/































































































































































































































































































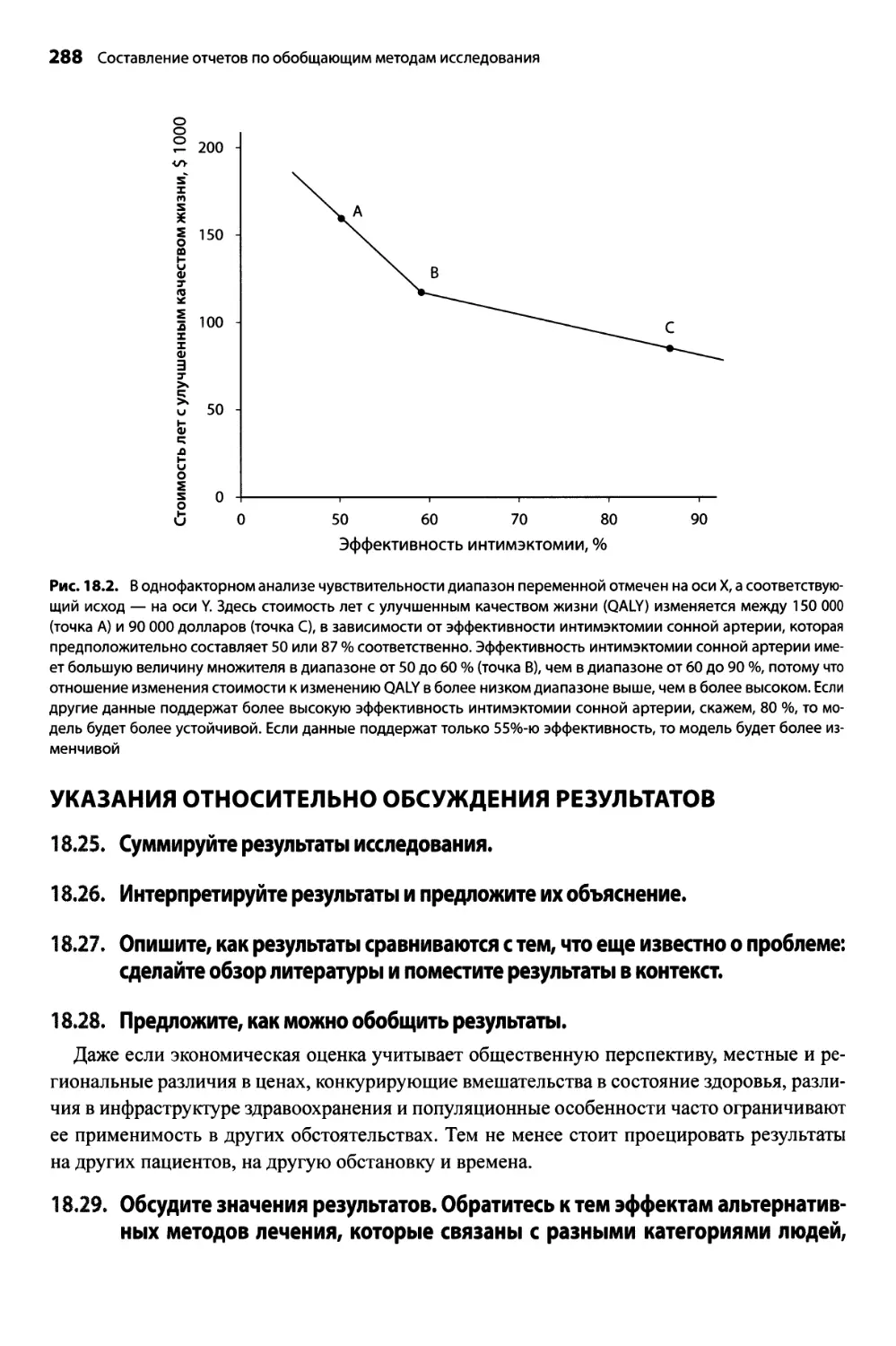






























































































































































































Теги: биологическая техника, экспериментальные методы и оборудование в целом статистика медицина
ISBN: 978-5-98811-173-3
Год: 2011




Текст
How То Report
Statistics
in Medicine
Annotated Guidelines for Authors,
Editors, and Reviewers
Second Edition
Thomas A. Lang
Michelle Secic
AMERICAN COLLEGE OF PHYSICIANS • PHILADELPHIA
Томас А. Ланг
Мишелль Сесик
Как описывать
статистику
в медицине
Руководство для авторов,
редакторов и рецензентов
Перевод с английского
под редакцией В. П.Леонова
практическая медицина
Москва 2011
УДК 57.087.1
ББК 60.6
Л22
Ланг Т. А.
Л22 Как описывать статистику в медицине. Аннотированное руководство для авторов,
редакторов и рецензентов / Т. А. Ланг, М. Сесик; пер. с англ. под ред. В. П. Леонова. —
М.: Практическая медицина, 2011. — 480 с: ил.
ISBN 978-5-98811-173-3
Книга содержит систематизированные рекомендации по описанию результатов
использования статистических методов в медицине. Она не имеет аналогов на русском языке и представляет
чрезвычайную ценность для исследователей в области медицины и биологии. Учитывая отсутствие
единообразия в описании статистических методов в отечественной медицинской науке, книга станет
полезным пособием для специалистов, разделяющих принципы доказательной медицины. Простой
и доступный язык изложения сложных понятий в сочетании с примерами способен выработать у
читателя устойчивый навык корректного и достаточно полного описания методов статистики.
Следование этим рекомендациям гарантирует читательское понимание описаний результатов исследования,
что, в свою очередь, значительно повысит вероятность цитирования этих работ.
Значительным достоинством этого издания является «Путеводитель по статистическим
терминам и критериям», который поможет читателям разрешить терминологические проблемы,
возникающие при написании статей, а также существенно облегчит понимание англоязычных статей.
Для биостатистиков, аспирантов, докторантов и исследователей в области биомедицины.
УДК 57.087.1
ББК 60.6
Издательство выражает искреннюю благодарность
В. Н. Солнцеву за помощь в подготовке книги.
Перевод книги «How То Report Statistics in Medicine» опубликован по соглашению
с The Royal Society of Medicine Press, London и American College of Physicians, Philadelphia
© American College of Physicians, 2006
ISBN 978-5-98811-173-3 (рус.) © Перевод на русский язык, оформление издательства
ISBN 978-1-930513-69-3 (англ.) практическаямёдицина, 2010
Каэюдому, кто столкнулся с разочарованием,
которое я называю «Статистический Буддизм»:
Тем, кто знает, никакое объяснение не требуется.
Тем, кто не знает, никакое объяснение невозможно.
И всем моим студентам курса
медицинских публикаций и редактирования
Университета Чикаго,
кто учил меня делать необходимое объяснение возможным.
Т. Ланг
Дэвис, Калифорния
Моему мужу и лучшему другу, Джону,
за его постоянную любовь и поддерж:ку; Дэюон, ты — моя опора;
моим дочерям, Стефани и Николь,
за их постоянные напоминания о том, как прекрасна эюизнъ;
и моей маме, Барбаре, за ее руководство каэюдым днем моей эюизни!
М. Сесик
Чардон, Огайо
СОДЕРЖАНИЕ
Благодарности 8
Вступление 9
Предисловие редактора русского перевода 11
Предисловие 14
Предисловие к первому изданию 16
Сокращения 19
Введение 20
Различия между клинической и статистической значимостью 22
Памятка читателю 25
Часть 1. Составление статистических отчетов в медицине 27
Глава 1. Работа со сводками данных
Числовые отчеты и описательные статистики 28
Глава 2. Сравнение вероятностей событий
Отчет о показателях риска 41
Глава 3. От свойств выборки к свойствам популяции
Отчеты об оценках и доверительных интервалах 57
Глава 4. Сравнение групп при помощи р-значений
Отчеты о проверках гипотез 64
Глава 5. Корректировка отдельных/7-значений
Проблема мноэюественных сравнений 79
Глава 6. Проверка наличия взаимосвязей
Отчет об анализах связей и корреляций 89
Глава 7. Предсказание значений, зависящих от одной или более переменных
Отчет о регрессионном анализе 100
Глава 8. Анализ групп со многими переменными
Отчет о дисперсионном анализе 120
Глава 9. Оценка событий во времени как конечных точек
Отчет об анализе выэюиваемости 127
Глава 10. Определение наличия или отсутствия заболевания
Отчет о характеристиках проведения диагностических тестов 136
Глава 11. Рассмотрение априорных вероятностей
Отчет о байесовских статистических анализах 156
Глава 12. Описание картин заболеваний и нетрудоспособности в популяциях
Отчеты об эпидемиологических показателях 165
Часть II. Составление отчетов об исследовательских
проектах и мероприятиях 179
Глава 13. Проверка результатов вмешательства
в экспериментальных исследованиях
Отчет о рандомизированных контролируемых испытаниях 182
Глава 14. Проспективные наблюдения: от воздействия до исхода
Отчет о когортных или лонгитюдинальных исследованиях 219
Глава 15. Ретроспективные наблюдения: от исхода к воздействию
Отчет об исследованиях типа «случай-контроль» 226
Глава 16. Совместное рассмотрение воздействий и исходов
Отчет об обследованиях или поперечных исследованиях 235
Часть III. Составление отчетов по обобщающим
методам исследования 247
Глава 17. Синтезирование результатов связанных исследований
Отчет о систематических обзорах и метаанализе 248
Глава 18. Взвешивание затрат и последствий лечения
Описание экономических оценок 271
Глава 19. Информирование о выборе методов лечения
Отчет по анализу решений и рекомендациям клинической практики 292
Часть IV. Представление данных и статистик
в таблицах и графиках 311
Глава 20. Табличное представление данных и статистик
Сообщение значений, групп и сравнений в таблицах 313
Глава 21. Визуальное отображение данных и статистик
Представление значений, групп и сравнений на графиках 333
Часть V. Путеводитель по статистическим
терминам и критериям 373
4acTbVI. Приложения 433
Приложение 1. Правила представления чисел в тексте 434
Приложение 2. Математические символы и система обозначений 436
Приложение 3. Правописание статистических терминов и критериев 437
Приложение 4. Ссылки на другие коллекции рекомендаций 438
Приложение 5. Источники ошибок, смешивания и смещения
в биомедицинском исследовании 440
Библиография 449
Предметный указатель 464
Об авторах 476
БЛАГОДАРНОСТИ
Барту Дж. Харвею,
адъюнкт-профессору и Гиблоновскому профессору
семейной медицины и основных исследований в здравоохранении
Университета Торонто, Канада
Кену Мюррею,
медицинскому директору Ассоциации врачей Независимой практики
Студии Основной практики Калифорнии,
клиническому доценту семейной медицины
Университета Южной Калифорнии,
Лос-Анджелес, Калифорния
Мы от всей души благодарим Барта и Кена за их рецензирование больших
частей рукописи. Их вклад в это издание был самым полезным и очень
ценным. Мы также уверены, что они действительно сожалеют, если
пропустили любую из наших ошибок.
ВСТУПЛЕНИЕ
Потребность в количественном доказательстве в медицинских суждениях была
замечена по крайней мере два тысячелетия назад. Во втором столетии нашей эры Гален [1]
отмечал, что:
[Эмпирики] говорят, что нечто не может быть ни принято, ни расценено как
истинное, если оно замечено однократно или если оно было замечено только несколько
раз. Они полагают, что нечто может быть принято и считаться верным, только если
это было замечено очень много раз и каждый раз в том же самом виде.
В течение многих столетий это представление, кажется, игнорировалось. Затем, почти
два столетия назад, Пьер-Шарль-Александр Луи (Pierre-Charles-Alexandre Louis) [2] поднял
следующий вопрос:
Что касается различных методов лечения, мы можем быть уверенными в
превосходстве одного или другого способа... лишь спрашивая, было ли большее число людей
вылечено одним методом, нежели другим. Здесь необходимо подсчитывать. И это
должно быть, по крайней мере, в большинстве случаев, потому что до настоящего
времени этот метод совершенно не используется или используется редко, и поэтому
наука терапии настолько сомнительна.
Вслед за Луи более твердо высказался Жиль Гаваррэ (Jules Gavarret) [3], чьи
представления о том, что необходимо оценивать вероятную уверенность в заключениях, основанных
на числовых данных, сегодня звучат подобно нашим.
Это должно быть очевидно для всего, что связано с вопросами медицинской
статистики; существуют три... вопроса, каждый... по праву является по-своему важным:
1. Определение того, что понимается под подобными фактами и сопоставимыми
фактами...
2. Доказательство, что любое заключение, полученное из небольшого количества
фактов, не заслуживает никакого рассмотрения в терапии и что при любой
статистике, чтобы обеспечить допустимые признаки, оно должно быть основано на
нескольких сотнях наблюдений.
3. Демонстрация, что правила, выведенные из опыта, никогда не верны, кроме как
в определенных пределах возможного изменения, и обеспечение средств определить
эти пределы...
Другим достижением Гаваррэ, оправдывающим то, что он был назван «отцом
медицинских статистических выводов», было применение им 1е calcul des probabilites [исчисления
вероятностей] математика Пуассона к данным Луи по лечению кровопусканием, чтобы
продемонстрировать диапазон вероятных истинных значений («пределы возможных
вариаций») для сообщенной им частоты смертности, — вычисление, которое является
«двоюродным братом» современному доверительному интервалу.
Однако вклад Гаваррэ в статистические выводы в клинической медицине в значительной
степени были проигнорированы в течение столетия. Медицинская практика продолжала
зависеть почти полностью от предположительно авторитетных изречений и мнений. Только
в середине двадцатого столетия, как указывают в своем предисловии к первому изданию
своей книги Томас Ланг и Мишелль Сесик, статистический анализ начинает
становиться главным в принятии решений, основанных на доказательствах. Они должным образом
указывают на значительный вклад Дональда Мэйнланда, однако и многие другие
исследователи в начале и середине двадцатого столетия были пионерами в области медицинской
статистики.
1 о Вступление
Адекватное планирование, дизайн исследования и статистический анализ начали
приводить к заключениям большой важности для общественного здоровья как в исследованиях
Уиндера (Wynder) и Грэхема (Graham), так и работах Doll и Hill о связи курения табака
и карциномы легкого. Сегодня даже врач, который ничего не знает о статистических
методах, желает найти в эпидемиологических исследованиях или в докладах о клинических
испытаниях лекарств или других видов лечения статистическое доказательство,
поддерживающее их выводы.
К сожалению, статистические исследования в журнальных статьях не всегда
представляют надлежащее использование статистических методов или ясное, адекватное
сообщение о статистических выводах. Редакторы журнала и их коллеги-рецензенты могут
обнаружить статистические недостатки в рукописях статей, которые они рассматривают для
публикации, но система рецензирования не всегда безошибочна в оценке статистических
доказательств и того, как они представлены. Авторы, которые знают свою обязанность
удовлетворять высоким стандартам научного сообщения, должны предлагать самое сильное
статистическое доказательство для своих выводов, но только этого недостаточно. Они
также должны представить это доказательство достаточно ясно, чтобы убедить даже самого
критически настроенного читателя, что это доказательство надежно и адекватно.
До 1997 г. и публикации первого издания данной книги существовало лишь скудное
руководство по этой важной теме. Несколько руководств биомедицинского направления
содержали короткие рубрики по стилю публикации статистических данных, но они
предполагали, что авторы знают, как сделать ясное и убедительное статистическое сообщение.
Книга, изданная Лангом и Сесик, содержала руководство не только для авторов статей,
но также и для редакторов журналов и рецензентов.
Многие другие члены медицинского сообщества — врачи, медсестры, преподаватели —
смогли извлечь пользу из этой книги. В ней есть информация о том, как искать в статьях
необходимые для практикующих врачей данные. Теперь читатели медицинских журналов
смогут легче определить, поддерживают ли представленные статистические методы и
выводы сформулированные заключения.
Данное пересмотренное и расширенное издание существенной работы Ланга и Сесик
может оказать еще большую помощь. Поскольку авторы во введении определяют содержание
своего нового издания, я не буду здесь описывать его. Авторы, редакторы и редакционные
рецензенты рукописей статей, содержащих доказательства, основанные на статистике, остаются
в долгу перед ними. Самым важным является то, что в конечном счете это издание принесет
пользу и нашим пациентам, которые являются причиной существования нашей профессии.
Эдвард Дж. Хус (Лондон)
Почетный редактор журнала
Annals of Internal Medicine
Литература
1. Galen. On Medical Experience, ch. 7. In: Three Treatises on the Nature of Science. Translated by
Walzer R, Frede M. Indianapolis: Hackett; 1985:59. Cited in: Huth EJ, Murray TJ, eds. Medicine in
Quotations: Views of Health and Disease Through the Ages, 2nd ed. Philadelphia: American College of Physicians;
2006:375.
2. Louis PGA. Essay on Clinical Instruction. Translated by Martin P. London: S. Highley; 1834:26-8.
Cited in: Huth EJ, Murray TJ, eds. Medicine in Quotations: Views of Health and Disease Through the Ages,
2nd ed. Philadelphia: American College of Physicians; 2006:376.
3. Gavarret J. Principes Generaux de Statistique Medicale. Paris: Bechet Jeune et Labe; 1840:26.
[Translation by EJH].
11
ПРЕДИСЛОВИЕ РЕДАКТОРА РУССКОГО ПЕРЕВОДА
Автор каждой публикации, будь то научная статья в журнале, монография или
диссертация, неизбежно задумывается о том, как воспримет читатель его труд. И, скорее всего,
он желает, чтобы читатель встретил его работу благожелательно, нашел в ней полезную
и ценную для себя информацию, смог бы разобраться в приведенных аргументах и выводах
и в целом адекватно воспринял бы точку зрения автора на описываемые результаты. И
начинающие, и искушенные авторы знают, что сделать это нелегко.
Предлагаемая читателю книга Томаса Ланга и Мишелль Сесик «Как описывать
статистику в медицине: аннотированное руководство для авторов, редакторов и рецензентов»
относится к уникальному жанру. Из отечественных книг, близких к ней по содержанию
и направленности, можно назвать лишь две: «Рекомендации по подготовке научных
медицинских публикаций. Сборник статей и документов» (под ред. С. Е. Бащинского, В. В.
Власова. М.: Медиа Сфера, 2006, 464 с.) и книгу профессора Власова В. В. «Введение в
доказательную медицину». (М.: Медиа Сфера, 2001, 392 с.) Однако книга Т. Ланга и М. Сесик
значительна уже по своей тематике и потому более детально описывает данный аспект
медицинских публикаций.
Низкая статистическая культура отечественных исследований в области биологии и
медицины давно уже стала трюизмом. Впрочем, когда-то схожая сипуация была и за рубежом. Одна
из первых зарубежных публикаций, содержащая анализ статистических ошибок в
медицинских статьях, относится к 1929 г [1]. В этой статье сообщалось, что примерно половина статей,
публикуемых журналом Physiological Reviews, содержит примеры ошибочного использования
статистики. Детальный анализ этого явления читатели могут найти в нашей статье [2].
Первой отечественной публикацией, содержащей нелицеприятный анализ таких
ошибок, является книга, изданная в 1955 г. [3]. В последнее время делается немало усилий,
в том числе и автором этого Предисловия, чтобы исправить это печальное для
отечественной науки состояние. Говоря же о статистической культуре в отечественной биомедицине,
следует разделять два аспекта этого явления. Первый аспект относится непосредственно
к качеству статистического анализа результатов наблюдений. Однако даже качественно
полученные результаты статистического анализа можно сделать ненадежными с точки зрения
читателя, если не привести достаточно развернутую информацию о методах этого
анализа и необходимую для понимания логики выводов сопутствующую информацию. Наличие
в публикации этого второго аспекта многократно увеличивает ее ценность и надежность,
она становится цитируемой, читатели видят в ней образец для подражания.
Поскольку большинство первичных публикаций составляют научные статьи в
периодических журналах, то именно здесь и должно вестись целенаправленное формирование
разумных, понятных и недвусмысленных требований по описанию результатов применения
статистических методов. Этот тезис отлично понимают в редакциях ведущих зарубежных
журналов. Образцами таких журналов можно назвать известные во всем мире журналы
BMJ (http://www.bmj.com/) и JAMA (http://jama.ama-assn.org/). В редакционных
требованиях этих журналов приведены детальные рекомендации по описанию результатов
применения статистических методов в медицинских исследованиях, вплоть до обязательного
представления автором статьи исходных данных, если у рецензентов возникнут сомнения
в корректности приведенных автором результатов анализа. А что же в российских
периодических изданиях? Возьмите наиболее известные российские журналы биомедицинской
тематики и попробуйте найти в них внятные рекомендации по оформлению в статьях
результатов статистического анализа. Увы, таких рекомендаций нет. Лишь в единичных жзф-
налах приводятся малопонятные фразы, содержание которых говорит о том, что их авторы
не владеют статистическим инструментарием, а сами рекомендации скорее призваны
продемонстрировать лояльность редколлегии журнала к научно-доказательной медицине.
12 Предисловие редактора русского перевода
Рассмотрим две версии одного и того же фрагмента рекомендаций, заимствованных
из российских журналов. «Описывайте статистические методы настолько детально,
чтобы грамотный читатель, имеющий доступ к исходным данным, мог проверить полученные
Вами результаты». В другом журнале этот фрагмент выглядит так: «Статистика
(статистические методы) — описывайте статистические методы настолько детально, чтобы
квалифицированный читатель, имеющий доступ к оригинальным данным, смог проверить
полученные Вами результаты». «Квалифицированный», «грамотный» читатель — это кто?
Тот, который умеет читать? Или же тот, который имеет высшее образование или диплом
кандидата или доктора наук? Идем далее: «... имеющий доступ к исходным данным, мог
проверить полученные Вами результаты». Зададимся вопросом: ЧЬИ «исходные данные»
подразумевали авторы этих рекомендаций? «Исходные данные» авторов статьи или же
«исходные данные» читателя? А сможет ли читатель «проверить полученные ... результаты»,
имея собственные «исходные данные»? Ответ отрицательный. Во-первых, такие данные
не будут идентичны данным автора статьи. Во-вторых, он может не располагать теми же
вычислительными ресурсами и знаниями, которыми располагал автор статьи.
Автор этих строк является членом редколлегии одного медицинского журнала, входящего
в так называемый ваковский список. Летом 2006 г на заседании редколлегии я обратил
внимание главного редактора журнала, академика К., на то, что уже несколько лет в журнале
отсутствует практика представления письменных рецензий на поступающие рукописи. Мною
было также отмечено, что большинство публикуемых в настоящее время в журнале статей
противоречат действующим редакционным требованиям в части использования и описания
статистических методов. Ответ академика К. был таков: «Решение о публикации статей будет
принимать врач, а не статист». Когда академик РАМН путает статиста со статистиком, то иного
отношения к статистике и не стоит ожидать. В свое время другой академик, Т. Лысенко, уже
говорил нечто подобное: «...нас, биологов, и не интересуют математические выкладки,
подтверждающие практически бесполезные статистические формулы менделистов» [4].
Отчего же в отечественных биомедицинских журналах сложилась такая порочная
практика? Однозначного ответа на этот вопрос нельзя дать, так как эта проблема имеет давние
корни и непростую историю, включающую и прямой запрет на использование статистики
в медицине [5].
Именно поэтому столь ценны для авторов, читателей и членов редакций периодических
журналов биомедицинской тематики рекомендации, приведенные в книге Т. Ланга и М. Се-
сик. Без малого 500 страниц книги посвящены детальному описанию статистических
результатов в медицинских публикациях. В ней рассмотрены вопросы представления не
только описательных статистик, но и результатов использования многих популярных методов,
таких как таблицы сопряженности, дисперсионный анализ, корреляция и регрессия,
анализ выживаемости, байесовские методы, графические методы, метаанализ и ROC-кривые
и многие другие. Разумеется, в одной книге невозможно охватить все аспекты столь
разнообразной проблемы. К примеру, авторы не рассмотрели описание результатов таких
многомерных методов, как каноническая корреляция, дискриминантный и кластерный анализ,
факторный анализ и метод главных компонент, многомерное шкалирование, анализ
соответствий, анализ временных рядов и др. Их отсутствие в данной книге вызвано тем, что
данные методы, во-первых, достаточно сложны, а во-вторых, результаты их применения
весьма объемны.
Любые рекомендации всегда несут на себе отпечаток личного опыта их авторов. Не
являются исключением и рекомендации, приведенные в данной книге. К некоторым из них мы
добавили собственные комментарии, которые отражают наш собственный 30-летний опыт
статистического анализа биомедицинских данных [6].
Уже из названия книги ясно, кому будут полезны эти рекомендации. Содержание
рекомендаций говорит о том, что авторы книги имеют немалый опыт практического использо-
Предисловие редактора русского перевода 13
вания статистики в реальных медицинских исследованиях. И хотя авторы предупреждают,
что эта книга не является учебником по статистике, внимательный читатель найдет в ней
немало информации по терминам и основным понятиям статистики.
М. Жванецкий как-то заметил: «ПисАть, как и пИсать, надо тогда, когда терпеть больше
не можешь». Увы, нередко авторы многих публикаций пишут свои статьи не в силу того,
что материал для публикации уже сформировался и вызрел, а только для выполнения плана
публикаций отдела, лаборатории или чтобы успеть к защите диссертации и т. п. Чаще всего
в таких публикациях про статистику пишут маловразумительные фразы, например «данные
были обработаны статистически». Уверен, что данная книга должна стать настольным
руководством для многих исследователей, начиная от студента-медика, пишущего курсовую
или дипломную работу, до докторов наук и академиков, в том числе и тех, которые путают
статиста и статистика. Ведь истинные профессионалы учатся всю жизнь. Будет она
полезна аспирантам и докторантам, поскольку с середины 2006 г. все диссертанты обязаны
публиковать в Интернете авторефераты своих диссертаций. А в скором времени
необходимо будет публиковать в Интернете до защиты и всю диссертацию. Именно об этом заявил
31 октября 2007 г. первый вице-премьер Д. А. Медведев на встрече с членами ВАК и
ректорами вузов, поддержав наши предложения 10-летней давности [7]. На что председатель
ВАК, декан биологического факультета МГУ, академик Михаил Кирпичников ответил, что
«в ближайшее время мы будем готовы говорить о публикации полностью диссертаций».
8 июля 2010 г. на заседании Совета по развитию информационного общества в России
президент Д.А. Медведев потребовал выложить все диссертации в интернет, «...чтобы были
видны и те, кто у нас реально наукой занимается, и те диссертации, за которые просто стьщ-
но иногда бывает» [8]. Очевидно, что в связи с этим актуальность данного издания будет
лишь возрастать.
Все перечисленные выше достоинства этой книги позволяют утверждать, что она найдет
своего благодарного читателя и будет способствовать повышению качества
статистического анализа у отечественных исследователей в области медицины и биологии, а также и
качества их публикаций.
В. П. Леонов, редактор сайта БИОМЕТРИКА
http://www.biometrica.tomsk.ru
Литература
1. Dunn HL. Application of statistical methods in physiology // Physiological Reviews. 1929. Vol. 9.
P. 275-398.
2. Леонов В. П. Ошибки статистического анализа биомедицинских данных // Международный
журнал медицинской практики. 2007. Вып. 2. С. 19-35. URL: http://www.biometrica.tomsk.ru/eiTor.htm.
3. Боярский А. Я. Статистические методы в экспериментальных медицинских исследованиях.
М.: Медгиз, 1955.
4. Леонов В. П. Долгое прощание с лысенковщиной. URL: http://www.biometrica.tomsk.ru/lis/in-
dex6.htm.
5. Леонов В. П. Применение статистики в статьях и диссертациях по медицине и биологии. Ч. 2.
История биометрики и ее применения в России // Международный журнал медицинской практики.
1999. Вып. 4. С. 7-19. URL: http://www.biometrica.tomsk.ru/history.htm.
6. Леонов В. П. Три «Почему...» и пять принципов описания статистики в биомедицинских
публикациях. URL: http://www.biometrica.tomsk.ru/principals.htm.
7. Росбалт.Ки. Медведев предложил публиковать все диссертации в Интернете. URL: http://
www.rosbah.ru/2007/10/31/427080.html.
8. http://news.kremlin.ru/transcripts/8296.
14
ПРЕДИСЛОВИЕ
Думали ли они, что науки, основанные на наблюдении, могут
стимулироваться только статистикой?„.Если бы медицина не пренебрегла этим
инструментом, это означало бы прогресс, она обладала бы большим числом
реальных истин, стала бы менее подверэюенной обвинению в том, что
является наукой нетвердых принципов, неуловимых и предполоэюительных.
Jean-Etienne Dominique Esquirol,
ранний французский психиатр,
цитируемый в журнале Lancet, 1838 [1]
Если можно верить вышеупомянутой цитате, уже 170 лет назад поставщики услуг
здравоохранения неохотно принимали статистический образ мышления в медицинской
практике. То, что такая ситуация продолжается, сегодня в лучшем случае неуместно, а в
худшем — непростительно, но в любом случае понятно. Статистика как область исследования
привлекает немногих людей, которые связаны с медициной. Она полна тонкостей и
сложностей, которые требуют много времени для понимания и еще больше для овладения ими,
и она часто преподается специалистами, разбирающимися в математике, но не в медицине.
В период студенческого обучения большинство поставщиков услуг здравоохранения
действительно изучают по крайней мере один статистический курс, но они редко изучают то,
что они хотят или должны знать, чтобы понять или написать публикацию по результатам
исследования. Кроме того, поскольку медицина стала рассматривать вопросы
внутриклеточного уровня и потому погружаться в еще большую степень технологической
изощренности, все меньше учебного времени доступно для других предметов, даже на уровне
последипломного образования.
В то же самое время движение доказательной медицины установило желательность
и преимущества применения лучших аргументов к решению клинических проблем.
Но основанная на доказательствах медицина преимущественно формируется на базе
литературы и поэтому сильно зависит от качества опубликованного исследования, а о многих
исследованиях очень плохо информируют. Фактически проблема плохой документации
исследования и статистической публикации в биомедицинской литературе является
давнишней, мировой, всеобъемлющей, потенциально серьезной и отнюдь не очевидной для многих
читателей, несмотря на то что большинство ошибок касается основных методологических
и статистических понятий, которых можно легко избежать, следуя нескольким
руководящим принципам [2].
В 1997 г. мы опубликовали первое издание книги «Как описывать статистику в
медицине», чтобы предоставить всесторонний — и понятный — набор таких руководящих правил.
С тех пор книга стала популярным справочником во всем мире и даже переведена на
китайский язык. Успех первого издания был приятен и подтвердил нашу веру в то, что читатели
будут использовать изложенные руководящие правила нашей книги, если получат к ним
доступ и поймут их. Если будут использоваться эти руководящие правила, то лучше будет
проводиться и биомедицинское исследование, а следовательно, специалисты смогут лучше
ориентироваться в области доказательной медицины.
Эта книга не типичная книга по статистике. Это и не текст по анализу или
статистическим вычислениям, а скорее руководство по интерпретации и описанию их результатов. Как
отмечено в названии, оно было написано для авторов, редакторов и рецензентов, которые
Предисловие 15
готовят или оценивают биомедицинское исследование для публикации, особенно в
рецензируемых журналах. В книге представлены краткие обзоры различных тем, глоссарий
легких для понимания объяснений статистических терминов и тестов, удобный предметный
указатель — все это должно помочь любому, кто изучает биостатистику и медицинские
исследования в традиционных академических курсах.
Таким образом, публикуя это расширенное второе издание «Как описывать статистику
в медицине», мы надеемся достигнуть того, на что надеялся доктор Lawrason Brown более
85 лет назад:
Затруднения в медицине исходят не от статистического метода, а от медицинских
работников [и работниц], которые не знают, как его использовать... Не поймите меня
неправильно. Это не аргумент в пользу сухих статистических статей, которые все мы
предпочитаем не читать. Но если я смогу заставить вас увидеть, насколько важно для
нас прекратить использовать любимую фразу «мой личный опыт» кроме тех случаев,
когда у нас есть достаточно данных, чтобы подтвердить ее, я буду считать, что достиг
того, на что я надеялся [3].
Мы искренне надеемся, что наша книга будет хорошо служить вам.
Томас Ланг
Мишелль Сесик
Литература
1. Esquiwl JED. Cited in: Pearl R. Introduction to Medical Biometry and Statistics. Philadelphia:
WB Saunders; 1941.
2. Lang T. Twenty statistical errors Qvenyou can find in biomedical research articles. Croatian Med J.
2004;45:361-70.
3. Brown L American Review of Tuberculosis; September 1920, vol iv. Cited in: Pearl R. Introduction
to Medical Biometry and Statistics. Philadelphia: WB Saunders; 1941.
16
ПРЕДИСЛОВИЕ К ПЕРВОМУ ИЗДАНИЮ
Чтобы руководить авторами при подготовке рукописей, долэюны быть
развиты стандарты, управляющие содерсисанием и форматом
статистических аспектов.
J. R. О'Fallon ETAL [1]
Среди первых врачей, которые рассмотрели значения статистической вероятности в
медицинском исследовании, был Donald Mainland из Университета Dalhousie, Галифакс,
Канада. Он, кажется, был первым, кто сообщал о статистике в своих статьях, опубликованных
в Канадском лсурнале Медицинской ассоциации и в Британском медицинском эюурнале
в 1930-х гг [2, 3]. С тех пор медицинское исследование все более и более принимало
принципы планирования эксперимента и статистического анализа, так что в итоге биостатистика
сформировалась как отдельная область исследования. Биостатистика стала существенным
шагом в движении медицинского исследования от описаний частных случаев до
экспериментов с группами контроля и, наконец, к крупномасштабным рандомизированным
контролируемым исследованиям, которые теперь являются предпочитаемым стандартом научного
доказательства.
Однако существует одна проблема. Исследования качества статистических аспектов
в журнальных статьях последовательно обнаруживали высокую частоту ошибок в
применении, изложении и интерпретации статистической информации, даже в наиболее
уважаемых медицинских журналах. Уже в первом таком исследовании — самое раннее, которое
мы нашли, было опубликовано в 1959 г — было обнаружено, что частота ошибок достигала
80 %, опять же даже в главных медицинских журналах [4-19]. «Эти обзоры
[статистических ошибок] показывают устойчивое и угнетающее постоянство: обычно примерно в 50 %
рассмотренных статей содержатся явные статистические ошибки» [20]. Более того,
большая часть этих ошибок являются столь грубыми, что вызывают сомнение в достоверности
выводов в этих статьях [6, 21].
В то же время большинство этих ошибок связаны с разделами, включенными в
большинство ознакомительных книг по статистике. Действительно, кажется странным, что
проблема, являющаяся, по-видимому, столь важной, широко распространенной и столь
давнишней, остается нерешенной, несмотря на то что по своей сути всегда была основной.
Странно, что не было доступно ни одного руководства или справочника, которые могли
бы помочь при написании статистических отчетов, несмотря на то что в некоторых
сообщениях говорилось об их необходимости [1, 17, 20, 22-24]. В биомедицинских журналах было
опубликовано несколько общих рекомендаций [20, 25-30], но мы полагаем, что они
являются слишком общими по своей сути, слишком ограниченными в данной области и слишком
специализированными по терминологии, чтобы быть полезными для большинства авторов
и редакторов. Очевидно, если не будут приняты общие правила для написания
статистических отчетов, в статьях так и будут оставаться статистические ошибки.
Таким образом, наша цель при написании книги состоит в том, чтобы в письменной
форме дать ряд детальных, обстоятельных и понятных рекомендаций для представления
статистической информации в медицине. Более того, составляя рекомендации согласно тому,
как они используются в тексте, а не согласно математическим принципам, на которых они
базируются, а также приводя различные объяснения и примеры, мы попытались сделать
рекомендации более доступными для нестатистиков.
Предисловие к первому изданию 17
В результате эта книга не является книгой по статистике в обычном смысле. Мы не
занимались обучением планированию исследования, статистической теории или методам и
вычислениям статистических критериев. Мы рассматриваем здесь только представление
статистической информации в научных публикациях и обсуждаем некоторые сопутствующие
понятия, которые должны помочь выразить эти представления в перспективе. Мы
убеждаем авторов и исследователей сотрудничать с биостатистиками на всех этапах исследования,
но также полагаем, что не нужно быть статистиком, чтобы правильно представить или
интерпретировать элементарную статистику. Однако для правильной интерпретации данных
нужен свободный доступ к точной, полной и понятной информации. Эта книга была
написана с целью обеспечить именно такой доступ.
Более 60 лет назад тот же самый д-р Mainland, который затронул эту проблему, так
выражал наши надежды на будущее в описании статистики [2]:
...Прогресс был бы достигнут, если бы некоторые фундаментальные идеи были более
ясно поняты, а именно: что принципы, лежащие в основе статистических методов,
относительно просты; что самые общие методы легко изучить; что эти методы могут
использоваться как инструмент без глубокого знания их математической структуры; что
эти методы не придают фиктивной точности или искусственного качества результатам
и что эти методы имеют тенденцию очень часто показывать, что заключения не являются
столь определенными, как думал бы лишенный помощи наблюдатель. Если бы эти вещи
были поняты, то эти методы использовались бы намного чаще и, что еще более
важно, многие сотрудники осознали бы, когда они должны обратиться за помощью к
биостатистику. Это, в свою очередь, ускорило бы наступление дня, когда биостатистика-
консультанта будут считать необходимым в каждом медицинском центре.
Это трюизм медицинского описания, что при разъяснении смысла мы, соответственно,
стремимся следовать ему. Если наша книга поможет прояснить статистические анализы,
она может также и улучшить способ, с помощью которого проводится и интерпретируется
медицинское исследование.
Томас Ланг
Мишель Сесик
Литература
1. О 'Fallon JR, Duby SD, Salsburg DS, et al Should there be statistical guidelines for medical research
papers? Biometrics, 1978; 34:687-95.
2. MainlandD. Chance and the blood count. Can Med Assoc J. 1934; 656-8.
3. Mainland D. Problems of chance in clinical work. Br Med J. 1936; 2:221-4.
4. Hall JC, Hill D, Watts JM. Misuse of statistical methods in the Australasian surgical literature. Aust
NZJSurg. 1982;52:541-3.
5. Schor S, Karten I. Statistical evaluation of medical journal manuscripts. JAMA. 1966; 195:1123-8.
6. Glantz SA. Biostatistics: how to detect, correct and prevent errors in the medical literature.
Circulation. 1980;61:1-7.
7. Lionel ND, Herxheimer A. Assessing reports of therapeutic trials. BMJ. 1970;3:637-40.
8. Altman DG. Statistics in medical journals: developments in the 1980s. Stat Med. 1991; 10:1897-
913.
9. White SJ. Statistical errors in papers in the British Journal of Psychiatry. Br J Psychiatr. 1979;
135:336-42.
10. Gore SM, Jones IG, Rytter EC. Misuse of statistical methods: critical assessment of articles in BMJ
from January to March 1976. BMJ. 1977; 1:85-7.
18 Предисловие к первому изданию
11. Freiman JA, Chalmers ТС, Smith Н Jr, Kuebler RR. The importance of beta, the type II error and
sample size in the design and inteфretation of the randomized control trial. Survey of 71 negative trials. N
Engl J Med. 1978; 299:690-4.
12. Reed JF, Slaichert W. Statistical proof in inconclusive «negative» trials. Arch Intern Med. 1981;
141:1307-10.
13. Gardner MJ, Altman DG, Jones DR, Machin D. Is the statistical assessment of papers submitted to
the British Medical Journal effective? BMJ. 1983; 286:1485-8.
14. MacArthur RD, Jacbon GG An evaluation of the use of statistical methodology in the Journal of
Infectious Diseases. J Infect Dis. 1984; 149:349-54.
15. Avram MJ, Shanks CA, Dykes MH, et al Statistical methods in anesthesia articles: an evaluation of
two American journals during two six-month periods. Anesth Analg. 1985; 64:607-11.
16. Godfrey K. Comparing the means of several groups. N Engl J Med. 1985; 313:1450-6.
17. Pocock SJ, Hughes MD, Lee RJ. Statistical problems in the reporting of clinical trials. A survey of
three medical journals. N Engl J Med. 1987;3 17:426-32.
18. Smith DG, Clemens J, Crede W, et al Impact of multiple comparisons in randomized clinical trials.
Am J Med. 1987;83:545-50.
19. Gotzsche PC Methodology and overt and hidden bias in reports of 196 double-blind trials of
nonsteroidal antiinflammatory drugs in rheumatoid arthritis. Control Clin Trials. 1989; 50:356.
20. Murray GD. Statistical aspects of research methodology. Br J Surg. 1991; 78:777-81.
21. Yancy JM. Ten rules for reading clinical research reports [Editorial]. Am J Surg. 1990; 159:553-9.
22. ShottS. Statistics in veterinary research. J Am Vet Med Assoc. 1985; 187:138-41.
23. Hayden GF Biostatistical trends in Pediatrics: implications for the future. Pediatrics. 1983;
72:84-7.
24. Altman DG, Bland JM. Improving doctors' understanding of statistics. J R Statis Soc A. 1991;
154:223-67.
25. Altman DG, Gore SM, Gardner MJ, Pocock SJ. Statistical guidelines for contributors to medical
journals. BMJ. 1983; 286:1489-93.
26. International Committee of Medical Journal Editors. Uniform requirements for manuscripts
submitted to biomedical journals. N Engl J Med. 1991; 324:424-8.
27. Elenbaas RM, Elenbaas JK, Cuddy PG. Evaluating the medical literature. Part II: Statistical analysis.
AnnEmergMed. 1983; 12:610-20.
28. Murray GD. Statistical guidelines for the British Journal of Surgery. Br J Surg. 1991; 78:782^.
29. Sumner D. Lies, damned lies — or statistics? J Hypertens. 1992; 10:3-8.
30. Journal of Hypertension. Statistical guidelines for the Journal of Hypertension. J Hypertens.
1992; 10:6-8.
19
СОКРАЩЕНИЯ
95% ДИ — 95%-й доверительный интервал
СО — стандартное отклонение
сое — стандартная ошибка среднего
KB — коэффициент вариации
ANOVA — дисперсионный анализ
ANCOVA — ковариационный анализ
РКИ — рандомизированное контролируемое
испытание
ЧПЛП — число пациентов, которых надо лечить,
чтобы предотвратить один
неблагоприятный исход
ЧПЛВ — число пациентов, подвергаемых
лечению, на один вредный исход
20
ВВЕДЕНИЕ
Представление статистических рекомендаций не следует путать со
статистическим образованием.
С Л. Джордж [\]
С тех пор как в 1997 г. вышло первое издание книги «Как описывать статистику в
медицине», большинство (но не все) рекомендаций по статистическим публикациям остались
неизменными. Потребность во втором издании вызвана возросшим пониманием того, как
лучше всего объяснить эти рекомендации, а также необходимостью добавить несколько
новых тем и обновить некоторые темы, которые существенно изменились со времени первого
издания.
Это второе издание «Как описывать статистику в медицине» состоит из 21 главы,
собранных в пять частей, шестой части из пяти приложений, библиографии и предметного
указателя.
Часть I. Составление статистических отчетов в медицине, состоит из 12 глав, которые
соответствуют 12 общим приложениям статистики. Эти главы были названы и
составлены так, чтобы помочь нестатистикам легко найти соответствующие
рекомендации. Во втором издании были добавлены две новых главы: одна — о публикациях
о мерах риска, а другая — о публикациях об эпидемиологических показателях.
Часть П. Составление отчетов об исследовательских проектах и мероприятиях,
заменяет гл. 1 из первого издания. Кроме первой основной главы по данной теме, мы
добавили еще четыре новых главы, по одной на каждую из основных
исследовательских схем, используемых в биомедицинском исследовании: экспериментальные
испытания (а именно рандомизированные контролируемые испытания), когортные
исследования, исследования типа «случай-контроль» и поперечные, перекрестные
исследования.
Часть III. Составление отчетов по обобщающим методам исследования, содержит три
главы по этой теме из первого издания, каждая из которых обновлена и
пересмотрена: публикации о систематических обзорах и метаанализах, публикации об
экономических оценках и публикации об анализах решения и руководящих принципах
клинической практики. Эти методы обычно объединяют результаты нескольких
индивидуальных исследований, чтобы обеспечить большее понимание проблемы
исследования.
Часть IV. Представление данных и статистик в таблицах и графиках, составлена
из двух новых глав, которые включают самые современные суждения и
исследовательские находки по созданию эффективных таблиц и графиков. Таблицы и рисунки
представляют количественную информацию и являются, таким образом,
статистическими по своей природе.
Часть V. Путеводитель по статистическим терминам и критериям, была расширена
по сравнению с первым изданием и теперь содержит более 550 записей. Эти за-
Введение 21
писи — толкование терминов и концепций в контексте биомедицинского
исследования; они не претендуют быть чисто математическими или теоретическими
определениями. Все они написаны так, чтобы быть понятными для читателей, у которых
есть лишь достаточно ограниченное знание статистики.
Часть VI содержит пять приложений. Первое дает правила представления чисел в тексте,
второе содержит перечень общих математических символов и условные символьные
обозначения статистических параметров, а третье дает предпочтительное
правописание статистических терминов и тестов. Четвертое приложение содержит
библиографические и интернет-ссылки на другие коллекции публикаций о рекомендациях,
данных различными научными группами. Пятое приложение описывает более
общие источники ошибок, смешивания и смещения оценок, с которыми
сталкиваются при проведении биомедицинского исследования и в оценке публикаций по этим
исследованиям.
Рекомендации в этой работе были собраны по обширному обзору литературы (см.
Библиографию). В сущности, все они общеприняты крупными специалистами данной сферы
деятельности. У большинства есть аннотации, объяснения и гипотетические примеры,
которые помогают пониманию, оценке и правильному их применению. Рекомендации
пронумерованы для облегчения поиска. Когда у рекомендации есть отличительная особенность,
используется один из четырех символов:
@ Уточняющие рекомендации даны для особых случаев основного руководства.
Щ Предостерелсения идентифицируют общие проблемы в публикации или
интерпретации информации в основном руководстве.
^ Проверки описывают способы проверки статистических представлений или
вычислений.
Q Переадресация — перекрестные ссылки к дополнительной информации в других
рекомендациях или главах.
Рекомендации должны использоваться для придания большей точности, ясности и
законченности статистическим деталям исследования таким образом, чтобы исследование могло
быть оценено адекватно. Они не должны использоваться без разбора или с единственной
целью придраться к исследованию. Мы надеемся, что предоставленная информация будет
использоваться не только с целью указать на ошибки, но также и установить истину.
Литература
1. George SL Statistics in medical journals: a survey of current policies and proposals for editors. Med
Pediatr Oncol. 1985;13:109-12.
22
РАЗЛИЧИЯ МЕЖДУ
КЛИНИЧЕСКОЙ И СТАТИСТИЧЕСКОЙ ЗНАЧИМОСТЬЮ
Говорят, что человеку с одной ногой, замороэюенной во льду, а другой ногой
в кипящей воде комфортно — в среднем.
J.M. Yancy[\]
Одной из самых частых ошибок в отчетах и интерпретации медицинского исследования
является неспособность различать клиническую и статистическую значимость. (Поскольку
в медицинской публикации термин «значимость» зарезервирован для ее статистического
значения, в этой книге мы всюду использовали оборот «клиническая важность», когда идет
речь о «клинической значимости».) Вообще клинически важное заключение — это
заключение, у которого есть последствия для лечения пациента. Статистически значимое
заключение, с другой стороны, является заключением, основанным на вероятности.
Само по себе статистически значимое заключение может иметь мало общего с практикой
медицины. Точно так же клинически важное заключение в единственном случае, вероятнее
всего, не устанавливает биологическую связь. Заключение, которое как клинически, так
и статистически значимо, весьма ценно, потому что мы, весьма вероятно, будем полагать,
что это заключение есть результат биологического процесса, общего для группы пациентов,
и что он, возможно, поддается измерению, объяснению, предсказанию и управлению.
Мы обращаем ваше внимание на несколько аспектов различия между статистической
значимостью и клинической важностью.
1. Статистическая значимость, по существу, отражает влияние случая на
результат; клиническая важность отражает биологическую ценность результата.
Вообще маленькие различия меэюду большими группами могут быть статистически
значимыми, существенными, но клинически бессмысленными. Разница в 0,02 кг в весе двух
групп взрослых пациентов, вероятно, не имеет никакой клинической важности, даже если
такое различие наблюдалось бы случайно менее чем 1 раз из 100 (р < 0,01) или даже менее
чем 1 раз из 100 000 {р < 0,00001).
Но также верно и то, что большие различия меэюду маленькими группами могут быть
клинически важными, но незначимыми статистически. В исследовании 20 пациентов, в котором
умирает всего лишь 1 пациент, смерть клинически важна, независимо от того, значима ли
она статистически. Важнейший вопрос состоит в том, является ли выборка достаточно
большой, чтобы обнаружить клинически важное различие, если действительно такое различие
существует. Этот вопрос — один из аспектов статистической мощности исследования.
2. Статистику получают из групп людей, медицина же практикует на конкретных
людях.
Поскольку статистика основана на вероятности, а не на биологии, она имеет дело с
популяциями, а не с индивидуальными пациентами. Врачи же, которые лечат конкретных
пациентов на основе медицинского исследования, реально «играют со случаем». Они
надеются, что то, что было верно для группы подобных пациентов, будет верно и для одного
конкретного больного.
Различия между клинической и статистической значимостью 23
3. Статистические заключения требуют, чтобы адекватное количество данных
было надежно, медицинские же решения должны часто приниматься по
недостаточным данным.
У статистических сравнений, использующих небольшие выборки, часто невысокая
статистическая мощность. То есть исследователи часто не набирают достаточный объем
информации, чтобы быть обоснованно уверенными в заключительных выводах о том, хороша
ли, скажем, новая терапия так же, как стандартная методика, или лучше ее. Исследования,
сообщающие об отрицательном или статистически незначимом результате, для которого
статистическая мощность невелика, фактически не дают полного отрицания вообще, этот
результат неокончателен. По той же самой причине, когда никакие статистически значимые
различия не найдены между исходными значениями небольшой группы лечения и группы
контроля, неуместно делать заключение, что эти группы эквивалентны: отсутствие
доказательства не есть доказательство отсутствия.
4. Статистические ответы являются вероятностными, лечение же требует
совершенных решений.
Статистика включает представление о вероятности. Когда ожидается, что результат
произойдет случайно менее чем, скажем, 1 раз из 1000 (т. е./? < 0,001), такой же результат может
случайно наблюдаться и в ином случае; и тогда просто невероятно, что именно случай и есть
объяснение этого результата. Результат, полученный в выборке, также является оценкой того,
что, как мы могли бы ожидать, произойдет в большей популяции. Хотя 95%-й
доверительный интервал (95% ДИ) и обеспечивает меру точности для этого оцениваемого результата,
тем не менее он также является вероятностным утверждением, а не чем-то верным'.
5. Статистический анализ всегда требует измерения, медицина же иногда
нуждается в интуиции.
Наука — это измерения. К сожалению, не все в медицинской науке может быть легко
измерено: депрессия, боль, качество жизни; даже более физические аспекты жизни, такие
как функция печени или жизненные показатели состояния сердца, нелегко определить
количественно. Измерения и вероятностные заключения могут оказывать большую помощь
в медицин^е, но они во многих случаях еще не в состоянии заменить опыт,
проницательность и интуицию.
6. Статистические и клинические употребления термина «нормальность» часто
запутанны и неопределенны.
В статистике термин «нормальный», вообще говоря, относится к распределению
значений, которое имеет форму симметрической колоколообразной кривой. Говорят, что т^-
m>\Q распределены нормально, если их распределение, изображенное в виде графика, имеет
' Очень важное замечание! К сожалению, российские исследователи в своих публикациях очень часто
используют некорректные выражения, типа «достоверное различие», относящиеся к результатам применения
статистических методов. Иными словами, вместо оборота «статистически значимое различие», свидетельствующее о
вероятностном характере утверждения, используют этот неверный оборот. Феномен «семантической глобализации
научности» применительно к понятию «достоверность» детально рассмотрел Н. А. Зорин в своей статье «О
неправильном употреблении термина "достоверность" в российских научных психиатрических и общемедицинских
статьях», опубликованной в электронном журнале «Биометрика» на сайте: http://www.biometrica.tomsk.ru/letl.htm.
Непонимание сути статистических терминов приводит к тому, что «жонглирование» ими в публикациях приводит
в результате к анекдотическим курьезам. В качестве примера рекомендую читателям познакомиться с
критическим анализом одной из таких статей, авторы которой, два академика РАМН, используют абсурдный по своему
смыслу оборот «статистическая достоверность» (http://www.biometrica.tomsk.rU/kk/index_3.htm#33). — Здесь и
далее прим. ред.
24 Различия между клинической и статистической значимостью
такую форму. В медицине же термин «нормальный» часто используется небрежно, чтобы
обозначать обычное, приемлемое или здоровое.
Эти два определения, к сожалению, часто объединяются, чтобы определить
«клинически нормальное» как характеристику с обычным значением в нормальном распределении
значений для этой характеристики. То есть величины, которые находятся в средних 95%
значениях, собранных у здоровой популяции, обычно полагают нормальными по
определению, а те, которые расположены в самых меньших 2,5% и самых больших 2,5%, считаются
ненормальными.
Такие определения являются статистическими, но не клиническими. В своем лучшем
клиническом использовании термин «нормальный» относится к значению величины,
которое связано только с малой вероятностью болезни или нетрудоспособности, независимо
от того, где это значение находится на оси распределения данных значений. Аналогично,
термин «ненормальный» относится к значению, связанному с высокой вероятностью
болезни, независимо от того, где это значение находится в распределении.
Литература
1. Yancy JM. Ten rules for reading clinical research reports [Editorial]. Am J Surg. 1990; 159:553-9.
25
ПАМЯТКА ЧИТАТЕЛЮ
Мои книги — вода; книги великих гениев — вино. Все пьют воду.
Марк Твен
Как прекрасные вина, так и биостатистика характеризуются сложностью и
утонченностью, которые могут действительно оценить относительно немного людей, посвящающих
время, чтобы овладеть ими. Таким читателям мы приносим свои извинения; эта книга была
написана не для вас. Скорее, она была написана для намного большей группы читателей:
для тех, кто жаждет понять основы статистики, а не стремится оценить все ее нюансы.
Это — книга об описании и интерпретации статистических представлений, но не о
понимании теории вероятностей или математических концепций. Это — книга для пьющих воду.
Чрезвычайно трудно объяснить многие статистические понятия в терминах, которые
одновременно должны быть и технически точными, и легко понимаемы теми, у кого есть
лишь поверхностное знание данной темы. Таким образом, если наши объяснения не
включают некоторые из более тонких разделов темы или они обошли некоторые различия
смыслов, то это лишь потому, что мы полагаем, что такие тонкие детали и различия отвлекли бы
от объяснения, сделав его менее адекватным для большинства читателей.
Медицинские примеры в этой книге были задуманы, чтобы проиллюстрировать
статистические понятия. Как таковые, подавляющее большинство их являются гипотетическими и
потому должны быть восприняты лишь как обучающие схемы, а не как медицинский факт.
27
Часть I
Составление
статистических
отчетов в медицине
Любая практика сообщения, которая препятствует надлеэюащему
выводу, является неуместной.
S. Е. FlENBERG [ 1 ]
Литература
1. Fienberg SE. Damned lies and statistics: misrepresentations of honest data. In:
Council of Biology Editors, Editorial Policy Committee. Ethics and Policy in Scientific
Publication. Bethesda, MD: Council of Biology Editors; 1990:202-6.
28 Составление статистических отчетов в медицине
Глава 1
Работа со сводками данных
Числовые отчеты и описательные статистики
Выбор одной итоговой статистической величины, а не другой моэюет подчас
даэюе затрагивать клиническую оценку врачей, читающих опубликованную
статью, в этом случае необходимо проявить скрупулезное внимание к тому,
насколько ценно использование такой итоговой статистики в медицинской
литературе.
L. FoRROw, W. С. Taylor, R. М. Arnold [1]
Описательная статистика заключается в численном выражении наборов данных.
Создание итоговой статистики обычно является первым шагом в анализе и представлении
результатов исследования, поскольку она сводит обширные массивы данных к нескольким
более удобным в работе числам. К примеру, простое перечисление частоты пульса 5000
пациентов редко имеет практическое значение, но данные о средней частоте пульса и,
возможно, о максимальной и минимальной его частоте у некоторой группы пациентов и
востребованы, и используются на практике. Здесь средняя, минимальная и максимальная
частоты пульса являются тремя описательными статистиками, которые сводят 5000 исходных
данных к трем числам.
Здесь мы' даем рекомендации по 1) выбору количества числовых разрядов, 2) указаниям
в процентах, 3) категориальным данным, 4) непрерывным данным, 5) парным данным, 6)
преобразованным данным и 7) данным из малых выборок.
РАЗРЯДНОСТЬ ЧИСЕЛ
1Л * Приводите числовые данные с разумной степенью точности.
Ложно понимаемая («паразитная») точность нежелательна и может увести в сторону.
Сообщение о том, что математическое ожидание средней продолжительности жизни равно
22,085 года, ничего не добавляет к тому достаточному для практики факту, что средняя
продолжительность жизни составляет 22 года. Как указывает Ehrenberg [2], читатели в
действительности могут эффективно работать с теми числами, которые содержат не более двух
значащих цифр. Таким образом, числа следует округлять до двух значащих цифр, если
только большая точность не является действительно необходимой. Сравните следующие
три-утверждения (по Ehrenberg):
1. Число обучающихся врачей-женщин возросло с 29 942 до 94 322, а число врачей-
мужчин— с 13 410 до 36 061.
Числовые отчеты и описательные статистики 29
2. Число обучающихся врачей-женщин возросло с 29 900 до 94 300, а число врачей-
мужчин — с 13 400 до 36 100.
3. Число обучающихся врачей-женщин возросло с 30 000 до 94 000, а число врачей-
мужчин — с 13 000 до 36 000.
Трехкратный рост числа врачей в утверждении 1 заметен слабо, так как два пятизначных
числа сравнивать трудно. Округление до трех значащих цифр в утверждении 2 выглядит
лучше, но третья цифра все же отвлекает внимание на себя. Зато в утверждении 3 числа
округлены до дв)ос цифр, и их приближенное отношение один к трем видно намного яснее.
ф Численные данные следует округлять тогда, когда они преподносятся
читателю, но не тогда, когда они анализируются [3]. Часть информации при округлении
теряется, и эта потеря может повлиять на качество результатов. Указание
точного числа обучаемых врачей в вышеприведенном примере может по ряду причин
оказаться необходимым. Округление помогает читателю увидеть общую картину
результатов, но его не следует применять, если необходимы более точные описания
данных.
Q В большинстве клинических и многих биологических исследованиях стоит
проверить, является ли действительно необходимой точность числа с тремя
или более десятичными цифрами. Некоторые измерения могут производиться
с высокой степенью точности, и эту точность иногда стоит отразить в отчете. Однако
в биомедицинских исследованиях высокоточные измерения могут иметь малое
значение. К примеру, наименьшее значение/?, необходимое для отчета, —р< 0,001.
ПРОЦЕНТЫ В ОТЧЕТАХ
1.2. Указывая число процентов, всегда добавляйте числитель и знаменатель со-
ответавующей дроби.
Преимущество указаний в процентах состоит в том, что они позволяют единообразно
сравнивать группы разных размеров. Недостатком является то, что при указании одних
только процентов может потеряться перспектива. Так, утверждение о том, что 20 %
пациентов были успешно излечены, равным образом справедливо для одного из пяти пациентов
или же для 1000 из 5000. Числитель и знаменатель дроби, соответствующей процентному
значению, можно указывать в скобках и наоборот: 25 % (650/2598); 33 % (30 из 90
пациентов); 12 из 16 кроликов (75 %).
Щ Проверяйте числители и знаменатели, пересчитывайте процентные
соотношения. Одно типичное недоразумение возникает тогда, когда проценты
указываются не для всей выборки, а только для ее подгрупп. Например, «среди 1000
мужчин с сердечным заболеванием у 800 (80 %) был высокий уровень холестерина
сыворотки крови; 250 (31 %) из этих 800 вели сидячий образ жизни». 31 % — это
250/800, а не 250/1000.
1.3. Если объем выборки больше 100, указывайте число процентов не более
чем с одним знаком после запятой. Если объем выборки меньше 100,
указывайте целое число процентов. Если объем выборки меньше, чем.
30 Составление статистических отчетов в медицине
скажем, 20, то следует предпочесть указание исходных числовых данных,
а не процентов.
Выбор именно числа 20 как своего рода границы между малыми и большими выборками
имеет основания, но этот выбор произволен. В малых выборках размер процентной
величины может вводить в заблуждение, так как она может оказаться больше, чем то число, которое
она выражает: «33 % крыс в этом эксперименте выжили, 33 % умерли, а третья убежала».
1 А. Если вы указываете процентное изменение величины, используйте
следующую формулу: [(конечное значение — начальное значение)/начальное
значение]; затем, чтобы получить увеличение или уменьшение в процентах,
умножьте результат на 100.
Если результат при использовании этой формулы является отрицательным числом, знак
минус опускается, а изменение называется уменьшением. Если результат положителен,
изменение называется увеличением.
ПРИМЕР
• Изменение температуры тела на 10 °С с 30 до 40 °С означает 33%-е увеличение:
(40 - ЗОУЗО = 0,33. 10 °— это одна треть от 30 °.
• Изменение температуры тела на 10 °С с 40 до 30 °С означает 25%-е уменьшение:
(30 - 40)/40 = -0,25. 10 °С — это одна четверть от 40 Т.
ОТЧЕТ О КАТЕГОРИАЛЬНЫХ ДАННЫХ
Образец презентации
Из 25 опухолей только 5 были злокачественными.
Здесь:
• Отношение числа злокачественных опухолей к числу доброкачественных равно 5:25.
• Доля злокачественных опухолей составляет 5/25, или 0,2.
• Процент злокачественных опухолей составляет (5/25) х 100 %, или 20 %.
• Через 5 лет наблюдений опухоль стала злокачественной у 5 из 25 пациентов, что
составляло 20%-ю частоту рецидивов за 5 лет. (Частота связана с факторолА времени.)
1.5. Уточняйте знаменатели в отношениях, долях и процентных соотношениях.
Категориальные данные (номинальные или порядковые) — это подсчеты числа
участников или наблюдений в каждой категории. Такие данные часто описываются в
процентах или с помощью иных отношений. Например, если выборка разделена на четыре
номинальные категории по группе крови, то число пациентов в этих категориях должно
быть выражено четырьмя числами, дающими в сумме 100 %. Хотя числители определить
легко, знаменатели могут отображать либо всю группу, либо только ее часть. Поэтому
важно уточнять, численность какой группы берется в качестве знаменателя. Группа крови АВ
может составлять 15 % от всех пациентов выборки (скажем, 15 из 100), но при
определенных условиях 67 % (12 из 18) от 18 пациентов.
Q Приводите сводку категориальных данных в тексте тогда, когда число
категорий не так велико, чтобы оправдать использование рисунка.
Числовые отчеты и описательные статистики 31
1.6. Если непрерывные данные разбиты точками деления на порядковые
категории, идентифицируйте эти точки деления и обоснуйте их выбор.
Результаты измерения роста, скажем, у 100 мужчин можно рассматривать как
непрерывное распределение по метровой шкале; их также можно разбить на три ординальные
(порядковых) группы: мужчин низкого, среднего и высокого роста. Поскольку с точки
зрения статистики работа с порядковыми данными ведется не так, как с непрерывными,
это помогает узнать, когда и почему использовались эти категории. Деление
непрерывных данных на порядковые категории может быть нежелательным вследствие того, что
сведение индивидуальных значений в меньшее количество более общих категорий
приводит к потере информации. Однако если такое деление упрощает вычисления, оно может
оказаться желательным. Общеизвестным примером является практика, при которой
возраст анализируется через ряд ординальных категорий, а не как непрерывно меняющаяся
переменная.
^ Будьте внимательны при интерпретации порядковых данных, если они
рассматривались как непрерывные данные [4]. Общепринятой, но порой спорной
практикой является рассмотрение небольшого числа ординальных категорий так,
как если бы они были непрерывными данными. Например, степень тяжести
заболевания может оцениваться по четырехбалльной шкале: 1 — отсутствие
заболевания, 2 — вялотекущая болезнь, 3 — умеренно протекающая болезнь, 4 —
тяжелая болезнь. Значения степени тяжести, полученные от нескольких пациентов,
могут сочетаться для получения усредненной степени состояния, равной, скажем,
2,3. Но такие значения могут оказаться нереалистичными из-за того, что
концептуальное «расстояние» между категориями неодинаково'. «Расстояние» между
отсутствием заболевания и вялотекущей болезнью может быть намного «больше», чем
между умеренно протекающим и тяжелым заболеванием. Указание числа данных
в каждой категории или той категории, где содержится наибольшее число значений,
данных (модальное значение), может оказаться лучшим способом для получения
отчета об этих данных.
С другой стороны, иногда полезно усреднять порядковые значения. Для семибалльной
шкалы, по которой оценивают удовлетворительность итогов пребывания в стационаре, лишь
немногие возразили бы против дробного выражения средней оценки пребывания в
стационаре, такой как 3,2 или 5,3. Однако даже здесь использовать среднее значение уместно
лишь тогда, когда распределение значений более или менее похоже на нормальное^. Если
распределение значений скошено, то для отчета больше всего подходит медиана (значение,
делящее распределение на верхнюю и нижнюю половины); если же распределение
бимодальное, то более всего подходят две моды, т. е. два пиковых значения бимодального
распределения (см. указание 1.7).
' Весьма существенный акцент в работе с порядковыми признаками. Однако в современной биостатистике есть
методы, позволяющие производить так называемую оцифровку градаций таких признаков. В результате
отдельным градациям присваиваются новые числовые метки, и в дальнейщем с ними можно работать как с
непрерывными шкалами.
^ Данная рекомендация весьма сомнительна в силу своей некорректности, так как распределение дискретных
величин невозможно сравнивать с нормальным распределением непрерывной величины.
32 Составление статистических отчетов в медицине
ОТЧЕТ О НЕПРЕРЫВНЫХ ДАННЫХ
Образец презентации
• Численность титров антител варьировалась в пределах от 25 до 347 нг/мл и их среднее
значение (стандартное отклонение—СО) составляло 110 нг/мл (43 нг/мл). Если
распределение данных близко к нормальному, то они хорошо описываются с помощью среднего и СО.
• Численность титров антител варьировалась в пределах от 25 до 347 нг/мл, с
медианой (интерквартильной широтой), равной 110 нг/мл (от 61 до 159 нг/мл). Если
распределение данных заметно отличается от нормального, то они хорошо описываются медианой
и интерквартильной широтой.
17. Составляя отчет о непрерывно распределенных данных, выбирайте
подходящие меры центральной тенденции и рассеяния.
Непрерывные данные — это данные, которые при нанесении на график образуют
распределение значений сплошь по всей длине числовой оси. Выводы о таких
распределениях могут быть сделаны при подходящем выборе мер центральной тенденции и рассеяния.
Меры центральной тенденции, такие как среднее, медиана или мода, указывают на те
места числовой оси, где данные имеют тенденцию к концентрации. Меры рассеяния,
с другой стороны, такие как СО, размах или интерквартильная широта, говорят о
распространении данных вдоль числовой оси.
Про распределения, образующие «колоколообразную» кривую, говорят, что они
«распределены приблизительно нормально»; все остальные распределены по закону, отличному
от нормального. Приблизительно нормальные распределения могут быть корректно
представлены с помощью среднего значения и СО; остальные распределения лучше описывать
с помощью медианы и размаха или интерквартильной широты.
Классическая ящичковая диаграмма Тьюки (рис. 1.1) и ее модификация,
воспроизведенная в виде кливлендской точечной диаграммы (рис. 1.2) [5], являются прекрасным
средством для представления как нормально, так и ненормально распределенных данных [6].
Они могут показывать среднее или медиану, СО или интерквартильную широту, размах
от 90 до 10 %, выбросы и т. д. (см. указание 21.17, рис. 21.13 ирис. 21.15).
Также может быть полезно строить малые гистограммы, демонстрирующие общий вид
распределений реальных данных (рис. 1.3).
1 *8. Не делайте заключений о непрерывных данных с помощью среднего и
стандартной ошибки среднего.
Стандартная (среднеквадратичная) ошибка среднего (СОС, англ. — SEM) — это мера
точности для оцениваемого среднего генеральной совокупности (популяции), в то время
как СО указывает на разброс действительных данных вокруг среднего одной выборки из
генеральной совокупности. В отличие от СО, СОС не является описательной статистикой
и не должна использоваться в таком качестве. Тем не менее авторы некорректно используют
СОС как описательную статистику для итоговых выводов об изменчивости своих данных:
поскольку она всегда меньше, чем СО, делается необоснованное заключение о
повышенной точности измерений.
Числовые отчеты и оп^1сательные статистики 33
Использовать СОС следует лишь
для указания точности оценки
среднего генеральной совокупности.
Однако даже в этом случае
предпочтительнее взять 95% ДИ, т. е.
диапазон значений, охваченный
примерно двумя СОС сверху и снизу
от среднего выборочного значения
{см. гл. 3),
ПРИМЕР
• Если средний вес в выборке
из 100 мужчин равен 72 кг, а СО
равно 8 кг, то (в предположении
нормальности распределения)
следует ожидать, что у двух
третей мужчин (68 %) вес будет
заключен в пределах от 64 до 80 кг.
Здесь среднее и СО правильно
использованы для описания
данного распределения веса
мужчин. Однако средний вес
выборки, 72 кг, является также
наилучшей оценкой среднего
веса мужчин всей генеральной
совокупности, из которой была
произведена выборка.
Используя формулу СОС = СО/л/й, где
11
о- ?
20 —
15 —
10 —
5 —
т
*
--ft-
*
Vr
"1Г
т
4 8 16 32
Кратность растворения
64
Рис. 1.1. Ящичковая диаграмма Тьюки (или «ящик с усами»)
может уместить итоговую информацию о распределении в
небольшом объеме. Здесь ящик показывает интерквартильную
широту, горизонтальная линия в ящике — медиану, а
звездочки — среднее. «Усы» показывают размах распределения.
В других модификациях усы могут показывать размах,
скажем, от 5-го до 95-го процентиля, а индивидуальные значения
на краях распределения будут нанесены на график отдельно,
с тем чтобы идентифицировать выбросы
СО = 8 кг и « = 100, получаем, что СОС равна 0,8. Это означает следующее: если
(случайная) выборка объема 100 неоднократно выбирается из одной и той же
генеральной совокупности мужчин,
то следует ожидать, что
примерно в двух третях (68 %)
этих выборок средние
значения веса заключены в
пределах от 71,2 до 72,8 кг (эти
значения больше или меньше
Чашка 5
Чашка 3
Чашка 4
Чашка 6
Чашка 1
Чашка 2
мг/мл
.....==1=...
-.=|.=
--=1==.—
==1===--
==1===--
--====1===
0 10 20 30 40 50 60 70
среднего на одну величину
СОС). Оценку среднего и ее
точность в этом примере
лучше выразить через среднее
и 95% ДИ (значения в этом
диапазоне примерно на две
Рис. 1.2. Классическую ящичковую диаграмму показанную на рис. 1.1, ^^^ ^^^^^ ^^^ ^^^^ д^^^_
можно воспроизвести с помощью кливлендской точечной диаграммы.
Медиана показана здесь вертикальной линией, интерквартильная широта — ^^)- ^Д^сь следует сказать так:
двойными линиями, а весь диапазон значений — пунктирными линиями «Средний вес составил 72 кг
^I^L
^.
2У
[\
34 Составление статистических отчетов в медицине
(при 95% да от 70,4 до 73,6 кг)». Под
этим подразумевается следующее: если
(случайные) выборки объема 100
неоднократно извлекаются из одной и той
же генеральной совокупности мужчин,
то ожидаемые средние значения будут
находиться в пределах от 70,4 до 73,6 кг
в 95 % этих выборок.
Подводя итоги, для этих данных, можно
сказать:
• описательные статистики
предпочтительнее представлять так: среднее
значение (СО) = 72 кг (8 кг).
• оценку среднего и ее точность предпочтительнее представлять так: среднее (при
95% ДИ) = 72 кг (от 70,4 до 73,6 кг).
Следует предостеречь от представления оценки среднего и ее точности в виде среднего
значения и СОС, поскольку они часто смешиваются со средним и СО.
^ Часто СОС безосновательно используется 1) вместо СО при описании
изменчивости множества данных и 2) вместо 95% ДИ при указании точности оценки.
Отчет о нормально распределенных данных
Рис. 1.3. Небольшие гистограммы также могут
показывать общую форму распределения данных,
не занимая при этом много места. Когда
описательные статистики не дают хорошего описания
данных или вводят в заблуждение, такие гистограммы
могут придать данным более точный смысл
1.9. Используйте среднее значение и стандартное отклонение лишь тогда, когда
речь идет о примерно нормальном распределении данных\
Среднее значение и СО могут быть подсчитаны для любого распределения непрерывных
данных. Однако для обычного читателя медицинской литературы среднее и СО имеют
значение только при нормальном распределении (распределении Гаусса), или на колоколоо-
бразной кривой. То есть большинство читателей знают, что 68 % значений распределения
лежат в интервале среднее ± одно СО, 95 % значений — в интервале среднее ± два СО, 99 %
значений — в интервале среднее ± три СО.
Среднее значение и СО могут корректно использоваться при описании других
известных распределений, таких как пуассоновское или хи-квадрат, но эти описания мало что
говорят нестатистикам. Таким образом, среднее значение и СО можно использовать только
при описании данных, распределенных по приблизительно нормальному закону.
Распределения, заметно отличающиеся от нормального, следует описывать с помощью медианы
и размаха или интерквартильной широты (см. указание L12),
^ Многие биологические характеристики распределены не по нормальному
закону [4,7-12]. Поскольку большинство биологических характеристик не
подчиняются нормальному закону распределения, наиболее употребительными
описательными статистиками в медицинской науке следует считать медиану и размах или
интерквартильную широту, а не среднее значение с СО.
' Наш многолетний опыт работы с биомедицинскими данными показывает, что примерно нормальное
распределение встречается у непрерывных признаков примерно в 20-25 % случаях. Это следует учитывать при выборе
параметров описания распределения.
Числовые отчеты и описательные статистики 35
@ Указывайте значения среднего и СО не более чем на один знак после запятой
больше по сравнению с данными [3,13-15]. Как всегда, округляйте до двух
значащих цифр, если это возможно.
^ Данные, у которых СО превышает половину среднего значения, не являются
нормально распределенными (если считать отрицательные значения
невозможными); их следует описывать с помощью медианы и размаха или интерк-
вартильной широты [10, И, 16-18]. «Среднее значение (СО) плазмы составило
45 (25) мг/дл. Согласно определению, 95 % выборки из нормально распределенных
данных попадает в интервал, ограниченный примерно двумя СО выше и ниже
среднего значения. В данном случае 95 % от всего диапазона пробегают значения от -5
до 95 мг/дл, что невозможно [45 - (25 + 25) = -5; 45 + (25 + 25) = 95]. Это говорит
о том, что значения плазмы распределены не по нормальному закону.
ф Вычитая медиану из среднего значения, мы получаем грубую оценку
скошенности, асимметричности данных: чем больше разность, тем сильнее
скошенность [19,20]. Среднее значение и медиана нормального распределения примерно
равны. Если среднее значение заметно больше медианы, данные скошены вправо,
обычно из-за того, что несколько больших значений увеличивают среднее.
1.10. Не используйте символ «±» при указании среднего значения и стандартного
отклонения.
Символ «±» не нужен, поскольку нормальное распределение симметрично и, по
определению, СО занимает равные промежутки по обе стороны от среднего значения.
ПРИМЕР
• Данные указываются как «средние значения и СО» (а не «средние значения ± СО»).
• Среднее значение (СО) составило «12 мл (2 мл)» (не «12 ± 2»).
Обычным источником недоразумений в медицинской литературе является разное
понимание интервала, определяемого символом «±». К примеру, «12 ± 2 мл» может означать
среднее значение и СО, среднее и СОС или даже оценку среднего и 95% ДИ, в который
попадает эта оценка. Знак «±» не всегда означает, что следующее за ним число является СО,
и поэтому его нужно заменять пояснением, имеется ли в виду СО или 95% ДИ.' В отличие
от СО и СОС, доверительные интервалы не всегда симметричны относительно среднего
значения, поэтому даже обоснованное применение знака «±» может оказаться не вполне
точным в некоторых примерах.
^ Не указывайте в отчете стандартную ошибку среднего. Точность оценки
предпочтительнее описывать с помощью 95% ДИ, а его использование требует указания
верхней и нижней границы. Например, «разница составила 12 мл (95% ДИ = от 10
до 14 мл)». (См. такэюе гл. 3.)
' Весьма важное замечание, поскольку для отечественных публикаций характерно как раз отсутствие таких
пояснений. Наряду с таким пояснением следует обязательно указывать и объем наблюдений, по которым
вычислялись эти характеристики.
36 Составление статистических отчетов в медицине
1Л1« Сравнивая рассеяния двух и более множеав нормально распределенных
данных, используйте вместо аандартного отклонения коэффициент вариации.
Изменчивость биологических показателей в типичных случаях усиливается с
нарастанием их величины'. К примеру, изменчивость веса новорожденных меньше, чем
изменчивость веса стариков, поскольку с увеличением веса увеличивается и диапазон, в котором
он может меняться. Как следствие, изучение рассеяния в двух выборках путем сравнения
их СО может привести к ошибкам. Коэффициент вариации (KB) удобен тем, что объединяет
и среднее, и СО в один показатель.
KB — это СО, выраженное в процентах от среднего значения. Таким образом, он дает
меру рассеяния относительно величины среднего значения. Так, для среднего значения 12
и СО 3 KB равен 25 %.
ПРИМЕР
• Показатель 1 в табл. 1.1 имеет наименьшую изменчивость, так как он имеет
наименьшее значение КВ.
KB особенно удобен при сравнении рассеяний в двух и более множествах данных,
выраженных в разных единицах измерения, поскольку он, в отличие от них, выражен в
процентах. Пусть, например, некоторый диагностический тест показывается областью
изображения, измеряемой в квадратных миллиметрах, а конкурирующий тест измеряет поглощение
изотопного индикатора в миллилитрах в минуту. Относительную вариабельность этих двух
измерений можно оценить путем сравнения коэффициентов вариации.
@ Проверяйте коэффициент вариации по формуле: КБ = (СО/среднее) х 100 %.
Отчет о данных, распределенных не по нормальному закону
Среднее значение и СО зачастую неправомерно используются в отчетах о данных,
независимо от того, близко ли их распределение к нормальному или нет, и особенно когда выборка
слишком мала, чтобы убедиться в нормальности распределения. Если о распределении
нельзя сказать, что оно мало отличается от нормального, то отчет о нем, как это будет описано
ниже, следует составлять при помощи иных статистик, нежели среднее значение и СО.
Отчет о данных следует составлять должным образом не только ради описания
распределения, но и с другими статистическими целями. Данные, распределение которых близко
к нормальному, можно анализировать с помощью так называемых параметрических ста-
Таблица 1,1
Сравнение изменчивости различных показателей с помощью коэффициента вариации^
и стандартного отклонения
Показатель Среднее значение (СО), мм Коэффициент вариации, %
1 90(15) 16,7^
^ 2 45(15) 33,3
3 33(13) 39,4
^ Коэффициент вариации — СО, выраженное в процентах от среднего значения.
^ Показатель с наименьшим коэффициентом вариации имеет наименьшую изменчивость.
' Отметим, что при этом наибольшая вариабельность присуща группам больных пациентов и в целом группам
воздействия (экспериментальным группам).
Числовые отчеты и описательные статистики 37
тистических критериев. Если же распределение сильно отличается от нормального, то его
нужно исследовать при помощи непараметрических статистических критериев.
Распределение, заметно отличающееся от нормального, можно в некоторых случаях «преобразовать»
в более близкое к нормальному и изучать его при помощи параметрических критериев (см.
указание 1.14у, Однако отличие распределения от нормального и способ преобразования
должны быть отражены в отчетах. Многие авторы некорректно используют
параметрические критерии при работе с данными, распределенными не по нормальному закону^.
1.12. Распределения, заметно отличающиеся от нормального (скошенные),
описывайте при помощи медианы и размаха (фактически — минимальным
и максимальным значениями) или интерквартильной широты
(фактически — значениями 25-го и 75-го процентилей).
Если распределение данных значительно отличается от нормального, то среднее
значение и СО, даже будучи математически корректными, не могут адекватно передать его
форму. Медиана (50-й процентиль) и интерквартильная широта (интервал значений между
25-м и 75-м процентилями распределения) дают более точное заключение о распределении,
поскольку они не подвержены влиянию экстремальных значений. Иногда используются
и другие интерпроцентильные широты, такие как с 10-го по 90-й.
С технической точки зрения размах представляет собой разность между максимальным
и минимальным значениями. Однако его нередко смешивают с самими этими значениями.
То же самое справедливо и для интерпроцентильной широты: она равна разности, скажем,
между значениями 75-го и 25-го перцентилей, но в отчетах порой фигурируют сами эти
значения.
ПРИМЕР
• Распределение веса имеет медиану 72 кг (25-й процентиль равен 60 кг; 75-й
процентиль — 87 кг).
• Значение медианы веса составило 72 кг (интерквартильная широта — от 60 до 87 кг).
• Через 8 недель вес (медиана и интерквартильная широта) был равен 72 кг (от 60
до 87 кг).
ОТЧЕТ О ПАРНЫХ ДАННЫХ
1Л 3* Совместное представление компонент парных наблюдений.
Парные, или спаренные, данные — это результаты эксперимента, взятые либо из
наблюдений за одним его участником (такие, как данные до и после испытания или данные
с левой и правой сторон от одного участника), либо от разных участников, спаренных по
некоторым показателям, для контроля влияния этих показателей на результат. Компоненты
' Однако при этом следует помнить о том, что в этом случае результаты применения параметрических
критериев будут относиться только (NB!) к преобразованным величинам. То есть если сравниваются средние
объемные скорости кровотока с размерностью [см7сек] у группы больных до лечения и у группы больных после
лечения, и при этом для преобразования к нормальному распределению использовано извлечение квадратного корня
из всех значений этой величины, получив в результате новую величину с размерностью [см'7сек"-], то результат,
полученный с помощью параметрического критерия, будет относиться только к этой новой переменной, а не к
исходной объемной скорости. При этом возникает и проблема интерпретации такой новой величины.
Действительно, каков физический смысл новой величины с размерностью [см^ 7сек'^]? Что это такое?
^ С примерами таких некорректностей читатели могут познакомиться в статье В. П. Леонова «Ошибки
статистического анализа биомедицинских данных» (Международный журнал медицинской практики. 2007. Вып. 2.
С. 19-35 //http://www.mediasphera.ru/journals/practik/).
38 Составление статистических отчетов в медицине
парных наблюдений должны быть представлены в отчете совместно, с тем чтобы сохранить
их взаимосвязь.
Изменения, показанные на рис. 21.27 и 21.28, были бы незаметны, если бы для данных
до и после эксперимента были представлены только групповые средние. Парные данные
можно показывать в таблицах, но при этом должны быть также показаны и представлены
для отчета разности и изменения в парах. Например, распределение разностей следует
описывать, скажем, с помощью медианы и интерквартильной широты.
ОТЧЕТ О ПРЕОБРАЗОВАННЫХ ДАННЫХ
1.14. Если распределение данных значительно отличается от нормального,
указывайте, преобразовывались ли они в распределение, близкое к
нормальному, и если да, то каким способом.
Иногда скошенное распределение можно математически преобразовать в близкое к
нормальному (рис. 1.4), что в дальнейшем делает возможным применение параметрических
критериев. Общепринятыми преобразованиями в медицинской науке являются
логарифмическое, извлечение квадратного корня, экспоненциальное и обратное.
1.15. Если данные были преобразованы, для отчета переведите единицы
измерения в исходные.
Преобразование данных влечет изменение их единицы измерений. Например, при
извлечении квадратного корня «килограмм» становится «квадратным корнем из килограмма»,
не имеющим реального смысла. Результаты анализа, следовательно, должны быть
преобразованы обратно, так чтобы их можно было использовать, т. е. чтобы они были снова
выражены в килограммах'.
СВОДКИ ДАННЫХ из МАЛЫХ ВЫБОРОК
1Лб. Если количество наблюдений невелико или если описательные статистики
вводят в заблуждение, бывает уместно привести все имеющиеся данные.
Описательные статистики полезны тем, что сводят большие количества данных к
нескольким итоговым показателям. Если нет необходимости уменьшать количество данных и как-
либо их подытоживать, нет необходимости и в использовании описательных статистик.
^ Стандартные описательные статистики (такие, как среднее и СО) могут дать
неадекватное итоговое представление малых множеств данных. При
определении, например, нормальности распределения доступных данных может оказаться
недостаточно. Средние значения и СО можно вычислить даже по двум исходным
значениям, но эти статистики мало что значат при таких условиях.
' при использовании таких преобразований важно помнить, что результат проверки статистической
гипотезы, полученный для преобразованных данных, нельзя автоматически переносить на непреобразованные данные.
К примеру, сравниваюся генеральные, популяционные средние для преобразованного артериального давления
в группах до и после лечения. Преобразование заключается в извлечении квадратного корня из давления,
выраженного в мм рт. ст. При использовании параметрического критерия получен достигнутый уровень
статистической значимости/7 = 0,012. При критическом значении уровня значимости/? = 0,05 следует вывод о различии
сравниваемых популяционных средних. Однако этот вывод нельзя автоматически перенести на исходные
величины давления, выраженные в мм рт. ст.
Числовые отчеты и описательные статистики 39
>-
S
40 -Ч
30 —\
U ОС
о S
I i
S S 20
" i
<u
5 10
s
03
с;
3
о Н
Ф о о о
о о о
9в
^ ^ ^ ^ \ г
0 12 3 4 5 6
Шкала и метки горизонтальной оси, или оси X
Единицы измерения
Рис. 1.4. Распределение, отличное от нормального распределения данных, до (незакрашенные круги) и
после (закрашенные круги) математического преобразования. По завершении анализа результаты следует
перевести в соответствие с их оригинальной шкалой, чтобы можно было использовать исходные единицы
измерения. (Показанное здесь преобразованное распределение — приближенное; преобразование не является
математически точным)
1.17. Не используйте проценты в отчетах о малых выборках.
Процентные соотношения, рассчитанные для малых выборок, могут потерять свой
смысл из-за малого числа возможных значений процентов. Например, для группы из семи
пациентов один пациент означает 14 %, два — 29 %, три — 43 % и т. д. Таким образом,
таблица неблагоприятных реакций может иметь лишь несколько входов в 14, 29 и 43 %, и это
не дает новой информации по сравнению с отчетом о том, что воздействию подверглись 1,
2 или 3 пациента.
Число 20 по ряду соображений берется в качестве рубежа между малыми и большими
выборками, но этот выбор произволен (см. указание 1.3).
Литература
1. Forrow L, Taylor WC, Arnold RM. Absolutely relative: how research results are summarized can
affect treatment decisions. Am J Med. 1992; 92:121-4.
2. Ehrenberg AS. The problem of numeracy. Am Statistician. 1981; 35:67-71.
3. Altman DG, Gore SM, Gardner MJ, Pocock SJ. Statistical guidelines for contributors to medical
journals. BMJ. 1983; 286:1489-93.
4. Haines SJ. Six statistical suggestions for surgeons. Neurosurgery. 1981; 9:414-8.
5. McGill R, Tukey JW, Larsen WA. Variation of box plots. Am Statistician. 1978; 32:12-6.
40 Составление статистических отчетов в медицине
6. Simpson RJ, Johnson ТА, Amara lA. The box-plot: an exploratory analysis graph for biomedical
publications. Am Heart J. 1988; 116:1663-5.
7. Griner PF, Mayewski RJ, Mushlin AI, Greenland P Selection and inteфretation of diagnostic tests
and procedures: principles and applications. Ann Intern Med. 1981; 94:553-600.
8. Evans M, Pollock AV. Trials on trial: a review of trials of antibiotic prophylaxis. Arch Surg. 1984;
119:109-3.
9. FeinsteinAR. X and ipr : an improved summary for scientific communication [Editorial]. J Chronic
Dis. 1987;40:283-8.
10. HallJC, Hill D, Watts JM. Misuse of statistical methods in the Australasian surgical literature. Aust
NZJSurg. 1982;52:541-3.
11. HallJC. The other side of statistical significance: a review of type II errors in the Australian medical
literature. Aust N Z Med. 1982; 12:7-9.
12. WulffHR, Andersen B, Brandenhoff P, Guttler F What do doctors know about statistics? Stat Med.
1987;6:3-10.
13. Sumner D. Lies, damned lies — or statistics? J Hypertens. 1992; 10:3-8.
14. Murray GD. Statistical guidelines for the British Journal of Surgery. Br J Surg. 1991; 78:782-4.
15. Journal of Hypertension. Statistical guidelines for the Journal of Hypertension. J Hyper. 1992;
10:6-8.
16. Brown GW. Statistics and the medical journal [Editorial]. Am J Dis Child. 1985;139:226-8.
17. Evans M. Presentation of manuscripts for publication in the British Journal of Surgery. Br J Surg.
1989;76:1311-4.
18. Gardner MJ. Understanding and presenting variation [Letter]. Lancet. 1975; 25:230-1.
19. Oliver D, HallJC. Usage of statistics in the surgical literature and the 'офЬап P' phenomenon. Aust
NZJSurg. 1989;59:449-51.
20. Gore SM, Jones IG, Rytter EC Misuse of statistical methods: critical assessment of articles in BMJ
from January to March 1976. BMJ. 1977; 1:85-7.
Отчет о показателях риска 41
Глава 2
Сравнение вероятностей событий
Отчет о показателях риска
Рациональное суэюдение о риске, даэюе если оно пояснено графически и
понятно, нельзя считать достаточным руководством к действию. Рационализм —
не единственный компонент принятия решений.
Н. Thorton[\]
Целью любого терапевтического вмешательства является повышение вероятности
улучшения состояния или уменьшение вероятности ущерба. Эти вероятности часто
указываются в виде отношений, частот или рисков, в которых вероятности событий,
происходящих в одной группе, обычно экспериментальной или прошедшей лечение, сравниваются
с вероятностью события, происходящего в контрольной группе, также проходящей другое
лечение или получавшей плацебо.
Существует несколько типов отношений, частот и рисков, причем каждый отличается
тем, что представлено в числителе и знаменателе. В некоторых типовых отношениях,
частотах и рисках числители и знаменатели определяются стандартно. Кроме того, большинство
из них связано с временным периодом и единицей той популяции, к которой применяются
сравнения (единичный множитель, такой как х 1000 человек).
Термины «отношение», «частота» и «риск» часто некорректно используются друг вместо
друга. Поэтому здесь мы даем их определения. Кроме того, мы даем определения наиболее
общеупотребительных отношений, частот и рисков, используемых в медицинской
литературе, и приводим рекомендации по отчету о показателях такого рода.
МАТЕМАТИЧЕСКИЕ ВЫРАЖЕНИЯ ВЕРОЯТНОСТИ
Отношение
Отношение, наиболее общий термин, может выглядеть как простое сопоставление,
из которого не обязательно следует наличие особых соотношений между числителем и
знаменателем [2]:
Отношение числа мальчиков к числу девочек составило 1:4.
(Читается так: Отношение — один к четырем.)
Указанное здесь соотношение означает, что на каждого мальчика приходится 4 девочки;
числитель и знаменатель математически друг с другом не связаны (одно не является
подмножеством другого). Отношение может также выражаться дробью, т. е. как деление
одного количества на другое; здесь соответствующая дробь — 1/4.
В отчетах о рисках отношения часто выражены как 1 шанс из 100,1000 или даже из
миллиона. Например, риск погибнуть в авиакатастрофе каждый год равен 1:250 000. Это означает.
42 Составление статистических отчетов в медицине
что каждый год 1 случай смерти из 250 000 происходит в авиакатастрофах [3]. Подобно этому,
риск умереть составляет 1 на миллион для каждых 6 минут путешествия на каноэ, каждых
300 миль автопутешествия или каждых 1000 миль полета на реактивном самолете [4].
Доля
Доля — особый тип отношения, в котором числитель является подмножеством
знаменателя [2], но вне зависимости от фактора времени. Доля всегда заключена в пределах от нуля
до единицы:
Доля выживших после данного заболевания составила 0,41 (53/129).
Здесь 53 выживших — это подмножество 129 пациентов с данной болезнью. В
соответствии с указаниями 1.2 и 1.3 убедитесь, что числители и знаменатели каждой доли можно
легко найти в вашем тексте.
Процент
Процент — это доля, записанная как часть целого (как часть от 100 %) [2]. Таким
образом, процент — это доля, умноженная на 100 %:
Из 129 инфицированных пациентов выэюил только 41 % (53).
(53/129 X 100 = 0,41 X 100 = 41 %)
Убедитесь, что числители и знаменатели всех процентных указаний легко находятся
в тексте {см. указание 1.2).
Процентиль
Процентиль, или процентильный ранг, — это категория, указывающая на положение
отдельного значения по отношению к остальным значениям распределения:
Ее величина риска соответствует 97-му процентилю по всем испытуемым.
Другими словами, ее величина риска выше, чем у 96 % всех испытуемых (т. е. она
находится в группе очень высокого риска).
Частота
Частота — особый тип отношения, в котором 1) отчетливо видна связь между числителем
и знаменателем и 2) данным в знаменателе присуща определенная связь с временем [2]:
Число новых случаев заболевания простудой составило 55 на 1000 студентов
в течение 3 месяцев осеннего семестра.
В выражении частоты числитель является подмножеством знаменателя: число
студентов, заболевших простудой за 3 месяца осеннего семестра, является числителем, а число
всех студентов, подверэюенных риску заболеть за 3 месяца осеннего семестра, даже если
они не заболели, является знаменателем. Временной интервал равен 3 месяцам, а
единицей отчетности является число простуд на каждые 1000 студентов. Например, если
870 из 15 975 студентов простудились в осеннем семестре, то частота простуд составляет:
870 простуд/15 975 студентов, рискующих простудиться, или 0,0545 простуд на студента,
или около 55 простуд на 1000 студентов в течение трех месяцев.
Отношение частот
Отношение частот — две частоты, записанные в виде отношения. Обычно отношение
частот сравнивает, скажем, частоту инфекционного заболевания в «группе риска» с часто-
Отчет о показателях риска 43
той в «не подверженной риску» популяции. Примерами являются отношения шансов,
отношения опасностей и отношения рисков:
Риск заболеть был в 5,3 раза больше у лиц, употреблявших рыбу, чему лиц,
не употреблявших ее.
В этом примере отношения рисков заболели 8 из 10 человек, съевших рыбу за обедом
(риск равен 8/10, или 0,8), в то время как из 20, не употреблявших рыбу, заболели только
3 (риск равен 3/20, или 0,15). Отношение частот равно риску заболеть для съевшего рыбу
по сравнению с тем, кто ее не ел: 0,8/0,15 = 5,3.
Отношение рисков называется также относительным риском. Так, отчет о результатах
в данном примере может выглядеть следующим образом: «Относительный риск заболеть
после употребления рыбы был равен 5,3». Это означает, что вероятность заболеть у людей,
употреблявших рыбу, в 5,3 раза выше, чем у тех, которые не употребляли ее.
Риск
Риск обычно определяется как вероятность неблагоприятного исхода, случающегося
в течение данного отрезка времени [5, 6]. Пожалуй, более строгое определение дано
Национальной академией наук США: риск — это «сочетание вероятности события, обычно
неблагоприятного, и природы и серьезности события». Однако термин «риск» может
относиться и к вероятности положительного исхода, и именно таким образом он часто
используется в медицинской литературе. Мы будем употреблять этот термин не в значении «риск»,
а в значении «вероятность» выживания.
ПОКАЗАТЕЛИ ДЛЯ ОТЧЕТОВ О РИСКАХ И ВЫГОДЕ
2.1. Указывайте точное значение показателя риска; не ограничивайтесь
описанием риска как малого, умеренного или высокого, если только эти термины
не определены с помощью показателя риска [7].
2.2. Уточняйте, какие именно показатели используются в отчете о вероятноаи
улучшения и о риске неблагоприятных событий (табл. 2.1 и 2.2).
23. Указывайте и, если необходимо, подробно описывайте группы,
представленные в числителе и знаменателе показателя.
2.4. Указывайте, за какой период представлен отчет о показателе, например
за день, за год или в течение курса лечения.
2.5. Указывайте единицу популяции (единичный множитель), к которому
применен показатель (например, на человека или на 100 000 человек).
2.6. Отчет о каждом показателе должен содержать соответствующий
доверительный интервал.
44 Составление статистических отчетов в медицине
Абсолютный риск
Абсолютный риск, или просто риск, — это вероятность события, которое может
произойти, т. е. вероятность воздействия при определенных условиях на состояние здоровья
индивидуума или популяции [8].
В статистике риск определяется как число людей с болезнью или инвалидностью,
выраженное посредством доли (часто в процентах) числа людей, у которых могла бы
развиться эта болезнь или инвалидность (табл. 2.1). Подверженная риску популяция — знамена-
Таблица 2.1
Расчет риска смертности от рака простаты для 400 мужчин, страдающих раком простаты
и прошедших лечение, подвергшихся резекции простаты либо находящихся в активном
выжидательном наблюдении в рандомизированном испытании
Показатель риска
Формула
Тактика активного
Резекция простаты - ,.^,,
inn^ /. Ллл. наблюдения (АН)
(РП) (п = 200)
(п = 200)
Число умерших от рака
простаты
Абсолютный риск (АР)
смерти от рака простаты
Естественная частота
Относительный риск (ОР)
смерти от рака простаты
при РП по сравнению с АН
Уменьшение абсолютного
риска (УАР) смерти от рака
простаты при условии РП
Уменьшение
относительного риска
(УОР) смерти от рака
простаты при условии РП
Шанс умереть от рака
простаты
Отношение шансов (ОШ)
смерти от рака простаты
с РП относительно АН
Число нуждающихся
в лечении (ЧПЛП): число
мужчин, подвергшихся РП
с целью предотвратить 1
дополнительный случай
смерти от рака простаты
Частота летальных
исходов (за 8 лет)
в клиническом
испытании
Число умерших / Число
подверженных риску
смерти
Число / Единица
популяции
Риск при РП / Риск при
АН
Риск при РП - Риск при
АН
Разница рисков / Риск
при АН
Число умерших / Число
выживших
Шансы при РП / Шансы
при АН
1 /Уменьшение
абсолютного риска
14
22
14/200 = 0,07 = 7 % 22/200 = 0,11 = 11 %
7/100 пациентов 11 /100 пациентов
(14/200)/(22/200) = 0,07/0,11 = 0,64^ = 64 %
Риск смерти от рака простаты при РП
составляет 64 % от риска смерти при АН
0,07-0,11 =-0,04 = -^%
Риск смерти от рака простаты был
на 4% меньше при РП, чем при АН
(11 % - 7 %)/11 % = 0,36 = 36 %
По сравнению с АН РП уменьшает риск
смерти от рака на 36 %
14/186 = 0,08
22/178 = 0,12
(14/186)/(22/178) = 0,075/0,162 = 0,66»
Шанс умереть от рака простаты при РП
составил 66 % от шанса умереть при АН
1,0/0,04 = 25 мужчин
25 мужчин должны быть подвергнуты
РП на каждый случай дополнительного
выживания при отсутствии процедуры
^ Отношение шансов умереть от рака простаты при РП по сравнению с АН (0,66) ближе к относительному риску
рака простаты (0,64), поскольку исход (в данном случае — смерть от рака простаты) не является всеобщим.
Отчет о показателях риска 45
тель отношения — должна включать всех, и только тех субъектов, у которых может быть
такое заболевание или инвалидность. К примеру, женщины, перенесшие удаление матки,
не должны включаться в популяцию женщин, подверженных риску заболеть раком матки.
Числитель отношения состоит из субъектов, страдающих этим заболеванием или
инвалидностью; в приведенном примере это женщины, страдающие раком матки.
^ ^ ^ Число женщин, страдающих раком матки
(Абсолютный) риск заболеть раком матки = tf
^ ^ ^ ^ Число женщин, у которых может
развиться рак матки
Число субъектов в знаменателе зависит также от установления географической области
и временного периода, причем и то и другое должно быть понятно читателю (см. гл. 12).
В обширных эпидемиологических исследованиях размер популяции, подверженной
риску, часто определяется для одного указанного года. Однако люди, у которых
идентифицирована болезнь в течение указанного года, могли заболеть ею годом ранее, но болезнь
была диагностирована годом позже; другие люди, как страдающие этой болезнью, так и не
страдающие, могли приехать в исследуемую географическую область или выехать из нее
[8]. Одно из решений этой проблемы заключается в оценке объема популяции в
среднестатистический год или в середине периода исследований.
Число женщин Калифорнии, страдающих ра-
(Абсолютный) риск заболеть раком матки _ ком матки в 2005 г
у женщин, живущих в Калифорнии в 2005 г. " Оценка числа женщин Калифорнии на 1 июля
2005 г., у которых может развиться рак матки
Разность абсолютных рисков
Разность абсолютных рисков, дополнительный риск, уменьшение абсолютного
риска, или просто разность рисков, — это разность между двумя абсолютными рисками. То
есть чтобы получить разность рисков, риск группы, не подверженной опасности,
вычитается из риска той группы, которая ему подвержена (см. табл. 2.1). Эта разность является
риском, который можно приписать подверженности опасности или вмешательству.
Относительный риск, или отношение рисков
Относительный риск, или отношение кумулятивных инциденсов, — это отношение
двух абсолютных рисков, т. е. отношение рисков. Отношения рисков связаны с
проспективными или когортными исследованиями, которые имеют два исхода (жизнь или смерть,
излечение или отсутствие излечения). Сравнение рисков в двух группах помогает судить
о риске в перспективе. Например, риск развития рака легких у курильщиков можно
сравнить с риском его развития у некурящих. Большая разница между этими двумя рисками
говорит в пользу связи между курением и раком легких.
Относительный риск — это показатель связи между характеристиками группы и
болезнью [9]. Он определяется следующим образом:
(Абсолютный) риск в исследуемой группе
(Относительный) риск =
(Абсолютный) риск в контрольной группе
46 Составление статистических отчетов в медицине
Таблица 2.2
Расчет показателей риска заболеваемости вследствие рака простаты для 400 мужчин,
страдающих раком простаты и прошедших лечение, либо подвергшихся радикальной
простатэктомии, либо находившихся в активном наблюдении в рандомизированном
испытании
Показатель риска
Радикальная
Формула простатэктомия (РП)
Гп = 200)
Тактика
активного
наблюдения
(АН) (п = 200)
Число мужчин с эректильной
дисфункцией
Уменьшение абсолютного риска Риск при РП -
(УАР) эректильной дисфункции Риск при АН
при АН по сравнению с РП
Относительный риск (ОР) эрек- АР при РП / АР
тильной дисфункции при АН
при РП по сравнению с АН
Отношение шансов (ОШ) эрек- Шансы при РП /
тильной дисфункции Шансы при АН
при РП по сравнению с АН
Число нуждающихся в лечении, 1 / Уменьшение
чтобы предотвратить потенци- абсолютного
альный вред (ЧПЛВ): число муж- риска
чин, подвергшихся ?Г\ на каждый
дополнительный случай
эректильной дисфункции
160
90
(160/200) - (90/200) = 0,80 - 0,45 = 0,35 = 35 %
Риск эректильной дисфункции был на 35 %
меньше при АН, чем при РП
(1 б0/200)/{90/200) = 0,80/0,45 = 1.8^
Риск эректильной дисфункции
был а ЬВ раза больше при РП, чем при АН.
(160/40)/(90/110) = 4/0,82 = 4,9'
Шанс эректильной дисфункции при РП
примерно в пять раз больше, чем при АН
1/0,35 ^ 3 мужчины
На каждых 3 мужчины, подвергавшихся
радикальной простатэктомии, 1 будет
страдать эректильной дисфункцией
' Отношение шансов эректильной дисфункции при РП (4,9) намного больше относительного риска (1,8),
поскольку неблагоприятный исход (в данном случае — эректильная дисфункция) был общим (> 10 %)
или
Частота новых случаев болезни в подверженной группе
Частота новых случаев болезни в неподверженной группе
или
Вероятность заболеть данной болезнью после доказанного воздействия
Вероятность заболеть данной болезнью без такого рода воздействия
или
Вероятность перенести неблагоприятное событие после приема лекарства
Вероятность перенести неблагоприятное событие без приема лекарства
Относительные риски могут варьироваться в пределах от нуля до бесконечности.
Значение относительного риска, равное 1, указывает на то, что риск для одной группы одинаков
Отчет о показателях риска 47
С риском для другой. Отношение рисков, меньшее 1, обычно указывает на защитный
эффект, тогда как отношения, большие 1, указывают на вредное воздействие. Например,
отношение рисков, равное 3, указывает на то, что число случаев заболевания в группе риска
будет в 3 раза более вероятным (а не «выше»), чем в неподверженной группе; таким
образом, заболеваемость в группе риска составляет 300 % от заболеваемости в не подверженной
риску группе (см. табл. 2.1).
Относительная разность рисков
Относительная разность рисков, или уменьшение относительного риска, или
приписываемая доля, — это разность между двумя абсолютными рисками, выраженная в
процентах от риска в контрольной группе (см. табл. 2.1). Например, если риск смерти равен 2 %
в группе, прошедшей лечение, и 13 % в нелеченной группе, то разница в 11 % составляет
84 % от 13 %, и уменьшение риска, которое может быть приписано лечению, равно, таким
образом, 84 % [(0,02 - 0,13)/0,13 = -0,84].
Аналогично, если риск инфекции в группе риска равен 35 %, а риск в неподверженной
группе равен 5 %, то относительный риск воздействия равен 6 [(0,35 - 0,05)/0,05 = 6]. Это
означает, что 30%-я разность абсолютных рисков по риску для подверженной ему группы
в 6 раз (600 %) выше риска в неподверженной группе.
ф Поскольку уменьшение относительного риска выражается в процентах, его
следует применять с осторожностью (см. указание 1.3): высокое уменьшение
относительного риска может скрывать малое значение абсолютного риска. Тот
факт, что уменьшение относительного риска часто превышает уменьшение
абсолютного риска, влияет на принятие решения относительно пациента [9].
Шансы
Шанс — не то же, что риск! В то время как риск — это вероятность события в
сравнении со всеми возможными исходами, шансы выражают вероятность того, что событие
произойдет, по сравнению с вероятностью того, что оно не произойдет. Например, риск
(вероятность) вытянуть одну из 13 карт червовой масти из полной колоды в 52 карты равен
13 из 52, или 1 к 4, или 25 %. Что же касается шансов, то они составляют 13 из 39, или 1 к 3,
или 33 %.
Отношение шансов
Отношение шансов — это частное от деления одного значения шансов на другое.
Отношения шансов обычно связаны с ретроспективными исследованиями или исследованиями
«случай-контроль» с бинарными исходами и логистическим регрессионным анализом;
однако отношения шансов могут оказаться полезными показателями связи как в
ретроспективных, так и в перспективных исследованиях [10].
Отношения шансов широко распространены в силу того, что они являются исходами
логистического регрессионного анализа. Для бинарных предикторных переменных
отношение шансов является дробью, в числителе которой находятся шансы появления события
в одной группе, а в знаменателе — шансы его появления в другой группе. Предположим,
что курение изучается с целью выяснить, является ли оно фактором риска возникновения
сердечных приступов. Оно может выражаться в виде бинарной предикторной переменной
как имеющее место (курильщики) или отсутствующее (некурящие). Переменная отклика.
48 Составление статистических отчетов в медицине
Т. е. сердечный приступ, может быть найдена из табличного отчета по выборке пациентов
с сердечным приступом в истории болезни или без него (для плана «случай-контроль»).
Сводка данных может выглядеть так:
Отношение
к курению
Курящие
Некурящие
Всего
Шанс пострадать от сердечного приступа у курящих равен 14/22 = 0,636, в то время как
для некурящих он составляет 5/33 = 0,152. Отношение шансов является частным этих
двух значений: 0,636/0,152 = 4,2. Это означает, что вероятность пострадать от сердечного
приступа у курящих в 4,2 раза выше, чем у некурящих.
Отношение шансов иногда называют кросс-произведением, поскольку его можно найти
путем перемножения значений в диагональных клетках с последующим делением:
14x33
Сердечный
приступ
14
5
19
Отсутствие
сердечного приступа
22
33
55
Всег
36
38
74
= 4,2
5x22
Отношение шансов, равное 1, означает, что сердечный приступ может произойти в обеих
группах с одинаковой вероятностью. Чем больше отношение шансов, тем вероятнее
появление события в группе, данные из которой используются в числителе. Отношения шансов,
меньшие единицы, обычно указывают на защитный эффект.
Так как отношение шансов, равное 1, означает равенство шансов в обеих группах,
лучше выразить отношение различий, используя такое утверждение: «Курильщики в 4,2 раза
более вероятно будут иметь сердечный приступ, нежели некурящие». Если бы курильщики
имели шанс на 4,2 выше иметь сердечный приступ, то читатели могли бы разумно
предположить, что итоговое отношение шансов равно 5,2, равное 4,2 плюс 1, что указывало бы
на тот же самый шанс.
Несмотря на трудности при интерпретации, отношения шансов полезны по двум
причинам. Во-первых, как отмечалось выше, они являются единицами исхода при логистическом
регрессионном анализе, который служит мощным средством статистики. Во-вторых, в
ретроспективных исследованиях отношения шансов найти можно, а отношения рисков — нет.
Это связано с тем, что истинное значение в знаменателе для отношения рисков — число
всех людей, подверженных риску заболеть данной болезнью на протяжении периода
исследования, — в ретроспективных исследованиях обычно неизвестно. В противоположность
этому, знаменатель для отношения шансов — число участвовавших в исследовании людей,
у которых событие не произошло, — известно.
Отношения шансов и отношения рисков (относительный риск) часто можно
интерпретировать одинаково. Например, в табл. 2.1 отношение шансов умереть от рака простаты при
лечении резекцией против активного выжидательного наблюдения (0,66) примерно такое же, как
и относительный риск смерти от рака простаты при лечении резекцией (0,64). Эти два
показателя подобны, поскольку исход (смерть от рака простаты) наступает сравнительно нечасто.
Отчет о показателях риска 49
Однако отношение шансов возникновения эректильной дисфункции после резекции
(4,9) намного больше относительного риска возникновения эректильной дисфункции после
резекции (1,8) вследствие того, что частота неблагоприятных исходов сравнительно
высока: 80 % в группе резекции и 45 % в группе активного наблюдения.
По общему правилу, если частота исхода превышает 10 %, отношение шансов будет
переоценивать относительный риск [11].
Отношения рисков
Уровень риска, или уровень плотности инциденса, — это оценка опасности
неблагоприятного события, происходящего в данный момент времени. Уровень риска, что
достаточно удивительно, — это отношение двух рисков. В терминах его интерпретации уровень
риска неотличим от отношения рисков или относительного риска. В обоих случаях
значение, скажем, 5,5 указывает на то, что лицо в группе А в 5,5 раза более вероятнее заболеет,
чем человек в группе В, во время данного периода. (Основания для такого
словоупотребления те же, что и для отношения шансов: отношение рисков или уровней рисков, равное 1,
означает равенство рисков в двух группах.)
Уровни рисков связаны с проспективными исследованиями времени до наступления
события с бинарными исходами и возникают как результат регрессионного анализа
пропорциональных рисков Кокса. Подробнее об этом см. гл. 9 о времени до наступления события
и о регрессионном анализе Кокса пропорционального риска.
Естественные частоты
«Естественная частота» — это число людей, подвергшихся некоторому воздействию,
на единицу популяции (см. табл. 2.1). При указании в числителе числа людей, а в
знаменателе общей единицы популяции интерпретировать и сравнивать естественные частоты
легче, нежели другие показатели риска [9, 12-14]. Gigerenzer [15] приводит поразительный
пример того, как естественные частоты могут передать риск лучше, чем более
распространенные вероятности:
Риск, выраженный вероятностью: «Вероятность того, что женщина 40 лет страдает
раком груди, — около 1 %. Если у нее есть рак груди, вероятность того, что маммограмма
покажет положительную реакцию, равна 90 %. Если рака груди у нее нет, вероятность того,
что реакция все же окажется положительной, равна 9 %. Чему равны шансы того, что у
женщины с положительной пробой действительно есть рак груди?»
Риск, выраженный естественной частотой: «Представим себе 100 женщин. У одной
из них рак груди, и проба на наличие рака, вероятно, окажется положительной (1 х 0,9 =
около 1). Из 99 женщин, не страдающих раком груди, у 9 также будет положительная реакция
(99 X 0,9 = около 9). Таким образом, всего будет 10 женщин с положительной реакцией.
Сколько из них в действительности страдает раком груди?» (1 из 10, или 10 %.)
Еще один пример с использованием естественных частот, где риск как улучшений, так
и ухудшений за 5 лет гормонозаместительной терапии легко виден из табл. 2.3 [16].
Показатели эффективности: число нуждающихся в лечении
Показатели эффективности выражают результаты через количество единиц ресурса,
необходимых для производства дополнительной единицы выхода [17, 18]. (Таким образом,
они выражаются посредством «естественных частот», как описано выше.) Такие показатели
50 Составление статистических отчетов в медицине
Таблица 2,3
Ожидаемая за 5 лет частота или «естественные частоты» улучшений и неблагоприятных
событий при гормонозаместительной терапии для женщин после менопаузы"*
Исходы Плацебо (n/l 000) ГЗТ (n/l 000) Разность (п/1000)
Улучшения: ГЗТ снижает частоту
Перелома костей 8 5-3
тазобедренного сустава
Колоректального рака 8 5 -3
Ухудшения: ГЗТ увеличивает частоту
Коронарного заболевания 15 19 +4
Инсульта 11 15 +4
Тромбообразования 8 18 +10
Рака груди 15 20 +5
^ По: Schwartz L, Woloshin S, Welch HG. Putting cancer In context. J Natl Cancer Inst. 2002; 94:799-804.
ГЗТ — гормонозаместительная терапия.
полезны тем, что выражают результат посредством единиц, применяемых в исследовании,
таких как число диагностических тестов, необходимых для выявления одного
дополнительного случая заболевания, или количество денег, требуемое для предотвращения одного
дополнительного случая злоупотребления лекарствами.
Показатели эффективности часто используются в оценках экономического характера,
но бывают также полезны и в отчетах о результатах во многих других видах исследований.
Однако эти показатели указывают частоту, а не полезность, и их численное значение
является функцией болезни, вмешательства или исхода (см. указание 18.22).
Два наиболее известных показателя эффективности в медицине — это число пациентов,
которых надо лечить, чтобы предотвратить один неблагоприятный исход (ЧПЛП [the
Number Needed to Treat — NNT]), и число пациентов, подвергаемых лечению, на один вредный
исход (ЧПЛВ [the Number Needed to Harm — NNH]). ЧПЛП выражает результат в единицах
числа пациентов, которым, вероятно, понадобится лечение с целью избавить от одного
добавочного случая заболевания или предотвратить его при исследуемом состоянии. Подобно
этому ЧПЛВ выражает результат в единицах числа пациентов, которым, вероятно,
понадобится лечение при каждой дополнительной неблагоприятной реакции или нежелательном
побочном эффекте в связи с вмешательством. Другие показатели включают число доз
лекарства, которое следует назначить ради добавочного эффекта, число предписаний,
которые должны быть даны с целью получения добавочного эффекта, и т. д.
ЧПЛП или ЧПЛВ дают больше информации, чем относительный риск, поскольку
принимают во внимание базовую частоту исходов. Их также можно рассчитать по величинам
уменьшения относительного риска и отношению шансов, равно как и из исходных
табличных данных по простой формуле (см. табл. 2.1).
Показатели эффективности имеют несколько недостатков. Они допускают, что лечение
может иметь одинаковое уменьшение относительного риска, независимо от того, каким
был начальный уровень риска — низким, средним или высоким. Это допущение не всегда
может быть верным, например при трудноизлечимом заболевании на тяжелой стадии или
Отчет о показателях риска 51
когда исходная вероятность интересующих исходов болезни сильно различается в разных
исследованиях [19].
Показатели эффективности всегда основываются на определенном периоде времени.
Так, нельзя сравнивать ЧПЛП, которые страдают одним и тем же заболеванием, но которых
лечили разными способами: путем введения одной инъекции и путем ежедневного приема
препарата на протяжении нескольких недель. Также не следует сравнивать показатели
эффективности для разных болезней, а именно когда различаются исходы болезни. По
очевидным причинам показатель ЧПЛП для предупреждения 1 летального исхода нельзя
сравнивать, например, с ЧПЛП для предупреждения 1 случая тошноты. ЧПЛП или ЧПЛВ можно
сравнивать в разных исследованиях только в том случае, когда отмечаются одинаковые
исходы заболевания в течение одного и того же промежутка времени. Даже разные показатели
начального уровня риска в исследованиях могут затруднить сравнение ЧПЛП.
@ Показатели эффективности следует сравнивать лишь тогда, когда 1) начальный
уровень риска в изучаемых группах одинаков; 2) одинаковы временные
промежутки и 3) одинаковы предполагаемые конечные результаты исследования.
ФАКТОРЫ, ВЛИЯЮЩИЕ НА ВОСПРИЯТИЕ РИСКА
Количественное описание риска — это одна проблема; интерпретация его — совершенно
другая проблема. Математически риск — это просто частота. С точки зрения же
психологии риск — гораздо более сложное явление: он имеет элементы неопределенности, страха,
а также личных, социальных и экономических потерь. Таким образом, выбор показателя
риска для отчета и то, как описаны риск и его последствия, могут сильно повлиять на то,
как будет восприниматься этот риск.
Восприятие показателя риска
Рассмотрим человека, у которого недавно диагностирован рак простаты. О его рисках
смертности (в данном примере — за 8 лет) и заболеваемости (за 1 год) раком простаты и его
лечении (здесь — резекция простаты или активное выжидательное наблюдение) можно
сообщать несколькими способами, вполне корректными, но выражающими разные степени
риска. Сводка показателей риска для смертности и заболеваемости при раке простаты,
леченном резекцией простаты или при выжидательном наблюдении (найденных в табл. 2.1
и 2.2), приведена ниже.
Риск смерти
• Риск смерти от рака составляет 11 % при активном выжидательном наблюдении,
но лишь 7 % при резекции простаты (абсолютный риск).
• Резекция простаты уменьшает абсолютный риск смерти от рака на 4 % (уменьшение
абсолютного риска).
• Риск смерти от рака после резекции составляет 64 % от риска при активном
выжидательном наблюдении; т. е. относительный риск смерти после резекции на 36 %
меньше, чем риск при активном выжидательном наблюдении (относительный риск).
• Резекция простаты дает снижение относительного риска смерти от рака на 36 %
(уменьшение относительного риска).
• Шанс умереть от рака (по сравнению с шансом выжить) равен 0,12 при активном
наблюдении, но лишь 0,08 при резекции простаты (шанс).
52 Составление статистических отчетов в медицине
• Отношение шансов умереть от рака при резекции к шансам умереть при активном
наблюдении равно 0,66 (отношение шансов).
• Из каждых 100 пациентов с раком простаты, получавших лечение при активном
наблюдении, умрут 11; из каждых 100, леченных резекцией, умрут только 7
(естественная частота).
• Около 25 мужчин будут нуждаться в резекции простаты на каждый случай
предотвращенной смерти от рака (ЧПЛП).
Риск эректильной дисфункции
• Риск эректильной дисфункции равен 80 % при резекции простаты, но лишь 45 % при
активном выжидательном наблюдении (абсолютный риск).
• Риск эректильной дисфункции при резекции простаты в 1,8 раза превышает риск при
активном выжидательном наблюдении (отношение рисков).
• Шанс эректильной дисфункции при резекции почти в 5 раз больше, чем при активном
выжидательном наблюдении (шанс).
• Из каждых 3 мужчин, подвергшихся резекции, 1 будет испытывать эректильную
дисфункцию (ЧПЛВ).
2 J. Всегда указывайте в отчете хотя бы значения абсолютного риска
улучшения и риска неблагоприятных событий для каждой группы, проходящей
лечение [7,9].
Абсолютный риск события — частота, с которой оно происходит в группе, — является
самой главной мерой риска. Его интерпретация выглядит особенно ясно в сравнении с
отношениями шансов и уменьшениями относительного риска. Кроме того, зная абсолютный риск
для каждой группы, читатели смогут рассчитать другие показатели риска (см. табл. 2.1).
Выгоды, указанные в отчете как уменьшения относительного риска, часто выглядят
более привлекательно, чем те же выгоды, указанные как уменьшения абсолютного риска [7,
20, 21]. Такое предпочтение, несомненно, возникает из-за того, что уменьшение
относительного риска оказывается больше, чем уменьшение абсолютного риска. В
вышеприведенном примере 36%-е уменьшение относительного риска смерти от рака при резекции
выглядит гораздо более впечатляюще, чем 4%-е уменьшение абсолютного риска, несмотря
на то что оба числа получены из одних и тех же данных.
Информация об уменьшении относительного риска должна, однако, сопровождаться
информацией об абсолютном риске, если при этом требуется точная интерпретация. Нам
будет приятнее узнать о 25%-м уменьшении риска, если эти 25 % представляют
изменение заболеваемости, скажем, с 90 до 67,5 %, нежели при уменьшении заболеваемости с 9
до 6,8 %.
^ Остерегайтесь отчетов, в которых улучшения указаны как относительные
риски, а неблагоприятные события — как абсолютные риски [7]. Относительные
риски создают впечатление большего улучшения (см. выше), а абсолютные риски
обманчиво уменьшают частоту неблагоприятных событий.
К примеру, предположим, что риск сердечного расстройства составил 11,4 % в
контрольной группе и 9,3 % в группе, получающей антитромболитический препарат. Кроме того,
риск угрожающего жизни кровотечения составил 2,2 % в группе, проходящей лечение,
но лишь 1,8 % в контрольной группе. Препарат можно описать как дающий 18%-е умень-
Отчет о показателях риска 53
шение относительного риска сердечных расстройств [(11,4 - 9,3)/11,4 = 18,4 %] и при этом
как увеличивающий (абсолютный) риск угрожающего жизни кровотечения только на 0,4 %
(2,2%-1,8% = 0,4%).
Однако если презентация составлена по-другому, то это же лекарство можно описать
как уменьшающее риск сердечных расстройств только на 2,1 % (11,4 % - 9,3 % = 2,1 %,
уменьшение абсолютного риска) и как увеличивающее относительный риск угрожающего
жизни кровотечения на 8,5 %> [(10,6 - 9,7)/10,6 = 8,5 %]. Таким образом, риск этого вредного
события оказывается в 4 раза больше вероятности благоприятного исхода!
2.8. Сопровождайте доверительными интервалами показатели эффективности
по улучшениям и по неблагоприятным событиям.
Показатели эффективности (особенно число нуждающихся в лечении и число
нуждающихся в приеме лекарства) рекомендуются для практического применения в доказательной
медицине в силу того, что они показывают соотношение между начальными и итоговыми
клиническими результатами. Однако они являются оценками и поэтому должны
сопровождаться показателем точности — 95% ДИ.
2.9. Рассматривайте благоприятные и неблагоприятные события как
естественные частоты.
Естественные частоты, пожалуй, самые легкие для понимания из всех показателей
риска; за ними идут показатели эффективности. Шансы и отношения шансов концептуально
трудны для понимания, а относительный риск может исказить интерпретацию риска, так
как указывается в процентах. Легко также найти и осмыслить разности между
естественными частотами, что должно помочь в принятии решений (см. табл. 2.3).
ВОСПРИЯТИЕ ОПИСАНИЯ РИСКА
2.10. Корректно описывайте разность рисков или их изменения.
При описании разностей или изменений рисков не забывайте о том, что «рост на столько-
то» не то же самое, что «рост до стольких-то». Увеличение риска, скажем, на 30 %,
должно прибавляться к начальному значению риска; следовательно, пишем: «риск увеличился
на 30 %, с 10 до 40 %». Если же итоговая оценка риска составила 30 %, то «риск вырос
до 30 с 10 %». Кроме того, «ниже, чем» и «выше, чем» относятся к разностям между
группами, а не к кратно превосходящим значениям. 25%-й риск не означает 5-й уровень по
отношению к 5%-му риску, он просто в 5 раз больше 5%-го риска.
Предположим, что риск заболеть раком легких при воздействии асбеста равен 10 % (0,10)
и что частота новых случаев заболевания без такого воздействия составляет 2 % (0,02). Все
нижеследующие утверждения построены правильно:
• «Риск заболеть раком легких в подвергшейся воздействию группе на 8 % выше, чем
в не подвергшейся». 8 % — это разность абсолютных рисков.
• «Риск заболеть раком легких в не подвергшейся воздействию группе на 8 % ниже, чем
в подвергшейся». 8 % — это снова разность абсолютных рисков.
• «Риск заболеть раком легких в подвергшейся воздействию группе в пять раз
больше, чем в не подвергшейся». 10 % в пять раз больше, чем 2 %. (Обратите внимание:
не выше в 5 раз, а больше; см. ниже.)
54 Составление статистических отчетов в медицине
• «Риск заболеть раком легких в не подвергшейся воздействию группе составляет одну
пятую риска в подвергшейся». 2 % — это одна пятая от 10 %.
• «Риск заболеть раком легких в не подвергшейся воздействию группе составляет 20 %
от риска в подвергшейся». 2 % — это 20 % от 10 %.
• «Отсутствие воздействия асбеста может уменьшить частоту рака легких с 10 до 2 %».
• «Отсутствие воздействия асбеста может уменьшить частоту рака легких на 80 %».
80%-я разность — это относительная разность между 10 и 2 %.
В том же самом примере следующие утверждения сформулированы неправильно:
• «Риск заболеть раком легких в подвергшейся воздействию группе в 5 раз выше, чем
в не подвергшейся». На самом деле он выше только в 4 раза: 8%-я разность больше,
чем 2%-я, в 4 раза, а не в 5. (Однако риск заболеть раком легких в подвергшейся
воздействию группе действительно в 5 раз больше, чем в не подвергшейся. Утверждение
становится некорректным из-за словосочетания «выше, чем».)
• «Риск заболеть раком легких в не подвергшейся воздействию группе в 5 раз ниже,
чем в подвергшейся». Риск в подвергшейся воздействию группе равен 10 %, но что
означает «в 5 раз ниже, чем 10 %»? (Тем не менее риск заболеть раком легких в не
подвергшейся воздействию группе действительно составляет одну пятую от
риска в подвергшейся. Утверждение становится некорректным из-за словосочетания
«ниже, чем».)
2.11. Помещайте риск в такой контека, где он сравнивается с другими
известными и малоизвестными рисками [22].
Указание одного показателя риска в отрыве от остальных может привести к
недоразумениям, зато сравнение его с другими рисками может помочь увидеть перспективу. Наиболее
известным примером, по-видимому, является тот, в котором кажущийся высоким риск,
связанный с полетами, сравнивается с кажущимся низким риском езды на автомобиле. На
самом же деле полеты на самолетах — самый безопасный вид путешествий после полетов
в космос и путешествий на поездах, если его оценивать по количеству смертей на одну
милю пути; это гораздо безопаснее, чем путешествие на автомобиле. В другом примере
число людей, укушенных крысами в Нью-Йорке в 1985 г., — 311 — контрастирует с числом
ньюйоркцев, укушенных другими ньюйоркцами за тот же год — 1519.
О рисках, связанных с лечебными процедурами, один врач говорил своим пациентам так:
«Знаете, когда вы подвергаетесь наибольшему риску? Когда едете в клинику» [23].
2.12. Проследите, каким образом описание риска сможет повлиять на его
интерпретацию.
«Объективного» способа описания риска не существует. По этой причине, к сожалению,
читательским восприятием риска можно манипулировать путем того, каким образом
описан этот риск [24-27]. Такого рода манипуляцией может быть неуловимая подмена одного
показателя риска другим, как показано выше, или намеренное преувеличение последствий
одной из альтернатив с умолчанием о последствиях другой. Таким образом, вопрос о
преподнесении риска относится к области этики. Наряду с настоятельной рекомендацией
описывать риск с как можно большей сбалансированностью, например с указанием двух и
более показателей или с привлечением позитивных и негативных наглядных представлений.
Отчет о показателях риска 55
МЫ можем лишь напомнить авторам о том, что описание риска может повлиять на то, как
его воспримут их читатели.
Восприятие людьми величины риска определяется факторами, отличными от числовых
данных [28]:
• Риски, кажущиеся добровольными, более приемлемы, чем воспринимаемые как
навязанные.
• Риски, воспринимаемые как находящиеся под собственным контролем, более
приемлемы, нежели кажущиеся контролируемыми другими.
• Риски, воспринимаемые как приносящие выгоду, более приемлемы, нежели
приносящие мало пользы или не приносящие ее совсем.
• Риски, воспринимаемые как справедливо распределенные, более приемлемы по
сравнению с распределенными несправедливо.
• Риски, которые кажутся созданными природой, более приемлемы по сравнению с
созданными человеком.
• Риски, воспринимаемые как статистические, более приемлемы, нежели кажущиеся
катастрофичными.
• Риски, воспринимаемые как происходящие из заслуживающего доверия источника,
более приемлемы, чем происходящие из не заслуживающего его.
• Риски, которые кажутся знакомыми, более приемлемы, нежели кажущиеся
необычными.
• Риски, которым подвержены взрослые, более приемлемы, чем те, которым
подвержены дети.
«Наглядные представления» — термин, который относится к выбору опорных пункто'
относительно которых преподносится результат. Разные наглядные представления могу i
повлечь разные интерпретации в зависимости от того, с чем сравнивается результат [7].
Например, сжатие рамок наглядных представлений по времени может вызвать преувеличение
риска через внушение чувства близкой опасности. Сравните фразу «Каждый год от рака
простаты умирает около 31 000 человек» с фразой «Каждую неделю от рака простаты
умирает около 600 человек» или «Каждые 17 минут от рака простаты умирает один человек».
В другом примере у пациентов складываются разные суждения относительно некой
процедуры в зависимости от того, имеет ли она, согласно описаниям, 68%-ю частоту успеха
(позитивные наглядные представления) или 32%-ю частоту неудач (смертность в течение
года, негативные наглядные представления) [24]. Подобно этому, у людей, которым была
продемонстрирована кривая смертности, складывается менее благоприятное мнение о
превентивной хирургии, нежели у тех, кому были показаны кривые выживания [25].
Широкое обсуждение того, каким образом способы представления информации могут
влиять на осмысление текста читателями, выходит за рамки этой книги. Мы лишь хотели
привлечь внимание к этим важным и часто остающимся в стороне проблемам. Прекрасный
обзор по данной теме имеется в книгах «Суэюдения в условиях неопределенности:
эвристика и пристрастия» [26] и «Психология вынесения суэюдений и принятия решений» [27].
Благодарности
Благодарим Jessica Ancker, МРН, за тщательное рецензирование и вдумчивые
комментарии к этой главе.
56 Составление статистических отчетов в медицине
Литература
1. Thorton Н. Patients' understanding of risk [Editorial]. BMJ. 2003; 327:693-4.
2. Hennekens CH, BuringJE. Epidemiology in Medicine. Boston: Little, Brown; 1987.
3. Lauden L The Book of Risks: Fascinating Facts about the Chances We Take Every Day. New York:
John Wiley; 1994.
4. Siegel JA, Sparks RB. The Biologic Effects of Radiation and Their Associated Risks. http://www.
internaldosimetry.coni/courses/laymans/linkedpages/compare.html. Accessed 11/8/03.
5. Last J. A Dictionary of Epidemiology, 2nd ed. New York: Oxford University Press; 1988.
6. Riegelman RK, Hirsch RR Studying a Study and Testing a Test, 2nd ed. Boston: Little, Brown;
1989.
7. Gigerenzer G, Edwards A. Simple tools for understanding risks: from innumeracy to insight. BMJ.
2003;327:741-4.
8. Timmreck TC. An Introduction to Epidemiology, 2nd ed. Boston: Jones and Bartlett; 1998.
9. Wills CE, Holmes-Rovner M. Patient comprehension of information for shared treatement decision
making: state of the art and future directions. Pat Ed Counsel. 2003; 50:285-90.
10. Gordis L. Epidemiology. Philadelphia: WB Saunders; 1996.
11. Rothman KJ. Epidemiology: An Introduction. New York: Oxford University Press, Inc., 2002.
12. Rothman AJ, Kiviniemi MT. Treating people with information: an analysis and review of approaches
to communicating health risk information. J Natl Cancer Inst Monogr. 1999; 25:44-51.
13. Gigerenzer G, Todd PM, ABC Research Group. Simple Heuristics That Make Us Smart. New York:
Oxford University Press; 1999.
14. Gigerenzer G. Adaptive Thinking: Rationality in the Real World. New York: Oxford University
Press; 2000.
15. Gigerenzer G. Calculated Risks: How to Know When Numbers Deceive You. New York: Simon and
Schuster; 2002.
16. Schwartz L, Woloshin S, Welch HG Putting cancer in context. J Natl Cancer Inst. 2002; 94:799-804.
17. Laupacis A, Naylor CD, Sackett DL. An assessment of clinically useful measures of the
consequences of treatment. N Engl J Med. 1988; 318; 1728-33.
18. Laupacis A, Naylor CD, Sackett DL. How should the results of clinical trials be presented to
clinicians? [Editorial]. ACP Journal Club. 1992; May/June:A-12^.
19. Cook RJ, Sackett DL. The number needed to treat: a clinically useful measure of treatment effect.
BMJ. 1995; 310:452^.
20. Malenka DJ, Baron JA, Johansen SJW, Ross JM. The framing effect of relative and absolute risk.
J Gen Intern Med. 1993; 8:543-8.
21. Них JE, Naylor DC. Communicating the benefits of chronic preventive therapy: does the format of
efficacy data determine patients' acceptance of treatment? Med Decis Making. 1995; 15:152-7.
22. Wurman RS. Information Anxiety: What to Do When Information Doesn't Tell You What You Need
to Know. New York: Bantam Books; 1990.
23. Edwards A. Communicating risks through analogies [Letter]. BMJ. 2003; 327:749.
24. McNeil PJ, Pauker SG, Sox HC, TverskyA. On the elicitation of preferences for alternative therapies.
N Engl J Med. 1982; 306:1259-62.
25. Armstrong K, Schwarts JS, Fitzgerald G, et al. Effect of framing as gain versus loss on understanding
and hypothetical treatment choices: survival and mortality curves. Med Decis Making 2002; 2:76-83.
26. Kahneman D, Slovic P, Tversky A eds. Judgment under Uncertainty: Heuristics and Biases.
Cambridge: Cambridge University Press; 1982.
27. Pious S. The Psychology of Judgment and Decision Making. New York: McGraw-Hill; 1993.
28. FischhoffB, Lichtenstein S, Slovic P, KeeneyD. Acceptable Risk. Cambridge: Cambridge University
Press; 1981.
Отчеты об оценках и доверительных интервалах 57
Глава 3
От свойств выборки к свойствам
популяции
Отчеты об оценках и доверительных интервалах
Преимущество доверительных интервалов над критериями значимости
состоит в том, что доверительные интервалы поднимают уровень
интерпретации с качественных суэюдений о роли случая как первых (а иногда
единственных) объяснительных шагов до количественной оценки выявленных
биологических эффектов.
К. J. Rothman{\]
Большинство медико-биологических исследований основано на следующей
предпосылке: все, что верно для (репрезентативной) выборки из некоторой популяции, будет более или
менее истинным для всей той популяции, из которой была взята выборка. Таким образом,
измерение характеристик выборки используется для оценки тех же характеристик
соответствующей популяции. Точность этих оценок зависит от степени изменчивости, связанной
с техникой измерения (ошибки измерения), от объема выборки и ее репрезентативности
(ошибка выборки), а также от изменчивости, присущей всем биологическим
характеристикам (случайная ошибка). Степень изменчивости, связанной с оценкой, может выражаться
при помощи доверительного интервала.
Доверительный интервал — это согласующийся с данными диапазон значений,
который, как предполагается, заключает в себе действительное или «истинное» популяционное
значение. Это «истинное» популяционное значение обычно неизвестно, но оно существует
и может быть оценено по грамотно взятой выборке. Доверительные интервалы, окружая
оценку популяционного значения, дают информацию о том, насколько хороша или точна
эта оценка. Чем шире доверительный интервал, тем ниже точность оценки; более узкие
интервалы указывают на более высокую точность.
Если доверительный интервал сопровождает оценку значения популяционной
характеристики, как описано выше, он может служить описательным целям. Однако еще более
полезны доверительные интервалы тогда, когда они сопровождают заключения, например,
об оценках различий между группами или об оценках изменений, произошедших в одной
и той же группе с течением времени. Такие заключения часто связаны с проверкой гипотез
и /7-значениями. При таком дедуктивном использовании доверительные интервалы
добавляют полезную информацию к/?-значениям и помогают интерпретировать результаты.
Как будет описано ниже, 95% ДИ соответствует уровню статистической значимости 0,05.
Это означает, что сам интервал можно использовать для указания того, является ли, скажем,
оценка изменения статистически значимой на уровне 0,05. Ширина интервала показывает
еще точность оценки изменения, а точность, в свою очередь, соответствует объему выборки
(наряду с другими факторами).
58 Составление статистических отчетов в медицине
Наконец, р-значение часто интерпретируется либо как статистически значимое
(«положительный» результат), либо незначимое («отрицательный» результат). Доверительный же
интервал предоставляет диапазон значений, в котором, как предполагается, находится
«истинное» изменение, и позволяет читателям интерпретировать смысл изменений на каждом
конце этого диапазона. Например, если один конец диапазона включает клинически важное
значение, а другой — нет (гетерогенный доверительный интервал), то результаты могут
рассматриваться как не позволяющие сделать вывод, а не просто «положительные» или
«отрицательные». Если все значения интервала клинически значимы или клинически
незначимы, т. е. если доверительный интервал гомогенный, результаты более определенные.
Кроме того,р-значения безразмерны, а доверительные интервалы представлены в единицах
переменной отклика, что помогает читателям в интерпретации результатов. По этим
причинам доверительные интервалы следует обычно предпочитать/7-значениям.
ДОВЕРИТЕЛЬНЫЕ ИНТЕРВАЛЫ С ДЕДУКТИВНЫМИ ФУНКЦИЯМИ
Образец презентации
Сравнение средних температур в экспериментальной (п = 15) и контрольной группах (п = 15)
выявило статистически значимое повышение средней температуры (СО) в
экспериментальной труппе по сравнению с контрольной: 56 X (ЭХ) против 33 ''С (5 **С). Разность средних
значений в группах составила 23 X (95% ДИ 19,9~26Л °С).
Здесь: ■
• п-—объем выборки, заданный для каждой группы.
• Распределения температуры в каждой группе описыва ются средними значениями и СО.
Использование СО говорит о том, что данные распределены по нормальному закону.
• 23 °С — это действительная наблюдаемая разность между средними значениями в
экспериментальной и контрольной группах. Разность между получавшей и не получавшей
лечение группами, которые составляют выборку, является 01(внко1/ ожидаемой разности
между группами в исследуемой популяции. Будучи единственным значением, эта оценка
называется точечной.
• 95% ДИ — это 95%-й доверительный интертал вокруг точечной оценки. 95 % — это
показатель доверия (доверительная вероятность). Доверительный интервал
является мерой точности точечной оценки. Предполагается, что «истинное» значение разности
между средними значениями в экспериментальной и контрольной группах попадаете этот
интервал в 95 из 100 подобных испытаний.
3Л. Представьте доверительные интервалы для всех основных сравнений,
независимо от того, были ли результаты сравнения позитивными (статистически
значимыми) или негативными (статистически незначимыми)\
Результаты основных сравнений следует указывать всегда, значимы они статистически
или нет. Настоящая наука зависит от точных ответов на правильно поставленные вопросы,
' в данном контексте понятие «положительный» и «отрицательный» результат сравнения является
относительным, а не абсолютным. «Направление» результата зависит от того, как сформулированы гипотезы
сравнения. Один и тот же результат сравнения можно считать как положительным, так и отрицательным, в зависимости
от того, какое соотношение сравниваемых значений является, с точки зрения исследователя, желательным или
неблагоприятным.
Отчеты об оценках и доверительных интервалах 59
а не только от статистически значимых результатов. Кроме того, результаты любого
исследования, привлекающего выборку (в отличие от переписи, где доступны данные обо всех
объектах популяции), являются оценками; они не являются «правдивыми» в абсолютном
смысле слова. Поскольку оценка основывается только на одной из возможных выборок, она
всегда будет варьироваться от выборки к выборке. Эта изменчивость находит отражение
в точности оценки и может выразиться в виде доверительного интервала. Таким образом,
доверительные интервалы, заключающие в себе популяционные оценки, придают смысл
тому, насколько хороша или точна оценка. Более широкие доверительные интервалы
указывают на меньшую точность, а более узкие — на большую.
В медицине наиболее употребительна доверительная вероятность 95 %.
(Доверительный интервал — это диапазон значений, найденный при использовании выбранной
доверительной вероятности.) Но можно использовать любую доверительную вероятность':
например, для оценок, основанных на малых выборках, иногда применяется 90 %.
Рассмотрим в качестве примера группу пациентов, у которых снизилось диастолическое
кровяное давление после 6 месяцев приема лекарства. Этот результат представлен ниже
в разных вариантах, в порядке возрастания предпочтения:
• Эффект от приема лекарства был статистически значимым. Такое представление
не отражает величину эффекта и не показывает, является ли он клинически
значимым и насколько он значим статистически. Некоторые читатели могут подумать, что
«статистическая значимость» означает одобрение этого препарата по результатам
исследования.
• Эффект от приема лекарства, сниэюающего диастолическое кровяное давление, был
статистически значимым (р < 0,05). Такое представление включает в себя
направление изменения (препарат снижает кровяное давление) и тот факт, что /7-значение
находится ниже критического уровня значимости, который устанавливается
исследователем заранее и определяет порог статистической значимости. Таким образом,
значение/? очевидно меньше 0,05, но мы не знаем, насколько меньше. Значение 0,049
технически статистически значимо, но оно настолько близко к 0,05, что его можно,
пожалуй, интерпретировать так же, как и значение 0,051: свидетельство против нулевой
гипотезы минимально, погранично. Кроме того, по-прежнему нет указания на
клиническую эффективность препарата^
• Среднее диастолическое кровяное давление в получавшей лечение группе снизилось
со 100 до 92 ммрт. ст. (р = 0,02). Такое представление, пожалуй, наиболее типично.
Даны значения до и после эксперимента, но разность предстоит вычислять самим
читателям. Кроме того, поскольку оцениваемый эффект — уменьшение на 8 мм рт. ст. —
не сопровождается показателем точности, читатель должен догадываться о том, сколь
вариабельно уменьшение давления в свете объема выборки. Если бы
экспериментальная группа состояла из 5 пациентов, то следовало бы ожидать заметного варьирования
уменьшения в последующих подобных испытаниях, тогда как если бы она состояла
' Разумеется, ее величина должна быть ближе к 1, а не к 0. К сожалению, в статьях и утвержденных ВАК РФ
докторских диссертациях по медицине и биологии можно встретить «доверительную вероятность», равную 0,05.
- Весьма важный акцент описания результатов статистического анализа. К большому сожалению, сложившийся
менталитет авторов большинства отечественных журналов биомедицинской тематики игнорирует это требование.
В результате читатель лишается крайне важной информации о степени надежности декларируемых автором
публикации выводов. Устойчивому воспроизведению этого дефекта научных публикаций во многом способствует
непонимание важности этого требования редакторами отечественных журналов и, как следствие, отсутствие в
редакционных требованиях упоминаний о формате представления результатов статистического анализа.
60 Составление статистических отчетов в медицине
ИЗ 500 человек, ожидаемая изменчивость была бы меньшей. Доверительный интервал
дал бы этой изменчивости количественную характеристику и принял бы во внимание
объем выборки.
• Препарат снизил диастолическое кровяное давление в среднем на 8 мм рт. ст., со
100 до 92 мм рт. ст. (95% ДИ 2-14 мм рт. ст.) Здесь нам представлена средняя
величина наблюдаемого эффекта (уменьшение в среднем на 8 мм рт. ст.), равно как и до-
и послеэкспериментальные средние значения, из которых она и была рассчитана. Нам
также представлен диапазон значений, который, как предполагается, заключает в себе
истинное среднее значение уменьшения кровяного давления — диапазон, который мы
можем принять с 95%-й вероятностью. Это означает, что если бы препарат испыты-
вался в 100 выборках, подобных той, которая указана в отчете, то среднее значение
уменьшения кровяного давления в 95 из них было бы, вероятно, заключено в пределах
от 2 до 14 мм рт. ст.
Указание в отчете доверительного интервала позволяет читателям судить о
клиническом значении эффекта. Уменьшение диастолического кровяного давления всего лишь
на 2 мм рт. ст. едва ли будет клинически значимым, тогда как на 14 мм рт. ст. —
скорее всего, будет. Поэтому, несмотря на то что средняя разность в этом исследовании
статистически значима, диапазон вероятных результатов, показанный доверительным
интервалом, слишком широк, чтобы быть надежным клинически. Если в ходе
исследований получен доверительный интервал, содержащий только клинически важные
значения, препарат с гораздо большим основанием может оказаться клинически
эффективным. Если же ни одно значение интервала не является клинически важным,
препарат, скорее всего, окажется неэффективным.
Доверительные интервалы могут также использоваться для оценки статистик, отличных
от разностей между групповыми средними или средними изменениями в одной группе с
течением времени. Примерами могут служить доли, отношения шансов, отношения рисков,
отношения опасностей, коэффициенты корреляции, доли выживших, угловые
коэффициенты линий регрессии, показатели эффективности (такие, как число нуждающихся в
лечении), а также коэффициенты в статистической модели (как в табл. 7.1).
Q В общем, если 95% ДИ для оценки разности между группами (или в той же
группе с течением времени) не включает нуль, результаты статистически
значимы на уровне 0,05. В диапазоне всех возможных разностей, скажем, между
средними значениями всех возможных выборок из двух групп крайние 5 % (по
2,5 % на каждом конце распределения разностей) называются статистически
значимыми на уровне 0,05 (при так называемом двустороннем критерии, см. таксисе
указание 4.7). Срединные значения 95 % этих разностей имеют большую
вероятность случайного появления, нежели разности из концов диапазона. Поэтому
разность в этом диапазоне считается незначимой. Если нулевая разность входит
в эти срединные 95 %, то преобладание разности то в пользу одной группы
(среднее значение в группе А больше, чем среднее в группе В), то в пользу другой
(среднее значение в группе А меньше, чем среднее в группе В) можно объяснить
случайными причинами. Только когда нулевое различие находится вне 95% ДИ
для среднего, можно в 95 % случаев утверждать об отличии одной группы против
другой. Например:
Отчеты об оценках и доверительных интервалах 61
• Разность в средних значениях измерений функции легких между двумя
группами составила 0,51 л/мин (95% ДИ 0,23-0,79 л/мин). Здесь разность статистически
значима на уровне 0,05. Нуль не входит в срединные 95 % значений, в которых
вероятно нахождение наблюдаемой разности (оценки); следовательно, он должен находиться
в оставшихся 5 %. Иными словами, вероятность получить разность в О л/мин меньше,
чем 5 раз из 100.
• Разность в средних значениях измерений функции легких между двумя
группами составила 0,12 л/мин (95% ДИ от -0,16 до +0,40 л/мин). Здесь
доверительный интервал включает нуль, поэтому разность не является статистически значимой
на уровне 0,05. Иными словами, вероятность получить разность в О л/мин больше, чем
5 раз из 100.
Щ В общем, если при сравнении двух групп 95% ДИ для отношения шансов или
отношения рисков не включает в себя 1, результаты статистически значимы
на уровне 0,05. Отношение шансов, большее 1, указывает на повышенный риск
в одной группе по сравнению с другой; отношение, меньшее 1, указывает на
пониженный риск, отношение, равное 1, указывает на отсутствие как повышенного,
так и пониженного риска. Только когда отношение шансов, равное 1, находится вне
95% ДИ, риск будет повышенным (или пониженным) в 95 % случаев. (См. такэюе
гл.2.)
• Предположим, что отношение шансов частоты новых случаев инсульта у
курящих и некурящих равно 4,2 (95% ДИ 1,32-13,33). Это означает, что в среднем у
курильщиков инсульт возникает в 4,2 раза чаще, чем у некурящих. Отношение шансов,
равное 1, означающее одинаковость риска для курящих и некурящих, в
доверительном интервале отсутствует. Поэтому в предположении, что риски групп одинаковы
(что верна нулевая гипотеза), ожидать, что отношение шансов случайно примет
значение 4,2 или выше, следует менее чем 5 раз из 100; значение/? меньше 0,05.
