/

































































































































































































































































































































Текст
М. М. БОНГАРД
ПРОБЛЕМА УЗНАВАНИЯ
ИЗДАТЕЛЬСТВО «НАУКА»
ГЛАВНАЯ РЕДАКЦИЯ
ФИЗИКО-МАТЕМАТИЧЕСКОЙ ЛИТЕРАТУРЫ
МОСКВА 1 967
6П2.15 Михаил Моисеевич Бонгард
Б 81 ПРОБЛЕМА УЗНАВАНИЯ
УДК 519.95 Mj 1967 Tf 320 стр. с илл.
Редактор Р. С. Гутер
Художник Я. И. Максимов
Худ. редактор И. И. Румянцев
Техн. редактор И. Ш. Аксельрод
Корректор С. Я. Емельянова
Сдано в набор 2/ХИ 1966 г. Подписано к печати 26/IV 1967 г.
Бумага 84 х 108!/<й- Физ. печ. л. 10. Условн. печ. л. 16,8.
Уч.-изд. л. 16,77. Тираж 20 000 экз. Т-06903. Цена книги 78 коп.
Заказ № 462.
Издательство «Наука»
Главная редакция физико-математической литературы.
Москва, В-71, Ленинский проспект, 15.
Ленинградская типография № 2 имени Евгении Соколовой
Главполиграфпрома Комитета по печати
при Совете Министров СССР. Измайловский проспект, 29.
3-3-14
177-Ь7
Предисловие
В настоящее время многие исследователи занимаются созданием
устройств, моделирующих способность человека решать широкий
круг разнообразных задач. Возникающая при этом принципиальная
трудность заключается в том, что эти задачи часто ставятся не в
формализованном виде, а путем показа нескольких примеров,
указания аналогичных случаев, ссылок на некоторое сходство и т. п.
Разные авторы называют подобные устройства «узнающими»,
«ведущими эвристический поиск» и т. п. Данная книга не является
ни учебником, ни, тем более, обзором многочисленных' работ,
ведущихся в этих направлениях. Она содержит главным образом
соображения, возникшие в результате совместной работы группы, в
которую кроме автора входили М. Н. Вайнцвайг, В. В. Максимов,
и М. С. Смирнов.
Выбор неформализованных задач в качестве объекта
исследований создает трудности не только при построении устройств,
способных решать эти задачи. Трудность возникает и при попытке
теоретически оценить возможности того или другого устройства.
Создается необычная для математики (разделом которой,
по-видимому, целесообразно считать «проблему узнавания») ситуация,когда
трудно доказать какие-либо теоремы, а приходится прибегать к
эксперименту. Такое положение является, вероятно, временным,
однако предпринятые до сих пор попытки формализовать постановку
вопроса в проблеме узнавания приводили или к «выплескиванию
ребенка» (подмене задачи узнавания другой более примитивной
задачей), или к определениям, которые пока мало плодотворны, так
как мы еще не умеем оговорить некоторые существенные
ограничения.
Может возникнуть вопрос: а стоило ли писать книгу о столь
неопределенном и неустоявшемся предмете? Автору кажется, что
стоило. Дело в том, что сейчас, по-видимому, уже вырисовываются
достаточно общие подходы к проблеме. С другой стороны, много
людей, не дожидаясь появления строгой математической теории,
начинает заниматься различными аспектами проблемы узнавания.
Инженеры и психологи, физики и врачи, математики и физиологи
сталкиваются с необходимостью понять или промоделировать такие
функции мозга, как способность «находить сходство», «обобщать»,
«создавать абстрактные понятия», «действовать на основе интуиции»
и т. п. Знакомство с уже проделанной работой может облегчить
труд этих людей, сделать их поиск более целеустремленным,
предостеречь от движения в мало перспективных направлениях.
Многие понятия вводятся в книге на интуитивном уровне.
В принципе это может привести к недоразумениям. Для уменьшения
3
вероятности таких недоразумений нужно, чтобы запасы
фактических сведений (на которых в значительной мере базируется
интуиция) читателя и автора были близки между собой. Поэтому в
книге приводится описание нескольких конкретных программ, в
процессе работы над которыми формировались взгляды автора. Особое
внимание уделяется неудачным блокам, так как именно выяснение
причин неудач обычно помогает двигаться вперед.
Желание автора дать чига1елю конкретный материал для
размышлений привело к тому, что описание программы Арифметика
(на примере которой вводятся понятия признак, преобразование
пространства рецепторов и т. п.) предшествует более абстрактному
вопросу об имитации автоматом другого автомата, хотя, согласно
принятой в книге логической схеме, именно нмикация является
«первичным» понятием.
Таким образом, порядок глав не всегда отражает внутреннюю
структуру материала (да и вряд ли он сегодня может быть
хорошо линейно упорядочен). Однако в тексте имеется очень много
явных и неявных ссылок на ранее изложенные факты и
соображения, поэтому есть смысл читать книгу подряд. Исключение,
пожалуй, составляет глава VII о полезной информации, которая
довольно естественно следует за главами V и VI, но вовсе не обязательно
должна предшествовать главе VIII и потому практически без
ущерба для понимания дальнейшего может быть пропущена при чтении.
Можно также рекомендовать читателю уже при чтении главы II
ознакохмиться с приложением 3 («задачник»). Это поможет ему
почувствовать природу трудностей проблемы узнавания.
Одной из главных задач автора было обратить внимание
читателя на взаимосвязь различных разделов проблемы узнавания
между собой и на аналогии между проблемой узнавания и смежными
областями. Разнообразие таких «точек соприкосновения» привело
к тому, что разные аспекты одного и того же вопроса иногда
обсуждаются в нескольких главах.
В создании описанных в книге программ, в экспериментах
с ними и в психофизиологических опытах принимали участие Л.
Дунаевский, Г. М. Зенкин и А. П. Петров, которым автор приносит
искреннюю благодарность.
Автор глубоко признателен Э. М. Бравермаиу, Р. С. Гутеру и
Н. Д. Нюбергу, подробно ознакомившимся с рукописью и
высказавшим ряд полезных замечаний.
Автору выпало счастье неоднократно обсуждать проблему
узнавания с оригинальным, необыкновенно тонко чувствующим новые
направления ученым М. Л. Цетлиным. Буквально за несколько дней
до своей трагической скоропостижной кончины Михаил Львович
прочел рукопись книги и дал много ценных советов. Светлая память
об этом замечательном человеке в сердцах многих будет неразрывно
связана с любыми вопросами, возникающими при исследовании
организации сложного поведения, а значит, и с проблемой
узнавания.
М, Бонсард
25.6 1966 г.
ВВЕДЕНИЕ
В течение последних десяти лет на страницах
научно-фантастических рассказов фигурирует все больше
и больше «роботов», «киберов» и прочих устройств,
снабженных «электронным мозгом». Эти автоматы
ведут непринужденную беседу с человеком на
всевозможные темы и обладают целесообразным поведением.
Поведение их настолько сложно, условия, к которым
они могут приспособиться, настолько разнообразны, что
иначе чем разумными такие машины не назовешь. В
зависимости от сюжета роботы бывают добрыми или
злыми, коварными или готовыми на самопожертвование,
комически ограниченными или всезнающими
мудрецами, но во всех случаях авторское отношение писателя
к такому роботу напоминает скорее отношение к
человеку, чем к машине.
Ничего сколько-нибудь напоминающего подобных
роботов мы сегодня в реальной жизни не видим. Для
сравнения вспомним, что, например, прообразы всех
конструкций, описанных у Жюля Верна, имелись в
технике того времени. Возникает вопрос: что же в
рассказах «из жизни роботов» — «научно», а что — «чистая
фантастика»? Не придумали ли писатели в погоне за
необычными ситуациями нечто, чего быть
принципиально не может? Ведь изобретение вечного двигателя тоже
могло бы послужить неплохой темой фантастического
рассказа, если бы только читатели не были поголовно
«испорчены» знанием закона сохранения энергии.
Ответ на этот вопрос таков: создание роботов, сколь
угодно близко имитирующих поведение человека, не
противоречит никаким известным в настоящее время
законам природы. Более того, писатели-фантасты не сами
Додумались до принципиальной возможности такой
имитации. Эту идею они позаимствовали у ученых*).
*) См., например, А. Тьюринг, Может ли машина мыслить?
Физматгиз, М., 1960.
5
Почему же ученые, уже несколько десятилетий
понимающие принципиальную возможность создания
думающих машин, до сих пор их не сделали?
После появления универсальных вычислительных
машин с программным управлением у
ученых-энтузиастов возникло ощущение некоего всемогущества
программиста. Захочет — заставит машину решать систему
уравнений, захочет — она будет играть в шахматы,
захочет— займется переводами с английского языка на
русский. А если написать соответствующую программу,
то универсальная машина воспроизведет любой вид
человеческой деятельности. Конечно, чем сложнее
деятельность, тем длиннее получится программа и тем
больше врехмени потребуется машине для работы. По
существу, отсюда следовало: дайте нам большую
память и большую скорость работы — и мы сделаем
«думающую» машину.
Можно сказать, что кибернетика выдала крупный
вексель. Однако он до сих пор практически совсем не
оплачен. И в основном не из-за малой скорости и
недостаточного объема памяти современных машин.
Причина в другом — не хватает идей. Идей о способах
построения программ для имитации сложного поведения
человека в разнообразных обстоятельствах. В чем же
причина трудности?
Очень легко написать программу, если машина
должна всегда (при всех обстоятельствах, с которыми
она может столкнуться) совершать одну и ту же
последовательность операций. Например, чтобы вычислить
значение выражения a2 + b—-ab + b2, она должна (при
любых а и Ь) возвести число а в квадрат, к результату
прибавить Ъ и т. д.
Иначе обстоит дело в случае, когда при разных
обстоятельствах требуется разный порядок действий.
Однако сложность возрастает не намного, если можно
заранее четко сформулировать, чем должен определяться
выбор следующей операции в тех или иных случаях.
Например, если требуется при любых а вычислять йп
(п — целое положительное число), то машина должна
каждый раз перед умножением ранее полученного
результата на а сравнивать число уже произведенных
умножений с /г. В зависимости от результата этого
сравнения нужно или произвести очередное умножение (если
6
их было сделано еще недостаточно), или напечатать
ответ и остановиться. Ясно, что написать программу
такой работы несложно.
Серьезные трудности начинаются тогда, когда
нельзя заранее решить, чем должен определяться выбор
порядка операций в машине. Когда принцип этого выбора
зависит от многих обстоятельств и характер
зависимости тоже не может быть указан заранее, а должен
определиться в результате рассмотрения некоторых других
обстоятельств, однако метод рассмотрения нельзя
задать один и тот же на все случаи машинной жизни. Он
должен быть выбран машиной в соответствии с
конкретными особенностями задачи, а принцип выбора... (см.
начало предыдущей фразы и повтори этот цикл 20, а то
и 100 раз).
Именно такая степень сложности программы
понадобится, если мы захотим имитировать способность
человека решать множество задач и приспосабливаться
к очень разнообразным условиям. Заметим при этом,
что поведение машины, управляемой подобной
многоступенчатой программой, будет выглядеть вовсе «не
машинным». Ее действия будут настолько сложно зависеть
от такого великого множества обстоятельств (в том
числе и далеко отстоящих во времени), что внешне будет
полная иллюзия свободы воли в принятии решений (так
же как есть иллюзия «свободы воли» у человека).
«Ну и пусть нужна сложная программа, — может
подумать тут читатель. — Почему бы не начать писать
команду за командой программу такой деятельности?
Даже если тратить по часу на одну команду, то,
глядишь, за 5 лет кое-что интересное и получится!»
К сожалению, такой метод «штурма проблемы в
лоб» вряд ли может удаться. Причин этого несколько;
мы остановимся на одной из них, главной с нашей
точки зрения. Программист, который попытался бы шаг за
шагом писать программу для думающей машины, очень
скоро заметил бы, что он сам не в состоянии просле*
дить, какие обстоятельства, на что и по каким законам
должны влиять. А при рассматриваемом способе
создания программы без таких знаний программист работать
не может. Нельзя требовать от человека (а программист
тоже человек) очень детального знания устройства
очень сложной системы.
7
Проиллюстрируем это соображение примером.
Допустим, соотношение скоростей развития техники и
различных наук на Марсе было совсем не таким, как на
Земле. Марсиане уже постигли законы взаимодействия
элементарных частиц, но еще не знают ни химии, ни
даже механики больших тел. Единственный их способ
передвижения на большие расстояния — это верхом
(колесо еще неизвестно). Пусть некий великий
марсианский ученый догадался, что способность передвигаться
за счет внутренних запасов энергии не есть
исключительное свойство живых организмов*). На основе этого
открытия решено построить автомобиль. (Пока что это
слово для марсиан отражает чисто функциональное
свойство будущей конструкции — способность к
«самодвижению».)
Задача, поставленная перед конструкторским бюро,
звучала на языке марсиан так: требуется найти такое
расположение некоторого числа атомов в пространстве,
чтобы их совокупность могла перевозить человека по
хорошей дороге со скоростью не меньшей, чем лошадь.
Конструкторы взялись за работу. Их вдохновляло
понимание того, что такое расположение атомов в
пространстве заведомо существует (лошадь-то тоже состоит
из атомов!). Однако, как расположены атомы в лошади,
они выяснить, при своем уровне экспериментальной
техники, не могли. Поэтому было решено шаг за шагом
(атом за атомом) усложнять конструкцию, пока она не
начнет сама двигаться...
Нам понятно, что затея марсиан обречена на
неудачу. Нельзя понять работу столь сложного устройства,
как автомобиль (или ткацкий станок, или
радиоприемник и т. п.), думая о нем только в терминах
элементарных частиц и их взаимодействия.
Для понимания (а тем более для придумывания
вновь) совершенно необходимо уметь коротко
описывать большие группы частиц. Затем нужны короткие
описания совокупностей таких групп и т. д. В примере
с автомобилем это значит, что сначала должно
выработаться понятие материала. Это дает возможность
коротко описывать (сохраняя всю существенную для дела
*) Фантастические романы марсиан, издаваемые рукописно на
березовой коре, сразу переполнились описаниями «самоходов».
8
информацию) очень большие группы атомов. Например,
вместо указания местоположения и связей всех 3-Ю27
атомов, находящихся внутри бензобака, вполне
достаточно сказать, что там имеется 40 литров бензина с
такой-то теплотворной способностью, таким-то удельным
весом, таким-то октановым числом и т. д.
Благодаря коротким описаниям свойств бензина,
латуни, стали и т. д. может работать, например,
конструктор двигателя, который, вероятнее всего, ничего не
смыслит в химии, не говоря уж о квантовой механике.
И, наконец, конструктор «автомобиля в целом»
видит в двигателе агрегат с такими-то габаритами, весом,
мощностью и т. п. Ему нет нужды, продумывая
вопрос— впереди или сзади лучше расположить
двигатель,— каждый раз вспоминать, в какой
последовательности открываются клапаны.
Именно умение думать «не атомами, а крупными
блоками» и дало возможность людям создать
достаточно сложные устройства. И именно отсутствие такой
возможности лишает марсиан надежды на успех. Пока они
не создадут предпосылок для «крупноблочного
мышления» (механики, химии, технологии материалов и т. п.),
им придется довольствоваться сознанием того, что
изготовить автомобиль в принципе возможно, ездить же
на автомобилях будут только герои фантастических
романов.
В отношении создания «думающих машин»
человечество находится примерно в том же положении, что
описанные марсиане в отношении «самодвижущихся
машин». Мы понимаем, что из отдельных команд
универсальной вычислительной машины можно построить
программу мышления, так же как марсиане понимают,
что из атомов можно построить автомобиль. И так же
как марсианам не хватает знания того, из каких
агрегатов (гораздо более крупных, чем отдельные атомы)
должен состоять автомобиль, нам не хватает
понимания того, из каких крупных блоков можно
составить «мышление», из каких более мелких (но все еще
состоящих из очень многих команд) блоков должны
состоять крупные и т. д.
Поэтому, если мы хотим перейти от фантастических
рассказов к делу, то нужно искать блоки намного более
простые, чем мышление в целом, но намного более
9
сложные, чем отдельные команды. При этом
необходимо, чтобы свойства блока (существенные для
построения мышления) можно было описать гораздо короче,
чем перечислением всех команд, из которых он состоит.
Тогда появится возможность построить из этих блоков
более сложные блоки и т. д.
По-видимому, узнавание является одним из таких,
важных для построения мышления, блоков. В данной
книге мы будем рассматривать его именно в этом
аспекте. Такой подход предопределяет, что будет казаться
нам в проблеме узнавания интересным и что — не
интересным. Например, мы почти не будем рассматривать
необучаемые узнающие системы, так как они не
моделируют способности мозга гибко приспосабливаться к
разным обстоятельствам. И вообще, когда в книге будет
идти речь о том, что что-то интересно или не интересно
для проблемы узнавания, всегда будет
подразумеваться, что проблема узнавания — это часть проблемы
мышления. Естественно, деление вопросов на интересные и
не интересные будет изменяться со временем.
Интересное и нетривиальное сегодня может стать скучным и
тривиальным завтра. Деление, проводимое в книге,
отражает сегодняшнюю точку зрения автора.
Когда химик ищет способ синтеза нового вещества,
он никогда не начинает с постройки специального
завода для производства этого вещества. Он
экспериментирует с небольшими количествами реактивов,
пользуясь одними и теми же пробирками и колбами для
самых разнообразных опытов. И лишь потом, когда метод
разработан, строится специализированный завод,
выпускающий большие количества, скажем капрона, но уже
непригодный для экспериментов в другой области.
Работы по созданию интересных узнающих систем
находятся сейчас в стадии начальных опытов. Поэтому
нет смысла строить для этих опытов
специализированные машины. Гораздо выгоднее писать программы для
универсальных машин. Так в большинстве случаев и
поступают. Сам способ работы подчеркивает то
обстоятельство, что главная трудность построения узнающей
системы — не поиск элементов, из которых нужно ее
делать, а отыскание логики совместной работы большого
количества элементов. Программист может не
интересоваться, собрана универсальная машина на лампах,
Ю
транзисторах или криогенных «нейристорах». Ему
достаточно знать, какую команду нужно отдать машине,
чтобы она совершила то или иное действие. Поэтому все
внимание программиста сосредоточено на тех
преобразованиях, которым нужно подвергнуть исходный
материал, чтобы получить требуемый результат. Конечно,
каждая программа учитывает специфику той машины,
на которой ведется работа, однако путем несложной
переделки программу можно приспособить к любой
универсальной машине. Особенности той или другой
узнающей системы в основном определяются свойствами
программы, а не машины. Поэтому мы часто будем
отождествлять программу (или алгоритм) с узнающей
системой. В книге будут встречаться слова: программа
учится, программе показали, программа ответила и т. п.
Последнее выражение, например, означает, что машина,
управляемая программой, напечатала ответ.
Еще несколько слов о словах. Мы будем называть
узнаванием совокупность всех процессов в системе,
включая и процесс обучения. Чтобы не возникло
путаницы, процесс применения сведений, запасенных во
время обучения, будет называться экзамен. Таким образом,
узнавание состоит из обучения и экзамена.
В литературе часто можно встретить выражения:
узнавание образов или распознавание образов. При
этом разные авторы вкладывают в слово «образ»
разный смысл. Некоторые подразумевают, что образ — это
единичный объект. Другие понимают под образом класс
объектов. Третьи считают, что образ — это класс, но не
любой, а лишь удовлетворяющий некоторым, раз
навсегда заданным (и довольно жестким) условиям. Согласно
этой системе терминологии возможны классы,
являющиеся образами, и классы, не являющиеся образами.
При таком разнобое, в каком бы смысле мы ни стали
применять слово образ, кто-нибудь да поймет его
неверно. Поэтому в книге оно нигде не встречается. Мы
будем говорить об объектах и о классах объектов.
В тех же случаях, когда по смыслу дела нужно будет
наложить ограничения на разрешенные способы
классификации, эти ограничения (они разные в различных
случаях) будут отдельно оговариваться.
Глава I
МЕСТО УЗНАВАНИЯ В РАБОТЕ МОЗГА
§ 1. Поведение и условные рефлексы
Во введении говорилось, что для построения
думающей машины необходимо уметь разбить операции,
выполняемые мозгом, на достаточно крупные блоки. При
этом нужно, чтобы свойства каждого блока могли быть
коротко описаны. Описание должно включать в себя
указание на способы, которыми блоки соединяются
между собой.
Не целесообразно ли обратиться за помощью к
сведениям о работе мозга? Многие из физиологов ведь
специально занимаются выяснением того, как организуется
сложное поведение животных. Почему бы не применить
открытые' ими принципы при построении искусственных
систем?
В течение некоторого времени многим казалось, что
принцип работы высших отделов мозга, по крайней
мере в общих чертах, разгадан. После исследований
И. П. Павлова в области условных рефлексов создалось
впечатление, что с помощью комбинации большого
числа условных рефлексов различных порядков можно
организовать сколь угодно сложное поведение. Еще
пятнадцать лет тому назад многие физиологи, подражая
Архимеду, рискнули бы сказать: «Дайте нам
достаточное количество блоков, способных вырабатывать
условный рефлекс, и мы построим из них систему, которая
путем обучения будет приспосабливаться к внешней
обстановке. Эта система будет целесообразно вести себя
в условиях, изменяющихся в очень широких пределах».
Может быть, «условные рефлексы» и есть те блоки, из
которых имеет смысл собирать думающую машину?
К сожалению, физиологи не дали четкого определения,
12
что же такое «условный рефлекс», а без определения
невозможно ответить на поставленный вопрос. Поэтому
попробуем сами дать определение условного рефлекса,
постаравшись, конечно, чтобы с ним могли согласиться
физиологи — специалисты в этой области.
Пусть штриховой прямоугольник на рис. 1
изображает «условный рефлекс». Этот блок имеет два входа
(А и В) и один выход (С). Вход Л является
«безусловным раздражителем». Сигнал с него всегда, независимо
A i ГТ ч С
Н Г W Г 1 *»
Рис. 1. Схема условного рефлекса.
от обучения, передается на выход С. Вход В является
условным раздражителем. Вначале контакт К
находится в разомкнутом состоянии и сигнал, приходящий от В,
не проходит к С. Однако, если сигналы Л и В несколько
раз приходят одновременно, то блок совпадений (Б. С)
замыкает контакт К. Теперь сигнал В начинает
вызывать реакцию С и без сигнала А. Так будет до тех пор,
пока несколько раз подряд не случится, что сигнал В
придет в отсутствие сигнала А («без подкрепления»).
Тогда блок совпадений разомкнет контакт К
(«условный рефлекс угаснет»). Вентили, изображенные в
каналах А и В, предотвращают попадание сигнала из
капала Л в В и наоборот, и защищают блок Б. С. от
«самоподкреплений» после того, как контакт К замкнется. Мы
весьма упрощенно описали правило работы блока
совпадений. На самом деле весьма существенны временные
соотношения между приходами сигналов Л и В,
перерывами в приходе сигналов, перерывами в «подкреплении»
сигнала В и т. п. Именно исследование свойств блока
совпадений и составляло содержание многих работ по
изучению условных рефлексов. (Например, часть
классических опытов И. П. Павлова велась в условиях,
когда сигналом Л являлся сигнал о вкусе пищи, В —
был сигнал о загоревшейся лампочке, а С — сигнал,
стимулирующий выделение слюны.)
13
Легко построить из таких «условных рефлексов»
«рефлекс второго порядка»*). Для этого достаточно
соединить выход одного блока «условный рефлекс» с
одним из входов второго блока (рис. 2).
Очевидно, соединяя между собой большое число
«условных рефлексов», можно получить рефлексы
Лища
СЗет
Збук
У
-И—' !
"I Слюна
о)
Лаща
Сбет
ча-
Збуп
л
-Of-
"1 Слюна
*J \
*)
Рис. 2. Схемы рефлексов второго порядка. Схема а)
позволяет вырабатывать рефлекс второго порядка, сочетая звук
со светом как до, так и после выработки условного рефлекса
на свет. Схема б) работает только в том случае, если звук
сочетается со светом после того, как выработан рефлекс на
свет. (Зато можно выработать рефлекс на звук, сочетая его
непосредственно с пищей).
третьего, четвертого и т. д. порядков. Вернемся к
вопросу: любую ли форму поведения можно получить,
комбинируя между собой блоки типа «условный рефлекс»?
Теперь, когда под условным рефлексом мы понимаем
(пусть хотя бы временно) вполне определенную вещь,
этот вопрос решается отрицательно.
Начнем с того, что система, составленная из
произвольного числа условных рефлексов, может совершать
лишь такие действия, для которых с самого начала
*) Физиологическим примером может служить ситуация, когда
пища сочетается со светом, свет (без пищи) сочетается со звуком,
после чего звук (в отсутствие пищи и света) начинает вызывать
выделение слюны.
14
имелись безусловные раздражители. В самом деле,
«обучение» (сочетание разных раздражителей) такой
системы может привести лишь к замене (в смысле
стимулирования действия) безусловного раздражителя
условными. Если для какого-то действия нет
безусловного (врожденного) раздражителя, то и заменять
нечего. Например, получить после обучения выделение
слюны в ответ на свет или звук в схемах на рис. 2, а и
2,6 возможно лишь потому, что есть безусловный
раздражитель (пища) для слюноотделения.
Животные же обучаются множеству действий, для
которых не существует безусловных стимулов. Никакое
сочетание звуков, вкусовых воздействий или световых
эффектов не заставит необученную собаку пройти 5
метров на передних лапах, сохраняя равновесие. В ходе
дрессировки происходит не замена одного стимула
другим, а выработка новой, ранее не существовавшей
реакции.
Заметим, что невозможность выработать новые
действия с помощью совокупности условных рефлексов
является следствием общей структуры этого блока, а не
какого-то конкретного алгоритма работы блока
совпадений. Наш вывод остается в силе, например, при
любых законах «выработки рефлекса» или «угасания
рефлекса» и т. п.
Ограничимся теперь на время лишь такими
реакциями, для которых существуют безусловные
раздражители. Можно ли хоть в этом случае воспроизвести с
помощью условных рефлексов все доступные животным
формы поведения?
Если собаке давать пищу после
одновременного воздействия света и звука и не давать после того,
как включали только лампочку или только звонок,
то она очень быстро начнет выделять слюну в ответ на
одновременное включение лампочки и звонка и не
реагировать на эти раздражители порознь. И такую
нехитрую реакцию на «комплексный раздражитель»
невозможно свести ни к какому количеству условных
рефлексов.
«Ладно, — скажет здесь читатель, — согласен, что
условный рефлекс не является универсальным блоком,
из которого можно построить всю деятельность мозга.
Но, может быть, если к «условному замыкателю»,
15
изображенному на рис. 1, добавить еще несколько
типов блоков, то удастся получить универсальный набор?
Другими словами, не является ли условный рефлекс
одним из основных блоков, на которые
распадается мышление?»
Это замечание частично справедливо. Действительно,
очень небольшое число типов блоков может быть
достаточным для построения сколь угодно сложного
поведения. Например, если к «условному рефлексу» добавить
еще безусловное торможение (один сигнал размыкает
цепь другого сигнала) и «спонтанное возбуждение»
(внутренний источник сигнала), то получится
универсальная система.
Отсюда, однако, вовсе не следует, что
целесообразно строить думающую машину из условных
рефлексов, безусловных торможений и спонтанных
возбуждений. Дело в том, что существует много разных
универсальных наборов блоков. Например, из блоков,
выполняющих логическую операцию «И», «логическое
отрицание», и линий, задерживающих сигнал, также
можно собрать машину, реализующую любое
поведение. И, наконец, просто система команд любой
универсальной машины дает возможность построить любую
программу. Вспомним, что, уже обладая
универсальной, системой команд, мы поставили
вопрос о тех крупных (по сравнению с отдельной
командой) блоках, из которых можно строить сложное
поведение. Именно в поисках таких блоков мы
заинтересовались условными рефлексами. Поэтому нам важна
не столько принципиальная возможность построить что
угодно (она гарантируется уже системой команд
машины), сколько удобство построения функций,
являющихся более крупными блоками, чем условные
рефлексы.
С этой точки зрения условные рефлексы не
являются особо удачными «кирпичами» мышления. Во-первых,
они выполняют только весьма примитивную функцию —
учитывают совпадение во времени некоторых событий.
Можно сказать, что они еще недалеко ушли от
элементарных команд (являются слишком мелкими блоками).
Во-вторых, даже функции, весьма близкие к простому
условному рефлексу (например, рефлексы на комплекс-
16
ные раздражители), довольно сложно строятся из
блоков типа «условный рефлекс»*). Поэтому мы
продолжим в следующем параграфе поиск крупных кирпичей
мышления.
§ 2. Множество ситуаций и множество реакций
Представим себе совокупности сигналов,
являющиеся для мозга входными и выходными. От глаз, ушей и
прочих органов чувств приходят сообщения о внешнем
мире. Целый ряд внутренних рецепторов**) шлет
сообщения о положении частей тела (позе), о составе крови
и т. п. Все эти сигналы являются для мозга входными.
На основе учета этих сообщений он принимает решение,
выражаемое в виде сигналов, управляющих скелетной
мускулатурой, железами и другими внутренними
органами.
Сигнал, посылаемый каждым рецептором (например,
палочкой сетчатой оболочки глаза или тепловым
рецептором в коже пальца), можно выразить некоторым
числом. Совокупности сигналов от всех рецепторов в
данный момент времени соответствует набор, состоящий из
стольких чисел, сколько есть в организме рецепторов
(у человека — около 109). Каждую последовательность
таких входных наборов за некоторый промежуток
времени (иногда за очень большой) мозг должен
преобразовать в определенный набор выходных приказов.
Очевидно, существует чрезвычайно много различных
ситуаций (входных наборов чисел), с которыми может
столкнуться нервная система человека. Даже если
считать, что каждый рецептор может находиться только
в двух состояниях («возбужден» и «не возбужден»),
то в принципе может существовать 21°9 разных
мгновенных ситуаций.
Будем для простоты считать, что мозг отдельно
реагирует на каждую входную ситуацию (а не на их
последовательность, как это имеет место в действительности).
Если бы все ситуации, различающиеся состоянием хотя
бы одного рецептора, требовали разных реакций, то
управлять поведением животного было бы неимоверно
сложно. К счастью, это не так. Мы знаем, что при
*) При этом необходимо включать в конструкцию и блоки
других типов.
*•*) См. стр. 24.
17
решении каждой конкретной задачи есть обстоятельства
существенные и несущественные для выбора
целесообразного поведения. Например, когда мы окликаем на
улице по имени своего приятеля, нам безразлично,
видим мы его на фоне белого или серого дома. Нам также
все равно, видим мы его в профиль или анфас. Хотя
ситуации, с точки зрения колбочек сетчатки, и разные, мы
реагируем одним и тем же возгласом: «Коля,
здравствуй!» Наш мозг совершает при этом преобразование
многих разных ситуаций в одно и то же действие
(совершает вырожденное отображение множества ситуаций
на множество реакций).
Однако не всегда ситуации, соответствующие виду
одного и того же человека, требуют одинакового
действия. Когда автор-юморист читает «на пробу» свой
рассказ нескольким людям, его интересует не кто они,
а смеются ли они. Если смеются — рассказ можно
печатать, если нет — нужно переделывать. Решая эту
задачу, мозг тоже совершает вырожденное
отображение, но теперь существенными оказались другие
обстоятельства. При решении третьей задачи существенным
может оказаться лишь расстояние до человека (а не его
имя или настроение); в четвертой задаче важным
окажется— во что человек одет, и т. д.
Процесс выделения существенных (для данной
задачи) обстоятельств можно описать и иначе. Можно
сказать, что мозг разбивает входные ситуации на
классы, обладающие тем свойством, что все ситуации из
одного класса требуют одного и того же действия.
Разделим теперь мысленно процесс преобразования
совокупности входных сигналов в целесообразное
действие (вся деятельность мозга) на два этапа. Первый
этап — разбиение ситуаций на классы, требующие
одинакового (пока безразлично какого) действия. Второй
этап — выбор (синтез) действия, целесообразного для
всей группы ситуаций.
Первый этап принято называть узнаванием. Этому
крупному блоку, входящему в состав мышления, и
посвящена наша книга.
Второй этап (синтез действия) изучен гораздо
меньше. Этот вопрос лишь косвенно затрагивается в главе VI.
Любопытно, однако, что синтез действия, по-видимому, в
свою очередь включает в себя блоки типа «узнавание».
18
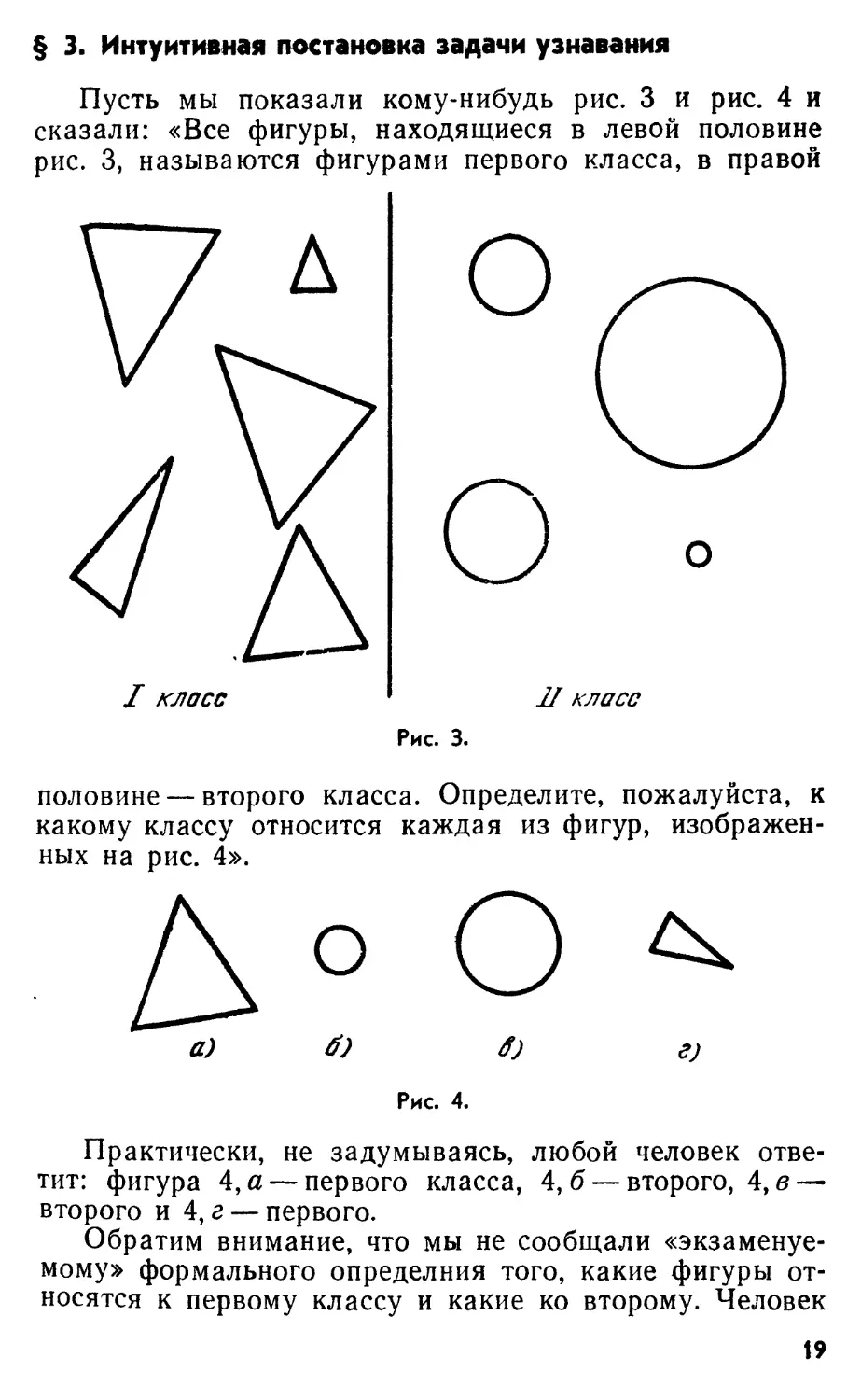
§ 3. Интуитивная постановка задачи узнавания
Пусть мы показали кому-нибудь рис. 3 и рис. 4 и
сказали: «Все фигуры, находящиеся в левой половине
рис. 3, называются фигурами первого класса, в правой
/ класс
Л класс
Рис. 3.
половине — второго класса. Определите, пожалуйста, к
какому классу относится каждая из фигур,
изображенных на рис. 4».
а) б) б) г)
Рис. 4.
Практически, не задумываясь, любой человек
ответит: фигура 4, а — первого класса, 4,6 — второго, 4, в —
второго и 4, г — первого.
Обратим внимание, что мы не сообщали
«экзаменуемому» формального определния того, какие фигуры
относятся к первому классу и какие ко второму. Человек
19
сам, пользуясь примерами, данными на рис. 3, создает
гипотезу о принципе разделения на классы. В момент
экзамена человек использует эту гипотезу для
классификации. «Отметка за экзамен» (число правильных
ответов и ошибок) будет зависеть от того, насколько
близка гипотеза к принципу, которым пользовался
составитель задачи.
Иногда называют «узнающим устройством» систему,
которая осуществляет классификацию, пользуясь
некоторым постоянным принципом. Такая система может
очень хорошо решать какую-нибудь одну задачу. Она
все наперед знает об этой задаче и ничему новому не
учится. Примером необучаемой узнающей системы
может служить приемная часть любого монетного
автомата. Она проверяет размеры, вес, материал, из
которого сделана опущенная монета, и узнает монету того
достоинства, на которое рассчитан автомат. Устройство
отличает нужные монеты от фальшивых и от настоящих
монет другого достоинства.
Нас такие системы интересовать не будут. В этой
книге будут рассматриваться только устройства,
предназначенные решать много разных задач. Основным
в работе такого устройства является выяснение вопроса,
с какой задачей оно столкнулось сейчас. Трудность
состоит в том, что сведения о принципе разбиения
объектов на классы устройство получает не в виде
формального определения, а путем наблюдения некоторого
числа примеров (как в задаче па рис. 3 и 4). Мы будем
называть процесс составления принципа классификации,
которая будет использоваться при экзамене, обучением.
Объекты, использованные при обучении, будут
называться материалом обучения, а при экзамене —
материалом экзамена. Везде, где это несущественно, мы
будем для простоты рассматривать примеры, в которых
объекты разбиваются на два класса.
Любопытно, что эволюция животного мира
развивалась и по пути совершенствования специализированных
почти необучаемых систем, и по пути создания систем,
способных обучиться решению весьма разнообразных
задач. Примерами являются насекомые и позвоночные.
Пчелы практически всё умеют от рождения. Они,
конечно, и учатся тоже, но благоприобретенные знания
составляют незначительную часть унаследованных.
20
Человека также многому не надо учить.
Новорожденный ребенок сразу «умеет» дышать, переваривать
пищу, сжимать зрачок глаза под влиянием света и т.п.
Однако в жизни взрослого человека весьма
существенную часть составляет деятельность, которой необходимо
учиться. Без обучения человек не может ни говорить,
ни трудиться, ни даже ходить на двух конечностях.
В отношении всего того, что отличает его поведение от
поведения более примитивных животных, человек
рождается не со знаниями, а со способностью
учиться. Но благодаря этой возможности он
приспосабливается к очень разным задачам.
§ 4. «Творческие» задачи и узнавание
При решении задачи, представленной на рис. 3 и 4,
человек правильно узнает не только фигуры 4, а и 4, в,
которые являются точными копиями некоторых фигур
из материала обучения, но и фигуры 4, б и 4, г, которые
не совпадают с ранее встречавшимися. Психолог,
столкнувшись с подобным явлением, «объяснил» бы его так.
«Человек, глядя на рис. 3, вырабатывает абстрактные
понятия «треугольник» и «окружность», являющиеся
обобщением всех фигур в материале обучения. При
экзамене эти абстрактные понятия оказываются
применимыми не только к тем фигурам, на которых шло
обучение, но и ко всем треугольникам и окружностям.
Поэтому-то человек и узнает фигуры 4,6 и 4, г». Мы
поставили в кавычки слово «объяснил» потому, что эти
слова психолога являются лишь описанием в др.у-
гих терминах того факта, что человек узнает не
только объекты, входящие в материал обучения. И все
же высказывание психолога интересно для нас тем, что
устанавливается связь между такими «творческими»
актами, как обобщение, абстрагирование, и узнаванием.
Оказывается, это просто разные названия одного и того
же процесса. Точнее говоря, «обобщение» — это другое
название той части процесса узнавания, которую мы
называем «обучением». Таким образом, машина,
решающая достаточно большую совокупность задач
узнавания, умеет создавать соответствующий набор
абстрактных понятий.
21
Есть и другая область соприкосновения «творческого
процесса» (например, в работе ученого) и узнавания.
Известно, что многие научные открытия могли быть в
принципе сделаны методом проб и ошибок. В
простейшем случае можно прямо пробовать разные
формулировки закона. Примером может служить открытие
формулы Бальмера (для длины волн линий в спектре
водорода) или третьего закона Кеплера (связь между
периодами обращения планет вокруг Солнца и большими
полуосями орбит). Имея достаточный набор
эмпирических данных и терпеливо пробуя разные формулы,
можно наткнуться на такую, которая достаточно хорошо
описывает весь экспериментальный материал. В более
сложном случае объектами проб могут быть не
формулы, а методы исследования, причем применение
каждого метода часто также требует многих проб. В
результате общее число проб может оказаться слишком
большим.
Если мы понаблюдаем за собой (или другим
человеком) в подобной ситуации, то заметим, что пробе
подвергаются далеко не все известные нам методы решения
различных задач. Мы «с первого взгляда» отбираем те
методы, которые не имеют отношения к задаче, и те
методы, которые дают надежду ее решить. В предельно
утрированной форме один математик выразил эту
мысль так: «Берясь за трудную математическую задачу,
никто не пытается найти решение путем подметания
комнаты». Ясно, что переход от слепого поиска к поиску
«умному» связан с нахождением у данной задачи общих
черт с некоторыми ранее решенными задачами, т. е.
требует узнавания.
В главе I мы постарались показать, что процесс
узнавания играет чрезвычайно важную роль во всей
деятельности мозга, начиная с организации самых
примитивных форм поведения и кончая работой
ученого. В настоящее время имеются доводы за то, что и
синтез действия также содержит несколько этапов
узнавания.
Несмотря на безусловную связь проблемы узнавания
с нейрофизиологией и психологией, рассматривая пути
построения узнающих систем, мы не будем использовать
22
физиологические данные. Основной причиной этого
является малочисленность сведений, имеющих отношение
к интересующему нас вопросу. Таким образом, здесь
мы стремимся осуществить не подход ученого,
исследующего, как природа решила некоторую задачу, а
подход инженера, самостоятельно эту задачу
решающего.
Тем интереснее будет потом сопоставить результаты
таких «инженерных» построений с данными, добытыми
физиологами при изучении в первую очередь
анализаторных структур. Можно надеяться, что подобное
сопоставление позволит более целенаправленно искать те
элементарные операции, с помощью которых в нервной
системе осуществляется узнавание.
Глава II
РАЗЛИЧНЫЕ ПОДХОДЫ
§ 1. Исходное описание объектов
Всякое узнающее устройство получает сведения об
объектах с помощью некоторых датчиков. В принципе
это могут быть произвольные измерительные устройства
(фотоэлементы, микрофоны, термопары, измерители
концентрации некоторых газов и т. п.). По аналогии с
термином, принятым в физиологии, мы будем называть
такие датчики рецепторами. Анализируя свойства
объекта, каждый рецептор выдает некоторое число*).
Набор чисел, появившихся на выходе всех
рецепторов, является той информацией, на основе которой
узнающее устройство будет решать задачу (принимать
решение о принадлежности объекта к тому или иному
классу). Для решения задачи показания рецепторов
каким-то образом перерабатываются. Алгоритм этой
переработки будет зависеть от двух обстоятельств. Во-
первых, от того, какая задача решается, и, во-вторых, от
набора рецепторов, которым обладает узнающее
устройство.
Очевидно, задача, требующая при одном наборе
рецепторов сложной переработки информации, может
оказаться совсем простой при другом наборе. Пусть,
например, требуется определить удельный вес некоторого
кристаллического вещества. Допустим, имеющиеся в
нашем распоряжении рецепторы позволяют измерять
интенсивности рентгеновых лучей, рассеянных кристаллом
под различными углами, и определить химический
состав кристалла. Этих данных часто оказывается доста-
*) Для простоты мы нигде не будем рассматривать случай,
когда объект изменяется во времени (это вызвало бы и изменение
во времени показаний рецептора).
24
точно для определения удельного веса. Однако расчет
получится очень сложным. Придется по результатам
исследований рентгеновыми лучами вычислять структуру
кристаллической решетки. Затем соображать, какие
атомы в каких узлах решетки находятся. А после этого
уже можно найти удельный вес кристалла.
Все становится гораздо проще, если в качестве
рецепторов мы обладаем весами и приспособлением для
измерения объема. В этом случае вся обработка
сигналов от рецепторов будет заключаться в делении одного
числа на другое.
Возникает вопрос: не сводится ли проблема
построения узнающих систем к выбору подходящих
рецепторов? К сожалению, в большинстве случаев набор
рецепторов системы определяется не тем, что было бы
нужно измерить для решения той или другой
задачи, а тем, что удается измерить.
Например, для узнавания окружающих предметов
нам весьма полезно знать коэффициенты отражения их
поверхностей (в том числе и в разных длинах волн).
Для их определения было бы нужно отдельно
измерить интенсивность света, падающего на поверхность, и
интенсивность отраженного света. Однако «по
техническим причинам» (устройство глаза) удается
измерить только отраженный свет. Мозгу приходится
весьма сложным путем, сопоставляя свет, отраженный от
многих мест одного предмета и от многих предметов,
уштывая форму предметов-и т. п., приближенно
определять коэффициент отражения поверхности.
Есть и другое обстоятельство, мешающее заменить
сложную обработку сигналов созданием специальных
рецепторов. Мы ведь рассматриваем системы,
способные решать широкий круг разнообразных задач.
Поэтому, если бы мы пошли по пути подгонки рецепторов под
отдельные задачи, то понадобилось бы слишком много
разных рецепторов. В рассмотренном выше примере
нужен был бы выносной фотоэлемент (для определения
интенсивности света, падающего на предмет). Для
определения расстояния до предметов понадобилось бы что-
то вроде радиолокатора. Чтобы отличить гладкую
поверхность от шероховатой, понадобился бы прибор,
определяющий коэффициенты отражения в разных
направлениях и т. д.
25
Человек решает все эти задачи (и еще великое
множество других), пользуясь одними и теми же
рецепторами сетчатки глаза. Универсальность достигается не
за счет разнообразия типов рецепторов, а за счет
разнообразия алгоритмов обработки сигналов, посылаемых
палочками и колбочками сетчатки. Например, для
определения расстояния до некоторого предмета мозгу
человека приходится сопоставлять между собой сигналы,
приходящие от двух глаз (стереоскопический эффект),
учитывать дымку, принимать во внимание, какой
предмет на какой проектируется, и т. п. В результате мы и
без радиолокатора, пользуясь только двумерными
изображениями на сетчатках, восстанавливаем
пространственное расположение предметов.
Ставя перед собой цель построить узнающую
систему для того или иного круга задач, мы будем всюду
в этой книге считать, что набор рецепторов системы
определен заранее. Например, все системы,
моделирующие зрительный анализатор человека, будут получать
исходную информацию в следующем виде: «поле
зрения» системы разбито на некоторое число участков,
количество света, попадающего на каждый участок,
сообщается системе. Если в качестве узнающей системы
используется универсальная машина, то можно считать,
что рецепторами системы являются те ячейки памяти ма-»
шины, куда введены числа, характеризующие
количество света на разных участках поля зрения.
Итак, мы будем считать, что к моменту начала
работы конструктора узнающей системы (программиста)
исходное описание объектов уже задано. В его власти
только выбрать способ обработки этого исходного
описания. Возможные принципы обработки входной
информации рассматриваются в этой главе.
§ 2. Запоминание материала обучения
Можно попытаться решить задачу узнавания
следующим способом: запомним исходные описания всех
объектов материала обучения (например, фигур на рис. 3)
вместе с указаниями, к какому классу они принадлежат.
При экзамене сравниваем описание неизвестного
объекта с описаниями, запасенными в памяти в ходе
обучения. Если описание неизвестного объекта полностью
26
совпало с описанием некоторого объекта первого
класса, значит он принадлежит к первому классу, аналогии*
но — со вторым классом.
Для системы, работающей по этому принципу,
описание класса треугольников заключается в перечислении
описаний всех когда-либо виденных ею треугольников,
описание класса окружностей — в перечислении
виденных окружностей и т. д.
Очевидно, этим методом можно узнавать лишь те
объекты, которые встречались в материале обучения.
Например, фигуры 4, б и 4, г не были бы узнаны.
Психолог сказал бы, что такая система не
вырабатывает абстрактных понятий. И действительно, чтобы
узнавать новые (не участвовавшие в обучении) объекты,
необходимо найти нечто общее во всех объектах одного
класса. Нужно отвлечься от различий внутри класса и,
наоборот, обратить особое внимание на то, чем
отличается один класс от другого. Всего этого не умеет
делать система, запоминающая исходные описания
объектов.
Мы же заинтересовались узнаванием именно в связи
с желанием промоделировать такие функции, как
«обобщение», «рассуждение по аналогии» и т. п. Поэтому
системы, запоминающие материал обучения, в книге
практически рассматриваться не будут..
§ 3. Поиски близости в пространстве рецепторов
В этом и следующем параграфах будет идти речь о
системах, предназначенных для узнавания плоских
геометрических объектов. Поэтому будем считать, что
сведения об объектах имеют вид некоторого распределения
темных и светлых мест на ограниченном участке
плоскости. Зададимся пространственной разрешающей
способностью системы (грубостью растра изображения).
Тогда описанием объекта является конечный набор
чисел. Если считать, что каждое число является
координатой в многомерном пространстве *) (число измерений
*) Подобно точке на плоскости или в (трехмерном)
координатном пространстве, многомерной (точнее, n-мерной) точкой
называют упорядоченную систему из п чисел. Эти числа называют
координатами соответствующей точки. Совокупность всех
возможных многомерных (м-мерных) точек называют многомерным (п-мер-
21
равно числу участков растра), то объект представляется
некоторой точкой в этом пространстве. Следуя
установившейся традиции, мы будем называть это
пространство пространством рецепторов.
Естественно, нет нужды допускать непрерывные
изменения координат в этом пространстве. Всегда можно
разбить степень светлоты на конечное число уровней.
В большинстве сделанных до настоящего времени
работ авторы пользуются только двумя уровнями («черно-
белые» системы). Такая идеализация вполне допустима
на современном этапе работы, так как при этом
сохраняются многие (хотя и не все) принципиальные
трудности проблемы узнавания геометрических объектов.
Переход к рассмотрению пространства рецепторов
сам по себе не является шагом вперед (это лишь
описание задачи на другом языке). Но после такого
перехода возникает соблазн ввести в пространстве
рецепторов понятие «близости» объектов*).
Конечно, хорошо, если бы удалось так определить
расстояние между точками пространства рецепторов,
чтобы все объекты одного класса оказались близкими
между собой, объекты другого класса — тоже близкими,
а расстояние между объектами различных классов было
бы велико. Разумеется, нужно, чтобы это соотношение
имело бы место для всех интересующих нас задач.
Тогда во время обучения было бы достаточно
приблизительно определить (наблюдая, куда попадают точки из
ным) пространством. Пространство называют метрическим, если в
нем задана числовая функция, которая каждой паре точек
пространства ставит в соответствие расстояние между ними. Эту функцию
называют метрикой пространства Предполагается, что метрика
пространства должна удовлетворять некоторым естественным
условиям. В евклидовом я-мерном пространстве расстояние между
точками Л с координатами (аь #2, •-., an) и В (b\, b2, ..., Ьп)
определяется по формуле
ЛВ = K(a,-*i)2-Ha2-/;2)2+ ... +(аа-Ья)*.
*) Вообще говоря, эта процедура не обязательно определяет
метрику в пространстве рецепторов. Например, расстояния между
точками этого пространства могут не удовлетворять аксиоме
треугольника (расстояние между двумя точками не превосходит суммы
их расстояний до любой третьей. При введении метрики
удовлетворение этой аксиомы считается необходимым). Однако в
большинстве работ рассматриваемого направления вводится некоторая
метрика в пространстве рецепторов.
28
материала обучения) области пространства,
соответствующие разным классам. Дальнейшее — уже дело
вкуса. Можно запомнить границы этих областей и при
экзамене смотреть, куда попадет точка,
соответствующая неизвестному объекту. Можно найти «центры
тяжести» этих областей и при экзамене измерять расстояния
от неизвестной точки до центров тяжести и т. п.
К сожалению, разные задачи предъявляют разные
требования к понятию «близость точек». Для некоторых
задач нужно, чтобы близкими являлись объекты, почти
совпадающие при наложении (имеющие много общих
и мало несовпадающих точек). Для других задач
нужно, чтобы близкими оказались два объекта,
полученных друг из друга путем переноса или поворота. Третьи
задачи потребуют, чтобы близкими в пространстве
рецепторов считались подобные фигуры. Встретится и
задача, в которой будут полезны близость между собой
всех мужских портретов и большое расстояние от них
до всех женских. Существенно, что при этом появятся
и противоречивые требования.
Требование близости между собой всех
окружностей (независимо от диаметра) и удаленности их от
всех треугольников придет в противоречие с
требованием близости между собой всех маленьких
фигур (независимо от формы) и удаленности их от
больших фигур и т. п.
Иногда говорят не о близости точек, относящихся к
разным классам, а об их разделимости в пространстве
рецепторов с помощью гиперплоскостей*) или других
гладких поверхностей. Однако при этом трудность не
исчезает, а лишь маскируется. Дело в том, что точки,
относящиеся к разным классам, оказываются (для
многих задач) очень сильно «перемешанными» в
пространстве рецепторов. Грубо говоря, они расположены как
частицы губки и воды в случае, когда вода
пропитывает губку. Невозможно провести достаточно
гладкую поверхность так, чтобы по одну сторону от нее
была только вода, а по другую — только губка.
*) Гиперплоскостью в /z-мерном пространстве называют
множество таких точек X(xit х2, ..., *п), координаты которых
удовлетворяют уравнению вида A\Xi+А2х2+ .ч+Апхп^В. В частности,
при п~2 гиперплоскостью является прямая, а при rt = 3 — обычная
плоскость.
29
Несмотря на указанную трудность, в некоторых
работах производится разделение классов
непосредственно в пространстве рецепторов. Упомянем систему,
использующую «гипотезу компактности» *), так
называемый алгоритм секущих плоскостей Э. М. Браверма-
на**). В этой системе пространство рецепторов
рассматривается как многомерное евклидово пространство.
Расстояние между точками в нем ***) равно
квадратному корню из суммы квадратов разностей координат
(или, что практически безразлично, какой-нибудь
монотонной функции от этой величины). Разделяющая
поверхность в этом алгоритме состояла из кусков
гиперплоскостей.
Легко заметить, что такая метрика хороша лишь в
том случае, если по условию задачи нам
целесообразно считать близкими фигуры, имеющие мало
несовпадающих точек (почти тождественные). И, действительно,
программой Бравермана был получен хороший
результат на таких объектах: растр из 60 элементов (6X10).
На этом растре нарисованы цифры, удовлетворяющие
следующим условиям: цифра
должна касаться и верхнего и
нижнего краев растра (быть
стандартной высоты) и быть
центрированной по горизонтали.
Неудивительно, что при соблюдении
этих условий цифры,
принадлежащие к одному классу (двойки,
Рис. 5. В пространстве четверки и т. п.), имеют много
рецепторов цифра 3 общих ТОЧеК.
ближе к одной из дво- Однако, если взглянуть на
ек, чем двойки между \j ' J
собой. Рис- 5, то легко заметить, что в
пространстве рецепторов цифра 2
в левом верхнем углу поля зрения будет гораздо
«ближе» к цифре 3, чем к двойке в правом нижнем углу.
Поэтому описываемая система не может узнавать,
например, цифры произвольных размеров и произвольно
расположенные на растре (в поле зрения машины).
*) Компактность не в математическом смысле.
**), См. А. Г. Аркадьев и Э. М. Браверман, Обучение
машины распознаванию образов, «Наука», М., 1964.
***) См. подстрочное примечание на стр. 27.
30
Вопреки изложенной ситуации, «гипотеза
компактности» предполагает, что таких «плохих» взаимных
расположений классов в пространстве рецепторов
практически не бывает*). А если и случится такое
«перемешивание» точек, относящихся к разным классам, то задача
становится неразрешимой никаким устройством. Как же
быть со случаем, изображенным на рис. 5? Точки
перемешаны, а существует система (человек!), прекрасно
решающая задачу? Сторонники гипотезы компактности
отвечают так: действительно, есть некоторые
преобразования фигур (например, параллельный перенос), при ко-»
торых фигуры остаются очень похожими для человека,
но находятся на большом расстоянии в пространстве
рецепторов. Однако таких преобразований мало —
перенос, поворот, подобное преобразование — и все.
Давайте заранее совершим все эти преобразования:
перенесем фигуру в центр растра, доведем ее размеры до
стандартной величины и повернем ее в стандартное по-*
ложение, — вот тогда все станет (в пространстве
рецепторов) «компактным».
В отношении цифр это верно. Но существует множе-»
ство задач, которые не могут быть решены указанным
способом. Приведем несколько примеров.
На рис. 6, 7 и 8 показаны разные задачи. На левой
половине каждого рисунка даны примеры объектов
одного класса, на правых — другого.
Человек, посмотрев на рис. 6, быстро замечает, что
первый класс от второго отличается формой
внутренней фигуры. Если внутренняя фигура — треугольник,
значит объект принадлежит второму классу, если
прямоугольник— первому. Попробуем решить задачу
«методом приведения к компактному виду». Для этого нам
нужно поместить на одно и то же место растра, довести
до стандартного размера и повернуть в стандартное
положение... не всю фигуру, а лишь ее внутреннюю часть.
Именно после такого преобразования все объекты пер^
вого класса легко отделятся (например,
гиперплоскостью) от объектов второго класса. Трудность, однако,
в том, что система «не знает», какие части фигур нужно
*) Термин «компактность» возник именно от предположения, что
точки, соответствующие одному классу, расположены в
пространстве рецепторов кучно («компактно»),.
31
приводить в стандартное положение. Для того чтобы
осуществить необходимое преобразование, система
должна заранее знать, чем различаются классы.
Получился порочный круг.
//гласе
В класс
Рис. 6.
I ила ее
Лпласс
Рис. 7.
В задаче, поставленной на рис. 6, невозможно
отыскать хорошее преобразование объектов, но
такое преобразование все-таки существует. Для задач,
показанных на рис. 7 и 8, «хороших» (в указанном смысле)
преобразований просто нет. Как ни меняй масштаб, как
ни поворачивай фигуры и ни передвигай их по растру,
32
все равно в пространстве рецепторов всевозможные
многоугольники не соберутся в область, которая легко
отделится от области всех криволинейных фигур (рис. 7).
То же самое относится и к задаче на рис. 8. В
пространстве рецепторов выпуклые и невыпуклые фигуры не
образуют компактных областей, и никакими заранее
предписанными сдвигами, поворотами и растяжениями дела
не поправить.
Человек решает подобные задачи с легкостью. И это
непосредственно опровергает исходные позиции
гипотезы компактности. Оказывается, можно решать задачи
(класс
Д класс
Рис. 8.
(и весьма разнообразные), в которых классы плохо
разделяются в пространстве рецепторов. Слово плохо
в предыдущей фразе означает, что точки, относящиеся
к разным классам, не удается отделить друг от друга
плоскостью или некоторой поверхностью, для
геометрического*) описания которой понадобится
значительно меньше параметров, чем существует объектов в
каждом классе.
