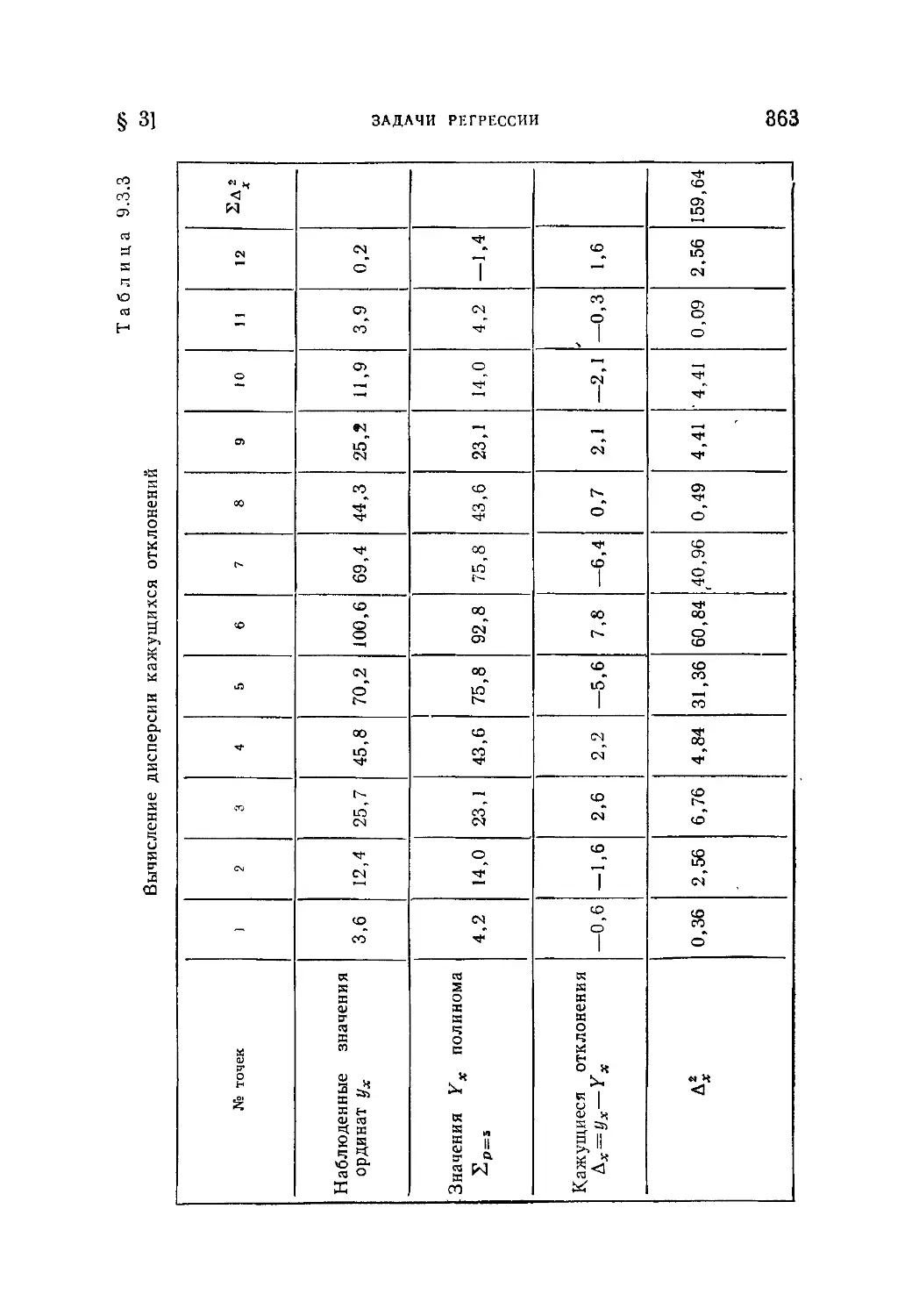
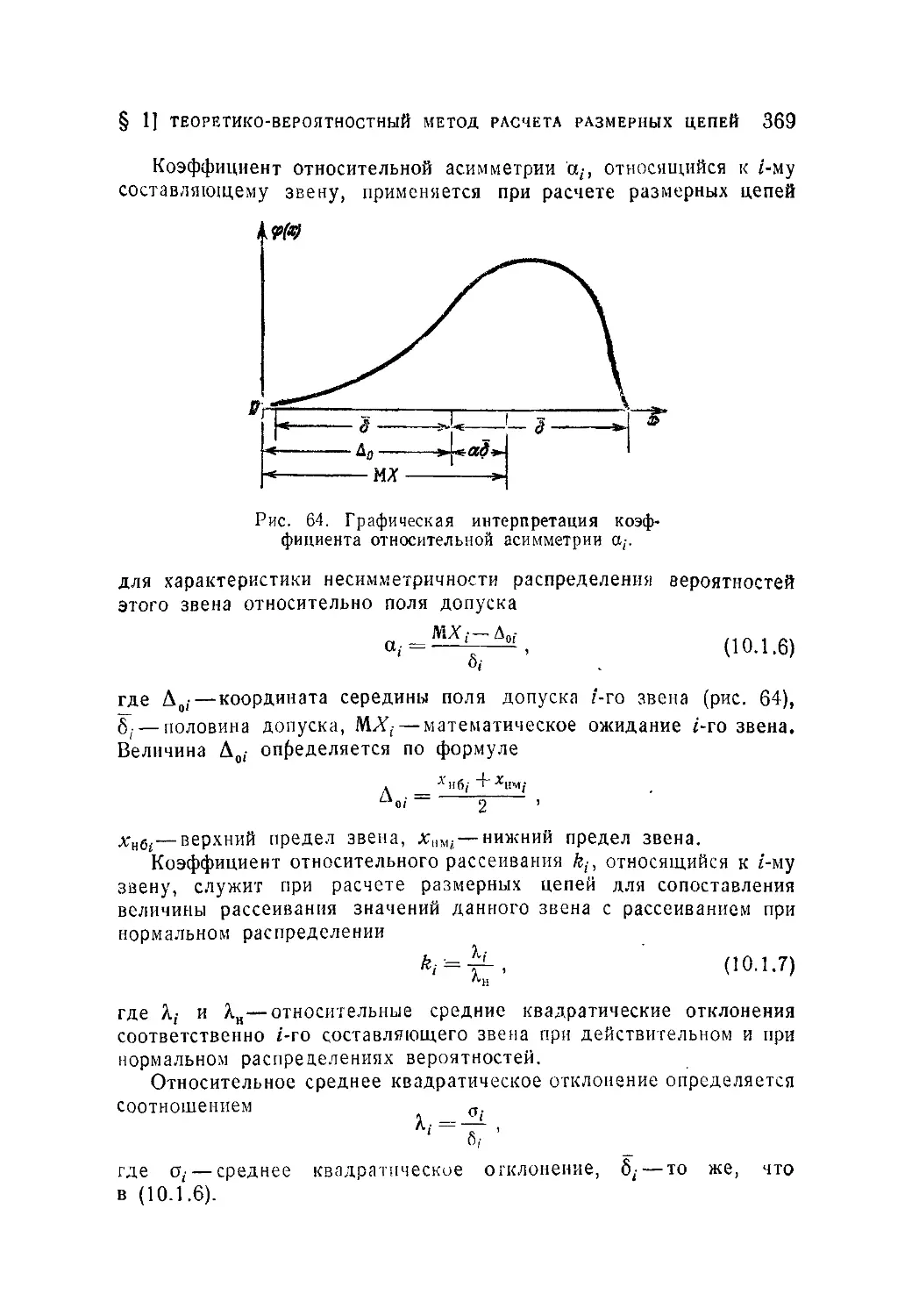
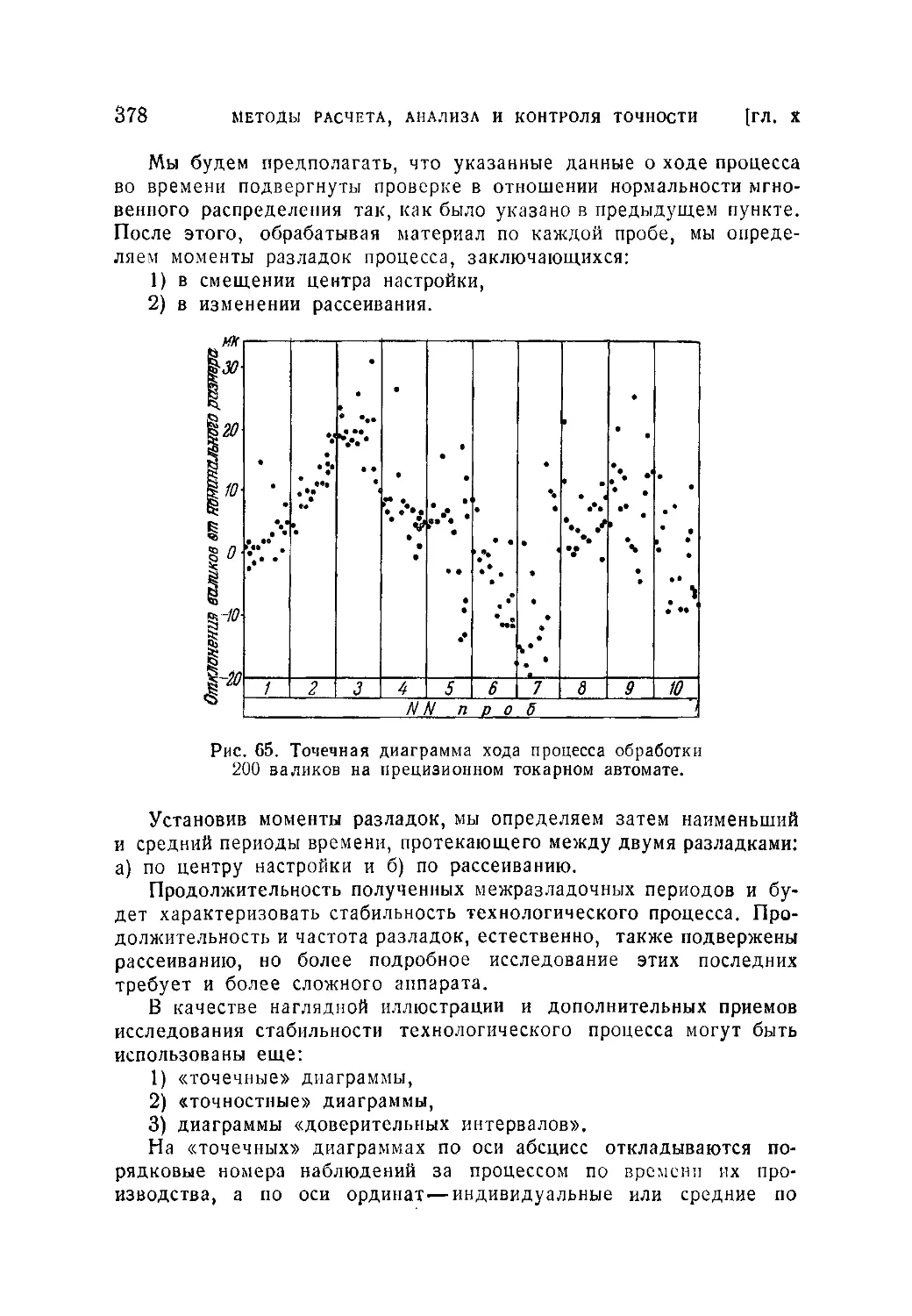
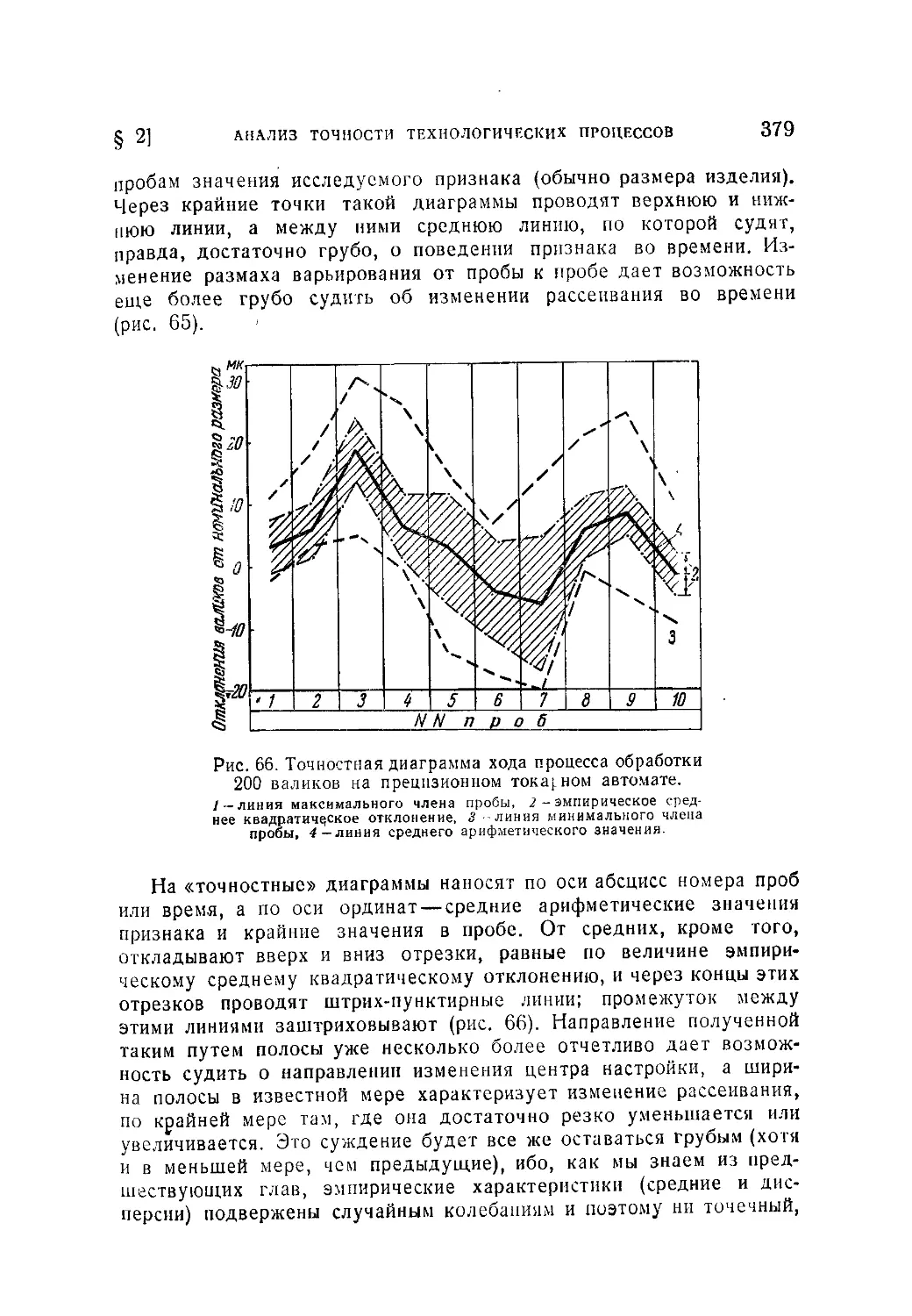
/




































































































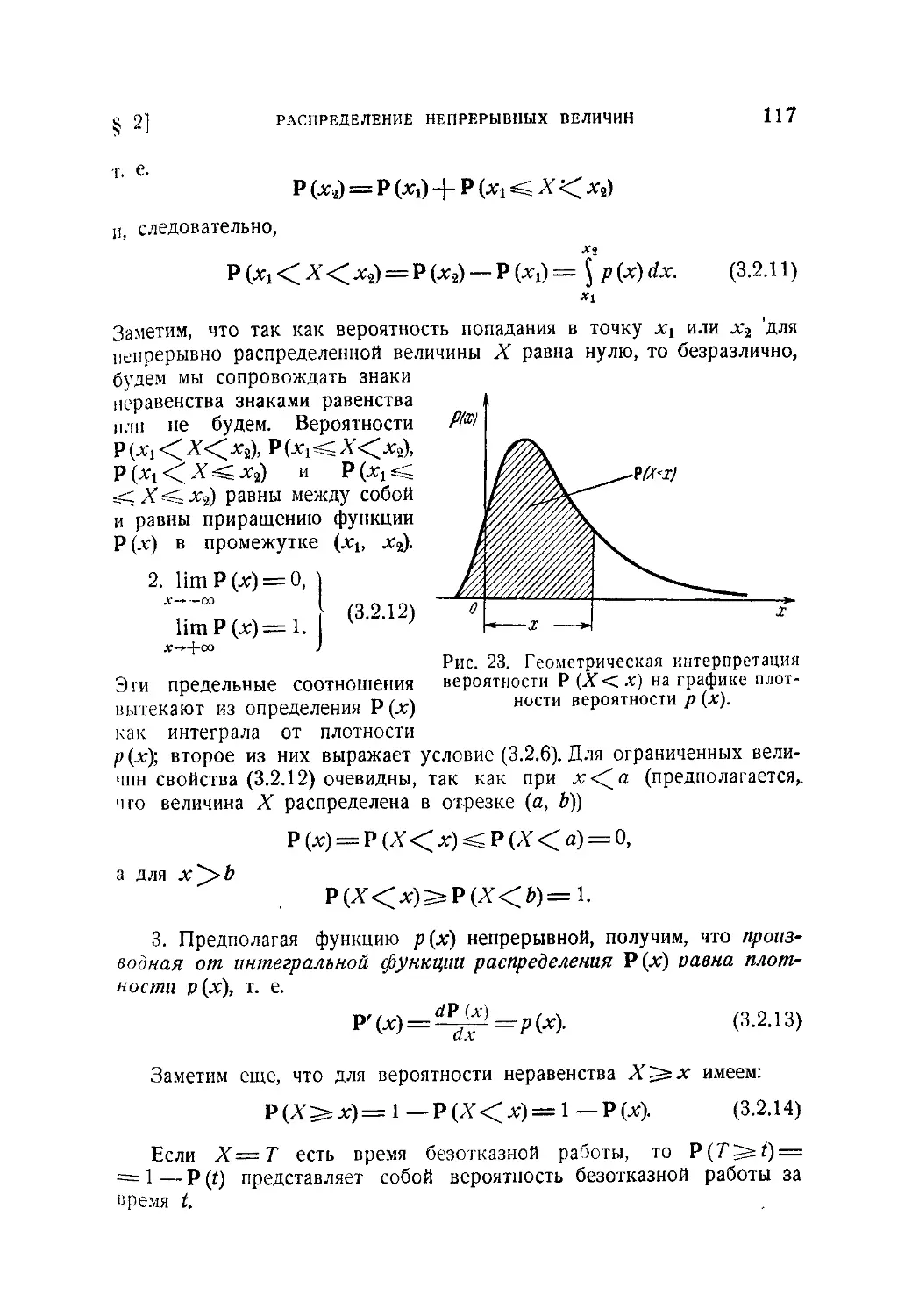
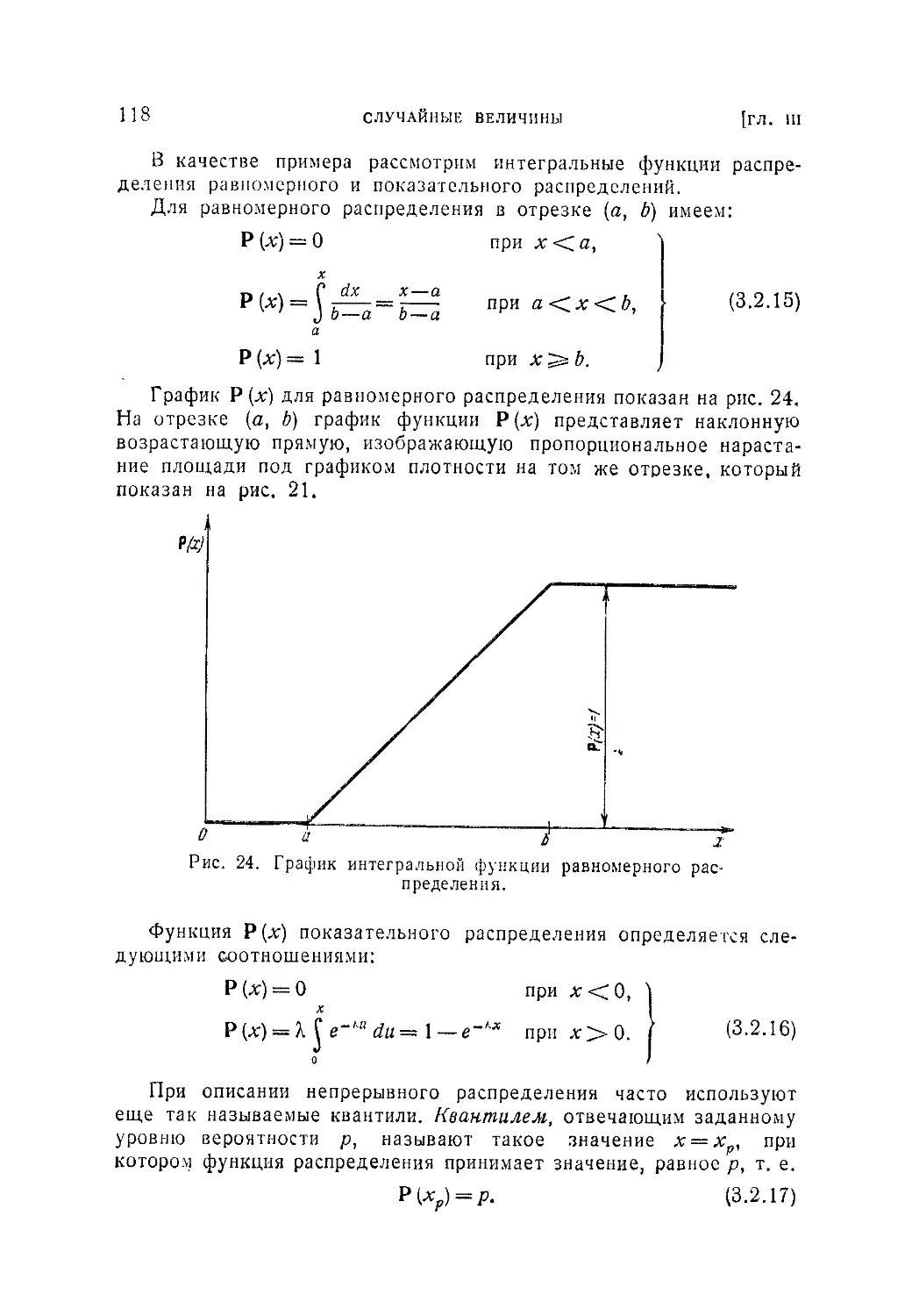






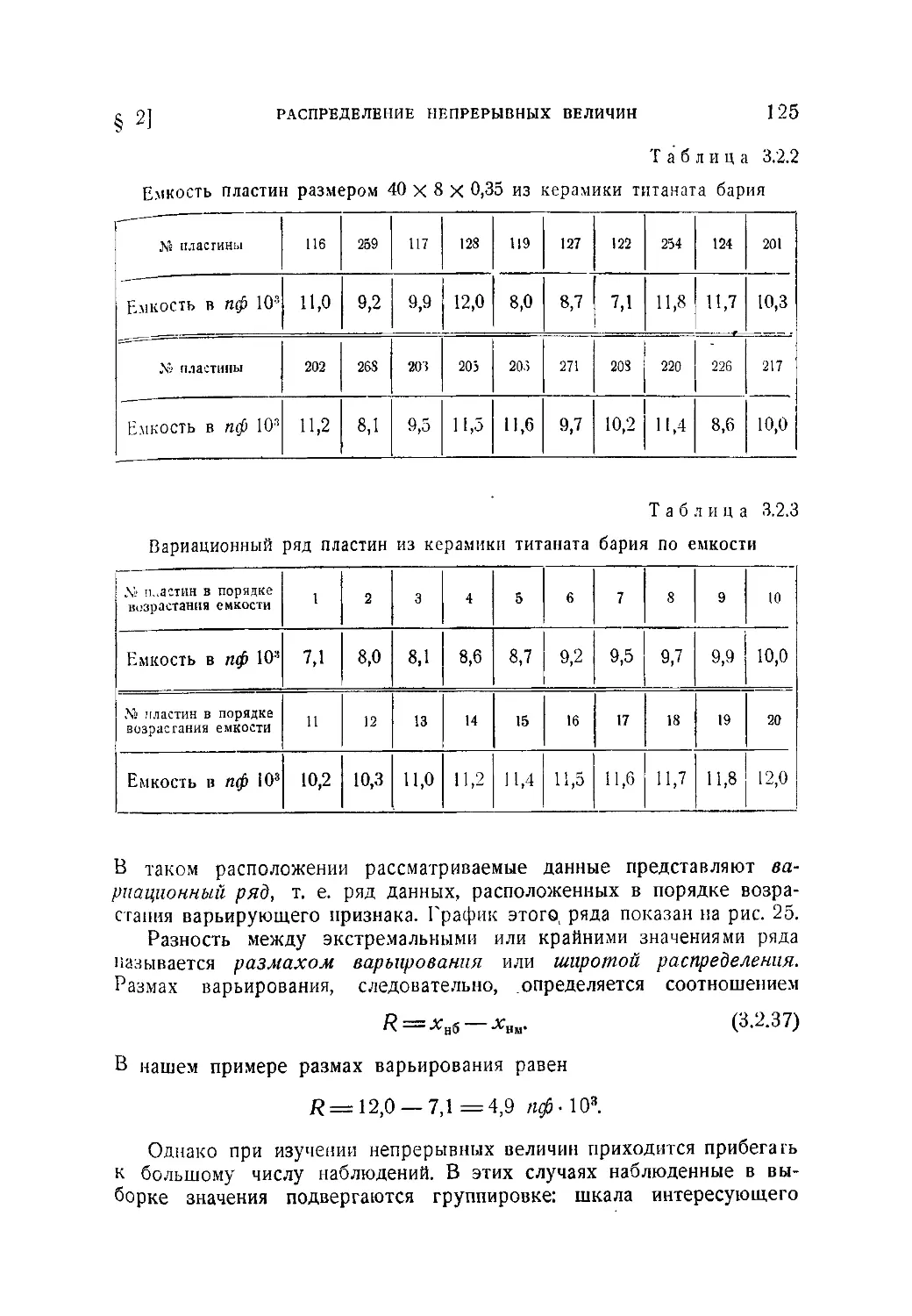
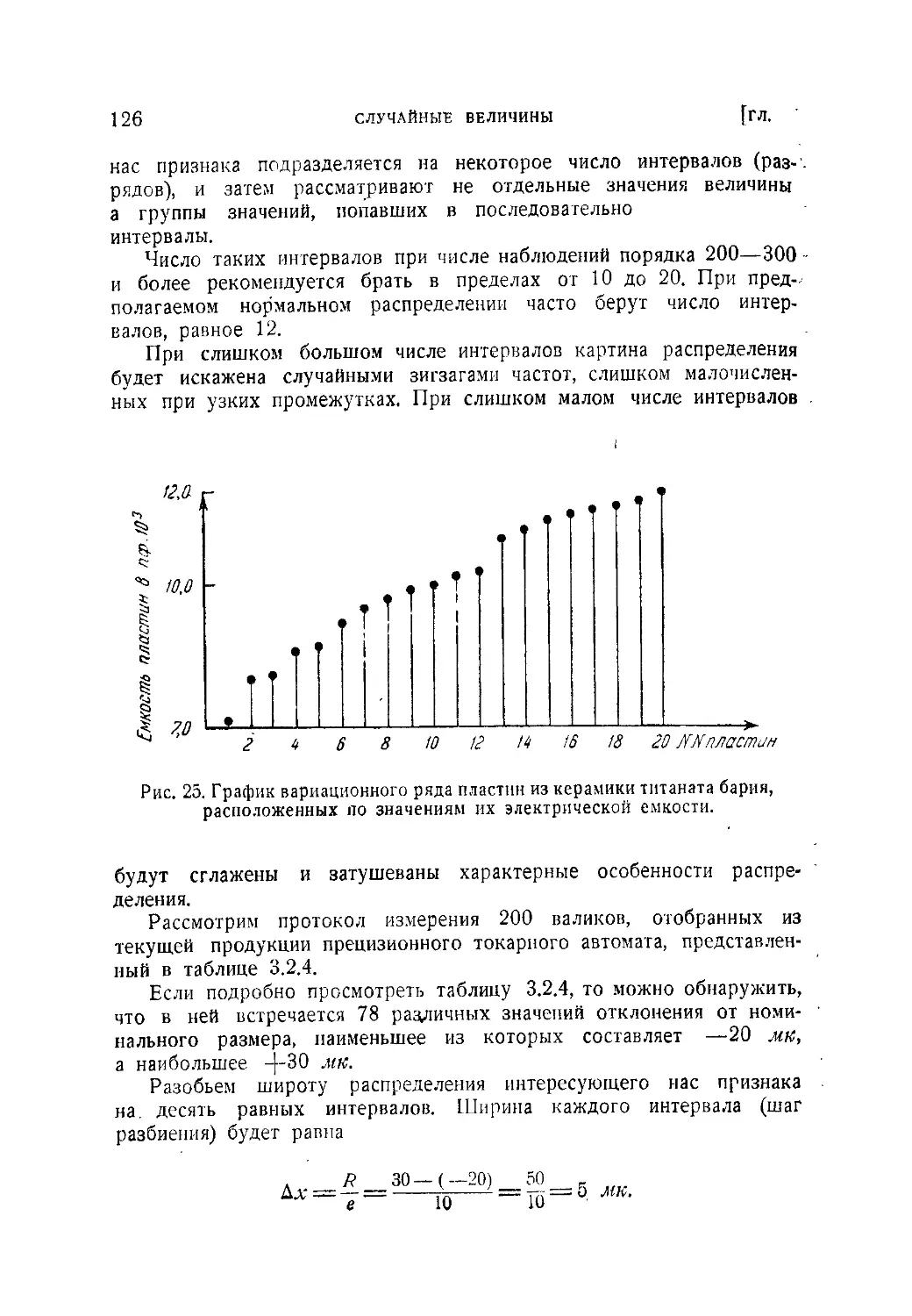


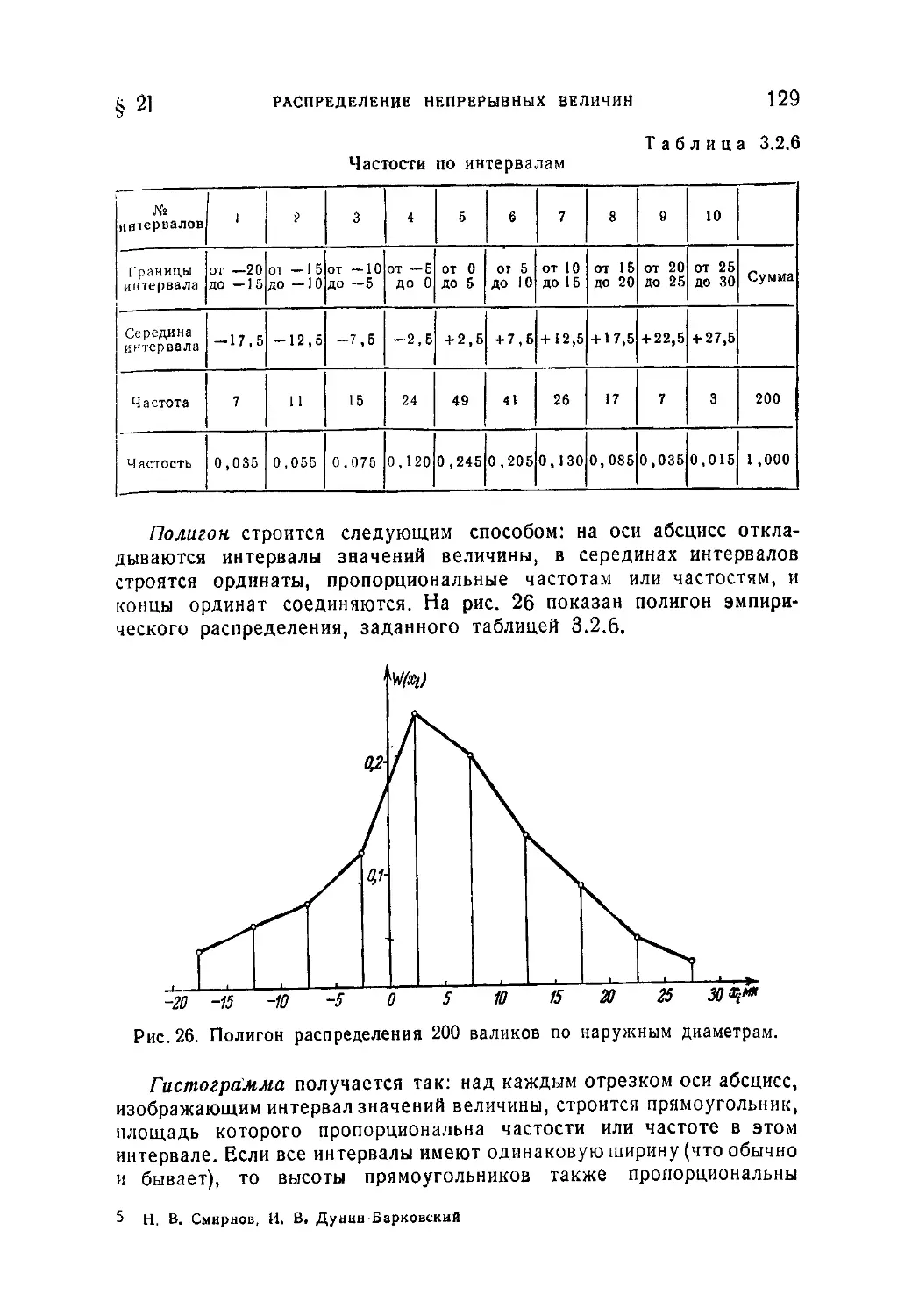
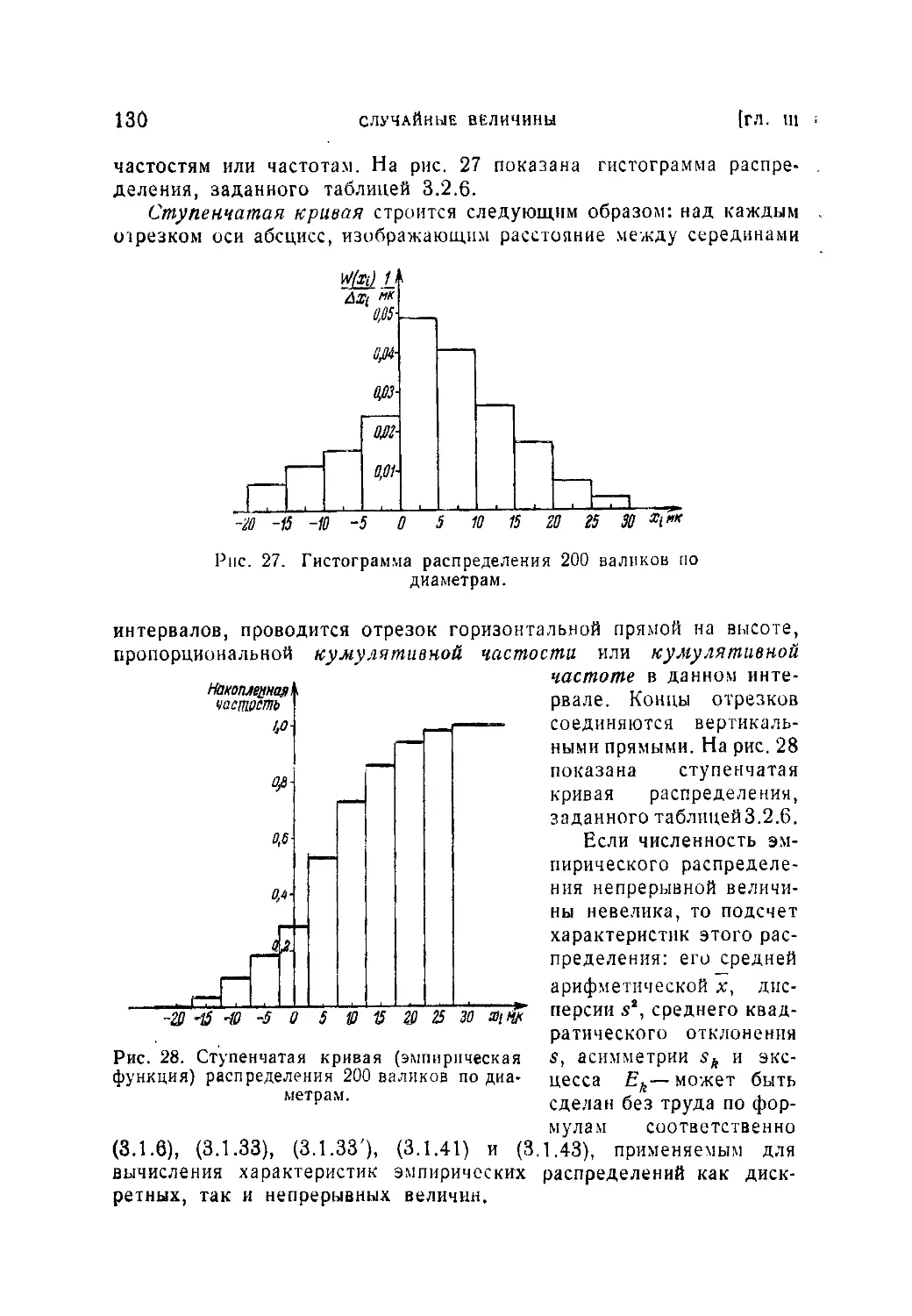
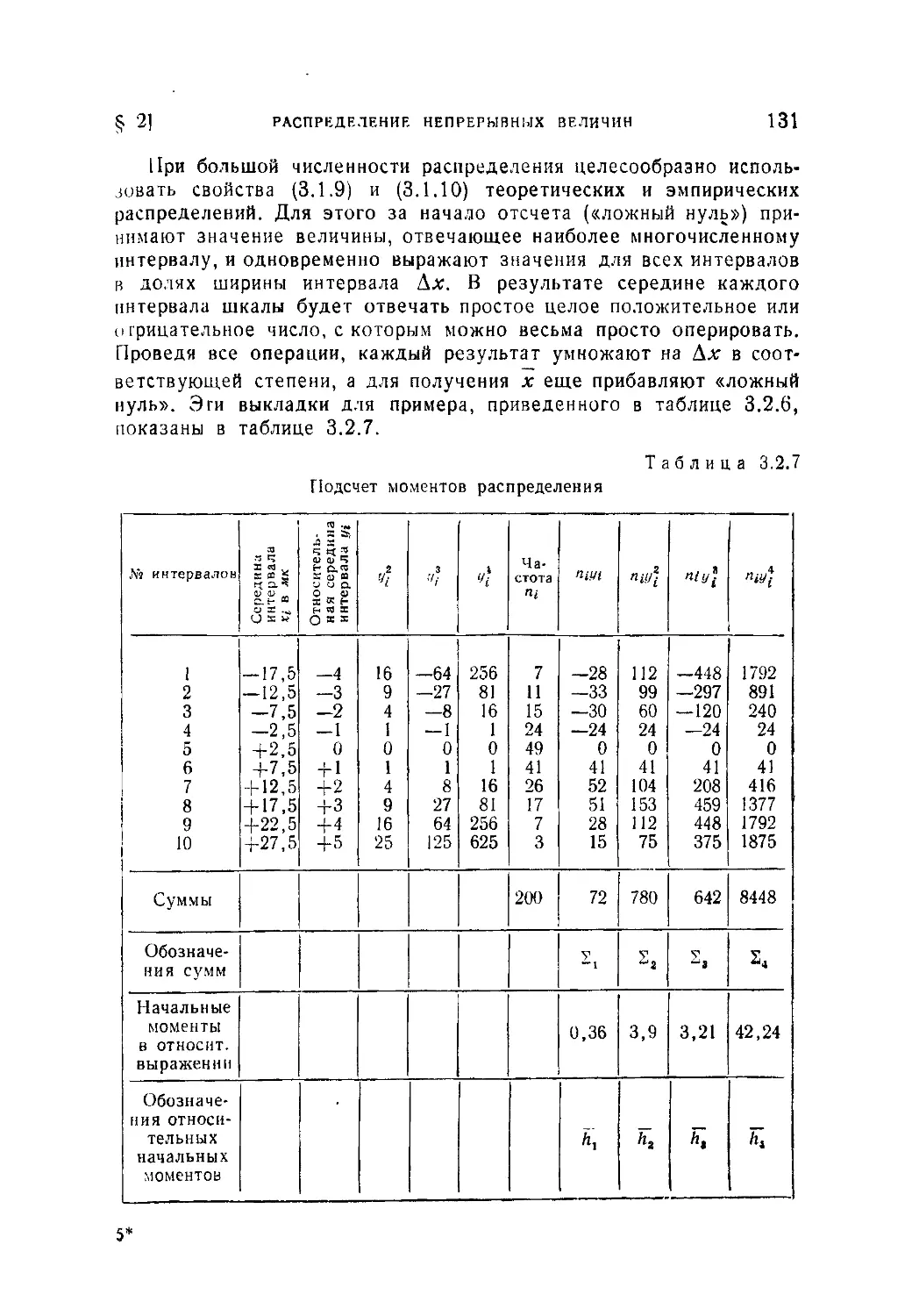

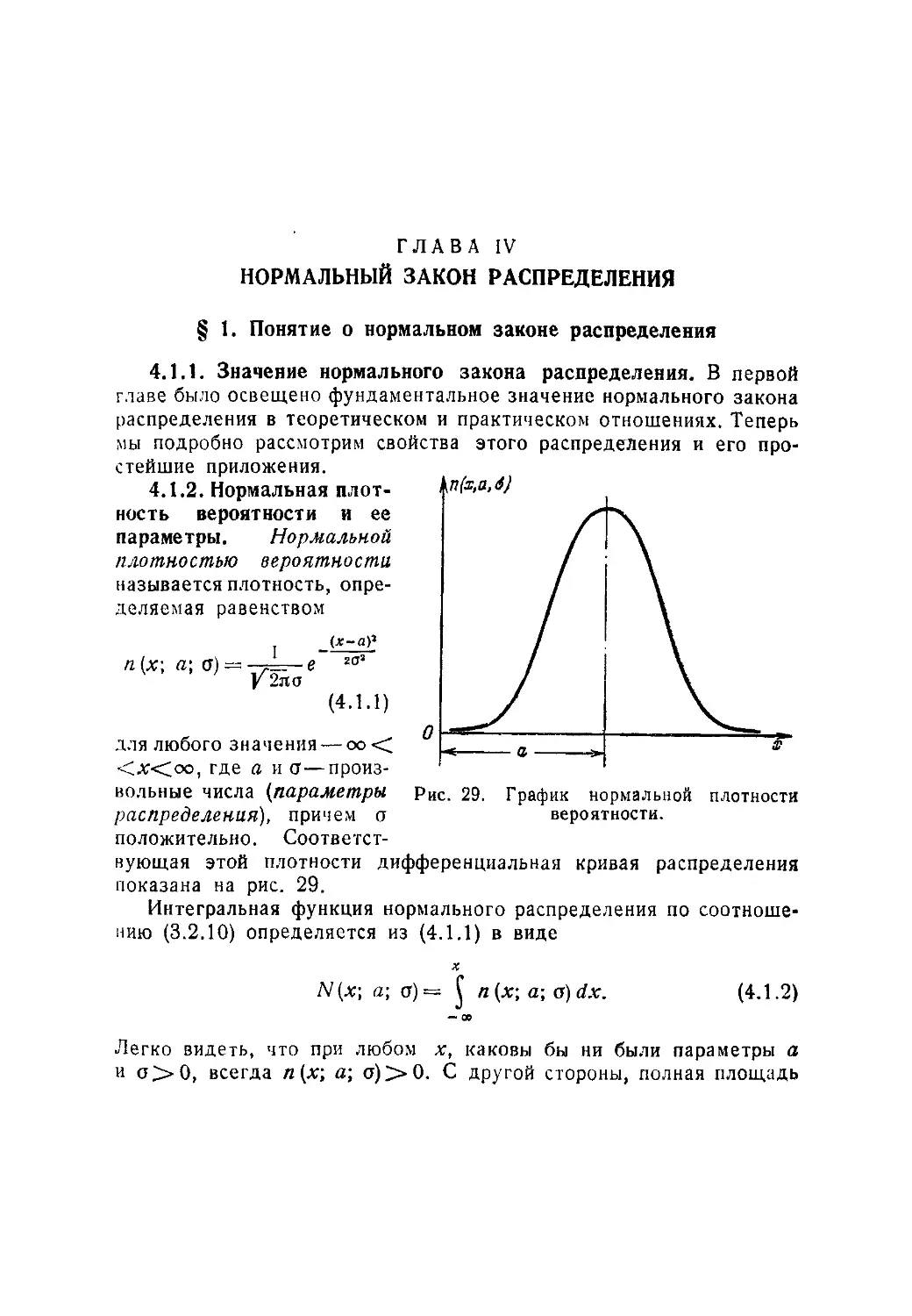







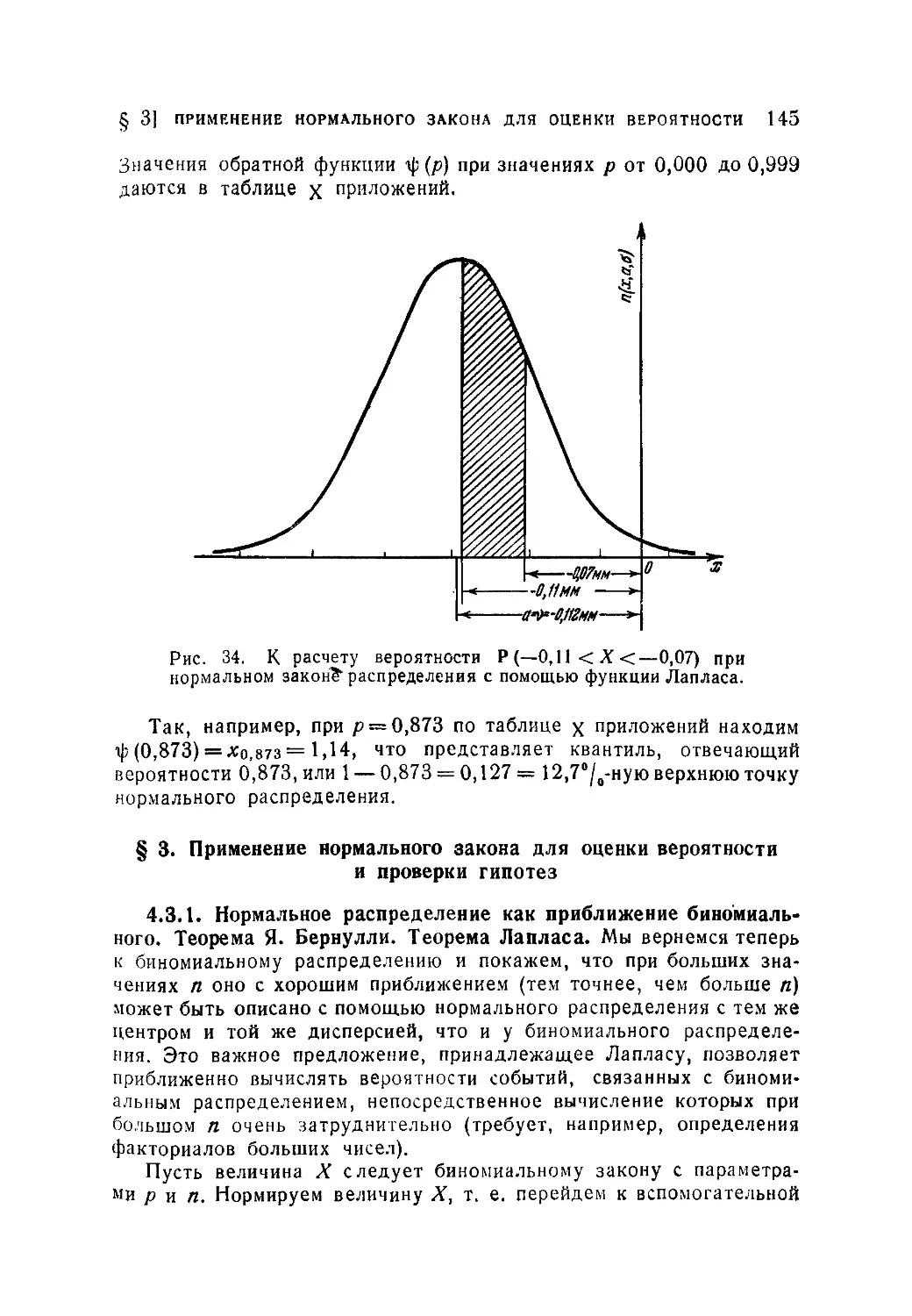




































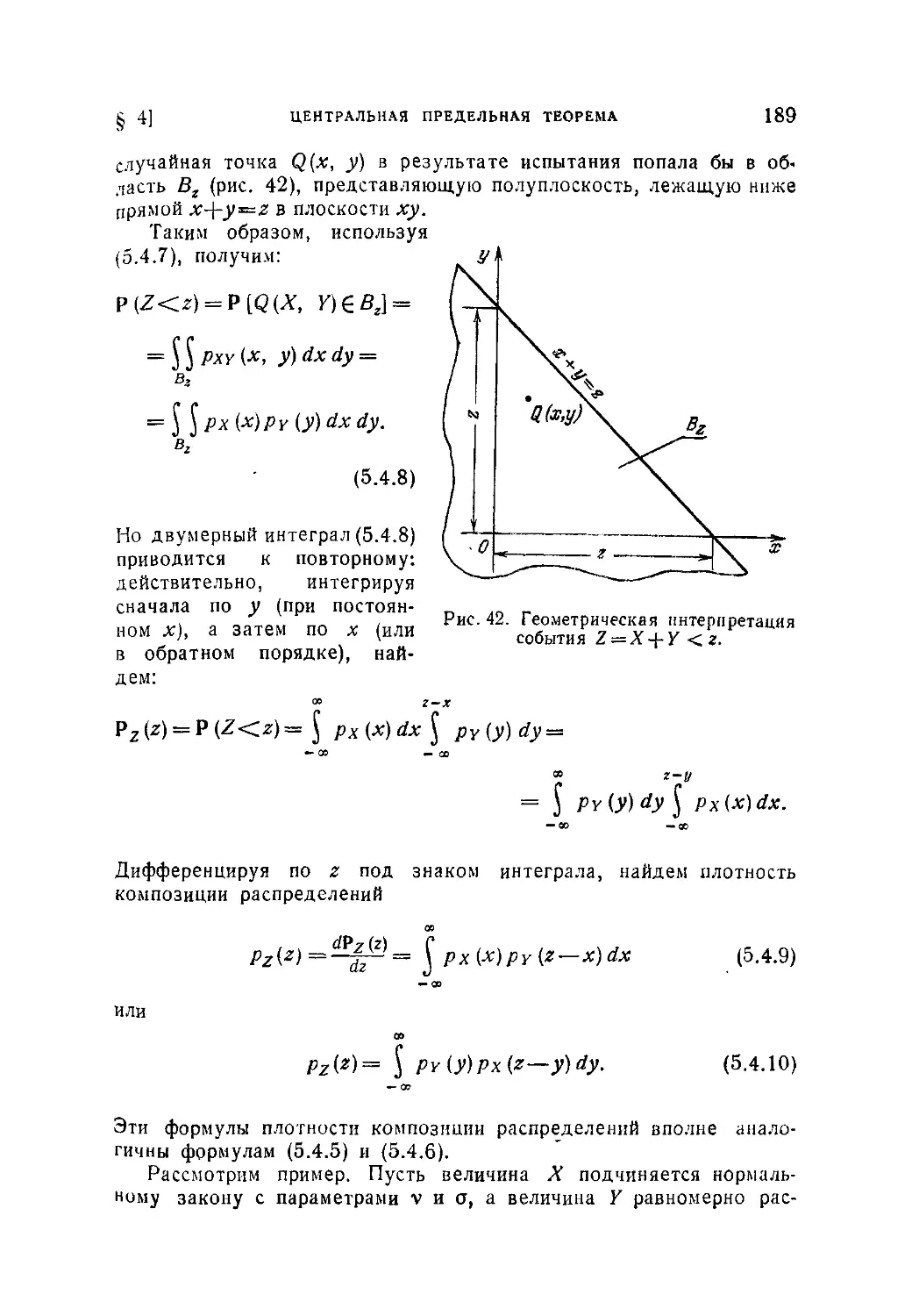

































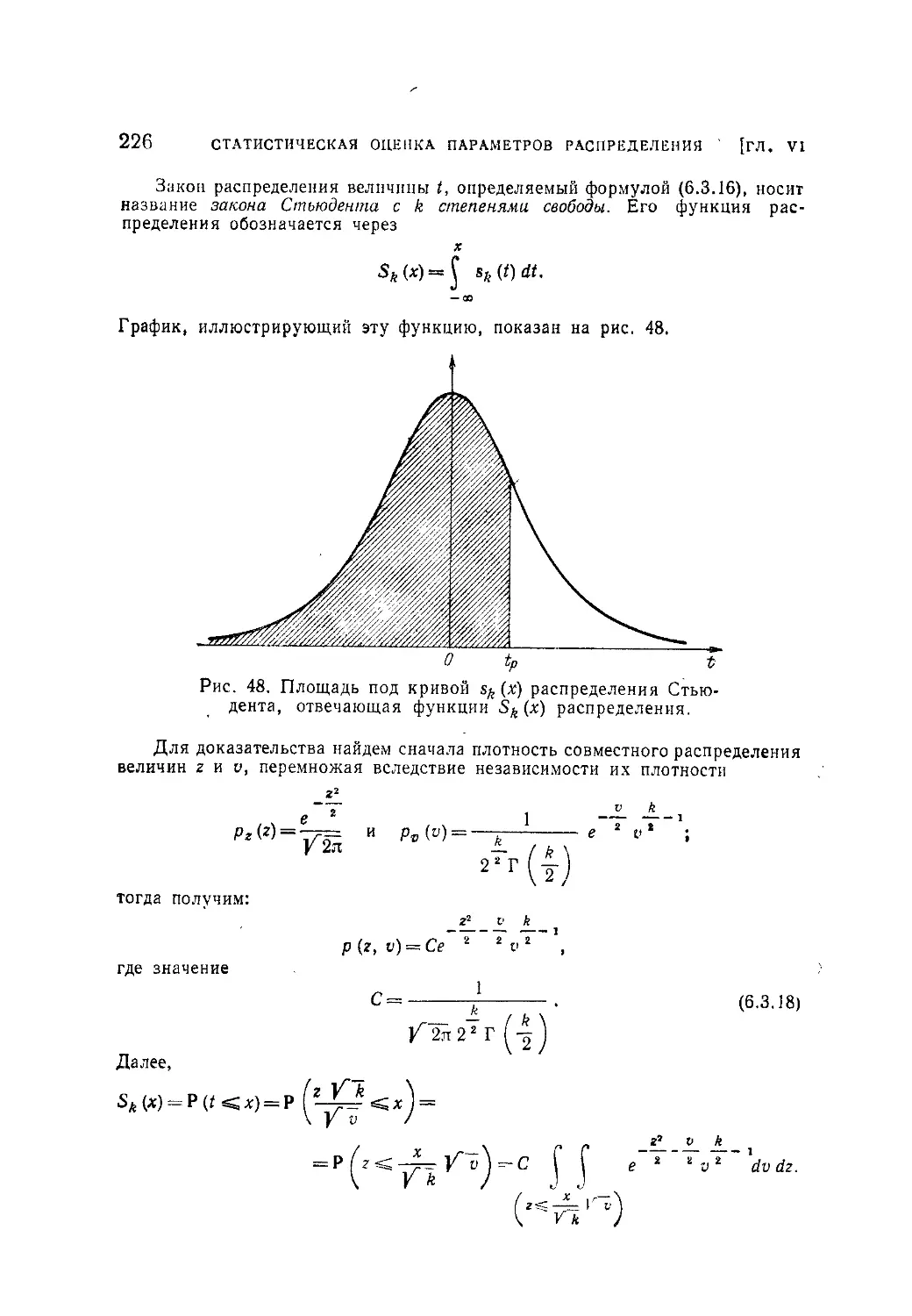

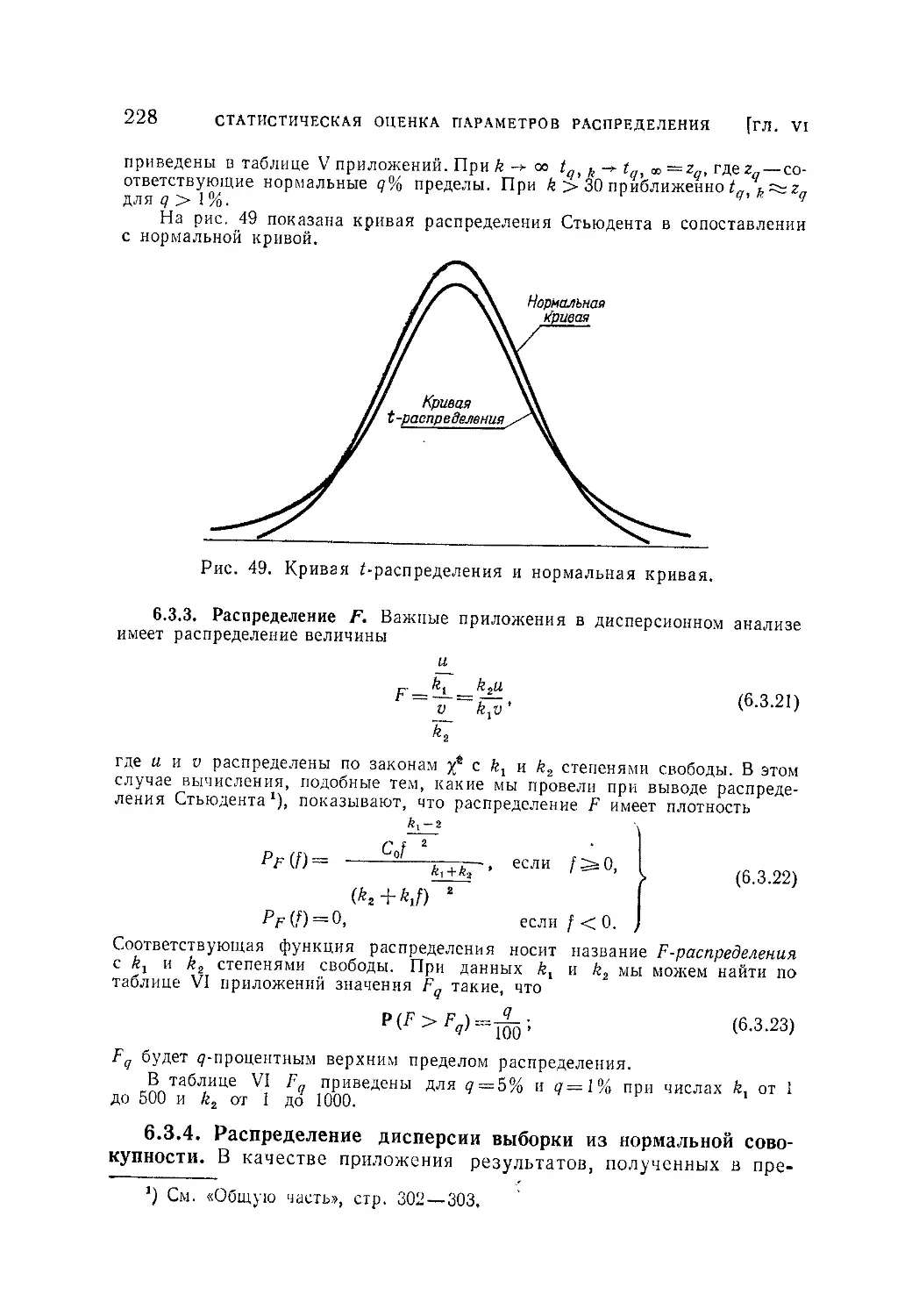





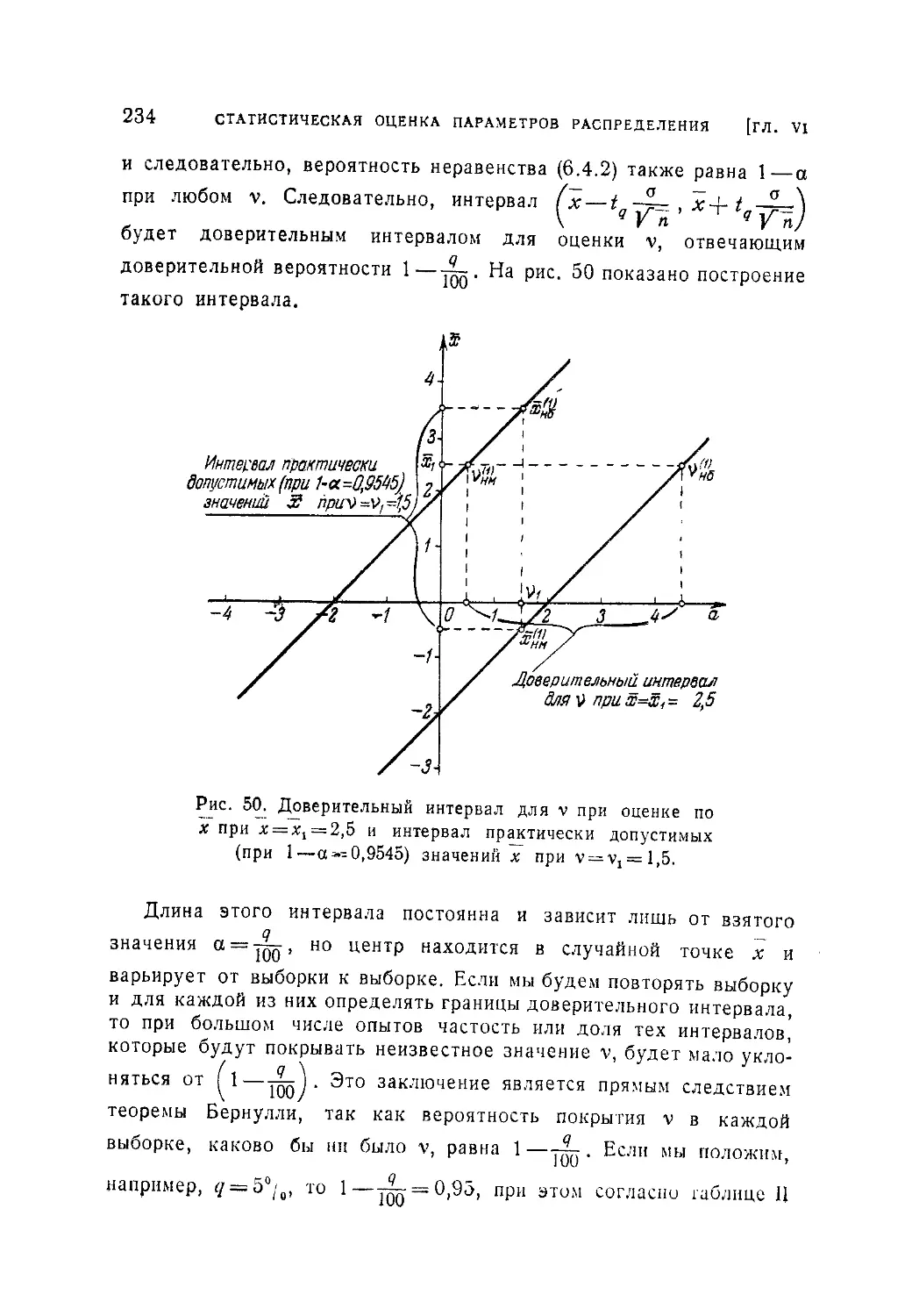




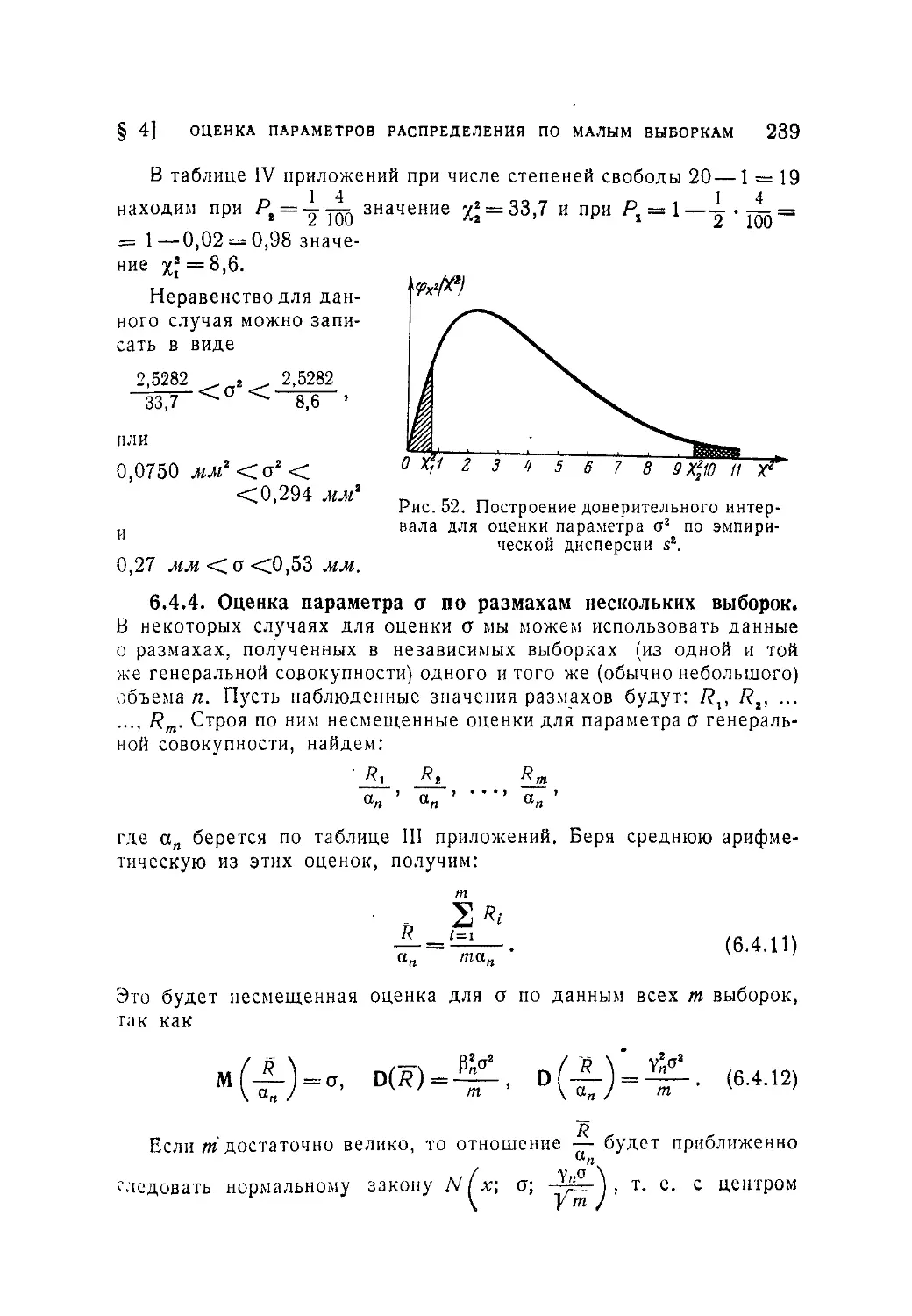



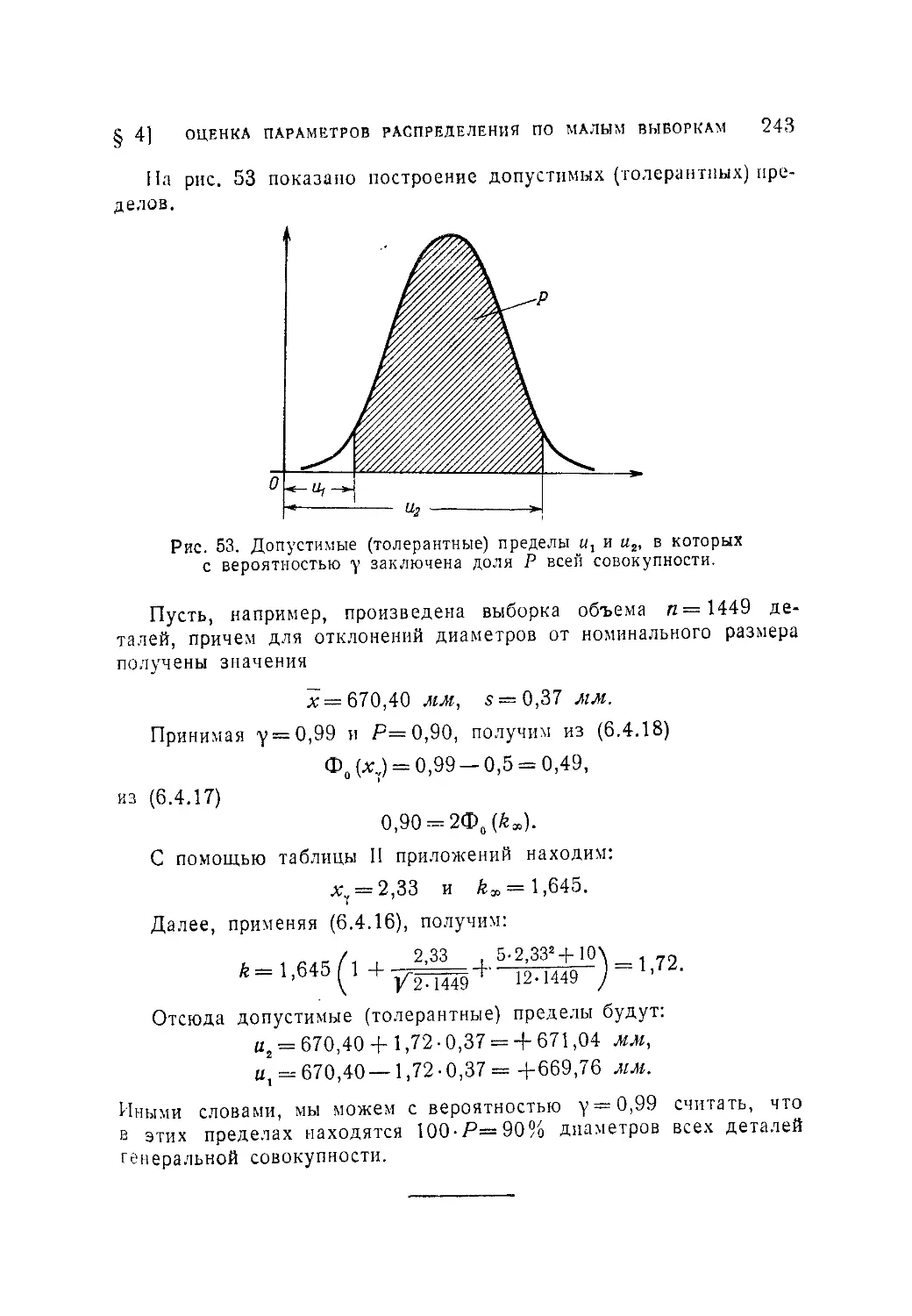


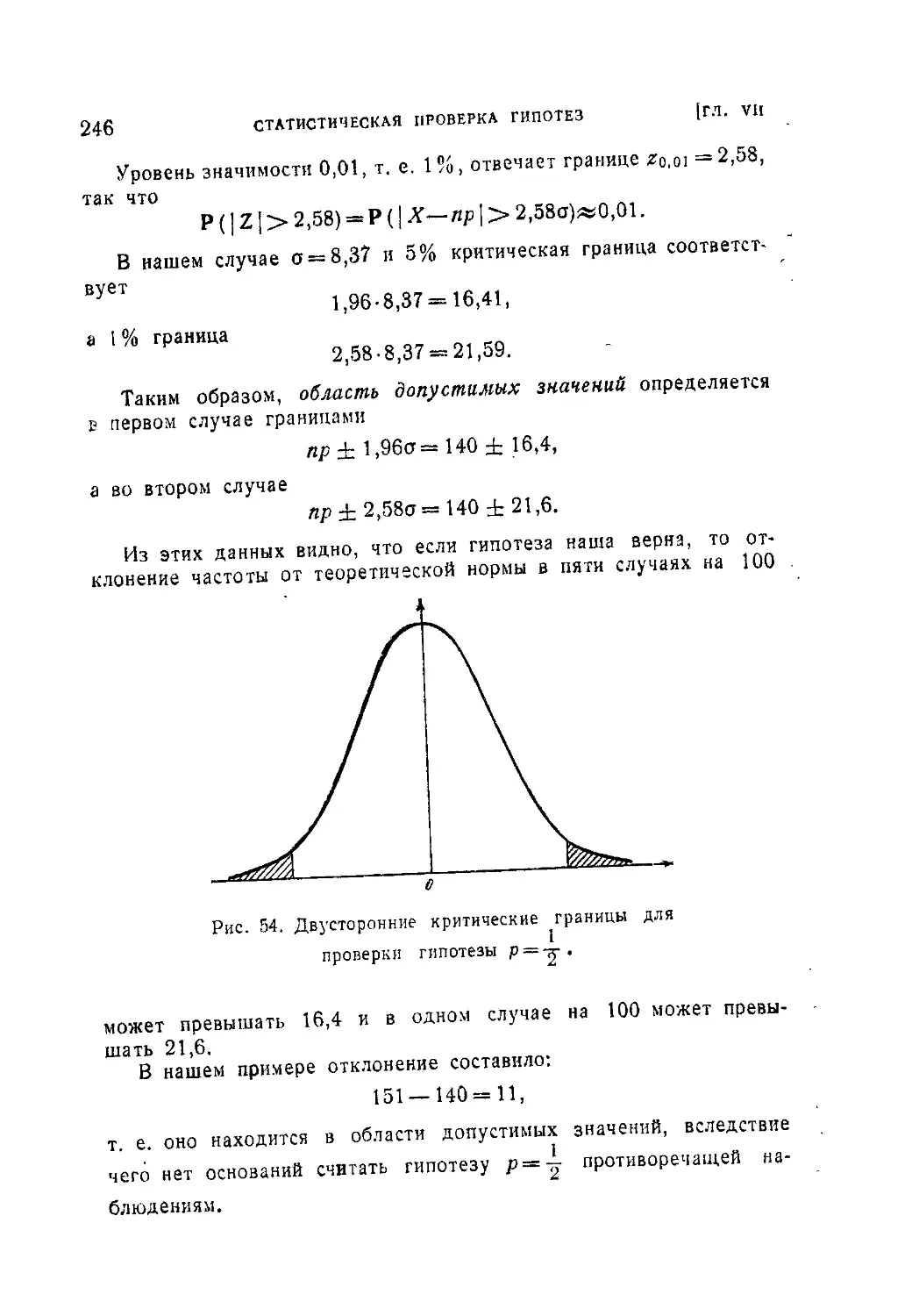

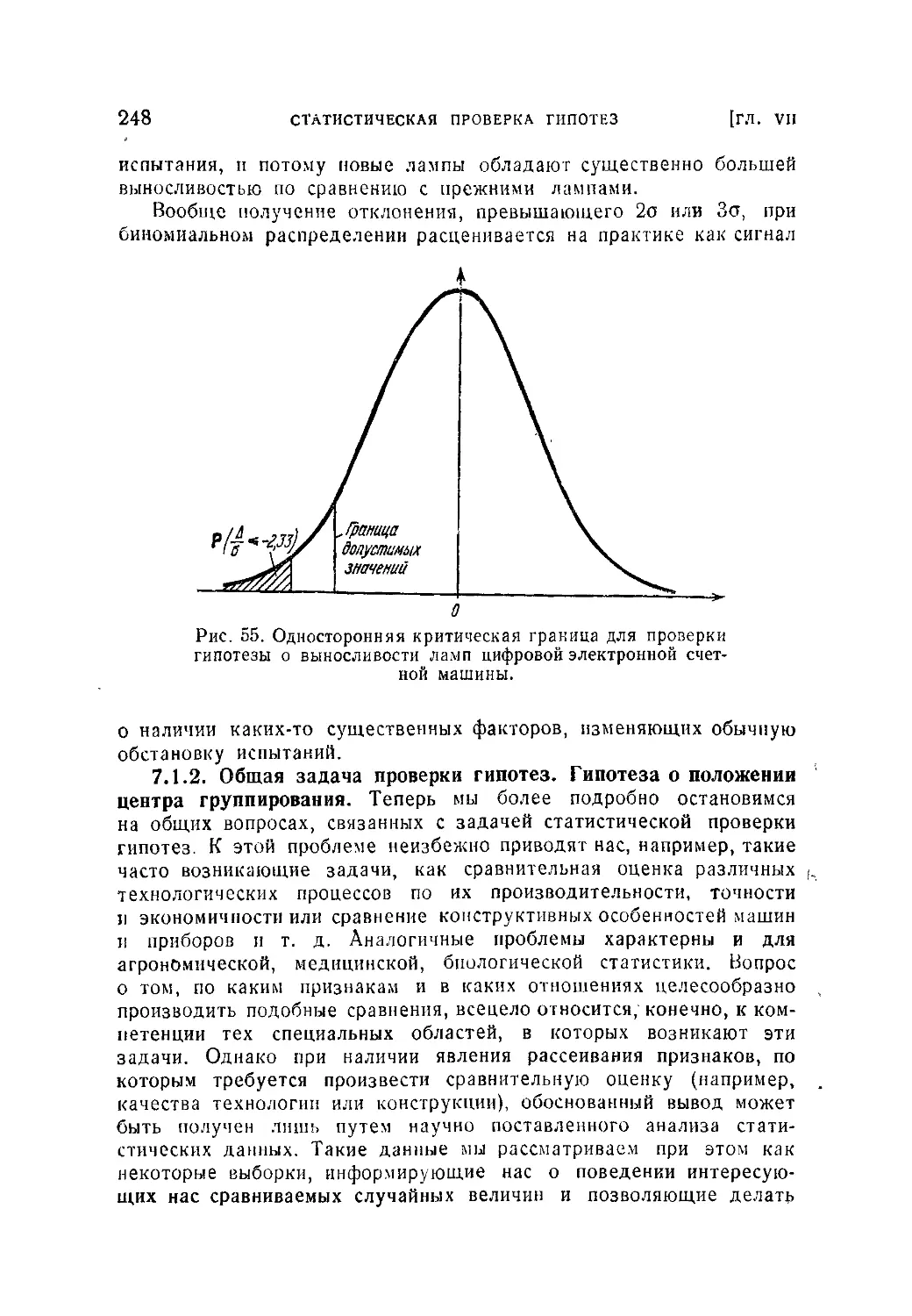


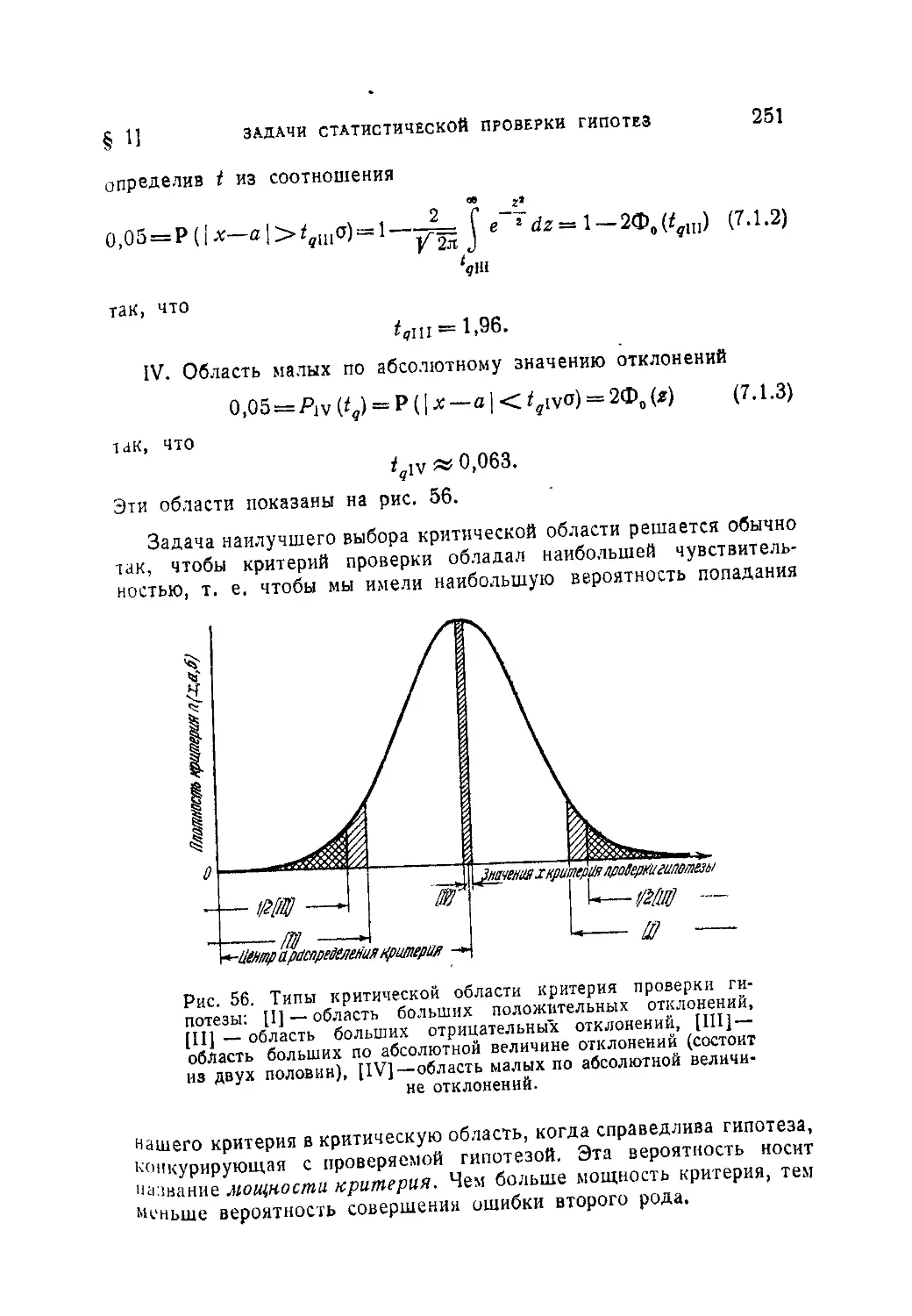













































































































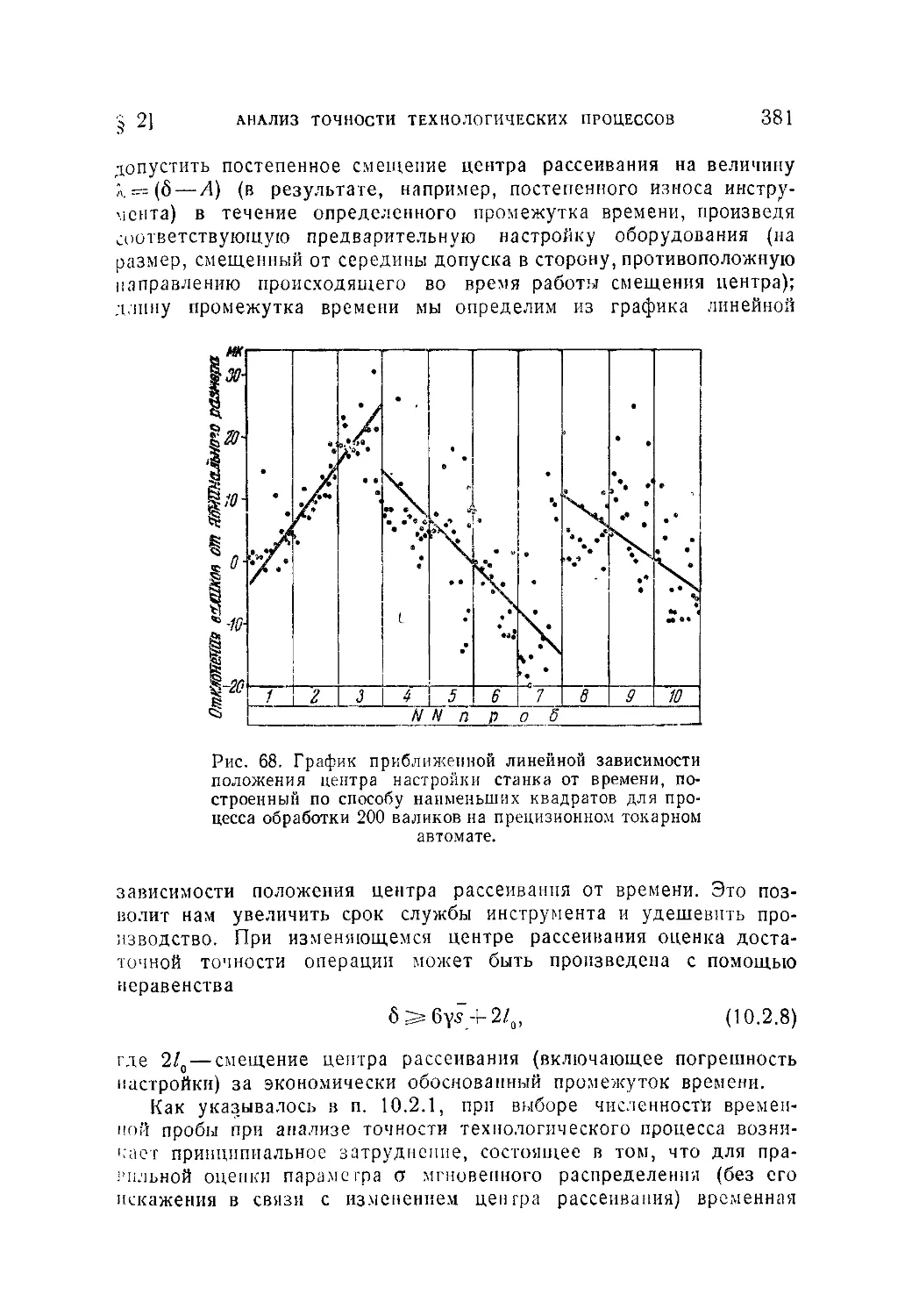


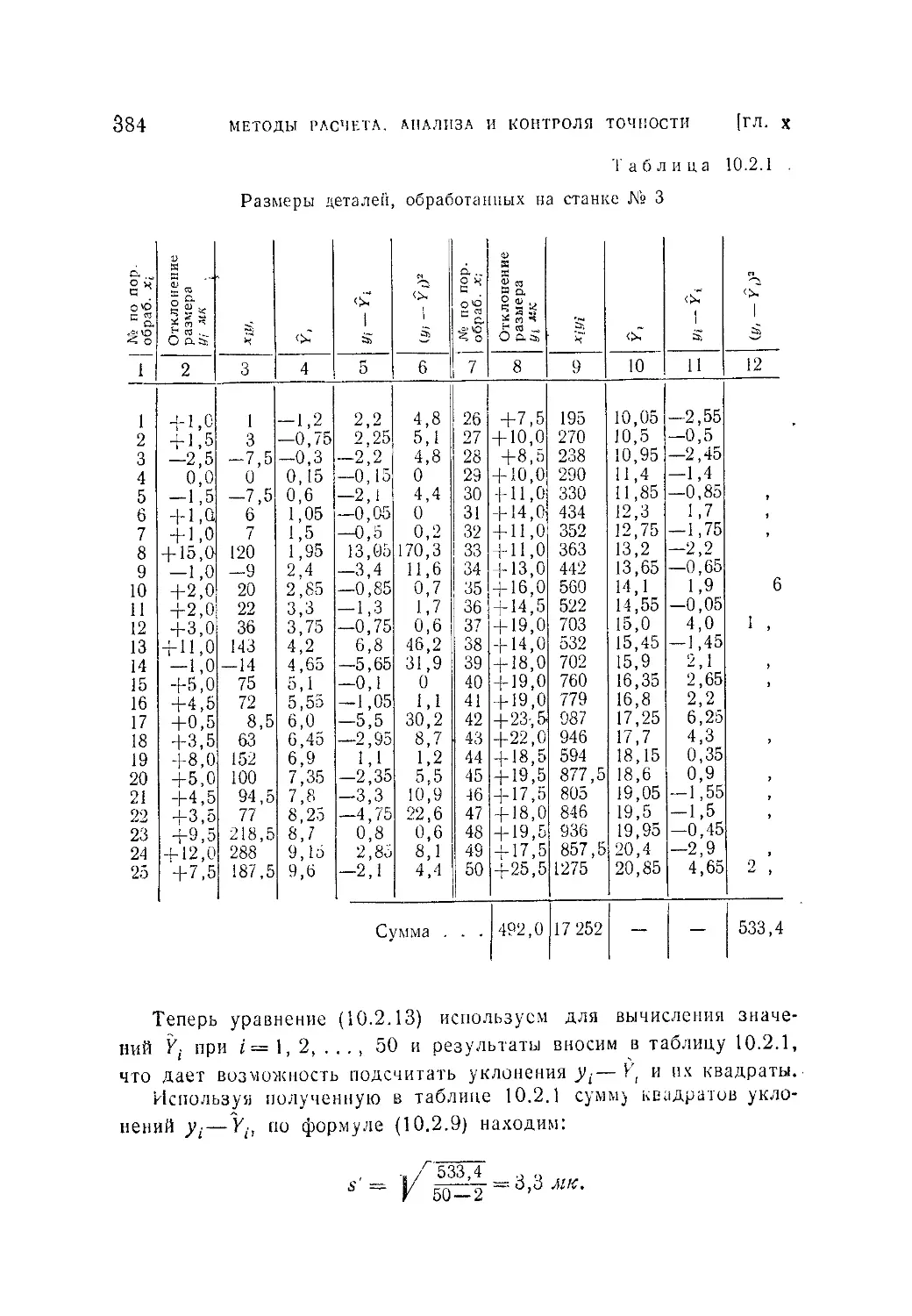
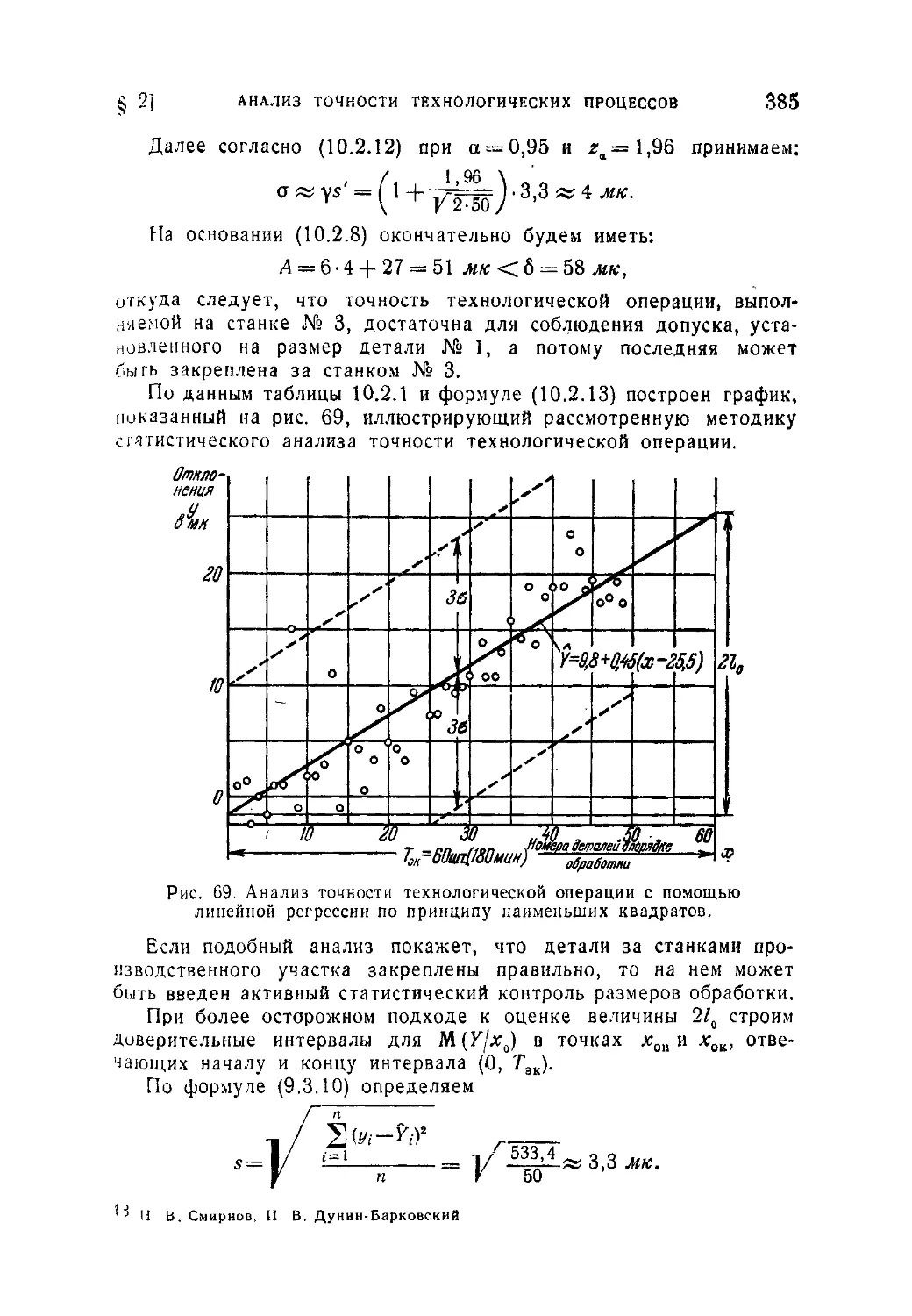