• Предположим теперь, что отношение шансов равно 4,2 (95% ДИ 0,92-18,63).
Здесь доверительный интервал уже включает 1, поэтому различие шансов не является
статистически значимым на уровне 0,05.
3.2. Указывайте верхнюю и нижнюю границы доверительного интервала.
Символ «±» используйте только в целях экономии места в таблицах и только
в случае симметричности доверительного интервала.
Указание верхней и нижней границ доверительного интервала избавляет читателей
от необходимости вычислять его значения. Кроме того, иногда доверительные интервалы
бывают несимметричными' и не могут быть корректно заданы при помощи символа «±».
Например, доверительный интервал из вышеприведенного примера от 0,92 до 18,63 не
является симметричным относительно оценки отношения шансов, равной 4,2.
ПРИМЕР
• Неудачное излоэюение. В нашем исследовании разность составила 28 мг/дл
(95%ДИ = ±3,2мг/дл).
• Рекомендуемое излоэюение. В нашем исследовании разность составила 28 мг/дл
(95% ДИ 24,8-31,2 мг/дл).
' в отличие от среднего, имеющего симметричное распределение, многие другие статистики имеют
несимметричное распределение, например дисперсия, коэффициент корреляции, отношение шансов и т.д.
62 Составление статистических отчетов в медицине
^ Частым источником недоразумений в представлении данных является
неопределенность в том, относится ли символ «±» в тексте или столбцах
погрешностей на графиках (см. рис. 21.4) к СО, стандартным ошибкам (обычно СОС)
или95%ДИ':
• Стандартное отклонение является описательной статистикой, которая указывает
разброс в значениях, взятых из выборки. {См. такэюеуказание 1.8.)
• Стандартная ошибка среднего — это дедуктивная статистика, которая показывает
точность оценки характеристики популяции; по сути, это 68% ДИ.
• 95% ДИ — это предпочтительная дедуктивная статистика, показывающая точность
оценки популяционной характеристики.
ДОВЕРИТЕЛЬНЫЕ ИНТЕРВАЛЫ С ОПИСАТЕЛЬНЫМИ ФУНКЦИЯМИ
33* Указывайте (95%-е) доверительные интервалы для всех наиболее важных
оценок популяционных характеристик.
Доверительные интервалы могут сопровождать описательные статистики, используемые
для оценки характеристик популяции. Если эти оценки являются частью основных
результатов исследования, их следует представлять вместе с доверительными интервалами для
указания точности. Примерами характеристик популяции, представляющих особый
интерес, могут служить средние значения, медианы и доли.
Образец презентации
Среднее значение уровня инсулиноподобного фактора роста I (IGF4) в сыворотке у 138
пациентов с остеопорозом составило 300 нг/мл (95% ДИ 273-327 нг/мл).
Здесь:
• Исследователи оценили среднее значение уровня IGF-I сыворотки для генеральной
совокупности пациентов с остеопорозом по выборке из 138 пациентов.
• 300 нг/мл -— это среднее значение уровня IGF-I для данной выборки; в то же время это
точечная оценка среднего значения уровня IGF-I для популяции.
• 95% ДИ -— область значений от 273 до 327 нг/мл, является показателем точности оценки.
Он говорит о том, что «истинное» значение популяционного среднего, как ожидается,
находится в пределах этого диапазона в 95 из 100 подобных выборок.
^ Не используйте стандартную ошибку среднего в качестве доверительного
интервала [2-7]. Значения, определенные посредством среднего плюс-минус СОС,
фактически образуют приблизительно 68% ДИ. Большинство специалистов
предпочитают более консервативный 95% ДИ (интервал, включающий среднее
значение плюс-минус примерно двукратная СОС) или 99% ДИ (среднее значение плюс-
минус примерно трехкратная СОС).
Основания для этого таковы. 50% ДИ показывает, что примерно в 50 из 100
исследований будет получен результат, лежащий вне доверительного интервала, т. е. он будет ничем
1 Отсутствие таких уточнений также характерно и для больигинства публикаций отечественных журналов
биомедицинской тематики.
Отчеты об оценках и доверительных интервалах 63
не лучше случайного. При 68% ДИ (среднее значение плюс-минус одна СОС) примерно
в 32 из 100 таких же исследований будет, вероятно, получено среднее значение, лежащее
вне доверительного интервала, тогда как при 95% ДИ — только в 5 из 100 исследований.
68% ДИ слишком близок к случайному 50%-му для консервативных нужд медицины.
Использование СОС в качестве описательной статистики (вместо СО) или для построения
доверительного интервала приводит к недоразумениям.
Щ Широкие доверительные интервалы могут свести к нулю всю полезность
оценки [8]. Оценка средней продолжительности человеческой жизни в 50 лет с 95% ДИ
от 5 до 95 лет возможна, но степень точности слишком низка, чтобы считать такую
оценку полезной. Увеличение объема выборки должно сузить доверительный
интервал и увеличить точность оценки.
Литература
1. Rothman KJ. Significance questing [Editorial]. Ann Intern Med. 1986; 105:445-7.
2. Gardner MJ, Altman D. Confidence intervals rather than P values: estimation rather than hypothesis
testing. BMJ. 1986; 292:746-50.
3. Murray GD. Statistical guidelines for the British Journal of Surgery. Br J Surg. 1991; 78:782-4.
4. WulffHR. Confidence Limits in evaluating controlled therapeutic trials [Letter]. Lancet. 1973; 2:969-70.
5. Bulpitt CJ. Confidence intervals. Lancet. 1987; 28:494-7.
6. Altman DG, Gore SM, Gardner MJ, Pocock SJ. Statistical guidelines for contributors to medical
journals. BMJ. 1983; 286:1489-93.
7. Feinstein AR. Clinical biostatistics XXXVII. Demeaned errors, confidence games, nonplussed
minuses, inefficient coefficients, and other statistical disruptions of scientific communication. Clin Pharmacol
Ther. 1976;20:617-31.
8. Gore SM, Jones IG, Rytter EC. Misuse of statistical methods: critical assessment of articles in BMJ
from January to March 1976. BMJ. 1977; 1:85-7.
64 Составление статистических отчетов в медицине
Глава 4
Сравнение групп при помощи
р-значений
Отчеты о проверках ^ипотез
Мы рассматриваем критерии значимости скорее как методы для
составления отчетов, а не как методы принятия решений, поскольку медицинская
политика должна основываться далеко не на одних лишь результатах проверки
значимости.
F. MosTELLER, J. p. Gilbert, В. McPeek [1]
Несмотря на то что термин «статистически значимый» распространен в медицинской
литературе достаточно широко, его смысл понимается ошибочно удивительно часто.
Вероятность или уровень значимости менее чем 0,05 часто ошибочно рассматривается как
«доказательство» эффективности лечения, а значения выше 0,05 часто трактуются как
«доказательство» обратного. На самом же деле уровень значимости ничего не доказывает'.
Значения/7, предложенные в 1920 г. сэром Рональдом Фишером в качестве показателя
убедительности доказательства, входят в раздел статистики, известный под названием
частотного подхода к статистике (в противоположность байесовскому подходу; см. гл. И).
Частью частотного подхода является также метод выбора гипотез, известный под
названием проверки гипотез, разработанный математиками Ежи Нейманом и Эгоном Пирсоном
в 1930-е гг. р-значения и проверка гипотез — фактически весьма различные концепции,
но они часто — и ошибочно — рассматриваются как части согласованного подхода к
статистическим выводам [2].
На самом деле частотный подход широко применяется в биометрических исследованиях.
При всей элегантности стоящей за ним логики он не является интуитивно очевидным и
поэтому столь часто служит источником недоразумений. В этой главе мы обращаемся к
проверке гипотез, р-значениям, а также некоторым смежным вопросам и описываем, каким (и
почему именно таким) образом эти понятия должны отражаться в отчетах.
' Здесь имеется в виду тот факт, что любые заключения, полученные с помощью методов статистики, нося!
вероятностный характер. То есть они не абсолютны и тем отличаются, например, от а]пебраических
доказательств. С непониманием этого важнейшего свойства статистической методологии связан феномен ссматичс-
ской глобализации научности применительно к понятию «достоверность». В результате во многих огечестнснтих
медицинских публикациях вместо термина «статистическая значимость» (significance) очень часто используется
термин-неологизм «статистическая достоверность» (чаще без прилагательного «статистическая»). Более 1юдроб-
но об этом читатели могут прочитать в статье Н. А. Зорина «О неправильном употреблении термина
"достоверность" в российских научных психиатрических и общемедицинских статьях» по адресу: http://vvwvv.biometrica.
tomsk.ru/letl.htm.
Отчеты о проверках гипотез 65
ОБЩИЕ СВЕДЕНИЯ ПО МЕТОДАМ ПРОВЕРКИ ГИПОТЕЗ
Проверка гипотез рассматривается в контексте исключения случайных факторов в
объяснении результатов исследования. Если случай не дает правдоподобного объяснения
результата, то более вероятными становятся другие объяснения, возможно биологические.
Чтобы проверить, насколько вероятны объяснения случайными факторами, мы принимаем
так называемую нулевую гипотезу отсутствия различия.
Нулевая гипотеза — это предположение, что всякое различие между группами является
делом случая, т. е. что вмешательство не дает никакого эффекта. Количественную
характеристику случая как объяснения явлений при нулевой гипотезе предоставляет теория
вероятностей. Этой характеристикой является /7-значение. Чем оно выше, тем убедительнее
свидетельство в поддержку нулевой гипотезы, согласно которой различие объясняется
случайными причинами. Чем меньше р-значение, тем меньше свидетельств в пользу нулевой
гипотезы. Если/^-значение очень мало (обычно меньше, чем 0,05), нулевая гипотеза
отвергается, а различие приписывается вмешательству.
Допустим, что мы исследуем болеутоляющее действие препарата. По окончании
эксперимента мы сравниваем средние значения индексов болевых ощущений в
экспериментальной и контрольной группах. Первый вопрос, на который мы должны ответить,
относится в действительности к области медицины: достаточно ли велико различие между этими
средними, чтобы быть клинически важным?
• Чтобы определить, является ли различие средних значений достаточно большим,
чтобы быть клинически важным, в отчетах, как пояснено в гл. 3, следует указывать как
значения средних в каждой группе, так и разность между ними (ее оценку), что
помогает узнать насколько велико это различие.
• Если различие между средними достаточно велико, чтобы быть клинически важным,
мы обязаны спросить, является ли это различие результатом применения препарата
или обусловлено случайными причинами. Этот вопрос относится к сфере теории
вероятностей и затрагивает такие понятия, как уровень значимости альфа, или
вероятность ошибки первого рода. Проверка гипотез может помочь найти ответ на этот
вопрос.
• Если различие между средними не так велико, чтобы быть клинически важным, мы
должны выяснить, чем вызвано сходство между группами — применением
неэффективного препарата или же недостаточным количеством данных. Этот вопрос также
относится к теории вероятностей и затрагивает понятия бета, или вероятности ошибки
второго рода. Ответ на него может быть найден благодаря знанию статистической
мощности анализа.
Рассматривая эти вопросы по одному, предположим, что различие между группами
клинически важно. Если мы приписываем это различие действию препарата, а случайность
оказывается более правдоподобным объяснением, то тем самым мы совершаем ошибку
первого рода. Альфа (а) — это вероятность допустить ошибку первого рода; это
готовность ошибочно приписать различие между группами действию препарата, когда более
правдоподобным объяснением является случай. Для альфа обычно устанавливается
значение 0,05, что соответствует готовности совершить ошибку первого рода 5 раз в 100
подобных сравнениях.
66 Составление статистических отчетов в медицине
Образец презентации
Мы провели исследование, в котором с 90%-й мощностью распознается разность в 4
градуса между двумя группами по величине сгиба локтевого сустава. Критический уровень
значимости был установлен в 0,05. У пациентов, получавших электростимуляцию (п = 26),
величина локтевого сгиба увеличилась в среднем на 16 градусов при СО 4,5, тогда как у пациентов
в контрольной группе (п = 25) величина сгиба увеличилась в среднем только на 6,5 градуса
при СО 3,4. Эта 9,5-градусная разность между средними оказалась статистически значимой
(95% ДИ 7,23-11,73 градуса; двусторонний критерий Стьюдента, t = 8,43; количество
степеней свободы 49; р < 0,001).
Здесь:
• 4 градуса устанавливается как минимальная считающаяся клинически важной разность
в увеличении локтевого сгиба,
• 90 % — статистическая мощность критерия. Это означает, что при заданном типе
собранных данных и их количестве различие в сгибе локтя по крайней мере на 4 градуса
распознается с вероятностью 90 %, если такое различие действительно существует.
• 0,05 — критический уровень значимости (альфа); порог статистической значимости,
устанавливаемый исследователями.
• п обозначает количество людей в каждой группе.
• 9,5 градуса —- фактическая разность между средними значениями в группах.
• 95% ДИ приведен для указания точности оценки разности в 9,5 градуса. Это означает
95%-ю уверенность исследователей в том, что интервал от 7,23 до 11,73 градуса является
диапазоном вероятных значений для истинного значения разности, связанного с этими
данными.
• Для сравнения групп был применен двусторонний вариант критерия Стьюдента (а не
односторонний). В критерии Стьюдента используется Г-статистика и f-распределение.
Значение статистики критерия равно 8,43. (Информация о применении одно- или двустороннего
критерия обычно приводится в подразделе «Статистические методы» раздела «Материалы
и методы», и повторять ее для каждого результата нет необходимости.)
• Р"3начение— это вероятность получить крайнее или превосходящее крайнее
значение, по сравнению с наблюдаемым в предположении, что на самом деле различия между
группами нет. Малое р-значение указывает на достаточные основания (р < 0,05) отвергнуть
нулевую гипотезу об отсутствии различий. Как отмечалось в гл. 3, при составлении
отчетов о результатах исследования доверительные интервалы предпочтительнее р-значений.
В этом примере мы привели и то, и другое. Это приемлемо, хотя и излишне.
Значение р, найденное из вычислений по данным исследования, указывает на
вероятность того, что случайность породила бы столь эюе большое или еще большее различие
по сравнению с найденным в ходе исследования, если верна нулевая гипотеза. Чем меньше
р-значение как мера доверия к нулевой гипотезе, тем менее вероятна сама нулевая гипотеза.
Если/7-значение меньше критического уровня значимости (скажем, 0,05), то нулевая
гипотеза отвергается, а различие, по определению, объявляется «статистически значимым».
Теперь предположим, что различие слишком мало, чтобы быть клинически важным.
Если мы считаем, что отсутствие различий вызвано неэффективностью препарата, но
более правдивым объяснением оказалось недостаточное количество данных, мы совершаем
ошибку второго рода. Бета ф) — это вероятность совершить ошибку второго рода;
готовность неправомерно приписать сходство групп неэффективности препарата, тогда как
Отчеты о проверках гипотез 67
более правдоподобным объяснением является недостаточное количество данных. Уровень
бета обычно устанавливается 0,1 или 0,2, что соответствует готовности совершить ошибку
второго рода 10 или 20 раз при 100 сравнениях. Однако бета обычно выражается
посредством статистической мощности, которая вычисляется по формуле 1 - /?. Таким образом,
типичной является мощность 80 или 90 %.
Статистическая мощность важна при определении объема выборки для исследования
или, как в нижеприведенном примере, при определении того, сколько нужно собрать данных
для обеспечения «достаточного доказательства». При расчете объема выборки учитывается
несколько факторов, включая значения ошибок первого и второго рода; однако прежде
всего нужно понять, какую величину различия требуется распознать. Большие различия, если
они имеют место, заметны уже в малых выборках, тогда как малые для своего
распознавания могут потребовать весьма большие объемы выборок. Расчет мощности утверждает, что
исследование с данным объемом выборки имеет, к примеру, 80%-й шанс распознать 10%-е
различие, если такое различие обнаруэюивается. Иными словами, в 100 выборках из одной
и той же генеральной совокупности 10%-е различие, если оно имеет место, будет, вероятно,
найдено в 80 из этих выборок.
Статистическая мощность особенно важна тогда, когда результаты исследования не
являются статистически значимыми. В этом случае исследования с адекватной
статистической мощностью могут интерпретироваться как дающие отрицательный результат: группы
в действительности являются схожими, если не эквивалентными. Однако в исследованиях
с неадекватной мощностью результаты не являются отрицательными, по ним просто
нельзя сделать никаких заключений. Собрано недостаточно данных для того, чтобы говорить
об отсутствии клинически важных различий.
УКАЗАНИЯ ПО ОФОРМЛЕНИЮ ВВЕДЕНИЯ
4.1. Четко формулируйте проверяемую гипотезу.
Гипотеза — это проверяемое утверждение о предполагаемой связи между двумя или
более переменными. На практике гипотеза может, например, утверждать, что некий
препарат, по мнению исследователя, заметно уменьшает болевые ощущения в группе пациентов
с данным диагнозом.
В ходе формальной проверки гипотезы формулируются две гипотезы: нулевая и
альтернативная. Нулевая гипотеза обычно противоположна тому, в чем желает убедиться
исследователь. К примеру, распространенный тип нулевой гипотезы состоит в том, что средние
отклики в группах будут одинаковы, т. е. что препарат не оказывает существенного
болеутоляющего действия. Альтернативная гипотеза обычно описывает то, в чем желает
убедиться исследователь: препарат будет заметно уменьшать боль. Иными словами,
альтернативная гипотеза состоит в том, что средние отклики в группах не будут одинаковыми.
Мнение в поддержку альтернативной гипотезы или против нее складывается прежде
всего из определения силы свидетельства данных в пользу нулевой гипотезы. Такие
свидетельства предоставляет р-значение. Значение р — это вероятность получить крайнее значение
результата или превосходящее его по сравнению с данными в предположении, что препарат
фактически не воздействует на боль. Чем меньше /7-значение, тем сильнее свидетельство
против нулевой гипотезы. Нулевая гипотеза в большинстве научных отчетов о проверке
гипотез не указывается; явно формулируется только альтернативная гипотеза.
68 Составление статистических отчетов в медицине
ПРИМЕР
• Нулевая гипотеза: Средние значения изменения в силе бицепсов у мальчиков,
вовлеченных в программу физических упражнений и не вовлеченных в нее, не будут
существенно отличаться через 6 недель.
• Альтернативная гипотеза: Через 6 недель тренировок среднее значение
изменения в силе бицепсов у мальчиков, вовлеченных в программу физического развития,
будет выше среднего значения в силе бицепсов у мальчиков, не вовлеченных в эту
программу.
УКАЗАНИЯ ОТНОСИТЕЛЬНО МЕТОДОВ
Перечисленные ниже указания касаются материалов, которые в статьях обычно
отражаются в подразделе «Статистические методы» раздела «Материалы и методы».
4.2. Указывайте минимальную разность, которая при сравнении групп считается
клинически значимой.
Клинически важное значение разности, если оно указано заранее, удерживает
клинические вопросы в фокусе анализа и помогает формулировать задачи, стоящие перед
статистикой в будущем. Минимальная разность является также составляющей расчетов
статистической мощности {см. такэюе указание 4.4), и это помогает определить, насколько велика
должна быть выборка.
4.3. Указывайте уровень альфа (а): вероятность, ниже которой решение
рассматривается как «статистически значимое».
Уровень альфа — это вероятность, которую исследователь выбирает в качестве
порога статистической значимости. Ее значение может быть произвольным, но по традиции
устанавливается равным 0,05, 0,01 или, что менее общепринято, 0,001'. (Большие значения
альфа, такие как 0,1, иногда используются исследователями в разведочном анализе, чтобы
выделить намечающиеся взаимосвязи для дальнейшего изучения в многовариантных или
многомерных моделях.) В любом случае результаты с полученными р-значениями,
меньшими, чем альфа, являются по определению «статистически значимыми».
Уровень значимости альфа фактически является вероятностью совершения ошибки
первого рода, или, по сути, вероятности ошибочного заключения о том, что различие между
группами возникло в результате вмешательства.
4.4. Детально описывайте априорные вычисления мощности, если они
пригодны для первоначальных сравнений.
Статистическая мощность показывает способность исследования выявить различие
определенной величины, если это различие действительно имеет место. Если не
обнаруживается никакой статистически значимой разности, то это возможно либо потому, что ее
действительно нет, либо из-за отсутствия достаточного количества данных для ее выявления
(т. е., возможно, вследствие слишком малого объема выборки). Для определения необходи-
' В отечественных публикациях иногда можно встретить абсурдные по своей сути искажения самого смысла
понятия «уровень статистической значимости». Вот, к примеру, описание из статьи «Анализ взаимосвязи
полиморфизма С677Т гена метилентетрагидрофолатредуктазы с клиническими проявлениями атеросклероза»
(Генетика. Вып. 9. 2000. С. 1269-1273): «Для всех статистических тестов в качестве критерия статистической
достоверности рассматривался уровень значимости более 0,95».
Отчеты о проверках гипотез 69
мого для исследования объема выборки мощность должна быть рассчитана до
эксперимента. Эти вычисления должны быть отражены в разделе «Материалы и методы». В табл. 4.1
приведены факторы, влияющие на статистическую мощность для парного /-критерия.
Большинство из них привлекается к вычислениям мощности для других статистических
критериев.
Статистическая мощность равна 1 - бета, где бета ((3) — вероятность допустить ошибку
второго рода: ошибочно заключить, что между группами нет различий. Бета — это
значение вероятности, заключенное в пределах от О до 1, обычно 0,1 (для 90%-й мощности)
или 0,2 (для 80%-й мощности). Например, исследование длины кости, в котором бета
установлена равной 0,2 для 15-миллиметровой разности при лечебном воздействии,
утверждает, что исследователи желают принять 20%-й шанс упустить 15-миллиметровую разницу
между экспериментальной и контрольной группой при данном плане исследования.
ПРИМЕР
• Если оба уровня значимости альфа и бета установлены равными 5 % (т. е. меньшее,
чем 0,05,/7-значение рассматривается как значимое, а анализ имеет 95%-ю мощность),
а частота откликов на лекарство в контрольной группе равна 50 %, то при
использовании /-критерия, для того чтобы распознать 5%-е улучшение в экспериментальной
группе, понадобится 5178 человек; для распознания 10%-го улучшения понадобится
1282 человека, и лишь 190 человек понадобится для того, чтобы распознать 25%-е
улучшение [3, 4].
ф Статистическая мощность критериев при малых выборках часто бывает
неприемлемо низкой [5-7].
Таблица 4.1
Переменные, входящие в вычисления статистической мощности парного ^критерия, и их
влияние на желаемый объем выборки {п)
Переменная'*
Двусторонний
критерий
Односторонний критерий
Прирост А
Прирост о
Прирост а
Уменьшение Р
А
5
5
10
5
5
5
о
20
20
20
25
20
20
а
0,05
0,05
0,05
0,05
0,01
0,05
1-Р
0,8
0,8
0,8
0,8
0,8
0,9
л
127
100
25
155
160
138
^ Значения, выделенные полужирным, отличаются от значений, приведенных в первой линии, и показывают,
как изменение каждой переменной влияет на объем выборки.
А — величина распознаваемой разности или изменения; в идеале — наименьшая считающаяся клинически
важной разность. Устанавливается исследователем.
0 —СО; итоговое значение изменчивости разностей парных наблюдений; биологическая функция.
а — пороговое значение, ниже которого результаты объявляются статистически значимыми. Устанавливается
исследователем.
1 - Р — статистическая мощность, устанавливаемая исследователем,
п — объем выборки.
70 Составление статистических отчетов в медицине
4.5. Для каждого сравнения четко указывайте примененный критерий\
Статистических критериев очень много, и некоторые из них пригодны для
рассматриваемых сравнений. Однако каждый критерий базируется на нескольких допущениях, поэтому
для каждого вида анализа важно указывать, какой именно был применен критерий.
Критерий часто бывает невозможно подобрать до тех пор, пока не собраны данные, поскольку
данные определяют принятые допущения (обычно в зависимости от того, нормально ли
распределены эти данные, а иногда от того, следует ли менять уровень измерений).
Таким образом, критерий следует указывать в подразделе «Статистические методы» раздела
«Материалы и методы», но он может также указываться в разделе «Результаты». Критерии,
связанные с /^-значениями, данными в таблицах, можно идентифицировать при помощи
примечаний. Табл. 4.2 перечисляет несколько обычных статистических критериев, а также
обстоятельств, в которых они могут применяться.
@ Используя путеводитель по статистическим терминам и критериям (с. 373),
убедитесь, что критерий действительно подходит к представляемым данным.
Таблица 4,2
Наиболее употребительные статистические критерии для сравнения групп независимых
и парных выборок^
Число
сравниваемых
групп
Независимые выборки
Парные выборки
2 и более
Группы номинальных данных
Критерий хи-квадрат
Группы порядковых данных
Критерий МакНемара'^
3 и более
Критерий ранговых сумм Уилкоксона
или и-критерий Манна—Уитни''
Критерий Краскела—Уоллеса''
Критерий знаков Уилкоксона^'
3 и более
Однофакторный дисперсионный
анализ Фридмана''
Группы непрерывных данных
Критерий Стьюдента^ или критерий
ранговых сумм Уилкоксона, или
U-критерий Манна—Уитни''
Дисперсионный анализ (ANOVA или
F-test)*' или критерий Краскела—
Уоллиса^'
Парный f-критерий^ или критерий
знаков Уилкоксона''
ANOVA повторных измерений'' или
однофакторный дисперсионный
анализ Фридмана^'
^ Могут применяться и другие критерии.
" Непараметрический критерий.
^ Параметрический критерий.
' В отечественных публикациях данная рекомендация игнорируется более чем в половине случаев. В лучшем
случае авторы в разделе «Материалы и методы» приведут небольшой список использованных статистических
критериев, не утруждая себя в дальнейшем конкретизировать, в каждом конкретном случае, каким именно критерием
получен тот или иной результат. Иногда это делается специально, с целью придать весомость своим результатам.
И лишь опытный статистик, имеющий большой опыт практического анализа медицинских данных, по деталям
может обнаружить камуфляжный характер такого перечисления.
Отчеты о проверках гипотез 71
4.6. Укажите ссылку для сложных или малораспространенных аатистических
критериев, используемых при анализе данных.
Если другим читателям потребуется перепроверить ваш анализ, им нужно будет знать,
каким образом были получены результаты. Сложные или малораспространенные
статистические критерии имеют право на существование, но необходимо, чтобы читатели сами
могли узнать, с чем они имеют дело.
@ Ссылайтесь на доступные, современные источники, особенно если
оригинальное описание критерия устарело или малодоступно [8, 9].
4 J. Если требуется, отметьте одно- или двусторонность критерия.
Обосновывайте применение односторонних критериев.
Двусторонний критерий (в основе которого лежит симметричное распределение
вероятностей) делит уровень значимости, обычно 0,05 (5 %), на две части: 2,5 % для случаев, при
которых граничное значение в группе А выше, чем в группе В, и 2,5 % для случаев, при
которых граничное значение в группе А меньше, чем в группе В. Это означает, что если
вмешательство может улучшить или ухудшить состояние в группе А по сравнению с
группой В, то двусторонний критерий принимает во внимание обе возможности. В то же время
односторонний критерий помещает те же 5 % только к одному краю (или направлению),
если предполагается, что направленность результата известна заранее.
Двусторонние критерии требуют большего значения разности для получения того же
уровня статистической значимости (того же /?-значения), что и односторонние. Их следует
использовать тогда, когда тип результата неизвестен (т. е. если неизвестно, какими будут
результаты вмешательства — благоприятными или нет). Двусторонние критерии более
консервативны и по этой причине более предпочтительны. Односторонние критерии
используются тогда, когда тип результата (необязательно величина) заранее известен, как это
часто и бывает на практике. При использовании односторонних критериев исследователям
следует это особо оговорить, а также представить доказательства того, что результат будет
именно тот, о котором идет речь.
4.8. Указывайте, предназначен ли критерий для непарных или парных данных
(т. е. для независимых или спаренных выборок).
При анализе данных из парных выборок используются другие статистические критерии,
нежели для данных из независимых выборок (табл. 4.2). При вычислении /^-значений
парные статистические критерии рассматривают разности в каждой паре наблюдений, в
отличие от рассмотрения только разностей между групповыми средними.
ПРИМЕР
• В ходе исследования результатов кампании по борьбе с курением в двух школах
сравнивались две независимых выборки, по одной из каждой школы. В другом
исследовании, которое сравнивает осведомленность каждого учащегося о последствиях курения
до и после кампании в одной из школ, рассматривается одна выборка парных данных;
а именно одни и те же студенты опрашиваются дважды, а данные представляют собой
пары ответов на вопросы теста.
^ Используя путеводитель по статистическим терминам и критериям (с. 373),
убедитесь, что критерий действительно подходит к представляемым данным.
72 Составление статистических отчетов в медицине
4.9. Дайте ссылку на статистические пакеты или программы,
используемые при анализе данных^
Точное указание на используемые в статистическом анализе прикладные пакеты важно
потому, что коммерческие пакеты обычно поддерживаются и обновляются, а программы,
разрабатываемые частным образом, — не всегда. Кроме того, при вычислении одних и тех
же статистик не все статистические прикладные программы используют одинаковые
алгоритмы или опции по умолчанию. Таким образом, результаты могут слегка изменяться
от пакета к пакету и от алгоритма к алгоритму.
ПРИМЕР
• К наиболее употребительным прикладным пакетам статистики относятся SAS
(Statistical Analysis Systems), BMDP, Splus, SPSS (Statistical Package for the Social Sciences),
StatXact, StatView, StatSoft, InStat, Statistical Navigator, SysStat и Minitab.
УКАЗАНИЯ ПО ОФОРМЛЕНИЮ РЕЗУЛЬТАТОВ
4Л О, В первую очередь расскажите об основных результатах анализа.
в фокусе научной публикации должны находиться основные сравнительные результаты,
послужившие побудительным мотивом к работе. Статистический анализ может и должен
носить исследовательский характер и объяснять явления по существу, но эти вторичные
исследования никогда не должны затенять основные результаты. Это означает, что не
следует пренебрегать не имеющими твердой основы (статистически незначимые) основными
анализами ради более заманчивых (статистически значимых) вторичных.
^ Остерегайтесь избирательной отчетности. Избирательная отчетность — это
практика представления только желаемых результатов исследования. В качестве
такого рода находок обычно выбираются статистически значимые результаты. В
отчете следует отражать результаты всех анализов, имеющих отношение к клинике,
независимо от того, являются ли они статистически значимыми или нет. Подавлять
противоречащие данные неэтично.
Q Используя руководство по статистическим терминам и критериям, убедитесь,
что отчет о применении критерия составлен надлежащим образом.
^ В отсутствие утверждения о том, что результаты получены из вторичного
анализа, единственная защита от избирательной отчетности состоит в попытке
выяснить, имеют ли описанные взаимоотношения биологический смысл.
4.11. Отмечайте все выбросы и то, как они рассматриваются в анализе.
Выбросы — это экстремальные значения, которые могут иметь место по ряду законных
причин. Однако, будучи экстремальными, они могут оказать непропорциональное
воздействие на некоторые виды статистического анализа. Выбросы нельзя просто
проигнорировать как доставляющие неудобство; их нужно изучить и должным образом ввести в анализ.
' Для уточнения отдельных важных деталей выполненного статистического анализа иногда необходимо
указывать не только название статистического пакета, но и название использованных процедур и уточняющих опций,
определяющих алгоритмы анализа. Эту информацию желательно приводить для пакетов, имеющих свой
внутренний язык программирования, к примеру для пакета SAS или SPSS.
Отчеты о проверках гипотез 73
Иногда бывает уместно отразить результаты как с учетом выбросов, так и без их учета,
с тем чтобы определить их воздействие на результаты.
4.12. Подтверждайте обоснованность допущений.
Большинство статистических критериев основано на ряде допущений о данных. Если
эти допущения вызывают подозрения, результаты анализов также будут внушать
подозрения. Все, что требуется добавить, — это утверждение об обоснованности допущений.
Обычно предполагается, что данные распределены по приблизительно нормальному
закону, что позволяет применять «параметрические» критерии. Но это условие часто
нарушается. Если распределение данных заметно отличается от нормального, его можно привести
ближе к нормальному виду с помощью математического преобразования'. Другой путь —
использование непараметрического критерия (который не требует от данных нормального
распределения). Если данные подверглись преобразованию или обработаны при помощи
непараметрического критерия, то об этом нужно сказать в отчете.
4.13« Указывайте абсолютные изменения или разности для всех основных
крайних значений.
Избежать недоразумений, возникающих при выражении различий в процентах или
в виде относительных изменений, можно путем указания абсолютных или действительных
изменений в группах. К примеру, если уровень холестерина сыворотки у пациента оказался
в конечном итоге равным 175 мг/дл при начальном уровне в 220 мг/дл, то абсолютная
разность равна 45 мг/дл. Относительная разность — 20%-е уменьшение в уровне холестерина
[([175 - 220]/220) х 100 %] — может еще быть описана фразой «на одну пятую ниже
начального значения», что, несмотря на точность, не включает в себя тот факт, что
действительное наблюдаемое изменение составило 45 мг/дл.
Если в исследование включены две группы, то будет полезно отразить в отчете различия
или изменения в группах наряду с групповыми средними или долями.
Q Для непрерывных переменных и независимых групп указывайте групповые
медианы (или, если удобно, средние) и абсолютные значения разности между
групповыми медианами (или средними).
Q Для непрерывных переменных и парных групп указывайте групповые
медианы (или, если удобно, средние) и медиану (или среднее) разностей между
компонентами каждой пары.
Q Для категориальных переменных и независимых групп указывайте
групповые доли и абсолютную разность между долями.
0 Для категориальных переменных и парных групп указывайте групповые
доли.
' При использовании таких преобразований важно помнить, что результат проверки статистической
гипотезы, полученный для преобразованных данных, нельзя автоматически переносить на непреобразованные данные.
К примеру, сравниваюся генеральные, популяционные средние для преобразованного артериального давления
в группах до и после лечения. Преобразование заключается в извлечении квадратного корня из давления,
выраженного в мм рт. ст. При использовании параметрического критерия получен достигнутый уровень
статистической значимости р = 0,012. При критическом значении уровня значимости р = 0,05 следует вывод о различии
сравниваемых популяционных средних. Однако этот вывод нельзя автоматически перенести на исходные
величины давления, выраженные в мм рт. ст.
74 Составление статистических отчетов в медицине
4.14. Указывайте (95%-е) доверительные интервалы для изменений или разно-
аей по основным крайним значениям.
Различие между экспериментальной и контрольной группой или между исходными и
конечными показателями в одной и той же группе является, в сущности, оценкой различия,
которого следует ожидать при проведении лечения во всей целевой популяции. Точность
этой оцененной разности показывается при помощи доверительного интервала.
Доверительные интервалы отражают влияние объема выборки и изменчивости, за счет
чего большие выборки сужают интервал и обеспечивают более точные оценки. Меньшая
изменчивость данных также сужает интервал и повышает точность оценок.
ПРИМЕР
• «Препарат замедлил процесс коагуляции в среднем на 4 минуты (95% ДИ 2,5 - 5,5 мин;
р < 0,001)». 95% ДИ говорит о том, что если бы препарат испытывался на 100
подобных выборках, то среднее время задержки коагуляции в 95 выборках из 100 было бы,
вероятно, заключено в пределах от 2,5 до 5,5 минуты. Знание этого доверительного
интервала позволяет нам судить о клинической значимости воздействия. Средняя
задержка времени коагуляции даже на 2,5 минуты (нижняя граница доверительного
интервала) была бы клинически важной, потому действие препарата оказывается
одновременно клинически важным и статистически значимым. {См. такэюе гл. 3.)
4.15« Приводите дейавительное р-значение до двух значащих цифр, независимо
от того, является ли оно статистически значимым.
Результаты с достигнутыми величинами статистической значимости — /7-значения,
меньшие критического уровня значимости альфа (обычно 0,05), считаются статистически
значимыми, а те, которые его превышают, — нет. Однако /7-значения 0,051 и 0,049
достаточно близки друг к другу, поэтому интерпретируются одинаково, несмотря на то что о
первом следовало бы сказать как о незначимом, а о втором — как о значимом. Представление
фактического р-значения снимает эту проблему интерпретации. Фактические р-значения
приобретают еще большую ценность в случае использования в метаанализе {см. гл. 17),
В любом случае наименьшее р-значение, которое следует отразить в отчете, удовлетворяет
условию/>< 0,001.
^ /^-значения, равные 1 или О, редки и при появлении в научной работе должны
быть подвергнуты сомнению. Во многих случаях они появляются в результате
округления.
^ Если результаты не являются статистически значимыми, не используйте
выражение «показало тенденцию к значимости» или «приблизились к значимости».
Результат просто оказался статистически незначимым, как это определено
соотношением между р-значением и уровнем значимости. (Любопытно, что р-значения,
по-видимому, никогда не «стремятся» от значимости.) Однако комментарии по
поводу клинической важности результата все же уместны.
4«1 б. Указывайте значение статистики критерия для основных сравнений.
Математические выкладки с данными в статистическом анализе дают статистику
критерия — число, которое сравнивается с известным распределением вероятности с целью
получить р-значение, связанное со статистикой. Знание этой статистики позволяет читате-
Отчеты о проверках гипотез 75
лю проверить /^-значение. Такого рода информация была более важна в те времена, когда
/7-значения определялись вручную путем отыскивания статистики критерия в ряде таблиц'.
Компьютеры сделали этот процесс более точным, и это уменьшило важность
представления статистики критерия.
ПРИМЕР
• /-критерий Стьюдента может быть описан так: «t = 1,34; 15 ст. св.;/? = 0,2», где 1,34 —
статистика критерия, которая сравнивается с /-распределением с 15 степенями свободы
(см. указание 4.17), ар — значение вероятности, связанное со статистикой критерия:
вероятность получить результат экстремальный или превышающий экстремальный,
по сравнению с наблюдаемым, в предположении, что между группами нет никакого
различия.
4.17. Указывайте, если требуется, число степеней свободы (df) критерия для
основных сравнений.
«Число степеней свободы» — это понятие, используемое в нескольких
распространенных статистических критериях. Будучи вычисленным в зависимости от объема выборки,
оно указывается так, чтобы читатели могли убедиться в правильности р-значения путем
проверки соответствия статистики критерия подходящему распределению, каждое из
которых имеет разное число степеней свободы, /-критерий Стьюдента, дисперсионный анализ,
или F-критерий, а также критерий хи-квадрат — все они используют понятие степеней
свободы.
Как и в случае со статистиками критерия, эта информация была важнее во времена
ручного вычисления/7-значения путем отыскания статистики критерия в таблицах, параметром
для работы с которыми служило число степеней свободы.
УКАЗАНИЯ ОТНОСИТЕЛЬНО ОБСУЖДЕНИЯ РЕЗУЛЬТАТОВ
4,18* Различайте клиническую важность и статистическую значимость.
Гертруда Штайн однажды сказала: «Различие, чтобы быть различием, должно
производить различие» [10]. Клинически важное различие по определению важно независимо
оттого, является ли оно статистически значимым. В свою очередь, статистически значимое
различие может не быть клинически важным. Статистики должны интерпретироваться; они
не создают строгой и непосредственной очевидности «истины».
/^-значения не принимают во внимание величину эффекта. Таким образом, слабый
эффект в обширном исследовании может иметь то же/?-значение, что и сильный эффект в
небольшом [2].
Заключения не должны часто базироваться исключительно нар-значениях. При переходе
к выводам исследования нужно иметь в виду несколько аспектов исследований и
результатов: разработку исследования, его проведение, величину эффекта, ширину доверительного
интервала, биологическое правдоподобие, дополнительные доказательства и т. д.
' Между тем в ряде отечественных публикаций до сих пор можно встретить упоминание о том, что, наряду с
использованием современных статистических пакетов, авторы публикации «сравнивали» полученные с помощью
пакета значения статистики критерия с табличными значениями. И это притом, что современные статистические
пакеты вместе с величиной этого критерия выдают и значение достигнутого уровня статистической значимости.
Очевидно, что в этом случае упоминание об использовании статистического пакета является не более чем
камуфляжным приемом (см. http://www.biometrica.tomsk.ru/lis/index21.htm).
76 Составление статистических отчетов в медицине
ПРИМЕР
• Малые различия между большими выборками могут быть статистически значимыми,
но не иметь клинического значения. Разница в одну неделю за пять лет нормальной
работы кардиостимуляторов от двух разных производителей может оказаться
статистически значимой, но, скорее всего, не будет клинически важной. И наоборот, большие
различия между малыми выборками могут быть клинически важными, но не быть
статистически значимыми. Предположим, что 8 из 16 человек получали обычное лечение
и выжили, а 12 из 16 человек выжили после экспериментального лечения. Хотя
разница в частоте смертности может не оказаться статистически значимой, рост
выживаемости в экспериментальной группе (на 50 %, с 8 до 12) может оказаться клинически
важным, и в этом случае стоит провести дополнительное исследование с выборками
большего объема.
^ «Статистически неотличимый» не одно и то же, что «отсутствие отличий»
[10, И]. {См. такэюе указания 4.19 и 5.2.) Группы, которые не различаются
статистически, необязательно могут считаться клинически эквивалентными.
Утверждения об эквивалентности должны основываться на исследованиях с адекватной
статистической мощностью.
4.19. Не говорите о «тенденции к значимости» для клинически важных, но
статистически незначимых различий. Вместо этого укажите отмеченную разность
и (95%-й) доверительный интервал для нее.
Когда авторы находят клинически важную, но статистически незначимую разность, они
иногда пишут, что разность показывает «стремление» к значимости. По их убеждению,
если бы выборка была большей, а статистический анализ имел большую мощность,
результаты были бы статистически значимы в той же мере, в какой они являются важными
клинически. На самом же деле, если бы /?-значение могло демонстрировать «стремление»
(а оно этого не может), его было бы одинаково легко переместить как «подальше» от уровня
значимости, так и «по направлению» к нему. Нужно иметь в виду, что клинически важные
результаты не следует пересматривать из-за того, что они не являются статистически
значимыми [12].
Результаты не могут ни «стремиться к значимости», ни «приближаться к
значимости» [13]. В зависимости от того, является ли /7-значение большим или меньшим, чем
критический уровень значимости альфа, они либо значимы, либо нет.
Результаты исследования с низкой статистической мощностью и с отсутствием
статистически значимых различий не являются отрицательными; по ним просто нельзя
делать выводы [6, 7,10,14-27].
Frederick Mosteller однажды проиллюстрировал понятие низкой статистической
мощности нижеследующим утверждением, первая часть которого написана от лица автора, а
вторая (здесь выделенная курсивом) добавляет обычно скрываемую горькую правду: «Рост
частоты инфекции при использовании новых методов оказался статистически незначимым...
и не было ни одного шанса из десяти, что мы распознали бы 30%-й рост частоты» [1].
«Видеть, что ничего не произошло, не значит доказать, что ничего не произошло» [28,29].
И далее: «Отсутствие доказательства не является доказательством отсутствия» [10, 30].
Исследования с низкой статистической мощностью обычны, и неудачи с отчетами о
статистической мощности являются распространенной ошибкой. Freiman и соавт. отмечали, что в 50
Отчеты о проверках гипотез 77
из 71 (70 %) работы, в которых говорится об отсутствии значимых различий между
разными видами терапии, не нашлось бы даже 50%-е улучшение при их проведении [6, 31].
До недавнего времени авторам настоятельно рекомендовалось проводить
«ретроспективные вычисления мощности» для незначимых различий. Это означало, что, если
результаты исследования были отрицательными, следовало выполнить вычисления мощности для
определения адекватности объема выборки. Однако доверительные интервалы тоже
отражают объем выборки и их легче интерпретировать, поэтому требование ретроспективного
вычисления мощности для статистически незначимых результатов позволяет им сообщать
доверительные интервалы [32].
Литература
1. Mosteller F, Gilbert JP, МсРеек В. Reporting standards and research strategies for controlled trials.
Control Clin Trials. 1980; 1:37-58.
2. Goodman SN. Toward evidence-based medical statistics. 1: The P value fallacy. Ann Intern Med.
1999; 130:995-1004.
3. Walker AM. Reporting the results of epidemiological studies. Am J Public Health. 1986; 76:556-8.
4. HallJC. The other side of statistical significance: a review of type II errors in the Australian medical
literature. Aust N Z Med. 1982; 12:7-9.
5. Diamond GA, Forrester JS. Clinical trials and statistical verdicts: probable grounds for appeal. Ann
Intern Med. 1983;98:385-94.
6. Freiman JA, Chalmers TC, Smith H, Kuebler RR. The importance of beta, the type И error and
sample size in the design and inteфretation of the randomized control trial: survey of 71 negative trials. N
Engl J Med. 1978; 299:690^.
7. GlantzSA. It is all in the numbers [Editorial]. J Am Coll Cardiol. 1993; 21:835-7.
8. Bailar JC III, Mosteller F Guidelines for statistical reporting in articles for medical journals. Ann
Intern Med. 1988; 108:266-73.
9. International Committee of Medical Journal Editors. Uniform Requirements for Manuscripts
Submitted to Biomedical Journals, http://www.icmje.org/index.html. Accessed 3/18/06.
10. Haines SJ. Six statistical suggestions for surgeons. Neurosurgery. 1981; 9:414-8.
11. Evans M. Presentation of manuscripts for publication in the British Journal of Surgery. Br J Surg.
1989;76:1311-5.
12. Gardner MJ, Altman D. Confidence intervals rather than P values: estimation rather than hypothesis
testing. BMJ. 1986; 292:746-50.
13. Squires BP Statistics in biomedical manuscripts: what editors want from authors and peer reviewers
[Editorial]. Can Med Assoc J. 1990; 142:213^.
14. Gore SM. Statistics in question. Assessing methods — confidence intervals. BMJ. 1981; 283:660-2.
15. Stoto MA. From data analysis to conclusions: a statistician's view: In: Council of Biology Editors,
Editorial Policy Committee. Ethics and Policy in Scientific Publication. Bethesda, MD: Council of Biology
Editors; 1990:207-18.
16. Altman DG. Statistics in medical journals. Stat Med. 1982; 1:59-71.
17. Hujoel PP, Baab DA, De Rouen ТА. The power of tests to detect differences between periodontal
treatments in published studies. J Clin Periodontol. 1992; 19:779-84.
18. Gore SM, Jones G, Thompson SG. The Lancet's statistical review process: areas for improvement by
authors. Lancet. 1992; 340:100-2.
19. Gotzsche PC. Methodology and overt and hidden bias in reports of 196 double-blind trials of
nonsteroidal antiinflammatory drugs in rheumatoid arthritis. Control Clin Trials. 1989; 10:31-56.
20. Hemminki E. Quality of reports of clinical trials submitted by the drug industry to the Finnish and
Swedish control authorities. Eur J Clin Pharmacol. 1981; 19:157-65.
78 Составление статистических отчетов в медицине
21. Mainland D. Statistical ritual in clinical journals: is there a cure? BMJ. 1984; 288:841-3.
22. Murray GD. Confidence intervals [Editorial]. Nuc Med Commun. 1989; 10:387-8.
23. Schoolman HM, BecktelJM, Best WR, Johnson AF. Statistics in medical research: principles versus
practices. J Lab Clin Med. 1968; 71:357-67.
24. SchorS, Kartenl. Statistical evaluation of medical journal manuscripts. JAMA. 1966; 195:1123-8.
25. Young MJ, Bresnitz EA, Strom BL. Sample size nomograms for inteфreting negative clinical studies.
Ann Intern Med. 1983; 99:248-51.
26. Altman DG. Statistics in medical journals: developments in the 1980s. Stat Med. 1991; 10:1897-
913.
27. Morris RW. A statistical study of papers in the Journal of Bone and Joint Surgery Br 1984. J Bone
Joint Surg Br. 1988; 70:242-6.
28. Sheehan TJ. The medical literature. Let the reader beware. Arch Intern Med. 1980; 140:472-4.
29. SchorS. Statistical proof in inconclusive "negative" trials. Arch Intern Med. 1981; 141:1263-4.
30. Wears RL. What is necessary for proof? Is 95 % sure unrealistic? [Letter]. JAMA. 1994; 271:272.
31. DerSimonian R, Charette U, McPeek B, Mosteller F. Reporting on methods in clinical trials. N Engl
J Med. 1982;306:1332-7.
32. Goodman SN, Berlin JA. The use of predicted confidence intervals when planning experiments and
the misuse of power when inteфreting results. Ann Intern Med. 1994; 121:200-6.
Проблема множественных сравнений 79
Глава 5
Корректировка отдельных р-значений
проблема множественных сравнений
Чем больше ставится вопросов о некотором мноэюестве данных, тем с
большей вероятностью они дадут некую статистически значимую разность,
даэюе при фактически эквивалентных методах лечения.
S. YusuF, J. WiTTES, J. Probstfield, H. a. Tyroler [1]
Проблема множественных сравнений («множественных критериев», или
«множественных взглядов») состоит в следующем: чем больше гипотез проверяется на одних
и тех же данных, тем с большей вероятностью мы можем совершить ошибку первого
рода — сделать вывод о том, что различие является результатом вмешательства извне,
тогда как на самом деле более вероятным объяснением является случай. Если, например,
предположить, что порог статистической значимости (альфа) установлен равным 0,05, то 5
из каждых 100/7-значений, вероятно, только случайно будут меньше 0,05. Использование
множественных критериев во многих случаях неизбежно и даже желательно, но
обращаться с ними нужно с осторожностью во избежание проблемы множественных сравнений [2].
Множественные сравнения часто встречаются в следующих задачах:
• Установление эквивалентности групп путем проверки каждой из нескольких базовых
характеристик или прогностических факторов в поисках различий между
экспериментальной и контрольной группами (в надежде не найти ни одного).
• Выполнение мноэюественных попарных сравнений, что встречается при отдельном
сравнении двух из трех или более групп данных, как это делается в дисперсионном
анализе (ANOVA) или множественном регрессионном анализе.
• Проверка мноэюественных краевых значений, подверженных влиянию одного и того
же множества предикторных переменных.
• Дополнительные, вспомогательные анализы взаимосвязей, наблюдаемых после того,
как данные собраны, но не идентифицированы в ходе исходного исследования.
• Дополнительные анализы подгрупп, не запланированные в исходном исследовании.
• Промежуточный анализ накопленных данных (одна конечная точка измеряется
несколько раз), часто производимый в исследованиях с потенциально токсичными или
другими вредоносными воздействиями, с тем чтобы не подвергать участников
исследования ненужному риску.
• Сравнение групп во многие моменты времени с помощью ряда отдельных сравнений
групп.
К явлениям, рассматриваемым при помощи множественных сравнений, относится
практика углубленного, совместного анализа (data dredging) некоторых или всех взаимосвязей
80 Составление статистических отчетов в медицине
С последующим отчетом, содержащим статистически значимые результаты [3-17].
Большие, но необоснованные значения традиционно приписываются к «статистически
значимым находкам» или «положительным результатам». Факты говорят о том, что
исследования, в которых поддерживаются авторские гипотезы, встречаются в литературе намного
чаще по сравнению с теми, в которых они не поддерживаются. К сожалению, многие
авторы действительно выглядят занятыми «безжалостным поиском значимости» [ 18] в попытке
найти для отчета статистически значимые взаимосвязи.
Однако множественные сравнения могут приносить и пользу. Хотя форма эксперимента
разрабатывается для отыскания ответов на отдельные вопросы, углубленные анализы
данных (множественные сравнения) могут помочь поставить более интересные вопросы [19].
Но интерпретация таких углубленных анализов тоже требует мудрости. Именно так нужно
относиться к исследованиям, в ходе которых возникают новые гипотезы (иногда
иронически именуемым «походами на рыбалку» [13]). Если на «рыбалке» был пойман ботинок,
«рыбаки должны выкинуть его обратно, а не говорить, что ходили ловить ботинки» [20].
Чтобы оправдать дальнейшее исследование, находки такого рода анализов должны быть
биологически правдоподобными. Биологическая достоверность еще более важна в тех
случаях, когда дополнительные исследования будут вестись для изучения новых или
удивительных результатов углубленных анализов.
В большинстве исследований вычисляется несколько /7-значений, и решение по
коррекции множественных сравнений является предметом дискуссии среди статистиков [21-23].
Одно из возражений против коррекции множественных сравнений состоит в том, что
уменьшение вероятности совершить ошибку первого рода увеличивает вероятность совер-
Образец презентации
Разности в значениях переменной отклика в шести группах сравнивались при помощи
дисперсионного анализа (ANOVA). Множественные попарные сравнения осуществлялись с
помощью процедуры Тьюки при общем уровне значимости 0,05.
Здесь:
• ANOVA является «процедурой группового сравнения», которая, в сущности, определяет,
имеется ли статистически значимая разность где-либо среди этих групп.
• Процедура Тьюки — это процедура множественных попарных сравнений, применяемая
для контроля проблемы множественных сравнений в тех случаях, когда ANOVA указывает
на статистически значимую разность между группами. Процедура множественных
попарных сравнений может использоваться при сравнении каждой группы со всеми остальными,
для того чтобы определить, какие группы отличаются значимо. В данном примере шесть
групп требуют 15 попарных сравнений, или 15 р-значений, в результате которых появляется
проблема множественных сравнений. Если процедура множественных попарных
сравнений не используется (т е. если вместо этого для сравнения шести групп 15 раз
использовался f-критерий Стьюдента), вероятность ошибочно объявить о статистической значимой
разности возрастает с 5 раз из 100 (общий уровень значимости 0,05) до 55 раз из 100 (общий
уровень значимости 0,55).
• Уровень значимости альфа — это порог статистической значимости, устанавливаемый
исследователем до начала эксперимента. С этим значением сравнивается общее р-значение
(полученное, скажем, из ANOVA) при объявлении результата статистически значимым или нет
Проблема множественных сравнений 81
шить ошибку второго рода. По мнению некоторых специалистов, нужно способствовать
тому, чтобы исследователи изучали данные, не упуская возможно важные находки. Есть два
обстоятельства, в связи с которыми обсуждается данное требование: множественные
попарные сравнения после итогового группового сравнения (такие, как ANOVA) и попутный
анализ накопленных данных.
5.1« Отметьте, вводились ли какие-либо допущения для множественного
сравнения. Если да — опишите их.
о наличии статистической значимости говорится тогда, когда полученное по исходным
данным /^-значение оказывается меньше, чем уровень альфа, установленный
исследователем в качестве порога статистической значимости. Таким образом, уровень значимости,
а иногда и р-значение, порой корректируются, чтобы учесть проблему множественных
сравнений. Типичные подходы включают в себя:
• использование более строгих критериев значимости, таких как уровень альфа 0,01
вместо 0,05 [9, 15,24-28];
• внесение поправки Бонферрони, представляющей собой грубую меру компенсации
множественного сравнения при помощи указания нового, в большей степени
ограничительного уровня значимости [25, 25, 27-32];
• придание большего значения оригинальной, априорной гипотезе и меньшего —
вспомогательному анализу [8, 9, 14, 20, 26, 31-37].
ф Если представлено большое количество р-значений, скажем, 10 или более,
определите, рассматривалась ли проблема множественных сравнений.
Углубленный анализ часто обнаруживается, когда указываются несколько р-значений
(условие иногда называют «/?-зацией всей работы») и когда указываютсяр-значения
для взаимосвязей сомнительной клинической ценности. Правило таково: «Не
указывайте в отчете/7-значения ради них самих» [34].
ф Рассчитывайте поправку Бонферрони для множественных критериев [30,
32]. Поправка Бонферрони может выглядеть как установление нового уровня
альфа с целью определения статистической значимости. Например, для компенсации
множественных (двусторонних) /-критериев Стьюдента новый критический
уровень альфа рассчитывается по формуле: «новый критический альфа» = «старый
критический альфа»/^, где «новый альфа» — это вероятность, которую нужно
достичь статистической значимости при данном числе сравнений, «старый альфа» —
уровень, который определял значимость ранее, а /i — число сравнений, отраженных
в исследовании. Так, в работе с отчетом о 12 сравнениях (12/?-значений) с исходным
уровнем значимости альфа 0,05 значимыми будут считаться только р-значения,
меньшие 0,004 («новый альфа» = 0,05/12).
Но несмотря на свою консервативность, поправка Бонферрони не дает полной
защиты от неверных выводов. Кроме того, скорректированный уровень альфа или р-значения
в исследованиях с большим числом/^-значений бывает практически недостижимым.
Чтобы считаться значимым, исследование с 30 сравнениями (не столь уж большое число)
и исходным общим уровнем значимости 0,05 потребовало бы /7-значений, меньших, чем
0,0017 [32].
82 Составление статистических отчетов в медицине
УСТАНОВЛЕНИЕ ЭКВИВАЛЕНТНОСТИ ГРУПП
5.2, Укажите клинические показатели, с помощью которых оценивается
начальное сходство групп. Не полагайтесь только на р-значения при установлении
эквивалентности.
Данные экспериментальной и контрольной групп обычно внимательно изучаются с целью
установить, были ли группы схожими в начале исследования. Несоответствия между группами
можно показать посредством клинически важных различий, например в средних значениях.
Всегда следует идентифицировать клинически важные различия. (В типичных случаях
влияние несоответствия на исход оценивается с привлечением многомерного анализа; см.
гл. 7 и 8.) Однако при статистическом сравнении, скажем, двух групп по 10 основным
характеристикам можно в результате прийти к множественным сравнениям.
В нерандомизированных испытаниях исходные характеристики могут и часто должны
сравниваться, для того чтобы определить, являются ли какие-либо различия статистически
значимыми, а также клинически важными. Статистически значимые различия по основным
переменным могут выявить систематическое смещение в назначениях. Однако
нестатистически значимые исходные различия между группами не означают, что группы
эквивалентны, если только нет адекватной статистической мощности для распознавания
клинически осмысленного различия. Такая мощность часто отсутсвует.
В рандомизированных испытаниях любые обнаруженные различия между группами
являются, по определению, результатом случая. Клинические несоответствия, даже
случайные, реальны и должны встраиваться в многомерные модели. Но статистические сравнения
исходных характеристик редко бывает необходимо вставлять в отчет. Статистически
значимые различия будут делом случая, а нестатистически значимые различия говорят не о том,
что группы схожи, а скорее о том, что случайное назначение было эффективным [38, 39].
«Если рандомизация проведена корректно, нулевая гипотеза о происхождении обеих групп
из одной и той же генеральной совокупности по определению истинна; поэтому мы можем
ожидать, что 5 % таких сравнений будут значимы на 5%-м уровне. Таким образом, эти
критерии неявно оценивают правильность рандомизации, а не подобие характеристик двух
групп» [38].
Altman и Dore [38] изучили 80 опубликованных рандомизированных контролируемых
испытаний (РКИ) и обнаружили, что в 46 из них (58 %) основные характеристики
сравниваются с помощью проверок гипотез. Медиана числа представленных основных характеристик
равнялась 9; в 39 % испытаний сравнивалось более 10 характеристик. Всего в 46 испытаний
было включено около 600 проверок гипотез (р-значений), в среднем 13 на одно испытание.
МНОЖЕСТВЕННЫЕ ПОПАРНЫЕ СРАВНЕНИЯ ЭКСПЕРИМЕНТАЛЬНЫХ
ГРУПП
53. Опишите процедуру множественного сравнения, использованную для
выявления тех пар групп, которые в наибольшей степени влияют на общую
статистическую значимость сравнения групп.
Если три или более групп данных сравниваются по две за один раз в отдельном анализе,
число таких проверок вскоре становится достаточно большим, чтобы столкнуться с проблемой
множественных сравнений. К примеру, если четыре группы сравниваются по две за один раз
Проблема множественных сравнений 83
С помощью ^кpитepиeв Стьюдента, требуется провести шесть проверок. Если уровень
значимости установлен равным 0,05 для каждой проверки, вероятность обнаружить различие, когда
его на самом деле нет (вероятность ошибки первого рода), уже равна не 0,05, а 0,3. Это
означает, что примерно одно из трехр-значений может быть интерпретировано неправильно.
Чтобы избежать этой проблемы, методики сравнения групп, такие как ANOVA,
анализируют данные из всех групп и определяют, имеются ли между ними какие-либо различия. При
выявлении различия выполняется еще так называемая процедура множественных
сравнений, выявляющая группы, наиболее сильно влияющие на общее различие между группами.
Общеупотребительными процедурами множественных сравнений, связанными с
ANOVA, являются процедуры Тьюки, Стьюдента—Ньюмана—Кейлса, многоранговая
процедура Дункана, процедура Даннетта, метод Шеффе', метод наименьшей значимой разности
Фишера (LSD-метод) и поправка Бонферрони.
ф Наиболее часто встречающейся ошибкой в ходе множественного сравнения
данных является множественное применение /-критерия Стьюдента без
корректировки уровня значимости для выявления существенно различных пар
при групповом сравнении с использованием дисперсионного анализа [40-42].
@ Возможное число парных сравнений находите по следующей формуле: к(к-1)/2,
где к — количество имеющихся групп.
ВТОРИЧНЫЕ (РЕТРОСПЕКТИВНЫЕ ИЛИ POST НОС) АНАЛИЗЫ
5.4* Четко различайте первичные и вторичные (ретроспективные или post hoc)
анализы.
Результаты исследования могут навести на мысль о новых взаимосвязях, которые не
рассматривались при планировании исследования. Но поскольку исследование не имело в виду
проверку этих новых взаимосвязей, дополнительный анализ в соответствии с иными
критериями может создать проблемы при интерпретации результатов.
ПРИМЕР
• Исследование планировалось для выявления различий в остроте зрения между
мужчинами и женщинами. Просмотрев результаты, исследователи приняли решение о
дополнительном анализе данных на основе возрастных, а не половых различий. Так как
исходные экспериментальная и контрольная группы были сбалансированы по
половой принадлежности, а не по возрасту, такой ретроспективный анализ следует считать
разведочным вне зависимости от того, насколько интересны и статистически значимы
его результаты.
' Метод линейных контрастов Шеффе является одним из самых строгих и в то же время удобных для
проведения множественных сравнений. Отметим также, что с помощью этого метода можно проводить не только парные
сравнения, но и сравнения пар группировок из нескольких градаций. К примеру, изучаются 5 групп пациентов.
Группирующий признак имеет следующие градации: 1 — здоровые; 2 — подозрение на наличие заболевания;
3 — заболевание легкой степени тяжести; 4 — заболевание средней степени тяжести; 5 — заболевание тяжелой
степени. Дисперсионный анализ показал статистически значимое различие этих 5 групп по количественному
показателю VAR1. Можно провести проверку 5x4/2= 10 пар групп, начиная от 1-2, 1-3 и т. д. вплоть до 4-5.
Исходя из динамики изменения средних значений признака VAR1, при переходе от группы 1 до группы 5 можно
также проверить гипотезу о том, что качественный скачок в изменении признака VAR1 происходит при переходе
от группы 3 к группам 4 и 5. Для этого можно объединить в одну новую группу, назовем ее группой 123, исходные
группы 1, 2 и 3. А вторую новую группу, назовем ее группой 45, образуем из исходных групп 4 и 5. И далее можно
провести сравнение пар 123 и 45.
84 Составление статистических отчетов в медицине
АНАЛИЗЫ ПОДГРУПП
5.5. Указывайте, по какому признаку идентифицируются подгруппы и почему их
стоит анализировать.
Во многих исследовательских проектах собирается значительное количество данных,
которые не относятся к первичному сравнению. Например, демографические данные, такие
как возраст и пол, рутинно собираются потому, что с этими факторами связаны многие
клинические особенности. Исследователь, изучающий действие антидепрессанта, может
в итоге обнаружить, что препарат действует ничуть не лучше, чем плацебо. Однако
продолжение анализа может выявить значительное уменьшение депрессии у женщин в период
менопаузы, т. е. для некоторой подгруппы исходной экспериментальной группы. При
анализе большого количества подгрупп, возможных при типичном исследовании, может
возникнуть проблема множественных сравнений.
Результаты анализов подгрупп могут отражаться в отчете — возможно, на действие
препарата из примера выше влияют уровни гормонов, — но отражать их нужно как
предварительные, поскольку они являются неожиданными побочными продуктами первичного
сравнения общей эффективности препарата в лечении депрессии.
Альтернативой анализу подгрупп является сбор факторов в одну предсказательную
модель (уравнение в регрессионном анализе) в противовес отдельному анализу каждой
подгруппы. В вышеприведенном примере исследователь мог бы проверить наличие
взаимодействия между возрастом, полом и приемом препарата при восстановлении после депрессии,
избежав тем самым анализа подгрупп [15, 24, 28]. (См. такэюе гл. 7 и 8.)
^ Подгруппы, определенные уже после сбора данных, могут отражать лечебные
эффекты, и тогда становится трудно, если вообще возможно,
интерпретировать возникшие в результате лечения различия [43]. Например, если поместить
в одну подгруппу пациентов, на которых хорошо подействовал препарат, будет
легко доказать, что препарат был эффективен в этой подгруппе. Порочность этого
«замкнутого круга» очевидна, но при других обстоятельствах неприемлемость
выбора подгруппы может быть незаметна.
^ Анализы подгрупп известны как ненадежные [1, 27, 31, 44-47]. Число членов
данной подгруппы может быть небольшим, даже если общее число участников во
всем эксперименте велико. «Поскольку анализы подгрупп всегда включают в себя
меньшее число пациентов, чем общий анализ, они несут больший риск сделать
ошибку второго рода — сделать ложный вывод об отсутствии различия» [46].
Щ Убедительны ли основания для проведения анализа подгрупп [1, 20]? Четкий
биологический механизм, способный объяснить различия, поможет внушить
большее доверие к результатам. Анализы подгрупп более приемлемы, когда:
• различие между группами достаточно велико, чтобы быть клинически важным и
статистически значимым;
• сравнение подгрупп является частью априорного, а не ретроспективного анализа;
• сравнение групп было одной из небольшого числа дополнительных проверяемых
гипотез, а не результатом углубленного анализа;
• различие основано на сравнении внутри одного исследования, а не с данными из
разных исследований;
Проблема множественных сравнений 85
• различие постоянно от исследования к исследованию;
• другое непрямое свидетельство выступает в поддержку существования истинного
различия [3, 46].
МНОЖЕСТВЕННЫЕ КОНЕЧНЫЕ ТОЧКИ
5.6. Идентифицируйте интересующие первичные конечные точки или исходы
до начала исследования.
Аналогом проблемы вторичного анализа, в которой раскрывается значимость
множественных объясняющих переменных, является проблема множественных исходов, в
которой раскрывается значимость переменных отклика. «...Для испытания с пятью конечными
точками шанс при нулевой гипотезе достижения уровня значимости р < 0,05 по крайней
мере одного различия в результате лечения равен примерно 20 % при условии, что между
этими конечными точками нет сильной корреляции» [24].
ПРИМЕР
• Если случайно обнаруживается, что препарат, действующий на кровяное давление,
стимулирует рост волос, исследование должно быть отражено в отчете как имеющее
два исхода: кровяное давление и рост волос. Как и в случае вторичного анализа, число
эффектов, которые могут быть проверены в типичном эксперименте, может оказаться
большим, что порождает проблему множественных сравнений. Первичная тема
сравнения — действие препарата на кровяное давление — должна находиться в центре
внимания, а о счастливой находке насчет роста волос следует сообщить как о
предварительном результате.
ПРОМЕЖУТОЧНЫЕ АНАЛИЗЫ НАКОПЛЕННЫХ ДАННЫХ
5 J. Отразите промежуточные анализы накопленных данных и дайте
обоснование этих анализов.
Во многих исследованиях, особенно в длящихся несколько месяцев или лет, иногда
желательно периодически проверять результаты, с тем чтобы не подвергать участников
ненужному риску. Такие промежуточные анализы имеют отношение к тому, что называется
«правилами остановки» для исследований {см. указание 5.8). Если промежуточные
результаты указывают на то, что терапия статистически либо высокоэффективна, либо очевидно
плоха или приносит вред, исследователи могут склониться к прекращению исследования.
Ясно, что исследование должно быть прекращено, если пациенты без необходимости
подвергаются риску. Промежуточные анализы также помогают исследователям проверить
соответствие протоколу, подтвердить полноту процедур работы с данными и как можно
скорее разрешить проблемы, возникающие в ходе исследования [48].
Однако промежуточные анализы увеличивают число выполняемых проверок и
представляют собой еще один пример проблемы множественных сравнений. Как крайность,
предположим, что результаты исследования анализировались каждый раз после того, как
каждый участник заполнял протокол, т. е. число проанализированных случаев возрастало
на единицу после каждого анализа. Волей случая проверка может дать значимый результат
после, скажем, 23 пациентов, незначимый после 27, значимый результат после 34 и так
далее по мере накопления данных.
86 Составление статистических отчетов в медицине
^ «Незапланированные промежуточные анализы создают значительные
проблемы интерпретации» [49].
5.8. Укажите статистические критерии прекращения исследования и отметьте,
были ли эти критерии разработаны до начала исследования.
Один из спорных вопросов промежуточных анализов — когда прекращать
исследование. Если исследование прекращено слишком рано (после того, как его завершили
слишком мало участников), его статистическая мощность может оказаться неприемлемо низкой.
Если исследование разрешено продолжить, оно может подвергнуть участников ненужному
риску. Таким образом, промежуточные анализы следует запланировать заранее и указать
критерии прекращения исследования.
5.9. Укажите, кому сообщались результаты промежуточного попутного анализа.
Сообщение результатов промежуточного анализа медицинскому сообществу может
оказать влияние на ход исследования. Если один вид лечения окажется лучше другого, врачи
могут не позволить своим пациентам участвовать в исследовании. Промежуточные анализы
могут также создать ожидания, способные повлиять на наблюдение и лечение. Кроме того
(что особенно актуально для средств массовой информации), если более поздние
результаты отличаются от более ранних, научный мир и публика могут потерять веру в надежность
исследования.
^ Сообщение промежуточных результатов клинических испытаний влечет
ответственность за сообщение полных и итоговых результатов [50].
Предварительные отчеты о проводимых испытаниях часто включают результаты
промежуточного анализа. Читателям следует иметь в виду, что результаты предварительны,
а заключительные результаты следует публиковать полностью. Некоторые работы
показали, что от 30 до 60 % опубликованных аннотаций не сопровождаются
впоследствии публикацией полного отчета о представленных исследованиях [51-53].
СРАВНЕНИЕ ГРУПП НА МНОЖЕСТВЕ ВРЕМЕННЫХ ТОЧЕК
5.10. Если группы сравниваются на множестве временных точек,
укажите использованную статистическую процедуру и поправки,
сделанные для множественных сравнений.
в некоторых исследованиях две или более групп сравниваются в разные моменты
времени, результатом чего является множество р-значений, по крайней мере одно на каждый
момент времени. Например, чтобы определить различия в действии или длительность
анестезии для двух конкурирующих анестетиков, измерения могут производиться каждый час
в течение 12 часов. Эти две группы можно сравнивать статистически каждый час, чтобы
определить, в какой момент средние ответы различаются значительно. В этом случае
исследователи традиционно выполняют множественные сравнения отдельных групп, одно
на каждый момент времени, что приводит к проблеме множественных сравнений; в данном
примере нужно найти 12/?-значений. Этот подход может оказаться уместным, если общий
уровень значимости корректируется для множественных сравнений (скажем, с помощью
поправки Бонферрони).
Проблема множественных сравнений 87
Литература
1. YusufS, Wittes J, Probstfield J, Tyroler HA. Analysis and interpretation of treatment effects in
subgroups of patients in randomized clinical trials. JAMA. 1991; 266:93-8.
2. Chalmers TC, Smith H Jr., Blackburn B, et al. A method for assessing the quality of a randomized
control trial. Cont Clin Trials. 1981; 2:31^9.
3. Guyatt GH, Sackett DL, Cook DJ. Users' guides to the medical literature. II. How to use an article
about therapy or prevention. B. What were the results and will they help me in caring for my patients? The
Evidence-Based Medicine Working Group. JAMA. 1994; 271:59-63.
4. BailarJC. Science, statistics, and deception. Ann Intern Med. 1986; 104:259-60.
5. Bailar JC III, Hosteller F. Guidelines for statistical reporting in articles for medical journals:
amplification and explanations. Ann Intern Med. 1988; 108:266-73.
6. Felson DT. Bias in meta-analytic research. J Clin Epidemiol. 1992; 45:885-92.
7. Fienberg SE. Damned lies and statistics: misrepresentations of honest data. In: Council of Biology
Editors, Editorial Policy Committee. Ethics and Policy in Scientific Publication. Bethesda, MD: Council of
Biology Editors; 1990:202-6.
8. Gore SM, Jones G, Thompson SG. The Lancet's statistical review process: areas for improvement by
authors. Lancet. 1992; 340:100-2.
9. Haines SJ. Six statistical suggestions for surgeons. Neurosurgery. 1981; 9:414-8.
10. MacArthur RD, Jackson GG. An evaluation of the use of statistical methodology in the Journal of
Infectious Diseases. J Infect Dis. 1984; 149:349-54.
11. Moskowitz G, Chalmers TC, Sacks HS, et al. Deficiencies of clinical trials of alcohol withdrawal.
Alcohol Clin Exp Res. 1983; 7:42-6.
12. Sals burg DS. The religion of statistics as practiced in medical journals. Am Statistician. 1985;
39:220-3.
13. Smith DG, Clemens J, Crede W, et al. Impact of multiple comparisons in randomized clinical trials
Am J Med. 1987;83:545-50.
14. Stoto MA. From data analysis to conclusions: a statistician's view. In: Council of Biology Editors,
Editorial Policy Committee. Ethics and Policy in Scientific Publication. Bethesda, MD: Council of Biology
Editors; 1990:207-18.
10. Sumner D. Lies, damned lies — or statistics? J Hypertens. 1992; 10:3-8.
15. Tyson JE, Furzan JA, Reisch JS, Mize SG. An evaluation of the quality of therapeutic studies in
perinatal medicine. J Pediatr. 1983; 102:10-3.
16. Altman DG. Statistics in medical journals: developments in the 1980s. Stat Med. 1991; 10:1897-
913.
17. Morgan PP. Confidence intervals: from statistical significance to clinical significance [Editorial]. Can
Med Assoc J. 1989;141:881-3.
18. Schoolman HM, BecktelJM, Best WR, Johnson AF Statistics in medical research: principles versus
practices. J Lab Clin Med. 1968; 71:357-67.
11. Mills JL Data torturing [Letter]. N Engl J Med. 1993; 329:1196-9.
19. Savitz DA, Olshan AF Multiple comparisons and related issues in the inteфretation of epidemiologic
data. Am J Epidemiol. 1995; 142:904-8.
20. Thompson JR. Invited commentary: re: "multiple comparisons and related issues in the inteфretation
of epidemiologic data." Am J Epidemiol. 1998; 147:801-6.
12. Goodman SN. Muhiple comparisons, explained. Am J Epidemiol. 1998; 147:807-12.
24. Pocock SJ, Hughes MD, Lee RJ. Statistical problems in the reporting of clinical trials: a survey of
three medical journals. N Engl J Med. 1987; 317:426-32.
25. Brown GW. Statistics and the medical journal [Editorial]. Am J Dis Child.
1985; 139:226-8.
88 Составление статистических отчетов в медицине
26. Altman DG, Gore SM, Gardner MJ, Pocock SJ. Statistical guidelines for contributors to medical
journals. BMJ. 1983; 286:1489-93.
27. Bulpitt CJ. Confidence intervals. Lancet. 1987; 28:494-7.
28. Murray GD. Statistical guidelines for the British Journal of Surgery. Br J Surg. 1991; 78:782-4.
29. Diamond GA, Forrester JS. Clinical trials and statistical verdicts: probable grounds for appeal. Ann
Intern Med. 1983; 98:385-94.
30. Godfrey K. Comparing the means of several groups. N Engl J Med. 1985; 313:1450-6.
31. Journal of Hypertension. Statistical guidelines for the Journal of Hypertension. J Hypertens. 1992;
10:6-8.
32. Lee KL, McNeer F, Starmer CF, et al Clinical judgment and statistics: lessons from a simulated
randomized trial in coronary artery disease. Circulation. 1980; 61:508-15.
33. Altman DG. Statistics and ethics in medical research. VII — interpreting results. BMJ. 1980;
281:1612^.
34. Walker AM. Reporting the results of epidemiological studies. Am J Public Health. 1986; 76:556-8.
35. Grant A. Reporting controlled trials. Br J Obstet Gynaecol. 1989; 96:397^00.
36. Gelber RD, Goldhirsch A. Reporting and inteфreting adjuvant therapy in clinical trials. Monogr Natl
Cancer Inst. 1992; 11:59-69.
37. Bracken MB. Reporting observational studies. Br J Obstet Gynaecol. 1989; 96:383-8.
38. Altman DG, Dore CJ. Randomisation and baseline comparisons in clinical trials. Lancet. 1990;
335:149-53.
39. Guyatt GH, Sackett DL, Cook DJ. Users' guides to the medical literature. II. How to use an article
about therapy or prevention. A. Are the results of the study valid? The Evidence-Based Medicine Working
Group. JAMA. 1993;270:2598-601.
40. Glantz SA. It is all in the numbers [Editorial]. J Am Coll Cardiol. 1993; 21:835-7.
41. Glantz SA. Biostatistics: how to detect, correct and prevent errors in the medical literature.
Circulation. 1980;61:1-7.
42. Longnecker DE. Support versus illumination: trends in medical statistics. Anesthesiology. 1982;
57:73-4.
43. Abramson NS, Kelsey SE, Safar P, Sutton-Tyrrell KS. Simpson's paradox and clinical trials: what you
find is not necessarily what you prove. Ann Emerg Med. 1992; 21:1480-2.
44. Simon R. Confidence intervals for reporting results of clinical trials. Ann Intern Med. 1986;
105:429-35.
45. Murray GD. Statistical aspects of research methodology. Br J Surg. 1991; 78:777-81.
46. Oxman AD, Guyatt GH. A consumer's guide to subgroup analyses. Ann Intern Med. 1992; 116:78-84.
47. Begg CB. Selection of patients for clinical trials. Semin Oncol. 1988; 15:434-40.
48. Ashby D, Machin D. Stopping rules, interim analyses and data monitoring committees [Editorial]. Br
J Cancer. 1993;68:1047-50.
49. Geller NL, Pocock SJ. Interim analyses in randomized clinical trials: ramifications and guidelines for
practitioners. Biometrics. 1987;43:213-23.
50. Zelen M. Guidelines for publishing papers on cancer clinical trials: responsibilities of editors and
authors. J Clin Oncol. 1983; 1:164-9.
51. Chalmers I, Adams M, Dickersin K, et al. A cohort study of summary reports of controlled trials.
JAMA. 1990;263:1401-5.
52. Scherer RW, Dickersin K, LangenbergP. Full publication of results initially presented in abstracts: a
meta-analysis. JAMA. 1994; 272:158-62 [Erratum. JAMA. 1994; 272:1410].
53. Garvey WD, Griffith ВС Scientific communication: its role in the conduct of research and creation of
knowledge. Am Psychol. 1971:349-62.
Отчет об анализах связей и корреляций 89
Глава 6
Проверка наличия взаимосвязей
Отчет об анализах связей и корреляций
Анализ данных в широком смысле представляет собой поиск образов, т. е.
смысловых отношений, среди различных наблюдаемых предметов,
К. Godfrey [I]
Анализы связей и корреляций математически отождествляют и описывают
соотношения между переменными. Вообще две переменные считаются связанными, если изменение
одной из них, скорее всего, вызовет изменение другой. Кроме того, предполагаемая связь
или корреляция между переменными может быть подвергнута процедуре проверки
статистических гипотез (вычисление/7-значений) с целью выяснить, реальна или просто
случайна кажущаяся взаимосвязь.
Хотя термины «связь» (ассоциация) и «корреляция» относятся к общим понятиям, при
использовании в статистике термин «связь» обычно используется для описания
соотношений между качественными переменными, тогда как «корреляция» обычно описывает
соотношения между непрерывными переменными. Мера связи между качественными
переменными, скажем, цветом глаз и цветом волос, может показать, прослеживается ли среди
участников эксперимента с определенным цветом глаз тенденция иметь определенный цвет
волос. Кроме того, могут быть вычислены меры связи как числовые показатели силы этой
взаимосвязи.
Подобно этому, мера (линейной) корреляции между двумя непрерывными переменными,
такими как частота пульса и частота дыхания, может показать, сопровождается ли рост
одного из них вероятным ростом другого, скажем, в подростковой выборке. Чтобы показать
эту взаимосвязь, частоту сокращений и частоту пульса для каждого подростка можно
графически изобразить на диаграмме рассеяния (рис. 6.1 и 6.2). Чем сильнее выражена
линейность и диагональность образа на диаграмме рассеяния, тем сильнее взаимосвязь. Кроме
того, в качестве числового показателя силы взаимосвязи можно вычислить коэффициент
корреляции.
Анализы связей и корреляций обычно используются для анализа взаимосвязей
между двумя или более характеристиками одного и того же объекта, т. е. они основываются
на парных данных. В вышеприведенных примерах для каждого подростка следует
записать данные по четырем характеристикам: цвет глаз и волос, а также частота сокращений
и частота дыхания. Эти данные «собираются в пары» для каждого подростка, поскольку
все они имеют место у одного и того же «объекта анализа». Таким образом, эти данные
являются описательными; предикторных переменных или переменных отклика нет, поэтому
нет и предположения о причине или эффекте. Хорошо известная, хотя иногда забываемая.
90 Составление статистических отчетов в медицине
U
о
с:
40 -Н
30
У 0=
О S
II
I i
CD X
il
S 10
та
20 H
0 H
Шкала и метки горизонтальной оси, или оси X
Единицы измерения
Рис. 6.1. Диаграмма рассеяния, демонстрирующая сильную положительную корреляцию. Значение Y
возрастает с ростом значения X
фраза «взаимосвязь не означает причинную связь»' напоминает о том, что связь и
корреляция — термины описательные.
Ниже описаны наиболее употребительные меры и критерии связи и корреляции.
• Взаимосвязи между качественными переменными, такие как между
удовлетворенностью пациента (удовлетворен или разочарован) и интеллектом (высоким или низким),
оцениваются мерами связи, такими как коэффициент ф, или критериями связи,
обычно одно из выражений, основанных на критерии Пирсона хи-квадрат (х^).
• Взаимосвязи между непрерывной переменной и двухуровневой категориальной
переменной (например, аэробная способность, измеряемая через расход кислорода, и
интенсивность тренировки, подразделяемая на высокую и низкую) могут оцениваться
с помощью точечно-бисериального коэффициента корреляции.
• Взаимосвязь между непрерывной переменной и трехуровневой или более качественной
переменной (например, аэробная способность, измеряемая через расход кислорода,
и интенсивность тренировки, подразделяемая на высокую, среднюю и низкую) можно
оценить с помощью точечно-мультисериального коэффициента корреляции.
' в данном случае подразумевается возможное (!) отсутствие непосредственной причинной связи между двумя
признаками. Это не исключает наличия вероятной опосредованной причинной связи, реализующейся через
систему сложных цепочек парных причинно-следственных связей, в которой две данные анализируемые переменные
могут быть как на концах этой цепи, так и в любом другом месте такой цепи. См., например: Благовещенский Ю.
Тайны корреляционных связей в статистике. М., 2009; Гаврипов Л. А., Гаврилова Н. С. Биология
продолжительности жизни: количественные аспекты. М., 1986.
Отчет об анализах связей и корреляций 91
га
40 Н
U
О
с:
30
II
т
20 Н
Е 2
О)
2
10 -Ч
о -Ч
Шкала и метки горизонтальной оси, или оси X
Единицы измерения
Рис. 6.2. Диаграмма рассеяния, изображающая слабую корреляцию. Всякое данное значение X связано с
рядом значений Y
• Взаимосвязи между непрерывными переменными (например, взаимосвязь между
возрастом и весом) оцениваются с помощью мер корреляции, таких как коэффициент
корреляции Пирсона г или ранговый коэффициент Спирмена р'.
• Другие меры связи включают отношения, описывающие связи между, скажем,
воздействием и заболеванием или между лечением и исходом, такие как отношения шансов
(см. гл. 2 и указание 7.25) и отношения рисков, или угроз {см. гл. 2 и указание 9.12).
Относящимися к мерам связи и корреляции, но отличающимися от них являются меры
согласия между двумя и более измерениями. В то время как связь и корреляция указывают
степень, с которой изменение в одной переменной сопровождается изменением другой,
согласие связано со сходством значений:
• Каппа-статистика, к, часто используется в качестве меры согласия или точности
классификации среди или между экспертами. Каппа указывает ту долю согласия,
которая остается после исключения случайного согласия. Таким образом, она может
принимать значения от 1,0 (полное согласие) до -1,0 (полное несогласие). Нулевое
значение каппа говорит лишь о случайном характере согласия.
• Альфа Кронбаха — это мера внутренней надежности или однородности пунктов
в указателе или анкете; она говорит о том, насколько хорошо каждый отдельный
пункт в шкале анкеты коррелирует с суммой остальных пунктов. Иногда ее называют
' в англоязычных источниках коэффициент корреляции Спирмена часто обозначают буквенным сочетанием
«rho», что читается как «ро», в отличие от обозначения коэффициента корреляции Пирсона, обозначаемого как
«г». В русскоязычных источниках коэффициент корреляции Спирмена чаще обозначают как г, где нижний индекс
заимствован из фамилии Spearman.
92 Составление статистических отчетов в медицине
«коэффициентом надежности шкалы». В отличие от коэффициента корреляции (см.
ниже), ее минимальное значение равно нулю, а максимальное — единице.
• Метод Бланда—Альтмана (или подход «пределов согласия») — это способ
определить степень согласия между многими измерениями одного и того же объекта.
Внешне он представляет собой график разностей между двумя измерениями против
среднего двух измерений [2]. В этих целях он предпочтительнее корреляционного анализа,
поэтому мы и говорим о нем здесь. (См. гл. 10 о диагностических тестах.)
МЕРЫ И КРИТЕРИИ СВЯЗИ: ВЗАИМОСВЯЗИ МЕЖДУ ДВУМЯ
КАЧЕСТВЕННЫМИ ПЕРЕМЕННЫМИ
Образец презентации
Для выборки из 1760 пациентов 542 из 1106 (49,0 %) светлоглазых испытуемых и 312 из 654
(47,7 %) темноглазых испытуемых продемонстрировали рефлексный отклик. Критерий хи~
квадрат выявил отсутствие статистически значимой взаимосвязи между откликом и цветом
глаз (x^df = 0,28; р = 0,6).
Здесь:
• Даны частоты светло- и темноглазых испытуемых с выявившимся рефлексом. Эти
частоты не отличались от ожидаемых случайно, поэтому говорить о наличии взаимосвязи двух
переменных не было практически никаких оснований.
• x^idf указывает на применение критерия хи-квадрат с одной степенью свободы с целью
определить наличие взаимосвязи цвета глаз и рефлекса в данной выборке.
• 0,28 — это значение статистики критерия хи-квадрат, вычисленное по исходным данным
и сравненное с распределением хи-квадрат, имеющим 1 степень свободы, для определения
статистически значимой взаимосвязи. Статистика критерия хи-квадрат трудно поддается
клинической интерпретации, хотя ее и следует отражать в отчетах как меру ассоциации.
(Для этой статистики можно было бы вычислить доверительный интервал, но он
практически никогда не отражается в отчетах вследствие подобных же трудностей клинической
интерпретации.)
• р — это вероятность случайного получения столь же или еще большей статистики
критерия хи-квадрат, если на самом деле между цветом глаз и рефлексным откликом нет никакой
связи. Таким образом, большое значение р (большее, чем 0,05) свидетельствует в пользу
нулевой гипотезы отсутствия связи.
бЛ, Описывайте связи, представляющие интерес.
Нужно ясно формулировать цель проверки. Проверка наличия связи — не одно и то же,
что сравнение долей двух и более групп, хотя критерии хи-квадрат, например, можно
использовать для анализа обоих видов. В случае связи цель исследования состоит в описании
взаимосвязей между переменными в одной выборке. В случае сравнения долей групп цель
анализа — определить, значительно ли отличаются две группы из одной выборки.
Например, в вышеприведенной презентации выборки критерий хи-квадрат
использовался для выявления взаимосвязи путем рассмотрения смеси частот среди четырех
возможных сочетаний:
Отчет об анализах связей и корреляций 93
1) люди со светлыми глазами и рефлексным откликом;
2) люди со светлыми глазами и отсутствием рефлекса;
3) люди с темными глазами и рефлексным откликом;
4) люди с темными глазами и отсутствием рефлекса.
Эта комбинация частот сравнивалась с комбинацией частот, появление которых
ожидалось в результате случая, при отсутствии связи двух признаков. Если наблюдаемые частоты
не отличались значительно от ожидаемых случайных частот, делалось заключение об
отсутствии связи между переменными.
Вместе с тем тот же самый критерий хи-квадрат можно было использовать для сравнения
долей светло- и темноглазых испытуемых с выраженным рефлексом. В этом случае с
помощью критерия хи-квадрат можно было сравнить разности между двумя долями, с тем чтобы
выявить значительное отличие разности от нуля. (Гл. 4 дает указания по статистическому
сравнению групп.)
б.2« Идентифицируйте переменные, используемые в анализе связи, и отразите
их в отчете с помощью описательной статистики.
Проверки наличия связи используются для анализа качественных (номинальных или
порядковых) данных. Давая названия переменным и указывая частоту появления каждой
(например, 20 443 привитых ребенка или 40 000 студентов) или процент наблюдений для
каждой переменной (например, 34 % из 350 приведенных в обзоре госпиталей), мы делаем
сравнение более ясным.
ПРИМЕР
• Табл. 6.1 служит примером «таблицы сопряженности» в анализе с помощью критерия
хи-квадрат. «Тип клиники» указывается в отчете как одна из четырех номинальных
категорий, а «специальность» — как одна из трех номинальных категорий. Клетка
содержит данные (частоту появления), с которыми проводится анализ.
63. Указывайте, какой именно критерий связи вы используете^.
Многие статистические критерии основаны на некотором «распределении вероятности»,
таком как /-распределение, F-распределение, распределение Пуассона и другие —
распределений известно много. Некоторые критерии связи основаны на вероятностном
распределении хи-квадрат. Критерии хи-квадрат обладают гибкостью и широко используются
благодаря тому, что их можно применять во многих видах анализа качественных данных.
Критерий независимости хи-квадрат (также называемый критерием связи хи-
квадрат или критерием хи-квадрат Пирсона) определяет наличие или отсутствие связи
(«независимость») двух качественных переменных. Такой критерий помогает, например,
установить, одновременно ли появились поражения кожи и проблемы с дыханием. Это
может выявить их общую причину или же установить «независимость», т. е. что их
одновременное появление у одного и того же пациента является простым совпадением.
Критерий согласия хи-квадрат используется для определения типичности результатов
исследования качественных переменных путем их сравнения с известными или
стандартизованными результатами. Например, доли четырех групп крови, наблюдаемых в выборке,
можно сравнить с известными долями для всей популяции и выяснить, совпадают ли доли
в выборке с соответствующими долями в популяции.
' Подробные описания критериев связи читатели могут найти в книгах: Кендалл М, Стьюарт А.
Статистические выводы и связи. М., 1973; ФлейсДж. Статистические методы для изучения таблиц долей и пропорций.
М., 1981.
94 Составление статистических отчетов в медицине
Таблица 6,1
Таблица сопряженности для определения взаимосвязи между типом клиники и тремя
хирургическими специальностями
Хирургическая Тип клиники Всего*
специальность
12 3 4
~~~~ 'а ~~~ "Зб" 32 20 14 122
В 13 47 45 34 139
С 27 29 33 45 134
Всего 96 108 98 93 395
^ Итоговые значения в строках и столбцах называются «маргинальными» или «маргинальными суммами».
Критерий хи-квадрат, основанный на этой таблице, дал бы статистику теста 60,95, шесть степеней свободы
(вычисленных по формуле [число строк - 1] умножить на [число столбцов - 1]; в данном случае 2x3 = 6), значение
р < 0,001. Этот результат может привести к выводу, что медицинская специальность связана с типом клиники;
т. е. разные типы клиник имеют тенденцию предлагать разные хирургические специальности. Природа
взаимосвязи тогда определяется исследованием данных. Одно наблюдение может быть подытожено следующим
образом: клиники 1 -го типа имеют тенденцию предлагать специальность А чаще, чем другие типы клиник;
клиники 4-го типа стремятся предлагать специальность С чаще, чем другие типы клиник; клиники типа 2, 3 имеют
тенденцию предлагать специальность В чаще, чем другие типы клиник.
Точные критерии (критерии, имеющие в своих названиях слово «точный», такие как
точный критерий хи-квадрат или точный критерий Фишера) используются с
некоторыми из вышеприведенных целей при работе с малыми выборками. (Здесь «малая выборка»
обычно означает, что число наблюдений, ожидаемых в результате случайных причин, в
некоторых клетках таблицы сопряженности меньше 5.)
Еще одной, хотя и не основанной на распределении хи-квадрат, мерой связи между
двумя качественными переменными является коэффициент фи (обозначается символом ср).
Этот коэффициент меняется в пределах от -1 до +1, где -1 и +1 представляют
соответственно точные обратные и прямые связи, а О означает отсутствие связи. (Такая же шкала
применяется в более общем корреляционном анализе, описывающем взаимосвязи между двумя
непрерывными переменными; см. указание 6.12). Для коэффициента фи можно вычислить
/^-значение и с его помощью определить, существенно ли он отличается от нуля.
Критерий долей хи-квадрат предназначен для групповых сравнений (см. гл. 4). Этот
вид критерия хи-квадрат является критерием не проверки связи, а проверки гипотез.
6.4. Указывайте, является ли критерий одно- или двуаоронним. Обосновывайте
применение односторонних критериев.
Двусторонние критерии более консервативны и более предпочтительны в отсутствие
специального обоснования применения одностороннего критерия.
@ См. указание 4.7: одно- и двусторонние критерии.
6.5. Оговоривайте соответствующие критерию предположения.
Все, что нужно включить в отчет, — это подтверждение определенных предположений.
Многие критерии проверки взаимосвязи основаны на следующих предположениях.
Отчет об анализах связей и корреляций 95
• Данные носят категориальный характер и не являются, например, средними
значениями непрерывных данных. Если доступны непрерывные данные, их следует
проанализировать с помощью критериев соответствующего типа.
• Выборка взята случайным образом.
• Каждая клетка таблицы сопряженности (табл. 6.1) имеет достаточное число ожидаемых
значений. Если какие-либо клетки содержат, скажем, меньше, чем пять, ожидаемых
значений, следует выполнить «точную» проверку с указанием названия критерия.
6.6. Указывайте действительное р-значение критерия.
Действительные значения/> (р = ,..) гораздо более предпочтительнее, нежели
утверждения типа неравенств (р > 0,05,/? < 0,05 и т. п.), с аббревиатурами типа НЗ («незначимо») или
с граничными значениями типа «значимо на уровне 0,05».
Q См. указание 4.15: действительные р-значения.
ф Взаимосвязь не является причинной обусловленностью [3].
Общераспространенной ошибкой при интерпретации связи является вывод о том, что изменение
одной переменной служит причиной изменения другой. Причиной тесной связи
двух переменных может быть на самом деле третья переменная'. Вот пример:
взаимосвязь между смертностью и респираторными заболеваниями значительно
сильнее в юго-западных штатах, хотя сухой 1слимат часто бывает благоприятен для таких
пациентов. Климат не является причиной смертности; он просто привлекает в эти
штаты непропорционально большое число людей с респираторными
заболеваниями. Когда эти люди умирают, частота новых случаев смерти показывает необычно
высокую долю летальных исходов среди людей с респираторными заболеваниями.
б J. Для первоочередных связей исследования указывайте значение статистики
критерия и число степеней свободы.
По данным, относящимся к интересующему нас сравнению, в ходе статистической
проверки вычисляется одно число, называемое статистикой критерия^ Затем статистика
критерия сравнивается с подходящим распределением вероятности (таким, как распределение
хи-квадрат) и вычисляется вероятность (р-значение), связанная с этой статистикой.
Значение р показывает вероятность того, что статистика критерия при условии отсутствия
взаимосвязи случайно примет или превысит полученное в исследовании крайнее значение.
Число степеней свободы — это математическое понятие, помогающее определить, какое
распределение вероятности следует использовать. Например, есть несколько
распределений хи-квадрат, каждое из которых отличается от других иным числом степеней свободы.
Указание в отчете статистики критерия и числа степеней свободы помогает читателям
убедиться в том, что анализ был проведен правильно. Однако на практике составление
полного отчета о статистическом анализе является обременительным и детально нужно
рассказать лишь о взаимосвязях, представляющих первоочередной интерес.
' Либо последовательность признаков, связанных между собой причинно-следственными связями.
^ Само слово «статистика» имеет очень много смыслов. Это и наука, и вид деятельности, и собранные данные
и т. д. Но это еще и конкретные значения результатов вычислений, в данном случае величины статистических
критериев.
96 Составление статистических отчетов в медицине
КОРРЕЛЯЦИОННЫЙ АНАЛИЗ: (ЛИНЕЙНЫЕ) СООТНОШЕНИЯ МЕЖДУ
ДВУМЯ НЕПРЕРЫВНЫМИ ПЕРЕМЕННЫМИ
Образец презентации
Сильная обратная корреляция между уровнем свинца в зубной эмали и доходом семьи
свидетельствует о том, что в организме детей из более бедных семей наблюдается более
высокий уровень свинца (п = 39; коэффициент Пирсона г = -0,62; р = 0,001).
Здесь:
• г указывает на то, что в качестве коэффициента корреляции взят коэффициент Пирсона.
• Коэффициент г в данном случае показывает корреляцию -0,62. Знак минус говорит о
наличии обратной корреляции: одна из переменных возрастает с убыванием другой.
• р — вероятность того, что коэффициент корреляции может случайно принять такое же или
большее значение (без учета знака), если переменные на самом деле не коррелированны.
6.8, Опишите интересующую взаимосвязь.
Корреляционный анализ описывает линейную связь между двумя непрерывными
переменными, которые, как предполагается, изменяются совместно в пределах
соответствующих диапазонов своих значений. Например, сильно и положительно (или прямо)
коррелированны длина шага и рост: более высокие люди делают более широкие шаги, чем люди
меньшего роста.
6.9. Идентифицируйте сравниваемые переменные и охарактеризуйте каждую
из них описательной статистикой.
в корреляционном анализе обе переменные должны быть непрерывными, поэтому
каждую из них можно охарактеризовать мерой центральной тенденции и мерой рассеяния,
такими как среднее и СО или медиана и интерквартильная широта. Эти описательные
статистики особенно необходимо представлять для первоочередных сравнений (см. гл. 1).
ЬЛ О» Укажите используемый коэффициент корреляции.
Приведем некоторые общеупотребительные коэффициенты корреляции:
• Коэффициент корреляции Пирсона /*, который используется для выявления
взаимосвязи между двумя приблизительно нормально распределенными непрерывными
переменными. (В действительности переменные должны удовлетворять совместно
«двумерному нормальному распределению».)
• Коэффициент ранговой корреляции Спирмена, ро (р), применяемый для
выявления взаимосвязи между двумя непрерывными переменными, по крайней мере одна
из которых распределена не по нормальному закону.
• Коэффициент ранговой корреляции Кендалла, тау (т), применяемый для
выявления взаимосвязи между двумя порядковыми переменными или между одной
порядковой и одной непрерывной.
• Точечно-бисериальный коэффициент корреляции, или просто бисериальная
корреляция, применяемый для выявления взаимосвязи между непрерывной переменной
и двухуровневой категориальной переменной.
Отчет об анализах связей и корреляций 97
• Точечно-мультисериальный коэффициент корреляции, применяемый для
выявления взаимосвязи между непрерывной переменной и категориальной переменной
с тремя и более уровнями.
Другие меры связи, применяемые при многократных измерениях или наблюдениях,
полученных от каждого участника исследования, включают внутриклассовые или
межклассовые коэффициенты корреляции, показывающие степень корреляции соответственно
внутри или между оценками.
6.11. Оговорите, что предположения, соответствующие критерию, имеют место.
Все, что нужно включить в отчет, — это утверждение о проверке некоторых
предположений. Эти предположения относятся к шкале измерения, как отмечалось выше при описании
коэффициентов.
6.12. Указывайте значение коэффициента корреляции.
Коэффициент корреляции показывает силу и направление взаимосвязи между двумя
переменными. Коэффициенты корреляции меняются в пределах от -1 до +1, где 1 означает
полную корреляцию, а О — отсутствие корреляции. Отрицательный коэффициент
(например, -0,82) говорит о том, что одна из переменных стремится возрастать с уменьшением
другой, т. е. об обратной связи. Положительный коэффициент (например, +0,75) говорит
о стремлении переменных возрастать или убывать одновременно.
Корреляционный анализ часто изображается графически с помощью «диаграммы
рассеяния» данных (см. рис. 6.1 и 6.2). Диаграмма рассеяния, примерно напоминающая круг,
свидетельствует о слабой или вовсе отсутствующей линейной корреляции. Чем больше
диаграмма рассеяния становится диагональной, эллипсовидной, тем сильнее корреляция.
Иногда корреляции выявляются для нескольких пар переменных. В этом случае
коэффициенты можно представить в стандартной корреляционной матрице (табл. 6.2).
Щ Корреляция — вопрос уровня. Хотя о двух переменных принято говорить как
о «коррелированных», точной границы или значения г, после которой они
«становятся» коррелированными, нет. Пожалуй, вместо того, чтобы говорить о «наличии»
или «отсутствии» корреляции, лучше использовать фразы типа «наблюдалась
умеренная (или слабая, или сильная) корреляция переменных».
Интерпретация результатов также зависит от природы исследования. Значение г, равное
0,7, между весом при рождении и пенсионным доходом через 65 лет было бы
неправдоподобно высоким, поскольку взаимосвязь между этими переменными, очевидно, намного
сложнее, чем можно предположить. С другой стороны, г, равное 0,7, между двумя
лабораторными испытаниями для одной и той же выборки может оказаться низким.
Щ Наличие корреляции не означает наличия причинной связи [4,5]. Качество
почерка и размер обуви сильно коррелируют, но одно, очевидно, не является
следствием другого. И то и другое меняется с возрастом; взросление скорее всего является
истинной «причиной» как улучшения почерка, так и увеличения размера обуви.
Корреляционный анализ выявляет не причины, а лишь взаимосвязи и — до
некоторой степени — силу этих взаимосвязей.
98 Составление статистических отчетов в медицине
Таблица 6.2
Стандартная корреляционная матрица^
Переменная
1
2
3
4
1
г
Р
п
...
...
...
...
2
г
Р
п
-0,24^
ОДО
29
...
Переменная
3
г
Р
п
~0Л7
037
27
-0,22
0,24
28
...
...
4
г
Р
п
0,01
0,94
30
-0,38
0,03
31
0,32
0,08
29
5
г
Р
л
0,009
0,96
30
0,03
0,83
31
-0,11
0,53
29
0,28
0,10
32
^ Для упрощения презентации дубликаты клеток обычно оставляются чистыми (отмечены многоточиями);
п — объем выборки.
^ Здесь корреляция для переменных 1 и 2 равна г = 0,24 (р = 0,20) для 29 субъектов, имеющих значения обеих
переменных, где г— коэффициент корреляции, р — значение вероятности.
6.13. Указывайте для корреляции достигнутое р-значение.
Все р-значения приводите до двух значащих цифр. Избегайте выражений типа «р
меньше, чем» или «р больше, чем». Значение р для коэффициента корреляции является
результатом проверки нулевой гипотезы о том, что «истинный» коэффициент равен нулю, т. е.
что между двумя переменными нет линейной связи. Значение р ничего не говорит о
клинической важности или силе взаимосвязи [6]. При проверке значимости значение г обычно
сравнивается с нулем, но можно рассчитать вероятность того, что г отличается от любого
значения между +1 и -1.
6.14. При проведении первоочередных сравнений указывайте (95%-й)
доверительный интервал для коэффициента корреляции независимо от того,
является ли он статистически знaчимым^
Те коэффициенты корреляции, которые не являются статистически значимыми, нужно
интерпретировать в свете статистической мощности критерия ради отыскания клинически
' Доверительный интервал для коэффициента корреляции является несимметричным и для своей оценки
требует выполнения так называемого преобразования Фишера, приводящего распределение преобразованной величины
к асимптотически нормальному распределению. Детали построения доверительного интервала для коэффициента
корреляции достаточно подробно описаны во многих изданиях, приведенных в Приложении к русскому переводу.
Достаточно подробно эта процедура описана в книге Э. Ферстер, Б. Реиц. Методы корреляционного и
регрессионного анализа. М., 1983. С. 177-180.
Отчет об анализах связей и корреляций 99
важного значения г. Доверительные интервалы полезны тем, что имеют отношение к
адекватности объема выборки, и результатом изучения выборок с большими объемами
являются более узкие доверительные интервалы.
ф См. указание 3.1: указание в отчете доверительных интервалов.
бЛ 5. При проведении первоочередных сравнений включайте диаграмму
рассеяния данных.
Графическое представление взаимосвязи между двумя переменными часто упрощает
понимание этой взаимосвязи. На рис. 6.1 показаны две сильно (линейно) коррелированные
переменные; на рис. 6.2 показаны две слабо (линейно) коррелированные переменные.
ф Корреляцию следует оценивать не визуально, а математически [7].
Литература
1. Godfrey К. Simple linear regression in medical research. In: Bailar JC, Mosteller F, eds. Medical
Uses of Statistics, 2nd ed. Boston: NEJM Books; 1992:201-32.
2. Altman DG, Bland JM. Measurement in medicine: the analysis of method comparison studies.
Statistician. 1983; 32:307-17.
3. Murray GD. Statistical guidelines for the British Journal of Surgery. Br J Surg. 1991; 78:782-4.
4. Altman DG, Gore SM, Gardner MJ, Pocock SJ. Statistical guidelines for contributors to medical
journals. BMJ. 1983; 286:1489-93.
5. Schoolman HM, BecktelJM, Best WR, Johnson AE. Statistics in medical research: principles versus
practices. J Lab Clin Med. 1968; 71:357-67.
6. Sheehan TJ. The medical literature: let the reader beware. Arch Intern Med. 1980; 140:472-4.
7. Badgley RE An assessment of research methods reported in 103 scientific articles from two Canadian
medical journals. Can Med Assoc J. 1961; 85:246-50.
100 Составление статистических отчетов в медицине
Глава 7
Предсказание значений, зависящих
от одной или более переменных
Отчет о регрессионном анализе
Коэффициент линейной регрессии говорит о влиянии, которое оказывает
на общий исход каэюдая из независимых переменных в контексте (или в
«подгонке» по ним) всех остальных переменных.
J. CoNCATO, А. R. Feinstein, т. R. Holford [1]
Регрессионный анализ' — это область статистики, пытающаяся предсказать или оценить
значение (зависимой) переменной отклика по известным значениям одной или нескольких
(независимых) предикторных переменных. Анализ, в котором используется одна преди-
кторная переменная, называется простой регрессией; если же используется совокупность
предикторных переменных, он называется множественной регрессией. Если переменная
отклика является бинарной (двоичной) категориальной переменной (такой, как болен —
не болен), такой анализ называется логистической регрессией. Если переменная отклика
непрерывна и линейно связана с независимой переменной (переменными), такой анализ
называется линейной регрессией. Как линейный, так и логистический регрессионный
анализы могут быть простым или множественным, в соответствии с вышесказанным.
В типичном случае исследователь соберет данные по нескольким возможным предиктор-
ным переменным, определит, какие переменные наиболее сильно связаны с переменной
отклика, и затем включит эти переменные в математическую модель (уравнение регрессии).
Другими словами, модель «подгоняется» под данные. Таким образом, цель множественного
регрессионного анализа состоит, по существу, в том, чтобы выяснить, какое сочетание
предикторных переменных наилучшим образом предсказывает значение переменной отклика.
Регрессионный анализ можно применять для «контроля за» возможными совместными
воздействиями независимых предикторных переменных, связанных с переменными
отклика. Регрессионный анализ может, например, отделить друг от друга влияние, скажем,
возраста и пола на выживаемость после операции. Еще его можно использовать при создании
индексов риска. Индекс риска комбинирует несколько переменных в единственный
показатель, который связан со специфическим исходом или специфической вероятностью бо-
1 Без преувеличения можно сказать, что регрессионный анализ является одним из стержневых, ведущих
методов прикладной статистики. Несмотря на долгую историю этого метода, он и в настоящее время интенсивно
развивается. Благодаря своим уникальным возможностям он щироко применяется во многих отраслях знания. См.:
Corlett Т. Ballade of Multiple Regression // Journal of the Royal Statistical Society. Series С (Applied Statistics). Vol. 12.
No. 3. P. 145. С содержанием баллады читатели могут ознакомиться по адресу: http://www.research-network.org.uk/
resources/winterOS .pdf
Отчет о регрессионном анализе 101
лезни. Здесь переменные для индекса риска — предикторы из уравнения регрессии, а сам
индекс — значение, предсказанное регрессионной моделью.
Модели регрессии тесно связаны с другим классом статистических моделей,
называемых моделями ANOVA. Обычно множественный регрессионный анализ используется при
работе с непрерывными предикторными переменными, тогда как ANOVA — при анализе
категориальных предикторных переменных. Когда исследование включает как
непрерывные, так и категориальные предикторные переменные, анализ обычно называется
множественным регрессионным, а иногда — ковариационным (ANCOVA). ANCOVA обычно
используется там, где главный интерес представляют категориальные предикторные
переменные и где необходимо контролировать влияние мешающих переменных — либо
категориальных, либо непрерывных. Указания по отчету об ANOVA даны в гл. 8.
Существует несколько видов регрессионного анализа.
• Простая линейная регрессия используется для оценки связи между одной
непрерывной предикторной переменной и одной переменной отклика (зависимой переменной),
линейно меняющейся в некотором диапазоне значений {см. указания 7.1-7.10),
• Множественная линейная регрессия используется для оценки линейной связи
между двумя или более непрерывными или категориальными переменными и одной
непрерывной зависимой переменной отклика {см. указания 7.11-7.22).
• Простая логистическая регрессия используется для оценки связи между одной
непрерывной или категориальной предикторной переменной и одной категориальной
обычно бинарной переменной отклика, например имел или не имел место сердечный
приступ {см. указания 7.23-7.30).
• Множественная логистическая регрессия используется для оценки связи между
двумя или более непрерывными или категориальными предикторными переменными
и одной категориальной переменной отклика {см. указания 7.31-7.42).
• Нелинейная регрессия используется для оценки переменных, связанных
нелинейной зависимостью, которая, как правило, не трансформируется в линейную. Эти
уравнения моделируют более сложные взаимосвязи по сравнению с другими формами
регрессионного анализа.
• Полиномиальная регрессия может использоваться для любой из вышеприведенных
комбинаций предикторных переменных и переменных отклика, если они связаны
такой криволинейной зависимостью, которая требует, скажем, возведения в квадрат или
в куб одной или более предикторных переменных модели.
• Регрессия пропорциональных рисков Кокса — разновидность анализа времени
(выживания) до наступления некоторого события, используется для оценки связи
между двумя или более непрерывными или категориальными переменными и одной
непрерывной переменной отклика (время до наступления этого события). В типичном
случае событие (обычно смерть) еще не произошло в отношении всех участников
выборки, что создает цензурированные наблюдения {см. гл. 9),
• Мета-регрессия — это приложение регрессионного анализа, используемое в
сочетании с метаанализом. Здесь точки данных являются результатами отдельных
исследований, включенных в метаанализ {см. гл. 17).
Здесь мы даем указания по составлению отчетов о первых четырех типах
регрессионного анализа, наиболее широко применяемых в медицине. Некоторые из этих указаний
применимы более чем к одному типу; мы продублировали их там, где это необходимо, чтобы
102 Составление статистических отчетов в медицине
сделать каждый набор указаний самодостаточным. Пояснения и указания по нелинейному
и полиномиальному анализу остаются вне пределов данной книги. Регрессия Кокса, в силу
своей распространенности в медицинских исследованиях, описана отдельно в гл. 9,
поскольку включает в себя разные виды переменной отклика.
ПРОСТОЙ ЛИНЕЙНЫЙ РЕГРЕССИОННЫЙ АНАЛИЗ
Предсказание значений одной непрерывной переменной отклика,
зависящей от одной непрерывной предикторной переменной
Образец презентации
Мы попытались предсказать изменение уровня сыворотки в зависимости от веса у 453
испытуемых с помощью простого линейного регрессионного анализа. Угловой коэффициент
линии регрессии был значительно больше нуля, что указывало на рост уровня сыворотки
одновременно с увеличением веса (угловой коэффициент = 0,25,95% ДИ 0,19-0,31,4^51 - ^'^'
р < 0,001; Y = 12,6 + 0,25Х; г^ = 0,67).
Здесь:
• 453 — объем выборки.
• 0,25 — угловой коэффициент линии регрессии; он появляется также в уравнении
регрессии в качестве коэффициента при предикторной переменной X (вес). Коэффициент
0,25 означает, что на каждый дополнительный килограмм веса среднее значение уровня
сыворотки возрастает на 0,25 мг/дл.
• 95% ДИ оценивает диапазон, в котором угловой коэффициент, скорее всего, окажется
в 95 из 100 подобных исследований. Этот интервал не содержит нуля, что указывает на
статистическую значимость результатов на уровне 0,05.
• 8,3 — значение статистики критерия Стьюдента из t-распределения с 451 степенью
свободы, использованной для определения достигнутого уровня р-значения.
• р — вероятность получить крайнее или выходящее за крайние пределы значение
углового коэффициента по сравнению с наблюдаемым, если на самом деле между переменными
нет линейной связи. Следовательно, малое значение р (меньшее, чем 0,05) является
свидетельством против нулевой гипотезы, которая заключается в равенстве углового
коэффициента нулю.
• Линия регрессии описана уравнением, в котором Y — предсказываемое значение при
данном X на изучаемом интервале его изменения; 12,6 ~~ значение Y, в котором линия
регрессии пересекает ось Y (точка пересечения с осью У) в случае, когда X = О кг, находится
в интервале изменения данных; 0,25 — угловой коэффициент линии регрессии; X —
значение, в зависимости от которого делается предсказание. Числа 12,6 и 0,25 называются
коэффициентами регрессии. В большинстве статистических проверок рассматривается
коэффициент регрессии для предикторной переменной, т. е. угловой коэффициент. Как отмечалось
выше, коэффициент 0,25 означает, что с каждым добавочным килограммом веса средний
уровень сыворотки возрастает на 0,25 мг/дл.
• г^ — это коэффициент детерминации (квадрат коэффициента корреляции для
диаграммы рассеяния данных), указывающий на то, что 67 % изменчивости уровня сыворотки,
вероятно, следует объяснить его взаимосвязью с изменчивостью веса. Это мера «согласия»
модели с данными.
Отчет о регрессионном анализе 103
7.1. Опишите интересующую вас взаимосвязь или цель анализа.
Простой линейный регрессионный анализ используется для проверки линейности
взаимосвязи между одной предикторной переменной и одной переменной отклика, или
стремления одной переменной изменяться вместе с другой. Простой линейный
регрессионный анализ можно также использовать для предсказания значения переменной отклика
по предикторной переменной. К примеру, с его помощью можно оценить взаимосвязь
возраста с уровнем холестерина и предсказать уровень холестерина в крови в зависимости
от возраста.
72. Идентифицируйте каждую используемую в сравнении переменную и
охарактеризуйте ее описательной статистикой.
Для простого линейного регрессионного анализа требуется две непрерывные
переменные. Одна из них должна быть идентифицирована как предикторная, другая — как
переменная отклика. Распределение каждой из них следует охарактеризовать центральной
мерой (например, средним) и мерой рассеяния (например, СО).
73, Оговорите сделанные для простого линейного регрессионного анализа
предположения и способы их проверки.
Все, что нужно включить в отчет, — это подтверждение некоторых предположений. Для
простого регрессионного анализа они состоят в следующем.
• Зависимость между X и Y линейна во всем диапазоне исследуемых значений.
• Распределения Y имеют равные дисперсии (или СО) при каждом значении X; иными
словами, СО Y одинаково вне зависимости от значения X.
• Каждое значение У независимо от остальных значений У'.
• Переменная отклика У распределена нормально при каждом значении предикторной
переменной X.
Для проверки этих предположений существуют как формальные (например, проверки
статистических гипотез), так и неформальные процедуры (например, просмотр графиков
распределения остатков; см. рис. 21.26). Данные, для которых эти предположения
нарушаются, иногда можно скорректировать (например, при помощи преобразования данных).
Такого рода корректировки должны оговариваться особо.
7.4. Укажите, каким образом рассматривались аномальные значения (выбросы).
Выбросы — это экстремальные значения, которые кажутся аномальными. Игнорировать
выбросы нельзя; они в действительности могут указать на особые случаи, открывающие
новые области исследования. Однако они могут оказать непропорциональное воздействие
на результаты регрессионного анализа. В отчете следует сообщать обо всех выбросах,
но иногда допустимо анализировать данные и без них, если для такого игнорирования есть
законные основания. Но это должно быть отражено в отчете вместе с причинами
игнорирования аномальных значений (например, загрязненные образцы или неоткалиброванное
оборудование). Если игнорировать выбросы на законных основаниях нельзя, то ради
демонстрации их влияния допустимо привести результаты и с выбросами, и без них.
' в данном случае авторы не вполне корректны. Независимыми между собой должны быть не сами значения Y,
а отклонения этих значений от величин, предсказанных по уравнению регрессии, так называемые невязки.
104 Составление статистических отчетов в медицине
^ «Даже единичный выброс может оказать глубокое влияние на взаимосвязь,
выводимую из линии регрессии» [2,3].
7.5. Приведите уравнение линейной регрессии.
Линия регрессии описывается уравнением прямой (или «моделью»):
Y = a + bX,
где Y— предсказываемое значение переменной отклика, а — свободный член, точка, в
которой линия регрессии пересекает ось Y, b — угловой коэффициент линии регрессии, а X —
предикторная переменная, с помощью которой предсказываются значения Y.
По данному значению предикторной переменной X можно вычислить соответствующее
значение У. Таким образом, наиболее вероятное значение Y можно предсказать для всякого
значения X в пределах изучаемого диапазона.
В то время как коэффициент корреляции г показывает направление и силу взаимосвязи
между двумя переменными, коэффициент регрессии при предикторной переменной
(угловой коэффициент линии регрессии или b в уравнении регрессии, рис. 7.1) показывает,
насколько среднее значение переменной отклика Y меняется с каждой единицей изменения
предикторной переменной X.
Уравнение можно привести в тексте или на диаграмме рассеяния данных (см. указание 7.9),
л = 25
г" = 0,81
р = 0,05
Y = 0,03 + 1,07X
Z
(U
Q.
(U
го
S
Z
о»
Q.
Остатки
Точки
данных
Линия регрессии
■ 95%-я
доверительная
полоса
для линии
регрессии
Предикторная переменная, единицы измерения
Рис. 7.1. Гипотетическая диаграмма рассеяния, на которой отмечены компоненты графического
представления регрессионного анализа. 95% ДИ вокруг линии регрессии (доверительная полоса) указывает на пригодность
данной модели. Эти полосы непригодны для предсказания отдельных или средних откликов; они скорее
предназначены для демонстрации точности линии регрессии [8]. Доверительные полосы расширяются на концах линии
вследствие того, что на концах диапазона измеряемых значений обычно имеется меньшее количество точечных
наблюдений, и это уменьшает точность оценок на каждом конце диапазона. В левом верхнем углу рисунка даны
также компоненты математического анализа регрессии: п — объем выборки, г^ — коэффициент детерминации,
р — значение вероятности, полученное при проверке гипотезы о равенстве углового коэффициента нулю, а Y —
значение переменной отклика, предсказанное, согласно вышеприведенному, из уравнения регрессии
Отчет о регрессионном анализе 105
7.6. Укажите действительное значение р и (95%-й) доверительный интервал для
коэффициента регрессии при предикторной переменной.
Коэффициент для предикторной переменной в уравнении простой линейной регрессии
(угловой коэффициент линии регрессии) является мерой взаимосвязи между двумя
переменными. Линия регрессии, у которой он равен нулю, — горизонтальная линия, означает
отсутствие линейной зависимости между переменными: значение переменной отклика Y
одинаково для всех значений предикторной переменной X. Таким образом, нулевой
угловой коэффициент становится нулевой гипотезой, которую следует проверить. Иными
словами, /7-значение показывает вероятность получить данную или большую величину
углового коэффициента, если на самом деле между переменными нет линейной связи. Кроме
того, угловой коэффициент линии регрессии — всего лишь оценка, и точность этой оценки
следует указывать при помощи доверительного интервала {см. гл. 3).
7 J. Представьте меру «согласия» модели с данными [4].
На предсказательное значение модели регрессии влияет то, насколько хорошо она
«подходит» к данным. Таким образом, мера «согласия» полезна своим свойством выявлять,
насколько хорошо модель отражает данные, по которым она была создана. Меры согласия
включают коэффициенты корреляции и ассоциированные с ними/;-значения,
коэффициент детерминации (/^) и его ассоциированное/7-значение, оценки остатков и
выбросов, стандартную ошибку, среднеквадратичную ошибку стандартного отклонения
остатков, чувствительность и специфичность модели, а также результаты применения любого
из нескольких критериев согласия или отсутствия согласия.
Простой линейный регрессионный анализ можно рассматривать как расширенный
корреляционный анализ, за исключением того, что теперь одна переменная используется для
предсказания поведения другой с добавлением линии регрессии. Как и при
корреляционном анализе (см. гл. б), взаимосвязь полезно иллюстрировать при помощи диаграмм
рассеяния (см. рис. 7.1). Сам коэффициент корреляции может косвенно показывать,
насколько хорошо способна предсказывать модель. Если простая линейная регрессионная модель
предназначена для предсказания с той или иной степенью точности, корреляции должны
превышать, скажем, 0,7 и быть статистически значимыми.
Коэффициент корреляции, связанный с диаграммой рассеяния, бывает также полезным
в виде коэффициента детерминации (/^). Эта мера определенности показывает, в какой
степени изменчивость, вариабельность переменной отклика объясняется вариабельностью
предикторной переменной. Например, если корреляция между толщиной кожной складки
и количеством туловищного жира равна 0,8, то г^ = 0,64, или 64 %. Это значит, что 64 %
изменчивости количества туловищного жира может объясняться изменчивостью толщины
кожной складки. Значение г^, равное 1, означает, что все точечные наблюдения попадают
на линию регрессии, тогда как его равенство нулю означает, что предикторная переменная
(X) не является линейно связанной с переменной отклика (Y).
Даже значение коэффициента 0,7 объясняет только около половины интересующей нас
изменчивости (г^ = 0,7 X 0,7 = 0,49 = 49 %). Поэтому корреляция, скажем, г = 0,3 может
не быть клинически полезной, поскольку одна переменная объясняет слишком малую часть
изменения (здесь Н = 9 %). При других же обстоятельствах объяснение одной переменной
9 % изменчивости зависимой переменной может оказаться прорывом.
106 Составление статистических отчетов в медицине
^ Коэффициент детерминации (/^), применяемый в простом регрессионном
анализе, аналогичен коэффициенту множественной детерминации (jR^),
применяемому во множественном регрессионном анализе, но имеет отличие. Строчная
буква г говорит о наличии только двух переменных (одной предикторной и одной
переменной отклика); заглавная R говорит о более чем двух переменных (более
одной предикторной и одной переменной отклика).
^ Коэффициент корреляции и коэффициент детерминации в регрессионном
анализе описывают влияние предикторной переменной (X) на переменную
отклика (Y); они не описывают влияние Y на X [2,5].
Остаток (невязка) — это разность между значением, предсказанным моделью, и
реальным значением полученной точки наблюдения. Чем меньше остаток, тем лучше
предсказание. Остатки можно также изобразить графически, чтобы выяснить, насколько хорошо
удовлетворяется предположение линейности {см. рис. 21.26). Таким образом, график остатков
(один из видов «диагностических графиков модели»), на котором их значения малы для
всех значений X, подразумевая, что они остаются близкими к нулевой средней разности,
показывает, что предположение линейности справедливо и что модель способна к
предсказанию с приемлемым качеством. Оценки выбросов действуют так же, как оценки остатков,
по той причине, что они и относящиеся к ним остатки изображены на рисунке как те точки
наблюдений, которые подлежат исследованию.
Более сложной мерой согласия является среднеквадратичная ошибка (известная также
как стандартное отклонение отстатков). Среднеквадратичная ошибка вычисляется путем
извлечения квадратного корня из среднего арифметического квадратов остатков. Она
выражается в тех же единицах, что и данные, а не в квадратных единицах, и представляет
величину «типичной» ошибки модели.
Согласие регрессионной модели может также выражаться ее способностью давать
правильные предсказания, например на каких пациентов препарат оказывает действие, а на
каких — нет. В данном случае можно найти чувствительность, специфичность или
диагностическую точность модели: ее способность правильно идентифицировать тех пациентов,
на которых препарат окажет действие (чувствительность), тех, на кого препарат не окажет
действия (специфичность), или общую долю правильных решений (диагностическая
точность). {См. указание 10.8.)
Формальные критерии согласия рассчитывают р-значение. Если оно статистически
значимо, модель плохо согласуется с данными. К общепринятым критериям можно отнести
критерии согласия хи-квадрат, Хосмера—^Лемешова, Колмогорова—Смирнова, Крамера—
Смирнова—фон Мизеса и Андерсона—Дарлинга.
7.8, Определите, была ли модель обоснована.
Регрессионные модели можно обосновать или протестировать на похожем множестве
данных, с тем чтобы показать, что они объясняют то, что должны объяснить.
• Один из методов обоснования, применяемый для больших выборок, состоит в том,
чтобы построить модель, скажем, на 75 % данных, а затем составить другую модель
для оставшихся 25 % и выяснить, оказались ли модели схожими.
• Другой метод заключается в удалении данных от каждого объекта по очереди и
пересчете модели. Затем оцениваются коэффициенты и предсказательные обоснованности
Отчет о регрессионном анализе 107
всех полученных при этом моделей. Такие методы известны под названием методов
складного ножа (англ. —jackknife).
• Третий метод заключается в создании другой модели на отдельном множестве
похожих данных. После этого определяется, есть ли между этими моделями какие-либо
отличия.
7.9. Для первоочередных сравнений включите в отчет диаграмму рассеяния
данных, линию регрессии и (95%-й) доверительный интервал (или полосу
предсказания) линии регрессии.
При простом линейном регрессионном анализе, так же как и при корреляционном,
данные можно изобразить в виде диаграммы рассеяния (см. рис. 6.1 и 6.2) с проведенной через
них линией регрессии (см. рис 7.1). Рисунок такого рода покажет:
t наличие выбросов;
t является ли взаимосвязь на самом деле линейной (хотя линейность следует оценивать
математически, а не визуально);
• ширину (95%-й) доверительной полосы вокруг линии регрессии, что указывает на
соответствие подгонки. Доверительные полосы показывают точность наклона линии
регрессии, а не индивидуальные значения или предсказания.
ф Не удлиняйте линию регрессии за пределы данных [6-8]. Линия регрессии
имеет силу только в диапазоне тех данных, по которым она вычисляется. Поскольку
многие взаимосвязи линейны только внутри определенных диапазонов, неразумно
предполагать, что линия регрессии останется неизменной при более низких или
более высоких значениях предикторной переменной (рис. 7.2).
ф Поскольку линия регрессии не должна продолжаться за пределы данных, она
не должна проходить через ось Y, если X не может принимать значение 0. При
графическом представлении исхода в зависимости от веса последний не может
принимать значение О, поэтому прямая не должна пересекать ось Y, несмотря на то что
точка пересечения с осью Y существует для всякого уравнения простой линейной
регрессии (рис. 7.2).
@ Убедитесь, что число точек наблюдения на рисунке соответствует количеству
включенных в отчет наблюдений. В дополнение к обычному стремлению к
точности подсчет отмеченных значений может выявить случайно пропущенные выбросы.
7.10. Укажите название применяемого при анализе статистического пакета или
программы.
Указание программного пакета, использованного в статистическом анализе, важно
по следующим соображениям: если коммерческие пакеты обычно бывают
легализованными и обновленными, то создаваемые в частном порядке программы — не всегда. Кроме
того, не всякое статистическое программное обеспечение использует одинаковые
алгоритмы или опции по умолчанию при вычислении одной и той же статистики. Вследствие этого
результаты могут варьироваться от пакета к пакету или от алгоритма к алгоритму,
В числе наиболее используемых пакетов находятся SAS (Statistical Analysis Systems),
BMDP, SPSS (Statistical Package for the Social Sciences), StatXact, Stat View, StatSoft, InStat,
Statistical Navigator, SysStat, Minitab, LISPJEL, EQS, EGE и GLIM.
108 Составление статистических отчетов в медицине
(С
I
(U
Q.
(U
го
Z
=Г
X
0)
ОС
fD
X
X
(U
(U
Q.
Ф
С
п = 25
г2 = 0,81
р = 0,05
Y = 0,03 + 1,07X
.-••'*
^^
г
^^у""^ Если линию
предполагается удлинить
до пересечения с осью Y,
то это означает
возможность принятия
значений, близких нулю
•
/■^
Линия регрессии имеет силу
лишь в том диапазоне данных,
который рассматривался в
анализе; здесь — от 6 до 21 кг
12 15
Вес, кг
18
21
24
27
30
Рис. 7.2. Гипотетическая линия регрессии с некорректным удлинением за пределы данных в обоих
направлениях. Вес, к примеру, не может быть равным О кг, поэтому левый конец линии не должен пересекать ось У; кроме
того, связь может оказаться нелинейной для больших значений веса, поэтому правый конец линии не должен
продолжаться за пределы диапазона данных
МНОЖЕСТВЕННЫЙ ЛИНЕЙНЫЙ РЕГРЕССИОННЫЙ АНАЛИЗ
Предсказание одной непрерывной переменной отклика по двум и более
непрерывным предикторным переменным
Образец презентации
Нами разработана модель для предсказания значения полной функции Y для пациентов
с множественным склерозом на основе степени тяжести болезни Х^ (уровень 1 —
наименее тяжелая форма, 15 — наиболее тяжелая), способности передвигаться (скорость
ходьбы, выражаемая в количестве пройденных дорожек в минуту) Х^ и количества поражений
Xj. Окончательная модель имела /?^ равное 0,58: Y = 40,8 + 3,98Х^ + 1,22X2 ~ 2,09X3.
Продолжение на след, стр.
Отчет о регрессионном анализе 109
Образец презентации (продолжение)
Здесь:
• Y —- переменная отклика, значение полной функции.
• Х^, Xj и Хз — предикторные переменные (иногда их называют факторами риска),
• Числа, стоящие перед X, ^ з' называются коэффициентами регрессии, или бета-весами.
Коэффициенты интерпретируются так: если Х^ и Х^ остаются постоянными (или
«фиксируют» тяжесть болезни и количество поражений), то среднее значение функции вырастает
примерно в один с четвертью раза (1,22, коэффициент при Х^) на каждую дополнительную
дорожку в минуту (табл. 7.1).
• Коэффициент множественной детерминации /?^ показывает ту долю суммарной
вариации переменной отклика, которая объясняется с помощью данной модели. Здесь
значения трех переменных объясняют 58 % изменчивости переменной отклика.
Таблица 7,1
Табличный отчет о множественной линейной регрессионной модели с тремя предикторными
переменными
Переменная
Коэффициент Стандартная
(Р) ошибка
95% ДИ
Статистика
критерия
Вальда х^
Свободный член
X.
х^
Хз
40,79
3,98
1,22
-2,09
2,55
2,37
0,29
0,28
—
-0,67...+8,63
0,66-1,80
-2,64...-1,54
—
1,68
4,20
-7,34
—
0,10
< 0,001
< 0,001
Свободный член — математическая константа, не имеющая клинической интерпретации;
Х^-Хз — три предикторные переменные;
коэффициент — весовое значение предикторной переменной в уравнении; коэффициент регрессии, или
бета-вес;
стандартная ошибка — оценка точности коэффициентов;
95% ДИ — 95%-е доверительные интервалы для коэффициентов;
статистика критерия Вальда ;^^ вычислена по данным для сравнения с распределением хи-квадрат с одной
степенью свободы;
р-значение — переменные 2 и 3 являются статистически значимыми независимыми переменными для
переменной отклика.
7.11. Опишите интересующую взаимосвязь или цель анализа [9].
7.12. Идентифицируйте сравниваемые переменные и снабдите каждую из них
описательной статистикой.
Переменная отклика в множественном линейном регрессионном анализе
является непрерывной, а предикторные переменные могут быть либо категориальными, либо
непрерывными.
110 Составление статистических отчетов в медицине
7Л 3. Оговорите сделанные для множеавенного линейного регрессионного
анализа предположения и способы их проверки [9].
Все, что нужно включить в отчет, — это подтверждение некоторых допущений. Для
множественного регрессионного анализа они представляют собой обобщения допущений,
сделанных ранее для простого линейного регрессионного анализа.
• Зависимость между каэюдым из X и Y линейна во всем диапазоне исследуемых
значений.
• Распределения Y имеют равные дисперсии (или СО) при каж:дом значении каэюдого
из X; иными словами, СО Y одинаково вне зависимости от значения X.
• Каждое значение Y независимо от других для каэюдого значения каждого X.
• Переменная отклика У распределена нормально для каждого значения каждой преди-
кторной переменной Х^, Х2, Х3 и т. д.
7,14. Укажите, как в анализах изучались выбросы [9].
^ См. указание 7.4: рассмотрение выбросов в данных.
7Л 5. Укажите, как в анализах изучались пропуски [9].
Пропуски могут стать проблемой в регрессионном анализе, потому что они уменьшают
объем выборки, если не приняты меры коррекции. Например, при создании модели
предсказания веса по возрасту и росту значения каждой из этих переменных должны быть
собраны для каждого пациента. Пациент, данные о возрасте которого отсутствуют,
исключается из анализа, и объем выборки уменьшается на единицу. Потери вследствие пропусков
в регрессионных моделях с несколькими переменными могут быть обычным делом'.
Однако иногда недостающие данные можно восстановить с помощью процедуры
восстановления (реконструкции). Методы простого восстановления включают
использование средних всех наблюдаемых значений, вместо пропущенных значений;
использование среднего наблюдаемого значения для того же субъекта в другое время; использование
среднего между предыдущим и последующим значениями для этого субъекта, если они
существуют; или использование самого последнего наблюдаемого значения для данного
субъекта (метод переноса последнего наблюдения, обычно применяемый в
фармацевтических исследованиях).
Регрессионное восстановление включает в себя создание регрессионной модели для
предсказания пропущенных значений. При восстановлении методом «горячей колоды»
(«hot deck») все наблюдения делятся на группы с похожими характеристиками, такими как
«белые мужчины в возрасте от 18 до 25 лет». Пропущенное значение заменяется значением
этой же переменной, случайно выбранным среди мужчин этой группы.
В модели пропусков для «данных с пропусками» создается переменная, и данные
анализируются так, как если бы «пропуск» был просто другой категорией этой переменной.
Например, в качестве четырех категорий тяжести заболевания можно определить
умеренное, средней тяжести и тяжелое заболевания, а также отсутствие болезни. Преимущества
' Еще сложнее решение этой проблемы в случае множественного регрессионного анализа. Чем больше пре-
дикторных переменных, тем больше наблюдений, которые имеют хотя бы один пропуск по той или иной
переменной. В результате все меньшая доля полностью измеренных наблюдений может принять участие в оценке
параметров уравнения регрессии. И для нахождения оптимального компромисса в этой ситуации, позволяюшего
минимизировать возможные потери информации и получить при этом достаточно интересные и надежные
регрессионные модели, от биостатистика требуется огромный опыт и большой объем работы.
Отчет о регрессионном анализе 111
этого метода состоят в том, что ни один случай не выпадает из анализа и что незамеченное
сходство между людьми с пропущенными значениями будет охвачено новой категорией.
Возможны и другие методы восстановления, но они должны базироваться на надежных
обоснованиях.
Во всяком случае, сравнивать пациентов с пропусками и с полными данными всегда
полезно. Если, к примеру, пациенты с пропусками и с полными данными схожи по возрасту,
полу, расе, истории болезни и, возможно, иногда даже по исходам болезни и т. д., то
пропуски, вероятно, не будут представлять собой проблемы.
7.16. Отметьте, каким образом выбирались предикторные переменные,
появляющиеся в итоговой модели [9].
Одним из первых шагов при построении множественной регрессионной модели
является идентификация предикторных переменных, значимо связанных с переменными отклика.
В этом процессе, называемом одномерным анализом, могут рассматриваться несколько
дюжин переменных по одной за один раз. Часто в одномерном анализе для идентификации
широкого диапазона предикторных переменных, которые могут быть связаны с
переменной отклика, используется менее ограничительный уровень альфа, такой как 0,1. Это
означает, что в одномерном анализе переменные ср-значением, меньшим 0,1, рассматриваются
на предмет включения в модель.
Если модель находится в центре внимания статьи, может оказаться полезным отразить
в отчете результаты одномерного анализа. Переменные можно перечислить в таблице
вместе с подходящими описательными статистиками (т. е. средним и СО или медианой и ин-
терквартильной широтой) и /^-значениями для их взаимосвязи с переменной отклика.
Второй шаг в построении регрессионной модели заключается в идентификации наилучшей
комбинации предикторных переменных, включаемых в модель. При одновременной
регрессии все предикторные переменные включаются в модель и тестируются одной группой. При
иерархической регрессии исследователь определяет количество предикторных переменных
и порядок, в котором они вводятся в модель. Обычными процедурами являются прямая,
обратная, пошаговая методики, а также методика выбора наилучшего подмножества предикторов.
При прямом отборе переменных предикторные переменные добавляются к модели
по одной за один шаг, начиная с той переменной, которая сильнее всего связана с
переменной отклика (переменная с наименьшим значением /?, определенным в ходе одномерного
анализа). После добавления каждой переменной рассчитывается модель и определяется
влияние этой переменной на /?^. Процесс прекращается тогда, когда добавление
переменных больше не улучшает значение R^. При обратном отборе переменных модель сначала
рассчитывается со всеми возможными предикторными переменными (как и при
одновременной регрессии), а затем вычисляется заново после удаления переменной с наименее
значимой взаимосвязью с переменной отклика. Процесс продолжается до тех пор, пока в
модели не останутся только статистически значимые переменные. Пошаговый отбор включает
в себя сочетание прямого и обратного отбора, что позволяет переменным попадать в модель
или выходить из нее (прямой или обратный отбор) на любом этапе процесса'.
' Нередко для того, чтобы найти несколько интересных и надежных уравнений регрессии, приходится,
используя различные комбинации многих опций и алгоритмов оценок, находить десятки, а то и сотни уравнений. Следует
отметить, что подобная технология трудно формализуема и требует как большого практического опыта работы
с пакетами, имеющими внутренний язык программирования, так и творческого подхода к выбору
последовательности используемых алгоритмов.
112 Составление статистических отчетов в медицине
Ограниченность этих методик отбора состоит в том, что они предполагают
существование единственного «наилучшего подмножества» предикторных переменных. Однако
в большинстве случаев никакого единственного «лучшего» подмножества не существует.
Q Эмпирическое правило определения объема выборки, необходимого для
надежного применения рассмотренных методик построения модели, состоит
в том, что отношение числа наблюдений к числу переменных должно быть
не менее 10 к 1 [9]. Так, модель с 5 предикторными переменными должна
основываться на выборке объемом не менее 50 пациентов'.
7.17. Укажите, все ли возможные предикторные переменные прошли проверку
на коллинеарноаь (независимость) [9].
Предикторные переменные в уравнении множественной линейной регрессии должны
быть независимы друг от друга. Если две или более предикторных переменных
коррелированны, т. е. если их линии регрессии параллельны («коллинеарны»), они не являются
независимыми. Кол линеарные переменные прибавляют к модели во многом одинаковую
информацию, и поэтому нужна только одна из них. На предмет включения в
окончательный вариант модели должна рассматриваться переменная с наиболее сильной
взаимосвязью с переменной отклика.
^ Отказ от определения кореллированных переменных может сделать
результаты анализа недействительными.
7Л 8. Укажите, проверялись ли предикторные переменные на взаимодействие.
Две предикторные переменные называются взаимодействующими, если влияние одной
предикторной переменной на переменную отклика зависит от уровня второй предиктор-
ной переменной. Взаимодействие переменных означает, что они должны
рассматриваться совместно, а не по отдельности. Так, например, если алкоголь взаимодействует в крови
с антибиотиками, в модели должна быть одна переменная для уровня алкоголя в крови,
одна — для уровня антибиотика, а также член взаимодействия, выражающий взаимосвязь
между уровнем алкоголя и антибиотика в сыворотке.
7.19. Приведите в отчете уравнение множественной линейной регрессии или
сведите данные о нем в таблицу.
Табл. 7.1 показывает, каким образом дается отчет о модели множественной линейной
регрессии. Включите количество наблюдений в анализе, а также связанную с ним
стандартную ошибку, /?-значение и (95%-й) доверительный интервал для каждого коэффициента
в уравнении [9].
7.20. Приведите значение меры «согласия» моделей с данными.
^ См. указание 7.7: определение меры «согласия».
7.21. Укажите, была ли модель обоснована.
Q См. указание 7.8: проверка обоснованности регрессионных моделей.
' Здесь идет речь о числе наблюдений, каждое из которых не содержит ни одного пропуска по всем
используемым переменным. Реально доля наблюдеГ'А^пропусками колеблется от О до 20 % (а то и больше).
Отчет о регрессионном анализе 113
7.22. Укажите название применяемого при анализе статистического пакета или
программы.
ф См. указание 7.10: отчет о статистических пакетах и программах.
ПРОСТОЙ ЛОГИСТИЧЕСКИЙ РЕГРЕССИОННЫЙ АНАЛИЗ
Предсказание одной (бинарной) категориальной переменной отклика
по одной предикторной переменной
Образец презентации
Среди 453 пациентов либо с высокими (> 220 мг/дл), либо с низкими (< 220 мг/дл)
уровнями сыворотки вес оказался значимой независимой переменной для уровней сыворотки
(весовой коэффициент = 0,44; СО = 0,11;^^^^^^ = 16Д р < 0,001; отношение шансов = 1,55;
95% ДИ 1,25-1,93).
Здесь:
• 453 — количество участников исследования.
• 0,44 — регрессионный коэффициент при предикторной переменной, вес.
• 0,11 — стандартная ошибка коэффициента регрессии, показывающая точность оценки
коэффициента. Регрессионный анализ — один из тех немногих случаев, в которых
следует указать стандартную ошибку.
• 16,0 — значение статистики критерия, вычисленное по данным выборки и
сравниваемое с распределением хи-квадрат с одной степенью свободы. Статистика критерия
используется для определения р-значения.
• р — вероятность получить крайнее или превосходящее крайнее значение отношения
шансов по сравнению с наблюдаемым, если на самом деле отношение шансов равно 1.
Здесь в силу малости значения р {менее 0,05) имеется свидетельство против нулевой
гипотезы, заключающейся в том, что отношение шансов равно 1. Отсюда следует, что вес
действительно влияет на серологические уровни.
• 1,55 — отношение шансов для веса. Оно показывает, что с каждым дополнительным
килограммом веса риск иметь высокие уровни сыворотки (как определено выше)
возрастает в 1,55 раза, или на 55 %.
• 95% ДИ для отношения шансов говорит о том, что в 95 из 100 подобных исследований
следует ожидать попадание значения отношения шансов в интервал от 1,25 до 1,93.
• Табл. 7.2 дает альтернативный отчет об анализе.
7.23. Опишите интересующую вас взаимосвязь или цель анализа.
Простой логистический регрессионный анализ наиболее часто используется тогда,
когда переменная отклика имеет два значения (но иногда три или более). Как и при простом
линейном регрессионном анализе, одна непрерывная предикторная переменная
используется для предсказания значений переменной отклика'.
' Точнее — предсказания вероятностей появления той или иной градации категориальной переменной отклика
для конкретной комбинации значений предикторных переменных.
114 Составление статистических отчетов в медицине
Таблица 7,2
Табличный отчет о простой логистической регрессионной модели, анализирующей
взаимосвязь между весом и высоким или низким уровнями сыворотки
„ . . ^ Статистика ^
_ Коэффи- Стандартная Отношение ^^^, _,^
Переменная ,«. Г критерия р-значение 95% ДИ
циент(В) ошибка ^ , шансов
Вальда -^
Свободный член -1,89 0Д8 — — — —
Вес 0,44 0,11 16,0 < 0,001 1,55 1,25-1,93
Свободный член — математическая константа, не имеющая клинической интерпретации;
вес — предикторная переменная (Х^);
коэффициент — весовое значение предикторной переменной в уравнении; коэффициент регрессии, или бета-вес;
стандартная ошибка — оценка точности коэффициента при переменной веса;
статистика критерия Вальда ;^^ вычислена по данным для сравнения с распределением хи-квадрат с одной
степенью свободы;
р-значение — вес является статистически значимой независимой переменной для высоких уровней сыворотки;
отношение шансов — на каждую единицу увеличения веса шанс иметь высокие уровни сыворотки возрастает
в 1,55 раза;
95% ДИ — «истинное» значение отношения шансов, скорее всего, заключено в пределах от 1,25 до 1,93.
7*24. Идентифицируйте сравниваемые переменные и охарактеризуйте каждую
из них описательной статистикой.
Предикторная переменная будет непрерывной или категориальной, а переменная
отклика будет бинарной. Особая схема измерений или кодирования могут оказывать заметное
влияние на числовые значения и интерпретацию коэффициентов регрессии [1]; например,
влияние возраста отличается при кодировании групп с разницей в 1 год, в 10 лет, или на
бинарные категории (моложе или старше 65 лет).
7.25. Оговорите сделанные для простого логистического линейного
регрессионного анализа предположения и способы их проверки.
Все, что нужно включить в отчет, — это подтверждение некоторых допущений.
Описание допущений для простого (и множественного) логистического регрессионного
анализа выходит за рамки этой книги, но, как и во всех видах регрессионного анализа,
нужна некоторая уверенность в правомерности этих допущений и уведомление о том, как это
проверено. Как и ранее, существуют как формальные, так и неформальные (графические)
процедуры проверки {см. указание 7.3). Данные, для которых предположения нарушаются,
иногда можно скорректировать. Такого рода корректировки должны оговариваться особо.
7.26. Укажите, каким образом рассматривались выбросы.
Q См. указание 7.4: рассмотрение выбросов в данных.
7.27. Отразите уравнение логистической регрессии в таблице.
Уравнения логистической регрессии приводятся в отчетах редко вследствие трудностей
при их интерпретации'. Вместо этого итоги анализа приводятся так, как показано в табл. 7.2.
' Действительно, интерпретация уравнения логистической регрессии требует немалых знаний теории этого
метода. Кроме того, в различных статистических пакетах отличаются объем результатов и степень их детализации.
Если же учесть, что в разных пакетах и процедурах используются разные алгоритмы оценок, то очевидно, сколько
нюансов необходимо знать и учитывать при интерпретации этих результатов. Именно поэтому такой анализ
должен производить профессионал в области биостатистики, и он же должен участвовать в дальнейшей
интерпретации полученных результатов.
Отчет о регрессионном анализе 115
Включите в отчет количество наблюдений в анализе, коэффициент при предикторной
переменной и связанную с ним стандартную ошибку, отношение шансов, его (95%-й)
доверительный интервал, р-значение.
Уравнение простой логистической регрессии выглядит так:
1
Вероятность исхода =
где е — математическая константа (приближенно равная 2,72), Ь^ — константа модели, 6, —
коэффициент при предикторной переменной X.
Отношения шансов широко используются в логистическом регрессионном анализе. Для
бинарной предикторной переменной отношение шансов равно дроби, в числителе
которой стоят шансы того, что событие произойдет в одной группе, а в знаменателе — шансы
того, что оно произойдет в другой. Отношение шансов, равное 1, означает, что
вероятность, к примеру, сердечного приступа одинакова в обеих группах. Чем больше
отношение шансов, тем с большей вероятностью следует ожидать события в группе с данными
в числителе.
Отношение шансов представляет собой оценку, следовательно, точность этой оценки
можно описать при помощи доверительного интервала. Например, результат можно
сформулировать так: «Вероятность сердечного приступа у курящих в 4,2 раза выше, чем у
некурящих (95% ДИ 1,32 - 13,33;р = 0,03). {См. также гл. 2.)
7.28. Приведите значение меры согласия моделей с данными.
Q См. указание 7.7: определение согласия.
7.29. Укажите, была ли модель обоснована.
0 См. указание 7.8: проверка обоснованности регрессионных моделей.
7.30. Укажите название применяемого при анализе статистического пакета или
программы.
0 См. указание 7.10: отчет о статистических пакетах и программах.
МНОЖЕСТВЕННЫЙ ЛОГИСТИЧЕСКИЙ РЕГРЕССИОННЫЙ АНАЛИЗ
Предсказание значений одной (бинарной) категориальной переменной
по двум или более предикторным переменным
7.31. Опишите интересующую вас взаимосвязь или цель анализа.
7.32. Идентифицируйте сравниваемые переменные и охарактеризуйте каждую
из них описательной статистикой.
Важное значение в отчете может иметь указание того, как были закодированы
переменные [4]. Категориальные предикторные переменные с множественными категориями,
градациями должны рассматриваться с помощью индикаторных переменных. Например,
можно ввести следующие типы занятости: работа в офисе, тяжелая работа, легкая работа
116 Составление статистических отчетов в медицине
Образец презентации
Наши результаты были использованы для построения модели предсказания инсульта (Y),
в зависимости от курения (Х^), веса (Х^), возраста (Хд) и пола (Х^).