Итак, мы пришли к выводу о безнадежности поиска
близости в пространстве рецепторов для широкого круга
задач.
*) Речь идет об описании разделяющей поверхности в
терминах ее геометрических свойств потому, что если никак
не ограничить допустимые описания, то придется считать описанием,
например, и такую фразу: «Поверхность, отделяющая все точки,
соответствующие многоугольникам, от точек, соответствующих
криволинейным фигурам».
33
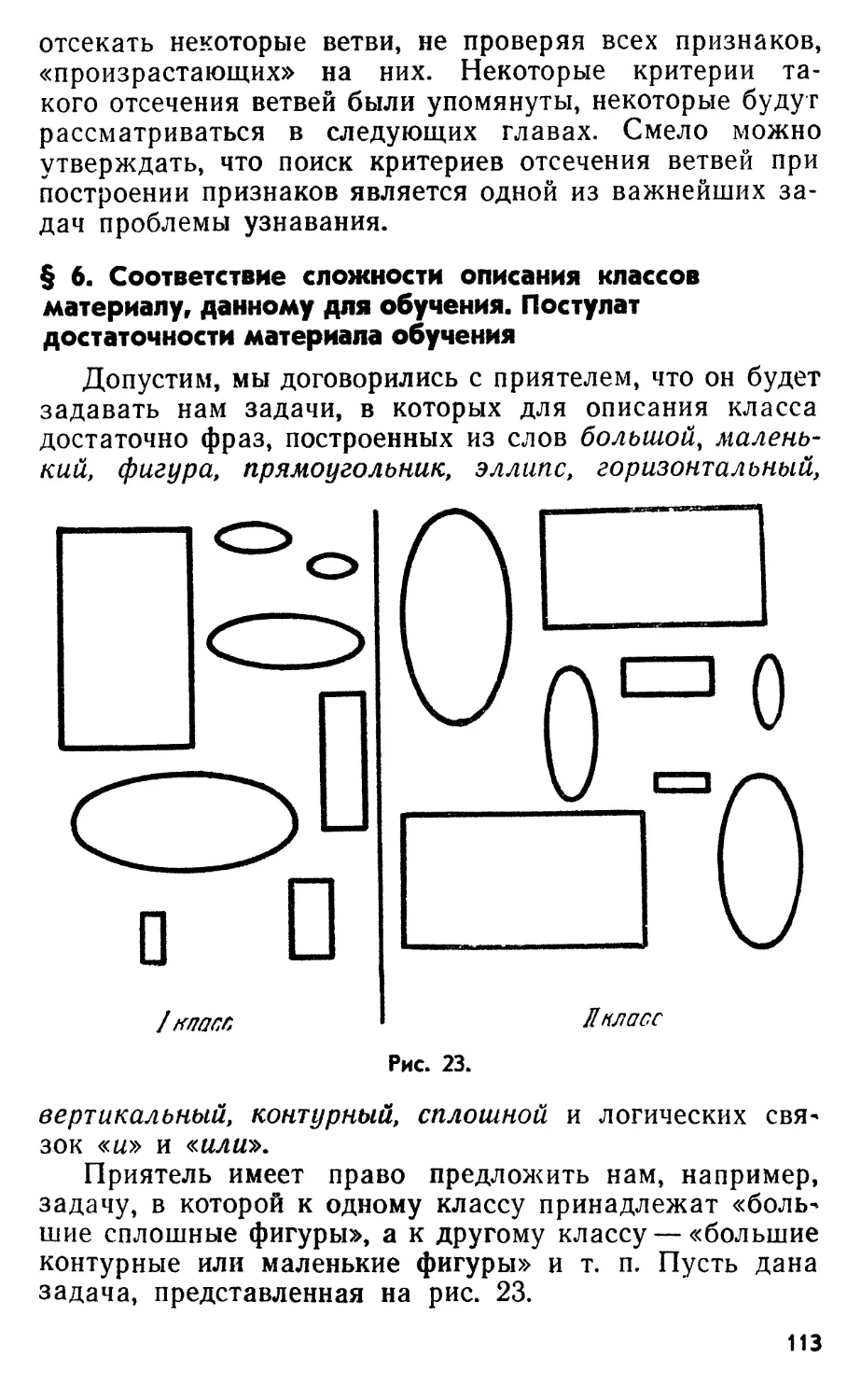
§ 4. Стандартное (не зависящее от конкретной задачи)
преобразование пространства рецепторов. Перцептрон
Лоле рецепт ороЗ
Ассоциот Усилители Решающее
элементы устройство
Рис. 9. Схема перцептрона. Изображение объекта при
обучении и экзамене проектируется на поле рецепторов S.
Каждый рецептор в зависимости от того, попало на него
белое или черное место картинки, может перейти в состояния
О или 1. Все рецепторы соединены (для простоты на схеме
показано лишь несколько соединений) с ассоциативными
элементами (Ai,...,An) связями, которые могут быть
«возбуждающими» (И-) и «тормозящими» (—). Возбуждающая
связь в зависимости от состояния рецептора передает
сигнал, равный 0 или +1, а тормозящая 0 или —1. Каждый
А-элемент суммирует все приходящие к нему сигналы. Если
эта сумма превосходит некоторый порог, то А-элемент
возбуждается. Система связей А-элементов и их пороги
возбуждения выбираются заранее (например, с помощью жребия).
Они не меняются ни при решении какой-либо задачи, ни при
переходе от одной задачи к другой. Если А-элемент не
возбужден, то он не посылает никакого сигнала. Возбужденные
А-элементы посылают в решающее устройство (сумматор) R
сигналы через усилители, которые могут изменять как
величину, так и полярность (знак) сигналов. До начала обучения
коэффициенты усиления к всех усилителей равны нулю. На
рисунке черные кружки условно изображают
невозбужденные рецепторы, а белые — возбужденные. Сигналы в
ассоциативные элементы приходят только от возбужденных
рецепторов (обозначены 4-1 и —1). Знаки ( + ) и (—)
соответствуют «возбуждающим» и «тормозящим» связям, по
которым в данный момент сигналы не идут.
небольшом числе интересующих нас задач. Естественно
возникает вопрос: нельзя ли так преобразовать про-
М
В предыдущем параграфе было указано, что классы
легко разделяются в пространстве рецепторов лишь в
странство рецепторов в некоторое другое пространство,
чтобы в этом новом пространстве легко разделялись
классы для большей части интересных задач?
По-видимому, первой работой в этом направлении
было создание «перцептрона» *). В настоящее время
есть тенденция любые обучаемые узнающие системы
называть перцептронами. Нам это кажется неудобным, и
в нашей книге перцептроном будет называться только
первоначальная конструкция Розенблатта.
Перцептрон (см. рис. 9) состоит из элементов трех
типов, которые мы будем называть S-элементами, Л-
элементами и /^-элементом. S-элементы являются
рецепторами. Рецепторы соединены с Л-элементами с
помощью связей, которые могут быть возбуждающими или
тормозящими. Каждый рецептор может находиться в
одном из двух состояний, которые можно обозначить
нулем или единицей. Возбуждающая связь передает
Л-элементу состояние рецептора без изменения,
тормозящая связь изменяет знак сигнала. Л-элементы (ассо*
циативные элементы) перцептрона являются
сумматорами с порогом. Каждый Л-элемент возбуждается, если
сумма пришедших к нему от рецепторов по связям
сигналов превосходит некоторый порог. Сигнал от
возбудившихся А-элементов передается в сумматор R, причем
сигнал от элемента Лг- передается с коэффициентом k{.
Система связей всех Л-элементов и их пороги
выбираются заранее (например, некоторым случайным
образом) и в дальнейшем не изменяются ни при
решении какой-либо задачи, ни при переходе от одной
задачи к другой.
Обучение заключается только в выборе
коэффициентов k{. Этот процесс идет, например**), следующим
образом: сначала принимаем все коэффициенты k
равными нулю. Затем перцептрочу «показывают» объект
первого класса. Некоторые Л-элементы при этом
возбудятся; коэффициенты 6, соответствующие этим Л-эле-
ментам, увеличиваем на 1. Потом «показываем» объект
*) Наиболее подробно перцептроны описаны в вышедшей
недавно в русском переводе книге Ф. Розенблатта. Принципы ней-
родинамики (перцептроны и теория механизмов мозга), «Мир», 1965.
**) Мы рассматриваем для простоты так называемый а-пер-
Цептрон. В рамках данного вопроса другие схемы обучения перцеп-
тронов не имеют принципиального отличия.
35
второго класса и коэффициенты, соответствующие
возбудившимся теперь Л-элементам, уменьшаем на 1.
Продолжаем процесс до исчерпания всего материала
обучения. В результате обучения сформировались
коэффициенты к, которые будут использованы при экзамене.
Во время экзамена перцептрону «показывают»
неизвестный объект. Возбудившиеся Л-элементы подают в
R сигнал, равный соответствующим коэффициентам k.
Если сумма этих сигналов положительна, то
принимается решение, что показанный объект принадлежит к
первому классу, если отрицательна — то ко второму.
Можно считать состояния (0 или 1) Л-элементов
координатами точек «-мерного пространства*) (Л-про-
странство). Тогда система связей и порогов Л-элемен-
тов задает некоторое фиксированное (для данного
перцептроиа) преобразование пространства рецепторов
в Л-пространство **). Совокупность коэффициентов k
задает в Л-пространстве некоторую (п—1)-мерную
гиперплоскость, проходящую через начало координат.
Таким образом, общая схема работы перцептрона такова:
сначала производится некоторое стандартное, не завися*
щее от задачи, преобразование пространства
рецепторов в Л-пространство. Затем с помощью обучения
ищется в Л-пространстве гиперплоскость, отделяющая
объекты одного класса от объектов другого.
Попытаемся представить себе смысл этих операций
и соответственно понять возможности перцептрона.
Допустим вначале, что все Л-элементы имеют
только по одной возбуждающей связи и не имеют
тормозящих связей. Пусть порог каждого из них равен 1 (в
этом случае каждый Л-элемент просто повторяет
реакцию некоторого S-элемента). Каков смысл
образовавшихся к концу обучения коэффициентов А? Очевидно,
модуль ki показывает, насколько чаще встречалась
некоторая точка на растре в картинках одного класса,
чем в картинках другого. Знак ki показывает, в каком
классе (первом или втором) эта точка встречалась чаще.
При экзамене перцептрон проверяет, из каких точек
состоит неизвестная картинка. Если из таких, которые
*) п — число Л-элементов.
**) Преобразование однозначное, но не обязательно взаимно
однозначное.
36
чаще входили в картинки первого класса, значит она и
сама принадлежит первому классу. Ограниченность
возможностей такой системы не нуждается в пояснениях.
Допустим теперь, что все Л-элементы имеют по две
связи, причем обе положительны. Пороги равны 2.
Теперь в kt накапливается информация о частоте
появления сочетания каких-то двух точек на растре. По
каким парам точек ведется учет — задано раз и
навсегда конструкцией перцептрона (связями Л-элементов).
При экзамене «голосование» будет происходить по тем
парам точек, которые встретятся в неизвестной картинке.
В общем случае в k{ накапливается информация о
числе картинок, в которых встретился некоторый
фрагмент из возбужденных и невозбужденных S-элементов.
При низких порогах элемент А{ может срабатывать на
несколько разных фрагментов. Соответственно в k\
будет фиксироваться число появлений хотя бы одного из
этих фрагментов.
Теперь понятно, что для перцептрона должны быть
доступны лишь те задачи, в которых объекты каждого
класса имеют много общих фрагментов. «Сходство» для
перцептрона есть сходство при наложении картинок друг
на друга. Совпадения считаются не по точкам, а пс
фрагментам (точнее, по группам фрагментов, на
которые срабатывают Л-элементы). Естественно ожидать,
что для перцептрона окажутся недоступными
обобщения типа переноса фигуры или подобного
преобразования.
Сам Розенблатт не описал задач, которые оказались
для перцептрона «трудными». Поиск таких примеров
был произведен А. П. Петровым*). Опыты велись на
растре размером 16X16. В разных вариантах перцеп-
трон имел от 400 до 1300 Л-элементов. Число связей**)
каждого Л-элемента менялось от 5 до 30. Поскольку
результаты практически не зависели от этих
параметров, приводятся результаты одного из вариантов; их
можно считать относящимися к любому трехслойному
перцептрону.
1-я задача. Требовалось научиться отличать
прямоугольники, вытянутые в горизонтальном направлении,
*) А. П. Петров, О возможностях перцептрона, Известия
АН СССР, Техническая кибернетика. № 6, 1964,
**) Возбуждающих вместе с тормозящими.
37
от прямоугольников, вытянутых в вертикальном
направлении. (Подобный опыт делал и Розенблатт.) После
показа 15 фигур каждого класса при экзамене на 30
фигурах перцептрон дал 6% ошибок. Результат, в общем,
удовлетворительный.
2-я задача. Требовалось научиться отличать
треугольники от окружностей. Те и другие были
произвольных размеров и произвольно расположены на растре.
Даже после обучения на 45 фигурах каждого класса
перцептрон сделал при экзамене 33% ошибок. Эта
задача для перцептрона недоступна.
3-я задача. Требовалось отличать прямоугольники
от эллипсов. Те и другие произвольно повернуты и
расположены. После обучения на 45 фигурах каждого типа
перцептрон делал при экзамене 50% ошибок!
Возникает вопрос: каким образом перцептрон смог
удовлетворительно решить первую задачу? Ведь и в ней
прямоугольники были разных размеров и по-разному
расположены. Вспомним, однако, что весь растр имел
всего 16 вертикалей и 16 горизонталей. Поэтому при
«любом» расположении, скажем, вертикально
ориентированный прямоугольник неизбежно имел много общих
фрагментов с некоторыми фигурами из материала
обучения. Из-за малости растра при обучении были
показаны хотя и не все возможные фигуры, но почти все
возможные фрагменты. Их-то и запомнил перцептрон*).
Аналогичное обстоятельство, вероятно, помогло перцеп-
трону найти общие фрагменты (куски прямых) во
второй задаче и удержать количество ошибок на уровне,
меньшем 50%. На большем растре (например, ЮОх
X 100) перцептрон не смог бы научиться (при том же
материале обучения) и решению первой задачи.
Мы видим, что переход от пространства рецепторов
к Л-пространству мало помог делу. В Л-пространстве
тоже не выполняется соотношение компактности точек,
*) Заметим, что объем памяти при 1300Л-элементах в принципе
достаточен для запоминания практически всего материала обучения.
Действительно, для одной картинки нужна емкость 256 бит, для
30 картинок ~7500 бит. С другой стороны, 1300 элементов должны
иметь емкость около 5 бит каждый (для записи чисел от —15 до
.+ 15), что составляет ~6500 бит. (Бит или двоичная единица —
единица количества информации. Бит соответствует количеству
информации, достаточному для выбора одной из двух
равновероятных возможностей. \
38
относящихся к объектам одного класса ( для достаточно
разнообразных задач). Поэтому для многих задач
поиски плоскости, делящей классы в Л-пространстве,
обречены на неудачу. Не потому, что мы плохо ищем
(учимся), а потому, что такой плоскости нет. Для перцептро-
на цифра 3 (на рис. 5) «ближе» к одной из двоек, чем
разные двойки между собой.
Перцептрон — система, осуществляющая стандартное
преобразование пространства рецепторов, — мало
приближает нас к решению проблемы узнавания.
§ 5. Переменное (различное для разных задач)
преобразование пространства рецепторов
Вернемся к задаче, представленной на рис. 6. Поче*
му она оказалась трудной для системы, ищущей
близость в пространстве рецепторов (и для перцептрона
тоже)? Одна из причин заключается в том, что
картинки на рис. 6 содержат много лишней
информации. Действительно, каждая картинка несет
информацию о том, является наружная фигура выпуклой или
вогнутой, большой или маленькой, где по отношению к
наружной фигуре расположена внутренняя и т. д. Все
эти сведения для решения данной задачи не
нужны.
В результате обучения система должна перестать
обращать внимание на несущественные
обстоятельства. Это значит, что будет найден
такой метод отображения картинок, при котором л,иш-
няя информация утеряется.
Как ни парадоксально это звучит, но основная
задача узнающей системы (в противоположность задаче
линии связи) вовсе не в сохранении всей информации, а в
максимальном сокращении несущественной информации
о каждом объекте. С этой точки зрения всякое преобра^
зование входных данных, дающее надежду на успех,
Должно быть вырожденным.
На это можно возразить: «конечно, для решения
задачи, предложенной на рис. 6, полезно иметь
преобразователь (фильтр), который пропустит только
внутреннюю фигуру и задержит внешнюю. Однако для
Других задач этот фильтр может оказаться не только
бесполезным, но и вредным (выбросит существенную
39
информацию). Для других задач нужны другие выро*
жденные отображения, и заранее неизвестно, какое
именно отображение полезно для данной задачи».
Возражение это справедливо, но вспомним, что мы
рассматриваем системы, которые и не должны
заранее (до обучения) знать, какие преобразования
полезны для данной задачи. Достаточно, если в ходе
обучения (например, путем проб и ошибок) система найдет
вырожденное отображение, помогающее разделить
классы.
В жизни мы часто пользуемся неполными
описаниями, характеризующими только некоторые стороны
предмета. Отличительной особенностью этого способа
описания является то, что очень разным объектам могут
соответствовать одинаковые характеристики (отображение
множества объектов на множество характеристик
является вырожденным). Например, характеристика белая
может относиться и к лошади, и к кошке, и к чашке.
В таких случаях мы говорим, что указан некоторый
признак объекта. Строго говоря, слово белый
содержит два совершенно разных указания.
Первое — это, с помощью каких приборов можно
получить интересующие нас сведения. В данном случае
нужно измерить коэффициент отражения поверхности
предмета в разных длинах волн*).
Второе — это, каков результат такого измерения.
В нашем примере «коэффициент отражения по всему
видимому спектру достаточно высок и примерно одинаков
для разных длин волн».
Признаку зеленый соответствует та же
измерительная процедура, но другой результат измерения. В
обиходном языке эти две стороны понятия «признак» не
всегда четко различаются. Чтобы избежать путаницы,
мы будем называть признаком алгоритм
вырожденного отображения. Результат же отображения будет
называться характеристикой объекта по данному признаку.
Таким образом, признаком в нашем понимании будет,
например, программа, измеряющая площадь фигуры,
или программа, считающая количество углов, или про«
грамма, проверяющая четность числа.
*) При определении цвета «на глаз» мы приближенно
выполняем эту же операцию.
40
Характеристикой (результатом работы программы)
по первому признаку может быть неотрицательное чис*
ло, по второму признаку — целое неотрицательное число,
по третьему — суждение «да» или «нет». Кроме того,
каждая из программ может отказаться выдать ответ,
так как признак может быть неприменим к
предложенному объекту. Например, для числа 7,32 третий признак
не может сказать ни «да», ни «нет», так как он
применим только к целым числам.
Как же ищутся признаки, полезные для данной
задачи?
Пусть мы столкнулись с такой задачей. На столе
стоят пять стоек с пробирками. В каждой стойке по
нескольку пробирок с каким-то веществом. В пробирках,
находящихся на разных стойках, — разные вещества.
Затем нам приносят новую пробирку с каким-то из
этих пяти веществ. Мы должны поставить ее на нужную
стойку («рассортировать» или «узнать»). Имеется очень
много неполных характеристик содержимого пробирок.
Признаками являются цвет, запах, состояние вещества
(жидкость, кристаллы и т. д.), удельный вес,
разлагается ли при нагревании, горит ли и т. д.
Предположим, на трех стойках пробирки с
жидкостями, а на двух — с твердыми веществами. Одно из
твердых веществ белое, а другое — синее. Две жидкости
прозрачные, а третья — синяя. Понюхав пробирки, мй
замечаем, что на одной стойке с прозрачной жидкостью
они имеют резкий запах, а на остальных совсем не
пахнут. Теперь можно составить таблицу описаний классов
в терминах признаков.
ТАБЛИЦА 1
№ стойки
1
2
3
4
5
Состояние
1
1
0
0
0
Цвет
0
1
0
0
1
Запах 1
0
о
0
1
0
В табл. 1 в столбце «Состояние» единица означает
твердое тело, а нуль — жидкость; в столбце «Цвет»
41
единица означает синий цвет, а нуль — отсутствие
окраски; в столбце «Запах» единица означает наличие, а
нуль — отсутствие запаха. В таблице нет одинаковых
строчек, поэтому набор отобранных трех признаков даст
нам возможность узнавать новые пробирки.
При «экзамене» нужно присвоить неизвестному
веществу характеристики по всем трем признакам. Набор
полученных характеристик затем сравнивается со
строчками табл. 1. Пробирка ставится на стойку с номером
той строки, в которой все характеристики совпадают с
характеристиками неизвестного вещества. Видно, что
процесс отбора полезных признаков состоит из проб и
ошибок. Мы выдвигаем гипотезы о том, является ли
данный признак полезным, и затем проверяем их.
Критерием полезности, как мы видели, служило то, дает ли
характеристика по признаку сечение множества
объектов. Мы сочли полезным признак «состояние» потому,
что у нас случились и твердые и жидкие вещества.
Признак «цвет» также оказался полезным. Но если бы на
всех пяти стойках оказались прозрачные жидкости, то
признаки цвет и состояние следовало бы забраковать
как бесполезные.
Рассмотренный пример в некотором смысле является
простейшим. Здесь среди проверенных признаков
нашлись такие, которые дают одинаковую характеристику
всем объектам одного класса (все пробирки на одной
стойке имели одинаковый цвет, запах и т. д.). Задача
усложнилась бы, если бы вещество на одной и той же
стойке могло фигурировать иногда в твердом виде, а
иногда в растворе. Трудности возникли бы и с
веществами вроде медного купороса, который в безводном
виде белый, а в растворе синий, и т. п. В этих случаях
описание класса в терминах признаков звучало бы не
просто перечислением характеристик по этим
признакам, а имело бы вид некоторой более сложной
логической функции от характеристик.
Это, естественно, наложит отпечаток и на способ
оценки полезности признака. В подобных случаях
придется учитывать не только разнообразие
характеристик объектов разных классов по данному признаку,
но и степень однообразия характеристик объектов
одного и того же класса. В разных узнающих
программах применяются несколько разные критерии полезно-
42
сти признаков. Они будут всегда оговариваться в
соответствующих местах, а глава XI практически вся
посвящена этому вопросу.
Мы видим, что в результате обучения возникает
описание классов объектов. При этом описание данного
класса зависит не только от того, какие объекты в
него входят, но и от того, какие объекты входят в д р у-
гие классы (от чего данный класс нужно
отличать). Это следует из самого смысла отбора полезных
признаков.
Попробуем теперь в этих терминах описать работу
перцептрона.
В принципе можно считать, что плоскость в Л-про-
странстве перцептрона тоже является признаком.
Характеристикой по этому признаку является положение
точки по одну или по другую сторону от плоскости. Может
показаться, что в «арсенале» перцептрона много
разных признаков; однако мы уже видели, что среди них
нет очень многих необходимых. Вопреки
распространенной точке зрения, перцептрон является не «системой без
наперед заданных признаков», а системой с очень
жестким, бедным и неудачным для многих задач набором
признаков. Распространенная точка зрения возникла,
вероятно, потому, что конструктор перцептрона доверяет
часть операций формирования арсенала признаков
случайному процессу. Но после реализации случайного
процесса перцептрон становится системой со строго
фиксированным набором признаков. И как бы этот процесс
ни реализовался, среди доступных перцептрону
признаков нет нужных для многих часто встречающихся задач.
Такова цена, которую мы платим за «экономию
мышления» при конструировании перцептрона.
Итак, в отличие от систем, ведущих поиск сходства
в жестко заданном пространстве, одном и том же для
разных задач, мы будем пытаться строить системы,
производящие перебор и проверку большого числа
вырожденных преобразований пространства рецепторов. При
этом в ходе обучения выбираются признаки, полезные
именно для данной задачи.
Поскольку нас интересует построение системы,
которая могла бы решать много разных задач, нужно,
чтобы в ходе обучения могли отбираться весьма
разнообразные признаки. Другими словами, система
43
должна обладать способностью производить очень много
разных вырожденных отображений. Ясно, что хранить
в памяти алгоритмы всех отображений в готовом виде
практически невозможно. Поэтому нужно суметь
разбить все возможные отображения на некоторые
элементарные операции и хранить только способ построения
разнообразных признаков из этих элементарных
«кирпичей».
Грубо говоря, признаки должны собираться из
«кирпичей», как из деталей детского конструктора
собираются модели мостов, подъемных кранов* и др. При таком
способе действительно удается сделать доступным для
системы колоссальное количество разных признаков.
Именно такие системы и будут рассматриваться в
следующих главах.
Глава 111
ПРОГРАММА АРИФМЕТИКА
§ 1. Постановка задачи
В этой главе рассматривается программа,
предназначенная для узнавания числовых таблиц, построенных по
разным арифметическим законам. Выбор таких
несколько искусственных объектов для узнавания определился
тем, что на этой модели удалось организовать
построение большого числа признаков из сравнительно
небольшого числа «кирпичей». При этом весьма естественно
возникла идея использования логических функций для
построения признаков. Любопытно, что некоторые блоки
этой программы с очень небольшими изменениями
перекочевали и в программы для узнавания геометрических
объектов и для решения геофизических задач.
По-видимому, эти блоки решают какую-то часть проблемы
узнавания, общую для задач разной природы.
Объектами для программы Арифметика являлись
таблицы чисел, состоящие из нескольких строк по три
числа в каждой строке. Пример объекта показан на
табл. 2.
Во всех строках числа столбца С получены из чисел
столбцов А и В с помощью одного и того же закона.
Нетрудно убедиться, что все строки табл. 2
удовлетворяют закону АВ(А—В) = С. Ясно, что, используя
разные числа А и В, можно с помощью одного и того же
закона строить неограниченное количество разных
таблиц. Все таблицы, построенные по одному и тому же
закону, мы будем считать объектами одного класса.
Табл. 3 не принадлежит тому же классу, что табл.2,
так как она построена по другому закону. В ней
С=*+А+В.
45
ТАБЛИЦА2 ТАБЛИЦАЗ
А
4
3
—6
5
2,5
в
1
4
2
2,5
—2
с
э
7,75
—7
9,5
—0,75
А
4
з
2
5,5
6
в
1
5
7
3
6,3
с
12
—30
—70
41,25
—11,34
Первоначально программа предназначалась для
узнавания таблиц, в которых С образовывалось из Л и В
с помощью любых трех последовательно примененных
арифметических действий. В этом случае число
возможных разных классов равно числу различных*)
арифметических «трехходовок» от Л и В.
Цель состоит в следующем: пусть программе
показали несколько объектов первого класса (таблиц,
построенных по одному и тому же закону), несколько —
второго класса, третьего и т. д. При этом программе не
сообщают, по каким законам таблицы построены.
Для нее классы просто занумерованы. Затем при
экзамене программе показывают новую (не содержащуюся
в материале обучения) таблицу, принадлежащую
одному из классов, участвовавших в обучении. Программа
должна указать номер класса этой таблицы.
Какими же методами можно пытаться решить эту
задачу? Сразу видно, что запоминание материала
обучения никак не приближает нас к успеху. Ведь при
экзамене дадут новую таблицу. Сравнение ее с
материалом обучения, хранимым в памяти, не даст совпадения
ни с одним «прецедентом». Программа всегда будет
отвечать: «Этому меня не учили».
Если считать каждое число таблицы одной из
координат, то вся таблица может рассматриваться как точка
в многомерном пространстве рецепторов. Например,
таблицы 2 и 3 есть точки в 15-мерном пространстве. Не
окажутся ли точки, соответствующие объектам одного
класса, расположенными компактно в этом
пространстве? Надеяться на это нет никаких оснований.
Близкими в пространстве рецепторов являются точки, у кото-
*) То есть не тождественных. Например, трехходовка
(А + £) (Л — В\ считается одинаковой с Л2 —В2 и с (Л — В)(В+А).
46
рых все соответствующие координаты
близки. Две таблицы, принадлежащие к разным
классам, могут оказаться гораздо ближе друг к другу
(например, из-за совпадения чисел Л и В), чем разные
таблицы одного класса. Ситуация «губки и воды» здесь
безусловно имеет место.
Не поможет ли тут какое-нибудь стандартное слу*
чайное преобразование пространства рецепторов (пер-
цептрон)? Допустим, что пространство рецепторов
преобразовано в Л-пространство, например, с помощью
таких преобразователей: первый берет число Л из чет-4
вертой строки, В из первой, С из третьей и складывает
их; второй — В из второй строки складывает с Л из
первой; третий берет сумму Л из первой и пятой строк и
вычитает из нее В из второй строки и т. д. Затем каж«
дый преобразователь проверяет, превосходит ли
полученный результат некоторый постоянный порог.
Довольно очевидно, что от такого преобразования задача
разделения классов легче не стала.
Заметим, что описанная выше процедура
преобразования является не пародией на перцептрон, а точным
применением духа и буквы метода к данной задаче. Ведь
«вся прелесть» перцептрона и заключается в том, что
делается никак не мотивированное, но зато простое
преобразование пространства рецепторов в надежде на
легкую разделимость классов в Л-пространстве.
Но даже если и не строго следовать «духу и букве»
перцептрона и попробовать найти хоть не
бессмысленное, но стандартное преобразование
пространства рецепторов, то заранее вовсе неизвестно, найдется
ли универсальное преобразование для многих
разных задач. Кто может поручиться, что для разделения
классов лв и (-£-) -\-В понадобится такое же
преобразование, что и для разделения классов (А + В + В)В
Л — В '
Поэтому мы решили делать программу, которая
каждый раз искала бы признаки, полезные для данной
конкретной задачи. При этом, естественно, надо было
позаботиться, чтобы среди доступных для программы
прнзнаков имелись необходимые для любой задачи из той
совокупности, на которую рассчитывалась программа.
47
Эта часть работы, особенно на первых порах, в
основном опиралась на интуицию экспериментатора, так
как множество доступных признаков задавалось в
неявной форме и было невозможно (из-за их слишком
большого количества) продумать, к каким последствиям
приведет отбор того или другого признака.
§ 2. Формальное описание программы
а) Объекты работы. Объектами являются
таблицы чисел, описанные в предыдущем параграфе.
Программа может обучаться различать от двух до 24
классов объектов. Каждый класс при обучении
представляется двумя таблицами. Программе сообщается, что эти две
таблицы относятся к первому классу, следующие две —
ко второму и т. д. Законы, по которым построены
таблицы, в машину не вводятся. Каждая таблица может
иметь от одной до восьми строчек*).
Для экзамена вводятся другие таблицы, построенные
по тем же самым или по другим законам. Число строк
в таблице для узнавания может быть от 1 до 8, не
обязательно такое же, как было при обучении. Задача
программы заключается в том, чтобы относительно каждой
таблицы, введенной для экзамена, определить: «Более
всего это похоже на класс номер г». Одновременно для
узнавания может быть введено от одной до 24 таблиц.
б) Построение признаков. Напомним, что
признаком называется алгоритм, осуществляющий
вырожденное отображение объекта. В разбираемой
программе характеристика таблицы по любому признаку
может иметь два значения: 0 и 1. Признаки строятся
следующим образом: берется простая арифметическая
функция от А, В и С (Л, В и С — числа из одной строки
таблицы)—fi(A, В, С), например, А+В или С : В и т. д.
Затем полученное число подставляется в один из трех
описанных ниже логических операторов. Логический
оператор превращает это число в логическое переменное,
принимающее два значения: 0 и 1.
*) Может показаться, что две таблицы, относящиеся к одному
классу, можно было бы заменить одной таблицей двойной длины
(содержащей строчки из обеих таблиц). Однако, как будет видно
дальше, логика программы такова, что это — не эквивалентные
условия для отбора полезных признаков.
48
В программе применяются три логических оператора:
Li — проверка на целочисленность, L2 — проверка знака,
Lz — сравнение с 1 по модулю.
Таким образом,
Z,JV=1,
L,N=^0,
L2N=1,
LJV = 0,
LJJ=\,
L,N = 0,
если
если
если
если
если
если
N — целое,
N — дробное,
ЛГ>0,
iV<0,
MV|>i,
|7V|<1.
Приведем пример. Пусть fi(A, В, С) есть В : А, тогда
AM?; 9; з) = о,
Z2f.(7; 9; 3)=1,
LMb 9; 3) = 1.
Очевидно, не любые комбинации арифметических
функций и логических операторов будут независимыми.
Например, 12АВе^Ь2-^^г L2-j (знак произведения
совпадает со знаком частных). Для сокращения
времени обучения из всех эквивалентных комбинаций
рассматривается только одна. Всего используются 33 разных
сочетания арифметических функций и логических
операторов. (Опыты велись на машине М-2 ИНЭУМ АН
СССР, имеющей ячейки длиной 33 разряда, и было
удобно заполнять одну ячейку машины логическими
переменными, относящимися к одной строке таблицы.)
Обозначим Ljfi через lji(lji = lji (А, В, С)). Возьмем
два логических переменных /у,,-, и /;-2/2. Они могут быть
построены с помощью разных (или тех же)
арифметических функций и логических операторов. ПустьFm(a, b)
есть некоторая логическая функция двух переменных а
\\ b. Fm(ljxiv, lj2h) будем считать признаком для одной
строки таблицы. Напомним, что имеется всего 16
логических функций двух переменных а и Ь. Из них две
(тождественные 0 и 1) вообще неинтересны. Четыре
являются функциями только одного переменного (а, а,
Ь, Ь). Таким образом, остается 10 функций двух
переменных: это ab\ ab\ ab, ab\ аУЬ\ aVb, aVft; aVb\
<*bVab\ abVab.
49
Программа рассматривает все эти функции.
Признаком для всей таблицы является логическое произведение
признаков для отдельных строк. Таким образом, при*
знак для таблицы имеет вид
Fm[Lhfh(Av Bv Сг); Lhfi2(Av Bv СХ)\Л
AFm[Lhftl(A2, 52, C2); LjJi2(A2, B2t C2)] Л
f\Fm[Lhfh{A„ Вп, Сл); LjJbiA» Вп, Сп)].
Здесь индексы при А, В, и С соответствуй^ номеру
строки таблицы. Разные признаки отличаются друг от
друга значением /ь i2, /1, h, m> что соответствует выбору
разных арифметических функций, логических
операторов и логических функций. Всего программа имеет
возможность выбирать из 5346 признаков.
в) Отбор признаков. Само собой разумеется,
что имеет смысл запоминать не все признаки, а только
полезные. Какие же признаки мы должны относить
к их числу?
Первое требование, предъявляемое к полезному
признаку: он должен давать сечение на множестве объектов
(таблиц), по которым ведется обучение. Это значит, что
признак не должен присваивать всем таблицам одну и
ту же характеристику (безразлично, 0 или 1), так как
характеристика по такому признаку не несет никакой
информации о номере закона таблицы. Ясно, что
наибольшую информацию дает признак, который половину
таблиц характеризует нулем, а половину — единицей.
Кроме того, малополезны признаки, дающие сечения,
совпадающие с сечением, произведенным одним из уже
отобранных признаков*).
Второе требование к полезному признаку: он
должен присваивать двум таблицам одного класса
одинаковые характеристики.
В соответствии с этими замечаниями программа
отбора признаков работает так: таблицы, на которых идет
обучение, разбиты на две группы. Первая — рабочая,
вторая — контрольная. Каждая группа содержит по од-
*) Мы не рассматриваем сейчас вопроса о помехоустойчивости
системы. Признак, дублирующий сечение, может повышать
помехоустойчивость и быть с этой точки зрения небесполезным.
50
ной таблице из всех классов. Программа берет признак,
подлежащий проверке, и присваивает по нему
характеристики всем таблицам рабочей группы. Затем
проверяется, сколько таблиц имеют характеристику 1.
Пусть обучение идет на 5 классах (2<S<124). Если
5 S 1
число единиц не равно -у при четном S или у ± -у
при нечетном 5, то признак бракуется. Если он
выдержал эту проверку, то проверяется, не дает ли он уже
встречавшееся ранее сечение. В случае, если признак
выдержал и это испытание, программа присваивает
характеристики по этому признаку таблицам контрольной
группы. Затем проверяется совпадение характеристик
таблиц рабочей и контрольной групп. В случае
совпадения их для всех классов признак запоминается, в случае
несовпадения — бракуется.
После исчерпания запаса всех 5346 возможных
признаков программа уменьшает строгость первого этапа
отбора и снова просматривает первоначально
отвергнутые признаки. Теперь пропускаются признаки, дающие
S S I
•J ± 1 единиц при четном 5 и у±1упри нечетном 5*).
Затем снова уменьшается строгость отбора и т. д.
Процесс заканчивается тогда, когда или отобрано 30
полезных признаков, или дальнейшее уменьшение строгости
отбора привело бы к запоминанию бесполезных
признаков (не дающих сечения на множестве 5 классов).
Легко доказать, что при любом способе разбиения
двойного набора таблиц на рабочую и контрольную
группы будут отобраны те же самые признаки.
Разумеется, программа могла бы работать и в условиях, когда
каждый класс представлен не двумя таблицами, а
большим их числом.
В результате обучения в памяти записываются
программы полезных признаков (30 или меньше) и
характеристики таблиц по всем признакам (внутри класса
таблицы имеют всегда одинаковые характеристики).
г) Экзамен. Программа экзамена присваивает
неизвестным таблицам характеристики по всем
отобранным при обучении признакам. Затем полученные харак-
*) Для сокращения времени обучения в программе
предусмотрена возможность начинать и с менее строгого, чем S/2, отбора.
51
теристики сравниваются с характеристиками таблиц,
использованных при обучении. Сравнение заключается в
подсчете числа признаков, по которым характеристики
не совпадают. В результате получаются, например,
такие сведения: характеристики этой неизвестной таблицы
расходятся с характеристиками таблиц первого класса
по 17 признакам, второго класса — по трем признакам,
третьего класса — по 14 признакам и т. д. Далее
программа выбирает три наименьших числа и печатает
номера относящихся к ним классов в порядке возрастания
количества расходящихся характеристик.
Для удобства работы программа печатает не только
окончательный результат — суждения о том, на какие
знакомые таблицы более всего похожи таблицы, данные
на экзамене, но и некоторые промежуточные сведения:
запоминаемые полезные признаки; сечения,
производимые этими признаками на множестве классов, данных
для обучения; характеристики по всем отобранным
признакам классов, применявшихся при обучении;
характеристики по всем признакам таблиц, данных на
экзамене.
§ 3. Содержательное описание признаков
В предыдущем параграфе было формально описано
множество признаков, доступных программе. При этом
весь упор был сделан на четкое изложение алгоритма,
по которому каждый признак отображает таблицу
чисел в 0 или 1. Однако даже пробившись через
нагромождение «арифметических функций», «логических
операторов» и т. д., очень трудно понять, что же такое
«признаки» на самом деле. Во всяком случае, автор
вынужден сознаться, что сам он из такого описания
ничего бы не понял. Поэтому попробуем «заглянуть в
кухню» придумывания данной«апрограммы.
Допустим, мы решили, что из соображений удобства
представления характеристик в машинной памяти
каждый признак может давать таблице только одну из
двух характеристик: 0 или 1. (Сделанное предположение
не принципиально, оно нужно лишь для придания
конкретности дальнейшим рассуждениям.) Тогда каждый
признак будет разбивать классы, данные для обучения
(например, 24 класса) на две группы. Подумаем, на ка-
52
кие группы могут «естественно» распадаться разные
арифметические законы.
Сразу приходят в голову, например, такие разбиения:
законы, содержащие деление и не содержащие его;
законы, содержащие относительно высокие степени А и В
и не содержащие, и т. д. Ясно, что таких «естественных»
разбиений может быть много. Нам не нужно
придумывать большое число их, достаточно сообразить, какого
вида они могут быть. Возьмем первое попавшееся
разбиение — законы, содержащие и не содержащие
деление. Каким должен быть признак принадлежности
таблицы к классу, входящему в ту или иную группу?
Вспоминаем, что деление — единственное действие,
создающее дробные числа из целых. Значит, неплохо иметь
среди «кирпичей», из которых будут строиться признаки,
проверку числа на целочисленность.
Нетрудно, однако, заметить, что сама по себе
проверка, например, числа С на целочисленность еще не может
быть признаком, говорящим, есть ли деление в
арифметическом законе, по которому построена таблица, или
нет. Мешают этому два обстоятельства. Во-первых, если
числа А и В сами дробные, то С может быть не целым
и в том случае, если никакого деления в законе нет. Во-
вторых, может быть случай, когда и А — целое, и В —
целое, и деление есть, а С получается не дробное.
Например, закон выражается формулой (А/В)+А+В = С.
Тогда при А = 6, В = 2 получаем, что С равно 11.
Начнем с первой из указанных трудностей. Она
заключается в том, что дробность С является признаком
наличия деления только при условии выполнения
некоторых ограничений на Л и В. Истинным является не
высказывание «если С — дробное, то в законе есть
деление», а высказывание «если А и В — целые и
одновременно С — дробное, то в законе есть деление». Если мы
хотим поручить программе составлять подобные
высказывания, то самый простой путь — дать ей возможность
строить логические функции от более элементарных
высказываний. При этом, составляя признак типа «если
\jr- < 1 и А -f- В !>0, то присваивай характеристику О,
а в остальных случаях—1», программа «не
задумывается» над целесообразностью такого признака сточки
зрения законов арифметики. Критерием целесообразно-
53
сти (или отсутствия таковой) для программы будет,
разбиваются ли таблицы этим признаком на группы и
устойчива ли характеристика по этому признаку внутри
классов.
Обратимся теперь ко второй трудности. Она
заключалась в том, что совокупность обстоятельств: А и В —
целые и С — дробное — является не необходимым, а
только достаточным признаком наличия в законе
деления. Поэтому в отношении не одной строки, а таблицы
в целом имеет смысл пользоваться высказыванием: «если
хотя бы в одной строке таблицы А и В —целые, а С —
дробное, то в законе есть деление». Вот почему в
качестве признака для таблицы в целом используется
логическая функция (произведение) от признаков для
отдельных строк.
Правда, может показаться, что для построения
достаточного признака нужно применить логическую
сумму (а не произведение) строк, но дело в том, что
поскольку для строк ищутся все логические функции, то
среди них встретится и отрицание нужной нам
зависимости. А логическое произведение отрицаний есть
отрицание логической суммы. Так как нам безразлично,
какую именно характеристику (0 или 1) признак будет
присваивать данной группе таблиц (например,
построенным по законам, содержащим деление), то
применение логического произведения дает возможность
проверять и необходимые и достаточные признаки. (Програм-
ма использует тождество aVbV ... Vk = aKb/\ ... Ak.)
Теперь понятно, почему не безразлично, показать ли
программе две таблицы одного класса по три строки
или одну таблицу из шести строк, являющуюся
объединением двух по три строки. Возможна ситуация, когда
таблица из шести строк обладает некоторым
достаточным признаком, а после того, как ее разбили на две
части, этим признаком обладает только одна из таблиц
по три строчки. Программа решит, что признак
неустойчивый, и забракует его.
§ 4. Эксперименты с программой
а) Зависимость отобранных признаков
от материала обучения. Первые же опыты
показали, что отбор признаков зависит не только от набора
54
классов, участвующих при обучении, но и от того,
какие числа использованы для построения таблиц.
Например, если все строчки всех таблиц содержат только
целые Л и В, то отбирается (разумеется, если среди
законов есть содержащие деление) признак «если хоть в
одной строчке С — дробное, то ставь О»,
Если мы добавляем в таблицы строчки, содержащие
дробные Л и В, то этот признак перестает быть
полезным. Он присваивает теперь практически всем таблицам
характеристику 0. Чем же заменяет его программа?
Идеальный с точки зрения законов арифметики признак
звучал бы так: «если хоть в одной строчке таблицы Л —
целое и В— целое и С — дробное, то ставь 0». Однако
этот признак является функцией трех логических
переменных, а рассматриваемая программа умеет строить
функции не более двух переменных (функции одного
переменного получаются как частный случай при
совпадающих аргументах, например aS/a = a). Поэтому
программа находит «суррогат» идеального признака. В
нашем случае она отобрала такой признак: «если хоть в
одной строчке Ах В— целое и С — дробное, то ставь 0».
Вместо целочисленности А и В порознь программа
потребовала целочисленности произведения А на В.
С точки зрения математика признак не так уж плох.
В самом деле, если Л и В не подбирали специально, то
редко будет встречаться случай, когда Л или В —
дробные, а их произведение — целое. В тех дробных Л и В,
которые мы показали машине, таких случаев не было.
Ясно, что если бы такое случилось, то этот признак не
отобрался бы, а заменился бы чем-нибудь более
подходящим к случаю. То же самое, разумеется, относится
к соотношению признаков, отобранных при
положительных Л и В и отобранных при Л и В произвольных
знаков. В первом случае признаки никогда не используют
проверки знака Л или В, а во втором — эти проверки
приходится использовать.
Снятие некоторых ограничений, наложенных на
область, откуда берутся Л и В, иногда приводит к тому,
что для внесения необходимых «оговорок» в признак
программе не хватает логических возможностей.
Поэтому не удивительно, что если для Л и В возможны и
целые и дробные, и положительные и отрицательные
значения, то после обучения программа узнает таблицы
55
хуже, чем, например, тогда, когда А и В только целые
положительные. Для нас сейчас интересно, что
программа сама приспосабливается к области допустимых
значений А и В. Мы подчеркнули сама, потому что никаким
способом программе не сообщали, какие признаки
хороши «в мире» целых чисел, а какие — в мире дробных.
Как только появляются ограничения на область
допустимых А и В, программа тут же использует
«освободившийся резерв» логических возможностей для
построения более разнообразных признаков.
б) Узнавание арифметических законов»
участвовавших в процессе отбора
признаков. В опытах этой серии в машину для обучения
вводились таблицы, содержащие натуральные числа А и В.
Все строчки таблиц одного и того же класса были
построены по одному и тому же арифметическому закону.
Таблицы разных классов строились по разным законам.
При экзамене предъявлялись таблицы тех же классов,
которые участвовали в обучении, но содержащие
другие числа А и В. В материале экзамена числа А и В
также были натуральными.
На машине со средней скоростью работы 2000 трех-
адресных операций в секунду Обучение по шести
классам при трех строчках в каждой таблице занимало
6 мин. При обучении по 24 классам при восьми
строчках в каждой таблице требовалось около 35 мин. При
экзамене на каждую таблицу уходило 7—10 сек
(включая время печати ответа).
Применялись два набора по 24 арифметических
закона, приведенные в табл. 4. Проводились опыты с
обучением по 6, 8, 9 и 24 классам. При обучении по 6,
8 и 9 классам использовались первые 6, 8 или 9 законов
из первого набора. При числе классов 9 или меньше
экзамен дал полное узнавание таблиц. Это значит, что
номер соответствующего класса всегда печатался на
первом месте. При 24 классах не все таблицы узнавались
правильно. Иногда номер соответствующего класса
попадал на второе или даже на более далекое место.
Каким параметром имеет смысл характеризовать
качество узнавания? Вообще говоря, в зависимости от
того, для чего будет использоваться эта
характеристика, полезными окажутся разные параметры. Иногда
интересен процент случаев, когда верный номер класса
S6
ТАБЛИЦА 4
1 |
2 |
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
Набор 1
II
VI
IV
II
HI
Hi
I
HI
II
VI
HI
IV
IV
I
I
II
II
III
HI
HI
I
I
II
I
IV
V
VI
IV
HI
I
IV
HI
II
HI
VI
I
I
IV
IV
IV
Набор 2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
HI
III
I
II
HI
V
I VI
HI
III
HI
HI
I
HI
III
V
I
I
V
I
HI
IV
IV
VI
Ij
IV
I
I
IV
IV
IV
IV
VI
IV
IV
I
VI
VI
VI
VI
I
57
Продолжение
Набор 1
21
22
23
24
В
В + 2А
АВ + В2
4А2В2
А*
В
III
I
V
V
V
VI
VI
I
Набор 2
21
22
23
24
В А
А В
А
В —В2
А
А
4В
III
IV
IV
IV
IV
III
III
III
попадает на первое место. Однако эта величина не очень
удобна, если нужно сравнивать работу двух программ,
выбирающих из разного числа классов. В самом деле,
мы ведь не скажем, что программа, выбирающая из
двух классов и дающая 60% верных узнаваний,
работает лучше, чем программа, выбирающая из 1000
классов и дающая 10% узнаваний. Более того, мы будем
склонны считать очень хорошей даже программу,
которая при выборе из 1000 классов никогда не печатает
правильный номер на первом месте, но зато этот номер
всегда попадает в первую десятку номеров.
Нам будет удобно сравнивать работу программы
после обучения с работой, условно принятой за эталон
программы, «гадающей наудачу». Действительно, мож*
но представить себе, что есть программа, которая
вообще не обучалась и во время экзамена даже «не
смотрит» на таблицу. Она просто бросает жребий и
некоторым случайным образом расставляет в ряд числа от 1
до S, где S — число классов, из которых надо выбирать.
При этом она будет как-то узнавать, но правильный но-
5 + 1
мер в среднем окажется на месте ЛГГ =
—:^—-Очевидно, среднее место правильного номера, равное Мг,
покажет и программа, которая обучалась, но которой обу*
чение «не пошло впрок» (мы имеем в виду случай,
когда для экзамена одинаково часто дают таблицы,
принадлежащие к разным классам).
58
Идеально узнающая программа даст среднее место
М0=1. Пусть реальная программа показала при
выборе из S классов среднее место Мс. Мы будем
характеризовать соотношение «гадания» и «знания»
программы в момент экзамена величиной
_ Мс — MQ _ Afc —1
^ ~~ Mr — MQ ~ Afr —1 '
При идеальной работе т] = 0, при случайном гадании
4=1.
Вернемся теперь к узнаванию таблиц, построенных
по арифметическим законам. После обучения на 24
классах первого набора (табл. 4) экзамен на других
таблицах этих же классов дал ц = 0,025. При работе со
вторым набором (табл. 4) ц = 0,036. Таким образом, при
выборе из 24 классов элемент случайного гадания
составлял около 3% *).
в) Узнавание арифметических законов,
не участвовавших в процессе отбора
признаков. При обучении на законах второго
набора программа отобрала в основном не те
признаки, что при обучении на первом наборе. В связи с этим
возник вопрос о степени специфичности отобранных
признаков.
Уточним смысл вопроса. Тридцать полезных
признаков, отобранных во время обучения, например, на
втором наборе законов, осуществляют отображение
каждой числовой таблицы в некоторую вершину
тридцатимерного куба. Будем считать, что расстояние в этом
пространстве измеряется в смысле Хемминга**). Как
показал опыт, при этом отображении таблицы одного
класса попадают или в одну и ту же, или в близкие
*) Такое же среднее место было в случае, если бы 3% задач
поручили решать «гадающей» программе, а 97% задач — идеально-
узнающей программе.
**) Расстоянием в смысле Хемминга между двумя вершинами
гс-мерного куба (см. подстрочное примечание на стр. 28)
называется число несовпадающих координат. Например, расстояние в
смысле Хемминга между четырехмерными точками (1, 1, 0, 0) и
(0, 1, 0, 0) равно 1, а между точками (1, 1, 0, 0) и (1, 0, 1, 0)
равно 2. Из определения следует, что расстояние в смысле
Хемминга может принимать лишь целые неотрицательные значения, не
превосходящие размерности (т. е. числа координат точки) пространства.
5*
точки. Разные классы попадают в среднем *) в далекие
друг от друга области. Другими словами, классы
объектов, бывшие в пространстве рецепторов совсем не
компактными, после отображения стали компактными в
пространстве характеристик по полезным признакам.
На этом языке вопрос о специфичности признаков
звучит так: будет ли отображение, найденное при
обучении на втором наборе, давать при воздействии на
классы первого набора также компактное размещение
классов в тридцатимерном пространстве характеристик
по полезным признакам? Или это отображение годится
только для классов из второго набора и совсем не
подходит для классов из первого?
Эксперимент ставился так: обучение производилось
по 24 классам второго набора (табл. 4). Отобранные
30 полезных признаков запоминались и в дальнейшем
во время опыта меняться не могли. Затем в
машину вводились таблицы, построенные по законам
первого набора, и программа присваивала им
характеристики по закрепленным признакам (отображала их с
помощью найденного преобразования) и
характеристики запоминались. После этого для экзамена вводились
другие таблицы, построенные по законам первого
набора. Им снова присваивались характеристики, и они
сравнивались с характеристиками, находящимися в
памяти. Было получено ц~0,029. Сравнение с
результатами опытов серии б) (ri = 0,025 и ц = 0,036) показывает,
что узнавание при помощи «чужих» признаков
происходило в этом опыте не хуже, чем при помощи «своих».
Это значит, что отображение, найденное при обучении
на втором наборе, оказалось достаточно хорошим и для
классов первого набора.
Итак, программе показывали одни арифметические
законы, а она отыскала пространство, в котором
хорошо разделяются не только эти, но и другие
арифметические законы. Естественно было попробовать добиться
такого же результата путем показа не 24, а меньшего
числа законов. Было проведено обучение по шести
арифметическим законам (первые 6 из первого набора). За-
*) Были случаи, когда программа не сумела разделить
некоторые классы: например, законы 16, 17 и 19 из второго набора
спроектировались в одну и ту же точку пространства»
60
тем по отобранным признакам (так же, как в
предыдущем опыте) проводилось узнавание 24 законов.
Экзамен на первом наборе дал т^ = 0,007, на втором наборе
П = 0,025.
Любопытно отметить, что в этом опыте узнавание
по чужим признакам дало результат, даже несколько
лучший, чем при использовании признаков, специально
подобранных для узнаваемых законов. Причина этого
вовсе не в том, что признаки, отобранные при обучении
на шести законах, работали более надежно, чем
отобранные при обучении на 24 законах. Наоборот,
просмотр результатов показывает, что количество ошибок
на экзамене в характеристиках по признакам,
полученным при обучении по шести законам, составляет 4,2%,
а для признаков, полученных при обучении по 24
законам,— только 1,4%. Чем же объясняется, что более
надежно работающие признаки дают иногда худшее
узнавание? Дело в том, что качество узнавания
определяется не только надежностью признаков, но и тем,
по скольким признакам отличаются друг от
друга классы (как далеко друг от друга попадают их
отображения). При обучении по 24 классам
характеристики некоторых классов по всем признакам могут по-
л>чаться очень похожими (этот недостаток можно было
бы исправить некоторым изменением критерия
«новизны» признака). Ясно, что при этих условиях ошибки в
малом числе признаков могут привести к ухудшению
результатов экзамена. Признаки же, отобранные в ходе
обучения на шести классах, хотя и работали менее
надежно, но зато давали для разных классов более
далекие друг от друга отображения. В данном случае это
привело к некоторому улучшению узнавания.
Во всяком случае, отображение, найденное при
обучении по шести арифметическим законам, оказалось
пригодным для вполне удовлетворительного узнавания,
по крайней мере, 48 законов (а в действительности,
вероятно, и гораздо большего числа.)
Не противоречит ли этот факт мысли, которую мы
настойчиво пытаемся внушить читателю, о том, что не
может существовать универсального (годящегося для
широкого круга задач) преобразования пространства
рецепторов? Преобразования в пространстве
сравнительно малого числа измерений (30), в котором легко
61
объединятся между собой объекты каждого класса
(например, по принципу близости) и разделятся
разные классы? Окончательный ответ на этот вопрос (нет,
не противоречит!) будет дан в разделах д) и е) этого
параграфа при описании задач, требующих
другого преобразования пространства рецепторов. Пока
же можно лишь сказать, что задачи узнавания разных
арифметических законов являются для этой программы
похожими и могут решаться иногда одним и тем же
преобразованием.
г) Классификация арифметических
законов. В этом опыте в машину при обучении были
введены шесть групп законов (табл. 5). Каждая
группа состояла из двух законов, похожих один на другой в
отношении применяющихся в них арифметических
действий. Таблицы, построенные по законам каждой
группы, занимали места, предназначенные для рабочей и
контрольной таблиц одного закона в предыдущих
сериях опытов. Поэтому программа при обучении
отбирала признаки, которые давали для законов одной группы
одинаковые характеристики.
ТАБЛИЦА 5
I
(А + В)АВ
АВ + А + В
п
(Я — А)АВ
А — АВ — В
ш
А + В
АВ
А
(Л + В)В
IV
А — В
АВ
В — 2А
А
V
А2В*
А*В2
VI
2Л + ЗЯ
ЗА + 2В\
На экзамене вводили 24 закона и программа
решала, на какую группу данный закон более всего похож.
Два первых места для законов, входящих в первый и
второй наборы, приведены в табл. 4 (римские цифры).
Читатель может сопоставить «мнение» программы с тем,
как бы он сам разбил эти арифметические законы по
группам табл. 5. В этом опыте программа произвела
классификацию уже не таблиц, а законов, по принципу,
заданному не строгим алгоритмом, а примерами.
д) Узнавание логических законов.
Описываемая программа предназначалась для узнавания
62
таблиц, построенных по арифметическим законам.
Однако могло случиться, что границы ее возможностей
окажутся шире, чем предполагали авторы. Поэтому
были поставлены опыты с узнаванием таблиц,
построенных не по арифметическим законам.
Примеры таких законов представлены на табл. 6 и 7.
ТАБЛ И ЦА 6 ТАБЛ И ЦА 7
А
2
7
-з
5
-А
в
3
—2
5
2
—3
с
1
0
0
1
0
А
2
7
—3
5
—1
в
3
—2
5
2
—3
с
0
1
0
1
1
Поскольку в этих таблицах С принимает только два
значения: 0 и 1, возникает мысль, что таблицы
построены по логическим законам. И действительно, легко
убедиться, что С в табл. 6 эквивалентно высказыванию:
«и А и В положительны». В табл. 7 С эквивалентно
высказыванию: «Л больше В». п
Подобные законы мы будем называть логическими.
Обучение производилось на таблицах, построенных по
четырем разным логическим законам. Для экзамена
были даны другие таблицы, построенные по тем же
четырем законам. Все четыре закона были узнаны
правильно (ti = 0).
Таким образом, во время обучения программа нашла
хорошее для данной задачи преобразование
пространства рецепторов. Но, может быть, для этой задачи
оказалось бы хорошим и преобразование, которое
вырабатывалось при обучении на арифметических законах?
Для проверки были отобраны признаки путем обучения
на девяти арифметических законах. Затем в машину
ввели четыре таблицы, построенные по логическим
законам, и программа присвоила им характеристики по
отобранным признакам (т. е. нашла «место»
логических законов в пространстве, хорошем для
арифметических законов). Для экзамена ввели другие таблицы,
построенные по логическим законам. Выбор среди
четырех логических законов дал результат: rj=l,0! После
63
обучения на арифметических законах программа
оказалась совершенно неспособной узнавать логические
законы.
Сравнение характеристик четырех логических
законов показало, что в пространстве, хорошем для
арифметических законов, все четыре логических закона
попали в одну и ту же точку. Какое уж тут
узнавание!
Итак, программе доступны и преобразование,
хорошее для арифметических законов, и преобразование,
хорошее для логических законов, но эти преобразования
разные. И если мы хотим, чтобы программа решала
ту и другую задачу, то нельзя ограничиться
каким-нибудь одним жестко закрепленным преобразованием и
искать только области, в которые проектируются те или
другие классы (когда мы так поступали с разными
наборами арифметических законов, это приводило к
хорошему результату). Нужно, чтобы программа при
решении разных групп задач пользовалась разными
отображениями пространства рецепторов в пространстве
характеристик по полезным признакам.
Любопытно отметить, что точка, в которую попали
все четыре логических закона в пространстве
«арифметических признаков», оказалась достаточно удаленной
от точек, в которые попали разные арифметические
законы. Поэтому при экзамене программа про все
логические законы «говорила», что они «не похожи» ни на
один арифметический, а «похожи» на логические (не
различая при этом их между собой).
В аналогичном положении оказывается, например,
европеец, когда он впервые сталкивается с
необходимостью различить в лицо несколько китайцев. Признаки,
отобравшиеся в мозгу европейца и весьма полезные для
различения лиц европейского склада, не дают
возможности хорошо различать между собой китайцев, хотя и
очень надежно отличают их от всех лиц европейцев.
Известно, что ситуация в мозгу китайца, не общавшегося
с европейцами, прямо обратная (в пространстве
характеристик по полезным признакам все лица европейцев
попадают в близкие точки). Не следует думать, что
наличие в мозгу человека того или другого отображения
определяется генетическими причинами. Китаец,
воспитанный в Европе, или европеец, выросший в Китае, пре*
64
красно узнают лица европейского или китайского
склада. Да и взрослый человек, попав в новое окружение,
через некоторое время «доучивается» (находит
дополнительные признаки).
