-
вании (избыточность) было по возможности малым, а
кодирование и декодирование могли быть осуще-
ствлены эффективно (т. е. с малой вычислительной
сложностью).
При вероятностной постановке задачи канал описы-
вается не только типами ошибок, которые могут в нем
происходить, но и их вероятностными характеристи-
ками. Вероятности ошибок могут, вообще говоря, зави-
сеть от передаваемых символов, значений входов и вы-
ходов канала в предыдущие моменты времени и т. д.
М.ы будем рассматривать канал простейшего вида —
двоичный симметричный канал. В нем каждый из сим-
волов 0 и 1 может перейти в противоположный (сим-
метричная ошибка), причем вероятность искажения
символов 0 и 1 одинакова и постоянна.
Задача состоит в том, чтобы на основании характе-
ристик канала указать такую схему передачи информа-
ции по каналу (способ разбиения сообщения на куски,
способ кодирования и декодирования), при применении
которой вероятность ошибки, определенная соответ-
ствующим образом, была бы меньше наперед заданной
величины. Одновременно с этим ставится задача макси-
мизации скорости передачи (минимизации избыточно-
сти). Определенные требования предъявляются и к
268
ПОМЕХОУСТОЙЧИВОЙ КОДИРОВАНИЕ
[ГЛ. VI
эффективности вычислительных процедур, связанных с
кодированием и декодированием.
Еще один круг задач связан со сжатием сообщений.
Источник информации часто может быть охарактери-
зован вероятностями появления отдельных букв, соче-
таний букв, слов, словосочетаний и др. Задача состоит
в том, чтобы предложить такое кодирование продукции
источника последовательностями из 0 и 1, чтобы сред-
няя длина сообщений была по возможности малой. Мы
будем рассматривать задачу сжатия для простейшего
источника, который характеризуется лишь вероятностя-
ми появления отдельных символов.
Детерминированная постановка задачи, связанной с
надежной передачей информации, рассматривается в
данной главе VI. Вероятностной постановке посвящена
следующая глава VII. Там же изложены результаты,
относящиеся к сжатию информации.
§ 6.2. Равномерное кодирование
6.2.1. Кодирование и декодирование. Кодирующее
устройство осуществляет некоторое преобразование на-
боров (всюду, если не оговорено противное, наборы бу-
дем считать двоичными). Набор а, поступающий на
вход устройства, будем называть информационным, а
набор р, снимаемый с выхода, — кодовым. Различным
наборам а должны соответствовать разные р, иначе
даже в случае отсутствия искажений по принятому (ко-
довому) набору не всегда можно определить исходный.
Будем рассматривать случай, когда все информацион-
ные наборы имеют одинаковую длину k. Отображение,
осуществляемое кодером, может быть задано таблицей
кодирования (см. табл. 6.1), в которой перечислены все
2* возможных информационных наборов и для каждого
из них указан соответствующий кодовый набор.
Совокупность всех кодовых слов образует код. Ко-
дирование, при котором кодовые слова имеют одинако-
вую длину (обозначим ее через п), будем называть
равномерным. В этом случае код представляет собой
множество, содержащее 2fe из 2Л наборов длины п (п >
>й). За счет соответствующего выбора этого множе-
ства обеспечиваются нужные корректирующие свойства
§ 6.2]
РАВНОМЕРНОЕ КОДИРОВАНИЕ
269
Таблица 6.1
Информацион- ный набор Кодовый набор
00 0000
01 1001
10 оно
11 1111
кода (т. е. свойства обнаруживать и исправлять ошиб-
ки). Всюду дальше, если не оговорено противное, под
кодированием понимается равномерное кодирование.
Как уже говорилось в § 6.1, по каналу посимвольно
передается кодовый набор [3. В результате искажений
он может перейти в некоторый другой набор у длины п.
Цель состоит в том, чтобы по у восстановить § (затем
с помощью таблицы кодирования можно найти исход-
ный набор а). В пределах данной главы под декодиро-
ванием, как правило, будем понимать восстановление
по у кодового набора |3.
Способ декодирования может быть задан разбие-
нием множества всех 2" наборов длины п на 2й подмно-
жеств, в каждом из которых содержится ровно один
кодовый набор. При декодировании набору у сопостав-
ляется кодовый набор, принадлежащий тому же множе-
ству, что и у. Указанное разбиение может быть описано
таблицей декодирования. Первую строку таблицы обра-
зуют кодовые слова, а под каждым из них перечислены
слова, относящиеся к тому же классу разбиения.
Таблица 6.2
Кодовые слова 0000 1001 ОНО 1111
0001 1011 0111
Другие слова 0010 0100 1000 ООН 0101 1010 1100 1101 1110
270
помехоустойчивое кодирование
[ГЛ. VI
В качестве примера рассмотрим таблицу декодиро-
вания 6.2 для кода, представленного в таблице 6.1.
Приведенные код и схема декодирования позволяют
исправлять одну несимметричную ошибку типа {0->-1}.
Это следует из того, что каждое слово, образованное
из кодового заменой одного символа 0 на 1, располо-
жено под ним. Кроме того, слова ООН, 0101, 1010 и
1100, полученные в результате двух ошибок типа {0->-
->1), также декодируются правильно (из кодовых
слов, отличных от нулевого, они произойти не могли).
При равномерном кодировании информационная по-
следовательность длины k представляется с использо-
ванием п символов. Если передача одного символа по
каналу занимает единицу времени, то на передачу k
единиц информации расходуется п единиц времени. Та-
k
ким образом, отношение — = R характеризует скорость
передачи, информации.
Размеры таблиц кодирования и декодирования рас-
тут экспоненциально с ростом параметров k и п. По-
этому методы, основанные на таблицах, фактически
реализованы быть не могут. Они либо требуют чрезвы-
чайно большого объема памяти для хранения таблиц,
либо (при выполнении кодера и декодера в виде спе-
циализированных устройств) приводят к устройствам
большой сложности. В связи с этим ставится задача
разработки конструктивных методов построения кодов
с эффективными алгоритмами кодирования и декодиро-
вания.
6.2.2. Примеры кодов. Рассмотрим некоторые коды,
на основе которых введем ряд необходимых понятий.
Код с повторением. Выбирается некоторое на-
туральное число s, и при передаче по каналу каждый
символ информационной последовательности дублирует-
ся 2s + 1 раз (вместо символа а передается последо-
вательность а ... а = a.2s+1). Если на выходе канала
взамен а ... а принята последовательность у1у2 ...
• •• T2s+i, то считается, что передавался тот из симво-
лов 0 и 1, который встречается в этой последовательно-
сти не менее s -f- 1 раз (метод декодирования по боль-
шинству) . При s = 1 получаем так называемый код с
утроением.
§ 6.2]
РАВНОМЕРНОЕ КОДИРОВАНИЕ
271
Предположим, что передача ведется по двоичному
симметричному каналу, в котором каждый символ ис-
кажается с вероятностью р < -%. Подсчитаем вероят-
ность ошибки передачи при использовании кода с ут-
роением. Поскольку вероятность искажения в канале не
зависит от передаваемого символа, можно считать, что
информационным символом является 0 и, следователь-
но, по каналу передается последовательность ООО. Ре-
зультат декодирования будет отличен от 0, если на вы-
ходе канала принята одна из последовательностей
011, 101, НО и 111. Вероятность этого составляет*)
Зр2 (1 — р) + р3 = р (Зр — 2р2).
Это и есть вероятность ошибки передачи. При Р <~^
функция Зр — 2р2 возрастает (ее производная положи-
тельна ), поэтому Зр — 2р2 < 3 • у — 2 (у) — 1. Отсюда
заключаем, что вероятность ошибки передачи строго
меньше вероятности р ошибки в канале.
Можно доказать, что с ростом s вероятность ошибки
передачи при использовании кода с повторением экспо-
ненциально стремится к 0. Это означает, что даже при
достаточно большой вероятности ошибки в канале
можно добиться сколь угодно надежной пе-
редачи. Однако в данном случае это достигается за счет
n k 1
того, что скорость передачи К = ~п ~'2Г+Т с'гРемится
к 0. Один из основных дальнейших результатов будет
состоять в том, что можно вести сколь угодно надеж-
ную передачу при любой скорости, меньшей некоторой
константы (зависящей от канала).
Код с проверкой на четность. Пусть тре-
буется передать информационный набор ... &k. Ко-
довый набор получается в результате дописывания к
последовательности символа ощ-ь который назначается
*) Поскольку в двоичном симметричном канале символы иска-
жаются независимо с вероятностью р, то вероятность получения на
выходе канала определенного набора, отличающегося от передан-
ного набора в v позициях и совпадающего с ним в w позициях,
равна р’(1 — p)w.
272
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
|ГЛ. V!
так, чтобы число единиц в последовательности он ...
... а«ак+1 было четным (так, например, набору 011010
сопоставляется набор 0110101). Если при передаче про-
изошла одна ошибка (0->1 или 1->0), то число единиц
в принятом наборе Vi ... VaVs+i станет нечетным. Это
и указывает на наличие ошибки. Место ошибки найти
не удается, поэтому декодирование не производится.
Если известно, что произошла ошибка, можно, напри-
мер, послать запрос, чтобы передачу повторили. Таким
образом, код с проверкой на четность обнаруживает
(но не исправляет) / ошибку. Отметим, что он также
обнаруживает любое нечетное число ошибок.
Кодовые слова си ... ocaoca+i содержат четное число
единиц, поэтому для них справедливо соотношение
а1Ф ... ФайФа*+1 — 0, (6.1)
которое называется проверочным (здесь ф — знак сум-
мирования по mod 2). Код образуется всеми наборами
длины n = k-\-\, удовлетворяющими этому соотноше-
нию.
6.2.3. Код Хемминга. Пусть, как и раньше, п озна-
чает длину кодовых наборов. Обозначим через г число
цифр в двоичном представлении числа п наименьшей
длины (первой цифрой является 1). Нетрудно видеть,
что
r = ]log(n+1)[ (6.2)
(напомним, что логарифмы всюду предполагаются дво-
ичными, а ]х[ означает ближайшее к х целое число, не
меньшее х).
Код Хемминга определим как множество наборов
а = (ось •••, ая), удовлетворяющих г проверочным со-
отношениям
Ф; (а) = 0 (/ = 1, ..., г). (6.3)
Каждое из них представляет собой сумму по mod 2 не-
которых разрядов набора а, причем в j-e соотношение
входят те и только те разряды, двоичная запись номе-
ров которых (длины г) содержит 1 на j-м месте.
В качестве примера приведем проверочные соот-
ношения для кода Хемминга при п = 6. Для него г,
вычисленное в соответствии с (6.2), равно 3 и, таким об-
$ 6.2J
РАВНОМЕРНОЕ КОДИРОВАНИЕ
273
разом, должны быть составлены 3 проверочных соот-
ношения. Представим каждое из чисел 1, 2, .6 дво-
ичной записью длины 3:
и на основании этого выпишем проверочные соотноше-
ния (они соответствуют строкам таблицы)
<Р1 (а)=а4®а5фа6=0, '
Ч>2 (а) = а2 Ф а.з Ф «6 = 0, >
<р3 (а) = щ ф а3 ф а5 = 0. ,
(6.4)
Отметим, что для составления проверочных соотно-
шений не обязательно иметь двоичные записи чисел
1....п. Рассмотрим удлиненный набор, полученный
приписыванием спереди к набору (ai, .... ап) разряда
ао- Для составления соотношения <р,(а) нужно первые
2Г-/ разрядов набора («о, аь ..., ап) пропустить, сле-
дующие 2Г~> разрядов включить в соотношение, затем
2Г~> разрядов пропустить, 2г-; включить и т. д., пока не
исчерпаются все разряды.
Пусть при передаче кодового набора а произошла
ошибка в одной позиции, в результате чего принят на-
бор у. Номер искаженного разряда обозначим через I.
Вычислим значения проверочных соотношений ф/(у)
(/ = 1, ..., г). Те из соотношений, в которые входит
i-й разряд, нарушатся и примут значение 1. По по-
строению соотношений в наборе (cpi(y), •фг(у))
единицы появятся на тех же местах, на каких они на-
ходятся в двоичном представлении числа I, и, следова-
тельно, набор проверочных соотношений совпадет с
двоичной записью искаженного разряда. Это позволит
исправить происшедшую ошибку. Таким образом, код
Хемминга исправляет 1 ошибку..
==!Рассмотрим пример. Пусть при передаче кодового
набора а = (1, 0, 1, 1, 0, 1) (проверьте, что он удовлет-
274
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
[ГЛ. VI
воряет соотношениям (6.4)) произошла ошибка в 3-м
разряде, в результате чего принят набор у = (1,0, 0,1,
0, 1). Вычислим значения проверочных соотношений:
Ф1 (V) = 1 ® 0 ® 1 = о,
Фг (у) = 6 ф 0 ф 1 = 1,
Ф3(у)= 1 ф0ф0= 1.
Набор (<pi(y), фг(у), Фз(т)) — (0,1, 1) является двоич-
ной записью номера искаженного разряда.
Рассмотрим теперь вопрос, который до сих пор не
затрагивался: существуют ли наборы а, удовлетворяющие
всем проверочным соотношениям (т. е. не является ли
код пустым), и как можно строить кодовые наборы.
Число 2Z (/=0, 1, ..., г—1) содержит единицу в
двоичной записи только на (г — /)-м месте, поэтому
разряд a2z входит лишь в соотношение с номером j =
= г — I. Прибавив по mod 2 к обеим частям равенства
Ф; (а) = 0 разряд a2r-/, получим эквивалентное ему соот-
ношение а2г-! = — ф' (а), где Фу (а) получается из Фу (а)
в результате удаления слагаемого а2г_/. Суммы ф'.(а) (/=
= 1, ..., г) содержат лишь те разряды а> номера кото-
рых отличны от степеней двойки. В кодовом векторе эти
п — г разрядов можно назначить произвольно, тогда
остальные г разрядов си, аг, а2г, ..., a2r_i определятся
равенствами
= (/=1, ..., г). (6.5)
Таким образом, код Хемминга с заданным п можно ис-
пользовать для кодирования произвольных информа-
ционных наборов длины k = п — г, где г определяется
из (6.2).
Продолжим рассмотрение примера. При п = 6 зна-
чение £ = п— г равно 3, поэтому можно кодировать
информационные последовательности длины 3. Найдем
кодовый набор для последовательности (1,0,1). Раз-
местим ее в разрядах аз, as, as (номера которых от-
личны от степени 2), а остальные разряды найдем из
равенств a4 = as ф ag, а2 = аз Ф а6 и а4 = а3 ф аз, об-
разованных из соотношений (6.4) переносом слагаемых
а4, аг, ai в левую часть. Полученный кодовый набор
§ 6.2] РАВНОМЕРНОЕ КОДИРОВАНИЕ 275
имеет вид (1,0, 1, 1,0, 1) (он использовался нами рань-
ше в качестве примера кодового набора).
Значение k вычислялось нами по заданному п. Од-
нако, если требуется кодировать информационные по-
следовательности определенной длины k, нужно решать
обратную задачу: найти п по k. Легко видеть, что в
этом случае нужно взять наименьшее целое число г,
удовлетворяющее неравенству
k + r^2r- 1,
и положить п = k + г.
6.2.4. Обсуждение рассмотренных конструкций. От-
метим теперь некоторые общие черты, присущие всем
рассмотренным конструкциям кодов.
1. В кодовых наборах выделены k разрядов, в кото-
рых записывается информационная последовательность
(эти разряды будем называть информационными). Ими
однозначно определяются значения остальных г — п — k
проверочных разрядов.
Так, в коде с повторением информационным разря-
дом можно считать си, а проверочными — остальные 2s
штук: их значения совпадают со значением информа-
ционного разряда. В коде с проверкой на четность
информационными являются первые k разрядов, а зна-
чение проверочного задается равенством a*+i = ai ф ...
... В коде Хемминга информационными разря-
дами являются такие, номера которых отличны от сте-
пени 2, а значения проверочных разрядов находятся
согласно (6.5).
Два кода будем считать эквивалентными, если один
из них может быть получен из другого в результате пе-
рестановки разрядов. Для типов ошибок, которые не
зависят от нумерации разрядов (в том числе симмет-
ричной, несимметричной, ошибки стирания), эквива-
лентные коды обладают одинаковой корректирующей
способностью. Код называется систематическим, если
первые k компонент кодового набора занимает инфор-
мационная последовательность, а остальные п — k ком-
понент однозначно определяются ею. Из сказанного
следует, что коды с повторением и с проверкой на чет-
ность являются систематическими, а код Хемминга эк-
вивалентен некоторому систематическому коду.
276
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ [ГЛ. VI
§ 6.3]
КОДОВОЕ РАССТОЯНИЕ
277
2. Каждый из перечисленных кодов может быть за-
дан с помощью некоторого множества проверочных со-
отношений вида 2аг/ = 0.
Для кода с повторением соотношения имеют вид
ом ® «2 = 0, а\ ф а3 — 0, ..., оц ф «2s+i — 0, а для ос-
тальных двух кодов они приведены в (6.1) и (6.4). Та-
кой способ задания кодов является довольно распро-
страненным.
3. Кодирование и декодирование указанных кодов осу-
ществляются достаточно просто и не используют таблиц.
Указанные свойства, как правило, будут присущи
и другим конструкциям кодов, которые будут изучаться
в дальнейшем.
§ 6.3. Кодовое расстояние
и его связь с корректирующей способностью
6.3.1. Расстояние по Хеммингу. При изучении кон-
струкций кодов удобно пользоваться геометрическими
понятиями. Наборы d при этом считаются точками про-
странства, в котором введена
оД некоторая метрика (заданы
расстояния). Метрика вводит-
/oaJ/ ~ \ ся в зависимости от типов
! ; ошибок, для исправления (или
\ J обнаружения) которых пред-
назначен код.
Пусть кодовые точки рас-
Рис. 6.4. положены «достаточно дале-
ко» друг от друга, а всякий
набор, полученный из кодо-
вого в результате допустимого числа ошибок, нахо-
дится в «достаточно малой» окрестности последнего.
Тогда по искаженному набору с допустимым числом
ошибок переданный восстанавливается однозначно.
Эта ситуация иллюстрируется на рис. 6.4, где точки а,
р и у являются кодовыми, а точка а' получена в ре-
зультате искажения d . В данном параграфе изучается
связь корректирующей способности кода с расстоя-
ниями между кодовыми наборами в соответствующей
метрике.
В качестве основного типа ошибки обычно рассмат-
ривается симметричная (дальше будем называть ее
просто ошибкой). Для симметричных ошибок корректи-
рующие свойства кодов определяются расстояниями
между наборами в метрике Хемминга.
Расстоянием по Хеммингу p(d, р) между двоичными
наборами d=(a,, ..., аД и р = (pi, ..., рп) назы-
вается число компонент, в
Рис. 6.5.
которых они различаются.
Если двоичные наборы дли-
ны п изображать в виде вер-
шин «-мерного куба со сто-
роной 1, то р(а, р) совпа-
дает с минимальным путем
из а в р при условии, что
допускается движение лишь
по ребрам куба. На рис. 6.5
жирной линией выделен ми-
нимальный путь из верши-
ны а = (0, 1, 0) в р =
= (0,0,1), пунктиром пока-
зан некоторый более длинный путь. Величина р(а, Р) об-
ладает обычными свойствами расстояния (р(а, Р)=0
лишь при а = р, р (а, Р) = р (р, а), р(а, Р) + р (р, у) ф
р(а, у)), так что при рассуждениях можно
ваться привычным геометрическим языком.
Расстояние р(а, Р) может быть вычислено
ПОЛЬЗО-
по фор-
муле
p(d, р) = оу(афр),
(6.6)
где а ф Р = («1 ф Pi, ..., апфРп), а оу (у) называется
весом набора у и означает число его единичных компо-
нент. Действительно, в наборе афр единицы нахо-
дятся во всех тех позициях, где а и Р различаются, а
ш(афр) совпадает с числом этих единиц. В качестве
примера рассмотрим наборы а = (0, 1, 1, 0, 1, 0) и ₽ =
= (1, 1, 0, 1, 1, 0). Набор а ф р = (1, 0, 1, 1, 0, 0) содер-
жит 3 единицы, поэтому р(а, р) = 3.
278
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
[ГЛ. VI
6.3.2. Кодовое расстояние и корректирующая способ-
ность. Пусть К — некоторый код. Его кодовым рассто-
янием называется величина
d = min р (а, Р). (6.7)
а, В е К, а В
Выясним зависимость корректирующей способности ко-
да от величины d.
Если код используется только для обнаружения
ошибок, то для того чтобы код обнаруживал все комби-
нации из b и менее ошибок, необходимо и достаточно
выполнение неравенства
d^b+\. (6.8)
Действительно, если минимальное расстояние между
кодовыми наборами не меньше b1, то при искажении
в кодовом слове не более b разрядов получится слово,
отличное от кодового, и наличие ошибок будет обнару-
жено. Если же d Ь, то существует пара кодовых слов,
расстояние между которыми не больше Ь. Найдется
комбинация не более b ошибок, переводящая одно из
них в другое, и эти ошибки обнаружены не будут.
Для того чтобы код исправлял любую комбинацию
из t и менее ошибок, необходимо и достаточно выпол-
нение неравенства
d>2/+I. (6.9)
Если это соотношение будет выполнено и при передаче
кодового слова произошло t' t ошибок, то принятое
слово будет отстоять от всякого другого кодового сло-
ва не менее чем на 2t + 1 — t' > t, и тем самым пере-
данное слово определится однозначно. В случае, когда
d 2t, имеются кодовые слова а и g, для которых
р(а, p)^2f. Поэтому найдется слово у, отстоящее от
каждого из них не далее чем на t. Если в результате ис-
кажения получится набор у, то будет невозможно уста-
новить, из какого набора (а или р) он произошел в ре-
зультате не более t ошибок.
Полученный результат имеет следующую геометри-
ческую интерпретацию (рис. 6.6). Рассмотрим про-
странство двоичных наборов с введенной на нем метри-
кой Хемминга. Проведем вокруг каждой кодовой точки
§ 6.3]
КОДОВОЕ РАССТОЯНИЕ
279
шар радиуса t. Все наборы, полученные из кодового в
результате не более t искажений, содержатся в преде-
лах шара. Если расстояние между кодовыми точками
не меньше 2?-]- 1, то шары не пересекаются, и по иска-
женному набору кодовый (центр шара) восстанавли-
вается однозначно. Если расстояние между какими-
либо кодовыми точками не превосходит 2/, то соответ-
ствующие шары пересекаются (в частности, касаются),
и по точкам, находящимся в пересечении, центры шаров
однозначно найдены быть не могут.
6.3.3. Расстояния для других типов искажений. Рас-
стояние по Хеммингу может быть использовано и для
ошибок типа стирания. Код
исправляет любую комбина-
цию из с и менее стираний
тогда и только тогда, когда
d^c + 1. (6.10)
Действительно, если это не-
равенство выполнено, то для
всякого набора с стер-
тыми разрядами существует
не более одного кодового Рис- 6-6-
набора, совпадающего с ним
в нестертых позициях (в противном случае имеются два
кодовых вектора, различающихся не более чем в с' < d
позициях, которые стерты). Таким образом, если сти-
рания произошли в кодовом наборе, то этот набор вос-
станавливается однозначно. В случае, когда условие
(6.10) не выполнено и имеет место d с, взяв два ко-
довых набора, на которых достигается расстояние d, и
стерев разряды, в которых они различаются, получим
слово, не позволяющее восстановить, из какого кодо-
вого слова оно произошло в результате d с стираний.
При исправлении стираний ослабление требований к
величине кодового расстояния (ср. (6.9) и (6.10)) вы-
звано тем, что здесь известны номера ошибочных (стер-
тых) позиций.
Для несимметричных ошибок (типа {0->- 1} или
{1 -> 0}) используется расстояние другого вида
Р (а» Р) = Р (а, Р) + | w (а) — w ф) |, (6.11)
280
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
(ГЛ. VI
где р—расстояние по Хеммингу, a w означает вес на-
бора. Оно введено Р. Р. Варшамовым. С учетом (6.6)
равенство (6.11) может быть переписано в форме
р (й, р) = w (а ф р) + | w (а) — w (р) |.
Величина р обладает обычными свойствами расстояния.
На основе р аналогично (6.7) можно ввести понятие
кодового расстояния d.
Код исправляет любую комбинацию из t и менее не-
симметричных ошибок тогда и только тогда, когда
d>2/+l. (6.12)
Рассмотрим для определенности случай ошибок типа
{0-> 1}. Пусть а и р — произвольные наборы. Будем
считать без ограничения общности, что w (а) w (р),
и величину да (а) —да (р) обозначим через Ада. Переста-
вив разряды, представим наборы аир, как показано
на рис. 6.7, где Аю— число разрядов i таких, что а, —
= 1, р/ = 0, Ап — число разрядов с а/ = 1, р< = 1 и т. д.
Легко видеть, что Ащ = Aoi + Ада, поэтому
р(й, р) = р(й, р) + Ада = (А10 + А01) + Ада = 2А,0. (6.13)
Предположим, что выполнено неравенство d 2t ф-
'+ 1 и наборы аир являются кодовыми. Тогда р(а, р) 7>
>21ив силу (6.13) AI0 > t. Если в каждом из набо-
ров а и р произошло не более t ошибок типа {0->1},
то они не могут перейти в один и тот же набор, по-
5 6.3]
КОДОВОЕ РАССТОЯНИЕ
281
скольку на участке I (длины Д10) все разряды набора a
останутся после искажения единичными, а среди разря-
дов набора 0 сохранится не менее Дю—/ > 0 нулевых.
Отсюда следует, что переданный набор восстанавли-
вается по искаженному однозначно.
Обратно, пусть d 2/, а а и 0 — кодовые наборы,
для которых р (а, 0) — d. Тогда в силу (6.13) выполнено
Дю t и тем более AOi = Дю — Aw t. Заменив нуле-
вые разряды наборов а и 0, расположенные соответ-
ственно на участках III и I, единичными, получим один
и тот же набор. По нему невозможно определить, из
какого кодового набора (а или 0) он произошел в ре-
зультате не более t искажений типа {0-> 1}.
Из выражения (6.11) для р видно, что для одного
и того же кода выполнено d d, и, следовательно, воз-
можность исправления им несимметричных ошибок не
меньше, чем для симметричных. К тому же заключению
можно прийти и исходя из того, что симметричные
ошибки имеют более общий вид, чем несиммет-
ричные.
Рассмотрим в качестве примера код К. = {0000, ОНО,
1001, 1111}. Для него d = 2, и согласно (6.9) он не мо-
жет исправлять симметричных ошибок (может лишь
обнаруживать 1 ошибку). В то же время этот код имеет
d = 4 и в соответствии с (6.12) исправляет 1 несиммет-
ричную ошибку. В том же самом мы убедились раньше
непосредственно по таблице декодирования 6.2.
В разделе 6.7.4 мы встретимся еще с одним видом
расстояния (для арифметических ошибок). Всюду даль-
ше, если не оговорено противное, под расстоянием бу-
дем понимать расстояние Хемминга.
6.3.4. Оптимальность некоторых кодов. Код называ-
ется оптимальным, если он имеет максимальную мощ-
ность (число наборов) среди всех кодов с той же кор-
ректирующей способностью. Докажем с использованием
введенных геометрических понятий, что некоторые из
рассмотренных в § 6.2 кодов являются оптимальными.
Код с проверкой на ч ет н о с т ь. Первые п—1
разрядов кодовых векторов являются информацион-
ными и могут принимать произвольные значения (по-
следний разряд однозначно определяется ими). Мощ-
282
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
[ГЛ. VI
ность кода совпадает с числом 2"-1 вариантов заполне-
ния информационных разрядов.
Покажем, что любой код, обнаруживающий 1 ошиб-
ку, имеет мощность, не превосходящую 2"-1. Предполо-
жим, что это не так и мощность некоторого кода больше
2"-1. Образуем из каждого кодового набора путем от-
брасывания последнего разряда укороченный набор
длины п—1. Число различных укороченных наборов
не превосходит общего числа 2П-1 наборов длины п—1,
а потому среди укороченных наборов встретятся оди-
наковые. Кодовые наборы, из которых они произошли,
отличаются лишь в последнем разряде и расстояние
между ними равно 1. Это противоречит неравенству
(6.8), согласно которому кодовое расстояние должно
быть не меньше 2.
Код Хемминга. Докажем оптимальность этого
кода при длинах
n = 2r — 1, (6.14)
где г — целое число. Из (6.2) и (6.14) заключаем, что
число
г = log (п 4~1) (6.15)
представляет собой количество проверочных разрядов
кода. Мощность кода равна числу 2"-'" вариантов при-
писывания значений информационным разрядам и с
2"
учетом (6.15) составляет п_^_
Убедимся теперь, что мощность любого кода К,
2"
исправляющего 1 ошибку, не превосходит (это
справедливо для чисел п произвольного вида). Прове-
дем вокруг каждой кодовой точки шар радиуса 1
(рис. 6.6 при t=l). Эти шары не пересекаются, ибо
d 3. Один шар радиуса 1 содержит п 4- 1 наборов
(центр и п наборов, отличающихся от него в 1 раз-
ряде), а суммарное число наборов, попавших в шары,
Доставляет |K|(«4- 1), где |К|—мощность кода К.
Число наборов в шарах не превосходит общего коли-
чества наборов длины п:
| К | (п 4- 1) < 2й,
§ 6.3]
КОДОВОЕ РАССТОЯНИЕ
283
откуда
2"
(6.16)
Тем самым установлена оптимальность кодов Хем-
минга для чисел п = 2Г—1 (г=1, 2, ...). При произ-
вольном п число проверочных разрядов удовлетворяет
неравенству (см. (6.2))
г < log (п + 1) + 1,
и, следовательно, мощность кода 2п~г превосходит
2п
2(п+ О ' ОТС1°Да с Учетом (6.16) заключаем, что при
произвольном п код Хемминга отличается по мощности
от оптимального менее чем в 2 раза.
6.3.5. Границы мощности кодов. Рассуждения, с по-
мощью которых получена оценка (6.16), очевидным
образом распространяются на случай кодов, исправ-
ляющих t ошибок. Если код Kt исправляет t оши-
бок, то шары радиуса t, описанные вокруг кодовых
точек, не пересекаются. Каждый такой шар содержит
1 + п + Сп + ... + Сп наборов (они отличаются от
центра не более чем в t позициях), откуда
| Kt | (1 + п + С* + ... + С*п) < 2",
и, следовательно,
Эта оценка носит название верхней границы Хем-
минга. Она относится к произвольному коду и, в частно-
сти,— к оптимальному. Найдем теперь нижнюю оценку
мощности оптимального кода K°t, исправляющего /оши-
бок.
Построим код, исправляющий t ошибок, с использо-
ванием следующей процедуры. В качестве первого ко-
дового набора Й1 возьмем произвольный. Затем к коду
отнесем любой набор а2, лежащий вне шара радиуса
2t с центром в щ. На следующем шаге в код включим
набор а3, не принадлежащий шарам радиуса 2/, опи-
санным вокруг ai и аг, и т. д. Процедура завершается
284
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
|ГЛ. VI
§6.4]
ЛИНЕЙНЫЕ КОДЫ
285
после того, как не останется наборов, расположенных
вне шаров радиуса 2t с центрами в точках, выбранных
на предыдущих шагах. Построенный код {cci, аг, ...