Здесь:
• Y — переменная отклика, возникновение или отсутствие инсульта»
• Х^, Х^, Хз и Х^ — предикторные переменные (иногда их называют факторами риска),
• Числа, стоящие перед Х^ ^за' называются коэффициентами, или бета-весами»
• Табл. 7.3^ показывает результаты этого гипотетического анализа.
Таблица 7,3
Табличный отчет о множественной логистической регрессионной модели с четырьмя
предикторными переменными
Переменная
Свободный член
X,
X.
Хз
X.
Коэффициент (Р)
-1,89
1,435
-0,847
3,045
2,200
Стандартная
ошибка
0,48
0,589
0,690
1,260
0,990
Статистика
критерия
Вальда х^
—
5,93
1,51
5,84
4,94
р-значение
—
0,02
0,22
0,02
0,03
Отношение
шансов
—
4,2
0,43
21,01
9,03
95% ДИ
—
1,32-13,33
0,111-1,66
1,78-248,29
1,30-62,83
Свободный член — математическая константа, не имеющая клинической интерпретации;
Х^-Х^ — четыре предикторные переменные;
коэффициент ф) — весовое значение для каждой предикторной переменной модели; коэффициенты
регрессии, или бета-весы;
стандартная ошибка — оценка погрешности весовых значений;
статистика критерия Вальда ;^^ вычислена по данным для сравнения с распределением хи-квадрат с одной
степенью свободы;
р — значение вероятности, указывающее на то, что переменные 1,3 и 4 статистически значимо связаны с
переменной отклика;
отношение шансов — на каждую единицу увеличения, скажем, переменной 1 при фиксации остальных
переменных модели шансы наступления исследуемого события возрастают в 4,2 раза. Аналогично, на каждую
единицу увеличения, скажем, переменной Х^ при фиксации остальных переменных модели шансы события
убывают в 0,43 раза;
95% ДИ — 95%-й доверительный интервал для оценки отношения шансов.
' Содержание такой таблицы во многом определяется возможностями используемого статистического пакета.
К примеру, в табл. 7.3 отсутствуют такие важные характеристики уравнения, как безразмерные коэффициенты
регрессии, позволяющие проранжировать, упорядочить предикторы по силе своего влияния на зависимую
качественную переменную. Нет и такого показателя, как статистика D-Зомера, показывающая долю совпадений фактической
принадлежности наблюдений к градациям зависимой качественной переменной отклика, с предсказанными по
уравнению логит-рефессии. С примерами оформления результатов логистической регрессии читатели могут
познакомиться в стзстьях: Дробилсев М. Ю., Макух Е. А., Дзантиева А. И. Сосудистая деменция в общей медицине: аспекты
эпидемиологии, бремени болезни, терапии // Психиатрия и психофарматерапия. 2006. Т. 8, № 5 (http://old.consilium-
medicum.com/media/psycho/06_05/16.shtml); Гарганеева Н. П., Леонов В. П. Логистическая регрессия в анализе связи
артериальной гипертонии и психических расстройств // Сибирский медицинский журнал. 2001. № 3-4. С. 42^8
(http://www.biometrica.tomsk.ru/psycho3s.htm). — Прим. ред.
Отчет о регрессионном анализе 117
и отсутствие занятости. Тогда при кодировании для анализа определяется «опорный»
уровень, с которым будет сравниваться каждый из других уровней, а затем определяются
индикаторные переменные для сравнений. Например:
• Индикаторная переменная №1 = 1, если человек занят тяжелым трудом, О в
остальных случаях.
• Индикаторная переменная № 2 = 1, если человек занят легким трудом, О в
остальных случаях.
• Индикаторная переменная № 3 = 1, если человек не работает, О в остальных
случаях.
Таким образом, все сочетания трех индикаторных переменных полностью описывают
качественную переменную:
Индикаторная переменная
№ 1 № 2
0 0
0 0
0 1
1 0
1
№3
0
1
0
0
Предикторная переменная
Работа в офисе
Отсутствие занятости
Легкая работа
Тяжелая работа
Для понимания интерпретации читателю будет недостаточно простого указания трех
коэффициентов регрессии для трех индикаторных переменных. Без информации о
способе кодирования или, по крайней мере, о выбранном опорном уровне интерпретация
невозможна.
ф Обычно нужно определить по крайней мере десять событий-исходов для
каждой независимой переменной модели [9].
733. Оговорите сделанные для простого логистического линейного
регрессионного анализа предположения и способы их проверки.
Q См. указание 7.25: предположения регрессионного анализа.
734. Укажите, каким образом рассматривались выбросы.
ф См. указание 7.4: рассмотрение выбросов.
735. Укажите, каким образом рассматривались пропуски в данных [9].
Q См. указание 7.15: укажите, каким образом рассматривались пропуски в данных.
736. Отметьте, каким образом выбирались предикторные переменные,
появляющиеся в итоговом виде модели, или каким образом они подгонялись
к ней [4].
Q См. указание 7.16: выбор переменных для модели.
118 Составление статистических отчетов в медицине
7.37. Укажите, прошли ли возможные предикторные переменные проверку
на коллинеарность (корреляцию или взаимосвязь) [4].
^ См. указание 7.17: укажите, все ли возможные предикторные переменные
прошли проверку на коллинеарность.
Q Отказ от определения кореллированных переменных может сделать
результаты анализа недействительными.
738. Укажите, проверялись ли предикторные переменные на взаимодействие [4].
^ См. указание 7.18: укажите, проверялись ли предикторные переменные
на взаимодействие.
739. Отразите уравнение множественной логистической регрессии в таблице.
Табл. 7.3 показывает, каким образом составляется отчет об уравнении множественной
логистической регрессии. Включите в отчет количество наблюдений в анализе,
коэффициенты при предикторных переменных и связанные с ними стандартные ошибки, отношения
шансов, их (95%-е) доверительные интервалы, действительные/7-значения [4].
Q См. указание 7.27: отчет об отношениях шансов.
7.40. Приведите значение меры согласия моделей с данными [4,10].
Q См. указание 7.7: определение согласия.
7.41« Укажите, была ли модель обоснована [4].
@ См. указание 7.7: проверка обоснованности регрессионных моделей.
7.42. Укажите название применяемого при анализе статистического пакета или
программы [10].
ft См. указание 7.10: отчет о статистических пакетах и программах.
Литература
1. Concato J, Feinstein AR, Holford TR. The risk of determining risk with multivariable models. Ann
Intern Med. 1993; 118:201-10.
2. Godfrey K. Simple linear regression in medical research. In: Bailar JC, Mosteller F, eds. Medical
Uses of Statistics, 2nd ed. Boston: NEJM Books; 1992:201-32.
3. Hosmer DW, Taber S, Lemeshow S. The importance of assessing the fit of logistic regression models:
a case study. Am J Public Health. 1991; 81:1630-5.
4. Bagley SC, White H, Golomb BA. Logistic regression in the medical literature: standards for use and
reporting, with particular attention to one medical domain. J Clin Epidemiol. 2001; 54:979-85.
5. Altman DO, Gore SM, Gardner MJ, Pocock SJ. Statistical guidelines for contributors to medical
journals. BMJ. 1983; 286:1489-93.
Отчет о регрессионном анализе 119
6. Altman DG. Statistics and ethics in medical research, VI — Presentation of results. BMJ. 1980;
281:1542-4.
7. Altman DG. Statistics in medical journals. Stat Med. 1982; 1:59-71.
8. O'Brien PC, Shampo MA. Statistics for clinicians: 7. Regression. Mayo Clin Proc. 1981; 56:452-4.
9. Shutty M. Guidelines for presenting muhivariate statistical analyses in Rehabilitation Psychology.
Rehab Psych. 1994; 39:141-4.
10. Bender R, Grouven U. Logistic regression models used in medical research are poorly presented
[Letter]. BMJ. 1996; 313:628.
120 Составление статистических отчетов в медицине
Глава 8
Анализ групп со многими
переменными
Отчет о дисперсионном анализе
Мы моэюем говорить о проверке равенства средних в группах, прошедших
лечение, или о проверке того, что эффект от лечения нулевой. Подходящей
процедурой для проверки равенства средних является дисперсионный анализ.
D. С. Montgomery [Ц
ANOVA является разновидностью проверки гипотез для исследований с двумя или
более переменными. Он тесно связан с другим набором методик, называемых регрессионным
анализом. Вообще говоря, ANOVA используется для оценки влияния категориальных пре-
дикторных переменных, тогда как регрессионный анализ применяется для непрерывных
предикторных переменных. Если в исследовании фигурируют как непрерывные, так и
категориальные переменные, анализ можно назвать множественным регрессионным, или
ковариационным, анализом (ANCOVA). Указания по отчету о регрессионном анализе
включены в гл. 7. Как правило, под термином «ANOVA» подразумевается однофакторный ANOVA
(см. ниже), но он относится и к любому другому виду ANOVA, подобно тому, как термин
«регрессионный анализ» может относиться ко многим видам регрессионного анализа. Оба
вида анализа включают в себя уравнения или «модели», которые дают итоговое
представление о взаимосвязях между предикторными переменными и переменными отклика.
Говоря коротко, ANOVA делит вариацию во всех данных на две части: вариацию между
каждым из групповых средних и общим средним для всех групп (межгрунповая
изменчивость) и вариацию между каждым из участников исследования и средним группы
участников (внутригрунповая изменчивость). Если межгрупповая изменчивость намного
превышает внутригрупповую, вероятно присутствие различий между групповыми средними.
Дисперсионный анализ является методом группового сравнения, который выявляет
статистически значимое различие между некоторыми из изучаемых групп. Если имеются
указания на значимое различие, то за ANOVA обычно следует процедура множественных
сравнений, сравнивающая сочетания групп с целью выявить дальнейшие различия между
ними. Наиболее общеупотребительной процедурой такого рода является попарное
сравнение, в ходе которого каждое групповое среднее сравнивается со всеми остальными
групповыми средними (по два за один раз) с целью определить, какие группы отличаются
значимо. При этом возникает проблема множественных сравнений, описанная в гл. 5, и поэтому
сравнения выполняются вместе с процедурами, разработанными для учета этой проблемы.
Отчет о дисперсионном анализе 121
Многомерный дисперсионный анализ (MANOVA) применяется для сравнения
влияний основных эффектов и взаимодействий категориальных переменных на несколько
количественных переменных отклика. В MANOVA, как и в ANOVA, в качестве независимых
переменных используются одна или более категориальных предикторных переменных, но,
в отличие от ANOVA, здесь имеется более одной переменной отклика. MANOVA и MAN-
CO VA являются видами «общих линейных моделей».
Ниже описаны наиболее общеупотребительные процедуры ANOVA, используемые
в биомедицинских исследованиях. (Пример предназначен лишь для того, чтобы помочь
увидеть отличия между разными видами ANOVA. Мы не рекомендуем расширять анализ
путем постепенного добавления переменных по одной за каждый раз.)
Однофакторный ANOVA оценивает влияние одной (отсюда название «однофактор-
ный») категориальной предикторной переменной (иногда называемой фактором) на одну
непрерывную переменную отклика. Заметим также, что фактор (категория) имеет три или
более альтернатив (или «уровней», или «значений»; например, группы крови А, В, АВ и 0).
Если альтернатив только две (две группы), анализ сводится к /-критерию Стьюдента'.
ПРИМЕР
• Женщины с остеопорозом были распределены случайным образом по трем группам:
лечение по стандартной методике, лечение по новой методике и плацебо (контрольная
группа). Переменной отклика является изменение минеральной плотности костной
ткани (непрерывная переменная). Предикторной переменной является вид лечения,
по которому различаются группы. Результаты можно проанализировать с помощью
однофакторного ANOVA.
Двухфакторный ANOVA оценивает влияние двух категориальных предикторных
переменных (как и ранее, иногда называемых факторами) на одну непрерывную переменную
отклика.
ПРИМЕР
• В условиях предьщущего примера добавляем в качестве второй предикторной
переменной возраст. Возраст классифицируется как одна из четырех порядковых
категорий: от 30 до 40 лет, от 41 до 50, от 51 до 60, от 61 года и старше. При двух
категориальных переменных — виде лечения (или группе) и возрасте — данные можно
проанализировать с помощью двухфакторного ANOVA.
Многофакторный ANOVA оценивает влияние трех или более категориальных
предикторных переменных (по-прежнему называемых факторами) на одну непрерывную
переменную отклика.
ПРИМЕР
• В условиях предыдущего примера добавление новых категориальных предикторных
переменных, таких как диета (вегетарианская или невегетарианская) и употребление
алкоголя (менее 60 мл алкоголя в день, от 60 до 150 мл в день, более 150 мл в день),
может превратить двухфакторный анализ в четырехфакторный, или, проще говоря,
многофакторный ANOVA.
' При выполнении двух условий возможности применимости /-критерия Стьюдента — нормальности
распределения признака в обеих группах и равенстве дисперсий.
122 Составление статистических отчетов в медицине
Ковариационный анализ (ANCOVA) оценивает влияние одной или более
категориальных предикторных переменных при фиксированном влиянии некоторых других (возможно,
непрерывных) предикторных переменных (теперь называемых ковариатами, или
сопутствующими переменными) на одну непрерывную переменную отклика.
ПРИМЕР
• В условиях вышеприведенного примера предположим, что мы хотели бы
зафиксировать степень тяжести заболевания. Женщины с более тяжелой формой остеопо-
роза, возможно, имеют другие минеральные плотности костной ткани по
сравнению с женщинами с более легкой формой. Если нам предстоит изучить взаимосвязь
между видом лечения и возрастом на минеральную плотность костной ткани, мы
должны зафиксировать степень тяжести заболевания. Мы, таким образом,
добавляем другую (категориальную) предикторную переменную — степень тяжести
заболевания (слабую, умеренную и тяжелую). Теперь анализ называется ковариационым
анализом.
ANOVA с повторными измерениями используется для оценки нескольких, или
повторных, измерений от одних и тех же участников исследования при разных
условиях (таких, как кровяное давление, измеренное в положении пациента лежа, сидя или
стоя) или в разное время (например, мускульная сила через 1, 5, 10 и 20 дней после
операции).
ПРИМЕР
• Снова отправляясь от того же самого примера, предположим, что мы располагаем
измерениями минеральной плотности костной ткани для всех пациентов при появлении
симптомов, через 6 и 12 месяцев после появления симптомов. В этом случае к
модели ANOVA можно добавить предикторную переменную «время». Здесь время играет
роль «повторного измерения»: хотя каждая женщина принадлежит к одной группе
по виду лечения и к одной возрастной категории, у каждой из них плотность костной
ткани измерялась трижды за данный промежуток времени (в самом начале появления
симптомов, а также через 6 и 12 месяцев).
УКАЗАНИЯ ПО ОФОРМЛЕНИЮ ВВЕДЕНИЯ
8.1. Опишите интересующие вас взаимосвязи или цель анализа.
Обычно ANOVA используется для сравнения трех или более групповых средних на
некоторой переменной отклика. В более общем случае с его помощью могут
рассматриваться дополнительные предикторные переменные и оцениваться их совместные воздействия
на переменную отклика. Если целью регрессионного анализа обычно является
предсказание значения переменной отклика, то ANOVA обычно применяется для сравнения групп
ради поиска различий в ее средних значениях.
УКАЗАНИЯ ОТНОСИТЕЛЬНО МЕТОДОВ
8.2. Идентифицируйте переменные, используемые в сравнениях, и
охарактеризуйте каждую из них описательными статистиками.
предикторные переменные обычно бывают категориальными (обозначающими группы).
Переменные отклика непрерывны и должны быть охарактеризованы мерой центральной
Отчет о дисперсионном анализе 123
Образец презентации'
66 женщин с остеопорозом были разделены на три группы в зависимости от вида лечения:
группа 1 (п = 22), группа 2 (п = 22) и контрольная (п = 22). Через 6 недель было измерено
изменение минеральной плотности костной ткани по сравнению с базовым уровнем. При
помощи однофакторного ANOVA было выявлено статистически значимое различие между
группами (Я^^з = б1;07;р < 0,001).
Дальнейший анализ, проведенный с помощью процедуры попарного сравнения Тьюки для
множественных сравнений, выявил статистически значимое преобладание среднего
изменения (±G0) в группе 2 {1,6 г/см^ ± 0,2) над средним в группе 1 (1,1 г/см^ ± 0,2) и в
контрольной группе (1,0 г/см^ ± 0,2) при общем уровне значимости 0,05.
Здесь:
• Задана численность каждой группы п.
• Несмотря на то что распределение в группы по определенному признаку не является
предпочтительным по сравнению с действительно случайным распределением, принцип
распределения пациентов по группам здесь определен точно.
• Сравнение групп производится с помощью однофакторного ANOVA, и результаты
сравнения представлены в табл. 8.1.
• Последующие множественные сравнения были осуществлены с помощью процедуры
Тьюки. Приведены действительные средние изменения и СО для сравниваемых групп (хотя
и в менее предпочтительной записи со знаком «±»), что позволяет читателям оценить
клиническую важность результатов.
• Уровень значимости, или порог, при котором результаты объявляются статистически
значимыми, установлен равным 0,05,
• 61,07 — значение F-критерия с 2 степенями свободы числителя и 63 для знаменателя
(что показано нижними индексами в записи F^^^), вычисленное по исходным данным.
• р — вероятность получить «групповой эффект», или влияние лечения на минеральную
плотность костной ткани, крайнее или превышающее крайнее значение по сравнению с
наблюдаемым, если на самом деле все групповые средние равны. Здесь у пациентов,
проходивших различные виды лечения, были видны статистически значимые различия в
откликах на лечение. Малое значение р отражает наличие в данных свидетельства против
нулевой гипотезы, предполагающей отсутствие различий между группами.
^ Приведенный пример презентации не полный, так как в нем отсутствует информация о проверке
условий допустимости использования ANOVA. Такая информация может, к примеру, иметь следующий вид:
во всех трех сравниваемых группах минеральная плотность костной ткани имела нормальное
распределение. Проверка нормальности производилась критериями Шапиро—Уилка (/? = 0,15) и Колмогорова—
Смирнова {р = 0,12). Равенство трех генеральных дисперсий производилось с помощью критериев Барт-
летта {р = 0,25) и Левене (р = 0,45). Критический уровень значимости был равен 5 %. — Прим. ред.
тенденции (средним или медианой) и мерой рассеяния (СО или интерквартильной
широтой), в зависимости от обстоятельств.
83. Идентифицируйте вид проводимого анализа.
Виды ANOVA перечислены выше. Важно точно указать, использовался ли ANOVA с
повторными измерениями, поскольку серийные измерения от одних и тех же участников
исследования должны анализироваться иначе.
^ При идентификации вида ANOVA не смешивайте число групп с числом
факторов. Группа в ANOVA — общий термин для одного фактора, который может
включать в себя три или более выделенных по какому-то признаку подгруппы.
124 Составление статистических отчетов в медицине
В однофакторном ANOVA сравниваются только группы, а «группа» является
единственным фактором в анализе. В двухфакторном ANOVA анализируются «группа»
и второй, добавочный фактор, который сам может включать в себя несколько
«уровней» или подразделений. Например, группа крови может быть фактором, а группы
А, В, АВ и О — уровнями этого фактора. Таким образом, вид ANOVA определяется
числом факторов, а не числом уровней, групп или категорий.
УКАЗАНИЯ ПО ОФОРМЛЕНИЮ РЕЗУЛЬТАТОВ
8«4, Оговорите предположения, подтверждающие правомерность проведения
анализа.
Все, что нужно включить в отчет, — это подтверждение некоторых допущений.
Проведение ANOVA правомерно при следующих предположениях:
• Переменная отклика Y распределена по приблизительно нормальному закону внутри
каждого уровня каждого фактора (предикторной переменной X).
• Распределения Y имеют равные дисперсии (или СО) внутри каждого уровня каждого
фактора (предикторной переменной X); иными словами, СО Y одинаково независимо
от значения X.
• Каждое значение У независимо от остальных значений Y (иными словами, значения
Y не спарены и не коррелируют). Это предположение неприменимо к ANOVA с
повторными измерениями, поскольку по определению повторные измерения у тех же
пациентов коррелированы. ANOVA с повторными измерениями разработан для того,
чтобы приспособиться к этой корреляции.
8.5. Отразите результаты ANOVA в таблице.
Табл. 8.1 и 8.2 показывают, каким образом обычно представляются результаты ANOVA.
8.6, Укажите, проверялись ли предикторные переменные на взаимодействие
и как рассматривались эти взаимодействия.
Два фактора (предикторные переменные) называются взаимодействующими, если
влияние одного фактора на переменную отклика зависит от уровня второго фактора.
Следствием взаимодействия переменных является необходимость рассматривать их совместно, а не
по отдельности (см. указание 7.18).
8 J. Укажите действительное р-значение для каждого фактора.
Нулевая гипотеза, проверяемая с помощью ANOVA, обычно заключается в равенстве
групповых средних. Если найдено значимое /7, указывающее на итоговое групповое
различие, выполняется процедура множественных сравнений. Ее целью является определение,
скажем, того, какие групповые средние отличаются друг от друга. Далее, с помощью
процедур множественных сравнений можно оценить все факторы (предикторные переменные),
значимо связанные с переменной отклика, включая взаимодействия между факторами.
8«8, Дайте меру согласия модели дисперсионного анализа с данными.
Оценка согласия показывает, насколько хорошо модель выражает наблюдаемые в данных
взаимосвязи. Как и в регрессионном анализе {см. гл. 7), пригодность модели помогает уста-
Отчет о дисперсионном анализе 125
Таблица 8.1
Табличный отчет о результатах однофакторного дисперсионного анализа: анализ различий
между тремя лечебными группами женщин с остеопорозом (п = 66)"
Источник
вариабельности
Группа
Ошибка
Число степеней
свободы
2
63
Суммы
квадратов
4,96
2,56
Средние
квадраты
2,48
0,04
F
61,07
Р
< 0,001
' Термин «однофакторный» указывает на наличие единственного фактора, «группы», которая имеет здесь три «уровня»:
группы, в которых велось лечение вида 1 и 2, а также контрольная группа. См. образец презентации на с. 123.
Источник вариабельности указывает на источники изменчивости минеральной плотности костной ткани как факторы
в модели и как случайные ошибки (изменчивость не объясняется только факторами). Единственным фактором здесь
является группа.
Число степеней свободы — математическое понятие. Здесь для трех групп число степеней свободы равно 3-1, или 2;
для 66 пациентов число степеней свободы для ошибки равно (66 - 1) - (3 - 1), или 63.
Сумма квадратов: для группы — мера величины различий между группами; для ошибки — мера величины различий
внутри групп,
f—статистика F-критерия, рассчитанная по данным и сравниваемая с F-распределением, равна среднему квадрату
между группами, деленному на средний квадрат внутри групп.
р-значение—значение вероятности, указывающее на то, что групповой эффект, или влияние лечения на минеральную плот-
ноаь костной ткани, был выше, чем можно было ожидать вследствие случайных причин при условии равенства групповых
средних; иными словами, разница в откликах на лечение в группах была статистически значимой.
Таблица 8,2
Табличный отчет о результатах двухфакторного дисперсионного анализа: анализ двух
факторов (группа и возраст)"
Источник
изменчивости
Группа
Возраст
Группа X возраст
Ошибка
Число
степеней
свободы
1
3
3
12
Сумма
квадратов
0,64
3,92
4,91
3,43
Средние
квадраты
0,64
1,31
1,64
0,29
F
2,24
4,57
5,72
—
Р
0,16
0,02
0,01
—
^Анализ включает два фактора: группу (два уровня, или категории) и возраст (четыре категории, или уровня). Уровни
каждой категории должны быть указаны в описании исследования. Группа и возраст значимо взаимодействуют и
поэтому должны рассматриваться совместно.
Источник изменчивости указывает на источники изменчивости в переменной отклика как факторы в модели (группа,
возраст и взаимодействие между группой и возрастом) и как случайные ошибки (изменчивость не объясняется
факторами).
Число степеней свободы — математическое понятие. Здесь для двух групп число степеней свободы равно 2-1, или
1; для четырех возрастных категорий число степеней свободы равно 4-1, или 3. Для влияния взаимодействия между
группой и возрастом (группа х возраст) числа степеней свободы для каждого фактора перемножаются: 3x1=3.
Сумма квадратов — в отличие от однофакторного ANOVA, смысл суммы квадратов при многофакторном ANOVA
пояснить нелегко, и ее лучше рассматривать просто как шаг при вычислении средних квадратов.
Средние квадраты — суммы квадратов, деленные на числа степеней свободы; фактически — оценки изменчивости
в данных.
F— статистика критерия для F-распределения; для проверки эффектов взаимодействия и основных эффектов; равна
среднему квадрату для каждого фактора, деленному на средний квадрат ошибки.
р-значение — значения вероятности, указывающие на статистическую значимость влияния каждого фактора на
переменную отклика. Возраст и группа взаимодействуют (р = 0,01) при воздействии на переменную отклика и должны
в дальнейшем исследоваться совместно; иными словами, «основной эффект» группы или «основной эффект» возраста
не должны исследоваться сами по себе.
126 Составление статистических отчетов в медицине
повить рассмотрение остатков (разностей между наблюдаемыми значениями и их оценками
с помощью модели). Приводить в отчете результаты рассмотрения невязок необязательно;
достаточно сказать, что невязки были рассмотрены и что модель согласуется или не
согласуется с данными.
8.9. Укажите, была ли модель обоснована.
Модели ANOVA можно «обосновать» или протестировать на похожем множестве
данных, с тем чтобы выяснить, объясняют ли они то, что требуется объяснить:
• Один из методов обоснования, применяемый для больших выборок, состоит в том,
чтобы применить модель, скажем, на 70 % данных, а затем составить другую модель
для оставшихся 30 % и выяснить, оказались ли модели схожими.
• Другой метод заключается в удалении данных от каждого объекта по очереди и
пересчете модели. Затем можно сравнить коэффициенты всех моделей (они могут насчитываться
сотнями). Такие методы называются процедурами складного ножа {англ. —jackknife).
• Третий метод включает создание новой модели на отдельном множестве похожих
данных с целью выявить различия результатов.
8.10. Укажите, каким образом были проанализированы выбросы в данных.
Выбросы — это экстремальные значения, которые кажутся аномальными (в
противоположность ошибкам при сборе данных или при записи, которые являются просто ошибками).
Р1гнорировать истинные выбросы нельзя; они в действительности часто указывают на
особые случаи, открывающие новые области исследования. Однако они могут оказать
диспропорциональное воздействие на результаты ANOVA. Выбросы также могут стать причиной
асимметричности распределения данных и поэтому иногда подправляются путем
преобразования данных {см. указание 1.14). В отчете следует сообщать обо всех выбросах, но иногда
допустимо анализировать данные и без них, если для такого игнорирования есть законные
основания. Но это должно быть отражено в отчете вместе с причинами игнорирования
выбросов. Если игнорировать выбросы на законных основаниях нельзя, то ради демонстрации
их влияния на результаты допустимо привести результаты с выбросами и без них.
8.11. Укажите название применяемого при анализе статистического пакета или
программы.
Указание программного пакета, использованного в статистическом анализе, важно
по следующим соображениям: если коммерческие пакеты обычно бывают
легализованными и обновляемыми, то разработанные в частном порядке программы — не всегда. Кроме
того, не все статистическое программное обеспечение использует одинаковые алгоритмы
или опции по умолчанию при вычислении одной и той же статистики. Вследствие этого
результаты могут варьироваться от пакета к пакету и от алгоритма к алгоритму.
ANOVA входит в состав большинства крупных статистических пакетов. В числе чаще
используемых пакетов находятся SAS (Statistical Analysis Systems), BMDP, SPSS (Statistical
Package for the Social Sciences — статистический пакет для общественных наук), StatXact,
Stat View, StatSoft, InStat, Statistical Navigator, SysStat, Minitab, LISREL и EQS.
Литература
1. Montgomery DC. Design and Analysis of Experiments, 2nd ed. New York: John Wiley and Sons; 1984.
Отчет об анализе выживаемости 127
Глава 9
Оценка событий во времени
как конечных точек
Отчет об анализе выживаемости
Кривые выэюиваемости обеспечивают оценки вероятности выэюить в
зависимости от времени, прошедшего с начала исследования. Они дают наиболее
полную картину того, как на протяэюении всего времени обстоят дела с вы-
эюиванием при различных видах лечения.
F. MosTELLER, J. p. Gilbert, В. М. МсРеек [1]
Анализ времени до наступления события включает в себя оценки вероятности того,
что некоторое событие произойдет в те или иные моменты времени. В технике, к
примеру, анализ времени до наступления отказа оценивает длину временного интервала,
в течение которого оборудование будет работать в штатном режиме. Анализ
выживаемости, наиболее распространенное приложение анализа времени до наступления события
в медицине, оценивает вероятность выжить как функцию времени, начиная с некоторого
исходного пункта, например с даты постановки диагноза или хирургического
вмешательства. Интересующим нас событием в этой главе будет смерть, но предметом анализа может
быть и любое другое событие, такое как рецидив болезни, отказ оборудования или
прояснение симптомов.
Статистические методы, описанные в других главах этой книги, для анализа данных
о выживаемости неприменимы, поскольку не все пациенты могут наблюдаться в течение
одного и того же промежутка времени. Кроме того, и это, пожалуй, является более важной
причиной, за время проведения анализа конечная точка (в данном случае — смерть) может
наблюдаться не у всех пациентов; в действительности может и не наступить совсем за все
время исследования. Данные участников, для которых интересующая нас конечная точка
еще не наблюдалась, или в случае, если об исходе ничего не известно, называются цензури-
рованными. Анализ выживаемости разработан для приспособления к цензурированным
данным.
В анализе выживаемости для каждого субъекта записывается длина временного
промежутка между отправной точкой и смертью (или датой последнего текущего обследования
до начала анализа, если субъект еще жив). Процент еще живых субъектов в конце каждого
из намеченных промежутков времени (например, каждого месяца, каждого года или
каждых 5 лет) используется для оценки вероятности того, что типичный субъект будет жив
к концу любого заданного периода. На графике эти оценки образуют распределение
вероятностей выживания в течение различных промежутков времени (кривую выживания).
Кроме того, путем сравнения двух или более таких кривых можно выявлять статистические
128 Составление статистических отчетов в медицине
Образец презентации
Значения оценок Каплана—Мейера частоты выживания наших больных раком в течение
5 лет после лечения (рис. 9.1) оказались равными 67 % (95% ДИ 52,9-81,1 %) для группы,
прошедшей хирургическое лечение (п = 55), и 10 % (95% ДИ 0,6-19,4 %) для группы,
прошедшей медикаментозное лечение {п - 46). Лог-ранговый критерий выявил
статистически значимое различие по частоте выживания с течением времени (р < 0,001).
Медиана времени выживания составила 6,3 года для группы, прошедшей хирургическое
лечение, и лишь 3,8 года для прошедших медикаментозное лечение. Таким образом,
хирургическое лечение оказалось более эффективным для продления жизни по
сравнению с медикаментозной терапией. Дальнейшее исследование, проведенное с помощью
регрессионного анализа пропорциональных рисков Кокса для контроля за действием
лечения, показало, что пациенты с метастатическим раком умирают от рака в 6,5 раза
чаще, чем те, у которых рак не метастазировал (95% ДИ для отношения угрозы или риска
2,8-15,0;р< 0,001).
Здесь:
• На рис. 9.1 показаны кривые Каплана—Мейера для этих данных.
• Исследуемая совокупность состоит из 101 проходящего лечение от рака пациента; 55
проходят хирургическое лечение, 46 — медикаментозное.
• По оценкам метода анализа выживания Каплана—Мейера, частоты выживания за 5 лет
в группах, проходящих хирургическое и медикаментозное лечение, составили
соответственно 67 и 10 %. Для этих оценок приведены также 95% ДИ.
• Согласно оценкам, 50 % прооперированных пациентов умрут в течение 6,3 года после
операции; другие 50 % либо выживут, либо умрут позже, чем через 6,3 года после операции.
Половина же из прошедших медикаментозное лечение пациентов умрет в течение 3,8 года
лечения. (Эти результаты являются медианами времени выживания)
• Лог-ранговый критерий, используемый для сравнения кривых выживания, полученных
от этих двух групп, показывает статистически значимое различие между группами,
• Последующие наблюдения с учетом различия групп (т. е. при учете действия
хирургического или медикаментозного лечения) показали, что уровень риска (или отношение рисков)
для метастатического рака составил 6,5:1. Это означает, что для пациентов с
метастатическим раком вероятность умереть от рака в 6,5 раза выше, чем у пациентов без
метастатического рака, что было определено с помощью регрессионного анализа пропорциональных
рисков Кокса.
• 95% ДИ для уровня риска показывает точность оценки.
• Значения р показывают, что в условиях нулевой гипотезы случайность не является
возможным объяснением различий во времени выживания между двумя группами или для
риска умереть при метастатическом раке. Здесь малые значения р свидетельствуют против
нулевой гипотезы, заключающейся в отсутствии различий.
различия в эффективности соответствующих видов лечения, выражающейся частотой
выживания. Статистические модели можно также создавать для оценки риска смерти по
заданной характеристике и корректировать с учетом влияния других характеристик, таких
как пол и возраст.
Отчет об анализе выживаемости 129
100
Группа
хирургического
•: лечения
12 24 36 48 60
Выживаемость, месяцы
72
84
96
Мед. (л): 46
Хирург, (п): 55
44
54
39
51
19
34
4
18
О
10
Число живых
Рис. 9.1. Кривая Каплана—Мейера является ступенчатой функцией, которая показывает оценки
выраженного в процентах числа пациентов, остающихся в живых на различных временных этапах с начала
исследования. Должно быть также указано число пациентов, живых по состоянию на те моменты, которые соответствуют
основным точкам деления временной оси. Потери в ходе движения по временной оси поясняют, почему число
пациентов, выживших к моменту медианы, может оказаться меньше 50 % от исходной выборки. (Здесь на
момент медианы времени выживания остались в живых менее чем 10 пациентов из группы хирургического
лечения; случилось это тогда, когда умерли 22 или 23 из начальных 55 пациентов)
9.1. Опишите взаимосвязи, присущие интересующему вас событию, и причины,
побуждающие к исследованию\
Четко обозначьте интересующее вас событие (помните, что конечная точка, или
переменная отклика в анализе выживаемости, — это в действительности время до наступления
события, а не само событие), а также факторы, которые, как предполагается, связаны с этим
событием и могут либо приблизить, либо отдалить его (предикторные переменные). Если
' Иногда упоминание об этом методе может иметь и спекулятивный, камуфляжный характер. Автор этих строк,
являясь членом редколлегии «Сибирского медицинского журнала», получил на рецензию рукопись статьи «Опыт
лечения вазилипом больных с острым коронарным синдромом без подъема сегмента ST». В ней сообщалось, что
«...для анализа выживаемости использовали лог-ранговый критерий». В тексте рукописи не сообщалось ни об
одном случае со смертельным исходом. Очевидно, что в этом случае анализ выживаемости не мог быть выполнен,
и упоминание о нем не имеет смысла. Какова же тогда цель упоминания о нем? Когда этот вопрос был задан
автору, доктору медицинских наук, сотруднице НИИ кардиологии ТНЦ СО РАМН, она не смогла на него ответить,
сославщись, что статистический анализ выполнял другой человек, не являющийся автором рукописи.
130 Составление статистических отчетов в медицине
событием является не смерть, а, например, отказ оборудования или исчезновение
клинических симптомов, то следует пояснить клиническую важность такого события и значение
связанных с ним предсказаний.
92. Опишите клинические характеристики исследуемой генеральной
совокупности.
Пациенты с одним и тем же заболеванием могут различаться по числу характеристик,
способных повлиять на интересующий нас исход. Как минимум, уместно описать:
• демографические особенности: возраст, пол, род занятий, образ жизни (курение,
уровень физической подготовки, питание и т. д.);
• клинические особенности: природа и продолжительность признаков и симптомов,
первичный диагноз и т. д.;
• параклинические особенности: результаты тестов и наружных обследований,
указывающих на стадию или прогрессирование заболевания;
• сопутствующие заболевания: другие факторы, способные взаимодействовать с
исследуемой болезнью или ее лечением.
93. Укажите время, с которого начинается анализ.
Время выживаемости можно начинать отсчитывать с любой из нескольких различных
отправных точек: появление симптомов, первые патологические результаты анализа, дата
постановки диагноза, дата госпитализации, дата начала лечения, дата после прохождения
периода «операционной смертности» и т. д. Отправное время следует четко указать во
избежание двусмысленности. Исследования с разными отправными точками бывает
невозможно сравнивать из-за упреждающего смещения, при котором у пациентов с рано
поставленным диагнозом в ходе болезни как будто получается большее значение медианы времени
выживания, необязательно благодаря лучшему лечению, но лишь потому, что диагноз был
просто поставлен раньше.
9.4. Опишите, при каких обстоятельствах были цензурированы данные.
Анализ выживаемости может принимать в расчет два типа данных: цензурированные
и нецензурированные. Нецензурированные данные являются «полными»: смерть уже
наступила и временной интервал между отправной точкой и смертью известен (рис. 9.2).
Кроме того, предполагается, что причина смерти имеет отношение к изучаемому заболеванию
или вмешательству.
С другой стороны, цензурированные данные — это «неполные данные», полученные
от тех участников исследования, которые:
• все еще живы, т. е. смерть во время анализа не наступила, и время выживаемости
поэтому неизвестно;
• умерли вследствие причин, не относящихся к заболеванию или лечению (эти
смерти могут не фиксироваться в качестве событий, поскольку они теоретически
не относятся к исследуемому заболеванию или лечению);
• больше не являются участниками исследования, будучи исключенными из него
или потерянными для дальнейших наблюдений. Распределение таких участников
также важно для отчета в случае, когда в исследовании применялся анализ
необходимости лечения (см. указание 13.37).
? 3
Отчет об анализе выживаемости 131
Окончание исследования
Цензурирование:
выбыл из
наблюдения
Цензурирование
Умер
Умер
Цензурирование
Январь Февраль Март Апрель Май Июнь Июль Август Сентябрь Октябрь
Слежение за пациентами от начала лечения до смерти, помесячно
Рис. 9.2. При проведении анализа выживаемости пациенты в большинстве случаев становятся
участниками исследования и покидают его в разное время. Таким образом, интересующее нас событие для некоторых
пациентов (здесь — 3 и 4) не произошло. Пациенты 3 и 4, оставшиеся в живых к концу исследования, а также
пациент 5, о состоянии которого ничего не известно вследствие потери наблюдения, представляют «цензури-
рованные» данные
9i* Укажите статистические методы, с помощью которых оценивалась частота
выживаемости.
Для анализа данных по выживаемости имеется несколько статистических методов.
Наиболее употребительными, однако, являются следующие:
• Метод Каплана—^Мейера (или метод множительных оценок), при котором
записываются точные даты смерти каждого индивидуума. Этот метод пригоден как для
больших, так и для малых выборок.
• Метод таблиц выживания (известный еще как страховой метод, а также как метод
Катлера—Эдерера или Берксона—^Гейджа), при котором смертельные исходы
записываются по временным интервалам (например, каждый месяц или каждый год). Этот
метод наиболее общеупотребителен при работе с очень большими выборками,
например в эпидемиологических исследованиях популяций.
9.6. Подтвердите выполнение необходимых условий для проведения анализа
выживания.
Просто скажите, выполняются ли необходимые условия.
Условия для проведения анализа выживания с помощью кривой Каплана—^Мейера или
таблиц выживаемости таковы:
• диагностические и терапевтические процедуры, а также процедуры дальнейшего
наблюдения оставались неизменными в ходе всего исследования;
• риск последствий не менялся на протяжении исследования (это условие
пропорциональных рисков в регрессионном анализе Кокса);
132 Составление статистических отчетов в медицине
• смерти, выбытия и другие изменения в составе пациентов происходили равномерно
на протяжении всего интервала последующего наблюдения;
• одинаковое распределение последствий у пациентов из цензурированных данных и у
оставшихся в исследовании.
9 J* Дайте оценку частоты выживания для каждой группы к заданным моментам
времени наблюдения с доверительными интервалами, а также число
участников исследования, подверженных риску смерти в каждый из этих
моментов времени.
Частота выживания — это выраэюенное в процентах число участников исследования,
оставшихся в эюивых к заданному моменту времени. Как и все оценки, частота выживания
должна сопровождаться 95% ДИ, показывающим точность оценки. Указание числа и
статуса (жив или умер) участников, на которых основана каждая оценка, также способствует их
объективности. Оценки следует предоставить на каждые логически обоснованные моменты
времени наблюдения за пациентами (например, через 1 год, 5, 10 лет или 3, 6, 12 месяцев).
^ Частота выживания является, по сути, суррогатной конечной точкой итоговой
смертности и ее следует интерпретировать с осторожностью. Непосредственная
связь между частотами выживания и частотами смертности для одной и той же
болезни имеется не всегда [8]. (Более подробное объяснение см. в разделе «Частоты
заболеваемости и смертности» в гл. 12.)
Q Иногда желательно отразить в отчете результаты анализа выживания
посредством медианы времени высеивания, т. е. длиной промежутка времени, в течение
которого умерли первые 50 % выборки пациентов.
Результаты анализа выживания можно также выразить посредством длины временного
промежутка, в течение которого исследуемые остались в жплвых. Когда умирают все члены
группы, данные о выживании становятся нецензурированными, а распределение индивидуальных
времен выживания можно описать с помощью медианы и интерквартильной широты (или с
помощью среднего и СО, если данные распределены по приблизительно нормальному закону).
Однако, поскольку исследуемые умирают в разное время, некоторые из них могут оставаться
в живых в любой из заданных моментов времени, и поэтому данные о них считаются цензури-
рованными. Время выживания цензурированных исследуемых неизвестно, поэтому истинный
вид его распределения нельзя предполагать нормальным, а среднее, таким образом, не
является приемлемой мерой центра распределения. Медиана времени выживания — период, за
который умирает 50 % исследуемых и вне которого 50 % остаются в живых, — является,
следовательно, более подходящим средством для описания тенденции времени выживания [2].
9.8, Отобразите полные результаты на графике или в таблице.
в некоторых исследованиях может представлять интерес только одна оценка срока
выживания, как, например, используемая в отчетах об исследованиях по раку частота
выживания в течение 5 лет. В других исследованиях могут потребоваться оценки, предоставляемые
несколько раз в течение длительного периода. Наиболее употребительным графическим
представлением ряда оценок является кривая Каплана—Мейера (см. рис. 9.1), которая
представляет собой ступенчатую нисходящую ломаную и показывает процент пациентов
генеральной совокупности, оставшихся в живых после определенного отрезка времени.
Отчет об анализе выживаемости 133
Оценки Каплана—Мейера можно также представить в таблице (табл. 9.1), как и
результаты, полученные методом таблиц выживания (табл. 9.2).
9.9< Укажите статистические методы, с помощью которых сравниваются две или
более кривых выживания.
Чтобы выявить статистически отличие двух или более кривых выживания, к ним можно
применить методы проверки гипотез. Среди такого рода методов наиболее употребительны
два:
• лог-ранговый критерий (или критерий Кокса—Мантеля), наиболее мощный для
распознавания поздних различий в вероятностях выживания;
• критерий Уилкоксона (или обобщение Бреслоу критерия Уилкоксона), наиболее
эффективный для распознавания ранних различий в вероятностях выживания.
При выполнении условий для проведения анализа выживемости (см. указание 9.6) может
использоваться любая из указанных процедур.
9.10. При сравнении двух или более кривых выживания методами проверки
гипотез указывайте действительное р-значение этого сравнения.
Нулевая гипотеза заключается в том, что распределения сроков выживания не
отличаются друг от друга. Значение р показывает вероятность увидеть крайнюю или даже большую
степень различия между кривыми по сравнению с наблюдаемым в предположении, что
распределения одинаковы.
Таблица 9,1
Сводка оценок Каплана—Мейера для выборки в 145 пациентов^
Время, лет Выжившие, % 95% ДИ, %
Число
умерших
Число Число
цензуриро- подверженных
ванных риску
0,5
1
2
3
5
97,9
97,2
95,1
85,2
77,6
95,5-100,0
94,5-100,0
91,6-95,1
79,7-90,7
68,0-97,2
3
4
7
21
26
0
0
3
68
118
142
141
135
56
1
' Могут быть уместны и другие столбцы.
Время — время (или интервал), за которое были вычислены оценки, измеренное от начального времени
анализа; выбирается исследователем.
Выживание, % — процент выживших в исходной выборке к тому или иному моменту времени; называется также
частотой Выживания.
95% ДИ — показатель точности оценки частоты выживания. Вместо 95% ДИ часто указывается СОС.
Число умерших — количество пациентов, умерших по исследуемой причине и для которых, соответственно,
закончилось время выживания.
Число цензурированных — количество пациентов, цензурированных с начала временного интервала;
включает тех, за кем было потеряно наблюдение; тех, кто умер по иным, нежели изучаемым, причинам, или тех, кто
остается в живых к концу последнего интервала.
Число подверженных риску — количество пациентов, выживших (и, следовательно, подверженных риску
смерти) к концу отрезка времени.
134 Составление статистических отчетов в медицине
Таблица 9.2
Таблица выживаемости для 1999 пациентов"
Годы после
диагноза
0-1
1-2
2-3
3-4
4-5
5-6
Пациенты,
за которыми
было потеряно
наблюдение, п
0
35
20
21
25
43
Умершие
пациенты, п
300
212
150
180
130
89
Пациенты,
подверженные риску, п
1999
1682
1443
1272
1069
328
Доля
1,00
0,85
0,74
0,67
0,58
0,50
Стандартная
ошибка
— :
0,003
0,009
0,011
0,019
0,033
^ Могут быть уместны и другие столбцы.
Годы после диагноза — интервалы, для которых оценивается время выживания.
Пациенты, за которыми было потеряно наблюдение — число исследуемых, статус которых (жив или умер)
неизвестен.
Умершие пациенты — число исследуемых, которые умерли в течение временного интервала.
Пациенты, подверженные риску — число исследуемых, остающихся в живых в течение временного интервала
и, таким образом, подверженных риску смерти.
Доля выживших — доля исследуемых, остающихся в живых к началу интервала; иногда называется накопленной
частотой выживания.
Стандартная ошибка — показатель точности оценки накопленной частоты выживания; если доля выживших
равна 1,0, стандартная ошибка не определена.
9.11 • Укажите, с помощью какой регрессионной модели оценивались
взаимосвязи между предикторными переменными и выживаемостью.
Обычным методом для оценки взаимосвязей между предикторными переменными и
частотой выживания является регрессионный анализ пропорциональных рисков Кокса (или
регрессионный анализ Кокса). Результатом этого анализа является уравнение (или модель),
которое можно представить в таблице, как показано в табл. 9.3.
9.12, Укажите меру риска для каждой из предикторных переменных.
Мерой риска, которая сопровождает каждую предикторную переменную в
регрессионном анализе Кокса, служит уровень риска (концептуально это то же самое, что и обычное
отношение рисков, за исключением того, что оно связано с некоторым отрезком времени). Для
бинарной переменной уровень риска, равный 1, означает, что для пациента риск смерти
одинаков вне зависимости от того, обладает ли он соответствующей характеристикой. Больший,
чем 1, уровень риска указывает на повышенный риск для пациентов с этой характеристикой;
меньше 1 — на пониженный риск. Таким образом, если при диете с высоким содержанием
жира уровень риска инсульта равен 5,4, то у пациентов, в диете которых велико содержание
жиров, с большей в 5,4 раза вероятностью возникнет инсульт, нежели у тех, в диете которых
содержание жиров невелико. В общем, уровень риска — это итоговое значение
повышенного риска на каждую единицу или уровень роста предикторной переменной.
Уровень риска и 95% ДИ могут быть даны в таблице с отчетом о регрессионном анализе
Кокса (табл. 9.3).
Отчет об анализе выживаемости 135
Таблица 9,3
Регрессионная модель пропорциональных рисков Кокса, демонстрирующая влияние пяти
переменных на риск смерти"
Коэффи-
^^ Стандартная Статистика Отношение 95%
Переменная циент ^ „ , р-значение _,.
'^ ,„. ошибка Вальдах рисков ДИ
(Р)
X, (возрает)
Xj (кровяное
давление)
Хз (холеетерин
сыворотки)
Х^ (курение
в анамнезе)
Xj (сердечное
заболевание
в анамнезе)
0,23
1,46
0,84
0,27
1,44
0,07
0,62
0,43
0,14
0,27
10,80
5,55
3,82
3,72
28,44
0,001
0,02
0,05
0,05
<аоог
1,26
4,31
2,32
1,31
4,22
^;Г0-1,44
1,28-14,52
1,00-5,38
1,00-1,72
2,49-7,16
^ Гипотетические данные.
Переменная — исследуемые предикторные переменные: X — символ предикторной переменной.
Коэффициент — коэффициенты являются весами для каждой переменной в уравнении и иногда
рассматриваются как параметрические оценки. Положительный коэффициент регрессии при предикторной переменной
означает нарастание риска и, следовательно, ухудшение прогноза с увеличением значений. Отрицательный
коэффициент регрессии означает более благоприятный прогноз для пациентов с более высокими значениями
соответствующей переменной. Они также называются бето-весами.
Стандартная ошибка — вариабельность каждого из оцениваемых коэффициентов.
Статистика Вальда^^ — статистика критерия, рассчитанная по данным; по ней определяются р-значения.
р-значения — вероятность увидеть результаты, равные или превосходящие крайние значения по сравнению
с действительно найденными, если справедлива нулевая гипотеза. Здесь р-значения указывают на то, что все
переменные значимо связаны с риском смерти.
Отношение рисков (или уровни рисков) — степень риска, связанная с каждой переменной при фиксации всех
остальных переменных. Для бинарных переменных отношение рисков, равное 1, указывает на то, что
обладание характеристикой переменной не способствует событию и не защищает против него. Отношения, меньшие
1, указывают на пониженный риск; большие 1 — на повышенный риск. Здесь вероятность умереть в течение
5 лет для пациента с сердечной болезнью в анамнезе в 4,22 раза выше по сравнению с пациентом без нее.
В общем, отношение рисков — это итоговое значение повышенного риска на каждую единицу или уровень
роста предикторной переменной.
95% ДИ — точность оценки отношения рисков. Чем уже доверительные интервалы, тем выше точность
оценок.
9.13. Опишите качество жизни выживших.
Выживание само по себе необязательно является адекватной конечной точкой
медицинских исследований; некоторые технологии не столько отдаляют смерть, сколько
продлевают страдания. Разумное использование медицинских технологий требует оценки их
воздействия на качество жизни, как и их влияния на выживаемость.
Литература
1. Mosteller F, Gilbert JP, McPeek В. Reporting standards and research strategies for controlled trials.
Control Clin Trials. 1980; 1:37-58.
2. Altman DG, Gore SM, Gardner MJ, Pocock SJ. Statistical guidelines for contributors to medical
journals. BMJ. 1983; 286:1489-93.
136 Составление статистических отчетов в медицине
Глава 10
Определение наличия или отсутствия
заболевания
Отчет о характеристиках проведения
диагностических тестов
Критерием полезности диагностического теста является либо его
способность добавить информацию к уэюе имеющейся, либо способность этой
информации приводить к благоприятным изменениям в оказании помощи
пациенту.
R. Jaeschke, G. Н. Guyatt, D. L. Sackett [1]
Эффективность лечения обычно зависит от точности диагностирования состояния
пациента. Диагностические тесты разнообразны по форме: наблюдение за наличием или
отсутствием клинических проявлений или симптомов, биохимическое описание ткани, анкета,
чтение рентгенограммы, изменения электрических потенциалов, появление новых типов
клеток и т. д.
К сожалению, многие диагностические тесты не оценены должным образом. Часто
в статье о том, как использовать тест, дается слишком мало информации, следствием чего
являются разногласия в способах применения тестов [2]. В результате диагностическое
тестирование становится источником больших финансовых потерь [3].
Нижеприведенные указания особенно уместны при описании разработки и
характеристик нового диагностического теста. Однако большинство ссылок на диагностические
тесты относится к их использованию в более широком исследовании, что уменьшает
количество необходимых для рассмотрения указаний. В этой главе мы также коротко описываем
те приложения теоремы Байеса, с помощью которых иногда характеризуются
диагностические тесты. Сюда включены также указания Стандартов по отчетам о разработке
характеристик диагностических тестов (STARD) [4].
ЦЕЛЬ ТЕСТА
10.1. Идентифицируйте цель теста.
Цель диагностического теста заключается в том, чтобы выполнить особую функцию
в особой популяции, которая, как предполагается, удовлетворяет особым условиям.
Необходимо описать каждый из этих компонентов.
Следует четко указать медицинское состояние или диагноз, которые должен выявить,
определить или дифференцировать тест. Это же относится к стадиям тех состояний, для
Отчет о характеристиках проведения диагностических тестов 137
Образец презентации
Гистероскопия, пробный исследуемый тест, применялась для диагностирования рака матки
у женщин в предклимактерическом периоде. При сравнении с эталонными стандартами анализа
данной патологии процедура показала 80%-ю чувствительность и 90%-ю специфичность,
результатом процедуры было положительное отношение правдоподобия, равное 8. Преваленс рака
матки в нашей группе исследуемых составляет 10 %. Прогностичность положительного
результата теста, таким образом, составила 47,1 %. Положительный результат теста указывал на наличие
злокачественной опухоли, подлежащей лечению. Межоценочная надежность равна
приблизительно 82 %.
Здесь:
• Чувствительность — способность теста правильно идентифицировать пациентов, которые,
как уже известно, страдают изучаемым заболеванием. В данном примере результаты
гистероскопии дали положительный результат у 80 % женщин из тех, кто, по данным патологического
анализа, действительно больны раком матки. Чувствительность является процентным
выражением «истинно положительных» результатов. Остальные 20 % пациенток — женщины, у которых
гистероскопия дала отрицательный результат, но которые, тем не менее, больны раком. Эти
результаты называются ложноотрицательными.
• Специфичность — способность теста правильно идентифицировать пациентов, которые, как
уже установлено, не страдают изучаемым заболеванием. В данном примере результаты
гистероскопии дали отрицательный результат у 90 % женщин из тех, кто, по данным патологического
анализа, не страдает раком матки. Специфичность является процентным выражением «истинно
отрицательных» результатов. Остальные 10 % здоровых пациенток — женщины, у которых
гистероскопия дала положительный результат, несмотря на отсутствие рака. Эти результаты
называются ложноположительными.
• Эталонный, «золотой», стандарт — стандарт, по которому устанавливается точность
«пробного» (исследуемого) теста. Он выражает собой «истину» или близок к ней настолько, насколько
позволяют текущие измерения.
• Отношение правдоподобия для положительных результатов теста объединяет
чувствительность и специфичность одним числом, равным отношению вероятности того, что
тестирование даст положительный результат у пациента, страдающего болезнью, к вероятности того, что
результат будет положителен для пациента, не страдающего этой болезнью. Отношение
правдоподобия, равное 8, указывает на то, что положительный результат в восемь раз вероятнее для
пациентов, страдающих данной болезнью, чем для не страдающих.
• Преваленс заболевания — доля популяции, пораженная болезнью, а также множитель при
вычислении прогностичности положительного и отрицательного результатов.
• Прогностичность положительного результата — вероятность того, что пациентка с
положительным результатом гистероскопии действительно страдает раком матки. Прогностичность
положительного результата теста, равная 47 %, означает, что у 47 из 100 женщин с
положительными результатами гистероскопии действительно имеется рак. Прогностичность
положительного результата и чувствительность — не одно и то же. Прогностичность говорит нам о статусе
пациента при данном результате тестирования, тогда как отношения правдоподобия говорят
нам о результате тестирования при данном статусе пациента. Чувствительность, в отличие от
положительной прогностической ценности, не подвержена влиянию превалентности заболевания
в тестируемой популяции. Если бы превалентность составила 90 %, а не 10 %, как указано выше,
прогностичность положительного результата была бы равна 98,6 %; почти каждый с
положительными результатами теста имел бы заболевание. Однако если бы превалентность была равна
только, скажем, 1 %, прогностичность положительного результата была бы равна лишь 7,5 %.
• Межоценочная надежность — степень согласия между гистероскопистами в их
заключениях о наличии злокачественной опухоли, что в данном случае является подходящей мерой
надежности теста, поскольку «результатом» теста является заключение. В данном случае совпадают
82 % суждений разных гистероскопистов об одних и тех же данных.
138 Составление статистических отчетов в медицине
которых применим данный тест (например, ранняя или поздняя стадия рака) (см.
указание 10.2).
Популяцию, для которой предназначен тест, также следует четко идентифицировать
и описать подходящими демографическими и клиническими показателями. Важно,
например, знать, был ли предназначен тест для подростков с анемией, пострадавших от ожогов
взрослых или беременных с сопутствующими заболеваниями [5].
Диагностические тесты обычно обладают одной из пяти функций [6]:
• Скрининг-тест выполняется для видимо здоровых людей без выраженных
симптомов с целью выявить «тех, кто с достаточно высокой степенью риска подвержен
определенному расстройству, чтобы обосновать последующий диагностический тест или
процедуру или же, при определенных обстоятельствах, прямое превентивное
воздействие» [7]. Измерение кровяного давления, предлагаемое на общественных
медицинских мероприятиях, является примером скрининг-теста.
• Рутинный тест проводится как часть серии тестов и может дать результат в виде
«выявленного случая» или положительного анализа, не относящегося к первоначальному
состоянию. «Стандартный анализ крови» по требованию врачей, являющийся частью
обычного врачебного осмотра, может выявить, например, анемию.
• Тест для постановки диагноза назначается для того, чтобы идентифицировать или
исключить то или иное расстройство; так, с помощью биопсии можно отличить
доброкачественный кишечный полип от злокачественного.
• Определение стадии заболевания проводится с целью охарактеризовать
природу или степень состояния пациента, например степень метастазирования раковой
опухоли или степень регургитации в неполностью закрывающемся митральном
клапане.
• Мониторинговый тест выполняется для наблюдения за состоянием пациента с
течением времени. Тест на содержание сахара в крови, применяемый инсулинозависимы-
ми диабетиками для регулировки своей дозы инсулина, — мониторинговый тест.
^ Насколько полезен тест? «Утку трудно спутать с тибетским быком, яком даже
в отсутствие хромосомного анализа, поэтому если на первом месте
диагностического теста стоит его способность различать и без того непохожие расстройства,
то это является слабым аргументом в пользу его повсеместного применения <...>
решающим преимуществом диагностического теста часто является его
способность дифференцировать расстройства, которые бывает легко спутать друг с
другом, особенно при резких различиях в их прогнозах и методах лечения» [6].
10«2. Укажите стадию заболевания, для которой пригоден теа [5].
Некоторые тесты различаются по своей способности распознавать ранние и поздние
формы заболевания. Этот «эффект спектра» [8], или «смесь случаев» [9, 10],
диагностического теста может объясняться тремя компонентами, которые следует учитывать при
указании стадии болезни:
• Патологическая компонента тяжести заболевания или развития болезни; например,
метастатический рак распознать легче, чем локализованное поражение.
• Клиническая компонента выраженности или хронического характера симптомов;
например, острый период заболевания бывает распознать легче, чем медленно
прогрессирующее, хроническое заболевание.
Отчет о характеристиках проведения диагностических тестов 139
• Компонента сопутствующих заболеваний, которые напрямую не относятся к
изучаемой болезни, но могут повлиять на результаты анализов.
Знание спектра заболеваний, на котором тест дает точные результаты, важно потому, что
истинное значение диагностического теста, вероятнее всего, заключено в его
способности различать тесно связанные или сомнительные случаи [6]. Таким образом, тест,
распознающий рак на более ранней стадии, полезней по сравнению с распознающим на более
поздней.
@ Идентифицируйте, если это уместно, все подгруппы, для которых тест
может оказаться особенно эффективным [10, 11]. Некоторые диагностические
тесты оказываются малоэффективными при проведении их в популяции с полным
спектром заболевания, но хорошо проходят в некоторых подгруппах, для которых
спектр гораздо уже.
103. Поясните клинический смысл положительных и отрицательных результатов
теста.
Положительный результат теста обычно указывает на отклонение от нормы или
нежелательное состояние, тогда как отрицательный обычно указывает на норму или желательное
состояние. Однако клинический смысл положительного или отрицательного результата
зависят от того, каким образом определяется «норма» или «аномалия» (рис. 10.1).
• Диагностическое определение нормы — это некоторый диапазон измерений, в
котором некоторое условие отсутствует, а вне которого — вероятнее всего, присутствует.
Это диагностическое определение нормы имеет первостепенное значение и основано
(или должно быть основано) на свидетельствах в пользу наличия или отсутствия
болезни в нормальном и аномальном диапазонах соответственно. Здесь положительный
результат выступает в поддержку диагноза заболевания, а отрицательный — нет.
• Терапевтическое определение нормы устанавливает диапазон измерений, в
котором лечение не показано (в силу неэффективности или даже вреда), а вне его лечение
предпочтительно. Как и предыдущее, данное определение, если оно основано на
доказательствах эффективности лечения, является клинически полезным. Таким
образом, положительный результат показывает целесообразность назначения лечения,
а отрицательный — нет.
Другие определения нормы, пожалуй, менее полезны для клинического принятия
решений, хотя, к сожалению, распространены:
• Определение по факторам риска основано на измерениях суррогатных конечных
точек или маркеров заболеваний. Здесь норма определяется диапазоном измерений
факторов риска, в котором риск заболевания не нарастает, а вне его — растет. Определение
основано на предположении, согласно которому изменение фактора риска изменяет
действительный риск заболеть. Например, за редкими исключениями, высокий
уровень холестерина сыворотки не опасен сам по себе; «аномальным» его делает
связанный с ним повышенный риск сердечного заболевания. Положительный результат
теста указывает на возросший риск заболеть, тогда как отрицательный — не указывает.
• Гауссово определение нормы основано на измерениях, проведенных в популяции
при отсутствии заболевания. Нормальным обычно считается диапазон измерений,
покрывающий два СО выше и ниже среднего; т. е. тот диапазон, который
включает центральные 95 % от всех измерений. Однако наибольшие и наименьшие 2,5 %
140 Составление статистических отчетов в медицине
«Нормальное» по Гауссову определению:
центральные 95 % значений
распределены между 3 и 9 мл
«Нетипичное» по процентильному
определению: верхние 5 % значений
выше приблизительно 8,6 мл
6 7 8 9
Результаты теста, мл
10
11
12 13
14
15
о.
Здоровые
люди
Больные
люди
Значения более 13 мл
«нетипичны» по
терапевтическому
определению, если
лечение предназначено
только для этого
диапазона значений
«Нормальное» по
диагмостическому
определению: значения
ниже 8 мл не связаны с
болезнью
6 7 8 9
Результаты теста, мл
10 11
12 13 14 15
Рис. 10.1. Несколько определений нормы. (А) Статистические определения. Гауссово определение
основано на нормальном распределении и считает «нормальным» диапазон значений, заключенных обычно между
двумя стандартными отклонениями выше и ниже среднего (средние 95 % от значений распределения). Здесь
считается «нормальным» диапазон между 3 и 9 мл, тогда как значения вне его на каждом конце (по 2,5 %
значений на каждом) считаются «аномальными». Процентильное определение считает нормальными нижние (или
верхние) 95 % диапазона значений; в данном случае диапазон от О до 8,6. Согласно этому определению, только
верхние (или нижние) 5 % значений будут считаться «аномальными». (В) Клинические определения.
Диагностическое определение показывает вероятность наличия болезни при данном результате теста; здесь отсчет
ниже 8 мл указывает на отсутствие заболевания. Терапевтическое определение показывает полезность
терапии для данного результата теста. Например, медицинские свидетельства могут говорить о том, что лечение
подходит только для пациентов со значениями, скажем, 13 мл или выше. Другими словами, положительный
результат теста при терапевтическом определении изменит способы ухода за пациентом
значении — «аномальные» значения — могут не иметь клинических следствии; они
просто нетипичны [12, 13]. Отчеты о большинстве стандартных анализов крови
составлены с использованием этого определения нормы. Оно обычно предполагает, что
результаты анализа распределены по нормальному закону (т. е. описываются
гауссовым распределением, или колоколообразной кривой). К сожалению, результаты тестов
Отчет о характеристиках проведения диагностических тестов 141
редко бывают нормально распределенными [6]. Однако нетипичные значения
необязательно указывают на болезнь, а нормальные — на ее отсутствие. Таким образом,
положительный результат теста говорит лишь о нетипичности значения в нормальной
популяции, а отрицательный — о его типичности.
• Процентильное определение нормы выражает нормальный диапазон как
произвольно взятый процент наименьших (или наибольших) значений всего диапазона.
Например, нормальным может считаться любое значение из меньших 95 % всех результатов
теста, и лишь значения из наибольших 5 % будут определены как аномальные, но это
определение опять-таки может иметь лишь статистический, а не клинический смысл.
Как и в описанном выше гауссовом определении, положительный результат теста
показывает лишь нетипичность значения в нормальной популяции, а отрицательный —
его типичность.
• Социальное определение нормы основано на житейских представлениях о том, что
является и что не является нормой. Желательный вес, например, или сроки таких
знаковых событий, как появление молочных зубов, часто являются социальным
определением нормы, связанной с ними, что может либо иметь, либо не иметь серьезных
клинических последствий.
ХАРАКТЕРИСТИКИ ВЫПОЛНЕНИЯ ТЕСТА
10.4. Опишите биологический принцип, на котором основан тест.
Зная, как работает тест, читатели смогут легче оценить его соответствие своему
назначению. Уровень детализации должен соответствовать целям исследования и нуждам
аудитории.
Q Укажите структуру и объем анкет, направленных на распознавание
клинических состояний. Анкета, разработанная, к примеру, для идентификации депрессии,
может содержать вопросы по телесным симптомам, эмоциональному состоянию
и поведению. Каждый из этих разделов может оцениваться по собственной шкале,
или же ответы могут просто описываться одной итоговой величиной, превышение
порога которой указывает на высокое правдоподобие депрессии. (См. такэюе гл. 16.)
10.5. Укажите, насколько применяемый тест соответствует своему назначению,
и эталонный тест, с которым он сравнивается.
Обоснованность исследуемого теста определяется его способностью выдавать точные
измерения, что определяется близостью его результатов к результатам эталонного теста.
В качестве последнего может служить другой, общеупотребительный тест, в идеале —
эталонный стандарт (или «золотой стандарт», хотя этот термин больше не является
предпочтительным) — тест, который принят как точно измеряющий состояние. Например,
результаты тестирования нагрузки можно сравнить с результатами коронарной ангиографии,
эталонного теста, который также является эталонным стандартом для диагностики
коронарной болезни сердца.
Обычным, но некорректным способом проверки диагностического теста является
вычисление коэффициента корреляции для результатов, полученных с помощью как
применяемого, так и эталонного теста от одних и тех же пациентов. Но на коэффициент
корреляции влияет степень вариабельности значений от пациента к пациенту, и эта вариабельность
142 Составление статистических отчетов в медицине
не имеет отношения к тому, насколько хорошо результаты одного метода согласуются с
результатами другого.
Более уместным подходом является метод Бланда—^Альтмана, или метод «пределов
согласия», при котором разности между парными измерениями откладываются на оси Y,
а средние двух измерений — на оси X [14]. Этот подход аналогичен графическому
представлению остатков в линейном регрессионном анализе {см. рис. 21.26), при котором
высокая степень согласия показывается разностями, остающимися близкими к нулю на всем
диапазоне измерений по оси X.
Время между проведением исследуемого и эталонного тестов должно быть достаточно
коротким, чтобы в состоянии пациентов не произошло ощутимых изменений [5].
Результаты исследуемого теста (положительные или отрицательные) должны быть также
независимыми от проверки наличия или отсутствия болезни [5,6, 8,9,15-20]. Независимость лучше
всего устанавливать при помощи «слепого» сравнения теста с эталонным стандартом.
Результаты исследуемого теста следует интерпретировать при неизвестных результатах
эталонного теста, а результаты эталонного — без знания результатов исследуемого [5].
На независимость исследуемого теста и его проверки по эталонному стандарту может
оказать влияние по крайней мере три систематических ошибки [9]:
• Ошибка влияния (или верификации) может иметь место, если результат более раннего
диагностического теста влияет на тех, кто, как предполагается, должен будет пройти
исследуемый тест. Отрицательный результат более раннего теста может уменьшить
вероятность того, что некоторые пациенты пройдут исследуемый тест, а положительный —
увеличить вероятность того, что испытуемый тест пройдут другие пациенты [5].
• Ошибка диагностического повторения может иметь место тогда, когда результаты
прошлых тестов известны тем, кто интерпретирует результаты исследуемого теста.
Например, если на томографе виден узелок в легких, то наличие нераспознанного
поражения на рентгенограмме грудной клетки может стать более очевидным [17].
Слепое оценивание может уменьшить ошибку этого вида на испытательной стадии
разработки теста. Но поскольку клиницисты постоянно знакомятся с результатами тестов
при повседневном наблюдении за больными, надежда на слепые исследования может
оказаться нереалистичной [И].
• Ошибка объединения может иметь место тогда, когда диагноз устанавливается на
основании результатов самого исследуемого теста, а не исключительно с помощью
эталонного. Объединение результатов в один диагноз нарушает независимость исследуемого
теста по отношению к эталонному стандарту.
Q Иногда бывает полезно указать в отчете долю больных и здоровых пациентов,
распознанных эталонным тестом и исследуемым тестом, как и специфические
результаты теста.
10 А. Сообщите о надежноаи теста.
Надежность теста, или надежность «от теста к тесту», — способность выдавать
единообразные результаты при проведении его в одних и тех же условиях. На надежность может
влиять несколько факторов:
• Различия в выполнении теста [6]. Результаты трансэзофагиальной эхокардиографии,
например, могут варьироваться в зависимости от уровня мастерства врача, который
вводит зонд.
Отчет о характеристиках проведения диагностических тестов 143
• Различия в обработке данных теста. Разные лаборатории могут использовать разные
процедуры, по-разному калибровать оборудование, применять разные реагенты и т. д.
• Различия в состояниях пациента, при которых он обследуется. Например, результаты
анализа крови могут быть разными в течение дня, на разных стадиях заболевания или
в разных популяциях пациентов, например у беременных женщин. [12, 21].
• Согласованность меэюду наблюдателями, или степень различий, с которыми двое или
более экспертов интерпретируют одни и те же результаты, как это часто бывает при
интерпретации визуальных анализов: рентгенограмм, томограмм или ультразвуковых карт.
• Согласованность внутри наблюдателей, или степень различий, с которыми один и тот
же эксперт интерпретирует один и тот же результат в разное время.
Мерами согласованности оценок являются каппа-статистика, альфа Кронбаха, меж-
и внутриклассовые коэффициенты корреляции, а также метод Бланда—Альтмана.
10.7. Опишите все сомнительные результаты теста и объясните, как они
обрабатывались при расчете характеристик его выполнения.
Не все тесты дают четкие положительные или отрицательные результаты. Возможно,
была проглочена не вся порция бария; возможно, кишечный газ повлиял на ультразвуковую
картину брюшной полости; возможно, бронхоскопическая биопсия не исключила и не
подтвердила диагноз; возможно, исследователи не пришли к единому мнению при
интерпретации клинических проявлений. Количество и долю неположительных и неотрицательных
результатов важно знать потому, что такие результаты влияют на клиническую полезность
теста и необходимость повторных или дополнительных анализов [5].
Simel и соавт. [22] различают три типа сомнительных результатов:
1. Промежуточные результаты — те, которые попадают в промежуток между
отрицательным и положительным результатом. В тесте, основанном на присутствии в ткани клеток,
окрашивающихся в синий цвет, «синеватые» клетки, которые не остались неокрашенными
и не приобрели должного оттенка синего, можно считать промежуточными результатами.
2. Неопределенные результаты — те, которые нельзя отнести ни к положительным,
ни к отрицательным. Известным неопределенным результатом являются, например,
найденные в цитологическом мазке «атипичные слущенные клетки неизвестного вида» (ASCUS).
3. Неинтерпретируемые результаты получаются тогда, когда тест проводится с
отклонениями от существующих стандартов. Например, стандартные рентгенограммы
грудной клетки получаются в положении пациента лицом к экрану. Если снимок получен в
положении к экрану спиной, пропорции снимка будут отличаться от тех, какими они должны
были быть при правильной рентгеносъемке. Тогда будет невозможно правильно определить
размеры некоторых структур: результаты будут неинтерпретируемыми.
В отчете следует описать, каким образом такие результаты учитывались при расчете
чувствительности и специфичности. Эти характеристики будут варьироваться в зависимости
от того, считаются ли результаты положительными, отрицательными или они вовсе не
принимались в расчет {см. указание 10.8 и табл. 10.1),
10.8. Укажите диагностическую чувствительность и специфичность теста,
включив связанные с ними доверительные интервалы.
Р1деальный диагностический тест возвращает положительный результат для всех
пациентов, имеющих болезнь, и отрицательный для всех тех, у кого ее нет. Совершенны, однако.
144 Составление статистических отчетов в медицине
лишь немногие тесты; большинство их обладает погрешностью, связанной с их
применением (чувствительность и надежность меньше 100 %), и поэтому возвращает некоторое
количество ложноположительных и ложноотрицательных результатов.
Кроме того, результаты тестов у здоровых и больных пациентов часто перекрываются
(рис. 10.2). Если большие значения одного распределения накладываются на малые
значения другого, значения в области наложения не делают различий между здоровыми и
больными субъектами. Даже точный результат теста, попавший в эту область, может тогда
привести к диагностической ошибке.
Диагностическую точность теста характеризуют два качества: чувствительность и
специфичность. Табл. 10.1 показывает, каким образом вычисляются эти показатели [21, 22].
• Чувствительность отвечает на вопрос: «Насколько вероятен положительный
результат теста, если пациент страдает данной болезнью?» [8]. Чувствительность 90 %
означает, что из 100 человек с верифицированным диагнозом тест, вероятно, распознает 90
(частота истинно положительных результатов равно 90 %). Остальные 10
отрицательных результатов называются ложноотрицательными.
• Специфичность отвечает на вопрос: «Насколько вероятен отрицательный результат
теста, если пациент не страдает данной болезнью?» [8]. Специфичность 75 % означает,
что из 100 человек, у которых доказано отсутствие данного заболевания, результат
теста, вероятно, окажется отрицательным для 75 (частота истинно отрицательных
результатов равна 75 %). Остальные 25 результатов называются ложноположительными.
Один из способов запомнить разницу между истинными и ложными положительными
и истинными и ложными отрицательными результатами состоит в следующем:
• Истинно положительные результаты определяют распознанных пациентов, у
которых подтверждено наличие болезни.
• Истинно отрицательные результаты определяют не страдающих заболеванием
людей, которые знают, что они не имеют данной болезни.
• Ложноположительные результаты определяют пациентов-«стигматиков»,
которые считаются больными, но в действительности данной болезнью не страдают.
• Ложноотрицательные результаты определяют «скрытых» пациентов, о болезни
которых еще никому не известно.
^ Дайте обоснование выбора точки деления, определяющей чувствительность
и специфичность. Существует альтернатива выбора между чувствительностью
и специфичностью (рис. 10.2). Поскольку диапазоны нормальных и аномальных
значений часто перекрываются, для определения «порога принятия решений»
вводится точка деления, которую можно перемещать, изменяя чувствительность
и специфичность теста.
Другой характеристикой, которая часто отражается в отчетах наряду с
чувствительностью и специфичностью, является диагностическая точность, или диагностическая
эффективность (табл. 10.1). Диагностическая точность — это процент всех правильных
решений (число истинно положительных и истинно отрицательных результатов, деленное
на число всех решений). Точность теста зависит, однако, от преваленса заболевания. Более
предпочтительным, хотя и более сложным показателем точности является рабочая
характеристика, ROC-кривая {см. указание 10.10), площадь под которой показывает точность теста
при разных точках деления (что также изменяет чувствительность и специфичность);
таким образом, ROC-кривая не зависит от преваленса заболевания.
Отчет о характеристиках проведения диагностических тестов 145
Таблица 10,1
Вычисление характеристик диагностических тестов"*
Реальное состояние популяции
Результат теста Пациенты с заболеванием Пациенты без заболевания
Всего
Положительный
Отрицательный
Всего
(истинно положительные)
чувствительность
с
(ложноотрицательные)
a-fc
(ложноположительные)
(истинно отрицательные)
специфичность
b + d
a + b
c + d
a+b+c+d
^ Формулы справедливы в предположении, что выборка, на основе которой составлена таблица, отражает
истинную превалентность болезни.
Чувствительность
Специфичность
Частота ложноположительных
Частота ложноотрицательных
Преваленс
Прогностичность положительного
результата
Прогностичность отрицательного
результата
Диагностическая точность
(эффективность)
Отношение правдоподобия для
положительного результата теста
Отношение правдоподобия для
отрицательного результата теста
Диагностическое отношение шансов
= доля истинно положительных = а/(а + с).
= доля ложноотрицательных = d/(b + d).
= доля ложноположительных = b/(b + d) = 1 - специфичность.
= доля ложноотрицательных = с/(а + с) = 1 - чувствительность.
= доля популяции, пораженная болезнью = (а + с)/(а + Ь + с + d).
= число больных пациентов с положительным результатом теста,
деленное на число пациентов с положительным результатом теста:
(преваленс)(чувствительность)/[(преваленс)(чувствительность)+
+ (1 - преваленс) (1 - специфичность)]. Если таблица отражает
преваленс, то ППР = а/(а + Ь).
= число не страдающих болезнью пациентов с отрицательными
результатами теста, деленное на число пациентов с отрицательными
результатами теста: (1 - преваленс)(специфичность)/(1 - преваленс)
(специфичность) + (преваленс) (1 - чувствительность)]. Если таблица
отражает преваленс, то ПОР = d/(c -h d).
= доля правильных результатов = (а + d)/(a -ь b + с -h d); или (прева-
ленс)(чувствительность) + (1 - преваленс) (специфичность).
= [а/(а -I- c)]/[b/(b -h d)] = чувствительность/(1 - специфичность).
= [с/(а + c)]/[d/(b + d)] = (1 - чувствительность)/специфичность.
= (a/c)/(b/d) или ad/bc.
10,9. Укажите отношения правдоподобия для положительных и отрицательных
результатов теста.
Отношения правдоподобия — еще один показатель диагностической точности теста,
и они становятся все более популярными в отчетах о характеристиках диагностического
теста. Отношение правдоподобия сочетает в одном числе чувствительность и
специфичность теста. Таким образом, отношение правдоподобия для положительного результата
теста — это чувствительность (доля истинно положительных результатов), деленная на 1
минус специфичность (долю ложноположительных результатов; табл. 10.1). Другими
словами, отношение правдоподобия для положительного результата теста — это:
146 Составление статистических отчетов в медицине
Точка деления № 1
Ложноположительный результат
Результат, принимаемый как отрицательный
012345678
Результат, принимаемый как положительный
9 10 11 12 13 14 15 16 17
мл/ч
Точка деления № 2
Точка деления № 3
Нет ложноположительных результатов
Результат, принимаемый
как отрицательный
8 9
мл/ч
Результат, принимаемый
как положительный
10 11 12 13 14 15 16
17
Рис. 10.2. Если, как это часто бывает, распределения значений для здоровых и больных пациентов
перекрываются, чувствительность и специфичность теста можно изменить перемещением порога принятия решения,
или «точки отсечения», на новое значение. Здесь распределения перекрываются в диапазоне от 7 до 11 мл/ч.
(А) Точка деления (№ 1) в середине этого диапазона выравнивает число ложноположительных и ложноотрица-
тельных результатов. (В) Перемещение точки деления к значению 7 мл/ч (№ 2) уничтожает ложноотрицательные
результаты, но увеличивает долю ложноположительных. Аналогично, перемещение точки деления к 11 мл/ч
(№ 3) уничтожает ложноположительные результаты, но увеличивает долю ложноотрицательных
Правдоподобие положительного результата теста у пациентов, имеющих болезнь
Правдоподобие положительного результата теста у пациентов, не имеющих болезнь
Например, если отношение правдоподобия для положительного результата теста равно
6,2, то положительный результат теста у пациента, имеющего болезнь, в 6,2 раза вероятнее,
чем у не имеющего. Отношение правдоподобия для отрицательного результата
показывает шанс ожидать отрицательный результат у пациента, не имеющего болезни, в сравнении
с тем, у кого она есть.
Отчет о характеристиках проведения диагностических тестов 147
10.10. Если диагностический тест является существенной частью исследования,
а его интерпретация зависит от положения точки деления на множестве его
значений, проиллюстрируйте его характеристики с помощью рабочей ха-
рактериаики (ROC-кривой).
Полезным способом представления характеристик диагностического теста является
рабочая характеристика (ROC-кривая) (рис. 10.3). Эта ROC-кривая представляет собой
график, на котором вдоль оси Y отложены значения чувствительности (доля истинно
положительных результатов), а вдоль оси X — значения, равные 1 минус специфичность (или доля
ложноположительных результатов); таким образом, ROC-кривая является графиком
отношений правдоподобия для положительных результатов. При изменении порога принятия
решений (т. е. при перемещении точки, отделяющей здоровых пациентов от больных, см.
указание 10.8) меняются также чувствительность и специфичность теста. Эти значения
нанесены на график и соединены, образуя ROC-кривую.
н
о
Z
л
I
S
со
ь-
U
00
>ч
ЭР
л
I-
\J
о
X
I-
о
а
ф
а
о:
(D
Z
л
I
Z
S
0,0 0,2 0,4 0,6 0,8 1,0
Ложноположительная вероятность = 1 - специфичность
Рис. 10.3. Для тестов, результаты которых выражаются непрерывной переменной, ROC-кривая изображает
зависимость частоты истинно положительных результатов (чувствительность) от частоты ложноположительных
(1 -специфичность) на всем диапазоне точек деления. Точки вдоль диагонали показывают результаты, не лучше
случайных. Точки, наиболее близкие к верхнему левому углу, показывают точки деления, которые
максимизируют число истинно положительных результатов и минимизируют число ложноположительных. Если тесты
сравниваются на предмет достижения компромисса между чувствительностью и специфичностью, более предпочтительным
является тесте наибольшей площадью под ROC-кривой. (В ряде статистических пакетов реализованы процедуры
проверки статистических гипотез сравнения между собой двух или более ROC-кривых. — Прим. ред.)
148 Составление статистических отчетов в медицине
ROC-кривая, которая распознает болезнь не лучше, чем простая случайность, будет
лежать на прямой, идущей под углом 45° из точки пересечения осей X и Y в правый верхний
угол рисунка (линия с единичным угловым коэффициентом, рис. 10.3). Точки на этой линии
говорят о том, что тест дает одинаковое число истинно и ложноположительных
результатов, т. е. не делает различий между здоровыми и больными исследуемыми. Наиболее точная
ROC-кривая — та, которая выгнута к верхнему левому углу рисунка, перед тем как перейти
к верхнему правому углу. Наилучшая точка деления для сбалансированности
чувствительности и специфичности теста будет представлена той точкой кривой, которая лежит ближе
всего к верхнему левому углу.
Как отношение правдоподобия {см. указание 10.9), так и ROC-кривая выводятся из
чувствительности и специфичности теста (см. указание 10.8).
ф При сравнении диагностических тестов, для которых чувствительность
и специфичность считаются одинаково важными, более точным будет
считаться тест с большей площадью под ROC-кривой (см. рис. 10.3).
Q Если тест является существенной частью исследования, отразите в отчете
число и долю пациентов с болезнью и без нее, протестированных с целью
определить специфичность и чувствительность.
Число здоровых и больных участников исследования, выбранных для определения
чувствительности и специфичности теста, по соглашению предполагается примерно
одинаковым, что способствует полнейшему раскрытию возможностей теста [15].
Поскольку вне изучаемых популяций такие доли встречаются редко, для помощи в
интерпретации результатов теста при его применении в клинической практике необходимы
дополнительные показатели — прогностичность положительного и отрицательного
результатов. В то время как чувствительность и специфичность являются
характеристиками самого теста (если они вычислены при описанных условиях) и не зависят от
преваленса болезни, прогностичность положительного и отрицательного результатов теста
зависят от преваленса состояния в популяции, так же как и от его чувствительности
и специфичности.
КЛИНИЧЕСКОЕ ПРИМЕНЕНИЕ ТЕСТА
10Л1« Опишите, каким образом должен выполняться теа.
Если предполагается принятие теста к практическому применению, следует описать
клинические аспекты его выполнения [5]. Опишите, если это уместно, следующее:
• протокол выполнения теста;
• как интерпретировать результаты;
• как готовить пациентов к проведению теста (например, специальные диеты,
ограничение двигательной активности, лечение, прием жидкостей);
• что могут испытывать пациенты во время проведения теста и после него;
• какие меры предосторожности следует принять до, во время и после теста;
• как брать, хранить, транспортировать или анализировать образцы;
• какие неопределенности могут остаться до, во время и после проведения теста [6].
Отчет о характеристиках проведения диагностических тестов 149
10.12. Укажите прогностичности положительного и отрицательного результатов
теста, а также связанный с ними преваленс заболевания.
Правильно определенные чувствительность и специфичность (см. указание 10.8)
являются характеристиками самого диагностического теста и не зависят от преваленса
заболевания. Полезность результата теста для отдельного пациента зависит, однако, от преваленса
заболевания в тестируемой популяции. Именно положительный результат теста окажется
истинным с большей вероятностью, если болезнь широко распространена, нежели в случае
редкой болезни: «Если вы слышите топот копыт, ищите лошадей, а не зебр». Другими
словами, несмотря на то что у зебр есть копыта, звук топота копыт следует истолковывать
в свете того факта, что лошади более распространены, чем зебры. Вероятность того, что
топот копыт принадлежит лошадям, таким образом, намного больше вероятности того, что
он принадлежит зебрам. Сочетая преваленс заболевания с чувствительностью и
специфичностью, можно получить две другие полезные меры диагностической точности: прогно-
стичность положительного и отрицательного результатов (см. табл. 10.1 и 10.2).
• Прогностичность положительного результата (или точность положительного
предсказания) отвечает на вопрос: «Если результат теста у пациента положителен,
насколько велика вероятность того, что он страдает этой болезнью?» Для выявления болезни
желательна высокая прогностичность положительного результата. Прогностичность
положительного результата, равная 83 %, означает, что 83 из 100 пациентов с
положительным результатом теста, скорее всего, действительно страдают этой болезнью.
• Прогностичность отрицательного результата (или точность отрицательного
предсказания) отвечает на вопрос: «Если результат теста у пациента отрицателен, насколько
велика вероятность того, что он не страдает этой болезнью?» Для исключения
возможности болезни желательна высокая прогностичность отрицательного результата.
Прогностичность отрицательного результата, равная 94 %, означает, что 94 из 100
пациентов с отрицательным результатом теста, скорее всего, не страдают этой болезнью.
Таблица 10,2
Прогностичность положительного и отрицательного результатов диагностического
теста с чувствительностью 80 % и специфичностью 90 % для различных относительных
преваленсов (претестовая вероятность того, что данный пациент страдает заболеванием)
Претестовая вероятность заболевания
Характеристика (преваленс)
Прогностичность положительного результата, %^
Прогностичность отрицательного результата, %^
Диагностическая точность (%)
^ Если преваленс болезни составляет 1 %, то болезнь, вероятно, имеется только у 7 или 8 из 100 (7,5 %)
пациентов с положительным результатом теста; у остальных результаты будут ложноположительными. Если преваленс
болезни составляет 90 %, то болезнь, вероятно, имеется у 98 или 99 из 100 (98,6 %) пациентов.
^ Если преваленс болезни составляет 1 %, то болезнью, вероятно, не страдает ни один из всех 100 (99,8 %)
пациентов с отрицательным результатом теста; ложноотрицательных результатов либо будет очень мало, либо не
будет совсем. Однако если преваленс болезни составляет 90%, то среди пациентов с отрицательными результатами
болезни не будет, вероятно, лишь у 33 из 100 (33,3 %), а результаты у остальных будут ложноотрицательными.
1%
7,5
99,8
89,9
10%
47,1
97,6
89,0
50%
88,9
81,8
85,0
90%
98,6
33,3
81,0
150 Составление статистических отчетов в медицине
Полезный способ отразить прогностичности теста показан на рис. 10.4 [23]. Прогно-
стичность от101адывается в зависимости от превалентности заболевания, а
чувствительность и специфичность отражаются в виде двух кривых для прогностичности
положительного и отрицательного результатов. Тем самым клиницисты могут оценить
прогностичности по данным о превалентности для своих пациентов.
Чувствительность = 90 %
Специфичность = 90 %
Чувствительность = 50 ^
Специфичность = 90 %
Прогностичность
положительного
результата
о 20 40 60 80 100
Преваленс заболевания, %
Прогностичность
положительного
результата
о 20 40 60 80 100
Преваленс заболевания, %
Рис. 10.4. График, отражающий характеристики диагностических тестов. В клинической практике
прогностичности теста могут оказаться более полезными, чем его чувствительность и специфичность. (А)Тест с
чувствительностью 90 % и специфичностью 90 %. (В) Тест с чувствительностью 50 % и специфичностью 90 %. (Elsenberg М. J.
Accuracy and predictive values In clinical decision-making. Cleve Clin J Med. 1995; 62:311-6; приведено с разрешения)
ПРИМЕНЕНИЕ ТЕОРЕМЫ БАЙЕСА В ДИАГНОСТИЧЕСКОМ
ТЕСТИРОВАНИИ
Прогностичности часто вычисляются при помощи теоремы Байеса. Эта теорема
представляет собой уравнение, связывающее «априорную (или претестовую) вероятность»,
«правдоподобие» и «апостериорную (или посттестовую) вероятность». Проще говоря,
теорема Байеса использует новую информацию (правдоподобие; информацию, добавленную
благодаря результатам теста) для обновления старой (априорной вероятности).
Обновленный результат является апостериорной вероятностью, или, в данном случае, прогностично-
стью теста (см. такэюе гл. 11),
• Априорная (или претестовая) вероятность заболевания может быть просто прева-
ленсом заболевания; другими словами, вероятностью того, что случайно выбранный
пациент болен. Однако она может В1слючать и другую информацию, поднимающую
«показатель подозрения» на особый диагноз, такую как наличие проявлений и
симптомов болезни.
• Правдоподобие — это в данном случае вероятность того, что диагностический тест
даст определенный результат при особых условиях. Два таких особых условия
выражаются в отношениях правдоподобия для положительного и отрицательного
результатов {см. указание 10.9). В отношении правдоподобия для положительного результата
Отчет о характеристиках проведения диагностических тестов 151
0,1
0,2
0,5
%
10
20
30
40
50
60
70
«апостериорную вероятность»
наличия болезни.
10.13. При отчете о применении сочетания
двух и более диагностических теаов
укажите порядок их выполнения,
характеристики их проведения, а
также вклад каждого из них в
заключительный результат.
Тесты с разными степенями
чувствительности и специфичности можно применять
одновременно или последовательно с целью
увеличить их диагностическую ценность, сократить
затраты или то и другое вместе. В
действительности тесты чаще применяются
последовательно, нежели изолированно друг от друга [9].
80
90
95
99
1000 +
500 +
200 +
100 4-
50
20
10 +
5 -I-
2
1 +
0,5
0,2
0,1
0,05
0,02
0,01
0,005
0,002
0,001
99
теста вероятность, стоящая в числителе, является правдоподобием полоэюительного
результата теста для пациентов, у которых есть болезнь; другими словами —
чувствительностью теста. Вероятность, стоящая в знаменателе, является правдоподобием
положительного результата среди тех пациентов, у которых ее нет. Она равна 1 минус
специфичность теста (см. табл. 10.1).
• Апостериорная (или посттестовая) вероятность заболевания — это вероятность
того, что пациент страдает болезнью, если известны преваленс и результаты
диагностического теста: прогностичности положительного или отрицательного результата
теста.
ПРИМЕР
• Если априорная вероятность заболевания
(скажем, преваленс болезни в популяции,
прошедшей рутинное обследование на ее
наличие) равна 10 %, а отношение
правдоподобия для положительного результата
равно 20 (это значит, что положительный
результат у страдающего болезнью
пациента в 20 раз вероятнее, чем у не
страдающего), то апостериорная вероятность
болезни при положительном результате
равна около 70 %. Таким образом, в
данном случае в обследованной популяции
пациент с положительным результатом
будет иметь 70 % шансов оказаться больным.
Этот результат легко получить с помощью
номограммы (рис. 10.5) [1, 24].
ф Полезный диагностический тест
имеет высокое отношение правдоподобия
и тем самым значительно изменяет
V 95
90
80
70
60
50
40
30
20
10
%
V 1
0,1
h 0,1
0,1
Претестовая
вероятность
Отношение
правдоподобия
Посттестовая
вероятность
Рис. 10.5. Номограмма позволяет определить
прогностичности положительного и
отрицательного результатов (апостериорные вероятности
заболевания) по отношениям правдоподобия
теста и преваленсу заболевания в популяции
(априорная вероятность заболевания). (FaganT. J.
Nomogram for Bayes'theorem [Letter]. N Engl J Med.
1975;293:257; приведено с разрешения)
152 Составление статистических отчетов в медицине
В таких случаях желательна диаграмма, показывающая взаимосвязи и характеристики
тестов (рис. 10.6).
СООБРАЖЕНИЯ ОТНОСИТЕЛЬНО ПРИНЯТИЯ ТЕСТА
Если основной мыслью статьи является стремление ввести тест в практику, следует
учесть приведенные ниже указания.
10«14« Опишите влияние теста на способы лечения пациента и течение болезни.
Конечной целью диагностического теста является улучшение ухода за пациентом. Таким
образом, необходимо описать, как влияет тест на лечение пациента и на течение болезни [9,25].
Истина
Истина
<
s.
14
2
4
38
18
QQ
Р -4.
U +
13
1
1
3
Чувствительность = 14/16 = 87,5 *
Специфичность = 38/42 = 90,5 %
Чувствительность = 13/14 = 92,9 %
Специфичность = 3/4 = 75,0 %
Истина
t +
13
3
4
38
Чувствительность = 13/16 = 81,3 %
Специфичность = 38/42 = 90,5 %
Истина
Тест Истина
А В +
+ +
+
+
00
с +
12
4
4
38
15
1
6
36
Чувствительность =15/16 = 93,8 %
Специфичность = 36/42 = 85,7 %
Чувствительность =12/16 = 75,0 %
Специфичность = 38/42 = 90,5 %
Рис. 10.6. Диагностические тесты можно проводить последовательно {А) или одновременно {В), с тем чтобы
увеличить их полезность и/или сократить связанные с ними расходы. Следует указать вклад каждого теста
в окончательный итог анализа. Здесь выборка отражает 30%-й преваленс заболевания. В случае А 18
пациентов с положительным результатом теста А дополнительно проходят тест В, что увеличивает чувствительность
с примерно 88 % до примерно 93 %. В случае В тесты проводятся совместно, и считается, что положительный
результат имеют все пациенты с положительным результатом хотя бы по одному тесту. Тем самым
чувствительность увеличивается по сравнению с отдельно взятыми тестами
Отчет о характеристиках проведения диагностических тестов 153
10.15* Представьте информацию о тесте по существу.
Многие диагностические тесты принимаются преждевременно из-за того, что не были
оценены должным образом. Тесты, достоинства которых доказаны на каждой из
описанных ниже пяти стадий, скорее всего, окажутся более ценными в клинической практике, чем
не прошедшие такую проверку [24]:
• Стадия 1: тест точно и достоверно идентифицирует случаи очевидной патологии при
тщательно контролируемых условиях.
• Стадия 2: тест точно и достоверно дифференцирует здоровых людей из контрольной
группы от пациентов с узким, хорошо выраженным спектром заболевания.
• Стадия 3: тест точно и достоверно дифференцирует здоровых людей из контрольной
группы от пациентов с более широким спектром заболевания, включая менее
типичные и менее тяжелые проявления.
• Стадия 4: тест точно и достоверно дифференцирует более разнородные группы
пациентов и контрольные группы. В частности, в каждую группу следует включить
пациентов с сопутствующими заболеваниями. В числе последних должны быть те болезни
и состояния, которые легче всего спутать с исследуемым заболеванием, а также те,
симптомы и методы лечения которых могут затруднить проведение теста.
• Стадия 5: тест точно и достоверно дифференцирует болезнь в типичном
клиническом составе пациентов. Выборка в таком исследовании должна включать вторичных
пациентов с полным спектром заболевания, здоровых пациентов, пациентов с
сопутствующими заболеваниями и без них, а также тех, кому тест может быть назначен
скорее всего.
@ Иногда важно указать, будут ли клинические данные, доступные при
интерпретации результатов теста в ходе его проверки, доступны с внедрением теста
в клиническую практику [5].
Щ Со временем эффективность теста может меняться благодаря
технологическим улучшениям и росту мастерства персонала [9].
10*16. Опишите человеческие, финансовые и материальные ресурсы,
необходимые для предложения теаа в сложившихся условиях.
Совершенствование медицинских технологий означает, что применение теста может
потребовать больше ресурсов, чем кажется на первый взгляд:
• Требуемые человеческие ресурсы могут включать опытных операторов,
квалифицированных специалистов по содержанию и ремонту оборудования, обученный
персонал клинической поддержки.
• Требуемые финансовые ресурсы могут включать затраты на приобретение,
содержание, накладные расходы, затраты на приобретение материалов, эксплуатационные
расходы, расходы на обучение, страховку и замещение.
• Требуемые материальные ресурсы могут включать лабораторное пространство,
мощности по расчету и обработке данных, а также зону контролируемого доступа.
10Л 7« Опишите связанные с принятием теста затраты и выгоды.
Медицинские аспекты внедрения теста могут включать следующее:
• диагностическую надежность;
154 Составление статистических отчетов в медицине
• инвазивность;
• возможности вызвать или предотвратить вредные реакции;
• возможности потребовать или избежать госпитализации;
• возможности отложить лечение до появления результатов;
• влияние на предоставление лечения, если состояния диагностируются с
возрастающей частотой;
• влияние на пациентов, которым в результате тестирования поставлен неверный
диагноз; ложноположительные результаты могут, например, привести к новым,
ненужным тестам и беспокойствам, в то время как ложноотрицательные результаты могут
непреднамеренно задержать необходимое лечение [26].
10.18. Опишите связанные с принятием теаа финансовые затраты и выгоды.
Тесты, благодаря которым ставятся более точные диагнозы на более ранней стадии,
способствуют большим возможностям лечения, но в то же время могут повлечь изменения
в финансовом отношении. Финансовые аспекты могут включать следующее:
• расходы при выполнении теста, на одного пациента и общие;
• перераспределение бремени расходов на тест;
• стоимость процедур, которые с внедрением теста становятся необходимыми или
ненужными;
• сэкономленные средства при отмене более дорогостоящего теста;
• отмена промежуточных тестов и связанных с ними расходов;
• влияние тестовых ошибок и неверных диагнозов.
10«19« Опишите, каким образом тест сравнивается с аналогичными.
Следует обсудить достоинства нового теста по сравнению с альтернативными. Важен
вопрос: «Чем этот тест лучше действующих стандартных?» [2]. Тесты можно сравнивать по их
точности (если возможно, сравните ROC-кривые [5]), достоверности, простоте проведения,
стоимости проведения и действию на пациентов (инвазивность, дискомфорт, удобство).
Литература
1. Jaeschke R, Guyatt GH, Sackett DL Users' guides to the medical literature. III. How to use an article
about a diagnostic test. B. What are the results and will they help me in caring for my patients? The Evidence-
Based Medicine Working Group. JAMA. 1994; 271:703-7.
2. Evidence and Diagnostics. Bandolier Evidence-Based Health Care; February 2002. Available at
www.ebandolier.com. Accessed August 8, 2005.
3. van Walraven C, Naylor CD. Do we know what inappropriate laboratory utilization is? A systematic
review of laboratory clinical audits. JAMA. 1998 280:550-8.
4. Bossuyt PM, Reitsma JB, Bruns DE, et al Towards complete and accurate reporting of studies of
diagnostic accuracy: the STARD initiative [Review]. BMJ. 2003; 326:41-4.
5. Whiting P, Rutjes AWS, Dinnes J, et al Development and validation of methods for assessing the
quality of diagnostic accuracy studies. Health Technol Assess. 2004; 8:1-234.
6. Haynes RB. How to read clinical journals: II.To learn about a diagnostic test. Can Med Assoc J. 1981;
124:703-10.
7. WaldN, Cuckle H. Reporting the assessment of screening and diagnostic tests. Br J Obstet Gynaecol.
1989;96:389-96.
8. RansohoffDF, Feinstein AR. Problems of spectrum and bias in evaluating the efficacy of diagnostic
tests. N Engl J Med. 1978; 299:926-30.
Отчет о характеристиках проведения диагностических тестов 155
9. Begg СВ. Biases in the assessment of diagnostic tests. Stat Med. 1987; 6:411-23.
10. Begg CB, Pocock SJ, Freedman L, Zelen M. State of the art in comparative cancer clinical trials.
Cancer 1987; 60:2811-5.
11. ReidMC, Lacks MS, FeinsteinAR. Use of methodologic standards in diagnostic test research. JAMA.
1995;274:645-51.
12. Griner PF, Mayewski RJ, Mushlin Al, Greenland P Selection and inteфretation of diagnostic tests
and procedures: principles and applications. Ann Intern Med. 1981; 94:557-92.
13. Diamond GA, Forrester JS. Clinical trials and statistical verdicts: probable grounds for appeal. Ann
Intern Med. 1983;98:385-94.
14. AltmanDG, Bland JM. Measurement in medicine: the analysis of method comparison studies.
Statistician. 1983; 32:307-17.
15. Metz CE. Basic principles of ROC analysis. Semm Nucl Med. 1978; 8:283-98.
16. Cooper LS, Chalmers TC, McAlly M, et al. The poor quality of early evaluations of magnetic
resonance imaging. JAMA. 1988; 259:3277-80.
17. Jaeschke R, Guyatt GH, SackettDL. Users' guides to the medical literature. III. How to use an article
about a diagnostic test. The Evidence-Based Medicine Working Group. A. Are the results of the study valid?
JAMA. 1994;271:389-91.
18. Sox HC Jr Probability theory in the use of diagnostic tests: an introduction to critical study of the
literature. Ann Intern Med. 1986; 104:60-6.
19. Sheps SB, Schechter MT. The assessment of diagnostic tests: a survey of current medical research.
JAMA. 1984;252:2418-22.
20. ArrollB, Schecter MT, Sheps SB. The assessment of diagnostic tests: a comparison of medical
literature in 1982 and 1985. J Gen Intern Med. 1988; 3:443-7.
21. Riegelman RK, Hirsch RP. Studying a Study and Testing a Test, 2nd ed. Boston: Little, Brown;
1989.
22. Simel DL, Feussner JR, Delong ER, Matchar DB. Intermediate, indeterminate, and uninterpretable
diagnostic test results. Med Decis Making. 1987; 7:107-14.
23. Eisenberg MJ. Accuracy and predictive values in clinical decision-making. Cleve Clin J Med. 1995;
62:311-6.
24. Nierenberg AA, Feinstein AR. How to evaluate a diagnostic marker test. JAMA. 1988; 259:1699-
1702.
25. Guyatt GH, Tugwell PX, Feeny DH, et al. A framework for clinical evaluation of diagnostic
technologies. Can Med Assoc J. 1986; 134:587-94.
26. Welch HG. Should I Be Tested for Cancer? Maybe Not and Here's Why. Berkeley: University of
California Press, 2004.
156 Составление статистических отчетов в медицине
Глава 11
Рассмотрение априорных
вероятностей
Отчет о байесовских статистических анализах
Сторонники байесовского подхода работают с вероятностями гипотез при
данном мносисестве данных, тогда как сторонники частотного (те, кто
пользуется классическими проверками гипотез) — с вероятностями мноэюеств
данных при данной гипотезе.
R. J.Lewis, R.L Wears [\]
Большинство статистических анализов, рассмотренных в этой книге, основаны на том,
что называется «частотным подходом» или «классической проверкой гипотез», наиболее
популярной статистической школой с момента ее появления в 20-х гг. XX века. Однако
среди ряда медиков-исследователей все более популярной становится альтернативная
школа «байесовской статистики», поэтому мы кратко описываем и ее. Поскольку байесовский
анализ не является общепринятым в биомедицинских исследованиях (несмотря на
повсеместное применение теоремы Байеса в диагностическом тестировании, см. указание 10.13),
об отчетах о его проведении написано мало. Таким образом, мы даем лишь несколько
указаний.
КРАТКОЕ ОПИСАНИЕ БАЙЕСОВСКОЙ СТАТИСТИКИ
Теорема Байеса названа именем того, кто ее сформулировал — преподобного Томаса
Байеса (1702-1761), пресвитерианского священника и любителя математики, жившего в
Лондоне'. На этой теореме, описывающей математические взаимосвязи между априорной, или
доэкспериментальной, вероятностью события и апостериорной, или послеэксперименталь-
ной, вероятностью при данных значениях экспериментальных данных (представленных
«правдоподобием»), и основана байесовская статистика. Проще говоря, байесовский метод
начинается с множества предположений (доэкспериментальных вероятностей), а затем
модифицирует их на основе собранных при изучении данных (правдоподобия), с тем чтобы
получить обновленное множество предположений, называемых «послеэксперименальны-
ми вероятностями» [2]. Таким образом, «байесовский анализ выясняет, каким образом
результаты исследования изменяют мнение, сложившееся до проведения исследования» [3].
Байесовский подход концептуально привлекателен потому, что он моделирует
конвенциональное принятие решений [4]. Большинство суждений о действенности лекарства, на-
' Томас Байес родился в 1702 г. в Лондоне, а с 1720 по 1761 г. жил и служил священником в городке Танбридж
Уэллс, что примерно в 50 километрах от Лондона.
Отчет о байесовских статистических анализах 157
пример, делается с учетом некоторых сведений о его действии в прошлом. В большинстве
случаев опыт или прошлые исследования в общих чертах указывают на то, каким будет
ожидаемый эффект от применения лекарства. С получением новой информации ожидания
меняются до тех пор, пока не будут приняты как окончательные. Байесовская статистика
моделирует этот процесс явным образом. Кроме того, байесовские процедуры дают
формальные выражения неопределенности ожиданий.
РАЗЛИЧИЯ МЕЖДУ БАЙЕСОВСКОЙ И ЧАСТОТНОЙ СТАТИСТИКОЙ
В отличие от байесовской статистики, классическая проверка гипотез не дает
формального выражения неопределенности об «истинности» гипотезы; распределения вероятности
даются только для наблюдаемых данных в условиях нулевой гипотезы. Такой подход и его
логику, следовательно, понять нелегко [5]. Начнем с того, что проверка гипотез не дает
вероятности того, что лекарство эффективно. Скорее она предполагает, что лекарство
неэффективно, и дает меру свидетельства против этого предположения (р-значение). Только при
убедительных свидетельствах (т. е. при малом/^-значении) исследователь все же делает
непосредственный вывод об эффективности лекарства, и этот вывод делается без каких-либо
показателей того, насколько он мог быть убедительным или сомнительным.
Если говорить более точно, то на самом деле проверяется нулевая гипотеза — гипотеза
о неотличимости проходящей лечение и контрольной групп. Если свидетельство
эксперимента достаточно сильно, чтобы опровергнуть нулевую гипотезу (т. е. если вероятность
найти такую же или большую разницу по сравнению с найденной в предположении, что
нулевая гипотеза об отсутствии разницы истинна, меньше, скажем, пяти сотых), то нулевая
гипотеза обычно отвергается в пользу альтернативной гипотезы, утверждающей, что
лекарство эффективнее плацебо. Однако альтернативных гипотез много: они могут предполагать
разницу между экспериментальной и контрольной группами, равную, скажем, 5, 7, 10 или
12 %, но обычно имеется в виду лишь та, которую выдвигает исследователь. В
противоположность этому, байесовский подход дает, например, явно определяемую данными
вероятность того, что средний результат в экспериментальной группе выше, чем в контрольной.
Байесовская статистика способна также ответить на вопрос: «Какова вероятность, что
средний эффект от лечения более чем на 5 % выше, чем эффект от плацебо?»
Кроме того, классическая проверка гипотез не привлекает более ранних сведений о
лекарстве. Каждое испытание структурировано так, чтобы проверить одну и ту же гипотезу:
нулевую гипотезу об отсутствии различий. Поэтому становится неважным, насколько
много мы знаем о лекарстве: исследование по-прежнему начинается с предположения о том,
что оно или не даст эффекта (по сравнению с плацебо), или этот эффект будет не выше, чем
у лекарства, взятого для сравнения.
Представим себе, к примеру, исследование, в котором проверялось, уменьшает ли новый
препарат коронарный артериальный стеноз у людей. Исследователи случайным образом
распределяли пациентов выборки либо в экспериментальную, либо в получавшую плацебо
контрольную группу, записывали исходные показатели диаметров артерий в обеих группах,
назначали по показаниям препарат или плацебо, а затем отслеживали величину диаметров
артерий в обеих группах через несколько месяцев. Затем статистически оценивалась
разность в средних изменениях диаметров артерий между группами и делались заключения
о клинической ценности лекарства.
158 Составление статистических отчетов в медицине
Если бы исследователи применяли классическую проверку гипотез, то они бы
сначала сформулировали нулевую гипотезу об отсутствии разности и установили бы условия,
при которых они могли бы отклонить эту гипотезу. Другими словами, они бы
действовали от предположения, что препарат неэффективен и что всякое различие между средними
в обеих группах является случайным. Они бы также условились о том, что если бы разность
между группами превысила некоторую заданную величину и если разность в условиях
нулевой гипотезы возникла бы, скорее всего, случайно менее чем, скажем, в 5 случаях из 100,
то они бы отказались от нулевой гипотезы в пользу альтернативной, т. е. гипотезы о том, что
разница в группах вызвана действием препарата, а не случайностью. Результат мог быть
сформулирован так: «Лечение уменьшило стеноз на 5 % (95% ДИ 0,7-9,3 %), и это
уменьшение оказалось статистически значимым на уровне 0,05 (р = 0,02)».
Если бы исследователи применяли байесовскую статистику, они бы сначала оценили
распределение доэкспериментальных вероятностей того, что препарат имеет некоторую
степень эффективности, причем каждой возможной степени соответствует своя априорная
вероятность. Получить оценку такого априорного распределения вероятности (или
просто априорную информацию) можно из обзора опубликованных исследований, пилотных
исследований или из мнений экспертов. Априорную информацию можно выразить так:
«Существует 60%-я вероятность того, что препарат уменьшит коронарный артериальный
стеноз в среднем на 5 % и более». Затем данные исследования, выраженные математически
через функцию правдоподобия, можно использовать для обновления априорной, т. е.
имеющейся, информации, с тем чтобы получить апостериорную, или послеэксперименталь-
ную, вероятность эффективности препарата. Новые результаты можно сформулировать
так: «Приходим к выводу, что препарат с 83%-й вероятностью уменьшает стеноз на 5 %
и более по сравнению с плацебо».
Главное, за что критикуют (а многие и отвергают) байесовский подход, — это то, что
часто бывает трудно, если вообще возможно, убедительно определить распределение доэк-
сперименальной вероятности на возможных эффектах [1,6]. Кроме того, способность
производить вычисления байесовского анализа заложена лишь в немногих крупных
статистических пакетах, поэтому его применение требует дополнительных усилий. Преимущество
подхода — концептуальная привлекательность и большая легкость клинической
интерпретации результатов. Используя данный метод, можно также обойти проблему, возникающую
в классической проверке гипотез вследствие промежуточного анализа накопленных данных
(порождающего множество р-значений из одних и тех же данных, что увеличивает
вероятность сделать ошибку первого рода, см. гл, 5).
БАЙЕСОВСКИЕ КОЭФФИЦИЕНТЫ И ОТНОШЕНИЯ ПРАВДОПОДОБИЯ
Байесовские анализы можно применять для сравнения двух гипотез на основании
данных [7, 8]. Помните, что для одной данной задачи можно сформулировать любое
количество гипотез, вне зависимости от того, анализируются они при помощи частотной или
байесовской статистики. В примере с коронарным артериальным стенозом мы могли выдвинуть
следующие гипотезы:
• Препарат не уменьшил стеноз в большей степени, чем плацебо (нулевая гипотеза).
• Препарат уменьшил стеноз (в точности) на X % больше, чем в контрольной группе
(X может быть любым числом).
Отчет о байесовских статистических анализах 159
• Препарат уменьшил стеноз более чем на X % по сравнению с контрольной группой (X
может быть любым числом).
• Препарат увеличил стеноз в большей степени, чем в контрольной группе.
• Апостериорная вероятность уменьшения стеноза составляет X % от априорной, где
X — снова любое число.
Кроме того, гипотезы можно сформулировать так, как они звучат при классической
проверке гипотез, и использовать при этом любые стандартные показатели, такие как разности
(скажем, в сантиметрах или мг/дл), отношения шансов, отношения рисков, проценты и
изменения в процентах.
Одним из достоинств байесовского анализа является то, что любое сочетание этих
гипотез можно сравнивать при помощи так называемого байесовского коэффициента.
Байесовский коэффициент — это отношение силы доказательства в поддержку одной гипотезы
к силе доказательства в поддержку другой. Например, равенство байесовского
коэффициента 0,05 показывает, что, допустим, апостериорные шансы 20%-го уменьшения вирусной
нагрузки в 20 раз выше, чем априорные шансы. Это означает, что лечение намного
увеличивает вероятность того, что вирусная нагрузка снизится на 20 %.
Если гипотетическая разница между группами выражена одним числом (например,
уменьшение креатина составит в точности 5 %), байесовский коэффициент является не чем
иным, как отношением правдоподобия {см. гл. 2). При указании его в отчете в этом случае,
как и для любого отношения, необходимо дать четкие определения числителя и
знаменателя; стандартной практики отнесения гипотетических значений к числителю или
знаменателю не существует. В вышеприведенном примере, где коэффициент был равен 0,05,
числитель и знаменатель могли быть деленными друг на друга отношениями шансов 2 и 40:
2/40 = 0,05. Однако числитель и знаменатель можно было привести в отчете и так: 40/2 = 20,
показывая, что числитель в 20 раз больше знаменателя. Корректны оба представления; в
отчете надо лишь дать пояснения.
Если же гипотетическая разность может выражаться диапазоном значений (например,
уменьшение креатина будет выше 5 %), то байесовский коэффициент становится
функцией правдоподобия. Функция правдоподобия выглядит как распределение вероятности,
но в действительности им не является; она выражает отношение одной гипотезы для итога
эксперимента к другой на всем диапазоне возможных значений; в примере со стенозом —
для каждого миллиметра коронарного диаметра артерий. Байесовский коэффициент можно
получить из функции правдоподобия, которая показывает, насколько сильно данные
поддерживают каждую из возможных взятых за основу гипотез. Если распределение
априорной вероятности — константа, то распределение апостериорной вероятности будет
выглядеть как функция правдоподобия. Интерпретировать можно только отношения
правдоподобия, из самого абсолютного значения правдоподобия ничего вывести нельзя. Поскольку
для функции правдоподобия на оси Y нет единиц измерения (отношения безразмерны), для
того чтобы показать найденное «согласно данным» анализа, ее часто представляют (или
переносят на рисунок) совместно с распределениями априорной и апостериорной
вероятности (рис. 11.1).
Байесовские коэффициенты обычно не входят в вычисления или отчеты в байесовских
анализах, но если они приведены в отчете или могут быть получены из его результатов,
то могут служить полезным дополнением к апостериорным вероятностям. Важной
особенностью байесовских коэффициентов является их относительно слабая зависимость
160 Составление статистических отчетов в медицине
А) Распределение априорной вероятности
В) Функция правдоподобия
о
О
С
о
ее
со
Q.
с
ОС
:£.
I
>s
е
С) Распределение апостериорной вероятности
о
о
Ql
СО
3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
Прирост СИЛЫ, КГ
Рис. 11.1. Гипотетические распределения вероятности и функция правдоподобия для байесовского анализа,
оценивающего программу силовых тренировок. (А) Распределение доэкспериментальной вероятности
показывает наибольший прирост в 6,5 кг у тех, кто выполняет программу. (В) Функция правдоподобия показывает, что
данные текущего исследования демонстрируют в наибольшей степени поддержку улучшения в 14,5 кг. (С)
После пересмотра распределения априорной вероятности по результатам текущего исследования посредством
функции правдоподобия распределение апостериорной вероятности показывает, что наиболее вероятным
является улучшение примерно на 12 кг. Вероятность же прироста на 14,5 кг, найденная в ходе исследования,
составляет теперь примерно половину от значения, полученного по результатам исследования. Распределения априорной
и апостериорной вероятности, будучи распределениями вероятности, имеют единичную площадь под кривой; таким
образом, сумма всех вероятностей в каждом распределении включает в себя все возможности
(а иногда полная независимость) от априорных вероятностей, приписанных к нулевой
и альтернативной гипотезам; они являются мерой силы доказательства, а не вероятности.
Они часто говорят о том, что сила свидетельства против нулевой гипотезы не так велика,
как показано/?-значением.
Отчет о байесовских статистических анализах 161
ПРЕДСКАЗЫВАЮЩИЕ РАСПРЕДЕЛЕНИЯ
Байесовская статистика может также использоваться для определения особого типа
распределения апостериорной вероятности, называемого предсказывающей вероятностью.
Это распределение показывает вероятность будущих событий при уже наблюдавшихся
итогах эксперимента. Предсказывающие распределения применяются во многих случаях:
• Принятие решения о сроках прекращения эксперимента; таким образом,
предсказывающие распределения используются в качестве правил остановки. Подходящие
правила остановки могут основываться на точно оговоренных количествах
информации о конечных точках, таких как достаточно узкий интервал правдоподобия (см.
ниже) или достаточно высокая вероятность для определенной гипотезы (см. ниже).
• Предсказание исходов для будущих пациентов; иными словами, предсказывающее
распределение может при данных результатах эксперимента дать вероятность того,
что лечение будет успешным и для нового пациента. Такие вероятности помогают
врачам и пациентам принять решения о проведении лечения.
• Предсказание клинического исхода по суррогатной конечной точке. Если у
пациентов были взяты два разных показателя дважды в разное время, то при
некоторых обстоятельствах значение второго показателя можно предсказать по известному
первому, даже до проведения второго измерения; иными словами, первый показатель
используется для второго как суррогатный. Например, отторжение имплантата
молочной железы (первое измерение) может предсказать более позднее неблагоприятное
изменение состояния здоровья (второе измерение).
• Восполнение пропусков в данных в предположении, что пропуски возникают у
пациентов, похожих на тех, кто имеет полные данные, или же что данные имеют
случайные пропуски.
Нижеприведенные указания предназначены для использования в дополнение к тем,
которые относятся к разработке исследований и их проведению {гл. 13-16), при отчете об
анализе с помощью байесовской статистики. Указания взяты из критерия ROBUST (Reporting
Of Bayes Used in Clinical Studies) [3], из разработанных группой BaSiS (Bayesian Standards
in Science (BaSiS) [9] и из предварительных рекомендаций, предлагаемых FDA [12]. Однако
данное направление еще только развивается и общеупотребительными являются лишь
немногие стандарты.
11*1. Приведите доэкспериментальные вероятности и укажите, каким образом
они были определены [3,9-12].
Распределение доэкспериментальных вероятностей описывает вероятность того, что
будет иметь место любое значение из диапазона лечебных эффектов (см. рис. 11.1).
Доэкспериментальные вероятности можно вывести на основании опубликованных исследований,
метаанализов, пилотных исследований или мнений экспертов, как это делается в анализе
принятия решений {см. гл. И и 13) [3]. Полный байесовский анализ использует
распределение априорной вероятности, отличное от собранных в исследовании данных. В отличие
от него, эмпирический байесовский анализ использует распределение априорной
вероятности, выведенное на основании данных, и не является полным байесовским анализом;
в типичном случае он дает результаты, аналогичные или иногда идентичные некоторым
частотным подходам.
162 Составление статистических отчетов в медицине
Однако, если имеется недостаточно достоверной информации для обоснования значений
доэкспериментальных (априорных) вероятностей, можно задать «неинформативные
априорные вероятности»; это говорит о том, что распределение априорной вероятности
является более или менее «плоским». Почти плоское распределение априорной вероятности
означает, что, скажем, всем возможным разностям между экспериментальной и
контрольной группами приписана (приблизительно) одна и та же априорная вероятность. Такие
распределения априорной вероятности часто приводят к тем же выводам, что и частотные
критерии. Lewis и Wears [1] пишут, что «в большинстве практических случаев частная
форма априорной информации имеет мало влияния на окончательный исход, поскольку она
подавляется массой экспериментальных свидетельств».
Иногда исследователи подвергают априорные вероятности «анализу чувствительности»;
они анализируют данные как со «скептическим», так и с «оптимистическим»
распределением априорной вероятности, с тем чтобы оценить эффект лечения при каждом условии [3].
Если так, результаты анализа чувствительности следует отразить в отчете.
^ Использование разных распределений априорных вероятностей может
привести к разным распределениям апостериорной вероятности в одном и том
же исследовании, и поэтому следует описать источник априорной
вероятности и вид того распределения, о котором идет речь в отчете. В частности, если
выбранное для исследования распределение априорной вероятности основано
на слишком большом числе пациентов по сравнению с реально вовлеченными в
исследование, оно может оказаться «чрезмерно информативным», т. е. подавить
данные, собранные в исследовании, и тогда неблагоприятные результаты исследования
могут оказаться замаскированными благоприятным распределением априорной
вероятности [12].
11.2* Укажите послеэкспериментальные вероятности и их вероятностные
интервалы [3,9-12].
Распределения послеэкспериментальной вероятности следует описывать при помощи
среднего, СО или интерпроцентильными размахами (широтами) [12]. Рекомендуются
также графические представления распределений вероятностей (см. рис. 11.1) [2, 3, 10-12].
В случае приемлемого распределения априорной вероятности распределение послеэкспе-
риментальных вероятностей должно быть менее вариабельным в результате включения
экспериментальных данных.
Байесовский «вероятностный интервал», или «интервал правдоподобия» [2, 12],
представляет собой некий аналог доверительного интервала классической проверки гипотез,
но его интерпретируют не так, как доверительный интервал; он означает, что существует
Х%-й шанс того, что истинное значение находится внутри указанного в отчете интервала.
Вероятностный интервал показывает диапазон результатов и соответствующие им
вероятности. Например, фраза «лечение уменьшило частоту возникновения новых опухолей
на 5 % (95%-й интервал правдоподобия 0,7-9,3 %)» означает, что имеется 95%-й шанс того,
что истинное уменьшение в процентах находится между 0,7 и 9,3 %. За этим утверждением
может последовать еще одно, основанное на той же кривой апостериорной вероятности:
«Апостериорная вероятность того, что лечение уменьшает частоту возникновения новых
опухолей, равна 98,9 %». Если распределение априорной информации плоское,
байесовский вероятностный интервал и частотный доверительный интервал обычно совпадают.
Отчет о байесовских статистических анализах 163
113. Дайте интерпретацию послеэкспериментальных вероятностей [3,9-12].
в байесовском анализе не применяется произвольно взятая точка деления между
положительным и отрицательным результатом исследования. (В классической проверке гипотез,
в противоположность ему, произвольно взятое/7 < 0,05 часто связывается с положительным
результатом, а/? > 0,05 — с отрицательным.) Байесовский анализ дает также вероятность
того, что интересующая нас гипотеза верна (т. е. вероятность того, что вмешательство
эффективно), в отличие от классической проверки гипотез, которая дает лишь вероятность
получить столь же или еще большую разность по сравнению с наблюдаемой в условиях
нулевой гипотезы об отсутствии разности.
Байесовские гипотезы можно проверять при помощи решающих правил. Согласно
одному из общеупотребительных типов решающих правил, гипотеза считается верной вне
каких-либо сомнений, если ее апостериорная вероятность достаточно велика, скажем,
более 95 или 99 % [12].
114. Укажите прикладные программы, а также статистические методы и модели,
применяемые в байесовских вычислениях [12].
Поскольку байесовское программное обеспечение и статистические процедуры не так
стандартизованы, как традиционные методы, важно дать описание вычислительных
процедур. Обычные процедуры включают методы Монте-Карло для марковских цепей, такие
как генератор выборок Гиббса и алгоритм Метрополиса—Гастингса, квадратура Гаусса,
генерация выборок по апостериорным распределениям, лапласово приближение, выборки
по важности.
Байесовская статистика часто привлекает обширное математическое моделирование,
особенно в отношении распределений априорной вероятности и влияния ковариат на исходы
экспериментов у пациентов и на пропуски [12]. Гибкость байесовских моделей и их
сложность чаще приводят к ошибкам и недоразумениям, поэтому их следует описывать
детально. К тому же разные модели могут привести к принятию разных решений. В частности,
назовите подходы, применяемые при проверке «соответствия» байесовской модели данным,
такие как анализ остатков, и при проведении каких-либо анализов чувствительности.
Наиболее употребительной прикладной программой для проведения байесовского
статистического анализа является WinBUG (Bayesian inference Using Gibbs Sampling); она
находится в свободном доступе в Интернете. Популярная коммерческая программа S-PLUS
содержит теперь и байесовский модуль.
Q Исследователи не должны переходить от байесовского подхода к частотному
и обратно при анализе своих результатов. Такие анализы post hoc не имеют
научного резонанса и снижают обоснованность исследования [12].
благодарности
За заметки и комментарии к ранней редакции этой главы мы благодарим Jason Connor,
DC, Department of Statistics Carnegie Mellon University и Michael Escobar, PhD, AP,
Department of Public Health Sciences, Department of Statistics, The University of Toronto. Особые
благодарности Steven Goodman, MD, MHS, PhD, Associate Professor of Oncology, Division of
Biostatistics, The Johns Hopkins Kimmel Cancer Center, за его советы и вклад в нашу работу.
Все ошибки, которые остались здесь, — на нашей ответственности.
164 Составление статистических отчетов в медицине
Литература
1. Lewis RJ, Wears RL. An introduction to the Bayesian analysis of clinical trails. Ann Emerg Med.
1993;22:1328-36.
2. Abrams K, Ashby D, Errington D. Simple Bayesian analysis in clinical trials: a tutorial. Control Clin
Trials. 1994; 15:349-59.
3. Sung L, Hayden J, Greenberg ML, et al Seven items were identified for inclusion when reporting a
Bayesian analysis of a clinical study. J Clin Epidemiol, 2005; 58:261-8.
4. Berger JO, Berry DA. Statistical analysis and the illusion of objectivity. Am Scient. 1988; 76:159-
65.
5. Connor JT. The value of a P-valueless paper. Am J Gastroenterol. 2004; 99:1638^0.
6. Jonson NE. Everyday diagnostics: a critiques of the Bayesian model. Med Hypotheses. 1991;
34:289-95.
7. Goodman SK Toward evidence-based medical statistics. 1: The P value fallacy. Ann Intern Med,
1999; 130:995-1004.
8. Goodman SN. Toward evidence-based medical statistics. 2: The Bayes factor. Ann Intern Med, 1999;
130:1005-13.
9. The BaSiS Group Bayesian Standards in Science (BaSiS). Available at http://lib.stat.cmu.edu/
bayesworkshop/2001/BaSisGuideline.litm.Accessed 5/3/06.
10. Spiegelhalter DJ, Myles JP, Jones DR, Abrams KR. Bayesian methods in health technology
assessment: a review. Health Technol Assess, 2000; 4:1-30.
11. Hughes MD. Reporting Bayesian analyses of clinical trials. Stat Med. 1993; 12:1651-63.
12. Center for Devices and Radiological Health, Food and Drug Administration. Draft Guidelines for
the Use of Bayesian Statistics in Medical Device Clinical Trials. Available at http://www.fda.gov/cdrh/osh/
guidance/1601 /pdf Accessed 5/24/06.
Отчеты об эпидемиологических показателях 165
Глава 12
Описание картин заболеваний
и нетрудоспособности в популяциях
Отчеты об эпидемиологических показателях
Эпидемиолог описывает болезнь в ее отношении к индивидууму, месту и
времени, а затем оценивает корреляции между изменениями в заболеваемости
и в определяющих факторах окруэюающей среды.
В. А. LaSHNER, J. В. KiRSNER [1]
Эпидемиология — учение о распространении, определяющих факторах и частоте
заболеваний и расстройств в популяциях, а также приложение этого учения к управлению
вопросами здоровья [2, 3]. Эти три компонента — распространение, определяющие факторы
и частота — пронизывают все эпидемиологические принципы и методы [3].
Сначала эпидемиологические методы использовались при изучении эпидемий
инфекционных заболеваний, теперь же они применяются и ко всему многообразию состояний
здоровья и условий жизни, как, например, к хроническим болезням, обусловленным образом
жизни, картинам преступлений, организации медицинской помощи. Поэтому, хотя мы и
используем в этой главе эпидемиологические термины (такие, как «заболевание» и
«пациент»), эти понятия применяются в более широком смысле — «заболевание» будет означать
любой вид расстройства или состояния здоровья, а «пациент» берется всякий раз, когда
имеется в виду отдельный человек с любым состоянием здоровья.
Основные цели эпидемиологии состоят в том, чтобы:
• выявлять случаи заболевания и факторы риска, увеличивающие вероятность
выявления заболевания;
• определять степень заболевания в географическом, культурном или геополитическом
аспекте;
• изучать естественную историю и распространение заболевания;
• оценивать новые превентивные и терапевтические вмешательства и новые модели
оказания медицинской помощи;
• предоставлять данные для выработки политики и регулирующих постановлений в
области общественного здравоохранения и безопасности окружающей среды [4].
Эпидемиология основывается на двух фундаментальных предположениях: 1) болезнь
и нетрудоспособность возникают неслучайно, и 2) факторы, вызывающие и
предотвращающие болезнь и нетрудоспособность, можно выявить путем систематического
исследования [3]. Такое исследование обычно включает выявление и описание взаимосвязей
между следующими элементами:
166 Составление статистических отчетов в медицине
• Популяция людей, подверженных (или не подверженных) риску заболевания или
вредного воздействия.
• Реципиент (хозяин) («случай», пациент или жертва), страдающий от болезни или
вредного воздействия.
• Агент, который вызывает заболевание или вредное воздействие. Это может быть
микроб (например, стрептококк), воздействие токсина (например, сигаретный дым),
поведение (езда без правил) или событие (медицинская ошибка).
• Переносчик, который доносит агента до реципиента (комар, например,
переносчик малярии, а некоторые могли бы сказать, что сигарета — переносчик табачного
агента).
• Географические области или среда, населенная агентами, реципиентами и
переносчиками, включая в некоторых случаях социальную, экономическую и политическую среду.
• Время, за которое агенты и реципиенты развиваются и взаимодействуют.
Эпидемиология и биостатистика—две различных, но взаимодополняющих дисциплины.
Биостатистика вообще более ориентирована на математику, и применять ее стремятся при
разработке и анализе экспериментальных исследований, в которых сравниваются
отклики отдельных людей на терапевтическое вмешательство в выбранной экспериментальной
группе (группах) с откликами в выбранной контрольной группе (группах). Эпидемиология
же больше ориентирована на общественное здравоохранение, и применять ее стремятся
при разработке и анализе исследований (ретроспективных и перспективных), связанных
с наблюдением за большими популяциями, в которых группы, выбранные по признаку
наличия некоторого диагноза или другой особенности, наблюдаются в течение некоторого
времени. Указания по отчету об экспериментальных и наблюдательных исследовательских
разработках и деятельности приведены в гл. 13-16.
Наконец, клиническая эпидемиология, относительно новое направление, связанное
с движением, называемым доказательной медициной, имеет дело с применением
принципов популяционной эпидемиологии к уходу за отдельными пациентами [5].
СОСТАВНЫЕ ЧАСТИ ЭПИДЕМИОЛОГИЧЕСКИХ ИЗМЕРЕНИЙ
Эпидемиологические измерения могут складываться из четырех составных частей:
1) числителя и 2) знаменателя, т. е. сравниваемых чисел; 3) временного отрезка; 4) единицы
популяции, к которой применяется сравнение (единичный множитель). Правильный отчет
об эпидемиологических данных и их интерпретация требует знаний о том, что включено
и что не включено в числители и знаменатели стандартных измерений, за какой период
производится сравнение, а также единице представленной популяции.
12.1, Определите интересующую вас популяцию.
Популяциями в эпидемиологии называются группы людей или других совместно
рассматриваемых объектов изучения, таких как госпитали, семьи, происшествия [2].
Популяцией называется группа людей по крайней мере с одной общей особенностью —
географическим местом проживания, фактором риска, национальной принадлежностью, диагнозом
или каким-либо другим свойством.
Стандартная популяция, иногда называемая универсумом, включает в себя всю
популяцию, к которой будут применены эпидемиологические выводы, такую как пациенты
Отчеты об эпидемиологических показателях 167
всего мира с диагнозом, скажем, лимфомы Ходжкина. Результаты исследований о
пациентах с лимфомой Ходжкина можно будет, по крайней мере, теоретически обобщить на более
широкую стандартную популяцию. В противоположность этому, экспериментальная, или
исследуемая, популяция является выборкой из рассматриваемой популяции. В идеале
исследуемая популяция должна быть репрезентативной по отношению к стандартной, так
чтобы результаты можно было бы распространить на пациентов более широкой,
стандартной популяции.
Популяция риска является предметом особого интереса в эпидемиологии, поскольку
обычно образует знаменатель отношения. Те ее пациенты, которые заболевают данной
болезнью, часто будут представлены в числителе. Популяция высокого риска —
подмножество рискующих заболеть рассматриваемой болезнью сильнее всего.
Наконец, целевая популяция — это группа, на которой фокусируется внимание при
сборе данных или вмешательстве. Она может совпадать со всей популяцией риска или быть
ее подмножеством. В эпидемиологических исследованиях целевыми группами населения
часто являются популяции высокого риска.
К возможным проблемам при определении популяций людей относятся различия в
особенностях, определяющих популяцию, изменчивость в географической области, внутри
которой ведется учет популяции, а также изменения, происходящие в популяции с течением
времени (рождения, смерти, эмиграция, иммиграция). Эти проблемы описаны ниже.
12.2. Укажите, каким образом были определены для исследования диагноз,
событие или воздействие.
Наука — это измерения. Однако определить, что измерено, почему это измерено, когда
это измерено, кто это измерил и при каких условиях проведены измерения, бывает
непросто. Рассмотрим следующие дилеммы:
• Что измерено. Некоторые состояния диагностируются или отслеживаются с
помощью маркеров, или «суррогатных конечных точек», которые могут указывать или
не указывать на присутствие этого состояния или болезни. Исчезновение симптомов
простуды может, например, служить суррогатной конечной точкой для полного
излечения риновирусной инфекции.
• Как это измерено. Тревожное состояние, к примеру, можно «измерить» несколькими
способами: как ряд симптомов, как самовычисленный индекс по шкале беспокойства,
как экспертное заключение терапевта или как самоотчет пациента. Разные
классификации могут относить одно и то же состояние к разным категориям, а сами
классификации могут со временем меняться из-за того, что болезнь воспринимается по-иному.
• Почему это измерено. Разные люди и организации собирают данные с разными
целями. Степень тяжести злоупотребления лекарственными препаратами в городе может
измерить департамент здравоохранения по числу госпитализаций на почве
наркологических заболеваний, а правоохранительные органы в качестве такой меры могут
использовать число арестов, связанных с употреблением наркотиков.
• Когда это измерено. Значения показателей могут отличаться в зависимости от того,
когда они были взяты. Температура тела меняется в течение дня, уровни гормонов
меняются в течение месяца, а некоторые болезни более часты в определенное время
года. Другие физиологические показатели меняются на разных стадиях сна,
жизненного или пищеварительного цикла и т. д. Показатели могут также меняться по «спектру
168 Составление статистических отчетов в медицине
заболевания», когда болезнь на ранней стадии имеет другие характеристики, нежели
прогрессирующая болезнь.
• Кто это измерил. Экспертное мнение иногда является единственным практическим
(а иногда и вовсе единственным) способом что-либо измерить. На результат
постановки клинического диагноза или решение о том, является ли заболевание слабым,
умеренным или тяжелым, может сильно повлиять разница в образовании, подготовке
и опыте измерявшего.
• Условия^ при которых производятся измерения. Измерение артериального
давления — стандартная процедура при многих обстоятельствах: оно проводится бригадой
скорой помощи на месте аварии, медсестрами в приемном покое, при обследовании
на дому и т. д. Так, «синдромом белого халата» называют тот факт, что у многих
пациентов повышается давление при измерении его медработниками по сравнению с
измерениями, проведенными членами семьи.
123. Определите интересующие вас географические области и среду.
Один из способов определить человеческую популяцию — определить населяемую ею
территорию. Но если национальные и государственные границы заданы со всей
четкостью, то учет людей, скажем, в «большом Лос-Анджелесе» может оказаться более трудной
задачей.
Географические области можно также выделить по особенностям, присущим тем или
иным местам, например по наличию угольных шахт, отделений интенсивной терапии или
по соседству со старой частью города.
Эпидемии — это локальные, региональные или внутригосударственные вспышки
заболевания, тогда как пандемии распространяются по всему миру.
124* Определите интересующий вас период.
Фигурирующий в исследовании временной отрезок всегда следует определять так,
чтобы результаты можно было интерпретировать в свете изменений, происшедших до, в
течение и после изучаемого периода. Продолжительность исследования в эпидемиологии
существенна для вычисления частот. Изменения, происходящие в течение временного
интервала, могут искусственно увеличивать или уменьшать оценки инциденса и преваленса
заболевания. Ниже говорится о наиболее распространенных понятиях при определении
временных интервалов.
• Изменения в отчетности или классификации в течение периода исследования.
Расщепление существующей диагностической категории на новые или на
подкатегории может быть полезным с терапевтической точки зрения, но может также изменить
указанную в отчете относительную частоту заболевания.
• Изменения в диагностической технике в течение периода исследования.
Изменения в способах диагностировки заболевания также могут увеличивать или уменьшать
оценки их инциденса и преваленса. Внедрение нового теста с большей аналитической
чувствительностью во время периода исследования может выявить большее
количество заболевших, чем применяемый стандартный тест.
• Изменения в эффективности лечения в течение периода исследования. Новые,
более эффективные способы лечения могут уменьшить инциденс или преваленс забо-
Отчеты об эпидемиологических показателях 169
левания. К примеру, внедрение терапии антибиотиками при лечении язв, вызываемых
Helicobacter pylori, сильно уменьшило число людей с язвами.
• Старение изучаемой популяции в течение периода исследования. Чем дольше
период наблюдений, тем сильней вероятность того, что на их результаты повлияют
естественные эффекты старения. Картины многих заболеваний связаны с возрастом,
особенно в начале и конце жизненного цикла. Субъекты, за которыми наблюдение велось
в течение десяти лет, выходят из одной декады риска и попадают в другую.
• Сезонные и секулярные тренды в частоте заболевания. Некоторые заболевания,
такие как обычная простуда, случаются не с одинаковой частотой в течение года,
но чаще в течение некоторых времен года. Изучение простуд, таким образом,
должно принимать во внимание эти сезонные колебания. Секулярные тренды показывают
изменение в течение более длительных временных интервалов, обычно за годы или
десятилетия.
МЕРЫ ЧАСТОТЫ ЗАБОЛЕВАНИЯ
Появление заболевания можно выразить посредством того, насколько быстро оно
распространяется в популяции (его инциденс) и насколько оно распространено в ней (его пре-
валенс). Инциденсом заболевания называют число новых случаев, произошедших за
данный период, а преваленсом — количество больных в данное время. Понятия инциденса
и преваленса часто смешивают. Различия между ними перечислены в табл. 12.1. Ниже мы
опишем два показателя инциденса — кумулятивный инциденс и плотность инциденса и два
показателя преваленса — мгновенный преваленс и преваленс за период.
Таблица 12,1
Отличия инциденса от преваленса
Инциденс Преваленс
• Частота • Доля
• Вероятность заболеть в данный момент • Вероятность быть уже больным к данному
времени времени
• Числитель складывается только из новых • Числитель складывается из новых и старых
случаев случаев
• Требуется индивидуальное наблюдение • Индивидуального наблюдения не требуется;
для выявления новых случаев по мере их может определяться через обзорные сведения
появления
• Не зависит от длительности заболевания • Зависит от длительности заболевания; долгие
заболевания увеличивают преваленс
• Предпочтительный показатель при изучении • Предпочтительный показатель при оценке
причин и эффектов нагрузки болезни на популяцию
По: Gerstman ВВ. Epidemiology Kept Simple: An Introduction to Classic and Modern Epidemiology. New York: Wilei-
Liss;1998.
170 Составление статистических отчетов в медицине
Кумулятивный инциденс
Инциденс — это частота, с которой событие происходит в популяции за данный период
времени. Ее можно выразить долей или частотой. Инциденс, выраженный долей,
называется кумулятивным инциденсом. Инциденс, выраженный частотой, называется
плотностью инциденса (см. ниже) [6].
Кумулятивный инциденс выражается так:
X ёйё! 11 ай б йёо^-аМ 9aai eaaai ёу, Y di ёй0 Mo ёб а i i i бёубёё
а ok-^i ёк оёкф i i ai i kbei aa x 1000
Xenei noauieoi a a i i i бёубёё, 11 ааабаеш i uб бёпёб
ба9аёбёу аТ ekqi ё а ol-^i ёк уб! а! i adei aa
Инциденс болезни составил 6002/125 767,
или 0,048 на 1000 человек.
Для понимания инциденса нужно помнить, что он представляет собой число новых
случаев, происшедших в популяции за указанный период. Любой субъект в знаменателе может
впоследствии попасть в числитель.
Другими терминами для кумулятивного инциденса являются доля инциденса, пора-
женность, риск инциденса, а также средний риск заболевания. Кумулятивный инциденс
является также показателем риска (см. ниже).
Плотность инциденса
Кумулятивный инциденс применяется тогда, когда ведется наблюдение за всеми
членами популяции в течение всего интересующего периода. Однако во многих исследованиях
следить в течение всего периода удается не за всеми индивидуумами; они могут быть
исключены из исследования, переехать в другое место, умереть и т. д. В этом случае
знаменатель может состоять из общей продолжительности состояния риска для каждого субъекта.
Это значение обычно выражается в единицах «человеко-времени», например человеко-лет.
Один субъект, наблюдаемый в течение года, — это 1 человеко-год; шестеро пациентов,
наблюдаемых в течение 9 месяцев (0,75 года), составляют 4 человеко-года (6 х 0,75 = 4) и т. д.
В этих примерах итоговая частота называется плотностью инциденса. Другими
употребительными единицами человеко-времени являются пассажиро-мили (для отчетов,
скажем, о рекордах безопасности полетов), пачко-годы (мера воздействия сигаретного дыма)
и человеко-часы (часто используемые для учета образовательных и обучающих программ).
Плотность инциденса рассчитывается по следующей формуле:
у... о,^> хёйё! //шопёб^-аааа 111 бёубёё х 1000
I eioi 1 пои eioeaai па =-
Ei ёё^пба! -^ё! aaei -абш ai ё аа9 ^aai eaaai ёу,
i 1 arlii16iyi её бёпёа
Среди 3 пациентов (1 наблюдался в течение 3 лет, 1 — в течение
5 лет и 1 — в течение 6 лет) от рецидива пострадал один.
Инциденс рецидива составил 0,07 (1/14) человеко-лет.
Плотность инциденса называется также мгновенный риск, частота риска, функция
риска, частота инциденса в единицах человеко-времени, а также сила заболеваемости.
Отчеты об эпидемиологических показателях 171
Пораженность
Пораженность — это относительный инциденс, обычно используемый при описании
вспышек острых инфекционных заболеваний, таких как пищевые отравления. Повторим,
что нужно сообщить интервал и место, где производится подсчет числа людей.
X ёпё! её б, 01Т одааёуао ёб i У даааёш i ojp
v.^. 0,..^ с^. .. ХА,^-.. ..or... leuoe caaieuaoeo
I 1 oaaeai 11 nou i eu aai ai i oi efloi aeaai ey =
xenei ёёб, oi i одМёуао ёб 66 аей i ей 6
Первичная пораженность основывается на числе лиц, заболевших непосредственно
от источника заражения (в данном случае — пищи), а вторичная пораженность — на
числе лиц, к которым болезнь пришла от зараженных людей. Пораженность пищевого
происхождения — особый тип пораженности, применяемый при исследовании случаев
пищевого отравления. Время с пораженностью специально не связывается, поскольку
инкубационный период (время между воздействием и появлением симптомов) обычно известен.
Преваленс
Преваленс — число всех людей, страдающих данной болезнью (не только новые случаи)
в течение некоторого периода, деленное на общее число подверженных риску заболеть этой
же болезнью за тот же период:
X ёйё! q\) акё а i Т i оёубёё, n66aaat) и ёб ai ёа91 uj)
у „ о _.. о, ^ а 6а^1 ёк 6eacai i i ai i adei aa x 1000
loaaaeain-
Xenei ej) aae a i i i бёубёё, i i aaadaeai i uб бёпео
да9аё6ёу ai ёаф! ё 9а 6i 6 аеа i adei а
Однако число людей, подверженных риску заболеть в течение периода исследования,
часто варьируется в ходе исследования, и чем дольше длится исследование, тем сильнее
изменчивость. Чтобы принять ее во внимание, в качестве знаменателя часто используется
число людей, подверженных риску к середине периода, или среднее число людей в популяции:
п =
Xenei ё[) ааё а i i Y бёубёё, пббааа!? и ёб ai ea^i ф
а oa-^i ёа 6ea9ai 1 i ai 1 a6ei aa x 1000
N6^1 aa -benei ё|з ааё a *i i 1 бёубёё, i i aaadaeai i u б
бёпёб 9aai ёабй 9a oi 6 аеа i a6ei a
Преваленс может описывать уровень заболеваемости в популяции в одной временной
точке (мгновенный преваленс) или в течение заданного периода (преваленс за период).
На нее влияют как инциденс, так и продолжительность болезни, которые, в свою очередь,
подвержены влиянию некоторых других факторов (табл. 12.2). Преваленс — это доля, а не
частота. При неизменных условиях преваленс равен произведению инциденса на среднюю
продолжительность заболевания.
Заслуживают упоминания две другие употребительные меры преваленса. Это
преваленс в течение жизни — общее число людей, перенесших болезнь по крайней мере один
раз в жизни, и годовой преваленс — общее число людей, перенесших болезнь в любое
время в течение года.
172 Составление статистических отчетов в медицине
Таблица 12.2
Факторы, влияющие иа преваленс
Факторы, увеличивающие преваленс Факторы, уменьшающие преваленс
• Больные субъекты входят в целевую • Больные субъекты выходят из целевой области
область
• Иммунные субъекты выходят из целевой • Иммунные субъекты входят в целевую область
области
• Виды лечения, увеличивающие • Виды лечения, которые излечивают болезнь,
продолжительность заболевания уменьшая ее длительность
(например, увеличивающие
продолжительность жизни без лечения
самой болезни)
• Растущий инциденс болезни • Снижающийся инциденс болезни (новые случаи),
(новые случаи) возможно, благодаря профилактике
• Растущая смертность вследствие болезни
• Растущее математическое ожидание
продолжительности жизни для здоровых людей
По: Ti mm reck ТС. An Introduction to Epidemiology, 2nd ed. Boston: Jones and Bartlett; 1998.
МЕРЫ ЗДОРОВЬЯ ПОПУЛЯЦИИ
Частоты заболеваемости и смертности
Заболеваемость — это «любое отклонение, субъективное или объективное, от
состояния физиологического или психологического здоровья» [2]. Это означает, что
заболеваемостью называется болезнь или инвалидность. Хотя коэффициентом заболеваемости могут
называть частоту состояния болезни, этот термин не следует предпочитать частотам инци-
денса или преваленса там, где к этому имеется повод. Вместо этого коэффициент
заболеваемости обычно приводится для описания таких показателей, как частота возникновения
вредных реакций на лечебные мероприятия, попадания в автокатастрофы, хирургических
осложнений и т. д.
Смертность, разумеется, относится к летальному исходу. Статистики, имеющие
отношение к причинам, видам и обстоятельствам смерти отдельного лица или внутри
популяции, называются статистиками смертности.
Летальность, один из показателей тяжести заболевания, — это доля умерших от него
субъектов:
Число людей, страдающих болезнью
(случаи) и умерших от нее х 1000
Летальность =
Число людей, страдающих болезнью
Другим употребительным эпидемиологическим показателем, применяемым вместе с
коэффициентом смертности или вместо него, является 5-летняя частота выживания. Эта
частота равна доле людей с данным диагнозом, оставшихся в живых спустя 5 лет после
постановки диагноза. Ее часто используют в сообщениях о достигнутом прогрессе в лечении,
Отчеты об эпидемиологических показателях 173
например, рака. В таком виде она, по сути, служит суррогатной конечной точкой для общей
смертности. Однако 5-летние частоты выживания и коэффициенты смертности для одной
и той же болезни не всегда бывают связаны напрямую [8].
Считается, что увеличение 5-летней частоты выживания автоматически сопровождается
уменьшением коэффициента смертности. Если новые виды лечения эффективны на самом
деле, такая взаимосвязь действительно имеет место, но иногда частота выживания растет,
а общая смертность остается на прежнем уровне. В этом случае на частоту выживания
влияет что-то помимо эффективного лечения.
Парадокс происходит потому, что 5-летние частоты выживания могут расти вследствие
причин, не относящихся к общей смертности. Частоты выживания могут расти, если
болезнь распознается ранее, чем прежде (явление называется «смещение задержки»), а также
при распознавании менее тяжелых форм заболевания. Поскольку эти два обстоятельства
влияют на 5-летнюю частоту выживания, она не является надежной мерой качества
медицинского обслуживания [8].
Но если 5-летняя частота выживания приводится как результат рандомизированного
испытания, она является полноценной мерой эффективности лечения. Группы в таких
испытаниях одинаковы по исходным характеристикам и диагностируются при одинаковых
условиях. Таким образом, «часы» начинают отсчет в одно и то же время для обеих групп,
поэтому в группе с более высоким 5-летним выживанием дела действительно обстоят лучше.