е) Смешанные законы (ловушка для
программы). После сообщения об устройстве и
работе программы Арифметика некоторым слушателям
захотелось придумать задачу, которая оказалась бы
своеобразной «ловушкой» для программы. Ход
рассуждения был примерно таким: автор программы с самого
начала рассчитывал на то, что все строчки таблиц
одного класса построены по одному и тому же
арифметическому закону. Поэтому в качестве
характеристики таблицы в целом берется логическое
произведение характеристик отдельных строк. Вероятно,
программе будет трудно, если построить разные строчки
одной и той же таблицы по разным арифметическим
законам, в зависимости от некоторых дополнительных
логических условий. При этом с некоторой «достаточно
возвышенной» точки зрения вся таблица будет
построена по одному закону, но этот закон не будет сводиться
к не слишком сложной арифметической зависимости.
Примеры таблиц, построенных по таким
«смешанным» из логики и арифметики законам, приведены в
табл. 8 и 9. Строчки табл. 8 построены по закону:
С = Л+£, если А>0 и В>0; С = А—В, если Л>0 и В<0;
С = А:В, если Л<0 и В>0; С=ЛВ, если Л<0 и £<0.
Табл. 9 построена по другому закону такого же типа.
ТАБЛИЦА 8 ТАБЛИЦА9
А
2
7
-3
5
—2
в
3
—2
5
2
-3
с
—1
—3,5
—15
3
—5
А
2
7
—3
5
-2
в
3
—2
5
2
—3
с
5
9
-0,6
7
6
Обучение производилось по 10 смешанным законам.
При экзамене вводились 10 новых таблиц, построенных
по тем же законам. Все десять были узнаны правильно.
65
Таким образом, хотя разные строчки каждой таблицы и
строились по разным арифметическим законам,
логических возможностей программы хватило для того, чтобы
не попасться в ловушку.
Были проведены и опыты с узнаванием
арифметических и логических законов в пространстве
характеристик по признакам, отобранным при обучении на
смешанных законах. Результаты этих и аналогичных
опытов*) (например, описанных в п. д) этого параграфа)
сведены для наглядности в табл. 10.
ТАБЛИЦА 10
1 Отбор признаков ^"**ч,**х\^
Арифметические (9 зако-
Смелшшые (10 законов)
Логические (4 закона)
Арифметические
(9 законов)
у) = 0,00
г) = 0,06
Смешанные
1 (Ю закоаое)
Х\ » 0,20
т) = 0,00
Логические
(4 закона)
11 «1,00
П = 0,83
т) = 0,00
Видно, что смешанные законы оказались для данной
программы в каком-то смысле промежуточными между
арифметическими и логическими законами. При этом,
хотя они и «ближе» к арифметическим, чем логические,
но все-таки преобразование, наилучшее для
арифметических законов, далеко не является наилучшим для
смешанных, и наоборот.
§ 5. Особенности алгоритма
а) Части алгоритма экзамена. Мы все
время говорим, что после разных обучений (например,
после обучения на арифметических или на логических
законах) программа выбирает разные отображения
пространства рецепторов в пространство характеристик
по признакам. Программа выбирает разные 30-мерные
подпространства 5346-мерного пространства
характеристик по всем доступным для программы признакам.
Существует, однако, и другой — формально
законный— способ описания сущности процесса обучения.
*) В опытах, вошедших в табл. 10, использовались целые, но не
обязательно положительные числа А и В..
66
Можно говорить, что разделение классов всегда ведется
водном и том же 5346-мерном пространстве, а в
ходе обучения выбирается лишь способ разделения
классов. Заметим при этом, что если не наложено
никаких ограничений на допустимую сложность способа
разделения, то, последовательно продолжая эту линию,
мы можем перестать говорить и о жестком (не
зависящем от задачи) преобразовании пространства
рецепторов в 5346-мерное пространство характеристик по
признакам и все свести к нахождению способа разделения
в пространстве рецепторов. Однако, если мы хотим
описать программу на языке, позволяющем читателю
представить себе, что в ней делается и каковы черты ее
сходства и различия с другими программами, то такое
превращение алгоритма в «черный ящик» вряд ли про*
дуктивно. Поэтому мы и стараемся разбить алгоритм
отображения пространства рецепторов в множество
окончательных ответов программы при экзамене на не-*
сколько этапов, каждый из которых уже нетрудно себе
представить. Разбиение, естественно, является
условным, но после того, как оно принято, возникает
возможность сравнивать между собой соответствующие части
разных алгоритмов.
Мы будем считать, что окончательное разделение
классов всегда идет в некотором евклидовом
пространстве. Способы разделения: или разбиение пространства
на части*) плоскостями, или указание некоторых точек
(«центров классов») и выделения вокруг «центров
классов» некоторых окрестностей. Классификации подлежат
только точки, попадающие внутрь этих окрестностей,
остальные признаются не принадлежащими ни одному
классу**). Пространство, в котором идет разделение
классов, в соответствии с уже использованной
терминологией будет называться пространством полезных при*
знаков.
Отображение пространства рецепторов в
пространство полезных признаков имеет смысл в свою очередь
подразделить на части. Мы будем называть жесткой ту
*) По одной на класс.
«•*) В пространстве, состоящем из вершин многомерного куба,
второй способ эквивалентен проведению плоскости,
перпендикулярной к главной диагонали и отсекающей одну из вершин с
окрестностью.
67
часть преобразования, которая при экзамене
совершается всегда, независимо от задачи и конкретного хода
процесса обучения. По самому смыслу дела, алгоритм
жесткой части преобразования полностью задан
программистом, писавшим программу.
Назовем формируемой ту часть преобразования,
которая может и отсутствовать в алгоритме экзамена (при
обучении на некоторых других классах). Формируемая
часть преобразования всегда является подмножеством
некоторого множества возможных преобразований,
заданного программистом. Программа обучения
производит выбор этого подмножества, и результат выбора
зависит от конкретного материала обучения.
Формируемым является и способ разделения
классов в пространстве полезных признаков, так как в ходе
обучения находятся или параметры плоскостей,
осуществляющих разделение, или центры классов и радиусы
допустимых областей.
Хорошей иллюстрацией целесообразности
рассмотрения формирования преобразования пространства
рецепторов и формирования способа разделения классов как
независимых процессов служат опыты, описанные в
предыдущем параграфе в пунктах д) и е). В этих опытах
преобразование пространства рецепторов
формировалось во время обучения на законах одного типа
(например, арифметических), а формирование способа
разделения происходило во время обучения на законах
другого типа (например, смешанных). Посмотрим теперь,
на какие части распадается алгоритм экзамена в
программе Арифметика. Разделяющим правилом в этой
программе является нахождение расстояний от
отображения неизвестной таблицы в пространстве полезных
признаков. Выбор минимума из этих расстояний
эквивалентен первому способу разделения классов. Если
относить объект к некоторому классу только в том
случае, когда расстояние до центра этого класса меньше
некоторой наперед заданной константы, то это
соответствует второму способу разделения классов.
Пространство полезных признаков, в котором
реально работает любое из этих решающих правил, —
30-мерное. Поскольку при решении разных задач используется
разный набор полезных признаков, отображение
пространства рецепторов не является целиком жестким, а
68
содержит и формируемую часть. В Арифметике жестким
являются отображения строчек таблицы с помощью
арифметических функций ft и затем логических
операторов Lj. Если таблица имеет / строчек (К^<8), то она
жестко отображается в 33/-мерное пространство.
Нахождение 30 логических функций от координат таблицы
в этом 33/-мерном пространстве является уже
формируемой операцией.
Для сравнения рассмотрим по этой же схеме
структуру алгоритмов экзамена в упомянутой ранее
программе Бравермана и в перцептроне.
В программе Бравермана разделяющее правило —
первого типа (набор плоскостей). Разделяющее
правило (как и во всех обучаемых программах) формируется
при обучении. Пространство полезных признаков
совпадает с пространством рецепторов. Таким образом,
в этой программе нет ни жесткого, ни формируемого
преобразования пространства рецепторов.
В перцептроне разделение классов происходит с
помощью одной плоскости в Л-пространстве. Отсюда
пространство полезных признаков совпадает с Л-простран-
ством. Преобразование пространства рецепторов в
пространство полезных признаков (Л-пространство) —
жесткое. Формируется при обучении в перцептроне
только разделяющее правило (параметры делящей
плоскости).
Вернемся теперь к вопросу о том, нельзя ли описать
работу Арифметики во время экзамена, не прибегая к
понятию «формируемое преобразование пространства
рецепторов». В реально сделанной программе, как мы
видели, это не удается. Поэтому попробуем «дополнить»
программу некоторыми операциями с тем, чтобы
дополненная программа оказалась с жестким
преобразованием. Пусть дополненная программа при экзамене
отображает пространство рецепторов не в 30-мерное, а
в полное 5346-мерное пространство всех возможных
признаков (это отображение будет жестким).
Легко сообразить, что в дополненном пространстве
невозможно найти хорошо работающее разделяющее
правило. Дело в том, что добавление новых
координат— операция, влияющая на расстояние между
точками. Точки, находившиеся в 30-мерном пространстве в
69
близкой окрестности центра класса, в расширенном
пространстве окажутся (наверняка, если учесть число
добавленных измерений) весьма далекими друг от друга.
В расширенном пространстве характерной величиной
расстояния в смысле Хемминга будет величина
порядка 2500. При этом лишь часть этой величины, поряди
ка 100 *), будет зависеть от существа дела
(принадлежности к тому или иному классу), а остальное —от
случайных для данной задачи обстоятельств.
Заметим, что расширение пространства с 30 до 5346
измерений (хотя и не решившее, по существу, задачу
построения жесткого преобразования) оказалось
возможным благодаря тому, что любой из 5346 признаков
может быть применен к любой таблице. Существуют,
однако, признаки, которые принципиально применимы
не для всех объектов. Для числовых таблиц этим
свойством обладает, например, такой признак: «А больше,
чем общее наименьшее кратное В и С>. Признак
неприменим для таблиц, содержащих среди В или С хотя бы
одно дробное число (напомним, что неприменимость не
значит, что признак присваивает характеристику 0, а
означает, что он не может присвоить никакой
характеристики).
В дальнейшем мы будем рассматривать такие
программы, в арсенале которых будут признаки, применимые
не ко всем объектам. После обучения будет отбираться
преобразование пространства рецепторов в
пространство признаков, применимое для объектов
данной задачи. Для тех программ вообще будет
невозможным рассматривать «расширенное» пространство всех
возможных признаков, так как оно не является
пространством, в которое отображаются хоть какие-нибудь
объекты.
б) Объем памяти, занятый после обуче-
н и я. Часто приходится слышать, что создание
«думающих машин» тормозится малым объемом памяти
современных электронных машин. Посмотрим, каков объем
информации, занесенной в память машины в ходе
обучения.
*) Учитывая неоднозначность выбора полезных признаков для
данной задачи.
70
По своему характеру эта информация делится на
две совершенно разные группы. Первая — это
информация о том, какие признаки оказались полезными. Во
время экзамена эта информация разворачивается в
программу отображения пространства рецепторов в
пространство полезных признаков.
Вторую группу составляет информация о
положении центров классе© в пространстве полезных
признаков. При экзамене она используется для нахождения
близости неизвестного объекта к тому или другому
классу.
При обучении отбирается до 30 признаков.
Информация о структуре одного признака с запасом
укладывается в 16 разрядов. Таким образом, все сведения о
преобразовании пространства рецепторов можно
уместить в 15 ячеек машины. (Фактически ради удобства
обращения они занимают 30 ячеек). Этот объем мало
зависит от числа классов (при увеличении числа
классов он будет расти по примерно логарифмическому
закону).
Координаты центра класса в пространстве полезных
признаков занимают 30 разрядов*).
Объем памяти, занятый информацией второй грувпы,
должен быть примерно пропорционален числу классов
(в действительности он растет несколько быстрее из-за
увеличения числа полезных признаков).
Сравним объем памяти, приходящийся на один класс
после обучения, и объем, необходимый для записи
самих таблиц.
На каждый из 24 классов таблиц приходится после
обучения по 50 разрядов (30—координаты центра и
20 — доля одного класса в 480 разрядах, занятых под
запись полезных признаков).
Обучение происходило на двух таблицах каждого
класса (хотя, судя по результатам, было бы не вредно
«выжимать информацию» из трех — пяти таблиц). Это
составляет 48 (3X8X2) разных чисел на класс.
Фактически каждое число записывалось в отдельную ячейку
(33 разряда), однако в принципе его с достаточной для
*) В одном разряде ячейки памяти может быть записана одна
двоичная цифра, т. е. нуль либо единица. Поэтому один занятый
разряд соответствует количеству информации в один бит (см.
примечание на стр. 38).
71
этой задачи точностью можно записать в 17 разрядов.
(Дальнейшее уменьшение точности может привести к
признанию программой некоторых дробных чисел
целыми.) Таким образом, для записи таблиц,
относящихся к одному классу, необходимо 17X48^800
разрядов.
Итак, результат обучения занимает в 16 раз меньше
места в памяти, чем исходный материал*). После
обучения «пропала» большая часть информации о
таблицах.
Например, пропала информация о порядке строчек
в таблице. Пропала информация о различии двух
таблиц одного класса и т. д. Зато, судя по качеству
экзамена, сохранилась информация о принадлежности
таблицы к тому или другому классу.
Мы уже говорили, что основная задача узнающей
системы — перестать обращать внимание на
несущественные для данной задачи обстоятельства. При
рациональном способе записи это должно привести
к малому объему памяти, занятой после обучения.
в) Описание классов. Набор характеристик
класса по всем признакам можно рассматривать как
описание этого класса на некотором языке. Как мы
видим, описания получаются короткими. Происходит
это за счет подбора программой специального языка
(из множества доступных для нее языков), удобного
для данного набора классов. При этом, например,
получилось, что язык, подобранный для шести
арифметических законов, оказался удобным для очень многих
арифметических законов. (Описания их на этом языке,
естественно, были разными.) Для логических же
законов этот язык оказался неподходящим: логические
законы можно описать на этом языке, но описания
получаются одинаковыми.
Поясним ситуацию примером. Пусть для
различения между собой слонов, жирафов, кошек, зайцев и
гусей используются описания, элементами которых
являются следующие высказывания (или их отрицания):
вес больше 30 кг, длина шеи больше 50% длины
туловища, длина хвоста больше 20% длины туловища.
*) Сравни с аналогичным подсчетом для перцептрона (сноска
на стр. 38).
72
На этом языке все перечисленные животные будут
иметь разные описания. Попробуем использовать этот
же язык для того, чтобы отличить друг от друга
тигров, львов и пантер. Каждого из этих животных можно
описать на этом языке, но все они будут описаны
одинаково, как тяжелые, длиннохвостые, и короткошеие
животные.
Таким образом, языки, отбираемые программой для
арифметических и логических законов, хоть и неудобны
для другого типа законов (не разделяют классов), но в
принципе применимы для всех объектов (таблиц).
Это является серьезным недостатком программы. В
самом деле, задачу обучения можно сформулировать как
задачу составления таких описаний материала, которые,
с одной стороны, являются короткими, а с другой — еще
сохраняют возможность различения классов. Требование
краткости описания равносильно требованию отсутствия
в описании сведений об индивидуальных различиях
объектов внутри классов. А это и дает возможность
при экзамене экстраполировать описание на новые
объекты. Длинное описание материала получить легко.
Можно, например, взять логическую сумму
(дизъюнкцию) подробных описаний всех объектов (из
материала обучения), входящих в данный класс. Именно
так поступают программы, запоминающие материал
обучения. При этом теряется возможность
экстраполяции, а значит, возможность узнавать объекты, не
входящие в материал обучения.
Итак, чем описания класса короче (при сохранении
различий между классами), тем большая степень
абстракции достигнута, тем меньше в описании
сохранилось информации о случайных свойствах материала
обучения.
Посмотрим теперь, какие языки дают возможность
получать короткие описания. Мы постоянно пользуемся
специализированными языками, пригодными
только для сравнительно узкой области явлений,, но
зато позволяющими получать короткие описания объектов
внутри этой области. Язык, который применяется для
списания хода судебного заседания, принципиально
неприменим, например, для описания работы паровой
машины (и наоборот, разумеется). Невозможно применить
понятия «защитник», «состав преступления», «приго-
73
вор», «сильный аргумент» и т. п. к паровой машине.
Точно так же не описать смысл дела, слушавшегося в
суде, применяя понятия «поршень», «отсечка пара» или
«шатун». Существует ли единый язык, на котором
можно описать оба круга явлений? Вероятно, да, но он
настолько далек от наших обычных представлений о
рациональном языке, что его трудно даже вообразить*).
Может быть, описание на таком универсальном языке
будет содержать сведения о координатах всех
элементарных частиц, входящих в систему (судили паровая
машина), за все рассматриваемое время. Описания
получатся длинными. Кроме того, попробуйте с помощью
такого описания отличить судебный процесс, на котором
обвиняемого оправдали, от процесса, на котором его
осудили! За возможность (лишь принципиальную!)
использовать этот же язык для того, чтобы отличить
дизель от паровой машины, мы расплачиваемся
(реальной!) утратой возможности отличить виновного от
невиновного.
Итак, короткие описания мы получаем благодаря
использованию специализированных языков,
принципиально непригодных для более широкого
круга вопросов. Недаром все специальные области знаний
порождают свои жаргоны, приводящие в ужас
филологов, так как жаргонные выражения затем неизбежно
«расползаются» вне той области, где они возникли.
В главе IX мы будем рассматривать алгоритм,
который строит для одних задач язык, неприменимый к
объектам, входящим в другие задачи, и за счет этого
достигает еще более короткого описания классов. Здесь
же мы отмечаем отсутствие этого свойства как
недостаток программы Арифметика.
г) Перебор при обучении. При обучении
программа выбирает 30-мерное подпространство 5346-
мерного пространства. Вообще говоря, такой выбор
можно сделать С5346 ~ 1080 способами. Даже если
учесть, что «хорошее» подпространство отнюдь не
единственное (например, «хороших» 1070 штук), то все
равно нет никакой надежды наткнуться на него путем
перебора разных подпространств.
*) Напомним, что описанием мы называем набор характеристик
по всем признакам, входящим в данный язык.
74
Положение спасает то обстоятельство, что можно
подвергать проверке не подпространство в целом, а
порознь его координаты (Эшби назвал это «отбор по
компонентам» *).
Соответствующие 5346 проверок программа делает
всегда, независимо от того, какие таблицы даны для
обучения. Поэтому имеет смысл говорить, что
программа обучения (в отличие от экзамена) является жесткой.
Это — недостаток программы, приводящий к
увеличению времени обучения.
Некоторого сокращения времени работы программы
обучения удается достигнуть и благодаря тому, что
выбор пространства полезных признаков (наиболее
трудоемкая часть работы) можно проводить на малом
количестве классов, а потом находить в этом пространстве
центры многих классов.
д) Структура признаков. В программе
Арифметика все разнообразие признаков получается в виде
комбинаций очень небольшого числа алгоритмов. Они
работают последовательно и делятся на три группы.
Первая — арифметические функции U — их всего 12—16
(в разных вариантах), вторая — логические операторы
Lj — их всего 3, третья — логические функции Fm — их
10. Это дает возможность хранить в памяти малое
количество (~30) весьма простых алгоритмов.
Хотя «кирпичи», из которых складываются признаки,
и очень простые, выбраны они совсем не случайно. Этим
программа Арифметика также отличается от перцептро-
на. Программа учится на таблицах, но начинает это
делать от довольно высокого уровня организации**).
е) Гибкость программы. Может возникнуть
вопрос о степени критичности набора арифметических
функций и логических операторов в программе
Арифметика. Не в том ли причина успеха, что авторам
посчастливилось найти именно те 33 комбинации, которые
только и могут обеспечить хорошую работу системы?
*) Такое сокращение перебора в принципе не всегда возможно,
так как может и не существовать критерия качества для отдельных
координат.
**) Мы не согласны с точкой зрения, согласно которой перцеп-
троны не имеют начальной организации. Просто она низка и
несколько замаскирована выбором связей с помощью случайного
процесса.
75
Для проверки была произведена замена 20 комбинаций
(из 33) на другие. После обучения на арифметических
законах программа узнавала их не хуже, чем при
старом наборе.
Был произведен также опыт с уменьшением
доступного программе числа логических операторов. Вместо
трех их оставляли только два. И в этом случае не
получилось сколько-нибудь существенного ухудшения
результатов экзамена.
Любопытно было наблюдать поведение программы
при слегка неисправной машине. Если неисправность не
приводила к полной остановке машины, а влекла
только ошибки в счете, то при повторных обучениях на
одном и том же материале отбирались разные*)
полезные признаки. При экзамене по любому из таких
наборов полезных признаков узнавание было
по-прежнему хорошим. Внешне не создавалось впечатления, что
машина неисправна. Скорее, это выглядело как
наличие у машины «свободы воли» или «фантазии», не
мешающей достижению цели, но делающей путь к ней
неоднозначным.
*) Проверка «новизны сечения», даваемого кандидатом в
полезные признаки, приводит к тому, что одиночные сбои счета (пропуск
признака или отбор одного лишнего) вызывают заметное изменение
всего комплекта признаков, отобранных после сбоя.
Глава IV
УЗНАВАНИЕ И ИМИТАЦИЯ
§ 1. Описание узнающей системы
в терминах теории автоматов
«Как, еще один способ описания узнающей
системы!» — может воскликнуть здесь читатель. — «Мало
было автору объяснить одно и то же сначала в
терминах отображения пространства рецепторов в
пространство полезных признаков, затем в терминах описания
классов на некотором языке. Теперь ему понадобились
и автоматы!».
Дело в том, что разные стороны работы узнающих
систем легче (короче) описываются на разных языках.
Перевод с одного языка на другой очень нетруден,
поэтому мы и в дальнейшем будем в разных местах
пользоваться разными способами описания.
Сейчас нам будет удобно рассматривать
обучающуюся узнающую систему как автомат, распадающийся
на две части (рис. 10).
Часть К является автоматом со многими
состояниями. Выбор состояния производится «нажимом кнопки».
Разные кнопки условно обозначены стрелками в верхней
части блока К. В каждом состоянии (после «нажима
одной из кнопок») автомат К осуществляет
классификацию объектов по некоторому жесткому алгоритму.
Каждый объект, попавший на вход К, будет отнесен или к
первому классу, или ко второму классу, или ни к тому,
ни к другому («мусор»).
Обучение состоит в выборе состояния К («кнопки, на
которую надо нажать»). Этот выбор производит блок L
на основе изучения материала обучения. Во время
экзамена работает только блок /С.
Разделение узнающей системы на блоки К и L
является в значительной степени условным. Например, в
77
большинстве реальных обучаемых систем блок L
содержит в качестве своей части почти точную копию блока
К (для проверки на материале обучения результата
«нажатия» той или иной «кнопки»). Нас, однако, сейчас не
интересует, как устроены блоки.
Итак, на входе блока L — набор объектов, о
каждом из которых сказано, к какому классу он принадле-*
жит. Можно также считать, что для каждого класса есть
1нлабС |
Материал обучения
Л масс
Материал энзамена
L
Выбор состояния
±J
' '
| '
' i
! ?
Н
1 Ifi/iacc
\Днласс
т
<< Мусор £»
Рис. 10. Схема обучаемой узнающей
системы. Блок К осуществляет
классификацию. Блок L выбирает состояние
блока К.
свой вход. На выходе блока L — выбор одного из
состояний блока /С.
На входе К — последовательность объектов, о кото-»
рых не сказано, к какому классу они принадлежат.
На выходе — высказывания о принадлежности объектов
к какому-нибудь классу (или к «мусору»).
§ 2. Возможные причины плохой работы
узнающей системы
Пусть мы имеем большое количество объектов двух
классов. Подадим часть из них на входы блока L
(рис. 10). В результате будет нажата одна из кнопок
блока /С. После этого подадим оставшиеся (не
участвовавшие в обучении) объекты на вход блока К- Каждый
из них будет отнесен к какому-то классу. Допустим, что
система делает при этом много ошибок. В принципе это
может происходить по двум разным причинам.
78
Во-первых, может оказаться, что блок К вообще яе
имеет состояния, нужного для решения данной задачи.
Какую бы кнопку мы ни нажали, разбиение объектов,
производимое блоком /С, не будет совпадать с
классификацией, заданной по условию.
Во-вторых, может быть положение, когда нужное
состояние существует, но блок L не сумел его найти.
То, что система может иметь слишком бедный для
данной задачи набор состояний, довольно очевидно.
Например, если система имеет только три состояния — в
одном отделяет большие фигуры от маленьких, в другом
отделяет фигуры, находящиеся в левой половине кадра
от находящихся в правой половине, и в третьем —
выпуклые фигуры от вогнутых, то она никогда не научится
отличать окружности от треугольников. И никакое
усовершенствование блока L (процесса обучения) в этом
случае не поможет.
Более неожиданным для читателя будет, вероятно,
тот факт, что человек является примером системы,
обладающей недостатком второго рода. С помощью какого
опыта можно обнаружить ограниченность возможностей
«блока L» у человека? (Разумеется, может идти речь
только об ограниченности «блока L» по сравнению с
«блоком К».)
Посмотрите на рис. 11. На левой половине рисунка
показано пять картинок, принадлежащих I классу.
(Объектом является набор фигурок, заключенный в прямо*
угольную рамку.) На правой половине — картинки,
относящиеся ко II классу. Попробуйте, глядя на эти
примеры, найти принцип, на основании которого при
экзамене Вы могли бы узнавать новые объекты. Пожалуйста,
не читайте дальше, пока не найдете принципа
классификации (Ваш «блок К» перейдет в нужное
состояние) или не убедитесь, что за такое-то время (3—5 мин)
«блок L» не нашел нужного состояния.
Большинству людей не удается за 10 мин решить эту
задачу. Заметим, что дело не в малом числе примеров,
которое дано для обучения. Если бы дело было в этом,
то Вы обнаружили бы несколько признаков, по
которым можно отделить все картинки первого класса на
рис. 11 от всех картинок второго класса. («Блок L»
нашел бы несколько разных состояний.) Вы же, вероятно,
не нашли ни одного подходящего состояния «блока /С».
79
Рис. 11.
I класс
Дкласс
Увеличение материала обучения вряд ли упростило бы
задачу.
Человеку обычно просто не приходит в голову, что
нужно проверить признак «разность числа всех углов и
числа всех фигур на картинке». Характеристика всех
картинок I класса по этому признаку равна 6, а
картинок II класса — 7.
Смело можно утверждать, что мозг любого человека,
дочитавшего книгу до начала этой главы, имел
состояние, нужное для решения задачи. Но иметь нужное
состояние и уметь найти его — разные вещи.
Для тех изобретательных и находчивых людей,
которые решили задачу, данную на рис. 11, предложим еще
одну (см. рис. 12).
Вряд ли Вам удалось обнаружить, что к первому
классу принадлежат картинки, на которых или три глав-
ные диагонали шестиугольника пересекаются в одной
точке и имеется четное число окружностей, или
диагонали не пересекаются в одной точке и имеется нечетное
число окружностей, а ко второму классу принадлежат
картинки с остальными двумя сочетаниями этих
параметров. Прочитав выделенные в предыдущей фразе
слова, Вы без особого труда сможете узнавать
экзаменационные картинки и тем докажете существование
необходимого для этого состояния Вашего мозга. Но
перевести мозг в это состояние удалось выделенной
фразой и не удалось показом рис. 12.
Конечно, рассматривать мозг человека, как автомат,
распадающийся на блоки L и /С, можно только очень
условно. В действительности, например, после решения
некоторой задачи и «блок L» и «блок К» человека
устроены уже несколько иначе, чем до решения этой
задачи. Примеры, которые приводились, имели целью
лишь показать, что в каждый момент не все
состояния «блока К» могут быть достигнуты путем показа
объектов из материала обучения.
Итак, человек оказался примером системы, у
которой не все возможные состояния достижимы путем
обучения (напомним, что обучением мы называем только
процесс показа некоторого числа объектов и выбор на
основе этого показа состояния блока /С). А
может ли существовать система, у которой все
возможные состояния блока К могут быть достигнуты путем
81
о
о
о
'класс
°о
О
о
о
Пнласс
Рис. 12.
обучения и все-таки она никогда не может научиться
правильно узнавать, даже в тех случаях, когда имеется
необходимое для данной задачи состояние?
Приведем пример такой системы. Объектами для нее
будут служить черно-белые картинки на растре 10X10
82
(рис. 13,а). Будем считать все точки растра
занумерованными (рис. 13,6). Блок К системы имеет 100 со-»
стояний. В состоянии i он относит к I классу все
картинки, имеющие не менее 51 черной точки, у которых точка
с номером i — черная, ко второму классу все картинки,
имеющие не менее 51 черной точки, у которых точка с
номером i — белая, и сваливает в «мусор» все картинки,
имеющие менее 51 черной точки. Будем называть 1-й
/
//
2
12
3
13
4
5
Б
7
8
38
9
...
S9
Ю\
20\
Ш
о)
6)
Рис. 13.
задачей набор картинок, разбитый на классы так, что
они будут правильно узнаваться блоком К в t'-м
состоянии.
Пусть блок L имеет следующий алгоритм работы:
берется первая картинка первого класса из материала
обучения и накладывается на первую картинку второго
класса. На растре оставляются только те черные
точки, которые были черными на обеих картинках (логичен
ское произведение картинок). Затем на этот же растр
накладывается логическое произведение вторых
картинок из материала обучения и снова берется логическое
произведение и т. д. На каждом шагу число черных
точек может только уменьшиться. Ищется номер
последней оставшейся черной точки (если в некоторый момент
исчезло сразу несколько черных точек и образовался
пустой растр, то берется наименьший из номеров этих
последних точек). Блок К переводится в состояние с
номером, равным номеру последней оставшейся точки.
83
Во-первых, покажем, что блок L никогда не
находит нужного состояния. Для этого заметим, что
после обработки первой пары картинок (по одной из
каждого класса) на растре обязательно останется хоть
одна черная точка (из-за того, что каждая картинка
имела не менее 51 черной точки). С другой стороны,
если обучение ведется на примерах t'-й задачи, то после
первого шага /-я точка обязательно будет белой, так как
любая картинка II класса имеет t-ю точку белой. Таким
образом, последняя оставшаяся точка будет заведомо
иметь номер не i, поэтому после обучения на материале
/-й задачи система не может перейти в i-e состояние.
Покажем теперь, что соответствующим подбором
материала обучения i-и задачи можно, обучая систему,
перевести ее в любое состояние /, если только ]Ф1.
Включим в материал обучения (в обоих классах) только те
картинки, у которых /-я точка — черная. (Таких
картинок в каждом классе не меньше половины.) Возьмем
для обучения набор, имеющий не менее 1 белой точки
на всех полях, кроме /-го. Это всегда возможно,
независимо от номера задачи. После пересечения картинок
этого материала обучения останется только одна черная
точка на /-м месте, и система перейдет в /-е состояние.
Таким образом, как и следовало ожидать,
достижимость любого состояния в ходе обучения еще не
гарантирует хорошей работы системы. Заметим, что описанная
предельно «глупая» система переходит в оптимальную
(для всех 100 задач, для которых имеется
соответствующее состояние блока К) после небольшого
изменения алгоритма работы блока L. Пусть блок L на
каждом шагу обучения для образования логического
произведения берет картинку первого класса и «негатив»
картинки второго класса. В остальном алгоритм
остается прежним. Легко видеть, что теперь система всегда
правильно обучается и притом на минимальном
материале обучения, достаточном для однозначного выбора
состояния блока /С
§ 3. Поиск причины плохой работы узнающей системы
Пусть мы имеем обучающуюся систему, которая
плохо решает некоторый круг задач. Конструктора,
желающего улучшить работу этой системы, в первую очередь
84
заинтересует причина ошибок на экзамене. В том ли дело,
что блок К не имеет нужного состояния, или в том, что
блок L не находит этого состояния, хотя оно, может быть,
и имеется.
Вопрос этот решается просто (и практически вообще
не возникает), если система настолько примитивна, что
есть возможность теоретически предсказать работу
блока К во всех возможных состояниях и работу блока L
при достаточно разнообразном обучении. К сожалению,
такой аналитический подход неприменим ко многим,
даже не очень сложным системам. Допустим, оказалось
(в действительности такие опыты не делались), что
программа Арифметика не может научиться узнавать
таблицы, построенные по законам, являющимся
логическими функциями от арифметических законов.
Предполагается, что до этого опыта мы никаких других опытов
с программой Арифметика не делали. Вряд ли
кто-нибудь, зная и алгоритм обучения и алгоритм экзамена,
взялся бы ответить на вопрос: в чем причина плохого
узнавания*). А ведь программа Арифметика далеко не
самая сложная из тех, с которыми приходится уже сей-*
час иметь дело.
Попытаемся поэтому найти такой способ
экспериментирования с блоками К и L, чтобы по
результатам этих экспериментов можно было ответить на
вопрос о причине плохой работы не зная структуры
самих блоков (относясь к ним, как к «черным ящикам»).
Допустим, перед нами второй, «умный» вариант
системы, рассмотренной в предыдущем параграфе. Нам ничего
не сказали обустройстве блока К (какиеон имеет
состояния) и блока L (умеет ли он находить нужное состояние,
если оно есть). Попытка научить эту систему отличать
вертикальные линии (белые на черном фоне) от
горизонтальных приводит к неудаче. Как выяснить (не залезая
внутрь блоков К и L), какой блок в этом виноват?
*) Число возможных состояний блока К при различении
24 классов равно Cfjj^ • (230)24 > 10290. Поэтому для выяснения,
например, вопроса о качестве блока К нужно или доказать теорему
об отсутствии нужного для данной задачи состояния, или вручную
найти подходящее состояние. Доказать перебором отсутствие
нужного состояния невозможно, даже если учесть, что многие из этих
состояний — «близкие» между собой. Что означает термин «близость
состояний», будет сказано дальше.
85
Возьмем блок К, являющийся точной копией блока К
исследуемой системы. Переведем его в какое-нибудь с<>
стояние (нажмем одну из кнопок). После этого блок К
превратится в автомат, производящий жесткую
классификацию. Будем подавать на его вход
последовательность случайных картинок*) (рис. 14). Часть картинок
Генератор
случайных
шртинон
Hill
F
i / -
1 /нласс
Дпласс
1
<< Мусор $>
Рис. 14. Система, генерирующая
задачи, для которых блок К
узнающей системы заведомо имеет
нужные состояния
попадет в «мусор» (независимо от того, какая кнопка
нажата, это будут картинки, имеющие менее 51 черной
Генератор
случайных
нортинон
ММ
\/*ЛОСС / Г
X
\ \
^
<< Мусор i>
обучение
энзамеа
L
Т. м'
\ \
к
| 1/1ЛОСС
1 Запасе^
<< Мусор *>
Рис. 15. Схема проверки работы блока L.
точки), а остальные будут разбиты на два класса.
Теперь мы можем использовать одну часть
расклассифицированных картинок для подачи на блок L при обучении,
а другую часть — для экзамена (рис. 15). После
обучения блок L переведет подчиненный ему блок К в какое-
то состояние. При экзамене мы заметим, что
классификация, производимая блоком /С, совпадает с той,
которую делает блок К.
*) Случайные картинки можно получать, например,
последовательно решая с помощью бросания монеты, черной или белой
должна быть первая точка, вторая точка и т. д.
86
Другими словами, на экзамене ошибок не будет.
Повторим тот же опыт, «нажав другую кнопку» автомата
К. Снова после обучения система будет хорошо
узнавать при экзамене.
В этих экспериментах проверяется работа только
блока L. Действительно, способ, которым мы первона*
чально разбиваем картинки на классы (с помощью К%
являющегося копией блока /С), гарантирует, что у К
есть нужное состояние. Поэтому за неудачу обучения
всегда будет ответствен блок L и, наоборот, достаточно
большое количество удачных опытов при
разнообразных состояниях блока К будет свидетельствовать, что
блок L «не так уж плохо» устроен *).
В примере, который мы рассматриваем, все опыты
дадут хорошее узнавание. На основании этого мы
придем к выводу, что блок L умеет находить нужное
состояние, если только оно существует. В то же время система
в целом не может научиться отличать горизонтальные
линии от вертикальных. Значит, блок К не имеет
необходимого для этого состояния.
Если бы такому же испытанию был подвергнут
первый («глупый») вариант системы, описанной в
предыдущем параграфе, то опыты с узнаванием картинок,
разделенных на классы блоком К, показали бы неумение
блока L находить нужные состояния (даже когда они
есть). В этом случае вопрос о наличии состояний,
необходимых для отделения вертикальных линий от
горизонтальных, остался бы открытым.
Итак, опыты по схеме рис. 15 позволяют
«локализовать дефект» в одном из блоков. Если «дефектны» оба
блока, то обнаруживается плохая работа блока L.
§ 4. Общая постановка задачи узнавания. Имитация
Мы неоднократно говорили: «Такая-то система
научилась решать такую-то задачу и не научилась решать
такую-то». (Например, перцептрон научился различать
*) Конечно, никакое число опытов, если не перепробованы все
состояния /(, не может гарантировать хорошей работы блока L при
решении новой задачи. Однако мы, естественно, будем возлагать на
него разные надежды в случае, когда он хорошо сработал в 50 из
50 опытов, которые производились при случайно выбранных
состояниях блока /С, и в случае, когда при этих же условиях система
обучилась только 1 раз из 50.
67
между собой прямоугольники, вытянутые в
горизонтальном и вертикальном направлениях, и не научился
отличать прямоугольники от эллипсов.) Эти слова заменяли,
по существу, утверждение, что в одном случае на
экзамене было мало ошибок, а в другом — много. Однако
говорить о числе ошибок системы бессмысленно до тех
пор, пока не указаны способ отбора объектов для
экзамена и алгоритм проверки истинности (или
ошибочности) классификации, которую производит система при
Рис. 16.
экзамене. Кто тот верховный судья, который решает,
ошиблась машина или правильно определила класс?
«Казуистика!» — воскликнет на этом месте
читатель. — «Сколько систем и задач уже рассмотрели, и
ни разу не возникало спорных вопросов, для решения
которых понадобился бы судья. Уж если программа
Арифметика напечатала на первом месте номер того
арифметического закона, по которому в
действительности построена таблица, то какой может быть спор!»
И все-таки вопрос о судье не праздный. И если до
сих пор он не возникал в явной форме, то лишь потому,
что во всех предыдущих примерах нам удавалось
(возможно, не для всех читателей) сделать алгоритм
проверки качества экзамена само собой очевидным.
I класс
88
Л класс
Теперь приведем пример, когда очевидным является
отсутствие такой очевидности. Пусть некоторая система
обучалась на фигурах, показанных на рис. 16. Затем ей
дали на экзамене фигуру, изображенную на рис. 17.
Какой ответ системы следует
признать правильным? Возможны три
точки зрения. Согласно одной,
верным надо считать ответ, что
экзаменационная фигура принадлежит
I классу (как большая). Вторая
точка зрения заключается в том, что
правильно было бы отнести ее ко
второму классу (как эллипс).
Наконец, не менее законным будет и
мнение о том, что экзаменационную
фигуру нужно отправить «в мусор». Доказать истинность
любой из этих позиций, естественно, невозможно. Итак,
что бы ни сделала узнающая система, без «верховного
судьи» не обойтись. По существу, трудность вызвал
вопрос: «что значит узнать объект, которого не было в
Рис. 17.
^пласс ч\
« Мусор »
Рис. 18. Схема общей постановки задачи узнавания.
i Узнающая
| система
I \ 1
«•' i i
.-/ ; '1
V | 1
L
| 1/
Y Т
У
К
L
'
| \ 1ллосе
1 \Енласс
материале обучения?» Ответ на него будет содержаться
в формальной схеме процесса узнавания, к которой мы
переходим.
Имеется конечное множество объектов M = {rrii}.
Блок Ki (рис. 18) имеет Ni состояний. Блок S имеет
столько же состояний, причем они находятся во
взаимно однозначном соответствии с состояниями блока Ки
В дальнейшем мы будем считать, что номера соответ-
89
ствеиных состояний блоков S и К\ совпадают.
Находясь в состоянии /, блок S на каждом такте работы
осуществляет выбор одного объекта из М с
распределением вероятностей pj{nii); pj(m2)\ ...; pj(nii); ...
г
»..,Pj(/wr), причем *2i р)(т1)=\* Выбранный объект
блок S подает на вход бло^а Ки В каждом состоянии
автомат /G относит любой попадающий к нему на вход
объект к одному из двух классов или ни к какому
классу («мусор»).
Мы будем называть систему, состоящую из М и
блоков S и Ки находящихся в зафиксированном состоянии,
задачей. Та же система без указания состояния блоков
S и /Ci будет называться совокупностью задач.
На выходе каждой задачи — некоторое
подмножество множества М, разбитое на классы. Нумерация
задач будет совпадать с нумерацией состояний блоков /Ci
и S. Узнающая система, как и раньше, состоит из
блока К (отнюдь не обязательно являющегося копией
блока /Ci!) — автомата, имеющего jV состояний, и блока L,
производящего выбор состояния на основании изучения
материала обучения.
Мы будем говорить, что блок К в состоянии / слабо
имитирует блок /Ci в состоянии /, если эти блоки в
упомянутых состояниях производят одинаковую
классификацию всех объектов из М9 кроме тех, которые отнесены
блоком Ki в состоянии / в разряд «мусора» *).
В случае, если блоки производят одинаковую
классификацию всех объектов из М, будем говорить, что блок К в
состоянии / сильно имитирует блок К± в состоянии /.
Приведенные определения требуют полной имитации
в 100% случаев. Совершенно аналогично можно
говорить о сильной или слабой имитации блоком К в
состоянии i блоков S и /Ci в состоянии / с точностью 1-е,
если соответствующие классификации расходятся с
вероятностью 8 **).
*) Для определенности будем считать, что все объекты, которые
блок S в состоянии / выбирает с нулевой вероятностью, блок К\ в
состоянии / относит в «мусор».
**) Надо иметь в виду, что совпадение или расхождение
классификаций есть не число, а событие. Для каждого объекта
классификации могут или совпадать, или расходиться. Число е относится
к вероятности расхождения по всему множеству объектов.
90
Введем также понятие расстояния между
состояниями н и k блока /(. Назовем расстоянием между этими
состояниями относительно задачи /
вероятность расхождения классификаций выходного материала
задачи / блоком К в состоянии i\ и в состоянии /2.
В дальнейшем, когда будет упоминаться близость
между собой каких-нибудь состояний узнающей системы,
следует понимать ее как малость расстояния между
ними*). Легко показать, что если расстояние ме&ду
состояниями i'i и k блока К относительно задачи /
равно а и блок К в состоянии А слабо имитирует блоки S
и /d в состоянии / с точностью х, то блок К в
состоянии i2 слабо имитирует блоки S и Ки в состоянии / с
точностью, не меньшей к—а и не большей к + а. Это
значит, что близкие состояния мало отличаются
точностью имитации.
Будем говорить, что узнающая система научилась
решать задачу / (или решать ее с точностью и), если
блок К перешел в состояние, в котором он слабо
имитирует блок /Ci в состоянии / (или слабо имитирует с
точностью х блоки S и К\ в состоянии /) **).
Назовем способностью системы решить совокупность
задач (с данной точностью) ее способность научиться
решать (с не меньшей точностью) любую задачу из этой
совокупности. (Мы нарочно не останавливаемся на том,
сколько и каких о б ъ е к т о в нужно показать
блоку L для достижения состояния, обеспечивающего
достаточную точность имитации. Об этом будет речь дальше.)
При таком определении не может возникнуть
конфликт по вопросу о том, правильно или ошибочно
классифицирован некоторый объект при экзамене.
Правильно (по определению)—это так, как он
классифицирован блоком К\ задачи. Таким образом, «верховный
*) Равенство нулю расстояния между состояниями i\ и Ь
относительно задачи / еще не означает полной тождественности этих
состояний. Выходной материал задачи / может не содержать всего
множества М. Поэтому относительно другой задачи расстояние
между состояниями i\ и fe может оказаться не нулевым.
**) Может возникнуть вопрос, почему про блоки К и К\ не
говорится просто, что они делят объекты на три класса, а вместо
этого считается, что они разбивают множество М на два класса и
«мусор». Дело в том, что третий класс («мусор») блока К\ не
равноправен с остальными двумя. Объекты этого класса не
попадают на вход блока L при обучении и блока К при экзамене.
91
судья» является неотъемлемой частью самой задачи.
Пока он не задан, нельзя говорить о поставленной
задаче, а значит, бессмысленно пытаться построить
систему, которая решала бы эту задачу.
§ 5. Интересные и неинтересные для проблемы
узнавания совокупности задач
В настоящее время создано уже много
экспериментальных узнающих систем. Каждая из них
приспособлена для решения некоторой совокупности задач. Эти
совокупности различаются как множествами М, так и бло*
ками Ки Некоторые системы неплохо справляются со
своей совокупностью задач. Возникает вопрос, в чем
причина успеха — найден ли достаточно широкий подход
к построению узнающих систем или дело в том, что
была выбрана «легкая» совокупность задач? Ведь
пользуясь терминами, взятыми из проблемы узнавания, мож^
но описать много задач, в которых «узнавательная
специфика» настолько слаба, что их естественнее и проще
рассматривать другими методами и вообще не причин
лять к задачам узнавания.
Например, можно сказать, что «замок узнает ключи»
(делит их на два класса). Однако вряд ли стоит саму
по себе вполне достойную задачу создания хороших
замков относить к проблеме узнавания.
Положение дополнительно усложняется тем, что
каждый автор описывает устройство своей конструкции на
своем языке. И иногда трудно понять, что нового в
конструкции, а что — только в способе ее описания.
Поэтому полезно договориться о тех критериях, соблюдение
которых необходимо для того, чтобы имело смысл
относить некоторую совокупность задач к проблеме
узнавания.
Предположим, что блок К\ имеет только одно
состояние (совокупность задач состоит из одной
единственной задачи). Тогда узнающая система может вообще не
учиться. Блок L делается излишним. Остается лишь
трудность (иногда очень большая) построения
«жесткого» автомата /С, слабо имитирующего с достаточной
(заданной техническими условиями) точностью
автоматы S и /Ci- В этом случае исчезли все трудности,
связанные с построением автомата, имеющего много доста-
92
точно разнообразных состояний, и трудности построения
блока L, производящего выбор состояния. Поэтому
первым требованием, соблюдение которого необходимо, для
«интересности» задачи с точки зрения проблемы
узнавания будет наличие у блока К\ многих состояний.
Точнее говоря, нужно, чтобы при требуемой точности
решения задач был большим минимум числа тех
состояний блока /С, при которых решаются все задачи из
данной совокупности. (Уменьшение требуемой точности
решения, естественно, уменьшает число состояний
блока /С, необходимых для решения совокупности задач, и
может привести к тому, что система станет
малоинтересной для проблемы узнавания.)
Итак, первое требование заключается в том, чтобы
при обучении пришлось выбирать одно из многих
состояний блока /С.
Приведем теперь пример совокупности, которая
удовлетворяет первому требованию и все-таки совершенно
неинтересна.
На вокзалах и в аэропортах имеются автоматические
камеры хранения багажа. Это — ящики с
открывающейся передней стенкой. На внутренней стороне дверцы
находится нумератор, состоящий из четырех дисков.
Каждый диск имеет 10 фиксированных положений, а весь
нумератор имеет 104 состояний. Желающий
воспользоваться камерой кладет в нее вещи, устанавливает
нумератор в произвольное положение («обучение») и
запоминает набранное число. Затем захлопывает дверцу
(надо еще опустить монету, но это уже совсем не
относится к вопросу об узнавании). На наружной стороне
дверцы имеется такой же нумератор, как на внутренней.
Для того чтобы получить назад свои вещи, нужно
набрать на наружном нумераторе тот же номер, что был
набран на внутреннем. После этого дверца легко
откроется («узнавание объекта I класса»). Если набрать
любой другой номер, дверца не открывается
(«узнавание объектов II класса»).
Рассматриваемая система может научиться решать
совокупность, состоящую из 104 задач. При обучении
происходит выбор одного состояния из 10 000. Все
остальные состояния недопустимо (по смыслу задачи)
далеки от нужного. И все-таки ни конструкторам
системы, ни тем, кто ею пользуется, вероятно, никогда не
93
придет в голову называть ее «узнающей». Какого же
свойства не хватает для этого системе? Обратим
внимание на то, что один нз классов, на которые система
должна после обучения разбивать числа, содержит
только один объект»
Поэтому все «обучение» может свестись к
запоминанию этого числа, а экзамен — к сравнению неизвестного
объекта с содержимым памяти (так, разумеется, и
устроена камера хранения). Узнающими же в отличие от
«запоминающих» есть смысл называть системы, которые
способны узнавать новые объекты (не участвовавшие
в обучении). Узнавание всегда ассоциируется у нас с
процессом обобщения, с экстраполяцией
закономерности, подмеченной при обучении, на новую область. Нет
обобщения в механизме автоматической камеры
хранения, и за это мы отказываемся признать его узнающей
системой.
Итак, второе требование заключается в том, чтокаж*
дый класс задачи должен содержать много разных
объектов. При обучении показывают небольшую
часть их. Экзамен же происходит на новых
объектах.
И опять можно привести пример совокупности задач,
которая удовлетворяет и первому и второму требова*
ниям, и все равно ее нет смысла считать интересной.
Допустим, механизм описанной выше автоматической
камеры хранения несколько переделан. Пусть теперь
дверь открывается, когда совпадают два первых (стар*
ших) знака чисел на внутреннем и внешнем
нумераторах. Можно сказать, что механизм «округляет с
недостатком» до третьего знака. Теперь совокупность задач
состоит из 100 задач (не так уж мало), зато в каждой
задаче первый класс содержит уже не один, а 100
объектов! При обучении из этих 100 достаточно показать
лишь один.
В самом деле, если мы наберем на внутреннем ну*
мераторе число 4726, то потом дверца откроется и на
число 4711, и на 4794. Имеется «обобщение». Однако оно
нас почему-то не радует. Дело в том, что округление,
которое производит система, приводит просто к
неразличимости объектов внутри класса при любом
состоянии блока К. А это все равно, что в классе есть
только один объект.
94
Итак, дополнение ко второму требованию — после
слов «каждый класс каждой задачи должен содержать
много разных объектов» следует добавить «причем
разными считаются только такие пары объектов,
которые хотя бы в одной задаче из совокупности попадают
в разные классы».
Оценим, основываясь на этих критериях, некоторые
системы, которые часто причисляются к узнающим-
Какую совокупность задач решает буквочитающая
система? Например, система, вводящая в
вычислительную машину печатный текст.
Такой машине приходится всегда иметь дело с одним
и тем же разбиением объектов на классы (правда, этих
классов не два, а больше). Другими словами,
совокупность задач состоит из одной-единственной задачи
(нарушено первое требование). Система может быть
сделана «жесткой» без всякого обучения. Построение
хорошо работающей читающей системы требует,
по-видимому, преодоления целого ряда инженерных трудностей,
однако это — трудности, не специфические для
задачи построения обучающихся узнающих систем.
Другое дело, если речь идет о системе, решающей
совокупность задач, в которую входит и узнавание букв
и другие задачи, представленные в приложении 3 и т. п.
Построение такой системы следовало бы считать
некоторым успехом в области узнавания.
По-видимому, именно для подобной совокупности
задач был предназначен его автором перцептрон. Однако,
как мы видели, он оказался не в состоянии решить
многие задачи из такой совокупности. В чем причина этого?
Какой из блоков перцептрона {К или L) «оказался не
на высоте». Не вдаваясь в подробности, скажем, что
если перцептрон имеет не очень много разных
Л-элементов (все реально осуществленные перцептроны
попадают в этот класс), то блок L кое-как справляется
с обучением (не наилучшим из возможных способом).
Это значит, что если для данной задачи существует под-
ходящее состояние блока К (у перцептрона состояние
определяется набором коэффициентов £г), то
перцептрон перейдет в него или в близкое состояние после не
слишком большого обучения. Но перцептрон с малым
числом Л-элементов просто не имеет состояний,
подходящих для многих задач из упомянутой совокупности.
95
С другой стороны, при очень большом числе Л-эле-
ментов (~2т, где т — число клеток растра) и
некотором изменении устройства Л-элементов перцептрон
может иметь необходимые состояния для решения любой
задачи, но тогда при обучении понадобится полный
показ всех объектов, входящих в классы.
Нарушится второе требование. Система станет
неинтересной.
Остановимся еще на вопросе о блоках Ki интересных
сегодня совокупностей задач. Есть области (например,
узнавание фигур и изображений предметов), где имеет
смысл в качестве блока Ki использовать человека. При
этом на первых порах придется накладывать различные
дополнительные ограничения на допустимые задачи. По
мере совершенствования узнающих систем эти
ограничения будут, вероятно, постепенно уменьшаться. Сейчас
имеет смысл, например, наложить дополнительное
ограничение разрешимости задач для другого человека. Это
исключит из совокупности задач, например, задачи,
представленные на рис. 11 и 12. Имитация человека
целесообразна потому, что при узнавании геометрических
объектов человек гораздо лучше имитирует «блоки К\
природных задач», чем любая уже созданная
искусственная система.
В некоторых же областях, например всякого рода
диагностика (медицинская, химико-технологическая,
геологическая и т. п.), в качестве блока К\ нужно
непосредственно использовать имеющиеся в этих разделах
знания алгоритмы абсолютной проверки класса
объектов. Здесь нет смысла делать конструкции, имитирующие
человека, так как сейчас уже есть системы, которые
имитируют природу точнее, чем человек.
§ 6. «Самообучение»
Во время обучения мы не сообщаем узнающей
системе принципа, по которому классифицирует объекты
блок Ki. Хорошо работающая система сама открывает
этот принцип, после того, как ей покажут несколько
объектов и скажут, что с ними сделал блок К\.
А нельзя ли пойти еще дальше? Нельзя ли сделать
«самообучающуюся» систему, которой достаточно показать
объекты, ничего не говоря о том, куда их отнес
блок /G?
96
Для простоты начнем со случая, когда блок S во
всех задачах с одинаковыми вероятностями выбирает
объекты из множества М.
Если мы хотим сделать так, чтобы блок L и в самом
деле не получал никакой информации о том, как
поступил с объектами блок Ки то мы должны подавать на
вход L без разбора все объекты, выбранные блоком 5,
в том числе и те, которые блок Ki отнес в «мусор». Ясно,
что в этом случае «самообучиться» ничему нельзя, ибо
материал обучения вообще не зависит от задачи
(состояния блока /G).
Пусть теперь на вход блока L попадают не все
объекты, выбранные блоком S, а лишь те, которые блок К\
задач
М
щ.
i_i_
к,
т
Утес у-
Шасс ч о
Узнаюшая
система
\1/1ласс
\Дпласс
«Мусор»
Рис. 19. Схема работы, при которой блок L получает
сведения о принадлежности материала обучения «не к
мусору», но не получает сведений о классе объектов.
отнес «не в мусор» (рис. 19). Тем самым мы уже
сообщаем узнающей системе некоторые сведения об
отношении блока Ki к объектам. Тут возможны три
ситуации.
а) Блок Ki во всех своих состояниях относит в «му-
сор» одно и то же подмножество множества М. Эта
ситуация совпадает с уже рассмотренным случаем
«самообучения». В самом деле, в этой ситуации единственная
разница материала обучения для разных задач
заключается в разбиении «избежавших мусорной корзины»
объектов на классы. Но этой информации блок L не
получает. В качестве примера на рис. 20 изображен
97
Рис. 20. Разные сечения на одном и том же множестве объектов.
Обучение по схеме рис. 19 невозможно,
материал обучения трех разных задач. Легко видеть,
что для всех трех задач материал обучения содержит
одни и те же восемь объектов. Задача от задачи
отличается только способом разбиения этих
объектов на классы. Система, работающая
по схеме рис. 19, решить эту совокупность задач не
может.
б) Имеется одно единственное состояние блока Ки
в котором он производит данное разбиение объектов на
«мусор» и «не мусор». Система, изображенная нэ рис. 19,
в принципе может решить такую задачу. Однако при
этом не имеет смысла говорить о «самообучении». В этой
ситуации сообщение о том, что данный набор объектов
(материал обучения) является «не мусором», несет
очень большую информацию о состоянии блока Ки а
значит, и о разбиении объектов на классы. Получает же
это сообщение блок L извне тем же способом, что и
сообщение о принадлежности объектов к тому или
иному классу в схеме рис. 18.
в) Промежуточный случай, когда имеется некоторое
количество (большее единицы и меньшее N^) состояний
блока Ки в которых он одно и то же подмножество
множества М относит в «мусор». В этой ситуации работа
по схеме рис. 19 позволит отобрать группу состояний
блока К, дающих необходимое разбиение на «мусор» и
«не мусор», но не даст возможности выбрать одно
состояние внутри этой группы.
Если мы снимем ограничение, заключавшееся в том,
что блок 5 осуществлял для всех задач одинаковое
распределение вероятностей выбора объектов, то ничто
принципиально не изменится. Правда, теперь мы можем
извлекать информацию о задаче не только из факта
попадания некоторых объектов в первый класс, во второй
класс или в «мусор», но и из частоты появления разных
объектов. Однако это не повлияет на основной наш
вывод: где Возможна обучение, там оно не «само»^ а где
«само», там оно невозможно.
Заметим, что вопрос о возможности или невозмож*
ности самообучения не имеет никакого отношения к
вопросу об участии человека в процессе обучения.
Учителем автомата, в указанном выше смысле, может быть
человек, другой автомат или природа (с которой,
пользуясь различными приборами, автомат может общаться
99
без помощи человека), существенно лишь, что учитель
необходим.
Соотношения, имеющие место при рассмотренных
выше второй и третьей (промежуточной) ситуациях,
показывают, что иногда есть смысл обращать внимание не
только на то, как объекты из материала обучения
разбиты на классы, но и на сам факт попадания их «не в
мусор». Другими словами, добиваться не слабой, а
сильной имитации блока /С4.
Действительно, если совокупность задач такова, что
существует относительно мало задач с одинаковым
делением объектов на «мусор» и «не мусор», то
предварительная работа по схеме рис. 19 может заметно
сократить перебор, связанный с окончательным выбором
состояния блока /С. Этому посвящена часть следующей
главы.
Этот вопрос также тесно связан с вопросом о
создании узнающей системой специализированного
языка для описания объектов данной задачи,
непригодного для объектов некоторых других задач
(относящего их в «мусор»). Подробнее о таких системах
будет идти речь в главе IX. Здесь же мы только отмечаем,
что термин «самообучение» является чрезвычайно
неудачным. Он противоречит самому смыслу процесса
обучения, во время которого узнающая система получает
сведения о состоянии блока /G, наблюдая объекты, про
которые сообщается, что с ними сделал блок /Сь
Иногда про них сообщается, к какому классу они
отнесены, в других случаях (например, для выработки
специализированного языка, или когда имеется
единственная задача с таким материалом) достаточно
сообщить, что они попали не в «мусор». Однако всегда
пользу может принести наблюдение только того объекта,
про который что-то сказано*).
*) Мы считаем, что узнающая система не нуждается в
сведениях о множестве М. В самом деле, это множество одно и то
же для всей совокупности задачи и поэтому сведения о нем незачем
получать путем обучения. Их можно жестко заложить в
узнающую систему. Так оно всегда и делается. Если, например, система
предназначена узнавать геометрические фигуры на растре 100X100,
то это заложено в самой ее конструкции. Поэтому просто показ
некоторой картинки без всякого сообщения о том, куда она
отнесена блоком /Ci, не несет никаких новых для узнающей системы
сведений.
100
Итак, никакого самообучения быть не может.
Разговоры об «обучении без учителя» являются
недоразумением. Оно вызвано тем, что бывают случаи, когда
для достижения некоторой цели от учителя требуется
лишь информация о принадлежности объекта «не к
мусору».
§ 7. Нечетко поставленные задачи и имитация
Для «проверки сообразительности» детей психологи
часто применяют такой тест: ребенку показывают
группу слов и предлагают вычеркнуть из этой группы одно
«лишнее»*). Например, может быть предложена такая
группа слов:
1. Кровать.
2. Шкаф.
3. Чемодан.
4. Стол.
5. Диван.
Ребенок должен догадаться, что «чемодан» нужно
вычеркнуть.
Какую задачу при этом решает ребенок? Было бы
ошибкой думать, что «чемодан» «в действительности»
сильнее отличается от остальных предметов, чем они
между собой. Все зависит от того, какой признак мы
сочтем наиболее важным. Трудно было бы убедить
ребенка, что он «ошибся», если бы он вычеркнул «шкаф»,
мотивируя это большой высотой шкафа и малой
высотой всех остальных предметов. Перед нами нечетко по*
ставленная задача, для которой нельзя доказать, какой
ответ правильный, а какой — неправильный.