..., as} исправляет t ошибок, поскольку расстояния
между любыми входящими в него наборами не меньше
2t 4- 1 (если бы было p(az, a/) 2i (i < /), то набор а,
принадлежал бы шару, описанному вокруг а/).
Оценим число s шагов указанной процедуры. Каждый
шар радиуса 2t содержит V2t = 1 ф п ф С2п ф • • • + Сп
точек. Если выполнено неравенство sVu < 2п, то су-
ществует набор, лежащий вне шаров с центрами в ai,...
..., as, и процедура может быть продолжена. Поэтому
имеет место противоположное неравенство sV2i 2",
откуда
С учетом выражения для Уы и того, что мощность оп-
тимального кода К? не меньше мощности s построен-
ного кода, получаем оценку
ко\>_________________
1 + л + С2 +
(6.18)
которая носит название нижней границы Гилберта.
Код, на основе которого доказана оценка (6.18), по-
строен с помощью некоторой переборной процедуры.
Поэтому трудно рассчитывать на то. что он будет иметь
какую-либо упорядоченную структуру, и допускать ко-
дирование и декодирование без использования таблиц.
Конструктивный способ построения практически хоро-
ших кодов с заданной корректирующей способностью
будет изложен дальше. Но для этого вначале понадо-
бится изучить некоторые специальные классы кодов.
§ 6.4. Линейные коды
6.4.1. Определение линейного кода. При рассмотре-
нии примеров кодов в § 6.2 мы видели, что одним из
средств задания кодов являются проверочные соотно-
шения. В этом случае код определяется как множество
всех двоичных наборов a — (ai, .... a„), удовлетво-
ряющих системе некоторых соотношений вида — 0.
/
Всякий такой код К обладает следующим свойством
(L):
— если а, р е К, то и a ® р <= К.
Действительно, вычислив значение произвольного про-
верочного соотношения на наборе a © р, получим
g(ai/®P//) = gat/®gpi/ = 0©0 = 0
i i /
(каждая из двух сумм обращается в 0, поскольку аир
являются кодовыми наборами). Таким образом, на на-
боре афр все проверочные соотношения выполняются,
и он принадлежит коду.
Всякий код, обладающий свойством (А), будем на-
зывать линейным (в частности, линейными являются
коды, задаваемые посредством проверочных соотноше-
ний). Такое название кода связано с тем, что множество
его наборов образует линейное векторное пространство,
если рассматривать векторы с компонентами 0 и 1, а
суммой векторов а и Р считать a © р.
Напомним, что множество векторов V образует ли-
нейное пространство, если для любых a, b е V и числа с
имеет место а Ц-b V и с-а^У. В нашем случае пер-
вое из условий принимает вид а ф р е К для a, р s К
и совпадает со свойством (L). Для пространства двоич-
ных наборов имеет смысл рассматривать в качестве
констант с лишь 0 или 1. Поэтому набор с-а равен a
или нулевому набору 0 и второе условие с-aeK для
а евыполнено тривиально (0 всегда принадлежит
коду по свойству (Л), ибо а® а = 0). Отметим, что при
замене обычного сложения операцией © все основные
свойства линейного векторного пространства сохра-
няются, и мы будем ими пользоваться без особых ого-
ворок.
286
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
[ГЛ. VI
Кодовое расстояние d линейного кода совпадает с
минимальным весом wmin кодовых наборов, отличных от
нулевого.
Действительно, если а^К и O’(a)=t0min, то
d<p(a, б)= шт!п.
С другой^стороны, если (3 и у — кодовые векторы такие,
что р(р, y) = d, то в силу (6.6) и включения рфуеК
Й = wmin.
Из сопоставления этих неравенств получаем требуемое
утверждение. Приведенное свойство кодового расстоя-
ния оказывается очень удобным при изучении линейных
кодов.
6.4.2. Порождающая матрица. Рассмотрим некото-
рый линейный код К. Он образует линейное простран-
ство; пусть его размерность составляет k. Найдутся k
линейно независимых векторов ai, а2, ..., as (базис),
порождающих все пространство. Это означает, что вся-
кий кодовый вектор а может быть представлен в виде
некоторой линейной комбинации cyxi ф с2а2 ф ... фс*а4
(с коэффициентами 0 и 1) базисных векторов и, наобо-
рот, всякая такая линейная комбинация дает кодовый
вектор. Всего имеется 2fe линейных комбинаций (по чис-
лу наборов констант (щ, с2, ...,£*)) и все они раз-
личны, ибо если С1Й!® ... фсййй = С1й.ф ... ®c£ak,
то (с,фс[) й]ф ... ф(с4фс/е) ak = б, что в случае
(ci......cfe)#=(cl, ..., c'k) противоречит линейной незави-
симости базисных векторов. Таким образом, мощность
кода К равна 2й.
Составим матрицу G, строками которой являются
базисные векторы
an СС]2 ... ain~"
a21 И22 • . . И2п
_ _ Clfel a&2 • • _
Всякий кодовый набор есть сумма (по mod 2) некото-
рых строк этой матрицы и, обратно, сумма любых ее
строк принадлежит коду. Поэтому G называется порож-
§ 6.4]
ЛИНЕЙНЫЕ КОДЫ
287
дающей матрицей кода К. Один и тот же код может
быть задан различными порождающими матрицами.
Порождающие матрицы G используются для целей
кодирования информационных последовательностей.
С помощью кода мощности 2fe можно кодировать произ-
вольные информационные последовательности длины k
(их 2fe штук). Пусть задана последовательность Р —
= (Рь ..., Pfe). Сопоставим ей кодовый набор
й = PG = Р1Й1ФР2Й2Ф ••• ©PfcSfe.
Поскольку все линейные комбинации базисных векто-
ров различны, то при таком способе разным р будут
соответствовать различные наборы й.
6.4.3. Приведенно-ступенчатая форма порождающей
матрицы. Образуем матрицу G* из всех 2k кодовых век-
торов
~ Й1
Й2
g*= ;
Иц
«21
012
0.22
О.\п
О2П
а2к,
Ее ранг совпадает с размерностью k кодового простран-
ства, поэтому она имеет k линейно независимых столб-
цов. Переставим столбцы так, чтобы линейно независи-
мыми были первые k штук. При этом получим матрицу
некоторого эквивалентного кода. Дальше будем считать,
что линейно независимыми столбцами матрицы G* яв-
ляются бь ..., б*. Остальные г = п— k столбцов вы-
ражаются в виде их линейных комбинаций:
k
Vk+j = ^psivs (j—1, •••> г), (6.19)
S=1
где /7S;s{0, 1}. Пусть й=(аь ..., ап) — произвольный
кодовый набор. Он является некоторой строкой матри-
цы G*, и в применении к ней равенства (6.19), расписан-
ные покомпонентно, дают
k
ak+j = ^psias (/ = 1, ..., г). (6.20)
S=1
288 ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ [ГЛ. VI § 6.4]
ЛИНЕЙНЫЕ КОДЫ
289
Таким образом, кодовый вектор а полностью опреде-
ляется компонентами cci....аь, и разные кодовые век-
торы имеют разные начала длины k.
Поскольку число кодовых векторов равно 2\ то сре-
ди их начал встречаются все наборы длины k и, в част-
ности,— наборы (1,0, 0), (0,1, ..., 0), ..., (0,
0, ..., 1) с 1 единицей. Обозначим через кодовый на-
бор с началом (0, ..., 0,1,0, ..., 0), где 1 находится
на i-м месте. Из (6.20) находим, что его компонента
с номером & + / (/= 1, .... г) равна щ/. Наборы
(1=1, ..., k) линейно независимы, ибо линейно неза-
висимы их начала длины k. Следовательно, они обра-
зуют базис пространства, а составленная из них мат-
рица
' Л, " 1 0 . .. 0 Р11 Pl 2 .. pir
Л2 0 1 . .. 0 Pai P22 .. p2r
Go = — _ 0 0 . .. 1 Pfei Pk2 • • Pkr-
(6.21)
является порождающей матрицей кода. Такая форма
матрицы носит название приведенно-ступенчатой.
При использовании для кодирования информацион-
ных последовательностей (3 = (pi, р*) матрицы Go
в приведенно-ступенчатой форме кодовые наборы
й — pG0 — PiM ® Р2^2® • • • ® РД*
в первых k разрядах будут совпадать с р. Таким обра-
зом, код с порождающей матрицей в приведенно-сту-
пенчатой форме является систематическим (раздел
6.2.4). Его первые k разрядов являются информацион-
ными, остальные — проверочными. В результате уста-
новлено, что всякий линейный код эквивалентен некото-
рому систематическому коду (напомним, что при
построении матрицы Go мы допускали перестановку
столбцов).
Преобразование порождающей матрицы к приведен-
но-ступенчатой форме может быть осуществлено обыч-
ным методом исключения, используемым для решения
систем линейных уравнений (модифицированным с уче-
том того, что элементами матриц являются 0 и 1, а
роль сложения играет ®). В качестве элементарных
преобразований допускаются перестановки строк и
столбцов и прибавление (по mod 2) к одним строкам
других.
Применение метода исключения рассмотрим на при-
мере. Пусть порождающая матрица кода имеет вид
1 1 Ol-
io 1 0 .
1110.
Переставим в ней строки 1 и 2 с тем, чтобы верхний
диагональный элемент стал равным 1:
rl 1 0 1 fl-
01 1 0 1 .
.01110.
Первый столбец имеет нужный вид. Исключим во вто-
ром столбце 1 в строках 1 и 3, сложив их со строкой 2:
-10111-
0 110 1 .
.000 1 1.
Осуществим перестановку столбцов 3 и 4 с тем, чтобы
нижний элемент в столбце 3 стал равным 1:
-10 111-1
0 10 1 1 .
.0 0 1 0 1 J
Исключив в третьем столбце верхний элемент 1 прибав-
лением к первой строке третьей, получаем матрицу нуж-
ного вида:
г 1 0 0 1 01
Go = р 1 0 1 1 . (6.22)
L0 0 1 0 1J
Чтобы проиллюстрировать, как осуществляется коди-
рование на основе матрицы Go, найдем кодовый вектор
для информационной последовательности (1, 0, 1);
[10 0 10-1
0 10 11 =(10101).
0 0 1 0 1 J
Начало кодового вектора совпадает с исходной после-
довательностью (код систематический) .
10 Л. А. Шоломов
290
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
[ГЛ. VI
В дальнейшем нам понадобится следующее свой-
ство. Если Go = [EfeiP] и матрица Р' получена из Р в
результате некоторой перестановки строк, то коды, по-
рождаемые матрицами Go и Go = [Ek IР'], эквивалентны.
Это следует из того, что от Go к Go можно перейти в
результате подходящей перестановки строк и такой же
перестановки столбцов. Так, например, чтобы в мат-
рице Go (6.22) поменять местами фрагменты (10) и (01)
строк 1 и 3, нужно вначале переставить сами строки
(целиком), а затем осуществить перестановку столбцов
1 и 3:
-10 0 1
0 10 1
.0010
01 Г0
1 ~ о
1J L1
0 11
1 1 I
1 о J
0 1
1 о
о о
о
1
1
о
1
о
о
о
1
Найдем теперь порождающие матрицы в приведен-
но-ступенчатой форме для кода с проверкой на четность
и кода Хемминга (эти коды линейны, поскольку могут
быть заданы проверочными соотношениями).
Код с проверкой на четность. Для него
k = п—1, а потому матрица Р в (6.21) состоит из 1
столбца (г = 1). Каждая строка матрицы Go принадле-
жит коду и, следовательно, содержит четное число еди-
ниц. В любой строке матрицы Ek имеется ровно 1 еди-
ница, поэтому столбец, дописываемый к Ek для образо-
вания Go, должен быть сплошь единичным. В резуль-
тате
” 1 0 ... oil"
01 ... 0 I 1
Gq— , . . | .
i
_о 0 ... 1 I 1 _
Код Хемминга. Будем рассматривать случай
п = 2Г—1, когда код имеет наиболее хорошую струк-
туру- Код Хемминга исправляет 1 ошибку, поэтому для
него d 3 и веса всех ненулевых кодовых векторов
не меньше 3. Каждый кодовый вектор, являющийся
строкой матрицы Go, содержит в первых k разрядах
ровно одну единицу (см. (6.21)), в связи с чем в под-
матрице Р у него должно быть не меньше 2 единиц.
Все строки матрицы Р различны, ибо в противном слу-
§ 6.4]
ЛИНЕЙНЫЕ КОДЫ
291
чае, сложив 2 строки порождающей матрицы, совпадаю-
щие в подматрице Р, можно получить кодовый набор
веса 2 (что противоречит условию d^3). Матрица Р
(как и Go) имеет k = n— г = 2Г — г—1 строк. Число
различных строк длины г, содержащих не менее двух
единиц, равно 2Г — г—1 (из общего числа 2Г строк ис-
ключаются нулевая и г строк с одной единицей). Сле-
довательно, матрица Р составлена из всех строк с ве-
сом 2 и выше. Перестановка строк матрицы Р приво-
дит к эквивалентному коду, поэтому они могут быть
записаны в произвольном порядке. Таким образом, в
качестве Go может быть взята матрица
О о О 1 1 "
О О ... 1 0 1
1 1 ... 1 1 1 _
6.4.4. Проверочная матрица. Всякий кодовый вектор
б = (ai, ..., ап) удовлетворяет соотношениям (6.20),
которые могут быть переписаны в виде
k
afe+/® (/=1,..., г). (6.23)
Обратно, если для некоторого набора а выполнено
(6.23), то он является кодовым. Действительно, взяв
кодовый набор, который имеет первые k символов (ин-
формационные) те же, что и б, из равенств (6.20) за-
ключаем, что и остальные разряды этих наборов совпа-
дают. Таким образом, всякий линейный код может быть
задан посредством проверочных соотношений. В начале
этого параграфа был установлен обратный факт, что
код, определенный с использованием проверочных соот-
ношений, является линейным.
Введем матрицу
Ри
р21
р22
Pkl I 1 о
Pk2 1 0 1
0 “
о
-Р1Г р2Г
pkr i 0 0
10*
292
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
[ГЛ. VI
которую будем называть проверочной матрицей кода.
Система проверочных соотношений (6.23) может быть
переписана в виде
йЯо = 0, (6.25)
где Т означает транспонирование. Сравнивая (6.25) и
(6.21), заключаем, что Но = [Р' = Ег].
Найдем проверочные матрицы для кодов, рассмат-
ривавшихся выше.
Код с проверкой на четность. Для него
матрица Р имеет вид столбца длины п— 1, составлен-
ного из единиц, поэтому Но является строкой длины п:
До = [11 ... 11]
(последняя единица возникает за счет ЕД. Матрице Но
соответствует проверочное соотношение а1фа2ф ...
... фал = 0.
Код Хемминга (при n = 2r — 1). Проверочная
матрица состоит из всех 2r—1 ненулевых столбцов
длины г (к матрице Рт, содержащей столбцы с весом
2 и больше, дописываются столбцы с одной единицей)
’ 1 1
1 о
1=1 0 ... 0“
1 ] 0 1 ... о
1 i о о ... о
0 0 ... 1 ; 0 0 ... 1
Для двоичных векторов й = (ссь ..., а„) и Р =
= (pi, РД определим скалярное произведение
йр = axpi ф а2р2 ф ... ф а„Р„.
Векторы й и р будем называть ортогональными, если
йр = 0. Обозначим через Q множество всех двоичных
наборов 7 = (71.....qn), ортогональных каждому кодо-
вому вектору (оно, в частности, содержит строкитр, ...
..., щ проверочной матрицы (см. (6.25)). Если qi,q2^
е Q, то для любого кодового набора й выполнено
й (?1 ф 72) = Й71 ф Й72 = 0 ф 0 = 0
и, следовательно, qi ф q2 е Q. Поэтому множество Q
является линейным векторным пространством. Пока-
ЛИНЕЙНЫЕ КОДЫ
293
§ 6.4]
жем, что строки г]!, . fjr матрицы Но составляют его
базис.
Рассмотрим произвольный вектор Q. Образуем
вектор
р = ©7*+2Л2® •••
который имеет те же последние г разрядов qk+i, qk+i,
..., qn, что и q. Покажем, что р совпадает с q. Если
р #= q, то набор § = р ® q имеет вид (sb s2, Sk,
О, ..., 0), причем среди компонент $1, ..., Sk есть от-
личные от 0. Поскольку se Q, то произвольный кодовый
вектор а удовлетворяет проверочному соотношению
as = aiSi® ... ф UkSk — 0. Это противоречит тому,
что информационные разряды ось ..., а* могут быть
назначены произвольно. Таким образом, р совпадает с
q и всякий вектор из Q есть линейная комбинация строк
проверочной матрицы. Эти строки линейно независимы
(линейно независимы их правые концы длины г), и,
следовательно, они составляют базис пространства Q.
Тот же самый код К. можно задать с помощью про-
верочных соотношений
аНт = 0,
где матрица Н образована некоторыми другими г ба-
зисными векторами пространства Q. Это следует из того,
что если набор а ортогонален каждому базисному век-
тору, то он ортогонален любой их линейной комбинации
и, в частности, — строкам матрицы Но. Матрицу Н так-
же будем называть проверочной.
6.4.5. Декодирование линейных кодов. Как мы ви-
дели, порождающие матрицы используются для целей
кодирования информационных последовательностей.
Проверочные матрицы применяются в задачах декоди-
рования. Опишем, как осуществляется декодирование
линейных кодов.
Если |3 = (Р1, ..., рп) —некоторый двоичный вектор,
то двоичный набор &НТ длины г (здесь Н — провероч-
ная матрица) будем называть синдромом вектора Р-
Кодовые векторы имеют нулевые сийдромы (6.25).
Пусть при передаче кодового набора а произошла
ошибка и в результате принят вектор Р. Вектор ё =
== (б1, ..., е„), у которого компонента ег (г — 1, ..., п)
294
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
[ГЛ. VI
равна 1, если at =/= р,-, и нулю в противном случае, бу-
дем называть вектором ошибки. Таким образом, ё = йф
фр, а принятый вектор выражается через переданный
и вектор ошибки посредством соотношения р= йфё.
Вычислим синдром вектора р с учетом того, что й —
кодовый вектор.
$НТ = (й ф ё) Нт = аНт ф гНт = гНт.
Это равенство показывает, что вектор ошибки находит-
ся среди векторов, имеющих тот же синдром, что и р.
С другой стороны, всякий вектор 6 такой, что ЪНТ=
= рЯг, может являться вектором ошибки. Действитель-
но, рассмотрим набор й' = рфб. Для него
й'Дг = рДгфбДг = 0,
и, следовательно, й' является кодовым набором. Век-
тор Р мог образоваться при передаче й' в результате
ошибки 6.
Для того чтобы из векторов, имеющих тот же синд-
ром, что и Р, выбрать предполагаемый вектор ошибки,
применяются следующие вероятностные соображения.
Будем считать, что передача ведется по двоичному сим-
метричному каналу с вероятностью ошибки р (р < у) ’
Вероятность того, что при передаче произойдет ошибка
ё, составляет
p^ = pwm(l-Pr~wW, (6.26)
где w (ё) — вес вектора ё (да (ё) разрядов искажены и
п — w (ё) приняты правильно). Поскольку р < у и
1—-р>у, то, как показывает (6.26), наиболее вероят-
ной является ошибка ё наименьшего веса (для нее р (ё)
максимально). Таким образом, из всех кандидатов на
роль ошибки ё естественно выбрать тот, который имеет
наименьший вес (если таких векторов несколько, то лю-
бой из них). Назначив ё, находим кодовый набор а —
= Р©ё, который считается переданным.
С учетом того, что
р (й, Р) = w (й Ф Р) — w (ё),
§ 6.5] ЦИКЛИЧЕСКИЕ КОДЫ 295
а значение w (ё) минимально, заключаем, что а являет-
ся ближайшим к Р кодовым вектором. В связи с этим
описанный метод носит название метода декодирования
в ближайший кодовый вектор. Тривиальный способ оты-
скания ошибки ё состоит в переборе всех векторов 6 =
— (61....6,0 в порядке возрастания w (6). Первый из
встреченных 6, для которого ЪНТ = $НТ, может быть
принят в качестве ё.
Описанный метод декодирования применим к линей-
ным кодам произвольного вида. Коды, используемые на
практике, обычно допускают более простые способы де-
кодирования. Так, например, в случае кода Хемминга
(при п = 2Г— 1) в качестве вектора ошибки принимает-
ся набор (0, ..., О, 1, 0, ..., 0) с одной единицей, пози-
ция которой задается числом, двоичной записью кото-
рого является синдром (отметим, что синдром равен
набору значений проверочных соотношений).
В данном параграфе мы видели, что линейные коды
обладают рядом существенных преимуществ в сравне-
нии с кодами произвольного вида. Для линейного кода
всегда имеется эквивалентный ему систематический код.
Последний полностью описывается матрицей Р (см.
(6.21) и (6.25)) размера («— &)ХА В то же время
для задания кода произвольного вида, имеющего ту же
мощность, требуется таблица размера nX2ft. Кодиро-
вание и декодирование для линейных кодов осуществ-
ляются гораздо проще, чем в общем случае. При этом
линейные коды обладают достаточно высокой коррек-
тирующей способностью: в главе VII будет показано,
что при передаче по двоичному симметричному каналу
они могут обеспечить скорость передачи, сколь угодно
близкую к максимальной. Абсолютное большинство из
всех известных к настоящему времени наилучших (в том
или ином смысле) кодов составляют линейные.
§ 6.5. Циклические коды
6.5.1. Порождающий многочлен. Для конструирова-
ния циклических кодов будут использоваться много-
члены
f(x) = ₽ox'"®₽Ix"’-1® ...®₽га
296
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
[ГЛ. VI
с коэффициентами 0 и 1. Над такими многочленами
можно производить операции сложения, умножения и
деления. Сложение многочленов осуществляется по мо-
дулю 2 (т. е. по mod 2 складываются их коэффициен-
ты), а при выполнении умножения и деления подобные
члены приводятся также по модулю 2. В качестве при-
мера осуществим перемножение многочленов
(х3фхф1)(х2ф1) =
= Х5фх3фх2фх3фхф 1 =Х5фх2фхф 1.
Многочлены указанного вида и операции над ними об-
ладают всеми привычными свойствами, и мы будем ими
пользоваться без каких-либо особых оговорок.
Код называется циклическим, если он является ли-
нейным и для любого кодового набора (а0, tzi, ...
..., ал-i) набор (си, ..., ал-i, а0), образованный из
него циклическим сдвигом, принадлежит коду. Отсюда
следует, что циклический код содержит все наборы, по-
лученные из кодовых в результате произвольного числа
циклических сдвигов. Примером циклического кода мо-
жет служить код с проверкой на четность. Циклический
сдвиг не изменяет числа единичных компонент и, следо-
вательно, не нарушает четности.
Приведем способ построения циклических кодов.
Пусть g(x)— некоторый многочлен, делящий хлф1.
Рассмотрим множество всех многочленов Цх) степени
не выше п—1, которые делятся на g(x). Каждому та-
кому многочлену f(x) = ао*"-1 ф aixn~2 ф ... фсся-1
сопоставим набор его коэффициентов й = (схо, «ь •••
..., ccn-i). Полученное множество наборов й обозначим
через К.
Покажем, что множество К образует циклический
код. Пусть й и р—произвольные наборы из К. По усло-
вию многочлены с наборами коэффициентов й и р делят-
ся на g(x):
/б(х) = а0х,г-1фа1Х,1-2ф ... фа„-! = g(x)tz(x),
(х) = РоХ"-1 ф РхХ«-2 ф . . . ф Р„_ J = g (х) V (х).
§ 6.5]
ЦИКЛИЧЕСКИЕ КОДЫ
297
Тогда многочлен
fe®fSW = («o®₽o)^‘® • • • =
= g(x) (и (х)фи(х))
также делится на £(х)и, следовательно, афреК. Это
доказывает, что код К является линейным. Возьмем те-
перь произвольный набор а = (а0, аь ..., an-i)^K и
образуем из него циклическим сдвигом набор зи =
= (он, ..., а,-г-i, «о). Соответствующий многочлен fa,(x)
может быть преобразован следующим образом:
fa, (х) = alxn~l®a2xn~2® ... фа„_1Хфа0 =
= х(а0х"-,фа1х'г-2ф ... фа„_1)фа0(хлф1) =
= хМх)фао(хпФ1). (6.27)
Поскольку fa (х) и хп ф 1 делятся на g(x), то тем же
свойством обладает и fa, (х). Поэтому феД' и код К
является циклическим. Многочлен g(x), на основе кото-
рого построен код, носит название порождающего мно-
гочлена.
Убедимся теперь, что всякий циклический код К мо-
жет быть получен указанным способом. Будем предпо-
лагать, что код К помимо нулевого набора (0, ..., 0)
содержит некоторые ненулевые наборы (в противном
случае в качестве g(x) может быть взят многочлен
хп ф 1). Каждому набору а сопоставим многочлен f а (х)
с коэффициентами из а. Среди всех многочленов, соот-
ветствующих кодовым наборам, выберем тот, который
имеет наименьшую степень (если их несколько, то —
любой из них). Этот многочлен обозначим через g(x);
пусть его степень равна г:
^(х) = уохгфу1Х'-1ф ... фуг-1Хфуг (Vo=0- (6-28)
Покажем, что всякий многочлен fa(x) (а е К) делится
на g(x). Осуществим деление с остатком:
/в (х) = g (х) и (х) ф г (х) =
= g(x) (Рох"-'-1ф . .. ФРп-г-1)Ф(еоХг-1Ф • • фег_1).
Отсюда
еохг-1 ф .. . ф 8Г_ 1 =
=fa (х)фрохга-'- 'g (х)ф... ®P„_r_2xg (х)фр„_г_ ig (х).
298
помехоустойчивое кодирование
[ГЛ, VI
Рассмотрим следующие наборы длины п— 1:
У°==(0, 0, О, уо, Y1, • • •, Yr),
у1 = (0, .. О, уо, Yi, • • •> Yr, °)> • • •,
Y"-''-1 = (Yo, Yi, • •, Yr, °, 0, • • •> °)-
Им соответствуют многочлены g(x), xg(x), ...
..., xn~r~lg(x); поэтому
Box'-1® ... ®er_! =
= faW®₽ofv«-r-i(x)® ... ®|3„_r_2fv, (x)©P„_r_1fVo(x)>
и, следовательно
8 = б®₽оу”“Г_1® • • • ©Lr4W-r-lY°,
где ё = (0, О, е0, ..., 6Г_1). Наборы й, у0, у1,.... уга-г-1
принадлежат К, ибо fa(x) = g(x), а у1, у"-''-1 по-
лучены из у0 циклическим сдвигом. Набор ё, являясь
их линейной комбинацией, также содержится в К. Если
многочлен г (х) — (х) отличен от 0, то он имеет сте-
пень меньшую, чем степень g(x), а это противоречит
выбору g(x). Таким образом, г(х)= 0 и многочлен /а(х)
делится на g(x)
Осталось показать, что хп ф 1 делится Ha~g(x). Из
(6.27) следует, что если набор aj получен из а сдвигом
на 1 разряд, то
ао(хлФ1) = к(х)фхМх). (6.29)
Из всякого ненулевого вектора путем циклических сдви-
гов можно получить вектор, у которого крайняя левая
компонента равна 1. Поэтому код К содержит набор
а = (ссо, ось ..., ая-i) такой, что ао=1. Применив к
нему (6.29), с учетом того, что fa(x) и fat(x) делятся на
g(x), заключаем, что g(x) делит х"©1. Итак, всякий
циклический код может быть задан с помощью порож-
дающего многочлена, являющегося делителем хпф1.
Рассмотрим пример. Возьмем g(x)=x©l. Мно-
гочлен хп ф 1 делится на х ф 1:
х"ф 1 = (х ф 1) (х"-1 Ф х«-2© ... ©X ф 1),
поэтому х ф 1 может служить порождающим многочле-
ном. Пусть К —соответствующий ему циклический код.
§ 6.5!
ЦИКЛИЧЕСКИЕ КОДЫ
299
Если as К, то для некоторого и(х) выполнено
fa (х) = аоХге-1 ф сцх"-2 © ... ©(*„_! = (хф 1)м(х).
Подставляя в это равенство х = 1, получаем
<ХоФа1 ф • • • Ф'Аг-1 = (1 ф1)W(1) ~ 0 U (1) = 0.
Если же а ф К, то /а (х) = (хф 1) v (х)ф 1 и при х~ 1
имеем аоф«1ф ... фan-i = (1 ф l)v(1)ф 1 — 1. Та-
ким образом, а <= К тогда и только тогда, когда «о ф
ф ai ф ... ф an-i = 0, т. е. х ф 1 является порождаю-
щим многочленом для кода с проверкой на четность.
6.5.2. Порождающая матрица и кодирование. Всякий
циклический код является линейным, поэтому для него
существует порождающая матрица. Покажем, что если
порождающий многочлен имеет вид (6.28), то в каче-
стве порождающей матрицы может быть взята
Vo yi ... уг
Yi ... Уг 0
(6.30)
Действительно, строкам у0, у1, ..., у'1-''-1 соответствуют
многочлены (х) = g (х), (x)=xg(x), ..., (х)==
= хга-г-1£(х), которые делятся на g(x). Следовательно,
строки матрицы G принадлежат коду. Рассмотрим про-
извольный кодовый набор а. Многочлен /а(х) представ-
ляется в виде
fa (х) = g (х) U (x)=g (X) (Р0Х"-'-1 фр1Хга~'-2ф . . . фр„_г_1)=
— Pof^n-r-1 (х) ф Plf^n—г—2 (х) ф . . . ФР„_г_1^о (х),
поэтому вектор а является линейной комбинацией строк
а = р0у”-'-1ФР1у'г-'-2Ф ... Фрге_г_!у°.
Поскольку уо= 1, строки матрицы G линейно незави-
симы (независимы их начала длины п — г). Из сказан-
ного вытекает, что G является порождающей матрицей.
Число ее строк п — г обозначим, как и в § 6.4, через k.
Степень г порождающего многочлена, равная при этом
300
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
[ГЛ. VI
п — k, совпадает с числом проверочных символов в ко-
довых векторах.
Для рассмотренного выше примера (кода с провер-
кой на четность) порождающим многочленом является
g(x) = хф 1. Ему соответствует порождающая матрица
"00
0 о
1 1
0 11"
1 1 о
0 0 0
Для циклического кода существует простой способ
нахождения порождающей матрицы Go в приведенно-
ступенчатой форме. При этом получается матрица того
же кода, а не эквивалентного. Это обстоятельство яв-
ляется существенным, поскольку перестановка разря-
дов может нарушить свойство цикличности. Для по-
строения матрицы Go осуществим деление с остатком
многочленов хп~1, хп~2, ..., хп~к = хг на g(x):
хп~х = g (х) at (х) ® Г1 (х),
Xя-2 = g (х) а2 (х) © г2 (х),
xn~k = g(x) ak(x)®rk (х).
Многочлен хп~' ® г,(х) = g (х) а, (х) (Z = 1, ..., k) де-
лится на g(x), поэтому набор его коэффициентов при-
надлежит коду. Степень остатка п(х) не превосходит
г — 1; пусть
/•/(х) = Лпхг-1®Л/2хг-2® ... ®А<Г
Матрица
1 0 ... 0 Ли Л12 •••
0 1 ... 0 Л21 Л22 • • •
0 0 ... 1
Go =
строки которой соответствуют многочленам xn~i ф г;(х),
имеет приведенно-ступенчатую форму. Таким образом,
всякий циклический код является систематическим.