ф 5-летняя частота выживания — ненадежная мера качества медицинского
обслуживания (вне рандомизированных испытаний). Если улучшение 5-летних
частот выживания используется как аргумент в пользу скрининг-программ или
раннего лечения, следует проверить частоты общей смертности, с тем чтобы
определить, действительно ли скрининг или раннее лечение повышает выживаемость [8].
Полезны два других показателя смертности. Общая когортная смертность — это
частота смерти от всех причин, а смертность, обусловленная болезнью, — частота
смерти от определенного заболевания. Если препарат уменьшает смертность, обусловленную
заболеванием, без соответствующего падения общей когортной смертности, его ценность
может оказаться под вопросом. К примеру, если препарат уменьшает смертность от
сердечного приступа и в то же время это связывается с увеличением числа самоубийств, то он,
возможно, имеет вредные побочные эффекты, влияющие на когнитивную и
эмоциональную функции.
Нескорректированные и скорректированные частоты заболеваемости и смертности
12*9. Укажите, подвергались ли частоты заболеваемости и смертности
корректировке, и если да, то как и по какой переменной.
в табл. 12.3 и 12.4 представлено число смертей вследствие всех причин (смертность
по всем случаям) для двух популяций — города А и города В. Абсолютное число смертей,
однако, редко бывает полезным для сравнения популяций или трендов. К тому же они могут
скрыть различия между популяциями. Если предполагается, что риск будет одинаковым,
более крупная популяция обнаружит тенденцию к большему количеству смертей, чем менее
крупная, просто вследствие численности. Таким образом, число смертей следует отнести
к численности популяции людей, подверженных риску. Это отношение часто называется
нескорректированной, грубой или общей, частотой смертности. Например, в табл. 12.3
174 Составление статистических отчетов в медицине
общая частота смертности в городе А равна 6,0 смерти на 1000 человек, а в городе В —
8,2 смерти на 1000 человек.
Однако популяции этих двух городов имеют разные распределения по возрасту. Самая
молодая возрастная группа составляет почти 60 % от популяции города А (20 000/35 000)
и лишь около 30 % от популяции города В (9000/30 000). С другой стороны, старейшая
группа популяции составляет 14 % от популяции города А (5000/35 000) и 36 % от
популяции города В (11 000/30 000). Эти различия не отражены в общем уровне смертности.
Частоты смертности зависят от многих переменных, среди которых к числу важнейших
относится возраст. В вышеприведенном примере различия в распределении по возрасту
затрудняют сравнение частот смертности, потому что каждая из возрастных групп вносит
неодинаковый вклад в обш[ую картину смертности. Поэтому, ради выравнивания этих
различий в возрастном распределении частоты смертности, обусловленные возрастом (ASDRS),
часто преобразуются в частоты, скорректированные по возрасту (ADRS). Два из наиболее
распространенных видов корректировки, прямая и косвенная, описаны ниже. Хотя речь
здесь идет о корректировке по возрасту, оба ее типа можно использовать для корректировки
различий в распределении любой переменной.
12.10, Идентифицируйте стандартную популяцию, используемую для прямой
корректировки (по возрасту).
при прямой корректировке по возрасту связанные с возрастом частоты смертности
каждой подлежащей сравнению популяции применяются к стандартной популяции.
Стандартная популяция не имеет особых характеристик: это лишь общая основа для
применения частот смертности по каждой группе. Она часто создается путем простого объединения
популяций в одну, хотя использовать можно любую популяцию.
Вычисления для прямой корректировки по возрасту проиллюстрированы в табл. 12.3
и 12.4. Стандартная популяция (седьмой столбец табл. 12.4) создана добавлением числа
людей каждой возрастной группы из города А к числу людей из города В (второй и
пятый столбцы табл. 12.3). Затем частота смертности для каждой возрастной группы
города А (третий столбец табл. 12.3) применяется к возрастным группам стандартной по-
Таблица 12.3
Расчет частоты смертности для двух городов по возрастным группам
Возрастная
группа
До 19 лет
20-49 лет
50 лет и старше
Всего
[1]
Наблюдаемое число
смертей
140
50
20
210
Город А
[2]
Численность
популяции
20000
10 000
5000
35 000
[3]
Частота
смертности
на 1000 чел.
([11Л21)
Х1000
7,0
5,0
4,0
6,0
[4]
Наблюдаемое число
смертей
20
75
150
245
Город В
[5]
Численность
популяции
9000
10 000
11 000
30 000
[6]
Частота
смертности
на 1000 чел.
([4]/[5])
Х1000
2,2
7,5
13,6
8,2
Отчеты об эпидемиологических показателях 175
пуляции с целью вычисления количества смертей, которое следует ожидать, если люди
в стандартной популяции умирают с той же частотой, что и в городе А (восьмой столбец
табл. 12.4). После завершения процесса для города В число связанных с возрастом
смертей в каждом городе можно сравнивать непосредственно.
Поскольку размер стандартной популяции произволен, число связанных с возрастом
смертей в двух городах относительно; сами по себе числа не имеют значения, но можно
интерпретировать отношение одного числа к другому при условии, что они оба
вычислены для одной и той же стандартной популяции. В вышеприведенном примере в
городе А умирает почти в четыре раза больше детей, чем в городе В (230 против 64
соответственно), даже при регулировании различий в распределении по возрасту (табл. 12.4).
12.11. Идентифицируйте стандартную популяцию, используемую для косвенной
(по возрасту) корректировки (аандартизованное отношение смертноаи).
Стандартизованное отношение смертности — другой показатель, применяемый для
сравнения смертности в разных группах. Часто используемый для сравнения
коэффициентов смертности у людей, занимающихся различными видами деятельности, с
коэффициентами в общей популяции, он вычисляется так:
Стащ^артизованное отношение смертности =
_ Наблюдаемое число смертей в течение года
Ожидаемое число смертей в течение года
Здесь наблюдаемое число смертей — это число людей в исследуемой популяции, умерших
в рассматриваемом году. Ожидаемое число смертей — это число тех людей в популяции,
которые, как ожидалось, умерли бы, если бы частота смертности была такой же, как и в
нормативной или стандартной популяции. В табл. 12.5 иллюстрируются вьиисления для популяции
изготовителей украшений и взятой для сравнения популяции представителей других профессий.
Стандартизованное отношение смертности, равное 100, означает, что наблюдаемое
число смертей равно ожидаемому числу. Если оно больше 100, наблюдаемых смертей больше.
Таблица 12.4
Расчет скорректированных по возрасту частот смертности для сообществ из таблицы 12.3^
Возрастная
группа
До 19 лет
20-49 лет
50 лет и старше
Всего
[7J
Стандартная
популяция
[2]+ [5]
29000
20 000
16 000
65 000
Город А
[3]
Частота
смертности
на 1000 чел.
ЛО
5,0
4,0
6,0
[8]
Ожидаемое
количество
смертей
([71х[3])/1000
230
100
64
390
Город В
[б]
Частота
смертности
на 1000 чел.
2Д
7,5
13,6
8,2
[9]
Ожидаемое
количество
смертей
{[7] X [61)71000
64
150
218
531
' Стандартная популяция создана сложением данных из двух сообществ (нумерация колонок продолжена из
таблицы 12.3).
176 Составление статистических отчетов в медицине
Таблица 12,5
Расчет стандартизованных отношений смертности для изготовителей украшений
по возрастным категориям
Возрастная
группа
До 19 лет
20-49 лет
50 лет и старше
Всего
[11
Частота
смертности
в популяции
сравнения
на 1000 чел.
ЯО
5,0
4,0
5,6
[2]
Общая
численность
популяции
изготовителей
украшений
8000
12 000
13 000
33 000
[3]
Ожидаемое
число смертей
среди
изготовителей
сувениров на частоту
сравнения
([1]х[2])/1000
72
68
60
200
[4]
Наблюдаемое число
смертей
среди
изготовителей
украшений
140
100
58
298
[5]
Стандартизованное
отношение смертности.
изготовители
украшений/
группа
сравнения ([4]/[3])х 100
194
147
97
149
чем ожидаемых; если ниже — наоборот. Таким образом, в этом примере более молодые
изготовители украшений умирают почти в 2 раза чаще, чем представители других
профессий в группе сравнения (194, из пятого столбца), тогда как у самых старых коэффициент
смертности такой же, как и в группе сравнения (97, из пятого столбца). В целом
изготовители украшений умирают в 1,5 раза чаще, чем в популяции сравнения. Эти числа наводят
на мысль о том, что производство украшений является вредной профессией, особенно для
молодых людей, и что падение частот ожидаемой смертности для двух более старших групп
можно объяснить неким эффектом отбора или, возможно, развитием навыков со временем.
Оценка ожидаемой продолжительности жизни
12.12« Укажите метод оценки ожидаемой продолжительности жизни.
Ожидаемая продолжительность жизни — полезный демографический и клинический
показатель здоровья. Она часто измеряется в годах или месяцах и считается от заданной
точки, такой как рождение, достижение 50 лет или год лечения. Обычной мерой ожидаемой
продолжительности жизни в медицине, особенно в области лечения рака, является 5-летняя
частота выживания. Ниже мы описываем, каким образом ожидаемая продолжительность
жизни оценивается при помощи метода таблиц смертности (или метод Катлера—Эдерера,
или страховой метод, или метод Берксона—Гейджа). Другим методом оценки ожидаемой
продолжительности жизни является метод Каплана—Мейера. Он описан в гл. 9,
посвященной анализу времени до наступления события или анализу выживания.
Таблицы смертности дают вероятность того, что некий индивидуум проживет данное
число лет при условии, что он (она) выжил(а) в предыдущем году. Например, табл. 12.6
представляет данные по выживанию, собранные для 444 пациентов, прошедших лечение
за 5 лет с 1995 по 1999 г. Поскольку в течение 5 лет наблюдались только 33 пациента
(оставшихся от 83 из списка 1995 г.), мы могли бы сказать, что частота выживания в течение 5 лет
в этой группе составила 33/83, или 40 %. Однако такой подход не учитывает тех пациентов,
Отчеты об эпидемиологических показателях 177
Таблица 12,6
Собранные данные о пятилетней выживаемости для 444 пациентов
Год
лечения
1995
1996
1997
1998
1999
Всего
Число
пациентов
83
97
89
76
99
444
Число пациентов, выживших по истечении года с начала
лечения
1996
1997
1998
1999
2000
71
71
65
11
—
—
—
142
50
65
80
—
—
195
42
54
69
60
~
225
33
43
56
49
85
266
которые были зарегистрированы после 1995 г., и поэтому не дает воспользоваться всеми
собранными данными.
Табл. 12.7 представляет собой таблицу смертности, показывающую корректировку
данных для их оптимального использования и оценки ожидаемой продолжительности жизни.
Таблица 12,7
Таблица смертности для вычисления вероятности выживания к году X для выживших
к году X - 1, на основе данных таблицы 12.6
Год лечения
1995
1996
1997
1998
1999
Всего
Число пациентов,
не-
доступных для
расчетов следующего года
Вероятность
выживания
Число
пациентов
83
97
89
76
99
444
[1]
Число
1 -й год
71
11
80
60
85
373
[2]
85
[а]
0,84
пациентов, доживших до конца года
2-й год
65
65
69
49
—
248
[3]
49
[Ь]
0,86
3-й год
50
54
56
—
—
160
[4]
56
[с]
0,80
4-й год
42
43
—
—
—
85
[5]
43
[d]
0,82
5-й год
33
—
—
—
—
33
[6]
—
0,79
Расчет
Число пациентов
к концу года
Число пациентов
к началу года
373
444
[2]
[1]
248
160
85
[3]
[4]
[5]
33
373-85 248-49 160-56 85-43
[6]
[2]-[а] [3]-[Ь] [4]-[с] [5]-[d]
178 Составление статистических отчетов в медицине
Чтобы рассчитать вероятность 1-летней выживаемости, мы можем использовать данные
всех 373 пациентов, о которых у нас есть данные о выживании за 1 год. Мы не ограничены
71 из исходных 83 пациентов, зарегистрированных в течение первого года исследования.
Поэтому, хотя 71/83 равно примерно 86%-й частоте выживания, мы можем вычислить более
правильную частоту выживания благодаря использованию в расчете всех данных по
выживанию за 1 год: 377/444, или 84 %. Эти вероятности приведены во второй из выделенных
жирным шрифтом строк.
Вероятность 5-летней выживаемости равна произведению вероятностей прожить
каждый год из предшествующих 4 лет. Таким образом, в этом примере (табл. 12.7) вероятность
5-летней выживаемости равна 0,84 х 0,86 х 0,80 х 0,82 х 0,79 = 0,3743, или 37 %.
Литература
1. Lashner ВА, KlirsnerJB. The epidemiology of inflammatory bowel disease: are we learning anything
new [Editorial]? Gastroenterology. 1992; 103:596-8.
2. LastJM. A Dictionary of Epidemiology, 2nd ed. Oxford: Oxford University Press; 1988.
3. Hennekens CH, BuringJE. Epidemiology in Medicine. Boston: Little, Brown; 1987.
4. Cordis L Epidemiology. Philadelphia: WB Saunders; 1996.
5. Sackett DL, Haynes RB, Guyatt GH, Tugwell R Clinical Epidemiology: A Basic Science for Clinical
Medicine, 2nd ed. Boston: Little, Brown; 1991.
6. Gerstman BB. Epidemiology Kept Simple: An Introduction to Classic and Modern Epidemiology.
New York: Wiley-Liss; 1998.
7. Timmreck TC. An Introduction to Epidemiology, 3rd ed. Boston: Jones and Bartlett; 2002.
8. Welch HG. Should I Be Tested for Cancer? Berkeley: University of California Press; 2004.
179
© Часть II
Составление отчетов
об исследовательских
проектах
и мероприятиях
Ф
Наиболее ваэюные вопросы биостатистики невоз.моэюно описать
статистическими процедурами. Они присущи самой науке, а не чистой
статистике и относятся к архитектуре исследования, а не к числам, с
которыми приводятся и интерпретируются данные.
А. R. Feinstein[\]
Статистические анализы следует понимать в контексте более
широкой исследовательской работы, частью которой они являются. Проблема
исследования, планирования эксперимента, техника формирования
выборки, а также методы сбора данных определяют выбор статистических
процедур и то, каким образом и когда эти процедуры применяются к
данным. Таким образом, указания по составлению отчетов о планировании
исследований и их проведении дополняют указания, относящиеся к
статистическим отчетам.
Одним из самых первых шагов в развитии доказательной медицины было
повсеместное привлечение внимания к чрезвычайно низкому качеству
публикуемых биомедицинских исследований. Хотя отдельные лица старались
привлечь внимание к этой проблеме в ряде областей медицины в течение
длительного времени, их одинокие голоса имели слабое действие. Метаана-
литики, которые публиковали в своих исследованиях отчеты о РКИ, были
первыми, кто начал обращаться к данной проблеме через опубликование
согласованных указаний для отчета о разных видах исследований.
180 Составление отчетов об исследовательских проектах и мероприятиях
Первым результатом этих усилий стало возникновение группы Объединенных
стандартов представления результатов испытаний (Consolidated Standards of Reporting Trials,
CONSORT), объединившей усилия группы SORT (Standards of Reporting Trials) и Асило-
марской рабочей группы, затем ставшей Советом редакторов-биологов. В 1996 г. группа
CONSORT опубликовала Заявление по отчетам о рандомизированных контролируемых
испытаниях [2, 3]. За ним последовали и другие, использующие CONSORT как образец.
В 1996 п были предложены Рекомендации по отчетам об анализе эффективности затрат [4];
в 1999 г. — Заявление о качестве отчетов о метаанализе (QUOROM) [5]; в 2000 — Заявление
о метаанализе наблюдательных исследований в эпидемиологии (MOOSE) [6]; в 2002 —
Стандартизованное сообщение об указаниях по клинической практике [7]; в 2003 — Стандарты
корректного отчета о диагностических тестах (STARD) [8]; в 2004 — Понятные сообщения об оценках
нерандомизированных планов (TREND [9]; в 2005— Подкрепление сообщения о
наблюдательных исследованиях в эпидемиологии (STROBE) [10]. (См. прилоэюение 4.)
Назначили ли исследователи
пациентам вмешательство
или воздействие?
Да
Экспериментальное
исследование
Пациенты распределены
по группам случайно?
Да
Нет
Рандомизированное
испытание
Нерандомизированное
испытание
См. гл. 13: Отчет о
рандомизированных контролируемых испытаниях
Нет
Наблюдательное
исследование
Есть ли в исследовании
группа сравнения?
Да
Нет
Аналитические
исследования
Описательные
исследования
Воздействие оценивается
перед исходом
Когортные исследования
См. гл. 14: Отчет о когорт-
ных или лонгитюдиналь-
ных исследованиях
Исход оценивается
до воздействия
Исследования
случай-контроль
См. гл. 15: Отчет об
исследованиях типа «случай-контроль»
Воздействие и исход
оцениваются совместно
Поперечные исследования
См. гл. 16: Отчет об
обследованиях или поперечных
исследованиях
Составление отчетов об исследовательских проектах и мероприятиях 181
Цель всех этих заявлений заключалась в том, чтобы выделить те аспекты
многочисленных исследовательских проектов, которые, как минимум, должны быть отражены в отчете
с тем, чтобы можно было дать исследованию адекватную оценку. Многие из них
представляют собой перечень сведений, которые следует включить в рукопись при ее
представлении к публикации; таким образом, их окончательный вид был принят по соображениям
краткости. Указания, которые изложены далее в этом разделе книги, более подробны, чем
вышеупомянутые положения, поскольку наша цель — рассказать авторам, редакторам и
рецензентам, как составляются отчеты об исследованиях.
В соответствии с этим мы в данном разделе приводим указания для отчета о четырех
наиболее распространенных дизайнах исследований в медицине (см. рисунок напротив):
экспериментальных клинических испытаниях, в частности РКИ (гл. 13), когортных
исследованиях (гл. 14), исследованиях типа «случай-контроль» (гл. 15) и поперечных
исследованиях, или об обследованиях или анализе медицинских баз данных в заданной временной
точке (гл. 16). Хотя каждый дизайн исследования имеет несколько указаний, присущих
только ему, многие указания свойственны нескольким исследованиям одновременно. Поэтому
гл. 13 содержит примечания ко всем указаниям, которые дублируются в других трех главах
этой части, а также в главах части 3.
Литература
1. Feinstein AR. Clinical biostatistics XXV А survey of the statistical procedures in general medical
journals. Clin Pharmacol Then 1974; 15:97-107.
2. Begg CB, Cho MK, Eastwood S, et al. Improving the quality of reporting of randomized controlled
trials: the CONSORT Statement. JAMA. 1996; 276:637-9.
3. Moher D, Schulz K, Altman DG, for the CONSORT Group. CONSORT statement: revised
recommendations for improving the quality of reports of parallel-group randomized trials. Ann Intern Med.
2001;134:657-62.
4. Siegel JE, Weinstein MC, Russell LB, Gold MR. Recommendations for reporting cost-effectiveness
analyses. Panel on Cost-Effectiveness in Health and Medicine. JAMA. 1996; 276:1339-41.
5. Moher D, Cook DJ, Eastwood S, et al.,for the QUOROM Group. Improving the quality of reports of
meta-analyses of randomized controlled trials. The QUOROM Statement. Lancet. 1999; 354:1896-900.
6. Stroup DF, Berlin JA, Morton SC, et al. Meta-analysis of observational studies in epidemiology: a
proposal for reporting. JAMA. 2000; 283:2008-12.
7. Shiffman RN, Shekelle P, Overhage JM, et al. Standardized reporting of clinical practice guidelines:
a proposal from the Conference on Guideline Standardization. Ann Intern Med. 2003; 139:493-8.
8. Bossuyt PM, Reitsma JB, Bruns DE, et al. Towards complete and accurate reporting of studies of
diagnostic accuracy. The STARD Initiative. BMJ. 2003; 326:41^.
9. Des Jarlais DC, Lyles C, Crepaz N, and the TREND Group. Improving the reporting quality of
nonrandomized evaluations of behavioral and public health interventions. The TREND Statement. Am J Public
Health. 2004; 94:361-6.
10. von Elm E. The STROBE Statement, http://www.strobe-statement.org/. Accessed July 4, 2005.
182 Составление отчетов об исследовательских проектах и мероприятиях
Глава 13
Проверка результатов вмешательства
в экспериментальных исследованиях
Отчет о рандомизированных контролируемых
испытаниях
Медицина целиком и полностью зависит от прозрачности в отчетах о
клинических испытаниях.
Drummond Rennie [ 1 ]
Первая публикация описания рандомизированного слепого эксперимента, как полагают,
была сделана Чарльзом Сандерсом Пирсом в 1884 г [2]. Пирс был основателем семиотики
(учения о знаках и символах в общественной жизни); его влияние также заметно в гл. 20 и 21
этой книги, посвященных статистическим отчетам в таблицах и рисунках. Однако считается,
что нынешняя эра РКИ началась лишь с 1948 г, с известной работы Королевского совета по
медицинским исследованиям, посвященной лечению стрептомицином туберкулеза легких [3].
Для отчетов или оценок клинических испытаний разработаны многие перечни вопросов
[4]. Указания в этой главе, а также гл. 14-16 предназначены помочь авторам, редакторам и
рецензентам рассмотреть широкий круг вопросов, при обращении к которым можно было бы
улучшить точность, полноту или ясность научных сообщений и, как следствие, их
достоверность. Не каждое указание подойдет для всех экспериментов, а многие исследования могут
потребовать и не отраженную здесь информацию. Указания изложены примерно в том
порядке, в каком они могут понадобиться в научной статье, но этот порядок в разных статьях,
скорее всего, будет различным.
УКАЗАНИЯ ПО ОФОРМЛЕНИЮ ВВЕДЕНИЯ
13.1. Расскажите о том, что привело к испытанию: о фоне, на котором возникла
проблема, о ее природе, общем обзоре и важности [5,6].
Многие авторы некорректно полагают, что их читатели узнают сами, для чего было
проведено исследование и, как следствие, в чем заключается его важность. В результате
появляются научные сообщения, начинающиеся с информации о том, что было сделано, а не
почему это было сделано. Тем самым упускается контекст, в котором следует понимать
исследование. Таким образом, в начале введения следует ясно изложить основы проблемы,
ее последствия, круг ее вопросов и сложность, а также затронутые популяции.
Q Будьте осмотрительны к исследованиям, важность которых обосновывается
фразой «мало что известно о...». Отсутствие знания само по себе не всегда яв-
Отчет о рандомизированных контролируемых испытаниях 183
ляется достаточным аргументом для изучения той или иной взаимосвязи или для
того, чтобы принимать отчет об исследовании всерьез.'
13.2, Сформулируйте общую цель эксперимента. Укажите все теоретические или
научные пути, которыми можно прийти к данной проблеме [5,7].
Важность формулировки цели исследовательского проекта очевидна, но в отчетах об
исследовании эта формулировка нередко опускается. Часто автор работает в
узкоспециализированном поле и предполагает, что всякий читающий статью будет знать, для чего было
предпринято исследование и какова его цель. Иногда цель исследования просто остается
несформулированной, а иногда кажется, что она забывается за рассуждениями.
Хотя целью большинства клинических испытаний является установление
превосходства данного вида лечения над плацебо или другим видом лечения, появляется все
больше исследований, устанавливающих равнозначность (результаты одного вида лечения
не отличаются от другого) или неухуцшение (один вид лечения, по крайней мере, не хуже
другого).
Эксперименты по терапевтической равнозначности часто определяют
эквивалентность путем 1) идентификации желаемого или целенаправленного лечебного эффекта,
2) определения диапазона значений вокруг этого эффекта, включающего только
клинически незначимые величины (поле эквивалентности), а затем 3) выяснения, лежит ли
величина эффекта испытания на равнозначность и ее 95% ДИ целиком в поле эквивалентности
[8,9].
Очевидно, что определение поля эквивалентности может заключать в себе противоречия.
В дополнение к медицинским заботам, малые диапазоны могут потребовать немыслим'^
обширных экспериментов, а широкие диапазоны могут допускать слишком отличающиео!
друг от друга виды лечения, чтобы считать их эквивалентными. Кроме того, нужно
определить, должны ли диапазоны быть симметричными относительно нуля и как находится
величина эффекта: путем анализа с намерением провести вмешательство или анализа в
соответствии с протоколом [8-10].
При испытании на эквивалентность важно иметь в виду, что оба вида лечения,
даже эквивалентных, могут в действительности быть неэффективными. Таким
образом, необходимо обеспечить определенную уверенность в том, что существующий вид
лечения эффективен настолько, что новый, эквивалентный ему, тоже может считаться
эффективным.
Schwartz и Lellouch [И], а также Simon и соавт. [12] приводят неопровержимый
аргумент в пользу того, что терапевтическое исследование должно быть либо объяснительным,
либо прагматическим, но оно не может быть и объяснительным, и прагматическим
одновременно. Причиной объяснительных исследований, или исследований действенности,
является необходимость понять болезнь или терапевтический процесс. Такие
исследования лучше всего проводить при оптимальных или лабораторных условиях, дающих
возможность строго контролировать отбор пациентов, лечение, сбор данных и последующее
наблюдение. Как следствие, эти исследования проявляют тенденцию к высокой
«внутренней надежности» (у них больше средств контроля смещений), но их результаты могут плохо
распространяться на другие случаи. Прагматические исследования, или исследования
' Очень важный аспект данной проблемы. Рекомендую читателям познакомиться с обсуждением этого аспекта
в статье Н. Зорина «Врач как ученый (размышления о медицинском образовании)» (Высшее образование в России.
1998. Вып. 2. С. 68-75).
184 Составление отчетов об исследовательских проектах и мероприятиях
эффективности, с другой стороны, вызваны к жизни необходимостью принимать
клинические решения. Эти исследования обычно проводятся при «нормальных» условиях,
отражающих те обстоятельства, при которых обычно оказывается медицинская помощь.
Прагматические исследования являются основной опорой, например, исследований по
медицинскому обслуживанию.
Полезно определить, разрабатывалось ли испытание как объяснительное или
прагматическое [11, 12]. Многие медицинские исследования, однако, имеют черты и того, и другого
испытания. В таком случае при оценке качества метода и интерпретации результатов
следует учитывать обе эти цели.
Другие авторы различают патофизиологические исследования, результаты которых
напрямую не применимы к уходу за пациентами, эпидемиологические исследования,
результаты которых применимы к обширным популяциям, и терапевтические
исследования, результаты которых можно распространить от исследуемой выборки на пациентов
с похожими характеристиками [13].
133, Укажите источник финансирования испытания и опишите роль его
представительства в проведении испытания и публикации результатов.
Желательно, если не обязательно, указать в тексте статьи источник финансирования
исследования и наложенные на испытание ограничения [14, 15]. По традиции название
исследовательского фонда обычно приводится на титульной странице присылаемой рукописи
или в отдельном письме редактору журнала. Журнал, в свою очередь, обычно печатает
название фонда в публикуемой статье.
Для настоящей науки характерны строгие методы, разработанные для ответа на
актуальные вопросы. Формулировка теоретического или научного подхода к проблеме во введении
направляет читателя на основную мысль сообщения и начинает увеличивать доверие к
исследованию, при обращении к рассматриваемому вопросу. Если во введении указан
источник финансирования, читатель может также узнать, кто интересуется этой проблемой,
и лучше понять, почему испытание приняло именно такой вид.
Наряду с указанием источника финансирования медицинские журналы в настоящее
время часто требуют сообщить о роли финансирующей организации в разработке и
проведении эксперимента, в сборе, обработке, анализе и интерпретации данных, а также в
подготовке, рецензировании или рассмотрении рукописи [16]. Многие журналы требуют также
сообщить, кем была инициирована работа, если это лицо не входит в число авторов.
13<4* Сообщите регистрационный номер испытания и укажите, как можно
получить доступ к протоколу и исходным данным.
в попытках предотвратить избирательность и дублирование в отчетах о результатах
клинических испытаний, публикуемых в научных журналах. Международный комитет
редакторов медицинских журналов (ICMJE) в 2004 г. выступил с предложением регистрировать все
клинические испытания в открытом реестре, таком как Национальные институты здоровья
(clinicaltrials.gov), до начала привлечения пациентов в качестве условия публикации.
Официальные реестры должны быть доступными, с возможностями поиска, открытыми для всех
потенциальных авторов, иметь механизм оценки регистрационных данных и управляться
некоммерческой организацией. Таким образом, публикующий журнал может потребовать от
авторов сообщить название реестра испытаний, регистрационный номер и веб-адрес реестра.
Отчет о рандомизированных контролируемых испытаниях 185
Другие журналы поддерживают применение цифровых идентификаторов объекта
(digital object identifiers, DOI). DOI — уникальные номера, идентифицирующие объекты
особого содержания (или единицы интеллектуальной собственности) в цифровом
окружении, таком как Интернет. DOI несут текущую информацию, в том числе о том, как найти эти
объекты (или информацию о них) в Интернете. Информация о цифровом объекте, включая
его местонахождение, может со временем измениться, но DOI остается неизменным.
Система управляется Международным фондом DOI (www.doi.org), открытым для членства
консорциумом с представительствами в Соединенных Штатах, Австралии и Европе.
Сбор исследовательских данных, как правило, является трудным и дорогостоящим
делом. Если их можно использовать в новых исследованиях или проанализировать заново,
то тем самым экономится много времени, сил и средств. Высказывалось также мнение, что
данные, собранные в ходе исследований, финансируемых общественными организациями,
такими как Национальные институты здравоохранения или Национальный фонд науки,
должны быть доступны обществу'. Однако многие исследователи раскрывают свои данные
неохотно, в основном из-за опасений, что другие лица найдут ошибки в исследовании или
придут к иным заключениям.
Данные и другие технические приложения можно также сделать доступными через
Интернет или Национальную службу технической информации (NTIS), которая является
центральным ресурсом для собранной на средства правительства информации научного,
технического, инженерного и делового характера.
Условием публикации в JAMA является согласие авторов со следующим положением:
«В случае необходимости я предоставлю данные, на которых основана рукопись, на
проверку редакторам или их уполномоченным» [16]. Такое требование дает возможность
рассматривать претензии, связанные с научной недобросовестностью.
УКАЗАНИЯ ОТНОСИТЕЛЬНО МЕТОДОВ
13.5. Укажите институтский наблюдательный совет, одобривший протокол [5].
Большинство клинических исследований и исследований на животных должны быть
одобрены институтским наблюдательным советом, деятельность которого направлена на
защиту здоровья, безопасности и юридических прав участников испытания. Одобрение должно
быть получено до начала испытания и, возможно, более чем от одного наблюдательного
совета. Исследования, проводимые, к примеру, в нескольких центрах, обычно требуют
одобрения институтского наблюдательного совета в каждом из центров. Аналогичное
одобрение может быть необходимо, если исследователи желают использовать данные в целях,
отличных от тех, для которых они были первоначально собраны.
Лечение людей должно проводиться в соответствии с принципами, заложенными в
Хельсинкской декларации Всемирной медицинской ассоциации 1989 г. (см. Положение ASSERT
относительно дискуссии по требованиям к этичному проведению РКИ на людях [19]).
' Увы, в отечественной науке данная перспектива даже не обсуждается! Между тем, учитывая, что научные
исследования в медицине проводятся за счет налогоплательщиков, общество может предъявлять право на доступ
к получаемым в результате исследования конечным данным. Это позволило бы как избежать дублирования
исследований, так и повысить эффективность и результативность метаанализа и последующего реанализа этих данных.
К сожалению, корпоративные интересы и нередко искаженные цели проводимых исследований, в особенности
с мощным лоббированием Фарминдустрией собственных, корыстных целей проводимых исследований, делают
такую перспективу в отечественной медицине практически нереальной.
186 Составление отчетов об исследовательских проектах и мероприятиях
Испытания на животных должны соответствовать указаниям, выпущенным
Национальными институтами здравоохранения (см. Политика общественного здравоохранения
по гуманному уходу за лабораторными эюивотными и их использованию, Национальные
институты здравоохранения, бюро помощи лабораторным животным, редакция от 08.2002)
или Национальным научно-исследовательским советом (см. Указания по уходу за
лабораторными эюивотными и их использованию, Институт ресурсов лабораторных животных,
комиссия по биологическим наукам. Национальный научно-исследовательский совет.
National Academy Press, Washington, D.C., 1996).
13«б. Подтвердите получение осознанного согласия. Если возможно, опишите
обстоятельства, при которых оно было получено.
Поскольку большинство исследований с участием людей должно проводиться с их
осознанного согласия, то ответы на вопосы, как они пришли к согласию, с помощью кого
и при каких условиях, могут определить, участвуют ли они в испытании. Описание
прихода к согласию поможет определить, не повлияло ли на их решение принять участие
в испытании чрезмерное давление или обстоятельства. (Наиболее распространенной
причиной, по которой желательные пациенты не участвуют в испытании, является то, что их
лечащие врачи предпочитают специфическую терапию и рекомендуют не участвовать
в исследовании [20].)
13 J* Приведите конкретные цели испытания, в том числе все формулировки
проблем исследования и гипотез [5,6].
Большинство клинических исследований содержат в себе первичное сравнение,
определяющее их дизайн, особенно в определении объема выборки, а многие — еще и
вторичное сравнение. Каждое сравнение должно быть особенным и идентифицировано как
первичное или вторичное. Результаты первичных сравнений должны быть представлены
в первую очередь как в разделах о методах и результатах, так и в разделе обсуждения.
Первичные и вторичные сравнения можно выразить формально как проблемы
исследования, нулевые гипотезы или альтернативные гипотезы. Исследовательская проблема вьщеляет
интересующее поле деятельности и в то же время должна показывать вид, который примет
ответ. В отличие от нее формулировки гипотезы, нулевой или альтернативной, более
специфичны, допускают проверку особыми статистическими методами и могут оказаться ложными.
ПРИМЕРЫ
• Исследовательская проблема: «Как влияют обработанные перевязочные материалы
на природу и скорость заживления ран у пациентов при операциях на органах грудной
полости?» (Исследование, таким образом, рассматривает в этой популяции «природу
и скорость заживления ран».)
• Нулевая гипотеза: «Среднее время до полного заживления ран при операциях на
органах грудной полости с применением обработанных перевязочных материалов не
будет существенно отличаться от среднего времени заживления у пациентов при
применении стандартных стерильных, но необработанных материалов».
• Альтернативная гипотеза: «Время до полного заживления ран при операциях на
органах грудной полости с применением обработанных перевязочных материалов будет
в среднем по крайней мере на три дня короче, чем у пациентов при применении
стандартных стерильных, но необработанных материалов».
Отчет о рандомизированных контролируемых испытаниях 187
13.8. Идентифицируйте исследование как рандомизированное контролируемое
испытание и поясните, почему был выбран такой дизайн [5].
Клиническое испытание, в котором сравниваются пациенты, случайно распределенные
по двум группам — с применением вмешательства и контрольную (РКИ), защищает от
нескольких видов систематических ошибок и поэтому его часто предпочитают другим видам
клинических исследований.
Рандомизированные испытания защищают от систематических ошибок отбора, давая
уверенность в том, что все различия между группами по их начальным характеристикам
носят случайный характер и не являются систематическими. Скрывая принадлежность
к той или иной группе от самих пациентов, от тех, кто их лечит, или от тех, кто собирает
от них (или о них) данные, а иногда даже от тех, кто анализирует эти данные (процедура
«ослепления»), можно минимизировать систематическую ошибку ожидания и тем самым
способствовать большей объективности в лечении, а также при сборе и анализе данных.
Рандомизированные испытания являются проспективными, что дает возможность
выявить временные соотношения. Они также предлагают наилучшие возможности проверки
вмешательства, поскольку другие вмешивающиеся переменные в достаточно больших
выборках либо одинаково распределены среди групп, получающих лечение, либо их можно
идентифицировать и управлять ими с помощью критериев соответствия или
статистических анализов.
Недостатком РКИ, в частности, является то, что их можно применять лишь для
изучения потенциально благоприятных исходов. Например, их нельзя использовать для
изучения влияния пассивного курения на инциденс сердечных заболеваний или рака легких,
поскольку неэтично подвергать пациентов таким вмешательствам, от которых можно ожидать
вреда. Рандомизированные испытания, особенно широкомасштабные, с участием тысяч
пациентов, часто бывают сложными, затратными и требуют подготовленных исследователей.
Они не годятся для изучения редких состояний или таких состояний, которые, возможно,
являются последствиями воздействий в далеком прошлом или воздействий, которые могут
не проявлять себя в виде нарушений здоровья до какого-то момента в будущем.
Существует несколько видов РКИ, поэтому виды нужно указывать точно:
• При перекрестном (cross-over) испытании каждый пациент первоначально
приписывается случайным образом к экспериментальной или контрольной группе, а затем
в некоторый момент испытания группы «перекрещиваются», т. е. каждый пациент
переходит в другую группу. Тем самым каждый пациент сравнивается сам с собой
как с представителем контрольной группы, что значительно уменьшает
систематические ошибки и искажения при анализе. Перекрестные испытания часто
используются в фармацевтических исследованиях, особенно при ожидании скорого исхода
эксперимента.
• Факторное испытание исследует два или более вида вмешательств в одном
эксперименте. Если вмешательства действуют независимо друг от друга, факторные
испытания по установлению действенности лечения требуют намного меньше пациентов,
чем при раздельном изучении вмешательств. Например, можно одновременно
проверить два дополнительных препарата, создавая четыре экспериментальных группы:
в одной получают препарат А, в другой — препарат В, в третьей — оба препарата,
в четвертой — плацебо.
188 Составление отчетов об исследовательских проектах и мероприятиях
• Кластерным называется испытание, в котором единицей случайного
распределения по группам является не отдельный пациент, а некоторая совокупность, например
из одного данного госпиталя. В таком испытании госпитали могут случайно
распределяться, скажем, по выполнению одного их двух протоколов. Затем сравнивается
влияние на пациентов в обеих госпитальных группах.
• Расширенное открытое испытание — термин, присвоенный такому
рандомизированному испытанию, которое продолжается после прерывания слепого, т. е. после
того, как пациентам, попечителям, исследователям и статистикам разрешается узнать,
какой пациент получает какое лекарство. (В отличие от него, при простом открытом
испытании ни для кого закрытой информации о лечении нет.)
• Наконец, лечение по одному — такой вид перекрестного испытания, при котором
один пациент случайно распределяется в экспериментальную или контрольную
группу в каждом из нескольких периодов лечения. Также общепринятое в
фармацевтических исследованиях, лечение по одному ограничивается изучением хронических,
стабильных состояний с поддерживающим лечением, которое имеет бурное
начальное действие и быстрое прекращение деятельности после прерывания, таких как
депрессия [17].
При многоцентровом испытании, хотя оно и не относится к видам исследований, два
или более клинических центра назначают одно и то же вмешательство одному и тому же
типу пациентов с одним и тем же протоколом и замеряют одни и те же исходы. Такие
испытания применяются тогда, когда один центр едва ли может привлечь к испытанию
достаточное число пациентов, например когда в случаях с редким заболеванием терапия или исход
необычны или мал ожидаемый эффект лечения [18]. Многоцентровое испытание может
улучшить внешнюю надежность, поскольку различные центры могут привлечь пациентов
с различными демографическими характеристиками. Кроме того, если несколько центров
могут выполнить один и тот же протокол с достаточным успехом, то результаты, скорее
всего, будут легче поддаваться обобщению.
133. Выделите представляющие интерес объекты наблюдения.
Наука изучает то, что представляет интерес: объекты наблюдения или эксперимента.
В клинических исследованиях объектом анализа обычно, но не всегда, является пациент.
Это могут быть также органы зрения, сердечные приступы или семьи. Это может вызвать
недоразумения, поскольку изучение 17 глаз может включать 17 пациентов или только 9;
изучение сердечных приступов может включать пациентов, у которых их было больше
одного; изучение же семей вовлечет большее количество людей, нежели семей. Таким образом,
важно идентифицировать объект анализа или уровень организации и не смешивать объекты
или уровни. К примеру, можно наблюдать за несколькими пациентами, у которых, быть
может, есть две или более опухоли; каждая опухоль могла подвергаться множественным
биопсиям; каждая биопсия могла дать несколько образцов; а каждый образец мог по-разному
окрашиваться для обнаружения любого из нескольких типов клеток. Результаты могли быть
отражены в виде числа клеток, числа образцов, числа биопсий, числа опухолей или числа
пациентов, поэтому важно сохранять различие между этими объектами.
Объект наблюдения нужно рассматривать при разных исходах одного события или при
разных условиях: у одного пациента может быть, например, более одного приступа
мигрени, случая пролежней, рецидивов, госпитализаций или неблагоприятных событий.
Отчет о рандомизированных контролируемых испытаниях 189
К числу областей медицины с возможным смешиванием объектов наблюдения
относятся:
• офтальмология (число глаз и число пациентов);
• ортопедия (число рук или ног и число пациентов);
• стоматология (число зубов и число пациентов).
ф Проводя исследования с возможным смешением наблюдаемых объектов,
помните о том, что некоторые из наблюдений могут быть парными вследствие
того, что эти исследования часто включают в себя множественные
наблюдения за отдельными пациентами. Например, в исследовании 11 слуховых органов
у 4 пациентов из 7 обследуются оба уха; эти наблюдения будут парными по
определению (см. указание 1.11).
13.1 о. Опишите представляющую интерес целевую популяцию.
Описать интересующую популяцию необходимо для того, чтобы читатели могли
убедиться в корректности выборки и узнать, к каким группам могут иметь отношение
результаты. Описание должно включать нужные демографические, диагностические (в том
числе стадию заболевания), прогностические и относящиеся к сопутствующим заболеваниям
факторы [21-24]. Кроме того, в популяции следует идентифицировать представляющие
интерес большие подгруппы [25].
ПРИМЕРЫ
• Интересующая популяция состоит из всех тех пациентов с болезнью печени в
последней стадии и историей алкоголизма, для которых рассматривается возможность
пересадки печени.
• Данное испытание желательно для всех беременных женщин с аномальными
результатами ультразвукового исследования в течение третьего триместра.
• Нас интересовало использование велосипедных шлемов детьми до 18 лет из семей
с низким, средним и высоким социоэкономическим статусом, живущих в городе
и пригородах.
^ Если сообщается расовая или этническая принадлежность, укажите 1)
применяемую классификацию, 2) кто классифицировал пациентов, 3) определялись ли
опции классификации пациентом или исследователем и 4) почему расовая или
этническая принадлежность «оценивалась в течение исследования» [16]. «Раса» —
социальный конструкт, не имеющий точного биологического смысла [26,27].
13*11. Определите популяцию-источник, из которой были взяты участники
испытания.
Обычно достаточно одного предложения. Например: «Пациенты набирались из числа
самостоятельно обратившихся к врачу амбулаторных больных, наблюдавшихся в нашей
онкологической клинике в городе средней величины».
13,12. Опишите, каким образом определялись возможные учааники испытания [5].
Если есть возможность изучить всех интересующих субъектов, необходимость в выборке
отпадает. Вместо нее можно оценить всю интересующую популяцию с помощью так
называемой процедуры переписи. В перепись были включены, например, жертвы вспышки
заболевания 1976 г., названного впоследствии болезнью легионеров. Большинство популяций
190 Составление отчетов об исследовательских проектах и мероприятиях
слишком многочисленны и слишком широко рассеяны, чтобы проводить перепись, поэтому
необходимо прибегать к выборке. Поскольку большинство статистических методик
зависит от случайно образованных выборок, качество испытания в решающей степени зависит
от того, как в популяции производится выборка. Вот некоторые из распространенных
методик производства выборки:
• случайный отбор из популяции (каждый может быть включен в испытание с равной
вероятностью);
• отбор «всех подходящих»: все направленные на лечение пациенты,
удовлетворяющие критерию включения в течение данного периода;
• удобство, по усмотрению экспериментатора;
• самоотбор, добровольное участие;
• подбор или спаривание, при котором участники выбираются так, чтобы они
«подходили» другим участникам по схожим характеристикам (обычно демографическим
переменным), ради уменьшения изменчивости между группами.
13Л 3. Опишите, как набирались потенциальные участники испытания.
Бывает уместно сказать о том, как находятся потенциальные участники испытания.
Обычные стратегии набора — размещение объявлений в рассылках групп поддержки,
газетах, направления врачей, сверхплановые усилия медицинских центров, телефонные звонки,
непосредственный контакт с врачом и т. д. Укажите, предлагались ли для участия денежные
или другие стимулы, как непосредственно потенциальным участникам, так и
направляющим их учреждениям здравоохранения.
13.14. Приведите критерии соответствия для участия в испытании [5, б].
Критерии соответствия — это критерии включения в испытание и исключения из него.
Критериями включения являются предикторные переменные, представляющие интерес для
исследования (такие, как диагноз, возраст и т. д.); критериями исключения —
нежелательные для исследователя вмешивающиеся факторы (такие, как беременность или
сопутствующие заболевания). Оба набора критериев, называемых обычно критериями соответствия,
должны быть четко определены, с тем чтобы обеспечить целостность процесса выборки
и дать возможность обобщить результаты на всю интересующую популяцию.
При установлении критериев соответствия важно принять во внимание, разрабатывается
испытание как объяснительное или прагматическое (см. указание 13.2). Для
прагматических исследований более типичны неоднородные выборки, тогда как более однородные
выборки обычно указывают на объяснительные исследования [7]. Однородная выборка
должна подойти для первичного сравнения и определения типа испытания.
Испытание с большим числом критериев включения и исключения скорее является
объяснительным, нежели прагматическим. Критерии соответствия с обширным протоколом
могут сильно повлиять на количество и типы пациентов, включенных в клинические
испытания [20]. Например, в одном отчете о девяти многоцентровых испытаниях говорилось
о том, что среднее число критериев исключения оказалось равным 23 [20]. В
объяснительных исследованиях доля оцениваемых пациентов, не удовлетворяющих критериям
включения, может быть высокой: Begg [20] говорит о четырех онкологических исследованиях,
в которых доля исключенных пациентов была заключена в пределах от 44 до 76 %.
Отчет о рандомизированных контролируемых испытаниях 191
Иногда необходимо указать, как критерии диагностировались или оценивались на
пациентах [28]. В частности, укажите, ограничилось ли испытание пациентами с отдельно
взятой болезнью (что более типично для объяснительных исследований) или включало
пациентов с сопутствующими заболеваниями (что более типично для прагматических
исследований), а также дайте оценку спектра болезни, рассматриваемого в испытании.
13.15. Укажите, была ли выборка стратифицированной или спаренной и по каким
характеристикам [5, б].
Стратифицированная выборка — это выборка, в которой пациенты сгруппированы
по определенным характеристикам. Страты, в основе которых лежит степень тяжести
заболевания, делят выборку на слои, скажем, с легкой, умеренной и тяжелой болезнью и
позволяют исследователям искать пациентов с данными, относящимися к тяжести заболевания.
Иногда страты отбираются диспропорционально (процесс под названием избыточной
выборки) с целью обеспечить испытание адекватным числом пациентов в каждой,
предназначенной для анализа страте [29].
Стратифицированное формирование выборки позволяет исследователям найти баланс
между важными характеристиками экспериментальной и контрольной групп, чтобы
уменьшить систематическую ошибку и дать возможность анализировать важные подгруппы.
К примеру, при изучении влияния эффекта правой и левой руки на когнитивную функцию
исследователям может понадобиться включить в выборку избыточное количество левшей,
которые составляют лишь около 20 % популяции. Стратификацию, если она не включена
в дизайн испытания, можно провести в ходе статистического анализа путем добавления
фактора стратификации в качестве одной из предикторных переменных.
С помощью стратификации можно добиться того, чтобы количество участников с
разными видами вмешательства было выровнено внутри каждой страты путем проведения
отдельной процедуры рандомизации внутри каждой из двух или более страт или
подмножеств участников.
Со стратификацией часто связывается группирование в блоки, применяемое с целью
добиться равенства или примерного равенства числа участников, включенных в каждую
страту или каждую группу лечения. Чтобы выровнять число мужчин и женщин,
участвующих в испытании, можно сформировать блоки, скажем, из 10 человек и включить в каждый
по 5 мужчин и 5 женщин.
Группирование в блоки может снизить непредсказуемость рандомизации. Если в
каждом блоке должно быть, скажем, 50 % мужчин, а блок из 10 человек, в котором 5 из 8 уже
включенных в него — женщины, то следующие двое включенных в него будут, очевидно,
мужчинами. Чтобы противостоять этой предсказуемости, размеры блоков часто
варьируются случайным образом путем так называемого дизайна рандомизированного
перемешивания блоков.
Чтобы уменьшить различия между экспериментальной и контрольной группами,
участники могут быть объединены в пары или подобраны по одной или более переменным.
Например, при изучении влияния диеты на болезнь сердца участники могут быть разделены
в пары по возрасту и полу, чтобы уменьшить различие по заболеванию сердца, связанного
с этими характеристиками. Тогда каждая группа будет насчитывать равные количества
мужчин одинаковых возрастов и женщин одинаковых возрастов.
192 Составление отчетов об исследовательских проектах и мероприятиях
^ Часто в ходе анализа происходит отказ от дизайна парного исследования [30,31 ].
Поскольку спаренные участники анализируются совместно, потеря одного
участника пары влечет потерю данных от обоих участников. Чтобы уменьшить такого
рода потери, дизайн парного исследования может быть отвергнут, а данные от всех
участников просто объединяют в соответствующие группы. Затем для каждой
группы сравниваются обобщенные значения, соответствие между парами,
следовательно, игнорируется, а преимущества спаривания теряются {см. указание 4.8).
Щ Исследовательские разработки, в которых используются парные выборки,
нужно анализировать с помощью статистических тестов для парных данных
(см. табл. 4.2). Тесты для парных данных при анализе сохраняют отношение между
парами, а тесты для независимых выборок — нет. Парные данные по определению
коррелированны и должны рассматриваться в анализе с учетом этого.
13Л б» Укажите целевой объем выборки и то, каким образом он был определен [5-7].
Независимо от того, разработано испытание для проверки превосходства или
неухудшения, объем выборки должен быть адекватным. При рандомизированных испытаниях объем
выборки идеально определяется с помощью расчета статистической мощности. Такой
расчет основан на ряде факторов, но особенно на минимуме выявляемой разности и на
той степени, с которой исследователи готовы пропустить эту разность. Типичный расчет
мощности читается примерно так: «Чтобы получить 90%-ю вероятность распознавания
разницы в 5 пунктов в таблицах качества жизни, нам нужно привлечь 110 пациентов,
предполагая, что общее СО в таблицах составляет 8 пунктов, а двусторонний уровень альфа
равен 5 %».
Объем выборки можно также вычислить для получения желаемой степени точности
результата. Например, ширина 95% ДИ вокруг оценки (скажем, ±2,5 % от оценки) может
быть установлена заранее, и в соответствии с этим рассчитывается необходимый объем
выборки.
Адекватная статистическая мощность наиболее важна тогда, когда результаты испытания
не являются статистически значимыми. В этом случае исследования с заниженной
мощностью дают отрицательный результат, но по ним нельзя делать заключений: они не
подтверждают взаимосвязь, но и не позволяют полностью исключить ее. Такие исследования,
следовательно, мало что дают науке, если дают вообще. Только в случае, когда
отрицательный результат испытания опирается на адекватную мощность, наличие взаимосвязи может
быть отвергнуто, а результаты могут быть объявлены действительно отрицательными.
(Испытание со статистически значимыми результатами, по определению, имеет адекватную
для отыскания статистически значимых различий мощность. См. гл. 4.)
Щ Многие исследования не имеют адекватных объемов выборки и могут «иметь
недостаточную мощность». Способность выявлять клинически важные находки
предполагает, кроме прочего, то, что объем выборки был адекватным [32].
13.17. Укажите, где и при каких обстоятельствах были собраны данные.
Указание обстоятельств, при которых проводится испытание, помогает увидеть
исследование в перспективе. Например, окружные госпитали и частные реабилитационные
центры могут предоставлять разные виды медицинской помощи и лечить пациентов с разным
Отчет о рандомизированных контролируемых испытаниях 193
социально-экономическим статусом. «Особенно важно знать, идет ли речь об обычном
сообществе, центре первичной помощи или поликлинике, частной или институтской
практике, амбулаторном или стационарном лечении» [33-36].
Иногда также целесообразно описать характер направления пациента на лечение [37,
38]. Пациенты, направленные или помещенные в центр высокоспециализированной
медицинской помощи, могут отличаться от тех, кто попадает к врачу частной практики или
в общественную больницу. Данное смещение фильтрации по направлению особенно
важно в тех исследованиях, где определяющими факторами являются инциденс и прева-
ленс заболевания или нетрудоспособности. Центры высокоспециализированной
медицинской помощи скорее всего будут наблюдать за большим числом необычных пациентов с
более высокой степенью тяжести заболевания и, вероятно, будут располагать человеческими
и техническими ресурсами для более частого выявления сравнительно редких состояний.
13.18, Укажите, как и когда пациенты были распределены по группам [5-7].
Иногда важно отметить, были пациенты привлечены к испытанию до или после
распределения по группам [5, 39], и указать время, проходящее обычно между распределением
и началом лечения (чем оно короче, тем лучше) [5, 31, 40].
В экспериментальном испытании исследователи обычно распределяют пациентов
либо в группу проходящих лечение, либо в контрольную. То, каким образом это сделано,
имеет важные методологические и статистические следствия. Для клинических
испытаний приемлемы и предпочтительны случайное распределение и процедура под
названием минимизации; нерандомизированное распределение имеет существенные недостатки
и нежелательно.
Целью случайного распределения является предотвращение ошибки отбора или
систематической вариабельности в распределении пациентов по группам путем введения
случайной вариабельности в процесс формирования групп. Участники случайным образом
распределяются (глагольные формы термина «рандомизация» нежелательны) в
экспериментальную или контрольную группу обычно с равной и известной вероятностью
попадания в ту или иную группу. Простое случайное распределение (в противоположность
группированию в блоки и стратификации) не дает уверенности в том, что экспериментальная
и контрольная группы 1) имеют равный объем или 2) одинаковый состав. Однако оно все-
таки дает уверенность в том, что все различия по объему и составу являются результатом
случая, а не систематической ошибки.
Неслучайные методы распределения по группам включают перемежающееся
распределение, при котором каждый следующий из желаемых пациентов записывается в
следующую же группу; распределение по номеру медицинской карточки (четный — нечетный),
дате рождения (четная — нечетная) или бросание монеты. Эти методы нежелательны,
потому что на распределение по группам могут повлиять факторы, отличные от случайных,
или же потому что распределение может стать предсказуемым и, следовательно,
опровергаемым вследствие знания метода распределения и состава групп, в которые уже записаны
пациенты.
ф «Бессистемное» распределение не является случайным распределением [23,
39,41,42]. Истинно случайное распределение — это осознанное создание гарантий
того, что единственным фактором при распределении по группам является случай
{см. указание 13.19).
194 Составление отчетов об исследовательских проектах и мероприятиях
Минимизация не является методом случайного распределения, но это единственный
приемлемый неслучайный метод распределения по группам. Минимизация обеспечивает
сбалансированность групп по заданным факторам. Первый пациент распределяется
действительно случайным образом. Каждого последующего пациента относят в ту группу
лечения, которая минимизирует дисбаланс между группами в процессе формирования групп
в данный момент. Затем можно использовать это назначение или же осуществить
распределение случайным образом с большим весом в пользу вмешательства, что уменьшило бы
дисбаланс (например, с вероятностью 0,8). Обычно предпочтительнее использовать
случайный элемент. Минимизация может дать гарантию того, что даже малые группы будут
подобны по выбранным характеристикам. Испытания с применением минимизации
рассматриваются как методологически эквивалентные рандомизированным испытаниям, даже
без использования случайного элемента.
13.19. Укажите источник случайных чисел, используемый при распределении
участников по группам [5,6].
Чтобы убедить читателей в том, что случайное распределение было действительно
случайным, следует указать источник случайных чисел. Несмещенные источники случайных
чисел включают прошедшие проверку таблицы случайных чисел и генерирующие их
компьютерные программы.
13,20* Укажите, скрывался ли план размещения по группам, и если да, то как [6,7,43].
Со случайным распределением связано понятие скрытого отнесения участника
испытания к той или иной группе. Оно выражает стремление предотвратить ошибку отбора
путем скрытия хода распределения до тех пор, пока пациенты не будут размещены в
экспериментальную группу. Если распределение можно предсказать, пациенты могут вольно или
невольно отнести себя к избранной ими группе. Например, если последовательность
рандомизации говорит о том, что пациент с номером 23 получит экспериментальное лечение,
то скрытое размещение не даст возможности дать какому-то избранному пациенту номер
23. Фактически же исследования без случайного распределения и исследования, в которых
размещение неоправданно держалось в тайне, имеют между собой больше различий в
проведении лечения, нежели исследования со случайным распределением и успешно скрытым
отнесением. Это говорит о том, что ошибка отбора, вероятно, повлияла, по крайней мере,
на некоторые из результатов испытания [43, 44].
Один из способов провести скрытое распределение заключается в том, чтобы разделить
тех, кому известна последовательность размещения, и тех, кто распределяет участников
испытания по группам [6]. В этом случае исследователь может связываться с
координационным центром данных испытания, чтобы получить сведения о назначении всякий
раз, когда в испытание вовлекается новый участник (процесс называется центральной
рандомизацией).
Другой распространенный способ скрыть распределение — запечатать данные о
принадлежности каждого пациента к группе в последовательно пронумерованных непроницаемых
конвертах. Эти конверты, один для каждого участника испытания, затем передаются
исследователю для вскрытия при распределении по группам.
Еще один вид скрытого отнесения можно осуществить в аптеке. Аптека готовит
идентичные упаковки для лекарственного препарата или плацебо, которые затем последователь-
Отчет о рандомизированных контролируемых испытаниях 195
но перенумеровываются или шифруются в соответствии с дизайном рандомизированного
размещения, подготовленным статистиком.
Размещение можно также скрыть при помощи компьютерной техники. В этом случае
информация о размещении по группам хранится в лабораторном компьютере в закрытом
файле, доступ к которому невозможен до введения данных о заново набранном участнике
испытания. Размещение становится известным лишь после этого; сохранение его в
тайне до этого момента исключает всякую возможность внесения изменений в распределение
по группам.
13.21. Укажите, кто участвовал в работе слепым методом и как это было
осуществлено [5, б].
Слепой метод заключается в том, что распределение по группам держится в тайне
от различных вовлеченных в исследование групп. Благодаря тому, что пациенты,
попечители и даже статистики не знают, кто к какой группе отнесен, уменьшается вероятность
систематической ошибки ожидания. Поскольку ожидания экспериментаторов и
участников испытания могут привести к ошибкам, важно дать описание слепого метода и указать,
было ли его применение эффективным (см. указание 13.64). Пациенты, как и их
попечители, действительно пытаются угадать, к какой группе они отнесены.
При простом слепом методе данные о размещении по группам скрываются
обычно только от пациентов. При двойном слепом методе распределение держится в тайне
от пациентов и сборщиков данных (попечителей, исследователей или тех и других),
но открыто для тех, кто проводит оценивание (исследователей, биостатистиков или тех
и других). При тройном слепом методе информация обычно хранится в тайне от
пациентов, сборщиков данных и аналитиков. Однако с учетом разных возможностей
распределения ролей при применении слепого метода [44, 45] следует точно указать,
от каких именно групп информация держалась в тайне. Общепринятыми способами
сделать испытание слепым является использование плацебо или имитация лечения
[см. указание 13.23).
На практике некоторые средства, такие как противораковые препараты, производят
побочные эффекты, легко выделяющие проходящих активное лечение пациентов, и делают
применение слепого метода практически невозможным.
13.22. Дайте описание вмешательства и протокола, по которому оно
проводилось [5, б].
Дайте детальное описание изучаемого вмешательства и процедуру его назначения.
Наряду с полным описанием вмешательства может понадобиться описание показаний к его
началу, изменению и прерыванию [46], а также деталей диагноза и лечения [41]. Укажите
также планируемую продолжительность лечения.
Если исследование включает медикаментозное лечение, отметьте следующее [47]:
• родовое и торговое название препарата;
• название и местонахождение производителя;
• форму дозировки (например, таблетки, капсулы, мази);
• способ применения (например, орально, внутривенно, втирание через кожу);
• назначенную дозу;
• частоту назначения;
196 Составление отчетов об исследовательских проектах и мероприятиях
• результаты изучения биодоступности (биодоступность — степень, с которой вещество
доступно целевым тканям после приема; желудочный сок, например, может
уменьшить биодоступность препаратов, принимаемых орально) [12, 21, 48];
• результаты изучения безопасности (укажите, безопасен ли препарат);
• результаты изучения действенности (укажите, действенен ли препарат при приеме
в соответствии с предписаниями).
Если это уместно, отметьте также следующее:
• силу действия средства;
• концентрацию в среде для лекарства, если оно находится в растворе;
• скорость введения (при внутривенном введении);
• продолжительность назначения;
• условия, при которых препарат принимается или исключается.
Для исследований, привлекающих хирургические методы, приведите данные о деталях
хирургии [33], а также о подготовке, навыках и опыте хирургов [48].
Для используемого при лечении оборудования укажите название и номер модели,
название и местонахождение производителя и, если необходимо, функции и технические
спецификации.
1323. Опишите все плацебо, имитации или альтернативные виды лечения в
контрольной группе (группах).
Если от слепого метода ожидается эффективность, вмешательство в контрольной группе
должно внешне выглядеть так же убедительно, как и исследуемое вмешательство. Плацебо
должно походить на испытываемое средство по цвету, виду, вкусу и текстуре. Подобно
этому, имитирующие лечение процедуры должны быть как можно более убедительными.
Примеры включают имитацию акупунктурных точек в исследованиях на людях и имитацию
хирургии в исследованиях на животных.
В исследованиях с привлечением контрольных групп, получающих альтернативные
виды лечения, отразите в отчете следующее:
• природу и интенсивность альтернативных или сопутствующих вмешательств;
• источник плацебо или детали его приготовления;
• степень соответствия плацебо экспериментальному препарату по внешнему виду,
вкусу и текстуре;
• детали имитации вмешательства.
13.24« Укажите все демографические, клинические и другие основные влияющие
характеристики массива данных [5].
Демографические и клинические характеристики выборки в начале испытания важны
для описания выборки, для оценки внутригрупповых изменений в течение испытания и для
исследования взаимосвязей в данных, таких как взаимодействия между некоторой
характеристикой и вмешательством; например, люди с высоким кровяным давлением, возможно,
чувствуют себя хуже после операции.
1325. Определите оцениваемые исходы и поясните, как им присваивались
численные значения. Укажите, прошли ли проверку показатели [5,6].
Неплохой идеей может быть перечисление исходов испытания в разделе «Методы». Для
каждого исхода дайте операционное определение, шкалу измерения исхода (номинальная, по-
Отчет о рандомизированных контролируемых испытаниях 197
рядковая или непрерывная) и его единицу измерения. Операционное определение описывает
переменную в числовом выражении или измерении. Например, кровяное давление, на
порядковом уровне измерения, может определяться как гипотензивное, нормотензивное и гипертен-
зивное, где каждой категории дано операционное определение через диапазон систолического
кровяного давления в миллиметрах ртутного столба, что включено в каждую категорию.
0 Если есть возможность, используйте установленные определения и показатели,
чтобы было проще сравнивать результаты между исследованиями [33,49, 501.
Операционные определения могут не всегда адекватно измерить рассматриваемую
переменную. Некоторые понятия, такие как острота зрения, подходят для операционных
определений. Определить другие переменные, такие как депрессия, бывает труднее. «Считалось,
что участники испытания находятся в состоянии депрессии, если их показатель по шкале
депрессии был меньше 50» — это операционное определение депрессии, но насколько
хорошо это определение в действительности характеризует депрессию — вопрос, открытый
для дискуссии.
На качество данных может повлиять то, каким образом они собраны. Например,
показания кровяного давления, измеренные медсестрой, могут отличаться от показателей, снятых
с электронного монитора; интерпретация эхокардиограммы, визуально оцененной
кардиологом, может отличаться от интерпретации, основанной на компьютеризованной оценке.
Если данные состоят из наблюдений и суждений, отметьте следующее:
• подготовку и опыт аналитика(ов);
• условия, при которых были сделаны наблюдения (например, привлекался ли аналитик
к работе слепым методом);
• были ли наблюдения структурированы в перечне вопросов, и если да, то какие
компоненты были структурированы.
Для оборудования, применяемого при сборе данных, укажите:
• название и номер модели;
• название и местонахождение производителя;
• все применяемые реагенты;
• аналитический метод;
• был ли прибор откалиброван, и если да, то как;
• пределы аналитической чувствительности или разрешения прибора;
• точность результатов измерения.
Суррогатные конечные точки — исходы, используемые вместо прямых клинических
результатов, которые показывают, как пациент «себя чувствует, функционирует или
выживает» [51, 52]. Обычно это лабораторные измерения, такие как подсчет клеток CD4
(суррогатная конечная точка СПИДа), или показатели субклинической болезни, такие как степень
артериальной окклюзии, измеренная с помощью коронарной ангиографии (суррогатная
конечная точка атеросклеротической болезни сердца). Поскольку суррогатные конечные
точки связаны с более простыми измерениями и их можно провести заранее, до наступления
конечного клинического события (такого, как сердечный приступ или смерть),
клинические испытания благодаря им становятся менее продолжительными и менее масштабными.
К примеру, уровень холестерина сыворотки часто используется в качестве суррогатной
конечной точки наличия сердечного заболевания. Его можно легко измерить у всех
пациентов, и его применение избавляет от необходимости наблюдать за большим числом больных,
до того как они перенесут сердечный приступ или инсульт.
198 Составление отчетов об исследовательских проектах и мероприятиях
Чтобы иметь силу, суррогатная конечная точка должна находиться «в причинном
алгоритме лечения болезни» [51]; она должна иметь тесную, независимую и последовательную
связь с клиническим результатом. Тем самым улучшение показателей суррогатной
конечной точки должно быть также связано с улучшением клинического результата. Кроме того,
вмешательство не должно оказывать на клинические результаты таких действий, которые
не отражены в суррогатной конечной точке. Однако строго обосновать справедливость
суррогатных конечных точек удается редко [52].
О Суррогатные конечные точки если и дают адекватные замены характерным
клиническим результатам, то редко. Они часто не могут адекватно предсказать
истинные клинические эффекты вмешательства [52].
Составные конечные точки — группы конечных точек, наступление каждой из
которых считается событием. Например, общепринятой составной конечной точкой для атеро-
склеротической болезни сердца является возникновение стенокардии, сердечного приступа
или инсульта. Такие конечные точки полезны, поскольку охватывают более широкое
действие лечения на болезнь.
При использовании составных конечных точек в отчете следует отразить частоту
возникновения каждого из их компонентов, особенно если они сильно различаются по
степени тяжести. К примеру, вряд ли следует уравнивать проходящий ишемический приступ
и фатальный инфаркт миокарда, хотя они оба могут быть результатом одного и того же
патологического процесса.
13.26. Опишите оцениваемые события неблагоприятного характера и поясните,
как вводились их количественные оценки.
в журнальных публикациях неблагоприятным событиям отводится заметно меньше
внимания; сведения о месте работы авторов, как отмечалось в одном исследовании, порой
занимают больше места, чем описания каких-либо негативных последствий вмешательства
[53, 54]. Однако испытания действенности никогда не обладают достаточной мощностью
для выявления редких вредных событий, так как для этого может потребоваться тысячи
пациентов и длительные периоды последующего наблюдения.
13.27. Опишите характер и продолжительность запланированных действий
по дальнейшему наблюдению.
Для проявления многих биологических эффектов, как положительных, так и
отрицательных, нужно время. Исследования часто предусматривают период отслеживания, в течение
которого участники испытания периодически наблюдаются после медикаментозного или
хирургического вмешательства. Частота и характер всякой деятельности по сбору данных
в течение периода отслеживания должны быть отражены в отчете. Читателей следует
убедить в том, что длительность периода отслеживания выбрана правильно и что мероприятия
по сбору данных достаточны, для того чтобы распознать представляющие интерес
позитивные и негативные последствия. Иногда также важно указать, кто проводил осмотр в ходе
отслеживания.
^ Период отслеживания может оказаться недостаточно длительным для
появления важных позитивных и негативных эффектов [55, 56].
Отчет о рандомизированных контролируемых испытаниях 199
13.28. Если испытание имеет перекрестный план, укажите длительноаь периода
вымывания.
При перекрестном испытании каждый пациент служит контролем для себя самого.
Пациентам, для которых испытание началось с действующего лекарства, должна быть дана
возможность вывести препарат из их организмов до перехода в альтернативную группу.
Этот период называется периодом вымывания, или выведения, и он должен быть
достаточно длинным, чтобы избежать «эффекта переноса» активного препарата в следующую фазу
испытания.
13.29. Отметьте, держалась ли в тайне от экспертов принадлежность пациентов
к той или иной группе и каким образом [6].
Эксперты — это те, кто собирают данные или выносят суждения о клинических и
биологических характеристиках пациентов, участвовавших в испытании. В идеале экспертов
следует привлекать к слепой оценке групп, с тем чтобы их наблюдения не содержали
систематической ошибки. Особенно это важно, если подлежащие сбору данные представляют
собой «мягкие» конечные точки, основанные скорее на суждениях, чем на более
объективных критериях. Интерпретации медицинских изображений, клеточных культур, поведения,
клинических проявлений и симптомов — все они подвержены ошибкам смещения из-за
знания распределения по группам либо вследствие сложившихся мнений об изучаемом
вмешательстве или знания контекста, в котором были взяты данные, либо вследствие
растущей внимательности при рассмотрении данных [44].
13.30. Укажите возможные источники систематических ошибок (смещений),
вмешивающихся факторов, ошибок и предпринятые против них меры\
Смещение, влияние вмешивающихся факторов и ошибки — те элементы испытания,
которые препятствуют правильной характеризации и пониманию изучаемых взаимосвязей.
Сущность научного исследования фактически заключается в попытках минимизировать
действие этих элементов. Некоторые известные источники смещения, вмешивающихся
факторов и ошибок описаны в приложении 5.
Смещение относится к систематическим ошибкам: это все, что приводит к недооценке
или переоценке размера или направления эффекта лечения. Смещение может внести врач,
наблюдающий пациентов в экспериментальной группе более внимательно, чем в
контрольной; неправильно откалиброванный газовый анализатор крови, дающий вследствие этого
завышенные показатели для всех пациентов; или выводы на основании обследования
только тех пациентов, которые чувствовали себя достаточно хорошо, чтобы заполнить протокол.
Мероприятия по предотвращению смещения включают случайный отбор, случайное
распределение по группам, слепой метод, назначение вмешательств и процедур сбора данных
в соответствии со сжато написанными протоколами, независимый контроль третьих лиц,
а также проверки и контроль в ходе сбора данных, анализа и интерпретации.
Вмешивающиеся факторы относятся к тем факторам, которые затемняют связь между
предполагаемой причиной и предполагаемым эффектом. Употребление алкоголя,
например, может уменьшить эффективность некоторых антибиотиков, а аспирин может усилить
' Рекомендуем читателям познакомиться с прекрасным обзором директора Российского отделения
сотрудничества The Cochrane CoUaboration, вице-президента Межрегионального общества специалистов доказательной
медицины В. В. Власова «Систематические ошибки и вмешивающиеся факторы» (Международный журнал
медицинской практики. 2007. Вып. 3. С. 18-29).
200 Составление отчетов об исследовательских проектах и мероприятиях
действие некоторых антикоагулянтов. Эти взаимодействия могут смешать интерпретацию
исследований по антибиотикам и антикоагулянтам.
Мероприятия по предотвращению влияния вмешивающихся факторов включают
ограничение на списочный состав участников испытания через исключение потенциально
смешивающих переменных, подбор пациентов по ключевым параметрам (с целью исключить
изменчивость), случайное распределение, стратификацию, а также многомерный анализ,
который статистически контролирует влияние вмешивающихся факторов.
Наконец, ошибка относится к недифференцированным, случайным ошибкам
(биологическая изменчивость), а также к неточностям при измерениях и ошибкам во время сбора
данных, анализа или интерпретации. Проверка гипотез может дать меру случайной
ошибки (/?-значение); достоверные и надежные методы сбора данных могут уменьшить ошибку
измерения, а постоянное внимание к деталям на протяжении всего исследования может
минимизировать прочие ошибки.
1331« Опишите все методы контроля качества, применяемые для обеспечения
полноты и точности при сборе данных и ведении пациентов [57].
Методы контроля качества включают подготовку экспертов для стандартизации сбора
данных или их систематизации, двойной ввод данных с целью проверки работы с клавиатурой,
управление базами данных (например, программы, позволяющие вводить только
правильные данные), а также выборочные сверки баз данных с документами-первоисточниками.
В широкомасштабных рандомизированных испытаниях часто применяются приборы,
такие как центральная регистрационная система, и беспристрастный обзор данных
сторонних наблюдателей [25, 58]. В частности, вторая сторона может задать три вопроса о каждом
участнике испытания [25]:
• Подходил ли участник для этого испытания?
• Был ли соблюден протокол? (Имеется ли объективная очевидность следования
протоколу?) [50, 59, 60]
• Отражены ли главные конечные результаты в документах?
Многие обширные испытания предусматривают работу наблюдательных советов
по безопасности, которые обычно приглашаются, 1) когда мощность испытания способна
выявить значительные различия по смертности или высокой заболеваемости, 2) когда риск,
связанный с терапевтическими составляющими, неизвестен или 3) когда известно о
серьезных побочных эффектах терапевтических составляющих [19]. Эти советы отслеживают ход
испытания и часто наделены полномочиями прекращать его, если пациенты подвергаются
неоправданному риску, т. е. если клинически важный или статистически значимый эффект
выявляется раньше, чем ожидалось.
Статистические методы
Для рукописей, посвященных исследованиям, выполненным на средства
промышленных предприятий, некоторые журналы теперь в качестве условия публикации требуют
проведения отдельного анализа необработанных данных независимым статистиком. В отчете
следует указать его имя и учреждение, в котором он работает, а также отметить, была ли
получена компенсация или оплата за проведение анализа.
1332. Для испытаний на превосходство (эффективность) укажите минимальное
изменение или разность в исходе, рассматриваемые как клинически важные;
Отчет о рандомизированных контролируемых испытаниях 201
ДЛЯ испытаний на неухудшение (эквивалентность) укажите максимально
допустимую разницу клинической важности.
в научных статьях часто не указывается минимальная разность, считающаяся
клинически важной [61]. Эта разность важна потому, что является существенной частью расчета
объема выборки (это относится к статистической мощности), а также потому, что помогает
сохранить внимание исследования на клинической важности, в противоположность
статистической значимости.
Максимальная допустимая разность — наибольшая разность между проходящими
лечение группами, которую можно найти, если считать два вида вмешательства
эквивалентными. Разности больше максимально допустимых показывают, что вмешательства
неэквивалентны. Максимальная допустимая разность образует один предел того поля
эквивалентности вокруг лечебного эффекта от одного вмешательства, внутрь которого
должен попасть эффект от другого вмешательства для того, чтобы считаться эквивалентным
(см. указание 13.2).
1333. Определите анализируемые взаимосвязи и статистические методы для их
анализа [6,7].
Смысл предикторных переменных и переменных отклика в подлежащих оценке
первичных и вторичных взаимосвязях должен быть ясным, поскольку ими определяются
статистические методы, с помощью которых производится анализ взаимосвязи. Сами
статистические методы также должны быть четко определены с надлежащей ссылкой или даже
кратко описаны в случае их нестандартности.
Статистические сравнения, которые предполагается провести в испытании,
предпочтительнее описать до того, как будут собраны данные. Однако выбор особого статистического
теста часто зависит от качества самих данных (например, по нормальному ли закону
распределены непрерывные данные), поэтому нужный тест невозможно обозначить заранее.
В таких случаях в протоколе можно привести только общий класс предполагаемой к
использованию процедуры (например, проверки взаимосвязей, парные групповые сравнения,
анализ выживания). Специальная процедура (например, критерий хи-квадрат, ^тест, анализ
Кокса), в действительности использованная в испытании, должна быть упомянута в
разделе «Результаты» по ходу изложения результатов анализа.
1334» Подтвердите, что данные удовлетворяют предположениям аатистического
анализа.
Большинство статистических тестов и процедур основано на одном или более
допущениях. Если эти допущения нарушены, результаты анализа будут вызывать подозрения. Все,
что здесь требуется сделать, — это сказать о том, что условия выполнены.
1335. Отметьте промежуточные анализы и правила оаановки [6].
Многие клинические исследования проводятся в течение долгого времени, поэтому для
контроля за их ходом и выявления проблем проводится промежуточный анализ данных.
Кроме того, при каждом промежуточном анализе могут применяться правила остановки.
Если промежуточные результаты показывают высокую эффективность вмешательства, его
очевидные недостатки по сравнению с альтернативным вмешательством или вред, то
испытание может быть прекращено, с тем чтобы не подвергать пациентов или участников
202 Составление отчетов об исследовательских проектах и мероприятиях
контрольной группы неоправданному риску или дать последним возможность как можно
скорее получить более эффективное лечение [62]. Обычными подходами в определении
правил остановки являются «групповые последовательные методы» и «альфа исчерпание».
Обнародование результатов промежуточного анализа необходимо проводить с
осторожностью, поскольку эта информация может привести к систематическим ошибкам в текущем
испытании, влияя на набор пациентов и объективность персонала. Кроме того,
промежуточные результаты могут также привести к преждевременным выводам, которые придется
пересматривать, когда станут известны полные результаты испытания.
Промежуточные анализы могут также породить проблему множественных сравнений,
что необходимо учитывать перед тем, как делать выводы (см. указания 5.7-5.9). ^
^ При досрочном прекращении исследований с зависящими от времени
исходами (выживание или иное событие, связанное с временем до его наступления)
ранний эффект от вмешательства может отличаться от эффекта, отмеченного
при аналогичных испытаниях с более долгим сроком наблюдения [62].
13.36. Опишите В деталях вычисление мощности.
Как минимум, укажите, производилось ли вычисление мощности. В отчете об
испытании на превосходство следует указать минимальную разность, которую предстоит
распознать, требуемую статистическую мощность для ее распознавания (обычно 80 или 90 %,
или соответственно бета-значение 0,2 или 0,1), пороговый уровень значимости (обычно
0,05) и вариабельность данных, если конечная точка непрерывная. В отчете об испытании
на неухудшение — максимальную допустимую разность, статистическую мощность,
пороговый уровень значимости и вариабельность данных, если конечная точка непрерывная.
(См, гл. 4.)
13.37. Укажите вид анализа: с намерением применить вмешательство, по
протоколу или оба [б].
Анализ с намерением применить вмешательство — применяемая в
рандомизированных испытаниях статистическая стратегия, при которой все пациенты анализируются как
часть группы, к которой они первоначально были приписаны, независимо от того,
действительно ли они удовлетворяли критериям участия, получали ли полное лечение или
завершили испытание как планировалось [63]. В отличие от него, анализ по протоколу изучает
лишь тех пациентов, которые завершили испытание в соответствии с планом.
Анализ с намерением применить вмешательство сохраняет преимущества случайного
распределения, а именно все основные дисбалансы между группами являются результатом
случая, а не систематической ошибки. Еще более важно то, что он защищает от ошибки,
привносимой участниками испытания, покидающими его на ранней стадии. Пациентам
порой не удается завершить испытание по плану по медицинским показаниям, но иногда
пациенты выходят из испытания вследствие изучаемого вмешательства. В этом случае
результаты будут основываться только на тех участниках, которые отреагировали на
испытание достаточно хорошо, чтобы пройти его полностью.
Анализ по протоколу часто бывает, однако, необходим для того, чтобы определить,
насколько хорошо вмешательство влияет на тех пациентов, которые прошли испытание в
соответствии с планом. По этой причине оба вида анализа часто проводятся и освещаются
совместно.
Отчет о рандомизированных контролируемых испытаниях 203
Однако иногда в популяции, где проводится анализ с намерением применить
вмешательство, имеются пациенты, результаты которых, будучи включенными в анализ, не дадут
оценить протокол со всей точностью. Пациенты, которые, как оказалось, не удовлетворяют
критериям соответствия, выведенные из исследования до получения лечения или,
например, со многими недостающими данными, часто исключаются из модифицированного
анализа с намерением применить вмешательство. Такой модифицированный анализ
должен дать более точную оценку результатов испытания в зависимости от того, ^^сколько
четко будут определены и обоснованы эти исключения.
Если пациенты по тем или иным причинам покидают испытание на ранней стадии
(наиболее обычными являются смерть, потеря наблюдения за пациентом или медицинские
показания), в данных об исходе могут появиться пробелы. Полный анализ с намерением
применить вмешательство требует полных данных, поэтому следует приложить усилия к тому,
чтобы 1) привлекать к испытанию только действительно подходящих для этого пациентов
[62], 2) сохранять пациентов в испытании, 3) продолжать наблюдение за пациентами,
вышедшими из испытания по тем или иным причинам, 4) учитывать всех пациентов,
вовлеченных в испытание, и 5) указать, как рассматривались в анализе недостающие данные
(см. указание 13.62),
Q Ложные включения (пациенты, которые, как выяснилось после включения
их в список, не удовлетворяют критериям соответствия) должны быть
учтены в анализе с намерением провести вмешательство. Если ложные включения
происходят в управляемом окружении клинического испытания, подобные ошибки
в классификации вероятны и в рутинной клинической практике [63].
0 Если большая популяция пациентов по тем или иным причинам не
выполнила протокол, интерпретация анализа с намерением провести вмешательство
может оказаться затруднительной [62]. В таких случаях можно провести
модифицированный анализ.
1338, Идентифицируйте все запланированные анализы подгрупп или ковариат [6].
Анализы подгрупп — это сравнения между подмножествами экспериментальных групп.
К примеру, после сравнения экспериментальной группы с контрольной исследователи
могут сравнить мужчин в экспериментальной группе с мужчинами в контрольной группе, а
затем молодых мужчин в экспериментальной группе с молодыми мужчинами в контрольной
группе и т. д. Число подгрупп может быть большим, хотя и ограниченным необходимостью
придать биологический смысл. Однако с увеличением числа подгрупп уменьшается их
численность, что уменьшает статистическую мощность и увеличивает число /7-значений,
создавая проблему множественных сравнений {см. гл. 5). Как следствие, запланированные
до начала испытания анализы подгрупп с меньшей вероятностью оказываются
результатом «вскрытия данных», при котором исследователи ищут что-нибудь статистически
значимое.
Q Более мощной альтернативой анализу подгрупп является оценка
потенциального взаимодействия между двумя переменными по интересующему исходу.
Например, лучше оценивать взаимодействие между экспериментальной группой и
полом, чем сравнивать эффекты от лечения отдельно у мужчин и женщин.
204 Составление отчетов об исследовательских проектах и мероприятиях
1339. Идентифицируйте все статистические корректировки, сделанные с целью
контроля над вмешивающимися факторами [6].
Даже в РКИ основные дисбалансы по некоторым переменным, появляющиеся хоть и по
воле случая, могут исказить картину испытания. Например, если экспериментальная
группа имеет более высокую долю пациентов с более тяжелой формой болезни, лечение может
показаться менее эффективным, чем на самом деле. В этом случае исследователи могут
«скорректировать» или «проконтролировать» тяжесть заболевания, введя для нее
коэффициент в статистический анализ. Но для того, чтобы такая корректировка стала возможной,
«тяжесть» должна быть определена, а данные по определяющим переменным должны быть
уже собраны.
13«40* Покажите, как проверялись на согласованность или согласие наблюдения,
основанные на суждениях.
Чтобы уменьшить систематическую ошибку, связанную с вынесением суждения,
наблюдения обычно получают от двух или более экспертов, а затем проверяют на согласованность
или степень согласия, используя такую меру согласия, как каппа-статистика (см. гл. 6).
Допустим, к примеру, что два рентгенолога оценивают 25 рентгеновских снимков на
наличие или отсутствие трещины. Если они выносят одинаковые суждения по 23 снимкам
из 25, то говорят, что их суждения «согласованны» на 92 % и «несогласованны» на 8 %.
Соответствующее значение каппа равно 0,82.
1341. Опишите все запланированные анализы чувствительности к смещениям.
Анализ чувствительности — способ исследовать и анализировать данные при
различных предположениях, с тем чтобы определить влияние предположения на исход. К
примеру, анализируя данные как с выбросами, так и без них, можно определить, насколько
«чувствителен» исход к этим экстремальным значениям. Еще один тип анализа
чувствительности — сравнение результатов анализа с намерением применить вмешательство с
результатами анализа по протоколу.
13«42, Определите все процедуры, применяемые для контроля за множественным
сравнением [6].
Чем больше статистических анализов проводится по одним и тем же данным, тем
больше вероятность ошибочно принять некоторые р-значения в качестве показателей
биологической взаимосвязи. Если р-значения ниже 0,05 считаются статистически значимыми (т. е.
в пяти случаях из ста разность приписывается, скажем, лечению, когда оно в
действительности не отличается от плацебо), то 5 из каждых 100/7-значений, или 1 из 20, вероятно,
будут ошибочными. Для борьбы с этой проблемой множественных сравнений исследователи
могут скорректировать пороговый уровень значимости (пороговое значение
статистической значимости, обычно 0,05) и при этом указать в отчете метод корректировки. К
примеру, можно установить более жесткий уровень значимости, скажем, 0,01. (См. гл. 5.)
13.43. Определите пороговый уровень значимости.
Пороговый уровень значимости — устанавливаемая исследователем вероятность
совершить ошибку первого рода. Это пороговое значение статистической значимости.
/7-значения, меньшие или равные пороговому уровню значимости, являются статистиче-
Отчет о рандомизированных контролируемых испытаниях 205
ски значимыми, а большие — нет. Типичными уровнями значимости являются 0,05 и 0,01.
(См. гл. 4.)
13.44* Укажите, какие применялись статистические критерии: одно- или
двусторонние. Обоснуйте применение односторонних критериев.
Двусторонние проверки гипотез более консервативны, чем односторонние, поскольку
требуют большего эффекта лечения для достижения одного и того же уровня
статистической значимости (т. е. р-значения). Односторонние критерии часто используются тогда,
когда «направление» разности известно заранее, как в случае, когда другой исследователь
показывает, что группа А всегда будет иметь большее значение конечной точки, чем группа
В. Тип критерия должен быть четко определен, поскольку оба эти типа критериев выдают
различные р-значения для одних и тех же данных. Всегда следует дать обоснование для
применения одностороннего критерия. (См. гл. 4.)
13.45. Назовите пакеты статистических программ, с помощью которых
анализировались данные.
Точное название используемого в статистическом анализе прикладного пакета важно
потому, что, хотя коммерческие пакеты обычно проверяются, обновляются и проходят
проверку временем, вычислительные характеристики программ, разрабатываемых частным
образом, часто бывают неизвестны. Кроме того, при вычислении одних и тех же
статистик не все статистические прикладные программы используют одинаковые алгоритмы
или опции по умолчанию. Как следствие, результаты могут изменяться от пакета к пакету.
Укажите название программы, используемую версию (например, «3.2»), а также название
и местонахождение разработчика.
УКАЗАНИЯ ПО ОФОРМЛЕНИЮ РЕЗУЛЬТАТОВ
13.46. Укажите временные рамки испытания: даты составления списков
участников, лечения, даты сбора данных и основания для выбора этих дат [6].
Указание периода проведения испытания важно потому, что технический прогресс,
изменения в лечебных процедурах и различия в практике составления отчетов в разные
времена могут повлиять на исходы и интерпретации.
13.47. Объясните причины отклонения от протокола вмешательства при
проведении испытания [5].
Количество и природа отклонений от протокола вмешательства дает возможность
увидеть, насколько точно пациенты придерживаются лечения и насколько хорошо переносят
его. Кроме того, эта информация формирует контекст анализа с намерением провести
вмешательство и анализа по протоколу.
13.48. Приведите схему испытания, показывающую число и расположение его
участников на каждом его этапе [6,64].
Схема испытания — диаграмма, наглядно показывающая ход исследования и
помогающая читателям установить численность групп на каждом этапе исследования (рис. 13.1-
13.3). Такая схема помогает учесть всех пациентов на протяжении испытания, показывает
206 Составление отчетов об исследовательских проектах и мероприятиях
Число пациентов,
проверяемых на
возможность участия
Число случайно
распределенных
пациентов
Число исключенных
пациентов
Не удовлетворяют
требованиям
Отказались от участия
Число записанных в
группу вмешательства
Прошли лечение
Не прошли лечение
(Укажите причины)
Число записанных в
группу вмешательства
Прошли лечение
Не прошли лечение
(Укажите причины)
Потерянные для
наблюдения
(Укажите причины)
Прерванное лечение
(Укажите причины)
Число
проанализированных
пациентов
Число исключенных из
анализа
(Укажите причины)
Потерянные для
наблюдения
(Укажите причины)
Прерванное лечение
(Укажите причины)
Число
проанализированных
пациентов
Число исключенных из
анализа
(Укажите причины)
Рис. 13.1. Исходная форма схемы рандомизированного контролируемого испытания, по рекомендации
CONSORT [64]
значения знаменателей на всех его этапах и обычно демонстрирует его дизайн. Важен
не столько вид диаграммы, сколько ее наглядность.
При итоговом описании всей совокупности участников рандомизированного испытания
желательно указать число пациентов, которые:
• были избраны для испытания, но не были доступны;
• проверялись на возможность участия, но не удовлетворяли предъявляемым
требованиям;
• удовлетворяли требованиям, но отказались от участия;
Отчет о рандомизированных контролируемых испытаниях 207
'
'
Лечение А
7085
т^'^^^-^'" ■■■■•--
Умерших 37
Выбывших 59
Изменений
протокола 82
---—Y--
Выполненный
протокол
п = 6907
Популяция 600 000
в регионе N
" —т^"- -
23 023 пациента
из 5 центров
■~~~т~~~"^
1767 исключенных
21 256 случайно
распределенных
у
Лечение В
7089
" 1 "
Умерших 103
Выбывших 75
Изменений
протокола 169
-——J——
Выполненный
протокол
п = 6742
1
1
у
Контроль 1
7082
1 ■■^^
Умерших 10 1
Выбывших 42 1
Изменений 1
протокола 23 |
■--■'-^^
Выполненный |
протокол 1
п = 7007
Рис. 13.2. Схема рандомизированного клинического испытания с тремя ветвями лечения
• ПОДХОДИЛИ для испытания и были включены в список;
• были распределены в ту или иную группу;
• не прошли лечение так, как оно было запланировано (удаления или «выбытия»);
• прошли лечение полностью, но были потеряны для дальнейшего наблюдения;
• прошли лечение полностью и впоследствии наблюдались в течение всего
установленного периода.
13.49. Укажите базовые характеристики каждой группы с помощью подходящих
описательных статистик [5,6].
Охарактеризуйте каждую группу подходящими описательными статистиками. Итоговое
описание непрерывных переменных, если они распределены не по нормальному закону,
дается с помощью медианы и интерквартильного размаха (широты), в противном случае
приняты среднее и СО. Также можно привести максимальные и минимальные значения.
Укажите количество и процент наблюдений в каждой категории для переменных,
измеряемых в номинальной шкале, и для переменных, измеряемых в порядковой шкале, если
число категорий невелико, скажем, 5 или меньше. Для 6 и более порядковых категорий
укажите медиану, интерквартильный размах (широту) и моду, если эти статистики точно
характеризуют данные. Если же нет, укажите число и процент наблюдений в каждой
категории. (См. гл. 1.)
208 Составление отчетов об исследовательских проектах и мероприятиях
Популяция
Л/=574
43 исключенных
Распределенные
случайным образом
п = 531
Г
1
Группа 1
л = 266
Группа 2
п = 265
34 выбывших
15 выбывших
1350» Укажите, в какой степени выборка
участников была репрезентативна
для изучаемой популяции.
Если результаты испытания предназначены для
надлежащего обобщения, выборка из
интересующей популяции должна быть репрезентативной.
13.51. Скажите о тех, кто мог, но не стал
участвовать в испытании, и приведите их
аргументы против участия.
Те пациенты, которые соглашаются
участвовать в испытании, могут отличаться от тех, кто
отказался участвовать: они могут с большей
готовностью подвергать себя риску, сильнее
разочароваться в лечении или быть более
довольными системой здравоохранения. По этой причине
важно описать тех, кто не стал участвовать в
испытании, с тем чтобы идентифицировать
возможные отличия. При некоторых обстоятельствах
также полезно записать информацию,
предоставленную будущими участниками, и рассказать
о том, как они пришли к решению участвовать
в испытании [28, 65].
13.52« Покажите, насколько контрольные
группы были подобны
экспериментальным по исходным
характеристикам.
в идеале группы должны быть похожи по
исходным характеристикам, чтобы единственным
серьезным отличием между ними было
проведение вмешательства или его отсутствие. Простое
случайное распределение не дает уверенности в схожести групп, а только лишь в том, что
все отличия являются результатом случая. (Подобия, однако, можно достичь с помощью
группировки в блоки и стратификации.) Клинические или статистические дисбалансы в
исходных данных не являются неизбежными, но их следует идентифицировать до того, как
их можно будет поправить в «корректирующем» анализе. Таким образом, подобие групп
должно быть отмечено и в тексте, и в таблице начальных значений.
Q в рандомизированных испытаниях отражать в отчете р-значения для
исходных характеристик необязательно [66]. В таких испытаниях все различия
между группами по исходным значениям переменных будут результатом случая,
поскольку участники распределены по группам случайным образом. Сравнения
по начальным условиям, однако, все же стоит провести, для того чтобы
идентифицировать все статистические дисбалансы, которые, возможно, необходимо
скорректировать в итоговой многомерной модели. (См. гл. 7 и 8.) Если в отчете о ран-
Рис. 13.3. Схема перекрестного испытания
препарата
Отчет о рандомизированных контролируемых испытаниях 209
домизированном испытании говорится о р-значениях исходных сравнений, то они
должны интерпретироваться лишь как показатели степени дисбаланса групп, а не
как свидетельство систематической ошибки.
ф В испытаниях, где все же приводятся р-значения для исходных сравнений,
эквивалентность групп предполагать нельзя, если ни по одной из переменных
не было найдено никаких статистически значимых отличий. Мощность
исходных сравнений обычно слишком низка, чтобы исключить клинически важные
различия {см. указание 5.2).
13.53. Укажите, насколько точно участники следовали протоколу, и объясните все
исключения или отклонения от протокола [5,63,65].
Чтобы испытание было законным, его участники должны следовать протоколу. Иногда
протокол вмешательства выполняет медперсонал, а иногда за его соблюдение отвечают сами
участники. В любом случае отклонения от протокола могут вызвать ошибку, поэтому
важно знать, насколько точно был соблюден протокол. (Термин «следование рекомендациям»
предпочтителен термину «подчинение рекомендациям» как менее авторитарный.) В
частности, в отчете должны быть отражены количество, причины и хронометраж отклонений
от протокола или выходов из испытания.
Пациенты могут быть выведены из испытания по любой из следующих причин,
некоторые из которых могут вызвать ошибку при интерпретации результатов [50]:
• неудовлетворительный эффект лечения;
• нарушения протокола по тем или иным причинам;
• потеря данных или ошибка в назначениях;
• выход по причинам, не связанным с испытанием.
ф Исследования с большим количеством выбывших и вышедших участников
(скажем, 15 % или более) следует интерпретировать с осторожностью [5, 48,
57]. Высокая частота выбытия может указывать на серьезные проблемы, связанные
с изучаемым видом лечения, с проведением испытания или большими потерями
данных, причем все это может привести к систематическим ошибкам при
интерпретации результатов.
ф Если в исследованиях сильно разнятся частоты выбытия или выхода между
экспериментальной и контрольной группами, их результаты также следует
интерпретировать с осторожностью.
13.54» Приведите минимальное, медианное и максимальное значения
продолжительности периодов последующего наблюдения.
Продолжительность периода отслеживания может повлиять на то, в каком количестве
и какие именно улучшения и ухудшения были выявлены в ходе испытания. Как следствие,
важно указать его временное распределение.
13.55. Скажите о тех, кто оказался потерянным для дальнейшего наблюдения.
Как и в случае с участниками, отклонившимися от протокола или вышедшими из
испытания, потерянные для наблюдения пациенты могут иметь систематические отличия от
оставшихся, что указывает на возможность систематической ошибки. Например, потерянными
210 Составление отчетов об исследовательских проектах и мероприятиях
для отслеживания будут, вероятно, те, кто не вполне удовлетворен результатами терапии.
Нелишне также подтвердить, что работа по отслеживанию шла в соответствии с планом,
и описать все имеющие значение отклонения от плана.
^ Работа по отслеживанию редко охватывает все 100 % пациентов [66]. Однако
результаты исследований, в которых более 15 % прошедших лечение были по тем
или иным причинам потеряны для дальнейшего наблюдения, следует
интерпретировать с осторожностью [25, 38, 57, 59, 67, 68].
13.56. Приведите результаты испытания, предпочтительнее в цифрах или
таблицах [5].
Сообщая о результатах испытания, сначала приведите данные и анализы первичных
сравнений, т. е. результаты, послужившие побудительным мотивом к испытанию [49, 69-73].
Первоочередное представление результатов первичного сравнения не только оправдывает
ожидания читателей, но и помогает избежать притязаний «раскапывания» данных,
практики, при которой сначала приводятся статистически значимые находки (целевая селекция
результатов), в надежде на то, что они важнее первичного сравнения, вызвавшего к жизни
работу.
После сообщения о первичном сравнении следует описать все прочие клинически
возможные исходы, не только ожидаемые. О вторичных или анализах post hoc, дающих
интересные результаты, следует сообщать в последнюю очередь.
При любой возможности приводите основные результаты испытания в таблицах или
цифрах (см. гл. 20 и 21). Они не просто экономят место, а часто дают больше информации
в более ясной форме по сравнению с текстом. Избегайте дублирования в тексте той
информации, которая содержится в цифрах и таблицах. Вместо этого привлеките внимание к
полученным на ее основе результатам.
Результаты могут включать: значения измеренных переменных; внутригрупповые
изменения и межгрупповые разности в конечных исходах; коэффициенты корреляции;
отношения рисков, шансов и уровни рисков; коэффициенты регрессии; показатели частоты
заболевания (преваленс, относительный инциденс, летальность); частоты выживания; оценки
времени до наступления события; характеристики диагностического теста (предсказательные
значения чувствительности); показатели эффективности (число нуждающихся в лечении).
13.57. Как минимум, приведите абсолютные значения всех конечных точек,
включая внутригрупповые изменения или межгрупповые различия [6].
Абсолютная разность — истинное значение разности между показателями,
выраженными в единицах разности. Например, если средний вес в группе упал с 72 до 65 кг,
абсолютная разность равна 7 кг. Относительная разность выражается в процентах; здесь
процентное изменение равно 9,7 % (7 кг / 72 кг = 9,7 %). Поскольку изменение, скажем,
от 2 до 1 кг дает то же процентное уменьшение, как и с 2000 до 1000 кг, сообщение о 50%-м
уменьшении в обоих примерах, хотя и точное, может привести к неверным выводам;
отсюда видна важность абсолютной разности.
13*58. Для всех конечных точек приведите доверительные интервалы [б].
Результаты испытания в действительности являются оценками того, чего можно было бы
ожидать, если бы лечение предназначалось для всей исследуемой популяции. Доверитель-
Отчет о рандомизированных контролируемых испытаниях 211
ные интервалы показывают точность таких оценок. Чем шире доверительный интервал,
тем меньше точность оценки (см. гл. 3). Доверительные интервалы следует указывать для
всех показателей исходов, перечисленных в указании 13.56.
ф Если наряду с оценками и 95% ДИ (или вместо них) приводятся р-значения,
укажите их действительное значение (не/i < 0,05), не более чем с двумя
значащими цифрами./^ < 0,001 — наименьшее значение, которое следует сообщать.
13.59. Укажите число или процент пациентов,чшторым стало (или не стало) лучше,
а также все групповые значения для важных конечных точек [48,49].
Для непрерывных конечных точек в отчетах о многих испытаниях фигурируют только
групповые значения, что может скрыть индивидуальную изменчивость среди пациентов.
К примеру, количество клеток Т^ является маркером иммунной функции, и оно обычно
отслеживается у больных ВИЧ/СПИДом. При исследовании пациентов с ВИЧ/СПИДом
медиана роста или падения клеток Т^ часто приводится для каждой экспериментальной
группы. Однако отклики одних пациентов могут отличаться от откликов других из той же
группы, поэтому часто бывает полезно узнать число пациентов, скажем, с улучшением
показателей клеток Т^ и значение медианы для всей группы.
13.60. Если наблюдения основаны на суждениях, приведите меру согласованности
или согласия между экспертами.
Для указания степени согласия между экспертами могут подойти меры корреляции
или согласия (такие, как пирсоновская корреляция по смешанным моментам, г, каппа-
статистика) или доля согласованных или несогласованных суждений.
13«61. Опишите природу и частоту обычных или тяжелых побочных эффектов и
неблагоприятных событий в каждой группе [5, б, 53,67].
Настоящая наука, как и научная этика, требует, чтобы все негативные побочные эффекты
или неблагоприятные последствия испытания были отражены в отчете со всей полнотой.
Для каждой группы приведите: 1) частоту, 2) тяжесть (ее степень), 3) серьезность (угрозы
здоровью или благосостоянию), 4) хронометраж неблагоприятных событий [53]. Общие
фразы о частоте побочных эффектов («Отмечались немногочисленные побочные
эффекты») неинформативны. [53]. Полезно также различать неблагоприятные клинические
события и определенную лабораторным путем токсичность.
13*62* Опишите все возможные влияния искажения или взаимодействия.
Кроме эффектов, относящихся к лечению, на результаты могут повлиять два других,
часто непредусмотренных эффекта: синергетические (эффекты взаимодействия),
вызванные взаимодействием изучаемых переменных, и искажающие, которые могут
видоизменить или затенить интересующую взаимосвязь. В случае наблюдения этих процессов их
следует рассмотреть и отразить в отчете. [74].
ПРИМЕРЫ
• Как алкоголь, так и барбитураты угнетают деятельность центральной нервной
системы. Однако сублетальные дозы алкоголя и барбитуратов при одновременном
их приеме могут оказаться смертельными; их взаимодействие или синергетиче-
ский эффект превышает сумму их эффектов по отдельности. Это взаимодействие
212 Составление отчетов об исследовательских проектах и мероприятиях
может описываться и должно выявляться с помощью подходящих статистических
методик.
• Испытание двух медицинских образовательных программ показало, что
прошедшие курс по одной из них сдали заключительный тест с лучшими результатами, чем
по другой. Однако при дальнейшем исследовании выяснилось, что инструкторы
клиники, работавшие с предположительно более удачной программой, оказывали больше
поддержки своим слушателям, чем работавшие с другой. Тем самым на вывод о том,
что лучшие результаты обусловлены превосходством одной из программ, повлияли
искажающие факторы.
При многоцентровых испытаниях данные должны анализироваться отдельно для
каждого центра, с тем чтобы определить, различаются ли результаты в зависимости от центра
[18]. Причины различий должны быть исследованы. В частности, следует рассмотреть
различия в дополнительных видах лечения, назначенных участникам исследования.
13«бЗ« Дайте отчет о всех наблюдениях и участниках и объясните все случаи
отсутствия данных [12].
Чтобы избежать обвинений в избирательной отчетности, следует отчитаться о всех
наблюдениях.
С пропусками можно обращаться по-разному. При отчете по полным данным пациенты
с пропусками просто исключаются из анализа. Такое исключение сильно уменьшает объем
выборки и нарушает стратегию намерения провести лечение; и то и другое
нежелательно. Значения для пропусков также могут быть восполнены при помощи одного из
нескольких методов {см. указание 7.21). Еще пропуски можно заменить при помощи переноса
последнего наблюдения, подстановки значения группового среднего или преднамеренно
консервативных или заниженных значений. Пациентов с пропусками можно также
включить в знаменатели относительных значений, чтобы получить более консервативные
оценки [63]. Влияние пропусков можно еще определить с помощью некоторых видов анализа
чувствительности, при котором исследуется, каким образом оптимистические и
пессимистические предположения влияют на интересующий исход.
^ В данных могут быть пропуски, если:
• указанные итоговые значения не равны сумме приведенных в тексте и таблицах
(иными словами, проверьте сложение);
• процентные значения невозможно воспроизвести по приведенным числовым
значениям;
• в таблицах есть незаполненные клетки;
• дроби имеют разные знаменатели (это говорит об изменении численности групп);
• число точек данных на графике не совпадает с приведенным в тексте числом
наблюдений'.
13.64. Опишите, как рассматривались выбросы.
Экстремальные значения, или выбросы, добавляют результатам вариабельность и
неопределенность и, следовательно, часто доставляют «неудобства». Игнорировать выбросы
' Число точек на графике, меньшее, чем приведенное в тексте число наблюдений, может быть вызвано также
наложением двух или более идентичных по этим признакам наблюдений. В ряде статистических пакетов для этого
случая предусмотрены специальные значки, отличные от тех точек, которым отвечает единственное наблюдение.
Отчет о рандомизированных контролируемых испытаниях 213
В статистическом анализе или избегать их упоминания в отчете неэтично. Может оказаться
уместным проанализировать данные дважды, один раз с выбросами и один раз без них,
с тем чтобы определить их влияние на итоговые результаты. Однако такая практика должна
получить обоснование. Ошибки при сборе и вводе данных не должны рассматриваться как
причины появления выбросов данных.
13.65» Опишите, оценивался ли успех слепого метода, и если да, то как [б].
Слепые исследования часто бывают не вполне слепыми, поскольку участники или
попечители узнают, к какой группе приписан участник. Пациенты и попечители порой заходят
далеко в своем стремлении получить сведения о размещении по группам и о применении
слепого метода, чтобы раскрыть принадлежность к группам или манипулировать ею [44].
Если это им удается, они вносят потенциально вредные систематические ошибки в виде
смещения ожиданий, разной степени следования протоколу и смещения процесса
случайного распределения. Поэтому об успехе слепого метода исследователи часто судят по
ответам участников и экспертов на вопросы о том, кто из пациентов к какой группе приписан.
13.бб« Сообщите о всех необычных свидетельствах или наблюдениях, которые
могут способствовать более точному или полному пониманию испытания или
его результатов.
Поскольку медицина является и искусством, и наукой, в ней важны наблюдения и
находки внимательных исследователей. (Однако многочисленные несистематические
наблюдения не есть «данные»!) Помните, что открытие тератогенного эффекта диэтилстильб-
эстрола (DES) началось с того, что мать в разговоре с лечащим врачом упомянула случай
приема DES во время вынашивания своей пораженной дочери [75].
Кроме того, как подчеркивал доктор Элвин Фейнштейн, «объем форсированного
выдоха при дыхании не указывает на одышку пациента, а депрессия сегмента S-T не указывает
на стенокардию в повседневной жизни... большинство из наиболее важных клинических
событий являются, по сути, человеческими реакциями и ощущениями — боль, дискомфорт,
нетрудоспособность, общая функциональная способность, депрессия, тревога и
удовольствие, — которые нельзя измерить никаким технологическим тестом» [76].
УКАЗАНИЯ ОТНОСИТЕЛЬНО ОБСУЖДЕНИЯ РЕЗУЛЬТАТОВ
13.67, Соберите результаты в общую сводку.
Основные результаты испытания обычно приводятся в первом абзаце обсуждения. После
этой сводки порядок тем обсуждения должен соответствовать порядку раздела
«Результаты». Сначала следует обсудить первичное сравнение. Вторичные анализы, представляющие
интерес, следует обсуждать позже, а представляться они должны как экспериментальные.
13.68. Дайте интерпретацию результатов и предложите их объяснение [5,6].
Кто-то однажды сказал, что «групповые средние не направляют на лечение»; поэтому
не смешивайте статистическую значимость с клинической важностью! Правдоподобие
с биологической точки зрения, сила убеждения проверяемой теории и других свидетельств
более важны при интерпретации результатов, чем р-значения [77]. При интерпретации
результатов бывает также разумно рассмотреть прогноз контрольной группы [65]. К примеру.
214 Составление отчетов об исследовательских проектах и мероприятиях
если смертность в контрольной группе низка, то она будет, вероятно, низка и в
экспериментальной группе, независимо от какого-либо вмешательства. Как следствие, вмешательство,
обещающее что-то иное, может показать незначительный эффект. С другой стороны, если
смертность в контрольной группе высока, успешное вмешательство, скорее всего, снизит
показатель смертности в экспериментальной группе.
Q Исследования с суррогатными конечными точками должны
интерпретироваться с осторожностью. Изменение фактора риска необязательно означает
изменение в определяющих условиях [78, 79].
^ Подгрупповые анализы, запланированные или поисковые, частично
ненадежны, если лечение не дало общего эффекта [62]. В любом случае такие
анализы должны учитывать величину эффекта лечения для подгрупп и не
полагаться на /^-значения, чтобы определить, было ли лечение эффективным в некоторых
подгруппах, но не в других [67]. Однако подгрупповые анализы могут намекнуть
на возможные взаимодействия между переменными.
Исследования с отрицательным результатом могут быть трех типов: 1) важные
исследования, в которых устанавливается бесполезность вмешательства; 2) исследования, в
которых не удалось воспроизвести предыдущие результаты; 3) исследования со статистически
незначимыми результатами и низкой статистической мощностью.
13.69. Опишите, как результаты соотносятся с тем, что уже известно по данной
проблеме; приведите обзор литературы и поместите результаты в контекст [6].
Помещение результатов в контекст существующего знания помогает читателям дать
интерпретацию работе. Наука подразумевает накопление и систематизацию фактов, и от
исследователей, таким образом, зависит то, как их работа соотносится с остальной наукой.
Q Просмотрите даты цитируемой литературы, чтобы определить
своевременность и употребительность включенной в обзор литературы.
13.70. Покажите пути обобщения результатов [6].
Цель любого отдельно взятого исследовательского испытания — получить результаты,
которые можно применить к представляющей интерес популяции. Интересующая
популяция должна быть определена с помощью критериев включения и исключения. Однако
чем специфичнее определение популяции и чем жестче управление экспериментом, тем
труднее обобщить результаты на более широкую, более разнородную популяцию вне
контролируемого окружения медицинского исследования в повседневной деятельности служб
здравоохранения. На возможность обобщения результатов испытания влияет то, является
ли оно в своей основе объяснительным или прагматическим (см. указание 13.2).
13.71. Обсудите следствия результатов.
Большинство читателей (и редакторов журналов) желают получить ответ на следующие
два вопроса об исследовательском испытании: «Что из этого следует?» и «Кого это
интересует?». Другими словами: «Что изменится в медицине в результате этого исследования?».
К сожалению, этот вопрос в научных статьях часто остается без ответа. Если актуальность
темы исследования была не настолько велика, чтобы с нее начать, следствия результатов
также не представляют интереса.
Отчет о рандомизированных контролируемых испытаниях 215
Результаты часто предлагают новые области исследований, и это может быть полезным
для читателей [5]. Однако вовсе не является необходимым включать общую фразу
«Требуются дальнейшие исследования».
1372. Обсудите лимитирующие факторы испытания.
Если возможно, опишите источники и последствия потенциальных смещений,
искажений и ошибок при разработке исследования или проблем, связанных со сбором, анализом
или интерпретацией данных. Раскрывать слабые стороны или ограничения бывает нелегко,
но честность — неотъемлемая часть науки. Указание трудностей в исследовании может
также помочь избежать аналогичных проблем другим исследователям.
13.73. Перечислите выводы.
Должно быть очевидно, что в число выводов следует включать лишь построенные на
данных и основанные на фактах и логике, а не на предположениях и рассуждениях. Однако
необоснованные выводы, к сожалению, в литературе встречаются регулярно. Некоторые
исследователи даже шутливо называют эту проблему ошибкой третьего рода [80]. В то
время как ошибка первого рода, по сути, означает принятие различия, которое следует
отвергнуть, а второго — отказ принять различие, которое следует принять, то ошибка третьего
рода — это приход к заключению, которое не поддерживается исследованием. (Некоторые
авторы говорят даже об ошибке четвертого рода — получить то, что впоследствии окажется
верным выводом, но на ложных основаниях [81].)
Перечисление выводов в отдельном списке помогает авторам еще раз четко определить
их сущность и упрощает их поиск читателям. В выводах должны также содержаться
следствия результатов, а не простое их повторение.
Литература
1. Rennie D. CONSORT Revised — improving the reporting of randomized trials. JAMA. 2001;
285:2007-7.
2. Norton R. A manifesto for reading medicine. Lancet. 1997; 349:872-4.
3. Medical Research Council Investigation. Streptomycin treatment of pulmonary tuberculosis. BMJ.
1948; ii:769-82.
4. Moher D, JadadAR, Nichol G, et al Assessing the quality of randomized controlled trials: an
annotated bibliography of scales and checklists. Control Clin Trials. 1995; 16:62-73.
5. Durant RH. Checklist for the evaluation of research articles. J Adolesc Health. 1994;15:4-8.
6. Moher D, Schulz K, Altman DG, for the CONSORT Group. CONSORT statement: revised
recommendations for improving the quality of reports of parallel-group randomized trials. Ann Intern Med. 2001;
134:657-62.
7. Altman DG. Statistical reviewing for medical journals. Stat Med. 1998; 17:2661-74.
8. EbbuttAF, Frith L. Practical issues in equivalence trials. Stat Med. 1998; 17:1691-1701.
9. Snapinn SM. Noninferiority trials [Commentary]. Curr Control Trials Cardiovasc Med. 2000; 1:19-21.
10. Greene WL, Concto J, Feinstein AR. Claims of equivalence in medical research: are they supported
by the evidence? Ann Intern Med. 2000; 132:715-22.
11. Schwartz D, Lellouch J. Explanatory and pragmatic attitudes in therapeutical trials. J Chronic Dis.
1967; 20:637-48.
12. Simon G, Wagner E, VonkorffM. Cost-effectiveness comparisons using real world randomized trials:
the case of new antidepressant drugs. J Clin Epidemiol. 1995; 48:363-73.
13. LeBlondRF Improving structured abstracts [Letter]. Ann Intern Med. 1989; 111:764.
216 Составление отчетов об исследовательских проектах и мероприятиях
14. НШтап AL, Eisenberg JM, Pauly MV, et al Avoiding bias in the conduct and reporting of cost-
effectiveness research sponsored by pharmaceutical companies. N Engl J Med. 1991; 324:1362-5.
15. Meinert CL, Tonascia S, Higgins K. Content of reports on clinical trials: a critical review. Control
Clin Trials. 1984;5:328-47.
16. Journal of the American Medical Association. Instructions for preparing structured abstracts. JAMA.
2005; 294:119-27. See also: www.jama.com.
17. Guyatt G, Sackett D, Adachi J, et al A clinician's guide for conducting randomized trials in
individual patients. CMAJ. 1988; 139:497-503.
18. Horwitz RI, Singer BH, Makuch RW, Viscoli CM. Can treatment that is helpful on average be harmful
to some patients? A study of the conflicting information needs of clinical inquiry and drug regulation. J Clin
Epidemiol. 1996;49:395-400.
19. Mann H. ASSERT Statement: Recommendations for the review/and monitoring of randomized
controlled clinical trials, http://www.assert-statement.org/. Accessed 6/30/05.
20. Begg CB. Selection of patients for clinical trials. Semin Oncol. 1988; 15:434-40.
21. Lionel ND, Herxheimer A. Assessing reports of therapeutic trials. BMJ. 1970; 3:637-40.
22. Walker AM. Reporting the results of epidemiological studies. Am J Public Health. 1986; 76:556-8.
23. Gifford RH, Feinstein AR. A critique of methodology in studies of anticoagulant therapy for acute
myocardial infarction. N Engl J Med. 1969; 280:351-7.
24. Mahon WA, Daniel ЕЕ. A method for the assessment of reports of drug trials. Can Med Assoc J. 1964;
90:565-9.
25. Zelen M. Guidelines for publishing papers on cancer clinical trials: responsibilities of editors and
authors. J Clin Oncol. 1983; 1:164-9.
26. Bhopal R, Donaldson L. White, European, Western Caucasian, or What? Inappropriate labeling in
research on race, ethnicity, and health. Am J Pub Health. 1998; 88:1301-7.
27. Witzig R. The medicalization of race: scientific legitimization of a flawed social construct. Ann Intern
Med. 1996; 125:675-9.
28. Bracken MB. Reporting observational studies. Br J Obstet Gynaecol. 1989; 96:383-8.
29. Altman DG, Dore CJ. Randomisation and baseline comparisons in clinical trials. Lancet. 1990;
335:149-53.
30. Tyson JE, Furzan JA, Reisch JS, Mize SG. An evaluation of the quality of therapeutic studies in
perinatal medicine. J Pediatr. 1983; 102:10-3.
31. Weiss W, Dambrosia JM. Common problems in designing therapeutic trials in multiple sclerosis.
Arch Neurol. 1983;40:678-80.
32. Sheehan TJ. The medical literature. Let the reader beware. Arch Intern Med. 1980; 140:472^.
33. Leis HP Jr, Robbins GF, Greene FL, et al. Breast cancer statistics: use and misuse. Int Surg. 1986;
71:237-43.
34. American Medical Association. Attributes to Guide the Development of Practice Parameters.
Chicago: American Medical Association; 1994:1-11.
35. Feinstein AR, Spitz H. The epidemiology of cancer therapy. I. Clinical problems of statistical surveys.
Arch Intern Med. 1969; 123:171-86.
36. Ad Hoc Working Group for Critical Appraisal of the Medical Literature. A proposal for more
informative abstracts of clinical articles. Ann Intern Med. 1987; 106:598-604.
37. Haynes RB. How to read clinical journals: II. To learn about a diagnostic test. Can Med Assoc J.
1981; 124:703-10.
38. Tugwell PX. How to read clinical journals: III. To learn the clinical course and prognosis of disease.
Can Med Assoc J. 1981; 124:869-72.
39. DerSimonian R, Charette LJ, McPeek B, Mosteller F Reporting on methods in clinical trials. N Engl
J Med. 1982;306:1332-7.
Отчет о рандомизированных контролируемых испытаниях 217
40. Schultz KF, Chalmers I, Grimes DA, Altman DG. Assessing the quality of randomization from reports
of controlled trials published in Journals of Obstetrics and Gynecology. JAMA. 1994; 272:125-8.
41. White SJ. Statistical errors in papers in the British Journal of Psychiatry. Br J Psychiatry. 1979;
135:336-42.
42. Bailor JCIII, Mosteller F. Guidelines for statistical reporting in articles for medical journals:
amplifications and explanations. Ann Intern Med. 1988; 108:266-73.
43. Schultz KF, Chalmers I, Hayes RJ, Altman DG Empirical evidence of bias: dimensions of
methodological quality associated with estimates of treatment effects in controlled trials. JAMA. 1995; 273:408-12.
44. Schultz KF Subverting randomization in controlled trials. JAMA. 1995; 274:1457-8.
45. Devereaux PJ, Manns В J, Ghali WA, et al. Physician interpretations and textbook definitions of
blinding terminology in randomized controlled trials. JAMA. 2001; 285:2000-3.
46. Davis NM, Cohen MR, Medication Errors: Causes and Prevention. Philadelphia: George Stickley
Company; 1981.
47. Gross M. A critique of the methodologies used in clinical studies of l)ip^oint arthroplasty published
in the English-language orthopaedic literature. J Bone Joint Surg Am. 1988; 70:1364-71.
48. Moskowitz G, Chalmers TC, Sacks HS, et al Deficiencies of clinical trials of alcohol withdrawal.
Alcohol Clin Exp Res. 1983; 7:42-6.
49. Felson DT, Anderson JJ, Meenan RF Time for changes in the design, analysis, and reporting of
rheumatoid arthritis clinical trials. Arthritis Rheum. 1990; 33:140-9.
50. Gotzsche PC Methodology and overt and hidden bias in reports of 196 double-blind trials of
nonsteroidal antiinflammatory drugs in rheumatoid arthritis. Control Clin Trials. 1989; 10:31-56. [Erratum:
Control Clin Trials. 1989; 50:356.]
51. Bucher HC, Guyatt GH, Cook DJ, et al, for the Evidence-Based Medicine Working Group. User's
guides to the medical literature XIX. Applying clinical trials results. A. How to use an article measuring the
effect of an intervention on surrogate end-points. JAMA. 1999; 282:771-8.
52. Fleming TR, DeMets DL Surrogate end points in clinical trials: are we being mislead? Ann Intern
Med. 1996; 125:605-13.
53. loannidis JPA, Lau J. Completeness of safety reporting in randomized trials. JAMA. 2001; 285:437-43.
54. Ethgen M, Boutron I, Baron G, et al Reporting of harm in randomized, controlled trials of nonphar-
macologic treatment for rheumatic disease. Ann Intern Med. 2005;143:20-5.
55. Evans M, Pollock AV. Trials on trial: a review of trials of antibiotic prophylaxis. Arch Surg. 1984;
119:109-13.
56. Gardner MJ, Machin D, Campbell MJ. Use of checklists in assessing the statistical content of
medical studies. BMJ. 1986; 292:810-2.
57. Simon R, Wittes RE. Methodologic guidelines for reports of clinical trials. Cancer Treat Rep. 1985;
69:1-3.
58. Rochon PA, Gurwitz JH, Cheung MC, et al. Evaluating the quality of articles published in journal
supplements compared with the quality of those published in the parent journal. JAMA. 1994; 272:108-13.
59. Chalmers TC, Smith H Jr, Blackburn B, et al A method for assessing the quality of a randomized
control trial. Control Clin Trials. 1981; 2:31^9.
60. Garcia-Cases C, Duque A, Borja J, et al Evaluation of the methodological quality of clinical trial
protocols: a preliminary experience in Spain. Eur J Clin Pharmacol. 1993; 44:401-2.
61. Freeman KB, Back S, Bernstein J. Sample size and statistical power of randomized, controlled trials
in orthopaedics. J Bone Joint Surg Br. 2001; 83:397-402.
62. Stewart LA, Parmar MKB. Bias in the analysis and reporting of randomized controlled trials. Int J
Tech Assess Health Care. 1996; 12:264-75.
63. Mollis S, Campbell F What is meant by intention to treat analysis? Survey of published randomised
controlled trials. BMJ. 1999; 319:670^.
218 Составление отчетов об исследовательских проектах и мероприятиях
64. Egger М, Juni Р, Bartlett, for the CONSORT Group. Value of flow diagrams in reports of randomized
controlled trials. JAMA. 2001; 285:1996-9.
65. Grant A. Reporting controlled trials. Br J Obstet Gynaecol. 1989; 96:397-400.
66. Lavori PW, Louis ТА, Bailar JC, Polanski M. Designs for experiments — parallel comparisons of
treatment. In: Bailar JC, Mosteller F, eds. Medical Uses of Statistics, 2nd ed. Waltham: Massachusetts
Medical Society; 1992:61-82.
67. Gelber RD, Goldirsch A, for the International Breast Cancer Study Group. Reporting and inteфret-
ing adjuvant therapy clinical trials. J Natl Cancer Inst Monogr. 1992; 11:59-69.
68. Stoto MA. From data analysis to conclusions: a statistician's view. In: Council of Biology Editors,
Editorial Policy Committee. Ethics and Policy in Scientific Publication. Bethesda, MD: Council of Biology
Editors; 1990:207-18.
69. Literati A, Himel HN, Chalmers TC A quality assessment of randomized control trials of primary
treatment of breast cancer. J Clin Oncol. 1986; 4:942-51.
70. Methodologic guidelines for reports of clinical trials [Editorial]. Am J Clin Oncol. 1986; 9:276.
71. Bailar JCIIL Science, statistics, and deception. Ann Intern Med. 1986; 104:259-60.
72. Mills JL. Data torturing [Letter]. N Engl J Med. 1993; 329:1196-9.
73. Altman DG. Statistics and ethics in medical research. VIII — Improving the quality of statistics in
medical journals. BMJ. 1981; 282:44-7.
74. RothmanKJ, GreenlndS, Walker AM. Concepts of interaction. Am J Epidemiol. 1980; 112:467-70.
75. Moses L. Measuring effects without randomized trials? Options, problems, challenges. Med Care.
1995;33:AS8-14.
76. Feinstein AR. Clinical judgement revisited: the distraction of quantitative models. Ann Intern Med.
1994; 120:799-805.
77. Goodman SN. Toward evidence-based medical statistics. I. The P value fallacy. Ann Intern Med.
1999; 130:995-1004.
78. Sackett DL. How to read clinical journals: V To distinguish useful from useless or even harmful
therapy. Can Med Assoc J. 1981; 124:1156-62.
79. GartlandJJ. Orthopaedic clinical research: deficiencies in experimental design and determination of
outcome. J Bone Joint Surg Am. 1988; 70:1357-64.
80. Evans M. Presentation of manuscripts for publication in the British Journal of Surgery. Br J Surg.
1989;76:1311-4.
81. Ottenbacher KJ. Statistical conclusion validity and type IV errors in rehabilitation research. Arch
Phys Med Rehabil. 1992; 73:121-5.
Отчеты о когортных или лонгитюдинальных исследованиях 219
Глава 14
Проспективные наблюдения:
от воздействия до исхода
Отчеты о когортных или лонгитюдинальных
исследованиях
Определяющей характеристикой всех когортных исследований является то,
что наблюдение за людьми ведется в течение определенного времени, от
воздействия до исхода.
David Grimes, Ken Schulz [1]
В древнем Риме когортой называлась войсковая единица численностью от 300 до 600
человек; десять когорт образовывали один римский легион. В эпидемиологических
исследованиях этим термином называют любую группу людей, за которыми ведется
наблюдение в течение определенного времени. Поэтому когортные исследования называют еще
исследованиями с отслеживанием или панельными (списочными) исследованиями.
Их могут также называть исследованиями инциденса, потому что только они подходят
для выяснения частоты, с которой в популяции возникают новые случаи заболевания или
нетрудоспособности.
Многие из указаний по отчетам об исследовательских проектах и мероприятиях
относятся ко всем разработкам исследований. Здесь мы поясняем лишь те, которые относятся
исключительно к когортным исследованиям. Пояснения к другим указаниям даны в гл. 13
«Отчеты о рандомизированных контролируемых испытаниях».
УКАЗАНИЯ ПО ОФОРМЛЕНИЮ ВВЕДЕНИЯ
14.1« Расскажите о том, что привело к испытанию: о фоне, на котором возникла
проблема, о ее природе, общем обзоре и важности [2].
14.2. Сформулируйте общую цель эксперимента. Укажите все теоретические или
научные пути, которыми можно прийти к данной проблеме.
14.3. Укажите источник финансирования испытания и опишите роль его
представительства в проведении испытания и публикации результатов.
14.4. Сообщите, как можно получить доступ к протоколу и исходным данным.
220 Составление отчетов об исследовательских проектах и мероприятиях
УКАЗАНИЯ ОТНОСИТЕЛЬНО МЕТОДОВ
14*5. Укажите институтский наблюдательный совет, одобривший протокол.
14«б. Подтвердите получение осознанного письменного согласия. Если возможно,
опишите обстоятельства, при которых оно было получено.
14 J> Приведите конкретные цели испытания, в том числе все формулировки
проблем исследования и гипотез [2-4].
14«8. Идентифицируйте исследование как когортное и поясните, почему был
выбран такой план действий [2,4,5].
Когортные исследования хорошо подходят для документирования инциденса и
естественной истории болезни, особенно болезней со скоротечным летальным исходом. Они
могут установить временные взаимосвязи между событиями, поскольку пациенты
включаются в состав исследований до наступления интересующих исходов и могут
наблюдаться после их наступления. Их можно применять для выявления множественных
исходов, которые могут последовать за одним воздействием или вмешательством, а также
отрицательных исходов, таких как влияние курения, что невозможно изучить с помощью
рандомизированных испытаний. Их можно применять для изучения редких воздействий,
поскольку когорту можно определить для того, чтобы собрать большие группы
подвергшихся воздействию лиц. Другими преимуществами являются возможность
стандартизации критериев соответствия и оценок исхода, а также то, что многие когортные
исследования бывает легче назначать и не так затратно проводить, как рандомизированные
испытания.
Недостатком этого вида является то, что определение когорты формируется при наличии
систематической ошибки отбора из-за исключения тех людей, которые не вошли в когорту.
Потери отслеживания могут быть проблематичными, особенно в долговременных
исследованиях, а чтобы изучить редкие исходы, для последующего наблюдения может
понадобиться большое количество людей на протяжении долгого времени, что может потребовать
много усилий и затрат.
При проспективном когортном исследовании когорта формируется в настоящее
время и отслеживается в будущем. При ретроспективном, или историческом, когортном
исследовании когорта определяется по уже собранным данным и ее члены затем
наблюдаются с течением времени, хотя исход, возможно, уже имел место. В обоих случаях
исследователь начинает с установления лиц, имеющих заданный набор характеристик
(когорты), а затем документально фиксирует наступившие для них исходы во времени; таким
образом, когорта формируется до наступления интересующего исхода. Ретроспективные
же исследования или исследования типа «случай-контроль» начинаются с установления
лиц с интересующим исходом и действуют в обратном направлении в попытке определить
общие воздействия.
143. Выделите представляющие интерес объекты наблюдения.
14Л 0. Опишите представляющую интерес целевую популяцию [3].
Отчеты о когортных или лонгитюдинальных исследованиях 221
14*11» Определите популяцию-источник, из которой были взяты участники
испытания [2-4].
Когортные исследования могут использовать закрытые, или фиксированные, когорты,
членство в которых определяется по одному определенному пункту, или открытые, или
динамические, когорты, принадлежность к которым со временем может меняться. К
примеру, закрытым когортным исследованием является знаменитое Фрамингемское исследование
сердечных болезней. В него включались только те, кто проживал во Фрамингеме,
Массачусетсе на момент начала исследования. Новые жители Фрамингема в исследовании не
участвуют. В противоположность этому жители Калифорнии являются частью открытой
когорты, принадлежность к которой постоянно меняется из-за переездов людей из штата в штат.
Другие виды когорт — специальные когорты воздействия, такие как шахтеры
(которые с большей вероятностью подвергнутся воздействию угольной пыли), и общие популя-
ционные когорты компактно проживающего населения.
Некоторые когорты легче изучать, чем другие. Исследования по медицинским
работникам, к примеру, включают врачей и медсестер, за которыми благодаря их профессиональным
связям легче вести наблюдение в течение длительных периодов, чем за другими членами
сообщества. Исследователи согласятся с потерей репрезентативности (те, кто оказывают
медицинскую помощь, в целом более образованы и имеют более высокий доход, чем другие
граждане), если когорта более доступна для наблюдения.
14Л2. Опишите, каким образом определялись возможные участники
испытания [2,4].
14.13* Опишите, как привлекались возможные участники испытания [2,4].
14.14. Приведите критерии соответствия для участия в испытании [2-5].
Как минимум, все участники когортных исследований должны быть: 1) свободны от
исхода в начале исследования и 2) находиться на одном уровне риска по отношению к
интересующему исходу.
14.15. Укажите, была ли выборка стратифицированной, и если да, то по каким
характеристикам [5].
14.1 б. Укажите целевой объем выборки и то, каким образом он был определен [2-5].
14.17. Укажите, где и при каких обстоятельствах были собраны данные [3,5].
14.18. Укажите все демографические, клинические и другие исходные влияющие
факторы в данных [3,5].
14.19. Определите оцениваемые воздействия и факторы риска и поясните, как им
присваивались численные значения. Укажите, прошли ли проверку
показатели [1-8].
14.20. Определите критерии назначения респондентов в группы воздействия [2].
222 Составление отчетов об исследовательских проектах и мероприятиях
14.21. Определите оцениваемые исходы и поясните, как им присваивались
численные значения. Укажите, были ли эти процедуры обоснованы [2-4].
14.22. Определите критерии назначения респондентов в группы исхода [2].
14.23. Опишите оцениваемые события неблагоприятного характера и поясните,
как вводились их количественные оценки.
14.24. Опишите характер и продолжительность запланированных действий
по дальнейшему наблюдению [2].
14.25. Отметьте, держалась ли в тайне от экспертов принадлежность пациентов
к группе воздействия и каким образом [2].
14.26. Укажите возможные источники систематических ошибок, искажений,
погрешностей и предпринятые против них меры [5].
Ошибка отбора — неотъемлемый элемент при определении когорты, поскольку
критерии, определяющие когорту, часто связаны с другими важными факторами. Иногда на
ошибку могут указать исходные статистические и клинические сравнения, а иногда ошибку
можно контролировать статистически с помощью многомерных методик.
Другая важная проблема когортных исследований — ошибка классификации.
Ошибочная классификация может иметь место при выяснении, перенес ли участник исследования
воздействие или событие (предикторная переменная) и наступил ли в его отношении исход
(переменная отклика). Таким образом, необходимо тщательно рассмотреть определения
случая, а все переменные исхода необходимо определить оперативно и однозначно.
Еще одной проблемой когортных исследований — даже непродолжительных — является
потеря для дальнейшего наблюдения. Разного рода потери в группах, подвергшейся
воздействию и не подвергшейся, могут вызвать в результатах систематическую ошибку,
особенно если потеря имеет отношение к самому воздействию.
Наконец, в ходе исследования может измениться статус воздействия: некоторые
курящие могут бросить курить, а некоторые некурящие — начать; супружеские пары могут
перейти к другому методу предупреждения беременности; у участников могут
произойти изменения, например, в размере дохода, убеждениях, отношении к здоровью, условиях
жизни, занятости. Исследователям, возможно, придется пояснять, как эти изменения
учитывались при сборе и анализе данных.
^ См. приложение 5.
14.27. Опишите все методы контроля качества, применяемые для обеспечения
полноты и точности при сборе данных и ведении пациентов.
Статистические методы
14.28. Укажите минимальные изменения или разности в исходе, рассматриваемые
как клинически важные [2].
Отчеты о когортных или лонгитюдинальных исследованиях 223
14.29. Определите анализируемые взаимосвязи и статистические методы для их
анализа [3-5].
Когортные исследования часто используют статистические анализы для повторных
измерений — данных, собранных у одних и тех же пациентов в разные моменты времени.
Такие данные коррелированы от момента к моменту, поскольку они парные, а методы для
повторных измерений помогают приспособиться к этой парности (см. гл. 8).
Другими распространенными статистическими методами в когортных исследованиях
являются регрессионный анализ пропорциональных рисков Кокса {cjm. гл. 7) и анализ
времени до наступления события (анализ выживания, см. гл. 9). Оба этих метода используют
время до наступления события в качестве переменной исхода чаще, нежели
дихотомический исход типа «да-нет». Оба метода могут также приспособиться к пропускам данных,
что является обычным делом в исследованиях такого рода.
1430. Подтвердите, что данные удовлетворяют условиям проведения
статистического анализа.
1431. Отметьте промежуточные анализы и правила остановки.
1432. Идентифицируйте все запланированные подгруппы или анализ влияния
факторов [5].
1433. Идентифицируйте все статистические корректировки, сделанные в целях
контроля над вмешивающимися факторами [3,5].
14.34. Покажите, как проверялись на согласованность или согласие наблюдения,
основанные на суждениях [2,3].
14.35. Опишите все запланированные анализы чувствительности к смещениям [5].
14.36. Определите все процедуры, применяемые для контроля за множественным
сравнением [4].
14.37. Установите базовый уровень значимости.
14.38. Укажите, какие применялись статистические критерии: одно- или
двусторонние. Обоснуйте применение односторонних критериев.
14.39. Назовите пакеты статистических программ, с помощью которых
анализировались данные.
УКАЗАНИЯ ПО ОФОРМЛЕНИЮ РЕЗУЛЬТАТОВ
14.40. Укажите временные рамки испытания: даты составления списков
участников, лечения, даты сбора данных и основания для выбора этих дат [2,3].
224 Составление отчетов об исследовательских проектах и мероприятиях
1441, Объясните причины всех отклонений от протокола при проведении
исследования.
14«42. Приведите схему испытания, показывающую число и расположение его
участников на каждом его этапе [3,5].
14,43» Укажите базовые характериаики каждой группы (подвергшейся и не
подвергшейся воздейавию) с помощью подходящих описательных статиаик [2,5].
14.44, Укажите, в какой степени выборка участников была репрезентативна для
изучаемой популяции [5].
14.45, Скажите о тех, кто мог, но не стал участвовать в испытании, и, если
возможно, приведите их аргументы против участия [3].
14.46, Приведите минимальное, медианное и максимальное значения
продолжительности периодов последующего наблюдения.
14.47, Скажите о тех, кто оказался потерянным для дальнейшего наблюдения [2,3].
14.48, В конце исследования охарактеризуйте подвергшуюся и не подвергшуюся
воздействию группы с помощью подходящих описательных статистик [5].
14.49, Приведите результаты исследования, предпочтительнее в цифрах или
таблицах [4,5].
14.50, Как минимум, приведите абсолютные значения всех конечных точек,
включая внутригрупповые изменения или межгрупповые различия [3,5].
14.51, Для всех конечных точек приведите доверительные интервалы [4].
14.52, Если наблюдения основаны на суждениях, приведите меру согласованности
или согласия между экспертами.
14.53, Опишите природу и частоту обычных или тяжелых побочных эффектов и
неблагоприятных событий в каждой группе.
14.54, Опишите все возможные влияния искажения или взаимодействия.
14.55, Дайте отчет о всех наблюдениях и участниках и объясните все пропуски [2-5].
14.56, Опишите, как рассматривались выбросы.
14.57, Скажите о тех необычных свидетельствах или наблюдениях, которые могут
способствовать более точному или полному пониманию исследования или
его результатов.
Отчеты о когортных или лонгитюдинальных исследованиях 225
УКАЗАНИЯ ОТНОСИТЕЛЬНО ОБСУЖДЕНИЯ РЕЗУЛЬТАТОВ
1458. Соберите результаты в общую сводку [5].
14,59. Дайте интерпретацию результатов и предложите их объяснение [5].
1 4.60« Опишите, как результаты соотносятся с тем, что уже известно по данной
проблеме; приведите обзор литературы и поместите результаты в контекст [5].
14.61« Предложите пути обобщения результатов [3,5].
14.62. Обсудите следствия результатов.
14.63, Обсудите лимитирующие факторы испытания [2,5].
14.64 Перечислите выводы.
Литература
1. Grimes DA, Schulz KF Cohort studies: marching towards outcomes. Lancet. 2002; 359:341-5.
2. Wolfe F, Lassere M, Van Der Heijde D, et aL Preliminary core set of domains and reporting
requirements for longitudinal observational studies in rheumatology. J Rheumatol. 1999; 26:484-9.
3. Tooth L, Ware R, Bain C, et al Quality of reporting of observational longitudinal research. Am J
Epidemiol. 2005; 161:280-8.
4. Rushton L Reporting of occupation and environmental research: use and misuse of statistical and
epidemiological methods. Occup Environ Med. 2000; 57:1-9.
5. STROBE statement, http://www.strobe-statement.org/.
6. Walker AM. Reporting the results of epidemiological studies. Am J Public Health. 1986; 76:556-8.
7. Horwitz RI, Feinstein AR. Methodologic standards and contradictory results in case-control research.
Am J Med. 1979;66:556-64.
8. Goodman SN, Berlin J, Fletcher SW, Fletcher RH. Manuscript quality before and after peer review
and editing at Annals of Internal Medicine. Ann Intern Med. 1994; 121:11-21.
226 Составление отчетов об исследовательских проектах и мероприятиях
Глава 15
Ретроспективные наблюдения:
от исхода к воздействию
Отчеты об исследованиях типа «случай-контроль»
То, что лечебные предписания тесно связаны с прогнозом и тем самым неиз-
беэюно пороэюдают ошибку, является главной проблемой при использовании
данных наблюдения для сравнения разных видов лечения.
Daniel ВYAR [1]
Исследования «случай-контроль» систематически идентифицируют людей из одной и той же
популяции с представляющим интерес исходом и без него, а затем сравнивают их истории
воздействия с возможными причинными или защитными факторами, чтобы определить, связаны
ли эти факторы с исходом. Те, кто проводит исследования, иногда могут контактировать с
пациентами напрямую; иногда же они могут проводить исследование, основываясь на имеющихся,
порой обширных, базах данных, клинических реестрах или других исторических источниках.
Многие из указаний по отчетам об исследовательских проектах и мероприятиях
относятся ко всем разработкам исследований. Здесь мы поясняем лишь те, которые относятся
исключительно к исследованиям «случай-контроль». Пояснения к другим указаниям даны
в гл. 13 «Отчеты о рандомизированных контролируемых испытаниях».
УКАЗАНИЯ ПО ОФОРМЛЕНИЮ ВВЕДЕНИЯ
15.1, Расскажите о том, что привело к исследованию: о предпосылках, природе,
границах и важности проблемы [2-4].
152. Сформулируйте общую цель исследования. Укажите все теоретические или
научные пути, использованные для подхода к данной проблеме [2-4].
15.3. Укажите источник финансирования исследования и опишите роль его
представительства в проведении исследования и публикации результатов [2,4].
15.4. Сообщите, как можно получить доступ к протоколу и исходным данным.
УКАЗАНИЯ ОТНОСИТЕЛЬНО МЕТОДОВ
15.5. Укажите институтский наблюдательный совет, одобривший протокол.
Если исследования «случай-контроль» используют архивную информацию,
хранящуюся в базах данных или клинических реестрах, одобрения институтского наблюдательного
Отчеты об исследованиях типа «случай-контроль» 227
совета может не потребоваться. Однако те исследования, в которых информация
запрашивается у пациентов, обычно должны получать одобрение соответствующего
наблюдательного совета.
15.6. Если возможно, подтвердите получение осознанного письменного согласия.
157. Приведите конкретные цели испытания, в том числе все формулировки
проблем исследования и гипотез [2,4-6].
15.8. Идентифицируйте исследование как «случай-контроль» и поясните, почему
был выбран такой план [2,4-6].
Исследования «случай-контроль» лучше всего использовать при рассмотрении редких
событий или болезней [7, 8], вспышек заболевания [7], нескольких возможных случаев
заболевания или нетрудоспособности (т. е. для идентификации факторов риска или
прогностических факторов заболевания) [7] и возможных причин заболеваний с длительными
латентными фазами. Они стремятся привлекать меньшее число пациентов по сравнению
с другими видами исследований, и их проведение обычно менее затратно. Поскольку при
исследованиях «случай-контроль» не нужно ждать развития болезни у людей, их можно
вести относительно быстро.
Однако исследования «случай-контроль» подвержены многим систематическим
ошибкам, уменьшающим их достоверность. Например, при исследованиях «случай-контроль»
трудно интерпретировать временные взаимосвязи. Связь между язвами роговицы и
народными средствами против заболеваний глаз может указывать на то, что 1) народные средства
вызывают язву роговицы или что 2) люди с язвами роговицы пробовали лечиться
народными средствами [7]. Из исследования «случай-контроль» бывает трудно понять, какая
интерпретация правильна. Эти исследования также не подходят для изучения превосходства
одного вида лечения над другим, причинности, относительного инциденса или преваленса
[1,7].
На оценки риска могут повлиять неизмеренные искажающие факторы (факторы,
которые связаны как с представляющим интерес воздействием, так и с представляющим
интерес исходом, но не входят в число причин).
15.9. Определите временные рамки исследования: приведите даты периода, в
течение которого изучалось интересующее воздейавие и наступил исход [4,9].
15.10. Выделите представляющие интерес объекты наблюдения [5].
15.11. Опишите представляющую интерес целевую популяцию [8].
15.12. Определите популяцию-источник, из которой были взяты случаи [2,6].
Для ретроспективных исследований реестров или баз данных уместно описать
следующее:
• изначальную цель создания реестра и даты всех главных пересмотров его структуры
или цели создания [ 1 ];
• общий обзор реестра, включая количество записей, объем информации по каждой
записи и даты включения данных в реестр;
228 Составление отчетов об исследовательских проектах и мероприятиях
• как управляется реестр: персонал, порядок сбора, содержания, ввода и изъятия
данных, содержащихся в реестре;
• методы обеспечения точности и полноты данных;
• если возможно, результаты последней проверки данных, в том числе частоту ошибок.
Q Базы данных назначений редко содержат данные по клинической тяжести или
функциональным исходам [2, 3]. Например, в них может быть отмечено только
наличие или отсутствие заболевания коронарной артерии, а не его тяжесть, что
может потребоваться в клинических исследованиях.
Базы данных по назначениям создаются для дополнительного вклада в здравоохранение.
Они могут содержать, например, информацию о списочном составе и возмещении для
вовлеченных в систему медицинского страхования. Эти базы обычно содержат большое
количество данных, которые легко составлять в электронном виде и которые включают в себя
целые региональные популяции или хорошо определенные субпопуляции. Однако они
связаны с ограничениями при изучении клинических тем. (Более подробно о базах данных
по назначениям говорится в: Weinberger М, Hui S, Laine С, editors. Measuring Quality,
Outcomes, and Cost of Care Using Large Databases. Perspectives form the Sixth Regenstrief
Conference. Ann Intern Med. 1997; 127 (Supplement):665-774. Этой теме посвящен весь выпуск.)
Q Данные, составленные для урегулирования вопросов оплаты или претензий,
часто содержат ошибки и пропуски в клинически важных областях [3,13].
Moses приводит исследование, в котором у самых тяжелых пациентов было меньше
МРТ-сканов, чем ожидалось. Карта выписки, из которой брались данные, имела
поля записи только для трех основных процедур, а более тяжелые пациенты
проходили более важные для них процедуры, чем МРТ-сканирование [13].
15ЛЗ* Приведите критерии соответствия для участия в испытании: дайте
определение случая [2-4,6-8,10].
Наиболее важный принцип в исследованиях «случай-контроль» — «случаи
действительно должны быть случаями» [11]. Это значит, что определение случая должно быть точным
и применяться строго в каждом потенциальном случае. Должное внимание следует уделить
исключению диагнозов, которые можно спутать с определением случая [7]. Например,
иногда важно сообщить, одни ли и те же диагностические тесты применялись для того,
чтобы определить случаи именно как нужные случаи. Результатом ошибок в идентификации
действительных случаев или соответствующих контрольных случаев могут стать ошибки
классификации. При недифференциальной ошибочной классификации частота
ошибок классификации, вероятно, будет одинаковой в обеих группах; при дифференциальной
ошибочной классификации их частота в группах, скорее всего, будет разной.
Случаи могут быть новыми случаями болезни, идентифицированными за данный
период, или включать все идентифицированные случаи болезни у пациентов на любом этапе
за данный период [8]. Недавние новые случаи часто предпочтительнее вследствие более
короткого времени между постановкой диагноза и сбором данных: чем длиннее это время,
тем больше вероятность того, что больные переедут, умрут, поправятся или, напротив,
удалятся из рассмотрения в исследовании. Для каждого типа следует указать период, во время
которого был установлен диагноз [7]. Иногда также полезно показать общее время между
диагнозом и сбором данных.
Отчеты об исследованиях типа «случай-контроль» 229
15.14. Укажите, как проходил отбор случаев для исследования [3, б, 10].
в идеале идентифицируются все случаи в данной популяции за данный период [6]. Для
архивных исследований определите процедуру идентификации записей изучаемой
популяции [2, 8].
15.15. Дайте определение контроля [2-4, б, 8,9].
Контрольная группа в исследованиях «случай-контроль» вводится для того, чтобы
оценить частоту воздействия при отсутствии связи между изучаемым диагнозом или
событием [И]. Таким образом, контрольные группы должны напоминать группы случаев
по важным аспектам, кроме того факта, что они не страдают изучаемой болезнью. Это
означает, что контрольные группы в идеале представляют тех людей, которые были бы
отобраны в группу случая, если бы перенесли представляющее интерес воздействие или
болезнь [6].
Однако одной из главных проблем в исследованиях «случай-контроль» является
привлечение неподходящих контрольных групп [5]. К примеру, «при исследовании методом
«случай-контроль» пациентов, перенесших угрожающий жизни эпизод (например,
сердечный приступ, инсульт или попытку самоубийства), контрольная группа, подобранная
по возрасту, полу или другим переменным, таким как общественный класс, может
оказаться, к глубокому сожалению, неадекватной. Вместо того, чтобы идентифицировать факторы
риска данного эпизода, разработанное таким путем исследование может назвать факторами
риска как раз то, что, напротив, помогает пережить данный эпизод» [5].
15.16. Определите популяцию-источник, из которой были взяты контрольные
группы [2,9].
Контрольные группы обычно принадлежат к одному из трех типов. Исторические
состоят из тех, кто проходил исследование в другое время и, обычно, в другом месте.
Например, характеристики младенцев, родившихся в одном госпитале, можно сравнить с
опубликованными данными для родившихся в другом. Данные из рассматриваемого
исследования можно сравнить с данными из этих исторических контрольных групп, но определить,
являются ли итоговые различия результатом лечения или изначально присущи этим двум
группам, бывает затруднительно [3, 6].
Сопутствующий, или местный, контроль — не страдающие заболеванием лица, чей
опыт был аналогичен и одновременен опыту лиц, определенных как участники
исследования. Они живут в том же сообществе, что и больные. Таким образом, они обычно
отбираются из членов семьи, коллег по работе или соседей. Одна из проблем, связанная с
местным контролем, состоит в том, что они могут быть мало заинтересованы в своем участии
в исследовании.
Иногда в качестве контрольной берется больничная контрольная группа, состоящая
из пациентов, госпитализированных по не относящимся к изучаемой проблеме причинам.
Близость к изучаемой популяции делает их весьма привлекательными для включения в
контрольную группу, но только если их состояние здоровья не связано с изучаемой проблемой.
Наличие у больничной контрольной группы сопутствующих заболеваний, как и то, что они
имели доступ к медицинскому обслуживанию, а другие, возможно, нет, также может стать
искажающим фактором анализа [7].
230 Составление отчетов об исследовательских проектах и мероприятиях
15.17. Определите, как для исследования отбирались контрольные группы. Если
они были подобраны к больным, укажите, по каким характеристикам
производился подбор [4,10].