Поэтому единственный смысл стоящей перед
ребенком задачи: догадаться, какой признак
считал существенным автор задачи.
Другими словами, нужно имитировать мышление
«экзаменатора».
Легко видеть, что сведений для такой имитации в
приведенном списке предметов явно недостаточно.
«Экзаменатор» мог задумать в качестве «лишнего»
предмета и «кровать» (как единственный металлический
предмет), и «диван» (как единственный обитый кожей
*) Иногда показывают группу картинок.
101
или материей предмет) и т. д. Несмотря на это,
большинство людей одинаково (и притом «правильно»)
отвечает на вопрос. Это означает, что различные
состояния блока Ki («экзаменатора») неравновероятны и
наиболее вероятное состояние блока К (решающего
задачу) после наблюдения материала обучения совпадает с
наиболее вероятным состоянием блока /G.
Итак, решение задачи возможно потому, что все
люди «устроены» в какой-то мере одинаково. Сразу
возникает мысль, что подобные тесты могут выявить
индивидуальные отклонения мышления. И действительно, как
обнаружили психиатры, при шизофрении 'часто
наблюдается другое (по сравнению с большинством людей)
распределение вероятностей состояний блока /С
Например, если больному шизофренией показать четыре
картинки, на которых изображены кусок туалетного мыла,
тюбик зубной пасты, мочалка и груша, то он может
признать «лишней» в этой группе мочалку. Мотивировка
будет такой: все остальные предметы сильно пахнут, а
мочалка не пахнет. Никто не сможет доказать, что он
ошибся. Просто для большинства людей такой ответ
будет очень неожиданным. Больной плохо имитирует
мышление большинства людей, хотя и нельзя сказать,
кто из них думает «правильнее».
Ученому часто приходится решать подобные нечетко
поставленные задачи. Задачи, которые, строго говоря,
решить невозможно из-за недостаточности информации
в материале обучения. При этом дело каждый раз
сводится к имитации состояния генератора задачи, к
созданию в голове модели изучаемого процесса. Допустим,
мы хотим построить машину, заменяющую человека на
этой работе. Если она будет просто выбирать первое
попавшееся состояние блока КУ не противоречащее
материалу обучения, то, вероятнее всего, нам будет
казаться, что машина «страдает шизофренией». Чтобы этого
не было, блок L должен с самого начала обла*
дать некоторыми сведениями о свойствах совокупности
задач.
Таким образом, конструктор машины должен
стремиться не создать устройство, «ничего не знающее о
задаче», а, наоборот, заложить в блоки L и К как можно
больше сведений. Но не об отдельной задаче, а о
большой совокупности задач. Сведения об ограничениях, на-
102
кладываемых на возможные задачи устройством блока
/Сь должны храниться в форме, «удобной для
употребления». Это значит, что выбор состояния блока К буде^
производиться небольшим числом операций и для
выбора достаточно небольшого материала обучения.
Оценивать качество сконструированной системы следует не по
тому, «сколько в нее заложено сведений», а по тому,
сколь большую совокупность задач система может
решить, какой нужен материал обучения и сколько проб
уходит на поиск состояния блока /С Следующая глава
и будет посвящена вопросу о переборе (числе операций)
при обучении и экзамене.
Глава V
ПЕРЕБОР
А. Перебор при экзамене
§ 1. Запоминание материала обучения
В главе II (§ 2) рассматривалась система, которая
запоминает положение объектов, входящих в материал
обучения, в пространстве рецепторов. В результате к
концу обучения в памяти хранится столько эталонов,
сколько было показано объектов при обучении. Описанием
класса является описание всех объектов материала
обучения, входящих в этот класс. Описание получается,
естественно, тем длиннее, чем больше материал обучения.
При экзамене приходится сравнивать неизвестный
объект со всеми эталонами, хранимыми в памяти.
Вследствие этого, число операций машины при экзамене
зависит не только от того, из скольких классов нужно
выбирать, но и от того, сколько объектов каждого класса
было показано при обучении*).
Большой объем перебора при экзамене в программе
такого типа является прямым следствием малой
степени абстрактности описания класса, вырабатываемого
при обучении.
*) Мы предполагаем здесь, что сравнения с хранимыми в
памяти эталонами происходят последовательно. В принципе поиск
совпадающего с объектом эталона может производиться
дешифратором за короткое время. Но в большинстве случаев нужно
искать не точно совпадающий, а близкий (в пространстве
рецепторов) эталон. Для такой операции была бы нужна очень большая
память (число адресов должно быть равно числу всех точек в
пространстве рецепторов). Поэтому такую возможность сокращения
числа операций при экзамене мы не рассматриваем ни здесь, ни
дальше.
104
§ 2. Запоминание разделяющего правила
Перцептрон уже свободен от рассмотренного выше
недостатка. В памяти перцептрона (правда, в очень
громоздкой форме) хранится описание разделяющего
правила. Длина описания классов зависит от числа
Л-элементов и не зависит от объема материала обуче-
ния. Поэтому время узнавания одного объекта не
зависит от того, на скольких объектах шло обучение.
Еще лучше это видно на примере программы
Арифметика. Программа запоминает положение объектов
(числовых таблиц) в пространстве полезных признаков.
При этом, однако, запоминается не столько точек,
сколько строк или таблиц было в материале обучения, а
только по одной точке на класс. Это становится
возможным благодаря тому, что программа ищет такое
пространство признаков, в котором все объекты,
относящиеся к одному классу, попадают в одну и ту же точку.
При экзамене идет перебор по расстояниям до центров
классов. Поэтому время экзамена зависит только от
числа классов, но не от числа таблиц, данных при
обучении.
§ 3. Синтез названия класса
При обучении мы всегда сообщаем блоку L, к
какому классу относится данный объект (см. § 6
предыдущей главы). До сих пор было безразлично, как
закодировано это сообщение. Например, для программы
Арифметика не имеет значения нумерация (порядок) разных
законов. Поскольку программа должна сообщить свое
«мнение» о классе экзаменационного объекта в том же
коде, ей приходится перекодировать набор
характеристик по признакам в номер («название») класса. Эта
операция и требует перебора всех эталонов классов.
Положение может измениться, если отказаться от
произвола в кодировании названия класса. Если с са«
мого начала в качестве языка для общения человека с
программой избрать набор некоторых свойств
к л а с с а, то запоминать в ходе обучения можно не
эталоны классов, а эталоны свойств классов*). Их может
*) Разумеется, кроме этого, нужно найти и запомнить
алгоритмы, реализующие соответствующие признаки.
105
быть меньше, чем классов, соответственно меньше будет
и перебор при экзамене. Поясним сказанное примером.
Рис. 21.
Пусть машине показали шесть классов объектов
(рис. 21, а —е). Первый класс (рис. 21,а) назвали:
«находящиеся справа сплошные прямоугольники». Второй
класс (рис. 21,6) —«находящиеся слева контурные пря-
106
///
в)
001
б)
wo
в)
000
г)
010
д)
011
е)
моугольники». Третий класс (рис. 21,в)—-«находящиеся
справа контурные эллипсы» и т. д. Разумеется, нет
необходимости сообщать машине названия классов на
русском языке. Достаточно закодировать слово «справа»
символом 1, а «слева» — 0, «сплошной»—1,
«контурный»— 0, «прямоугольник»—1, «эллипс» — 0. Тогда
каждое название класса заменяется трехразрядным
двоичным числом, которое и можно сообщить машине. (Эти
числа стоят на рис. 21 справа от соответствующих
классов картинок.)
Пусть теперь программа ищет не признаки
принадлежности объекта (картинки) к данному классу, а
отдельно признак того, что картинка содержит фигуру
справа или слева, признак того, что эта фигура
сплошная или контурная, и признак того, что это —
прямоугольник или эллипс.
Другими словами, ищутся признаки того, что на
первом месте «машинного» названия класса стоит 1 или 0,
на втором месте стоит... и т. д. Если такие признаки
будут найдены, то программа сможет при экзамене
синтезировать название класса. При этом нет нужды
перебирать и даже хранить эталоны классов. Перебрать нужно
только эталоны свойств классов. В
удачном случае число свойств может быть
порядка логарифма от числа классов, что
и даст заметное сокращение перебора
при экзамене.
Программа, синтезирующая по частям
название класса на понятном челове- Рис. 22.
ку языке, обладает, помимо скорости
экзамена, еще одним очень важным свойством. Она
может «узнавать» (правильно называть) объекты,
принадлежащие классам, не показанным программе
при обучении. В самом деле, допустим, программе,
обучавшейся на шести классах рис. 21, покажут на
экзамене объект, представленный на рис. 22. Он не
принадлежит ни к одному из шести классов, однако это не
помешает программе установить, что на первом месте
машинного названия класса стоит 1, на втором — 0,
на третьем—1. На человеческом языке это
соответствует описанию: «находящийся справа контурный
прямоугольник», которое человек безусловно признает
правильным.
137
Таким образом, получается следующая иерархия
свойств:
а) Система, запоминающая материал обучения,
узнает только объекты, участвовавшие в обучении.
б) «Обычная» узнающая система узнает и объекты,
не участвовавшие в обучении, но только если они
принадлежат классам, участвовавшим при обучении.
в) Система, «синтезирующая название класса»,
«узнает» и объекты, принадлежащие к некоторым
классам, не участвовавшим в обучении.
Мы поставили слово «узнает» в кавычки, потому, что
в данном случае «узнавание» не совсем соответствует
формальному определению, данному в § 4 предыдущей
главы. Любопытно отметить, что программа
Арифметика, казалось бы, очень близка к программе,
синтезирующей названия классов. Вспомним один из опытов,
описанных в главе III, § 4в). Программу обучали на шести
арифметических законах, а затем она «узнавала»
24 арифметических закона. Что значит «узнавала»? Ей
показали таблицы, построенные по новым законам.
Программа присвоила им наборы характеристик (названия
классов на машинном языке), однако эти названия были
для человека непонятны. И программе пришлось
запомнить эти наборы вместе с «человеческими»
названиями классов (их номерами). Теперь, когда программе еще
раз показали таблицы, построенные по новым законам,
она уже умела переводить названия законов со
своего языка (набор характеристик по признакам) на
человеческий язык (номер закона). Перебор же требовался
именно для поиска в словаре при переводе. Итак,
Арифметике не хватает «общего языка с человеком» для
того, чтобы она превратилась в программу,
синтезирующую названия классов. Глава VI будет посвящена
именно задаче создания программы, синтезирующей
названия классов на языке обычной алгебры.
Б. Перебор при обучении
Число операций, производимых машиной при
обучении, возрастает при увеличении количества объектов,
необходимых для обучения. Это является общим
свойством всех типов программ и поэтому сейчас нас не
интересует. Будем для простоты считать, что обучение
108
идет на минимальном достаточном материале. Это
значит, что существует только одно состояние блока Ki
совокупности задач, при котором материал обучения
данным способом разбивается на классы.
§ 4. Поиск разделяющего правила
в фиксированном пространстве
Большинство испробованных к настоящему времени
программ разделяет объекты с помощью
гиперплоскости или нескольких гиперплоскостей. Перцептрон
проводит плоскость в фиксированном пространстве
признаков (Л-пространстве), а упомянутая в главе III
программа Бравермана ведет разделение непосредственно
в пространстве рецепторов. Для этих алгоритмов
обучение сводится только к поиску параметров
разделяющей плоскости или системы плоскостей.
Простейшим способом подошел к поиску плоскости
автор перцептрона. Как легко видеть, координатами
нормали к гиперплоскости, которая используется при
экзамене, являются коэффициенты k{ (см. стр. 35). При
обучении каждый коэффициент ищется независимо от
остальных. Поэтому число операций, производимых
программой при обучении, имеет порядок произведения
числа Л-элементов на количество объектов в материале
обучения. Это число много меньше всего количества
различных состояний перцептрона, но за это сокращение
перебора при обучении заплачено дорогой ценой:
перцептрон иногда не находит плоскости, разделяющей
объекты материала обучения, даже если такая плоскость
и существует.
Однако, как мы знаем, для многих задач объекты,
принадлежащие разным классам, не разделяются в
пространстве рецепторов гиперплоскостью или другой
достаточно простой поверхностью. А для многих
совокупностей задач не существует и фиксированного
отображения пространства рецепторов в такое пространство,
где легко (например, плоскостью) разделяются классы
любой задачи из совокупности. В этом случае цель
обучения состоит не столько в нахождении разделяющего
правила (например, гиперплоскости), сколько в
отыскании пространства признаков, в котором такое
разделение возможно. Заметим, что при поисках пространства
109
полезных признаков критерием качества пространства
является разделимость в нем объектов из материала
обучения. Поэтому после того, как «хорошее»
преобразование пространства рецепторов в пространство
признаков уже найдено, практически не возникает вопроса
о нахождении разделяющего правила. Оно к этому
времени найдено автоматически.
Система, решающая такую совокупность задач, при
обучении тратит время в основном на поиск
пространства полезных признаков.
§ 5. Перебор при поиске преобразования
пространства рецепторов
Любой реальной системе доступно лишь конечное
число преобразований пространства рецепторов.
Потому в принципе можно отыскать нужное
преобразование, проверяя по очереди все возможные
преобразования (полный перебор). Однако если число доступных
отображений очень велико, то полный перебор за
приемлемое время произвести нельзя. Каковы же
возможные пути сокращения перебора?
Не имеет ли смысла вместо систематического
перебора решать с помощью жребия, какое преобразование
стоит проверить? Иногда это может дать сокращение
ожидаемого максимума числа проб.
Предположим, всего системе доступно I08 разных отображений
пространства рецепторов. Пусть 105 из них являются
удовлетворительными для нашей задачи. Тогда, если
выбирать объект проверки с помощью жребия,
равновероятно выпадающего на все 108 отображений,
понадобится около 103 проб. Очень редкое «невезение» будет
приводить к увеличению числа проб, скажем, до 104.
При систематическом же переборе может оказаться, что
все 105 «хороших» (для данной задачи) преобразований
попали в хвост последовательности перебора, и поэтому
придется сделать почти 108 проб. Таким образом,
случайный поиск может быть полезным, если имеется много
пригодных преобразований. Однако это условие
противоречит другому требованию (о нем будет речь ниже),
которое гласит: хорошая узнающая система должна
содержать блок /С, имеющий те и, по возможности,
только те состояния, что и блок Ki совокупности за-
110
дач. Поэтому при разумном построении системы,
решающей данную совокупность задач, не имеет смысла
рассчитывать на преимущества случайного поиска
преобразования пространства рецепторов.
В программе Арифметика отбиралось не целиком
пространство полезных признаков, а проверялись
отдельные признаки (координаты искомого пространства).
Сокращение перебора, даваемое таким отбором «по
компонентам», общеизвестно, и на нем мы останавливаться
не будем. Сейчас нас будут интересовать пути
сокращения перебора при поиске отдельных признаков.
Если узнающая система должна иметь в своем
арсенале очень много разных признаков, то практически
единственный способ осуществить это — строить
признаки из относительно небольшого числа операторов
(«кирпичей»).
Например, как уже упоминалось, 5000 разных
признаков программы Арифметика получаются в виде
комбинаций менее 30 операторов (12 арифметических
функций, 3 логических оператора, 10 логических функций).
При этом отображение таблицы в 0 или 1
осуществляется не сразу, а в несколько этапов. Сначала каждая
строчка таблицы двенадцатью способами отображается
в число, затем каждое число тремя способами
отображается в 0 или 1 и т. д.
В принципе такой способ построения признаков
открывает возможность на каждом этапе производить
отбор и пропускать для последующей обработки лишь
часть отображений. Очевидно, что такая процедура,
если бы ее удалось проделать, резко сократила бы
перебор. Однако сразу возникает вопрос о критериях для
отбора на промежуточных этапах построения
признака. Как, например, догадаться: нужно ли подвергать
дальнейшей обработке результаты применения
оператора С/В (программа Арифметика), или это только
увеличит перебор на последующих этапах?
Существует соотношение, достаточное для
«отбраковки» промежуточных результатов, — это
одинаковость результатов отображения для всех объектов. Если,
например, во всех строках всех таблиц число С —
дробное, то не имеет смысла строить какие-либо логические
функции, использующие это обстоятельство в качестве
аргумента.
111
Другим достаточным для отбраковки
обстоятельством является неприменимость оператора для
всех объектов из материала обучения. Пусть,
например, программа может строить оператор, проверяющий
равенство между собой всех углов фигуры. Очевидно, в
сочетании с другими операторами этот оператор будет
полезен, если придется отличать правильные
многоугольники от неправильных или прямоугольники от
ромбов и т. п. Однако если все объекты, представленные в
обучении, являются криволинейными фигурами, не
имеющими явно выраженных углов, то при решении данной
задачи пользоваться этим оператором бессмысленно.
Заметим, что неприменимость некоторого оператора
лишь к части объектов из материала обучения еще не
является основанием для его отбраковки. Примером
может служить задача, в которой к одному классу
относятся правильные многоугольники и окружности, а к
другому классу — неправильные многоугольники и
прочие криволинейные фигуры.
К сожалению, трудно назвать еще какие-нибудь
соотношения, позволяющие столь же безоговорочно
браковать промежуточные результаты и не допускать их в
дальнейшую обработку. Поэтому приходится искать
критерии, применение которых сопряжено с некоторым
риском. Может оказаться, что будет забракован
«полуфабрикат» полезного признака. Зато сильно сокращается
перебор. Естественно, что хороший критерий
промежуточного отбора должен в каком-то смысле
соответствовать структуре блока Ki совокупности задач. В
дальнейшем мы обратим внимание на некоторые
обстоятельства, которые позволяют сокращать перебор в случаях,
когда «генератором задач» является человек или
некоторый физический процесс.
Итак, представляется целесообразным для
сокращения перебора при обучении строить признаки путем
последовательного наращивания цепочек сравнительно
простых операторов. Поскольку каждую цепочку можно
наращивать многими способами, процесс аналогичен
движению по веткам дерева*). При этом иногда удается
*) Вообще говоря, признак может сопоставлять результаты
преобразования объекта несколькими разными цепочками
операторов. Поиску признака в этом случае будет соответствовать
движение не по дереву, а по более сложной сети.
112
отсекать некоторые ветви, не проверяя всех признаков,
«произрастающих» на них. Некоторые критерии
такого отсечения ветвей были упомянуты, некоторые будут
рассматриваться в следующих главах. Смело можно
утверждать, что поиск критериев отсечения ветвей при
построении признаков является одной из важнейших
задач проблемы узнавания.
§ 6. Соответствие сложности описания классов
материалу, данному для обучения. Постулат
достаточности материала обучения
Допустим, мы договорились с приятелем, что он будет
задавать нам задачи, в которых для описания класса
достаточно фраз, построенных из слов большой,
маленький, фигура, прямоугольник, эллипс, горизонтальный,
I ttfiann
Рис. 23.
вертикальный, контурный, сплошной и логических
связок «и» и «или».
Приятель имеет право предложить нам, например,
задачу, в которой к одному классу принадлежат
«большие сплошные фигуры», а к другому классу — «большие
контурные или маленькие фигуры» и т. п. Пусть дана
задача, представленная на рис. 23.
Л нпппг
113
Тот факт, что все объекты материала обучения
являются контурными фигурами, избавляет нас от
необходимости проверять высказывания содержанием слова
контурный или сплошной. Это несколько сокращает
область поисков, и мы довольно быстро обнаруживаем,
что первый класс может быть описан словами
«горизонтальные эллипсы или вертикальные прямоугольники»,
а второй класс — «горизонтальные прямоугольники или
вертикальные эллипсы».
Согласившись с тем, что эта фраза соответствует
задуманному им принципу классификации, приятель
предлагает новую задачу (рис. 24).
I класс
Л класс
Рис. 24.
Всем людям свойственна некоторая «инерция
мышления». Если она приведет к попытке разделить классы
в задаче, данной на рис. 24, с помощью описания
классов, найденного для предыдущей задачи, то мы увидим,
что это описание подходит. В то же время, если бы мы
предварительно не решали задачу рис. 23, то нам
никогда не пришло бы в голову давать такое описание
классов в задаче рис. 24. Мы бы просто сказали, что
к первому классу принадлежат эллипсы, а ко второму —
прямоугольники. Более осторожный человек мог бы
сказать, что первый класс — это контурные горизонтальные
эллипсы, а второй — контурные горизонтальные
прямоугольники.
114
Почему же нам не приходит в голову описание клао
сов, найденное при решении задачи рис. 23? Ведь
формально оно подходит и для рис. 24! Дело в том, что
если предположить, что приятель задумал принцип клас*
сификации такой сложности, как на рис. 23, то мате^
риал на рис.24 недостаточен для выбора
одного описания из всего возможного
множества описаний такой же примерно
сложности. В самом деле, для задачи на рис. 24 подойдут и
такие описания:
1) Первый класс —горизонтальные эллипсы или
вертикальные фигуры.
Второй класс — горизонтальные прямоугольники.
2) Первый класс — горизонтальные эллипсы.
Второй класс — горизонтальные прямоугольники или
вертикальные фигуры.
3) Первый класс — контурные эллипсы или
сплошные прямоугольники.
Второй класс — контурные прямоугольники или
сплошные эллипсы.
Таких описаний можно придумать еще очень много.
Ни одному из них материал рис. 24 не будет
противоречить, а значит, на основании материала обучения
нельзя выбрать одно описание.
Приступая к решению задачи, мы, естественно,
предполагаем, что материал обучения достаточен для
выбора единственного описания. Тем самым на исходное
множество описаний, в котором идет поиск,
накладывается дополнительное ограничение. Другими словами,
мы ограничиваем сложность рассматриваемых описаний
до такой степени, что материал обучения начинает
однозначно ограничивать описание классов. Область
(различных описаний классов), в которой идет поиск,
меняется в зависимости от конкретного материала
обучения. Можно сказать, что мы пользуемся постулатом
достаточности материала обучения для решения
задачи.
Любопытно, что этот процесс идет совершенно
незаметно для человека, если на него не обратить
специально внимания. Вероятно, мало кто заметил, что столь
естественное описание классов в задаче на рис. 23 было
нами найдено тоже с помощью постулата
достаточности.
t15
Действительно, материал обучения на рис. 23 не
противоречит и такому описанию классов:
Первый класс — горизонтальные контурные эллипсы
или вертикальные контурные прямоугольники, или
вертикальные сплошные эллипсы или горизонтальные
сплошные прямоугольники.
Второй класс — горизонтальные контурные
прямоугольники или вертикальные контурные эллипсы, или
вертикальные сплошные прямоугольники или
горизонтальные сплошные эллипсы.
Интуитивно мы отвергаем такое описание, как
слишком сложное (точнее, сложность описания не
соответствует материалу обучения. При другом материале
обучения мы могли бы принять такое описание).
Формально это описание было отвергнуто (см. стр. 114) потому,
что все фигуры на рис. 23 контурные. На основании
этого мы не стали рассматривать описание, содержащее
слова контурный и сплошной.
Приведем некоторое обобщение этого формального
правила. Будем считать, что описание класса имеет вид
дизъюнкции нескольких высказываний (несколько
высказываний соединено связкой «или»). Тогда каждое
высказывание (член дизъюнкции) должно быть истинно
хотя бы на одном объекте материала обучения из
данного класса. Действительно, если описание класса
содержит дизъюнктивный член, не удовлетворяющий этому
требованию, то мы можем изъять его из описания
данного класса и прибавить в качестве нового
дизъюнктивного члена в описание противоположного класса. Если
исходное описание классов правильно классифицировало
объекты из материала обучения, то новое описание
будет также правильно их классифицировать. Материал
обучения не дает возможности выбирать одно из этих
двух описаний, а значит, исходное описание было
слишком сложным и не удовлетворяло постулату
достаточности материала обучения.
Заметим, что если материал обучения ограничен
внешними (по отношению к обучающейся системе)
обстоятельствами, то действия, основанные на принятии
постулата достаточности материала обучения, не таят
в себе опасности ухудшения работы системы по той
простой причине, что если в данном случае постулат
окажется ложным, то никакие другие действия все равно
116
не помогут. Другое дело, если система имеет
возможность запрашивать дополнительный материал для
обучения. В этом случае система должна уметь
оценивать степень достаточности переработанного
материала обучения и при неудовлетворительной оценке —
запрашивать новый материал.
§ 7. Извлечение сведений из материала экзамена
До сих пор мы всегда говорили, что узнающая
система сначала изучает материал обучения,
вырабатывает описание классов (переводит блок К в некоторое
состояние) и лишь после этого к ней на вход попадают
объекты из материала экзамена.
Сейчас мы рассмотрим случай, когда во время
обучения система имеет возможность наблюдать и
материал экзамена. Может показаться, что от этого не
должно быть никакого выигрыша. Вспомним, однако, что
/класс
Л нласс
Рис. 25.
наблюдение материала экзамена дает возможность
уточнить, какие объекты бывают и какие не бывают «в мире
данной задачи». А такое знание может иногда
сократить поиск описания классов.
Попробуем решить задачу, показанную на рис. 25.
Нам показывают только по одному объекту каждого
класса. Глядя на них, невозможно понять, что же
задумал автор задачи. Отличаются классы размерами
фигур или числом углов, или еще чем-нибудь? Материал
обучения явно недостаточен для выбора описания
классов даже из очень небольшого начального множества.
117
Рис. 26.
Теперь гипотеза «достаточности материала обучения»
может помочь выбрать описание классов. В самом деле,
нельзя предположить, что объекты разных классов
отличаются числом углов, так как в этом случае
материала рис. 25 было бы недостаточно для решения вопроса:
куда следует относить четырехугольники или
пятиугольники? Нельзя также предположить, что делить классы
надо по признаку — сторона или угол фигуры находится
118
Можно только ожидать, что описания эти должны быть
весьма простыми (показано очень мало примеров).
Допустим, однако, что одновременно с рис. 25 нам
показали рис. 26 и сказали, что все это — объекты из
материала экзамена.
снизу, — потому что при этом было бы неясно, куда
относить окружности и эллипсы и т. д. Зато если
предположить, что классы отличаются размерами фигур, то
материал обучения становится достаточным. Поэтому
Рис. 27.
человек, посмотрев одновременно на рис. 25 и 26,
начинает классифицировать фигуры на рис. 26 по их
размеру.
Другое описание классов вырабатывается у человека,
если одновременно с тем же материалом обучения
(рис. 25) показать материал экзамена, представленный
на рис. 27. В этом случае уже нельзя предположить, что
объекты надо классифицировать по их размерам, так
как для выработки критерия разделения явно не хватит
119
материала обучения. Вместо этого человек начинает
разделять фигуры на треугольники и шестиугольники.
Итак, некоторые описания классов могут быть
отвергнуты не потому, что материал обучения им
противоречит, а потому, что материал обучения недостаточен
для выделения одного описания из нескольких, в
каком-то смысле однотипных. При этом может оказаться
полезным наблюдение во время обучения объектов из
материала экзамена, хотя про них и не говорится, к
какому классу они относятся.
§ 8. «Развал на кучи»
Пусть среди операторов, из которых программа
может строить признаки, имеются операторы,
отображающие объект в число, которое может принимать много
значений (иногда говорят о «непрерывной величине»,
но из-за конечной точности измерений это то же самое).
Примерами таких операторов могут служить
программы, измеряющие площадь фигуры, отношение сторон,
различные углы, длину диаметра и т. п.
Наличие в арсенале программы подобных
параметров сильно затрудняет обучение. Затруднение возникает
по двум причинам: во-первых, приходится выбирать из
колоссального набора описаний классов, которые могут
существовать в виде сочетаний значений «непрерывных»
параметров. Кроме того, поскольку заранее неизвестно,
какие параметры являются существенными, а какие —
нет, при обучении придется проверять очень много
сочетаний.
Во-вторых, нужен очень большой материал обучения
для того, чтобы произвести выбор описания классов. При
этом необходимый материал обучения увеличивается не
только при увеличении числа существенных параметров
(увеличение сложности описания), но и при увеличении
количества несущественных параметров (требуется много
примеров, чтобы показать, что данный параметр или
данное сочетание параметров несущественны).
Описанное затруднение имеет место в общем случае,
когда не наложено никаких ограничений на значения,
которые принимают «непрерывные» параметры. Однако
бывает, что параметр, который внутри совокупности
задач действительно принимает произвольные значения,
120
в данной задаче оказывается вовсе не произвольным.
Получается это тогда, когда блок К\ совокупности
задач, находясь в состоянии, соответствующем данной
задаче, относит в разряд «мусора» объекты с некоторыми
значениями параметра.
На рис. 28, а показано, какие значения принимает
площадь фигур в задаче, представленной на паре рис. 25
и 27, а на рис. 28, б — то же самое для задачи,
представленной на паре рис. 25 и 26 (см. предыдущий
параграф). Вертикальные штриховые линии соответствуют
площадям фигур из материала обучения (рис. 25).
Видно, что в случае а) площадь бывает какой угодно (в
некоторых пределах, разумеется). В случае же б)
значения площади «распадаются на кучи». Но ведь это и
была та самая задача (рис. 25 и 26), при решении
которой мы, приняв гипотезу достаточности материала
обучения, стали классифицировать объекты по площади!
Действительно, в этом случае достаточно малого числа
примеров, чтобы найти принцип разделения объектов по
площади. В задаче рис. 25 и 27 площади объектов
таковы (рис. 28,а), что с помощью малого числа примеров
121
Рис. 28. Иллюстрация случаев, когда
некоторый параметр распадается или не
распадается на кучи.
нельзя задать принцип разделения классов по площади.
Зато если бы мы нарисовали графики, аналогичные
рис. 28, для параметра «число углов», то он бы
«развалился на кучи» в задаче рис. 25 и 27 и «не
развалился» в задаче рис. 25 и 26.
Итак, нам может хватать небольшого материала
обучения в тех случаях, когда некоторый параметр
принимает (в данной задаче, но не обязательно во всей
совокупности) мало значений. Если это «непрерывный
параметр», то он должен «разваливаться на кучи». При этом
используется то обстоятельство, что блок К\ пропускает
объекты не со всеми значениями параметра. Нам удает-*
ся выбрать с помощью малого материала обучения нуж->
ное состояние блока К благодаря тому, что выбор идет
только среди тех состояний, которые тоже
отправляют в «мусор» объекты с «запрещенными» значениями
параметра. Другими словами, рассматриваются только
состояния блока /С, сильно имитирующие блок
/(t. В рассмотренных примерах сильная имитация достиг
галась с помощью наблюдения объектов из материала
экзамена, однако это не является обязательным.
«Развал на кучи» некоторого параметра является как раз
тем случаем, когда полезна предварительная работа по
схеме рис. 19 (см. § 6 предыдущей главы).
Не следует думать, что принадлежность некоторого
параметра к той или другой «куче» обязательно сама
по себе сигнализирует о принадлежности объекта к тому
или другому классу. Рассмотрим задачу,
представленную на рис. 29. Объекты различаются между собой
положением фигуры по отношению к рамке, видом фигуры
(прямоугольник или эллипс), углом наклона большого
диаметра к вертикали и площадью. Наблюдение
материала обучения показывает, что вертикальная
координата центра тяжести всех фигур одна и та же. Значит,
ее можно не рассматривать. Углы наклона фигур
бывают самые разнообразные, т. е. этот параметр «не
распадается на кучи». То же можно сказать о
горизонтальной координате центра тяжести. А вот площади фигур
резко распадаются на две кучи. И число углов бывает
только 4 (четырехугольники) и 0 (эллипсы). (Ничего не
изменится, если считать, что у эллипса бесконечное
число углов.) Однако ни по размерам фигуры, ни по числу
ее углов нельзя определить, к какому классу она отно«
сится. В каждую кучу (по каждому параметру) попа-»
дают объекты из обоих классов.
Описание классов достигается одновременным
учетом характеристик по обоим «распадающимся на кучи»
параметрам. Первый класс может быть обозначен ело-*
вами «большие эллипсы или маленькие прямоугольник
ки», а второй — «большие прямоугольники или малень-
кие эллипсы». Для того чтобы найти это описание,
приходится перебрать различные функции от элементарных
высказываний, но перебор получается сравнительно не*
122
большим благодаря тому, что в качестве аргументов мы
рассматривали только «распадающиеся на кучи»
параметры.
Конечно, при этом мы потеряли возможность
обнаружить описание классов, использующее параметры, не
I класс
Еипасс
Рис. 29.
«распадающиеся на кучи». Однако в случае большого
числа параметров, принимающих много значений, выбор
единственного описания классов возможен только при
очень большом материале обучения. Поэтому если
материал обучения невелик и мы постулируем его
достаточность для выделения описания классов, то имеет
смысл рассматривать только параметры,
«распадающиеся на кучи».
123
I класс
Впласс
Рис. 30.
Вероятно, со временем будут найдены оценки,
показывающие, при каком числе объектов в обучении и при
каких свойствах параметров целесообразно
рассматривать только параметры, «распадающиеся на кучи».
Не следует думать, что все параметры,
«распадающиеся на кучи», обязательно входят в описание классов
(как это было в задаче на рис. 29). На рис. 30 показан
пример задачи, в которой «распадаются на кучи» три
параметра (горизонтальная координата, площадь и
наклон фигуры), а в описание классов входят только два
из них (горизонтальная координата и наклон). Наклон
штриховки на кучи не распадается. Задача на рис. 30
является примером «быстрого роста неопределенности»
описания классов, если ввести в рассмотрение
параметры, не распадающиеся на кучи. Если не отбрасывать
наклона штриховки, то существует уже три описания, не
противоречащих материалу обучения на рис. 30.
Вопрос о «развале на кучи» рассматривался здесь с
точки зрения сокращения перебора, в частности, в связи
с «постулатом достаточности материала обучения».
Однако этот вопрос имеет и другую сторону, связанную с
созданием коротких описаний классов. Поэтому мы
вернемся к нему в главе IX.
Глава VI
СИНТЕЗ ФОРМУЛ
§ 1. «Открой закон»
Полностью сознавая всю антипедагогичность своего
поступка, я все же рискну предложить карточную (!)
игру для детей дошкольного возраста.
Взрослый раскладывает перед ребенком игральные
карты на две кучи, задумав некоторый принцип разбие--
ния. Например, в одну кучу кладет черные масти, в дру«
гую — красные, или в одну — картинки, в другую — не
картинки, или в одну — четные не картинки, а в
другую— нечетные и т. п. После того как некоторая часть
колоды в соответствии с выбранным принципом уже
разложена, можно, доставая следующую карту, перед
тем как положить ее на стол, спрашивать ребенка: «В
какую кучу ее надо положить?» Отвечая на вопрос, ре*
бен'ок будет решать типичную задачу узнавания. Но
можно дать ребенку и другое задание: пусть он четко и
коротко сформулирует закон, по которому карты
разбиты на кучи. Требование краткого изложения не дает
возможности ребенку заменять общую формулировку
перечислением всех частных случаев. Например, вместо
слова «картинки» ребенок может пытаться сказать:
«тузы», «дамы», «валеты» и «короли». Это является
«запрещенным приемом»*).
В применении к числовым таблицам, построенным по
разным арифметическим законам, эта игра (уже не для
*) Не следует думать, что ребенок, пытающийся дать
определение перечислением, и при узнавании пользуется большим набором
эталонов вместо обобщения. Это легко доказать следующим
образом: покажем ему две кучи карт, в одной из которых лежат только
не картинки,, а в другой — тузы, дамы и валеты, но нет королей.
Если теперь показать короля и спросить, куда его нужно положить,
го обычно ребенок показывает на кучу картинок.
126
ТАБЛИЦА tl
А
4
9
6
1 15
В
2
3
4
9
с I
8
27
з
25
дошкольников) будет выглядеть так: «Известно, что все
строчки табл. 11 построены по одной и той же не очень
сложной арифметической формуле. Требуется найти эту
формулу».
Посмотрев на первые две строчки, человек обычно
выдвигает гипотезу, что С—А* В. Однако уже
следующая строчка опровергает эту
гипотезу. Подумав еще некоторое
время, человек находит подхо-
А2
дящий закон C = -g-.
Легко заметить, что эта игра
сродни очень серьезным занятиям.
В самом деле, если числа Л, В
и С*) в первой строчке
получены в результате измерения
каких-то физических величин
(например, среднего расстояния некоторой планеты до
Солнца и ее периода обращения), а в других строчках —
путем измерения тех же величин, но для других
объектов (в нашем примере — расстояний и периодов
обращения других планет), то нахождение общего закона
для всех строчек есть открытие закона природы
(здесь — третьего закона Кеплера). Рассмотрение
таблиц, построенных на основе других экспериментов,
приведет играющего в «открой закон» к открытию закона
всемирного тяготения или формулы линзы, или закона Ома.
Когда такие открытия делают люди, принято
говорить, о «творческом анализе экспериментальных
данных». Действительно, трудно указать регулярный
способ нахождения общего закона для таблицы. Это, в
частности, зависит от интуиции и чутья. Мало кто,
вероятно, способен открыть формулу Бальмера.
Поэтому интересно сделать программу, которая
хорошо играла бы в «открой закон».
С другой стороны, эта программа будет осуществлять
синтез названия класса (ср. главу V, § 3). Поэтому есть
надежда, что программы такого типа могут совершать
относительно мало операций при обучении и экзамене,
производя при этом выбор из многих классов.
*1 Разумеется, могут встретиться случаи, когда этих чисел не
три, а больше или меньше»
1Л
§ 2. Случайный поиск закона
Первая программа, искавшая арифметические
законы для таблиц, работала следующим образом: сначала
строится некоторая случайная цепочка арифметических
команд. Для этого с помощью жребия выбирается,
будет ли в первом арифметическом действии на первом
месте стоять А или В. Затем (тоже с помощью жребия)
решается, А или В будет стоять на втором месте. После
этого новый жребий определяет, какое действие будет
произведено. Команда для второго арифметического
действия строится аналогично, с той лишь v разницей, что
в качестве объекта операции могут быть использованы
не только А и В, но и результат первого действия.
Объектом третьего действия могут быть Л, В, результат
первого действия и результат второго действия и т. д.
После построения каждой команды (работа велась на трех-
адресной машине, поэтому каждому арифметическому
действию соответствовала одна команда) с помощью
жребия решалось, не оборвать ли на этом цепочку
арифметических операций.
Легко сообразить, что при таком алгоритме может
быть построена цепочка, соответствующая любому
закону, выражающемуся через конечное число
арифметических операций. Появление каждой формулы будет
иметь отличную от нуля вероятность. Чем сложнее*)
формула, тем меньше вероятность ее появления.
После построения цепочки программа проверяет,
подходит ли получившаяся формула к данной таблице. Для
этого в качестве А и В подставляются соответствующие
числа из первой строчки таблицы и выполняются
команды построенной цепочки. Число, получившееся в
результате проделанной последовательности
арифметических действий, сравнивается с числом С из первой
строчки. Если они не совпадут, значит формула не
подходит. Если совпадут — проверке подвергаются числа Л,
В и С из второй строки и т. д. Если все строчки
таблицы удовлетворяют формуле, программа печатает эту
формулу и останавливается. Если хотя бы одна строка
не подходит —формула бракуется, программа начинает
с помощью жребия строить новую формулу и так «до
победного конца».
*) Здесь— чем больше арифметических действий содержит,
128
Коротко схему работы программы можно описать
так: имеется генератор случайного шума, шум с
помощью специального дешифратора истолковывается как
гипотеза о законе, гипотеза проверяется подстановкой
чисел из таблицы.
Эта программа была опробована на машине со
средней скоростью 2000 трехадресных операций в секунду.
На «открытие закона», содержащего только одно
арифметическое действие (одноходовка), машина тратила
около 2 сек. Двухходовки решались в среднем за 20 сек.
Трехходовки отнимали 10—20 мин. Повторные решения
одной и той же задачи требовали разного времени (из-
за случайности жребия, решая двухходовку, машина
иногда печатала ответ через 5 сек, а иногда «думала»
целую минуту).
Приведенные выше данные о затрате времени
являются средними. Кроме того, например, закон
АВ(А+В), который может быть записан и в виде
(В+А)АВУ и в виде В(А + В)А и т. п., естественно, оты-
л А — В D
скивается в среднем быстрее, чем закон—^ />,
который в виде трехходовки может быть записан
единственным способом.
На более сложных законах из-за недостатка
машинного времени программа не проверялась.
Заметим, что третий закон Кеплера является
трехходовкой, соотношение обратных квадратов в законе
всемирного тяготения — двухходовкой, соотношение
расстояний от линзы до источника и изображения —
трехходовкой *).
§ 3. Поведение человека и программы случайного
поиска при игре в «открой закон»
Программа отыскивает формулу, подходящую к
данной таблице, ценой большого числа проб. Человеку тоже
приходится проверить несколько формул, прежде чем
он подберет подходящую. Однако человек, как правило,
достигает результата, сделав гораздо меньше проб.
*) Для открытия всех этих законов программу нужно было бы
чуть-чуть изменить. Вместо сравнений результатов действий над А
и В с С нужно сравнивать между собой результаты действий над
А и В в разных строчках. Отбирается формула, дающая один и тот
же результат во всех строчках.
129
Об этом свидетельствует, например, сравнение
времени, необходимого человеку и машине для решения
одной и той же задачи. Эти величины часто совпадают*).
Скорость счета у машины во много раз больше. Значит,
человек просто не мог успеть сделать столько же
проверок разных формул, сколько машина. За счет чего
же ему удается сократить число проб?
Попробуем давать людям таблицы, построенные по
одному и тому же закону, но с использованием разных
чисел А и В. Например, по тому же закону, что табл. И,
построены табл. 12 и 13, Опыт показывает, что если
ТАБЛИЦА 12 ТАБЛИЦА 13
А
зл
4,3
8,9
4,7
в
4,2
3,8
5,6
8,4
с
2,29
4,86
14,16
2,63
А
з
4
9
4
в
4
3
5
8
с
2,25
5,33
16,2
2
вместо табл. 11 человеку предложить табл. 12, то он
находит закон -g~ заметно быстрее. Причина этого
понятна: в табл. 11 числа А и В подобраны так, что
присутствие в формуле деления оказывается
замаскированным. Несмотря на наличие деления, все числа С
оказались целыми. Это приводит к тому, что человек
начинает с испытания формул, не содержащих деления,
и в результате теряет время.
Глядя же на табл. 12, человек сразу замечает, что
формула содержит деление. Более того, внимательный
наблюдатель отметит, что произведение С на В всегда
является целым числом**). Отсюда можно заключить,
что в формуле имеется деление именно на В. По-види-
*) Программа случайного поиска арифметических законов была
первой написанной нами программой (1958 г.). Она была сделана
весьма неумело и совершала много лишних операций. За счет их
устранения время работы машины можно сократить примерно в
10 раз. Это, однако, не изменит справедливости дальнейших
рассуждений.
**) С точностью до последнего приведенного знака С.
130
мому, эти или аналогичные соображения (очень часто
они могут даже не доходить до сознания) и помогают
человеку быстрее подобрать формулу.
Найти закон по табл. 13, напротив, труднее, чем по
табл. П. Конечно, производить действия с двузначными
и трехзначными числами труднее, чем с однозначными,
но дело не только в этом. В случае дробных Л и В
исчезают простые признаки, свидетельствующие о наличии
в законе деления, или признак того, что является дели-'
телем, и т. п. В результате — увеличение числа проб
разных формул.
Мы видим, что человек не просто случайно
выдвигает гипотезы о формуле и затем проверяет их. Он
предварительно применяет признаки целых классов формул
и в зависимости от характеристик таблицы по этим
признакам выбирает порядок испытаний формул. Иначе
ведет себя описанная выше программа. Независимо от
того, показали ей табл. 11, 12, 13 или таблицу,
построенную вообще по другому закону, программа будет
проверять различные формулы в одном и том же порядке
(он определяется только жребием). Таблицу программа
использует только для проверки гипотезы о законе. Чис*
ла, входящие в таблицу, на процесс построения гипотез
никакого влияния не оказывают.
Итак, программа проигрывает на том, что она не
использует информации, содержащейся в таблице, при
построении гипотезы о формуле (или, иначе, при выборе
порядка проверки формул). Очевидно, если мы хотим
сократить число операций, совершаемых машиной при
поисках закона, то нужно устранить этот недостаток.
Нужно сделать программу, которая, «бегло взглянув»
на таблицу, сама решает, имеет ли смысл, например,
проверять те законы, в которых есть деление на В,
О возможном пути построения такой программы и
будет идти речь в следующем параграфе.
§ 4. Пути сокращения перебора
Мы видели, что заметного сокращения числа проб
можно достигнуть, используя примерно такие сведения:
«в формуле есть деление на В» или «в формуле нет
вычитаний и есть несколько умножений» и т. п. Нельзя ли
для получения этих сведений использовать программу
131
Арифметика? Ведь она искала признаки именно
подобных обстоятельств (ср. главу III, § 3).
К сожалению, дело обстоит не так просто.
Действительно, после обучения Арифметика выработает,
например, признак, по которому в одну группу попадут все
законы, в которых есть деление, а в другую — законы,
не содержащие деления (разумеется, если только в
материале обучения будут представители и тех и других
законов). Однако программа «не будет знать», какое
именно обстоятельство объединяет законы в эти группы.
Да и откуда ей это знать? Ведь программе Арифметика
не сообщали, по какой формуле построен^ таблицы.
Очевидно, если мы хотим, чтобы после обучения
программа отыскивала формулы путем небольшого числа
проб, то во время обучения ей нужно не только
показывать таблицы, но и говорить, по какому закону они
построены. Возникает вопрос: на каком языке
целесообразно это делать?
Первое, что приходит в голову, — это сообщить
программе закодированную формулу. Пусть единица в
первом разряде кода означает, например, что первое
действие в формуле — сложение. Единица на втором месте
означает, что первое действие — вычитание, и т. д.
Легко сообразить, что таким способом можно шаг за шагом
описать, что надо сделать с Л и В, чтобы получить С,
т. е. закодировать формулу. Можно придумать несколько
различных способов кодирования, имеющих свои
достоинства и недостатки. Трехходовая арифметическая
формула записывается такими способами в 14—30
двоичных разрядах.
Теперь возникает идея: пусть программа ищет
признаки того, что на первом месте кода стоит единица,
признаки того, что на втором месте стоит единица,
и т. д. Если бы удалось найти такие признаки, то задача
была бы решена. В самом деле, при экзамене
программа с помощью первой группы признаков определила бы
первый разряд кода формулы, с помощью второй
группы признаков — второй разряд, и так всю формулу.
Результаты «голосования» признаков можно использовать
для управления распределением вероятностей жребия
в программе случайного поиска закона. Теперь
вероятность проверки той или другой формулы уже зависела
бы от показанной таблицы. И, очевидно, если бы замет-
132
ное большинство разрядов кода было определено пра«
вильно, число проб сократилось бы.
Примерно такая программа была сделана. Однако
она работала чрезвычайно «неровно». Для некоторых
законов она действительно давала существенное
сокращение числа проб, для других же — число проб
практически не отличалось от случайного гадания. Почему
получился такой результат?
Подвело отсутствие однозначного соответствия
между законом и формулой. В самом деле, разные формулы
могут выражать один и тот же закон. (А+В)-А-В и
А* В *(В+А)— это одно и то же с точки зрения всех
признаков, но разные вещи с точки зрения кодов
формул. Один код будет говорить, что первое действие —
сложение, а другой — что первое действие — умножение,
и т. д. Бывает и хуже. Формула А—(В— А) вообще не
содержит сложения, а эквивалентная ей А+А—В
содержит это действие. Поэтому практически не существуют
надежные признаки того, что, например, второе
действие есть непременно деление чего-то на А, и т. п.
Сейчас готовится новая программа, которая будет
искать признаки того, что вданнном разряде кода
может стоять единица при условии, что на
некотором другом месте кода стоит
единица. При обучении этой программе будут показывать
все эквивалентные формулы, описывающие данный
закон (точнее, программа будет сама по одной формуле
строить другие, ей эквивалентные).
В рассмотренном примере формул (Л+В)«Л«В и
А -В> (А + В) мы надеемся, что программа скажет, что
первое действие может быть и умножением и
сложением, а второе может быть только уАмножением, если в
качестве первого было выбрано (например, жребием)
сложение, и наоборот (сложение, если первое действие —
умножение).
Насколько оправдаются эти надежды, может пока*
зать, разумеется, только эксперимент. Но в случае
неудачи есть смысл продолжать поиски. Очень уж нужно
научиться делать программы, узнающие классы, не
показанные при обучении, и сокращающие перебор,
сопряженный с такой творческой задачей, как «открой
закон».
Глава VII
ПОЛЕЗНАЯ ИНФОРМАЦИЯ
§ 1. Количество информации и полезность сообщения
В предыдущей главе была описана программа,
которая методом проб и ошибок находила арифметический
закон. Таблицу чисел эта программа использовала
только для проверки гипотез о законе. Такой подход
приводил к очень большому числу проб. Затем обсуждалась
возможность и другого использования таблицы чисел, а
именно, для выбора разумного порядка выдвижения
гипотез (разумного в смысле уменьшения числа проб).
В этом случае естественно сказать, что программа
сокращает число проб за счет информации, содержащейся
в таблице.
Задумаемся, какой смысл имеет слово информация
в предыдущей фразе. Если считать слово информация
синонимом не имеющего точного смысла слова
сведения, то фраза ни у кого, вероятно, не вызовет
возражений. Однако при этом она станет весьма
малосодержательной. Хотелось бы, чтобы информация имела
количественную меру и эту меру можно было бы связать с
изменением числа проб. Не выполнятся ли наши
пожелания, если воспользоваться мерой количества
информации, предложенной Шенноном? Оказывается, энтропия
как мера неопределенности не всегда будет нас
устраивать, если мы захотим связать эту меру с успешностью
деятельности программы при решении некоторой задачи.
Дело в том, что теория информации появилась как
теория передачи сообщений по каналам связи.
Связистов, естественно, мало интересует, как будет
использовано сообщение на приемном конце канала. Поэтому
телеграф взимает по 3 коп. за слово и в случае
сообщения о совершенно неожиданном событии и в случае со-
134
общения о том, какое сегодня число. С «житейской»
же точки зрения вторая телеграмма вообще не
содержала бы полезной информации.
Дополнительные затруднения возникают, если
попытаться увязать количество переданной информации с
поведением получателя, решающего некоторую задачу.
В этом случае даже два совершенно неожиданных
сообщения могут быть весьма неодинаково информативными
с точки зрения получателя. Например, ошеломляющее
сообщение о победе довольно слабой футбольной
команды не имеет ценности для биржевика, играющего на
сталелитейных акциях. Для него гораздо полезнее
сообщение о начале строительства нефтепровода.
Обратное соотношение имеет место для хозяина
тотализатора.
При этом для биржевика сообщение о нефтепроводе
может привести и к обогащению и к банкротству, в
зависимости от того, как он его истолкует. Он ведь может
подумать, что сообщение истинно, и скупить акции, или
что оно злонамеренно распространяется, и продать их.
Для него сообщение может содержать и информацию и
дезинформацию.
Итак, нам хочется иметь такую меру информации,
которая отражала бы степень полезности сообщения
для получателя. При этом, естественно, эта мера
должна зависеть от того, какую задачу решает получатель,
что он знает до прихода сообщения и как он это
сообщение истолковывает. Настоящая глава и посвящена
в основном введению понятия «полезная информация»,
удовлетворяющему перечисленным требованиям.
Для этого мы будем рассматривать модельную
систему, которая при решении задачи ведет
экспериментальную работу (метод проб и ошибок) и таким путем
извлекает некоторые сведения, которых она вначале не
имела. В качестве «меры трудности» задачи для этой
системы принимается некоторая функция числа проб,
необходимых для нахождения решения. Кроме того,
система может получать сведения о задаче через канал
связи. Следствием этого является изменение
последовательности проб. В результате этого изменится число
требуемых проб, а значит, и трудность задачи.
В данной главе в качестве меры трудности
используется логарифм среднего числа проб. При такой оценке
135
получаются простые соотношения между пропускной
способностью канала связи и максимальным
сокращением трудности, которое можно получить, используя этот
канал. Забегая вперед, заметим, что введенные
Шенноном меры неопределенности и пропускной способности
канала оказываются предельным случаем более общих
выражений.
Основные понятия вводятся, по существу,
независимо от конкретной функции цены трудности
(логарифмической) и могут быть применены к довольно
широкому классу функций цены. Одна из сторон этого
вопроса рассматривается в приложении 2.
Традиционное «житейское» значение слова информа^
ция, по-видимому, ближе к предлагаемой ниже мере,
чем к шенноновской. Однако термин информация уже
занят, и для новой меры мы будем пользоваться
названием полезная информация.
§ 2. Решающий алгоритм. Неопределенность
Пусть мы имеем конечное множество объектов
Af = {m,}, на котором задано распределение
вероятностей p(mj), ..., p(nti)y ..., р(тг). Это множество
разбито на п подмножеств А{ таких, что i4iU-A2U •••
U А;[) ... цАп = М и А^А^фпрм 1Ф). Такую
ситуацию мы будем называть задачей Л. Легко видеть,
что это определение совпадает с определением, данным
в главе IV, § 4, за исключением числа подмножеств, на
которые разбито М.
Решение задачи в отношении некоторого объекта mi
заключается в нахождении такого i, что т^А{. В
соответствии с этим будем говорить: «нам нужно решить
задачу Л», если с вероятностью р{т^) нам придется
решать задачу в отношении ти с вероятностью р(т2) —
в отношении тг и т. д.
Пусть мы обладаем алгоритмом проверки
утверждения rriidAu назовем его W-алгоритмом. (Например, в
программе «открой закон» ^-алгоритм — это та
подпрограмма, которая подставляет числа Л и В в
предполагаемую формулу и проверяет, совпадает ли результат
с числом С.)
В дальнейшем мы рассматриваем некоторый класс
алгоритмов, которые будут называться решающими.
136
Описание решающего алгоритма. С
помощью жребия с некоторым распределением
вероятностей выбирается одно из подмножеств Л*. Затем
подставляется в W-алгоритм объект т/, в отношении
которого решается задача, и выбранное с помощью
жребия Лг. Если ответ — «истина», то решение закончено,
если — «ложь», то снова бросаем жребий, и т. д. При
этом распределение вероятностей быть выбранными для
разных At может оставаться постоянным, а может
изменяться от шага к шагу.
Различные решающие алгоритмы отличаются друг
от друга начальными распределениями вероятностей
жребия и законами их изменения.
Решающие алгоритмы и будут той моделью, с
помощью которой мы введем понятие полезная информация.
Если заданы объект гщ и решающий алгоритм, то
число применений W-алгоритма (проб), приводящее к
отысканию ответа, есть случайная величина K(mt).
Назовем неопределенностью задачи в отношении объекта
mi для данного решающего алгоритма логарифм
математического ожидания К (mi) числа проб, т. е.
Nim^logKimj). (1)
Неопределенностью задачи А для данного решаю-
щего алгоритма будем называть математическое
ожидание неопределенности в отношении всех объектов
N(A)^p(mi)N(ml) = ^p(ml)\ogK(ml). (2)
§ 3. Связь между неопределенностью и энтропией
В §§ 3—5 мы будем всюду рассматривать, не
оговаривая этого каждый раз, решающие алгоритмы с
постоянным (не изменяющимся от шага к шагу)
распределением вероятностей выбора А\.
Обозначим через Цх вероятность выбора решающим
алгоритмом подмножества A(2<7,= l)- Среднее
число проб при решении задачи относительно любого
объекта, входящего в Л2, равно—-. Неопределенность
Hi
задачи относительно всех объектов, входящих в Aiy
137
будет одной и той же, поэтому мы ее обозначим через
N(At). Имеем
N{Al) = -loggi.
Обозначим через pi сумму вероятностей р{т{) для
всех m^Ai. Другими словами, pi есть вероятность того,
что некоторый объект входит в класс с номером L Тогда
N (А) = S PlN (Ад = - £ A log?,. (3)
Нам придется довольно часто пользоваться
однотипными выражениями, поэтому введем сокращенные
обозначения:
п
п(р!я) = — 21 a log?,
И
п
Н(р) = — S Л log л-
Последнее есть общепринятое обозначение энтропии
распределения вероятностей ри /ь, /?з, • ♦ •, Рп- Таким
образом, H(/i)=N (/>//>).
Итак, неопределенность задачи с распределением
вероятностей ответов ри ..., рп для решающего алгоритма
с распределением вероятностей жребия <7i»..., qn равна
N(p/flf).
Пусть мы хотим построить для данной задачи
наилучший (в смысле минимальности неопределенности)
решающий алгоритм. Какое распределение вероятностей
жребия приведет к наименьшей неопределенности?
Легко показать*), что если р% фиксированы, то
неопределенность задачи минимальна тогда, когда qi=pi.
В этом случае N(p/q) =N(p/p) =Н(р), т. е.
неопределенность задачи равна энтропии распределения
вероятностей ответов. В общем случае
N(f/^)>N(p//,) = H(p). (4)
Таким образом, если при построении решающего
алгоритма мы знаем вероятности ри то нужно выбрать
4i = Pi-
*) См., например, А. М. Я г лом и И, М. Яглом, Вероятность
и информация, Физматгиз, М, 1960.
138
Допустим теперь, что имеется задача с распределен
нием вероятностей ри рг, ..., рп, мы же, по какой-то
причине, полагаем, что распределение вероятностен
р\, p'v.-, p'n (вообще говоря, р\ф />,). Стремясь
построить наилучший решающий алгоритм, мы сделаем
Qi^P'i (*"=Ь 2, ..., п). Неопределенность при этом
будет N(A) = N(p/p').
Мы видим, что выражение N(p/q) можно
рассматривать как неопределенность задачи с распределением
вероятностей ответа р для наблюдателя, исходящего из
гипотезы, что распределение равно q. Поэтому мы
будем распределение вероятностей q называть гипотезой
наблюдателя.
С этой точки зрения энтропия Н(р) является
частным случаем неопределенности. Энтропия —
неопределенность для алгоритма, знающего и наилучшим
образом использующего распределение вероятностей ответов
задачи. Всякое незнание приводит к увеличению
неопределенности.
Вообще говоря, незнание может быть двоякого рода.
Мы можем знать «правду, только правду, но не всю
правду», и мы можем «знать» то, чего нет на самом
деле (заблуждаться).
Попытка формально разделить эти случаи приведена
в приложении 1.
§ 4. Декодирование сигнала. Полезная информация
На рис. 31 показана схема решающего алгоритма,
иллюстрирующая описание, данное в § 2.
Жребий бросается с помощью рулетки, условно
изображенной в виде круга, разбитого на п секторов.
Площади секторов относятся между собой как
соответствующие qu В центре круга на оси укреплена
вращающаяся стрелка. Если ее толкнуть достаточно сильно»
то она совершит несколько оборотов и остановится, с
вероятностью q{ указывая на t'-й сектор. После остановки
стрелки на вход ^-алгоритма подается Л*. На другой
вход ^-алгоритма подан объект ти относительно
которого решается сейчас задача. В зависимости от
истинности соотношения т^Аи или печатается номер / и
решение заканчивается, или снова толкается стрелка
рулетки и т. д.
139
Рассмотрим теперь систему (рис. 32), состоящую из
решающего алгоритма /?, канала связи и алгоритма £>,
\
АпАг-, - %А«
Печать „I
Рис. 31. Схема решающего алгоритма.
Ломал одязи
соединяющего выходной конец канала с решающим
алгоритмом R.
Этот дополнительный алгоритм мы будем называть
декодирующим. Его функция заключается в следующем:
каждому значению приходящего сигнала Ck и
распределению вероятностей в
решающем алгоритме q
декодирующий алгоритм
ставит в соответствие
некоторое новое
распределение q' и заменяет в
решающем алгоритме
всеяна q\. В терминах модели
рис. 31 декодирующий
алгоритм снимает с
рулетки разбитый на
секторы круг и заменяет его другим, с новым соотношением
площадей секторов. Благодаря этому пришедшее
сообщение изменяет неопределенность задачи.
Пусть до прихода сообщения задача имела для
данного решающего алгоритма неопределенность N0, а
после прихода сообщения NL. Мы будем говорить, что по
каналу передана полезная информация
ln = Nu-Nv (5)
Печать „ь"
Рис. 32.
\А0
Из приведенного определения следует, что не имеет
смысла говорить о полезной информации, содержащейся
в сигнале, если не указаны: задача, которая решается,
начальное состояние решающего алгоритма и свойства
декодирующего алгоритма.