Для циклических кодов кодирование может быть
осуществлено без использования матрицы Go. Пусть за-
дана информационная последовательность a s= (а0, а1(...
§ 6.5]
ЦИКЛИЧЕСКИЕ КОДЫ
301
as-i). Образуем многочлен xrfa (х) = aoxrt ’фс^х™ 2ф
••• ®ak-iXr и разделим его на g(x) (с остатком):
xrfa (x) = g(x)q(x)®p(x).
Многочлен xrfa. (х) ф р (х) = g (х) q (х) делится на g(x),
и, следовательно, набор его коэффициентов принадле-
жит коду. Поскольку степень остатка р(х) не превосхо-
дит г— 1, первые k компонент этого набора совпадают
с информационной последовательностью а.
6.5.3. Проверочный многочлен, проверочная матрица
и декодирование. По определению порождающего мно-
гочлена g'(x) он делит многочлен х"ф 1. Результат де-
ления (х" ф 1 )/g(x) называется проверочным многочле-
ном циклического кода и обозначается через й(х) (его
степень п — г равна k). Покажем, что если
h (х) = SgXfe Ф b\Xk *ф ... Фбй-1Хфб£, (% = 1,
то проверочная матрица может быть задана в виде
~... 6i 6о о о ... о "
0 dft ... 6, 60 о ... о
"д0 “
д1
_у-1_
(6.31)
0
0 ... О dfe ... di д0
Убедимся, что строки матриц G (6.30) и Н ортогональ-
ны. Поместим строки у (i = 0, 1, ..., k — 1) и & (j =
= 0, 1, ..., г — 1) друг под другом:
к-i-1 г • I I
То'М.цл- 'li.i кчч---'1г 0 - ..0 0...0
.0-0 0 -0. Ф Ф • «о.О-»
./ ' J '
Скалярное произведение этих строк
Тг'+/_ё+1бйФТ/+/-й+2^_1Ф • • • фуЛ i +/— г+1
совпадает с коэффициентом многочлена g(x)/i(x) =
~ хп ф 1 при степени x”~o+/)-i (соответствующий член
произведения g(x)/z(x) равен (y.;+,_A:+iXn_,~/"l)Ss Ф
ф (?i+H+2x"-;-H) (6.-JX) @ ... ф у, (6z+/_,+1 х”-^/-1) ) .
Сумма i ф j заключена между 0 и п — 2, следовательно,
1 ф п — (i Ч- j) — 1 ф п — 1.
302
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
[ГЛ. VI
Поскольку коэффициенты многочлена хп © 1 при степе-
нях х, х2, ..., хп~1 равны 0, скалярное произведение
у'ц обращается в 0. Это доказывает ортогональность
векторов у‘ и д'.
Каждый кодовый вектор является линейной комби-
нацией строк порождающей матрицы G, поэтому он
ортогонален всем строкам д' матрицы Я. Строки мат-
рицы И линейно независимы (ибо бо = 1). Отсюда и
из того, что число строк равно г — п — k, вытекает, что
Н является проверочной матрицей кода.
В качестве примера снова рассмотрим код с провер-
кой на четность. Для него проверочным многочленом
является
/г(х)==4ж' = х'г_1фх'г“2® ••• b
поэтому проверочная матрица имеет вид
Я = [11 ... 11]
(ту же матрицу мы получили в разделе 6.4.4).
Остановимся коротко на вопросе декодирования цик-
лических кодов. Пусть при передаче кодового вектора
б = (а0, ai, ..., ап-\) произошла ошибка ё = (е0, ei, ...
..., еп-1), и в результате принят вектор Р — а © ё. По-
скольку fg(x) — fe(x)®fs(х) и многочлен f& делится на^(х),
то (х) и /г (х) при делении на g(x) имеют одинаковый
остаток. Следовательно, ошибка находится среди тех
наборов, которым соответствует многочлен, дающий при
делении на g(x) тот же остаток, что и многочлен /д(х),
соответствующий принятому набору. Обратно, всякий
набор б, обладающий указанным свойством, может ока-
заться ошибкой. Действительно, многочлен ^©§(х) де-
лится на g(x) и, следовательно, рфб принадлежит
коду. Набор р мог произойти из Р © б в результате
ошибки 6. Из вероятностных соображений (раздел
6.4.5) в качестве ошибки ё нужно принять набор б с
наименьшим весом. Его отыскание может быть осу-
ществлено перебором двоичных векторов в порядке воз-
растания их весов вплоть до вектора, которому соответ-
ствует многочлен с нужным остатком. Практически ис-
§ 6.5]
ЦИКЛИЧЕСКИЕ КОДЫ
303
пользуемые коды обычно допускают существенно более
просп/ю процедуру декодирования.
6.5.4. Операции по модулю многочлена. Как мы ви-
дели, для решения многих задач, связанных с цикличе-
скими кодами, требуется вычисление остатков от деле-
ния многочленов на фиксированный многочлен g(x).
Это относится к задаче нахождения порождающей мат-
рицы в приведенно-ступенчатой форме, задачам кодиро-
вания и декодирования. Поэтому удобно ввести специ-
альные операции для действий с остатками.
Многочлены fi(x) и f2(x), дающие при делении на
g(x) одинаковый остаток, будем называть сравнимыми
по модулю g(x). В этом случае будем записывать
fi (х) = /2 (х) (mod g (х)).
Множество всех многочленов, сравнимых с f(x) (по
modg(x)) будем обозначать {((х)} и называть классом
вычетов по модулю g(x). Для классов вычетов выпол-
нено соотношение
{fi (*)} Ф {f2 (X)} = {/, (х) ф f2 (X)}, (6.32)
которое понимается в следующем смысле. Если иДх)^
е={Л(х)}, н2(х)е{/2(х)}, то «i(x)©H2(x)e{f1(x) ф
ф)2(х)}. Действительно, имеет место «i(x)®fi(x) =
= g(x)ai(x) и н2(х)ф f2(x) = g(x)a2(x) (для некоторых
щ(х) и а2(х)). Поэтому
их (х) ф и2 (х) = g (х) («1 (х) ф а2 (х)) ф (Л (х) ф f2 (х))
и при делении на g(x) многочлены Н1(х)фн2(х) и
ft(x)®f2(x) дают одинаковый остаток. Соотношение,
аналогичное (6.32), выполнено и для умножения:
{Л(Х)} {/2(х)) = {Л (х)/2(х)}. (6.33)
При тех же предположениях относительно иДх) и и2(х)\
имеем
«1 (х) и2 (х) = (fx (х) ф g (х) at (х)) (f2 (х) ф g (х) а2 (х)) =
=g (х) (fi (х) а2 (х)ф/2 (х) «1 (х)ф£ (х) ai (х) а2 (x))®fi (х) /2(х).
Отсюда следует (6.33).
Операции над классами вычетов обладают обыч-
ными свойствами коммутативности, ассоциативности,
304
помехоустойчивое кодирование
[ГЛ. VI
дистрибутивности. Докажем, например, дистрибутив-
ность:
{М ({М Ф О = {fl} {f2 Ф f3} = {f i (h Ф О =
= {f if 2 ® ш = {f Ф {Ш = {fl} {М Ф {fl} {М-
Приведенные правила действия с классами вычетов зна-
чительно упрощают многие рассуждения и выкладки.
Рассмотрим пример. Пусть п = 7 и g(x) = x3©
ф х ф 1. Можно проверить непосредственно, что х7 ф 1
делится на g(x) и результатом деления является много-
член h(x) = х4 фх2 ф х ф 1. Таким образом, g(x) мо-
жет быть взят в качестве порождающего многочлена
циклического кода. Порождающая и проверочная мат-
рица этого кода имеют вид (см. (6.30) и (6.31))
-000101 1"
0 0 10 1 10
0 10 110 0
10 110 0 0
-1 1
0 1
.0 о
1 О 0“
0 1 о
1 0 1
1 о
1 1
1 1
н =
Столбцами проверочной матрицы являются все ненуле-
вые наборы длины 3. Следовательно, данный цикличе-
ский код эквивалентен коду Хемминга.
Найдем его порождающую матрицу в приведенно-
ступенчатой форме. Для этого надо вычислить остатки
от деления х3, х4, х5, хб на g(x). Воспользуемся опера-
циями по модулю g(x) = х3 ф х ф 1. Имеем
х3 = хф 1 (modg(x)),
х4 = х • х3 = х (хф 1) = х2фх (modg (х)),
х5 = х • х4 = х(х2фх) = х3фх2 = (хф 1)фх2 =
= х2 ф х ф 1 (mod g (х)),
х6 = х • х5 = х (х2 ф х ф 1) — х3 ф х2 ф х = (х ф 1) ф х2 ф х =
= х2ф 1 (mod g (х)).
Порождающей матрицей кода в приведенно-ступенчатой
форме является
1000101"
г = 0 10 0 111
UlJ 0 0 10 110'
0 0 0 1 0 1 1
§ 6.51
ЦИКЛИЧЕСКИЕ КОДЫ
305
6.5.5. Схемная реализация. Процедуры кодирования
и декодирования циклических кодов связаны с нахож-
1-х7® 0-х6 ®0-х5 Ф/-я?4Ф/?-ж3 Ф 0-хг® 1-х Ф 0 \1-х3®0-хг®1-х®1
Ф 1-й?®0-х6®1-х6 ®1-х* /•«* ®0-х5®1-х2®0х®1
Ох6® 1-х5 ФОх1-® 0-х3
0-х6® О-х5® О-х1® 0-х3
1-х5 ®0-хА®0-х3®0-хг
®1-х5 ®0х^®1-х5®1-х2
О-х1,®1-х3 ®1-хг ®1-х
Ф/7-д4Ф 0-хА®0-х2®0-х
^х5®1 -хг ®1-х® О
1-х5 ®0-хг®1-х®1
1-х2®0-х®1
Рис. 6.8.
дением остатков от деления многочленов на порождаю-
щий многочлен g(x). Вычисление остатков может быть
осуществлено с помощью достаточно простых устройств.
Они составляют основу оборудования, используемого
при кодировании и декодиро- вании циклических кодов. JOO1OO1O! !юн
Прежде чем описать конст- рукцию таких устройств, оста- новимся более подробно на том, как осуществляется деле- ние многочленов. Рассмотрим в качестве примера многочле- ны f(x) =х7фх4фх и g(x) = — х3 ф х ф 1. На рис. 6.8 при- ведена обычная схема деления д 23х ' 10101
' 1 ®1011 joioo
® 0000 dQQQ, д У
"3 ® 1011 А 2х
f(x) на g(x) столбиком. Если вместо многочленов использо- вать наборы их коэффициен- тов, эта схема может быть пе- реписана более компактно £ П\ ТЯг, хлхх гх « ® 0000 J110, д х
® 1011 101 Я ^“7—’
НИЯ ВИДНО, ЧТО алгоритм нахо- рис ждения остатка состоит в сле- дующем. На каждом шаге 1 к набору А/, полученному после предыдущего шага, прибавляется по mod 2 набор,
306
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
ЦЛ. V5
соответствующий делителю, если левая компонента в
Ai равна 1, и нулевой набор, если эта компонента рав-
на 0. Результатом шага является набор Л,+1, образован-
ный из этой суммы путем отбрасывания левого разряда
(равного 0) и дописывания очередного разряда из на-
бора, соответствующего делимому. На' последнем шаге
7г! 7г=0 7г-г!
Рис. 6.10.
получается набор В коэффициентов остатка от деления
f(x) на g(x).
Вычисления, связанные с нахождением остатка от
деления на многочлен g(x) = хг ф yixr~l ф ... ф
ф уг-1Х ф у, могут быть осуществлены устройством, по-
казанным на рис. 6.10. Оно представляет собой схему
mod 2. Выход задержки 30 подается через элементы ф
на выходы задержек 3i при тех i, для которых у> = 1.
На рис. 6.11 изображено устройство, соответствую-
щее многочлену g(x) = x3®xffil. Для пояснения его
работы рассмотрим пример. Пусть требуется найти ос-
таток от деления многочлена f(x) = х7 ф х4 ф х на
g(x) = х3 ф к ф 1. Первоначально все задержки устрой-
ства находятся в состоянии 0. На вход подаются коэф-
фициенты многочлена /(х) (по одному за каждый такт).
До тех пор пока состоянием задержки Зй является 0,
§ 6.6] ЭФФЕКТИВНОЕ ПОСТРОЕНИЕ КОДОВ 307
устройство осуществляет сдвиг последовательности
коэффициентов влево. Через 3 сдвига в устройстве бу-
дет записан набор Ai (рис. 6.9): первые 3 разряда яв-
ляются состояниями задержек, а четвертый — состоя-
нием входа. На следующем такте первый разряд
набора Д1 прибавляется по mod 2 к третьему и четвер-
тому, осуществляется сдвиг полученной последователь-
ности (с отбрасыванием первого разряда). После этого
набор, образованный состоянием задержек и значением
входа, совпадает с А2 (рис. 6.9). Далее А2 перерабаты-
вается аналогично А\ и т. д. После того как на вход
подан последний коэффициент многочлена f(x), состоя-
ния задержек дают набор В коэффициентов остатка.
Как мы видели, циклические коды обладают рядом
преимуществ в сравнении с линейными. Циклический
код полностью описывается г -ф 1 коэффициентами по-
рождающего многочлена или k -)- 1 коэффициентами
проверочного многочлена, в то время как для линей-
ного необходимо знание rk элементов матрицы. Опера-
ции, связанные с кодированием и декодированием, осу-
ществляются на основе многочленов (без перехода к
матрицам), а операции над многочленами могут быть
выполнены с применением достаточно простых техни-
ческих средств. В следующем параграфе будут описаны
наилучшие из известных кодов для исправления задан-
ного числа ошибок. Эти коды являются циклическими.
§ 6.6. Эффективное построение кодов
с заданной корректирующей способностью (БЧХ-коды)
6.6.1. Алгебра наборов. Циклический код полностью
определяется своим порождающим многочленом. Задача
состоит в том, чтобы выбрать порождающий многочлен,
обеспечивающий коду нужные корректирующие свой-
ства (заданное кодовое расстояние).
Для решения этой задачи нам понадобится ввести
новые операции над двоичными наборами. Определим
произведение наборов ц и v одинаковой длины т сле-
дующим образом. Фиксируем некоторый многочлен сте-
пени т:
р(х) = x"i®plxm~l® ... ®pm-ix®pm.
308
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
[ГЛ. VI
Найдем остаток от деления произведения многочленов
= ... ф|1,;^1хф|1„[,
fv W = V“’' ® • • • ® Vm-lx ®
на p(x). Набор длины m коэффициентов многочлена-
остатка будем называть произведением наборов ц и v
и обозначать |iv. Из свойств вычетов по modp(x) вы-
текает, что так определенное произведение обладает
обычными свойствами ассоциативности, коммутативно-
сти и дистрибутивности (относительно сложения набо-
ров по модулю 2). Произведения рр, црц и т. д. будем
обозначать через ц2, р3 и т. д. Наборы (0, ..., 0, 0) и
(0, ..., 0,1), которым соответствуют многочлены 0 и
1, играют при умножении роль обычных нуля и еди-
ницы-, иногда эти наборы будем обозначать просто сим-
волами 0 и 1.
Рассмотрим пример. Произведение наборов длины
3 определим на основе многочлена
р (х) =Х3фхф1.
Найдем набор (ПО)-(101). Для этого вычислим произ-
ведение соответствующих многочленов:
Л10 W /101 (х) = (х2 ф X) (X2 ф 1) = X4 ф X3 Ф X2 Ф X.
Остаток от деления многочлена х4фх3фх2фх на
х3 фх ф 1 равен х ф 1, поэтому (ПО) • (101) = (011).
Обозначим через х набор (00 ... 010) длины т, со-
ответствующий многочлену х. При любом т существует
многочлен р(х) степени m такой, что если определить
умножение наборов длины ш на основе р(х), то среди
степеней х, х2, х3, ... набора х встретятся все ненуле-
вые наборы длины т. Такой многочлен р(х) называется
примитивным. Доказательство этого факта содержится,
например, в [1]. В таблице 6.3 приведены некоторые
примитивные многочлены для первых значений т.
Рассмотрим в качестве примера многочлен р(х) =
— х3 ф х ф 1 из этой таблицы. Определив умножение
наборов длины 3 на основе р(х), вычислим последова--
тельные степени набора х = (010). Отметим, что й/со-
§ 6.6]
ЭФФЕКТИВНОЕ ПОСТРОЕНИЕ КОДОВ
ЗОЭ
Таблица 6.3
т Р (х) т Р (х)
2 х2 ф х © 1 9 X9 ф X4 ф 1
3 х3фхф 1 10 х!0ф X3 ф 1
4 X* фх ф 1 11 X11 фх2ф 1
5 х5 фх2 ф 1 12 Х12фх5фх4фхф1
6 Xs ф X ф 1 13 х!3фх4фх3фхф1
7 X1 ф X2 ф 1 14 х14фх'°фх6фхф1
8 X8 Ф X4 ф X3 ф X2 ф 1 15 Х!5фхф1
впадает с набором коэффициентов остатка от деления
хг‘ на р(х). Применяя операции по modp(x), имеем
x = x(modp(x)),
x2 = x2(mod р (х)),
х3 = хф 1 (mod р(х)),
х4 = х3 • х = (х ф 1) х — х2 ф х (mod р (х)),
х5 = х4 • х = (х2фх)х = х3фх2 = (хф 1)фх2 =
= х2 ф х ф 1 (mod р (х)),
х6 = х5 -х = (х2фхф 1)х = х3фх2фх = (хф 1)фх2фх =
= х2 ф 1 (mod р (х)),
х7 = хв • х = (х2ф 1) х = х3фх = (хф 1)фх = 1 (mod р (х)).
Отсюда получаем таблицу 6.4.
Таблица 6.4
й й2 й3 й4 й3 й8 й7
010 100 ОН НО 111 101 001
Среди наборов й, й2, ..., й7 встречаются все нену-
левые наборы длины 3. Это подтверждает, что много-
член р(х) — х3 ф х ф 1 является примитивным.
Дальше будем считать, что многочлен р(х), на базе
которого определено умножение наборов длины т,
310
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
[ГЛ. VI
является примитивным. Установим некоторые свойства
такого умножения.
1°. Каждый из 2т — 1 ненулевых наборов длины т
встречается среди первых 2т — 1 степеней набора % (по
одному разу). Предположим, что это не так и какой-
то ненулевой набор ц среди них отсутствует. Тогда либо
некоторые из наборов й1, й2, ...,й2 -1 совпадают между
собой, либо среди них содержится нулевой набор. Если
имеет место первый случай и Xs = хг (1 $ < t 2т —
— 1), то вслед за хг будут циклически повторяться на-
боры, расположенные между Xs и хг:
-1 + 1 -s+l ~t+ (t~ s) -s -Z+(/—s)+l ~s+l
X = X , . . ., X = X , X = X >•••
и набор jl не возникнет ни на каком шаге (это проти-
воречит примитивности многочлена р(х)). Во втором
случае, если йх — (0, ..., 0), то и все последующие сте-
пени х дадут нулевые наборы и набор ц среди степеней
х также не встретится.
2°. Набор (0 ... 01)= 1 получается на шаге 2т—1,
т. е. имеет место соотношение
x2m-'=l. (6.34)
Действительно, если предположить, что й/ = 1 при
s < 2т— 1, то набор xs+1 совпадет с х и среди первых
2т — 1 степеней набора й в противоречии со свойством
1° будет отсутствовать некоторый ненулевой набор.
3°. Последовательность й, й2, ..., й2"*-1 периодически
повторяется. Действительно, %2т = х2ГЛ-1й = 1 • х = х,
^2m+l _ ~2т-1^2 _ J . й2 = й2 и т. д.
Произведение произвольных ненулевых наборов ц и
v удобно вычислять на основе таблицы степеней наборах.
Пусть, например, требуется перемножить наборы ц =
= (Н0) и v = (101). По табл. 6.4 находим, что ц = х4,
v = хб, откуда
jlv = х4й6 — й10 = х7х3 =1 • х3 = х3.
Пользуясь таблицей 6.4, заключаем, что pv = x3 =
= (011). Тот же результат ранее нами был получен не-
посредственно.
§ 6.6]
ЭФФЕКТИВНОЕ ПОСТРОЕНИЕ КОДОВ
311
4°. Произведение ненулевых наборов дает ненуле-
вой набор. Произведение ненулевых наборов является
некоторой степенью набора й, не превосходящей 2т—1.
Среди этих степеней нулевой набор отсутствует (свой-
ство 1°).
5°. Всякий ненулевой набор у. удовлетворяет равен-
Действительно, пусть р = Xs при некотором s. Тогда
в силу (6.34)
= (я^-т = (x2m-')s = Г = 1.
Операции сложения наборов (по mod 2) и умноже-
ния наборов обладают всеми обычными свойствами, и
мы будем ими пользоваться без особых оговорок.
6.6.2. Минимальный многочлен. Пользуясь введен-
ными операциями, можно вычислять значения многочле-
нов от наборов. Найдем, например, значение многочлена
р(х) = х3 А х ф 1 при х = р = й4. Имеем (с использо-
ванием табл. 6.4)
р (у) = ц3 ф ц ф 1 = й12 ф й4 ф 1 = й5 ф й4 ф 1 —
= (111)ф(110)ф(001) = (000) = 0.
В таком случае будем говорить, что набор у является
корнем многочлена р(х) или корнем уравнения р(х) =
= 0.
Из (6.35) следует, что всякий ненулевой набор у
является корнем уравнения
(6.36)
Нулевой набор удовлетворяет уравнению х = 0. Таким
образом, всякий набор является корнем некоторого мно-
гочлена. Многочлен наименьшей степени, корнем кото-
рого является набоо у, будем называть минимальным
многочленом (для р.). Изучим некоторые свойства ми-
нимальных многочленов для ненулевых наборов.
1°. Минимальный многочлен единствен. Предполо-
жим противное, что для набора у имеются два мини-
мальных многочлена f(x) и g(x)' и их степень равна k.
Многочлен [(*)©§(*) имеет степень меньше k и у,
312
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
(ГЛ. VI
является его корнем, ибо f(p) A g(p) = 0 © 0 = 0. Это
противоречит минимальности f(x) и g(x). Единствен-
ный минимальный многочлен для набора р будем обо-
значать дальше через тй (х).
2°. Минимальный многочлен неприводим, т. е. не раз-
лагается в произведение многочленов меньшей степени.
Предположим, что это не так и
W =11 (*) v (Д
Тогда и (р,) v (р) = пг~ (р) = 0, а потому р является кор-
нем многочлена и(х) или и(х) (ибо произведение нену-
левых наборов м(р) и о(р) отлично от нуля). Посколь-
ку степени многочленов и(х) и о(х) меньше, чем у
т. (х), это противоречит минимальности ng (х).
3°. Если р является, корнем многочлена f(x), то f (х)
делится на пг& (х). В частности (см. (6.36)), многочлен
х2™'1©! делится на тр. (х) (для любого р). Представим
f(x) в виде
f(x) = m^ (х)м(х)фг(х),
где степень остатка г (х) меньше степени ng (х). При
х —р с учетом того, что f (р) = т. (р) = 0, заключаем,
И
что г(р)=О. Остаток г(х) тождественно равен 0, ибо
в противном случае набор р является корнем много-
члена г(х), степень которого меньше, чем ут.(х).
4°. Степень минимального многочлена не превосхо-
дит т. Рассмотрим т © 1 наборов рт, рт-1, ..., ц,
1 — (0 ... 01). Поскольку любые т © 1 наборов длины
т линейно зависимы, найдутся константы ао, «1, ..., ат
такие, что
<Хор фа1р?! ф . .. ©а,п_[рфаш = 0.
Это означает, что р является корнем многочлена <zoxm ф
ф <%ixm-1 ф ... ф <Zm-ix А степени не выше т.
5°. Произведение всех различных минимальных много-
членов совпадает с .д ~1А 1.
Отсюда и из 4° вытекает, что многочлен ххП1~'1 А1
разлагается в произведение многочленов степени не
§ 6.6]
ЭФФЕКТИВНОЕ ПОСТРОЕНИЕ КОДОВ
313
выше т. Обозначим через Q(x) произведение всех раз-
личных минимальных многочленов (если один и тот же
многочлен соответствует нескольким й, он участвует в
произведении 1 раз). Каждый из минимальных много-
членов делит х2 ф 1 (свойство 3°) и в силу их не-
приводимости (свойство 2°) многочлен х2 -1ф1 делит-
ся на произведение Q(x). Всякий ненулевой набор й
является корнем многочлена (х), входящего в каче-
стве сомножителя в Q(x), и, следовательно, является
корнем Q(x). Число ненулевых наборов длины т со-
ставляет 2т — 1 и, поскольку степень многочлена не
меньше числа его корней, Q(x) имеет степень не ниже
2т— 1. Из того, что Q(x) делит многочлен >/‘'’'$1 него
степень не меньше 2т — 1, вытекает равенство этих мно-
гочленов.
Замечание. При людом и многочлен х2 ф 1 раз-
лагается в произведение многочленов степени не выше и.
Для того чтобы в этом убедиться, достаточно про-
вести все предыдущие рассуждения при m = и (взять
примитивный многочлен степени и, определить на его
основе умножение наборов длины пит. д.).
6°. Для любого й имеет место равенство
(*) = W-
Если v и п — произвольные наборы длины пг, то
(v ф л)2 = v2 ф vft ф л v ф л2 = v2 ф л2
(ибо л?лфлу = 0). Это равенство может быть последо-
вательно распространено на любое число слагаемых:
(V ф л ф р)2 = V2 Ф (л ф р)2 = V2 ф Л2фр2
и т. д. Рассмотрим минимальный многочлен (х) =
= аохт ф а!хт“1ф ... фат. Воспользовавшись получен-
ным правилом возведения в квадрат, с учетом равен-
ства а2~а. для а{ е {0, 1} имеем
(тДйВМ^®^-1® ••• =
= Щ (йт)2фai (йт~‘)2© • • Ф4 =
= ао (ЙТ Ф а, (йГ~‘ Ф • • • Ф W (й2).
314
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
[ГЛ. VI
Поскольку т- (р) = 0, то отсюда следует, что mfi (р2) = 0.
На основании свойства 3° заключаем, что (х) делится
на т.2(х). Из неприводимости т^(х) (свойство 2°) выте-
кает равенство m. (x) = mft!(x).
7°. Степень многочлена т~ (х) совпадает с минималь-
ным и, при котором выполнено равенство (12“ = jl (дом-
ножив обе части (6.35) на р, заключаем, что такое и
существует и не превосходит т). Рассмотрим и, указан-
ное в формулировке свойства. Убедимся, что наборы
р, р2, р22, ..., р2“-1 различны. Действительно, если это
не так и для некоторых s и/(1^«</^м—1) выпол-
нено p2S = p2Z, то, возведя это равенство в квадрат и — t
раз, получаем
-os + u— t -Oil
г =р- = р.
Поскольку s 4- и — t <Z и, это противоречит минималь-
ности и. Далее, согласно свойству 6°
m. (х) = т-2 (х), (х) = (х), ...
•./п.гИ-2(х) = /п И-1(Х),
и, следовательно, все эти многочлены совпадают. Та-
ким образом, и наборов р, р2, ..., p2“-1 являются кор-
нями многочлена (х). С учетом того, что степень мно-
гочлена не меньше числа его корней, заключаем, что
степень (х) не ниже и. С другой стороны, набор р,
удовлетворяя соотношению р2“=р, является корнем
многочлена х2“фх — х (х2“-1®1), и в соответствии
со свойством 3° этот многочлен делится на т- (х).
По замечанию к свойству 5° многочлен х2<1
раскладывается в произведение многочленов сте-
пени не выше и. Отсюда и из неприводимости те- (х)
(свойство 2°) вытекает, что его степень не пре-
восходит и. В силу сказанного степень т~ (х) совпадает
с и.
Способ построения минимального многочлена про-
иллюстрируем на примере. Пусть требуется найти мно-
гочлен Шц (х) для набора р =(011). Вначале на осно-
вании свойства 7° определим степень /п. (х). Из таб-
§ 6.6]
ЭФФЕКТИВНОЕ ПОСТРОЕНИЕ КОДОВ
315
лицы 6.4 находим, что р = и3. Пользуясь этим, вычис-
ляем наборы р2, р4, ... Имеем
р = х3, р2 = йв, р4 = х12 = й5, р8 = й'° — й3 = р.
Таким образом, р23 = р, и, следовательно, степень
т- (х) равна 3. Сам многочлен может быть найден мето-
дом неопределенных коэффициентов. Пусть т~(х) = х3Ф
фа^фагхфаз. Условие
т. (р) = р3 ф с^р2 ф а2р ф а3 = О
с учетом того, что р3 = х9 = х2 = (100), р2 = х6 = (101),
р = (011), 1 =(001), может быть записано в виде
GHMD4?HD-
Это приводит к уравнениям 1 ф cci = 0, «2 = 0, си ф
ф «2 ф осз ~ 0, откуда ai = l, а2 — 0, «з = 1, что дает
многочлен
mR (х) = х3фх2ф1.
6.6.3. Еще один способ задания циклического кода.
Будем рассматривать случай кодов длины п = 2"1—1,
где т— произвольное целое число. Пусть рь р2, ...
..., ps—различные двоичные наборы длины т. Рас-
смотрим множество 8Г всех многочленов f(x) степени
не выше п— 1, для которых каждый из наборов pi, ...
..., ps является корнем. Всякому многочлену из ST со-
поставим набор длины п его коэффициентов и получен-
ное множество наборов обозначим через /(. Покажем,
что множество К образует циклический код.
Для каждого набора р(- (/ = 1, ..., х) возьмем ми-
нимальный многочлен тп (х) и среди этих многочленов
выберем все различные; пусть это будут т. (х).
.... ш(ф(х) (s^s). Образуем произведение
g(х) = /па] (х) ... m'v(х). (6.37)
Покажем, что g(x) является порождающим многочле-
ном кода К. По свойству 5° многочлен хпф1 =х2т-1ф1
делится на g (х).
316
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
[ГЛ. VI
Рассмотрим произвольный многочлен f(x)^S?~. Каж-
дый из наборов щ (i= 1, у) является корнем f(x)
и в силу свойства 3° /(х) делится па (х) (i — 1, .. .,v).
Поскольку все (х) (i = 1, ..., v) различны и неприво-
димы (свойство 2°), f (х) делится на их произведение g(x).
Обратно, всякий многочлен степени не выше п — 1,
который делится на g’(x), содержится в ST. Действи-
тельно, если некоторый многочлен делится па g(x), то
среди его корней содержатся все корни многочленов
т^(х), ..., (х) и, в частности, все наборы цр ..ps.
Тем самым установлено, что К является цикличе-
ским кодом с порождающим многочленом g(x) (6.37).
6.6.4. Циклический код Хемминга. Рассмотрим мно-
жество всех многочленов степени не выше п—1,
для которых набор й = (0 ... 010) является одним из
корней. Тот факт, что й есть корень многочлена
C4oxrt~l ф оих"-2 ф ... фая-1 (п — 2т— 1), записывает-
ся в виде
аой2т“2©ай2т“3® . • •®а2т_2йфат_1 = 0,
а в матричной форме — в виде
(а0, ар ..., а2т_2, a2m-i)[й2т-2й2Ш_3 .. . й 1]г = 0.