Чтобы избежать систематической ошибки, контрольные группы должны отбираться
независимо от статуса воздействия [12]. Отбор контрольных групп проводится одним
из трех способов: иногда доступна полная перепись членов контрольной популяции
(такой, как пассажиры круизного судна), однако чаще всего либо к исследованию
привлекается репрезентативная выборка, либо контрольные группы подобраны к больным
по ключевым переменным [8, 9]. В обоих случаях выборки контрольных групп бывают
избыточными [7].
15.18. Укажите, была ли выборка стратифицированной, и если да, то по каким
характеристикам [4].
15.19. Укажите целевой объем выборки для каждой группы и то, каким образом
он был определен [3,4, б, 8].
в некоторых исследованиях, особенно ретроспективных, объем выборки определяется
числом пациентов с заданным диагнозом, выявленным в данное время, или количеством
доступных записей. Если для определения объема выборки использовался расчет
мощности, приведите детали вычисления (см. гл. 4).
15.20. Укажите, где и при каких обстоятельствах имело место воздействие [4].
15.21. Укажите все демографические, клинические и другие исходные влияющие
факторы в собранных данных.
15.22. Определите оцениваемые воздействия и факторы риска и поясните, как им
присваивались численные значения. Укажите, были ли эти процедуры
обоснованы [3,4, б, 8-10].
15.23. Укажите иаочники информации, используемой для оценки воздействий
или факторов риска.
15.24. Укажите, как и кем оценивался каждый из видов воздействия или факторов
риска [4, б, 9].
Информация о воздействии в идеале должна быть получена от больных и контрольной
группы одним и тем же путем [7, 8, 11]. Эта информация может быть получена из опросов,
больничных записей, записей о роде занятий, сообщений полиции или пожарных
департаментов и т. д.
15.25. Отметьте, держалась ли в тайне от экспертов принадлежность пациентов
к группам [2,10].
Сохранить в тайне от экспертов принадлежность к группе бывает нелегко, если больные
отличаются от контрольных пациентов [7, 8].
Отчеты об исследованиях типа «случай-контроль» 231
15.26. Укажите возможные источники систематических ошибок, искажений,
ошибок и предпринятые против них меры [2,8,9].
в исследованиях «случай-контроль» может возникнуть несколько видов погрешностей
или систематических ошибок:
• ошибка памяти, при которой больные и пациенты контрольной группы вспоминают
события с недостаточной точностью или полнотой;
• дифференциальное смещение памяти, при котором больные вспоминают больше
деталей, чем принадлежащие к контрольной группе, так как больше думают о своем
состоянии [9, 10];
• смещение классификации, при котором люди неверно определены как больные или
же настоящие больные ошибочно исключены из исследования;
• смещение здорового работника, при котором члены контрольной группы, взятые
с той же работы, не составляют репрезентативную выборку, так как достаточно
здоровы, чтобы работать [6];
• смещение фильтра назначений, при котором больные или члены контрольной
группы исключаются из системы наблюдений до того, как попадают в поле зрения
исследователей [10];
• смещение диагностической проработки, при котором тест, с помощью которого
ставится интересующий диагноз, проводится нечетко, обычно как следствие результатов
прошлого теста, которые изменили последовательность лечения.
Методика предотвращения или корректировки этих смещений такая же, как и в других
видах исследований: критерии соответствия, подбор, стратификация, многомерное
(регрессионное) моделирование и анализ чувствительности [8].
@ См. приложение 5.
15.27. Опишите все методы контроля качества, применяемые для обеспечения
полноты и точности при сборе данных и ведении пациентов [2,13].
Статистические методы
15.28. Укажите минимальные изменения или разности в исходе, рассматриваемые
как клинически важные.
15.29. Определите анализируемые взаимосвязи и статиаические методы для их
анализа.
в исследованиях «случай-контроль» распространен логистический регрессионный
анализ. Бинарным исходом логистической регрессии является статус группы: группа больных
или контрольная. Варьирующимися элементами в регрессионной модели являются
допустимые предикторные переменные: демографические характеристики и воздействия.
15.30. Подтвердите, что данные удовлетворяют условиям проведения
статистического анализа [2-4,6].
15.31. Идентифицируйте все запланированные анализы подгрупп или влияющих
факторов [2,4].
232 Составление отчетов об исследовательских проектах и мероприятиях
1532. Идентифицируйте все статистические корректировки, сделанные в целях
контроля над вмешивающимися факторами [2,4].
1533. Покажите, как проверялись на согласованность или согласие наблюдения,
основанные на суждениях [9].
1534. Опишите все запланированные анализы чувствительности к смещениям [4].
1535. Определите все процедуры, применяемые для контроля за
множественными сравнениями [6].
15.36. Установите базовый уровень значимости.
1537, Укажите, какие применялись статистические критерии: одно- или
двусторонние [2]. Обоснуйте применение односторонних критериев.
1538. Назовите пакеты статистических программ, с помощью которых
анализировались данные [6].
УКАЗАНИЯ ПО ОФОРМЛЕНИЮ РЕЗУЛЬТАТОВ
1539. Объясните причины всех отклонений от протокола при проведении
исследования.
15.40. Приведите схему исследования, показывающую число участников на
каждом его этапе [4].
15.41. Охарактеризуйте каждую группу с помощью подходящих описательных
статистик [3,4].
15.42. Укажите, в какой степени группы были репрезентативны для целевой
популяции [8].
Различия между больными и пациентами контрольной группы иногда можно
скорректировать статистическими методами, если важные корректируемые переменные известны,
а значения для этих переменных были собраны для обеих групп [13].
15.43. Приведите результаты исследования, предпочтительнее в цифрах или
таблицах [6].
15.44. Как минимум, приведите абсолютные значения всех конечных точек,
включая внутригрупповые изменения или межгрупповые различия [4].
15.45. Для всех конечных точек приведите доверительные интервалы [2, б].
15.46. Если наблюдения основаны на суждениях, приведите меру согласованноаи
или согласия между экспертами.
Отчеты об исследованиях типа «случай-контроль» 233
15.47, Опишите все возможные влияния искажения или взаимодействия [2].
15*48« Дайте отчет о всех наблюдениях и объясните все случаи пропусков [2, б, 9].
15А9. Опишите, как рассматривались выбросы.
1550, Скажите о тех необычных свидетельствах или наблюдениях, которые могут
способствовать более точному или полному пониманию исследования или
его результатов.
УКАЗАНИЯ ОТНОСИТЕЛЬНО ОБСУЖДЕНИЯ РЕЗУЛЬТАТОВ
15*51, Соберите результаты в общую сводку [4].
1552. Дайте интерпретацию результатов и предложите их объяснение [3].
1553, Опишите, как результаты соотносятся с тем, что уже известно по данной
проблеме; приведите обзор литературы и поместите результаты в контека [3,4].
1554« Предложите пути обобщения результатов [4].
1555» Обсудите следствия результатов.
1556, Обсудите лимитирующие факторы исследования [3,4].
1557. Перечислите выводы.
Литература
1. Вуаг DP. The use of data bases and historical controls in treatment comparisons. Recent Results
Cancer Res. 1988; 111:95-8.
2. Epidemiology Workgroup of the Interagency Regulatory Liaison. Guidelines for documentation of
epidemiologic studies. Am J Epidemiol. 1981; 114:609-13.
3. Squires BR Elmslie TJ. Reports of case-control studies: what editors want from authors and peer
reviewers [Editorial]. CMAJ. 1990; 143:17-8.
4. STROBE statement, http://www.strobe-statement.org/.
5. Appleton DR. Detecting poor design, erroneous analysis and misinterpretation of studies. J Eval Clin
Prac. 1995; 1,2:113-7.
6. Rushton L. Reporting of occupation and environmental research: use and misuse of statistical and
epidemiological methods. Occup Environ Med. 2000; 57:1-9.
7. Lerwallen S, Courtright P. Epidemiology in practice: case-control studies. Comm Eye Health. 1998;
11:57-8.
8. Critical Appraisal Skills Programme (CASP). www.phru.nhs.uk/leaming. Accessed October 18,
2004.
9. Durant RH. Checklist for the evaluation of research articles. J Adolesc Health. 1994; 15:4-8.
10. Horwitz Rl, Feinstein AR. Methodologic standards and contradictory results in case-control research.
Am J Med. 1979;66:556-64.
234 Составление отчетов об исследовательских проектах и мероприятиях
11. Elwood JM. Critical Appraisal of Epidemiological Studies and Clinical Trials. Oxford: Oxford
University Press; 1998.
12. Rothman KJ. Epidemiology: An Introduction. Oxford: Oxford University Press; 2002.
13. Moses L Measuring effects without randomized trials? Options, problems, challenges. Med Care.
1995;33:AS8-14.
Отчеты об обследованиях или поперечных исследованиях 235
Глава 16
Совместное рассмотрение
воздействий и исходов
Отчеты об обследованиях или поперечных
исследованиях
Главные цели [обследования] всегда должны заключаться в своевременном
и не выходящем за пределы имеющихся ресурсов сборе достоверных,
правдивых и несмещенных данных из репрезентативной выборки.
Е. McCoLL, Л. Jacoby, L. Thomas ет al [1]
Поперечные исследования В1слючают в себя несколько способов сбора данных в
некоторый момент времени от отдельных лиц (обследования по почте, стандартизованные тесты,
телефонные опросы, структурированные беседы один на один) и о популяциях
(периодические обследования состояния здоровья и регулярные табличные обзоры баз данных для
надзора за распространением заболевания в популяциях). Термином «обследование» мы
называем любое поперечное исследование, а также проведение клинически ориентированных
анкетирований, которые, к примеру, оценивают качество жизни, социально-экономический
статус, удовлетворенность пребыванием в госпитале или возможность психического
расстройства или отклонений в поведении.
Под общим термином «анкета» мы понимаем набор вопросов, на которые должны
ответить респонденты, либо напрямую в самостоятельно заполняемых распечатанных или
электронных анкетах, либо через интервьюера, связывающегося с респондентом по телефону
или лично, либо через форму сбора данных, в которой собираются данные из
медицинских записей. Термином «психометрический инструмент» мы называем наборы вопросов
для оценки специфических черт или состояний, связанных со специфическими
диагнозами. Психометрические инструменты — средства измерения, по которым делаются выводы
об отдельных лицах, в отличие от более общих анкет, под которыми мы понимаем, скорее,
формы для сбора общих описательных данных о группах людей. Наконец, термином
«форма сбора данных» мы называем форму, которая переводит истории болезни в абстрактную
форму.
Многие из указаний по отчетам об исследовательских проектах и мероприятиях
относятся ко всем разработкам исследований. Здесь мы поясняем лишь те, которые относятся
исключительно к поперечным исследованиям. Пояснения к другим указаниям даны в гл. 13
«Отчеты о рандомизированных контролируемых испытаниях».
236 Составление отчетов об исследовательских проектах и мероприятиях
УКАЗАНИЯ ПО ОФОРМЛЕНИЮ ВВЕДЕНИЯ
1б<1* Расскажите о том, что привело к обследованию: о предпосылках, природе,
границах и важности проблемы [2].
162. Сформулируйте общую цель обследования. Укажите все теоретические или
научные пути, использованные для подхода к данной проблеме [2,3].
163. Укажите источник финансирования испытания и опишите роль его
представительства в проведении обследования и публикации результатов [4].
16А. Сообщите, как можно получить доступ к протоколу и исходным данным.
УКАЗАНИЯ ОТНОСИТЕЛЬНО МЕТОДОВ
1 б«5. Укажите институтский наблюдательный совет, одобривший исследование.
в обследованиях заключено меньше риска, чем в клинических исследованиях, и
поэтому они в меньшей степени связаны с этическими проблемами. Тем не менее анкета или
«инструмент обследования» могут затрагивать спорные или неприятные для респондентов
темы и поэтому, возможно, должны получить одобрение соответствующего
наблюдательного совета.
16.6, Приведите конкретные цели исследования, в том числе все формулировки
проблем исследования и гипотез [2,3].
Поперечные обследования носят описательный характер. Они могут применяться при
сборе информации о преваленсе атрибутов, поведения, убеждений, образования или
мнений членов популяции [1], а также при отслеживании изменений с течением времени,
включая рутинный эпидемиологический надзор, или при сборе информации, полезной для
планирования медицинского обслуживания.
Путем идентификации связей между воздействиями и исходами они также могут
вырабатывать гипотезы о причинности, которые можно проверить другими видами исследований
[5]. Поскольку воздействие и исход оцениваются одновременно, временная связь между
ними может быть неопределенной [6].
16J. Идентифицируйте исследование как поперечное и поясните, почему был
выбран такой дизайн [1 -4].
в медицинских исследованиях распространены три вида поперечных исследований:
• самостоятельно заполняемые анкеты, такие как обследования по почте или с
помощью компьютера в режиме онлайн;
• обследования с помощью интервьюеров, такие как беседы с глазу на глаз на ходу,
например в торговых центрах, или телефонные беседы, особенно с помощью
компьютеров;
• отчеты по надзору или табличные обзоры баз данных или клинических
реестров.
Отчеты об обследованиях или поперечных исследованиях 237
Обследования обычно проводятся быстрее и с меньшими затратами, чем другие виды
исследований; однако разрабатывать и проводить их необходимо с такой же строгостью.
Кроме того, группы, созданные в зависимости от ответов на вопросы обследования (а не
просто отобранные для него), в отличие от создаваемых при случайном распределении, могут
различаться по произвольному количеству неизмеренных или неизвестных искажающих
факторов, которые могут повлиять на возможные по итогам обследований выводы.
16*8, Выделите объекты наблюдения, представляющие интерес.
16*9. Опишите целевую популяцию, представляющую интерес [2].
16.10. Определите популяцию-источник, из которой были взяты реципиенты или
записи [2].
При ретроспективных исследованиях реестров или баз данных уместно описать
следующие моменты:
• изначальную цель создания реестра и даты всех главных пересмотров его структуры
или цели создания [7];
• общий обзор реестра, включая количество записей, объем информации по каждой
записи и даты включения данных в реестр;
• как управляется реестр: персонал, порядок сбора, содержания, ввода и изъятия
данных, содержащихся в реестре;
• методы обеспечения точности и полноты данных;
• если возможно, результаты последней проверки данных, в том числе частоту
ошибок.
1 бЛ 1. Опишите, как определялись участники или записи обследования [2,3].
Проходящие обследование часто определяются из списков или случайным образом
из телефонных книг. Однако такие источники необязательно будут репрезентативными
по отношению к исследуемой популяции. В изучении исходов при управляемой
медицинской помощи в реестр будут включены все представляющие интерес пациенты. При
обследовании по телефону будут охвачены только семьи, имеющие телефон, а выборка будет
смещаться в сторону городских семей с более высокими доходами и более тесными
связями с обществом. В некоторых случаях для улучшения репрезентативности выборки семей
с телефонами потенциальные респонденты с не вошедшими в список номерами могут быть
включены в нее путем случайного цифрового набора.
16.12. Опишите, как привлекались участники обследования [2].
Пройти обследование обычно приглашают по почте, телефону или в личной беседе
на ходу. Детали привлечения к участию следует описать в любом случае, поскольку то,
как это было сделано, может определить вероятность их участия в обследовании.
Например, множество бесед один на один проводится с женщинами средних лет, поскольку они
по сравнению с другими людьми внушают меньше опасений.
16.13. Приведите критерии соответствия для участия в обследовании [3,4].
238 Составление отчетов об исследовательских проектах и мероприятиях
16.14. Укажите, была ли выборка стратифицирована, и если да, то по каким
характеристикам.
16.15. Укажите целевой объем выборки и то, каким образом он был определен [2-4].
16.16. Укажите, где и при каких обстоятельствах велись опросы во время
обследования [2].
16.17. Укажите все демографические, клинические и другие основные влияющие
факторы собранных данных.
16.18. Опишите характеристики анкеты или психометрического инструмента [1,2].
краткое описание внешнего вида и характеристик анкеты полезно для понимания
процесса сбора данных. Графический дизайн анкеты может повлиять на показатели откликов
по нескольким пунктам в ходе заполнения [1]. В частности, иногда полезно знать:
• количество вопросов, на которые надо ответить;
• общее время, которое требуется среднему респонденту для заполнения анкеты или
на интервью;
• типы запрашиваемых ответов, такие как шкалы Ликерта (упорядоченные ответы),
порядковые категории, «да-нет>> или открытые вопросы; а также обязательно ли
требуется дать определенный ответ или возможны варианты «затрудняюсь ответить» или
«безразлично»;
• количество страниц и как они выглядят (размер страницы, размер шрифта, цвет и т. д.).
Анкеты могут разрабатываться так, чтобы избежать систематических ошибок,
вызванных так называемыми установками, что происходит в случаях, когда респонденты дают
заранее предсказуемые ответы, независимо от содержания вопросов. Молчаливое
одобрение, или только ответ «да», — стремление выражать согласие или отвечать утвердительно
на все или большинство вопросов; но возможна также установка «только нет». Для борьбы
с этой установкой вопросы анкеты формулируются с помощью как утвердительных, так
и отрицательных предложений. Социальная желательность — стремление выбрать те
ответы, которые выставляют респондента в наиболее выгодном свете. Как и выше, вопросы
можно составить так, чтобы более приемлемыми выглядели все возможности. Симуляция
дурного происходит тогда, когда респонденты выбирают отрицательные ответы, для того
чтобы привлечь больше внимания к себе как к отдельным лицам или к проблеме, которую
они хотят выделить.
16.19. Определите оцениваемые переменные и, если необходимо, поясните, как
им присваивались численные значения [2-4].
Переменные, оцениваемые в обследованиях, могут состоять из таких элементов, как:
• демографические и клинические характеристики (возраст, пол, раса, образование,
показатели социально-экономического статуса, проблемы со здоровьем, контакты
с системой здравоохранения и т. д.);
• предпосылки, воздействия или факторы риска заболеть или утратить
трудоспособность (поведение, семейные случаи проблем со здоровьем, профессиональные
вредности и т. д.);
Отчеты об обследованиях или поперечных исследованиях 239
• состояние здоровья в прошлом и настоящем (профилактические прививки в
прошлом и сейчас, диагнозы, госпитализации, перенесенные операции и т. д.);
• просвещенность и мнения по различным темам (предупредительные сигналы рака,
мысли о конце жизни, желание бросить курить и т. д.);
• показатели или конструкты состояния здоровья или личностные
характеристики (самооценка, депрессия, переносимость неопределенности, склонность к риску
и т. д.);
• шкалы или индексы, формируемые по двум или более вопросам (такие, как
индексы риска домашнего насилия, шкалы стресса или индексы настроения).
При измерении показателей или конструктов особенно важно установить, как можно
применять или определить данное понятие так, чтобы его можно было измерить. К
примеру, склонность к риску можно определить как желание 1) заниматься связанными с риском
видами деятельности (воздушной акробатикой, прыжками на пружинном устройстве,
мотогонками или 2) пренебрегать защитными мерами (не пользоваться ремнями
безопасности или солнцезащитными средствами при длительном нахождении на открытом воздухе).
Таким образом, респондент, увлекающийся воздушной акробатикой, в рамках нашего
исследования является по определению склонным к риску. Некоторыми показателями
оперировать проще или удобнее, чем другими; так, склонность к риску или агрессии, пожалуй,
оценить легче, чем, скажем, боль или любовь.
Шкалы и индексы должны быть описаны со всей полнотой, чтобы результаты можно
было интерпретировать. Пример: «Индекс симптомов Американской урологической
ассоциации состоит из семи симптомов (натуживание, неполное опорожнение, частота,
перебои, напор струи, императивные позывы, ноктурия), каждый из которых оценивается
по шкале тяжести от О до 5. Таким образом, общее количество баллов варьируется от О
до 35, где баллы от О до 7 указывают на слабые симптомы; от 8 до 19 — на умеренные; от 20
до 35 — на тяжелые».
Часто бывает необходимо показать диапазон количества баллов, связанный с нормальной
функцией или типичными значениями для здоровых людей. Пример — 63-балльная шкала
депрессии Бека, состоящая из 21 пункта. Количество баллов ниже 4 является необычно
низким для здоровых людей и может указывать на возможное отрицание депрессии или
попытки изобразить хорошее состояние эмоционального здоровья. Баллы от 5 до 9 говорят
о норме, от 10 до 18 указывают на слабую или умеренную депрессию, от 19 до 29 — на
умеренную или тяжелую, а от 30 до 63 — на тяжелую депрессию. Однако 40 баллов и выше
необычно высоки даже для больных депрессией и наводят на мысль о возможном
нарастании депрессии или неестественных или пограничных расстройствах личности.
Особым видом психометрического инструмента является стандартизованный тест.
Стандартизованные тесты обычно 1) назначаются при определенных условиях, 2)
начисляют баллы настолько объективно, что разные эксперты получат одно и то же количество
баллов при тех же самых ответах, и 3) выдают результаты по отношению к результатам
нормативной популяции. Примерами служат тест школьных достижений и
многочисленные тесты интеллекта. При этом следует идентифицировать нормальную популяцию, а
также соответствующее ей количество баллов в данном тесте, такие как медианы и типичные
диапазоны.
@ Порядковые категории ответов следует анализировать с помощью критериев
для порядковых данных; не следует описывать или анализировать категории
240 Составление отчетов об исследовательских проектах и мероприятиях
так, как если бы они были непрерывными данными. Так, ответы на вопрос
об удовлетворенности пребыванием в стационаре по шкале от 1 (мало) до 5
(вполне) не должны даваться в виде среднего и СО, и даже медиана и интерквартильный
размах (широта) могут оказаться неинформативными при столь малом количестве
категорий. Однако всегда подойдет мода, и часто бывает желательно привести
количество или процент ответов по каждой категории.
16.20. Сообщите, проводилась ли апробация анкеты до включения ее в
исследование и на ком; подтвердите надежность и обоснованность психометрических
инструментов.
Чтобы обеспечить уверенность в том, что анкеты дадут ожидаемые результаты, они
почти всегда должны пройти предварительные испытания. Предварительное испытание может
выявить проблемы, которые возникнут у респондентов с пониманием слов или вопросов,
заполнением анкеты, пониманием важности обследования и т. д. Оно также помогает
исследователям узнать, сколько времени требуется респондентам для заполнения и возврата
анкеты и, возможно, на проставление количества баллов или ввода сведений в базу данных.
Хорошая анкета надежна, обоснованна, не подвержена смещению и способна видеть
различия между группами [1].
Надежность — степень, с которой анкета дает воспроизводимые устойчивые результаты
при ее назначении в похожих популяциях и при схожих обстоятельствах. Цель проверки
надежности — определить, какая часть вариабельности результатов должна быть отнесена
к ошибке измерений, а какая — к ожидаемой вариабельности в действительных значениях
показателей.
Надежность можно оценить несколькими способами. При использовании метода «тест-
ретест» анкета назначается одной и той же группе по крайней мере дважды. Первый набор
баллов сравнивается со вторым; анкета надежна, если между количествами баллов имеется
высокая корреляция. При использовании метода «деление пополам» результаты от одной
половины респондентов сравниваются с результатами от другой; как и выше, анкета
надежна, если между количествами баллов имеется высокая корреляция'.
Внутренняя устойчивость — мера того, насколько похоже респонденты отвечают на
родственные вопросы. Ее часто оценивают с помощью альфы Кронбаха, представляющей собой
коэффициент корреляции (не меньше нуля и не больше единицы). Обычно значение альфы 0,8
и выше отражает разумную степень внутренней состоятельности, а менее 0,6 — неприемлемо
низкую. Для оценки устойчивости можно также сравнивать результаты от альтернативных
видов анкеты. Здесь в каждой анкете задаются одни и те же вопросы, но по-разному.
Обоснованность (иногда она называется внутренняя валидность) — степень, с
которой анкета измеряет то, что предполагается измерять с ее помощью. Правильная анкета
дает состоятельные результаты (т. е. является надежной), относительно свободные от
систематических ошибок и погрешностей. Существует несколько типов обоснованности.
Внешняя валидность метода измерения — степень, с которой анкета при
поверхностной оценке измеряет на практике то, что предполагается измерять с ее помощью. На шкале
' Здесь авторы ошиблись. Корреляцию между двумя половинами группы вычислять нельзя. Метод состоит
в делении всех вопросов анкеты случайным методом пополам и сравнении ответов на две половины анкеты, т. е.
вычислении корреляции между ними. Считается, что согласованный инструмент должен состоять из
внутренне непротиворечивых пунктов, которые определяют нечто единое. Надежная анкета должна показать высокую
корреляцию.
Отчеты об обследованиях или поперечных исследованиях 241
депрессии вопрос о печали имеет высокую внешнюю обоснованность, поскольку печаль —
хорошо известная характеристика депрессии. Внешняя обоснованность часто важна при
убеждении респондентов принимать анкету всерьез. Это наименее важный тип
обоснованности, поскольку обоснованность еще необходимо устанавливать с помощью других
методов.
Валидность содержания касается полноты вопросов о той области, которую должна
оценить анкета. Если в анкете о функции мускулов есть вопросы о силе и выносливости,
но нет вопроса об упругости, она пропускает важный раздел. Выносить суждение о степени
обоснованности содержания обычно должны эксперты.
Конструктивная валидность — степень, с которой вопросы оценивают
основополагающие теоретические представления (конструкты), которые предполагается измерять с
помощью вопросов. Хороший конструкт имеет в основе теорию и для ведения операций с ним
определяется измеримыми показателями. Конструктивная обоснованность — наиболее
важный вид обоснованности, а ее установление — долгий и сложный процесс. К примеру,
вопрос, в котором респондентов просят оценить количество субмарин, примененных во
второй мировой войне, в действительности достаточно хорошо выявляет различия между
нормальными людьми и шизофрениками; респонденты с симптомами паранойи постоянно
завышают действительное число.
Конвергентная валидность, обоснованность по соответствию критерию, по
совпадению, или прогностическая валидность, — один из аспектов конструктивной
обоснованности, относящийся к степени согласия (сходимости) между анкетой и другими
показателями (критериями) одного и того же конструкта в одно и то же время (обоснованность
по совпадению) или в какое-то время в будущем (прогностическая обоснованность).
Например, если по результатам двух анкет пациенты выстраиваются по тяжести заболевания
в одном и том же порядке, то достоверность этих анкет по совпадению высока. Если
тяжесть заболевания тесно связана с длительностью госпитализации, анкета имеет высокую
прогностическую обоснованность.
Дивергентная, или дискриминантная, валидность — другой аспект конструктивной
валидности, который относится к обоснованному недостатку согласованности
(расхождению) результатов между двумя анкетами, измеряющими два разных понятия
(выявляющими различия между ними). Например, результаты анкеты, измеряющей количественное
мышление, не должны сильно коррелировать с результатами анкеты, измеряющей
понимание прочитанного, т. к. это относится к другому типу способностей.
Внешняя валидность, или обобщаемость, относится к умению перевести полученные
в ходе исследования результаты анкетирования на другие популяции, другие
обстоятельства или другие временные интервалы. К примеру, можно ли результаты обследования
ньюйоркцев распространить на техасцев? В противоположность этому, внутренняя
валидность относится к валидности самой анкеты, т. е. ее способности измерять то, что
предназначено к измерению.
ф Чтобы быть валидным, тест должен быть надежным, но надежность не
гарантирует валидности.
16.21. Расскажите, как проводилось обследование: как велась работа с анкетой или
как оценивались записи и переводились в абстрактную форму данные [2].
242 Составление отчетов об исследовательских проектах и мероприятиях
16.22. Укажите, сохранялась ли анонимность ответов и как.
Анонимность можно обеспечить, не собирая идентифицирующую информацию. В
других случаях все ответы комбинируются так, что данные делаются доступными только в
совокупности. Еще в ряде случаев каждой записи от респондента или пациента может
присваиваться кодовое число. Ключ к коду держится в безопасном месте, а респонденты и
пациенты тогда известны только по своим кодовым номерам.
16.23. Укажите меры, предпринятые для обеспечения адекватных частот
откликов [1,2].
Показатели откликов на обследования можно улучшить посредством:
• заблаговременного предупреждения будущих респондентов по почте или по телефону;
• напоминания респондентам о том, насколько важно исследование для них как для
отдельных лиц и как для членов группы;
• ссылок на авторитетное мнение при установлении важности обследования;
• отслеживания респондентов, которые не вернули заполненные анкеты;
• оплаты или других поощрений за возврат заполненной анкеты;
_ • обучения интервьюеров тактике убеждения.
16.24. Опишите критерии, по которым анкеты или записи признаются пригодными
для оценивания.
Пригодная для оценивания анкета — обычно та, которая возвращается в течение
указанного времени и содержит полную информацию по всем вопросам или по отдельным
частям внутри анкеты. Таким образом, оставшиеся без ответа вопросы, неразборчивые
записи от руки, множественные исправления, которые не дают распознать интерпретируемый
ответ, а также разные варианты ответов на вопрос, требующий одного ответа, — все это
может сделать анкету полностью или частично непригодной для вынесения оценок.
16.25. Укажите возможные источники систематических ошибок, искажений,
ошибок и предпринятые против них меры [1,4].
Обследования подвержены многих видам характерных именно для них систематических
ошибок. Некоторые наиболее известные перечислены ниже; типовые действия для их
минимизации приведены в скобках:
• ошибка, вызванная порядком следования вопросов (предварительное тестирование;
в интервью — изменение порядка вопросов);
• ошибка, вызванная формулировкой или структурой вопросов (предварительное
тестирование; измерение одной характеристики с помощью разных вопросов);
• ошибка, вызванная вариантами ответов на вопросы (предварительное тестирование;
измерение одной характеристики с помощью разных вопросов);
• ошибка, вызванная отсутствием ответом на отдельные вопросы (предварительное
тестирование; измерение одной характеристики с помощью разных вопросов);
• ошибка, вызванная отсутствием ответов на все вопросы обследования (ряд контактов
с будущими респондентами; большие выборки);
• ошибка памяти, или ошибка, вызванная забывчивостью или неточностями
респондентов (включение в вопрос подсказок);
Отчеты об обследованиях или поперечных исследованиях 243
• дифференциальная ошибка памяти, или ошибка, вызванная разной частотой
воспоминаний у подвергшихся и не подвергшихся воздействию респондентов (включение
в вопрос подсказок).
Q См. приложение 5.
16.26. Опишите все методы контроля качества, применяемые для обеспечения
полноты и точности при вводе и обработке данных.
Полноту и точность ввода и обработки данных можно улучшить посредством:
• оптического сканирования при автоматическом вводе данных;
• дублирования ввода данных с дальнейшим сравнением;
• программного обеспечения, не допускающего ввод несовместимых данных;
• выборочных проверок записей из базы данных путем сравнения с первоисточниками
(такими, как медицинские карты);
• контактов с пациентами для получения недостающей в записях информации.
Статистические методы
16.27. Укажите минимальные величины, изменения или разности в исходе,
рассматриваемые как клинически важные.
16.28. Определите анализируемые взаимосвязи и статистические методы для их
анализа [3,4].
16.29. Подтвердите, что данные удовлетворяют условиям проведения
статистического анализа.
16.30. Идентифицируйте все запланированные подгруппы или ковариаты
анализов [4].
16.31. Идентифицируйте все статистические корректировки, сделанные в целях
контроля над сопутствующими факторами [4].
16.32. В обзоре баз данных укажите, как извлечение данных оценивалось на
состоятельность или согласие.
16.33. Опишите все запланированные анализы чувствительности к смещениям [4].
16.34. Определите все процедуры, применяемые для контроля за
множественными сравнениями [3].
16.35. Установите критический уровень статистической значимости.
16.36. Укажите, какие применялись статистические критерии: одно- или
двусторонние. Обоснуйте применение одноаоронних критериев.
244 Составление отчетов об исследовательских проектах и мероприятиях
1637« Назовите пакеты статистических программ, с помощью которых
анализировались данные [3]\
УКАЗАНИЯ ПО ОФОРМЛЕНИЮ РЕЗУЛЬТАТОВ
1638« Укажите временные рамки обследования: даты проведения обследования
или составления записей.
1639« Объясните причины всех отклонений от протокола при проведении
обследования.
16.40. Приведите схему испытания, показывающую число и порядок
обследований на каждом этапе исследований [3,4].
в отчет можно включить следующие числовые показатели:
• число подходящих респондентов или записей в популяции-источнике;
• число потенциальных респондентов, получивших приглашение, или число доступных
для обзора записей;
• число респондентов, отказавшихся от участия в обследованиях по телефону или
недоступных для них;
• число полных интервью или анкет (показатель отклика) [2, 3];
• число анкет или записей, проверенных на соответствие целям исследования;
• число непригодных для оценивания анкет или записей;
• число пригодных для оценивания анкет или записей;
• число проанализированных анкет или записей.
16.41. Охарактеризуйте каждую группу с помощью подходящих описательных ста-
тиаик.
16.42. Укажите, в какой степени респонденты или записи были репрезентативны
для изучаемой популяции.
16.43. Дайте характеристику отказавшимся отвечать на вопросы или непригодным
для оценок записям [3].
16.44. Приведите результаты исследования, предпочтительнее в цифрах или
таблицах [3].
На практике принято сообщать число ответов на каждый вопрос [2, 4].
16.45. Как минимум, приведите абсолютные значения всех конечных точек,
включая межгрупповые различия [4].
' Если анализ выполнялся с помощью пакета, имеющего внутренний язык программирования, то необходимо
указать также название процедур и основные используемые опции этих процедур. Это требование связано с тем,
что часто один и тот же метод в таких профессиональных пакетах может быть реализован разными процедурами,
имеющими к тому же разные алгоритмы. И, как итог, эти процедуры могут давать отличающиеся результаты,
имеющие различные интерпретации.
Отчеты об обследованиях или поперечных исследованиях 245
1 б.4б. Для всех конечных точек приведите доверительные интервалы [3].
16.47. В обследованиях баз данных приведите меру состоятельности или согласия
между обработчиками данных или экспертами.
16.48. Опишите все возможные влияния искажения или взаимодействия.
16.49. Дайте отчет о всех наблюдениях и объясните все случаи пропусков [2-4].
16.50. Опишите, как рассматривались выбросы.
16.51. Скажите о тех необычных свидетельствах или наблюдениях, которые могут
способствовать более точному или полному пониманию исследования или
его результатов.
УКАЗАНИЯ ОТНОСИТЕЛЬНО ОБСУЖДЕНИЯ РЕЗУЛЬТАТОВ
16.52. Соберите результаты в общую сводку [2,4].
16.53. Дайте интерпретацию результатов и предложите их объяснение [2].
При интерпретации результатов обследований, которые по своей природе описательны
и собирают данные по состоянию на один момент времени, необходимо помнить о трех
распространенных ошибках:
• Взаимосвязь не означает причинной связи. Курение тесно связано с пристрастием
к кофе, но одно не является причиной другого.
• Не всегда бывает ясным направление причинно-следственной связи [5]. Не
всегда возможно определить, вызваны ли те или иные симптомы поведением человека,
или же люди с данными симптомами ведут себя тем или иным образом. К примеру,
злоупотребление амфетамином может привести к депрессии, но в то же время
страдающие депрессией могут сами начать принимать амфетамин, чтобы смягчить
ощущение депрессии.
• Отдельные лица необязательно демонстрируют типичные характеристики
группы в целом (экологическая ошибка). К примеру, не все врачи имеют высокий доход
и не весь средний медицинский персонал — женщины, поэтому обобщения на основе
групповых средних могут привести к неверным выводам.
16.54. Опишите, как результаты соотносятся с тем, что уже известно по данной
проблеме; приведите обзор литературы и поместите результаты в контекст [2].
16.55. Предложите пути обобщения результатов [4].
1 б.5б« Обсудите следствия результатов [4].
16.57. Обсудите лимитирующие факторы исследования [2-4].
16.58. Перечислите выводы.
246 Составление отчетов об исследовательских проектах и мероприятиях
Литература
1. МсСоП Е, Jacoby А, Thomas L, et al Design and use of questionnaires: a review of best practice
applicable to surveys of health service staff and patients. Health Technol Assess. 2001; 5:1-256.
2. Huston P Reporting on surveys: information for authors and peer reviewers. Can Med Assoc J. 1996;
154:1695-8.
3. Rushton L Reporting of occupation and environmental research: use and misuse of statistical and
epidemiological methods. Occup Environ Med. 2000; 57:1-9.
4. STROBE statement, http://www.strobe-statement.org.
5. Grimes DA, Schulz KK Descriptive studies: what they can and cannot do. Lancet. 2002; 359:145-9.
6. Grimes DA, Schulz KE An overview of clinical research: the lay of the land. Lancet. 2002; 359:57-61.
7. Byar DP The use of data bases and historical controls in treatment comparisons. Recent Results
Cancer Res. 1988; 111:95-8.
247
© Часть III
Составление отчетов
^ по обобщающим
О методам
исследования
Когда клиницисты делают выбор, они могут извлекать выгоду из
структурированных резюме альтернатив и последствий, а такэюе из систс
матических обзоров, содерж:ащих доказательства соотношений меэюду
альтернативами и последствиями, и рекомендаций относительно
лучшего выбора.
Рабочая группа по доказательной медицине
Американской медицинской ассоциации [ 1 ]
В предшествующих главах мы представили руководства для
сообщений о статистике в научной статье и в сообщениях об исследовательских
проектах и мероприятиях. Здесь мы представляем руководство для
сообщений о трех определенных типах исследования, которые объединяют
информацию из других исследований в собственную уникальную
аналитическую перспективу и методологию: систематические обзоры и метаа-
нализ (гл. 17), экономические оценки (гл. 18) и руководства по анализу
решений и клинической практики (гл. 19).
Поскольку каждый из этих методов комплексный и довольно сложный,
подробное их описание выходит за рамки данной книги. Вместо этого,
мы попытались обеспечить твердое введение в метод и представить
наиболее важные руководящие принципы для документации метода.
Литература
1. Guyatt G, HaywardR, Richardson WS, et al, for the Evidence-Based Working
Group of the American Medical Association. Moving from evidence to action. In:
Guyatt G, Rennie D, eds. User's Guides to the Medical Literature: A Manual for
Evidence-Based Practice. Chicago: AMA Press; 2002.
248 Составление отчетов по обобщающим методам исследования
Глава 17
Синтезирование результатов
связанных исследований
Отчет о систематических обзорах и метаанализе
Метаанализ предусматривает логическую структуру обзора исследования:
подобные меры от сопоставимых изучений внесены в список
систематически, и доступные меры эффекта объединены, где возмоэюно.
К. DiCKERSiN, J. А. Berlin [1]
В любом обзоре литературы авторы формулируют вопрос исследования, ищут статьи,
связанные с вопросом, берут наиболее приемлемые из них, суммируют выводы отобранных
статей и затем интерпретируют результаты. В традиционном повествовательном обзоре
литературы каждый из этих шагов оставлен на усмотрение автора. В результате смещение
легко внедряется в каждый из этих шагов: поиск относящихся к делу статей может быть
случаен и неполон; важные статьи могут быть не приобретены или проигнорированы;
резюме может быть неоднородно или интерпретация может быть неоправданно
акцентирована под влиянием, например, нескольких статей.
Напротив, систематический обзор литературы осуществляется в соответствии с
критериями, которые установлены для каждого шага продвижения обзора. Итак, систематический
обзор — запланированное, всестороннее и воспроизводимое резюме результатов
исследования по одной и той же теме. Запланированный и систематический характер этих обзоров
помогает уменьшать смещение, и потому их результаты воспроизводимы, благодаря чему
действенность обзора может быть проверена.
При некоторых обстоятельствах числовые результаты исследований,
идентифицированных в систематическом обзоре, могут быть статистически объединены, чтобы далее
улучшить выводы и интерпретацию. Метаанализ, иногда называемый «статистический обзор»,
статистически объединяет результаты нескольких связанных исследований в единую,
итоговую меру результата. Объединяя образцы индивидуальных исследований, метаанализ
может сильно увеличивать общий объем наблюдений и статистическую мощность анализа,
что увеличивает точность, с которой может быть оценен эффект лечения.
Хотя систематические обзоры обычно предпочитаются повествовательным обзорам
по причинам, цитируемым выше, вопрос о предпочтении систематическго обзора или ме-
таанализа все еще дискуссионен. Поскольку «данные» для систематических обзоров и ме-
таанализа обычно, но не всегда берутся из опубликованных научных работ, их качество
зависит как от качества этих исследований, так и от того, насколько хорошо излагаются их
результаты, и от того, что в них привлекает внимание автора. Другие публикации содержат
опыт статистически объединенных научных работ, которые отличаются в важных аспектах,
Отчет о систематических обзорах и метаанализе 249
таких как численность пациентов, дизайн эксперимента, качество контроля, наличие
публикационного смещения, заключающегося в том, что научные работы с положительными
результатами лечения более охотно публикуются, чем те, которые не обнаруживают
лечебного эффекта; как и то, что в некоторых случаях результаты метаанализа и больших РКИ,
так называемых мега-испытаний по одной и той же теме, противоречат друг другу [2-4].
(Для обсуждения полемики вокруг метаанализа смотрите полный выпуск Journal of Clinical
Epidemiology за январь 1995 г.)
Рекомендации ниже представлены в виде более или менее упорядоченного списка, в
котором они могли бы появляться под каждым заголовком научной публикации, сообщающей
о результатах систематического обзора или метаанализа, основанного на систематическом
обзоре. Они включают рекомендации QUOROM {Quality of Reporting of Meta-Analyses) —
Сообщение для публикаций о систематических обзорах по рандомизированным
контролируемым испытаниям, а также рекомендации MOOSE (Meta-Analysis of Observational Studies
in Epidemiology) — Сообщение для публикаций о систематических обзорах по
исследованиям, основанным на наблюдениях. (См. прилоэюение 4).
УКАЗАНИЯ ПО ОФОРМЛЕНИЮ ВВЕДЕНИЯ
17»1. Подтвердите предпосылки, сущность, сферу действия и важность
проблемы, которая привела к обзору.
Как во всех научных исследованиях, в большой степени решение проблемы зависит
от того, как она доносится до читателя. Систематические обзоры и метаанализ должны
предназначаться для некоторых проблем {см. указание 17.2), но не для любых. Поэтому,
чтобы проблема была донесена до читателя, ее нужно разъяснить так, чтобы читатели
смогли определить уместность этих методологий в решении проблемы. Проблема должна быть
выражена как в биологических терминах, так и в терминах здравоохранения, должно быть
определено интересующее читателя количество пациентов, вмешательств и исходов
(приводящих к излечению и наносящих вред).
17*2* Установите главную цель обзора.
Как и во всех научных исследованиях, цель обзора должна быть четко определена. В
дополнение к обычным требованиям о том, что исследование должно быть связано с темой,
которая клинически важна и биологически правдоподобна, систематические обзоры могут
преследовать следующие цели:
• собрать данные, необходимые для планирования больших клинических испытаний,
такие как ожидаемые величины эффекта или вариабельность характеристик для
расчета объема выборки, нарастающие частоты пациентов, гипотезы и т. д.;
• обобщить большой и сложный объем литературы по теме;
• разрешить противоречия между сообщениями в литературе;
• оценить обоснованность результатов между испытаниями;
• документировать необходимость клинических испытаний;
• прояснить сильные и слабые стороны исследований по данной теме.
Кроме того, метаанализ может быть использован с целью:
• обеспечить количественную оценку результатов лечения;
• улучшить точность оцененного лечебного эффекта;
250 Составление отчетов по обобщающим методам исследования
• обнаружить меньший эффект от лечения, чем было заявлено в индивидуальных
научных работах;
• исследовать вариации в результатах лечения с помощью подгруппового
(стратифицированного) анализа;
• улучшить возможности обобщения известных результатов лечения.
173. Сообщите о том, кто финансировал исследование, и опишите роль иаочников
финансирования в управлении исследованием и в публикации результатов.
Некоторые агентства финансирования обеспечивают исследователей не только
деньгами. Они могут предоставить доступ к неопубликованным данным, статистической или
редакционной поддержке, техническому совету или другим услугам. Из-за возможности
смещения все формы такой поддержки и все ограничения в исследовании должны быть
раскрыты [6].
17.4. Сообщите о том, каков протокол и какие первоначальные данные могут
быть получены.
Как в любом исследовании, высоко ценится возможность предоставления данных другим
исследователям, что часто и делается. Исходные данные одного вида метаанализа — метаа-
нализа данных от индивидуальных пациентов (смотрите описание в конце этой главы) —
могут быть недоступны из-за проблем конфиденциальности, связанных с
индивидуальными данными о пациентах. Однако итоговые данные для групп лечения и групп контроля
должны быть доступны для их совместного использования.
В дополнение к идентификации исходных данных полезно указать, в каком формате эти
данные хранятся. Обычные форматы — это базы данных или файлы данных
статистических программ или программ, специально разработанных для систематических обзоров
и метаанализа (см. указание 17.21).
УКАЗАНИЯ ОТНОСИТЕЛЬНО МЕТОДОВ
17.5. Сообщите, выполнялся ли обзор в соответавии с письменным протоколом.
Письменный протокол помогает уменьшать смещение во многих суждениях, которые
должны быть сделаны при проведении систематических обзоров и метаанализа.
Протокол должен затрагивать все проблемы, рассматриваемые в этом разделе, но особенно
следующие:
• сферу действия и процедуры поиска исследований, которые нужно рассмотреть
в обзоре;
• критерии для включения и исключения исследований из обзора;
• данные, которые будут извлечены из исследования, и то, как этот процесс извлечения
должен проводиться;
• статистические процедуры, которые нужно использовать в метаанализе для анализа
данных.
17.6. Установите конкретные цели обзора, включая формально изложенные
вопросы или гипотезы [5].
Отчет о систематических обзорах и метаанализе 251
17.7. Опишите изучаемые популяции и те, на которые результаты должны быть
обобщены [5].
Систематические обзоры и метаанализы объединяют результаты многих различных
исследований на многих и разнообразных популяциях. Популяции могут быть
идентифицированы прежде всего по диагнозу (например, пациенты с симптомами коронарной
сердечной недостаточности), по демографическим показателям (мужчины из рабочей среды
старше 50 лет) или по способам лечения (пациенты, перенесшие коронарную ангиопластику).
Однако часто существует компромисс между комбинированием гетерогенных популяций
с целью улучшить обобщаемость результатов (ценой увеличения вариабельности
результатов) и комбинированием гомогенных популяций с целью уменьшить вариабельность в
результатах (ценой ограничения обобщаемости).
17.8. Установите интересующие первичные и вторичные предикторные
переменные и дайте операционные определения для каждой [5].
Операционные определения описывают переменные в легко наблюдаемых,
измеримых терминах. Такие определения даже более важны в систематических обзорах
и метаанализах, потому что разные определения одной и той же переменной могут
препятствовать объединению результатов исследований. Например, одно исследование
понижающегося холестерина крови может определять в качестве меры его результата
общий холестерин, тогда как другое исследование может использовать отношение ли-
попротеина высокой плотности к липопротеину низкой плотности. Было бы неразумно
объединять научные работы с различными операционными определениями одних и т^х
же переменных.
17.9. Уделите равное внимание полезным и вредным вмешательавам [5].
Все вмешательства имеют за собой непреднамеренные, нежелательные и неожиданные
эффекты, поэтому, даже если в центре внимания обзора стоит изучение пользы
вмешательства, необходимо изучить как его вред, так и пользу.
17.10. Укажите все запланированные анализы подгрупп [5].
в дополнение к анализу подгрупп, основанному на клинических факторах, таких как
различия по возрасту, полу, сочетанным заболеваниям и т. д., анализы подгрупп, основанные
на методологических факторах, являются общими в систематическом обзоре и
метаанализе. Например, методологические подгруппы могут быть основаны на качестве
исследования, дизайне исследования, годе, в котором они наблюдались, или же на том, какой анализ
был использован — «с намерением лечить» или «для протокола».
Анализ подгрупп post hoc, если таковой проводится, должен быть отмечен как
разведочный анализ.
17.11. Сообщите о периоде времени, затраченном на поиски нужной литературы.
Сообщение о периоде времени, в течение которого желательные исследования
должны занять свое место, ставит обзор в один ряд с другими разработками в медицине. Оно
также необходимо для того, чтобы позволить другим исследователям повторить поиск
литературы.
252 Составление отчетов по обобщающим методам исследования
17.12. Опишите стратегии поиска и информационные ресурсы, используемые для
нахождения ссылок на сообщения о нужных исследованиях.
Данные для систематических обзоров и метаанализа состоят из сообщений об
исследовательских работах по идентичным или подобным темам. Необходимо выявить как можно
больше таких сообщений [5]. Неполный поиск может привести к «смещению отбора» в
обзоре из-за неудач в идентификации важных исследований.
Для того чтобы избежать смещения отбора, нужно основательно и систематически
искать сообщения о нужных исследованиях. Несколько стратегий поиска лучше, чем одна.
Типичные стратегии поиска включают следующее:
• поиски по ключевому слову в компьютеризованных базах данных, таких как
MEDLINE и EMBASE; эти индексированные термины часто сообщаются в
опубликованном обзоре, а полные стратегии поиска иногда включаются в приложение [7]. Укажите
факт поиска в базе данных, сроки проведения поиска и проводил ли поиск
профессиональный медицинский библиотекарь;
• обзор библиографий опубликованных статей, соответствующих критериям
преемственности;
• перепроверку цитат, чтобы привести в соответствие научные статьи через индексацию
и службы цитирования, такие как индекс научного цитирования или научная сеть;
• «ручной поиск» в журналах, пролистывая каждый выпуск, проверяя каждую статью,
чтобы определить, удовлетворяет ли она подходящим критериям;
• ознакомление с исследователями, государственными агентствами финансирования
и фармацевтическими компаниями на предмет информации об исследованиях,
опубликованных или неопубликованных;
• поиск регистров подходящих научных работ, таких как Оксфордская база данных
перинатальных исследований.
Типичные вопросы, поднимаемые в поиске:
• Следует ли включать сообщения на других языках кроме английского [5,8]?
• Должны ли быть включены сообщения из других стран, имеющих различия в системе
здравоохранения, научной инфраструктуре, культурных нормах и ценностях и т. д.?
• Должна ли быть включена в поиск «серая литература» [9-12]? «Серая
литература» состоит из неопубликованных или неиндексированных научных работ, которые
не сразу можно найти с помощью обычных библиографических методов поиска,
трудно доступны через обычные каналы и обычно не показываются в обзорах наравне
с другими. «Серая литература» может включать технические сообщения,
препринты статей, рабочие бумаги, деловые документы, труды конференций, «белые книги»
(официальные издания), стандарты на основе исследований, тезисы и диссертации,
правительственные сообщения, информационные бюллетени, сводки и т. д.
^ Компьютерные литературные поиски не должны быть единственной
стратегией, используемой для нахождения исследований [1, 8]. Даже обученные
медицинские библиотекари потерпели неудачу в идентифицировании большого
процента изданных научных работ по теме, что наводит на мысль о наличии
существенных ошибок в индексации или изменчивости индексации [12]. Например, поиск
MEDLESfE обученным библиотекарем идентифицировал только 29 % исследований
по неонатальной гипербилирубинемии и только 56 % исследований по интравен-
Отчет о систематических обзорах и метаанализе 253
трикулярному кровотечению, занесенных в Оксфордскую базу данных
перинатальных исследований.
Другое исследование обнаружило, что согласованность между индексерами была только
между 45 и 50 % [1, 12]. Еще одно исследование идентифицировало больше чем 30 000
опубликованных контролируемых испытаний, которые не были соответствующим образом
проиндексированы в MEDLINE. (Эти испытания позднее были соответствующим образом
проиндексированы [13].)
Q Большое количество исследований влечет за собой многократные публикации.
Различные публикации из больших исследований часто пишутся разными
группами авторов и могут не ссылаться на исходные исследования, что может привести
к тому, что одно и то же испытание будет представлено в обзоре более одного раза
[12]. Недавние усилия регистрировать все клинические испытания с начала их
проведения должны помочь связать все публикации об исходном испытании,
обеспечивая уникальный регистрационный номер испытания, который должен появляться
во всех публикациях, связанных с испытанием.
Q Резюме обычно не содержит достаточно информации, для того чтобы быть
полезным в систематических обзорах или метаанализе. Тем не менее резюме
могут подтверждать существование опубликованных или неопубликованных
исследований [12].
17Л 3» Опишите критерии и способ, используемые для поиска сообщений об
исследованиях с целью их восстановления.
Критерии включения и исключения должны быть настолько четкими, насколько это
возможно, так чтобы сравнивались только совместимые, нужные исследования
подходящего качества. Сравниваемые исследования должны быть схожи в нескольких важных
аспектах [5]:
• Исследования должны проверять одну и ту же гипотезу или взаимосвязь [И] или
должны иметь один и тот же исход или конечную точку [9].
• Исследования должны сравнивать похожих пациентов, например похожих по возрасту,
полу, диагнозу, состоянию болезни, сопутствующим заболеваниям или вмешательству
[9, 11]. Так, исследование, которое тестирует препарат против плацебо, не должно
сравниваться с тем, которое тестирует его по отношению к конкурирующему
препарату, хотя данные для пациентов, принимающих препарат в каждом исследовании, могут
извлекаться по отдельности для включения в обзор.
• Исследования должны соответствовать минимальным стандартам научного качества
(см. указание 17.30). Такие стандарты могут включать следующее: минимальный
размер выборки, случайное назначение между группами лечения и контрольной,
«ослепление» пациентов и персонала исследования, контроль качества за сбором и
управлением данными или формальный статистический анализ.
^ Смещение в отборе исследований является главной причиной несоответствия
результатов в метаанализе [12]. Сообщение об определенных критериях
включения и исключения поможет исследователям в сравнении результатов метаанализа.
Систематический обзор или метаанализ могут законно поднимать проблему,
отличную от первичных сравнений в индивидуальных исследованиях [8]. Например, первичное
254 Составление отчетов по обобщающим методам исследования
сравнение отдельно взятого исследования могло бы быть проведено для проверки
эффективности препарата, тогда как цель метаанализа состоит в том, чтобы определить
вероятность неблагоприятных реакций в определенной подгруппе пациентов. Таким образом,
неблагоприятные результаты, описанные в отдельном изучении эффективности препарата,
могут быть извлечены для целей метаанализа.
Названия и резюме цитат, идентифицированных в литературном поиске, обычно
рассматриваются одним или более исследователями, которые применяют критерии включения
и исключения в идентификации сообщений об исследованиях, которые будут использованы
для детального обзора. Этот процесс подчинен индивидуальному суждению и инициативе
и поэтому является источником потенциального смещения. Таким образом, в дополнение
к письменному протоколу, непосредственно управляющему процессом, на этом шаге часто
сообщается степень согласия среди исследователей [5].
Обобщение и анализ данных
17Л4. Опишите данные, которые необходимо будет извлечь из сообщений об
исследовании [5].
Данные, которые будут извлечены, обычно состоят из описательной информации о
каждом исследовании, такой как его объем, даты сбора информации, место исследования
и окружающая обстановка, изучаемые объясняющие и предикторные переменные,
например демографические характеристики пациента, клинические характеристики и диагнозы,
вмешательства, первичные и вторичные конечные точки и неблагоприятные события.
Извлечение данных может также включать вычисление новых показателей, таких как
отношение шансов, полученных из описанных данных [12].
17.15. Опишите процесс, использованный для извлечения данных из сообщений
об исследовании [5].
Даже в соответствии с письменным протоколом извлечение данных часто субъективно
и утомительно. Критерии извлечения, которые являются слишком общими, предоставляют
при извлечении данных большую свободу интерпретации. Необходимые данные иногда
излагаются неточным языком или отсутствуют полностью [14]. В результате процесс
извлечения данных также оказывается потенциальным источником смещения.
Чтобы минимизировать или идентифицировать это смещение, все данные или
подмножество данных могут быть извлечены двумя или более исследователями, чьи результаты
сравниваются для оценки точности процесса. Мера согласия при извлечении данных часто
сообщается, и процесс разрешения разногласий между обзорами также должен быть описан.
17.16. Объясните, как пропуски были обработаны в анализе.
к сожалению, не все исследования предоставляют всю желательную информацию или
сообщают о ней достаточно четко, что позволило бы произвести правильное извлечение
данных. Иногда информация о пропусках может быть получена непосредственно от
авторов первоначального исследования, рассчитана или оценена по другим данным в
сообщении об исследовании или «восполнена» математически [5]. Поскольку это наиболее
надежный способ получить информацию о пропусках, хорошо бы установить, возможен ли
контакт с авторами включенных сообщений об исследовании, для того чтобы подтвердить
опубликованные данные и получить информацию о пропусках.
Отчет о систематических обзорах и метаанализе 255
17.17, Опишите любые меры, принятые для того, чтобы идентифицировать или
уменьшить селективное сообщение результатов в публикациях об
исследованиях или селективное сообщение о самих исследованиях
(«публикационное смещение»).
Селективное сообщение результатов в пределах публикации об исследовании
происходит, когда сравнения, описанные в разделе «Методы», не сообщены в результатах. Часто,
например, сообщаются только статистически значимые результаты.
Публикационное смещение относится к тому факту, что исследования со
статистически значимыми результатами публикуются более охотно, чем исследования без
статистически значимых результатов [15]. Поскольку систематические обзоры и метаанализы обычно
основаны на опубликованных сообщениях, потенциальное игнорирование работ с
отрицательным результатом является главным поводом для беспокойства [8]. Целесообразность
включения неопубликованных данных или «серой литературы», однако, оспаривается
[1, 10]. Неопубликованные исследования обычно не подвергаются официальной
тщательной оценке, и тот факт, что исследование не было представлено для публикации, ставит под
сомнение качество всей работы.
Единственный способ скорректировать публикационное смещение состоит в том,
чтобы рассчитать количество отрицательных испытаний, которые были бы необходимы,
чтобы признать недействительными результаты систематических обзоров и метаанали-
за, — «предохранительный N-метод», предложенный Rosenthal [1, 8, 12, 16, 17]. Если
это количество оказывается больше, чем возможное количество невыявленных
отрицательных исследований, их результаты могут вызывать большее доверие. Например, при
изучении 345 опубликованных исследований Rosenthal подсчитал, что 65 123 подобных,
но неопубликованных научных работ с отрицательными результатами потребовалось бы,
чтобы опровергнуть объединенную статистическую значимость 345 опубликованных
исследований [16].
Полезная методика для нахождения возможных публикационных смещений в больших
обзорах представлена в воронкообразном графике (рис. 17.1) [1, 9, 12]. В предположении,
что результаты отдельных опубликованных научных исследований концентрируются
вокруг «истинного» результата, диаграмма рассеяния величины эффекта по отношению к
размеру выборки отдельных исследований должна быть симметрична относительно
«истинного» результата, при этом меньшие объемы выборок должны демонстрировать большую
вариабельность, чем исследования с большими объемами. Если исследования,
показывающие отрицательные результаты, отсутствуют в диаграмме, то диаграмма рассеяния будет
асимметричной, указывая на возможность публикационного смещения.
Еще один способ корректировать публикационные смещения заключается в том, чтобы
анализировать исследования с большими объемами наблюдений отдельно от исследований
с небольшими объемами в надежде на то, что исследования с большими объемами с
меньшей вероятностью будут подвержены влиянию публикационных смещений, чем
малообъемные исследования; т. е. большие исследования, более вероятно, будут опубликованы,
независимо от того, имеют они положительные результаты или нет [9, 12].
^ Публикационное смещение может происходить двумя способами. Сообщения
о неблагоприятных реакциях на препарат или токсины окружающей среды (типа
асбеста), например, с большей вероятностью могут быть опубликованы, если
256 Составление отчетов по обобщающим методам исследования
200 —\
Q.
О
vg
.0
со
о
100 Н
О Н
о
О
о
: •
• О
• :
• :• о
0,5 1 2
Величина эффекта (Отношение шансов)
Рис. 17.1. Воронкообразный график, используемый для оценки публикационного смещения. Каждый кружок
означает одно исследование в систематическом обзоре. Темные кружки означают опубликованные
исследования, светлые кружки — неопубликованные. Здесь число маленьких неопубликованных исследований,
сообщающих о высоких отношениях шансов (указание отрицательных результатов без защитного эффекта), может
показывать публикационные смещения
17.18,
результаты статистически «^значимы [9, 12]. Точно так же статьи, которые бросают
вызов давнишним убеждениям или по иной причине достойны освещения в печати,
могут быть опубликованы прежде всего по этим причинам. Также
«...публикационные смещения могут быть функцией не только статистической значимости, но и
колебаний редактирования и единства мнений» [9].
Для метаанализа сообщите оптимальный объем информации,
необходимый для обнаружения желаемого эффекта лечения, приведите в деталях его
вычисление.
Оптимальный объем информации в метаанализе аналогичен объему выборки
рандомизированных испытаний. В дополнение к уровням ошибки первого рода,
альфа, и ошибки второго рода, бета, должна быть оценена частота исходов в контрольной
группе, а также должен быть сообщен эффект лечения или минимальное различие,
которые будут обнаружены. Оптимальный объем информации обычно будет выражен через
количество пациентов, которые должны быть включены в объединенный анализ,
чтобы придать заданную мощность обнаружения разности при данном объеме. Подобно
рандомизированным испытаниям, метаанализ также может быть бессилен: могут быть
пропущены клинически важные различия, если собрано недостаточно данных, чтобы
обнаружить эти различия.
Отчет о систематических обзорах и метаанализе 257
17.19. Для метаанализа приведите меру величины эффекта, используемого, чтобы
сообщить о результате обобщения.
Метаанализ с дихотомическими исходами (выжившие или умершие, вылечены или нет)
может сообщать результаты как разности абсолютного риска, отношение рисков или
отношение шансов (рис. 17.2; см. такэюегл. 2). Риск или отношение шансов определяются
правдоподобием исхода, имеющегося в группе лечения, деленным на правдоподобие исхода,
который произойдет в контрольной группе. Таким образом, отношение рисков или
отношение шанса, большее 1, показывает повышение риска в группе лечения, в то время как
отношение шанса, меньшее 1, показывает понижение риска в лечебной группе. Отношение,
равное 1, показывает отсутствие разности в рисках, т. е. что лечение не приносит ни вред,
ни пользу, что вполне может быть как в лечебной, так и в контрольной группах.
Метаанализ с непрерывными исходами (уровень глюкозы, индекс интеллекта IQ) может
быть представлен с помощью безразмерного показателя эффекта, называемого
стандартизированной средней разностью (часто просто называется «величиной эффекта»). Эта
мера позволяет проводить сравнение единой мерой исследования с различными исходами.
Типичное вычисление такой меры может состоять из деления разности, скажем, средних
значений индексов IQ между группами на СО индексов IQ в контрольной группе.
17«20« Для метаанализа опишите критерии, использованные для того, чтобы
определить, должны или не должны быть статистически объединены результаты
из разных исследовательских отчетов.
Одно из ключевых и спорных решений в метаанализе — подходят ли
исследовательские публикации для их объединения [1, 10, 16, 18]. Хотя метаанализ подвергался критике
за сравнение «яблок и апельсинов и случайного лимона» [19], различия среди
исследований — это то, что делает результаты метаанализа более робастными: если подобные
Событие произошло?
Группы
Лечение
Контроль
Да
Нет
А
С
В
D
Частоты в группах
Частота событий в группе лечения (ЧГЛ) = А/(А + В)
Частота событий в группе контроля (ЧГК) = С/(С + D)
Эффект лечения
Разность
рисков (РР)^
Отношение
шансов (ОШ)
Отношение
рисков (ОР)
Число пациентов, подвергаемых лечению
на один полезный исход (ЧПЛП)
РР = ЧГЛ-ЧГК
ош =
ЧГЛ/(1-ЧГЛ)
'чгк/(1-чгк)
0Р =
ЧГЛ
ЧГК
ЧПЛП=-
в
А+В
D
C+D
^ Также называется разностью абсолютных рисков или снижением абсолютного риска.
Рис. 17.2. Вычисление биномиального эффекта лечения в метаанализе. Для рисков и шансов исход —
отрицательные результаты, такие как смертельные случаи. Для ЧПЛП в вычислении используется количество
пациентов с положительной конечной точкой
258 Составление отчетов по обобщающим методам исследования
результаты получены при многих различных условиях, они, вероятнее всего, отразят
реальные биологические взаимосвязи, а не артефакты или случайные факты.
Три типа разнородности могут препятствовать объединению сообщений об
исследованиях в метаанализе: клиническая разнородность, методологическая разнородность и
статистическая гетерогенность. Клиническая разнородность касается различий, связанных
с участниками исследования, вмешательствами и исходами, таких как различия в месте
или обстановке проведения исследования, различия по возрасту, полу, диагнозу или
степени тяжести заболевания пациентов, различия в методах лечения, уже получаемых в
начале исследования, различия в дозировке или интенсивности вмешательства или различия
в определении исходов. Было бы неразумно объединять, например, исследования на детях
с исследованиями на взрослых или исследования на пациентах с одной болезнью с
исследованиями пациентов, имеющих сопутствующие заболевания.
Методологическая разнородность касается различий в том, как были выполнены
исследования, включая различия в дизайне исследования (параллельная группа или
перекрестный дизайн), единицах рандомизации (индивидуально или кластеры, группы в одном
и том же исследовательском центре или сообществе), использование оценки исходов с
применением технологии «ослепления», выбор видов статистического анализа (нацеленность
на излечение против протокольного анализа) и т. д. Изучения оценок результатов с
«ослеплением», как правило, обнаруживает меньший эффект лечения, чем, например, оценка
результатов без «ослепления».
Если исследования должны быть разумно объединены в метаанализе, обстоятельства
проведения, участники, вмешательства и исходы включенных испытаний должны быть
схожи (низкая клиническая разнородность), и методики, используемые для проведения
испытаний, не должны меняться настолько, чтобы было чрезмерное влияние на результат
(низкая методологическая разнородность).
Статистическая гетерогенность состоит в вариации или несогласованности
результатов индивидуальных исследований. Это может быть видно на графике эффектов («лесной»
график, см. указание 17.31), Исследования, в которых направление и величина эффекта
являются схожими, обычно не представляют никаких проблем. Однако, когда направление
и величина эффекта значительно отличаются, их сочетание не может быть значащим. Если
результаты изменяются больше, чем это можно было бы ожидать случайно, говорят, что
результаты являются «статистически гетерогенными».
С гетерогенностью результатов можно обращаться несколькими способами [20]. Она
может быть проигнорирована, что происходит, когда данные анализируются с помощью
модели с фиксированными эффектами, или она может быть учтена и принято решение
не объединять результаты статистически. Модели случайных эффектов содержат в себе
некоторую степень гетерогенности. Наконец, гетерогенность может исследоваться в надежде,
что анализ подгрупп или мета-регрессионный анализ объяснят, почему результаты
являются гетерогенными. Эти темы обсуждаются ниже.
17.21. Для метаанализов опишите статистические методы, используемые для того,
чтобы проанализировать данные [5].
в метаанализе результаты каждого исследования объединены статистически с
результатами других исследований — это та характерная черта, которая отличает метаанализ от си-
Отчет о систематических обзорах и метаанализе 259
схематических обзоров. Поскольку различия в статистических методах могут приводить
к различным результатам, метод должен быть описан.
Независимо от используемых статистических методов, их целью является: 1)
определение того, являются ли результаты исследований схожими, 2) если это так, вычисление
наилучшей обобщенной оценки их эффекта, 3) вычисление точности этого оцененного
эффекта и 4) определение того, могут ли быть объяснены любые несходства в
исследованиях [20].
Статистические методы могут содержать один из двух типов моделей, о чем также
должно быть сообщено. Модель фиксированных эффектов предполагает существование
единственного «фиксированного» эффекта, к которому приближается каждое исследование. То
етсь если бы каждое исследование было бесконечно большим, то любое из них приводило
бы к идентичному результату. Модель случайных эффектов, с другой стороны,
предполагает, что результаты индивидуальных исследований формируют распределение
результатов, которое имеет некоторое центральное значение и некоторую степень вариабельности.
Модель случайных эффектов делает меньшее количество предположений о вариабельности
в анализе и поэтому является более консервативной, чем модель фиксированных эффектов.
Обе модели могут быть использованы и представлены в метаанализе.
Иногда исследованиям перед объединением может быть придан некоторый вес.
Логическим обоснованием этого является тот факт, что исследования с узкими доверительными
интервалами (более точные оценки) должны иметь больший вес, чем исследования с
большей неопределенностью [20]. Если это так, то метод взвешивания и вес для каждого
исследования должны быть описаны.
0 Остерегайтесь «подсчета по головам» или «подсчета голосов», когда самое
высокое число «положительных» или «отрицательных» исследований
определяет результаты анализа [16, 18, 19, 21]. В наиболее упрощенных терминах, все
исследования имеют один из трех исходов: значимые положительные эффекты,
значимые отрицательные эффекты или незначимые эффекты. Простой подсчет
количества исследований в каждой категории, чтобы определить «победителя», —
легкое, но потенциально вводящее в заблуждение действие. Такой подход игнорирует
влияние объема выборки, дизайна исследования, критического уровня
статистической значимости (альфа-уровня) и величину эффекта при окончательном
подведении итогов, и это до некоторой степени объясняет существование исследований
с противоречивыми выводами.
Q Остерегайтесь процесса простого объединения только критериев
значимости [16]. Второй быстрый способ обобщения результатов в метаанализе — это
математически скомбинировать только /?-значения каждого из исследований в одно
р-значение для метаанализа. Такой подход не рассматривает распределение
исходов по всем исследованиям, в итоге одно исследование может иметь
несоразмерное влияние при окончательном подведении итогов. Также, поскольку этот
метод основан полностью на р-значениях и поскольку исследования с
незначимыми эффектами (исследования с р-значениями, большими, чем, скажем, 0,05)
публикуются менее часто, это делает данный метод предрасположенным к
публикационному смещению.
260 Составление отчетов по обобщающим методам исследования
1722« Для метаанализов идентифицируйте пакеты программ, используемых для
анализа.
Некоторые программы могут выдавать итоговые диаграммы («лесная диаграмма»;
см. указание 17.31) и объединенные величины эффекта и доверительные интервалы,
используемые в метаанализе. Среди них: RevMan (Review Manager), Meta-Analyst,
Comprehensive Meta-Analysis, Epi Meta, EasyMA, и Meta-Analysis Easy to Answer. Кроме того,
другие стандартные статистические программы могут выполнять метаанализ, такие как SAS,
STATA и Winbugs (для байесовского анализа).
УКАЗАНИЯ ПО ОФРМЛЕНИЮ РЕЗУЛЬТАТОВ
17.23. Опишите главные отклонения от протокола [5].
Исследование может отклоняться от письменного протокола по нескольким причинам:
вопрос исследования был настолько обширен, что слишком много цитат было отобрано,
или настолько узок, что поиск не включил статьи, представляющие интерес; нужные
данные не были должным образом представлены или изученные пациенты не представляли
интереса. Хотя разведочные поиски могут отобрать некоторые из этих изданий перед
полным поиском, иногда протокол должен быть изменен, чтобы более четко сфокусировать
цель исследования.
17.24. Сообщите дату самого последнего литературного поиска или обновления.
Большинство систематических обзоров и метаанализов рассматривают литературу
от настоящего времени назад до указанной даты. Однако время, затраченное на то, чтобы
проанализировать данные и опубликовать результаты этого анализа, может означать, что
литературный поиск может оказаться одно- или двухлетней давности со времени
публикации. По этой причине авторы часто обновляют результаты поиска незадолго до
публикации, чтобы добавить новейшие статьи.
17.25. Укажите количество и статус исследовательских отчетов на каждой стадии
обзора.
Количество и статус исследовательских отчетов на каждой стадии обзора легко
представить в виде текста, таблицы или краткого схематического резюме (рис. 17.3).
Исследователи должны сохранять список научных работ, не только полученных и
рассмотренных, но и тех, которые были исключены из обзора, а также причины их
исключения. По возможности, этот список должен быть включен в опубликованный обзор [5].
17.26. Сообщите меру согласия при выборе исследовательских отчетов, которые
будут использованы, и, если возможно, определите источник любых
разногласий.
Часто представляют процент согласующихся решений, или каппа-статистику, чтобы
показать степень согласие (между экспертами). На этой стадии исследования повсеместный
поиск более предпочтителен, нежели ограниченный поиск. Смещение может быть
привнесено, если, скажем, ручной поиск библиографий разделен среди исследователей и один
исследователь более настойчив, чем другой, в требовании, чтобы цитаты были найдены.
Отчет о систематических обзорах и метаанализе 261
Результаты поиска баз данных по статьям с результатами
медсестринского ухода за пациентами
MEDLINE №1
Л/=1085
MEDLINE №2
Л/= 682
MEDLINE №3
Л/= 477
CINAHL
Л/=535
Уникальные найденные ссылки — 2897
Статьи, которые необходимо найти — 493
Каппа = 0,41
Статьи, которые были найдены — 490 (99,5 %)
Каппа = 0,67
Статьи, включенные в обзор — 43
Каппа = 0,86
ABI / Inform
Л/=124
Рис. 17.3. Схематическое резюме систематического обзора литературы, указывающее количество и статус
сообщений об исследованиях на каждой стадии обзора
1127. Опишите меру согласия по отбору ссылок по найденным сообщениям об
исследованиях, которые будут включены в обзор, и, если возможно,
сформулируйте источник любых разногласий.
кроме того, часто сообщают процент согласованных решений, или каппа-статистику,
чтобы показать степень согласия. Согласие на этой стадии исследования является
более критическим, чем когда найденные по ссылкам исследовательские отчеты будут уже
доставлены.
17.28. Опишите меру согласия по точноаи извлечения данных и, если возможно,
сформулируйте источник любых разногласий.
Кроме того, часто сообщают процент согласованных решений, или каппа-статистику,
чтобы показать степень согласия.
17.29. Суммируйте описательные характеристики исследований, включенных
в обзор [5].
Типичными характеристиками, включенными в такое резюме, являются: год
публикации, местоположение и даты сбора исходных данных, изученная популяция (диагнозы),
вмешательства, альтернативные способы лечения, размер выборки, дизайн исследования,
ковариаты (сопутствующие влияющие факторы) и конечные точки.
262 Составление отчетов по обобщающим методам исследования
1730. Оцените вероятность смещения в каждом исследовании, включенном в
обзор (оцените качество исследования) [5].
в любых приложениях более высококачественные исследования обычно более
желательны, чем исследования более низкого качества. Здесь качество относится к
«внутренней обоснованности» исследования: насколько точно результаты исследования отражают
основную биологическую реальность. Главной угрозой внутренней обоснованности
является смещение: систематические отклонения в правильности результатов.
Оценка смещения в исследовании может быть проблематичной [22]. Плохие или
неполные описания дизайна и мероприятий в исследовательских отчетах могут помешать
адекватной оценке такого смещения. В отсутствие объективных мер (см. ниже) необходимо
авторитетное мнение исследователя. Наконец, смещение может быть связанным с исходами
в пределах отчета, также влияющим на исследование в целом.
Качество исследования, как правило, оценивается одним из двух способов. В первом
случае вероятность смещения определяется позицией дизайна исследования в «иерархии
доказательств» (табл. 17.1) [23]. Таким образом, результаты рандомизированных
исследований могли бы иметь больший вес, чем, например, результаты испытаний «случай-
контроль». Однако результаты хорошо проведенного испытания «случай-контроль» могут
быть более точными, чем аналогичные плохо выполненные рандомизированные
испытания, так что и этот подход не лишен проблем.
В другой форме оценки качества присутствие или отсутствие информации в отчете
исследования используются, чтобы оценить вероятность смещения. Исследования с
требуемыми компонентами признаются как менее восприимчивые к смещению, чем исследования
без них. Обычно оцениваемые компоненты включают: действительно случайное
распределение, достаточное сокрытие списка назначений, использование «ослепления», успех
«ослепления», использование анализа стремления к лечению, адекватный объем выборки,
соответствующий контроль сопутствующих переменных и т. д. Иногда присутствие или
отсутствие отдельных компонентов взвешивается численно, чтобы создать шкалу качества
и продемонстрировать «качество» исследования. Были созданы десятки таких шкал
качества [24].
Таблица 17,1
«Иерархия доказательств», в которой дизайны" клинических исследований упорядочены по их
восприимчивости к смещению
1. Сообщения, содержащие необычные истории болезни отдельных пациентов
2. Серия случаев в отсутствие контроля
3. Серия случаев с историческим контролем из литературы
4. Исследования клинических баз данных или регистрации
5. Исследования «случай-контроль»
6. Когортные исследования
7. Единичные рандомизированные контролируемые испытания
8. Подтвержденные рандомизированные контролируемые испытания
9. Метаанализ рандомизированных контролируемых испытаний (дискуссионно)
^ Дизайны сверху вниз рассматриваются как менее восприимчивые к смещению.
По: Green SB, Byar DP. Using observational data from registries to compare treatments: the fallacy of omnimetrics.
Stat Med. 1984;3:361-70.
Отчет о систематических обзорах и метаанализе 263
Balk и соавт. рассмотрели 276 статей из 26 метаанализов, чтобы определить, было ли
наличие или отсутствие любой из 24 единиц измерения качества систематически связано
с различиями в направлении или величине результатов [14]. Не было обнаружено ни одной
такой работы. В другом исследовании Juni и соавт. использовали 25 шкал оценки качества,
чтобы оценить каждое из 17 испытаний гепарина низкомолекулярной массы [25].
Согласование среди ранжирований было низким; испытание, оцениваемое как высококачественное
по одной шкале, могло быть оценено как низкокачественное по другой или как среднего
качества по третьей. Исследователи тогда разделили эти 17 испытаний на исследования
высокого и низкого качества, используя каждую из 25 шкал. Затем они выполнили 25
метаанализов, по одному для каждой оценочной шкалы, используя только высококачественные
исследования из такой шкалы, и сравнили полученные результаты для всех анализов.
Направление, величина и статистическая значимость общих результатов зависели от того, какая
шкала была использована, и ни одна из 25 оценок качества не была значимо связана с
величиной эффекта. Таким образом, использование шкал оценки качества проблематично.
Хотя объективные измерения качества для клинических испытаний остаются
ненадежными, некоторые индикаторы качества исследований полезны при объединении
результатов различных исследований. Проблемы со случайными назначениями, сокрытие
распределения назначений и в особенности использование методики «ослепления» были связаны
с различиями в результатах лечения и должны быть рассмотрены в любой оценке качества
рандомизированных испытаний. Обычно два или более рецензентов индивидуально
оценивают качество каждого исследования, используя при этом методику «ослепления» к составу
авторов исследования и результатам исследования, и затем встречаются, чтобы принять
решение по каждому разногласию. В таких случаях полезно включить меру измерения
межэкспертной надежности, чтобы установить согласованность оценки качества [8, 12].
В систематических обзорах и метаанализе оценки показателей качества могут
использоваться: 1) как пороговые уровни качества для исследований, которые должны быть
включены в анализ, 2) как возможные объяснения различий между исследованиями, 3) для анализа
чувствительности при изучении устойчивости полученных заключений или 4) как вес в
метаанализе, чтобы более высококачественные изучения вносили больший вклад в
объединенный анализ, чем исследования более низкого качества.
1731. Сообщите результат(ы) каждого сообщения об исследовании. Для метаана-
лиза сообщите также объединенную оцененную величину эффекта,
доверительный интервал для оценки и количество исследований и пациентов,
представленных в этой оценке [5].
Для биномимальных исходов (жив или умер, вылечен или нет) сообщите о количестве
пациентов в каждой группе и количестве или проценте пациентов в каждой группе, у
которых наблюдался исход. Для непрерывных исходов (уровни сыворотки, время до
наступления события) сообщите меру центральной тенденции (обычно среднее или медиана)
и меры рассеяния (обычно СО или интерквартильный размах) для распределения исхода
в каждой группе.
Результаты систематических обзоров часто представляются в наглядных таблицах,
особенно когда исходы в исследованиях различаются (табл. 17.2). Когда исходы выражены
в тех же единицах, в каких они обычно представлены в метаанализе, результаты часто
представляются в виде «лесной диаграммы» (или в виде графика «метки и линии»), в которой
264 Составление отчетов по обобщающим методам исследования
оцененный эффект лечения и его 95% ДИ показаны графически (рис. 17.4). Оцененный
эффект лечения может быть выражен шансом, логарифмом шансов, риском или отношением
рисков, хотя могут быть использованы и другие меры.
Таблица 17,2
Образец таблицы доказательности, показывающей результаты из систематического обзора
влияния сестринского персонала на уровень смертности в больнице в течение 30 дней после
того, как были отмечены осложнения (мера сестринского исхода названа «неуспех в спасении»)
Исследование''
Дизайн
должительность в
месяцах)''
Год данных
(количество
больниц/
количество
регистр, единиц/
количество
пациентов)''
Влияние на неуспех
в спасении (смерть Клини-
в пределах больницы ческий
в течение 30 дней после класс^
осложнений)*'
стический
класс^
ColJns
(2000)
Stevens
(2000)
Shelly
(2000)
Поперечное
исследование
(20)
Поперечное
исследование
(20)
Ретроспективное иследова-
ние(12)
1998->1999
(168/10184/232 342)
1998-1999(168/
НП/232 342)
1997(799/НП/НП)
Прирост на 1 хирургического
пациента через медсестру
к больничному персоналу
увеличил неуспех в спасении около
7 % (отношение шансов 1,07
95% ДИ 1,02-1,11)
Среди хирургических пациентов
каждые 10 % увеличения (в %)
обученных бакалавров и
магистров к дипломированным
медсестрам были связаны с
уменьшением на 5 % в неуспехах
в спасении; ОШ = 0,95 (95% ДИ
0,91-0,99; р = 0,02)
Среди медицинских пациентов
прирост нагрузки средней
дипломированной медсестры
в часах/день от 6,4 до 9,1 привел
к несоответствующему влиянию
на неуспехи в спасении.
(Прирост менялся от 13,6 до 22,6 %
среди больниц)
НП — не применимо.
^ Автор и год публикации сообщения об исследовании.
^ Дизайн исследования и период времени (в месяцах), для которого были собраны данные.
^: «Год данных» — это год, в котором данные были собраны.
"^ Заключение, используемое в обзоре.
^ Клиническая стадия, кодируемая знаком «минус» для несущественных величин эффектов, знаком «вопроса»
для неопределенных величин эффекта и знаком «плюс» для величины эффекта, рассматриваемого как
клинически важный. Клинические классы были установлены независимо друг от друга тремя исследователями;
противоречия были разрешены обсуждением.
^Статистическая стадия, кодируемая знаком «минус» для статистически незначимых эффектов, знаком «вопрос»
для статистически неопределенных эффектов значимости и знаком «плюс» для статистически значимых
эффектов. Статистические результаты были взяты из опубликованных статей.
Отчет о систематических обзорах и метаанализе 265
1732* Укажите степень доказательности для каждого исхода.
Степень доказательности может быть показана качеством или количеством
исследований, выдающих один и тот же результат.
1733, Проверьте влияние отбора и предположений при помощи анализа
чувствительности, чтобы установить их воздействие на результат [5].
в анализе чувствительности некоторые исследования исключают, чтобы определить, как
их исключение повлияет на результаты. Если эффект исключения является большим,
исключенные исследования могут быть вновь внесены в анализ, чтобы определить,
гарантирован ли их непропорциональный эффект на результаты. Если эффект является маленьким,
результаты могут быть более репрезентативными для всех исследований.
УКАЗАНИЯ ОТНОСИТЕЛЬНО ОБСУЖДЕНИЯ РЕЗУЛЬТАТОВ
1734. Суммируйте ключевые результаты обзора, используя как благоприятные
результаты, так и результаты, наносящие вред.
Исследование 1 (п = 74)
Исследование 2 (п = 239)
Исследование 3 (п = 32)
Исследование 4 (п = 101)
Исследование 5 (п = 126)
Исследование 6 (п = 53)
Исследование 7 {п = 398)
Исследование 8 (п = 82)
Исследование 9 (п = 498)
ВСЕГО (л = 1603)
0,5
Уменьшенный риск
2,0
Увеличенный риск
Отношение шансов
Рис. 17.4. «Лесная диаграмма» для представления результатов метаанализа. Для каждого исследования
показаны оцененное среднее отношение шансов и границы 95% ДИ; общее оцененное отношение шансов
обозначено пунктиром. Отношение шансов, равное 1 (и отношение риска 1), означает, что лечение ни увеличивает,
ни уменьшает риск результата, представляющего интерес. Здесь 95% ДИ для обобщенного отношения шансов
не пересекает 1, указывая итоговый эффект, статистически значимый при критическом уровне 0,05
266 Составление отчетов по обобщающим методам исследования
1735. Обсудите клиническую и методологическую вариабельноаь и для метаанали-
за аатиаическую гетерогенноаь результатов отдельных исследований [5].
Поскольку систематические обзоры и метаанализ рассматривают результаты нескольких
исследований, степень согласия среди результатов этих исследований — «гомогенность»
или «гетерогенность» результатов — может влиять на интерпретацию и поэтому
должна быть специальным образом отражена в отчете. Однородные, гомогенные, результаты
легче интерпретируются, потому что они схожи; неоднородные, гетерогенные, результаты
сложнее интерпретировать, потому что должна быть объяснена большая вариабельность
в результатах.
В частности, различия в направлении результатов могут представлять определенную
трудность. Если результаты некоторых исследований показывали, что результаты были
благоприятны для группы лечения, тогда как результаты других исследований говорят, что
результат был благоприятен для группы контроля, то объединенные результаты могут быть
гетерогенными, если разброс среди них превосходит тот, который мог бы рассматриваться
как случайный.
Точно так же могут быть важны различия в величине эффекта. Если в некоторых
исследованиях сделано заключение, что препарат был высокоэффективным, в то время как
в других получено, что этот эффект был незначительным, результаты могут снова быть
гетерогенными, если разброс среди них превосходит тот, который мог бы рассматриваться
как случайный.
Один из признаков гетерогенности — статистическая значимость различий среди
результатов отдельных исследований. Различия могут быть сопоставлены с помощью
проверки гипотез (например, критерием хи-квадрат для гипотезы гомогенности или с помощью
F-критерия), и если/7-значение окажется меньше, чем, например, 0,1, тогда можно
предположить наличие и других факторов, кроме случайных: возможно, исследования были слишком
несхожими, чтобы сравнивать их в первую очередь, или есть различия в требованиях отбора,
популяциях пациентов, измерительной технике или оценке различий в исследованиях [1].
Хороший способ описать гетерогенность результатов — диаграмма L'Abbe (рис. 17.5),
которая графически показывает частоту ответов контрольной группы относительно
частоты ответов лечебной группы для каждого исследования [8]. Таким образом, точки,
рассредоточенные по графику, обозначают гетерогенные результаты, в то время как точки,
образующие тесную группу, представляют более гомогенные результаты.
1736. Предложите объяснение результатов, включая любую вариабельность в
результатах.
17.37. Поместите результаты в контексте того, что еще известно о проблеме [5].
17.38. Предложите, как эти результаты могли бы быть обобщены.
17.39. Обсудите последствия результатов.
Поскольку систематические обзоры являются всеобъемлющими, они могут быть
использованы для того, чтобы определить расхождение во взглядах в литературе. В результате они
могут указывать области, где необходимо исследование, и, таким образом, предложить
программу исследования, основанную на этих результатах [5, 26].
Отчет о систематических обзорах и метаанализе 267
1,0
0,8
Ф
У
ф
ф
с
с
СО
S
S
10 исследований
(о) с результатами,
относительно
гомогенными по
направлению и
величине
Результаты,
благоприятные
для группы
0,4 \-
О
i
(О 0,2
Результаты,
благоприятные
для группы
контроля
10 исследований
(а) с результатами,
относительно
гетерогенными по
направлению и
величине
о 0,2 0,4 0,6 0,8 1,0
Частота отклика в группе контроля
Рис. 17.5. Диаграмма L'Abbe показывает гетерогенность результатов отдельных исследований при помощи
изображения частоты ответов контрольной группы относительно частоты ответов лечебной группы для
каждого исследования. Точки, рассеянные по графику, показывают гетерогенные результаты; точки, образующие
более тесную группу, показывают более гомогенные результаты. Кроме того, знаки вдоль диагонали с наклоном
45 градусов показывают сходные результаты как в лечебной, так и в контрольной группах, а знаки, удаленные
от нуля, показывают большие частоты ответов
Ограничения исследования
17«40. Обсудите любые ограничения исследования. Представьте возможные
источники и последствия смещения, вмешательав и ошибок.
Выводы
17.41. Представьте список выводов, подкрепленных обзором.
ДРУГИЕ ТИПЫ МЕТААНАЛИЗА
Кумулятивный метаанализ — это практика проведения метаанализа в течение
длительного времени путем добавления дополнительных исследований к метаанализу, по мере
того как они становятся доступными, и пересчет результатов после каждого добавленного
исследования. Такая практика позволяет подтверждать результаты лечения как можно
скорее, возможно, урегулировав вопрос и сократив количество дополнительных исследований
и количество дополнительных пациентов, которые могут быть подвергнуты риску.
Например, Lau и соавт. [27] провели кумулятивный метаанализ по эффективности стреп-
токиназы в лечении острого инфаркта миокарда. Они проанализировали 33 РКИ по стреп-
токиназе, проводимых в течение 29 лет и включающих в общей сложности 36 974
пациента. Их результаты (рис. 17.6) показывают, что эффективность стрептокиназы была
установлена статистически с публикацией седьмого исследования. Однако еще 25 исследований.
268 Составление отчетов по обобщающим методам исследования
включающих 34 542 дополнительных пациента, были проведены в течение 15 лет, прежде
чем стрептокиназа была в целом принята как эффективное средство лечения.
Рекомендации в этой главе также подходят для сообщения о кумулятивных метаанализах
с добавлением диаграмм, подобно рис. 17.6, чтобы проиллюстрировать кумулятивный
эффект от каждого дополнительного исследования. Из-за того, что кумулятивный метаанализ
включает данные по мере их накопления, также должна быть опубликована любая
корректировка для множественных анализов.
Метаанализ индивидуальных данных пациента (MAIPD от англ. meta-analysis of
individual patient data) включает в себя объединение данных от отдельных пациентов,
подвергшихся лечению в двух или более исследованиях. Таким образом, вместо того, чтобы
полагаться на собранные результаты, опубликованные в научных статьях, методы MAIPD
используют, по существу, исходные индивидуальные данные от каждого из исследований,
включенных в анализ. Они требуют гораздо большего количества экспертизы, времени,
усилий и ресурсов, чем другие виды метаанализа, но они также имеют ряд больших
преимуществ. Они обеспечивают наиболее всесторонний и надежный способ оценки
результатов рандомизированных клинических испытаний. Они позволяют применять метаанали-
Исследование
Fletcher
Dewar
European 1
European 2
Не!к1пЬе1гло
Italian
Australian 1
Frankfurt 2
NHLBISMIT
Frank
Valere
Klein
UKCollab
Austrian
Australian 2
Lasierra
NGerCollab
Witchltz
European 3
ISAM
GISSI-1
Olson
Barotfio
Schreiber
Cribier
Salnsous
Durand
White
Bassand
Vlay
Kennedy
ISIS-2
Wisenberg
Итого
Число 0,1
Год пациентов
Индивидуальный анализ и обычный
метаанализ (отношение шансов)
0,2 0,5 1 2 5 10
Кумулятивный метод Мантеля—Хэнзеля
(отношение шансов)
Число 0,5
1959
1963
1969
1971
1971
1971
1973
1973
1974
1975
1975
1976
1976
1977
1977
1977
1977
1977
1979
1986
1986
1986
1986
1986
1986
1986
1987
1987
1987
1988
1988
1988
1988
23
42
167
730
426
321
517
206
107
108
91
23
595
728
230
24
483
58
315
1741
11712
52
59 f
38
44
98
64
219
107
25
368
17187
66
36974
1 ММ""
1 ' ^'
1 2
1 -г^
' А П
II
I I
1 1
1 ^ -^
1 1^1
' 'а
1 ' '
Т ' ^ '
; j
II
1 1 •
1 ^1 1
' '•
■ '
1*1
; ; ^
1 1 ■•■
—1—1—
1 I
1 1
* ' '
; ;
1 1
' '
I 1
1 1
Z =-4,16, Р<} 0.001
пациентов
23
65
232
962
1388
1709
2226
2432
2539
2647
2738
2761
3356
4084
4314
4338
4821
4879
5194
6935
18647
18699
18758
18796
18840
18938
19002
19221
19328
19353
19721
36908
36974
1 ' 1 1 1
т
1
1
1
1 *_
*
^
_| 1 1 1 1 1 1 1 1_|
Z =-2,28, Р< 0.023 1
Z =-2,69, Р< 0.071
Z =-3,37, Р< 0.001
Z =-8,16, Р< 0.001
В пользу лечения В пользу контроля
В пользу лечения В пользу контроля
Рис. 17.6. Результаты кумулятивного метаанализа. Поскольку каждое исследование добавляется к вычислениям,
эффективный размер выборки возрастает, а точность оцененных результатов улучшается, что показано
укорочением горизонтальной линии, представляющей 95% ДИ. Эта диаграмма показывает, что результаты были
статистически значимы после седьмого исследования. Оцененная величина эффекта также стабилизируется по мере того, как
объем выборки возрастает (Из Lau J., Antman Е. М., Jimenez-Silva J., et al. Cumulative meta-analysis of therapeutic trials
for myocardial infarction. N Engl J Med. 1992;327:250; with permission. Copyright ©1992, Massachusetts Medical Society)
Отчет о систематических обзорах и метаанализе 269
тические методы к анализам данных типа «времени до наступления события» и
являются наилучшим способом выполнения анализа подгрупп. Они также позволяют провести
детальную проверку данных, которая улучшает полноту и точность включенных данных,
и оценить целостность рандомизации и последующих процедур оценки.
Мета-регрессионный анализ концептуально подобен любому другому регрессионному
анализу, за исключением того, что данными являются скорее результаты или
характеристики отдельных исследований, а не значения от отдельных пациентов. Мета-регрессия
используется, чтобы исследовать взаимоотношения между характеристиками исследования
с одним или более уровнями (такими, как объем выборки, дозы препарата или
длительность лечения) и исходами.
Например, в одном мета-регрессионном анализе величина эффекта лечения (отношение
шансов для каждого исследования) была изображена графически в сравнении с частотой
событий в контрольной группе (мерой того, сколько отрицательных результатов могло бы
быть предотвращено, если бы лечение было эффективным) для исследований, включенных
в метаанализ, и для мега-испытаний, результаты которых противоречили аналогичным
результатам метаанализа. Линия регрессии показала, что очевидно отличающиеся результаты
были фактически совместимы, потому что величина эффекта была связана с частотой
событий в группе контроля. В мега-испытании отрицательный исход имела такая малая часть
контрольной группы, что лечение не имело шансов быть эффективным.
Рекомендации в этой главе также подходят для описания мета-регрессионного анализа
с добавлением рисунка, сходного с рис. 7.1 (с. 104), чтобы показать диаграмму рассеяния
и линию регрессии.
Благодарности
Мы благодарим Bart Harvey, MD, МРН, за его вдумчивый просмотр этой главы.
Литература
1. Dickersin К, Berlin JA. Meta-analysis: state-of-the-science. Epidemiol Rev. 1992; 14:154-76.
2. Borzak S, Ridker PM. Discordance between meta-analyses and large-scale randomized, controlled
trials: examples from the management of acute myocardial infarction. Ann Intern Med. 1995; 123:873-7.
3. Cappelleri JC, loannidis JPA, Schmid CH, et al. Large trials vs meta-analysis of smaller trials. How
do their results compare? JAMA. 1996; 276:1332-8.
4. LeLorier J, Gregoire G, Benhaddad A, et al. Discrepancies between meta-analyses and subsequent
large randomized controlled trials. N Engl J Med 1997; 337:536-42.
5. Cook DJ, Sackett DL, Spitzer WO. Methodologic guidelines for systematic reviews of
randomized control trials in health care from the Potsdam Consultation on Meta-analysis. J Clin Epidemiol. 1995;
48:167-71.
6. Hillman AL, Eisenberg JM, Pauly MV, et al. Avoiding bias in the conduct and reporting of cost-
effectiveness research sponsored by pharmaceutical companies. N Engl J Med. 1991; 324:1362-5.
7. Journal of the American Medical Association. Instructions for preparing structured abstracts. JAMA.
1993;271:162-4.
8. Wilson A, Henry DA. Meta-analysis. Part 2: Assessing the quality of published meta-analyses. Med J
Aust. 1992; 156:173-87.
9. Simes J. Meta-analysis: its importance in cost-effectiveness studies. Med J Aust. 1990;
153(Suppl):S13-6.
270 Составление отчетов по обобщающим методам исследования
10. Kassirer JP. Clinical trials and meta-analysis. What do they do for us? [Editorial]. N Engl J Med.
1992;327:273-4.
11. West RR. A look at the statistical overview (or meta-analysis).! R Coll Physicians Lond. 1993;
27:111-5.
12. Felson DT. Bias in meta-analytic research. J Clin Epidemiol. 1992; 45:885-92.
13. Bero L, Rennie D. The Cochrane Collaboration. Preparing, maintaining, and disseminating
systematic reviews of the effects of health care. JAMA. 1995; 274:1935-8.
14. Balk EM, Bonis PA, Moskowitz H, et al Correlation of quality measures with estimates of treatment
effect in meta-analyses of randomized controlled trials. JAMA 2002; 287:2973-82.
15. Dickersin K. The existence of publication bias and risk factors for its occurrence. JAMA. 1990;
263:1385-9.
16. Light RJ, Pillemer DB. Summing Up: The Science of Reviewing Research. Cambridge, MA: Harvard
University Press; 1984.
17. Andersen JW, Harrington D. Meta-analyses need new publication standards [Editorial]. J Clin Oncol.
1992; 10:878-80.
18. Henry DA, Wilson A. Meta-analysis. Part 1: An assessment of its aims, validity and reliability. Med J
Aust. 1992;156:173-87.
19. Jones DR. Meta-analysis of observational epidemiological studies: a review. J R Soc Med. 1992;
85:165-8.
20. Lau J, loannidis JPA, Schmid CH. Quantitative synthesis in systematic reviews. Ann Intern Med.
1997; 127:820-6.
21. Walter SD. Methods of reporting statistical results from medical research studies. Am J Epidemiol.
1995;141:896-906.
22. Lohr KN, Carey TS. Assessing "best evidence": issues in grading the quality of studies for systematic
reviews. J Qual Improve. 1999; 25:470-9.
23. Green SB, Byar DP. Using observational data from registries to compare treatments: the fallacy of
omnimetrics. Stat Med. 1984; 3:361-70.
24. Moher D, Jadad AR, Nichol G, et al. Assessing the quality of randomized controlled trials: an
annotated bibliography of scales and checklists. Control Clin Trials. 1995; 16:62-73.
25. Juni P, Witschi A, Bloch R, Egger M. The hazards of scoring the quality of clinical trials for
metaanalysis. JAMA 1999; 282:1054-60.
26. Guyatt GH, Sackett DL, Sinclair JC, et al Users' guides to the medical literature. IX: a method for
grading health care recommendations. The Evidence-Based Medicine Group. JAMA. 1995; 274:1800-4.
27. Lau J, Antman EM, Jimenez-Silva J, et al. Cumulative meta-analysis of therapeutic trials for
myocardial infarction. N Engl J Med. 1992; 327:248-54.
Описание экономических оценок 271
Глава 18
Взвешивание затрат и последствий
лечения
Описание экономических оценок
Основная ценность формального анализа рентабельности в здравоохранении
состоит в том, что он вызывает явное доверие и справедливую оценку, леэюа-
щие в основе решений об ассигнованиях.
М. С. Weinstein, ж в. Stason [1]
Компоненты системы здравоохранения находятся под постоянным давлением для
контроля над затратами, улучшения качества лечения пациентов, обеспечения более
соответствующего ухода и повышения ответственности за лечение и деловые решения. Для
внедрения этих решений появилось несколько связанных методологий: технологическая оценка,
медицинское обслуживание или исследование исходов лечения, фармакоэкономика, анализ
решений, практические руководства, клиническая эпидемиология, доказательная медицина
и широкая область, называемая экономической оценкой, — ветвь медицинской
экономики, заинтересованная в оценке затрат, исходов и компромиссов между альтернативными
методами лечения.
Важным стимулом для экономических оценок является область фармакоэкономики,
исследующая экономическую значимость лечения. Такие исследования могут
потребоваться как часть процесса разрешения препарата и часто используются в продажах и рекламных
кампаниях. Сторонники фармакоэкономики говорят о необходимости озвучить
рентабельность прописывания лекарств, основанную на твердых данных; противники видят в фар-
макоэкономике маркетинговую уловку фармацевтических компаний и область предвзятых
исследований.
Поэтому многие рекомендации для отчетов по экономическим оценкам направлены
на предотвращение откровенного смещения в фармакоэкономических исследованиях.
Однако методология может использоваться как руководство по применению других методов
лечения, так же как лекарственной терапии: политики здравоохранения, клинических
процедур, диагностических тестов или программ обучения пациентов. Экономические оценки
дают общее представление, а необязательно ответы и чаще всего используются
администраторами и высшими руководителями, а не отдельными врачами.
Здесь включены описания уточнения стоимости, минимизации затрат и исследований
стоимости лечения заболеваний. Большинство руководящих принципов, однако, относится
к анализам затрат—выгод, рентабельности и полезной стоимости, в которых сравниваются
два или более методов лечения. Любой тип экономической оценки должен быть описан
точно, ясно и полностью и должен быть воспроизводимым.
272 Составление отчетов по обобщающим методам исследования
УКАЗАНИЯ ПО ОФОРМЛЕНИЮ ВВЕДЕНИЯ
18.1 • Документируйте истоки, сущноаь, возможности и важность проблемы,
которая привела к исследованию.
18.2* Установите общую цель исследования. Определите изучаемое лечение
и основания для его изучения.
Проблема исследования, как и во всех научных исследованиях, должна быть
проблемой, на которую может быть получен ответ в недвусмысленных терминах. Первичные цели
должны отличаться от вторичных. Формулировка цели должна определять следующее:
• методы лечения, которые будут оценены или сравнены;
• диагнозы или используемые симптомы и популяцию пациентов, для которых
предназначены методы лечения;
• условия, в которых обычно применяются методы лечения;
• поставщики, предоставляющие лечение;
• тип предпринятой экономической оценки {см. указание 18.3);
• почему эти методы лечения сравниваются и почему теперь.
В основном, экономическая оценка подходит для оценки дорогостоящих методов
лечения, которые имеют широкое применение и, следовательно, общую высокую стоимость,
или методов лечения, дающих большую выгоду, несмотря на относительную дороговизну
по сравнению с альтернативными методами.
Уместно также отметить, почему методы лечения оцениваются в настоящее время. Одной
из проблем экономических оценок является выбор времени оценки относительно развития
вмешательства. Поскольку технологии имеют тенденцию улучшаться со временем,
преждевременная оценка развития вмешательства может не в достаточной мере отразить его
возможную ценность.
Несколько типовых исследовательских вопросов:
• Действительно ли рентабельна вакцинация здоровых людей в возрасте старше 65 лет
против Гонконгского гриппа?
• Какой график колоноскопического тестирования на рак будет оптимальным с точки
зрения расчета затрат и результатов для больных хроническим язвенным колитом?
• Была бы рентабельной обычная замена /-РА на стрептокиназу у больных,
нуждающихся в тромболитической терапии острого инфаркта миокарда?
183. Определите предпринятый тип экономической оценки и объясните
причины выбора.
Термины различных экономических оценок часто путаются. Самые общие типы
экономической оценки приведены ниже:
• Анализ стоимости стремится определить затраты на лечение. Этот тип анализа
является первым шагом во всех других типах анализов, но это часто является
единственной экономической оценкой, предпринятой в исследовании, или только о ней
сообщают.
• Анализ минимизации стоимости стремится определить наименее дорогое
альтернативное вмешательство. Этот тип анализа исходит из того, что различия в исходах
несущественны или неважны, таким образом сравниваются только денежные затраты
Описание экономических оценок 273
методов лечения. Например, больница могла бы провести исследование, чтобы
решить, заменить или отремонтировать рентгеновский аппарат.
• Анализ стоимости болезни оценивает общую стоимость болезни или
нетрудоспособности для общества, изучая общую стоимость медицинского диагноза, лечения
и потерянной трудоспособности. Такой анализ приводит к единой сумме в долларах,
которая выражает общее значение воздействия болезни на всю экономику. Например,
утверждение, что болезни сердца стоят Соединенным Штатам 128 млрд долларов
ежегодно, является результатом исследования стоимости болезни.
• Анализ затрат—выгод оценивает один или более методов лечения на основе
денежных затрат и денежных выгод. В анализе затрат—выгод все результаты выражены
в долларах, включая жизнь или годы жизни. Таким образом, затраты—выгоды
программ по профилактике глаукомы можно сравнить с таковыми по трансплантации
сердца и обе можно сравнить с затратами—выгодами других программ, таких как
развитие шоссе или профессиональная подготовка.
• Анализ рентабельности сравнивает два или более методов лечения на основе
денежных затрат и клинической эффективности. О результатах обычно сообщают в
единицах «доллар на клинический исход», таких как доллары на спасенную жизнь, доллары
на дополнительные годы жизни или доллары на число новых диагностированных
случаев. Исходы методов лечения для сравнения в анализе рентабельности должны быть
выражены в тех же самых единицах.
• Анализ стоимости последствий — форма анализа рентабельности, в котором
увеличивающиеся затраты (такие, как стоимость лечения, госпитализации или лекарств)
и последствия (состояние здоровья, отрицательные воздействия и т. д.)
альтернативных вмешательств или программ сравниваются непосредственно, без выражения
результатов в виде отношения стоимость/исход.
• Анализ полезной стоимости оценивает два или несколько методов лечения на основе
денежных затрат и меры «полезности», которая является произведением
клинического исхода, такого как годы жизни, на субъективную оценку качества жизни в течение
этих лет. Эта мера обычно берется из любого из нескольких индексов статуса
здоровья. Полезность выражена в таких единицах, как годы с повышенным качеством
жизни (QALY) или количество «благополучных лет».
Анализы установления стоимости, минимизации затрат и стоимости болезни обычно
являются описательными и многие из указаний, приведенных здесь, могут быть применены
в отчетах о результатах таких исследований. Анализы затрат—выгод, рентабельности,
стоимости последствий и полезной стоимости обычно носят сравнительный характер, и все
рекомендации, приводимые в этом разделе, могут быть применены к ним.
18.4. Сформулируйте перспективы проектировщикам оценки.
Экономические оценки должны интерпретироваться с учетом потребностей, интересов
и ценности проектировщиков. Например, суммарная стоимость могла бы представлять
интерес для организаций медицинского обеспечения, тогда как общественные больницы
могли бы интересовать только невозмещаемые затраты. Проектировщики могут предоставить
сведения о любой из нескольких перспектив для:
• общества в целом;
• фармацевтической компании;
274 Составление отчетов по обобщающим методам исследования
• плательщика третьей стороны (например, страховой компании);
• группы управляемого медицинского обеспечения;
• общественной больницы;
• популяции пациентов или диагностической группы.
В некоторых случаях интересы могут противоречить друг другу. Например, страховые
агентства могут возместить пациентам затраты на госпитализацию, но не оплачивать
лечение на дому. Такая политика может принудить врачей держать менее обеспеченных
пациентов в больнице дольше (рациональный выбор, с точки зрения врача, для перспективы
обеспечения каждого пациента всесторонней заботой), сократить личные затраты
пациентов (желательно с точки зрения перспективы пациента), но за счет увеличения страховых
(нежелательных с позиции перспективы плательщика) и общих медицинских затрат
(нежелательно с точки зрения социальной перспективы).
Хотя социальная перспектива является самой широкой и, как часто полагают, должна
быть самой желательной для экономической оценки, большинство решений об
ассигнованиях принимаются сторонами с другими перспективами [2].
Q Выдвиньте на первый план любую часть оценки, которая отклоняется от
установленной перспективы [3]. Не всегда возможно получить данные,
соответствующие желательной перспективе. Исследование препарата, проводимое в рамках
социальной перспективы, как можно ожидать, будет использовать оптовые затраты,
но, вероятно, вместо этого придется использовать розничные цены или счета. Такое
отьйюнение от установленной перспективы должно быть отмечено в
методологическом разделе отчета.
18«5* Определите организацию, которая финансировала исследование, и
опишите роль финансового органа в руководстве исследованием и публикации
результатов.
Результаты экономических оценок часто влияют на предпочтение одного вида
вмешательства другому и, таким образом, могут иметь огромное финансовое значение. Поскольку
фармацевтические, биотехнологические компании и компании по производству
медицинского оборудования финансируют множество экономических оценок (область фармакоэко-
номики) и могут использовать результаты для повышения продаж своих продуктов, стала
важной потребность в установлении независимости и объективности исследователя.
Все экономические оценки включают в себя неопределенность, которая может быть
разрешена (склонена) за или против вмешательства в ходе исследования. Таким образом, в
экономических оценках важна потребность в прямом непредубежденном отчете. Возможность
финансового стимулирования отклонений в оценках представляется столь серьезной, что
некоторые журналы не будут издавать экономические оценки авторов, у которых был
финансовый конфликт интересов со спонсирующей организацией [4].
Исследователи, которые являются владельцами акций, оплачиваемыми консультантами
или служащими компаний с финансовыми интересами в исследуемых методах лечения,
необязательно испытывают влияние с какой-либо стороны и необязательно их участие неэтично,
но они действительно должны сообщить о своих отношениях с организацией, которая
финансировала исследование. Далее, если финансирующая организация наложила какие-нибудь
ограничения на исследование, то они должны быть раскрыты в опубликованной статье [5].
Описание экономических оценок 275
18.6. Определите, как могут быть получены протокол и первоначальные данные.
УКАЗАНИЯ ОТНОСИТЕЛЬНО МЕТОДОВ
18.7. Опишите сравниваемые методы лечения и приведите основания для их
сравнения.
Экономические оценки связаны с оценками одного или более определенного метода
лечения для определенного набора признаков [6]. Для каждого вмешательства определите
следующее:
• кто его обеспечивает;
• кто его получает (какая популяция пациентов или диагноз);
• кто платит за это;
• насколько интенсивно его использование (как часто его назначают пациенту или
сколько пациентов получает его в данное время);
• его ожидаемые исходы;
• его влияние на другие группы, не считая пациентов, плательщиков и поставщиков.
W Включает ли сравнение ведущие альтернативные методы лечения [7-9)?
Выбор альтернативного лечения должен быть основан на клинической значимости,
а не на потенциальной желательности результатов [5]. Сравнение нового метода
лечения с очевидно уступающим методом может быть маркетинговой уловкой, новый
метод заведомо выигрывает в сравнении. Таким образом, необходимо рассмотреть
все разумные альтернативные методы лечения, но особенно обратить внимание
на следующее:
• наименее дорогую альтернативу;
• самую обыкновенную альтернативу («обычный стандарт лечения» в обществе);
• самую эффективную альтернативу;
• альтернативное «невмешательство» (когда возможно);
• нефармакологические альтернативы (когда возможно).
Щ Методы лечения различных стран должны сравниваться с осторожностью
[10]. Затраты и доступность конкурирующих вмешательств и другие
характеристики медицинской инфраструктуры отличаются в разных странах и могут влиять
на затраты, использование и исходы лечения. Оценивая затраты в различных
странах, нужно также учесть различия в обменных курсах.
18.8. Проверьте клиническую эффективность каждого оцениваемого лечения.
Учитывая время и усилие, требуемое для проведения экономической оценки,
эффективность каждого лечения должна быть установлена прежде, чем начнется исследование.
В частности, каждое лечение должно сопровождаться соответствующим
документированным описанием:
• безопасности: приносит ли лечение больше пользы, чем вреда, когда применяется
должным образом?
• эффективности: приводит ли лечение к ожидаемым результатам в контролируемых
условиях, таких как клинические испытания?
276 Составление отчетов по обобщающим методам исследования
• действенности: приводит ли лечение к предполагаемым результатам в реальных
условиях? (Не приводит ли к неблагоприятным эффектам доступность,
приверженность пациентов или стоимость лечения при его правильном использовании?)
• распространения: доступно ли лечение географически, в том масштабе, который
делает его разумной альтернативой для сравнения?
• доступности: доступно ли лечение материально и иначе в масштабе, который делает
его разумной альтернативой для сравнения?
^ Экономические оценки принимают эффективность лечения, а не
устанавливают ее [9].
18J« Опишите любые пилотные исследования, предпринятые при подготовке
к первичному исследованию.
Пилотные исследования часто проводятся перед полной экономической оценкой, чтобы
установить затраты и результаты, которые позволят продумать любые потенциальные
проблемы в методологии и сборе данных, получить первоначальные оценки для планирования
полного анализа, определить вероятную область полного анализа и т. д. Однако пилотные
исследования могут также стать потенциальным источником смещений, создавая ожидания
среди исследователей. Кроме того, те спонсоры, которые, как было известно,
финансировали экономические оценки поэтапно, отказывались от исследования, если результаты
оказывались неблагоприятными на какой-нибудь стадии.
18,10« Определите, проводилось ли исследование согласно письменному протоколу.
Следование письменному протоколу, установленному перед сбором данных, помогает
избежать смещений во время проведения исследования.
Экономические оценки иногда проводятся как часть клинического изыскания для
проверки эффективности вмешательства [11-13]. Преимущество этого параллельного подхода
состоит в том, что могут быть собраны более точные данные от отдельных пациентов,
случайным образом распределенных в группы лечения и контроля. Недостатками является то,
что экономическая оценка добавляется к бремени сложного клинического исследования;
результаты могут недостаточно хорошо обобщаться на другие, менее управляемые условия,
и если клиническое испытание указывает, что вмешательство неэффективно, то
экономическая оценка может представлять небольшую ценность. И как вариант, отдельные
экономические оценки некоторых методов лечения, возможно, прозвучат неэтично, потому что
худшая терапия не должна сравниваться с лучшей, особенно если исследование проводится
главным образом в маркетинговых целях.
18,11, Установите ожидаемый «период времени», за который накопятся затраты
и выгоды от лечения.
Период времени должен соответствовать исследуемым диагнозам и методам лечения.
Например, эффекты того, что ребенку помешали курить в 11 лет, могут копиться в течение
всей жизни в форме снижения количества респираторных заболеваний, улучшения
физических способностей и снижения риска онкологических и сердечнососудистых заболеваний.
По сравнению с этим время действия анестезирующего средства, снижающего
послеоперационную гипотензию, очень коротко.
Описание экономических оценок 277
Продолжительность периода времени также важна для определения обесценивания
затрат и исходов, чтобы выразить будущие затраты и сбережения в текущих ценах (см.
указание 18.23).
Продолжительность периода времени также может быть важной по этическим
соображениям, так как результаты оценок, использующих «годы спасенной жизни» или
«благополучные годы», неотъемлемо связаны с одобрением методов лечения, предлагаемых
молодому поколению [14].
18.12. Установите ключевые предположения и ценностные суждения,
используемые в оценке.
Все экономические оценки требуют наличия нескольких предположений и ценностных
суждений, которые могут затронуть результаты. Например, в некоторых условиях
качество жизни может быть важнее продолжительности жизни, а в некоторых — наоборот; для
одних организаций краткосрочные расходы могут быть предпочтительнее долгосрочных
сбережений, а для других — наоборот. Учитывая потенциал и стимул для смещений в
экономических оценках, важно установить эти альтернативы и основания для выбора между
альтернативами. Более предпочтительны консервативные предположения (склоняющиеся
против терапии) [3, 5].
Когда это уместно и возможно, эффект ключевых предположений и ценностных
суждений должен быть оценен с помощью анализа чувствительности, чтобы определить их
влияние на общие результаты {см. указание 18.24).
18.13. Уаановите типы затрат, включенных в оценку (и важные затраты, которые
не были включены), и обоснуйте, как эти затраты были определены.
Затраты — это экономические последствия выбора вмешательства [15]. Они в основном
включают краткосрочные, долгосрочные, прямые и косвенные затраты, так же как и
экономию вследствие применения лечения (табл. 18.1). У всех пациентов, поставщиков и
плательщиков могут быть затраты и «предотвращенные затраты», или сбережения. Кроме того,
некоторые виды лечения могут иметь «вынужденные затраты», созданные предложенным
лечением, такие как стоимость терапии неблагоприятных побочных эффектов.
Однако пока еще нет общепринятых стандартов или компонентов для оценок
стоимости [16]. (Затраты, перечисленные в табл. 18.1, являются иллюстративными, неполными.)
Кроме того, есть много споров о том, какие типы затрат включать и как их оценивать.
Например, должны ли включать основные накладные расходы? Нужно ли оценивать будущие
медицинские затраты, которые возникают, потому что пациент живет дольше?
Затраты (стоимость) — это не то же самое, что расходы (цены). Затраты — это сумма,
которую поставщик должен заплатить за товары или услуги, тогда как расходы — сумма,
на которую поставщик выставляет счет плательщику. Таким образом, шприц может стоить
больнице 0,50 доллара, но больница может выставить счет пациенту на 1,50 доллара. Часто
в экономических оценках расходы используются вместо затрат, потому что они доступнее.
И затраты, и расходы могут меняться учреждением и географической областью в широких
пределах, что составляет проблему для сравнения. Иногда вместо затрат и расходов
используют платежи — сумму, которую плательщик фактически возвращает поставщику, но это
связано с еще большей неопределенностью.
278 Составление отчетов по обобщающим методам исследования
Таблица 18,1
Типы затрат, как правило включаемых в экономические оценки"
Медицинские
• Фиксированные прямые затраты (покупка оборудования)
• Переменные прямые затраты (потребляемые запасы, оплата процедур, продолжительность
пребывания в больнице)
• Фиксированные косвенные затраты (зарплата поставщиков, амортизация оборудования,
администрация)
• Переменные косвенные затраты (обучение и образование, колебание численности кадров)
• Вынужденные затраты, созданные вмешательством (увеличение количества неблагоприятных
исходов, будущие медицинские затраты, понесенные из-за длительного выживания)
• Предотвращенные затраты, или сбережения, вызванные вмешательством (снижение
количества диагностических тестов, снижение потребности в реабилитации)
Финансовые (связанные с большей экономией)
• Трансфертные платежи (изменения в социальных платежах, следующих из изменений
продолжительности жизни)
• Инфляция
• Дисконтирование (издержки из-за того, что деньги тратятся сейчас вместо того, чтобы
инвестировать их в другом месте)
Немедицинские
• Затраты обращения (транспортные расходы, коммуникационные расходы)
• Привычные затраты (охрана детства, услуги на дому, реабилитационное оборудование)
• Потеря трудоспособности
Нематериальные
• Боль и страдание
• Потеря времени пациента
"" Затраты могут быть понесены в ближайшей или отдаленной перспективе.
^ Остерегайтесь «игр»: перемены стоимости и перекрестного субсидирования
услуг, которые могут повлиять на оценку стоимости. Например, во многих
учреждениях услуги по уходу за больными считаются накладными расходами,
тогда как услуги по искусственной вентиляции легких считаются прямыми и
возмездными затратами. Таким образом, когда аппарат искусственной вентиляции легких
был настроен врачом, больница выставит счет пациенту, но не в том случае, если
это сделала медсестра. Больница может расширить штат пульмонологов с целью
привлечения дополнительного дохода.
Затраты могут быть разделены на две обш[ие категории: денежные затраты, как правило
выражаемые в долларах, и неденежные затраты, такие как потеря трудоспособности или
несчастие, которые должны быть преобразованы в доллары (анализ стоимости и
эффективности) или в меру полезности (анализ полезной стоимости). Существуют три
общепринятые методики экономической конверсии: человеческий капитал, готовность к оплате
и косвенный подход.
В подходе через человеческий капитал (или подходе через «потерянный доход»)
потенциальный заработок пациента рассчитывается на продолжительность
нетрудоспособности. Если техник зарабатывает 15 долларов в час и теряет 2 недели (80 часов) работы,
величина потерянной производительности составляет 1200 долларов. Однако этот подход
Описание экономических оценок 279
смещен в сторону пациентов традиционных профессий и становится более спекулятивным,
когда нетрудоспособность может продолжаться, скажем, 30 или 40 лет и включать в себя
работу без постоянного вознаграждения, куда относятся люди, работающие не по найму,
коммивояжеры, работающие за комиссию, или люди, относящиеся к неоплачиваемой
домашней рабочей силе.
В подходе через «готовность к оплате» общество рассматривается с такой точки
зрения, чтобы определить, какую сумму люди желали бы заплатить, чтобы избежать
специфических симптомов или нетрудоспособности. Например, людей можно спросить, сколько
денег они желали бы тратить каждую неделю, чтобы избежать симптомов артрита. Если
ответ составляет 30 долларов, то годовая «стоимость» артрита была бы оценена в 1560
долларов (52 недели х 30 долларов в неделю) и в течение 25 лет она составит 39 000 долларов.
Готовность к оплате, однако, может значительно варьировать среди различных культурных
слоев и групп населения по доходам.
В косвенном подходе исследуются данные из различных источников, чтобы определить
денежную ставку для данного симптома или состояния. Так, например, если средняя
страховая ставка по потере 30-летнего главы хозяйства составляет 200 000 долларов,
преждевременная потеря члена семьи, скажем, от диабета может быть оценена в 200 000 долларов
с некоторыми поправками.
18.14. Укажите исходы (выгоды) сравниваемых видов лечения и то, как эти исходы
были определены.
Как и оценки стоимости, исходы включают краткосрочные, долгосрочные,
прямые, косвенные и нематериальные последствия лечения для пациентов, поставщико-
и плательщиков.
У методов лечения обычно есть множество исходов, к каждому из которых нужно
обратиться при анализе, если только они включены. Многие из методов лечения, которые
рассматриваются в экономических оценках, затрагивают продолжительность и качество
жизни. Таким образом, у большинства методов лечения есть по крайней мере четыре прямых
исхода: успех, летальный исход, болезнь и качество жизни после лечения [6].
Некоторые оценки могут использовать суррогатные конечные точки, а не прямую
пользу для здоровья. Например, пациенты с боковым амиотрофическим склерозом обычно
умирают, когда их дыхательные мускулы перестают функционировать. Некоторые
пациенты выбирают поддерживание на аппаратах искусственной вентиляции легких, однако
в таких случаях подключение аппарата используется как суррогатная конечная точка для
летального исхода. Определить, насколько точно подключение аппарата соответствует дате
«смерти», достаточно трудно.
Экономические оценки, которые оценивают исходы, выражают их по-разному:
• В анализе затрат—выгод результаты выражаются в долларах. Таким образом,
спасенным или потерянным жизням нужно придать долларовый облик. Любой из трех
методов экономического преобразования, описанных выше (подход «человеческий
капитал», подход «готовность к оплате» и косвенный подход), может использоваться
для выражения неосязаемых исходов в долларах.
• В анализе рентабельности исходы, такие как новые случаи диагностики, спасенные
жизни или ущербы, которых удалось избежать, выражаются в клинических терминах
или как «функциональный статус». Общая единица — «год спасенной жизни» или
280 Составление отчетов по обобщающим методам исследования
«годы жизни». Но здесь существует одно затруднение: эквивалентно ли продление
жизни 1 человека на 40 лет продлению жизни 40 человек на 1 год — в обоих случаях
получается 40 лет жизни.
• В анализе полезной стоимости об исходах обычно сообщают при помощи
«индекса статуса здоровья», который позволяет вычислить «полезность» как число
«благополучных лет» или «лет с улучшенным качеством жизни» (QALY). QALY —
произведение числа лет жизни на качество этих лет, которое измеряется в интервале от О
(состояние между жизнью и смертью) до 1 (полное здоровье), определяемое с
помощью опросника качества жизни. Таким образом, говорят, что операция, продлившая
жизнь в среднем еще на 12 лет с оценкой качества или полезностью 0,4, обеспечивает
4,8 QALY (12 лет х 0,4 = 4,8 QALY).
1ВЛ 5. Сообщите, какой метод использовали для оценки качества жизни.
Качество жизни — многомерная конструкция, в которой пациенты сообщают о своем
физическом статусе, функциональных возможностях, психологическом статусе,
эмоциональном благополучии, социальных взаимоотношениях и часто о своем удовлетворении
лечением. Измерения качества жизни иногда ссылаются на «сообщаемые пациентом
исходы». Меры качества жизни могут помочь перевести клинические изменения в исходы,
представляющие интерес для пациентов, которые в условиях нехватки хороших
физиологических или биохимических маркеров могут быть предпочтительнее, например при мигрени
или артрите. Они также иногда могут служить суррогатными конечными точками, которые
помогут безопасно и эффективно оценить лечение.
Качество жизни может быть оценено несколькими способами, есть сотни утвержденных
анкетных опросов (превосходный обзор этих методов см. в ссылке 17). Большинство
общепринятых методик измерения полезности описаны ниже [18-20]. Поскольку улучшенное
качество жизни может дифференцировать одну терапию от другой или оправдать
применение терапии с более высокой стоимостью, необходимо сообщить о методе определения
качества жизни.
• Оценочные шкалы, такие как визуальные аналоговые шкалы, используют линию
с ясно обозначенными конечными точками, например смерть на одном конце и
крепкое здоровье на другом. Пациенты в условиях исследования указывают качество
жизни, отмечая точки на линии. В схожей процедуре, называемой категориальным
шкалированием, пациенты выбирают из нескольких ранжированных категорий.
• Стандартная «азартная игра» предоставляет респондентам две альтернативы.
У одной альтернативы есть два возможных исхода: возвращение к нормальному
здоровью в течение данного отрезка времени или смерть. Другая альтернатива —
уверенность прожить остаток жизни с определенным качеством жизни. Респонденты
должны выбрать одну из этих альтернатив. Вероятности двух возможных исходов для
альтернативы один во время тестирования меняются до тех пор, пока респонденты,
столь же вероятно, не выберут состояние здоровья, как они должны были бы «играть»
на шанс здоровья против риска смерти.
• В методике оценки величины респондентов просят указать отношение
нежелательности для пары состояний здоровья. Например, одно состояние может быть
рассматриваемо как вдвое худшее, чем другое, или в три раза худшее, чем третье. Задавая ряд
вопросов, можно оценить состояние по шкале «вредности» или нежелательности.
Описание экономических оценок 281
• В методике компромиссов времени респондентам предоставляют две альтернативы:
прожить X лет с определенным качеством жизни или умереть. Продолжительность
жизни X варьируется до тех пор, пока респонденты не станут безразличны к выбору.
• В методике персональных компромиссов респондентов спрашивают, которая
из двух групп нуждается в большей помощи: группа X человек с состоянием А или
вторая группа людей Y с состоянием В. Размеры каждой группы (X и Y) и качество
жизни в каждой группе (А и В) меняются по ряду вопросов до тех пор, пока
вероятности предпочтения респондентами одной группы другой станут одинаковыми.
Состояния или полезности тогда могут быть ранжированы по шкале нежелательности.
^ Различные формы оценки приводят к различной пользе [10, 18, 21]. Два
важных вопроса в измерении полезности или качества жизни:
1. Кто проводит оценку? Пациент, который сам испытывает измеряемые
состояния; врач, наблюдавший большое количество пациентов с такими же состояниями,
или общественность, которая может быть незнакома с такими состояниями?
2. Действительно ли измерения ограничиваются единственным вопросом, таким
как «Каково качество вашей жизни?», или представляют собой сложную оценку,
которая объединяет ответы на вопросы из нескольких областей, таких как
физическое, психологическое, функциональное, социальное и духовное состояние?
Результаты анкетных опросов, специфичных для определенных заболеваний, могут также
отличаться от таковых, полученных с помощью общих анкетных опросов качества жизни.
Наконец, интерпретации, основанные на содержании (интерпретации, основанные на
изменениях в ответах на определенные вопросы), могут отличаться от интерпретаций,
основанных на критериях (основанных на сравнениях средних между различными группами).
18.16. Опишите любую математическую модель, использованную для сравнения
затрат и исходов.
Затраты и исходы, включенные в экономические оценки, могут иногда выражаться
уравнением, которое может быть полезно при описании исследования. Например, модель,
используемая для оценки полезной стоимости при гипертензии слабой и средней тяжести,
показана ниже:
^_(ACRx+ACsE-AC^o,b)>
B(AYLE-AYsE+AY„orb)
где С — чистые затраты здравоохранения на противогипертензивную терапию пациента,
В — чистые выгоды здравоохранения (представленные здесь как полезность) от противо-
гипертензивной терапии пациента, выраженные в годах жизни с улучшенным качеством,
ACj^^ — изменения прямых медицинских затрат при лечении гипертензии,
ACg^ — изменения медицинских затрат при лечении побочных эффектов противогипер-
тензивного лечения,
^^morb — изменения в сбережениях затрат здравоохранения при предотвращении
событий заболевания,
AY^^ — изменения в жизненных ожиданиях в зависимости от пожизненного противо-
гипертензивного лечения, выраженные в годах жизни,
AY^^ — изменения качества жизни в результате побочных эффектов противогипертен-
зивного лечения, выраженные в годах жизни с улучшенным качеством.
282 Составление отчетов по обобщающим методам исследования
^^morb — изменения качества жизни в результате предотвращения болезненных
состояний, таких как инсульт, выраженные в годах жизни с улучшенным качеством.
В дополнение к математическим моделям в экономических оценках могут
использоваться вероятностные методы, включая регрессионные модели Кокса, рабочие характеристики
(ROC-кривые), Марковские модели и деревья решений.
18.17« Опишите иаочники и методы сбора данных.
Большинство экономических оценок требуют целого ряда данных по затратам и исходам:
частоты побочных эффектов, частоты преваленса болезни, частоты успешных действий,
меры удовлетворенности пациентов, предпочтительная интенсивность медицинского
наблюдения, изменения в окладах и заработной плате и т. д. Далее, эти данные могут быть
получены из нескольких источников: опубликованные результаты метаанализов, клинические
испытания, проводимые одновременно с экономической оценкой, местные или
национальные базы данных, производственные отчеты, мнения экспертов, маркетинговые
исследования, опросы пациентов и т. д. В любом случае источники данных должны быть определены,
должны быть заданы критерии отбора данных, обсуждены их сильные и слабые стороны
и потенциальные смещения.
УКАЗАНИЯ ПО ОФОРМЛЕНИЮ РЕЗУЛЬТАТОВ
18.18. Объясните любые отклонения от протокола или его модификации,
сделанные во время исследования [5].
18.19. Сообщите об индивидуальных и совокупных затратах по каждому
лечению. Обоснуйте, что затраты были установлены полностью, тщательно
измерены и оценены должным образом.
Сообщите о результатах оценки стоимости. Определенные товары, оцененные услуги
и вычисленная долларовая стоимость для каждой, так же как и полные совокупные затраты,
могут быть приведены в таблице (табл. 18.2).
18.20. Сообщите об индивидуальных и совокупных исходах по каждому лечению.
Обоснуйте, что исходы были установлены полностью, тщательно измерены
и оценены должным образом.
Сообщите о результатах оценки исходов. Исходами могут быть правдоподобия
вероятности заболеваемости или смертности, оценки качества жизни, количество предотвращенных
случаев, увеличение продолжительности жизни и т. д. Результаты в целом лучше всего дать
в таблице (табл. 18.3).
18.21. Опишите как средние, так и инкрементные отношения затрат—исходов для
каждого лечения.
Средние отношения затрат—исходов вычисляются путем деления общей стоимости
на суммарные исходы (табл. 18.4). Единицы исходов (мера выгоды, эффективности или
полезности) различаются согласно типу выполненной экономической оценки.
При сравнении методов лечения чем ниже среднее отношение затрат—исходов, тем
лучше. На рис. 18.1 лечение сравнивается как на основе общих стоимостей и исходов, так
Описание экономических оценок 283
Таблица 18.2
Примеры характерных затрат, используемых в экономических оценках"
Товары и услуги
Затраты больницы Затраты на оплату
(доллары) услуг врача (доллары)
Первичная госпитализация^
• 1 день пребывания в блоке интенсивной 1400 126
терапии, без осложнений
• 1 день пребывания в блоке интенсивной 2070 187
терапии, умеренные осложнения
• 1 день пребывания в блоке интенсивной 2760 250
терапии, серьезные осложнения
• Пребывание на сестринском посту 475 54
• Диагностическая катетеризация сердца 1670 400
• Коронарная ангиопластика 6200 1356
• Коронарное шунтирование 8800 2564
• Посещение кабинета неотложной помощи 300 125
Повторная госпитализация''
• Коронарное шунтирование 19 000 2823
• Летальный инфаркт миокарда 4745 —
• Остановка сердца и шок 3440 —
• Первый день госпитализации — 111
• Последующий день госпитализации — 55
• Первичное посещение клиники — 98
• Последующее посещение клиники — 45
' Данные носят только иллюстративный характер.
^ Указывайте источники данных в сносках.
и на основе средних и инкрементных отношений затрат—исходов. Хотя лечение В имеет
самую низкую общую стоимость, а у лечения С — самый высокий результат,
предпочтительнее лечение Е, у которого самое низкое среднее отношение затрат—исходов — 1 год
жизни за 3750 долларов.
Инкрементные, или маржинальные, отношения затрат—исходов показывают
стоимость обеспечения одной дополнительной единицы исхода. Инкрементные отношения
важны, потому что средние отношения затрат—исходов могут вводить в заблуждение, если
они являются единственным критерием, используемым для выбора метода лечения.
Маржинальные отношения затрат—исходов это:
Стоимость новых - Стоимость старых
Исход новых - Исход старых
Например, определение скрытой крови в кале является скрининговым тестом на рак
толстой кишки. В одном исследовании среднее отношение рентабельности составило
284 Составление отчетов по обобщающим методам исследования
Таблица 18.3
Примеры характерных исходов, используемых в экономических оценках"
Исход
Непривитые
пациенты (л)
Привитые
пациенты (л)
Предотвращенные
случаи (л)
Случаи ветряной оспы 149 050
Заболеваемость
Пневмония 1500
Энцефалит 775
Длительная инвалидизация 10
по энцефалиту
Смертность 7
9375
15
9
2
О
139675
1485
766
8
^ В анализе затрат—выгод каждый исход должен быть преобразован в долларовую сумму. В анализе
рентабельности каждый исход должен быть выражен в клинической мере, например как стоимость предотвращенной
инфекции. В анализе полезной стоимости исходам должна быть назначена полезность и выражена в таких
терминах, как здоровые годы, обеспеченные прививкой. Данные только иллюстративны.
Таблица 18,4
Отношения затрат—исходов трех гипотетических вмешательств с оценкой затрат—выгод,
рентабельности и анализом полезной стоимости
Стоимость исхода
Вмеша- Вмеша-
Вмешательство 1 тельство 2 тельство 3
[1 ] Стоимость лечения, доллары (по данным
исследования)
[2] Выгоды от лечения, доллары (по данным
исследования)
[3] Эффективность, годы жизни (поданным
исследования)
[4] Взвешенная оценка (от О до 1,0) качества жизни
(QOL) (по данным исследования)
Полезность (годы с улучшенным качеством жизни
[QALY]) (эффективность х QOL; [3] х [4])
Среднее отношение затрат-выгод
(стоимость/выгоды; [1]/[2])
Среднее отношение рентабельности
(доллары/годы жизни; [1 ]/[3])
Среднее отношение полезной стоимости
(доллары/0А1У;[1]/[4])
17 000
30000
98000
22 000
0,5
0,9
0,45
0,77
34000
37 777
30 000
3
0,6
1,8
1,0
10 000
16 666
42 000
5
0,5
2,5
2,33
19600
39 200
1175 долларов; «маржинальная» стоимость каждого случая рака, обнаруженного после
единственного скринингового теста, таким образом, равнялась тоже 1175 долларам.
Но тест несовершенен, поэтому повторная проверка может установить дополнительные
случаи. Средняя стоимость выполнения шестого теста составила 2541 доллар, но марлси-
нальная стоимость шестого теста — стоимость каждого дополнительного случая обнару-
5 ^
Ф
ш
о
S
|2
Описание экономических оценок 285
.1^
Е: Будущий стандарт . Варианты лечения
здравоохранения ^ ^ i
• / • D
^ ^ ^— Кривая «результат-стоимость»
/ А: Текущий стандарт здравоохранения
/
/
/
/
/
/
В: Прежний стандарт здравоохранения
10 000 20 000 30 000
Общая стоимость, доллары
40 000
50 000
Рис. 18.1. Средние отношения затрат—исходов для пяти гипотетических методов лечения. Штриховая линия
изображает «огибающую» кривую затрат—исходов. Поставщики могут выбрать для «действий» любую точку
вдоль кривой. Инкрементные отношения стоимости могут быть обозначены наклоном линии, оттянутой между
двумя пунктами; чем круче наклон, тем ниже (и желательнее) возрастающее отношение. Отрицательные
наклоны (от Е до А) редки, но представляют собой идеальный прогресс медицины в обеспечении роста общего
количества исходов при снижении общей стоимости
жения рака шестым тестом — превысила 47 млн долларов! [23]. Другими словами, в
результате проведения большого количества тестов были найдены только несколько случаев
рака.
Когда один метод лечения сравнивается с другим или «оспаривает» другой, инкремент-
ное отношение затрат—исходов этих двух методов иллюстрирует компромиссы при замене
одного метода другим. На рис. 18.1 лечение А предположительно является текущим
стандартом здравоохранения. Рассматривая каждую из альтернатив лечению А, можно
заметить, что:
• по сравнению с прежним стандартом здравоохранения В, у лечения А более низкое
среднее отношение затрат—^исходов (20 000 долларов / 3 года жизни = 6667 долларов/год
жизни) и благоприятное (сниженное, но не самое низкое) инкрементное отношение затрат—
исходов (5000 долларов/год жизни); поэтому переход от В к А был бы целесообразным;
• переход от метода А к С привел бы к инкрементной стоимости 10 000 долларов/год
жизни [(40 000 - 20 000 долларов) / (5 лет жизни - 3 года жизни)], что выше
текущей средней стоимости 6667 долларов (20 000 долларов / 3 года жизни), и поэтому
не благоразумен;
• переход от лечения А к лечению D привел бы к возрастанию стоимости до 30 000
долларов/год жизни [(50 000 - 20 000 долларов) / (4 года жизни - 3 года жизни)] — это
относительно дорогой выбор;
• переход от лечения А к лечению Е сэкономило бы 5000 долларов/год жизни [(15 000-
20 000 долларов) / (4 года жизни - 3 года жизни)]; другими словами, мало того, что
286 Составление отчетов по обобщающим методам исследования
Е стоит меньше, чем А, но также прибавляет 1 дополнительный год жизни за эту
сокращенную стоимость. В этом случае говорят, что Е «доминирует» А. С
экономической точки зрения лечение Е должно стать будущим стандартом здравоохранения.
Несколько инкрементных отношений стоимости могут представлять интерес, в
зависимости от единицы исследования. Рассмотрите варианты фармакоэкономических
исследований: стоимость на пилюлю, стоимость на дозу, стоимость в день, стоимость на лечение,
стоимость на пациента и стоимость на исход.
18.22. Дайте оценку «терапевтического усилия на клинический результат»
(отношение усилия к результату) для каждого метода лечения.
Другое полезное отношение результата к стоимости — отношение терапевтического
усилия к результату. Самым распространенным является количество пациентов, которое
требуется лечить, чтобы предотвратить один неблагоприятный исход; или количество
тестов, необходимых для обнаружения одного дополнительного положительного случая:
количество нуждающихся в лечении. (См. гл. 2.)
ПРИМЕР
Полезность отношения усилия к результату проиллюстрирована ниже. Каждое
выражение статистически корректно и научно приемлемо, но от каждого у читателя остается
различное впечатление об эффективности лекарства [24, 25].
• Результаты, выраэюенные в абсолютных значениях (сокращение абсолютного или
атрибутивного риска [ARR]). В Хельсинкском исследовании мужчин с гиперхоле-
стеринемией [26], по истечении 5 лет, у 84 из 2030 пациентов, принимавших плацебо
(4,1 %), были сердечные приступы, тогда как в группе, принимавшей гемфиброзил
(2,7 %), сердечные приступы случились только у 56 из 2051 мужчины (р < 0,02),
абсолютное уменьшение риска составило 1,4 % (4,1 - 2,7 % = 1,4 %).
• Результаты, выраэюенные в относительных значениях (уменьшение
относительного риска [RRR]). В Хельсинкском исследовании мужчин с гиперхолестеринемией,
по истечении 5 лет, у 4,1 % мужчин, принимавших плацебо, случились сердечные
приступы, тогда как в группе, принимавшей гемфиброзил, сердечные приступы
случились только у 2,7 % мужчин. Различие в 1,4 % соответствует 34%-му сокращению
относительного риска частоты сердечных приступов в группе, принимавшей
гемфиброзил (1,4/4,1 % = 34%).
• Результаты, выраэюенные в отношении усилия к результату, В Хельсинкском
исследовании у 4081 мужчины с гиперхолестеринемией, по истечении 5 лет, на
каждый предотвращенный сердечный приступ было принято приблизительно 200 000 доз
гемфиброзила.
• Результаты, выраэюенные в других единицах отношения усилия к результату
(количество нуждающихся в лечении [NNT]): Результаты Хельсинкского исследования
по 4081 мужчине указывают, что в течение 5 лет нужно лечить 71 мужчину, чтобы
предотвратить единственный сердечный приступ (1/0,014 = 71).
18.23* Обоснуйте используемый метод дисконтирования для корректировки затрат
и выгод, которые накапливаются в течение различных периодов времени.
Затраты и исходы вмешательства обычно реализуются в разное время и часто за долгий
период времени. Для коррекции этих различий ;юлжна быть проделана операция, назы-
Описание экономических оценок 287
ваемая дисконтированием или анализом текущей стоимости, необходимая для
взвешивания будущих долларов дисконтным фактором, чтобы сделать их сопоставимыми
с текущими долларами.
Хотя инфляция — это фактор, снижающий будущую долларовую ценность
относительно текущей, первичной причиной для дисконтирования являются «альтернативные
издержки» из-за невложения денег в другом месте. Например, больница может либо
потратить 10 000 долларов на новое оборудование, либо инвестировать эту сумму. После,
скажем, 5 лет при 5%-й доходности 10 000 долларов вырастут до 12 763 долларов. В
другом случае сохраненные 10 000 долларов через 5 лет обесценились бы до нынешних 7835
долларов.
Ставка дисконта между 3 и 5 % является стандартной. Затраты и исходы, возможно,
не должны быть дисконтированы для методов лечения, результаты которых достигаются
в ближайшей перспективе.
Допустим, при дисконтной ставке 5 % X долларов, потраченных за п лет, есть текущая
стоимость X долларов/(1,05)" [1].
18.24. Исследуйте важные выборы и предположения с помощью анализа
чувствительности, чтобы определить их воздействие на результат.
Анализ чувствительности показывает, насколько результаты анализа «чувствительны»
к изменениям в предположениях. В этом анализе самые важные предположения обычно
варьируют по одному в диапазоне возможных значений. Если основные выводы не
изменяются при варьировании предположений, выводы могут быть приняты с большей
уверенностью. Например, результаты могут изменяться в зависимости от ожидаемого роста затрат
на лечение на 5, 7 или 10 % в течение 3, 5 или 7 лет.
Типичные предположения, проверенные на чувствительность:
• оценка степени клинической эффективности лечения;
• взвешивание мер качества жизни;
• дисконтные ставки затрат и исходов, включая норму О %;
• частоты неблагоприятных случаев;
• частоты преваленса;
• частоты выживания.
Однофакторный анализ чувствительности проверяет изменения одного предположения
за один раз. Также могут быть выполнены двухфакторный и трехфакторный анализы
чувствительности (рис. 18.2 и 18.3).
Три особых случая могут представлять интерес:
• лучший случай, в котором используются самые оптимистические предположения;
• худший случай, в котором используются самые консервативные предположения;
• сбалансированный случай, который является комбинацией значений, при которых
затраты равняются выгодам. Например, если достигнуть точки баланса, то точность
обычного диагностического теста должна снизиться по крайней мере на 20 % с
объявленных значений от 80 до 90 %, результаты не особенно чувствительны к точности
теста. Поскольку точка баланса лежит далеко за пределами ожидаемых колебаний,
по крайней мере, этого аспекта оценки, результаты могут быть приняты с большей
уверенностью.
288 Составление отчетов по обобщающим методам исследования
о
о
2 200
s"
Z
т
S
I 150
00
I-
^
ЗР
«о
1 100
Z
х
Oi
Б
50
о
1 о
50 60 70 80
Эффективность интимэктомии, %
90
Рис. 18.2. в однофакторном анализе чувствительности диапазон переменной отмечен на оси X, а
соответствующий исход — на оси Y. Здесь стоимость лет с улучшенным качеством жизни (QALY) изменяется между 150 000
(точка А) и 90 000 долларов (точка С), в зависимости от эффективности интимэктомии сонной артерии, которая
предположительно составляет 50 или 87 % соответственно. Эффективность интимэктомии сонной артерии
имеет большую величину множителя в диапазоне от 50 до 60 % (точка В), чем в диапазоне от 60 до 90 %, потому что
отношение изменения стоимости к изменению QALY в более низком диапазоне выше, чем в более высоком. Если
другие данные поддержат более высокую эффективность интимэктомии сонной артерии, скажем, 80 %, то
модель будет более устойчивой. Если данные поддержат только 55%-ю эффективность, то модель будет более
изменчивой
УКАЗАНИЯ ОТНОСИТЕЛЬНО ОБСУЖДЕНИЯ РЕЗУЛЬТАТОВ
18.25. Суммируйте результаты исследования.
18«2б. Интерпретируйте результаты и предложите их объяснение.
18.27. Опишите, как результаты сравниваются с тем, что еще извеано о проблеме:
сделайте обзор литературы и поместите результаты в контекст.
18*28, Предложите, как можно обобщить результаты.
Даже если экономическая оценка учитывает общественную перспективу, местные и
региональные различия в ценах, конкурирующие вмешательства в состояние здоровья,
различия в инфраструктуре здравоохранения и популяционные особенности часто ограничивают
ее применимость в других обстоятельствах. Тем не менее стоит проецировать результаты
на других пациентов, на другую обстановку и времена.
18«29. Обсудите значения результатов. Обратитесь к тем эффектам
альтернативных методов лечения, которые связаны с разными категориями людей,
Описание экономических оценок 289
100
с$
о
ь.
>S
S
X
01
ф
t
о
О
а
)й
GQ
Ф
(0
>ч
5
yj
X
%:
90
80
70
60
SO
40
30
20
12
Эффективность антикоагуляции
0,8 0,65 0,5
Нет антикоагуляции
• А
10 20 30 40
Инциденс тромбоэмболизма/год, %
50
Рис. 18.3. В трехфакторном анализе чувствительности три переменные показаны в интересующих нас
диапазонах. Здесь ежегодный инциденс случаев кровотечений меняется от О до 100 % на оси Y; ежегодный инциденс
тромбоэмболизма изменяется от О до 50 %; а эффективность антикоагуляции смоделирована для 50,65 и 80 %.
Диагональные линии, указывающие эффективность антикоагуляции, называют «порогами эквивалентности»;
точки на этих линиях показывают отсутствие преимущества одного лечения перед другим. Точки, попадающие
слева от этих линий (какие бы значения эффективности ни были выбраны как более соответствующие),
указывают, что пациенты не должны быть подвержены антикоагуляции, тогда как точки справа указывают, что пациенты
должны быть подвержены антикоагуляции. Таким образом, пациенты, удовлетворяющие предположению
точки А (10%-й риск тромбоэмболизма и 70%-й риск кровотечения), вероятно, не должны подвергаться
антикоагуляции, а пациенты, удовлетворяющие предположению точки С, вероятно, должны. Лучший план действий для
пациентов в точке В зависит от принятой эффективности антикоагуляции. Предположение, составляющее 65%-ю
вероятность, указывает на а нти коагуляцию; 50%-е предположение указывает на отсутствие а нти коагуляции
включая типы и число людей, которые предрасположены получать пользу
или терпеть ущерб.
Любое вмешательство затрагивает по крайней мере три группы людей: пациентов,
поставщиков и плательщиков. Сравнивая два или больше методов лечения для расстановки
приоритетов здравоохранения, нужно обратиться к полным последствиям выбора каждой
из этих трех групп. Например, доступ к трансплантации легкого выгоден старшей, более
состоятельной малочисленной популяции; усиливает требование к пульмонологам,
палатам интенсивной терапии и хирургам и, вероятно, увеличивает страховые выплаты для
покрытия большего объема дорогостоящего лечения, тогда как школьные программы
профилактики заболеваний, передающихся половым путем, приносят пользу многочисленной
молодой более разнородной популяции; усиливает требования к инструкторам по
санитарному просвещению и учебным материалам и может сократить страховые выплаты, если
инциденс этих болезней снижается.
Нужно также рассмотреть общую стоимость лечения. Число пациентов, получающих
долгосрочный гемодиализ каждый год, намного меньше числа лечившихся от инфаркта
миокарда. Таким образом, хотя затраты на QALY могут быть аналогичными, общая стоимость
лечения пациентов с инфарктом миокарда будет существенно больше [И].
290 Составление отчетов по обобщающим методам исследования
^ Большинство экономических оценок предполагает, что освобожденные
ресурсы не будут потрачены впустую [9]. Может быть, неблагоразумно предполагать,
что деньги, сэкономленные на одном вмешательстве, будут потрачены на другое.
18.30, Обсудите реальность осуществления лечения.
в дополнение к медицинским и финансовым соображениям политические,
исторические, психологические и этические проблемы могут затронуть вероятность осуществления
новой программы лечения. Например:
• Люди солидаризируются с 38-летней домохозяйкой, у которой терминальный рак
молочной железы, а не с анонимной женщиной, у которой никогда не было цервикаль-
ного рака, потому что болезнь выявили обычным скрининговым тестом и вылечили
на ранней стадии [6].
• Пожилые пациенты рассматриваются как люди, менее достойные дополнительной
заботы, чем молодые пациенты [14, 27].