Изменение неопределенности задачи под влиянием
пришедшего сигнала можно интерпретировать как
процесс запасания полезной информации в виде
распределения вероятностей q. За нулевой уровень часто удобно
принимать запас полезной информации при ^ =
= ~ (/= 1, 2, ...,#)*) и от него отсчитывать полезную
информацию. При таком подходе запас полезной
информации, содержащийся в гипотезе q относительно задачи
с распределением вероятностей ответа р, дается
соотношением
/n = \ogn — N{p!q).
Приведем пример, иллюстрирующий определение.
Некто X хочет застать в учреждении, открытом с 10 до
18 часов, сотрудника К, о котором известно, что он
бывает там по два часа ежедневно. Желая уточнить эти
сведения, X обратился к знакомому, работающему в
том же учреждении. Знакомый ответил, что У бывает
на работе после 14 часов в два раза чаще, чем до 14.
После этого X позвонил секретарю в учреждение. В
ответ на свой вопрос он услышал:
«.. .на будущий месяц расписание еще не составлено,
но товарищ Y всегда принимает пять раз в неделю с 12
до 14 и один раз в неделю с 14 до 16. Ой, простите, я
ошиблась. Один раз с 12 до 14 и пять раз с 14 до 16».
Последний ответ соответствовал действительности.
Какую полезную информацию получил X по
интересующему его вопросу:
1) из ответа знакомого?
2) из ответа секретаря?
3) получил бы из ответа секретаря, если бы она не
исправила ошибки?
Для удобства все вероятности сведены в табл. 14.
*) В приложении 1 показано, что если мы ничего не знаем о
распределении вероятностей pf то в некотором смысле гипотеза
Ш = — (/ = 1, 2, ..., п) является оптимальной.
141
ТАБЛИЦА 14
10-12 12-14 14-16
16-18
Истинное распределение
вероятностей
Начальная гипотеза
Гипотеза после сообщения знакомого
Гипотеза после ответа секретаря . .
Гипотеза после ошибочного ответа
секретаря
6
J_
4
J_
6
6
J5
6
6
J_
4
J_
3
5_
6
J_
6
Будем выражать неопределенность и полезную
информацию в битах.
Начальная неопределенность:
Неопределенность после ответа секретаря:
Если бы секретарь не исправила ошибки, была бы
неопределенность:
^з = - i log2 4 —| log21« 2,20.
Таким образом, полезная информация, полученная от
знакомого:
/Я| = ЛГ0 —^«0,25.
Ответ секретаря содержал полезную информацию:
/Яа = ЛГ,-ЛГ2~1,1.
142
Неопределенность после ответа знакомого:
Если бы тот же самый разговор с секретарем
произошел до ответа- знакомого, то он содержал бы N0—Af2~
«1,35 бита полезной информации.
Ошибочный же ответ нес полезную информацию
/Яа = Л^, — Nz »—0,45. Другими словами, он
содержал 0,45 бита дезинформации.
При рассмотрении этого примера мы молчаливо
подразумевали, что алгоритм декодирования сообщения
сводится к переносу сообщенных вероятностей прямо в
решающий алгоритм («полное доверие»). Разумеется,
при другом декодирующем алгоритме полезная
информация, содержащаяся в рассмотренных сообщениях,
была бы другой. Например, со стороны X было бы
естественно, получив ошибочное сообщение секретаря,
резко противоречащее сообщению знакомого, не поверить
ему, а верному сообщению поверить не полностью, во-
первых, из-за некоторого расхождения с сообщением
знакомого, во-вторых, из-за предварительной ошибки
секретаря.
Следует отметить, что величина полезной
информации зависит также от кода, которым передается
сообщение. «Те же» сообщения могли быть иначе
закодированы, например произнесены на незнакомом для X
языке. В этом случае декодирующее устройство вообще не
перераспределило бы qt в решающем алгоритме (X не
понял бы даже, что сигнал имеет отношение к
интересующему его вопросу). Полезная информация была бы
равна нулю.
Во всех руководствах по теории информации
подчеркивается, что если в сообщении, закодированном с
помощью двузначного алфавита, заменить нули на
единицы и обратно, то количество информации не
изменится. Как мы видим, к полезной информации это
соотношение не относится. Полезная информация от такого
преобразования может резко измениться и даже
изменить знак на обратный.
Еще одно свойство заметно отличает полезную
информацию от «классической информации». Какая
информация может храниться в коде набора чисел
Qu Цг, ..., ?п?
В классической теории ответ на этот вопрос зависит
от того, с какой точностью мы знаем qu #2, ..., Qn- Чем
эта точность больше, тем больше информация. Полезная
143
же информация, запасенная в распределении qiy q2, ...
..., qn относительно задачи с распределением
вероятностей ответа ри Рг, ..., Рп, равна log я—N(plq)
и не зависит от точности, с которой известны qim
Полезная информация зависит совсем от другого
обстоятельства: от того, насколько q соответствует р. Знание q\
с малой точностью приведет к малой точности
определения /?ь но не к малому значению этой величины.
§ 5. Пропускная способность канала связи
для полезной информации
Рассмотрим теперь соотношение между
неопределенностью задачи (после прихода сообщения) и
пропускной способностью канала связи.
Назовем два сигнала С4 и С2 неразличимыми для
системы, если после прихода как Си так и С2 система
перейдет в одно и то же состояние, иначе говоря,
решающий алгоритм будет пользоваться одной и той же
гипотезой q'v q'v ..., q'n. Задавшись определенной
точностью измерения qu мы можем про любые два сигнала
сказать, различимы они или нет. Реальная система
может иметь лишь конечное число состояний. Пусть число
различных наборов qu <7г, ..., qn равно /. Разобьем
множество всех сигналов на классы d, С2, ..., Ст
неразличимых между собой сигналов. Очевидно т^/*).
Свойства декодирующего устройства при фиксированном
начальном распределении q исчерпываются разбиением
сигналов на классы и табл. 15, определяющей
распределение qr после прихода сигнала из класса С&.
Здесь rfifc, d2k, ... , dnk — значения q'v q'v ..., q'n
после прихода сигнала из класса Ch. Поэтому d^X) и
п
2^=1.Всякую таблицу, составленную из d^, обла-
/ = i
дающих такими свойствами, можно считать
декодирующим устройством.
*) Сигналы, неразличимые для системы, находящейся в одном
состоянии, могут оказаться различимыми для системы, находящейся
в другом состоянии. Однако для всего дальнейшего нам достаточно
рассматривать лишь классы сигналов, неразличимых для системы,
находящейся в данном состоянии.
144
ТАБЛИЦА 15
Ч\
1 /
?2
1 г
4l
Яп
с,
<?п
dn\
L>2 •
dl2 . .
dW •
rf*2 •
dn2
Ck
. dlk .
. . dik .
- * dnk -
• • ^m 1
• • rflm
• • d2m
• • dim
• • "/ш
Рассмотрим ситуацию, когда перед решением задачи
относительно объекта т\ систему извещают с помощью
некоторого сообщения о том, к какому классу А{
принадлежит т\. При этом, если mi£Au то посылается
сообщение фь если т1^А2у посылается ф2 и т. д.
Вероятности прихода сигналов Ck после посылки различных
сообщений определяются матрицей \\РцЛ (табл. 16).
ТАБЛИЦА 16
Ф1
ф/
Фл
с, .
л, .
Ри ■
Рпх ■
. с* •
• я.» •
• Pik ■
• Рак •
^т
• Рш
• ' im
Р
• * пт
Сразу возникает вопрос: почему мы рассматриваем
такой сложный случай? Почему после посылки
сообщения фг- о принадлежности mi к классу А% могут прийти
разные сигналы С\ и почему после посылки разных ф,-
может прийти один и тот же сигнал? Предположим, что
решающий алгоритм ищет формулу, по которой
построена числовая таблица. Сообщением, с помощью которого
декодирующий алгоритм может пытаться уменьшить
145
неопределенность задачи, является сама таблица.
Очевидно, что в этом примере в случае принадлежности
объекта к одному и тому же классу, могут прийти
разные сигналы. Другой случай: решающий алгоритм
должен определить по фотографии, кто снимался, —
мужчина или женщина. Пришедший сигнал (фотография)
чаще всего содержит сведения, достаточные для
однозначного (с высокой степенью достоверности) ответа на
вопрос. Но встретятся фотографии, которые могут
принадлежать и мужчине и женщине. Это бывает из-за
низкого качества фотографий («помехи») и из-за того, что
сами лица некоторых мужчин и женщин 'очень похожи
друг на друга. Итак, на практике и в строке и в столбце
табл. 16 может быть более одного отличного от нуля
числа. Поскольку после посылки сообщения ср* какой-то
сигнал прийти должен, имеет место соотношение
т
k — l
Чему станет равна неопределенность задачи, если
сигнал, переданный по каналу связи, характеризуемому
матрицей ЦР^Н, будет декодирован с помощью
алгоритма, характеризуемого матрицей llrf^ll?
Допустим, объект принадлежит классу Лг-. Тогда с
вероятностью Рц придет сигнал Си а значит, среднее
число проб будет -г—. С вероятностью Р;2 среднее число
проб будет —г- и т. д. Таким образом,
т
Вероятность этой ситуации равна /?*. Поэтому
п т
NAA) = -Iipl^Pik\ogdik.
Введем обозначения
п
Pk = 2j PiPik '
m
dt = S P*dik-
(6)
(j)
(8)
146
Легко показать, что
т
2Р*=1. (9)
Для оценки неопределенности снизу преобразуем (6):
п т I - - - \
^i(A) = ~^Pi^Pik[logdi-\ogPk + \og^j =
л m т п
= —У) A log rf* J]Р'* + S S АЯ'*log ^* —
я /и _
П П
= ^(pld)-H{P)-^ipiyiPlk\og^f
Pkd,k
Учитывая (4) и (8), получаем
Л^(4)>Н(р)-[Н(Р)-Н(/>)}, (И)
_ п т
где Н (Я) = — 21Л 2 Л** log Л* есть средняя энтропия
распределения вероятностей сигналов С& в
сообщениях фг\
Выражение, стоящее в формуле (11) в квадратных
скобках (энтропия среднего сигнала минус средняя
энтропия сигналов), совпадает с пропускной способностью
канала, характеризуемого матрицей \\Рш\\, при
вероятностях различных сообщений рь р2, ... , /?п. Поэтому
(11) означает, что, как бы мы ни декодировали сигналы,
неопределенность задачи после декодирования будет не
меньше, чем энтропия распределения вероятностей
ответов минус пропускная способность канала.
Возникает вопрос: насколько можно приблизиться к
этой теоретической границе?
147
Пусть мы построили матрицу декодирующего
алгоритма по формуле
<11к = £ф±. (12)
Эта матрица может служить декодирующим
алгоритмом, так как ^>0 и из (7) следует, что
п
*-1
Найдем неопределенность задачи после
декодирования сигнала таким алгоритмом:
я т
PjPjk
Pk
/«1 k~i k
п т
= — %Pi^Pik(logPi — logPk + logPik)==
т п т п
/=1 Л-1
Итак, если построить декодирующий алгоритм по
формуле (12), то неопределенность достигает минимума*
Можно также доказать единственность оптимального
декодирующего алгоритма (для краткости мы
доказательства не приводим).
Чтобы воспользоваться формулой (12), мы должны
заранее знать все pi и Pih. В действительности же.
однако, это требование часто не удовлетворяется.
Допустим, некоторый наблюдатель имеет гипотезу q\, q2 ... ,
qn о вероятностях ответов задачи и гипотезу, что канал
связи характеризуется матрицей HQ^II. Стремясь
максимально сократить неопределенность задачи, он
построит декодирующий алгоритм по формуле
**~*Ф-> (И)
14$
где
В результате неопределенность задачи для такого
наблюдателя окажется равной (пропускаем
промежуточные выкладки)
л т
= N(p/«)-[N(P/Q)-N(P/Q))f (15)
где
п т
Формулу (15) можно переписать в виде
N Ш - N, (А) - N (PJQ) - N (PIQ). (16)
В левой части равенства стоит изменение
неопределенности задачи после прихода и декодирования сигнала.
В самом деле, N(p/q) =No(A) —начальной
неопределенности задачи для наблюдателя, исходящего из
гипотезы q, a Ni(A)—конечная неопределенность. Таким
образом, N(p/q) — Ni(A)~N0(A)—Ni(A) — по
определению— количество полезной информации, пришедшее
по каналу связи. Поэтому есть смысл назвать разность
N(P/Q)-N(P/Q) (17)
пропускной способностью канала для полезной
информации в ситуации р и Р относительно наблюдателя,
исходящего из гипотез q и Q. Для наблюдателя, все
правильно знающего о задаче и о канале связи (qi = Pi\
Qtk^Pih), получается «классическая» пропускная
способность
ЩР)-ЩР). (18)
Любопытно отметить, что (17) может быть и меньше
и больше, чем (18). Например, если наблюдатель все
правильно знает о канале (Qik^Pik), но исходит из
неоптимальной гипотезы о задаче (дг=£рг), то всегда
N (PIQ) -N(Pj'Q) > Н (Р) - Н (/>).
149
Такой наблюдатель экспериментально обнаружит *)
большую пропускную способность канала, чем
наблюдатель, исходящий из оптимальных гипотез. Несмотря
на это, остаточная неопределенность задачи будет для
такого наблюдателя все-таки больше, чем для
«всеведущего».
Формула (16), по существу, и устанавливает связь
между свойствами задачи, свойствами сигнала, тем, что
наблюдатель раньше думал о задаче, как он относится
к сигналу, и той пользой, которую он при этих
обстоятельствах извлечет из сигнала.
§ 6. Системы с обратной связью
До сих пор мы рассматривали решающие
алгоритмы, не изменяющие q{ в процессе решения задачи. Они
«ничего не помнили». После того как применение
^-алгоритма показало, например, что Ai не содержит ти
решающий алгоритм продолжал бросать жребий со
старым распределением вероятностей q> хотя уже стало
известно, что q\ можно сделать равным нулю. После
неудачной пробы неопределенность задачи оставалась
такой же, как и до нее.
Такие «глупые» алгоритмы понадобились нам в
качестве модели, которая дает возможность ввести понятие
неопределенности задачи для наблюдателя, исходящего
из некоторой вполне определенной гипотезы 0. В самом
деле, если q меняется в ходе решения, то теряется
возможность сопоставить число проб с какой-либо
гипотезой.
Однако если наша цель состоит в построении
оптимального решающего алгоритма, то нет никаких
оснований пренебрегать информацией, которую дают
применения W-алгоритма. Системы, в которых результат
применения W-алгоритма влияет на распределение
вероятностей жребия при следующих тактах работы, мы будем
называть системами с обратной связью.
Примером системы с обратной связью может слу~
жить такой алгоритм: в случае неудачной пробы по цепи
обратной связи посылается сигнал «не Л*». Получив та-
*) Сравнивая число проб при решении задачи до и после
прихода сигнала.
150
кое сообщение, система делает <^ = 0, а остальные
вероятности пропорционально увеличивает так, чтобы их
сумма равнялась единице. Теперь после каждой
неудачной пробы неопределенность задачи уменьшается.
Система с обратной связью пользуется на каждом
следующем шаге новой (уточненной в результате
эксперимента) гипотезой. В частности, для подобной системы число
проб никогда не будет больше, чем п.
В § 3 говорилось, что при построении алгоритма без
обратной связи наименьшая неопределенность
достигается, если бросать жребий с распределением
вероятностей р. Следует ли отсюда, что если дополнить этот
процесс выбрасыванием проверенных At и
перенормировкой остальных вероятностей, то мы получим
оптимальный алгоритм с обратной связью? Оказывается, нет.
В приложении 2 доказывается, что оптимальным будет
следующий алгоритм с обратной связью: упорядочим
индексы при At так, чтобы А1>Л2>А3> ••• >А„.
Пробуем Atx; если ответ — «ложно», то пробуем Л/2
и т. д. Таким образом, оптимальный решающий
алгоритм с обратной связью фактически обходится без
жребия (все выборы происходят с вероятностями
единица). Каждый ответ Лг- характеризуется для этого
алгоритма не вероятностью выбора qiy а натуральным
числом zi — порядковым номером «в очереди на
проверку».
При повторном решении задачи относительно объекта
гщ£А{ решающий алгоритм с жестким порядком
перебора будет всегда находить ответ на одном и том же
шаге Z{. Поэтому неопределенность N(mt) для такого
алгоритма равна просто log гг-. Отсюда
т п п
N(A)= 2 Л log г* = 2 Pts log г, = 2 Pts log s, (19)
/ = 1 5 = 1 s s s = l s
где s — номер pt в ряду pit расставленных в порядке
убывания.
Естественно, что если при построении решающего
алгоритма мы исходим из гипотезы q о распределении
вероятностей ответов, то в порядке убывания будут
расположены qx. Соответственно в формуле (19) 5 нужно
считать номером qt в убывающем ряду qu
151
Докажем, что в этом случае
JV(i*)=SA>gs<N(p/f). (20)
Заметим, что имеют место соотношения
Следовательно,
log 1 < — log^,
log2<-rlog^2,
log/*< —logfy,.
Отсюда формула (20) получается автоматически.
Пусть мы имеем два решающих алгоритма с жестким
порядком перебора, один исходит из гипотезы q, а
другой— из гипотезы q'. Допустим, что qt Ф q'p но zi^=z/i.
Мы не сможем «по поведению» отличить один алгоритм
от другого. Поэтому имеет смысл говорить, что для
алгоритмов с обратной связью гипотезой является не
распределение вероятностей, а лишь порядок проверки
ответов.
Декодирующее устройство, связанное с таким
решающим алгоритмом, целесообразно характеризовать
таблицей, определяющей очередь проверки ответа А{ после
прихода сигнала Ck (см. табл. 17).
В столбце zik; гг^\ ...; znh все целые числа от 1
до п встречаются по одному разу.
Очевидно, оптимальным будет декодирующее
устройство \\ZikW, построенное следующим образом. Возьмем
матрицу \\dihW с элементами, определенными по
формуле (12). Расставим элементы &-го столбца в порядке
убывания: dt{k ^>dt2k > ... >*/*я*. Пусть t = /s; тогда
152
ТАБЛИЦА 17
л
Аг
At
Ап
с< .
Zi\
zn\
с2 . .
*12 •
^22
2/2 •
2/12
. с* .
*2*
*/*
^л*
^т
z2m
zim
znm
Zik = s. Учитывая соотношение (20), легко заметить, что
для такого алгоритма формула (13) переходит в
Ъ(А)<Н(р)-[Н(Р)-ЩР)]. (21)
§ 7. Две функции условия задачи
В §§ 2 и 4 были введены понятия: ^-алгоритм,
решающий алгоритм, декодирующий алгоритм. Как
перевести на этот язык такое привычное всем понятие, как
«условие задачи»?
Возьмем «школьную» арифметическую задачу:
«У двух мальчиков есть двенадцать книг. У Коли на две
книги больше, чем у Пети. Сколько книг у Коли и
сколько у Пети?»
Во-первых, условие содержит W-алгоритм.
Действительно, в принципе можно найти ответ, генерируя
случайным образом пары чисел и проверяя, удовлетворяют
ли они условию.
Во-вторых, условие является сигналом, который
после соответствующего декодирования может сократить
неопределенность задачи.
Наличие у «условия» двух существенно разных
функций трудно заметить на самом себе или на другом
взрослом человеке. Зато очень явно оно выступает в опытах
с детьми и с некоторыми программами.
Если предложить эту задачу ребенку лет восьми-де-
вяти, уверенно считающему до ста и легко
производящему сложение, вычитание и деление на два в
пределах первых двух десятков, но не решавшему подобных
153
задач, то он, как правило, не пользуется условием как
У/-алгоритмом. Он высказывает непроверенные
предположения, предпочитая использовать в качестве №-алго-
ритма взрослого, давшего ему задачу. При этом, однако,
легко заметить, что он пользуется условием для
сокращения области поисков (хотя часто и не наилучшим
образом). В нашем примере ребенок почти никогда не
назовет чисел больших 12. Очень многие дети пробуют
только пары, дающие в сумме 12. Иногда бывают
случаи, когда пробуются пары с разностью два. Если
ребенок знает дроби, то он все-таки называет только целые
числа (количество книг не бывает дробным!), в то же
время, если изменить формулировку условия и сказать:
«...двенадцать килограммов конфет...», то появятся дроб*
ные пробы.
Все это указывает на наличие процесса
декодирования условия на стадии, когда в качестве W-алгоритма
условие еще не используется.
«Правильно составленное» условие задачи из
школьного задачника после оптимального декодирования
уменьшает неопределенность до нуля. Это приводит к
тому, что иногда в 3—4-м классе ребята умеют
выдавать правильный ответ задачи, но не умеют (или во
всяком случае не имеют привычки) его проверить.
Возможно, поэтому с трудом решаются «нестандартные»
задачи, в которых оптимальное декодирование условия
лишь снижает неопределенность до такой степени, что
становится возможным перебор оставшихся вариантов.
Иначе ведет себя программа, которая ищет
арифметический закон путем случайных проб. Она использует
таблицу чисел только для проверки гипотез, т. е. как
объект для W-алгоритма, совершенно не пытаясь
декодировать ее и тем уменьшить неопределенность задачи.
Итак, разные системы используют разные свойства
условия задачи. Какой же вид операций над условием
является характерным для узнающих систем?
§ 8. Декодирование и узнавание
Вспомним, что делала программа Арифметика во
время экзамена. Присвоив неизвестной таблице
характеристики по всем признакам, она сравнивала
полученный набор характеристик с наборами, хранимыми в па-
154
мяти. После этого она печатала номера трех «самых
похожих» законов. Могла ли программа вместо этого,
совершив несколько дополнительных проверок, с
гарантией напечатать номер именно того закона, по которому
составлена таблица? Естественно, нет. Программа ведь
не обладала сведениями о формулах, по которым были
построены таблицы, данные при обучении. Более того,
она даже не знала, построены ли таблицы по
арифметическим или по логическим законам. Другими
словами, программа не содержала W-алгоритма.
Очевидно, эта ситуация характерна для всех задач
узнавания. Обратимся к рис. 18, на котором дана схема
процесса узнавания. «Верховным судьей»
(^-алгоритмом) является блок /Сь находящийся вне узнающей
системы. Задачей системы при экзамене является
декодирование вида объекта для уменьшения
неопределенности, но узнать, какова же остаточная
неопределенность, сама система не в состоянии.
Иными словами, при экзамене происходит выбор
Qu Q2, ... , Яп, и на этом процесс заканчивается из-за
отсутствия ^-алгоритма. Оценить полученную
неопределенность (или число необходимых проб) может лишь
экзаменатор (который заведомо обладает
^-алгоритмом*)). Так мы и поступали, оценивая качество работы
программы Арифметика.
Таким образом, экзамен — это декодирование
некоторого сигнала о классе, к которому принадлежит
объект. Обучение же — процесс создания декодирующего
устройства. Обучающаяся система должна сама
синтезировать декодирующее устройство, хорошее для
данной задачи.
Иными словами, система должна выбрать из
некоторого множества доступных ей декодирующих
устройств одно устройство, подходящее в данном частном
случае. В качестве ^-алгоритма этого выбора служит
проверка результатов декодирования объектов из
материала обучения. Таким образом, синтез
декодирующего устройства сам по себе является некоторой
*) Разумеется, можно автоматизировать процесс экзамена,
написав дополнительную программу, снабженную ^-алгоритмом, и
поручив ей вести проверку гипотез. Так устроены программы
«открой закон». Но эта надстройка не является собственно узнающей
программой,
155
задачей, неопределенность которой, очевидно, тем
больше, чем больше разных декодирующих устройств может
построить система.
Сразу возникает идея сократить неопределенность
этой задачи путем декодирования материала обучения.
Один из путей для этого — сделать раз и навсегда до*
полнительный декодирующий алгоритм, который, «по*
смотрев» на материал обучения, выберет порядок
проверки разных декодирующих устройств (тех, которые
декодируют одиночный объект и могут работать при
экзамене). Дополнительный декодирующий алгоритм
являлся бы системой, узнающей не объекты, а задачи.
Может показаться, что есть смысл стремиться к по^
строению такого универсального (для данной совокуп*
ности задач) декодирующего алгоритма. Вспомним, од*
нако, что совокупность задач содержит весьма много
задач, причем мы зачастую даже не знаем, сколько их,
и не можем на сколько-нибудь формальном языке
описать всю совокупность. При этих условиях построение
универсального декодирующего устройства становится
безнадежным делом. Для сложных совокупностей задач
вряд ли удастся свести обучение к однократному
декодированию.
Вероятнее всего, придется строить многоступенчатый
процесс следующим образом: на первом этапе
происходит выбор некоторого подмножества совокупности задач,
к которому принадлежит наша задача, представленная
материалом обучения. Выбор происходит частично за
счет декодирования материала обучения и частично за
счет некоторого перебора.
В результате решения задачи первого эгапа
программа, во-первых, сокращает область дальнейших поисков
и, во-вторых, приобретает возможность построить уже
несколько специализированное декодирующее
устройство. Это декодирующее устройство годится отнюдь не
для всех задач из совокупности. Оно приспособлено для
выбранного подмножества. Затем процесс повторяется.
Выбранное подмножество снова делится на части и т. д.
Декодирующее устройство, возникающее на каждом
этапе, состоит из двух частей: блока, преобразующего
отдельные объекты, и блока, сопоставляющего
результаты преобразований разных объектов. При этом на
вход блока, преобразующего объекты на 1-м этапе, по-
156
ступает результат работы соответствующего блока на
(/—1)-м этапе, а сопоставление разных объектов
происходит наново. Сопоставление объектов на (I—1)-м
этапе лишь помогло выбрать преобразователь /-го этапа.
Процесс естественно остановить на таком этапе,
когда после преобразования все объекты одного класса
станут неразличимы между собой, второго класса —
также неразличимы между собой, но первый класс еще
будет отличаться от второго. Очевидно, найденное
преобразование можно прямо использовать при экзамене.
В описанном процессе есть одно, мягко говоря,
непонятное место: что должно служить ^-алгоритмом на
промежуточных этапах? Для последнего этапа W-алго-
ритм указан в предыдущем абзаце, а как быть на всех
остальных этапах? Каким критерием руководствоваться
при отборе преобразований объектов? Вообще говоря,
для разных совокупностей задач эти критерии должны
быть различными. Некоторые из таких критериев
рассматриваются в V, VIII и IX главах. Там же идет речь
о совокупностях задач, для которых эти критерии могут
оказаться полезными.
Глава VIII
ПРОГРАММА ГЕОМЕТРИЯ
§ 1. Уроки перцептрона
В главе II рассматривался алгоритм работы
простого перцептрона Розенблатта. Там же были описаны
опыты, показавшие, что, например, задача различения
прямоугольников и эллипсов для перцептрона слишком
трудна. Попробуем проанализировать причины плохой
работы перцептрона и подумаем, нельзя ли
сравнительно небольшой переделкой алгоритма исправить его
недостатки.
Начнем со сразу бросающегося в глаза
обстоятельства— связи Л-элементов с рецепторами (рис. 9) не
зависят от того, какую задачу должен решать перцептрон.
В самом деле, эти связи устанавливаются с помощью
жребия еще до того, как перцептрону показывают
материал обучения. Поэтому и отличать треугольники от
окружностей и отличать выпуклые фигуры от вогнутых
перцептрон вынужден с помощью тех же самых связей
Л-элементов. В схеме перцептрона мало обучаемых
мест. Обучение влияет только на коэффициенты
усиления k.
Возникает идея: выбирать связи Л-элементов с
помощью обучения. Для этого можно, например,
по-прежнему случайно генерировать связи, но закреплять в
памяти только те, которые после проверки окажутся
полезными для данной задачи. Однако даже при таком
способе организации связей вероятность получения
хорошего набора Л-элементов будет очень низкой.
Допустим, что для данной задачи полезно отличать
углы от гладких линий. Пусть после большого числа
бросаний жребия образовался Л-элемент с нужными
свойствами. Он будет обнаруживать угол в каком-то
158
одном участке поля зрения. Но ведь перцептрону-то
нужно замечать углы, где бы они ни встретились! Ясно,
что пройдет очень много времени, прежде чем
образуется набор Л-элементов, обнаруживающий углы в
любой части поля зрения.
Поэтому следующее приходящее в голову
усовершенствование перцептрона— это «размножение» хороших
Л-элементов. Можно сделать так: как только нашелся
один Л-элемент, обнаруживающий углы, аналогичные
Л-элементы строятся для других частей поля зрения уже
без всяких проб.
Возникает вопрос, все ли сведения машина должна
получать путем обучения? В самом деле, есть операции
над картинкой, которые нужны редко (только для
небольшой части задач из совокупности). Их имеет смысл
находить при обучении. Но есть операции, которые
приносят пользу очень часто. Зачем их каждый раз
искать заново? Не лучше ли заложить в программу
заранее набор таких операторов и не заставлять
машину каждый раз тратить время на их поиск.
Примерами таких операторов могут быть выделение контура
фигуры, нахождение углов, точек пересечения линий
и т. п.
Наконец, бросается в глаза ограниченность
логических возможностей перцептрона. Ведь при экзамене все
Л-элементы просто голосуют с весами, отобранными при
обучении. При этом вес данного Л-элемента не зависит
от того, какие другие Л-элементы возбудились
одновременно с ним. Из-за этого перцептрону не под силу
задачи, в которых вес некоторого обстоятельства должен
меняться в зависимости от наличия или отсутствия
какого-либо другого обстоятельства. Примером может
служить задача на рис. 30.
Очевидно, можно улучшить дело, дав программе
возможность искать достаточно разнообразные логические
функции от высказываний типа: «/-й Л-элемент
возбудился».
Настоящая глава в основном посвящена описанию
программы, которая содержала перечисленные выше
усовершенствования, и экспериментов с этой
программой. Она предназначалась для разбиения картинок на
четыре класса и была сделана М. Бонгардом, М.
Смирновым, В. Максимовым и Г. Зенкиным.
159
§ 2. Структура программы Геометрия
Объектами для программы Геометрия являются
черно-белые (без полутонов) картинки, заданные на растре
32X36. Примеры возможных картинок даны на рис.33.
Программа состоит из четырех блоков, которые при
экзамене последовательно обрабатывают информацию.
На вход первого блока поступает картинка, на вход
второго— результат обработки картинки первым блоком
и т. д.
Обучение каждого блока происходит после обучения
предыдущих и до обучения последующих блоков. При
этом во время обучения, например, третьего блока
состояние второго изменяться уже не может (при
обучении нет длинных обратных связей). Это позволяет нам
рассматривать работу каждого блока, забывая на время
об остальных.
При выборе наименований блоков мы
воспользовались аналогией с работой глаза. В сетчатке глаза
позвоночных сигнал от рецепторов попадает сначала в
слой биполярных клеток, а затем в слой ганглиозных
клеток. Отростки ганглиозных клеток (аксоны) идут
уже в мозг, в подкорковые центры и далее в кору. Мы
сочли удобным придать блокам программы Геометрия
такие же названия. Читатель, однако, должен иметь
в виду, что упомянутая аналогия является весьма
поверхностной и употребляемые нами ниже термины
биполярные клетки, ганглиозные клетки, подкорка и
кора являются лишь короткими названиями блоков
программы. Перейдем теперь к описанию работы этих
блоков.
а) Биполярные клетки. Биполярные клетки
являются необучаемым блоком. Они делают те
преобразования картинок, которые, согласно ожиданиям, нужны
часто.
Биполярные клетки делятся на три слоя. Каждый из
них отображает картинку размером 32x36 в поле тех
же размеров. Первый слой выделяет контуры фигур.
Второй обнаруживает углы. Третий производит
(Интерполяцию, которая устраняет небольшие помехи. ЕсЛ|* на
картинке есть одинокая черная точка на белом фЬне,
то третий слой ее стирает, а если есть белая точка на
черном фоне, то он ее закрашивает.
160
Рис. 33. Примеры картинок для программы Геометрия
Для примера рассмотрим алгоритм работы первого
слоя.
Расположим мысленно (рис. 34) все точки выходной
картинки первого слоя над соответствующими точками
исходной картинки (слоя рецепторов). Будем считать
соседями каждого нижнего квадратика те квадратики,
Рис. 34. К описанию алгоритма работы «биполярных
клеток».
которые имеют с ним или общую сторону или общую
вершину. Квадратики, находящиеся внутри, имеют
восемь соседей, граничные — меньше.
Закрасим квадратик верхнего поля в черный цвет,
если одновременно выполняются два условия: 1) точно
под ним расположен черный квадратик, 2) по крайней
мере один сосед находящегося под ним квадратика
белый. Остальные квадратики верхнего поля остаются
белыми. Легко видеть, что при таком алгоритме работы
на верхнем поле мы получим контур фигуры. Алгоритмы
работы двух других слоев организованы аналогично, и
мы не будем подробно разбирать их.
Таким образом, после работы биполярных клеток
одно поле 32X36 превратилось в четыре поля тех же
размеров (исходное поле рецепторов и результат
работы трех слоев). Эти четыре поля и служат исходным
материалом для ганглиозных клеток.
б) Ганглиозные клетки. Ганглиозные клетки
являются первым обучаемым блоком программы.
Однако их обучение происходит только один раз (для всей
совокупности задач, а не для каждой задачи отдельно).
162
Блок ганглиозных клеток состоит из 45 слоев. Все
слои устроены аналогично и отличаются друг от друга
только тем, на чем они обучались. Слой содержит поле
32X36 клеток. Каждая из этих 1152 клеток является
Л-элементом. Другими словами, каждая ганглиозная
клетка имеет некоторое число возбуждающих и тормозящих
Рис. 35. Связи «ганглиозных клеток».
связей, которые приходят от рецепторов и
биполярных клеток (рис. 35). В случае, если сумма пришедших
сигналов превосходит некоторый порог, ганглиозная
клетка возбуждается. Если мы спроектируем все слои
на одну плоскость, то рецепторы и биполярные клетки,
с которыми связана данная ганглиозная клетка,
окажутся внутри квадрата 8X8 (рис. 36).
На рис. 36 изображены связи трех ганглиозных
клеток (сами ганглиозные клетки заштрихованы). Внутри
данного слоя связи всех ганглиозных клеток
организованы одинаково. Каждая ганглиозная клетка имеет
12 связей (на рис. 36 для простоты показаны лишь шесть
t63
из них*). При обучении (с помощью жребия) решалось,
сколько из них будет тормозящими (0, 2, 4 или 6). После
этого, также с помощью жребия, про каждую связь
решалось, из какого слоя и из какой клетки внутри
квадрата 8X8 этого слоя будет приходить сигнал в гангли-
озную клетку. Поскольку все клетки слоя строятся «по
Рис. 36. К описанию структуры слоя «ганглиозных клеток».
одному плану», жребий бросался один раз для всех
1152 клеток.
Обучение состояло в отборе таких слоев ганглиозных
клеток, которые оказывались полезными для различения
между собой некоторых пар картинок. Примеры таких
пар приведены на рис. 37.
Процесс обучения строился таким образом: в машину
вводится пара картинок (например, рис. 37,в). Блок
*) Для клеток, расположенных вблизи границы, число связей
оказывается меньшим, так как «из-за границы» поля 32X36
сигналы, естественно, не приходят,
164
биполяров превращает каждую картинку в четыре поля
32X36. Теперь бросается жребий и формируется слой
ганглиозных клеток. Этот слой обрабатывает обе
картинки. Затем программа проверяет: можно ли подобрать
Рис. 37. Примеры пар картинок для отбора ганглиозных
клеток.
такой порог для ганглиозных клеток, чтобы количество
клеток, возбудившихся одной картинкой, сильно
отличалось от количества клеток, возбудившихся другой
картинкой. Если такой порог удалось найти, то в память
записывалась структура слоя вместе с подобранным
порогом. Если слой плохо различал пару картинок, то в
165
память он не записывался и жребий бросался снова. На
каждой паре картинок отбиралось два-три слоя гангли-
озных клеток. Всего было отобрано 45 слоев.
Пары картинок подбирались таким образом, чтобы
«обратить внимание» программы на те обстоятельства,
которые часто будут входить элементами в задачи. При
этом следили, чтобы, по возможности, «не отвлекать»
программу побочными обстоятельствами. Например, в
паре, изображенной на рис. 37а, число отдельных линий
и их суммарная длина были на обеих картинках
одинаковыми. Хотелось, чтобы различие было только в
том — прямые линии или кривые.
Выходом каждого из отобранных 45 слоев ганглиоз-
ных клеток являлось целое число от 0 до 1152
(количество возбудившихся клеток).
в) Подкорка. Программа Геометрия
приспособлена различать четыре класса картинок. Соответственно
обучение блока подкорка происходит на картинках
четырех классов (например, буквы А, Б, В и Г). Каждый
класс должен быть представлен 6 картинками.
Задачей подкорки является подготовка материала
для логического блока кора. На входе коры должен
быть набор логических переменных, принимающих два
значения. Поэтому подкорка превращает 45 чисел*),
которыми характеризуют каждую картинку 45 слоев
ганглиозных клеток, в 45 нулей или единиц.
Обучение подкорки происходит следующих образом:
входным материалом для программы служат 24 числа—
результат обработки всех картинок четырех классов
ганглиозными клетками первого слоя. Интервал между
наибольшими и наименьшими числами делится на десять
частей. Это дает возможность попробовать девять
разных порогов. Каждый порог превращает 24 числа в
24 нуля или единицы. Возникает вопрос выбора
оптимального порога. Нужно, чтобы характеристика
картинки двоичным переменным несла, по возможности,
большую информацию о принадлежности картинки к тому
или иному классу. На основании некоторого критерия
такой информативности (о нем будет более
подробный разговор дальше) программа опирает наилучший
порог.
*) Принимающих значения от 0 до 1152.
166
Затем программа пытается получить еще лучший
результат путем использования данных не только слоя
ганглиозных клеток, но и привлечения сведений, давае-*
мых рецепторами и биполярами. Для этого производится
для всех 24 картинок счет числа возбужденных клеток
в слоях биполяров и в рецепторах. Получается четыре
набора по 24 числа. Каждый набор тремя способами ком-*
бинируется с числами, даваемыми слоем ганглиозных
клеток. Проверяются разности соответствующих чисел,
частные от деления одного на другое и частные от де->
ления одного числа на дополнение другого до 1152.
Всего получается 12 комбинаций. Для каждой комбинации
ищется наилучший порог и затем отбирается наилучший
вариант из всех 13 способов использования первого слоя
ганглиозных клеток для данной задачи. Отобранный
вариант преобразования запоминается.
По той же схеме идет обучение подкорки и для
остальных 44 слоев ганглиозных клеток.
Вернемся теперь к критерию информативности
набора нулей и единиц. Очевидно, самым лучшим
вариантом является такой, когда все картинки каких-нибудь
двух классов (в общем виде — половины классов) полу-*
чают характеристику «О», а все картинки остальных
классов — характеристику «1». В этом случае
характеристика уменьшает неопределенность на 1 бит. Однако
такой идеальный случай будет редкостью. Рассмотрим
общий случай. Пусть частота появления единицы в i-u
классе равна рхг а нуля — р] (/?] -+-Р? = 1)- Через Н (pL)
обозначим величину —p)logp]— P0^ogp°r
Информативность рассматриваемого признака равна (см., напри-*
мер, предыдущую главу)
Н(й-Н(р), (22)
где рх — среднее из р], р° — среднее из рРр а И(р)—
среднее из Н (/**)•
Если считать, что картинки из разных классов будут
предъявляться одинаково часто, то
п п п
^=4S^ ?=42'i и н(р)=42н(а)' (23)
где п — число классов.
167
В Принципе можно оценивать информативность прямо
по формуле (22), однако в подкорке оценка*щюизводи-
лась с помощью приближенной формулы (24) (см. ниже).
Зависимость Н(р) хорошо аппроксимируется
параболой Ар\\—р1). Пользуясь этим и соотношениями (23),
можно заменить разность (22) выражением
4 [?(!-/»)-4 £/>!(!-/>!)]
— 4
^(■~5>!)Ч2>!0-4>
Поскольку не имеет значения масштаб, в котором мы
будем измерять информативность, можно пользоваться
формулой
п%у$-{%р)), (24)
причем вместо р\ просто брать число единиц в /-м
классе. При таком способе счета второй член в (22) есть
квадрат общего числа единиц.
Первый вариант блока подкорка работал по
формуле (24).
При экспериментах выяснилось, что существенным
недостатком такого способа является отсутствие
различения «видов информации». В самом деле, признак
может отличать, например, 1-й и 2-й классы от 3-го и 4-го,
а может 1-й и 4-й от 2-го и 3-го. С точки зрения
количества информации эти два случая могут быть
неразличимы. При отборе же, скажем, двадцатого признака
такие варианты могут быть очень неравноценны, если,
например, предыдущие девятнадцать признаков уже
хорошо производят деление первого типа и плохо — второго.
Для устранения этого недостатка во втором варианте
подкорки порознь учитывалось шесть видов
информации (отличие 1-го класса от 2-го, 1-го от 3-го и т. д.).
В зависимости от свойств предыдущих ганглиозных
клеток менялась «цена» на разные виды информации.
Отбор порога в подкорке производился на основе цены,
сложившейся на этой своеобразной «бирже».
168
Таким способом удалось добиться более
равномерной характеризации классов. Но знутри класса разные
картинки все же иногда были охарактеризованы очень
неравномерно.
г) Кора. Подкорка характеризует каждую картинку
набором 45 нулей и единиц (табл. 18). Задача коры —
отыскать такие сочетания столбцов в табл. 18, чтобы по
ним можно было с достаточно высокой достоверностью
вынести суждение о принадлежности картинки к тому
или другому классу. Например, если мы^ обратим
внимание на сочетание 5-го и 10.-го столбцов в табл. 18, то
заметим, что по цифрам, стоящим в них, можно
однозначно определить класс картинки. В самом деле,
сочетание 1, 1 встречается только в I классе, сочетание 0,1 —
только во II и т. д. Несколько худшими свойствами
обладает сочетание 1-го и 10-го столбцов. Пользуясь им,
мы бы, в зависимости от способа узнавания, или
сделали (на материале обучения) четыре ошибки, или
.19 раз отказались отвечать. Картинки, на которых
были бы ошибки или отказы при использовании 1-го и
10-го столбцов, помечены на таблице галочками и
минусами.
Еще худший результат дала бы попытка
использовать для узнавания сочетание 1-го и 2-го столбцов.
Мы рассмотрели несколько сочетаний по два
столбца. Ясно, что можно использовать сочетания и большего
числа столбцов. Блок кора проверяет все сочетания из
двух и трех столбцов. Отбираются такие пары или
тройки, которые дают достаточно большую информацию о
принадлежности картинки к какому-либо классу. В коре,
так же как и в подкорке, работает «биржа», которая
следит за тем, какие классы узнаются уже хорошо, и
понижает цену на соответствующую информацию.
Минимальная цена, при которой признак запоминался,
набиралась на пульте машины.
Допустим, что «в соответствии со сложившейся
ценой» кора отобрала пару, состоящую из 1-го и 10-го
столбцов. Как их использовать при экзамене? Пусть
неизвестная картинка имеет в 1-м столбце
характеристику 1, а в 10-м — характеристику 0. Теперь мы можем
рассуждать двумя способами.
Можно обратить внимание на то, что сочетание 1, О
встречалось в IV классе гораздо чаще, чем в III, а в
169
остальных и вообще не встречалось. Основываясь
на этом, можно отнести неизвестную картинку к
IV классу.
Но можно, заметив, что сочетание 1, 0 в
рассматриваемых столбцах встречается более чем в одном классе
(не только в IV, но и в III), вообще отказаться от
высказывания. Рассуждая этим способом, мы выскажемся
только в отношении тех картинок, которые будут
характеризоваться сочетанием 0, 1. Галочки и минусы на
табл. 18 соответствуют двум рассмотренным способам
экзамена.
Каждый из этих подходов имеет свои достоинства и
недостатки. При втором способе каждый признак
(сочетание столбцов) будет редко ошибаться, но зато и
редко высказываться. Поэтому окончательное суждение
придется принимать на основании малого числа
высказываний, что иногда может привести даже к увеличению
числа ошибок на экзамене.
При первом способе использования признаков на
экзамене естественно присвоить разным сочетаниям
переменных (например, 0, 1 и 0, 0) разный вес.
В самом деле, сочетание 0, 1 с большой
достоверностью голосует за то, что картинка принадлежит ко
II классу. Сочетание же 0, 0 менее уверенно
высказывается в пользу III класса, так как оно встретилось там
меньшее число раз, да еще, к тому же, 0, 0 иногда
встречается и в IV классе.
В программе Геометрия блок кора делался в двух
вариантах. В одном варианте признаки отбирались по
первому описанному выше способу и при экзамене
голосовали с разным весом. Во втором варианте отбирались
только «правила без исключений» (достаточные
признаки) и при экзамене они голосовали «демократически»
(у каждого один голос). Результаты работы обоих
вариантов оказались примерно одинаковыми.
Заметим, что вся проверка признаков ведется только
на материале обучения. Поэтому, когда мы говорим:
«признак часто работает» или «правило без
исключений», то это всегда является незаконной индукцией от
материала обучения на всю задачу. Естественно, чем
обширнее и разнообразнее материал обучения, тем больше
надежда, что такой незаконный переход не приведет к
ошибке.
170
ТАБЛИЦА 18
Результат обработки сведений подкоркой
[ 1 картинка 110 0 10 110 10
10 11110 0 111
110 11110 0 10
10 10 10 0 1111
10 0 1110 0 110
1110 10 110 11
0 0 10 0 110 0 11
0 1110 0 110 11
00000001110
0 1110 0 110 10
0 10 0 0 110 0 11
10 0 10 0 110 11
0 10 10 0 1110 0
0 110 0 1110 0 1
0 0 0 10 0 1110 1
00100000100
11 1 10 10 0 0 0 0
10000000101
1111110 0 10 0
10 0 0 1 1 10 0 0 0
10 0 110 110 0 0
0 0 10 10 0 110 1
110 0 110 0 10 1
10 1110 0 0 0 0 1
• <
класс
И <
класс
Ш
класс
IV ,
класс
2
3
4
5
6
Г 1
2
3
4
5
6
Г 1
2
з
4
5
k 6
Г 1
2
3
4
5
6
»
»
»
»
»
У>
»
»
»
»
»
»
»
»
»
»
»
»
»
»
»
5 3
0 1
1 0
0 0
1 1
1 1
1 1
0 0
0 0
0 0
0 1
1 0
1 1
1 1
0 0
1 1
0 1
1 1
1 0
1 0
0 1
1 0
0 1
1 0
0 1
о 5
V -
V -
V -
V -
171
Кора могла проводить обучение на четырех классах
объектов, причем каждый класс мог быть представлен
числом объектов от 1 до 23. При обучении отбиралось
до 80 признаков.
В случае, когда нужно было обучаться более чем на
шести объектах каждого класса, работа велась
следующим образом: подкорка, обучившись на шести объектах,
присваивала затем характеристики нужному числу
объектов. Эти характеристики, уже служили исходным
материалом для коры.
§ 3. Эксперименты с программой
Программа Геометрия была написана для машины
М-20. Поскольку программа содержала в основном
логические действия, скорость машины равнялась
примерно 40 000 операций в секунду. В оперативной памяти
машины (4096 слов по 45 разрядов слово) умещалась
вся программа, 24 картинки, рабочие поля и результаты
обучения. Единственное, что пришлось (на время
обучения подкорки) поместить на барабан, — это результаты
отображения 24 картинок слоями биполярных клеток.
Время обработки каждой картинки слоями
биполярных клеток составляло 1—2 сек. Так как такая
обработка происходила только один раз, то всего биполяры в
ходе обучения отнимали около 1 мин.
При отборе ганглиозных клеток проверка каждого
типа слоя на двух картинках занимала 0,6 сек. Однако
следует помнить, что структура слоя генерировалась
случайным процессом и поэтому один «хороший» слой
приходился на очень много «плохих». Всего на отбор
45 слоев ушло около двух часов машинного времени.
Обучение подкорки по 24 картинкам занимало
12 мин. Время обучения коры по 48 картинкам (по 12 в
каждом классе) равнялось 10 мин.
Таким образом, 2 часа ушло на обучение,
относящееся ко всей совокупности задач (ганглиозные клетки)
и около 20 мин на обучение, относящееся к данной
задаче (подкорка и кора).
Каждая картинка для Геометрии (рис. 33) занимала
по 36 разрядов в 32 ячейках памяти. Изготовление ма«
териала для обучения и экзамена оказалось весьма тру-*
доемкой работой. Поэтому опыты велись на сравнитель-
172
но небольшом материале (6—12 картинок каждого
класса). Больше всего было заготовлено картинок с
изображением букв. Степень разнообразия, например, букв А
иллюстрирует рис. 38.
В опытах с буквами подкорка всегда обучалась на
четырех классах по шести представителей в каждом
классе. После обучения
коры на тех же объектах
программа узнавала 75%
букв (выбор из четырех
классов). Результат
отличается от случайного
гадания, но, в общем-то,
весьма скверный. Был
проделан опыт, в
котором кора обучалась тоже
на шести объектах
каждого класса, но брались
не те объекты, что для
подкорки. На экзамене
было узнано 77% букв.
После обучения коры
на 12 объектах каждого Рис 38.
класса было узнано 87%
букв. Все эти проценты вычислялись на очень малом
материале (48 картинок).
После экспериментов создалось впечатление, что еще
некоторого улучшения работы программы можно
достигнуть за счет увеличения материала обучения коры. Однако
такие опыты не были проделаны из-за дефицита картинок.
Вообще целый ряд мест программы, вероятно, можно
было бы усовершенствовать и за счет этого увеличить
процент узнавания букв. Однако этого не стали делать
в связи с критическим анализом принципиальных
возможностей программ типа Геометрия. К разбору
особенностей этой программы мы и переходим.
§ 4. Достоинства и недостатки Геометрии
Общее число состояний, в которое может перейти
Геометрия после обучения, очень велико. В самом деле,
каждая связь ганглиозной клетки может попасть
в 256 разных клеток (по 64 в слое рецепторов и каждом
173
слое биполяров). Поэтому все связи могут быть
организованы «1020 способами. При этом мы еще не учли, что
связи бывают тормозящие и что ганглиозная клетка мо-*
жет иметь разные пороги.
Далее, подкорка выбирает для каждого слоя гангли-
озных клеток один из 117 способов обработки (13
функций и 9 порогов для каждой функции). Это дает для
всех слоев более 1090 способов обработки.
И, наконец, кора выбирает сочетания столбцов в
табл. 18 из «14 000 сочетаний.
Ясно, что полный просмотр всех (в .принципе
возможных) наборов признаков занял бы невообразимое
время. Сокращение перебора достигается, во-первых,
отбором по компонентам (см. главу III, § 5). Например,
подкорка делает не 1090 проверок, а только 117X45.
Второй способ сокращения перебора заключается в «много-*
этажном» обучении. Кора ищет сочетания столбцов не
для всех возможных вариантов подкорки, и даже не
для 117 вариантов, а только для одного варианта, того
единственного, который был отобран при обучении
подкорки. Точно так же и подкорка ищет
преобразования не для 1020 ганглиозных клеток, а только для
отобранных 45.
Мы уже несколько раз говорили о принципиальной
возможности такого способа сокращения перебора при
обучении. При этом каждый раз отмечалось, что
необходимо найти критерии для обучения нижних
этажей.
В Геометрии для ганглиозных клеток критерием
является качество разделения некоторых пар картинок
(например, рис. 37), а для подкорки — информация о
разделении на классы.
Многоэтажную структуру Геометрии стоит, по-види-*
мому, отнести к достоинству программы. В будущем,
вероятно, сможет найти применение и мысль, что
результат обучения разных этажей может обладать разной
степенью всеобщности (биполяры не обучаются, гангли-
озные учатся для совокупности задач, подкорка и
кора— для данной задачи). При таком подходе можно
будет делать программы, которые, встретившись с новой
задачей, начинают переучивать верхние, наименее
стабильные этажи. И только если такое переучивание не
дает результата («резко изменился мир»), начинается
474
переучивание нижних этажей. Несомненно, в живой
природе этот принцип очень распространен.
Перейдем теперь к недостаткам программы
Геометрия. Почему, несмотря на всю ее громоздкость, на
многоступенчатое обучение, она так посредственно узнавала
буквы? Начнем с бросающегося в глаза обстоятельства.
Каждый слой ганглиозных клеток посылает в подкорку
одно число (от 0 до 1152), которое говорит лишь о том.
сколько клеток слоя возбудилось. При этом теряется вся
информация о том, где расположены возбудившиеся
клетки. В дальнейшем эта информация уже не может
быть восстановлена ни подкоркой, ни корой. Тем более
не доходят в кору сведения о взаимном расположении
возбужденных ганглиозных клеток в разных слоях. Из-за
этого Геометрия принципиально не может, например,
решить задачу, изображенную на рис. 39, а, если
расстояние между вертикальными и горизонтальными
линиями больше восьми клеток растра.
Заметим, что Геометрия не может решить эту или
изображенную на рис. 39, б задачу не потому, что плохо
организован процесс обучения, а потому, что среди
великого множества доступных ей состояний нет
состояний, нужных для таких задач. Большое (и даже «очень
большое») количество состояний само по себе еще не
гарантирует, что среди них найдется нужное для
некоторой задачи. В самом деле, число различных картинок
на растре Геометрия равно 21152. Их можно разбить на
два класса
221152 > К)!»340 способами. Количество
состояний Геометрии составляет ничтожную долю этого числа.
Поэтому нет никакой надежды, что случайно среди
них найдется нужное для той или иной задачи. И вот
вследствие недосмотра программистов на языке
Геометрии нельзя выразить такие понятия, как справа, сверху,
часть, расстояние, равенство (углов, длин), выпуклый,
площадь (контурной фигуры), внутри, диаметр.
Поэтому-то Геометрия плохо решает задачи, легкие для
человека. У нее нет с человеком «общего языка». Геометрия
не может имитировать человека из-за различия в
блоках К (ср. главу IV, § 2).
Мы заметили, что очень много информации теряется
из-за того, что каждый слой ганглиозных клеток
сообщает подкорке только свое «среднее возбуждение».
Нельзя ли улучшить работу Геометрии, если изменить
175
это место программы? Что, если вместо того, чтобы про-
сто пересчитывать количество возбужденных ганглиозных
б) 1пласс Лпласс
Рис. 39. Задачи, недоступные программе Геометрия.
клеток, построить второй этаж ганглиозных клеток,
которые соединялись бы с первым этажом связями при*
176
а) I класс Лнласс
мерно так же, как первый этаж соединен с биполярами
(рис. 35)? Тогда на возбуждение каждой клетки второго
этажа уже будет влиять взаимное расположение
возбужденных клеток первого этажа. Очевидно, можно
продолжить процесс и построить третий, четвертый и т. д.
этажи. Если при этом сделать число клеток в каждом
последующем этаже меньше числа клеток в
предыдущем, то получится «пирамида», у которой возбуждение
«вершины» может быть весьма сложной функцией от
возбуждения клеток «основания». Будет ли такая
многоэтажная «пирамида» иметь «общий язык» с
человеком?
Вообще говоря, если на структуру «пирамиды» не
наложено никаких ограничений, то она может осуществить
любое разбиение картинок на классы. Например, можно
вообразить следующую «универсальную» систему.
Имеется 2т (где т — число элементов растра) ганглиозных
клеток (Л-элементов). Каждая клетка возбуждается при
попадании на растр рецепторов одной определенной
картинки. Для этого клетка соединена со всеми т
рецепторами, причем возбуждающие связи подходят к
светлым местам данной картинки, а тормозящие — к
темным. Легко видеть, что если для такой клетки
установить порог, равный числу возбуждающих связей, то
она будет возбуждаться данной картинкой и не будет
возбуждаться никакой другой. Таким образом, можно
сделать набор из 2т клеток так, что на каждую
возможную картинку отзывается одна и только одна
клетка. Если теперь соединить эти клетки с клеткой
второго этажа, то, делая соответствующие связи
возбуждающими и тормозящими (или нейтральными), можно
выделить произвольное подмножество картинок.
Соответственное количество клеток второго этажа может
осуществить разбиение картинок на любое число
классов.
Однако реально создать такую (или хоть
сколько-нибудь приближающуюся к такой) систему совершенно
невозможно. Даже если ограничиться очень скромным
растром Геометрии, то понадобится 21152>10340
ганглиозных клеток. Это число неизмеримо превосходит
количество электронов во всей видимой части Вселенной.
Не станет ли положение легче, если вместо двухэтажной
«пирамиды» сделать многоэтажную? Очевидно, нет, так
177
как для создания «универсальной»*) системы, мы все,
равно должны иметь около 2т степеней свободы.
Итак, любая реальная система будет иметь
относительно очень мало возможных состояний. Поэтому среди
них почти наверное не окажется тех, которые
соответствуют «человеческим» понятиям окружность, внутри,
симметрия, связанный и т. д., если только мы специально
не позаботимся о такой структуре системы, чтобы ей
были доступны эти понятия. План системы, имеющей
«общий язык» с человеком, будет обсуждаться в
следующей главе, здесь же мы остановимся на одном, к
сожалению, весьма распространенном заблуждении.
§ 5. «Самоорганизующиеся нервные сети»
Часто слышишь такое рассуждение: «Конечно, нет ни
возможности, ни необходимости делать универсальную
(решающую все задачи) систему. Однако можно
разными способами наложить ограничения на возможности
системы. Например, ограничения накладываются числом
и устройством элементов, из которых система построена.
Поэтому, если мы построим систему из элементов,
похожих по своим свойствам на нервные клетки животных,
то, вероятно, и возможности системы окажутся
похожими на возможности мозга. Свойства нервных клеток, в
первом приближении, удовлетворительно моделируются
пороговыми элементами. Значит, если мы построим
систему из большого числа пороговых элементов, то она
будет моделировать мозг. А если окажется, что большая
совокупность пороговых элементов плохо моделирует
мозг, то нужно будет строить систему из других элементов,
еще точнее воспроизводящих свойства нервных клеток».
В чем ошибочность такой точки зрения? Дело в том,
что структура элементов по большей части не
накладывает ограничений на возможности системы. Например,
с помощью логических элементов «И» и «НЕ» в
принципе можно осуществить произвольное разбиение кар-
*) Даже если бы имелась возможность создать «универсальную»
систему, она нас не интересовала бы, так как для ее обучения
необходим полный показ всех картинок, которые могут встретиться на
экзамене. Такая система не вырабатывает коротких описаний
классов (обобщенных понятий). Вместо этого она просто запоминает
все показанное при обучении.
па
тинок на классы. То же относится и к «пороговым
элементам», и к «штрихам Шеффера», и к элементам
«ИЛИ» и «НЕ», и вообще к любому логически полному
набору элементов. При этом число элементов, которое
понадобится для реализации того или иного разбиения
на классы, мало зависит от типа элементов*). Таким
образом, ограничения возникают не от выбора типа
элементов, а от выбора системы связей между ними.
Именно организация связей определит, будет система иметь
«общий язык» с человеком или нет. Очевидно,
организация связей является главной и труднейшей частью
построения узнающей системы.
На это сторонники «самоорганизующихся нервных
сетей» отвечают: «Мы тоже признаем, что очень
существенно, каковы связи между элементами. Но разве
обязательно нужно человеку придумывать систему связей?
Пусть связи установятся сами в ходе предварительного
обучения (например, как у ганглиозных клеток в
программе Геометрия). А вначале пусть будет лишь
способность образовывать произвольные связи. После
предварительного обучения система будет обладать
«человеческими» понятиями и уже сможет обучаться тем задачам,
которые будут генерировать люди».
Допустим, этот план был бы реализован.
Подсчитаем, сколько картинок пришлось бы показать системе
за время предварительного и окончательного обучения.
Если человек не накладывал при конструировании
никаких ограничений на связи между элементами, то после
обучения (предварительного и окончательного) система
может решать любую задачу. (Будем, для конкретности,
вести расчет для растра Геометрии.) Это значит, что
система должна выбрать какое-то состояние из 21о34°
возможных. Итак, начальная неопределенность 10340 бит.
Каждая показанная при обучении картинка (при самом
оптимальном декодировании) несет полезную
информацию «103 бит. Для обучения понадобится более 10330
картинок! Положение не спасет и то обстоятельство,
что для каждой задачи найдется много состояний,
достаточно близких от искомого. Даже 210 состояний,
*) Легко доказать, что при переходе от некоторого набора
элементов а к набору Р число необходимых элементов увеличится не
более чем в /Са, а раз, где /Са, а — константа, зависящая только от
аир. Р Р
,179
удовлетворительно решающих задачу, оставляют
необходимое число показов выше всяких мыслимых
возможностей. Не утешает и мысль, что большая часть показов
придется на предварительное обучение, которое
совершается только один раз.