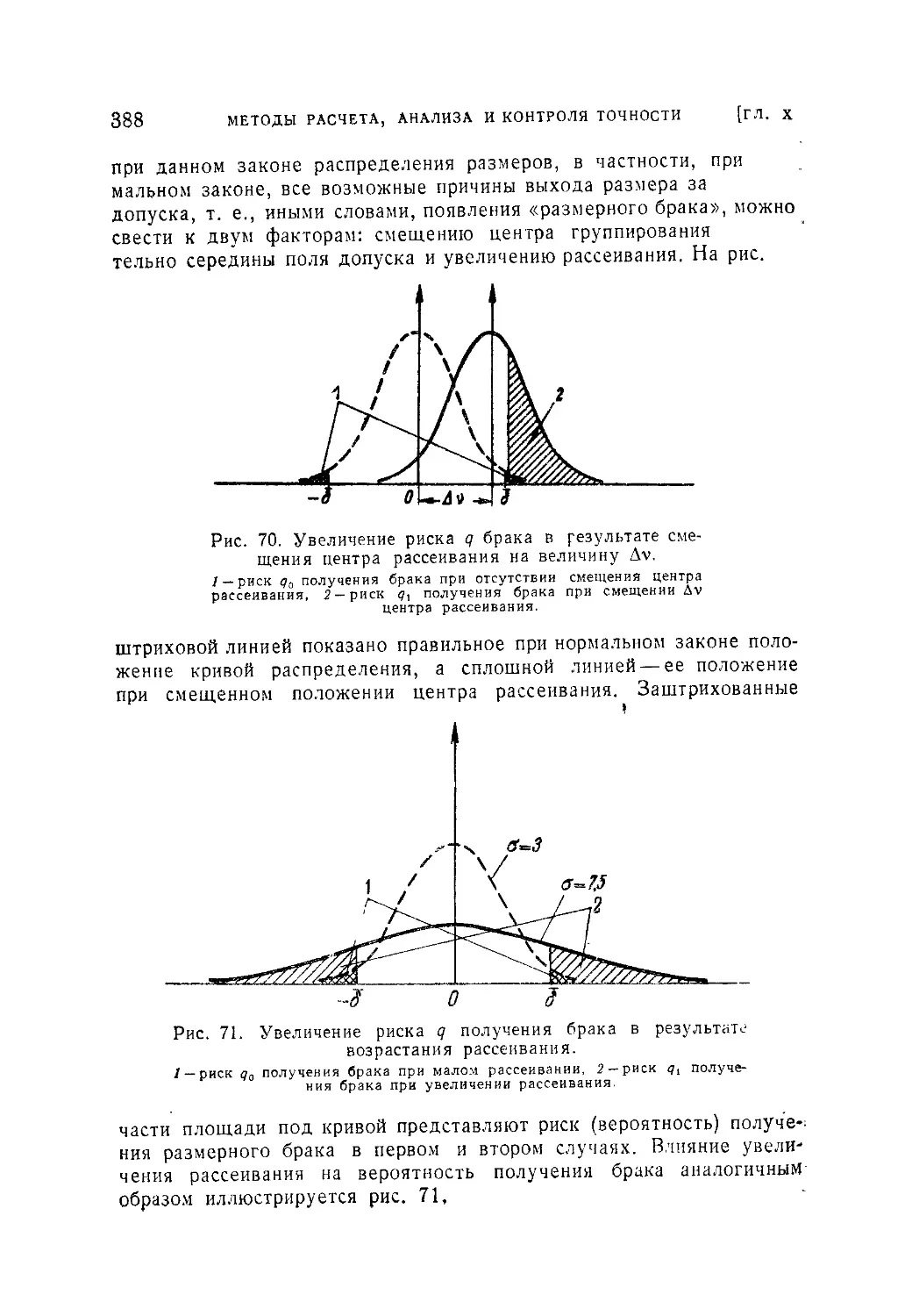
















































































Текст
Н.В.СМИРНОВ.И.В.ДУНИН БАРКОВСКИЙ
Курс
ТЕОРИИ
ВЕРОЯТНОСТЕЙ
МАТЕМАТИЧЕСКОЙ
СТАТИСТИКИ
ДЛЯ ТЕХНИЧЕСКИХ
ПРИЛОЖЕНИЙ
517.8
С 50
УДК 519.24
АННОТАЦИЯ
Книга излагает основные сведения по мате-
матической статистике и теории вероятностей,
необходимые для приложений. Важнейшие ста-
тистические методы и приемы иллюстрируются
примерами из опыта советских и зарубежных
предприятий. Детально разбирается методика
расчетов. Изложение доступно для читателя, вла-
деющего лишь основами математического анализа
в объеме программы втуза. Книга рассчитана
на студентов втузов и инженеров.
2—2—3
17-69'
ОГЛАВЛЕНИЕ
Предисловие ко второму изданию......................................... 8
Предисловие к первому изданию.......................................... 9
\Г лава I. Предмет и задачи теории вероятностей и математической
статистики ...............................................................11
'/Глава II. Случайные события.............................................21
'/ § 1. Частость и вероятность........................................21
2.1.1. Испытание. Поле событий, Операции над событиями (21). 2.1.2.
Частость и вероятность (26). 2.1.3. Основные аксиомы теории вероятно-
стей (30). 2.1.4. Задача о безвозвратной выборке. Случайные числа (36).
§ 2. Условные вероятности...........................................40
2.2.1. Понятие условной вероятности (40). 2.2.2. Свойства условных
вероятностей. Правило умножения и общее правило сложения вероят-
ностей (44). 2.2.3. Независимость событий. Правило умножения незави-
симых событий (48). 2.2.4. Формула полной вероятности (50). 2.2.5. Фор-
мула вероятностей гипотез (Бейеса) (51).
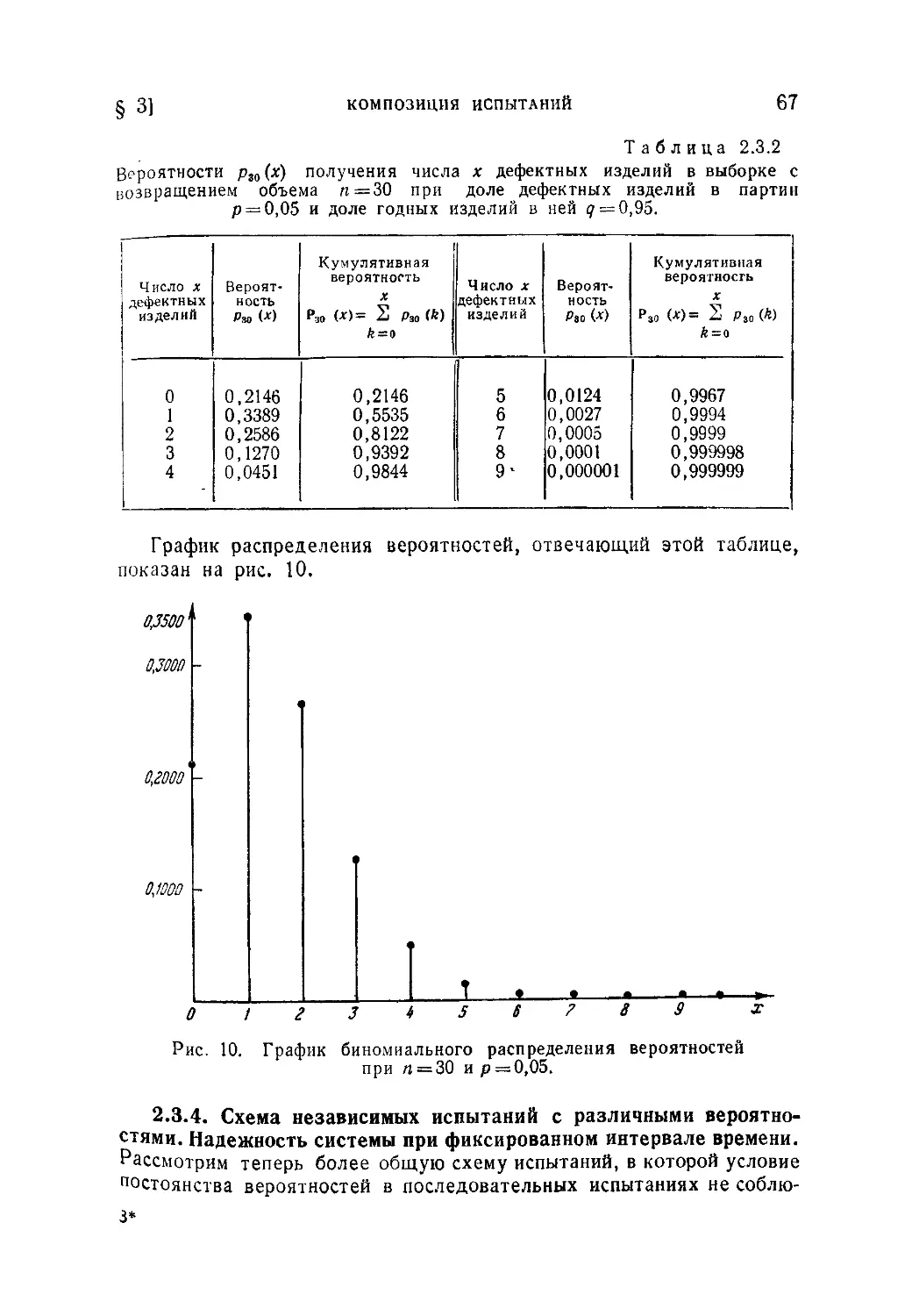
§ 3. Композиция испытаний...........................................52
2.3.1. Понятие о композиции испытаний. Повторение независимых
испытаний (52). 2.3.2. Понятия теории передачи информации. Энтропия.
Задача о телеграфном коде (53). 2.3.3. Биномиальное распределение (63).
2.3.4. Схема независимых испытаний с различными вероятностями. На-
дежность системы при фиксированном интервале времени (67).
/ Глава III. Случайные величины...........................................73
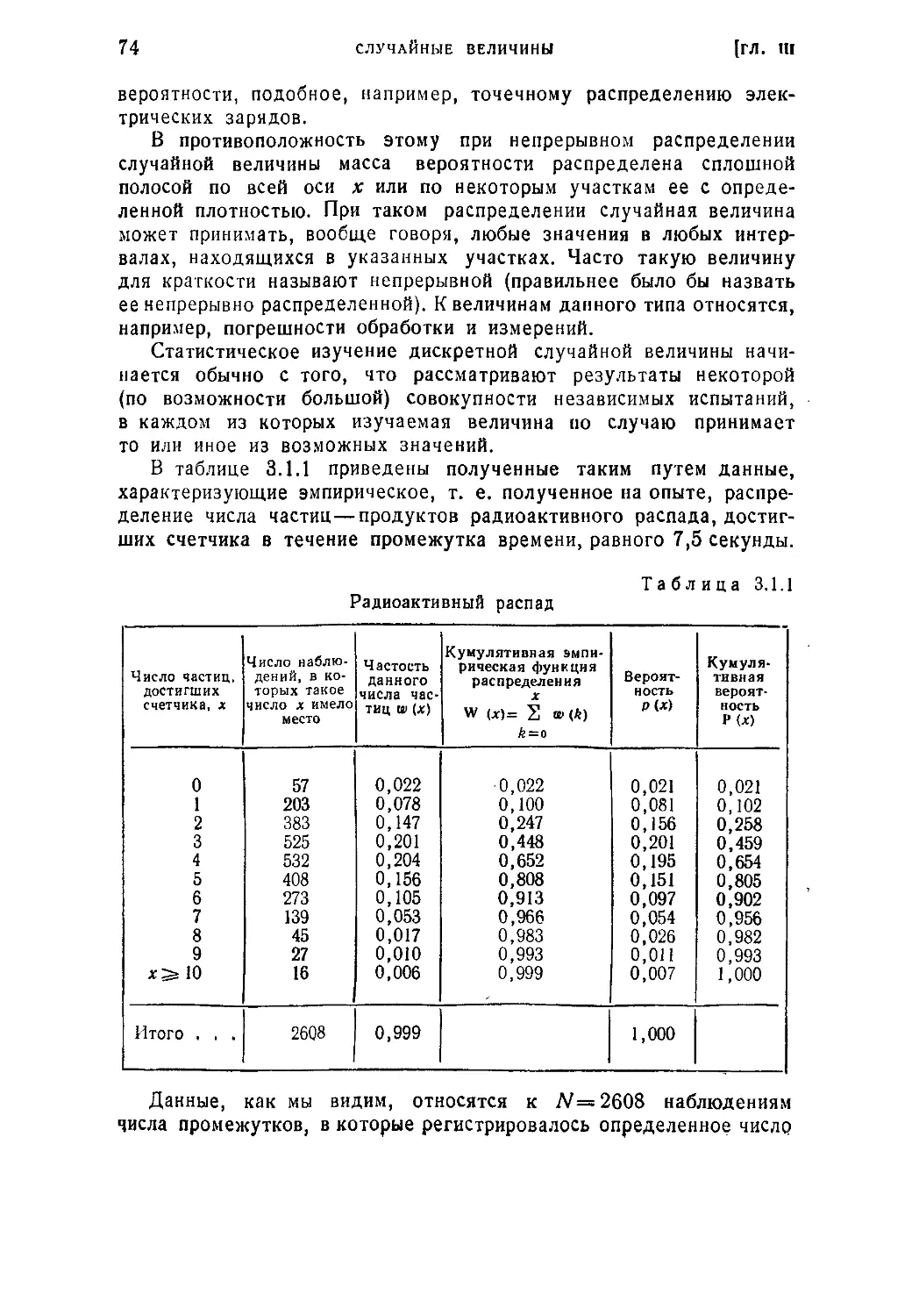
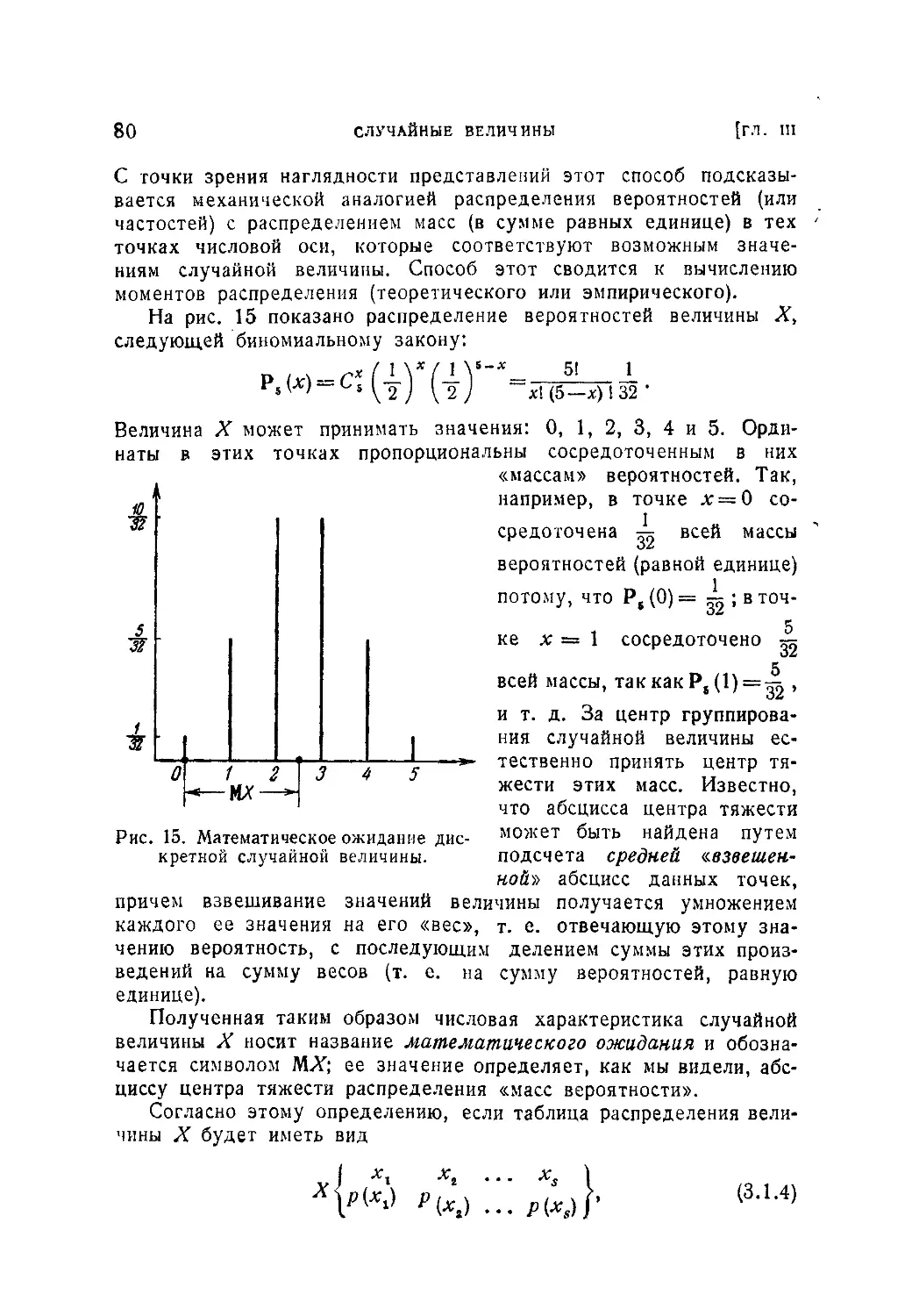
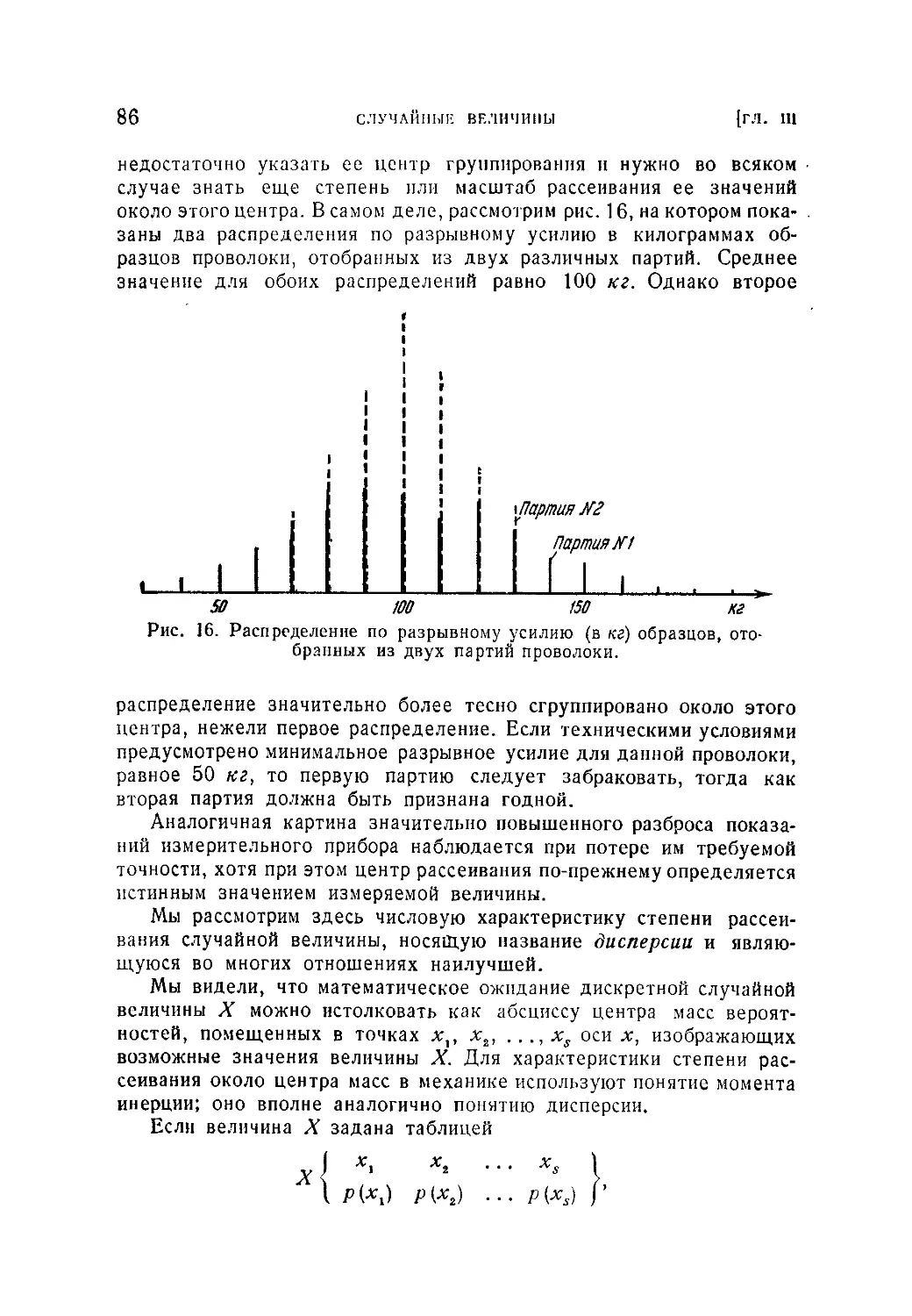
§ 1. Распределение дискретных величин........................... . 73
3.1.1. Понятие о распределении дискретной случайной величины (73)
3.1.2, Среднее значение и математическое ожидание. Мода (79). 3.1.3.
Центральные моменты. Дисперсия и среднее квадратическое отклонение.
Коэффициент вариации. Среднее абсолютное отклонение. Характеристики
асимметрии и эксцесса (85). 3.1.4. Характеристики биномиального рас- v
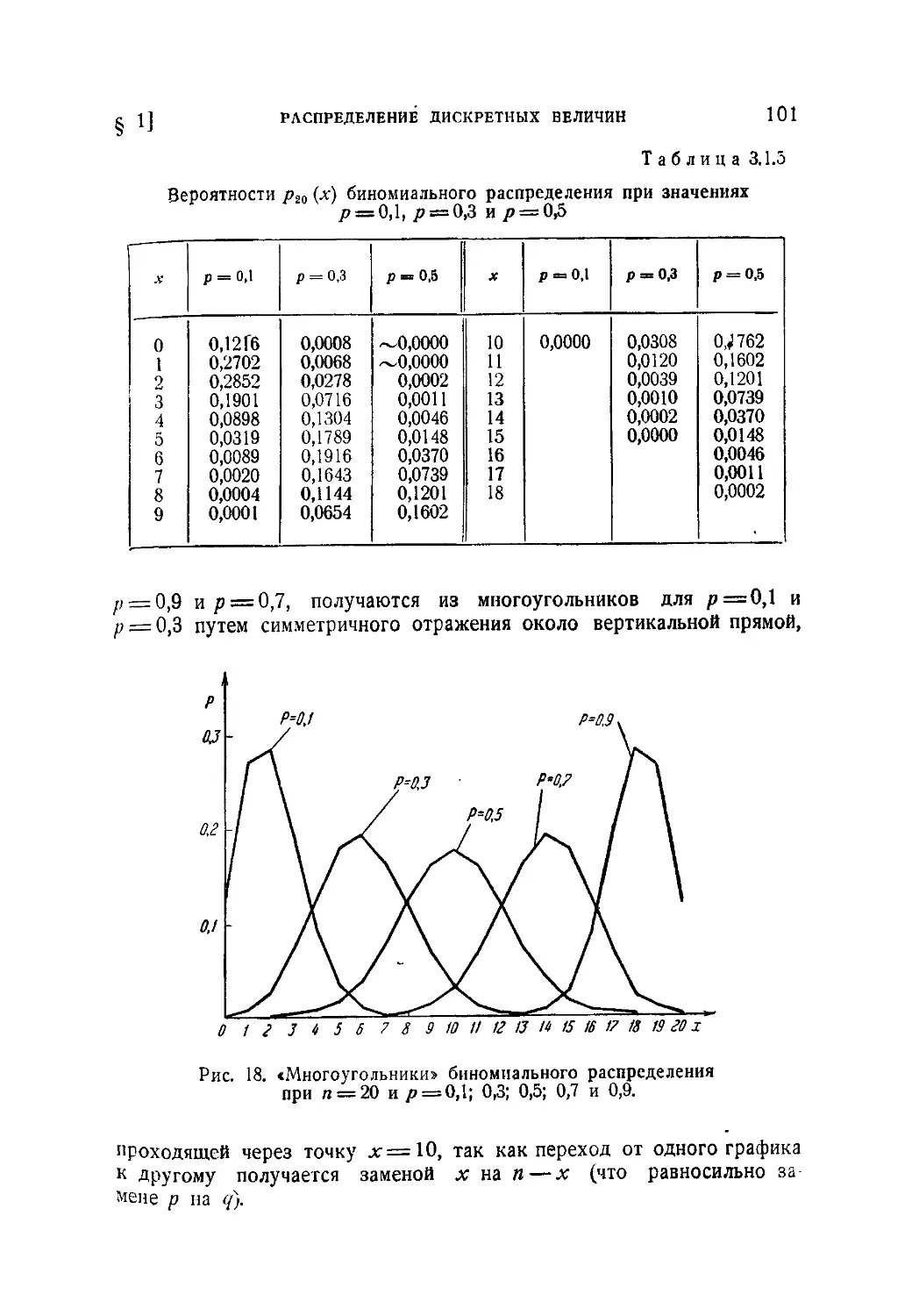
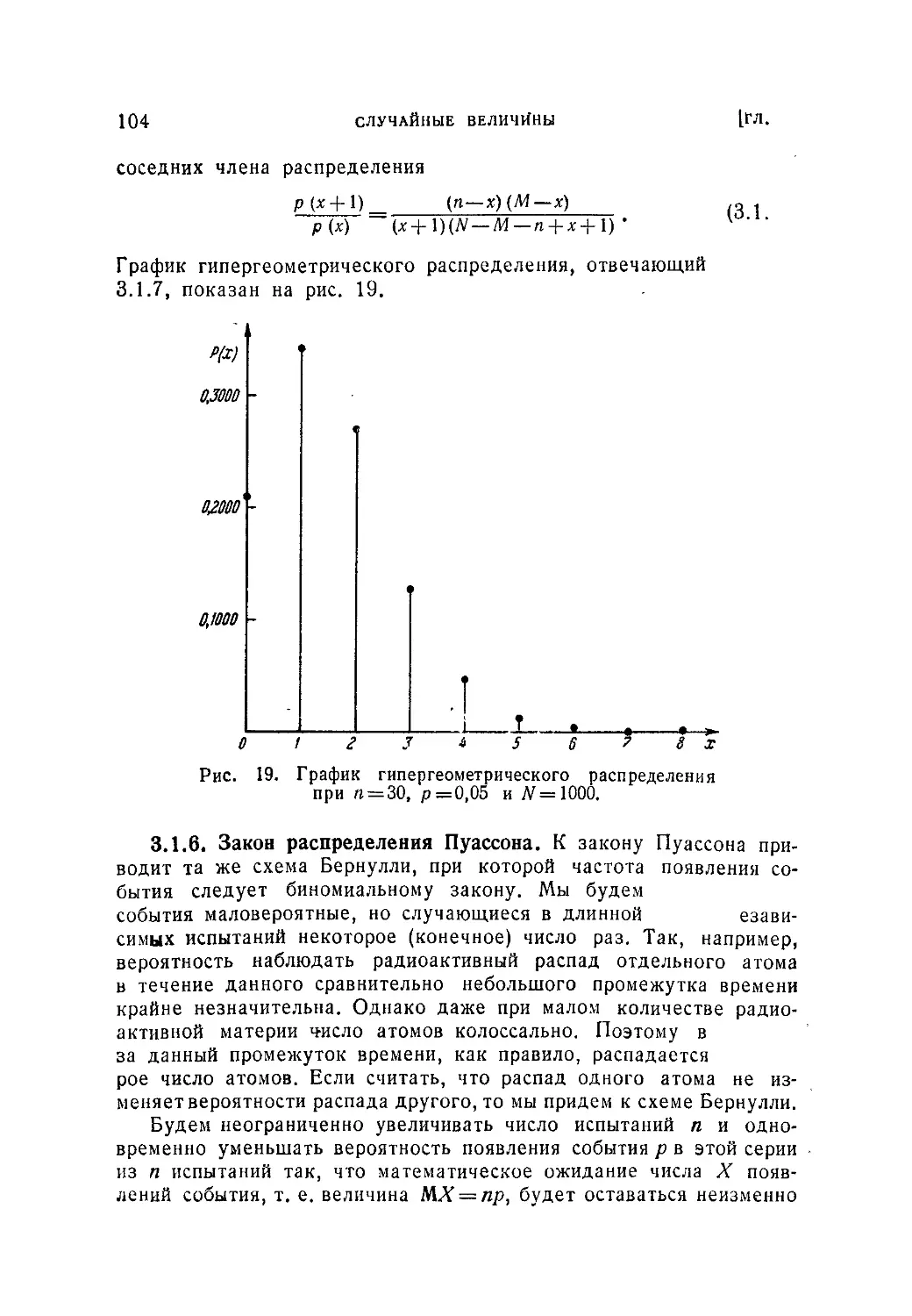
пределения. Понятие о производящей функции (95). 3.1.5. Гипергеометри-
ческое распределение (102). 3.1.6. Закон распределения Пуассона (104).
3.1.7. Закон Пуассона в схеме независимых испытаний с различными
вероятностями и его применение в теории надежности (108).
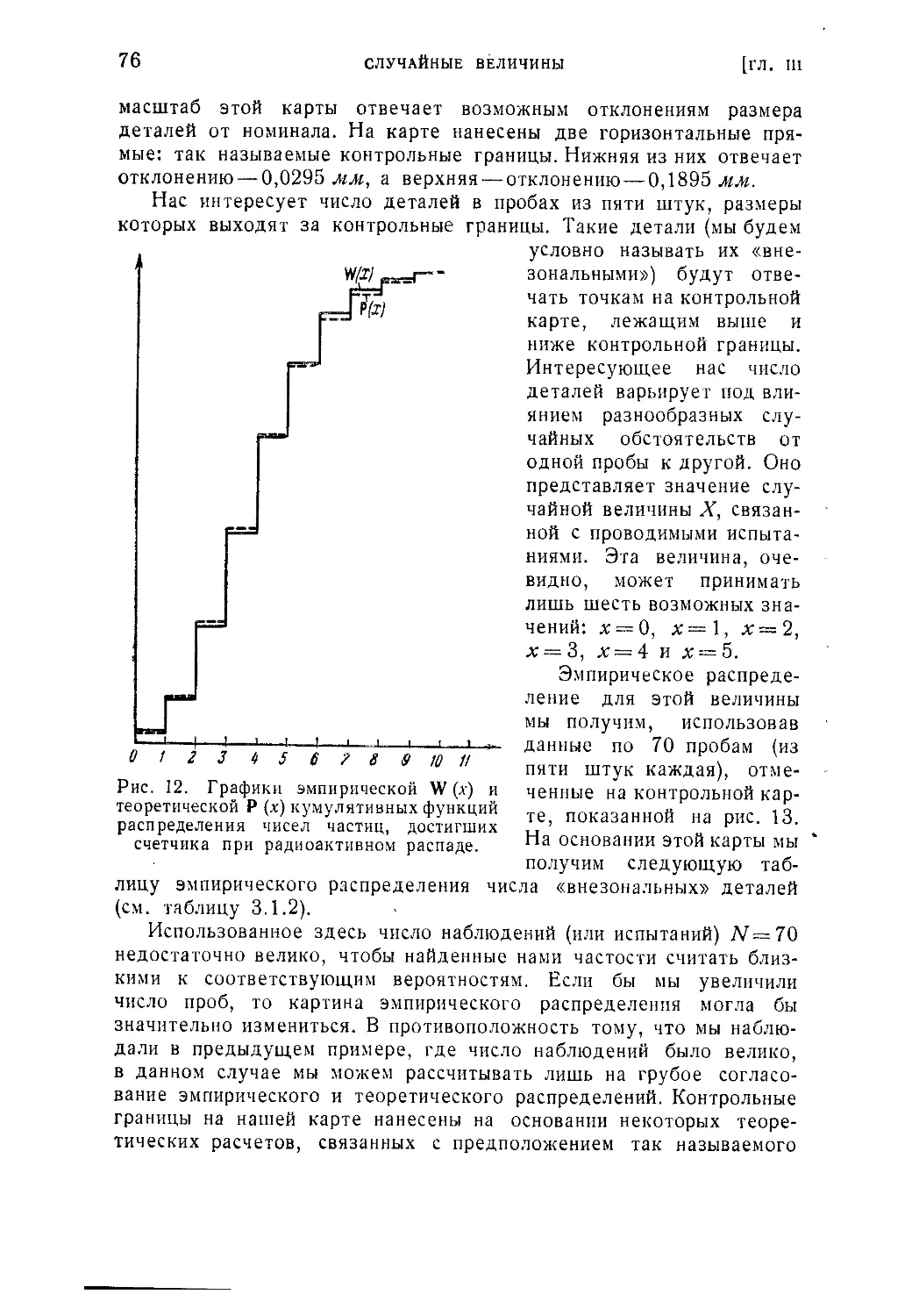
§ 2. Распределение непрерывных (непрерывно распределенных)
величин...........................................................111
3.2.1. Основные теоретические характеристики распределения непре-
рывной случайной величины: плотность распределения вероятности и
функция распределения. Квантили. Медиана (111). 3.2.2. Моменты непре-
рывного распределения. Математическое ожидание и дисперсия. Мода
(119). 3.2.3. Надежность элемента системы при изменяющемся времени
работы (122). 3.2.4. Эмпирическое распределение непрерывной величины,
построение его графиков и получение характеристик (124).
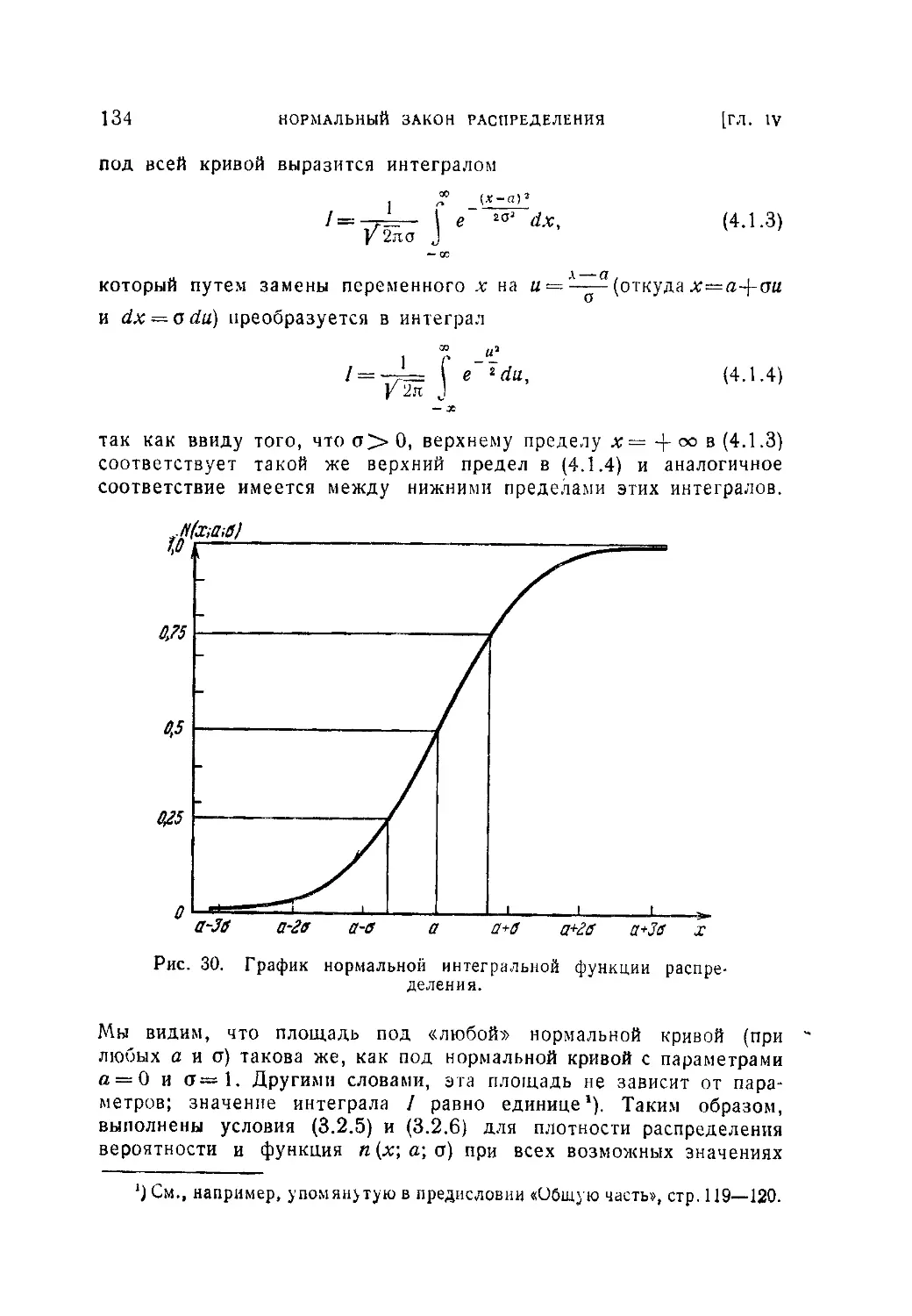
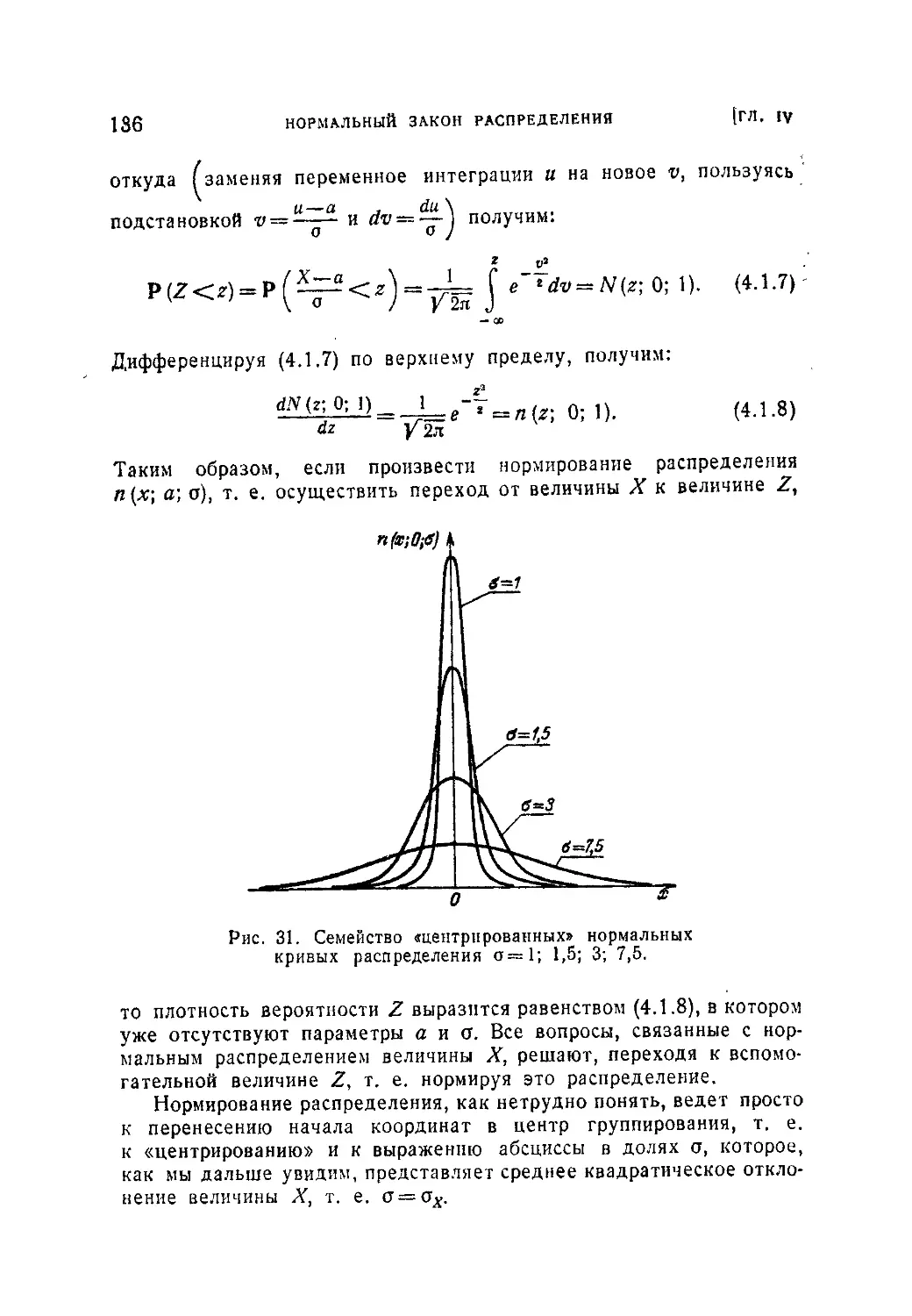
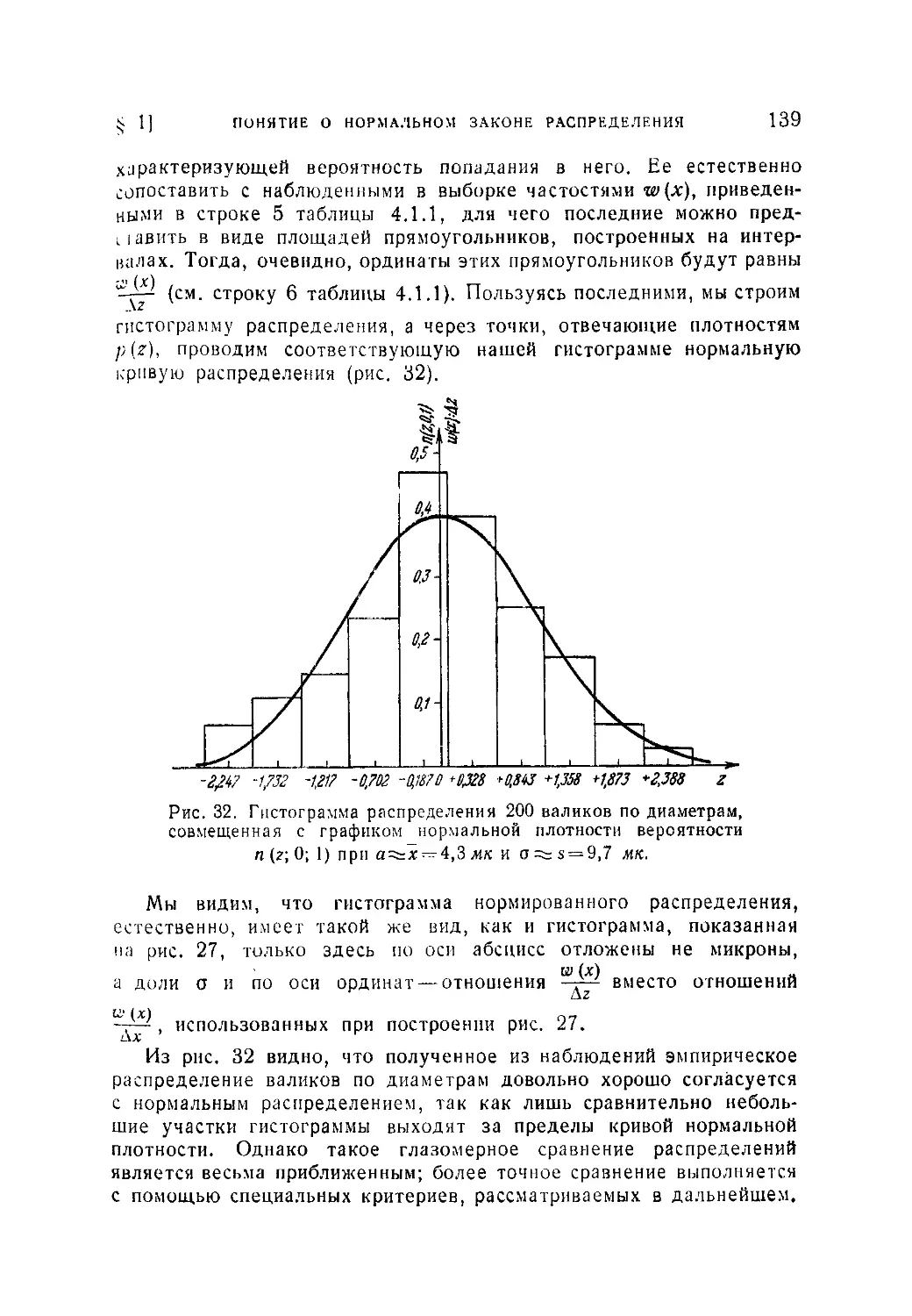
Ч Глава IV. Нормальный закон распределения...............................133
§ 1. Понятие о нормальном законе распределения.....................133
4.1.1. Значение нормального закона распределения (133). 4.1.2.
Нормальная плотность вероятности и ее параметры (133). 4.1.3. Произ-
1*
4
ОГЛАВЛЕНИЕ
водящая функция, моменты, асимметрия и эксцесс нормального распре-
деления (140).
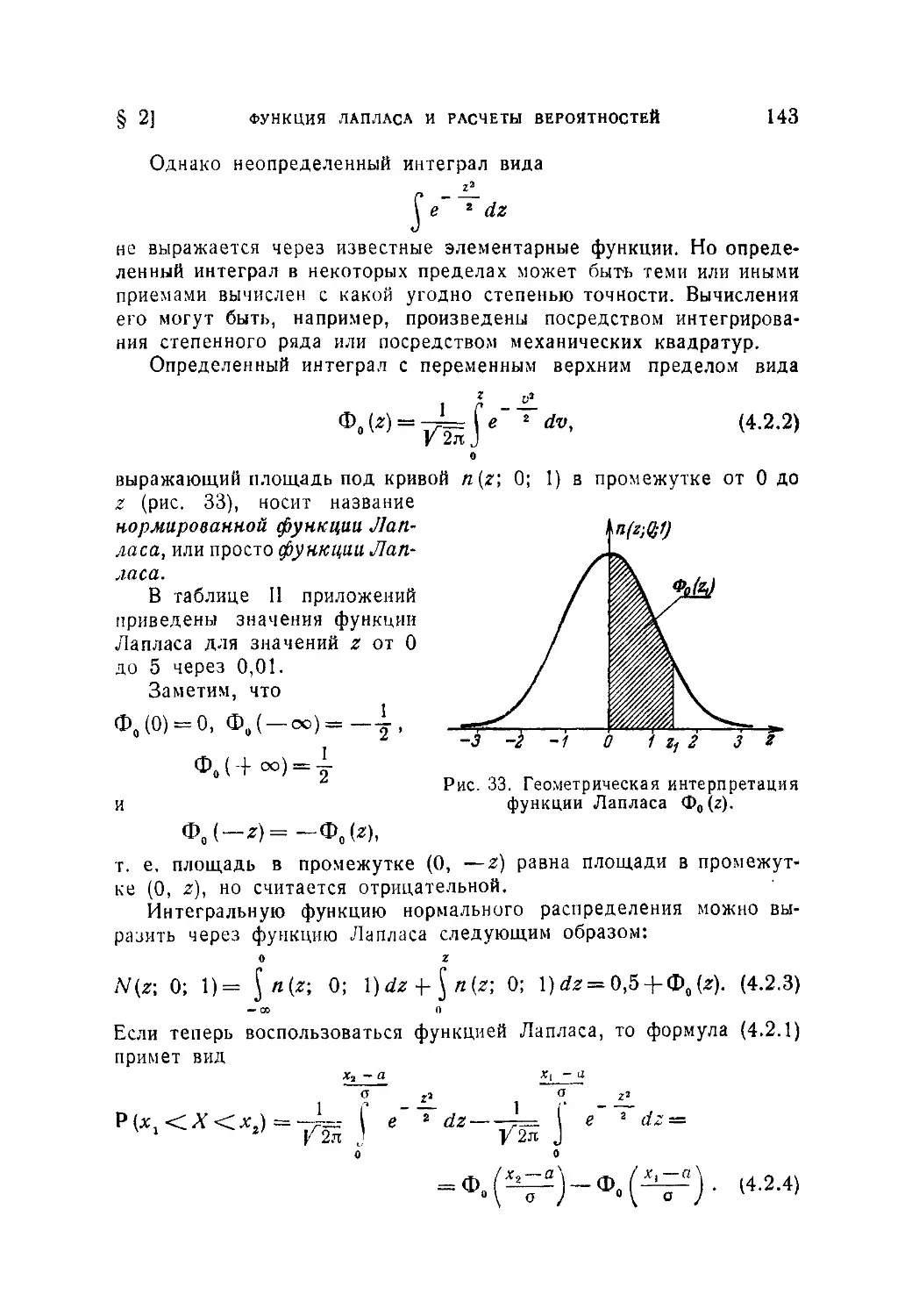
§ 2. Функция Лапласа и расчеты вероятностей при нормальном
распределении ................................................. 142
4.2.1. Функция Лапласа (142). 4.2.2. Вычисление вероятностей при
нормальном распределении (144).
§ 3. Применение нормального закона для оценки вероятности и
проверки гипотез ...............................................145
4.3.1. Нормальное распределение как приближение биномиального.
Теорема Я. Бернулли. Теорема Лапласа (145). 4.3.2. Доверительные
интервалы для неизвестной вероятности (152).
Глава V. Многомерные распределения. Закон больших чисел. Цент-
ральная предельная теорема ............................................ 157
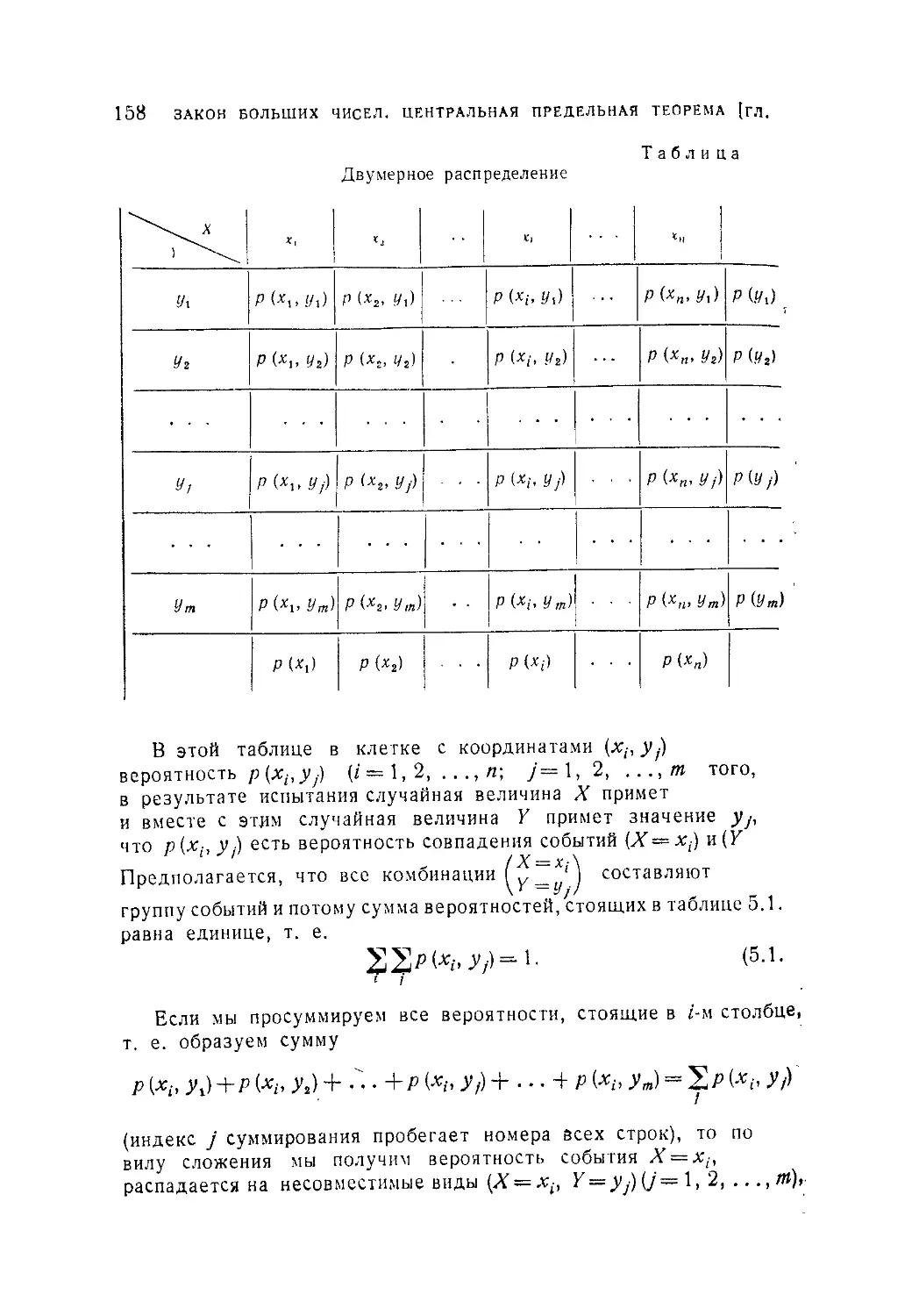
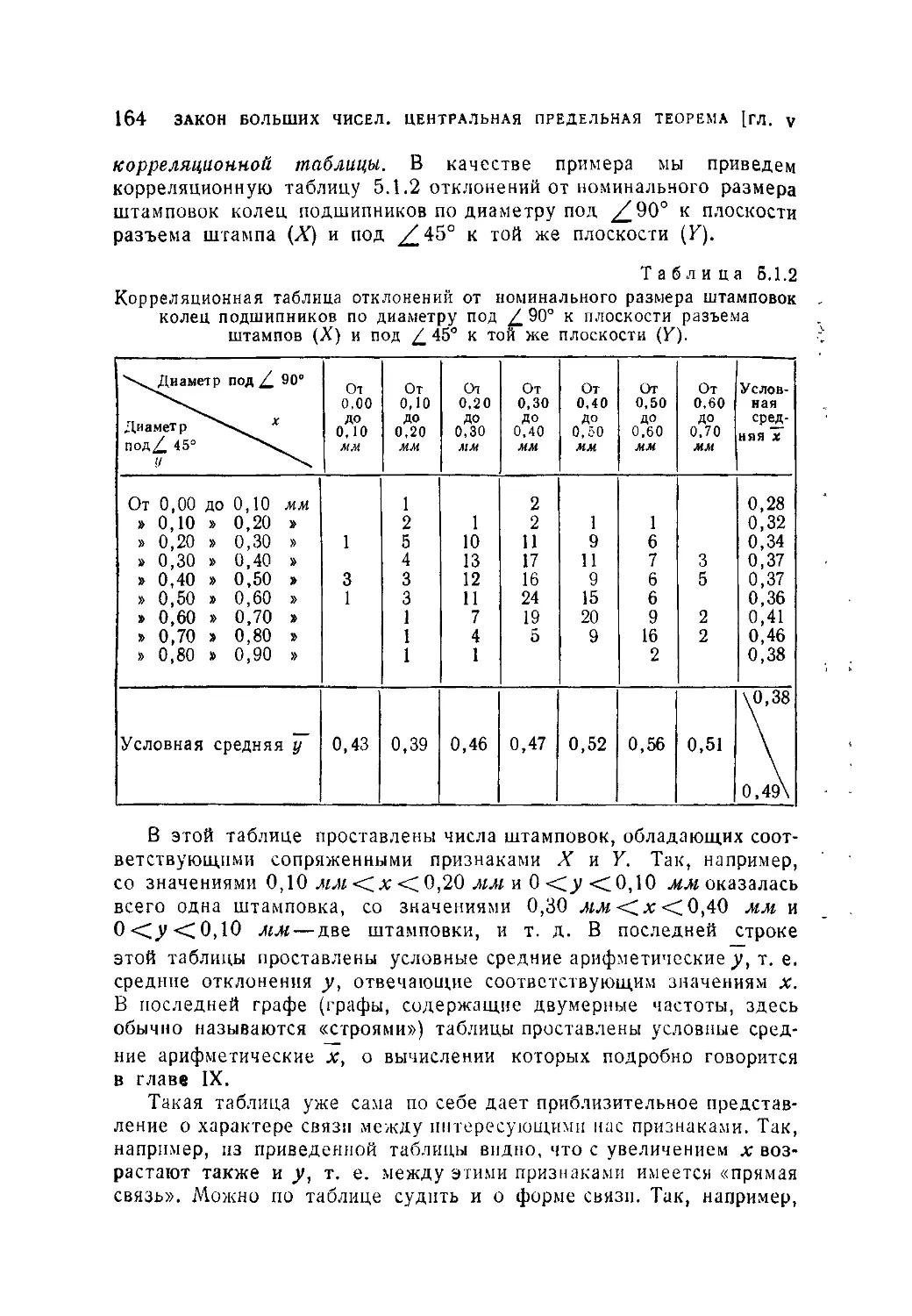
§ 1. Двумерные распределения........................................157
5.1.1. Двумерные распределения и их условные законы (157). 5.1.2.
Понятие о независимых величинах (165).
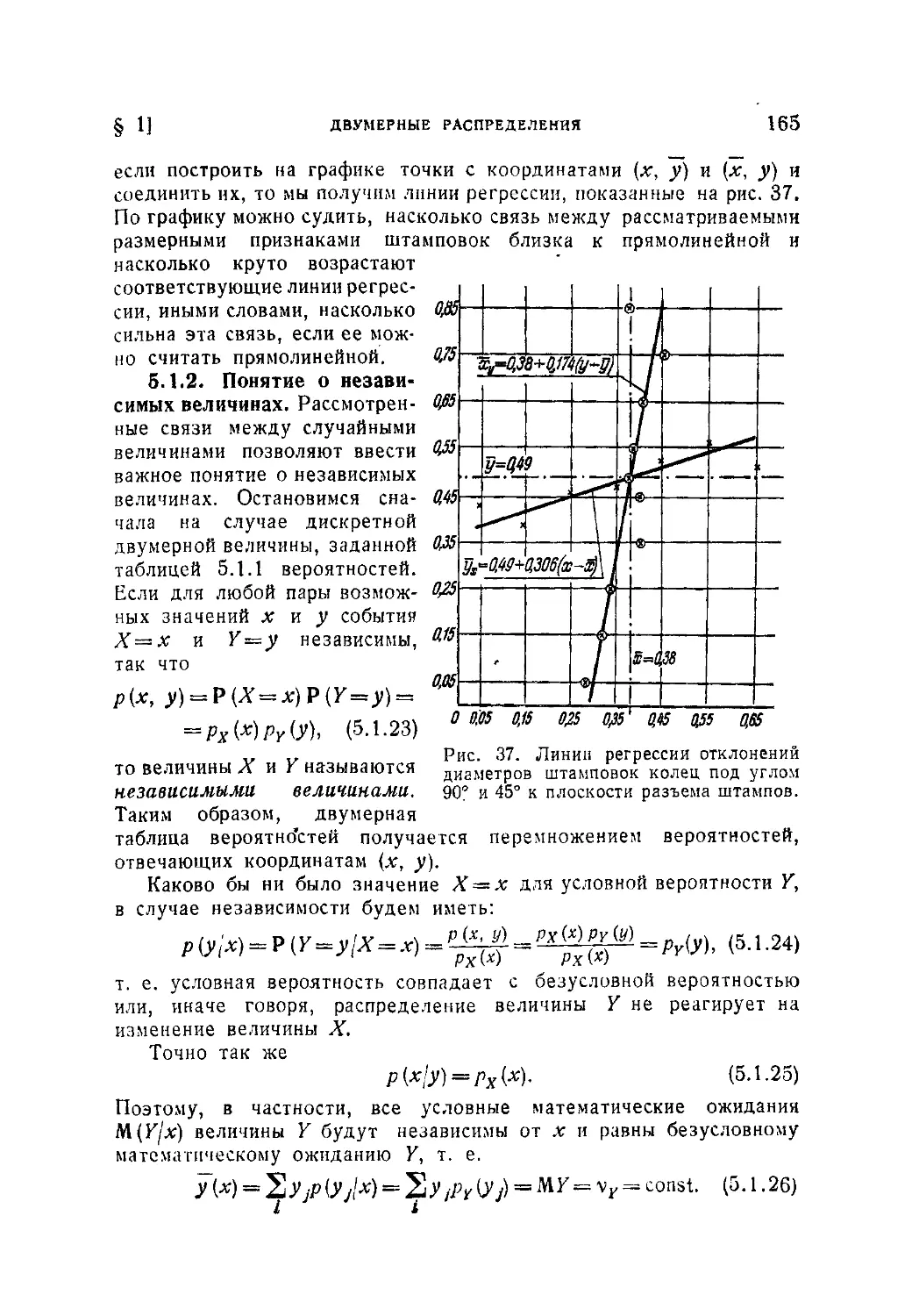
§ 2. Характеристики многомерных распределений.......................166
5.2.1. Математическое ожидание функции многих переменных. Тео-
ремы о математическом ожидании суммы и произведения (166). 5.2.2.
Понятие о ковариации (моменте связи) и коэффициенте корреляции.
Дисперсия суммы (169). 5.2.3. Приближенное определение математиче-
скою ожидания и дисперсии функции (175). 5.2.4. Двумерное нормаль-
ное распределение (176).
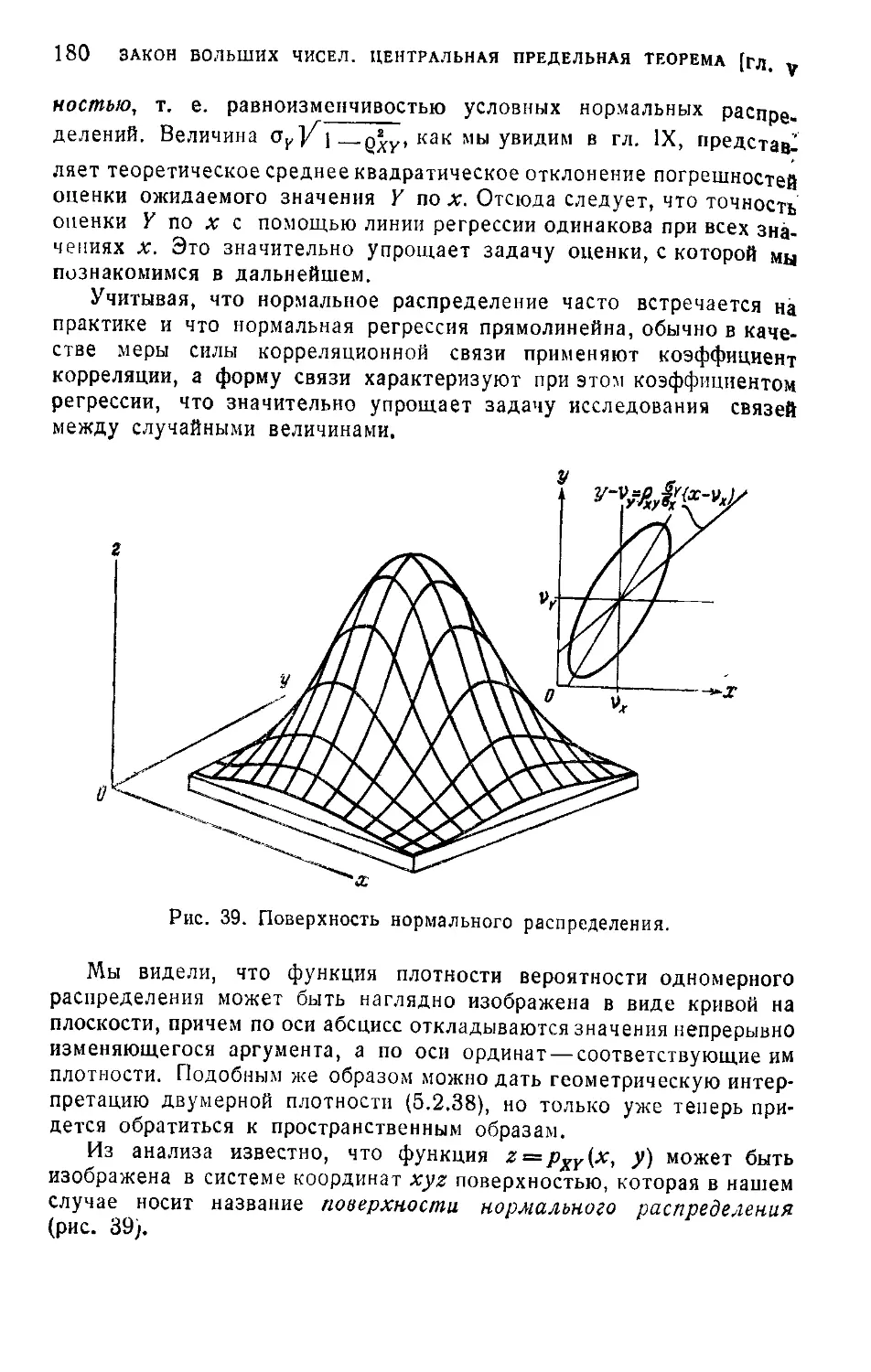
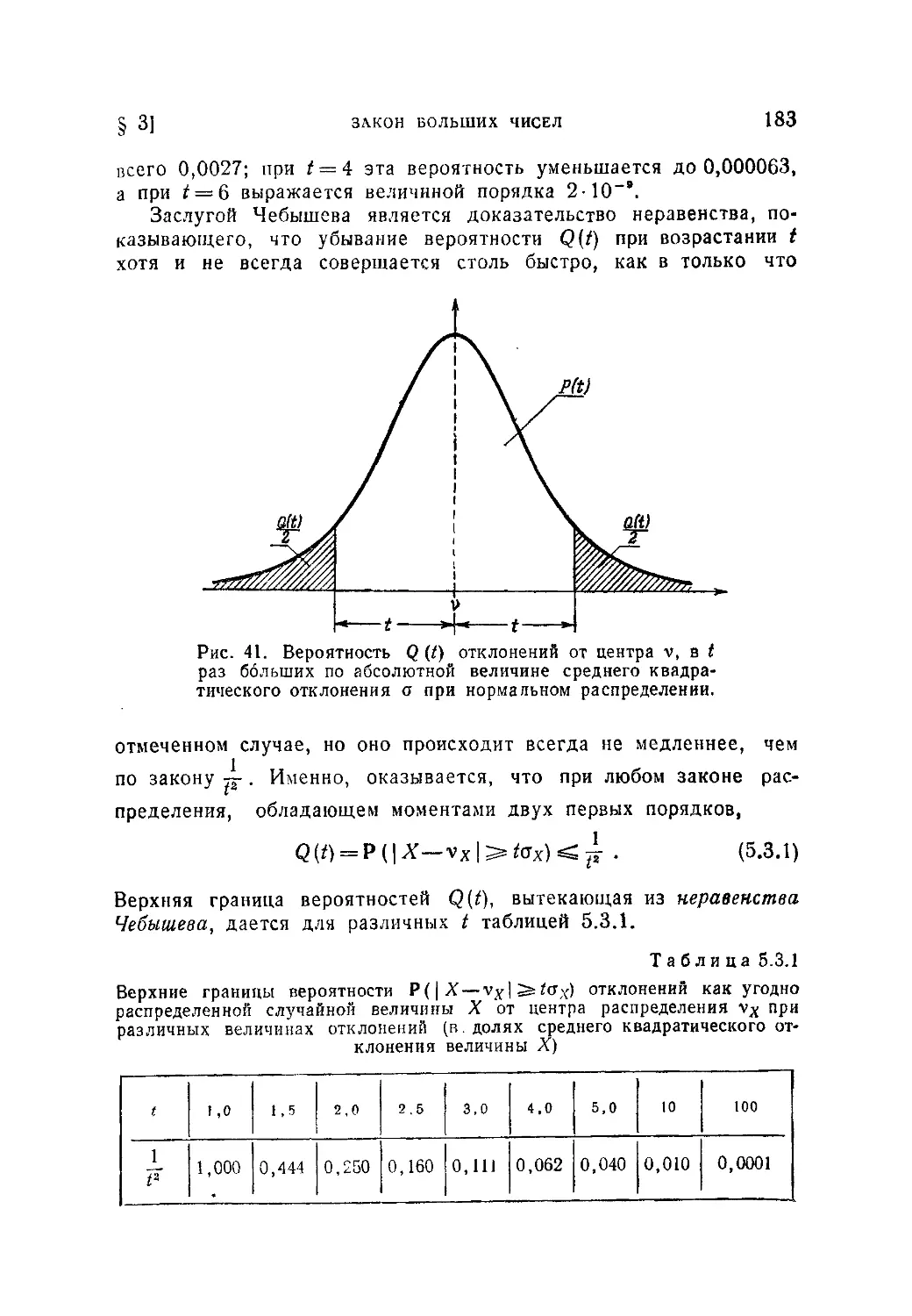
§ 3. Закон больших чисел........................................ . 182
5.3.1. Неравенство Чебышева (182) 5.3.2. Основные предельные
законы теории вероятностей (185) '
§ 4. Композиция распределений случайных величин. Центральная
предельная теорема ............................................ 187
5.4.1. Общие понятия о композиции распределений (187). 5.4.2.
Производящая функция композиции. Центральная предельная теорема
(192). 5.4.3. Роль нормального распределения в приложениях (198).
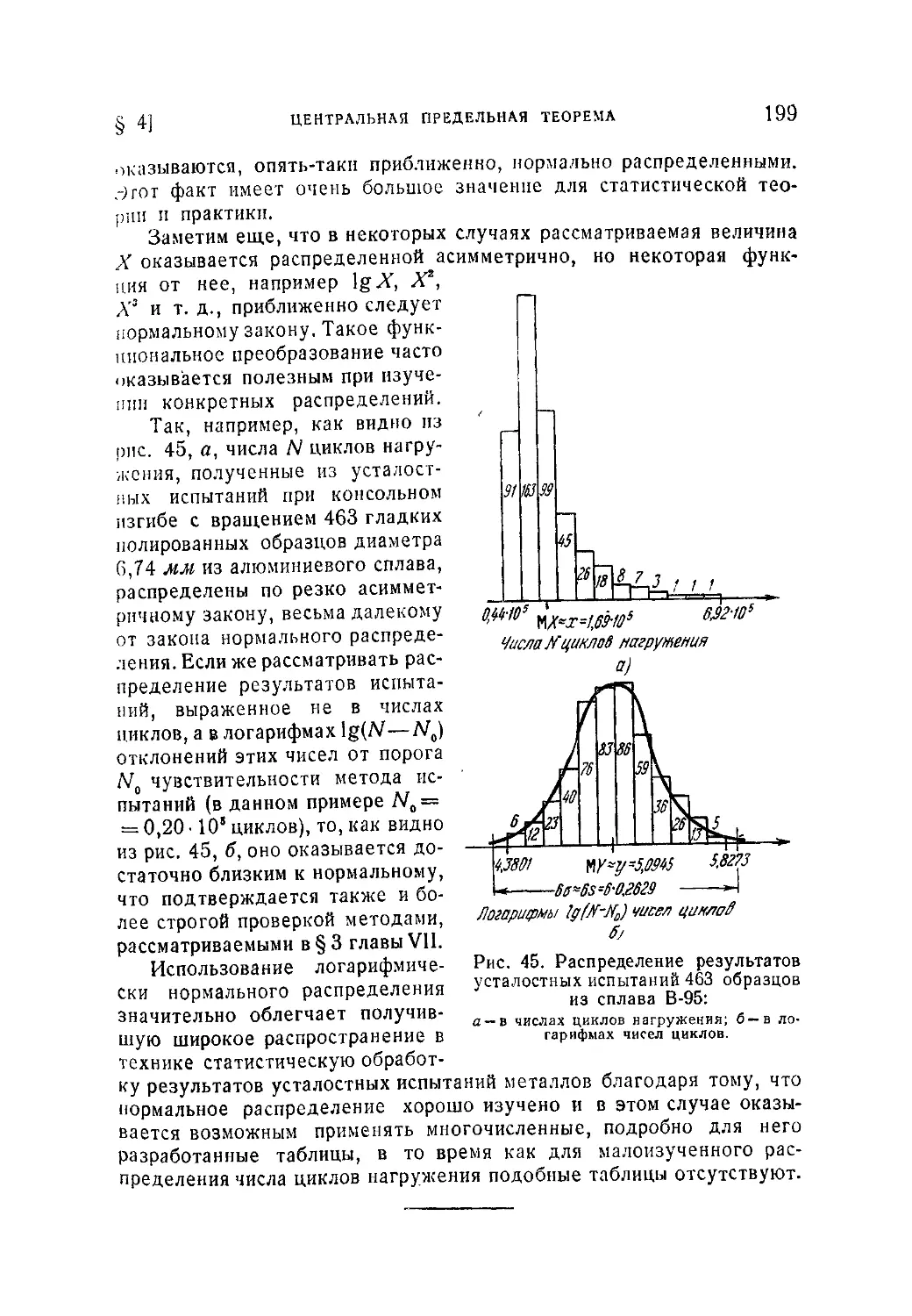
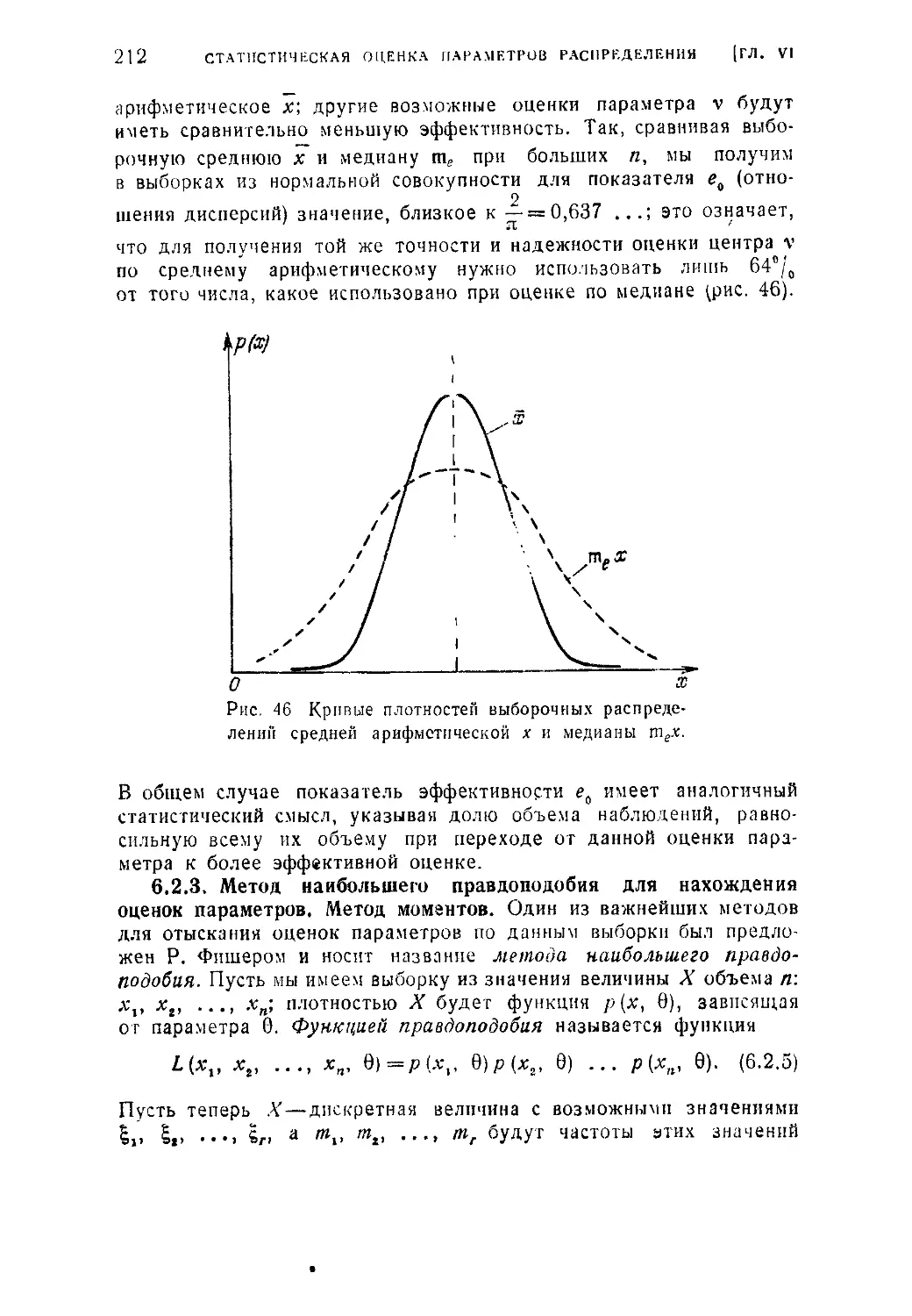
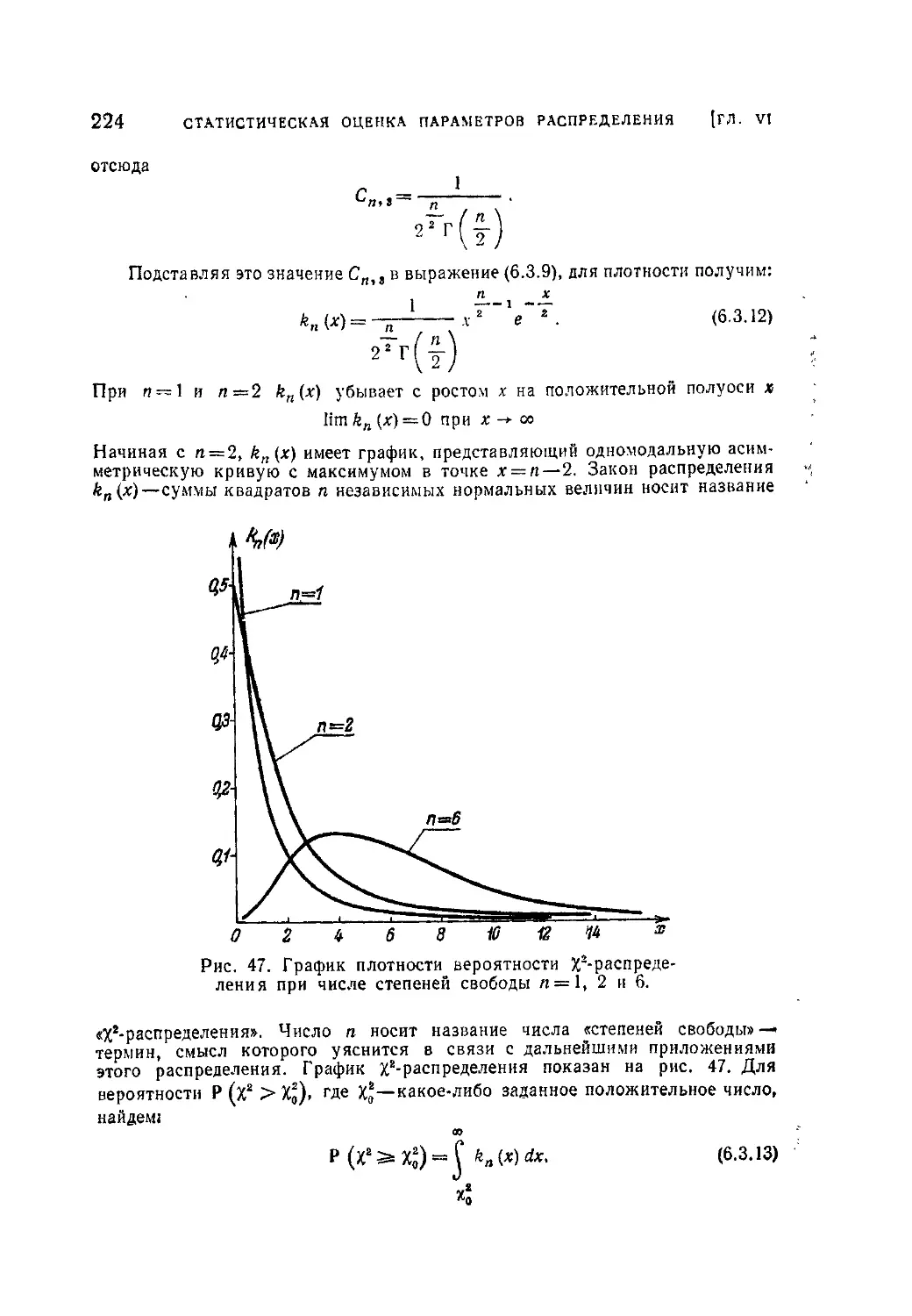
Глава VI. Статистическая оценка параметров распределения .... 200
§ 1. Основные понятия выборочного метода и задачи математической
статистики..........................................................200
6.1.1. Общие понятия о выборке (200). 6. 1.2. Распределение выборки
и выборочные характеристики. Состоятельные и* несмещенные оценки.
Несмещенная оценка дисперсии (202).
§ 2. Статистические оценки параметров распределения при больших
выборках ...........................................................208
6.2.1. Значение состоятельности, несмещенности и эффективности
оценок (208). 6.2.2. Асимптотические распределения выборочных харак-
теристик (210). 6.2.3. Метод наибольшего правдоподобия для нахождения
оценок параметров, Метод моментов (212). 6.2.4. Оценка центра распре-
деления по неравноточным наблюдениям (216).
§ 3. Точные распределения некоторых выборочных характеристик 221
6.3.1. Распределение %2 (221). 6.3.2. Распределение t Стьюдента
(225). 6.3.3. Распределение F (228). 6.3.4. Распределение дисперсии
выборки из нормальной совокупности (228). 6.3.5. Распределение крите-
рия Стьюдента (232).
§ 4. Оценка параметров распределения по малым выборкам .... 233
6.4.1. Понятие доверительного интервала. Доверительный интервал
для центра распределения при известном G (233) 6.4.2. Доверительный
интервал для центра распределения при неизвестном а (236). 6.4.3. Дове-
рительный интервал для а (238) 6.4.4. Оценка параметра <7 по размахам
нескольких выборок (239) 6.4.5. Доверп бельные интервалы в случае
асимпто1ически нормальных оценок (240). 6.4.6. Допустимые (толерант-
ные) пределы (242).
ОГЛАВЛЕНИЕ
5
лава VII. Статистическая проверка гипотез............................244
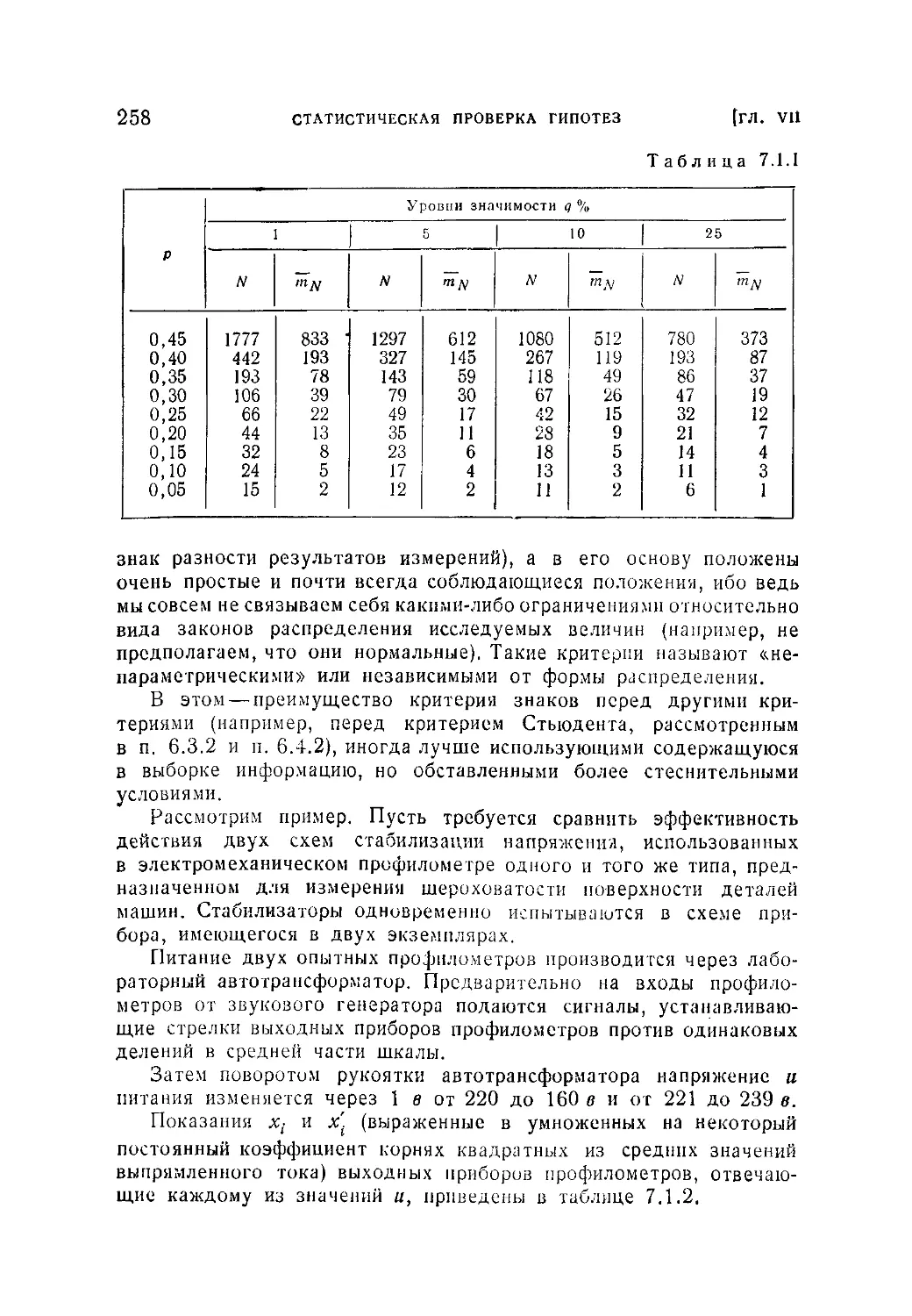
§ 1. Задачи статистической проверки гипотез. Проверка гипотез
о вероятностях, распределениях и средних .....................244
7.1.1. Статистическая проверка гипотезы относительно вероятности
(244). 7.1.2. Общая задача проверки гипотез. Гипотеза о положении
центра группирования (248), 7.1.3. Критерий знаков (254). 7.1.4. Про-
верка гипотезы о равенстве двух центров распределения (260).
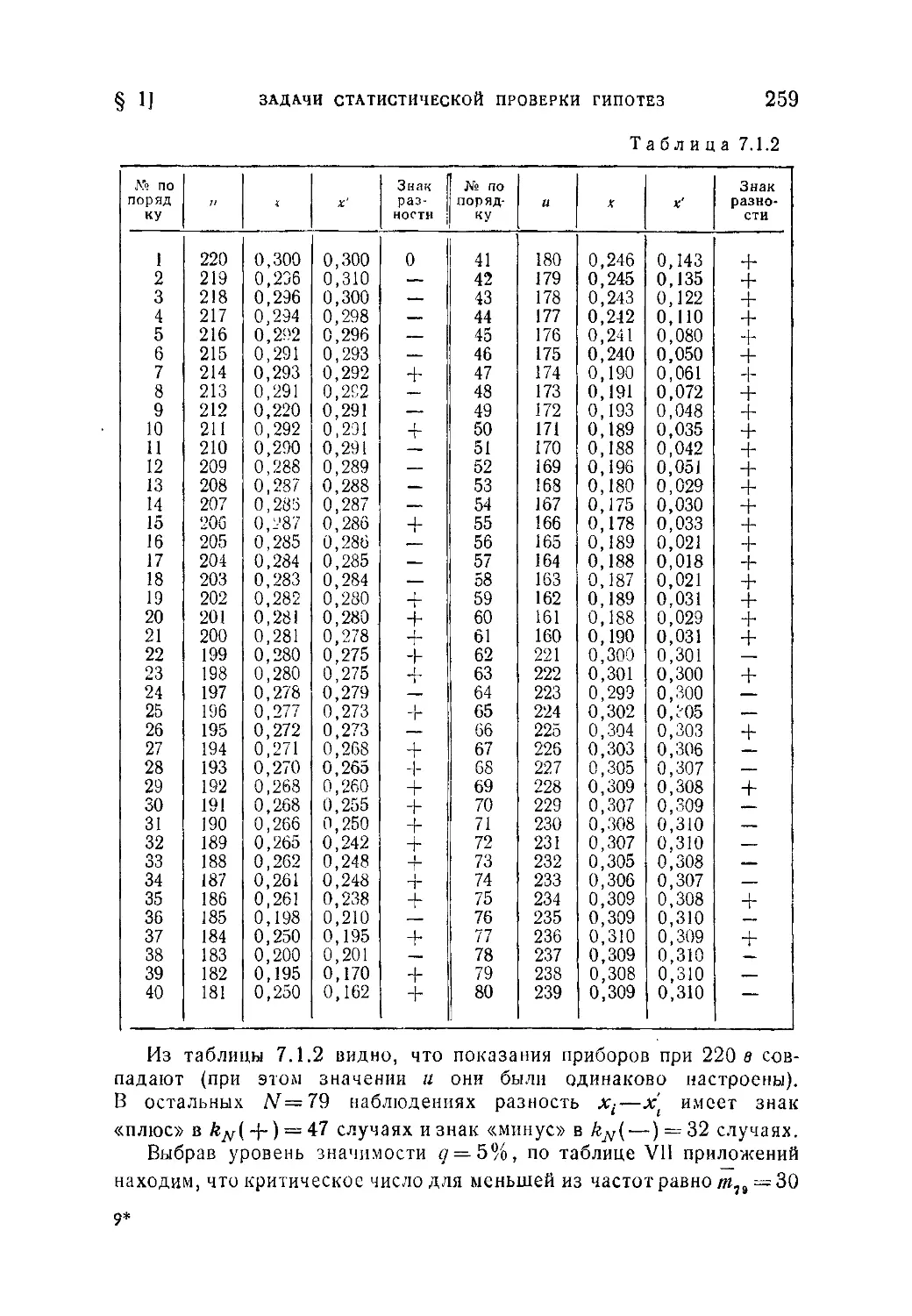
§ 2. Проверка гипотез о дисперсиях ................................263
7.2.1. F-распределение и проверка гипотезы о равенстве дисперсий
(263). 7.2.2. Проверка гипотезы об однородности ряда дисперсий (266)
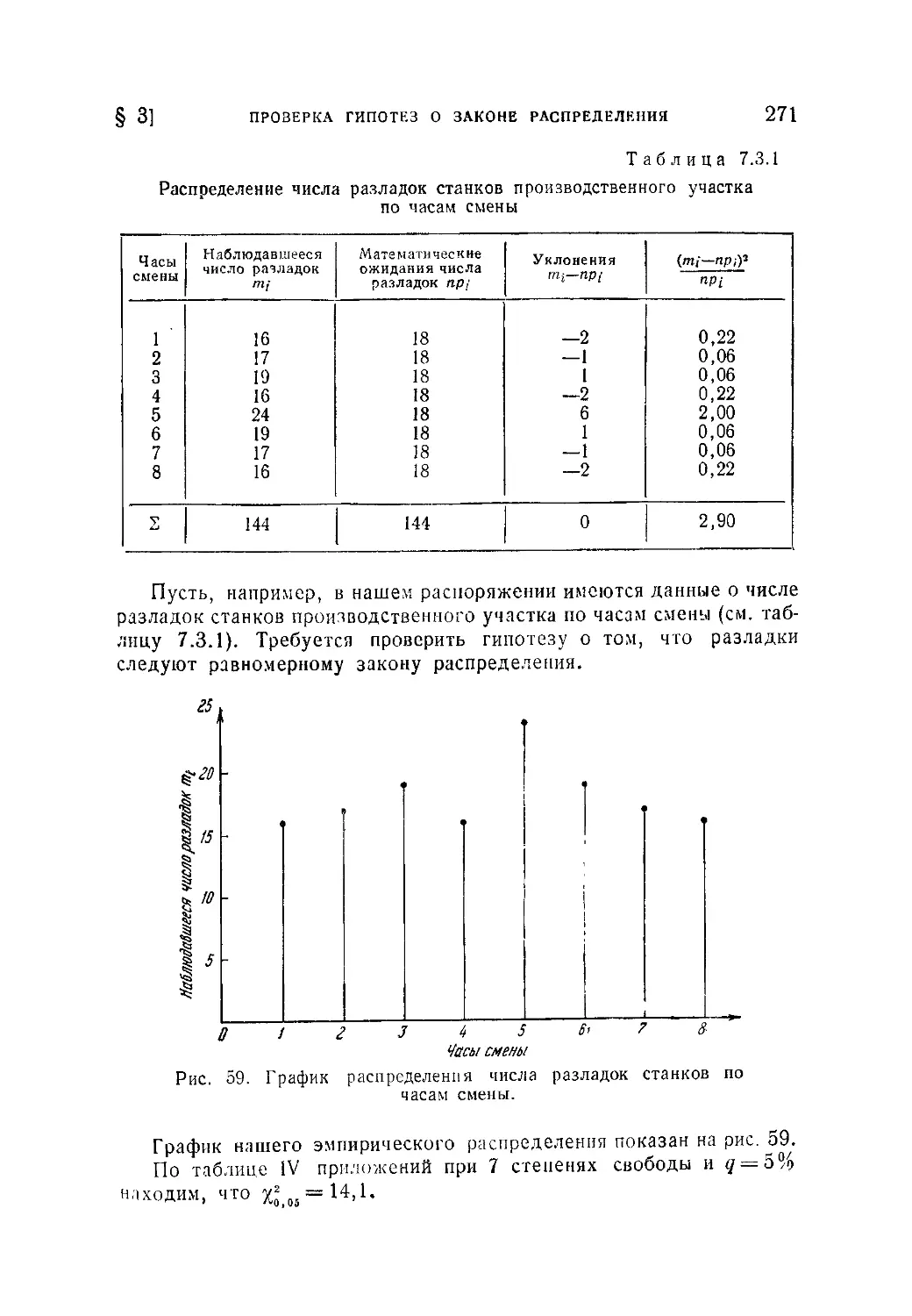
§ 3. Проверка гипотез о законе распределения.......................267
7.3.1. Критерий соответствия х2 (267). 7.3.2. %2 как критерий одно-
родности распределений (27 5). 7.3,3. Приближенная проверка гипотезы
нормальности с помощью асимметрии и эксцесса (277). 7.3.4. Критерий
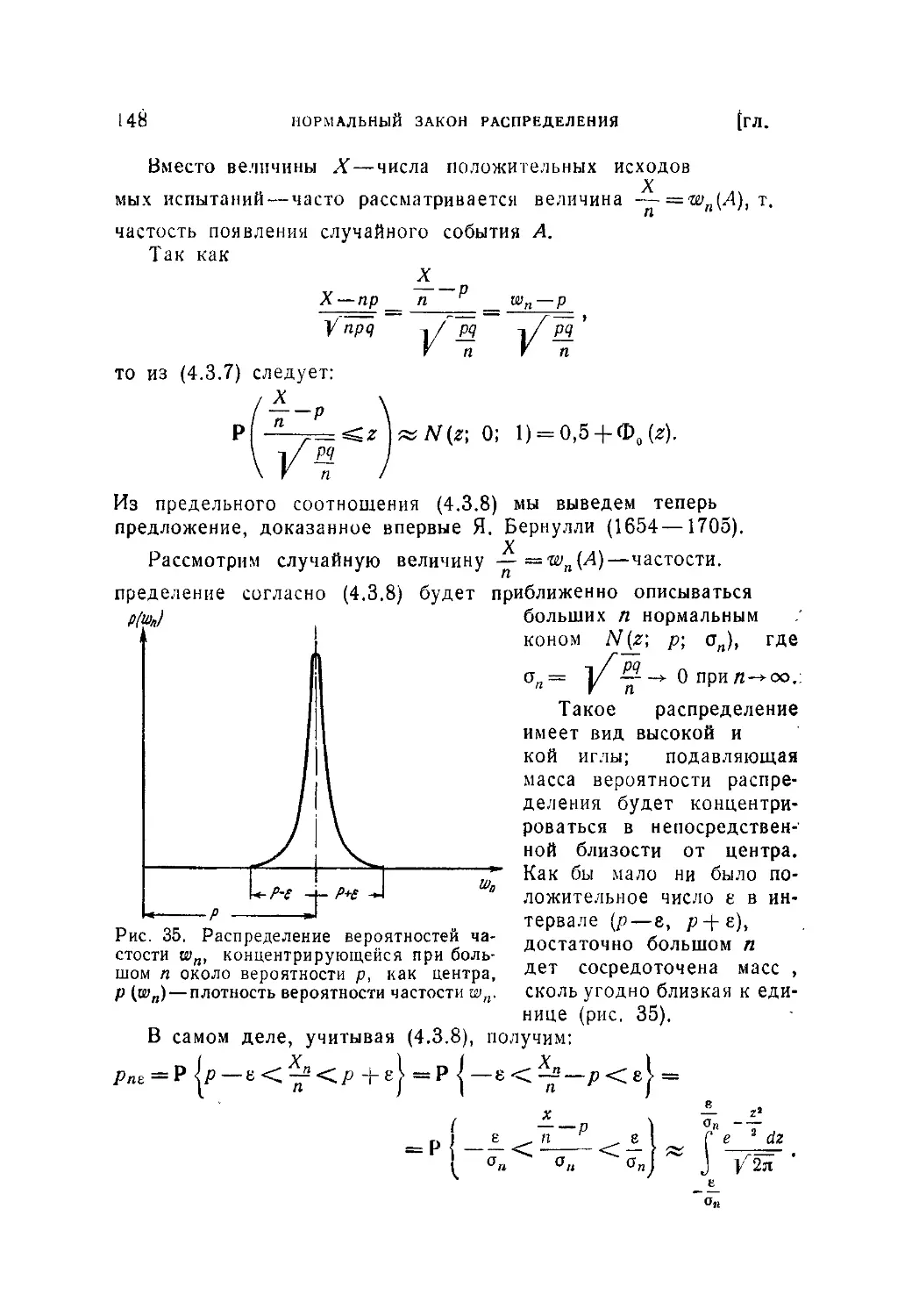
соответствия со2 (277). 7.3.5. Критерий принадлежности двух выборок
одной и той же генеральной совокупности (281). 7.3.6. Критерий грубых
ошибок наблюдений (284). 7,3.7. Проверка гипотезы нормальности по
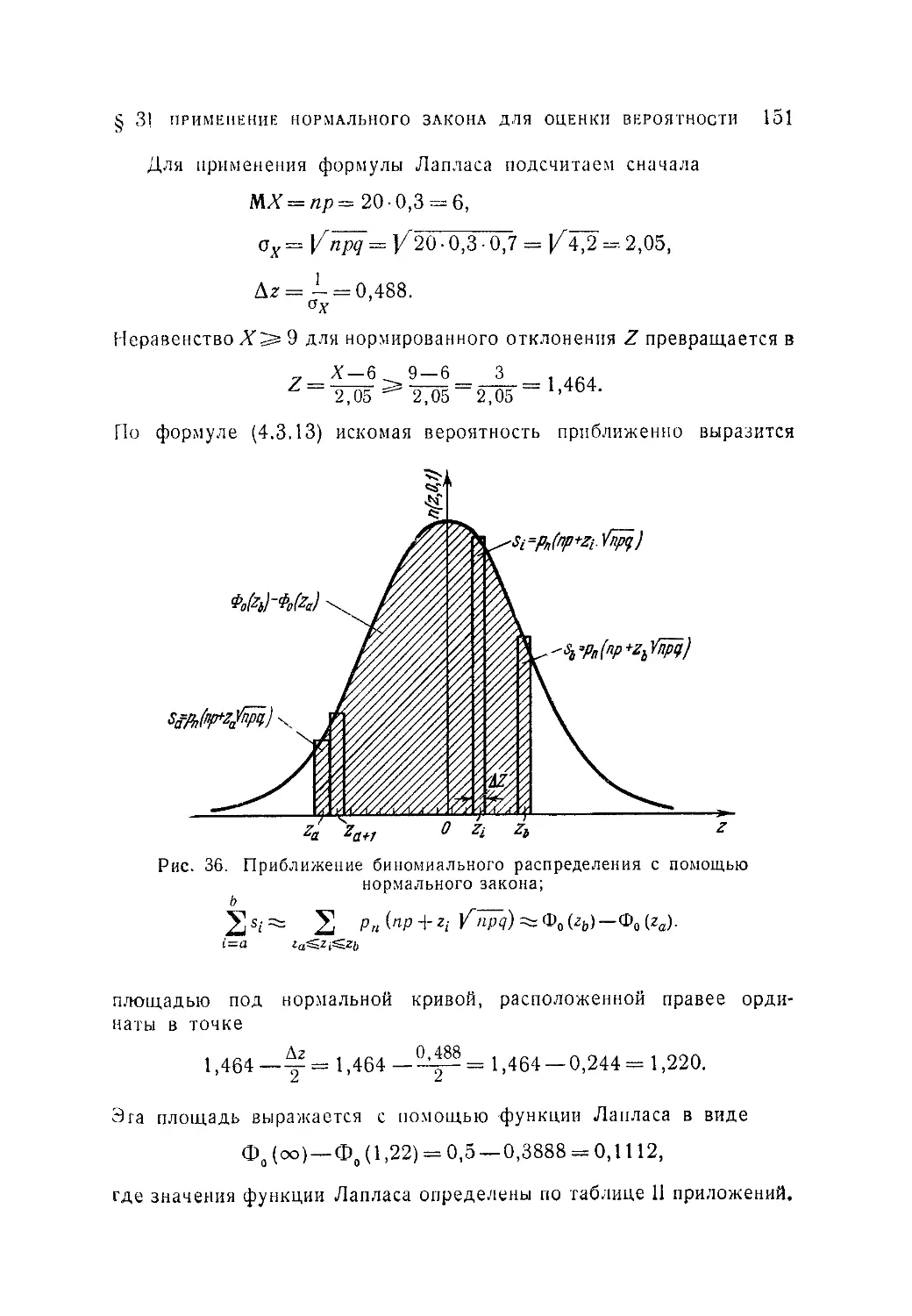
совокупности малых выборок (287).
Г 'лава VIII. Основы дисперсионного анализа................................294
§ 1. Общие понятия о дисперсионном анализе. Однофакторный
анализ...................................................... 294
8.1.1. Задачи дисперсионного анализа (294). 8.1.2. Понятие об одно-
факторном дисперсионном анализе (295).
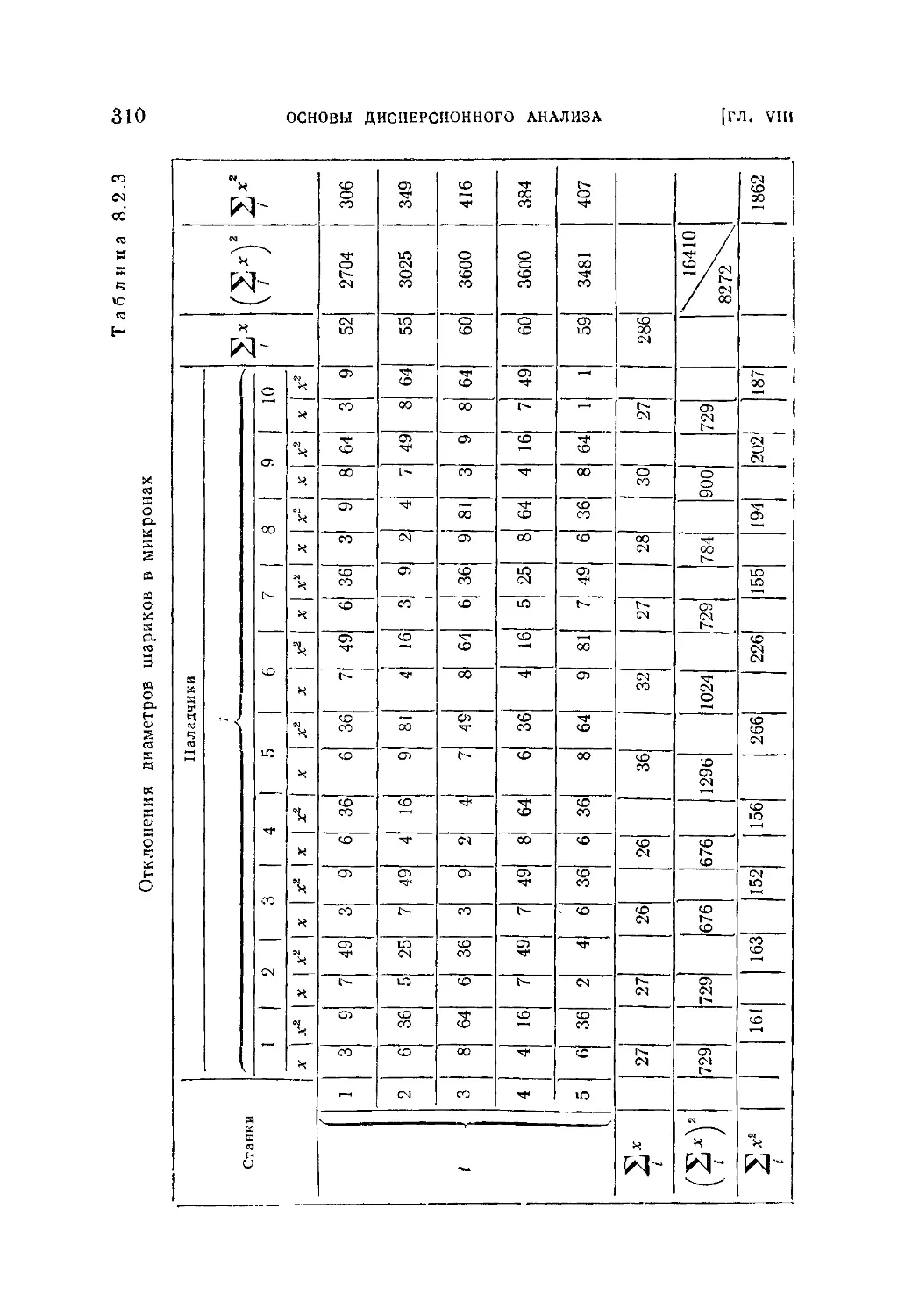
§ 2. Многофакторный дисперсионный анализ...........................306
8,2.1. ДвухфактэрныЙ анализ (306) 8.2.2. Пример двухфакторного
анализа (309).
Г лава IX. Основы теории корреляции...................................... 313
§ 1. Понятие о корреляции и регрессии..............................313
9.1.1. Стохастическая связь (313). 9.1.2. Кривые регрессии. Услов-
ные дисперсии (314). 9.1.3. Коэффициент корреляции и прямые прибли-
женной регрессии (317). 9.1.4. Случай линейной корреляции (321). 9-1.5.
Корреляционное отношение (322)
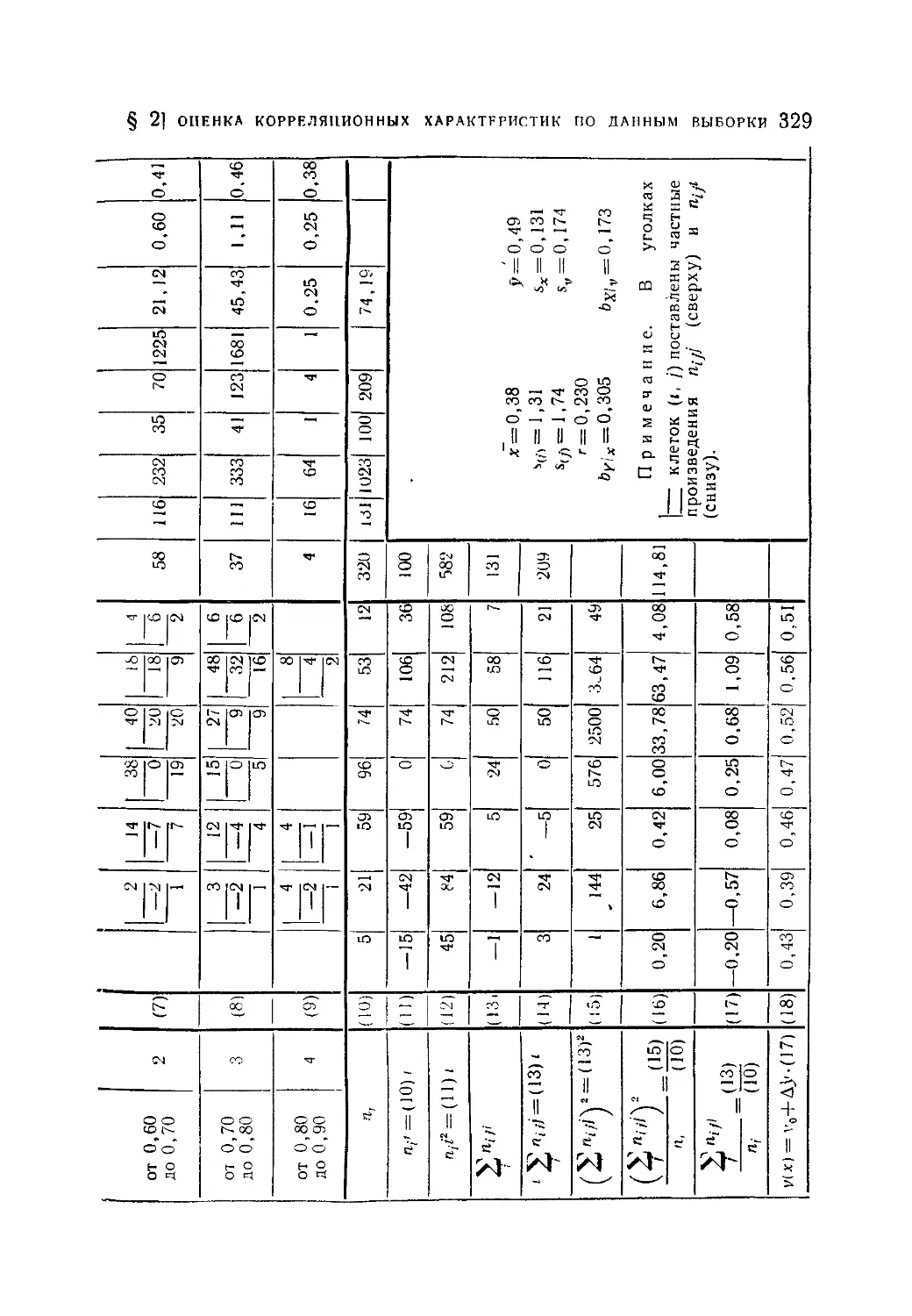
§ 2 Оценка корреляционных характеристик по данным выборки . . 323
9.2.1. Выборочные характеристики связи н их вычисление (323).
9.2.2. Эмпирическое корреляционное отношение (330). 9.2.3. Оценка
достоверности коэффициентов связи (331) 9.2.4. Проверка гипотезы об
отсу1сгвии корреляционной связи (333).
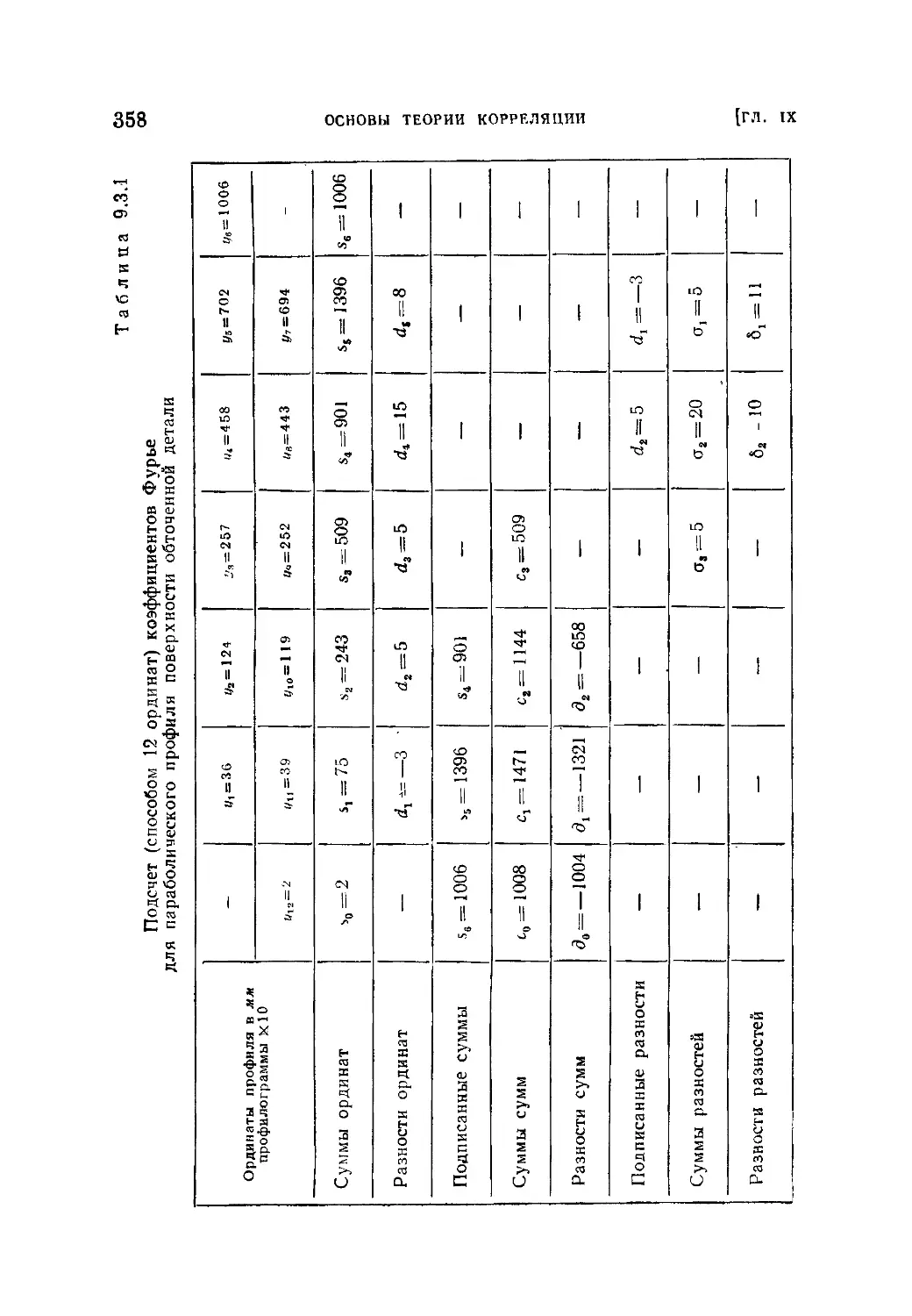
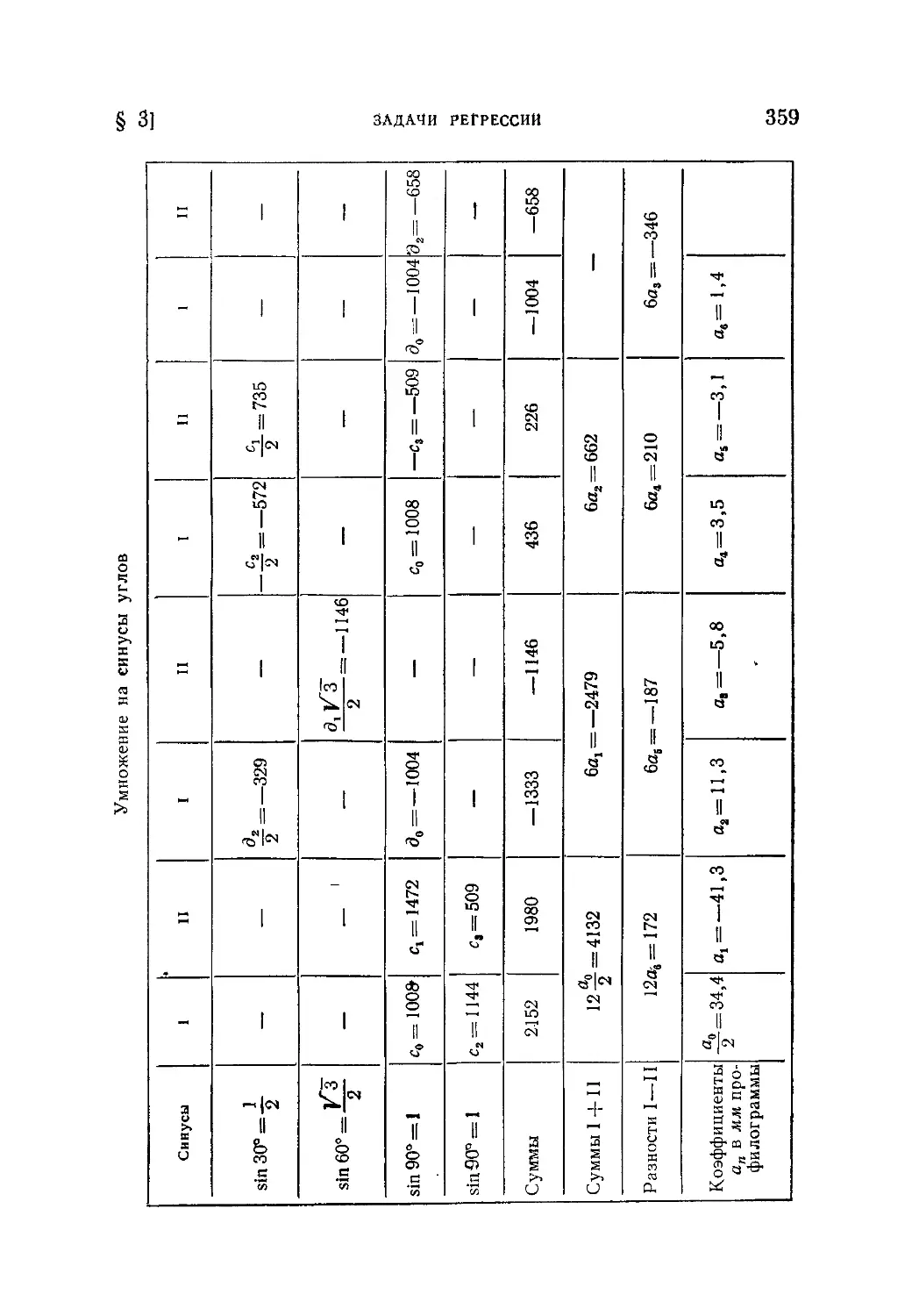
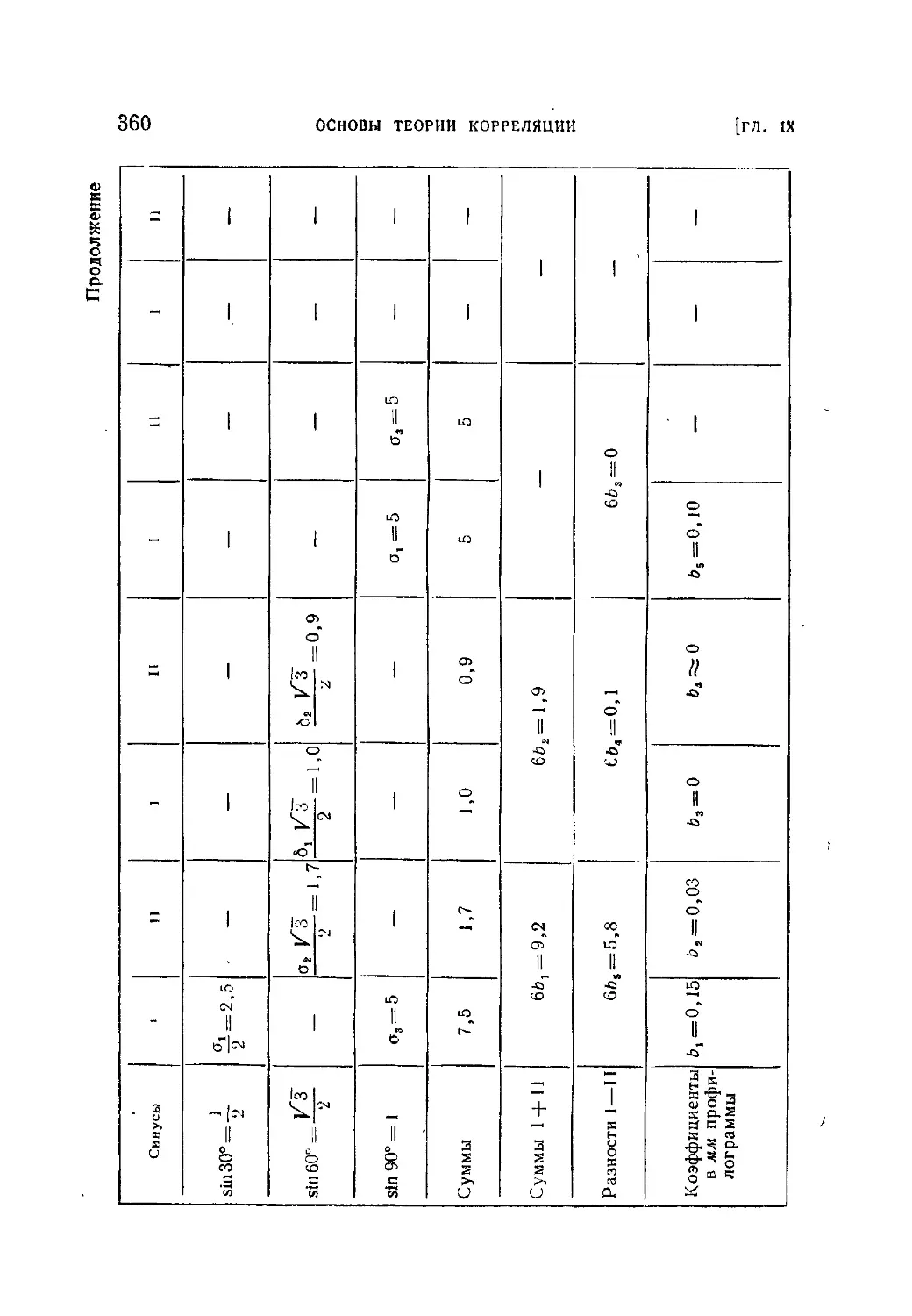
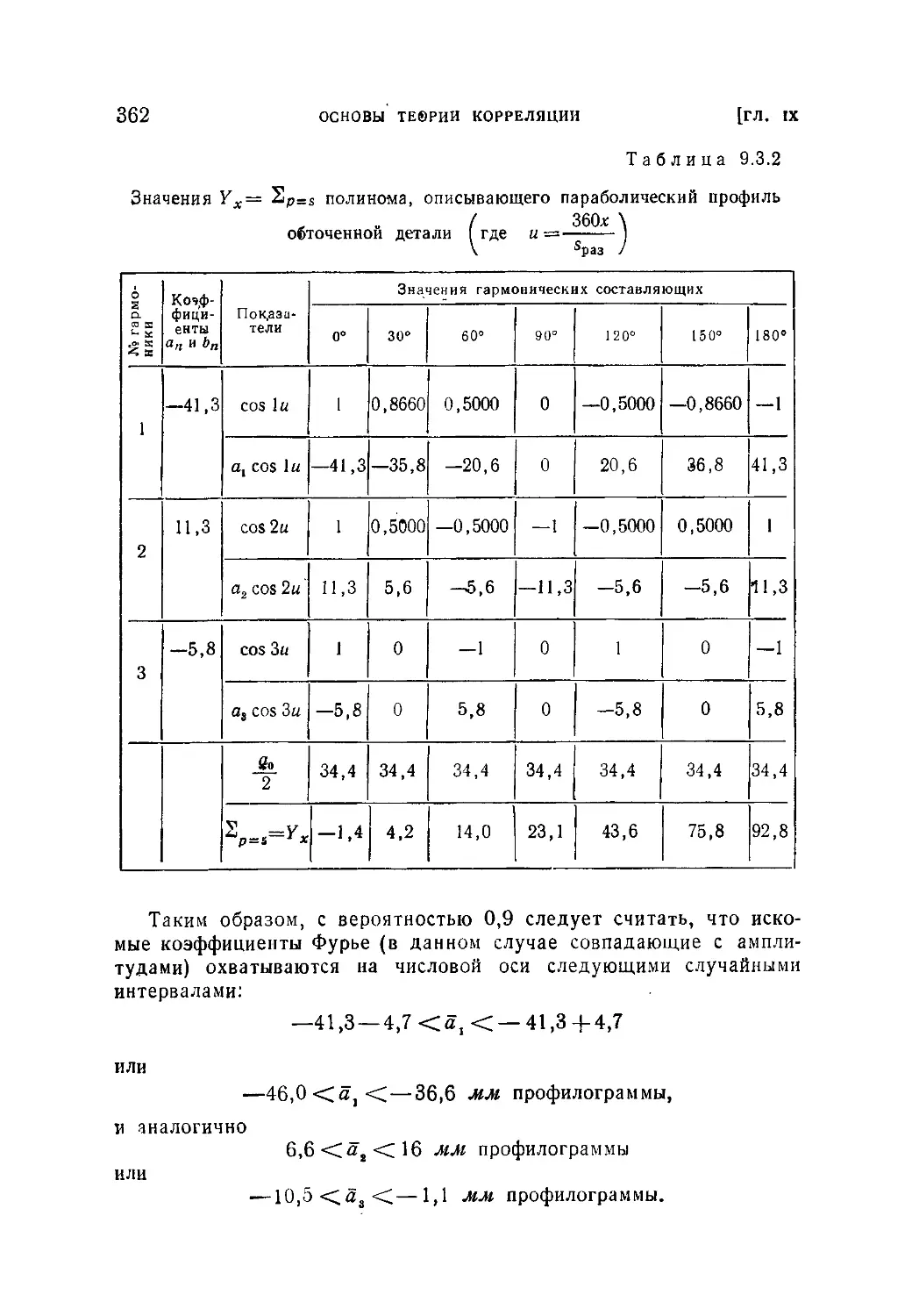
§ 3. Задачи регрессии..................-г..........................333
9.3.1. Постановка вопроса (333). 9.3.2. Оценка параметров линей-
ной зависимости по методу наименьших квадратов (335). 9.3.3. Общий
случай регрессии (346).
Г 'лава X. Вероятностно-статистические методы расчета, анализа и
контроля точности ........................................................ 365
§ 1. Теоретико-вероятностный метод расчета размерных цепей . . . 365
10.1.1. Понятие о размерных цепях (365). 10.1.2. Расчет размерной
цепи (368).
§ 2. Статистические методы анализа точности и стабильности техно-
логических процессов..........................................371
10.2.1. Статистические методы анализа точности технологического
процесса (371). 10.2.2. Статистические методы анализа стабильности
технологического процесса (377).
§ 3. Статистические методы текущего предупредительного контроля
качества продукции............................................386
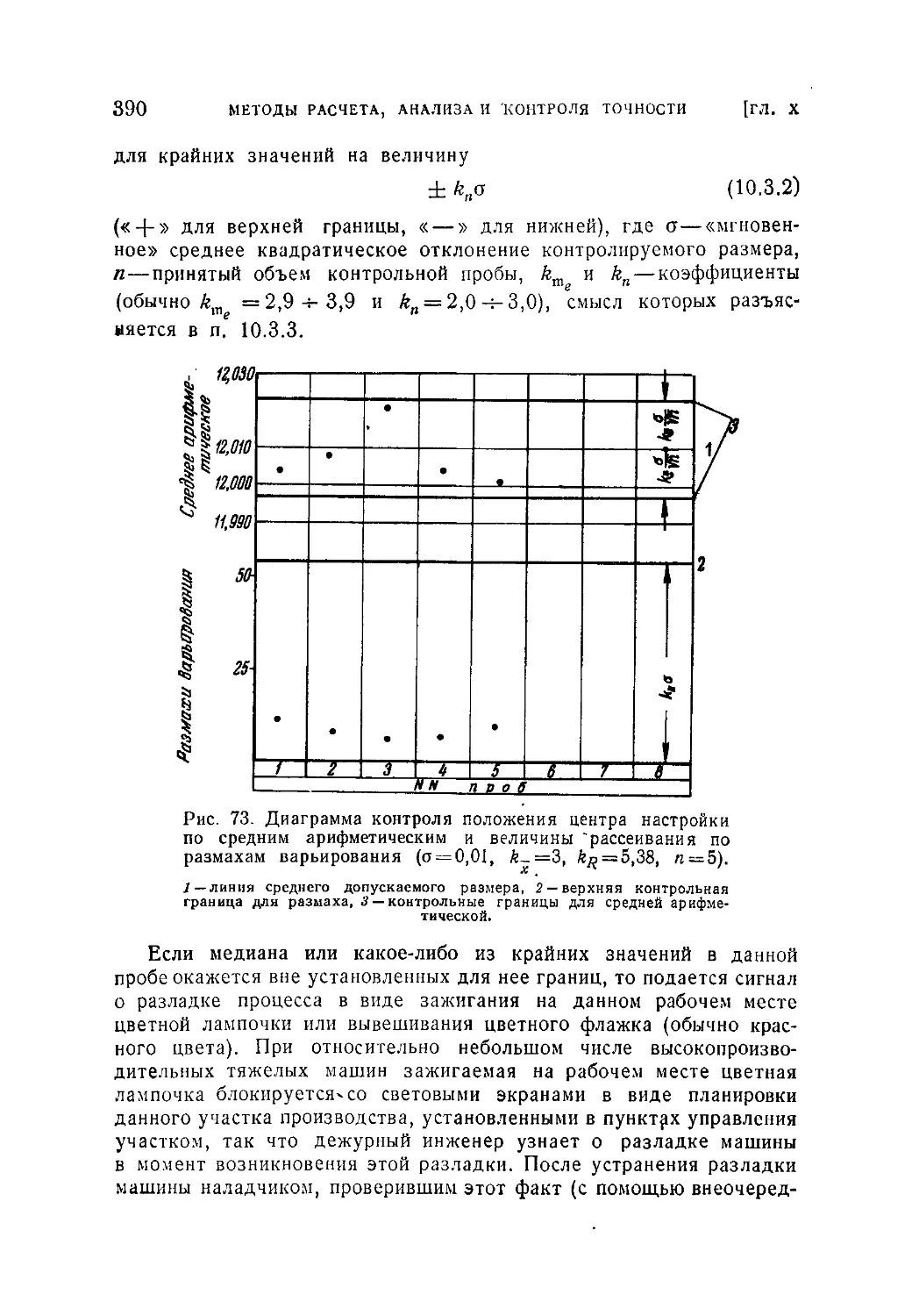
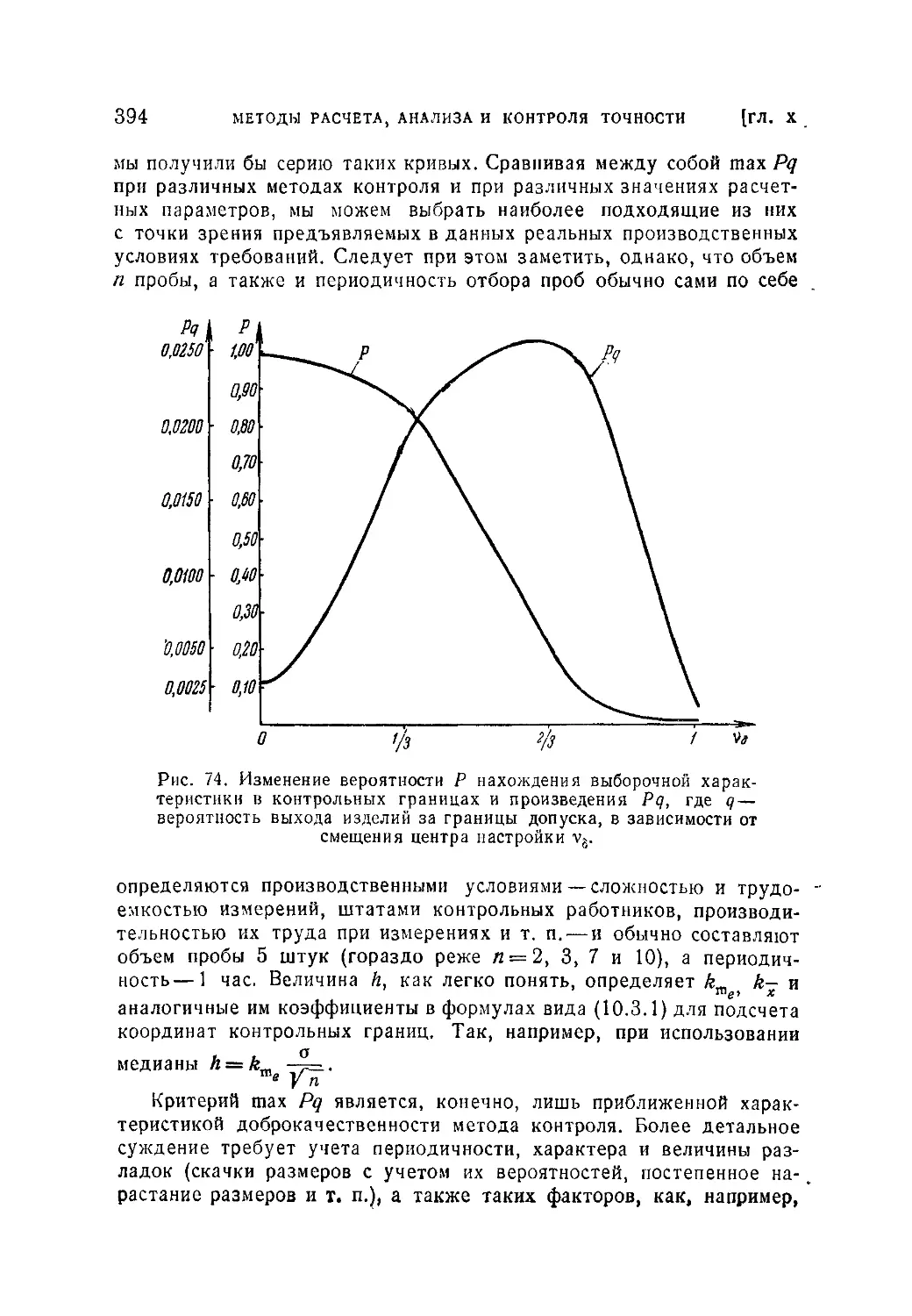
10.3.1. Общие понятия и основные задачи (386). 10.3.2. Некоторые
варианты статистического текущего предупредительного контроля (387).
10.3.3. Понятие о выборе варианта метода контроля и его парамет-
ров (391).
6
ОГЛАВЛЕНИЕ
§ 4. Статистические методы приемочного последующего контроля
качества продукции ..............................................395
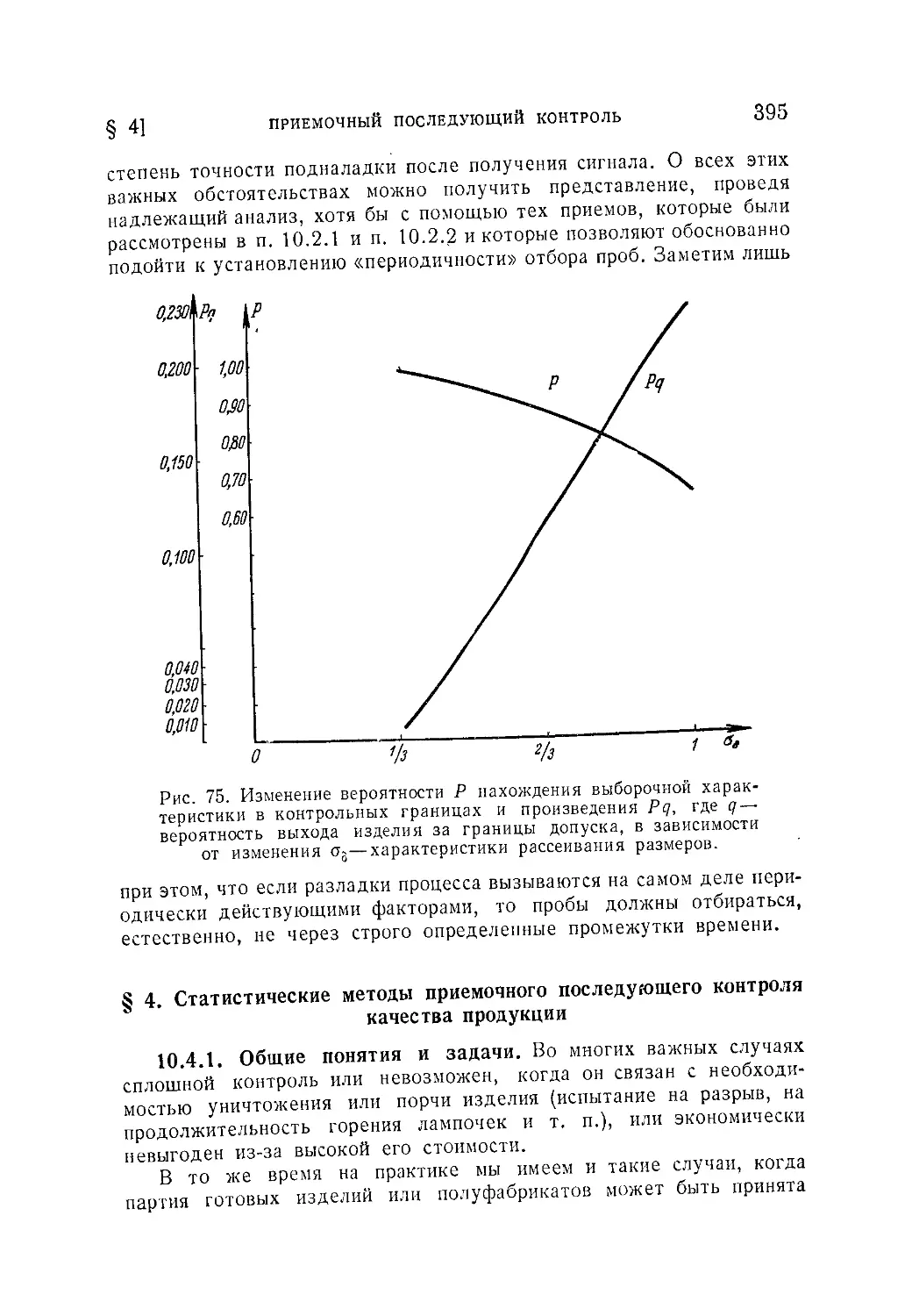
10.4.1. Общие понятия и задачи (395). 10.4.2. Однократная выборка
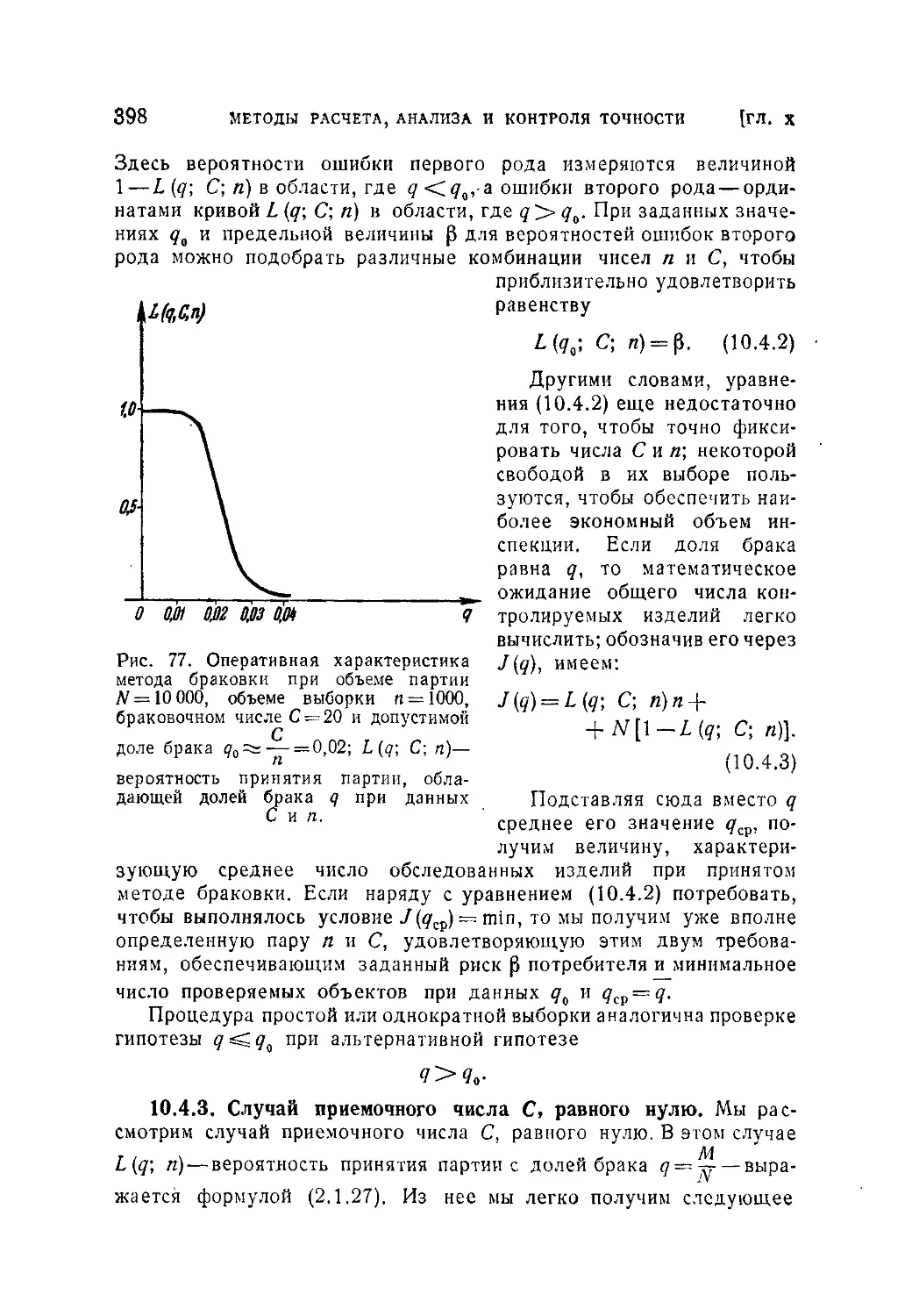
(396). 10.4.3. Случай приемочного числа С, равного нулю (398).
§ 5. Приложение теории распределения крайних членов выборки
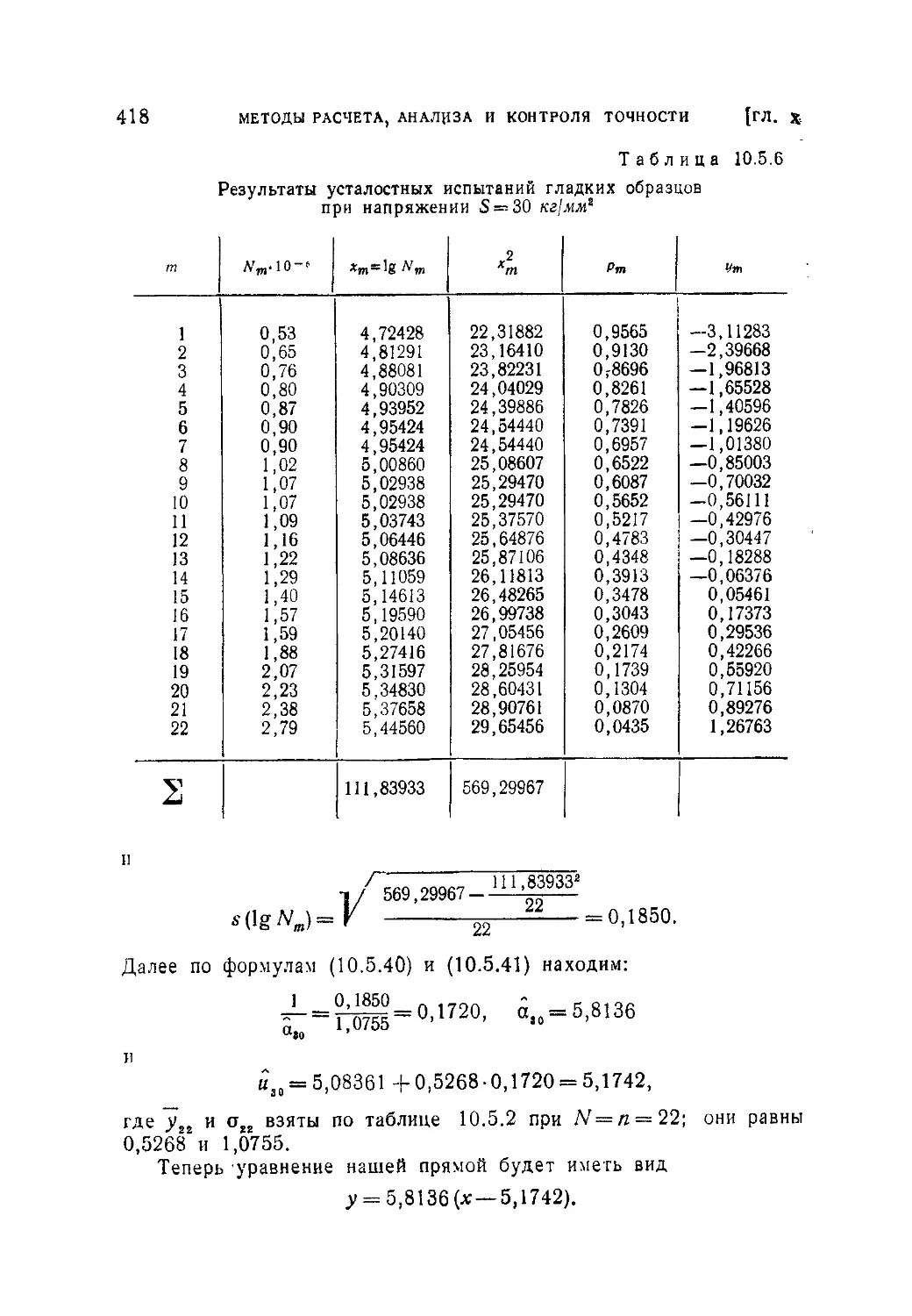
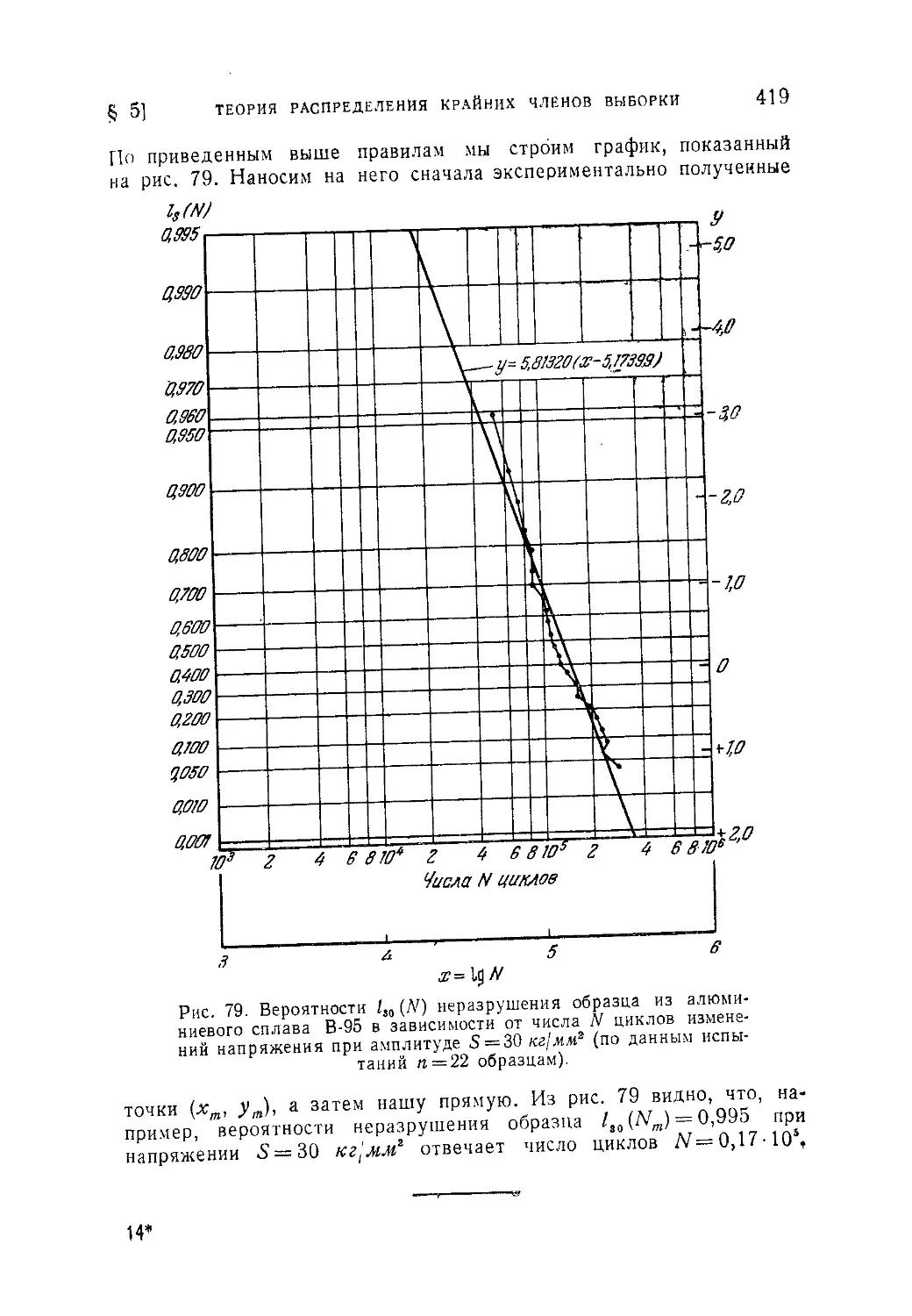
в расчетах и испытаниях прочности................................400
10.5.1. Теория «наиболее слабого звена» и законы распределения
крайних членов выборки (400). 10 5.2. Применение закона первого типа
распределения крайних членов для определения экстремальных расходов
воды в реках (405). 10.5.3. Статистическая интерпретация результатов
испытаний материалов деталей машин на выносливость при переменных
напряжениях (414).
Глава XI. Понятие о теории случайных процессов и некоторых, ее
приложениях.........................................................420
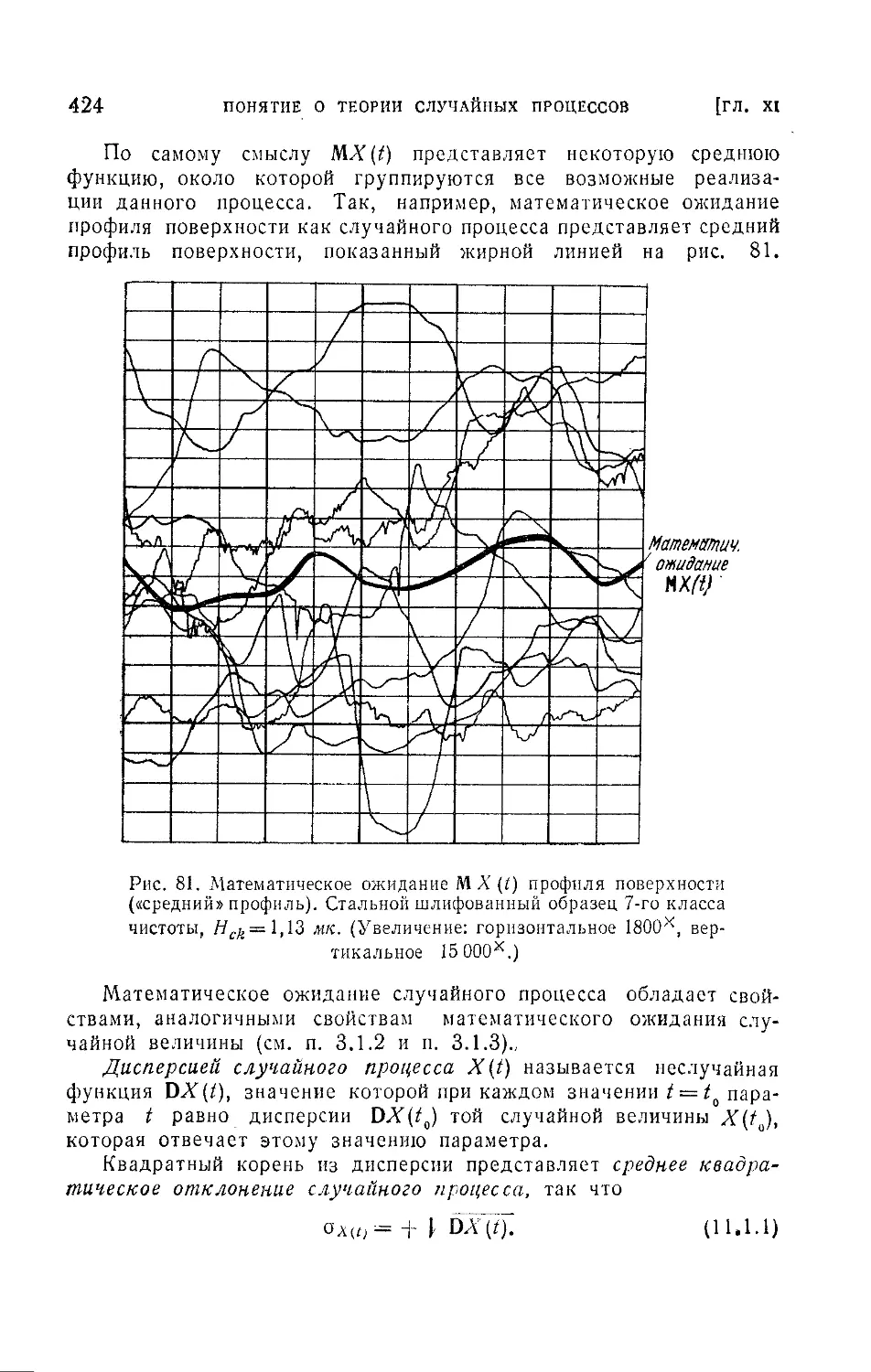
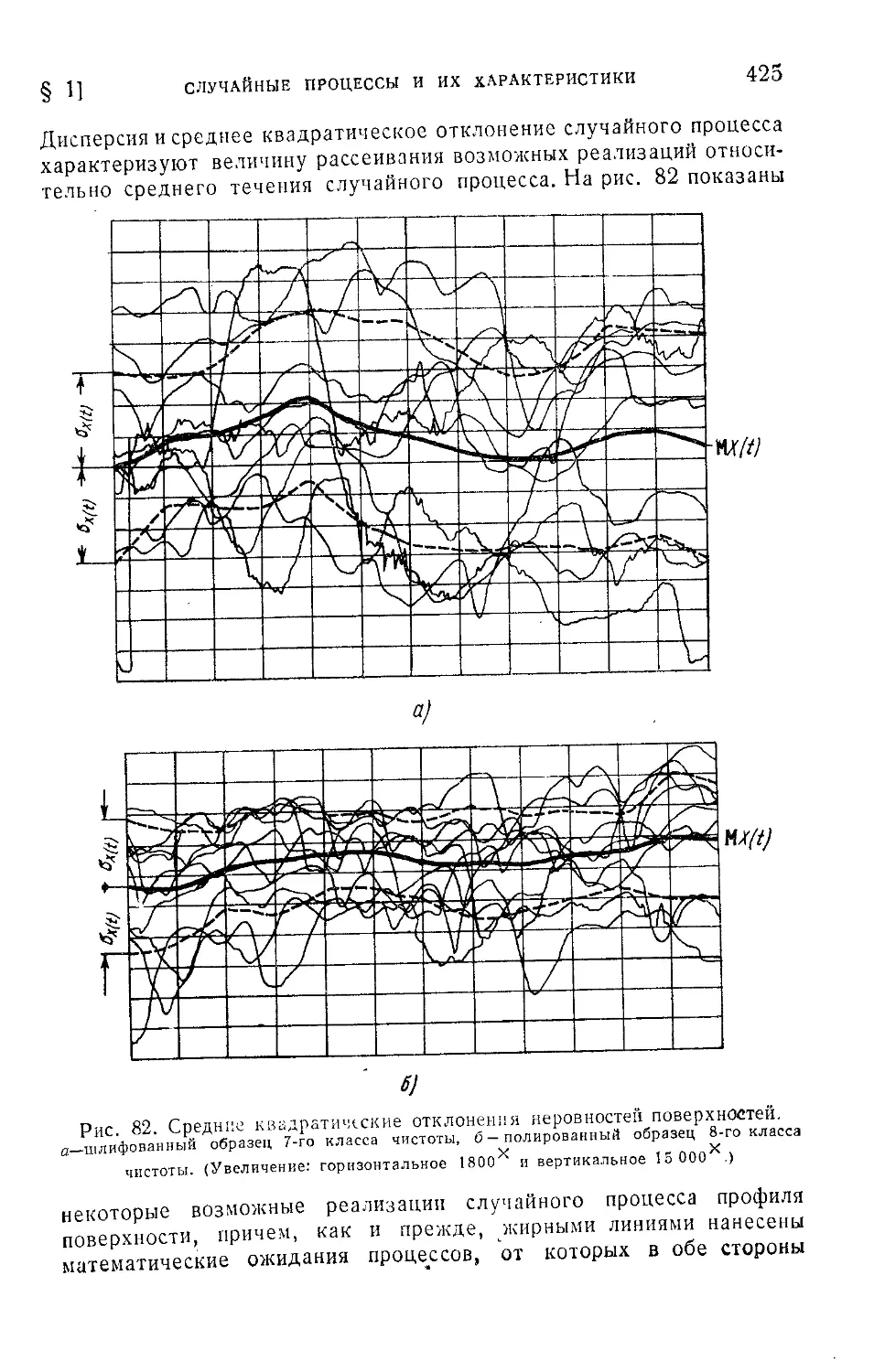
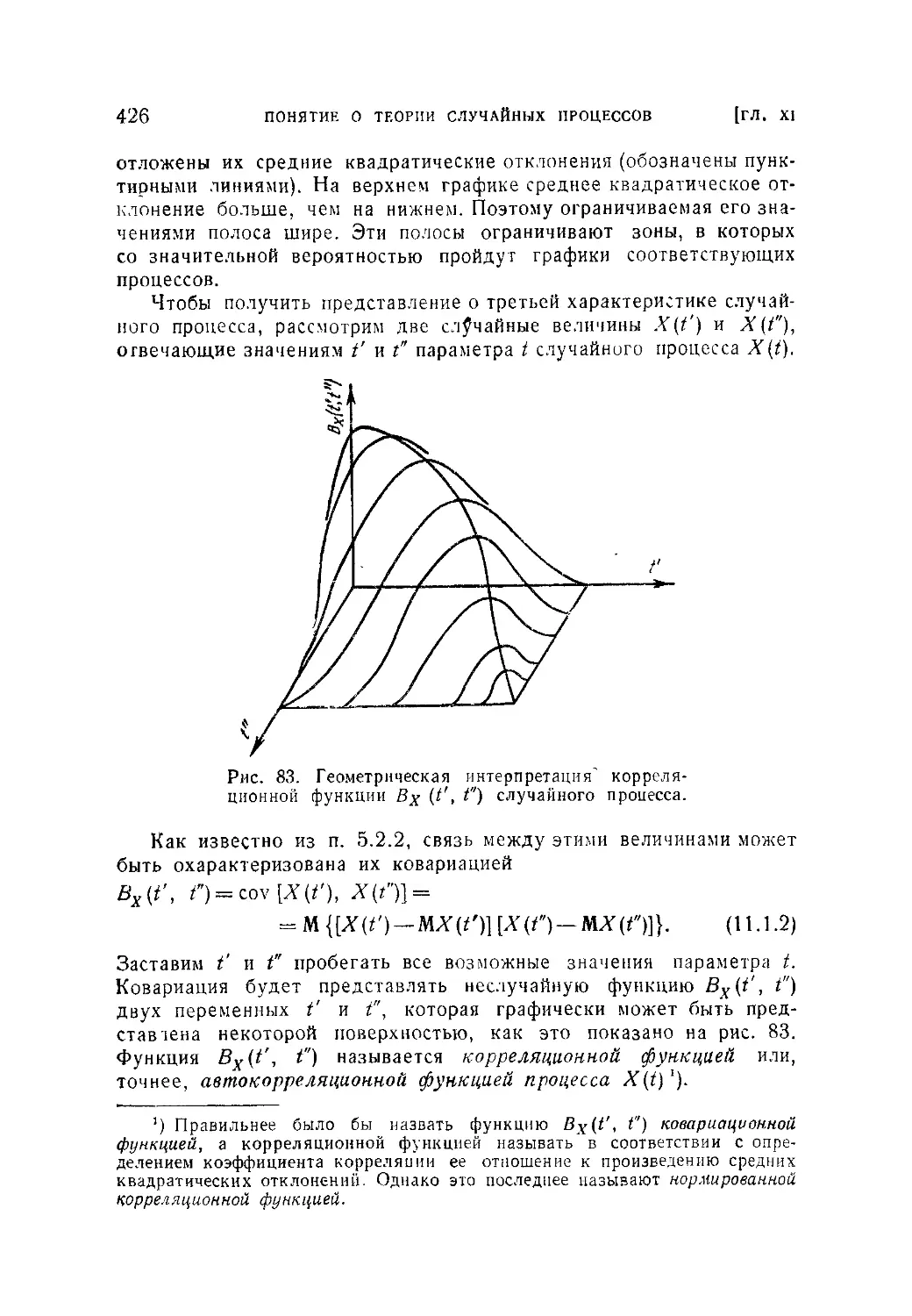
§ 1. Случайные процессы и их характеристики......................420
11.1.1. Понятие о случайных процессах (420). 11.1.2. Математическое
ожидание, дисперсия и корреляционная функция случайного процесса
(423).
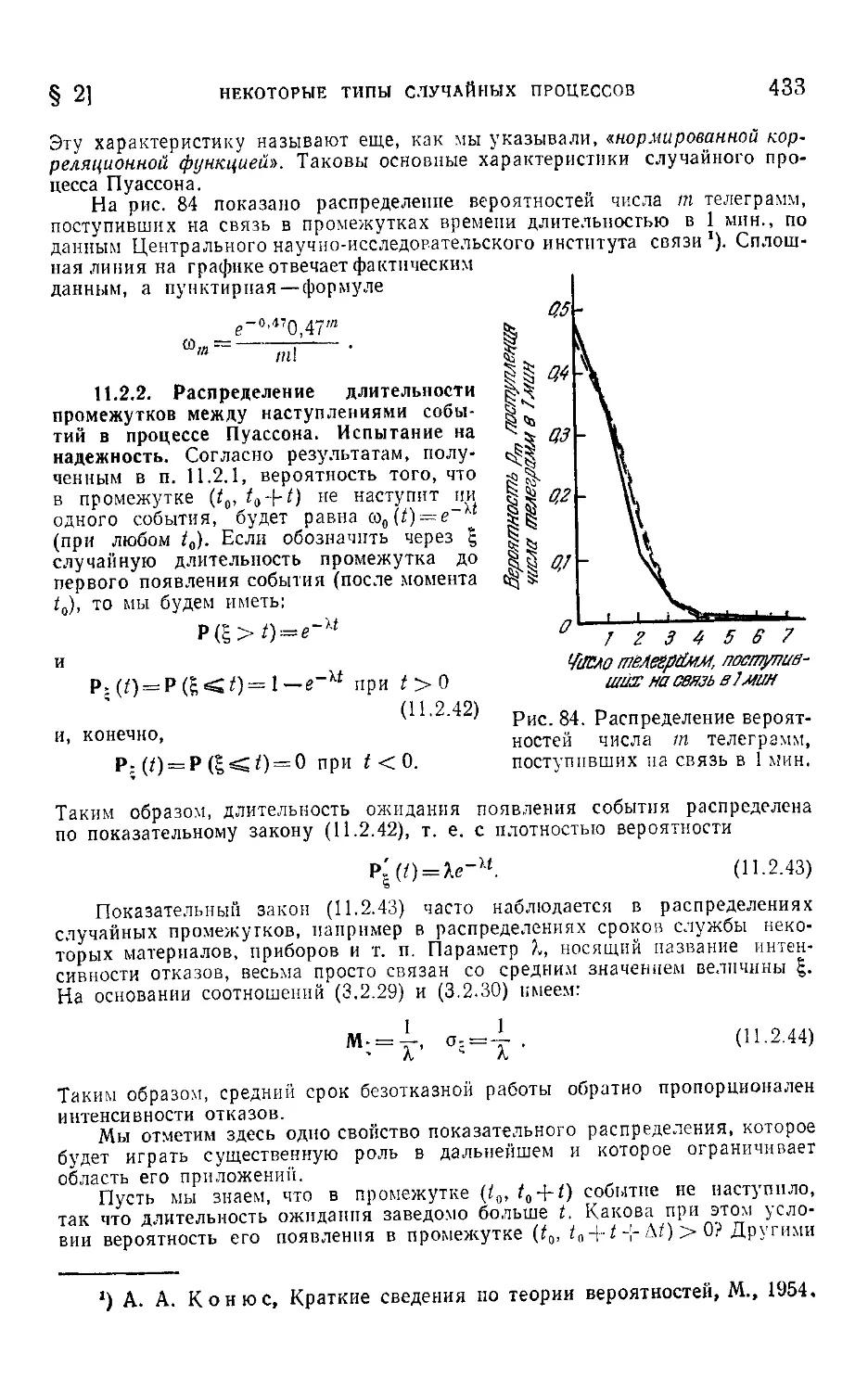
§ 2. Некоторые типы случайных процессов..........................427
11.2.1. Процесс Пуассона (427). 1 1.2.2. Распределение длительно-
сти промежутков между наступлениями событий в процессе Пуассона.
Испытание на надежность (433). 11.2.3. Понятие о процессах Маркова
(437). 1 1.2.4. Задача Эрланга для конечного пучка линий (440). 1 1.2.5.
Статистическая модель работы водохранилища (447). 11.2.6. Ста-
ционарные случайные процессы (449). 1 1.2.7. Определение «несущей по-
верхности» деталей машин, работающих при трении (454).
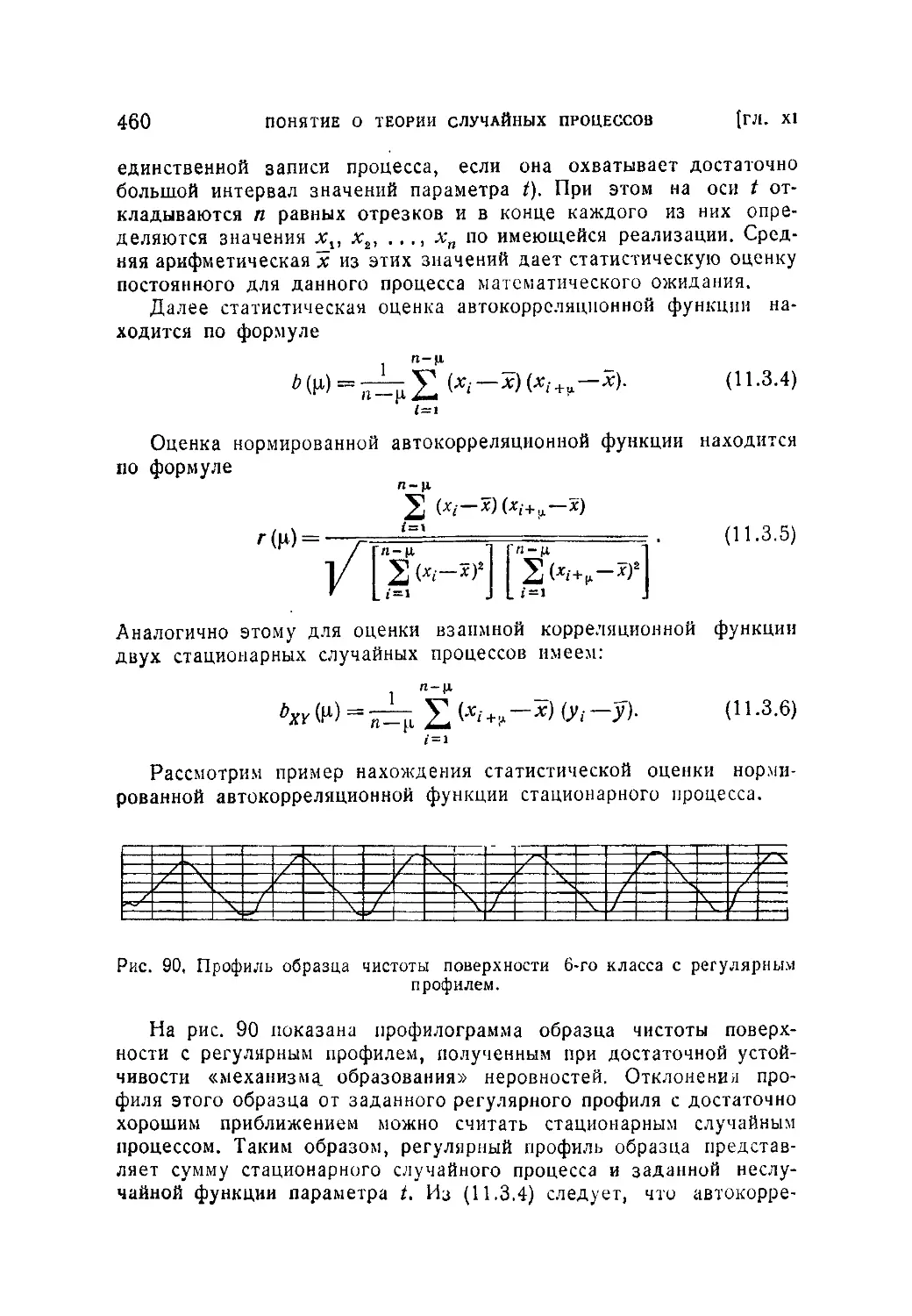
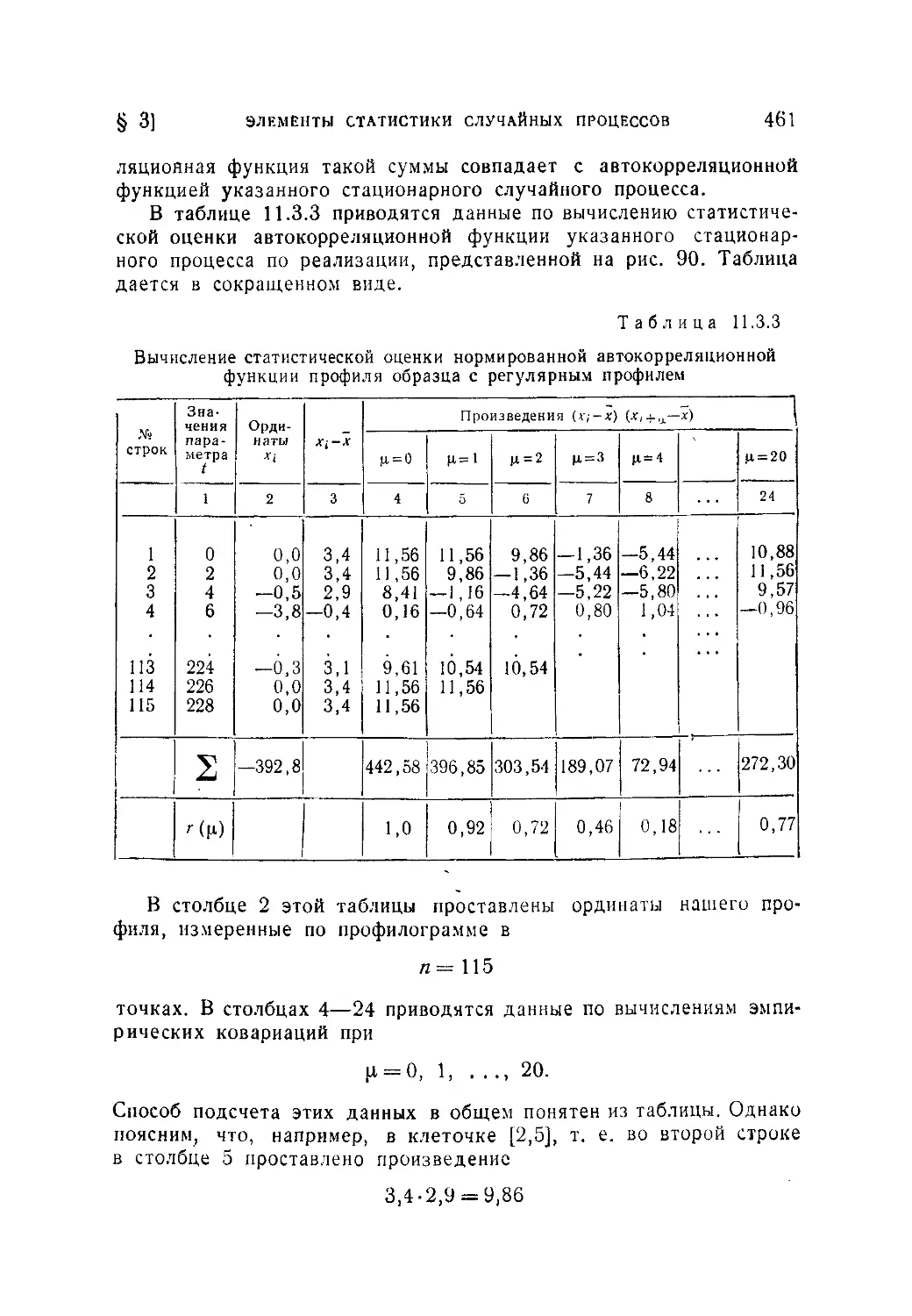
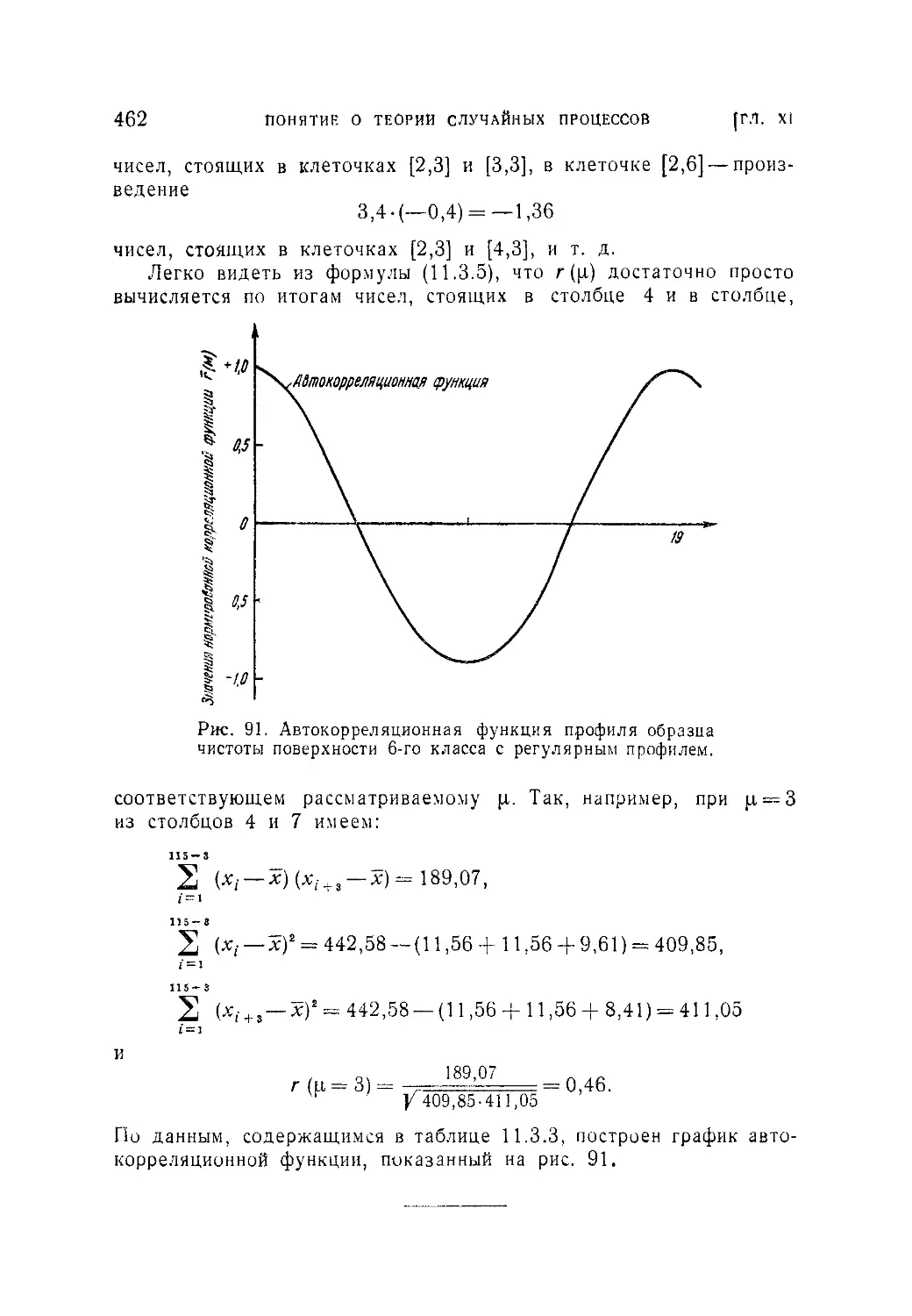
§ 3. Элементы статистики случайных процессов.....................457
11.3.1. Определение статистических оценок математического ожида-
ния и корреляционной функции случайного процесса (457), 1 1.3.2.
Нахождение статистических оценок характеристик стационарного слу-
чайного процесса (459).
Приложения...........................................................463
г3
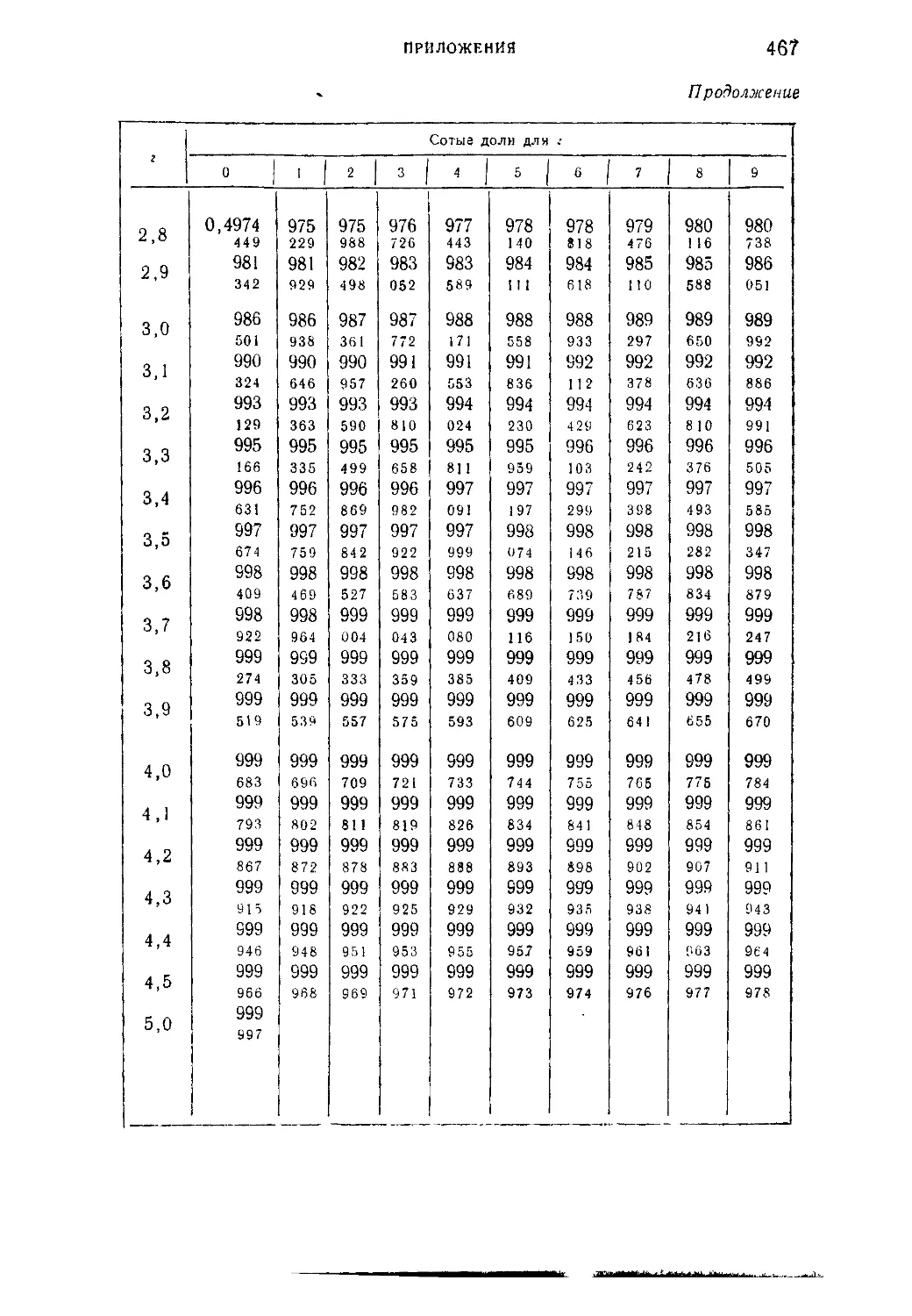
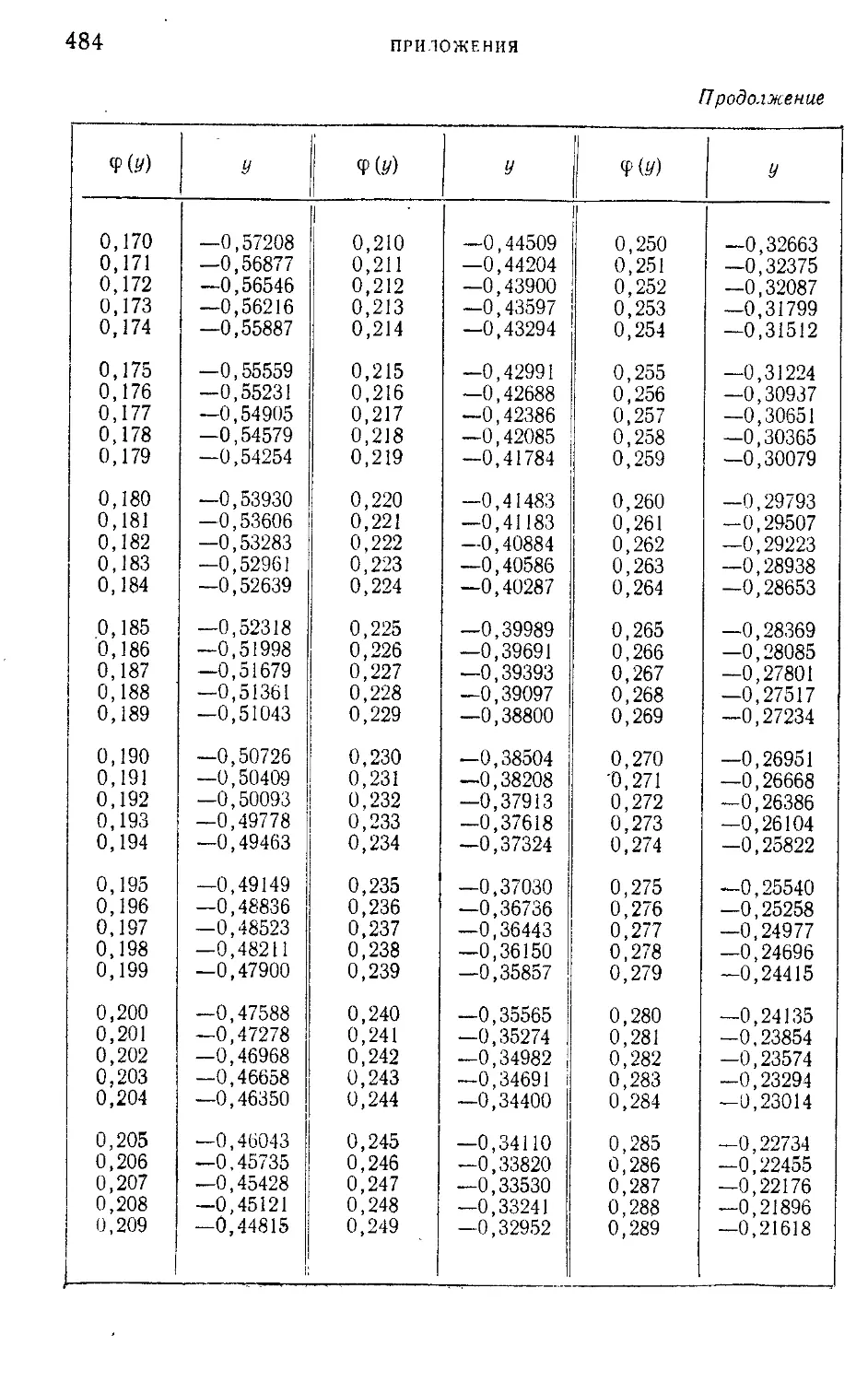
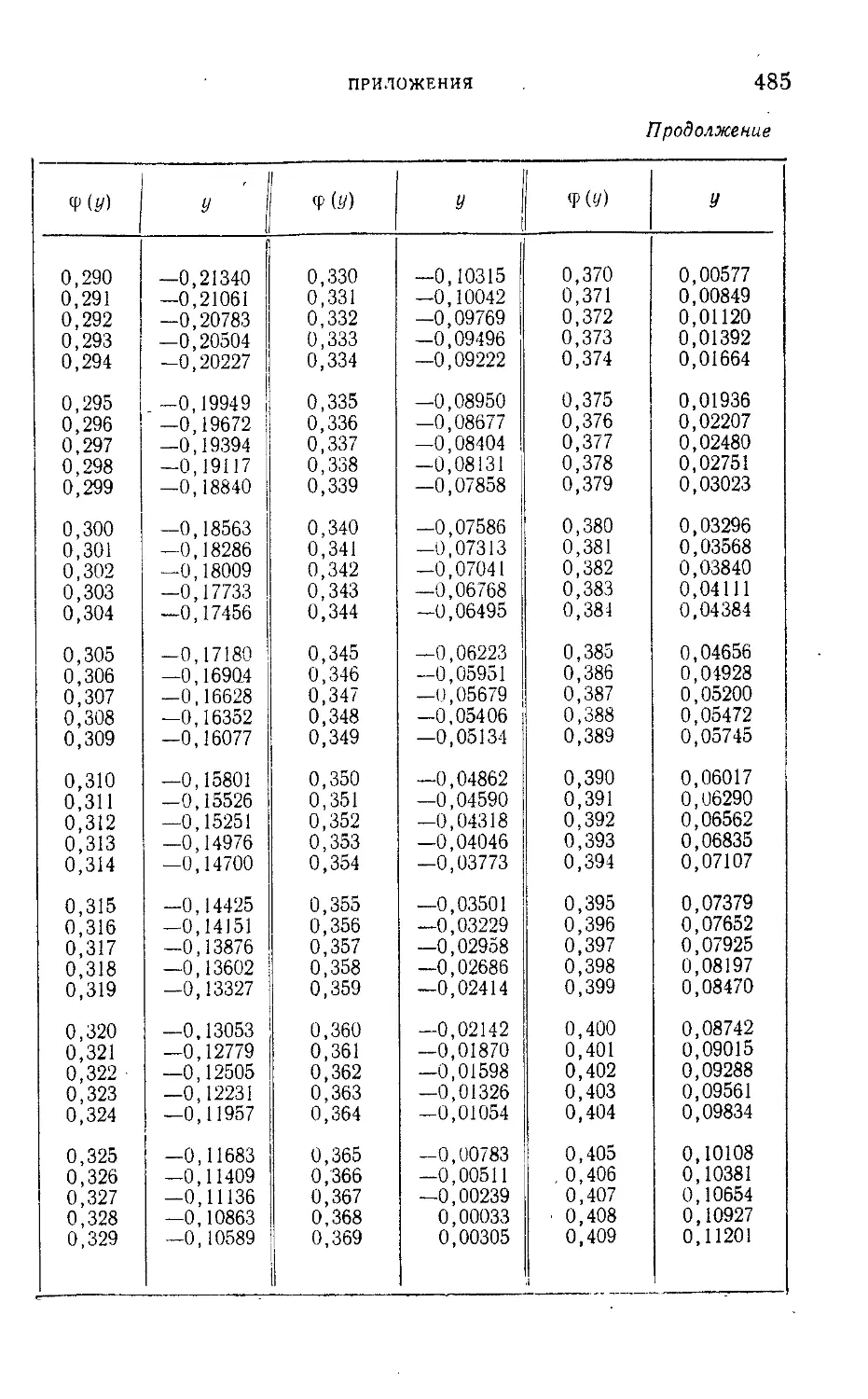
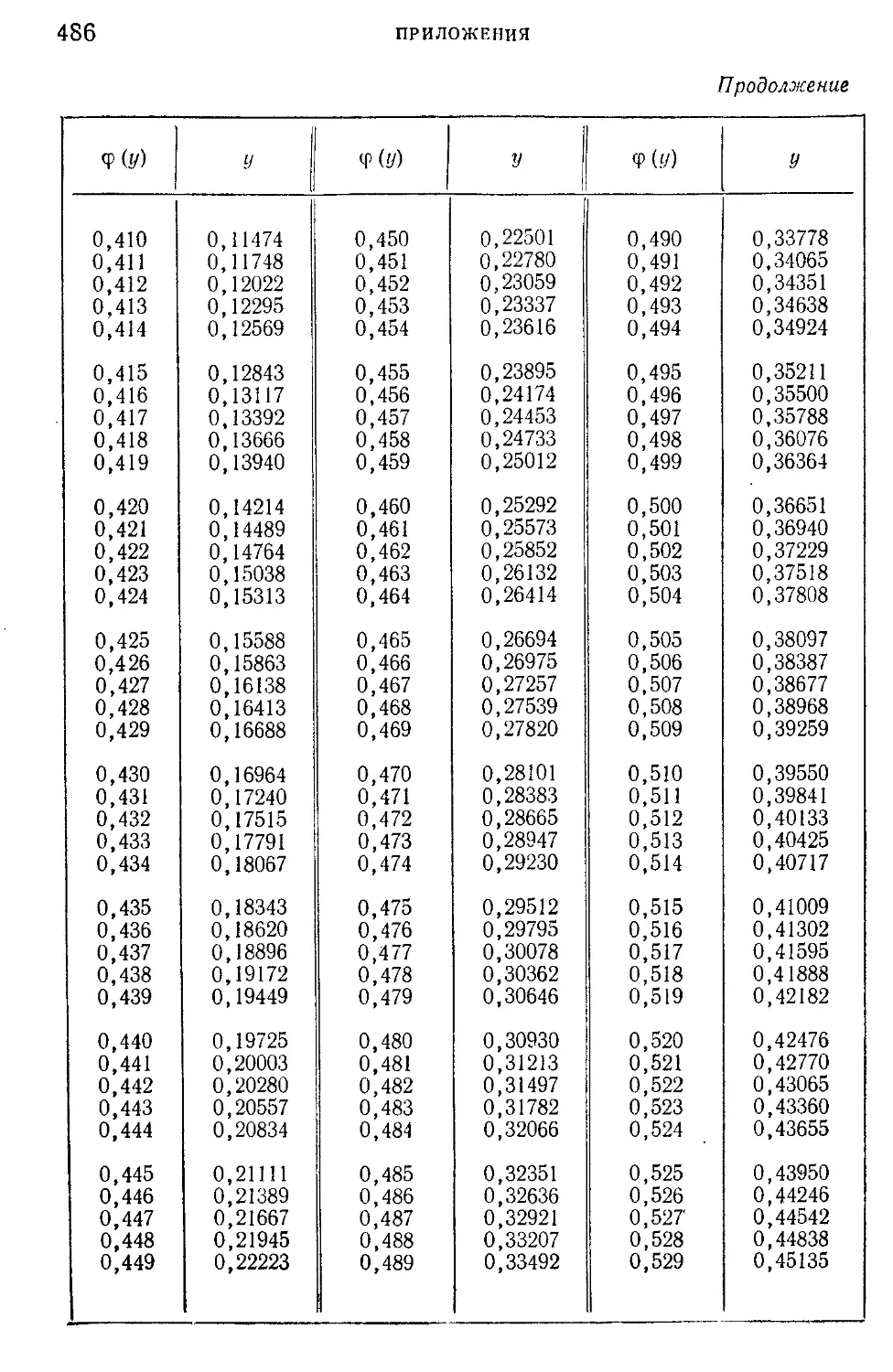
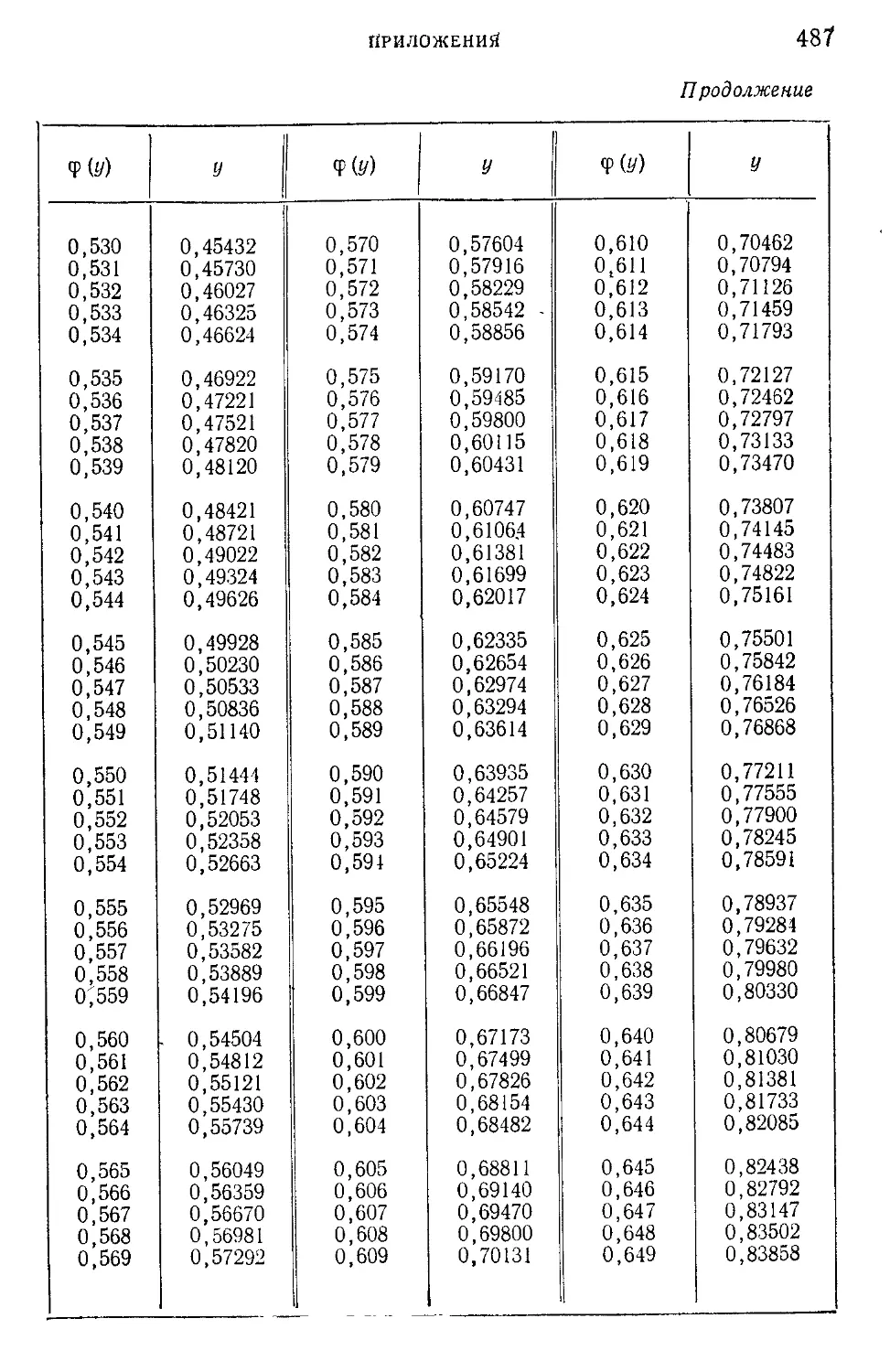
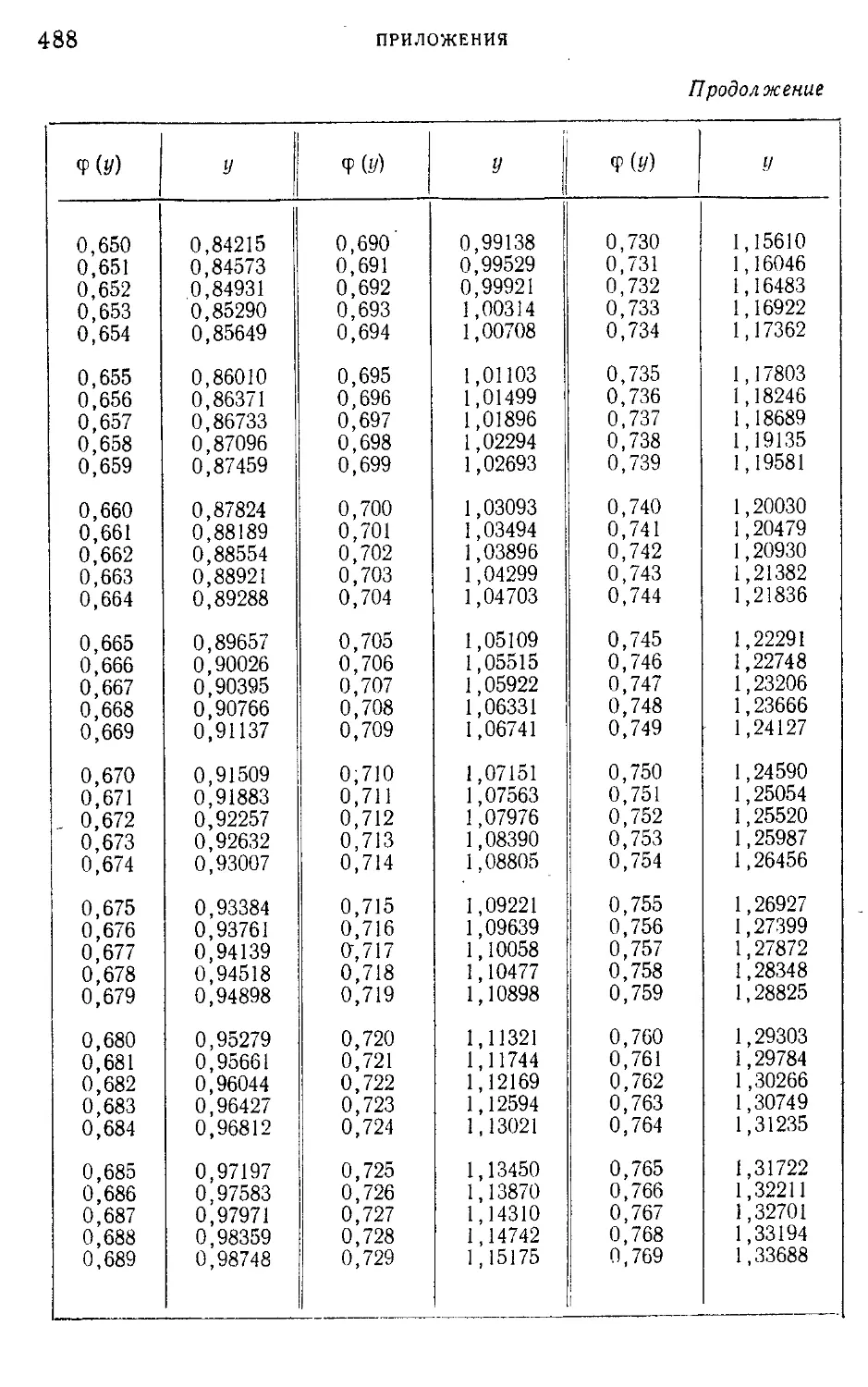
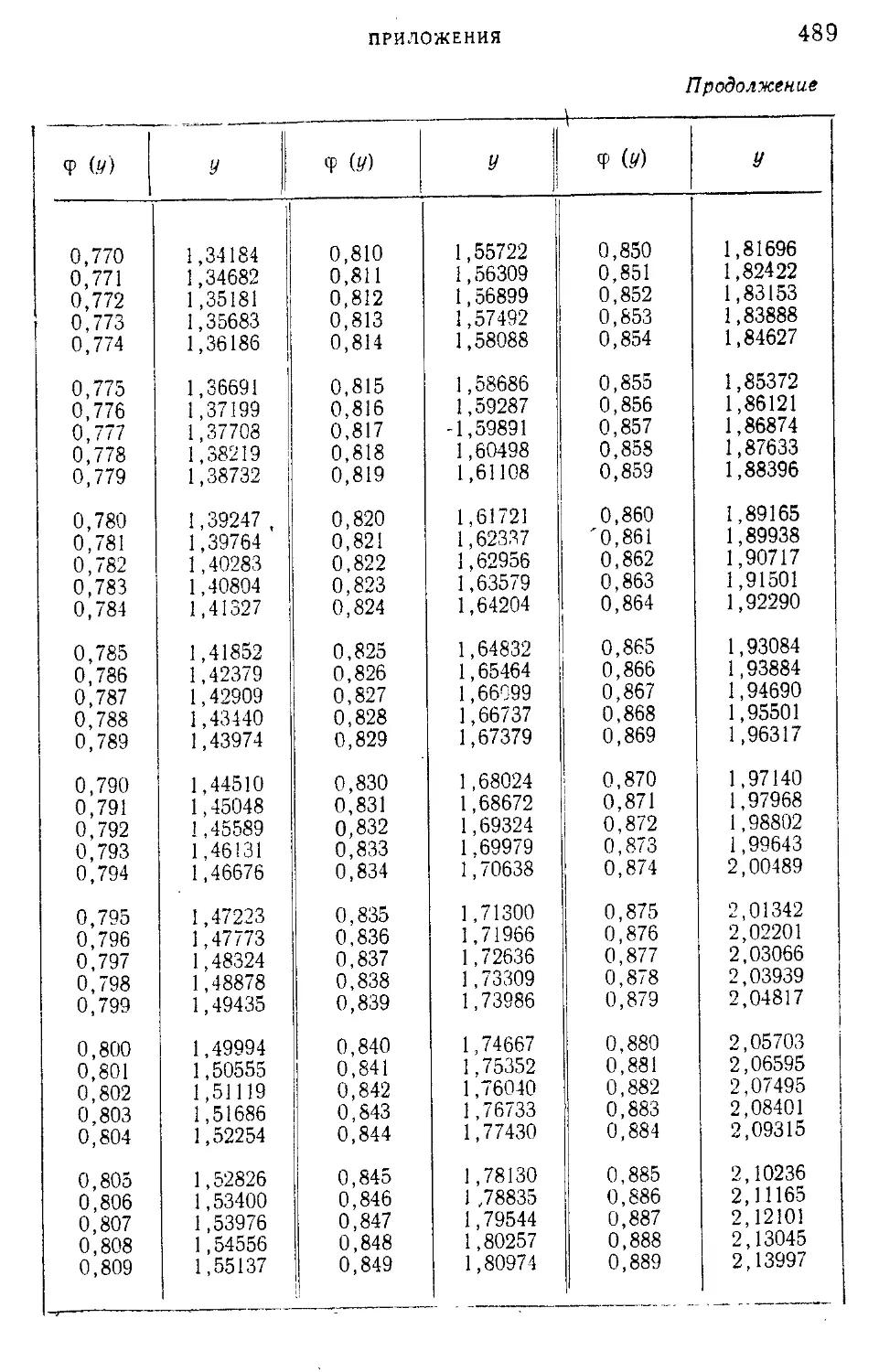
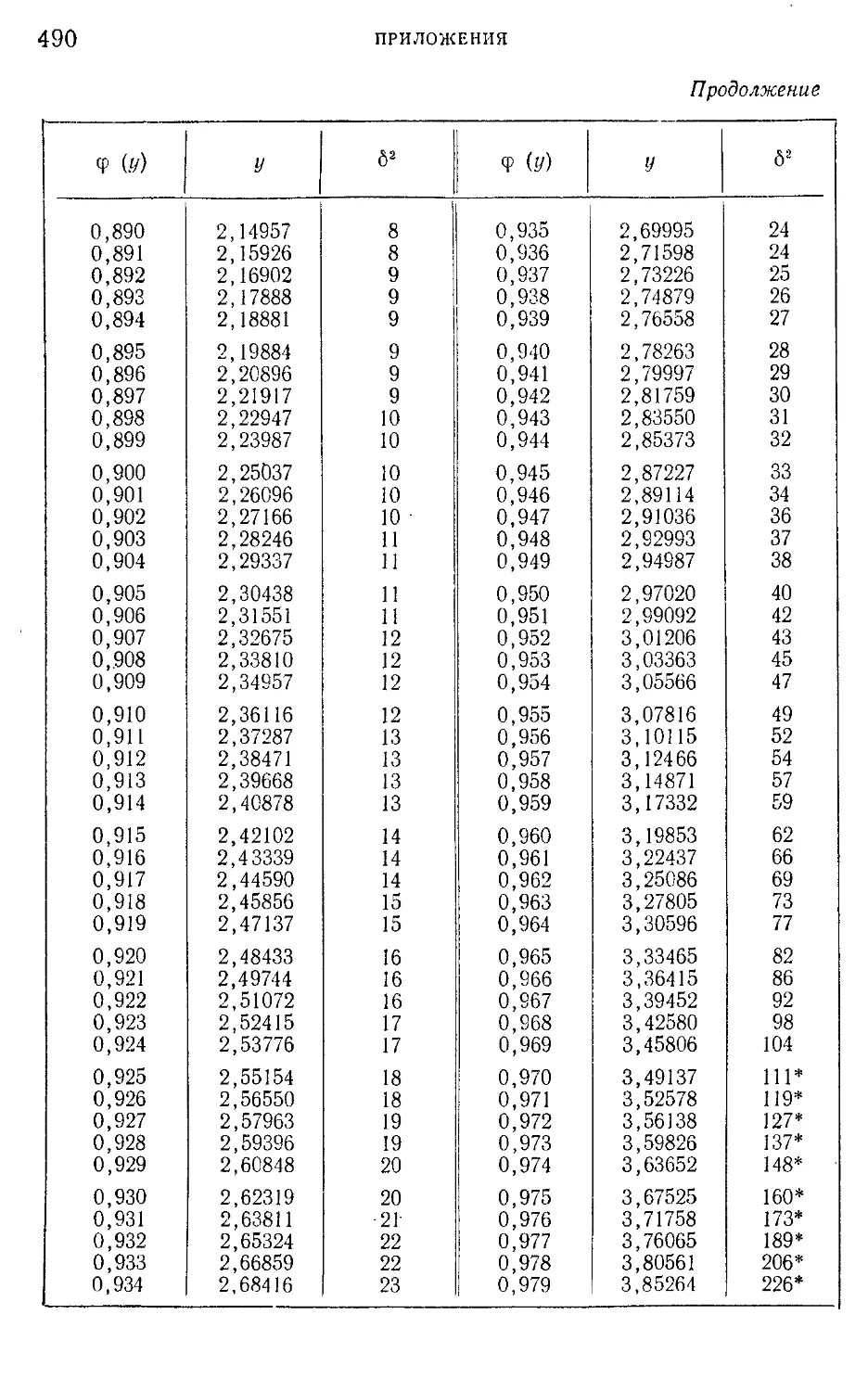
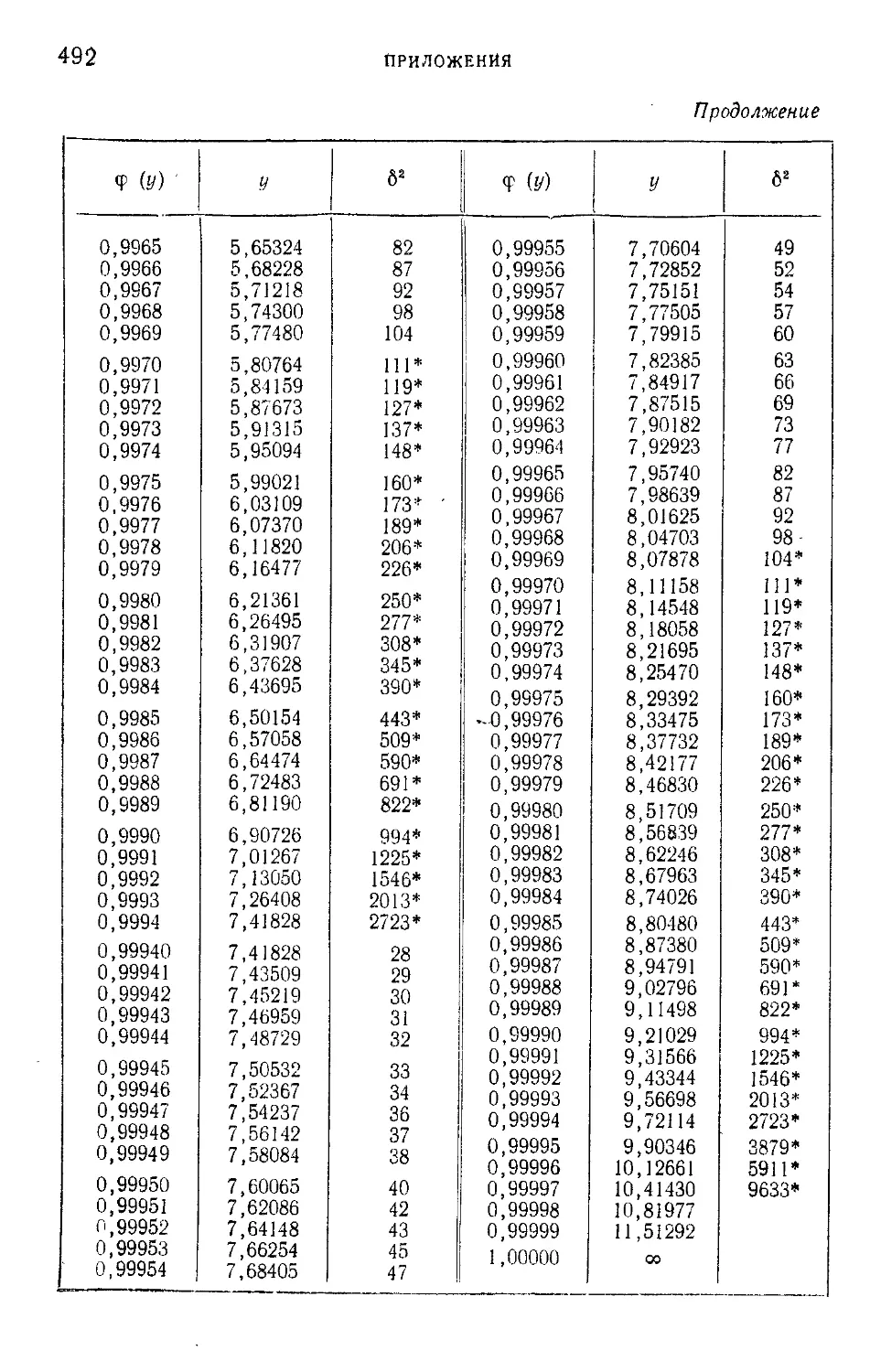
Таблица I. Плотности вероятности п (г; 0; \) — N' (г-, 0; 1) = —е 2
нормированного нормального распределения.....................465
г
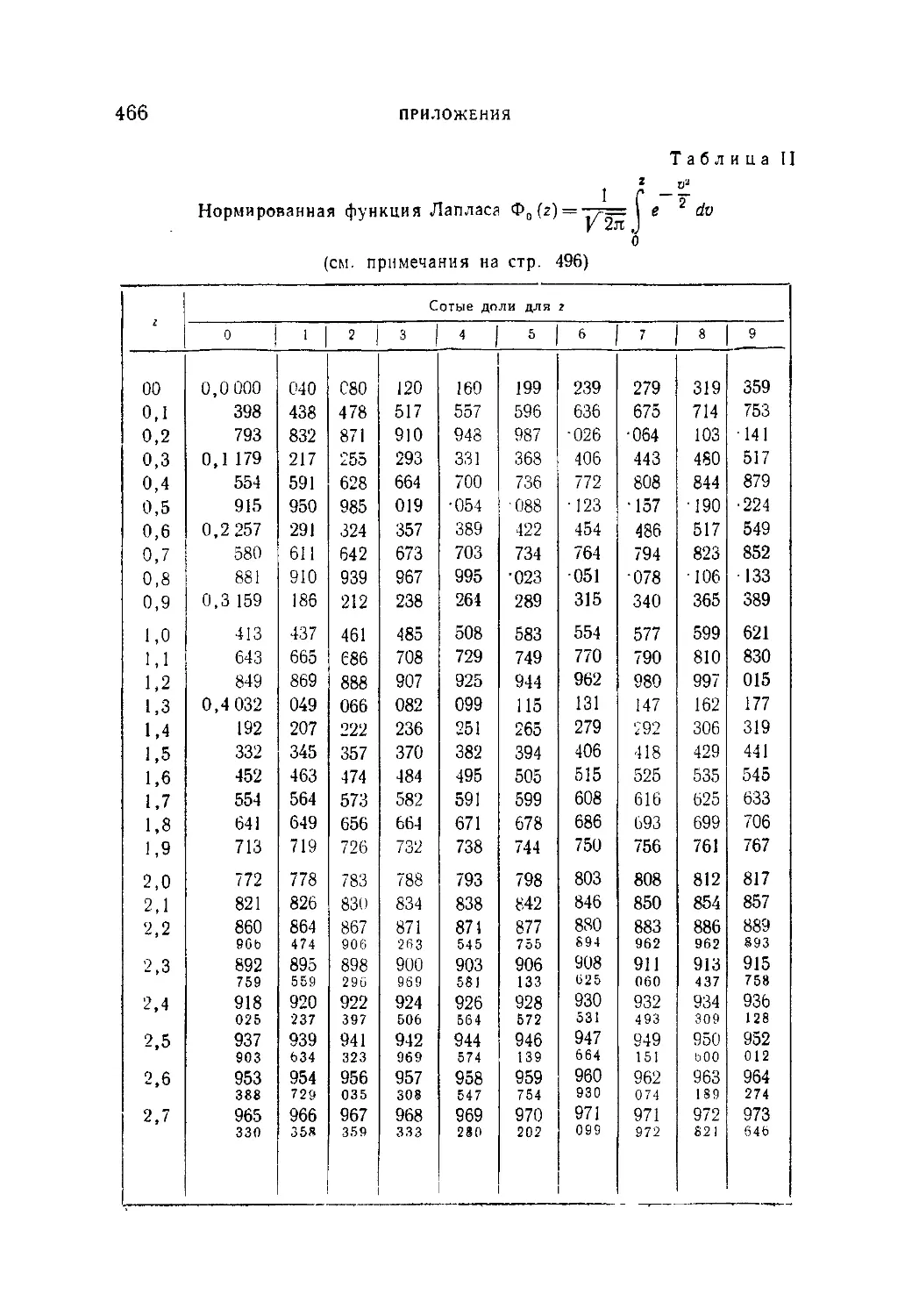
Таблица II. Нормированная функция Лапласа Фо (2) = —^=: I е 2 dv 466
V 2л J
о
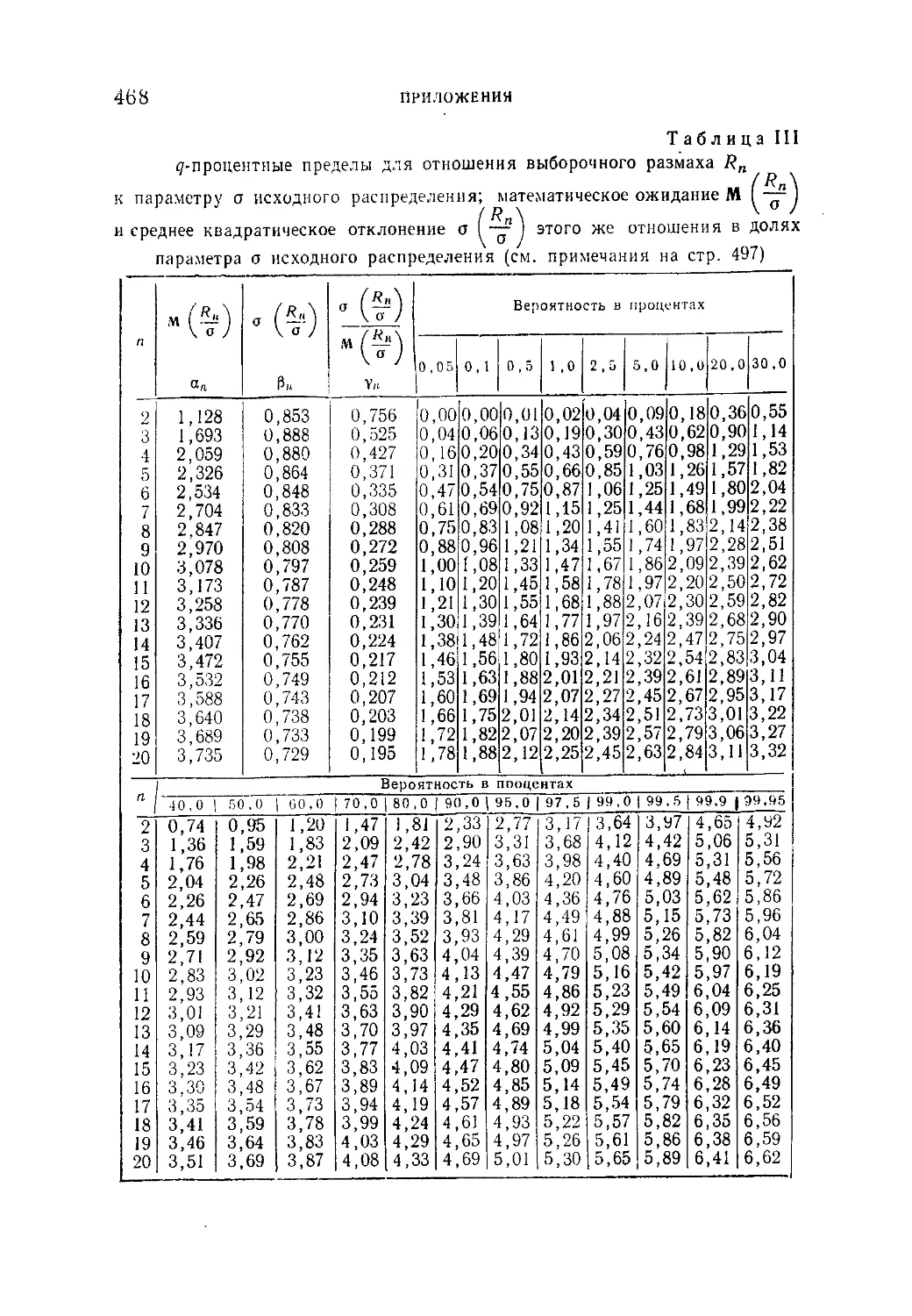
Таблица III. ^-процентные пределы для отношения выборочного
размаха R„ к параметру а исходного распределения; матема-
тическое ожидание М f— и среднее квадратическое откло-
(Rn\ ° 7
нение о ( — ) этого же отношения в долях параметра а исход-
ного распределения...........................................468
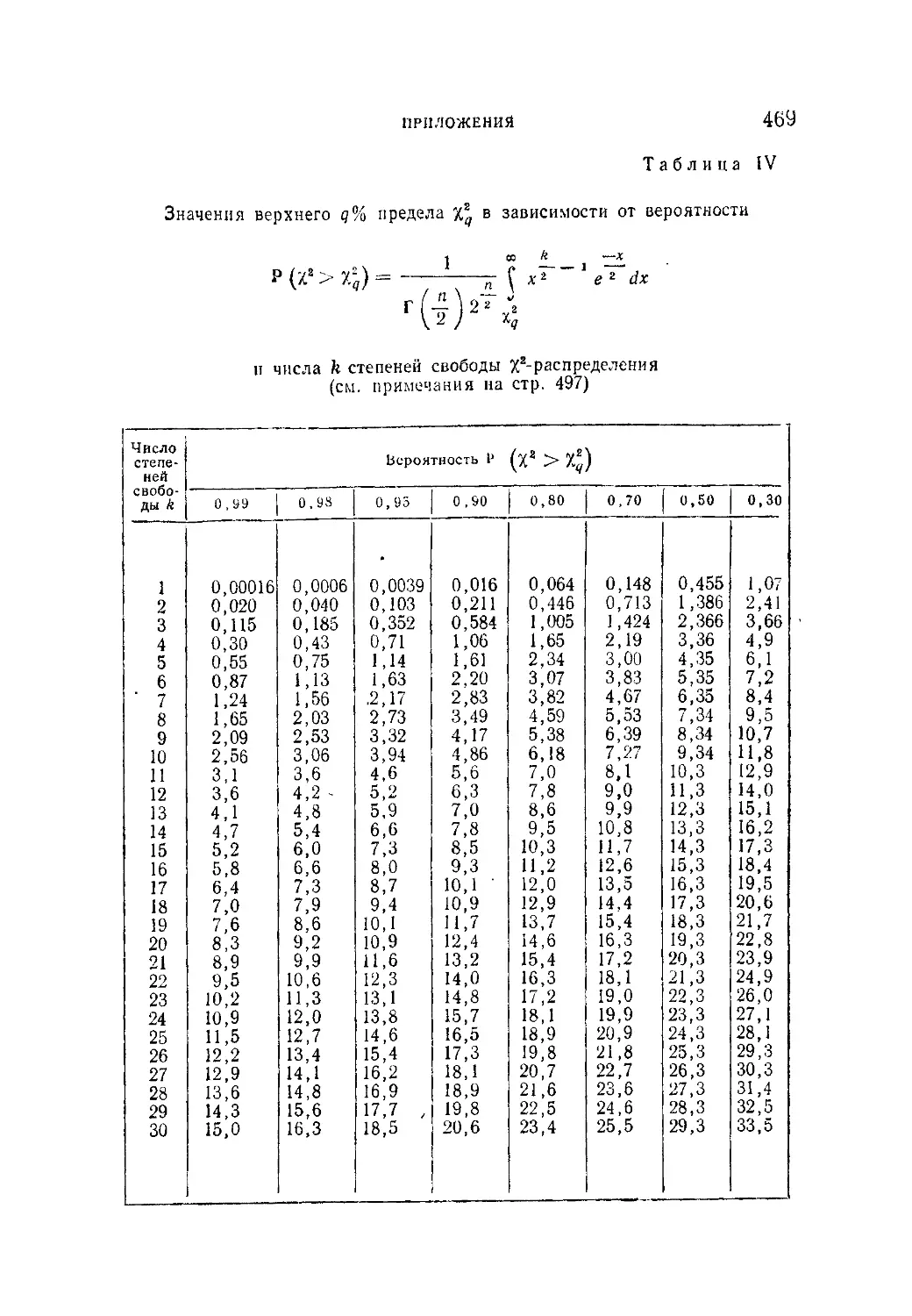
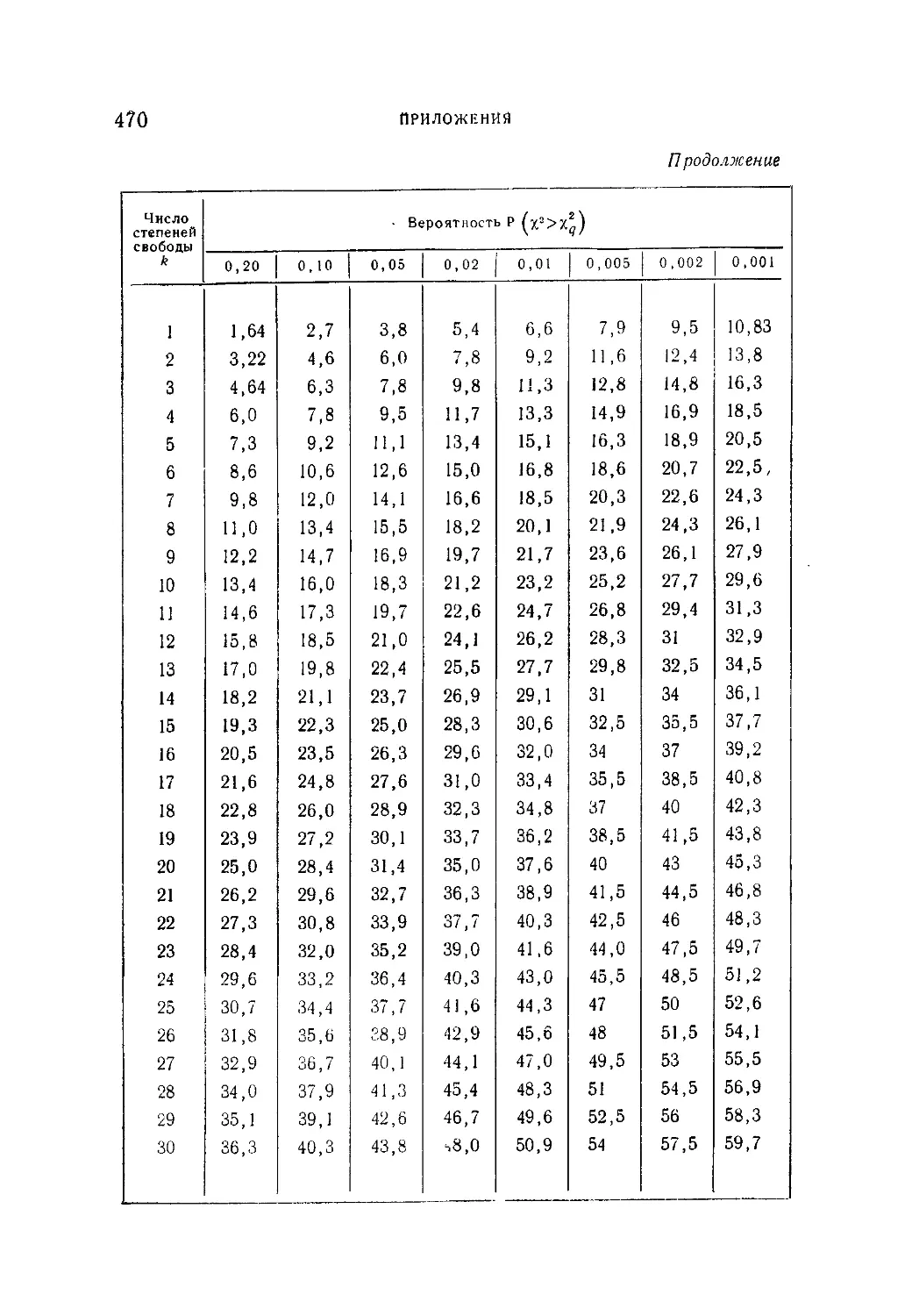
Таблица IV. Значения верхнего q ° je предела в зависимости от ве-
роятности
со £ _ — ж
Р(Х2>%2) =--------!----- С х2 ' е2 dx
и числа п степеней свободы %2-распределения..................469
ОГЛАВЛЕНИЕ
7
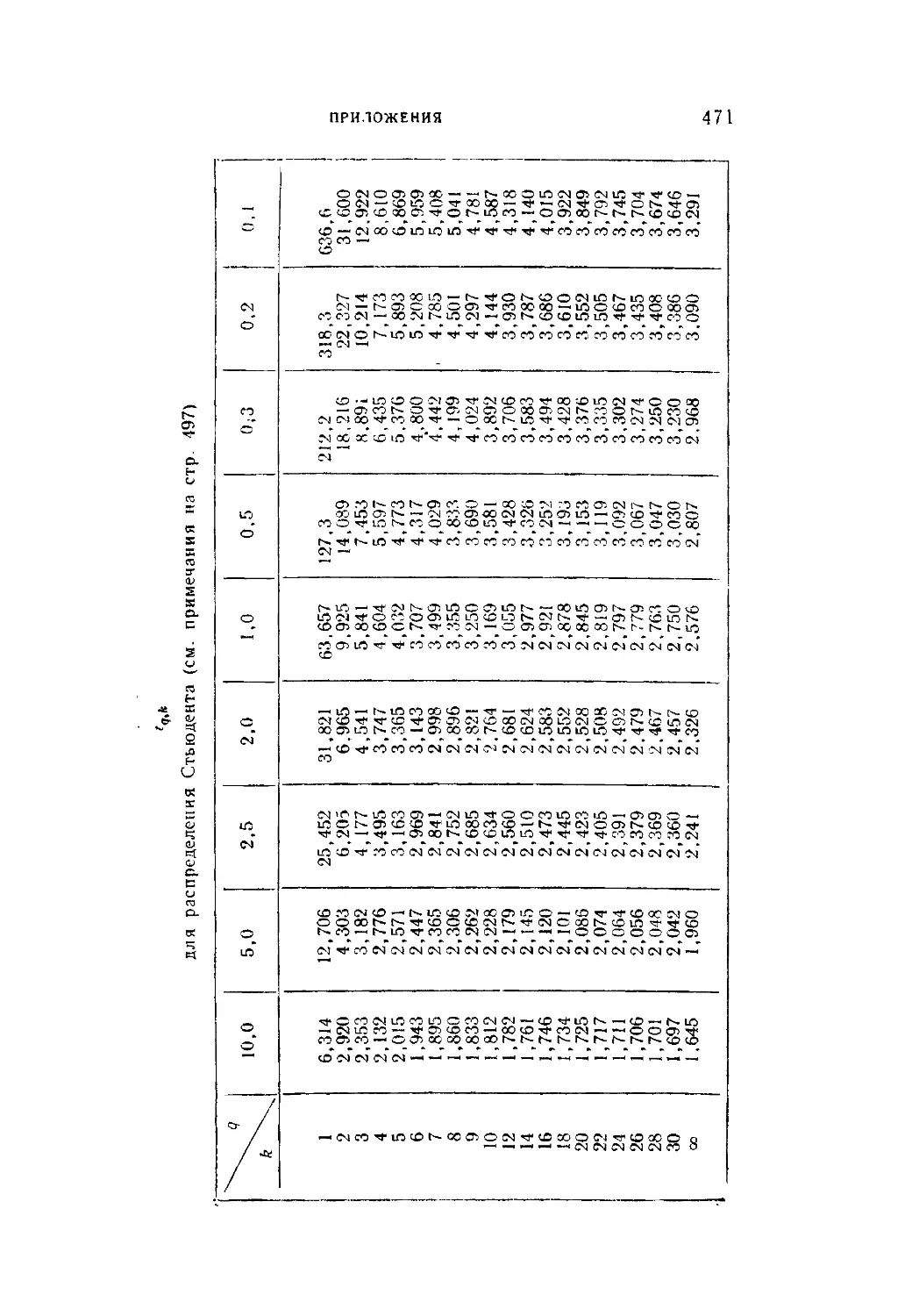
Таблица V. Значения g-процентных пределов tq>k в зависимости от
1 числа k степеней свободы и от вероятности
fe + 1
СО —•
и“Ч (1+т)
для распределения Стьюдента..............................471
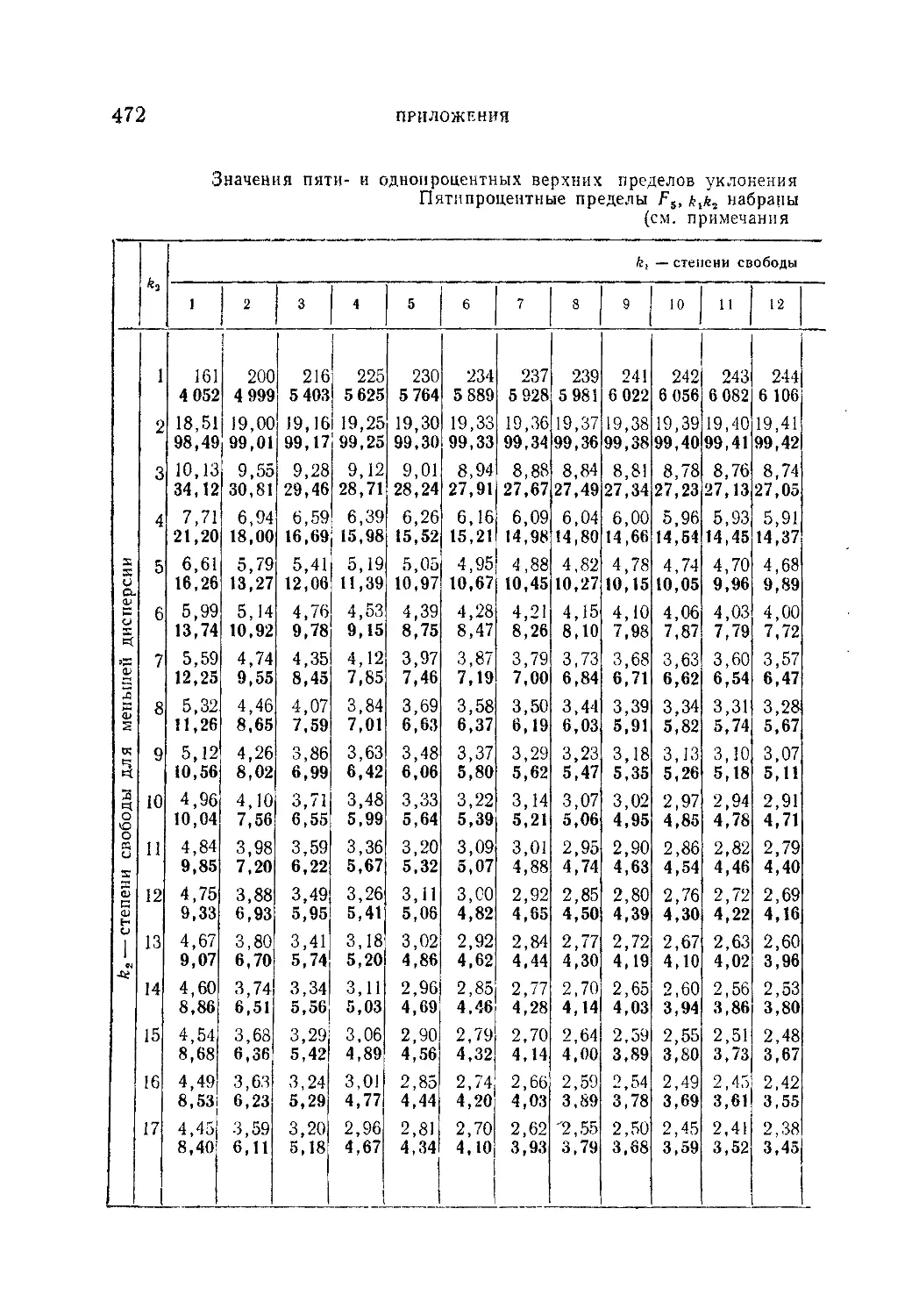
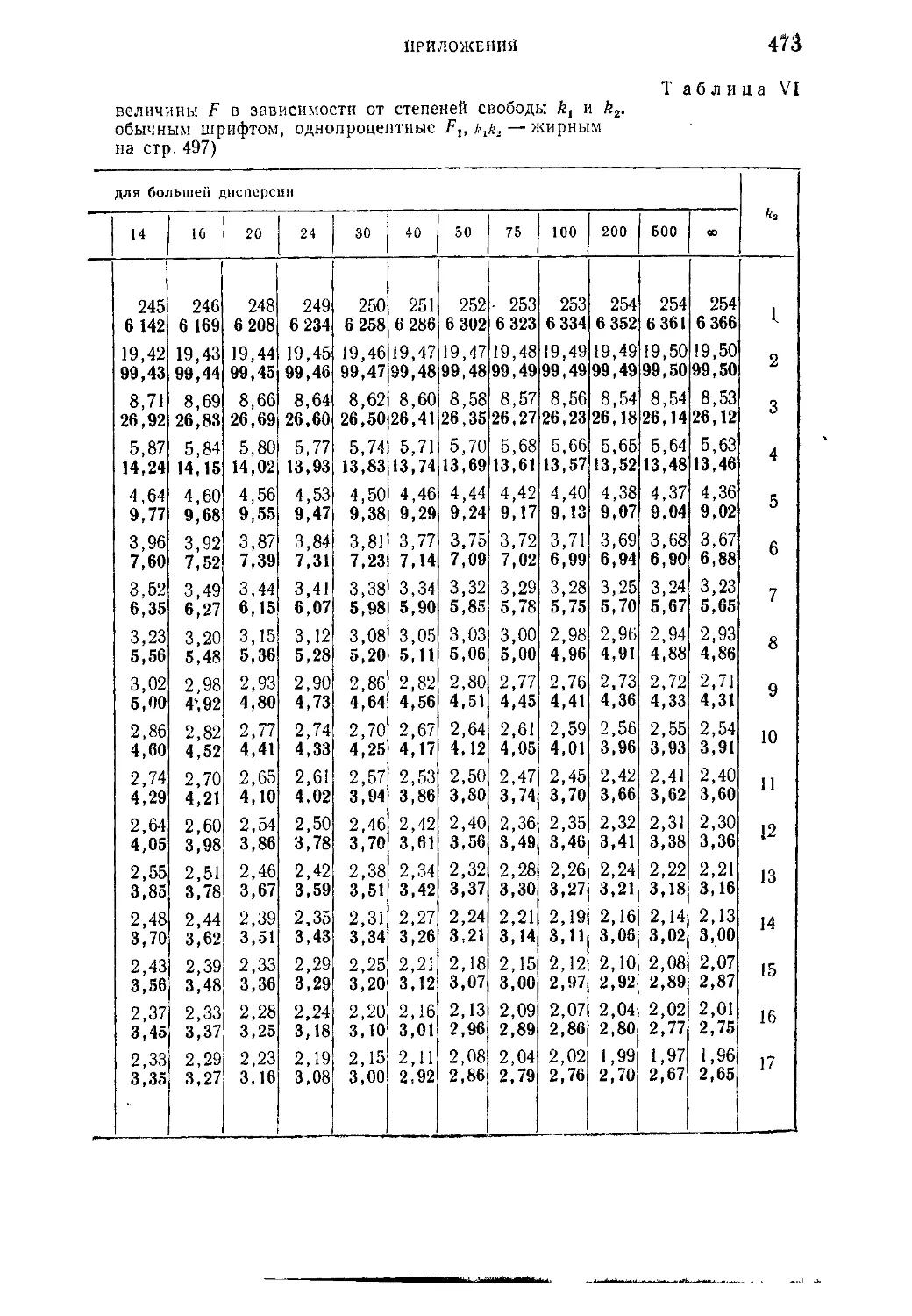
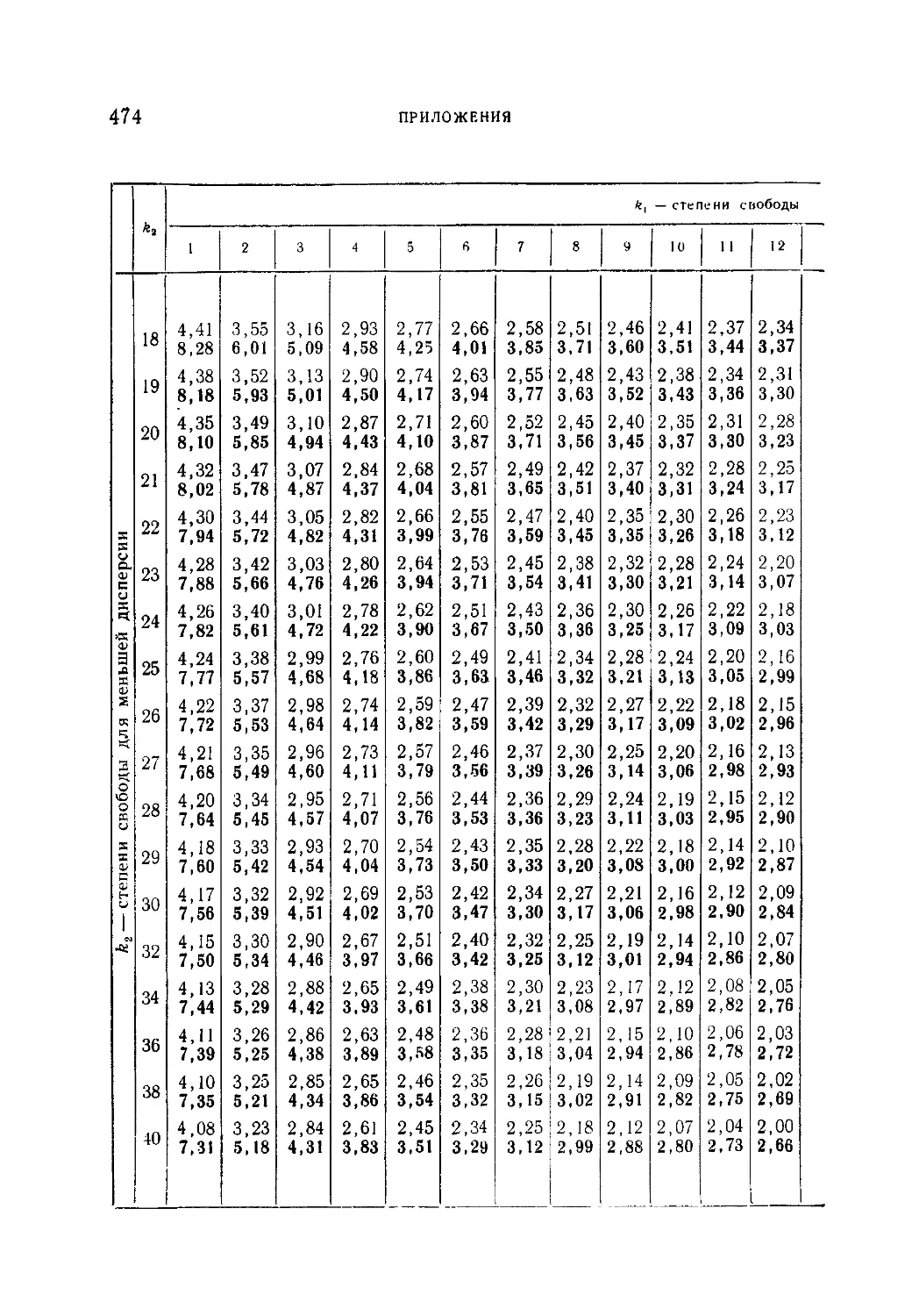
Таблица VI. Значения пяти- и однопроцентных верхних пределов
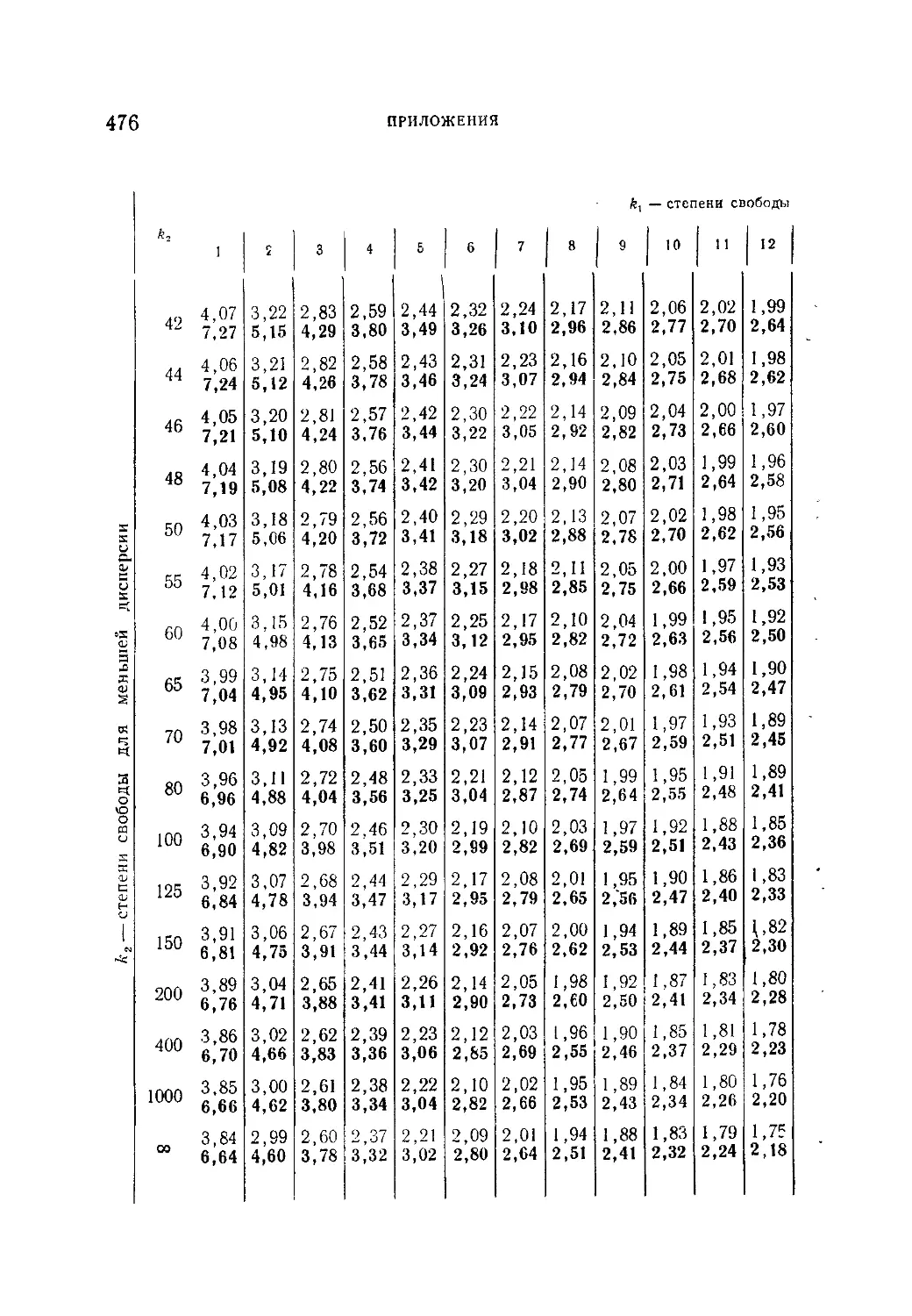
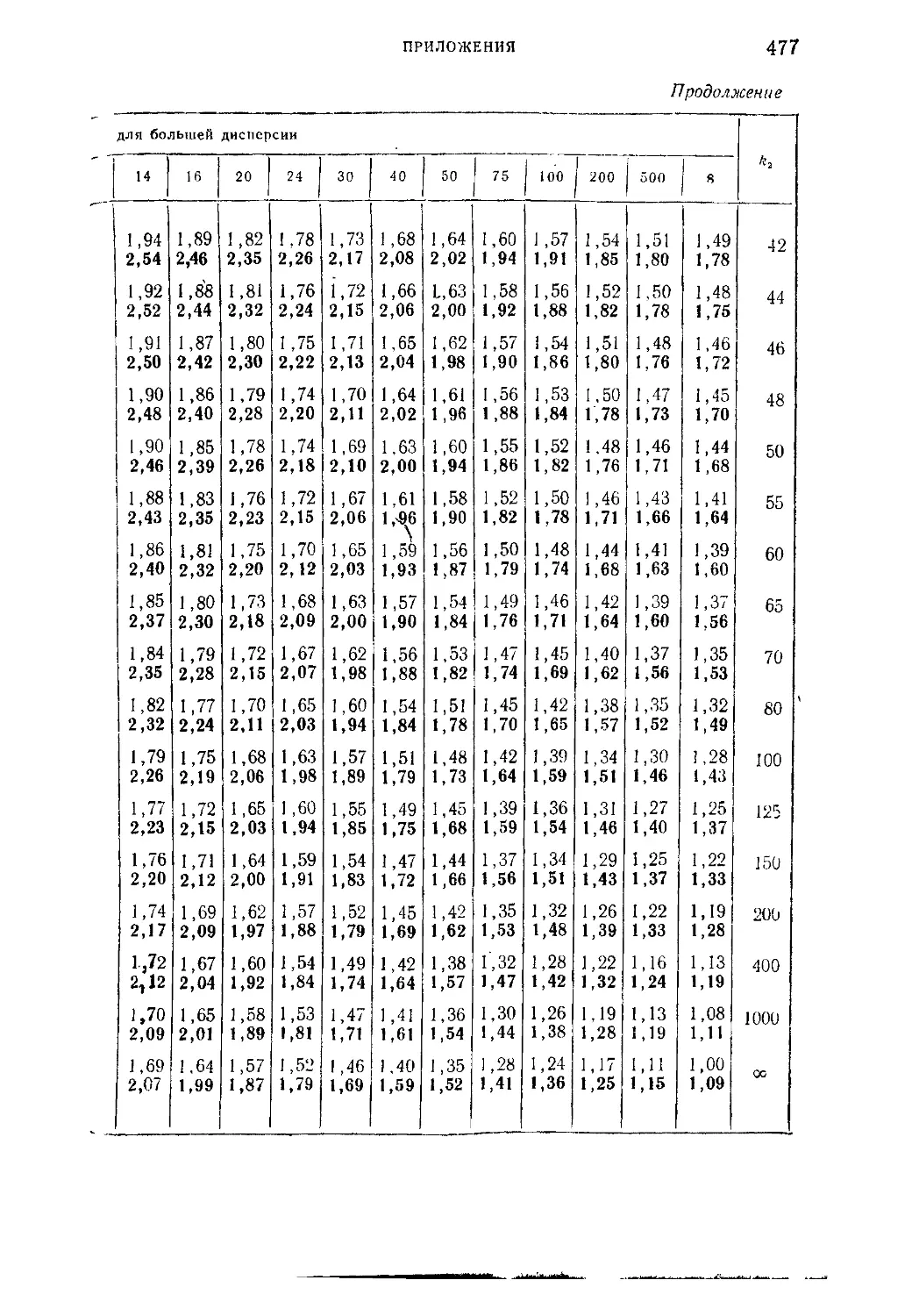
уклонения величины F в зависимости от степеней свободы k.
*kt..............................................................472
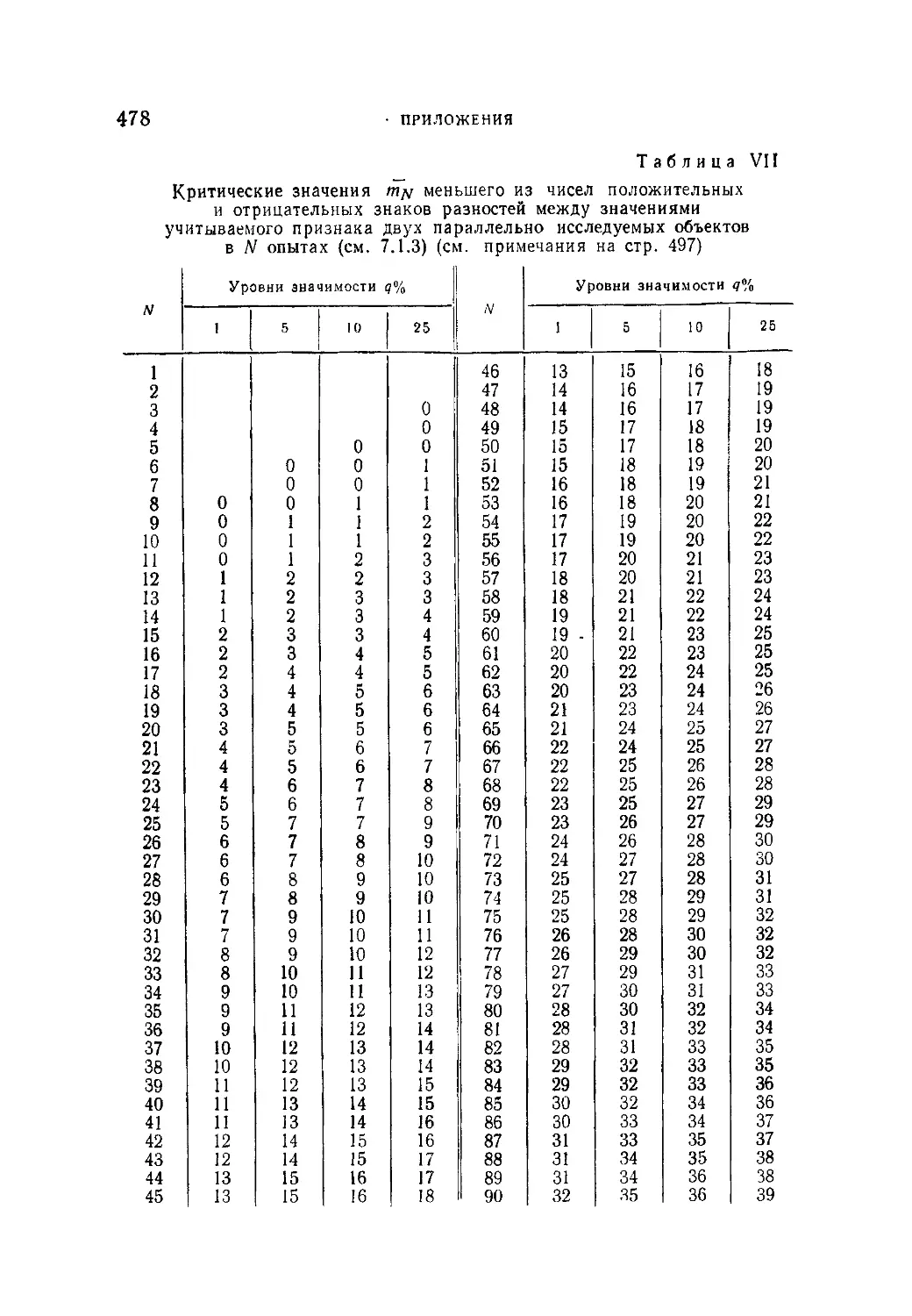
Таблица VII. Критические значения меньшего из чисел положи-
тельных и отрицательных знаков разностей между значениями
учитываемого признака двух параллельно исследуемых объек^
тов в N опытах......................................•...........478
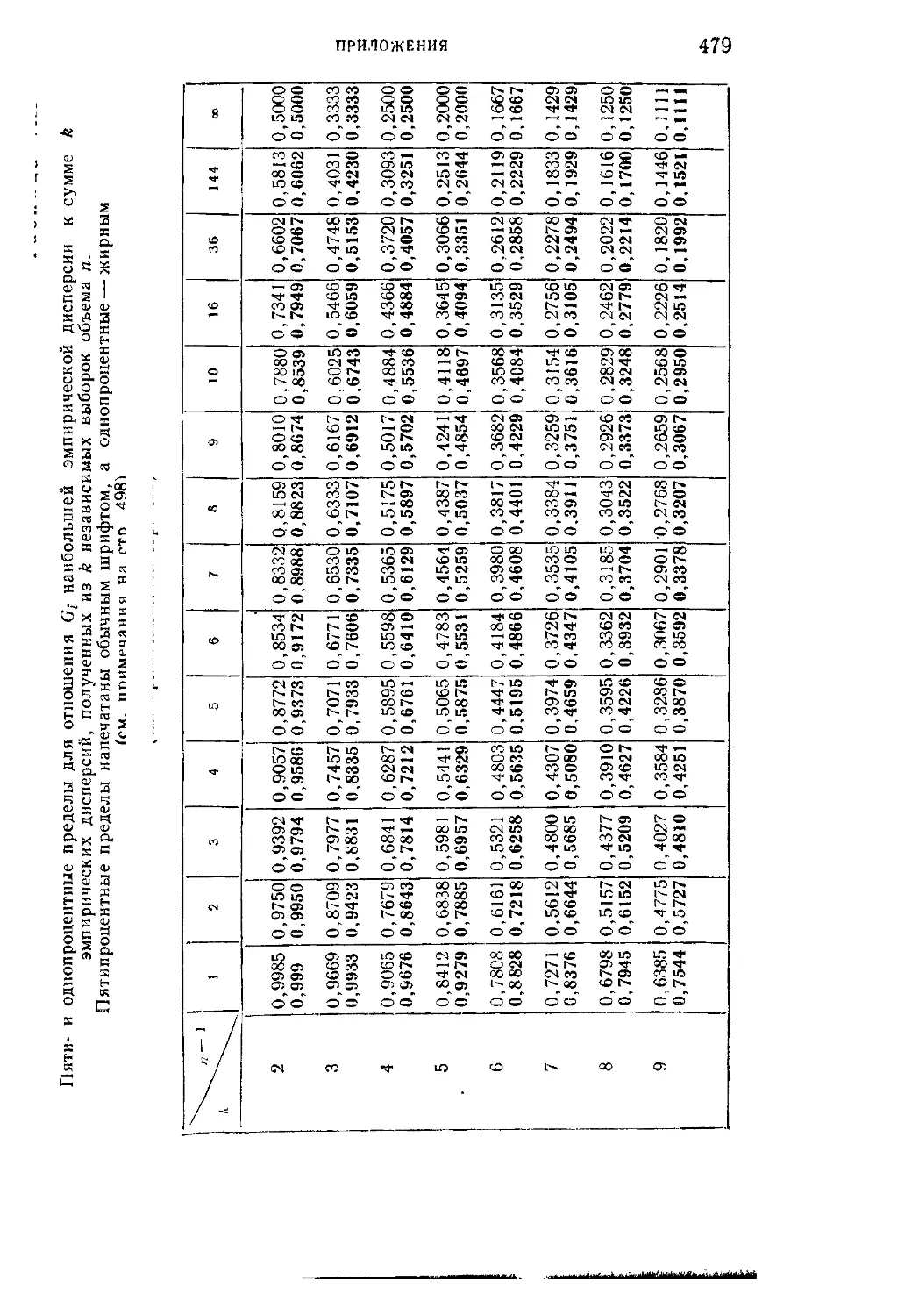
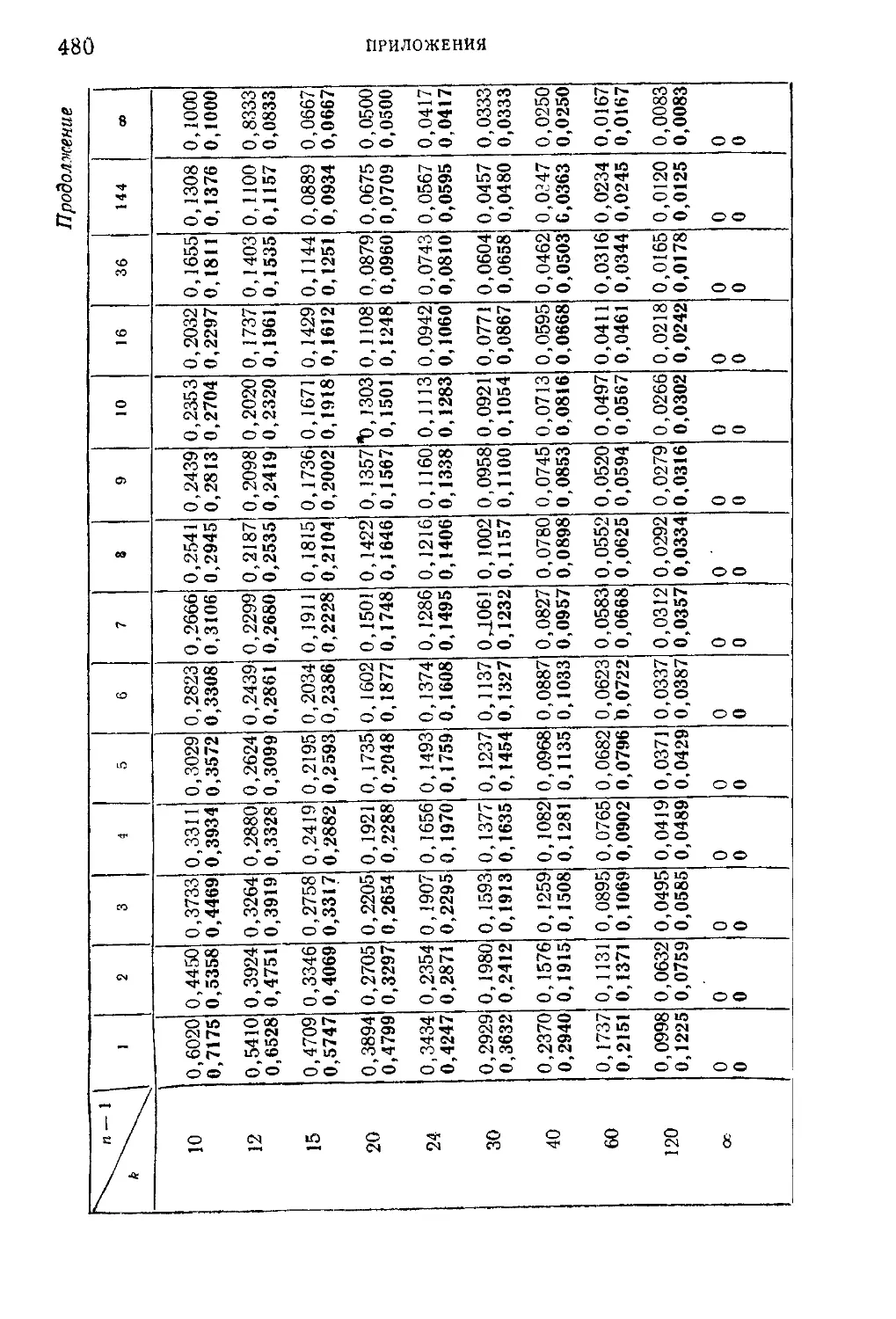
Таблица VIII. Пяти- и однопроцентные пределы для отношения О,-
наибольшей эмпирической дисперсии к сумме k эмпирических
дисперсий, полученных из k независимых выборок объема п 479
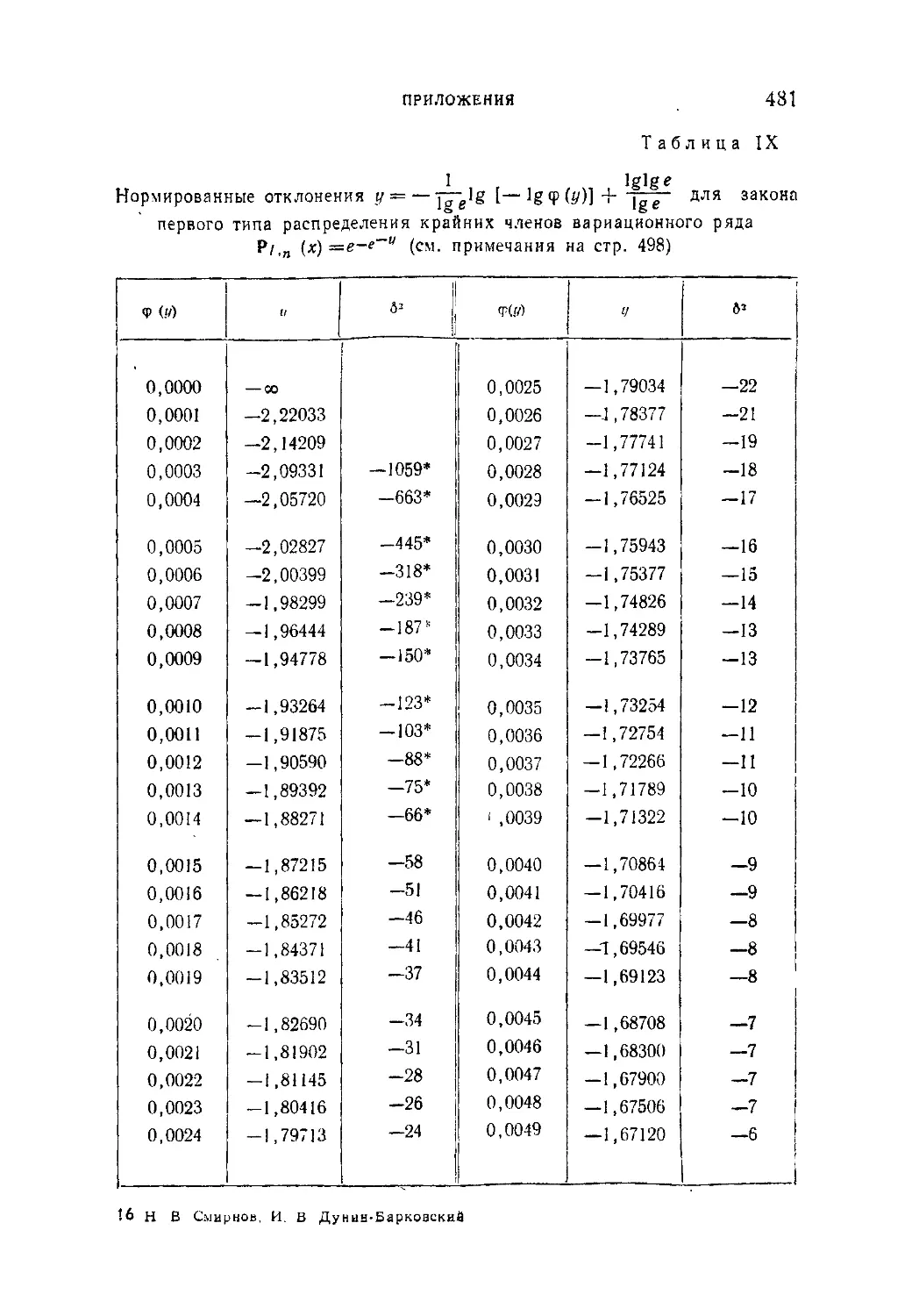
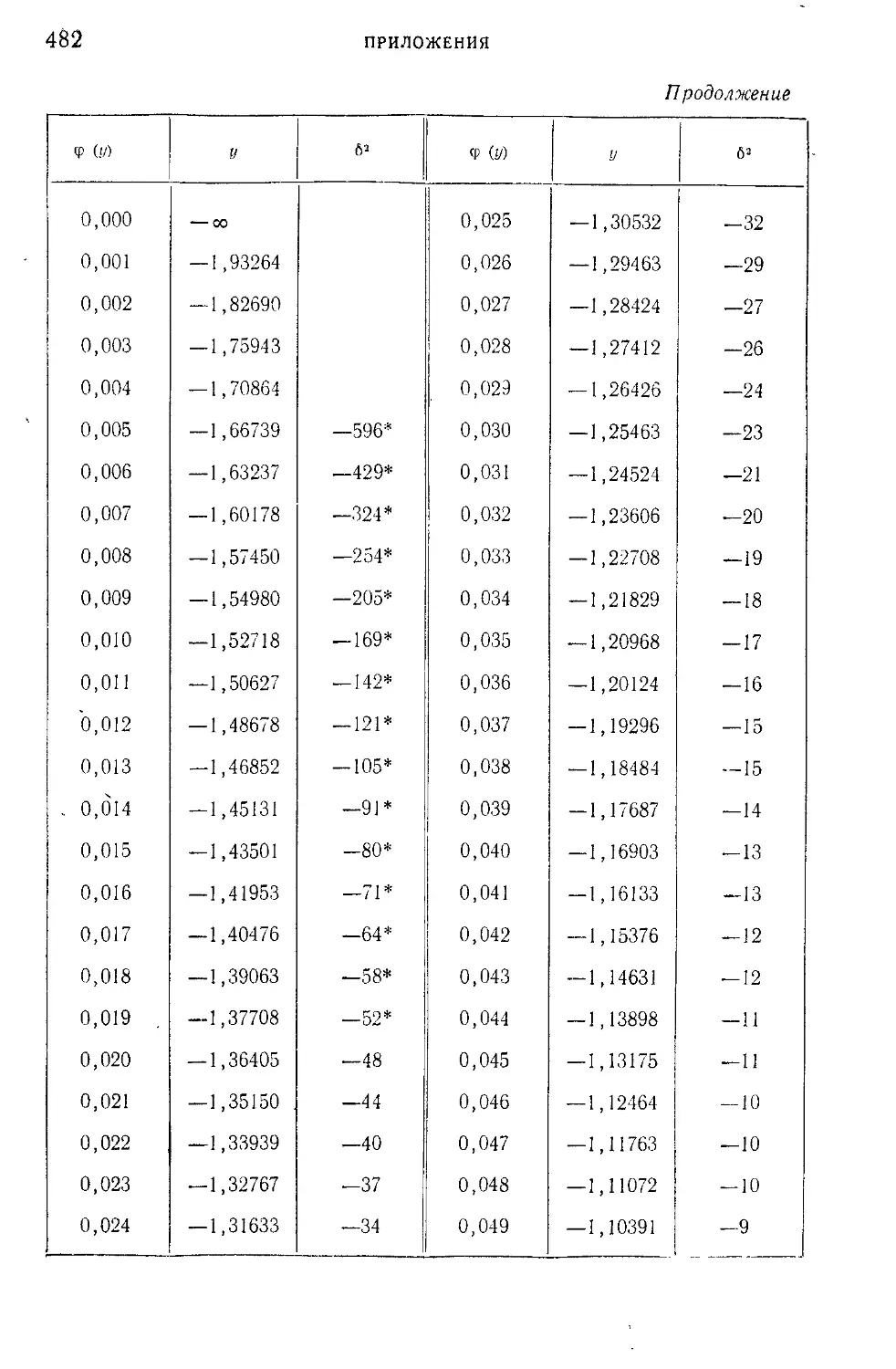
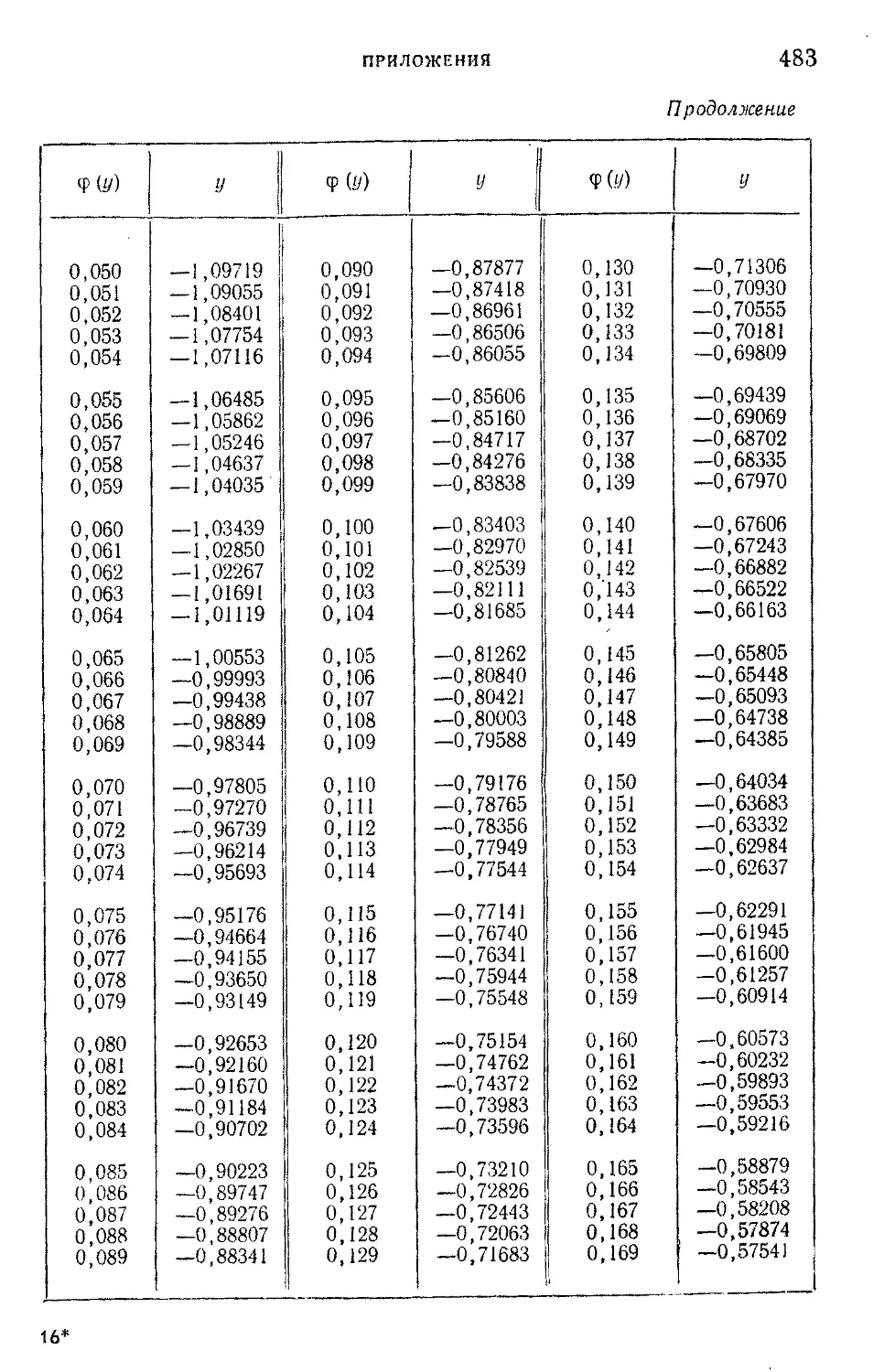
Таблица IX. Нормированные отклонения у = — lg |— lg <j> (i/)J -f-
lg lg e
4- для закона первого типа распределения крайних
членов вариационного ряда Р; „(х)=е~е *..................
481
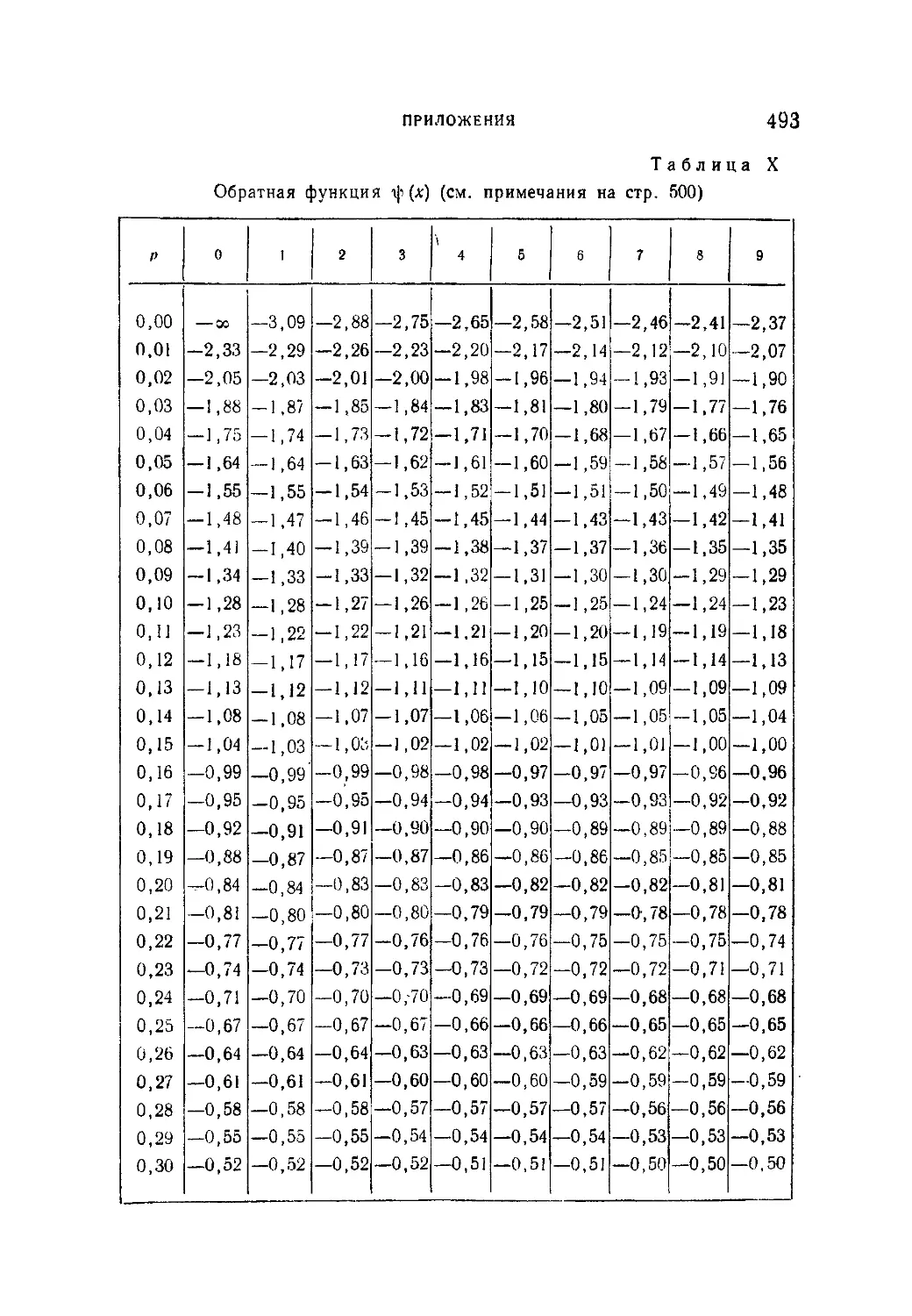
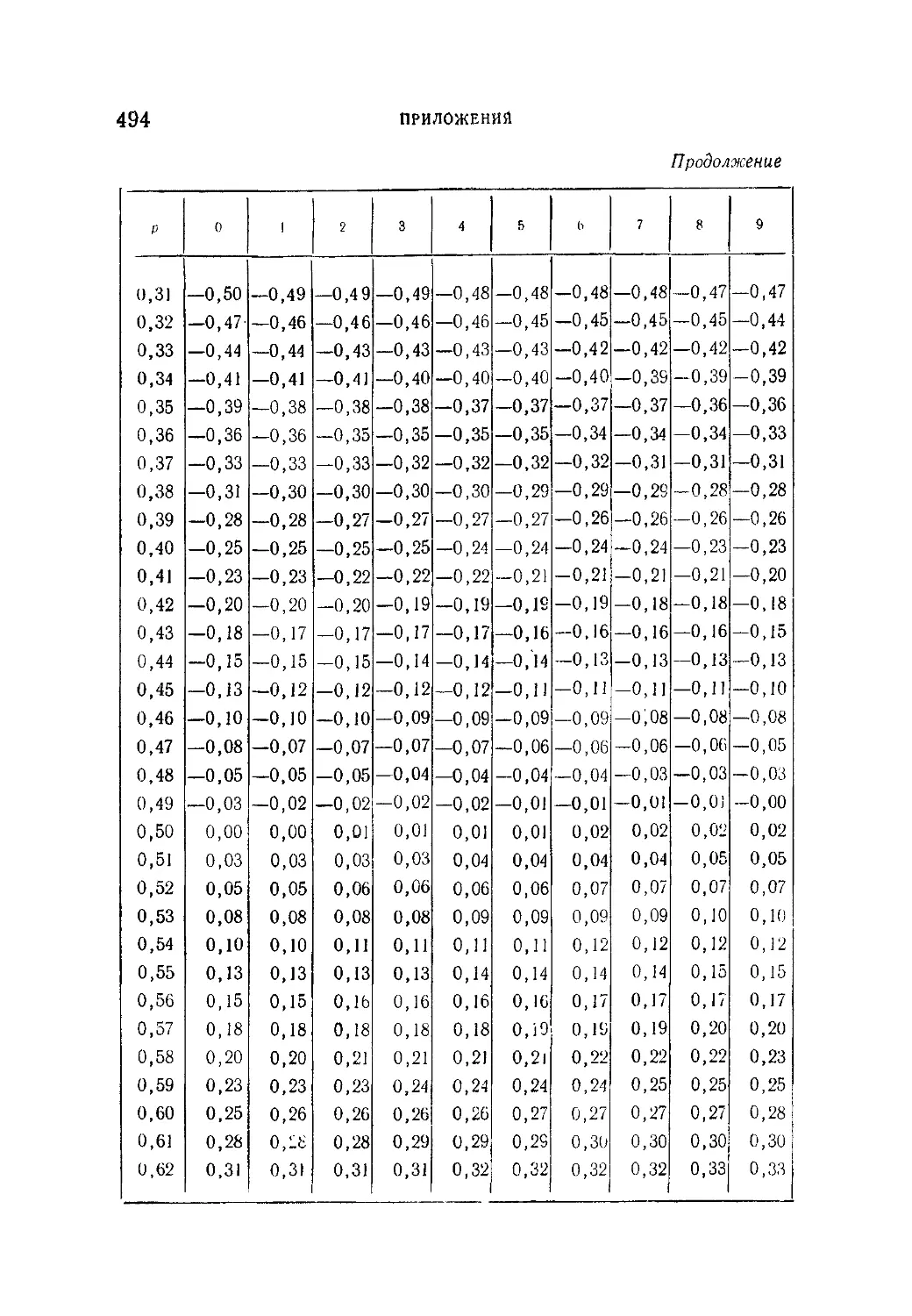
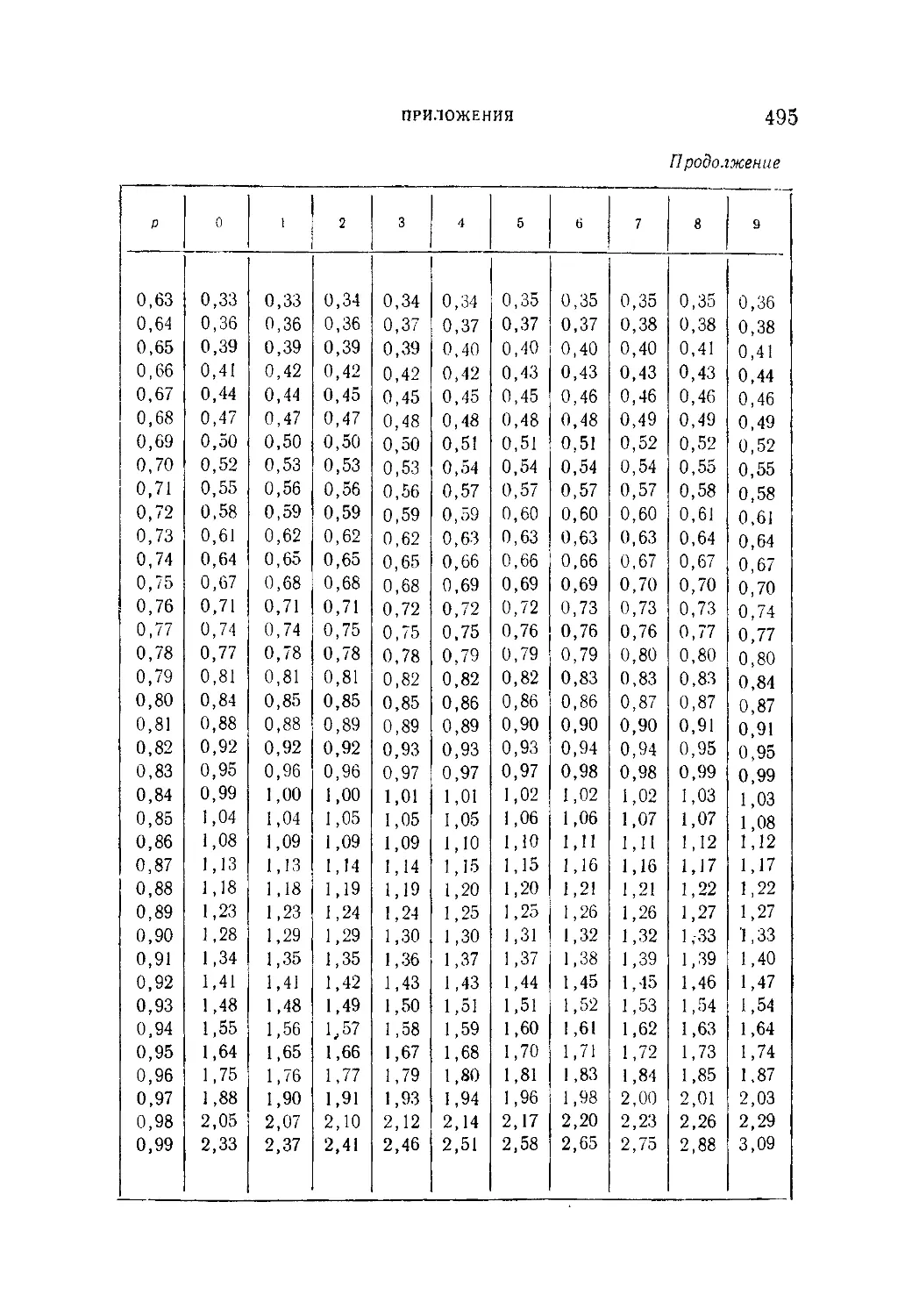
Таблица X. Обратная функция ф(х)................................493
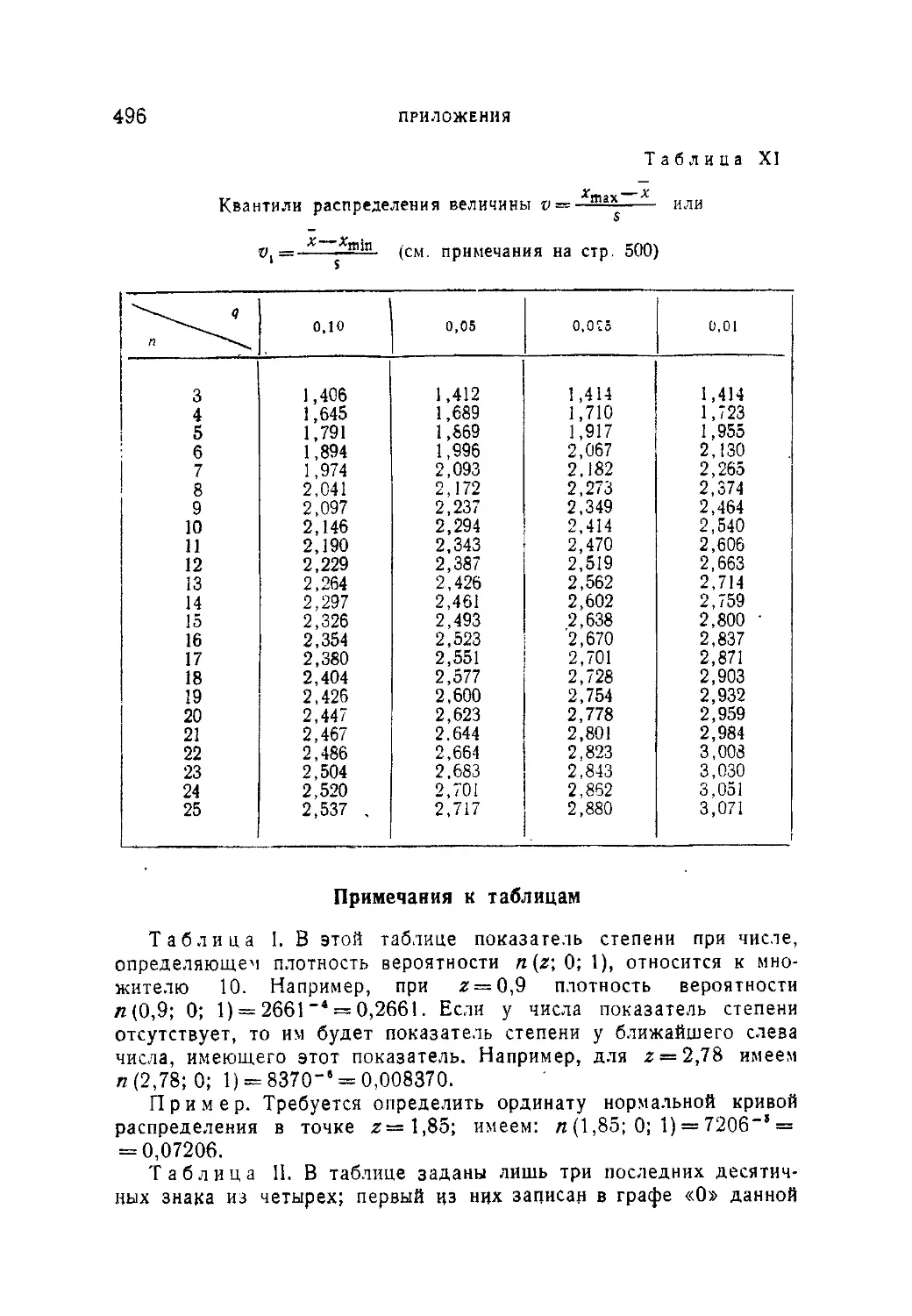
Таблица XI. Квантили распределения величины v*max х или
/ s
v =L_5ni».............................496
1 S
Литература...................................501
Предметный указатель.........................506
ПРЕДИСЛОВИЕ КО ВТОРОМУ ИЗДАНИЮ
Во второе издание по сравнению с первым внесены следующие
изменения и дополнения: расширено изложение вопросов, относящихся
к теории информации (п. 2. 3. 2.), рассмотрены вероятностные методы
в теории надежности (пп. 2.3.4, 3.1.7 и 3.2.3), расширено рас-
смотрение композиций распределений (и. 5.4. 2), добавлено рассмо-
трение ряда вопросов математической статистики (приближенная дис-
персия эмпирической дисперсии в п. 6.1.2, регрессия тригонометри-
ческого полинома и способ 12 ординат в п. 7.3.3, критерий
соответствия о>‘2 в п. 7.3.4, критерий грубых ошибок в п. 7.3.6,
проверка гипотезы нормальности по совокупности малых выборок
в п. 7.3.7), расширено рассмотрение статистических методов анализа
точности технологических процессов (п. 10.2.2) и применений теории
случайных функций (п. 11.2.7). В приложениях добавлены таблицы
обратной функции (табл. X) и квантилей распределения экстремаль-
ных членов вариационного ряда (табл. XI). Изменено также название
книги.
Выражаем глубокую признательность всем лицам и организациям,'
сообщившим свои замечания по первому изданию.
Авторы
Третье издание печатается с матриц второго с незначительными
исправлениями.
ПРЕДИСЛОВИЕ К ПЕРВОМУ ИЗДАНИЮ
Настоящий «Краткий курс математической статистики для техни-
ческих приложений» предназначен для студентов втузов, изучаю-
щих математическую статистику и теорию вероятностей, а также
для инженеров, использующих в своей работе статистические
методы.
Курс охватывает основы теории вероятностей и математической
статистики, их важнейшие современные методы и приемы, проиллю-
стрированные на примерах, почерпнутых из производственной, кон-
структорской и исследовательской практики нашей страны и зару-
бежных стран.
Назначение книги и ее объем предопределили характер изложе-
ния материала. Книга рассчитана на читателя, знающего математику
в объеме программы высших технических учебных заведений. Поэтому
опущены разъяснения более сложных вопросов и доказательства
многих теорем, которые требуют знаний, выходящих за пределы этой
программы. Рассматриваемые в книге примеры выбраны по возможности
краткими. Более подробные сведения ио ряду изложенных здесь
вопросов даются в нашей книге «Теория вероятностей и математи-
ческая статистика в технике (общая часть)», вышедшей в 1955 г. в
серии «Физико-математическая библиотека инженера».
Однако содержание данной книги шире, чем указанного выше
издания. В ней изложены, в частности, некоторые понятия теории
передачи информации и их применение к решению задачи о телеграф-
ном коде, оценка центра рассеивания по неравноточным наблюдениям, ис-
пользование для проверки статистических гипотез ряда дополнительных
критериев (критерия знаков, критерия, основанного на числе
инверсий, критерия /2 для оценки однородности распределе-
ний), дается понятие о многофакторном дисперсионном анализе,
рассматриваются приложения теории распределений крайних членов
вариационного ряда к расчету максимального расхода воды в реках
и к интерпретации усталостных испытаний, основы теории случай-
ных процессов и ее приложения к расчету телефонных станций,
опорных поверхностей при трении, систем автоматического регули-
рования и др.
10
ПРЕДИСЛОВИЕ К ПЕРВОМУ ИЗДАНИЮ
Следует отметить, впрочем, что изложение прикладных вопро-
сов и примеров, хотя и доведенное до окончательных числовых
решений, и поэтому могущее быть использованным на практике,
имело целью главным образом иллюстрацию соответствующих тео-
ретических положений. Детальное их освещение читатель может
найти в работах, перечисленных в имеющемся в конце книги ука-
зателе литературы.
В отличие от упоминавшейся выше нашей книги здесь наряду
с примерами из машиностроения и приборостроения приводятся при-
меры из электротехники, радиотехники, гидротехники и других
областей.
В приложении дается лишь минимум таблиц, необходимых для
выполнения практических расчетов по излагаемой в книге методике.
Среди них наибольший объем занимает впервые публикуемая в оте-
чественной литературе подробная таблица (IX), предназначенная для
выполнения гидротехнических расчетов и расчетов, связанных с про-
ведением испытаний материалов на выносливость.
Напечатанные мелким шрифтом разделы читатель в первом чте-
нии может опустить без ущерба для ясности понимания предмета.
К ним можно вернуться при более углубленном изучении соответ-
ствующих вопросов и, в частности, вопросов применения теории
случайных процессов к расчету систем автоматического регулирова-
ния. Выпущенная за последнее время по этим вопросам литература
требует надлежащего математического введения.
Считаем своим долгом выразить благодарность академику АН УССР
Б. В. Гнеденко и В. С. Михалевичу за очень ценные советы, ре-
дактору этой (и упоминавшейся выше) книги А. Ф. Лапко, а также
А. Н. Карташевой, оказавшим большую помощь при подготовке
рукописи к печати.
Критику и замечания читателей мы примем с благодарностью
и постараемся использовать в дальнейшем.
Авторы
ГЛАВА I
ПРЕДМЕТ И ЗАДАЧИ ТЕОРИИ ВЕРОЯТНОСТЕЙ
И МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ
В научных исследованиях, технике и массовом производстве мы
часто встречаемся с опытами, операциями или явлениями, много-
кратно повторяющимися в неизменных условиях. При этом,, несмотря
на постоянство основного комплекса условий, с возможной тща-
тельностью воспроизводимых в отдельных опытах, результаты их
всегда более или менее разнятся друг от друга, т. е. они испыты-
вают случайное рассеивание. Классическим примером могут слу-
жить измерения каких-либо величин (длины, массы, тока и т. д.).
Давно известно, что при повторении измерений одного и того же
объекта, выполняемых с помощью одного и того же измеритель-
ного прибора с одинаковой тщательностью, мы никогда не получаем
одинаковых данных. Если даже исключить возможность системати-
ческих погрешностей (путем специального исследования и проверки
метода измерений) и грубых промахов, то все же окажется, что на
измерениях будет сказываться влияние многочисленных факторов,
не поддающихся контролю и варьирующих от одного измерения
к другому. К числу таких факторов относятся случайные вибрации
отдельных частей прибора, физиологические изменения органов
чувств исполнителя, различные неучитываемые изменения в среде
(температура, оптические, электрические и магнитные свойства,
влажность и т. д.). Измерения обнаруживают, как правило, настолько
характерную картину случайного рассеивания, что в тех случаях,
когда последовательные их результаты оказываются одинаковыми,
можно говорить о недостаточной тщательности выполнения отсчетов
или о малой чувствительности прибора, или о грубости используе-
мой шкалы, и т. п.
Хотя результат каждого отдельного измерения при наличии
случайного рассеивания невозможно заранее предсказать, это еще
не означает, что повторные измерения не обнаруживают никакой
закономерности. Эта закономерность теперь хорошо изучена. Мате-
матически она описывается так называемой «нормальной кривой рас-
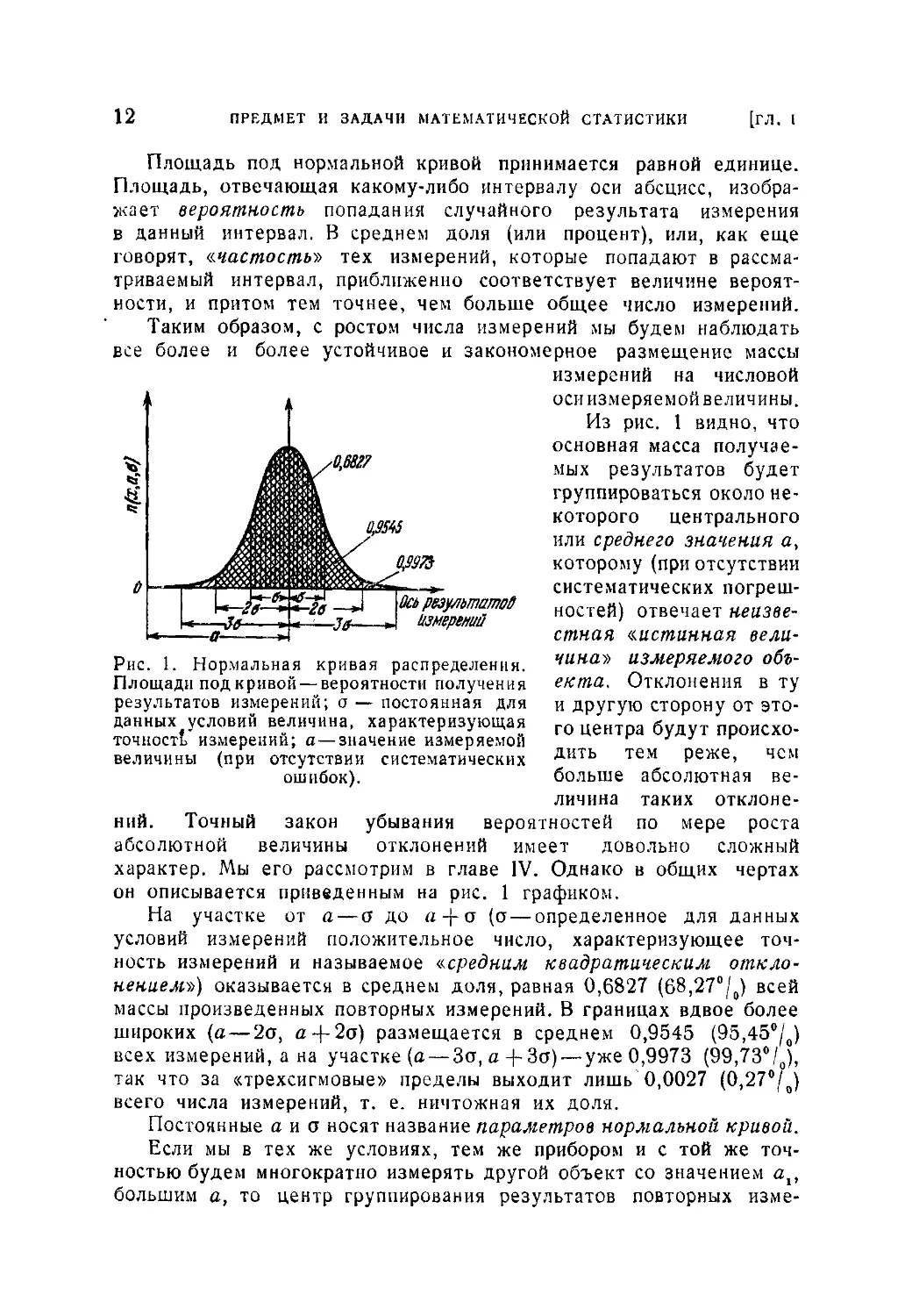
пределения», показанной на рис. 1.
12 ПРЕДМЕТ И ЗАДАЧИ МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ [ГЛ.I
Площадь под нормальной кривой принимается равной единице.
Площадь, отвечающая какому-либо интервалу оси абсцисс, изобра-
жает вероятность попадания случайного результата измерения
в данный интервал. В среднем доля (или процент), или, как еще
говорят, «частость'» тех измерений, которые попадают в рассма-
триваемый интервал, приближенно соответствует величине вероят-
ности, и притом тем точнее, чем больше общее число измерений.
Таким образом, с ростом числа измерений мы будем наблюдать
все более и более устойчивое и закономерное размещение массы
измерений на числовой
оси измеряемой величины.
Из рис. 1 видно, что
основная масса получае-
мых результатов будет
группироваться около не-
которого центрального
или среднего значения а,
которому (при отсутствии
систематических погреш-
ностей) отвечает неизве-
стная «истинная вели-
чина» измеряемого объ-
екта. Отклонения в ту
и другую сторону от это-
го центра будут происхо-
дить тем реже, чем
больше абсолютная ве-
личина таких отклоне-
Рис. 1. Нормальная кривая распределения.
Площади под кривой — вероятности получения
результатов измерений; о — постоянная для
данных условий величина, характеризующая
точност! измерений; а—значение измеряемой
величины (при отсутствии систематических
ошибок).
ний. Точный закон убывания вероятностей по мере роста
абсолютной величины отклонений имеет довольно сложный
характер. Мы его рассмотрим в главе IV. Однако в общих чертах
он описывается приведенным на рис. 1 графиком.
На участке от а—о до а-(-о (о—определенное для данных
условий измерений положительное число, характеризующее точ-
ность измерений и называемое «средним квадратическим откло-
нением») оказывается в среднем доля, равная 0,6827 (68,27°/0) всей
массы произведенных повторных измерений. В границах вдвое более
широких (а — 2о, а-ф2о) размещается в среднем 0,9545 (95,45°/0)
всех измерений, а на участке (а — Зо, а -|- Зо)— уже 0,9973 (99,73°/0),
так что за «трехсигмовые» пределы выходит лишь 0,0027 (0,27°/о)
всего числа измерений, т. е. ничтожная их доля.
Постоянные а и о носят название параметров нормальной кривой.
Если мы в тех же условиях, тем же прибором и с той же точ-
ностью будем многократно измерять другой объект со значением а,,
большим а, то центр группирования результатов повторных изме-
Г.1. 1]
ПРЕДМЕТ И ЗАДАЧИ МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ
13
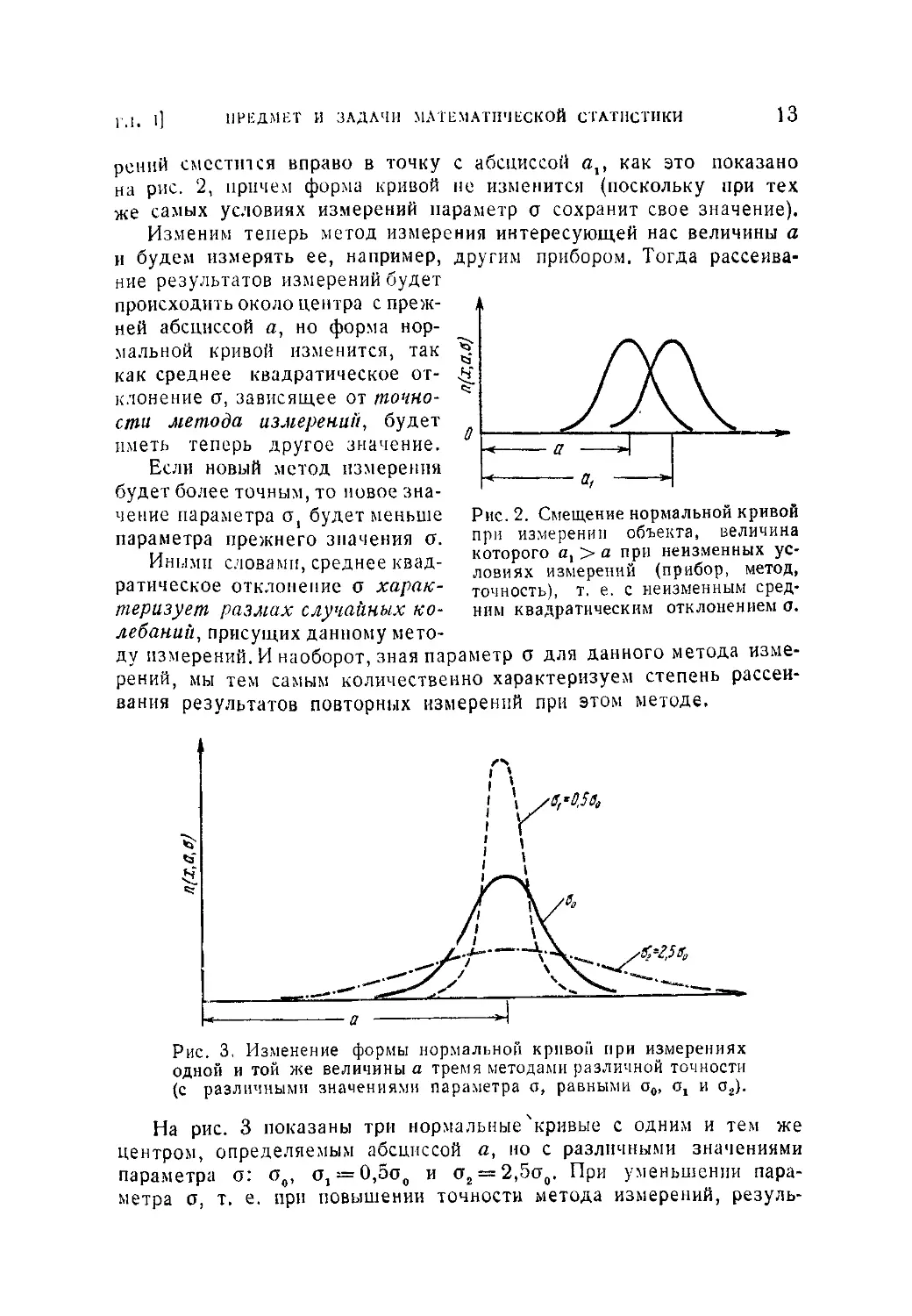
рений сместится вправо в точку с абсциссой а,, как это показано
на рис. 2, причем форма кривой не изменится (поскольку при тех
же самых условиях измерений параметр о сохранит свое значение).
Изменим теперь метод измерения интересующей нас величины а
и будем измерять ее, например, другим прибором. Тогда рассеива-
ние результатов измерений будет
происходить около центра с преж-
ней абсциссой а, но форма нор-
мальной кривой изменится, так
как среднее квадратическое от-
клонение о, зависящее от точно-
сти метода измерении, будет
иметь теперь другое значение.
Если новый метод измерения
будет более точным, то новое зна-
чение параметра а, будет меньше
параметра прежнего значения о.
Иными словами, среднее квад-
ратическое отклонение о харак-
теризует размах случайных ко-
лебаний, присущих данному мето-
Рис. 2. Смещение нормальной кривой
при измерении объекта, величина
которого а, > а при неизменных ус-
ловиях измерений (прибор, метод,
точность), т. е. с неизменным сред-
ним квадратическим отклонением а.
ду измерений. И наоборот, зная параметр о для данного метода изме-
рений, мы тем самым количественно характеризуем степень рассеи-
вания результатов повторных измерений при этом методе.
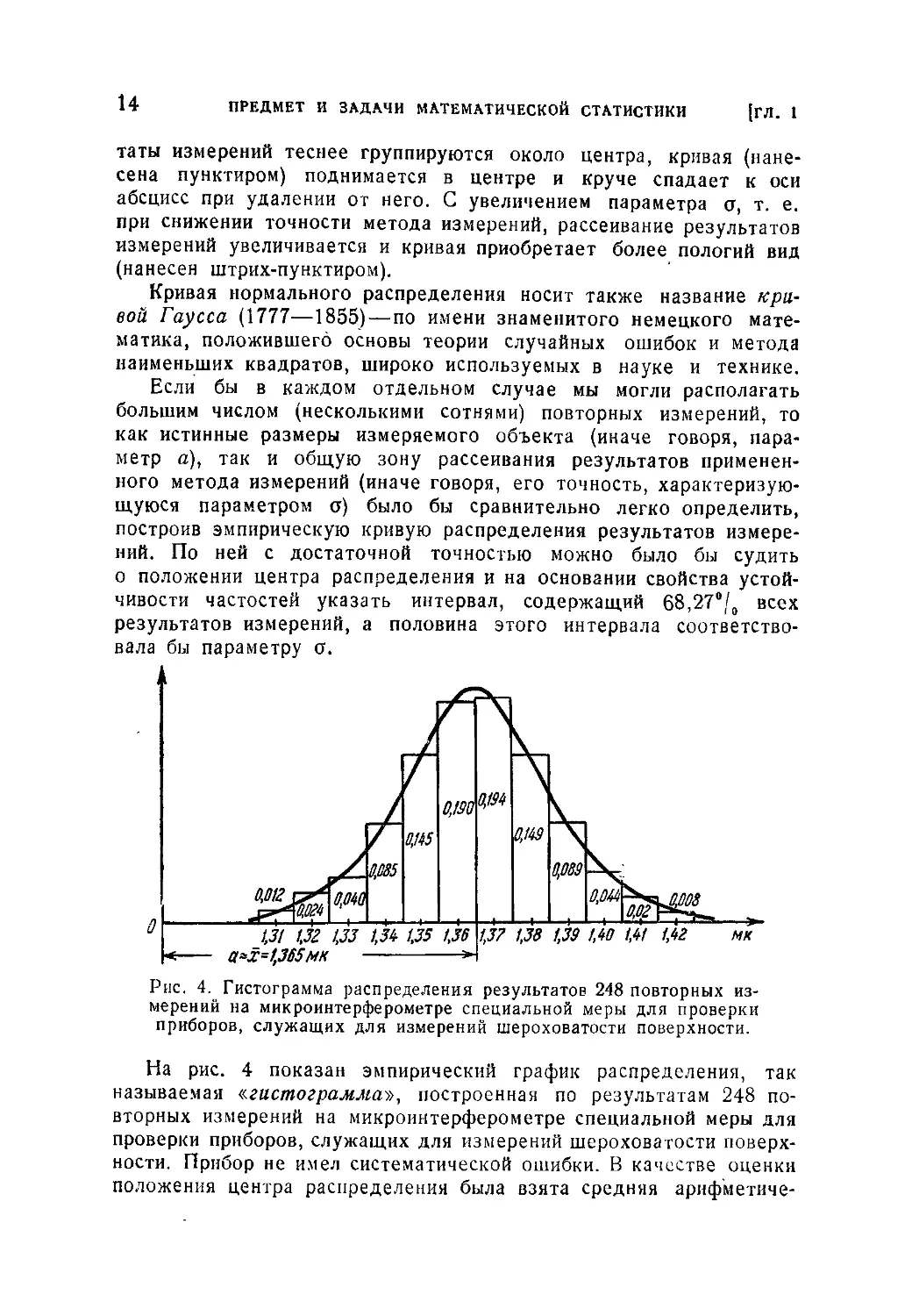
(с различными значениями параметра о, равными о0, о, и о2).
На рис. 3 показаны три нормальные'кривые с одним и тем же
центром, определяемым абсциссой а, но с различными значениями
параметра о: о0, о, —О,5о0 и о2 = 2,5о0. При уменьшении пара-
метра о, т. е. при повышении точности метода измерений, резуль-
14 ПРЕДМЕТ И ЗАДАЧИ МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ [ГЛ. t
тэты измерений теснее группируются около центра, кривая (нане-
сена пунктиром) поднимается в центре и круче спадает к оси
абсцисс при удалении от него. С увеличением параметра ст, т. е.
при снижении точности метода измерений, рассеивание результатов
измерений увеличивается и кривая приобретает более пологий вид
(нанесен штрих-пунктиром).
Кривая нормального распределения носит также название кри-
вой. Гаусса (1777—1855)—по имени знаменитого немецкого мате-
матика, положившего основы теории случайных ошибок и метода
наименьших квадратов, широко используемых в науке и технике.
Если бы в каждом отдельном случае мы могли располагать
большим числом (несколькими сотнями) повторных измерений, то
как истинные размеры измеряемого объекта (иначе говоря, пара-
метр а), так и общую зону рассеивания результатов применен-
ного метода измерений (иначе говоря, его точность, характеризую-
щуюся параметром о) было бы сравнительно легко определить,
построив эмпирическую кривую распределения результатов измере-
ний. По ней с достаточной точностью можно было бы судить
о положении центра распределения и на основании свойства устой-
чивости частостей указать интервал, содержащий 68,27°/0 всех
результатов измерений, а половина этого интервала соответство-
вала бы параметру ст.
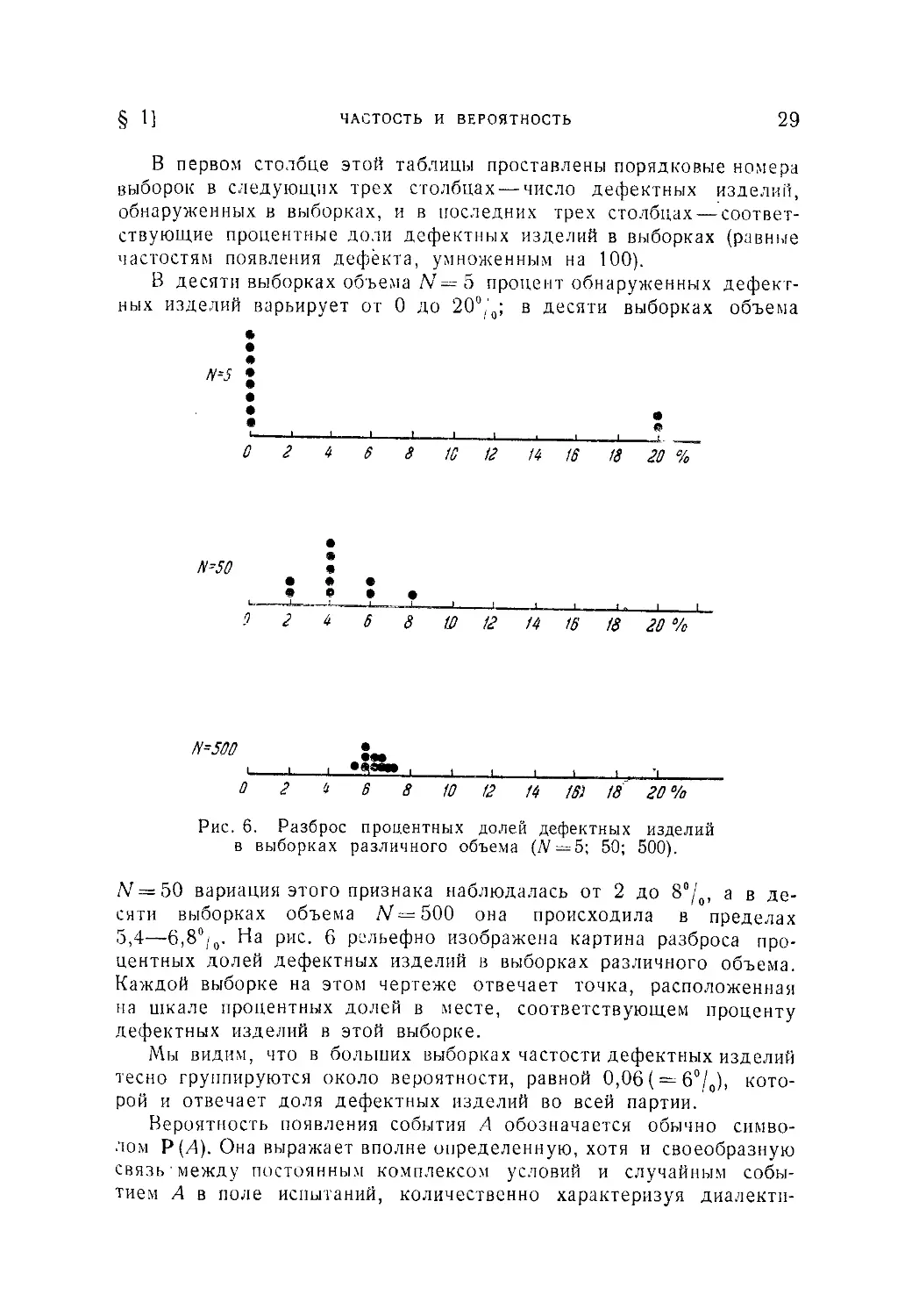
Рис. 4. Гистограмма распределения результатов 248 повторных из-
мерений на микроинтерферометре специальной меры для проверки
приборов, служащих для измерений шероховатости поверхности.
На рис. 4 показан эмпирический график распределения, так
называемая «гистограмма-», построенная по результатам 248 по-
вторных измерений на микроинтерферометре специальной меры для
проверки приборов, служащих для измерений шероховатости поверх-
ности. Прибор не имел систематической ошибки. В качестве оценки
положения центра распределения была взята средняя арнфметиче-
ГЛ. I] ПРЕДМЕТ И ЗАДАЧИ МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ 15
ская из результатов всех измерений. Она оказалась равной 1,365 мк.
Вся зона рассеивания результатов измерений от 1,31 до 1,42 мк
при построении графика была разбита на 12 равных интервалов.
Частость результатов, оказавшихся в каждом интервале, опреде-
лила площадь построенного на нем прямоугольника.
Параметр а, оцененный при помощи приема, описанного в главе VI,
оказался равным 0,022 мк.
Однако столь большое число повторений измерений каждой ве-
личины требует очень много труда и сопряжено с затратой большого
количества времени и значительных средств, а потому оно встре-
чается лишь в исключительных случаях. Обычно на практике число
повторных измерений бывает малым, и как раз в этих условиях
особенно важны приложения теории случайных ошибок для оценки
параметров распределения (а и о). Эта теория указывает, как
из имеющегося числа повторных измерений вывести надежные сред-
ние показатели, которые являлись бы наилучшими оценками вели-
чин а и о. Выбор средних показателей, оценки их точности и
надежности, проверка предположений относительно существенности
(т. е. неслучайности) отличия средних в двух сериях измерений
одного и того же объекта, сравнение точности двух методов изме-
рений, вывод обобщающих средних из нескольких серий неравно-
точных измерений, оценка значений различных функций от изме-
ренных величин (при так называемых косвенных измерениях)
представляют довольно многообразный круг задач теории случай-
ных ошибок. Ее математическим основанием и исходным пунктом
является закон нормального распределения.
В настоящее время теория случайных ошибок измерений является
отделом другой, более обширной науки—математической статистики,
разрабатывающей рациональные приемы обработки опытных дан-
ных, относящихся к массовым явлениям и отражающих влияние рас-
сеивающих случайных факторов. Эти приемы, существенно связан-
ные с допущением устойчивости частостей и наличием вероятностных
законов рассеивания, носят название математико-статистических
методов.
Закономерность случайного рассеивания, выражаемая нормаль-
ной кривой распределения, носит довольно общий (хотя и не уни-
версальный) характер. Она наблюдается, например, при артилле-
рийской стрельбе. Рассеивание точек попадания снарядов, выпущенных
из одного и того же орудия при неизменном прицеле, как правило,
следует также закону, описываемому Нормальной кривой. При этом
параметр а определяет центр рассеивания, отвечающий данному при-
целу, а параметр а характеризует точность стрельбы в данных усло-
виях. Эти положения служат основой теории артиллерийской стрельбы.
Аналогичная картина рассеивания сопровождает изготовление мас-
совой продукции, складывающееся из повторения определенных
16
ПРЕДМЕТ И ЗАДАЧИ МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ
[гл. I
технологических операций, хотя и регламентированных установлен-
ным технологическим процессом, но испытывающих, кроме того,
влияние большого числа изменяющихся от случая к случаю воздей-
ствий, связаных с неоднородностью обрабатываемого материала,
вибрациями- оборудования, колебаниями режимов обработки и т. д.
Работа разнообразных систем автоматического управления во
многом также подвержена воздействию многочисленных случайных '
факторов.
Еще большую роль случайное рассеивание играет в биологии,
агротехнике, медицине, метеорологии, гидрологии, гидротехнике,
мелиорации и других областях науки и техники. Варьирование, на-
пример, различных признаков живых организмов под действием
разнообразных факторов из окружающей среды часто приводит
к той же закономерности рассеивания. Известно, какое большое
практическое значение имеют изменчивость человеческого роста,
объема груди, размеров ступни и т. д. для массового изготовления
предметов личного потребления (одежды, обуви и т. д.). Рацио-
нальное распределение выпуска этих изделий по размерам, учиты-
вающее относительную величину спроса на изделия разных размеров,
должно отвечать поэтому все той же закономерности, описываемой
нормальной кривой.
Во всех указанных областях математико-статистические методы
находят широкое применение при решении задач, аналогичных зада-
чам теории ошибок (сравнение средних, оценка степени рассеивания,
проверка различных предположений и т. д.).
Однако законы случайного рассеивания могут часто приобретать
и другие формы, отличные от нормального закона. Существенным
является то, что во многих случаях мы находим вполне закономер-
ную связь между числовыми значениями варьирующих признаков
и вероятностью реализации этих значений в массе приводимых на-
блюдений. Именно это обстоятельство дает возможность по-
строить общую теорию, показывающую, какие приемы обработки
наблюдений, какие средние показатели, выводимые из данного
обычно ограниченного материала наблюдений, наилучшим образом
отвечают специфике случайного рассеивания в той или иной
задаче.
Начальный раздел математической статистики — описательная
статистика рассматривает вопросы описания картины случайного рас-
сеивания по данным наблюдений массовых явлений. Вопрос о выборе
надлежащих средних показателей для такого описания достаточно
строго и полно можег быть решен лишь в том случае, когда теоре-
тическая форма распределения вероятностей задается в виде кри-
вой, принадлежащей известному семейству кривых распределения,
причем каждая кривая такого семейства выделяется значениями
некоторого числа параметров. Таких параметров, например, у нор-
гл. 1] ПРЕДМЕТ И ЗАДАЧИ МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ 17
мальвой кривой два: это — а и а. Тогда вопросы, связанные с вы-
явлением закона распределения для каждого случая, сводятся
к задаче оценки (возможно более точной и надежной) неизвестных
параметров по имеющемуся запасу наблюдений.
Раздел оценки параметров законов распределения является одним
из наиболее развитых в математической статистике (см. главу VI).
Случайное рассеивание, изучаемое статистическими методами,
имеет важное практическое значение. Оно должно учитываться при
проектировании и расчете различных машин, приборов, сооружений,
таких, как корабли, самолеты, станки, системы автоматического
управления, измерительные приборы, плотины, водохранилища и
т. д., когда наряду с контролируемыми факторами приходится счи-
таться и с таким, как колебания силы ветра, расхода воды, качки
корабля и т. д. Только знание законов распределения и их надле-
жащий учет в инженерных расчетах можно обеспечить в подобных
случаях надежную работу устройств и сооружений.
Другой раздел математической статистики составляет статисти-
ческая проверка гипотез, т. е. предположений, относящихся к рас-
сматриваемым распределениям опытов или наблюдений массовых
явлений.
В условиях, когда запас наблюдений ограничен и данные о мас-
совом процессе обнаруживают значительное рассеивание, объектив-
ное суждение о преимуществах того или иного метода измерений,
стрельбы, технологического процесса, о пользе вносимого или пред-
лагаемого удобрения, лекарства и т. д. можно вынести лишь на
основе статистического анализа и сопоставления данных наблюдений
или опытов, относящихся к соответствующей области.
Математическая статистика разрабатывает приемы такого сопо-
ставления, стараясь исчерпывающим образом использовать всю инфор-
мацию, содержащуюся в имеющемся ограниченном материале, и полу-
чить обоснованные выводы (см. главу VII).
Большой раздел математической статистики составляет учение
о зависимости между величинами, каждая из которых испытывает
вариации под действием случайных факторов. Этот раздел носит
название теории корреляции (см. главу IX).
Задачи анализа влияния различных факторов на поведение инте-
ресующей нас величины рассматриваются в дисперсионном анализе
(см. главу VIII>
В начальный период развития математической статистики имели
большое значение работы А. Кетле (1796—1874), Ф. Гальтона
(1822—1911) и, в особенности, К. Пирсона (1857—1936).
Развитие естествознания и техники выдвинуло перед .математи-
ческой статистикой ряд новых проблем, решение которых привело
к дальнейшему совершенствованию математических методов стати-
стики. В ее современном развитии определяющую роль сыграли
18
ПРЕДМЕТ И ЗАДАЧИ МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ
[гл.л
труды Р. Фишера (1890—1962), Ю. Неймана, А. Вальда (1902—1950),
Г. Крамера и др.
Большое значение в развитии математической статистики имели
работы советских ученых Е. Е. Слуцкого (1880—1948), А. Н. Кол-
могорова, В. И. Романовского (1880—1954) и др.
Отметим некоторые особенности упоминавшейся выше законо-
мерности случайного рассеивания. В отличие от механических и,
вообще, от причинных закономерностей, которые говорят о неиз-
бежном получении того или иного результата в каждом опыте, коль
скоро в нем соблюдаются определенные условия, вероятностная
(так называемая стохастическая) закономерность ничего не говорит
о каждом отдельном опыте (например, о величине погрешности
какого-либо индивидуального измерения); она предуказывает только
средний результат большого числа опытов.
Во всех рассмотренных нами примерах необходимость в форме
тех или иных механических, химических и других законов, опреде-
ляющих лишь в целом или в среднем течение процесса, проклады-
вает себе дорогу сквозь массу случайностей, хотя и имеющих каждый
раз свои причины, но не вытекающих из внутренних закономерно-
стей явлений данного типа.
Хорошей иллюстрацией к тому, что в массовых явлениях, имею-
щих место в больших совокупностях равноправных объектов (не-
смотря на кажущуюся хаотичность и произвольность поведения
каждого из них в отдельности), возникают тем не менее своеобразные
устойчивые закономерности вероятностного типа, являются известные
положения молекулярной физики. Движения и соударения отдельных
молекул газа происходят хаотически. Каждая из них описывает
весьма сложную и запутанную траекторию, так что не представляется
возможным предсказать, где она будет находиться через определен-
ный отрезок времени. Тем не менее, выделив на стенке сосуда
площадку, мы обнаружим, что среднее число молекул газа, столкнув-
шихся со стенкой в данной площадке в данный отрезок времени,
и средний импульс, переданный стенке при соударениях, будут
вполне устойчивой величиной, определяющей упругость и давле-
ние газа.
В искусственно разреженном газе, как известно, уже начинают
давать себя знать флуктуации плотности, давления и других величин.
Подобным же образом при повторении измерений истинные раз-
меры объекта определяют положение центра рассеивания результатов
измерений; установка орудия, тип снаряда и начальная скорость
определяют положение центра рассеивания попаданий; настройка
станка определяет центр рассеивания размеров обработанных на
нем изделий и т. д.
Вероятностные закономерности подобного рода в абстрактном
виде изучает особая математическая дисциплина — теория вероятно-
ГЛ. i] ПРЕДМЕТ И ЗАДАЧИ МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ 19
стей. Она разрабатывает схемы или модели массовых явлений, свя-
зывая с каждым из возможных результатов опытов особую число-
вую меру объективной возможности его появления — вероятность.
Конкретно величина вероятности каждого возможного результата
опыта или события проявляется в той частоте, с которой оно встре-
чается при массовых повторениях опыта. Теория вероятностей рас-
сматривает методы вычисления вероятностей сложных результатов
массового явления по известным вероятностям более простых исхо-
дов. Тем самым открывается путь для анализа и выявления вероят-
ностных закономерностей случайных явлений.
Подобно тому как математический анализ (и теория дифферен-
циальных уравнений в особенности) является основным математиче-
ским аппаратом при изучении физических закономерностей, теория
вероятностей представляет наиболее подходящий инструмент при
исследовании процессов, испытывающих большее или меньшее влия-
ние случайных факторов.
Закономерность случайного рассеивания, выражаемая нормальным
распределением, получила свое научное обоснование в теоретико-
вероятностных исследованиях выдающихся русских математиков
П. Л. Чебышева (1821—1894), А. А. Маркова (1856—1922) и
А. М. Ляпунова (1857—1918), значительно расширивших результаты
классических исследований Якова Бернулли (1654—1705), Муавра
(1667—1754), Лапласа (1749—1827) и Пуассона (1781 —1840).
Оказалось, что нормальному распределению будет, как правило,
следовать всякая случайно-варьирующая величина, представляющая
сумму большого числа независимых случайных слагаемых, подобно
тому как погрешность измерения прибора складывается из погреш-
ностей его отдельных частей. Схема суммирования случайных сла-
гаемых охватывает довольно широкий круг явлений, наблюдаемых
на практике. Наглядным примером такого суммирования может слу-
жить суммарное потребление электроэнергии многочисленными неза-
висимыми друг от друга потребителями.
Теория вероятностей исследует разнообразные типы случайных
процессов, приводящих к различным закономерностям; лишь с про-
стейшими из них мы познакомимся в этой книге.
Современное развитие теории вероятностей и математической
статистики складывалось в результате международного сотрудниче-
ства очень большого числа исследователей.
Советская школа теории вероятностей представлена крупнейшими
учеными: С. Н. Бернштейном, А. Н. Колмогоровым, А. Я. Хинчй-
ным (1894—1959), Б. В. Гнеденко, Ю. В. Линником и др.
Как и все математические теоремы, положения теории вероятно-
стей носят абстрактный, безразличный к конкретной природе массо-
вых явлений характер. Например, при определенных предположениях,
рассматриваемых в главе 111, теория вероятностей показывает, что
20 ПРЕДМЕТ И ЗАДАЧИ МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ [1'Л. I
вероятность наступления случайного явления в промежутке времени,
равном I секунд, определяется соотношением
р (t) — 1 —e~Kt,
где X—постоянное положительное число.
Оказывается, что схема, лежащая в основе вывода этого соотно-
шения, с большим или меньшим приближением может быть приме-
нена к поступлению телефонного вызова на автоматической теле-
фонной станции, к остановкам станка в цехе из-за неполадок,
к обрыву нити на ткацком станке, к распаду атома радиоактивного
вещества и т. д.
Однако во всех этих случаях параметр X имеет различные зна-
чения в соответствии с природой и особенностями данной области
явлений. Чтобы в конкретных условиях использовать эту законо-
мерность для научного прогноза или инженерных расчетов, необ-
ходимо сопоставить общую формулу для вероятности с материалом
наблюдений массового явления. Таким образом, мы снова приходим
к статистическим проблемам оценки параметров и проверки стати-
стических гипотез.
Теория вероятностей служит фундаментом для всех приемов
математической статистики, и мы начнем с изложения ее основ
в следующей главе.
ГЛАВА II
СЛУЧАЙНЫЕ СОБЫТИЯ
§ 1. Частость и вероятность
2.1.1. Испытание. Поле событий. Операции над событиями.
Математическая статистика широко использует понятия и методы
теории вероятностей; поэтому мы начнем с изложения основных
положений этой математической дисциплины.
Как уже упоминалось, массовые явления и процессы характери-
зуются, прежде всего, многократным повторением при постоянных
условиях некоторых опытов, операций и т. п. Абстрагируясь от спе-
циальных свойств этих опытов, в теории вероятностей вводят поня-
тие испытания; испытанием называется осуществление какого-
нибудь определенного комплекса условий, который может быть
воспроизведен сколь угодно большое число раз. Явления, происхо-
дящие при реализации этого комплекса, т. е. в результате испы-
тания, называются событиями. О всяком новом испытании мы
говорим, как о повторении прежнего, чтобы подчеркнуть, что
испытания происходят в одних и тех же условиях (хотя, конечно,
о полной тождественности условий можно говорить лишь с некото-
рым приближением). Заметим, что при данном определении испы-
тания вовсе не обязательно наличие наблюдателя, ставящего опыт;
под схему «испытаний» могут быть подведены самые разнообразные
явления, в которых одни и те же условия реализуются многократно.
Так, например, для каждого атома- радиоактивного вещества можно
рассматривать испытание, в результате которого может произойти
или не произойти распад атома в течение некоторого фиксирован-
ного промежутка времени: число испытаний здесь будет равно
числу всех атомов.
Массовое явление всегда есть результат большого, иногда не-
обозримо большого, числа испытаний.
Некоторые события происходят неизбежно в результате каждого
испытания: они называются достоверными-, другие вовсе не могут
произойти и потому получили название невозможных.
22
СЛУЧАЙНЫЕ СОБЫТИЯ
[ГЛ. II
В общем случае в результате испытания в зависимости от
меняющихся случайных обстоятельств может произойти то или иное
событие из множеств событий, возможных при данном испытании.
Такое множество называется «полем событий», связанным с ис-
пытанием, а события этого поля называются «случайными собы-
тиями».
При каждом розыгрыше госзайма выигрыши разных размеров
падают на некоторую группу номеров, публикуемых обычно в виде
таблицы номеров серий, из общего числа их, подлежащих розыгрышу.
Все возможные группы подобного типа образуют «.поле случайных
событий» при розыгрыше. Выигрыши, павшие на серию с номе-
ром 138462 или на серию с одним из десяти номеров от 138460
до 138469 включительно и т. д., будут примерами случайных со-
бытий, принадлежащих этому полю.
Сама процедура розыгрыша при этом такова, что благодаря
специальным приемам гарантируется «случайность» событий поля.
Рассмотрим еще один пример.
Пусть имеется некоторое значительное число п мотков (так назы-
ваемых «бухт») стальных тросов, из них надо отобрать небольшое
число образцов (по одному от бухты) с целью их испытаний на
выносливость. Эти испытания отличаются значительной длительностью
и трудоемкостью, и практически невозможно подвергнуть всю пар-
тию этим испытаниям. Чтобы сделать отбор образцов или, на языке
статистики, произвести «.выборку», обладающую представительностью
или репрезентативностью, т. е. правильно отражающую качество
мотков во всей партии, надо хорошо перемешать бухты и наугад
выбрать те, от которых должны быть отрезаны образцы. Но вес
каждой бухты бывает велик, и потому было бы трудно добиться
хорошего перемешивания. Чтобы облегчить случайный отбор, каждой
бухте можно присвоить свой порядковый номер и выписать его на
отдельную карточку;-л карточек, отвечающих отдельным экземпля-
рам бухт, тщательно перемешиваются и затем уже наудачу отби-
рается нужное число карточек и согласно их номерам отрезаются
образцы от бухт, имеющих те же порядковые номера. Ясно, что
отбор каждой карточки из картотеки представляет испытание в упо-
мянутом в начале этого раздела смысле. Рассмотрим поле возмож-
ных событий при каждом таком одном испытании. Для простоты
мы предположим, что каждая вынутая карточка после регистрации
ее номера и перед отбором следующей возвращается обратно в карто-
теку. Тогда, очевидно, любая карточка имеет равную со всеми осталь-
ными возможность оказаться вынутой из картотеки и при всех испы-
таниях (тиражах), протекающих при постоянных условиях. Таким
образом, наше поле включает, прежде всего, равновозможные события
£1( Д2, .... Ek, .... Еп,
ЧАСТОСТЬ И ВЕРОЯТНОСТЬ
23
§ 11
где Ек означает появление карточки с номером k. Эти события мы
будем называть элементарными событиями или элементарными
исходами испытания-, множество этих событий мы будем называть
основным множеством данного поля.
Мы можем, далее, рассматривать более сложные события. Пусть
бухты тросов с углом свивки 6, имеют порядковые номера с 1 по 5
и с углом свивки 62 имеют номера 7, 10 и 12. Сложное событие
«появление карточки с номером, меньшим 6» будет наступать при
появлении события Ех или Ег, или Еа, или £\, или Es. Обозначим
его для краткости символом {1, 2, 3, 4,5}. Оно равносильно тому,
что отобранный образец имеет угол свивки 6Г
Точно так же событие {7, 10, 12} будет обозначать, что испы-
тание закончится появлением события £,, или Е1а, или £12. Вообще,
пусть номерами пх <Спг < . . . <.nk, где пх 1 и nk^n, зануме-
рованы бухты тросов, обладающие признаком А (например, угдом
свивки, лежащим в пределах от 6, до 63). Тогда сложное' событие
А{пх, п2, ..., nk} соответствует отбору карточки с одним из
номеров л, или л2, ..., или пк, т. е. тому, что произойдут собы-
тия ЕПу или ЕПг, .... или ЕПк.
Мы видим, что каждому возможному событию Аг нашего поля
отвечает некоторая часть или подмножество элементарных исходов,
из которых как бы «составлено» /г.
Мы будем говорить, что событие А влечет за собой событие В,
или из А следует В, если при наступлении А неизбежно насту-
пает В. Это соотношение обозначают так
А с В. (2.1.1)
Пусть, например, А представляет событие {1, 2, 3, 4, 5, 6},
а В — событие {1, 2, 3, 4, 5, 6, 7, 8, 9}; тогда, очевидно, А а В.
Вообще, если А с В, то элементарные события, составляющие А,
представляют некоторую часть подмножества элементарных собы-
тий В.
Если А с В и одновременно В с. А, то события А и В называют
эквивалентными, что обозначается обычным равенством
А = В. (2.1.2)
Множества элементарных исходов, отвечающих наступлению А
и В, в этом случае совпадают.
Можно сказать, что каждое событие поля представляет «логиче-
скую сумму» некоторых событий из множества (£,, Е2, .... Еп).
Например, событие В {7, 10, 12} можно записать так:
В = Е, + Еха + Ех 2,
здесь знак « + » заменяет союз «или». Событие {1, 2, 3, 4, 5} есть
«сумма» двух событий {1, 2, 3} 4- {4, 5}. Последняя сумма есть
24 СЛУЧАЙНЫЕ СОБЫТИЯ [гл. II
сумма двух несовместимых событий, т. е. таких, которые не могут
произойти вместе (т. е. в одном и том же испытании).
Вообще, сумма
S^A^A^...-^ (2.1.3)
представляет событие, заключающееся в появлении Ai или Д.2, ...,
или А*, или некоторых из них вместе, т. е. в наступлении хотя бы
одного из них. События — члены суммы могут наступать вместе,
т. е. оказываться совместимыми только в тех случаях, когда среди
исходов, составляющих одно из них, есть исходы, одинаковые
с составляющими другие события. Так, например, события {1, 2, 3}
и {3, 4, 5} совместимы: они наступают вместе в тех испытаниях, в
которых вынутая карточка имеет номер 3. Сумма {1, 2, 3, 4, 5}-|-
-1-{7, 10, 12} представляет событие {1, 2, 3, 4, 5, 7, 10, 12}, за-
ключающееся в том, что отобранный образец будет иметь угол
свивки Sj или 32. Мы видим, что сумме событий отвечает подмно-
жество элементарных событий, полученное объединением исходов,
из которых составлены события—«слагаемые», причем каждый
элементарный исход, разумеется, входит в сумму только один раз.
Поэтому, например, сумма {1, 2, 3}-)- {1, 2} будет, при нашем
определении, тождественна событию {1, 2, 3}.
Очевидно, что сумма любых событий поля будет событием
того же поля. В поле всегда входит достоверное событие
(/{1, 2, ..., «}, заключающееся в том, что на вынутой из карто-
теки карточке будет стоять какой-нибудь один из номеров от 1
до п. Невозможное событие будет состоять в том, что появится
карточка с номером, меньшим 1, большим п, или с двумя номе-
рами, или совсем без номера, и т. д., т. е. появится то, что про-
тиворечит самой постановке нашего испытания. Мы будем причис-
лять невозможное событие к событиям нашего поля по формальным
соображениям, обозначая его буквой V. В противоположность другим
событиям именно событию V не благоприятствует ни один из эле-
ментарных исходов (ни один из них не является его «составляю-
щим»); невозможному событию отвечает «пустое» подмножество.
Два события поля А и А называются взаимно-дополнительными
или противоположными, если они несовместимы и в сумме состав-
ляют достоверное событие. Так, например, два события: «появление
номера, равного или меньшего 5» и «появление номера, большего
пяти» — противоположны. По определению
A-\-A = U. (2.1.4)
Таким образом, достоверно, что наступит А или Д (последнее
можно прочесть как «не А»), Появление четного дополняет появле-
ние нечетного номера — эти события также противоположны. Вся-
кий раз, когда указываются два противоположных события, тем
ЧАСТОСТЬ И ВЕРОЯТНОСТЬ
25
самым множество элементарных исходов разбивается на две допол-
няющие друг друга части без общих элементов. Например,
{1,2....л} = {1, 2, 3, 4, 5} 4- {6, 7,...,
где п > 5.
Невозможное событие V противоположно достоверному, т. е.
U-\-V=U. . (2.1.5)
Нам нужно определить еще произведение событий. Под произ-
ведением событий Аь А.2, ..., А* нашего поля мы будем понимать
одновременное или совместное наступление их всех, т. е. наступле-
ние и А(, и А.>, и ..., и А* вместе. Произведение несовместимых
событий (например, противопо-
ложных) есть невозможное
событие.
Произведение событий
А {2, 3, 4, 5, 6} и В {1,2, 4, 7,8}
есть событие С = АВ = {2, 4},
так как А и В наступают вмес-
те тогда и только тогда,
когда наступит или событие
{2}, или {4}. Ясно, что про-
изведение А А —А и т. д.
Событие, дополнительное
к сумме Aj-f-Aj заключается
в том, что не произойдут ни
Ai, ни А.2, т. е. наступят одно-
временно события Aj и Д2.
Таким образом,
А7+А2 = А1А2, (2.1.6)
Рис, о. Графическая интерпретация
поля событий. События: А {1, 4, 7),
В (4, 5, 7, 8}, С {3}, D {8}. События А, С
и D несовместимы. События А и В совме-
стимы. Событие D влечет событие В,
т. е. Вс=В; А-В= {4, 7}; А + В =
= {1,4, 5, 7, 8); B + D = B {4, 5, 7, 8};
B-D — D {8}.
т. е. событие, дополнительное к сумме, равно произведению собы-
тий, дополнительных к слагаемым.
Мы видим, что события поля допускают некоторые операции со
своеобразными алгебраическими правилами сложения и умножения.
Нетрудно ввести понятие разности событий, но мы не будем углуб-
ляться в. эти вопросы.
Операции над событиями можно графически интерпретировать
с помощью рис. 5, на котором некоторое поле, включающее мно-
жество из девяти элементарных занумерованных исходов, изображено
в виде девяти точек, расположенных внутри прямоугольника. Собы-
тию А отвечает подмножество из трех точек за номерами 1, 4 и 7,
событию В — подмножество из четырех точек, имеющих номера 4,
5, 7 и 8, событию С — одна точка за номером 3 и событию D —
26 СЛУЧАЙНЫЕ СОБЫТИЯ [ГЛ. II
точка 8. Эти подмножества мы будем обозначать теми же буквами,
что и соответствующие им события.
Точки 2, 3, 5, 6, 8 и 9, не входящие в множество А, образуют
дополнительное множество А. Событие D влечет за собой событие В,
так как множество D составляет часть множества В. Сложению
событий А и В отвечает объединение точек двух множеств А и В
в одно множество, т. е. сумме А-'-В отвечают точки 1, 4, 5, 7
и 8. Произведению АВ отвечает пересечение этих двух множеств,
т. е. множество, состоящее из точек 4 и 7, принадлежащих одно-
временно А и В.
Поле событий, которое мы рассматриваем, обладает следующими
свойствами:
1. Оно содержит достоверное событие Z7{1, 2, 3, 4, 5, 6, 7 8,9}.
2. Наряду с каждым событием А, В, С и D оно содержит А,
В, С и D.
3. Если поле содержит события А и В, то в поле входят также
события Д-j-B и АВ.
В дальнейшем мы всегда с каждым испытанием будем связывать
поля событий, обладающих указанными тремя свойствами.
Посмотрим еще, сколько всего различных событий содержит
поле, если основное множество состоит из п элементарных событий.
Если л = 3, то эти события легко перечислить:
1. «Одноточечные» события: {1}, {2}, {3} — всего три события —
их число равно числу сочетаний из трех элементов по одному
в каждом, т. е. С'3.
2. «Двухточечные» события: {1, 2}, {1, 3} и {2, 3}, т. е. их
будет С,,— также три события.
3. «Трехточечные» события: {1, 2, 3}, т. е. С3,— одно досто-
верное событие.
4. Невозможное событие одно, т. е. С,— 1.
Таким образом, в этом случае поле содержит восемь событий.
При произвольном п поле содержит следующее число событий:
1 ... +Ckn + ... + С" = (1-j-1)" = 2", (2.1.7)
где Сп обозначает число сочетаний из п элементов по k элементов
(k — 1, 2, ... , п).
2.1.2. Частость и вероятность. Рассмотрим серию из N испы-
таний, произведенных в одних и тех же условиях. Допустим, что
нас интересует определенное событие А поля испытания. Если
в нашей серии испытаний событие А произошло k^(A) раз, то от-
ношение
^=W„(4) (2.1.8)
числа появлений события А к общему числу произведенных йены-
ЧАСТОСТЬ И ВЕРОЯТНОСТЬ
27
§ п
таний данной серии, как уже говорилось в главе 1, называется
частостью WJV(X) в данном случае события А в этой серии испы-
таний. Частость иногда называют еще относительной частотой.
Очевидно, что
0^VJN(A)^\. (2.1.9)
Если событие А невозможно, т. е. A=V, то в любой серии
произведенных испытаний мы, естественно, будем иметь kN(A) = 0
и W7V(24)==O; если же событие А достоверно, то всегда будет
kN(A) = N и WJV(»)=1.
Обратные заключения по равенству W.v(4) —О о невозможности
события А или по равенству WN(A)—l о достоверности события,
вообще говоря, несправедливы. Если серия испытаний уже произве-
дена-, то определение частости WN{A) события сводится к простому
подсчету отношения (2.1.8).
Это отношение представляет пример случайной величины: его
значение зависит от случайных обстоятельств, сопутствующих нашему
испытанию; если невелико, то частость может сильно изме-
ниться, когда мы вновь повторим нашу серию из N испытаний.
Однако в весьма обширном и важном классе случаев в длинных
повторных сериях испытаний частость события А обнаруживает
устойчивость, т. е. редко сколько-нибудь значительно отклоняется
от некоторого постоянного числа.
Это положительное число, меньшее единицы, представляет собой
как бы количественную меру возможности реализации случайного
события А в испытании и называется его вероятностью.
Пусть, например, наша задача состоит в том, чтобы в обширной
партии изделий оценить долю изделий, обладающих признаком А
(таким признаком может быть пониженное качество, размерный
признак изделия и т. п.). Сплошная проверка партии часто бывает
слишком трудоемкой, а в тех случаях, когда проверка связана
с порчей изделия,— просто невыполнимой. Поэтому в подобных
случаях производят выборку, аналогичную описанной выше на при-
мере с бухтами стальных канатов. По доле изделий с признаком А
в выборке судят о доле их во всей партии.
Если выборка не многочисленна, то частость WN(A) еще мало
показательна: например, среди пяти отобранных изделий случайно
может оказаться 0, 1, 2, 3, 4 и даже 5 изделий с признаком А.
Повторяя выборку малого объема много раз, мы будем получать
сильно отличающиеся друг от друга частости >Nn(A), они обнаружат
значительный «разброс» значений или рассеивание. С ростом объема N
выборки этот разброс частостей не исчезает, но становится все
меньше и меньше, что указывает на возрастание устойчивости
частостей, которые при этом все более и более приближаются
к доле признака А во всей обследуемой партии.
28
СЛУЧАЙНЫЕ СОБЫТИЯ
[ГЛ. 11
Это обстоятельство интуитивно довольно очевидно. Пусть мы
производим очень большую выборку объема W (с возвращением)
из совокупности S изделий. Ввиду полной равноправности изделий
каждое из них должно появиться в большой выборке примерно
одинаково часто. Если некоторые изделия появлялись бы значительно
чаще, чем другие, то это противоречило бы принципу случайности
отбора, которым всегда при подобных обстоятельствах руковод-
ствуются на практике.
Поэтому можно считать, что каждое изделие при отборе появится
примерно у раз. И если число изделий с признаком А равно а, то
в выоорке они появятся kN(Л) «у раз и потому
----~у,
где -|г—доля изделий с признаком А во всей совокупности 5 изде-
лий. Доля признака в партии и будет в данном примере совпадать
с вероятностью появления события А в отдельном испытании.
Картину уменьшения разброса и роста устойчивости частостей
можно проиллюстрировать на следующем примере, относящемся
к выборкам из одной и той же партии численностью в 700 штук
промышленных изделий, доля дефектных изделий в которой соста-
вляла 0,06 или 6°/0. Из этой партии было произведено по 10 вы-
борок объемов Лг.шт., М=50 шт. и ^=500 шт. Результаты
произведенных испытаний приводятся в таблице 2.1.1.
Таблица 2.1.1
Проценты дефектных изделий в выборках разного
объема (N — 5, 50 и 500 шт.) из одной и той же
партии промышленных изделий, содержащей
6% дефектных изделий
№ вы- борок Число дефектных изделий в выборке объема % дефектных изделий в выборке объема
N — 5 W = 50 А = 500 <V = 5 ,V = 50 А = 500
1 2 ' 3 4 5 6 7 8 9 10 0 0 0 0 1 1 0 0 0 0 4 3 2 2 1 3 2 2 2 1 32 31 29 31 29 33 34 32 27 29 0 0 0 0 20 20 0 0 0 0 8 6 4 4 2 6 4 4 4 2 6,4 6,2 5,8 6,2 5,8 6,6 6,8 6,4 5,4 5,8
§ 1] ЧАСТОСТЬ И ВЕРОЯТНОСТЬ 29
В первом столбце этой таблицы проставлены порядковые номера
выборок в следующих трех столбцах—число дефектных изделий,
обнаруженных в выборках, и в последних трех столбцах — соответ-
ствующие процентные доли дефектных изделий в выборках (равные
частостям появления дефекта, умноженным на 100).
В десяти выборках объема 5 процент обнаруженных дефект-
ных изделий варьирует от 0 до 2О°/о; в десяти выборках объема
*
• »
1--1---1--1--11--------1--1---1-L __
0 г 4 6 8 к 12 14 16 18 20 %
N~50 •
• • •
• е • •
। - 1 । । । ! i ! ;. I
o 2 4 6 8 W 12 14 16 18 20 %
N=500
i i i iii it i ~i
0 2 i 6 8 10 12 14 16) 18 20%
Рис. 6. Разброс процентных долей дефектных изделий
в выборках различного объема (N = 5; 50; 500).
Л/= 50 вариация этого признака наблюдалась от 2 до 8°/0, а в де-
сяти выборках объема ;V=500 она происходила в пределах
5,4—6,8°/0. На рис. 6 рельефно изображена картина разброса про-
центных долей дефектных изделий в выборках различного объема.
Каждой выборке на этом чертеже отвечает точка, расположенная
на шкале процентных долей в месте, соответствующем проценту
дефектных изделий в этой выборке.
Мы видим, что в больших выборках частости дефектных изделий
тесно группируются около вероятности, равной 0,06 (— 6°/0), кото-
рой и отвечает доля дефектных изделий во всей партии.
Вероятность появления события А обозначается обычно симво-
лом Р(Л). Она выражает вполне определенную, хотя и своеобразную
связь между постоянным комплексом условий и случайным собы-
тием А в поле испытаний, количественно характеризуя диалекти-
30
СЛУЧАЙНЫЕ СОБЫТИЯ
[ГЛ. II
ческое единство необходимого и случайного. В теории вероятностей
рассматривают абстрактные модели подобного рода реальных испы-
таний; вероятность понимается как идеальная мера возможности
появления событий, распределенная между всеми событиями поля;
чем ббльшая вероятностная мера приходится на данное событие, тем
больше возможность его появления в рассматриваемом испытании.
Но конкретный смысл вероятности заключается как раз в том,
что она определяет среднюю частость, с которой можно ожидать
появления события А в длинных сериях испытаний.
Благодаря устойчивости и близости частости VJN(A), полученной
из длинной серии испытаний, к вероятности Р(Л) частость может
служить приближенной оценкой вероятности, тем более точной, чем
больше число испытаний в серии. В свою очередь знание вероят-
ности наступления события А позволяет предсказывать с той или
иной точностью и надежностью его частости в предстоящих испы-
таниях, по крайней мере при больших N. Очень часто мы встре-
чаемся на практике с таким положением, когда оценивать непосред-
ственно вероятности интересующих нас событий крайне затрудни-
тельно, а иногда даже невозможно, но мы вместе с тем распола-
гаем данными о вероятностях других, обычно простейших событий
того же поля. Задача теории вероятностей как раз и заключается
в том, чтобы, зная вероятности некоторых простейших событий,
полученные из опыта или теоретических допущений относительно
природы данного процесса, получить путем анализа и вычислений
вероятности интересующих нас сложных событий, а значит, тем
самым иметь возможность предсказывать частости этих событий при
массовом производстве испытаний.
2.1.3. Основные аксиомы теории вероятностей. Из того, что
частости в больших сериях испытаний, стабилизируясь, приближенно
воспроизводят вероятности, следует, что вероятности должны во
всяком случае удовлетворять таким же формальным требованиям,
каким естественным образом удовлетворяют частости событий. Эти
требования формулируются в виде трех аксиом.
Аксиома I. С каждым событием А данного поля испытаний
связывается число РИ), называемое вероятностью и удовлетво-
ряющее условию
0<Р(А)^1. (2.1.10)
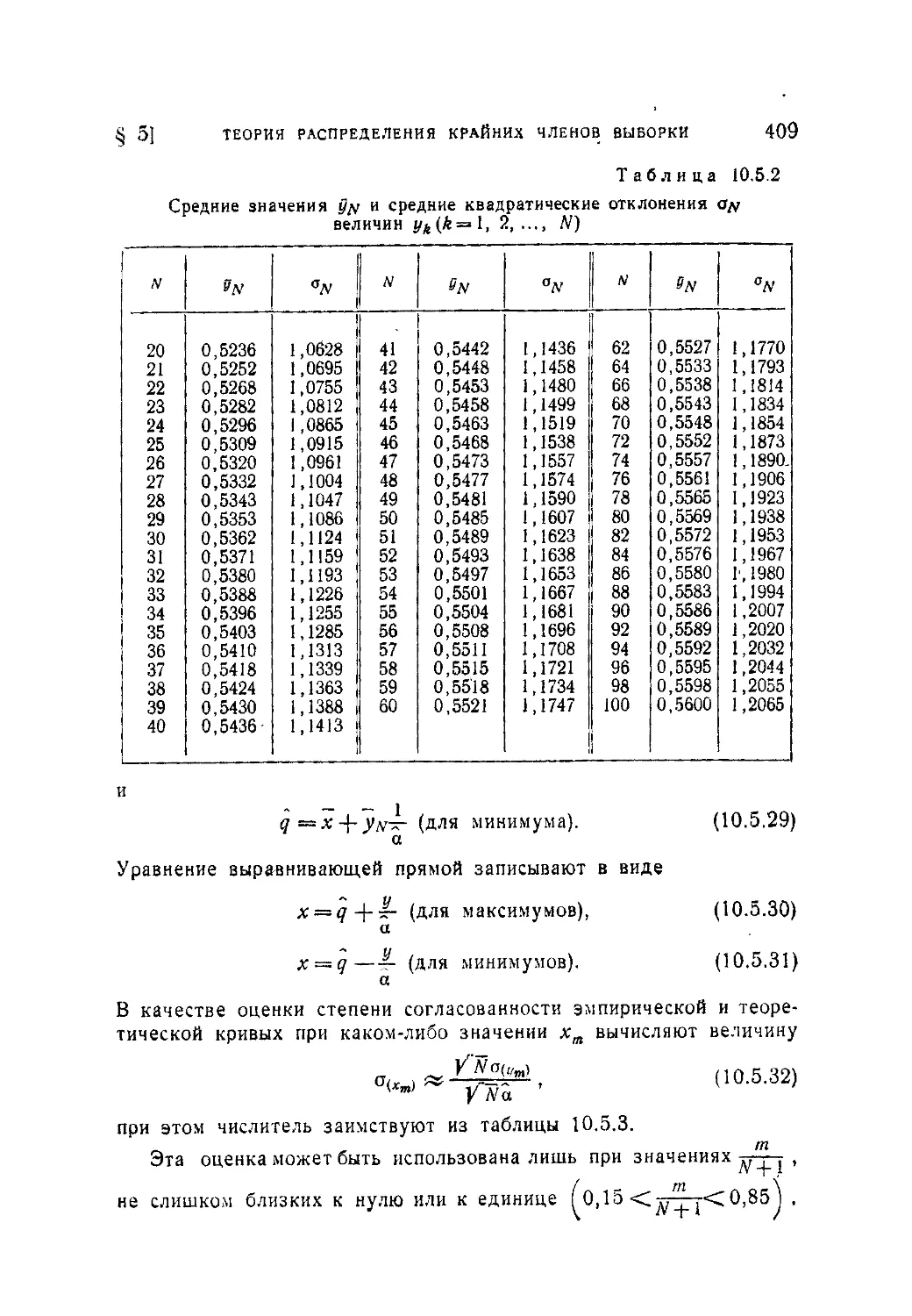
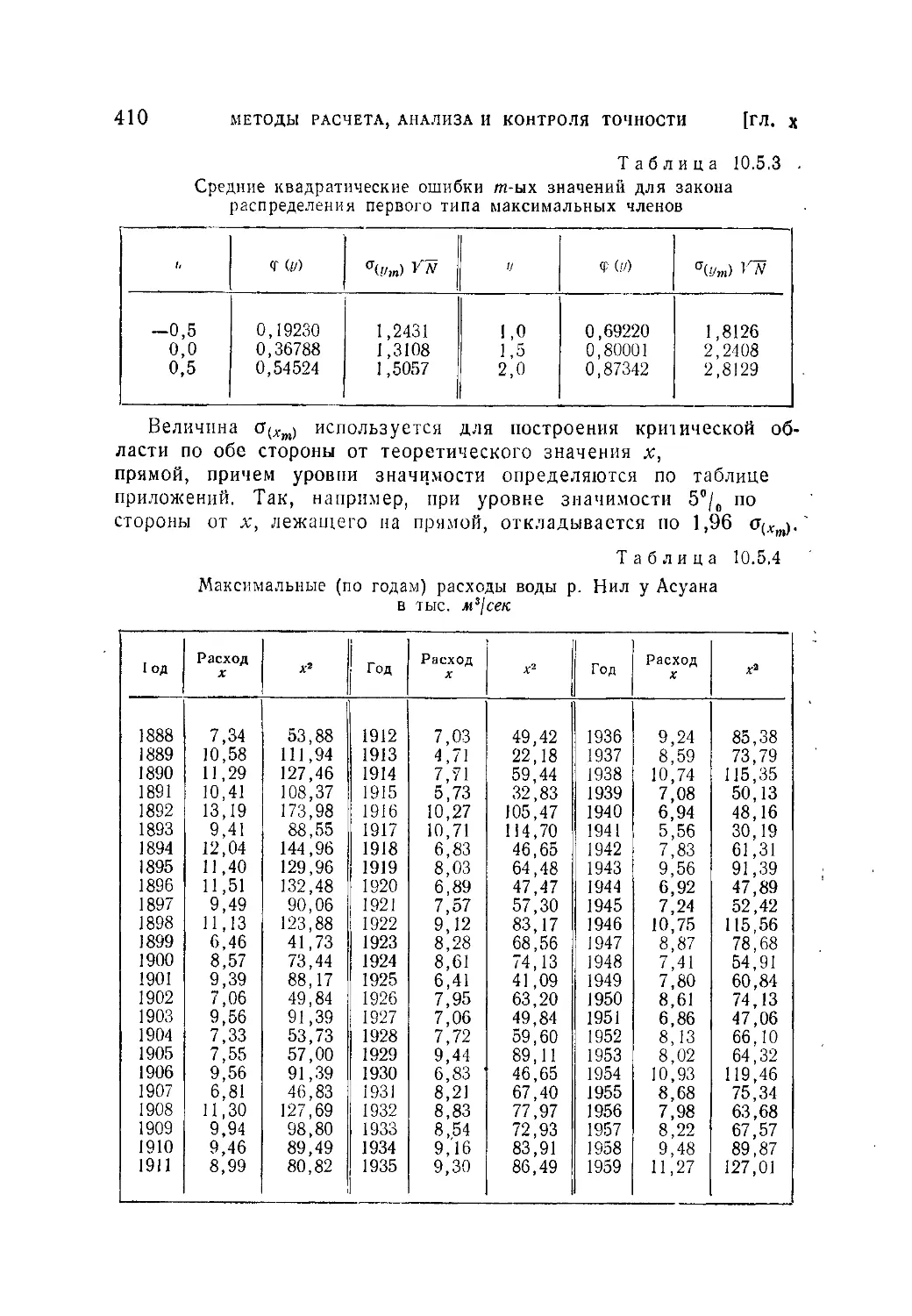
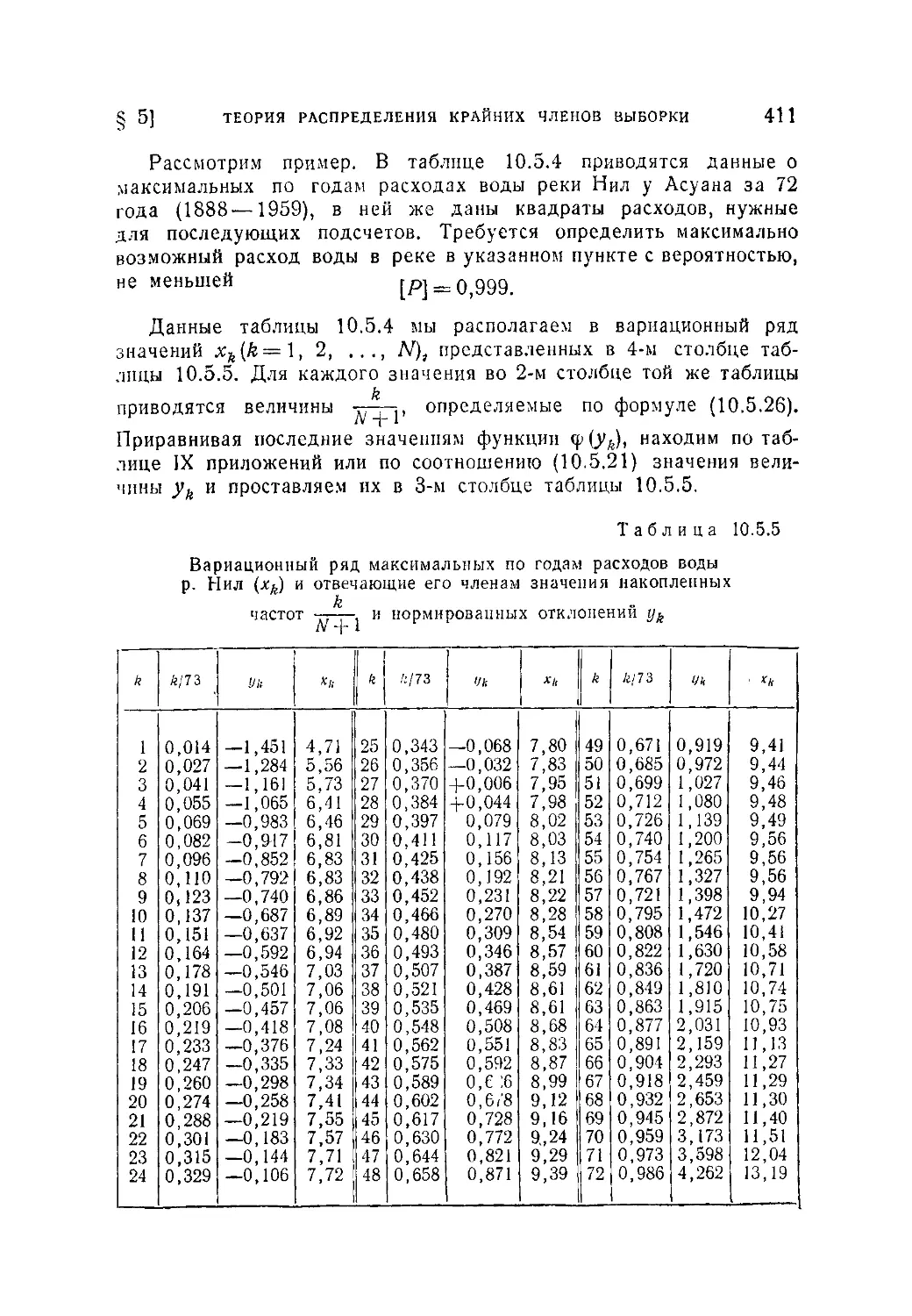
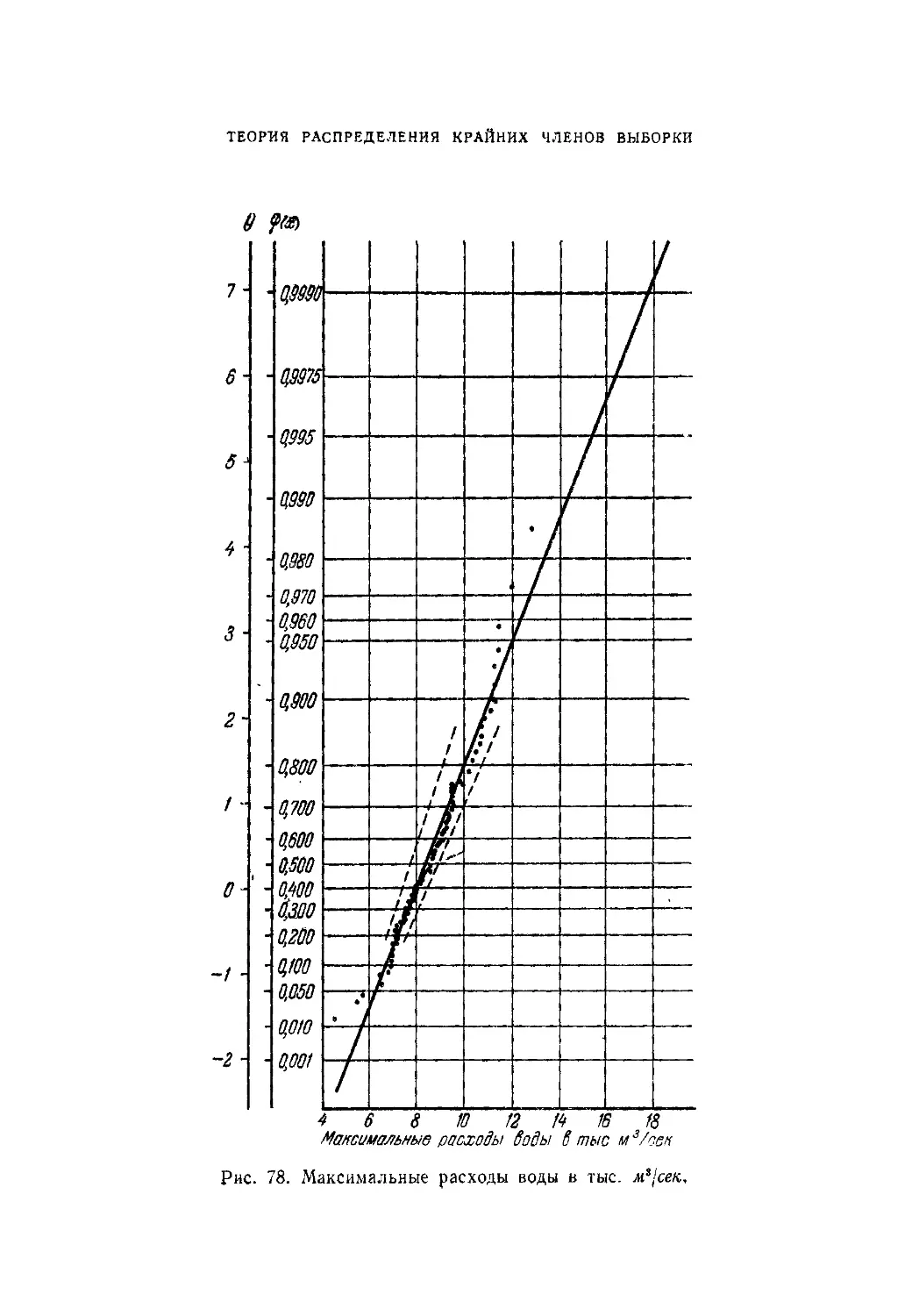
Аналогичное требование (2.1.9) для частости выполняется всегда
очевидным образом.
Аксиома И. Вероятность достоверного события поля
равна единице, так что
Р(Ц)=1- (2.1.11)
И это требование отвечает очевидному свойству частости досто-
верного события.
§ 1] ЧАСТОСТЬ И ВЕРОЯТНОСТЬ 31
Аксиома III. Если событие S поля подразделяется на не-
совместимые события Av А2, Ат того же поля, т. е. пред-
ставляет собой сумму этих событий, так что
5=а1 + а2+...+аю « V
при любых i и j Ц, /=1, 2, т), то
Р(5 = А,+Д24- ... +AJ = P(AJ+P(A2)+ .. . + P(AJ, (2.1.12)
т. е., иными словами, вероятность суммы несовместимых собы-
тий поля равна сумме их вероятностей.
В этом случае говорят еще, что событие 5 подразделяется на т
несовместимых видов, так как наступление события S согласно
(2.1.3) может осуществиться или в виде А,, или в виде А2, ..., или
в виде Ат (и ни в каком другом виде осуществиться не может).
Эта аксиома называется еще правилом сложения вероятностей
несовместимых событий.
Легко заметить, что и этому требованию естественным образом
удовлетворяют частости. В самом деле, пусть частости несовмести-
мых событий Ар А2, ..., Ат поля в длинной серии испытаний будут
WAr(A1) = ^-), Wa,(A2)=^A^, .... Wjv(AJ = ^l,
где обозначения аналогичны обозначениям в (2.1.8).
Из несовместимости рассматриваемых событий следует, что
в числе N произведенных испытаний нашей серии нет таких испы-
таний, в которых какие-либо два события А,- и Aj появились вместе.
Поэтому событие S в нашем случае появилось всего ft(A)-f-
+ k (А2) + ... 4 &(Am) раз (из них fe(AJ раз в виде А,, й(А2) раз
в виде А2, и т. д.), следовательно, частость события составляет:
иг _^ (^)4-fe (Аг)+• • • 4-МАя)
Идгр)-------------~-----------—
= W^A.) -Ь WjV(A2) 4-... + W^(AJ, (2.1.13)
т. е. равна сумме частостей всех несовместимых видов этого события.
Таким образом, мы видим, что и правило сложения вероятностей
отвечает очевидному свойству частостей несовместимых событий.
Если некоторые два события А, и А2 не являются несовмести-
мыми, то
Р(А,+А2)У=Р(А1)+Р(А2),
и мы увидим далее, что
Р(А14-А±)<Р(А,)-|-Р(А1); (2.1.14)
так, например, если мы производим выборку из партии валиков,
среди которых имеются овальные (признак AJ и конусные (при-
знак Аг) валики, то событие A2-j-A2 будет заключаться в отборе
32 СЛУЧАЙНЫЕ СОБЫТИЯ [гл. и
валика, дефектного по какому-либо из этих двух признаков, ио так
как возможно, что отобранный валик будет одновременно оваль-
ным и конусным, то события Aj и As совместимы, и мы можем на-
писать лишь неравенство (2.1.14).
Пусть события Alt Ait ..., As нашего поля несовместимы между
собой и в сумме составляют достоверное событие того же поля, т. е.
Ai а2 -[- • • • 4" As — та
Это значит, что одно из них, и только одно, неизбежно появляется
в каждом испытании. Мы будем говорить тогда, что события Аь
А.2, .... As образуют полную группу событий. Так как события Аг
несовместимы, то по правилу сложения
P(a14-a2+...4-As)=p(a,) + P(A2)-h...4-P(As);
с другой стороны,
р (At 4~ ^2 • • • 4~ As)= 1 >
поэтому
P(Aj) + P(A2)-4-... + P(As)=1, (2.1.15)
т. е. сумма вероятностей несовместимых событий, составляю-
щих полную группу, равна единице.
В частности, для противоположных событий А и А, которые по
определению удовлетворяют равенству (2.1.4), будем на основании
(2.1.15) иметь:
Р(А)4-Р(А)=1, (2.1.16)
т. е. вероятность противоположного события дополняет вероят-
ность данного события поля до единицы. Заметим, что событие U,
противоположное достоверному событию U, будет представлять не-
возможное событие V, т. е.
77= V,
и, следовательно,
P(t/)4-P(i/)=i,
но по второй аксиоме P(t7)= 1 и потому
P(V) = 0, (2.1.17)
т. е. вероятность невозможного события равна нулю.
Предположим, что каждое событие поля рассматриваемого нами
испытания может быть представлено как сумма некоторых элемен-
тарных событий Ei (из основного множества £'ь Ег, ..., Еп), как
это было в примере с выборкой образцов из п бухт стальных тро-
сов. Элементарные события Е-, несовместимы и образуют полную
группу Et 4- Ei 4-... — Еп = U.
ЧАСТОСТЬ И ВЕРОЯТНОСТЬ
33
§ 11
Если известны вероятности Р(Е{) при каждом Z, то мы можем
вычислить любые вероятности нашего поля по правилу сложения.
В самом деле, если событие А «составлено» из k элементарных
событий Е/,, Ei2, Eik, так что А = Е1х 4- Eti 4~ • . 4~ Eilc, где
Z,, Z8, .... ik—некоторая группа из k чисел, взятых из множества
(1, 2.....«), то согласно правилу сложения (2.1.12)
Р (Л) = Р (Elt) 4- Р (EJ 4-... 4- Р (Eik). (2.1.18)
Таким образом, вероятность каждого события поля есть сумма
вероятностей элементарных событий, составляющих данное
событие. В частности
Р (Е) = Р (Е,) 4- Р (Ег) 4-... 4- Р (£„)== 1. (2.1.19)
Если событие А влечет за собой событие В, то, как мы видели,
это означает, что все элементарные события Е{, «составляющие»
событие А, входят также в состав события В, но кроме них в со-
став В могут входить и другие события Еу, не относящиеся к со-
ставу события А. Легко понять теперь, приняв во внимание (2.1.18),
что вероятность события А при этом всегда не больше вероятности
события В. Значит, если А с В, то
Р(Л)<Р(В). (2.1.20)
Предположим теперь, что мы рассматриваем такое испытание,
в котором элементарные исходы Еи Е2, ..., Е„ по самой постановке
опыта совершенно равноправны и, следовательно, должны быть
равновероятны. Во всех искусственных опытах, с изучения кото-
рых исторически развивалось исчисление вероятностей, и в примере
с выборкой карточки из картотеки дело обстояло именно так. Здесь
можно наметить такую полную группу равновероятных (или, как
еще всегда говорят, равновозможных) элементарных событий, что
любое событие поля можно представить как сумму некоторых собы-
тий из этой полной группы. При этих условиях
Р(Е,) = Р(Е2)= ... =Р(Еп)=р.
Но так как согласно (2.1.19)
2 Р(Е1.) = лр=1,
t=i
1
то р — — , т. е.
‘ п ’
Р (ЕЛ = —.
' " п
Если событие А может быть представлено как сумма т соста-
вляющих его элементарных событий Ег, например, если
Л = Е/14-ЕГа4-...+^и, (2-1.21)
2 Н. В. Смирнов, И. В. Дунин-Барковский
34
СЛУЧАЙНЫЕ СОБЫТИЯ
[гл. II
Рис. 7. Поле допуска валика, подразде-
ленное на четыре равных групповых
поля допуска. rfHM и rf„6— наименьший
и наибольший предельные размеры вала
соответственно, 8В—допуск вала, 6,, 8 ц,
8П1 и 8V1—групповые допуски.
то согласно (2.1.18)
Р(А) = Р(£г1) + Р(Е/2)+ ... +Р(£/т) = ОТ1 = ^. (2.1.22)-
Мы рришли к так называемому классическому определению
вероятности, которое обычно читается так: вероятность события А
есть отношение числа т благоприятствующих этому событию
исходов к общему числу п всех
возможных элементарных
несовместимых и равновоз-
можных исходов испытания.
Следует отметить, что это
определение, годное, правда,
в ограниченных условиях,
согласуется со статистическим
подходом к приближенному
определению вероятности при
помощи подсчета частости.
Оно позволяет предвидеть
(по крайней мере интуитивно)
устойчивость частостей при
многократных испытаниях.
В самом деле, предположение
о равновозможности элемен-
тарных событий (исходов) следует понимать так, что при многократ-
ном повторении испытания каждое из них встретится примерно
одинаковое число раз.
Отсюда, повторяя рассуждения, которыми мы пользовались
в выборке большого объема 5 (с возвращением), найдем, что частость
г- X 1
каждого элементарного исхода Ek будет равна примерно —, а частость
события А (см. (2.1.21)) будет приближенно равна Значит, для
частости события А будем иметь:
w(A)^~ = ”=pG4). (2.1.23)
Различные искусственные эксперименты подтверждают это при-
ближенное равенство.
В ’дальнейшем мы будем встречаться с полями, содержащими
бесконечное множество событий. В этом случае мы можем встре-
титься с событием S, которое может быть представлено как сумма
бесконечной последовательности А), Е.2, ..., Еп несовместимых
событий нашего поля. Мы будем и в этом случае предполагать,
что выполняется правило сложения;
ЧАСТОСТЬ И ВЕРОЯТНОСТЬ
35
Аксиома ПГ.
p(S)sP(£1 + £1+ ... ...) =
= Р (£04- Р (£2)+ ... 4-р(£„)4- ..., (2.1.24)
где бесконечный ряд в правой части сходится.
Рассмотрим примеры.
Пусть допуск диаметра валика подразделен на четыре равных
групповых допуска (на рис. 7 дано осевое сечение валика). В сбо-
рочном цехе имеется партия валиков численностью в 100 штук, из
которых 15 штук с разме-
рами в пределах первой
группы (BJ, 40 штук — в
пределах - второй группы
(В2), 30 штук — в пределах
третьей группы (В3) и 1о
штук — в пределах четвер-
той группы (В4) (рис. 8).
Сборщик из партии ва-
ликов вынимает наугад один
валик.
Полная группа событий
в условиях данной задачи
состоит из 100 несовмести-
мых и равновозможных исхо-
дов потому, что по условию
при испытании сборщик вынимает наугад один валик, тем самым
один из 100 валиков будет обязательно вынут, при этом вынутым
валиком может оказаться (в равной мере) любой из 100 валиков.
Событие £?1 составлено из 15 элементарных равновозможных
событий этой полной группы, так как в партии имеется 15 штук
валиков с размерами в пределах допуска первой группы, и если
сборщик вынет один из этих 15 валиков, то событие В\ наступит.
Если бы 100 валиков были пронумерованы в порядке возраста-
ния их размеров так: В), В2, ..., £100, то к первой группе по
размерам относились бы валики Е* .... Ец> т. е. событие В\
подразделялось бы на 15 несовместимых видов так, что
В\ — е^ 4- 4-... в)8.
Но поскольку все 100 элементарных исходов равновозможны, то
вероятность события Bj равна
₽(/?.)= 1^ = 0,15.
Аналогично могут быть найдены вероятности
1'0°0-0,4, Р(74)-Х-0,3 и Р(В4)=^ = 0,13.
2*
36
СЛУЧАЙНЫЕ СОБЫТИЯ
[гл. И
Невозможное событие V в данном случае заключается в том, что
вынутая из партии наугад деталь окажется по своему размеру не
относящейся ни к одной из четырех групп. Так как таких деталей
в партии нет, то событие V не может произойти ни при одном
испытании: _______
В1В2з3в4=к,
тогда как
Bi В% В3 -j- В4 = и.
Событие Si, противоположное событию Blt заключается в том, что
вынутая из партии деталь окажется не принадлежащей по своим раз-
мерам к первой группе, т. е. она будет принадлежать ко второй,
третьей или четвертой группе:
+ +
по определению
Р(В1) = ^0 = 0Ж
Точно так же
Р(В2) = ^ = 0,60.
События Bi и В2 совместимы, так как если вынутая деталь ока-
жется принадлежащей к третьей или четвертой группе, то оба они
наступят одновременно.
Отсюда следует, что событие В3-]-В4 влечет за собой как собы-
тие Bi, так и событие В.2, т. е.
и Вз4-В4СЯ,;
мы видим, что
Р (Вз + В4) = 0,45 < Р (ВО = 0,85
и
Р (В3 + В4) = 0,45 < Р (В2) = 0,60.
2.1.4. Задача о безвозвратной выборке. Случайные числа.
В качестве другого примера на вычисление вероятности, пользуясь
классическим определением, рассмотрим задачу о выборке без воз-
вращения, когда каждый из отобранных предметов не возвращается
обратно перед очередным отбором.
Пусть каждый из N объектов некоторой совокупности обладает
одним из двух признаков А или А, причем признаком А обладают М
объектов и, следовательно, признаком А обладают N — М объектов.
Число М и доля М объектов, обладающих признаком А, неизве-
стны. Для того чтобы приближенно оценить эту долю, отбираем
§ ]] ЧАСТОСТЬ И ВЕРОЯТНОСТЬ 37
группу из п объектов и определяем число т объектов, обладающих
признаком А в выборке. В дальнейшем мы покажем, что при неко-
торых условиях отношение будет почти наверное приближенно
равно интересующей нас доле Посмотрим, какова вероятность
получить в выборке из п объектов в точности т объектов с при-
знаком А. Будем различать между собой отдельные объекты сово-
купности, например, пронумеровав их в некотором порядке. Множе-
ство возможных элементарных исходов данного испытания (т. е,
выборки) будет представлять совокупность различных групп
по п номеров из числа 1, 2, ..., N. Отдельные группы будут
различаться хотя бы одним номером, порядок же номеров в группе
не существен. Таким образом, каждая такая группа будет пред-
ставлять одно из CnN сочетаний из W номеров по п.
Число всех сочетаний по т объектов, обладающих признаком А,
равно См, а число сочетаний по п — т объектов, обладающих при-
знаком А, равно С^-м-
Так как все сочетания по п объектов, представляющие благо-
приятные комбинации, мы получим, комбинируя каждое из См соче-
таний первого типа с каждым из CyZ™ сочетаний второго, то об-
щее число всех благоприятных комбинаций п отобранных объектов
будет, следовательно, равно произведению
На основании классического определения интересующая нас ве-
роятность РЛ,Л1 (п, х) того, что в выборке из п объектов окажется х
объектов с признаком А, окончательно будет равна
рх X
= — (2.1.25)
сл/
Этой формуле можно придать еще вид
РЛЛ1 (Л> х) = х! (п-х)1 х
v Л1 (/И — 1)...(Л1— х-(-1) (2V —М) (Af— М — — М—(п— Х) + Ц
Х N(N— l)...(N-n+V) ~~
nl Ml(N—M)l(N—n)l /0 , ос.
“ xl(n-x)i(M-х)! [N-M — (n—х)] ! ЛИ ‘ '
В частности, вероятность не получить в выборке ни одного пред-
мета с признаком А получится из (2.1.25) при х = 0 в виде
О А. (Д' —Л1) (Л7—/И — 1).. .(/V—М—n-|-1)
Д'Л1(Л, и)— .(дг—n + D
38
СЛУЧАЙНЫЕ СОБЫТИЯ
[гл. II
На основании полученных формул рассчитывается наиболее
выгодный с точки зрения трудоемкости и надежности вариант
выборки в смысле ее объема п и объема W проверяемой
партии предметов при заданной Рл-уИ(л,х) и предполагаемых зна-
чениях М.
Так, например, вероятность того, что в выборке из трех штук,
отбираемых из 100 предметов, окажется один предмет с признаком А
(например, дефектная дёталь), если среди общего числа предметов
будет 30 предметов, обладающих этим признаком, согласно (2.1.25)
равна
Р /я п— 30'70'69-3 _ о
Pm, .о<3> 1) = -7Г-= ЮО-99-98 = 0>448-
100
Следует подчеркнуть, что понятие случайной выборки является
основным в математической статистике. Но не всякий отбор наудачу
дает выборку в том смысле, как это мы условились понимать выше.
Мы можем, например, отобрать ряд чисел, взятых наудачу, но не
осуществить при этом случайный отбор элементов в данной сово-
купности потому, что, как показывает опыт, мы склонны бессозна-
тельно оказывать предпочтение одним числам перед другими, напри-
мер четным перед нечетными или малым по сравнению с большими
и т. д.
Случайность выборки, гарантирующая полную беспристрастность
отбора, должна проявляться, прежде всего, в невозможности по по-
лученным в выборке номерам строить какой-либо прогноз в отно-
шении следующих отбираемых номеров.
Выборка с возвращением будет случайной лишь при том условии,
что каждый элемент рассматриваемой совокупности имеет равную
со всеми остальными элементами вероятность оказаться в выборке
при каждом очередном отборе.
Несмотря на кажущуюся простоту этих интуитивно очевидных
требований, предъявляемых к выборке, их осуществление на прак-
тике оказывается не таким уж простым.
В настоящее время случайный отбор осуществляется обыч-
но при помощи специальных таблиц так называемых «случайных
чисел». »
В таблице 2.1.2 приводится выдержка из «Таблицы случайных
чисел» М. Кадырова, Ташкент, изд. САГУ, 1936, стр. 4 (верхняя
половина страницы). Четырехзначные числа в этой таблице сгруп-
пированы в группы по пять чисел, расположенных столбиком,
причем таких столбиков в каждом столбце страницы содержится
десять и столбцов на странице также десять. Таким образом, на
каждой странице помещается 5x 10x10 = 500 четырехзначных чи-
сел. Способ составления этих таблиц гарантирует равновероятность
S II
ЧАСТОСТЬ И ВЕРОЯТНОСТЬ
39
Таблица 2.1.2
Таблица случайных чисел
3393 6270 4228 6069 9407 1865 8549 3217 2351 8410
9108 2330 2157 7416 0398 6173 1703 8132 9065 6717
7891 3590 2502 5945 3402 0491 4328 2365 6175 7695
9085 6307 6910 9174 1753 1797 9229 3422 9861 8357
2638 2908 6368 0398 5495 3283 0031 5955 6544 3883
1313 8338 0623 8600 4950 5414 7131 0134 7241 0651
3897 4202 3814 3505 1599 1649 2784 1994 5775 1406
4380 9543 1646 2850 8415 9120 8062 2421 6161 4634
1618 6309 7909 0874 0401 4301 4517 9197 3350 0434
4858 4676 7363 9141 6133 0549 1972 3461 7116 1496
5354 9142 0847 5393 5416 6505 7156 5634 9703 6221
0905 6986 9396 3975 9255 0537 2479 4589 0562 5345
1420 0470 8679 2328 3939 1292 0406 5428 3789 2882
3218 9080 6604 1813 8209 7039 2086 3369 4437 3798
9697 8431 4387 0622 6893 8788 2320 9358 5904 9539
0912 4964 0502 9683 4636 2861 2876 1273 7870 2030
4636 7072 4868 0601 3894 7182 8417 2367 7032 1003
2515 4734 9878 6761 5636 2949 3979 8650 3430 0635
5964 0412 5012 2369 6461 0678 3693 2928 3740 8047
7848 1523 7904 1521 1455 7089 8094 9872 0898 7174
5192 2571 3643 0707 3434 6818 5729 8614 4298 4129
8438 8325 9886 1805 0226 2310 3675 5058 2515 2388
8166 6349 0319 5436 6838 2460 6433 0644 7428 8556
9158 8263 6504 2562 1160 1526 1816 9690 1215 9590
6061 3525 4048 0382 4224 7148 8259 6526 5340 4064
цифр 0, 1,2, 3, 4, 5, 6, 7, 8, 9 на каждом месте каждого четы-
рехзначного числа таблицы ’).
Рассмотрим пример использования этой таблицы. Пусть совокуп-
ность состоит из 543 элементов (объектов) и нам нужно отобрать
из нее случайную выборку с возвращением из 12 элементов. Прежде
всего мы должны пронумеровать все объекты нашей совокупности,
начиная с номера ООО и кончая номером 542. Затем мы используем
таблицу случайных чисел. Откроем наугад страницу и выберем на ней
наугад столбец, а в нем, также наугад, число, три первых знака ко-
торого составят номер первого объекта, попавшего в совокупность. Ос-
тальные 11 номеров объектов мы возьмем, следуя какому-нибудь опре-
деленному заранее установленному правилу, например: 1) подряд
’) Таблица М. Кадырова на самом деле не удовлетворяет условию
Равновероятности, что можно обнаружить путем довольно кропотливого
статистического исследования (см. Л. М. Большее, О случайных числах
Кадырова, Теория вероятности и ее применения 9:1 (1964).
40
СЛУЧАЙНЫЕ СОБЫТИЯ
[ГЛ. П
вниз по столбцу, 2) подряд вверх по столбцу, 3) подряд вправо по
столбцам, 4) подряд влево по столбцам и т. д. Любое из этих правил
дает нужный результат. Пусть мы взяли число 2157, второе
сверху в первом столбике третьего столбца, решив применить первое
правило. Тогда мы получим выборку из следующих номеров: 215, 250,
062, 381, 164, 084, 438, 050, 486, 501, 364, 031. Идя подряд сверху
по столбцу, мы пропускали числа, первые три знака которых дают чис-
ло, большее 542. Отобранные нами 12 номеров позволяют взять 12 объ-
ектов из нашей совокупности, имеющих те же порядковые номера.
Если нужно отобрать выборку без возвращения, то мы пропу-
скаем также числа, дающие номера, уже попавшие в выборку. В на-
шем примере совпавших номеров нет, а потому в этом частном
случае выборка с возвращением и выборка без возвращения содер-
жали бы одни и те же объекты.
§ 2. Условные вероятности
2.2.1. Понятие условной вероятности. Как мы неоднократно
подчеркивали, вероятность события связана с условиями испытания
и, как правило, меняет свою величину как только изменяются эти
условия. Так, например, вероятность получения размерного брака
при изготовлении деталей, естественно, изменяется с изменением в той
или иной части технологического процесса (станок, инструменты,
приспособления и т. п.).
Рассмотрим испытание, возможными исходами которого являются
события А, А, В и В с вероятностями соответственно Р(Л), Р(Л),
Р (В) и Р(В), причем события А и В противоположны событиям А
и В. На основании определения вероятности можно рассчитывать,
что в длинной серии из N испытаний частости этих событий ока-
жутся приближенно равными их вероятностям, какова бы ни была
зависимость событий А и Вдруг от друга. Но если мы теперь будем
рассматривать какие-либо определенные испытания нашей серии: напри-
мер, только те из них, в которых произошло событие А, или те,
в которых оно не произошло (иначе говоря, произошло событие Д),—
то частость события В может оказаться в рассматриваемой части
нашей серии совсем не такой по величине, какой она оказалась
во всей серии из W испытаний; это будет связано с характером за-
висимости событий А п В друг от друга. Если событие В является
следствием события А (т. е. .4 с В), то при подсчете частости собы-
тия В по той части серии, в которой событие А появилось, мы
всегда получим значение, равное единице. Если событие А исклю-
чает появление события В, то при аналогичном подсчете мы получим
частость события В, равную нулю. В общем случае мы должны раз-
личать в каждой серии из N испытаний: безусловную частость Wл(В)
УСЛОВНЫЕ ВЕРОЯТНОСТИ
41
§ 2]
события В, подсчитанную по всем N испытаниям (при большом W
опа почти наверное будет приближенно равна вероятности Р(В)
того »е события); «условную» частость VJN(B[A), подсчитанную
по той части испытаний нашей серии, в которой событие А произошло,
ити, иначе говоря, частость события В при условии наступления А
1Пи еше просто «при условии Л»; «условную» частость W^(S//4),
подсчитанную по той части испытаний той же серии, в которой
произошло событие А (или, что то же самое, не произошло собы-
тие Л), т. е. частость события В при условии А.
Перечисленные три частости, вообще говоря, могут резко отли-
чаться друг от друга по величине. Это объясняется тем, что ком-
плекс условий в тех испытаниях, в которых Л произошло, может
совершенно в иной степени благоприятствовать событию В, нежели
в тех испытаниях, когда А не произошло. Другими словами, если А
происходит, то обстановка опыта складывается по-иному для собы-
тия В, чем в тех случаях, когда А не происходит, и частости WN(B[A)
и VJN(BjA) как раз учитывают изменившуюся ситуацию, вызванную
появлением или непоявлением события А.
Рассмотрим следующую таблицу результатов поверки партии
плоскопараллельных концевых мер длины (плиток) (рис. 9) в отно-
шении соблюдения норм по срединной длине и плоскопараллельности,
Т а б л и ц а 2.2. J
Плитки с отклонениями срединной длины Всего плиток
в норме (Л) не в норме (Л)
штук о/ /о штук % штук %
Плитки с плоско- параллельностью В норме (В) . . Не в норме (В) 203 16 92,7 7,3 45 18 71,4 28,6 248 34 87,4 12,6
Итого . . . . 219 100,0 63 100,0 282 100,0
Таблица 2.2.1 рисует картину трех распределений плиток по
плоскопараллельности: из последней графы видно, что «безусловная»
частость плиток, находящихся в норме по плоскопараллельности (со-
оыгис В), во всех плитках составляет:
W (£) = g= 0,874.
42
СЛУЧАЙНЫЕ СОБЫТИЯ
[ГЛ. II
Если же рассматривать только плитки, нормальные по срединной
длине, то для них условная частость нормальных также и по плоско-
параллельное™ плиток, т. е. частость события В при условии А,
по определению будет равна
904
W(B/X) = g| = 0,927,
так как произошло всего 219 испытаний (т. е. получено 219 плиток),
в которых А появилось, и среди них 203 таких, в которых вместе
с тем произошло В, а если рассматривать плитки, не нормальные
по срединной длине (условие А), то условная частость события В
будет равна
— 45
W (В'Л) = =я= 0,714.
Ои
Эти три частости не равны между собой, что казалось бы указы-
вает на зависимость плоскопараллельности плиток от отклонений их
срединной длины.
Рис. 9. Плоскопараллельная концевая мера длины (плитка).
Однако о том, по каким признакам можно судить, существенна ли
полученная из опыта подобная зависимость или она обусловлена слу-
чайными обстоятельствами опыта, мы выясним в дальнейшем.
Рассматривая, далее, данные этой же таблицы, получим частости
каждой из попарных комбинаций событий:
903
W (АВ) = Jg = 0,720,
Z6Z
W(AB) = ^> = 0,057,
ZoZ
— 4K
W(/IB)=^ = 0,160,
W (AB) = ~ = 0,064.
zoz
§
УСЛОВНЫЕ ВЕРОЯТНОСТИ
43
[4з нее же еще непосредственно следуют:
W (А) = Щ = 0,777 = = 0,720 + 0,057 = W (АВ) + W (АВ)
(2.2.1)
и аналогичные равенства для W (A), W (В) и W (В).
Далее,
203
W (ВМ) - § - 0,927 = g (2.2.2)
282
Точно так же
W (В/А) = || = 0,714 = ,
v 1 63 W(A)
W / Д 'Ri — 203 — 0 R1 О W(?1S)
W W = 248 = 0,8 1 9 = ,
W (A/B) = || = 0,476 = W(^ .
v ' ' 34 W(B)
Совершенно аналогичным образом мы будем говорить об услов-
ных вероятностях события В при условии А или при условии А,
обозначая их символами Р(В.А) и Р(В/А), и будем отличать их
от «безусловной» вероятности наступления события В, когда исход
испытания, т. е. наступление А или А, не предрешается. При этом
для условных вероятностей примем следующие их равенства:
₽iw=W'
(2.2.3)
Вычисление «условных» вероятностей на основании «безусловных»
производится по следующему правилу: условная вероятность собы-
тия В при условии А равна частному от деления вероятности
совместного наступления этих двух событий, на вероятность
условия.
Согласно этому правилу, например,
PiAB} = P(AB}
{ ' 1 Р(В) '
Разумеется, условная вероятность имеет определенный смысл лишь
в том случае, если вероятность условия не равна нулю.
Следует заметить также, что различие между «условной» и «без-
условной» вероятностями не принципиально; каждая из них, конечно,
44
СЛУЧАЙНЫЕ СОБЫТИЯ
(ГЛ. П
отвечает определенному комплексу условий. Говоря об условной
вероятности события В, мы лишь добавляем к основному комплексу
условий некоторые добавочные условия, связанные с появлением
события А.
Так как частости ХМ^ДДЙ) и WAr(H) при большом числе N испы-
таний приближенно воспроизводят вероятности Р(ДВ) и Р(Л), то и
условная частость будет при этом приближенно равна услов-
ной вероятности Р(В[А). Таким образом, конкретный смысл условной
вероятности заключается в том, что она приближенно, «в среднем»,
определяет долю тех случаев, когда событие В наступает при насту-
плении события А.
2.2.2. Свойства условных вероятностей. Правило умножения
и общее правило сложения вероятностей. Заметим, что условные
вероятности, вычисленные при одном и том же условии, обладают
свойствами, аналогичными свойствам безусловных вероятностей. Так,
например, если событие А может произойти только в одном из двух
несовместимых видов At или Д2 так, что А — А^Аг и Д1Д2 = У,
то
Р (AjB) Р + А,){В] = Р (AJB) + Р (AJB). (2.2.4)
Таким образом, условная вероятность суммы несовместимых
между собой событий равна сумме условных вероятностей этих
событий.
Равенство (2.2.3) можно записать в другом виде:
Р (АВ) = Р (Д) Р (BiА) (2.2.5)
и аналогично
Р (АВ) = Р (В) Р (А[В).
Это равенство представляет так называемое правило умножения ве-
роятностей: вероятность произведения двух событий равна про-
изведению вероятности одного из них на условную вероятность
другого при условии, что первое из них произошло. Частотное
истолкование этого правила делает его совершенно очевидным. Пусть,
2 3
например, Р(Д)= у и P(B)A) — -^. Это значит, что событие А встре-
2 3
тится в среднем в-у всех испытаний; при этом ввсех испытаний,
О 4
закончившихся появлением события Л, произойдет событие В. Сле-
довательно, вместе А и В появятся в у • — = = 0,5 (= 50%) всех
испытаний, а это и значит, что вероятность наступления события А
вместе с событием В равна 0,5. Заметим, что вероятность совпа-
дения АВ событий А и В, вообще говоря, меньше вероятности
любого из них в отдельности.
УСЛОВНЫЕ ВЕРОЯТНОСТИ
45
§ 21
Рассматривая таблицу с вероятностями различных комбинаций
событий А, А, В и ~В вида
Таблица 2.2.2
X. События События X. А А
в V (АВ) Р (АВ)
в Р(АВ) Р(АВ)
аналогичную таблице 2.2.1 для частостей, мы по правилу сложения
получим равенство
Р (А) = Р (АВ)Р (АВ), (2.2.6)