Таким образом, в качестве проверочной матрицы кода Л
может быть взята матрица [й2Ш“2 ... й 1]- Ее столбцами
являются 2т—1 наборов й2™-2, ..., й, 1=й2пг-1 длины т.
Поскольку все они различны и отличны от нулевого,
это есть проверочная матрица кода Хемминга. В ре-
зультате показано, что код Хемминга является цикли-
ческим.
Найдем его порождающий многочлен g(x). Остаток
от деления хт на примитивный многочлен р(х) =
= хт ф pixm~l ф ... ф рт-\Х ф рт, на основе которого
определено умножение наборов, равен щх'71-1 ф ...
. . . ф рт-1Х ф рт. ПОЭТОМУ
= (Pl....Рт-l, Рт) = Р1Йт-1ф . . . ф/?т_1Й ®рт.
Это означает, что xm ffl = о u rnonr..
?; 6.6]
ЭФФЕКТИВНОЕ ПОСТРОЕНИЕ КОДОВ
317
вательно, х является корнем примитивного многочлена
р(х). Наборы й, й2, ...,й2‘! 'различны, а й.2,;! совпадает
с й. Отсюда в силу свойства 7° заключаем, что мини-
мальный многочлен для й имеет степень т и, таким об-
разом, g (х) — ni- (х) = р (х), т. е. в качестве порож-
дающего многочлена кода Хемминга может быть взят
примитивный многочлен.
В разделе 6.5.4, рассматривая в качестве примера
код длины 7 с порождающим многочленом g(x) =
= х3©х®1, мы видели, что он является кодом Хем-
минга. Это обстоятельство не случайно, поскольку мно-
гочлен х3 Рх® 1 является примитивным.
6.6.5. БЧХ-коды. Опишем теперь способ построения
циклических кодов с заданным кодовым расстоянием.
Рассмотрим множество всех многочленов ссоХ"-1 ф
ф «1Х'г~2 ф ... ®ал-1 (п = 2т—1), корнями которых
являются х, х2, ..., xd-1. Множество соответствующих
наборов (ссо, «1, •••, an-i) называется кодом Боуза —
Чоудхури — Хоквингема (БЧХ-кодом) с парамет-
ром d.
Теорема 6.1. БЧХ-код с параметром d имеет ко-
довое расстояние, не меньшее d.
Доказательство. Для линейного кода (и, в ча-
стности, для циклического) кодовое расстояние совпа-
дает с минимальным весом кодовых векторов, отличных
от нулевого. Поэтому достаточно доказать, что в коде
нет ненулевых векторов веса меньше d.
Предположим противное, что некоторый кодовый
вектор сс = (ссо, cci, ..., оьг-i) имеет вес d' <Z d. Ему со-
ответствует многочлен fa(x), имеющий d' ненулевых ко-
эффициентов; пусть
fa (х) = х!> ф х!> ф ... фхЧ
Каждый из наборов х, х2, ..., х'/-1 обращает этот мно-
гочлен в 0:
Ш) = (*')'© © • • • © (й’У*' = 0 (/ = 1, .. ., d - 1).
(6.38)
318
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
[ГЛ. VI
Рассмотрим матрицу
... (х1)^'
(Я2)л (й2)л ... (x2)/d'
_(xdy‘ (xd')/2 ... (xd')/d'
Ее столбцы At, А2, ..., Adf линейно зависимы, ибо из
(6.38) и условия d'^.d—1 следует, что ДфЯгф
ф...фЛй/ = 0. Поэтому ее строки Вь В2, ..., Bd'
также линейно зависимы, и найдутся константы рь
Р2, ..., fid' е {0,1} такие, что
РАФР2В2Ф ...®fid'Bd' = Q.
Расписывая это равенство для каждого столбца, полу-
чаем равенства
Мх'^ФМх2)7*© ©РИ^'Ч^О
(s=l....d')
или, что то же самое,
Р,йА ф р2 (хЧ2 Ф • • Ф fid>W = 0
(s = 1..........d').
Это означает, что многочлен
Р,хфр2х2ф ... ®P£/,.rd' = x(P1©P2x® ... ©Р^'-1)
имеет в составе своих корней х?!, хЧ ..., v!d>. Наборы
хЛ, x\ . .., zZ</' различны, ибо jv j2, . . ., jd,^n = 2m — 1.
Кроме того, они отличны от нулевого набора и, следо-
вательно, являются корнями многочлена
PiФр2хф ...©РХ”1
степени d' — 1. Это противоречит тому, что число корней
многочлена не может превзойти его степени. Теорема
доказана.
Рассмотрим пример. Пусть требуется построить
код длины п = 24— 1 = 15, исправляющий 3 ошибки.
§ 6.6] ЭФФЕКТИВНОЕ ПОСТРОЕНИЕ КОДОВ 319
По таблице 6.3 найдем примитивный многочлен сте-
пени т = 4:
р (х) = х4 ф х ф 1.
На его основе выпишем степени набора й=(0010).
Ниже при написании степеней мы не различаем набо-
ров и соответствующих им многочленов, а все операции
осуществляем по модулю р(х):
й = х = (0010),
й2 = х2 = (0100),
й3 = х3 = (1000),
й4 = х4 = х©1 =(0011),
й5 = х5 = х (х® 1) = х2® х = (0110),
й6 = х (х2фх) = х3фх2 = (1100),
й7 = х(х3фх2) = х4®х3 = х3®х® 1 =(1011),
й8 = х(х3фх® 1) = х4фх2фх = х2ф1 =(0101),
й9 = х(х2ф 1) = х3фх = (1010),
Й'° = х(х3фх) = х4фх2 = х2фхф1 =(0111),
йи = х(х2фхф1) = х3фх2фх = (1110),
й12 = х(х3фх2фх) = х4фх3фх2 = х3фх2фх® 1 =(11 И),
Й‘3 = х(х3фх2фхф1) = х4фх3фх2фх =
= х3фх2® 1 =(1101),
й14 = X (Х3фх2ф 1) = х4®х3 ©х =х3ф 1 = (1001),
й13 = х(х3® 1) = х4фх= 1 =(0001).
Исправление 3 ошибок обеспечивается кодовым рас-
стоянием, не меньшим 7, поэтому воспользуемся БЧХ-
кодом с параметром 7. Порождающий многочлен этого
кода равен произведению всех различных многочле-
нов, содержащихся в множестве рпй(х), тй2(х), ...
Л ., тй6 (х)}. В силу свойства 6° тй (х) = /пй, (х) = тй, (х) и
m.3 (х) = m.?s (х). В связи с этим надо найти лишь много-
члены /пя(х), 7/гй1(х) и л«й- (х). Как было показано в разделе
6.6.4, т,- (х) совпадает с примитивным многочленом р (х).
320
помехоустойчивое кодирование
(ГЛ. VI
В нашем случае
тй (х) = х'1 ф х © 1.
Чтобы вычислить тй.(х), найдем его степень. Введем
обозначение ц = й3; тогда
Ц=Й3, Ц2 = Й6, Ц4 = й12, fl3 = й24 = й9, ц16 = й18 = Й3 = fi.
По свойству 7° степень /пя!(х) равна 4. Положим
тя= W = х4 © с^х3 ® а,х2 © а3х ф а4.
С учетом того, что й12 = (1111), й’ = (1010), й6 = (1100),
й3 = (1000), 1 = (0001) и й3 является корнем многочлена
йй3(х), получаем соотношение
0\
0 I
0 )
0/
Решая эту систему уравнений, находим сс, == 1, а2 = 1,
аз = 1, «4 = 1. Таким образом,
тяз (х) = х4®х3®х2®х® 1.
Определим степень многочлена тй5 (х). Положив v = x5,
получаем
V = Й6, V2 = Й10, V4 — Й20 = Й5 = V.
Отсюда заключаем, что степень m-s(x) равна 2. Пусть
тй5 (х) = х2®Р1х®Р2.
Поскольку т.-5(й5)==0 и й1о = (О111), й5 = (0110), 1 =
= (0001), коэффициенты Pt и р2 удовлетворяют соот-
ношению
(0\ /0\ /0\ /0\
; j®pj; ®р2 о = j ].
1/ \о/ \1/ \о/
Отсюда Pi = р2 = 1 и тй5(х) = х2фх® 1.
Зная /71й(х), тйа(х) и тй6(х), находим порождающий
многочлен кода
g (х) = Шй (х) тйз (х) тйз (х) = х10 © х8 ф х5 ® х4 © х2 ® х ® 1.
ЭФФЕКТИВНОЕ ПОСТРОЕНИЕ КОДОВ
321
§ 6.61
Порождающий многочлен имеет степень г = 10, по-
этому код содержит 2* = 2п~~г = 25 = 32 наборов.
6.6.6. Некоторые оценки. БЧХ-код, исправляющий
t ошибок, должен иметь кодовое расстояние, не мень-
шее 2t + 1. Поэтому его порождающий многочлен g(x)
есть произведение различных минимальных многочле-
нов из множества {m.-.(x), тйа(х), ..., шй2<-1 (х), шй2;(х)}.
В силу свойства 6° m.-^i (х) = m^i (х) (t=l, ..., /),
и, следовательно, указанное множество содержит
не более t различных многочленов тй(х), тяз(х), ...,
(х). Степень каждого из них не превосходит
т (свойство 4°), поэтому степень многочлена g(x) не
больше mt. Число г проверочных символов совпадает
со степенью порождающего многочлена и не превышает
mt. С учетом того, что m = log(n+l) (ибо п — 2т —
— 1), окончательно получаем
г «С t log (п + 1).
Таким образом, в БЧХ-коде на исправление одной
ошибки расходуется log(«+ 1) проверочных символов,
т. е. столько же, сколько в коде Хемминга (длины п —
— 2т—-1), который, как было доказано, является оп-
тимальным.
Рассмотрим теперь вопрос построения кодов произ-
вольной длины, п с заданной корректирующей способ-
ностью. Пусть требуется построить код длины п, ис-
правляющий t ошибок. Найдем число т из условия
2m~' - 1 < п^2т- 1 (6.39)
и построим БЧХ-код длины п0 = 2т — 1 с кодовым рас-
стоянием 2/+1. Порождающий многочлен имеет сте-
пень г, которая с учетом (6.39) оценивается следующим
образом:
г ^.mt < t (log (п + 1) + 1). (6.40)
Как мы видели, в качестве информационных разрядов
циклического кода могут быть взяты первые k = по—
— г = 2т— 1 — г штук. Рассмотрим множество всех ин-
формационных последовательностей длины k, у которых
на первых 2т — 1 — п местах находятся нули. Им соот-
ветствует множество тех векторов из построенного БЧХ-
322
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
[ГЛ. VI
кода, которые на первых 2'" — 1—п местах содержат
нули. Поскольку сумма таких векторов дает вектор
того же вида, это множество является линейным (но не
циклическим) кодом. Отбросив первые 2т—1—п нуле-
вых компонент, получим линейный код длины п, для ко-
торого число проверочных символов удовлетворяет
оценке (6.40).
Покажем, что при достаточно широких предположе-
ниях относительно числа t исправляемых ошибок линей-
ный код длины п, построенный на основе БЧХ-кода (а
при п=2т—1—совпадающий с ним), имеет асимпто-
тически минимальное число проверочных символов.
Мощность произвольного кода, исправляющего t оши-
бок, удовлетворяет границе Хемминга
1 4 п + .. + С*п
Число информационных символов кода, равное
[MME не превосходит п — log(l + п + ... + Cfy, а
число г проверочных символов оценивается следующим
образом:
г = п —log (1+«+... + С£)> log С'=
_ i га (га — 1) ... (га —/+ 1)
. (га — /)*
>log—
= /log(n — /) — /log/. (6.41)
Если имеет место соотношение
log/ = о (log п), (6.42)
то log(н— /)-~ logn и /log(n—/)—t log t ~ t logn.
Отсюда и из (6.41) заключаем, что при выполнении ус-
ловия (6.42) справедливо
г ^>, / logn.
В то же время неравенство (6.40) показывает, что чис-
ло проверочных символов линейного кода, построенного
на основе БЧХ-кода, асимптотически не превосходит
/ log п.
Отметим, что на базе (6.40) и того, что мощность
кода составляет 2k, может быть получена нижняя оцен-
ка мощности кода, исправляющего / ошибок. При /,
§ 6.7]
ДРУГИЕ ТИПЫ ИСКАЖЕНИЙ
323
удовлетворяющем условию (6.42), она является даже
существенно более высокой, чем оценка Гилберта (6.18),
установленная «неэффективно» (на основе переборной
процедуры).
§ 6.7. Другие типы искажений
6.7.1. Введение. До сих пор изучались лишь симмет-
ричные ошибки, т. е. ошибки типа {0-> 1, 1+0}. Для
них был описан метод построения кодов, обладающих
заданной корректирующей способностью. Настоящий
параграф посвящен ошибкам других видов. Некоторые
из них (несимметричные, стирания) нам уже встреча-
лись, другие (пачки, арифметические) будут опреде-
лены ниже.
В разделе 6.3.3 было установлено, что код исправ-
ляет любую комбинацию из с и менее стираний тогда
и только тогда, когда его кодовое расстояние (вычис-
ленное на основе метрики Хемминга) не меньше с+ 1.
Таким образом, БЧХ-код с параметром с+1 решает и
задачу исправления с стираний.
Код, исправляющий t симметричных ошибок, может
исправить такое же количество несимметричных оши-
бок. Поэтому БЧХ-коды могут быть использованы и для
исправления несимметричных ошибок. Однако, посколь-
ку способность кода исправлять несимметричные ошиб-
ки определяется расстояниями в метрике, отличной от
хемминговой (см. (6.11)), можно пытаться строить коды
специально для несимметричных ошибок.
Данный параграф носит иллюстративный характер,
и в нем сообщаются лишь некоторые элементарные све-
дения.
6.7.2. Несимметричные ошибки. Опишем конструк-
цию кода, исправляющего 1 несимметричную ошибку
(для определенности рассматривается ошибка типа
{0+1}).
В кодовое множество Ко отнесем все двоичные на-
боры а = (аь а2, для которых величина
I (а) = сц + 2а2 + ... + + ... + пап
делится на п +1. Предположим, что из кодового на-
бора d в результате искажения разряда at (который
324
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
[ГЛ. VI
вместо 0 стал равным 1) образовался набора'. В этом
случае
I (б') = I (б) + I
и, поскольку t<n+l, a /(d) делится на оста-
ток от деления I (б') на п + 1 равен I. Он указывает но-
мер искаженного разряда.
Если образовать множество Kj (j = I, .... п),
включив в него все двоичные наборы а = (czi, ап),
для которых остаток от деления /(d) на п1 равен /,
оно также будет являться кодом, исправляющим 1
ошибку типа {0—>1}. Это следует из того, что если в
результате искажения б в одном разряде образовался
набор а' и остаток от деления / (б') на п + 1 равен h,
то номер / искаженного разряда находится однозначно:
( h — j, если h О j,
(. ft — j + n + 1, если h < /.
Каждый из 2" двоичных наборов попадает ровно в
одно из п + 1 множеств /<0, Ki, Кп- Отсюда выте-
кает, что мощность хотя бы одного из этих множеств не
2Л
меньше и, следовательно, существует код, ис-
правляющий 1 несимметричную ошибку, мощность кото-
рого не меньше - • Можно доказать, что таким ко-
дом является Ко-
Если для исправления несимметричной ошибки ис-
пользовать код, исправляющий 1 симметричную ошиб-
ку, то его мощность (как показывает (6.16)), не будет
превосходить В то же время мощность Ко не
меньше этой величины, а если 2'! не делится на п + 1
(т. е. п имеет вид, отличный от 2Г—1, где г — целое),
то — строго больше. Отметим, что код Ко не является
линейным. С учетом того, что мощность линейного
кода равна степени двух, легко видеть, что если для
исправления одной несимметричной ошибки использо-
вать линейный код, то для некоторых значений п его
мощность будет примерно в 2 раза меньше, чем у Ко-
6.7.3. Пачки ошибок. Будем говорить, что ошибки
образуют пачку длины Ь, если все они находятся среди
b последовательно расположенных компонент набора,
§ 6.7]
ДРУГИЕ ТИПЫ ИСКАЖЕНИЙ
325
причем крайние из этих b компонент являются иска-
женными. Так, например, если вместо набора 01101010
был принят 01000110, то ошибки образуют пачку длины
4. Ясно, что если код исправляет любую комбинацию
из & и менее симметричных ошибок, то он исправляет
и всякую пачку длины не больше Ь. Однако такой спо-
соб исправления является неэкономным, и имеются спе-
циальные коды для исправления пачек ошибок [26].
Мы на этом останавливаться не будем, а покажем
лишь, что произвольный циклический код хорошо при-
способлен для обнаружения пачки ошибок. А именно,
если степень порождающего многочлена равна г, то код
обнаруживает любую пачку, длина которой не больше г.
Действительно, пусть при передаче кодового набора
а == (ссо, со.ал-i) произошла ошибка ё = (е0, ец ...
..., en-i). Она не будет обнаружена, если набор 0 =
= афё принадлежит коду и, следовательно, ошибка
ё = аф0 является кодовым вектором. В этом случае
многочлен f6 (х) = еохга“1 ф е1хп"2 ф .. . ф ега_1 должен де-
литься на порождающий многочлен g(x). Предполо-
жим, что последним отличным от 0 разрядом ошибки
является en-,. Пусть длина пачки ошибок не превосхо-
дит г, тогда многочлен fg(x) может быть представлен в
виде
(х) = х'-Д (х),
где и(х) имеет степень, меньшую г. Порождающий
многочлен g(x) имеет свободный член, равный 1 (ибо
хп ф 1 делится на g(x)), поэтому он взаимно прост с
х'-1. Если многочлен fs(x) делится на g(x), то на g(x)
делится и р(х). Но это невозможно, поскольку степень
многочлена v(x) строго меньше степени г порождаю-
щего многочлена g(x).
Таким образом, всякая пачка длины не больше г
будет обнаружена. Отметим, что код будет обнаружи-
вать значительную часть и более длинных пачек. Необ-
наруживаемыми будут лишь ошибки ё, для которых
многочлен (х) имеет очень специальный вид g’(x)u(x),
где ц(х)—некоторый многочлен.
6.7.4. Арифметические ошибки. Пусть имеется устрой-
ство для сложения натуральных чисел (сумматор),
326
ПОМЕХОУСТОЙЧИВОЕ кодирование
[ГЛ. VI
которое осуществляет действия над числами в двоичной
записи. Если в одном из разрядов слагаемого произо-
шла ошибка, то вследствие переносов она распростра-
няется на ряд разрядов суммы. Несмотря на то, что
исказилось несколько разрядов, эту ошибку следует
трактовать как одиночную (ибо она является следствием
искажения одного разряда). В связи с этим понятие
расстояния по Хеммингу здесь неприменимо и необхо-
димо ввести другую метрику.
Для пояснения сказанного рассмотрим пример.
Пусть требуется осуществить сложение двоичных чисел
(10011110)= 222 и (1000001) = 65:
, 11 011 ПО
1 000 001
100 011 111 (=287)
Если второе слагаемое подано с ошибкой в одном раз-
ряде (третьем справа), то вместо этого будем иметь
, 11 011 НО
+ 1 000 101
100 100011 (= 291)
Ошибочный результат отличается от правильного в че-
тырех разрядах (они подчеркнуты), так что расстояние
по Хеммингу равно четырем. Легко видеть, что ошибка
в одном разряде слагаемого может привести к искаже-
нию произвольно большого числа разрядов суммы.
Если в некотором разряде слагаемого происходит
ошибка типа 0—>1, то само слагаемое и сумма увели-
чиваются на 2‘ (i зависит от номера разряда), если про-
исходит ошибка типа 1->0, то они уменьшаются на 2‘.
В рассмотренном примере сумма изменилась на 291—
— 287 = 22. Ошибки типа {±2‘} (i = 0, 1, ...), при ко-
торых величина чисел, соответствующих двоичным на-
борам, изменяется па 2', будем называть арифметиче-
скими. Арифметическим весом натурального числа N
назовем минимальное число слагаемых в представлении
этого числа в виде *)
^=2)2Л + е22/г + . . . (Ё> /2 >•..),
*) При этом числу 0 соответствует пустое множество слагае-
мых и его вес считается равным 0.
§ 6.7'1
ДРУГИЕ ТИПЫ ИСКАЖЕНИЙ
327
где каждый коэффициент е, принимает значение +1 или
—1 (указанное представление числа N неоднозначно).
Арифметическим расстоянием между числами Ai и N%
будем называть арифметический вес числа |Ai— А2|.
Так, например, если Ai = 115 и А2 = 129, то |Ai—
— ^2|= 14 = 24 — 21 и арифметическое расстояние ме-
жду этими числами равно 2 (оно не может равняться 1,
ибо 14 не есть степень двух). Аналогично тому, как это
сделано в § 6.3, можно доказать, что код обнаруживает
b (исправляет /) арифметических ошибок тогда и толь-
ко тогда, когда его арифметическое кодовое расстояние,
определенное аналогично (6.7), не меньше &+1 (не
меньше 2/ + 1).
Код для обнаружения одной арифметической ошиб-
ки можно построить следующим образом. Число N бу-
дем представлять в виде ЗА. Поскольку
3Ai + ЗА2 = 3 (Aj + А2),
то код суммы двух чисел совпадает с суммой кодов
отдельных слагаемых и закодированные числа могут
суммироваться обычным сумматором. При представле-
нии в двоичном виде число ЗА требует в сравнении с А
не более двух дополнительных разрядов (так, например,
если А = 12 = (1100), то ЗА = 36 =(100010)). Для не-
равных чисел Ai и А2 величина
|ЗА1-ЗА2| = 3|А1-А2|
отлична от 2г (делится на 3). Поэтому арифметическое
кодовое расстояние не меньше 2, и код обнаруживает
1 арифметическую ошибку.
Этот код может применяться для контроля работы
сумматора. Для определенности мы говорили об ошибке
в одном из слагаемых. Однако все то же самое приме-
нимо и к ошибке при переносе (она также имеет тип
{±2;}).
Отметим, что, в отличие от всех описанных ранее,
этот код является неравномерным. Натуральные числа
представляются в нем наборами разной длины. Если
код применяется для контроля работы сумматора с фик-
сированным числом разрядов, он фактически исполь-
зуется как равномерный.
328
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
[ГЛ. VI
§ 6.8. Самокорректирующиеся схемы
6.8.1. Самокорректирование. Результаты, относя-
щиеся к передаче информации, могут быть использо-
ваны и для надежной переработки информации. Ниже
дается пример такого применения.
Будем рассматривать реализацию булевых функций
схемами из логических элементов (раздел 2.1.2). В про-
цессе работы некоторые элементы схемы могут функ-
ционировать неправильно, и значения их выходов могут
отличаться от тех, которые они должны иметь при пра-
вильной работе. Задача состоит в том, чтобы построить
схему, которая бы при одновременной неправильной ра-
боте не более заданного числа t элементов реализовала
ту же функцию. Такую схему будем называть t-само-
корректирующейся, либо просто самокорректирующейся.
Самокорректирующаяся схема должна содержать
некоторое число абсолютно надежных элементов (кото-
рые всегда функционируют правильно). Таким, в част-
ности, должен быть выходной элемент, ибо в случае его
неправильной работы вся схема будет работать непра-
вильно. Следовательно, в базисе, из которого строятся
самокорректирующиеся схемы, наряду с ненадежными
должны присутствовать абсолютно надежные элементы.
Как и раньше, в целях простоты будем рассматри-
вать схемы из элементов, реализующих функции &, V и
“. Будем предполагать, что для каждой из этих функ-
ций в базисе имеется как ненадежный элемент, так и
абсолютно надежный, но при этом абсолютно надеж-
ные элементы являются гораздо более дорогими. Будем
считать, что каждый ненадежный элемент имеет вес
(стоимость) 1, а веса всех абсолютно надежных элемен-
тов равны А, где А — некоторая большая константа.
Под сложностью L(S) схемы S будем понимать сумму
весов всех входящих в нее элементов.
Для каждой функции f существует /-самокорректи-
рующаяся схема, которая ее реализует. Такой, напри-
мер, является схема, построенная из абсолютно надеж-
ных элементов (в ней ошибки не происходят).
Будем рассматривать задачу синтеза самокорректи-
рующихся схем в асимптотической постановке (ср. с
§ 2.5), Обозначим через минимальную из сложно-
S 6.8]
САМОКОРРЕКТИРУЮЩИЕСЯ СХЕМЫ
329
стер"] /-самокорректирующихся схем, реализующих f, а
через Lt(n)—максимум Lt(f) по всем функциям f от п
аргументов. Функцию Lt(n) назовем функцией Шенно-
на для t-самокорректирующихся схем. Будем рассмат-
ривать случай, когда t фиксировано, а п бесконечно
возрастает.
Следующая теорема, доказанная с использованием
полученных в § 6.6 результатов о кодах, исправляющих
t ошибок, показывает, что требование /-самокорректи-
руемости асимптотически не влияет на функцию Шен-
иона и что для почти всех функций /-самокорректирую-
щиеся схемы имеют асимптотически ту же сложность,
что и схемы, построенные из дешевых (ненадежных)
элементов без учета самокорректирования (§ 2.5).
Теорема 6.2. При / = const и п оо имеет место
асимптотическое равенство
пП
2п
Нижняя оценка Lt (п) — следует из того, что она
имеет место даже в случае, когда требование самокор-
ректирования отсутствует, верхняя доказывается на ос-
нове специальной конструкции схемы.
6.8.2. Конструкция схемы. Возьмем линейный код
длины N, исправляющий / ошибок, для которого число
проверочных символов удовлетворяет оценке, получен-
ной в разделе 6.6.6,
г </(log(/V + 1) + 1). (6.43)
Если k — число информационных разрядов, то
ft = A/-r>A/-/(log(A/ + 1) + 1).
В случае / = const имеет место /(log(/V4-1)4-1) =
— o(jV); поэтому при всех достаточно больших N вы-
полнено
откуда
log(/V + l)<log k+ 1.
С учетом этого из (6.43) получаем
N = k-\-r^.k + i (log k 4- 2).
330
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
[ГЛ. VI
Таким образом, если взять код длины
N = [k + t (log k + 2)], (6.44)
он будет иметь не менее k информационных разрядов.
Рассмотрим произвольную булеву функцию f(xi, ...
..., хп) от п аргументов. Разложим ее по / аргумен-
там (число I будет назначено позже):
f(xlt хп) =
= . V xpf(orp ...,ort, хг+1> ...,хп).
(ai..°i)
Получающиеся в результате разложения функции
f(oi, csi,xi+i, ..., хп) перенумеруем и в дальнейшем
будем обозначать через fj(xi+i, ..., хп) (/'= 1, ..., 2Z).
Возьмем линейный код длины 2‘ + t(/ + 2), имею-
щий не менее 2г информационных разрядов (см. (6.44)
при k = 2г) и исправляющий t ошибок. Выделим из
информационных разрядов 21 штук, остальные будем
полагать равными 0 и считать проверочными. В резуль-
тате будем иметь код с 2‘ информационными и /(/ + 2)
проверочными разрядами. С помощью этого кода и
функций fi(xi+i, ..., хп) (/= 1, ..., 2‘) построим вспо-
могательные («проверочные») функции am(xi+i, ..., хп),
т=1, ..., /(/ + 2), где значение am(oi+i, .... ап) со-
впадает с т-м проверочным разрядом кодового набора,
у которого значениями информационных разрядов яв-
ляются (ст;+1....(Т„)....f2i (ffz+1, ..., ап).
Самокорректирующаяся схема S для функции f
строится следующим образом (рис. 6.12).
Б л о к В выдает совокупность 2г + / (/ + 2) функций
fv ..., f2i, (Op . ..,®мг+2) от п — I аргументов. Он стро-
ится из ненадежных элементов и реализует каждую
функцию независимо (отдельной схемой). Для реализа-
ции одной такой функции по методу О. Б. Лупанова
2п~^
(раздел 2.5.2) требуется асимптотически не более z
элементов; сложность блока В удовлетворяет оценке
пп-1
L(B)^(2l + t(l + 2))^T.
В связи с тем, что некоторые из элементов могут рабо-
§ 6.8]
САМОКОРРЕКТИРУЮЩИЕСЯ СХЕМЫ
331
тать неисправно, на выходе блока В при подаче набора
(ст/+1, ап) вместо значений f/(cr/+i........сц>) (/=
= 1, .... 2') и (om(a/+i, .... ст„) (т = 1, ф + 2))
появляются, вообще говоря, другие значения f/(ff/+i, ...
..., ап) и 6>m (щ+1, ..., ап). В схеме S, а следовательно,
и в блоке В, допустимо не более t сбоев элементов.
^7?
Рис. 6.12.
Поскольку функции реализуются независимо, ошибоч-
ные значения могут одновременно присутствовать не
более чем на t выходах блока В.
Блок D строится из абсолютно надежных элемен-
тов. Он представляет собой декодирующую схему для
используемого кода и по набору значений fj(ai+l, ...
..., ап) (/=1, .... 2') и йт(щ+1, ..., ап) (т=1, ...
..., Ц1-\-2)), содержащему не более t ошибочных, вы-
дает нужные значения ............сц>) (/ = 1....2Z).
Блок D реализует 2' функций от 2‘ + /(/ + 2) аргумен-
тов. При
1—гоо его сложность оценивается величиной
L (D) А21
22Z+Z(I+2)
2; + Н' + 2)
< 492Z+i (1+2)
где А— стоимость абсолютно надежного элемента.
332
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
[ГЛ. VI
Блок Е реализует систему всех конъюнкций от ар-
гументов А'ь .... Xi и строится из абсолютно надежных
элементов. Воспользовавшись оценкой, полученной в
разделе 2.5.2, заключаем, что
L (Е) < А121.
В блоке F образуются всевозможные произведения
... *;+i> •••.*„)
(каждая из функций f(ah .... щ, xi+\, ..., хп) совпадает
с некоторой fj(xi+], хп) и выдается блоком D).
Блок F строится из абсолютно надежных элементов и
его сложность составляет
L(F) — А21.
Блок G из абсолютно надежных элементов осу-
ществляет дизъюнкцию выходов блока F:
L(G)< Д21.
На его выходе реализуется функция f.
Если одновременно происходит не более t сбоев эле-
ментов, блок D выдает правильные значения функций
f(tri, ..., щ, x;+i.хп). В блоках Е, F и G ошибок не
происходит (они из абсолютно надежных элементов).
Поэтому схема S является /-самокорректирующейся.
Отсюда
Lt(f)^L(S)^
(2l + t (/ + 2)) + A2?+t (Z+2) + A (Z + 2) 21.
При /->0О И t — const
2l +1 (I + 2) ~ 2l,
а член X(/ + 2)2Z мал в сравнении с А22+z (Z+2), по-
этому
Li (f)^-^? + X22+i(Z+2).
Выбрав функцию 1 = 1 (п) достаточно медленно растущей
/ Г 1 2п 2п
^например, 1 = Н- log/г И, будем иметь -- _ — и
5 7.11
НЕОПРЕДЕЛЕННОСТЬ И ИНФОРМАЦИЯ
333
(^+2)
В результате
пП
что и требовалось.