Мы видим, что система, способная обучаться на
разумном числе примеров, обязательно должна обладать
достаточно высокой начальной организацией. И эта
организация не может быть достигнута в ходе
предварительного обучения. Она должна быть привнесена извне
конструктором системы.
В реальных экспериментах с обучающимися
системами человек, хочет он этого или нет, накладывает очень
сильные ограничения на число возможных состояний.
Однако, если это обстоятельство ускользает от внимания
конструктора (как это было с перцептроном и со
многими «нервными сетями»), для системы оказываются
недостижимыми именно те состояния, которые нужны для
имитации человека. Как правило, вместе с водой
выплескивается и ребенок.
Единственный способ избежать этого — придумать
систему, которая, имея состояния, имитирующие
человека, имела бы, сверх того, относительно мало*) других
состояний. Именно придумать, ибо надежда, что такая
система организуется сама, не более обоснована, чем
надежда на то, что, бросив в ящик куски металла и
набор инструментов, после долгой тряски мы вынем из
ящика хорошо идущие часы.
Конечно, когда будут найдены хорошо работающие
алгоритмы и начнут строить специализированные
обучающиеся узнающие системы, возникнет вопрос о том,
из каких элементов их целесообразнее собирать. Однако
это будет вопрос всего лишь о технической
целесообразности и решаться он будет, вероятно, очень конкретно
для тех или иных машин или их блоков. Примерно так
же, как сейчас решается — строить ли некоторый блок
в машине на транзисторах, ферритах или вакуумных
лампах. Во всяком случае, до появления хороших
узнающих алгоритмов совершенно преждевременно
обсуждать, на каких элементах эти алгоритмы следует
реализовать.
*) Например, только в 103 или в 105 раз больше.
Глава IX
ЯЗЫК УЗНАЮЩЕЙ ПРОГРАММЫ (СЛОВАРЬ)
§ 1. Язык перцептрона и язык человека
Вспомним, в каких терминах перцептрон описывает
классы картинок. Каждый Л-элемент перцептрона
может возбудиться или не возбудиться данной картинкой.
Про картинку перцептрон говорит: какие Л-элементы
она возбудила и какие не возбудила. Различие между
классами перцептрон описывает так: «Первый
Л-элемент чаще возбуждается картинками II класса, второй
Л-элемент одинаково часто возбуждается картинками
обоих классов, третий Л-элемент возбуждается только
картинками I класса и т. д.». Какую бы задачу ни
предложить перцептрону, он будет использовать все тот же
язык. При этом перцептрон «берется описать» на этом
языке любую картинку. Для него не существует понятия
«мусора». В крайнем случае он может высказать
неуверенность в определении класса, к которому относится
картинка, но никогда не возникает ситуации, при
которой новую картинку принципиально невозмож-
н о описать на языке перцептрона.
Совершенно не так ведет себя человек, если
попросить его описать различие между двумя классами
картинок. Посмотрев на рис. 20, а, человек скажет, что один
класс — это треугольники, а другой — круги. Классы на
рис. 20, б он характеризует словами: сплошные и
контурные, а на рис. 20, в — маленькие и большие. Во всех этих
случаях человек дает весьма короткое описание
классов, причем достигается это за счет нестандартности
терминов, в которых происходит описание.
Действительно, чтобы отличить треугольник от круга, картинки
нужно подвергнуть совсем не такой обработке, как в
случае необходимости отличить большие фигуры от
маленьких, или сплошные от контурных. При этом степень
181
нестандартности терминов так велика, что для многих
картинок они оказываются принципиально
неприменимыми. Допустим, нам показали задачу рис. 40. Легко
заметить, что к первому классу относятся картинки,
содержащие разные фигуры, "а ко второму—картинки,
Рис. 40.
содержащие одинаковые фигуры. Можно ли в этих
терминах описать картинки, изображенные на рис. 41?
Очевидно нет, так как описание классов задачи
рис. 40 применимо только для тех картинок, которые
четко делятся на отдельные фигуры, а картинки рис. 41
не обладают этим свойством.
Заметим, что трудность возникла не из-за того, что
новые картинки оказались «промежуточными» между
классами и мы затрудняемся отнести их к тому или
другому классу (например, могла бы встретиться картинка,
на которой две фигуры почти одинаковы). Подобную
Дкласс
182
1пласс
трудность можно обойти, уточнив, где проходит граница,
разделяющая классы (в нашем примере — какая
степень сходства нужна для признания фигур
одинаковыми). Здесь же дело не в точности, а в неприменимости
понятия к данному объекту.
Такая ситуация вовсе не является редким
исключением, скорее это правило. Если перед нами два класса—
животные и растения, то куда отнести сковородку? Если
Рис. 41.
мебель и посуда, то куда относится лошадь? Если
монеты и медали, то как классифицировать скрипку,
гребенку или брюки?
Итак, в отличие от перцептрона, человек дает
короткие описания классов и при этом пользуется разными
терминами (преобразованиями) при решении разных
задач. Терминами очень специализированными, очень
неуниверсал ьными.
§ 2. Сильная имитация и короткие описания
Пусть нам нужно решить задачу, представленную на
рис. 42. Очевидно, блок К\ совокупности задач (рис. 18)
отправляет в «мусор» все картинки, не являющиеся
треугольниками, а треугольники делит на остроугольные
(I класс) и тупоугольные (II класс). Прикинем, велик
ли «процент отсева» картинок при этом состоянии /G.
Допустим, картинки рисуются на растре 100X100
элементов. Всего на таком растре существует 210000^103000
черно-белых картинок. Разных способов выбрать три
(104)3
точки на таком растре ~/ ~ Ю11. Пусть, после того
как выбрано положение вершин треугольника, мы мо*
жем миллиардом миллиардов способов соединить
каждую пару вершин так, чтобы блок К\ еще признал бы
183
фигуру за треугольник. Тогда существует 1011 X (1018)3 =
= 1065 картинок, не попадающих в «мусор».
Итак, 1065 из 103000! Ничтожная часть всех картинок
является треугольниками. Boj почему человеку удается
?ак коротко описать классы. Когда он говорит:
остроугольные треугольники и тупоугольные треугольники, то
слово треугольник сразу производит резкое уменьшение
числа объектов, которые могут встретиться на экзамене,
а значит, и еще большее (относительно) сокращение
числа возможных задач. На подмножестве, называемом
треугольники, существует гораздо меньше задач, чем на
бсех возможных картинках. Поэтому, если узнающая
система ведет поиск только среди состояний, сильно
имитирующих задачу, то неопределенность резко
уменьшается.
В главе IV мы говорили, что целью узнающей системы
является слабая имитация задачи. Действительно*для
хорошего узнавашш достаточно, если блок /(будет
слабо имитировать блок К\ (рис. 18), ведь 0Лок К
никогда не получает на экзамене «мусора».
Теперь же мы видим, что полезно делать систему,
сильно имитирующую задачи. Такая система будет
производить выбор из гораздо меньшего числа
возможных состояний блока К, а значит, сможет обучаться
быстрее и на меньшем материале.
Человек обычно не замечает, что, отделив треуголь*
ники от всех остальных фигур, он, по существу, произвел
многократный отсев «мусора». Он отделил одвосвязные
фигуры, затем многоугольники и, йаконец, треугольники.
Каждый шаг уменьшал неопределенность задачи поиска
состояния блока К. Все эти ступени объединены словом
треугольники. В искусственной узнающей системе,
вероятно, целесообразно сохранить память о всех ступенях
этого процесса и, не вводя нового слова (треугольник),
говорить, например, об односвязной области,
ограниченной замкнутой ломаной линией, состоящей из трех
отрезков. При таком способе мы сможем с помощью
комбинаций небольшого количества терминов многими
способами отделять «мусор».
Очевидно, нет смысла делать различие между
набором терминов, которые нужны для разделения классов,
и набором терминов для выбрасывания «мусора». В
разобранном примере термин односвязная область помог
184
отделить нужные нам фигуры от «мусора», но в другой
задаче он же может и разделить классы.
Процесс нахождения состояния, сильно
имитирующего задачу, можно представить себе следующим образом:
идет поиск описания всего материала обучения (бе:*
учета того, что он разделен на разные классы). Другими
словами, ищется общее во всех картинках. На
некотором этапе это становится невозможным, тогда среди
параметров, которыми картинки отличаются друг от
друга, ищутся те параметры, с помощью которых можно
найти короткое описание различия между классами.
В задаче на рис. 42 это выглядит так: все картинки
обоих классов объединены тем, что они являются одно-
связными фигурами. Затем можно заметить, что границы
Innacc
И ил ас с
Рис. 42.
всех фигур состоят из прямолинейных отрезков. Число
этих отрезков всюду одинаковое — три. Больше ничего
общего для всех картинок найти не удается. Картинки
отличаются друг от друга многими параметрами,
например длиной наибольшей стороны. Однако характеристика
по этому признаку не разделяет классы. То же самое
относится и к величине наименьшего угла треугольника.
А вот если рассмотреть величину наибольшего
185
угла, то эта характеристика сразу отделяет класс от
класса.
Как уже отмечалось, окончательный поиск идет среди
описаний, пригодных далеко up для всех картинок. В
самом деле, можно ли говорить, например, о наименьшей
стороне или о наибольшем угле для картинки,
изображенной на рис. 43? Мы несколько идеализировали
схему поиска, строго разделив ее во времени на две части
Рис. 43.
(поиск общего и поиск различий). Вероятно, иногда
окажется целесообразным вести обе части поиска
«вперемежку», но и в этом случае поиск описаний,
непригодных для «мусора», будет сокращать перебор.
Согласно определению, принятому в главе IV,
сильной называется имитация, при которой узнающая
система относит в «мусор» все объекты, которые относит
в «мусор» (бракует) блок К\ задачи. Здесь мы
рассматривали последовательность состояний узнающей
системы, когда все больше и больше объектов, бракуемых
блоком /Сь попадает в «мусор». Очевидно, некоторое
сокращение перебора возникает и тогда, когда еще не
весь лишний материал попал в «мусор». Поэтому
полезным является не только достижение, но и «приближение»
(в указанном выше смысле) к сильной имитации.
§ 3. Что позволяет создавать короткие описания
На языке, пригодном для всех без исключения
картинок, описания не могут быть короткими. Если, как в
предыдущем параграфе, мы будем рассматривать,
например, растр 100X100, то для описания произвольной
186
картинки нам понадобится 104 бит. Меньшим
количеством информации обойтись не удастся, так как каждая
точка картинки независимо от цвета остальных точек
может оказаться белой или черной. В то же время лкь
бой треугольник можно описать гораздо короче.
Треугольник в строго геометрическом смысле однозначно
задается положением его вершин. Каждая вершина
может попасть в одну из 10 000 точек растра. Поэтому для
описания положения одной вершины достаточно 14 бит
(214« 16000), а для трех вершин — 42 бита. Даже если
мы захотим описать не только положение вершин
треугольника, но и мелкие зазубрины на сторонах,
возникающие из-за случайностей проекции на растр, то и для
этого понадобится всего около 200 бит.
Причина такого сокращения необходимой
информации понятна — цвета разных точек картинки, на которой
изображен треугольник, отнюдь не являются
независимыми. Например, если некоторые две точки растра
оказались черными и не имеют белых соседей, то все
лежащие между ними точки также будут черными*).
Отмеченная зависимость между цветом разных точек
растра далеко не исчерпывает всех взаимозависимостей
для треугольника (например, она свойственна всем
выпуклым фигурам). Но она иллюстрирует одну из
причин избыточности сообщения, содержащего сведения
о цвете всех без исключения точек. Действительно,
пользуясь этой связью, мы можем восстановить цвет
(черный) большинства внутренних точек, и не получив о нем
никакого сообщения.
Итак, зависимость между разными частями — вот
причина, допускающая короткие описания картинок.
Существует много разных видов корреляции, помогающих
давать короткие описания. Например, для
симметричных фигур избыточным является сообщение об одной их
половине. Для окружностей достаточно сообщить
положение центра и радиус. На рисунках,
изображающих человека, возможное место головы очень сильно
*) Слово «треугольник» имеет два смысла: а} замкнутая
ломаная из трех звеньев, б) часть плоскости, ограниченная такой
ломаной. Здесь (как и на рис. 42) мы пользуемся вторым значением
термина. Оговорка относительно отсутствия белых соседей сделана
для исключения граничных точек, так как на границе из-за
дискретности растра возможны некоторые отклонения.
187
ограничивается положением остальных частей тела
и т. д. Типы зависимостей, которые узнающая система
сможет обнаруживать и использовать для короткого
описания, и определяют возможности системы.
В предыдущей главе были рассмотрены причины, по
которым узнающая система не может
«самоорганизоваться». Поэтому вопрос о том, какие типы корреляций
сделать доступными для системы, должен решать
конструктор. При этом должны учитываться свойства
совокупности задач, для решения которых предназначена
система. Если генератором задач является человек, то
нужно по возможности учесть доступные ему
корреляции (ограниченность его мышления!). Если генератор —
некоторое физическое устройство, то нужно учесть
ограничения, накладываемые на объекты законами природы.
Проверка наличия корреляции, очевидно, и есть то
«сито», с помощью которого отделяется «мусор». Мы
уже говорили, что целесообразно один и тот же набор
терминов использовать и для отсева «мусора», и для
разделения классов. Поэтому выбор типов доступных
системе корреляций, по существу, определяет весь
«родной язык» системы. Законы построения классов,
которые коротко записываются на этом языке, будут для
системы «простыми». Это значит, что такие законы она
будет открывать за малое время и ей будет достаточно
малого материала обучения.
§ 4. Словарь для геометрических задач
Здесь и в дальнейшем, когда будет обсуждаться план
программы для «геометрических» задач, мы будем иметь
в виду следующую совокупность задач: объектами
являются черно-белые (без полутонов) картинки,
заданные на некотором растре. Генератором задач является
человек. Мы видели (глава IV, § 2), что человек может
решить далеко не все задачи, генерируемые другим че*
ловеком. Поэтому вводится дополнительное
ограничение— задачи должны быть такими, чтобы их мог р ет
шить другой человек (иными словами, мы хотим иметь
систему, имитирующую человека не столько в роли
генератора задач, сколько в роли узнающего устройства).
Мы, естественно, исключаем задачи, при решении
которых человек пользуется информацией об объектах, не
188
содержащейся в картинках. Например, человек легко
объединит в один класс изображения автомобиля,
парохода и самолета, а в другой — почтового ящика,
радиостанции и телеграфного столба с проводами. При*
экзамене он уверенно отнесет локомотив к первому классу,
а телефонный аппарат ко второму. Однако для этого
он использует сведения, которые невозможно почерпнуть
из рассматривания картинок. Просто человек
заранее знает, что, например, пароход — это средство
передвижения по воде, приводится в движение винтом
за счет сгорания топлива, имеет много металлических
частей и т. д. Любое из этих заранее ему известных
обстоятельств человек может использовать для
объединения парохода с другими объектами в классы.
Искусственная система, которая лишена этих
предварительных сведений, не может справиться с такой задачей, но
мы и не будем от нее этого требовать.
Внешним признаком, дающим основание усомниться
в «подсудности» задачи искусственной системы, может
служить человеческое описание классов. Если оно
дается в терминах геометрических свойств картинок, то все
в порядке. Если же человек описывает классы словами:
средства связи или хищные животные, или смешные
ситуации и т. п., то весьма вероятно, что картинки
не содержат информации, необходимой для решения
задачи.
Оговорив, какие задачи будут называться
«геометрическими», вернемся к языку программы.
Мы уже неоднократно говорили, что если узнающая
система должна иметь очень много разных состояний,
то ее надо делать на манер детского «конструктора».
Несколько типов «кирпичей», соединяясь в различных
сочетаниях, порождают много разных моделей.
Нетрудно заметить аналогию между желаемой
схемой узнающей системы и описаниями классов, которое
дает человек на своем человеческом языке. Он ведь
тоже применяет сравнительно небольшое количество
терминов для разделения классов, например, во всех
геометрических задачах, которые встречаются в этой
книге. Соединяя эти термины во фразы, человек может
сконструировать очень разнообразные описания классов.
Возникает мысль использовать эту аналогию.
Попробуем составить примерный список терминов, с помощью
189
которых есть надежда решить интересующую нас
совокупность задач. С первого взгляда может показаться,
что таких терминов понадобится очень много. В самом
деле, даже для очень простых задач, с которыми мы
имели до сих пор дело, уже были нужны слова:
окружность, эллипс, треугольник, четырехугольник,
пятиугольник, шестиугольник, прямоугольник, большой,
маленький, справа, слева, посередине, сверху, ориентированный
вертикально, ориентированный горизонтально и т. д. Не
придется ли при переходе к более сложным задачам
создавать такой громоздкий словарь, 4tq им будет очень
неудобно пользоваться?
Вряд ли. Дело в том, что нет необходимости
держать термины треугольник, четырехугольник, прямо-
угольник и т. п. в качестве основных слов. В § 2 уже
встретился случай, когда слово треугольник заменялось
фразой область, граница которой состоит из трех
прямолинейных отрезков. Ясно, что те же слова граница,
прямая в сочетании с числительным четыре дадут
возможность образовать понятие четырехугольник. А
набор числительных пригодится и в задачах, где
существенным будет количество фигур, и в задачах, где
надо будет обращать внимание на число дырок в
фигуре и т. п.
Таким образом, в словарь нужно ввести понятия
настолько «мелкие», чтобы их оказалось не очень много.
С другой стороны, эти понятия должны быть настолько
«крупные», чтобы фразы, описывающие классы,
получились не слишком длинными. (Самый короткий словарь
состоит из слов белая точка и черная точка, но мы уже
знаем, что описание классов на таком языке получается
невообразимо длинным.) Итак, нужен компромисс. В
качестве рабочего варианта словаря, с которым есть
смысл экспериментировать, можно предложить,
например, такой набор терминов:
Оболочка Координаты
Контур Расстояние
Направление Экстремум
Кривизна *Часть (фигуры, кон-
Площадь тура)
Длина Конец
Центр тяжести Сосед
190
Диаметр Негатив
Осевая линия Разброс
Разность *Подмножество (об-
Отношение ладающее некото-
Число (результат рым свойством)
счета) Узел
Внутренний Среднее
Каждому из этих слов в программе должен
соответствовать некоторый оператор (подпрограмма). Оператор
получает входную информацию и выдает результат
своей работы в строго определенной форме. Например,
оператор площадь должен иметь на входе картинку
(растр), а на выходе дает число. Оператор контур после
обработки картинки даст на выходе тоже картинку, на
которой останутся только контуры фигур. Оператор
длина может работать, если ему на вход подать
линию (например, результат работы контура), но не
может обрабатывать числа или произвольные картинки
и т. п.
Вследствие этого некоторые сочетания слов являются
«законными», а некоторые — запрещены. Например,
фраза направление максимального диаметра самой
верхней фигуры на картинке законна, а сочетание слов
площадь координат центра тяжести незаконно, так как
оператор площадь не может обрабатывать чисел.
Чтобы программа не пыталась строить незаконные
фразы, в нее кроме словаря нужно заложить еще и
«правила грамматики». В данном случае они очень
просты. Вся информация, которой обмениваются между
собой операторы, делится на несколько видов. Это может
быть двумерная картинка, набор картинок, одномерная
линия, число или набор чисел. Поэтому достаточно
поставить на каждый вид информации свою метку и
поручить каждому оператору проверять, подходит ли ему
данная метка. Теперь законы грамматики будут
соблюдаться автоматически.
Добавим, что наличие в словаре термина разность
заставляет нас различать между собой несколько видов
чисел по их размерности. Без этого программа вычитала
бы углы из площади или длину из числа фигур.
Аналогично максимум или минимум имеет смысл искать
только в наборе чисел одной размерности.
191
Среди операторов, входящих в рассматриваемый
словарь, есть два (они помечены звездочкой), несколько
отличающихся от остальных. Все остальные операторы
обрабатывают свою входную информацию всегда
одинаково. Результат работы, например, оператора контур
зависит только от того, какая картинка попала к нему
на вход. Не таковы оператор, делящий картинку на
части, и оператор, выделяющий подмножество чисел.
Пусть мы имеем дело с набором чисел, полученным
при измерении площадей различных фигурок, входящих
в картинки. По какому принципу следует разбить этот
набор на подмножества? Очевидно,- не существует
общего ответа на этот вопрос. Если фигурки, например,
делятся на треугольники и круги (рис. 44), то есть
л °
о
Рис. 44.
смысл рассмотреть отдельно площади треугольников и
кругов. Если бы фигурки четко делились на верхние и
нижние^ то стоило бы отдельно обратить внимание на
площадь верхних и нижних фигурок и т. д.
Таким образом, результат работы оператора
подмножество должен зависеть не только от того, какой
набор чисел попал к нему на вход, но и от того, на
какие группы распались картинки или их части в
результате работы других операторов.
Сходным образом должен вести себя оператор часть.
В одном случае он разделит картинки на отдельные фи-
о
о
1 у!
1 класс
Ia
192
гуры, в другом разделит фигуры человечков на «руки»,
«ноги», «головы» и «туловища», в третьем выделит
отдельные стороны многоугольников и т. п. И опять
избранный метод разделения должен зависеть от
особенностей всего материала обучения.
Итак, в общей схеме программы нужно
предусмотреть блоки, которые будут управлять работой
операторов часть и подмножество. О принципах такого
управления будет идти речь в § 6 и в главе X.
Свойства операторов часть и подмножество приводят
к тому, что программа, умея в принципе строить очень
много разных фраз, при решении каждой конкретной
задачи проверяет далеко не все доступные ей описания
классов. При этом получаются описания, пригодные не
для всякой картинки, т. е. сильно имитирующие задачу.
§ 5. Короткое кодирование без потери информации
В § 3 обсуждалось уменьшение длины описания
картинки, которое возникает благодаря корреляциям
между различными ее частями.
Если мы готовы примириться с потерей информации,
то сократить длину описания можно всегда (и без
наличия каких-либо ограничений на допустимые виды кар-»
тинок). Например, можно сделать более грубый растр,
содержащий меньше элементов. Или, пожертвовав всей
информацией о расположении белых и черных точек,
ограничиться сведениями о «средней серости» картинки
и записать только, чему равно число черных точек.
Таких способов сокращения описания можно придумать
очень много, но все они приводят к потере некоторой
информации.
Существенное отличие от этих способов, например,
короткого описания треугольников заключается в том,
что здесь краткость достигается без потери инфор-*
м а ц и и. Действительно, если нам сообщили координаты
вершин треугольника, то все остальное мы можем
восстановить сами. Правда, нужно еще сообщить само
понятие треугольник, но это можно сделать один раз, а
затем описывать очень много треугольников.
По существу, используется то, что «в мире, куда
мы попали» (например, в мире треугольников), не все
возможно, в этом мире существуют какие-то законы,
193
накладывающие ограничения на объекты. Заметим, что
в физическом мире, в котором мы живем, реально
возможна лишь ничтожная доля (в принципе мыслимых)
событий. Не любой заряд может иметь элементарная
частица. Нельзя поднять самого себя за волосы. Далеко
расположенное тело не может прикрывать от нашего
взгляда близко находящийся предмет и т. д.
Наша способность думать о невозможных событиях
сама по себе знаменательна. Она возникла из-за свойств
той системы координат, в которой мы привыкли
описывать события (эта система задана строением наших
органов чувств). При таких привычных описаниях
создается впечатление, что имеется гораздо больше степеней
свободы, чем их существует в действительности. По мере
развития науки выясняется, что некоторые параметры
первоначального описания не независимы. Тогда
говорят: «открыт закон природы». В пределе этот процесс
стремится к описанию мира в системе координат, где
все координаты событий независимы. В такой системе
все сочетания координат возможны, в ней нет никаких
запретов. Как ни парадоксально это звучит — «наука
стремится создать мир полного беззакония». К этому,
конечно, нужно добавить, что в задачу науки входит
также — найти и способ отображения наших привычных
координат на координаты «мира, в котором все
возможно».
В аналогичном положении находится узнающая
программа. Система координат, в которой мы для нее
описываем треугольник, задана самой конструкцией ее
«органа чувств» — это растр. Поэтому кажущееся число
степеней свободы намного превышает истинное. Задача
программы — произвести декорреляцию описания. После
этого появится описание (например, координаты
вершин), во-первых, короткое, а во-вторых, не требующее
введения дополнительных ограничений на допустимые
описания. Всякому набору трех вершин соответствует
треугольник. При таком описании нет «мусора». Он
выброшен в процессе декорреляции.
Итак, сильная имитация, открытие внутренних
связей, короткое перекодирование без потери информации —
все это синонимы. Однако в качестве формального
критерия, управляющего поведением программы,
по-видимому, удобнее всего использовать последнюю формули-
194
ровку. Действительно, для проверки того, достигнута ли
сильная имитация, программа должна иметь в своем
распоряжении заведомо «мусорные» картинки, а откуда
их взять? Далее, не очень ясно, как программа может
выяснить, открыла ли она внутреннюю связь. А
обнаружить возможность короткого перекодирования без
потери информации, по крайней мере в некоторых
случаях, можно. Для рассмотрения этих случаев нам
придется вернуться к обстоятельству, которое упоминалось
в главе о переборе, — к развалу на кучи.
§ 6. «Развал на кучи» и схема программы
для геометрических задач
Сколько бит необходимо для описания площади
фигуры? Для того чтобы ответить на этот вопрос, нужно
оговорить, в каких пределах изменяется площадь и с
какой точностью ее нужно описать. Пусть фигуры заданы
на растре 100X100, следовательно, их площадь может
принимать значения от 1 до 104. Описание площади
с точностью до одного элемента растра займет 14 бит.
Если мы удовлетворимся меньшей точностью и
согласимся одинаково обозначать фигуры, отличающиеся по
площади меньше чем вдвое, то нам хватит четырех бит.
При такой точности существует всего 14 градаций и,
значит, номер градации можно записать в четырех
двоичных разрядах.
Попытка еще короче закодировать величину площади
приведет в общем случае к дальнейшей потере точности.
Мы не случайно оговорили, что это произойдет в общем
случае, ибо в частном случае это может быть и не так.
Посмотрим на рис. 28 (стр. 121). График 28, а
иллюстрирует как раз общий случай. На нем изображены
значения, которые принимает площадь разных фигур в
задаче, показанной на рис. 25 и 27. Здесь невозможна
короткая кодировка без потери точности.
На рисунке же 28, б изображен случай, когда
значения площадей фигур «разваливались на кучи»
(задача на рис. 25 и 26). Это и есть тот самый «частный
случай», когда возможна короткая кодировка без
потери точности. В самом деле, площади фигур внутри
«кучи» различаются не сильно. Поэтому, один раз
указав, что левая куча имеет площадь 1,5, а правая — 60,
195
мы можем в дальнейшем про каждую фигуру говорить
только, — в какую кучу она попала. Если теперь
обозначить принадлежность к левой куче, например,
нулем, а к правой — единицей, то описание площади
займет 1 бит. Очевидно, при таком способе кодирования
используются ограничения, имеющие место «в мире,
куда мы попали».
Итак, во всех случаях, когда какой-нибудь параметр
«распадается на кучи», программа может коротко
закодировать значение этого параметра без потери
информации. Поэтому есть смысл (об этом уже говорилось в
главе V) при поиске короткого описания классов
обратить особое внимание на параметры, развалившиеся на
кучи. Заметим, что использовать развал на кучи
некоторого параметра можно двумя способами.
Для начала вспомним, что задача программы во
время обучения — найти правило, разделяющее классы.
Это правило, очевидно, будет высказыванием,
являющимся функцией от значений некоторых параметров.
Поскольку мы хотим проверять короткие описания
классов, то есть смысл рассматривать лишь простые
функции и только от коротко кодируемых параметров. Но
ведь коротко кодируемый — это и есть параметр,
развалившийся на кучи. Поэтому программа может
проверять функции только от параметров, распавшихся на
кучи. Нетрудно понять, что это во многих случаях
приведет к заметному сокращению перебора.
Существенно и следующее обстоятельство. Мы хотим
сделать систему, имитирующую человека. Человек легко
строит высказывания из аргументов типа большой —
маленький или справа — слева, или угловатый — округ-
лый и т. п. И практически не способен рассматривать
высказывания типа «площадь 7 или 11 или 22 или от 40
до 48 сочетается с длиной наибольшего диаметра 10
или от 12 до 17 или 23 или от 32 до 35», т. е. человек
легко оперирует параметрами, распадающимися на кучи,
и плохо справляется с поиском разделяющего правила
в остальных случаях. Поэтому программа, которая
будет строить функции только от распавшихся на кучи
параметров, упустит мало правил, доступных человеку.
Справедливости ради следует сказать, что есть и
другой способ короткого кодирования непрерывной
величины (правда, с потерей информации). Это высказы-
196
вание типа больше — меньше (введение порога).
Правила типа «площадь меньше 26 сочетается с диаметром
больше 14» записываются достаточно коротко. Но, в
отличие от случая развала на кучи, поиск таких правил
требует большого перебора. По-видимому, разумным
является компромисс, заключающийся в том, что на
предварительных этапах отбора аргументов для
разделяющей функции программа пропускает только параметры,
распадающиеся на кучи, а на последнем этапе ей
разрешают проверять и разделение по порогу. В
следующем параграфе будут описаны опыты, позволяющие
сравнить трудность для человека задач, в которых
можно использовать развал на кучи, н задач, в которых
нужно вводить порог.
Итак, первое, для чего можно использовать развал
на кучи, — это отбор тех аргументов, которые могут
входить в разделяющую функцию. При этом благодаря
очень короткой кодировке аргументов (0 или 1 при двух
кучах) можно ограничиться рассмотрением логических
функций.
Второе применение развала на кучи — это
управление операторами подмножество и часть. В конце § 4
говорилось, что наборы чисел имеет смысл делить на
подмножества в том случае, если объекты, к которым
относятся эти числа, четко делятся на группы по
какому-то другому признаку. Например, в задаче рис. 44
было полезно рассмотреть отдельно площади
треугольников, т. е. фигур, резко отличающихся по некоторому
параметру (число углов) от остальных фигур. Но ведь
«резкое различие» по какому-нибудь параметру и есть
развал этого параметра на кучи!
Проследим работу программы при решении этой
задачи. На некотором этапе она измерит площади всех
фигур (треугольников и кругов). Проверка покажет, что
площадь на кучи не разваливается. Затем, на каком-то
другом этапе, программа найдет число углов у каждой
фигуры. Выяснится, что этот параметр разваливается на
кучи. Однако принадлежность к той или другой куче
ни сама по себе, ни в сочетании с другими
развалившимися на кучи параметрами класс от класса не отделяет.
Тогда программа начинает делить наборы чисел, не
распавшиеся на кучи, на подмножества в соответствии
с числом углов фигуры. Дойдет дело и до площади.
197
Выяснится, что площади кругов на кучи не
разваливаются, а площади треугольников — разваливаются. В данном
случае, принадлежность к той или другой куче сразу
говорит о принадлежности к классу. Очевидно, могут
встретиться и более сложные задачи.
Сложнее обстоит дело с оператором часть*). Однако
и здесь, по крайней мере в некоторых случаях, можно
использовать развал на кучи. Например, измерив
кривизну контура во всех точках, можно обнаружить, что
она резко распадается на кучи. В одном случае это
будут точки с нулевой кривизной и с очень большой
кривизной, и мы разобьем фигуру на стороны и углы.
В другом случае будет много точек с положительной
кривизной, много точек с отрицательной кривизной и
некоторое количество (должен же быть переход!)
с приблизительно нулевой кривизной. Контур разобьется
на выпуклые и вогнутые части и т. д. В каждом из этих
случаев произойдет разбиение, приспособленное к миру
данной задачи. У многоугольников выделятся стороны,
а овал программа даже не будет пытаться разделить
на части.
Теперь выявляется общая схема программы для
геометрических задач. Имеется словарь (набор операторов,
умеющих обрабатывать картинки, линии и числа). Из
слов строятся фразы, отображающие картинки в числа
или в наборы чисел. Эти числа поступают в фильтр,
который отбирает аргументы для делящих функций
(развал на кучи) и проверяет, не разделяет ли данный
параметр классы (введение порога). Имеется обратная
связь, управляющая операторами часть и подмножество;
она осуществляется «развалом на кучи». Затем имеется
логический блок, ведущий окончательный поиск
разделяющей функции. Он для геометрических задач должен
состоять из нескольких этажей и будет описан в
следующей главе. От логического блока (поскольку его
функция, с некоторой точки зрения похожа на «развал
на кучи») также имеет смысл подать обратную связь
на оператор подмножество. И наконец, разумеется,
нужна программа, которая будет координировать работу
*) Вообще говоря, оператор часть тоже выделяет
подмножества, но не чисел, а точек на растре. Поэтому его удобнее
реализовать в виде отдельной подпрограммы, хотя с достаточно общей
точки зрения он очень похож на подмножество.
198
всех подпрограмм. В частности, она должна проследить
за тем, чтобы ни одно описание класса, выразимое на
языке системы, не миновало бы проверки иначе как по
причине «сознательного» отбрасывания его программой
из-за специфики материала обучения.
Очевидно, что, когда такая программа будет
осуществлена, сравнительно легко можно будет заменять в
ней словарь (набор исходных операторов), сохраняя
основную схему перебора и отсева. Не исключено, что
эта схема окажется полезной и не только для
геометрических задач.
§ 7. Помогает ли человеку развал на кучи
Обычно, когда человек решает некоторую задачу,
очень трудно определить, из какого множества описаний
классов он производит выбор. Более того, можно
поручиться, что для разных людей это множество будет
Рис. 45.
разным. Один и тот же человек при решении разных
задач производит выбор из различных множеств. Все
это затрудняет получение сравнимых между собой
данных, например данных, говорящих о том, какие свойства
материала обучения помогают или мешают человеку
решать задачи узнавания.
t99
Iплаос
Рис. 46. Пример задачи,
Л класс
предлагавшейся испытуемым.
Для преодоления этой трудности был выбран
следующий метод*). Каждая картинка представляла собой
поле стандартных размеров. На этом поле находилась
одна фигура, которая была прямоугольником или
эллипсом (рис. 45). Кроме типа фигуры, картинки могли
отличаться друг от друга площадью фигуры (4
градации), положением центра тяжести фигуры (2
координаты по 5 градаций), степенью вытянутости фигуры
(4 градации) и углом наклона «большой оси» к
вертикали (8 градаций). Таким образом, картинка
однозначно описывалась значениями шести параметров. Описание
классов во всех задачах, предлагавшихся испытуемым,
являлось функцией каких-либо двух параметров из этих
шести. Например, в задаче на рис. 46 принадлежность
к тому или другому классу определяется площадью
фигуры и высотой ее центра тяжести.
Испытуемым давались тренировочные задачи. Решая
их, испытуемые привыкали к тому множеству описаний,
из которого нужно было производить выбор. Основные
опыты велись с людьми, уже достаточно освоившимися
с совокупностью задач.
Эксперименты ставились с целью узнать,
свойственно ли человеку в первую очередь проверять функции от
тех параметров, которые разваливаются на кучи. В
случае, если эта гипотеза справедлива, следовало ожидать
уменьшения времени решения тех задач, в которых
«существенные» переменные разваливаются на кучи.
Поэтому в большом ряду предлагавшихся задач были
специально избранные пары (они шли, разумеется, не
подряд), в которых существенными являлись те же самые
переменные, а различие было только в том,
разваливаются они на кучи или нет.
Времена решения одних и тех же задач разными
испытуемыми оказались различными. Однако каждый
испытуемый решал задачи с разваливающимися на кучи
существенными переменными заметно быстрее, чем
«парные» к ним задачи. Для резкого увеличения
времени достаточно было, чтобы хотя бы одно из двух
существенных переменных перестало разваливаться на
кучи. Приведем средние данные. При решении десятью
*) Опыты, описанные в этом параграфе, проделаны Л.
Дунаевским.
202
испытуемыми задач, в которых оба существенных
переменных разваливались на кучи, среднее время на одну
задачу оказалось 54 сек. Те же испытуемые, решая
«парные» задачи, в которых оба переменных не разваливав
лись на кучи, показали среднее время 142 сек.
Эти данные относятся к случаю, когда в «парных»
задачах тоже существовало короткое описание класса,
но оно требовало введения порога по переменному,
которое не распадалось на кучи. Другими словами,
короткое описание существовало, но оно «не бросалось в
глаза» (нужен был больший перебор для того, чтобы его
найти).
В случае, когда задача требовала более длинного
описания классов (например, нужно было ввести два
порога по каждому существенному переменному), время
решения еще больше увеличивалось, а иногда
испытуемые оказывались не в состоянии решить задачу и за
5—10 мин.
По-видимому, человек в основном и в первую
очередь проверяет функции от распадающихся на кучи
параметров (они «бросаются в глаза»). Это и делает
целесообразным применение развала на кучи в качестве
критерия для сокращения перебора при решении
геометрических задач, доступных для человека.
Глава X
ЯЗЫК УЗНАЮЩЕЙ ПРОГРАММЫ (ЛОГИКА)
§ 1. В чем задача логического бпока(норы)
В предыдущей главе говорилось, что в качестве
составных частей разделяющего правила имеет смысл
рассматривать не все возможные на данном языке фразы,
а только те, которые дают на выходе коротко
закодированную информацию. Если мы выполним это
требование, то каждый аргумент разделяющего правила будет
или категорическим высказыванием типа да — нет (если
на выходе фразы один двоичный разряд), или будет
состоять из очень небольшого числа таких
высказываний. Поэтому целесообразно рассматривать
разделяющее правило как некоторую логическую функцию
высказываний.
При таком подходе окончательный поиск
разделяющего правила должен вести блок, умеющий строить и
проверять различные логические функции. То, какими
функциями может оперировать логический блок, и
определяет (вместе со словарем и грамматикой) класс
высказываний, выразимых на языке программы (класс
доступных разделяющих правил).
Логические блоки имелись и на выходе Арифметики,
и на выходе Геометрии. В Геометрии этот блок
назывался корой, поэтому мы будем и в других случаях
применять термин кора для обозначения блоков, ведущих
поиск разделяющего правила среди логических функций.
Каждый объект представлен для коры в виде
некоторого двоичного кода. Именно кода, а не числа, так
как отдельные разряды кода могут быть никак между
собой не связаны.
Вспомним, например, с чем приходилось иметь дело
коре в программе Арифметика. Словарь Аримфетики со-
204
держал операторы двух типов: чисто арифметические
(сумма, разность, произведение и частное), объектами
для которых служили непосредственно числа Л, В и С,
составляющие таблицу, и операторы, содержащие
некоторую процедуру сравнения (величина модуля, знак и
проверка целочисленности). Объектами для операторов
второго типа могли служить как числа А, В и С, так
и результаты работы операторов первого типа. Фразы,
построенные из этих операторов, были не длиннее двух
слов (например, знак суммы Л и С), поэтому
грамматика языка свелась к перечислению тридцати трех
разрешенных фраз. Каждая фраза отображала строчку
таблицы в 0 или 1, а все фразы вместе — в
тридцатитрехразрядный код. Таблица могла состоять из нескольких
строк, поэтому на входе коры она представлялась в виде
нескольких тридцатитрехразрядных кодов (табл. 19).
1-я
таблица
2-я
1 таблица
24-я
1 таблица
1
[10 1
1 1 0
L 1 0 0
(000
0 1 0
[001
[10 1
1 1 1
1 0 1
ТАБЛИЦА 19
33 разряда
10 10 0
10 110
10 10 1
110 10
1110 0
10 0 10
0 10 10
0 10 10
0 0 0 0 1
0 0 1 1 0 1
10 10 1
10 0 10
110 0 0
1110 1
10 0 0 1
0 1110
0 0 1 10
0 1111
Каждый столбец в табл. 19 имеет совершенно
определенное содержание. Например, 8-й столбец может
обозначать целочисленность С, а 18-й — величину модуля
205
произведения ВхС. Однако именно этих
содержательных сведений кора не получает.
Для нее существуют только номера столбцов и нули и
единицы в этих столбцах. Поэтому кора относится ко
входному материалу предельно формально. Она ищет
логические функции от пар столбцов, совершенно «не
задумываясь» над смыслом этих функций.
Единственный критерий поиска — сечение, производимое функцией
на множестве таблиц (в конечном итоге, полезная
информация, которую несет признак относительно задачи).
С одной стороны, в этом — слабость коры. Она
проверяет все логические функции от всех пар столбцов,
в то время как, «понимая» смысл столбцов, кора могла
бы иногда сократить перебор. Дело в том, что
различные столбцы могут быть не вполне независимы. От
этого функция некоторой пары столбцов может
содержательно совпадать с уже рассмотренной функцией от
другой пары столбцов. Устройство, знающее (в смысле
умения совершать дедукцию) законы арифметики,
могло бы не рассматривать второй раз ту же функцию.
Для коры же это — другая функция, и она ее снова
проверяет.
С другой стороны, в таком бездумно формальном
подходе — источник универсальности коры. Алгоритм
работы коры не зависит от того, каково содержательное
значение того или иного столбца. Поэтому можно вместо
результатов обработки числовых таблиц некоторым
оператором (как в Арифметике) ввести в каждый столбец
исходного материала коры любую другую коротко
закодированную информацию. Так было сделано в
программе Геометрия, так можно в принципе делать в
самых разнообразных программах.
Итак, задача коры — поиск разделяющего правила
после того, как найдены операторы, дающие достаточно
четкие (коротко кодируемые) характеристики объекта
или его частей. При этом несущественна структура
операторов и то, как они найдены. Их мог в готовом,
окончательном виде придумать человек (Арифметика), они
могут иметь некоторые степени свободы, закрепляемые
в ходе определенных стадий обучения (Геометрия,
блоки ганглиозные клетки и подкорка), и т. д.
Как и всякая программа (или ее часть), кора не
может годиться «для всех задач». Однако про некоторый
206
конкретный вариант коры не имеет смысла говорить,
что он приспособлен для узнавания геометрических
фигур или болезней, или звуков речи, ибо это скорее
свойство словаря программы. Специфика каждой конкрет-*
ной коры в другом — в том классе логических функций,
который она рассматривает, в критериях отбора и
способе применения отобранных функций во время
экзамена. Может оказаться, что одна и та же кора хорошо
справляется и с медицинской диагностикой, и с узнава*
нием звуков речи, и с узнаванием числовых таблиц, и
в то же время разные совокупности геометрических
задач могут потребовать разных систем коры.
В этой главе мы рассмотрим несколько модификаций
коры и обсудим, какие особенности совокупности задач
могут служить доводом за применение той или иной
модификации коры.
§ 2. Поиск логической функции по частям
Логические блоки имелись в программах
Арифметика и Геометрия, но устроены они были несколько по-
разному.
В программе Арифметика искались признаки,
являющиеся функциями двух логических переменных. При
этом от признака требовалась устойчивость
характеристики внутри каждого класса. Вспомните (глава III,
§ 2), что признаки браковались, если они присваивали
разные характеристики рабочей и контрольной
таблицам (хотя бы для одного закона). Поскольку логических
функций от двух переменных немного, Арифметика
прямо проверяла их все подряд. Это уложилось в
приемлемое время, тем более, что благодаря малому количеству
функций (меньше, чем разрядов в ячейке) логические
произведения по строкам искались сразу для всех функций.
Однако ясно, что искать таким же способом
функции от большего числа переменных мало реально. Пусть
мы хотим искать функции s переменных, которые надо
выбрать из L «кандидатов» (в Арифметике s = 2, L = 33).
От данных s аргументов существует 22* разных
логических функций. Кроме того, можно Cl способами
выбрать s аргументов из L кандидатов. Всего, таким
образом, число подлежащих проверке функций Т = 22'УС£.
207
Если L«40-f-50, то при 5 = 2 получаем Г—104, при 5 = 3
уже 7^106>5, а при 5 = 4 находим Т~ 10i0; наконец, при
5 = 5 даже Г«1015*5. На машинах со скоростью 104—105
действий в секунду искать полным перебором функции
трех переменных трудно, а четырех — уже невозможно.
Идея, с помощью которой удалось заметно сократить
число проверок, принадлежит М. Н. Вайнцвайгу *) и
состоит в следующем.
Как известно, всякую логическую функцию можно
представить в виде логической суммы (дизъюнкции) не
более 2s членов, каждый из которых является
логическим произведением (конъюнкцией) аргументов или их
отрицаний (содержит 5 сомножителей). Если функция
обращается в единицу при некотором значении
аргументов, то при этих значениях обязательно равен
единице хотя бы один член суммы. Отсюда предложенный
способ: вместо 22* функций проверять только 2s
конъюнкций от 5 сомножителей.
Правда, при этом каждая конъюнкция уже не будет
являться признаком, присваивающим устойчивую
характеристику объектам данного класса (или данной
группе классов, как в Арифметике). Действительно, если
функция принимает значение 1 на всех объектах класса,
то некоторая, входящая в нее конъюнкция может на
многих объектах принимать значение 0 (на этих
объектах обращаются в 1 другие конъюнкции). Таким
образом, если признаки Арифметики работали по принципу
да — нет (были необходимыми и достаточными
признаками группы классов), то отдельные конъюнкции
являются признаками типа да — не знаю (т. е.
достаточными признаками). В некоторых случаях это
несколько мешает, а в некоторых, наоборот, очень удобно.
Особенно заметно преимущество способа Вайнцвайга в
тех задачах, где разделяющая функция является логн*
ческой суммой конъюнкций, содержащих в качестве
сомножителей разные переменные.
Число проверок по сравнению с перебором всех
функций сокращается при 5 = 3 в 101»5 раз, при 5 = 4 уже в
'103'5 раз, при 5 = 5 даже в 108 раз. К этому надо
добавить, что реализация одной конъюнкции требует мало
*) М. Н. Вайнцвайг, Проблемы передачи информации,
вып. 3, 1966.
208
операций по сравнению с реализацией произвольной
функции.
Нетрудно заметить, что уже рассмотренный в
главе VIII логический блок программы Геометрия ведет,
по существу, проверку отдельных конъюнкций двух и
трех переменных.
§ 3. Критерии отбора конъюнкций
Допустим, мы строим кору, которая ведет поиск
признаков в виде отдельных конъюнкций. Какими
критериями она должна пользоваться при отборе признаков
и как применять признаки во время экзамена?
Для простоты будем считать, что объекты задачи
делятся на два класса и каждый объект представлен
в коре одной строкой нулей и единиц (как в Геометрии,
а не как в Арифметике). Для обучения дано по iV
объектов каждого класса. В этом случае входной материал
коры имеет вид табл. 20. Признаками являются
логические произведения вида xix Лх/2 Л.. .Ла;^, где каждый
сомножитель может быть некоторым переменным или
его отрицанием. Подстановка в конъюнкцию
конкретных характеристик некоторого объекта обращает ее в 1
или в 0. Описанием класса должна быть логическая
сумма нескольких конъюнкций.
1
1 I класс
N
1 И класс
N
ТАБЛИЦ
Х1Х2ХгХ4ХЬХ6 ' ' XL-
10 1110 . . 1
10 0 10 1 . . 1
110 10 0 . . 0
[010011 . . 0
I 0 1 1 0 1 0 . . 0
liioooi . . о
А 20
-\х А
0
1
0
1
0
1
До сих пор мы все время считали, что программа
ищет короткие описания классов. В частности, в
кору попали только коротко кодируемые параметры.
209
Естественно наложить то же ограничение и на кору.
В применении к коре рассматриваемого типа краткость
означает, что описание содержит малое число
конъюнкций*). Другими словами, описание классов должно
состоять из небольшого числа высказываний,
соединенных связкой «или».
Этим соображением непосредственно подсказывается
один из критериев отбора при обучении: запоминаемая
в качестве признака конъюнкция должна быть истинна
на достаточно большом числе объектов обучения
некоторого класса.
Пусть мы ищем описание I класса. Оно, естественно,
должно все N объектов, показанных при обучении,
относить к I классу. Для этого нужно, чтобы на каждом
объекте хотя бы одна конъюнкция была истинна.
Назовем объект, на котором некоторая конъюнкция истинна,
объектом, охарактеризованным этой конъюнкцией.
Обозначим через ki число объектов, охарактеризованных
первой отобранной конъюнкцией, k2 — число объектов,
охарактеризованных второй конъюнкцией, ..., kn —
последней из п отобранных конъюнкций. Пусть X — число
объектов, охарактеризованных хотя бы одной
конъюнкцией. Имеет место очевидное соотношение X^ki + k2+...
...4-&п. Отсюда следует, что если все kt малы, то для
описания всего материала обучения потребуется много
конъюнкций.
Итак, при отборе конъюнкций имеет смысл ввести
некоторый порог k0 и запоминать только те из них, для
которых число охарактеризованных объектов
превышает k0. Очевидно, при разных задачах (и при разных N)
целесообразно пользоваться разными порогами. Как же
поступать при переходе к новой, неизвестной задаче?
Можно начать с обучения при большом k0. Если
найдутся описания классов — хорошо. Если окажутся
охарактеризованными не все объекты материала обучения,
можно уменьшить k0 (это эквивалентно готовности
удовольствоваться более длинными описаниями) и т. д.
Может, однако, случиться, что, хотя все k были
большими, отобранные конъюнкции характеризуют недостач
точное число объектов. Это произойдет, например, вслу«
*) Естественно также полагать, что сами конъюнкции не очень
длинны.
210
чае, когда все конъюнкции характеризуют одни и те же
(или почти одни и те же) объекты. Поэтому необходим
второй критерий отбора, проверяющий степень
независимости разных признаков. В программе этот критерий
может быть реализован по-разному, но во всех
вариантах сечение, производимое «кандидатом в признаки» на
множестве объектов, должно тем или иным способом
сравниваться с сечениями, произведенными уже
отобранными признаками.
В соответствии с определением, данным в главе IV
(§ 4), мы считаем классы непересекающимися. Для
каждого объекта существует способ (автомат /Ci!) с полной
достоверностью сказать, к какому классу он
принадлежит. Отображение, осуществляемое операторами,
преобразующими входную информацию в нули и единицы
для коры, вообще говоря, является вырожденным.
Однако мы, естественно, стремимся сделать систему,
которая при отборе операторов для данной задачи
заботится о том, чтобы эти операторы «не выплеснули
ребенка», не выбросили информации, необходимой для
определения класса объекта. Будем считать, что это
требование выполнено*).
Тогда кора может стремиться к построению
описания не только короткого, но и безошибочного.
Отсюда третий критерий отбора конъюнкций.
Конъюнкция, характеризующая объекты одного класса,
не должна характеризовать ни одного объекта другого
класса. Эта рекомендация, очевидно, справедлива
только при соблюдении обстоятельств, оговоренных в
предыдущем абзаце. В ряде практических задач классы
могут пересекаться или при преобразованиях
информации может теряться существенная ее часть и т. п. В
результате могут не существовать короткие безошибочные
описания. Здесь мы на этих случаях не останавливаемся,
им будет посвящена часть следующей главы.
Требование, чтобы каждая конъюнкция характерна
зовала много объектов, по существу, совпадает с тре«
бованием создания обобщенного описания класса, а
не запоминания объектов из материала обучения.
Действительно, если снять это требование, то очень легко
*) Примером программы, где упомянутое требование не
выполнялось, является Геометрия. После подкорки уже никакая кора не
смогла бы хорошо разделить классы.
211
построить логическую функцию, принимающую
значение единица на всех объектах обучения I класса.
Каждая конъюнкция этой функции содержит произведения
всех L переменных хи *2, ..., **, ..., xL или их
отрицаний. Первая конъюнкция строится так, чтобы она
принимала значение 1 на первом объекте первого класса
и 0 на любых других объектах. Для этого она включает
все переменные, которые у первого объекта равны 1,
и отрицания всех переменных, равных 0. Для таблицы,
изображенной на рис. 20, она будет иметь вид: Fi=X[A
ЛхоЛХьАЪЛХьЛх*/\ • • - Axl-i'Axl. Аналогично можно
построить вторую конъюнкцию, характеризующую
только второй объект: F2 = XiAx~2 Ахз Л^Л^Л^вЛ • • • Л
Axl-\Axl и т. д. до Fx=xiAx2Ax^AxAAxbAx%A-
...Axl-\Axl.
Очевидно, функция FA/F^A/.. .\/FN характеризует все
объекты материала обучения I класса. Тем же способом
можно построить функцию для II класса. Однако
полученные функции не будут давать при экзамене
«экстраполяцию». Они будут характеризовать объект только
в том случае, если он совпадает с каким-либо объектом
из материала обучения. Все остальное они выбрасывают
в «мусор». Получилось это потому, что каждая
конъюнкция слишком «подогнана» к какому-то объекту, является
его слишком детальным описанием.
Другое дело, если мы ищем конъюнкции не L, а
меньшего числа переменных, характеризующие сразу
много объектов из материала обучения. В ходе такого
поиска и обнаруживаются те сочетания переменных,
которые при разнообразных значениях остальных
переменных (тем более разнообразных, чем больше объектов
характеризует конъюнкция!) свидетельствуют о
принадлежности объекта данному классу. При экзамене может
быть надежда, что такая конъюнкция охарактеризует
объект с новым (не встречавшимся при обучении)
набором остальных переменных.
§ 4. Надежность признаков. Предрассудки
В двух предыдущих параграфах обсуждался поиск
конъюнкций, которые являлись бы достаточными
признаками, т. е. иногда встречались бы в одном классе и
никогда не встречались в противоположном. Вспомним,
212
однако, что проверку отсутствия противоречивых
примеров программа может производить только на объектах
из материала обучения. Поэтому всегда существует
вероятность того, что, хотя на материале обучения второго
класса конъюнкция и не встретилась, она все же не
является достаточным признаком первого класса.
Поясним это примером. Пусть человеку, не
знающему ни итальянского, ни испанского языков, показали
стопку итальянских и стопку испанских книг и сказали,
что это объекты соответственно I и II классов. Во время
поиска достаточных признаков этот человек (ничего не
знающий об истинном принципе деления на классы)
будет проверять формат книг, число страниц, размеры
шрифта, четкость печати, твердость переплета, цвет
обложки и т. п. И если ему дали для обучения небольшое
количество книг каждого класса, то весьма вероятно,
что он отберет ложные признаки (у него появятся
«предрассудки»). Если, например, случилось, что все
итальянские книги были переплетены, а среди испанских
нашлись две без переплета, то у человека может
создаться «предрассудок», что отсутствие переплета
свидетельствует о принадлежности книги ко II классу.
Такие же предрассудки могут появиться и у коры.
Среди конъюнкций, в действительности не имеющих
отношения к делу*), могут найтись такие, что они
несколько раз встретятся в одном классе и ни разу
в другом. Если порог k0 меньше числа
охарактеризованных этой конъюнкцией объектов, то признак будет
ошибочно отобран как полезный.
Вероятность появления у коры предрассудка
уменьшается при увеличении N (числа примеров при
обучении) и k0 (порога отбора). Эти соотношения очевидны
и не нуждаются в пояснениях.
Мы остановимся на другом, менее бросающемся в
глаза обстоятельстве. Переход к рассмотрению
отдельных конъюнкций вместо необходимых и
достаточных признаков был в основном вызван желанием
сделать доступными для коры функции большего числа
логических переменных (см. § 2). Если мы хотим, чтобы
*) Здесь, как и всюду в этой главе, мы для простоты делим
признаки на «полезные» и «чистые предрассудки». Промежуточные
случаи, требующие вероятностной оценки качества признака,
рассматриваются в следующей главе-
213
программа могла вскрывать сложные закономерности,
то нужно рассматривать сочетания нескольких
параметров сразу. Создается впечатление, что, чем более
сложные функции может проверять программа, тем лучше
она будет решать различные задачи. Однако, это не
всегда так.
Вернемся к примеру с итальянскими и испанскими
книгами. Пусть человеку показали при обучении
большое число книг каждого класса, и он решил отбирать
только признаки, характеризующие много книг. В этом
случае вероятность того, что, например, свойство
переплета отберется в качестве полезного признака, будет
мала. То же самое можно сказать и о любом другом
предрассудке (толщине книги, формате и т. п.).
Посмотрим, что произойдет, если человек перейдет от проверки
таких простых признаков к сложным, составным
признакам. Он может проверить разность числа слов на
четных и нечетных страницах. Или ту же разность на
двадцать второй и двенадцатой страницах. Или
произведение средней длины абзаца на число страниц, начи^
нающихся с абзаца. Или частное от деления числа
точек на высоту шрифта и т. д. Вероятность того, что
каждый такой предрассудок выдержит проверку, мала. Но
сложных признаков существует чрезвычайно много.
Поэтому может случиться, что, несмотря на малую
вероятность отбора каждого из них, математическое ожидание
числа отобранных предрассудков окажется большим.
А это Значит, что память начнет забиваться
предрассудками. Таким образом, «богатый выбор» не только
увеличивает возможности коры, но и чреват появлением
предрассудков.
Допустим, что для описания объектов были выбраны
обстоятельства, совершенно побочные для существа
задачи. Например, коды, описывающие объекты обоих
классов (табл. 20), выбираются просто случайно, с
равной вероятностью для всех кодов. Такая задача,
естественно, принципиально неразрешима. Всякий признак,
отобранный корой при этих обстоятельствах, будет
чистым предрассудком. Поэтому хочется, чтобы в этом
случае вероятность отбора корой признаков была мала. Это
соображение накладывает ограничения на допустимую
длину кода L. В самом деле, при любых N, k0 к s
(число членов конъюнкции) существует такое L, что матема-
214
тическое ожидание М числа отобранных предрассудков
будет больше А10, где М0 — произвольное число.
Итак, любую конкретную кору нельзя перегружать
слишком длинными описаниями объектов. Очевидно,
допустимая длина зависит от числа объектов, данных для
обучения.
Математическое ожидание появления предрассудка
при прочих равных условиях зависит от 5. При малых k0
число М может увеличиваться с ростом 5 (из-за
увеличения числа проверяемых конъюнкций). Поэтому нужно
соизмерять сложность функций, проверяемых корой, с
числом объектов, данных для обучения, и со степенью
их однородности или разнообразия (от последнего
зависит значение k0y при котором возможно обучение).
Как до экзамена выяснить, велик ли процент
предрассудков среди признаков, отобранных корой для
данной конкретной задачи? Исходя из алгоритма отбора
конъюнкций, можно оценить вероятность
«проникновения» чистого предрассудка. Умножение этой величины
на число проверяемых конъюнкций даст М. Если
количество реально отобранных признаков В
близко к М, значит велика вероятность, что кора не открыла
настоящего закона классификации, а лишь создала
предрассудки. Если же В^>МУ то есть основания
надеяться, что найденные признаки отражают закон
классификации. Если бы это было не так, то очень
маловероятным было бы большое число отобранных
признаков.
Отсюда правило: чем короче формулируется закон,
тем суровее должны быть критерии отбора, чтобы
уменьшить вероятность появления предрассудков. Наоборот,
в задачах, где классы описываются не очень коротко и
при обучении отбирается много признаков, можно вести
отбор более «мягко» и допустить несколько большую
вероятность «проникновения предрассудка».
Как уже было оговорено, все рассуждение велоеь в
терминах полярных понятий «чистый предрассудок» и
«полезный признак». В следующей главе будут
обсуждаться методы оценки результата обучения (оценки до
экзамена), в случае, когда каждый признак может
занимать промежуточное положение между полюсами.
В этом случае не имеет смысла говорить о вероятности
появления предрассудка, зато можно оценить вероятность
215
того, что отобранный признак ошибется при
экзамене. В основе оценки также будет "сравнение числа
реально отобранных признаков с некоторой априорной
величиной, являющейся функцией от алгоритма отбора.
§ 5. Алгоритм экзамена
Когда мы начали рассматривать отдельные
конъюнкции, предполагалось, что разделяющая функция будет
являться логической суммой найденных признаков. При
таком подходе программа на экзамене относит объект
к I классу, если хотя бы один из признаков,
характеризующих объекты I класса («признак I класса»),
принимает значение 1 на этом объекте. Аналогично ко II
классу относятся объекты, на которых принимает значение
1 хотя бы один признак, характеризующий объекты II
класса («признак II класса»).
Если среди отобранных признаков нет ни одного
предрассудка, то такая процедура никогда не приведет
к противоречию. Объект может быть отнесен к I классу,
или ко II классу, или ни к какому классу, причем в
случае отнесения к какому-либо классу ошибки быть
не может.
К сожалению, эта стройная картина рушится, если
среди отобранных признаков имеется некоторый
процент предрассудков. Теперь уже возможен случай, когда
объект на экзамене будет отнесен сразу к двум
классам. Можно, конечно, считать, что программа в этом
случае «воздержалась от ответа», однако количество
таких отказов может оказаться слишком большим.