так как событие А может наступить лишь в двух несовместимых
между собой видах: или вместе с В или без него, т. е. с В.
Рассмотрим еще событие А -1- В, т. е. наступление по крайней
мере события А или ,В. Очевидно, дополнительным событием к
A-j-B будет АВ, т. е. непоявление ни А, ни В. Поэтому согласно
(2,1.16) будем иметь: Р (Л В) -|- Р (АВ) = 1 или
Р (А + В) = 1 — Р (АВ). (2.2.7)
Так как сумма всех четырех вероятностей, стоящих в клеточках
таблицы 2.2.2, равна единице, то, учитывая (2.2.7), получим:
1 — Р (АВ) = Р (АВ) + Р (АВ) + Р (АВ) = Р (А) + Р (АВ), (2.2.8)
с другой стороны,
Р(АВ) = Р(В) —Р(АВ). (2.2.9)
Из (2.2.7), (2.2.8) и (2.2.9) находим:
Р (А + В) = Р (A)-j-P (В)— Р (АВ), (2.2.10)
т. е. вероятность суммы двух событий (совместимых или несов-
местимых) равна сумме вероятностей этих событий без вероят-
ности совместного их наступления.
Это предложение составляет общее правило сложения вероят-
ностей.
Легко заметить, что если события несовместимы и, следовательно,
(4В) = 0, то (2. 2. 10) приводится к (2. 1. 12) при да = 2.
Правило умножения вероятностей легко распространить на слу-
Чай произвольного числа событий: так, например, в случае трех
46
СЛУЧАЙНЫЕ СОБЫТИЯ
[гл. И
событий А, В и С вероятность наступления их вместе равна
Р (АВС) = Р (А) Р (В/А) Р (С/АВ). (2. 2. 11)
В самом деле, рассматривая АВ как одно событие D, согласно (2.2.5)
будем иметь: • P(DC) — P(D)P(C/D). С другой стороны, Р(£>) =
= Р(А5) = Р(А)Р(5/А) и потому
Р (АВС) = Р (DC) = Р (А) Р (В) А) Р (С/D = АВ).
Аналогично для произведения событий АЛЛ- .. Ак найдем:
Р (АЛ... Ak) = Р (А,) Р (A.2/Aj) Р (А3'АЛ)... Р (Ак АЛ... Aft_,)>
(2. 2. 12)
т. е. вероятность произведения событий равна произведению
вероятности первого события на условную вероятность второго
в предположении, что первое произошло, на условную вероятность
третьего в предположении, что первые два произошли, и т. д., на
условную вероятность последнего в предположении, что все k — 1
предшествующие произошли. Это предположение представляет общую
формулировку правила умножения вероятностей.
В качестве примера рассмотрим следующую задачу из теории
выборки без возвращения: пусть мы имеем партию из N изделий,
контроль качества которых связан с их порчей (проверка радио-
ламп на долговечность, контроль боеприпасов и т. д.). Из партии
отбирают по одной штуке п изделий, проверяют их и при отсут-
ствии среди них дефектных изделий всю партию принимают; если
же из и проверенных изделий хотя бы одно окажется дефектным, то
всю партию бракуют. Требуется вычислить вероятность того, что
партия, содержащая Л1 дефектных изделий, будет принята при ука-
занной методике проверки. Пусть А,- обозначает появление годного
изделия при z-м по порядку отборе. Партия принимается, если собы-
тия А1( Аг, А3,..., А„ произойдут вместе, т. е. наступит событие
АЛА3... Ап. Но согласно (2.2. 12) имеем:
Р (АЛ • • • А„) = Р (АО Р (А../А0 Р (Аз/АИз)... Р (А„Л А.2... Ап л).
С другой стороны, «при отборе первого изделия» («при первом
отборе») мы имеем N элементарных равновероятных между собой
исходов, из которых А4 исходов благоприятствуют появлению дефект-
ного изделия, N—M исходов — появлению годного. Поэтому, со-
гласно классическому определению вероятности, мы найдем:
Р(А1) = ^/=1-|.
Если при первом отборе изделие оказалось годным, то перед
вторым оборотом при этом условии будет W— М—1 годных и Л1
дефектных изделий, а всего N—1 изделий. Поэтому условная
== 1
£ 2] УСЛОВНЫЕ ВЕРОЯТНОСТИ 47
вероятность вынуть годное изделие при втором отборе будет равна
рМ!А)- АГ-М-1 _ j _ Л1
Точно так же при третьем обороте будем иметь:
п/ « / , . X N—M— 2 . м
Р(Аз/Л1Д2) n________2 —1 n_______2’
и т. д., и, наконец, при я-м отборе
Р (А 'А, А. А А - _ М
р Ил, • • • &п- 1) дг_ (п— 1) 1 •
Принимая во внимание (2. 2. 12), получим:
ри(Л1)=Р(АА2...А) = (1-4) (1 - дст)---(1
Я \
n—п +1;
Таким образом, мы пришли к формуле (2. 1. 27).
Эта вероятность при заданных N и М с ростом п уменьшается,
так как представляет произведение п сомножителей, меньших еди-
ницы. С ростом М она также убывает, так как при этом убывает
каждый из сомножителей.
Применяя выборочный контроль качества продукции, основанный
на безвозвратной выборке, мы не можем дать 100%-ную гарантию в
том, что в принятой партии совершенно не будет дефектных изделий.
Так, например, электровакуумным приборам не гарантируется индиви-
дуальная долговечность. Однако обычно в подобных случаях выдви-
гают требование того, чтобы число дефектных изделий не превосхо-
дило некоторого предела Л4о> п0 крайней мере в подавляющем боль-
шинстве принятых партий. Этому требованию можно удовлетворить,
если выбрать п достаточно большим, чтобы выполнялось неравенство
Рл(Ж0)<а,
(2. 2. 13)
где г — заданное малое число (0,005; 0,01 и т. п.). Если при задан-
ных Л1о и г подобрать такое п, чтобы (2.2.13) удовлетворялось, так
что я = и(Л10, г), т. е. я есть функция Мо и г, то мы будем также
иметь:
Рл(/И)^Рл(Л4о)^® (2.2.14)
при любом Л1^>Л10.
С другой стороны при малых М вероятность РЛ(7И) близка к
единице, а при /И = 0, очевидно, Рл(0) = 1.
Таким образом, хорошие партии (с малым значением Л4) в боль-
шой доле случаев будут приниматься, хотя в некоторой малой доле
они могут быть случайно забракованы. Однако во всяком случае
плохие партии (М^>М0) будут приниматься, в общем, не чаще, чем
доле случаев, равной е; например, в 10 случаях на 1000 при
г==0,01 и в 5 случаях на 1000 при г = 0,005.
48
СЛУЧАЙНЫЕ СОБЫТИЯ
[ГЛ. 11
Пусть, например, на контроль предъявлено N— 1000 радио-
ламп, из которых отбирается выборка объема п =10 для проверки
долговечности. Вычислим вероятность того, что партия будет при-
нята на основании отсутствия дефектных ламп в выборке, если на
самом деле она будет содержать 5%, т. е. 50 штук дефектных
ламп. По (2.1.27) находим: v
« - (1 - ws) (1 -91) • • (1 ) =°'597-
Вероятность принять партию с довольно высоким процентом
дефектных ламп оказывается большой, так как объем выборки мал.
Если его увеличить до п = 20, то получим по той же формуле
Р20 (50) = 0,355, а при п = 30 уже Рзо (50) = 0,204, т. е. 20,4%.
Увеличивая объем выборки, мы можем добиться того, что ве-
роятность Р„(Л4) снизится до приемлемой малой величины.
2.2.3. Независимость событий. Правило умножения незави-
симых событий. Понятие условной вероятности позволяет сфор-
мулировать важное определение независимости событий: событие В
называется независимым от события А, если наступление со-
бытия А не изменяет вероятности события В, т. е.
Р(В/Л) = Р(5), (2.2.15)
или
^ = Р(В). (2.2.16)
Последнее равенство может быть написано в равносильном виде
Р(ЛВ) = Р(Л)Р(В). (2.2.17)
Пользуясь (2.2.17), мы находим также, что
Р(Л/В) = Рр^ = ^И^ = Р(Л), (2.2.18)
т. е. вероятность наступления события А не изменяется при на-
ступлении события В, а это значит, что Л не зависит от В. Таким
образом, свойство независимости событий взаимно и симметрично:
если В не зависит от А, то и А не зависит от В.
Равенство (2.2.17) выражает так называемое правило умноже-
ния независимых событий-, вероятность совместного наступле-
ния двух независимых событий равна произведению их без-
условных вероятностей.
Конкретный смысл независимости событий заключается в том,
что в длинной серии испытаний частости события В\ 1) во всех
испытаниях и 2) в тех из них, в которых появилось событие А,—
оказываются приблизительно равными между собой.
Примером зависимых событий является только что рассмотренная
выборка без возвращения: появление дефектного изделия при пер-
УСЛОВНЫЕ ВЕРОЯТНОСТИ
49
§ 2]
вом отборе здесь сказывается на вероятности появления дефектного
изделия при втором отборе, так как если первое отобранное изде-
лие оказалось дефектным, то доля дефектных изделий среди остав-
шихся изделий, естественно, стала меньше.
Иначе обстоит дело при выборке с возвращением, рассмотренной
в 2.1.1. После каждого отбора из картотеки карточки и возвра-
щения ее обратно в картотеку перед следующим отбором обста-
новка опыта полностью восстанавливается в прежнем виде. Поэтому
получение дефектного изделия при первом, втором, третьем и т. д.
отборах будут независимыми событиями.
События Л,, Л2, ..., As какого-либо поля называются незави-
симыми в совокупности, когда условная вероятность появления
любого события из их числа, вычисленная при условии, что какие-
либо другие события в этой группе (совокупности) произошли,
равна безусловной вероятности события:
Р(Л/,/Л^Ли..,) = Р(ЛД (2.2.19)
где Ak, Ah Ат — некоторые события рассматриваемой группы.
Для независимости нескольких событий в совокупности недо-
статочно их попарной независимости, т. е. независимости любой
пары событий, взятых из совокупности событий.
Из правила умножения в свою очередь следует, что если со-
бытия Л,, А2, ..., As независимы в совокупности, то из (2.2.17)
и (2.2.19) вытекает:
/ S \ S
Р(Л/2 ... Л) = Р ПА = II Р(А). (2.2.20)
\/=1 ] <=1
т. е. вероятность совместного наступления нескольких неза-
висимых в совокупности событий равна произведению вероят-
ностей {безусловных) этих событий. Это предложение составляет
правило умножения независимых в совокупности событий.
Рассмотрим пример.
Мы видели, что в выборке из партии.без возвращения вероят-
ность PjvM {п, 0) не получить ни одного дефектного изделия выра-
жается равенством (2.1.27), причем предполагается, что партия из /V
изделий содержит всего М дефектных изделий. Если бы выборка
производилась с возвращением, то события Л,, Л2, ..., Л„, заклю-
чающиеся в получении годного изделия соответственно при первом,
втором......л-м отборе, были бы независимы и каждое из них
, , N—M . М
имело бы вероятность ——= 1—а потому для вероятности
РмЛ1(л, 0) мы имели бы простое выражение согласно теореме умно-
жения (2.2.20)
Р№1 {п, 0) = ( 1 ( 1 . ( 1 = ( 1-^)П. (2.2.21)
50
СЛУЧАЙНЫЕ СОБЫТИЯ
[гл. п
2.2.4. Формула полной вероятности. При вычислении вероятно-
стей часто используют одног^еменно правила сложения и умноже-
ния. Примером является следующая задача. Система состоит из двух
параллельных ветвей: одна с последовательными независимыми звеньями
1 и 2, другая — 3 и 4. В середине ветви соединяются независимым
элементом 5. Система работает, если работает любая из ветвей (нет
отказов элементов 1 и 2 или 3 и 4, но может не работать элемент 5),
а также когда сигнал проходит по любой диагонали 1—5—4 или
3—5—2. Вероятности безотказной работы элементов даны и для
простоты составляют/?! ==/>.2==ft—Л—Ps==0,9. Требуется вычислить
вероятность безотказной работы системы (событие Л). Это событие
подразделяется на несовместимые события ВГА и В%А, где Bt и Bt —
отсутствие и наличие отказа элемента 5, называемые гипотезами
относительно А; иначе говоря,
А = В1Л + В2Л.
Применяя (2.1,12.) и (2.2.12), получим
Р (А) = Р (Bi А) 4- Р (В2А) = Р (ВО Р (А/ВО + Р (В2) Р (А/В2).
Очевидно, P(Bj) =/>s = 0,9 и Р(В2)=1—/?8==0,1. Событие А при
условии В2 равносильно безотказности системы из двух последова-
тельных подсистем с двумя параллельными элементами каждая, для
которой имеем
P(A/Bi) = [l -(1 -Я)(1 -Л)][1 -С ~Рз)(1 -/>4)1 = 0,9801.
Событие А при условии В2 равносильно безотказности системы из
двух заданных ветвей без элемента 5, для которой по правилу (2.2.10)
найдем
Р (А/В2) =№ -'-ptfi — №№ = 0,9639.
Подстановка этих значений дает
Р (А) = 0,97848.
Обобщение рассмотренной задачи, когда событие А осуществляется
лишь при одной из несовместимых гипотез В; (/=1, 2, ..., я), при-
водит к формуле «полной» вероятности:
Р (А) = Р (Bi) Р (А/Bi) - Р (В2) Р (А/В2) +... + Р (Вл) Р (А/В„).
(2.2.22)
В самом деле, по правилу умножения каждое слагаемое вида
P(Bft)P(A'Bfc) представляет вероятность одновременного наступ-
ления А вместе с Bh, v. е. Р(В*А). Но сумма
В=Р (В»А) + Р (В2 А) +... + Р (В„А)
21 УСЛОВНЫЕ ВЕРОЯТНОСТИ 51
110 правилу сложения несовместимых событий представляет вероят-
ность события ВуА /- В.гА .-j- ВпА, т. е. наступления события А
вместе с одним из событий В,, а так как А по условию может на-
ступить лишь вместе с одной из несовместимых гипотез Blt В2,...,В„,
то
ВМ4-...4-ВлА = Л и S = P BiA | = Р(А).
2.2.5. Формула вероятностей гипотез (Бейеса). Пусть, как и
в п. 2. 2. 4, событие А может осуществиться тогда и только тогда,
когда осуществляется какая-нибудь гипотеза В/ из числа п несовме-
стимых гипотез В\, Bit..., Вп. Это значит, что событие А подразделяется
па виды BiA, BiA,..., В„А так, что
А = BiA.
i = 1
Безусловные вероятности гипотез BIt В.2, ..., Вп и условные ве-
роятности BlBt предлагаются данными.
Если факт А наблюдается, то, естественно, возникает вопрос
о том, как вероятна каждая из конкурирующих гипотез, при которых
только и мог этот факт произойти.
Условная вероятность гипотезы В, при условии А подсчитывается
по формуле
р (Вц'А) = ~P[Bi)P<'AIBi) (2.2.23)
2 Р(В;)Р(А/Д/)
1-1
(мы применили в знаменателе правой части индекс / только потому,
что индекс I нами уже использован в левой части и в числителе).
Эта формула называется формулой вероятностей гипотез (Бейеса).
Проиллюстрируем ее применение на примере. Пусть в условиях
примера, рассмотренного в п. 2.2.4, произведено наблюдение техни-
ческой системы и она оказалась в работоспособном состоянии, т. е.
произошло событие А. Требуется определить при этом условии веро-
ятности (апостериорные) того, что элемент 5 безотказно работал
Р(Д'А) и отказал Р(В2/А):
Р(Д/м_ PiBAPlA/BA _
' 1 Р(В1)Р(А1В1)+Р(ВАР(.А:В1)~~
— °’^ • = 0,90149
0,9.0,9801 4-0,1.0,9639
и
0,1-0,9639 ппок1
р (Вг, А) — 0,9.098щ Ojl . 0)9б39 — 0,9801.
52
СЛУЧАЙНЫЕ СОБЫТИЯ
[гл. И
Таким образом, произошла переоценка гипотез: если априорная
вероятность гипотезы В\ (безотказность элемента 5) составляла
Р (5,) = 0,9, то ее апостериорная вероятность после наблюдения
события А стала Р(51/Д) = 0,90149; если априорная вероятность
гипотезы 52 (отказ элемента 5) составляла Р(52) = 0,1, то после
наблюдения события А апостериорная вероятность стала
Р(К2/Д) = 0,09851.
Формула (2.2.23) выводится так: пусть событие А может осущест-
виться тогда и только тогда, когда осуществляется хотя бы
одно какое-нибудь событие Bt из несовместимых событий В1;
В.г, ..., Вп. Требуется найти вероятность В,, если известно, что А
произошло.
На основании определения условной вероятности имеем:
р (R / л\ _ ₽ (BtA) _ Р (Bi) Р (AlBt)
к (bd А) — р(Д) — .
Используя формулу полной вероятности (2.2.22), находим:
Р (В,/А) = дР Р ,
2 р (В/) Р (Л/Ву)
7=1
что и требовалось.
§ 3. Композиция испытаний
2.3.1. Понятие о композиции испытаний. Повторение незави-
симых испытаний. Рассмотрим два каких-либо испытания: пусть
первое из них имеет элементарных событий — исходов E’t, Е[, ...
..., E'Sl, а второе — s2 исходов Е[', Е'2, ..., E'Ss. Поле первого
испытания согласно (2.1.7) содержит 2si событий, которые со-
ставлены из элементарных событий E'k (k = 1, 2, ..., хД а поле вто-
рого— 2s2 событий, составленных из элементарных исходов E'i
(/ = 1, 2,..., s.2).
Совокупность двух испытаний можно рассматривать как некото-
рое сложное испытание, элементарными исходами которого будут все
возможные комбинации исходов первого с s.2 исходами второго
испытания, т. е. события вида E'k E'i, где £=1, 2, ..., 1=1,
2, ..., да.
События в поле сложного испытания будут «составлены» из эле-
ментарных событий E'k E'i, т. е. будут представлять всевозможные
суммы слагаемых этого типа (например, полю этого испытания при-
надлежит сумма Е[ E'i 5' E'i). Мы будем называть сложное испы-
тание композицией испытаний.
§31
КОМПОЗИЦИЯ ИСПЫТАНИЙ
53
Вероятности событий в поле, полученном композицией испытаний,
будут определены по правилу сложения, если известны вероятности
элементарных событий вида Отметим, что хотя вероятности
р(£й) и Р (£/) в отдельности известны и останутся такими же
и в сложном испытании, но вероятность события EkEt лишь в част-
ном случае определяется по P(Ek) и Р(£/).
Мы будем называть два испытания независимыми, если в поле,
образованном их композицией, вероятности элементарных событий
g'kEi определяются по правилу умножения независимых событий
так, что
Р (ад) = Р (£*)₽(£';). (2.3.1)
Это значит, что результаты первого испытания не влияют на
вероятность получения того или иного исхода во втором испытании.
Отсюда легко вывести более общий результат для независимых
испытаний: пусть событие Д2 связано с первым испытанием (т. е.
может быть представлено как сумма некоторых элементарных со-
бытий Ek) и событие Аг связано со вторым испытанием (т. е. пред-
ставляет сумму некоторых элементарных исходов £/), тогда вероят-
ность получить в сложном испытании событие AtAt будет равна
произведению Р(Д1)Р(Д2).
Пусть мы производим я испытаний. Возможные результаты их
образуют сложное поле событий. Это поле мы назовем компози-
цией п независимых испытаний, если для любого возможного
результата /ЦД,, ... Д„, где Д, есть результат первого испытания,
Д2— второго, и т. д., Ап—п-го испытания, мы будем иметь:
Р (Д, ... д,.... Д„) = Р (Д,)... Р (Д,.) ... р (Д„), (2.3.2)
где вероятность Р(Д() определена для возможного исхода /-го ис-
пытания независимо от всех других испытаний.
Вообще, для полного описания сложного поля событий, полу-
чающихся в результате п произвольных испытаний, следует знать
вероятность Р(Л,Д2 .., Д; ... Ап), где Д(- — какой-либо из возможных
исходов z'-ro испытания. <
2.3.2. Понятия теории передачи информации. Энтропия. За-
дача о телеграфном коде. Каждое конечное поле событий испытания
вместе с вероятностями этих событий может иметь количественную
Характеристику. Такой характеристикой, имеющей первостепенное
значение в современной теории информации, является энтропия,
представляющая число, определяющееся вероятностями Р(Д) всех
элементарных событий данного поля.
Простейшая задача теории информации состоит в следующем.
Имеется канал связи, передающий при отсутствии помех прерыви-
54
СЛУЧАЙНЫЕ СОБЫТИЯ
(гл. 11
стые сигналы двоякого рода (например, телеграфные «двоичные»
сигналы вида «посылка — пауза» или «положительная'посылка—отри-
цательная посылка» и т. п.); для их обозначения ради простоты
пользуются 0 и 1. Передаваемые сообщения приходится предвари-
тельно кодировать, т. е. обозначать каждую содержащуюся в них
букву алфавита комбинацией определенного числа нулей и единиц.
Например, для буквы «а» используют сигнал 00001, для «л» 01000
и т. д. Можно предложить множество телеграфных кодов. Спраши-
вается, какой из них обеспечивает при данных условиях передачу
наибольшего числа сообщений в единицу времени.
Исходным положением при решении такой задачи является ко-
личественная мера передаваемой информации, не зависящая от со-
держания последней. Такая мера для многих случаев практики может
быть получена уже на основе рассмотренной выше теории.
Пусть Е,, Et, ..., Es—полная группа элементарных событий
рассматриваемого испытания или, иными словами, поля Е, вклю-
чающего конечное число $ элементов; рх, pv .... ps—вероятности
$
этих событий, причем Таким полем может быть, например,
1=1
алфавит, из которого выбираются буквы—элементы передаваемого
сообщения. Вероятности pv рг, ..., ps в этом случае будут зависеть
от употребительности букв в данном языке или, как говорят, от
статистической структуры этого языка.
Со всяким вероятностным полем такого1 типа связана известная •
степень неопределенности результата испытаний, которым может
быть одно из событий Et (/=1, 2, ...,$) с определенной вероят-
ностью pt. Степень этой неопределенности различна в различных
полях.
Сравним два поля
/Е1 Ег Еа ё4\ / g £• Е' Е’\
Е 1 1 1 1 ) и Е' ( ’ г ’ 4 )
\4" Т Г 47 \0,97 0,01 0,01 0,01/
с одними и теми же элементарными событиями Ег, Ег, Еа и Et,
равновероятными в поле Е, но имеющими различные вероятности
в поле Е'. Очевидно, что неопределенность поля Е больше, чем Е',
так как в поле Е' события Е, мы можем ожидать почти наверное
(е/ Еа и Е4 представляются редкими исключениями), а в поле Е
подобный прогноз невозможен. Поле
/ е е’ е F"
I С1 С2 ‘ t
\0,5 0,4 0,05 0,05
КОМПОЗИЦИЯ ИСПЫТАНИЙ
55
§ 3]
занимает промежуточное место между Е и Е’ в смысле возможности
прогноза.
Вообще испытание, связанное с конечным полем событий, ха-
рактеризуется таблицей вероятностей
/£, £,... £Л
\Pj Рг P.J '
Для того чтобы измерить степень неопределенности, присущую
каждому полю, в теории передачи информации вводят функцию
Р» • • •> ^) = — i PjgPft- (2-3.3)
k=i
называемую энтропией поля; при этом условливаются при pk—§
считать pftlg/?A = 0. Логарифмы берут обычно при основании,
равном 2. Это означает, что за единицу неопределенности прини-
мается неопределенность поля
/£, £а\
£о 1 1)
\2 2/
с двумя равновероятными элементарными событиями Д, и Ег так,
что
У ’ у) ~ ” (У У У у) ~ у) = lga 2 = 1.
Эту единицу называют двоичной единицей и обозначают через bit
или bt (сокращенное обозначение двух слов binary digit—по-анг-
лийски «двоичная единица»). Известным основанием для выбора
такой единицы служит распространение на практике элементарных
«двоичных сигналов» (0 и 1).
Знак «минус» в правой части (2.3.3) позволяет считать энтро-
пию любого поля неотрицательным вещественным числом. При этом
//---О тогда и только тогда, когда все вероятности />,•-—О, кроме
одной, равной единице. Равенство нулю энтропии показывает, таким
образом, что поле дает вполне определенный, предсказываемый
с достоверностью результат. Для всякого поля, связанного с неопре-
деленностью результата, энтропия всегда положительна. Интуитивно
представляется очевидным, что максимум неопределенности при
Данном числе 5 элементарных исходов достигав гея в поле испыта-
ния с равновероятными исходами Ех, Ег, ..., Es, когда для каж-
дого I имеем р = —.Что этому условию удовлетворяет функция
(2.3.3), можно убедиться, исследуя ее на экстремум и приняв во внима-
$
1111е, ч ю аргументы/^ связаны с условием V р^—\. При ь — 3 для
56
СЛУЧАЙНЫЕ СОБЫТИЯ
[ГЛ. II
функции
Р2, P3)=PjgP, +-PJgP2 + 0—Р>—PaHgO—Л—
найдем частные производные
= IgPj + м~ М~ lg (1 “ Р> — Р2),
U = lg^ + Al_Al_lg(l_pi_p2),
иР 2
где М—модуль перехода от натуральных логарифмов к логарифмам
при данном основании; приравнивая их нулю, получим в качестве
условия экстремума
1g Р, = 1g Р2 = 1g (1 —Р, —Р2), Р1 = Р2 = Р3 = у •
Легко проверить, что системе д =р2 =... = у отвечает мак-
симум функции P/0 = lg2s. Таким образом,
0<P7<lg25. (2.3.4)
Количество неопределенности на одну букву сообщения, изме-
ряемое энтропией Н, в то же время является мерой количества
информации, содержащейся в одной букве сообщения. Так, напри-
л 1
мер, при s=4, р1=р2=:р8 = р4 = —и
, , , . „ двоичная единица
п = 1 g, 4 = 2-j,
°2 буква
передав одну букву сообщения, мы уменьшаем неопределенность
на две двоичные единицы, и следовательно, количество переданной
информации (т. е. переданных новых сведений) также составляет
две двоичные единицы.
Пусть, далее, мы имеем два конечных поля событий двух испы-
таний
Р.
Е ... ЕX Р(Ег Е2
2 s и г 2
Р2 - PJ \А Чг
<hj
Композиция этих двух испытаний будет иметь сложное поле
(ЕЕ) элементарных событий Е^ с вероятностями р^, причем
4=1, 2,..., s и j= 1, 2,..., I. Данные вероятности можно представить
КОМПОЗИЦИЯ ИСПЫТАНИЙ
57
§ 31
в виде следующей таблицы:
E’t
Рп ...
* •
Ei Pzl ...
Es Psi
E'i ... E'i
Р1/ Pit
•
Р/7 Ри
J
Psj Psi
Здесь на пересечении z-й строки и у-го столбца находится ве-
роятность ри совместного наступления событий Et и Ej, т. е. про-
изведения Efi^Ey.
Обозначим через Н(Е), H{F) и Н(ЕР) энтропии полей событий
Е, F и ЕЕ. Имеет место следующее важное неравенство:
H(EF)^H(E) + H(F). (2.3.5)
Знак равенства здесь имеет место тогда, когда рассматрива-
емые два испытания независимы друг от друга, т. е. когда
Pij = PjQj. В самом деле,
н (ef)= — 2 ig PiQj = — 2 Pt Pi 2 я j—2^ 's я j 2 Pi =
ij i i i i
= -^Pi^Pi-^4jiggj = Pi(E) + El(F).
i i
Реализация сложного испытания (EF), очевидно, равносильна
Реализации как поля испытания Е, так и независимого от него по-
;,я испытания F. Естественно считать поэтому, что информация
58
СЛУЧАЙНЫЙ события
[гл. 11
от реализации композиции испытаний (EF) равна сумме информа-
ций, получаемых из двух независимых полей испытаний Е и F
в отдельности. Функция Н обладает таким свойством.
Перечисленные до сих пор свойства энтропии уже оправдывают
выбор этой функции в качестве меры количества информации.
Неравенство (2.3.5) служит еще для следующего важного опре-
деления.
Пусть так же, как и раньше, Е и F будут двумя конечными
полями событий, содержащимися в общем поле композиции EF.
Тогда величина
J(E,F}^H{E) + H{F) — H(EF} (2.3.6)
будет представлять взаимную информацию, т. е. информацию о по-
ле испытания Е, содержащуюся в реализации поля испытания F
(или наоборот). На основании (2.3.5) J(£, F)^0.
Рассмотрим канал связи, на вход которого поступают три раз-
личных сигнала: Ег и £3. В канале эти сигналы подвергаются
различным случайным воздействиям (шумы), вследствие чего на вы-
ходе канала не всегда получаются сигналы, одинаковые с послан-
ными. Здесь могут быть приняты три других сигнала: £,, £г и £,.
Явления на входе передающей системы мы описываем с помо-
щью поля событий £, а явления на выходе — с помощью поля собы-
тий F.
Из поля событий £ фиксируются определенные события на вхо-
де при любых явлениях на выходе, а из поля F фиксируются оп-
ределенные события на выходе при любых явлениях на входе.
Элементарные события поля £ представляют собой события, пе-
редаваемые как Ej (/=1,2,3) и принимаемые как Ft, или £г, или
Ft. Обозначим через F, (/=1,2,3) события, передававшиеся как
£,, или £г, или Еа и принятым как F-.
Для полного описания передающей системы введем общее поле
событий EF, композицию полей £ и F.
Поле EF должно состоять из всех событий, которые могут
встретиться на входе и выходе. Элементарные события этого поля,
посланные как события £, и принятые как Fj, обозначим через £(у.
Если известны вероятности Р (£,-,) всех элементарных событий поля
EF, то можно определить статистические свойства рассматривае-
мого канала связи.
Предположим, что сигналы на входе имеют следующее распре-
деление вероятностей:
я\
\0,5 0,3 0,2/ ’
а на выходе имеет место такое же распределение
F,
0,5
0,3
0,2
КОМПОЗИЦИЯ ИСПЫТАНИЙ
59
§ 3]
Энтропии входа и выхода будут одинаковы:
Я(£) - Н(Р) = -(0,5 1g, 0,5 4- 0,3 1g, 0,3 + 0,2 lg, 0,2) =
= 0,500 4-0,521 4- 0,464= 1,485bt.
Возникает вопрос о том, можно ли считать, что если принят
сигнал Fj (с определенным индексом /=1,2,3), то и послан был
сигнал Ej с точно таким же индексом.
Однако ответ на этот вопрос зависит от статистических свойств
канала связи, которые могут быть описаны таблицей распределе-
ния вероятностей общего поля событий EF.
Рассмотрим три варианта таких таблиц.
1) Пусть распределение элементарных событий Е^ поля ЕЕ за-
дано в виде таблицы
А', f 2 Сумма
ЕЕ' 0,5 0 0 0 0,3 0 0 0 0,2 0,5 0,3 0,2
Сумма 0,5 0,3 0,2
Из этой таблицы видно, что при каждом поданном на вход сиг-
нале Ej на выходе канала принимается сигнал с тем же индек-
сом /, а сигналы с другими индексами невозможны.
В этом примере вычисление трех энтропий дает Н (EF} = Н (Е) =
— И(F), а поэтому из (2.3.6) следует
J (Е, F) = Н (Е} = Н (F) = 1,485 bt.
Это как раз и означает, что принятое сообщение образуется из
посланных сигналов без погрешностей и в канале связи не проис-
ходит потери информации.
2) Пусть теперь таблица имеет вид
Г, Р3 Сумма
£i 0,4 0 0,1 0,5
£2 0,1 0,1 0,1 0,3
Е, 0 0,2 0 0,2
Сумма 0,5 0,3 0,2
60 СЛУЧАЙНЫЕ СОБЫТИЯ [ГЛ.
Здесь вероятности событий Ei и Fj, взятые по отдельности,
же, что в первом примере, однако посланному сигналу,
£,, имеющему вероятность 0,5, на выходе могут отвечать
нал Ft с вероятностью 0,4 или сигнал F, с вероятностью 0,
Вычисления дают
Н(Е, F) = —(0,4 lg2 0,4 + 4 • 0,1 lg2 0,1 + 0,2 lg2 0,2) =
= 0,529 4- 1,329 + 0,464 = 2,322 bt.
Таким образом,
ЦЕ, F) = 1,485 4- 1,485—2,322 = 0,648 bt.
Следовательно, в канале связи теряется больше половины по-
сланной информации: посылается информация величиной Н (Е)=
= 1,485 bt, содержащаяся в поле Е, а принимается в сообщениях
(представляющих события поля F) информация о поле Е, оценивае-
мая величиной ЦЕ, F) — 0,648 bt.
3) Наконец, пусть
F, F2 F, Сумма
е, 0,25 0,15 0,10 0,50
0,15 0,09 0,06 0,30
е» 0,10 0,06 0,04 0,20
Сумма 0,50 0,30 0,20
Энтропия поля событий EF в данном случае будет
H(EF) = —(0,25 1g, 0,25 4-2-0,15 Ig, 0,15 + 2-0,10 lg2 0,10 +
+ 0,09 Ig, 0,09 + 2-0,06 Ig, 0,06 + 0,04 Ig, 0,04) =
= 0,500 + 0,821 + 0,664 + 0,313 + 0,486 + 0,186 = 2,970 bt.
Следовательно,
ЦЕ, F)= 1,485 + 1,485—2,970 = 0,
t. e. вся посланная информация поглощается шумом.
Если в этом примере подсчитать по формуле (2.2.3) условную
вероятность P(Ek/Fj) какого-нибудь события Et, или £,, или Ft при
условиях Ц (j— 1,2,3), то получим
P(5ft/F,) = P(£ft) (/=1,2,3).
Иными словами, события Е, независимы от Ff, т. е. происходя-
щее на выходе канала связи не зависит от происходящего на его
§3]
КОМПОЗИЦИЯ ИСПЫТАНИЙ
61
входе, и никакой информации о поле Е в принимаемых сообщениях
р. не содержится.
1 Рассмотренные положения теории информации имеют широкое
значение. Если под каналом связи понимать какой-нибудь прибор
для измерений физической величины, то оценка потери информации
в подобном «канале связи» позволяет подойти, например, к обосно-
ванию приемлемого соотношения между ценой деления шкалы и пре-
дельной случайной погрешностью показаний прибора.
Вернемся теперь к задаче о телеграфном коде, сформулирован-
ной в начале этого раздела.
Распространенные на практике буквопечатающие телеграфные
аппараты позволяют передавать 32 буквы алфавита при помощи
кода Бодо, в котором каждая буква обозначена одной из пятизначных
комбинаций двоичных знаков. Известно, что всего таких различных
комбинаций существует 2s = 32. Постоянное число знаков в кодовых
обозначениях букв позволяет уверенно различать их. Однако оно, как
легко заметить, рационально лишь при равновероятных появлениях
букв в сообщениях, когда />1=/л2 = .. ,=/?82 = А. Энтропия
такого поля на букву сообщения согласно (2.3.3) равна
„ . 1 к bt
Н = — Igo дх = О-;----.
® 32 буква
В действительности вероятности букв в современных языках не
одинаковы: в русском языке наибольшую вероятность появиться в
сообщении имеет буква о, в английском — е и т. д. С учетом этого,
а также вероятностей комбинаций букв и длин слов, подсчет энтро-
пии для английского языка дает результат:
/7 = 2,35
буква
Это означает, что при рациональном построении кода тот же канал
телеграфной связи может передавать в среднем в единицу времени
в два раза больше буквенных сообщений, нежели это делается при
пятизначном телеграфном коде.
Возьмем для простоты «алфавит» Е, состоящий из четырех букв
с вероятностями
p(Ei ЕЛ
А 1 11-
\2 4 8 8 /
Для этого алфавита код № 1 при использовании двоичных элемен-
тарных сигналов 0 и 1 и постоянной длине кодового обозначения
(т- е. постоянном числе сигналов, обозначающих одну букву)
Е\ Е% Ея Е^
00 01 10 11
62
СЛУЧАЙНЫЕ СОБЫТИЯ
[гл.
будет, как указывалось, соответствовать равновероятной схеме
1
при pl=pi—pi—pi = — t для которой энтропия равна
Н (Е^ = 2
v ' буква
Энтропия схемы Е равна
Н (Е) - - (± lg.l +1 lg. 1 + 4 Ig.l) = 1.73 ,
т. е. энтропия схемы Е меньше энтропии схемы £', а потому для
нее можно найти код более рациональный, чем код № 1.
При неодинаковых длинах кодовых обозначений для
разграничения букв необходимо для каждой буквы выбрать такую
последовательность сигналов, которая не являлась бы
комбинации сигналов для какой-либо другой буквы. Этому условию,
очевидно, удовлетворяет код № 2
fi £3 Ei
О 10 110 111
так, что переданная прследовательность 1 000 110 может быть
шифрована только следующим образом:
Е^ Ei Е\ £3.
Подсчитаем для кода № 2 среднюю длину кодового
Буква Вероятность появления Кодовое обозначение Число знаков (сигналов) в кодовом обозначении Произведение (2) X (4)
1 2 3 4 5
£1 1 2 0 1 0,5
1 4 10 2 0,5
Е3 1 8 по 3 0,375
Е3 1 8 111 3 0,375
Итого 1,75
КОМПОЗИЦИЯ ИСПЫТАНИЙ
63
§
jулучается, что средняя длина кодового обозначения одной буквы
равна 1,75 двоичного знака. А это означает, что, применяя код
Да 2, мы В' среднем за единицу времени передадим по тому же
каналу связи на 100— 100^ = 14,3% букв больше, чем при
использовании кода № 1.
Скромный выигрыш в этом примере получился благодаря мало-
му числу букв в нашем гипотетическом «алфавите». Выше мы при-
водили данные о том, что при кодировании настоящих алфавитов
выгода получается во много раз больше.
Рассмотренные здесь положения применимы также в телевиде-
нии, телефонии и радиосвязи. В этих случаях, как и в телеграфии,
можно считать, что сообщение состоит из отдельных сигналов,
каждый из которых имеет одну из конечного числа градаций
яркости или громкости, так как наш глаз или ухо могут различать
лишь не слишком близкие друг другу участки экрана и не слиш-
ком быстро следующие друг за другом звуки.
Эти положения применимы также при определении «объема
памяти» запоминающих устройств современных вычислительных
машин, для расчета радиолокационных установок и т. д.
Мы видим, что теория передачи информации, имеющая весьма
большое практическое значение, опирается в своей основе на изло-
женные выше положения теории вероятностей.
2.3.3. Биномиальное распределение. Рассмотрим теперь про-
стейший случай повторения одного и того же испытания при по-
стоянных условиях, причем в качестве элементарных исходов каж-
дого отдельного испытания мы будем различать лишь ‘два исхода:
появление некоторого события А и непоявление его А (т. е. появ-
ление события, противоположного А), так что А A — U. Вероят-
ность появления события для каждого испытания постоянна и рав-
на Р(А)=р, где 0<^р<^ 1. Для события А будем иметь:
Р(А) = 1 — Р(А)=1 — p~q, p-\-q—\.
Пусть произведено п независимых испытаний, которые мы будем
Рассматривать как одно сложное испытание. Результат каждого
нспы гания мы будем отмечать, ставя букву А или А па соответ-
ствующем месте, так что, например, при двух испытаниях возмож-
ны следующие 22 = 4 исхода: А А, АА, АА и АА (событие А два
раза не появилось, событие А не появилось в первом и появи-
лось во втором испытании, событие А появилось в первом и не
появилось во втором испытании, событие А два раза появилось).
При трех испытаниях возможны следующие 23 = 8 исходов: ААА,
йаа, ааа, ааа, ааа, ааа, ааа, ааа.
64
СЛУЧАЙНЫЕ СОБЫТИЯ
[ГЛ. П
Каждому возможному результату п испытаний (всего будет 2”
результатов) будет соответствовать последовательность п букв
и А, чередующихся в том порядке, в котором появляются эти
бытия в п испытаниях, например
А ААА... А.
Так как испытания независимы, то вероятность каждого такого -
результата найдется путем перемножения вероятностей событий А
и А в соответствующих испытаниях; так, например, для написан-
ного выше результата найдем:
Р (Л) Р (А) Р (А) Р (А)... Р(А) = pqqp.. .q
ввиду того, что в каждом испытании Р(А) = р и Р(А) = q. Ясно,
что если в написанной нами последовательности буква А встреча-
ется х раз и, значит, буква А встречается п—х раз, то вероят-
ность такого результата будет pxqn~x, независимо от того, в каком
порядке чередуются эти х букв А и п—х букв А. Для восьми
возможных исходов трех испытаний подсчитанные таким способом
вероятности приведены в таблице 2.3.1.
Таблица 2.3.1
Вероятности восьми исходов трех независимых испытаний
Исходы ААА ААА ААА ААА ААА ААА ААА ААА
Вероят- ности qqi>~q-P qpq = q2p pqq~pq~ PPq-P2q pqp=p2q qpp=qp2 PPP=PS
Непоявление события А во всех трех испытаниях имеет вероятность
рз(0) = ^3, отвечающую только одному исходу ~ААА. Пусть р,(1)
есть вероятность появления события А ровно один раз в течение
трех испытаний. Это может произойти, если осуществится какой-
нибудь из трех вариантов: ААА, или ААА, или АЛА, имеющих
каждый вероятность q2p. Поэтому
р3 (1) = Р (ААА) + Р (ААА) + Р (ААА) = 3qsp.
Аналогично этому из таблицы 2.3.1 находим, что вероятность на-
ступления А ровно два раза при трех испытаниях равна
рг (2) == Р (ААА) + Р (ААА) Р (ААА) = 3qp2
и, наконец,
^(3) = Р(ААА) = р’.
КОМПОЗИЦИЯ ИСПЫТАНИИ
65
§ 3]
Сумма р, (0) + р, (1) + р} (2) + р,(3) = qs ~\-3q!p + 3^р! + ps = (? + р)’
равна единице ввиду того, что ^4~р=1; этого и следовало ожи-
дать, так как мы рассматривали сумму вероятностей событий,
образующих полную группу; достоверно, что событие А при трех
испытаниях произойдет или 0, или 1, или 2, или 3 раза.
Если мы рассмотрим вероятность рп(х) ровно х раз наблюдать
событие А в течение п испытаний, то, рассуждая аналогично пре-
дыдущему, найдем:
Pll(x) = CnPq ~х1{п-хуР я ~-----------------------РЯ .(2.3.7)
В самом деле, число таких исходов п испытаний, которые за-
писываются последовательностями из х букв А и п—х букв А,
расположенными в различных порядках, будет равно числу сочета-
ний из п элементов по х, так как каждая последовательность по-
добного рода полностью определится, если из п порядковых мест
выбрать ровно х для буквы А, а остальные л—х мест оставить
для буквы А. Но такой выбор х номеров мест из л мест можно
произвести различными способами, так как группы, составленные
из номеров, должны независимо от порядка отличаться хотя бы од-
ним элементом. Например, при л = 5 событие А может наступить ров-
5 • 4 • 3 1 п
но три раза при одном из C$ = -j-^-z = 10 исходов следующего вида:
123 124 12 S 134 13 5
ААААА, ААААА, ААААА, ААААА, ААААА,
1 4 3 234 2 3 S 2 4 3 343
ААААА, ААААА, ААААА, ААААА, ААААА.
Соответствующие сочетания порядковых номеров мест, занятых
буквой 4, указаны над каждым исходом. Так как каждый элемен-
тарный исход л испытаний, в котором А появляется ровно х раз,
имеет вероятность pxqn~x, то по правилу сложения мы и получим
(2.3.7). В частности, для вероятности /?5(3) найдем:
р, (3)=c,W-’’=io/>v*
Совокупность вероятностей рп(х) при х = 0, 1, 2, ... , л, т. е.
Pn(ty, р„(1), • • • ,Рп(п), называется биномиальным распределением
вероятностей. Так как эти вероятности соответствуют несовмести-
мым событиям, образующим полную группу, то
п
'ЪРп (*)= 1,
х = о
(2.3.8)
з
Н В. Смирнов, И. В. Дунин-Барковский
66
Случайные событий
[гл. И
что легко проверить, так как вероятности рп(х) согласно (2.3,7)
образуют члены бинома (^-Ер)”, за что они и получили свое на-
звание.
Часто нужно вычислить вероятность того, что событие А встре-
тится не более чем х раз в п испытаниях, т. е. О, или 1, или 2,
или ... , или х раз. Эта вероятность называется кумулятивной,
или «накопленной», вероятностью биномиального распределения и
обозначается символом Р„(х), причем по правилу сложения получим:
P„(x) = pn(0)+p„(l)+...+p„(x)= (2-3.9)
Если число п велико, то вычисление вероятностей рп(х) и Ря(х),
зависящих от больших чисел, производится по специальным «асимпто-
тическим» формулам, о которых мы будем говорить дальше. При
небольших п можно использовать простое соотношение, связывающее
два соседних члена ря(х) и рп(х-|-1):
ря (х+!)_(« — х)р
Рп(х) (х+1) q '
(2.3.10)
Если найдено ря(х), то с помощью (2.3.10) легко рассчитать
Ря(х+1).
Описанная схема независимых испытаний представляет простей-
шую теоретическую схему случайного процесса, который будет
подробнее рассмотрен в главе XI.Она носит название схемы Якова
Бернулли (1654—1705) по имени швейцарского математика, впервые
исследовавшего ее основные закономерности.
Рассмотрим выборку с возвращением объема л = 30 из большой
партии изделий. При соблюдении случайного отбора она соответ-
ствует схеме Бернулли. Роль вероятности р здесь играет доля де-
фектных изделий во всей партии. Допустим, что р = 0,05. Мы можем
при этом предположении рассчитать по формулам (2.3.7) и (2.3.10)
вероятности обнаружения в выборке того или иного числа х дефект-
ных изделий. По формуле (2.3.7) находим:
Р{0 (0) = Сзо0,05°0,95’0_0 = 0,95” = 0,2146.
Далее, из (2.3.10) имеем:
. .. 30—х р , (30—х)0,05 30—х , ,
Рго <х+ 1)— x+i q РаоМ— (х+1) о,95 /’’»^~(х+1) 19 P»oW’
откуда при х — 0 р8 J0-Н) = ттЗтйгпГ °,2146 = 0,3389, при х= 1
30-1 1 '
Р>(1(1 4~ 1) = г. ~, и ю~ 9.3389 = 0,2586 и г. д. Результаты вычисле-
U “г и I
ний приводятся в таблице 2.3.2.
§ 3]
КОМПОЗИЦИЯ ИСПЫТАНИЙ
67
Таблица 2.3.2
Вероятности р30(х) получения числа х дефектных изделий в выборке с
возвращением объема л =30 при доле дефектных изделий в партии
р = 0,05 и доле годных изделий в ней 9 = 0,95.
Число X дефектных изделий Вероят- ность Рзд М Кумулятивная вероятность X Р3О S Рзо (k) k-o Число X дефектных изделий Вероят- ность Рзо М Кумулятивная вероятность Р30 (х)= 2 Рзо (*) к = о
0 0,2146 0,2146 5 0,0124 0,9967
1 0,3389 0,5535 6 0,0027 0,9994
2 0,2586 0,8122 7 0,0005 0,9999
3 0,1270 0,9392 8 0,0001 0,999998
4 0,0451 0,9844 9' 0,000001 0,999999
График распределения вероятностей, отвечающий этой таблице,
показан на рис. 10.
2.3.4. Схема независимых испытаний с различными вероятно-
стями. Надежность системы при фиксированном интервале времени.
Рассмотрим теперь более общую схему испытаний, в которой условие
постоянства вероятностей в последовательных испытаниях не соблю-
3*
68
СЛУЧАЙНЫЕ СОБЫТИЯ
[ГЛ. II
дается, но испытания, как и в схеме Бернулли, остаются незави-
симыми. Эта схема впервые была подробно исследована Пуассоном
и носит его имя.
Пусть испытание с порядковым номером k (k— 1, 2, ... , s) может
закончиться одним из двух возможных исходов Ak и Ak, имеющих
вероятности соответственно pk и —pk. При этом для двух
различных значений индекса k — i и k—j (i j} вероятности pk и qk,
вообще говоря, различны, т. е. р^р^ и q^qj. -Ввиду того, что
условие независимости испытаний сохраняется, вероятность какого-
либо общего исхода s независимых испытаний, например исхода,
представляющего комбинацию At, Аг, А3, Ait ... , исходов каждого
из $ испытаний в отдельности, найдется по соотношению (2.3.2)
как вероятность исхода композиции испытаний.
Р(Л„ а2, а„ 4,... ,4) =
= Р (Л,) Р Й2) Р (А,) Р (AJ ... Р (A,) = p1W1 (2.3.11)
Если s — 3, т. е. й=1, 2, 3, то возможно всего восемь- исходов
для композиции трех испытаний. Эти исходы вместе с их вероят-
ностями приводятся в таблице 2.3.3.
Таблица 2.3.3
Восемь возможных исходов сложного испытания (состоящего из трех первых
последовательных испытаний) и вероятности этих исходов
Исходы а\а,л» А,АгА, AiA2A,|ai34s4, AjA2A,
Вероят- ности исходов QiPtPi PIPtpt PiPsPs PlPtPs Ч1РгР> Pipzps
Вероятности Р, (х) того, что в трех первых последовательных
испытаниях события вида А,-(/= 1,2,3) произойдут ровно х раз
(х = 0, 1, 2, 3), легко подсчитываются по таблице 2.3.3:
А (0) = Р ЙЙЛ.) =
Р, 0) == Р й,AtЛ,) -ь Р (AtA,At) -Ь Р (A,A,Aj = q^p, + qap2q, + paqtqv
P, (2) = p И,А2А,) + P (A, A A) + P(A2A2A,) = paptqt -f-p2<72p, + qxptpv
P,(3) = P(AIA£A,)=plp2p,.
КОМПОЗИЦИЯ ИСПЫТАНИЙ
69
§ 3]
Для удобства вычисления этих вероятностей применяется фор*
мальный прием: рассматривается произведение трех биномов
П (р Л+= (рЛ+9,) (р Л + чг) (рЛ + ?,) =
« р^рЛ’ +р&рЛ2 +РгР»чЛг +‘ШгрЛ+<ЬРг<1Л+
+ Р&Ч,В + + (Ш, + + РЛ9,) £ + (ргр2?, +
+ РЛРз + ?1Р2Р,)^+Р1Р2Р8^’ = Ра (0)1° +/>, (1) В’+Ра (2) I2 + />, (3) Is.
Отсюда видно, что вероятности ps (х) равны коэффициентам
при вспомогательной величине £ в тех же степенях х.
Полученная формула легко обобщается на любое число $
испытаний
П (рЛ -I- Qk> = (рЛ+(рЛ+?„)••• (рЛ+gs) =
= P,(0)+ps(1) £ + р,(2) Г + ... +p,(s) В2. (2.3.12)
По формуле (2.3.12) можно вычислять вероятности ps(x) того, что
в $ последовательных испытаниях события вида Ai{i = 1, 2, . . . , s)
произойдут ровно х раз (х = 0, 1, 2, ... , $), не прибегая к предвари-
тельному построению таблиц вида 2.3.3 и лишь просто перемножая
биномы вида (Р/Л~ЬУ/г)- После приведения подобных членов коэф-
фициенты при дают вероятности ps(x).
Схема испытаний Пуассона является обобщением схемы Бернулли.
Если р, = р2== ... =PS = P и q^q^ ...=qs = q, то по формуле
(2.3.12) получим:
П(рЛ+^)=(р1+?Г= Sp,W5*. (2.3.13)
k = l k=0
где вероятность ps{x) определяется формулой (2.3.7). Ясно, что при-
менение формулы (2.3.13) для вычисления вероятностей сложных
испытаний по схеме Бернулли не имеет преимуществ перед их
вычислением по формуле (2.3.7).
Рассмотрим работу в течение фиксированного интервала времени
Т некоторой физической системы, состоящей из $ определенным
образом соединенных элементов (деталей, узлов и т. п.). Надеж-
ность этой системы в узком смысле количественно определяется веро-
ятностью безотказной работы в течение интервала времени Т.
Возникновение отказов системы вызывается отказами ее элементов
и, следовательно, надежность системы зависит от надежности ее
элементов.
70
СЛУЧАЙНЫЕ СОБЫТИЯ
[ГЛ. И
Различают два основных типа соединения элементов системы:
последовательное и параллельное (см. рис. И); часто встречается
и их комбинация.
Последовательное соединение приводит к тому, что отказ хотя бы
одного элемента вызывает отказ всей системы. При параллельном
соединении резервирующих (дублирующих) друг друга элементов
б)
Рис. 11, Два типа соединений элементов системы: а) последо-
вательное соединение, б) параллельное соединение.
отказ системы происходит лишь при отказе всех параллельно со-
единенных элементов. Сделаем теперь допущение: отказы отдельных
элементов независимы в совокупности, т. е. отказ одного элемента
и даже отказ некоторой группы элементов не меняют вероятности
безотказной работы остальных (в заданном интервале времени Г).
Обозначим безотказность работы Z-ro элемента в течение заданного
промежутка времени при последовательном соединении через Д(П0С
и при параллельном через А{ пар, а Д1П0С и Л(пар будут обозначать
отказы в работе i-ro элемента за то же время при тех же типах
соединений соответственно.
Рассмотрим сначала случай последовательного соединения. Обо-
значим вероятность безотказной работы системы из $ последовательно
соединенных элементов через Р4ПОС, по определению
Pj ПОС Р И1 ПОС ' ^2 ПОС • • • AS пос)'
Ввиду допущения независимости
S
Р, ПОС = Р пос) Р Ис пос) - • • Р (4 пос) = П Р И, пос), (2.3.1 4)
т. е. вероятность безотказной работы системы последовательно со-
единенных независимых элементов за данный промежуток времени
КОМПОЗИЦИЯ ИСПЫТАНИЙ
71
§ 31
равна произведению вероятностей безотказной работы этих элемен-
юв (за тот же промежуток).
При параллельном соединений для вероятности безотказной
работы системы будем иметь по -определению:
пар ~ Р Mi пар 4" ^2 пар 4“ • • 4" пар)>
так как для безотказной работы системы нужно чтобы наступило
хотя бы одно из событий Д1пар, или Аг пар, или,..., или Дапар.
Однако события At пар, • • ,\пар> вР°бще говоря, совместимы и
поэтому для определения Psnap нельзя применять аксиому сложения
(2.1.1). Непосредственное выражение Р^, пар через вероятности Р(Л( пар)
с помощью соотношения (2.2.10) привело бы к довольно громоздким
формулам. Например, при s — 2 согласно (2.2.10) получаем:
пар = Р Mi пар 4" пар) Р Mi пар) 4* Р М» пар) Р Mi пар' А пар)"
а при $ = 3
A nap = Р Ml пар 4" А пар 4“ A nap) ~ Р Mi пар) 4" Р М 2 пар) 4" Р М, пар)
Р Mi пар42 пар) Р Mi пар' А пар) Р Mt пар ’ А пар) 4"
4" Р (А пар ‘ А пар ’ А пар)-
Проще выражается вероятность противоположного события, т. е.
совместного наступления отказов всех параллельно соединенных
элементов. Это сложное событие, представляющее произведение
П Aj пар событий — появлений отказов отдельных элементов, про-
4=1
S
тивоположно сумме 2-^inap событий—безотказной работы элементов,
так как если наступает хотя бы одно событие Л;пар, то не могут
совместно произойти все события Д|пар (и наоборот). В силу этого
и благодаря независимости отказов имеем:
1 Р$пар = Р Mi пар '4г пар • • • А пар) = И Р М/пар)>
1=1
откуда
Р,пар=1-ПП-РМ.пар)Ь (2.3.15)
4 = 1
Вероятность (1—Pinap), как видно из (2.3.15), равна вероятности
получения максимально возможного числа отказов, равного числу $
элементов системы (предполагается, что вышедшие из строя элементы
"е восстанавливаются). Обозначим через psaiB(x) вероятность полу-
72
СЛУЧАЙНЫЕ СОБЫТИЯ
[ГЛ. II
чения х отказов параллельно соединенных элементов за время Т,
т. е. осуществления x(xcSs) каких-либо событий из множества
событий Д1пар, Д2пар, , 4пар.
В силу независимости этих событий вероятности рг.пар(х) могут
быть получены по формуле (2.3.12) как коэффициенты при g*.
Рассмотрим пример. Пусть для простоты система состоит из че-
тырех параллельно соединенных элементов с вероятностями безот-
казной работы, равными Р(Д, пар) = 0,6, Р (Д2пар) = 0,7, Р(Дапар) =
= 0,8 и Р (Д4 пар) = 0,9. Требуется найти вероятность Р4пар безотказ-
ной работы системы за фиксированный интервал времени Т и веро-
ятности отказов 1, 2, 3 и 4 элементов.
Обозначив вероятности отказов через р4, р2, р3 и р4, по формуле
(2.3.12) находим:
П (М +?/) = (0,4g + 0,6) (0,3g + 0,7) (0,2g + 0,8) (0,1 g + 0,9) =
= 0,3024 + 0,4404g + 0,2144g2 + 0,0404g’ + 0,0024g4.
Вероятности получения x отказов будут равны:
пар (°) = 0,3024, р1Пар(1) = 0,4404, р4 пар (2) = 0,2144,
Л пар (3) = 0,0404 и р4 пар (4) = 0,0024.
Далее, очевидно,
П f 1 -Р И,. пар)] = р4 пар (4) = 0,0024
1 = 1
и по формуле (2.3.15) находим:
Р4па₽= 1—0,0024 = 0,9976.
ГЛАВА III
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ
§ 1. Распределение дискретных величин
3.1.1. Понятие о распределении дискретной случайной вели-
чины. Мы определили в 2.1.2 на примере частости события случайную
величину как переменную, принимающую в результате испытания
то или иное числовое значение в зависимости от случайного исхода
испытания. Таким образом, случайная величина рассматривается как
функция, аргументом которой служит элементарное случайное со-
бытие поля испытания.
Среди случайных величин, с которыми приходится встречаться
в технике, можно выделить два основных типа: величины дискрет-
ные и величины непрерывные.
Дискретной случайной величиной называется такая, которая
может принимать конечное или бесконечное счетное множество
значений, т. е. такое множество, элементы которого могут быть
занумерованы в каком-нибудь порядке и выписаны в последователь-
ность х1( хг, ... , хп, ... В приложениях часто встречаются диск-
ретные величины, могущие принимать лишь целочисленные значения.
В качестве типичных примеров дискретных величин укажем на число
дефектных изделий в выборке, число вызовов, поступающих на
телефонную станцию в час наибольшей нагрузки, число остановок
станка для подналадки в смену и т. д.
Дискретное распределение считается теоретически заданным,
если известны все возможные значения х2, ... , х„, .. . , прини-
маемые величиной, и вероятности р(х,)для каждого события Х — х:
в нашем поле испытания. Так как эти события должны образовывать
полную группу, то мы на основании (2.1.15) будем иметь:
Ер(х,) = 1. (3.1.1)
i
При дискретном распределении общая масса вероятности, равная
единице, сосредоточена в счетной или конечной системе точек xt
(l’=l, 2, ...). Другими словами, это—точечное распределение массы
74
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ
[гл. ш
вероятности, подобное, например, точечному распределению элек-
трических зарядов.
В противоположность этому при непрерывном распределении
случайной величины масса вероятности распределена сплошной
полосой по всей оси х или по некоторым участкам ее с опреде-
ленной плотностью. При таком распределении случайная величина
может принимать, вообще говоря, любые значения в любых интер-
валах, находящихся в указанных участках. Часто такую величину
для краткости называют непрерывной (правильнее было бы назвать
ее непрерывно распределенной). К величинам данного типа относятся,
например, погрешности обработки и измерений.
Статистическое изучение дискретной случайной величины начи-
нается обычно с того, что рассматривают результаты некоторой
(по возможности большой) совокупности независимых испытаний,
в каждом из которых изучаемая величина по случаю принимает
то или иное из возможных значений.
В таблице 3.1.1 приведены полученные таким путем данные,
характеризующие эмпирическое, т. е. полученное на опыте, распре-
деление числа частиц—продуктов радиоактивного распада, достиг-
ших счетчика в течение промежутка времени, равного 7,5 секунды.
Таблица 3.1.1
Радиоактивный распад
Число частиц, достигших счетчика, ж Число наблю- дений, в ко- торых такое число х имело место Частость данного числа час- тиц и> (ж) Кумулятивная эмпи- рическая функция распределения X W (х)= S tc (А) k-0 Вероят- ность Р W Кумуля- тивная вероят- ность Р(х)
0 57 0,022 •0,022 0,021 0,021
1 203 0,078 0,100 0,081 0,102
2 383 0,147 0,247 0,156 0,258
3 525 0,201 0,448 0,201 0,459
4 532 0,204 0,652 0,195 0,654
5 408 0,156 0,808 0,151 0,805
6 273 0,105 0,913 0,097 0,902
7 139 0,053 0,966 0,054 0,956
8 45 0,017 0,983 0,026 0,982
9 27 0,010 0,993 0,011 0,993
10 16 0,006 0,999 0,007 1,000
Итого . . . 2608 0,999 1,000
Данные, как мы видим, относятся к AZ=2608 наблюдениям
числа промежутков, в которые регистрировалось определенное число
§ 1] РАСПРЕДЕЛЕНИЕ ДИСКРЕТНЫХ ВЕЛИЧИЙ 75
частиц, приведенных во втором столбце. В третьем столбце про-
ставлена частость, соответствующая каждому значению числа
наблюденных частиц. В четвертом столбце приведена кумулятив-
ная эмпирическая функция распределения W (х), полученная сум-
мированием частостей w(x) всех значений, не превосходящих х,
так что
W (x) — w (0) -ф от(1)4~да (2) + ... + w(x), (3.1.2)
В пятом столбце приведены вероятности для каждого значения
числа частиц, рассчитанные теоретически в предположении, что
рассматриваемая случайная величина (число частиц, достигших
счетчика) точно следует закону распределения Пуассона, с которым
мы познакомимся позже. Наконец, в шестом столбце приведена
кумулятивная теоретическая функция распределения Р (х), пред-
ставляющая сумму вероятностей р(х), не превосходящих х, так что
Р(х) = /3(0) + р(1)+...+р(х). (3.1.3)
Отметим, что в таблице 3.1.1 для значений числа частиц, не мень-
ших 10, даны лишь суммарные частость и вероятность.
Таблицы значений случайной величины и отвечающих им частостей
или вероятностей называются таблицами распределения.
Распределение частостей получается из опыта и поэтому назы-
вается эмпирическим (или статистическим) распределением слу-
чайной величины. Если число наблюдений велико, то частости
приближенно отвечают соответствующим вероятностям значений
величины.
Распределение вероятностей носит название теоретического
распределения случайной величины. В случаях, подобных только
что рассмотренному, мы приходим к теоретическому распределению,
исходя из некоторых предположений относительно простейших
закономерностей данного явления.
В таблице 3.1.1 мы видим достаточно хорошее согласование
эмпирического и теоретического распределений. Однако в этом
важном вопросе нельзя ограничиваться глазомерной оценкой, и мы
должны будем осветить его более подробно в дальнейшем.
Оценку приближения теоретической кривой распределения к эмпи-
рической кривой можно производить, пользуясь сравнением кумуля-
тивных функций W (х) и Р(х), графики которых для рассмотренного
выше примера приведены на рис. 12.
Рассмотрим еще пример сопоставления эмпирического и теоре-
тического распределений дискретной случайной величины.
Пусть из текущей продукции устойчиво работающего автомати-
ческого станка мы периодически отбираем пробы (малые выборки)
по пяти деталей, измеряем их размеры и отмечаем результаты
измерений точками на особой (контрольной) карте. Вертикальный
76
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ
[ГЛ. III
масштаб этой карты отвечает возможным отклонениям размера
деталей от номинала. На карте нанесены две горизонтальные пря-
мые: так называемые контрольные границы. Нижняя из них отвечает
отклонению — 0,0295 мм, а верхняя —отклонению — 0,1895 мм.
Нас интересует число деталей в пробах из пяти штук, размеры
которых выходят за контрольные границы. Такие детали (мы будем
условно называть их «вне-
зональными») будут отве-
чать точкам на контрольной
карте, лежащим выше и
ниже контрольной границы.
Интересующее нас число
деталей варьирует под вли-
янием разнообразных слу-
чайных обстоятельств от
одной пробы к другой. Оно
представляет значение слу-
чайной величины X, связан-
ной с проводимыми испыта-
ниями. Эта величина, оче-
видно, может принимать
лишь шесть возможных зна-
чений: х = 0, х—1, х~2,
х = 3, х = 4 и х = 5.
Эмпирическое распреде-
ление для этой величины
мы получим, использовав
данные по 70 пробам (из
пяти штук каждая), отме-
ченные на контрольной кар-
те, показанной на рис. 13.
На основании этой карты мы
получим следующую таб-
01 23 456788 10 1!
Рис. 12. Графики эмпирической W (х) и
теоретической Р (х) кумулятивных функций
распределения чисел частиц, достигших
счетчика при радиоактивном распаде.
лицу эмпирического распределения числа «внезональных» деталей
(см. таблицу 3.1.2).
Использованное здесь число наблюдений (или испытаний) ;V----70
недостаточно велико, чтобы найденные нами частости считать близ-
кими к соответствующим вероятностям. Если бы мы увеличили
число проб, то картина эмпирического распределения могла бы
значительно измениться. В противоположность тому, что мы наблю-
дали в предыдущем примере, где число наблюдений было велико,
в данном случае мы можем рассчитывать лишь на грубое согласо-
вание эмпирического и теоретического распределений. Контрольные
границы на нашей карте нанесены на основании некоторых теоре-
тических расчетов, связанных с предположением так называемого
§ 1]
РАСПРЕДЕЛЕНИЕ ДИСКРЕТНЫХ ВЕЛИЧИН
77
«нормального распределения». Об этом распределении и его при-
менениях мы узнаем подробнее из дальнейшего; сейчас для нас
Номера про?
Суммарное распределение размера/ Оетал/О но ШПпероалам
наРл/одаОшНхся отклонении отноммашого размера
Отклмеи^
'^азмер^мм
0229-0,210
0209-0,190
•0209-0270 •
0259-0250
9249-0230 •
-0229-0110
0209-0990 •
-0909-0,070
-0,009-0.050 •
-Q.049-0.030
-0229-ООЮ •
0909^009
>•••••*
1970
Рис. 13. Карта статистического контроля с нанесенными на нее ре-
зультатами проверки 70 проб по пять деталей в каждой.
существенно лишь то, что вероятность выхода наугад выбранной
обработанной детали за контрольные границы (т. е. вероятность
78 СЛУЧАЙНЫЕ ВЕЛИЧИНЫ [гл. Ill
Таблица 3.1.2
Эмпирическое распределение числа «внезональных» деталей
в пробе из пяти штук
Возможные значения х, величины X 0 1 2 3 4 5 Сумма
Частоты iij 55 12 3 0 0 0 70
Частости w (х) ... . 0,786 0,171 0,043 0 0 0 1,000
Кумулятивные частости W (х) 0,786 0,957 1,000 1,000 1,000 1,000 1,000
получения «внезональной» детали) при сделанных во время построе-
ния контрольных границ предположениях равна р = 0,05. Следова-
тельно, вероятность появления противоположного события — полу-
чения детали с размерами, лежащими в контрольных границах,—
будет q~\—р—\—0,05 = 0,95.
С некоторым основанием мы можем считать испытания, отве-
чающие отбору для пробы пяти деталей, независимыми. Поэтому
мы можем для расчета вероятности получения х(х = 0, 1, 2, 3,
4, 5) «внезональных» деталей при л = 5 испытаниях использовать
формулу биномиального закона распределения (2.3.7)
р (X = х) = С„р xqn~x = С^О, 05*0,95s" х.
Вычисляя по этой формуле вероятности, мы получим таблицу
3.1.3 теоретического распределения случайной величины X (числа
внезональных» деталей).
Таблица 3.1.3
Теоретическое распределение величины X (числа «внезональных» деталей)
в пробе из пяти штук
Значения X =х 0 1 2 3 4 5 Сумма
Р W 0,774 0,204 0,021 0,001 0 0 2 р w= = 1,000
Кумулятивная вероят- ность Р (х) 0,774 0,978 0,999 1,000 1,000 1,000
В третьей строке приведены кумулятивные вероятности Р (х).
§ П
РАСПРЕДЕЛЕНИЕ ДИСКРЕТНЫХ ВЕЛИЧИН
79
Сравнивая их с третьей строкой таблицы 3.1.2, мы видим, что
согласие получалось довольно хорошее. Разумеется, что эта оценка
пока еще недостаточно обо-
снована.
На рис. 14 показаны гра-
фики кумулятивной частоты
W (х) и кумулятивной веро-
ятности Р(х) числа «внезо-
нальных» деталей в пробе из
пяти штук.
3.1.2. Среднее значение
и математическое ожидание.
Мода. Мы видели, что эмпи-
рическое распределение часто-
стей и соответствующее ему
теоретическое распределение
вероятностей могут быть за-
даны в виде таблиц или ку-
мулятивных функций распре-
деления. Отсюда мы получаем
наиболее полную, хотя иногда
и трудно обозримую информа-
цию о поведении случайной
величины в ходе испытаний.
Однако на практике часто бы- 0 / г 3 4 s'
вает достаточно знать значи- рис. 14. Графики эмпирической W (х)
тельно меньше, а именно: и теоретической Р(х) кумулятивных
1. Знать примерное распо- Функций распределения числа «внезо-
, „ нальных» деталей в пробе из 5 штук,
ложение того более или менее . 1
узкого интервала значений ве-
личины, в котором находится основная масса вероятности (или
частости); иначе говоря, знать некоторое «среднее» из значений
величины, вокруг которого группируются (более или менее тесно)
эти значения.
Наличие такого центра группирования в распределении многих
случайных величин вытекает из самой природы явления рассеивания.
2. Знать, как и насколько разбросана масса вероятности или
частости около центра группирования, т. е. точно охарактеризовать
с помощью числового показателя степень рассеивания.
Обе эти задачи—определение положения центра рассеивания и
числовой характеристики рассеивания—могут решаться различными
способами.
Ограничиваясь пока дискретным распределением, мы остано-
вимся здесь на одном способе получения нужных характеристик,
теоретические преимущества которого выяснятся в дальнейшем.
80
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ
[ГЛ. III
С точки зрения наглядности представлений этот способ подсказы-
вается механической аналогией распределения вероятностей (или
частостей) с распределением масс (в сумме равных единице) в тех '
точках числовой оси, которые соответствуют возможным значе-
ниям случайной величины. Способ этот сводится к вычислению
моментов распределения (теоретического или эмпирического).
На рис. 15 показано распределение вероятностей величины Л,
следующей биномиальному закону:
Р5(х) = С1
1 / 1 5! 1
2 / \ 2/ ~х!(5—х)132 •
Величина X может принимать значения: 0, 1, 2, 3, 4 и 5. Орди-
наты в этих точках пропорциональны сосредоточенным в них
Рис. 15. Математическое ожидание дис-
кретной случайной величины.
«массам» вероятностей. Так,
например, в точке х = 0 со-
1
средоточена ™ всей массы
OZ
вероятностей (равной единице)
потому, что Р. (0) = ^=;вточ-
i 5
ке х = 1 сосредоточено ™
«52
всей массы, так как Р. (1) = ™ ,
• ' 32
и т. д. За центр группирова-
ния случайной величины ес-
тественно принять центр тя-
жести этих масс. Известно,
что абсцисса центра тяжести
может быть найдена путем
подсчета средней «.взвешен-
ной» абсцисс данных точек,
причем взвешивание значений величины получается умножением
каждого ее значения на его «вес», т. е. отвечающую этому зна-
чению вероятность, с последующим делением суммы этих произ-
ведений на сумму весов (т. е. на сумму вероятностей, равную
единице).
Полученная таким образом числовая характеристика случайной
величины X носит название математического ожидания и обозна-
чается символом МА) ее значение определяет, как мы видели, абс-
циссу центра тяжести распределения «масс вероятности».
Согласно этому определению, если таблица распределения вели-
чины X будет иметь вид
| Хг
Х\Р^ Р{хг)
Xs >
pWJ’
(3.1.4)
§ 1] РАСПРЕДЕЛЕНИЕ ДИСКРЕТНЫХ ВЕЛИЧИН 81
ТО
м у _ +Р (+) + хгр (хг) +...+xsp (xs)
Р(хг) + р(хг) + ... +p(xs) •
а так как сумма всех вероятностей (иначе говоря, «масс») равна
единице, то
М* = XJ (xj 4- хгр (хг) + ... + xsp (xs).
Сумму в правой части мы можем кратко записать, пользуясь знаком
$
суммирования, в виде 2лч/’(х/) или> еще более кратко, в виде
i: = 1 ч
2^хр(х), причем суммирование во всех случаях распространяется
х
на все значения величины X
В рассмотренном примере имеем:
.. v n 1 . , 5 п 10 . Q 10 . . 5 , с 1 80 ое
МЛГ—0-32+ 1 •з2 + 2-32 + 3 - 32 + 4 - 32 + 5.д2- 32 — 2,5.
Если возможные значения дискретной случайной величины обра-
зуют счетное множество, то вместо конечной суммы в правой части
мы будем иметь бесконечный ряд, сумма которого определяется
путем предельного перехода:
со п
мл = 2 (xi) = lim S xiP (xt)-
rt —► co 1 = 1
Предполагается при этом, что ряд в правой части сходится абсо-
лютно (т. е. сходится ряд У | xiР (xi) | из абсолютных величин чле-
нов данного ряда), а потому сумма ряда не зависит от порядка
расположения отдельных членов в ряду.
Таким образом, математическое ожидание дискретной случайной
величины может быть, вообще говоря, определено суммой
МХ=^хр(х). (3.1.5)
X
Для эмпирического распределения аналогичная характеристика
положения центра рассеивания дается в виде средней арифметиче-
ской, взвешенной по частостям значений величины. Так, например,
для эмпирического распределения, приведенного в таблице 3.1.2,
такая средняя арифметическая будет равна
?__0.55+М2 + 2-3_п 55 12 3 _
554- 12 + 3 “u’70't"‘'ТО-1" 70~
= 0 • 0,786 + 1 • 0,171 4- 2 • 0,043 = 0,257.
Общая формула для вычисления средней арифметической эмпи-
рического распределения случайной величины X, задаваемого
82 СЛУЧАЙНЫЕ ВЕЛИЧИНЫ [гл. 14
таблицей
/ xt х2 ... хв \
Х (*») l~=w(x2) ... = w (xs)J ’
будет
j s
Х = ^ (x>) = -^'^xini. (3.1.6)
х i=i
Очевидно, с чисто алгебраической стороны, выражение средней
арифметической х вполне аналогично выражению математического
ожидания NLX для теоретического распределения величины X. Мех.а-
ническое истолкование этих характеристик для абсцисс центра тяжести
соответствующих «масс» так же вполне аналогично.
Заметим еще, что при большом числе наблюдений частости
ш>п(х) = ^-(событий Х = х) буАут близки к соответствующим веро-
ятностям р(х) и потому получаемое из опыта выражение x = ^lxwa(x)
X
должно быть близким к fAX ==^хр(х).
X *
Как мы увидим в следующем параграфе, математическое ожида-
ние непрерывной величины определяется совершенно аналогично,
только вместо простого суммирования «взвешенных» по вероятности
значений величины здесь приходится прибегать к интегрированию
вдоль числовой оси.
Физический смысл математического ожидания как характеристики
положения центра группирования распределения можно проиллю-
стрировать на ряде примеров. Так, при многократных измерениях
или экспериментальных определениях некоторой величины в одних
и тех же условиях (при отсутствии систематических погрешностей)
математическое ожидание можно рассматривать как «истинное» зна-
чение этой величины. При наблюдении рассеивания размеров обра-
батываемых на станке деталей математическое ожидание имеет смысл
размера, на который настроен станок. При наблюдении флуктуаций
тока или напряжения в электрической цепи ему естественно припи-
сать смысл среднего значения тока или напряжения. В артилле-
рийской стрельбе его следует рассматривать как центр поражения
цели.
Из определения математического ожидания следуют его простые
арифметические свойства.
Первое свойство. Математическое ожидание постоянной
величины равно самой этой постоянной'.
М(С) = С, (3.1.7)
где С—постоянная.
§ 1] РАСПРЕДЕЛЕНИЕ дискретных величин 83
Доказательство. Постоянную можно рассматривать как
дискретную случайную величину, могущую принимать только одно
значение С с вероятностью, равной единице:
М(С) = С-1==С.
Второе свойство. Математическое ожидание произведе-
ния постоянной величины на случайную величину равно произ-
ведению постоянной на математическое ожидание этой случай-
ной величины-.
М(С¥) = С-М¥. (3.1.8)
Доказательство.
М (СХ) = 2 хСр (х) = С 2 хр (х) = СМХ.
X X
Третье свойство. Математическое ожидание суммы по-
стоянной и случайной величины равно сумме постоянной вели-
чины и математического ожидания случайной величины:
М (С + ?0 = с 4- M.Y. (3.1.9)
Доказательство.
м (с+*)=2(с+х) р (х) = 2 ср (*) +2 хр <*)=
X XX
= c2pW+2x/’(x) = c-1 +MzY=c+mx
Из второго и третьего свойств вытекает более общее свойство.
Математическое ожидание линейной функции Y=kX^-b
случайной величины X равно той же линейной функции от ма-
тематического ожидания величины X:
NIY= kMX-\-b, (3.1.10)
причем k и b—два произвольных постоянных числа.
Все эти свойства равным образом распространяются на среднюю
арифметическую х эмпирического распределения. Их можно исполь-
зовать для упрощения вычислений средней арифметической. Пусть,
например, эмпирическое распределение задано таблицей 3.1.4.
Здесь мы можем считать, что' «вес» каждого из двадцати значе-
ний равен единице. Мы можем вычислить среднюю арифметиче-
скую х этого распределения просто по формуле (3.1.6), но тогда
нам придется оперировать, четырехзначными числами. Вычисления
можно упростить, используя свойство (3.1.9). Для этого выберем
84 СЛУЧАЙНЫЕ ВЕЛИЧИНЫ [гл. III
Таблица 3.1.4
Распределение штамповок колец подшипников по высоте
№ колец по по- рядку . . . 1 2 3 4 5 6 7' 8 9 10
Высота в мм 31,60 31,70 31,73 31,74 32,17 32,25 32,26 32,28 32,28 32,29
№ колец по по- рядку . . . 11 12 13 14 15 16 17 18 19 20
Высота в мл! 32,30 32,36 32,46 32,47 32,48 32,61 32,63 32,68 32,74 32,92
срединное значение нашего распределения хи = 32,30 за начало
отсчета и тогда получим:
jc (—0,70—0,60—0,57 —0,56—0,13 —0,05 —0,04 —
—0,02—0,02—0,01 4-0 + 0,06 + 0,16 + 0,17 + 0,18 +
+ 0,31 + 0,33 + 0,38 + 0,44 + 0,62) + 32,30 =
= _ + 32,300 = 32,298
Мы здесь оперировали только однозначными и двузначными
числами.
Произведенную нами операцию можно записать в виде
х = й,+С. (3.1.11)
где
S жс)
Выражение (3.1.4) таблицы распределения случайной величины X
определяет полностью не только саму эту величину, но также, и
распределение любой функции U = f(X'} этой величины. Из выра-
жения (3.1.4) получим:
J/М Ж) ... Ж)\
V(-*>) Р(*г) ... Ж)1 ’
так называемое событие uk=f{x^ имеет вероятность p(xk} =
= р(Х = хк). Поэтому мы можем говорить о математическом
§ 1] РАСПРЕДЕЛЕНИЕ ДИСКРЕТНЫХ ВЕЛИЧИН 85
ожидании величины U=f(X), определяя его равенством
М£7=М[/(Х)] = 2 /(x,)p(xA) = S/(x)p(x).
k = l X
В случае бесконечной последовательности в правой части будет
стоять бесконечный ряд, который предполагается абсолютно схо-
дящимся.
Особенно часто наряду с величиной X рассматриваются различ-
ные целые ее степени. Математическое ожидание Хк называется
моментом k-го порядка величины X (или начальным момен-
том k-го порядка} и обозначается символом vA(X) или просто vk.
Таким образом, по определению имеем:
= = (3.1.12)
В частности, момент нулевого порядка будет:
у0 = МЛ’ = М1 = 1, (3.1.13)
и момент первого порядка представляет:
v1 = MAT=v. (3.1.14)
Аналогичным образом моменты эмпирического распределения
определяются как средние взвешенные k-x степеней полученных
в наблюдениях значений
j s
= (3.1.15)
В частности, при й=1 будем иметь:
К^^-^х^^х. (3.1.16)
i=i
В качестве характеристик положения центра группирования рас-
пределения на практике наряду с математическим ожиданием МА
и средней арифметической х иногда используются еще две харак-
теристики: мода и медиана.
Модой теоретического распределения называется наиболее вероят-
ное значение случайной величины, обозначаемое символом МоА; мо-
дой тйХ эмпирического распределения называется значение, имею-
щее наибольшую частость. Понятие о медиане дано в п. 3.2.1.
3.1.3. Центральные моменты. Дисперсия и среднее квадрати-
ческое отклонение. Коэффициент вариации. Среднее абсолютное
отклонение. Характеристики асимметрии и эксцесса. В 3.1.2 уже
Указывалось, что для самого краткого описания случайной величины
86
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ
[гл. 111
недостаточно указать ее центр группирования и нужно во всяком
случае знать еще степень или масштаб рассеивания ее значений
около этого центра. В самом деле, рассмо трим рис. 16, на котором пока-
заны два распределения по разрывному усилию в килограммах об-
разцов проволоки, отобранных из двух различных партий. Среднее
значение для обоих распределений равно 100 кг. Однако второе
।Партия Х2
| Партия/И
100
Рис. 16. Распределение по разрывному усилию (в кг) образцов, ото-
бранных из двух партий проволоки.
распределение значительно более тесно сгруппировано около этого
центра, нежели первое распределение. Если техническими условиями
предусмотрено минимальное разрывное усилие для данной проволоки,
равное 50 кг, то первую партию следует забраковать, тогда как
вторая партия должна быть признана годной.
Аналогичная картина значительно повышенного разброса показа-
ний измерительного прибора наблюдается при потере им требуемой
точности, хотя при этом центр рассеивания по-прежнему определяется
истинным значением измеряемой величины.
Мы рассмотрим здесь числовую характеристику степени рассеи-
вания случайной величины, носящую название дисперсии и являю-
щуюся во многих отношениях наилучшей.
Мы видели, что математическое ожидание дискретной случайной
величины X можно истолковать как абсциссу центра масс вероят-
ностей, помещенных в точках х,, хг, ...,xs оси х, изображающих
возможные значения величины X. Для характеристики степени рас-
сеивания около центра масс в механике используют понятие момента
инерции; оно вполне аналогично понятию дисперсии.
Если величина X задана таблицей
х J Х2 XS
I Р (*,) Р (Хг) ... Р (Xs)
РАСПРЕДЕЛЕНИЕ ДИСКРЕТНЫХ ВЕЛИЧИН
87
§ П
то центр группирования ее определится как МА = v = 2хр (х). Вспо-
К
могательную величину X' = X—МЛ называют отклонением случай-
ной величины X.
Эта величина будет иметь следующую таблицу распределения:
(х—V X,—V ... X. — v)
Заметим, что центр группирования величины X' лежит в точке с коор-
динатой, равной нулю. В самом деле, так как МЛ—постоянная ве-
личина, то на основании (3.1.7) и (3.1.9)
МЛ' = М(Л—МЛ) = М(Л— v) = МЛ—МЛ=0. (3.1.18)
Таким образом, средняя величина отклонения (т. е. момент первого
порядка величины Л') равна нулю. Моменты величины Л' называются
центральными моментами величины Л или моментами Л относи-
тельно центра распределения у. Центральный момент А-го порядка
теоретического распределения случайной величины Л обозначается
греческими буквами причем
На = М [(Л')А] = М (Л- v)k = 2 (х- # р (х), (3.1.19)
X
т. е. он представляет среднюю величину (математическое, ожидание)
&-й степени отклонения случайной величины Л от центра.
Аналогичным образом центральный момент k-го порядка эмпи-
рического распределения определяется соотношением
mk==H (,xi — x)'l-w(xi) = ^'^i{xi—x)lini. (3.1.20)
i <
По аналогии с механикой в качестве меры рассеивания рассмат-
ривается центральный момент второго порядка рг, т. е. математи-
ческое ожидание квадрата отклонения величины X,— его называют
дисперсией и обозначают символом ВЛ, полагая
ВЛ = = М (Л- V)2 = 2 (х—v)s р (х), (3.1.21)
X
т. е. для получения дисперсии нужно квадрат каждого значения
отклонения помножить на вероятность этого значения и все про-
изведения такого вида сложить.
Если Л принимает счетную последовательность (множество) зна-
чений, то дисперсия определяется как сумма бесконечного ряда
00
ВЛ= 2 (xA-v)2p(xft). (3.1.22)
88 СЛУЧАЙНЫЕ ВЕЛИЧИНЫ [гл. Ill
Очевидно, что дисперсию можно истолковывать как момент инерции
«масс вероятности», расположенных в точках xt оси х относительно
нормальной оси оу', проходящей через точку x—v.
При рассмотрении флуктуаций электрических величин дисперсия
приобретает очень простой смысл. На основании закона Джоуля —
Ленца мощность, расходуемая на нагревание проводников, как из-
вестно, может быть выражена формулой
P—i‘R, (3.1.23)
где Р—мощность, расходуемая на нагревание проводников, г — мгно-
венное значение силы изменяющегося тока, R— сопротивление.
Сопоставляя (3.1.23) с (3.1.21), замечаем, что дисперсию тока
можно трактовать как среднее значение мощности флуктуаций,
которая рассеивалась бы на единице сопротивления.
Если дисперсия равна нулю, то величина может принимать
с вероятностью, равной единице, лишь единственное значение, сов-
падающее с математическим ожиданием, и, обратно, постоянная
величина имеет дисперсию, равную нулю.
При вычислении дисперсии часто бывает полезно использовать
формулу
DA’ = ps = MX2 — (MX)2 = v2 —< (3.1.24)
которая читается так: дисперсия равна начальному моменту второго
порядка минус квадрат начального момента первого порядка.
Для доказательства (3.1.24) заметим сначала, что согласно
определению
DA = 2 (x—vj’p (х) = 2 [х2 ~ 2v,x+vf ] р (х) =
— ^lx‘p(x)—2vi %хр (х)-Hi 2 £(•*)• (3.1.25)
X XX
Вместе с тем по определению •
^хгр(х) = хг, %xp{x) = vv =
XXX
и потому (3.1.25) можно переписать в виде
DX — v2 — 2г^, + vj = va —- 2vJ + v2 = v2 — vf,
что и доказывает (3.1.24).
Из формулы (3.1.24) следует:
DX=[x2<v2, (3.1.26)
где v2 — второй момент относительно произвольного начала коорди-
нат. Знак равенства достигается тогда, когда v^O, т. е. начало
отсчета совпадает с математическим ожиданием. Таким образом,
§ 1] РАСПРЕДЕЛЕНИЕ ДИСКРЕТНЫХ ВЕЛИЧИН 89
второй центральный момент произвольного распределения (масс)
получает минимальное значение, если он берется относительно
центра распределения (центра масс). Благодаря этому дисперсия
является естественной мерой рассеивания около центра распределе-
ния, когда последний характеризуется математическим ожиданием.
Из соотношений (3.1.18) и (3.1.24) следует, что дисперсия откло-
нения случайной величины равна математическому ожиданию квад-
рата этого отклонения, т. е.
DX' = D(X— MLY) = М (А")2. (3.1.27)
Важное значение имеет также следующее свойство дисперсии,
вытекающее из ее определения, как характеристики рассеивания:
величины X и Y=X-}-C, где С—любое вещественное число (по-
ложительное или отрицательное), имеют одинаковую дисперсию,
т. е.
DX = D(A + C). (3.1.28)
В самом деле согласно свойству (3.1.9) математического ожи-
дания
МУ=М(Л+С) = МЛ+С
или
vz-vA. + C.
Отсюда для отклонения величины Y получим:
Г' = У— vr = X + C—(vx + C) = X—vx = X', (3.1.29)
т. е. отклонения величин X и Y тождественны, а это значит, что
все центральные моменты и, в частности, дисперсии величин X и
Y—X-f-C одинаковы. Другими словами, значения центральных мо-
ментов (и, в частности, дисперсии) не зависят от выбора начала
отсчета величины, так как при всяком его изменении новый отсчет
отличается от старого на постоянную величину.
Другое арифметическое свойство дисперсии связано с тем обстоя-
тельством, что дисперсия есть величина, имеющая размерность
квадрата данной величины, в отличие от математического ожидания,
которое выражается всегда в тех же единицах, что и сама случай-
ная величина X. Поэтому для величины
Y=AX,
где k — любой постоянный множитель, имеем:
DK=A2DX (3.1.30)
Ь самом деле, согласно (3.1.8)
или yy=kvx
90
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ
[ГЛ. 1П
и, далее,
У' = У— vY = kX— kvx = k (X— vx) = kX',
т. e. отклонения величин У и X также отличаются множителем k.
Поэтому
DK= М (Г)1 = М (АА")2 = М [k* (X')2] = А2М [(А")]2 = /e2DA.
Для того чтобы получить характеристику рассеивания, имеющую
размерность, одинаковую с размерностями случайной величины и ее
математического ожидания, используют корень квадратный из дис-
персии, взятый с положительным знаком и обозначаемый симво-
лом <зх или просто а, т. е.
ax=V~OX. (3.1.31)
Эта величина называется средним квадратическим или стандарт-
ным отклонением. ‘
Очевидно, при любом k будем иметь:
0(АХ) = J/D (ААГ) = /АЧ)Л =1 k | УОХ= | A | сту. (3.1.32)
Среднее квадратическое отклонение является наиболее часто
используемой на практике характеристикой рассеивания. Вычислим
его для распределения числа «внезональных» деталей, заданного
таблицей 3.1.3. Сначала определим:
МА2 = 0* • 0,744 + I2 • 0,204 + 22 • 0,021 +
+ 32-0,001 + 42-0 + 5*-0 = 0,297
и
(ЛХ= 0-0,744 + 1 -0,204 + 2-0,021 + 3-0,001 + 4 • 0 + 5 • 0 = 0,249.
Затем, пользуясь (3.1.24), находим:
DX = 0,297 — 0,2492 = 0,235.
Далее, на основании (3.1.31) получаем:
ох=/0,235 = 0,485.
Для эмпирического распределения наряду с характеристикой по-
ложения центра группирования, которая даётся первым начальным
моментом ht — x, мы определяем также эмпирическую дисперсию s2
и эмпирическое среднее квадратическое отклонение $ с помощью
второго центрального момента тг эмпирического распределения:
s2 = т2 = У, (х, —х)2 w (х,) = - У2 (X, —х)‘ nit (3.1.33)
s=^m2. (3.1.33')
1] РАСПРЕДЕЛЕНИЕ ДИСКРЕТНЫХ ВЕЛИЧИН 9]
Соотношение, аналогичное (3.1.24), справедливо и для эмпирического
распределения; его мы получаем, заменив в (3.1.24) теоретические
моменты соответствующими эмпирическими моментами:
s2 = m2 = A2 —й2, (3.1.34)
или, принимая во внимание (3.1.16), мы можем записать:
s2 =-------п------• (3-1.35)
Вычислим эмпирическое среднее квадратическое отклонение для
эмпирического распределения числа «внезональных» деталей, задан-'
ного таблицей £>.1.2. Определяем сначала суммы произведений:
0-55 4-1-12 4-2-3 4-3-0 4-4-0 4-5-0= 18,
^х‘п1 = О2-55 4- I2-12 + 22-3 4-32-0 4-42-04~52-0 = 24.
Затем по соотношению (3.1.35) находим:
24-1*
$2 =---^-=0,277, х = *| = 0,257.
Пользуясь (3.1.33'), определяем:
J =/0,277 = 0,526.
В качестве относительной характеристики рассеивания исполь-
зуется еще коэффициент вариации, обозначаемый для теоретиче-
ского распределения через представляющий среднее квадрати-
ческое отклонение в процентах к математическому ожиданию.
Следовательно,
Yx = ife1O()O/o- (3-1.36)
Здесь предполагается, что NIX 0, а ох мало. Коэффициент вариа-
ции показывает, насколько велико рассеивание по сравнению со
средним значением случайной величины.
Коэффициент вариации vx эмпирического распределения выра-
жается аналогичным образом через процентное отношение эмпири-
ческого среднего квадратического отклонения к средней арифмети-
ческой, т. е.
^ = 4-100о/о. (3.1.37)
Определим теоретический и эмпирический коэффициенты вариации
Для только что рассмотренных теоретического и эмпирического
92
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ
[ГЛ. Ill
распределений числа «внезональных» деталей. Согласно (3.1.36)
теоретический коэффициент вариации будет равен
^=М1007.“СТ5-|0П“19П-
Пользуясь соотношением (3.1.37), находим:
^ = 4- 100»/o = gl00’/o = 205‘/0.
Мы отмечали, что дисперсия представляет лишь одну из воз-
можных мер рассеивания; в качестве аналогичной меры мы могли
бы использовать, например, математическое ожидание отклонения
любого четного порядка или математическое ожидание абсолютной
величины отклонения
И! lt = M(|X—MX|) = 2lx—(3.1.38)
X
Его называют средним абсолютным отклонением.
В качестве эмпирической оценки для Ц| !) рассматривают величину
п п
sb \=:^\Xi—x\w(xi) = -^^l\xi—x\ni. (3.1.39)
t=i ;=i
По своим аналитическим свойствам и в качестве статистической ха-
рактеристики рассеивания эта мера значительно уступает дисперсии
и среднему квадратическому от-
клонению, как это будет пока-
зано в дальнейшем.
Из центральных моментов бо-
лее высокого порядка на прак-
тике используют только моменты
третьего и четвертого порядков.
Моменты порядка выше четвер-
того почти не употребляются,
так как они сами обладают очень
высокой дисперсией и их сколько-
нибудь надежное определение
потребовало бы выборок очень
большого объема.
Центральный момент р, используется для числового измерения
асимметрии распределения. В приложениях часто встречаются од-
номодальные распределения типа, изображенного на рис. 17. По
одну сторону центра группирования и моды расположена «длинная»,
а по другую сторону «короткая» часть распределения. Когда «длин-
ная» часть распределения лежит справа от центра, тогда р.} будет
положительным, так как взвешенная сумма кубов больших поло-
Рис. 17. Распределение с положи-
тельной асимметрией.
РАСПРЕДЕЛЕНИЕ ДИСКРЕТНЫХ ВЕЛИЧИН
93
§ 1]
жительных отклонений превысит сумму кубов отрицательных откло-
нений. Асимметрия считается в этом случае положительной. Про-
тивоположный случай отрицательной асимметрии соответствует форме
распределения, при которой «длинная» часть лежит слева от центра.
Чтобы иметь дело с безразмерной характеристикой, момент
третьего порядка делят на куб среднего квадратического отклоне-
ния, и показатель асимметрии, обозначаемый символом опре-
деляется равенством
у ___Ms
(3.1.40)
Естественно, что для симметричного распределения сумма положи-
тельных кубов и сумма отрицательных кубов равны между собой,
и потому Sft = 0.
Характеристика асимметрии эмпирического распределения выра-
жается аналогичным соотношением
(3.1.41)
В качестве характеристики большей или меньшей «вершинности»
т. е. большего или меньшего подъема графика по сравнению с нор-
мальной кривой распределения, о которой упоминалось в главе I
и будет сказано подробнее в дальнейшем, используют другой пока-
затель, носящий название эксцесса ek, определяемый в виде
8
= (к —
А
(3.1.42)
В «нормальном» случае эксцесс равен нулю, так как для нормаль-
ного распределения отношение равно 3.
Эксцесс эмпирического распределения определяется характери-
с гикой
= 3
A s«
(3.1.43)
Показатели асимметрии и эксцесса, отличные от нуля, указывают
на отклонение рассматриваемого распределения по форме от нор-
мального распределения.
Вычислим теперь характеристики асимметрии и эксцесса для эм-
нирического распределения, заданного таблицей 3.1.2, и теоретиче-
ского распределения, заданного таблицей 3.1.3.
94
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ
[ГЛ. Щ
С помощью (3.1.20) находим:
т, = X (Xi ~x)s «/ = ^ [(° - °.257)’ • 55 + (1 - 0,257)’ • 12 +
+ (2 — 0,257)’
/»4 = | £ ^x‘ ni = A [(° ~ ° > 257)*• 55 + (1 - 0,257)* -12 +
+ (2—0,257)*-3)] = 0,451,
откуда по соотношениям (3.1.41) и (3.1.43) получаем:
Для теоретического распределения, пользуясь (3.1.19) и учитывая,
что, как было выше найдено, v = ALY= 0,249, подсчитываем:
р, = (0 — 0,249)’ 0,774 + (1 — 0,249)’ • 0,204 +
+ (2 — 0,249)’-0,021 +(3 — 0,249)’-0,001 =0,232, :
р,4 = (0 — 0,249)* • 0,774 + (1 -0,249)*- 0,204 +
+ (2—0,249)*-0,021 +(3 — 0,249)*.0,001 = 0,322.
Теперь с помощью (3.1.40) и (3.1.42) получаем:
у 0,232 9 _ 0,322 о 9я<)
“ 0,485’ ~ 2,03 И еА-б^85г — д-2’82-
Полученные значения характеристик асимметрии и эксцесса указы-
вают на несущественное отличие распределений, заданных таблицами
3.1.2 и 3.1.3, от нормального распределения.
При вычислениях третьего и четвертого центральных моментов
часто бывает полезна следующая их связь с начальными моментами:
3vsv, + 2vJ, (3.1.44)
K = v4 —4v,vl + 6v!v;—3vJ, (3.1.45)
и аналогично
/в3 = й3 —ЗйД+ 2й;, (3.1.46)
= й4—4й3й3 + 6й2й’—Зй^. (3.1.47)
Эти соотношения легко выводятся с помощью разложения по биному
Ньютона. Так, например, (3.1.45) получим следующим образом;
р,4 = М (А’—МА')* = М [Ам — 4А”МА' + 6.Y2 (МА^—
— 4А(МА)’+(МА+] = МА* — 4МА[’МЛ + 6МА'2(МА)2 — 3(МА)* =
= v4—4v,Vj + 6v3vx—3v’.
§ 1] Распределение дискретных величин 95
Законность разложения математического ожидания суммы в сумму
математических ожиданий слагаемых при любой зависимости между
последними доказывается в главе V; в отношении же аналогичных
эмпирических характеристик справедливость этого разложения вы-
текает из элементарных алгебраических преобразований.
3.1.4. Характеристики биномиального распределения. Понятие
о производящей функции. Мы рассмотрим теперь некоторые важ-
нейшие распределения дискретных величин. Обратимся сначала к
биномиальному закону распределения, с которым мы познакомились
в 2.3.3. В этом случае величина X может принимать значения
О, 1, 2, ..., л с вероятностью
(2.3.7')
при ЭТОМ <? = 1—р.
Постоянные л и р, входящие в выраж&ние рп{х), называются
параметрами биномиального закона.
Исследуем сначала внешний вид биномиального закона. Заменяя
в (2.3.7')х на х—1, получим для отношения члена рп(х) к пред-
шествующему члену рп(х—1) следующее выражение:
Рп(х) _ (п—х+1)р = । . Г (п—х+1)р J1 _
p„(x—l) xq L xq J
__ (n-x-(-l)p —xq == । (ra-H)p—x(p + <7)_
' xq ' xq
= . (3.1.48)
ЛЧ
В зависимости от того, будет ли х меньше или больше (л-|-1)р,
правая часть (3.1.48) будет больше или меньше единицы и в соот-
ветствии с этим рп(х) >рп(х — 1) или pn(x)<Zpn(x~ 1). Следова-
тельно, пока х<(л-)-1)р, каждый член рп(х) больше предшест-
вующего рп(х—1), т. е. последовательность вероятностей возрастает,
и, наоборот, как только будет х)>(л4-1)/>, то последовательность
вероятностей станет убывать. Пусть х0—наибольшее целое число,
содержащееся в (л-)-1)р. Например, при л=100 и р = Х имеем:
О
1 2
(« + 1)р = (100+ 1) у = 33 у, а потому х0 = 33. Тогда при изме-
нении х от 0 до п вероятности р„(х) сначала возрастают, достигая
максимума при х = х0, а затем убывают. Если (л-|-1)р = х0 — целое
число, то существуют две максимальные (одинаковые) вероятности
РЛх<>) и Рп ~ 1)> так как в этом случае из (3.1.48) видно, что
Рп (Xq) !
Рп Uo— Ь
96
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ
(ГЛ. Itt
Значение х0 = Мо.¥, на которое падает наибольшая вероятность,
представляет моду биномиального распределения. Как правило,,
биномиальное распределение имеет одну моду и относится к числу
одномодальных. При этом наибольшая вероятность может прийтись
на какое-либо из двух крайних значений: 0 или /г, так что вероят-
ности в ряду рп (х) будут все время убывать или возрастать. Кар-
тина постоянного убывания рп(х) наблюдается при малых р, если
п не слишком велико—в этом случае целая часть (л-|-1)р равна
нулю. Противоположный случай постоянного возрастания рп (х) мо-
жет наблюдаться при р, близких к единице, и небольших л. При
больших л мы всегда будем иметь моду в центральной части рас-
пределения и по обе стороны от нее вероятности рп(х) будут убы-
2
вать. Два значения моды мы будем иметь при л = 4 и р — у,
когда (л-Ь1)р==2. В этом случае по формуле (2.3.7') найдем:
81 /,\ 216 /ох 96 ... 16
625’ /М1)—Р4(2) — 625’ Pl ~ 625 ’ 625’
2
Но при л = 10 и при том же значении р =-=- получим:
□
22
(л+1)р = ^ = 4,4.
и
Следовательно, мода равна х0 = 4. Как мы увидим, мода бино-
миального распределения будет близка к математическому ожиданию.
Для вычисления моментов биномиального распределения мы
используем искусственный прием, который окажется полезным и во
многих других случаях: мы введем понятие о производящей функ-
ции. Наряду с величиной X, подчиненной закону (2.3.7'), мы рас-
смотрим функцию этой величины U—ext, где t — вспомогательный
параметр, которому в дальнейших рассуждениях мы будем припи-
сывать различные полезные для рассмотрения величины X значения.
Математическое ожидание величины U будет некоторой функцией
от /, т. е.
лгА.(0 = М^'. (3.1.49)
Эта функция называется Производящей функцией случайной ве-
личины X. В частности, для дискретного распределения будем иметь1
mx(t) = !Aext = ^ext р (х), (3.1.50)
X
где суммирование распространяется на все возможные значения ве-
личины X. Докажем следующее предложение, представляющее пер-
вое свойство производящей функции:
Начальные моменты vk распределения, заданного вероятно-
стями рп(х), равны значениям k-й производной от функции
§ 1] РАСПРЕДЕЛЕНИЕ ДИСКРЕТНЫХ ВЕЛИЧИН 97
1П (/) в точке /==0, т. е.
dk I
= (й=1,2, ...). (3.1.51)
Кроме того,
/»A-(O) = v,= l.
Второе равенство проверяется непосредственно. Ввиду равенства
й° == 1, имеем;
/их(0) = Ме* х° = М(1) = 1.
С другой стороны, при любом х, как известно,
— ext = xkext,
dtk
и потому из (3.1.50) после дифференцирования k раз по t получим '):
Полагая в этом тождестве / — 0, получим:
l^mx(t)\ =^xkp{x)--=M.X6 = vk,
\dt Jf=o %
что и доказывает (3.1.51)').
Из первого свойства следует, что разложение в степенной ряд
по степеням t функции mx(t) имеет вид
mx(0=l+^+^-2 + ... + ^ + ..., (3.1.52)
где vfe = MA*. В самом деле, по формуле Маклорена коэффициент
при в разложении mx(t} должен равняться
а= Актх(П I = JL V
kldt* |; = 0 k- k‘
Отметим второе свойство производящей функции mx(t).
Пусть mx(t) — производящая функция X, тогда производящая
Функция величины Y — aX-фЬ будет
my{t) = eb,mx(at). (3.1.53)
') В случае, когда у представляет сумму бесконечного ряда, мы пред-
х
полагаем сходимость получаемых здесь рядов, по крайней мере, при малых
'.начениях 11 ].
4
Н. В. Смирнов, И. В. Дунин-Барковский
98
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ
[гл. щ
В самом деле, опираясь на возможность вынесения согласно
(3.1.8) постоянного множителя за знак математического ожидания,
будем иметь:
ту (/) = Mer' = Me <аХ+Ь) * = М (eatxebi) = eb1MeaiX = ebtmx (at),
причем JAeatx отличается от MeZA только тем, что t заменено на ,
t' = at.
Из второго свойства мы выведем следующее важное для нас
следствие: для производящей функции величины Х' = Х—у, т. е.
для отклонения величины от ее центра группирования, мы имеем: .
(3.1.54) ,
положим
тх, (f) — e~vtmx(t).
В самом деле, (3.1.54) следует из (3.1.53), если мы
а=1 в Ь=—V. С другой стороны, получим
1 + ^ + ^ + - • - + ^ + • • •>
так как согласно (3.1.52) мы должны иметь:
(3.1.55)
откуда ввиду того, что р.А = М(Л")А, следует (3.1.55).
Отметим еще два основных положения общей теории
дящих функций, не приводя здесь их доказательств.
произво-
Первое из этих положений называется теоремой единственности
и утверждает, что производящая функция однозначно определяет
распределение вероятностей так, что не только каждому закону
отвечает определенная производящая функция, но и, обратно, каж- .
дой производящей функции соответствует единстве иное распределение, i
Второе, еще более важное по своим приложениям положение —
так называемая теорема «непрерывности»— утверждает, что если
последовательность производящих функций законов распределения
р,{х), р2(х), ..., рп(х), ... сходится к производящей функции закона
р(х) некоторого распределения, то и сами законы р, (х), pt(x),...
..., рп(х) сходятся к закону р(х). Мы будем в дальнейшем опи-
раться на эти положения.
Для производящей функции биномиального распределения, зада-
ваемого вероятностями рп(х), согласно (3.1.50) будем иметь:
тх U) = V —и pxqH~xexl,
х ' Хй xl (п—х) И 7 ’
Л = 0
§ 1] РАСПРЕДЕЛЕНИЕ ДИСКРЕТНЫХ ВЕЛИЧИН 99
и заметив, далее, что ех* = (е*У, находим:
п
тх (0 = У v, - хЯ (Р^Г Чп~х = (Ре* + (3.1.56)
лвщЛ »v • 174 “ л II
х=0
так как сумма в (3,1.56) представляет обычное разложение бинома
(ре1 -д- Я)п •
Дифференцируя (3.1.56) по t, получим:
/Их(<) = нр4 (ре* 4- q)n-\
т'х (t) = п(п— 1)р V (ре* -L qf- -p-pipe* (ре* q)n=
г=пре* (q 4~p4),J*2 [(/г — \)ре* -*-ре* - q] =
= пре* (q 4-ре*)'1 (пре* q). (3.1.57)
Полагая £ = 0, принимая во внимание (3.1.51) и замечая, что
(ре* 4- ?)/=0 ==р 4- q = 1,
на Идем:
т'х (0) = Mi = ч — МХ=пр, (3.1.58)
т'х (0) = м2 = М№ = п*р'2 -\-pq. (3.1.59)
Дисперсию распределения найдем, используя (3.1.24):
DA’ = <гх = м.2 — м' =(и2/Д пРЯ) — ^Р* — npq, (3.1.60)
п, значит, среднее квадратическое отклонение биномиального рас-
пределения
^х^У npq. (3.1.61)
Зная математическое ожидание и дисперсию величины X, мы
легко можем найти математическое ожидание и дисперсию вели-
чипы —, которую можно всегда истолковать как частость насту-
пления события в п независимых испытаниях, если вероятность его
равна р. В самом деле, согласно свойствам математического ожида-
ния и дисперсии найдем:
= (3.1.62)
\п 1 п п v ’
D f—'l = -7 DX= (3.1.63)
\ n / n- n- n ’ 7
ах=1/д- (З-1-64)
4*
100
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ
[ГЛ. Ш
Первая из этих формул интуитивно очевидна, так как вероятность р,
вообще, понимается как среднее значение (иначе говоря, математи-
. А'
ческое ожидание) частности —.
Для того чтобы получить центральные моменты высшего порядка
биномиального распределения, проще всего перейти к производя-
щей функции отклонения