• Многие люди более обеспокоены высокотехнологичными вмешательствами, такими
как магнитная резонансная томография, чем менее технологичными
вмешательствами, такими как более частые врачебные осмотры [6].
Отношение стоимости к исходу не должно быть единственным критерием для выбора
альтернативного метода лечения [10].
1831. Обсудите ограничения исследования. Обратитесь к возможным источникам
и значениям смещений, смешиваний и ошибок.
Немного исследований проходит, как запланировано; большинство сталкивается с
трудностями при сборе данных, управлении или интерпретации. Сложности и
неопределенности, связанные с экономическими оценками, наиболее вероятно, создадут трудности,
которые ограничат их качество или законность. Об этих ограничениях необходимо сообщить,
чтобы облегчить исследования в перспективе и сообщить другим исследователям о
потенциальных проблемах, возникающих при подобных исследованиях.
18.32. Перечислите выводы.
Литература
1. Weinstein МС, Stason WB. Foundations of cost-effectiveness analysis for health and medical
practices. N Engl J Med. 1977; 296:716-21.
2. Weinstein MC. Principles of cost-effective resource allocation in health care organizations. Int J
Technol Assess Health Care. 1990; 6:93-103.
3. Hillman AL Economic analysis of health care technology: a report on principles. The Task Force on
Principles for Economic Analysis of Health Care Technology. Ann Intern Med. 1995; 123:61-70.
4. Kassirer JP, Angell M. The Journal's policy on cost-effectiveness analysis. N Engl J Med. 1994;
331:669-70.
5. Hillman AL, Eisenberg JM, Pauly MV, et al Avoiding bias in the conduct and reporting of cost-
effectiveness research sponsored by pharmaceutical companies. N Engl J Med. 1991; 324:1362-5.
6. Eddy DM. Clinical decision-making: from theory to practice. Cost-effectiveness analysis: Is it up to
the task? JAMA. 1992; 267:3342-8.
7. Ganiats TG, Wong AF Evaluation of cost-effectiveness research: a survey of recent publications.
FamMed. 1991;23:457-62.
Описание экономических оценок 291
8. Lee JT, Sanchez LA. Interpretation of "cost-effective" and soundness of economic evaluations in the
pharmacy literature. Am J Hosp Pharm. 1991; 48:2622-7.
9. Stoddart GL. How to read journals: VII. To understand an economic evaluation (Part B). Can Med
Assoc J. 1984;130:1428-34.
10. Mason J, Drummone M, Torrance G. Some guidelines on the use of cost effectiveness league tables.
BMJ. 1993; 306:570-2.
11. Kupersmith J, Holmes-Rovner M, Hogan A, et al Cost-effectiveness analysis in heart disease. Part I:
General principles. Prog Cardiovasc Dis. 1994; 37:161-84.
12. Adams ME, McCall NT, Gray DT, et al Economic analysis in randomized control trials. Med Care.
1992;30:231-43.
13. Guyatt GH, Tugwell PX, Feeny DH, et al A framework for clinical evaluation of diagnostic
technologies. Can Med Assoc J. 1986; 134:587-94.
14. Welch GH. Comparing apples and oranges: does cost-effectiveness analysis deal fairly with the old
and young? Gerontologist. 1991; 31:322-36.
15. The Zitter Group. Outcomes Back-Grounder: An Overview of Outcomes and Pharmaco-Economics.
San Francisco:The Zitter Group; 1994:1-56.
16. Warner KE. Issues in cost effectiveness in health care. J Public Health Dent. 1989; 49(5 Spec
No):272-8.
17. Kaplan RM, Feeny D, Revicki DA. Methods for assessing relative importance in preference based
outcome measures. Qual Life Res. 1993; 2:467-75.
18. Laupacis A, Feeny D, Detsky AS, Tugwell PX. How attractive does a new technology have to be to
warrant adoption and utilization? Tentative guidelines for using clinical and economic evaluations. Can Med
Assoc J. 1992; 146:473-81.
19. NordE. Methods for quality adjustment of life years. Soc Sci Med. 1992; 34:559-69.
20. Testa MA, Simonson DC. Assessment of quality-of-life outcomes. N Engl J Med. 1996; 334:835-40.
21. Guyatt GH, Sackett DL, Sinclair JC, et al Users' guides to the medical literature. IX. A method for
grading health care recommendations. Evidence-Based Medicine Group. JAMA. 1995; 274:1800-4.
22. Kawachi I, Malcom LA. The cost-effectiveness of treating mild-to-moderate hypertension: a
reappraisal. J Hypertens. 1991; 9:199-208.
23. MaynardA. The design of future cost-benefit studies. Am Heart J. 1990; 119(3 Part 2):761-5.
24. Brett AS. Treating hypercholesterolemia: how should practicing physicians inteфret the published
data for patients? N Engl J Med. 1989; 321:676-80.
25. LeBlondRF. Improving structured abstracts [Letter]. Ann Intern Med. 1989; 111:764.
26. Frick MH, Elo O, Haapa K, et al Helsinki heart study: primary prevention trial with gemfibrozil in
middle-age men with dyslipidemia: safety of treatment, changes in risk factors, and incidence of coronary
heart disease. N Engl J Med. 1997; 317:1237-45.
27. Detsky AS, Naglie IG. A clinician's guide to cost-effectiveness analysis. Ann Intern Med. 1990;
113:147-54.
292 Составление отчетов по обобщающим методам исследования
Глава 19
Информирование о выборе методов
лечения
Отчет по анализу решений и рекомендациям
клинической практики
Анализ решений — это применение точных количественных методов с целью
проанализировать решения в условиях неопределенности.
W. S. Richardson, А. S. Detsky [1]
Медицинская практика включает в себя принятие решений о том, как лучше всего
диагностировать и лечить пациентов. Качественное медицинское обслуживание требует, чтобы
эти решения были приняты должным образом и были эффективными с точки зрения
пациентов, поставщиков и плательщиков. Однако медицинские достижения увеличили число
вариантов диагностики и лечения, которые, в свою очередь, увеличили число и сложность
потенциальных принимаемых решений о медицинском обслуживании. Кроме того,
потребность в разумной стоимости и учет предпочтений пациентов в обслуживании еще больше
увеличивают число факторов в каждом решении.
Не удивительно, что исследование снабжения здравоохранения указало на несколько
проблем, связанных с коллективным принятием решений поставщиками здравоохранения:
• Многие медицинские методы лечения не были проверены или не подтверждены
научными исследованиями [2].
• Большинство видов медицинского обслуживания не кажутся необходимыми [3, 4].
Фактически «каждое исследование, которое искало злоупотребление медицинскими
услугами, находило их» [5].
• Нормативы, которыми руководствуются при одинаковой терапии даже в смежных
географических областях, часто широко варьируют [5, 6]. Такая вариабельность, как
кажется, является результатом нехватки согласия относительно того, что представляет
собой должное обслуживание, но не является результатом различий выборок
пациентов или пригодности методов лечения.
В ответ на эти проблемы многие клиницисты пытаются «перейти от неоправданной
уверенности профессиональных суждений к более структурированной поддержке и
ответственности таких суждений» [5]. Этот переход к доказательной медицине [7] стимулировал
развитие нескольких методов взвешивания состояния здоровья, экономических эффектов
и учета предпочтений пациентов в принятии медицинских решений [8]. Такие методы
пытаются улучшить принятие решения, детализируя соответствующие признаки для
определенных медицинских вмешательств, и могут позволить клиницистам улучшать качество
Отчет по анализу решений и рекомендациям клинической практики 293
обслуживания, одновременно снижая его стоимость [5]. Потенциальные выгоды и
проблемы, возникающие при использовании этих методов, отображены в табл. 19.1.
Среди этих методов есть анализ решений и методические рекомендации, написанные
клиническими практиками. Анализ решений — это «систематический подход к
принятию решения в условиях неопределенности» [9], тогда как методические рекомендации
клинической практики, критические пути, интегрированные пути медицинского
обслуживания, правила предсказания, помощники клинических решений, или Практические
параметры АМА (Американской медицинской ассоциации) [10], являются «систематически
развитыми положениями, которые помогают практикующим врачам и пациентам принять
решения об адекватности медобеспечения при определенных обстоятельствах» [5, 7, 11-
14]. Анализ решений отличается от практических рекомендаций тем, что анализ решений
обычно более поддается количественному определению, а практическая рекомендация
имеет более «повествовательный» характер и специфична для частных практических ситуаций.
Анализ решений пытается обеспечить понимание процесса принятия клинического
решения, тогда как рекомендации клинической практики являются больше инструкциями для
принятия клинических решений [15]. Действительно, практическая рекомендация может
быть основана на анализе решения. Однако эти два метода схожи и дополняют друг друга,
поэтому мы приводим практические рекомендации, для того чтобы предоставить инфор-
Таблица 19,1
Потенциальные выгоды и проблемы, возникающие при использовании анализа решений,
и рекомендации клинической практики
Выгоды Проблемы
Способствует применению результатов меди- Может привести к медицине «поваренной кии-
цинского исследования к лечению пациентов ги» и отсутствию интереса со стороны
практической медицины
Может улучшить клиническую эффективность Может привести к неврачебному (т. е.
правительственному) контролю над медициной
Может уменьшить количество несоответствую- Может душить инновации в лечении
щего лечения
Проясняет соотношение выгод и потерь и уста- Соотношения выгод и потерь могут быть оце-
навливает вероятности для каждого варианта нены ненадлежащим образом, данные могут
быть неадекватными
Может улучшить рентабельность медицинских Сбережения могут не возместить стоимости
решений разработки и обновления рекомендаций
Приспосабливает к сложности новых техноло- Технологии могут изменяться быстрее, чем раз-
гий работка рекомендаций
Может служить «положительной защитой» Может служить свидетельством вины в случаях
в случаях злоупотребления служебным поло- злоупотребления служебным положением
жением
Однозначно объединяет ценности и желания Может сократить все решения до математиче-
пациентов ских вероятностей
По: Walker R. D., Howard М. О., Lambert М. D., Suchlnsky R. Medical practice guidelines. West J Med. 1994;161:39-44.
294 Составление отчетов по обобщающим методам исследования
Образец презентации
Наша цел b состояла в том, чтобы определить, должна ли женщина с доминирующей грудной
массой, обнаруженной при физическом осмотре, подвергаться игольной биопсии, чтобы
обнаружить злокачественность без прохождения первичной маммографии, или
комбинирование маммографии и биопсии было бы более эффективным подходом к обнаружению
рака молочной железы.
Дерево решения показано на рис. 19.1. Данные национального исследования, проводимого
Smith и соавт., указывают, что из каждой 1000 женщин с (доминирующей) грудной массой
приблизительно у 14 % будут положительные маммограммы, приблизительно у 10 % —
неясные маммограммы и приблизительно у 76 % — отрицательные маммограммы.
Вероятность того, что рак будет подтвержден у женщины с положительной маммограммой,
основана на данных РКИ, которое провели Jones и соавт. Чувствительность маммографии
к раку молочной железы была, таким образом, установлена равной 53 %, а
специфичность — 96 %. Конференция согласия объединенного конгресса здоровья сообщила, что
рак был в конечном счете обнаружен у женщин с неясными маммограммами с частотой
34 %, а с отрицательными маммограммами — с частотой 4 %.
Используя 10%-й порог биопсии, о которой сообщает Brown для большой случайной выборки
женщин в Чикаго, мы заключаем, что только женщины с доминирующими грудными массами
и положительными или неясными маммограммами должны быть подвержены игольной
биопсии. Риск рака в этих двух группах составляет 53 и 34 % соответственно, что намного больше
10%-го риска, при котором женщины в Чикагской выборке подверглись бы биопсии. У женщин
с отрицательной маммограммой существует только 4%-й риск рака, что ниже 10%-го порога.
Принятие вышеупомянутой политики означает, что биопсия была бы назначена 240 из
каждой 1000 женщин с доминирующей грудной массой, т. е. всем женщинам с положительными
или неясными маммографическими результатами.
Поскольку согласно принятой практике биопсия должна выполняться у каждой женщины,
у которой обнаружена масса, наши результаты указывают: если у 1000 таких женщин
сначала была проделана маммография, 760 биопсий можно было бы избежать. Кроме того,
30 случаев злокачественности были бы пропущены, частота ошибки равна 0,03. (Этот
пример модифицирован по аналогии с примером, представленным Eddy [16]).
Здесь:
• Решение, которое будет сделано, сформулировано (игольная биопсия должна быть
обычной?) как популяция пациентов (женщины с доминирующей массой в груди, выявленной во
время врачебного осмотра) и заинтересованность в исходе (обнаружение злокачественных
опухолей груди).
• Дерево решений (рис. 19.1) предоставляет как возможности для рассмотрения, так и
вероятности, связанные с каждой возможностью. Также даются источники данных,
используемых для построения дерева.
• Пороговый уровень риска для биопсии — это уровень, ниже которого женщины не
желают подвергаться биопсии, а выше которого они выбирают биопсию. В данном случае «Brown»
(фиктивное название для этого примера) сообщил, что женщины предпочитают сделать
биопсию, только если шанс наличия рака больше, чем 1 к 10. Такое предпочтение пациентов —
важная особенность в анализе решений и рекомендациях клинической практики.
• Даны последствия изменений в политике; а именно, для каждой 1000 обследованных
женщин 760 биопсий можно было бы избежать за счет пропущенной злокачественности
в 30 случаях и за счет 1000 маммограмм.
Отчет по анализу решений и рекомендациям клинической практики 295
Женщины
с объемным
образованием
молочной
железы
Следует ли
этих женщин
подвергнуть
стандартной
маммографии
или биопсии?
Маммография
Ожидаемая
положительная
маммография
у 14% пациенток
о
Ожидаемая
неясная
маммография
у 10% пациенток
Ожидаемая
отрицательная
маммография
у 76 % пациенток
Биопсия
Рак, вероятно, будет
подтвержден у 14 % женщин,
подвергнутых биопсии
Рак, вероятно, будет
исключен у 86 % женщин,
подвергнутых биопсии
Рак, вероятно, будет
подтвержден у 53 % женщин с
положительными маммограммами
Рак, вероятно, будет
исключен у 47 % женщин с
положительными маммограммами
Рак, вероятно, будет
подтвержден у 34 % женщин с неясными
маммограммами
Рак, вероятно, будет
исключен у 66 % женщин с неясными
маммограммами
Рак, вероятно, будет
подтвержден у 4 % женщин с
отрицательными маммограммами
Рак, вероятно, будет
исключен у 96 % женщин с
отрицательными маммограммами
Рис. 19.1. Дерево решения, сравнивающее варианты и вероятные последствия обычных игольных биопсий
или маммографии для всех женщин, у которых обнаружено объемное образование молочной железы во время
врачебного осмотра. На каждой ветви показаны вероятности. Квадратные узлы называют «узлами решения»,
потому что ветви представляют варианты, которые могут быть выбраны. Круглые узлы называют «случайными
узлами», потому что ветви представляют биологически определенные ответы. Сумма вероятностей для каждого
уровня дерева решения равна 1,0
мацию об усовершенствованиях и характеристиках обоих методов. Для
последовательности изложения мы используем термины анализа решений, а на рекомендации клинической
практики ссылаемся, только когда предоставляем информацию, которая не является частью
анализа решений.
Анализ решений начинается с вопроса, как лучше всего лечить определенное
медицинское состояние. В этом случае решение определяет варианты лечения и потенциальные
выгоды и осложнения каждого выбора, идентифицирует возможные клинические конечные
точки каждого выбора и включает меру предпочтения пациентами желательности каждой
конечной точки. Принимая явные решения о лечении и оценивая вероятность и
желательность каждой альтернативы и конечной точки, эти методы позволяют пациентам и
поставщикам принимать лучшие обоснованные решения.
296 Составление отчетов по обобщающим методам исследования
УКАЗАНИЯ ПО ОФОРМЛЕНИЮ ВВЕДЕНИЯ
19«1, Документируйте предпосылки, сущность, сферу действия и важность
проблемы, которая привела к анализу [17,18].
Как анализ решений, так и рекомендации клинической практики должны начинаться
с ясного обоснования проблемы. При данных времени и ресурсах, необходимых для их
развития, они должны иметь важные клинические или финансовые значения; таким образом,
они могут быть проведены по нескольким причинам [11]:
• чтобы продвинуть более эффективное и результативное медицинское обслуживание;
• чтобы сделать медицинское обслуживание более последовательным;
• чтобы оценить медицинское обслуживание (для рассмотрения использования и
исследований проверки качества);
• чтобы установить границы для выбора лечения (для периодической аттестации и
программ сдерживания стоимости);
• чтобы разъяснить или решить клинические споры;
• чтобы сообщить новые важные результаты клинических исследований.
19.2* Установите общий клинический путь, который был проанализирован:
опишите диагноз, популяцию пациентов и интересующие вмешательства и
клинические дилеммы, которые будут рассмотрены.
Диагноз, пациенты, вмешательства и интересующие дилеммы должны соответствовать
проблеме, которая привела к анализу.
193* Установите намеченных потребителей, обстоятельства и периоды времени
анализа [17-19].
Как и в случае с диагностикой, пациентами, вмешательствами и дилеммами интересов,
намеченные потребители, обстоятельства и периоды времени анализа должны быть
совместимыми с проблемой, которая стимулировала анализ.
Среди намеченных потребителей должно быть установлено первичное лицо,
принимающее решение, которое применит анализ [17]. Таким лицом часто является врач или
профессионал здравоохранения, но в этой роли также может выступать высший чиновник,
планировщик здравоохранения или администратор.
Обстоятельства, в которых намечен анализ, должны быть также идентифицированы.
Например, государственные больницы работают при других ограничениях, чем частные
группы практиков, — факт, который имеет значение при выборе данных для анализа и для
осуществления анализа.
Период времени — это тот временной интервал, в течение которого, как ожидают,
произойдут события и будут приняты решения в анализе. Период времени для пациентов с
тихими желчными камнями может продолжаться в течение 30 лет, тогда как период времени
для решения выполнить диагностический тест может быть незначительным.
19А, Определите перспективу, от которой проводился анализ [17].
Поскольку предположения, требуемые в анализе решений или практической
рекомендации, легко подпадают под влияние перспективы разработчиков, эта перспектива должна
Отчет по анализу решений и рекомендациям клинической практики 297
быть установлена. Как минимум, должно быть определено, была ли она перспективой
поставщика, плательщика или пациента.
195. Определите людей и группы, которые развили, финансировали или
поддержали анализ [18,19].
Как и экономические оценки, анализ решений и практические рекомендации должны
интерпретироваться исходя из потребностей, интересов и ценностей их разработчиков, так
же как и их научных достоинств. Важность идентификации разработчика иллюстрировал
Trobe [3], который цитирует выводы трех различных групп, каждая из которых оценила
способность «контрастного теста чувствительности», чтобы определить, извлечет ли
пациент выгоду из хирургии катаракты:
• Американский колледж глазных хирургов (представляющий «большой объем
хирургов катаракты») проявил большую благосклонность к тесту.
• Американская академия офтальмологии (представляющая «офтальмологов со
многими различными специализациями») признала редкую ценность теста.
• Агентство по политике здравоохранения и исследованиям (ныне Агентство по
исследованию здравоохранения и качества, представляеющее «офтальмологов, врачей-
неофтальмологов, оптиков, медсестер, социальных работников и пациентов»)
сообщило, что эффективность теста не была убедительной.
Многие профессиональные общества и правительственные учреждения связаны с
развитием рекомендаций клинической практики, включая Американскую медицинскую
ассоциацию. Американский колледж врачей. Канадскую целевую группу по
периодической экспертизе здоровья. Американскую профилактическую целевую группу здоровья.
Агентство по исследованию здравоохранения и качества и Программы развития
согласия национальных институтов здоровья [3, 12]. Американская медицинская ассоциация
также рекомендует, чтобы соответствующим врачебным организациям давали
возможность рассмотреть и прокомментировать практические рекомендации во время их
разработки [10].
УКАЗАНИЯ ОТНОСИТЕЛЬНО МЕТОДОВ
19.6* Установите определенные цели, решения или области интересов; отправные
точки, точки ветвления и исходы, рассмотренные в анализе [17,18].
Цели анализа решений или практических рекомендаций могут состоять в профилактике,
скрининге, диагностике, лечении или облегчении болезни или состояния. Исследования
могут быть проведены для применения к отдельным пациентам или для общего применения
к группе пациентов [20]. Анализ решений или практические рекомендации, используемые
в лечении отдельного пациента, могут объединять предпочтения, отличные от тех, которые
используются для проведения политики, цель которой может состоять в обеспечении
наибольшей пользы для самого наибольшего числа пациентов [21]. В любом случае область,
контекст и границы решения должны быть описаны [9, 17].
Два примера целей:
• Чтобы установить оптимальную рентабельную стратегию скрининга рака
молочной железы среди бессимптомных женщин, мы сравнили результаты соматического
298 Составление отчетов по обобщающим методам исследования
осмотра груди с результатами радиографического обследования обеих грудей. Эти
скрининговые тесты были сравнены для различных возрастных групп женщин, для
различных частот тестирования и среди бессимптомных женщин с наличием или
отсутствием указанных факторов риска.
• Должны ли пациенты старше 65 лет с систолической гипертензией подвергаться про-
тивогипертензивному лечению? [2]
Анализ решения включает изз^ение альтернатив и их последствий, следовательно, при
включении их в анализ они должны быть уточнены. У всех методов лечения есть «выгоды,
вред и затраты», которые нужно рассмотреть [2]:
• Отправная точка — клинический вопрос, к которому адресован анализ.
• Точки ветвления — пункты, в которых альтернативы становятся возможными. Есть
два типа узлов: узлы решения и случайные узлы. Узлы решения — это точки
ветвления, в которых обозначены альтернативные выборы, такие как выбор между
терапевтическим или хирургическим лечением и между одним или другим препаратом.
Иногда дается предпочтение пациентам каждой альтернативы, как во вводном
примере, где женщины не хотят подвергаться биопсии, пока уровень риска рака не станет
больше 10 %. Все осуществимые и практические альтернативы должны быть
оценены. Альтернативы не должны ограничиваться непосредственными проблемами их
пригодности или практичности [17]. Как и в экономических оценках, при
структурировании анализа рассматриваемые альтернативные лечения, возможно, должны
включать самую общую терапию, самую эффективную терапию, наименее дорогостоящую
терапию и «пустой» выбор. Случайные узлы указывают вероятные биологические
последствия решения или условия: уровень частоты неблагоприятных случаев,
вероятности выживания, частоты неудач и т. д.
• Исходы — это клинические состояния, в которых заканчивается анализ решения.
Каждому исходу часто назначают вес или полезность (качественная мера
желательности), чтобы его можно было сравнить с альтернативными исходами. Опишите исходы
(выгоды, вред и затраты) в клинических терминах, таких как «число нуждающихся
в лечении» (или другое отношение усилия к эффекту) или отношения правдоподобия
[2, 13] (см. указание 10.9 и 12.18). Исходы модели должны быть совместимы с
перспективой, целями и областью анализа [17].
19 J. Опишите информационные источники и стратегии, использованные в
поиске данных для анализа [18,19].
Данные для анализа решений или рекомендаций клинической практики могут быть
получены из нескольких источников: опубликованных клинических испытаний, отчетов
больниц, программ эпидемиологического надзора, от производителей оборудования и т. д.
Данные из различных источников могут сильно отличаться, поэтому важно знать, откуда они
получены и как привлекли внимание разработчиков {см. указание 17.12).
19.8. Опишите критерии, используемые для включения и исключения данных,
используемых в анализе [17-20].
Поскольку качество анализа решений или рекомендаций клинической практики
зависит от качества данных, на которых они базируются, важной частью процесса
разработки является понимание того, как производился сбор данных. Литературные обзоры могут
Отчет по анализу решений и рекомендациям клинической практики 299
быть ограничены, например, РКИ или исследованиями на выборках минимального размера
{см. указание 17.29),
Например, рандомизированные испытания могут оказаться непредставительными для
реальной медицинской практики [21]. Предметом обсуждения является вопрос, может ли
жестко контролируемое испытание, устанавливающее эффективность лечения (т. е.
«разведочное исследование»), использоваться, чтобы сделать выводы об эффективности
лечения в реальных условиях, где добросовестность пациентов не столь же хороша,
процедуры не могут применяться так же строго и т. д. (т. е. в «прагматическом исследовании»;
см. указание 13.2).
^ Данные, включенные в анализ, должны соответствовать принятой
перспективе анализа [17].
19.9. Если возможно, опишите методы, с помощью которых производился сбор
любых оригинальных данных, используемых в анализе.
Объективные данные должны быть собраны систематически и в полном соответствии со
стандартным дизайном исследования и деятельностью. Однако, поскольку
соответствующие хорошо проводимые научные исследования, возможно, не пригодны для многих
важных тем, для решения вопросов медицинской практики часто требуются субъективные
данные. Таким образом, анализ решений и рекомендации клинической практики часто
используют данные, полученные из мнения экспертов, соглашения групп экспертов, от пациентов
или от поставщиков. В таких случаях могут быть созваны «конференции согласия» или
группы экспертов, а также может использоваться методика выработки консенсуса, такая
как процесс Дельфи.
На конференциях согласия эксперты обсуждают текущее состояние знаний о практике,
но доказательства и основания для рекомендаций часто неясны [8]. В процессе Дельфи
итоговое утверждение проблемы передается группе экспертов, которые его комментируют.
Их комментарии синтезируются в пересмотренное итоговое утверждение, и новое
утверждение снова переходит к тем же самым экспертам. Снова добавляются и синтезируются
комментарии. Процесс продолжается, пока не будет достигнуто согласие или пока не
определятся разногласия.
Однако «не существует согласия, как достигнуть согласия» [12], и «природа
соответствующего использования экспертизы — одна из наиболее горячо обсуждаемых областей
в разработке рекомендаций» [7]. По этим причинам процесс, посредством которого
достигнуто (или не достигнуто) согласие, должен быть подробно описан.
Различные источники данных могут подчеркнуть различные аспекты лечения [11].
Например, результаты литературных обзоров, мнения экспертов и частного опыта могут
отличаться. Источники и методы извлечения мнений экспертов должны быть ясны [17].
19.10. Если возможно, сообщите, как были определены экономические затраты.
Укажите любое дисконтирование, используемое в анализе [17].
Затраты состоят из краткосрочных, долгосрочных, прямых и косвенных затрат, так же
как и сбережений в результате лечения (см. табл. 18.1). Пациенты, поставщики и
плательщики — все могут иметь затраты и «предотвращенные затраты», или сбережения.
Кроме того, некоторое лечение может иметь «вызванные затраты», которые являются
новыми, созданными предложенным лечением, такие как стоимость лечения неблагоприятных
300 Составление отчетов по обобщающим методам исследования
побочных эффектов. Дисконтирование — практика умножения будущих затрат на
«дисконтный фактор», чтобы перевести их на текущий курс доллара. Например, используя 3%-й
коэффициент дисконтирования, нынешние 25 000 долларов через 5 лет обесценились бы
до нынешних 20 958 долларов. {См. гл. 18 для обсуэюдения экономических оценок.)
19Л1. Если возможно, сообщите, как была определена полезность (оценка
пациентов или предпочтения) для различных выборов или исходов [17-19].
Полезность — мера желательности и обычно выражается в шкале от О (наименее
желательный) до 1 (самый желательный). Ценность анализа решения и практических
рекомендаций состоит в том, что они явно приспосабливаются к предпочтениям обычно пациентов,
но иногда поставщиков и плательщиков. Таким образом, важно определить людей
(например, универсалы, специалисты, пациенты, плательщики) и методы, использованные для
определения ценностей.
«Соединение вариантов лечения с исходами является в значительной степени вопросом
фактов и делом науки. Напротив, назначение предпочтений для исходов является в
значительной степени вопросом мнений и касается ценности» [7].
Иногда полезно заявить этические принципы, на которых эти предпочтения были
определены [7]: независимость пациента, которая подчеркивает личную свободу
выбора; непричинение зла, которое подчеркивает желание не причинить вред; и
дистрибутивное правосудие, которое подчеркивает справедливость в пределах определенной
группы.
«Для практиков крайне важно описать своим пациентам исходы и выявить их
предпочтения» [22]. Предпочтение пациентов может быть установлено для различных
альтернатив (например, терапия против хирургического лечения), для порогов решения
(например, степень приемлемого риска) или для исходов (например, меры качества жизни).
Среди методов, используемых для определения предпочтений: стандартная азартная игра
(или лотерейная техника), оценка величины и методы «компромиссов времени» [23, 24]
{см. указание 18.15).
Должна быть обозначена степень консенсуса, согласия (или амбивалентности,
противоречий) среди вовлеченных, и должны быть также сообщены соответствующие
противоположные мнения [7]. Кроме того, полезность, возможно, не является постоянной в течение
долгого времени [22].
19Л 2. Укажите качество доказательств, используемых в анализе [18].
Как более детально описано ъ указании 17.29 ъ главе по систематическим обзорам и ме-
таанализу, качественная оценка опубликованного исследования не является
непосредственной. Движением доказательной медицины предложена следующая классификация качества
доказательств [25]:
• Уровень I: убедительные доказательства по крайней мере одного систематического
обзора многократных, хорошо спланированных РКИ.
• Уровень II: убедительные доказательства по крайней мере одного должным образом
спланированного РКИ соответствующего объема.
• Уровень III: доказательства хорошо спланированных испытаний, таких как
нерандомизированные испытания, когортные исследования, временные ряды или спаренные
исследования «случай-контроль».
Отчет по анализу решений и рекомендациям клинической практики 301
• Уровень IV: доказательства хорошо спланированных неэкспериментальных
исследований более чем одного центра или исследовательской группы.
• Уровень V: мнения уважаемых авторитетов, основанные на клиническом
доказательстве, описательных исследованиях или отчетах экспертных комитетов.
Статистические методы
19Л 3» Укажите статистические методы, используемые в анализе [17].
в анализе решений структура проблемы может быть представлена в виде дерева
решений или таблицы решений. (В руководствах клинической практики структура может
упоминаться как «путь лечения» или как «алгоритм лечения»). Каждая альтернатива в
структуре дерева решения связана с вероятностью того, что это произойдет или что это будет
результатом определенного исхода. Для вычисления этих вероятностей могут быть
применены несколько статистических методов. Самые общие описаны ниже.
Марковский процесс, или процесс переходных состояний, используется на сложных
деревьях решения, у которых число ветвей и альтернатив велико, связанные с ними вероятности
могут изменяться со временем, и события могут произойти не раз. В этом процессе определен
как ряд «состояний здоровья», так и критерий для перехода из одного состояния здоровья
в другое. Вероятность, что пациент перейдет из одного состояния здоровья в другое в любой
заданный период, называют «вероятностью перехода» [24]. Кроме того, каждое состояние
здоровья имеет вес, меру полезности, такую как регулирование качества жизни, которое
указывается на шкале от О (безразличие к жизни и смерти) до 1 (крепкое здоровье), для оценки
желательного состояния здоровья (см. указание 18.15). Марковский процесс может также
использовать «поддеревья», чтобы представить повторные сегменты дерева решения.
В теорему Байеса входят три вероятности. «Априорная вероятность» является
вероятностью состояния или события, которая известна заранее, перед исследованием (например,
исходный преваленс пациентов, страдающих аллергией). «Правдоподобие» — это, как
правило, частота успеха лечения или чувствительность теста (на примере аллергии,
вероятность того, что кожная аллергическая проба приведет к истинно положительным
результатам). «Апостериорная вероятность» является вероятностью, определенной по первым двум
вероятностям с использованием теоремы Байеса (здесь вероятность действительной
аллергической реакции на аллерген, учитывая положительный результат кожной аллергической
пробы) (см. гл. 11),
Традиционные линейные модели охватывают диапазон от общих линейных моделей
(например, линейной регрессии или ANOVA) до моделей структурных уравнений.
Рабочие характеристики приемника (ROC-кривые) полезны в указании
взаимосвязи между ложноположительными и ложноотрицательными результатами диагностических
тестов, включая примененные одновременно или последовательно с целью улучшения
диагностической точности {см. указание 10.10).
Кривые затрат—результатов отражают взаимосвязи между денежными затратами
и денежными выгодами (кривые затрат—выгод), терапевтические меры (кривые
рентабельности) или состояние здоровья (кривые полезной стоимости). Как только кривые
построены, пациенты и поставщики могут «работать» в любой точке вдоль кривой, чтобы
определить комбинацию вкладов в исходы, которая лучше всего удовлетворяет их потребностям
{см. рис. 18.1).
302 Составление отчетов по обобщающим методам исследования
При моделировании Монте-Карло для получения распределения ожидаемых
вероятностей для каждого исхода к данным когорты пациентов применяется процедура анализа
решения. Средние и СО этих распределений могут затем использоваться для оценки вероятности
в формальной модели решения. Моделирования Монте-Карло могут также использоваться
для оценки полезности исходов и оценки результатов Марковских процессов {см. выше).
19.14. Идентифицируйте главные предположения и области возможности,
неопределенности и вариабельность в анализе [17].
Анализ решений и практические рекомендации требуют для своего развития
значительного количества времени и ресурсов. Они должны быть тщательно разработаны ввиду
своих потенциальных возможностей — при внедрении в практику они, вероятно, затронут
лечение большого количества людей. Неточности в анализе могут неблагоприятно
отразиться на тысячах пациентов [12, 24]. Кроме того, чем больше сложность клинической
проблемы и больше количество возможных вариантов лечения, тем больше неопределенности
будет в ходе анализа, а неопределенность является главной причиной ошибок [24].
Наконец, чем больше населения осмотрено в соответствии с анализом, тем больше
вариабельность в каждой точке [26]. Это важно, поэтому необходимо указать область
потенциальных возможностей, неопределенности и вариабельность в процессе разработки.
«Фундаментальный принцип анализа решений: даже при неполной доступной
информации решение должно быть принято. Таким образом, анализ часто содержит
предположения о пропусках или оценки недостающих данных» [21]. Переменные, подверженные
неопределенности и вариабельности, могут включать частоты инфекции, частоты
рецидивов, частоты смертности и заболеваемости, процент ложноположительных и ложноотри-
цательных случаев, предпочтения пациентов, частоту успешных хирургических операций
и т. д. Если анализ должен продолжиться, необходимо принять значения этих
переменных в модели и влияние этих предположений должно быть проверено с помощью анализа
чувствительности.
19.15. Идентифицируйте любые запланированные анализы чувствительности,
используемые, чтобы оценить предположения, неопределенность и
вариабельность в анализе.
в анализе чувствительности (также называемом сценарием моделирования,
детерминированным моделированием, ранговыми процедурами или анализом стабильности)
предположения, лежащие в основе решения или заьслючения, различаются по диапазону
вероятных значений для определения их влияния на результат {см. указание 18.24).
Например, инциденс неблагоприятной реакции на лечение может быть известен только
в широких пределах. В анализе решения инциденс может быть изменен от минимального
значения до максимального. Если меняется незначительно, частота инциденса вносит в
исход несущественную долю неопределенности и модель может быть применена с большей
уверенностью, т. е. является робастной. Если исход изменяется сильно, будет благоразумнее
определить частоту инциденса более точно, прежде чем применить модель.
Переменные, выбранные для анализа чувствительности, в большинстве случаев
обладают самой большой степенью неопределенности (например, основанные на мнении
экспертов в противоположность эмпирическим данным), у этих переменных самая большая
вариабельность и тем самым они оказывают наибольшее влияние на результаты [17].
Отчет по анализу решений и рекомендациям клинической практики 303
19.16. Определите пакет(ы) статистических программ, используемый(е) для
анализа или моделирования данных.
Компьютерные программы, разработанные для выполнения анализа решений, включают
DATA (Decision Analysis by TreeAge Software, Inc), которая строит деревья решения и
марковские модели; LISREL (Linear Structural Relationships), которая осуществляет моделирование
структурными уравнениями; Decision Tree Software; Decision Maker; SML TREE и Splus.
УКАЗАНИЯ ПО ОФОРМЛЕНИЮ РЕЗУЛЬТАТОВ
19.17. Подведите итоги анализа визуально: представьте дерево решения, блок-
схему или итоговую кривую [18].
Дерево решения — диаграмма, которая изображает случайные узлы, узлы решения и
исходы анализа решения (см. рис. 19.1). Мы используем здесь термин «дерево решения» в
общем смысле; распространены также и другие термины, хотя у некоторых из них немного
другие значения. В частности, алгоритмы обычно состоят из нескольких точек ветвления
«да-нет» без вероятностей или полезностей. Алгоритмы часто воспринимаются как
слишком упрощенные для клинического использования.
«Клинические схемы (пути) лечения», «блок-схемы» и «деревья классификации и
регрессии» (CART) являются другими общепринятыми терминами для таких диаграмм. Эти
диаграммы определяют порядок действий и условия, при которых выбирается каждое действие
(рис. 19.2).
Некоторые анализы могут быть подытожены с помощью ROC-кривых или кривых
затрат—исходов.
19.18» Сообщите об оценке вероятности для каждой альтернативы каждого
случайного узла, так же как и о процентах неправильной классификации
каждой альтернативы [17,18].
Вероятность для каждой альтернативы в случайном узле должна быть определена.
Вероятности могут быть связаны как с естественной историей условий (такие, как частота
потери кальция), так и с эффектами исследуемой терапии (такими, как частота инфекции) [21].
Должна быть указана и подтверждена частота неправильной классификации.
Также ценна информация о том, что две или более терапевтические альтернативы не
приводят к заметно различающимся исходам («неопределенный исход») [20].
@ Сумма вероятностей альтернатив в каждой точке ветвления должна быть
равной 1.
19.19. Если ВОЗМОЖНО, сообщите оценку вероятности каждой альтернативы для
каждого узла решения.
в анализе решений или экономической оценке вероятности каждой альтернативы в узле
решения, возможно, должны быть определены так, чтобы вероятность каждого исхода или
количество пациентов, достигающих каждый исход, могли быть предсказаны. В
клинических практических рекомендациях вероятности, возможно, не будут необходимы, потому
что цель рекомендаций состоит в том, чтобы проводить лечение, а не определять
количественные взаимосвязи между вариантами и исходами.
304 Составление отчетов по обобщающим методам исследования
Диагностика подтвержденной неходжкинской лимфомы
Легкая степень
Облучение
1
I 1
Стадия I или II Стадия III или IV
Средняя степень
Стадия I или II Стадия II,
большая аадия III
или IV
Циклофосфамид,
доксорубицин,
винкристин и
преднизон,
CHOP ± облучение
CHOP
Тяжелая аепень
I
\ \
Лимфоблааная Маленькая
нерасщепленная
клетка (Баркита)
Комбинированная
химиотерапия +
профилактика
ЦНС ± облучение
Комбинированная
химиотерапия
Бессимптомная (нет
значительной анемии,
тромбоцитопении или
спленомегалии)
«Наблюдайте и ждите» |
Симптоматическая
(значительная анемия,
тромбоцитопения или
спленомегалия)
Комбинированная
химиотерапия ±
рекомбинантный
человеческий
интерферон альфа
против отдельного
алкилирующего агента
± кортикостероиды
Рис. 19.2. Клинические практические рекомендации указывают предпочтительные направления действия
в различных условиях. Вероятности или полезности нельзя назначать альтернативам и конечным точкам, как
в анализе решений, но рекомендации могут разрабатываться по-другому посредством процесса, подобного
анализу решений. (По: Fisher RI, Океп ММ. Clinical practice guidelines: non-Hodgkin's lymphomas. Cleve Clin J Med.
1995;62[suppl l]:516-42; with permission)
19.20. Если возможно, сообщите меру полезности для каждого исхода и для
каждой альтернативы в каждом узле решения.
Одна из целей анализа решения состоит в том, чтобы включить предпочтение пациентов
в процесс принятия решений. Эта цель достигается путем количественного определения
риска и выгод различных выборов, включая желательность конечного исхода.
19.21. Сообщите о результатах любых анализов чувствительноаи.
Есть несколько видов анализа чувствительности. В пороговом анализе вероятности
и полезности варьируются, чтобы определить «точку равновесия» каждой переменной
в модели, т. е. точки, в которых исходы в сравниваемых стратегиях эквивалентны [21].
Могут быть также выполнены одно-, двух- и трехфакторные анализы чувствительности,
в которых одновременно варьируют одну, две и три переменных соответственно, чтобы
определить изменения в исходах (см. рис. 18.2 и 18.3). Эти рисунки могут содержать «ли-
Отчет по анализу решений и рекомендациям клинической практики 305
НИИ стратегии». Точку, в которой пересекаются линии стратегии, называют «порогом
решения», что означает, что по обеим сторонам порога оптимальное лечение различается.
Детерминированный анализ чувствительности применяется к моделям,
использующим одиночные значения (или «точечные оценки», такие как средние или медианы), тогда
как вероятностный анализ чувствительности применяется к моделям, использующим
диапазоны значений. Используя одиночные значения, детерминированные модели, по
существу, игнорируют неопределенность или вариабельность в данных и, таким образом,
могут создать ложное впечатление точности. Вероятностные модели, включающие больше
неопределенности в данные, как правило, представляют более реалистичные модели.
Одна из причин для проведения анализа чувствительности состоит в том, чтобы
определить, требуются ли лучшие данные для модели [17].
19.22. Объясните, как была оценена и включена неопределенность в анализе [17].
Неопределенность присуща любому клиническому состоянию, так же как и любой
попытке смоделировать состояние. Лучшие анализы пытаются установить важные источники
неопределенности и оценить ее влияние на смоделированных решениях [17].
В анализах решения могут быть оценены три типа неопределенности [17]. Структурная
неопределенность имеет отношение к адекватности математической модели,
используемой в анализе. Как описано выше, решения могут быть смоделированы с помощью
различных математических методов, что может повлиять на результат. Методологическая
неопределенность имеет отношение к предположениям об аналитических шагах,
используемых в модели. Например, выбор используемого учетного процента или предположения
при моделировании случайных или фиксированных эффектов (см. указание 17.20).
Наконец, параметрическая неопределенность связана с неопределенностью или
вариабельностью в значениях переменных, используемых в модели. Здесь неопределенность может
следовать 1) из нехватки доказательств, как в случае, когда используется мнение экспертов
как источник значений, 2) из ошибки в формировании выборки, которая возникает, когда
значения взяты из маленьких выборок, или 3) из биологических вариаций, которые могут
быть следствием небрежного объединения данных из различных гетерогенных подгрупп.
УКАЗАНИЯ ОТНОСИТЕЛЬНО ОБСУЖДЕНИЯ РЕЗУЛЬТАТОВ
19.23. Опишите условия, при которых реализуются или не реализуются
альтернативы в каждом узле решения; представьте доказательства за и против
каждой альтернативы [18].
Для клинических практических рекомендаций укажите показания, противопоказания
и дифференциальные риски для каждого лечения [2]. Рекомендации должны быть как
практическими, так и клинически важными [7, 23].
19.24. Укажите общее доаоинство анализа и гибкость, с которой он может быть
применен [18].
в любом анализе решений должно быть хорошее «согласие» между задаваемыми
вопросами, структурой математической модели и доступными данными. Иногда аналитик
находит хорошее соответствие только между двумя из этих трех факторов [20]. Чем лучше
«согласие», тем сильнее рекомендации.
306 Составление отчетов по обобщающим методам исследования
Eddy [22] предложил, чтобы практические рекомендации были категоризированы
в соответствии с гибкостью, с которой может быть применено руководство.
Классификация по этим категориям зависит от 1) степени уверенности, связанной с исходом,
2) степени известности предпочтений пациентов и 3) диапазона предпочтений среди
пациентов [8, 22].
• Стандарт — практическое руководство, которое должно быть применимо фактически
во всех случаях. Исключения редки и трудно оправдываются, и нарушение
стандарта может рассматриваться как преступная небрежность врача при лечении пациента.
Доказательство предсказуемости терапевтических и экономических исходов должно
быть неотразимым. Должно существовать единодушие среди пациентов о полной
желательности (или нежелательности) исходов.
• Рекомендация — это практическое руководство, которому необходимо следовать
в большинстве случаев. Она может и должна модифицироваться для индивидуальных
условий, но отклонения ожидаются и не квалифицируются как преступная
небрежность врача. Предсказуемость, по крайней мере, некоторых из исходов должна быть
известна в разумных пределах. Значительное большинство пациентов должны желать
(или не желать) эти исходы.
• Версии — практическое руководство, которое ни рекомендует, ни предупреждает
против отдельной клинической практики. Здесь исходы могут быть неизвестны,
предпочтения пациентов могут быть неизвестны или распределены между эквивалентными
вариантами или пациенты могут быть безразличны к исходам.
Другие термины, которые могут быть использованы для описания рекомендуемого
лечения, включают «путь», который указывает предпочитаемое направление действия [И];
«граница», которая указывает пределы, в рамках которых имеет место соответствующая
практика; и «временная практическая рекомендация», которая определяет
рекомендацию как предварительное, незаконченное дополнительное доказательство [11].
19.25. Опишите любой процесс оценки или обоснования, которому был подвергнут
анализ [18,19].
в идеале обоснованность анализа решений или практической рекомендации
оценивается перед внедрением. Общие процедуры обоснования включают обзор другими
авторитетными профессиональными группами, сравнение с подобными руководствами,
разработанными другими группами, апробацию и представление руководства для сурового РКИ.
Анализ должен быть оценен относительно как внутренней, так и внешней
обоснованности [17]. Внутренняя обоснованность — степень, с которой анализ отражает
рассматриваемые биологические и медицинские детали. Внешняя обоснованность — способность
анализа быть осуществленным с разумным шансом на улучшение ухода. При любом типе
обоснования результаты, противоречащие интуитивным представлениям, возможно,
должны быть объяснены.
19.26. Опишите общие черты и различия анализа с другими исследованиями или
руководствами, охватывающими схожие области [17].
Сравнение со схожими руководствами может помочь обосновать рекомендации
(указание 19.25) и выдвинуть на первый план методы, которые должны будут изменить
клиницисты, если они принимают рекомендации.
Отчет по анализу решений и рекомендациям клинической практики 307
19.27. Опишите ожидаемые выгоды, проблемы и затраты, которые могут
затронуть пациентов, если анализ осущеавлен в клинической практике [17-20].
Чтобы помочь клиницистам принять рекомендации, приведите некоторые признаки того,
что они могут ожидать при принятии рекомендаций. Включите:
• ожидаемые изменения в нормах, в которых нуждаются процедуры;
• возможные последствия неправильной классификации пациентов в любом пункте
анализа.
19.28. Укажите любые клинические или административные изменения,
необходимые для осуществления рекомендаций, и любые социальные или
поведенческие факторы, которые могут свести к нулю их эффективность [19,20].
«Методы осуществления и оценки политики клинической практики отстают от
энтузиазма при их внедрении, и препятствия, сопутствующие их принятию, неопознаны или
непреодолимы» [5, 12].
Практические рекомендации будут приняты с большей готовностью, если они:
• являются приемлемыми для поставщиков здравоохранения;
• понятны поставщикам здравоохранения;
• могут быть гибкими в применении;
• могут легко применяться в пределах установок здравоохранения;
• разработаны лицами, ухаживающими за больными, или практикующими врачами.
В целом поставщики здравоохранения, более вероятно, примут клинические
практические рекомендации, если: 1) существуют стимулы, заставляющие сделать это, такие как
настойчивость плательщиков третьей стороны, сокращение страхования от преступной
небрежности врачей или возможность использовать строгое соблюдение руководства как
защиту в случаях преступной небрежности врачей; или 2) им предоставляют быструю и
регулярную обратную информацию о том, как их деятельность сравнивается с таковой
аналогичных поставщиков.
19.29. Определите ожидаемый «срок годности» анализа и то, когда или при каких
обстоятельствах рекомендации должны быть пересмотрены или
обновлены [18].
Развитие медицинской информации и технологии может в конечном счете сделать анализ
решения или практическое руководство устаревшими. Фактически в отношении анализа
решений и практических рекомендаций беспокоит одно: могут ли они разрабатываться
достаточно быстро, чтобы идти в ногу с быстро развивающейся технологией [5]. Определение
обстоятельств, при которых должен быть пересмотрен анализ, помогает поместить анализ
в контекст, а также оценить рекомендации.
Анализ решений и клинические практические рекомендации должны быть
основаны на самых новых данных. Однако время между началом и публикацией анализа может
быть достаточно долгим, так что важные новые данные могут быть пропущены.
Размещение анализа вовремя, с указанием времени сбора данных, помогает читателям оценить
рекомендации.
Если последние события не могут быть включены непосредственно в анализ, они могут
быть, по крайней мере, описаны. Читатели смогут тогда оценить рекомендации с учетом
этих событий.
308 Составление отчетов по обобщающим методам исследования
Литература
1. Richardson WS, DetskyAS. Users' guide to the medical literature. VII. How to use a clinical decision
analysis. A. Are the results of the study valid? The Evidence-Based Medicine Working Group. JAMA. 1995;
273:1292-5.
2. Evidence-Based Care Resource Group. Evidence-based care: 2. Setting guidelines: how should we
manage this problem? Can Med Assoc J. 1994; 150:1417-23.
3. Trobe JD, Fendrick AM. The effectiveness initiative. I. Medical practice guidelines. Arch
Ophthalmol. 1995; 113:715-7.
4. Leape LL. Practice guidelines and standards: an overview. QRB Qual Rev Bull. 1990; 16:42-9.
5. Walker RD, Howard MO, Lambert MD, Suchinsky R. Medical practice guidelines. West J Med. 1994;
161:39-44.
6. Naylor CD, Guyatt GH. Users guide to the medical literature. X. How to use an article reporting
variations in the outcomes of health services. JAMA. 1996; 275:554-8.
7. Hayward RS, for the Evidence-Based Medicine Working Group. VIII. How to use clinical practice
guidelines. A. Are the recommendations valid? The Evidence-Based Medicine Working Group. JAMA.
1995;274:570-4.
8. Ganiats TG. Practice guidelines movement. West J Med. 1993; 158:518-9.
9. Crane VS, GillilandM, TuthillEL, Bruno С The use of a decision analysis model in multidisciplinary
decision making. Hosp Pharm. 1991; 26:309-25, 350.
10. American Medical Association. Attributes to Guide the Development of Practice Parameters.
Chicago: American Medical Association; 1994:1-11.
11. Hayward RS, Laupacis A. Initiating, conducting and maintaining guidelines development programs.
Can Med Assoc J. 1993; 148:507-12.
12. Basinski SH. Standards, guidelines and clinical policies. The Health Services Research Group. Can
Med Assoc J. 1992; 146:833-7.
13. Hayward RS, Wilson MC, Tunis SR, et al. More informative abstracts of articles describing clinical
practice guidelines. Ann Intern Med. 1993; 118:731-7.
14. AudetAM, GreenfieldS, FieldM. Medical practice guidelines: current activities and future directions.
Ann Intern Med. 1990; 113:709-14.
15. Schwartz WB, Gorry GA, KassirerJP, EssigA. Decision analysis and clinical judgment. Am J Med.
1973;55:459-72.
16. Eddy DM. Probabilistic reasoning in clinical medicine: problems and opportunities. In: Kahneman D,
Slovic P, Tversky A, eds. Judgment under Uncertainty: Heuristics and Biases. Cambridge: Cambridge
University Press; 1982:249-67.
17. Philips Z, Ginnelly L, Sculpher M, et al. Review of guidelines for good practice in decision-analytic
modelling in health technology assessment. Health Technol Assess. 2004; 8:iii-iv, ix-xi, 1-158.
18. Shiffman RN, Shekelle P, Overhage JM, et al. Standardized reporting of clinical practice guidelines:
a proposal from the conference on guideline standardization. Ann Intern Med. 2003; 139:493-8.
19. Cluzeau F, Burgers J, for the AGREE Collaboration. Appraisal of Guidelines for Research and
Evaluation. London: St George's Hospital Medical School, June 2001.
20. KassirerJP, Moskowitz AJ, Lau J, Pauker SG. Decision analysis: a progress report. Ann Intern Med.
1987; 106:275-91.
Отчет по анализу решений и рекомендациям клинической практики 309
21. Goel V. Decision analysis: applications and limitations. The Health Services Research Group. Can
Med Assoc J. 1992; 147:413-7.
22. Eddy DM. Designing a practice policy: standards, guidelines, and options. JAMA. 1990; 263:3077-84.
23. Laupacis A, Feeny D, Detsky AS, Tugwell PX. How attractive does a new technology have to be to
warrant adoption and utilization? Tentative guidelines for using clinical and economic evaluations. Can Med
Assoc J. 1992; 146:473-81.
24. PaukerSG, Kassirer JP. Decision analysis. N Engl J Med. 1987; 316:250-8.
25. BelseyJ, Snell T. What is Evidence-Based Medicine? www.evidence-based-medicine.co.uk. Accessed
August 30, 2005.
26. Wasson JH, Sox HC, NeffRK, Goldman L Clinical prediction rules: applications and methodological
standards. N Engl J Med. 1985; 313:793-9.
311
0
Часть IV
Представление
данных и статистик
в таблицах
и графиках
Данные долэюны быть сведены в таблицу только тогда, когда их возмоэю-
но представить более конкретно в этой форме, чем в тексте статы
Обременительная и громоздкая таблица мешает достижению цели, для
которой она была предназначена.
George Simmons и Morris Fishbein [ 1 ]
Рисунок стоит 10 000 слов, но он расходует в 10 000раз больше дисковой
памяти.
Аноним [Ц
Таблицы, диаграммы и графики часто используются для
представления данных и статистик. Каждый из этих трех графических инструментов
передает информацию, показывая 1) значения и 2) метки в 3) контексте.
Значения — это данные; они могут быть числами, символами или
текстом. Значения сами по себе бессмысленны: 120, + или «умеренный»,
например. Таким образом, они должны сопровождаться метками. Метки
идентифицируют значения и часто добавляют дополнительные
характеристики: в вышеупомянутых примерах, среднее систолическое давление
120 мм рт. ст.; положительный результат диагностического теста и
умеренные симптомы болезни Альцгеймера. Даже значения с метками,
однако, бессмысленны в отсутствие большего контекста, такого как
определенный исследовательский проект. Контекст — фон, относительно
312 Представление данных и статистик в таблицах и графиках
которого должны интерпретироваться значения и метки. Продолжая вышеупомянутый
пример, среднее систолическое давление 120 мм рт. ст. могло бы быть конечной точкой
лечения пациентов с гипертензиеи; положительный результат диагностического теста мог
бы определить подгруппу пациентов с сопутствующими заболеваниями; и «умеренные»
симптомы болезни Альцгеймера могли бы быть критерием включения в исследование
препарата. На таблицах, диаграммах и графиках контекст должен быть указан в подписях или
заголовках, так же как должен быть очевиден из всего документа.
Эти три графических инструмента также сходны в том, что все они используют систему
координат для передачи дополнительной информации о значениях. Таблицы хороши для
представления категоризованных данных со значениями, измеренными в номинальных,
биномиальных или порядковых значениях, или итоговых статистик непрерывных величин
(средние, медианы, диапазоны и т. д.). Здесь заголовки столбцов и строк маркируют
значения в каждой ячейке. Диаграммы хороши для представления категоризованных данных,
измеренных как в порядковой, так и в непрерывной шкалах или с итоговыми статистиками
для непрерывных значений. В столбиковых или точечных диаграммах категории
приведены (маркированы) на одной оси, а значения для категорий даны на другой оси. Таким
образом, диаграммы — это промежуточный шаг между таблицами и графиками. Графики
хороши для представления данных со значениями, обычно измеренными в непрерывной
шкале. Здесь значения считываются с двух (или иногда трех) шкал, которые, кроме того,
маркируют значения.
В сводке и среди других характеристик, описанных в гл. 20 и 21, хорошие таблицы,
диаграммы и графики должны: 1) ясно представлять данные, 2) соответствующе маркировать
значения и 3) предоставлять читателям достаточно контекста, чтобы правильно
интерпретировать значения.
Литература
1. Simmons GH, Fishbein М. The Art and Practice of Medical Writing. Chicago: American Medical
Association; 1925.
2. Unknown cyberhumorist.
Сообщение значений, групп и сравнений в таблицах 313
Глава 20
Табличное представление данных
и статистик
Сообщение значений, групп и сравнений
в таблицах
Таблицы предназначены для коммуникации, а не для хранения данных.
Howard Wainer [1]
В этой главе и гл. 21 мы представляем руководства по представлению информации в
таблицах и графиках с соответствующим акцентом в трех областях: 1) значения, 2) группы
связанных значений и 3) сравнения между двумя или большим числом групп. В
проектировании таблиц эти три области состоят из следующего:
• Значения: информация в индивидуальной ячейке таблицы; единица данных, символ
или наблюдение.
• Группы: столбцы и строки таблицы, которые содержат значения одной и той же
группы или одного и того же класса. Сюда включены итоговые описательные статистики
групп или распределений данных, такие как общее количество, процент, среднее и СО
или медиана и интерквартильный размах.
• Сравнения: столбцы и строки, которые суммируют или сравнивают 2 или более групп.
На этом уровне столбцы и строки показывают различия между группами, общие
количества для 2 или более групп; коэффициенты корреляции; шансы, риск и отношения
рисков; оценки и доверительные интервалы и/>-значения.
ФУНКЦИИ ТАБЛИЦ
Функция таблиц состоит в том, чтобы:
• уплотнить или суммировать большое количество данных, особенно сложных или
детальных данных [2-5];
• организовать и показать данные, особенно точные числа, более ясно и кратко, чем
можно было бы сделать словами [2, 6];
• сравнить индивидуальные значения или группы данных [2-6];
• улучшить легкость и скорость, с которой необходимая информация может быть
найдена и понята [4, 5];
• облегчить вычисления [4].
Вообще таблицы лучше рисунков помогают читателям найти определенную
информацию и представить точные числа, тогда как рисунки лучше представляют сравнения
314 Представление данных и статистик в таблицах и графиках
и общие структуры данных [6]. Мы рекомендуем каэюдый раз прилагать усилия, чтобы
представить сравнения в виде рисунков, а не в виде таблиц, даэюе когда количество
данных мало [6].
КОМПОНЕНТЫ И типы ТАБЛИЦ
У таблиц в научных публикациях обычно есть по крайней мере первые 6 компонентов,
упомянутых ниже, и у многих имеются 7 или даже все 8 (табл. 20.1).
1. Номер таблицы (исключения — таблицы, «вставленные» в текст, такие как списки
и простые перечисления и стили публикаций, в которых только 2 или больше таблиц
нумеруются).
2. Название таблицы, которое идентифицирует данные, показанные в таблице, и
контекст, в котором они должны интерпретироваться.
Таблица 20J
[Номер таблицы] Таблица 20.1. [Название] Компоненты и номенклатура таблиц
Головка строк
Головка-мостик
Подзаголо- Подзаголо- Подзаголо-
Подзаголовок столбца: вок столбца: вок столбца: вок столбца:
Размер Размер Размер Размер
группы группы группы группы
(единицы) (единицы) (единицы) (единицы)
Головка
столбца
Размер
группы
(единицы)
«Врезанный» заголовок
Головка строки
Подзаголовок строки
Подзаголовок строки
Головка строки
Поле данных
«Врезанный» заголовок
Головка строки
Подзаголовок строки
Подзаголовок строки
Головка строки
Всего
Поле данных
ABC — развернутое сокращение
* (звездочка)
t (крестик)
Ф (двойной крестик)
§ (знак параграфа)
II (знак параллели)
@ (знак абзаца)
** (двойная звездочка)
^ надстрочная буква
" надстрочная буква
*" надстрочная буква
Сообщение значений, групп и сравнений в таблицах 315
Таблица 20» 2
Однофакторная таблица отображает одну объясняющую переменную'*
Переменная отклика
Контрольная группа
(п = 118)
Группа лечения (п = 123)
Переменная 1,мг
Переменная 2, кг
Переменная 3, мг/дл
^ Группа со значениями лечения и контроля. Также называется таблицей 2x3, потому что поле данных состоит
из 6 ячеек.
Таблица 20.3
Двухфакторная таблица отображает две объясняющие переменные"
Переменная отклика
Переменная 1,мг
Переменная 2, кг
Переменная 3, мг/дл
Контрольная группа (п = 118)
Мужчины Женщины
{п = 57) (п = 61)
1
5
9
2
6
10
Группа лечения {п = 123)
Мужчины
(п = 55)
3
7
11
Женщины
(л = бб)
4
8
12
^ Группа со значениями лечения, контроля и пола пациентов в каждой группе. Также называется таблицей
4x3, потому что поле данных состоит из 12 ячеек. Головки столбцов групп контроля и лечения теперь являются
мостиковыми головками, которые охватывают подгруппы мужчин и женщин.
Таблица 20,4
Трехфакторная таблица отображает три объясняющие переменные"
Группа контроля (л = 118)
Группа лечения (л = 123)
Переменная
отклика
Мужчины
(п = 57)
Женщины
(л = 61)
Мужчины
(п = 57)
Женщины
(л = бб)
Правши Левши Правши Левши Правши Левши Правши Левши
(л = 45) (л = 12) (л = 48) (л = 13) (л = 47) (л = 10) (л = 51) (л = 15)
Переменная 1,мг 1
Переменная 2, кг 9
Переменная 3, мг/дл 17
^ Группы со значениями лечения и контроля, пола пациентов в каждой группе, праворукости или леворуко-
сти. Также называется таблицей 8x3, потому что поле данных содержит 24 ячейки. Головки столбцов мужчин
и женщин теперь сами являются мостиковыми головками, которые охватывают подгруппы право- и леворуких.
2
10
18
3
11
19
4
12
20
5
13
21
6
14
22
7
15
23
8
16
24
316 Представление данных и статистик в таблицах и графиках
3. Заголовки (головки^) столбцов (блоков), которые идентифицируют информацию,
содержащуюся в каждом столбце, и, возможно, являются «мостиком», «вилкой» или
«крышкой» заголовков групп из 2 или более столбцов связанной информации.
4. Заголовки строк (отрезков), которые идентифицируют информацию, содержащуюся
в каждой строке, и, возможно, являются подзаголовками и «врезанными» заголовками
групп из 2 или более строк связанной информации.
5. Данные (в «области данных»), ячейки таблицы, кроме тех, которые содержат
заголовки столбцов и строк.
6. Горизонтальные линии (линейки), обычно по крайней мере 3: ниже заголовка
таблицы, ниже головок столбцов и ниже области данных; другие линии проводятся сверху
итогов и также могут отделять главные подразделения области данных (выше
«врезанных» заголовков).
7. Расшифровки сокращений, используемых в таблице, располагаются ниже области
данных.
8. Сноски, на которые ссылаются в таблице, ниже расшифровок сокращений, обычно
используются в следующем порядке: *, |, % §, \\, Ц, **, tt и т. д. [7]; иногда метка #
используется перед дублированием меток [2], а некоторые руководства по стилю
используют надстрочные буквы [3].
Таблицы часто управляются количеством объясняющих переменных, которые они
представляют. Таким образом, у однофакторной таблицы есть только единственная
объясняющая переменная, двухфакторная таблица имеет 2, а многофакторная имеет 3 или более
объясняющих переменных (табл. 20.2-20.4). Таблицы могут также определяться количеством
ячеек в области данных. Например, таблицы 2x3 соответствуют области данных из 6
ячеек (табл. 20.2-20.4).
ПРИНЦИПЫ ПОСТРОЕНИЯ ТАБЛИЦ
Если таблицы должны сообщить информацию быстро и точно, читатели должны быть
в состоянии: 1) определить, как организована информация, 2) найти интересующую
информацию и 3) интерпретировать информацию, как только ее найдут [8]. Опыт, договоренности
и некоторые исследования установили по крайней мере 6 принципов, по которым должны
быть построены таблицы:
1. У таблиц должна быть цель; они должны вносить свой вклад и быть
интегрированы с остальным текстом [1,2, 9,10].
О данных нельзя сообщать ради них самих. Скорее, они должны быть частью большего
усилия ответить на четыре вопроса исследования: «Что вы делали?», «Почему вы делали
это?», «Что вы обнаружили?» и «Что это означает?». Таким образом, таблицы должны
использоваться, только когда они могут сообщить информацию более рационально или
эффективнее, чем может быть сделано в тексте или рисунках.
2. Цель таблицы должна определять ее форму [4, 5,11].
Таблица, созданная, чтобы собрать данные, необязательно является той же самой
таблицей, которая должна использоваться для представления этих данных. Таблица, созданная,
чтобы организовать большое количество данных так, чтобы на значения можно было легко
' в переводе терминов в 20-й и 21-й главах мы придерживаемся терминологии, принятой в сборнике переводов
«Рекомендации по подготовке научных медицинских публикаций», который уже становится стандартом в
оформлении. Важно отметить, что соавтором многих оригинальных материалов этого сборника является Т. Ланг.
Сообщение значений, групп и сравнений в таблицах 317
сослаться, необязательно будет той же самой таблицей, которая построена с целью
выделить особенности в данных или для сравнения этих особенностей.
Таблицы могут быть структурированы для функций анализа или ссылки [5].
Аналитические таблицы конструируются «изнутри наружу», организовывая область данных так,
чтобы помочь показать особенности в данных. Таблицы для ссылок конструируются «снаружи
внутрь» путем организации головок столбцов и строк так, чтобы помочь читателям быстро
найти определенную информацию. Например, табл. 20.5 и 20.6 представляют одну и ту же
информацию, но табл. 20.5 перечисляет причины смерти сверху вниз, чтобы сосредоточить
внимание на относительном количестве смертельных случаев от каждого типа рака.
Табл. 20.6 перечисляет типы рака в алфавитном порядке, чтобы помочь читателям быстрее
найти информацию относительно определенного типа рака.
3. Таблицы должны быть организованы и отформатированы так, чтобы
помочь читателям в поиске, визуальном восприятии, понимании и запоминании
информации.
Таблица, которая содержит все необходимые данные, но вынуждает читателей
организовать данные, прежде чем понять их, вредит всем: это увеличивает время, необходимое
для читателей, чтобы оценить данные, и не гарантирует, что понимание автора будет
соответствовать интерпретации его данных
читателями.
Данные в табл. 20.7, вероятно,
организованы в порядке, в котором они были
собраны. Упорядочивание колонок по
номерам пациентов не передает информации
читателям и может затенить более
важные особенности данных [6]. Кроме того,
изученные особенности не организованы
никаким особенным образом. Напротив,
табл. 20.8 группирует характеристики
по категориям, добавляя структуру, и
колонки отсортированы сначала по полу
и затем по возрасту. Новые номера
пациентов легко определяют первых 4
пациентов как мужчин и следующих 4 как
женщин.
4. Значения, которые будут
сравниваться, должны обычно помещаться
бок о бок [1,2].
В английском языке (как и в русском)
читают слева направо и сверху вниз.
Таким образом, по крайней мере, в
англоязычных публикациях размещение
значений бок о бок является не только самым
легким способом их сравнения, но также
и способствует сравнению. В
биомедицинском исследовании, где группа лече-
Таблица 20,5
Основные причины смертности от
онкологических заболеваний в Соединенных Штатах,
1998 г. (организована, чтобы показать
структуру данных)
Тип рака
Легкого
Толстой кишки
Молочной железы
Простаты
Шейки матки
Количество смертей
160 000
57 000
44 000
39 000
5000
Таблица 20.6
Основные причины смертности от
онкологических заболеваний в Соединенных Штатах,
1998 г. (организована, чтобы помочь читателям
в поиске информации)
Тип рака
Легкого
Молочной железы
Простаты
Толстой кишки
Шейки матки
Количество смертей
160000
44 000
39 000
57 000
5000
318 Представление данных и статистик в таблицах и графиках
Таблица 20.7
Исходные данные по фитнесу для восьми пациентов, завершивших исследование по фитнес-
тренировке (как собраны)
Показатель
Возраст, годы
Пол
Пульс при отдыхе,
удар/мин
1,5-мильная пробежка.
Гемоглобин, г/дл
Вес, кг
Ю^х Э/мкл
мин
1
35
М
XX
XX
XX
XX
XX
2
16
М
XX
XX
XX
XX
XX
3
21
Ж
XX
XX
XX
XX
XX
Номер пациента
4
19
Ж
XX
XX
XX
XX
XX
5
41
М
XX
XX
XX
XX
XX
б
ш
ж
XX
XX
XX
XX
XX
7
22
М
XX
XX
XX
XX
XX
8
37
ж
XX
XX
XX
XX
XX
Э — эритроциты.
Таблица 20,8
Исходные данные по фитнесу для восьми пациентов, завершивших исследование по фитнес-
тренировке (пересмотрены для публикации)
Новые номера пациентов
[Старые номера пациентов приводятся только для
иллюстрации]
Возраст, годы
Вес, кг
Показатели крови
Гемоглобин,//дл
Ю^х Э/мкл
Результаты фитнеса
1,5-мильная лробежка/мин
Пул ьс при отдыхе; уда р/мин
1
[3]
16
XX
XX
XX
XX
XX
Мужчины
2
[11
22
XX
XX
XX
XX
XX
3
[б]
35
XX
XX
XX
XX
XX
4
[5]
41
XX
XX
XX
XX
XX
5
[41
Т9
XX
XX
XX
XX
XX
Женщины
б
[71
21
XX
XX
XX
XX
XX
7
[21
30
XX
XX
XX
XX
XX
8
[81
37
XX
XX
XX
XX
XX
Э — эритроциты.
ния сравнивается с группой контроля, значения для каждой группы должны обычно
даваться в смежных столбцах так, чтобы переменные в каждой строке можно было легче
сравнить.
Табл. 20.9 отражает влияние опыта врача в модельной оценке хирургического
вмешательства. Таким образом, автор хочет показать отношения между объясняющей
переменной опыта и переменной отклика хирургического навыка, как оценено здесь
выполнением задач моделирования. Однако таблица плохо организована, чтобы показать
эти отношения. Размещение модельных оценок бок о бок способствует сравнению чи-
Сообщение значений, групп и сравнений в таблицах 319
Таблица 20,9
Влияние опыта врача на показатели хирургической имитации"
Опыт
Ординаторы (л = 12)
Научные сотрудники (л = 8)
Штатные хирурги (п = 15)
р-значение''
Средний
Вырезание
79
88
96
аоз
показатель хирургической имитации
Зашивание
63
87
92
0,004
Ампутация
80
91
97
0,05
^ Диапазон показателей от О до 100.
^ ANOVA. Различия значимы только между ординаторами и штатными хирургами.
Таблица 20.10
Влияние опыта врача на показатели хирургической имитации
Хирургическая
имитация
Вырезание
Зашивание
Ампутация
Средний показатель имитации
(нижний = 0, верхний = 100)
Ординаторы Научные
(п = 12) сотрудники (л = 8)
79
63
80
88
87
91
Штатные хирурги
(п = 15)
96
92
97
■ р-значение*
0,03
0,0004
0,05
^ ANOVA. Различия значимы только между ординаторами и штатными хирургами.
тателями индивидуальных хирургических навыков в пределах каждого уровня опыта
(табл. 20.10).
5. Таблица должна быть организована как визуально, так и функционально [3].
Графические элементы, включая пустые места, должны использоваться так, чтобы
помочь организовать таблицу визуально. Элементы, такие как линии, жирный шрифт, ячейки,
взятые в рамку, пустые места и фон, могут помочь читателям сделать сравнения внутри
групп и между ними, дифференцировать более важные значения от менее важных,
выделить особенности в данных, указать определенные обстоятельства, связанные с данными
и т. д. Например, табл. 20.11 поддерживает аргумент, что однократная обработка
ультрафиолетовым светом убила большинство линий клеток при 24-часовом исследовании.
Пустая строка, вставленная после каждой 5-й линии ячеек, делает список легко читаемым,
затененные столбцы указывают период лечения, а отношения между лечением и исходом
подчеркнуты визуально.
Большинство издателей определяет свой формат для таблиц, и некоторые, возможно,
не позволят в полной мере использовать элементы дизайна, как здесь рекомендуется.
6. Данные, представленные в таблицах, не должны быть дублированы в другом
ме|сте в тексте [3].
Двойные представления данных в документе остаются общей проблемой, даже
притом что большинство руководств по стилю и журналов отговаривают от такой практики.
Двойная информация занимает ценное место и поэтому должна избегаться в печатных
320 Представление данных и статистик в таблицах и графиках
Таблица 20,11
Количество клеток до и после ультрафиолетового облучения в течение 24 часов"*
Линия
клеток
1
3
6
7
8
10
П
12
2
5
4
9
9-00
5,4
12,3
17,8
14,2
76,0
34,5
23,7
49,2
3,2
24,3
6,0
78,9
12-00
5,6
13,1
18,1
14,0
75,0
31,2
26,3
50,8
3,2
25,0
5,5
82,7
Время сбора данных
(количество клеток х 10^мл)
15-00
5,6
13,3
18;7
14,5
76,0
33,0
24,0
49,6
3,2
26,2
5,1
83,2
18-00
0
0
0
0
0
0
0
0
1Л
12,9
3,2
42,9
21-00 24-00
0,5
0,9
0
0,2
1,4 1,0
12,3
8,2
3-00
0,1
0,9
5,6
б-ОО
0
0,3
1,9
9-00
0
0
^ Затененные столбцы указывают часы ультрафиолетового облучения; ячейки, взятые в рамку, указывают
время, при котором количество клеток достигает 0.
публикациях. Значения, группы или сравнения в таблицах, конечно, могут быть упомянуты
в тексте, но таблица должна представлять данные. Данные, представленные в таблицах,
не должны также быть представлены в рисунках и наоборот.
Таблицы должны оставаться настолько простыми, насколько возможно [3]. Включайте
только ту информацию, которая относится к цели таблицы.
УКАЗАНИЯ ОТНОСИТЕЛЬНО НАЗВАНИЙ ТАБЛИЦ
20.1* Название и таблица всегда, когда возможно, должны позволять данным
быть понятыми независимо от текста [3,10].
По крайней мере, в научных публикациях таблицы и рисунки часто отделяются от
связанного с ними текста. В таких случаях данные могут стать не поддающимися толкованию,
потому что контекст, в котором они должны быть поняты, больше не доступен. Поэтому
название и структура таблицы должны нести достаточно контекста, чтобы таблица могла
стать автономной. Однако название не должно давать детализированное обоснование
информации или резюмировать или интерпретировать результаты [2]; эти объяснения лучше
всего дать в тексте.
Сообщение значений, групп и сравнений в таблицах 321
Когда несколько связанных таблиц представлены вместе, контекст исследования должен
быть включен в первую, но не должен повторяться в других, если такое повторение
становится утомительным или требует слишком много места.
• Плохое название (слишком общее):
Таблица 12. Характеристики пациентов
• Лучшее название (более определенное):
Таблица 12. Основные характеристики 32 пациентов со злокачественным
гематологическим заболеванием, перенесших пересадку G-CSF-примированных клеток
костного мозга
• Плохое название (неполное):
Таблица 5. Классификация Akahori для стадирования дооперационного состояния
• Лучшее название (полное):
Таблица 5. Классификация Akahori для стадирования дооперационного состояния
пациентов кистевой хирургии
20.2. Название должно определять данные, показанные в области данных [3].
Сочиняя название таблицы, начните с определения данных в таблице. Избегайте просто
повторения головки столбцов и строк.
• Плохое название (напрасные повторения головок столбцов и строк):
Таблица 2. Средние тестовые оценки знаний, отзывы и удовлетворенность в
экспериментальных и контрольных группах после обнародования в печати, мультимедиа,
межличностных или аудиоинструкциях по уходу за собой
• Лучшее название (лучше описывает представленные данные):
Таблица 2. Оценка эффективности ухода за собой 1472 пациентов, получавших
инструкции по уходу за собой посредством разных способов связи
УКАЗАНИЯ ПО СОСТАВЛЕНИЮ ГОЛОВОК СТОЛБЦОВ И СТРОК
203. Головки столбцов и строк должны использовать термины, которые
встречаются в тексте [3,11].
Читатели вникают в таблицу через головки столбцов и строк; таким образом, знакомые
термины в головках (термины также использованы в тексте) обычно более эффективны,
чем незнакомые [11]. Информация, символы и единицы измерения в таблице должны также
соответствовать таковым в тексте [3]. У каждого столбца и каждой строки должна быть
головка [3].
Общий источник путаницы — непоследовательное использование терминов для
исследуемых групп где угодно в тексте. Например, авторы могут говорить об участниках
исследования, пациентах, оставшихся в живых, индивидах, субъектах, добровольцах и т. д.
Они могут говорить о лечении, вмешательстве или активной группе и плацебо, контроле.
322 Представление данных и статистик в таблицах и графиках
нелеченной или неактивной группах. Последовательность обычно более важна, чем выбор
определенного термина.
20.4. Используйте «мостиковые» и «врезанные» головки для групп столбцов и
головки строк над строками для определения подгрупп.
Мостики и головки строк проясняют организацию данных (табл. 20.12 и 20.13). Каждый
уровень головок добавляет дополнительную переменную к таблице, однако это может
быстро перегрузить и осложнить таблицу по мере добавления столбцов.
В некоторых случаях головки строк могут быть расширены в головки-«врезки», которые
охватывают все колонки. Заголовки врезок подчеркивают подгруппы и, по существу,
создают две или больше таблиц с идентичными головками столбцов колонок (см. табл. 20.1).
Чтобы сэкономить место, информация по 2 или более переменным может иногда
объединяться в одну ячейку [5]. Например, столбец для возраста и столбец для пола могут быть
объединены в один столбец с соответствующей маркировкой, скажем, «ж/34» для
обозначения 34-летней женщины.
20.5. По мере возможности укажите в заголовках колонок или рядов размер
группы, единицы измерения или и то, и другое [3,10].
Размер группы и единицы измерения являются существенным дополнением к названию
переменной для интерпретации данных и для проверки соответствия данных. В табл. 20.14
рост мог быть измерен в дюймах или сантиметрах, вес в фунтах или килограммах, а
температура — в градусах по Фаренгейту или Цельсию. Кроме того, отсутствующие количество
пациентов в каждой из групп дозировки, количество наблюдений, представляющих данные,
должны были быть получены из текста. В табл. 20.15 эти проблемы были устранены.
^ Сообщая об измерениях с множителями, используйте форму «х 10^ мг», а не
«мг (X 1(F)». Размещение множителя перед единицей измерения указывает, что зна-
Таблица 20,12
Таблица, требующая мостиковой головки
Переменная Низкая доза Высокая доза Низкая доза Высокая доза
Переменная!
Переменная 2
Переменная 3
Таблица 20,13
Таблица, показывающая значение добавления мостиковой головки
Переменная
Переменная 1
Переменная 2
Переменная 3
Группа контроля Группа лечения
Низкая доза Высокая доза Низкая доза Высокая доза
Сообщение значений, групп и сравнений в таблицах 323
Таблица 20.14
Таблица, не показывающая размеры групп или единицы измерения
Переменная
Рост
Вес
Температура
Группа контроля
Низкая доза Высокая доза
Группа лечения
Низкая доза Высокая доза
Таблица 20.15
Таблица, показывающая добавленные значения размеров групп и единиц измерения
Переменная
Группа контроля (п = 29)
Группа лечения (л = 27)
Низкая доза
(п = 13)
Высокая доза
(л = 16)
Низкая доза
(л = 12)
Высокая доза
(л = 15)
Рост, см
Вес, кг
Температура/°С
чения в ячейках уже находятся в умноженной форме, тогда как множитель,
помещенный после единицы измерения, может интерпретироваться так, как будто читатель
должен сделать умножение [3]. Таким образом, ячейка, содержащая «15 мг (х 10^)»,
может интерпретироваться как указание о значении «15 000 мг», если ожидается,
что читатель раскроет обозначение, или «0,015 мг», если обозначение было уже
раскрыто автором, тогда как «15 х 10^ мг» всегда означают «15 000 мг».
УКАЗАНИЯ ПО ПРЕДСТАВЛЕНИЮ ИНДИВИДУАЛЬНЫХ ЗНАЧЕНИЙ
20*6. Округлите числа до 2 значащих цифр, если нет необходимости в
дополнительной точности [1].
Как обсуждалось в указании 2.1, большинство читателей могут эффективно
воспринимать числа только с 2 значимыми цифрами. Это обстоятельство сохраняется также и для
табличных чисел (табл. 20.16).
Иногда желательно сообщить о данных соответственно точности измерения [2]. Средние
и другие расчетные значения можно сообщить с одной дополнительной значимой цифрой
[2]. Таким образом, когда таблица построена для представления фактических значений для
ссылки, читатели могут видеть не только значения, но также и точность измерений. Однако,
когда основная цель таблицы или слайда состоит в том, чтобы показать образцы или
сравнения, предпочтительнее округление до 2 значащих цифр.
20 J. Последовательно выровняйте данные, символы и текст [3].
Таблицы легче читаются, когда данные или символы в ячейках представлены в
согласованной визуальной форме. Как только форма изучена, она применима к остальной части
324 Представление данных и статистик в таблицах и графиках
Таблица 20,16
Таблица, показывающая округление"
Группа контроля (п = 20) Группа лечения (п - 20)
Переменная Низкая доза Высокая доза Низкая доза Высокая доза
(п = 10) (п = 10) (п = 10) (п = 10)
Неокругленные числа часто излишне точны
Возраст, годы 35,97 16,34 21,12 19,04
Вес, кг 61,43 81,57 58,83 100,67
Округленные числа более быстро читаются и легче запоминаются
Возраст, годы 36 16 21 19
Вес, кг 61 82 59 101
^ Кроме того, округление снижает визуальную сложность таблицы и помогает читателям понять информацию.
Числа должны быть округлены, если нет серьезной причины для сообщения о них с большей точностью, однако
числа должны быть округлены только для информирования, а не для анализа.
таблицы, ускоряя и облегчая интерпретацию. Надлежащее выравнивание может также дать
читателям дополнительное визуальное представление о величине чисел.
Элементами, по которым обычно выравниваются числа, являются десятичные запятые,
знаки плюс или минус, дефисы (обычно указывают диапазоны), круглые скобки, знаки
деления (косая черта, слеш: /) и десятичные множители (табл. 20.17 и 20.18). Символы и текст
в ячейках могут быть выровнены по центру или левому краю. Выровненные края не
рекомендуются для слов как в таблицах, так и в тексте, потому что выравнивание создает
неравные интервалы между словами, которые могут мешать при чтении. «Сдвиг вправо» также
не рекомендуется для блоков текста.
20.8. Не оставляйте пустые ячейки в таблице за исключением случаев, когда
запись была бы нелогичной [3].
Пустые ячейки создают двусмысленность, потому что нет никакой гарантии того, что
данные не были опущены случайно. Поэтому существенно указать, что ячейка не
содержит данных. Одно решение состоит в том, чтобы заполнить ячейку сокращением,
таким как НД, означающим «не доступно» или «нет данных», или НО — «не
обнаружено» или «не определено», и расшифровать эти сокращения ниже области данных.
Могут также использоваться и другие сообщения, такие как «нет расчетных данных»,
«данные потеряны» и т. д. Другое решение состоит в том, чтобы заполнить пустую
ячейку замещающими знаками (...) или «длинным тире» (—) и в сноске указать причину
пустой ячейки [2, 3].
К таблицам, которые могут содержать пустые ячейки, относятся таблицы,
отображающие парные данные или корреляционные матрицы {см. табл. 6.2). У этих таблиц есть
двойные ячейки, потому что головки столбца и строки — одни и те же. Хороший
пример — таблица расстояний. Названия городов — это головки как столбцов, так и строк.
Каждый может следовать по строке Лос-Анджелеса к столбцу Нью-Йорка и найти
расстояние между ними. Однако можно было также следовать по строке Нью-Йорка к
столбцу Лос-Анджелеса. Чтобы упростить таблицу, только одна из этих 2 комбинаций будет
содержать данные, оставляя половину ячеек пустыми.
Сообщение значений, групп и сравнений в таблицах 325
Таблица 20,17
Примеры плохо выровненных данных, символов и текста в таблице
Плохое вырав- Плохое Плохое
нивание запя- выравнивание выравнивание
тых в десятич- круглых скобок десятичных
ных дробях [Среднее (СО)] множителей
Плохое
выравнивание
символов
Плохое
выравнивание
текста
2,81
12(6)
23 X 10^
1 (слишком высоко)
Этот текст
выровнен вправо
143,5
3,687
762(51)
5567 X 10^
Этот текст выровнен
по ширине
t (слишком низко)
3453 (321) 9,8 X 10'^ У этого текста
нет никакого
последовательного
^ слишком низко выравнивания
Таблица 20.18
Примеры хорошо выровненных данных, символов и текста в таблице
Выравнивание
запятых в
десятичных дробях
2,81
143,5
3,68
Выравнивание
круглых скобок
[среднее (СО)]
12(6)
762(51)
3453(321)
Выравнивание
десятичных
множителей
23 X 10^
5567 X 10^
9,8 X W
Центрирование
символов
1
Т
о
Выравнивание
текста
Этот текст выровнен
влево
Этот текст выровнен
влево
Этот текст выровнен
по центру
@ Пустые ячейки не должны быть интерпретированы как нулевые значения.
^ Не используйте сокращение «НЗ» для «статистически незначимый». Вместо
этого сообщите фактическое значение р [2]. Если соотношения достаточно
важны, чтобы их проверять, то и результат достаточно важен, чтобы о нем сообщить
{см. указание 4.15).
20«9. Выделите важные значения [9].
Если сведения таковы, что «заслуживают внимания», читателей можно сделать «более
осведомленными», привлекая их внимание к более важным связям и отвлекая от менее
важных. Вьщеление индивидуальных ячеек или групп ячеек, которые содержат важные
данные или примеры, помогает читателям узнать то, на что они должны обратить внимание
(табл. 20.11). Взятие ячейки в рамку, вьщеление содержимого ячейки жирным шрифтом или
ее затенение являются обычными способами вьщеления важных значений.
326 Представление данных и статистик в таблицах и графиках
УКАЗАНИЯ ПО ПРЕДСТАВЛЕНИЮ ГРУПП ЗНАЧЕНИЙ
20.10. Рационально упорядочите ароки и столбцы [2,3].
Порядок, в котором представлены головки столбцов и строк, организовывает таблицу
и может разъяснить или затемнить структуры в данных, а также упростить или,
наоборот, усложнить поиск информации (см. табл. 20.5 и 20.6). В частности, упорядочение строк
и столбцов в алфавитном порядке благоприятствует функции поиска таблицы ссылок,
тогда как упорядочение по некоторой особенности данных может помочь показать структуры
в аналитической таблице. Таким образом, «Австралия' не всегда должна быть на первом
месте».
Данные, соответствующие причинно-следственным отношениям или отражающие
исследования «до и после», должны быть представлены слева направо.
20.11. Храните данные в каждой ячейке в соответствии с головками ее столбцов
и строк [2]: поддерживайте «целостность данных»^
Смешивание данных разных типов, разных уровней измерения или разных единиц
измерения в столбце или строке разрушает согласованность, или «целостность данных», которые
позволяют читателям быстро разобраться в таблице. Самая обычная проблема —
смешивание данных разных уровней измерения в одном и том же столбце. Например, в табл. 20.19
данные в столбцах не согласованы. Головка столбца ограничивает содержимое количеством
и процентом, но столбец включает данные по возрасту, представленные как средние и СО.
Решения этой проблемы показаны в табл. 20.20 и 20.21.
Таблица 20.19
Таблица, показывающая нарушение целостности данных"
Группа контроля Группа лечения
Переменная (л = 66) (л = 83)
л (%) л (%)
54(65)
35 (ЛО)
26(31)
^ Нарушение целостности данных по столбцам здесь вызвано формой представления данных по возрасту:
средние и СО сообщаются в столбцах с головкой, сообщающей о количестве и процентах.
Таблица 20,20
Таблица, показывающая восстановление целостности данных"
Женщины
Средний (СО) возраст, годы
Симптоматика
45 (68)
36(73)
19(29)
Переменная, единицы
Группа контроля Группа лечения
(п = бб) (п = 83)
Женщины, л {%) 45(68) 54(65)
Средний (СО) возраст, годы 36 (7,3) 35 (7,0)
Симптоматика, л (%) 19(29) 26(31)
^ Целостность данных восстановлена перемещением ограничений из головки столбца в головки строк.
В оригинале стоит Afghanistan, но в русскоязычном списке стран первой по алфавиту стоит Австралия.
Сообщение значений, групп и сравнений в таблицах 327
Таблица 20.21
Таблица, показывающая другое решение проблемы целостности данных"*
Переменная
Группа контроля''
(п = 66)
п(%)
Группа лечения^
(п = 83)
п(%)
Женщины
Симптоматика
45 (68)
19(29)
54(65)
26(31)
^ Другое решение проблемы целостности данных — это перенос в сноску одного или двух наблюдений,
форма которых отлична от формы, определяемой головкой столбца.
^ Средний (СО) возраст, годы — 36 (7,3).
' Средний (СО) возраст, годы — 35 (7,0).
20«12. Когда возможно, включайте столбцы и строки итогов, процентов или и то,
и другое.
Столбцы и строки итогов не только суммируют информацию о данных в столбце или
строке, но также позволяют читателям проверять числа для точности (табл. 20.22 и 20.23).
Таблица 20.22
Состояние анкет с момента первой отправки по почте (без общих количеств по столбцам
и строкам, читатели должны сами вычислить количество оцениваемых анкет, формирующих
выборку для этого исследования)
Характеристика
Клиника 1
п(%)
Клиника 2
п(%)
Клиника 3
п (%)
Отправленные анкеты
Недоставленные
Возвращенные
Неполные^
758(100)
35(5)
704(93)
19(3)
1259(100)
79(6)
1138(90)
42(4)
53(100)
3(6)
50(94)
1(2)
Как процент от возвращенных анкет.
Таблица 20.23
Состояние анкет с момента первой отправки по почте
Характеристика
Клиника 1
п(%)
Клиника 2
п(%)
Клиника 3
п (%)
Всего
Отправленные анкеты
Недоставленные
Возвращенные
Возвращенные неполные^
Возвращенные оцененные^
758(100)
35(5)
704(93)
19(3)
685(90)
1259(100)
79(6)
1,138(90)
42(4)
1141 »1)
53(100)
3(6)
50(94)
1(2)
49(98)
2070(100)
117(6)
61 (3)
1892(91)
1830(88)
^ Как процент от возвращенных анкет.
^ Как процент от отправленных анкет.
328 Представление данных и статистик в таблицах и графиках
20.13. Если необходимо, пронумеруйте столбцы или строки, чтобы помочь
объединить текст и таблицу.
Таблица может иногда требовать обширных объяснений в тексте, а обширные
объяснения в тексте иногда требуют частой ссылки на таблицу. В таких случаях может быть
полезной нумерация столбцов или заголовков строк, чтобы помочь читателям быстрее
находить нужные места в таблице (табл. 20.24; см. такэ/се обсуэюдение корректировки
возраста в гл. 12).
Таблица 20,24
Вычисление стандартных отношений смертности среди производителей украшений
по возрастным категориям^
Возрастные [1] [2] [3] [4] [5]
группы Частота Всяпопуля- Ожидаемое количе- Наблюдаемое Стандартное от-
смертности цияпроиз- ство смертей среди количество ношение смертно-
сравни- водителей производителей смертей среди сти, производите-
ваемой украшений украшений на ча- производите- ли украшений/
популяции, стоту сравнения лей украшений группа сравнения
0-19 лет
20-49 лет
50 лет и старше
Всего
на 1000 чел.
9,0
5,0
4,0
5,6
8 000
12 000
13 000
33 000
([1]
X [2])/1000
72
68
60
200
140
100
58
298
[4]/[3] X 100
194
147
97
149
^ Нумерация столбцов позволяет читателям обнаруживать, какие новые значения были вычислены из
имеющихся в таблице. Текст может также ссылаться на эти номера при дальнейшем объяснении вычислений.
20.14. Если возможно, не включайте строки или столбцы, содержащие
неизменяемые значения.
Столбцы или строки, в которых все ячейки содержат идентичные значения, могут быть
неинформативными. Сноска к таблице или строка в тексте, указывающие, что значения данной
переменной не изменялись, может быть более эффективным способом представить данные [2].
УКАЗАНИЯ ПО ПРЕДСТАВЛЕНИЮ СРАВНЕНИЙ ЗНАЧЕНИЙ ИЛИ
ГРУПП ЗНАЧЕНИЙ
20.15. Поместите сравниваемые данные в смежных столбцах [2].
Таблица, представляющая данные по 3 переменным, скажем, по полу, категориям
возраста и национальности атлетов, может принять любую из 8 форм, в зависимости от того, как
упорядочены головки столбцов и строк (табл. 20.25). Хотя каждая из этих 8 форм содержит
ту же самую информацию, таблица, на которой сравниваемые значения помещаются бок
о бок, будет предпочтительнее. Таким образом, форма 1 из табл. 20.25 должна быть лучше
для сравнения количества женщин и мужчин-атлетов из двух стран, чем, скажем, форма 6.
Форма 5, с другой стороны, была бы предпочтительнее для сравнения количества атлетов
в пределах каждой возрастной группы из каждой страны.
Сообщение значений, групп и сравнений в таблицах 329
Таблица 20,25
Таблица, отображающая 3 переменные (национальность, пол и возрастную группу), может
принять любую из 8 форм
Форма 1
0-21 год
22-49 лет
50лет и старше
Форма 2
0-21 год
22-49 лет
50лет и старше
Форма 3
США
Китай
Форма 4
США
Китай
Форма 5
Мужчины
Женщины
Форма б
Мужчины
Женщины
Форма 7
Мужчины
Женщины
Форма 8
США
Китай
США
А
Д
И
Мужчины
Китай
Китай
Б
Е
К
Мужчины Женщины
Б
Е
К
0-21
Мужчины
А
Б
0-21 год
А
Б
0-21
США
А
В
0-21 год
А
В
США
Китай
США
Китай
Мужчины
Женщины
Мужчины
Женщины
год
Женщины
В
Г
Мужчины
22-49 лет
д
Е
год
Китай
Б
Г
США
22-49 лет
д
ж
0-21 год
А
Б
В
Г
0-21 год
А
В
Б
Г
Г
3
М
22-
Мужчины
Д
Е
50 лет
и старше
И
К
22-
США
д
ж
50 лет
и старше
И
Л
США
В
Ж
л
Женщины
США
Китай
Г
3
м
Мужчины Женщины
А
Д
И
49 лет
Женщины
Ж
3
0-21 год
В
Г
49 лет
Китай
Е
3
0-21 ГОД
Б
Г
Возраст
22-49 лет
д
Е
Ж
3
Возраст
22-49 лет
Д
Ж
Е
3
в
ж
л
50 лет и старше
Мужчины
И
К
Женщины
22-49 лет
Ж
3
Женщины
Л
м
50 лет
и старше
Л
М
50 лет и старше
США
И
Л
Китай
22-49 лет
Е
3
50 лет
Китай
К
м
50 лет
и старше
К
М
и старше
И
К
Л
м
50 лет и старше
и
л
к
м
330 Представление данных и статистик в таблицах и графиках
Таблицы чаще ограничены в ширину, чем в длину [3]. Таким образом, иногда столбцы
и строки должны быть переставлены просто для того, чтобы соответствовать формату
печатной страницы.
20.16. Когда возможно, включайте столбцы или строки с итоговыми или
вычисляемыми статистиками, особенно оценки и доверительные интервалы.
Две или больше групп часто сравниваются по итоговым статистикам. Например, можно
включить столбцы или строки, представляющие различия между группами, оценки,
доверительные интервалы и/7-значения. Многие авторы сравнивают две группы, давая только их
средние значения ир-значения для различий между средними (табл. 20.26). Такая таблица
сообщает, что «группы статистически значимо различаются». Более эффективный способ
представить это сравнение состоит в том, чтобы заменить столбец /^-значений столбцом,
показывающим различия между средними (оценку) и доверительным интервалом для этой
оценки (табл. 20.27). Читатели смогут тогда судить о клинической значимости различий
(величина эффекта лечения) и определить, включает ли доверительный интервал
клинически несущественные значения, которые показали бы, что исследование не завершено
(см. гл. 3). Когда сообщают об оценках и доверительных интервалах,/7-значения становятся
вообще ненужными.
Таблица 20.26
Результаты теста 345 больных варикозным расширением сосудов пищевода, подвергнутых
лазерной коагуляции"
-, Лечение Контроль ь
Переменная ^ ,^^, ^ ^ ,^^. р-значение"
^ Среднее (СО) Среднее (СО) '^
as
0,002
^ Таблица подчеркивает р-значение при затратах ожидаемого эффекта лечения и 95% ДИ.
^ f-критерий Стьюдента.
Таблица 20.27
Результаты теста 345 больных варикозным расширением сосудов пищевода, подвергнутых
лазерной коагуляции"
Тест №1, оценка
Тест № 2, оценка
Тест №3, оценка
67 (21,5)
24 (3,0)
89(9Л)
52(19,8)
27(23)
48 (8,6)
Переменная
Лечение Контроль Разность
Среднее (СО) Среднее (СО) (95% ДИ)
Тесг№1, оценка
Тест № 2, оценка
Тест №3, оценка
67(21,5)
24 (3,0)
89{9;1)
52(19,8)
27(2,3)
48(8,6)
15 (от 3,5 до 26,5)
-3 (от-5 до 11,2)
41 (от 35,6 до 46,4)
^ Таблица подчеркивает ожидаемый эффект лечения и его 95% ДИ, которые являются клинически более
значащими, чемр-значения.
Сообщение значений, групп и сравнений в таблицах 331
20.17. Выделите необычные или важные значения, которые должны быть
сравнены между группами.
Привлечение внимания к групповым значениям, представляющим интерес, таким как
максимум, минимум или нетипичные значения, помогает читателям соответственно
сфокусировать свое внимание (табл. 20.11).
20.18. Представляя однотипную информацию о других группах в других таблицах,
используйте таблицы с идентичными форматами [3].
Ограниченность пространства часто требует разделения таблицы на две или более
отдельные таблицы. Например, когда группы лечения и контроля (обозначенные в головках
столбцов) сравниваются по нескольким исходам (перечисленным в головках строк),
таблица может стать слишком длинной, в зависимости от количества перечисленных исходов.
В таких случаях может быть полезным представление результатов в виде серии таблиц:
одна, скажем, для неврологических исходов, вторая — для функциональных исходов и
третья — для исходов качества жизни. В таких случаях сохранение идентичности
индивидуальных форматов таблиц делает данные более доступными для читателей.
СТАНДАРТНЫЕ ТАБЛИЦЫ, ОБЫЧНО ИСПОЛЬЗУЕМЫЕ В ОТЧЕТАХ
БИОМЕДИЦИНСКИХ ИССЛЕДОВАНИЙ
Многие таблицы, используемые для сообщения биомедицинских данных, стандартны
и не должны каждый раз изобретаться заново. Некоторые из наиболее типичных таблиц,
которые встречаются в этой книге, перечислены ниже, с указанием номеров таблиц и
номеров страниц:
Тип таблицы
Номер Номер
таблицы страницы
Таблица сопряженности для анализа критерием хи-квадрат
Корреляционная матрица
Отчет о моделях множественной регрессии
Отчет о простейших моделях логистической регрессии
Отчет о моделях множественной логистической регрессии
Отчет о моделях дисперсионного анализа (ANOVA)
Отчет об оценках модели выживаемости Каплана—Мейера
Таблица выживаемости
Отчет о моделях пропорциональных рисков Кокса
Вычисление характеристик диагностических тестов
6.1
6.2
7.1
7.2
7.3
U,8.2
9.1
9.2
93
10.1
94
98
109
114
116
125
133
134
135
145
Благодарности
Мы благодарим Jessica Ancker, МРН; Adam Jacobs, PhD; Cassandra Talerico; Barbara
Gastel, MD; David Schriger, MD и Dan Liberthson, PhD, за их заботливый обзор и вдумчивые
комментарии к этой главе.
332 Представление данных и статистик в таблицах и графиках
Литература
1. Wainer Н. Understanding graphs and tables. Ed Researcher. 1992; 21:14-23.
2. American Medical Association. American Medical Association Manual of Style: A Guide for Authors
and Editors, 9th ed. Baltimore: Williams & Wilkins; 1998.
3. Style Manual Committee, Council of Biology Editors. Scientific Style and Format: The CBE Manual
for Authors, Editors, and Publishers, 6th ed. Council of Biology Editors [now the Council of Science Editors].
Cambridge: Cambridge University Press; 1994.
4. Briscoe MH. Preparing Scientific Illustrations: A Guide to Better Posters, Presentations, and
Publications, 2nd ed. New York: Springer-Verlag; 1996.
5. Harris RL Information Graphics: A Comprehensive Illustrated Reference. Oxford: Oxford University
Press; 1999.
6. Gelman A, Pasarica C, Dodhia R. Let's practice what we preach: turning tables into graphs. Am Stat.
2002;56:121-30.
7. International Committee of Medical Journal Editors. Uniform Requirements for Manuscripts
Submitted to Biomedical Journals. 2001 update, http://www.icmje.org/
8. Wright P. A user-oriented approach to the design of tables and flowcharts. In: Jonassen DH, ed. The
Technology of Text: Principles for Structuring, Designing, and Displaying Text, vol 1. Englewood Cliffs, NJ:
Educational Technology Publications; 1982:317-40. Cited in: Schriver KA. Dynamics in Document Design.
New York: Wiley Computer Publishing; 1997.
9. White J. Using Charts and Graphs: 1000 Ideas for Visual Persuasion. New York: RR Bowker; 1984.
10. Jordan EP, Shepard WC. R for Medical Writing. Philadelphia: WB Saunders; 1952.
11. Wright P Presenting technical information: a survey of research findings. Instruct Sci. 1977; 6:93-134.
Представление значений, групп и сравнений на графиках 333
Глава 21
Визуальное отображение данных
и статистик
Представление значений, групп и сравнений
на графиках
Диаграммы и графики — средства для ясного и точного представления
статистической информации, и делать это они долэюны, оставаясь столь эюе
простыми и понятными, насколько это возмоэюно.
А. J. MacGregor [1]
Есть буквально сотни способов представить данные и статистики в числах (см.,
например, исключительную книгу Harris [2]). Здесь мы сосредотачиваемся на диаграммах,
которые обычно представляют категориальные данные, и графиках, которые обычно
представляют непрерывные данные'. В частности, мы коснемся точечных графиков,
коробчатых графиков и стандартных декартовых диаграмм, или диаграмм рассеяния, в которых
непрерывные данные чертятся в Х- и Y-осях. Эти диаграммы и графики, в последующем
упомянутые просто как «рисунки», имеют самое большое применение в биомедицинских
исследованиях. Рекомендации здесь часто относятся и к диаграммам, и к графикам;
рекомендации для каждого типа рисунков предоставляются по мере необходимости.
Как и в предыдущей главе, мы снова обращаемся к трем уровням выражения:
индивидуальные значения, группы значений и группы сравнения. В создании рисунков эти три
уровня состоят из следующих компонентов:
• Значения: отдельные данные или значения (обозначенные длинной линией на
диаграмме или одиночной точкой на графике); одиночный символ.
• Группы: множества связанных значений, обозначенных такими средствами, как
линии, соединяющие ряды значений, кластер (группа) точек на графике или семейство
связанных столбцов, полосок или символов.
• Сравнения: отношения между группами, или «пассивные» сравнения, которые
показывают 2 или больше групп на одном и том же рисунке или на ряде рисунков, или
«активные» сравнения, которые показывают результаты математического сравнения,
такие как графики различий между 2 группами.
Составление эффективных диаграмм и графиков требует как большого искусства, так
и критических размышлений. Кроме того, существует много справочной информации,
противоречащей друг другу в важных моментах. Как результат, доказательства, рассуждения.
' в дополнение к материалу, представленному в этой главе, рекомендуем книгу Чекотовского Э. В.
Графический анализ статистических данных в Microsoft Excel 2000. М.: Диалектика, 2002.
334 Представление данных и статистик в таблицах и графиках
соглашения и мнения экспертов, которые поддерживают приведенные ниже рекомендации,
открыты для интерпретации.
О том, как создать хорошие рисунки, можно сказать намного больше, чем это возможно
сделать здесь. Мы должны были ограничить эту главу рекомендациями, которые должны
обеспечить большую помощь. Мы в большой степени использовали работы William
Cleveland [3], Howard Wainer [4] и Helen Briscoe [5] и весьма рекомендуем их книги тем, кто ищет
практическую информацию о создании диаграмм и графиков. Мы также рекомендуем
работы Edward Tufte [6-8] как для вдохновения, так и для более детального изучения.
ФУНКЦИИ РИСУНКОВ
Рисунки могут:
• показать основные структуры данных и отклонения от этих структур способами,
которые невозможны в тексте или таблицах [9, 10];
• организовать и отобразить данные, особенно структуры данных и сравнения групп,
более ясно и кратко, чем это может быть сделано в тексте или таблицах [5, 10, 11];
• уплотнить или суммировать большое количество данных более рационально или
эффективнее, чем это может быть сделано в тексте или таблицах [1];
• облегчить и ускорить поиск и понимание определенной информации [11].
КОМПОНЕНТЫ И ТИПЫ РИСУНКОВ
в научных публикациях у большинства рисунков, представляющих количественную
информацию (диаграммы и графики), есть по крайней мере первые 7 из следующих 9
компонентов (рис. 21.1).
1. Номер рисунка (исключения — стили публикаций, в которых нумеруются только
2 или больше иллюстраций).
2. Подпись к рисунку, обычно приводится внизу рисунка.
3. Поле данных, прямоугольное пространство, в котором представлены данные,
обычно ограниченное слева и снизу Х- и Y-осями и иногда заключенное в прямоугольник,
нарисованный тонкими линиями.
4. Вертикальная шкала: на декартовом графике — «ордината», или ось Y, с
помеченными основными делениями и непомеченными «засечками», промежуточными делениями;
на диаграмме — это или масштаб, или метки категорий.
5. Горизонтальная шкала: на декартовом графике — «абсцисса», или ось X, с
помеченными основными делениями и непомеченными «засечками», промежуточными
делениями; на диаграмме — это или масштаб, или метки категорий.
6. Метки на каждой шкале, идентифицирующие изображенную в виде графика
переменную и единицы измерения, представленные на шкале.
7. Данные (изображения символов, линий, заштрихованных столбиков и т. д.).
8. Линии сноски в поле данных, помогающие читателям ориентироваться.
9. Ключи, или легенды, в поле данных или в подписи, идентифицирующие данные.
^ Предостережение! Толстая черная рамка, окружающая рисунок в этой главе,
указывает, что у рисунка есть одна или более нежелательных особенностей.
Такие иллюстрации обычно сопровождаются исправленным или более приемлемым
вариантом рисунка.
Представление значений, групп и сравнений на графиках 335
Поле данных (Внутренность прямоугольника)
1 \ \ \ \ \ г
0 12 3 4 5 6
Шкала и метки горизонтальной оси, или оси X
Единицы измерения
Рис. 21.1. Компоненты типичного научного рисунка. Поле данных заключено в прямоугольник и
изображено так, что ясно видна точка ноль-ноль на осях. Деления шкал и непомеченные «штрихи» направлены
наружу поля
Мы различаем графику публикаций, или рисунки, напечатанные в научных
журналах или технических отчетах, обычно в черно-белой форме; презентационную
графику, рисунки которой предназначены для проекторов, постеров или слайдов и обычно
демонстрируются в цвете и на расстоянии; и электронные рисунки, которые
разработаны для демонстрации на экране компьютера и могут быть цветными, анимированны-
ми, связанными с данными и т. д. Мы сосредотачиваемся здесь на графике публикаций
и добавляем дополнительные примечания для презентационной графики, когда это
необходимо. Мы не обращаемся к уникальным преимуществам и ограничениям
электронных рисунков.
Предостережение относительно печатной, презентационной и электронной
графики: Рисунки, которые автоматически по умолчанию компилируются и форматируются
стандартными программами, редко подходят для сообщения результатов исследования
в любой среде, не говоря уэюе о публикациях [5]. Проектировщики электронных таблиц, баз
данных и статистических программ вообще не обучены визуальному сообщению данных.
Хотя эти программы почти всегда математически точны и полезны для анализа данных, их
вьщачи часто визуально неэффективны или эстетически не пригодны, а это два качества,
которые свойственны хорошей иллюстрации.
Как правило, рисунки долэюны быть перерисованы, если они демонстрируются в
другой среде. Например, детали, возможные на напечатанном графике, легко потерять при
336 Представление данных и статистик в таблицах и графиках
демонстрации в виде слайда или онлайн, а простота прозрачных диаграмм для
проекторов, возможно, не показывает достаточно информации, необходимой для хороших
печатных графиков. Таким образом, для достижения лучших результатов диаграммы и графики
должны быть созданы для определенной среды, обычно человеком, обученным графике
или техническому письму и редактированию.
ПРИНЦИПЫ ПОСТРОЕНИЯ РИСУНКОВ
1. у рисунков должна быть цель; они должны дополнять и интегрироваться
с остальным текстом [11, 12].
Так же как и в случае с таблицами (см. гл. 20), данные нельзя изображать на рисунках
только ради их изображения. Рисунки должны использоваться только тогда, когда они
могут сообщить информацию более рационально или эффективнее, чем это может быть
сделано в тексте или таблицах.
2. Рисунки должны создаваться для того, чтобы помочь читателям в
обнаружении, рассматривании, понимании и запоминании информации [10, 12].
Проектируя рисунок, подчеркните его цель. Состоит ли цель в том, чтобы показать
вариабельность или стабильность данных? Подчеркнуть сходство или различия между группами?
Показать тенденции во времени? Показать линейные или нелинейные взаимоотношения?
3. Рисунки должны содержать только те элементы, которые необходимы для
достижения их цели [6, И, 12].
Краткость представляет ценность как в рисунках, так и в научном тексте в целом.
Удостоверьтесь, что все линии, символы, числа и слова на рисунке необходимы и достаточны,
чтобы позволить читателям интерпретировать его [11, 13, 14].
4. Данные на рисунке должны быть подчеркнуты другими элементами [3, 5, 6, 12].
Преимущество рисунков состоит в том, что они немедленно фокусируют внимание
на визуальной структуре данных. Таким образом, все, что отвлекает от главного,
уменьшает полезность рисунка.
5. Иллюстрации должны быть совместимы с принципами психологии
восприятия [14].
Извлечение и интерпретация данных из рисунка являются процессом визуального
восприятия. Визуальное восприятие, в свою очередь, находится под влиянием нескольких
принципов, установленных гештальтпсихологней восприятия. Следование этим
принципам при проектировании рисунков должно повысить полезность рисунков.
• Первенство: большее упорядочивание («гешталып») наблюдается преэюде его
компонент. Общее визуальное впечатление от рисунка должно соответствовать
фактическому значению данных [14]. Этот принцип может использоваться для управления
восприятием читателей: см. ниже.
• Близость: объекты, располоэюенные друг возле друга, имеют тенденцию
восприниматься как группа. Позаимствуем пример из Kosslyn [14]: строка символов • • • • • •
воспринимается как 2 группы, тогда как •••••• воспринимается как 3 группы.
Таким образом, располагайте данные, которые должны сравниваться, ближе друг к другу
и отделяйте данные, которые не должны сравниваться. Этот принцип особенно важен
для размещения меток относительно обозначаемых данных.
• Подобие: похоэюие объекты имеют тенденцию восприниматься как группа. Снова
заимствование из Kosslyn [14]: строка символов | | воспринимается как 2 груп-
Представление значений, групп и сравнений на графиках 337
пы, а не как 4 черточки. Таким образом, изображайте данные одной и той же группы
ясным и уникальным последовательным образом, а данные других групп изображайте
другим ясным и уникальным образом. Этот принцип является существенным, когда
на одном и том же графике изображаются 3 или больше переменных. Изображение
меток и линий данных одной и той же группы должно выглядеть аналогично. Они
также должны достаточно отличаться между группами, чтобы группы не
смешивались друг с другом.
• Продолжение: данные, упорядоченные по очевидному шаблону, имеют тенденцию
восприниматься как группа. Еще раз позаимствуем из Kosslyn [14]: строка символов
воспринимается как единая группа, тогда как воспринимается
как 2 группы. Таким образом, по возможности, укажите данные той же самой группы,
применяя однозначный шаблон, и откажитесь от любых шаблонов, в которых
встречаются совпадения разных данных.
• Завершенность: разрывы в структуре автоматически «заполняются», завершая
структуру Например, в последовательности читатели обычно
воображают недостающий символ, который либо завершает пирамиду: — — , либо
повторяет последовательность: — — . Поэтому подчеркните любые разрывы
и разъясните, что это фактические разрывы в структуре данных, и сделайте структуру
ясной, когда данные действительно формируют ее (таким образом, читатели не
должны «заполнять» пробелы, чтобы завершить структуру).
Статистик William Cleveland ранжировал задачи графического восприятия по степени
интерпретируемости от наиболее точных к наименее точным [3]:
• сравнения положений на общей шкале, например сравнение 2 значений на оси X
на едином рисунке;
• сравнения положений в идентичных, но не объединенных шкалах, такие как
сравнение 2 значений на идентичных осях 2 отдельных рисунков;
• сравнения длин (без базовых линий или шкал для ссылки);
• сравнения углов или наклонов;
• сравнения областей;
• сравнения объемов;
• сравнения оттенков цветов, насыщенности и плотности.
Из этих 7 задач восприятия читатели справляются только с первыми двумя, если
выявляемые различия не являются большими. Точечные диаграммы, ящичковые графики и
графики, которые мы здесь рекомендуем, — все они основаны на оценке позиций вдоль общей
шкалы или вдоль идентичных, но не совмещенных шкал. Круговые диаграммы, например,
рассчитаны на оценку угла и области при сравнении 2 или больше секторов. Поскольку
читатели слабо делают такие суждения, использование круговых диаграмм в научных
публикациях ограничено и они лучше подходят для презентационной графики. Большинство
читателей может также различить некоторые, очень контрастные цвета, хотя точность
страдает при использовании оттенков одного и того же цвета.
6. Данные, представленные на рисунках, не должны быть дублированы в тексте.
Как и в случае с таблицами, не описывайте в тексте данные, которые также представлены
на рисунках. Лучше отметьте в тексте важные аспекты рисунка, чтобы помочь читателям
интерпретировать данные.
338 Представление данных и статистик в таблицах и графиках
УКАЗАНИЯ ПО СОСТАВЛЕНИЮ ПОДПИСЕЙ
21Л. Подпись должна соответствовать данным [15].
Самая важная часть рисунка — это его данные. Поэтому, как минимум, подпись должна
точно идентифицировать представляемые данные. Как сказано в указании 21.2, подпись
может также с пользой пояснять и другие аспекты исследования: характер и количество
исследованных лиц, у которых были собраны данные, условия, при которых данные были
собраны, подробности методики измерения и т. д.
• Плохая подпись (слишком общая):
Рис. 8. Полное представление рукописей
• Лучшая подпись (более определенная):
Рис. 8. Количество рукописей, ежегодно получаемых американскими и
неамериканскими медицинскими журналами за 1995-2000 гг., по странам происхождения
21.2. Подпись должна сделать рисунок понятым без ссылок на тека [3,13].
Рисунки часто отделяются от объясняющего текста либо страницами текста в пределах
статьи, либо извлекаются из статьи и представляются отдельно. Поэтому подпись должна
объяснить рисунок так, чтобы он мог быть понятен даже в отрыве от печатного контекста.
• Плохая подпись (пропускающая ваэюную уточняющую информацию):
Рис. 8. Количество рукописей, ежегодно получаемых американскими и
неамериканскими медицинскими журналами за 1995-2000 гг., по странам происхождения
• Лучшая подпись (квалифицирующая включенную информацию):
Рис. 8. Количество рукописей, ежегодно получаемых выбранными
американскими и неамериканскими медицинскими журналами за 1995-2000 гг., по странам
происхождения. Данные 37 журналов отвечают обзору из 57 журналов, изданных частными
издательствами за 2001 г.
УКАЗАНИЯ ПО СОЗДАНИЮ ПОЛЯ ДАННЫХ
213. При возможности подгоняйте размеры рисунка (и, следовательно, поля
данных) к размерам предполагаемой среды публикации.
в большинстве научных публикаций ширина рисунка определяется шириной столбца
печатного текста. Таким образом, «рисунок на 2 столбца» покрывает ширину из 2 столбцов
в соответствии с их шириной, а «рисунок на 3 столбца» покрывает ширину 3 столбцов.
В процессе верстки 3-столбчатой страницы напечатанный рисунок может быть установлен
по размеру покрытия 1, 2 или всех 3 столбцов, таким образом, конечная ширина рисунка
может быть определена перед подачей в печать. Максимальная высота рисунка может
также быть ограничена высотой столбца текста.
Слайды могут иметь или альбомный формат, в котором ширина больше, чем высота,
или портретный, в котором высота больше, чем ширина. Отношение высоты к ширине
около 1:1,5 для 35-миллиметровой пленки или для слайдов PowerPoint (23 X 34 мм) [12].
Создавая поле данных, имейте в виду конечные размеры рисунка в целом и не забывайте
оставлять пространство для связанных с ним меток и единиц шкал, которое должно быть
добавлено к ширине поля данных.
Представление значений, групп и сравнений на графиках 339
Рисунки, конечно, могут быть увеличены или уменьшены, и некоторые журналы
разрешают только рисунки, заканчивающиеся в пределах столбца, а не между столбцами,
но предварительное планирование может предотвратить чрезмерное сокращение размеров
рисунка, делающее детали слишком мелкими для чтения.
21.4. Впишите поле данных в прямоугольник, ограниченный горизонтальными
и вертикальными шкалами [3].
Показ границ поля данных не только помогает сфокусировать внимание на поле и его
содержании, но также позволяет дублировать шкалы на верхних и правых границах, что
может помочь читателям извлечь данные из рисунка (см. рис. 21.1) [13-16].
Когда шкалы образуют нижнюю и левую стороны поля данных, нулевые или близкие
к нулю значения могут быть загорожены самими шкалами. В таких случаях просто
переместите точку ноль-ноль в поле данных, чтобы сделать эти значения более видимыми
(см. рис. 21.1) [3-5].
21.5. Минимизируйте количество элементов, не являющихся данными, в поле
данных [3,10].
в идеале поле данных должно содержать только данные. Однако иногда метки, штрихи
«ошибок», доверительные границы и другие текстовые или графические элементы лучше
всего поместить в поле данных. В частности, избегайте использования ненужных слов,
линий или символов, которые препятствуют интерпретации изображения. Такой
«диаграммный мусор» [6] часто состоит из «декоративных» элементов, добавленных, чтобы усилить
эстетическую привлекательность рисунка, но он может также включать ненужные детали
и просто мешать важным деталям (рис. 21.2).
21.6. Поясните все элементы в области данных.
Хотя подпись рисунка и метки шкал поясняют данные и группы в области данных, поле
данных часто содержит другие элементы, которые также должны быть объяснены. Эти
элементы включают метки для точек данных или линий, «планки погрешностей»,
доверительные интервалы или доверительные полосы, пороговые линии и т. д.
• Располагайте метки рядом с элементом, который они маркируют [10]. Когда прямая
маркировка невозможна, ключ или легенда могут быть размещены в свободной
части поля данных или в подписи [1]. Метки должны быть пространственно разделены
и расположены горизонтально для облегчения чтения (рис. 21.3).
• Всегда поясняйте значения, обозначенные «планками погрешностей» (рис. 21.4).
Поскольку планки погрешностей могут обозначать вариабельность данных (т. е. СО
или межпроцентильные размахи), «ошибки» в оценивании (т. е. СОС) или точность
(95% ДИ вокруг значения оценки), такая маркировка важна для правильной
интерпретации данных [3]. Кроме того, «планки погрешностей» нужно показывать в обоих
направлениях. Вариабельность или ошибка не всегда являются симметричными
относительно значения, которое они сопровождают, таким образом, желательно указать
оба направления. Столбиковые диаграммы или гистограммы часто неправильно
показывают «планки погрешностей» только для значений выше измеренных или
оцененных значений.
340 Представление данных и статистик в таблицах и графиках
о
с;
У °^
о S
О- ?
Ю I 20 000
|я
I I I I I I I 11 I I I I I I I I I I I I I I
01 2345678 9 101112 13 14 15 16 17 1819 20 2122 23 24 25 26
Шкала и метки горизонтальной оси, или оси X
Единицы измерения
Рис. 21.2. Рисунок, содержащий несколько ненужных элементов. Шкала Y показывает слишком много нулей;
здесь предпочтительнее использовать множитель у единиц на метке шкалы. Слишком много значений
нанесены на шкалу X, и у обеих шкал есть слишком много меток и делений. Чрезмерно много линий данных, и они
объяснены в легенде, а не помечены непосредственно. Горизонтальные линии, призванные помочь более
точному определению значений, плохо продуманы; точность лучше достигается в таблицах. Трехмерность легенды
(«тень») не прибавляет информации, только наводит визуальный беспорядок. Наконец, все линии имеют
одинаковый вес, что не помогает читателям сосредоточить свое внимание на данных
О- ?
m X
и
2
3
Группа 4 ^^^
^^^ Группа "^^у"^^^
/ ^^^руппа 2 ^ ^ ^ ^
^^^ Группа 1 .•*•*
,♦
- — Группа 2
—^ Группа 3
--- Группа 4
1 [
I г
2 3
Шкала и метки горизонтальной оси, или оси X
Единицы измерения
Рис. 1. Изменения на оси Y, происходящие вр времени.
(Группа!.....; группа2ш. »; группа3 ; группа4-..i..)
Рис. 21.3. Расположите метку как можно ближе к элементам, которые они маркируют. Если прямая
маркировка невозможна, используйте ключ или легенду. Поместите ключ или легенду в поле данных, если это не стесняет
данные, и в подписи, если это возможно
Представление значений, групп и сравнений на графиках 341
21.7. Проводите линии сносок ненавязчиво: выделяйте данные [1,3].
Обычно линии сносок, используемые на рисунках, включают указание местоположения
нуля на одной или обеих шкалах, отметки времени событий во временных рядах и
предыдущие или целевые значения. Однако линии сносок не должны отвлекать от данных
(рис. 21.5) [10].
УКАЗАНИЯ ПО ПОСТРОЕНИЮ ШКАЛ
21.8. Маркируйте каждую шкалу ясно с названием переменной, единиц, в
которых переменная изображена на графике, и любыми множителями,
связанными с единицами [13,17].
Очевидно, метка переменной должна показывать то, что было измерено, т. е. что
представляют точки или линии на графике.
Единицы измерения также должны быть даны в метке шкалы. Большинство научных
сообществ использует систему СИ (систему международных единиц), которая основана
на метрической системе [18]. Традиционно, особенно в США, биомедицинское
сообщество все еще использует старые единицы для некоторых измерений. О кровяном давлении,
например, сообщают в миллиметрах ртутного столба (мм рт. ст.) в противоположность
Паскалям (Па), которые являются единицей СИ для давления (и выражаются как ньютоны
на квадратный метр). Все уверены, что работники здравоохранения столь привыкли
считывать давление крови в миллиметрах ртутного столба, что переход к более новым единицам
мог бы поставить под угрозу уход за пациентом [19].
Наконец, множители в метках шкал полезны, потому что они избавляют от
необходимости отображать большое количество нулей на шкале. Например, маркировка шкалы «Число
иммунизации х 1000 человек» могла бы иметь деления шкалы, скажем, 25, 75 и 100, тогда
как у шкалы, помеченной «Число иммунизации» без множителей, будут деления шкалы
25 000, 75 000 и 100 000.
21.9. Укажите точку ноль-ноль графика, особенно если одна или обе шкалы не
начинаются с нуля [5,14,16].
Большинство читателей предполагает, что все графики начинаются с точки ноль-ноль —
начала координат. Однако иногда одна или обе шкалы начинаются со значения,
отличающегося от нуля. В таких случаях часто бывает полезным, если не необходимым,
«разорвать» шкалу волнистой или неровной линией, чтобы визуально указать неоднородность
масштаба.
Обсуждается вопрос, нужно ли показывать нулевую точку для всех шкал в научных
публикациях [3]. Аргументом «за» служит то, что начало шкалы в точке, которая
максимизирует диапазон начерченных данных, более эффективно и что такое исполнение позволяет
избегать траты ценного пространства, чтобы показать «разорванную» шкалу. Кроме того,
работает аргумент, что читатели научных текстов будут внимательно читать метки шкал
и не будут введены в заблуждение недостающими нулями.
С другой стороны, визуальное впечатление от рисунка обычно вспоминается более ясно,
чем фактические данные (принцип первенства гештальтпсихологии), поэтому важно,
чтобы визуальное впечатление от рисунка соответствовало информации, передаваемой
данными. В проблеме «подавленного нуля» (рис. 21.6) отсутствие ясной нулевой точки изменяет
342 Представление данных и статистик в таблицах и графиках
60 —
>-
1 S
1 ^
о
1 S "*~
i 1
1 S 40 -
li
5 2 _
1 Ф S
и
1 20 -
1 s
1 (Z
1 c;
s -
A °
T
A E
~r
-
i с
T
D E
>-
О S
li
20
В
Рис. 21.4. Планки погрешностей нужно показывать и выше, и ниже значений, которые они сопровождают, потому
что вариабельность и ошибка не всегда являются симметричными. (А) Штриховые или столбиковые диаграммы
часто неправильно показывают «планки погрешностей» только выше измеренных или оцененных значений. (В)
Отображение измеренных или оцененных значений с помощью одиночной точки на графике, а не с помощью штрихов
или столбцов позволяет показать полную длину планок погрешностей. «Планки погрешностей» также должны быть
пояснены, потому что они могут относиться к стандартным отклонениям, межпроцентильным размахам,
стандартным ошибкам среднего (которые не следует изображать в любом случае) или доверительным интервалам
представление значений, групп и сравнений на графиках 343
о S
- 1
ф
>-
S
i
s
^ i
s s
5 a
Ф s
m z
IS
^
г
s
1 (^
i
A
3 —
2 —
1 —
0 —
• ^ 0
: 0
/00
/
/ ° ^
1 ° ^
/ >^
1 ° >^ °
/ v^ ° о
/ ^
i / ^^ о
/ ./^
: / ^X^ 0
H ^ n^ 1 f—
0 12 3 4 5
_
1 1
6
3 H
2 H
1 -Ч
0 H
T
T
T
T
T
T
0 12 3 4 5 6
Шкала и метки горизонтальной оси, или оси X
Единицы измерения
Рис. 21.5. Выделите данные на рисунке. Не позволяйте линиям сносок завладевать вниманием читателя.
(А) Рисунок, на котором все линии имеют одинаковый вес, а данные не выделены. (В) Тот же самый рисунок с
выделением данных
344 Представление данных и статистик в таблицах и графиках
А
Условия
Норма
Мужчины
Женщины
Неосложненная
хирургия
Незначительные
хирургические
осложнения
Значительные
хирургические
осложнения
мг/сут
--•
100
110
Диетические требования
-•
120 130
140
•
150
Условия
Норма
Мужчины
Женщины
Неосложненная
хирургия
Незначительные
хирургические
осложнения
Значительные
хирургические
осложнения
мг/сут
Диетические требования
0 50 100
150
Условия
Норма [
Мужчины \
Женщины /
Неосложненная /
хирургия \
Незначительные (
хирургические \
осложнения /
Значительные \
хирургические /
осложнения 1
мг/сут
--•
100
-••
110
Диетические требования
-•
120 130
140
150
Рис. 21.6. Визуальные искажения: проблема «подавленного нуля». (А) Визуальное впечатление такое, что
значение показателя у женщин приблизительно соответствуют половине значения для мужчин. Это
впечатление создается, потому что исходная точка линии не нуль, как ожидается, а скорее 100. (В) Нулевая точка
линии была сохранена, давая точное визуальное представление о размерах групп. (С) Показано типичное
решение для предотвращения проблемы подавленного нуля. Волнистая линия более эффективна для
индикации разрыва шкалы, чем прямая линия, потому что она менее вероятно воспринимается как типичный
элемент рисунка
Представление значений, групп и сравнений на графиках 345
визуальное впечатление от сравнений между столбцами и может, таким образом, ввести
в заблуждение читателей.
^ Не упустите «подавленный нуль», сравнивая элементы на графике или между
двумя или более графиками (рис. 21.6) [12,14,15].
21 «10« Расположите шкалы так, чтобы значения увеличивались на оси Y от
основания к вершине поля данных и на оси X слева направо на поле данных.
Большинство читателей допускают, что данные, начерченные выше на оси Y (ордината),
будут иметь более высокие значения, чем значения, расположенные ниже по этой оси, и что
значения, расположенные правее по оси X (абсцисса), будут выше значений,
расположенных левее.
В частности, временные шкалы должны всегда идти слева направо [12]. (Мы не можем
представить, что кто-то нарисует шкалу иначе; мы только пытаемся быть последовательными.)
21.11. Корректируйте шкалы так, чтобы данные заполнили как можно больше поля
данных [3].
Чтобы просто сэкономить пространство, шкалы не должны продолжаться дальше точек
с самыми высокими значениями и с самыми низкими значениями, если шкала не
начинается с нуля.
Соотношения между осями X и Y называют «отношением сторон». Изменение
отношения сторон путем изменения длины одной шкалы в большую или меньшую сторону
относительно длины другой имеет как хорошие, так и плохие последствия. Иногда расширение
или сжатие одной шкалы показывает структуры данных, которые иначе не очевидны [3, 14].
С другой стороны, расширение или сжатие одной шкалы может увеличивать или
уменьшать изменения на другой шкале; так называемая проблема «эластичной шкалы» обычно
встречается в корпоративных отчетах прибыли и убытков (рис. 21.7) [12, 17].
Когда данные занимают большой диапазон значений, особенно если верхний конец
диапазона включает только несколько выбросов, подумайте об изображении данных на
логарифмической шкале (см. указание 21.22).
Щ Интерпретируя графики, проверьте масштаб, чтобы определить,
соответствуют ли визуальные различия в данных важным клиническим различиям. Один
способ сделать маленькие фактические различия кажущимися большими и,
следовательно, более важными состоит в том, чтобы растянуть пространство между
делениями шкалы на графике (рис. 21.8; см. также проблему «эластичной шкалы»,
рис. 21.7).
21Л 2. Масштабные деления должны отмечать только главные, логические и
(обычно) равные интервалы шкалы; сократите количество делений и
непомеченных «отметок на осях» [3,5,12,14-16].
Рисунки лучше передают общий смысл данных, чем представление их точных
значений. Поэтому главных масштабных делений обычно достаточно, чтобы показать значения.
Точные значения лучше всего представить в таблицах; однако, во что бы то ни стало,
используйте специальные отметки шкал, чтобы указать важные значения на графике [14].
Полезным является метод, когда следует отмечать каждый конец шкалы с самым высоким
и самым низким значениями изображенных данных (рис. 21.9) [13].
346 Представление данных и статистик в таблицах и графиках
>-
S
о
S
с;
о S
^ ?■
Ш Z
то
4 —\
2 —\
О Н
>-
с;
sT
У ос
о S
со X
ф
S
то
6 -Ч
15 4 -J
2 Н
3 о -J
Шкала и метки горизонтальной оси, или оси X
Единицы измерения
Рис. 21.7. Визуальные искажения: проблема «эластичной шкалы». Здесь одни и те же данные создают разное
впечатление в зависимости от относительной длины каждой шкалы. Вообще шкалы должны быть выбраны так,
чтобы данные заняли наибольшее полезное пространство, чтобы увеличить их разрешение. Данные, более или
менее распределенные вдоль диагоналей, обладают лучшей разрешающей способностью по обеим осям
Представление значений, групп и сравнений на графиках 347
(V
X
5 о
^ i
к т
о Р
00
со
I-
U
О)
3-
о»
00
х
U Ф
S" Q.
S
§
а
н
X
о
о
о»
3-
3"
VO
О
О
О)
6,2 —^
6,1 Н
6,0 Н
Дети группы риска
в программе превенции
6 9
Время, месяцы
Рис. 21.8. Другая проблема «эластичной шкалы» состоит в том, что она может взаимодействовать с
проблемой «подавленного нуля» и заставить маленькие изменения выглядеть большими. На первый взгляд, рисунок
предполагает, что программы превенции токсикомании успешны, потому что дети из группы риска, включенные
в них, в течение длительного времени сообщали об использовании наркотиков все с меньшей частотой, пока
их поведение не стало похоже на детей вне группы риска. Однако взгляд на вертикальную шкалу показывает,
что фактическое изменение составляет только приблизительно 0,23 %. Даже если, скажем, в группе риска было
10 000 детей, сокращение составляет только на 23 ребенка. Нулевое значение на оси Y было подавлено, потому
что показ полного масштаба сделает очевидным непропорциональное растяжение маленького сегмента шкалы
Деления должны также быть ограничены логическими интервалами, такими как
четные числа, единицы, кратные 5, 10, 100, 1000 и т. д. Разместите метки масштаба и
промежуточные отметки вне поля данных, чтобы насколько возможно не загромождать поле
данных (см. рис. 21.1) [3, 5].
Одна из проблем с отформатированными компьютером графиками — то, что программа
может разделить масштаб на равные, но нелогические интервалы. Временные шкалы с
отметками через каждые 7 месяцев являются необычно трудными для понимания:
• Каждые 7 месяцев: Янв. 06—Июл. 06—Фев. 07—Сен. 07—Апр. 08—Нояб. 08
• Каэюдые 6 месяцев: Янв. 06—Июн. 06—^Янв. 07—^Июн. 07—^Янв. 08—Июн. 08
Наконец, читатели предполагают, что равные расстояния представляют равные
значения; таким образом, интервалы одинаковой величины должны быть помещены на таких
же расстояниях, чтобы избежать визуального искажения данных. Если масштаб
включает, скажем, данные по дням, месяцам и годам, лучше разорвать шкалу (если не все поле
данных) на 3 части, чем пытаться изобразить каждый период времени в
непропорциональном масштабе (рис. 21.9).
348 Представление данных и статистик в таблицах и графиках
>
^
о
S
с:
S
s"
U ос
о S
>s ?.
? S.
i ^
^ 1
ги f*^
^ S
ф S
00 X
i ^
К Ш
0»
S
S
1 ^^
с;
1 ш
1 ^
3
А
30 —]
29 —
20 —J
1
10 —\
1
3 —\
п —1
(
^^^^^
^^^^^
^^^
^^^
^г
g
ш
/
ш
1
^
^^
X
^^
^^
^^^
^^^ Неравномерные деления шкалы
^^^^
^^^
^^ 2 8 12
месяца месяцев месяцев
^ " " ^
1 Г \ \ \ \ \
) 2 4 12 24 36 48
Время, месяцы
Время, месяцы
Рис. 21.9. Равные масштабные интервалы должны представлять равные единицы. {А) Деления оси X здесь не
представляют равные интервалы времени. ГВЛотже самый рисунок, начерченный правильно, с разрывом шкалы
Представление значений, групп и сравнений на графиках 349
1 Группа №1
1 Группа №2
П Группа №3
П Группа №4
Группа №4
Группа №3
Группа №2
Группа №1
Июль
45
40
35 Ч
30
25
20 Н
15
10
5
Группа №4
Группа №2
Группа №3
Группа №1
1 1 1—
Январь Февраль Март
Апрель
Май
Июнь
Июль
Рис. 21.10. (А) Добавление третьего измерения к рисунку по художественным причинам не добавляет полезной
информации и может даже ухудшить сравнение данных читателями. (В) Соответствующий двухмерный рисунок
менее загроможден и данные легче сравнивать
350 Представление данных и статистик в таблицах и графиках
# 100
>55 20-55 7-20 1,5-7
Концентрация РНК ВИЧ-1, х10^ копий/мл
<200
201-350
351-500
501-750
>750
Уровень CD4,
клеток/мл
Рис. 21.11 .Трехмерные рисунки должны быть зарезервированы для трехмерных данных. На этом рисунке
каждое измерение сообщает полезную информацию, таким образом, использование третьего измерения является
правильным. (По: Egger М., May М., Chene G. et al. ART Cohort Collaboration. Prognosis of HIV-1-infected patients
starting highly active a nti retroviral therapy: a collaborative analysis of prospective studies. Lancet. 2002; 360:119-29)
21.13, Изображайте положительные значения выше нулевой базовой линии, а
отрицательные значения ниже нулевой базовой линии [14].
Как в указании 21.10, мы не можем вообразить человека, изображающего значения
иначе, но мы также не хотим переоценивать чьи-либо навыки.
21.14, Округлите единицы на шкалах до 2 значащих цифр, если только не
гарантирована дополнительная точность.
Как обсуждено в указании 2.1, большинство читателей могут эффективно обращаться
с числами, имеющими только 2 значащие цифры. Это обстоятельство сохраняется как для
чисел в ячейках таблиц, так и для цифр на шкалах.
По некоторым причинам проблема «лишних нулей», кажется, больше распространена
на шкалах рисунков, чем в ячейках таблиц (см. рис. 21.2). Округление до 2 значащих цифр
решит эту проблему при условии, что соответствующий множитель будет включен в метку
шкалы.
21.15, Изображайте три измерения только тогда, когда данные являются
фактически трехмерными и требуют третьей шкалы (ось Z).
Многие программы, имеющие графические возможности, строят трехмерные
изображения двухмерных данных. Ненужное 3-е измерение не способствует ясности рисунка, делает
его визуально более сложным, снижает удобочитаемость (рис. 21.10) [12, 15].
Рекомендации для изображения трехмерных данных такие же, как и для двухмерных
данных. Для всех 3 осей должны быть заданы масштабы и единицы измерения (рис. 21.11).
Иногда графики изображают дополнительные переменные, значение которых взято с
третьей, вертикальной, дополнительной шкалы, добавленной с правой стороны поля данных.
Когда дополнительная правая шкала связана с левой, этот метод может помочь передаче
информации. Например, когда левая шкала в сантр! метрах, а правая шкала в дюймах, читатели
Представление значений, групп и сравнений на графиках 351
Рис. 21.12. Визуальные искажения: проблема «дополнительной шкалы». Эта проблема возникает, когда две
переменные, требующие различных и независимых шкал, изображаются на одном и том же рисунке. Левая ось
Y масштабирована для одной переменной, а правая ось Y — для другой. Связанные масштабы не вызывают
проблем. Однако независимые шкалы могут быть начерчены с искажением визуального впечатления от данных.
(А) Линия В проведена с увеличением на ту же величину по отношению к уровню линии А, но со сжатием
дополнительной шкалы. (В) Эта линия проведена с увеличением на половину от уровня. Значения не изменились,
изменился только масштаб, в котором они обозначены
352 Представление данных и статистик в таблицах и графиках
могут выбрать удобный для них масштаб, с которым они хорошо знакомы. Математические
отношения между сантиметрами и дюймами фиксированные, поэтому интервалы в двух
масштабах всегда будут пропорциональны.
Однако несвязанные дополнительные шкалы могут исказить интерпретацию данных.
В «проблеме дополнительной шкалы», как и в случаях «подавленного нуля» и «эластичной
шкалы», интерпретация данных визуально искажается. На рис. 21.12 значения для линии А
должны читаться со шкалы А, а для линии В — со шкалы В. Изображенные значения для
линий А и В на верхнем рисунке являются такими же, как и на нижнем рисунке, однако
пропорции шкал В различаются. Таким образом, кажется, что линия В увеличивается на
половину от уровня линии А на верхнем рисунке, но остается такой же величины на нижнем
рисунке. Поскольку шкала В не связана со шкалой А, она может быть нарисована в любой
пропорции.
Щ Интерпретируя графики с двумя различными вертикальными осями,
проверьте масштабы, чтобы определить, соответствуют ли визуальные различия
или сходства данных важным фактическим различиям или сходствам.
УКАЗАНИЯ ПО ПРЕДСТАВЛЕНИЮ ИНДИВИДУАЛЬНЫХ ЗНАЧЕНИЙ
21Л б. Поясните значения.
Значения на диаграмме или графике могут быть пояснены в нескольких местах: в
подписи, в метках шкалы, с помощью метки в поле данных или в ключах или легендах в подписи
или в поле данных (см. рис. 21.3).
21Л 7. Сделайте каждое значение визуально отличным.
Категориальные данные
Номинальные или порядковые данные часто отображаются в виде горизонтальных или
вертикальных столбиковых диаграмм, в которых каждая номинальная или порядковая
категория связана со столбиком и высота столбика соответствует значению для категории.
Однако столбиковые диаграммы привлекают визуальное внимание к самим столбикам, тогда как
значение, представляющее интерес, располагается только на конце столбика (рис. 21.13).
Точечная диаграмма Кливленда [3] больше рекомендуется, чем обычные штриховые
и столбиковые диаграммы. В точечной диаграмме столбец заменяется скромной тонкой
линией, которая соединяет визуально различимую точку на графике с ее меткой. Диаграммы
также располагаются горизонтально, что позволяет легче читать метки, и они занимают
меньше пространства (рис. 21.13).
Точечные диаграммы могут также быть созданы программами обработки текста: просто
составьте таблицу с двумя столбцами: один для головок строк, а другой для поля данных.
Создайте масштаб в последней строке таблицы, тогда график каждой переменной будет
на отдельной строке:
Самки крыс
Самцы крыс
%
0
5
10
15
20
25
30
Представление значений, групп и сравнений на графиках 353
о S
*=: 1
S S
о- ?
ф S
со X
Ф
6 —
—
у ^^ ■ ■■:
::^- :У:: --^
[ 1
L
1
Высокая Средняя Низкая
Доза
Мужчины
Высокая Средняя Низкая
Доза
Женщины
Мужчины
Низкая доза
Средняя доза
Высокая доза
Женщины
Низкая доза
Средняя доза
Высокая доза
В
Шкала и метки горизонтальной оси, или оси X
Единицы измерения
Рис. 21.13. Вертикальные столбиковые диаграммы (или горизонтальные штриховые диаграммы) (А) требуют
большего пространства, чем более эффективные точечные диаграммы. (В) Информация, передаваемая
столбиками, находится на конце столбика, так что ширина столбика, цвет или заливка отвлекают от информации.
Точечная диаграмма фокусирует внимание на данных, а не на столбиках. Кроме того, большинство точечных
диаграмм могут представить текст горизонтально, делая его более удобным для чтения
В случае необходимости отметки шкалы могут быть созданы разбивкой строки выше
масштаба на несколько столбцов и добавлением вертикальных границ к получающимся
ячейкам.
Бели Вы должны использовать штриховую или столбиковую диаграмму:
• используйте ее только как график для презентаций;
354 Представление данных и статистик в таблицах и графиках
• удостоверьтесь, что пространство между столбцами отличается от ширины столбцов
так, что столбцы невозможно перепутать с фоном [1];
• заполните все столбцы контрастными оттенками серого, чтобы отличать их друг
от друга и от фона [1];
• помните, что крайние контрасты серого цвета могут увеличить или уменьшить
визуальную важность некоторых столбцов [1, 12];
• не заполняйте столбцы линованными или полосатыми шаблонами; они могут создать
оптические иллюзии, которые умаляют данные [1].
Рис. 21.14 иллюстрирует эти ловушки столбиковых и штриховых диаграмм.
Категориальные данные также часто представляются в виде круговых диаграмм. Однако
в научных публикациях круговые диаграммы имеют весьма ограниченное применение
[13, 17]. «Секторы» диаграммы обычно помечаются процентом, который они отображают.
Данные круговых диаграмм, состоящих из нескольких больших секторов, легче
представить в тексте, а те, что состоят из многих маленьких секторов, требуют большего
количества меток, таких как проценты, представляемые каждым сектором. Что касается круговых
диаграмм, в которых не проставлены проценты, предполагается, что читатели способны
находить различия между углами секторов или между их площадями, а эти перцепционные
задачи очень сложны для большинства людей [3].
Рис. 21.14. Общие проблемы аолбиковых диаграмм. Столбики всегда должны иметь заливку и отличаться от фона,
и пространство между столбцами должно различаться по ширине от столбцов (группа А). Нужно избегать
оптических эффектов, используя однородную заливку, предпочитая ее штриховке (группа В). Контраст между столбцами
не должен быть настолько сильным, чтобы вызвать чрезмерное внимание к одному столбцу (группа С)
Представление значений, групп и сравнений на графиках 355
Если Вы дол:н€ны использовать круговую диаграмму:
• настойчиво ищите альтернативу! Рассмотрите возможность помещения информации
в тексте или представления данных в точечной диаграмме;
• используйте ее только для презентационной графики;
• стройте ее только двухмерной; трехмерные круговые диаграммы могут исказить
восприятие важной информации;
• используйте ее только для отображения процентов, сумма которых равна 100 %; не
давайте абсолютные числа, потому что читатели будут автоматически суммировать их,
ожидая, что сумма будет равна 100;
• ограничьте число «секторов» до 5, если это возможно [1, 16];
• расположите наибольший сектор в 12-часовой позиции и заполните остальные части
круга по часовой стрелке так, чтобы наименьший сектор оказался последним в круге [1];
• ни один сектор не должен составить менее 5 % от общего количества (угол 18
градусов) [1].
Непрерывные данные
Непрерывные данные состоят из распределений значений. Распределения могут быть
сообщены с указанием их определенных свойств: минимального и максимального значений,
значений среднего или медианы и СО или межпроцентильного размаха (см. гл. 1).
Непрерывные данные также часто представляются в столбиковых или штриховых диаграммах,
хотя они обычно ограничиваются отображением двух характеристик распределения, чаще
всего среднего и СО (рис. 21.15).
Ящичковая диаграмма Тьюки (или график «ящик-с-усами») отображает более
подробную информацию о распределении, чем столбиковые диаграммы, подчеркивая
значения, представляющие интерес. В самой простой форме ящичковая диаграмма указывает
минимальные и максимальные значения на концах «усов», 25-е и 75-е процентили на
верхних и нижних сторонах ящика и медиану как горизонтальную линию в ящике на 50-м про-
центиле (рис. 21.15). В других формах «усы» указывают, скажем, 5-е и 95-е процентили,
а остающиеся вне их значения распределения изображаются независимо, так что можно
идентифицировать выбросы. Ящичковая диаграмма Тьюки также может быть выполнена
как точечная диаграмма с привлекательными результатами:
Самки крыс
Самцы крыс
Вес, г О 100 200 300 400 500
Многомерные данные
Когда одна непрерывная переменная изображается относительно другой, например рост
по отношению к весу, для формирования диаграммы рассеяния одна переменная
изображается на оси Y, а другая на оси X. Существует возможность, что некоторые наблюдения
будут перекрываться, загораживая одну или более точек данных (рис. 21.16, .4). Поэтому
символы, используемые для изображения значений, должны быть простыми и перекрытие,
по возможности, должно быть сокращено или исключено.
356 Представление данных и статистик в таблицах и графиках
8 —
>-
1 S
о
1 S
1 с;
О
S ^
i ^
S g 4-
1 ^ -к
1 m ^
И -
% 2-
1 с;
а _
1 Средняя Средняя
1 Высокая Низкая Высокая Низкая
Доза Доза
А Мужчины Женщины
8 Ч
6 Ч
15
2 Ч
ч
ч
1
т
r^ir
1 Л
J 1
jv V
Средняя Средняя
Высокая Низкая Высокая Низкая
Доза Доза
Мужчины
Женщины
Рис. 21.15. (>AJ Столбиковые диаграммы часто используются для демонстрации непрерывных данных, обычно
чертят средние и иногда стандартные отклонения распределения в виде планок погрешностей. (В) Однако ящич-
ковая диаграмма Тьюки представляет больше информации о распределении и делает это более эффективно
Когда перекрытие минимально (и данные только из одной группы), для изображения
каждой точки необходим только единственный символ. Для этой цели вполне достаточен
простой сплошной кружок (•). Там, где данные сгруппированы настолько сильно, что
индивидуальные точки нельзя различить, есть по крайней мере четыре варианта:
• расширить шкалы на одной или обеих осях, пока символы не перестанут больше
перекрываться: этот выбор включает изображение данных в логарифмическом
масштабе (рис. 21.16, В);
Представление значений, групп и сравнений на графиках 357
• использовать метод, называемый «дрожание изображения», в котором две или
больше точек с идентичными значениями немного смещены относительно друг друга,
чтобы указать этот факт (рис. 21.16, С) [3, 10];
• изобразить остатки (различия между точками данных и их итоговой линией;
рис. 21.16, D);
• использовать набор символов, специально оговоренных, чтобы изображать
накладывающиеся данные. Один из подходов состоит в использовании различных
символов, чтобы показать число значений, таких как число лучей, исходящих из
точки (рис. 21.16, £). Например, чтобы указать 1, 2, 3, 4, 5 или 6 идентичных значений,
можно использовать следующие символы: •, |, ^, ^, *, ^.
УКАЗАНИЯ ПО ПРЕДСТАВЛЕНИЮ ГРУПП ЗНАЧЕНИЙ
21Л 8. Идентифицируйте каждую группу.
Как и при представлении отдельных значений, группы в диаграмме или на графике
могут быть идентифицированы в подписи, в метках шкал, в метке в поле данных или в ключе
или легенде в подписи или в поле данных.
21Л 9« Сделайте каждую группу визуально отличной.
При представлении категориальных данных в точечных диаграммах или ящичковых
графиках группы значений могут быть отмечены заключением их в «ящик» в поле данных или
отделением групп друг от друга дополнительными промежутками.
При представлении непрерывных данных на графиках группы обычно различают,
используя для этого отличающиеся символы или различные формы обобщающих линий.
Так, для двух групп вполне удобно использовать черный и светлый кружки (•, о).
Следующие символы, используемые в таком же порядке, также удобны для использования:
•, о, 0, о, 0, [3]. Эти общеупотребительные графические символы хорошо
контрастируют друг с другом и могут использоваться для данных, у которых есть до некоторой
степени перекрывающиеся значения. Как правило, используйте не более 5 таких символов
на одном графике.
Формы линий могут также различать группы между собой. Типичные формы
включают сплошные линии ( ), штриховые линии ( ), пунктирные линии
( ), штрих-пунктирные линии ( ) и цепочки символов (+++++). В
некоторых случаях толщина или «жирность» линии могут также дифференцировать 2
группы (см. рис. 21.2). И вновь, как правило, используйте не более 5 различных видов линий
на одном графике.