Заметим, что на основе свойств БЧХ-кодов можно по-
строить существенно более простую схему D, осуществ-
ляющую декодирование. Это позволяет повысить число
допустимых сбоев элементов до 20(,t) при той же асимп-
тотике функции Шеннона [14].
Глава VII
ПЕРЕДАЧА ДИСКРЕТНОЙ ИНФОРМАЦИИ
ПРИ НАЛИЧИИ ПОМЕХ
§ 7.1. Неопределенность и информация
7.1.1. Неопределенность случайного опыта. В дан-
ной главе рассматривается задача надежной передачи
дискретной информации в вероятностной постановке.
При известных вероятностных характеристиках канала
требуется осуществить передачу так, чтобы вероятность
ошибки не превосходила некоторой наперед заданной
величины.
Нам придется иметь дело со случайными объектами
(передаваемое сообщение, ошибка в канале и др.), в
связи с чем понадобятся некоторые «информационные»
характеристики таких объектов. Дискретный случайный
объект А задается состояниями щ, в которых он может
находиться, и их вероятностями Р (ai) ~ Pi (X Pi= Q-
Мы будем рассматривать случайные объекты А с конеч-
ным числом состояний. Они могут быть заданы табли-
цами
fli |а2| |afe
Pi I P2I • • • \pk
В качестве примера рассмотрим случайный объект
«ошибка» при передаче символа сообщения по двопч-
334
ПЕРЕДАЧА ИНФОРМАЦИИ ПРИ НАЛИЧИИ ПОМЕХ [ГЛ. VII
ному симметричному каналу. Он имеет состояния at и
а2, первое из которых означает наличие ошибки, а вто-
рое— отсутствие, при этом pi совпадает с вероятностью
р ошибки в канале, а р2 — с величиной 1 — р.
Более употребительной является несколько иная тер-
минология, которой мы и будем придерживаться. Мы
будем говорить об осуществлении случайного опыта А.
Состояния ai, ..., йк будем называть исходами опыта
А. Величины pi, ..., pR представляют собой вероятно-
сти исходов.
Для одних опытов предугадать исход легко, для
других — почти невозможно. Поэтому об исходах раз-
личных случайных опытов можно говорить с разной сте-
пенью неопределенности. Численная мера неопределен-
ности случайного опыта была предложена К. Шенно-
ном.
Мы приведем набросок соображений, послуживших
основой для введения такой меры. Этим рассуждениям
можно придать и вполне строгий характер (см. теорему
7.5 из § 7.4).
Пусть случайный опыт А осуществляется независимо
п раз. Вероятность того, что в результате получится
конкретная цепочка исходов a/t, а/2, а/п, составляет
= (7.1)
где mi — число появлений в цепочке исхода at (i= 1, ...
..., k). Согласно закону больших чисел, если длина
цепочки достаточно велика, частота —, с которой
встречается исход at (1=1, ..., k), в «типичном» слу-
чае близка к вероятности pi (здесь и дальше мы не
уточняем, какой смысл вкладывается в слова «типич-
ный», «близко», «примерно» и др.). Поэтому для «ти-
пичных» цепочек величина mi примерно равна pin. Под-
ставляя в (7.1) вместо mt это значение, получаем при-
ближенную величину вероятности «типичной» цепочки
рр^пррцп ... р№.
Отсюда с учетом того, что суммарная вероятность «ти-
пичных» цепочек примерно равна 1, заключаем, что чкс-
§ 7.1]
НЕОПРЕДЕЛЕННОСТЬ И ИНФОРМАЦИЯ
335
ло «типичных» цепочек приблизительно составляет
__________________________1______
pPSpW ... Ppkn ’
Предположим, что мы хотим передать информацию
о полученных п исходах с помощью двоичной последо-
вательности. Почти наверняка цепочка исходов будет
«типичной», а для того чтобы различным «типичным»
цепочкам можно было сопоставить разные двоичные по-
следовательности, длина последовательностей должна
быть примерно равной
10g =
= п (— pl log Pl — р2 log р2 — ... — рк log рк).
При этом на один исход будет затрачено в среднем
— Pi log pi — р2 log р2 — ... — рк log рк (7.2)
двоичных символов. Эта величина и была принята
К. Шенноном в качестве меры неопределенности слу-
чайного опыта (чем более «неопределенным» является
опыт, тем больше в среднем символов нужно затратить
на то, чтобы сообщить о его результате). Приведен-
ные соображения являются лишь наводящими, а то,
насколько удачно выбрана мера неопределенности, бу-
дет видно из результатов, полученных на ее основе.
Функция
H(pi, р2....Pk) = — £ pjogpz, (7.3)
z=i
принятая в качестве меры неопределенности случайного
опыта, оказалась идентичной с функцией, характери-
зующей в термодинамике величину энтропии. Поэтому
вместо неопределенности опыта часто говорят о его
энтропии. Для энтропии опыта А наряду с Н(рь ...
..., рк) применяется обозначение И (А).
Появление в выражении (7.2) логарифмов по осно-
ванию 2 связано с тем, что для представления исходов
опыта использовались двоичные последовательности.
Если применять последовательности с г символами, воз-
никнут логарифмы ио основанию г. Величина основания
336
ПЕРЕДАЧА ИНФОРМАЦИИ ПРИ НАЛИЧИИ ПОМЕХ [ГЛ. VII
определяет единицу измерения энтропии (и, как мы
увидим дальше, — единицу измерения информации).
В случае двоичных логарифмов эта единица носит на-
звание бит.
7.1.2. Вогнутые функции. При установлении свойств
энтропии будут существенно использоваться свойства
вогнутых функций.
Функция f(x) является (строго) вогнутой*) на не-
котором участке (отрезке, интервале, полуинтервале),
если (см. рис. 7.1) хорда, соединяющая любые две точ-
ки кривой f(x) (расположенные в пределах участка),
лежит под отрезком кривой,
заключенным между этими
точками. Если функция f(x)
дважды дифференцируема,
то отрицательность второй
производной на рассматри-
ваемом участке является до-
статочным условием ее во-
гнутости.
Пусть f(х) — вогнутая
ФУНКЦИЯ, а «1, <7.2, ..., CCs —
произвольные положитель-
ные числа такие, что сц +
Рис. 7.1.
+ <7.2 + +as= 1. Тогда для любых Xj, х2, ..., xs
(из участка вогнутости f(x)) выполнено неравенство
aif Ui) + (х2) + .. . + asf (xs)
f (alxl + а2*2 + • • • + asxs)> (7-4)
причем равенство в (7.4) имеет место тогда и только
тогда, когда
Х\= Х2 = . . . = Xs.
(7.5)
Для доказательства обозначим через А4, точку (х,.
f(Xi)) (i — 1, ..., s). Рассмотрим множество точек
Р1Л41 + Р2ДТ2 + ... + Р$ЛД для всевозможных наборов
(Pi, ₽2, • , РД таких, что 0 (i = 1, . .. , s) и pi +
+ р2 + ... -j- p.s — 1. Оно заполняет многоугольник
М[М2 ... ЛЕДД (на рис. 7.2 он заштрихован). В частно-
сти, этому многоугольнику принадлежит и точка Q =
*) Такие функции иногда называются также выпуклыми вверх.
§ 7.1]
НЕОПРЕДЕЛЕННОСТЬ И ИНФОРМАЦИЯ
337
= ociAfi + ссгтИг + . •. + asAls. Она имеет координаты
х0 = «1X1 + а2х2 + ... + asxs,
у0 = «J (xi) + а2/ (х2) + . .. + asf (xs).
Поскольку точка Q' = (х0, f (х0)) расположена выше Q
(см. рис. 7.2), то
f Uo) = f («|Х! + ... + asxs) > (/о = aj (х,) + ... + asf (xs).
Этим установлено (7.4).
Равенство может иметь место лишь в случае, когда
Q совпадает с одной из точек Mi, а это при положи-
тельных ai, ..., as может быть лишь при совпадении
всех точек ЛД, .... Л15, т. е. при выполнении условия
(7.5).
7.1.3. Свойства энтропии. Энтропийную функцию бу-
дем считать осмысленной и в случае, когда некоторые
из вероятностей pt равны 0. При этом, поскольку при
х->0 величина х log х стремится к 0, будем полагать
0 log 0 = 0.
Установим теперь некоторые свойства энтропии.
1°. Энтропия И (А) неотрицательна, причем Н(А) =
= 0 тогда и только тогда, когда одна из вероятностей
pi равна 1, а остальные равны 0. Действительно, если
338
ПЕРЕДАЧА ИНФОРМАЦИИ ПРИ НАЛИЧИИ ПОМЕХ [ГЛ. VII
Pi > 0, то (поскольку pi 1) имеет место — logpz =
= log—— ^>0 и, следовательно, —p/logpi 0. Если же
Pi
pi = 0! то —pt log pt = —0 log 0 = 0. Таким образом,
всегда —pi log pi 0. Просуммировав эти неравенства
по всем i (1 i k), заключаем, что
Н(А) = — X Pi log >0.
Равенство И ( А) нулю имеет место лишь в слу-
чае, когда все слагаемые (—pilogp/) являются ну-
левыми, т. е. когда при всех i выполнено pi = 0 либо
log pi = 0 (т. е. pi = 1). Поскольку pi + ... + Pk = 1,
то среди вероятностей pi принять единичное значение
может лишь одна, а остальные равны 0.
Приведенное свойство означает, что неопределен-
ность опыта равна 0 тогда и только тогда, когда его
исход заранее известен (исходы, имеющие вероятность
0, фактически произойти не могут). В остальных слу-
чаях неопределенность положительна.
2°. Имеет место оценка
И (А) < log k, (7.6)
где k— число исходов, причем равенство в (7.6) дости-
гается лишь в случае, когда исходы равновероятны, т. е.
1
pi = ... — Pk Для доказательства воспользуемся
соотношением (7.4) при s = k, at=^-,xi = pi (t=l, ...
..., k). С учетом того, что pi + ... + Pk = 1, получаем
ХтНл)</(Хт) = /(т)-
i \ i /
Взяв в качестве f(x) функцию (—xlogx) (в ее вог-
нутости можно убедиться по второй производной), при-
ходим к неравенству
i
§ 7.t]
НЕОПРЕДЕЛЕННОСТЬ И ИНФОРМАЦИЯ
339
Домножив обе части на k, получаем (7.6). Условие (7.5)
равенства в данном случае имеет вид р\ = р2 = ... — pk.
Доказанное свойство означает, что неопределенность
опыта максимальна в случае,
невероятны. При этом опа
равна логарифму числа ис-
ходов.
Особый интерес для нас
будет представлять случай
событий с двумя исходами.
Поскольку вероятности pi и
р2 исходов связаны соотно-
шением pi + Pi = 1, вели-
чина Я(Р1, ,О2) = #(£!, 1 —
— Pi) является функцией
одного аргумента. Функцию
Н (р, 1 — р) в дальнейшем
будем обозначать через
Н(р). В силу свойства I0'
она равна 0 лишь при р — О
ству 2° достигает максимума,
1 17
Р — ~2 • Кроме того,
когда все его исходы рав-
и р = 1, а согласно свой-
равного log 2= 1 в точке
Н(р)=Н(1-р)
и, следовательно, функция Н (р) симметрична относи-
тельно вертикальной прямой р = -^-. График функции
Н (р) приведен на рис. 7.3.
3°. Для любых qi, , qk таких, что qi О (j =
= 1, ..., k) и <7i + ... + qk — 1, имеет место неравен-
ство
k k
— L piiogqi> — L Pi log Pi,
i =» 1
(7.7)
причем равенство достигается лишь при qi = px, ...
..., qk = рк. Таким образом, значение энтропии миними-
зирует функцию — У pi log qt. Рассмотрим вначале слу-
чай, когда все р, отличны от 0. Воспользовавшись нера-
<7,
венством (7.4) при s = k, а, — pi, х{ = — (i = 1, ..., k)
Pi
340
ПЕРЕДАЧА ИНФОРМАЦИИ ПРИ НАЛИЧИИ ПОМЕХ [ГЛ. VII
для вогнутой функции f(v)— log %, получим
У Pi log у- < log Гу дЛ = log 1 = 0,
откуда
X pi log qi — Z Pl log Pl C 0,
что эквивалентно (7.7). Условие (7.5) равенства имеет
вид—— . Это означает, что векторы (<?i, ...
..., qk) и (рь ..., Рй) должны быть пропорциональ-
ными. Поскольку для обоих векторов сумма компонент
равна 1, эти векторы обязаны совпасть.
Пусть теперь некоторые из р, равны 0. Рассмотрим
набор (<?“...qty, на котором достигается минимум
функции —Xp/log^i- Убедимся, что если рц = 0, то
соответствующее q°u также должно быть равным 0. Дей-
ствительно, если это не так и q°u #= 0, то, заменив </°
нулем, а компоненту <7°, соответствующую некоторому
ненулевому р0, значением 7® + ^, получим набор, на
котором величина функции — Xp/log7i меньше, чем
на наборе (</“, .... qty, ибо
- 0 log q°u — pv log <7° > - 0 log 0 - pD log + qty.
Исключив из набора (pb ..., pk) все нулевые компо-
ненты ри, а из набора (<7“, ..., qty — соответствующие
компоненты <7° (также нулевые) и применив к укоро-
ченным наборам доказанный выше результат, можно
заключить, что q°i = pi для всех I. Таким образом, ми-
нимум достигается на наборе, совпадающем с (pi, ...
..., pk). Свойство доказано.
Пусть имеются случайные опыты А и В:
щ|а2|• • • | Пй
Р1Ы • • • 1?й
fei | ^21 • • р;
71 Ы • • • I ’
§ 7.1]
НЕОПРЕДЕЛЕННОСТЬ И ИНФОРМАЦИЯ
341
Рассмотрим опыт, состоящий в том, что параллельно
осуществляются опыты А и В, его исходами являются
пары (щ, bj). Этот опыт будем обозначать АВ и назЫ'
вать произведением опытов А и В. Если величину
p(aibi') вероятности пары (щ, &/) обозначить через Гц,
то опыт АВ может быть описан таблицей:
bl ь2 . .. bt
а1 Г11 Г12 • • Г1/
Г21 Г22 • • Г21
ak гы rk2 • • rkl
Поскольку совокупность пар (a,-, b}), {at, b2j, ..., '{at, btj
исчерпывает все случаи, когда исходом опыта А являет-
ся at, и события (at, Ь/) (/ — 1, I) не пересекаются,
имеет место равенство
i
^p{atbj) = p{aj) (z = l, ...,&). (7.8)
Аналогично,
fe
Z/ф^) = ?(£>;) (/=1, ...,/). (7.9)
1 = 1
В соответствии с определением энтропии
Н{АВ) = — £ p(aibj)\ogp{aib}) = — Ln/logG/. (7.10)
i, j i, I
Опыты А и В называются независимыми, если для
всех i и / выполнено
p(a^/) = p(a,)p(Z>/).
В общем случае вероятность p{atbj) связана с picit),
и p(bj) посредством условных вероятностей
р (athj) = р (а,-) р {bj \aj) = p{bj) р {at |bj). (7.11)
Введем одно важное для дальнейшего понятие. Если
известно, что исходом опыта А является at, то вероят-
ности исходов Ь/ (j —1, ..., Г) опыта В в этом случае
определяются условными вероятностями p{bj\aj).
342
ПЕРЕДАЧА ИНФОРМАЦИИ ПРИ НАЛИЧИИ ПОМЕХ [ГЛ VII
Поэтому величину
#(£1^)== — X p(bj\ai) logp(bt\ai)
естественно назвать условной энтропией опыта В при
условии исхода at. Математическое ожидание величины
Н (В | а,) по всем а» носит название средней условной
энтропии опыта В при условии выполнения опыта А и
обозначается через НА(В). Таким образом,
НА(В)=^р(а1)Н(В\а1). (7.12)
i
Эту величину в дальнейшем будем называть и просто
условной энтропией (опыта В при условии выполнения
Опыта Л).
4°. Условная энтропия НА(В) неотрицательна, при-
чем равенство HA(B) = Q имеет место тогда и только
тогда, когда всякий исход опыта А однозначно опреде-
ляет исход опыта В (т. е. когда опыт А несет полную
информацию об опыте В). Действительно, каждая из
условных энтропий H(B\ai) неотрицательна (в этом
можно убедиться, применив рассуждения, использован-
ные при доказательстве свойства Г, к условным ве-
роятностям p(bj\at) (/'— 1, ..., /)). Поэтому величина
НА(В), вычисленная в соответствии с (7.12), также не-
отрицательна. В случае, когда Яд(В)==0, для всех i
выполнено p(ai)H(B\ ai) = 0. Если исход щ может
произойти, он имеет ненулевую вероятность и, следова-
тельно, для него H(B\ai)=Q. Исходя из этого можно
заключить (как и при доказательстве свойства Г),что
имеется единственный исход bj опыта В, совместимый
с at (для него p(bj\ai)= 1). Этот исход и будет иметь
место в результате осуществления опыта В.
Данное свойство содержательно означает, что если
опыт А несет полную информацию о В, то в результате
его осуществления целиком снимается неопределенность
опыта В. Если же он не несет полной информации, то
некоторая неопределенность остается.
5°. Для любых случайных опытов А и В имеет место
следующее правило сложения энтропий:
Н(АВ) = Н(А) + НЛ(В). (7.13)
§ 7.1]
НЕОПРЕДЕЛЕННОСТЬ И ИНФОРМАЦИЯ
343
Для доказательства преобразуем выражение Н(АВ) с
использованием (7.11):
Н (АВ) = — '£р (aibj) log р (afij) =
i, i
= — E P (<*/) P (fy I ^) log (p (a,) p (bj |a,)) =
i, !
= —llp (at) p (bj | at) (log p (at) + log p (b} | a,)) =
= — E P (aj P (b} I ai) log p (at) —
i, !
— IZp (at) p (bj | a.) log p (bj | a).
i, i
Представив первую из полученных сумм в виде повтор-
ной суммы по i и по j и учитывая, что У, р (bj | a;) = 1, по-
!
лучаем
— 2 Е p(ai)p(bj |a;)logp(a() =
i I
= ~1Lp (at) log p (at) У p (bj |a;) =
i i
= ~1Lp (di) log p (a() = H (A),
i
Преобразуем вторую сумму:
— E E P (at) p (bj I aj log p (bj | a() =
= — E P (at) E P (bj | at) log p (bj | at) =
j i
= yjp(ai)H(B\ai) = HA (B).
i
В итоге приходим к (7.13).
6°. Для любых случайных опытов А и В выполнено
соотношение
Н(АВ)^Н(А) + Н(В), (7.14)
причем равенство справедливо тогда и только тогда,
когда опыты А и В независимы. Пусть, как и раньше,
p(ai)=pi, p(bj)= qj, p(aibj) = rij. Воспользовавшись
равенствами (7.8) и (7.9), имеющими в данном случае
344
ПЕРЕДАЧА ИНФОРМАЦИИ ПРИ НАЛИЧИИ ПОМЕХ [ГЛ. VII
ВИД Pi= S fit И <?/= S Гц, получим
/ 1
Н(А) + Н(В) = — s Pilogp,— s 9/log9/ =
i /
= — Е rijiogpt — YL rtjlosQi = — S rillog(piql). (7.15)
i, j i, j i, j
В силу свойства 3° энтропийной функции
— £ G71og(/W/)>— X Гц log Гц = Н (АВ) (7.16)
i, ! 1
(этим свойством можно воспользоваться, ибо Ещ<7/ =
= Е Д'Е 9/— 1)- Сравнивая (7.15) и (7.16), приходим
к (7.14). '
Равенство в (7.16), а следовательно и в (7.14), имеет
место тогда и только тогда, когда при всех i и / выпол-
нено ptqj = rtj, т. е. когда опыты А и В независимы.
7°. Условная энтропия не превосходит безусловную,
НА(В)^Н(В),
причем равенство имеет место тогда и только тогда,
когда опыты А и В независимы. Для доказательства до-
статочно представить Н (АВ) в виде (7.13) и воспользо-
ваться свойством 6°.
Таким образом, если А и В независимы, то, проде-
лав опыт А, мы в среднем не уменьшаем неопределен-
ности опыта В. В других случаях средняя неопределен-
ность снижается.
7.1.4. Информация и ее свойства. Разность Н(В) —
—На(В) характеризует среднее изменение неопреде-
ленности опыта В после выполнения опыта А. Поэтому
эту разность можно трактовать как среднюю величину
информации, приобретаемой об опыте В в результате
осуществления А. В связи со сказанным величину
I (А, В) — Н (В) — Н А(В) (7.17)
будем называть средней информацией в опыте А об
опыте В (иногда слово «средняя» будем опускать).
Приведем некоторые свойства этой меры информа-
ции.
§ 7.1]
Неопределенность и информация
345
1°. Информация неотрицательна, причем 1(А, В)=0
тогда и только тогда, когда опыты А и В независимы.
Это свойство является прямым следствием определения
информации и свойства 7° энтропии. Оно хорошо согла-
суется с интуитивным представлением о том, что неза-
висимые опыты не несут информации друг о друге.
2°. Имеет место соотношение
7 (А, В)^Н(В),
причем равенство выполнено тогда и только тогда, ког-
да всякий исход опыта А однозначно определяет исход
опыта В. Это свойство вытекает из определения инфор-
мации и свойства 4° энтропии. Оно хорошо согласуется
с содержательным представлением о том, что величина
приобретаемой информации не может превзойти неопре-
деленности, первоначально содержащейся в опыте.
В случае, когда опыт несет полную информацию о дру-
гом, в результате приобретаемой информации неопре-
деленность полностью снимается.
Поскольку опыт В несет полную информацию о себе
самом, из доказанного свойства вытекает, что
ЦВ, В) = Н(В).
В связи с этим энтропию иногда называют собственной
информацией (в опыте о себе самом).
3°. Информация симметрична:
ЦА, В) = 1(В, Л).
Заменив в выражении для информации (7.17) величину
На(В) на основе (7.13), получаем
I (А, В)=Н(В)-ИА(В)=И (В) - (И (АВ) - И (А)) =
=/7 (А) +/7 (В) -/7 (АВ). (7.18)
Доказываемое свойство следует из того, что в выраже-
ние (7.18) опыты А и В входят симметрично (заметим,
что АВ и ВА представляют собой фактически один и
тот же опыт). Поскольку информация симметрична, ее
иногда называют взаимной (в одном опыте о другом).
4°. Если А, В, С и D — случайные опыты, причем
АС и BD независимы, то
1 (АВ, CD) = 1(А,С)-\-1 (В, D),
346
ПЕРЕДАЧА ИНФОРМАЦИИ ПРИ НАЛИЧИИ ПОМЕХ 1ГЛ VI!
Вначале отметим, что если опыты АС и ВО независимы,
то опыты А и В, А и D, С и В, С и D также попарно
независимы. Действительно, рассмотрим в качестве
примера опыты Л и В. С учетом независимости АС и
BD имеем
Р {a-ib)'} = Е Р (.aibjCudv) = Е Р (a-icu) р (bjdv) =
U, V U, V
= Е Р (а.Си) Е Р (bjdv) = р (at) р (&;),
U V
что свидетельствует о независимости А и В.
Канал
d -----------
—*> Канал
Рис. 7.4.
Рис. 7.5.
Рис. 7.6.
Представим / (АВ, CD) в симметричной форме (7.18)
и преобразуем, воспользовавшись независимостью опы-
тов АС и BD, А и В, С и D и свойством 6° энтропии:
I (АВ, CD) = Н (АВ) + Н (CD) - И (ABCD) =
= (Н (Д) + Н (В)) + (Н (С) + Н (D)) - (Н (АС) + Н (BD)) =
= (Н (А) + Н (С) -Н (АС)) + (Н (В) + H(D)-H (BD)) =
= 1 (Л, С) +1 (В, D).
Доказанное свойство имеет следующую содержа-
тельную интерпретацию. Пусть случайные сообщения А
и В передаются по двум независимым каналам и на вы-
ходах каналов принимаются случайные сообщения С и
D (рис. 7.4), В этом случае общая переданная инфор-
§ 7.1]
НЕОПРЕДЕЛЕННОСТЬ И ИНФОРМАЦИЯ
347
мация складывается из информаций, прошедших через
каждый канал.
Пусть имеется некоторое устройство ср для детерми-
нированной переработки данных. На его вход посту-
пают символы ai (i = 1, ..., k), а с выхода снимаются
значения ср (а,) (рис. 7.5). Если на вход этого устрой-
ства подавать исходы случайного опыта А, то значения
выхода можно рассматривать как исходы некоторого
другого случайного опыта, который будем обозначать
ср (А). Преобразователь ср фактически может осущест-
вить лишь «склеивания» некоторых исходов. Для пояс-
нения этого рассмотрим пример преобразования, пока-
занного на рис. 7.6. Поскольку ср (а;) = ср (а2) = ср (а3) =
= то исходы на входе а{, а2 и а3«склеиваются» в один
исход а'.. на выходе, причем р (а,) = р (а,) + р (а2) +
+ Р (аХ
5°. Имеет место неравенство
7(<р(Л), В)^ЦА,В), (7.19)
т. е. в результате преобразования информация не уве-
личивается. Если преобразование ср взаимнооднозначно,
то выход преобразователя с точностью до переименова-
ния исходов совпадает с входом и
/((Р(Л), В) = /(Д, В).
Рассмотрим теперь случай, когда преобразование ср не
взаимно однозначно. Для доказательства (7.19) доста-
точно ограничиться вариантом «склеивания» двух исхо-
дов (остальные случаи последовательно сводятся к это-
му) . Итак, пусть преобразователь ср «склеивает» исходы
ai и йг в а', а остальные не изменяет. Как и раньше,
будем использовать обозначения p(at)= pt, p{a,ibt) =
= гу. При этом
р (а') = pl + р2, (7.20)
p(a'bi) = rl! + r2! (/= !,...,/). (7.21)
Поскольку 1(А, В) = Н(В) —НА(В), а 7(<р(А),В) =
= Н(В)— Hq(A)(B), то для доказательства (7.19) до-
статочно установить, что
НА(В)^НщА)(В). (7.22)
348
ПЕРЕДАЧА ИНФОРМАЦИИ ПРИ НАЛИЧИИ ПОМЕХ [ГЛ. VII
Сравнивая выражения
НА (В) = Z р (аг) Н (В | ад
i
И
(Л) (В) = р (а') Н (В | а') + £ р (az) Н (В | аД
i >3
заключаем, что (7.22) эквивалентно неравенству
р (ад Н (В lad-bp (а2) Н (В | а2) < р (а') Н (В | а'). (7.23)
Согласно определению и (7.11)
Н (В |az) = — У р (bj | ад log р (Ь} | ад =
<7-24’
(считаем, что нет исходов at с нулевыми вероятностями
pi — иначе их можно удалить). Аналогично с учетом
(7.20) и (7.21) можно записать
Н (В \а') = - У-Ч j---' log Г1/1-'2" (7.25)
v 1 ’ pt + рг 6 pt + pi ' '
i
С использованием (7.24) и (7.25) неравенство (7.23)
превращается в
р-26)
Применив соотношение (7.4) к вогнутой функции
f(x) = —х log*
о Pl Р2 rli r2J
прих = 2, ai = - -Т-- , а2 = „ -i „ , *1 = —. х2 = —
r Pi + Pi Pi + Pi Pt Рг
получаем
-4- (_ Ш 10g м + _Jk_ (_ hL 10g^L)
Pl + Pi \ Pl & Pl ) Pl + P2 \ Pi & Pi /
Pl + Pi & Pl + Pi
§ 7.1]
НЕОПРЕДЕЛЕННОСТЬ И ИНФОРМАЦИЯ
Домножив обе части на р} + р2 и просуммировав по /,
приходим к (7.26), что и требовалось.
Свойство 5° показывает, что обработка данных не
увеличивает количества информации. Несмотря на это,
во многих случаях такая обработка производится. Она
необходима для прояснения «смысла» информации.
Понятия, связанные с неопределенностью (энтро-
пией) и информацией, будут использоваться нами при-
менительно к передаче данных. Однако они имеют зна-
чение, выходящее за рамки теории передачи информации.
7.1.5. Вспомогательное неравенство. Ниже приводит-
ся оценка одной комбинаторной величины (полиноми-
ального коэффициента) через энтропийную функцию.
Эта оценка понадобится в дальнейшем.
Имеет место неравенство
Полиномиальный коэффициент
J,, ...ik
через Ст и, кроме того,
, . —т-. обозначим
zi!‘2‘ • • Lk’
введем величину
(по определению считаем 0° = 1). Индукцией по m ус-
тановим соотношение
С^2................Ч (7.28)
При m = 1 каждое из чисел k может принимать зна-
чение 0 или 1. Непосредственной проверкой можно убе-
диться, что при этом
CZp '2.lk^D\vl2....Z*=l
и, таким образом, для m = 1 (и произвольных допусти-
мых /ц 12, ..., Ik) в (7.28) имеет место равенство.
Предположим теперь, что неравенство (7.28) выпол-
нено для числа иг—1 (при любом разбиении m—1 на
k слагаемых), и докажем его справедливость для числа
т. Пусть для определенности отличным от 0 является
350
ПЕРЕДАЧА ИНФОРМАЦИИ ПРИ НАЛИЧИИ ПОМЕХ (ГЛ. VII
слагаемое /*. Вычислим отношение
Dlv •••• lk-v lk m
llkk
k
(7.29)
1__\m-’
m — 1 )
" i а^-г
lk-J
В курсе математического анализа при доказательстве
существования предела последовательности 0
устанавливается, что величина (1 4~ — 1 монотонно воз-
растает с ростом п. С учетом этого и соотношения т
Ik приходим к неравенству
D1^..................‘k~v lk т
tn
Принимая во внимание
C!^ lk~v lk m
fit’ lk-v lk~l l>,
'm— 1
из (7.29) заключаем, что
r/1.lk-f lk ..!k—V !k
________________________________
r/i............................. lk~i- lk~! pl\' zfe-v ?fe-1
um-\ Gm-1
Это неравенство, переписанное в виде
rtl................................lk-V lk~l
n;i...lk > clv •’ lk m~1______
.....lk-v lk-l’
bm-l
с использованием предположения индукции
rjip .... ik-v ik~i rit...........ik-i
ит-\
дает (7.28).
Поскольку
log^m....lk==
^miogm — ^l! log/,-
^/,(Iog/( — Iogm) =
i i
Il 21
m ’ ' * * ’ m
!S 7.2]
ХАРАКТЕРИСТИКИ СИСТЕМЫ ПЕРЕДАЧИ
351
Z,..1Ь тН\ —........—
то Dm = 2 'ч"! и неравенство (7.28) пре-
вращается в (7.27).
При k = 2, в частности, получаем оценку числа со-
четаний
(7.30)
§ 7.2. Характеристики системы передачи информации
7
4
Канал
7.2.1. Пропускная способность канала. Подадим на
вход (двоичного) канала некоторую (двоичную) слу-
чайную величину £. На выходе канала в результате слу-
чайных ошибок получим дру-
гую случайную величину т]
(рис. 7.7). Можно вычислить
информацию /(ц, £) выхода
канала относительно его вхо-
да. При варьировании случай-
ной величины на входе
количество информации /(r],g)
Рис. 7.7.
изменяется. Значение
С = max I (т], £)
(7-31)
называется пропускной способностью канала. Пропуск-
ная способность характеризует максимальное количе-
ство информации, которое может быть передано через
канал за один такт.