Х'—Х— v = X—пр (так как v = — пр).
Согласно (3.1.54) получим:
тх< (0 = e~npimx (t) = е~пр* {ре* q)n =
— [ер* (ре* + ?)]» = (ре* + qe-pt)n. (3.1.65)
Дифференцируя (3.1.65) k раз (k — 1,2,3,4) и полагая t — О, найдем:
[4 = 0,
[4 = ^(1 — p) = npq,
^ = npq(q—p),
р.4 = 3napV npq (1 — 6p 4- бр2).
Отсюда получим выражения для асимметрии и эксцесса:
npq
(3.1.66)
(3.1.67)
(3.1.68)
(3.1.69)
(3.1.70)
(3.1.71)
С ростом n eft и очевидно, стремятся к нулю. Это, как мы
увидим далее, связано с приближением биномиального закона к сим-
метричному нормальному закону.
В таблице 3.1,5 приведены вероятности р^(х) для значений
р = 0,1, р = 0,3 и /> = 0,5.
Чем ближе вероятность р к значению, равному 0,5, тем больше
распределение приближается к симметричной форме; при р <4 0,5
асимметрия положительна, а при р = 0,5 распределение строго сим-
метрично; при р^>0,5 асимметрия отрицательна.
На рис. 18 приведены «многоугольники» распределения, по-
строенные по данным таблицы 3.1.5. Многоугольники, отвечающие
§
РАСПРЕДЕЛЕНИЕ ДИСКРЕТНЫХ ВЕЛИЧИН
101
Таблица 3.1.5
Вероятности р№ (х) биномиального распределения при значениях
р == 0,1, р = 0,3 и р = 0£>
X Р =И 0,1 р = 0,3 р = 0,5 X р = 0,1 р = 0.3 р = 0,5
0 0,12Гб 0,0008 ~0,0000 10 0,0000 0,0308 о; 762
1 0,2702 0,0068 ~0,0000 11 0,0120 0,1602
2 0,2852 0,0278 0,0002 12 0,0039 0,1201
3 0,1901 0,0716 0,0011 13 0,0010 0,0739
4 0,0898 0,1304 0,0046 14 0,0002 0,0370
5 0,0319 0,1789 0,0148 15 0,0000 0,0148
6 0,0089 0,1916 0,0370 16 0,0046
7 0,0020 0,1643 0,0739 17 0,0011
8 0,0004 0,1144 0,1201 18 0,0002
9 0,0001 0,0654 0,1602
/> = 0,9 ир = 0,7, получаются из многоугольников для р = 0,1 и
/> = 0,3 путем симметричного отражения около вертикальной прямой,
Рис. 18. <Многоугольники» биномиального распределения
при п = 20 и р = 0,1; 0,3; 0,5; 0,7 и 0,9.
проходящей через точку х = Ю, так как переход от одного графика
к другому получается заменой х на п — х (что равносильно за
мене р на у).
102
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ
[ГЛ. щ
В соответствии с изменением графиков изменяются средние ква-
дратические отклонения и показатель асимметрии, которые приве-
дены в таблице 3.1.6.
Таблица 3.1.6
Средние квадратические отклонения оу и показатели
асимметрии биномиального распределения при
значениях р=0,Г, 0,3;.0,5; 0,7; 0,9
р = 0,1 р = 0,3 р=0,5 р=0,7 р = 0,9
1,34 2,05 2,24 2,05 1,34
+0,597 +0,195 0 —0,195 —0,597
3.1.5. Гипергеометрическое распределение. Мы встретились
с гипергеометрическим распределением, рассматривая задачу о вы-
борке без возвращения. Вероятность того, что случайная величина
X—число объектов в выборке, обладающих признаком А,
возможное значение х, определяется, как мы видели в п.
равенством
, , и!
Р U) — -г-;-гт X
1 ' х! (п—х) 1
М (М — 1)...(M —x+l)(2V— M)(W—м — 1)...(А?— М— rt + x+1) '
Х п+1)
Здесь М—число объектов с признаком А среди всех объектов
совокупности, из которой отбирается выборка. При этом х может,
естественно, принимать значения, удовлетворяющие неравенствам
О^х^п, Q^-Х^М, п—xs^N—М.
М . „
Обозначая долю через р и разделив каждый из х-^п—х — п
множителей числителя и знаменателя на N, получим:
р(х) — Схпх
(3.1.72)
РАСПРЕДЕЛЕНИЕ ДИСКРЕТНЫХ ВЕЛИЧИН
103
§ ”
^()1 видим, что распределение X зависит от трех параметров: п, р
н ;V. Если N неограниченно возрастает, а -^=р — const, то, как
э10 видно из (3.1.72),
р (х)—> С* рх — р)п~х,
т е/ члены гипергеометрического распределения стремятся к соот-
вегствующим членам биномиального распределения как к своему
пределу.
Гипергеометрическое распределение обладает свойствами, ана-
логичными свойствам биномиального распределения; оно также
принадлежит к числу одномодальных распределений.
Центр этого распределения равен
М
\\ = у = п-, = пр, (3.1.73)
и дисперсия
°x = DX=y-?npq, (3.1.74)
В таблице 3.1.7 приведены вероятности гипергеометрического
распределения при л = 30, р = ^ = 0,05 = 5% и Дг= 1000.
Таблица 3.1.7
Вероятности гипергеометрического распределения
при п — 30, р = 0,05 и М=1000
X 0 1 2 3 4 5 6 7 8
Р (X) 0,2097 0,5512 0,8143 0,9421 0,9859 0,9973 0,9996 0,9999 1,0000
/-’ (X) 0,2097 0,3415 0,2631 0,1278 0,0438 0,0114 0,0023 0,0003 0,0001
Сравнивая эти вероятности с вероятностями соответствующего бино-
миального распределения, приведенными в таблице 2.3.2, обнару-
живаем довольно хорошую близость этих вероятностей друг к другу.
Вычисление вероятностей гипергеометрического распределения
модаю так же, как в биномиальном распределении, вести после-
довательно, используя простое соотношение, связывающее два
104 СЛУЧАЙНЫЕ ВЕЛИЧИНЫ [гл.
соседних члена распределения
р(х4-1)_ (п—х)(М—-х) .
р(х) (x+\)(N—М — п + х+1) • ' ' •
График гипергеометрического распределения, отвечающий
3.1.7, показан на рис. 19.
Рис. 19. График гипергеометрического распределения
при /г —30, р=0,05 и М=1000.
3.1.6. Закон распределения Пуассона. К закону Пуассона при-
водит та же схема Бернулли, при которой частота появления со-
бытия следует биномиальному закону. Мы будем
события маловероятные, но случающиеся в длинной езави-
симых испытаний некоторое (конечное) число раз. Так, например,
вероятность наблюдать радиоактивный распад отдельного атома
в течение данного сравнительно небольшого промежутка времени
крайне незначительна. Однако даже при малом количестве радио-
активной материи число атомов колоссально. Поэтому в
за данный промежуток времени, как правило, распадается
рое число атомов. Если считать, что распад одного атома не из-
меняет вероятности распада другого, то мы придем к схеме Бернулли.
Будем неограниченно увеличивать число испытаний п и одно-
временно уменьшать вероятность появления события р в этой серии
из п испытаний так, что математическое ожидание числа X появ-
лений события, т. е. величина МХ = лр, будет оставаться неизменно
РАСПРЕДЕЛЕНИЕ ДИСКРЕТНЫХ ВЕЛИЧИН
105
§ П
равной постоянному числу Х>0, т. е. пр—К и, следовательно,
Тогда для вероятности р„(0) события Л=0 будем иметь:
Рп (0) = (1 - р')п = (1-1)"; (3.1.76)
при п—и», переходя к пределу, будем иметь:
(1—^)"^е-х = л%(0), (3.1.77)
где ль (0) обозначает предел вероятности />„(0) при п—>оо и, значит,
P„(0)-*rtA(0) = e-\
С другой стороны, из (2.3.10) найдем:
. ... - х(1
Рп(х + 1) _ п~х п \ п)
р„(х) *+1 !_Л (х+])Л_1у
п \ п J
и, переходя к пределу при п—*оо, получим:
В частности,
Р„(1) , Ь
Р„(0) 1 ’
откуда, принимая во внимание (3.1.77), будем иметь:
P„(D — ^- = лл(1). (3.1.79)
Точно так же из (3.1.78) и (3.1.79) получим:
Р„(2) . 1
Р«(1) 2
и
р„(2)->^ = лх(2). (3.1.80)
Вообще, применяя рассуждение по методу математической индукции,
мы убедимся в справедливости следующего положения:
Теорема 3.1.6. Если число испытаний п неограниченно воз-
растает, а математическое ожидание числа появлений события
остается постоянным и равным X, то вероятность рп(х) бино-
миального распределения при каждом х = 0, 1, 2, ... стремится
к пределу
Р„(Ж)—лх(ж) = -^- . (3.1.81)
106 СЛУЧАЙНЫЕ ВЕЛИЧИНЫ [ГЛ. Щ
«Предельные» значения лх(х) и образуют распределение Г7уас-
сона.
Возможные значения величины X, подчиняющейся закону
сона, образуют бесконечную последовательность целых
О, 1,2, ... Вероятность Р(Л’=х) = лх(х) выражается равенством
(3.1.81); при этом
ух
£ л\ (х) == е-А2^ -^1 = е_> е1- = 1,
Х=0 Л=0
так как ряд
£т-^ + 2Й + ---
х=о
как известно из анализа, имеет суммой е\
Для вычисления вероятностей лх(х) и кумулятивных вероятностей
X
Пх(х) = 22лх (х)
Л^ = 0
используются специальные таблицы.
Доказанная выше теорема дает вместе с тем возможность при- .
ближенного вычисления биномиальных вероятностей (с помощью
формулы Пуассона) в тех случаях, когда точный их расчет ослож-
нен необходимостью нахождения факториалов и степеней больших
чисел. Такого рода упрощение вычислений часто практикуется в за-
дачах, связанных с оценкой эффективности статистического прие-
мочного контроля (см. главу X, § 4). Для более наглядного пред-
ставления скорости и степени приближения распределения Пуассона
к биномиальному распределению в таблице 3.1.8 приведены в сопо-
ставлении с законом Пуассона вероятности биномиальных распреде-
лений с различными п и р, но одним и тем же математическим
ожиданием np = Z = 3.
Мы видим, что по мере увеличения п точность приближения
к пуассоновским вероятностям (^.==3), помещенным в последнем
столбце таблицы, заметно улучшается. Для многих практических
целей приближение, получающееся при и 5= 60, оказывается уже
достаточным.
Отметим, что закону Пуассона приближенно следуют также
и вероятности гипергеометрического распределения, если параметр
М . .
р — мал, п велико, а пр—к имеет конечное (не слишком малое
и не слишком большое) значение.
Для определения моментов распределения Пуассона рассмотрим
сначала его производящую функцию. Подставляя (3.1.81) в (3.1.49),
.4 I]
РАСПРЕДЕЛЕНИЕ ДИСКРЕТНЫХ ВЕЛИЧИН
107
Таблица 3.1.8
Биномиальное распределение и закон Пуассона
Вероятности рп (я) биномиальных распределений Вероятность л^(х)закона Пуассона
р =0,5, р = 0,2, р=0,1, р = 0,05, р=0,02, р=0,01,
п = 6 п = 15 п=30 п = 60 п = 150 п = 300
0 0,0156 0,0352 0,0424 0,0461 0,0483 0,0490 0,0498
1 0,0937 0,1319 0,1413 0,1455 0,1478 0,1486 0,1494
2 0,2344 0,2309 0,2276 0,2259 0,2248 0,2244 0,2240
3 0,3125 0,2501 0,2361 0,2298 0,2263 0,2252 0,2240
4 0,2344 0,1876 0,1771 0,1724 0,1697 0,1689 0,1680
5 0,0937 0,1032 0,1023 0,1016 0,1011 0,1010 0,1008
6 0,0156 0,0430 0,0474 0,0490 0,0499 0,0501 0,0504
7 -0 0,0138 0,0180 0,0199 0,0209 0,0213 ' 0.0216
8 ~0 0,0035 0,0058 0,0069 0,0076 0,0079 0,0081
9 ~0 0,0007 0,0016 0,0021 0,0025 0,0026 0,0027
10 ~0 0,0001 0,0004 0,0006 0,0007 0,0008 0,0008
11 ~0 ~0 0,0001 0,0001 0,0002 0,0002 0,0002
12 ~0 ~0 ~0 ~0 ~0 ~0 0,0001
найдем:
».т = Ме» = У£^-е-> (3.,.83)
л I лявЛ л, J
Х=0 х=0
Дифференцируя производящую функцию последовательно и вычисляя
затем значения производных в точке ( = 0, найдем:
v1 = m' (0) = X, (3.1.84)
v2 = т" (0) = X2 + X, (3.1.85)
vs = m"z(0) = X34-3X24 X, (3.1.86)
у4 = лг1У(0) = Х4 + бХ3Н-7Х2 + Х. (3.1.87)
Из (3.1.14) и (3.1.84) следует, что
MX=v, = X,
(3.1.88)
т. е. математическое ожидание случайной величины, следующей
закону Пуассона, равно параметру X этого закона.
Из (3.1.24), (3.1.84) и (3.1.85) выводим, далее,
DX = |i2 = v2 — vJ = X2+X—Х2 = Х, (3.1.89)
108
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ
[гл. III
т. е. дисперсия этой случайной величины равна тому же параметру X
и численно равна математическому ожиданию (хотя имеет другую
размерность).
Среднее квадратическое отклонение при распределении
будет: ___ _
Ox = /DX=/k.
Из (3.1.44), (3.1.84), (3.1.85) и (3.1.86) найдем центральный
третьего порядка
р.3 = к33k2-J-к — 3(к24-к)к4-2к3 = к. (3.1.91)
Из соотношения (3.1.40) найдем асимметрию распределения Пуассона
у __L____L_
(/к)3 /к '
Таким образом, асимметрия всегда положительна, так как положи-
тельно к.
Центральный момент четвертого порядка получим из (3.1.45),
(3.1.84), (3.1.85), (3.1.86) и (3.1.87):
=к4 4- бк3 4- 7к2 4- к—4 (к3 4- зк2+к) к 4-
4- 6 (к2 4- к) к2 — Зк4 == Зк2 4- к; (3.1.93)
на основании (3.1.42) получим эксцесс
__ Зк3 4- к q __ 1 /Э I -
•*= W т' ( *
Из (3.1.94) следует, что эксцесс распределения Пуассона всегда
положителен, так как к всегда положительно.
Отметим еще, что если случайная величина представляет сумму
двух независимых случайных величин, следующих каждая закону
Пуассона, то она также следует закону Пуассона.
3.1.7. Закон Пуассона в схеме независимых испытаний с раз-
личными вероятностями и его применение в теории надежности.
Мы видим, что при определенных условиях формула Пуассона
(3.1.81) может быть использована для приближенного вычисления
вероятностей биномиального распределения. Но та же формула имеет
и более широкое применение. Предположим, как и в п. 2.3.4, мы
имеем систему из независимых испытаний, причем в испытании с
номером I возможны два исхода А,- и с вероятностями Р(Д()==/7г
и Р(А() = 9,= 1 — qi. Вероятности ps (х) наступления ровно х раз
событий типа А, в s испытаниях и здесь выражаются коэффициентом
при $ в разложении
П № + ?/) (0) (1) ? +PS (2) 4- • • • (s) (2-3.12')
§ 1]
РАСПРЕДЕЛЕНИЕ ДИСКРЕТНЫХ ВЕЛИЧИН
109
I ели все вероятности равномерно малы, т. е. величина
X = max(pb ръ, ..,ps)
стремится к нулю при возрастании s, то при постоянном х
ps(x)_Wx=^2L. (3.1.81')
S -*ОЭ Л1
Можно уточнить эту формулу и показать, что для вероятности
р$ (х) справедливо следующее приближенное равенство*):
, . e'f'ix ! /,2 2Х , Л „
Ps(x)^ х! 2(х— 2)1 \(Х— 1)х (,r—i)+1) ПРИХ>2>
-хЬ 6(Х~ 2)]
(3.1.95)
где ^—Р1-\~Рч-\~. ..-\-ps, Ь=р\-[-р14~-••+/’!• При эксплуатации
сложных систем отказы возникают в случайные моменты времени,
образуя потоки. Если элементы системы независимы и соблюдаются
указанные вначале условия, то поток отказов будет простейшим и
для него формулы (3.1.95) позволяют облегчить вычисление вероят-
ностей числа х = т элементов, отказавших за фиксированный про-
межуток времени, и вероятностей Rms получения числа отказов,
большего т:
Rms-Psf™- 04^Ps(ff2~(-2)-|-...-‘-|B5(d'). (3.1.96)
Рассмотрим пример. Пусть система состоит из семи элементов,
отказы каждого из которых не зависят от отказов остальных. Ве-
роятности отказов элементов имеют следующие значения:
Таблица 3.1.9
Номера элементов Вероятности 1 2 3 4 5 6 7
Отказа qi 0,013 0,037 0,052 0,009 0,047 0,066 0,075
Безотказной работы pi 0,987 0,963 0,948 0,991 0,953 0,934 0,925
А. И. Колмогоров, Труды Матем. ин-та АН СССР 12 (1945),
110
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ
[ГЛ. П1
Требуется определить вероятность отказа х элементов системы
за фиксированный промежуток времени, где х = 1,2,..., 7.
Обозначим эту вероятность через q-(x) и для ее вычисления
образуем согласно (2.3.12') произведение
7
П +/’'•) = +л) JrPi) • + М
Здесь вспомогательное переменное 5 поставлено с коэффициен-
том qt, так как определяется вероятность числа х отказавших эле-
ментов с вероятностями отказов </,- для каждого /-го элемента из
семи элементов (/ = 1,2,..., 7).
Перемножение биномов и приведение подобных членов дает
многочлен
П = Ч- (0) Ч- <77 (1) + </7 (2Н2 +. 97 (7) Г =
= 0,73521 4- 0,23275^ 4~ 0,02996**4-0,00201?» -L- 7 • Ю'»?4 -L
4-15- 10-7Ss4-l. 10“8?64-5. 10~п?7.
Благодаря малым значениям qt вычисления можно существенно
упростить, воспользовавшись какой-нибудь из приближенных формул
(3.1.81') и (3.1.95).
Для иллюстрации точности приближения, даваемого этими фор-
мулами, в таблице 3.1.10 приводятся результаты определения с их
помощью вероятностей qr,(x).
Таблица 3.1.10
Число отказавшихся элементов х Вероятности отказа х ^Ч. элементов, вы- Ч. численные по формулам ^ч. 0 1 2 3 4
(2.3.12') (3.1.8Г) (3.1.95) 0,73521 0,74156 0,73544 0,23275 0,22173 0,23214 0,02906 0,03315 0,03041 0,00201 0,00330 0,00199 0,00007 0,00025 0,00003
Как видно из таблицы 3.1,10, формула (3.1.95) значительно
точнее, чем формула Пуассона (3.1.81'), приближает вероятности
</7(х). Однако при х = 5; 6 и 7 вычисления по формуле (3,1.95)
приводят к малым по абсолютной величине, но отрицательным
§ 2] РАСПРЕДЕЛЕНИЕ НЕПРЕРЫВНЫХ ВЕЛИЧИН 111
величинам. Так, например, при х = 5 вероятность <?, (5) =—86-10-’,
л при х — 7 имеем ^,(7)==—79-10-’. Данное несоответствие
объясняется тем, что формула (3.1.95) представляет сумму только
начальных членов бесконечйого ряда.
§ 2. Распределение непрерывных (непрерывно распределенных)
величин
3.2.1. Основные теоретические характеристики распределе-
ния непрерывной случайной величины: плотность распределения
вероятности и функция распределения. Квантили. Медиана. Мы
уже упоминали о непрерывной случайной величине как о перемен-
ной, которая может в результате испытания принять любое значение
в одном или нескольких заданных интервалах (или некоторых
областях плоскости или пространства). К таким величинам принад-
лежат, например, погрешности обработки, ошибки измерения, шумы
в радиоприемных устройствах, координаты молекул газа в сосуде,
расстояние точки поражения от цели и т. д. При описании рас-
пределения подобной величины мы сталкиваемся с тем затруднением,
что выписать в последовательность и занумеровать все значения
величины, попадающие даже в очень узкий интервал, принципиально
невозможно. Эти значения образуют несчетное бесконечное мно-
жество, носящее в математике название «континуума». События
Х=х, где х—какое-либо из возможных значений нашей величины
(х = 0,897, х~Ул, х=1,24 и т. д.), как и в случае дискретной
величины, представляют элементарные исходы испытания. Однако
при собственно непрерывном (или, как говорят математики, «абсо-
лютно непрерывном») распределении величины X с каждым воз-
можным событием Х=х мы можем связать (не нарушая аксио-
матики, введенной в п. 2.1.3) лишь вероятность нуль, что, правда,
не влечет за собой в данном случае невозможности события. Так,
например, только с вероятностью нуль мы можем говорить, что
первый с начала наблюдения распад атома произойдет в точно
фиксированное мгновение или что отклонение стрелки прибора до-
л
стигнет в точности угла, равного у , или что отклонение действи-
тельного размера от номинального размера составит ровно
4-0,05000017 мм. Во всех этих случаях практически невозможно
установить, произошло такое событие или нет, так как физические
и технические измерения реальных величин (времени, угла, длины
и т. д.) производятся всегда с ограниченной точностью и в качестве
результата измерения мы можем фактически указать лишь границы
более или менее узкого интервала, внутри которого находится
измеренное значение. Значениям непрерывной величины по самому
существу присуща некоторая неопределенность. Так, например, вряд
112
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ
[ГЛ. HI
ли имеет смысл различать два отклонения от номинального
равные +0,05 мм и +0,05000017 мм. Таким образом, в
случае вероятность, отличная от нуля, может быть связана только
с попаданием величины в заданный интервал (хотя бы и
узкий). Здесь дело обстоит так же, как в случае непрерывного рас-
пределения массы вдоль прямой, когда отсутствуют массы, сосредо-
точенные в определенных точках, и можно говорить лишь о массах,
попавших в определенный отрезок прямой.
Отправным пунктом при статистическом изучении распределения
непрерывной величины на практике являются таблицы с указанием
частостей (или частот) попадания измеренных значений
в интервалы, на которые мы разбиваем весь диапазон
величины. Примером такого полученного на опыте распределения
может служить таблица 3.2.1.
Таблица 3.2.1
Распределение отклонений размеров 350 валиков,
обработанных на автоматическом станке
№ Интервалы отклонений размеров в мм Частота т Частость т ю—— п Вероят- ность Р (х)
1 от —0,230 до —0,210 3 0,009 0,005
2 » —0,210 » —0,190 8 0,023 0,017
3 » —0,190 » —0,170 19 0,054 0,044
4 » —0,170 » —0,150 37 0,106 0,092
5 » —0,150 » —0,130 53 0,151 0,150
6 » —0,130 » —0,110 60 0,171. 0,191
7 » —0,110 » —0,090 64 0,183 0,191
8 » —0,090 » —0,070 49 0,140 0,150
9 » —0,070 » —0,050 31 0,088 0,092
10 » —0,050 » —0,030 17 0,049 0,044
11 » —0,030 » —0,010 7 0,020 0,017
12 * —0,010 » +0,010 2 0,006 0,005
Итого . . . 350 1,000 0,998
По свойству вероятностей таблица частостей будет приближенно
воспроизводить распределение вероятностей с тем большей точ-
ностью, чем большее число испытаний было произведено.
Для сопоставления мы приводим в таблице 3.2.1 вероятности
попадания отклонений размеров в наши интервалы, вычисленные
в предположении, что отклонения следуют нормальному закону
распределения, о котором мы говорили в главе 1. График распре-
деления, заданного в таблице 3.2.1, показан на рис. 20.
§ 2] РАСПРЕДЕЛЕНИЕ НЕПРЕРЫВНЫХ ВЕЛИЧИН 113
Подобный прием мы можем использовать практически при любом
непрерывном распределении. Однако такое табличное описание
предполагает уже выбор определенной системы интервалов, что
в известной степени зависит от нашего усмотрения и от точности
измерений. Для того чтобы избежать этих затруднений в описании
непрерывных величин при теоретическом их изучении, мы введем
Рис. 20. Распределение отклонений размеров 350 валиков,
обработанных на автоматическом станке.
(по аналогии с тем, как в механике вводится понятие плотности
материи) понятие плотности непрерывного распределения вероят-
ностей.
Рассмотрим для некоторого действительного числа х вероятность
неравенства
х < X < х Дх,
где Дх—длина малого интервала, начинающегося в точке х.
Пусть при Дх->0
-И*—д7*+ А-х)- — Р (х). (3.2.1)
Функция р(х) и есть плотность распределения величины X.
Для бесконечно малого интервала мы будем иметь (с точностью
До бесконечно малых более высокого порядка малости):
P(x<?f<x + Дх)—р (х) Дх, (3.2.2)
114
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ
[ГЛ. III
а для конечного интервала (хр х2), где
*2
Р (Xj < X < х2) = р (я) dx.
«1
(3.2.3)
В дальнейшем мы будем называть всегда плотностью распределения
величины X функцию р{х), обладающую свойством (3.2.3). Иначе
говоря, интеграл от плотности распределения по любому проме-
жутку оси х дает вероятность попадания величины X в этот про-
межуток. Выражение (3.2.2) называется вероятностью элементар-
ного события. Из (3.2.2) следует, что р(х)— неотрицательная
функция. Как видно из (3.2.3), вероятность попадания значения
величины X в любой интервал (х^ хг) изображается площадью над
этим интервалом под «.кривой распределения'», представляющей
график функции р(х).
Если вся «масса вероятности» распределена в интервале (а, Ь)
так, что величина X заведомо удовлетворяет неравенству a^X&zb,
то X называется- ограниченной величиной (понятно, что ограничен-
ные величины не обязательно непрерывны). В этом случае
ъ
Р (а - ~ X -С b) = р (х) dx = 1.
а
(3.2.4)
Мы, однако, для удобства и единообразия записи будем всегда
считать функцию р(х) определенной для всех значений X, полагая
ее равной нулю в тех точках оси х, которые не являются возмож-
ными значениями величины X.
Вообще говоря, плотностью распределения может служить любая
интегрируемая функция р(х), удовлетворяющая двум условиям:
1.
2.
Р (х) О,
р (х) dx = 1.
(3.2.5)
(3.2.6)
Эти условия вытекают из самого определения.
В качестве примера распределения ограниченной величины рас-
смотрим равномерное распределение ' X в отрезке (а, Ь). В этом
случае плотность вероятности постоянна внутри этого промежутка,
так что
р (х) = с при а х Ь, |
р (х) = 0 при х <_ а и х^> Ь. /
(3.2.7)
§ 2]
РАСПРЕДЕЛЕНИЕ НЕПРЕРЫВНЫХ ВЕЛИЧИН
115
График функции р(х) при этом изобразится «кривой распределе-
ния», показанной па рис. 21.
Часто встречаются случайные величины, не имеющие определен-
ных границ для своих значений. Примером неограниченного справа
распределения может служить
распределение Вейбулла, зада-
ваемое плотностью о.г
р (х) = 0 при х О,
где а и b — параметры рас- Рис. 21. График плотности вероятности
пределения.
Этому распределению не-
равномерно и непрерывно распределен-
ной на отрезке (а, Ь) величины.
редко следует время непояв-
ления внезапных (катастрофических) отказов некоторых элементов
радиоэлектронной аппаратуры.
При Ь — 2 это распределение называется распределением Релея,
а при b = 1 оно преобразуется в экспоненциальное (показательное)
распределение.
Экспоненциальное распределение, обычно применяемое для вы-
числения вероятностей безотказной работы (непоявления внезапных
отказов) технических систем, имеет плотность вида
р(х) = 'се при
р(х) = 0 при х<^0.
(3.2.9)
Единственный параметр Х = — этого распределения, рассматриваемый
в теории надежности как интенсивность отказов (в данном случае
постоянная), может иметь лишь положительные значения, что обес-
печивает выполнение условия (3.2.5). Условие (3.2.6) также выпол-
няется, так как
$ p(x)dx = \ be Ххdx — \d(—e'Xv) = [—=
Мы увидим в дальнейшем, что плотностью (3.2.9) может быть
задано распределение случайных отрезков времени между последо-
116
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ
[гл. Ht
нательными наступлениями редких событий. График этой плотности
показан на рис. 22.
Вероятность Р(Х<^х) того, что величина X меньше задан-
ного числа х, изобразится площадью под кривой р(х) слева от
Рис. 22. График плотности экспоненциального (показательного)
закона распределения X = 1.
ординаты р(х). Эта площадь заштрихована на рис. 23. Для вероят-
ности имеем:
Р(.А<х) = /ф)Лг = Р(х). (3.2.10)
(Здесь мы использовали для обозначения аргумента под интегра-
лом букву и' потому, что буква х использована для обозначения
верхнего предела интеграла.) Вероятность Р(х) в (3.2.10) как функ-
ция х называется интегральной функцией распределения в отличие
от плотности р(х\ которую иногда называют дифференциальной
функцией распределения.
По самому определению Р(х) обладает следующими свойствами:
1. Р(х)— непрерывная возрастающая функция; ее приращение
в промежутке (хь х^ равно вероятности для величины X попасть
в этот промежуток. В самом деле, по правилу сложения
Р (А' х.>) — Р (A’ xj Р (xj -С X <[ х.2),
РАСПРЕДЕЛЕНИЕ НЕПРЕРЫВНЫХ ВЕЛИЧИН
117
т. е.
Р (х2) = Р (х2) + Р (Xj х2)
л, следовательно,
х«
Р (*1 X <С Х2) = Р (Х2) — Р (Х1) — $ Р (*) dx.
Х1
(3.2.11)
Заметим, что так как вероятность попадания в точку xt или х2 'для
непрерывно распределенной величины X равна нулю, то безразлично,
будем мы сопровождать знаки
неравенства знаками равенства
пли не будем. Вероятности
P(Xj<X<x2), P(Xi<X<x2),
Р (xi <С X £' х2) и Р (Xj -
=< X х2) равны между собой
и равны приращению функции
Р(х) в промежутке (хь х2).
2. limP(x) = 0,
.Г-*—СО
1ппР(х)=1.
ЛГ-^4"00
(3.2.12)
Рис. 23. Геометрическая интерпретация
вероятности Р (Х< х) на графике плот-
ности вероятности р (х).
Э ги предельные соотношения
вытекают из определения Р (х)
как интеграла от плотности
р(х); второе из них выражает условие (3.2.6). Для ограниченных вели-
чин свойства (3.2.12) очевидны, так как при х<^а (предполагается,,
чго величина X распределена в отрезке (а, Ь))
а для х^>Ь
Р(х) = Р(Х<х)<Р(Х<а) = О,
P(X<x)SsP(X<£)=l.
3. Предполагая функцию р(х) непрерывной, получим, что произ-
водная от интегральной функции распределения Р(х) равна плот-
ности р(х), т. е.
p'w=^=m (3.2.13)
Заметим еще, что для вероятности неравенства Х^х имеем:
Р(Х^х)=1 — Р(Х<х) = 1 — Р(х). (3.2.14)
Если Х=Т есть время безотказной работы, то P(7'^i) =
= 1 — Р (t) представляет собой вероятность безотказной работы за
время t.
118
случайные величины
[гл. HI
В качестве примера рассмотрим интегральные функции распре-
деления равномерного и показательного распределений.
Для равномерного распределения в отрезке (а, Ь) имеем:
Р (х) = О
pM=J
а
Р(х)= 1
при x<Za,
при a <Zx <Z b,
при х b.
(3.2.15)
График Р(х) для равномерного распределения показан на рис. 24.
На отрезке (а, Ь) график функции Р(х) представляет наклонную
возрастающую прямую, изображающую пропорциональное нараста-
ние площади под графиком плотности на том же отрезке, который
показан на рис. 21.
Рис. 24. График интегральной функции равномерного рас-
пределения.
Функция Р(х) показательного распределения определяется сле-
дующими соотношениями:
Р (х) = О при х < 0, 1
Р (х) = X е-'" du — 1 — е~кх при х>0. [ (3.2.16)
О '
При описании непрерывного распределения часто используют
еще так называемые квантили. Квантилем, отвечающим заданному
уровню вероятности р, называют такое значение х = хр, при
котором функция распределения принимает значение, равное р, т. е.
Р(хр) = р. (3.2.17)
§ 2] РАСПРЕДЕЛЕНИЕ НЕПРЕРЫВНЫХ ВЕЛИЧИН 119
Некоторые квантили получили особые названия. Так, например,
медианей распределения !АеХ называют квантиль, отвечающий
1 1
значению р = -^; квантили, соответствующие значениям Р=-^ и
3 г,
у)==--> называют нижним и верхним квартилями. Если поло-
жить р = 0,90; р = 0,95 и т. д., то получим соответственно 90°/^-
и 95°/0 квантили. Эти квантили иногда называют еще соответственно
1О°/'о, 5°/0 и т. д. «верхними» точками распределения. Аналогично
квантили, отвечающие значениям р — 0,10; 0,05 и т. д., называют
1О°/о, 5°/0 и т. д. «нижними» точками распределения. Зная значения
достаточного числа квантилей, мы можем легко представить себе
ход возрастания функции распределения. Медиана используется
иногда в качестве характеристики цейтра распределения.
Медиана эмпирического распределения теХ представляет
«срединное» значение данного распределения. Так, например,
в «пробе» из пяти деталей с размерами, равными It),12; 10,01;
9,98; 10,07 и 10,03, медианой будет третье по порядку возраста-
ния значение, т. е. rneA"=xs = 10,03 мм.
3.2.2. Моменты непрерывного распределения. Математическое
ожидание и дисперсия. Мода. Обозначая через р (х) &х элементар-
ную вероятность, естественно математическое ожидание МАГ непре-
рывно распределенной величины X определить равенством
МАГ= J xp(x)dx=^, (3.2.18)
— 00
предполагая, что этот интеграл абсолютно сходится.
Точно так же математическое ожидание функции Y=f(X)
величины X определяется с помощью интеграла
МГ=М[/(А')]= J f(x)p(x)dx. (3.2.19)
— со
В частности, полагая f(X) = Xk, получим выражение k-ro началь-
ного момента в виде
vft= J xkp(x)dx. (3.2.20)
— 00
Для центрального момента fe-ro порядка будем иметь:
J (х—v)kр (х) dx. (3.2.21)
*-<35
120 СЛУЧАЙНЫЕ ВЕЛИЧИНЫ [ГЛ. Ц|
В частности, для дисперсии имеем:
се со
DA’ = p2 = (х—v)2p(x)dx — J xtp(x)dx—
— СО — 00
со со
— 2v § xptxjdx-f-v2 J p(x)dx — vt — 2v2-|-v2 = v2—v2, (3.2.22)
— 00 —00
аналогично тому, что мы имели для дискретного распределения.
Модой непрерывного распределения называется значение, при
котором р(х) достигает максимума; если максимумов два, то
распределение называется двумодальным, если три — то трех-
модальным, и т. д.
Все свойства математического ожидания и дисперсии, рассмотрен-
ные нами для дискретного распределения в пп. 3.1.2 и 3.1.3, имеют
место также и для непрерывного распределения. \
Если распределение симметрично около начальной ординаты,
так что функция р(х)— четная [р(х) = р(—х)], то математическое
ожидание равно нулю, так как
о оо
J х р (х) dx = — J х р (х) dx,
— 00 о
а потому
00
ML¥= xp(x}dx—0. (3.2.23)
— »
Если ось симметрии кривой у—р(х) проходит точку x = v, так что
при любом х' имеем
p(v + x') = p(v—х'),
то
(3.2,24)
В самом деле,
сс оо со
j xp(x)dx= J (v + x')p(v-b x'}dx' = v j p (v + x') dx' -f-
— co — co — co
00
+ x'p(v+x')dx' = v + 0 = v.
— 00
Все эти свойства полностью согласуются с механическим истолко-
ванием математического ожидания как абсциссы центра тяжести,
данным в п. 3.1.2. Поэтому математическое ожидание непрерывно
распределенной величины можно находить с помощью известных
§ 2] распределение непрерывных величин 121
из механики приемов нахождения центра тяжести фигуры, очерчен-
ной кривой плотности вероятности и осью абсцисс, а ее дисперсию —
ка’к момент инерции той же фигуры относительно оси, перпенди-
кулярной к оси ОХ и проходящей через точку, отвечающую мате-
матическому ожиданию.
Так, например, математическое ожидание равномерно распре-
деленной в отрезке (а, Ь) непрерывной величины X мы можем
найти по соотношениям (3.2.8) и (3.2.18) в виде
ь
MX=[x~dx^ = V, (3.2.25)
J Ъ—а 2(6—а) 2 ’ '
а
где v — абсцисса точки, через которую проходит ось симметрии
кривой.
Мы можем, однако, сразу прийти к этому же выражению,
замечая, что график плотности равномерного распределения, по-
казанный на рис. 21, симметричен относительно прямой х—-~—.
Дисперсию этой случайной величины мы также можем определить
двумя способами:
1) Определив сначала
ь
С 2 1 . 6’—а’
V, = \ X т-- dx = 7—7-Г ,
2 J Ь—а 3(Ь—а)’
а
затем по формуле (3.2.22), получим:
= = (3.2.26)
2) Пользуясь известным из механики соотношением для момента
инерции прямоугольника относительно центральной оси, найдем:
ВН3 _ Ь^а (Ь~а)’ _ (Ь—а)2
DA— lg — 12 — 12 ,
где В—основание прямоугольника (т. е. в нашем случае плотность
распределения , показанного на рис. 20, Н — высота прямо-
угольника (широта распределения), что совпадает с (3.2.26).
Обозначим теперь длину интервала (а, Ь) через 2/г, а его поло-
вину через 7г, т. е. b — a — 2h, и перенесем начало координат
в его середину; тогда в новой системе координат будем иметь
122
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ
[ГЛ. 111
интервал (— h, h). Для этого случая
/1
..V С 1 . 112 — >1г п
МХ = \ dx — —у;— = О,
J 2/г 4Л ’
-h
что согласуется с (3.2.23).
Далее,
к (2Л)’ м
DA'=2/z h (3.2.27,
□
и
ох
откуда
h — ]/ЛЗох 1,73ох
(3.2.28)
Возьмем еще показательный закон распределения, задаваемый
плотностью (3.2.9). Для него будем иметь:
СО со
AL¥= J хХе~'/'х dx — X\xe~:‘-':dx—4-,
О о
со
v2 = х2Хе-?“* dx = ^-г,
О
откуда с помощью (3.2.22) получим:
2 /IV 1
О¥=±-(1 = ±
л8 \ л / V
1
Таким образом, среднее квадратическое отклонение распределения
величины X, следующей показательному закону, численно равно
математическому ожиданию.
3.2.3. Надежность элемента системы при изменяющемся вре-
мени работы. Характеристики непрерывно распределенных случайных
величин используются, например, в теории надежности для решения
задач, несколько более сложных, чем рассмотренные в пп. 2.4.2
д 3.1.7.
Там важнейшая характеристика надежности—вероятность без-
отказной работы была известна для каждого элемента системы
при фиксированном отрезке времени и являлась постоянной вели-
чиной. Между тем одинаковые элементы очень часто используются
распределение непрерывных величин
123
§ 2]
на практике в различных системах, рассчитанных на разные про-
должительности работы. С изменением же времени работы, естест-
венно, изменяется и указанная вероятность, являющаяся, вообще
говоря, функцией времени. Часто приходится по некоторым данным
рассчитывать эту вероятность и другие характеристики для тех или
иных элементов при выбранном (в соответствии с практическими
задачами) отрезке времени. В подобных расчетах и используются
рассмотренные в предыдущих пунктах данного параграфа характе-
ристики случайных величин.
Обозначим через Р,-(/) вероятность того, что /-й элемент системы,
начавший работать в момент времени / = 0, не будет иметь ни
одного отказа до момента времени t. Вероятность Qz(/) возникно-
вения хотя бы одного отказа элемента в интервале времени (0, t),
как вероятность противоположного события, на основании соотно-
шения (2.1.16) равна Q;(/) = 1 — Рх(t).
Если рассматривать момент времени возникновения первого
отказа /-го элемента (начавшего работать при / = 0), как случайную
величину Т(, то на основании формулы (3.2.10) вероятность Qz (/)
является интегральной функцией распределения этой величины, т. е.
Р(Л.</) = 0(.(0, (3.2.31)
а ее плотность вероятности на основании соотношения (3.2.13) будет
= (3-2-32>
С помощью (3.2.20) и (3.2.32) находим А-й начальный момент
распределения величины
о
откуда, учитывая соотношение (3.2.32), интегрируя по частям
и принимая во внимание, что Р((0)=1 и limPz(/) = 0, получаем:
/ О
/А-’Р;(/)й?/. (3.2.33)
О
Из (3.2.33) определяем по формуле (3.2.18) среднее время без-
отказной работы элемента
М7} - J Рх (/) dt (3.2.34)
о
124
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ
[гл.
и по формуле (3.2.22) дисперсию времени безотказной работы этого,
элемента
о 'о '
С помощью соотношения (3.1.31) находим среднее квадратиче-
ское отклонение времени безотказной работы.
Нередко для вероятности безотказной работы элемента н
практике принимается экспоненциальный закон распределения
что
Q, (0=1— Р, (0 = 1— ел‘, (3.2.36);
где согласно (3.2.29) ^ = ^[у. — постоянное число.
Пусть, например,
срок службы составляет —
работы следует закону найти
вероятность безотказной такого в течение
1000 часов.
С помощью (3.2.36) при л=-^ находим
_ ю3 ______1_
Pf(103)=l — Ог(103) = е i°5 = e i«2 = 0,987,
т. е. вероятность безотказной работы непроволочного сопротивления
в течение 1000 часов составляет 0,987.
3.2.4. Эмпирическое распределение непрерывной величины,.
построение его графиков и получение характеристик. На
мы получаем эмпирические распределения непрерывной величины,
производя наблюдения над каким-либо признаком совокупности
объектов или опытов, количественное выражение которого в неко-
торых единицах может в принципе непрерывно изменяться. К числу.
таких признаков относятся, например, прочность образцов сплава,
измеряемая в кг/мм^ (килограммах на квадратный миллиметр), откло-
нения размеров изготовленных деталей от номинального размера в лк
(микронах), погрешность измерения в единицах измеряемой величины
(кг, мм, вольтах, амперах и т. д.), электрическая емкость пьезо-
элементов в пф (пикофарадах), и т. д.
Рассмотрим приведенные в таблице 3.2.2 данные об электри-
ческой емкости 20 пластин пьезоэлементов.
Мы видим, что емкость меняется от пластины к пластине, т. е.
является варьирующим признаком.
Расположим теперь наши данные в порядке возрастания значений
варьирующего признака (таблица 3.2.3).
§ 2]
РАСПРЕДЕЛЕНИЕ НЕПРЕРЫВНЫХ ВЕЛИЧИН
125
Таблица 3.2.2
Емкость пластин размером 40 х 8 х 0,35 из керамики титаната бария
№ пластины 116 259 117 128 119 127 122 254 124 201
Емкость в пф 103 11,0 9,2 9,9 12,0 8,0 8,7 7,1 11,8 11,7 10,3
№ пластины 202 26S 203 205 203 271 208 220 226 217
Емкость в пф 103 11,2 8,1 9,5 11,5 11,6 9,7 10,2 Н,4 8,6 10,0
Таблица 3.2.3
Вариационный ряд пластин из керамики титаната бария по емкости
№ пластин в порядке возрастания емкости 1 2 3 4 5 6 7 8 9 10
Емкость в пф 103 7,1 8,0 8,1 8,6 8,7 9,2 9,5 9,7 9,9 10,0
№ пластин в порядке возрастания емкости 11 12 13 14 15 16 17 18 19 20
Емкость в пф 103 10,2 10,3 11,0 П,2 11,4 11,5 11,6 Н,7 11,8 12,0
В таком расположении рассматриваемые данные представляют ва-
риационный ряд, т. е. ряд данных, расположенных в порядке возра-
стания варьирующего признака. График этого, ряда показан на рис. 25.
Разность между экстремальными или крайними значениями ряда
называется размахом варьирования или широтой распределения.
Размах варьирования, следовательно, определяется соотношением
/?=хн5-хнм. (3.2.37)
В нашем примере размах варьирования равен
R = 12,0 — 7,1 = 4,9 ддб-Ю3.
Однако при изучении непрерывных величин приходится прибегать
к большому числу наблюдений. В этих случаях наблюденные в вы-
борке значения подвергаются группировке: шкала интересующего
126 случайный величины [гл.
нас признака подразделяется на некоторое число интервалов (раз-',
рядов), и затем рассматривают не отдельные значения величины
а группы значений, попавших в последовательно
интервалы.
Число таких интервалов при числе наблюдений порядка 200—300 •
и более рекомендуется брать в пределах от 10 до 20. При пред-
полагаемом нормальном распределении часто берут число интер-
валов, равное 12.
При слишком большом числе интервалов картина распределения
будет искажена случайными зигзагами частот, слишком малочислен-
ных при узких промежутках. При слишком малом числе интервалов .
Рис. 25. График вариационного ряда пластин из керамики титаната бария,
расположенных по значениям их электрической емкости.
будут сглажены и затушеваны характерные особенности распре-
деления.
Рассмотрим протокол измерения 200 валиков, отобранных из
текущей продукции прецизионного токарного автомата, представлен-
ный в таблице 3.2.4.
Если подробно просмотреть таблицу 3.2.4, то можно обнаружить,
что в ней встречается 78 различных значений отклонения от номи-
нального размера, наименьшее из которых составляет —20 мк,
а наибольшее -]~30 мк.
Разобьем широту распределения интересующего нас признака
на. десять равных интервалов. Ширина каждого интервала (шаг
разбиения) будет равна
Дх =
£
е
30 — (—20) 50
10 “10“
5 мк.
Табл и ц а 3.2.Л
Протокол измерения деталей (отклонения в микронах)
№ детали Отклоне- ние № детали Отклоне- ние Nq детали Отклоне- ние № детали Отклоне- ние № детали Отклоне- ние № детали Отклоне- ние Хе детали Отклоне- ние
1 + 1,0 30 + 11,0 59 + 11,5 88 —3,0 117 —6,5 146 0,0 175 —4,5
2 + 1,5 31 + 14,0 '60 + 10,0 89 +5,0 118 4-2,0 147 +0,5 176 +6,0
3 —2,5 32 + 11,0 61 +7,5 90 +3,5 119 —11,0 148 +3,5 177 +9,5
4 0,0 33 + 11,0 62 +8,5 91 —3,0 120 — 17,5 149 +9,0 178 + 12,5
5 —1,5 34 + 13,0 63 +6,5 92 — 14,0 121 —15,0 150 +2,5 179 + 19,0
6 + 1,0 35 + 16,0 64 +8,5 93 + 17,0 122 -—15,5 151 +2,0 180 4-13,0
7 + 1,0 36 + 14,5 65 +5,5 94 —9,0 123 + 1,5 152 +7,0 181 + 1,5
8 + 15,0 37 + 19,0 66 +26,0 95 — 13,0 124 — 18,0 153 +7,5 182 +0,5
9 —1,0 38 + 14,0 67 + 12,5 96 — 12,5 125 —20,0 154 +3,5 183 + 12,0
10 +2,0 39 + 18,0 68 +6,5 97 +8,5 126 — 15,0 155 +7,0 184 + 4,0
11 +2,0 40 + 19,0 69 +8,5 98 + 12,0 127 —3,0 156 +4,5 185 +6,5
12 +3,0 41 + 19,0 70 +7,5 99 +6,0 128 —8,0 157 — 1,0 186 —9,5
13 + н,о 42 +23,5 71 +2,5 100 +8,5 129 — 1,0 158 + 11,0 187 —8,0
14 — 1,0 43 +22,0 72 +7,0 101 0,0 130 —6,5 159 +4,0 188 —4,5
15 4-5,0 44 + 18,5 73 +4,5 102 +7,0 131 —8,0 160 +9,0 189 +7,5
16 +4,5 45 + 19,5 74 —0,5 103 — 1,0 132 —13,5 161 +4,5 190 —4,0
17 +0,5 46 + 17,5 75 +4,0 104 —3,0 133 — 12,0 162 + 11,5 191 —9,0
18 +3,5 47 + 18,0 76 +5,5 105 +0,5 134 — 17,0 163 + 14,0 192 —9,0
19 +8,0 48 + 19,5 77 4-1,0' 106 0,0 135 — 10,5 164 4-Ю,0 193 -Н2,0
20 +5,0 49 + 17,5 78 + 4,0 107 —2,0 136 + 14,5 165 +20,0 194 —0,5
21 +4,5 50 +25,5 79 +6,5 108 —4,5 137 4-10,0 166 + 13,0 195 +3,5
22 +3,5 51 + 19,5 80 +5,0 109 +2,0 138 +9,5 167 +7,0 196 + 10,5
23 +9,5 52 +22,0 81 4-4,5 ПО —10,0 139 +7,0 168 4-12,0 197 —5,5
24 + 12,0 53 + 13,5 82 +5,0 111 —8,5 140 +0,5 169 +7,5 198 —6,0
25 +7,5 54 + 18,5 83 +7,5 112 —3,5 141 +21,0 170 +2,0 199 —6,5
26 +7,5 55 +21,5 84 +5,0 ИЗ —11,5 142 + 10,5 171 + 1,0 200 —8,0
27 + 10,0 56 +30,0 85 + 15,5 114 — 11,5 143 +5,0 172 +25,0
28 +8,5 57 +21,0 86 4-6,0 115 —7,5 144 +0,5 173 +0,5
29 + 10,0 58 + 13,5 87 4-6,5 116 —11,5 145 +4,0 174 —3,0
РАСПРЕДЕЛЕНИЕ НЕПРЕРЫВНЫХ ВЕЛИЧИН
128 СЛУЧАЙНЫЕ ВЕЛИЧИНЫ [гл.
Подсчитаем теперь частоты по интервалам, расположив
в виде «таблицы подсчета частот по интервалам» (таблица
Т а б л и ц а
№ интервалов Подсчет частот по интервалам
Границы интерва- лов (разрядов) Поде чет частот Частота в интервале Середина интервала
1 2 3 4 5
1 от —20 до —15 '~i 7 —17,5
2 » —15 » —10 ixi ’ 11 -12,5
3 » —10 » —5 ixi 15 -7,5
4 » —5 » 0 •Xi ixi. 24 -2,5
5 » 0 » 5 ixi ixi ixi ixi i/i 49 +2,5
6 » 5 » 10 ixi ixi ixi ixi ‘ 41 +7,5
7 » 10 » 15 ixi ixj ~i 26 + 12,5
8 » 15 » 20 ixi i 17 + 17,5
9 » 20 » 25 7 +22,5
10 » 25 » 30 « 3 +27,5
Итого . . 200
Третью графу мы заполняем, просматривая по порядку
наблюдений, и делаем отметку (в виде точки, а затем исче
пания четырех точек—в виде тире) в том интервале, в
по своему отклонению попадает данная деталь. Так,
первая по порядку деталь имеет отклонение + 1,0мк;
ставим первую точку в интервале № 5 (с границами от 0 до 5
вторая деталь имеет отклонение 4 1,5 мк, — ей будет
рая точка в том же интервале № 5, и т. д. Комбинация из
точек и шести тире в какой-либо строчке означает десяток
по своим отклонениям попавших в этот интервал.
Пройдя по порядку номеров все 200 деталей и расставив отве-
чающие им 200 значков (точек или тире) в строчках, отвечающих
интервалам отклонения, мы подсчитываем число значков в строчке,,
которое и будет равно частоте в данном интервале.
остальных граф таблицы 3.2.5 не требует пояснений.
В результате мы получили частости по интервалам, представлен-
ные в таблице 3.2.6.
Для наглядности эмпирическое распределение можно изобразить
графически в виде: 1) полигона, 2) гистограммы и 3) ступенчатой
кривой.
§ 21 РАСПРЕДЕЛЕНИЕ НЕПРЕРЫВНЫХ ВЕЛИЧИН 129
Таблица 3.2.6
Частости по интервалам
№ интервалов 1 2 3 4 5 6 7 8 9 10
Границы интервала от —2D до —15 от — 1 5 до —10 от —10 до —5 от —5 до 0 от 0 до 5 ОУ 5 до 10 от 10 ДО 15 от 15 до 20 от 20 до 25 от 25 до 30 Сумма
Середина интервала -17,5 -12,5 -7,5 -2,5 + 2,5 + 7,5 + 12,5 + 17,5 + 22,5 + 27,5
Частота 7 11 15 24 49 41 26 17 7 3 200
Частость 0,035 0,055 0,075 0,120 0,245 0,205 0,130 0,085 0,035 0,015 1 ,000
Полигон строится следующим способом: на оси абсцисс откла-
дываются интервалы значений величины, в серединах интервалов
строятся ординаты, пропорциональные частотам или частостям, и
концы ординат соединяются. На рис. 26 показан полигон эмпири-
ческого распределения, заданного таблицей 3.2.6.
Рис. 26. Полигон распределения 200 валиков по наружным диаметрам.
Гистограмма получается так: над каждым отрезком оси абсцисс,
изображающим интервал значений величины, строится прямоугольник,
площадь которого пропорциональна частости или частоте в этом
интервале. Если все интервалы имеют одинаковую ширину (что обычно
и бывает), то высоты прямоугольников также пропорциональны
5 Н. В. Смирнов, И. В. Дунин-Барковский
130
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ
[гл. 111
частостям или частотам. На рис. 27 показана гистограмма распре-
деления, заданного таблицей 3.2.6.
Ступенчатая кривая строится следующим образом: над каждым
отрезком оси абсцисс, изображающим расстояние между серединами
Рис. 27. Гистограмма распределения 200 валиков по
диаметрам.
интервалов, проводится отрезок горизонтальной прямой на высоте,
пропорциональной кумулятивной частости или кумулятивной
Рис. 28. Ступенчатая кривая (эмпирическая
функция) распределения 200 валиков по диа-
метрам.
частоте в данном инте-
рвале. Концы отрезков
соединяются вертикаль-
ными прямыми. На рис. 28
показана ступенчатая
кривая распределения,
заданного таблпцейЗ.2.6.
Если численность эм-
пирического распределе-
ния непрерывной величи-
ны невелика, то подсчет
характеристик этого рас-
пределения: его средней
арифметической х, дис-
персии s2, среднего квад-
ратического отклонения
у, асимметрии sk и экс-
цесса Ek— может быть
сделан без труда по фор-
мулам соответственно
(3.1.6), (3.1.33), (3.1.33'), (3.1.41) и (3.1.43), применяемым для
вычисления характеристик эмпирических распределений как диск-
ретных, так и непрерывных величин.
§ 21
РАСПРЕДЕЛЕНИЕ НЕПРЕРЫВНЫХ ВЕЛИЧИН
131
При большой численности распределения целесообразно исполь-
зовать свойства (3.1.9) и (3.1.10) теоретических и эмпирических
распределений. Для этого за начало отсчета («ложный нуль») при-
нимают значение величины, отвечающее наиболее многочисленному
интервалу, и одновременно выражают значения для всех интервалов
в долях ширины интервала Ах. В результате середине каждого
интервала шкалы будет отвечать простое целое положительное или
отрицательное число, с которым можно весьма просто оперировать.
Проведя все операции, каждый результат умножают на Дх в соот-
ветствующей степени, а для получения х еще прибавляют «ложный
нуль». Эги выкладки для примера, приведенного в таблице 3.2.6,
показаны в таблице 3.2.7.
Таблица 3.2.7
Подсчет моментов распределения
№ интервалов Середина интервала Ki в мк 1 Относитель- 1 ная середина 1 интервала yi •'7 '3 4 Ча- стота Щ niUi зд/’ ад*
1 2 3 4 5 6 7 8 9 10 -17,5 — 12,5 -7,5 -2,5 +2,5 +7,5 + 12,5 + 17,5 +22,5 +27,5 —4 -3 —2 -1 0 + 1 +2 +3 + 4 +5 16 9 4 1 0 1 4 9 16 25 —64 -27 —8 —1 0 1 8 27 64 125 256 81 16 1 0 1 16 81 256 625 7 11 15 24 49 41 26 17 7 3 -28 -33 -30 —24 0 41 52 51 28 15 112 99 60 24 0 41 104 153 112 75 —448 —297 —120 -24 0 41 208 459 448 375 1792 891 240 24 0 41 416 1377 1792 1875
Суммы 200 72 780 642 8448
Обозначе- ния сумм У — 1 S,
Начальные моменты в относит, выражении 0,36 3,9 3,21 42,24
Обозначе- ния относи- тельных начальных моментов Л, йг
5’
132 СЛУЧАЙНЫЕ ВЕЛИЧИНЫ [гл. Ill
В этой таблице «относительные середины интервалов», приве-
денные в третьей графе, получены по формуле
(3-2.38)
где с—«ложный нуль» (с= 4-2,5 мк), а Ах—ширина интервала
(Ах = 5 мк).
«Относительные начальные моменты» здесь подсчитаны по соот-
ношению
(3.2.39)
В нашем примере
Sj 72 * «л
й. —— 20Q—°>36-
Остальные действия понятны без особых пояснений.
Теперь, принимая во внимание формулы (3.1.11), (3.1.34), (3.1.46)
и (3.1.47), мы будем иметь:
х=АхЛ1 + с, (3.2.40)
$г = от2 = (Дх)2(/га—7г2), (3.2.41)
т3 == (Ах)’ (А, —ЗЛД 4- 2А,’), (3.2.42)
от4 = (Дх)4 (7г4 —4АД 4~6А2А2—ЗА4). (3.2.43)
По этим формулам в нашем примере получим:
х = 5-0,36 4-2,5 = 4,3 мк, ,
s2 = 52 (3,9 —0,362) = 94,26 мк\
от, = 5’(3,21— 3.3,9.0,364-2.0,36’)= —113,59 мк\
от4 = 54 (42,24—4 • 3,21 0,36 4- 6 • 3,9 • 0,362—3 • 0,364) = 25 375 мк*.
Асимметрию и эксцесс в этом случае мы подсчитываем по фор-
мулам (3.1.41) и (3.1.43):
\ f V"» , I
р ___ 25 375 „___ О1Ч.
94,262 3—
следует ожидать, что наше эмпирическое распределение мало отли-
чается от нормального распределения.
ГЛАВА IV
НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ
§ 1. Понятие о нормальном законе распределения
4.1.1. Значение нормального закона распределения. В первой
главе было освещено фундаментальное значение нормального закона
распределения в теоретическом и практическом отношениях. Теперь
мы подробно рассмотрим свойства этого распределения и его про-
стейшие приложения.
4.1.2. Нормальная плот-
ность вероятности и ее
параметры. Нормальной
плотностью вероятности
называется плотность, опре-
деляемая равенством
п (х; а\ о) == -т=— е г0’
/2яо
(4.1.1)
для любого значения — оо<
<х<С°о, где а и о — произ-
вольные числа {параметры
распределения), причем о
положительно. Соответст-
вие. 29. График нормальной плотности
вероятности.
вующая этой плотности дифференциальная кривая распределения
показана на рис. 29.
Интегральная функция нормального распределения по соотноше-
нию (3.2.10) определяется из (4.1.1) в виде
X
N(x-, а\ о)= п(х\ а\ a)dx.
— 00
(4.1.2)
Легко видеть, что при любом х, каковы бы ни были параметры а
и о>0, всегда п(х; а; а)>0. С другой стороны, полная площадь
134 НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ [ГЛ. IV
под всей кривой выразится интегралом
е 2°J dx, (4.1.3)
у 2 л a J
— со
л — а . ,
который путем замены переменного х на и = (откуда x—a-\-mi
и dx = adu) преобразуется в интеграл
/==-4= С e~*dii, (4.1.4)
/2л J
— X
так как ввиду того, что о>0, верхнему пределу х= + оо в (4.1.3)
соответствует такой же верхний предел в (4.1.4) и аналогичное
соответствие имеется между нижними пределами этих интегралов.
Рис. 30. График нормальной интегральной функции распре-
деления.
Мы видим, что площадь под «любой» нормальной кривой (при
любых а и о) такова же, как под нормальной кривой с параметрами
« = 0 и о=1. Другими словами, эта площадь не зависит от пара-
метров; значение интеграла / равно единице1). Таким образом,
выполнены условия (3.2.5) и (3.2.6) для плотности распределения
вероятности и функция п(х;а;а) при всех возможных значениях
‘)См., например, упомянутую в предисловии «Общую часть», стр. 119—120.
§ 1] ПОНЯТИЕ О НОРМАЛЬНОМ ЗАКОНЕ РАСПРЕДЕЛЕНИЯ 135
параметров —оо<а<;оо и о>-0 является плотностью распреде-
ления.
График интеграл! ной функции распределения показан на рис. 30.
Из (4.1.1) и рис. 29 видно, что нормальное распределение сим-
метрично относительно ординаты, отвечающей значению х, равному а.
Это значение является поэтому центром группирования (матема-
тическим ожиданием) распределения. Если изменять а, то кривая
у — п(х; а; а) будет перемещаться вдоль оси х, сохраняя свою форму.
возрастанием абсолютной величины уклонения (х— а), т. е. по
мере удаления точки х от точки а, ордината кривой п (х; а; о)
быстро убывает; наибольшая ордината, отвечающая значению х — а,
имеет величину____=п(а\ а\ о). Эта ордината и является осью
у 2л а
симметрии кривой. При а — 0 имеем семейство центрированных
(г. е. с центром в начале координат) нормальных кривых
К-
У =-^4^е'202 = я(х; 0; а), (4.1.5)
у 2л а
зависящих от одного параметра о.
Когда параметр о уменьшается, начальная ордината кривой растет.
Подъем кривой в центральной части компенсируется более резким
спадом ее к оси х, так что общая величина площади, как мы видели,
остается неизменной и равной единице. При очень малых значениях а
кривая становится похожей на тонкую иглу, направленную вдоль
оси у. Почти вся площадь под кривой сконцентрирована на неболь-
шом интервале с центром в нуле. При возрастании о, наоборот,
происходит «сплющивание» кривой, принимающей все более плоско-
вершинную форму (рис. 31).
Чаще всего, однако, рассматривая величину, подчиненную нор-
мальному закону N(x; а-, о), переходят к нормированному распре-
делению. Нормирование распределения, вообще говоря, заключается
в переходе от величины X к вспомогательной линейной функции
z Х—а
а ’
для которой
Р(2<д) = Р (^=£<д)-Р(Аг<а + до). (4.1.6)
При нормальном распределении из (4.1.6) и (4.1.2) будем иметь:
а + го (И-Я) ‘
Р (X < а -|- до) = N (а ф до; а; о) =f е 2°г du,
— сО
1S6
НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ
[ГЛ. IV
откуда ^заменяя переменное интеграции и на новое v, пользуясь
„ и—а , du\
подстановкой v = —— и av = — 1 получим:
Z о»
P(Z<z) = pfi^<^')=-7U f e~^dv — N(z; 0; 1). (4.1.7>
\ ° / У 2л J
— со
Дифференцируя (4.1.7) по верхнему пределу, получим:
та ’ Ая(г: к 8
dz /2л
Таким образом, если произвести нормирование распределения
п(х; а; о), т. е. осуществить переход от величины X к величине Z,
то плотность вероятности Z выразится равенством (4.1.8), в котором
уже отсутствуют параметры а и ст. Все вопросы, связанные с нор-
мальным распределением величины X, решают, переходя к вспомо-
гательной величине Z, т. е. нормируя это распределение.
Нормирование распределения, как нетрудно понять, ведет просто
к перенесению начала координат в центр группирования, т. е.
к «центрированию» и к выражению абсциссы в долях ст, которое,
как мы дальше увидим, представляет среднее квадратическое откло-
нение величины X, т. е. ст = стх.
§ 1] ПОНЯТИЕ О НОРМАЛЬНОМ ЗАКОНЕ РАСПРЕДЕЛЕНИЯ 137
Ординаты кривой (4.1.8) табулированы. В таблице I приложений
приведены значения этих ординат для значений z от 0 до 4,99.
Эта таблица используется, в частности, для построения теоретической
кривой распределения, когда эмпирическое распределение непрерыв-
ной величины хотят глазомерно сравнить с нормальным распреде-
лением.
Пусть, например, мы хотим провести такое сравнение распре-
деления, приведенного в таблице 3.2.6. Мы приближенно определяем
неизвестные нам параметры а и ст нормального распределения по
опытным данным: параметр а мы приравниваем средней арифмети-
ческой отклонений размеров
4-4,3 мк
и параметр <т приравниваем среднему квадратическому отклонению
эмпирического распределения
о«У$г = 9,7 мк
(эмпирические характеристики нами были подсчитаны в п. 3.2.4).
Законность подобного приближенного определения параметров
нами будет оправдана далее. Таким образом, мы получили нормаль-
ную плотность в виде
nix-, 4,3; 9,7) = е —.
}<2л9,7 мк
Пронормируем это распределение. Для этого ширину интервалов
выразим в долях <т и получим, что при Дх = 5 мк и 0=9,7 мк
ширина Az в долях о равна
= — = Д = 0,515.
о 9,7 ’
Перенеся начало координат в точку.t = -j-4,3 мк, получим абсциссу
середины первого интервала в долях о в виде
х,—а 17,5 — 4,3_ 9 247
Учитывая, что Az = 0,515, далее получим:
z8 = —2,247 4-0,515 = — 1,732,
г, = —1,732 4-0,515 = —1,217,
и т. д. (см. строку 2 таблицы 4.1.1).
Для этих точек мы находим по таблице 1 приложений значения
плотности (4.1.8) для величины Z, проставленные в строке 3
таблицы 4.1.1.
Помножая эти величины на ширину интервала Az, найдем при-
ближенную величину площади под кривой в каждом интервале,
№ интервалов 1 2 3 4 7 9 10 Сумма
1 Середины интерва- лов X — 17,5 — 12,5 —7,5 —2,5 +2,5 +7,5 + 12,5 + 17,5 +22,5 +27,5
2 1 Армированные середины интер- валов х — а г~ а —2,247 — 1,732 — 1,217 —0,702 —0,187 +0,328 +0,843 + 1,358 + 1,873 +2,388
3 Плотности вероят- ности р (г) в се- рединах интер- валов 0,032 0,089 0,189 0,312 0,392 '0,378 0,280 0,158 0,069 0,029
4 Произведение Р (г) Дг 0,016 0,046 0,097 0,161 0,202 0,195 0,144 0,081 0,036 0,015 0,993
5 Частости w (х) 0,035 0,055 0,075 0,120 0,245 0,205 0,130 0,085 0,035 0,015 1,000
6 Отношения W (х) Дг 0,068 0,107 0,146 0,233 0,476 0,398 0,252 0,165 0,068 1 0,029
НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ
ПОНЯТИЕ О НОРМАЛЬНОМ ЗАКОНЕ РАСПРЕДЕЛЕНИЯ
139
характеризующей вероятность попадания в него. Ее естественно
сопоставить с наблюденными в выборке частостями w(x), приведен-
ными в строке 5 таблицы 4.1.1, для чего последние можно пред-
иавить в виде площадей прямоугольников, построенных на интер-
валах. Тогда, очевидно, ординаты этих прямоугольников будут равны
•" (х)
(см. строку 6 таблицы 4.1.1). Пользуясь последними, мы строим
гистограмму распределения, а через точки, отвечающие плотностям
/;(г), проводим соответствующую нашей гистограмме нормальную
кривую распределения (рис. 32).
Рис. 32. Гистограмма распределения 200 валиков по диаметрам,
совмещенная с графиком нормальной плотности вероятности
п (г; 0; 1) при а^х — 4,3 мк и о s = 9,7 мк.
Мы видим, что гистограмма нормированного распределения,
естественно, имеет такой же вид, как и гистограмма, показанная
на рис. 27, только здесь по оси абсцисс отложены не микроны,
ш (х) м
а доли о и по оси ординат — отношения вместо отношений
(х) аг?
> использованных при построении рис. 27.
Из рис. 32 видно, что полученное из наблюдений эмпирическое
распределение валиков по диаметрам довольно хорошо согласуется
с нормальным распределением, так как лишь сравнительно неболь-
шие участки гистограммы выходят за пределы кривой нормальной
плотности. Однако такое глазомерное сравнение распределений
является весьма приближенным; более точное сравнение выполняется
с помощью специальных критериев, рассматриваемых в дальнейшем.
140
НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ
[ГЛ. IV
4.1.3. Производящая функция, моменты, асимметрия и эксцесс
нормального распределения. Найдем теперь моменты нормального
распределения. Для этого сначала определим его производящую
функцию; она может быть получена из (3.1.49) и (4.1.1)
+ « (х-ау +® х; (х-аУ
my(t) — !Aext — —r==— е 202 ext dx = / е 2°! dx.
х ' /2л о J /2л a J
— 00 — со
„ х—а , dz \ ,
Сделаем подстановку z = —, x — zo-j-a, — dx — udz и
со 22
... 1 С 1!С+а’'‘---Г /
тх (0 = е 2 dz.
у 2л J
— со
Так как
(za+ a)t—^ — at—-^(z‘—2tza) — at-{-^-—^-(z—to)2,
то
at + — 1 г (z-tay
тх (t) = e 2 е 2 dz.
У 2л J
— со
С другой стороны, интеграл
1 л _
-7= I е 2 dz
/ 2л J
— СО
после подстановки z—at —и приводится к виду
1 г - —
-+= е 2 du = 1,
/2л J
— со
что отвечает свойству (3.2.6) дифференциальной функции распреде-
ления, и потому производящая функция нормального распределения
будет иметь вид
at + ™
mx{t) = e 2. (4.1.9)
Продифференцировав два раза производящую функцию (4.1.9),
получим:
+ —
m'x(t) = ea 1 (a + to‘), (4.1.10)
да'л(/) = / + 2 (f о4 2atG* -f- a2 -j- a2). (4.1.11)
§ 1] ПОНЯТИЕ О НОРМАЛЬНОМ ЗАКОНЕ РАСПРЕДЕЛЕНИЯ 141
Теперь на основании (3.1.51) при t = Q найдем из (4.1.10) и
(4.1.11) начальные моменты нормального распределения:
v, = т'х (0) = а, (4.1.12)
vt = т"х (0) = а2 +- о2. (4.1.13)
Из соотношения (3.1.14) следует, что
M^ = v, = a, (4.1.14)
т. е., как мы видели это ранее, математическое ожидание нормально
распределенной случайной величины равно параметру а.
Из соотношений (3.1.24) и (4.1.13) выводим:
D.Y = ц2 = v8 — V* = а2 + о2—а2 = а2, (4.1.15)
т. е. дисперсия нормально распределенной случайной величины
равна квадрату параметра о.
Среднее квадратическое отклонение получается из (3.1.31)
ах =/^¥=Ка2 = <г; (4.1.16)
оно равно параметру а.
Рассмотрим теперь высшие центральные моменты нормального
распределения.
Заметим, что по определению
^ = М(Х-а)*,
и, обозначая через |1А момент &-го порядка нормированного укло-
нения Z = ——найдем:
о
— X— a\k М(Х—a)* U&
\. O J ok ak
Таким образом,
Нй = ЙУ. (4.1.17)
С другой стороны, производящую функцию величины Z, распре-
деленной нормально с плотностью n(z; 0; 1), получим из (4.1.9),
полагая а = 0 и 0=1,
mz(f) = e2. (4.1.18)
Поскольку ряд, в который по формуле Маклорена может быть раз-
ложена эта функция по степеням и —-у-, будет содержать только
члены с четными степенями t, то, учитывая (3.1.52), получим:
Й1 = Й, = Й»= ••• =°> (4.1.19)
142
НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ
[ГЛ. IV
т. е. все нечетные центральные моменты нормированного нормаль-
ного распределения равны нулю.
И поэтому нечетные центральные моменты нормально распре-
деленной величины X ввиду (4.1.17) также равны нулю, т. е.
H1 = H. = HS= ••• =°- (4.1.20)
Таким образом, асимметрия нормального распределения, как и сле-
довало ожидать, равна нулю.
В то же время коэффициент при четной степени tik разложе-
ния mz(t) по известной формуле Маклорена равен . т. е. он
^2^ — |
отличается от производной—-mz(t)\ лишь множителем {2k)!,
dt2* I t=o
появляющимся при дифференцировании по t члена, содержащего
эту степень 2k раз. Поэтому
-^11-7, — Е**
Л2* z Ъ = о 2**1 а26’
(4.1.21)
В частности, при & = 1 будем иметь:
Й2_ 2!
а2 2-1!
и
что мы имели и раньше.
При k — 2 по (4.1.21) получим:
Й4==_£!_ —
о4 2221 —'
(4.1.22)
Сопоставляя (4.1.22) с (3.1.42), замечаем, что, действительно, экс-
цесс нормального распределения равен нулю; это отвечает тому
положению, что нормальная кривая принята за исходную при оценке
сглаженности всех других одномодальных кривых распределения.
§ 2. Функция Лапласа и расчеты вероятностей
при нормальном распределении
4.2.1. Функция Лапласа. Для определения вероятности
Р (Xj < X < хг) нахождения в интервале (х,, х2) случайной ве-
личины X, следующей нормальному закону, приходится вычислять
определенный интеграл вида
х3 - а
1 _ (*-п>г , р 21
Р(х,<Л<х,)=^4- г 202 (/х=-Л= е 2 dz. (4.2.1)
1 /2ло /2л J
Aj - а
а
§ 2]
ФУНКЦИЯ ЛАПЛАСА И РАСЧЕТЫ ВЕРОЯТНОСТЕЙ
143
Однако неопределенный интеграл вида
Z2
е 2 dz
не выражается через известные элементарные функции. Но опреде-
ленный интеграл в некоторых пределах может быть теми или иными
приемами вычислен с какой угодно степенью точности. Вычисления
его могут быть, например, произведены посредством интегрирова-
ния степенного ряда или посредством механических квадратур.
Определенный интеграл с переменным верхним пределом вида
z ui
О
(4.2.2)
выражающий площадь под кривой n(z; 0; 1) в промежутке от 0 до
z (рис. 33), носит название
нормированной функции Лап-
ласа, или просто функции Лап-
ласа.
В таблице II приложений
приведены значения функции
Лапласа для значений z от 0
до 5 через 0,01.
Заметим, что
Фо(0) = 0, Ф0(-со)=—1,
Фо( -1- °°) = 7
и
Ф0(-г)=-Ф0(г),
Рис. 33. Геометрическая интерпретация
функции Лапласа Ф0(г).
т. е. площадь в промежутке (0, —г) равна площади в промежут-
ке (0, z), но считается отрицательной.
Интегральную функцию нормального распределения можно вы-
разить через функцию Лапласа следующим образом:
7V(z; 0; 1)= \n(z-, 0; 1) dz -f- J n (z; 0; 1) dz = 0,5 + Ф0 (г). (4.2.3)
— со о
Если теперь воспользоваться функцией Лапласа, то формула (4.2.1)
примет вид
х2 ~ а х{ - а
<7 р <7 Z2
-ф.(М~ф-М- ,4-2-4)
144
НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ
[ГЛ. IV
Пользуясь соотношением (4.2.4) и таблицей II приложений, мы
легко можем определить вероятности попадания нормально распреде-
Таблица 4.2.1
Вероятности при нормальном
распределении
Границы интервала Вероятность попада- ния в интервал
а—а, а-[-о а—2а, a-j-20 а—За, а 4-За 0,68269^68°/,) =5:2/3 0,95450=;: 95’/„ 0,99730 =5: 99,7°/0
ленной величины в интервалы
(а — о, а 4- а), (а—2а, а 4-2а)
и (д— За, д4-3а), приведен-
ные в таблице 4.2.1.
4.2.2. Вычисление вероят-
ностей при нормальном рас-
пределении. Формула (4.2.4)
и таблицы функции Лапласа
позволяют очень просто вычи-
слять вероятности нахождения
любой нормально распределен-
ной величины X в интересующем нас любом интервале (л\, х2).
Для примера мы вычислим вероятности нахождения отклонений раз-
меров валиков в трех интервалах (— 0,11; —0,07), (— 0,19; —0,15)
и (—0,241; 0,017) при а=—0,112 мм и о = 0,043 мм.
Пользуясь формулой (4.2.4) и таблицей П приложений, находим:
Р(—0,11 <Х<—0,07) =
— Ф Г-0,07-(-0,112)1 ф Г— 0,11 — (—0,112)
“ » L 0,043 J [ 0,043
= Фо (0,98)—Фо (0,05) = 0,3365 — 0,0199 = 0,3166,
Р(—0,19 <Х<-0,15) = Ф„(— 0,88)—Фо(— 1,81) =
= —0,3106 4-0,4649 = 0,1543,
Р (— 0,241 < X < 4- 0,017) = Фо (3)- Фо (— 3) = 2Ф0 (3) =
= 2 • 0,4986501 = 0,9973002 « 0,9973.
Иллюстрация произведенных вычислений показана на рис. 34. Рас-
сматривая последний результат, мы видим, что вероятность нахож-
дений случайной величины в интервале (а — За, а 4-За) весьма
близка к единице; она с высокой точностью равна 0,9973. Поэтому
«трехсигмовые» границы а + Зо принимаются за границы практи-
чески предельных возможных значений нормально распределенной
случайной величины.
Весьма часто возникает необходимость определять квантили хр
нормального распределения, отвечающие по соотношению (3.2.17)
определенной вероятности р. Эти квантили определяются из урав-
нения
W(x; 0; 1)=р (4.2.5)
или проще с помощью обратной функции
W) = V (4.2.6)
§ 3] ПРИМЕНЕНИЕ НОРМАЛЬНОГО ЗАКОНА ДЛЯ ОЦЕНКИ ВЕРОЯТНОСТИ 145
Значения обратной функции ф (р) при значениях р от 0,000 до 0,999
даются в таблице х приложений.
Рис. 34. К расчету вероятности Р (—0,11<Х<—0,07) при
нормальном закон?" распределения с помощью функции Лапласа.
Так, например, при р — 0,873 по таблице х приложений находим
ф (О,873) = Хо,873= 1,14, что представляет квантиль, отвечающий
вероятности 0,873, или 1 — 0,873 = 0,127 = 12,7°/0-ную верхнюю точку
нормального распределения.
§ 3. Применение нормального закона для оценки вероятности
и проверки гипотез
4.3.1. Нормальное распределение как приближение биномиаль-
ного. Теорема Я. Бернулли. Теорема Лапласа. Мы вернемся теперь
к биномиальному распределению и покажем, что при больших зна-
чениях п оно с хорошим приближением (тем точнее, чем больше п)
может быть описано с помощью нормального распределения с тем же
центром и той же дисперсией, что и у биномиального распределе-
ния. Это важное предложение, принадлежащее Лапласу, позволяет
приближенно вычислять вероятности событий, связанных с биноми-
альным распределением, непосредственное вычисление которых при
большом п очень затруднительно (требует, например, определения
факториалов больших чисел).
Пусть величина X следует биномиальному закону с параметра-
ми р и п. Нормируем величину X, т. е. перейдем к вспомогательной
146
НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ
[ГЛ. IV
величине
Z X*—пр X'
~ о ~~ о ’
где г>=\/прд— среднее квадратическое отклонение величины X
и X' обозначает отклонение X от центра.
Центр распределения величины Z будет находиться при любом п
в точке 0, так как
М7 = 1М(Л— пр) = 0,
а среднее квадратическое отклонение этой величины при любом п
будет равно единице, так как по свойству дисперсии
DZ-1D (X—пр) = — = = 1
<г 1 npq npq
И потому СТ/ ~ 1.
x.f
Рассмотрим теперь производящую функцию величины Z = —. Пусть-
Мег/=мЛ 7 . (4’3J)
Но мы видели в п. 3.1.4, что
-=(реЧ1 +qe~Pl)n. (3.1.65)
Заменяя в этом выражении t на Т , получим для производящей функции
следующее выражение, очевидно, зависящее от п:
/ qt -р£\п
УпУ)=\реа +qe ° ) • (4'3'2)
С другой стороны,
— (—Г у А
ре°+qe + + + ) +
\ 1 ! Z ! и ! /
Или, принимая во внимание, что /? + <?= 1, откуда следует, что
w2-H/p2-=w (p+q)=pq,
а также, что в—У npq, получим:
qt pt
рео+че-^^]+^ + ^^Р^ ...
2/г 3! ( У npq)s
,, in 21 pq(q-p),
3! у n ( У pq)
= 1 + (4.3.3)
где
§ 3] ПРИМЕНЕНИЕ НОРМАЛЬНОГО ЗАКОНА ДЛЯ ОЦЕНКИ ВЕРОЯТНОСТИ 147
Следующие не выписанные нами члены разложения <»„(() содержат мно-
11 гч * ,
житель ____.__,___________ и т. д. Поэтому при любом t
(fn)‘ (Кп)
lim соп(/) = 0.
п -> со
Но из (4.3.2) и (4.3.3) следует:
<Рв(0 = <[ >+£(1+«„(()]}” (4.3.4)
Так как о>п (()-+() при п -+ оо, то, каково бы ни было положительное
число 8 при всех достаточно больших п, будет выполняться неравенство
— 8 < «„(/) < 8,
откуда
1-е< 1+соп (()< 1+8,
и ввиду (4.3.4)
[ 1+4 (1-8)]"<Фп(<)< [ 1+^ (1+₽)]'’- (4.3.5)
1 ь I I I
В силу известного «замечательного» предельного равенства
lim ( 1 + — =ег
п -> 00 \ И /
- 8)
(при любом г)1) левая часть (4.3.5) имеет своим пределом е “ , а пра-
-- (1+8) —
вая е 2 . Эти пределы отличаются от е 2 как угодно мало при до-
статочно малом е. Следовательно, при всех достаточно больших п и функ-
<»
ция (() отличается от е 2 как угодно мало так, что
г2
lim ф„ (() — е 2 . (4.3.6)
п -* »
Таким образом, с ростом п производящая функция нормированного бино-
миального закона неограниченно сближается с производящей функцией
нормального закона.
Применяя к данному случаю теоремы непрерывности и един-
ственности (см. п. 3.1.4), мы можем сформулировать так называе-
мую теорему Лапласа-, если п неограниченно возрастает, то при
любом Z
Р 1 f e"Tfi(w = )V(2.j о, 1) = 0,5+Ф.(г), (4.3.7)
\ F npq / ф2л J
— 00
т. е. вероятность того, что нормированная величина X, рас-
пределенная по биномиальному закону, будет меньше данного
числа z, стремится с ростом п к нормальной функции распре-
деления.
) См., например, ЭСМ, т. 1, кн. 1, стр 136.
148
НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ
[гл.
Вместо величины X—числа положительных исходов
X
мых испытаний—часто рассматривается величина = wn(,4), т.
частость появления случайного события А.
Так как
Х__
X— пр п ?
Vnpp 1 /~Р<
™п~Р
п
то из (4.3.7) следует:
/ А
pf — Д
П
N(z-, 0; 1) = О,5 + Фо(г).
Рис. 35. Распределение вероятностей ча-
стости wn, концентрирующейся при боль-
шом п около вероятности р, как центра,
р (wn) — плотность вероятности частости wn.
Из предельного соотношения (4.3.8) мы выведем теперь
предложение, доказанное впервые Я. Бернулли (1654—1705).
X
Рассмотрим случайную величину — =wn(/l) — частости.
пределение согласно (4.3.8) будет приближенно описываться
больших п нормальным
коном N(z; р; ап), где
оп= -> 0 при л-*оо.:
Такое распределение
имеет вид высокой и
кой иглы; подавляющая
масса вероятности распре-
деления будет концентри-
роваться в непосредствен-
ной близости от центра.
Как бы мало ни было по-
ложительное число 8 в ин-
тервале (р—8, р-\-е),
достаточно большом
дет сосредоточена
сколь угодно близкая
нице (рис. 35).
В самом деле, учитывая (4.3.8), получим:
г«(_ - ~<.р -pel =Р/—8 < —p<Z&
п I I п J
, х
I ----р
__pi е п __ е
I ап аи ап
п
масс ,
к еди-
РпЕ —
8
<Ъ<
1 "W
2 dz
°п
31 ПРИМЕНЕНИЕ НОРМАЛЬНОГО ЗАКОНА ДЛЯ ОЦЕНКИ ВЕРОЯТНОСТИ 149
8 1 / п
Цо — = е I/-----1 оо при п -> оо и потому
Оп ’ РЧ J
Рпе" (4,3,9)
V
Таким образом, вероятность того, что уклонение частости —
от вероятности р не превзойдет по абсолютному значению сколь
угодно малого е, стремится к единице при возрастании п. Это
предложение носит название теоремы Бернулли.
„ X—пр
Заметим, далее, что величина Z — -/- может принимать зна-
/ npq
чение z = , где х — 0, 1, 2, ..., п (и обратно, каждому та-
V пРЧ
кому значению Z отвечает х = пр-)-гУ npq). Эти значения на оси z
изобразятся точками, отстоящими друг от друга на величину
дг _ 1 = (* + 1)—яр х—пр
V~npq V npq Vnpq ’
(4.3.10)
стремящуюся к нулю при п -* оо. Каждой из этих точек отвечает
вероятность рп (х) — рп (пр -f- z У npq) биномиального распределения.
Точкам х(х>пр), лежащим справа от центра !ЛХ=пр, отвечают
положительные значения z, а при х<б,пр нормированные абсциссы z
отрицательны. Наивероятнейшее значение х0, как видно из п. 3.1.4,
будет отличаться от пр менее чем на единицу и потому будет
иметь нормированную абсциссу z0, близкую к нулю. Из теоремы (4.3.7)
следует, что сумма вероятностей
ъ ___
s = (X) = s Рп № + А Vnpq),
х=а Za^zi^Zb
отвечающая возможным значениям Z = Zj = —^=== (i — a, а-)-\, ..., Ь)
V npq
а—пр b — пр ,
в интервале от z=-x=. до zb=, при большом п приоли-
V npq V npq
женно выражается площадью под кривой
n(z; 0; 1) = -^=е 2
' /2л
в этом интервале, т. е. интегралом
г* г2
2а
а к ч то
5^Ф0(гь)-Ф0 (za).
(4.3.11)
150
НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ
[ГЛ. IV
Более детальное рассмотрение показывает, что вероятность
каждого отдельного значения Z — z приближенно при большом п*
можно считать равной площади «элементарного» прямоуголь-
ника, построенного на основании, совпадающем с интервалом-
—у-, z + у ) оси z, и с высотой, равной ординате кривой п (z; 0;
в точке z, представляющей центральную точку указанного
вала. Другими словами,
Рп (пр +• z VHpq) ж -4= е 2 Дг.
у 2л
(4.3.12)
Сумму S можно приближенно приравнять сумме площадей «элемен-
тарных» прямоугольников, построенных для всех значений z, попавших
в рассматриваемый интервал (za, zb); в частности, если крайние точки
zu и zb относятся к числу возможных значений z, то самый левый из
элементарных прямоугольников будет иметь основанием интервал
/ Az , Az\ „ ( Az . Az\
( za—2~ , za + у 1, а самый правый — интервал I zb—, zb + ~ j.
Сумму площадей всех таких прямоугольников можно приближенно
считать равной площади под нормальной кривой в интервале
/ Az , Az\
[Za §> + Т' е' ИНтегРаЛУ
как это показано на рис. 36. Таким образом,
Р (za Z zb} »Ф0 (гь + - фо - А?) , (4.3.13)
что, вообще, дает несколько более точное приближение, чем (4.3.11),
особенно при не слишком больших п. Чтобы иметь представление
о точности приближенной формулы (4.3.13), произведем расчет ве-
роятностей, которые могут быть определены точно по данным таб-
лицы 3.1.5.
Пусть п — 20 ир = 0,3. Найдем вероятность
20
Р(Х^9)= 2 Рго(х).
Поданным столбца 3 таблицы 3.1.5 точное значение этой суммы равно
0,0654 + 0,0308 4-0,0120 |-0,0039 (-0,0010 +0,0002 = 0,1133.
§ 3| ПРИМЕНЕНИЕ НОРМАЛЬНОГО ЗАКОНА ДЛЯ ОЦЕНКИ ВЕРОЯТНОСТИ 151
Для применения формулы Лапласа подсчитаем сначала
МХ = пр = 20-0,3 = 6,
оу = /20-0,3-0,7 = /ф2 =- 2,05,
Д2= — = 0,488.
Неравенство Х~г? 9 для нормированного отклонения Z превращается в
у_Х-6 9 — б_ 3
Z 2,05 2,05 “2,05 ~ 1,4Ь4‘
По формуле (4.3.13) искомая вероятность приближенно выразится
Рис. 36. Приближение биномиального распределения с помощью
нормального закона;
ь ___
2/:= 2 Рп (nP + 2i /«Р7)=^фо(гь)—фо(га)-
i=a
площадью под нормальной кривой, расположенной правее орди-
наты в точке
1,464— -^ = 1,464 — 1,464 —0,244= 1,220.
Эга площадь выражается с помощью функции Лапласа в виде
фдоо) —фо (1,22) = 0,5 — 0,3888 = 0,1112,
где значения функции Лапласа определены по таблице 11 приложений.
152 НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ [ГЛ.
Погрешность приближения равна
0,1133 — 0,1112 = 0,0021,
что составляет примерно 2%.
Точно так же для л = 20 и /? = 0,5
лр=10, Vnpq = /5 = 2,236, Дг = 0,4472.
По таблице 3.1.5 находим:
Р(7<А'<9) = 0,0739 + 0,1201 +0,1602 = 0,3542.
С другой стороны, согласно (4.3.13)
₽(7<*<9)=p(^<Z = ^=^<|=^U
\z,Z0O Z,2oo 2,zoo /
= P (— 1,342 Z < —0,447) « Фо ( — 0,447 + J _
-Фо ( -1,342 = фо (- 0,224) —Фо (-1,565) =
= Ф0 (1,565)—Фо (0,224) = 0,4412 — 0,0887 = 0,3525.
Ошибка равна 0,3525—0,3542 = —0,0017, что составляет 0,5%.
метим, что Фо (0,224) и Фо (1,565) определены с помощью
интерполяции по таблице II приложений.
Вообще, если &z = —~l= достаточно мало,
V npq
мое формулой (4.3.13), в большинстве случаев оказывается доста-
точно хорошим.
Когда р мало и пр не велико, можно воспользоваться, как мы *
видели, формулой Пуассона.
Применим теперь эти результаты к решению некоторых стати-
стических задач.
4.3.2. Доверительные интервалы для неизвестной вероятности.
Пусть результаты п независимых испытаний дали частость wn — ,
т. е. х появлений события А, вероятность которого Р(Д) = /> нам .
не известна. Мы уже видели, что естественно и
оправдано в длинной серии испытаний полагать ближенно
р fa =wn. Однако такое равенство даже при больших п сопря-
жено с некоторой погрешностью ввиду того, что w„ есть одно из
возможных значений случайной величины 1Г„ и нам всегда жела-
тельно знать вероятные пределы получаемой погрешности.
Если п достаточно велико и согласно (4.3.8) можно считать, что
величина
§ 3] ПРИМЕНЕНИЕ НОРМАЛЬНОГО ЗАКОНА ДЛЯ ОЦЕНКИ ВЕРОЯТНОСТИ 153
приближенно следует нормальному закону, то для каждого задан-
ного уровня вероятности Р можно найти такое число ip > 0, что
рН',<тЯ<Чя!й ) «4л=2®.(у=й <«•»)
V V 7Г ) ~*р
Это число приближенно определяется по таблицам функции Ф(г)
(см. таблицу II приложений) или по специальной таблице, которая
для некоторых особенно употребительных уровней Р прямо указы-
вает соответствующие значения tp. Предположим, что вероятность Р
задана настолько близкой к единице, что в данной обстановке мы
пренебрегаем событиями, имеющими вероятность, не большую 1—Р,
считая их настолько редкими, что можно без большого риска при-
знать их практически невозможными. Соответственно с этим мы будем
считать практически достоверным событие, имеющее вероятность Р
или ббльшую. В частности, согласно выбору пределов tp практи-
чески достоверно, что при каждом Р
или
p-tP УГрЛк7Г1< *п<Р+*р (4.3.16)
Неравенства (4.3.16) можно переписать в эквивалентной форме
(wn-pr < еР ,
или
или, наконец, в виде
Р1 0 + т)-р + т) + W* < °-
(4.3.17)
Многочлен второй степени относительно р в левой части (4.3.17)
имеет два действительных корня (между 0 и 1):
2nW -ptр—tP i/p
2пГ„ + ^ + ^ ^р
М ’П} 2(n + t’p)
154 НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ |ГЛ. щ
где
D = 4nWn(\~Wn)+tp и 0<р,(И7, n)<pt(W, «)< 1.
Если р лежит между pt (IF', п) и рг (IV', л), г. е.
Р, (№, «) <P<Pi(W< «)>
то, как легко видеть, выполняется (4.3.17) и, следовательно, (4.3.16).
Иными словами, (4.3.16) и (4.3.18) эквивалентны и гарантируются
с одной и той же вероятностью/3, но в (4.3.18) случайная величина
Wn входит в левую и правую части неравенства.
Таким образом, мы получили интервал [р, (IT, я), p2(W, л)],
покрывающий с вероятностью Р неизвестное нам значение р.
Такой интервал мы будем называть «.доверительным интерва-
лом^, отвечающим заданному уровню доверительной вероятности Р.
Все значения р, лежащие в доверительном интервале, мы считаем
согласующимися с наблюденной на опыте частостью 1ТП, а лежащие
вне его — не согласующимися с ней.
Основанием для этого служит следующее обстоятельство. По-
вторяя выборки объема п и определяя по каждой из них частость
Wn, а по ней строя доверительный интервал, мы будем утверждать,
что неизвестная вероятность р лежит в таком интервале. Вероятность
того, что это утверждение верно, равна Р. Поэтому согласно теореме
Бернулли мы почти наверное будем правы приблизительно в 100 Р
процентов случаев.
В качестве числовой иллюстрации изложенного метода оценки
неизвестной вероятности по частости рассмотрим следующий пример:
при п = 200 независимых испытаниях интересующее нас событие А
появилось М = 88 раз и мы хотим определить доверительные границы
с уровнем вероятности, равным Р — 0,95 для вероятности Р(А) = р.
Из таблицы 4.2.1 видно, что при РжО^б имеем /ов5 = 2,
88 1
Подсчитываем И7гоо = 200 = 0,44.
Пользуясь неравенством (4.3.18), находим:
УЪ = ]/4-200-0,44-0,56-)-2г =14,18,
Л (0,44: 200) = ^-200-°2^-2-14-18^0,37,
А(0,44; +
Таким образом, доверительной вероятности Р= 0,95 в данном
случае отвечает интервал
0,37 <р< 0,51.
Рассмотренный метод оценки вероятности пригоден лишь при
достаточно больших п. Практически удовлетворительный результат
§ 3] ПРИМЕНЕНИЕ НОРМАЛЬНОГО ЗАКОНА ДЛЯ ОЦЕНКИ ВЕРОЯТНОСТИ 155
получается, когда npq>^. Если это условие не соблюдено, то до-
верительный интервал для неизвестной вероятности строится на
несколько иных основаниях.
Для выяснения их возьмем сумму начальных членов биномиаль-
ного распределения (2,3.9), представив ее в виде от функции р:
\г.м (р) = Д Р,» = (1 - Р)п +С'пр(\-р)п-' +
+ С^(\-р)п->+...+с№(\-ру-м. (4.3.19)
Дифференцируя этот многочлен по аргументу р, найдем:
= — п (1 — р)п~1 — С„ (л — 1) р (1 — р}п~г —
-С‘ (л —2)р2 (1 (л-Af + 1)рл-' (1 — р)п-м-
-С* (п-Л1)рм (1 -р)п~м-' + л (1 -р)п~' Д 2С*пр (1 -р)п~г +
+ ЗС’р2 (1 -р)п-‘ + ... +МС^рм~' (1 —р)"~м =
— <4-3'20)
так как только последнему члену с отрицательным знаком не най-
дется равного по абсолютной величине положительного члена.
Производная функция 5пЛ1(р) отрицательна при ООр< 1. По-
эюму данная функция монотонно убывает, переходя от значения 1
при р=0 к значению 0 при р—1.Следовательно,функцияSnM (р)примет
один и только один раз любое значение а между нулем и едини-
цей (при постоянных л и /И).
Обозначим значение р, соответствующее значению а функции
через рл1а, т. е. примем
^п.м (Рл1а) а- (4.3.21)
Пусть теперь в результате испытаний мы получим частоту /И.
^Чверждение о том, что верхний доверительный предел для иско-
мой вероятности р, гарантируемый с вероятностью 1—а, равен риа,
будет ошибочно с вероятностью, не большей а. В самом деле, Пусть
истинное значение р вопреки этому утверждению больше рл]а, т. е.
Р>РЛ1я. Тогда по доказанному свойству функции (4.3.21) должно
иметь место неравенство
S,.A1(P)<-W/W>==a-
Обозначим через М наибольшее из тех значений частоты /И,
иля которых еще имеет место неравенс1во
S„m (Р) < а.
156 НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ [ГЛ.
Тогда наблюденная частота М наверняка не больше /И, т.
она равна одному из чисел 0, 1, 2, .. . , М. Но вероятность
нять какое-нибудь одно из этих значений на основании
сложения (2.1.12) как раз равна сумме $пм(р) и, значит,
Таким образом, в качестве верхнего доверительного
с вероятностью ошибки, меньшей а, мы действительно
взять корень уравнения (4.3.21).
Аналогичным образом можно показать, что в качестве
доверительного предела, отвечающего той же доверительной
роятности 1—а, следует взять корень уравнения
s^i(PaiJ= 2 Рп(т) = а.
т=М
Этот корень обозначим через рЛ!1. Теперь интервал
/’ль < < Рм*
будет доверительным интервалом для неизвестной вероятности
построенным по частоте М и отвечающим доверительной
ности, не меньшей 1—2а.
Для доверительных вероятностей 0,90 и 0,80 построены
граммы, позволяющие приближенно определять доверительные
ницы при числе наблюдений п 2э5.
Для доверительных вероятностей 0,95
в даются соответствующие пределы
р при различных значениях М = х и
события п—х в ерии из п
24
так, что частность равна адзо(Л) = — = 0,48. По этим данным
= х=24 и п — Л4=50 — 24 = 26. Пользуясь указанными
ми при 1—2а = 0,95 на пересечении строки х = 24 со
п—х = 26, найдем два 95-процентных доверительных предела
умноженных на 1000, т. е.
1000/?24; 2,5 = 626 и 1000/224; 2,5 = 337.
Отсюда искомый доверительный интервал будет
0,337 <р< 0,626,
т. е. с вероятностью, не меньшей 0,95, можно утверждать,
интервал (0,337; 0,626) охватывает искомое значение
события А.
*) См. таблицу XIX приложений в книге И. В.
Н. В Смирнова «Теория вероятностей и
нике (общая часть)», М., Гостехиздат, 1955.
ГЛАВА V
МНОГОМЕРНЫЕ РАСПРЕДЕЛЕНИЯ.
ЗАКОН БОЛЬШИХ ЧИСЕЛ.
ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА
§ 1. Двумерные распределения
5.1.1. Двумерные распределения и их условные законы. До
сих пор мы рассматривали величины, каждое значение которых
определялось одним числом: таковы, например, диаметр отверстия,
высота неровности в определенном месте поверхности, напряжение
на выходе электромеханического преобразователя и т. д.
Кроме таких одномерных величин, часто приходится рассматривать
одновременно системы из двух, трех и большего числа величин, напри-
мер, координаты точки попадания при стрельбе, координаты точки,
нанесенной на плоскость при разметке плиты, ток помех в электронном
усилителе со случайными амплитудой и фазой, пространственную
ошибку механизма, различные размеры одной и той же детали
И т. д.
Такие величины в зависимости от случайного исхода испыта-
ния принимают систему из двух, трех или большего числа значений
и могут изображаться точкой в пространстве соответствующего чи-
сла измерений. Они носят поэтому название двумерных, трехмерных
и т. д. по числу компонент такой величины.
Статистические данные о таких величинах принимают форму
таблиц с двумя, тремя и т. д. входами. Одну из таких таблиц
представляет таблица 5.1.2 (см. стр. 164), содержащая данные об
отклонениях от номинального размера диаметров штамповок, изме-
ренных под 2^90° к плоскости разъема штампа и под ^45° к той
же плоскости.
Мы рассмотрим обработку такой таблицы несколько позднее.
Георетически двумерную величину (А7, Г) можно рассматривать как
случайный вектор или точку плоскости со случайными координа-
тами (А, К). Дискретная случайная величина задается таблицей
распределения нижеследующего вида,
158 ЗАКОН БОЛЬШИХ ЧИСЕЛ. ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА [гл.
Двумерное распределение
Таблица
X 1 К)
У, Р (х,, /у,) Р (х2> у,) Р (Xj, у,) Р (х„, !/,) Р (.У1)
У2 Р(х,, уг) Р <х„, уг) Р (Х{, у2) Р (х„, Уг) Р (уг)
• . ,
у. Р (X,, (//) Р (хг, у,) Р (xh у]) Р (хп, yf) Р(У /)
У т ₽(*!, Ут) Р (хг, У,п) Р (Xh ут) Р (Х,„ Ут) Р(Ут)
Р (X,) Р (х2) Р (X,) Р (Х„)
В этой таблице в клетке с координатами (лг;, у^
вероятность р(хг-,_у;) (/ = 1,2, ...,«; у= 1, 2, ...,т того,
в результате испытания случайная величина X примет
и вместе с этим случайная величина Y примет значение у j,
что р(Х;, у) есть вероятность совпадения событий <Х=Х;} и (У
' / х = х-\
Предполагается, что все комбинации I '1 составляют
\' У j /
группу событий и потому сумма вероятностей, стоящих в таблице 5.1.
равна единице, т. е.
г 7
(5.1.
Если мы просуммируем все вероятности, стоящие в z-м столбце,
т. е. образуем сумму
Р У^ + р(хр Л) + • +р 1хр >/)+••• + Р ут) =^Р(хр У,У
(индекс j суммирования пробегает номера всех строк), то по
виду сложения мы получим вероятность события X = xiy
распадается на несовместимые виды (Х—х^ Y — у j) (J= 1,2,.. .,/»),
ДВУМЕРНЫЕ РАСПРЕДЕЛЕНИЯ
159
пегому
^Р^, j//) = P(¥=xi) = p(x1). (5.1.2)
J
'раким же образом, суммируя вероятности в строке номер у, найдем:
р (х„ yj) + Р (Хг, yj) + ... +/> (X,., у,) 4- ... +р (х„, у7.) =
= Р (xt, у^ = Р (Г=yj)=p(yj). (5.1.3)
Тем самым одномерные законы или таблицы распределения каждой
величины X и Y в отдельности полностью определяются, если
известна таблица распределения двумерной величины.
Мы видели раньше, что зависимость между двумя случайными
событиями сказывается в том, что условная вероятность одного
события при наступлении другого события отличается от безуслов-
ной вероятности первого события. Аналогично этому, чтобы исследо-
вать влияние одной величины на изменение другой величины, рас-
сматривают условные законы распределения первой величины при
фиксированных значениях второй величины. Пусть величина X полу-
чила одно из своих значений Х~хр, при этом другая величина Y
может принять, вообще говоря, любое из своих возможных значе-
ний ф,, уг, ..., ...; однако вероятности этих значений будут
отличаться от вероятностей р (>>,), р(72), . . ., P(jy), . . .
В самом деле, условная вероятность события Y — yj, если
наблюдалось событие Х = х,, согласно (2.2.3) будет равна отноше-
нию
Р (Xj, yj)
Р (*;)
Мы обозначим эту вероятность кратко через plyj^j)
так, что
, р(Х:. г/,)
Р(У/^ = Р(У=у//Х = х,4 = ^^. (5.1.4)
Совокупность условных вероятностей p(yjxj), p(yz’xj), . .., р(уj!xj),
Piyj + Jxi), ..., отвечающих одному и тому же условию X = xt, и
называют условным распределением Y при Л'=х,-. Заметим, что
сумма условных вероятностей, как это и должно быть, согласно
(5.1.2) и (5.1.4), равна единице, т. е.
\7 ^jP(Xi,Pj)
7д Р (У/lxt) = ' -Гр- = = 1 • (5.1.5)
I' р (х-) р(х:) ' '
Для краткого описания этих условных законов распределения
мы можем использовать различные характеристики из тех, которые
мы вычисляли для одномерных распределений.
Наиболее важной характеристикой является условное матема-
тическое ожидание M.(Yix) величины Y при фиксированном значе-
нии Х~х, где х может равняться х2, х................. х0 ...; это
160 ЗАКОН БОЛЬШИХ ЧИСЕЛ. ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА [гл.
математическое ожидание определяется равенством
М(Г/х) = 2^р(^/х), (5. .
I
где х — одно из значений х,, хг, ... Аналогично вводите
условная дисперсия и условные моменты более высоких
Приняв во внимание (5.1.2) и (5.1.4), мы можем
М(У/х) придать вид
2 У/Р (*.!//)
^(x) = M(K/x) = i—----(5.1.
ZjPkx, у,)
Последнее выражение позволяет истолковать М (F/х) как центр мае
p(Xj, yj), расположенных на вертикальной прямой Х = х — const
имеющих ординаты _у/(/=1,2, .. .). С изменением х, т. е.
переходе от одного столбца таблицы 5.1.1 к другому,
М(К/х). Мы можем, следовательно, рассматривать
М (К/х) —у (х) (определенную для значений х = х1,хг, ...,xt, ...
Эта функция носит название регрессии Y по X.
Хотя при каждом значении Х — х Y стается
однако зависи юсть Y от X часто в из
размеров Y при переходе от одного значения х к другому,
последнюю зависимость и описывает кривая регрессии у (х).
Аналогичным образом мы можем рассматривать условные
величины X при фиксированных значениях Y = yj,
совокупностью условных вероятностей
, , . Р(хь у])
(5J-
при i — 1, 2, ..., причем
Точно так же вводится регрессия величины X по Y
х (>) = М (Xjy) = xiP (xjy) = 1 р(--}— .
L
Эта функция описывает изменение центров тяжести масс вероятно-
стей на горизонтальных прямых Y = y = const.
В случае непрерывного распределения величин X и Y их совме-
стное распределение задается с помощью плотности вероятности—'-
интегрируемой функции р(х, у).
s 1] ДВУМЕРНЫЕ РАСПРЕДЕЛЕНИЯ 161
Для вероятности попадания в элементарный прямоугольник
с вершиной в точке (х, у) и сторонами Дх и Ду, параллельными
осям координат, будем иметь:
р () J toH₽ (to Н+ «1 Ду, (5.1.9)
где е—>-0 при Дх—>0 и Ду—>0.
Вероятность случайной точке Q(X, Y) попасть в какую-либо
область О плоскости (х, у) выразится в этом случае равенством
P[Q(X, У)сО] = ^p(x,y)dxdy. (5.1.10)
а
При этом вероятность попадания на множество из изолированно
лежащих точек оси, даже образующих кусок плоской кривой (на-
пример, границы области G), в данном случае равна нулю. Кроме
того, мы считаем р(х, у) равной нулю во всех точках, которые не
принадлежат к возможным значениям величины (X, К).
Геометрически функция Z — p (х,у) представляется так называемой
поверхностью распределения.
Функция
х у
P/у (х, у) = Р(Д<х, У<у)= р (х, у) dx dy, (5,1.11)
— оо — со
представляющая вероятность попадания точки Q(X, У) в часть
плоскости, называется интегральной функцией распределения дву-
мерной величины (Д, У). Эта функция возрастает при возрастании
каждого из переменных х и у и стремится к единице, когда оба
аргумента неограниченно возрастают.
Наиболее простым примером является равномерное распределе-
ние двумерной величины на каком-нибудь куске плоскости (х, у).
В этом случае
р(х, у) = С = const, когда (х, у)сО.
р (х, у) = 0 вне G.
Константа С определяется из условия
j J Cdx dy — С dxdy = CSQ = 1,
о а
так что
С=— > (5Л.12)
где 50—площадь области О.
6 Н. В. Сыирвив, И. В. Дунии-Барковский
162 ЗАКОН БОЛЬШИХ ЧИСЕЛ. ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА [ГЛ.
Вероятность попасть на площадку g, расположенную
области О, будет равна
^P(x,y)dxdy==^^ dxdy = ^, (5.1.13)
g g
где Sg—площадь g.
Она не зависит от положения площадки g внутри области G,
только от величины Sg ее площади.
Если плотность р(х, у) двумерного распределения задана, то
можно определить одномерные функции распределения и плотности.
В самом деле, согласно общей формуле (5.1.10) найдем:
Р {X <х) = Р (Х<х, К<оо)= dx J р(х, _у) dy. (5.1.14
со — оо
Поэтому для плотности рх (х) величины X имеем:
CD
рх(х)= J P{x,y)dy.
— <Х
Эта формула вполне аналогична (5.1.2), которую мы имели в ди-
скретном случае.
Точно так же
Ру (у)— J p(x,y)dx. (5.1.16) .
— се
Условные законы распределения Y при заданном значении Х—х
определяются в данном случае условной плотностью
= = (5.1.17)
Р (х, У) dy
- со
и аналогично для условной плотности X при заданном Y=y
J p (X, у) dx
— CD
Вероятностный смысл формул (5.1.17) и (5.1.18), вполне аналогич-
ных формулам (5.1.4) и (5.1.8) дискретного случая, легко уясняется,
если заметить, что вероятность р(х, у) &х ку попадания в элемен-
тарный прямоугольник с вершиной в точке Q{x, у) можно рассмат-
§ и
ДВУМЕРНЫЕ РАСПРЕДЕЛЕНИЯ
163
ривать согласно правилу умножения как вероятность совмещения
двух событий:
1) попадания X в интервал (х, х -|- Дх) с вероятностью рх(х) Дх и
2) одновременного попадания / в интервал (.у, j-j-Ду), условная
вероятность чего при условии, что первое событие произошло,
будет ру(у1х)ку.
Таким образом, мы должны (с точностью до бесконечно малых
высшего порядка малости) иметь равенство
р (х, у) Дх Ау — рх (х) Ахру (у/х) Ау. (5.1.19)
Рассматривая те же два события в другом порядке, придем к дру-
гому равенству:
р(х, у) Ay Ax==pY(y) Ау рх(х)у) Ах. . (5.1.20)
Из (5.1.19) и (5.1.20) по сокращении на Дх Ау получаем (5.1.17) и
(5.1.18).
Линии регрессии У по X и X по У определяются теперь как
условные математические ожидания
00
а J УР(х, y)dy
y(x) = ^(Yjx)= yp{ylx)dy = ~---------------, (5.1.21)
j P(x,y)dy
— co
co
\ x p (x, y) dx
CO J
x(y) = M(Xly)= J xp(xly)dx = ~^------------. (5.1.22)
~ “ J P (X, y) dx
Все эти понятия могут быть легко обобщены на случай любого
числа измерений. Так, например, в случае трехмерной величины
(X, У, Z) мы вводим трехмерную плотность р(х, у, z), по которой
можно вычислить три двумерные плотности
PXY (X, у), Pxz {X, Z) И PYZ (У, Z)
и три одномерные плотности
рх(х), Ру (у) и Pz(z).
Для того чтобы иметь конкретное представление о двумерном
распределении и его характеристиках и, в частности, о линиях рег-
рессии, на практике используются результаты п наблюдений,
в каждом из которых регистрируются совместные значения величин
X и У. Сводка таких данных обычно имеет вид так называемой
6*
164 ЗАКОН БОЛЬШИХ ЧИСЕЛ. ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА [гл. у
корреляционной таблицы. В качестве примера мы приведем
корреляционную таблицу 5.1.2 отклонений от номинального размера
штамповок колец подшипников по диаметру под ^/90° к плоскости
разъема штампа (А) и под / 45° к той же плоскости (К).
Таблица 5.1.2
Корреляционная таблица отклонений от номинального размера штамповок
колец подшипников по диаметру под / 90° к плоскости разъема
штампов (X) и под 45° к той же плоскости (Y).
\71иаметр под / 90° От От От От От От От Услов-
0,00 0,10 0,20 0,30 0,40 0,50 0.60 ная
V ДО до ДО До До до ДО сред-
Диаметр 0,10 0,20 0,30 0,40 0,50 0,60 0,70
под2( 45° ^ч. мм ММ мм ММ ММ мм ММ
У
От 0,00 до 0,10 мм 1 2 0,28
» 0,10 » 0,20 » 2 1 2 1 1 0,32
» 0,20 » 0,30 » 1 5 10 11 9 6 0,34
» 0,30 » 0,40 » 4 13 17 11 7 3 0,37
» 0,40 » 0,50 » 3 3 12 16 9 6 5 0,37
» 0,50 » 0,60 » 1 3 11 24 15 6 0,36
» 0,60 » 0,70 » 1 7 19 20 9 2 0,41
» 0,70 > 0,80 » 1 4 5 9 16 2 0,46
» 0,80 » 0,90 » 1 1 2 0,38
\0,38
Условная средняя у 0,43 0,39 0,46 0,47 0,52 0,56 0,51 \
0,49\
В этой таблице проставлены числа штамповок, обладающих соот-
ветствующими сопряженными признаками X и Y. Так, например,
со значениями 0,10 мм <х < 0,20 мм и 0 <_у <0,10 мм оказалась
всего одна штамповка, со значениями 0,30 лл<х<0,40 мм и
0<_у<0,10 мм—две штамповки, и т. д. В последней строке
этой таблицы проставлены условные средние арифметические у, т. е.
средние отклонения у, отвечающие соответствующим значениям х.
В последней графе (графы, содержащие двумерные частоты, здесь
обычно называются «строями») таблицы проставлены условные сред-
ние арифметические х, о вычислении которых подробно говорится
в главе IX.
Такая таблица уже сама по себе дает приблизительное представ-
ление о характере связи между интересующими нас признаками. Так,
например, из приведенной таблицы видно, что с увеличением х воз-
растают также и у, т. е. между этими признаками имеется «прямая
связь». Можно по таблице судить и о форме связи. Так, например,
§ П
ДВУМЕРНЫЕ РАСПРЕДЕЛЕНИЯ
165
если построить на графике точки с координатами (х, у) и (х, у) и
соединить их, то мы получим линии регрессии, показанные на рис. 37.
По графику можно судить, насколько связь между рассматриваемыми