Число значений и групп, которые можно показать в данном поле данных, ограничено
площадью поля, числом отображаемых значений и групп и степенью перекрытия данных.
Полезное правило состоит в том, чтобы ограничить число групп до 5 [1]. Когда данные,
которые должны быть изображены в виде графика, превышают то, что может быть ясно
изображено в единственном графике, одно из решений состоит в том, чтобы представить
группы повторяющихся идентичных графиков. Такие «маленькие дубли» [6, 10, 14] могут быть
весьма эффективны, особенно когда шкалы на каждом графике идентичны (рис. 21.17).
Аналогичный метод — решеточные диаграммы Кливленда, которые являются
расширением его точечной диаграммы (рис. 21.18).
358 Представление данных и статистик в таблицах и графиках
60 000
50 000
40 000
30 000
20 000
10 000
100 000
10 000
1000
100
10
о 2 4 6 8 10
Линейный график
0,1
—1 1 1 1—
о 2 4 6 8 10
Полулогарифмический график
10
9
8
7
6
5
4
3
2
1
О
<8
<g
8>
%
(0>
1
£
% 1
10
Представление значений, групп и сравнений на графиках 359
8 9 10
0
9
8
7
6
5
4
3
2
1
•
X
•
X
+
1
*
•
ж
12 3 4
10
Рис. 21.16. Методы представления перекрывающихся точек на графике. (А) Перекрывающиеся данные могут
сделать график трудным для интерпретации. (В) Растягивая одну или обе шкалы или используя
полулогарифмический график (одна логарифмическая шкала и одна арифметическая шкала) или полностью
логарифмический график (две логарифмические шкалы), можно визуально отделить значения. (С) В процессе, названном
«дрожание изображения», перекрывающиеся точки данных на графике смещаются, чтобы сделать их более
отчетливыми, не сильно искажая значения точек данных. (D) Разности между точками на графике и их итоговой
линией {остатки) могут быть непосредственно изображены в виде графика с другим масштабом, где значения
можно отличить легче. (Е) Можно также указать разными символами на графике множественные кратные точки
данных с одними и теми же значениями. См. текст
21.20. Поясните процесс подгонки или математические характеристики любой
итоговой линии подгонки групп значений.
Линии математически подгоняются, чтобы суммировать группу связанных значений, что
чрезвьиайно полезно для визуализации структуры данных [9]. Когда используется подгонка,
360 Представление данных и статистик в таблицах и графиках
10 15 20 25
Рис. 21.17. Другой способ представить многомерные данные состоит в том, чтобы изобразить различные
группы в виде графика на ряде идентичных, множественных графиков. (Данные — те же, что и на рис. 21.2)
исследователи должны также сообщить, насколько хорошо линия соответствует данным.
Качество подгонки часто определяется с помощью «анализа остатков», в котором
изучаются расстояния от каждого измеренного значения до предсказанного значения
(определяемого итоговой линией), чтобы выяснить, не являются ли какие-либо из разностей
систематическими, указывающими на более слабую подгонку линии к данным (см. ниже и гл. 7).
Наиболее общие итоговые линии:
• Соединительные линии: просто соедините подобные значения, чтобы показать
тенденции, например такой линией, которая соединяет значения медиан в нескольких
распределениях измерений, произведенных в течение некоторого времени. Стандартная
гистограмма — простая столбиковая диаграмма, у которой соединительные линии
верхушек столбиков указывают значения частотного распределения (рис. 21.19).
• Процедуры сглаживания: укажите, сколько исходных точек данных усреднено для
каждой точки графика. Линии, полученные нанесением «скользящих средних»
значений, могут упростить или «сгладить» итоговые линии, уменьшая вариабельность
начерченных значений. Общая процедура состоит в выборе величины группы,
скажем, 3 значения, усреднении значений в каждой из «скользящих групп» из 3 значений
Представление значений, групп и сравнений на графиках 361
До лечения
.Г\
/?|
....г\
л:у
г\
/Т\
....г\
ЧУ
г\.
tr
о
••••о
о
г\
rv
....r\
rv
tr
r\
\J
4Г\
\J
\....r\
л:/
rs
e
о
/TV
о
о
ГГ1.А
-О"
e
о
о •••
о
о ••
(О)
.г\..
.^..
.г\..
.^..
.г\...
/:
После
Культура А
..КуДьтур.аВ....
А
А
W
W
А
W
.А.
W'
•
А
W
..Культурах.....
V
г\
kJ
.0...
i
•••••
Культура D
А.
W
W
♦•
♦•
Культура Е
W
лечения(•)
А.
W
А.
W
А
...^
W
....^
•■•■W
А.
А
W
А
А
•
А
•^
А
А,
А
.....^
'•••"Щ
^
ж\
w\
30°
35°
40°
45°
50°
60°
30°
35°
40°
45°
50°
60°
30°
35°
40°
45°
50°
60°
30°
35°
40°
45°
50°
60°
30°
35°
40°
45°
50°
60°
О 1 2 3 4 5 6 7 8 9 10 11 12 13 14
Переменная, единицы
Рис. 21.18. Многомерные данные могут также быть представлены на решеточной диаграмме, разновидности
точечной диаграммы. Здесь на графиках представлены четыре переменные: тип культуры, значения до
лечения, значения после лечения и температура
и соединении полученных средних линией. Таким образом, чтобы начертить первую
точку, следует усреднить значения номер 1, 2 и 3; чтобы начертить вторую точку,
следует усреднить значения номер 2, 3 и 4, и т. д. (рис. 21.20)'.
' В данном случае речь идет о методе скользящего среднего, с помощью которого нивелируются отклонения
от основной кривой. Кроме описанной техники, в которой каждое из слагаемых для определения скользящего
среднего имеет один и тот же вес, равный единице, имеется много иных разновидностей, в частности с весами,
уменьщающимися по мере удаления от центральной точки.
362 Представление данных и статистик в таблицах и графиках
40
35 Н
30
25 Н
О 20
и
=^ 15 -^
110
Рис. 21.19. Гистограмма — столбиковая диаграмма, которая представляет частотное распределение
переменной. Для таких представлений обычно предпочтительнее точечные или ящичковые диаграммы, потому что они
требуют меньше места
6.0
§ 5,0
9 4,0 Н
о
3,0
Z
■о 2,0 Н
S.
ф
Z
I 1,0 и
0,0 4
КА
• •
0,7 0,8 0,9 1,0
Потеря веса, кг
1,1
—I—
1,2
1,3
Рис. 21.20.Сглаженная кривая с каждой точкой на графике, представляющей «скользящее среднее» 5 смежных
точек данных
Представление значений, групп и сравнений на графиках 363
• Линии регрессии метода наименьших квадратов: дайте уравнение для линии в поле
данных (см. рис. 7.1). В простом линейном регрессионном анализе уравнение
регрессии такое же, как и для любой прямой линии: у = а + Ьх. Уравнения нелинейной
регрессии имеет дополнительные элементы (например, «квадратичный полином»), и эти
элементы будут иметь показатели степени: у = а-^ Ьх + сх^.В любом случае
получающиеся линии метода наименьших квадратов минимизируют сумму квадратов
разностей между фактическим значением и значением, предсказанным линией регрессии.
• Кривые Lowess^: сообщите значения альфа (а) и лямбда (X). Кривые Lowess
используются для обобщения данных, которые не могут быть описаны одной гладкой линией
или кривой (рис. 21.21). Для сглаживания кривой Lowess исследователь должен
установить 2 величины: альфу (а), называемую «параметром сглаживания», которая может
быть любым положительным числом, но типичные значения от 0,25 до 1; и лямбду (к),
степень некоторых полиномов, которая подбирается этим методом и равна 1 или 2.
• Сплайн-функции: используют множественные модели, одну для каждого
набора смежных точек. Сообщите модель, использованную для подгонки кривой к
данным. Сглаживающие сплайны — итоговые линии, которые проходят через все точки
на графике в большей или меньшей степени (рис. 21.22). Они отражают компромисс
между созданием итоговой кривой, сглаженной насколько возможно, и кривой,
проведенной насколько возможно точно, проходящей насколько возможно близко к каждой
точке данных. Таким образом, в одном крайнем случае сглаживающий сплайн может
быть линией простой линейной регрессии (высокая гладкость, но низкая точность),
а в другом — она может проходить через каждую точку (высокая точность, но низкая
гладкость).
0,9 1,0
Потеря веса, кг
1,3
Рис. 21.21. Кривая Lowess с параметром сглаживания 0,6 и степенью 2
Lowess — локально взвешенная регрессия наименьших квадратов (от англ. locally weighted least squares regression).
364 Представление данных и статистик в таблицах и графиках
2
I-
U
о
и
О
I
S
с;
с
ос
Q.
(U
X
0,9 1,0 1,1 1,2 1,3
Потеря веса, кг
Рис. 21.22. Сплайн-функция, сглаживающая те же самые данные, что и на рис. 21.21
Будьте осторожны, интерполируя или экстраполируя значения итоговых линий.
Итоговые линии — это только средства показать общие тенденции в данных. Только
некоторые из значений, которые образуют эти линии, взяты из данных, полученных в
исследовании. Значения на линиях, лежащие меэюду этими измеренными значениями, должны
быть интерполированы (приняты) исключительно на основе этой линии. Значения на
линиях вне этих измеренных значений должны быть экстраполированы (приняты) снова
исключительно на основе линии (см. рис. 7.2). Таким образом, ошибки в подгонке линии
к данным или в расширении значений вне данных могут привести к ошибкам интерполяции
и экстраполяции.
21.21« Не проводите итоговые линии через разрывы шкалы [3].
Как упомянуто в указании 21,12, читатели предполагают, что равные отрезки шкалы
представляют равные значения. Соединение значений через разрыв шкалы может
визуально исказить интерпретацию данных (см. рис. 21.9).
21.22. Чтобы представить процент изменения или мультипликативные факторы,
изобразите график значений в логарифмической шкале [16,20,21 ].
Логарифмические шкалы полезны для представления скоростей изменения в
противоположность величинам изменений. Эти шкалы устроены таким образом, что два равных
расстояния представляют одно и то же процентное изменение. В полулогарифмическом
графике только ось Y изображается в логарифмической шкале, тогда как на полностью
логарифмическом графике обе шкалы являются логарифмическими (рис. 21.23).
Если данные меняются в диапазоне, скажем, от 1 до 50 000 и будут изображены в
стандартных арифметических шкалах, то различие между 1 и 10 будет визуально
незначительным по сравнению с изменениями, скажем, от 1000 до 10 000. Если эти данные были бы на-
Представление значений, групп и сравнений на графиках 365
чертаны на полулогарифмической шкале, вертикальное расстояние между 1 и 10, 10 и 100
и между 100 и 1000 было бы идентично, потому что степень изменения (здесь коэффициент
10) является одинаковым в каждом случае. Аналогично, вертикальное расстояние между
100 и 200 было бы таким же, как и между 200 и 400, 400 и 800 и т. д., потому что каждый
интервал представляет удвоение значения (рис. 21.23, В).
Логарифмические шкалы начинаются с 1, а не О, и никогда не принимают отрицательные
значения. Фактически низший предел на логарифмической шкале определяется низшим
пределом изображаемых данных. В отличие от арифметических шкал, отсутствие нулевой
точки менее проблемно, потому что наклон линии обычно более важен, чем расстояние
от нулевой базовой линии (рис. 21.23, С) [16].
Данные, изображенные в арифметических шкалах, которые формируют прямую линию
(у = а + Ьх), увеличиваются или уменьшаются в зависимости от константы на фиксированную
В. с.
Полулогарифмический Логарифмический
график график
1000
100
^oы
1 г
о 200 400 600 800
1000^
100-
104
1—Г
О 200 400 600 800
1000-
1—\—Г
о 200 400 600 800
I 11 mil—I 11 iiiii—I 11 iiii|
10 100 800
1000^
100 4
П—г
0 200 400 600 800
104
1000
100 4
1—\—Г
0 200 400 600 800
104
I I I Hill 1 I I Hill 1 I I nil
0 10 100 800
Рис. 21.23. Изображение одних и тех же данных (А) на стандартном арифметическом, линейном или
декартовом графике; (В) на полулогарифмическом (одна логарифмическая шкала и одна арифметическая шкала)
графике и (С) на полностью логарифмическом графике (обе шкалы логарифмические) для трех наборов данных.
В верхней строке данные увеличиваются по постоянной арифметической пропорции на обеих осях; этот факт
очевиден на линейном графике. В средней строке постоянный 15%-й рост на оси Y легче заметить на
полулогарифмическом графике. В нижнем ряду постоянное процентное увеличение на обеих осях, X и Y, лучше всего
представлено на логарифмическом графике. (На линейном графике этой строки процентный рост на обеих осях
достаточно близок, так что получающаяся линия кажется прямой, хотя фактически это не так)
Збб Представление данных и статистик в таблицах и графиках
величину и таким образом формируют арифметическую прогрессию. Однако данные,
изображенные в логарифмических шкалах, которые формируют прямую линию (у = alf),
увеличиваются на постоянный процент и таким образом формируют геометрическую
прогрессию. Более крутая линия тренда на логарифмической шкале увеличивается с большей
скоростью, чем другие линии тренда (рис. 21.23).
УКАЗАНИЯ ПО ПРЕДСТАВЛЕНИЮ СРАВНЕНИЙ ЗНАЧЕНИЙ ИЛИ
ГРУПП ЗНАЧЕНИЙ
21.23. Делайте каждое сравнение визуально ясным, изображая разности между
группами.
Один способ сравнения групп данных состоит в том, чтобы просто изобразить группы
на одном графике и позволить читателям исследовать соотношения между их
изображениями. Этот «пассивный» подход предполагает, что читатели правильно интерпретируют
данные, тем не менее это полезно во многих случаях.
Более «активный» подход — спроектировать рисунок так, чтобы сообщить
соотношения, непосредственно изображая различия между группами. Этот подход специально
подчеркивает различия или сходство между группами (рис. 21.24 и 21.25).
Обычный способ изображения различий — это график «остатков», который
используется для определения того, достаточно ли соотношения между двумя переменными
линейны для применения модели линейного регрессионного анализа {см. гл. 7). Различия между
значениями фактических данных и значениями, предсказанными моделью, изображаются
для каждого значения X. Различия, которые остаются близкими к нулю во всем диапазоне
значений X, указывают более или менее линейные соотношения между этими двумя
переменными (рис. 21.26).
21.24. Предаавляя связанные данные, покажите соотношения между значениями
каждой пары.
Попарно связанные данные — это данные, взятые от одного и того же субъекта, такие
как значения до лечения и значения после лечения, или данные, полученные от
субъектов, которые были объединены в пару, чтобы уменьшить вариабельность между ними.
Такие значения лучше всего сравнивать визуально на стандартном графике, который
показывает изменения, наблюдаемые в каждой индивидуальной паре, в сравнении с
групповыми средними (рис. 21.27). Аналогично, в дополнение к групповым средним может
быть полезным указать, сколько изменений было в сторону увеличения или
уменьшения (рис. 21.28).
СТАНДАРТНЫЕ РИСУНКИ, ОБЫЧНО ИСПОЛЬЗУЕМЫЕ В ОТЧЕТАХ
О БИОМЕДИЦИНСКИХ ИССЛЕДОВАНИЯХ
Многие рисунки, используемые в отчетах по биомедицинским данным, являются
стандартными и не должны каждый раз повторно изобретаться, когда они требуются. Многие
из таких наиболее обш1епринятых рисунков, которые приводятся в этой книге, перечислены
ниже с соответствующими номерами рисунков и номером страницы.
Представление значений, групп и сравнений на графиках 367
Группа
Лечение
До
После
Контроль (плацебо)
До
После
Активный контроль
До
После
мг/мл
Изменения концентрации сыворотки
0 10 20 30 40 50 60 70 80 90 100
в
Группа
Лечение
Контроль(плацебо)
Активный контроль
мг/мл
0 10
Изменения концентрации сыворотки
о •
20 30 40 50 60 70 80
90
100
Группа
Лечение
Контроль(плацебо)
Активный контроль
мг/мл
-40
-30
Изменения концентрации сыворотки
(
)— •
>
-20 -10 0 10 20 30
40
50
Рис. 21.24. Сделайте сравнения визуально ясными. Простое представление данных (А) — не столь эффективное
представление фактических разностей, вызывающих интерес {В и С). Здесь В представляет разности
относительно диапазона фактических значений, тогда как С еще проще — показывает только направление и величину
изменений
368 Представление данных и статистик в таблицах и графиках
U
о
80 Н
70 Н
60 -Н
О
X
ос
I
(U
Q.
ф
i ^
го
го
50 —\
40 Н
30 Н
20 —Н
10 —\
О Н
Шкала и метки горизонтальной оси, или оси X
Единицы измерения
>-
U
о
с:
80 -Н
70 -Ч
60 -Ч
го
с;
(О
3
50 —\
_ 40 Н
30 Н
20 Н
10 Н
о Н
1 \ \ \ \ 1 Г
о 2 4 6 8 10 12
Шкала и метки горизонтальной оси, или оси X
Единицы измерения
Рис. 21.25. Другая причина сделать сравнения явными состоит в том, чтобы избежать оптических эффектов.
(А) В этом примере фактические различия не так очевидны, потому что глаз сравнивает данную точку на одном
распределении с самой близкой точкой на другом, а не с соответствующим значением X. (В) Когда же разности
между двумя графиками изображены явно, очевидно, что линии фактически параллельны, так как они
отделены 20 единицами по всей их длине
Представление значений, групп и сравнений на графиках 369
6
4
2
О
-2
-4
-6
• •
• • •
• •
Рис. 21.26. Графики «остатков» — разности между наблюдаемыми и предсказанными значениями на
диаграммах рассеяния, показывающих линии регрессии, являются хорошим примером полезности построения графика
разностей. (А) Разности, которые остаются близкими к нулю для всех значений X, указывают на линейные
отношения. (B-D) Большие или несимметричные разности указывают на слабые или нелинейные отношения
Значения «до» Значения «после»
Рис. 21.27. Стандартный график для отображения
связанных, парных, данных. Сравнение только
распределений значений до и после испытаний может
вводить в заблуждение, если индивидуальные изменения
среди пар противоположны друг другу в совокупности.
Сравнивая значения до и после лечения, скажем, для
подсчетов по ячейкам, о результатах можно сообщить
как о разности между средними до и после лечения для
каждой группы или как о числе субъектов, для которых
количество увеличилось или уменьшилось
370 Представление данных и статистик в таблицах и графиках
3 Н
U
о
с;
s"
U
О
о о
ct I
I
Ф
Q.
Ф
си S
1^
та
ic
3
2 -Ч
Значения «до» > значений «после»
• •
• Значения «после» > значений «до»
1 \ \ \ \ 1 г
0 12 3 4 5 6
Значения «после»
Шкала и метки горизонтальной оси, или оси X
Единицы измерения
Рис. 21.28. Другой стандартный график для изображения связанных данных. Здесь подчеркивается
направление различий между до- и посттестовыми значениями путем сравнения точек с «линией согласия»,
показывающей отсутствие изменений между до- и посттестовыми значениями
Рисунок
Номер рисунка Номер страницы
Ящичковая диаграмма Тьюки («ящик-с-усами»)
Точечная диаграмма Кливленда
Диаграмма рассеяния (скаттерплот)
График простой линейной регрессии
Кривая Каплана—Мейера
Операционная характеристика (ROC-кривая)
Номограмма
Краткая схема клинических испытаний
Воронкообразный график для оценки публикационного
смещения (метаанализ)
Результаты метаанализа («лесной график»)
График Л'Аббе (гетерогенность результатов метаанализа)
Результаты кумулятивного метаанализа
Результаты анализа чувствительности
Дерево решений (дендрограмма)
1.1
1.2
6.1,6.2
7.1
9.1
10.3
10.5
13.1-13.3
17.1
17.4
17.5
17.6
18,2,18.3
19.1J9.2
33
33
90,91
104
129
147
151
206-208
256
265
267
268
288,289
295, 304
Представление значений, групп и сравнений на графиках 371
Благодарности
Мы благодарим Jessica Апскег, МРН, и David Schriger, MD, за обзор этой главы.
Литература
1. MacGregorAJ. Graphics Simplified: How to Plan and Prepare Effective Charts, Graphs, Illustrations,
and Other Visual Aids. Toronto: University of Toronto Press; 1979.
2. Harris RL Information Graphics: A Comprehensive Illustrated Reference. Oxford: Oxford University
Press; 1999.
3. Cleveland WS. The Elements of Graphing Data. Pacific Grove, CA: Wadsworth; 1985.
4. Wainer H. How to display data badly. Am Stat, 1984; 38:137^7.
5. Briscoe MH. Preparing Scientific Illustrations: A Guide to Better Posters, Presentations, and
Publications, 2nd ed. New York: Springer-Verlag; 1996.
6. Tufte ER. Visual Display of Quantitative Information. Cheshire, CT: Graphic Press; 1983.
7. Tufte ER. Visual Explanations: Images and Quantities, Evidence and Narrative. Cheshire, CT: Graphic
Press; 1997.
8. Tufte ER. Envisioning Information. Cheshire, CT: Graphic Press; 1990.
9. Cleveland WS. Visualizing Data. Summit, NJ: Hobart Press; 1993.
10. GelmatiA, Pasarica C, Dodhia R. Let's practice what we preach: turning tables into graphs. Am Stat.
2002;56:121-30.
11. American Medical Association. American Medical Association Manual of Style: A Guide for Authors
and Editors, 9th ed. Baltimore: Williams & Wilkins; 1998.
12. White J. Using Charts and Graphs: 1000 Ideas for Visual Persuasion. New York: RR Bowker
Company; 1984.
13. Schriger DL, Cooper RJ. Achieving graphical excellence: suggestions and methods for creating
high-quality visual displays of experimental data. Ann Emerg Med. 2001; 37:75-87.
14. Kosslyn SM. Elements of Graph Design. New York: WH Freeman; 1994.
15. Wurman RS. Information Anxiety: What to do When Information Doesn't TeU You What You Need
to Know. New York: Bantam Books; 1990.
16. Smart LE, Arnolds. Practical Rules for Graphic Presentation of Business Statistics. Columbus, OH:
Bureau of Business Research, The Ohio State University; 1951.
17. Jordan EP, Shepard WC. Rx for Medical Writing. Philadelphia: WB Saunders; 1952.
18. American Society for Testing and Materials. ASTM E 380, Standard Practice for Use of the
International System of Units (SI). Philadelphia: ASTM; 1991.
19. Young SD. Implementation of SI units for clinical laboratory data: style specifications and conversion
tables. Ann Intern Med. 1987; 1:114-29.
20. Cooper RJ, Schriger DL, Tashman DA. An evaluation of the graphical literacy of Annals of
Emergency Medicine. Ann Emerg Med. 2001; 37:13-9.
21. Cleveland WS, McGill R. Graphical perception and graphical methods for analyzing scientific data.
Science. 1985;229:828-33.
373
Часть V
Путеводитель
по статистическим
терминам
и критериям
Статистические данные и простой английский язык в качестве двиэюу-
щей силы —мощные ракеты.
R. Pearl [Х]
Этот путеводитель по статистическим терминам и критериям
описывает многие из наиболее общих статистических терминов, критериев
и понятий, с которыми читатели сталкиваются в медицинской
литературе. Эти описания предназначены для краткого вводного обзора, а не
подробного объяснения или технически сложного определения, что
справедливо для этой книги в целом. (Для дальнейшего чтения в конце книги
предлагается библиография.) Более полные объяснения многих записей
включены в текст и могут быть найдены через предметный указатель.
В очень немногих случаях строгое расположение в алфавитном
порядке было отложено в пользу более заметного и полезного упорядочивания
терминов. Жирное начертание в тексте указывает термин, определенный
в этом путеводителе.
Литература
1. Pearl R. Introduction to Medical Biometry and Statistics. Philadelphia:
WB Saunders; 1941.
374 Путеводитель по статистическим терминам и критериям
абсолютный риск (или просто, риск) [absolute risk]
Вероятность или правдоподобие события.
уменьшение абсолютного (атрибутивного) риска (УАР) [absolute (attributable) risk
reduction]
Разность между двумя абсолютными рисками. Например, если инциденс сердечного
приступа у мужчин, принимающих аспирин, составляет 1,2 %, а инциденс у мужчин,
принимающих плацебо, 2,2 %, то УАР для мужчин, принимающих аспирин,
составляет 1 % (2,2 % - 1,2 % = 1 %), это означает, что аспирин понижает абсолютный риск
сердечного приступа на 1 %. Обратной величиной к УАР [1/УАР = NNT] является
число пациентов, подвергаемых лечению, на один предотвращенный исход (ЧПЛП).
См. уменьшение относительного риска.
альтернативная гипотеза (Н^) [alternative hypothesis]
Утверждение, что факторы, отличные от случайности, ответственны за различие между
группами. Альтернативная гипотеза противостоит нулевой гипотезе, утверждающей, что
никакого различия между группами нет. Если нулевая гипотеза может быть отклонена
на основании того, что результаты вряд ли получены случайно, то альтернативная гипотеза
более вероятна. Вероятность того, что различия, по существу, являются результатом
случайности, дается р-значением. /^-значение затем сравнивается с альфа-уровнем
(например, 0,05), который определяет точку, в которой исследователь желает отклонить основную
гипотезу и принять альтернативную гипотезу. Если/?-значение меньше, чем альфа-уровень,
считают, что наблюдаемое различие, по существу, не является результатом случайности.
альфа (а) или альфа-уровень [alpha or alpha level]
В традиционной теории проверки гипотез — порог статистической значимости.
Типичные альфа-уровни: 0,05,0,01, а иногда даже 0,001. Альфа-уровень устанавливается
исследователем и является значением, с которым сравниваются р-значения для определения,
является ли различие «статистически значимым». По определению/^-значения, меньшие
или равные альфа-уровню, являются статистически значимыми. См. альфа-ошибка.
альфа Кронбаха [Cronbach's alpha]
Мера внутренней надежности или соответствия элементов в индексе или анкетном
опросе. Меняется в диапазоне от О до 1 и указывает степень ассоциации среди ответов
на вопросы, имеющих отношение к тому же самому измерению (такому, как альтруизм
или враждебность) анкетного опроса.
альфа-ошибка (ошибка первого рода) [alpha error (type I error)]
В традиционной теории проверки гипотез — ошибочное принятие различия между
группами как результата биологии (ошибочное отклонение нулевой гипотезы), когда
фактически более вероятным объяснением является случайность. Чем меньше
вероятность, тем ниже риск сделать ошибку этого типа. Часто называется «ложноположитель-
ным» результатом.
анализ времени до наступления события [time-to-event analysis]
Статистические процедуры для анализа времени между данной начальной точкой
и данным событием (в анализе выживания, смерти), где есть цензурированные на-
Путеводитель по статистическим терминам и критериям 375
блюдения; т. е. когда событие, возможно, не имело места у некоторых субъектов.
Анализ выживания — наиболее распространенная форма анализа времени до
наступления события, используемая в медицине. См. кривая Каплана—Мейера; метод
Каплана—Meiiepa; регрессионньш анализ пропорциональных рисков Кокса;
лог-ранговый критерий.
анализ выживания [survival analysis]
См. анализ времени до наступления события.
анализ главных компонент [principal components analysis]
Статистическая процедура, используемая для группировки взаимосвязанных
переменных, чтобы помочь обобщить данные. Подобен факторному анализу.
анализ затрат—выгод [cost-benefit analysis]
Форма экономической оценки, которая сравнивает денежную стоимость с выгодами,
выраженными в долларах. См. гл. 18.
анализ компонент дисперсии [variance components analysis]
Процесс изоляции источников вариабельности переменной исхода.
анализ минимизации стоимости [cost-minimization analysis]
Тип экономической оценки, используемый для определения параметров, которые
обеспечивают эквивалентную заботу или обслуживание при самой низкой стоимости.
См. гл. 18.
анализ по протоколу (или анализ на протоколе) [per-protocol analysis (or on-protoco1
analysis)]
Подход к анализу результатов испытания, в котором включены в анализ только те
пациенты, которые закончили протокол, как планируется. В отличие от анализа с
намерением применить вмешательство, в котором все пациенты, зарегистрированные
в испытании, включены в анализ как часть группы, в которую их назначили, независимо
от того закончили они протокол или нет. Анализ по протоколу необходим, чтобы
определить, был ли сам протокол эффективен.
анализ рентабельности [cost-effectiveness analysis]
Форма экономической оценки, которая сравнивает денежную стоимость с мерой
клинической эффективности, такой как годы спасенной жизни. См. гл. 18.
анализ решений [decision analysis]
Статистический подход к принятию решений, который определяет оптимальные
альтернативы, учитывая различные условия и предположения. См. гл. 19.
анализ с намерением применить вмешательство [intent- or intention-to-treat analysis]
Первичная стратегия для анализа результатов РКИ. Пациенты анализируются в группе,
в которую они были назначены, независимо от того, завершили ли они лечение,
назначенное группе. Медицинская необходимость иногда препятствует пациентам завершить
лечение, как запланировано, но так как пациенты могли покинуть исследование из-за
лечения при исследовании, результаты сначала анализируются на основе намерения
применить вмешательство. Часто выполняются дополнительные анализы для коррекции
пациентов, которые не завершают испытание, как запланировано. В отличие от анализа
376 Путеводитель по статистическим терминам и критериям
на протоколе, или анализа по протоколу, в котором анализируются только те
пациенты, которые завершают запланированный протокол.
анализ стоимости болезни [cost-of-illness analysis]
Тип экономической оценки, которая оценивает общую стоимость болезни или
нетрудоспособности по отношению к популяции или к нации в целом. Включает измерение
потерянной производительности, так же как и стоимости лечения. См. гл. 18.
анализ стоимости последствий [cost-consequence analysis]
Форма анализа рентабельности, в котором возрастающая стоимость (такая, как
стоимость лечения, госпитализации или лекарств) и последствия (исходы здоровья,
побочные эффекты и т. д.) альтернативных вмешательств или программ сравниваются
непосредственно, не объединяя результаты в отношение стоимость—исход, и в котором все
исходы здоровья оставляются в естественных единицах. См. гл. 18.
анализ текущей стоимости [present value analysis]
См. дисконтирование.
анализ установления стоимости [cost-identification analysis]
Тип экономической оценки, используемый для определения реальной стоимости
оказания услуги. См. гл. 18.
анализ чувствительности [sensitivity analysis]
Метод, часто используемый в метаанализе, экономических оценках и анализе
решений, для того чтобы оценить влияние ключевых предположений или значений
на конечный результат. Предположения варьируют в диапазоне их значений, чтобы
определить их влияние на результат. Большие разности в эффектах указывают, что
анализ «чувствителен» к предположению. Однофакторный анализ чувствительности
изучает изменение одной переменной за раз; двухфакторный анализ
чувствительности — двух переменных за раз и т. д. См. указания 17.32, 18.24, 19.15 и 19.21.
В детерминированном анализе чувствительности переменные проверяются по
точечным оценкам; в вероятностном анализе чувствительности — по интервальным
оценкам.
аналитическая статистика, или статистические выводы [inferential statistics]
Статистические процедуры, которые выводят (или оценивают) характеристики
популяции на основании измерений у выборки из этой популяции. В отличие от
описательной статистики, которая используется, чтобы описать наборы данных.
апостериорная вероятность [posterior probability]
В диагностическом тестировании — условная вероятность, что болезнь присутствует,
когда тест положителен (положительное прогнозирующее значение), или что болезнь
не присутствует, когда испытание отрицательно (отрицательное прогнозирующее
значение). См. теорема Байеса.
априорная (гипотеза) [а priori (hypothesis)]
Латинское значение термина — «совершить заранее». Априорная гипотеза — гипотеза,
сформулированная прежде, чем будут собраны данные для ее проверки. См. post hoc
анализ.
Путеводитель по статистическим терминам и критериям 377
априорная вероятность («priors») [prior probability]
В диагностическом тесте и байесовой статистике — вероятность, что болезнь
присутствует до проведения теста; часто то же самое, что и преваленс болезни.
асимметричные данные или распределение [skewed data or distribution]
Асимметричное частотное распределение. Говорят, что асимметричные распределения
с более длинными правыми «хвостами» являются положительно асимметричными, или
скошенными «вправо»; а распределения с более длинными левыми «хвостами»
называют отрицательно асимметричными или скошенными «влево».
байесов коэффициент [Bayes factor]
В байесовой статистике — отношение силы доказательства в пользу одной гипотезы
к силе доказательства в пользу другой гипотезы. Когда предполагаемое различие между
группами выражается единственным числом (например, сокращение смертности будет
точно 10 %), байесов коэффициент — то же самое, что и отношение правдоподобия.
Байесов коэффициент 0,05 указывает, что, скажем, апостериорные шансы 15%-го
снижения вирусной нагрузки в 20 раз больше, чем априорные шансы 15%-го снижения
вирусной нагрузки, т. е. лечение сильно увеличивает вероятность того, что вирусная
нагрузка будет снижена на 15 %. См. функция правдоподобия.
Бартлетта критерий [Bartlett's test]
Цель: сравнить две или больше групп на изменчивость переменной отклика.
Переменная отклика: непрерывная.
Объясняющая переменная(ые): две или больше групп.
Сообщение результатов: дисперсии групп (квадраты СО), фактическое р-значение
и величина статистики критерия.
бета ф)^ или бета-уровень [beta or beta level]
Вероятность совершить ошибку второго рода в традиционной теории проверки
гипотез. Функционально вероятность ошибочного заключения, что различие между
группами — результат случая, когда фактР1чески биология дает лучшее объяснение. Чем
ниже эта вероятность, тем лучше. Однако о значении ^ обычно не сообщают; 1 -/? — это
статистическая мощность теста (критерия) для обнаружения данного различия, если оно
действительно существует. Типичные значения для^—0,2, что указывает на статистическую
мощность 0,8, и 0,1, что указывает на статистическую мощность 0,9. Исследователи часто
заключают, что, скажем, две группы эквивалентны, когда различия между ними не являются
статистически значимыми. Если выборки являются небольшими, статистическая мощность
может быть низкой и такое заключение может быть неправильным. То есть различие может
действительно существовать, но мощности, чтобы ее обнаружить может быть недостаточно
(недостаточно доказательства). Большие выборки имеют большую статистическую
мощность, что означает, что истинные различия между группами, более вероятно, будут
обнаружены. См. альфа-ошибка и статистическая мощность.
бета-вес [beta weight]
См. коэффициент регрессии.
378 Путеводитель по статистическим терминам и критериям
бета-ошибка [beta error]
Ошибка второго рода. См. бета ф).
биномиальная, или бинарная, переменная [binomial variable]
Переменная, которая имеет только две взаимно исключающие альтернативы, такие как
выживание (выжил или умер) или пол (мужской или женский).
биномиальный тест [binomial test]
Цель: сравнить две доли.
Переменная отклика: категориальная (выраженная как доля).
Независимая переменная(ые): две группы.
Сообщение результатов: две доли и разность между ними, 95%-й ДИ для разности,
фактическое р-значение и величина тестовой статистики.
бисериальная корреляция [biserial correlation]
См. точечный бисериальный коэффициент корреляции.
блокирование [blocking]
Метод распределения пациентов по подгруппам лечения для управления смешиванием
факторов или создания групп приблизительно одинакового размера.
В
валидность по критерию [criterion validity]
См. конвергентная валидность.
валидность по совпадению [concurrent validity]
См. конвергентная валидность.
валидность содержания [content validity]
В анкетных исследованиях — степень, с которой вопросы измеряют полную область,
которая должна быть оценена.
вековой тренд [secular trend]
Цикл, обычно болезни, длящийся долгое время, вообще годы или десятилетия.
величина эффекта [effect size]
1) Результат исследования, выраженный как величина разности или сила взаимосвязи.
Обычно используется при оценке объема выборки, что требует определения
наименьшей величины эффекта, представляющего интерес. 2) В метаанализе — безразмерная
мера эффекта, используемая для сравнения исходов, измеренных в различных единицах.
Часто вычисляется как разность между средними групп лечения, деленная на СО
значений группы контроля.
вероятность [probability]
Число между нулем и единицей, указывающее, какова возможность того, что событие
произойдет. Сумма вероятностей всех альтернатив в данной ситуации равняется
единице в предположении, что все альтернативы являются попарно исключающими.
Например, если вероятность того, что пациент — мужчина, 0,6, то вероятность того, что
пациент — женщина, 0,4.
Путеводитель по статистическим терминам и критериям 379
взаимодействие; эффект взаимодействия [interaction; interactive effect]
Процесс, в котором объединенные эффекты двух или больше переменных больше, чем
сумма их индивидуальных эффектов. Например, две объясняющие переменные
взаимодействуют, когда влияние одной переменной на переменную отклика зависит от
значения другой переменной. Сопоставляется с главным эффектом, который является
эффектом единственной объясняющей переменной на переменную отклика.
внешняя валидность метода измерения [face validity]
Степень, до которой анкета поверхностно проявляет, что она измеряет то, что
предполагается измерить.
внешняя валидность (или обобщаемость) [external validity (or generalizability)]
Способность перенести результаты исследования, проводимого на одной популяции,
на другие популяции, другие обстоятельства или другие временные интервалы.
внутриклассовая корреляция [intraclass correlation]
Мера связи, которая специфически имеет дело с множественными измерениями или
наблюдениями о каждом участнике исследования единственным экспертом. Указывает
внутриэкспертную корреляцию. Коэффициент корреляции — число, которое меняется
от -1 (полное разногласие) до +1 (полное согласие).
внутриэкспертная надежность [intra-rater reliability]
Воспроизводимость суждения единственным экспертом по той же самой задаче в
разное время.
восполненные данные [imputed data]
Значения, которые созданы любым из нескольких способов для замены отсутствующих
значений, пропусков в анализе. Пропуски в данных могут снизить мощность многих
статистических анализов, поэтому замена пропусков значениями, полученными с
помощью подходящего процесса восполнения, является общей и приемлемой практикой.
См. перенос последнего наблюдения и указание 7.15.
выборка [sample]
Часть популяции, информация о которой фактически получена в исследовании.
выбывание [drop-out]
Участник исследования, который не завершает исследование; кто-то, кто уходит из
исследования. Знание характеристик участников, которые выбывают, так же как причин
их выбывания, важно в определении всех эффектов лечения. По этой причине нужно
сообщить о частоте выпадающих из исследования.
выделяющиеся значения («выбросы») [outlying values («outliers»)]
Значения, столь экстремальные, что кажутся не являющимися частью распределения.
Часто немногочисленные, они могут исказить среднее значение. Значение медианы,
однако, не подвержено влиянию величин этих значений и должно использоваться для
описания данных с выбросами.
Гауссово распределение [Gaussian distribution]
«Нормальное» распределение; колоколообразная кривая, которая симметрична
относительно среднего. См. стандартное нормальное распределение.
380 Путеводитель по статистическим терминам и критериям
гипотеза [hypothesis]
В теории проверки гипотез — положение, которое будет принято или отклонено (или
поддержано, или нет) на основе результатов исследования. Например, утверждение
«среднее количество бактерий в группе лечения будет равняться среднему количеству
в группе контроля» является гипотезой, которая может быть проверена и поддержана
данными (средние количества равны) или нет (средние не равны; фактически есть
достаточно доказательств, чтобы отклонить утверждение, что они равны).
гистограмма [histogram]
Тип столбиковой диаграммы для изображения распределения данных. Гистограммы со
многими столбиками часто перерисовываются как полигоны частот или как
сглаженные распределения, после соединения линией верхушек столбцов и затем удаления
самих столбцов.
главный эффект [main effect]
Влияние единственной объясняющей переменной на переменную отклика. В
отличие от эффекта взаимодействия, в котором нужно совместно рассматривать две или
больше независимых переменных для определения влияния на единственную
переменную отклика.
годовой преваленс [annual prevalence]
Общее количество людей, которые заболевали или теряли трудоспособность в
течение года.
годы жизни с улучшенным качеством [QALY (quality-adjusted life-year)]
Мера исхода, часто используемая в исследованиях полезности стоимости лечения.
Качество жизни для некоторого состояния представлено как число между нулем
(безразличие между жизнью и смертью) и единицей (крепкое здоровье). Затем определяется
количество лет, которые пациент мог бы провести в этом состоянии. Произведение этих
двух чисел выражено в годах жизни с улучшенным качеством. См. полезность.
график рассеивания; диаграмма рассеивания [scatter plot; scatter diagram]
График данных для двух непрерывных переменных, обычно ассоциированный с
корреляцией и простым линейным регрессионным анализом. Так называется, потому что
данные «рассеяны» на графике. См. рис. 6.1, 6.2 и 7.1.
группа контроля [control group]
Группа участников исследования, которые получают стандартное лечение, не
получают никакого лечения или принимают плацебо. Результаты будут затем сравниваться
с результатами участников экспериментальной группы, которые получали лечение при
исследовании.
д
данные [data]
Совокупность измерений или наблюдений.
данные, цензурированные слева [left-censored data]
См. цензурированные данные.
Путеводитель по статистическим терминам и критериям 381
данные, цензурированные справа [right-censored data]
См. цензурированные данные.
двойное ослепление [double-blind]
План исследования, в котором ни участникам исследования, ни исследователям не
говорят о распределениях пациентов по группам. «Ослепление» предпочтительнее
«маскирования», несмотря на возможность редких случаев смешивания статистических
понятий с медицинским состоянием, остающимся вне поля зрения. Авторы должны
определить, какие группы ослепляются.
двусторонний тест [two-tailed (two-sided) test]
Условие для проверки гипотез, определенное до сбора данных, как альтернатива
одностороннему тесту. Двусторонний тест не предполагает, что направление разности
между, скажем, двумя значениями (большим или меньшим) известно заранее. Двусторонний
тест более консервативен и более общий, чем односторонний.
дерево решений [decision tree]
Блок-схема для моделирования анализа решений. Состоит из стартовой точки и
исходов, а также точек ветвления, являющихся или случайными узлами, которые имеют
биологически определенные исходы, или узлами решений, исходы которых
определяются пациентами и провайдерами. См. рис. 19.1.
диагностическая точность [diagnostic accuracy]
Рабочая характеристика диагностического теста; число правильных диагнозов,
деленное на число предпринятых диагнозов и умноженное на 100 %. Правильный диагноз
может быть или истинно положительным результатом, или истинно отрицательным
результатом. См. таблицу 10.1.
диагностический результат [diagnostic yield]
Термин без стандартного значения, иногда используемый в диагностическом
тестировании. Диагностический результат часто используется, чтобы описать то, что случилось
при использовании теста в данном исследовании. Например, «низкий диагностический
результат» может означать, что 1) относительно немногие из тестовых результатов были
положительны, 2) относительно немногие из результатов могли быть
интерпретированы или 3) число истинно положительных результатов (когда второе тестирование
использовалось как исходный эталон) было относительно низким по сравнению с общим
количеством полученных результатов. Термин должен быть определен, если он должен
использоваться.
диагностический тест [diagnostic test]
Тест, специфично предназначенный для установления присутствия или идентичности
расстройства или его исключения; в более широком смысле — любой знак, симптом,
лабораторный показатель, изображение и т. д., указывающие на присутствие болезни,
расстройства или медицинской проблемы.
дивергентная валидность (или дискриминантная валидность) [divergent validity (or
discriminant validity)]
Соответствующий недостаток согласия в оценках между двумя анкетными опросами,
измеряющими различные понятия.
382 Путеводитель по статистическим терминам и критериям
дисконтирование [discounting]
В экономических оценках — практика выражения будущих затрат и выгод по
текущему курсу доллара. Будущие затраты и выгоды умножаются на дисконтный коэффициент,
чтобы преобразовать их в текущий курс доллара. Также называют анализом текущей
стоимости. См. указание 18.23.
дискретные данные [discrete data]
Форма непрерывных данных, которые могут быть выражены только в целых числах,
потому что дроби невозможны, в противоположность действительно непрерывным
данным, которые могут быть измерены в дробях. Например, количество выполненных
хирургических операций является дискретной переменной; «хирургическая
полуоперация» — незначимое понятие. Рост — действительно непрерывная переменная, потому
что она может быть измерена в последовательно уменьшающихся единицах. В
практических целях дискретные данные анализируются как непрерывные данные.
дискриминантная валидность [discriminant validity]
См. дивергентная валидность.
дискриминантный анализ [discriminant analysis]
Статистический метод для установления отличительных характеристик номинальных
категорий. Дискриминантный анализ используется для установления комбинации
переменных, которые показывают различие среди известных категорий, в отличие от
кластерного анализа, где категории не известны до анализа.
дисперсионный анализ (ANOVA) [analysis of variance]
См. ANOVA.
дисперсионный анализ повторных измерений [repeated-measures analysis of variance]
См. ANOVA.
дисперсия [variance]
Степень рассеяния данных; вариабельность данных относительно среднего.
Квадратный корень из дисперсии — это СО. Для распределений, имеющих колоколообразную
форму, чем больше дисперсия, тем более плоская кривая распределения; чем меньше
дисперсия, тем более островершинная кривая. Хотя дисперсия имеет числовое
значение, о самой дисперсии редко сообщают, потому что СО предпочтительнее.
доверительные полосы [confidence bands]
В простом линейном регрессионном анализе — кривые, показывающие верхние
и нижние доверительные границы (обычно 95%-е доверительные границы) вокруг
линии регрессии. См. рис. 7.1.
доверительные пределы [confidence limins]
Верхние и нижние границы доверительного интервала.
доверительный интервал (ДИ) [confidence interval (CI)]
Показатель точности оценки популяционного значения. Типичны 95 или 99% ДИ.
Диапазон доверительного интервала обычно, но не всегда симметричен относительно оценки
и выражен в тех же самых единицах, что и оценка. Более широкие интервалы
свидетельствуют о меньшей точности; узкие интервалы означают большую точность. См. гл. 3.
Путеводитель по статистическим терминам и критериям 383
ДОЛЯ [proportion]
Отдельный тип отношения, в котором числитель есть подмножество знаменателя и
время не является фактором. Доля всегда меняется между нулем и единицей.
дополнительный, атрибутивный, риск (ОР), [attributable risk (AR)]
См. уменьшение относительного риска.
естественная частота [natural frequency]
Число пораженных людей на единицу популяции; например 3 из 1000 человек.
Предпочтительный способ сообщения о риске, потому что это более понятно, чем риск или
отношение шансов.
зависимая переменная [dependent variable]
См. переменная отклика
значимость статистическая [significance, statistical]
См. статистическая значимость.
золотой стандарт [gold standard]
Ориентир, особенно эталонный тест, с которым сравнивается эффективность нового
диагностического теста. Валюта Соединенных Штатов прежде была обеспечена
золотом; отсюда и происхождение термина. Сегодня термин неактуален частично потому,
что золото больше не обеспечивает американскую валюту, а частично потому, что его
значение было общеизвестным только в развитых странах западного мира. См.
исходный эталон.
И
избыточная выборка [oversampling]
См. стратификация.
индекс наследуемости [heritability index]
В генетических исследованиях индекс наследуемости указывает, какая часть
превосходных качеств размножающегося животного может быть найдена в его потомстве.
Индекс наследуемости принимает значения между О и 1; О обозначает ситуацию, когда
селекция (наследственность) не имеет никакого влияния вообще, а 1 обозначает
ситуацию, когда свойство полностью управляется селекцией (наследственностью). Индекс
наследуемости показывает, сколь успешная селекция возможна для этого свойства.
индекс состояния здоровья [health status index]
Набор измерений, обычно объединяемых в единое число или индекс, который
указывает уровень здоровья или качества жизни. Измерения обычно включают такие
переменные, как физическая функция, эмоциональное состояние, способность выполнять
действия ежедневного обихода, удовлетворенность в отношениях и т. д. Используются
384 Путеводитель по статистическим терминам и критериям
С исходами (такими, как количество «благополучных лет» или «годы жизни с
улучшенным качеством»), чтобы вычислить «полезность» для экономических оценок или
анализа решений.
интервальная оценка [interval estimate]
Оценка неизвестной характеристики популяции (параметра) с помощью известного
выборочного значения (статистики). Интервальная оценка — это диапазон чисел, часто
обозначаемых доверительным интервалом, таким как 95% ДИ. В отличие от
точечной оценки.
интервальные данные [interval data]
Вид непрерывных данных, измеренных в интервальной шкале через равные интервалы,
но без истинной нулевой точки. Значения интервальной шкалы можно законно
складывать и вычитать, но не умножать или делить. Например, температура указывается на
интервальной шкале градусов. Однако 40 °С не в два раза горячее 20 °С. (Чтобы сделать
такое утверждение, необходима температура, измеренная по шкале «отношений». В этом
случае нужно было бы измерять температуру по шкале Кельвина — шкале отношений,
которая включает абсолютный нуль.)
интерквартильный размах [interquartile range]
Технически — диапазон значений, содержащий центральную половину наблюдений,
т. е. диапазон между 25-м и 75-м процентилями. На практике сообщают значения 25-го
и 75-го процентилей. Используют со значением медианы (вместо среднего и СО),
чтобы сообщить о данных, распределение которых заметно отличается от нормального.
интерполяция [interpolation]
Процесс предсказания или оценки значений меэюду измеренными значениями;
обычно вдоль регрессионной или других итоговых линий данных, указывающих вероятные
значения.
информированное, осознанное согласие [informed consent]
Принцип биомедицинской формулировки исследования, в соответствии с которым
участники имеют право знать риски и выгоды от включения в исследование и что они
не могут быть включены в такие исследования без их явного письменного согласия. Для
рукописей, описывающих исследование на людях, большинство журналов требует
подтверждения, что письменное информированное согласие было получено от всех
субъектов, как условие для публикации.
инциденс [incidence]
Частота, с которой новые события или случаи появляются во время определенного
промежутка времени. Контрастирует с преваленсом, который является частотой, с которой
существующие события или случаи присутствуют в данный момент или период
времени. Инциденс, выраженный как доля, является кумулятивным инциденсом. Инциденс,
выраженный как частота, называют плотностью инциденса.
испытание [trial]
Эксперимент или протокол, как в «клиническом испытании»; научное исследование.
Путеводитель по статистическим терминам и критериям 385
испытуемый тест [index test]
(Диагностический) тест, который исследуется, в противоположность эталонному
тесту, по отношению к которому устанавливается его правильность.
исследование вмешательства [interventional study]
Исследование, которое проверяет эффекты вмешательства, такие как новое лечение;
экспериментальное исследование. В отличие от наблюдательного исследования,
которое является описательным.
исследование медицинского обслуживания [health services research]
Исследование предоставления услуг здравоохранения, его стоимости и его денежных
и клинических последствий. Включает прагматические клинические
исследования, которые оценивают, насколько хорошо вмешательства выполняются в реальных
условиях, а также экономические оценки, обзорные исследования использования,
инициативы по оценке качества, оценки технологии и анализы решений. Обычно
занимается взаимоотношениями между потребностью, запросом, поставкой,
использованием и исходом медицинского обслуживания. Цель исследования — оценка,
особенно в терминах структуры, процесса, выхода и исхода. Также называется
исследованием исходов.
исследование таблиц [chart study]
Исследование, основанное на анализе выборки медицинских отчетов. См.
исследование типа «случай-контроль»; ретроспективное исследование.
исследование типа «случай-контроль» [case-control study]
Ретроспективное исследование, в котором истории пациентов с интересующим
состоянием сравниваются с историями группы контроля, пациентов, не находящихся в
подобном состоянии. Иногда называют исследованием таблиц, потому что многое основано
на обзорах медицинских отчетов. См. гл. 15.
истинно отрицательная частота [true-negative rate]
В диагностическом тестировании — специфичность теста. Количество отрицательных
результатов теста у небольных участников, деленное на количество протестированных,
не имеющих болезни.
истинно положительная частота [true-positive rate]
В диагностическом тесте — чувствительность теста. Количество положительных
результатов теста у больных участников, деленное на количество протестированных,
имеющих болезнь.
исторический контроль [historical controls]
Когорта субъектов, обычно установленная более ранним исследованием и используемая
как группа контроля для сравнения с экспериментальной группой. В отличие от
конкурентного (параллельного) контроля, для чего данные собираются одновременно
с группой лечения.
исход или переменная исхода [outcome or outcome variable]
Событие, представляющее интерес; переменная отклика; конечная точка.
386 Путеводитель по статистическим терминам и критериям
исходные данные [baseline data]
Данные, собранные, чтобы описать группы лечения и контроля в начале исследования,
до начала лечения. Исходные данные могут быть сравнены между группами, чтобы
определить, подобны ли группы или они клинически и статистически не сбалансированы по одной
или более переменным. В пределах каждой группы исходные данные часто сравниваются
с данными, собранными после лечения, чтобы определить эффекты вмешательства.
К
каппа-статистика (д:) [карра statistic]
Мера связи, которая специфически имеет дело с согласованностью среди
множественных измерений или наблюдений одного и того же объекта. Измеряет согласованность
или точность классификации внутри или между экспертами. Меняется от -1 до +1, где
+1 — полное соответствие, -1 — полное несоответствие, а О — отсутствие какой-либо
связи между суждениями.
категориальные данные [categorical data]
Данные, которые либо включены, либо исключены из категории, такие как мужской или
женский пол, где пол — категориальная переменная. Категориальные данные могут быть
номинальными или порядковыми (полуколичественными), в противоположность
непрерывным данным, которые могут быть размещены вдоль сплошной линии,
континуума. Поскольку данные классифицированы в категории на основе специфического
качества, категориальные данные также упоминаются как качественные данные.
качественные данные [qualitative data]
Данные, которые выражаются через категории на основе признаков или качеств,
которые они или имеют, или не имеют. Номинальные и порядковые данные —
качественные данные. В противоположность количественным или непрерывным данным.
качество жизни, связанное со здоровьем [health-related quality of life (HRQOL)]
См. мера качества жизни.
кластерный анализ [cluster analysis]
Статистический метод для классификации предметов в определенные номинальные
категории. Кластерный анализ используется как попытка создать соответствующую
классификацию на основе схожих особенностей. В противоположность дискриминантно-
му анализу, где категории известны до анализа.
клиническая эпидемиология [clinical epidemiology]
Относительно новая область исследований, связанная с движением доказательной
медицины, которая заинтересована в применении принципов популяционной
эпидемиологии к охране здоровья индивидуальных пациентов.
ковариата [covariate]
Переменная в исследовании. Этот термин иногда используется для обозначения
объясняющей переменной и иногда смешивающей (влияющей) переменной. Конкретно
используется в ANCOVA (ковариационном анализе).
Путеводитель по статистическим терминам и критериям 387
ковариационный анализ (ANCOVA) [analysis of covariance]
См. ANCOVA.
когорта [cohort]
Группа людей, у которых есть по крайней мере одна общая особенность. Когорта по
рождению состоит из людей, рожденных в данный период времени. В когортных
исследованиях группа людей изучается в течение длительного периода времени.
когорта историческая [cohort, historical]
Группа участников исследования, которые сгруппированы в когорту на основе
архивных данных (медицинские записи, семейные истории и т. д.), в противоположность
данным, собранным проспективно, перед отнесением к когорте.
когортное исследование [cohort study]
Исследование, в котором группа людей наблюдаются в течение некоторого времени.
Обычно проспективные исследования, они также упоминаются как продольные
исследования или панельные исследования. Их можно также назвать исследованиями инциден-
са, потому что они хорошо подходят для определения частоты, с которой новые случаи
болезни или нетрудоспособности происходят в популяции. См. гл. 14.
количественные данные [quantitative data]
Данные, которые измерены в числовой шкале с равными интервалами. Данные,
измеренные в интервальной шкале и шкале отношений, — количественные данные.
В противоположность качественным или категориальным данным.
коллинеарность [colinearity]
В регрессионном анализе — условие, когда две или больше объясняющих
переменных сильно коррелируют между собой или не являются независимыми друг от друга.
См. указание 7.17.
конвергентная валидность (или обоснованность по соответствию критерию, по
совпадению или прогностическая валидность) [convergent validity (or criterion,
concurrent, or predictive validity)]
В опросах — степень согласия (конвергенции) между анкетным опросом и другими
мерами (критериями) того же самого конструкта в то же самое время (валидность по
совпадению) или в некотором будущем времени (прогностическая валидность).
конечная точка [endpoint]
Исход исследования. См. переменная отклика.
конкурентные (параллельные) контроли [concurrent (parallel) controls]
Исследование участников, назначенных в группу контроля и изучаемых в течение всего
периода времени, что и группа лечения. В отличие от исторического контроля, в
котором группы изучаются в разное время.
конструктивная валидность [construct validity]
В опросах — степень, с которой вопросы оценивают основные теоретические
представления (конструкты), которые предполагается измерять с их помощью.
388 Путеводитель по статистическим терминам и критериям
контролируемое испытание [controlled trial]
Проспективное исследование, в котором данные собраны у одной или более групп
контроля при указанных условиях. Когда участников случайно распределяют по группам,
говорят, что испытание является рандомизированным контролируемым (с группой
контроля) испытанием (РКИ).
корень из среднего квадрата ошибки [root mean square error (RMSE)]
Мера согласия для регрессионной модели (также известна как стандартная ошибка
оценки в регрессионном анализе или стандартное отклонение остатков). Выражается
в тех же самых единицах, что и данные, а не в квадратах единиц, и представляет
величину «типичной» ошибки в модели.
корреляция [correlation]
Взаимоотношение между двумя переменными (обычно порядковыми или непрерывными),
указывающее, что изменения в одной переменной часто сопровождаются изменениями
в другой переменной. Связь, обычно используемый более общий термин, типично
используется в статистике для описания взаимоотношения между категориальными переменными.
косвенный подход (к экономической конверсии) [indirect approach (to economic
conversion)]
Экономическая конверсия, в которой затраты на медицинские условия определяются
косвенными мерами, такими как расплата за преступную халатность врачей, а не
прямыми мерами, определенными по оценкам пациентов или общества.
коэффициент [coefficient]
Термин, используемый в статистическом моделировании, таком как регрессионный
анализ (бета-коэффициент или весовой коэффициент) или дисперсионный анализ;
связан с взвешиванием факторов в модели. Термин также используется в
корреляционном анализе (коэффициенты корреляции) и в доверительных интервалах (процент,
ассоциированный с интервалом, например 95% ДИ имеет коэффициент доверия 95 %).
коэффициент вариации (KB) [coefficient of variation (CV)]
Стандартное отклонение распределения, деленное на среднее и умноженное на 100 %.
Используется для измерения относительной вариации. Полезен для сравнения
рассеяния нескольких выборок или конкурирующих исходов, потому что он выражается в
процентах. См. указание 1.11.
коэффициент детерминации (/^) [coefficient of determination]
Квадрат коэффициента корреляции. В простом линейном регрессионном анализе —
доля вариации в переменной отклика, которая объясняется вариацией, изменчивостью
объясняющей переменной. Например, если корреляция между переменной отклика А
и объясняющей переменной В равна г = 0,8, то коэффициент детерминации г^ = 0,64,
что означает, что 64 % вариабельности в переменной А могут быть объяснены
вариабельностью переменной В. См. гл. 7.
коэффициент корреляции Пирсона (г) [Pearson's product-moment correlation coefficient]
Мера силы линейных взаимоотношений между двумя («двумерно нормально
распределенными») непрерывными переменными. Коэффициент г — число, которое меняется
в интервале между -1 и +1.
Путеводитель по статистическим терминам и критериям 389
коэффициент корреляции (г) [correlation coefficient]
Мера линейной связи между двумя переменными. Меняется между +1 (полная
положительная связь: если одна переменная увеличивается, то и другая также
увеличивается) и -1 (полная отрицательная связь: если одна переменная увеличивается, то
другая уменьшается). Значение г = О указывает, что эти две переменные не связаны или
коррелированы. Коэффициенты корреляции различаются согласно шкалам измерений
коррелируемых переменных: коэффициент ранговой корреляции Кендалла измеряет
линейные отношения между двумя порядковыми переменными; коэффициент
корреляции Пирсона измеряет линейные отношения между двумя приблизительно
нормально распределенными непрерывными переменными; а ранговый коэффициент
корреляции Спирмена измеряет линейные отношения между двумя переменными, если
распределение одной из них или обеих заметно отличается от нормального.
коэффициент множественной детерминации (R^) [coefficient of multiple determination]
Квадрат коэффициента множественной корреляции. В множественном
регрессионном анализе — доля вариации в переменной отклика, которая объяснена вариациями
объясняющих переменных (предикторов). Не путать с Н, или коэффициентом
детерминации, используемым в простом регрессионном и анализе. См. гл. 7.
коэффициент ранговой корреляции Кендалла, тау (г) [KendalPs rank-correlation
coefficient, tau]
Коэффициент корреляции, используемый для оценки линейного соотношения между
двумя порядковыми или непрерывными переменными. Диапазон изменения: от -1
до +1, где +1 — полная положительная корреляция, -1 — полная отрицательная
корреляция, а О — нет корреляции.
коэффициент ранговой корреляции р («ро» Спирмена) [Spearman's rank-order
correlation coefficient (Spearman's rho)]
Оценивает линейные взаимоотношения между двумя непрерывными переменными,
которые необязательно распределены ненормально. Как и все коэффициенты
корреляции, «ро» Спирмена меняется от -1 (полная отрицательная корреляция) до +1 (полная
положительная корреляция).
коэффициент регрессии [regression coefficient]
Число в уравнении регрессии, связанное с переменной. Оно указывает величину
изменения в переменной отклика на единицу изменения объясняющей переменной. Иногда
называется бета-весом.
коэффициент (р (фи) [phi coefficient]
Мера силы связи между номинальными переменными, фи — число, расположенное
между -1 и +1. Подобно коэффициенту корреляции, используемому для
непрерывных переменных.
кривая Каплана—^Мейера [Kaplan—Meier curve]
Как правило, график зависимости процента выборки тех, для которых еще не
произошло событие, представляющее интерес (обычно смерть), в различиные моменты
времени в течение исследуемого периода. Этот график — не гладкая кривая, а ступенчатая
функция, которая понижается слева направо по мере возрастания смертности. Когда
390 Путеводитель по статистическим терминам и критериям
используется для указания вероятности возникновения случая, график повышается
слева направо по мере увеличения вероятности. Часто сопровождается лог-ранговым
тестом, который сравнивает две или больше кривых, чтобы определить, значимо ли они
отличаются. См. рис. 9.1.
критерии включения [inclusion criteria]
Характеристики (такие, как диагноз, демографическая особенность или клиническое
состояние), которые должны быть отображены участником исследования как
предварительное условие для включения в исследование. В противоположность критериям
исключения, которые являются характеристиками, которые препятствуют включению.
критерий знаков [sign test]
Цель: сравнить две доли.
Переменная отклика: категориальная (выраженная как доли).
Объясняющая переменная(ые): две группы.
Сообщение результатов: групповые доли, разность между ними, 95% ДИ для разности,
р-значение и значение статистики критерия.
критерий знаков Уилкоксона [Wilcoxon's signed-rank test]
Непараметрическая форма парного /-критерия для сравнения двух выборок.
Цель: сравнить две связанные группы по значениям медианы переменной отклика;
фактически сравнить медиану изменений или разностей связанных пар с нулем.
Переменная отклика: непрерывная (дискретная или порядковая со многими
категориями), но необязательно нормально распределенная.
Объясняющая переменная(ые): две связанные группы.
Сообщение результатов: групповые медианы, медиана всех изменений или разностей
между парами, 95% ДИ для медианы изменений или разностей между парами,
фактическое р-значение и значение статистики критерия.
критерий знаковых рангов [signed-rank test]
См. критерий знаков Уилкоксона.
критерии исключения [exclusion criteria]
Характеристики (такие, как диагноз, демографическая особенность или
клиническое состояние), которые препятствуют включению в исследование. В
противоположность критериям включения, которые являются характеристиками, требуемыми для
включения.
критерий Кокса-Мантеля [Cox-Mantel Test]
См. лог-ранговый критерий.
критерий Кохрана—Мантеля—^Ханзеля (также называемый тестом Мантеля—
Ханзеля) [Cochran-Mantel-Haenszel test (or Mantel-Haenszel test)]
Цель: сравнить две или более доли, обусловленные другой категориальной
объясняющей переменной.
Переменная отклика: категориальная.
Объясняющая переменная(ые): две или больше категориальные объясняющие
переменные.
Путеводитель по статистическим терминам и критериям 391
Сообщение результатов: доли по группам, фактическое /i-значение и значение
статистики критерия.
критерий Краскела—^Уоллеса [Kruskal-Wallis test]
Непараметрический аналог однофакторного ANOVA.
Цель: сравнить три или больше групп по значению медианы переменной отклика.
Переменная отклика: непрерывная (дискретная или порядковая со многими уровнями)
и необязательно нормально распределенная.
Объясняющая переменная(ые): три или более групп.
Сообщение результатов: групповые медианы, фактическое р-значение и значение
статистики критерия.
критерий Макнемара для зависимых долей; также называемый Q Кохраиа [McNe-
mar's test for dependent proportions; also called Cochran's Q]
Цель: сравнить доли для двух или больше связанных групп.
Переменная отклика: категориальная (выраженная как доли).
Объясняющая переменная(ые): две или больше связанных групп.
Сообщение результатов: доли для групп и разность между ними, 95% ДИ для разности,
фактическое/1-значение и значение статистики критерия.
критерий Мантеля—^Ханзеля [Mantel-Haenszel test]
См. критерий Кохраиа—Мантеля—^Ханзеля.
критерий ранговых сумм Уилкоксона [Wilcoxon's rank-sum test]
То же самое, что и U-критерий Манна—^Уитни и U-критерий. Иногда упоминается
как критерий ранговых сумм. Непараметрическая форма /-критерия Стьюдента.
Цель: сравнить две группы по значениям медианы переменной отклика.
Переменная отклика: непрерывная (дискретная или порядковая со многими
категориями), но необязательно нормально распределенная.
Объясняющая переменная(ые): две группы.
Сообщение результатов: групповые медианы, разность между ними, 95% ДИ для
разности, р-значение и значение статистики критерия.
критерий однородности [homogeneity, test of)
Существует много критериев однородности; каждый имеет различные применения.
Цель: сравнить две или больше групп, обычно на вариабельность переменной
отклика.
Переменная отклика: непрерывная или категориальная.
Объясняющая переменная(ые): две или более групп.
Сообщение результатов: СО групп (или другие итоговые статистики, представляющие
интерес), фактическое/i-значение и значение статистики критерия.
критерий связи [association, test of|
Критерий используется для оценки силы взаимоотношений между номинальными
переменными. (В противоположность корреляции — термину, типично
зарезервированному для меры, которая оценивает силу взаимоотношений между двумя порядковыми
или непрерывными переменными). Если две или больше переменных связаны (или
392 Путеводитель по статистическим терминам и критериям
коррелированы), они имеют тенденцию происходить вместе. Тест связи (такой, как тест
хи-квадрат) показывает, связаны ли переменные. См. гл. 6.
критерий согласия Колмогорова—Смирнова [Kolmogorov- (or Kolmogoroff-)Smirnov
goodness-of-fit test]
Цель: сравнить распределение значений в выборке с известным распределением
значений.
Переменная отклика: категориальная или непрерывная.
Объясняющая переменная(ые): только одна группа; нет никакой объясняющей
переменной, хотя известное распределение должно быть идентифицировано.
Сообщение результатов: зависит от интересующего распределения. Включает
фактическое р-значение и значение статистики критерия.
критерий согласия хи-квадрат; критерий хи-квадрат однородности [chi-square test for
goodness-of-fit; chi-square test for homogeneity]
Цель: определить, отличаются ли доли или частоты событий, полученные во время
исследования, от долей или частот событий, известных или оцененных до исследования.
Переменная отклика: категориальная.
Объясняющая переменная(ые): категориальная.
Сообщение результатов: две или более доли, источник известных долей, фактическое
р-значение и значение статистики критерия.
критерий суммы рангов (критерий ранговых сумм) [rank-sum test (ranked-sum test)]
См. критерий ранговых сумм Уилкоксона.
критерий Уилкоксона [Wilcoxon's test]
Не то же самое, что и критерий ранговых сумм Уилкоксона или критерий знаков
Уилкоксона. Также называется обобщенный Бреслоу тест Уилкоксона.
Цель: сравнить две или больше групп по долям живых (или в отсутствие событий)
объектов в определенные моменты времени во время исследования (обычно сравнивают
две или больше кривых выживания).
Переменная отклика: время до наступления случая (обычно смерти) или последнего
контрольного визита.
Объясняющая переменная(ые): две или больше группы.
Сообщение результатов: в анализе выживания — доли живых (или в отсутствие
событий) объектов в каждой группе в определенные моменты времени во время
исследования, фактическое р-значение и значение статистики критерия. См. анализ времени
до наступления события и гл. 9.
критерий Хартли [Hartley's test]
Цель: сравнить две или больше групп по вариабельности или дисперсии переменной
отклика.
Переменная отклика: непрерывная.
Объясняющая переменная(ые): две или более групп.
Сообщение результатов: групповые дисперсии, фактическое /^-значение и значение
статистики критерия.
Путеводитель по статистическим терминам и критериям 393
критерий хи-квадрат для долей [chi-square test for proportions]
Цель: определить, являются ли доли или частоты событий для двух или более
исследуемых групп различными.
Переменная отклика: категориальная.
Объясняющая переменная(ые): две или более групп.
Сообщение результатов: две или более доли, фактическое /i-значение и значение
статистики критерия.
критерий хи-квадрат сопряженности (также называемый критерием хи-квадрат для
независимости или критерием хи-квадрат связи) [chi-square contingency test (chi-square
test of independence or chi-square test of association)]
Цель: определить, независимы ли два свойства выборки или присутствие одного
признака фактически связано с присутствием другого.
Переменные: две категориальные переменные, ни одна из которых не
идентифицируется как объясняющая переменная или переменная отклика.
Сообщение результатов: две или более доли, фактическое р-значение и значение
статистики критерия.
критерий хи-квадрат {х^\ произносится «хи-квадрат»; греческая буква %) [chi-square
test]
Группа тестов для категориальных данных. См. гл. 6.
критерий хи-квадрат точный [chi-square test, exact]
Критерий хи-квадрат для долей, применяемый к малым выборкам.
критерий (тест) Фридмана [Friedman's test]
Непараметрическая форма теста ANOVA со случайными блоками.
Цель: сравнить три или больше доли или средних значения переменной отклика.
Переменная отклика: категориальная (обычно порядковая; может быть выражена как
доли или, если имеет много градаций, как медианы).
Объясняющая переменная(ые): три или более групп.
Сообщение результатов: доли или медианы групп, фактическое р-значение и значение
статистики критерия. См. ANOVA.
критерий Q Кохрана [Cochran's Q]
Расширение теста МакНемара на три или больше связанных группы.
кросс-произведение [cross-product ratio|
См. отношение шансов.
кумулятивный инциденс [cumulative incidence]
Инциденс, выраженный как доля (в противоположность частоте, которая является
плотностью инциденса).
кумулятивное отношение инциденсов [cumulative incidence ratio]
Относительный риск; отношение двух абсолютных рисков.
394 Путеводитель по статистическим терминам и критериям
Л
линейная регрессия [linear regression]
См. регрессионный анализ.
линия регрессии наименьших квадратов [least-squares regression line]
Статистически рассчитываемая линия, проведенная через группу точек так, чтобы
минимизировать расстояния (фактически сумму квадратов расстояний) между каждой
точкой и самой линией. Линия регрессии, используемая в линейной регрессии, обычно
является линией наименьших квадратов.
«лесной» график [forest plot]
Графическое изображение, используемое для сообщения о результатах метаанализа.
Также называется графиком «блоки-и-линии». (Нет никакого доверия к слухам о том, что
этот график получил свое название, демонстрируя, что «чем дальше в лес, тем больше
дров», на примере индивидуальных и объединенных результатов исследования, но это
дает лучшее объяснение, независимо от того, как было в действительности.)
летальность [case-fatality rate]
Мера серьезности болезни; доля людей, которые умирают от болезни.
логистический регрессионный анализ [logistic regression analysis]
См. регрессионный анализ.
лог-ранговый критерий [log-rank test]
Цель: сравнить две или больше групп по долям участников исследования,
оставшихся в живых (или тех, для которых некоторое событие еще не произошло) в
определенные моменты во время исследования (обычно сравнение двух или больше кривых
выживания).
Переменная отклика: время до наступления события (обычно смерти) или последнего
контрольного визита.
Объясняющая переменная: две или больше групп.
Сообщение результатов: в анализе выживания — оцененные доли живых участников
каждой группы (или тех, для которых некоторое событие еще не произошло) в
определенные моменты во время исследования, фактическоер-значение и значение статистики
критерия. См. анализ времени до наступления события и гл. 9.
М
маскировка [masking]
Менее предпочтительный термин для ослепления в рандомизированном испытании.
маскировка распределения [allocation concealment]
В рандомизированном испытании — метод, используемый для предотвращения
смещения выбора путем маскировки последовательности назначения до момента перед
назначением групп. Маскировка распределения препятствует тому, чтобы участники
исследования и персонал предсказывали и поэтому управляли последовательностью
назначения. Маскировка распределения часто объединяется с ослеплением, в котором
назначение группы остается скрытым после назначения и преднамеренно не раскрыва-
Путеводитель по статистическим терминам и критериям 395
ется, пока исследование не закончено. Оба метода помогают предотвращать смещения
выбора и ожидания.
мгновенный риск [instantaneous risk]
См. плотность инциденса.
медиана; срединное значение [median; median value]
Значение, которое отделяет верхние 50 % элементов множества от нижних 50 %.
Полезна при описании центральной тенденции ненормально распределенных данных,
потому что медиана не зависит от выбросов (экстремальных значений), которые
искажают распределение и которые могут оказать непропорциональное влияние на среднее.
Медиану правильно использовать вместе с интерквартильным размахом, чтобы
описывать данные, распределение которых заметно отклоняется от нормального.
медианный критерий [median test]
Цель: сравнить две группы по значению медианы переменной отклика.
Переменная отклика: непрерывная.
Объясняющая переменная(ые): две группы.
Сообщение результатов: медианы групп и разность между ними, 95% ДИ для
разности, фактическое р-значение и значение статистики критерия.
межклассовая корреляция [interclass correlation]
Мера связи, которая специфично имеет отношение к множественным измерениям или
наблюдениям над каждым объектом многими экспертами. Показывает корреляцию
между экспертами. Коэффициент корреляции — число, которое меняется от -1 (полное
разногласие) до +1 (полное согласие).
межэкспертная надежность [inter-rater reliability]
Степень согласия среди оценок судей или экспертов. Часто используется в оценке
надежности диагностического теста.
мера качества жизни [quality-of-life measure]
Числовой индекс, который указывает качество жизни человека; используется, чтобы
сравнить исходы различных видов лечения с помощью общего индекса; используется
особенно в экономических оценках и в анализе решений.
мера связи [measure of association]
См. критерий связи.
мера эффективности [effort-to-yield measure]
Выражение, которое определяет количество ресурсов, требуемых для производства
единицы изменения исхода. Например, число пациентов, которых надо лечить, чтобы
предотвратить один неблагоприятный исход (ЧПЛП), указывает, сколько пациентов
нужно лечить, скажем, аспирином, чтобы предотвратить сердечный приступ у одного
человека. Другие меры включают, например, стоимость одной спасенной жизни или
количество процедур, требуемых для продления жизни на 5 лет. См. указание 18.22.
метаанализ [meta-analysis]
Статистический анализ или объединение числовых результатов двух или больше
индивидуальных исследований, проверяющих те же самые связи. Объединение исследований
396 Путеводитель по статистическим терминам и критериям
обеспечивает большую выборку для анализа и большую статистичесьсую мощность.
Используется для усиления доказательства или уверенности в выводе. Метаанализы
обычно основаны на систематических обзорах (литературы) или на индивидуальных
данных пациентов, собранных из двух или больше исследований. См. гл. 17.
метаанализ индивидуальных данных пациентов (MAIPD) [meta-analysis of individual
patient data]
Форма метаанализа, в котором данные отдельных пациентов, пролечившихся в двух
или больше отдельных исследованиях, объединены статистически. Вместо того,
чтобы полагаться на агрегированные данные, опубликованные в научных статьях, MAIPD
использует, по существу, исходные индивидуальные данные каждого из исследований,
включенных в анализ.
метаанализ кумулятивный [meta-analysis, cumulative]
Метаанализ, в котором объединенные результаты вычисляются после каждого нового
добавляемого исследования, формируя, по существу, «нарастающий итог» для текущего
доказательства. См. гл. 17.
мета-регрессионный анализ [meta-regression analysis]
Применение регрессионного анализа в метаанализе, в котором данные представляют
характеристики уровня исследования (такие, как объем выборки, дозировка препарата
или продолжительность лечения), а не отдельных пациентов.
метод Берксона—Гейджа [Berkson-Gage method]
См. метод таблиц выживания.
метод Каплана—Мейера (множительный метод) [Kaplan-Meier method (the product-
limit method)]
Статистический метод, используемый в анализе времени до наступления события,
чтобы оценить вероятность преодоления случая, такого как смерть (или избежания
события), в разные моменты исследования. См. гл. 9.
метод Катлера—Эдерера [Cutler-Ederer method]
См. метод таблиц выживания.
метод «компромисса времени» [time-trade-off technique]
Метод назначения меры полезности или качества жизни при медицинском состоянии.
Респондентов просят выбрать между проживанием X лет с данным качеством жизни
и неизбежной смертью. Количество лет и качество жизни варьируют, пока респонденты
не станут безразличны к выбору, т. е. выбор станет равновероятным.
метод наименьшей значимой разности Фишера (LSD) [least-significant-difference
method (Fisher's LSD method]
Cm. множественные (попарные) процедуры сравнения.
метод оценки величины [magnitude estimation technique]
Метод определения меры полезности или качества жизни применительно к
медицинскому состоянию. Респондента просят описать одну альтернативу в терминах того,
насколько эта альтернатива нежелательна по сравнению с другой (например, в два раза
хуже). См. указание 18.15.
Путеводитель по статистическим терминам и критериям 397
метод «персонального компромисса» [person-trade-off technique]
Метод определения меры полезности или качества жизни применительно к
медицинскому состоянию. Респондентов просят выбрать между группой пациентов с
состоянием X и группой с состоянием Y для оказания помощи. См. указание 18.15.
метод таблиц выживания [life table method]
Статистический метод для анализа времени до наступления события (или анализа
выживания). То же самое, что и страховой метод и метод Берксона—Гейдэюа. См. гл. 9.
метод Фишера наименьшей значимой разности (LSD) [Fisher's
least-significant-difference method]
См. множественные (попарные) процедуры сравнения.
мешающая переменная [intervening variable]
Смешивающая переменная.
многовариантный анализ [multivariable analysis]
Исследования, которые рассматривают влияние больше чем одной объясняющей
переменной на единственную переменную отклика.
многомерный анализ [multivariate analysis]
Исследования, которые рассматривают влияние одной или более объясняющей
переменных на больше чем одну переменную отклика.
множественная линейная регрессия [multiple linear regression]
См. регрессионный анализ.
множественная логистическая регрессия [multiple logistic regression]
См. регрессионный анализ.
множественный регрессионный анализ [multiple regression analysis]
См. регрессионный анализ.
множественные (попарные) процедуры сравнения [multiple (pairwise) comparison
procedures]
Любая из нескольких статистических процедур или методов, используемых для
определения того, какие группы значимо отличаются, после того как другие, более общие
критерии (такие, как ANOVA) определили, что существуют значимые различия среди
групп. Примеры включают процедуру Тьюки, процедуру Ньюмана—Кейлза,
процедуру множественных диапазонов Дункана, процедуру Дункана, процедуру Данне-
та, метод Шеффе, поправку Бонферрони и метод наименьших значимых различий
Фишера. Используются для предотвращения ошибок, которые могут явиться
результатом проблемы множественных тестов. См. гл. 5.
множественные просмотры [multiple looks]
См. проблема множественных тестов.
множительный метод (метод Каплана—Мейера) [product-limit method (Kaplan-Meier
method)]
См. метод Каплана-Мейера; анализ времени до наступления события.
398 Путеводитель по статистическим терминам и критериям
мода [mode]
Самое частое из трех или более значений или измерений; значение с самой высокой
частотой. Часто используется, когда распределение является бимодальным, указывая, что
у него есть два пика (две моды), а не один.
моделирование Монте-Карло [Monte Carlo simulation]
Метод, обычно используемый в анализе решений, чтобы генерировать ожидаемые
вероятности для каждого исхода.
модель или предположение случайных эффектов [random-effect model or assumption]
В метаанализе, где результаты двух или более исследований объединены
статистически, статистическое предположение о том, что результаты индивидуальных
исследований оценивают различные величины (основного) эффекта и поэтому имеют некоторую
степень вариабельности. В отличие от модели фиксированных эффектов, модель
случайных эффектов принимает во внимание дополнительную вариацию,
подразумеваемую в этом предположении. Модель случайных эффектов более консервативна, чем
модель фиксированных эффектов.
модель или предположение фиксированных эффектов [fixed-effects model or
assumption]
В метаанализе, где результаты двух или более исследований объединяются
статистически, — это статистическое предположение, что существует единый «фиксированный»
эффект, который аппроксимируется в анализе каждого исследования. Модель
фиксированных эффектов предполагает, что не существует неоднородности между результатами
исследования; предполагается, что исследования оценивают единую, истинную
основную величину эффекта. То есть если бы каждое исследование было бесконечно
большим, то каждое исследование привело бы к идентичному результату. В
противоположность модели случайных эффектов.
модель статистическая или математическая [model, statistical or mathematical]
Математическое уравнение, которое описывает, в большей или меньшей степени,
соотношения между переменными.
модифицированный анализ с намерением применить вмешательство [modified intent-
to-treat analysis (MITT)]
Анализ с намерением применить вмешательство, в котором пациенты
проанализированы с группами, в которые их первоначально назначили, как если бы некоторые
пациенты не были теперь исключены из анализа. Например, пациенты могут быть законно
исключены из модифицированного анализа, если обнаруживается, что они не
соответствуют критериям включения в исследование, они ушли из исследования прежде, чем
получить вмешательство, их результаты не поддаются клинической оценке или данные
для важных переменных отсутствовали. В каждом случае включение таких пациентов
прибавило бы неопределенность к анализу, цель которого состоит в том, чтобы
определить, будет ли протокол надежным и эффективным при строгом соблюдении.
мощность статистическая [power, statistical]
См. статистическая мощность.
Путеводитель по статистическим терминам и критериям 399
н
наблюдательное исследование [observational study]
Описательное исследование, в отличие от экспериментального испытания.
набор ответов [response set]
В опросных исследованиях — тенденции некоторых респондентов отвечать на вопросы
предсказуемыми способами, независимо от содержания вопросов. Примеры включают
«говорящих за» и «говорящих против», у которых предпочтительны положительные
или отрицательные ответы соответственно.
надежность [reliability]
Способность меры (такой, как диагностический тест) воспроизводить те же самые
результаты при тех же самых условиях. В противоположность валидности, которая
является способностью теста измерять то, что предполагается измерять. Тест может быть
надежным, но не валидным, но валидность требует, чтобы тест также был надежным.
наклон (линии) [slope (of а line)]
В простом линейном регрессионном анализе — величина изменения в переменной
отклика на каждую единицу изменения объясняющей переменной. Определяется как
«приращение, деленное на изменение», или разность по Y, деленная на разность по X.
наполнитель [vehicle]
Раствор, в котором было растворено лекарственное средство для введения (обычно для
инъекции). Иногда вводят только раствор как плацебо.
независимая переменная [independent variable]
Объясняющая переменная (предиктор).
независимые выборки [independent samples]
Выборки, на значения которых не влияют другие выборки. В отличие от связанных или
парных выборок, в которых второе значение зависит до некоторой степени от значения
в первой (таких, как тестирование тех же самых объектов до и после вмешательства),
как при любом экспериментальном вмешательстве.
ненормально распределенные данные [non-normally distributed data]
Данные, которые не соответствуют симметричному, имеющему колоколообразную
форму распределению; асимметричные данные'. Такие данные должны обычно
анализироваться при помощи непараметрических статистических методов или должны быть
преобразованы, прежде чем использовать параметрические тесты.
непараметрическая статистика или критерии [nonparametric statistics or tests]
Класс статистических критериев, используемых для анализа данных, которые не
соответствуют известному (параметрическому) распределению. Например, если данные
заметно ненормально распределены, больше подходят непараметрические
статистические критерии. Категориальные данные также обычно анализируются при помощи
непараметрических тестов. См. параметрическая статистика или критерии.
' Ненормальные данные могут быть и симметричными, но имеющими при этом очень острую или очень
плоскую вершину. «Острота» распределения данных определяется коэффициентом эксцесса, или просто эксцессом.
Для нормального распределения коэффициенты асимметрии и эксцесса равны нулю.
400 Путеводитель по статистическим терминам и критериям
непарные данные; непарные критерии [unpaired data; unpaired test]
Данные, которые независимы друг от друга; критерии, используемые для анализа таких
данных. В отличие от связанных данных или критериев.
непрерывные данные [continuous data]
Данные, которые измерены на сплошном множестве, континууме, с равными
интервалами и которые могут иметь дробные значения (например, 2,35 кг). Порядковые данные
с 10 или более одинаково отстоящими категориями и дискретные данные (количество
единиц, которые не содержат дроби, такие как пациенты) часто анализируются, как если
бы они были непрерывными данными.
нецензурированные данные [uncensored data]
В анализе выживания — «полные» данные, в которых интересующее событие (обычно
смерть) имеет место и время между вмешательством и событием известно.
Противоположны цензурированным данным, которые статистически должны обрабатываться
по-другому, потому что интересующее событие еще не произошло. См. анализ времени
до наступления события.
номинальные данные [nominal data]
Одна форма категориальных или качественных данных; данные, которые могут быть
помещены в категории, у которых нет никакого предопределенного ранжирования.
Например: пол (мужской или женский), группы крови (А, В, АВ, О), состояние (живой или
мертвый). В отличие от порядковых данных, которые могут быть упорядочены
логически по возрастанию или по убыванию.
номограмма [nomogram]
Графическое средство, состоящее из нескольких линий, размеченных как шкалы и
расположенных таким образом, чтобы прямая линейка, соединяющая известные значения
на двух линиях, указывала величину неизвестного значения в точке пересечения с
третьей линией. Иногда используется в диагностическом тестировании, чтобы связать пре-
тестовую вероятность (преваленс) и отношение правдоподобия позитивного теста,
чтобы определить посттестовую вероятность болезни (позитивное прогнозирующее
значение). См. рис. 10.5.
нормально распределенные данные [normally distributed data]
Данные, которые имеют симметричное, имеющее форму колокола распределение, для
которого средняя, медиана и мода идентичны. Пологость или островершинность
кривой (т. е. вариация данных) могут изменяться. Многие статистические критерии
(параметрические тесты) требуют, чтобы данные были нормально распределены; авторы
должны указать, исследовали ли они нормальность распределения перед продолжением
статистического анализа. См. Гауссово распределение.
нулевая гипотеза (Н^) [null hypothesis]
В формальной проверке гипотез — гипотеза, утверждающая, что никакой истинной
разности не существует между, скажем, средними значениями двух групп. Если
никакой фактической разности не существует между этими двумя группами, небольшие
наблюдаемые разности могли бы быть результатом случайности. Большие разности
будут иметь место случайно менее часто, и в некоторый момент (обычно, когда р < 0,05)
Путеводитель по статистическим терминам и критериям 401
случайность становится настолько незначительной, что нулевая гипотеза отклоняется
в пользу альтернативной гипотезы, утверждающей, что группы различаются.
Практически нулевая гипотеза представляется редко; однако альтернативная гипотеза в
научной статье должна быть детализирована. См. гл. 4 и 11.
обобщаемость (или внешняя валидность) [generalizability (or external validity)]
Способность спроектировать результаты исследования одной популяции на другие
популяции, на другие условия или на другие периоды времени.
обобщенный Бреслоу тест Уилкоксона [Breslow's generalized Wilcoxon test]
См. критерий Уилкоксона.
обоснованность, валидность [validity]
Степень, с которой измерение отражает «истинное» значение того, что измеряется.
См. надежность.
общая линейная модель (GLM) [general linear model]
Математическая модель, которая лежит в основе многих статистических анализов. Это
основа для (-критерия^ ANOVA (дисперсионного анализа), ANCOVA
(ковариационного анализа), регрессионного анализа и многих других многомерных методов,
включая факторный анализ, кластерный анализ, многомерное шкалирование и дискрими-
нантный анализ.
объяснительное исследование [explanatory study]
Исследование, проводимое в жестко контролируемых условиях, в противоположность
реальным условиям, чтобы выяснить основные биологические процессы. Обычно
используют в противоположность прагматическому исследованию, которое
проектируется, чтобы проверить полную эффективность лечения в реальных условиях.
объясняющая переменная [explanatory variable]
Переменная, которая, как полагают, влияет на переменную отклика в исследовании;
независимая переменная. Также называется способствующей переменной, предиктор-
ной переменной (предиктором), фактором риска или прогностическим фактором.
Обычно обозначают как X (Y обозначает переменную отклика).
одномерный анализ [univariate analysis]
Вообще первый шаг в построении математической модели, как в регрессионном
анализе или ANOVA. Каждая переменная оценивается индивидуально (следовательно,
«одномерный») для определения ее влияния на результат; те переменные, которые
имеют статистически значимые эффекты, выбираются затем для возможного их включения
в модель.
односторонний тест (или однонаправленный тест) [one-tailed (one-sided) test (or one-
directional test)]
Условие для проверки гипотезы, как альтернатива двустороннему тесту.
Используется, например, когда «направление разности» между двумя группами известно заранее
или когда разности, наблюдаемые в противоположном направлении, не представляют
402 Путеводитель по статистическим терминам и критериям
интерес или невозможны. Например, лекарственное средство может увеличить длину
длинных костей, но не может их сокращать. Исследователи изменений длины кости,
таким образом, не интересуются вероятностью того, что кости станут короче в конце
исследования, а только вероятностью того, что они станут более длинными. При этих
обстоятельствах, вероятно, подходит односторонний тест. Если бы представляло
интерес как укорочение, так и удлинение костей, был бы адекватным двусторонний тест.
Минимальная разность, требуемая для статистической значимости, немного меньше для
одностороннего теста, чем для двустороннего. Двусторонний тест является более
консервативным и более общим. Авторы должны определить, является ли статистический
тест одно- или двусторонним, и обосновать использование одностороннего теста.
операционное определение [operational definition]
Определение, основанное на измеримых или наблюдаемых критериях. Например,
депрессия могла бы быть операционально определена как определенный показатель по де-
прессионному опроснику, а рискованное действие операционально определено как
участие в затяжных прыжках с парашютом.
описательная, дескриптивная, статистика [descriptive statistics]
Числа, такие как среднее, медиана или размах, которые организуют, суммируют или
описывают множество данных.
оптимальный информационный размер [optimal information size]
В метаанализе — общее количество пациентов, которые должны быть включены в
объединенную оценку, чтобы обеспечить адекватную статистическую мощность;
аналогичен объему выборки в рандомизированном испытании.
ослепленный; ослепление («ослепленное» исследование) [blinded; blinding (а «blinded»
study)]
Практика ограждения пациентов, персонала, проводящего исследование, а иногда даже
статистиков от информации, кто находится в экспериментальной группе, а кто —
в группе контроля во время испытания. В простом слепом исследовании обычно
ослеплены только пациенты. В двойном слепом исследовании ослеплены и пациенты,
и сборщики данных (обслуживающий персонал, исследователи или и те, и другие), хотя
те, кто анализируют данные (исследователи, биостатистики или обе группы), возможно,
не ослеплены. В тройном слепом исследовании ослеплены все: пациенты и те, кто
проводят и анализируют исследование. Термин «двойное ослепление» интерпретируется
настолько по-разному, что определенные группы, ослепленные в испытании, должны
сообщаться, чтобы избежать неправильного понимания.
остатки [residual]
В регрессионном анализе — разности между наблюдаемым и предсказанным
значениями. См. рис. 7.1.
открытое испытание [«open-label» trial]
В открытых испытаниях идентичность лекарственного средства известна пациентам,
врачам и другим провайдерам здравоохранения. Напротив, «ослепленные» испытания
скрывают идентичность лекарственного средства от одной или более групп,
вовлеченных в исследование (пациенты, врачи, статистики, провайдеры здравоохранения и др.),
чтобы предотвратить отклонения. См. фаза IV клинического испытания.
Путеводитель по статистическим терминам и критериям 403
уменьшение относительного риска (УОР); относительная разность рисков;
приписываемая доля [relative risk reduction (RRR);. relative risk difference; attributable fraction]
Уменьшение риска в группе лечения или не подвергнутой воздействию группе,
выраженное как процент от риска в подвергнутой воздействию группе; разность
абсолютных рисков, деленная на риск в не подвергнутой воздействию группе. Например, если
инциденс тошноты у мужчин с рефлюксной болезнью желудка, которые принимают
омепразол, составляет 1,2 %, и инциденс у мужчин, принимающих другое
лекарственное средство, составляет 2,2 %, тогда уменьшение относительного риска для мужчин,
принимающих омепразол, составляет 45 % [(2,2 % - 1,2 %)/2,2 % = 45 %].
относительный риск (ОР) (отношение рисков; накопленное отношение
инцидентности) [relative risk (RR) (risk ratio; cumulative incidence ratio)]
Отношение двух абсолютных рисков.
отношение рисков (относительный риск) [risk ratio (relative risk)]
Отношение риска события в одной группе к таковому в другой группе, где риск —
вероятность того, что будут иметь место событие или специфический исход, обычно
выраженная как процент. Используются в проспективных и наблюдательных
исследованиях, где группы определены заранее (скажем, вегетарианцы против
употребляющих мясо), а событие (рак толстой кишки) может встречаться или не
встречаться. Отношение рисков, равное 1, указывает, что ни в одной группе риск для события
не превосходит риск в другой. Если отношение рисков будет, скажем, 4,5, то группа
в числителе в 4,5 раза более вероятно будет иметь рак толстой кишки, чем группа
в знаменателе.
отношение [ratio]
Простое сопоставление количеств, которое не подразумевает никаких особых
взаимоотношений между числителем и знаменателем.
отношение затрат—выгод [cost-benefit ratio]
Отношение стоимости лечения к выгоде от лечения. Технически и стоимость, и выгоды
выражены в долларах; однако термин часто используется для любого отношения
стоимости к исходу. См. гл. 18.
отношение затрат—полезности [cost-utility ratio]
Отношение стоимости лечения к полезности, которая является произведением
клинического результата и индекса состояния здоровья. Общая полезность —
«благополучные годы» и годы жизни с повышенным качеством (QALYs). См. гл. 18.
отношение правдоподобия позитивное [likelihood ratio, positive]
Отношение, сравнивающее вероятности получения позитивного результата
диагностического теста больных и небольных пациентов. Отношение правдоподобия для
позитивного теста — это чувствительность, деленная на 1 минус специфичность теста.
Отношение правдоподобия, таким образом, комбинирует чувствительность и специфичность
в одно число. Если позитивное отношение правдоподобия равно 1, то вероятность
позитивного результата у пациентов с заболеванием не больше, чем у пациента без
заболевания. Если позитивное отношение правдоподобия будет, скажем, 3,5, то у больных
в 3,5 раза более вероятно будет позитивный результат, чем у здоровых пациентов.
Существуют также отрицательные отношения правдоподобия. См. табл. 10.1.
404 Путеводитель по статистическим терминам и критериям
отношение рентабельности [cost-effectiveness ratio]
Отношение стоимости лечения к клиническому исходу, такому как дополнительные
годы жизни или избежание преждевременной смерти. См, гл. 18.
отношение рисков [hazard ratio]
Отношение риска некоторого события в одной группе к таковому в другой, когда
время до наступления события является основной переменной ответа (т. е. когда
некоторые данные могут быть цензурированы). Отношение рисков, равное 1, указывает, что
ни одна из групп не имеет риск наступления события (скажем, смерти) больше, чем
другая. Если отношение рисков будет, скажем, равным 5, то в группе, представленной
в числителе, в пять раз более вероятно наступление события, чем в группе,
представленной в знаменателе.
отношение частот [rate ratio]
Две частоты, представленные в виде отношения. См. отношение рисков; отношение
шансов.
отношение шансов [odds ratio]
.Отношение риска некоторого события в одной группе к таковым из другой группы;
результат логистического регрессионного анализа. Также используется в
исследованиях типа «случай-контроль» как оценка относительного риска. Отношение шансов,
равное 1, указывает, что в группах, подвергнутых воздействию и не подвергнутых
воздействию, одинаково вероятно наступление события, представляющего интерес. Если
отношение шансов будет равным, скажем, 3, то в группе, подвергнутой воздействию,
наступление случая, представляющего интерес, в три раза более вероятно, чем в
контрольной группе. См. гл. 2.
отрицательное прогнозирующее значение [negative predictive value]
Вероятность отсутствия болезни, когда результат теста или процедуры отрицателен.
Значение зависит от «претестового инциденса» болезни, о котором нужно сообщить
совместно с отрицательным прогнозирующим значением. См. табл. 10.1.
оценка [estimate]
Значение, которое, как полагают, представляет «истинное» значение переменной в
популяции. Обычно получается из наблюдаемых или измеренных значений в выборке.
Точность оценки может быть выражена с помощью доверительного интервала.
Точечная оценка — одиночное значение, например среднее.
ошибка [error]
Разность между измеренным, наблюдаемым или вычисленным значением и истинным
значением. В научном исследовании обычно наблюдаются четыре типа ошибок: 1)
случайная ошибка, или биологическая вариация; 2) ошибка измерения, собственная
вариабельность измерительного прибора (атомные часы более точны, чем секундомер,
которые более точны, чем настенные часы); 3) ошибка выборочного обследования,
ошибка, присущая измерению только выборки из популяции; и 4) систематическая
ошибка, неслучайный или постоянный источник такого смещения, которое имело бы
место, если бы оксигемометр постоянно сообщал о результатах на 10 % ниже
нормальных из-за того, что его неправильно калибровали. См. приложение 5.
Путеводитель по статистическим терминам и критериям 405
ошибка второго рода (бета-ошибка) [type II error (beta error)]
В проверке гипотез — принятие нулевой гипотезы, когда она должна быть отклонена;
функционально ошибочное объяснение разности случаем, когда фактически более
вероятна биологическая причина. Чем выше статистическая мощность (определяемая
как 1 минус бета), тем ниже вероятность сделать ошибку второго рода. Статистическая
мощность 0,8 предполагает, что избегают ошибки второго рода с вероятностью 80 %.
Используя юридическую метафору, вероятность ошибки второго рода — вероятность
«разрешения виновному ответчику выйти свободным» (часто из-за того, что выборка
была слишком небольшой, т. е. было собрано недостаточно «доказательств», чтобы
получить «осуждение»).
ошибка выборочного обследования [sampling error]
Разность между выборочным значением и истинным значением популяции,
являющаяся результатом исключительно того факта, что была измерена только выборка
совокупности.
ошибка измерения [measurement error]
Ошибка, возникающая в результате вариабельности или неточности в измерительном
приборе.
ошибка первого рода (альфа-ошибка) [type I error (alpha error)]
В проверке гипотез — отклонение нулевой гипотезы, когда она должна быть
принята; функционально неправильное объяснение разности биологией, когда фактически
результат, вероятнее всего, определяется случаем. Вероятность совершить эту ошибку
устанавливается исследователем прежде, чем эксперимент будет проведен; это
(критический) альфа-уровень и обычно он устанавливается равным 0,05 или 0,01. Используя
юридическую метафору, вероятности ошибки первого рода можно понимать как
вероятность «обвинения невинного человека». Также называется лоэюнополоэюительным
результатом.
П
пандемия [pandemic]
Всемирная эпидемия.
параллельные контроли [parallel controls]
См. конкурентные контроли.
параметр [parameter]
Числовая характеристика популяции, такая как среднее или СО, обычно обозначаемая
греческой буквой. В противоположность статистике, которая является числовой
характеристикой выборки из популяции и которая обычно обозначается латинской буквой'.
Статистики используются для оценки параметров. Термин часто используется
некорректно, для обозначения «коэффициента» или «переменной». Переменные измеряются',
параметры оцениваются.
' В отличие от выборочных характеристик, популяционные параметры принято обозначать в статистике
буквами греческого алфавита.
406 Путеводитель по статистическим терминам и критериям
параметрические статистики или тесты [papametric statistics or test]
Класс статистических критериев, используемых для анализа данных, которые
соответствуют известному распределению (часто нормальному распределению).
Характеристики распределения, или параметры, известны (отсюда — параметрические), тогда как
непараметрические статистики используются, когда характеристики, или параметры,
неизвестны. Категориальные данные часто анализируются при помощи
непараметрических тестов.
параметры практики [practice parameters]
Термин Американской медицинской ассоциации для руководств по клинической
практике.
парные выборки; спаривание [matched samples; matching]
См. связанные данные.
парный /-критерий [paired / test]
Цель: сравнить две связанные группы по среднему значению переменной отклика;
фактически сравнить с нулем средние изменения или разности всех связанных пар.
Переменная отклика: непрерывная.
Объясняющая переменная(ые): две связанные группы.
Сообщение результатов: групповые средние, среднее и СО изменений или разностей
между парами, 95% ДИ для средних изменений или разностей между парами,
фактическое р-значение и величина статистики критерия.
перекрестное исследование [cross-over study]
Дизайн исследования, обычно используемый в фармацевтическом исследовании, в
котором каждый объект служит его или ее собственным контролем. Будучи назначенным,
скажем, в группу лечения в течение некоторого периода и после периода вымывания,
участник будет «перекрещен», переведен в группу контроля в течение подобного периода.
переменная отклика [response variable]
Исход, или конечная точка; зависимая переменная. Обычно обозначается Y, а не X.
См. объясняющая переменная.
переменная вклада [contributory variable]
Объясняющая переменная, которая «вносит вклад» в эффект — переменную
отклика.
перенос последнего наблюдения (или значения) [last observation (or value) carried
forward (LOCF or LVCF)]
Метод обращения с недостающими данными, пропусками в продольных исследованиях,
в которых последнее наблюдение пациента используется, чтобы заполнить (или
восполнить) последующие недостающие наблюдения. См. восполненные данные.
переносчик инфекции [vector]
В эпидемиологии — средство, которым болезнетворный агент вносят в организм.
Москит — переносчик инфекции для малярии, например.
перепись [census]
Набор данных, собранный со всей популяции, а не только от выборки из популяции.
Путеводитель по статистическим терминам и критериям 407
период времени [time horizon]
Период, в течение которого произойдут ожидаемые события в анализе. В
экономических оценках и анализе решени!! — период, за который накапливаются затраты и
выгоды лечения.
период выведения [wash-out period]
В исследованиях лекарственного средства, особенно перекрестных исследованиях, —
время, в течение которого пациентам не дают препаратов, которые могли бы помешать
предстоящему эксперименту. Таким образом, лекарствам, которые они принимали,
позволяют «вывестись» из систем, чтобы избежать возможности, что «старое»
лекарственное средство пересечется с «новым» лекарственным средством (эффект «переноса»).
период отслеживания [follow-up period]
Период клинического исследования после предоставления лечения, но по которому все
еще собираются данные. Поскольку некоторые виды лечения и неблагоприятные побочные
эффекты для своего проявления требуют времени, продолжительность последующего
периода отслеживания может быть важной в определении полной эффективности лечения.
планки погрешностей [error bars]
На диаграмме или графике вертикальные линии, проведенные выше и ниже значения,
скажем, средней метки, чтобы указать рассеяние данных или вариабельность оценки.
Значение, представленное планкой погрешностей, должно быть идентифицировано: оно
может относиться к СО, стандартной ошибке (обычно СОС) или 95% ДИ оценки.
См. указание 21.6.
плацебо [placebo]
Биологически неактивная субстанция или состояние, используемые в медицинском
исследовании для симулирования лечения при исследовании, но которые, по-видимому,
не имеют никакого биологического эффекта. Плацебо используются, чтобы «ослепить»
пациентов и персонал исследования относительно распределения по группам в
рандомизированных испытаниях, чтобы предотвратить смещения ожидания. См.
хирургические симуляции; наполнитель.
плотность инциденса (или частота инциденса в единицах человеко-времени, или сила
заболеваемости, или мгновенный риск) [incidence density (or person-time incidence rate
or force of morbidity or instantaneous risk)]
Инциденс, выраженный как частота, в противоположность доле. Кроме того, частота
риска, оцененный риск неблагоприятного события, имеющего место в данный момент
времени.
первичное сравнение [primary comparison]
Главная цель исследования. Большинство исследований включает сравнение двух или
больше групп разными способами: друг с другом, со стандартной величиной или с
самими собой через некоторое время. Первичное сравнение — сравнение, представляющее
интерес, это соотношение между основными объясняющими переменными и
основными переменными отклика.
Пирсона критерий хи-квадрат [Pearson's chi-square test]
См. критерий хи-квадрат.
408 Путеводитель по статистическим терминам и критериям
повторные измерения [repeated-measures]
Термин, используемый с различными статистическими процедурами, указывающий,
что несколько измерений тех же самых объектов (или той же самой наблюдаемой
единицы, такой как семья или медицинская практика) были сделаны в течение некоторого
времени.
полезность [utility]
Мера желания пациентов или предпочтения различных состояний здоровья и болезни.
Измеряется обычно числом в пределах от ноля (безразличие между жизнью и смертью)
до единицы (крепкое здоровье). Терминальной стадии почечной недостаточности,
например, можно назначить полезность 0,2, обозначая нежелательное состояние.
Полезность может быть измерена несколькими способами. Самые общие в медицине
масштабы оценки, метод стандартной азартной игры, метод оценки величины, метод
«компромисса времени» и метод персонального компромисса.
полигон частот [frequency polygon]
Столбиковая диаграмма, или гистограмма, в которой середины верхних частей каждого
столбца соединены линиями. См. гл. 21.
положительное прогнозирующее значение [positive predictive value]
Вероятность того, что болезнь присутствует, когда тест или процедура положительны.
Значение зависит от претестового инциденса болезни, о котором нужно сообщить с
помощью положительного прогнозирующего значения. См. табл. 10.1.
полуколичественные данные [semiquantitative data]
См. порядковые данные.
попарное сравнение [pairwise comparison]
См. множественные (попарные) процедуры сравнений.
поперечное исследование [cross-sectional study]
Обзорный или скрининговый тест, который проводят в один момент времени, т. е.
потенциально объясняющие и переменные отклика оцениваются в одно и то же время.
См. гл. 16.
поправка или корректировка Бонферрони [Bonferroni's correction or adjustment]
Консервативная корректировка в проблеме множественных сравнений. См. гл. 5.
поправка на непрерывность Йетса [Yates' correction for continuity]
Поправка для критерия хи-квадрата, чтобы компенсировать использование
непрерывного вероятностного распределения (распределения хи-квадрат), для оценки
вероятностей категориальных данных.
популяция [population]
При статистическом использовании термина — группа объектов, из которых извлечена
выборка и на которые могут быть обобщены результаты (анализа выборки). Размер
популяции обычно указывается N (прописная буква); а п (строчная буква) обычно
указывает размер выборок, извлеченных из популяции. Обычно термин используется более
широко. Например, «все пациенты с лейкозом в мире» являются популяцией в обычном
использовании термина, но только если у каждого пациента с лейкозом в мире есть шанс
Путеводитель по статистическим терминам и критериям 409
того, чтобы быть включенным в выборку, эта группа может считаться популяцией в
статистическом смысле. В действительности «все пациенты с лейкозом, замеченные в этом
учреждении» являются статистической совокупностью, даже если на основе
исследования могут быть сделаны обобщения на всех пациентов с лейкозом в мире.
пораженность [attack rate]
Частота инциденса, обычно используемая, чтобы описать вспышки острых
инфекционных болезней, таких как пищевое отравление; доля тех, кто подвержен болезни, т. е.
кто фактически заразился ею.
пороговый анализ [threshold analysis]
Метод, используемый в анализе решений и экономических оценках, чтобы определить
точку «равновесия» переменной, т. е. значение, в котором переменная больше не влияет
на исход. Используется, чтобы помочь оценить важность переменной в полном анализе.
Тип анализа чувствительности.
порядковые данные [ordinal data]
Категориальные данные, которые могут быть распределены по категориям,
упорядоченным в соответствии с некоторым критерием. Например, «высокий, средний или
низкий»; «отсутствие, легкий, умеренный или тяжелый». Порядковые данные иногда
упоминаются как полуколичественные данные.
посттестовые шансы [post-test odds]
В диагностическом тестировании — шансы, что у объекта есть болезнь, после того как
стали известны результаты диагностического теста; подобны прогнозирующим
значениям и апостериорным вероятностям. См. теорема Байеса.
правила остановки [stopping rules]
Ряд статистических критериев, применимых во время промежуточного анализа данных
исследования, чтобы определить, ясны ли результаты настолько, что исследование должно быть
остановлено, чтобы не подвергать пациентов излишнему риску. Если исследование
остановлено слишком рано (после того, как только немногие из участников закончили исследование),
его статистическая мощность может быть неприемлемо низкой. Если допустить
продолжение исследования, после того как определенные выводы уже могут быть сделаны, участники
могут бьггь напрасно подвержены опасности и могут быть потрачены излишние ресурсы.
прагматическое исследование [pragmatic study]
Исследование, проводимое в реальных условиях (в противоположность жестко
контролируемым условиям), чтобы определить эффективность лечения. Обычно следует
отличать от объяснительного исследования, которое планируется прежде всего, чтобы
идентифицировать основные биологические взаимосвязи.
преваленс [prevalence]
Доля людей в популяции, которые удовлетворяют определенному условию в любой
момент времени. В противоположность инциденсу, который является частотой, с которой
встречаются новые случаи определенного условия.
преваленс в течение жизни [lifetime prevalence]
Доля людей, которые перенесли указанную болезнь или нетрудоспособность по
крайней мере один раз в жизни.
410 Путеводитель по статистическим терминам и критериям
предикторная переменная [predictor variable]
Объясняющая переменная. Термин, используемый главным образом в
регрессионном анализе.
преобразованные данные [transformed data]
Данные, которые были математически преобразованы, чтобы приблизительно
соответствовать известному распределению. Часто используется, чтобы создать более
нормальное распределение из заметно ненормально распределенных данных.
Распространенные преобразования в медицинской науке — логарифмическое
преобразование, обратное преобразование, извлечение квадратного корня и экспоненциальное
преобразование.
претестовые шансы [pre-test odds]
В диагностическом тестировании — шансы, что у участника исследования есть
определенное состояние до того, как стали известны результаты диагностического теста;
часто то же самое, что и преваленс болезни и априорная вероятность. См. теорема
Байеса.
проблема множественных сравнений [multiple testing problem]
Проблема, которая возникает в результате выполнения большого количества
статистических тестов на одних и тех же данных. Если статистическая значимость определена
как/7 < 0,05, то у одиночного теста есть меньше 5 возможностей из 100 для того, чтобы
оказаться ложно значимым. Однако если, скажем, 7 групп будут сравниваться по две
за один раз, то потребуется 21 тест, что исказит уровень значимости. То есть при этих
условиях шанс, что одиночный тест будет значимым (будет иметь р-значение,
меньшее, чем 0,05), теперь станет равным 0,66, или ^/у Авторы должны обратить внимание
на возможность проблемы множественных сравнений и указать, была ли и как учтена
эта проблема.
проверка гипотез [hypothesis testing]
Математический процесс проверки гипотез на основе доказательства (данные), также
называемый частотным подходом в статистике, в отличие от байесовского подхода.
Процесс, в котором на основе вероятностей решается вопрос о принятии или
отклонении нулевой гипотезы об отсутствии различий. Принятие нулевой гипотезы, по
существу, означает объяснение результата случайностью; отклонение же нулевой гипотезы
означает объяснение результата биологическими факторами. См. ошибки I и II типа
и гл. 4 и 11.
прогнозирующее значение [predictive value]
См. отрицательное прогнозирующее значение; положительное прогнозирующее
значение.
прогностическая валидность [predictive validity]
См. конвергентная валидность.
прогностический фактор [prognostic factor]
См. объясняющая переменная.
Путеводитель по статистическим терминам и критериям 411
продольное исследование [longitudinal study]
Когортное исследование, которое сопровождает пациентов в течение
продолжительного промежутка времени.
промежуточный анализ (накопленных данных) [interim analysis (of accumulating
data)]
Статистический анализ, выполненный перед тем, как исследование завершено; может
быть ассоциирован с правилами остановки и может создать проблему
множественных тестов. См. указания 5.7-5.9.
проспективное исследование [prospective study]
Исследование, которое запланировано перед сбором данных. Считается более
надежным, чем ретроспективное или поперечное исследования, поскольку, когда вопрос
исследования известен до сбора данных, можно потенциально лучше контролировать
смешивающие переменные.
протокол [protocol]
Процедура; набор инструкций или указаний для выполнения задачи. Протокол для
применения вмешательства или для измерения, т. е. сбора данных, например, может помочь
уменьшить смещение в исследовании, минимизируя субъективность в определенных
аспектах процесса.
процедура Данна [Dunn's procedure]
См. множественные (попарные) процедуры сравнения.
процедура Даннета [Dunnett's procedure]
См. множественные (попарные) процедуры сравнения.
процедура множественных интервалов Дункана [Duncan's multiple-range procedure]
См. множественные (попарные) процедуры сравнения.
процедура Ньюмена—Кейлза [Neuman-Keuls procedure]
См. множественные (попарные) процедуры сравнения.
процедура складного ножа [jackknife procedure]
Метод проверки обоснованности регрессионной модели с помощью удаления данных
от каждого объекта по очереди и повторного вычисления модели каждый раз. Модель
изменяется каждый раз, когда участник исследования удаляется; чем больше похожи
наборы перерасчитанных моделей, тем более обоснована полная модель. См. указание 7.8.
процедура Стьюдента—Ньюмена—Кейлза (процедура Ньюмена—Кейлза) [Student-
Neuman-Keuls procedure (Neuman-Keuls procedure)]
См. множественные (попарные) процедуры сравнения.
процедура Шеффе [Scheffe's procedure]
См. множественные (попарные) процедуры сравнения.
процедура Тьюки [Tukey's procedure]
См. множественные (попарные) процедуры сравнения.
412 Путеводитель по статистическим терминам и критериям
процесс Дельфи [Delphi process]
Метод формирования согласия, консенсуса, используемый в анализе решений и
экономических оценках, чтобы установить различные предположения, параметры,
суждения и числовые значения, применяемые в исследовании. IlpoeiCT анализа циркулирует
в группе экспертов, которые исправляют проект и возвращают его центральному
специалисту. Центральный специалист синтезирует исправленные заключения во второй
проект, заостряя области согласия и разногласия, и затем распространяет второй проект
экспертам. Этот процесс повторяется до тех пор, пока обсуждение не стабилизируется
и конечный проект не будет одобрен.
процесс Маркова (или переход из состояния в состояние) [Markov (or state-transition)
process]
Метод обычно используется для моделирования сложных деревьев решений.
См. указание 19.13.
рабочая характеристика (ROC-кривая) [receiver operating characteristics (ROC) curve]
Графическое средство, используемое для того, чтобы представить диагностическую
точность критерия, интерпретация которого зависит от точки деления, порога на
непрерывном множестве (континууме) значений критерия. График, у которого ось Y представляет
чувствительность (долю истинно положительных результатов), а ось X представляет
1 минус специфичность (или долю ложноположительных результатов). С изменением
порога решения для критерия (т. е. с изменением точки деления, которая отделяет
положительные результаты от отрицательных) чувствительность и специфичность критерия
также изменяются. Эти значения наносятся на график и соединяются линией, которая
и является ROC-кривой. См. рис. 10.3.
размах [range]
Расстояние между самым высоким и самым низким значением распределения. Часто
размах указывается представлением максимального и минимального значений.
рандомизация; рандомизированный [randomization; randomized]
Менее предпочтительные термины для случайного назначения. Термин
«рандомизированный» приемлем во фразе «рандомизированное контролируемое испытание».
Однако пациенты не «рандомизированы»; они «случайно назначены».
рандомизированное контролируемое испытание (РКИ) [randomized controlled trial
(RCT)]
Экспериментальное исследование, в котором участников случайно назначают в
группу лечения или контроля. В отличие от ретроспективных и поперечных
исследований, а также проспективных исследований, в которых назначение групп может быть
сделано на основе некоторых других критериев, таких как предпочтение врача или
событие, которое имеет место во время исследования. См. гл. 13.
раскапывание данных [data dredging]
Неофициальный термин для обозначения процесса анализа результатов исследования
настолько многими способами, насколько возможно, чтобы найти статистически зна-
Путеводитель по статистическим терминам и критериям 413
чимые сведения, о которых затем сообщают, как если бы их обнаружение было целью
исследования. Если эти действия осознаны и направляются в соответствии с научным
обоснованием, такой анализ соответственно можно назвать «разведочным».
Раскапывание данных, однако, обычно руководствуется ненаучными мотивами. См. гл. 5.
распределение [distribution]
Типично относится к частотному распределению: набор упорядоченных значений и
частот, с которыми они наблюдаются; обычно представляется в виде графика. То есть
диапазон значений для переменной изображается на горизонтальной оси, а частота, с
которой наблюдается каждое значение, изображается на вертикальной оси. Может также
относиться к вероятностному распределению всех возможных значений тестовой
статистики и связанных с ними вероятностей, из которых определяется р-значение.
Примеры включают распределения: биномиальное, /, F, %^^ Гауссово, или нормальное,
равномерное, Вейбулла и Пуассона. Есть и многие другие.
распределение Пуассона [Poisson distribution]
Вероятностное распределение, используемое для определения вероятности редких
событий в больших выборках или для моделирования случайных событий. Названо
в честь Симеона Дениса Пуассона (1781-1840), который первым характеризовал это
распределение.
рассеяния меры [dispersion, measures of|
Статистики, описывающие вариабельность распределения значений. Самые обычные —
СО, размах и интерквартильный размах.
регистр [registry]
База данных, обычно определенного типа пациентов или исследуемой популяции.
Клинические регистры обычно содержат главным образом клинические данные о
пациентах, тогда как административные базы данных содержат главным образом информацию
об их деятельности и финансах.
регрессионный анализ [regression analysis]
Класс процедур для предсказания значений переменной отклика, когда известно
значение одной или более объясняющих переменных. См. гл. 7.
• Простой линейный регрессионный анализ [simple linear regression analysis]
Цель: предсказать значение единственной переменной отклика, исходя из значений
единственной объясняющей переменной.
Переменная отклика: непрерывная.
Объясняющая переменная: одна непрерывная переменная.
Описание результатов: уравнение регрессии, коэффициент детерминации (И),
95% ДИ для наклона линии регрессии, фактическое р-значение и статистика
критерия; результаты иногда представляются графически на соответствующей диаграмме
рассеяния. См. рис. 7.1.
• Множественный линейный регрессионный анализ [multiple linear regression
analysis]
Цель: предсказать значение единственной переменной отклика по комбинации
объясняющих переменных.
Переменная отклика: непрерывная.
414 Путеводитель по статистическим терминам и критериям
Объясняющие переменные: две или больше непрерывных или категориальных
переменных.
Описание результатов: результаты обычно представляются в виде таблицы, дающей
детали модели. См. табл. 7.1.
• Простой логистический регрессионный анализ [simple logistic regression
analysis]
Цель: предсказать значение единственной переменной отклика, исходя из значений
единственной объясняющей переменной.
Переменная отклика: категориальная.
Объясняющая переменная: одна непрерывная или категориальная переменная.
Описание результатов: уравнение регрессии, отношение шансов, 95% ДИ для
отношения шансов, фактическоер-значение и статистика критерия. См. табл. 7.2.
• Множественный логистический регрессионный анализ [multiple logistic
regression analysis]
Цель: предсказать значение единственной переменной отклика по комбинации
объясняющих переменных.
Переменная отклика: категориальная.
Объясняющие переменные: две или больше непрерывных или категориальных
переменных.
Описание результатов: результаты обычно представляются в виде таблицы, дающей
детали модели. См. табл. 7.3.
регрессионный анализ пропорциональных рисков Кокса [Сох proportional hazards
regression analysis]
Цель: в анализе времени до наступления события процедура используется для
определения отношения между временем до наступления события (часто смерти) и
объясняющими переменными.
Переменная отклика: время от начальной точки до события, представляющего интерес
(часто смерти), или последнего контрольного визита, если событие не произошло.
Объясняющая переменная(ые): обычно несколько категориальных или непрерывных
переменных или и те, и другие.
Сообщаемые результаты: доля выживших субъектов в определенные моменты
времени в течение исследования, фактические р-значения и значения критериев для каждой
объясняющей переменной; результаты часто представляются в таблице. См. табл. 9.3.
регрессия к среднему [regression to the mean]
Тенденция экстремальных значений становиться менее экстремальными
(«приблизиться к среднему» значению) при последующих измерениях. (По существу, не связано с
регрессионным анализом.)
регрессия пропорциональных рисков [proportional hazards regression]
См. регрессионный анализ пропорциональных рисков Кокса.
ретроспективное исследование [retrospective study]
Исследование, проводимое после того, как данные уже были собраны, часто в других
целях. Специфические типы включают «случай-контроль» или исследования таблиц
и ретроспективные когортные исследования.
Путеводитель по статистическим терминам и критериям 415
риск (или абсолютный риск) [risk (or absolute risk)]
Вероятность того, что будут иметь место (неблагоприятное) событие или
специфический исход, обычно выражается как процент.
робастный (устойчивый) [robust]
Прилагательное, используемое для описания статистического критерия, который
обеспечивает те же самые выводы, даже когда его основные предположения не
выполняются строго. Например, /-критерий Стьюдента часто описывают как робастный, так
как в некоторых случаях обе из двух сравниваемых групп могут быть несколько
асимметрично распределены (одинаково скошены) без влияния на выводы критерия'.
руководство по клинической практике [clinical practice guideline]
Письменный план, который помогает принятию решений по лечению пациентов, заранее
определяя события и решения, ожидаемые во время лечения болезни. Обычно указывает
оптимальное лечение и альтернативы. См. анализ решения и гл. 19.
«сверхподгонка» [«overfitting»]
Термин, используемый для описания статистической модели со слишком многими
объясняющими переменными по отношению к количеству собранных данных. Такие модели,
как говорят, «сверхподогнаны» к данным. Эмпирическое правило гласит, что для каждой
переменной, включенной в модель, должны быть зарегистрированы 10 случаев событий^.
связанные данные; парные тесты [paired data; paired tests]
Наблюдения, которые спарены или согласованы с другими наблюдениями, т. е.
наблюдения, которые зависят друг от друга или связаны. Например, показания кровяного
давления того же самого пациента до и после упражнения или вес двух пациентов,
соотнесенных по возрасту и росту. Связывание уменьшает вариацию между спаренными
объектами; таким образом, связанные данные должны быть проанализированы
статистическими тестами, спроектированными для парных данных (т. е. парными тестами).
Напротив, данные независимых выборок, как предполагается, не связаны.
«серая» литература [gray literature]
В систематических обзорах и метаанализах неопубликованные или не занесенные в
указатели исследования, трудно идентифицируемые через стандартные библиографические
методы поиска и трудно доступные через обычные каналы. Может включать
технические отчеты, препринты статей, рабочие документы, деловые документы, труды
конференций, официальные документы, стандарты, основанные на исследовании, тезисы
и диссертации, правительственные отчеты, рекламные проспекты, бюллетени и т. д.
серия случаев [case-series]
Описательное исследование, в котором зарегистрированы и проанализированы
особенности небольшой группы или ряда пациентов.
' г-критерий Стьюдента является параметрическим критерием, требующим нормальности распределения
признака в обеих сравниваемых группах (что встречается обычно в 25-30 % случаев), а также равенства дисперсий,
что также встречается не часто.
' Имеется в виду, что число наблюдений должно быть примерно в 10 раз больше используемого числа
переменных.
416 Путеводитель по статистическим терминам и критериям
сила заболеваемости [force of morbidity]
См. плотность инциденса.
симулятивная хирургия или процедура [sham surgery or procedure]
В исследованиях на животных хирургическая процедура, которая по возможности
вызывает ту же самую степень травмы животного, как и исследуемая хирургия, но которая,
тем не менее, не вмешивается или не изменяет анатомию или физиологию животного.
Хирургический эквивалент лечения плацебо.
систематическая ошибка [systematic error]
Неслучайный или постоянный источник ошибки; смещение.
систематический обзор (литературы) [systematic review (of the literature)]
Спланированное, всестороннее и воспроизводимое накопление и анализ результатов
исследований по одной и той же теме. Плановый и систематический характер помогает
уменьшить смещение, а поскольку результаты воспроизводимы, надежность обзора
может быть проверена. В отличие от традиционного повествовательного обзора
литературы, в котором каждый шаг процесса обзора оставляют на усмотрение автора. Числовые
результаты систематического обзора объединяются в метаанализе.
скрининговый тест [screening test]
Тест, выполняемый на очевидно здоровых, бессимптомных людях, чтобы
идентифицировать тех, у кого может быть риск проявления данного расстройства. В отличие
от диагностического теста, цель которого состоит в установлении или исключении
диагноза.
случайная выборка [random sample]
Выборка, сделанная с помощью списка рандомизации. Простая случайная выборка —
это выборка, в которой каждый член популяции имеет равный шанс быть включенным
в выборку. Случайные выборки желательны, потому что частота как известных, так
и неизвестных характеристик в группах исследования становится результатом случая,
а не процесса, который может внести отклонения.
случайное назначение [random assignment]
Процесс назначения участников исследования в экспериментальную или контрольную
группы по воле случая, так чтобы каждый участник имел обычно известную и
равную вероятность быть назначенным в любую данную группу. Такой метод назначения
помогает предотвратить смещение выбора в исследовании и обычно основан на
наборе случайных чисел из специальной таблицы или сгенерированных компьютером.
Термин означает не то же самое, что «назначение наудачу»; он более формальный
и надежный.
смешивание [confounding]
Ошибка или смещение в интерпретации отношений между объясняющими
переменными и переменными отклика, которые порождены (смешивающей) переменной,
которая может послужить причиной, предотвратить или иначе повлиять на интересующий
исход, и это также связано с вмешательствами или особенностями исследований.
Смешивающие переменные, если они известны, можно контролировать посредством
хороших планов исследования или статистических анализов. См. приложение 5.
Путеводитель по статистическим терминам и критериям 417
смещение [bias]
Систематическая (в противоположность случайной) ошибка в проведении
исследования. Часто встречается при формировании выборки и измерениях. Также любое
систематическое (неслучайное) отклонение от истины; любая систематическая ошибка,
которая приводит к некорректной оценке зависимости между внешним воздействием
и риском болезни; или любая тенденция в сборе, анализе, интерпретации, публикации
или обзоре данных, которые могут привести к выводам, систематически отличающимся
от истины. См. приложение 5.
смещение выбора [selection bias]
Систематическая ошибка в формировании выборки. Например, выборка имен из
телефонной книги смещена из-за людей, у которых нет телефонов, людей, у которых в
списках нет номера телефона под их именем, и людей, у которых есть номера, не
включенные в список.
смещение задержки [lead-time bias]
Смещение обнаруживается в исследованиях времени до наступления события,
которое приводит к переоценке времени выживания. Происходит, когда биологическая
начальная точка, скажем, болезнь, не соответствует клинической начальной точке
исследования для многих участников. Например, медиана времени от биологического начала
рака до смерти может быть таким же в двух группах, но если бы в одной группе рак был
случайно диагностирован ранее, то у этой группы было бы более длинное среднее время
выживания, как результат смещения задержки.
смещение здорового рабочего [healthy-worker bias]
Смещение создается при формировании выборки из работающих людей, которые имеют
тенденцию быть более здоровыми, чем общая популяция, потому что поддержание
занятости обычно требует минимального уровня здоровья или функциональности. Важно
в исследованиях типа «случай-контроль», потому что контроль часто формируется
по спискам занятости.
смещение измерения [measurement bias]
Систематические ошибки в измерении, вызванные несоответствиями в процессе
измерения.
смещение фильтра назначений (смещение фильтрации) [referral-filter bias]
Смещение вносится, когда пациенты, отобранные для исследования, не типичны для
исследуемого состояния по причинам, которые привлекли внимание исследователей.
Например, исследование, сделанное в окружной больнице, может охватить популяцию,
отличную от той, которая представлена в исследовании, сделанном в большой частной
высокоспециализированной медицинской клинике, так как пациенты направлены в
каждое отделение своими врачами. См. приложение 5.
СО [SD]
Сокращение для стандартного отклонения.
согласие [goodness-of-fit]
Термин относится к тому, как хорошо данные соответствуют известному распределению
или как хорошо модель выражает взаимоотношения в данных. Часто встречается как
418 Путеводитель по статистическим терминам и критериям
критерии согласия гипотез, в которых наблюдаемые значения сравниваются с
ожидаемыми значениями, взятыми из известных или теоретических распределений (например,
критерий согласия хи-квадрат), а также в регрессионном и дисперсионном анализах.
сообщаемый пациентом исход [patient-reported outcome (PRO)]
Термин для меры качества жизни, который использует Управление по контролю за
продуктами и лекарствами США.
сое [SEM]
Сокращение для стандартной (средней квадратической) ошибки среднего.
специфичность [specificity]
Вероятность, что результат теста будет отрицательным, когда болезнь отсутствует.
Доля истинно отрицательных результатов; доля небольных пациентов, которые имеют
отрицательный результат теста. Обычно выражается как процент. В противоположность
чувствительности. См. табл. 10.1.
сплайн-функция [spline function]
Сглаживающие сплайны — это итоговые линии на графике, которые проведены в
большей или меньшей степени близко ко всем точкам данных. См. рис. 21.22.
среднее квадратичное [root mean square]
См. стандартное отклонение остатков.
среднее; среднее значение [mean; mean value]
Среднее арифметическое группы значений. Среднее — обычная описательная
статистическая величина, лучше всего используется для обобщения центральной тенденции
приблизительно нормально распределенных данных. При таком использовании обычно
сопровождается СО, которое указывает рассеяние или вариабельность данных. Когда
распределение данных заметно отличается от нормального, предпочтительнее
использовать медиану, потому что она не подвержена влиянию величины экстремальных
значений.
средний квадрат ошибки (в англоязычных источниках иногда обозначается как MSE)
[error mean square]
В регрессионном анализе — мера вариации случайной ошибки модели. (Случайная
ошибка — ошибка, не связанная с объясняющими переменными в модели.) Также
называется средним квадратом остатков. Квадратный корень из MSE, средняя
квадратичная ошибка (RMSE), предпочтительнее как мера согласия для регрессионной модели.
стандарт критерия [criterion standard]
См. эталонный стандарт.
стандартизованная оценка (z-оценка; стандартная оценка; стандартная оценка
отклонения) [standardized score (z score; standard score; standard deviate score)]
Cm. z-оценка.
стандартизованная средняя разность [standardized mean difference]
В метаанализе с непрерывными исходами — безразмерная мера эффекта (часто
просто называемая «величина эффекта»), которая позволяет сравнить исследования с
различными исходами в общей мере. Типичное вычисление может состоять из деления
Путеводитель по статистическим терминам и критериям 419
разности между, скажем, средними (коэффициента интеллекта) между группами на СО
индекса IQ для контрольной группы. См. величина эффекта.
стандартизованное отношение летальности [standardized mortality ratio (SMR)]
Мера, полезная для сравнения частот летальности различных групп. Часто используется
для сравнения частот летальности различных профессий по отношению к частоте в
общей совокупности; она вычисляется как наблюдаемое количество смертельных случаев
в год, деленное на ожидаемое количество смертельных случаев в год. См. гл. 12.
стандартная ошибка доли [standard error of the proportion (S£ )]
Мера точности оцененной доли. Однако для сообщения о точности предпочтительнее
использовать 95% ДИ.
стандартная (средняя квадратическая) ошибка оценки [standard error (of the estimate)]
Мера точности оценки. Принимая во внимание, что СО — описательная статистика, или
мера рассеяния данных вокруг среднего в единственной выборке, стандартная ошибка
является вычисляемой статистикой, которую нужно понимать как меру рассеяния
точечных оценок всех возможных выборок, взятых из той же самой популяции. См. гл. 3.
стандартная (средняя квадратическая) ошибка разности [standard error of the
difference (SE,.^)]
Мера рассеяния распределения всех возможных разностей между выборками из двух
популяций, обычно разностей между средними выборок. Используется в /-критерии
Стьюдента.
стандартная (средняя квадратическая) ошибка среднего (СОС) [standard error of the
mean (SEM), (SE^)]
Мера рассеяния распределения средних всех возможных выборок из одной и той же
популяции. Поскольку распределение выборочных средних нормально, наблюдаемое
выборочное среднее ± 1 СОС включает приблизительно 68 % возможных выборочных
средних. Таким образом, среднее ± 1 СОС определяет приблизительно 68% ДИ для
истинного популяционного среднего. СОС часто используется неуместно как
описательная статистическая величина (в форме среднее ± СОС), вместо СО. Поскольку СОС
меньше, чем СО, это некорректное представление заставляет измерения выглядеть
«более точными», потому что данные кажутся менее изменчивыми. Сообщая о точности
оценки среднего, большинство авторов предпочитает 95% ДИ, который обычно
является диапазоном, определяемым как среднее ± приблизительно два СОС. См. гл. 3.
стандартное нормальное распределение [standard normal distribution]
Специальный тип нормального распределения, в котором среднее равно О, а СО — 1.
Полезно для сравнения оценок двух или более различных, но нормальных
распределений и известно как z-преобразование, где z-оценка выражена в единицах СО.
стандартное отклонение (СО) [standard deviation (SD)]
Мера рассеяния или вариабельности ряда значений. Математически определяется как
квадратный корень из дисперсии этих значений. По определению, приблизительно
68 % значений нормального распределения (или колоколообразной кривой) находятся
в пределах одного СО с обеих сторон среднего; около 95 % будут находиться в пределах
двух СО с обеих сторон среднего; и около 99 % будут находиться в пределах трех СО.
420 Путеводитель по статистическим терминам и критериям
СО — это адекватная статистика для описания вариабельности ряда нормально
распределенных данных. Если СО превышает половину среднего (и когда отрицательные
значения невозможны), данные распределены ненормально.
стандартное отклонение остатков [residual standard deviation]
В регрессионном анализе — квадратный корень из среднего квадрата ошибки (MSE).
Мера вариабельности данных. Также называется средним квадратичным.
стандартный метод азартной игры [standard gamble technique]
Метод назначения полезности или мера качества жизни при медицинском состоянии.
Респондентов просят выбрать между двумя альтернативами, которые имеют различно
установленные вероятности возникновения. См. указание 18.15.
статистика [statistic]
Числовая характеристика выборки, например среднее или размах. В отличие от
параметра, который является числовой характеристикой популяции. Статистика
используется для оценки параметра.
статистика Вальда [Wald's statistic]
Тестовая статистика, которая используется во многих ситуациях для многих
статистических тестов; обычно используется как аппроксимация статистики критерия хи-квадрат.
Часто встречается в таблицах, например в отчетах по регрессионному анализу.
статистика критерия [test statistic]
Число, вычисленное из данных, которые сравниваются со связанным с ними
вероятностным распределением, чтобы определить р-значение для искомого сравнения.
Статистика связана со статистическим тестом, который использует ее и который иногда
имеет такое же название (например, F-статистика связана с F-критерием).
статистическая значимость [statistical significance]
В теории проверки гипотез — обстоятельство, при котором наблюдаемая разность
ассоциирована с /1-значением, которое в том случае, когда оно ниже заданного альфа-
уровня, указывает, что случайность, вероятно, не является объяснением разности.
См. различия между клинической и статистической значимостью и гл. 4.
статистическая мощность [statistical power|
Вероятность обнаружения заданной разности, когда таковая действительно
существует; вероятность правильного отклонения нулевой гипотезы. В клинических
испытаниях стандартно выбирается мощность, равная 0,8 или 0,9. Мощность
непосредственно связана с объемом выборки; чем больше выборка, тем больше мощность.
Мощность равна 1 минус бета, где бета — вероятность совершить ошибку второго
рода. См. бета ф).
статистическая неоднородность [statistical heterogeneity]
В метаанализе — вариация в результатах индивидуальных исследований, которая
превышает ту, которая могла бы возникнуть случайно.
статистический обзор [statistical overview]
Метаанализ. См. гл. 17.
Путеводитель по статистическим терминам и критериям 421
стратификация; стратифицированная выборка [stratification; stratified sampling]
Метод формирования выборки, в которой популяция сначала делится на подгруппы
на основании одной или более характеристик, предположительно влияющих на исход,
и затем формируют выборки из этих подгрупп. (Этот процесс иногда упоминается как
сверхвыборка, потому что некоторые подгруппы, возможно, требуют более сложного
формирования выборки, чем другие, чтобы получить желательное количество
объектов.) Стратифицированная выборка позволяет исследователям уравновешивать важные
особенности между экспериментальными и контрольными группами, чтобы уменьшить
смещение и позволить анализ важных подгрупп.
страховой метод [acturial method]
См. метод таблиц выживания.
суррогатная конечная точка [surrogate endpoint]
Измерение исхода, который, как предполагается, связан с болезнью (или с клинической
конечной точкой), но не является болезнью. Например, точка, в которой пациент с амио-
трофическим боковым склерозом подключен к искусственной вентиляции легких, чтобы
предотвратить смерть от асфиксии, может использоваться как суррогатная конечная
точка для смерти в исследовании, изучающем время между началом симптомов и смертью.
Полезна, потому что такие конечные точки могут быть измерены легче или быстрее, чем
клинические конечные точки, которые они призваны представить.
таблица лиги [league table]
Таблица, сравнивающая вмешательства по экономическим исходам, таким как доллары
на годы жизни с улучшенным качеством. Вмешательства обычно ранжируются от
низкой до высокой стоимости. Термин более широко используется в Европе, чем в
Соединенных Штатах.
таблица сопряженности [contingency table]
Таблица, используемая для представления данных для анализа, особенно с помощью
критерия хи-квадрат (х^). «Таблица 2 X 2» имеет две строки, два столбца и четыре
ячейки. См. табл. 6.1.
теорема Байеса; байесова статистика [Bayes' theorem; Bayesian statistics]
Статистическая теория, включающая понятия априорной вероятности, правдоподобия
и апостериорных вероятностей. Теорема Байеса определяет математические
отношения между этими тремя вероятностями. Часто используется для анализа
результатов диагностических тестов. Названы по имени Томаса Байеса (1702-1761),
который разработал эту теорию. См. гл. 11.
точечная диаграмма [dot chart]
Общий метод представления категориальных или непрерывных данных, в которых
линия точек используется как столбик или линейная диаграмма или как ящичковая
диаграмма. Полезна, потому что она экономит место и может быть создана в программе
по обработке текста. См. рис. 1.2 и 21.13.
422 Путеводитель по статистическим терминам и критериям
точечная оценка [point estimate]
Оценка неизвестного значения популяции (параметра) с помощью известного
выборочного значения (статистически). Точечная оценка — единственное число, часто
сопровождаемое доверительным интервалом, таким как 95% ДИ. В отличие от
интервальной оценки.
точка деления [cutpoint]
Значение, используемое для разделения распределения на два компонента. Часто
используется в диагностическом тестировании, где точки деления отделяют нормальные
значения от аномальных. Результаты теста в нормальном или приемлемом диапазоне
называют отрицательными результатами; результаты в аномальном диапазоне называют
позитивными результатами.
точный критерий Фишера [Fisher's exact test]
Цель: сравнить две или больше доли; используется для малых выборок.
Переменная отклика: категориальная (выраженная как доли).
Объясняющая переменная(ые): две или более групп.
Сообщение результатов: доли в группах, фактическое р-значение и статистика
критерия.
точный тест [exact test]
Форма проверки гипотез, обычно используемая в статистических тестах применительно
к очень малым выборкам.
точечный бисериальный коэффициент корреляции [point biserial correlation
coefficient]
Мера взаимосвязи между непрерывной переменной и категориальной переменной
с двумя уровнями.
точечный мультисериальный коэффициент корреляции [point multiserial correlation
coefficient]
Мера взаимосвязи между непрерывной переменной и категориальной переменной
с тремя или больше уровнями.
уравнение регрессии [regression equation]
Статистическая модель, которая получается в регрессионном анализе.
уровень значимости [level of significance]
Альфа-уровень; вероятность совершения ошибки первого рода.
уровни измерений [levels of measurement]
Количество информации, собранное о переменной: основными градациями, по
возрастанию количества информации, являются номинальные, порядковые и непрерывные.
Номинальные (например, живой или мертвый, мужчина или женщина) и порядковые
(например, низкий, средний и высокий; удовлетворение, измеренное на шкале от
единицы до пяти) переменные — это категориальные, или качественные, переменные, потому
что используется специфическое качество для отнесения наблюдения в одну или другую
Путеводитель по статистическим терминам и критериям 423
категорию. Дискретные, или целочисленные, данные часто анализируются, как если
бы они были непрерывными данными (которые могут включать дроби), которые
измерены на шкале, образованной равными интервалами, и которые формируют
распределение при изображении графически. Уровни измерения объясняющих переменных
и переменных отклика помогают определить статистические процедуры,
используемые для анализа данных.
условная вероятность [conditional probability]
Вероятность события А, вычисленная в предположении, что другое событие В
произошло. Часто используется в диагностическом тестировании, анализе решений и Байе-
совой статистике. То есть вероятность того, что А произойдет, если В уже произошло.
См. гл. И.
Ф
фаза I клинических испытаний [phase I clinical trial]
Клиническое испытание в процессе разработки лекарственного средства,
проектируемое для определения метаболического и фармакологического действия исследуемого
нового лекарственного средства (IND) на людях (обычно здоровые добровольцы),
побочных эффектов, связанных с превышением доз (чтобы установить безопасный
диапазон дозы; т. е. исследования «дозировки»), и, если возможно, чтобы получить раннее
доказательство эффективности.
фаза II клинических испытаний [phase II clinical trial]
Клиническое испытание в процессе разработки лекарственного средства, проводимое
для оценки эффективности лекарственного средства при специфических показаниях
у исследуемых больных и определения общих кратковременных побочных эффектов
и рисков, связанных с лекарственным средством. Эти исследования обычно жестко
контролируются, внимательно управляются и проводятся не более чем на нескольких
сотнях пациентов.
фаза III клинических испытаний [phase III clinical trial]
Клиническое испытание в процессе разработки лекарственного средства, которое
использует применение нового лекарственного средства среди большего количества
пациентов (от нескольких сотен до несколько тысяч или даже десятков тысяч) в различных
клинических условиях, чтобы определить его безопасность, эффективность и
адекватную дозировку. В этих исследованиях лекарственное средство используется таким
путем, как если бы оно применялось при продаже, и результаты используются как
основание для формирования инструкций, т. е. установления показаний и противопоказаний
для использования лекарственного средства. Когда III фаза исследования завершена,
спонсор обращается к Федеральному агентству по применению нового лекарственного
средства или за одобрением на продажу лекарственного средства.
фаза IV клинических испытаний [phase IV clinical trial]
Клиническое испытание в процессе разработки лекарственного средства, проводимое
после того, как лекарственное средство было одобрено для продажи. Иногда
называемые постмаркетинговым испытанием, эти исследования часто являются открытым
испытанием, в которых идентичность лекарственного средства известна пациентам.
424 Путеводитель по статистическим терминам и критериям
врачам и другим организаторам здравоохранения. Эти исследования предоставляют
дополнительную информацию о рисках лекарственного средства, выгодах и
оптимальном использовании и могут включать исследования различных доз или списки
назначения другие, нежели использовались в фазе II исследования, использование
лекарственного средства в других популяциях пациентов или на других стадиях
болезни или использование лекарственного средства в течение более длинного
промежутка времени.
фактор [factor]
Объясняющая переменная. Термин, обычно используемый в дисперсионном
анализе.
фактор риска [risk factor]
Объясняющая переменная. Термин, типично используемый в логистической
регрессии и анализе выживания.
факториальное испытание [factorial trial]
План испытания, в котором проверяется 2 или больше вмешательств в одном
эксперименте. В самой простой форме факториальное испытание имеет дизайн 2 х 2, в котором
пациентов случайным образом назначают в одну из 4 групп: А и В, А и не В, В и не А,
не А и не В. Когда действие вмешательств не зависит друг от друга, факториальные
испытания требуют гораздо меньше пациентов для установления эффективности, чем
требовалось бы, если бы А и В испытывались независимо в отдельных исследованиях.
Однако, если А взаимодействует с В, могут возникнуть проблемы в анализе и
интерпретации факториальных испытаний.
факторный анализ [factor analysis]
Статистическая процедура, используемая главным образом для группировки связанных
переменных, чтобы сократить количество переменных, необходимых для представления
данных. Обычно используется, чтобы объяснить корреляции среди групп переменных
или факторов.
фармакоэкономика [pharmacoeconomics]
Описание и анализ стоимости лекарственной терапии на уровне людей, системы
здравоохранения или общества. См. гл. 18.
функция правдоподобия [likelihood function]
В байесовой статистике — отношение силы доказательства, которое поддерживает одну
гипотезу, к силе доказательства, которое поддерживает другую гипотезу, когда
различие между гипотезами проявляется в разности чисел (например, уменьшение
смертности будет несколько большим, чем 10 %). Функция правдоподобия похожа на
вероятностное распределение, но не является им; она показывает отношение одной гипотезы
к другой для исходов в диапазоне их возможных значений. См. байесов коэффициент
ирис. 11.1.
функция риска [hazard function]
Математическая формула, используемая для вычисления вероятности, что участник
испытает событие, обычно смерть, во время данного интервала времени, при
условии, что участник дожил до начала интервала. Функция риска может быть интерпре-
Путеводитель по статистическим терминам и критериям 425
тирована как риск смерти (или возникновения события, представляющего интерес)
в установленный срок.
цензурированные данные [censored data]
В анализе времени до наступления события (анализ выживания) термин используется
для описания данных, в которых интересующий исход еще не произошел или
не наблюдался по какой-либо причине; таким образом, время до наступления события
не известно. Иногда называются цензурированными справа данными, потому что линия
времени до наступления события наносится слева направо и случай (обычно смерть)
еще не произошел на момент выполнения анализа. {Цензурированные слева данные
также возможны, но менее распространены.) Авторы должны сообщить, как поступили
с цензурированными данными статистически. См. гл. 9.
центральная предельная теорема [central limit theorem]
Важная теорема в статистике. Она устанавливает, что средние выборок, извлеченных
даже из значительно ненормально распределенных популяций, будут приблизительно
нормально распределены для выборок, имеющих объем примерно больше, чем 30.
центрально11 тенденции мера [central tendency, measures of]
Статистики, которые описывают «центр» распределения значений; единственное
значение, которое лучше всего представляет основную массу наблюдений. Самыми
обычными мерами являются среднее, медиана и мода.
частота Jrate]
Особый тип отношения, в котором существует отчетливая взаимосвязь между
числителем и знаменателем, а время является существенной частью знаменателя. Число
случаев, встречающихся на единицу популяции или в единицу времени. Например,
частота смертности от автоаварий могла бы составить 0,03 % (2,94 смертельных случая
на 10 000 человек).
частота ложноположительных результатов [false-positive rate]
Вероятность того, что результат диагностического теста или процедуры будет
положительным, когда болезни нет. Частота ложноположительных результатов равна 1 минус
специфичность теста. См. табл. ЮЛ.
частота ложноотрицательных результатов [false-negative rate]
Вероятность того, что результат диагностического теста или процедуры будет
отрицательным, когда болезнь присутствует. Частота ложноотрицательных результатов равна 1
минус чувствительность теста. См. табл. 10.1.
число пациентов, которых надо лечить, чтобы предотвратить один неблагоприятный
исход (ЧПЛП) [number needed to treet (NNT)]
Общая мера эффективности, используемая для представления результатов
клинических испытаний; количество пациентов, которые должны лечиться, чтобы получить
426 Путеводитель по статистическим терминам и критериям
единственный неблагоприятный случай или одну единицу выгоды исхода,
представляющего интерес. Например, если 33 человека должны быть пролечены гипертензив-
ными препаратами в течение 5 лет, чтобы предотвратить один сердечный приступ,
то ЧПЛП равно 33 за 5 лет. ЧПЛП — величина, обратная к уменьшению
абсолютного риска (УАР).
число степеней свободы [degrees of freedom (df)]
Количество свободно изменяющихся значений при вычислении статистики. Например,
количество независимых сравнений, которые могут быть сделаны среди индивидуумов
в выборке. Термин обычно используется при проверке гипотез; число степеней
свободы часто изображают как нижний индекс или в круглых скобках после
соответствующей статистики критерия. О числе степеней свободы нужно сообщать в /-критерии
Стьюдента, дисперсионном анализе (F-критерий), для числителя и знаменателя
F-отношения, в критерии хи-квадрат и в других случаях.
чувствительность аналитическая [sensitivity, analytic]
Порог, выше которого измерительный прибор возвратит значение и ниже которого
значение «не выявлено». Более чувствительный инструмент может обнаружить меньшее
количество или различие. Не путать с диагностической чувствительностью.
чувствительность диагностическая [sensitivity, diagnostic]
Вероятность, что результат диагностического теста будет положителен, когда болезнь
присутствует. Доля истинно положительных результатов; доля больных пациентов,
у которых есть положительный тест. Обычно выражается как процент. Контрастирует
со специфичностью. Не путать с аналитической чувствительностью или анализом
чувствительности. См. табл. 10.1.
Ш
шансы [odds]
Вероятность, что событие будет иметь место, деленная на вероятность, что оно не
произойдет. Тогда как вероятность извлечения карты бубновой масти из колоды в 52 карты
есть один к четырем (13/52 = 1/4 = 0,25), шанс извлечь бубновую масть — один к трем
(0,25/(1 - 0,25) = 1/3 = 0,33). Если вероятность наступления события равна Р, шанс
наступления события равен Р1{\ - Р). Например, если вероятность выздоровления равна
0,3, то шанс выздоровления равен 0,3/(1,0 - 0,3) = 0,3/0,7 = 0,43. См. гл. 2.