Рассмотрим случай, когда кора отобрала при
обучении много признаков. Каждый из них характеризовал
несколько (не менее k0) объектов. Поэтому каждый объект
из материала обучения в среднем охарактеризован
многими признаками. Благодаря проверке независимости
признаков число признаков, характеризующих каждый от*
дельный объект, не очень сильно отличается от среднего,
т. е. тоже велико. В случае, если материал обучения
хорошо представляет задачу, объекты при экзамене также
будут характеризоваться многими признаками
одновременно. На экзамене возникнет следующая ситуация:
объект, например, I класса будет охарактеризован
многими признаками I класса и, кроме того, некоторыми
216
предрассудками, которые программа считает
признаками II класса. Однако если предрассудки составляют
небольшую долю всех отобранных признаков, то число
признаков I класса, характеризующих этот объект,
окажется больше числа признаков II класса (в
действительности, предрассудков), характеризующих его же.
Отсюда возникает мысль: в случае большого числа
отобранных признаков устроить при экзамене
«голосование». Конечная величина вероятности проникновения
►
i
I класс
о
о
о
О
о
Днласс
Рис. 47.
предрассудка делает целесообразным применять в
качестве разделяющей функции не логическую, а
арифметическую сумму отдельных конъюнкций.
Естественно возникает вопрос о том, не нужно ли
разным конъюнкциям присвоить разный вес (например,
пропорциональный их k)? Теоретически обосновать
целесообразность какой-нибудь конкретной системы весов
затруднительно, пока не указаны точные статистические
характеристики задачи. Опыты с некоторыми
практическими задачами не показали преимущества какой-либо
системы перед «демократическим голосованием».
217
Теперь рассмотрим случай,-когда .при обучении
отовралось мало признаков, которые тем не менее
охарактеризовали весь материал обучения. Допустим, оценка
показала, что Л1<С1. (В противном случае при малом
числе отобранных признаков есть смысл считать, что
кора просто не смогла обучиться.) Другими словами,
мы должны считать, что предрассудков нет.
В этих условиях голосование становится бессмысленным.
В случае противоречивых высказываний объект следует
или отнести в «мусор», или полностью описать, по
каким признакам (содержательно!) объект похож на I
класс, а по каким — на II.
В качестве примера такой задачи рассмотрим рис. 47.
Пусть во время обучения программа нашла такие
признаки I класса: 1) фигура расположена в правой
половине поля, 2) фигура — треугольник, 3) фигура черная.
Соответственно признаками II класса будут: 1) фигура
расположена слева, 2) фигура — окружность, 3) фигура
контурная. Допустим, при экзамене программе показали
рис. 48.
Два признака будут утверждать, что это объект
II класса, а один —что I класса. Очевидно, в этом
случае не стоит решать вопрос «большинством голосов».
Имеет смысл устроить программу или
так, чтобы она отнесла рис. 48 в «мусор»,
или так, чтобы она выдала
характеристики по всем существенным (в этой
задаче) признакам. В последнем случае
программа должна сказать, что на рис. 48
находится расположенный слева контур-
ный треугольник. Это описание вместе с
описанием классов, найденным при
обучении, должно быть передано той системе, по
заказу которой решается задача. Ею может
быть человек или некоторая надпрограмма узнающей
программы. Окончательное решение о целесообразном
поведении в этом случае должна принимать надсистема.
Таким образом, выбор алгоритма экзамена для коры
должен зависеть от ожидаемой вероятности наличия
предрассудков. В принципе возможно построение
программы, которая сама производит после обучения
соответствующие оценки и выбирает алгоритм экзамена
применительно к свойствам данной конкретной задачи.
ь
218
§ 6. Логика для геометрических задач
(многоэтажная кора)
В предыдущей главе было начато описание плана
программы для геометрических задач. Особенности
коры, которая понадобится для завершения этого плана,
удобнее всего разобрать на примере.
Пусть программа должна решить задачу,
представленную на рис. 49. К первому классу относятся большие
вертикально ориентированные или маленькие
горизонтально ориентированные прямоугольники, а ко второму
классу — большие горизонтальные или маленькие
вертикальные прямоугольники.
Программа, естественно, начнет с «общего осмотра»
картинок, т. е. с применения операторов, описывающих
картинку в целом, а не разбивающих ее на части.
Окажется, что значения горизонтальной координаты центра
тяжести фигур не распадаются на кучи и поэтому
допускать их в кору нет смысла. То же самое относится к
вертикальной координате. Дойдет дело до оператора
площадь. Площади фигур распадаются на кучи.
Значение площади будет коротко закодировано и поступит в
кору в виде первого столбца (табл. 21).
ТАБЛИЦА 21
I
класс
II
1 класс
Плошадь 1
1
Вакантные места
[ 0 1
1
0
L1
f 1
1
0
0
Кора немедленно попробует использовать столбец для
разделения классов, однако это в данном случае ей не
удастся. Программа перейдет к проверке следующих
219
1нласс
Л нласс
Рис 49.
операторов. Периметр фигур также распадается на кучи,
однако если коротко закодированные значения
периметра попали бы в кору, то в ней появился бы столбец,
неотличимый от первого ,(в данной задаче все фигуры,
имеющие бблыную площадь, имеют и больший
периметр). Поэтому «фильтр новизны» не пропустит такой
столбец в кору.
Допустим, словарь, которым пользуется программа,
таков, что к моменту, когда исчерпаны все операторы,
преобразующие фигуру в целом, в коре не появилось
новых столбцов, а значит, классы остались
неразделенными. Тогда программа перейдет к разделению фигур
на части. Направления нормали к контуру фигур резко
распадаются на кучи. Используя это обстоятельство,
ТАБЛИЦА 22
1-Я
1 картинка
2-я
I картинка '
1
1 3-я
1 картинка
1
1
1 4я
1 картинка
1
X
с £<
« н
£ о Вакантные места
1
0
1
[ 0
1
0
1
[ 0
, 1
'0
[1
[ 0
1
>0
,1
5-я
картинка '
Направление 1
стороны 1
[ °
1
0
1
Г
6-я ! 1 •
картинка 1 о
1 1 •
ГО
7-я
картинка
8-я
картинка
1
0
1
( °
1 •
| 0
1
Вакантные места |
221
оператор часть разобьет каждый прямоугольник на
четыре части (стороны).
Каждая сторона имеет направление, которое в
данной задаче может быть коротко закодировано. Однако
в коре нет места для обозначения направления
сторон! В самом деле, прямоугольник имеет четыре
стороны, а в коре отведена только одна строчка на всю
фигуру.
Возникает мысль сделать «младшую кору», в которой
имелось бы по строке на каждую часть фигуры (кора
такого типа была в Арифметике, где строка коры
соответствовала строке таблицы). В младшую кору также
допускаются лишь коротко кодируемые описания, но не
картинок в целом, а их отдельных частей. В нашем при-
ТАБЛИЦА 23
1-Я ^
картинка
2-я
картинка
3-я
1 картинка
X
&§§!
X о О * Вакантные места
[ 0 1
1 0
0 1
1 0
( 0 0
1 1
0 0
И 1
[ 0 1
j 1 0
jo l
1 1 0
Г 0 0
4-я 11
«картинка J о 0
111
5-я
картинка
| б-Я
картинка
7-я
картинка 1
8-я
картинка 1
Направление 1
стороны 1
Относит. 1
длина 1
в» 1
я 1
х 1
° 1
[ 0 1
1 0
0 1
1 0
[ 0 1
1 0
0 1
1 0
| 0 0
11 1
} 0 0
1
места]
[ 1 1
( 0 0 1
1 1
jo о
Ill
222
мере код, характеризующий направление старой,
попадает в первый столбец младшей коры (табл. 22).
Младшая кора начнет искать способ отделить с помощью
этого столбца одни картинки от других. Однако ни
наличие или отсутствие единиц, ни наличие или отсутствие
нулей не является признаком, отделяющим одни
картинки от других. Подсчет числа нулей или единиц также
не дает возможности отличить одни картинки от других.
Поэтому программа начнет применять другие
операторы для преобразования частей фигур (сторон
прямоугольников). На каком-то этапе программа дойдет
до отношения длины стороны к периметру фигуры. Эта
величина развалится на кучи и попадет в качестве
столбца в младшую кору (табл. 23). Сам по себе второй
столбец столь же бесполезен, как и первый. Но их
совокупность уже позволяет разбить картинки на две группы.
Например, сумма по модулю 2 этих столбцов равна
1 для всех частей 1, 3, 5 и 6-й картинок и равна 0 для
частей 2, 4, 7 и 8-й картинок.
Мы видим, что на этом этапе младшей коре удалось
получить некоторое короткое описание картинок.
Содержательно оно означает ориентацию прямоугольника.
Есть смысл послать это описание в виде нового столбца
в старшую кору, которая имеет дело только с
описаниями картинок, а не их частей. В результате в старшей
коре появится второй столбец (табл. 24).
ТАБЛИЦА 24
я
о
ч
С
(°
*
0
11
f 1
! 1
i °
1 о
н
Я
си
О
1
0
1
0
1
1
0
0
223
Старшая кора обнаружит, что сумма по модулю 2
первого и второго столбцов равна 1 для всех картинок
I класса и 0 для всех картинок II класса. Это и будет
правило, разделяющее классы.
Итак, наличие в словаре операторов, делящих кар*
тинки или наборы чисел на части, делает
целесообразным построение многоэтажной коры. Старшая кора имеет
дело с описаниями объектов, и критерием для нее
является разделение классов. Материал в нее может
поступить непосредственно от операторов, преобразующих
всю картинку, или от младшей коры.
В младшую кору попадают короткие описания частей
картинки. Ее задача — отделить одни картинки от дру»
гих, и если это удается, то результат попадает в
старшую кору в качестве нового исходного материала.
Заметим, что, поскольку критерием для младшей коры
является не отделение класса от класса, а лишь
разделение картинок на два подмножества, в нее можно даже
не вводить информацию о принадлежности картинок
тому или другому классу.
Если, как уже говорилось в предыдущей главе,
задача программы — имитировать человека в области
узнавания «геометрических картинок», то, по-видимому*
нет смысла позволять младшей коре проверять функции
многих столбцов сразу. Зато целесообразно сделать для
нее доступными высказывания типа «...имеет место хотя
бы для некоторых частей», «...имеет место для всех
частей», «...ни для одной части не имеет места», «...имеет
место не для всех частей». Стоит также дать ей
возможность считать число частей объекта, обладающих
некоторым свойством, и если эти числа распадутся на кучи,
то кодировать номер кучи и отсылать код в старшую
кору.
Может встретиться задача, для решения которой
придется рассматривать части от частей картинки.
Например, задача на рис. 50 требует разделения картинки ва
отдельные фигуры, а затем разделения контура фигур на
части (стороны или углы), чтобы можно было эти част
пересчитать. Естественно поручить обработку кодов «ча*
стей от частей» «младшей коре второго ранга». Ее за-:
дача будет — поставлять материал для «младшей коры
первого ранга», т. е. давать описания частей картинки
(в данном случае отдельных фигур). Соответственно
224
критерием при отборе функций в младшей коре второго
ранга будет отделение одних частей от других.
Очевидно, в случае необходимости можно построить
кору третьего ранга, четвертого ранга и т. д. При этом
материалом для коры /-го ранга будет служить или
результат непосредственной обработки описания частей
/-го ранга оператором развал на кучи, или выход коры
/ нласс
Л класс
Рис. 50.
(/-Ь1)-го ранга (здесь частью /-го ранга названа часть
от части (/—1)-го ранга. Вся картинка является «частью
нулевого ранга»).
До сих пор мы рассматривали только одну функцию
коры (/-И)-го ранга — поставлять коротко
закодированные описания частей /-го ранга в кору /-го ранга. Однако
ее есть смысл использовать также в качестве
устройства, управляющего оператором подмножество.
Действительно, что означает передача корой (/-Н)-го ранга в
кору /-го ранга нового столбца? Это — сигнал о том, что
кора (/+1)-го ранга нашла резкое отличие одних
частей /-го ранга от других. Следовательно, может
оказаться полезным рассмотреть отдельно подмножество
частей /-го ранга, имеющих в этом столбце
характеристику 1 и отдельно подмножество с характеристикой 0.
Поэтому каждый раз, когда кора (/+J)-ro ранга
225
передает столбец в кору /-го ранга, есть смысл
включить оператор подмножество.
* . В предыдущей главе говорилось, что оператор раз-
вал на кучи должен управлять оператором
подмножество. Вспомним теперь, что в случае развала на кучи
некоторого параметра, описывающего части /-го ранга, в
коре /-го ранга тоже должен появиться новый столбец
(или даже несколько). Поэтому можно не подразделять
способы управления оператором подмножество на два
типа (обратные связи от развала на кучи и от коры),
как говорилось ранее. Общий рецепт такой: по какой бы
причине ни появился в коре /-по ранга новый столбец,
есть смысл рассмотреть отдельно подмножества частей
t-го ранга с характеристикой 1 и с характеристикой 0.
Потребность в многоэтажной коре возникла у нас в
связи с построением плана программы для
геометрических задач. Однако ясно, что такая кора может
принести пользу и в других случаях. Всюду, где разумно
считать объекты состоящими в каком-то смысле из
«частей», может оказаться целесообразным строить
высказывания, опирающиеся одновременно как на свойства
частей, так и на свойства объектов в целом. Именно это
и умеет делать многоэтажная кора. Очевидно, что
необходимость в отдельном рассмотрении некоторых
подмножеств частей тоже может встретиться во многих
случаях.
Глава XI
РОЛЬ СТАТИСТИЧЕСКИХ КРИТЕРИЕВ
§ 1. Непересекающиеся классы
Согласно определению, данному в главе VI,
узнавание есть слабая имитация устройства, генерирующего
задачу.
При таком подходе вопрос об истинной
принадлежности объекта к тому или другому классу совершенно
не содержит вероятностных элементов. Действительно,
блок Ki совокупности задач (рис. 18) является просто
конечным автоматом. Находясь в каком-нибудь
определенном состоянии, блок К\ производит совершенно
«жесткое» разбиение объектов на классы. При этом,
если некоторый объект был однажды отнесен к I классу,
то сколько бы раз еще мы ни подавали его на вход
блока Ки объект всегда будет опять отнесен к I классу.
Эта ситуация соответствует тому, что принято
называть непересекающимися классами. Нет объектов,
которые «с некоторой вероятностью могут принадлежать как
к I, так и ко II классу». Поэтому в принципе возможно
осуществить устройство, безошибочно решающее задачу
(им будет, например, точная копия блока К\).
И все же, несмотря на полную детерминированность
принадлежности объектов к классам, практически
никогда нельзя ручаться, что программа после обучения
будет безошибочно узнавать на экзамене. Действительно,
программа, отбирая признаки, имеет возможность
проверять их только на небольшой части всех возможных
объектов, и не исключено, что признак, безошибочно
работавший на материале обучения, окажется
«предрассудком».
Всякая программа ведет отбор признаков во время
обучения, пользуясь некоторыми критериями. Например,
227
кора, ведущая поиск конъюнкций, являющихся
достаточными признаками, пользуется критерием: «часто
встречается в одном классе и никогда не встречается з
другом». Однако, как уже говорилось, проверка
производится лишь на материале обучения. Отсюда
возможность делать на экзамене лишь утверждения
вероятностного характера. Одновременно возникает
необходимость оценки степени статистической
достоверности тех критериев, с помощью которых
производится отбор признаков. В предыдущей главе мы
столкнулись, например, со случаем, когда критерий,
бывший достаточно надежным при коротких описаниях
объектов, при длинных описаниях начинал пропускать
предрассудки.
Таким образом, даже в случае непересекающихся
классов, из-за ограниченности материала обучения
возникает необходимость в статистических оценках.
Заметим, что сам критерий (например, «часто на одном
классе и никогда на другом») является, по существу,
статистическим.
Очевидно, блоки, производящие оценку статистической
достоверности признаков, никак не заменяют блоков,
производящих отображение объектов в пространство
признаков. Наличие статистической обработки не
снижает специфических особенностей узнающих систем:
умения строить очень много признаков (специально
выбрав это «доступное программе» множество) и умения
в каждом конкретном случае сократить число
проверяемых признаков. Если назвать для краткости эти
специфические особенности «узнаванием», то можно сказать,
что статистика нужна не вместо узнавания, а в
дополнение кнему.
§ 2. Пересекающиеся классы
Заглавие этого параграфа может озадачить
читателя. Только что автор объяснил, почему классы не
могут пересекаться, и вдруг «пересекающиеся классы»!
Объясним, в чем дело.
До сих пор мы для краткости говорили «объект
подается на вход блока /(». Однако ясно, что в
действительности всякий реальный автомат обрабатывает не
сам объект (который имеет бесконечное число свойств),
228
а лишь некоторое конечное описание объекта. Например,
если мы делаем систему, которая должна отличать
звезды одного типа от звезд другого типа, то вряд ли
целесообразно вводить исследуемый объект внутрь узна-
юдцей системы. Вместо этого на вход программы будет
подаваться некоторое описание звезды: спектральный
состав света, яркость, расстояние до нее, постоянство
блеска, наличие планет и т. д. Даже в тех случаях,
когда объект реально вводится внутрь узнающей
системы (скажем, в,читающих автоматах), все равно система
имеет дело лишь с некоторыми свойствами объекта.
Свойства, доступные системе, определяются характером
се «органов чувств». Например, читающий автомат,
имеющий в качестве органа чувств набор фотоэлементов,
может использовать для обработки описание
расположения темных и светлых мест на объекте, но не получает
сведений о запахе типографской краски, толщине бумаги
и т. п. Поэтому, слова «на вход автомата К подается
объект» мы должны, вообще говоря, дополнить
указанием того, какое именно описание объекта подается.
Представим себе теперь, что автоматы К\ и/С (рис. 18)
имеют не тождественные системы органов чувств. Из-за
этого они будут иметь на входе разные описания. В
частности, автомат К может не получить именно той
информации, которой пользовался автомат Ки производя
разбиение на классы. В этом случае задача безошибочного
узнавания может оказаться неразрешимой для
автомата К Ему будет казаться, что автомат К\ работает
статистически, относя одни и те же (с точки
зрения К) объекты то к I, то ко II классу.
Приведем пример. Пусть объектами классификации
являются паспорта людей. Автомат К\ умеет прочесть
все записи в паспорте, а автомат К — только фамилию
владельца. Допустим, К\ разбивает объекты, на паспорта
мужчин и паспорта женщин. Автомат К вынужден
понять принцип классификации, «видя» только фамилии.
Это может ему в принципе удаваться, пока будут
встречаться такие фамилии, как Иванов, Петров,
Зиновьева, Санина. Но как только дело дойдет до фамилий
Бойко или Груздь, безошибочное узнавание станет
принципиально невозможным.
Итак, впечатление пересекающихся классов
возникает из-за того, что автомат К получает описание
229
объектов, недостаточное для строгого решения задачи.
Не значит ли это, что узнавание в таких случаях
невозможно? Ответ зависит от требований, которые мы
предъявим к точности имитации. Очевидно, что безошибочная
имитация для всех объектов в случае пересекающихся
классов невозможна. Однако, если согласиться на
меньшую точность имитации*), то может оказаться, что
задача не безнадежна. Дело в том, что среди параметров,
составляющих описание объекта, подаваемое на вход
блока К, могут найтись некоторые связанные (хоть
и не взаимно однозначно) с истинным принципом
классификации.
В приведенном выше примере классификации
паспортов имеет место именно такая ситуация. Суффикс и
окончание фамилии, хотя и не являются признаком, по
которому людей делят на мужчин и женщин, все же
тесно связаны с полом владельца паспорта. Устройство,
достаточно хорошо знающее законы русского языка,
может разбить фамилии на мужские, женские и
«нейтральные». Как поступать с мужскими и женскими
фамилиями— понятно, а вот что делать в случае появления
нейтральной фамилии?
Разумный ответ на этот вопрос зависит от свойств
блока S генератора задач (рис. 18), точнее, от того,
каковы вероятности появления мужских и женских
паспортов с нейтральными фамилиями. Может, например, быть,
что дело происходит в деревне, где все коренные
жители имеют четко мужские или женские фамилии.
Нейтральные фамилии принадлежат только приезжим, среди
которых, скажем, мужчин гораздо больше, чем женщин.
Тогда целесообразно относить паспорта с нейтральными
фамилиями к классу паспортов мужчин. При таком
алгоритме работы система в данном случае сделает минимум
возможных ошибок.
Легко представить себе ситуации, при которых
окажутся целесообразными другие алгоритмы
классификации паспортов с нейтральными фамилиями, например
отказ от классификации или отнесение их к классу
женских паспортов.
Откуда же система может узнать, как в данном
случае следует классифицировать паспорта с нейтраль-
*) См. стр. 90.
230
ными фамилиями? Очевидно, только путем наведения
статистики в ходе обучения. Если окажется, что в
данной задаче (состояние блока S\) нейтральные фамилии
чаще бывают у мужчин, то и при экзамене их стоит
относить к этому классу; если у женщин, то наоборот
и т. п.
Может создаться впечатление, что в области
пересечения классов (нейтральные фамилии) статистическая
обработка материала обучения играет более заметную
роль, чем в областях, где классы не пересекаются.
Вспомним, однако, как программа «догадается»,
например, что фамилии, оканчивающиеся на ов, ев, ин,
являются обязательно мужскими? В ходе обучения
программа будет подвергать фамилии различным
преобразованиям и затем проверять, не являются ли эти
преобразования полезными для разделения фамилий на
мужские и женские. Например, будет проверено, нет ли
смысла обратить внимание на то, гласная или согласная
буква стоит в начале фамилии. Статистика покажет,
что нет. Аналогично будут забракованы в качестве
полезных признаков число букв или слогов и т. п. Когда
дойдет дело до выделения отдельных окончаний, то ста-
т и с т и к а покажет, что «ов» иногда встречается в
одном классе и никогда в другом, т. е. является
достаточным признаком мужской фамилии.
Совершенно тот же процесс покажет, что окончание
«о» гораздо чаще встречается в мужских фамилиях, чем
в женских (для конкретности мы продолжаем
рассматривать пример с деревней). Поэтому если программа
будет считать это окончание признаком мужской
фамилии, то она сделает меньше ошибок, чем если
пренебрежет этим признаком.
Таким образом, статистика занимает одинаковое
место как в случае непересекающихся, так и в случае пере*
секающихся классов. Правда, может возникнуть вопрос
о целесообразности использования различных критериев
отбора признаков в этих двух случаях. В самом деле,
если для непересекающихся классов есть надежда найти
«правила без исключений», то в случае пересекающихся
классов необходимо с самого начала согласиться на
отбор лишь «доводов за...». Однако и в том и в другом
случае необходима проверка большого количества
«кандидатов» з полезные признаки, а значит, нужны блоки,
231
умеющие совершать соответствующее множество
преобразований исходного описания объектов.
Итак, и в случае пересекающихся классов статистика
не заменяет, а дополняет узнавание.
§ 3. Выбор критерия
Вернемся теперь к вопросу о том, нужны ли на
практике разные критерии при отборе признаков для
пересекающихся и непересекающихся классов. Мы говорим,
что если классы не пересекаются, то есть.надежда
найти достаточные признаки классов. Почему же только
«есть надежда», а не «будут найдены»? Дело в том, что
любая конкретная программа может проверить лишь
ограниченное число признаков (хотя бы из-за
ограниченности времени). И может случиться, что достаточный
признак («правило без исключений») для данной
задачи не попадет в проверяемое множество признаков.
Грубо говоря, достаточный признак хотя и существует, но
может оказаться слишком сложным для программы.
В то же время некоторый гораздо более простой
признак может оказаться весьма хорошим
приближением к строгому правилу, и его есть смысл отобрать при
обучении, раз уж строгое правило для программы
недоступно.
В качестве примера такой ситуации рассмотрим
достаточные признаки женских фамилий. В предыдущем
параграфе в качестве примеров достаточных признаков
мужских фамилий были указаны окончания ов, ев, ин.
Действительно, никто не усомнится, что Сидоров,
Силантьев и Зимин являются мужчинами, так как если бы
речь шла о женщинах, то их фамилии обязательно
имели бы вид: Сидорова, Силантьева, Зимина. Можно
поставить вопрос, не являются ли окончания (в
именительном падеже) ова, ева, ина достаточным признаком
женской фамилии? В очень многих случаях, увидев
фамилию с таким окончанием, мы и правда совершенно
уверены, что она женская (например, Кузнецова,
Каменева, Васина). Однако, хоть и редко, встречаются
фамилии, относительно которых нельзя сказать, мужские они
или женские, хотя они и имеют такие окончания.
Действительно, увидев фамилию Обнова, мы не знаем,
мужчина это или женщина. Нас не удивит ни сочетание
232
Петр Обнова, ни Мария Обнова. Причем в случае, если
Обнова — это женщина, то ее отец (или муж) может
иметь и фамилию Обнова и фамилию Обнов. Те же
свойства имеют, например, фамилии Малина или Бичева.
Что же объединяет те слова, оканчивающиеся на овау
ева, ина, которые могут быть не только женскими, но и
мужскими фамилиями?*) Все это — русские
существительные. Поэтому достаточным признаком женской
фамилии будет такое правило: «слово оканчивается на ова
или ева, или ина и в то же время не является русским
существительным».
Очевидно, выработать такое правило может лишь
очень сложная программа (в частности, содержащая
большой словарь русских слов). Любая из мыслимых
сегодня программ такого признака не найдет (хотя он
и существует!). Зато сравнительно несложная программа
может обнаружить, что окончания ова, евау ина
гораздо чаще встречаются в женских фамилиях, чем в
мужских, т. е. найти упрощенное приближенное (и
потому небезошибочное) правило.
Итак, и в случае пересекающихся классов и иногда
в случае непересекающихся классов есть смысл
отбирать признаки типа часто — редко. В то же время, если
классы не пересекаются и строгие признаки типа часто —
никогда доступны для программы, то обидно отобрать
вместо них менее достоверные признаки. Как же быть?
Неопределенность положения усугубляется еще и тем,
что по большей части заранее неизвестно, пересекаются
классы или нет.
Учитывая эти обстоятельства, по-видимому,
невозможно заранее назначить разумный критерий отбора
признаков. Вместо этого есть смысл подбирать
критерий применительно к данной задаче. Можно,
например, начинать такой подбор с проверки самых жестких
критериев. Для коры, ведущей поиск отдельных
конъюнкций, это соответствует запоминанию только
достаточных признаков при большом k0. Если при таком
критерии найдутся признаки, разделяющие все объекты
*) Приводимое ниже правило опирается на законы русского и
некоторых родственных языков. Поэтому мы рассматриваем здесь
только фамилии русского и близкого к русскому (например,
украинского, белорусского), происхождения.
233
материала обучения, то на этом можно остановиться.
При достаточно представительном материале обучения
такой результат означает, что классы не пересекаются.
Если при жестком критерии признаки не отбираются,
то независимо от причины этого есть смысл начать
постепенно «смягчать» критерий. В рассматриваемом
варианте коры смягчение может идти по двум путям;
уменьшение k0 и допуск некоторого числа противоречий
(объектов другого класса, охарактеризованных
признаком). Целесообразный способ сочетания этих путей тоже,
вообще говоря, зависит от задачи, т. е. может быть
установлен лишь после некоторых проб.
О способах оценки различных критериев отбора
признаков будет идти речь в § 5. Здесь же обратим
внимание на появление у процесса обучения существенно
новой обязанности. До сих пор все время говорилось,
что обучение заключается в отборе признаков, полезных
для данной задачи. Теперь мы столкнулись с
положением, когда сам критерий этого отбора нужно
подгонять под задачу, а значит, он должен
вырабатываться (отбираться из некоторого множества) в ходе
обучения.
В принципе можно представить себе иерархически
построенную систему, содержащую несколько этажей, в
которой верхние этажи отбирают с помощью обучения
критерии работы нижних. При этом нижний этаж
переучивается каждый раз при переходе к новой задаче, а
верхние этажи могут быть сделаны тем более
«инерционными», чем выше они находятся. Чем больше этажей
будет содержать такая система, тем меньше оснований
утверждать, что она ведет отбор признаков, пользуясь
критериями, предрешенными человеком.
§ 4. Доучивание
Не следует думать, что разные «степени жесткости»
критерия бывают полезны лишь в различных задачах.
Может встретиться случай, когда в рамках одной
задачи полезно часть признаков отобрать с «жестким»
критерием, а часть — с «мягким».
Вернемся еще раз к примеру с фамилиями. Допустим,
мы начали обучение с попытки отобрать «правила без
исключений». Несколько таких признаков найдется (на-
234
пример, упомянутые достаточные признаки мужских
фамилий). Однако найденными признаками будут
охарактеризованы далеко не все объекты из материала
обучения. При жестком критерии отбора программа не
найдет признаков для нейтральных фамилий (оттого, что
классы в этой области пересекаются) и для некоторых
женских фамилий (оттого, что признаки слишком
сложны).
Назовем «отстающими» те объекты, которые
оказались не охарактеризованными отобранными
признаками. На рассматриваемом этапе обучения отстающими
окажутся, например, все паспорта с нейтральными
фамилиями.
Продолжение обучения должно быть направлено на
поиск признаков именно для отстающих объектов. При
этом необходимо (независимо от причины отставания)
смягчить критерий отбора признаков. Конечно,
признаки, отобранные при более мягком критерии, будут чаще
ошибаться на экзамене, но зато с их участием программе
удастся высказать суждение о большем количестве
объектов. И если это суждение будет чаще правильным,
чем неправильным, то в некоторых случаях программа,
пользующаяся такими признаками, может оказаться
предпочтительнее.
Очевидно, продолжение обучения при сниженных
требованиях к признакам («доучивание») может
происходить несколько раз. Поскольку перед каждым этапом
доучивания происходит выделение отстающих объектов,
описанный процесс является частным случаем «подгонки
критерия отбора признаков под задачу». В самом деле,
если классы не пересекаются и достаточные признаки
доступны по своей сложности для программы, то уже
после первого этапа отбора с помощью жесткого
критерия не останется отстающих объектов и обучение
остановится. В случае же, если эти условия не
выполняются, то некоторые (а может быть, и все) объекты
окажутся отстающими. Программа начнет снижать
требования к качеству признаков до тех пор, пока не придет
к некоторому компромиссу между вероятностью ошибки
при экзамене и процентом объектов, оставшихся
отстающими.
Для того чтобы вовремя остановиться и не запомнить
признаки, которые при экзамене будут слишком часто
235
ошибаться, программа должна уметь до экзамена
оценить, насколько критерий отбора признаков
соответствует данной задаче. Следующий параграф и посвящен
этому вопросу.
§ 5. Оценка критериев отбора признаков
Для вопроса, рассматриваемого в данном параграфе,
мало существенно, какого типа признаки ищет
программа. Ради конкретности мы будем всюду считать, что
речь идет о коре, ведущей поиск отдельных конъюнкций.
Поскольку мы хотим предсказать ожидаемое
качество экзамена на основании наблюдений, сделанных во
время обучения, нам придется сделать какое-то
предположение о соотношении статистических свойств
материала обучения и материала экзамена. Будем считать, что
выбор объектов rrti из множества М (глава IV, § 4 и
глава VII, § 2) происходит при обучении и при экзамене
с одним и тем же распределением вероятностей p(mi).
Кроме того, предположим, что это распределение
вероятностей таково, что объекты I и II классов будут
встречаться одинаково часто. В силу этого последнего
предположения наши выводы о проценте ошибочных
высказываний признаков на экзамене будут относиться к
случаю, когда показывают поровну объектов I и II классов.
Всюду ниже мы считаем задачу (разбиение на классы)
зафиксированной.
Пусть перед нами некоторая конъюнкция а.
Обозначим через (pi(cpi = (pi(a)) вероятность того, что эта
конъюнкция характеризует объект I класса*), а через <р2 —
вероятность того, что она характеризует объект II
класса. Допустим, что эта конъюнкция будет отобрана во
f 1, если а характеризует ти
где 6 (/я/, a) = \ Л
^ 0, если а не характеризует /и^.
236
*) Так как
время обучения в качестве признака, «голосующего» в
пользу принадлежности объекта к I классу. При
экзамене она будет встречаться с частотой ц — ф1 "Гф2 *
Пусть р =
, есть доля тех встреч, которая
приходится на объекты I класса. Очевидно, величина р и
характеризует степень надежности признака а. Если
/?=1, признак никогда не
ошибается, если /? = 0,5,
признак бесполезный.
Таким образом, каждой
конъюнкции можно
поставить в соответствие два
числа т|(а) и /?(а), которые
характеризуют, как часто она
будет встречаться и как
часто она будет ошибаться
на экзамене. Если перейти
ко множеству всех
конъюнкций, проверяемых
программой при обучении, то можно
говорить о функции
распределения /?(т), р), которая
характеризует плотность вероятности *) того, что
некоторой конъюнкции соответствуют величины ц и р. Будем
считать, что
(25)
Рис. 51. Область допустимых
значений ц и р.
Следует точнее описать область определения /?. Она
несколько необычна (рис. 51) из-за того, что лишь при
/?=0,5 возможны произвольные значения tj. Если же
р равно, например, единице (т. е. конъюнкция встречается
только в I классе), то ц не может быть больше, чем 0,5.
Рассмотрим теперь некоторый критерий отбора
признаков при обучении. Естественно, было бы очень удобно,
*) Строго говоря, из-за конечности множества всех проверяемых
конъюнкций /?(т), р) есть доля конъюнкций с характеристиками ц
и р. Однако при реальном числе конъюнкций для многих программ
(107—106), если брать не слишком малые по площади участки в
области определения /?, то с разумной степенью точности можно
считать, что существует плотность вероятности. Брать же очень малые
участки бессмысленно, хотя бы из-за возможных неточностей
определения t] и р.
237
если бы он мог пропустить признаки с параметра-*
мит] и/? только из некоторой наперед заданной области.
Например, задав область пропускания, обозначенную на
рис. 52 штриховкой, мы могли бы быть уверены, что при
экзамене математическое ожидание ошибок отдельных
признаков будет не более 10% (мы все время для
краткости говорим только о признаках I класса, не приводя
симметричных
рассуждений для II класса).
К сожалению, это
невозможно. Всякий
критерий может быть
сформулирован только в
терминах свойств материала
обучения, а они связаны
с параметрами ц и р лишь
статистически. При одних и
тех же т] и р разные
выборки могут отличаться
Рис 52. между собой как числом
объектов,
охарактеризованных данной конъюнкцией, так и той долей из них,
которая принадлежит I классу. Поэтому данной паре т],
р критерий отбора может поставить в соответствие
только некоторую вероятность W(r\t p) того, что конъюнкция
с такими характеристиками будет отобрана.
Функция W(r\y p) не зависит от задачи. Она
определяется только критерием отбора конъюнкций и в
отличие от /?(г), р) может быть вычислена заранее.
Например, если кора отбирает конъюнкции, характеризующие
не менее k0 объектов (из N) I класса и ни одного
объекта (из N) II класса, то
так как ф1 = 2т)/? и ф2=2т](1—р). Эта функция
приближенно изображена на рис. 53. При любом k0(k0^N) она
достигает максимума, равного единице в точке р=1,
г)=0,5. Крутизна спада, естественно, увеличивается при
увеличении kQ.
238
Пусть обучение производилось с помощью критерия
с вероятностью отбора конъюнкций W(\\, p).
Математическое ожидание вероятности правильной работы
найденных признаков М(р) в этом случае будет
(26)
Очевидно, чем больше M(p), тем более надежной
работы признаков на экзамене следует ожидать. Труд*
ность оценки состоит в
том, что для вычисления
по формуле (26) мы
должны знать функцию
/?(т|, р) для данной
задачи. До обучения о
функции R(r\yp) ничего не
известно. Какую
информацию об этой функции
можно извлечь из
результатов обучения?
Некоторые сведения
дает уже число
отобранных признаков. Пусть во
время обучения было проверено G конъюнкций и из них
отобрано g признаков. Математическое ожидание числа
отобранных признаков равно
Рис. 53.
поэтому
Соотношение (27) в сочетании с (25) накладывает
некоторые ограничения на /?(т), р). Например, при
большом g совершенно невероятно, чтобы /?(т|, р) было мало
в области больших р. Дело в том, что если бы все
конъюнкции в данной задаче имели малое р, то была бы
мала вероятность их отбора (W(r\, p) мало при
малых р) и отобралось бы мало признаков. Поэтому
если отобралось много признаков, то /?(г|, р) велико в
области больших р и, следовательно, М(р) тоже велико.
739
(27)
Ситуация здесь аналогична рассмотренному в § 4
главы X соотношению для «чистых предрассудков». Там
оказалось, что большое число отобранных признаков
говорит о том, что среди них мал процент предрассудков.
Если считать М(р) мерой «средней степени предрассу-
дочности» признаков, то снова большое число
отобранных признаков — довод в пользу их «высокого
качества».
К сожалению, перевод слов много и мало, которые
так часто встречались в двух предыдущих абзацах, на
строгий язык приводит к весьма трудным vДля
практических вычислений соотношениям. Для оценки М{р) нам
нужно найти минимум выражения (26) при условии
выполнения соотношений (25) и (27). Соответствующий
расчет получается весьма громоздким.
Кроме того, этот метод может иногда привести к
сильно заниженной оценке М{р). Допустим, что все G
конъюнкций имеют /?=1, но весьма малое rj. Тогда от-
берется мало признаков и расчет будет гарантировать
малую границу для М(р) *).
До сих пор мы учитывали только одну форму
сведений, полученных во время обучения: число
отобранных признаков. Получились громоздкий расчет и
возможность заниженной оценки. Однако есть возможность
сравнительно «дешево» (потратив мало дополнительного
времени) собрать во время обучения более
непосредственную информацию о R(\]y p). Во время проверки
конъюнкций мы можем каждый раз подсчитывать,
сколько объектов первого и второго классов из
материала обучения она характеризует. Пусть это будут
числа t\ и t'2. Допустим, что -^- = Ф1, а -~- = <р2, В этом
случае Л = ^ 2 и Р = т~~7Т"' Будем запоминать,
сколько раз случались конъюнкции с различными
сочетаниями т| и р (независимо от того, отобраны ли они
в качестве полезных признаков). К концу обучения мы
получим распределение /?(т|, р).
*) Для получения хорошей оценки в этом случае нужно было
бы провести обучение при очень больших N и относительно малом
k. Тогда W(r\, р) медленнее спадало бы в области малых ц при
больших р. В результате увеличилось бы число отобранных
признаков и улучшилась бы оценка их качества.
240
Конечно, отношение -—-, вообще говоря, не равно фь
а -~г не равно фг, так как ti и t2 были сосчитаны лишь
на некоторых выборках из N объектов. Однако мало
вероятно, что это приведет к серьезной погрешности.
Если мы считаем материал обучения достаточно
представительным для отбора признаков, то не меньше
оснований считать его представительным для измерения
/?(т], /?). Современные программы проверяют сотни
тысяч конъюнкций. При этом область определения R(r\,p)
будет покрыта (в среднем) достаточно плотно и
случайные отклонения отдельных точек мало повлияют на
общую картину*). После того как R(r\, р) найдено,
расчет по формуле (26) уже не представляет
сложности.
Легко представить себе программу, которая, один раз
определив R(r\, /?), производит оценку М(р) для
некоторого множества различных критериев отбора признаков
(разных W(r\, /?)), отбирает наилучший критерий, а
потом ищет признаки, пользуясь этим критерием.
§ 6. Вопрос о независимости признаков
Мы все время говорили о вероятности ошибки
отдельного признака и о возможном пути уменьшения
этой вероятности. Возникает вопрос о том, нужно ли
очень заботиться об уменьшении вероятности отдельных
ошибок? Может быть, вместо этого стоит просто
увеличить число отбираемых признаков? Если один признак
ошибается в 10% случаев, то не дадут ли три таких
признака около 3%, а пять признаков около 1% ошибок
(если принимать решение голосованием признаков)? Так
действительно и было бы в случае взаимной
независимости признаков. Однако во многих случаях
внешне различные признаки оказываются сильно
коррелированными. Из-за этого вероятность ошибки
совокупности признаков может быть не на много меньше
вероятностей ошибки отдельных признаков.
*) Строго говоря, полученное таким способом распределение
будет систематически иметь «более мягкий рельеф», чем истинное
/?(П,р). В принципе можно ввести соответствующую поправку,
однако в этом вряд ли возникнет практическая целесообразность.
241
Например, если мы хотим отличать мужчин от жен-»
щин, то высокий рост может служить доводом за то, что
перед нами мужчина. Обувь на низком каблуке тоже
является признаком мужчины, так как женщин,
ходящих на низком каблуке, меньше, чем мужчин. Может
показаться, что второй признак взят из совсем другой
области. В то же время Ясно, что число женщин,
которых мы ошибочно примем за мужчин, пользуясь обоими
признаками, будет почти таким же, как и при
использовании только первого признака. Все дело в том, что
признаки зависимы: высокие женщины редко ходят на
высоких каблуках.
Очевидно, при данном качестве признаков «самих по
себе» совокупность их будет работать тем лучше, чем
более они независимы между собой. Возникает желание
сделать степень независимости признаков
дополнительным критерием отбора при обучении. Программа может
сравнивать сечение, производимое на материале
обучения «кандидатом в признаки», с сечениями,
производимыми уже отобранными признаками. В случае близости
к какому-нибудь уже имеющемуся сечению кандидат
бракуется.
Дополнительная проверка признаков путем
сравнения сечений применялась в программе Арифметика.
В программе Геометрия о независимости признаков
заботились «биржи» в подкорке и коре (см. §§ 2—4
главы VIII). Наибольшее число опытов было произведено
с программой Арифметика. В ней можно было менять
допустимую степень несовпадения сечений (степень
независимости признаков). Опыты показали, что
требование высокой степени независимости признаков оказывает
существенное влияние на работу программы. Во-первых,
число отобранных признаков может резко уменьшиться.
Во-вторых, появляется сильная зависимость того, какие
признаки отберутся, от порядка проверки кандидатов.
В результате узнавание на экзамене часто ухудшалось.
Количественные результаты экзаменов, приведенные в
главе III, относятся к случаям, когда к степени
независимости признаков предъявлялись весьма слабые
требования (программа браковала кандидатов только в
случае полного совпадения сечений). Об этих
обстоятельствах следует помнить и более жесткие критерии
независимости признаков вводить очень осторожно.
242
До сих пор речь шла о содержательной
независимости признаков (сечениях, которые они производят на
множестве объектов). Заранее точно предусмотреть
степень содержательной независимости некоторых
признаков невозможно, так как она зависит от задачи. Однако
вопрос о независимости признаков имеет и другой
аспект. Программист, конструирующий кору, может
рассуждать так: «Я ничего не знаю о степени независимо-*
сти столбцов, которые моя кора будет обрабатывать.
Это зависит от задачи и от блоков, которые поставляют
материал для коры. Тут я ничего сделать не могу. Моя
цель — позаботиться лишь о том, чтобы признаки, про*
веряемые корой, оказались бы независимыми,
если независимыми будут исходные столба
ц ы. Другими словами, нужно, чтобы кора не
добавляла взаимозависимости к исходному материалу».
В качестве грубого примера системы, не удовлетво-*
ряющей этому требованию, может служить программа,
которая много раз проверяет какую-нибудь одну
единственную функцию. Все проверенные такой программой
признаки будут предельно сильно взаимозависимы, даже
если исходные столбцы совершенно независимы.
К сожалению, кора, проверяющая конъюнкции
нескольких переменных, тоже строит не вполне
независимые признаки. В самом деле, если уже известно, например,
что функции Xi/\x2 и Xi/\xz являются достаточными при*
знаками I класса, то относительно функции x2Axs
можно без всякой проверки утверждать, что она тоже есть
признак I класса.
В принципе можно сделать кору, обладающую тем
свойством, что если входные столбцы независимы, то она
строит только совершенно независимые между собой
признаки.
§ 7. «Статистика вместо узнавания»
Когда в науке появляется новая область, то никогда
не бывает, чтобы в ней все оказалось совершенно
новым, непохожим на старое. Любая новая область
пользуется результатами и методами, которые уже были
известны ранее. С другой стороны, человеческая
психология обладает тем свойством, что если Вы кому-нибудь
начнете о чем-нибудь рассказывать, то слушатель
243
прежде всего поймет ту часть рассказа, которую он уже
знал и без Вас.
Сочетание этих двух обстоятельств приводит к тому,
что почти про любую новую область кто-нибудь из
очень серьезных ученых скажет, что ничего в ней н^т
нового и все это давно известно.
История не сохранила соответствующего предания,
но легко себе представить, что, ознакомившись с
численным алгоритмом извлечения квадратного корня, кто-
то сказал: «Не вижу ничего нового, все сводится к
умножениям, вычитаниям, приписываниям цифры к числу
и сравнениям с нулем». Можно согласиться с этим
высказыванием в той части, что для извлечения корня
действительно приходится совершать перечисленные
действия. Однако изобретатель алгоритма придумал и
новое — это способ определять, какие числа на
какие нужно множить, что из чего
вычитать, что к чему приписывать и т. д.
Критики такого рода не избежала и проблема
узнавания. Мы видели, что блок отбора признаков всегда
(даже в случае непересекающихся классов) пользуется
статистическими критериями. Далее, поскольку обучение
идет на небольшой выборке, можно предсказать лишь
вероятность того, что отберутся признаки с теми или
иными свойствами. Не удивительно, что некоторым
ученым показалось, что никакой самостоятельной проблемы
узнавания нет, а все сводится к теории статистических
решений.
Надеюсь, что читатель, дочитавший книгу до этого
места, воскликнет: «Но ведь есть еще много операций,
которые нужно проделать, прежде чем наводить
статистику по результатам применения признаков к
материалу обучения! Нужно выбрать доступное программе
множество признаков. Чтобы не перегрузить память,
нужно научить программу строить много признаков из
малого числа кирпичей. Затем нужно сделать так, чтобы
при решении каждой конкретной задачи программа
перебирала не все принципиально доступные ей признаки,
а лишь малую их часть (естественно, эта часть должна
быть разной при решении разных задач). Для этого
нужно придумать критерии (статистические, конечно!) для
«полуфабрикатов» признаков. И лишь после всего этого
появится необходимость в применении статистики!»
244
Автор будет очень рад такому высказыванию
читателя, так как это есть и его точка зрения. При
конструировании узнающих систем придется преодолевать ряд
специфических трудностей, не рассматриваемых обычно
в теории статистических решений. Некоторые из них
(например, вопрос о сокращении перебора) скорее
роднят узнающие программы с игровыми. Поэтому вряд ли
целесообразно отрицать наличие проблемы узнавания.
Справедливости ради следует сказать, что многие
работы по узнаванию дают серьезные основания для
упомянутой выше критики. Особенно это относится к
попыткам (часто очень успешным) применить узнающие
программы для решения практических задач.
В настоящее время с помощью вычислительных
машин ставят медицинские диагнозы, отличают
нефтеносные пласты от водоносных, различают
радиолокационные сигналы, отраженные от различных объектов,
прогнозируют качество изделий и т. д.
Как в большинстве случаев ведутся подобные
работы? Целью каждого такого исследования, естественно,
является не изучение проблемы узнавания вообще, а
получение хороших результатов в конкретной области.
Поэтому (и вполне разумно!) ту часть работы, для
которой сегодня еще нет эффективно работающих
программ, авторы делают вручную. Используя годами (а в
медицине и тысячелетиями) накопленный опыт, они
отбирают обстоятельства, которые с высокой вероятностью
могут оказаться полезными признаками. При этом
используются (и это хорошо!) и эмпирические наблюдения
и теории явлений (например, в радиолокации или
геофизике).
В результате этой работы создается сравнительно
небольшой набор параметров, с помощью которого
описываются объекты для узнающей программы.
Благодаря тому, что отобраны «хорошие параметры» и их мало,
от программы не требуется построения сложных
функций от исходного описания объекта и сокращения
перебора признаков. В качестве проверяемых признаков она
может использовать или введенные в нее параметры,
или (в самых сложных из применявшихся до сих пор
программ) сочетания по два, три и т. д. параметра.
Таким образом, заметная часть специфической узна-
вательной работы выполняется человеком. На долю же
245
машины приходится главным образом статистическая
оценка признаков (или поиск достаточно простой
разделяющей поверхности в сформированном человеком
пространстве параметров). Не удивительно, что многие,
знакомящиеся с проблемой узнавания по практическим
приложениям, приходят к выводу, что работа узнающих
программ сводится к чистой статистике.
Итак, при решении большинства практических задач
конструкторы пока что поручают машине лишь мало
интеллектуальную работу. Поэтому даже в тех случаях,
когда задачи очень естественно формулируются в
терминах проблемы узнавания, применяемые сегодня
системы имеют мало специфических «узнавательных» черт.
Именно поэтому в книге не разбирались подробно
работы по чтению печатного текста, выделению сигнала
из-под шума, медицинской диагностике, разведке
полезных ископаемых и т. п., хотя в них и достигнуты
заметные успехи.
Отсюда, конечно, не следует делать вывод, что
практика не нуждается в «высокоинтеллектуальных»
программах. Когда такие программы появятся, они,
несомненно, найдут спрос. Однако разрабатывать их,
по-видимому, более целесообразно на модельных задачах, где
можно позволить себе принцип: «пусть пока хуже меня,
но зато сама».
Вспомним, что и мастер никогда не тренирует
ученика на изготовлении деталей срочного и важного
заказа. Получалось бы медленно и плохо. Поэтому, когда
дело доходит до таких заказов, он подменяет
ученика у станка и сам делает ответственные детали.
Ученика же учат на поделках, имеющих малую
практическую ценность.
При таком методе нет возможности использовать
«критерий практики» для оценки успехов ученика.
Мастер оценивает работу ученика не по ее ценности для
потребителя, а по тому, как выполнены отдельные
детали задания: как точно ученик выдержал размеры, как
отполировал деталь и т. д., т. е. по тем параметрам,
которые потом будут определять потребительную
стоимость продукции ученика.
Очевидно, если мы хотим на модельных задачах
учиться создавать узнающие программы, то также
необходимо найти замену «критерию практики» (иначе
246
есть риск очень долго заниматься игрой в работу вместо
самой работы). Этому будет посвящен предпоследний
параграф книги.
Резюмируя вопрос о роли статистики, можно сказать,
что статистическая обработка является лишь частью
операций, производимых узнающей системой. Поскольку
эта часть более изучена, она является сегодня более
простой для программирования. Выбирая метод решения
конкретной практической задачи, конструктор
системы программирует для машины легкую часть
(статистическую обработку) и поручает людям (обычно
специалистам в данной области — врачам, геофизикам и
т. д.) создание описания объектов, подогнанного к
задаче. В результате этого и возникает та ошибочная
точка зрения, которая послужила заголовком этого
параграфа.
Глава XII
ЗАКЛЮЧЕНИЕ
§ 1. Родители и педагоги
Цифровые вычислительные машины часто называют
универсальными. Причина этого понятна — на одной
машине можно решать много задач из различных
областей. Вычисление интегралов, составление
железнодорожных расписаний и игра в крестики-нолики — всем
этим (и многим другим) занимаются цифровые машины.
Как уж тут не назвать их универсальными! Вспомним,
однако, что эта универсальность дорого обходится тем,
кто эксплуатирует машину. Новенькая, только что с
завода, вполне исправная машина не может решить ни
одной задачи. Необходима весьма квалифицированная
работа программиста для того, чтобы «вдохнуть душу
в безжизненное тело», изготовленное на заводе.
Иногда говорят, что программист обучает машину
решению задачи. При этом рассуждают примерно
так: «Что такое обучение? Это — сообщение
обучаемому некоторой информации. Программист сообщает
машине информацию о методе решения задачи, значит, он
учит ее».
Мне кажется, что термин обучение является в
данном случае неудачным, потому что не любой способ
вкладывания информации принято называть обучением.
Чего хочет добиться педагог, когда учит ребенка,
например, решать арифметические задачи? Цель
педагога—изменить в определенном направлении состояние
некоторых клеток детского мозга. Прямой путь
достижения этой цели состоял бы в непосредственном
воздействии (например, с помощью пропускания
электрического тока или введения химических веществ) на те
именно клетки, состояние которых необходимо изменить.
248
Однако педагог этого не делает*). Вместо воздействия
на клетки мозга, участвующие в процессе решения
арифметической задачи, педагог воздействует на
рецепторы ребенка (органы зрения, слуха). Он изменяет
распределение света на сетчатке глаза ребенка,
«сотрясает воздух» перед его барабанными перепонками, и
эти косвенные воздействия вызывают уже
изменения в клетках мозга.
Такой способ обучения требует гораздо более
сложного устройства мозга, чем способ непосредственного
воздействия прямо на нужные клетки. Различные
сочетания возбуждений одних и тех же рецепторов, скажем,
рецепторов улитки уха, должны вызывать изменения в
совершенно разных отделах мозга. Значит, нужен
специальный механизм, принимающий решение о том, как
в каждом случае нужно изменить состояние нервных
клеток. При непосредственном же воздействии такой
механизм был бы не нужен.
Почему же природа не забраковала второй путь
получения животным информации? Дело в том, что,
предъявляя более суровые требования к ученику, этот способ
требует гораздо меньше знаний от учителя. В самом
деле, для использования первого способа учитель
должен знать, как устроен мозг. Притом знать детально,
вплоть до того, в каких клетках и с помощью каких
алгоритмов осуществляется та или иная функция. Кроме
того, учитель должен Знать, какие воздействия на
клетку могут изменить ее состояние в нужную сторону, и
иметь физическую возможность оказать такие
воздействия на миллионы (а может быть, и миллиарды)
клеток. Ни один педагог не обладает такими знаниями и
такими возможностями. Поэтому природе пришлось за
счет усложнения мозга снизить требования к учителям.
Не следует думать, что природа не использует и
первого способа передачи информации молодому
животному. Он широко распространен, но в этом случае
принято называть тех, кто поставляет информацию, не
учителями, а родителями. Родители «точно знают», в
каких клетках мозга и с помощью каких алгоритмов должно
*) Исключением является система подготовки
«дипломированных специалистов», описанная в чудесном фантастическом рассказе
А. Азимова «Профессия».
249
осуществляться управление дыханием, зрачковым
рефлексом, сосанием и т. д. Конечно, эти знания они хранят
не в виде состояния клеток своего мозга, а в виде
генетического кода хромосом. Поэтому свои знания родители
не могут выразить словами, зато имеют возможность
построить по хранимому в хромосомах плану организм
ребенка.
Вернемся теперь к работе программиста. Он.
сообщает машине информацию путем непосредственного
занесения ее в те места памяти, где она должна храниться.
Он точно знает, какие алгоритмы осуществляет та или
иная подпрограмма и где она находится. Программист
не пользуется (или почти не пользуется) косвенными
методами воздействия на программу. По своим знаниям
и возможностям он скорее напоминает не педагога,
а родителя.
Отсюда проистекает и могущество и слабость
программиста. Сила его в том, что он может заложить
любое содержимое в любую ячейку памяти машины. Он
может заставить машину произвести любую обработку
материала, если знает, из каких операций эта обработка
должна состоять. Однако для того чтобы создать
машину, решающую некоторую задачу, программист
должен сначала иметь в себе (в мозгу) модель этой
будущей машины. В этом его слабость. Как родители не
могут передать по наследству свойства, для которых нет
модели в генетическом коде, так и программист не
может создать систему, если ее модели нет в его мозгу.
Многие делают отсюда вывод, что машина никогда
не будет способна решать задачи, которые не умеет
решать ее создатель (программист).
Ошибочность такого утверждения очевидна. Ребенок
совершенно неграмотных родителей может стать
великим ученым. От родителей он унаследовал не знания
(которых они не имели), а структуру мозга,
способного обучаться. Знания же он получцл от других
людей или в результате экспериментов над природными
объектами. Его учителя (люди и природа) могут и не
иметь сведений об устройстве его мозга. Скорее
наоборот, в ходе обучения он сам строит в мозгу модели
изучаемых явлений.
Все эти соображения в полной мере приложимы и
к обучающимся программам. Они тоже получают инфор-
250
мацию не только от «родителей» (инженеров и
программистов), но и от «учителей» (тех, кто подобрал
примеры для обучения). Любопытно, что учителя машины,
как и учителя детей, не применяют непосредственного
вмешательства в произвольную часть памяти. Они
воздействуют лишь на рецепторы — небольшую
выделенную часть ячеек, куда вводят коды объектов (например,
картинок, числовых таблиц и т. п. ). В ходе обучения
программа сама изменяет состояние многих других
ячеек, например тех, где запоминаются отобранные
признаки. К моменту начала экзамена состояние машины не
совпадает с тем, которое было продумано
программистом. В частности, оно зависит от того, какие объекты
были показаны при обучении. Образно говоря, машина
во время обучения построила в себе модель задачи
(явления). Модель, которой не было в мозгу программиста.
Программист наградил свое детище (как и родители —
ребенка) способностью учиться. Он сделал, в некотором
смысле, универсальную программу. За эту
универсальность приходится расплачиваться, так же как и за
универсальность цифровой машины, тем, что обучающаяся
программа «сразу после рождения» не умеет решать ни
одной задачи. Необходима специализация программы —
обучение.
Итак, программа может о некоторых вещах «знать»
больше, чем программист, который ее написал. После
успешного обучения она знает, в каком состоянии
находится блок К\ генератора задачдак как она построила
в себе модель этого состояния. А может ли программа
знать больше своего учителя? Очевидно, да, так как
человек, показывавший машине материал обучения, может
и не знать принципа классификации (не уметь
узнавать).
Это вовсе не значит, что талантливый и бездарный
учителя будут одинаково успешно обучать машину. От
понимания педагогом смысла задачи и природы ее
трудности будет зависеть подбор материала обучения.
Особенно важен педагогический талант учителя при
обучении многоступенчатых программ, у которых нижние
этажи обучаются не на главной, а на вспомогательных
задачах (так была устроена Геометрия и о таких
программах будет идти речь в последнем параграфе).
Выбор вспомогательных задач («наводящих вопросов»),
251
произведенный учителем, может предопределить
успешность или неудачу обучения в целом. При этом учитель
совсем не обязательно должен сам уметь решать
вспомогательные задачи. Он только должен понимать, что
умение решать их может пригодиться при решении главной,
задачи. Учитель машины, как и учитель ребенка, может
совершенно не знать устройства программы. Ему нужны
лишь сведения о рецепторах: куда и в каком коде нужно
вводить объекты. Очевидно, эти сведения необходимы и
учителю ребенка (например, слепых детей приходится
учить не так, как зрячих).
Может возникнуть вопрос: откуда же Мишина берет
сведения, которыми не обладал ни программист, ни
учитель? Ответ на него очевиден: во время обучения
программа действует методом проб и ошибок, по существу,
ведет экспериментальную работу. Не удивительно, что
результаты эксперимента могут быть новыми и для
программиста и для учителя*).
§ 2. Голы, очки, секунды
В правилах соревнований по любому виду спорта
обязательно оговариваются две вещи. Прежде всего,
условия, соблюдение которых необходимо для того, чтобы
результат был засчитан (в беге — не должно быть
сильного попутного ветра, в баскетболе — нельзя
делать пробежки или находиться в зоне нападения
более трех секунд и т. д.). Кроме того,
устанавливается, какой параметр определяет победителя (бег или
плавание — время, баскетбол — о ч к и, штанга — вес
и т. д.). Смешно прозвучала бы претензия человека,
прибежавшего последним, присудить ему первое место
потому, что все бежали в спортивной форме, а он с грузом
на плечах. Груз в соревнованиях по бегу не ценится.
В настоящее время появляется потребность
выработать какие-то оценки для сравнения различных
узнающих программ. Программы могут отличаться друг от
друга числом команд, временем обучения, временем экза-
*) Законным будет и другое описание явления: программа
обладает более мощным, чем учитель, методом декодирования
материала обучения и поэтому извлекает из него больше полезной
информации.
25?
мена, качеством экзамена, решаемой совокупностью
задач, занятым результатами обучения объемом памяти
и т. д.
Про новую программу иногда трудно сказать, « к
какому виду спорта следует отнести ее достижения».
Поэтому необходимо договориться о критериях оценки
достижений в области проблемы узнавания, чтобы не
путать их с достижениями в области экономии
машинной памяти или в области экономии мышления или
работы программиста.
Начнем с обязательных условий. Как уже говорилось,
неинтересен случай, когда система экзаменуется на тех
объектах, на которых она обучалась. Поэтому
естественное первое требование — экзамен идет на новых
объектах. При этом разными считаются лишь такие пары
объектов, которые хоть в одной задаче (из
совокупности) попадают в разные классы.
Второе требование тривиально: процент ошибок на
экзамене должен быть мал*).
Далее, не велика заслуга системы, если к ней на
вход попадает уже сильно переработанный материал.