размерными признаками штамповок близка к прямолинейной и
насколько круто возрастают
соответствующие линии регрес-
сии, иными словами, насколько
сильна эта связь, если ее мож-
но считать прямолинейной.
5.1.2. Понятие о незави-
симых величинах. Рассмотрен-
ные связи между случайными
величинами позволяют ввести
важное понятие о независимых
величинах. Остановимся сна-
чала на случае дискретной
двумерной величины, заданной
таблицей 5.1.1 вероятностей.
Если для любой пары возмож-
ных значений х и у события
Х — х и У—у независимы,
так что
р(х, у) = Р(1=х)Р(У=у) =
= Рх W Рг (5.1.23)
то величины X и У называются
независимыми величинами.
Таким образом, двумерная
Рис. 37. Линин регрессии отклонений
диаметров штамповок колец под углом
90° и 45° к плоскости разъема штампов.
таблица вероятно’стей получается перемножением вероятностей,
отвечающих координатам (х, у).
Каково бы ни было значение Х — х для условной вероятности У,
в случае независимости будем иметь:
р (у[х) = Р (К=у[Х = X) = = Ру(у), (5.1.24)
т. е. условная вероятность совпадает с безусловной вероятностью
или, иначе говоря, распределение величины У не реагирует на
изменение величины X.
Точно так же
p(x/j) = px(x). (5.1.25)
Поэтому, в частности, все условные математические ожидания
М(К/х) величины У будут независимы от х и равны безусловному
математическому ожиданию У, т. е.
JT(x) = 2^рСу/х) = 2У/?гО'/) = = vr = const. (5.1.26)
166 ЗАКОН БОЛЬШИХ ЧИСЕЛ. ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА (ГЛ.
Другими словами, в случае независимости все центры масс на верти-
кальных прямых лежат на одной горизонтальной прямой. Анало-
гично этому для линии регрессии X по Y имеем:
х (у) = JAX = vy = const, (5.1.27)
так что эта линия совпадает с прямой, параллельной оси Y и про-
ходящей через общий центр масс.
В случае непрерывного распределения величины Хи Y назы-
ваются независимыми, если выполняется равенство
Р(А<х, Г<у) = Р(Х<х)Р(У<у), (5.1.28)
справедливое для любых х и у. Пользуясь определением интег-
ральных функций распределения, (5.1.28) можно записать так:
Руу(х, у) = Рх (х) Ру (у). (5.1.29)
Аналогичное равенство имеет место и для плотностей
pyV(x, У)=рх(х)ру(у). (5.1.30)
Оно выражает независимость двух событий x^A^x-f-Ax и
у < У^У +• Ау.
Линии регрессии и в данном случае совпадают с прямыми,
параллельными осям координат x = Vy, y = vY, проходящими через
общий центр масс.
Совместная плотность п независимых непрерывных величин
А„ А„ ..., Ап Рх,хг.. .xn(xt, х2, ..., х„) выразится через плот-
ности компонент равенством, аналогичным (5.1.30),
Pa1x,...x„(a;1, хг, .... х„) = рА1(х1)рЛа(х2) ... Рхп(х„). (5.1.31)
§ 2. Характеристики многомерных распределений
5.2.1. Математическое ожидание функции многих переменных.
Теоремы о математическом ожидании суммы и произведения.
В качестве характеристик многомерного распределения используют
математические ожидания некоторых функций от рассматриваемых
случайных величин. Математическое ожидание функции Z —
==(р(А, /) двух переменных определяется для дискретного распре-
деления как сумма произведений из значений функции при каждой
возможной комбинации аргументов на соответствующие вероятности
этой комбинации
М[<р(А, Г)] = 2<р(х, у}р{х, У) = 2£ф(хр У7)р(х(-, уД
х. У ‘ <
(5.2.1)
§ 2] ХАРАКТЕРИСТИКИ МНОГОМЕРНЫХ РАСПРЕДЕЛЕНИЙ 167
В непрерывном случае вместо суммы мы будем иметь аналогичный
двойной интеграл
М[ф(АГ, К)] = у J Ф (х, y)pXY(x, y)dxdy, (5.2.2)
х и
где pXY(x, у) — плотность двумерной величины (X, К).
В общем случае п-мерной величины (А/1, Х2, ..Хп), задаваемой
плотностью p(xv х2, ..., хп), мы будем иметь:
М[ф(Л„ Xt, .... .¥„)] =
= П” х‘> •••’ Х^Р(Х>‘ х2> •••’ xjdx^x*.. .dxn.
(5.2.3)
Мы, конечно, предполагали при этом, что все написанные инте-
гралы (суммы рядов) существуют и сходятся абсолютно; отсюда
следует, в частности, что порядок интегрирования и суммирова-
ния не является существенным: его можно менять без изменения
результата.
Рассмотрим ф(А\ Y) = X+Y и докажем теорему.
Теорема. Математическое ожидание суммы случайных
величин равно сумме их математических ожиданий
М (АГ + Y) = МЛГ-Ь МУ. (5.2.4)
Пусть величины X и Y дискретны и их совместное распределе-
ние задается таблицей вероятностей р(х, у)~Р (Х=х; Y=y).
По определению математического ожидания
М(Х-ЬГ)= 2 (х+у)р(х, у)-=^х^р(х, у) + '^.у^1р{х, у),
(х, у) X у ух
где 2 распространяется на все возможные комбинации х и у
(X, у)
величин X и Y.
Но согласно (5.1.2) и (5.1.3) внутренние суммы ^р(х, у) и
У
2р(х, У) представляют вероятности рх(х) n pY{y) соответственно,
X
и потому
М (Л + Y) = 2 хрх (х) + 237V (у) = МУ,
X у
что и требовалось доказать.
Для случая непрерывных величин, совместное распределение
которых задается плотностью р (X, у), мы поступаем аналогично,
168 ЗАКОН БОЛЬШИХ ЧИСЕЛ. ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА [гл.’у'
приняв во внимание соотношения (5.1.15) и (5.1.16):
СО со
M(A+r)=J J (х-)-у)р(х, y)dxdy =
- оо — со
оо <ю оо оо
= xdx J р(х, у) dy -f- J у dy J p (x, y)dx —
— 00 — 00 — 00 — 00
CO (30
= J XPx(x)dx4- J уPy(y)dy = MLY4-MK
— oo - op
Мы пришли к тому же результату.
Теорема, очевидно, справедлива при любом числе слагаемых.
Она имеет чрезвычайно широкое применение, так как не наклады-
вает каких-либо ограничений на слагаемые величины: они могут
произвольным образом зависеть друг от друга.
Докажем вторую теорему.
Теорема. Математическое ожидание произведения незави-
симых случайных величин X и У равно произведению их мате-
матических ожиданий:
!Л(ХУ) = !ЛХ-1ЛУ. (5.2.5)
По определению имеем:
М(ХУ)= ^хур(х, у).
(х, и)
Но в случае независимости случайных величин X и У из (5.1.30)
имеем:
^(х, У) — рх(х) ру(у),
и потому
М(АГ) = 2 [хрх(х)][у Ру(у)]-(^хрх(х)\^1у Ру(у)^МХ.МУ,
(X. у) \ X /у
что и требовалось доказать.
В случае непрерывных величин А и К с плотностью р(х, у) не-
зависимость влечет равенство
р(х, у) —рх(х) ру(у),
и поэтому
оо оо
М (ХУ) — у у ху р (х, у) dx-dy —
— ® — оо
оо де
= j xpx(x)dx у py(y)dy — MXMY,
-QB — ®
т. е. мы приходим к тому же.
§ 2]
ХАРАКТЕРИСТИКИ МНОГОМЕРНЫХ РАСПРЕДЕЛЕНИЙ
169
Теорема верна при любом числе независимых между собой мно-
жителей. Требование независимости весьма существенно. Если оно
не соблюдено, заключение теоремы вообще несостоятельно; было бы
неправильным, например, такое
==МАГ-МЛ'=(МХ)2, так как
оба сомножителя одинаковые,
они зависимы.
Применение теоремы о ма-
тематическом ожидании суммы
величин можно проиллюстри-
ровать на следующем простом
примере: обозначим через X
погрешность индикатора часо-
вого типа (рис. 38), через
К—погрешность концевой ме-
ры, по которой индикатор
установлен в нулевое положе-
ние, и через Z—общую по-
грешность измерений.
Пусть систематические (т.е.
в простейшем случае постоян-
ные во всех измерениях при
данной установке прибора)
погрешности составляют:
AL¥=: + 5 мк (например, сме-
щение нулевого штриха ци-
ферблата по отношению к
исходному положению стрелки
при настройке прибора по кон-
цевой мере) и МУ=—1 мк
(отклонение действительного
размера меры от ее номиналь-
ного размера, по которому
настроен индикатор).
Тогда на основании теоремы
преобразование MX2 — М (X• X) —
Рис. 38. Индикатор часового типа.
о математическом ожидании суммы
случайных величин мы можем определить общую систематическую
ошибку следующим образом:
MZ = M(JC+r) = MAr+MT=5 —1 =4 мк.
5.2.2. Понятие о ковариации (моменте связи) и коэффи-
циенте корреляции. Дисперсия суммы. Простейшей характеристикой
связи между случайными величинами X и Y служит математическое
ожидание произведения отклонений X и Y от их центров, т. е.
cov (X, Г) = рХУ = М[(Л—vx)(r—vr)], (5.2.6)
где vx = MX и vr = M/.
170 ЗАКОН БОЛЬШИХ ЧИСЕЛ. ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА [гл.
Характеристика рХУ получила название ковариации
связи. Выражение ковариации (5.2.6) может быть
основании свойств математического ожидания (см. . 3.1.2)
цхг = М (XY— Yvx—Xvr + vxvy) = М (AT)—М (Yvx}—M (Xvy) 4-
+ М (vyvj,) = М (XY)—vxM (У) — vyM (А) + vxvy =
= М(АУ)—М(А)М(У)—М(У)М(А) + М(А)-М(У),
откуда получим:
cov (А, У) = р.хг = М(АУ) — М(А)-М(У). (5.2.7)
Если величины А и У независимы, то на основании
мулы (5.2.5)
cov (A, У)=цхг=0.
Величина cov (A, Y) зависит от единиц измерения, в которых выра-
жают А и У, поэтому она сама по себе еще не может служить
показателем связи. Чтобы иметь дело с безразмерным показателем,
рассматривают ковариации нормированных отклонений
A* = X-V* и y*-Y~vy
°х °г
Каждая из них имеет центром нуль и дисперсию, равную еди-
нице,
e„ = eov(X«,
_ М[(Х—ух)(У—vy)] а= cov (X, У) 2
ОуОу OyOy
Показатель оХУ называется коэффициентом корреляции вели-
чин А и У. Для независимых величин он равен нулю, так как для
них cov(A, У) —0. Однако обратного заключения сделать нельзя:
величины могут быть даже связаны функционально, а коэффи-
циент их корреляции при этом будет равен нулю. Пусть, например,
величина А симметрично распределена около начала координат,
которое и будет центром величины А, т. е. МА=0.
Пусть, далее, У=А2. Тогда в силу симметрии А
М (УА) = МА’ = 0 = МА-МУ
и, значит, cov(A, У) = 0, и также qxz=0, несмотря на то, что У
является функцией А.
Заметим еще, что рХУ не меняет своей абсолютной величины,
если вместо случайной величины А рассматривать величину А, =
= А-(-а или величину X^ — kX. (где а и k—постоянные числа),
так что при перемене начала отсчета или при изменении масштаба
величины А коэффициент корреляции сохраняет прежнее значение
или меняет только свой знак (если меняется направление возрастания
§ 2] ХАРАКТЕРИСТИКИ МНОГОМЕРНЫХ РАСПРЕДЕЛЕНИЙ 171
величины, что бывает при А<0). Это объясняется тем, что при
переходе к величинам А, и Хг нормированное отклонение не ме-
няется или меняет только свой знак. То же самое имеет место при
общем линейном преобразовании величины А, т. е. при переходе
к величине As = kX-]-a. Сказанное по поводу X в равной мере
относится и к К.
Коэффициент корреляции между линейными функциями ве-
личин X и Y будет по абсолютному значению равен коэффи-
циенту корреляции между самими этими величинами.
Воспользуемся теперь понятием ковариации, чтобы выразить
дисперсию суммы и разности двух величин.
По определению
О(А4-У) = М(А4-У-*Х+Г)2,
где по теореме (5.2.4)
vx+r = М (Д+У) = МЛЧ МУ = vx +vr;
поэтому
D (А 4- У) = М [А 4- У—(vx+ vv)]2 = М ((A—vx) + (У—vx)]2 =
= М [(A-vxy 4- 2 (X— vx) (У— vr) 4- (У— vr)2) =
= М (A- vx)2 + 2М [(А- тх) (У— vF)] + М (У— vr)s ==
= DA 4-2 cov (А, У) 4-ОУ.
Таким образом,
D (2С 4-У) = DA’4 ОУ 4-2 соv (А, У) (5.2.10)
или
a(x+y) = Gx + °y + 2exrCTxffr-
так как согласно (5.2.9)
cov (А, У) = Qxyoxav.
Аналогичным образом для разности величин А—У получим:
D(A— У) = DA 4-ОУ—2 cov (А, У), (5.2.12)
Ст?х-У) = ах + °2у~2ехиохау (5-2-13)
Формулы (5.2.12) и (5.2.13) для разности величин следуют из
соответствующих формул для суммы, если заметить, что X— У =
= А4-( — У) и что
D(—У) = ОУ, (5.2.14)
а также
cov [А, (— У)] = — cov (А, У) (5.2.15)
и
(5.2.16)
0х<-п ~ Оху
172 ЗАКОН БОЛЬШИХ ЧИСЕЛ, центральная предельная ТЕОРЕМА [гл. v
Формулы для дисперсии суммы и разности могут быть записаны ’
совместно в следующем виде:
D(X±K) = DA4-Dy±2covH, Y). (5.2.17)
Применим (5.2.17) к двум нормированным величинам
X* = Л~„Ух и у * =
ах
В этом случае DX* = 1, DF*=1 и cov(X*, У*) = (?хг, поэтому
(5.2.17) запишется так:
О(^*±П=1 +1±2оуг = 2(1±оХУ). (5.2.18)
Так как D(X*±X*) всегда неотрицательна, то из (5.2.18) следует:
i + exr^o, 1-6хк>о,
откуда
— l==SeXK<l. (5.2.19)
Мы получили важное свойство коэффициента qxy: по абсолютной
величине коэффициент корреляции не больше единйцы. Покажем,
что 2Х?=±1 тогда и только тогда, когда между Хи К суще-
ствует строгая линейная зависимость, т. е. Y— kX -УЬ, где k и
b— два постоянных числа. В самом деле, если = -|- 1, то ~
D(A* — У*) —0, а это значит, чго X*—Y* с вероятностью, равной
единице, принимает одно постоянное значение, равное нулю, так
как М (X*—У*) = 0 и Р(А"*—У*)~1, а потому с той же вероят-
ностью
X— vx__У — Vy
ах ау ’
откуда
Y=6X-f-b,
где k=— и b — Vy—— vx.
Аналогичное заключение мы можем сделать при Qxr = —1,
так как в этом случае D (А* + У*) — 0.
С другой стороны, если Y— kX-\~b, то, как мы видели,
IбрхI=I 2(*у+ь>х I= I Qxx I-
Но Qxx= 1 и, следовательно,
lQrcl = l-
Таким образом, значения Qxr, близкие к единице, указывают на
близость связи X и Y к линейной функциональной зависимости.
В предельном случае, когда QXK = ±:i, все двумерное распреде-
§ 2] ХАРАКТЕРИСТИКИ МНОГОМЕРНЫХ РАСПРЕДЕЛЕНИЙ 173
лепие масс вероятности сосредоточено на прямой
X—\’х Y—vy
° У
Из формул (5.2.8) и (5.2.17) вытекает для важного частного
случая независимых между собой слагаемых X и Y следующее со-
отношение:
D(X±y) = D^+DF (5.2.20)
или
о<х±У) —V °х + ау • (5.2.21)
Таким образом, дисперсия суммы или разности двух незави-
симых величин равна сумме дисперсий слагаемых. Это положение
легко распространяется на сумму любого числа независимых слагае-
мых с помощью тех же рассуждений, что и в случае двух слагаемых.
Мы имеем,следовательно, при условии независимости слагаемых
D (X. + Х2 + ... + Хп) = DAT, + О¥2 + ... + DXn (5.2.22)
и ______________________
а(х,+х2 + •••+xn) = о2Ха 4-... + о\п. (5.2.23)
Обобщение на случай произвольно зависимых слагаемых дается
формулой
п
0(Хг + Х2+...+Хп)= g DXf + 2cov(Xt, хг)+...
...+2 cov (.¥„_„ Хп) (5.2.24)
или
°(Х, + Х2 +•••Ч-Хи)~____________________________________________
= ]/"а2х,+ • • • +ox„ + 2exIx2Ox1-^A'2+ • • • .
(5.2.25)
Формулу (5.2.23) можно записать в виде
п
=2Хг (5-2.26)
2Х, 1
В том случае, когда величины Xt имеют одинаковую дисперсию,
например, если все Xt одинаково распределены, из (5.2.26) следует:
<т2 = ло2у, (5.2.27)
2Х(
1
где через X мы обозначаем любую из величин Х;. Таким образом,
а этом случае рост дисперсии суммы происходит пропорционально
174 ЗАКОН БОЛЬШИХ ЧИСЕЛ. ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА [ГЛ. V
числу слагаемых; среднее же квадратическое отклонение растет
пропорционально квадратному корню из числа слагаемых, так как
из (5.2.27) следует:
<т„ (5.2.28)
2*.
Пусть, например, рассеивание погрешностей обработки при вы-
полнении размера детали на станке характеризуется средним квад-
ратическим отклонением о0, а рассеивание погрешностей измерения
того же размера при пользовании микрометром — величиной <ти;
тогда рассеивание результатов измерений размеров, получаемых при
обработке, будет характеризоваться средним квадратическим откло-
нением ав, равным согласно (5.2.21) величине
Важным следствием из формул (5.2.27) и (5.2.28) являются
формулы для дисперсии средней арифметической. Из (5.2.22) вы-
текает для независимых величин Xt
РХЛ ,п ' 2DX;
dx=d\-—ЕЛ ;
в случае, когда величины Xi одинаково распределены,
DA’ = ^ = — (5.2.29)
п2 п ' '
и, следовательно,
и
= . (5.2.30)
л У п
где X обозначает любую из величин Хг, Хг, ..., Хп.
Пусть, например, мы рассматриваем п повторных независимых
измерений одной и той же величины одним и тем же инструментом
в неизменных условиях. Благодаря наличию случайных ошибок из-
мерений каждый результат будет представлять случайную величину.
Если среднее квадратическое отклонение единичного результата
будет ох, то среднее квадратическое отклонение средней арифмети-
ческой из п измерений будет иметь и / л раз меньшее значение.
В этом сказывается компенсация отклонений в сторону плюс
и в сторону минус от фактического измеряемого значения, которая
§ 2] ХАРАКТЕРИСТИКИ МНОГОМЕРНЫХ РАСПРЕДЕЛЕНИЙ 175
имеет место при сложении результатов отдельных измерений. Мы
увидим позже, какое значение имеет эта закономерность.
5.2.3. Приближенное определение математического ожидания
и дисперсии функции. Пусть мы имеем какую-либо функцию
U — f(Xx, Х2, Х„) случайных переменных Xt, Хг, ..., Хп.
Пусть характеристики MAt = Vx„ 1VIA2 = vx2, ...; DX, — а‘х ,
DA2 = ox, ... и cov^, Х2), ... для аргументов U известны. Точ-
ное вычисление характеристик Mf7 и D(7 для величины U часто прак-
тически невыполнимо, так как закон распределения U весьма
сложен. В том случае, когда массы вероятности распределения
(Ар А2, ..., Х„} сконцентрированы в основном в малой окрестности
точки /’(vx,, vx2, ...)—общего центра, как это'часто бывает, мы
можем с некоторым приближением заменить функцию f(Xlt Xit .. .)
линейной функцией, ограничиваясь линейными членами в разложении
Тейлора около точки Р:
f{Xv Х2.......A„)«/(vx„ vx2, .... vXn} + ^Xt-vXi) +
+ + (5-2.31)
обозначает, что в частной производной аргумент Xit Xv ..Хп
заменен на vx, vXi, . ..,Vxn соответственно.
Приравнивая математические ожидания правой и левой частей
(5.2.31) и замечая, что M(At—vx) = M(A2—vXa)=...=0, по-
лучим:
М [f(Xv Xt, ..., Хп)] « /(VX1, vX2, ..., vxn) =/(МАр МА2,... ,МА„).
(5.2.32)
В частности, если Z=f(X), то
М[/(А)1«/(МА), (5.2.33)
т. е. математическое ожидание функции приближенно равно
функции от математического ожидания аргумента.
Далее, заметим, что, опираясь на свойство дисперсии (3.1.29) и
теорему о дисперсии суммы, мы будем иметь следующую общую
формулу для дисперсии линейной функции:
Z = С + atXt + atX2 -(-... -J- а„А„,
D (Z) = a* D (At) 4- a’D (Aa) +- ... + 2a,aa cov (A„ A2) -f- ...
...+2a„_, a„cov (.¥„_,, A’„), (5.2.34)
где вторая часть суммы содержит все возможные слагаемые вида
‘ZapjZON (Хф А,), причем i<J.
176 ЗАКОН БОЛЬШИХ ЧИСЕЛ. ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА [ГЛ. V
На основании этой формулы для дисперсии функции U, поль-
зуясь (5.2.31), получим:
х<.....
+2 Ш, “v +• • <5-2 зз>
Для случая, когда аргументы Xt, Ха, Хп независимы (или не-
коррелированы), мы будем иметь:
х„ .... хп)1 = ]/(Д)/х1 + (4Х°х2+ •• - + (дУ;)Хп-
(5.2.36)
В частности, для функции Z — f(X] одного переменного найдем:
<^(Х) = |/' (vx)|ax. (5.2.37)
Пусть, например, /(А) = у. Математическое ожидание вели-
чины X есть МА', и ее среднее квадратическое отклонение есть ох.
Тогда математическое ожидание найдем по соотношению (5.2.33)
в виде
мт1~й-
Среднее квадратическое отклонение согласно (5.2.37) будет равно
СТ/(Л)Л; (MX)2'
Возьмем еще пример. Пусть f(X, У) = /А2п- К2, X и У незави-
симы и МА' и МУ—их математические ожидания, a DA' и DV—их
дисперсии.
На основании (5.2.32) математическое ожидание величины £/
будет равно
М[/(А', У)] /(МАГ)2 + (МУ)2
и дисперсия согласно (5.2.35) будет равна
п 1 f(X У11 (MX)2 .____(МУ)2 „у
L’L/A'A, r)J ~ (МА)2 + (МУ)2,?Л + (М/\')2+(МУ;2
5.2.4. Двумерное нормальное распределение. Важным случаем
двумерного распределения, наблюдающегося по крайней мере
с некоторым приближением, во многих случаях практики является
двумерное нормальное распределение, возникновение которого
можно теоретически объяснить на основе теорем теории вероят-
§ 2]
ХАРАКТЕРИСТИКИ МНОГОМЕРНЫХ РАСПРЕДЕЛЕНИЙ
177
постей. В этом случае плотность распределения задается следую-
щим, довольно сложным выражением:
РХУ (х, у) --------7= е~~* Q (Х' > (5.2.38)
2Л0ХОГ1/ 1 —q2xv
где
Q(x, у)
1 Г(Х-Уу)* , (У-Vy)* О„ Х-ухУ-у/|
1_ог п2 'а2 а у Оу
1—"ХУ L °Х °Y х Y J
Здесь vx и vr представляют центры распределения величин X
и У, ох и —их средние квадратические отклонения, a qxv—коэф-
фициент корреляции этих величин.
Покажем, что выражение (5.2.38) действительно является плот-
ностью двумерного распределения двух линейно коррелированных
величин X и У, каждая из которых в отдельности нормально
распределена с соответствующими значениями центра и дисперсии.
В одном частном случае это обстоятельство делается очевидным.
Если величины X и У независимы и нормально распределены
с плотностями соответственно n(x;vx; ох) и п(у; vf; crr), то плот-
ность их совместного распределения получается из (5.2.38) при
QXy = O.
В самом деле, если величины независимы, то коэффициент кор-
реляции Qyy = 0, как было показано в п. 5.2.2, а плотность их сов-
местного распределения рХУ(х, у) будет согласно (5.1.23) равна
произведению плотностей п (х; vx; сх) и п (у; уу; Оу) их одномер-
ных распределений. Но при QXy — 0 как раз и получаем из (5.2.38)
рхг(х, у} = п(х; vx; ох)п(у>, Vy, or) =
_2_
Из этого еще следует, что если нормально распределенные
величины не коррелированы, то они вместе с тем и независимы.
Таким образом, равенство £?Ху = О при наличии нормальной кор-
реляции говорит о полной независимости величин X и У. Этого
вывода, как мы знаем, вообще нельзя оправдать при произвольном
законе распределения X а У.
Покажем теперь, что если плотность совместного распределения
задана равенством (5.2.38), то исходные плотности одномерных
распределений величин X и У будут соответственно нормальны
п (х; vx; ох) и п (у\ vr; Оу).
178 ЗАКОН БОЛЬШИХ ЧИСЕЛ. ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА [ГЛ.
Мы знаем,
интегрированием плотности по
менным. Для плотности величины X получим:
Интегрируя по у, сделаем подстановку v = —-
РХ(Х) =--------у-:....- С е ' XY> dv
2lTOxy l-e2xy_J,
, X — Vv
где для краткости мы обозначим —л — и.
Прибавляя и вычитая по Qxyus в показателе степени при
мы получим:
И3 1 , . о
е~2 о “2 П-о2
рх(х) —-------2r2== С е XY dv.
2лахт/ 1—Qxy J
Сделаем теперь подстановку z ——....
у 1—6 хк
и получим:
Ру W
Z2
е 2 dz.
Интеграл в правой части согласно п. 4.1.2 равен У 2л, и выра-
жая и снова через х, мы окончательно получим:
e~vx)2
1 20х
рх(х)=~7=—е = л(х; vx; су), (5.2.40)
У 2Л Uy
что и требовалось доказать.
Из симметрии следует, что распределение величины У также
нормально с параметрами vF и
Рассмотрим теперь условное нормальное распределение. Из (5.2.38)
и (5.2.40) и пользуясь снова обозначениями и и v для нормированных
{j 2] ХАРАКТЕРИСТИКИ МНОГОМЕРНЫХ РАСПРЕДЕЛЕНИЙ
уклонений, получаем:
179
p(ylx)
------------- (иг + V2-SQXyUV) _и*_
_ PXY (X, у} _ е 2(* Слу) . е =
PxW 2лахсу]/1 —о2Ау ' УГ2лол
К2лаг/ i__q^y
, / у
, ,[-У-е'хг1
V~2MYy 1-g^,
Если теперь в полученном выражении заменить и и к на хи .у,
то мы получим:
ff-Vy-Oyygu-wT
"Т _ ' °Y V 1-QxY
Р {у Iх) = --7=--->— -- --• {5.2,41)
К2лОг]/1_е*у
Правая часть (5.2.41), действительно, представляет плотность —
в данном случае плотность условного распределения Y при дан-
ном значении х. Мы видим, что условное распределение Y (так
же как и совместное распределение X и У) является нормальным
с центром
М (Yjx) = Vy ,х = vr + oxr (х—vx), (5.2.42)
который так же, как при всяком нормальном распределении, является
математическим ожиданием Y (при данном х), т. е.
М(К/х) = тщ;
точно так же условное среднее квадратическое отклонение будет:
(Тум — ОуУ 1 —QXY-
(5.2.43)
Уравнение (5.2.42) представляет вместе с тем согласно (5.1.21)
уравнение линии нормальной регрессии Y по X, которая, как видно
из этого уравнения, является прямой линией. Аналогично регрессиях
по У будет также линией, а условная дисперсия Охц, = ох(1—бхг)-
Итак, нормальная регрессия является прямолинейной.
Далее, из (5.2.43) ясно, что условное среднее квадратическое
отклонение при нормальной корреляции Y постоянно при всех зна-
чениях х. Это последнее свойство называют часто гомоскедастич-
180 ЗАКОН БОЛЬШИХ ЧИСЕЛ. ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА [гл. у
ностью, т. е. равноизменчивостью условных нормальных распре,
делений. Величина oy]/i как мы увидим в гл. IX, представ-
ляет теоретическое среднее квадратическое отклонение погрешностей
оценки ожидаемого значения Y по х. Отсюда следует, что точность
опенки Y по х с помощью линии регрессии одинакова при всех зна-
чениях х. Это значительно упрощает задачу оценки, с которой мы
познакомимся в дальнейшем.
Учитывая, что нормальное распределение часто встречается на
практике и что нормальная регрессия прямолинейна, обычно в каче-
стве меры силы корреляционной связи применяют коэффициент
корреляции, а форму связи характеризуют при этом коэффициентом
регрессии, что значительно упрощает задачу исследования связей
между случайными величинами.
Рис. 39. Поверхность нормального распределения.
Мы видели, что функция плотности вероятности одномерного
распределения может быть наглядно изображена в виде кривой на
плоскости, причем по оси абсцисс откладываются значения непрерывно
изменяющегося аргумента, а по оси ординат — соответствующие им
плотности. Подобным же образом можно дать геометрическую интер-
претацию двумерной плотности (5.2.38), но только уже теперь при-
дется обратиться к пространственным образам.
Из анализа известно, что функция z = pxr(x, у) может быть
изображена в системе координат xyz поверхностью, которая в нашем
случае носит название поверхности нормального распределения
(рис. 39).
§ 2] ХАРАКТЕРИСТИКИ МНОГОМЕРНЫХ РАСПРЕДЕЛЕНИЙ 181
Пользуясь (5.1.17) и (5.1.18), мы получим из (5.2.41) уравнение
этой поверхности в виде
Г 1 *
J J/-Vr-QyiZ—(X-Vy)
z = РХ (х)е--------— . (5.2.44)
Рассечем эту поверхность плоскостями х = хя, перпендикуляр-
ными к оси х. Уравнение линии пересечения нашей поверхности
с каждой из этих плоскостей может быть получено из (5.2.44) путем
подстановки в него значения х — хъ. Мы видим, что все эти кривые
будут иметь форму нормальных кривых с центрами, лежащими на
линии регрессии, задаваемой уравнением (5.2.42), со средними
квадратическими отклонениями, равными orp i_и с варьирую-
щими вместе с х0 максимумами
'>*W '
Кривая с наивысшим максимумом будет лежать в той из секущих
плоскостей, которая отвечает значению x0 = vx, т. е. в этом слу-
чае рх(х0) имеет абсолютно наибольшее значение. Из условий сим-
метрии ясно, что в сечениях нашей поверхности плоскостями, пер-
пендикулярными к оси у и параллельными оси х, мы получим кривые,
обладающие аналогичными свойствами. Рассечем теперь эту поверх-
ность плоскостью z = = const, параллельной плоскости (х, у).
Очевидно, постоянному значению z0 функции z — pXY(x, у) отвечает
постоянное значение показателя в уравнении (5.2.38). Поэтому урав-
нение нашей линии пересечения может быть записано в виде
(^У+-с- <“•«>
где параметр Со отвечает выбранному нами значению z. Полученное
уравнение есть уравнение кривой второго порядка вида
А (х—vx)2 + 2В (х—vx) (у — vY) + С (у — VyY 4 Г— О
с центром в точке (vx, vr). Вычисляя инвариант кривой ’) 8 — АС—Вг,
получим:
1 1 _ ехи _ 0
a2 ay о2. aY °у "
(5.2.46)
') См. И. И. Привалов,
издат, 1952, стр. 183—187,
Аналитическая геометрия, М.—Л., Гостех-
182 ЗАКОН БОЛЬШИХ ЧИСЕЛ. ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА [ГЛ.
Этот результат показывает, что рассматриваемое сечение
ставляет эллипс (за исключением тривиального случая
когда QxY = ib- Давая z различные значения,
нии соответствующими плоскостями эллипсы различны
и с одинаковой ориентировкой их главных осей,
некоторый угол с осями координат. Следует при этом
что главные оси этих эллипсов не могут быть паралле
X У не
Это последнее есть
Рис. 40. Эллипсы горизонтальных сечений
поверхностей совместных распределений ве-
личин X и Y при отсутствии (а) и при нали-
чии (б) корреляционной связи между ними.
ны и,
Qxy = 0, то
(5.2.45) преобразуется
уравнение
уравнение эллипса сцен'
тром в точке (v.x, vr)
с главными осями,
раллельными осям
и у.
Таким образом, с увеличением силы корреляционной
между величинами X и У происходит все больший поворот
ных осей эллипсов относительно координатных осей.
На рис. 40 показаны эллипсы при независимости X от У
(рис. 40, а) и при их корреляционной зависимости (рис. 40, б),
характеризующейся величиной коэффициента корреляции Qxy>0.
§ 3. Закон больших чисел
5.3.1. Неравенство Чебышева. Мы видели, что характеристика
Ох — VDX представляет некоторую среднюю меру или «стандарт»
отклонений от центра распределения. Поэтому естественно ожидать,
что отклонения, значительно превышающие по абсолютной вели-
чине Ох, должны быть маловероятны. В случае нормального рас-
пределения вероятность
<?(/)== P(|*-Vx |> /Ох),
где f>0 изображается площадью под нормальной кривой вне ин-
тервала (— t, -j-1) (рис. 41). Для t = 3 эта вероятность составляет
§ 3]
ЗАКОН БОЛЬШИХ ЧИСЕЛ
183
всего 0,0027; при t = 4 эта вероятность уменьшается до 0,000063,
а при t = 6 выражается величиной порядка 2-10"’.
Заслугой Чебышева является доказательство неравенства, по-
казывающего, что убывание вероятности Q(t) при возрастании t
хотя и не всегда совершается столь быстро, как в только что
Рис. 41. Вероятность Q (/) отклонений от центра v, в t
раз больших по абсолютной величине среднего квадра-
тического отклонения о при нормальном распределении.
отмеченном случае, но оно происходит всегда не медленнее, чем
1 тл
по закону р-. Именно, оказывается, что при любом законе рас-
пределения, обладающем моментами двух первых порядков,
Q(/) = P(|X-vx|Xffx)^l . (5.3.1)
Верхняя граница вероятностей Q(t), вытекающая из неравенства
Чебышева, дается для различных t таблицей 5.3.1.
Таблица 5.3.1
Верхние границы вероятности Р(|Х— vx| <<тх) отклонений как угодно
распределенной случайной величины X от центра распределения vx при
различных величинах отклонений (в. долях среднего квадратического от-
клонения величины X)
t 1 ,0 1.5 2,0 2.5 3,0 4,0 5,0 10 100
1_ /2 1,000 0,444 0,250 0,160 0,111 0,062 0,040 0,010 0,0001
184 ЗАКОН БОЛЬШИХ ЧИСЕЛ. ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА [ГЛ. V
Большая простота и универсальность позволяет использовать не-
равенство Чебышева для важных теоретических заключений, хотя
для практических расчетов оно оказывается слишком грубым. До-
казательству его мы предпошлем вывод несколько более общего
неравенства. Мы рассмотрим сначала величину Z, могущую прини-
мать лишь неотрицательные значения.
Пусть т—любое положительное число. Докажем, что всегда
имеет место следующее неравенство:
P(Z>r)^^. (5.3.2)
Для определенности предположим, что величина Z непрерывно
распределена с плотностью p(z). По условию p(z) = 0 при z<0
и для тОО
00
Р (Z > т) = J р (z) dz.
%
Кроме того,
СО Т 00
MZ — z р (z) dz = z р (z) dz + [z р (z) dz,
о о т
причем оба слагаемых в правой части не отрицательны; поэтому
отбрасывая первое из них, мы будем иметь:
СО 00 со
MZ:> Jzp (z) dz > Jrp (z) dz = x \p(z} dz = xP (Z2s t),
TIT
(5.3.3)
так как в области интегрирования всегда под интегралом z^T.
Из (5.3.3) следует (5.3.2). Для дискретных величин доказательство
проводится вполне аналогично: рассматриваются лишь вместо ин-
тегралов соответствующие суммы.
Пусть теперь X—произвольная случайная величина, для кото-
рой существует М (X—а)2, где а—произвольное действительное
число. Положим в (5.3.2) Z=(X—а)2 и т = б2. Замечая, что не-
равенства (х—а)2 е2 и | х— а | б (б>0) равносильны, мы получим:
Р( | Л-а |>б) = Р( |А-—а |2 в2) М-(*~а)2 (5.3.4)
или, в частности, при a = v = M.¥
Р{|Л'-v|> б } . (5.3.5)
§ 3] ЗАКОН БОЛЬШИХ ЧИСЕЛ 185
Наконец, при Е — ia, где />0, из (5.3.5) следует неравенство
Чебышева:
(так как DX = o2).
5.3.2. Основные предельные законы теории вероятностей.
Теперь мы рассмотрим две фундаментальные теоремы теории веро-
ятностей, имеющие обширный круг приложений. Обе эти теоремы
представляют естественное обобщение уже известных нам теорем
Я. Бернулли и Лапласа (см. п. 4.3.1), относящихся к закону рас-
пределения частости (или числа появлений) случайного события в
данной серии независимых испытаний. Заметим, прежде всего, что
число появлений события в п независимых испытаниях можно рас-
сматривать как сумму п независимых величин. В самом деле,
представим себе наблюдателя, который после каждого испытания
записывает результат его, ставя (против номера испытания) 1 или
О, в зависимости от того, появилось или не появилось событие в
этом испытании. Очевидно, тем самым с испытанием номер $(« =
= 1, 2, ...) будет связана случайная двузначная, т. е. могущая
принимать два значения, величина Xs. Все величины X независимы
между собой (ввиду независимости испытаний) и одинаково рас-
пределены согласно таблице распределений
0 П
Z* I 4 J •
V— Р — Ч PJ
Мы можем представлять себе величины Xs как различные экземп-
ляры одной и той же величины X (без номера). Сумма 5R = A\-(-
-f-A,+ ... величин Xs имеет простое значение — она равна
числу т появлений события в серии испытаний, так как среди ее
слагаемых будет ровно т принявших значение 1 и п—т с ну-
левым значением. Частость события ~ представится средним
. Sn X, -f- X. Хп v
арифметическим ------- величин Xs.
Легко рассчитать, отправляясь от этого представления частости,
основные характеристики ее распределения. Для этого заметим,
что все величины Xs имеют одно и то же математическое ожида-
ние, равное
МЛ = (1—р)0+р-1=р,
и дисперсию
ЪХ= МХг — (МАГ)* = (1 — р) • О2 +р-1!— р* = р — р* = р (1 — р) =pq,
поэтому согласно теореме о математическом ожидании суммы
М(\) = нр, М(^„) = М =
186 ЗАКОН БОЛЬШИХ ЧИСЕЛ. ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА [ГЛ.
и согласно теореме о дисперсии суммы
' " г^’ \ п / пг п
Мы получили вновь формулы (3.1.62) и (3.1.63), ранее выведенные,
исходя из свойства биномиального распределения. Заметим, что
дисперсия частости согласно (5.3.6) стремится к нулю при неогра-
ниченно возрастающем п. Отсюда легко получить, опираясь на
неравенство Чебышева (5.3.1), теорему Якова Бернулли. В самом
деле, полагая в (5.3.4) Х = ~, будем иметь, как бы мало
число е>0,
/ч А2
114 1 А М(~ — р)
OcSP / р >е)<—- =
| [ п r I j е2 пе2 ’
но правая часть (5.3.7) стремится к нулю с ростом п при любом е;
поэтому и подавно
= р / | ±^2 + • + ±Л +_• ••+**) I > Д _о при л-^оо.
(I Я п I I
(5.3.8) ’
Мы видим, что теорема (5.3.8) Я. Бернулли утверждает, что сред-
нее арифметическое большого числа независимых величин (част-
ного вида—«двузначных») почти наверное будет как угодно близко
к своему математическому ожиданию—постоянной величине р. То
£
обстоятельство, что дисперсия величины стремится к нулю при '
п —► оо, имеет следствием устойчивость среднего арифметического:
случайные колебания взаимно погашаются, как бы замирают при
осреднении большого числа независимых величин, так что распре-
деление среднего (т. е. частости) в этом случае концентрируется
в сколь угодно малом интервале (р—е, pH-е), а вероятность, при-
ходящаяся на значения вне этого интервала, как угодно мала при
достаточно большом п. В таком случае говорят также, что после-
довательность средних арифметических при п—<• оо «сходится по
вероятности» к постоянной величине
р = М .
\ я /
Факт устойчивости средних арифметических большого числа
одинаково распределенных независимых величин, или, что то же
§ 4] ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА 187
самое, факт сходимости по вероятности к их общему математи-
ческому ожиданию MA'=v, имеет место и при произвольном рас-
пределении каждого слагаемого, если только при этом распреде-
лении величины обладают конечной дисперсией. В самом деле, как
мы видели, в этом случае (см. п. 5.2.2) для дисперсии среднего
арифметического
"v ^1 + Хг + ... 4- Хп DX
Х„ = -1-1——-----!" имеем: иХп = — ,
" п п п ’
п потому DXn —• 0 при п —► оо.
Отсюда, рассуждая совершенно так же, как и выше, на осно-
вании неравенства Чебышева получим при сколь угодно малом (но
постоянном) е>0
P(|*„-v|>e)<^ — О
II
Р{| v| <8}—1, (5.3.9)
что и доказывает сходимость последовательности Хп по вероят-
ности к пределу v при п—* оо. Осредняя достаточно большое
число независимых и одинаково распределенных случайных величйн,
мы получим с вероятностью, как угодно близкой к единице, зна-
чение, сколь угодно мало отличающееся от общего математического
ожидания величин. Это предложение, составляющее частный, но
важный случай так называемого «закона больших чисел», было
установлено П. Л. Чебышевым (1821 —1894). Оно выражает ос-
новную и общую закономерность, имеющую первостепенное зна-
чение как для обоснования статистических методов, так и для
теоретического объяснения большого круга явлений. С особенной
точностью проявляется нивелирующее действие закона больших
чисел в области молекулярных процессов, на что указывалось в
главе I.
§ 4, Композиция распределений случайных величин.
Центральная предельная теорема
5.4.1. Общие понятия о композиции распределений. Многие
задачи теории вероятностей и математической статистики связаны
с изучением суммы независимых величин. Мы уже, отчасти, встре-
чались с такими задачами, рассматривая теоремы, относящиеся к
закону больших чисел. Основной задачей, однако, являются нахож-
дение и изучение поведения закона распределения суммы большого
числа независимых слагаемых. Нахождение его по законам распреде-
ления слагаемых как раз и называется композицией распределений.
188 ЗАКОН БОЛЬШИХ ЧИСЕЛ. ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА [ГД.
Пусть сначала X и Y—две дискретные независимые
данного испытания и Z — X-i-Y, Возможное значение
= х-\-у всегда представляет сумму двух возможных
слагаемых Х=х и Y—y. По правилу сложения имеем:
P(Z = z) = 2 Р (* = •*> ^=J)>
х+у-г
где суммирование распространено на те пары возможных значений х
и у, которые в сумме дают z. Но в силу независимости X и Y
Р(Х = х, Y = y) = P(X = x)P(Y=y).
Таким образом, принимая во внимание,
P(Z = 2)= 2 Р(^ = л-)Р(У = у) =
x+y=z
ЧТО у==2 — X,
2' р(^=х)р(к-
X
причем, однако, последняя сумма 2' распространена не на все
значения х, а только на такие, для которых z—х одном
из возможных значений Y. Но если мы условимся
полагать равной нулю всякий раз, когда z—х не
числу возможных значений Y, то (5.4.2) можно и проще:
P(Z = z)=^P(X = x)P(Y=z—x), (5.4.3)
X
причем суммирование ведется по всем значениям х.
При аналогичном соглашении относительно Р(А’ = г—у) мы
будем иметь также
P(Z=z)=2P(K=y)P(X=2-y). (5.4.4).;
у <
Формулы (5.4.3) и (5.4.4) определяют композицию величин X и Y.
Используя несколько другое обозначение, мы можем их записать
в виде .
Pz(2)= 2^* *)> (5.4.5)
X
Pz(z}~ Spy (У)рх(х—у). (5.4.6)
у
Рассмотрим теперь случай непрерывных независимых величин X
и Y. Их плотность мы обозначим рх (х) и Ру(у) соответственно.
Плотность же Рху(ху) совместного распределения двух величин
X и Y будет в силу независимости иметь вид
Рху(х, y) = px(x)pY(y). (5.4.7)
Для того чтобы имело место событие Z — X-Y Y<Zz, где z —
какое-либо действительное число, необходимо и достаточно, чтобы
ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА
189
Рис. 42. Геометрическая интерпретация
события Z = X-[-Y <г.
§ 4]
случайная точка Q(x, у) в результате испытания попала бы в об-
ласть Вг (рис. 42), представляющую полуплоскость, лежащую ниже
прямой x-]-y=z в плоскости ху.
Таким образом, используя
(5.4.7), получим:
p(z<z) = p[Q(x, у}евг] =
= \^PXY (X, у) dxdy =
вг
= ^Pv (y^dxdy-
вг
(5.4.8)
Но двумерный интеграл (5.4.8)
приводится к повторному:
действительно, интегрируя
сначала по у (при постоян-
ном х), а затем по х (или
в обратном порядке), най-
дем:
Pz(z) = P (Z<Zz) — J px(x)dx^ pY(y)dy =
— 00 —оо
00 z~l/
= J Pv(y)dy $ px(x)dx.
— CD —00
Дифференцируя no z под знаком интеграла, найдем плотность
композиции распределений
= j px(x)py(z—x)dx (5.4.9)
— оо
или
а>
Pz(^)= $ Pv(y)px(z—y)dy. (5.4.10)
Эти формулы плотности композиции распределений вполне анало-
гичны формулам (5.4.5) и (5.4.6).
Рассмотрим пример. Пусть величина X подчиняется нормаль-
ному закону с параметрами v и а, а величина Y равномерно рас-
190 ЗАКОН БОЛЬШИХ ЧИСЕЛ. ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА [ГД.
пределена в интервале (—h, + h). В этом случае
1 (*-v)2
рх (X) ~ -г=: е 2012 (— оо<х<оо),
У 2по
{О при у <—h,
~ при — h^y^h,
О при у > h.
Применяя (5.4.10) и замечая, что ру{у)=Ё® лишь в промежутке
(—h, h), получим для плотности композиции X и Y ' '
h (Х-Р-У)2
1 р е 2°2
ТйГ (5.4.11)
-Л
Если в интеграле сделать подстановку у = г—v-{-ta(dy = odt},
то pz(z) выразится следующей формулой:
h-z+v
т
Нормально распределенная
Г компонента
(.Равномерно распределенная
компонента,
\ 'Композиция нормалью-
iX го и равномерного
пределений
(5.4.12)
Полагая v = 0 и |Л| = а, мы будем иметь график распределени
композиции величин
и Y вида, представлен-
ного на рис, 43. \
При малых h по
сравнению с о график
плотности композиции
имеет вид, мало отли-
чающийся от нормаль-
ной кривой с дисперси-
ей, равной сумме дис-
персий компонент, так
что в порядке приближения, с учетом (3.2.27), принимают:
г2
1 гае
(5'4'12')
где
fl
Рис. 43. Композиция нормального
мерного распределений.
и равно-
§ 4] ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА 191
Пусть, например, индикатор с ценой деления (2/г), составляющей
1 як, имеет предельную погрешность показаний (Зег), равную 6 мк
и распределенную нормально N(х; 0; 2 мк). Погрешность же от
деления шкалы равномерно
мк^ .
то на основании (5.4.12')
мы можем приближенно принять, что композиция погрешностей по-
казаний прибора и округлений при отсчете по шкале распределена
нормально:
округления при отсчете до олижаишего
( 1 1
распределена на отрезке ( —мк, у
Поскольку 1й| =4- mk<Zg = 2 мк,
N х; 0;
7 \
/12/
так
как
/2, + (т)Ч-/й=2’°2-'“-
В качестве другого примера мы приведем здесь композиции
равномерных одинаковых распределений на отрезке (0, 1). Плот-
ность /’/'(z) двух независимых величин имеет вид равнобедрен-
ного треугольника, основанием которого служит промежуток (0, 2)
(а вне этого промежутка плотность равна нулю). Плотность р%1 (z)
Плотность компоненты
Рис. 44. Плотности композиций равномерных одинаковых
распределений.
(композиция трех величин) будет отлична от нуля в промежутке
(0, 3) и графически изображаться тремя различными параболами в
промежутках 0<х<1, 1<х<2 и 2<х<3, имеющими общие
касательные в точках «склеивания» (рис. 44). Центр распределения
Pz!) (z) композиции п равномерно распределенных слагаемых лежит в
точке ¥<") — —, а среднее квадратическое ее о(П) = у. С воз-
растанием п плотность нормированного распределения pz'' (г) стре-
мится к нормальной плотности п (z; 0; 1).
192 ЗАКОН БОЛЬШИХ ЧИСЕЛ. ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА [ГЛ. у
5.4.2. Производящая функция композиции. Центральная пре.
дельная теорема. Отыскание и исследование распределения, пред,
ставляющего композицию многих распределений, облегчается при-
менением производящих функций, рассмотренных в п. 3.1.4.
Пусть величина
5 = 2^
i=i
представляет сумму независимых слагаемых Xt и
mx1(0 = M(eAir) (г = 1, 2, ... , /г),
— производящие функции этих величин (мы предполагаем, что они
существуют). Тогда производящая функция ms(t) легко опреде-
ляется с помощью следующей теоремы.
Теорема, Производящая функция суммы независимых вели-
чин равна произведению производящих функций компонент
ms{t) = mxAt)mx2(t) ••• (5.4.13)
В самом деле, по определению
(П \
e‘=I / =М(ех>/ех2< .ех**). (5.4.14)
Но величины ех**, ех*‘, ... , ех^ независимы так же, как и сами
величины 2Q(z=l, 2, ... , п). Поэтому, применяя теорему о ма-
тематическом ожидании произведения независимых случайных
величин, мы получим из (5.4.14)
/и5(/) = М(ех>9М(еА’2О ... М (ех^) — тх, (/) тх2 (О ... /»хп(0.
что и требовалось доказать.
В частном случае, когда все величины распределены одинаково,
/»х, {t) — mx2 (/) = ... = /»х„ (0 — (5.4.13) дает
Ws(/) = {/»«. (5.4.15)
В качестве примера рассмотрим композицию п «двузначных» (т. е.
принимающих два значения) величин X, , каждая из которых прини-
/ ° 1\
мает два значения . .В этом случае
\1— Р Pj
m(t) = !Aext — ре"‘ -(-(1—p)e<)‘t—[pet -|-(1—р)].
Следовательно, для производящей функции ms(t), согласно
(5.4.15), получим:
п
m5(i) = [pe' +(1-Р)Г= 2 (5-4.16)
§ 4] ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА 193
Композиция п двузначных величин приводит, как видно пз срав-
нения (5.4.16) с (3.1.56), к биномиальному закону. Если мы от
суммы S перейдем к нормированной величине
S — $—№($) _ S—np
°s V~np (1—p) ’
то, как видно из п. 4.3.1, распределение величины S при больших
п будет близко к нормальному закону п(х; 0; 1). Это обстоятель-
ство выражают несколько иначе, говоря, что при больших п рас-
пределение самой величины S асимптотически нормально (пр; о =
— \^пр (1—р)) (в скобках указывают параметры нормального за-
кона, приближенно выражающего распределение S).
С помощью теоремы (5.4.13) легко убедиться также, что ком-
позиция нескольких независимых случайных величин, следующих
биномиальному закону, распределена по тому же закону, а компо-
зиция нескольких нормально распределенных величин распределена
по нормальному закону.
Пусть X и Y—две независимые случайные величины, имеющие
обе биномиальные распределения с одним и тем же значением пара-
метра р в каждом из них и со значениями s, и s2 параметра s.
Случайными величинами X и Y могут, например, быть числа
появлений исхода А в двух независимых рядах а, и а, последова-
тельных испытаний. Тогда сумма X+Y будет равна числу появле-
ний исхода А в объединенном ряде «, + $, последовательных испы-
таний.
На основании (3.1.56) и (5.4.13) производящая функция случай-
ной величины X 4- Y будет
т (f) = Me1 (Х+Г) = Mezx -MetY —
— (pe* -hg,)s,(pet+ ?)s> 4-<7)S1+s*. (5.4.17)
Мы пришли к производящей функции биномиального распреде-
ления того же типа, что и (3.1.56), но с параметрами р и а,-(-52,
откуда на основании теоремы единственности следует, что-величина
Л+К при сделанных допущениях будет подчиняться биномиальному
закону.
Это положение легко обобщается на любое число величин.
Пусть теперь случайная величина X следует нормальному закону
{х-ахр
1
п,(х; ал о.) — -г— е ‘
* * 1 /2 л о,
7
Н В. Смирнов, И В. Дунин-Барковский
194 ЗАКОН БОЛЬШИХ ЧИСЕЛ. ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА [гЛ.
и случайная величина Y также нормальному закону
(х-агУ
, \ 1 2<Т2
у, X (I V U
Тогда производящие функции величин X и Y согласно (4.1.9)'
будут равны
Ра2 Га2
, „ aj +---- , „ а3< +--
т1 (() — е 2 и — e 2 .
Ha основании (5.4.13) производящая функция суммы будет равна-
Ра2 р(°*+01)
= — 2 -е'** 2 _e(ai+a2’<+ 2 . (5.4.18)
Мы пришли к производящей функции (5.4.18) того же типа,
что и функции величин X и Y, т. е. к производящей функции <
нормального распределения (4.1.9), но с параметрами a = aj4-at ;
и о = + Отсюда следует, что случайная величина X-\-Y
будет подчиняться нормальному закону п (х; at 4 аг\ у/~.
Это положение также легко обобщается на любое число величин.
Мы здесь встречаемся с закономерностью очень общего характера.
Рассмотрим подробнее одинаково, но произвольно распределен-
ные слагаемые, имеющие моменты двух первых порядков.
Пусть для простоты
ЛИ, = МЛ,= ...=0, 1
МЛ12 = МЛ!= ... =ог. j (5.4.19)
п
Для суммы S = 2 Л будем иметь:
1=1
MS = 0, DS = паг и os — a]/rn.
Более общий случай, когда МЛ, #= 0, легко привести к рассма-
триваемому, переходя от Л, к Л, = Л,—а.
Сделаем еще одно необязательное, но облегчающее дальнейшие
рассуждения предположение о том, что величины Л, ограничены
в совокупности, т. е. существует такое положительное число А, что
всегда
|Л,-| <4 (i=l, 2, ...). (5.4.20)
Другими словами, вся масса вероятности каждой величины Л, рас-
пределена на участке (—А, А). При этом функция ех>* при изме-
§ 4]
ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА
195
нении t в конечном интервале (— Т, Г) оказывается также ограни-
ченной, так как ее значения не превышают еАт.
Поэтому существует при каждом I ввиду (5.4.19)
(t) — Мех‘‘ — m (/)
при всех 111 < Т.
Для нормированной величины
~~°s ~а Уп~^а Уп
производящей функцией на основании (5.4.13) будет:
/ Д'* , Да* ,
ms(t) = lAA°y'r
aVnJ
“ШГ ,5-4-21>
С другой стороны, из анализа известно следующее представление
функции е“ по формуле Маклорена:
и , , , и‘ . и’ tju.
е =1+ц + _+_е’“,
где
О <0 < 1.
Полагая в этой формуле а = Х^, найдем
/ ха x2tz x9t3 \
т(0 = = М ( 1 + -j- ),
k I z <j! 1
откуда, принимая во внимание (5.4.19), получим:
m(t) = 1
0-t .aV
1 + 2
0(0,
где
Q(/) = M
, * л
и заменив аргумент г на —7=, будем иметь:
а у п
/ t \ , , Z2 . ft \
/И I----= 1 ф' л----------Ь О [ —,
\а Уп ) \а Уп }
(5.4.22)
причем
о Уп
ts \
а3 Упа}
7*
196 ЗАКОН БОЛЬШИХ ЧИСЕЛ. ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА [ГЛ. V
и ввиду (5.4.20) при |/|<Г
|0/ * JI |Z,L.
I \ а V п J | 6 ст3 У п*
Из (5.4.22) и (5.4.23) следует, что при 111 < Т
”(7F?) = 1+^(1+“"W1’
(5.4.23)
(5.4.24)
где функция w„(Z) удовлетворяет неравенству
А'1
I ^АгеаУп |/|
((} <------------ -4^
1 “ 1 3 о3 Кп
и потому при л-»оо, очевидно, со„(/)-»О.
На основании (5.4.21) и (5.4.24)
>ns(/) = {l+^[14-cM0]}"
и, повторяя рассуждения, сделанные по поводу (4.3.1), мы получим:
р
(5.4.25)
что на основании теоремы непрерывности доказывает сходимость
закона распределения нормированной суммы 6' к нормальному закону
N(z; 0; 1).
Так, например, при п повторных измерениях какого-либо объекта
погрешность округления каждого отсчета Xt до целого деления
шк^лы равномерно распределена с МАЗ = 0 и где h—поло-
вина цены деления шкалы измерительного прибора.
п
Средняя арифметическая — = — V, Л’,- погрешностей округления
- 1 — 1
согласно предыдущему будет распределена асимптотически нор-
мально, причем параметры распределения с учетом (3.1.8), (5.2.4)
и (5.2.30) будут:
м s о Л 1
М — — 0 и os—
« /з
Более тщательные исследования показывают, что при определен-
ных условиях сумма независимых величин распределена асимпто-
тически нормально или, что то же самое, при надлежащей
ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА
197
§ +1
нормировке композиция п распределений приводит к закону, как
угодно близкому к нормальному закону N(x; 0; 1).
Выяснение условий, при которых действует эта закономерность,
составляет заслугу выдающихся русских ученых академиков
А. А. Маркова (1856—1922) и, в особенности, А. М. Ляпунова
(1857—1918), установивших так называемую центральную предель-
ную теорему, утверждающую для очень широкого класса незави-
симых величин асимптотическую нормальность их суммы.
Теоретическое решение важнейших вопросов, относящихся
к композиции большого числа распределений, было дано в работах
советских математиков С. Н. Бернштейна, А. Я. Хинчина, А. Н. Кол-
могорова, Б. В. Гнеденко и др. (установивших, в частности, что
распределение суммы слабо зависящих друг от друга случайных
величин также асимптотически нормально), а также в работах
П. Леви, Г. Крамера, Эссена и др.
Мы не будем давать точной формулировки условий примени-
мости центральной предельной теоремы и лишь кратко выясним
ее смысл и значение.
После нормирования сумма
п
s=2x<-
i = l
перейдет в сумму
п п п п
2Х/-2МХ,- £(х,—мх;)
s = ----= 1^1--------= z-rL-, (5.4.26)
0$ aS °s
где ____
= KDS = |/ Д DX, = / ^4-27>
Заметим, что величина характеризует порядок величины случайной
переменной
п
S'^Zi
числителя, гак как по условию нормирования
mA . .
DS = D\ Ь1— =—=—= 1. (5.4.28)
\ °5 / °s as
Наиболее важным является тот случай, когда каждая величина Z,- будет
индивидуально пренебрегаема в сумме S' при л-* со. Это означает, что
при любом 8 > 0 вероятность
>805)^0, (5.4.29)
198 ЗАКОН БОЛЬШИХ ЧИСЕЛ. ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА [гл. V
так что при большом п вероятность для каждого индивидуального
емого Z, принять значение, сколько-нибудь сравнимое по порядку
п
ной as, а значит и со всей суммой S' — 2 Z,-, будет как угодно мала.
<==1
Индивидуальная пренебрежимость отдельных слагаемых не
вает еще асимптотическую нормальность суммы 6”. Хотя каждое
Ei (| Z | > eas) (1=1, 2, ..., п) в отдельности и бесконечно маловероятно,,
но среди большого их числа п мы можем встретить по меньшей мере одно
из них со значительной вероятностью.
Для того чтобы исключить эту возможность, нужно, чтобы вероятность
суммы событий была также мала при большом п. То же самое можно .
выразить, сказав, что вероятность того, что величина
67n = max(|Zl |, I Z21, I Z« I)
превзойдет ecs при любом е>0, должна стремиться к нулю с ростом п.
Если каждое Z,- индивидуально пренебрежимо, то сформулированное
нами условие является необходимым и дбетаточным для того, чтобы сумма
величии Z, была асимптотически нормальна.
5.4.3. Роль нормального распределения в приложениях.
Среди законов распределения, с которыми мы встречаемся в естест-
венно-научных и технических приложениях, нормальное распределение
играет особую роль. Дело в том, что интересующие нас случайные
величины могут часто рассматриваться как суммы большого числа
независимых между собой слагаемых, каждое из которых имеет лишь
незначительные размеры по сравнению со всей суммой. Но в таком
случае мы находимся как раз в условиях применяемости теоремы
Ляпунова и можем ожидать, что распределение данной величины
мало отклоняется от нормальной формы. Статистические исследова-
ния и в самом деле констатировали приближенную нормальность
распределения в достаточно широком классе случаев. Например, как
указывалось в главе I, потребление электрической энергии для быто-
вых нужд складывается из нагрузок отдельных потребителей, варьи-
• рующих более или менее нерегулярно, п потому суммарная нагрузка
приблизительно следует нормальному закону.
При устойчивом и отлаженном режиме работы станков, однород-
ности обрабатываемого материала п т. д. варьирование качества про-
дукции также принимает форму нормального распределения в силу
того, что производственная погрешность представляет результат сум-
марной погрешности станка, инструмента и т. д. Нормальному закону
приближенно следует время непоявления износовых (постепенных)
отказов технических систем.
Отклонения от него особенно часто вызываются преобладающим
влиянием некоторых слагаемых, играющих превалирующую роль в
образовании всей суммы.
Но в статистической практике мы оперируем часто такими функ-
циями от случайных величин (например, средней арифметической,'
медианой, моментами выборки), которые при большом объеме выборки
§ 4] ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА 199
оказываются, опять-таки приближенно, нормально распределенными.
,-)гот факт имеет очень большое значение для статистической тео-
рии и практики.
Заметим еще, что в некоторых случаях рассматриваемая величина
X оказывается распределенной асимметрично, но некоторая функ-
ция от нее, например \gX, X2,
X3 и т. д., приближенно следует
нормальному закону. Такое функ-
циональное преобразование часто
оказывается полезным при изуче-
нии конкретных распределений.
Так, например, как видно из
рис. 45, а, числа N циклов нагру-
жения, полученные из усталост-
ных испытаний при консольном
изгибе с вращением 463 гладких
полированных образцов диаметра
6,74 мм из алюминиевого сплава,
распределены по резко асиммет-
ричному закону, весьма далекому
от закона нормального распреде-
ления. Если же рассматривать рас-
пределение результатов испыта-
ний, выраженное не в числах
циклов, а в логарифмах lg(N—
отклонений этих чисел от порога
Na чувствительности метода ис-
пытаний (в данном примере N„~
— 0,20-10’циклов), то, как видно
из рис. 45, б, оно оказывается до-
статочно близким к нормальному,
что подтверждается также и бо-
лее строгой проверкой методами,
рассматриваемыми в§3 главыVII.
Использование логарифмиче-
ски нормального распределения
значительно облегчает получив-
шую широкое распространение в
технике статистическую обработ-
ку результатов усталостных испытаний металлов благодаря тому, что
нормальное распределение хорошо изучено и в этом случае оказы-
вается возможным применять многочисленные, подробно для него
разработанные таблицы, в то время как для малоизученного рас-
пределения числа циклов нагружения подобные таблицы отсутствуют.
Логарифмы IgfX-XJ чисел цимлоЛ
6j
Рис. 45. Распределение результатов
усталостных испытаний 463 образцов
из сплава В-95:
а — в числах циклов нагружения; б— в ло-
гарифмах чисел циклов.
ГЛАВА VI
СТАТИСТИЧЕСКАЯ ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ
§ 1. Основные понятия выборочного метода и задачи
математической статистики
6.1.1. Общие понятия о выборке. Основной задачей математи-
ческой статистики, как мы видели, является разработка методов
получения научно обоснованных выводов о массовых явлениях и про-
цессах из данных наблюдений или экспериментов. Эти выводы
и заключения относятся не к отдельным испытаниям, из повторения
которых и складывается данное массовое явление, а представляют
утверждения об общих вероятностных характеристиках данного про-
цесса, т. е. о вероятностях, законах распределения, математических
ожиданиях и т. д. Такое использование фактических данных как
раз и является отличительной чертой статистического метода.
Пусть мы располагаем материалом (обычно довольно ограничен-
ным), например, о числе дефектных изделий в изготовленной в опре-
деленных условиях продукции или о результатах испытаний мате-
риала на разрушение и т. п. Собранные нами данные могут
представлять непосредственный интерес в смысле информации о каче-
стве той или иной конкретной партии продукции. Статистические
же проблемы возникают тогда, когда мы на основе той же инфор-
мации пожелаем сделать выводы относительно более широкого круга
явлений. Так, например, нас может интересовать качество техноло-
гического процесса, для чего мы оцениваем вероятность получения
при нем дефектного изделия, среднюю долговечность изделия, точ-
ность изделий и т. д. В этом случае мы рассматриваем собранный
материал не ради него самого., а лишь как некоторую пробную
группу или выборку, представляющую только один из возможных
результатов, которые мы могли бы встретить при продолжении
наблюдений массового процесса в данной обстановке. Разумеется,
мы должны отдавать себе отчет в том, что выводы и оценки, осно-
ванные на ограниченном материале наблюдений, отражают случай-
ный состав нашей пробной группы и потому должны считаться
ОСНОВНЫЕ ПОНЯТИЯ ВЫБОРОЧНОГО МЕТОДА
201
§ 'I
приближенными оценками вероятностного характера. Теория указы-
вает, однако, во многих случаях, как наилучшим способом исполь-
зовать имеющуюся у нас информацию для получения по возможности
более точных и надежных характеристик, указывая при этом и сте-
пень надежности наших выводов, объясняющуюся ограниченностью
запаса сведений. Возможность такого рода оценок и придает нашим
заключениям научную ценность.
В наиболее простом виде соотношения между данными выборки
и вероятностными характеристиками процесса выступают в той схеме
независимых испытаний, которую мы рассмотрели в п. 2.3.3. Мы видели,
как по частости признака попавших в выборку объектов мы можем,
опираясь на теорему Лапласа, оценить долю признака во всей пар-
тии или, как принято говорить в теории выборочного метода, в гене-
ральной совокупности. Полученная выборка называется репрезен-
тативной (представительной), если она достаточно хорошо
представляет пропорции генеральной совокупности.
Наконец, мы можем производить выбор из некоторой совокуп-
ности, объекты которой обладают количественным признаком, варьи-
рующим от одного экземпляра к другому, таким, например, как
размеры деталей в некоторой партии. Задачами выборки в этом слу-
чае могут являться оценка доли деталей, признак которых лежит
в определенных границах, оценка среднего значения признака в пар-
тии, его дисперсии и т. д. В этих примерах выборка берется из
определенной генеральной совокупности, которая каждый раз точно
фиксируется и содержит конечное число объектов. Понятия веро-
ятности, закона распределения и др. здесь играют вспомогательную
роль, позволяя приближенно определять нужные нам характеристики
генеральной совокупности путем специально организованного про-
цесса случайной выборки.
В других случаях, когда мы исследуем массовое явление, в кото-
ром интересующие нас величины претерпевают случайные колебания,
мы в большинстве случаев также располагаем лишь ограниченным
материалом наблюдений; наши же выводы хотим отнести ко всему
протеканию процесса в целом при неизменных основных условиях,
а не только к той его части, которая попала в орбиту нашего
наблюдения. Такая экстраполяция может быть оправдана далеко не
всегда. Мы рассмотрим здесь только те случаи, когда данные наблю-
дения можно уподобить рассмотренной выше случайной выборке из
некоторой «генеральной» совокупности. К этим случаям, правда,
нередко оказывается возможным отнести различные физические
и производственные эксперименты наблюдения за ходом работы
оборудования, за протеканием различных технологических процес-
сов. Особенность последних случаев заключается в том, что здесь
обычно не представляется возможным очертить объем генераль-
ной совокупности.
202
СТАТИСТИЧЕСКАЯ ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ [ГЛ. VI
6.1.2. Распределение выборки и выборочные характеристики.
Состоятельные и несмещенные оценки. Несмещенная оценка дис-
персии. Рассмотрим исследование точности станка и приспособле-
ний, связанное с величиной отклонений размеров обрабатываемых
деталей от номинала. Последовательность х,, х2, ..., хп наблюдае-
мых значений мы здесь будем рассматривать как некоторую
«выборку», по которой мы хотим оценивать распределение вероят-
ностей размеров деталей в данных условиях, отвлекаясь от слу-
чайных обстоятельств, которые могли иметь место в процессе отбора
пробных деталей из текущей продукции станка. Обобщая исполь-
зованную ранее терминологию, мы здесь будем условно говорить
о «выборке» из «генеральной совокупности» размеров деталей.
Это будет означать, что в каждом случае отбора мы наблюдаем
значение некоторой величины X, следующей определенному закону
распределения. Мы предполагаем, следовательно, что основные
условия, в которых протекает процесс изготовления деталей, оста-
ются неизменными, а вероятностные законы, регулирующие пове-
дение величины, также сохраняют силу неопределенно долго.
Подобным же образом последовательность п наблюденных значе-
ний хр х2, ..., хп мы будем рассматривать как совокупность зна-
чений, принятых п одинаково распределенными независимыми вели-
чинами Х2, ..., Хп, представляющими п экземпляров одной
и той же случайной величины X, с которой мы встречаемся в п
последовательных и независимых наблюдениях. В этом случае гово-
рят, что наша выборка взята из «генеральной совокупности» вели-
чины X. Если величина X следует закону распределения Р(х), то
мы будем говорить, что «генеральная совокупность» распределена
по закону Р(х).
Так понимаемая генеральная совокупность имеет, конечно, опре-
деленный и вполне реальный смысл, хотя и иной, чем это было
в разобранных ранее примерах выборки из конечной совокупности.
Пусть х—некоторая точка оси X', обозначим через пх число
выборочных значений, расположенных левее х на той же оси, сле-
довательно, представляет частость наблюденных в выборке зна-
чений нашей случайной величины X, меньших х. Эта частость, оче-
видно, является функцией от х. Мы обозначим ее Wn (х) и назовем
функцией, распределения выборки или эмпирической функцией
распределения. Таким образом,
Wn(x) = nf (6.1.1)
является оценкой вероятности неравенства X<Zx, т. е. теоретиче-
ской функции распределения Р(х) ~ Р (А<х) величины X, или,
иными словами, функции распределения генеральной совокупности.
§ I] ОСНОВНЫЕ ПОНЯТИЯ ВЫБОРОЧНОГО МЕТОДА 203
Исследуя Wn(x), мы по ней можем приближенно оценить функцию
Р(х), так же как по частости в выборке мы оценивали в п. 4.3.2
вероятность события.
Формально функция Wn(x) обладает всеми свойствами функции
распределения Р(х); значения ее, однако, дают не вероятности, а
частости неравенства в данной выборке. Для х, меньших
(и равных) минимального члена выборки, Wn(x) = 0, для х, больших
максимального члена, W7n(x) = l.
Если мы расположим члены выборки в порядке возрастания их
величины, то в промежутке между двумя соседними членами Wn(x)
1 !
сохраняет постоянное значение, равное числу, кратному — I т. е.
, т\ п
равное дроби вида —При переходе через точки оси х, отвечающие
членам выборки, U7„(x) претерпевает разрыв, скачком изменяясь от
1
одного своего значения к другому на величину , а при совпадении k
наблюдений — на —.
п.
Заметим, что распределение это зависит лишь от положения вы-
борочных значений на оси х, а не от порядка их в выборке, гак
что две выборки с одинаковым составом членов, но с разным
их порядком, будут иметь одну и ту же функцию распределения
Для распределения выборки можно вычислить все характеристики
положения центра группирования, характеристики рассеивания, асим-
метрию, эксцесс и т. п. Эти характеристики будут эмпирическими
или выборочными характеристиками, полученными из наблюдений.
Так как Wn(x) мы считаем оценкой по выборке функции распреде-
ления Р (х) генеральной совокупности ’), то естественно считать выбо-
рочные характеристики оценками для соответствующих характеристик
Р(х). Так, например, среднее значение (среднюю арифметическую)
выборки
х = ~Ь Н~ хп
п
*) Мы опираемся на так называемую «основную теорему математической
статистики», доказанную советским математиком В. И. Гливенко (1897— 1940)
(см. Б. В. Гнеденко, Курс теории вероятностей, М., 1954, § 60). Согласно
этой теореме при и —со с вероятностью, равной единице, верхняя граница
отклонения [М7„(х)— Р (х)| на всей оси х стремится к нулю. Тем самым
гарантируется равномерное приближение W„ (х) к Р (х) на всей оси х. Сходи-
мость Wn (х) по вероятности к Р(х) при каждом фиксированном х есть пря-
г. Пг
мое следствие теоремы Бернулли, так как частость должна почти наверно
быть сколь угодно близкой к вероятности Р (А' < х) — Р (х), если п доста-
точно велико.
204
СТАТИСТИЧЕСКАЯ ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ (ГЛ. VI
мы будем считать оценкой математического ожидания МА вели-
чины X.
Аналогично этому медиану теХ выборочного распределения
можно считать оценкой теоретической медианы №еХ и т. д. Опре-
деление точности и надежности оценок, полученных на основе
выборки, будет рассматриваться нами далее.
Введенные определения непосредственно распространяются также
на выборки из многомерных генеральных совокупностей, т. е. таких,
в которых случайная величина является многомерной, имеющей
больше одного измерения. Такими многомерными величинами будут,
например, обработанные на станке детали с несколькими регистри-
руемыми размерами (диаметр, длина, высота неровностей поверх-
ности и т. п.).
Значения величины X(xt, х2, ..., х„), наблюденные в фактически
осуществленной выборке, образуют наблюденное «значение» «-мер-
ной случайной величины (А\, Хг, ..., Хп), где каждая величина А",-
представляет как бы один из экземпляров величины X, с которыми
мы встречаемся в z-м по порядку наблюдении.
Таким образом, мы рассматоиваем выборку как испытание,
в котором реализуется значение сложной величины (Ху, Хг, ..., Хп).
Повторяя выборки, мы, естественно, будем получать различные зна-
чения этой величины, распределение которой следует определенным
(хотя иногда нам и не известным) вероятностным законам.
Каждую характеристику, получаемую нами на основании данных
выборки, также следует рассматривать как значение некоторой слу-
чайной величины, варьирующей от выборки к выборке. Так, напри-
мер, вычисляя среднюю арифметическую из наблюденных данных,
мы получаем характеристику х. Если наблюденные значения
ху, хг, ..., хп рассматривать как реализованные значения величин
А',, Хг, ..., Хп, то величина х будет являться реализовавшимся
в выборке значением величины
X —- ^1 + ~Ь • •
п
В теоретических рассуждениях мы будем чаще всего говорить о сред-
ней арифметической х именно как о случайной величине х (не при-
бегая к специальному обозначению для подчеркивания этого обстоя-
тельства). Аналогичное замечание относится и ко всем другим
выборочным характеристикам; в дальнейшем они будут по преиму-
ществу рассматриваться как случайные величины, а не как конкрет-
ные значения этих величин, полученные в данной выборке.
Распределение каждой величины А) определяется одной и той же
функцией Р(х). А так как величины Ху, Хг, Хп считаются
§ 1| ОСНОВНЫЕ ПОНЯТИЯ ВЫБОРОЧНОГО МЕТОДА 205
независимыми, то закон распределения случайной величины
(*.. А2.....Хп)
полностью определяется этой же функцией. Для каждой системы
чисел t2, tn мы имеем:
X2<f2; X„<Q =
= р (Л. < /,) Р (х2 < и... р(Х„ < и - P{ti) . .P(U.
Таким образом, любая выборочная характеристика как функция
величин А,, Хг, ..Хп представляет случайную величину с законом
распределения, однозначно определяемым функцией распределе-
ния Р(х).
Так, рассматривая среднюю арифметическую выборки х как
среднее из независимых величин с одним и тем же законом Р(х),
согласно формулам (5.2.4) и (5.S.30) будем иметь при любом п:
МХ — Мх — v, оу — о- — .
х х и
Согласно закону больших чисел х стремится по вероятности к центру
распределения v при п -* оо и может быть использована во многих
случаях как надлежащая оценка этого параметра. Выборочные
оценки, сходящиеся по вероятностям к тому или иному параметру
закона распределения, называются его состоятельными оценками.
С другой стороны, выражение выборочной дисперсии
S2 = тг = -1 У, (х,—х)2
может быть записано в следующем виде (см. п. 3.1.3):
s2 —-^-У (х,. —v-bv—x)2 = i^(x,. —V)2 —(х —V)2. (6.1.2)
<=i /=i
Рассматривая х(- как независимые величины с одним и тем же
законом распределения Р(х) (величины А’ или «генеральной» сово-
купности для нашей выборки), мы будем иметь:
М (х,- - v)2 = М (X— МХ)2 «= <%,
М (х— v)2 = Dx = —,
и из (6.1.2) получим"
206 СТАТИСТИЧЕСКАЯ ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ [ГЛ. VI
В отличие от х выборочная характеристика s2 имеет математиче-
ское ожидание (6.1.3), не равное при любом п дисперсии с2х, но
<Jv п
меньше этой величины на —. При больших п расхождение несу-
щественно, при конечных же п мы можем «исправить» s2, помножив
ее на множитель ~Г\ Полученная таким образом исправленная
или уточненная величина выборочной дисперсии будет:
п
—s* = $2 = х)2, (6.1.4)
И — 1 /? —1 “ ' 1 ' ’ ' ’
1 = 1
откуда
/* п
~s^y (6.1.5)
” 1 /=1
Выборочные характеристики, обладающие тем свойством, что их
математические ожидания при любом объеме выборки равны оцени-
ваемому параметру, называются несмещенными оценками. Приме-
рами несмещенных оценок могут служить х и № (но не s2) для
параметров v = AL¥ и = при любых законах распределе-
ния Р(х). Заметим далее, что при любом законе Р(х) можно полу-
чить’) следующее выражение для Ds2:
2 (|14-2ц0 |14-Зц2
Ds =os2 = —--------------г---+ —-j—. (6.1.6)
I If Iv It
При n -> oo -* 0 и так как при том же условии Ms2 о2, то №
сходится по вероятности к о2; следовательно, s2 является состоя-
тельной, хотя и смещенной (немного) оценкой о2. Оценка s2 будет
и несмещенной, и состоятельной.
При малых zz (тг <С 30) обычно используют s2 вместо s2.
На основании (6.1.6) приближенное выражение для дисперсии
будет
Ds2«!^Z^ (6.1.7)
(если пренебречь членами с п2 и п3 в знаменателе) и отсюда
« ]/ ') См. «Общую часть», стр. 226. ' ii4—р2 (6.1.8)
§ 1] ОСНОВНЫЕ ПОНЯТИЯ ВЫБОРОЧНОГО МЕТОДА 207
Если выборка взята из нормальной генеральной совокупности,
то с помощью соотношений (4.1.15) и (4.1.22) мы можем соотно-
шения (6.1.3) и (6.1.6) привести к виду
(6.1.9)
2 п п2 ‘ п2 п2 п ’ ' '
]/4о1- (6.1.Н)
Если хотят оценить дисперсию или среднее квадратическое
отклонение величины s2, то при большом значении величины п заме-
няют в правой части формул (6.1.7) и (6.1.8) моменты и р2
величинами1) /»4 и m2 — s2. Таким образом получают
Ds2
п
(6.1.12)
(6.1.13)
Используя соотношение (5.2.37) для среднего квадратического
отклонения функции случайной величины, получим из (6.1.13)
с помощью (6.1.3) и (6.1.8), рассматривая функцию $ = Ух, где
А, = $2,
/ 1 \ 1 1/ р4 Иг l/’ii _п4
’• - ~ ОЙ?) °- ~ ' <6'1 •’4)
В случае нормального распределения с помощью (4.1.22)
и (6.1.14) получаем (6.1.15)
(6.1.4), при тех же условиях можно
Принимая во внимание
приближенно положить
V"2(n— 1) *
(6.1.16)
*) Это может быть оправдано на основании рассматриваемого в и. 6.2.3
метода моментов.
208
СТАТИСТИЧЕСКАЯ ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ
[ГЛ. V!
§ 2. Статистические оценки параметров распределения
при больших выборках
6.2.1. Значение состоятельности, несмещенности и эффектив-
ности оценок. Первая и основная задача математической стати-
стики заключается в получении по данным выборки наиболее рацио-
нально построенных статистических характеристик распределения.
Выяснение или оценка закона распределения по данным выборки
(так называемая параметризация) и составляет существенную про-
блему математической статистики: только овладев законами распре-
деления изучаемых величин, мы можем решать возникающие
на практике задачи по анализу, сравнению и предсказанию резуль-
татов массового процесса. На практике во многих задачах вид или,
иначе говоря, форма теоретического распределения может считаться
известной. Так, например, при обработке деталей на металлорежу-
щих станках по методу автоматического получения размера (при
устойчивом технологическом процессе) можно считать, что распре-
деление погрешностей деталей подчиняется нормальному закону
распределения. Точно так же на практике очень часто исходят
из того, что нормальному закону следуют и погрешности измере-
ний. Суммарную погрешность измерения можно рассматривать как
результат действия большого числа независимых или слабо зависи-
мых причин, и поэтому наблюденную ошибку можно представлять
как сумму «элементарных ошибок»; последние же в свою очередь
вследствие центральной предельной теоремы (см. п. 5.4.2) позволяют
с высокой степенью приближения считать наблюденную ошибку
нормально распределенной. В артиллерийских расчетах обычно,
опираясь на обширный опытный материал, полагают, что распреде-
ление точек поражения на плоскости следует двумерному нормаль-
ному закону распределения. В ряде физических и биологических
схем теоретическим законом распределения является, несомненно,
закон Пуассона или показательный закон вида р(х) = ке~Ух и т. д.
Такое положение наблюдается всегда, когда рассматриваемый
процесс может быть с некоторым приближением подведен под тео-
ретическую схему, анализируемую средствами теории вероятностей.
Во всех этих случаях мы можем считать, что теоретический
закон распределения принадлежит к некоторому семейству, завися-
щему от одного или нескольких параметров. Если бы точные зна-
чения параметров таких, как, например, v и о, при нормальном
законе (см. п. 4.1.1) или X при законе Пуассона (см. п. 3.1.6) были
известны, закон распределения для данного случая был бы пол-
ностью определен. Иными словами, здесь задача нахождения закона
распределения изучаемой величины (или величин) сводится к нахож-
дению неизвестных значений параметров, г. е. к параметризации.
Именно ради определения этих параметров весьма часто и произво-
§ 2] СТАТИСТИЧЕСКИЕ ОЦЕНКИ ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ 209
дится само статистическое исследование. Так, знание параметров v
иов вышеуказанных случаях,.связанных с нормальным распреде-
лением, дает возможность решать инженерные задачи из области
точности обработки и точности измерений.
Мы видели, например, в п. 6.1.2, что, образуя средние арифме-
тические из значений случайных величин, представляющих резуль-
таты выборочного наблюдения интересующего нас признака, можно,
основываясь на законе больших чисел, приближенно оценить мате-
матическое ожидание или параметр v нормального закона; анало-
гично можно рассматривать дисперсию выборки $2 как оценку тео-
ретической (генеральной) дисперсии о2. Тем самым будет с некоторым
приближением найдена и теоретическая функция нормального закона
распределения вероятностей данной задачи.
Пусть Р(х, 0) — закон распределения X, функциональная форма
которого известна, но он содержит неизвестный параметр 0 (для
простоты только один). Будем предполагать, что мы располагаем
выборкой, состоящей из значений х,, х2, ..., хп, взятой из «гене-
ральной совокупности» с законом Р(х, 0), причем параметр 0 имеет
постоянное, но неизвестное значение. Пусть 0(х,, х2, ..., хп) —
некоторая функция выборочных значений х2, х2, ..., хп, которую
мы хотим использовать в качестве оценки параметра 0. Спраши-
вается, какими свойствами должна обладать функция 0, чтобы ее
можно было бы считать хорошей оценкой для неизвестного значе-
ния 0? Рассматривая х2, х2, ..., хп как частную систему значений
одинаково распределенных независимых величин Л',, Х2, ..., Хп
с законом Р(х, 0) каждая, мы будем иметь случайную величину
0 (Xit Х2, ..., Хп), закон распределения которой будет зависеть
от параметра 0. Из выборки мы получаем лишь одно частное зна-
чение величины 0, отвечающее значениям АГ; = х,- аргументов.
Чтобы значение 0 (х2, ..., х„) было близко к 0, мы должны, оче-
видно, потребовать по возможности более тесной концентрации рас-
пределения вероятности 0(Л\, Х2, ..., Хп) вблизи значения неиз-
вестного параметра 0, другими словами, чтобы рассеивание слу-
чайной величины 0 около 0 было по возможности меньшим. Та-
ково основное условие, которому должна удовлетворять «хорошая»
оценка.
Во многих случаях естественно требовать несмещенности оценки,
г. е. выполнения равенства М0 = 0. Когда 0 является смещенной,
то исследование ее математического ожидания позволяет часто
внести надлежащее уточнение, как это мы сделали в случае $2.
Если «смещение» оценки 0 (т. е. разность М0 — 0) мало, как эго
обычно бывает при большом объеме выборок, то им пренебрегают
на практике, так как амплитуда случайных колебаний (измеряемая,
210 СТАТИСТИЧЕСКАЯ ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ [ГЛ. VI
например, средним квадратическим отклонением о9) бывает значи-
тельно больше смещения.
Требование несмещенности особенно важно при малом объеме
выборки. В распоряжении наблюдателя часто имеются данные
по большому числу малочисленных серий наблюдений (по 5 —10 в каж-
дой). Для того чтобы использовать оценки, выведенные для каждой
серии, и получить путем осреднения их более точную общую оценку,
нужно быть уверенным в отсутствии систематического смещения
у каждой частной оценки. Это будет тогда, когда частная оценка
для каждой серии является несмещенной.
Рассматривая в качестве меры концентрации распределения 0
около значения параметра 0 величину второго момента М(0—0)2,
мы можем теперь точно охарактеризовать сравнительную эффектив-
ность двух каких-либо оценок 0, и 02, оценивающих один и тот же
параметр 0. В качестве меры эффективности естественно принять
отношение
Если е>1, то оценка 02 более эффективна, чем 01 (и обратно),
так как ей соответствует меньшее рассеивание. Если 0, и 02 — не-
смещенные оценки, то е является отношением дисперсий
(6.2.2)
Для широкого класса распределений мы можем указать точную ниж-
нюю границу для дисперсий различных оценок одного и того же
параметра. Если существует оценка, дисперсия которой в точности
равна нижней границе, то она называется эффективной оценкой
с минимальной возможной дисперсией. В больших выборках есте-
ственно требование состоятельности оценок, т. е. сходимости их
по вероятности к оцениваемому параметру.
6.2.2. Асимптотические распределения выборочных характе-
ристик. Согласно центральной теореме (см. п. 5.4.2) средняя ариф-
метическая большой выборки х будет распределена асимптотически
нормально с параметрами
v = М.с и о- = —.
х V п
(6.2.3)
Тем же самым свойством будут обладать и многие другие симме-
тричные функции от выборочных данных: например, средние из л-х
степеней, т. е. моменты эмпирической функции Wtl(x) и различные
алгебраические функции от моментов. Так будет, например, обстоять
§ 2] СТАТИСТИЧЕСКИЕ ОЦЕНКИ ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ 211
дело (правда, в очень большой выборке) с показателями асиммет-
рии и эксцесса, а также с медианой и квантилями, определяемыми
по выборке. Все эти функции при очень широких предположениях
распределены при больших объемах выборки асимптотически нор-
мально. Это обстоятельство имеет большое значение, так как
позволяет при больших л с большой точностью охарактеризовать
распределение рассматриваемых оценок двумя параметрами — мате-
матическим ожиданием и дисперсией; точность и надежность оценки
тогда полностью определяются, так как можно указать предел или
границу, которую отклонение оценки от оцениваемого параметра
может превзойти лишь с малой вероятностью ; при = 0,27°/0
такая граница при нормальном законе равна За и часто называется
предельным отклонением.
На вопрос о том, каков должен быть объем выборки, чтобы
оценку параметра можно было с достаточной точностью считать
нормально распределенной, нельзя дать однозначного ответа; этот
объем зависит от того, как распределена данная характеристика.
Если мы имеем дело, например, со средним арифметическим вы-
борки из значений величины X, распределение которой не слишком
асимметрично, то приближение к нормальному закону можно считать
практически достаточным уже при л >30. Для таких характеристик,
как дисперсия, асимметрия, эксцесс, коэффициент корреляции,
меньший 0,2, для практической нормальности следует довести
выборку до размеров, не меньших 100 единиц. Если коэффициент
корреляции близок к единице, то при л = 300 нормальное прибли-
жение все еще не является достаточным.
Если для параметра 0 две статистические оценки 0, и 02, по-
строенные по одной и той же выборке, асимптотически нормальны,
то при обычных условиях их дисперсия в первом приближении
имеет вид
сг с*
М(0,-0)2»^- и M(02-0)2«-f, (6.2.4)
где с® и с2 — две постоянные.
Очевидно, большей эффективностью обладает та из оценок, для
которой коэффициент с меньше. В некотором классе случаев имеется
„ „ са
такая оценка 0О параметра 0, для которой М(0О—0)2 « , при-
чем с0 имеет наименьшее из возможных значений.
В этом случае оценка 0О называется асимптотически эффек-
тивной.
Можно показать, что для нормального распределения наиболее
эффективной оценкой положения центра v будет являться среднее
212
СТАТИСТИЧЕСКАЯ ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ [ГЛ. VI
арифметическое х; другие возможные оценки параметра v будут
иметь сравнительно меньшую эффективность. Так, сравнивая выбо-
рочную среднюю х и медиану т„ при больших п, мы получим
в выборках из нормальной совокупности для показателя ей (отно-
2
шения дисперсий) значение, близкое к — = 0,637 это означает,
что для получения той же точности и надежности оценки центра г
по среднему арифметическому нужно использовать лишь 64°/0
от того числа, какое использовано при оценке по медиане (рис. 46).
Рис. 46 Кривые плотностей выборочных распреде-
лений средней арифметической х и медианы тех.
В общем случае показатель эффективности еа имеет аналогичный
статистический смысл, указывая долю объема наблюдений, равно-
сильную всему их объему при переходе от данной оценки пара-
метра к более эффективной оценке.
6.2.3. Метод наибольшего правдоподобия для нахождения
оценок параметров. Метод моментов. Один из важнейших методов
для отыскания оценок параметров по данным выборки был предло-
жен Р. Фишером и носит название метода наибольшего правдо-
подобия. Пусть мы имеем выборку из значения величины X объема л:
X,, хг, .... хп; плотностью X будет функция р(х, 0), зависящая
от параметра 0. Функцией правдоподобия называется функция
/.(х,, х2, ..., х„, 0)=р(х,, 0)р(х2, 0) ... р(хп, 0). (6.2,5)
Пусть теперь X—дискретная величина с возможными значениями
6i> I,, •••> Sr> а •••> тг будут частоты этих значений
§ 2] СТАТИСТИЧЕСКИЕ ОЦЕНКИ ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ 213
в выборке, т. е. число тех выборочных значений, которые совпа-
дают с с £г, ..., с 1~г соответственно; очевидно, 2®/ —и
пусть
р (Ar==g.) = pf (0).
В этом случае функция правдоподобия определяется соотно-
шением
L{xx, хг, х„, 0)=^ (0)^(0) ... /^(0). (б.2.6)
Считая значения хх, х2, ..., хп данными, будем рассматривать L
как функцию неизвестного параметра 0. Сущность метода наиболь-
шего правдоподобия заключается в том, что в качестве оценки
параметра 0 берется значение аргумента 0, обращающее функцию L
в максимум. Это значение является функцией от хр х£, ..., хп и
называется оценкой наибольшего правдоподобия. Отсюда, согласно
известным правилам дифференциального исчисления, следует такое
аналитическое правило: для нахождения оценки наибольшего правдо-
подобия необходимо разрешить уравнение
W = 0
и отобрать то решение 0 = 0 (х,, х2, ..., х„), которое обращает L
в максимум. Вместо уравнения (6.2.7) чаще бывает удобнее рас-
сматривать уравнение
В случае двух параметров 0, и 02 -оценки их определяются
из двух совместно решаемых уравнений
д In 1_. ~ д In L_.п q q.
-10Г=° и -ж=о- <6'2'9*
Рассмотрим в качестве простейшего примера задачу оценки вели-
чины вероятности р по данному числу т появлений события А в п
независимых наблюдениях. Мы можем вероятность р рассматривать
как параметр, входящий в распределение дискретной двузначной
величины X, принимающей только два значения g, = 1 и £2 = 0,
в зависимости от того, появляется ли событие А в рассматриваемом
испытании или не появляется. Согласно (6.2.6) мы будем иметь:
L = pm(\ — р}п-'я,
и уравнение (6.2.8) напишется так:
д In L. т п—т
др ~ Р 1— Р~
214 СТАТИСТИЧЕСКАЯ ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ [ГЛ. VI
Оно имеет единственное решение
Р = (6.2.10)
следовательно, оценкой наибольшего правдоподобия будет частость
события. Мы знаем, что она является несмещенной, состоятельной
и асимптотически нормальной оценкой. Можно также доказать, что
при любом п эта оценка имеет наибольшую эффективность.
В качестве второго примера рассмотрим величину X, подчинен-
ную закону Пуассона с неизвестным параметром. Произведя вы-
борку, получаем наблюденные значения хь х2, ..., хп. Величина X
может принять любое из значений 0, 1, 2, ... Пусть г будет
наибольшее из этих чисел, наблюденных в выборке; числа /и0, ик, ...
.... тг пусть представляют частоты, с которыми встречаются в выборке
числа 0, 1, 2, ..., п. При этом, так как
есть вероятность равенства X = i (i = 0, 1, ...),то
Г
*=о
(6.2.11)
и потому уравнение наибольшего правдоподобия даст:
откуда
dlnZ. v
<=о
(6.2.12)
В этом случае X будет несмещенной, состоятельной и асимпто-
тически нормальной оценкой параметра 0, удовлетворяющей усло-
виям метода наибольшего правдоподобия.
В качестве примера рассмотрим, далее, оценку двух параметров
нормального распределения. Пусть мы по данным xlt хг, ..., хп
значениям нормально распределенной величины X, т. е. по данным
выборки Оп объема п, должны оценить неизвестные параметры v
§ 2] СТАТИСТИЧЕСКИЕ ОЦЕНКИ ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ 215
и а этого закона. В этом случае
Р{Оп' v’ =
\ f 2л су /
п
1пЛ = — у1п2л— 1по2—v)2 (6.2.13)
i = 1
Уравнения для определения оценок для v и о2 будут:
dL 1 VT/ ХА
i=i
_r . п
uL ft , 1 i \2 zx
dar~ ~'2& + 2а*1^Х1~v) =0‘
i-i
Из первого уравнения следует:
v„p=4- = x> (6.2.14)
и тогда второе даст;
<4=42>‘--х)2==л (6-2Л5)
Первая оценка не смещена, но вторая, как мы знаем из п. 6.1.2,
будет немного смещенной.
Существует, конечно, много других способов оценки центра и ха-
рактеристики рассеивания нормального распределения. Положение
центра можно, например, оценивать с помощью медианы, среднего
арифметического из квартилей или полусуммы крайних членов
выборки. Однако все эти характеристики имеют значительно мень-
шую эффективность, но в некоторых случаях они используются
благодаря простоте вычисления.
При нормальном распределении в качестве оценки характери-
стики рассеивания можно использовать размах выборки
R — Xmax ХпЦп. (6.2.16)
Можно показать, что
М/? = а„о, (6.2.17)
где ап — некоторая функция объема выборки, значения которой
приведены в таблице III приложений. Таким образом,
<6.2.18)
216 СТАТИСТИЧЕСКАЯ ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ [ГЛ. VI
что показывает несмещенность оценки —. При небольших п {п < 10)
ап
эта оценка параметра о имеет довольно значительную эффектив-
ность, но при больших п мало эффективна по сравнению с $.
В качестве последнего примера рассмотрим величину X с равномер-
ным на отрезке (0, 0) распределением, т. е. с плотностьюр (х, 0)=-^ .
Функция правдоподобия выборки (хр х2, ..., хп) в этом случае
будет L = ^, т. е. функцией, монотонно растущей с уменьше-
нием 0 до нуля. В этом случае оценка наибольшего правдоподобия
не может быть получена из уравнения вида (6.2.7). Однако оче-
видно, что наименьшее значение 0, совместимое сданными выборки,
будет равно 0 = 0 = хтаХ) т. е. наибольшему члену этой выборки;
он и будет представлять оценку наибольшего правдоподобия. Чтобы
сделать эту оценку несмещенной, достаточно помножить ее на мно-
л -f-1
житель ----- .
п
Метод наибольшего правдоподобия обладает важными достоин-
ствами: он всегда приводит к состоятельным (хотя иногда и смещен-
ным) оценкам, распределенным асимптотически нормально, имеющим
Наименьшую возможную дисперсию по сравнению с другими, также
асимптотически нормальными оценками, и наилучшим образом (в не-
котором смысле) использующим всю информацию о неизвестном
параметре, содержащуюся в выборке. Однако на практике он часто
приводит к необходимости решать весьма сложные системы уравнений.
Другим способом, часто приводящим к значительно более про-
стым и удобным характеристикам, является метод моментов. Мо-
менты выборки являются оценками для моментов распределения
величины X, которые зависят от неизвестных параметров. В свою
очередь оцениваемые параметры могут быть выражены в виде
определенных функций теоретических моментов. Заменяя эти послед-
ние их оценками, т. е. моментами выборочного распределения, мы
получим оценки для параметров. Например, зная, что показатель
асимметрии 2^ = ^, и заменяя теоретические моменты их оценками,
найдем выборочную оценку для
Нужно отметить, что этот метод иногда приводит к малоэффектив-
ным оценкам.
6.2.4. Оценка центра распределения по неравноточным наблю-
дениям. Теперь мы рассмотрим применение введенных в п. 6.2.3 по-
нятий для оценки центра распределения по неравноточным наблю-
§ 2] СТАТИСТИЧЕСКИЕ ОЦЕНКИ ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ 217
дениям, т. е. по наблюдениям, каждое из которых характеризует-
ся своей величиной рассеивания или, иначе говоря, имеет свою
точность.
Пусть мы имеем серию хА, хг, х^ независимых между со-
бой наблюдений одного и того же объекта.
Пользуясь введенными в п. 6.1.2 понятиями, мы допускаем, что
Мх,=Мхг = ... = Mx.v = «,
где а—центр распределения, но
Dx, = a2, Dx2 = о2, ..., Dx,v = o2v,
причем о2 =£ aj (i #= j), т. е. наши величины имеют одинаковые центры
и различные дисперсии. Последнее как раз и означает, что наблю-
дения являются неравноточными.
В этом случае для оценки центра рассеивания а вместо обыч-
ной средней арифметической целесообразно использовать «взвешен-
ную» среднюю арифметическую
... +gNxN, (6.2.20)
где gi— «вес» наблюдения х,-.
Для того чтобы оценка х была несмещенной (т. е. при любом а
Мх = а), необходимо ввести условие
a = g,a + g2a+ ... +gNa
или
^+^2+ ••• + &v=1- (6.2.21)
Ясно, что веса g,- следует выбрать так, чтобы оценка х имела
наименьшую возможную дисперсию (т. е. обладала наибольшей
возможной для нее эффективностью). Эта дисперсия согласно (3.1.29),
(5.2.22) и (6.2.20) равна
_ n w
al = Dx== SD(^iX;)= ^gio‘ (6.2.22)
l = 1 i = 1
или ввиду (6.2.21)
gl<rf + gs°2 + . . . + +(1 —gt---g2--- . . . —£дг-1)г °.V •
(6.2.23)
Дифференцируя (6.2.23) no gv g„ ..., gN_x и приравнивая частные
производные нулю, получим уравнение для определения «наилучших»
весов, обеспечивающих экстремум (который будет, как легко
показать, минимумом)
2&<^—2(1... —g'JV-l)a^=0
218
СТАТИСТИЧЕСКАЯ ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ [ГЛ. VI
grf = gN°N (z = l, 2, ..., /V-1). (6.2.24)
Отсюда следует такое правило: веса gt, g2, g# должны быть
обратно пропорциональны дисперсиям (т. е. квадратам средних
квадратических отклонений) отдельных наблюдений
••• •••4- (б-2-25)
Пусть gv g2, gN—положительные числа, удовлетворяю-
щие (6.2.25); чтобы еще удовлетворялось нормирующее усло-
вие (6.2.21), достаточно разделить каждое число gj на общую их
сумму, т. е. взять в качестве весов числа ~~ .
2а St
Тогда из (6.2.20) получим:
N
х=^-------, (6.2.26)
%Si
i~ 1
и (6.2.23) примет вид
ы
S
l/=N (6-2.27)
(2^)
\Z =1 /
Из (6.2.25), далее, следует, что произведения gtf постоянны, т. е.
gtf = g&= ••• = &v<^ = < (6.2.28)
где о2—общее значение этих произведений. Величина а носит
название среднего квадратического отклонения «фиктивного»
наблюдения, имеющего вес, равный единице. С помощью а2 диспер-
сии отдельных наблюдений выражаются просто
Подставляя эти значения в (6.2.27), будем иметь:
N
У gi
i= 1
§ 2] СТАТИСТИЧЕСКИЕ ОЦЕНКИ ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ 219
откуда
= (6.2.29)
S Si
i=l
Для оценки величины о3 по данным опыта используют следующую
оценку:
s* = лГ=П 2 8i {Xi ~ (6-2,30)
1=1
Легко показать, что это — оценка несмещенная, так что
Ms3 =4
Чтобы оценить величину пользуются ее выборочной оценкой
К оценкам а по взвешенной средней арифметической и а3 по s3
можно прийти, пользуясь методом наибольшего правдоподобия,
считая, что все величины хг распределены нормально около одного
и того же центра, но с разными дисперсиями <з(?, отношения которых,
3*
а следовательно, и веса наблюдений известны, гак что aj=~
Si
(i=\, 2, N). Функция правдоподобия (6.2.6) выборки тогда
будет:
_ 1X1 ~ _ <*2~g>3 - 'X|V ~ а'
L — е 3’? —L-e 3si ------L— е (6.2.31)
]/2r. Sj у2па2
Поэтому
S (*« — a)2 Si
\nL = i=' ---------N In а 4- С, (6.2.32)
где С не зависит от неизвестных параметров а и о. В соответствии
с (6.2.8), дифференцируя (6.2.32) по а и а и приравнивая произ-
водные нулю, получим уравнения для определения оценок
N
^gi (х,—а)==0
220
СТАТИСТИЧЕСКАЯ ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ [ГЛ. VI
Отсюда оценка центра а будет:
а
N
i =1
N
gi
т. е. совпадает с (6.2.26), и оценка дисперсии а2 будет:
о
JV-1
м
(эта оценка — немного смещенная).
Пусть, например, измерения специальной меры длины, произво-
дившиеся на приборах различной точности, дали результаты, при-
веденные в таблице 6.2.1.
Таблица 6.2.1
Порядковый № измерения Отклонения от номинального размера в мк
Вертикальный оптиметр Машина типа Цейсе Машина типа Сип Миниметр с ценой деления 1 мк
1 2 3 4
1 2 3 4 • 11,3 10,8 И,1 10,9 9,8 10,7 10,4 11,2 10,1 9,9
2 11,3 32,8 20,5 41,6
При этом известно, что дисперсии погрешностей измерений
на применявшихся приборах имели следующие значения в мкг\
а2 = 0,16, о2 = 0,64, о2 = 0,49 и о2 = 0,25.
Требуется оценить отклонение а действительного размера меры
от номинального ее размера.
§ 3]
ТОЧНЫЕ РАСПРЕДЕЛЕНИЯ НЕКОТОРЫХ ХАРАКТЕРИСТИК
2'21
Мы имеем 10 результатов измерений, из них некоторые (про-
изведенные на одном и том же приборе) имеют одинаковые дис-
персии.
На основании (6.2.25) имеем:
1 1 1
Р — ---- /Т = Р = О* -------- сг — <7 — ----
61 0,16’ 2,2 0,64’ bs Ьв 0,49’
— _ 1
q 25
И
Vo-— 1 I 3i 2 I 4 —Ч1О
— оТТб + 6764 -l- 6749 + 6725 — d 1 ’0 ’
( = 1
а потому на основании (6.2.26)
а = х~ 11,й‘о, 16-31 !':-8 XбГ'Я 8 20,О'0,49.31'*'
+ 4,'6ХЙ = 10’65
§ 3. Точные распределения некоторых выборочных
характеристик
6.3.1. Распределение %2. В случае, когда величина X подчиняется нор-
мальному закону, оценка параметров, а также проверка различных гипотез
относительно этих параметров основываются на знании точного распреде-
ления некоторых выборочных характеристик. С этими законами нам и сле-
дует теперь ознакомиться. Мы видели, что среднее арифметическое х нор-
/ о \