Вычислим теперь пропускную способность двоичного
симметричного канала. Напомним, что в двоичном сим-
метричном канале символы искажаются независимо:
ошибка в данный момент не зависит от того, что пере-
давалось по каналу и было принято в предыдущие мо-
менты (и тем более от того, что будет происходить в по-
следующие моменты). При этом вероятность искажения
символов 0 и 1 одинакова; обозначим ее через р. Веро-
ятность правильного приема символов на выходе ка-
нала составляет q = 1 — р.
Используя свойство симметрии информации, в соот-
ветствии с определением можно записать
/(n. s) = /(s, П) = Н(Т])-Я5(Л). (7.32)
352
ПЕРЕДАЧА ИНФОРМАЦИИ ПРИ НАЛИЧИИ ПОМЕХ [ГЛ. VII
Я5(т]) = РЙ= 1) Я(п lg= 1) + р(1 = 0)Я(г) |g = 0). (7.33)
Для двоичного симметричного канала
р (т] = 0 |g = 0) = р (ц = 1 |g — 1) = </,
р(т) = 1 |£ = О) = р(т] = 0|g = 1) = р
(р(т] = 11 g = 0), например, означает вероятность того,
что был передан символ 0 и принят символ 1, и совпа-
дает с вероятностью р ошибки в канале). Поэтому
|g== 1) == — р(г] == 1 ,1 = 1) logp (р == 1 |g= 1) —
— р (п = 0 | g = 1) log р (п = 0 | g = 1) =
= — q log q — р log р = Н (р).
Аналогично,
tf(n|g = O) = tf(p).
Подставляя эти значения Н (т] | § = 1) и Н (г] | g = 0) в
(7.33), получаем
Я5(П) = рЙ=1)Я(р) + р(? = 0)Я(р) = Я(р).
Отсюда и из (7.32) заключаем, что
Z(n,g) = 77(n) —/7(р). (7.34)
Случайная величина т] принимает 2 значения, по-
этому согласно свойству 2° энтропии
Н (т])<log2=1,
и, следовательно,
/(пД)<1-Я(р).
Откуда с учетом (7.31) находим, что
С<1-Я(р). (7.35)
Докажем теперь противоположное неравенство. По-
дадим на вход канала случайную величину go, прини-
мающую значения 0 и 1 с одинаковой вероятностью у ;
случайную величину на выходе обозначим т]о. Величина
т)о принимает значение 1 в случае, когда на вход подан
символ 1 и ошибки нет либо когда на вход подан сим-
S 7.2]
ХАРАКТЕРИСТИКИ СИСТЕМЫ ПЕРЕДАЧИ
353
вол 0 и произошла ошибка. Таким образом,
Р01о = 1) = р(^= 1)^4-р(& = О')Р = ^q + ур = у-
Следовательно, р (По= 1) = Р (По = 0) = у и согласно
свойству 2° энтропии
Я (T])) = log2= 1.
Принимая это во внимание, из (7.31) и (7.34) заклю-
чаем, что
С > 1 (По, У = Я (по) - Я (р) = 1 - Я (р). (7.36)
Объединив (7.35) и (7.36), получаем выражение для
пропускной способности двоичного симметричного ка-
нала:
С=1-Я(р). (7.37)
На основании графика Я (р) (рис. 7.3) можно полу-
чить график пропускной способности, показанный на
рис. 7.8. При р = 0 (ошибки в канале нет) значение
выхода канала совпадает со значением на входе, и за
1 такт передается 1 бит информации. В этом случае
С= 1.
При увеличении вероятности ошибки р в канале
от 0 до у его пропускная способность падает. При
р — у она становится равной 0. Последнее объясняется
1
тем, что при р = у> независимо от значения входа, ве-
личины 0 и 1 могут появиться на выходе с одинаковой
1
вероятностью у, ив этом случае выход канала факти-
чески не связан со входом. Если р = 1, то сигнал на
выходе является инверсией входного (ошибка происхо-
дит обязательно). В этом случае выход несет полную
информацию о входе и С = 1. Аналогично можно рас-
суждать для любой точки правой полуветви кривой:
1
если р >у - то, инвертируя сигналы на выходе канала,
мы попадаем в условия, когда вероятность ошибки
354
ПЕРЕДАЧА ИНФОРМАЦИИ ПРИ НАЛИЧИИ ПОМЕХ [ГЛ. VII
1 — р < (этим объясняется симметрия кривой отно-
сительно р — у У В дальнейшем будем считать, что
Р<у, (7.38)
ибо случай р > у сводится к этому инвертированием
1 X
выхода, а при р — ~ё[ передача по каналу фактически
невозможна.
Как будет видно из дальнейшего, пропускная спо-
собность канала определяет скорость, с которой может
вестись надежная передача
Z7| информации.
7.2.2. Характеристики пе-
редачи. Вернемся к общей
схеме передачи информации
и уточним некоторые детали.
Совокупность реальных
сообщений (записанных, на-
пример, на русском языке)
может быть в некотором
смысле аппроксимирована
О 1 1 ~Р совокупностью случайных
2 сообщений с довольно слож-
рис. 7.8 ными статистическими зави-
симостями, учитывающими
частоты появления в текстах
отдельных букв, сочетаний букв, слов, словосочетаний
и др. (подробнее см. в [40]). Такие сложные случайные
сообщения путем некоторого перекодирования могут
быть сведены к сообщениям простейшего вида, описы-
ваемым случайными двоичными последовательностями
с одинаковой вероятностью символов 0 и I, в которых
символы порождаются независимо. Такое перекодиро-
вание сообщений представляет собой отдельную задачу,
которая частично будет рассмотрена в § 7.4. Вплоть до
§ 7.4 будем предполагать, что источник информации
порождает двоичные сообщения, причем символы сооб-
щения выдаются независимо и символы 0 и 1 имеют
одинаковую вероятность Будем считать, что сооб-
§ 7.2] ХАРАКТЕРИСТИКИ СИСТЕМЫ ПЕРЕДАЧИ 355
Щение образует достаточно длинную (в идеале —бес-
конечную) последовательность.
В процессе передачи сообщение разбивается на ку-
ски, которые затем поступают на вход кодирующего
устройства. Будем рассматривать случай равномерного
кодирования (§ 6.2). При этом все куски сообщения
имеют одинаковую длину k, в дальнейшем будем назы-
вать их блоками. Каждый блок а = (аь ..., а*) коди-
руется посредством двоичного набора p==(Pi.......(К)
длины п. Последний посимвольно передается по ка-
налу (за п единиц времени).
В результате искажения в канале кодового набора
₽ = (pi, ..., рл) на входе принимается, вообще говоря,
другой набор у — (Ть •••>?«)• Он декодируется и к
адресату поступает набор (блок) б = (бц ..., б*). Спо-
соб передачи, использующий равномерное кодирование,
будем называть блоковым.
Важнейшей характеристикой передачи является ее
надежность, определяемая вероятностью ошибки. При
блоковом способе передачи под этим будем понимать
вероятность того, что принятый блок 6 отличается от
переданного блока а. Вероятность ошибки будем обо-
значать через р(е) (от английского слова error —
ошибка).
Другая важная характеристика передачи была вве-
дена в § 6.2 (при рассмотрении равномерного кодиро-
вания). Это скорость передачи
(на передачу k единиц информации расходуется п еди-
ниц времени).
При рассмотрении кодов с повторением (§ 6.2) мы
видели, что ошибки в канале не исключают возможно-
сти сколь угодно надежной передачи, а лишь приводят
к ее замедлению. Оказывается, что объективной харак-
теристикой замедления является пропускная способ-
ность канала. К. Шеннон доказал, что можно осуществ^-
лять сколь угодно надежную передачу с любой
скоростью, меньшей пропускной способности канала
(теорема кодирования). В то же время всякий способ
передачи со скоростью, большей пропускной способности,
356
ПЕРЕДАЧА ИНФОРМАЦИИ ПРИ НАЛИЧИИ ПОМЕХ [ГЛ. VII
приводит к тому, что вероятность ошибки будет больше
некоторой фиксированной величины (обращение тео-
ремы кодирования).
Эти факты будут установлены нами для случая дво-
ичного симметричного канала и блоковой передачи. Од-
нако они имеют место и для многих более сложных ти-
пов каналов и других видов передачи. При этом вели-
чины р (е), R и С, имеющие смысл вероятности ошибки,
скорости передачи и пропускной способности канала,
каждый раз вычисляются по-своему.
§ 7.3. Теорема Шеннона о передаче при наличии помех
7.3.1. Некоторые утверждения о линейных кодах.
Нашей ближайшей целью является доказательство того
факта, что при скорости, меньшей пропускной способно-
сти канала, возможна сколь угодно надежная передача
информации. На самом деле будет установлен более
сильный результат: такую передачу можно осуществ-
лять с помощью линейных кодов. В связи с этим нам
понадобятся некоторые утверждения относительно ли-
нейных кодов.
Будем рассматривать систематические (раздел 6.2.4)
линейные коды и дальше в пределах параграфа под
линейными кодами будем понимать систематические.
Всякий такой код может быть задан порождающей мат-
рицей в приведенно-ступенчатой форме, имеющей вид
(6.21). Для различных кодов длины п с k информацион-
ными разрядами матрицы в форме (6.21) различаются
лишь подматрицами Р с k строками и п — k столбцами.
Число различных линейных кодов совпадает с числом
таких подматриц и составляет 2k(n-k\
Подсчитаем теперь число линейных кодов, содержа-
щих фиксированный ненулевой набор а=(аь ..., ап).
Рассмотрим 2 случая.
1. Первые k разрядов набора а (информационные)
являются нулевыми. Такой набор не принадлежит ни
одному линейному коду, ибо кодовый набор с нулевыми
информационными разрядами должен иметь нулевые
проверочные разряды (как линейные комбинации ин-
формационных) и, следовательно, должен являться ну-
левым.
§ 7.3!
ТЕОРЕМА ШЕННОНА
357
2, Среди k информационных разрядов набора б
встречается ненулевой (пусть для определенности аг).
Всякий код К, содержащий б, может быть задан k— 1
строками порождающей матрицы (всеми, за исключе-
нием Лй) и набором б. Действительно, просуммировав
(по mod 2) набор б с подходящими строками порож-
дающей матрицы, можно добиться того, чтобы все ин-
формационные разряды полученного набора, за исклю-
чением z-ro, стали равными нулю. Тем самым опреде-
лится i-я строка порождающей матрицы. Таким обра-
зом, для задания кода при известном б достаточно
иметь k—1 строк порождающей матрицы. Они могут
быть выбраны способами (таким числом спо-
собов можно назначить k—1 строк подматрицы Р).
Поэтому набор б принадлежит кодам.
Объединяя оба случая, заключаем, что всякий нену-
левой набор содержится не более чем в 2(A-I)(n~4 линей-
ных кодах.
7.3.2. Теорема кодирования. В данном разделе с ис-
пользованием линейных кодов доказывается результат
К. Шеннона о том, что при скорости, меньшей пропуск-
ной способности канала, можно вести сколь угодно на-
дежную передачу информации.
Теорема 7.1 (о кодировании). Для любого числа
R, меньшего пропускной способности С канала, и лю-
бого е > 0 существует способ боковой передачи со ско-
ростью, не меньшей R, и вероятностью ошибки р(е), не
превосходящей е.
Доказательство. 1. Рассуждения будут прово-
диться при п -> оо, где п —длина линейного кода, ис-
пользуемого для передачи.
Обозначим через k ближайшее к nR целое число, не
меньшее nR (R взято из формулировки теоремы). Что-
бы не загромождать доказательства несущественными
деталями, будем считать, что
k = nR.
Рассмотрим множество всех линейных (систематиче-
ских) кодов длины п с k информационными символами.
Мы докажем, что средняя по этому множеству вероят-
ность ошибки стремится к 0 при п->оо. Поскольку
358
ПЕРЕДАЧА ИНФОРМАЦИИ ПРИ НАЛИЧИИ ПОМЕХ [ГЛ. VII
минимальная вероятность ошибки для кодов из этого
множества не меньше средней, тем самым будет уста-
новлено существование кодов со сколь угодно малой ве-
роятностью ошибки (причем эти коды обеспечивают
скорость передачи — = /?).
2. Пусть К — некоторый линейный код с парамет-
рами п и k. Обозначим через рк(е) вероятность ошибки
передачи при использовании этого кода. Согласно фор-
муле полной вероятности
Рк (*) = Е р(ё)рх(е|ё), (7.39)
е
где р(ё)— вероятность того, что в канале произошла
ошибка ё =(еь ел), а рк(е\ё)— вероятность ошиб-
ки передачи (т. е. вероятность того, что блок, посту-
пивший к адресату после декодирования, отличается от
переданного) при условии ошибки в канале ё.
3. Будем использовать способ декодирования в бли-
жайший кодовый вектор (раздел 6.4.5). Пусть при пере-
даче кодового набора Р в канале произошла ошибка ё
и принятый набор рфё декодирован неправильно. Это
может иметь место лишь в случае существования кодо-
вого набора Р' и вектора ошибки ё' таких, что
РфЁ = Р'фё' (7.40)
и и>(ё.') w (ё). Из (7.40) в силу линейности кода К
следует, что набор Ёфё' = рфр' принадлежит К. Та-
ким образом, ошибка передачи при ошибке в канале ё
может возникнуть лишь, если существует вектор ё', ко-
торый отличен от ё и удовлетворяет условиям
Г ё ф ё' е К,
I да(ё') w (ё).
Обозначим через А\(ё)—число всех таких векторов ё'.
Имеет место оценка
Рк(е|ё)<^(ё), (7.41)
ибо если ^(ё)=0, то и рк(е\ё) — 0 (ошибки при де-
кодировании не возникнет), а если Мк(ё)^ 1, то нера-
венство (7.40) вытекает из того, что вероятность не пре-
восходит 1.
§ 7.3]
ТЕОРЕМА ШЕННОНА
359
Зададимся некоторым натуральным числом т, не
превосходящим у (оно будет выбрано позже), и пред-
ставим (7.39) в виде
Рк(е)= 2 р(ё)рк(е|ё)+ 2 р (ё) рк (е | ё).
8|«»(SKm ё|да(ё)>т
В первой сумме величину рл(е|ё) оценим сверху со-
гласно (7.41), а во второй заменим единицей; в резуль-
тате получим
Лт(е)< S р(ё)^(ё)+ £ р(ё). (7.42)
e|w(8)<m ё|бу(е)>?п
4. Обозначим через р(е) среднюю вероятность ошиб-
ки по всем линейным кодам с параметрами п и k. Число
таких кодов составляет (см. раздел 7.3.1), по-
этому в силу (7.42)
к
Е Р(ё)ЛМё)+ Е
k ё|ш(ё)<т ё|®(ё)>/«
(вторая сумма в (7.42) не зависит от и при осред-
нении по всем кодам не изменяется). Меняя в первом
слагаемом местами суммирования по К и по ё и вынося
р(ё) из внутренней суммы, преобразуем полученную
оценку для р(е) к виду
Р&<^Гь Е Р(ё)Е^^+ Е Р^-(7АЗ)
К ё|ги(ё)>т
5. Оценим величину £ NK (ё) при фиксированном
К
ё. Пусть w(e) = j. Рассмотрим произвольный отличный
от ё вектор ё' с да(ё') = i j. Ненулевой набор ё®ё'
принадлежит не более чем кодам (см. раз-
дел 7.3.1), поэтому вектор ё' дает вклад в 2 Мк(ё), не
К
превосходящий Общий вклад в сумму от всех
векторов веса I (их С1п штук) не превышает C„2<fe~1,<rt~fe).
Учитывая, что z<J, получаем оценку
S Л^л(ё) < S C‘n2(k-l)(n~k>, (7.44)
К i
где / = ьу(ё).
360
ПЕРЕДАЧА ИНФОРМАЦИИ ПРИ НАЛИЧИИ ПОМЕХ [ГЛ. VII
6. Вероятность р(ё) ошибки ё веса j составляет (см.
(6-26))
р (ё) — р^*"1, (7.45)
где р — вероятность ошибки в канале, a q — 1 — р. От-
сюда и из (7.44) с использованием того факта, что чис-
ло векторов ё веса j равно Сп, заключаем, что
2 Р(ё) S (ё) < 2 С’пр’сТ1 2 С’2<fe-” (7.46)
ё | w (ё) < tn К i !
Поскольку и при J4yc ростом t вели-
чина Сп возрастает, то и
X С£<(/+ 1)С'<пС' (7.47)
к/
(ибо /+1<т+1С«). С учетом этого на основе
(7.46) приходим к оценке
X р(ё)Х^(ё)^п2^-1)<п-й) X (c02pV-/.(7.48)
ё | ьу (ё) < m К ! ^.т
Аналогично, воспользовавшись (7.45) и тем, что
число наборов ё веса / составляет С„, получаем
X Р(ё)= X Clnp!qn-i^ X Clnp'qn-1. (7.49)
S[ w[e)>tn !>m i > m
Подставив (7.48) и (7.49) в (7.43), находим, что
р(е)<^гЕ (c02pV-/+ Е (7.50)
/ < т / > m
7. Выберем параметр т таким, чтобы в первой сум-
ме максимальным было последнее слагаемое, а во вто-
рой—первое. Для этого составим отношение /-го члена
первой суммы к (/— 1)-му:
(с')2р1дп~} _ (п - / + 1)2р (и - /)2р
(Cl-ypl-lq"-'+l~ Рд Рд ’
и потребуем, чтобы было выполнено
(п — /)г р
i24
§ 7.3]
ТЕОРЕМА ШЕННОНА
361
Отсюда находим, что (п — /) д/р J и 1п г- Р г- •
•VP + yq
Тем самым получаем первое ограничение на т:
т <;С п
л/р
ур + л/q
(7.51)
Аналогично, составив отношение (/4-1)-го члена вто-
рой суммы к /-му,
Cz+1P/+1?n~z~' = О - /) р О - /) р
~ (/ + 1)<7^ iq
и потребовав, чтобы величина правой части не превос-
ходила 1, находим, что j п = пР- Это приводит ко
второму ограничению на т:
т пр.
(7.52)
Убедимся в совместимости условий (7.51) и (7.52). До-
у р г~
множив и разделив —на л]р и воспользовав-
УР + yq
шись тем, что р < q (ибо р < у) , получаем
Ур _ Р > Р = р
у'Р + Уq Р + УР л/q р + q
Следовательно, неравенства (7.51) и (7.52) могут быть
удовлетворены одновременно. Отметим, что из (7.51)
в силу р < q автоматически вытекает, что т (это
условие использовалось в (7.47)).
При выполнении (7.51) и (7.52) из оценки (7.50)
находим, что
Р (е)^-^гг(т4- 1)(Сп) р q +(п — т+\)Спр q <
'Р (пт\- „т„п~т I . т п — т
Р Я +пСпр q =
/ И2 „т । m п—т г-о\
= + п)Спр q . (7.53)
362 ПЕРЕДАЧА ИНФОРМАЦИИ ПРИ НАЛИЧИИ ПОМЕХ (ГЛ. Vtl
8. По условию теоремы
R — C = R — (\-Н(р))<0. (7.54)
Выберем константу р, удовлетворяющую ограничениям
р<р< (7.55)
-VP + V<7
столь близкой к р, чтобы имело место (7.54) с заменой
р на р:
/? - 1 + Н (р) < 0. (7.56)
Положим
т — пр
(мы пренебрегаем тем, что величина пр может оказать-
ся нецелой, фактически в качестве т нужно взять бли-
жайшее целое к пр); с учетом этого и неравенства
(7.30) перепишем (7.53) в виде
р {е) < 2пН (р) + n) 2пн <р) рпр qn (1~р).
Величина
с,пН (о)
— 9« (р)->+Я)
в силу (7.56) не превосходит 1, поэтому
р (е) < (п + п) 2лЯ wpnpqn (1-р) С 2п22пЯ wpnpqn .
Логарифмируя, получаем
log р (е) < log (2n2) + п (Н (р) — (— р log р — q log (1 — р))).
Согласно свойству 3° энтропии из неравенства р =И= р
(см. (7.35)) вытекает, что величина
Л (р) — (— р log р — q log (1 — р))
строго отрицательна; обозначим ее через —Д (здесь
Д — положительная константа). В результате
log р (е) 1 + 2 log п — пД = п (— Д + о (1)),
откуда следует, что при всех достаточно больших п
log р (е)< — Доп,
где До — положительная константа, меньшая Д, и, та-
ким образом, величина средней вероятности ошибки
§ 7.3]
ТЕОРЕМА ШЕННОНА
363
удовлетворяет неравенству
^(е)<2-Л”л.
(7.57)
Найдется код К с параметрами п и k такой, что
Рк (е)<р(е)<2-А“л.
Взяв п достаточно большим, можно добиться того,
чтобы величина рк(е) была меньше заданного числа е.
Теорема доказана.
7.3.3. О нахождении кодов, обеспечивающих ско-
рость передачи, близкую к пропускной способности. До-
казательство теоремы кодирования не дает конструк-
тивного способа построения кодов, обеспечивающих
нужную скорость передачи при исчезающе малой ве-
роятности ошибки. Оно лишь устанавливает факт су-
ществования таких кодов. Однако на основании нера-
венства (7.57) можно утверждать большее, чем просто
существование.
Доля тех линейных кодов К с параметрами п и k
(k = nR), для которых
До
рк(е)>2~~п, (7.58)
п
не превосходит 2 2 . Другими словами, для почти всех
линейных кодов с параметрами п и k вероятность ошиб-
ки будет исчезающе малой.
Для доказательства обозначим через N число ли-
нейных кодов К, для которых выполнено (7.58).. Тогда
Р (е) = 2fe (л-й) 2k S Рк (е) >
К I РК. (е)>2
Отсюда и из (7.57) заключаем, что
N < р(е) о~"Тп
nk (n — k) До
5- п
2 2
что и требовалось.
364
ПЕРЕДАЧА ИНФОРМАЦИИ ПРИ НАЛИЧИИ ПОМЕХ [ГЛ. V1I
Таким образом, взяв наугад линейный код К с пара-
метрами п и k (т. е. случайным образом заполнив под-
матрицу Р порождающей матрицы), можно с большой
степенью уверенности утверждать, что полученный код
будет обладать требуемыми свойствами. Проверить тот
факт, не превосходит ли вероятность ошибки заданный
уровень, можно, оценив рк(е) по формуле (7.42). Не-
достаток указанного способа состоит в том, что произ-
вольные (случайные) линейные коды не допускают хо-
рошего декодирования.
Задача конструктивного построения кодов, обеспе-
чивающих требуемые характеристики передачи, пока
Рис. 7.9.
остается открытой. Имеются некоторые подходы, позво-
ляющие частично преодолеть возникающие здесь труд-
ности [6,34].
7.3.4. Описание схемы передачи в терминах случай-
ных опытов. Рассмотрим общую схему передачи инфор-
мации (рис. 7.9). Удобно считать, что источник инфор-
мации порождает не отдельные символы, а целые блоки
a =(oci, .... а*). Выдачу блока можно рассматривать
как некоторый случайный опыт А, исходы а которого
имеют одинаковую вероятность р (й) = -^- (каждый из
k символов порождается независимо с вероятностью
Блок й поступает в кодер, который представляет собой
некоторый преобразователь информации ф, осуще-
ствляющий взаимно однозначное отображение (раз-
дел 6.2.1). Набор р = ф(а), выдаваемый кодером, бу-
дем считать исходом случайного опыта В,
В = у{А).
По прошествии через канал набор Р превращается в у.
Выходу канала сопоставим случайный опыт Г с исхо-
дами у. Декодер по набору у выдает блок 6, поступаю-
§ 7.3]
ТЕОРЕМА ШЕННОНА
335
щий к адресату. Декодер осуществляет некоторое пре-
образование информации ф, значение его выхода будем
рассматривать как исход случайного опыта А,
А = ф(Г).
Информация, содержащаяся в выходе А этой си-
стемы передачи относительно ее входа А, может быть
оценена с использованием свойства 5° информации и
взаимной однозначности отображения ср:
/(А, Л) = /(ф(Г), Д)</(Г, Д) = /(Г, <р-1(В)) = /(Г, В).
(7.59)
Неравенство (7.59) показывает, что информация выхода
А системы относительно ее входа А не превосходит ин-
формации /(Г, В), прошедшей через канал.
7.3.5. Обращение теоремы кодирования. В данном
разделе доказывается факт невозможности надежной
передачи информации со скоростью, превосходящей
пропускную способность канала. Превышение пропуск-
ной способности приводит к тому, что вероятность
ошибки передачи становится больше некоторого фикси-
рованного уровня.
Идея доказательства этого результата состоит в
следующем. Если вероятность р{е) ошибки мала, то
выход А (рис. 7.9) будет нести «большую информацию»
о входе А (в частности, если р(е) — 0, то — полную ин-
формацию). В то же время величина этой информации
ограничивается величиной информации, прошедшей че-
рез канал (см. (7.59)), определенным образом связан-
ной с пропускной способностью. Из сопоставления ука-
занных величин получается нижняя оценка вероятности
ошибки.
Эта идея реализуется ниже.
Теорема 7.2. Если величина R превосходит про-
пускную способность канала С, то найдется константа
е0 {зависящая от R и С) такая, что при любом способе
блоковой передачи со скоростью, не меньшей R, выпол-
нено неравенство
Р (е) > 80.
Доказательство. Предполагая воспользоваться
соотношением (7.59), оценим сверху величину /(А, Л).
366
ПЕРЕДАЧА ИНФОРМАЦИИ ПРИ НАЛИЧИИ ПОМЕХ [ГЛ. VII
1. Занумеруем все возможные входные блоки а (ис-
ходы опыта А) индексами 1 = 1, 2, ..., 2\ а все вы-
ходные блоки 6 (исходы опыта А)—индексами / = 1,
2, 2fe. При этом потребуем лишь, чтобы одинако-
вым блокам а и 6 был присвоен одинаковый индекс,
т. е. чтобы было выполнено а, = 6/ при всех i = 1, 2, ...
..., 2*. Обозначим через p(aj6/) вероятность того, что
был передан блок а, при условии, что к адресату по-
ступил 6/, а через р(е|6,)— вероятность ошибки при
этом условии. В соответствии с введенной нумерацией
блоков
р(е|6/)=1-р^б,) (7.60)
(ошибки нет, если передавался а;). Вероятность ошиб-
ки р(е) может быть вычислена по формуле полной ве-
роятности:
Р (е) = £ Р (6/) р (е 16/). (7.61)
/
2. В соответствии с определением
/ (А, А) = Я (А) — Яд (А), (7.62)
где
Яд (А) = X Р (6/) Я (А |6,), (7.63)
/
Я (A IS/) = — £ р (а,-16/) log р (air 6/).
i
Введя обозначение р (йр 6j = pf । jt преобразуем выра-
жение для Я (А |6у):
Я (A |S/) = - £ Pt । , log Pi । / =
= -P/i/logp/|/- S Pi|/10gPi|/ =
’ 1 ' 11 i * /
= -P/l/logP/|/-(l -p/|/)10g(l -pzl/) +
+ [(l-P/|/)log(l-p/M)-.|Z ^p^/logp/j/j. (7.64)
Воспользовавшись тем, что 1—p,.,= У p..
' 11 111 * / ‘ 11
Гибо У, p/(/ = 1), оценим величину, заключенную в
§ 7-3]
ТЕОРЕМА ШЕННОНА
367
квадратные скобки:
[•••1= Е Рл/10£(1-Р/|/)~ £ Pi|/l°gP<i/ =
i I i * / t I i + I
=- E Ри/(1оер«|/-1ое(1-р/1/))=
l I i + i
Поскольку V -=———=1,
Е 44-х
величина —
i I i + i ' ' " i I i * i ' ''1
X log -г--111— представляет собой энтропию некоторого
1 Pl11 k
случайного опыта с 2 —1 исходами, имеющими ве-
Р £ | у
роятности t _ р—, и по свойству 2° энтропии не пре-
восходит log (2fe — 1). Поэтому
[...]<(! -Pni) log (2ft- 1)<(1 ~pni)k. (7.65)
Далее, согласно (7.60)
— Р/l/logp,,, — (1 — р,, ,)log(l — р/(/) =
= —(1 — Р (е I б,)) log (1 — р(е|б;)) —р(е|б/) log р(е|б,) =
= //(6 16;). (7.66)
Подставляя (7.66) и (7.65) в (7.64), получаем с уче-
том (7.60)
//(А|б/)^//(е|б/) + р(е|б/)й.
Отсюда и из (7.63), используя (7.61), приходим к нера-
венству
Нл (А)^^Р (б/) И (е |б/) + k £ р (б;)р (е |б,) =
= //А (е) 4- kp (е).
Поскольку условная энтропия //д(б) не превосходит
безусловную //(e) (свойство 7° энтропии), окончательно
получаем
//д (А)< Н (е) + kp (е). (7.67)
368
ПЕРЕДАЧА ИНФОРМАЦИИ ПРИ НАЛИЧИИ ПОМЕХ [ГЛ VIT
Это неравенство имеет следующую наглядную ин-
терпретацию. Величина Яд (А) представляет собой сред-
нее количество информации, требуемое для восстанов-
ления по принятому блоку 6 переданного блока а. Вос-
становить а по 6 можно
— путем указания того, произошла ли ошибка (т. е.
отличается ли переданный блок от 6); на это требуется
Н(е) единиц информации;
— при наличии ошибки — путем указания передан-
ной последовательности б; на это с вероятностью р(е)
требуется k единиц информации.
Отсюда содержательно вытекает, что величина
Н(е) + kp(e) является верхней границей среднего ко-
личества информации, необходимого для того, чтобы
восстановить б по 6. Этот факт и утверждается нера-
венством (7.67).
Воспользовавшись (7.62), из (7.67) заключаем, что
/ (А, А) > Н (А) - Н (е) - kp (е). (7.68)
Опыт А имеет 21; равновероятных исходов б/, поэтому
Я(А)= k и неравенство (7.68) превращается в
I (А, А) > k - kp (е) - Н (е). (7.69)
3. Оценим величину I (Г, В) информации, прошед-
шей через канал. По каналу посимвольно передается
набор р = (рь .... Р«), а в результате ошибок прини-
мается набор у = (ть , ?«) В случае двоичного сим-
метричного канала и источника с независимым порож-
дением символов значения входа и выхода канала в
данный момент не зависят от значений в другие момен-
ты времени. Поэтому пара (yi, Pi) не зависит от (у2 ...
... уп, Ра ... Р«), пара (у2, р2) не зависит от (у3 ... у„,
рз ... рп) и т. д. С учетом этого и свойства 4° инфор-
мации можно записать
/(Г, В) = /(У1 ... yn, pt . . . Р„) =
= /(Yi, Pi) + /(V2 ... Yn, Р2 ... PJ =
= /(Yi, Pi) + /(Y2, P2) + /(V3 Уп, Рз ... P„)= ...
. = I (Yl. Pl) + I (Y2, P2) + + I (Yb, Pn).
§ 7.41
СЖАТИЕ ИНФОРМАЦИИ
369
Но определению пропускной способности С каждая из
величин /(у,, р() не превосходит С; следовательно,
/(Г, В)<С + С+ ... +С = пС. (7.70)
4. Сопоставляя на основании (7.59) оценки (7.69)
и (7.70), заключаем, что
k — kp(e} — Н (е) <1 пС,
откуда
р(с) + ~^>1 -у. (7.71)
п
Если скорость передачи не меньше R, то
р(е) + ^-> (7.72)
С
Согласно условиям теоремы величина 1 —является
некоторой положительной константой. Отсюда, учиты-
вая, что при р(е)->0 значение Н(е) = —p(e)logp(e)—
— (1 —- р (е)) log (1 — р (е)) также стремится к 0 (рис. 7.3),
заключаем, что величина р(е) ограничена снизу некото-
рой константой е0 > 0. Теорема доказана.