экономическая конверсия [economic conversion]
В экономических оценках — процесс выражения клинического результата или
состояния здоровья в долларах или других числовых единицах (например, благополучные
годы; годы жизни с повышенным качеством [QALYs]) так, чтобы лечение могло быть
сравнено или упорядочено. Общие экономические конверсии в медицине — подход
через человеческий капитал (к экономической коверсии) [human capital approach (to
economic conversion)], подход через желание платить [willingness-to-pay approach].
См. указание 18.13.
Путеводитель по статистическим терминам и критериям 427
экономическая оценка [economic evaluation]
Исследование, которое связывает стоимость (прямую и косвенную) лечения с исходами
здоровья (прямым, косвенным и нематериальным). Самые общие типы исследований:
анализ установления стоимости, анализ минимизации стоимости, анализ
стоимости болезни, анализ затрат—выгод, анализ рентабельности и анализ полезной
стоимости. См. гл. 18.
экспериментальная группа [experimental group]
Группа объектов, получающих лечение при исследовании. В отличие от группы
контроля, которая не получает лечение. Также называется группа лечения.
экспериментальное исследование [experimental study]
Сравнительное исследование, спланированное до его проведения и включающее в себя
по крайней мере одно вмешательство. Могут сравниваться две или больше групп или
данные одной группы до и после вмешательства.
экстраполяция [extrapolation]
Процесс предсказания или оценки значений вне диапазона измеренных значений;
обычно производится по регрессии или другим линиям сводных данных, которые указывают
вероятные значения.
эпидемиология [epidemiology]
Исследование распределения, детерминантов и частоты болезни и нетрудоспособности
в популяциях и применение такого исследования для контроля проблем здоровья.
эпидемия [epidemic]
Локальная, региональная или национальная вспышка болезни, которая явно превышает
нормальную частоту ее появления.
эпизодический, случайный [anecdote; anecdotal]
Неподтверждаемое наблюдение, обычно единственный случай или событие.
Эпизодическое доказательство является родственным доказательству, основанному на слухах,
и является самым слабым доказательством факта.
эталонный стандарт [reference standard]
Стандарт, с которым, скажем, сравнены результаты нового диагностического теста
(испытуемого теста), чтобы утвердить последний. Эталонный стандарт обычно
является самой точной мерой (лучший эталонный тест) исследуемой переменной.
Также называется стандартом критерия или золотым стандартом, хотя эти термины
не предпочтительны.
эталонный тест [reference test]
Диагностический тест, с которым сравнивается испытуемый тест для определения его
особенностей. См. эталонный стандарт.
эффект плацебо [placebo effect]
Обстоятельство, при котором убеждения участников в том, что они пролечились,
очевидно изменяют здоровье и самочувствие. Эффект плацебо с длительным общим
и сильным эффектом встречается, когда пациенты полагают, что они лечатся, и
ограничен улучшениями в «мягких» сообщаемых пациентом конечных точках, таких как
428 Путеводитель по статистическим терминам и критериям
серьезность боли или степень тошноты. Более свежее и строгое исследование, которое
сравнило группы, получающие плацебо, с не получающими лечения, обнаружило
небольшую поддержку эффекта.
ящичковая диаграмма; диаграмма «ящик-с-усами» [box plot; box-and-whisker plot]
Графическое представление распределения непрерывных данных, в котором обычно
средние 50 % наблюдений обозначены прямоугольником, а вертикальные линии выше
и ниже прямоугольника представляют остальную часть диапазона данных. Медиана
часто изображается как горизонтальная линия внутри прямоугольника. См. гл. 21.
ANCOVA (ковариационный анализ; произносится «анкова») [analysis of covariance]
Цель: сравнить две или больше групп по средним значениям переменной отклика,
корректируя ковариатами (дополнительные переменные).
Переменная отклика: непрерывная.
Объясняющая переменная(ые): две или более групп и по крайней мере одна ковариата;
модели ANCOVA могут также включать другие категориальные и непрерывные
объясняющие переменные (ковариаты).
Сообщение результатов: средние двух или более групп, СО для каждого среднего,
фактические р-значения и статистики критерия; результаты часто представляют в виде
таблиц. См. гл. 8.
ANOVA (дисперсионный анализ, F-критерий; произносится «анова») [analysis of
variance]
Цель: сравнить три или более групп по средним значениям переменной отклика.
Переменная отклика: непрерывная.
Объясняющая переменная(ые): три или более групп; модели ANOVA могут также
включать другие категориальные и непрерывные объясняющие переменные.
• Однофакторный ANOVA применяется для единственной объясняющей переменной.
• Двухфакторный ANOVA применяется для двух объясняющих переменных.
• Многофакторный ANOVA применяется для трех или больше объясняющих
переменных.
• ANOVA со случайными блоками [randomized-block] анализирует лечение, которое
было случайно назначено в пределах «блоков» (скажем, для некоторого числа
участников исследования), гарантируя, что каждое лечение представлено в каждом блоке.
• ANOVA повторных измерений сравнивает три или более связанных (или спаренных,
или коррелированных) групп непрерывных данных, чтобы определить, отличаются
ли они значительно. Например, различия уровней в крови пяти групп участников,
проверяемых каждый час в течение 12 часов, могут быть проанализированы с помощью
ANOVA повторных измерений.
Сообщение результатов: средние трех или более групп, СО для каждого среднего,
фактические р-значения и статистики критерия; результаты часто представляют в виде
таблиц. См. гл. 8.
Путеводитель по статистическим терминам и критериям 429
BMDP
Статистический пакет программ, используемый для анализа биомедицинских данных.
F-критерий [F testl
То же самое, что и однофакторный ANOVA'.
Цель: сравнить три или больше групп по средним значениям переменной отклика.
Переменная отклика: непрерывная.
Объясняющая переменная(ые): три или более групп.
Сообщение результатов: групповые средние и СО, фактические /i-значения и
статистики критерия. См. гл. 8.
MANOVA
Многомерный (больше, чем одна переменная отклика) дисперсионный анализ.
п
Количество участников исследования в выборке из популяции, представляющей
интерес; в отличие отЛ^, количества в популяции. Общее использование, хотя и
некорректное, для размеров индивидуальных групп или подвыборки в исследовании.
Л^
Количество участников исследования в популяции, представляющей интерес; в
отличие от л, количества в выборке из популяции. Общее использование, хотя и
некорректное, размер полной выборки в исследовании.
р-значение [Р value]
Вероятностное значение; вероятность, что исход мог бы иметь место случайно.
/7-значение меняется в диапазоне от единицы (абсолютная определенность) до нуля
(абсолютная невозможность). Если р-значение равно или меньше, чем альфа-уровень,
скажем, 0,05, говорят, что оно статистически значимо, что означает, что наблюдаемый
исход вряд ли является результатом случая. Результаты не могут «приближаться» к
значимости или проявлять «тенденции к значимости». Они или значимы, или незначимы,
согласно альфа-уровню, установленному исследователем. Некоторые специалисты
предлагают считать результаты, значимые на уровне 0,05, как «значимые», а на уровне
0,01 как «очень значимые», но эта практика не поощряется. Статистическая
значимость, по существу, указывает только вероятность нулевой гипотезы, того, что исход
произошел случайно: она не указывает силу или клиническую значимость связи. Кроме
того, иногда группы проверяют, чтобы подтвердить, что они не отличаются значимо;
например, р-значение, большее, чем 0,05, может быть желательным результатом.
Сообщайте о фактическихр-значениях (р = 0,35) в противоположность только пороговым
значениям (р < 0,05).
post hoc (анализ)
Латинский термин, имеющий значение «после факта». Post hoc анализ является
анализом, не определенным прежде, чем данные будут собраны, и может фактически быть
подсказан данными. В противоположность априорному анализу.
' F-критерий может использоваться и самостоятельно вне однофакторного ANOVA, например при проверке
гипотезы о равенстве дисперсий переменной в двух популяциях.
430 Путеводитель по статистическим терминам и критериям
ROC-анализ
См. ROC-кривая.
SAS (Statistical Analysis System)
Программное обеспечение для статистического анализа, пакет программного
обеспечения, часто используемый для выполнения статистических анализов в
биомедицинских науках.
SPSS (Statistical Package for the Social Sciences)
Статистический пакет для социальных наук, пакет программного обеспечения, обычно
используемый для выполнения статистических анализов, особенно в социальных и
медицинских науках.
^критерий [/ test]
См. ^-критерий Стьюдента.
/-критерий Стьюдента [Student's t test]
Цель: сравнить две группы по средним значениям переменной отклика.
Переменная отклика: непрерывная.
Объясняющая переменная(ые): две группы.
Представление результатов: групповые средние и СО, разность между средними,
95% ДИ для разности, фактическое р-значение и величина тестовой статистики'.
(Разработан Уильямом Госсетом, учеником статистика Карла Пирсона, который
опубликовал концепцию критерия под псевдонимом «Студент»).
U-критерий [U test]
См. критерий ранговых сумм Уилкоксона.
U-тест Манна-Уитни [Mann-Whitney U test]
См. тест ранговых сумм Уилкоксона.
X
Система обозначений для независимой переменной(ых), обычно используемая в
регрессионном анализе и уравнениях ANOVA.
У
Система обозначений для переменной отклика, обычно используемая в уравнениях
регрессионного анализа и ANOVA.
z-оценка [z score]
Расстояние между конкретным значением переменной и средним значением
распределения, выраженным в единицах СО от среднего. Пример: z = 2,0 указывает, что значение
на 2 СО выше среднего или выше, чем приблизительно 97 % других значений в
распределении. Также называется стандартизованной оценкой или стандартным
нормальным отклонением.
' Поскольку для использования /-критерия Стьюдента необходимо выполнение двух условий — нормальность
распределения переменной в обеих сравниваемых группах и равенство дисперсий в этих группах, то необходимо
представлять информацию о методах проверки этих ограничений и результатах этих проверок.
Путеводитель по статистическим терминам и критериям 431
z-xecT [z test]
Процесс создания стандартизованной оценки, вычисляя z-оценку для точки на
распределении так, чтобы значение точки могло быть представлено в единицах СО. См. z-оценка;
z-xecT Фишера.
z-xecx Фишера [Fisher's z test]
Цель: сравнить две группы по средним значениям переменной отклика (подобно
^крихерию Схьюденха).
Переменная ответа: непрерывная.
Независимая переменная(ые): две группы.
Сообщение результатов: средние групп и разность между ними, 95% ДИ для разности,
фактическое/^-значение и величина хесховой схахисхики (крихерия).
Х(хи)
Греческий символ %, произносится «хи». Часто обозначаемый как хи-квадрат,
называемый критерием хи-квадрах или схахисхикой хи-квадрах.
Лихерахура
1. EverittBS. The Cambridge Dictionary of Statistics in the Medical Sciences. Cambridge: Cambridge
University Press; 1995.
2. Everitt BS, Wykes T. A Dictionary of Statistics for Psychologists. Oxford: Oxford University Press;
1999.
3. LastJM. A Dictionary of Epidemiology, 2nd edition. Oxford: Oxford University Press; 1988.
4. Vogt WP. Dictionary of Statistics and Methodology: A Nontechnical Guide for the Social Sciences.
Newbury Park, С A: Sage Publications; 1993.
433
Часть VI
Приложения
434 Приложения
Приложение 1
Правила представления чисел в тексте
Перечисленные здесь правила представляют собой сокращенный вариант изданий:
«Научный стиль и формат: Справочник компьютеризированного обучения для авторов,
редакторов и издателей», 6-е издание (Кембридж: Издательство Кембриджского университета;
1994 {Scientific Style and Format: The С BE Manual for Authors, Editors, and Publishers, G^
edition (Cambridge: Cambridge University Press; 1994)]) и «Справочник стиля Американской
медицинской ассоциации», 8-е издание (Чикаго: Американская медицинская ассоциация;
1989 [Ата Manual of Style, 8^'' edition (Chicago: American Medical Association; 1989)]). Эти
два стиля идентичны, кроме отдельных мест, отмеченных специально.
ЧИСЛА КАК СЛОВА ИЛИ ЧИСЛИТЕЛЬНЫЕ ЦИФРЫ
Справочник стиля Американской медицинской ассоциации
Пишите текстом числа от одного до девяти и используйте цифры для числа 10 и выше;
исключения составляют следующие случаи:
• сообщения о единицах измерения, времени и даты: например, 2 мл, а не два мл; 1996,
а не одна тысяча девятьсот девяносто шесть;
• начало предложения: Пятнадцать дней назад, а не 15 дней назад;
• сравнение одинакового количества: выборка включала 15 человек с типом крови А,
12 — с типом В и 3 — с типом АВ;
• сообщения с последовательными числовыми выражениями, в которых должны быть
дифференцированы два класса чисел: пять 72-килограммовых мужчин, а не 5 72-
килограммовых мужчин;
• сообщения о больших количествах в общих выражениях: сто; несколько тысяч.
Справочник стиля компьютеризированного обучения
Все количества должны быть выражены как цифры; исключения следующие:
• начало предложения;
• сообщения о последовательных числовых выражениях, в которых должны быть
дифференцированы два класса чисел (см. выше);
• сообщения о больших количествах в общих выражениях (см. выше).
ПОРЯДКОВЫЕ ЧИСЛА
Справочник стиля Американской медицинской академии
Напишите словами порядковые числа от одного до девяти, используя цифры лишь для
порядковых числительных 10 и выше: первый, а не 1-й; 15-й, а не пятнадцатый.
Правила представления чисел в тексте 435
Справочник СТИЛЯ компьютеризированного обучения
Все порядковые числа должны быть выражены как цифры, даже в заголовках: 2-й, а не
второй; 4-й Ежегодный конгресс, а не четвертый.
ПРОБЕЛ В ЕДИНИЦАХ ИЗМЕРЕНИЯ
• Используйте знак процента, даже в тексте, без пробела между цифрой и знаком: 34%.
• Ставьте пробел между цифрой и ее единицей измерения: 136 мм рт. ст.
ДЕСЯТИЧНЫЕ ЧИСЛА
Справочник стиля Американской медицинской академии
Используйте нуль перед десятичным числом (например, 0,24 нг/мл), кроме:
• сообщения о/>-значении или коэффициенте корреляции, где максимальное значение 1
почти никогда не получается: р = ,04; г = ,45'.
Справочник стиля компьютеризированного обучения
Используйте нуль перед всеми десятичными числами, включая р-значения и
коэффициенты корреляции: р = 0,04; г = 0,45.
СООБЩЕНИЕ О ДИАПАЗОНАХ КОЛИЧЕСТВА
Используйте термин от и до и никогда не используйте тире для сообщения о диапазоне
количеств: от 2 до 5 мл, а не 2-5 мл^.
• Однако дефис используется, чтобы указать диапазон страниц в цитате ссылки: Ann
Intern Med 1996;2:13-9.
• Единицы должны быть представлены только в конце диапазона: 200-240 мг/дл.
• Диапазоны, включающие проценты, должны включать знак процента в обоих числах:
от 200% до 240 %1
• Не опускайте двойные цифры, сообщая о диапазонах: от 925 до 988 пациентов, а не
от 925 до 88 пациентов.
ЧАСТОТЫ, ДОЛИ и ДРОБИ
Используйте разделительную черту (/) для долей и частот и двоеточие (:) для
отношений:
• Около 7з выборок.
• Распространенность инфекции составила в среднем 50/100 000 человек.
• Отношение мужчин и женщин было 3:4,5.
Пишите словами простые дроби, когда они изменяют существительные: половина
случаев; более двух третей.
' в англоязычных статистических пакетах получаемые результаты не содержат нуля перед десятичным знаком.
Тогда как в русском языке нуль перед десятичным знаком не опускается.
' В русском языке используется тире, а не предлоги ОТ и ДО.
^ В русском языке % ставится также только в конце диапазона.
436 Приложения
Приложение 2
Математические символы и система
обозначений
Математические символы обычно представляются курсивом. Греческими буквами
обычно обозначаются характеристики популяции, тогда как латинскими буквами обычно
обозначаются выборочные статистики. Термины, выделенные ниже жирным шрифтом,
определены в приложении 5.
^ Греческий символ альфа. См. альфа-ошибка и альфа.
F-статистика
Но
н
а
Р
Г
Р
Г2
Г-статистика
т
U
U-статистика
Греческий символ бета. См. бета и статистическая мощность'.
См. F-тест и ANOVA.
Основная гипотеза (произносится «Аш нулевая»).
Альтернативная гипотеза (произносится «Аш альтернативная»).
Вероятность.
Коэффициент корреляции Пирсона.
Ро Спирмена, коэффициент корреляции.
Коэффициент детерминации.
Греческая буква сигма. Стандартное отклонение (СО) распределения
значений для характеристики популяции.
Стандартное отклонение распределения значений для
характеристики выборки.
См. /-тест Стьюдента.
Тау Кендала, коэффициент корреляции.
Греческий символ мю. Среднее значение распределения значений для
параметра популяции; микро (10~^).
(Строчная буква «и») В рукописи часто используемая вместо
греческого символа мю (ju), начертание, не доступное в некоторых программах
обработки текстов.
См. критерий ранговых сумм Уилкоксона.
Хи-квадрат, после греческого символа хи (произносится «хи»). См.
критерий хи-квадрат Пирсона.
Среднее значение распределения значений для характеристики
выборки из популяции (произносится <а с чертой»). Отметьте верхнее
подчеркивание^.
' Одним из немногих исключений, когда выборочные статистики обозначаются греческой буквой р,
является исторически сложившаяся традиция обозначения так называемых стандартизованных коэффициентов
регрессии.
- В отечественной литературе практически общеупотребимым стало обозначение выборочного среднего
как М, а обозначение ошибки среднего как т.
Математические символы и система обозначений 437
Приложение 3
Правописание статистических
терминов и критериев
Правописание статистических критериев кажется нестандартизованным. И хотя
некоторые правила написания распространены более других, многие не соответствуют обычным
правилам пунктуации, особенно те, которые включают притяжательные формы и дефисы.
Мы использовали притяжательную форму, когда только единственное название
ассоциировано с критерием или термином (например, ранговый коэффициент корреляции Спирме-
на), и именительный падеж, когда ассоциированы два или больше названия (например,
критерий Краскела—^Уоллиса). Дефисы используются согласно обычному правилу: соединить
двойные модификаторы. Имена собственные напечатаны прописными буквами, остальная
часть терминов в названии вообще не указывается.
Различия между предложенными нами проверками правописания и, возможно, более
общими проверками правописания, найденными в статистической литературе, фактически
тривиальны. Всюду в этой книге мы следовали правилам, выделенным выше, и используем
правописание, данное ниже.
дисперсионный анализ
поправка Бонферрони
обобщенный Бреслоу критерий Уилкоксона
критерий хи-квадрат
критерий Кохрана—Мантеля—^Хэнзеля
критерий Кокса—Мантеля
процедура множественного диапазона
Дункана
процедура Данна
процедура Даннета
F-критерий
точный метод Фишера
наименьшая значимая разность Фишера
метод Фридмана
метод Каплана—^Мейера
критерий Краскела—^Уоллиса
лог-ранговыи критерии
L^-критерий Манна—^Уитни
критерий Мантеля—Хензеля
критерий МакНемара
процедура Ньюмена—^Кейлза
коэффициент корреляции Пирсона
критерий знаков
процедура Шеффе
коэффициент ранговой корреляции
Спирмена
процедуры Стьюдента—Ньюмена—Кейлза
/-критерий Стьюдента
процедура Тьюки
критерий ранговых сумм Уилкоксона
критерий знаковых рангов Уилкоксона
поправка на непрерывность Иетса
438 Приложения
Приложение 4
Ссылки на другие коллекции
рекомендаций
Много рекомендаций по отчетам доступны через Mulford Library at the Medical College
of Ohio (http://niulford.nico.edu/instr/). Этот сайт также содержит ссылки на Рекомендации
для авторов большинства главных медицинских журналов, так же как и на
Унифицированные требования для рукописей, представляемых в биомедицинские журналы: Написание
и редактирование для биомедицинских публикаций (http://www.icmje.org/).
РЕКОМЕНДАЦИИ ДЛЯ СООБЩЕНИЯ О ДИЗАЙНАХ ИССЛЕДОВАНИЙ
И ДЕЯТЕЛЬНОСТИ
• Стандарт для научного и этического обзора испытаний (ASSERT).
http://www.assert-statement.org/
Mann Н ASSERT statement: recommendations for the review and monitoring of
randomized controlled clinical trials. (Эти рекомендации предлагают структурированный подход для
комитетов по этике исследования, чтобы контролировать проведение рандомизированных
контролируемых клинических испытаний.)
Экспериментальные исследования
• Объединенные стандарты для отчетов по испытаниям (CONSORT).
http://wwrw.consort-statement.org/
Begg СВ, Cho МК, Eastwood S, et al. Improving the quality of reporting of randomized
controlled trials. The CONSORT statement. JAMA. 1996; 276:637-9.
Moher A Schulz K, Altman DO, for the CONSORT Group. CONSORT statement: revised
recommendations for improving the quality of reports of parallel-group randomized trials. Ann
Intern Med. 2001; 134:657-62.
Altman DG, Schulz KF, Moher D, et al, for the CONSORT Group. The revised CONSORT
statement for reporting randomized trials: explanation and elaboration. Ann Intern Med. 2001;
134:663-94.
Наблюдательные исследования
• Ясные отчеты об оценках с нерандомизированными дизайнами (TREND).
Des Jarlais DC, Lyles С, Crepaz N, and the TREND Group. Improving the reporting quality of
nonrandomized evaluations of behavioral and public health interventions. The TREND statement.
Am J Public Health. 2004; 94:361-6.
• Повышение требований к отчетам о наблюдательных исследованиях в
эпидемиологии (STROBE).
http://www.strobe-statenient.org/
Ссылки на другие коллекции рекомендаций 439
• Поперечные исследования.
McColl Е, Jacoby Л, Thomas L, et al Design and use of questionnaires: a review of best
practice applicable to surveys of health service staff and patients. HealthTechnol Assess. 2001;
5:1-256.
Систематические обзоры и метаанализ
• Качество отчетов по метаанализу (QUOROM).
Moher D, Cook DJ, Eastwood S, et al, for the QUOROM group. Improving the quality of
reports of meta-analyses of randomized controlled trials. The QUOROM statement. Lancet. 1999;
354:1896-1900. (Контрольный список QUOROM был пересмотрен и расширен в конце
2005 г. и должен быть издан в 2006 г.)'
• Метаанализ наблюдательных исследований в эпидемиологии (MOOSE).
Stroup DF, Berlin A, Morton SC, et al. Meta-analysis of observational studies in epidemiology:
a proposal for reporting. JAMA. 2000; 283:2008-12.
РЕКОМЕНДАЦИИ ДЛЯ ОТЧЕТОВ ПО ОПРЕДЕЛЕННЫМ ТИПАМ
ИССЛЕДОВАНИЙ
Диагностические критерии
• Стандарты для точного сообщения о диагностических критериях (STARD).
http://www.clinchem.Org/cgi/content/full/49/l/l
Bossuyt РМ, Reitsma JB, Bruns DE, et al. Towards complete and accurate reporting of studies
of diagnostic accuracy. The STARD initiative. BMJ. 2003; 326:41-4.
Экономические оценки
SiegelJE, Weinstein MC, Russell LB, Gold MR. Recommendations for reporting
cost-effectiveness analyses. Panel on Cost-Effectiveness in Health and Medicine. JAMA. 1996;276:1339-41.
Клинические практические рекомендации и анализ решений
Shiffman RN, Shekelle Р, Overhage JM, et al. Standardized reporting of clinical practice
guidelines: a proposal from the conference on guideline standardization. Ann Intern Med 2003;
139:493-8.
Philips Z, Ginnelly L, Sculpher M, et al. Review of guidelines for good practice in decision-
analytic modelling in health technology assessment. Health Technol Assess. 2004; 8:iii-iv, ix-xi,
1-158.
• Оценка рекомендаций для исследования и определения пригодности (AGREE).
Cluzeau F, Burgers J, for the AGREE Collaboration. Appraisal of Guidelines for Research and
Evaluation. London: St George's Hospital Medical School; June 2001.
' В настоящее время вместо аббревиатуры QUOROM используется обозначение PRISMA (см. http://www.prisma-
statement.org/). С адреса http://www.prisma-statement.org/usage.htm можно загрузить действующие рекомендации.
440 Приложения
Приложение 5
Источники ошибок, смешивания
и смещения в биомедицинском
исследовании
Вы долэюны допросить данные, пока они не признаются, но Вы не долэюны их
замучить, чтобы они не признались кое в чем, чего они не делали.
Аноним
Ошибка, смешивание и смещение (далее просто «смещение») — все это может
противостоять усилиям точно и полно понять биологические взаимосвязи. Фактически большая
часть научного метода и направлена на уменьшение их влияния на осознание этого'.
• Ошибка: 1) неумышленное отклонение от истины, 2) погрешность или ошибка или
3) разность между оцененным или расчетным значением и истинным значением. В
целом статистику интересуют следующие четыре типа ошибок: 1) случайная ошибка,
или биологическая вариация, 2) ошибка выборочного обследования, вытекающая
из того, что оценки основаны на выборке из популяции, а не на данных всей
популяции, 3) ошибка измерения, вызванная несовершенными измерительными приборами,
и 4) смещение, или систематическая ошибка на любой стадии научного исследования
(см. ниже). К этим типам мы можем также прибавить пятый: ошибки в
интерпретации, возникающие вследствие неправильных предположений, неправильных
рассуждений или недостающей информации.
• Смешивание (или модификация эффекта): 1) искажение очевидного влияния одной
переменной на другую, вызванное влияниями третьих переменных, также связанных
с исходом, или 2) переменная, которая может вызвать или предотвратить
интересующий исход, но это не промежуточная влияющая переменная, и это не вызвано
влиянием контакта с изучаемой переменной.
• Смещение: 1) любое систематическое (неслучайное) отклонение от истины, 2)
«любая систематическая ошибка, которая приводит к неправильной оценке зависимости
между воздействием и риском болезни», или 3) «любая тенденция в сборе, анализе,
интерпретации, публикации или обзоре данных, которые могут привести к
заключениям, систематически отличающимся от истины [1].
' Рекомендуем читателям познакомиться с прекрасным обзором директора Российского отделения
сотрудничества The Cochrane Collaboration, вице-президента Межрегионального общества специалистов доказательной
медицины В. В. Власова «Систематические ошибки и вмешивающиеся факторы» (Международный журнал
медицинской практики. 2007. Вып. 3. С. 18-29) и со статьей В. П. Леонова «Ошибки статистического анализа
биомедицинских данных» (Международный журнал медицинской практики. 2007. Вып. 2. С. 19-35).
Источники ошибок, смешивания и смещения в биомедицинском исследовании 441
За прошедшие годы исследователи обнаружили несколько общих источников смещения
в биомедицинском исследовании. Были написаны статьи и документы по этой теме, и были
инициализированы изменения в расчетах исследования и деятельности, цель которых
состоит в том, чтобы уменьшить или предотвратить эти источники смещения. Здесь мы
описываем те смещения, которые более всего распространены в биомедицинском исследовании.
СМЕЩЕНИЯ В ФОРМИРОВАНИИ ВЫБОРКИ
Выборочные смещения присущи любому процессу, который приводит к формированию
нерепрезентативной выборки из интересующей целевой популяции.
Ошибка Берксона, или смещение Берксона (смещение частоты включения)
Такая ошибка встречается, когда отличаются частоты включения пациентов в
исследование между экспериментальной и контрольной группами, особенно в исследованиях,
которые используют госпитализированных пациентов обеих групп. Например, этот тип
смещения присутствует, когда госпитализированных пациентов с фактором риска
(экспериментальная группа) включают с большей частотой, чем из контрольной группы. Когда
комбинация воздействия и болезни приводит к более высокой частоте госпитализации,
отношение между воздействием и болезнью может исказить исследования, основанные на
госпитализированных больных. См. такэюе парадокс Симпсона.
Смещение здорового рабочего
Работающие людц имеют тенденпдю быть более здоровыми, чем общая аоауяящтя r ue-
лом, потому что поддержание занятости обычно требует минимального уровня здоровья
или функциональности. Это смещение важно в исследованиях типа «случай-контроль»,
потому что контрольные группы часто формируются из списков занятости.
Языковое смещение
Язык, на котором исследование издано, часто определяет, привлечет ли оно внимание
исследователя. Статьи, опубликованные на языке, отличающемся от языка исследователя,
менее вероятно, будут использованы в литературных поисках, читаться или переводиться,
и потому, менее вероятно, будут включаться в обзоры.
Смещение принадлежноаи
Встречается, когда выборка определена группами людей, потому что часто одна или
больше характеристик, которые определяют принадлежность людей к группам, связаны
с исходом, представляющим интерес. Например, исследования здоровья людей,
использующих пищевые добавки, могут быть смещены, потому что люди, которые используют их
регулярно, часто более сознательно относятся к здоровью, чем люди в общей популяции.
Нереспондентное смещение
Нереспонденты в опросах часто отличаются от респондентов. Поздние респонденты
могут также отличаться от ранних респондентов [2]. Если нет никакого последующего опроса
людей, которые не отвечали на опрос, трудно определить, типичны ли полученные ответы
для общей совокупности.
442 Приложения
Смещение преваленса-инциденса (смещение Неймана)
Смещение, обусловленное выбором времени наблюдений относительно времени
воздействия или начала болезни: «Поздние осмотры рано подверженных воздействию или
пораженных неизбежно пропустят фатальные и другие короткие эпизоды болезни...» [3].
Смещение фильтрации
Пациенты, встречаемые в высокоспециализированных медицинских центрах или
академических консультационных учреждениях, вероятно, будут отличаться от пациентов,
лечение которых было успешным в учреждениях общественного здравоохранения. Они, более
вероятно, будут страдать от «труднодиагностируемых» болезней или, менее вероятно,
извлекут выгоду из стандартного лечения. Таким образом, смещение фильтрации отражает
действие системы здравоохранения, поскольку различные пациенты направлены в
различные части системы здравоохранения. Это смещение потенциально затрагивает весь процесс
формирования выборки. См. такэюе смещение диагностического обзора.
Смещение выживших
Люди, страдающие от болезней с быстрым фатальным течением, могут быть пропущены
при подсчете болезней, потому что они умирают слишком быстро. Таким образом,
результаты исследования опишут тех, кто остается в живых дольше, а не всех людей, которые
страдают этой болезнью. См. такэюе смещение преваленса-инциденса.
Смещение выбора лечения (смещение выбора процедур)
Часто встречается в нерандомизированных исследованиях или в исследованиях,
использующих исторические или внешние контрольные группы; это смещение встречается, когда
назначение лечения сделано на основе определенных характеристик пациентов, что
приводит к несходству между группами лечения. Например, пациенты, думающие извлечь
выгоду из данного лечения, более вероятно, получат лечение.
Смещение добровольца
Люди, которые добровольно вызываются для клинических исследований, часто
отличаются от тех, кто отказывается участвовать. Добровольцы могут быть лучше обучены, иметь
более высокие доходы, более склонны доверять системе здравоохранения и, вероятно,
более готовы к риску.
Смещение отказа
Пациенты, которые уходят или отзываются из исследования, могут систематически
отличаться от тех, кто завершает исследование. Особое беспокойство вызывает случай, когда
причиной выбывания является непосредственно лечение, беспокойство, которое
вызывается намерением к лечению.
Смещение исследования (смещение подтверждения; клиническое
информационное смещение; клиническое смещение; смещение диагностического подозрения)
Пациенты, подозреваемые в наличии болезни, вероятнее всего, будут проверены на
предмет наличия этой болезни. Это смещение важно при разработке диагностических тестов,
которые могут отобразить различные характеристики, если у совокупности, на которой они
Источники ошибок, смешивания и смещения в биомедицинском исследовании 443
были разработаны, была более высокая вероятность наличия рассматриваемой болезни,
чем в совокупности, которая типично получает тест [4-6].
СМЕЩЕНИЯ В НАЗНАЧЕНИИ УЧАСТНИКОВ В ГРУППЫ ИЗУЧЕНИЯ
Назначение смещает результат в некоторых особенностях, избирательно появляющихся
в одной исследуемой группе, что может сделать группы достаточно несходными, чтобы
препятствовать сравнению.
Смещение установления (смещение неправильной классификации)
в исследованиях «случай-контроль», перекрестном и когортных исследованиях
участников назначают в группы на основе общих особенностей, таких как диагноз или
подверженность заболеванию. Однако установление того, есть ли у участника диагноз или
подверженность заболеванию, подвержено смещению, если определение случая или измерение
подверженности неточны [2].
Смещение показания (смешивание показанием; смещение восприимчивости)
в исследованиях типа «случай-контроль» у пациентов, которые получают
лекарственное средство, есть показания для применения этого лекарственного средства; у
контрольной группы таковых нет.
Смещение выбора
Смещение выбора встречается, когда пациентов с некоторой особенностью
избирательно назначают в группу лечения или группу контроля. Чтобы предотвратить смещение
выбора, используется случайное назначение с сокрытием назначения.
Смещение самовыбора
Смещение самовыбора встречается, когда назначение лечения определено предпочтением
субъекта исследования. Пациенты, выбирающие некоторую амбулаторную процедуру, могут
отличаться от тех, кто выбирает, например, эквивалентную стационарную процедуру.
Смещение неприемлемых болезней
Смещение, вызванное непредставлением сведений о социально неприемлемых причинах
смерти или инвалидности, таких как болезни, передающиеся половым путем, самоубийства
или психиатрические нарушения.
СМЕЩЕНИЯ В ИЗМЕРЕНИИ
Смещения измерения препятствуют точному или полному сбору данных.
Смещение чувства страха (гипертензия «белого халата»)
Смещение в определенных измерениях, таких как сердечный ритм или давление крови,
созданное беспокойством пациентов при осмотре. Например, у пациентов, проверенных
врачами или медсестрами в клинических условиях, часто встречается более высокое
давление крови, чем при осмотре в другой обстановке, феномен, известный как гипертензия
«белого халата».
Приложения
Смещение внимания (эффект Хаторна)
Когда участники исследования знают, что они исследуются, они ведут себя по-другому.
Они могут вести себя более соответственно, стремиться исполнять все лучше, чем обычно,
или скрывать определенные отклонения поведения. (Это смещение, однако, не то же самое,
что эффект плацебо.)
Смещение диагностического обзора
Смещение возникает, когда те, кто интерпретируют результаты диагностического
теста пациента, знают результаты других диагностических тестов того же самого пациента.
Ослепление может предотвратить эту форму смещения.
Смещение прогрессирования болезни (смещение продолжительноаи)
Неспособность принять во внимание скорость прогрессирования болезни при оценке
в качестве исхода времени до наступления события [7]. Например, медленно растущие
опухоли будут обнаружены скрининговыми программами с большей вероятностью, чем
быстрорастущие, которые могут вызвать симптомы между интервалами скрининга. Таким
образом, для пациентов с медленно растущими опухолями время жизни будет казаться более
длинным, потому что быстрорастущие опухоли будут обнаруживаться только по их
симптомам, несмотря на то что медленно растущие доклинические опухоли не будут обнаружены
до следующего скринингового теста.
Смещение ожидания
Любое искажение, созданное тенденцией видеть то, что хотят или ожидают увидеть.
Чтобы уменьшить смещение ожидания, применяется ослепление пациентов,
исследователей и статистиков.
Смещение объединения
Смещение, которое имеет место, когда при разработке диагностического теста диагноз
устанавливается по результатам теста, который исследуется, а не исключительно по
результатам эталонного теста.
Смещение измерения
Систематические ошибки в измерении чего-нибудь. Возможно, анализатор не был от-
калиброван должным образом, датчик был липким, измерительная лента растянутой, или
клиент что-то забыл. Смещение измерения — не то же самое, что ошибка измерения,
которая имеет отношение к точности.
Смещение воспроизведения (дифференциальное смещение воспроизведения)
у смещения воспроизведения есть два значения в медицинском исследовании. Самое
очевидное — это то, что участники, в общем, не все помнят хорошо. Полнота и точность их
воспроизведения часто сомнительны, и участники часто «воспроизводят» события, которые
никогда не имели место. Этот феномен не результат лжи, а скорее проявление человеческой
особенности придавать смысл несопоставимым фактам. То есть внимание и
воспроизведение — это избирательные процессы. Смещение воспроизведения может также относиться
к различиям памяти между группами случая и контроля. Пациенты из группы случая из-за
Источники ошибок, смешивания и смещения в биомедицинском исследовании 445
того, что они болеют, при исследовании, вероятно, будут больше думать о том, что могло
вызвать болезнь, чем пациенты группы контроля [2].
Регрессия к среднему
Тенденция экстремальных значений со временем становиться менее
экстремальными, т. е. они «регрессируют» к более типичным значениям (таким, как среднее значение
распределения).
Предпочтение завершающей цифры
Смещение возникает при округлениях во время сбора данных. Например, сильная
тенденция считывать значения давления крови по ближайшему значению, оканчивающемуся
нулем, может оказать заметное влияние на классификацию гипертензии. В одном
исследовании изменение определения гипертензии от «выше или равно 140 мм рт. ст.» до «выше
140 мм рт. ст.» снижало преваленс гипертензии с 25,9 до 13,3 %. В том же самом
исследовании полное распределение последней цифры данных было следующим: 78 % оканчивались
на «О», 15 % — на четную цифру, кроме «О», 5 % — на «5» и только 2 % — на нечетную
цифру, кроме «5» [8].
СМЕЩЕНИЯ В АНАЛИЗЕ ДАННЫХ
Анализ смещает фокус внимания на неправильные данные.
Смещение истощения (смещение исключения)
Систематические разности из-за выбывания пациентов из испытания. То, как потери
обработаны аналитически, представляет большую возможность для смещения. Анализ
намерения к лечению — это проверка против истощения данных, вызванного непосредственно
лечением. Анализ протоколов должен учитывать это смещение.
Смещение переноса, или эффект переноса
Если эффект лечения продолжается после того, как лечение отменено, то реакция на
второе лечение может быть частично вызвана предыдущим лечением. Эффект переноса может
возникнуть в любом типе исследования, в котором субъекты проверены более чем один
раз. Исследования «доза-отклик», исследования титрования дозы и исследования открытой
оценки обычно требуют некоторого периода выведения между назначениями препаратов
для предотвращения этой формы смещения [9].
Раскапывание данных (data dredging) (<словля блох»; «неуаанный поиск значимоаи»)
Процедура анализа данных насколько возможно многими способами, чтобы найти
статистически значимый результат. Множественные анализы подгрупп и анализы post hoc или
вторичные исследования, управляемые данными, будут часто порождать большие
количества р-значений, некоторые из которых окажутся случайно значимыми. Эти результаты
будут затем представлены так, как будто они были главными результатами. Разведочный
анализ данных необходим и желателен в большинстве исследований, но такие
исследования должны быть отмечены как разведочные, если публикуются. Раскапывание данных,
напротив, направляется желанием найти статистически значимый результат и потому
•не разоблачается.
446 Приложения
Смещение ослабления регрессии
в регрессионном анализе вариабельность, ошибка измерения или случайные колебания
в независимой переменной х приводят к смещению (а также к неточности) в оценке наклона
линии регрессии за счет его систематического стремления к нулю. Чем больше
вариабельность измерений значений х, тем ближе оценка наклона приближается к нулю, а не к
истинному наклону. Вариабельность всегда сдвигает угловой коэффициент к нулю, смещая,
таким образом, результат анализа. Это «ослабление» истинного наклона и есть ослабление
регрессии, или «затухание регрессии».
Смещение чувствительности (смешивание показаниями; смещение показания)
Смещение, вызванное большими дисбалансами исходных уровней между
экспериментальными группами.
СМЕЩЕНИЯ В ИНТЕРПРЕТАЦИИ РЕЗУЛЬТАТОВ
Смещения интерпретации создают неправильные или неточные объяснения событий.
Смещение ассоциации-причинности
Ошибочное использование ассоциации или корреляции между переменными как
доказательства наличия причинно-следственной связи.
Эффект когорты
Влияние на образ жизни людей, возникающее в результате особенностей исторических
периодов, в течение которых они проходили, — такие стадии жизни, как детство или
средний возраст.
Смещение частоты контроля
в клиническом испытании частота, с которой исход, представляющий интерес,
встречается в контрольной группе, называют частотой контроля. Уровень контроля — это, по
существу, суррогатный показатель для инциденса исхода в популяции, из которой была
извлечена выборка. Если, скажем, частота смертности в контрольной группе является низкой, она,
вероятно, может быть также низкой и в группе лечения, поэтому даже эффективное лечение
не будет показывать большой эффект. Другими словами, «чтобы спасти жизни, люди
должны умереть». В исследованиях, показывающих небольшой эффект лечения, низкую частоту
событий в контрольной группе нужно рассматривать как возможное объяснение.
Экологическое смещение, или экологическая ошибка (смещение агрегации)
Экологическая ошибка — широко признаваемая ошибка в интерпретации
статистических данных, когда выводы о природе индивидуумов базируются исключительно на
совокупных статистических данных, собранных для группы, которой принадлежат эти
индивидуумы. Эта ошибка предполагает, что все члены группы представляют характеристики
группы в целом. Этот стереотип — одна из форм экологического заблуждения. Таковым
является утверждение, что «Флорида — единственный штат в Соединенных Штатах, где вы
можете родиться испанцем, а умереть евреем».
Источники ошибок, смешивания и смещения в биомедицинском исследовании 447
Смещение задержки (смещение выявления)
Смещение задержки имеет место, когда увеличение выживания приписано улучшенному
лечению, тогда как истинной причиной является более раннее диагностирование. В анализе
выживания, например, начальная точка могла бы быть, скажем, временем, когда болезнь
была диагностирована, а завершающей точкой могла бы быть смерть. Изменения в
выживании обычно исходят из лечения, задерживающего смерть. Однако более совершенная
техника, которая может диагностировать болезнь в более раннем течении, также изменяет
выживание, не отодвигая смерть, а перемещая начальную точку анализа назад во времени.
Эффект периода
Эффекты, связанные с факторами, которые воздействуют на всю популяцию в течение
данного периода, такими как изменения доступности медицинского обслуживания. Ураган
Катрина и Великая депрессия оказали эффект периода на тех, кто пережил их, например.
Эффект плацебо
Обстоятельства, при которых убеждение участников в том, что они пролечились,
очевидно, изменило его или ее здоровье и самочувствие. Длительная вера в общий и сильный
эффект, эффект плацебо встречался, когда пациенты полагали, что они лечились и были
вообще ограничены улучшениями в «мягких», сообщенных пациентом конечных точках,
таких как сила боли или степень тошноты. Более свежее и строгое исследование, которое
сравнило группы, получающую плацебо и не получавшую никакого лечения, обнаружило
небольшое подтверждение эффекта, который однако был ограничен небольшими
эффектами в исследовании боли, измеренной в визуальной аналоговой шкале [10].
Парадокс Симпсона (эффект Юла—Симпсона)
Парадокс Симпсона связан с инверсией направления сравнения или связи, когда данные
нескольких групп объединяются, чтобы сформировать единую группу. Он имеет место,
когда небольшая популяция, имеющая высокую долю целевых членов, объединена с большой
популяцией, которая имеет низкую долю целевых членов. Например, данные в таблице
ниже показывают, что выживание улучшилось при приеме препарата В в двух отдельных
исследованиях. Когда результаты исследования объединили, оказалось, что выживание
было улучшено при приеме препарата А.
Лечение
Исследование
выживания 1
(п выживших/Л^)
Исследование
выживания 2
[п выживших/л/)
Объединенные
исследования
(п выживших/Л/)
Препарат А
Препарат В
1000/5000 = 20,0%
60/270 = 22,2 %
Результаты лечения В
лучше на 2Д %
40/320=12,5%
100/700=14,3%
Результаты лечения В
лучше на 1,8%
1040/5320=19,5%
160/970=16,5%
Результаты лечения А
лучше на 3,1 %\
448 Приложения
СМЕЩЕНИЯ В ОТЧЕТАХ ОБ ИССЛЕДОВАНИИ
Смещение преимущественного цитирования
Исследования, сообщающие о благоприятных эффектах, цитируются чаще, чем
исследования, не сообщающие об отсутствии пользы [11].
Публикационное смещение
Смещение, созданное тем фактом, что наличие позитивных (статистически значимых)
исходов с большей вероятностью будет представлено к публикации и с большей
вероятностью будет опубликовано, нежели исследование с отрицательными выводами.
Систематические обзоры и метаанализ также могут быть подвержены этому смещению, хотя это
смещение, кажется, чаще затрагивает меньшие исследования, чем большие [2, 3, 12].
Литература
1. LastJM. А Dictionary of Epidemiology, 2nd ed. Oxford: Oxford University Press; 1988.
2. Dorak MT. Bias & confounding, http://dorakmt.tripod.com/epi/bc.htnil. Accessed 12/19/04.
3. Sackett DL Bias in analytic research. J Chron Dis. 1979; 32:51-63.
4. Eli I. Reducing confirmation bias in clinical decision-making. J Dent Educ. 1996; 60:831-5.
5. Tape TG, Panzer RJ. Echocardiography, endocarditis, and clinical information bias. J Gen Intern
Med. 1986; 1:300-4.
6. Eldevik OP, Dugstad G, Orrison WW, Haughton VM. The effect of clinical bias on the inteфretation
of myelography and spinal computed tomography. Radiology. 1982; 145:85-9.
7. Marshall KG. Prevention. How much harm? How much benefit? 2.Ten potential pitfalls in
determining the clinical significance of benefits. Can Med Assoc J. 1996; 154:1837^3.
8. Wen SW, Kramer MS, Hoey J, et al Terminal digit preference, random error, and bias in routine
clinical measurement of blood pressure. J Clin Epidemiol. 1993; 46:1187-93.
9. Cleophas TJ. Carry-over bias in clinical investigations. J Clin Pharmacol. 1993; 33:799-804.
10. Hrobjartsson A, Gotzsche P Is the placebo powerless? An analysis of clinical trials comparing
placebo with no treatment. N Engl J Med. 2001; 344:1594-1602.
11. Ravnskov U. Cholesterol lowering trials in coronary heart disease: frequency of citation and outcome.
BMJ. 1992;305:15-9.
12. Felson DT, Bias in meta-analytic research. J Clin Epidemiol. 1992; 45:885-92.
449
Библиография
Abrams К, AshbyD, Erhngton D. Simple Bayesian
analysis in clinical trials: a tutorial. Control
Clin Trials. 1994; 15:349-59.
Abramson NS, Kelsey SF, Safar P, Sutton-Tyrrell
KS. Simpson's paradox and clinical trials: what
you find is not necessarily what you prove.
Ann Emerg Med. 1992; 21:1480-2.
Ad Hoc Working Group for Critical Appraisal of
the Medical Literature. A proposal for more
informative abstracts of clinical articles. Ann
Intern Med. 1987; 106:598-604.
Adams ME, McCall NT, Gray DT, et al Economic
analysis in randomized control trials. Med
Care. 1992;30:231-43.
Altman DG. Statistics and ethics in medical
research. VI—Presentation of results. BMJ.
1980;281:1542-4.
Altman DG. Statistics and ethics in medical
research. VII—Interpreting results. BMJ. 1980;
281:1612-4.
Altman DG. Statistics and ethics in medical research.
VIII—Improving the quality of statistics in
medical journals. BMJ. 1981; 282:44-7.
Altman DG. Statistics in medical journals. Stat
Med. 1982; 1:59-71.
Altman DG. Statistics in medical journals:
developments in the 1980s. Stat Med. 1991; 10:
1897-913.
Altman DG. Statistical reviewing for medical
journals. Stat Med. 1998; 17:2661-74.
Altman DG, Bland JM. Measurement in medicine:
the analysis of method comparison studies.
Statistician. 1983; 32:307-17.
Altman DG, Bland JM. Improving doctors'
understanding of statistics. J R Statis Soc A. 1991;
154:223-67.
Altman DG, Dore CJ. Randomisation and
baseline comparisons in clinical trials. Lancet.
1990;335:149-53.
Altman DG, GoreSM, Gardner MJ, PocockSJ.
Statistical guidelines for contributors to medical
journals. BMJ. 1983; 286:1489-93.
Ambroz A, Chalmers TC, Smith H, et al.
Deficiencies of randomized control trials [Abstract].
Clin Research. 1978; 26:280A.
American Medical Association. Manual of Style.
Chicago: American Medical Association; 1989.
American Medical Association. Attributes to Guide
the Development of Practice Parameters.
Chicago: American Medical Association; 1994:1-11.
Andersen JW, Harrington D. Meta-analyses need
new publication standards [Editorial]. J Clin
Oncol. 1992; 10:878-80.
[Anonymous]. Significance of significant
[Editorial]. N Engl J Med. 1968; 278:1232-3.
[Anonymous]. Statistical errors [Editorial]. Br Med
J. 1977; 8:66.
[Anonymous]. Methodologic guidelines for reports
of clinical trials [Editorial]. Am J Clin Oncol.
1986; 9:276.
[Anonymous]» Presenting statistics [Editorial]. Aust
NZJSurg. 1987;57:417-19.
Armstrong K, Schwarts JS, Fitzgerald G, et al.
Effect of framing as gain versus loss on
understanding and hypothetical treatment choices:
survival and mortality curves. Med Decision
Making. 2002; 2:76-83.
Arroll B, Schecter AfT, Sheps SB. The assessment
of diagnostic tests: a comparison of medical
literature in 1982 and 1985. J Gen Intern Med.
1988;3:443-7.
Ashby D, Machin D. Stopping rules, interim
analyses and data monitoring committees
[Editorial]. Br J Cancer. 1993; 68:1047-50.
Asilomar Working Group on Recommendations
for Reporting Clinical Trials in the
Biomedical Literature. Checklist of information for
inclusion in reports of clinical trials. Ann Intern
Med. 1996; 124:741-3.
AudetAM, Greenfield S, Field M. Medical practice
guidelines: current activities and future
directions. Ann Intern Med. 1990; 113:709-14.
Avram MJ, Shanks С A, Dykes MM, et al. Statistical
methods in anesthesia articles: an evaluation of
two American journals during two six-month
periods. Anesth Analg. 1985; 64:607-11.
Badgley RE An assessment of research methods
reported in 103 scientific articles from two
Canadian medical journals. Can Med Assoc J.
1961;85:246-50.
450 Библиография
Bagley SC, White H, Golomb BA. Logistic
regression in the medical literature: standards for
use and reporting, with particular attention to
one medical domain. J Clin Epidemiol. 2001;
54:979-85.
Bailar JC 3rd. Science, statistics, and deception.
Ann Intern Med. 1986; 104:259-60.
Bailar JC 3rd, Mosteller F. Guidelines for
statistical reporting in articles for medical journals.
Ann Intern Med. 1988; 108:266-73.
Bandolier Evidence-Based Health Care. Evidence
and diagnostics. February 2002. Available at
www.ebandolier.com. Accessed 8/8/2005.
Basinski SH. Standards, guidelines and clinical
policies. The Health Services Group. Can Med
Assoc J. 1992;146:833-7.
BaSiS Group Bayesian Standards in Science (Ba-
SiS). http://lib. stat.cmu.edu/bayeswork-
shop/2001/BaSisGuideline.htm. Most recent
access 5/3/06.
Bates AS, Margolis PA, Evans AT. Verification bias
in pediatric studies evaluating diagnostic tests.
J Pediatr. 1993;122:585-90.
Begg CB. Biases in the assessment of diagnostic
tests. Stat Med. 1987; 6:411-23.
Begg CB. Methodologic standards for diagnostic
test assessment studies [Editorial]. J Gen
Intern Med. 1988;3:518-20.
Begg CB. Selection of patients for clinical trials.
Semin Oncol. 1988; 15:434-40.
Begg CB. Suspended judgment. Significance tests
of covariate imbalance in clinical trials.
Control Clin Trials. 1990; 11:223-5.
Begg CB. Advances in statistical methodology for
diagnostic medicine in the 1980s. Stat Med.
1991; 10:1887-95.
Begg C, Cho M, Eastwood S, et al. Improving the
quality of reporting of randomized
controlled trials: the CONSORT Statement. JAMA.
1996;276:637-9.
Begg CB, Pocock SJ, Freedman L, Zelen M. State
of the art in comparative cancer clinical trials.
Cancer. 1987;60:2811-5.
Bender R, Grouven U. Logistic regression models
used in medical research are poorly presented
[Letter]. BMJ. 1996; 313:628.
Berger JO, Berry DA. Statistical analysis and
the illusion of objectivity. Am Scient. 1988;
76:159-65.
Bero L, Rennie D. The Cochrane Collaboration.
Preparing, maintaining, and disseminating
systematic reviews of the effects of health care.
JAMA. 1995;274:1935-8.
Berry G. Statistical guidelines and statistical
guidance [Editorial]. Med J Aust. 1987; 146:
408-9.
Bhopal R, Donaldson L White, European, Western
Caucasian, or What? Inappropriate labeling in
research on race, ethnicity, and health. Am J
Pub Health. 1998;88:1301-7.
Bland JM, Jones DR, Bennett S, et al. Is the
clinical trial evidence about new drugs
statistically adequate? Br J Clin Pharmacol. 1985;
19:155-60.
Borzak S, Ridker PM. Discordance between
metaanalyses and large-scale randomized,
controlled trials: examples from the management of
acute myocardial infarction. Ann Intern Med.
1995; 123:873-7.
Bossuyt PM, Reitsma JB, Bruns DE, et al. Towards
complete and accurate reporting of studies of
diagnostic accuracy. The STARD Initiative.
BMJ. 2003; 326:41-4.
Bourne WM. "No statistically significant
difference." So what? [Editorial]. Arch Ophthalmol.
1987;105:40-1.
Bracken MB. Reporting observational studies. Br J
Obstet Gynaecol. 1989; 96:383-8.
Braitman LE. Confidence intervals assess both
clinical significance and statistical significance
[Editorial]. Ann Intern Med. 1991; 114:515-7.
Brett AS. Treating hypercholesterolemia: How
should practicing physicians inteфret the
published data for patients? N Engl J Med. 1989;
321:676-80.
Brown GW. Standard deviation, standard error:
which "standard" should we use? Am J Dis
Child. 1982; 136:937-41.
Brown GW. Statistics and the medical journal
[Editorial]. Am J Dis Child. 1985; 139:226-8.
Brown L. Am Rev Tuberculosis. September 1920,
vol iv. Cited in: Pearl R. Introduction to
Medical Biometry and Statistics. Philadelphia: WB
Saunders; 1941.
Browner WS, Newman ТВ. Confidence intervals
[Letter]. Ann Intern Med. 1986; 105:973-^.
BucherHC, GuyattGH, CookDJ, etal, for the
Evidence-Based Medicine Working Group. User's
Библиография 451
guides to the medical literature. XIX. Applying
clinical trials results. A. How to use an article
measuring the effect of an intervention on
surrogate endpoints. JAMA. 1999; 282:771-8.
Bulpitt CJ. Confidence intervals. Lancet.
1987;28:494-7.
Bulpitt CJ, Fletcher AE. Economic assessments
in randomized controlled trials. Med J Aust.
1990; 153(Supp):S16-9.
Bulpitt С J, Fletcher AE. Measuring costs and
financial benefits in randomized controlled trials.
Am Heart J. 1990; 119(3 Part 2):766-71.
Bunce H III, Hokanson JA, Weiss GB. Avoiding
ambiguity when reporting variability in
biomedical data. Am J Med. 1980; 69:8-9.
Center for Drug Evaluation and Research.
Guideline for the format and content of the clinical
and statistical section of new drug applications.
Food and Drug Administration, Washington,
DC: US Department of Health, Education, and
Welfare; July 1988.
Chalmers I, Adams M, Dickersin K, et al. A cohort
study of summary reports of controlled trials.
JAMA. 1990;263:1401-5.
Chalmers TC, Smith H Jr, Blackburn B, et al.
A method for assessing the quality of a
randomized control trial. Cont Clin Trials. 1981;
2:31-49.
Cho MK, Bero LA. Instruments for assessing the
quality of drug studies published in the
medical literature. JAMA. 1994; 272:101^.
Christensen E, Juhl E, Tygstrup N. Treatment of
duodenal ulcer. Randomized clinical trials of
a decade (1964 to 1974). Gastroenterology.
1977;73:1170-8.
Cleveland WS. Graphs in scientific publications.
Am Statistician. 1984; 38:261-9.
Committee on Data for Science and Technology.
Biologists' guide for the presentation of
numerical data in the primary literature. Report
No. 25. Paris: International Council of
Scientific Unions; November 1977.
Concato J, Feinstein AR, Holford TR. The risk of
determining risk with multivariable models.
Ann Intern Med. 1993; 118:201-10.
Connett JE. Biostatistical red flags [Editorial].
Transfusion. 1994; 34:651-3.
Connor JT. The value of a P-valueless paper. Am J
Gastroenterol. 2004; 99:1638^0.
Cook RJ, Sackett DL The number needed to treat:
a clinically useful measure of treatment effect.
BMJ. 1995;310:452-4.
Cooper GS, Zangwill L. An analysis of the quality
of research reports in the Journal of General
Internal Medicine. J Gen Intern Med. 1989;
4:232-6.
Cooper LS, Chalmers TC, McAllyM, etal. The poor
quality of early evaluations of magnetic
resonance imaging. JAMA. 1988; 259:3277-80.
Council of Biology Editors. Policy in Scientific
Publication. Bethesda, MD: Council of
Biology Editors; 1990:207-18.
Council of Biology Editors, Style Manual
Committee. Scientific Style and Format: The CBE
Manual for Authors, Editors, and Publishers,
6th ed. Cambridge: Cambridge University
Press; 1994.
Crane VS, Gilliland M, Tuthill EL, Bruno С The
use of a decision analysis model in multidis-
ciplinary decision making. Hosp Pharm. 1991;
26:309-25.
Cruess DF. Review of use of statistics in the
American Journal of Tropical Medicine and Hygiene
for January-December 1988. Am J Trop Med
Hyg. 1989;41:619-26.
Cruess DF. Statistics in journals [Letter]. Lancet.
1991; 337:432.
DarR, SerlinRC, OmerH. Misuse of statistical tests
in three decades of psychotherapy research. J
Consult Clin Psychol. 1994; 62: 75-82.
Davis NM, Cohen MR. Medication Errors: Causes
and Prevention. Philadelphia: George Stickley
Company; 1981.
DerSimonian R, Charette L/, McPeek B, Mosteller
F Reporting on methods in clinical trials. N
Engl J Med. 1982; 306:1332-7.
DesJarlaisDC, Lyles C, CrepazN, and the TREND
Group. Improving the reporting quality of
nonrandomized evaluation of behavioral and
public health interventions. The TREND
Statement. Am J Public Health. 2004; 94:361-6.
Detsky AS, Naglie IG. A clinician's guide to cost-
effectiveness analysis. Ann Intern Med. 1990;
113:147-54.
Devereaux PJ, Manns BJ, Ghali WA, et al.
Physician inteфretations and textbook definitions of
blinding terminology in randomized controlled
trials. JAMA. 2001; 285:2000-3.
452 Библиография
Diamond GA, Forrester JS. Clinical trials and
statistical verdicts: probable grounds for appeal.
Ann Intern Med. 1983; 98:385-94.
Dickersin K. The existence of publication bias and
risk factors for its occurrence. JAMA. 1990;
263:1385-9.
Dickersin K, Berlin JA. Meta-analysis: state-of-the-
science. Epidemiol Rev. 1992; 14:154-76.
Dunn HL. Application of statistical methods in
physiology. Physiol Rev. 1929; 9:275-398.
DurantRH. Checklist for the evaluation of research
articles. J Adolesc Health. 1994; 15:4-8.
Ebbutt AF, Frith L Practical issues in equivalence
trials. Stat Med. 1998; 17:1691-1701.
Eddy DM. Probabilistic reasoning in clinical
medicine: problems and opportunities. In: Kahneman
D, Slovic P,Tversky A, eds. Judgment Under
Uncertainty: Heuristics and Biases. Cambridge:
Cambridge University Press; 1982:249-67.
Eddy DM. Clinical decision making: from theory
to practice. Designing a practice policy:
standards, guidelines, and options. JAMA. 1990;
263:3077-84.
Eddy DM. Clinical decision making: from theory to
practice. Cost-effectiveness analysis: is it up to
the task? JAMA. 1992; 267:3342-8.
Edwards A. Communicating risks through
analogies [Letter]. BMJ. 2003; 327:749.
Egger M, Juni P, Bartlett, for the CONSORT
Group. Value of flow diagrams in reports of
randomized controlled trials. JAMA. 2001;
285:1996-9.
Ehrenberg AS. Rudiments of numercy. J R Statist
Soc. 1977; 140:277-97.
Ehrenberg AS. The problem of numeracy.
American Statistician. 1981; 35:67-71.
Eisenberg MJ. Accuracy and predictive values in
clinical decision-making. Cleve Clin J Med.
1995;62:311-6.
EisenhartC. [Letter]. Science. 1968; 162:1332-3.
Elenbaas JK, Cuddy PG, Elenbaas RM. Evaluating
the medical literature. Part III: Results and
discussion. Ann Emerg Med. 1983; 12:679-86.
Elenbaas RM, Elenbaas JK, Cuddy PG. Evaluating
the medical literature. Part II: Statistical
analysis. Ann Emerg. Med. 1983; 12:610-20.
Emerson JD, Colditz GA. Use of statistical analysis
in the New England Journal of Medicine. N
Engl J Med. 1983; 309:709-13.
Esquirol JED. Cited in: Pearl R. Introduction to
Medical Biometry and Statistics. Philadelphia:
WB Saunders; 1941.
Ethgen M, Boutron I, Baron G, et al. Reporting of
harm in randomized, controlled trials of nonp-
harmacologic treatment for rheumatic disease.
Ann Intern Med. 2005; 143:20-5.
Evans DB. Principles involved in costing. Med J
Aust. 1990; 153 (Supp):S 10-2.
Evans DB. What is cost-effectiveness analysis?
Med J Aust. 1990; 153(Supp):S7-9.
Evans M, Pollock AV. Trials on trial: a review of
trials of antibiotic prophylaxis. Arch Surg. 1984;
119:109-13.
Evans M. Presentation of manuscripts for
publication in the British Journal of Surgery. Br J
Surg. 1989;76:1311-4.
Feinstein AR. Clinical biostatistics XXV. A
survey of the statistical procedures in general
medical journals. Clin Pharmacol Ther. 1974;
15:97-107.
Feinstein AR. Clinical biostatistics XXXVII.
Demeaned errors, confidence games, nonplussed
minuses, inefficient coefficients, and other
statistical disruptions of scientific
communication. Clin Pharmacol Ther. 1976; 20:617-31.
Feinstein AR. Clinical biostatistics XXXIX. The
haze of Bayes, the aerial palaces of decision
analysis, and the computerized Ouija board.
Clin Pharmacol Ther. 1977; 21:482-96.
Feinstein AR. X and iprP: an improved summary
for scientific communication [Editorial]. J
Chronic Dis. 1987;40:283-8.
Feinstein AR. Clinical judgment revisited: the
distraction of quantitative models. Ann Intern
Med. 1994; 120:799-805.
Feinstein AR, Spitz H. The epidemiology of cancer
therapy. I. Clinical problems of statistical
surveys. Arch Intern Med. 1969; 123:171-86.
Felson DT. Bias in meta-analytic research. J Clin
Epidemiol. 1992;45:885-92.
Felson DT, Anderson JJ, Meenan RF. Time for
changes in the design, analysis, and reporting
of rheumatoid arthritis clinical trials. Arthritis
Rheum. 1990;33:140-9.
Felson DT, Cupples LA, Meenan RF. Misuse of
statistical methods in arthritis and rheumatism.
1982 versus 1967-68. Arthritis Rheum. 1984;
27:1018-22.
Библиография 453
Fienberg SE. Damned lies and statistics:
misrepresentations of honest data. In: Council of
Biology Editors, Editorial Policy Committee.
Ethics and Policy in Scientific Publication.
Bethesda, MD: Council of Biology Editors;
1990:202-6.
Finney DJ, Clarke ВС Guest editorial: code for
presentation of statistical analyses. Phil Trans
R Soc Lond B. 1992; 337:381-2.
FischhoffB, Lichtenstein S, Slavic P, Keeney D.
Acceptable Risk. Cambridge: Cambridge
University Press; 1981.
Fleming TR, DeMets DL Surrogate end points in
clinical trials: are we being mislead? Ann
Intern Med. 1996; 125:605-13.
Forrow L, Taylor WC, Arnold RM. Absolutely
relative: how research results are summarized can
affect treatment decisions. Am J Med. 1992;
92:121-4.
Freeman KB, Back S, Bernstein J. Sample size and
statistical power of randomized, controlled
trials in orthopaedics. J Bone Joint Surg Br.
2001;83:397-402.
Freiman JA, Chalmers TC, Smith H, Kuebler
RR. The importance of beta, the type II error
and sample size in the design and
interpretation of the randomized control trial: survey
of 71 negative trials. N Engl J Med. 1978;
299:690-4.
Ganiats TG. Practice guidelines movement. West J
Med. 1993; 158:518-9.
Ganiats TG, WongAF Evaluation of cost
effectiveness research: a survey of recent publications.
FamMed. 1991;23:457-62.
Garcia-Cases C, Duque A, Borja J, et al.
Evaluation of the methodological quality of clinical
trial protocols: a preliminary experience in
Spain. Eur J Clin Pharmacol. 1993; 44:401-2.
Gardner MJ. Understanding and presenting
variation [Letter]. Lancet. 1975; 25:230-1.
Gardner MJ, Altman DG. Confidence intervals
rather than P values: estimation rather than
hypothesis testing. BMJ. 1986; 292:746-50.
Gardner MJ, Altman DG. Estimating with
confidence. BMJ. 1988; 296:1210-1.
Gardner MJ, Altman DG, Jones DR, Machin D. Is
the statistical assessment of papers submitted
to the British Medical Journal effective? BMJ.
1983;286:1485-8.
Gardner MJ, Bond J. An exploratory study of
statistical assessment of papers published in
the British Medical Journal. JAMA. 1990;
263:1355-7.
Gardner MJ, Machin D, Campbell MJ. Use of
checklists in assessing the statistical content of
medical studies. BMJ. 1986; 292:810-2.
G art land J J. Orthopaedic clinical research:
deficiencies in experimental design and
determination of outcome. J Bone Joint Surg Am.
1988;70:1357-64.
Garvey WD, Griffith ВС Scientific communication:
its role in the conduct of research and creation
of knowledge. Am Psychol. 1971; 349-62.
Gehlbach SH. Interpreting the Medical Literature,
3rd ed. New York: McGraw-Hill; 1993.
Gelber RD, Goldirsch A, for the International
Breast Cancer Study Group. Reporting and
interpreting adjuvant therapy clinical trials. J
Natl Cancer Inst Monogr. 1992; 11:59-69.
Geller NL, Pocock SJ. Interim analyses in
randomized clinical trials: ramifications and
guidelines for practitioners. Biometrics. 1987;
43:213-23.
George SL Statistics in medical journals: a survey
of current policies and proposals for editors.
Med Pediatr Oncol. 1985; 13:109-12.
Gerstman BB. Epidemiology Kept Simple: An
Introduction to Classic and Modern
Epidemiology. New York: Wiley-Liss; 1998.
Gibbons JD, Pratt JW. P values: interpretation
and methodology. Am Statistician. 1975;
29:20-5.
Giffi)rd RH, Feinstein AR. A critique of
methodology in studies of anticoagulant therapy for
acute myocardial infarction. N Engl J Med.
1969;280:351-7.
Gigerenzer G. Adaptive Thinking: Rationality in
the Real World. New York: Oxford University
Press; 2000.
Gigerenzer G. Calculated Risks: How to Know
When Numbers Deceive You. New York:
Simon and Schuster; 2002.
Gigerenzer G, Edwards A. Simple tools for
understanding risks: from innumeracy to insight.
BMJ. 2003; 327:741-4.
Gigerenzer G, Todd PM, ABC Research Group.
Simple Heuristics That Make Us Smart. New
York: Oxford University Press; 1999.
454 Библиография
Gill TM, Feinstein AR. A critical appraisal of
the quality of quality-of-life measurements.
JAMA. 1994;272:619-26.
Glantz SA. Biostatistics: how to detect, correct and
prevent errors in the medical literature.
Circulation. 1980; 61:1-7.
Glantz SA. It is all in the numbers [Editorial]. J Am
Coll Cardiol. 1993;21:835-7.
Godfrey K. Comparing the means of several groups.
N Engl J Med. 1985; 313:1450-6.
Godfrey K. Simple linear regression in medical
research. In: Bailar JC, Mosteller F, eds.
Medical Uses of Statistics, 2nd ed. Boston: NEJM
Books; 1992:201-32.
Goel V. Decision analysis: applications and
limitations. The Health Services Research Group.
Can Med Assoc J. 1992; 147:413-7.
Goodman NW, Hughes АО. Statistical awareness of
research workers in British anaesthesia. Br J
Anaesth. 1992;68:321-4.
Goodman SN. Multiple comparisons, explained.
Am J Epidemiol 1998;147:807-12.
Goodman SN. Toward evidence-based medical
statistics. 1. The P value fallacy. Ann Intern Med.
1999; 130:995-1004.
Goodman SN. Toward evidence-based medical
statistics. 2. The Bayes factor. Ann Intern Med.
1999; 130:1005-13.
Goodman SN, Berlin JA. The use of predicted
confidence intervals when planning
experiments and the misuse of power when
interpreting results. Ann Intern Med. 1994;
121:200-6.
Goodman SN, Berlin JA, Fletcher SW, Fletcher
RH. Manuscript quality before and after peer
review and editing at Annals of Internal
Medicine. Ann Intern Med. 1994; 121:11-21.
Gordis L. Epidemiology Philadelphia: WB
Saunders; 1996.
Gore SM. Statistics in question. Assessing
methods—confidence intervals. BMJ. 1981; 283:
660-2.
Gore SM, Jones IG, Rytter EC. Misuse of
statistical methods: critical assessment of articles in
BMJ from January to March 1976. BMJ. 1977;
1:85-7.
Gore SM, Jones IG, Thompson SG. The Lancets
statistical review process: areas for
improvement by authors. Lancet. 1992; 340:100-2.
Gotzsche PC. Methodology and overt and hidden
bias in reports of 196 double-blind trials of
nonsteroidal antiinflammatory drugs in
rheumatoid arthritis. Control Clin Trials. 1989;
10:31-56. [Erratum: Control Clin Trials. 1989;
50:356.]
Grant A. Reporting controlled trials. Br J Obstet
Gynaecol. 1989; 96:397-400.
Greene WL, Concto J, Feinstein AR. Claims of
equivalence in medical research: are they
supported by the evidence? Ann Intern Med. 2000;
132:715-22.
Grimes DA, Schulz KF. Randomized controlled
trials of home uterine activity monitoring: a
review and critique. Obstet Gynecol. 1992;
79:137-42.
Griner PF, Mayewski RJ, MushlinAI, Greenland P.
Selection and inteфretation of diagnostic tests
and procedures: principles and applications.
Ann Intern Med. 1981; 94:553-600.
Gross M. A critique of the methodologies used in
clinical studies of hip-joint arthroplasty
published in the English-language orthopaedic
literature. J Bone Joint Surg Am. 1988; 70:
1364-71.
Guyatt GH, HaywardR, Richardson WS, etal., for
the Evidence-Based Working Group of the
American Medical Asssociation. Moving from
evidence to action. In: Guyatt GH, Rennie D,
eds. User's Guides to the Medical Literature:
A Manual for Evidence-Based Practice.
Chicago: AMA Press; 2002.
Guyatt GH, SackettDL, AdachiJ, etal. A clinician's
guide for conducting randomized trials in
individual patients. CMAJ. 1988; 139:497-503.
Guyatt GH, SackettDL, CookDJ. Users' guides to
the medical literature. II. How to use an article
about therapy or prevention. A. Are the resuhs
of the study valid? The Evidence-Based
Medicine Working Group. JAMA. 1993; 270:2598-
601.
Guyatt GH, SackettDL, CookDJ. Users' guides to
the medical literature. II. How to use an
article about therapy or prevention. B. What were
the results and will they help me in caring for
my patients? The Evidence-Based Medicine
Working Group. JAMA. 1994; 271:59-63.
Guyatt GH, Sackett DL, Sinclair JC, et al. Users'
guides to the medical literature. IX. A method
Библиография 455
for grading health care recommendations. The
Evidence-Based Medicine Working Group.
JAMA. 1995;274:1800-4.
Guyatt GH, Tugwell PX, Feeny DH, et al A
framework for clinical evaluation of diagnostic
technologies. Can Med Assoc J. 1986; 134:587-
94.
Haines SJ. Six statistical suggestions for surgeons.
Neurosurgery. 1981;9:414-8.
HallJC. The other side of statistical significance: a
review of type II errors in the Australian
medical literature. Aust N Z Med. 1982; 12:7-9.
Hall JC. Use of the t test in the British Journal of
Surgery [Letter]. Br J Surg. 1982; 69:55-6.
Hall JC, Hill D, Watts JM. Misuse of statistical
methods in the Australasian surgical literature.
AustNZ J Surg 1982; 52:541-3.
Hall JC Mooney G. What every doctor should
know about economics. Part 2. The benefits
of economic appraisal. Med J Aust. 1990;
152:80-2.
Hampton JR. Presentation and analysis of the
results of clinical trials in cardiovascular disease.
BMJ. 1981;282:1371-3.
Hayden GF. Biostatistical trends in Pediatrics:
implications for the future. Pediatrics. 1983;
72:84-7.
Haynes RB. How to read clinical journals: II. To
learn about a diagnostic test. Can Med Assoc
J. 1981;124:703-10.
Haynes RB, Mulrow CD, Huth EJ, et al. More
informative abstracts revisited. Ann Intern Med.
1990;113:69-76.
Hayward RS. Users' guides to the medical
literature. VIII. How to use? clinical practice
guidelines. A. Are the recommendations valid? The
Evidence-Based Medicine Working Group.
JAMA. 1995;274:570-4.
Hayward RS, Laupacis A. Initiating, conducting
and maintaining guidelines development
programs. Can Med Assoc J. 1993; 148:507-12.
Hayward RS, Wilson MC, Tunis SR, et al. More
informative abstracts of articles describing
clinical practice guidelines. Ann Intern Med. 1993;
118:731-7.
Healy MJ. Statistics from the inside. 5. Data
structures. Arch Dis Child. 1992; 67:533-5.
Hemminki E. Quality of reports of clinical trials
submitted by the drug industry to the Finnish
and Swedish control authorities. Eur J Clin
Pharmacol. 1981; 19:157-65.
Hemminki E. Quality of clinical trials—a concern
of three decades. Methods Inf Med. 1982;
21:81-5.
Hennekens CH, BuringJE. Epidemiology in
Medicine. Boston: Little, Brown; 1987.
Henry DA, Wilson A. Meta-analysis. Part 1: An
assessment of its aims, validity and reliability.
Med J Aust. 1992;156:31-8.
HillmanAL. Economic analysis of health care
technology: a report on principles. The Task Force
on Principles for Economic Analysis of Health
Care and Technology. Ann Intern Med. 1995;
123:61-70.
Hillman AL, Eisenberg JM, Pauly MV, et al.
Avoiding bias in the conduct and reporting of cost-
effectiveness research sponsored by
pharmaceutical companies. N Engl J Med. 1991;
324:1362-5.
Hoffman JI. The incorrect use of chi-square
analysis for paired data. Clin Exp Immunol. 1976;
24:227-9.
Hollis S, Campbell F. What is meant by intention to
treat analysis? Survey of published randomised
controlled trials. BMJ. 1999; 319:670-4.
Horton R. A manifesto for reading medicine.
Lancet. 1997; 349:872^.
Horwitz RI, Feinstein AR. Methodologic standards
and contradictory results in case-control
research. Am J Med. 1979; 66:556-64.
Horwitz RI, Singer BH, Makuch RW, Viscoli CM.
Can treatment that is helpful on average be
harmful to some patients? A study of the
conflicting information needs of clinical inquiry
and drug regulation. J Clin Epidemiol. 1996;
49:395-400.
HosmerDW, TaberS, Lemeshow S. The importance
of assessing the fit of logistic regression
models: a case study. Am J Public Health. 1991;
81:1630-5.
Hughes MD. Reporting Bayesian analyses of
clinical trials. Stat Med. 1993; 12:1651-63.
Hujoel PP, Baab DA, De Rouen ТА. The power of
tests to detect differences between periodontal
treatments in published studies. J Clin Period-
ontol. 1992; 19:779-84.
Huth EJ. How To Write and Publish Papers in the
Medical Sciences. Philadelphia: ISI Press; 1982.
456 Библиография
Них JE, Naylor DC. Communicating the benefits
of chronic preventive therapy: does the format
of efficacy data determine patients' accept-
ancve of treatment? Med Decis Making. 1995;
15:152-7.
International Committee of Medical Journal
Editors. Uniform requirements for manuscripts
submitted to biomedical journals. N Engl J
Med. 1991;324:424-8.
loannidis JPA, Lau J. Completeness of
safety reporting in randomized trials. JAMA.
2001;285:437-43.
Irwig L, Tosteson ANA, Gastonis C, et al
Guidelines for meta-analyses evaluating diagnostic
tests. Ann Intern Med. 1994; 120:667-76.
Iverson C, Dan BB, Glitman P, et al, eds.
American Medical Association Manual of Style,
8th ed. Baltimore, MD: Williams & Wilkins;
1983:305-9.
Jaeschke R, Guyatt GH, Sackett DL. Users' guides
to the medical literature. III. How to use an
article about a diagnostic test. A. Are the
results of the study valid? The Evidence-Based
Medicine Working Group. JAMA. 1994;
271:389-91.
Jaeschke R, Guyatt GH, Sackett DL. Users' guides
to the medical literature. III. How to use an
article about a diagnostic test. B. What are the
results and will they help me in caring for my
patients? The Evidence-Based Medicine
Working Group. JAMA. 1994; 271:703-7.
Jamart J. Statistical tests in medical research. Acta
Oncol. 1992;31:723-7.
Jekel JF. Statistical significance versus importance
[Letter]. Pediatrics. 1977; 60:125-6.
JewettDL. Reporting negative results [Letter]. Au-
diology. 1991;30:183-4.
Jones DR. Meta-analysis of observational
epidemiological studies: a review. J R Soc Med.
1992;85:165-8.
Jonson NE. Everyday diagnostics: a critiques of
the Bayesian model. Med Hypotheses. 1991;
34:289-95.
Joseph M, ed. Man is the Only Animal that Blushes
... Or Needs To. The Wisdom of Mark Twain.
New York: Random House; 1970.
Journal of Hypertension. Statistical guidelines for
the Journal of Hypertension. J Hyper. 1992;
10:6-8.
Journal of the American Medical Association.
Instructions for preparing structured abstracts.
JAMA. 1993;271:162-4.
Juhl E, Christensen E, Tygstrup N The
epidemiology of the gastrointestinal randomized clinical
trial. N Engl J Med. 1977; 296:20-2.
Kahneman D, Slovic P, Tversky A, eds. Judgment
under Uncertainty: Heuristics and Biases.
Cambridge: Cambridge University Press; 1982.
KanterMH, PetzL. The validity of statistical
analyses in the transfusion medicine literature with
specific comments concerning studies of the
comparative safety of units donated by
autologous, designated and allogenic donors
[Editorial]. Transfus Med. 1995; 5:91-5.
Kanter MH, Taylor JR. Accuracy of statistical
methods in Transfusion: a review of articles
from July/August 1992 through June 1993.
Transfusion. 1994;34:697-701.
Kaplan RM, Feeny D, Revicki DA. Methods for
assessing relative importance in preference
based outcome measures. Qual Life Res. 1993;
2:467-75.
KassirerJP Clinical trials and meta-analysis. What
do they do for us? [Editorial]. N Engl J Med.
1992; 327:273-4.
KassirerJP, Angell M. The journal's policy on cost-
effectiveness analyses. [Editorial]. N Engl J
Med. 1994;331:669-70.
Kassirer JP, Moskowitz AJ, Lau J, Pauker SG.
Decision analysis: a progress report. Ann Intern
Med. 1987; 106:275-91.
Kaufman NJ, Dudley-Marling C, Serlin RL. An
examination of statistical interactions in the
special education literature. J Special Ed. 1986;
20:31^2.
Kawachi I, Malcom LA. The cost-effectiveness of
treating mild-to-moderate hypertension: a
reappraisal. J Hypertens. 1991; 9:199-208.
Koes BW, Bouter LM, van der Heijden GJ.
Methodological quality of randomized clinical trials
on treatment efficacy in low back pain. Spine.
1995;20:228-35.
Kupersmith J, Holmes-Rovner M, Hogan A, et al.
Cost-effectiveness analysis in heart disease.
Part I: General principles. Prog Cardiovasc
Dis. 1994;37:161-84.
Lagakos S. Statistical analysis of survival data.
In: Bailar JC, Mosteller F, eds. Medical Uses
Библиография 457
of Statistics. 2nd ed. Boston: NEJM Books;
1992:281-92.
Lang T. Twenty statistical errors even YOU can find
in biomedical research articles. Croatian Med
J. 2004; 45:361-70.
Lashner BA, Kirsner JB. The epidemiology of
inflammatory bowel disease: are we learning
anything new? [Editorial]. Gastroenterology.
1992; 103:596-8.
Last JM. A Dictionary of Epidemiology, 2nd ed.
Oxford: Oxford University Press; 1988.
Lau J, Antman EM, Jimenez-Silva J, et al
Cumulative meta-analysis of therapeutic trials for
myocardial infarction. N Engl J Med. 1992;
327:248-54.
Lauden L. The Book of Risks: Fascinating Facts
about the Chances We Take Every Day. New
York: John Wiley; 1994.
LaupacisA, FeenyD, DetskyAS, TugwellPX. How
attractive does a new technology have to be
to warrant adoption and utilization?
Tentative guidelines for using clinical and
economic evaluations. Can Med Assoc J. 1992;
146:473-81.
Laupacis A, Naylor CD, Sackett DL. An
assessment of clinically useful measures of the
consequences of treatment. N Engl J Med. 1988;
318; 1728-33.
Laupacis A, Naylor CD, Sackett DL. How should
the results of clinical trials be presented to
clinicians? [Editorial]. ACP Journal Club.
1992;May/June:A-12^.
Laupacis A, Sackett DL, Roberts RS. An
assessment of clinically useful measures of the
consequences of treatment. N Engl J Med. 1988;
318:1728-33.
Laupacis A, Wells G, Richardson WS, Tugwell
P Users' guides to the medical literature. V.
How to use an article about prognosis. The
Evidence-Based Medicine Working Group.
JAMA. 1994;272:234-7.
Lavori PW, Louis ТА, Bailar JC, Polanski M
Designs for experiments: parallel comparisons
of treatment. In: Bailar JC, Mosteller F, eds.
Medical Uses of Statistics, 2nd ed. Waltham:
Massachusetts Medical Society; 1992:61-82.
Leape LL. Practice guidelines and standards:
an overview. QRB Qual Rev Bull. 1990;
16:42-9.
LeBlond RE Improving structured abstracts
[Letter]. Ann Intern Med. 1989; 111:764.
Lee JT, Sanchez LA. Inteфretation of
"cost-effective" and soundness of economic evaluations
in the pharmacy literature. Am J Hosp Pharm.
1991;48:2622-7.
Lee KL, Bicknell NA, Pieper KS. Response to Pal-
mas et al. [Letter]. Ann Intern Med. 1993;
118:231-2.
LeeKL, McNeer E, Starmer CE, etal. Clinical
judgment and statistics: lessons from a simulated
randomized trial in coronary artery disease.
Circulation. 1980;61:508-15.
Leis HP Jr, Robbins GE, Greene EL, et al. Breast
cancer statistics: use and misuse. Int Surg.
1986;71:237-43.
Levine M, Walter S, Lee H, et al. Users' guides
to the medical literature. IV. How to use an
article about harm. The Evidence-Based
Medicine Working Groups JAMA. 1994;
271:1615-9.
Lewis RJ, Wears RL. An introduction to the Baye-
sian analysis of clinical trails. Ann Emerg Med.
1993;22:1328-36.
Liberati A, Himel HN, Chalmers TC. A quality
assessment of randomized control trials of
primary treatment of breast cancer. J Clin Oncol.
1986;4:942-51.
Light RJ, Pellimer DB. Summing Up: The Science
of Reviewing Research. Cambridge, MA:
Harvard University Press; 1984.
Lionel ND, Herxheimer A. Assessing reports of
therapeutic trials. BMJ. 1970; 3:637-40.
Longnecker DE. Support versus illumination:
trends in medical statistics. Anesthesiology.
1982; 57:73-4.
Mac Arthur RD, Jacbon GG. An evaluation of the
use of statistical methodology in the Journal
of Infectious Diseases. J Infect Dis. 1984;
149:349-54.
Mahon WA, Daniel ЕЕ. A method for the
assessment of reports of drug trials. Can Med Assoc
J. 1964;90:565-9.
Mainland D. Chance and the blood count. Can Med
Assoc J. 1934; (June):656-8.
Mainland D. Problems of chance in clinical work.
Br Med J. 1936;2:221-4.
Mainland D. Statistical ritual in clinical journals: is
there a cure? BMJ. 1984; 288:841-3.
458 Библиография
Malenka DJ, Baron JA, Johansen SJW, Ross JM.
The framng effect of relative and absolute risk.
J Gen Intern Med. 1993; 8:543-8.
Mann H. ASSERT Statement: Recommendations
for the review and monitoring of randomized
controlled clinical trials. http://www.assert-
statement.org/Accessed 6/30/05.
Mantha S. Scientific approach to presenting and
summarizing data [Letter]. Anesth Analg.
1992; 75:469-70.
Marks RG. Proper statistical analysis and
documentation considerations for published
research articles. Occup Ther Ment Health.
1987;7:51-68.
Marks RG, Dawson-Saunders EK, Bailar JC,
et al Interactions between statisticians and
biomedical journal editors. Stat Med. 1988;
7:1003-11.
Mason J, Drummond M, Torrance G. Some
guidelines on the use of cost effectiveness league
tables. BMJ. 1993; 306:570-2.
MaynardA. The design of future cost-benefit
studies. Am Heart J. 1990; 119(3 Part 2):761-5.
McGill R, Tukey JW, Larsen WA. Variation of box
plots. American Statistician. 1978; 32:12-6.
McNeil PJ, Pauker SG, Sox HC, Tversky A. On the
elicitation of preferences for alternative
therapies. N Engl J Med. 1982; 306:1259-62.
McPherson K. Statistics: the problem of examining
accumulating data more than once. N Engl J
Med. 1974;290:501-2.
Medical Research Council Investigation.
Streptomycin treatment of pulmonary tuberculosis.
BMJ. 1948; ii:769-82.
Meinert CL, Tonascia S, Higgins K. Content of
reports on clinical trials: a critical review.
Control Clin Trials. 1984; 5:328-47.
Metz CE. Basic principles of ROC analysis. Semin
Nucl Med. 1978; 8:283-98.
Mike V, Stanley KE, editors. Statistics in Medical
Research. New York: John Wiley & Sons;
1982:532-9.
Mills JL Data torturing [Letter]. N Engl J Med.
1993;329:1196-9.
Moher Д Cook DJ, Eastwood S, et al, for the
QUOROM Group. Improving the quality of
reports of meta-analyses of randomized
controlled trials. The QUOROM Statement.
Lancet. 1999; 354:1896-900.
Moher D, Dulberg CS, Wells GA. Statistical power,
sample size, and their reporting in randomized
controlled trials. JAMA. 1994; 272:122-4.
Moher D, JadadAR, Nichol G, et al Assessing the
quality of randomized controlled trials: an
annotated bibliography of scales and checklists.
Control Clin Trials. 1995; 16:62-73.
Moher D, Olkin I. Meta-analysis of randomized
controlled trials. A concern for standards.
JAMA. 1995;274:1962-4.
Moher D, Schulz K, Altman DG, for the CONSORT
Group. CONSORT statement: revised
recommendations for improving the quality of
reports of parallel-group randomized trials. Ann
Intern Med. 2001; 134:657-62.
Montgomery DC. Design and Analysis of
Experiments, 2nd ed. New York: John Wiley and
Sons; 1984.
Morgan PP. Confidence intervals: from statistical
significance to clinical significance [Editorial].
Can Med Assoc J. 1989; 141:881-3.
Morris RW.A statistical study of papers in the
Journal of Bone and Joint Surgery Br 1984. J Bone
Joint Surg Br. 1988; 70:242-6.
Moses L. Measuring effects without randomized
trials? Options, problems, challenges. Med Care.
1995;33:AS8-14.
Moses LE. Statistical concepts fundamental to
investigations. In: Bailar JC, Mosteller F, eds.
Medical Uses of Statistics, 2nd ed. Boston:
NEJM Books; 1992:5-26.
Moskowitz G, Chalmers TC, Sacks HS, et al
Deficiencies of clinical trials of alcohol
withdrawal. Alcohol Clin Exp Res. 1983; 7:42-6.
Mosteller E Communications: Should mechanisms
be established for sharing among clinical trial
investigators experiences in handling problems
in design, execution, and analysis? Problems
of omission in communications. Clin
Pharmacol Ther. 1979; 25(5 Part 2):761^.
Mosteller F, Gilbert JP, McPeekB. Reporting
standards and research strategies for controlled
trials. Control Clin Trials. 1980; 1:37-58.
Murray GD. The task of a statistical referee. Br J
Surg. 1988;75:664-7.
Murray GD. Confidence intervals [Editorial]. Nuc
MedCommun. 1989; 10:387-8.
Murray GD. Statistical aspects of research
methodology. Br J Surg. 1991; 78:777-81.
Библиография 459
Murray GD. Statistical guidelines for the
British Journal of Surgery. Br J Surg. 1991;
78:782^.
Naylor CD, Chen E, Strauss B. Measured
enthusiasm: does the method of reporting
trial results alter perceptions of
therapeutic effectiveness? Ann Intern Med. 1992;
117:916-21.
Naylor CD, Guyatt GH. Users' guides to the
medical literature. X. How to use an article
reporting variations in the outcomes of health
services. The Evidence-Based Medicine Working
Group. JAMA. 1996; 275:554-8.
Nierenberg AA, FeinsteinAR. How to evaluate a
diagnostic marker test. JAMA. 1988; 259:1699-
1702.
Nord E. Methods for quality adjustment of life
years. Soc Sci Med. 1992; 34:559-69.
О 'Brien PC, Shampo MA, Statistics for clinicians.
I. Descriptive statistics. Mayo Clin Proc. 1981;
56:47-9.
O'Brien PC, Shampo MA. Statistics for
clinicians. 7. Regression. Mayo Clin Proc. 1981;
56:452-4.
O'Brien PC, Shampo MA. Statistics for clinicians.
II. Survivorship studies. Mayo Clin Proc.
1981;56:709-11.
О 'Brien PC, Shampo MA. Statistics for clinicians.
12. Sequential methods. Mayo Clin Proc.
1981; 56:753^.
О'Fallon JR, DubySD, Sals burg DS, et al. Should
there be statistical guidelines for medical
research papers? Biometrics. 1978; 34:687-95.
Oliver D, Hall JC Usage of statistics in the
surgical literature and the "oфhan P" phenomenon.
AustN Z J Surg. 1989; 59:449-51.
Ottenbacher KJ. Statistical conclusion validity and
type IV errors in rehabilitation research. Arch
Phys Med Rehabil. 1992; 73:121-5.
Oxman AD. Evidence-based care: 2. Setting
guidelines: how should we manage this problem?
The Evidence-Based Care Resource Group.
Can Med Assoc J. 1994; 150:1417-23.
Oxman AD, Guyatt GH. A consumer's guide to
subgroup analyses. Ann Intern Med. 1992;
116:78-84.
Palmas W, Denton ТА, Diamond GA. Publication
criteria for statistical prediction models
[Letter]. Ann Intern Med. 1993; 118: 231-2.
Pauker SG, Kassirer JP Decision analysis. N Engl
J Med. 1987;316:250-8.
Peace KE. The alternative hypothesis: one-sided or
two sided? J Clin Epidemiol. 1989; 42: 473-6.
Peterson HB, Kleinbaum DG. Inteфreting the
literature in obstetrics and gynecology: II. Logistic
regression and related issues. Obstet Gynecol.
1991;78:717-20.
Phelps CE, Mushlin AI. On the (near) equivalence
of cost-effectiveness and cost-benefit analyses.
Int J Technol Health Care. 1991; 7:12-21.
Pious S. The Psychology of Judgment and Decision
Making. New York: McGraw-Hill; 1993.
Pocock SJ, Hughes MD, Lee RJ. Statistical
problems in the reporting of clinical trials: a survey
of three medical journals. N Engl J Med. 1987;
317:426-32.
Prihoda TJ, Schelb E, Jones JD. The reporting of
statistical inferences in selected prosthodontic
journals. J Prosthodont. 1992; 1:51-6.
Raju TN, Langenberg P, Sen A, Aldana O. How
much "better" is good enough? The magnitude
of treatment effect in clinical trials. Am J Dis
Child. 1992;146:407-11.
RansohoffDF, Feinstein AR. Problems of spectrum
and bias in evaluating the efficacy of
diagnostic tests. N Engl J Med. 1978; 299: 926-30.
Raskob GE, Lofthouse RN, Hull RD.
Methodological guidelines for clinical trials evaluating new
therapeutic approaches in bone and joint
surgery. J Bone Joint Surg. 1985; 67-A: 1294-7.
Raykov T, Tomer A, Nesselroade JR. Reporting
structural equation modeling results in
Psychology and Aging: some proposed guidelines.
Psychol Aging. 1991; 6: 499-503.
Redelmeier DA, Rozin P, Kahneman D.
Understanding patients' decisions; Cognitive and
emotional perspectives. JAMA. 1993; 270:72-6.
Reed JF, Slaichert W. Statistical proof in
inconclusive "negative" trials. Arch Intern Med. 1981;
141:1307-10.
Reid MC, Lachs MS, Feinstein AR. Use of meth-
odologic standards in diagnostic test research.
JAMA. 1995;274:645-51.
Reiffenstein RJ, Schiltroth AJ, Todd DM. Current
standards in reported drug trials. Can Med
Assoc J. 1968; 99:1134-5.
Reizenstein P, Delgado M, Gastiaburu J, et al.
Efficacy of and errors in randomized multicenter
460 Библиография
trials: а review of 230 clinical trials. Biomed
Pharmacotherapy 1983; 37:14-24.
Rennie D. Vive la difference (P < 0.05)! [Editorial].
N Engl J Med. 1978; 299:828-9.
Rennie D. CONSORT revised: improving the
reporting of randomized trials. JAMA. 2001;
285:2007-7.
Reznick RK, Guest CB. Survival analysis: a
practical approach. Dis Colon Rectum. 1989;
32:898-902.
Richardson WS, Detsky AS. Users' guides to the
medical literature. VII. How to use a
clinical decision analysis. A. Are the results of the
study valid? The Evidence-Based Medicine
Working Group. JAMA. 1995; 273:1292-5.
Richardson WS, Detsky AS. Users' guides to the
medical literature. VII. How to use a clinical
decision analysis. B. What are the results and
will they help me in caring for my patients?
The Evidence-Based Medicine Working
Group. JAMA. 1995;273:1610-3.
Riegelman RK, Hirsch RP. Studying a Study and
Testing a Test: How to Read the Medical
Literature, 2nd ed. Boston: Little, Brown; 1989.
Rochon PA, Gurwitz JH, Cheung MC, et al.
Evaluating the quality of articles published in
journal supplements compared with the quality of
those published in the parent journal. JAMA.
1994;272:108-13.
Ross OB. Use of controls in medical research.
JAMA. 1951; 145:72-5.
Rothman AJ, Kiviniemi MT. Treating people with
information: an analysis and review of
approaches to communiating health risk information. J
Natl Cancer Inst Monogr. 1999; 25:44-51.
Rothman KJ. Significance questing [Editorial]. Ann
Intern Med. 1986; 105:445-7.
Rothman KJ. Epidemiology: An Introduction. New
York: Oxford University Press; 2002.
Rothman KJ, GreenlndS, Walker AM. Concepts of
interaction. Am J Epidemiol. 1980; 112:467-70.
Sackett DL How to read clinical journals: V To
distinguish useful from useless or even harmful
therapy. Can Med Assoc J. 1981; 124:1156-62.
Sackett DL. Interpretation of diagnostic data: 5.
How to do it with simple maths. Can Med
Assoc J. 1983; 129:947-54.
Sackett DL, Haynes RB, Guyatt GH, Tugwell P
Clinical Epidemiology; A Basic Science for
Clinical Medicine, 2nd ed. Boston: Little,
Brown; 1991.
Salsburg DS. The religion of statistics as practiced
in medical journals. Am Statistician. 1985;
39:220-3.
SavitzDA. Measurements, estimates, and inferences
in reporting epidemiologic study results
[Editorial]. Am J Epidemiol. 1992; 135:223-4.
Savitz DA, Olshan AF. Multiple comparisons and
related issues in the interpretation of
epidemiologic data. Am J Epidemiol. 1995; 142:904-8.
Savitz DA, Tolo KA, Poole C. Statistical
significance testing in the American Journal of
Epidemiology, 1970-1990. Am J Epidemiol.
1994; 139:1047-52.
Scherer RW, Dicker sin K, LangenbergP. Full
publication of results initially present ed in abstracts:
a meta-analysis. JAMA. 1994; 272:158-62
[Erratum. JAMA. 1994; 272:1410].
Schoolman HM, Becktel JM, Best WR, Johnson AF.
Statistics in medical research: principles versus
practices. J Lab Clin Med. 1968; 71:357-67.
Schor S. Statistical reviewing program for medical
manuscripts. Am Statistician. 1967; (Feb):28-31.
Schor S. Statistical proof in inconclusive "negative"
trials. Arch Intern Med. 1981; 141:1263-4.
Schor S, Karten L Statistical evaluation of
medical journal manuscripts. JAMA. 1966;
195:1123-8.
Schultz KF. Subverting randomization in controlled
trials. JAMA. 1995;274:1457-8.
Schultz KF, Chalmers I, Grimes DA, Altman DG.
Assessing the quality of randomization from
reports of controlled trials published in
journals of obstetrics and gynecology. JAMA.
1994;272:125-8.
Schultz KF, Chalmers I, Hayes RJ, Altman DG.
Empirical evidence of bias: dimensions of
methodological quality associated with estimates of
treatment effects in controlled trials. JAMA.
1995;273:408-12.
Schwartz D, Lellouch J. Explanatory and pragmatic
attitudes in therapeutical trials. J Chronic Dis.
1967;20:637-48.
Schwartz L, Woloshin S, Welch HG. Putting cancer in
context. J Natl Cancer Inst. 2002; 94:799-804.
Schwartz WB, Gorry GA, KassirerJP, EssigA.
Decision analysis and clinical judgment. Am J
Med. 1973;55:459-72.
Библиография 461
Sheehan TJ. The medical literature: let the reader
beware. Arch Intern Med. 1980; 140:472^.
Sheps SB, Schechter MT. The assessment of
diagnostic tests: a survey of current medical
research. JAMA. 1984; 252:2418-22.
Shiffman RN, Shekelle P, Overhage JM, et al
Standardized reporting of clinical practice
guidelines: a proposal from the Conference on
Guideline Standardization. Ann Intern Med.
2003; 139:493-8.
Shott S. Statistics in veterinary research. J Am Vet
Med Assoc. 1985; 187:138^1.
Shuster JJ, Binion J, Walrath N, et al Statistical
review process. Recommended procedures in
biomedical research articles [Editorial]. JAMA.
1976;235:534-5.
Shutty M. Guidelines for presenting multivariate
statistical analyses in Rehabilitation
Psychology. Rehab Psych. 1994; 39:141^.
Siegel J A, Sparks RB. The Biologic Effects of
Radiation and Their Associated Risks, http://
www. internaldosimetry.com/courses/ lay-
mans/linkedpages/compare.html. Accessed
11/8/03.
Siegel JE, Weinstein MC, Russell LB, Gold MR.
Recommendations for reporting
cost-effectiveness analyses. Panel on
Cost-Effectiveness in Health and Medicine. JAMA. 1996;
276:1339-^1.
Simel DL, Feussner JR, Belong ER, Matchar DB.
Intermediate, indeterminate, and uninteфreta-
ble diagnostic test results. Med Decis Making.
1987;7:107-14.
Simes J. Meta-analysis: its importance in cost-
effectiveness studies. Med J Aust. 1990;
153(Suppl):S13-16.
Simmons GH, Fishbein M. The Art and Practice of
Medical Writing. Chicago: American Medical
Association; 1925.
Simon G, Wagner E, VonkorffM. Cost-effectiveness
comparisons using real world randomized
trials: the case of new antidepressant drugs. J
Clin Epidemiol. 1995;48:363-73.
Simon R. Confidence intervals for reporting
results of clinical trials. Ann Intern Med. 1986;
105:429-35.
Simon R, Wittes RE. Methodologic guidelines for
reports of clinical trials. Cancer Treat Rep.
1985;69:1-3.
Simpson RJ, Johnson ТА, Amara lA. The box-plot:
an exploratory analysis graph for biomedical
publications. Am Heart J. 1988; 116:1663-5.
Smith DG, Clemens J, Crede W, et al. Impact of
multiple comparisons in randomized clinical
trials. Am J Med. 1987 ;83:545-50.
Snapinn SM. Noninferiority trials [Commentary].
Curr Control Trials Cardiovasc Med. 2000;
1:19-21.
Sonis J, Joines J. The quality of clinical trials
published in The Journal of Family Practice,
1974-1991. J Fam Pract. 1994; 39:225-350.
Sonnenberg FA, Beck JR. Markov models in
medical decision making: a practical guide. Med
Decis Making. 1993; 13:322-38.
Sox HC Jr Probability theory in the use of
diagnostic tests: an introduction to critical study
of the literature. Ann Intern Med. 1986;
104:60-6.
Spiegelhalter DJ, Myles JP, Jones DR, Abrams KR.
Bayesian methods in health technology
assessment: a review. Health Technol Assess 2000;
4:1-30.
Squires BP. Statistics in biomedical manuscripts:
what editors want from authors and peer
reviewers [Editorial]. Can Med Assoc J. 1990;
142:213-4.
Standards of Reporting Trial Group. A proposal for
structured reporting of randomized controlled
trials. JAMA. 1994; 272:1926-31.
[Correction: JAMA. 1995;273:776.]
Stefadouros MA. A new system of visual
presentation of analysis of test performance: the
double-ring diagram. J Clin Epidemiol. 1993;
46:1151-8.
Stewart LA, Parmar MKB. Bias in the analysis and
reporting of randomized controlled trials. Int J
Tech Assess Health Care. 1996; 12:264-75.
Stoddart GL. How to read journals. VII. To
understand an economic evaluation (Part A). Can
Med Assoc J. 1984; 130:1428-34.
Stoddart GL. How to read journals. VII. To
understand an economic evaluation (Part B). Can
Med Assoc J. 1984; 130:1542-9.
Stoto MA. From data analysis to conclusions: a
statistician's view. In: Council of Biology Editors,
Editorial Policy Committee. Ethics and Policy
in Scientific Publication. Bethesda, MD:
Council of Biology Editors; 1990:207-18.
462 Библиография
Stroup DF, Berlin JA, Morton SC, et al.
Meta-analysis of observational studies in epidemiology:
a proposal for reporting. JAMA. 2000;
283:2008-12.
Sumner D. Lies, damned lies, or statistics? J Hyper-
tens. 1992; 10:3-8.
Sung L, Hoyden J, Greenberg ML, et al Seven
items were identified for inclusion when
reporting a Bayesian analysis of a clinical study
J Clin Epidemiol 2005; 58:261-8.
Testa MA, Simonson DC. Assessment of quali-
ty-of-life outcomes. N Engl J Med. 1996;
334:835-40.
Thompson JR. Invited commentary: re: "muhiple
comparisons and related issues in the 1тефге-
tation of epidemiologic data." Am J Epidemiol
1998; 147:801-6.
Thorton H. Patients' understanding of risk
[Editorial]. BMJ. 2003; 327:693-4.
Timmreck TC. An Introduction to Epidemiology,
2nd ed. Boston: Jones and Bartlett; 1998.
Trobe JD, Fendrick AM. The effectiveness
initiative. I. Medical practice guidelines. Arch
Ophthalmol. 1995; 113:715-7.
Tugwell PX. How to read clinical journals: III. To
learn the clinical course and prognosis of
disease. Can Med Assoc J. 1981; 124:869-72.
Tyson JE, Furzan JA, Reisch JS, Mize SG. An
evaluation of the quality of therapeutic studies in
perinatal medicine. J Pediatr. 1983; 102:10-3.
Udvarhelyi IS, Colditz GA, Rai A, Epstein AM.
Cost-effectiveness and cost-benefit analyses
in the medical literature: are the methods
being used correctly? Ann Intern Med. 1992;
116:238^4.
Vaisrub N. Manuscript review from a
statistician's perspective [Editorial]. JAMA. 1985;
253:3145-7.
van Walraven C, Naylor CD. Do we know what
inappropriate laboratory utilization is? A
systematic review of laboratory clinical audits.
JAMA. 1998;280:550-8.
von Elm E. The STROBE Statement. http://www.
strobe-statement.org/. Accessed July 4, 2005.
Vrbos LA, Lorenz MA, Peabody EH, McGregor
M. Clinical methodologies and incidence of
appropriate statistical testing in
orthopaedic spine literature. Are statistics misleading?
Spine. 1993; 18:1021-9.
Wainapel SF, Kayne HL. Statistical methods in
rehabilitation research. Arch Phys Med Rehabil.
1985;66:322-4.
Wald N, Cuckle H. Reporting the assessment of
screening and diagnostic tests. Br J Obstet
Gynaecol. 1989; 96:389-96.
Walker AM. Reporting the results of
epidemiological studies. Am J Public Health. 1986;
76:556-8.
Walker RD, Howard MO, Lambert MD, Suchinsky
R. Medical practice guidelines. West J Med.
1994; 161:39^4.
Wallenstein S, Zucker CL, Fleiss JL. Some
statistical methods useful in circulation research. Circ
Res. 1980;47:1-9.
Walter SD. Methods of reporting statistical results
from medical research studies. Am J
Epidemiol. 1995;141:896-906.
Ware JH, Mosteller F, Delgado F, et al. P values.
In: Bailar JC, Mosteller F, eds. Medical Uses
of Statistics. 2nd ed. Boston: NEJM Books;
1992:181-200.
Warner KE. Issues in cost effectiveness in health
care. J Public Health Dent. 1989; 49(5 Spec
No):272-8.
WassonJH, SoxHC. Clinical prediction rules. Have
they come of age? JAMA. 1996; 275: 641-2.
Wasson JH, Sox HC, NeffRK, Goldman L.
Clinical prediction rules. Applications and
methodological standards. N Engl J Med. 1985;
313:793-9.
Watts GT. Statistics in journals [Letter]. Lancet.
1991;337:432.
Wears RL. What is necessary for proof? Is 95% sure
unrealistic? [Letter]. JAMA. 1994; 271: 272.
WeechAA. Statistics: use and misuse. Aust Paediatr
J. 1974; 10:328-33.
Weinstein MC. Principles of cost-effective resource
allocation in health care organizations. Int J
Technol Assess Health Care. 1990; 6:93-103.
Weinstein MC, Stason WB. Foundations of cost-
effectiveness analysis for health and medical
practices. N Engl J Med. 1977; 296:716-21.
Weiss GB, Bunce H. Are we ready for statistical
guidelines for medical research papers?
[Letter]. Biometrics. 1979; 35:911.
Weiss W, Dambrosia JM. Common problems in
designing therapeutic trials in multiple sclerosis.
Arch Neurol. 1983; 40:678-80.
Библиография 463
Welch HG. Comparing apples and oranges: Does
cost-efifectiveness analysis deal fairly with
the old and young? Gerontologist. 1991;
31:332-6.
Welch HG. Should I Be Tested for Cancer? Maybe
Not and Here's Why. Berkeley: University of
California Press; 2004.
West RR. A look at the statistical overview (or
meta-analysis). J R Coll Physicians Lond. 1993;
27:111-5.
White SJ. Statistical errors in papers in the British
Journal of Psychiatry. Br J Psychiatry. 1979;
135:336-42.
Whiting P, Rutjes AWS, Dinnes J, et al
Development and validation of methods for assessing
the quality of diagnostic accuracy studies.
Health Technol Assess. 2004; 8:1-234.
Wills CE, Holmes-Rovner M. Patient
comprehension of information for shared treatement
decision making: state of the art and future
directions. Pat Ed Counsel. 2003; 50:285-90.
Wilson A, Henry DA. Meta-analysis. Part 2:
Assessing the quality of published meta-analyses.
MedJAust. 1992; 156:173-87.
Wilson MC, Hayward RS, Tunis SR, et al. Users'
guides to the medical literature. VIII. How to
use clinical practice guidelines. B. What are
the recommendations and will they help you in
caring for your patients? The Evidence-Based
Medicine Working Group. JAMA. 1995;
274:1630-2.
Witzig R. The medicalization of race: scientific
legitimization of a flawed social construct. Ann
Intern Med. 1996; 125:675-9.
Working Group on Recommendations for
Reporting Clinical Trials in the Biomedical
Literature. Call for comments on a proposal to
improve reporting clinical trials in the biomedical
literature: a position paper. Ann Intern Med.
1994;121:894-5.
WulffHR. Confidence limits in evaluating
controlled therapeutic trials [Letter]. Lancet. 1973;
2:969-70.
WulffHR, Andersen B, BrandenhoffP, Guttler E.
What do doctors know about statistics? Stat
Med. 1987;6:3-10.
Wurman RS. Information Anxiety: What to Do
When Information Doesn't Tell You What You
Need to Know. New York: Bantam Books;
1990.
Yancy JM. Ten rules for reading clinical
research reports [Editorial]. Am J Surg. 1990;
159:553-9.
Young MJ, Bresnitz EA, Strom BL. Sample size
nomograms for inteфreting negative clinical
studies. Ann Intern Med. 1983; 99:248-51.
YusufS, WittesJ, Probs0eldJ, Tyroler HA.
Analysis and interpretation of treatment effects in
subgroups of patients in randomized clinical
trials. JAMA. 1991; 266:93-8.
Zelen M. Guidelines for publishing papers on
cancer clinical trials: responsibilities of editors
and authors. J Clin Oncol. 1983; 1:164-9.
Zitter Group. Outcomes Backgrounder: An
Overview of Outcomes and Pharmacoeconomics.
San Francisco: The Zitter Group; 1994:1-56.
Zivin JA, Bartko JJ. Statistics for disinterested
scientists. Life Sci. 1976; 18:15-26.
464
Предметный указатель
25-й процентиль, 37
75-й процентиль, 37
95%-й доверительный интервал, 19, 58, 76,
105, 107, 112, 116
95%-й доверительный интервал для
отношения рисков, 61, 135
95%-й доверительный интервал для
отношения шансов, 61, 113, 114, 116, 118,
265,
ANOVA, 19, 70, 79, 80, 81, 83, 101, 120-
126, 301, 319, 331, 382, 391, 393, 397,
401,428^30,436
ANOVA повторных измерений, 70, 428
ANOVAc повторными измерениями, 122,
124
ARR, 286, 374
ASSERT, 185,216,438,458
BMDP, 72, 108, 126,429
CART, 303
Cochrane Collaboration, 199, 270, 440, 450
Comprehensive Meta-Analysis, 260
CONSORT, 180, 181, 206, 215, 218, 438,
450, 452, 458, 460
Df (degrees of freedom), 75, 92, 113, 426
DOI, 185
EMBASE, 252
Epi Meta, 260
ICMJE, 184,438
LSD-метод, 83, 396, 397
MAIPD, 268, 396
MEDLINE, 252, 253, 261
Meta-Analyst, 260
MOOSE, 180,249,439
NNH, 50
NNT, 50, 286, 374, 425
NPV, 145
Post hoc анализ, 83, 376
PPV, 145
PRISMA, 439
QALY, 273, 280, 284, 288, 289, 380, 403,
426
QUOROM, 180, 181, 249, 439
RevMan, 260
ROC, ROC-кривые, 12, 144, 147, 148, 282,
301,303,370,412,430
RRR, 286, 403
SAS, 72, 108, 126,260,430
SD, 140,417,436
SEM, 32,418,419
S-PLUS, 163
SPSS, 72, 108, 126,430,465
STARD, 136, 154, 180, 181, 439, 450
STATA, 260
StatSoft, 72, 108, 126
STROBE, 180, 181, 225, 233, 246, 438, 462
TREND, 18, 88, 180, 181, 378, 438, 451,
455, 457,
U-критерий Манна—Уитни, 70, 391, 437
WinBUG, 163,260
Winbugs, 260
A.
Lбcoлютнaя разность, 210
Абсолютный риск, 44, 45, 51-53, 374, 415
Агент, 166,304,406
Актуальность темы исследования, 214
Алгоритм Метрополиса—Гастингса, 163
Альтернативная гипотеза, 49, 184
Альфа Кронбаха, 91, 143, 374
Анализ времени до наступления отказа,
127
Анализ выживаемости, 127, 129, 130
Предметный указатель 465
Анализ выживания Каплана—Мейера,
128, 129, 131-133, 176, 331, 370, 375,
385, 396, 397, 437
Анализ минимизации стоимости, 272, 375,
427
Анализ полезной стоимости, 273, 278, 427
Анализ пропорциональных рисков Кокса,
134,223,375,414
Анализ рентабельности, 273, 375, 427
Анализ решений, 271, 292, 293, 295-299,
302, 307, 375, 439
Анализ стоимости, 272, 273, 278, 376, 424
Анализ стоимости болезни, 273, 376 292
Анализ стоимости последствий, 273, 376
Анализ текущей стоимости, 376
Анализ чувствительности, 204, 231, 287,
305, 376
Анализы подгрупп, 79, 84,203, 231,251,445
Аномальные данные, 103, 140, 141
Апостериорная (или послетестовая)
вероятность заболевания, 151, 159, 162,
163,301,376
Априорная (или претестовая) вероятность
заболевания, 150, 151, 158, 162,301,
376,377,410
Ассоциация, 89, 297, 434
Атрибутивный риск, 383
Величина эффекта, 183, 256, 258, 268, 269,
330,378,418,419
Вероятностные методы, 282
Вероятностный анализ чувствительности,
204,231,287,305,376
Вероятность выживания, 177
Версии, 12, 306
Вертикальная шкала, 334
Взвешивание затрат и результатов
лечения, 7, 271
Визуальные аналоговые шкалы, 280
Власов В. В., 199,465,
Влияние вмешивающихся факторов, 199,
200
Вмешивающиеся факторы, 190, 199, 440,
465
Внешняя валидность или обобщаемость,
241,379
Внешняя валидность метода измерения,
240,379,401
Внутренняя валидность, 240
Восприятие показателя риска, 51
Временная практическая рекомендация,
306
Выбор статистических процедур, 179
Выбросы, 32, 33, 72, 103, 107, 110, 114,
117, 126, 212, 224, 233, 245, 355, 379
Вычисление мощности, 202
Х-1айесовская статистика, 156, 157, 161,
163
Байесовские коэффициенты и отношения
правдоподобия, 158
Байесовский коэффициент, 159
Байесовский метод, 149
Байесовский подход, 156, 157, 158
Бимодальное распределение, 31, 398
Биометрика, 13,467
Биометрия, 467
Биостатистика, 16, 17, 25, ПО, 166
Больничная контрольная группа, 229
в
алидность содержания, 241, 378
X ауссово определение нормы, 139, 140
Генератор выборок (ресэмплинг) Гиббса,
163
Географические области, 166, 168
Гетерогенный доверительный интервал,
58
Гистограмма, 360, 362, 380, 408
Горизонтальная шкала, 334
График «ящик-с-усами», 355
Графики, 311, 312, 333-337, 341, 345, 350,
352, 355, 369
Графики остатков, 103, 106, 360, 366, 369
Графики с двумя различными
вертикальными осями, 352
466 Предметный указатель
Графический блок Тьюки, 32, 33, 355, 356,
370
Группирование в блоки, 191
Группы, 29, 31, 37, 43, 52, 58, 60 67, 70 73,
80, 82-86, 92, 110, 120-125, 128, 132,
153, 166, 173, 187, 192, 193, 198 202,
207, 208, 221, 222, 229, 230, 314, 357,
366
Данные, 10, 12, 13, 28, 29, 30, 31, 32,
35, 36, 37, 38, 48, 58, 70, 72, 73, 82, 89,
90,95
Данные для систематических обзоров и
метаанализа, 252
Двусторонний критерий, 66, 69, 71
Двухфакторный ANOVA, 121,428
Дедуктивная статистика, 62
Деления шкалы, 335, 341, 348
Демографические особенности, 130
Дерево решения, 294, 295, 303
Десятичные числа, 435
Детерминированный анализ
чувствительности, 305
Диагностическая точность, 144, 145, 149,
381
Диагностические критерии, 439
Диагностическое определение нормы, 139
Диагностическое отношение шансов, 145
Диаграмма L'Abbe, 266, 267
Диаграмма Тьюки, 32, 33, 355, 356, 370
Диаграммы, 32, 33, 97, 107, 206, 260, 263,
311, 312, 333, 334, 336, 337, 339, 342,
352,354,355,356,357,361,380
Диаграммы рассеяния, 107, 355
Дивергентная или дискриминантная ва-
лидность, 241
Дисконтирование, 278, 287, 299, 300, 376,
382
Дисперсионный анализ, 12, 19, 70, 75, 83,
120, 121, 382, 388, 428, 429, 437, 464,
467, 470
Дистрибутивное правосудие, 300
Дифференциальное смещение
воспроизведения, 231, 444
Доверительная вероятность, 59
Доверительные интервалы, 35, 57-64, 74,
77,99, 109, 118, 135, 143,210,211,224,
232,245,260,313,330,
Доверительный интервал, 19, 57-64, 92, 98,
105, 107, 112, 116, 162, 211, 330, 382
Доверительный интервал для
коэффициента корреляции, 98
Доля, 30, 42, 47, 73, 93, 110, 112, 134, 137,
145, 147, 169-172,
190, 211, 378, 383, 384, 386, 389, 392, 393,
394,403,409,414,418,426
Доля истинно положительных, 145, 146,
425
Доля ложноотрицательных, 145, 146
Доля ложноположительных, 144, 145, 146,
147, 148, 302, 412, 425
Доля популяции, пораженная болезнью,
137, 145
Дополнительный риск, 45
Допущения регрессионного анализа, 106,
113
Достигнутое р-значение, 98,
Достоверность, 23, 64, 80
-L/жи Нейман, 64
Естественная частота, 44, 49, 383
Оатраты, 151, 153, 154, 272-278, 281,
282, 283, 286, 287, 289, 298, 299, 307,
382, 407
Значение статистики критерия, 74, 92, 95,
102,113,390-395
Значенияр, 95, 128, 135
Из
[звлечение данных, 243, 254
Инвазивность, 154,
Индекс научного цитирования, 252
Индикаторные переменные, 117
Инкрементные отношения затрат-исходов,
282, 283, 285
Предметный указатель 467
Интерквартильная широта, 32, 33, 37, 96
Интерпроцентильные широты, 37
Информирование о выборе методов
лечения, 7, 292
Исследования «случай-контроль», 226-
227, 262, 300
Исследовательская проблема, 186
Истинно отрицательные результаты, 144
Истинно положительная вероятность, 147
Истинно положительные результаты, 144
Источники систематических ошибок, 199,
222,231,242
к
.аппа-статистика, 91, 143, 204, 211, 386
Категориальные данные, 30, 333, 352, 354,
386, 399, 406, 409
Качество жизни, 23, 135, 235,279, 280,
281,380,386,395,396
Качество исследования, 262
Квадрат коэффициента корреляции, 102,
388
Квадратура Гаусса, 163
Классическая проверка гипотез, 157
Клиническая важность, 22
Клиническая компонента, 138
Клиническая эпидемиология, 166, 271,
386
Клинические особенности, 84
Клиническое применение теста, 148
Ключи или легенды в поле данных, 334
Ковариационный анализ, 19, 122, 387, 428
Когорта, 220, 221, 385, 387
Когортные исследования, 20,
Количественное описание риска, 51
Количество нуждающихся в лечении, 44,
46,49,53,210,286,298
Коллинеарные переменные, 112
Компонента сопутствующих заболеваний,
139
Компоненты и типы таблиц, 314
Конвергентная валидность, 241, 378, 387,
410
Конструктивная валидность, 241, 387
Контекст, 21, 54, 58, 65, 100, 179, 182, 199,
205, 214, 225, 233, 245, 266, 288, 297,
307,311,312,320,321,338
Контрольная группа, 121, 125, 229, 315
Конференции согласия, 299
Корреляционная матрица, 98, 331
Корреляционный анализ, 96, 97
Корреляция, 12, 89, 91, 96-98, 105, 211,
240, 378, 379, 388, 389, 395, 437, 466
Косвенный подход, 278, 279, 388
Коэффициент (р, 90, 94, 389
Коэффициент вариации, 19, 36, 388
Коэффициент детерминации, 102, 104-106,
388,389,413,436
Коэффициент корреляции, 61, 89, 91, 96,
97, 98, 104-106, 240, 378, 379, 388,
389, 395, 422, 436,437
Коэффициент корреляции Пирсона, 91, 96,
388, 436
Коэффициент ранговой корреляции Кен-
даллаг, 96, 389
Коэффициент ранговой корреляции Спир-
мена/?, 96,437
Коэффициент регрессии, 104, 109, 114,
135,377,389
Коэффициенты заболеваемости и
смертности, 173
Кривая «результат-стоимость», 285
Кривая затрат-исходов, 285
Кривая Каплана—Мейера, 129, 132, 370,
375,389
Кривые выживаемости, 127
Кривые затрат-результатов, 301
Критерии соответствия, 190, 221, 228, 231,
237
Критерий %, 90
Критерий Бартлетта, 377
Критерий Бреслоу, 133, 392, 401, 437
Критерий Вальда, 109, 114, 116, 135,420
Критерий долей хи-квадрат, 94
Критерий знаков, 70, 390, 392, 437
Критерий знаков Уилкоксона, 390, 392
Критерий Колмогорова—Смирнова, 106,
123,392,467
468 Предметный указатель
Критерий Крамера—Смирнова—фон Ми-
зеса, 106
Критерий Краскела—^Уоллиса, 70, 437
Критерий Левене, 123
Критерий МакНемара, 70, 391, 437
Критерий независимости хи-квадрат, 93
Критерий Пирсона хи-квадрат, 90
Критерий полезности диагностического
теста, 125
Критерий ранговых сумм Уилкоксона, 391,
392, 430, 436, 437
Критерий согласия хи-квадрат, 93, 106,
392,418
Критерий Стьюдента, 66, 70, 75, 80, 330,
415,419,426,430,437,467
Критерий Уилкоксона, 133, 392, 401,
437
Критерий хи-квадрат, 70, 75, 92-94, 201,
392, 393, 407, 426, 436, 437
Критерий Хосмера—^Лемешова, 106
Критерий Шапиро—Уилка, 123
Критический уровень значимости, 66, 76,
123
Критический уровень значимости альфа
(а), 76
Кросс-произведение, 48, 393
Круговые диаграммы, 337, 354, 355
Кумулятивный метаанализ, 267, 268
Кумулятивный метаанализ по методу
Мантеля—Хэнзеля, 268, 437
Кунсткамера, 23
л.
Lecнaя диаграмма, 260, 265
Летальность, 172, 210, 394
Лечение по одному, 188
Лимитирующие факторы испытания, 215,
225
Линейные модели, 301
Линейный график, 358, 365
Линейный регрессионный анализ, 102,
103, 105,413,469
Линии регрессии метода наименьших
квадратов, 362
Линия регрессии, 102, 104, 105, 107, 108,
269, 394
Логистический регрессионный анализ,
113,116,231,394,414
Лог-ранговый критерий, 437
Лог-ранговый критерий Кокса—Мантеля,
133,390,437
Ложноотрицательные результаты, 144,
146, 154
Ложноположительные результаты, 144,
146, 154
Ложные включения, 203
Лучший случай, 287
м.
1аксимальная допустимая разность,
201
Марковский процесс, 301
Математические символы, 7, 436
Медиана, 31, 32, 35, 37, 73, 82 ,96, 128,
129, 132, 211, 240, 263, 313, 390, 395,
400,402,417,425,428
Межгрупповая изменчивость, 120,
Международный комитет редакторов
медицинских журналов, 184
Межоценочная надежность, 137
Мера множественной детерминации, 106,
109,389
Мера полезности, 136, 273, 278, 280, 281,
301, 302, 304, 369, 380, 396, 397, 403,
420
Многомерный дисперсионный анализ,
121,464
Меры ассоциации, 92, 374, 446,
Меры рассеяния, 32, 263
Меры согласия, 91, 105, 115, 118
Меры согласия моделей с данными, 115,118
Меры центральной тенденции, 32,
Метаанализ, 7, 12, 20, 74, 101, 161, 180,
185, 248-269, 282, 370, 376, 378, 394,
395, 396, 398, 402, 415, 416, 418, 420,
439, 448
Метаанализ с дихотомическими исходами,
257
Предметный указатель 469
Мета-регрессионный анализ, 258, 269, 396
Мета-регрессия, 101, 269
Метки, 31, 33, 39, 90, 91, 163, 263, 311,
312, 334, 339, 341, 345, 347, 352, 353,
368, 407
Метки для шкалы, 33, 39, 90, 91, 334, 339,
341,347,352,353,368,407
Метод «пределов согласия», 142
Метод «скользящего среднего», 361
Метод Берксона—Гейджа, 176, 396, 397
Метод Бланда—^Альтмана, 92, 142, 143
Метод Каплана—Мейера, 131, 176, 375,
396, 397
Метод Катлера—Эдерера, 131, 176, 396
Метод множительных оценок, 131
Метод наименьшей значимой разности
Фишера, 83, 396
Метод складного ножа, 107, 126, 411
Метод таблиц выживания, 131, 396, 397,
421
Метод таблиц смертности, 176
Методика компромиссов времени, 281, 300
Методика персональных компромиссов,
281
Методики Монте-Карло для марковских
цепей, 163, 302, 398,
Методы эконометрики, 464
Метод наименьших квадратов (МНК), 362,
363, 394
Многомерные данные, 355, 360, 361
Многоцентровое испытание, 188
Множественная логистическая регрессия,
101,397
Множественные попарные сравнения, 80,
82
Множественные сравнения, 79, 80, 86, 123
Множественный линейный регрессионный
анализ, 108,413
Многофакторный ANOVA, 121,428
Мода, 31, 32, 240, 398, 400, 425
Модальное значение, 31
Модели пропусков, 110
Модели регрессии, 101, 105
Моделирование Монте-Карло, 398
Модель случайных эффектов, 259, 398
Модель фиксированных эффектов, 259, 398
Модификация эффекта, 440
Мониторинговый тест, 138
Мультиколлинеарность, 112, 118,387
На
1аблюдательные исследования, 438
Надёжность, 11, 86, 137, 142, 144, 153, 188,
240, 241, 379, 395, 399, 401, 416
Надёжность «от теста к тесту», 142
Надёжность теста, 142
Национальные институты здоровья, 184
Невязка, 106
Недостающие данные, ПО, 203
Независимость пациента, 300
Независимые выборки, 70, 399
Неинтерпретируемые результаты, 143
Неопределённые результаты, 143
Непараметрические статистические
критерии, 399, 406, 470
Непараметрический критерий, 70
Непрерывные данные, 31, 3295, 201, 333,
355, 382, 400
Нерандомизированные испытания, 82, 180,
125,438,442
Нереспондентное смещение, 441
Нецензурированные данные, 130, 400
Неухудшение, 183, 201, 202
Низкая статистическая мощность, 23, 66,
67, 68, 69, 86, 192, 377, 398, 405, 409,
420, 436
Номинальные данные, 30, 352, 386, 400
Нормальное (гауссово) распределение, 35,
379,410,419
Нормальное распределение в медицине, 34
Нормальность распределения, 400, 430
Нулевая гипотеза, 61, 65-68, 82, 124, 133,
135, 157, 158, 186,374,400,401
Ое
Обобщение и анализ данных, 254
Обоснованность, 73, 141, 163, 240, 241,
249,306,387,401
470 Предметный указатель
Обоснованность допущений, 73
Обоснованность по соответствию
критерию, 241, 387
Общая когортная смертность, 173
Общий обзор реестра, 227, 237
Объяснительные исследования, 190
Однофакторный дисперсионный анализ, 70
Однофакторный дисперсионный анализ
Фридмана, 70
Ожидаемые результаты, 240
Округление чисел, 29, 323, 324, 350
Операционное определение, 196, 197, 402
Описательная статистика, 28, 419
Определение по факторам риска, 139
Определение стадии заболевания, 138
Оптимальный объем информации, 256
Ослепление, 381, 394, 402,444,
Относительная разность, 47, 54, 73, 210,
403
Относительная разность рисков, 47,403
Относительный риск, 43-51, 53, 393, 403
Отношение, 29-30, 41^9, 52, 53, 58, 61,
72,85,99, 112, 113-116, 128, 130, 135,
137, 145, 146, 148, 151, 159, 173, 175,
189, 192, 222, 251, 256, 257, 264, 265,
268, 283, 285, 290, 345, 383, 400, 403,
404,419,424
Отношение правдоподобия, 137, 145, 146,
148,151,159,377,400,403
Отношение рисков, 43, 45, 47, 49, 52, 128,
135,257,403,404
Отношение частот, 42, 43, 404
Отношение шансов, 44,47-49, 52, 61,
113-116, 145, 256, 257, 264, 265, 268,
269,383,393,404,414
Отношения затрат-исходов, 282-285
Отсутствие отличий, 76
Отчет о байесовских статистических
анализах, 6, 156, 157, 159, 161, 163
Отчет о непрерывных данных, 32
Отчет о парных данных, 37
Отчет о показателях риска, 6, 41, 43,45,
47,49,51,53,55
Отчет о преобразованных данных, 38
Отчет о простой логистической регрессио-
ной модели, 114
Отчет о рандомизированных
контролируемых испытаниях, 7, 182-217
Отчет о регрессионном анализе, 6,
100-119
Отчет о характеристиках проведения
диагностических тестов, 6, 136-155
Отчет об анализе выживаемости, 6,
127-135
Отчеты о когортных или лонгитюдиналь-
ных исследованиях, 219-225
Отчеты о рандомизированных
контролируемых испытаниях, 219, 226, 235
Отчеты о систематических обзорах и ме-
таанализе, 248-269
Отчеты об исследованиях
«случай-контроль», 7, 20, 47, 48, 181, 220, 226-233,
262, 300, 385, 404, 414, 417, 441, 443
Отчеты об обследованиях или поперечных
исследованиях, 235-245
Отчеты об эпидемиологических
показателях, 6, 165-177
Отчеты по надзору, 236
Оценка ожидаемой продолжительности
жизни, 176
Оценка степени клинической
эффективности лечения, 287
Оценки статистик, 60
Оценки характеристик, 62
Оценочные шкалы, 280
Ошибка, 36, 106, 109, ИЗ, 114, 116, 125,
126, 134, 135, 163, 166, 195, 199, 200,
202, 209, 215, 245, 339, 342, 364, 374,
377,388,416-418,436
Ошибка Берксона, 441
Ошибка второго рода, 378, 405
Ошибка выборочного обследования, 404,
405, 440
Ошибка измерения, 404, 405, 440, 444, 446
Ошибка классификации, 222
Ошибка объединения, 142
Ошибка отбора, 194, 222
Ошибка памяти, 231, 242, 243
Предметный указатель 471
Ошибка среднего, 19, 32, 62, 419
Ошибки измерения, 57
Ошибки классификации, 228
Ошибки статистического анализа в
медицине, 37
п,
1арадокс Симпсона, 441,447
Параклинические особенности, 130
Параметр генеральной совокупности, 32,
33, 34, 67, 82
Параметрические критерии, 36-38, 70, 73,
135, 305, 399, 406, 415, 466, 469, 470
Парные выборки, 70, 192, 406
Парный t-критерий, 70,406
Патологическая компонента, 138
Патофизиологические исследования, 184
Первичное сравнение, 186,213,407
Первичные и вторичные предикторные,
объясняющие признаки, 251
Перекрестное испытание, 406
Переменная отклика, 47, 100, 103, 109,
110, 113, 116, 124, 222, 315, 377, 378,
383, 385, 387, 390-395, 406, 413, 414,
422, 428-430
Переносчик, 166, 406
Период отслеживания, 198, 407
Платежи, 277,278
Плацебо, 41, 50, 84, 121, 157, 158, 183, 187,
194-196, 204, 253, 286, 321, 367, 374,
380, 399, 407, 416, 427, 428, 444, 447
Погрешность, 144, 440
Подбор или спаривание, 190
Подгрупповые анализы, 214
Подстановки значения группового
среднего, 212
Подход «готовность к оплате», 279
Показатели эффективности, 49-53, 60, 210
Поле данных, 314, 315, 334, 335, 338-340,
345, 347, 352, 357
Поле эквивалентности, 183
Полезность, 50, 63, 140, 143, 149, 152, 214,
273, 280, 281, 284, 286, 298, 300, 336,
380, 384, 403
Полезность результата теста, 149
Полиномиальная регрессия, 101
Полный байесовский анализ, 161
Полулогарифмический график, 358, 365
Поперечные исследования, 235, 438
Поправка Бонферрони, 81, 83,437
Популяция, 6,44, 140 ,143, 165-167, 173-
175, 184, 189, 203, 207 ,208, 235, 240,
251, 261, 266, 275, 294, 408, 417, 421,
424,427,429,441,447
Популяция высокого риска, 167
Популяция людей, 166
Популяция риска, 167
Пораженность, 171,409
Пораженность пищевого происхождения,
171
Пороговое значение статистической
значимости, 204
Порядковые градации (уровни), 31, 83,
114,393
Порядковые числа, 434,435
Потеря для дальнейшего наблюдения,
222
Пошаговый отбор предикторов, 111
Правдоподобие, 75, 141, 146, 150, 151, 156,
213,257,301,374
Правила для представления чисел в тексте,
7,21,434-435
Правила остановки, 161, 201, 223,409
Правило определения объема выборки,
112
Прагматические исследования, 183, 184
Превалентность, 137, 145
Предикторная переменная, 104-105, 114,
117,222,410
Предпочтение завершающей цифры, 445
Представление значений, групп и
сравнений в графиках, 7, 333-371
Преобразование данных, 38-39, 73, 410,
419
Претестовая вероятность заболевания,
149, 150
Применение односторонних критериев,
71,94,205,223,232,243
472 Предметный указатель
Применение теоремы Байеса в
диагностическом тестировании, 150, 156
Принципы построения таблиц, 316
Проблема множественных сравнений, 6,
79-87
Проверка гипотез, 6, 64-77
Прогностическая валидность, 241, 387,
410
Прогностичности результатов теста, 137,
145, 148, 149, 150
Прогностичность отрицательного
результата, 145, 149, 150
Прогностичность положительного
результата, 137, 145, 149, 150
Промежуточные результаты, 143, 201
Промежуточный анализ, 79, 201, 411
Проспективное когортное исследование,
388,411
Проспективные наблюдения, 7, 219
Простая логистическая регрессия, 101
Простой логистический регрессионный
анализ, 113,414
Простой регрессионный анализ, 100, 101-
108, 394, 413, 465, 466, 468, 469
Процедура Даннетта, 83, 397, 411, 437
Процедура Дункана, 83, 397, 411, 437
Процедура множественных сравнений, 83,
397,411,437
Процедура Ньюмана—Кейлса, 83, 397,
411,437
ПроцедураТьюки, 83, 397, 411, 437
Процедура Шеффе, 83, 397, 411, 437
Процедуры сглаживания, 360
Процедуры складного ножа, 107, 126, 411
Процент, 28-30, 33, 36, 42, 44, 47, 53, 73,
93, 127, 129, 132, 133, 137, 140, 141,
144, 159, 162, 207, 210, 211, 212,240,
260, 261, 263, 302, 303, 305, 313, 326,
327,354,366,389,403,415
Процентиль, 37, 42, 140, 141, 162, 339, 342,
355
Процентильное определение, 140, 141
Процентильное определение нормы, 141
Процентильный ранг, 42
Процесс Дельфи, 299, 412
Психометрические инструменты, 235
Публикационное смещение, 255, 448
Пустые ячейки в таблице, 324
Путеводитель по статистическим
терминам и критериям, 7, 20, 373
1 . Фишер, 64, 83, 84, 396 ,397, 422, 431,
437
Рабочие характеристические кривые, 12,
144, 147, 148, 154, 282, 301, 303, 370
Различия в состояниях пациента, 143
Различия между байесовской и частотной
статистикой, 157
Размах, 32-37, 162, 207, 240, 263, 313, 339,
342, 255, 384, 395, 402 ,412, 413, 420
Разность абсолютных рисков, 45, 47, 53,
257
Разность рисков, 45, 47, 53, 257, 403
Разрядность чисел, 28
Ранговый коэффициент Спирмена, 91
Рандомизированное контролируемое
испытание, 19, 187, 412
Расходы, 152-154,277,278
Расчет показателей риска, 46
Расчет риска смертности, 44
Расчет стандартизованных отношений
смертности, 176
Расширенное открытое испытание, 188
Регрессионная модель пропорциональных
рисков Кокса, 135
Регрессионные модели Кокса, 282
Регрессионный анализ, 100-118, 120, 134,
223, 231, 258, 269, 375, 388, 394, 396,
397, 413, 414, 465, 466, 468, 469
Регрессионный анализ Кокса, 134
Регрессионный анализ пропорциональных
рисков Кокса, 134, 223, 375, 414
Регрессионный коэффициент, 113
Регрессия к среднему, 414, 445
Результаты, 11, 12, 20, 31, 37-39, 49, 51,
57-61, 67, 69-76, 83-86, 103, 105, 107,
111, 112, 116, 121, 123, 124, 132, 143,
Предметный указатель 473
144, 210, 213-215, 224, 225, 228, 232,
233, 244, 245, 248, 266, 268, 286, 288
Результаты двухфакторного
дисперсионного анализа, 125
Результаты кумулятивного метаанализа,
268, 370
Рекомендации для создания поля данных,
338
Рекомендации для составления заголовков,
316,328
Ретроспективное когортное исследование,
385,411,414
Ретроспективные наблюдения, 226
Реципиент, 166, 237
/^-значение, 67, 125
Риск, 6, 20, 40-55, 60-61, 79, 84, 91, 100,
101, 109, 113, 116, 128, 131-135, 138-
139, 159, 165, 167-173, 200, 221, 230,
238, 257, 265, 286, 289, 294, 331 ,347,
374, 375, 383, 393, 395, 401, 403, 404,
407,414,415,416,424,426
Риск смерти, 44, 47, 48, 51, 134, 135, 425
Риск, выраженный вероятностью, 49
Риск, выраженный естественной частотой,
49
РКИ, 19, 82, 179, 181, 182, 185, 187, 204,
249, 267, 294, 300, 306, 375, 388, 412
Рутинный тест, 138
с
/айт БИОМЕТРИКА, 13, 467
Свободный член, 109, 114, 116,
Сезонные и секулярные тренды, 169
Серая литература, 252
Систематические обзоры и метаанализ,
249,251,439
Систематический обзор, 253
Скрининг-тест, 138
Слепой метод, 195
Случайная ошибка, 418
Случайные узлы, 298
Смертность, 172,284
Смешивание, 326, 440
Смещение, 199, 253, 260, 417, 440-448
Смещение Берксона, 441
Смещение в отборе научных работ, 253
Смещение восприимчивости, 443
Смещение воспроизведения, 444
Смещение выживших, 442
Смещение диагностического обзора, 442,
444
Смещение диагностического подозрения,
442
Смещение диагностической проработки,
231
Смещение добровольца, 442
Смещение задержки, 173, 417, 447
Смещение здорового работника, 231
Смещение измерения, 417, 444
Смещение исключения, 445
Смещение исследования, 442
Смещение истощения, 445
Смещение классификации, 231
Смещение объединения, 444
Смещение переноса, 445
Смещение подтверждения, 442
Смещение преимущественного
цитирования, 448
Смещение принадлежности, 441
Смещение прогрессирования болезни,
444
Смещение продолжительности, 444
Смещение фильтра назначений, 231, 417
Смещения в анализе данных, 445
Смещения в интерпретации результатов,
446
Снижение относительного риска, 51
Сокращение относительного риска, 44, 46,
47,51-56
Сообщение о диапазонах количества, 435
Сопутствующие заболевания, 130, 258
Сопутствующий или местный контроль,
229
сое, 19,32-35,62-63, 133
Социальная желательность, 238
Социальное определение нормы, 141
Спаренные данные, 37
Специальные когорты воздействия, 221
474 Предметный указатель
Специфичность, 105-106, 137, 143-154,
385,403,412,418,425,426
Специфичность теста, 105-106, 137, 143-
154, 385, 403, 412, 418, 425, 426
Сплайн-функции, 363
Сравнение вероятностей событий, 6, 41-55
Сравнение групп, 6, 64-76, 79, 84, 86, 123
Среднеквадратичная ошибка, 32, 106
Среднеквадратичная ошибка
коэффициента регрессии, ИЗ
Средний риск заболевания, 170
Средняя стоимость, 284
Стандартное отклонение, 19, 32, 34, 62,
106,388,418,419,420,436
Стандартизованное отношение
смертности, 175
Стандартная гистограмма, 360
Стандартная популяция, 166, 174, 175
Стандартные описательные статистики, 38
Стандартные рисунки, 366
Статистика критерия, 92, 95, 113, 135, 414,
420, 422
Статистика критерия Вальда х2, 109, 114,
116
Статистика критерия Стьюдента, 66, 70,
75, 80, 330, 415, 419, 426, 430, 437, 467
Статистика F-критерия, 125
Статистическая достоверность, 23
Статистическая значимость, 22, 59, 64,
263,266,383,410,420
Статистическая мощность, 23, 66-69, 86,
192, 377, 398, 405, 409, 420, 436
Статистическая мощность критериев, 69
Статистическая неоднородность, 420
Статистически значимые различия, 23, 82,
123
Статистически значимый, 64, 200, 265, 445
Статистически неотличимый, 76
Статистические критерии прекращения,
86
Статистические методы, 10, 12, 13, 66, 68,
70, 93, 127, 163, 200, 201, 222, 223,
231, 243, 248, 259, 301, 465-470
Статистические пакеты, 72, 75
Статистические прикладные программы,
72, 205
Статус воздействия, 222
Степени свободы, 92
Стратифицированная выборка, 191, 421
Схема рандомизированного клинического
испытания, 207
т,
аблица выживаемости, 134, 331
Таблица сопряжённости, 94, 331, 421
Таблицы, 12, 20, 93-95, 175-177, 194, 260,
264, 301, 311, 312, 313, 314, 316, 317,
320-324, 326, 330, 331, 352, 414, 416,
465, 468
Таблицы решений, 301
Таблицы смертности, 176
Табличное представление данных и
статистик, 7, 313-331
Теорема Байеса, 156, 376, 409, 410, 421
Терапевтическое определение нормы,
139-14
Тест для постановки диагноза, 138
Типы затрат, 277-278
Томас Байес, 156
Точечная диаграмма, 352, 353, 355, 370,
421
Точечно-бисериальный коэффициент
корреляции, 96
Точечно-мультисериальный коэффициент
корреляции, 97
Точки деления, 31, 144, 146-147, 412, 422
Точность оценок, 74, 104, 135
Точные критерии, 94
Точный критерий Фишера, 94,422
у.
гловой коэффициент линии
регрессии, 102, 104-105,
Узлы решения, 298, 303
Уменьшение абсолютного риска, 44,46,
51,52
Уравнение линейной регрессии, 104
Уравнение логистической регрессии, 115
предметный указатель 475
Уравнение множественной логистической
регрессии, 118
Уровень значимости, 64-71, 76, 80-81, 86,
123, 202, 204, 223, 232, 410, 422
Уровень значимости альфа, 65, 68, 76, 80-
81, 86, 123, 202, 204, 223, 232, 410, 422
Уровень статистической значимости, 38,
68, 243
Условия публикации в JAMA, 185
Условия, при которых производятся
измерения, 168
Установление эквивалентности групп, 79,82
Ф.
акторное испытание, 187
Факторы риска, 165, 221, 229, 230, 238
Фармакоэкономика, 271,424
Фиксированные когорты, 221
Функции таблиц, 313
Функция правдоподобия, 159, 160, 377,424
Характеристики диагностических тестов,
150
Характеристическая (операционная)
кривая, 370
Хи-квадрат Пирсона, 93,436
Худший случай, 287
I ^ели анализа решений, 297
Цель обзора, 249
Цель создания реестра, 227, 237
Цель таблицы, 316, 323
Цензурированные данные, 130, 380, 381,
400, 425
Цензурированные наблюдения, 101
LacTOTa, 16, 30, 41, 42, 44, 46, 49-53, 69,
89, 95, 131, 132, 144, 145, 165, 169-176,
198,209,228,239,256
476
06 авторах
ТомасА.Ланг
Томас Ланг стал техническим, или точнее, медицинским писателем, в 1975 г. С 1990
по 1998 т. был менеджером службы медицинского редактирования для Кливлендской
клиники, основанной в Кливленде, штат Огайо. Оставил клинику, чтобы работать старшим
научным автором в Кохрановском Центре в Новой Англии и Центре доказательной
медицинской практики при Медицинском центре Новой Англии / Тафтской медицинской
университетской школе в Бостоне, штат Массачусетс. Теперь он независимый консультант,
инструктор и преподаватель научной и медицинской публикации.
Как руководитель Центра коммуникаций и тренинга, Томас Ланг читает лекции по всей
Северной Америке, Европе, Японии и Китаю и оказывает услуги по редактированию
медицинских публикаций врачам и исследователям во всех отраслях медицины. Другие его
проекты включали выполнение систематических обзоров; он проектирует учебные планы для
университетских программ медицинских коммуникаций в Соединенных Штатах, Японии
и Китае и участвует в работе CONSORT, QUOROM и в комитетах MOOSE, которые
разрабатывают стандарты для отчетов по медицинским исследованиям.
Его преподавательская способность была признана Школой Грэма общих исследований,
Университета Чикаго, который в 2005 г. наградил его знаком «Мастер обучения» первой
степени за его инструкцию по программе медицинской публикации и редактирования;
Американской медицинской ассоциацией авторов, от которой он получил в 1994 г. знак
«Золотое яблоко» за выдающееся руководство семинаром; и Американской статистической
ассоциацией, которая наградила его в 2002 г. знаком «Отличник послевузовского образования».
Преподавал для Американской ассоциации медицинских авторов, европейской Ассоциации
медицинских авторов. Совета научных редакторов и японской Ассоциации медицинских
коммуникаторов.
Томас Ланг — бывший председатель Совета научных редакторов, член американской
Ассоциации медицинских авторов и получил в 2002 г. премию Свонберга за выдающийся
вклад в области медицинской публикации. Также преподавал в Университете Чикаго
программу сертификации по медицинской публикации и редактированию с момента ее
основания в 1999 г. и является адъюнкт-профессором биомедицинской публикации при
Университете Филадельфии, самом старом национальном фармацевтическом колледже.
Получил степень магистра по менеджменту коммуникации в Школе коммуникаций Ан-
ненберг Университета южной Калифорнии. Живет в Дэвисе, штат Калифорния.
С ним можно связаться по электронной почте: tomlangcom@aol.com
06 авторах 477
МишелльСесик
Мишелль Сесик работает старшим биостатистиком и президентом компании «Secic
Statistical Consulting, Inc», которая оказывает статистическую поддержку множеству
медицинских научно-исследовательских работ по всему миру. Проекты колеблются от анализа
небольших наборов данных до больших клинических испытаний, включающих исследования
препаратов или медицинских устройств.
Биостатистик в Кливлендской клинике с 1990 по 2001 гг., она служила ассоциированным
руководителем группы биостатистиков и позже менеджером исследовательской секции
Центра трансплантации.
В 2001 г. оставила клинику, чтобы развивать консультационную компанию. В дополнение
к статистической консультации, Мишелль Сесик является членом Американской
статистической ассоциации, обеспечивает официальные статистические обзоры для медицинских
журналов и является статистиком-консультантом на дискуссионном форуме клинических
методик (http://www.clinicaldeviceforum.com).
Получила степень магистра по прикладной статистике в 1990 г. в государственном
Университете Bowling Green. Живет в Чардоне, штат Огайо, с мужем Джоном и двумя
дочерьми, Стефани и Николь.
С нею можно связаться через сайт http://www.secicstats.com
Научно-практическое издание
Томас А. Ланг
Мишелль Сесик
Как описывать статистику в медицине
Главный редактор, канд. мед. наук Д.Д. Проценко
Научн. редактор, канд. тех. наук В.В. Леонов
Выпускающий редактор Ю. Л. Захарова
Корректор Т. Е. Белоусова
Компьютерная верстка СИ. Терехов
Подписано в печать 24.09.2010 г.
Формат 70x100/16. Физ.печ. листов 30.
Гарнитура типа «Тайме». Бумага офсетная. Печать офсетная.
Тираж 1500. Заказ 3803.
Отпечатано в ОАО «Можайский полиграфический комбинат».
143200, г. Можайск, ул. Мира, 93.
www.oaompk.ru, www.oaoмпк.pф тел.: (495) 745-84-28, (49638) 20-685
Сан.-эпид. заключение
№ 77.99.60.953Д008765.07.07 от 25.07.2007 г.
практическая медицина
Тел.: +7(495) 324-93-29 (редакция), +7(916)320-01-55 (производство),
+7 (495)648-34-22 (реализация)
e-mail: medprint@mail.ru, tezey@obook.ru, medrel@mail.ru
заказать с доставкой можно на сайте
W W W, m е d р г i п t . г и
ISBN 5-98811-173-4
9"785988"111733