мальной выборки распределено нормально, согласно закону N I х, v, .
\ V nJ
Для того чтобы найти распределение эмпирической дисперсии, мы предва-
рительно исследуем распределение характеристики:
х2=£4 (6-3.1)
t = 1
где хг—независимые, распределенные по закону N (х?, 0; 1) величины.
Очевидно, что у/г&О и Р(у2<0)=0.
Пусть для х > О
Кп (х) = Р (%2 < х); (6.3.2)
гак как величины х,- независимы и каждая из них имеет по условию плот-
носгь —-— е 2 , то совместная плотность величин л'2, ,хп выразится
V 2л
произведением (см. п. 5.4.2)
222
СТАТИСТИЧЕСКАЯ ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ (ГЛ. VI
Поэтому для Кя (х) мы найдем выражение
_ __L ( х® + ... +х2)
1 Г С 2 ' 1 П'
---- 5 ••• \е dxl..,dxn
(2л) г S x‘i х
(6.3.3) ;
в виде п-мерного интеграла, распространенного на область gn х, определяе-
мую неравенством ^]х2=Сх. Этот интеграл и выражает вероятность случай-
i
ной точки Q (х,, ..., х„) попасть в область gn ж; при п = 2 область g2 х,
определяемая неравенством xj-j-x’s^x, представляет круг с центром в на-
чале координат на плоскости (х„ х2), ограниченный окружностью х2-|-х2 = х :
радиуса Ух. В случае п = 3 область ga<x представляет сферу того же
радиуса V х с центром в начале координат. Область gnx в общем случае
представляет множество точек, лежащих внутри и на поверхности сферы
n-мерного пространства радиуса У х с центром в начале координат. Найдем
производную от функции К„(х). Давая х приращение h > 0, получим:
л
К„(х + Л)— К„(х) = (2л) 2 j ••
п
2 х2 S x+fl
(6.3.4)
где область интегрирования ограничена поверхностями двух концентрических .
сфер g„iX и g„lX+!i- Применяя теорему о среднем, мы получаем из (6.3.4):
(х+%) г -
(x + h) — K„ (х) = (2л) ге 2 J’"j dx,.. .dx„. (6.3.5)
х< У, x2<x+/i
—Д- (х+ th)
Здесь е 2 (0 < 0 < 1) есть некоторое среднее значение подынтеграль-
2 I
ной функции е 1 в области интеграции (6.3.5) (в которой У,х2 всегда
лежит в промежутке (х, x-j-Л)).
С другой стороны, положим
S„(x) = ^ ... dx, dx2...dxn. (6.3.6)
х2+х2+...+х2<х
Тогда интеграл в правой части (6.3.5) можно записать в виде 5„(х-|-/г)—
—S„(x). Заметим, что S„(x) представляет объем сферы gn x радиуса У х.
Этот объем пропорционален n-й степени радиуса (в случае п = 2 — квад-
рату, при п = 3—кубу радиуса и т. д.). Аналитически в этом свойстве
§ 3] ТОЧНЫЕ РАСПРЕДЕЛЕНИЯ НЕКОТОРЫХ ХАРАКТЕРИСТИК 223
функций Sn (х) легко убедиться, если произвести замену переменных в инте-
грале (6.3.6), полагая
*<• = «// V~х-
Тогда
dxt = V xdyt
S„ (x) = (V"x)n ... J dyl...dyn = Cn,lx2, (6.3.7)
2^'
где через C„tl обозначен объем «единичной (радиуса /? = 1) сферы» «-мер-
ного пространства.
Из (6.3.5) и (6.3.7) следует:
п п
кп (x+h) -Kn(x) = Cni (х + №> (x + ftF-zT . (б 3 8)
Переходя к пределу при h 0, найдем:
п 1
, —-I -—X
kn(x)=Kn(X)==Cn,txi е * . (6.3.9)
Значение С„>3 может быть найдено из условия
Р (x2«S оо) = Кп (оо)= J kn(x)dx = l,
О
откуда
« и X
Сп<г J е 2 dx=l
О
£
или, сделав подстановку -2=z> dx = 2dz,
22 Cnt, Jj e-zz2 ~'dz=l. (6.3.10)
О
Интеграл вида
Г (р) = J е“ггР-’& (6.3.11)
о
‘Ри р>0 носит название Г-функции (гамма-функции). Она табулирована.
Уравнение (6.3.10) может быть переписано так:
п
224
СТАТИСТИЧЕСКАЯ ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ [ГЛ. V!
отсюда
Подставляя это значение СП15 в выражение (6.3.9), для плотности получим:
1 —-1 - —
------»' « '• <в.з.ия
При п — 1 и л =2 kn(x) убывает с ростом х на положительной полуоси х
lim kn (х) = 0 при х -* со
Начиная с n = 2, kn(x) имеет график, представляющий одномодальную асим-
метрическую кривую с максимумом в точке х — п—2. Закон распределения
йп(х)—суммы квадратов п независимых нормальных величин носит название
«^’-распределения». Число п носит название числа «степеней свободы»—»
термин, смысл которого уяснится в связи с дальнейшими приложениями
этого распределения. График ^’-распределения показан на рис. 47. Для
вероятности Р (х2 > где %*—какое-либо заданное положительное число,
найдем:
<0
Р (№&=x’) = j (6.3.13)
§ 3]
ТОЧНЫЕ РАСПРЕДЕЛЕНИЯ НЕКОТОРЫХ ХАРАКТЕРИСТИК
225
Обратно, для каждого
ветствующий верхний
q
уровня вероятности мы можем рассчитать соот-
«<?% предел», т. е. найти такое число Хр что
р(«‘>«;)=то-
Аналогично этому % будет нижним пределом», если
Р (Х2< Х^) =-^q
Очевидно, Х^ отвечает квантилю для уровня вероятности — .
Значения xjj для некоторой сетки значения <?2 можно найти в таб-
лице IV приложений.
Распределения X2 обладают одним замечательным свойством, легко
доказываемым с помощью производящих функций. Производящая функция
kn (х) равна, как показывает вычисление,
СО П
о
(6.3.14)
Эта функция удовлетворяет соотношению
тп+р (/) = (1 = (1 - 2t)~n (1 -2t)~P = mn (t) тр (/).
Произведение справа можно считать согласно основному свойству (см.
п. 5.4.2) производящей функцией композиции законов kn (х) и kp (х). Так
как, с другой стороны, mn+p(t) есть производящая функция ' kn+p (х),
то мы приходим к выводу, (что композиция законов kn (х) и kp (х) совпа-
дает с законом kn+p(x). Другими словами: две независимые величины’X2
и X2, распределенные по законам X2 с п и р степенями свободы, соответ-
ственно дают в сумме величину Х2 + Х2, распределенную также по закону X2
с п-^-р степенями свободы. Используя (3.1.24), (3.1.52) и (6.3.14), найдем
МХ!=л, DX2 = 2/i. (6.3.14')
6.3.2. Распределение t Стьюдента. Многие задачи статистики приводят
к рассмотрению распределения величины вида
z У k
ТТ’
(6.3.15)
где величины г и v независимы, г распределена нормально N (г; 0; 1),
a v подчиняется закону X2 с k степенями свободы. При этих условиях
плотность вероятности величины t имеет вид
_A + i
sA(x) = B^l+ 2, (6.3.16)
где Bk зависит только от k и выражается с помощью Г-функции (6.3.11)
II. В. Смирнов, И. В Дунин-Барковский
226 СТАТИСТИЧЕСКАЯ ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ ' [ГЛ. VI
Закон распределения величины t, определяемый формулой (6.3.16), носит
название закона Стьюдента с k степенями, свободы. Его функция рас-
пределения обозначается через
х
Sk(x)=^ sk(t}dt.
— 00
График, иллюстрирующий эту функцию, показан на рис. 48.
Рис. 48. Площадь под кривой sk (х) распределения Стью-
дента, отвечающая функции Sk(x) распределения.
Для доказательства найдем сначала плотность совместного распределения
величин z и и, перемножая вследствие независимости их плотности
Z2
“V . v k .
Рг (г) = тогда получим: где значение Далее, S»W = P(f<x) = P Р . \ 1 2 2* 1 ‘ 11 ‘ 2‘г(т) р (г, и) — Се 2 2 и 2 , С= ± . (6.3.18) — f k \ К 2л 2 2 Г ( ) \ к? / г7 v k = РП<-^/1И=-С | 1 e"T'TVr" 'dvdz.
§ 3]
ТОЧНЫЕ РАСПРЕДЕЛЕНИЯ НЕКОТОРЫХ ХАРАКТЕРИСТИК
227
Область интегрирования определяется неравенствами —оо < z < *._•
и представляет множество точек плоскости (z, v), ограниченное ветвью
параболы z = -^=. V v.
Выполняя двойное интегрирование, сначала по г от —оо
а затем по v от 0 до оо, мы найдем:
j _v_ V k
e * dv (* e 1 dz.
(6.3.19)
Дифференцируя это равенство по х в правой части под
грала (что может быть оправдано), найдем:
V"k
GO k V I
s'k(x)=sk(x) = C Co2 e 2 \i
\ ax
k
oT"’a
хЧ>
Ik
После подстановки
е
знаком инте-
,!•
e ‘ dz I dv =
о
J~Xdv =
2u
v =
{+~k
. 2 du
dv =
хГ
k
о
принимая во внимание (6.3.18), будем- иметь:
A + l
c 2 2 p 1
s‘w“7t---------TiTlP ‘
(1+tY °
\ я J
k-±l fe+1 A+l
что и доказывает (6.3.16). Кривая sk (х) симметрична относительно оси
ординат, в связи с чем М(/)=0. Для больших значений k она очень близка
к нормальной кривой п (х; 0; 1). Но при малых k она значительно откло-
няется от этой кривой, более медленно спускаясь к оси х, вследствие чего
вероятность значений t, превышающих по абсолютной величине заданный
предел i0, гораздо больше, чем при нормальном распределении, a q% пре-
делы tg, удовлетворяющие условию
р ( U I > ig, k) = 2 [ 1 -sk (tg, A)] = , (6.3.20)
значительно больше при малых k, чем соответствующие нормальные q%
пределы Zg. Значения tg, к для некоторой сетки значений k при различных </
8*
228
СТАТИСТИЧЕСКАЯ ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ [ГЛ. VI
приведены в таблице V приложений. При k оо tq, k -> tq, <r,=zq, rp,ezq—со-
ответствующие нормальные q% пределы. При k > 30 приближенно tf,, k^za
для q > 1%.
На рис. 49 показана кривая распределения Стьюдента в сопоставлении
с нормальной кривой.
Рис. 49. Кривая ^-распределения и нормальная кривая.
6.3.3. Распределение F. Важные приложения в дисперсионном анализе
имеет распределение величины
и
й, _k2u
v ~ kxv ’
К
(6.3.21)
где и и о распределены по законам х4 с й, и k2 степенями свободы. В этом
случае вычисления, подобные тем, какие мы провели при выводе распреде-
ления Стьюдента ’), показывают, что распределение F имеет плотность
*! — 2 \
^’(/)= ----если ^0,1 (6 3 22)
(*2+V) 2
Pf(,f)=0, если f < 0. J
Соответствующая функция распределения носит название F -распределения
ей, и k2 степенями свободы. При данных й, и k2 мы можем найти по
таблице VI приложений значения Fq такие, что
P(F>^)=lfo; (6-3’23)
Fq будет (/-процентным верхним пределом распределения.
В таблице VI F„ приведены для </ = 5% и q=l% при числах от 1
до 500 и k2 от 1 до 1000.
6.3.4. Распределение дисперсии выборки из нормальной сово-
купности. В качестве приложения результатов, полученных в пре-
’) См. «Общую часть», стр. 302—303,
§ 3] ТОЧНЫЕ РАСПРЕДЕЛЕНИЯ НЕКОТОРЫХ ХАРАКТЕРИСТИК 229
дыдущих разделах, мы найдем теперь распределение выборочной
пли эмпирической дисперсии
определенной на основании выборки из нормальной совокупности
с некоторыми параметрами v и ст. Если мы заменим величину X
на величину отклонения X—v — X', каждое х,-заменится на х{—v = x'
и х на х—v = x', то величина s‘ не изменится. Отсюда следует,
что распределение № не зависит от v и потому без ограничения
общности мы можем предполагать V—0, а величины х(—независи-
мыми . и распределенными по закону /У(х; 0; ст). Перейдем теперь
от величин X; к системе величин yit связанных с xz следующими
соотношениями:
л =7Т?(Х-
Л=у^(*>+*г-2х,),
у» = Йп+х‘+х>~ 3О-
► (6.3.24)
Уп~1 — рО- . -[Х! + Х2 + ••• + ХП-1~ (п~
Г \' * L ) ’ П
Уп = (Xl+X2 + • • • + ХП)-
Мы покажем, что у{, так же как х(, нормально распределены
и независимы. Обратим внимание прежде всего на то, что коэф-
фициенты в линейных формах при переменных х; правой части
удовлетворяют так называемым условиям ортогональности. Если мы
выпише м эти коэффициенты в таблицу («матрицу»)
1 1 0 0 ... 0 0
/Т-2 /~Ь2
1 1 2 0 ... 0 о
/Тз /"Тз
и: 1 1 1 3 о о
-4 = SJ /Т4 /Тч /Т4 /Т4
1 1 1 1 1 п— 1
/(л-i) п V(n-i) п /(Л-1) п /(Л-1) л /(Л-1) л K(n-i) п
1 1 1 1 1 1
с V'n V п К п V п Кп /п
ti столбцов
230
СТАТИСТИЧЕСКАЯ ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ [ГЛ. VI
то в этой таблице имеем: 1) сумма произведений соответствующих
элементов двух параллельных строк равна нулю; 2) сумма произ-
ведений соответствующих элементов двух параллельных столбцов
равна нулю; 3) сумма квадратов элементов каждой строки или
каждого столбца равна единице. Все эти свойства легко проверяются
непосредственно. Например, сумма произведений элементов второй
и третьей строк будет равна '
.. 1 - . 2 + (___......
/2-3-3-4 \./2-3-3-4
Сумма произведений элементов третьего и четвертого столбцов равна
1 /______+ _____________1_д_ д_ _J___________1 ]
КЗ-4 V V 3-4/ 4-5 /4-5 п /(п-1) п
4-0 = 0.
~ 4 + •• • + (п — 1)п + п
и т. д.
Подобного рода «соотношения ортогональности» связывают коэф-
фициенты преобразования, которое претерпевают координаты какой-
либо точки при переходе к новой системе координат, получаемой
вращением первой системы около начала координат. Как известно
из аналитической геометрии, коэффициенты линейного преобразова-
ния координат при таком вращении представляют косинусы углов
наклона новых осей относительно старых и связаны соотношениями
ортогональности, выражающими взаимную перпендикулярность старых
и новых осей и то обстоятельство, что длина каждого орта — еди-
ничного вектора каждой оси—равна единице.
Далее, ввиду того, что расстояние от начала координат остается
неизменным при вращении системы, должно выполняться условие
п п
(6.3.25)
i-1 1=1
которое легко проверить, возводя в квадрат и складывая соотно-
шения (6.3.24), причем при сложении следует принять во внимание
соотношения ортогональности.
Из этих соотношений следует далее, что
My(- = 0, Dyf==cr* и М(у1у/) = 0, i=^J. (6.3.26)
Отсюда следует: 1) что _у;—как линейные комбинации нормальных
переменных — распределены также нормально с параметром (0, ст),
при каждом I; 2) коэффициенты корреляции между каждой парой
§ 3] ТОЧНЫЕ РАСПРЕДЕЛЕНИЯ НЕКОТОРЫХ ХАРАКТЕРИСТИК 231
нормальных переменных у,, и равны нулю. Как мы видели
в п. 5.2.4, если две нормально распределенные величины не кор-
релированы, они будут и независимы; то же самое справедливо при
любом числе переменных, если попарно они не коррелированы
друг с другом. Далее, так как согласно (6.3.24)
уп = хУп,
го из (6.3.25) будем иметь:
п п П п-1
ns1 = 2 W —*)2 = 2 Хг1 — ПХг = 2 У*
i~i 1 = 1 <=1 Z=1
и, значит,
п-1
$-£(?). <в.327)
1=1 '
Так как случайная величина представляет, как мы видим, сумму
квадратов (л—1) взаимно независимых случайных переменных — ,
распределенных согласно N(х,; 0; 1), то по доказанному в п. 6.3.1
ns‘ 1 , ,.
мы можем заключить, что распределена по закону % с (л— 1)
степенями свободы, т. е. с плотностью &п_,(х). Мы можем также
вывести еще одно замечательное следствие: так как ух, yt, ..., уп-1
п —1
- Уп 2 1 *
и У„ — хуп независимы, то величины х = —~ и $ =— 7. у»
п п Т?.
взаимно независимы. Таким образом, в выборке из нормальной
генеральной совокупности с параметрами (v, а) средняя арифмети-
ческая х и дисперсия s4 взаимно независимы; х распределена по
закону Л/^х; v; > а следует закону %4 с (л — 1) степенями
свободы.
Заметим, что в первоначальном выражении
п
л№ = 2 (xi—х)г
1
И правая часть представляет сумму п квадратов нормальных вели-
чин х;—х. Однако эти величины были связаны между собой одним
соотношением 2(^4—х) = 0, и независимых между собой откло-
нений х(—х было только л— 1. Переменные у,, . .., yn-v через
которые мы выразили ns4, были независимыми или, как иначе
говорят еще, свободными переменными.
232 СТАТИСТИЧЕСКАЯ ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ [гЛ. VI
6.3.5. Распределение критерия Стьюдента. Рассмотрим две независи-
мые по доказанному в предыдущем разделе величины
?_х—у
— о ’ ~ о2 ’
V~n
где Z распределено согласно V (г; 0; 1), V—согласно £„_t(x) (согласно
закону X2 с (п.— 1) степенями свободы). Образуя показатель t Стьюдента
/V s
и применяя к нему сказанное в п. 6.3.2, придем к выводу, что распределе-
ние t следует закону Sn_i(x)— закону Стьюдента с (п — 1) степенями сво-
боды; t называется критерием Стьюдента и используется для оценки
величины v и проверки гипотез относительно этой величины, что мы уви-
дим далее.
Пусть теперь хх, х2, ..., х/г, и уг, уПг—две выборки величин
X и Y, распределенных согласно законам N (х; vx; о) и N (у; vr; o') (с одной
П, п,
и той же дисперсией). Пусть х = -L х,- и s* = —J^(x£-—х)2 и у
П' i = i П' 1 = 1
и Sy—аналогичные значения среднего и дисперсии во второй выборке. Так
как дисперсия а2 одна и та же в генеральных совокупностях X и Y, то
величины
по предыдущему распределены по законам kn^ (х) и kn (х) соответ-
ственно. Поэтому согласно доказанному в п. 6.3.1 их композиция
. » + n.sj
V=x2+x22=
будет распределена по закону kn + г(х), тогда как х—у—(ух—уу)
распределена нормально с параметрами 0 и о- - =а ~у JL-L , так что
величина
v X—у—к—Уу)
«/Цц
Г п, п2
распределена нормально по закону N (г; 0; 1). Поэтому характеристика
. Z ^,+/1,-2 х-у-{ух -vv) Гп.п, (п, +п2-2)
t —------------= —т. —— I/---------------— (0.0.20)
/V + V п> + п*
распределена по закону Стьюдента Sn +п„_2(х).
Мы воспользуемся в главе VII этим результатом для проверки гипо-
тезы равенства средних генеральных совокупностей X и Y.
§ 4] ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ ПО МАЛЫМ ВЫБОРКАМ 233
§ 4. Оценка параметров распределения по малым выборкам
6.4.1. Понятие доверительного интервала. Доверительный
интервал для центра распределения при известном о. Мы рас-
смотрели способы оценки неизвестных параметров с помощью на-
ходимых по выборке числовых значений надлежащих характеристик.
Но такая точечная оценка параметров без указания степени точ-
ности и надежности еще мало определенна, так как указанные нами
числа представляют лишь частные значения некоторых случайных
величин. Для того чтобы получить представление о точности и
надежности оценки 0 для параметра 9, мы можем для каждого малого
указать такое б, что
р(|е —0|<б) = Р(—б<6—0 <б) = Р(б—б<0<0+б) = 1—а.
(6.4.1)
Чем меньше для данного а будет б, тем точнее наша оценка 0.
Соотношение (6.4.1) говорит, что вероятность того, что интервал
(0— б, 0 4- б) со случайными концами покроет неизвестный параметр,
равна 1—а. Такой интервал называют доверительным интервалом.
В более общем виде понятие о доверительном интервале может быть
сформулировано так. Пусть 0(х,, ..., х„) и 0 (а\, ..., х„)—две
функции выборки, или статистические характеристики, такие, что при
любом значении 0 имеем:
Р[0(х„ ...,х„)<0<0(х1, ..., х„)]=1— а.
Тогда интервал (0, 0) называют доверительным интервалом для
параметра 0, отвечающим доверительной вероятности 1—а.
Рассмотрим теперь построение доверительных интервалов для
некоторых параметров нормальной совокупности.
Пусть мы имеем нормально распределенную величину X с зако-
ном N(x‘, v; о). Параметр о мы считаем известным. Для оценки v
по выборке естественно использовать характеристику х, распреде-
. г / О \ ГТ О
ленную нормально N lx; v; Для всякого а = мы можем
найти такое tq, что
Р^[х — v| = \ --^ = 1—0,
но неравенство |х — v\<.tq-y= равносильно такому:
у п
(6А2)
234
СТАТИСТИЧЕСКАЯ ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ [ГЛ. VI
и следовательно, вероятность неравенства (6.4.2) также равна 1—а
при любом V. Следовательно, интервал (х — t , х~р tа-^
\ q V п q V п
будет доверительным интервалом для оценки v, отвечающим
доверительной вероятности 1—На рис. 50 показано построение
такого интервала.
Рис. 50. Доверительный интервал для v при оценке по
х при х = х,=2,5 и интервал практически допустимых
(при 1—а --0,9545) значений х при v = v1 = l,5.
Длина этого интервала постоянна и зависит лишь от взятого
значения а — , но центр находится в случайной точке х и
варьирует от выборки к выборке. Если мы будем повторять выборку
и для каждой из них определять границы доверительного интервала,
то при большом числе опытов частость или доля тех интервалов,
которые будут покрывать неизвестное значение V, будет мало укло-
няться от ^1—• Это заключение является прямым следствием
теоремы Бернулли, так как вероятность покрытия v в каждой
выборке, каково бы ни было V, равна 1 —. Если мы положим,
например, т/ = 5°'о, то 1—= 0,95, при этом согласно таблице Ц
§ 4] ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ ПО МАЛЫМ ВЫБОРКАМ 235
приложений tq— 1,96; когда л = 9 и 0 = 2, доверительный интервал,
отвечающий вероятности 0,95, будет (х—1,31, х+ 1,31), так что
при любом v
Р(х—1,31 <v<x+ 1,31) = 0,95.
На рис. 51 дана иллюстрация такой трактовки доверительного
интервала при доверительной вероятности, равной 1—а = 0,5. Здесь
Рис( 51, Доверительные интерваль! для парамет-
ра v, полученные по 15 выборкам при доверитель-
ной вероятности 1—а = 0,5.
случайными являются положение интервала и его длина, но примерно
половина доверительных интервалов (7 из 15) покрывает оцениваемый
параметр v. В п. 6.4.2 мы увидим, при каких обстоятельствах от вы-
борки к выборке меняется не только положение интервала, но и
его длина.
Вероятность мы связываем при этом с границами интервала,
определяемыми случайностью выборки, а не с значением у, которое,
вообще говоря, не зависит от случая. Поэтому было бы грубой
ошибкой, подставив вместо х найденное в выборке значение,
например х = 4,12, утверждать, что вероятность неравенства
2,81 <v<5,43
(6.4.3)
равна 0,95. На самом деле v есть постоянная величина и неравен-
ство (6.4.3) или достоверно, если v удовлетворяет этому неравенству,
пли невозможно, когда v не лежит в указанных границах. Таким
образом, единственные вероятности, которые могут связываться
с неравенствами вида (6.4.3), будут иметь значения 1 или 0. Зна-
чения V, попавшие в интервал вида (6.4.3) с фиксированными гра-
ницами, мы можем, однако, трактовать как согласующиеся с данными
произведенной выборки, тогда как те значения г, которые не попа-
дают в интервал, обладают тем свойством, что для них отклонения
236
СТАТИСТИЧЕСКАЯ ОПЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ [ГЛ. VI
1х—v| превосходят и считаются практически невозможными,
4 у п
так как вероятность получить подобного рода отклонения не пре-
q
вышает -^д = и-
6.4.2. Доверительный интервал для центра распределения
при неизвестном ст. Перейдем теперь к случаю, когда оба пара-
метра, v и ст, неизвестны и должны сами оцениваться по выборке.
Как мы видели в п. 6.3.2, величина критерия t = Vn — 1 )
распределяется по закону Стьюдента с (п—1) степенями свободы.
Поэтому для вероятности 1—~ мы можем, пользуясь таблицей V
приложений, найти ^°/0 пределы ±tq, такие, что
р { *?> п-i <Vn~1 ~ п-i—1 ~тоб
или
₽ п-i 7„zj} = 1 “Too (6-4-4>
при любом V. Следовательно, интервал
’ х+^.п-1 7^=7) (6Л,5)
будет доверительным интервалом, отвечающим доверительной ве-
. q
роятности Р — 1--.
Пусть требуется построить 99°/0-ный доверительный интервал
для оценки генерального среднего диаметра v валика по «пробе»
из 10 деталей, обработанных на токарном автомате, если отклонения
размеров этих деталей от середины поля допуска оказались сле-
дующими (см. таблицу 6.4.1).
Таблица 6.4.1
№ деталей по порядку 1 2 3 4 5 6 7 8 9 10
Отклонения размеров в мк +2 +1 —2 4-3 4-2 + 4 —2 4-5 + 3 4-4
Находим, что х = 4-2лг/с, $ = 2,3 мк. Из (6.4.4) имеем:
pfx —/|;9-г2А ,<у <х-Н1' 9---— Уо,99,
\ 1^10 — 1 ' П0-1У
§ 4) ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ ПО МАЛЫМ ВЫБОРКАМ 237
о гкуда
\ — P=Q= 1—0,99 = 0,01 = Г/о.
По таблице V приложений при <?=!% п k~n —1 = 10 —1=9
находим /ц э — 3,25. Далее,
/1; 9 =4== 3,25 44 = 2,49 мк,
У п—1 л
откуда
2 —2,49 < v < 2 4-2,49
или
— 0,49 <v <4,49. (6.4.6)
Таким образом, согласующиеся с нашими опытными данными
или, иными словами, «допустимые» (с надежностью в 99%) значе-
ния параметра v лежат в интервале (—0,49 мк; 4,49 мк).
Заметим, что если бы мы приняли найденное значение $ = 2,3 мк
за значение параметра о и исходили бы из нормального закона при
оценке, то «классические» 99%-ные доверительные границы были бы
значительно уже. В самом деле, вместо i\. 9 = 3,25 мы имели бы
по таблице II приложений Z =2,576 и Z,-4= = 2,58-44.= 188 и
1 ’/п 3,16
вместо неравенства (6.4.6) мы получили бы:
0,12<v<3,88. (6.4.7)
Таким образом, мы значительно преувеличили бы действитель-
ную точность нашей оценки.
Следует подчеркнуть, что получение при малом числе наблюде-
ний с помощью закона Стьюдента более широкого доверительного
интервала (или, иначе говоря, более широкой зоны неопределен-
ности) при оценке центра рассеивания, нежели при использовании
нормального закона, вовсе не является недостатком метода Стью-
дента, а связано с существом дела: ведь мы предположили, что
никакой дополнительной информации относительно величины пара-
метра о, кроме той, которую дает выборка, мы не имеем. В этом
случае мы не должны для построения доверительного интервала для
центра рассеивания применять нормальный закон, так как тем са-
мым мы преувеличим действительную точность нашей оценки, как
это видно из приведенного примера.
Заметим, что в некоторых случаях экспериментатор хотя и не
располагает точным значением о, однако может с уверенностью
гарантировать некоторую верхнюю границу для этого параметра.
Если ее принять за а и определить по нормальному закону распре-
деления доверительный интервал для центра рассеивания, то при
малом числе наблюдений этот интервал иногда оказывается все же
238 СТАТИСТИЧЕСКАЯ ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ [ГЛ. VI
более узким, чем по методу Стьюдента, и тем самым несколько
уточняется оценка центра рассеивания.
6.4.3. Доверительный интервал для о. Предполагая выборку
произведенной из нормальной совокупности N(х; v; а), построим
теперь доверительный интервал для параметра а или о₽. Отправным
пунктом будет при этом доказанное в п. 6.3.4 положение о том, что
MS2
величина распределена по закону %* с (п—1) степенями свободы.
Заметим, что для данного уровня доверительной вероятности 1 —
мы можем вообще построить бесконечным числом способов интер-
вал, которому отвечала бы вероятность, в точности равная 1—.
Целесообразно выбрать в данном случае два предела %* и %* так, чтобы
и, следовательно,
Р < %) = 1 -Р (X8 < Х!)-Р (X* > Х1) = 1 - fib • (6-4.8)
Из (6.4.8) следует:
(6.4.9)
или, что равносильно,
(6.4.10)
71S2 \
есть доверительный интер-
Таким образом, интервал [——-
\ .
для оценки о с до-
вал для оценки о , а интервал (—
верительной вероятностью 1—
На рис. 52 показано построение доверительного интервала для о*.
Пусть требуется определить при доверительной вероятности
в 0,96 доверительные границы дисперсии высоты штамповок внут-'
ренних колец подшипников по данным пробы объема 20 штук, если
распределение штамповок по высоте предполагается нормальным.
Средняя арифметическая высота 20 колец равна х~ 32,2975 мм,
20s’= 2,5282, q = 4%.
§ 4] ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ ПО МАЛЫМ ВЫБОРКАМ 239
В таблице IV приложений при числе степеней свободы 20—1 = 19
находим при Pt = -LA значение %’ = 33,7 и при ^ = 1—1.21 =
= 1—0,02 = 0,98 значе-
ние ^’ = 8,6.
Неравенство для дан-
ного случая можно запи-
сать в виде
2,5282 2,5282
33,7 <а < 8,6 ’
пли
0,0750 мм2 <о2 <
«<0,294 ям2
и
0,27 .и.и < ст <0,53 мм.
Рис. 52, Построение доверительного интер-
вала для оценки параметра о2 по эмпири-
ческой дисперсии s2.
6.4.4. Оценка параметра о по размахам нескольких выборок.
В некоторых случаях для оценки о мы можем использовать данные
о размахах, полученных в независимых выборках (из одной и той
же генеральной совокупности) одного и того же (обычно небольшого)
объема п. Пусть наблюденные значения размахов будут: ...
..., Rm. Строя по ним несмещенные оценки для параметра о генераль-
ной совокупности, найдем:
Ri Rj Rm
ап ’ ип....... а„ ’
где а„ берется по таблице III приложений. Беря среднюю арифме-
тическую из этих оценок, получим:
(6.4.11)
Это будет несмещенная оценка для а по данным всех т выборок,
так как
(6.4.12)
Если т достаточно велико, то отношение — будет приближенно
ап
к г / \
следовать нормальному закону N ( х; о; у— 1, т. е. с центром
240
СТАТИСТИЧЕСКАЯ ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ [ГЛ. VI
Y о
в точке о и средним квадратическим отклонением, равным .
У т
Более точное исследование показывает, что нормальный закон при-
меним для сравнительно небольших т, если объем каждой выборки
лежит в пределах между 5 и 10.
Основываясь на этом, можно построить доверительный интервал
для сг, исходя из эквивалентных неравенств
I R | о
------О < z у„ ,
Ут
или
or (1 — z — ) <0^1 4 ,
\ У mJ ап \ Ут)
или, наконец,
—_____L— -
ап 1-4-2 1__Z -
Ут Ут
(2>0),
(6.4.13)
причем вероятность каждого из этих неравенств приблизительно
равна 2Ф0(г). Последнее из них определяет доверительный интер-
вал с уровнем вероятности 2Ф0(с), Беря, например, 2Ф(г) = 0,95
и определив отсюда z = 1,96, мы найдем с помощью таблицы 111
приложений для л —5, т ==20
а5 = 2,326, у, = 0,371
и далее
14 2 = 1 + 1,96-^-= 1,17,
Ут У 20
1 — .г-^4= 1 —0,17 = 0,83,
Ут
Р (^326 ’ Tj7 :£: 4326 ' G 152 0,95.
Здесь R рассматривается как среднее арифметическое размахов 20
выборок объема 5.
6.4.5. Доверительные интервалы в случае асимптотически
нормальных оценок. В п. 6.4.2 мы видели, как построить (100—q)%
интервал для центра нормального распределения, когда известен
параметр о. С некоторым приближением то же построение можно
применить в случае выборки и для центра любого распределения
величины х, основываясь на центральной предельной теореме. В са-
мом деле, из приближенного равенства
р -У
X — V
0
Уп
1 100.
§ 4] ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ ПО .МАЛЫМ ВЫБОРКАМ
241
имеющего место при большом /г, вытекает:
Р[Х“Л
100 ’
— i в , о \
х—ta -<=) можно приближенно
4 V п 4 V п /
считать доверительным (100—q)% интервалом для V, если о из-
вестно. Но в случае неизвестного о мы можем при больших п
с высокой степенью надежности заменить о ее состоятельной оцен-
кой s и считать интервал (х—x-\-t-Л-) также прибли-
\ 4 у п 4 V п /
женно доверительным интервалом для v. Аналогично поступают и
в других случаях асимптотически нормально распределенных оценок
в больших выборках. Пусть для оценки параметра р мы исполь-
зуем некоторую характеристику по данным выборки Ь, распреде-
ленную асимптотически нормально со средним квадратичным от-
клонением <т(£), так что при большом п мы будем иметь:
Р [b —(b) < р < b + t4<j (b)]« . (6.4.14)
С другой стороны, если для о(Ь) мы можем найти состоятельную
оценку s(b) по выборочным данным, то, рассуждая, как в предыду-
щем случае, мы одновременно будем иметь:
+ (6.4.15)
Следовательно, интервал [/>—tqs(b), b+t s(b)} будет приближением
к доверительному интервалу для р.
Например, s и s'2— асимптотически нормальны со средними
квадратичными отклонениями
И 4 И 2
р,2га ’
и на основании этого интервалы с границами
будут доверительными для оценки о2 и о при больших выборках.
242 СТАТИСТИЧЕСКАЯ ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ [ГЛ. VI
В случае выборки из нормальной совокупности эти формулы
упрощаются, так как р.4 = 3|л| = 3о* и
i т/2 s
s.i = s I/ —, —
* г п ’ * ybi
Аналогично строятся оценки для асимметрии и эксцесса.
6.4.6. Допустимые (толерантные) пределы. Во многих случаях
о качестве выпускаемой продукции в отношении некоторого слу-
чайного признака Д’ судят по проценту изделий, заключающемуся
в интервале между двумя пределами, которые составляют как бы
пределы изменчивости, допустимой без существенного ущерба для
использования изделий,- Разумеется, при этом предполагается,
что все систематические причины, влияющие на величину признака,
остаются неизменными и вариация происходит лишь под влиянием
неучитываемых обстоятельств, сопровождающих процесс выборки.
При нормальном распределении признака X в генеральной сово-
купности мы можем по данным выборочным характеристикам х и
s найти такие пределы
и^ — х—ks и a2 = x-|-As,
что с вероятностью у мы можем гарантировать попадание в них
доли совокупности, не меньшей заданного предела Р. Эти пределы
называются допустимыми (толерантными) пределами. Отметим,
что толерантные пределы мы устанавливаем по данным выборки для
случайной величины—доли (ограничиваемой пределами) генераль-
ной совокупности. В этом их отличие от ранее рассмотренных до-
верительных интервалов для неслучайных параметров. Значение k,
являющееся функцией п, Р и у, приближенно выражается формулой
/ х„ 5x^,4-Ю\
+ (6-4,16)
где ka (значение k, которое мы использовали бы, зная истинные
значения центра распределения v и среднего квадратического откло-
нения о) определяется соотношением
р
[ е~<И = 2Ф'(/гх) = Р (6.4.17)
г 2л J
“"^аэ
и х? определяется из уравнения
е 2 dt — 0,5 — Фо (хт) — 1—у. (6.4.18)
Л<у
§ 4] ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ ПО МАЛЫМ ВЫБОРКАМ 243
На рис. 53 показано построение допустимых (толерантных) пре-
делов.
Рис. 53. Допустимые (толерантные) пределы и, и us, в которых
с вероятностью у заключена доля Р всей совокупности.
Пусть, например, произведена выборка объема «=1449 де-
талей, причем для отклонений диаметров от номинального размера
получены значения
х — 670,40 мм, s = 0,37 мм.
Принимая у = 0,99 и Р— 0,90, получим из (6.4.18)
фо (.^ = 0,99 — 0,5 = 0,49,
из (6.4.17)
0,90 = 2Ф0 (&ж).
С помощью таблицы II приложений находим:
ху = 2,33 и kx = 1,645.
Далее, применяя (6.4.16), получим:
, . /, . 2,33 , 5-2,332+ 10\ . 79
k = 1,645 ( 1 4- + 1О ,. .п - = 1,72.
’ /2-1449 12-1449 )
Отсюда допустимые (толерантные) пределы будут:
и2 = 670,40 + 1,72 • 0,37 = + 671,04 мм,
«,=-670,40—1,72-0,37= 4-669,76 мм.
Иными словами, мы можем с вероятностью у = 0,99 считать, что
в этих пределах находятся 1ОО-/э=9О9о диаметров всех деталей
генеральной совокупности.
ГЛАВА VII
СТАТИСТИЧЕСКАЯ ПРОВЕРКА ГИПОТЕЗ
§ 1. Задачи статистической проверки гипотез. Проверка
гипотез о вероятностях, распределениях и средних
7.1.1. Статистическая проверка гипотезы относительно ве-
роятности. В главе 1 уже упоминалось, что вторым после стати-
стической оценки параметров распределения и в то же время важ-
нейшим отделом математической статистики является статистическая
проверка гипотез. Мы рассмотрим сначала одну из простейших
задач этого отдела.
Допустим, что на основании каких-либо соображений мы пред-
полагаем вероятность некоторого события равной р. Располагая ре-
зультатом п независимых испытаний, в течение которых это событие
наблюдалось т раз, мы хотим проверить нашу гипотезу относи-
тельно величины р вероятности.
Пусть, например, на опыте в 280 независимых испытаниях интере-
сующее нас событие появилось 151 раз, причем гипотетическая веро-
ятность равна р — у. К такой гипотезе мы приходим, например,
когда рассматриваемое событие заключается в превышении (или
непревышении) медианы распределения по некоторому количествен-
ному признаку, которая при нормальном и других симметричных
одновершинных распределениях совпадает с математическим ожида-
нием и модой. На практике к этой гипотезе мы приходим естествен-
ным образом при проверке отсутствия систематической ошибки
измерений и при проверке настройки станка на среднюю точку
поля допуска и т. д.
Таким образом, среднее значение (математическое ожидание) ве-
личины равно z2/> = 280 • у = 140 и среднее квадратическое откло-
нение Упру = 1/^280 • у • -g- = 8,37. Нас интересует, можно ли
считать наблюденную частоту 151 достаточно близкой к теорети-
ческой норме 140, отвечающей гипотезе /> = Х.
ЗАДАЧИ СТАТИСТИЧЕСКОЙ ПРОВЕРКИ ГИПОТЕЗ
245
5 1]
Для того, чтобы определенно ответить на поставленный выше
вопрос, нужно выбрать границу допустимых при нашей гипотезе
отклонений частот (или частостей) от математического ожидания,
т. е. назначить такое «критическое» отклонение, превышение ко-
торого при нашей гипотезе настолько маловероятно, что его можно
считать практически невозможным, и потому, если оно фактически
наблюдалось, то это указывает на несовместимость нашей гипотезы
с наблюдениями. В этом случае говорят также, что наблюденная
частость «значимо отклоняется» от вероятности. И обратно, если
фактическое отклонение меньше критической границы, мы вправе
считать, что опыт не противоречит нашей гипотезе и наблюденное
отклонение можно объяснить случайностью испытания.
Обычно в качестве практически невозможных отклонений при-
нимают такие, вероятность которых не превышает 0,05 или 0,01
и т. п. Такую вероятность называют уровнем значимости, от-
вечающую ей область больших отклонений—критической областью,
а само правило проверки — критерием значимости.
Принцип, согласно которому маловероятные события считаются
практически невозможными и, наоборот, те события, вероятность
которых близка к единице, принимаются за достоверные, лежит
в основе большинства приложений теории вероятностей. Правда,
нельзя указать границу, годную для всех случаев практики, такую,
что событиями с вероятностью, меньшей этой границы, мы пренеб-
регаем, считая их невозможными. Дозволенная степень риска, кото-
рый связан с пренебрежением событиями с малой вероятностью,
зависит от различного рода обстоятельств и прежде всего связан
с практической важностью следствий, вытекающих из наступления
таких событий. В одних случаях считается возможным пренебрегать
событиями, имеющими вероятность меньше 0,05, в других случаях,
когда речь идет, например, о разрушении сооружений, гибели судна
п т. п., нельзя пренебрегать обстоятельствами, могущими появиться
с вероятностью, равной 0,001.
Критическую границу для отклонений в сторону «плюс» или
'минус» от теоретической нормы легко определить, пользуясь нор-
мальным приближением к биномиальному закону. Вероятность 0,95
отвечает при нормированном нормальном распределении интервалу
(—1,96, 4-1,96) около центра распределения, так что вероятность
абсолютной величине нормированного отклонения превысить 1,96
равна 0,05, т. е.
Р (| Z | > 1,96) = Р (| X— пр | > 1,96о)«0,05.
Площадь, отвечающая этой вероятности, заштрихована на рис. 54.
Такое отклонение во многих случаях считается практически не-
'"зможным.
246 СТАТИСТИЧЕСКАЯ ПРОВЕРКА ГИПОТЕЗ [ГЛ. VII
Уровень значимости 0,01, т. е. 1 %, отвечает границе zO1oi = 2,58,
так что
Р (| Z | > 2,58) = Р (| X—пр | > 2,58а)«0,01.
В нашем случае а = 8,37 и 5% критическая граница соответст-
вует
1,96-8,37 = 16,41,
а 1 % граница
2,58- 8,37 = 21,59.
Таким образом, область допустимых значений определяется
в первом случае границами
лр± 1,96а = 140 ± 16,4,
а во втором случае
пр ± 2,58а— 140 ± 21,6.
Из этих данных видно, что если гипотеза наша верна, то от-
клонение частоты от теоретической нормы в пяти случаях на 100
Рис. 54. Двусторонние критические границы для
1
проверки гипотезы р = у.
может превышать 16,4 и в одном случае на 100 может превы-
шать 21,6.
В нашем примере отклонение составило:
151 — 140=11,
т. е. оно находится в области допустимых значений, вследствие
чего нет оснований считать гипотезу противоречащей на-
блюдениям.
§ 1] задачи статистической проверки гипотез 247
В качестве другой иллюстрации возьмем пример, где прихо-
дится рассматривать критическую границу для отклонений только
в одну сторону.
Пусть, например, при периодической проверке на повышенных
режимах электронных ламп триггерных ячеек цифровой электрон-
ной счетной машины приходится заменять в среднем 3°/0 ламп.
При переходе к модернизированным лампам при периодической
проверке из 1024 ламп пришлось заменить 18. Можно ли утвер-
ждать, что новые лампы обладают существенно большей выносли-
востью?
При прежних лампах из 1024 ламп оперативного запоминающего
устройства могло требовать замены в среднем 1024-0,03 = 30,72
лампы. Однако это только средняя цифра, и следует иметь в виду,
что вероятность получения фиксированного числа «отказавших»
ламп вообще мала, в особенности в большой партии. Мы могли
случайно получить отклонение от среднего в 30,72 лампы в ту
или другую сторону.
Мы наблюдали отклонение в
А = 18 — 30,72 = — 12,72 лампы.
Рассмотрим, как часто можно наблюдать такое или еще большее
по абсолютной величине отклонение при прежнем уровне выносли-
вости ламп за счет действия лишь случайных обстоятельств наблю-
дения. Среднее квадратическое отклонение будет равно
о = Vnpq = V 1024-0,03-0,97 = 5,46.
Следовательно, нормированное отклонение составляет:
A = TgZ?„2,33.
а 5,46 ’
Такие и еще большие (по абсолютной величине) отклонения
при нормальном законе (которым мы с достаточным приближением
заменяем биномиальное распределение) можно получить с вероят-
ностью
2,зз) = 0,5—Фо(2,33) = 0,5—0,4900 = 0,01.
Площадь, отвечающая этой вероятности, заштрихована на рис. 55.
Следовательно, при использовании прежних ламп мы могли
получить такие или лучшие результаты проверки в одном случае
из 100. Если признать практически невозможными отклонениями
такие, вероятность которых не превышает 0,05, то мы приходим
к выводу, что результата, подобного полученному нами, мы не мог-
ли получить за счет одних только случайных обстоятельств
248
СТАТИСТИЧЕСКАЯ ПРОВЕРКА ГИПОТЕЗ
[ГЛ. VII
испытания, и потому новые лампы обладают существенно большей
выносливостью по сравнению с прежними лампами.
Вообще получение отклонения, превышающего 2о или За, при
биномиальном распределении расценивается на практике как сигнал
Рис. 55. Односторонняя критическая граница для проверки
гипотезы о выносливости ламп цифровой электронной счет-
ной машины.
о наличии каких-то существенных факторов, изменяющих обычную
обстановку испытаний.
7.1.2. Общая задача проверки гипотез. Гипотеза о положении
центра группирования. Теперь мы более подробно остановимся
на общих вопросах, связанных с задачей статистической проверки
гипотез. К этой проблеме неизбежно приводят нас, например, такие
часто возникающие задачи, как сравнительная оценка различных
технологических процессов по их производительности, точности
л экономичности или сравнение конструктивных особенностей машин
и приборов и т. д. Аналогичные проблемы характерны и для
агрономической, медицинской, биологической статистики. Вопрос
о том, по каким признакам и в каких отношениях целесообразно
производить подобные сравнения, всецело относится, конечно, к ком-
петенции тех специальных областей, в которых возникают эти
задачи. Однако при наличии явления рассеивания признаков, по
которым требуется произвести сравнительную оценку (например,
качества технологии или конструкции), обоснованный вывод может
быть получен лишь путем научно поставленного анализа стати-
стических данных. Такие данные мы рассматриваем при этом как
некоторые выборки, информирующие нас о поведении интересую-
щих нас сравниваемых случайных величин и позволяющие делать
ЗАДАЧИ СТАТИСТИЧЕСКОЙ ПРОВЕРКИ ГИПОТЕЗ
249
§ И
определенные заключения о законах распределения этих вели-
чин. В большинстве случаев мы не сомневаемся, что тип закона
распределения сравниваемых величин один и тот же (например,
нормальный, пуассонов и т. д.); но своеобразие закона распределения
каждой из них заключается обычно в различиях значений парамет-
ров: например, положения центра, дисперсии и т. д. Именно в изме-
нениях параметров и находят отражение различия в качестве техно-
логии, конструкции и т. п., обнаруживаемые путем сопоставления
статистических данных. В качестве простейшего и классического при-
мера можно привести сравнение двух серий измерений одной и той
же величины двумя различными измерительными приборами. Сопо-
ставляя эмпирические дисперсии в этих сериях, мы можем легко
выяснить вопрос о том, насколько точность одного из них отли-
чается от точности другого.
Таким образом, проверка гипотез часто сводится к сравнению
статистических характеристик, оценивающих параметры законов
распределения. В главе I мы уже указывали, что «статистическими
гипотезами» называются различного рода предположения о законах
распределения рассматриваемых величин. Практически большей
частью эти предположения сводятся к некоторым утверждениям
относительно значений параметров законов распределения (или, что
то же, рассматриваемых «генеральных» совокупностей).
Из этих предположений выводятся следствия и рассматривается,
насколько оправдываются они на практике. Эти следствия носят
характер вероятностных суждений о поведении некоторых статисти-
ческих характеристик при сделанных предположениях; проверка
заключается в вычислений значений этих характеристик по данным
произведенных наблюдений и в сравнении их с тем, что было
выведено на основе сделанных предположений. Такие характеристш.и
называются критериями проверки. Они представляют случайные
величины, значения которых определяются выборкой.
Для критериев проверки аналогично тому, как это в п. 7.1.1 было
сделано для отклонения частости от вероятности, выбираются над-
лежащие «уровни значимости» (? = 5°/0, 2°/0, 1°/0 и т. п.), от-
вечающие событиям, которые в данной обстановке исследования
считаются (с некоторым риском) практически невозможными. Далее,
мы определяем критическую область данного критерия, вероятность
попадания в которую в случае, когда гипотеза верна, в точности
равна уровню значимости. Значения критерия, лежащие вне крити-
ческой области, образуют дополнительную к ней область «допусти-
мых» значений. Если — уровень значимости, то вероятность по-
падания критерия в область допустимых значений при справедливости
ганной гипотезы равна 1—Это последнее событие признается
250 СТАТИСТИЧЕСКАЯ ИНОВЕРКА ГИПОТЕЗ [ГЛ. VII
практически достоверным при том же условии. Если значение нашего
критерия, вычисленное по данным произведенных наблюдений,
окажется в критической области, то мы бракуем гипотезу; в самом
деле, попадание в эту область при нашей гипотезе практически
невозможно, а потому несовместимо с ней. Если же оно окажется
в области допустимых значений, то мы не можем еще утверждать,
что гипотеза подтвердилась: мы можем только заключить, что
наблюденное значение критерия не противоречит ей, и признать
допустимость гипотезы по крайней мере до тех пор, пока более
обстоятельные исследования (например, по большему материалу
или с помощью других критериев) не приведут нас к противопо-
ложному заключению.
Чем меньше уровень значимости, тем меньше вероятность за-
браковать проверяемую гипотезу, когда она верна, или, как го-
ворят, совершить «ошибку первого рода», но с уменьшением уровня
понижается чувствительность критерия, так как расширяется
область допустимых значений и увеличивается вероятность совер-
шения «ошибки второго рода», т. е. принятия проверяемой гипотезы,
когда она не верна, а на самом деле верна гипотеза, близкая
к проверяемой и обеспечивающая поэтому большую вероятность
попадания критерия в область допустимых значений.
Уровень значимости критерия проверки контролирует лишь
ошибки первого рода, но отнюдь не измеряет степень риска, свя-
занного с принятием неверной гипотезы (т. е. с возможностью
ошибки второго рода).
Заметим, что при данном уровне значимости мы можем по-
разному устанавливать критическую область, гарантирующую этот
уровень. Пусть, например, в качестве критерия мы рассматриваем
некоторый показатель, распределенный при проверяемой гипотезе
нормально с плотностью п(х\ а; о). В качестве критической области,
отвечающей уровню значимости ^ = 5°/0, мы можем взять:
1. Область больших положительных отклонений так, чтобы
Р1(9 = Р(х>а + ^1о) = 0,05,
НО
оо р •
7 е~~ dt=(г)’ (7Л л)
и по таблице II приложений найдем, что £?| = 1,б4.
II. Область больших отрицательных отклонений
71 (^) = Р (х < а—/?иа) = Р (х < а — 1,64а).
III. Область больших по абсолютной величине отклонений
Ли (9 = Р (I х— а | > /9Шо) = 0,05,
§ 1] ЗАДАЧИ СТАТИСТИЧЕСКОЙ ПРОВЕРКИ ГИПОТЕЗ 251
определив t из соотношения
0,05 = Р (| х—а | > f?1Ho)== 1—--А= J e~d2==1_2<D0(fffI11) (7.1.2)
так, что
tqlll ~ 1,96.
IV. Область малых по абсолютному значению отклонений
0,05 = P1V (/,) = Р (| х-а | < /?lvo) = 2Ф0 (г) (7.1.3)
так, что
/?1У « 0,063.
Эти области показаны на рис. 56.
Задача наилучшего выбора критической области решается обычно
так, чтобы критерий проверки обладал наибольшей чувствитель-
ностью, т. е. чтобы мы имели наибольшую вероятность попадания
Рис. 56. Типы критической области критерия проверки ги-
потезы: [I] — область больших положительных отклонений,
[II] — область больших отрицательных отклонений, [III] —
область больших по абсолютной величине отклонений (состоит
из двух половин), [IV]—область малых по абсолютной величи-
не отклонений.
нашего критерия в критическую область, когда справедлива гипотеза,
конкурирующая с проверяемой гипотезой. Эта вероятность носит
название мощности критерия. Чем больше мощность критерия, тем
меньше вероятность совершения ошибки второго рода.
252
СТАТИСТИЧЕСКАЯ ПРОВЕРКА ГИПОТЕЗ
[ГЛ. VII
Пусть, например, с проверяемой гипотезой конкурирует другая
гипотеза, при которой распределение критерия проверки нормально
* с плотностью п{х\ах\а), где ах>а. Ясно, что в этом случае
(рис. 57) целесообразно выбрать в качестве критической области
для критерия область типа 1, т. е. область больших положительных
отклонений, так как только такой выбор гарантирует максимальную
мощность критерия. Ясно также, что выбор в качестве критических
областей критерия областей Л, Ш и IV типов нецелесообразен,
Рис. 57. Геометрическая интерпретация мощности критерия про-
верки гипотезы при различных типах критической области:
а—центр распределения критерия, когда проверяемая гипотеза
верна; а,— центр, когда верна гипотеза, конкурирующая с про-
веряемой; [I], [II], [III] и [IV]—критические области I, II, III
и IV типов; площади Ръ Рц, Рщ и Piv геометрически интер-
претируют мощность критерия при критических областях со-
ответственно I, II, III и IV типов; Рш частично перекрывается
с Pj и Ри.
так как при таких областях вероятность попадания в них критерия
при справедливости конкурирующей гипотезы была бы еще меньше,
чем 0,05, и мы браковали бы проверяемую гипотезу чаще тогда,
когда она верна, чем тогда, когда она не верна.
Пусть, например, требуется определить, будет ли новый способ
производства радиоламп изменять их долговечность. Предположим,
что средняя продолжительность службы ламп при существующем
способе производства составляет 500 часов. Испытывая новую
процедуру изготовления ламп, получим для некоторой (сравнительно
небольшой) партии среднюю продолжительность работы 560 часов.
Чтобы дать обоснованный ответ на поставленный вначале вопрос,
мы приводим задачу к сравнению двух генеральных совокупностей:
§ 1] ЗАДАЧИ СТАТИСТИЧЕСКОЙ ПРОВЕРКИ ГИПОТЕЗ 253
при старом способе производства с центром в v, = 500 часов и при
новом способе с центром в v2, точным значением которого мы не
располагаем, но можем приближенно оценить по данным произведен-
ного наблюдения.
Мы делаем гипотетическое допущение о равенстве генеральных
средних
V, = V2 = V.
Такого рода вспомогательные гипотезы об отсутствии интересующего
нас существенного различия между параметрами сравниваемых гене-
ральных совокупностей называются нулевыми гипотезами.
Таким образом, на основе выборки мы должны принять или
отбросить нулевую гипотезу. Предположим, что среднее квадрати-
ческое отклонение средней арифметической, о-=-^=, оказалось
х у п
равным 45 часам. В качестве критерия в данном случае естественно
будет принять нормированное уклонение средней х от центра v, т. е.
х—v
о-
X
Это уклонение приближенно нормально распределено. Поскольку
гипотеза, конкурирующая с нулевой гипотезой, состоит в том, что
то, учитывая ранее сказанное, мы выберем в качестве
критической области область «больших» (по абсолютному значению)
отклонений, т. е. область III типа, тогда при 5%-ном уровне
значимости, т. е. при ^ = 5%, критическая область определится из
соотношения (7.1.2).
Пользуясь таблицей 11 приложений, находим при 1—=
= 1 — 0,05 = 0,95 значение /бП1=1,96.
Критическая область будет задана неравенством
—500 | > 1,96• 45 = 88 часов.
Полученное нами в выборке значение х = 560 приводит к зна-
чению |х — 5001, которое лежит вне критической области и, сле-
довательно, легко может получиться из первой совокупности с гене-
ральной средней ¥, = 500 под действием лишь случайных факторов,
сопровождающих выборку. Таким образом, нулевая гипотеза не
О|фовергается, так как наблюденное отклонение не достигло «значи-
мых» или «существенных» размеров, и у нас нет еще достаточных
°снований считать, что новый способ производства радиоламп по
°беспечиваемой им долговечности существенно отличается от старого.
254 СТАТИСТИЧЕСКАЯ ПРОВЕРКА ГИПОТЕЗ [ГЛ. VII
Нужны повторные испытания, а если и тогда результат будет ана-
логичный, то надо будет искать другой способ повышения долго-
вечности ламп и не полагаться на предложенный.
Мы видели, что результат проверки гипотезы в значительной
мере зависит от выбранного уровня значимости. В нашем примере
мы выбрали 5% уровень, считая тем самым практически невоз-
можными события, имеющие вероятность 0,05. Если эту вероятность
увеличивать, то, как легко заметить, доверительные границы будут
суживаться, критическая область будет расширяться и тем самым
при прочих равных условиях гипотеза чаще будет «опровергаться»,
но эти опровержения могут стать ненадежными, т. е. могут отно-
ситься и к верной гипотезе, поскольку события со значительными
вероятностями, скажем порядка 0,2— 0,3, отнюдь нельзя уже
считать практически невозможными.
При уменьшении уровня значимости доверительные границы
будут расширяться, а критическая область будет суживаться, и
гипотеза все реже будет опровергаться даже в тех случаях, когда,
в сущности, она не является справедливой. Иначе говоря, как мы
уже указывали, критерий станет малочувствительным.
Допустим теперь, что при повторном испытании долговечности
радиоламп в условиях ранее рассмотренного примера получилась
долговечность, равная х=605 часам. Теперь гипотеза, конкурирующая
с нулевой гипотезой, состоит в том, что vt> vv а потому мощность
критерия —~ будет наибольшей при критической области I типа.
X
При том же 5% уровне значимости при помощи таблицы II при-
ложений по соотношению (7.1.1) найдем, что ^,д==1,64. Поэтому
критическая область в данном случае будет определяться нера-
венством
х — 500> 1,64-45 = 74 часа.
Отклонением — 500 = 605 — 500 = 105 часам является значимым,
и нулевая гипотеза тем самым опровергается. Иными словами,
новый способ производства радиоламп оказался все же способным
увеличить их долговечность.
7.1.3. Критерий знаков. Для лучшего уяснения введенных
в п. 7.1.2 понятий мы рассмотрим более детально одну простую
процедуру испытания гипотез. В экспериментальных исследованиях
часто требуется сравнить два параллельных ряда наблюдений над
объектами, принадлежащими к двум различным разновидностям, ти-
пам, сортам и т. п. При этом производится N опытов при систе-
матическом и планомерном изменении от опыта к опыту уровня
какого-либо фактора, различие в действии которого на каждую из
двух разновидностей объектов хотят выяснить. В каждом таком
§ 1] ЗАДАЧИ СТАТИСТИЧЕСКОЙ ПРОВЕРКИ ГИПОТЕЗ 255
опыте над парой объектов, производимом, естественно, в неизмен-
ных условиях, мы имеем два значения х,- их, (i— 1, 2, . . ., ZV)
сравниваемого признака двух объектов.
Мы предполагаем, что случайные величины Л) и Л”,, значения
которых наблюдаются в /-м опыте, независимы друг от друга, а
последовательные N наблюдений независимы между собой. Вопрос
заключается в том, можно ли считать наблюденные в W опытах
различия между xz и Х; значимыми, существенными, т. е. связан-
ными с различной способностью двух рассматриваемых разновид-
ностей объектов реагировать на изменения исследуемого фактора,
или, наоборот, разности х,-—xz = r(. следует отнести за счет слу-
чайного рассеивания значений учитываемого признака. Последнее
предположение представляет нулевую гипотезу об отсутствии суще-
ственного различия между двумя разновидностями объектов. Мы
допускаем, следовательно, что в каждом опыте рассматриваемые
независимые величины X/ и X' подчиняются одному и тому же
закону распределения так, что
Р(^<х(.) = Р(Х<х) = Р,.(х),
причем функции Рг(х) распределений (i=l, 2, ..., N) могут быть
различными в различных опытах.
Отсюда следует, что разности Х{—X't = Ri распределены сим-
метрично около нуля, т. е. отклонения положительного и отрица-
тельного знаков равновероятны.
Последовательность М знаков разностей xz—х' = г( при / = 1,
2, .... W мы можем рассматривать как запись результатов W по-
следовательных и независимых испытаний с двумя возможными
исходами («плюс» или «минус»), причем вероятность появлений
каждого из них будет равна
Р(« + ») = Р(«-») = 1.
При этом, естественно, не имеют значения абсолютные величины
разностей, а разности, равные нулю, исключаются из рассмотрения.
Пусть число знаков «-ф» в нашей последовательности соста-
вляет kN(+) и, следовательно, число знаков « —» М—йд, (-]-) =
= &ЛД—). Проверка нулевой гипотезы сведется тогда к уже рас-
смотренной нами в п. 7.1.1 проверке значимости расхождения
между частостью WjV(-{-)=и гипотетической вероят-
ностью Р (« -ф ») = у .
256
СТАТИСТИЧЕСКАЯ ПРОВЕРКА ГИПОТЕЗ
[ГЛ. VII
Если нет предварительных соображений о преимуществе в по-
лучении знака «-(-» или «—», то, задавшись уровнем значимости
выбирают критическую область больших по абсолютной вели-
чине отклонений (двустороннюю область III типа). Для этого выби-
рают число а так, чтобы точно или приближенно выполнялось
равенство
р(|М + )-|Г|^«) = Р [м + )> 1 + +
+ Р + + А = (7Л-4>
при этом на основании (2.3.6) получим
у
-j-а
i=o
(7.1.5)
(7.1.6)
Легко видеть, что если число mN—меньшее из чисел ^у( + )
N
и йА,( —) удовлетворяет неравенству —а, то осущест-
уУ
вляется одно из неравенств k1V( -[-) s^: -—а (если меньшим является
iV
Адг( Ч-) = от2у) или kN( 4-) 2s 2" + а (если меньшим является
Поэтому, на основании правила сложения несовместимых со-
бытий, для mN— min [&дг( +), kN( —)] имеем:
P(«Jv^^-«)=P1+A = I^. (7.1.7)
Вычисленные при помощи (7.1.7) целые критические числа mN для
уровней значимости <7=1?6, 5%, 10% и 25% и значений N—\,
2, ..., 90 приводятся в таблице VII приложений.
При /У>90 хорошее приближение можно получить на осно-
вании нормального приближения к биномиальному закону (см. п. 4.3.1).
За число mv можно принимать ближайшее меньшее целое число,
содержащееся в числе
^=2—1, (7.1.8)
S 1] ЗАДАЧИ СТАТИСТИЧЕСКОЙ ПРОВЕРКИ ГИПОТЕЗ 257
, де
k = 1,2879 при q = 1%,
k = 0,9800 » q = 5%,
А = 0,8224 » 9=10%,
А = 0,5752 » 9 = 25%.
Например, при
+ = 99 и 9 = 5%
для меньшего из чисел fyv( + ) и kN(—) получим:
777—0,9800 /99+7 = 39,2,
а потому т99 = 39, так что критическая область для меньшего из
чисел А99( + ) и А9,9( — ) будет содержать значения 0, 1, 2, . ..,39.
Для самого А99 (+ ) или А99 (—) критическая область (двусторонняя)
будет содержать также числа 60, 61, ..., 99.
Говоря о мощности критерия знаков, следует иметь в виду, что
при малом N он отбросит нулевую гипотезу Н0^р = ^ только
в тех случаях, когда р близко к 0 или 1. Поэтому числа наблюде-
ний +=10—15 могут применяться только для предварительных
и очень грубых суждений.
о 1 л 1
Если значения р, конкурирующие с р = -^, близки к у, то это
различие можно уловить только при больших значениях +.
Представляет интерес число испытаний (опытов) +, необходимое
для того, чтобы в среднем [3-100% случаях применения критерия
знаков мы получили бы значимый результат и забраковали бы не-
„ / 1 \
верную гипотезу +0 1р = — ), когда на самом деле верна гипо-
, 1
геза р+=-2 -
Сведения о таких числах N для 0 = 0,95 при 9=1%, 5%,
10% и 25% приводятся в таблице 7.1.1 (см. стр. 258).
Как видно из таблицы 7.1.1, для того чтобы, например, крите-
рий знаков в 95% случаев отбрасывал гипотезу +0 ^/> = 7-^, ког-
да на самом деле р = 0,35 с уровнем значимости 9= 10%, необходимо
произвести 118 наблюдений, причем в этом случае mlls = 49.
Критерий знаков получил широкое распространение в исследо-
вательских работах благодаря тому, что процедура его применения
исключительно проста, измерения учитываемого признака могут
производиться грубыми средствами (так как нас интересует лишь
9
Н. В. Смирнов, И, В. Дунин-Барковский
258
СТАТИСТИЧЕСКАЯ ПРОВЕРКА ГИПОТЕЗ [ГЛ. VII
Таблица 7.1.1
р Уровни значимости q %
1 5 10 25
N mN A? mN N N mN
0,45 1777 833 1297 612 1080 512 780 373
0,40 442 193 327 145 267 119 193 87
0,35 193 78 143 59 118 49 86 37
0,30 106 39 79 30 67 26 47 19
0,25 66 22 49 17 42 15 32 12
0,20 44 13 35 И 28 9 21 7
0,15 32 8 23 6 18 5 14 4
0,10 24 5 17 4 13 3 11 3
0,05 15 2 12 2 11 2 6 1
знак разности результатов измерений), а в его основу положены
очень простые и почти всегда соблюдающиеся положения, ибо ведь
мы совсем не связываем себя какими-либо ограничениями относительно
вида законов распределения исследуемых величин (например, не
предполагаем, что они нормальные). Такие критерии называют &не-
параметрическими» или независимыми от формы распределения.
В этом — преимущество критерия знаков перед другими кри-
териями (например, перед критерием Стьюдента, рассмотренным
в п. 6.3.2 и п. 6.4.2), иногда лучше использующими содержащуюся
в выборке информацию, но обставленными более стеснительными
условиями.
Рассмотрим пример. Пусть требуется сравнить эффективность
действия двух схем стабилизации напряжения, использованных
в электромеханическом профилометре одного и того же типа, пред-
назначенном для измерения шероховатости поверхности деталей
машин. Стабилизаторы одновременно испытываются в схеме при-
бора, имеющегося в двух экземплярах.
Питание двух опытных профилометров производится через лабо-
раторный автотрансформатор. Предварительно на входы профило-
метров от звукового генератора подаются сигналы, устанавливаю-
щие стрелки выходных приборов профилометров против одинаковых
делений в средней части шкалы.
Затем поворотом рукоятки автотрансформатора напряжение и
питания изменяется через 1 в от 220 до 160 в и от 221 до 239 в.
Показания и х' (выраженные в умноженных на некоторый
постоянный коэффициент корнях квадратных из средних значений
выпрямленного тока) выходных приборов профилометров, отвечаю-
щие каждому из значений и, приведены в таблице 7,1.2.
§ и
ЗАДАЧИ СТАТИСТИЧЕСКОЙ ПРОВЕРКИ ГИПОТЕЗ
259
Таблица 7.1.2
№ по поряд ку и * х' Знак раз- ности № по поряд- ку и X к' Знак разно* сти
1 220 0,300 0,300 0 41 180 0,246 0,143 +
2 219 0,206 0,310 — 42 179 0,245 0,135 +
3 218 0,296 0,300 — 43 178 0,243 0,122 +
4 217 0,294 0,298 44 177 0,242 0,110 +
5 216 0,292 0,296 — 45 176 0,241 0,080 +
6 215 0,291 0,293 — 46 175 0,240 0,050 +
7 214 0,293 0,292 + 47 174 0,190 0,061 4"
8 213 0,291 0,292 48 173 0,191 0,072 +
9 212 0,220 0,291 — 49 172 0,193 0,048 +
10 211 0,292 0,291 + 50 171 0,189 0,035 +
11 210 0,290 0,291 51 170 0,188 0,042 +
12 209 0,288 0,289 — 52 169 0,196 0,051 +
13 208 0,287 0,288 — 53 168 0,180 0,029 +
14 207 0,285 0,287 — 54 167 0,175 0,030 +
15 206 0,287 0,286 4- 55 166 0,178 0,033
16 205 0,285 0,286 — 56 165 0,189 0,021 +
17 204 0,284 0,285 — 57 164 0,188 0,018 +
18 203 0,283 0,284 — 58 163 0,187 0,021 +
19 202 0,282 0,280 + 59 162 0,189 0,031 +
20 201 0,281 0,280 + 60 161 0,188 0,029 +
21 200 0,281 0,278 + 61 160 0,190 0,031 +
22 199 0,280 0,275 + 62 221 0,300 0,301
23 198 0,280 0,275 + 63 222 0,301 0,300 +
24 197 0,278 0,279 64 223 0,299 0,300
25 196 0,277 0,273 —[— 65 224 0,302 0,305 —
26 195 0,272 0,273 — 66 225 0,304 0,303 +
27 194 0,271 0,268 + 67 226 0,303 0,306
28 193 0,270 0,265 + 68 227 0,305 0,307 —
29 192 0,268 0,260 + 69 228 0,309 0,308 +
30 191 0,268 0,255 + 70 229 0,307 0,309
31 190 0,266 0,250 + 71 230 0,308 0,310 —
32 189 0,265 0,242 + 72 231 0,307 0,310 —
33 188 0,262 0,248 + 73 232 0,305 0,308
34 187 0,261 0,248 -Г 74 233 0,306 0,307
35 186 0,261 0,238 + 75 234 0,309 0,308 +
36 185 0,198 0,210 76 235 0,309 0,310
37 184 0,250 0,195 + 77 236 0,310 0,309 +
38 183 0,200 0,201 78 237 0,309 0,310
39 182 0,195 0,170 79 238 0,308 0,310
40 181 0,250 0,162 + 80 239 0,309 0,310 —
Из таблицы 7.1.2 видно, что показания приборов при 220 в сов-
падают (при этом значении и они были одинаково настроены).
В остальных Лг=79 наблюдениях разность —x't имеет знак
«плюс» в kN( -(-) = 47 случаях и знак «минус» в kN{—) — 32 случаях.
Выбрав уровень значимости д = 5%, по таблице VII приложений
находим, что критическое число для меньшей из частот равно /и,9 — 30
2*
260 СТАТИСТИЧЕСКАЯ ПРОВЕРКА ГИПОТЕЗ [ГЛ. VII
и, таким образом, нулевая гипотеза не опровергается, т. е. если
рассматривать весь диапазон напряжений от 160. до 240 в, то схемы
стабилизации, казалось бы, можно считать равноценными, причем
из таблицы 7.1.1 видно, что при М=79 критерий знаков будет
браковать нулевую гипотезу /70 с надежностью Р = 0,95
(т. е. в среднем в 95 случаях из 100), если на самом деле вероят-
ность получения отрицательных отклонений будет /’(«—») = 0,30.
В нашем примере все же обобщение всех наблюдений было бы
не совсем правильным. Из таблицы 7.1.2 видно, что в интервале
от 160 до 180 в значения х существенно и систематически превы-
шают значения х'.
Если этот интервал значений и, где видно явное преимущество
первой схемы стабилизации, выделить отдельно, то в оставшихся
59 наблюдениях имеем &JV(-|-) = 26 и kN{— ) = 32.
При q = 5% по таблице VII приложений для N=58 находим,
что /и58=-21 и меньшая из частот ) —26 опять-таки не по-
падает в критическую область. Отсюда следует, что при напряже-
ниях от 180 до 240 в нет оснований отдавать предпочтение одной
из исследованных схем стабилизации перед другой. Правда, как
видно из таблицы 7.1.1, при М=58 чувствительность критерия зна-
ков будет ниже, чем при ^=79. Например, при М=49 он будет
браковать гипотезу Но с надежностью [3 = 0,95, когда на
1
самом деле будет р = -^.
7.1.4. Проверка гипотезы о равенстве двух центров рас-
пределения. Особенно часто в приложениях встает вопрос о сравне-
нии центров распределения двух нормально распределенных величин
X и Y. Пусть мы располагаем двумя независимыми выборками
объемов п1 и я2 из генеральных совокупностей X и Y и желаем
проверить «нулевую» гипотезу На, заключающуюся в предположении:
Vy = Vj,. Если дисперсии о2х и ву величин X и Y известны, то мы
легко можем организовать проверку На, использовав то обстоятель-
ство, что разность у—х двух выборочных средних следует, как мы
знаем (см. п. 6.3.5), закону W (z; vr—vx; где oj-_-) =
п Г Оу Оу
= I/------1---, и потому может считаться известной. В качестве
F ^2 _ _
_ у—*
критерия рассмотрим величину Z = —---------нормированную раз-
а(7-Г)
ность (у—х).
Если гипотеза На верна, то величина Z подчинена закону N (г; 0; 1)
и в качестве критической области естественно назначить область
больших по абсолютной величине отклонений |Z|> zg, где zq пред-
§ 1] ЗАДАЧИ СТАТИСТИЧЕСКОЙ ПРОВЕРКИ ГИПОТЕЗ 261
ставляет q% предел отклонения (определяемый по таблице И прило-
жений), удовлетворяющий условию Р (| Z [2> zq) — jgg .
Если с нашей нулевой гипотезой конкурирует альтернативное
предположение Нг, заключающееся в том, что vy—vx^> О (или —
— т0 критической областью проверки гипотезы Яо против
Н естественно считать область больших положительных отклонений
(или соответственно отрицательных отклонений). При том же уровне
значимости, равном q%, критическая область определяется неравен-
ством ZZ>ziq, так как по свойству нормального закона имеем:
Р (Z> ztq) = у Р (I Z | > г2?) = у jgg = jgg . (7.1.9)
Аналогично при альтернативном предположении —vx<0 крити-
ческая область определяется неравенством
(7.1.10)
Пусть, например, у нас имеются данные об испытаниях на разрыв
образцов от двух выборок по 50 бунтов (мотков) проволоки из про-
дукции двух заводов, причем оказалось:
х = 120,8 кг)мм2 (завод А), у — 128,2 кг(ммг (завод В).
При этом на основе предшествовавших наблюдений можно считать,
что ох = 8,0 кг)мм2 и ог = 9,4 кг 1мм2.
Требуется определить, имеется ли реальное различие в механи-
ческих качествах изготавливаемой заводами A v. В проволоки.
Определяя 0(у_7), найдем:
т/82 . 9,42 , , 2
%--?) = V Го + -50-= 1’75 кг'мм-
Выбирая (/ = 5% и пользуясь таблицей П приложений, находим
•24 = 1,96. Поэтому расхождение между средними, превосходящее
по абсолютной величине z5O(-_-) 1,96-1,75 = 3,43 кг/мм2, следует
считать существенным. Мы имеем у — х= 128,2—120,8 = 7,4 кг/мм2.
Это отклонение попадает в критическую область, и, следовательно,
расхождение в качестве продукции А и В существенно.
Для разности vY—vx центров распределений мы можем теперь
указать доверительные границы. Например, доверительной вероят-
ности Р = 0,95 соответствует интервал для vr—vx с границами
« = 7,4 — 3,43 = 3,97 кг/мм2 и ₽ = 7,4 + 3,43 = 10,83 кг!мм2.
Если при том же предположении нормальности распределений
-V и У дисперсии о2х и неизвестны, то описанный прием проверки
262
СТАТИСТИЧЕСКАЯ ПРОВЕРКА ГИПОТЕЗ
[ГЛ. VII
не применим. Однако во многих случаях мы можем считать обосно-
ванным предположение о равенстве дисперсий о^ = сф. ® том СЛУ‘
чае, как мы знаем (см. п. 6.3.5), величина
/*= 1/n,na (nt+ па —2) (у — х) — (уг—Уу)
Г п. + п, 1/ 2 , 2 1 '
F 11у> % I П>2'>у
имеет распределение Стыодента с числом степеней свободы л,+
+ лг — 2 = k. Пользуясь этим, мы можем построить (100—q) %
доверительный интервал для разности vy—vx вида
О' — *) ± tq.
(tli+n.) (п^х+пг5гу)
n^i^ + ^—2)
(7.1.12)
где tq^k—q% предел для закона Стыодента с k степенями свободы.
Мы можем теперь осуществить проверку гипотезы На (vr—= 0),
используя следующее простое правило: подсчитав доверительные гра-
ницы (7.1.12) по данным выборки, мы устанавливаем, будет ли зна-
чение точки 0 лежать внутри доверительного интервала или нет.
В первом случае гипотеза Нй принимается, а во втором — бракуется.
В самом деле, если Но верна, то, согласно определению доверитель-
ного интервала ^с доверительной вероятностью 1—вероятность
того, что точка 0 не попадает внутрь этого интервала, равна ,
и потому представляет событие практически невозможное. Посту-
пая согласно указанному правилу, мы получим, что вероятность ошибки
первого рода от неправильной браковки гипотезы не превышает — .
Практически проверка сводится к вычислению критерия
у — х
Vп^\ + nas‘y
/»1«2 (щ + щ—2)
«1 + П2
(7.1.13)
(который получается из t* при vY — vx, что соответствует нашей ги-
потезе) и .установлению того, выполняется ли неравенство
\t\^tq,k (7.1.14)
или неравенство
В первом случае мы можем считать нашу гипотезу 7/0 не противоре-
чащей опытным данным, тогда как во втором мы считаем наблюден-
ное расхождение значащим (с q% уровнем значимости, по меньшей
мере) и гипотезу Но бракуем.
§ 2] ПРОВЕРКА ГИПОТЕЗ О ДИСПЕРСИЯХ 263
Пусть, например, при обработке втулок на автоматическом станке
было отобрано две пробы по 10 деталей в каждой.
В пробе № 1 мы получили средний диаметр втулки, равный
х — 2,063 мм и пг8х = 86 мкг, а в пробе № 2 у = 2,059 мм и
пг$^ = 44мкг. Предположим, что изменение обстановки за проме-
жуток времени между двумя пробами может сказаться лишь на
средних размерах, но не изменяет дисперсии. Тогда, учитывая (7*.1.13),
определяем:
t = 2059—2063 Г 10.10(10-НО-*-2) _ „ ,,
К86 4-44 V 10+10 —
причем число степеней свободы k = 10 1>0—2 = 18.
Из таблицы V приложений мы находим, что при £=18 вели-
чина |/| = 3,3 попадает в критическую область даже при q = 0,5%,
так как /-о,5; is = 3,193.
Используя общепринятую терминологию, мы можем наблюденное
расхождение считать «высокозначимым». Это указывает на смещение
уровня настройки станка (центра распределения размеров обработки)
за промежуток времени, отделяющий момент отбора пробы № 2
от момента отбора пробы № 1.
С тем же уровнем значимости, равным ^ = 0,5%, мы будем
иметь для разности центров распределений следующие доверительные
пределы, получающиеся по формуле (7.1.12):
(vr-vx) = -4±(-3,3)
или
— 7,3 мм <(уу—vx) <—0,7 мм.
§ 2. Проверка гипотез о дисперсиях
7.2.1. F-распределение и проверка гипотезы о равенстве
дисперсий. Гипотезы о дисперсиях играют в технике очень большую
роль, так как измеряемая дисперсией величина рассеивания как раз
и характеризует такие исключительно важные конструкторские и
технологические показатели, как точность машин и приборов, по-
грешность показаний измерительных приборов, точность технологи-
ческого процесса и т. д. Для проверки гипотез равенства дисперсий
в двух генеральных совокупностях по независимым выборкам из них
необходимо знать такую функцию их статистических опенок, распреде-
ление которой не зависело бы от каких-либо неизвестных параметров.
264 СТАТИСТИЧЕСКАЯ ПРОВЕРКА ГИПОТЕЗ [ГЛ. VII
Этому последнему условию удовлетворяет распределение отно-
шения двух несмещенных оценок дисперсий, вычисляемых по фор-
муле (6.1.4) и полученных из независимых выборок, взятых из
нормальных совокупностей, т. ё. распределение величины
si
=-=/=•, (7.2.1)
s;
причем обычно в качестве числителя ($,) берут ббльшую из двух
несмещенных оценок дисперсии.
F-распределение (Р. Фишера), о котором говорилось в п. 6.3.3,
зависит только от чисел степеней свободы kx=nx— 1 и£, = л2—1,
если выборки имеют объемы—первая пх и вторая пг.
Пусть, например, при обработке втулок (по одному чертежу) на
двух токарных автоматах были отобраны две пробы: со станка № 1
численностью я, = 10 штук и со станка № 2лг=15штук. Подан-
ным этих проб были подсчитаны уточненные эмпирические дисперсии,
оказавшиеся равными: для первого станка «1 = 9,6л/л;! и для вто-
рого станка $2 = 5,7 мк2, откуда
с числами степеней свободы fe1 = 10—1=9 и fe2 = 15—1 = 14.
Чтобы проверить гипотезу о равенстве дисперсий о-^ = ст2, мы
должны еще построить критическую область для критерия F. Только
тогда мы сможем судить о том, будет ли полученное нами значение
слишком большим или слишком малым.
За эту критическую область принимают два интервала: интервал
«больших» значений, удовлетворяющий неравенству F^>F2, и интер-
вал «малых» значений 0 F <Z Fx, причем подбирают критические
точки так, что при уровне значимости 9%=а-100
P(F>F2) = | = 2^ и P(F<F,) = |. (7.2.2)
Такой выбор критической области, как можно показать, обеспе-
чивает большую чувствительность критерия F.
На рис. 58 изображена кривая распределения критерия F. Здесь
заштрихованные площади равны каждая ~ . Если выборочное значе-
ние F оказывается в критической области, т. е. вне области допу-
стимых значений (Fx, Fj, то гипотеза = of должна быть отвергнута.
г 1 SI
Пусть F =-=- Тогда в силу того, что /г= — имеет ^-распределение
• с*
§ 21
ПРОВЕРКА ГИПОТЕЗ О ДИСПЕРСИЯХ
265
(со степенями свободы и k2), то F' = —J имеет также F-pacnpe-
si
деление со степенями свободы k2 и kv
С помощью функции F' вероятность P(F<J\) может быть
выражена следующим образом:
| = Р (5<Лг) = Р (1 > 1) = Р (г > 1) . (7.2.3)
Этот результат показывает, что левая критическая точка ^-распре-
деления соответствует правой критической точке F'-распределения.
Рис. 58. График плотности вероятности F-распределе-
ния для типичных значений А, и fe2 и критические гра-
ницы F, и F2.
Таким образом, необходимо найти только правые точки для F и F’,
чтобы определить F, и F2.
Ввиду этого свойства табулированы только правые критические
точки этого распределения. К сожалению, таблица VI приложений
включает лишь 5%-ные и 1%-ные правые критические точки для
различных сочетаний kx и k2. Тем самым мы получаем возможность
строить критические области для уровней значимости </=10% и
<7 = 2%.
Для промежуточных значений уровня значимости нужные крити-
ческие точки можно получать из таблиц лишь путем грубой интер-
поляции.
Как было указано выше, критерий берется в следующем виде:
„__наибольшая из двух дисперсий Г, или
наименьшая из тех же двух дисперсий
266 СТАТИСТИЧЕСКАЯ ПРОВЕРКА ГИПОТЕЗ [ГЛ. VII
Если теперь условиться отбрасывать гипотезу равенства дисперсий,
когда так определенный критерий F превосходит правое (наибольшее)
критическое значение F, подсчитанное для уровня значимости ,
то критическая область такого критерия будет отвечать уровню
значимости ci = 2 • =-X;. Это получается потому, что отно-
шение наибольшей из двух выборочных оценок s, и $2 дисперсии
к наименьшей из них превзойдет верхнюю границу F , подсчитан-
2
О 2 2
ную при уровне ^ТТоб ’ п^и гипотезе равенства Ui=o2 в случае
sj s 2
реализации двух несовместимых событий — > F или — ^>F
S2 - S1 ~
2 2 1 2
причем вероятность каждого из них при указанной гипотезе равна
- и, следовательно, по правилу сложения вероятностей получим
\ I ? _ *7
2-100 2-100“ 100 ‘
2
Обращаясь к примеру и беря 10%-ный уровень значимости, мы на-
ходим по таблице VI приложений при q = 5%, — 9 и А2=14
значение 5)0 = 2,65. Таким образом, выборочное значение 5=1,68
является незначимым, т. е. предположение о равенстве дисперсий не
противоречит наблюдениям, иными словами, нет еще оснований счи-
тать, что станки № 1 и № 2 обладают различной точностью.
7.2.2. Проверка гипотезы об однородности ряда дисперсий.
Мы остановимся на одном из упрощенных приемов проверки одно-
родности ряда дисперсий, применимом при одинаковых объемах
ряда из k выборок, по которым проверяется однородность дисперсий
соответствующего ряда нормальных совокупностей. Этот прием
(Бар'глета) основан на рассмотрении последовательности величин Of.
где i— номер выборки.
Для максимального из членов этой последовательности Gmax,
который, очевидно, отвечает наибольшему значению из s2, т.е. max[s2],
найден закон распределения, с помощью которого построены таб-
лицы VIII приложений, в которых при числах k выборок от 2 до 120
и объемах выборок п от 2 до 145 даны значения показателя Gmax,
отвечающие 5% и 1% уровням значимости.
Если найденное из наблюдений значение Gmax окажется больше
указанного в таблице для соответствующих k и п—1, то вероят-
§ 3] ПРОВЕРКА ГИПОТЕЗ О ЗАКОНЕ РАСПРЕДЕЛЕНИЯ 267
ность получить такое или большее значение оказывается меньше
того уровня значимости, для которого составлена данная таблица,
и потому гипотеза об однородности ряда дисперсий с тем же уров-
нем значимости должна быть отвергнута.
Пусть, например, из текущей продукции горизонтально-ковочной
машины за семь смен ее работы отобрано семь «проб», по одной
пробе в смену численностью в 17 штамповок. По данным каждой
из этих проб подсчитаны эмпирические дисперсии, оказавшиеся
равными (в ммг):
$2 = 0,067; s22= 0,136; s| = 0,168; $* = 0,068; $| = 0,066;
№ = 0,102; № = 0,137.
Требуется проверить гипотезу однородности этого ряда дисперсий,
т. е., иначе говоря, гипотезу об отсутствии разладки машины
по рассеиванию размеров штамповок за семь смен ее работы.
Учитывая, что самой большой дисперсией является третья по
счету, строим критерий Отах по формуле (7.2.4):
q________________________168________________________„ 9258
« 0,0674-0,136 + 0,168 + 0,068 + 0,066 + 0,102 + 0,137 ~
По таблице VIII приложений при 5 %-ном уровне для п —1 = 17—1 =
= 16 и k = l находим, что табличное Q равно 0= 0,2756.
Полученный результат 0,2258 < 0,2756 указывает на незначимость
расхождений между дисперсиями, т. е. по данным проведенных
наблюдений мы не можем еще считать, что за семь смен имела
место разладка машины по рассеиванию размеров.
§ 3. Проверка гипотез о законе распределения
7.3.1. Критерий соответствия %2- Рассмотренные в предшест-
вующих параграфах методы проверки предполагали известной функ-
циональную форму закона распределения и касались лишь значений-
параметров этого закона. Однако в других случаях самый вид
закона распределения является гипотетическим и нуждающимся в ста-
тистической проверке. В п. 4.1.2 мы видели, как, сопоставляя ве-
роятности попадания в интервалы с соответствующими частостями,
полученными из наблюдений, или проводя графическое сравнение
полигонов и гистограмм с кривой распределения, можно составить
себе, по крайней мере с качественной стороны, представление о боль-
шей или меньшей близости теоретического и эмпирического распре-
делений. Мы поставим теперь вопрос о критерии проверки по данным
выборки гипотезы о том, что данная величина X подчинена закону
268 СТАТИСТИЧЕСКАЯ ПРОВЕРКА ГИПОТЕЗ (ГЛ. VII
распределения Р(х). Подобные критерии, называемые обычно «кри-
териями соответствия», основаны на выборе определенной меры
расхождения между теоретическим (или гипотетическим) и эмпири-
ческим распределениями. Если такая мера расхождения (т. е. критерий)
для рассматриваемого случая превосходит надлежаще установленный
предел, то гипотеза бракуется, и обратно.
Мы здесь кратко рассмотрим применение одного из наиболее
употребительных критериев — критерия %2 (К- Пирсона). Допустим
сначала, что наша гипотеза полностью определяет вид функции
распределения Р(х). Такая гипотеза называется простой. Пусть,
далее, вся область изменения величины разбита на конечное чи-
сло / множеств А,, Д2, ..., Дг, например, / интервалов в случае
непрерывной величины или групп, состоящих из отдельных значений
дискретной величины, и т. д. Пусть р1 есть вероятность для вели-
чины X при данном распределении Р\х} принять значение, принад-
лежащее г'-му множеству Д; (интервалу или группе), т(—число
значений X из общего числа их п в выборке O(xt, х2, ..., хп), по-
павших в Д,-. При этом, очевидно, должны выполняться условия
Р1 + Р2 + • • • Ч-/’/— (7.3.1)
/п, +/»2+...+• mz = л. (7.3.2)
Если проверяемая гипотеза верна, то mt представляет частоту появле-
ния события, имеющего в каждом из п произведенных испытаний ве-
роятность Рр, следовательно, мы можем рассматривать до,- как слу-
чайную величину,подчиняющуюся биномиальному закону распределе-
ния с центром в точке пр(п средним квадратическим а(- = Упр^ \ —рр.
Когда п велико, можно согласно п. 4.3.7 считать, что частота
распределена асимптотически нормально с теми же параметрами.
При правильности нашей гипотезы мы можем ожидать, что будут
асимптотически нормально распределены (в совокупности) также
величины
= (z = 1,2, ...,/), (7.3.3)
У npt
связанные между собой соотношением
(7.3.4)
вытекающим из (7.3.1) и (7.3.2).
§ 3] ПРОВЕРКА ГИПОТЕЗ О ЗАКОНЕ РАСПРЕДЕЛЕНИЯ 269
В качестве меры расхождения данных выборки /»,, т2, ..., tnt
с «теоретическими» данными npv пр2, ..прс рассмотрим величину
= = (7.3.5)
1^1 «7? npi
Для практических приложений часто удобно использовать следующее
легко выводимое равенство:
1 2
. v-i т ,
С-3.6)
Согласно (7.3.5) %2 представляет сумму квадратов асимптотически
нормальных величин, связанных линейной зависимостью (7.3.4).
Мы ранее встречались уже с аналогичным случаем, рассматривая
распределение величины
п ______
ns1 _ (Х[—х)!
а2 — Zw 02 »
причем нормально распределенные величины * были связаны
также линейной связью. Мы видели, что наличие этой связи привело
к тому, что результирующее распределение следовало закону у2
с уменьшенным на единицу числом степеней свободы. Аналогичным
образом может быть доказана следующая важная для нас теорема:
Если проверяемая простая гипотеза верна, то критерий (7.3.5)
имеет распределение, стремящееся при п—► оо к распределению
с I— 1 степенями свободы.
Для того чтобы дать правило проверки, следует, как всегда,
выбрать уровень значимости q°/o для критерия. Пусть %* обозна-
чает q% предел для закона у2 с (Z—1) степенями свободы, нахо-
димый по таблице IV приложений. Если гипотеза верна, то прибли-
женно при достаточно большом п мы будем иметь:
Р(Х->%;)-!?-„ Р.3.7)
Определив значение %2 по данным выборки, мы будем иметь одно
из двух: или у2 > т- е- критерий попадает в критическую область
и тогда расхождение выборочных данных с гипотетическим до-
пущением о законе распределения существенно, а потому гипотеза
бракуется, или имеет место неравенство у2 =^у2, т. е. расхождение
не существенно, а потому гипотеза принимается. Поступая по указан-
ному правилу, мы можем рассчитывать лишь в q% всех случаев
проверки отбросить верную гипотезу. При этом следует помнить
270
СТАТИСТИЧЕСКАЯ ПРОВЕРКА ГИПОТЕЗ
[ГЛ. VII
о ряде сделанных нами условных и ограничивающих допуще-
ний, которые сказываются на получаемом результате. Прежде всего,
самое подразделение на группы или множества Д. может быть про-
изведено различным образом и никак не связано с природой функ-
ции Р(х); если мы получаем подтверждение гипотезы, то это может
означать лишь существование некоторой функции Р\ (х), которая
приводит к тем же значениям pit как и проверяемая функция Р(х).
Далее, очевидно, что в случае критерия %2, как и в других
случаях проверки статистических гипотез, мы можем бесконечным
числом способов выбрать критическую область так, чтобы она
отвечала заданному уровню значимости. Мы могли бы, например,
в качестве такой области взять любой интервал (а, Ь), обладающий
тем свойством, что Р (а <; %2 <; 6) = . Мы могли бы также в ка-
честве критической области взять область малых значений вида %2<с,
где с подбирается так, что Р (%2 <; с) = ~ . Но в этом последнем
случае мы отвергали бы гипотезу всякий раз, когда мера расхожде-
ния получалась малой, и принимали бы гипотезу, если расхождение
было достаточно велико. Ясно, что последнее правило противоре-
чило бы требованию большей чувствительности критерия к конку-
рирующей гипотезе. Заметим, что если р( не будут вероятностями
попадания в Д;, т. е. если проверяемая гипотеза ложна, то каждое
(Ш; — ПО:)2 , ,
слагаемое —-----в выражении % будет порядка п и будет не-
ограниченно возрастать вместе с объемом выборки. Таким образом,
всякая ложная гипотеза будет почти наверное отброшена при доста-
точно большом п, если критическая область выбирается в области
больших отклонений.
Мы отмечали выше, что величины или да,- асимптотически нор-
мальны. Принято считать нормальное приближение достаточным для
практических расчетов, если для всех inp-^ 10. Если есть группы со
значениями npt, меньшими 10, то следует рекомендовать объединять
соседние группы так, чтобы новые группы удовлетворяли указанному
условию. В тех случаях, когда число степеней свободы k больше 30,
соответствующего значения %2 нельзя найти в таблице IV прило-
жений. В этом случае можно использовать следующую приближен-
ную формулу, основанную на том, что ]/ 2%2 оказывается асимпто-
тически нормальным с законом N(z; ]/‘2v—1); 1):
Х; = |(/27=1 + г29)г, (7.3.8)
где г2?есть2<7% предел абсолютного уклонения нормальной перемен-
ной, находимой по таблице II приложений, nv==/—1 — число сте-
пеней свободы.
§ 3]
ПРОВЕРКА ГИПОТЕЗ О ЗАКОНЕ РАСПРЕДЕЛЕНИЯ
271
Таблица 7.3.1
Распределение числа разладок станков производственного участка
по часам смены
Часы смены Наблюдавшееся число разладок mi Математические ожидания числа разладок пр/ Уклонения mt—npi (m/—пр;)3 nPi
1 ' 16 18 —2 0,22
2 17 18 —1 0,06
3 19 18 1 0,06
4 16 18 —2 0,22
5 24 18 6 2,00
6 19 18 1 0,06
7 17 18 —1 0,06
8 16 18 —2 0,22
S 144 144 0 2,90
Пусть, например, в нашем распоряжении имеются данные о числе
разладок станков производственного участка по часам смены (см. таб-
лицу 7.3.1). Требуется проверить гипотезу о том, что разладки
следуют равномерному закону распределения.
Рис. 59. График распределения числа разладок станков по
часам смены.
График нашего эмпирического распределения показан на рис. 59.
По таблице IV приложений при 7 степенях свободы и д = 5%
находим, что Xj05=14-,l.
272 СТАТИСТИЧЕСКАЯ ПРОВЕРКА ГИПОТЕЗ [ГЛ. VII
Полученное нами из опыта значение %2 = 2,90 лежит в области
допустимых значений, а потому у нас нет оснований считать гипотезу
противоречащей наблюдениям. Точный вид функции Р(х) фикси-
руется гипотезой лишь в редких случаях. Обычно предполагается
лишь, что функция Р(х) принадлежит некоторому семейству рас-
пределения Р(х, 0,, 02, ..., 0J, зависящему от k параметров 0р
0 ..., 0ft, и отвечает некоторой частной системе значений этих
параметров 0, = 0”, 02 = 02, ..., причем числа 0°, 02, ... нам неиз-
вестны. Например, допуская нормальность распределения, мы не
фиксируем точно значения центра v = v0 и дисперсии ог = а2.
В этом случае неизвестные значения параметров 0J, 02, ... при-
ходится оценивать по данным выборки, используя надлежащие
оценки 0;, получаемые, например, по методу наибольшего правдо-
подобия. Проверяемая гипотеза в этом случае называется сложной.
Вероятности Р., отвечающие различным группам Дг-, будут
также зависеть от оцениваемых параметров 0,-, и если мы в порядке
приближения заменим 0? их оценками 0(., то мы получим выборочные
оценки р[ для вероятностей р{.
Предположим, например, что мы проверяем гипотезу нормаль-
ности для некоторого наблюденного распределения. Заменяя неиз-
вестные параметры центра рассеивания v и дисперсии о2 их эмпи-
рическими оценками х и а2 соответственно1), мы будем в качестве
приближения к теоретической плотности рассматривать функцию
п (х; v; х; s) = r__: е 2S’ . (7.3.9)
У 2ns
В этом случае в качестве оценки вероятности попадания в какой-
нибудь интервал Д естественно считать:
Pb=\g(x> х; s) dx. {l.ZAQ)
д
Эти оценки />д зависят от выборочных характеристик х и $. В ка-
честве критерия соответствия в данном случае рассматривают величину
(f"z~np/)2 , (7.3.11)
7Z nPi
где Pj—оценки вероятностей для каждой z-й группы, г = 1, 2......Z,
на которые подразделено наше распределение.
’) х и s2 следует в данном случае вычислять по сгруппированному ма-
териалу.
ПРОВЕРКА ГИПОТЕЗ О ЗАКОНЕ РАСПРЕДЕЛЕНИЯ
273
§ 3]
Уклонения в данном случае связаны между собой более чем
i
одним линейным соотношением У, (от,- —/гр,) = 0.
i -1
Если число оцениваемых параметров равно с, то на уклонения
от(- — npi накладывается тем самым еще с связей; поэтому число
независимых между собой уклонений в этом случае будет I—с—1.
Можно показать, что при достаточно больших численностях групп
и в этом случае критерий (7.3.11) будет приближенно следовать
закону х2 с I—с—1 степенями свободы.
Методика его применения остается прежней; мы сравниваем полу-
ченное из выборки значение %2 с q% верхним пределом, отвечающим
I—с — 1 степеням свободы, и в том случае, когда у2 окажется пре-
восходящим этот предел, мы бракуем гипотезу соответствия.
Заметим еще, что в некоторых случаях критерий у_2 получается
настолько малым, что значения, большие полученного, можно ожидать
теоретически с вероятностью, близкой к единице. Такое положение
дела может являться следствием того, что большое число оцени-
ваемых по данному материалу параметров искусственно фиксирует
слишком хорошее согласование опытных данных с теорией. Поэтому
следует внимательно и осторожно анализировать причины получен-
ного согласования, используя и другие критерии и оценки.
Пусть, например, требуется оценить гипотезу о нормальном
законе распределения диаметров валиков, полученных на прецизион-
ном токарном автомате, по данным выборки объема 200 штук из
текущей продукции станка. После группировки данных в интервалы
мы вносим их в графы 1, 2 и 3 таблицы 7.3.2 (см. стр. 274).
Гистограмма этого распределения показана на рис. 32.
Далее, вычислив по формулам (3.1.40) и (3.1.41) значения
_г=4,30лгл: и № = 94,26 мк\ мы определяем координаты границ
интервалов относительно х, выраженные в долях s. Так, например,
учитывая, что s = ys2 =/94,26 = 9,71 мк, находим для начала
z второго интервала (гг — — оо — начало первого интервала, z2 — ко-
нец первого и одновременно начало второго интервала и г. д.)
и для начала zs третьего интервала
Вообще, длина нормированных интервалов, кроме первого и послед-
него,
к
Д2 = Уц = 0,515,
274
СТАТИСТИЧЕСКАЯ ПРОВЕРКА ГИПОТЕЗ [ГЛ. VII
Таблица 7.3.2
1 ; Кг интервалов 1 Границы интер- । валов в мк Частота в интер- вале ГП[ ты гра- эвалов относи- о л N* е Оценка вероят- ности попадания : в интервал р/ Оценка матема- тических ожида- ний Пр[ Взвешенные ' квадраты укло- нений (ml — пр;)'- < s с
1 Координа ниц инте| в долях S ЯЗ л ч <и
1 2 3 4 5 6 7 8
1 -20-?- -15 7 —оо -1,99 -0,5 0,0233 4,66 1,18
2 —15-?- -10 11 —1,99-?- -1,47 —0,4767 0,0475 9,50 0,24
3 -10-?- - 5 15 —1,47-?- -0,96 —0,4292 0,0977 19,54 1,05
4 - 5-? 0 24 -0,964- -0,44 —0,3315 0,1615 32,30 2,13
5 0-? 5 49 —0,44-? 0,07 —0,1700 0,1979 39,58 2,24
6 5-? 10 41 0,07-? 0,59 0,0279 0,1945 38,90 0,11
7 Ю-? 15 26 0,59-? 1,10 0,2224 0,1419 28,38 0,20
8 15-? 20 17 1,10-? 1,62 0,3643 0,0831 16,62 0,01
9 20-? 25 71 1,62-? 2,13 0,4474
г10 0,0526 10,52 0,03
10 25-? 30 з) 2,13-?- |-°о 0,4834
Сумма 200 1,0000 200,00 7,19
Полученные этим способом координаты вносим в графу 4.
Затем с помощью таблицы II приложений находим оценки ве-
роятностей попадания в интервалы. Так, например, для первого
интервала мы находим:
<1№) = Ф0(-°°) = -°.5 п Ф,(г2М.(-1-99) = -0,4767;
тогда
р, = — 0,4767 —( — 0,5) = 0,0233.
Результаты этих вычислений вносим в графу 6; интервал 10 при
этом ввиду его малочисленности (в него попало всего три наблюде-
ния) мы объединяем с интервалом 9. Во вспомогательной графе 5
проставлены взятые из таблицы II приложений значения функции
Лапласа в началах соответствующих интервалов. Сумма чисел р;
в графе 6 всегда будет равна единице. В графу 7 заносим оценки
математических ожиданий частот по интервалам, получаемые путем
умножения оценок вероятностей pt па общее число наблюдений п = 200.
Так, например, в первом интервале получаем = 200-0,0233 =
= 4,66. Итог по графе 7 должен равняться, конечно, итогу по
§ 3] ПРОВЕРКА ГИПОТЕЗ О ЗАКОНЕ РАСПРЕДЕЛЕНИЯ 275
графе 3. Наконец, в графе 8 проставляем взвешенные квадраты
уклонений частот от оценок их математических ожиданий; итог
по этой графе и дает критерий %2, определяемый формулой (7.3.11).
Таким образом, мы получим:
Х2 = 7,19.
Так как мы по данным выборки оценили два параметра (v и а)
нормального закона, то в нашем случае число степеней свободы
будет равно
k = l' — с — 1 =9 — 2 — 1 = 6,
где /' — 9 —число интервалов, получившееся после объединения
интервалов 9 и 10; с = 2.
По таблице IV приложений находим, что полученное по данным
выборки значение %2 = 7,19 меньше значения у? соответствующего
30% уровню значимости, другими словами, вероятность получить
такие же или еще большие значения %2 при нашей гипотезе
более 0,3. Отсюда заключаем, что результат нельзя считать значи-
мым, и гипотеза о нормальности генеральной совокупности, из ко-
торой получена наша выборка, не противоречит наблюдениям.
7.3.2. %2 как критерий однородности распределений. Критерий %2
может быть использован еще для проверки гипотезы однородности
распределений в рассматриваемых совокупностях. Пусть мы имеем
две независимые выборки объемов л, и л2, причем по рассматривае-
мому признаку наблюдения каждой выборки распадаются на I групп
с численностями
mlt т2, ..., mt и mlt т2, ..., mi
соответственно, так что
л?, "И т2 ... -ф mi = л,
и
'И. + 'ИаН- ... +т/ = Я2.
Требуется проверить гипотезу о том, что распределения признака
в двух генеральных совокупностях, из которых мы взяли выборки,
одинаковы. Для этого мы используем критерий %2 в следующем
виде:
х (7.3.12)
i = 1 1 1
Можно показать, что этот критерий при больших л, и л2 распре-
делен по закону х2 с I—1 степенями свободы.
276
СТАТИСТИЧЕСКАЯ ПРОВЕРКА ГИПОТЕЗ
[ГЛ. VII
Таблица 7.3.3
Распределения плавок стали по процентному содержанию примесей серы
Число
плавок
Содержание
серы в % х
£
ЕС
о
и
03
от
0,004-0,02
0,024-0,04
0,04 4-0,06
0,06-4-0,08
82
535
1173
1714
63 145
429 964
995 2168
1307 3021
69-Ю-4
10,4-10“4
4,6-10“4
3,3-10“4
0,0234
0,1526
0,3348
0,4892
0,0226
0,1535
0,3561
0,4678
0,6-10-®
0,8-10-®
453,7-10-’
458,0-10“’
4,1-10“’
0,8-10“’
208,7-10“’
151,1-10“’
Сумма 3504 2794 6298
1,0000 1,0000
364,7-10“’
Пусть, например, мы располагаем данными о наличии примесей
серы в углеродистой стали, выплавляемой двумя металлургическими
заводами (см.таблицу 7.3.3).
Мы хотим судить о том,
можно ли считать распре-
деления примеси серы в
плавках стали этих двух
заводов одинаковыми.
Графики распределения
плавок по содержанию се-
ры показаны на рис. 60.
По формуле (7.3.12) на-
ходим:
X2 = 3504-2794-364,7 X
X 10“’ = 3,39.
По таблице IV приложе-
ний при числе степеней
свободы I—1=4 —1=3 и
<? = 5°/0 определяем, что
%0, 05 = 7,8.
Полученное нами из опыта значение %2 = 3,39 лежит в области
допустимых значений, а потому у нас нет оснований считать, что
процентные содержания серы в стали, выплавляемой заводами А и
В, имеют различные распределения.
гвво
'а
0,00
Рис. 60.
стали по
______J
ЗбЗоЗ А
Завод В
о,ог о,оз о,оо о,оз
Содерттие г еры, 6 %
Графики распределения плавок
содержанию серы для завода А
и завода В.
§ 3] ПРОВЕРКА ГИПОТЕЗ О ЗАКОНЕ РАСПРЕДЕЛЕНИЯ 277
7.3.3. Приближенная проверка гипотезы нормальности с по-
мощью асимметрии и эксцесса. Для приближенной проверки гипо-
тезы нормальности могут быть использованы эмпирическая асим-
метрия и эксцесс Ek (см. п. 3.1.3). Хотя по ним не представляется
возможным сколько-нибудь просто построить доверительные интер-