Объединяя результаты теорем 7.1 и 7.2, можно ут-
верждать, что пропускная способность канала является
верхней границей скорости передачи, причем к этой гра-
нице можно подойти сколь угодно близко.
§ 7.4. Сжатие информации
7.4.1. Побуквенное кодирование. В предыдущих па-
раграфах предполагалось, что сообщение представляет
собой случайную двоичную последовательность с рав-
ной вероятностью 0 и 1, причем символы последова-
тельности порождаются независимо. Реальные же сооб-
щения обычно являются текстами не в двоичном алфа-
вите и различные символы появляются в них с разными
частотами. Так, например, в текстах русского языка
буква е встречается намного чаще, чем щ, а в цифро-
вых сводках обычно (за счет округлений) цифра 0
появляется чаще остальных. При передаче по двоич-
ному каналу сообщения представляются в виде двоич-
ных последовательностей, и наличие каких-либо
370
ПЕРЕДАЧА ИНФОРМАЦИИ ПРИ НАЛИЧИИ ПОМЕХ [ГЛ. VII
статистических закономерностей позволяет осущест-
влять это представление более компактно (сжато). Дан-
ный параграф посвящен этим вопросам.
Будем считать, что сообщения представляют собой
последовательности в алфавите {сц, а2, ..., аД и по-
рождаются источником S, который выдает символы
ai, а2, ..., ak независимо с положительными вероятно-
стями pi, р2, pk. Рассмотрим вначале простейший
способ кодирования сообщений — побуквенный.
В этом случае каждой букве а,- ставится в соответ-
ствие некоторое двоичное кодовое слово сц и всякое
сообщение кодируется путем приписывания друг к другу
кодовых слов его символов (сообщению а(а^ ... а1 со-
поставляется слово atat... йг ). Характеристикой сжа-
тия сообщений при побуквенном кодировании служит
среднее число кодовых символов (двоичных), приходя-
щихся на один символ сообщения:
k
leptin (7.73)
i=i
где I, — длина слова й,-. Ясно, что для уменьшения ве-
личины I более вероятные символы а, должны кодиро-
ваться словами at меньшей длины (тот же принцип
используется в азбуке Морзе). Таким образом, эконом-
ное кодирование должно быть, вообще говоря, нерав-
номерным (кодовые слова должны иметь разную длину).
При использовании неравномерных кодов возникает
проблема, связанная с однозначностью декодирова-
ния. Код должен позволять по всякому слову, кодирую-
щему сообщение, однозначно восстанавливать это со-
общение, т. е. слово й, а. ... й,- должно однозначно
разбиваться на кодовые группы at, at, . Код,
обладающий этим свойством, называется разделимым.
В качестве примера рассмотрим кодирование симво-
лов ai, а2 и я3 посредством кодовых групп =(1001),
а2 = (0) и й3 = (010). Слово 010010 может быть пред-
ставлено как й2й1й2 и как й3й3, поэтому данный код
разделимым не является.
§ 7.4]
СЖАТИЕ ИНФОРМАЦИИ
371
Дальше будем рассматривать лишь разделимые
коды. Заметим, что всякий равномерный код является
разделимым (все кодовые группы имеют одинаковую
длину) и для него указанных проблем не возникает.
7.4.2. Свойство префикса. Оно является одним из
простейших свойств, гарантирующих разделимость кода.
Код является префиксным, если в нем никакое ко-
довое слово не совпадает с началом другого кодового
слова. В рассмотренном выше примере слово а2 яв-
ляется началом а3 и, следовательно, свойство префикса
нарушено. Всякий префиксный код разделим. Для
того чтобы декодировать слово ... а{ , нужно, на-
чиная с его левого конца, последовательно набирать
символы, пока не получится кодовая комбинация. Она
обязана совпасть с а., ибо никакое меньшее слово по
свойству префикса кодовым не является. Далее тем же
способом выделяется кодовая комбинация а1г и т. д. Не
все разделимые коды являются префиксными. Так, на-
пример, разделимый код, использованный в разделе
4.4.1 для кодирования машин Тьюринга, не обладает
свойством префикса (все кодовые группы имеют вид
10 ... О и содержатся одна в другой).
Преимущество префиксных кодов заключается в
том, что для них декодирование может осуществляться
без задержки в процессе посимвольного поступления в
приемник кодирующей последовательности, ибо конец
каждого кодового слова опознается сразу без привле-
чения последующих символов. Другая особенность со-
стоит в том, что в этом классе кодов содержатся наи-
лучшие разделимые коды (минимизирующие среднюю
длину /). Этот факт будет доказан позже.
Удобное графическое представление префиксного
кода можно получить с использованием двоичного де-
рева (рис. 7.10). Для всякой вершины дерева левому
выходящему из нее ребру приписывается символ 0, пра-
вому— символ 1. Каждой вершине соответствует един-
ственный путь, ведущий в нее от корня дерева. Вершине
сопоставляется слово из символов, приписанных реб-
рам, лежащим на этом пути (на рис. 7.10 жирной ли-
нией выделен путь, ведущий в вершину 101). Легко ви-
деть. что если двоичное слово а является началом
372
ПЕРЕДАЧА ИНФОРМАЦИИ ПРИ НАЛИЧИИ ПОМЕХ [ГЛ. VII
двоичного слова Р, то вершина а лежит на пути, веду-
щем от корня в р. Отсюда следует, что концевые верши-
ны дерева образуют префиксный код (на рис. 7.10 это
код 00, 01, 100, 101, ПО, 1111) и, наоборот, всякому пре-
фиксному коду соответствует некоторая совокупность
концевых вершин.
Рассмотрим на рис. 7.10 вершину 111. Из нее исхо-
дит одно ребро. Если это ребро устранить, то. вместо
вершины 1111 концевой станет 111 и код останется пре-
фиксным. Такую операцию удаления ребра будем на-
зывать операцией усечения. Она приводит к укорачива-
нию некоторого кодового слова.
7.4.3. Неравенство Крафта — Макмиллана. Пред-
ставление префиксных кодов в виде концевых вершин
дерева позволяет получить важное соотношение для
длин кодовых слов.
Теорема 7.3 (Л. Крафт). Пусть /ь /2, ..., 1Г —
набор целых положительных чисел. Для того чтобы су-
ществовал префиксный код с длинами кодовых слов 1\,
I2, ..., 1г, необходимо и достаточно выполнение нера-
венства
(7.74)
i=i
Доказательство. Вершины дерева разобьем на
ярусы, как показано на рис. 7.10. Полным деревом по-
рядка п будем называть /г-яруспое дерево, содержащее
на ярусе п все 2" возможных вершин (на всяком преды-
дущем ярусе j оно содержит 2' вершин).
§ 7.4]
СЖАТИЕ ИНФОРМАЦИИ
373
Докажем необходимость условия (7.74). Пусть
префиксный код имеет длины кодовых слов, равные
/1, /г, 1г. Возьмем полное «-ярусное дерево, где
«>шах/г, и для каждой вершины а,, соответствующей
кодовому слову, выделим
в нем поддерево (на рис.
7.11 эти поддеревья изоб-
ражены в виде заштри-
хованных треугольни-
ков). Вершина а, принад-
лежит ярусу и исходя-
щее из нее поддерево со-
держит концевых
вершин. В силу префикс-
ности кода эти подде-
Рис. 7.11.
ревья не пересекаются, и общее число их концевых вер-
шин не превосходит числа концевых вершин полного
«-ярусного дерева. Поэтому
.п
(7-75)
Разделив обе части этого неравенства на 2", приходим
к (7.74).
Установим теперь достаточность условия. Пусть
числа /1, h, lr удовлетворяют неравенству (7.74).
Домножив его на 2'1, где п > max/(-, получаем (7.75).
i
Построим префиксный код с
длинами слов 1\, 1%, .. . , /г; бу-
дем считать /1 ^7 /2 ... сС 1Г,
Рассмотрим полное дерево
порядка п. В качестве кодово-
го слова di возьмем произ-
вольную вершину яруса 1\ и
поддерево, исходящее из
(на рис. 7.12 оно закрашено),
из дерева исключим. Все не-
устраненные вершины яруса /1
и вышележащих ярусов (они
принадлежат поддеревьям, выделенным на рис. 7.12
штриховкой) могут быть использованы для дальнейшего
374
ПЕРЕДАЧА ИНФОРМАЦИИ ПРИ НАЛИЧИИ ПОМЕХ [ГЛ. VII
построения кода. Число неустранеиных вершин яруса п
равно 2"— 2'*'~г'. Рассмотрим одну из них. Путь, ведущий
в нее от корня дерева, проходит через некоторую не-
исключенную вершину яруса /2 (/2^/i); выберем ее в
качестве следующего кодового слова а2 и устраним ис-
ходящее из нее поддерево. Все неустраненные вершины
ярусов не ниже 12 могут быть использованы для даль-
нейшего построения кода. На ярусе п имеется 2”—
— — 2п~'1‘ неисключенных вершин. Путь, ведущий в
одну из них, проходит через некоторую вершину яруса
/з, которая может быть взята в качестве йз, и т. д. Из
неравенства (7.75) следует, что эта процедура может
быть продолжена вплоть до выбора кодового слова а,
длины 1г-
Доказанный результат может быть распространен
на класс всех разделимых кодов, как это вытекает из
следующей теоремы.
Теорема 7.4 (Б. Макмиллан). Необходимым и до-
статочным условием существования разделимого кода
с длинами кодовых слов 1\, 12, ..., Т является выполне-
ние неравенства (7.74).
Доказательство. Достаточность следует из
того, что в качестве разделимого может быть взят пре-
фиксный код, существование которого гарантируется
теоремой 7.3.
Для доказательства необходимости рассмотрим
тождество
Подставив в него xt = 2 1 (г = 1, . .., г), получаем ра-
венство
Е2"'гГ= X 2-(f6+V"-+M (7.76)
(==1 ' ' < Д г2.< г
Обозначим через /max наибольшее из чисел /,. Сгруп-
пировав все слагаемые с одинаковыми значениями
I. 4-I, + ... +1, — j, запишем правую часть (7.76)
Ч ‘г 1т
§ 7.4)
СЖАТИЕ ИНФОРМАЦИЙ
375
в виде
m^max m^max
Е 2_/= Ё мр-1,
/=1 h<+h»+ •*• =/ /=1
И 12 1т
где М/ — число различных представлений числа / в форме
+ h2 + • • + lim- Каждому такому представлению
числа j можно сопоставить слово а, а. ... а, длины /
б (2
(здесь а( — кодовое слово длины /г). Поскольку код раз-
делим, слова af ... а1 для разных наборов
(z’i, i2, ..., im) различны и их количество не превосходит
числа 21 всех слов длины /, откуда следует, что Mj^.21 и
яНтах
Ё] Л4/2 ^^тах-
Объединяя все сказанное, заключаем, что
Or \ т
L 2 ‘J ^/7г/тах.
Извлекая из обеих частей неравенства корень степени
пг, получаем
Ё 2~'< < (m/max)^.
z=i
i
Переходя к пределу при т-*-оо, с учетом (m/raax)m -►!,
приходим к (7.74). Теорема доказана.
Соотношение (7.74) носит название неравенства
Крафта — Макмиллана. Рассмотрим произвольный раз-
делимый код. Длины его кодовых слов согласно тео-
реме 7.4 удовлетворяют неравенству (7.74). Но тогда
по теореме 7.3 существует префиксный код с теми же
длинами. В частности, если взять разделимый код, на
котором достигается минимум величины 1 в (7.73) (та-
кие коды будем называть оптимальными), то и пре-
фиксный код будет обладать тем же свойством. Таким
образом, оптимальный код можно искать в классе пре-
фиксных кодов.
7.4.4. Оптимальное кодирование Хаффмена. Метод
построения оптимального префиксного кода был пред-
ложен Д. Хаффменом (согласно сказанному этот код
376
ПЕРЕДАЧА ИНФОРМАЦИИ ПРИ НАЛИЧИИ ПОМЕХ [ГЛ. V1I
является оптимальным и в классе всех разделимых ко-
дов). При изложении метода будем пользоваться интер-
претацией префиксного кода как множества концевых
вершин некоторого двоичного дерева.
Изучим вначале некоторые свойства оптимальных
префиксных кодов. При этом будем считать, что сим-
волы а}, а2, ..., аг источника S занумерованы в поряд-
ке убывания их вероятностей, т. е. что
Pi>p2> • • • >рг- (7.77)
1°. В оптимальном коде длины It кодовых слов а, не
убывают, т. е.
(7.78)
Действительно, если это не так и для некоторых i и j
одновременно pt > р, и h > 7/, то, поменяв местами ко-
дирования символов ai и а/, получим код с меньшей
величиной 7, ибо
Pth + Pih — Pih + Pjh + (.Pi ~ Pj) (h ~~ h) > Pih + Pjh-
2°. Существует оптимальный код, в котором двум
наименее вероятным символам аг~\ и аг соответствуют
~ кодовые слова, имеющие одинаковую
Ч длину и различающиеся лишь в послед-
нем разряде. Рассмотрим произвольный
оптимальный префиксный код и соот-
ветствующее ему дерево. Обозначим
через а' вершину дерева, предшествую-
щую аг (рис. 7.13). Если из а' в следую-
щий ярус ведет лишь одно ребро (в вер-
Рис. 7.13. шину йг), то к коду можно применить
операцию усечения, в результате чего
ребро будет отброшено и вместо аг концевой вершиной
станет а'. Поскольку операция усечения уменьшает 7,
это противоречит оптимальности кода.
Таким образом, из а' исходят 2 ребра, и существует
кодовое слово а,, имеющее ту же длину h, что и аг. От-
сюда и из того, что h /г-i 1г, вытекает равенство
li = lr-\ = lr. Если вершина а, (рис. 7.13) соответствует
символу ai, отличному от ar-i, то, поменяв местами —
а, и аг-!, можно добиться того (рис. 7.14), чтобы вер-
шинам ar-i и аг предшествовала одна и та же вершина
§ 7.4]
СЖАТИЕ ИНФОРМАЦИИ
377
а'. Новый код также будет оптимальным (ибо U = 1г-\)
и, кроме того, он будет обладать нужным свойством.
Рассмотрим теперь источник S', полученный из S в
результате отождествления (склеивания) символов
«г-i и аг. Он выдает символы а\, ..., аг-ч с прежними
вероятностями plt pr-z, а новый символ а' (склеен-
ный)— с вероятностью р' = р,-\ + рг. Такой источник
S' будем называть редуцированным. Пусть имеется не-
который код {Й1,Й2, ..., аг_2, а'} для редуцированного
источника. По нему построим код для исходного источ-
ника S следующим образом. Для букв а!г ..., аг-2 со-
храним прежние кодовые комбинации а1г ..., йг_2, а в
качестве аг^ и а, возьмем слова, полученные в резуль-
тате дописывания к а’ соответ-
ственно символа 1 и символа 0 од
(рис.7.14). \ 1
3°. Если префиксный код для \ /
редуцированного источника S' яв- \ /
ляется оптимальным, то и код для Уфа'
исходного источника S, построен- х.
ный указанным способом, также
является оптимальным. Обозначим ,,
через Г и I соответственно сред-
нюю длину кода для редуцирован-
ного источника S' и кода для исходного источника S,
построенного указанным способом. Найдем соотноше-
ние между величинами 7 и Т с учетом того, что lr-i =
= lr = /' + 1 (/' — длина слова а') и р' — рг-\ + рг,
г г —2
I’ — Z Pih — 22 Pih + Рг-1 + О + РгЦ' + 1) =
1=1 1 = 1
Г-2
= X Pih + P'h + Pr-i + Pr — h + Pr-\ + Pr- (7.79)
<=i
Если код для источника S не является оптимальным,
то возьмем оптимальный код, удовлетворяющий свой-
ству 2°, и построим по нему код для редуцированного
источника S', сопоставив символу а' вершину а', пред-
шествующую вершинам аг_х и а, (рис. 7.14), и сохранив
за остальными символами ai (i — 1, ..., г — 2) те же
кодовые комбинации <7/, что и в оптимальном коде для
S. Средние длины 7 и Т для новых кодов удовлетворяют
378
ПЕРЕДАЧА ИНФОРМАЦИИ ПРИ НАЛИЧИИ ПОМЕХ [ГЛ. VII
соотношению (7.79), и поскольку новая величина 7 (для
оптимального кода) меньше прежней, то и новая вели-
чина 7' будет меньше прежней. Это противоречит опти-
мальности исходного кода для редуцированного источ-
ника.
На основании приведенных свойств может быть
предложена следующая процедура построения опти-
мального кода (изложение будем сопровождать приме-
ром, показанным на рис. 7.15). Символы источника S
аз
а5
Рис. 7.15.
упорядочиваются по убыванию вероятностей, и два наи-
менее вероятных символа (в данном случае это а$ и а$)
склеиваются в символ а1, которому приписывается ве-
роятность р1, равная сумме вероятностей склеенных
символов (в данном случае р1 — 0,07 Ц- 0,09 = 0,16).
Затем к редуцированному источнику применяется та же
процедура: его символы упорядочиваются по убыва-
нию вероятностей, и осуществляется склеивание двух
наименее вероятных символов (в данном случае, а4 и
а1) в символ а”, в результате чего получается новый
редуцированный источник. Процедура повторяется, пока
не окажется, что источник имеет один символ, которому
приписана вероятность 1 (на рис. 7.15 это av).
§ 7.41
СЖАТИЕ ИНФОРМАЦИИ
379
Рассматривая рис. 7.15, отражающий описанную
процедуру, мы видим, что на нем изображено дерево,
концевые вершины которого соответствуют символам ис-
точника S, промежуточные — символам, получавшимся
в результате склеиваний, а корень — символу, имею-
щему вероятность 1. Приписав каждой паре горизон-
тальных линий, обозначающей склеивание двух сим-
волов в один, значения 0 и 1, получим кодовое дерево.
В более привычном виде оно изображено на рис. 7.16.
Код символа а; задается словом, прочитанным при дви-
жении от корня к соответствующей вершине. На рис. 7.15
жирной линией выделен путь, определяющий код сим-
вола а3. В рассмотренном примере результатом построе-
ния является оптимальный код: ей = (0), й2 = (111),
а3 = (НО), а.>, — (100), а-5 = (1011), й6 = (1010). Для него
Z = 0,36 - 1+0,18-3 +
+ 0,18-3 +0,12-3 + 0,09 • 4 + 0,07 • 4 = 2,44.
7.4.5. Метод кодирования Шеннона. Метод Хаффме-
на дает возможность для каждого конкретного источ-
ника найти оптимальный код, но не позволяет дать
оценку средней длины 7, зависящую от параметров ис-
точника. Мы опишем метод построения кодов, близких
к оптимальным, и на его основе дадим оценку величины
I. Этот метод принадлежит К. Шеннону.
Пусть, как и раньше, р2, , рг означают вероят-
ности символов ai, 02..........Or источника S, причем
380
ПЕРЕДАЧА ИНФОРМАЦИИ ПРИ НАЛИЧИИ ПОМЕХ [ГЛ. VII
Pi р2 ... рг. Найдем числа h
(I = 1........г) из
(7.80)
условия
Образуем вспомогательные величины Pi (i = 1.....г),
где Р\ = 0, а при i > 1
i-i
Pi ='Lp!
/=1
(каждое из чисел Pi строго меньше единицы). Вычис-
лим первые после запятой Ц знаков (с недостатком) в
разложении числа Pi в двоичную дробь, и цифры этого
разложения, стоящие после запятой, объявим кодом
символа ai.
Убедимся, что полученный код {Й1, й2...й,} об-
ладает свойством префикса. Рассмотрим слова й,- и а(',
где i' > i. Разность Р^ — Pt ^Pl+i — Pt = pt в силу (7.80)
не меньше -Д-. Поэтому разложения чисел Pt и Р/
2 ‘
отличаются не далее, чем в позиции Ц. Из (7.80) с уче-
том неравенства Pi^Pf заключаем, что Кодо-
вые слова йг и й,' не являются началом одно другого,
ибо в силу сказанного они различаются не далее, чем
в Zz-й букве. Отметим, что к коду, построенному указан-
ным способом, часто оказываются применимыми опе-
рации усечения, за счет чего он может быть улучшен.
Метод Шеннона проиллюстрируем на том же при-
мере, что и метод Хаффмена. Исходные данные и ре-
зультаты вычислений сведены в таблицу 7.1. Для пояс-
Таблица 7.1
а1 Pi li pi Код Усеченный код
ai 0,36 2 0=0,00 00 00
аг 0,18 3 0,36=0,010 010 01
«3 0,18 3 0,54=0,100 100 100
0,12 4 0,72=0,1011 1011 101
«5 0,09 4 0,84=0,1101 1101 но
ае 0,07 4 0,93=0,1110 1110 111
§ 7-41
СЖАТИЕ ИНФОРМАЦИИ
381
нения проведем вычисления, связанные с нахождением
кодового слова й4. Величина Р4 = 0,12 заключена ме-
жду у и-^-, поэтому h = 4. Найдем первые /4 = 4 двоич-
ных цифр числа Р4 = 0,36 + 0,18 + 0,18 — 0,72 = -^|-.
Для этого представим 18 и 25 в двоичной системе: 18 =
— 10010, 25 — 11001 и осуществим деление с использо-
ванием обычного алгоритма
10010 Н001
- 11001 0,1011
101100
- 11001
100110
- 11001
1101
Таким образом, й4 = (1011). Средняя длина I по-
строенного кода после усечения составляет
0,36-2 4-0,18-2 + 0,18-3 +
+ 0,12 • 3 4- 0,09 • 3 + 0,07 • 3 = 2,46,
что несколько больше величины 2,44, достигнутой мето-
дом Хаффмена.
Найдем оценку средней длины кода, гарантируемую
методом Шеннона. Из правой части (7.80) заключаем,
что длины кодовых слов удовлетворяют неравенству
h < —logPi + 1.
Поэтому
pJogP/4- f p/ = //(S)+l, (7.81)
i = 1 i — \ i = l
где H (S) представляет собой энтропию источника S,
понимаемого как случайный опыт с исходами аь ..., аг
(имеющими вероятности pi, .... рг). Дальше мы уви-
дим, что оценка (7.81) является достаточно точной.
7.4.6. Кодирование блоками. До сих пор изучалось
побуквенное кодирование сообщений. Однако, как и в
случае исправления ошибок, более выгодным оказы-
382
ПЕРЕДАЧА ИНФОРМАЦИИ ПРИ НАЛИЧИИ ПОМЕХ ]ГЛ. VII
вастся кодирование целых кусков сообщения --- блоков.
Будем рассматривать блоки длины k. Опп представ-
ляют собой слова в r-буквенном алфавите {од, аг},
и их число составляет rk. Занумеруем всевозможные
блоки Б индексами i — 1, 2, ..., rk.
Как и раньше, будем рассматривать источник сооб-
щений S, который порождает символы щ, аг неза-
висимо с положительными вероятностями р1.....рг. При
этом блок Б1 — а1а1 ... а.^ имеет вероятность
Ж-W/A (7-82)
Источнику S соответствует случайный опыт с исхо-
дами аь .... аг. Можно рассматривать произведения
источников, понимаемые как произведения соответ-
ствующих случайных опытов. Обозначим через S1 про-
изведение / независимых источников S. Источник S1 вы-
дает /-буквенные слова at а1 с вероятностью
... рг В частности, источник Sk порождает
блоки Б, с вероятностью р(Б,), задаваемой (7.82). По-
этому задачу кодирования блоков можно понимать как
задачу кодирования источника Sk, «буквами» которого
являются блоки Bi.
Пусть каждому блоку Б, сопоставлено некоторое
двоичное слово Б; и при этом код Б2, ..., Бгь} яв-
ляется разделимым. Обозначим через /,• длину слова Б,.
Средняя длина кода
k
i=Yp(Bt)i
i=i
где p(Bi) вычисляется согласно (7.82), дает среднее
число кодовых символов, приходящихся на один k-бук-
венный блок. Характеристикой сжатия сообщений слу-
жит величина
rk
(7.83)
>1
представляющая собой среднее число кодовых симво-
лов, затрачиваемых на 1 букву сообщения.
5 7.4]
СЖАТИЕ ИНФОРМАЦИИ
383
Сформулируем и докажем основной результат, отно-
сящийся к сжатию сообщений.
Теорема 7.5 (К. Шеннон). Для данного источ-
ника S
1) при любом способе кодирования (разделимого)
и любом k
l^^H(S), (7.84)
2) существует способ кодирования блоков длины k,
для которого
< H(S) + ±-. (7.85)
Доказательство. По определению
rk rk
kl,k> = 2 р (50 lt = - £ р (50 log . (7.86)
z=i i=i 2
Согласно неравенству Крафта — Макмиллана имеет
место
rk
Положив = — (/ — 1, . ., rk) и <7о = 1 — , пе-
2 , 2 ‘
репишем (7.86) в виде
= — X р (50 log — 0 log (?0. (7.87)
i = l
По свойству 3° энтропийной функции
Л; г’л
— Zp (50 log <7/ — 0 log «/о > — S Р (St) log p (50 —
i=l i=l
rk
_ о log 0 = - у p (50 log p (50 = H (Sk). (7.88)
i=i
Воспользовавшись независимостью источников S, обра-
зующих произведение Sk, по свойству 6° энтропии
384 ПЕРЕДАЧА ИНФОРМАЦИИ ПРИ НАЛИЧИИ ПОМЕХ
[ГЛ VII
можно записать
Н (Sk) = Н (S Sk~l) =
== Н (S) + Н (Sk~l) = Н (S) + Н (S • Sk~’) =
= 2Н (S) + Н (Sk~2) = ... = kH (S). (7.89)
Объединение соотношений (7.87), (7.88) и (7.89) дает
kl(k)^H(Sw) = kH (S).
Разделив обе части этого неравенства на k, приходим
к (7.84).
Для доказательства второго утверждения теоремы
воспользуемся методом Шеннона, примененным к источ-
нику Sk. При этом неравенство (7.81) превращается в
kT® = l^H (Sk) + 1 = kH (S) + 1,
что эквивалентно (7.85). Теорема доказана.
Для нахождения минимального значения Z(ft) можно
осуществить кодирование источника S* методом Хафф-
мена. Теорема 7.5 показывает, что минимальное значе-
ние 7(й) заключено между Н(S) и /7 (S) +. С ростом
k эта величина стремится к H(S), поэтому энтропия
источника может служить характеристикой «сжимаемо-
сти» сообщений, порождаемых источником.
7.4.7. Универсальное кодирование блоками. До сих
пор предполагалось, что вероятности ..., рг, с ко-
торыми источник S порождает символы йь ..., аг,
известны. Величины этих вероятностей существенно ис-
пользовались как в методе Хаффмена, так п в методе
Шеннона, на базе которого была доказана теорема
7.5. Оказывается, что и без знания вероятностей можно
осуществить кодирование так, чтобы величина 7(й) с рос-
том k стремилась к H(S). Это кодирование одинаково
для всех источников с r-буквенным алфавитом и по-
этому называется универсальным.
Опишем, как производится универсальное кодирова-
ние. Блоки длины k разобьем на классы. К классу
7’(mi,m2, .... гпг) отнесем все такие блоки, в которых
символ «1 встречается ni\ раз, ..., символ аг встре-
чается т, раз (mi + nio + ... + mr = k). Поскольку
каждое из чисел mi может изменяться от 0 до k, коли-
§ 7.41
СЖАТИЕ ИНФОРМАЦИИ
385
чество таких классов не превосходит (k + 1)г. При этом
класс Г (mi,m2...... т,) содержит —;—Н---------Г бло-
v х 1П1 wg! . . . tnrl
ков *), и согласно (7.27) эта величина не превосходит
,ПгА
2 ' k ’ ’ k '. Все классы занумеруем двоичными по-
следовательностями длины ]log(& 4- 1)г[=]г log(£4~
4- 1) [, а все блоки из класса Т (т^ тг) — двоич-
ными последовательностями длины j kH (-у-, . • , -у-) [
(здесь, как и раньше, ]х( означает наименьшее целое
число, не меньшее х). Кодовым словом для блока £><•
объявим двоичное слово, полученное в результате при-
писывания к последовательности, нумерующей класс,
в котором находится блок, последовательности, нуме-
рующей блок внутри класса. Указанное кодирование
является префиксным. Действительно, если одно кодо-
вое слово является началом другого, то у них совпа-
дают и начала длины ] г log(# 4-1) [, т. е. блоки при-
надлежат одному классу. Но в этом случае кодовые
слова имеют одинаковую длину и обязаны совпасть.
Убедимся, что при указанном кодировании для вся-
кого r-буквенного источника S (независимо от вероят-
ностей Pi, ..., рг) величина /(<!> с ростом k стремится
к H(S). Для блока 6,еГ(/?11, ..., т,) длина кодо-
вого слова составляет
/,. = ]/-log(£4-l)[ + ]kH .............пг)[<
..., -^) 4- г log(£ 4- 1) 4- 2,
а вероятность вычисляется по формуле
= ---Prr- (7-9°)
*) Рассмотрим все /г! перестановок символов at, .... аг, пов-
торенных соответственно т1; ..., тг раз. Каждый из блоков будет
получен тр. .. . тР. способами (ибо перестановки одинаковых сим-
_ , , fe!
волов не изменяют блоков), и общее число блоков составит—-----
1 тр...тг1
386 ПЕРЕДАЧА ИНФОРМАЦИИ ПРИ НАЛИЧИИ ПОМЕХ
[ГЛ. VTI
Оценим среднюю длину кода с учетом того, что
/ = £р(ад<1>(^)^(-^.......^) +
i I
+ £p(5i)(Hog(Z;+l) + 2) =
= .....^) + rlog(£+ 1)4-2. (7.9!)
На основании экстремального свойства 3° энтропии, ис-
пользуя выражение (7.90) для p(Ei), найдем оценку ве-
, и ( тх тг\.
личины kH I—, .... — I:
(--y-iQgPi ~ ... --^10gpf) =
= —rnjogp,— ... — mr log pr = — log р(Б{).
Отсюда и из (7.91) заключаем, что
Sp(5Jlogp(SI) + Hog(ft+D + 2 =
= H(S*) + rlog(£+ l) + 2 = Z’//(S) + rlog(fe+ 1) + 2
и, следовательно,
1<к>=±1<н (S) + H°g(fe + 1)+.2_.
С ростом k правая часть этого выражения стремится к
H(S), что и требовалось.
7.4.8. Совмещение результатов о сжатии и помехо-
устойчивой передаче. Вернемся к задаче передачи ин-
формации при наличии помех, изучавшейся в §§ 7.2—
7.3. Как и раньше, будем считать, что передача ведется
по двоичному симметричному каналу, но, в отличие от
§§ 7.2—7.3, где мы имели дело с двоичным источником,
порождавшим символы 0 и 1 равновероятно, будем рас-
сматривать источник, который независимо порождает
символы ах......аг с вероятностями рх, .... рг.