Например, если уже построено пространство полезных
признаков, в котором классы компактны, или уже
найдены параметры, по которым есть смысл наводить
статистику, и т. п. Отсюда третье требование — поверхности,
разделяющие классы в пространстве рецепторов, для
большинства задач должны быть достаточно сложными
"(не должно существовать короткого описания этих
поверхностей в терминах их геометрических свойств).
Также не должно быть общего для существенной части всех
задач пространства полезных признаков, в котором
разделяющие поверхности становятся простыми. Интересен
лишь случай, когда системе самой приходится искать
пространство, хорошее для данной задачи.
Начальная неопределенность этого выбора (при
соблюдении обязательных условий) и характеризует
свойство, представляющееся главным для узнающей
системы,— ее универсальность. Программа тем интереснее,
чем больше начальная неопределенность выбора
пространства полезных признаков.
*) Строго говоря, нужна малая неопределенность после экза
мена (см. § 4 главы VII).
253
При этом необходимо сразу оговорить недоумение,
которое может возникнуть. Обязательные условия,
которые были приведены вначале, тоже допускают
количественную оценку. Например, количество ошибок при
экзамене может составлять 0,5%, а может быть и 6%.
Не следует ли оценивать программу и по этому
параметру (и еще по многим, естественно)?
Здесь, по-видимому, целесообразен подход, принятый
в спорте. Ведь и самый слабый ветерок в спину помогает
бегуну, но до некоторого предела его не учитывают, а
после этого предела не засчитывают результат. Так и
при оценке работы.программы. Имеет смысл заранее
решить, с каким процентом ошибок мы можем
примириться, и после этого не делать различия между
программами, укладывающимися в допуск. Мотивировкой такого
отношения может служить следующее обстоятельство:
размеры доступных программам совокупностей задач
могут меняться- на несколько порядков. Если мы
договорились, например, что при выборе из двух классов
должно быть не более 5% ошибок, то вызванный этим
относительный разброс количества собранной
программой полезной информации окажется гораздо меньше,
чем относительные различия неопределенности выбора
задачи из разных совокупностей.
Несколько особое место занимает параметр —врем я
обучения, Если ограничиться оценкой уже
достигнутого, то можно просто потребовать, чтобы время не
превосходило некоторого предельно допустимого значения
(например, 1/10 от среднего времени между сбоями
машины). Однако если смотреть вперед, то следует
помнить, что за счет увеличения времени всегда можно
увеличить решаемую совокупность задач, не вкладывая
в программу каких-либо существенно новых идей.
Поэтому есть смысл ценить время как принципиально
важный параметр.
Итак, предлагается ценить узнающие программы
главным образом за их универсальность, пусть иногда
даже в ущерб точности узнавания. Такой подход
согласуется с поставленной нами с самого начала целью
работ по узнаванию — промоделировать трудно
формализуемые функции мозга: интуицию, рассуждение по
аналогии и т. п. Ведь мозг поражает нас в основном именно
254
своей универсальностью, а вовсе не точностью («людям
свойственно ошибаться»).
Тот факт, что не точность работы отличает человека
от других животных, отметил еще К. Маркс, когда
писал: «...пчела постройкой своих восковых ячеек
посрамляет некоторых людей — архитекторов. Но и самый
плохой архитектор от наилучшей пчелы с самого начала
отличается тем, что, прежде чем строить ячейку из воска,
он уже построил ее в своей голове»*).
Большинство практических задач, принадлежащих с
первого взгляда к проблеме узнавания (медицинская
диагностика, различение радиолокационных сигналов
и т. п.), в своей сегодняшней постановке не
удовлетворяет третьему обязательному условию (об этом шла
речь в предыдущей главе). Поэтому построение
программ, успешно справляющихся с этими задачами, к
сожалению, еще не свидетельствует о серьезных успехах
в решении трудных мест проблемы узнавания.
Какие же совокупности задач могут сегодня служить
пробным камнем для узнающих программ? У нас еще
нет способов для формального описания больших
совокупностей задач, удовлетворяющих третьему условию.
Может быть, в будущем мы научимся описывать
совокупность задач через структуру автомата — генератора
задач. Может быть, через указание реакций на задачи
некоторого набора узнающих систем (вроде того, как
свойства сигнала можно описать через реакции набора
гармонических осцилляторов). Однако это дело
будущего. Поэтому сейчас имеет смысл описывать
интересные совокупности задач с помощью большого числа
примеров и слов «и тому подобные задачи», используя
умение человека экстраполировать и обобщать.
В приложении 3 этим способом задана
совокупность геометрических задач. Построение системы, которая
*) Маркс, правда, ошибся, думая, что отличие пчелы от
архитектора в том, что у архитектора есть предварительный план
будущей постройки, а у пчелы нет. В организме пчелы обязательно
должен быть точный план шестигранной ячейки. Без этого она не могла
бы создать соты. Отличие в другом — пчела имеет план только о д-
ного типа сооружения, а самый плохой архитектор может
построить и жилой дом, и театр, и подземный переход, и фонтан и т. п.
Именно степень универсальности отличает работу
человеческого мозга от деятельности нервной системы пчелы.
255
могла бы решать приведенную совокупность (или хотя
бы значительную ее часть), потребует преодоления
трудностей, специфических именно для проблемы узнавания.
По-видимому, решение этой и других модельных
совокупностей задач гораздо сильнее приблизит нас к
механизации творческих процессов, чем успешное узнавание
нефтеносных пластов, скарлатины или подводных лодок
по параметрам, отобранным человеком специально для
данного случая.
§ 3. Накопление опыта
На протяжении всей книги мы рассматривали
системы, которые начинали решение любой задачи с одного
и того же начального состояния. Приступая к новой
задаче, такая система начисто забывает все, чему
научилась раньше. В то же время ясно, что если система
находится в относительно стабильном мире, то разумно
пытаться использовать ранее полученные сведения.
Наиболее примитивный способ построения системы,
которая постепенно приобретала бы жизненный опыт,
такой: программа запоминает, как часто возникает
необходимость применения тех или иных признаков. Решая
некоторую новую задачу, программа проверяет признаки
в порядке убывания этих частот.
Такая программа даст заметное сокращение перебора
при обучении только в случае, если задачи, требующие
применения различных признаков, встречаются с очень
неодинаковой частотой. По существу, она использует
малую начальную неопределенность того, какой признак
нужен.
Гораздо больший интерес представила бы система,
которая могла бы использовать накопленный ранее опыт
и в том случае, когда все признаки нужны одинаково
часто. В принципе ее можно построить следующим
образом: после решения некоторого числа задач программа
сама собирает в одну группу задачи, требовавшие
применения некоторых признаков, а в другую — не
требовавшие. Возникает новая задача (назовем ее задачей
второго ранга), в которой объектами являются задачи
первого ранга. Решив ее, программа найдет признаки*
(второго ранга) того, что есть смысл пробовать данную
256
группу признаков первого ранга*). Очевидно, можно
создать ряд задач второго ранга (например, по числу
слов в словаре для описания признаков первого ранга).
При обучении новой задаче первого ранга такая
система начинает с того, что с помощью ранее найденных
признаков второго ранга решает, какие признаки
первого ранга стоит проверять сначала. Другими словами,
система сначала узнает, к какой группе принадлежит
данная задача, а потом применяет порядок перебора
признаков, целесообразный для этой группы задач. В
отличие от первой рассмотренной системы такая
программа хранит жизненный опыт не в виде распределения
вероятностей признаков, а в виде «признаков признаков»
(признаков второго ранга).
Допустим теперь, что мир, окружающий систему,
резко изменился (она столкнулась с новой совокупностью
задач). При этом может случиться, что отобранные
признаки второго ранга перестанут помогать (а может быть,
и начнут мешать). Сигналом такого происшествия для
системы послужит резкое увеличение перебора при
обучении задачам первого ранга.
Придется вернуться к большому перебору, пока не
наберется много решенных задач из новой совокупности.
Тогда можно опять провести обучение второго ранга и
отобрать новые признаки второго ранга. Если смена
совокупностей произошла несколько раз, то можно
построить задачу третьего ранга, в которой объектами
будут уже совокупности задач. Признаки третьего ранга
будут сокращать поиск признаков второго ранга при
переходе к новой совокупности задач.
Можно представить себе систему, строящую
признаки четвертого и т. д. рангов. Для успешной работы
такие системы должны обладать большой памятью, так
как объекты задач второго, а тем более следующих
рангов весьма громоздки. Однако смысл ее работы вовсе не
в механическом запоминании материала, а в выработке
алгоритмов анализа, приводящих к сокращению
перебора.
*) На этом этапе программе может заметно помочь хороший
педагог., Специально подбирая «наводящие вопросы» (задачи
первого ранга), он может добиться резкого сокращения времени
обучения и уберечь программу от появления предрассудков.
257
Построение многоэтажной системы для широкого
класса задач безусловно встретит много трудностей. Из
них можно указать, например, выбор словарей для
задач второго и следующих рангов, автоматическое
разбиение групп объектов на задачи второго и т. д.
рангов, организацию гибкого взаимодействия разных
этажей и т. п. Заметим, однако, что значительная часть
возникающих проблем не является совершенно новой.
Почти со всеми мы встречались при рассмотрении,
например, проекта программы для узнавания
геометрических объектов. Это позволяет надеяться, что успех в
построении хорошей геометрической программы
одновременно будет и шагом на пути к системам, способным
разнообразно и гибко использовать запасенный опыт.
Поведение многоэтажных систем при решении задач
первого ранга будет, вероятно, чрезвычайно занятным.
Наблюдатель увидит, что проверяется ничтожная часть
доступных программе признаков. Притом даже
признаки, оказывающиеся неподходящими, в общем-то
«разумные». Их и правда, без прямой проверки, на основании
«общих соображений» отвергнуть было бы трудно.
Перейдя к анализу использованных программой «общих
соображений» (признаков второго ранга), наблюдатель
заметит, что и они оказываются «подходящими к
случаю» и т. д.
Допустим теперь, что некто имеет возможность лишь
очень поверхностно наблюдать работу программы.
Например, он видит только конечный результат (качество
экзамена), время обучения и степень разнообразия
задач, решаемых программой. Прежде всего его удивиг
несоответствие между разнообразием задач и временем
обучения. Скорее всего он скажет, что система обладает
поразительной интуицией. Когда ему возразят, что
систему многому обучали, он ответит: «ну, и что из того,
что память системы забита всевозможными сведениями?
Ведь перебор всех сведений занял бы большое время, а
умение сразу, без длинных размышлений, находить в
памяти то, что нужно, называется развитой системой
ассоциаций, а это сродни интуиции».
Итак, функции, которые принято называть
ассоциативной памятью, интуицией, действительно, распадаются
на цепи узнавания разных рангов. Поэтому
многоступенчатая узнающая система будет обладать интуицией ров-
258
но в том же смысле, в каком ею обладает человек (хотя
на первых порах, безусловно, в гораздо более узкой
области). Добавим еще, что при поверхностном
наблюдении программа будет выказывать все признаки
недетерминированного поведения («свободы воли»). Она
будет использовать при решении задач «неформальный
подход», снова в том же смысле, как и человек (его-то
поведение мы всегда наблюдаем «очень поверхностно»!).
Поэтому исследования в области проблемы
узнавания, вероятно, окажутся существенной составной частью
работы по созданию думающих (без кавычек!) машин.
Следует отметить, что есть исследователи, в корне
не согласные с изложенной точкой зрения. Например,
высказывается такое возражение: «Мозг современного
человека возник в результате процесса эволюции,
который продолжался миллиарды лет. Машину нельзя
обучать столь продолжительное время. Поэтому никогда
не появятся думающие машины».
Несмотря на внешнюю убедительность, это
рассуждение содержит ошибку. Легко заметить, что
совершенно аналогично можно было бы «доказать»
невозможность создания, например, самолета. В самом деле,
«организм птицы возник в результате продолжительной
эволюции. Миллиарды лет потребовались, чтобы
появились такие сильные мышцы, легкие кости, совершенные
перья. Поскольку инженеры не могут заставить свою
конструкцию пройти столь же длинный эволюционный
путь, построение летательных аппаратов тяжелее
воздуха невозможно». Ошибка такого рассуждения состоит в
предположении, что машина будет выполнять функцию
(мышление, полет и т. п.), копируя метод и
эволюционный путь живой природы.
Человечеству понадобились сотни тысяч лет, чтобы
научиться перемножать и делить большие числа.
«Обучить» же этому искусству груду радиоламп,
сопротивлений и конденсаторов (собрать из них вычислительную
машину) можно за несколько дней. Конечно, люди,
создавая самолет или вычислительную машину, вложили
в них знания, которые тысячелетиями добывались
человечеством. Однако никто ведь не мешает и при
создании думающей машины использовать накопленный опыт.
И если мы, исчисляя «эволюционный стаж» человека,
вполне обоснованно включаем в него и время эволюции
259
всех его предков (млекопитающих, пресмыкающихся,
земноводных и т. д.), то в «эволюционный стаж»
думающей машины следует засчитать и время эволюции
человека. Машина будет начинать учиться, уже имея очень
высокую начальную организацию, заложенную в нее
человеком*). И учить ее поначалу будет человек. При
этих условиях ссылка на «миллиарды лет эволюции»
становится мало убедительной.
Другого типа возражения возникают в связи с тем,
что человек «животное общественное». Коротко эти
возражения сводятся к тезисам типа: «мышление возникло
в результате коллективной деятельности (общественной
жизни) людей. Машина же индивидуальна по своей
природе, следовательно она не может мыслить». Или:
«ребенок, предоставленный самому себе, не станет
человеком. Мышление — функция не человека, а
Человечества».
Эти соображения содержат ту же самую ошибку —
гипотезу о единственности пути к мышлению.
Спору нет, общение людей между собой сильно
повлияло на формирование мышления человека. Отсюда,
однако, вовсе не следует, что у машин ы, имеющей
достаточно высокую начальную организацию, мышление не
может развиваться в процессе индивидуального
решения все более сложных задач. Кроме того,
совершенно не исключено, что несколько машин
(«коллектив») будут совместно ставить и решать различные
задачи, вытекающие из необходимости удовлетворять
потребности человечества или самого этого коллектива**)
(снабжение энергией, добывание сырья, ремонт самих
*) В параграфе о самоорганизующихся нервных сетях
говорилось о том, что система без начальной организации не может чему-
нибудь научиться за разумное время.
**) Название «коллектив машин» является, конечно, условным,
так как, строго говоря, коллектив невозможно отличить от одной
большой машины.
Однако в тех случаях, когда обмен информацией внутри
некоторых частей системы намного превышает обмен между такими
частями, по-видимому, есть смысл говорить о «коллективе», состоящем
из отдельных «особей». (Идею такого определения понятия
«коллектив» автор заимствовал у М. Л. Цетлина.) В животном мире тоже
иногда не легко отличить организм от коллектива. Чем является,
например, пчелиный улей, в котором все рабочие пчелы не могут
размножаться, матка не может прокормить себя, а трутни имеют
половинный набор хромосом?
260
себя, создание новых машин, в том числе с новой
конструкцией или программой, и т. п.).
Итак, ссылки на роль общественных процессов в
формировании мышления как человечества в целом, так и
отдельных людей доказывают столь же мало, как и
ссылки на продолжительность эволюционного пути животного
мира. Как уже говорилось во введении, нет причин,
которые делали бы принципиально невозможным
построение думающих машин.
И снова, повторяя введение, напомним, что от
понимания принципиальной возможности до умения строить
думающие машины еще очень далеко.
Человечество находится сегодня в самом начале этого пути.
Трудно предсказать, сколько времени он займет. Трудно
также предвидеть те последствия, к которым приведет со-
здание думающих машин. Вероятно, они будут не менее
существенными, чем последствия создания
электрических генераторов или урановых котлов. Ясно одно — не
надо жалеть усилий на продвижение в этой области, ибо
игра стоит свеч!
Приложение 1
Гипотезы* содержащие только истину,
и оптимальная гипотеза
Мы кастет ош-исьшаеда различнее ситуаций словами:
«правдам ио we вся правда», «ее только правда» и т. п.
Каким формальным соютмшЕгендеям соответствуют эти
интуитивные горедетавлейдая? Наадев* с ироетейгаего
случая..
Предположим, некто 2 должен найти,, на какой
страннике кшштг содержащей 100 страниц, имеется ссылка на
работу интересующего его автора. Пусть ш
действительности эта ссылка находится на 45 странице. Допустим,
по мнению Z, ссылка находится в первой половине
книги. Очевидно, в этом случае мы скажем, что гипотеза
Z—истинна. Правда, гипотеза эта не очень сильная.
Более сильной мы бы признали, например, гипотезу, что
ссылка находится между 40 и 50 стр. Гипотеза о том, что
ссылка находится между 47 и 50 стр., будет еще более
сильной, но уже ложной.
Во всех рассмотренных примерах было очень легко
определить, является ли гипотеза истинной или ложной.
Нужно было только проверить, попадает ли ответ задачи
(номер страницы) в область, ограниченную гипотезой.
Существуют, однако, более сложные ситуации.
Допустим, книга печаталась двумя изданиями с тиражами
10 000 и 30 000 экземпляров. В первом издании ссылка
попала на 45 стр., а во втором — на 48. Мы не знаем,
к какому изданию относится имеющийся у нас
экземпляр. Что можно сказать про гипотезу о том, что ссылка
с вероятностью 0,3 находится между 30 и 46 стр. и с
вероятностью 0,7 — между 47 и 50 стр.? По-видимому, про
нее не имеет смысла говорить, что она истинна или
ложна. Для описания соотношения между гипотезой и
задачей в подобном случае необходимо какое-то новое
262
понятие. При этом хочется, чтобы в простых ситуациях
новое понятие не противоречило <ш обычной истянйфсти
или ложности.
Обратим внимание, что неопределенность задачи при
некоторой гипотезе сама по себе не является мерилом
истинности гипотезы. Вернемся к примеру с книгой.
Рассмотрим две гипотезы:
а) ссылка находится между 35 и 50 стр., причем
вероятность найта ее между 35 и 42 стр. больше, чем
между 43 и 50 стр., и
б) ссылка находится между 1 и 100 страницами.
Неопределенность задачи при гипотезе а) может быть
меньше, чем при гипотезе б) *). В то же время мы
интуитивно чувствуем, что гипотеза а) «содержит не
только истину». А гипотезу б) мы признаем истинной, хотя
она и приводит к большей неопределенности задачи.
Почему? По-видимому, при оценке истинности для нас
существенно не только то, что дает гипотеза, но и то, что
она «обещает» (сила гипотезы). Гипотеза б) мало дает,
но она ведь ничего и не обещает. Поэтому не возникает
ощущения, что нас обманули.
Мы употребили термин «гипотеза обещает». А как
измерить силу гипотезы (много или мяло она обещает)?
В простейшем примере, с которого начался этот
параграф, гипотеза была тем сильнее, чем больше она
ограничивала область поисков. В случае, когда гипотеза
заключается в распределении вероятностей qu #2, . • • > Яп
того, что объект принадлежит 1, 2, ..., п классу,
естественно считать мерой силы гипотезы энтропию этого
распределения вероятностей Н (д) **). В соответствии с
этим мы будем считать, что гипотеза д/ сильнее, чем
гипотеза q'\ если Н(^') <**(#")•
Теперь появилась возможность сравнить то, что
гипотеза обещает, с тем, что она реально дает. Сделаем
это для более общего случая, когда решающий
алгоритм имеет дело не с отдельной задачей, а с некоторой
совокупностью задач. В этом случае имеется не какое-то
*) Если по гипотезе а) вероятность области 35—42 стр. не
намного больше, чем области 43—50 стр.
**) Легко заметить, что гипотеза q обещает нам именно
неопределенность, равную H(q). В самом деле, если гипотеза абсолютно
точна, то Pf-=qi (/=1, 2, ... , n)t а значит, N(pIq)=U(q).
263
определенное распределение вероятностей ответов р, а
лишь некоторые соотношения типа:
fiiPv A> ••-. А)>0, |
hiPv Ръ •••> Рп)>°> l (28)
fkiPv Ръ •-•. А)>0, I
ограничивающие область возможных значений р- К
системе ограничений, конечно, всегда добавляются
соотношения
Л>0 и £а=1-
(=1
Будем считать, что система ограничений такова, что
существует, по крайней мере, одно распределение р,
удовлетворяющее всем неравенствам (совокупность
содержит хоть одну задачу).
Назовем распределение вероятностей д гипотезой,
содержащей только истину относительно ограничений
(28), если
max,N(p/f)<H6), (29)
где maxp есть точная верхняя граница, взятая по всем
распределениям/?, удовлетворяющим ограничениям (28).
Другими словами, мы будем называть гипотезу
содержащей только истину, если для всех задач из
совокупности она дает не большую неопределенность, чем
обещает.
Гипотезы, не удовлетворяющие соотношению (29),
будут называться содержащими не только истину.
Заметим, что при любой системе ограничений существует по
крайней мере одна содержащая только истину гипотеза
#/ = — (/—1, 2, ..., п). Действительно, в этом случае
N<*tf) = logn=H(#.
Назовем q° сильнейшей содержащей только истину
гипотезой, если q°—гипотеза, содержащая только
истину, и имеет место соотношение
Н(#>)<Н(£), (30)
где q—произвольная содержащая только истину
гипотеза.
264
Можно показать*), что множество всех гипотез,
содержащих только истину, является замкнутым, и так как
Н(#)>0, то H(q) достигает на этом множестве точной
нижней границы, а следовательно, сильнейшая
содержащая только истину гипотеза всегда существует.
Как говорилось в § 3 главы VII, если решающий
алгоритм без обратной связи имеет дело с отдельной за-
длчей, то наилучшей гипотезой для него будет q = р-
Обобщим понятие наилучшей гипотезы для случая, когда
имеется совокупность задач (действуют ограничения
(28)).
Назовем распределение вероятностей q° оптимальной
гипотезой относительно ограничений (28), если
max, N (p!q°) < max, N {pjq), (31)
где знак max, употребляется в том же смысле, что и в
(29), a q есть произвольная гипотеза.
Легко убедиться, что в случае, когда имеется
единственная задача (определенное р), оптимальная
гипотеза является гипотезой, содержащей только истину.
Возникает вопрос: не нарушается ли это соотношение в
более сложных случаях? Не имеет ли смысла, при
наличии совокупности задач, искать оптимальную гипотезу
также и среди гипотез, содержащих не только истину?
Ответ на этот вопрос дает следующая теорема:
Теорема. Для любой системы ограничений,
наложенных нар, существует единственная оптимальная
гипотеза q°. Оптимальная гипотеза q° совпадает с
сильнейшей содержащей только истину гипотезой q°. При
этом
maxpN(plq°) = H(q°).
Для доказательства нам будет удобно обратиться к
геометрической интерпретации понятий: «распределение
вероятностей ответов задачи», «гипотеза», «энтропия» и
«неопределенность».
Начнем со случая п = 2. Благодаря связи qi + qi=l
многообразие всех возможных гипотез является
одномерным. Будем изображать гипотезу точкой q на
отрезке [0; 1] оси абсцисс (рис. 54). На этом же отрезке
находятся точки р. Для отыскания неопределенности
*) Для краткости мы не приводим доказательства.
265
Рис. 54. Геометрическая
иллюстрация понятия «неопределенность».
задали, характеризуемой р', при гипотезе q — t строим
кривую y = H(q) и проводим прямую, касательную к ней
в точке,
соответствующей t. Касательная будет
графиком функции у=
В самом деле, N(p/t)=
==—/?, log/,— p2logt2есть
линейная функция от рл
N{t;t)=,H(t) и N (/>'/*)>
> Н(р') npu*p'=£t. Таким
образом,
y^N(pjt)должно быть прямой, имеющей
с y = H(q) общую точку
при p = t и лежащей
выше у = Н(д) при pi=t. Так
как, кроме того, y = H(q) выпукла, непрерывна и имеет
непрерывную производную всюду, кроме точек ^i = 0 и
<7t=l, то y = N{p!t) есть касательная к y = H(q).
Пусть ограничения, наложенные на/?, например,
таковы, что р может
находиться только на
отрезке ab (рис. 55).
Тогда из изображенных
на этом рисунке
гипотез гипотеза q
содержит только истину
относительно этих
ограничений, a ql и
q2—гипотезы, содержащие не
только истину, так как
maxpN(p/0i)>Hfai)
и
maxpN(p/02)>//fa2).
Рис. 55.
Очевидно, что в этом примере q° совпадает с точкой Ь.
Если п произвольно, то р и q являются точками
(п — 1)-мерного тетраэдра (симплекса). Обозначим
(п—1) -мерную гиперплоскость, содержащую этот
тетраэдр, через К. В я-мерном случае y = H(q) есть
(п— 1)-мерная выпуклая поверхность. Проведем (п—1)*
мерную гиперплоскость, касательную к поверхности у=
266
= Н(#) в точке, соответствующей q--t. Уравнение этой
гиперплоскости будет y = N(p/tf). Посмотрим, какими
свойствами она обладает. Образуем (п — 2)-мерное
пересечение гиперплоскостей y = N(plt) и y = H(t) = const.
Спроектируем полученное пересечение на К\ эта
проекция F также является (я— 2)-мерной плоскостью. Если
p^F, то N(/*//) =Н(*). F делит К на две части. Для
точек р, находящихся по одну сторону У7, имеет место
соотношение N(p!t)<H(t), для находящихся по другую
Рис. 56.
сторону — соотношение N(pjt)>H(t). Точка h с
координатами hi — —(г= 1, 2, ..., п) всегда попадает в
область больших неопределенностей. Действительно,
N(A//)>H(A)>H(<)- При t^h имеет место строгое
неравенство. При t = h плоскость y = N(p',t)
совпадает с y = H(t) и F заполняет весь тетраэдр.
Спроектируем теперь на К область, образованную
пересечением поверхности y = H(q) и плоскости y = H(t).
Обозначим эту проекцию через G. Очевидно, t£F> t£G
и jF касается G в точке t.
Обозначим через L множество всех точек тетраэдра,
удовлетворяющих ограничениям (28), а через L
замкнутое множество, содержащее L и его предельные точки.
Пересечение L и F обозначим через М.
На рис. 56 изображена плоскость К для случая п = 3.
267
Для того чтобы узнать, является ли t гипотезой,
содержащей только истину относительно ограничений (28)
(или, что то же самое, относительно области L), нужно
провести через t поверхность постоянной энтропии G и
построить касательную к ней в точке / гиперплоскость
F. Если F отделяет L от Л*), то t есть гипотеза,
содержащая только истину (при этом, очевидно, F отделяет
L от G).
Отсюда следствие: если область L такова, что не
существует (я—-2)-мерной
гиперплоскости, ^ отделяющей
ее от h, то единственной
содержащей только истину
гипотезой является q = h.
Пример такого случая
показан на рис. 57.
Теперь мы можем
сформулировать следующую
лемму.
Лемма. Если q°—
сильнейшая содержащая только
Рис. 57. истину гипотеза, то
найдутся такие точки m1; m2; ...
.. .; тЛ...; т\ mj£M(s^Cn--1), и такие числа а?>0,
что У} aJ = 1 и 2 а7#*; = q°-
Пусть В— выпуклая оболочка, натянутая на область
L. Рассмотрим соотношение между В и поверхностью G,
проходящей через q°. В принципе мыслимы четыре
случая: 1) В и G пересекаются, 2) В и G не имеют общих
точек, 3) В и G касаются, но не в точке q°, 4) В и G
касаются в точке q°>
Первый случай не может иметь места, так как при
этом не существует гиперплоскости, отделяющей В (а
значит, и L) от G.
Реализация второго случая противоречила бы
предположению, что q° есть сильнейшая содержащая
только истину гипотеза. Действительно, мы могли бы
построить другую поверхность G', охватывающую G и не
*) L может иметь точки на F.
268
пересекающуюся с В, На G' всегда найдется точка t
такая, что гиперплоскость, касательная в этой точке к G',
отделяет G' от В. Значит, t было бы гипотезой,
содержащей только истину. Но H(tf)<H(<f°), что и
доказывает противоречивость предположений.
Третий случай, как и первый, несовместим с
предположением, что q° содержит только истину. В самом деле,
G есть выпуклая поверхность, не имеющая плоских
частей. Поэтому гиперплоскости, касательные к ней в двух
разных точках, не могут совпадать. Так как В и G
касаются, то единственная разделяющая их
гиперплоскость касается G в этой же точке, а значит,
касательная к С в #° гиперплоскость не отделяет В от G.
Итак, остается только четвертая возможность. Это
значит, что q° обязательно принадлежит В. Так как В
есть выпуклая оболочка области L, то <5f° является
центром тяжести нескольких точек т\ т\ ..., т',..., ms об-
ласти L, которым приписаны положительные веса.
Последнее утверждение и означает, что найдутся
такие числа aJ и точки т^Ь, что
2ау = 1 (32)
и
i>W = #\ (33)
причем
а>>0 (у=1, 2,..., 5). (34)
Так как q° принадлежит гиперплоскости F, a L
расположена по одну сторону от F, то/и'б/7 и,
следовательно, т*£М. Лемма доказана.
Следствие . Если t = £°, то М не пусто.
Отсюда
maxpN(p/#) = H(#)- (35)
Переходим к доказательству теоремы. Из формулы
(33) следует
N(?W = 2^NHe); (36)
/-1
учитывая (32) и (34), получаем N(flf°/flf)<maxjN(mfiq),
269
где max? есть максимум, взятый по 5 точкамmJ. Так как
т>€. L, то
N(^/?)< max, N (/>/?). (37)
В случае q ф q°
H&>)<N(&iq). (38)
Сопоставив (35) и (38) с (37), получаем
max,, N (p;q») < max, N (Plq). (39)
Это и означает, что q° есть оптимальная гипотеза, и
притом единственная.
Следствия: а) Из соотношения (35) вытекает
тахрЫ(р/0°) = Н(0°). (40)
б) Из единственности оптимальной гипотезы следует
единственность сильнейшей содержащей только истину
гипотезы.
в) Если область L такова, что не существует (п—2)-
мерной гиперплоскости, отделяющей ее от точки А, то
оптимальной гипотезой является q° = h. Например, если
на рпе наложено никаких ограничений (кроме ^Pi = 1),
то оптимальной будет гипотеза q°.= \/n.
Следствие в) поясняет, в каком смысле
целесообразно пользоваться распространенным приемом: «поскольку
мы не имеем сведений о вероятности некоторых событий,
будем считать их равновероятными».
Рассмотрим случай, когда система ограничений (28)
имеет вид Pjx + Pj2 + ... + Pjs + ••• Ч-/>уЛ = °- Это
означает, что ответ может принимать не п, а только
п — k значений. Поскольку про остальные координаты
вектора/? ничего не сказано, очевидно, оптимальной
будет гипотеза /?г=0 при i = js и# = n___k при i Ф js.
Заметим, что, оценивая в первом примере, с которого
начался этот параграф, истинность гипотезы о том, что
ссылка находится в первой половине книги, мы
подсознательно считали, что эта гипотеза говорит о
равновероятности всех страниц первой половины. Другими
словами, мы подсознательно оптимизировали гипотезу в
пределах, допускаемых не сделанными явно оговорками.
270
В результате оптимизации получилась гипотеза,
содержащая только истину. При уменьшении свободы выбора
гипотеза о том, что ссылка находится в первой
половине книги, может оказаться содержащей не только
истину. Например, гипотеза: «ссылка с вероятностью 0,99
находится между 1 и 10 стр. и с вероятностью 0,01 —
между И и 50 стр.» — содержит не только истину,
хотя и утверждает, что
ссылка — в первой
половине книги.
Итак, оценивая
истинность гипотезы, мы
«додумываем» ее так, чтобы
оптимизировать. Если после
этого получается гипотеза,
содержащая только истину,
то мы склонны и исходное
высказывание
(ограничивающее некоторую область
гипотез) считать истинным. рис. 58.
Можно сказать, что имеет
место «презумпция истинности». Пока не доказано,
что некто лжет, мы полагаем, что он говорит правду.
В заключение рассмотрим еще одно обстоятельство,
поясняющее, почему гипотеза, удовлетворяющая
соотношению (29), названа содержащей только истину. Пусть
неравенства (28) определяют некоторую область L
(рис. 58), внутри которой в действительности
может находиться р. Допустим, нам сообщили не все
неравенства. Другими словами, нам сообщили «только
истину, но не всю истину». Сообщенные нам
ограничения определяют область Z/. Очевидно L'zzL. Если наша
задача состоит в том, чтобы найти оптимальную
гипотезу, то при имеющихся в нашем распоряжении
сведениях мы выберем #°-гипотезу, оптимальную
относительно области Z/. Относительно области L она не
обязательно будет оптимальной, но всегда будет содержащей
только истину.
Приложение 2
Вопрос об оптимальных решающих алгоритмах
при функциях цены трудности, отличных
от логарифмической
Начнем с того, почему в качестве характеристики
трудности задачи для данного решающего алгоритма мы
избрали в главе VII именно логарифм среднего числа
проб? Почему не число проб или не квадрат числа
проб? Совершенно очевидно, что в разных конкретных
случаях «цена» за применения ^-алгоритма должна
быть весьма разной. Например, если реализация W-ал-
горитма — относительно самое длинное место в счетной
программе, а ценим мы машинное время, то есть смысл
считать трудность просто пропорциональной числу проб.
В другом случае, если много времени и затрат уходит на
создание экспериментальной установки, а сами
эксперименты (применение ИР-алгоритма) «стоят дешево»
(особенно когда методика хорошо отработана),
целесообразная оценка трудности будет выражаться некоторой
функцией, очень быстро возрастающей вначале и
относительно замедляющей свой рост при увеличении числа проб.
Универсального способа оценки трудности не может
быть. Почему же столько места уделено в главе VII
некоторому частному случаю — логарифмической функции
цены?
Теория информации не является исключительной
областью, где возникают подобные вопросы. Что,
например, «лучше» — источник постоянного тока напряжением
12 вольт, дающий ток до 15 ампер, или источник
переменного тока 120 вольт, с пределом силы тока 1 ампер?
Ответить на этот вопрос невозможно, если не сказано,
для какой цели нам нужен источник тока. Допустим,
однако, что, кроме источника тока, мы имеем возможность
применять различные преобразователи тока. Это значит,
что можно ставить в цепь выпрямители, трансформато-
272
ры, умформеры н т. п. Если не наложено никаких
ограничений на эту дополнительную аппаратуру, то
появляется возможность сравнить описанные выше
источники. В самом деле, если с помощью понижающего
трансформатора и выпрямителя превратить 120 вольт
переменного тока в 12 вольт постоянного, то
максимальная сила постоянного тока не может быть больше, чем
10 ампер. Это ограничение возникает вследствие
наличия закона сохранения энергии. Если,
наоборот, превратить с помощью какого-либо
преобразователя постоянный ток от первого источника в переменный
с напряжением 120 вольт, то в принципе можно
получить ток, больший 1 ампера (теоретический прелел
1,5 ампера).
По существу, мы просто сравнили мощности двух
источников. У первого она 180 ватт, а у второго 120 ватт.
Если мы не имеем преобразователей, то мощность
может оказаться вовсе не решающим обстоятельством для
предпочтения одного источника другому. Например, для
питания лампочки 120 вольт 40 ватт второй источник
годится, а первый — нет. При наличии же
преобразователей мощность становится всеобщим эквивалентом
потому, что именно для нее (а не для напряжения,
частоты, формы импульсов и т. п.) существует закон
сохранения*) (точнее, закон невозрастания). Таким образом,
именно законы сохранения (при возможности
соответствующих преобразований) выделяют величины,
которые есть смысл возводить в ранг всеобщих эквивалентов.
Вспомним теперь, зачем нам понадобилось понятие
неопределенность задачи. Для решения некоторой
задачи система ведет экспериментальную работу. Система
изначально «знает», что ответом является одно из Лг-, но
в нее не заложены сведения, какое именно А\ есть ответ
данной задачи. Недостаток знаний решающий алгоритм
восполняет с помощью опытов. Существует и другой
способ получения сведений об ответе задачи. Это —
использование сообщений, приходящих по каналу связи. Мы
хотели найти «коэффициент эквивалентности» между
этими двумя способами получения сведений. В каких
единицах нужно «измерять» эксперимент, необходимый
*) Предполагается, что мы лишены возможности запасать
энергию (например, с помощью аккумуляторов).
273
для решения задачи, чтобы уметь предсказывать
изменения, которые могут возникнуть в этой величине после
прихода данного сигнала?
Формула (11) показывает, что связь между
количеством необходимого эксперимента и свойствами канала
связи устанавливается, если измерять необходимый
эксперимент неопределенностью задачи (в логарифмических
единицах).
Связь эта типа закона сохранения: неопределенность
задачи не может уменьшиться более чем на пропускную
способность канала связи.
Мы, однако, знаем, что одного лишь наличия закона
сохранения мало для того, чтобы имело смысл
сравнивать с помощью «сохраняющейся» величины различные
задачи, каналы или сигналы. Необходимо еще, чтобы
существовали преобразователи, позволяющие
осуществить сопряжение канала связи и сигнала с решающим
алгоритмом. Оказывается, в нашем случае такой
преобразователь есть. Формула (13) говорит, что если
построить матрицу декодирующего алгоритма
(преобразователь!) по формуле (12), то решающий алгоритм
сможет полностью использовать пропускную способность
канала связи. Эти соображения и объясняют, в каком
смысле логарифмическая функция цены трудности
является преимущественной.
Может возникнуть опасение, что искусственный и
ничем (кроме закона сохранения) не мотивированный
способ вычисления неопределенности должен приводить к
результату, мало соответствующему нашим
интуитивным представлениям об успешности работы системы.
Однако оказывается, что иногда этот искусственный метод
дает результат, гораздо более соответствующий нашей
интуиции, чем, например, естественное вычисление
среднего числа проб.
Приведем пример такой ситуации. Пусть имеется
задача, для решения которой алгоритм, исходящий из
гипотезы о равномерном распределении вероятностей
ответов, тратит в среднем 109проб. Пусть, далее, мы имеем
две системы, решающие эту задачу. Первая система
обладает следующим свойством: в 99% случаев она
решает задачу в среднем за 1000 проб, а в 1% случаев —
за 109 проб. Вторая система в 99% случаев находит
решение за 10 проб, а в 1% — за те же 109 проб.
274
На вопрос: какая из систем лучше решает задачу? —
всякий человек ответит, что вторая система заметно^Лучше.
Попробуем сравнить работу систем, опираясь на
среднее число проб. Для первой системы среднее число
проб равно 0,99- 1000+0,01 • 109~Ш7- 1,0001. Для
второй системы 0,99- 10 + 0,01 - W-IO7- 1,000001.
Относительная разница столь ничтожна, что, пользуясь
критерием «среднее число проб», мы признали бы обе
системы практически равноценными при решении этой задачи.
Сравним теперь системы, пользуясь
неопределенностью задачи для них (будем брать десятичные
логарифмы). Для первой системы неопределенность равна
0,99lg 1000+0,01 lg 10J = 0,99 . 3 + 0,01 -9-3,06.
Для второй системы
0,99 lg 10 + 0,01 lg 109 — 0,99- 1+0,01 -9—1,08.
Разница очень заметна и хорошо соответствует
интуитивному ощущению, что вторая система почти всегда
решает задачу в сто раз быстрее, чем первая, а в 1 %
случаев обе системы решить задачу просто не могут.
Итак, возможен случай, когда неопределенность
оказывается ближе к интуитивной оценке, чем среднее
число проб.
Доводы в пользу логарифмической функции цены
числа проб нисколько не умаляют того обстоятельства,
что в каждом конкретном случае нас может
интересовать своя (вовсе не логарифмическая) функция цены.
Возникает вопрос: не являются ли оптимальные
решающие и декодирующие алгоритмы, о которых шла речь в
§§ 3, 5, 6 (главы VII), оптимальными только для
неопределенности? Не придется ли для каждой функции
цены трудности искать свои решающие и декодирующие
алгоритмы? Это было бы, очевидно, очень неудобно.
Если ограничить класс решающих алгоритмов
алгоритмами без обратной связи, то, действительно, для
разных функций цены трудности наилучшими будут разные
распределения вероятностей жребия. Например, для
алгоритмов без обратной связи при /г = 2 наименьшее
среднее число применений ^-алгоритма
достигается при
__ Pi — Ур\ — р\ _ Р2 — Ур2 — р1
275
а не при 9i=/?i и 92=Р2> обеспечивающих наименьшую
неопределенность.
Вспомним, однако, что алгоритмы с постоянным
распределением вероятности жребия (алгоритмы без
обратной связи) не являются абсолютно оптимальными.
В случае же, если мы снимем запрещение использовать
информацию о предыдущих испытаниях для изменения
вероятностей жребия, то оптимальным для весьма
широкого класса функций цены оказывается один и тот же
решающий алгоритм. К доказательству этого положения
мы и переходим.
Пусть F(x)— неубывающая функция, определенная
при лг> 1. Будем называть F функцией цены трудности.
Трудностью задачи в отношении объекта пи для данного
решающего алгоритма будем называть T(trii) =F(Ki)>
где Ki — среднее число применений ^-алгоритма при
решении задачи в отношении объекта mh
Трудностью задачи А назовем величину
Т(А) = %р (/и,) Т («,) = S Р Ю F {Кг).
I I
Легко видеть, что неопределенность есть трудность с
логарифмической функцией цены. Назовем F(x)
выпуклой, если при ai>6, a2>0 и ai + a2=l
a{F (х}) + a2F (x2) <! F (a1xl -j- а2х2). (41)
Теорема. При любой выпуклой функции цены
наименьшей будет трудность для решающего алгоритма,
проверяющего At в порядке убывания вероятностей pi.
Вначале заметим, что повторные проверки одних и
тех же Ai могут лишь увеличить среднее число проб, а
значит и трудность. Поэтому мы рассматриваем только
алгоритмы с обратной связью. Будем считать, что
индексы при Ai расставлены так, что
рг>р2> ... >Аг
Обозначим через лг, ,• вероятность того, что если
ответ Ai, то он будет найден на /-м такте. Очевидно,
2я,,у=1, (42)
/«1
так как ответ обязательно будет найден не более чем за
276
п тактов. Можно также показать, что
У\ я. .= 1.
*>j
(43)
Соотношение (43) имеет место благодаря тому, что
появляется одновременно условной вероятностью проверки
А,- на /-м такте, если первые /— 1 тактов не обнаружили
ответа.
Трудность задачи А для решающего алгоритма,
характеризуемого матрицей ||яг\ jll, равна
T(A) = 2ptF(%jxt9j}. (44)
Обозначим Т(А) через/О, ||я;, ill).
Введем функцию /' следующим образом:
/'(р. ||я/в у)||) = S Л S я*. у^(Л. (45)
Благодаря выпуклости F и равенству (42)
f(p44;\\)>f'(p, \\4jW)- (46)
Рассмотрим матрицу
(47)
л.'
1,
уИ
Яц .
\Щи\ - •
\щ2, 1 .
• • я1, /i
. я,„ у, + а . .
•• я/2, у, —а •
• Л1. Л
. я,-,, Л —а .
. . я/л у2 + а .
. Я1, л
• Я/„ и
« • Л/2> л
Ял, 1
я«
, h
Ч h
полученную из ||лг\ jll изменением четырех элементов, где
а>0, /2>/i и i2>ii.
При этом
Г(р.||я,.,||)-Г(р.|Ку11) =
= « (Л, - А-2) [Z7 Ш - F (у,)] > 0. (48)
Свойства (42) и (43) сохраняются после преобразования
(47). Пусть jti, / — первое отличное от щ,\ и не равное
нулю число в первой строке матрицы \\щ,,-||, а яв,1—
первое отличное от jti, i и не равное нулю число в первом
столбце. Произведем преобразование (47), приняв /i=l;
277
*2 = s; /i=l; /2 = ^, а за а взяв меньшее из чисел Я1, f и
its, i. Если в исходной матрице ||лг\ jll элемент jtif i не был
равен единице, то после преобразования в матрице
||п'. у|| в первой строке или в первом столбце станет на
один нуль больше.
Будем повторять эту операцию до тех пор, пока не
получим матрицу вида
I1
0
1
0
1°
0
Л2,2
JT 2
л23.
<2
0 .
4, г ■
4,з ■
4 ч ■
п, 3
• ° 1
I2
• л2, п
■ 4 п\
3, п
п, п \
Для этого понадобится не более 2/г — 3 операций. Так
как при каждом преобразовании выполняется
соотношение (48), то
r(p. lKJ)>f(P. ||4,||>
Проделаем ту же серию операций со второй строкой и
вторым столбцом и т. д. до получения единичной
матрицы || я? у||. Очевидно,
Г(р.|Ку11)>/'(* \КЛ> (49)
Но f'(jp, ||я^ у||) совпадает с /(/?, ||я* у||)—трудностью
задачи Л для алгоритма, пробующего с вероятностью
единица на первом шаге Аи на втором А2 и т. д.
Сопоставив это с (49), (46) и (44), получаем
T(A)>f(P, KJD^Sa^C). <5°)
чем и доказана теорема *).
Так как логарифм является выпуклой функцией, то
для него справедлива эта теорема. Отсюда следует
оптимальность алгоритма с жестким порядком перебора,
использованная в § 6 главы VII.
*) Иногда может оказаться целесообразным определять
трудность задачи в отношении rrii через F(k), а не через F(k)t как это
сделано выше. В этом случае T(A)=f'(pt II я*, j II). Отсюда следует
справедливость доказанной теоремы и для трудности, введенной
таким способом. При этом отпадает требование выпуклости функции
F(x); необходимо только, чтобы она была неубывающей.
278
Доказанная теорема имеет еще одно важное
следствие: для всех выпуклых функций цены трудности
существует один и тот же оптимальный декодирующий
алгоритм, совпадающий с декодирующим алгоритмом,
оптимальным для неопределенности. Поэтому если,
например, цена трудности есть число проб (а не логарифм
числа проб), то нарушение неравенства (21) все равно
сигнализирует о том, что для выбранной цены
декодирующий алгоритм может быть улучшен (так как
линейная функция выпукла).
В приложении 1 рассматривалось понятие
оптимальной гипотезы для совокупности задач (для алгоритмов
без обратной связи). Его можно весьма естественно
распространить на случай нелогарифмических функций
цены трудности. Несколько сложнее с понятием
гипотезы, содержащей только истину. В определение (29),
кроме неопределенности, входит еще и энтропия
распределения q. Что будет аналогом энтропии при других
функциях цены трудности?
ПусУь F(x)—функция цены трудности. Обозначим
через HF(p) минимум трудности задачи А для
решающего алгоритма без обратной связи. Легко видеть, что
по отношению к рассматриваемой трудности функция
HF играет ту же роль, что и энтропия по отношению к
неопределенности. В частности, гиперплоскость,
касательная в точке t к поверхности с уравнением у =
= HF(</)*), выражает трудность задач при гипотезе t
(ср. рис. 54).
Поэтому если мы в определениях (29) и (30)
заменим Н(д) на HF(<7), то теорема о совпадении
оптимальной гипотезы с сильнейшей гипотезой, содержащей
только истину, останется справедливой при оценке
трудности с помощью функции F(x).
Например, Н. Д. Нюбергу удалось показать, что для
линейной функции цены трудности HF {р) = /2 Vfif.
Пользуясь вместо энтропии этим выражением, мы можем
говорить о «гипотезах, содержащих только истину» при
оценке не по неопределенности, а по среднему числу проб.
*) HF(p) выпукла, так как через каждую точку этой
поверхности можно провести гиперплоскость, не пересекающую Н^(р).
Приложение 3
Задачник для узнающей программы
В нескольких местах книги говорится об
«интересных» и «не интересных» совокупностях задач. Ниже
приводится пример интересной сегодня для проблемы
узнавания совокупности геометрических задач. Мы еще не
умеем формально описывать достаточно большие и
сложные совокупности. Поэтому приходится
использовать то обстоятельство, что читатель сам является
хорошей узнающей системой. Вместо формального
определения читателю предлагается 100 образцов задач,
входящих в совокупность. Автор надеется, что после такого
обучения читатель сможет самостоятельно придумывать
новые задачи, входящие в задуманную совокупность
{имитировать автора).
Каждая задача представлена 12 объектами (по шесть
картинок каждого класса). В конце даны ответы —
описания классов во всех 100 задачах.
Читатель без труда заметит, что одно и то же слово
(например, треугольник, часть, внутри, линия,
разветвление, угол и т. .п.) имеет разный смысл в ответах на
разные задачи. В этом одна из причин трудности
построения узнающей программы для данной совокупности
задач. Программа должна весьма гибко, применяясь к
многочисленным обстоятельствам, «не механически»
пользоваться имеющимся в ее распоряжении словарем
(набором элементарных операторов).
По-видимому, есть смысл использовать этот (или
другой подобный) сборник задач, для проверки
возможностей тех узнающих программ, которые создаются их
авторами с целью подхода к имитации более сложных
мыслительных процессов.
280
281
282
283
284
285
286
287
288
289
290
2*1
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
507
308
309
310
31*
312
313
Ответы
1. Пустая картинка — Не пустая картинка
2. Большие фигуры — Маленькие фигуры
3. Белые (контурные) фигуры — Черные фигуры
4. Выпуклые фигуры — Невыпуклые фигуры
5. Многоугольники — Криволинейные фигуры
6. Треугольники — Четырехугольники
7. Фигуры, вытянутые верти- — Фигуры, вытянутые горизон-
кально талыю
8. Фигуры справа — Фигуры слева
9. Контур гладкий — Контур извилистый
10. Треугольники — Четырехугольники
11. Сильно вытянутые фигуры — Мало вытянутые фигуры
12. Выпуклая оболочка фигуры —• Оболочка слабо вытянута
сильно вытянута
13. Вертикальные прямоуголь- — Вертикальные эллипсы и гори-
ники и горизонтальные эл- зонтальные прямоугольники
липсы
14. Большая длина линий — Малая длина линий
15. Замкнутые линии — Незамкнутые линии
16. Спираль закручивается вле- — Спираль закручивается вправо
во
17. Есть угол, направленный — Нет угла, направленного внутрь
внутрь
18. Есть перешеек — Нет перешейка
19. Перешеек расположен горн- — Перешеек расположен верти-
зонтально кально
20. Точки расположены по од- — Точки расположены по разные
ну сторону от перешейка стороны от перешейка
21. Есть маленькая фигура — Нет маленькой фигуры
22. Площади фигур примерно — Большой разброс площадей фи-
одинаковы гур
314
23. Одна фигура — Две фигуры
24. Есть круг — Нет круга
25. Че_рная фигура — треуголь- — Черная фигура — круг
ник
26. Есть черный треугольник — Нет черного треугольника
27. Черных фигур больше, чем — Белых фигур больше, чем чер-
белых иых
28. Черных кругов больше, чем — Черных кругов меньше, чем
белых белых
29. Внутри контура кружков — Внутри контура кружков мень-
больше, чем снаружи ше, чем снаружи
30. Линия имеет самопересече- — Линия не имеет
самопересечение ний
31. Одна .линия — Две линии
32. Есть хэстрый выступ («мож- — Нет острого выступа.
но уколоться»)
33. Есть острый угол — Нет острого угла
34. Большая «дыра» — Маленькая «дыра»
35. Ось «дыры» параллельна — Ось «дыры» перпендикулярна
оси фигуры °си фигуры
36. Треугольник выше круга — Круг выше треугольника
37. Треугольник выше круга — Круг выше треугольника
38. Треугольник больше круга — Треугольник меньше круга
39. Отрезки почти параллельны — Между отрезками бывают
большие углы
40. Есть три точки на одной — Нет трех точек на одной пря-
прямой мой
41. Белые кружки на одной — Белые кружки не на одной пря-
прямой мой
42. Точки внутри контура на — Точки внутри контура не на
одной прямой одной прямой
43. Амплитуда колебаний уве- — Амплитуда колебаний умень-
личивается слева направо шается слева направо
44. Кружки на разных дугах — Кружки на одной дуге
45. Белая фигура поверх чер- — Черная фигура поверх белой
ной
46. Треугольник поверх круга — Круг поверх треугольника
47. Есть треугольник внутри — Есть круг внутри треугольника
круга
48. Черные фигуры выше бе- — Белые фигуры выше черных
лых
49. Внутри контура точки рас- — Вне контура точки расположе-
положены более кучно, чем ны более кучно, чем внутри
вне контура контура
50. Есть оси симметрии — Нет оси симметрии
51. Есть два близких кружка — Нет двух близких кружков
52. Стрелки направлены в раз- — Стрелки направлены в одну
ные стороны сторону
53. У внутренней фигуры мень- — У внутренней фигуры больше
ше углов, чем у наружной углов, чем у наружной
54. Обход «крест, .круг, тре- — Обход «крест, круг, треуголь-
угольник» идет по часовой ник» идет против часовой
стрелке стрелки
315
55. Если смотреть изнутри, то — Если смотреть изнутри, то кру-
кружок левее впадины жок правее впадины
56. Все фигуры одного цвета — Есть фигуры разных цветов
57. Фигуры одинаковые — Фигуры не одинаковые
58. Черные квадраты одинако- — Черные квадраты не одинаковы
вы
59. Фигуры подобные — Фигуры не подобные
60. Есть подобные фигуры — Нет подобных фигур
61. Черта делит крестики по- — Черта делит крестики не
пополам полам
62. Концы кривой далеко — Концы кривой близко
63. Утолщение контура справа — Утолщение контура слева
64. На продолжении оси эллип- — На продолжении оси эллипса
са — крест круг
65. Множество треугольников — Множество треугольников вы-
вытянуто горизонтально тянуто вертикально
66. Свободные кружки лежат — Свободные кружки лежат на
на горизонтальной прямой вертикальной прямой
67. Правая ветка начинается — Правая ветка начинается ниже
выше левой левой
68. Конец правой ветки выше, — Конец правой ветки ниже, чем
чем левой левой
69. «Ягода растет на главной — «Ягода растет на боковой вет-
ветке» ке»
70. Нет боковых веток второ- — Есть боковые ветки второго по-
го порядка рядка
71. Есть внутренние фигуры — Нет внутренних фигур второго
второго порядка. порядка
72. Концы кривой параллельны — Концы кривой
перпендикулярны
73. Большие оси эллипса и пря- — Большие оси эллипса и прямо-
моугольника перпендику- угольника параллельны
лярны
74. Хвостик растет из тупого — Хвостик растет из острого кон-
конца Ца
75. Треугольник со стороны во- — Треугольник со стороны выпук-
гнутой части дуги лой части дуги
76. Длинные стороны вогнуты — Длинные стороны выпуклы
77. Угол разделен пополам — Угол разделен не пополам
78. Продолжения отрезков пе- — Продолжения отрезков не
пересекаются в одной точке ресекаются в одной точке
79. Черный круг ближе к бело- — Черный круг ближе к треуголь-
му кругу, чем к треуголь- нику, чем к белому кругу
пику
80. Точки находятся на одина- — Точки находятся на разных
ковых расстояниях от креста расстояниях от креста
81. Черные фигуры можно от- — Черные фигуры нельзя отде-
делить от белых прямой лить от белых прямой линией
линией
82. Оболочка, натянутая на — Оболочка, натянутая на кре-
кресты, образует равносто- сты, не образует равносторон-
ронний треугольник него треугольника
83. Круг внутри фигуры из кре- — Круг вне фигуры из крестов
стов
316
84. Квадрат вне контура из — Квадрат внутри контура из
кружков кружков
85. Три части — Пять частей
86. Три части — Пять частей
87. Четыре части — Пять частей
88. Три части — Пять частей
89. Три части — Пять частей
90. Три части — Четыре части
91. Три однородных элемента — Четыре однородных элемента
92. Цепочка не ветвится — Цепочка ветвится
93. Ветвится на белом кружке — Ветвится на черном кружке
94. Черный кружок в середине — Черный кружок на конце
95. Вертикальная штриховка — Горизонтальная штриховка
96. Треугольник — Четырехугольник
97. Треугольник — Круг
98. Треугольник — Четырехугольник
99. Контуры ~из треугольников — Контуры из треугольников и
и кругов пересекаются кругов не пересекаются
100. Буква «а» — Буква «б»
Оглавление
Предисловие 3
Введение 5
Глава I. Место узнавания в работе мозга 12
§ 1. Поведение и условные рефлексы 12
§ 2. Множество ситуаций и множество реакций 17
§ 3. Интуитивная постановка задачи узнавания 19
§ 4. «Творческие» задачи и узнавание 21
Глава II. Различные подходы 24
§ 1. Исходное описание объектов 24
§ 2. Запоминание материала обучения 26
§ 3. Поиски близости в пространстве рецепторов 27
§ 4. Стандартное (не зависящее от конкретной задачи)
преобразование пространства рецепторов. Перцептрон ... 34
§ 5. Переменное (различное для разных задач)
преобразование пространства рецепторов 39
Глава III. Программа Арифметина 45
§ 1. Постановка задачи 45
§ 2. Формальное описание программы 48
§ 3. Содержательное описание признаков 52
§ 4. Эксперименты с программой 54
§ 5. Особенности алгоритма 66
Глава IV. Узнавание и имитация 77
§ 1. Описание узнающей системы в терминах теории
автоматов 77
§ 2. Возможные причины плохой работы узнающей системы 78
§ 3. Поиск причины плохой работы узнающей системы . . 84
§ 4. Общая постановка задачи узнавания. Имитация ... 87
§ 5. Интересные и неинтересные для проблемы узнавания
совокупности задач 92
§ 6. «Самообучение» . 96
§ 7. Нечетко поставленные задачи и имитация 101
Глава V. Перебор 104
А. Перебор при экзамене • * . 104
§ 1. Запоминание материала обучения . . * 104
§ 2. Запоминание разделяющего правила 105
§ 3. Синтез названия класса 105
318
Б. Перебор при обучении до8
§ 4. Поиск разделяющего правила в фиксированном про^
странствс .... * Ю9
§ 5. Перебор при поиске преобразования пространства
рецепторов цо
§ 6. Соответствие сложности описания классов материалу,
данному для обучения. Постулат достаточности мйте^
риала обучения ИЗ
§ 7. Извлечение сведений из материала экзамена . . . ] 117
§ 8. «Развал на кучи» ! ! ! 120
Глава VI. Синтез формул . 126
§ 1. «Открой закон» J26
§ 2. Случайный поиск закона .♦.„". 128
§ 3. Поведение человека и программы случайного» поиска
при игре в «открой закон» 129
§ 4. Пути сокращения перебора «*...!". 131
Глава VII. Полезная информация 134
§ 1. Количество информации и полезность сообщения * . . 134
§ 2. Решающий алгоритм. Неопределенность 136
§ 3. Связь между неопределенностью и энтропией .... 137
§ 4. Декодирование сигнала. Полезная информация .... 139
§ 5. Пропускная способность канала связи для полезной
информации 144
§ 6. Системы с обратной связью 150
§ 7. Две функции условия задачи 153
§ 8. Декодирование и узнавание 154
Глава VIII. Программа Геометрия 158
§ 1. Уроки перцептрона 158
§ 2. Структура программы Геометрия 160
§ 3. Эксперименты с программой 172
§ 4. Достоинства и недостатки Геометрии 173
§ 5. «Самоорганизующиеся нервные сети» 178
Глава IX. Язык узнающей программы (словарь) 181
§ 1. Язык перцептрона и язык человека 181
§ 2. Сильная имитация и короткие описания 183
§ 3. Что позволяет создавать короткие описания 186
§ 4. Словарь для геометрических задач 188
<$ 5. Короткое кодирование без потери информации .... 193
§ 6. «Развал на кучи» и схема программы для
геометрических задач 195
§ 7. Помогает ли человеку развал на кучи 199
Глава X. Язык узнающей программы (логика) 204
§ 1. В чем задача логического блока (коры) 204
§ 2. Поиск логической функции по частям 207
§ 3. Критерии отбора конъюнкций 209
§ 4. Надежность признаков. Предрассудки 212
§ 5. Алгоритм экзамена 216
§ 6. Логика для геометрических задач (многоэтажная кора) 219
319
Глава XI. Роль статистических критериев 227
§ 1. Непересекающиеся классы 2Г
§ 2. Пересекающиеся классы 2гь
§ 3. Выбор критерия 2!л2
§ 4. Доучивание 234
§ 5. Оценка критериев отбора признаков 236
§ 6. Вопрос о независимости признаков 241
§ 7. «Статистика вместо узнавания» 243
Глава XII. Заключение 248
§ 1 Родители и педагоги 243
§ 2. Голы, очки, секунды 252
§ 3. Накопление опыта 256
Приложение 1. Гипотезы, содержащие только истину, и
оптимальная гипотеза . 262
Приложение 2. Вопрос об оптимальных решающих
алгоритмах при функциях цены трудности, отличных от
логарифмической 272
Приложение 3. Задачник для узнающей программы .... 280