валы для теоретических асимметрии и эксцесса е%, но степень
их точности может быть приближенно оценена по их средним
квадратическим отклонениям:
°— (7Л,3>
П _ l/~ 24л (п-2) (n-З) „
У (п—1)2(п + 3)(п-}-5) ’ (7.3.14)
где п — объем выборки.
Большие по сравнению с oS|. и ол(, значения Sk и Ek, полученные
из наблюдений, могут служить основанием для браковки гипотезы
нормальности исследуемого распределения.
Пусть, например, требуется проверить гипотезу нормальности
по данным примера, приведенного в п. 7.3.2.
Имеем Sk — — 0,12 и Ek — — 0,14 согласно вычислениям, вы-
полненным в (3.2.3), а по (7.3.14)
6 (200 — i) ~ п
(200+ 1) (200 + 3)
/ 24-200(200—2) (200 — 3) ~ „
(200—I)2 (200 + 3) (200 +5) ~ ”'d4-
Мы видим, что Sk и Ek не велики по сравнению с oS/t и aElc. По-
этому гипотезу нормальности нельзя считать противоречащей данным
наблюдения.
7.3.4. Критерий Соответствия ю2. Мы видели, что критерий
применяется к довольно разнообразным случаям проверки простых
п сложных статистических гипотез. Однако его приложение, на-
пример, к проверке соответствия между гипотетическим и факти-
чески наблюденным распределениями существенно зависит от сделан-
ного довольно произвольно подразделения результатов наблюдений
на группы; в силу этого результаты проверки даже в случае про-
стой гипотезы несколько условны. Сама группировка, т. е. объеди-
нение наблюденного материала в группы, связана с некоторой
потерей имевшейся в первоначальных данных информации. К тому
же для вероятностной оценки наблюденного соответствия, харак-
теризуемого величиной х2, мы вынуждены использовать предельный
закон распределения, лишь приближенно выполняющийся при конеч-
ных объемах выборки.
278 статистическая проверка ГИПОТЕЗ [гл. V1I
Все эти обстоятельства заставляют нас проявлять известную
осторожность и показания критерия %2 рекомендуется дополнять
показаниями других критериев. В некоторых случаях внимательный
просмотр знаков получившихся отклонений наблюденного распре-
деления частот от теоретически ожидаемых позволяет обнаружить
систематическое расхождение с проверяемой гипотезой даже в том
случае, когда критерий %2 не попадает в критическую область.
Предположим, например, что при проверке соответствия данного
распределения частот с нормальным законом мы замечаем, что
в группах, отвечающих «левому концу» распределения, устойчиво
наблюдаются отрицательные знаки отклонений, тогда как в груп-
пах, отвечающих центру и «правому концу» распределения систе-
матически удерживаются положительные знаки. В этом случае мы
имеем основание подозревать, что действительное нормальное рас-
пределение в генеральной совокупности сдвинуто вправо от пред-
полагаемого гипотетического распределения (при той же дисперсии).
В другом случае при аналогичной проверке соответствия мы могли
бы наблюдать, что положительные знаки отклонений встречаются
на краях распределения, тогда как в центральных группах наблю-
даются отрицательные знаки. При такой ситуации становится прав-
доподобной гипотеза, заключающаяся в том, что действительное
распределение имеет (при том же центре) дисперсию, значительно
большую, чем дисперсия, предполагаемая проверяемой гипотезой.
Мы приведем теперь еще один критерий соответствия при про-
стой гипотезе, полностью фиксирующей закон распределения гене-
ральной совокупности, из которой получена выборка. Этот крите-
рий, получивший название <в2 (омега-квадрат) критерия, в отличие
от %2, основывается на непосредственно наблюденных (несгруппи-
рованных) значениях рассматриваемой величины X. Пусть наша ги-
потеза заключается в том, что величина X распределена согласно
непрерывному закону распределения /э(х); непрерывная функция
Р(х) считается известной. По данной выборке построим эмпириче-
скую функцию распределения IF4(x). При больших объемах вы-
борки Wn(x) почти наверно будет равномерно близка к теоретиче-
ской функции распределения Р(х) (см. § 1 гл. VI) и, значит, укло-
нение (1Гп(х)—Р(х)] будет равномерно мало. В качестве меры для
величины уклонения функции Wn{x] от Р(х) мы рассмотрим сред-
ний квадрат отклонений по всем возможным значениям аргумента.
Рассмотрим величину
+ »
со2 = J [lF„(x)—P(x)YdP(x), (7.3.15)
- со
причем
dP(x) = Р' (х) dx,
ПРОВЕРКА ГИПОТЕЗ О ЗАКОНЕ РАСПРЕДЕЛЕНИЯ
279
§ 3]
предполагая, что функция Р(х) имеет производную (плотность рас-
пределения) Р (х) ’).
Пусть
х,<х2<х3<...<х„
(7.3.16)
— упорядоченная по величине членов выборка из генеральной со-
вокупности случайной величины X или вариационный ряд (см. п. 3.2.3)
этой величины.
Равенство любых двух членов в этом ряду ввиду непрерывно-
сти функции Р\х) практически невозможно; оно имеет вероятность,
равную нулю.
Согласно определению функции Wn(x) имеем:
1Г„(Х) = 0 при Х<Х3,
JF„(x) = £ при xft<x<xA+1 (k = 1, 2,
п— 1), >(7.3.17)
Wn (х) = k при
x^x„.
В точке разрыва х — xk функция Wn(x) скачком переходит от
____________1 6
значения —— (в интервале xk_t^x <Zxk) к значению — , удер-
живая это последнее значение в следующем интервале. Поэтому
разбиваем всю область интегрирования на интервалы
( — 00, X,), (X,, х2), .... (Х„_„ Х„), (Х„, + оо)
и из (7.3.15), принимая во внимание (7.3.17), получаем
Xi k — n 1 + J
0)!=j (0-P(x))2rfP+ £ J [А_р(д)рр+
-со * = 1 хк
+ J [1-Р(х)]2<7Р (7.3.18)
хп
В противном случае приходится
шении (7.3.15) в смысле Стилтьеса.
понимать интегрирование в соотно-
280
СТАТИСТИЧЕСКАЯ ПРОВЕРКА ГИПОТЕЗ
[ГЛ. VII
Далее имеем
J [1 — Р (х)]2 dP (х) = Ч- Р3(Х»)Г
(7.3.19)
to2
Таким образом, (7.3.18) преобразуется в соотношение
Р3
3
[ь 3 з
3
£
А=1
3
(7.3.20)
Наконец, объединяя члены,
&=1,2, . ..,л), находящиеся в
зависящие от Р(хй) (с данным
двух суммах (7.3.20), получим:
/г=п
I £
/? = ] L
со2
1
12п2
2fe—ГР
2ге J ’
(7.3.21)
Это равенство показывает, каким образом со2 зависит от инди-
видуальных членов вариационного ряда. Оно и служит для вычи-
сления со2 по данным выборки, которые для этой цели предвари-
тельно записывают в форме вариационного ряда. Математическое
ожидание и дисперсия величины со2 равны
М(й2) = ^, D(tt>2) = ^Vr- (7.3.22)
' ' 6п ' ' 180п8 ' '
Эти формулы вытекают из следующих соотношений:
M[TF„(x)] = P(x), В[1Г„И- -(х)-[17-Р(%П . (7.3.23)
Отсюда легко видеть, что ю* по вероятности сходится к нулю,
з х 1
однако произведение лд» в среднем близко к -g-.
§ 3] ПРОВЕРКА ГИПОТЕЗ О ЗАКОНЕ РАСПРЕДЕЛЕНИЯ 281
Точное распределение со2 очень сложно, но исследование пока-
зывает, что уже при л >40 распределение произведения пш2п близко
к некоторому предельному распределению, для которого вычислены
таблицы. По этим таблицам определены критические значения для
величины л®2.
Критерий со2 (или, точнее говоря, л®2) обладает рядом преиму-
ществ перед критерием %2. Критерий и2 полнее использует ин-
формацию, заключающуюся в данных выборки, основываясь непо-
средственно на наблюденных значениях рассматриваемой величины.
Кроме того, его распределение значительно быстрее сходится
к предельному закону, особенно в области больших значений ®2,
которые только и существенны для вероятностной оценки.
В таблице 7.3.4 мы даем ряд «критических точек» для произ-
ведения л®2, отвечающих ряду уровней вероятности Р(лм2>д9)==
, а именно <7 = 50; 40; 30; 20; 10; 5; 3; 2; 1; 0,1 процента.
Одно из применений критерия и2 мы рассмотрим в п. 7.3.7.
Таблица 7.3.4
Значения верхнего предела псо2 в зависимости от уровня значимости q%
Уровни значимости 4 = Р (пю2 > г9) 100% 50 40 30 20 10
Критические точки zq 0,1184 0,1467 0,1843 0,2412 0,3473
Уровни значимости q~P (nto2> zq) 100% 5 3 2 1 0,1
Критические точки zq 0,4614 0,5489 0,6198 0,7435 1,1679
7.3.5. Критерий принадлежности двух выборок одной и той же
генеральной совокупности. Нередко приходится сравнивать две
выборки или две серии независимых наблюдений однородных вели-
чин X и Y, причем наблюденные значения xt и у,- дают различные
значения средних (х=^=у) или обнаруживают различные рассеивания.
Возникает вопрос о том, можно ли считать эти расхождения суще-
ственными, значимыми или их следует приписать случайностям
выборок. Такая необходимость возникает, например, при сравнении
наблюдений погрешностей показаний двух экземпляров измеритель-
ных приборов, рядов наблюдений погрешностей обработки двух
станков и т. д.
282 СТАТИСТИЧЕСКАЯ ПРОВЕРКА ГИПОТЕЗ [гЛ. VII
Как и в ранее рассмотренных задачах, мы можем свести дело
к нулевой гипотезе А/о, заключающейся в том, что функции рас-
пределения Рх (t) и PY (/) тождественны для любых t. Вместе с этим
конкурирующая (альтернативная) гипотеза формулируется в виде
неравенства Рх (/) < Ру (Л-
Для проверки указанной нулевой гипотезы можно использовать
критерий Вилькоксона, основанный на числе инверсий, под кото-
рыми понимается следующее: наблюдения, полученные в двух
выборках, располагаются в общую последовательность в порядке
возрастания их значений, например в виде
ySSW^PW^,
где xv ...,xi — члены, принадлежащие первой выборке, и ylt ...
..., ув— члены второй выборки.
Если какому-либо значению х предшествует некоторый у, то
мы говорим, что эта пара дает инверсию. Так, например, в нашей
последовательности х, и х2 дают по одной инверсии суг, стоящим
на первом месте, х3 дает четыре инверсии (с _у4, у2, у2 и _у4) и х4
дает шесть инверсий (с уе, ys, yit у2, у2 и у,), а всего инверсий
в нашей последовательности будет:
и=1+ 1 + 4-1-6 = 12.
Гипотеза Н9 отвергается, если число и превосходит выбранную
в соответствии с уровнем значимости границу, определяемую из того
расчета, что при объемах п>10ит>>10 выборок число инвер-
сий и распределено приблизительно нормально с центром
Ма = ф (7.3.24)
и дисперсией
Du = ~ (да + и+1). (7.3.25)
Пусть, например, имеются данные в микронах об измерениях
неровностей поверхности одного и того же образца чистоты по-
верхности с регулярным профилем на двух двойных микроскопах
типа МИС-11 с заводскими номерами № 61 и 263, приводимые
в таблице 7.3.5.
Таблица 7.3.5
Заводской № прибо- ра Обо- значе- ния * Порядковые номера измеренных высот неровностей поверхности
1 12 3 4 5 ь 7 8 9 10 И 12
61 X 0,8 1,9 3,0 3,5 3,8 2,5 1,7 0,9 1,0 2,3 3,3 3,4
263 У 1.4 2,1 3,1 3,6 2,7 1,8 1,1 0,2 1,6 2,8 4,0 4,7
ПРОВЕРКА ГИПОТЕЗ О ЗАКОНЕ РАСПРЕДЕЛЕНИЯ
283
§ 3]
Требуется определить, можно ли считать, что между показаниями
приборов нет систематических расхождений и что они имеют одина-
ковые предельные погрешности. Иными словами, нужно проверить
нулевую гипотезу о том, что распределения погрешностей двух
приборов описываются одинаковыми функциями распределения.
Располагаем наши данные в общую последовательность в порядке
возрастания результатов измерений (см, таблицу 7.3.6).
Таблица 7.3.6
У X X х • ч У А' У X У X
0*2 0,8 0,9 1,0 1,1 1,4 1,6 1,7 1,8 1,9 2,1 2,3
X У У X У X X X У У У
2,5 2,7 2,8 3,0 3,1 3,3 3,4 3,5 3,6 3,8 4,0 4,7
Число инверсий для х будет равно
«=1 + 14-1+4-1-5+6 + 6-1-8 4-9 + 94-9 + 10 = 69.
По формулам (7.3.24) и (7.3.25) находим:
12-12 12-12
Ма = -^2~ = 72, D« =(12 + 12 4-1) = 300,
^ = /300 = 17,3.
Задавшись уровнем значимости = 5’/0 и учитывая, что оба при-
бора являются равноправными, мы строим критическую область
больших по абсолютной величине отклонений, используя соотноше-
ние (7.1.2) и принимая во внимание, что
ts in = 1196.
Критическая область для гипотезы Но будет:
«< 72 —1,96-17,3 « 38
и
«>72+1,96-17,3 « 106.
Полученное нами значение инверсии « = 69 не лежит в критиче-
ской области, а потому гипотеза /70 не опровергается и приборы
нет основания считать существенно различающимися по точности.
284
СТАТИСТИЧЕСКАЯ ПРОВЕРКА ГИПОТЕЗ
[ГЛ. VII
7.3.6. Критерий грубых ошибок наблюдений. При проведении
наблюдений иногда имеют место грубые ошибки, к которым от-
носятся:
1) ошибки в отсчетах показаний измерительного прибора,
2) ошибки в вычислениях при измерении,
3) ошибки, созданные неправильным использованием средства
измерений,
4) ошибки, возникшие из-за недостатка осторожности у оператора.
Результаты наблюдений, произведенных с такими ошибками,
как правило, резко отличаются от среднего результата данной се-
рии наблюдений.
Наиболее надежным методом исключения грубых ошибок является
браковка подозрительных результатов наблюдений, когда для этого
имеются достаточные основания в обстановке самого эксперимента.
Иногда этот момент бывает упущен или вообще по тем или иным
причинам приходится в последующем порядке решать вопрос о при-
надлежности того или иного резко выделяющегося результата на-
блюдений к генеральной совокупности подобных результатов на-
блюдений. Тогда обращаются к надлежащим образом обоснованному
критерию грубых ошибок наблюдений.
Предположим, что распределение результатов наблюдений, про-
изводимых в обычных условиях, следует нормальному закону
N(x’, а', о) и подозрительным является максимальный по своему
значению результат хтах из числа п произведенных наблюдений.
Нулевой гипотезой /70 в данном случае является предположение
о том, что хтах принадлежит той же генеральной совокупности,
как и все остальные п—1 наблюдения или, иными словами, что хгаах
не является результатом грубой ошибки.
Альтернативная (противоположная) гипотеза может заключаться
во внезапном сдвиге центра совокупности или увеличении ее диспер-
сии во время производства наблюдений, что и могло дать .ктах.
Проверка нулевой гипотезы заключается в том, что Хтах сравни-
вается по величине с некоторой критической границей х и гипо-
теза бракуется, если хтах превосходит эту границу. Граница
в свою очередь выбирается так, чтобы вероятность превзойти ее
отвечала некоторому уровню значимости q. Если параметры гене-
ральной совокупности а и а известны, то закон распределения мак-
симума хтах в выборке из п членов можно определить. Событие
хтах<х равносильно тому, что все л наблюдений будут меньше х.
Отсюда, принимая во внимание независимость наблюдений и пола-
гая х —a-j-fo, получим:
Р^таХ<х) = [Л/(х; о; о)]"= [w(—; 0; 1)] =
= 0; 1). (7.3.26)
§ 3] ПРОВЕРКА ГИПОТЕЗ О ЗАКОНЕ РАСПРЕДЕЛЕНИЯ 285
Таким образом, для нахождения верхней допустимой границы
при нашей гипотезе, отвечающей уровню значимости ~, нужно
найти квантиль нормального распределения (см. п. 3.2.1), отвечаю-
1
щпй вероятности п, или верхнюю процентную точку этого
распределения, отвечающую
<?„=Ю0 «р/о. (7.3.27)
В самом деле, определив такое /о (, мы будем иметь в силу
(7.3.26):
Р (*шах < х) = Р (xmax < а + tQno) = (t; 0; 1) - 1 -
и
Р С^тах а ~Ь ^<2и°) ]qq •
Таким образом, обозначая верхнюю допустимую границу для
хшах ПРИ п наблюдениях через «?>п, имеем:
(7.3.28)
Практически чаще встречаются случаи, когда параметры о и ст
неизвестны и мы можем для проверки гипотезы использовать лишь
полученные по выборке значения х и s. В этом случае верхнюю
допустимую границу для rjnax при некоторых уровнях значимости
можно определить, используя таблицу Х1 приложений. Эта граница
определяется следующим образом:
= x + (7.3.29)
Числа g для уровней д=10%; 5%; 2,5% и 1% берутся из
таблицы XI приложений.
Они вычислены на основании исследования вероятности
величины
(7.3.30)
где хтах, х и s определены по выборке объема п из нормальной
совокупности.
286 СТАТИСТИЧЕСКАЯ ПРОВЕРКА ГИПОТЕЗ [ГЛ. VII
Если вместо хтах в качестве подозрительного результата фи-
гурирует xmin, то применяется та же процедура, но критерий v
заменяется на v =------.
s
Наблюдение хт1п бракуется, если имеет место для данного q
неравенство
Хт\п<-~ Х gq.nS. (7.3.31)
Пусть, например, при поверке вариации показаний индикатора
было произведено шесть наблюдений, причем были получены сле-
дующие результаты (в мк):— 1; —0,5; 0; 0,5; 1 и 2 (расположены
в порядке возрастания). Требуется определить, не содержится ли
в результатах наблюдений таких, которые произошли вследствие
грубых ошибок, если предположить, что индикатор по точности
удовлетворяет норме на вариацию показаний [А] = 3 мк, а погреш-
ность его показаний распределена по нормальному закону.
Поскольку принято считать, что [А] = 6о, то
[А] 3 л -
о = — -т- = 0,5 мк.
6 о
При правильной исходной установке индикатора центр рассеи-
вания <2 = 0.
Выбрав уровень значимости q = 2,5!>(0, по формуле (7.3.27)
определяем:
Q»=100 [1-®],/’5=0'996°/o-
По таблице X приложений при p=Qa — 0,996 находим xp = ^Q8 =
= 2,65. Далее по формуле (7.3.28) находим:
«2,5; 6 = 0+2,65.0,5 1,3 мк.
В нашем примере хтах = 2 мк> иг.5; 6 = 1,3 мк, а потому
наблюдение хшах=2 мк при сделанных предположениях следует
считать с уровнем значимости ^ = 2,5°/0, получившимся в резуль-
тате грубой ошибки.
Пусть теперь при исследовании точности технологической
операции в одной из временных проб отклонения размеров дета-
лей от номинального размера оказались следующими (в мм): 0,07;
0,09; 0,10; 0,12; 0,13; 0,15; 0,16; 0,17; 0,25 (расположены в по-
рядке возрастания). Требуется определить, не содержат ли полу-
ченные результаты наблюдений таких, которые произошли вследствие
грубых ошибок (имевших место, например, при измерении разме-
§ 3] ПРОВЕРКА ГИПОТЕЗ О ЗАКОНЕ РАСПРЕДЕЛЕНИЯ 287
ров), если допустить, что распределение размеров в пробах следует
нормальному закону.
Подсчеты среднего арифметического значения х и эмпириче-
ского среднего квадратического отклонения $ результатов наблю-
дений по формулам (3.1.6) и (3.1.33') дают
— 0,07 + 0,09 + 0,10 + 0,12 + 0,13 + 0,15 + 0,16 + 0,17 + 0,25 1,24
х _ _ . _ __ в
= 0,138 мм,
s = ^0,072+-0,092 + 0,102+0,122 + 0,132 +0,152 + 0,16гН-0,1724-
, п окг 1,242\1| 0,152 пл_,
+ 0,25---------------------------------+- ) 2 — -у- = 0,051 мм.
Выбираем уровень значимости </ = 2,5% и по таблице XJ при-
ложений при п = 9 находим v = g2,s; э = 2,349 и, следовательно,
по формуле (7.3.29)
«2,5; 9 = 0,138+ 0,051.2,349 = 0,258 мм.
Поскольку наибольший из результатов наблюдений хтах =
= 0,25 «2,5; 9 = 0,258, то согласно (7.3.31*) с уровнем зна-
чимости, не меньшим </ = 2,5%, можно считать, что для отнесения
данного результата к грубым ошибкам не имеется оснований.
7.3.7. Проверка гипотезы нормальности по совокупности малых
выборок. Пусть мы имеем достаточно большое число п выборок
одного и того же объема nk независимых между собой. Требуется
проверить гипотезу нормальности генеральных совокупностей, из
которых взяты эти выборки, не предполагая, что параметры этих
совокупностей имеют тождественное значение во всех выборках
без исключения. Другими словами, мы предполагаем устойчивой
лишь форму распределения, а именно считаем ее нормальной, не
делая никаких допущений относительно центров и дисперсий
генеральных совокупностей. В данном случае проверка гипотезы
может быть основана на следующем.
Рассмотрим уклонение
' (7-3’32)
какого-либо наудачу взятого наблюдения из А-й выборки
объема nk от средней арифметической х той же выборки,
нормированного оценкой s(k> среднего квадратического отклоне-
ния, подсчитанного по той же выборке с помощью формулы (6.1.5);
Можно показать, что распределение величины т не зависит от
288
СТАТИСТИЧЕСКАЯ ПРОВЕРКА ГИПОТЕЗ
[гл. VII
параметров а и о нормальной совокупности, а зависит только от
объема nk выборки.
Плотность вероятности величины т’) равна
( г(пь~Ц
1 \ 2 J
( о
при | х | < Vпк — 1,
при IX-1 S3 |/«й — 1 •
(7.3.33)
Отсюда следует, например, при пк — 4, что распределение
эмпирических уклонений в выборках по 4 единицы имеет равно-
мерное распределение, подчиняющееся закону (3.2.7), если исход-
ные совокупности нормальны, хотя, быть может, имеют разные
центры и дисперсии.
Этим обстоятельством можно воспользоваться для проверки
нашей гипотезы, когда число выборок достаточно велико.
При пк=£Л плотность вероятности величины т не будет удоб-
ной для пользования при проверке гипотезы нормальности ввиду
отсутствия надлежащих таблиц. Поэтому в этих случаях прихо-
дится переходить от нее к величине
тКпй-2
П ГпА-1-т2 ‘
(7.3.34)
Можно доказать, что величина г] при исходных нормальных
распределениях следует закону (6.3.16) Стыодента с nk—2 сте-
пенями свободы, ^-процентные пределы для которого приведены
в таблице V приложений.
После перехода к величинам т и г| задача проверки гипотезы
нормальности приобретает непараметрический характер, ввиду чего
для ее решения можно воспользоваться критерием to2, рассмотрен-
ным в п. 7.3.4.
Процедура проверки гипотезы по большому числу малых вы-
борок сводится к следующему.
Из каждой выборки берем наудачу по одному значению. Если
выборка представляет, например, временные «пробы», взятые из
текущей продукции станка, то можно из каждой пробы взять по
одному, первому (или последнему) по времени порядковому наблю-
дению. Порядок отбора здесь не играет существенной роли; важно
‘) См. Г. Крамер, Математические методы статистики, М., ИЛ, 1948,
стр. 426.
§ 3] ПРОВЕРКА ГИПОТЕЗ О ЗАКОНЕ РАСПРЕДЕЛЕНИЯ 289
лишь то, чтобы отбор одного наблюдения из данной пробы про-
изводился без какого бы то ни было учета значений отбираемых
наблюдений из остальных проб. Если в каждой выборке число nh
наблюдений (оно должно быть одинаковым для всех данных вы-
борок, т. е. должно быть nk= const) велико, например 10,
то может быть сделана не одна, а две или даже три (при боль-
ших /2а) самостоятельных проверки гипотезы, например по первым
и по последним экземплярам каждой пробы.
Далее, если nk — 4, то для каждого отобранного значения вы-
числяется по формуле (7.3.32) показатель т; если же лА=/=4, то
вычисляется по формуле (7.3.34) показатель т]. Потом полученные
значения т или т] располагаются в вариационный ряд и для каж-
дого значения подсчитывается эмпирическая функция распределения
IF„(xft) по формуле
- = = (7.3.35)
где п—число рассматриваемых выборок.
Для каждой из этих точек вычисляется, кроме того, теорети-
ческая функция распределения P(xk), причем при п = 4 для этого
используется закон (3.2.7) равномерного распределения, а при
«^=4—таблицы закона (6.3.16) Стьюдента.
Затем по формуле (7.3.21) вычисляются значения ы2 и лев2.
Если полученное таким образом из наблюдений значение ли2 пре-
вышает критическую точку zg, взятую по таблице 7.3.4 при вы-
бранном уровне значимости q, то гипотеза о нормальной форме
распределения рассматриваемых совокупностей отбрасывается
с уровнем значимости q, как не соответствующая результатам
наблюдений. В противном случае считается, что гипотеза не про-
тиворечит наблюдениям.
Пусть мы имеем 40 временных «проб» по 4 штамповки в каждой
из текущей продукции горизонтально-ковочной машины, причем
мы не можем быть уверенными, что центр рассеивания и дисперсия
за период отбора всех 40 проб оставались постоянными. Требуется
проверить гипотезу о том, что форма распределения штамповок
но высоте совпадает с формой нормального распределения. Берем
из каждой пробы по штамповке (первую по времени изготовления)
и вычисляем для каждого из 40 значений показатель т. Резуль-
таты вычислений сводим в таблицу 7.3.7 (см. стр. 290).
В графы 1—5 этой таблицы внесены данные о 40 пробах по
4 штамповки каждая, причем в графах 2—5 записаны отклонения
в мм высоты штамповок (расположенных в каждой из проб в по-
рядке изготовления) от среднего допускаемого размера. В графах 6
и 7 записаны средние арифметические х и оценки $ средних квад-
ратических отклонений, вычисленные с помощью формул (3.1.6)
t0 Н. В. Смирнов, И. В. Дунин-Барковский
290
СТАТИСТИЧЕСКАЯ ПРОВЕРКА ГИПОТЕЗ
[ГЛ. VII
Таблица 7.3.7
№ проб в поряд- ке отбо- ра Наблюденные значения в поряд- ке произведенных наблюдений X S Xi — X X - xi~~x S
*3 X*
1 2 3 4 5 6 7 8 9
1 0,55 0,13 0,21 —0,20 0,172 0,308 0,378 1,23
2 0,98 0,52 0,10 0,42 0,505 0,364 0,475 1,30
3 0,68 —0,13 0,42 0,29 ,0,315 0,338 0,365 1,08
4 0,18 0,72 0,32 0,27 0,372 0,240 —0,192 —0,800
5 0,24 0,08 —0,68 0,21 -0,038 0,433 0,278 0,642
6 0,43 0,26 0,86 0,78 0,582 0,286 -0,152 —0,531
7 0,19 0,97 0,73 0,63 0,630 0,326 —0,440 —1,35
8 —0,21 0,07 0,82 1,03 0,428 0,591 —0,638 —1,08
9 0,02 -0,91 1,17 0,59 0,218 0,886 —0,198 —0,223
10 0,00 -0,30 0,56 0,51 0,192 0,415 —0,192 —0,463
И 0,23 0,04 —0,14 0,29 0,105 0,195 0,125 0,641
12 0,03 0,32 0,49 0,04 0,220 0,225 —0,190 —0,844
13 0,69 —0,99 0,27 0,23 0,050 0,726 0,640 0,882
14 0,04 0,41 0,01 —0,18 0,070 0,247 —0,030 —0,121
15 0,64 0,06 0,35 —0,11 0,235 0,330 0,405 1,23
16 0,57 0,31 0,26 0,20 0,335 0,163 0,235 1,44
17 —0,19 0,38 0,58 0,18 0,238 0,328 —0,428 —1,30
18 0,35 0,27 0,24 0,18 0,260 0,071 0,090 1,27
19 о,п 0,54 0,01 0,23 0,222 0,231 —0,112 —0,485
20 0,43 0,77 0,28 0,39 0,468 0,210 —0,038 —0,181
21 0,11 0,01 —0,12 0,10 0,025 0,107 0,085 0,794
22 0,54 0,31 -0,18 -0,36 0,078 0,418 0,462 1,11
23 0,36 —1,31 — 1,31 —0,21 —0,618 0,832 0,978 1,18
24 0,16 —0,38 0,68 —0,07 0,098 0,447 0,062 0,139
25 0,90 1,58 0,65 1,36 1,122 0,436 —0,222 —0,509
26 1,57 0,82 1,65 1,63 1,418 0,397 0,152 .0,383
27 1,35 1,81 1,13 1,41 1,425 0,283 —0,075 —0,265
28 1,19 1,13 1,08 1,35 1,188 0,110 0,002 0,018
29 0,87 1,46 1,18 1,54 1,262 0,306 —0,392 —1,28
30 0,92 1,42 1,14 1,49 1,242 0,266 —0,322 —1,21
31 0,92 1,36 1,43 1,04 1,188 0,243 —0,268 —1,10
32 0,02 0,64 0,08 —0,40 0,085 0,427 —0,065 —0,152
33 0,66 —0,26 0,63 —0,09 0,235 0,479 0,425 0,887
34 —0,12 0,40 0,40 0,75 0,358 0,358 —0,478 — 1,33
35 0,05 —0,05 0,20 0,40 0,150 0,196 —0,100 -0,510
36 0,90 —0,18 —0,22 0,36 0,215 0,528 0,685 1,30
37 —0,35 0,43 0,42 0,05 0,138 0,370 —0,488 —1,32
38 0,64 0,95 0,25 0,71 0,638 0,289 0,002 0,007
39 0,32 0,79 0,40 0,66 0,542 0,219 -0,222 -1,01
40 1,40 0,30 0,27 0,60 0,642 0,527 0,758 1,44
§ 3] ПРОВЕРКА ГИПОТЕЗ О ЗАКОНЕ РАСПРЕДЕЛЕНИЯ 291
и (6.1.5), В графе 9 указаны значения показателя т, вычисленные
по первому из наблюденных значений каждой пробы по формуле
(7.3.32).
Так, например, для первой пробы (k—l) получим:
0,55—0,172 ,
Т1 = Т308—== 1-23'
Далее полученные значения xk (k—\, 2, 3,..., я) располагаем
в вариационный ряд и вычисляем для каждой точки значение
эмпирической функции распределения Wh и теоретической функ-
ции P(tft) с целью подсчета величины со2. Наши вычисления сводим
в таблицу 7.3.8 (см. стр. 292).
В графе 2 этой таблицы мы расположили вычисленные с по-
мощью предыдущей таблицы показатели тА для каждой пробы
в порядке возрастания их значений так, что если для первой
пробы т== 1,23, то теперь это значение оказалось на тридцать
четвертом месте, а на первое место мы поместили т = —1,35,
получившееся в седьмой по порядку отбора пробе. В графу 3 мы
внесли теоретические значения функции распределения P(xk) для
соответствующих значений величины т, имеющей, как уже указы-
валось, равномерное распределение при nk — 4. Из формулы (7.3.33)
следует, что при яА = 4 плотность распределения величины т равна
PxW =
?_2 ' = —(при | х | < ]/ 3 ).
КЗлГ(1) 2 К 3 1 1
Далее, на основании формулы (3.2.10), принимая во внимание,
что рт(х) = 0 при х<]/з , имеем:
— J — 2 3 3 )‘
-Гз
(7.3.36)
С помощью (7.3.36), например, получаем при т, = —1,35:
Р 1 35) = —Ь35+/3_ = 0дw
Т \ ’ ' о -\Г Q ’
и при ts4 — 1,23:
Р (1,23) = 1,23 +У3- = 0,855.
т v ' 2 КЗ
10*
292
СТАТИСТИЧЕСКАЯ ПРОВЕРКА ГИПОТЕЗ
[ГЛ. VII
Таблица 7.3.8
№ в порядке возраста- ния Tl- ₽(т/,) IP's Р(Гк)~ (P(Tft)-W'fcl2
1 2 3 4 5 6
1 -1,35 0,110 0,0125 0,0975 0,009506
2 —1,33 0,116 0,0375 0,0785 0,006162
3 —1,32 0,119 0,0625 0,0565 0,003192
4 —1,30 0,124 0,0875 0,0365 0,001332
5 —1,28 0,130 . 0,1125 0,0175 0,000306
6 —1,21 0,157 0,1375 0,0195 0,000380
7 -1,10 0,182 0,1625 0,0195 0,000380
8 — 1,08 0,188 0,1875 0,0005 0,000000
9 —1,01 0,208 0,2125 —0,0045 0,000000
10 —0,844 0,256 0,2375 0,0185 0,000342
И —0,800 0,269 0,2625 0,0065 0,000042
12 —0,531 0,347 0,4875 0,0595 0,003540
13 —0,510 0,353 0,2125 0,0405 0,001640
14 —0,509 0,353 0,3375 0,0155 0,000237
15 —0,485 0,362 0,3625 -0,0005 0,000000
16 —0,463 0,366 0,3875 —0,0215 0,000462
17 —0,265 0,423 0,4125 0,0105 0,000110
18 —0,223 0,436 0,4375 -0,0015 0,000001
19 —0,181 0,448 0,4625 —0,0145 0,000210
20 —0,152 0,456 0,4875 —0,0315 0,000992
21 —0,121 0,465 0,5125 —0,0475 0,002256
22 +0,007 0,502 0,5375 —0,0355 0,001260
23 0,018 0,505 0,5625 —0,0575 0,003306
24 0,139 0,540 0,5875 —0,0475 0,002256
25 0,383 0,611 0,6125 —0,0014 0,600002
26 0,641 0,685 0,6375 0,0475 0,002256
27 0,642 0,686 0,6625 0,0235 0,000552
28 0,794 0,729 0,6875 0,0415 0,002162
29 0,882 0,755 0,7125 0,0425 0,001806
30 0,887 0,756 0,7375 0,0185 0,000342
31 1,08 0,812 0,7625 0,0495 0,002450
32 1,11 0,821 0,7875 0,0335 0,001122
33 1,18 0,841 0,8125 0,0275 0,000756
34 1,23 0,855 0,8375 0,0175 0,000306
35 1,23 0,855 0,8625 —0,0075 0,000056
36 1,27 0,867 0,8875 —0,0205 0,000420
37 1,30 0,876 0,9125 —0,0365 0,001332
38 1,30 0,876 0,9375 —0,0615 0,003782
39 1,44 0,916 0,9625 —0,0465 0,002162
40 1,44 0,916 0,9875 —0,0715 0,005112
Сумма 0,062548
ПРОВЕРКА ГИПОТЕЗ О ЗАКОНЕ РАСПРЕДЕЛЕНИЯ
293
§ 3]
В графе 4 помещаем значения эмпирической функции распре-
деления Wn(xk), подсчитываемые по формуле (7.3.35). Так, на-
пример, для 34-го по порядку значения rft = T51 имеем:
^0 = ^Йг==0-8375-
В графе 5 указана разность значений Р(гк) — Wk и в графе 6
квадрат этой разности.
Сумма по графе 6 использована для вычисления произведения
лев2, которое согласно соотношению (7.3.21) равно
ГС
+ S [PW-^T- (7.3.37)
Подставив в формулу (7.3.37) значения п = 40 и сумму по
графе 6, получаем:
ли2 = 12740 + °>062548 = 0.064631.
Выбирая 9 = 5% и используя таблицу 7.3.4, строим критическую
область для проверки нашей гипотезы в виде
ли2 >0,4614.
Полученное нами из наблюдения значение лсо2 ж 0,0646 лежит
в области допустимых значений, причем значительно левее кри-
тического предела.
Отсюда следует, что гипотеза нормальности распределения
штамповок по высоте не противоречит данным наблюдения.
ГЛАВА VIII
ОСНОВЫ ДИСПЕРСИОННОГО АНАЛИЗА
§ 1. Общие понятия о дисперсионном анализе.
Однофакторный анализ
8.1.1. Задачи дисперсионного анализа. Во многих случаях
практики нас интересует вопрос о том, в какой мере существенно
влияние того или иного фактора или комбинации таких факторов
на рассматриваемый признак. Так, например, при выполнении на
автоматической линии некоторой операции обработки параллельно
на нескольких станках, важно для правильного построения после-
дующей обработки знать, в какой мере однотипными являются
средние размеры деталей, получаемые на параллельно работающих
станках. Нередко приходится производить измерения какой-либо
физической величины параллельно на нескольких приборах несколь-
ким операторам. Иногда такие измерения специально ставятся для
испытания точности метода измерения. В этом случае нас интересует
влияние на результат измерения двух факторов: прибора и опера-
тора. Аналогичная задача возникает при выполнении химических
анализов нескольких партий химикатов несколькими химиками, при
испытании механических свойств металла, полученного при различ-
ных плавках, при выяснении влияния различных свойств сырья на
качество продукции, при использовании радиодеталей и приборов
(сопротивлений, емкостей, радиоламп и т. д.) из различных партий
и т. д.
Научно обоснованное решение подобных задач при некоторых
предположениях составляет предмет дисперсионного анализа, введен-
ного выдающимся английским математиком-статистиком Р. А. Фи-
шером.
Мы рассмотрим в этой главе лишь некоторые из простейших
приемов дисперсионного анализа, развившегося за последние годы
в довольно обширную систему, находящую применение в разнооб-
разных областях науки и техники.
§ 11 ОБЩИЕ ПОНЯТИЯ О ДИСПЕРСИОННОМ АНАЛИЗЕ 295
8.1.2. Понятие об однофакторном дисперсионном анализе.
Мы начнем с простейшего случая, когда проверяется действие только
одного фактора.
В довольно общем виде эту задачу можно поставить следующим
образом: пусть мы наблюдаем т независимых нормально распреде-
ленных величин Xt, Х2, ... , Хт, предполагая, что все они имеют
одно и то же среднее квадратическое отклонение о. Центры рас-
пределения этих величин v2, ... , vm, вообще говоря, различны.
Пусть над каждым переменным производится некоторая серия из п
наблюдений (для простоты мы ограничимся случаем равночисленных
наблюдений, хотя это обстоятельство несущественно для теории).
Данные z-й серии пусть будут:
xh, xi2, .... х!п (/=1, 2, ... , т).
Опираясь на эти статистические данные, мы желаем проверить
нулевую гипотезу, согласно которой v, = v2 = . . . = vm. Если про-
веряемая гипотеза верна, то, сопоставив средние в каждой серии,
мы не должны получить значимого расхождения между ними;
Рис. 61. Двойные микроскопы Линника для измерения чистоты поверхности,
обратно, если такое расхождение обнаружено, то нулевую гипотезу
приходится отбросить.
Если т = 2, то сопоставление средних и проверка нулевой
гипотезы производятся методом Стьюдента. В данном случае, однако,
мы хотим сопоставить одновременно произвольно большое число
средних.
Пусть, например, при совместном анализе точности группы из-
мерительных приборов — двойных микроскопов (рис. 61) — нас
296
ОСНОВЫ ДИСПЕРСИОННОГО АНАЛИЗА
(ГЛ. VIII
интересует вопрос о том, можно ли считать их систематические ошибки
одинаковыми. Иначе говоря, мы хотим проверить влияние одного
фактора — прибора — на погрешность показаний.
Пусть число приборов будет т и каждым прибором мы изме-
ряем чистоту поверхности одного и того же образца в определен-
ном месте п раз. Эти п измерений мы рассматриваем как случайную
выборку из генеральной совокупности показаний каждого прибора.
Всего мы располагаем тп измерениями, которые обозначим через xijy
где i есть номер прибора и j—номер произведенного на нем
измерения так, что i изменяется от 1 до т, a J—от 1 до п.
Таблица результатов измерений будет иметь следующий вид
(см. таблицу 8.1.1).
Таблица 8.1,1
Результаты измерений чистоты поверхности
№ № измерения
прибора 1 2 3 п
1 хп Х12 «1» х1п
2 хп хгг Х22 х&п
3 хз, хзг Х33 хзп
т хтх хтг хтз хтп
Обозначим через xv среднюю арифметическую из п измерений,
выполненных на первом приборе, через хг.— среднюю из показаний
второго прибора и т. д. так, что
п п
i=t
п
Если систематические ошибки приборов не одинаковы, то мы
должны ожидать повышенного рассеивания выборочных средних.
Обозначим через х общую среднюю арифметическую всех тп
измерений так, что
т п
(8.1.1)
§ 1) ОБЩИЕ ПОНЯТИЯ О ДИСПЕРСИОННОМ АНАЛИЗЕ 297
Суммирование по j при постоянном i дает сумму по всем наблю-
дениям z-й серии (т. е. по z-му прибору). Дальнейшее суммирова-
ние по I дает итог по всем приборам. Так как
/=•
то
т
X = — V xt. .
i=i
В то же время
т п т п
2 2 (Xi —x)2^ 2 s (xir~xb+Xi,—x)’=:
г=1/=i 7 z=i/=j
т п _ т п _ т п _ _
= 22 (*//-*,.)* 4- 22<хь-хУ + 222(х{/-хь)(хк—х),(8.1.2)
i=i j=i i=i /=> i=i j=i
причем
т п т п
5 = 2 2 (хц ХЬ)(ХЬ Х) — 2 (xi. *)2 (xij Хь).
i=i 1=1 i=i 1=1
Но
2 (хц—*,•.)=°,
i=i
так как представляет сумму отклонений наблюдений Z-й серии от
средней этой же серии и потому
5 = 0. (8.1.3)
Поэтому, приняв во внимание, что
т п т
2 2 (х,. — X)2 = п 2 (*;. —•*)', (8.1.4)
1=11=1 1=1
мы можем основное тождество (8.1.2) записать в следующем виде:
ст л _ п _ _ п п
22(х17-*)г = п2(Xi.-х)2 + 22(Xi-Xi.)2, (8.1.5)
< = 1 / = 1 1 = 1 « z = i /=1
или в сокращенном виде
Q=Qi + Qv (8.1.6)
298
ОСНОВЫ ДИСПЕРСИОННОГО АНАЛИЗА
[ГЛ. VIII
где
т п tn _ in п
<3 = 2 2 (хи—х)2, Qt = n^ (х,._—X)2, Q2 = 2 2 (Xi—Xi.)2.
is=i /=1 i—i f=si /=i
Слагаемое Q, правой части (8.1.6) представляет сумму квадратов
разностей между средними х{ отдельных серий (или в нашем при-
мере приборов) и общей средней по всей совокупности наблюдений.
Сумма называется суммой квадратов отклонений «между
сериями» (или группами); она характеризует степень расхождения
в систематических погрешностях приборов. Именно ее называют
также «рассеиванием по факторам» (т. е. за счет исследуемого
фактора).
С другой стороны, Q2 представляет сумму квадратов разностей
между отдельными наблюдениями и средней соответствующей
серии; эта сумма называется суммой квадратов отклонений «внутри
серий» (или групп); она характеризует «остаточное рассеивание»
случайных погрешностей опытов.
Наконец, Q называется «общей» или «полной» суммой квадра-
тов отклонений отдельных наблюдений от общей средней х.
Применительно к рассмотренному нами примеру равенство (8.1.6)
показывает, что «общее» рассеивание показаний приборов, изме-
ряемое суммой Q, складывается из двух компонент Q, и Q2, харак-
теризующих рассеивание между приборами, т. е. различие в их
систематических ошибках (QJ и рассеивание «внутри» приборов,
характеризующих одинаковую (по условию) для всех приборов
вариацию под действием случайных погрешностей.
Предположим теперь, что гипотеза равенства центров (равен-
ства систематических погрешностей) верна и потому нормальные
распределения всех величин Х„ Хг, ..., Хт (приборов) тождест-
венны, т. е. имеют одинаковый центр и дисперсию о2. Тогда все
тп наблюдений можно рассматривать как выборку из одной и той
о Q
же нормальной совокупности, а есть несмещенная оценка
дисперсии о2 по этой выборке. Как мы видели в п. 6.3.1,будет
следовать распределению %2 с (тп—1) степенями свободы,
С другой стороны, средние по группам нормально распреде-
„ о2 _
лены с дисперсией — каждая и независимы друг от друга. Средняя
арифметическая из т средних xt. равна х. Поэтому при нашей
гипотезе
m
-J- у (X. _ V?________
т— l^-i Ип х) — п(/п —1)
?=i
§ 1] ОБЩИЕ ПОНЯТИЯ О ДИСПЕРСИОННОМ АНАЛИЗЕ 299
есть несмещенная выборочная (основанная на т наблюденных вели-
— . о2
чин характеристика дисперсии — и, следовательно, согласно
п. 6.3.1 величина
tn п
— 2 2 *)г
n Q, ,=1/=1
о2 о2 = о2
п
распределена по закону %г с (т—1) степенями свободы. Наконец,
величина
i=j________
о2
распределена по закону %2 с (л—1) степенями свободы. Используя
свойство композиций, доказанное в п. 6.3.1, мы найдем, что ком-
понента
т п
2 2 (xi/~xi.)2
Ча 1 = 1 1=1______
О2 — О2
распределена по закону %2 с т(п — 1) степенями свободы; j)
есть также оценка параметра о2.
Более детальное изучение показывает далее, что Q, и Q2 при
нашей гипотезе независимы друг от друга.
Заметим, что этот вывод справедлив при любых предположе-
ниях относительно
Из сказанного вытекает, что критерий
—— Q,
F = ---- (8.1.7)
zn(n-l) Qa
при нашей гипотезе будет следовать ^-распределению с (т—1)
и т(п—1) степенями свободы. Выбирая q% уровень значимости,
найдем по таблице VI приложений соответствующий q% предел
так, что
Пусть, с другой стороны, наша гипотеза о равенстве центров
не верна и центры v не равны друг другу, но параметр о2 во всех т
300
ОСНОВЫ ДИСПЕРСИОННОГО АНАЛИЗА
[гл. VIII
совокупностях один и тот же. Тогда сумма Qt, не изменяющаяся
при замене х{, на х1;.— vit имеет, как мы говорили, по-прежнему
распределение у2 с —1) степенями свободы, а п0~пРеж~
нему является несмещенной оценкой для о2. С другой стороны,
числитель F учитывает систематические расхождения между цент-
рами распределения v; и имеет тенденцию расти при возрастании
этих расхождений. Тем самым и показатель F имеет тенденцию
расти и становиться тем больше, чем больше отклонения от пред-
полагаемого равенства центров v(-. Поэтому правило проверки гипо-
тезы дается в следующем виде: гипотеза v, = v2 =... = vm прини-
мается, если F^Fq, и отбрасывается, если F^>Fq.
Сравнивая дисперсию по факторам с остаточной дисперсией,
по величине их отношения судят, насколько рельефно проявляется
влияние факторов; в этом сравнении как раз и заключается основная
идея дисперсионного анализа.
Схему однофакторного дисперсионного анализа можно предста-
вить в форме таблицы 8.1.2,
Таблица 8.1.2
Схема однофакторного дисперсионного анализа
Компонента дисперсии Сумма квадратов Число степеней свободы Средний квадрат
Между приборами (по факторам) Ж-^)2 а т—1 т—1 1 7 и
Внутри приборов и тп—т —-—52(х1г~*‘-)2 тп—‘ И
Полная (общая) х)г и тп—1 if
В таблице 8.1.3 приводятся результаты пятикратного (п = 5)
измерения критерия Hck чистоты поверхности в одном и том же
месте образца чистоты поверхности с регулярным профилем 6-го клас-
са чистоты на трех двойных микроскопах МИС-11 (т = 3).
Подсчеты, выполненные в таблице 8.1.3, понятны без пояс-
нений.
§ 1] ОБЩИЕ ПОНЯТИЯ О ДИСПЕРСИОННОМ АНАЛИЗЕ 301
Таблица 8.1.3
Результаты определения критерия Hck в заданном участке образца чистоты
поверхности с регулярным профилем
№ прибора Отклонения НС(- от общей медианы в сотых долях микрона ) (?'“) З*2 7 ч
1 2 3 4 5
х“ *12 2 X (2 */8 2 >3 Х& 2 X В
1 2 3 S i +7 + 19 +22 16 49 361 426 —2 + Н +2 + П 4 121 4 129 —21 +30 —13 —4 441 900 169 1510 —4 +28 —9 + 15 16 784 81 881 —4 +27 +2 +25 16 729 4 749 -35 + 103 +1 +69 1225 10609 1 11835 493 2583 619 3695
Для упрощения вычислений, требующихся для анализа сумм
квадратов, мы используем следующее ранее часто применявшееся
преобразование:
n n />,\г
Ns* = £ (xk—х)* = £ *!—4" (S » N=mn.
fe=i k=i \k=i J
Учитывая это, непосредственно получим следующие удобные
во многих случаях расчетные формулы:
И
(8.1.8)
(8.1.9)
(8.1.10)
302
ОСНОВЫ ДИСПЕРСИОННОГО АНАЛИЗА
[гл. VIII
Из таблицы 8.1.3 имеем:
т п
Q = У. У (Xij—x)2 = 3695 — 3^5 692 = 3695 — 3 1 7 = 3378,
Z = 1 /=1
т
в 11 835 692
= = ~5------2367 — 317 = 2050,
т п
Q2 = У Ysxij—^if = 3695 — = 3695 — 2367 = 1328.
4 1 = 1 / = 1
Для нашего примера таблица однофакторного дисперсионного
анализа будет иметь следующий вид (см. таблицу 8.1.4).
Таблица 8.1.4
Дисперсионный анализ систематических ошибок
двойных микроскопов
Компонента дисперсии Сумма квадратов Число степеней свободы Средний квадрат
Между приборами 2050 2 1025,0
Внутри приборов 1328 12 110,7
Полная (общая) 3378 14 241,3
Производя теперь проверку нулевой гипотезы с помощью f-рас-
пределения, находим:
Средний квадрат между приборами___ 1025,0
Средний квадрат внутри приборов —’ 110,7
= 9,26 = F.
При двух степенях свободы большей дисперсии (^ = 2) и
12 степенях свободы меньшей дисперсии (£2 = 12) по таблице VI
приложений находим критические границы для F, равные при
5%-ном уровне значимости3,88и 1%-ном уровне — 6,93. Полученное
нами из наблюдений значение F превышает указанные границы, и
потому нулевая гипотеза должна быть отвергнута, т. е. приборы
имеют различные систематические ошибки.
В некоторых случаях числа наблюдений в сериях (группах)
могут быть разные. Обозначая через nt число наблюдений в /-й
§ 1] ОБЩИЕ ПОНЯТИЯ О ДИСПЕРСИОННОМ АНАЛИЗЕ 303
т
группе или серии и полагая ^n^N, имеем:
7—1
1
*<.= ^S^7> (8-1-И)
/=1
т П[ т
(8ЛЛ2)
/ = 1 / = 1 1=1
Основное соотношение (8.1.6) можно написать в следующем
виде:
т гц tn т гц
Q=S 5 (*,/—*)2=2 П&— х)г + 22 (*(7—= q1 + <?2.
i=i /=i <=1 i=i /=1
(8.1.13)
Рассмотрим еще пример. Предполагая, что долговечность элек-
трической лампы имеет нормальное распределение и различия
в материале или технологии влияют на средние значения, но не на
величину дисперсий ст2, рассмотрим данные, показанные в таблице
8.1.5, представляющие пробы, взятые из четырех партий, изготов-
ленных из разных материалов.
Таблица 8.1.5
№ партии Продолжительность горения в часах
1 1600 1610 1650 1680 1700 1700 1800
2 1580 1640 1640 1700 1750
3 1460 1550 1600 1620 1640 1660 1740 1820
4 1510 1520 1530 1570 1600 1680
Средние значения по этим четырем группам будут:
хг. = 1677, х2. = 1662, х,. = 1636, = 1568.
Расчеты, аналогичные тем, какие мы сделали в таблице 8.1.3,
приводят к следующим показателям (см. таблицу 8.1.6).
14 787
Для критерия F найдем, Г = ’d =2,15. Согласно данным
О, OOV
таблицы VI приложений, это значение F лежит ниже 5%-ного пре-
дела, равного F,. = 3,05, и, значит, расхождение между средними
не дает еще повода для отбрасывания гипотезы о равенстве сред-
них долговечностей ламп в рассмотренных четырех партиях.
304
ОСНОВЫ ДИСПЕРСИОННОГО АНАЛИЗА
[ГЛ. VIII
Таблица 8.1.6
Дисперсионный анализ влияния рода материала на долговечность
электрических ламп
Компонента дисперсии Сумма квадратов Число степеней свободы Средний квадрат
Между партиями Внутри партий Полная (общая) Q, = 44,361 Q2= 151,351 Q = 195,712 т—1=3 N—m = 22 ;V—1=25 14,787 6,880
Если в другом случае гипотеза о равенстве центров отвергнута,
но мы имеем основания считать а одной и той же, мы все же
можем оценить этот параметр, используя оценку для а2 в виде
s2 = - A- Ms* = o2, (8.1.14)
г т (п— 1) ’ 2 ~ '
и определить доверительный интервал для о по способу, указанному
т (п— 1) $2
в 6.4.3, помня, что --------- имеет распределение %2 с т (п—1)
степенями свободы.
Далее, можно показать, что в рассматриваемом случае, полагая
£ = (8.1.15) 1 т—1 1 ' '
будем иметь: M(6p=o2+^2;(vt.-7)2, (8.1.16) i=i
где т (8.1.17)
Из (8.1.14) и (8.1.16) следует:
М
т
i=i
(8.1.18)
где величину 6“ рассматривают как меру систематической измен-
чивости центров групп. По данным выборки мы можем на основа-
нии (8.1.18) оценить величину определяя характеристику
— №). (8.1.19)
V /ИЛ \ 1 2/ ' '
§ 1] ОБЩИЕ ПОНЯТИЯ О ДИСПЕРСИОННОМ АНАЛИЗЕ 305
В рассмотренном выше примере с двойными микроскопами
нашими оценками будут:
аг^8г2= 110,7-10-4 мк2, а3= 1025,0-Ю4 мк2,
откуда
= Г5 025’°—110,7) = 121 ’9'10”* MK*‘
Наконец для любой пары i и j мы можем по данным выборки
оценить расхождение между соответствующими центрами (vt-—v
и рассмотреть показатель
t = l/^ ху-(у,—у7) , (8.1.20)
который, как можно показать, следует распределению Стьюдента
с т(п—1) степенями свободы (в предположении o = const). Таким
образом, интервал
(%,—т (п-1> (8.1.21)
будет доверительным q% интервалом.
Так, например, используя данные таблицы 8.1.3 для оценки
расхождения между систематическими ошибками приборов № 2 и
№ 3, получаем:
х, = = 20,6- 10-2 мк, х =4 = 0,2-10-2 мк.
s 5 3 о
Выбирая q—10%, по таблице V при числе степеней свободы
т(п— 1) = 3(5—1)=12 находим /10 12 = 1,782.
Из того же примера имеем:
о2 _ Qa
% т(п— 1)
1328 , -7 1А-4 2
——^=110,7.10 *мк\
а2 = -1/>г==/110,7.10-2 = 10,5-10-2 мк,
х4—х, = (20,6-0,2)-10—2 = 20,4-10~2 мк.
Пользуясь (8.1.21), определяем:
<20,4-ЦВ • 10,5\ 10~2 < v — V. <<20,4 • 10,5V10"2
I Л ) V /Н
или
8,6-10~2 mk<Z —vs<32,2-10 2
мк.
306
ОСНОВЫ ДИСПЕРСИОННОГО АНАЛИЗА
[гл. VIII
Применяя указанный способ анализа, следует осторожно от-
носиться к истолкованию окончательных результатов, помня, что
они опираются в существенной мере на допущения:
1) нормальности распределения, .
2) тождественности дисперсий.
Каждое из этих допущений требует проверки, основанной на
тщательном анализе произведенных экспериментов, или если суще-
ственность расхождений между средними не обнаружена и нулевая
гипотеза получила подтверждение, следует помнить, что это сде-
лано лишь по наличному опытному материалу и, главное, при той
группировке материала, которой мы придерживались в данном
случае.
§ 2. Многофакторный дисперсионный анализ
8.2.1. Двухфакторный анализ. Когда число факторов больше
одного, т. е. при двух-, трех- и многофакторном анализе, процедура
остается принципиально такой же, как и при однофакторном ана-
лизе, но соответственно усложняются выкладки. Мы рассмотрим
здесь задачу оценки действия двух одновременно действующих
факторов. Допустим, что в примере с двойными микроскопами изме-
рения производились различными операторами. Пусть, например,
требуется оценить, обусловливается ли рассеивание полученных
значений критерия Яс/г и средних его значений в группах разли-
чием между приборами или различием между операторами, произ-
водившими измерения.
Основная идея дисперсионного анализа в данном случае заклю-
чается в разложении суммы квадратов отклонений общего среднего
на компоненты, отвечающие предполагаемым факторам изменчивости.
Предположим, что мы имеем два признака или фактора А и В,
по которым мы можем расклассифицировать данные наблюдения.
Пусть по признаку А все наблюдения делятся на г групп А1Г Аг>...
..., Аг, а по признаку В—на v групп ..., Bv так, что весь
материал разбивается на rv групп. Для простоты ограничимся слу-
чаем, когда в каждой группе имеется лишь одно наблюдение, так,
что общее число наблюдений N = rv. Через в данном случае
мы обозначаем наблюдение, попавшее в группу Ai по признаку А
и в группу Bj по признаку В. Пусть, далее,
V
<8-2-2»
1-1
§ 2] МНОГОФАКТОРНЫЙ ДИСПЕРСИОННЫЙ АНАЛИЗ 307
и, наконец,
Г V
= (8-2-3)
i-i j=i
Таблица с наблюдениями может быть представлена в сле-
дующем виде (см. таблицу 8.2.1).
Таблица 8.2.1
Результаты наблюдений над признаками А и В
Основному тождеству (8.1.5) однофакторного анализа в данном
случае отвечает тождество
го го
Q = 22 (Xi— х.)’ = 22 (xi.—xi.—xJ + x__+xi_—xii +
l=l/=l 1=1/=1
Г V
— Х_ )2 = 1?2 (•V;.— ~X.f+r 2 (Xj — X.J2 +
i = i / = i
r v
4 2 2 (Xj -—Xi. —x j~i-x_ )z — Qj 4- Qs 4- Qs. (8.2.4)
z=i/=i
Мы предполагаем, что величины х^ нормально распределены
по закону Д7(х; v; о), где о2 — общий, но неизвестный параметр
Дисперсии. Мы хотим использовать данные таблицы 8.2.1 для
проверки гипотезы о равенстве центров v;?.. Рассуждая, как и в
308
ОСНОВЫ ДИСПЕРСИОННОГО АНАЛИЗА
[гл. VIII
предшествующем параграфе, мы покажем, что при этой гипотезе
величины
Q Qi Qz и Q»
о2 ’ а2 ’ о2 а2
распределены по закону %2 с (rv — 1), (г—1), (и—1)и(г—l)(v—1)
степенями свободы соответственно, а потому Q, Qv Q2, Qs могут
быть использованы в этом случае для оценки о2. Эта оценка может
быть проведена с помощью несмещенных характеристик
rv— 1
22<х<7-х..)г
I i________
rv— 1
(8.2.5)
u2(x«-.-;os
,=1r-i ’ <8-2-6)
^=-4--’ <8-2-7)
= (r—l) (v-i) = (/ —!)(» —1) • (8.2.8)
Выражения Q, и Q2 носят название суммы квадратов разнос-
тей между «строками-» и между «.колонками-» таблицы 8.2.1 со-
ответственно. Q, называется «.остаточной» суммой квадратов.
Оценка параметра о2 с помощью указанных характеристик остается
в силе и в том случае, когда гипотеза о равенстве центров не
верна, лишь бы равенство параметра а2 имело место во всех
наблюдениях.
Для проверки степени значимости расхождений, обнаруженных
в средних по строкам или по колонкам, вычисляются критерии
______I Q
(г —1)(у —1)
и
(8.2.9)
г В-------1
(г-1) (^-l)Qs
s2'
(8.2.10)
МНОГОФАКТОРНЫЙ ДИСПЕРСИОННЫЙ АНАЛИЗ
309
§ 2]
Общая схема дисперсионного анализа по двум факторам может
быть представлена в виде таблицы 8.2.2.
Таблица 8.2.2
Схема двухфакторного дисперсионного анализа
Компонента дисперсии Сумма квадратов Число степе- ней свободы Оценка диспер- сии
Между средни- ми по стро- кам ^-1)^ = 0, = ^^.-»..)’ г—1 4
Между средни- ми по столб- цам (о —l)s| = Q2 = r2 (x.z— Х..)‘ /=1 0 — 1
Остаточная (г-1)(я-1)4 = <2,= = 2 х..)* (r-l)(o-l)
Полная (об- щая) (rv—l)s2 = Q =2 (*;/—*• •)* rv— 1 s2
8.2.2. Пример двухфакторного анализа. В качестве числового
примера мы рассмотрим данные об отклонениях диаметров ша-
риков в микронах от общего «ложного нуля» (см. п. 3.2.4), поду-
ченных на подшипниковом заводе десятью наладчиками, каждый из
которых обслуживал по пять доводочных станков. В таблице 8.2.3
эти данные даются вместе с необходимыми подсчетами, аналогич-
ными тем, которые были выполнены в таблице 8.1.3.
Требуется сравнить влияние на рассеивание диаметров шариков
точности станков и квалификации наладчиков.
Для практических расчетов можно использовать следующие
полезные формулы:
(8.2.11)
Таблица 8.2.3
Отклонения диаметров шариков в микронах
Станки Наладчики 2х 1 (И 2«! /
_Zx_
> 2 | 3 4 | 5 6 7 8 9 10
X л- X х х X2 X р X X2 X X2 х X2 X X2 X X2
t / 1 3 9 7 49 3 9 6 36 6 36 7 49 6 36 3 9 8 64 3 9 52 2704 306
2 6 36 5 25 7 49 4 16 9 81 4 16 3 9 2 4 7 49 8 64 55 3025 349
3 8 64 6 36 3 9 2 4 7 49 8 64 6 36 9 81 3 9 8 64 60 3600 416
4 4 16 7 49 7 49 8 64 6 36 4 16 5 25 8 64 4 16 7 49 60 3600 384
5 6 36 2 4 6 36 6 36 8 64 9 81 7 49 6 36 8 64 1 1 59 3481 407
i 27 27 26 26 36 32 27 28 30 27 286
(?ХУ 729 729 676 676 1296 1024 729 784 900 729 \16410 82 72 \
i 161 163 152 156 266 226 155 194 202 187 1862
310 ОСНОВЫ ДИСПЕРСИОННОГО АНАЛИЗА
§21
МНОГОФАКТОРНЫЙ ДИСПЕРСИОННЫЙ АНАЛИЗ
311
и аналогично
(8.2.12)
и, наконец, для остаточной суммы квадратов
Пользуясь этими соотношениями для нашего примера, имеем:
Qi = 1641,0 — 1635,9 = 5,1 мк2,
Q = 1635,9= 1654,4—1635,9 =--18,5 мк2,
Q,= 1862— 1641,0—1654,44 1635,9 = 202,5 мк2,
Q= 1862 —1635,9 = 226,1 мк2.
Тогда таблица двухфакторного
иметь следующий вид (см. таблицу
дисперсионного анализа будет
8.2.4).
Таблица 8.2.4
Дисперсионный анализ влияния на рассеивание диаметров
шариков точности станков и квалификации наладчиков
Компонента дисперсии Сумма квадратов Число степеней свободы Средний квадрат
Между станками 5,1 4 1,28
Между наладчиками 18,5 9 2,06
Остаточная 202,5 36 5,62
Общая 226,1 49 4,61
Производим проверку нулевой гипотезы при помощи F крите-
рия: для среднего квадрата «между станками» имеем:
д __ 22)2 — 4 эд
1.28
312
ОСНОВЫ ДИСПЕРСИОННОГО АНАЛИЗА
[гл. VIII
и для среднего квадрата «между наладчиками»—
По таблице VI приложений (интерполируя) находим, что для
первого случая критические границы будут Л5 = 5,72 и Л, = 13,78,
а для второго случая Fs = 2,84 и F1 = 4,59.
Таким образом, влияние станков и наладчиков на рассеивание
оказалось несущественным. Теперь в качестве оценки дисперсии
следует взять общий средний квадрат, т. е. принять а2 5= 4,61 мк2
и а^2,15.«'с. Тогда поле рассеивания диаметров шариков можно
при надежности в 99,73°/О принять равным
2-Зо = 2-3-2,15 = 12,9 мк.
Мы ограничимся этим кратким изложением весьма обширной
теории дисперсионного анализа ’).
’) Более подробно он изложен в книгах А. Хальд, Математическая
статистика с техническими приложениями, М., ИЛ, 1956; К- А. Браунли,
Статистические исследования в производстве, М., ИЛ, 1949.
ГЛАВА IX
ОСНОВЫ ТЕОРИИ КОРРЕЛЯЦИИ
§ 1. Понятие о корреляции и регрессии
9.1.1. Стохастическая связь. В естествознании и технике мы
часто имеем дело с понятием функциональной зависимости, существо
которой заключается в том, что какая-либо физическая величина
определяется как однозначная функция одной или нескольких вели-
чин. Так, например, зависимость между давлением, с одной стороны,
и объемом и температурой,— с другой, определяется, как известно,
уравнением
где р—давление газа, Т—температура его, v—его объем и А?—
постоянный коэффициент.
Таким образом, мы имеем дело с подобной зависимостью всякий
раз, когда вообще существует функция
У=Дх, z, ...,и),
т. е. когда величина у определена вполне значениями х, г, ..., «.
Функциональная связь может существовать, как мы видели, и
между случайными величинами; некоторые из относящихся сюда
вопросов были рассмотрены в главах Ill и IV. Но между случай-
ными величинами может существовать и связь другого рода, про-
являющаяся в том, что одна из них реагирует на изменение другой
изменениями своего закона распределения. -Такую связь мы будем
называть стохастической (вероятностной).
Стохастическая связь между двумя случайными величинами
появляется обычно тогда, когда имеются общие случайные факторы,
влияющие как на одну, так и на другую величину наряду с другими
неодинаковыми для обеих величин случайными факторами. Так,
например, если X представляет некоторую функцию от случайных
величин Zv Z2, ..., Zm, VJt V2, Vk.
X^f(Z„Z„ V2, ..., Vk),
314
ОСНОВЫ ТЕОРИИ КОРРЕЛЯЦИИ
[гл. IX
а У представляет функцию от тех же случайных величин
Z,, Z2, и некоторой совокупности других Ц, Ц, ..., Ц:
...,Zm; Ц, Ц......Ц),
то величины X и Y будут между собой стохастически связаны.
Задачи, связанные с изучением зависимостей между величинами,
отличных от строго функциональных, весьма разнообразны. Они
приобретают более определенный вид и могут быть поставлены
в рамках математико-статистического исследования, если мы пред-
положим, что зависимость носит стохастический характер, т. е.
имеет смысл говорить о законе распределения рассматриваемых
величин, о вероятности, с которой встречаются те или иные ком-
бинации их значений, и т. д.
Применительно к этому случаю и развивается математическая
теория корреляции. Примером стохастической зависимости, изучаемой
методами теории корреляции, может служить зависимость, о кото-
рой говорят данные корреляционной таблицы 5.1.2,
Пользуясь такой таблицей, мы можем вычислить по приведен-
ным данным выборочный или эмпирический коэффициент корреля-
ции, представляющий оценку соответствующей характеристики за-
кона распределения рассматриваемых величин. Далее, мы рассмотрим
практические приемы оценки силы и формы связи.
Основное применение, которое находит теория корреляции, от-
носится к решению задачи обоснованного прогноза, т. е. указания
пределов, в которых с наперед заданной надежностью будет содер-
жаться интересующая нас величина, если другие связанные с ней
величины получают определенные значения. Подобного рода задача
обобщает весьма разнообразные вопросы, возникающие на практике.
Так, например, нас может интересовать влияние на тот или иной
признак качества, такой, как чистота поверхности, биение, огранка
и т. и., тех или иных, иногда отдаленных производственных фак-
торов (припуски и допуски на предыдущих операциях и т. п.), или
связь признаков качества между собой, или, наконец, взаимная
связь производственных факторов. Все эти и подобные им вопросы
очень часто могут быть исследованы с помощью приемов теории кор-
реляции.
9.1.2. Кривые регрессии. Условные дисперсии. Наиболее важ-
ные особенности стохастической связи находят выражение в тех
изменениях, какие испытывает центр условного распределения одной
величины при изменении другой. Если рассматриваются две вели-
чины Хи У, то мы одновременно будем иметь две линии регрес-
сии (см. п. 5.1.1. и рис. 37):
М (Y[X — x) — у (х)— регрессия У по X
§ 1]
ПОНЯТИЕ О КОРРЕЛЯЦИИ И РЕГРЕССИИ
315
и
М (XjY—y) — х (у)— регрессия X по Y.
Эти «линии» представляют геометрическое место центров услов-
ных распределений, соответствующих заданным значениям одной из
переменных. Если представить вероятности Р (Х=х; Y = у) = р (х, у)
как систему масс, расположенных в точках (х, у) плоскости (X, У),
то _у(х) будет ординатой центра тяжести масс, расположенных на
вертикальной прямой Х=х, a x(j) будет абсциссой центра тя-
жести масс, расположенных на горизонтальной прямой Y=y. При
строгой функциональной зависимости переменная Y при данном зна-
чении Х=х может принять лишь одно определенное значение,
равное у(х). Этот случай может рассматриваться как своего рода
предельный к случаю стохастической зависимости, когда рассеива-
ние вокруг условного центра у (х) равно нулю. Как правило, мы
будем для данного значения Х= х наблюдать более или менее зна-
чительное рассеивание Y около центра у(х). Мерой этого рассеи-
вания может служить условная дисперсия Y при данном х, т. е.
дисперсия условного распределения р(у[х). Она определяется ра-
венством
Oy|X = D (Yjx't^'ZAy— y(x)]2p(yjx) (9.1.1)
У
или в случае непрерывного распределения
00
$ (J—(9-1.2)
— 00
где p(ylx)—условная плотность распределения Y при данном х.
Таким образом, наряду с линией регрессии у\(х) мы имеем еще
линию условных дисперсий о^, так называемую <<скедастическую1>
линию.
В теории корреляции в первую очередь рассматриваются эти
две характеристики (средние и дисперсии) условных распределений
и две аналогичные характеристики для условного закона Р(Х)у)—
условная средняя х(у) и условная дисперсия Ох/у и две сводные
характеристики точности прогноза по. линиям регрессии Оу/Х и Ох/у
Степень стохастической связи может быть проиллюстрирована
диаграммами рассеивания, показанными на рис. 62. Здесь коорди-
натами точек являются наблюденные значения случайных величин X
и Y. Рис. 62, а иллюстрирует наличие тесной стохастической связи.
На рис. 62, б показан случай, когда связь эта слаба, и, наконец,
на рцс. 62, в представлена диаграмма рассеивания при отсутствии
связи между величинами X и Y,
316
ОСНОВЫ ТЕОРИИ КОРРЕЛЯЦИИ
[гл. IX
Величину ау/х можно рассматривать как среднюю квадратиче-
скую погрешность прогноза величины Y по наблюденному значе-
нию х величины X, если использовать для прогнозирования извест-
ную функцию регрессии у(х). Величина и, следовательно, точ-
ность прогноза зависят от значения х. Если мы хотим составить
себе представление о точности прогноза Y по х во всем диапазоне
а} Х 6) Х 6) Х
Рис. 62. Диаграммы рассеивания наблюдений при различной тесноте
связи между случайными величинами X и Y:
а —тесная связь, б— слабая связь, в —отсутствие связи.
изменения X, мы должны взять среднее взвешенное из условных
дисперсий; мы получим тогда величину Оу<х— «среднюю из услов-
ных дисперсий»
^YIX = '2iP(x)UYlx. (9.1.3)
X
Она тем меньше, чем меньше в среднем условные дисперсии, т. е.
тем более точна и определенна зависимость Y по X, чем ближе
эта зависимость к строго функциональной Y=y(x) и чем точнее,
следовательно, прогноз величины Y по заданному значению X.
Так как из (9.1.1) и (9.1.3) и равенства р(х)р(у/х) = р(х,у)
следует, что
оу/х = Sp (х) 5 [J —у (х)]2 р (ylx) = 2 2 Р <х, у) [у—у (х)]2,
ХУ X у
и в правой части стоит М [К—_y(JV)]2, то
?щ = М[К-М1’.
Заметим, что если бы мы при каждом данном Х=х пользова-
лись для прогноза какой-либо другой функцией и{х)^= у (х), то
средняя погрешность оценки прогноза, измеряемая М [У—и (Л)]2,
была бы больше: из всех функций и (х) минимум величины
М [У—a(X)]2 даст функция _у(х) — кривая регрессии Y по X. Это
свойство вытекает из свойств минимальности рассеивания, измеряв-
§ 1] ПОНЯТИЕ О КОРРЕЛЯЦИИ И РЕГРЕССИИ 317
мого средним квадратом отклонения около центра распределения у (х)
при каждом х (т. е. величиной если при х рассеивание вы-
числяется около другого начала и(х)^=у(х), то средний квадрат
отклонения увеличивается. Поэтому можно сказать, что регрессия у(х)
есть функция, минимизирующая среднюю квадратическую погреш-
ность прогноза величины У по Л; аналогичным свойством обла-
дает функция х(у)—регрессия X по У.
9.1.3. Коэффициент корреляции и прямые приближенной рег-
рессии. Мы видели (см. п. 5.2.2), что некоторую информацию
о характере связи величин X и У дает коэффициент корреляции
0yv.^£-0V^’2> = _^
v oft Wr'
Основное его свойство, доказанное в п. 5.2.2, заключалось в том,
что он достигал своих предельных значений — 1 и -|~ 1 в том
и только том случае, когда двумерное распределение (X, К) все
концентрировалось на некоторой прямой плоскости (X, У), т. е.
между У и X имелась точная и притом линейная зависимость. Если
же |е|<1, то такого линейного расположения массы вероятности
мы наблюдать не будем, как бы тесна ни была зависимость между У
и X. Все же, как мы увидим далее, по мере приближения |g(
к единице распределение имеет тенденцию концентрироваться вблизи
некоторой прямой линии, и потому с некоторым основанием мы
можем считать это свойство мерой близости к полной линейной за-
висимости. В случае о = 0 говорят, что X и У не коррелированы,
в частности, так будет всегда, когда X и У независимы; однако
обратного заключения сделать нельзя, как показывают примеры, при-
веденные ранее, в п. 5.2.2.
Рассмотрим теперь построение так называемых «прямых» при-
ближенной регрессии, которые дают представление о форме линий
регрессии в тех случаях, когда они с достаточным приближением
могут быть описаны некоторыми прямыми.
Постави?>1 задачу—определить такую прямую в плоскости (X, У),
чтобы все распределение масс вероятностей концентрировалось по
возможности более плотно около этой прямой, т. е,
М (У— а — РЛ)2 = 2 (х, j) (у—ух)г = min.
X у
Этому требованию можно придать более четкую формулировку.
Пусть некоторая прямая задается уравнением у = а -f- Рх и (х, у) —
некоторая точка плоскости (X, У), в которой расположена масса
вероятности р(х, у). Квадрат расстояния вдоль оси У от точки (х, у)
с массой р(х,у) до соответствующей точки прямой с той же
318 ОСНОВЫ ТЕОРИИ КОРРЕЛЯЦИИ [гл. IX
абсциссой будет (у—yf — (y— а — рх)2. Возьмем теперь средний
взвешенный квадрат подобных расстояний по всем точкам, в кото-
рых размещены массы. Он равен
А(а, ₽) = 22р(-к, у)(у—а — $х)г. (9.1.4)
X U
В случае непрерывного распределения, рассуждая аналогично
будем иметь:
A (а, Р)= J ^Р{Х>У)(У—а — $x)2dxdy, (9.1.5)
— оо — со
где р (х, у) — плотность двумерного распределения. Примем Д(а,Р)
за меру концентрации распределения массы вероятности около пря-
мой _у = а4 |3х и потребуем теперь, чтобы коэффициенты а и Р
прямой обращали в минимум выражение Д (а, р). Заметим, что
(9.1.4) и (9.1.5) показывают, что имеет место равенство:
Д (а, Р) = М (У—а—РХ)2, (9.1.6)
которому можно придать следующий статистический смысл. Пусть
величина X приняла одно из своих возможных значений х и мы хо-
тим использовать это значение для прогноза величины У; исполь-
зуя для этого прогноза линейную функцию ^ = а-фрх, мы поло-
жим у~у. Разность у—у, где у — одно из возможных для дан-
ного значения х значение У, и дает возможное (с вероятностью
/)(х, _у)) значение ошибки прогноза, а величину Д (а, Р) естественно
считать мерой рассеивания этих ошибок. Для определения аир
мы должны найти минимум функции Д (а, р).
Из (9.1.6) следует, что Д (а, Р) можно записать в виде
Д(а, p) = M[y-vr-PH-Vx)+vr-a-pvx]\ (9.1.7)
где, как всегда,
vx=M(X), vr=M(y),
и далее, вычисляя (9.1.7), получим:
Д(а, Р) = о^ —2nxrp + o2xP2-Hvr—a —pvx)2, (9.1.8)
где
Hyy = cov (ХУ).
Необходимые условия минимума дают:
= (9.1.9)
§ 1] ПОНЯТИЕ О КОРРЕЛЯЦИИ И РЕГРЕССИИ 319
Решая (9.1.9) и (9.1.10) совместно, найдем значения а = «0 и
Р = Р0, обращающие А (а, Р) в минимум:
= (9-i.il)
°х аА vx
ao = v/—(9.1.12)
Можно доказать, что для этих значений а и р А (а, р) действи-
тельно принимает минимальное значение.
Уравнение минимизирующей А (а, Р) прямой приближенной рег-
рессии У по X будет:
^=^+е^(^-^), (9.1.13)
или, в эквивалентной форме,
(911)
Оу Су ' '
Легко видеть, что прямая (9.1.14) проходит через центр тяжести
всего распределения (vx, vr) и что угловой коэффициент этой пря-
мой имеет знак, совпадающий со знаком р. Определим теперь зна-
чение Amin(a, Р), получаемое, если вместо а и Р в (9.1.8) подста-
вим найденные значения а0 (9.1.12) и (9.1.11) соответственно; мы
получим:
Amin (a> Р) = сту - 26<ВД? + °2 =
= о2у — 2QS^Y + Q20zy = <^(1 —е8) (9.1.15)
или
м (У— У)2 = м (У— а0 — р Л)2 = Оу (1 — Q2). (9.1.16)
Вместо того чтобы измерять расстояние вдоль оси У, мы с таким же
правом могли оценивать его вдоль оси X и искать прямую вида
Х=а' + $'У,
(9.1.17)
около которой концентрируется наиболее тесно распределение масс
вероятностей. Очевидно, мы придем к искомой прямой, заменив У
на АГ и обратно в предшествующем решении (9.1.13) или (9.1.14)
и получим уравнение прямой приближенной регрессии А' по У в виде
(9.1.18)
320
ОСНОВЫ ТЕОРИИ КОРРЕЛЯЦИИ
[гл. IX
или
и, наконец,
X-~4y _ Y—vy
оу У оу
Y — Vj-_ 1 X—vy
6r “ё ох
(9.1.19)
(9.1.20)
Эта прямая также проходит через общий центр тяжести (vx, vr), но,
вообще, не совпадает с прямой (9.1.14), за исключением того случая,
когда Q обращается в ± 1. Средний квадрат расстояния минимизи-
рующей прямой (9.1.18) от точек распределения будет равен
М (X—а'— |ЗТ)2 = <j^ (1 — q2). (9.1.21)
Формула (9.1.16) дает возможность судить о точности прогноза Y
по X при использовании наилучшего линейного приближения (9.1.13).
Из полученного результата выводится несколько иное истолкование
коэффициента корреляции.
Положим Z=Y—Y=Y—а0 — |30Х.
Используя (9.1.11) и (9.1.12), мы легко получим:
MZ=0, cov (Z, X) М [Z (X—vx)]=0
и, следовательно, eZy = 0.
Далее, согласно (9.1.16)
o| = MZ2 = o^,(l— q2).
Величину Y можно представить теперь в виде двух компонент
K=F+(K-y) = (a0 + p0X) + Z,
из которых первая — линейная функция от X, а вторая — вовсе не
коррелирована с X.
Вместе с тем для дисперсии Y—как дисперсии суммы некор-
релированных величин — имеем:
<4 = D Y = D (а0 + Р0Х) + = 14 <4 + <40 - Л
или, принимая во внимание значение (30 (9.1.11),
<4 = 62<4 +'сту(1—Q2).
Отсюда видно, что Q2 представляет ту долю дисперсии величины Y,
которая обусловлена линейно прогнозируемой при каждом значении X
компонентой Y, а на остаточную не коррелированную с X компо-
ненту падает доля дисперсии, равная 1—q2.
Прямые (9.1.13) и (9.1.18) называются также прямыми регрес-
сий, проведенными по методу наименьших квадратов; первая при-
§ 1] ПОНЯТИЕ О КОРРЕЛЯЦИИ И РЕГРЕССИИ 321
ближенно описывает линию регрессии Y по X, а вторая — X по У.
Коэффициент при А' в первой и коэффициент при Y во второй
(т. е. при тех аргументах линейной функции, которые принимаются
за независимые переменные) называются коэффициентами регрессии
и обозначаются
Из формулы (9.1.15) следует, что чем ближе о2 к единице (т. е.
1—р2— к нулю), тем плотнее концентрируются массы распределе-
ния около каждой из прямых. В предельных случаях при Q=± 1
обе прямые сливаются в одну
Y—vy=^ , Х—^х
ау стх ’
Таким образом, Q2 или (1—Q2) действительно является надлежащей
мерой степени линейности связи Y с X.
В тех случаях, когда линейное приближение является явно не-
достаточным, мы можем рассматривать в качестве приближенных
кривых регрессий более сложные функции, например параболы $-го
порядка:
Y=a^aiX + atX2+ ...+asXs. (9.1.22)
Коэффициенты в (9.1.22) можно определить, исходя из требова-
ния метода наименьших квадратов:
A (а0, av ..., а,) = М (У— У,)2 =
— М (У—а„ — агХ— а2Х‘ — ... —asXy)2 = min.
Дифференцируя это выражение по а0, ар ..., as и приравнивая
дД с* А ЭД , , ,, „
т— , —, ..., — нулю, получим систему из (s 4- 1) линейных урав-
нений, из которых определяем неизвестные а0, а,, ...,
9.1.4. Случай линейной корреляции. Если точные линии регрес-
сии у=у(х), х = х (у) сами представляют прямые линии, то кор-
реляция называется линейной. Мы легко обнаружим в этом случае,
что прямые приближенной регрессии, проведенные по методу наи-
меньших квадратов, совпадают с точными, т. е. у(х)=_у(х) и
X(y) = i(y).
В самом деле, в этом случае у (х) и х(у) представляют такие
линейные функции, которые, как мы доказали в 9.1.2, минимизируют
средние квадратов отклонений М[У—у(Х)|2 и М [X—х(У)]2 по
сравнению с любыми, в том числе и линейными функциями и (х)
и v(y). Следовательно, у (х) и г (у) удовлетворяют условию метода
11 н В. Смирнов, И В. Дунин-Барковский
322 ОСНОВЫ ТЕОРИИ КОРРЕЛЯЦИИ [гл. IX
наименьших квадратов, а потому должны совпадать с (единствен-
ными) линейными функциями у (х) и х(у), которые построены по
этому методу; таким образом у (х) =у (х) и х(у) = х (у) и уравне-
ния (9.1.13) и (9.1.18) будут уравнениями (точных) прямых регрессии.
В случае линейной корреляции они будут проходить через центр
распределения (vx, vr) и иметь коэффициенты при х и у, равные
и Px/fz соответственно.
Из выражений (9.1.16) и (9.1.21) будет следовать, далее, в слу-
чае линейной корреляции
=м [У-У (*)]’ = (4(1-е‘)> (9.1.23)
У
2! = М|^(П1! = о>:(1-о!). (9.1.24)
Мы видим, что в этом случае коэффициент корреляции предста-
вляет надлежащую меру концентрации массы вероятности вблизи
линий регрессии.
9.1.5. Корреляционное отношение. Если линии регрессии не являются
прямыми, то коэффициент корреляции лишь с некоторым приближением
м'ожет рассматриваться как показатель силы связи между пепеменными
X и У.
В случае нелинейной связи представляют интерес показатели, характе-
ризующие концентрацию распределения (и, следовательно, тесноту связи)
около кривых у (х) и х (у) регрессии. Таким показателем является «корре-
ляционное отношение» и введенное К. Пирсоном. Чтобы понять
структуру показателя Г]у/Х, докажем следующее тождество:
<4 = 4/х + м [7(Х)~*г]2. (9.1.25)
где
сфм = М[У-7(Х)]2 (9.1.26)
представляет собой среднюю из условных дисперсий.
В самом деле,
Оу = М (У- vr)2 = М [У-~у (X) + ~у (X)—vK]2 =
= M[y-y(X)]2 + M[7(X)-vr]2 + 2M{[y-i(X)] (X)—vr]}; (9.1.27)
далее, предполагая для простоты распределение дискретным, будем иметь:
м {[У— У РО] [у (X) — vr]} =2Х 1у — у W1 [У (X)—vr] р (х, у) =
X у
= 2j [*/(*)—Vy]p(x)2}[</—У(х)\р (у/х) = 0,
л- и
так как при любом х
'У Р х) 1 — У (-)] “ У, Р(У'Х) y — yWyp (у, х) = у(х)-у(х) = 0
У
§ 2] ОЦЕНКА КОРРЕЛЯЦИОННЫХ ХАРАКТЕРИСТИК ПО ДАННЫМ ВЫБОРКИ 323
и, значит, на основании (9.1.26) и (9.1.27) получим (9.1.25). Определим ie-
перь показатель t\2y^x равенством
которое на основании (9.1.26) можно переписать в виде
Оу,
---Г"- (9-1.29)
°Y v
Из (9.1.28) и (9.1.29) следует, что всегда Т)у'/лг лежит между 0 и 1. Далее,
из (9.1.29) следует, что тф/А. = 1 тогда и только тогда, когда Оу/Х — 0, т. е.
все распределение сконцентрировано на кривой регрессии у=у(х) (Y по X)
и таким образом существует однозначная функциональная зависимость Y
от X. Из (9.1.29) следует далее, что Т)у/ж = 0 тогда и только тогда, когда
y(x) = vY = const, т. е. линия регрессии Y по X представлена горизонталь-
ной прямой, проходящей через центр тяжести распределения. В этом случае
говорят, что Y не коррелирована с X.
Аналогичными свойствами обладает другой показатель связи X с Y:-qY;
измеряющий степень концентрации распределения около кривой регрессии
X по Y, х = х(у). Не следует некоррелированность смешивать с независи-
мостью: в случае i)y/x = 0 Y может все же находиться в связи с X, но такой,
которая, не меняя значения центров условных распределений, сказывается,
например, на изменении условных дисперсий Оу/Х и т. д.
Между показателями г\у^х и i1x/v нет какой-либо простой зависимости.
Y может быть не коррелирована с X и т]А,у=0, тогда как другой показа-
тель т)у/х = 1’ Допустим, например, что все распределение концентрируется
в трех точках, лежащих на параболе у — х2, так что величина Y есть одно-
значная функция X и Y =Х2, а величина X принимает всего три значения:
х = ±1 и х=0, с вероятностью для каждого значения. В этом случае
T|y/X = l, тогда как Г]х^ = 0, так как линией регрессии х=х (у) служит
ось Y, но х (г/) = 0 в силу симметрии параболы около этой оси и симмет-
ричности распределения X около начала. Если Пу/Х =T)x/w= 1, то функцио-
нальная зависимость Y от X обратима и Y представляет монотонную функ-
цию от X.
Заметим еще, что во всех случаях
ег<пу,х " е’<Лх/У>
так что из равенства нулю хотя бы одного из показателей и r\x/t/ сле‘
дует, что р = 0.
§ 2. Сценка корреляционных характеристик по данным выборки
9.2.1. Выборочные характеристики связи и их вычисление.
Общий прием получения статистических оценок связи по данным
выборки подобен тому, который мы неоднократно уже использовали.
Он заключается в замене вероятностей в теоре1ических показателях
11*
324
ОСНОВЫ ТЕОРИИ КОРРЕЛЯЦИИ
[гл. IX
частостями, математических ожиданий — соответствующими средними
арифметическими, теоретических дисперсий — их статистическими
оценками, т. е. выборочными дисперсиями, и т. д.
Вместо двумерного теоретическою закона распределения выборка
доставляет эмпирический аналог его в виде п наблюдений, каждое
из которых фиксирует пару сопряженных значений интересующих
нас величин (х„ j,), (х2, _у2), ..., (х„, у„).
Если выборочные данные не сведены в корреляционную таблицу
(что бывает обычно, когда объем выборки невелик), корреляционные
характеристики вычисляют в следующем порядке. Сначала опреде-
ляют два средних значения:
1 Л 1 Л
/-j ' -1
затем три момента второго порядка, именно две эмпирические ди-
сперсии:
и эмпирический момент связи или эмпирическую ковариацию:
cov (X, >') = m = -1 у (х,.—х) (Л —у/) = Yx^i—xy =
(9.2.2)
По этим данным вычисляют коэффициенты корреляции выборки
'«Л>
(9.2.3)
и два коэффициента приближенной регрессии
bYx=r^~ и йл .к
ь,.
(9.2.4)
Все эти формулы вполне аналогичны тем, какими определяются соот-
ветствующие теоретические характеристики. Для получения суммы
§ 2] ОЦЕНКА КОРРЕЛЯЦИОННЫХ ХАРАКТЕРИСТИК ПО ДАННЫМ ВЫБОРКИ 325
п
^х^ можно использовать таблицу квадратов чисел, подсчитав
1
—j/.)2 или + Л)2> определяют, далее, из соот-
ношения
2 (xi ± л)2=2 ±2 2 -V/ + 2у1
В тех случаях, когда выборка многочисленна, обычно данные
сводят в корреляционную таблицу наподобие таблицы 5.1.2. В каждой
клетке этой таблицы приводятся численности тех пар (Аб, К.), ком-
поненты которых попадают в соответствующие интервалы по каждому
признаку. В рассматриваемом примере признаки X и У обозначают
отклонения от номинального размера диаметров штамповок, колец
подшипников под углом 90° (х) и углом 45° (у).
Непосредственными измерениями было установлено, что кольца
имели следующие отклонения:
кольцо № 1 .v, = 0,53дмт У1 =0,46 мм,
» № 2 х2 =0,30 » у2 =0,33 »
кольцо № 320 х„ =0,38лл у„. = 0,51 мм.
Весь диапазон изменения х (от 0,00 мм до 0,70 мм) был разбит
на семь интервалов длины Дх = 0,10 мм\ по признаку У имеется
девять интервалов той же длины Ду = 0,10 л/л. Но приведенным
данным измерений было подсчитано число колец, по своим откло-
нениям попадающих в каждый из интервалов А" и в нем в каждый
из интервалов У. Таким образом, п =320 колец распределились
в таблице 5.1.2 по клеточкам, каждой из которых отвечает опреде-
ленный интервал значений А" и в то же время определенный интер-
вал значений У. В таблице 9.2.1 эти данные помещены в клеточках
на пересечении строк 1—9 со столбцами 1—7 (нижнее число).
Так, например, в клетку х — 0,30-=0,40 и У= 0,50-г-0,60
попало 24 кольца. Приближенно можно считать, что для этих колец
х -- 0,35 мм и У = 0,55 мм, что соответствует серединам указанных
интервалов. Вычисления характеристик двумерного распределения
и связи по данным корреляционной таблицы опираются на свойства
этих характеристик, которые были нами "отмечены ранее: 1) харак-
теристика дисперсии и момент связи не зависят от выбора начала
отсчета, а при выборе другого масштаба изменяются в том же
отношении, в каком изменены единицы измерения; 2) коэффициент
корреляции предс:авляег безразмерную характеристику, независи-
мую от выбора начала отсчета по каждому признаку.
Пользуясь этими свойствами, мы упрощаем вычисления, принимая
за «ложное» начало отсчета середину интервала (0,30 ч- 0,40 мм)
326
ОСНОВЫ ТЕОРИИ КОРРЕЛЯЦИИ
[гл. IX
между
(9.2.5)
будем
также
по признаку X и середину интервала (0,40 н-0,50) по признаку Y,
т. е. новое начало координат отвечает точке О' (х0 = 0,35; уц = 0,45).
Далее, примем за новую единицу измерения Дх = 0,10 лм/ и А_у =
= 0,10 мм, т. е. длину интервала подразделения по каждому при-
знаку (в данном частном случае они равны).
В новом масштабе координаты середины каждого интервала пред-
ставятся целыми числами (от -—3 до 4-3 по признаку Д' и от —4
до 4-4 по признаку Y); мы будем называть эти координаты i и j
соответственно; они проставлены в таблице 9.2.1. Связь
старыми координатами и новыми дается формулами:
х = ха 4- Дх I, 1
y=y0 + ^yJ’ I
где (х0, у0)—координаты нового начала. В данном случае
иметь:
х = 0,35 4-0,10/, у = 0,45 4-0,10/.
Ясно, что эти формулы применимы не только к х и у, но
и к их средним х(_у), >'(х), х и у. Численность колец в клетке
таблицы 9.2.1 с координатами (/, /) мы будем обозначать теперь
через Пц. Вычисление начинают с получения суммарных распреде-
лений по признаку Л и по признаку Y в отдельности. Для этого
производят подсчет итогов по строкам и столбцам таблицы 9.2.1,
определяя
2/г>7 = л/ и 2«,7 = лу.
1 I
Итоговые данные я; и я, в строке (10) и столбце (8) таблицы 9.2.1
и дают наблюденное распределение каждого из признаков в отдель-
ности. Следующие два ряда (И), (12) и (9), (10) служат для,под-
счета средних и дисперсий по каждому признаку по формулам
§ 2] ОЦЕНКА КОРРЕЛЯЦИОННЫХ ХАРАКТЕРИСТИК ПО ДАННЫМ ВЫБОРКИ 327
Необходимые для вычисления суммы
2йА 2й/> 2йу- Iй/
ii/i
находятся в итогах (11), (12) строк (9) и (10) колонок.
От характеристик в условных координатах I и у можно перейти
к «натуральным» выражениям их в исходном масштабе:
J = x. + ix7, -y-y. + tvi.
sv = slJyby.
Затем переходят к вычислению момента связи по формуле
W«V> = T^,Z‘7^—(9-2-9)
или более удобной для вычисления
'”</> ==^ЙХЙ<Л'—11Й7'ХЙИ • (9.2.10)
' Ч I i '
Так как 2wiz и 2й/7 Уже найдены, вся трудность состоит в под-
«' ' кт
счете двойной суммы ее можно представить в двояком
виде; или в виде г'цу, = £*’2 Л/У» или в виде 2-/2лТ/г* Соответ-
tt I >
ственно этому и ведется подсчет двумя способами для проверки
результата. В строке (13) приведены значения сумм (для
1
каждого /); так, для 1 =—2 мы имеем:
j-1 •( —4)+ 2-(—3) 4-5-( —2) +
-Ь4-( — 1) +3.(0) -Ь3-1 4-1.2+ЬЗ-Ь1.4 =
= —4 — 6 — 10 — 4 + 0 + 3 + 2 4-3 + 4= —24+ 12= —12.
Частные произведения л записаны в уголках соответствую-
щих клеток (верхнее число); например, вверху в уголке клетки
(—2, —4) проставлено произведение л_2) _4у' = !•(—4)= —4; снизу
в уголке этой же клетки (среднее число) проставлено произведение
= I.(—2) = —2. В строке (14) каждая сумма строки (13)
помножается на соответствующее значение i и находится итог этих
произведений, который и дает сумму n^ij. В другом порядке эта
сумма подсчитывается в столбцах (11) и (12). Итог вычисления по
данным таблицы в том и другом порядке дает одно и то же зна-
чение, равное 209. Строки (15), (16) и столбцы (13), (14) содержат
результаты подсчета суммы необходимых для вычисления корреля-
ционных отношений, о чем мы скажем позднее. В (17), (18) стро-
ках и (15), (16) столбцах выписываются строевые средние в условном
Таблица 9.2.1
Корреляционная таблица
отклонений от номинального размера диаметров штамповок колеи подшипников под / 90° (х) и под 45°((/)
к плоскости разъема штампов
X Диаметр под z 90° X. * от 0,00 до 0,10 1 от 0,10 до 0,20 от 0,20 1 до 0,30 01 и,30 до 0.40 | от до 0.5о ог 0,50 до 0,66 oi 0,60 до 0,70 СП II г< 1 1 )=ХГ" О® + ;
Диаметр под / 45е V 1 -3 —2 —1 0 1 2 3 с if 1» >4 С Ct - (8) (II)
1 (1) '2) (3) < 4) (5) (6) (7) (8) (91 (10) (11) ( I 2) (13) (14' (15) (16)
от 0,00 до 0,10 —4 (1) н 1 н 2 3 — 12 48 —2 8 4 1,33 —0,67 0,28
от 0,10 до 0,20 —3 (2) 1 —6 1 —4 2 1 —3 1 —1 1 1 —6 1 б 2 —3 1 1 —3 2 1 7 —21 63 —2 6 4 0,57 —0,29 0,32
от 0,20 до 0,30 —2 (3) ы 1 1-10 1-10 5 1—20 |=Тб 10 —22 0 И — 18 9 9 — 12 12 6 42 —84 168 —2 4 4 0,10 —0,05 0.34
от 0,30 до 0,40 — 1 (4) g 4 1— 1—13 13 1 — 17 | 0 17 — 11 11 Н н 7 н 3 55 —55 55 13 — 13 169 3,07 0,24 0,37
от 0,40 до 0,50 0 (5) 1 0 1 —9 3 ы 3 |=Т2 12 н 16 0 9 9 1—° 1 12 6 1 0 |=5 5 54 0 0 9 0 81 1,50 0,17 0,37
от 0,50 до 0,60 1 (6) 1 1 |^3 ы 3 1 И 1 — 11 1 1 24 0 91 15 15 6 12 ft 60 60 60 7 7 49 0,82 0,12 0,36
1 1 i 1 1 i i 1 j 1 1 1 1 1
328 ОСНОВЫ ТЕОРИИ КОРРЕЛЯЦИИ [ГЛ. IX
от 0,60 до 0,70 2 (7) I 2 1 —2 i 1 14 1 —7 7 1 38 1 о 19 I 40 1 20 20 1— । 18 9 1 4 |~~6 2 58 116 232 35 70 1225 21,12 0,60 0,41
от 0,70 до 0,80 3 (8) н 1 12 | —4 4 15 0 5 27 9 9 48 32 16 f<l Oil о> 37 111 333 41 123 1681 45,43 1.11 0,46
от 0,80 до 0,90 4 (9) ы 1 1 4 |~ I 8 4 2 4 16 64 1 4 1 0,25 0,25 0,38
П, (Ю) 5 21 59 96 74 53 12 320 131 1023 100 209 74,19
П;< = (10) 1 (И) -15 —42 —59 0 74 106 36 100 х = 0,38 у = 0,49 >0=1,31 Sx = 0,131 s</>=1’74 Sv = 0,174 r = 0,230 й^/х = 0,305 —0,173 Примечание. В уголках 1 клеток (i, /') поставлены частные произведения n^-j (сверху) и n-tji (снизу).
n,i2 = (11) 1 (12) 45 84 59 0 74 212 108 582
^nil! (13. —1 —12 5 24 50 58 7 131
f (14) 3 24 —5 0 50 116 21 209
(15) 1 144 25 576 2500 3.64 49
(^"У_<.5> п, (10) (16) 0,20 6,86 0,42 6,00 33,78 63,47 4,08 114,81
У, nip / _(13) п,- (10) (17) —0,20 —0,57 0,08 0,25 0,68 1,09 0,58
v<x) = Vo+A5'-(17) (18) 0,43 0,39 0,46 0,47 0,52 0,56 0,51
§ 2] ОПЕНКА КОРРЕЛЯЦИОННЫХ ХАРАКТЕРИСТИК ПО ДАННЫМ ВЫБОРКИ 329
330
ОСНОВЫ ТЕОРИИ КОРРЕЛЯЦИИ
(гл. IX
((17) и (15)) и натуральном ((18) и (16)) масштабах, причем
переход от одного масштаба к другому осуществляется при помощи
формулы (9.2.5). Расчет характеристик по итоговым данным таблицы
приведен в правом нижнем углу таблицы. Не переходя к натураль-
ному масштабу, удобно вычислять коэффициент корреляции и два
коэффициента регрессии по формулам:
Применительно к нашему примеру получим:
_______320-209—100-131________= 538- 10S- * * 8 _ q 230
К320-582—1002 /320-1023—1318 420-557 ~ ’
и аналогично
Ьу!х = 0,305 и 7^ = 0,173.
Эти данные были использованы при построении линий регрессии,
показанных на рис. 37.
9.2.2. Эмпирическое корреляционное отношение. В том случае, когда
кривые регрессии значительно отклоняются от прямолинейной формы, в каче-
стве меры связи по данным выборки используют корреляционное отношение
S- S-
п — ~ /091ЧЧ
’ly/x — g > ^Х1у~ sx • (9.2.13)
где s- и s- — средние квадратические признаков;
s7 г,, = V S п‘& <x‘><9.2.14)
У I ft
1
(9.2.15)
— средние квадраты отклонений линии регрессии от соответствующих сред-
них. Эти формулы построены по тому же принципу, какой применялся до
сих пор для оценки корреляционных характеристик и аналогичны теорети-
ческим формулам (9.1.28) и (9.1.29). Впрочем, при вычислениях оказывается
более выгодным применить следующие расчетные формулы, вытекающие и?
§ 2] ОЦЕНКА КОРРЕЛЯЦИОННЫХ ХАРАКТЕРИСТИК ПО ДАННЫМ ВЫБОРКИ 331
Необходимые для вычисления этих показателей суммы получаются
в процессе обработки корреляционной таблицы. Для рассмотренного при-
мера они находятся в итогах строк (16), (13) и столбцов (10), (9) для пер-
вого показателя и соответственно в итогах столбцов (14), (11) и строк (12)
и (14)—для второго. Подсчет дает следующие значения:
_ ,/320-114,81 —1312_
У 320-1023—1312 ~
0,251,
, /320-74,19-ЮО2 „„
П^/г/ у 320-582—ЮО2 °’279'
Коэффициент корреляции г =0,230 лишь немного меньше минимального
из ц, что указывает на то, что регрессия приближенно линейна.
9.2.3. Оценка достоверности коэффициентов связи. Хотя
эмпирический коэффициент корреляции г представляет состоятель-
ную оценку для q, однако более или менее надежную оценку бли-
зости г к Q по данным выборки можно дать лишь в том случае,
когда распределение величин X и Y достаточно близко к нормаль-
ной форме. В этом случае для больших выборок можно использовать
следующую оценку для среднего квадратического отклонения г от q:
(9.2.18)
и считать, что г приближенно следует нормальному закону с па-
раметрами (Q, Ог).
Аналогично для коэффициента регрессии bY/x будем иметь:
_ sy 1-г8
ObYlx ~ 8Х /V
(9.2.19)
Определив для q% уровня соответствующий ему «/-предел абсолют-
ного нормального отклонения (таблица 11), будем иметь следующие
332
ОСНОВЫ ТЕОРИИ КОРРЕЛЯЦИИ
[ГЛ. IX
доверительные ишервалы с q% уровнем:
1 —гг
И п
sv 1 — гг sv ]—г2
Ьу1х~^^У^<?,у'х<:Ьу'х'{ {‘’Глу~
(9.2.20)
(9.2.21)
Пусть, например, требуется оценить коэффициент корреляции Q
и коэффициенты регрессии Ьу/Х и bxjy с доверительной вероятно-
стью Р=0,95 по данным примера, приведенного в и. 9.2.1.
Принимая <Jx~ss и Q~r, по формуле (9.2.18) вы-
числяем:
Sr
1 — 0,2302
/320
= 0,053.
По таблице II приложений при ^=0,95 находим =-(-1,96,
и доверительный интервал для Q будет:
0,230 —1,96-0,053 <q <0,230+ 1,96-0,053
или
0,126 < е < 0,334.
Далее, по формулам (9.2.7) и (9.2.8) находим:
sv = ^1^0,10 = 0,174 и s =^^0,10 = 0,131.
У ozU
Среднее квадратическое отклонение коэффициента регрессии на-
ходим по формуле (9.2.19):
О|,УМ
0,174 I — 0,2302 _
°-131 /320
0,070,
°ь
У lx
0,131 1— 0.2302
0,174 ]/’32О
0,040.
Тогда для коэффициентов регрессии при той же доверительной
вероятности Р=0,95 мы будем иметь:
0,305 — 1,96 -0,070 < рг ,д < 0,305 + 1,96• 0,070,
0,173— 1,96-0,040 <рЛ/г/<0,173Н 1,96-0,040,
или
0,168 < ру/д <0,442,
0,095 <pA,fr<0,251.
ЗАДАЧИ РЕГРЕССИИ
333
§ 3]
Если число наблюдений невелико: п < 30, то для оценки коэф-
фициента корреляции применяют другие приемы, предложенные Фи-
шером ').
9.2.4. Проверка гипотезы об отсутствии корреляционной связи.
При проведении корреляционного анализа, прежде всего, возникает
вопрос о реальности связи, т. е. о том, являются ли полученные
из наблюдений коэффициенты корреляции значимыми и не объяс-
няется ли получение их случайностями выборки. Таким образом,
требуется проверить гипоюзу р = 0. В качестве критерия в этом
случае служит статистический коэфс иниент корреляции г. Пользуясь
при больших выборках соотношением (9.2.20), строят критическую
область вида
И>^ (9.2.22)
с уровнем значимости q%, и если полученное по данным выборки
значение г окажется в этой области, то гипотезу о = 0 отбрасывают.
Пусть, например, требуется проверить реальность корреляцион-
ных связей, обнаруживаемых в предыдущих примерах. Пользуясь
1%-ным уровнем значимости, по таблице II приложений находим
/ = 2,58. Тогда по условиям примера из п. 9.2.2 кршическая область
будет (так как ar « sr):
|г|> 2,58-0,053 = 0,137.
Мы уже получили в п. 9.2.1 значение г = 0,230. Таким образом,
с вероятностью не менее 0,99 мы можем считать, что корреляционная
связь между диаметрами штамповки под / 90° и под ^/45°
к плоскости разъема действительно имеет место.
§ 3. Задачи регрессии
9.3.1. Постановка вопроса. Рассмотрим следующую задачу,
различные варианты которой часто встречаются в практике. Пусть
мы имеем k аргументов xt, х2, ...,хк и зависящую от них вели-
чину у. Переменные х;, вообще говоря, не случайные величины
и принимают в каждом наблюдении данной серии вполне определен-
ные значения. Наоборот, величина Y предполагается случайной ве-
личиной, имеющей нормальное распределение с центром распреде-
ления в точке
1ЛУ=у = а + р.х, + р2х2 + ... + (9.3.1)
и постоянной, не зависящей от х,-, дисперсией о2. Можно сказать,
что аргументы х(- определяют величину у лишь в среднем, оставляя
простор для случайных флуктуаций, следующих нормальному закону.
‘) См. «Общую часть», стр ЗУ4.
334 ОСНОВЫ ТЕОРИИ КОРРЕЛЯЦИИ [гл. IX
Предположим, что проведена серия из п независимых наблюде-
ний, дающих п систем значений:
Л- хй> хп> •••> xki (/=1, 2, ..., л). (9.3.2)
По этим данным требуется оценить неизвестные коэффициенты а
и р, (/=1,2, ..., k).
Так поставленная задача по аналогии с рассмотренной в п. 9.1.3
задачей теории корреляции носит название задачи «регрессии».
Пусть величина Y представляет какое-либо интересующее нас свой-
ство металлического сплава, например ударную вязкость образцов,
вырезаемых из стальных отливок, a xv хг, ...,хп выражают опре-
деленные факторы, от которых зависят свойства ударной вязкости
(содержание различных химических элементов, условия термической
обработки и т. д.). В качестве другого примера величины Y можно
Привести количество угля, потребляемое доменной печью на тонну
выплавляемого железа, в то время как роль переменных опять-таки
играет химическое содержание руды, температура печи и другие
факторы. Э|и последние в рассматриваемых экспериментах могут
принимать определенные значения, предписываемые постановкой
экспериментов в определенных пределах их изменения. В то же
время перечисленные и поддающиеся нашему контролю факторы не
исчерпывают всей совокупности факторов, определяющих значение
величины у. В числе этих последних, как правило, находятся также
случайные переменные, в результате чего и величина Y будет
испытывать, помимо функционально обусловленных, также и случай-
ные воздействия. Таким образом, мы при некоторых допущениях
придем к задаче определения коэффициентов в уравнении «регрес-
сии» (9.1.13).
В некоторых задачах, связанных с передачей информации по
каналам связи, мы встречаемся с величинами Y, которые предста-
вляют сумму зависящей от времени t определенной (неслучайной)
функции и случайной компоненты z (/), отражающей влияние «помех»
пли «шума»:
У=а + Р,/+Р2/2+ ... 4-+ *(/). (9.3.3)
В других задачах подобное же разложение у будет иметь вид
Y— а фр, cos (Kt -)- р.) 4- ... + z(t). (9.3.4)
При этом z (/) в этих задачах предполагается нормально распреде-
ленной переменной с центром, равным нулю, и постоянной дис-
персией о2, причем для любых моментов времени /р/2,
величины z (/,) предполагаются независимыми.
ЗАДАЧИ РЕГРЕССИИ
335
§ 3]
Нетрудно видеть, что если требуется определить по произведен-
ным в моменты времени /р /2, ...,tn измерениям величины К:
Л’Л’ • • • > Уп — значения параметров а, р2, ...,РЙ в формулах
(9.3.3) и (9.3.4), то мы придем к поставленной выше задаче.
Роль аргументов х(. играют при этом степени t‘ (Xi~tl;
т = 1, 2, ..., k) в уравнении (9.3.3) или выражения cos (Х? -4- р.)
в (9.3.4), причем X и и предполагаются известными.
Если задача оценки параметров будет решена, то мы сможем
с некоторой надежностью судить о поведении величины У в зависи-
мости от аргументов х,, х2, ..., х/г. Другими словами, мы можем
с определенной надежностью производить прогноз относительно
возможного значения МЕ = у при данной комбинации Л'р хг, ...,xk,
указывая, например, доверительные границы для МУ = у, гаранти-
руемые с заданным уровнем вероятности. Мы покажем в следующем
разделе на примере, что поставленная задача решается примене-
нием метода наименьших квадратов.
9.3.2. Оценка параметров линейной зависимости по методу
наименьших квадратов. Пусть мы имеем физические основания
предположить, что величина У зависит «в среднем» (т. е. отвлекаясь
от случайных погрешностей измерения) линейно от аргумента х.
Математически это означает, что для математического ожидания У
при данном х имеем:
М (У/х) = а + Рх. (9.3.5)
Допустим, что мы провели п независимых наблюдений при значе-
ниях Л’=х1, х2, ..., хп, причем измерения У при этих значениях
дали результаты yv уг, ..., уп. Нанося на график точки (х;, у,-),
мы получим обычно картину некоторого «разброса» точек, иска-
жающего точную линейную зависимость. Пусть, например, нас
интересует жесткость задней бабки токарного станка при нагруже-
нии ее вертикальной составляющей усилия резания. Для этой цели
мы повторно нагружаем и разгружаем ее, измеряя с помощью ди-
намометра при каждом значении отжатия хр ...,хп соответствую-
щие им нагружения у. Благодаря рассеиванию показаний динамометра
мы получим для одних и тех же значений отжатия различные
величины нагружений. Предполагая линейную зивисимость между
нагрузкой и деформацией, что является естественным для напряже-
ний, не превосходящих предела пропорциональности, мы придем
к определению параметров а и р в уравнении (9.3.5), причем вели-
чина М(У/’х) будет рассматриваться как среднее (точнее, математи-
ческое ожидание) значение У для фиксированного значения х.
Заметим, что в одном случае, как и во многих других, одному
значению х — х{ отвечают несколько наблюденных значений Г.
Будем, однако, предполагать, что имеются, по крайней мере, два
различные между собой значения х.
336
ОСНОВЫ ТЕОРИИ КОРРЕЛЯЦИИ
[гл. IX
Считая, что уклонения от линейности лежат в ошибках
S б2, ..., б,., сопровождающих последовательные измерения, мы
можем положить:
у; = М(К/Х;) = а-(-0Х; + б;. (9.3.6)
Предполагается также, что ошибки измерения 6;=_у(.— a — 0х(-
удовлетворяют условиям:
А) Мб,- = О,
D6; = M6/ = o2 (не зависит от х);
В) для различных х; погрешности б, независимы друг от друга;
С) б; при каждом i подчиняются одному и тому же нормаль-
ному закону распределения N (0, о).
Пусть даны п пар наблюдений над совместными значениями ве-
личин X и Y — a 4~|ЗЛ + б. Плотность распределения системы ошибок
б,, б2, . . ., б„ ввиду сделанных предположений на основании (5.1.30)
выразится произведением
2L 21 21
• e~Z ..
У 2ло У 2ло У 2ло \ У 2 л )
Но каждой системе ошибок бр б2, .... бге отвечает система
возможных наблюденных у:
_у, = ан рх. + б,, уп = а 4- 0х„-+ б„,
а потому плотность распределения наблюденных величин _у(. будет.
п
°~Пе~ г°2 — p(xy> •••; хп, а; ₽; °2)-
Наша задача заключается в оценке параметров ос, [5 и о2. При-
меняя метод наибольшего правдоподобия, мы должны в качестве
оценок взять их значения, которые обращают в максимум функцию
р(х,; ...; хп; а; 0; о2) при фиксированных значениях х,, х2, ..., хп.
Обозначим искомые значения а, 0 и о2 соответственно через а, 0
и №. Очевидно, что при данном о2 максимум функции р получится
в том случае, когда стоящая в показателе степени при е форма
Q=^l(yi—a — 0Х;)2
1 = 1
при а —а и 0 = 0 будет обращаться в минимум. Условием экстре-
мума, как известно из анализа, будет служить обращение в нуль