§ 7.41
СЖАТИЕ ИНФОРМАЦИИ
387
При передаче по схеме (см. рис. 6.2) источник — ко-
дер— канал — декодер — адресат сообщение разби-
вается на блоки длины k; они кодируются двоичными
последовательностями длины п, которые затем посим-
вольно передаются по каналу. Принятые последова-
тельности после декодирования поступают к адресату.
Как показывает теорема 7.5, порождаемые источником
последовательности могут быть закодированы так, что
на 1 символ сообщения в среднем будет приходиться
Н (S) двоичных кодовых символов, и лучше этого они
закодированы быть не могут. Таким образом, каждый
символ сообщения несет в среднем Н (S) битов инфор-
мации и за п тактов по каналу в среднем передается
kH (S) битов. Поэтому скорость передачи естественно
измерять величиной
„ kH (S)
(в случае двоичного источника, порождающего сим-
волы 0 и 1 равновероятно, эта величина совпадает с — I.
При таком определении скорости передачи для ис-
точников рассматриваемого вида остаются справедли-
выми теорема кодирования и ее обращение. Они имеют
ту же формулировку, что и теоремы 7.1 и 7.2. Доказа-
тельство обращения теоремы кодирования осуществ-
ляется прежним способом с единственным отличием.
Энтропия Н(Л) случайного опыта А, исходами которого
являются блоки сообщения, в данном случае совпадает
с Н (SA) = kH (S). Подставив эту величину в (7.68) и
повторив все выкладки, вместо неравенства (7.71) при-
дем к
p(e) + ^->/7(S)-|C = //(S)(l
откуда, как и из (7.71), следует утверждение о невоз-
можности превзойти пропускную способность канала.
О справедливости теоремы кодирования можно за-
ключить на основе следующих рассуждений. Кодирова-
ние блоков сообщения длины k можно осуществить с
использованием двоичных последовательностей со сред-
ней длиной, примерно равной ki = kH(S) (теорема 7.5).
Если число R меньше пропускной способности С, то
388 ПЕРЕДАЧА ИНФОРМАЦИИ ПРИ НАЛИЧИИ ПОМЕХ
[ГЛ. VII
двоичные блоки длины k\ можно передавать по каналу
со сколь угодно малой вероятностью ошибки посред-
ством кода длины п=-~ (теорема 7.1). При этом ско-
kH (8) k। .j л
рость передачи —« окажется равной R. Эти
рассуждения не являются доказательством теоремы ко-
дирования, но они могут быть оформлены в строгое до-
казательство.
Из сказанного следует, что при раздельном выпол-
нении кодирований для источника и канала (см. схему
передачи на рис. 6.3) можно добиться наилучших (в пре-
деле) характеристик передачи. Этот важный факт спра-
ведлив для многих типов источников и каналов. Он поз-
воляет рассматривать задачи сжатия информации (ко-
дирования для источника) и помехоустойчивой пере-
дачи (кодирования для канала) по отдельности.
ЛИТЕРАТУРА
1. Б ер ле кэмп Э. Алгебраическая теория кодирования,—
М.: Мир, 1971.
2. Биркгоф Г., Барти Т. Современная прикладная алгеб-
ра. — М.: Мир, 1976.
3. Варшамов Р. Р. О некоторых особенностях линейных
кодов, корректирующих несимметрические ошибки. — ДАН СССР,
157, № 3, 1964, 546—548.
4. В а р ш а м о в Р. Р., Тенненгольц Г. М. Код, исправ-
ляющий одиночные несимметрические ошибки. — Автоматика и те-
лемеханика, 26, № 2, 1965, 288—292.
5. Виноград С., Коуэн Дж. Д. Надежные вычисления
при наличии шумов. — М.: Наука, 1968.
6. Возенкрафт Дж., Р е й ф ф е н Б. Последовательное де-
кодирование.— М.: ИЛ, 1963.
7. Гаврилов Г. П., Сапоженко А. А. Сборник задач по
дискретной математике. — М.: Наука, 1977.
8. Галлагер Р. Теория информации и надежная связь.—
М.: Советское радио, 1974.
9. Г и л л А. Введение в теорию конечных автоматов. — М.:
Наука, 1966.
10. Глушков В. М. Синтез цифровых автоматов. — М.: Физ-
матгиз, 1962.
И. Дискретная математика и математические вопросы кибер-
нетики./Под ред. С. В. Яблонского и О. Б. Лупанова. Т. 1. — М.:
Наука, 1974.
12. 3 а к р е в с к и й А. Д. Алгоритмы синтеза дискретных авто-
матов.— М.: Наука, 1971.
13. Карп Р. М. Сводимость комбинаторных проблем. — Кибер-
нетический сборник, вып. 12. М.: Мир, 1975, 16—38.
14. К и р и е н к о Г. И. Синтез самокорректирующихся схем из
функциональных элементов для случая растущего числа ошибок в
схеме. — Сб. «Дискретный анализ», вып. 16. Новосибирск: изд. ИМ
СО АН СССР, 1970, 38—43.
15. К о б р и н с к и й Н. Е., Трахтенброт Б. А. Введение в
теорию конечных автоматов. — М.: Физматгиз, 1962.
16. Кук С. А. Сложность процедур вывода теорем. — Кибер-
нетический сборник, вып. 12. М.: Мир, 1975, 5—15.
17. Левин Л. А. Универсальные задачи перебора. — Проблемы
передачи информации, IX, вып. 3, 1973, 115—116.
18. Лупа нов О. Б. О синтезе некоторых классов управляю-
щих систем. — Сб. «Проблемы кибернетики», вып. 10, М.: Физмат-
гиз, 1963, 63—97.
19. Л у панов О. Б. Об одном подходе к синтезу управляю-
щих систем — принципе локального кодирования. — Сб. «Проблемы
кибернетики», вып. 14. М.: Наука, 1965, 31 — ПО.
20. Л у п а и о в О. Б. О методах получения оценок сложности
и вычисления индивидуальных функций. — Сб. «Дискретный ана-
лиз», вып. 25. Новосибирск: изд. ИМ СО АН СССР, 1974, 13—18.
390
ЛИТЕРАТУРА
21. Ляпунов А. А., Яблонский С. В. Теоретические про-
блемы кибернетики. — Сб. «Проблемы кибернетики», вып. 9. Мл
Фнзматив, 1963, 5—22.
22. Мальцев А. И. Алгоритмы и рекурсивные функции. — М.;
Наука, 1965.
23. М и н с к и й М. Вычисления и автоматы. — М.: Мир, 1971.
24. Орлов В. А. Простое доказательство алгоритмической не-
разрешимости некоторых задач о полноте автоматных базисов. —
Кибернетика, J\s 4, 1973, 109—113.
25. Орлов В. А. О сложности реализации ограниченно-детер-
мннированных операторов схемами в автоматных базисах. — Сб.
«Проблемы кибернетики», вып. 26. М.: Наука, 1973, 141—182.
26. ПитерсонУ. Коды, исправляющие ошибки.—М.: Мир, 1964.
27. П о с п е л о в Д. А. Логические методы анализа и синтеза
схем. — Л1.; Л.: Энергия, 1964.
28. Редькин Н. П. О сложности реализации недоопределен-
ных булевских функций. — Автоматика и телемеханика, № 9, 1969.
29. Редькин Н. П. Доказательство минимальности некоторых
схем из функциональных элементов. — Сб. «Проблемы кибернети-
ки», вып. 23, М.: Наука, 1970, 83— 101.
30. Роджерс X. Теория рекурсивных функций и эффективная
вычислимость. — М.: Мир, 1972.
31. Трахтеиброт Б. А., Барздинь Я. М. Конечные авто-
маты: Поведение п синтез. — М.: Наука, 1970.
32. Т р а х т е и б р о т Б. А. Алгоритмы и вычислительные авто-
маты.— М.: Советское радио, 1974.
33. Т р а х т е н б р о т Б. А. Сложность алгоритмов и вычисле-
ний. — Новосибирск: изд. НГУ, 1967.
34. Форни Д. Каскадные коды. — М.: Мир, 1970.
35. X р а п ч е и к о В. М. О сложности реализации линейной
функции в классе П-схем, — Мат. заметки, 1971, т. 9, № 1, 35—40.
36. Шеннон К. Э. Работы по теории информации и киберне-
тике.— М.: ИЛ, 1963.
37. Шоломов Л. А. О реализации недоопределенных булевых
функций схемами из функциональных элементов. — Сб. «Проблемы
кибернетики», вып. 21. М.: Наука, 1969, 215—226.
38. Энциклопедия кибернетики. Т. 1—2.— Киев: Главная редак-
ция УСЭ, 1975.
39. Яблонски й С. В. Об алгоритмических трудностях син-
теза минимальных контактных схем.— Сб. «Проблемы кибернетики»,
вып. 2, М.: Физматгиз, 1959, 75—122.
39а. Яблонский С. В. Введение в дискретную математи-
ку.— М.: Наука, 1979.
40. Я г лом А. М., Яглом И. М. Вероятность и информа-
ция.— М.: Физматгиз, 1960.
41. Curtis Н. A. A new approach to the design of switching
circuit, D. Van Nostrand Co., New Jersey, 1962.
42. Pauli M. C., Unger S. H. Minimizing the number of sta-
tes in incompletely specified switching functions. — IRE Trans,
v. EC-8, № 3, i959, 356—367.
43. P f 1 e e g e r C. State reduction in incompletely specified finite
state machines. — IEEE Trans. Comput., v. 22, № 12, 1973, 1099.
указатель обозначений
Символы
Л — пустой символ 159
и — символ истинности 169
Л — СИМВОЛ ЛОЖНОСТИ 169
П — обозначение правого сдвига
160
Л — обозначение левого сдвига
160
Н — обозначение отсутствия сдви-
га 160
Некоторые объекты
— единичная матрица размера
k 288
й — набор (0...010) 308
3 — элемент задержки 135
U — универсальная машина Тью-
ринга 195
Мп — машина Тьюринга с но-
мером п 198
$ — базис логических функций 27
<S — базис логических элементов
51
Л — базис автоматных элемен-
тов 150
Соотношения между величинами
а ~ Р — асимптотическое равен-
ство 94
а Р — асимптотическое нера-
венство 94
а=о(Р) — величина а существен-
но меньше р 94
/i (х) = fi (x)(mod g(x)) — равен-
ство по модулю многочлена 303
Логические функции и классы
х — отрицание (инверсия) 26
х&у — конъюнкция 26
х V у — дизъюнкция 26
х—> у — импликация 26
х ~ у — эквивалентность 26
х© у —сумма по mod 2 26
х | у — штрих Шеффера 39
х ф у — стрелка Пирса 39
п
& Xi — многоместная конъюик-
» = 1
ция 29
п
V X; — многоместная дизъюнк-
1 = 1
ция 29
п
5>. х, — многоместная сумма по
1=1
mod 2 36
ха — степень переменной 32
(х) — конъюнкция, соответ-
ствующая набору б 33
f* — двойственная функция 40
Vk(x, у) (V (х, у)) — функция
Вебба й-значной логики 48
То-класс сохранения нуля 40
Т[ — класс сохранения единицы
40
S — класс самодвойственных
функций 40
М — класс монотонных функций
42
L — класс линейных функций 42
Числовые функции
[х]— целая часть числа 98
]х[ — ближайшее целое, не мень-
ше х 250
log х — двоичный логарифм 98
Н (pi, pk) — энтропийная
функция 335
0(х)— функция нуль 175
s(х)— функция следования 175
(xi,..., хп) — функция выбора
аргумента 175
392
указатель обозначений
х — у — усеченная разность 177
sg (*) — сигнум 177
sg (х) — антисигнум 177
ост(х,у)— остаток от деления
179
дел (х, у) — функция делимости
179
стг(х)—двоичная степень 179
р (х, у) — номер пары (х, у) 180
I (п) — левый элемент пары с но-
мером п 180
г (га) — правый элемент пары с
номером п 180
(х) ~ характеристическая
функция множества А 206
Uk (п,х\,..Xk) — универсальная
фу нкция для ^-местных ча-
стично-рекурсивных функций
201
U (п, х) — то же при k = 1 200
Фп (*!...Xk) — /г-местная ча-
стично-рекурсивная функция
с номером п 202
фп(х) —то же при k = 1 199
Операции и операторы
йфР— сумма наборов (по
mod2) 277
йр — произведение наборов 308
а* — степень набора 368
р (й, р) — расстояние между на-
борами 277
М2« Mi— суперпозиция машин 168
Mi*M2 — композиция машин 168
Mi V М2 — ветвление машин 169
АВ — произведение случайных
опытов 341
Ф (Д) — преобразование случай-
ного опыта 347
Sk — степень источника 382
аЛ — произведение набора на
матрицу 287
А[ — транспонирование матрицы
292
pv — оператор минимизации
174, 178
(х) — многочлен, соответству-
ющий набору й 296
та W — минимальный многочлен
для набора й 312
Ш (id) — шифр объекта d 193
Элементы описания объектов
Ф£ (Xi,..., х0) — функция эле-
мента Е 52
Ф^и (х) — функция, вычисляемая
машиной М 199
’F — функция переходов автома-
та 111
Ф/ — функция выхода / автома-
та 111
G — порождающая матрица кода
286
Go — то же в приведенно-ступен-
чатой форме 288
Н — проверочная матрица кода
293
g (х) — порождающий многочлен
кода 296
h (х) — проверочный многочлен
кода 301
Параметры
и характеристики объектов
| А | — мощность множества А 282
| 7? ( — длина слова R 223
(т, п) — параметры системы
функций (число функций, чис-
ло переменных) 49
(га, т, р) — параметры автомата
(число входов, число выходов,
число состояний) 143
(га, k, г) — параметры кода (дли-
на, число информационных
символов, число проверочных
символов) 268, 275
d — кодовое расстояние 278
I — средняя длина кода 370, 382
lk — средняя длина кода на один
символ сообщения 382
С — пропускная способность ка-
нала 351
R — скорость передачи 270, 355,
387
р (е) — вероятность ошибки 355
И (Д) — энтропия опыта А 335
Н (Д | b i) — энтропия опыта А
при условии исхода 342
Нв (Д) — энтропия опыта А при
условии опыта В 342
указатель обозначений
393
/ (Л, В) — информация в опыте
А об опыте В 344
/ (z) — размерность задачи z 247
w (а) — все набора а 277
Pg — приведенный вес базиса <£
109
Показатели сложности объектов
L (S) — сложность схемы S 54,
148
ig (SyLM — то же в базисе
<S (базисе Л) 109, 157
L (/) (Д(В)) — сложность функции
f (системы В) 54, 93
Z.g (/) (В)) — то же в базисе
<S 109
LM (М) ’ сложность в базисе Л
автомата М 157
L (га) (В (in, п)) — функция Шен-
нона для функций от п аргу-
ментов (для систем с пара-
метрами (т, га)) 93, 107
7,g (га) (Ag (т, га)) — то же в ба-
зисе S 109
L (п, т, р) — функция Шеннона
для автоматов с параметрами
(га, т, р) 148
LM (п, т, р( — то же в базисе
Л 157
В/ (га) — функция Шеннона для
/-самокорректирующихся схем
329
I (Ф) — сложность формулы 59
L' (S) — сложность схемы без
ветвлений 58
/м (х) — временная сложность
230
SM W — ленточная сложность
230
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
Автомат автономный 150
— в алфавите А 155
— инициальный 111
— • комбинационный 12
— конечный 110..
---, диаграмма ИЗ
---, таблица 112
— —, уравнения канонические 111
---, функция выходов 111
---, —переходов 111
— Мили 112
— минимальный 120
---, единственность 125
— —, построение 124
— Мура 114
— неинициальный 111
—, реализуемый схемой из элементов
автоматных 154
—,------— логических и задержек
138
— частичный 117
---, детерминированность 119
---, доопределение 117
— — минимальный 121
---, область определения 119
---, таблица 117
Алгебра наборов 307
Алгоритм 158
Анализ схемы из логических элемен-
тов 52
---------и задержек 139
Анализа задача 14
Аргумент фиктивный 26
Арифметизация 186
Ассоциативность 29
Базис в алфавите А 155
--------полный 155
— инициальный 150
— неинициальный 150
~ функций Л-значной логики 47
--------полный 48
— — логических 27
— полный 39
— элементов автоматных 150
--- логических 51
-----полный 52
Бит 336
Блок 355, 382
Буква 10
БаЧ-код 317
Вектор ошибки 291
Вершина концевая 372
— схемы 51. 136, 151
Вес набора 277
— числа арифметический 326
— элемента 109
--приведенный 109
Ветвление программ 169
Время абстрактное 10
— дискретное 9
Вход автомата ПО
Выход автомата ПО
— схемы 52, 137, 153
Вычисление на машине Тьюринга
функции словарной 163
----------числовой 166
— с полиномиальной сложностью 248
— эффективное 247
Граница Гилберта 284
— мощности кода верхняя 283
-----нижняя 284
~ Хемминга 283
Граф полный 258
— схемы 102
Группа совместимости 127
--максимальная 127
Группировка 127
— замкнутая 130
— максимальная 127
Декодер 265
Декодирование 269
— в ближайший кодовый вектор 295,
358
— кода линейного 293
--Хемминга 273
-- циклического 302
Декомпозиция логической функции 85
-- — разделительная 86
— — —, условие существования 87
Дерево 101
— двоичное 372
— — полное 372
— с корнем 101
-----, оценка числа 101
Детерминированность автомата ча-
стичного 119
— алгоритма 158
Диаграмма автомата 113
-- частичного 118
Дизъюнктивная нормальная форма
(д. н. ф.) 66
— кратчайшая 66
-— —, оценка сложности 82
предметный указатель
395
Дизъюнктивная нормальная форма
(д. н. ф.) минимальная 66
---------- оценка сложности 82
----------совершенная 33
----------—, единственность 34
Дизъюнкция 26
— многоместная 29
Дистрибутивность 29
Длина кода средняя 382
Задача см. также Проблема
- выполнимости к. и. ф. 253
— индивидуальная 210
--, размерность 247
— исправления ошибок, постановка
вероятностная 267
------, — детерминированная 266
- о вершинном покрытии 260
— о минимизации частичного автома-
та 263
— о полном подграфе 258
— о сложности д. н. ф. 250, 261
— о тождественной истинности фор
мулы 250
— об изоморфизме графов 250
— переборная 352
-- универсальная 352
— ^P-пoлиaя 352
Закон двойного отрицания 29
Законы де Моргана 29
Запись числа i-ичная 186
-- унарная 164
Зона активная 162, 230
Идемпотентность 29
Импликант 66
— простой 67
— — частичной функции 80
Импликация 26
Инверсия 26
Информация взаимная 345
— двоичная 11
— дискретная 10
— , мера 344
— , свойства 345
— , симметрия 345
— словарная 10
— собственная 345
Источник 265, 370
- редуцированный 376
Канал 264, 351
— двоичный симметричный 267, 351
------, пропускная способность 351
— , пропускная способность 351
Класс вычетов по модулю многочлена
303
— сохранения единицы 40
-- нуля 40
— функций замкнутый 40
Класс функций линейных 42
---монотонных 42
— — самодвойственных 40
— эквивалентности состояний 121
Код 268
— { Боуза —Чоудхури—Хоквингема}
317
— { —}, избыточность 321
— { —}, кодовое расстояние 317
— , корректирующая способность 269,
278
— линейный 285
---, декодирование 293
— —. кодовое расстояние 286
— —, матрица порождающая 286
---, — проверочная 291, 293
— оптимальный 281, 375
— префиксный 371
— —, графическое представление 371
---оптимальный, свойства 376
— равномерный 268
— разделимый 370
— с повторением 270
— с проверкой на четность 271
----------, оптимальность 281
— с утроением 270
------, вероятность ошибки 271
— систематический 275
линейный 288
циклический 300
— слова 223
— Хаффмена 375
— Хемминга 272
---, матрица порождающая 290
---, — проверочная 292
---, оптимальность 282
— циклический 296
---, декодирование 302
— задание корнями 315
. кодирование 300
— —, матрица порождающая 299
---, — проверочная 301
---, многочлен порождающий 297
— —, — проверочный 301
---Хемминга 316
------, многочлен порождающий 317
— Шеннона 379
Кодер 265
Кодирование 268
— блоками 355, 381
— — универсальное 384
— побуквенное 370
— состояний автомата 147
Команда 160
Коммутативность 29
Композиция машин 168
— программ 168
Конструкция диагональная 234
Конфигурация 160
— заключительная 161
— , численное представление 186
Конъюнктивная нормальная форма
(к. н. ф.) 84
—-----кратчайшая 84
------, оценка сложности 84
------- минимальная 84
— — — —, оценка сложности 84
---— совершенная 35
------, единственность 36
396
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
Конъюнкция 26
— многоместная 29
Корень многочлена 311
— уравнения 311
Коэффициент полиномиальный 349
Куб n-мерный единичный 68
Лента 159
— двухэтажная 168
Набор двоичный 25
— информационный 268
— кодовый 268
Наборы ортогональные 292
Надежность 19
Неравенство асимптотическое 94
— Крафта —Макмиллана 375
Неразрешимость алгоритмическая 210
Нумерация машин 198
— наборов 180
— пар 180
— частично-рекурсивных функций
fe местных 202
---— одноместных 199
Массовость 158
Матрица инциденцнй 261
— порождающая в приведенно-ступен-
чатой форме 287
---кода линейного 286
------ с проверкой на четность 290
------Хемминга 290
— — — циклического 299
--------, преобразование к приведен
но ступенчатой форме 300
— проверочная кода линейного 291,
293
161
— — — с проверкой на четность 292
---— Хемминга 292
----- циклического 301
— смежности 250
Машина 13
— Тьюринга 159
---, арифметизация 186
---, вычисление функций 163
---, конфигурация 161
---, программа 160
---, связь с конечным автоматом
— —, состояние 159
---, — заключительное 160
---, — начальное 163
— — универсальная 195
-----, конструкция 197
Метод декомпозиции 90
— кодирования случайного 364
---Хаффмена 375
---Шеннона 379
— Лупанова синтеза схем 94
— мощностной получения нижних оце-
нок 99
— сводимости 211
Минимизация автомата 119
— д. н. ф. 66
— функции монотонной 73
--- частичной 80
Многочлен минимальный 311
---, нахождение 315
— —, свойства 311
---, степень 314
— по mod 2 296
— порождающий 297
— примитивный 309
— проверочный 301
Множество рекурсивное 206
Моделирование машины Тьюрнига си-
стемой подстановок 215
— системы подстановок системой про-
дукций 220
— — продукций автоматами 222
Обратная связь 136, 152
Обращение теоремы кодирования 365
Объект дискретный случайный 333
Операция минимизации 174, 178
— —, реализация на машине Тьюрин-
га 185
— по модулю многочлена 303
— рекурсии 173
---, реализация на машине Тьюрин-
га 184
— склеивания наборов 71
— суммирования по mod 2 26
— суперпозиции 172
---, реализация на машине Тьюрин-
га 183
— усечения кода 372
— устранения задержек 140
Оптимизация 17
Опыт случайный 334
---, исход 334
---, неопределенность 335
---, энтропия 335
Опыты независимые 341
---. энтропия 343
Отношение покрытия автоматов 121
--- состояний 120
Ошибка арифметическая 326
---. обнаружение 327
— несимметричная 266, 323
---, исправление 323
— симметричная 266
— стирания 267
Память 11, 49
Пачка ошибок 324
---, обнаружение 325
Перебор 18, 54
— сокращенный 18
Перевод унарной записи в двоичную
164
Подкуб 69
— максимальный 69
Подстановка базисная 214
Подформула 27
Покрытие вершинное 260
— функции 75
--- неизбыточное 75
Полином см. также Многочлен
— Жегалкина 37
---, единственность 38
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
397
Полноты свойство 16
Полюс схемы 51, 136, 151
Последовательности совместимые 127
Правило вычеркивания 31
— поглощения 31
— склеивания 31
— сложения энтропий 342
Преобразование информации 347
— формулы эквивалентное 28
Применимость входной последователь
ноет и к состоянию 119
— машины Тьюринга к конфигурации
161
Проблема см. также Задача
— алгоритмически неразрешимая 210
---разрешимая 208
— выводимости в системе подстано-
вок 213
---— — —, неразрешимость 215
--------- Продукций 218
----- —--, неразрешимость 219
— массовая 210
— останова 213
— полноты конечной системы автома-
тов 155, 222
---------, неразрешимость 222
— самоприменимости 212
---, неразрешимость 212
Программа машины Тьюринга 160
Продукция базисная 218
Произведение источников 382
— наборов 307
---, свойства 310
--- скалярное 292
— опытов 341
Пространство линейное 285
Работа в реальном масштабе време-
ни 14
Равенство асимптотическое 94
Разбиение состояний замкнутое 124
Разложение по переменным функции
логической 32
--------- частичной 60
Разряц информационный 275
— проверочный 275
Расстояние арифметическое 327
— кодовое 278
---БЧХ-кода 317
---линейного кода 286
---, связь с корректирующей способ-
ностью 278
— по Варшамову 280
— по Хеммипгу 277
Рекурсия совместная 181
Сверхслово 223
Сводимость 211
— полиномиальная 249
Свойство префикса 371
— функций нетривиальное 208
Сжатие информации 369
---, характеристики 370, 382
Символ двухэтажный 168
— пустой 159
Синдром 293
Синтез абстрактный 16
— блочный 16
— Методом декомпозиции 90
— надежностный 17
— структурный 16
— технический 17
Синтеза задача 15
Система подстановок 214
---, выводимость 214
— продукций 218
---, выводимость 219
Склеивание конъюнкций 70
— наборов 71
Скорость передачи информации 270,
355, 387
Слово 10
— машинное 215
Сложение логическое 27
Сложность временная 230
— д. и. ф. 82
— ленточная 230
— системы логических функций 54
— схемы без ветвлений 60
--------, оценка 64
---для частичной функции 64, 108
--- из логических элементов 54
--------и задержек 148
-----— —f оценка 106
Сообщение 264
Соотношение проверочное 276, 291
Состояние автомата 110
— головки 159
— заключительное 160
— начальное 111, 163
Состояния совместимые 127
---, нахождение 128
Сравнение по модулю многочлена 303
Стрелка Пирса 39
Сумма по mod 2 26
Сумматор параллельный 12, 50
— последовательный 12, 111
Суперпозиция машин 168
— программ 167
— функций 40, 172
Схема 11
— без ветвлений 57
------ —, оценка сложности 64
— , синтез 60
— , сложность 60
— из автоматных элементов 150
--------, анализ 154
—- ---, состояние 154
— из логических элементов 51- 52
— и задержек 136, 139
— --------1 оценка сложности 148
— — —, синтез 143
---__-------, состояние 139
— — минимальная 54
— —, оценка сложности 99, 105,
106
— — — числа схем 102
--------самокорректирующаяся 328
--------, сложность 52
— передачи информации 264
— — —, описание в терминах случай-
ных опытов 364
рекурсивная 176
398
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
Таблица автомата 112
--- частичного 117
— декодирования 269
— импликантная 75
— кодирования 268
— функции fe-значной логики 46
--- логической 25
---— частичной 56, 63
--------, доопределение 87
Такт 9
Тезис Чёрча 159
Теорема Блюма 239
— итерационная 204
- Клини 205
— кодирования 357
— Кратко 156, 222
— Крафта 372
— Кузнецова 48
— Лупанова 106
— Макмиллана 374
— о неподвижной точке 205
— о функциональной полноте 44
— об убыстрении 239
— Райса 206
— Шеннона о передаче при наличии
помех 356
---о сжатии сообщений 383
Тип ошибки 266
Точка неподвижная 205
Умножение логическое 27
Уравнения канонические автомата 111,
112
— — схемы 142
Устройство декодирующее 265
— дискретное 9, 48
— — автономное 14
— — асинхронное 116
— — без памяти 12, 49
— — вероятностное 13
— — детерминированное 13
— —, классификация 12
---неавтономное 14
— — с бесконечной памятью 12
— — с конечной памятью 12, 110
— — с недоопределенными условиями
работы 55, 117
--- синхронное 116
— —, сложность 17
---, состояние• 9
— кодирующее 265
Функция вогнутая, свойства 336
— выбора аргумента 175
— выходов 111
— «двоичная степень» 179
— делимости 179
— fe-значной логики 46
--—, таблица 46
— константа 176
— логическая 25
--, геометрическая интерпретация 68
— — двойственная 40
--, декомпозиция 85 .
-- константа 26
-- линейная 42
-- монотонная 42
--, разложение по переменным 32
— — самодвойственная 41
--, таблица 25
— — тождественная 26
-- частичная 55
------, доопределение 56
------, таблица 56, 63
-- элементарная 27
— «модуль разности» 178
— натурального аргумента 166
------ частичная 166
— нуль 175
— опровержения 235, 239
— «остаток от деления» 179
— , отличная от 0 в конечном числе
точек 180
— переходов 111
— показательно-степенная 176
— , реализуемая схемой 52
— , — формулой 28
— рекурсивная 175
— сигнум 177
— следования 175
— словарная 163
— — частичная 163
— сложения 176
— умножения 176
— универсальная для класса 199
— «усеченная разность» 177
— характеристическая 206
— «целая часть от деления» 178
— частично-рекурсивная 175
--, не доопределимая до рекурсив-
ной 203
-- универсальная 200
— Шеннона 94, 109, 148, 157
--для самокорректирующихся схем
329
Формула логическая 27
Формулы эквивалентные 28
Функции исходные 175
- -, реализация иа машине Тьюрин-
га 18э
— нумерационные 180
Функция антнсигнум 177
— булева 25 (см. также Функция ло-
гическая)
— Вебба 48
— вогнутая 336
Характеристики передачи 354
— сжатия информации 370, 382
— сложности вычислений 229, 244
Цикл 170
Шифр команды 194
— конфигурации 194
— машины 194
— символа 193
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
399
Штрих Шеффера 39
3квивалентиость 26
— автоматов инициальных 115
---неиннциальных 115, 120
— кодов 275
— моделей алгоритмов 182
— функций, вычислимых на машинах
Тьюринга, и частично-рекурсивных
192
Эквивалентные состояния 120
---, нахождение 121
Элемент 11
— автоматный 150
— базисный 51
— задержки 135
— канонические уравнения 135
— логический 50
Элементарность шагов алгоритма 158
Энтропия 335
— , свойства 337
— условная 342
Ячейка 159
Лев Абрамович Шоломов
ОСНОВЫ ТЕОРИИ ДИСКРЕТНЫХ
ЛОГИЧЕСКИХ И ВЫЧИСЛИТЕЛЬНЫХ
УСТРОЙСТВ
М.» 1980 г., 400 стр. с илл.
Редактор Ю. А. Гастев
Техн, редактор Н. В. Вершинина
Корректор О. М. Кривенко
ИБ Ns 11088
Сдано в набор 06.07.79. Подписано к печати 04.04.80.
Т-08108. Бумага 84Х108‘/з2, тип. № 1. Литератур-
ная гарнитура. Высокая печать. Условн. печ.
л. 21, Уч.-изд. л. 20,65. Тираж 8000 экз. Заказ № 304.
Цена книги 95 коп.
Издательство «.Наука»
Главная редакция
физико-математической литературы
117071, Москва, В-71, Ленинский проспект, 15
Ордена Трудового Красного Знамени Ленинград-
ская типография № 2 имени Евгении Соколовой
«Союзполиграфпрома» при Государственном коми-
тете СССР по делам издательств, полиграфии
и книжной торговли, 198052, Ленинград, Л-52,
Измайловский проспект, 29