§ 3] ЗАДАЧИ РЕГРЕССИИ 337
частных производных Q. Но, дифференцируя по а и р, получим;
л п п
-а - -ал- р ё
fsct t=i >=j
п ' п п п
- 4 <=Ё {у‘ ~а ~ } х‘=X xiy> ~а Z х< ~ р Ё *'•
(=i /=i i=i i=i
Приравнивая их нулю, будем иметь систему уравнений для опре-
деления оценок аир для аир. Эти уравнения особенно просто
записываются и решаются, если предположить, что система значе-
ний X удовлетворяет условию:
D) Ух,. = 0.
Этого всегда можно добиться, приняв за начало отсчета х сред-
нюю арифметическую
т. е., другими словами, если перейти от прежней системы абсцисс
хр ..., хп к новой системе х,, ...,хп, причем х, = х(—х. Тогда
в новой системе требуемое условие будет выполнено, так как
Хх-=2(х1—х) = о.
(=i /=1
Таким образом, вводимое нами условие D) сводится лишь к несу-
щественной замене прежних абсцисс х; новыми х((/=1, 2, п).
В дальнейшем мы будем предполагать условие D) для х выпол-
ненным.
Тогда уравнения для определения «наилучших» оценок аир
для а и Р соО1ветственно будут:
2 СУ, —а — рх,) = 0, 1
7 > (9.3.7)
2 О',— а— Рх;.)х, = 0,
338
ОСНОВЫ ТЕОРИИ КОРРЕЛЯЦИИ
[гл. IX
откуда ввиду условия 2xi = 0 следует:
и окончательно
(9.3.8)
Очевидно, что если условие D) не соблюдено, то для наилучшей
системы оценок мы получим несколько более сложные выражения:
п п п п п
2 2 уi п 2 х‘У‘ х' 2
а = , В = —--------------= —^1— ,(9.3.9)
П ’ “ П _ П / П \2 ’
2 (X, -х)2 п 2 х‘ - 2 х‘)
i=i i=i \i=i j
где а — ордината искомой прямой в точке х — х.
Дифференцируя функцию р по параметру ст2 и приравнивая част-
ную производную нулю, аналогичным образом получим для опреде-
ления оценки № параметра о2:
п
ns2 = 2(Л —«—lW-
' = 1
Таким образом,
п
= «—|Ц)2> (9.3.10)
Z=1
при этом оценки аир определяются формулами (9.3.8) и (9.3.9).
Использованный нами принцип для оценки неизвестныхкоэффициен-
тов а и р в выражении M{Y[Xj) составляет существо метода наи-
меньших квадратов, так как мы полагаем, что «наилучшие» оценки
обращают в минимум сумму квадратов уклонений наблюденных зна-
чений у,- от вычисленных при тех же значениях А' = х;, согласно
уравнению регрессии, т. е. сумму
П п.
2 (л—М(ВД2 - 2 (л-а-Ш)2.
i-l { = :
Посмотрим теперь, как оцениваются точность и надежность опре-
деления параметров. Заметим прежде всего, что а и р и их от-
§ 3] ЗАДАЧИ РЕГРЕССИИ 339
клонения от истинных значений параметров и и (3 мы можем вы-
п
разить через величины б(-. В самом деле, при условии 2-*j=0
<=1
имеем:
п п п п п
«+А) = 0 2^ + «а+ 2б, = ла-ь 2б,.,
/ = 1 / = 1 1 = 1 1=1 /й=1
откуда с учетом (9.3.8)
п п п п
а = —------—— = а — — , а —a=i=i—. (9.3.11)
п п п v 1
С другой стороны, при том же условии
2 З'Л = 2 (« + 0*7 + 6() •*,= а 2 xi + Р 2 А +
1 = 1 1 = 1 Z-1 1=1
п п п
I-* i=i <=1
откуда, принимая во внимание (9.3.8),
п п
ИЛИ
Мы видим, что уклонения a — а ир—|3 представляют линейные
функции от 6,-. Они будут подчиняться нормальному закону распре-
деления. Если бы параметр о8 был известен, то задача вероятност-
ной оценки а и В решалась бы полностью и мы могли бы очень
просто найти доверительные интервалы для а и |3. В случае неиз-
вестного параметра о2 мы используем прием, сходный с тем, кото-
рый был использован при оценке среднего значения по методу
Стьюдента при неизвестном о. Положим:
= а | dit (9.3.13)
340
ОСНОВЫ ТЕОРИИ КОРРЕЛЯЦИИ
|Г.т. lx
где dj— yi—У/ есть найденные или «кажущиеся» уклонения наблю-
денного от полученной путем вычисления ординаты прямой Yj-.
Yj = a + fjXj.
Очевидно, следует ожидать, что уклонения dt будут, как пра-
вило, меньше, чем неизвестные истинные уклонения 6Z, так как коэф-
фициенты а и р выбраны со специальным расчетом обратить в ми-
нимум сумму квадратов 2О71 — а — Рх,)2 при а = а и р = р.
Так как наряду с (9.3.13) мы имеем из (9.3.6) для выражение
yj = а + 0Х,. + 6г, (9.3.14)
то из (9.3.13) и (9.3.14) следует:
а + [Зх(. ф- dj = а -ф рх,- +Д-. (9.3.15)
Разности
и (9.3.12) в
п
г 1 V
И [XX] -
а — а и р — р мы представим теперь с учетом (9.3.11)
следующем виде:
п
(=1
а — а=—~=, где ri , = —,
/п 11 К п
2 х&
Р — Р = , где q =.
К [хх] V [хх]
х2. В этих обозначениях
Введенные нами величины 1]х и q2 будут обладать следующими
свойствами:
1) Mt]j = Мт]2 = 0,
2) =Dt]2 = o2,
3) М(т]1т]2) = 0. В * *
В самом деле, первое свойство вытекает из предположения
M6z=0 ввиду того, что х(-— не случайные величины, второе—из
независимости no 1еореме о дисперсии суммы независимых величин.
§ 3] ЗАДАЧИ РЕГРЕССИИ 341
Наконец, третье свойство легко проверяется:
М (ЛЛг) = 7--• М f УД- ^Lxfi/} = ~г 1 ~ 52 М fб, V х.-д.
12 КпК[хх] Vn[xx]f^ >!)
(9.3.16)
Далее, в силу независимости 6,- и 6Z {i~/= j)
М(йД)==М6(М6,. = О
и мы будем иметь:
м(б,- 2 xj^j / = х(Мб2 — xto2,
\ i=t /
и потому из (9.3.16) следует:
°2 S х>
M(V)2) = ^=ё = °-
у п [хх]
п
так как 2 xi по условию равна нулю.
1=1
Принимая во внимание, что величины и т]2 нормально распре-
делены, мы можем заключить отсюда, что они независимы между
собой (так как коэффициент корреляции между ними равен нулю).
Отсюда следует также, что а—-а и р— (3 независимы друг от
друга. Не приводя доказательства, мы заметим, что величина
и п
2 (Л— a-fk)2 24
Л£ _ 1 = 1____________/=1
а2 а2 о2
оказывается распределенной независимо от а и р по закону у?
с п — 2 степенями свободы. Это последнее число получается потому,
что уклонения di связаны между собой двумя линейными соотноше-
ниями:
п п п п
2^,=--2(Л—“ —= 0 и = Sty,—а — |Ц)х,. = 0,
i—y /=1
которые вытекают из уравнений (9.3.7) метода наименьших квад-
ратов.
На основании полученных выводов можно получить вероятност-
ную оценку коэффициентов а и (3, дисперсии о2, а также произвести
проверку гипотезы линейности.
y/.OS. сь
342
ОСНОВЫ ТЕОРИИ КОРРЕЛЯЦИИ
[гл. IX
Для того чтобы получить доверительный интервал для а, мы
примем во внимание, что величина
а—а,/— г].
и —----1/ я = -н
а ’ а
распределена нормально с единичной
С другой стороны, так как величина
от и по закону с п — 2 степенями
дисперсией и центром в нуле.
ns2
-^2 распределена независимо
свободы, то величина
f a) Уп- 2=a a (9.3.17)
a
где
s~ = -4= = 1/ -Ц • — У di (9.3.18)
a ^—2 У n—2 n ‘ '
и
d, = y/—= a —
распределена по закону Стыодента с п—2 степенями свободы.
Для каждого q мы можем, следовательно, найти такое tq, что
р<1('1>и = П0'
и построить для а доверительный интервал (а — tqs~, а+^5-).
Аналогичным приемом устанавливается и доверительный интервал
для р. При этом используется величина
_ (Р —Р) У (п — 2) [хх] _ Р —Р
У ~п$ Sfi
где
У ns
g ~ У (п — 2) [xxf
(9.3.20)
и s определяется по формуле (9.3.10). t" также распределяется по
закону Стыодента с п — 2 степенями свободы. Заметим еще, что
п п
символ [хх], равносильный У, х*, следует заменить на 2 (х/—х)2 ,
i ~ 1 i = 1
если начало отсчета по оси х не совпадает со средней арифметиче-
ской х 1ак, что х 0.
ЗАДАЧИ РЕГРЕССИИ
343
§ 3]
Для оценки о2 мы используем а2 и закон для ~ с п—2
степенями свободы.
Несмещенной оценкой для о2 в данном случае служит еще вели-
чина
^=^2- (9.3.21)
На практике часто возникает вопрос об оценке отклонения ис-
тинной прямой М(У/х) = а+рх от построенной нами ее оценки
К = а-|-рх при некотором заданном значении х
Разность У—у можно представить в следующем виде:
Y-M (Ylx) = (а —а) + (0-р) х = .
V п у [хх)
(п'ри х = 0),
отклонение величины Y—
Эта разность представляет сумму двух нормально распределен-
ных величин и потому также нормально распределена с центром
в нуле и дисперсией, равной
м[у-М(у;х)Г=£ + ^
следовательно, среднее квадратическое
— М(К/х) равно
OY-M(YIx) °
°Г-М(У/х) °
-4- —
: [хх] ’
1 , (Х — Х)1
п п _
2u,-^)2
если х = 0,
если х 0.
(9.3.22)
Можно показать, что величина
[У-М(Г/х)] уп — 2
Т =
(9.3.23)
распределена по закону Стьюдента с п—2 степенями свободы и
потому можно определить доверительный интервал для оценки раз-
ности [У—М (К/х)], соответствующий заданной доверительной вероят-
ности.
Таким образом, для выбранного значения х = х0 математическое
ожидание М (Т/Х,,) оценивается с помощью доверительного интервала
а I ±
п (х„—х)г
' п
>3
344
ОСНОВЫ ТЕОРИИ КОРРЕЛЯЦИИ
(гл. IX
или
При х— х = 0 (или при х~х) мы получаем ту же опенку,
что и для а. С увеличением х или (х— х), т. е. по мере удаления
01 среднего значения х, принятого нами за начало отсчета, точность
оценки будет заметно снижаться. Наименее надежная оценка по пря-
мой, проведенной по методу наименьших квадратов, будет полу-
чаться для ординат, отвечающих точкам, наиболее удаленным от
среднего значения х. Поэтому найденную прямую возможно исполь-
зовать для экстраполирования за пределами того промежутка, внутри
которого помешаются наблюденные данные, лишь соблюдая большую
осторожность.
Покажем на примере, как определяются коэффициенты а и |3
в уравнении прямой регрессии.
Пусть мы располагали следующими данными относительно зави-
симости у от х:
X & 1 К к d, о у—У
(1) (2) (3) (4) v5} (6) (7
3,4 4,5 15,30 11,56 4,58 —0,08 0,0064
4,3 5,8 24,94 18,49 5,59 +0,21 0,0441
5,4 6,8 36,72 29,16 6,82 -0,02 0,0004
6,7 8,1 54,27 44,89 8,27 —0,17 0,0289
8,7 10,5 91,35 75,69 10,51 —0,01 0,0001
10,6 12,7 134,62 112,36 12,64 +0,06 0,0036
39,1 48,4 357,20 292,15 — — 0,0835
Вычислив итоги первого и второго столбцов, находим:
х = = 6,52 и у =^ = 8,07.
п 6 ’ z 6 ’
В третьем и четвертом столбцах подсчитываются произведения ху
и х2. Затем по формулам (9.3.9) находим:
и = 8,07,
6-357,2-39,1.48,4
Р 6-292,15 —(39,1/~ ~ 1>1Z-
ЗАДАЧИ РЕГРЕССИИ
345
§ 3]
Таким образом, уравнение регрессии может быть записано в виде
У = 8,07 4- 1,12 (л—6,52),
или
У=0,77 + 1,12х.
Вычисляя значения Y по этой формуле, получим числа столбца (5).
В столбце (6) указаны отклонения d — y—Y. Для вычисления №
получим 2^/ — 0,0835, и тогда
Отсюда
S 0,12 Л „ „ ,/П 0,0835 „
S; = -7,. — = -/_ =0,06, Sa = 1/ 55 = 0,024,
' )Л1—2 |<6—2 в Г 6 — 2 37,35 ’ ’
так как
£(х,—x)s = — ^^- = 292,15 ——^ = 37,35.
Отсюда можно определить доверительные границы для коэффициен-
тов anf формулы регрессии. Беря, например, 95%-ный интервал,
получим для оценки [3 следующие доверительные границы (пользуясь
законом Стьюдента с 4 степенями свободы, по таблице V приложе-
ний находим /5>4 = 2,776):
1,12—2,776 0,024 < р < 1,12 -f- 2,776 - 0,024
или
1,05 < р < 1,19.
Найдем теперь доверительные границы для М(У,х) при значении
х„ = 5,4 при 9 = 5%. Ввиду того, что У = а+-|3хо = 6,82, х = 0,12,
i6 = 2,776 и
И V 6-292,15-39, Р
На основании (9.3.24) получим:
6,82 — 21, Ю < М (Y'X,) < 6,82 + ^77<12. 1,10
Кб-2 0 ><6 — 2
ИЛИ
6,65 <ЛЦГ(х0) <6,99.
346
ОСНОВЫ ТЕОРИИ КОРРЕЛЯЦИИ
(ГЛ. IX
9.3.3. Общий случай регрессии. Мы приведем теперь результаты, отно-
сящиеся к оценке параметров в общем уравнении линейной регрессии по
методу наименьших квадратов. Пусть для п систем значений аргументов
х, = х1(-, х2 = х2,-, ... , xn — xnj (/ = 1,2,..., п)
мы измерили значения величины Y = У(. Для большей простоты вычислений
мы запишем уравнение (9.3.5) в виде
у = а+ р, (х,—х,) + р2 (х2 —х2)+ ... + Pft (xk — xk), (9.3.25)
где Х(—среднее арифметическое из всех значений аргумента xz-, т. е.
п п п
f=l (=1 (=1
В таком случае для оценки параметра а мы будем иметь:
п
a = = y (9.3.26)
(=1
Чтобы записать выражение оценок (35 (для j3s), мы введем обозначение
IE-. *r) xs) 0 г 5 (9.3.27)
и
причем
п
lrr = — (Xrj — X,)8.
I =1
Кроме того, пусть
п
y}(xsi— xs) (9.3.28)
‘и ^12 • Ilk
L = ^21 /22 . hk (9.3.29)
(/г] •• ‘kk
и Ls обозначает определитель, получающийся из L заменой s-ro столбца
(т. е. элементов lAS, 1М, , lks) столбцом из членов /0„ 1„2, .... /оД,. Тогда
Р, = -^. (9.3.30)
Для неизвестной дисперсии а2 имеем оценку
Г,
® а Pi (хи xi) Ра (^2/ xz) • • • Ра ха)12* (9.3.31)
ЗАДАЧИ РЕГРЕССИИ
347
§ 3]
причем следует X2 распределению с (п — k — 1) степенями свободы.
Далее, (100 — q)% доверительные границы а и |За найдем в виде
а i tq, ri-i-i „г ' -. - ’ (9.3.32)
Y n — k — 1
± tq, n-k-1 ' ’ O-3.33)
УП—k—1 ' L
причем Lss есть главный минор определителя L, получаемый из L вычер-
киванием s-й строки и s-ro столбца.
Наконец, если требуется оценить среднее значение у для какой-нибудь
системы X,, Х2, ... , Xk— значений переменных ту, х2, ... , xk, т. е. найти
оценку для выражения
а + Pi (-^i —*1) + Рг (^2— хг) +••• + ₽* (Xk— Kk)’
то мы получим для этой оценки следующие (100 — q)% доверительные гра-
ницы:
а + Pi (X) —х,) + ... + Рд, (Хк — xk) ±
/ . к к ~
±^п-.-1?==тУ (9Л34)
i - 1 / = 1
причем Lq есть алгебраическое дополнение элемента I, j в детерминанте L.
Как мы указывали раньше, описанная методика пригодна, например,
для оценки коэффициентов параболической регрессии вида
У — а + Pi* + Ра*2 + • • + Ра-г*-
Для этого в приведенных выше формулах следует положить
Xm = X“ (m=l, 2........k)
и в соответствии с этим считать Хт! = Х™, где i — номер наблюдения.
Примером регрессии тригонометрического полинома можег слу-
жить оценка количественной характеристики профиля неровностей
поверхности детали машины или прибора, когда случайная состав-
ляющая профиля заведомо мала по сравнению с его система гической
составляющей. В этом случае точность оценки тригонометрического
полинома, описывающего профиль неровностей поверхности, зависит,
в основном, от погрешности самих произведенных наблюдений.
Пусть наблюдению подлежит систематическая составляющая
профиля поверхности, описанная тригонометрическим полиномом
р
аъ । V' ( ~ 2лпх , Ътх\ ... „
+ К cos ~тг + hn sln “>-)> (9.3.35)
где N—шаг (период) профиля, р — порядок многочлена ап, Ьп и
~~—коэффициенты Фурье и нулевой член разложения для кривой
профиля поверхности.
348 основы теории корреляции [гл. ix
Предполагается, что /V и р известны, причем Л7)>2р-1-1.
Допустим, что в равноотстоящих друг от друга точках оси
абсцисс х = 0, 1,2, ..., N—1 произведены измерения ординат
1|0, т],, ..., T]jV_, полинома. Благодаря наличию погрешностей изме-
рений, полученные результаты измерений не представляют истинные
значения указанных ординат г]*. Если случайная составляющая
профиля пренебрежимо мала, то каждый результат измерений
равен сумме истинных значений ординат и погрешностей измерения,
т. е.
= (9.3.36)
где — погрешность измерений.
Примем следующие допущения:
1) погрешности независимы между собой;
2) они нормально распределены;
3) математические ожидания погрешностей измерений равны
нулю, т. е.
М6х = 0, (9.3.37)
иными словами, систематические погрешности измерений отсутст-
вуют;
4) дисперсии погрешностей измерений постоянны и равны между
собой, т. е.
Мб, = о2. (9.3.38)
Из допущения 1) следует, что
= (9.3.39)
где X; и Xj—любые две точки на оси х.
Пусть по ординатам ух построены оценки а0, alt и Ьп для коэф-
фициентов а0, ап и Ьп, причем
й о II fell sMi Ч: (9.3.40)
W-i = л-c°s i=о 2лш (9.3.41)
W-i bn = £ л-sin 4=0 2mi ~~N~ ' (9.3.42)
где п = 1, 2, . . . , р.
Ввиду наличия погрешностей измерений оценки «0, ап и !>п будут
отличаться от ао, ап и Ьп.
ЗАДАЧИ РЕГРЕССИИ
319
§ 3]
С помощью а0, ап и Ьп строится тригонометрический полином вида
р
,, «о . V4 / 2лпх , , . 2лпх\ ,,
Гх = у + 2-1 ( ancos~ + bnsm~b (9.3.43)
п= 1 4 '
который является приближением к многочлену (9.3.35).
Ввиду того, что коэффициенты а0, ап и Ьп полинома (9.3.35),
как известно из теории рядов Фурье, могут быть представлены
соотношениями вида (9.3.40) и (9.3.42), если в последних заменить
эмпирически найденные ординаты их истинными значениями г](-,
то при почленном вычитании из правых частей (9.3.40) — (9.3.42)
аналогичных сумм, в которых заменены на i|(, на основании
(9.3.36) получим:
N-1
ао = ао — = 5i> (9.3.44)
i =о
ЛГ-1
= а— ап = ^-Т. б< cos ’ (9.3.45)
I =0
ЛГ-1
= = 6t.sin^, (9.3.46)
4=0
где п = 1, 2, . .. , р.
Таким образом, погрешности коэффициентов л0, ап и Ьп пред-
ставляют линейные функции от 6Z и поэтому они нормально распре-
делены при нормальном распределении 6Z (допущение 2) с центром
в нуле согласно (9.3.37).
Дисперсия коэффициента ап согласно (3.1.28) и (9.3.37) полу-
чается из (9.3.45) в виде
,V-1 N-1
„ ж- . 4 \'1 .,с. 2 2лпт 4 . V 22лш
4 = ^4 Мб* cos ° 2- cos ~ =
4=0 4 = 0
= (9.3.47)
так как ‘)
N-1
V" 2 2nni N . o.
>. cos2-ir = —. (9.3.48)
i — i
9 См. книгу [54j, стр zol.
350
ОСНОВЫ ТЕОРИИ КОРРЕЛЯЦИИ
[гл. IX
Аналогичным образом получаем из (9.3.46):
= (9.3.49)
и из (9.3.44):
Da0 = Ma2 = 4^. (9.3.50)
Для того чтобы оценить неизвестный параметр as, рассмотрим
так называемые «кажущиеся отклонения», т. е. отклонения резуль-
татов измерений ординат кривой МК(х) от их значений, вычислен-
ных с помощью полученного из результатов измерений полинома
(9.3.43). Кажущиеся отклонения представляют
= = + (9-3.51)
Дисперсия кажущегося отклонения Ах ввиду (9.3.37) согласно
(3.1.27) и (9.3.51) составляет:
D Ах = МАХ = М [(Пх- Yx) + = М (т)х- Ух)г + 2М (Лх- KJ] +
+ М6: = М (Ух-г)хГ-2М [6Х(ГХ -r)J] + М5Х. (9.3.52)
Используя коэффициенты а0, ап и 0П, введенные в (9.3.44) —
(9.3.46), мы можем, вычитая почленно (9.3.35) из (9.3.43), раз-
ность Ух—Т]х представить в виде
,, а„ . V ( , о • 2лш \ ,п „
ух~= у + X ( а«С05-дг+₽«5!П —) • (9.3.53)
П = 1 ' '
Пользуясь (9.3.53), можно найти М(г|х—Ух)г, если помимо ма-
тематических ожиданий Ma2, Ma2 и Мб2 знать еще моменты Maba„,
Maftf5M и Мр*а,я, где k^m.
Однако эти последние математические ожидания равны нулю
в силу условий ортогональности рассматриваемых систем тригоно-
метрических функций, а потому величины а4 и $т некоррелированы
и, следовательно, ввиду нормальности (допущение 2)) и (5.2.39)
независимы друг от друга.
Так например, используя соотношение (9.3.45), получим мате-
матическое ожидание произведения величин as и ат в виде
MaAaOT = ^2 М 6,- cos cos =
\/=о /=о /
tf-l AZ-i
' = 0 i=0
N -1 N -1
4 Ч" nt’ 2-rfef 2зт™ 4a2 v* 2лй«
= гтг- 2 'Ло< COS COS -77- = —= > COS —Т7 -
Д2 ‘ л Л/ Л2 « i\
1=0 i=0
COS
2nmi
~N~
0,
§ 3] ЗАДАЧИ РЕГРЕССИИ 351
так как в силу условий ортогональности при k=^m
N -1
ЕЫ/.i 2nmt п ,п „ _,,
cos -Jj- cos — = 0. (9.3.54)
f Si О
Таким образом, величины <х0, а,, . .., ар, р,, ..., 0р нормально
распределены с центром в нуле, с одной и той же дисперсией и
независимы друг от друга.
Пользуясь этим и применяя (9.3.44), (9.3.45), (9.3.47), (9.3.49)
и (9.3.50) из (9.3.53), найдем математическое ожидание квадрата
отклонения Ух от г)х, т. е. первый член правой части соотношения
(9.3.52)
11 «) р / \
,,, ,» mao , V'' / г 2 2лпх , .«О2 . 2 2лпх \
М (Ух— Пх) = — + > . ( Mancos — + Sin2 —iy- \ =
П = 1 X /
р
os , 2с2 Vs 7 2 2лпх , . 2 2лпх\ ог . 2о2 о2
= у+у! (cos ~7Г + sin ~лН = А/ + у-Р = у(2/’+1).(9.3.55)
Далее для 2-го члена соотношения (9.3.52) имеем
р
+ Е M(6xa„)cos-^ + M(6x₽n)sin^l ,(9.3.56)
П = 1 L *
где ввиду того, что М(6х6() = 0 при x=y=i согласно (9.3.44)
N-1
(6Л>=4 S м =4 °2* (9-3-57)
1 = 0
согласно (9.3.45)
W-1
г. 2 х4 .а . о с , 2л/ц 2 2 2ллх п
= -у 2- М cos — = У ° cos -дГ <9-3-58>
1 = 0
и согласно (9.3.46)
(9.3.59)
Подставляя (9.3.57) и (9.3.58) в (9.3.56), получим:
р
^[§Л(Ух-11х)]-_. —о 2^ (cos —+Sin — j =
П = 1 7
<9-3.60)
352
ОСНОВЫ ТЕОРИИ КОРРЕЛЯЦИИ
[гл. IX
Теперь, подставляя (9.3.38), (9.3.55) и (9.3.60) в (9.3.52), будем
иметь:
МД* = М (ух-Ух)г = ~(2р± 1)-~ (2р + 1) + о2 =
= ^-[N-(2p + l)], (9.3.61)
откуда на основании (5.2.4)
М
I
ДГ-(2р+1)
Л/-1
X —О
= а2.
(9.3.62)
Поэтому величина эмпирической дисперсии кажущихся откло-
нений
*9-3.вЗ>
Х = 0
служит несмещенной оценкой дисперсии о2.
Учитывая это и независимость а0, ап и [}„ от $ (что можно по-
казать), а также принимая во внимание (9.3.47), (9.3.49) и (9.3.50),
замечаем, что на основании сказанного в п. 6.3.2 величины
Тап= (9.3.64)
Ть,= JLaJi^n , (9.3.65)
г = 1/ А (9.3.66)
— г £ 2s
где а=1,2, ...,р, следуют закону распределения Стьюдента
с — 2р—1 степенями свободы и позволяют тем самым строить по
данным наблюдений доверительные интервалы для у, ап и Ьп.
Доверительный интервал для полинома при каждом фиксиро-
ванном значении х можно получить, замечая, что согласно сказан-
ному в п. 6.3.2 величина
(9'3'67)
при каждом х следует также закону Стьюдента с N— 2р—1
степенями свободы.
§ 3]
ЗАДАЧИ РЕГРЕССИИ
353
Задаваясь уровнем значимости °/0, найдем доверительный ин-
тервал для Г)х в ! иде
Yx-^qs /2-^1<МГ(х)<Ух + м~ ]/2-^. (9.3.68)
Для оценки средней точности приближения полученным из опыта
тригонометрическим полиномом (9.3.43) искомого полинома (9.3.35)
N
рассмотрим величину (2ру-1) S2 = J (Кх — Т]х)2 dx, которая согласно
О
(9.3.53) и формуле Парсеваля — Ляпунова1) равна
2лпх
a„cos —
п . 2лпх
М1Г> —
(9.3.69)
На основании (9.3.47), (9.3.49) и (9.3.50) найдем:
М[(2р+1)22] = о2 4-2ра2 = (2р+- 1)о2, (9.3.70)
а потому из (9.3.69) и (9.3.70) на основании (3.1.8) получим:
(9.3.71)
Таким образом, для о2 имеются две независимые оценки s2 с
числом степеней свободы &2 = /V—2р—1 и У2 с числом степе-
ней свободы k = 2/9-4- 1. Следовательно, отношение
V2
F = ^- (9.3.72)
S2
согласно сказанному в п. 6.3.3 имеет F-распределение с /( и Д
степенями свободы.
Учитывая (9.3.72) и задавшись доверительной вероятностью,
можно оценить значение среднего квадрата отклонений полинома
(9.3.43) от полинома (9.3.35), т. е. величину (9.3.69) следующим
образом.
Находим по таблицам ^-распределения значение Fp при числе
степеней свободы Ди/,, отвечающее выбранной доверительной
вероятности Р. Затем вычисляем величину s2 по формуле (9.3.63),
используя данные наблюдений у„, ух, уг, ..., и подсчеты по
-яим же данным в тех же точках значений Yx по формуле (9.3.43).
') См., например, Г. П. Толстов, Ряды Фурье, М., Физматгиз, 1960.
12 Н. В. Смирнов, И В. Дунин-Барковский
354
ОСНОВЫ ТЕОРИИ КОРРЕЛЯЦИИ
(гл. IX
Произведение Fp ss будет представлять опенку S2. После умно-
жения этого произведения на (2р 1) получим согласно (9.3.69)
искомую оценку средней точности приближения.
Для простоты пусть мы имеем профилограмму поверхности после
обточки детали из пластичного сплава на точном и жестком станке
при малом усилии резания. Случайная составляющая неровностей
поверхности предполагается малой по сравнению с систематической
составляющей т]х, а также по сравнению с погрешностями воспро-
изведения профиля и измерения его ординат, причем эти погреш-
ности удовлетворяют ранее приведенным условиям 1) — 4) и, следо-
вательно, для них справедливы соотношения (9.3.37) и (9.3.39).
На основании данных о характере неровностей обточенных по-
верхностей предполагается систематическую составляющую неров-
ностей рассматриваемой поверхности описать тригонометрическим
полиномом 3-го порядка, т. е. принимается р—3. Для получения
надежных данных принимается N = 12 > 2р+ 1 = 7.
Результаты измерений ординат ух в 12 равноотстоящих друг
от друга точках и подсчеты по ним коэффициентов Фурье способом
12 ординат'), упрощающим выкладки по сравнению с расчетами
непосредственно по формулам (9.3.40)—(9.3.42), приведены в таб-
лице 9.3.1. Для полноты в этой таблице подсчитаны коэффициенты
Фурье для 5—6 гармоник.
Способ 12 ординат или вообще числа ординат, кратного четырем,
заключается в следующем. Пусть число ординат, по которым под-
считываются коэффициенты Фурье (9.3.40) — (9.3.42), равно N—^q.
Часто общее число коэффициентов берут равным числу ординат,
т. е. представляют периодическую функцию полиномом
Ф(лг) = 7 + Й1 cos х + а2 cos 2х-ф ... + а2?_, cos (2q — 1) x +
-фа2? C0S2I/X + Z?! sin x ф- Ьг sin2x+ ... 4-^_,sin (2q— l)x.
Все коэффициенты an и bn, за исключением аг , вычисляются
по формулам (9.3.40)-—(9.3.42). При этом вспомогательная сумма
N-1
2 cos nxi cos kxit
1 = 0
, 2ni
где я—вспомогательное число и = , преобразовывается так:
7V-1 Л’-1
у ^2 cos(«+ k)Xi + ~^ X cos (л — k)x;.
i—o f = o
’) См., например, Я- С. Безикович, Приближенные вычисления,
М.-Л., Гостехиздат, 1949, 384—391.
§ 3]
ЗАДАЧИ РЕГРЕССИИ
355
При п = k = 2 ни одно из этих слагаемых не обращается в нуль,
2 л7
так как cos (л -ф k) = cos 4</ = 1
и cos (л — k) xi = cos 0 = 1 и,
л-i
следовательно: 2 c°s2 2qx~ N.
Таким образом, для определения коэффициента л2? имеем:
Л-1
Naiq = 2 У‘cos 2(^-
i = i
2зт i
Так как cos 2qxt = cos 2q — = cos ш = (—1)', to
= s’(-1)4-
1=0
Приведем сводку всех формул для определения коэффициентов
тригонометрического полинома в рассматриваемом случае N=4q:
Л-1 Л-1
= ^ = 12 (-П'Л-
i = о I ~ о
ДГ-1 ДГ-1
= y^ = 2^sinwi-
£=0 4 = 0
(9.3.73)
В последних двух формулах п может принимать значения:
1, 2, 2q—1. Замечая, чго
п2л(4р — i) („ 2лл1 \ 2лш
cos nxN_, = cos---= cos 2лл-------------— = cos -г— = cos nxt
w 1 4q \ 4q j 4q 1
и в то же время sinn.r^^ — sin nxt, мы можем каждые два члена,
равноудаленные от концов периода, соединить вместе.
Введем обозначения:
«о=Л9. s24=y^r 81=У1+У^-1> di=yi-yiq-i-
Тогда формулы (9.3.73) приведутся к такому виду:
Л 1 2 1 2
N V та»= 2^ si> -Vfl2<7= X ( —!)Ч
1=0 1 = 0
yv_
--1 2
N V1 2- (=0 4-^— X d-slnnx^ 1 = 0
(9.3.74)
12*
356 ОСНОВЫ ТЕОРИИ КОРРЕЛЯЦИИ [гл. IX
Число слагаемых в каждой сумме уменьшилось вдвое. При вы-
числении S; и dt ординаты располагаются в следующем порядке:
Л Л
У tq Улд-у Уьд-г Уьд-г • • •
Суммы: s0 s, s2 s, ... 4-2?_1 s2q
Разности: d, d d ... rf
J л 9 itj 1
Можно еще сократить число слагаемых в формулах. Заметим, что
для четных значений п: cos/гх( = cos nx2?_f, sin/ZA:,— —sinfl f, a
для нечетных значений: coswx;=—cos«x2?_1( sinnxt — sinnx2q_2.
Таким образом, в формулах (9.3.74) равноотстоящие члены мы
можем соединить в один член, введя величины:
ci = si + siq-i, =
&t = di—dsg_lt
где l принимает значения 0, 1,2, ...,<?— 1.
Формулы (9.3.74) приведутся к следующему виду:
N v
2 ао 2«< Ci ’
i
лч9=ф-1)Ч-.
N 'V
-2-«n==Z-c. coszzx,.,
i
N , v X •
= L Sln nxi
N V л
У an = 2- di cos nxi’
i
4*„=l>s-n nx‘
i
Величины c;, </(, <jf и di удобно
so s,
$2q Ssq-i
Суммы: c0 c, r2 ... c?_, cq
Разности: 6!0 dt d2 ... ,dq_2
при n
четном, ( (9.3.75)
при n
нечетном.
вычислять в следующем порядке:
s2 ... S<7
•S’ s
2(7—2 ’ ’ * u<7+ 1
ЗАДАЧИ РЕГРЕССИИ
357
§ 3i
и также
^1 ^2 • • • *^<7-1 ^<7
^zq— 1 ^2<7-2 ^2<у-2 • ' • ^2?+1
Суммы: о, о, о, ... о„_, о.
Разности: о, д2 63 ... д?_,
Если принять 9 = 3, то получим Д7 = 4-3=12. Вычисление коэф-
фициентов Фурье по приведенной выше схеме при N— 12 назы-
вается способом 12 ординат. Заметим еще, что ординаты всегда
можно перенумеровать, считая нулевое слагаемое первым, пер-
вое— вторым и т. д.
Тогда в формулах (9.3.40) — (9.3.42) и (9.3.73) суммирование будет
производиться от 7 = 1 до / = N, а в формуле (9.3.74) от / = 1 до / = у .
Из формул (9.3.75), сводя все входящие в них тригонометри-
ческие величины к синусам 30°, 60°, 90°, получим
12y=co + ci +сг + с.>
12a8==co—ci+c2-c3<
6 а, = д0 4 d, sin 60° 4 дг sin 30°,
6fla=c04ct sin 30°—сг sin 30°—с8,
6 а =д. —д_,
б^-^-^пЗО’ + с,, <9-37б>
6 а5 = дй — дг sin 60° 4 д2 sin 30°,
6 bt = a, sin 30° 4 а2 sin 60° 4 os,
6 />2 = 6г sin 60°4 62 sin 60°,
6Ь8=о, —os,
6 b4= 6, sin 60°— 62 sin 60°,
6 bs = o, sin 30е— a2 sin 60° 4 o3.
Для удобства расчетов по формулам (9.3.76) выкладки све-
дены в таблицу 9.3.1.
В первой части таблицы 9.3.1 сделаны подсчеты величин 50, s!t
с0, с,-, 30, dit о(- и 6( по рассмотренной выше схеме способом
12 ординат.
Далее каждая из букв с0, сь да и умножается на синус
угла, находящийся в одной строчке с этой буквой. Так, например,
О, умножается на sin 60°. Результаты умножения суммируются по
столбцам I и II, а затем вычисляются суммы сумм 14II и раз-
ности сумм 1 —11.
Подсчет (способом 12 ординат) коэффициентов Фурье
для параболического профиля поверхности обточенной детали
Таблица 9.3.1
Ординаты профиля в мм профилограммы Х10 — «, = 36 «2=124 4'2=257 w4 = 458 «5=702 «,= 1006
Р12 — «„ = 39 «,о=119 «ч = 252 «e=443 «7 = 694 -
Суммы ординат ь0=2 s,=75 s2 = 243 s3 = 509 s4=901 s5= 1396 s„ = 1006
Разности ординат — dx^=— з d2 =5 d3=5 d4 = 15 <4=8 —
Подписанные суммы s, = 1006 >5 = 1396 s4=901 — —- — —
Суммы сумм = 1008 с, = 1471 c3= 1144 c3 = 509 — — —
Разности сумм д0 =—1004 <4 = —1321 <4 = —658 — — — —
Подписанные разности — __ — d3 = 5 d, = —3 —
Суммы разностей — — — o3 = 5 a3 = 20 o, = 5 —
Разности разностей — — — — 62 -10 6, = 11 —
ОСНОВЫ ТЕОРИИ КОРРЕЛЯЦИИ [ГЛ. IX
Умножение на синусы углов
Синусы 1 П I п I 11 1 II
sin 30° =-|- — — Т=-329 — —-у = —572 т=735 —
Кз sin 60° =—~— — 1 — Ц2—114S — — — —
sin 90“ = 1 с0= 100& с, = 1472 д0 = —1004 — с0 = 1008 —с3 = —509 да =—1004 Э2= —658
sin90° = l с2 = 1144 с, = 509 — — — — — —
Суммы 2-152 1980 —1333 —1146 436 226 —1004 —658
Суммы I + U 12 ^ = 4132 6а, = —2479 6а2 = 662 —
Разности I—II 12аь = 172 6а3 = —187 6а4=210 6а3 = —346
Коэффициенты ап в мм про- филограммы -?=34’4 а, =—41,3 01=11,3 а, =—5,8 а4=3,5 а5 = —3,1 а.= 1,4
ЗАДАЧИ РЕГРЕССИИ 359
Са
Продолжение
Синусы 1 н 1 II I 11 I 11
sin 30° = -i- £-2.5 — — — — —
sin — Ог КЗ 2 1 ’' Ц1-.0 2 — — —
sin 90° = 1 о3 = 5 — — — а, =5 Оз = 5 — —
Суммы 7,5 1,7 1,0 0,9 5 5 — —
Суммы 1 + 11 6*, = 9,2 6*2 = 1,9 — —
Разности 1—II 6*s = 5,8 еб4=о, 1 6*3 = 0 —
Коэффициенты в мм профи- лограммы bt =0,15 й2 = 0,03 *2 = 0 *4=5:0 *5=0,10 — — —
ОСНОВЫ ТЕОРИИ КОРРЕЛЯЦИИ [гЛ. IX
§ 3] ЗАДАЧИ РЕГРЕССИИ 361
Коэффициенты Фурье, умноженные на числа 6 или 12, будут равны
соответствующим суммам сумм (1 + 11) или разностям сумм (I — II),
как это показано во второй части таблицы 9.3.1. Так, например,
6а, будет равно сумме 1 + 11 сумм по второй паре столбцов 1 и
11, а 12а, равно разности I —11 сумм по первой паре столбцов 1 и 11.
Окончательное вычисление коэффициентов а0, ап и Ьп произво-
дится путем деления соответствующих сумм или разностей соот-
ветственно на 6 или 12. Результаты подсчетов показывают, что
коэффициенты а4 — а6 и в особенности Ьх — bs малы по сравнению
с а,, что подтверждает целесообразность 1) описания полино-
мом 3-го порядка и 2) сохранения в нем только коэффициентов
при косинусах, т. е. ах, аг и а8.
Таким образом кривая т]х описывается полиномом 3-го порядка
т]х « Ух —
= у =34,4 — 41,3 cos —+ 11,3 cos — —5,8 cos— , (9.3.77)
р _8 spea spea Spes
где $рез—подача резца на 1 оборот детали. Он достаточно близок
к исходной кривой Т)х.
Чтобы построить доверительные интервалы для коэффициентов
Фурье, вычисляем сначала значения Ух с помощью полинома
(9.3.77) в тех точках, где измерялись ординаты ух, как это пока-
зано в таблице 9.3.2 при угловых абсциссах профиля от 0° до 180°.
Очевидно, что ввиду симметрии кривой в точках от 180° до 360°
будут те же значения ординат, но располагаться они будут в убы-
вающем порядке.
Вычисление дисперсии кажущихся отклонений приводятся в таб-
лице 9.3.3.
По данным таблицы 9.3.3 находим эмпирическое среднее квад-
ратическое кажущееся отклонение по формуле (9.3.63)
s2 ~ То—/<> 1Л х 159,64 « 32 мм2 профилограммы,
2 £ — • О ~г” 1)
а = ]/32 «5,7 мм профилограммы.
Задавшись доверительной вероятностью 0,90 по таблице V
приложений, находим в соответствии с формулами (9.3.64) — (9.3.66)
1О°/о-ные пределы (q= 100— 0,90-100 = 1О°/о) для искомых коэф-
фициентов Фурье , ап и Ьп. При числе степеней свободы & =
= 12—2-3—1=5 они составляют -
*ю,5 = 2,015,
или
Т 5 7
t-----^ = 2,015- "—:«4,7 мм профилограммы,
Ут Ут
362
ОСНОВЫ ТЕ8РИИ КОРРЕЛЯЦИИ
[ГЛ. !Х
Таблица 9.3.2
Значения Yx= Sp=s полинома, описывающего параболический профиль
л „ ( ЗбО.с
обточенной детали I где и =-----
\ 8раз
№ гармо- ники Коэф- фици- енты а„ и Ьп Показа- тели Значения гармонических составляющих
0° 30° 60° 90° 120° 150° 180’
1 —41,3 cos 1и 1 0,8660 0,5000 0 —0,5000 —0,8660 —1
a, cos 1и —41,3 —35,8 —20,6 0 20,6 36,8 41,3
2 11,3 cos 2и 1 0,5000 —0,5000 —1 -0,5000 0,5000 1
а2 cos 2и 11,3 5,6 —5,6 —11,3 —5,6 -5,6 11,3
3 -5,8 cos За 1 0 —1 0 1 0 —1
aa cos Зи —5,8 0 5,8 0 -5,8 0 5,8
Но 2 34,4 34,4 34,4 34,4 34,4 34,4 34,4
S =У р = 5 1 х —1,4 4,2 14,0 23,1 43,6 75,8 92,8
Таким образом, с вероятностью 0,9 следует считать, что иско-
мые коэффициенты Фурье (в данном случае совпадающие с ампли-
тудами) охватываются на числовой оси следующими случайными
интервалами:
—41,3 — 4,7 <а, < — 41,3+4,7
или
—46,0<а]<—36,6 мм профилограммы,
и аналогично
6,6 << < 16 мм профилограммы
или
— 10,5<as<—1,1 мм профилограммы.
075
Вычисление дисперсии кажущихся отклонений
Таблица 9.3.3
№ точек ) 2 3 4 5 6 7 8 9 10 11 12 2д/
Наблюденные значения ординат ух 3,6 12,4 25,7 45,8 70,2 100,6 69,4 44,3 25,2 11,9 3,9 0,2
Значения Yr полинома 2P=S 4,2 14,0 23,1 43,6 75,8 92,8 75,8 43,6 23,1 14,0 4,2 —1,4
Кажущиеся отклонения ^х = Ух VX —0,6 — 1,6 2,6 2,2 —5,6 7,8 —6,4 0,7 2,1 —2,1 —0,3 1,6
0,36 2,56 6,76 4,84 31,36 60,84 40,96 ( 0,49 4,41 ' 4,41 0,09 2,56 159,64
СО
ст>
со
ЗАДАЧИ РЕГРЕССИИ
364 ОСНОВЫ ТЕОРИИ КОРРЕЛЯЦИИ (гл. IX
Для того чтобы найти границы доверительной области для
искомого полинома, используем (9.3.67). Среднее квадратическое
отклонение величины т]*—Yx будет:
s К2р+Т 5,7 К2-3+1 . . .
- —= ——4,4 мм. профилограммы.
С вероятностью 0,9 по таблице V приложений находим 1О°(о-ные
пределы для ординат полинома (по закону Стыодента) при числе
степеней свободы &=12— 2-3 — 1 = 5):
5.4,4 = 2,015-4,4 аз 8,8 мм профилограммы.
Теперь находим среднюю точность приближения полученным из
опыта полиномом искомого полинома. Выбираем доверительную
вероятность 7^= 0,95. По таблице VI приложений находим, что
при числах степеней свободы /г, == 2-3 -|- 1 =-7 и = 12— 2-3 —1=5
этой вероятности соответствует предел 4,88 (5’/0-ный, так как
100—95 = 5). На основании (9.3.72) получим:
S2 = 4,88 • 32 лз 156 ммг профилограммы.
Далее согласно (9.3.69) находим:
л-
^(Ух—т|х)2 dx~ (2-3 -|- 1)-156= 1092 мм* профилограммы,
о
причем относительную величину этого критерия можно получить,
поделив его абсолютное значение на интеграл
= г" — 24-104 мм* профилограммы
(при s=120 и =18 мм профилограммы), откуда имеем:
$ (Yх—
Ъ= °’004 = °-4°/о-
J [МУ (х)]2 dx
о
что указывает на достаточно хорошее соответствие эксперимен-
тально полученного полинома Ух оценке его истинного значения т[х.
ГЛАВА X
ВЕРОЯТНОСТНО-СТАТИСТИЧЕСКИЕ МЕТОДЫ РАСЧЕТА,
АНАЛИЗА И КОНТРОЛЯ ТОЧНОСТИ
§ 1. Теоретико-вероятностный метод расчета
размерных цепей
10.1.1. Понятие о размерных цепях. Точность выполнения на
производстве размеров деталей машин играет важную роль. Многие
из этих размеров взаимно связаны между собой, составляя замкну-
тый контур, в котором невозможно менять величины одной соста-
вляющей без того, чтобы не изменилась другая составляющая. Такая
совокупность размеров и называется размерной цепью, а входящие
в нее размеры называются звеньями.
В состав размерной цепи обычно входит зазор, натяг, межосевое
расстояние или подобная им величина, определяющая эксплуатацион-
ные свойства данной сборочной единицы. Расчетным путем или на
основании опытных данных для этого звена обычно бывают опре-
делены границы допустимых с точки зрения эксплуатационных пока-
зателей пределы. Такое звено называют замыкающим, конечным
или исходным. Задача заключается в первую очередь в том, чтобы
для остальных так называемых составляющих' звеньев назначить
такие предельные отклонения в чертежах, при соблюдении которых
на производстве было бы обеспечено получение при сборке разме-
ров конечного ззена в заранее установленных границах, причем без
пригонки и доработки, т. е. на основе принципа взаимозаменяе-
мости. Определение расчетным путем вышеуказанных отклонений
составляющих звеньев называется проектным расчетом размерной
цепи. Если в чертежах уже проставлены отклонения размеров звеньев
и требуется лишь проверить, в какой мере они обеспечивают соблю-
дение заданных для конечного звена границ, то эта проверка, выпол-
няемая в расчетном порядке, называется поверочным расчетом раз-
мерной цепи.
Можно, конечно, по-разному подходить к решению указанных
расчетов. Если, например, назначить для составляющих размеров
настолько малые или, как говорят, строгие допуски, чтобы их сумма
366
МЕТОДЫ РАСЧЕТА, АНАЛИЗА И КОНТРОЛЯ ТОЧНОСТИ
[ГЛ. X
не превышала допуска конечного звена, то, естественно, что при
хорошей технологической дисциплине на производстве конечное звено
будет всегда оставаться внутри установленных для него границ.
Такой подход к расчету размерных цепей, именуемый расчетом по
методу «максимума-минимума-», несмотря на его простоту, далеко
не является наилучшим. Дело в том, что этот метод в совершенно
одинаковой мере учитывает любые возможные как большие, так и
малые отклонения размеров конечного звена. Между тем большие
по абсолютной величине отклонения обусловливаются соответственно
большими по абсолютной величине и редко встречающимися откло-
нениями составляющих звеньев, причем сочетания только таких откло-
нений представляют собой случайные события, имеющие настолько
малые вероятности, что они почти не встречаются на практике. При
учете таких отклонений приходится назначать строгие допуски на
размеры составляющих звеньев, чтобы уложиться в технические пре-
делы, установленные для конечного звена. Всякое уменьшение допу-
сков размеров сопряжено с увеличением затрат труда и времени на
производстве, причем производственные затраты растут в гораздо
большей степени, нежели сокращаются допуски. Поэтому выгоднее
допустить выход конечного звена за установленные для него техни-
ческие пределы с некоторой достаточно малой практически пренебре-
жимой вероятностью ^(например, О,5°/о; О,3°/0; О,1°/о и т. д.).
Если при этом в условиях массовой поточной сборки в среднем
один — пять сборочных узлов на 1000 не будут удовлетворять техни-
ческим условиям, то переборка их обойдется во много раз дешевле,
чем изготовление всех деталей узла по более высоким классам
точности. Поэтому расчет размерных цепей, основанный на учете
распределения вероятностей значений конечного звена, является
более прогрессивным, хотя, естественно, и несколько более слож-
ным. Этот метод расчета называется теоретико-вероятностным
методом расчета размерных цепей.
Заметим, что понятие размерной цепи и соответствующая мето-
дика расчета применимы не только к деталям, входящим в сбороч-
ный узел; это—только частный случай размерной цепи, а именно
сборочной размерной цепи. Кроме того, можно рассматривать еще,
например: подетальные размерные цепи, составленные из оконча-
тельных размеров одной только детали; пооперационные (техноло-
гические) размерные цепи, составленные из размера заготовки, по-
операционных технологических припусков на обработку и оконча-
тельного размера детали; цепи погрешностей измерения, включающие
погрешность измерения производственных объектов и их составляю-
щие, отвечающие ступеням поверочной схемы, через которые про-
исходит передача размера от эталона длины до размера изготов-
ленной на производстве детали машины.
§ 1] ТЕОРЕТИКО-ВЕРОЯТНОСТНЫЙ МЕТОД РАСЧЕТА РАЗМЕРНЫХ ЦЕПЕЙ 367
Звенья цепи могут быть по-разному расположены в пространстве,
и от этого зависит трудоемкость их расчета. Наиболее простой
является линейная цепь с коллинеарными звеньями; затем идет пло-
скостная цепь с компланарными звеньями и, наконец, встречаются
пространственные цепи с как угодно расположенными в простран-
стве звеньями.
Из числа звеньев цепи обычно сразу выделяют конечное звено,
по которому ведут расчет. Это звено практически получается в резуль-
тате суммирования всех
остальных звеньев. По
отношению к конечно-
му звену все остальные
звенья будут составля-
ющими.
Составляющие звенья
в свою очередь подраз-
деляются на:
1)увеличивающие (или
положительные},
2) уменьшающие (или
отрицательные}.
Увеличивающим (по-
ложительным) звеном
называется такое, с уве-
личением которого (при
постоянстве остальных
составляющих звеньев)
конечное звено увеличи-
вается. Уменьшающим
(отрицательным) зве-
ном называется'такое, с
увеличением которого
(при постоянстве остальных составляющих звеньев) конечное звено
уменьшается.
Примером размерной цепи может служить замкнутый контур,
образованный размерами А, В, С, L, S и К узла коробки передач,
показанного на рис. 63. Здесь конечным звеном является, естест-
венно, зазор К. Размеры А и В представляют увеличивающие, а
размеры С, L и 5 уменьшающие звенья.
Из рис. 63 ясно, что
К=(А±В} — (С-НЛ4-5). (10.1.1)
Если обозначить увеличивающие звенья через Р, (i — 1, 2, . . ., т),
а уменьшающие — через Nj(j= 1,2, ..., л), то, используя известную
теорему о проекциях составляющих и замыкающей на некоторую
368 МЕТОДЫ РАСЧЕТА, АНАЛИЗА И КОНТРОЛЯ ТОЧНОСТИ [ГЛ. X
ось, вообще будем иметь:
т п
(Ю.1.2)
I - I / = 1
Это соотношение называют основным уравнением размерной цепи.
10.1.2. Расчет размерной цепи. Под расчетом размерной цепи
обычно понимают две рассмотренные в п. 10.1.1 операции:
1) поверочный расчет,
2) проектный расчет.
Первая задача — однозначная и более простая.
Для решения второй задачи требуются дополнительные условия.
В качестве такого условия чаще всего служит назначение при-
мерно одного класса точности для всех составляющих звеньев. При
этом определяют среднюю точность всех составляющих звеньев
в единицах допуска и по числу единиц допуска определяют единый
класс точности составляющих звеньев, по которому и назначают
предельные отклонения размеров.
Часто по таблицам ОСТ берут скользящие посадки для всех
составляющих звеньев, кроме одного — резервного, для которого
вычисляют нестандартные отклонения, исходя из установленных
отклонений всех остальных звеньев.
Расчетные формулы при теоретико-вероятностном методе расчета
имеют вид:
а) для поверочного расчета
т _ п
КсР= 2 (РСр( + аД.)- 2 (<4PJ аД), (10.1.3)
i = 1 / = 1
б) для проектного расчета
где Pcpi (Z—1, 2, ..., m), 2Vcpj (/=1, 2, ,..,«) —средние
размеры (по чертежу) соответственно конечного, увеличивающего и
уменьшающего звена, 6К—допуск конечного звена, 6К, 6;, 6^—поло-
вины допусков соответственно конечного, увеличивающего (в фор-
муле (10.1.4) вообще составляющего звена) и уменьшающего звена,
т и п — числа соответственно увеличивающих и уменьшающих звеньев,
а — число единиц допуска, равных 0,5^/dcp, в допуске каждого
из составляющих звеньев, rfcpj— средний диаметр для того интервала
диаметров по ОСТ, в который попадает размер г-го звена.
§ 1] ТЕОРЕТИКО-ВЕРОЯТНОСТНЫЙ МЕТОД РАСЧЕТА РАЗМЕРНЫХ ЦЕПЕЙ 369
Коэффициент относительной асимметрии а,-, относящийся к /-му
составляющему звену, применяется при расчете размерных цепей
Рис. 64. Графическая интерпретация коэф-
фициента относительной асимметрии а,-.
для характеристики несимметричности распределения вероятностей
этого звена относительно поля допуска
где До,-—координата середины поля допуска z-ro звена (рис. 64),
б,- — половина допуска, МХ,- — математическое ожидание /-го звена.
Величина До1- определяется по формуле
. _ Л’н6| 4" хнм,-
“ 2 ' ’
л'нбг—- верхний предел звена, хнмг— нижний предел звена.
Коэффициент относительного рассеивания относящийся к /-му
звену, служит при расчете размерных цепей для сопоставления
величины рассеивания значений данного звена с рассеиванием при
нормальном распределении
Ь = (Ю.1.7)
ЛН
где Xj и Хн—относительные средние квадратические отклонения
соответственно z-го составляющего звена при действительном и при
нормальном распределениях вероятностей.
Относительное среднее квадратическое отклонение определяется
соотношением а.
А.,- = —- ,
б'-
где oi — среднее квадратическое отклонение, б,- — то же, что
в (10.1.6).
370 МЕТОДЫ РАСЧЕТА, АНАЛИЗА И КОНТРОЛЯ ТОЧНОСТИ [ГЛ. X
Значения а; и для различных законов распределения берутся
по таблицам ').
Формулы (10.1.3) — (10.1.5) легко выводятся с помощью (10.1.2),
(5.2.4) и (5.2.22) в предположении независимости (или слабой зави-
симости) звеньев, приводящей на основании центральной предельной
теоремы при достаточном их числе к приближенной нормальности
распределения конечного звена, при которой 0^=0 и kK=\.
Пусть, например, требуется определить размер конечного звена
узла, показанного на рис. 63, если коэффициенты az и /г;- соста-
вляющих звеньев заданы таблицей 10.1.1
(они взяты по таблицам ')).
По формуле (10.1.3) находим средний
размер конечного звена
Кср= [(30,025+ 0-0,075) +
+ (40,000+0-0,10)]—[(5,105—0,28-0,045) +
4- (59,8254-0,63-0,125) +
4- (4,115 + 0,33 -0,035)] =
= 70,025 — 69,123 = 0,902.
По формуле (10.1.4) находим половину поля
допуска конечного звена
&к = /12-0,0752 + 1,262-0,102 + 1,142-0,0452 + 0,752-0,1252 + 1,412-0,0352 =
= КО,035357 = 0,1880.
Кнб = 0,902 + 0,188= 1,090, Кнм = 0,902—0,188 = 0,714.
Выбираем номинальный размер равным единице (по таблице номи-
нальных диаметров ОСТ). Тогда окончательно
/<=1^.’29s6, дх = 0,376.
Предположим теперь, что из условий работы механизма отклоне-
ния конечного звена должны быть заключены в пределах 1 + 0,05 мм,
следовательно, получившийся у нас размер должен быть изменен
путем изменения отклонений составляющих звеньев. Требуется опре-
делить надлежащие отклонения. Имеем:
Кр, а ~ Кр, в 40, Кр, с = 415, Кр, l ~ 65, Кр, s==^>5.
По формуле (10.1.5) определяем число единиц допуска
2-100
а --- ----- ' — — =
У р.2425 + 1,262-4024 4. 1,142-4,524 + 0,752-65'2 ' + 1 ,412-4,52/з
Таблица 10.1.1
Звенья а. ki
А В С L S 0 0 —0,28 +0,63 +0,33 1 1,26 1,14 0,75 1,41
*) См. «Общую часть», стр. 508—511,
§ 2] АНАЛИЗ ТОЧНОСТИ ТЕХНОЛОГИЧЕСКИХ ПРОЦЕССОВ 371
По энциклопедическому справош ику «Машиностроение», т. V, 1947
(ЭСМ, т. V) находим, что а = 29,8 соответствует 3-му классу точности.
Пусть резервным звеном будет звено В. По ЭСМ, т. V, стр. 10,
берем для остальных звеньев отклонения по скользящей посадке
3-го класса точности в «системе отверстия», т. е.
4 = 30 — 0,045, С=5~0,025, £ = 60 — 0,06, 6'=4 —0,025.
Определим средний размер звена В:
^ср = ^ср~Иср + +Лд) + (Сср+ « А) + (^-ср + аА.) + (\р + а.А) =
= 1—(29,9775+0)+ (4,9875 —0,28 0,0125)Н-
+ (59,970 + 0,63 • 0,030) + (3,9875 + 0,33 0,0125) = 39,987 мм.
Вычислим половину допуска звена В\
йХ = ёк - йЖ - йЖ - йЖ - /г = 502 -12 -22,52 —
— 1,142 - 12,5s — 0,752-302 — 1,412 -12,52 = 974,
kB8B = }/974 = 31,2 мк, = = 24,8 мк.
Таким образом,
О__ л л + 0,012
В — * V—0,038*
При указанных размерах звеньев теперь уже будет обеспечен тре-
бующийся размер конечного звена /(—1 +0,05.
Мы видим, что для выполнения теоретико-вероятностного расчета
необходимо знать законы распределения составляющих звеньев,
в соответствии с которыми выбираются коэффициенты а,- и kt по
таблицам ’). В главе IV уже упоминалось, что в большинстве слу-
чаев погрешности обработки подчиняются нормальному закону.
Тем не менее гипотеза о том или ином законе распределения (в част-
ности, о нормальном) может быть проверена методами, рассмотрен-
ными в § 3 главы VII, на основании выборки из текущей про-
дукции станков, на которых выполняются финишные операции обра-
ботки соответствующих (или им аналогичных) деталей.
§ 2. Статистические методы анализа точности и стабильности
технологических процессов
10.2.1. Статистические методы анализа точности техноло-
гического процесса. Под статистическими методами анализа точ-
ности технологического процесса, точнее говоря, каждой отдельной
его операции, обычно понимают сопоставление «поля рассеива-
ния» интересующего нас признака качества (чаще всего размера) на
9 См. «Общую часть», стр. 508 — 511.
372 МЕТОДЫ РАСЧЕТА, АНАЛИЗА II КОНТРОЛЯ ТОЧНОСТИ [ГЛ. X
данной операции с заданным по технологической карте на эту опе-
рацию допуском. «Полем рассеивания», отвечающим некоторой
вероятности, называется зона, лежащая между границами значений
а
признака качества, вероятность выхода за которые практически
пренебрежимо мала. Если поле рассеивания не больше допуска, то
суммарная точность операции признается удовлетворительной (или
излишней, если допуск намного больше поля) и точность считается
недостаточной, если поле больше допуска. При детальном анализе
поле рассеивания строится с учетом погрешностей настройки, т. е.
с учетом уклонения центра рассеивания от соответствующего до-
пускаемого значения его положения (при симметричном рассеивании
допускаемые значения будут лежать в средней части поля допуска).
В ряде случаев учитываются еще и погрешности измерений, накла-
дывающиеся на погрешности обработки и увеличивающие поле рассеи-
вания измеренных размеров.
Таким образом, при анализе точности технологического про-
цесса, как мы видим, в статистическом отношении задача сво-
дится:
1) к оценке с нужным приближением закона распределения инте-
ресующего нас признака,
2) к нахождению (с помощью этого закона) поля рассеивания А,
отвечающего достаточно близкой к единице вероятности Рнахожде-
ния признака в пределах этого поля, и
3) к сопоставлению полученного таким образом поля с до-
пуском.
Говоря о функции распределения признака в совокупности обра-
ботанных изделий, обычно различают:
1) «мгновенное» распределение и
2) суммарное распределение.
Под мгновенным распределением понимается распределение при-
знака в совокупности, которое имело бы место, если бы действие
всех производственных факторов оставалось бы таким (или примерно
таким), каким оно является в данный момент времени. (Здесь мы
пока оставляем в стороне вопрос о преобразовании с течением вре-
мени нашего распределения; этот вопрос будет рассмотрен в сле-
' дующем разделе данного параграфа.)
Под суммарным распределением понимают получаемое при дан-
ном процессе результативное распределение, складывающееся под
действием изменяющихся с течением времени факторов, оказываю-
щих влияние на последовательное преобразование мгновенных рас-
пределений.
Если положение центра настройки непрерывно или систематически
контролируется, то поле рассеивания находят на основе параметров
мгновенного распределения. При относительно редкой проверке
§ 2]
АНАЛИЗ ТОЧНОСТИ ТЕХНОЛОГИЧЕСКИХ ПРОЦЕССОВ
373
центра настройки часто предпочитают исходить из параметров сум-
марного распределения, которое, правда, сравнительно не часто
бывает достаточно близким к нормальному.
При оценке закона распределения приходится начинать с выбора
числа наблюдений.
Остановимся теперь на выборе числа п наблюдений, обеспечи-
вающего нужную точность и надежность оценок параметра v с по-
мощью х и аналогично о с помощью 5.
Согласно центральной предельной теореме мы имеем:
-^'-<-мЛ«2ф0К) = а.
п
Пусть задана требуемая надежность а и желаемая точность
результатов наблюдений, т. е. верхний предел ошибки в определе-
нии v по х, так что мы требуем, чтобы неравенство
|х—v | <ДЧ
выполнялось с вероятностью, не меньшей а.
По данному а находим из уравнения 2Ф0(га)=а, пользуясь
таблицей II приложений. Решая относительно п неравенство
получим:
га °2
(10.2.1)
ИЛИ
где qv= ~ представляет предельную ошибку оценки параметра v,
выраженную в долях а.
Если величина о или, по крайней мере, верхняя граница ее
известна (например, по предварительной выборке), то с помощью
формул (10.2.1) или (10.2.2) легко определить нужное число п — пч
наблюдений, гарантирующее заданную надежность определения вели-
чины V.
Иногда задают предельную относительную погрешность j ,
требуя, например, чтобы она с надежностью а не превышала задан-
ного предела у. Тогда формулу (10.2.1), разделив числитель и
374
МЕТОДЫ РАСЧЕТА, АНАЛИЗА И КОНТРОЛЯ ТОЧНОСТИ
[ГЛ. X
знаменатель на V2, можно переписать следующим образом:
Y2
где 'О'х = ^- представляет коэффициент вариации.
Аналогичным образом получаем:
Р/—<^< + <) = 2Ф0(г#) = а
' \ V 2п '
И
Q2
(10.2.4)
2Д*
или
z2
/г==й5э—(10.2.5)
2<?а
где7я=^ представляет предельную ошибку оценки о, выражен-
ную в долях от самого же о.
Само собой разумеется, что а, А и q выбираются из конкретных
требований, предъявляемых к предполагаемым наблюдениям; в мате-
матической статистике не рассматриваются какие бы то ни было
рекомендации по их выбору.
Пусть, например, требуется определить числа и наблюде-
ний, если задано а ==0,95 и qv = q, = Q,2.
По таблице II приложений находим £„=1,96.
По соотношениям (10.2.2) и (10.2.5) находим:
1.96а __ 1,96а л.
о^=96 и йо^2ДГ22 = 48.
Заметим лишь, что теперь при выборе можно использовать то
обстоятельство, что допуск б нам обычно заранее известен. Чем
более узким является допуск и чем труднее его соблюдение на произ-
водстве, тем меньшей должна быть выбрана предельная относитель-
ная ошибка q3, а следовательно, и большее число наблюдений ла.
Так, например, если мы хотим, чтобы полученный из наблюдений
доверительный интервал при нормальном распределении с 95%-ной
гарантией (95 случаев из 100) шкрывал неизвестное нам значение а,
то, выбрав 50 наблюдений, мы будем иметь qa« 0,2, т. е. ошибка
в оценке о может составить $—(7 = J=0,2o. Поэтому действитель-
ное отношение допуска 6 к параметру рассеивания размеров о вполне
может оказаться равным 4,8 в тех случаях, когда мы на практике
§ 2] АНАЛИЗ ТОЧНОСТИ ТЕХНОЛОГИЧЕСКИХ ПРОЦЕССОВ 375
при 50 наблюдениях получаем' отношение б к $, равное 6. Следо-
вательно, вероятность выхода размеров изделий за границы допуска
(при центре в середине поля допуска) может составить не 0,0027
(как это имеет место при д = бо), а 0,0164 и ее никак нельзя бу-
дет считать пренебрежимо малой. Отсюда видна практическая важ-
ность учета величины доверительного интервала при оценке о по $
при анализе точности технологического процесса.
Пусть теперь число наблюдений л0 выбрано. Эти наблюдения мо-
гут быть произведены двумя способами:
1) подряд за определенный промежуток времени при более или
менее неизменных производственных условиях (станок, изделие, на-
стройка, режимы и т. д.);
2) собраны из групп изделий, полученных за разные промежутки
времени, при разных настройках.
Во втором случае иногда можно использовать даже наблюдения
над обработкой не на одном, а на разных станках, причем деталей
не одного и того же наименования, а нескольких наименований одно-
типных деталей, если есть достаточное основание предполагать на
этих станках в указанных условиях рассеивание размеров обработки
более или менее одинаковым, т. е. если считать, что их распреде-
ления нормальны и параметр о для них имеет одно и то же значе-
ние. Естественно, что при этом результат анализа будет менее опре-
деленным, чем при первом способе проведения наблюдений.
В обоих случаях по результатам наблюдений следует вначале
проверить гипотезу нормальности, например, теми приемами, кото-
рые изложены в § 3 главы VII.
После этого мы можем в первом случае оценить интересующий
нас параметр рассеивания так, как это указано в п. 6.2.3 (при боль-
шом числе наблюдений) или в п. 6.4.3 (при сравнительно малом
числе наблюдений), причем определяем доверительные границы при
ранее выбранном уровне надежности а для интересующего нас
параметра а.
Во втором случае мы, оказывается, тоже можем найти обосно-
ванную оценку интересующего нас параметра рассеивания о.
Если мы располагаем k группами наблюдений с численностями пх,
nk с различными центрами рассеивания (что бывает, напри-
мер, при разных настройках и при значительном «размерном» из-
носе инструмента), но с одинаковыми параметрами о2 —о2=...
.,. = о2=о2, то оценку параметра о2 (т. е. параметра «мгновен-
ного» распределения) мы можем получить по формуле
k
2 s2(«;—о
376 МЕТОДЫ РАСЧЕТА, АНАЛИЗА И КОНТРОЛЯ ТОЧНОСТИ [ГЛ. X
где sf, st, ..., si — несмещенные оценки дисперсии по группам,
п = Л]-(- «2 4- . .. + nk — общее число наблюдений, произведя при
этом проверку однородности ряда наших дисперсий of, of, . . ., of по
способу, описанному в п. 7.2.2. Доверительный интервал для общего
параметра «мгновенного» распределения мы строим на основе объе-
диненного числа наблюдений п.
В целях упрощения вычислений иногда еще стремятся оценить
параметр о по совокупности размахов варьирования, полученных по
более иДи менее значительному числу малых выборок (например,
по 20 и более) по способу, рассмотренному в п. 6.4.4. Следует
иметь в виду, однако, что, оценивая таким путем о с помощью,
например, таблицы III приложений, мы получим менее выгодную
оценку, чем $. Поэтому при пользовании размахом для обеспечения
равной надежности оценки потребуется больше наблюдений, труд-
ность производства которых может превысить трудность вычисле-
ний $.
Оценив одним из указанных способов параметр рассеивания о,
мы переходим к нахождению поля рассеивания А.
При нормальном законе распределения размеров обработки обычно
принимают для простоты
А = б0,
исходя из того, что, как легко подсчитать с помощью таблицы II
приложений, такой величине поля (при центре рассеивания в сере
дине) отвечает вероятность попадания в нее действительных разме-
ров обработанных деталей, равная Р= 0,9973— практически доста-
точно близкая к единице. Тогда оценка поля будет иметь вид
бр« < Л <; 6ys, (10.2.6)
где коэффициенты р и у, зависящие от принятого для доверитель-
ной оценки о уровня надежности а и от числа п произведенных на-
блюдений, будут различными при разных способах оценки о, а именно:
1) при большом п
2) при малом п (п <30)
_ У л—1 н л, __ Vя —1
2 %2 '2 X,
Здесь да есть аргумент функции Лапласа, отвечающий вероятности ,
Хг = и Х> = V^Xf, значения и берутся из таблицы IV
приложений при числе степеней свободы/г—1 и вероятностях соот-
§ 2) АНАЛИЗ ТОЧНОСТИ ТЕХНОЛОГИЧЕСКИХ ПРОЦЕССОВ 377
1+а 1—а , а
встственно —у и —у, поскольку а=1——, где q — уровень
значимости в процентах.
Оценку точности операции при практически постоянном центре
рассеивания естественно производить с помощью неравенства
д^бу^ (10.2.7)
причем, если по производственно-конструкторским соображениям
при контроле размеров за основу берутся только наибольшие или
только наименьшие значения размера отдельного экземпляра, то
в (10.2.7) допуск б должен быть уменьшен на величину допускае-
мого отклонения этого рода (за счет овальности, конусности и т. п.).
10.2.2. Статистические методы анализа стабильности техно-
логического процесса. Материалом для анализа стабильности техно-
логического процесса могут послужить те же данные, что и для
анализа точности, однако они будут пригодны лишь в том случае,
если представляют непрерывные наблюдения, охватывающие доста-
точный промежуток времени (сутки, смену), или если они составлены
из выборок, отобранных через определенные фиксированные проме-
жутки времени (например, через час или через полчаса по 10 —
30 штук). Понятно, что наблюдения должны быть зафиксированы
в протоколах строго в порядке их осуществления (т. е. в порядке
изготовления измеренных изделий). Интервалы между выборками,
называемыми в этом случае «временными пробами», или просто
«пробами», устанавливаются в зависимости от наблюдающейся частоты
разладок технологического процесса. О выборе общего числа всех
произведенных наблюдений уже было сказано ранее; теперь надо
только учесть, что информацию о состоянии процесса за данный
отрезок времени мы будем получать из отвечающей ему пробы;
поэтому численность последней должна быть подвергнута предва-
рительной оценке теми же приемами, что и прежде. Заметим, что
при выборе численности пробы мы встречаемся с противоречием: для
надежного и более или менее точного суждения о состоянии процесса
в данный момент времени проба должна быть достаточно большой,
но увеличение объема пробы ведет к тому, что она все в большей
мере включает происходящие с течением времени изменения в ходе
технологического процесса и, в частности, изменения центра настройки
и характеристики рассеивания, а поэтому проба должна быть воз-
можно меньшей. Выход из этого затруднения находят, производя
предварительные наблюдения частоты разладок хода процесса.
Для анализа технологического процесса было бы естественно
использовать теорию случайных процессов (см. главу XI). Однако
здесь мы подойдем к вопросу проще: мы будем рассматривать «пробы»
как выборки из совокупности объектов, составляющих продукцию
производства.
378
МЕТОДЫ РАСЧЕТА, АНАЛИЗА И КОНТРОЛЯ ТОЧНОСТИ [ГЛ. X
Мы будем предполагать, что указанные данные о ходе процесса
во времени подвергнуты проверке в отношении нормальности мгно-
венного распределения так, как было указано в предыдущем пункте.
После этого, обрабатывая материал по каждой пробе, мы опреде-
ляем моменты разладок процесса, заключающихся:
1) в смещении центра настройки,
2) в изменении рассеивания.
Рис. 65. Точечная диаграмма хода процесса обработки
200 валиков на прецизионном токарном автомате.
Установив моменты разладок, мы определяем затем наименьший
и средний периоды времени, протекающего между двумя разладками:
а) по центру настройки и б) по рассеиванию.
Продолжительность полученных межразладочных периодов и бу-
дет характеризовать стабильность технологического процесса. Про-
должительность и частота разладок, естественно, также подвержены
рассеиванию, но более подробное исследование этих последних
требует и более сложного аппарата.
В качестве наглядной иллюстрации и дополнительных приемов
исследования стабильности технологического процесса могут быть
использованы еще:
1) «точечные» диаграммы,
2) «точностные» диаграммы,
3) диаграммы «доверительных интервалов».
На «точечных» диаграммах по оси абсцисс откладываются по-
рядковые номера наблюдений за процессом по времени их про-
изводства, а по оси ординат—индивидуальные или средние по
§ 2]
АНАЛИЗ ТОЧНОСТИ ТЕХНОЛОГИЧЕСКИХ ПРОЦЕССОВ
379
пробам значения исследуемого признака (обычно размера изделия).
Через крайние точки такой диаграммы проводят верхнюю и ниж-
нюю линии, а между ними среднюю линию, по которой судят,
правда, достаточно грубо, о поведении признака во времени. Из-
менение размаха варьирования от пробы к пробе дает возможность
еще более грубо судить об изменении рассеивания во времени
200 валиков на прецизионном токарном автомате.
/ —линия максимального члена пробы, 2 - эмпирическое сред-
нее квадратическое отклонение, S - линия минимального члена
пробы, 4— линия среднего арифметического значения.
На «точностные» диаграммы наносят по оси абсцисс номера проб
или время, а по оси ординат — средние арифметические значения
признака и крайние значения в пробе. От средних, кроме того,
откладывают вверх и вниз отрезки, равные по величине эмпири-
ческому среднему квадратическому отклонению, и через концы этих
отрезков проводят штрих-пунктирные линии; промежуток между
этими линиями заштриховывают (рис. 66). Направление полученной
таким путем полосы уже несколько более отчетливо дает возмож-
ность судить о направлении изменения центра настройки, а шири-
на полосы в известной мере характеризует изменение рассеивания,
по крайней мере там, где она достаточно резко уменьшается или
увеличивается. Это суждение будет все же оставаться грубым (хотя
и в меньшей мере, чем предыдущие), ибо, как мы знаем из пред-
шествующих глав, эмпирические характеристики (средние и дис-
персии) подвержены случайным колебаниям и поэтому ни точечный,
380
МЕТОДЫ РАСЧЕТА, АНАЛИЗА И КОНТРОЛЯ ТОЧНОСТИ
[ГЛ. X
ни точностный графики не обнаруживают еще действительных из-
менений процесса.
Более определенное суждение об изменениях центра и парамет-
ра рассеивания можно сделать по диаграмме «доверительных ин-
тервалов», по оси абсцисс которой откладываются номера проб, а
по оси ординат — средние по пробам и эмпирические средние
квадратические отклонения. Кроме того, на диаграмму наносятся
Рис. 67. Диаграмма 95°/0-ных доверительных интервалов
для центра рассеивания v и среднего квадратического
отклонения размеров о при обработке 200 валиков на
прецизионном токарном автомате.
отклонения (рис. 67). В тех точках, где смежные доверитель-
ные интервалы не перекрываются, можно с достаточным основа-
нием судить о наличии изменения центра настройки или рассеива-
ния, смотря по тому, какие доверительные интервалы мы рассмат-
риваем.
Представление о приближенной линейной зависимости положе-
ния центра рассеивания от времени можно получить,
данные по пробам по способу наименьших квадратов,
в главе IX (см. рис. 68).
В результате проведенного изложенными приемами анализа ста-
бильности технологического процесса мы можем сделать более пол-
ное заключение о точности. Так, например, если операционный до-
пуск значительно больше мгновенного рассеивания, то мы
'J 21 АНАЛИЗ ТОЧНОСТИ ТЕХНОЛОГИЧЕСКИХ ПРОЦЕССОВ 381
допустить постепенное смещение центра рассеивания на величину
— (6 — А) (в результате, например, постепенного износа инстру-
мента) в течение определенного промежутка времени, произведя
соответствующую предварительную настройку оборудования (на
размер, смещенный от середины допуска в сторону, противоположную
направлению происходящего во время работы смещения центра);
длину промежутка времени мы определим из графика линейной
Рис. 68. График приближенной линейной зависимости
положения центра настройки станка от времени, по-
строенный по способу наименьших квадратов для про-
цесса обработки 200 валиков на прецизионном токарном
автомате.
зависимости положения центра рассеивания от времени. Это поз-
волит нам увеличить срок службы инструмента и удешевить про-
изводство. При изменяющемся центре рассеивания оценка доста-
точной точности операции может быть произведена с помощью
неравенства
б>6у$4-2/0, (10.2.8)
где 2/0 — смещение центра рассеивания (включающее погрешность
настройки) за экономически обоснованный промежуток времени.
Как указывалось в п. 10.2.1, при выборе численности времен-
ной пробы при анализе точности технологического процесса возни-
кает принципиальное затруднение, состоящее в том, что для пра-
вильной оценки параметра о мгновенного распределения (без его
искажения в связи с изменением центра рассеивания) временная
382 МЕТОДЫ РАСЧЕТА, АНАЛИЗА И КОНТРОЛЯ ТОЧНОСТИ [ГЛ. X
проба должна быть возможно меньшей, но для обеспечения за-
данной точности и надежности оценки она должна быть достаточно
большой.
Это противоречие в известной мере можно обойти, используя
метод регрессии, основанный на принципе наименьших квадратов
(см. гл. IX, § 3).
Если зависимость центра настройки М(К'х) от времени х можно
линейно аппроксимировать функцией (9.3.5), то параметры аир
этой функции оцениваются по соотношениям (9.3.9) величинами
аир. Тогда приращение функции М(К/х) на отрезке (0; Тзк),
где Тзк — экономически обоснованный период времени, дает оценку
величины 2/0 в неравенстве (10.2.8). Затем на основании соотно-
шения (9.3.21) определяется оценка s'2 параметра о2 по отклоне-
ниям результатов наблюдений у,- размеров обработки от значений
У, == а13 (х,- —х), вычисленных в тех же точках х(-. Из (9.3.21)
имеем:
/Ж—v
• (10.2.9)
где п — суммарная численность всех временных проб.
Если все п наблюдений производились непрерывно с равными
промежутками Дх между ними, равными продолжительности обра-.
ботки одной детали, и I—порядковый номер детали, то при вычис-
лениях по формулам (9.3.9) для упрощения удобно использовать
соотношения:
У х,- = Дх У i = (10.2.10)
1=1 1=1
и
и п
у х’ = (Дх)2 ]Г(2 = Ц11?^±1дх2. (10.2.11)
/=1 ,=1
Если мгновенное распределение следует нормальному закону,
то для оценки его параметра о будем иметь соотношение
о ~ ys'
(10.2.12)
где Za— коэффициент, зависящий от выбранной доверительной ве-
роятности а, приближенно определяемый с помощью таблицы II при-
ложений. Точность операции и в этом случае признается удовле-
творительной, если выполняется неравенство (10.2.8).
§ 2] Анализ точности технологических процессов 383
В случае необходимости можно для величины 2/0 определить
более осторожную оценку, построив для М(К/х) доверительный
интервал с помощью (9.3.24).
Пусть, например, требуется проверить целесообразность закреп-
ления обработки детали № 1 по размеру 0 10 — 0,058 за станком
№ 3, причем известно, что смещение центра а настройки линейно
зависит от времени Т в пределах межналадочного периода
7 = 180 мин, -а время, затрачиваемое на обработку одной дета-
ли № 1 на станке № 3, составляёт Ах = 3 мин.
Выбираем надежность (доверительную вероятность) оценки о
no s', равную а = 0,95, и предельную относительную погрешность
приближения о посредством s', равную q, = 0,2. Принимая во вни-
мание, что а = 0,95, из таблицы II приложений имеем Ztt=l,96.
По формуле (10.2.5) найдем:
1 об2
= 48,02 «50.
Производим 50 наблюдений подряд размеров деталей, анало-
гичных детали № 1, обработанных последовательно на станке № 3.
Данные наблюдений приводятся в таблице 10.2.1.
Используя итоговые данные таблицы 10.2.1 по формулам
(9.3.9), (10.2.10) и (10.2.11), положив Ах=1, находим:
Е 502 + 50 IT??
X,.= -J—= 1275,
<=1
У X; = 1275 2'503+ - =42 925,
I— 1
“ 1275 ог- е - 492 n q .
50 —25,5, а — 50 — 9,84,
д 50-17 252—1275-492
50-42 925—12752
и окончательно
Г(х) = 9,8 + 0,45 (х—25,5) мк. (10.2.13)
Число обрабатываемых деталей за период Твх равно
Так 180
пак = -т25- = =- = 60 шт.
эк Дх 3
Приращение функции (10.2.13) на отрезке (0; 60) равно
2/о = АК = Р6О— Yo = 9,8 4-0,45 (60 — 25,5) — [9,8 4- 0,45 (0 — 25,5)] =
= 27 мк.
384
МЕТОДЫ РАСЧЕТА. АНАЛИЗА И КОНТРОЛЯ ТОЧНОСТИ
[ГЛ. X
Таблица 10.2.1
Размеры деталей, обработанных на станке Ns 3
№ по пор. обраб. Х[ Отклонение размера У; МК 1 1 э № по пор. | обраб. X; Отклонение размера У1 <>г <>7 1 S 1
1 2 3 4 5 6 7 8 9 10 11 12
1 + 1,0 1 — 1,2 2,2 4,8 26 + 7,5 195 10,05 -2,55
2 + 1,5 3 —0,75 2,25 5,1 27 + 10,0 270 10,5 —0,5
3 —2,5 -7,5 —0,3 —2,2 4,8 28 +8,5 238 10,95 —2,45
4 0,0 0 0,15 -0,15 0 29 + 10,0 290 11,4 —1,4
5 -1,5 -7,5 0,6 —2,1 4,4 30 + 11,0 330 11,85 —0,85 »
6 + 1,0 6 1,05 —0,05 0 31 + 14,0 434 12,3 1,7 >
7 +1 >0 7 1,5 —0,5 0,2 32 + 11,0 352 12,75 -1,75
8 + 15,0 120 1,95 13,05 170,3 33 + н,о 363 13,2 —2,2
9 —1,0 —9 2,4 —3,4 11,6 34 + 13,0 442 13,65 —0,65
10 +2,0 20 2,85 —0,85 0,7 35 + 16,0 560 14,1 1,9 6
11 +2,0 22 3,3 — 1,3 1,7 36 + 14,5 522 14,55 -0,05
12 +3,0 36 3,75 —0,75 0,6 37 + 19,0 703 15,0 4,0 1 ,
13 +н,о 143 4,2 6,8 46,2 38 + 14,0 532 15,45 -1,45
14 -1,0 -14 4,65 -5,65 31,9 39 + 18,0 702 15,9 2,1 >
15 +5,0 75 5,1 -0,1 0 40 + 19,0 760 16,35 2,65 J
16 +4,5 72 5,55 -1,05 1,1 41 + 19,0 779 16,8 2,2
17 +0,5 8,5 6,0 —5,5 30,2 42 +23-5. 987 17,25 6,25
18 +3,5 63 6,45 —2,95 8,7 43 +22,0 946 17,7 4,3
19 +8,0 152 6,9 1,1 1,2 44 + 18,5 594 18,15 0,35
20 +5,0 100 7,35 —2,35 5,5 45 + 19,5 877,5 18,6 0,9 >
21 +4,5 94,5 7,8 -3,3 10,9 46 + 17,5 805 19,05 —1,55 ?
22 +3,5 77 8,25 —4,75 22,6 47 + 18,0 846 19,5 -1,5
23 +9,5 218,5 8,7 0,8 0,6 48 + 19,5 936 19,95 —0,45
24 + 12,0 288 9,15 2,8о 8,1 49 + 17,5 857,5 20,4 —2,9
25 +7,5 187,5 9,6 —2,1 4,4 50 +25,5 1275 20,85 4,65 2 ,
Сумма . 492,0 17 252 — — 533,4
Теперь уравнение (10.2.13) используем для вычисления значе-
ний Yj при /=1,2,..., 50 и результаты вносим в таблицу 10.2.1,
что дает возможность подсчитать уклонения yi— Vt и их квадраты.
Используя полученную в таблице 10.2.1 сумм) квадратов укло-
нений —Yi} по формуле (10.2.9) находим:
/
533,4 __
50 — 2 ~
3,3 мк.
§ 2] АНАЛИЗ ТОЧНОСТИ ТЕХНОЛОГИЧЕСКИХ ПРОЦЕССОВ 385
Далее согласно (10.2.12) при а==0,95 и га=1,96 принимаем;
/ 1 96 \
o«Y^ = (l+7=/3,3^4^.
На основании (10.2.8) окончательно будем иметь:
А — 6 • 4 + 27 == 51 мк < 6 = 58 мк,
откуда следует, что точность технологической операции, выпол-
няемой на станке № 3, достаточна для соблюдения допуска, уста-
новленного на размер детали № 1, а потому последняя может
быть закреплена за станком № 3.
По данным таблицы 10.2.1 и формуле (10.2.13) построен график,
показанный на рис. 69, иллюстрирующий рассмотренную методику
статистического анализа точности технологической операции.
Рис. 69. Анализ точности технологической операции с помощью
линейной регрессии по принципу наименьших квадратов.
Если подобный анализ покажет, что детали за станками про-
изводственного участка закреплены правильно, то на нем может
быть введен активный статистический контроль размеров обработки.
При более осторожном подходе к оценке величины 2/0 строим
доверительные интервалы для M(K/x0) в точках хон и хок, отве-
чающих началу и концу интервала (О, 7’эк).
По формуле (9.3.10) определяем
в
И В. Смирнов. И В. Дунин-Барковский
386 МЕТОДЫ расчета, анализа и контроля ТОЧНОСТИ [гл. х
По формуле (9.3.24) находим при хон = 0
, пЧхо-'х)2 1А , 50s (0-2S7F ! 29
1 +---П------[ п - V - у 1 + 50-42925—1275* ’
и при ,гок = 60
1А 50*(60^25+Г ~ ! 47
V т 50-42 925—1275*
Выбрав доверительную вероятность а = 0,95(9 = 5°/0), по табли-
це V приложений при числе степеней свободы й = л— 2 = 48
находим /,= 1,960.
Используя формулу (10.2.13), получаем:
У (х0 = 0) = 9,8 + 0,45 (0 — 25,5) « — 1,7 мк
в
У (Л, = 60) = 9,8+ 0,45 (60—25,5) « 25,3 мк.
Строим доверительный интервал при хон = 0
, , 1,960-3,3 f v. Л . 1,960-3,3 .
-1 ’ - 7W31 -29 < м Iг|х- “0 J <-1 ’+7ЖТ ’ '2Э
или
— 2,9 мк <М ^У|хон = 0^ < — 0,5 мк.
Аналогично
23,9 мк < М У(хок = бо) < 26,7 мк.
В худшем случае 2/о = 26,7 — (—2,9) = 29,6 «30 мк и А = 6-4 +
+ 30 = 54 jz/c<6 = 58 мк, откуда следует, что и при этом ранее
сделанный вывод о возможности закрепления детали № 1 за стан-
ком № 3 не изменяется.
§ 3. Статистические методы текущего предупредительного
контроля качества продукции
10.3.1 . Общие понятия и основные задачи. Как уже говори-
лось ранее (см. пп. 2.1.2 и 2.1.4), сущность статистических выбо-
рочных методов контроля состоит в том, чтобы по некоторой
выборке обоснованно судить о всей совокупности контролируемых
объектов, не прибегая к сплошной их проверке; такая постановка
дела, естественно, дает возможность облегчить контроль и сократить
затрачиваемое на него время, причем вероятность ошибочных суж-
дений о качестве иногда не превышает вероятности получения
ТЕКУЩИЙ ПРЕДУПРЕДИТЕЛЬНЫЙ КОНТРОЛЬ
387
§ 3]
ошибок за счет погрешностей измерений при сплошном контроле
больших партий изделий. Этот вид контроля получил название при-
емочного или последующего статистического контроля. Общую
идею статистического метода стали использовать еще для контроля не
только непосредственно самого качества уже изготовленной партии
объектов, но и для того, чтобы на протяжении изготовления такой
партии по пробам небольшого объема систематически контролировать
ход процесса в смысле обнаружения и предупреждения в нем таких
показателей, которые создают угрозу нарушения в конце обработки
требуемого совокупного качества продукции. Тем самым статистиче-
ский контроль стал означать переход от выявления брака в уже из-
готовленной партии к предупреждению его возникновения на всем
протяжении обработки. Второй вид контроля получил название те-
кущего предупредительного статистического контроля.
Указанные виды контроля оказались мощным средством борьбы
за повышение качества продукции при одновременном снижении за-
1рат на контроль.
10.3.2 . Некоторые варианты статистического текущего пре-
дупредительного контроля. Мы рассмотрим, для краткости, только
два варианта контроля, хотя существуют и другие варианты кон-
троля:
1) контроль положения центра настройки машины по медиане
и рассеивания по крайним значениям;
2) контроль положения центра по средней арифметической и
рассеивания размеров по крайним значениям, размаху варьирования
или среднему квадратическому отклонению.
Эти варианты текущего предупредительного контроля осуще-
ствляются на практике в форме ведения так называемых «карт ста-
тистического контроля», содержащих «контрольные диаграммы», для
которых общим является то, что по оси абсцисс в них отклады-
ваются номера отбираемых через более или менее определенные
промежутки времени (например, ежечасно) проб небольшого объема
(3—10 штук), по оси же ординат откладываются те статистические
показатели, которые положены в основу данного варианта (средняя
арифметическая, медиана и т. д.).
Обычно параллельно контролируют один и тот же процесс в отно-
шении положения центра рассеивания и величины рассеивания раз-
меров, причем это делается с помощью двух отдельных диаграмм
(например, одной для средних арифметических значений, а другой
Для размахов -варьирования) или просто одной диаграммы, на кото-
рой выделяются оба нужных показателя (например, медиана и край-
ние значения). В некоторых случаях, когда колебания величины
рассеивания во времени незначительны, ограничиваются лишь контро-
лем положения центра рассеивания, применяя тот или иной показатель
(медиану, среднюю арифметическую и т. п.). Легко заметить, что
13*
388
МЕТОДЫ РАСЧЕТА, АНАЛИЗА И КОНТРОЛЯ ТОЧНОСТИ
[ГЛ. X
при данном законе распределения размеров, в частности, при
мальном законе, все возможные причины выхода размера за
допуска, т. е., иными словами, появления «размерного брака», можно
свести к двум факторам: смещению центра группирования
тельно середины поля допуска и увеличению рассеивания. На рис.
Рис. 70. Увеличение риска q брака в результате сме-
щения центра рассеивания на величину Av.
/ — риск получения брака при отсутствии смещения центра
рассеивания, 2 — риск qx получения брака при смещении Av
центра рассеивания.
штриховой линией показано правильное при нормальном законе поло-
жение кривой распределения, а сплошной линией — ее положение
при смещенном положении центра рассеивания. Заштрихованные
Рис. 71. Увеличение риска q получения брака в результате
возрастания рассеивания.
/ — риск qQ получения брака при малом рассеивании, 2 —риск q^ получе-
ния брака при увеличении рассеивания,
части площади под кривой представляют риск (вероятность) получе-;
ния размерного брака в первом и втором случаях. Влияние увели-
чения рассеивания на вероятность получения брака аналогичным
образом иллюстрируется рис. 71,
§ 3]
ТЕКУЩИЙ ПРЕДУПРЕДИТЕЛЬНЫЙ КОНТРОЛЬ
389
В качестве примера мы приводим на рис. 72 диаграмму кон-
троля хода технологического процесса одновременно: 1) по центру
настройки с помощью медианы и 2) по величине рассеивания —
с помощью, крайних значений. На этой диаграмме, как мы видим,
отведен отдельный столбец для каждой ежечасно отбираемой пробы
в объеме 5—7 штук изделий из текущей продукции машины; каждый
Рис. 72. Диаграмма контроля положения центра настройки
станка по медианам и величины рассеивания по крайним
членам пробы (а = 0,01, йт,;=3,5, й„ = 2,5, п =5):
/ — сигнал о разладке процесса, 2 — граница наибольшего предельного
размера, 3 — контрольная граница для максимального члена, 4 —кон-
трольные границы для медианы, 5 — линия среднего допускаемого
размера, 6 — контрольная граница для минимального члена, 7 —гра-
ница наименьшего предельного размера.
в виде точки в данный столбец. Легко обнаруживаемая при этом
медиана (точка, оказавшаяся посередине остальных точек) обводится
кружком или каким-либо иным значком; другим знаком (например,
треугольником) обводятся точки, оказавшиеся при этом крайними
(самая верхняя и самая нижняя). Для медианы и для крайних
значений на диаграмме заранее проводятся две пары границ — так
называемых «контрольных границ» (одна пара для медианы, а дру-
гая—для крайних значений). Иногда на диаграмму наносятся еще
и границы поля допуска контролируемого размера. Контрольные
границы обычно откладываются от середины До поля допуска для
медианы на величину
±Ате^=, (Ю.3.1)
F п
890
МЕТОДЫ РАСЧЕТА, АНАЛИЗА И КОНТРОЛЯ ТОЧНОСТИ
[гл. X
для крайних значений на величину
± kn<5 (10.3.2)
(« + » для верхней границы, «—» для нижней), где <т—«мгновен-
ное» среднее квадратическое отклонение контролируемого размера,
п—принятый объем контрольной пробы, km и kn — коэффициенты
(обычно km = 2,9 ч-3,9 и £п = 2,0 -ч-3,0), смысл которых разъяс-
няется в п. 10.3.3.
Рис. 73. Диаграмма контроля положения центра настройки
по средним арифметическим и величины "рассеивания по
размахам варьирования (а = 0,01, А_=3, fe/? = 5,38, п=5).
/—линия среднего допускаемого размера, 2— верхняя контрольная
граница для размаха, 3 — контрольные границы для средней арифме-
тической.
Если медиана или какое-либо из крайних значений в данной
пробе окажется вне установленных для нее границ, то подается сигнал
о разладке процесса в виде зажигания на данном рабочем месте
цветной лампочки или вывешивания цветного флажка (обычно крас-
ного цвета). При относительно небольшом числе высокопроизво-
дительных тяжелых машин зажигаемая на рабочем месте цветная
лампочка блокируется'со световыми экранами в виде планировки
данного участка производства, установленными в пунктах управления
участком, так что дежурный инженер узнает о разладке машины
в момент возникновения этой разладки. После устранения разладки
машины наладчиком, проверившим этот факт (с помощью внеочеред-
ТЕКУЩИЙ ПРЕДУПРЕДИТЕЛЬНЫЙ КОНТРОЛЬ
391
§ 3]
ной пробы), контролер гасит красную лампочку и зажигает вновь
зеленую — признак налаженной работы машины.
Процедура контроля не изменяется, когда пользуются средней
арифметической и размахом варьирования; только в этом случае,
конечно, нет большой надобности наносить на диаграмму индиви-
дуальные значения и, кроме того, практически неудобно объединять
на одной диаграмме обе характеристики — среднюю и размах, вслед-
ствие чего приходится строить две разные диаграммы на одной карте
(рис. 73) или даже заводить две параллельные карты. При опреде-
лении положения контрольных границ по формулам вида (10.3.1) и
(10.3.2) в этом случае вместо коэффициентов km^ и kn применяются
коэффициенты k_ = 2,3 ч-3,1 —для средней арифметической и
йр = 4,4ч-6,0 (при n = 4-i- 10)—для размаха, причем обычно kR
возрастает с увеличением п.
Когда одновременно контролируется несколько признаков каче-
ства, то два-три наиболее важных из них наносятся на самостоя-
тельные диаграммы, помещенные, как правило, на одной карте,
другие же признаки фиксируются чаще всего просто в виде число-
вых данных или особых отметок в специально для этого отведенных
строках карты.
10.3.3, Понятие о выборе варианта метода контроля и его
параметров. Из описанных процедур контроля видно, что каждый
из его методов по существу представляет метод последовательной
во времени проверки статистических нулевых гипотез /7v; о поло-
жении центра v; настройки и //о,, о величине параметра рассеива-
ния <г(-, где z=l, 2, ...—порядковый номер отбираемой пробы,
причем предполагается, что
1) закон распределения размеров нормален,
2) размеры пробных деталей измеряются с достаточной точностью
(параметр рассеивания погрешностей измерения в несколько раз
меньше параметра рассеивания погрешностей обработки).
При этом гипотеза Hxi состоит в том, что vi = v„ = A0, иначе
говоря, что положение центра распределения, оцениваемое по г-й
пробе, совпадает с некоторым заданным настроечным размером vn,
т. е. практически со средним допускаемым размером До, гипотеза
же заключается в том, что <т(=о, т. е. параметр рассеивания,
оцениваемый по той же пробе, не отличается от исходного1, заранее
известного значения а параметра рассеивания размеров. Параметры
V,- и оцениваются каждый по различным выборочным характери-
стикам выборки объема п в зависимости от принятого метода конт-
роля. Так, например, параметр v(-оценивается с помощью медианы те,
средней арифметической хит. д., а параметр о;—посредством
крайних членов х, и хп пробы, размаха варьирования R и т. д. В
качестве области допустимых значений проверяемой характеристики,
892 МЕТОДЫ РАСЧЕТА, АНАЛИЗА И КОНТРОЛЯ ТОЧНОСТИ [ГЛ. X
например центра группирования, берется интервал вида
(До—h, До-)-А), где h—отклонение положения соответствующей
контрольной границы от среднего допускаемого размера До (для
удобства дальнейшего рассмотрения мы положим До = 0, т. е. примем
До за начало отсчета). Мы должны выбрать л и А, а также и
метод контроля таким образом, чтобы вероятности Р, и Рп
соответственно первого (неправильная браковка верной
и второго (неправильная приемка гипотезы, когда на самом
она должна быть отвергнута) родов были достаточно малы. Ошибка
первого рода при текущем контроле означает подачу ошибочного
сигнала о разладке процесса, что повлечет за собой вмешательство
в процесс и потерю времени на заранее обреченные на неудачу
поиски причин «разладки», которой на самом деле нет. Ошибка
второго рода, наоборот, состоит в успокаивающем заключении
о нормальном ходе процесса, когда на самом деле он уже разладился;
следствием этого будет появление через некоторый промежуток
времени брака, который просочится в состав годной продукции.
Здесь мы будем иметь потери от брака и затраты времени и средств
на последующую рассортировку изделий, если только мы как-либо
сможем заметить в дальнейшем этот незамеченно пропущенный брак.
Наглядное представление о достоинствах и недостатках того или
иного метода проверки гипотезы (например, A/v; или Wo,) может
быть составлено с помощью оперативных кривых
y = P(v, п\ А). (10.3.3)
Соотношение
P(v; л; Й) = Ф7^)-Ф/^) (10.3.4)
как раз и выражает зависимость, нужную для построения оператив-
ных кривых, в частности, для метода контроля положения центра
рассеивания по средним арифметическим. Для метода контроля центра'
рассеивания по медианам может быть использована приближенная
совершенно аналогичная формула
Р (у, о; л; А) = ф7^)-ф7^), (10.3.5)
\ / \ те /
где
о
•= W
Пусть вероятность Р(у\ о; л; А) представляет вероятность нахожде-
ния принятой за основу данного метода выборочной характеристики
в контрольных границах, т. е., иначе говоря, вероятность неполуче-
ния сигнала о разладке процесса. Практически удобно выражать
§ 3] ТЕКУЩИЙ ПРЕДУПРЕДИТЕЛЬНЫЙ КОНТРОЛЬ 393
величины v, о и h в долях половины допуска, обозначаемой через
б = -у, где 6 — допуск контролируемого размера. Приняв
• v о , h
V, = =7 , <J5 — — И hi = -ST ,
0 6 5 6 8 <5
будем обозначать интересующую нас вероятность через
P(v5; <js; л; й5).
Когда разладка процесса отсутствует, т. е. v3 мало отличается
от нуля и о6 блйзко кжелательно, чтобы вероятность P(v5; <тг; л; йг)
была как можно ближе к единице, так как неподача сигнала будет
в этом случае правильной и, наоборот, подача его будет оши-
бочной, а вероятность подачи сигнала, равная 1—Р(у%; п; hfj,
будет вероятностью Pt совершения ошибки первого рода, т. е. вероят-
ностью неправильной браковки нулевой гипотезы. Но как только
разладка достигнет существенной величины (v{ будет существенно
отличаться от нуля или о5 будет существенно больше необходимо,
чтобы вероятность Р (v6; л; й6) уменьшилась до достаточно малой
величины, так как неподача сигнала теперь будет ошибкой второго
рода, угрожающей пропуском незамеченного брака, а вероятность
P(v6; о5; л; й,) — Ри будет вероятностью ошибки второго рода. Таким
образом, желательно, чтобы вероятность Р круто понижалась при
приближении разладки к существенной величине.
Наличие допуска 8 контролируемого размера, определяющего
границы годности вырабатываемых при данном процессе изделий,
позволяет дополнить оперативную кривую еще кривой вероятности
q выхода изделий за границы допуска, т. е. вероятности получения
брака. Эта вероятность, как легко понять, определяется формулой
?(V8; 6)= 1— Ф0(ф)- Ф0(^г) =
= 1-Ф0(Ц~г)-Ф0(^); (10.3.6)
она зависит от величин v5, о6 и 8, но не зависит от объема пробы л.
Произведение Pq имеет смысл вероятности получения брака, про-
сочившегося в годную продукцию и оставшегося незамеченным.
Обозначим через max Pq максимальное значение этого произведения.
Тогда, естественно, предпочтительным будет тот метод контроля и те
его расчетные параметры (л и й), при которых max Pq будет достаточно
малым и удаленным от начала отсчета смещений центра настройки.
На рис. 74 показаны графики изменения вероятности Р и произ-
ведения Pq в зависимости от v3, на рис. 75 показаны графики изме-
з
нения их в зависимости от os при л = 4 и й = -х-о. Изменяя л и й,
*
394
МЕТОДЫ РАСЧЕТА, АНАЛИЗА И КОНТРОЛЯ ТОЧНОСТИ
[гл. X
мы получили бы серию таких кривых. Сравнивая между собой max Pq
при различных методах контроля и при различных значениях расчет-
ных параметров, мы можем выбрать наиболее подходящие из них
с точки зрения предъявляемых в данных реальных производственных
условиях требований. Следует при этом заметить, однако, что объем
п пробы, а также и периодичность отбора проб обычно сами по себе
Pq
0,0250
0,0200
0,0150
0,0100
'0,0050
0,0025
Рис. 74. Изменение вероятности Р нахождения выборочной харак-
теристики в контрольных границах и произведения Pq, где q —
вероятность выхода изделий за границы допуска, в зависимости от
смещения центра настройки vs.
определяются производственными условиями — сложностью и трудо-
емкостью измерений, штатами контрольных работников, производи-
тельностью их труда при измерениях и т. п. — и обычно составляют
объем пробы 5 штук (гораздо реже п = 2, 3, 7 и 10), а периодич-
ность— 1 час. Величина h, как легко понять, определяет km , k- и
аналогичные им коэффициенты в формулах вида (10.3.1) для подсчета
координат контрольных границ. Так, например, при использовании
. , о
медианы « = я —т=--
е у п
Критерий max Pq является, конечно, лишь приближенной харак-
теристикой доброкачественности метода контроля. Более детальное
суждение требует учета периодичности, характера и величины раз-
ладок (скачки размеров с учетом их вероятностей, постепенное на-
растание размеров и т. п.), а также таких факторов, как, например,
ПРИЕМОЧНЫЙ ПОСЛЕДУЮЩИЙ КОНТРОЛЬ
395
§ 4]
степень точности подналадки после получения сигнала. О всех этих
важных обстоятельствах можно получить представление, проведя
надлежащий анализ, хотя бы с помощью тех приемов, которые были
рассмотрены в п. 10.2.1 и п. 10.2.2 и которые позволяют обоснованно
подойти к установлению «периодичности» отбора проб. Заметим лишь
Рис. 75. Изменение вероятности Р нахождения выборочной харак-
теристики в контрольных границах и произведения Pq, где q—
вероятность выхода изделия за границы допуска, в зависимости
от изменения о5—характеристики рассеивания размеров.
при этом, что если разладки процесса вызываются на самом деле пери-
одически действующими факторами, то пробы должны отбираться,
естественно, не через строго определенные промежутки времени.
§ 4. Статистические методы приемочного последующего контроля
качества продукции
10.4.1. Общие понятия и задачи. Во многих важных случаях
сплошной контроль или невозможен, когда он связан с необходи-
мостью уничтожения или порчи изделия (испытание на разрыв, на
продолжительность горения лампочек и т. п.), или экономически
невыгоден из-за высокой его стоимости.
В то же время на практике мы имеем и такие случаи, когда
партия готовых изделий или полуфабрикатов может быть принята
396 МЕТОДЫ РАСЧЕТА, АНАЛИЗА И КОНТРОЛЯ ТОЧНОСТИ [ГЛ. X
при наличии некоторой доли дефектных экземпляров, допустимой
без существенного ущерба для потребителя или последующей пере-
работки.
Во многих случаях сплошной контроль выгодно комбинировать
с выборочным; в частности, выборочный характер, как правило, но-
сит различного рода инспекционная перепроверка качества про-
дукции.
Выборочный контроль заключается в том, что на пробу отби-
рается некоторое число изделий из данной партии и определяется
качество каждого из них. По Числу или доле дефектных изделий
в пробе судят о качестве всей продукции. Если результат испытания
дает основание считать долю брака во всей партии не превышающей
некоторого допустимого предела, партия принимается без сплошного
контроля. Если же проба дала отрицательный результат, то партия
подвергается сплошной проверке, причем все обнаруженные брако-
ванные изделия заменяются годными.
10.4.2. Однократная выборка. Организация контроля по про-
стейшему плану заключается в следующих трех правилах:
1) проверяется выборка объема п из всей партии большого
объема N изделий;
2) если число d дефектных изделий выборки окажется не больше,
чем некоторое назначенное число С—приемочное число изделий,
d^C, то партия принимается;
3) если число d дефектных изделий в выборке более
проверяются все N— п оставшиеся в партии изделия.
Задачей теории является обоснование выбора чисел пи С — ос-
новных параметров данной схемы.
Основная цель браковки заключается в том, чтобы гарантировать
достаточно малую долю брака в принятой продукции, не вызывая
притом излишне частой браковки партии с практически незначитель-
ной долей дефектных изделий и не увеличивая чрезмерно объем
выборки. Важнейшей характеристикой системы браковки с данными
параметрами и и С является условная вероятность принять партию,
обладающую некоторой долей брака q, другими словами, вероят-
ность L (q; С; п) получить d С изделий в выборке из п изделий,
если во всей партии число дефектных изделий будет равно Ng.
По правилу сложения эта условная вероятность равна
с
L(q; С; п) = Р (d < С | q) = У, Р (d = т | q)\
т—о
в случае безвозвратной выборки эта вероятность определяется соотно-
шением (2.1.25). Обычно отношение-^- мало, и мы с хорошим
приближением можем использовать более простую биномиальную
§ 4]
ПРИЕМОЧНЫЙ ПОСЛЕДУЮЩИЙ КОНТРОЛЬ
397
формулу (2.3.7). Вероятность L (q; С; п) уменьшается с возраста-
нием q при постоянных С и п, так что риск принять негодную
партию тем меньше, чем хуже качество партии, другими словами:
L(q'; С; п) >L(q”; С; п), если q' <iq".
Кривая, изображающая вероятность L (q\ С; п) при данных С и п,
как функцииq, называется «оперативной характеристикой» принятого
способа браковки. Если предельная доля брака полагается равной q^,
так что партии с считаются еще допустимыми, а партии
с <7 > — недопустимыми, то идеальной оперативной характеристикой
была бы кривая, изображенная на
Ее уравнение
L(q\ С; л) = 1,
L (q; С; п) = О,
где (?0 называется допускным качеством.
В этом случае возможность приема «плохих» партий с q~>qa
была бы исключена и вместе
всегда бы принимались. Но
такой формы оперативную ха-
рактеристику можно было бы
получить лишь при n — N,t. е.
при сплошном контроле. Выбо-
рочный контроль, конечно,
связан с необходимостью от-
браковывать иногда хорошие
партии (ошибка первого рода)
и принимать некоторую долю
таких, которые должны бы
быть забракованы при сплош-
ном контроле (ошибка второго
рода). На практике стараются
подбирать такие значения п
и С, чтобы оперативная харак-
теристика лишь с некоторым
приближением отвечала ука-
занной идеальной форме. Для
этого приходится при допусти-
мом С подбирать п так, чтобы
среднее значение числа дефектных изделий в выборке nqa прибли-
женно равнялось бы С (или близкому к нему числу).
На рис. 77 приведена оперативная характеристика для случая
N= 10 000, «=1000, С=20 и
q. — = 0,02,
” П ’
рис.
(10.4.1)
с тем «хорошие» партии с q^q^
L(q,C,n)
КР
О q
₽ис. 76.«Идеальная» оперативная харак-
теристика метода «браковки»;-! (<?;С; л)—
вероятность принятия партии, об-
ладающей долей брака q при данном
приемочном числе С и объеме выборки п.
398 МЕТОДЫ РАСЧЕТА, АНАЛИЗА И КОНТРОЛЯ ТОЧНОСТИ [ГЛ. X
Здесь вероятности ошибки первого рода измеряются величиной
1—L (q; С; я) в области, где q < ^0, а ошибки второго рода—орди-
натами кривой Z. (<?; С; п) в области, где При заданных значе-
ниях qa и предельной величины (3 для вероятностей ошибок второго
рода можно подобрать различные комбинации чисел п и С, чтобы
приблизительно удовлетворить
равенству
М<70; С; я) = р. (10.4.2)
Другими словами, уравне-
ния (10.4.2) еще недостаточно
для того, чтобы точно фикси-
ровать числа Сия; некоторой
свободой в их выборе поль-
зуются, чтобы обеспечить наи-
более экономный объем ин-
спекции. Если доля брака
равна q, то математическое
ожидание общего числа кон-
тролируемых изделий легко
вычислить; обозначив его через
J(q), имеем:
J(q) = L(q-, С; п)п +
+ N[]-L(q- С- я)].
(10.4.3)
Подставляя сюда вместо q
среднее его значение <7ср, по-
лучим величину, характери-
Рис. 77. Оперативная характеристика
метода браковки при объеме партии
# = 10 000, объеме выборки и =1000,
браковочном числе С = 20 и допустимой
Q
доле брака <?0== —= 0,02; L (<?; С; п)—
вероятность принятия партии, обла-
дающей долей брака q при данных
Сип.
зующую среднее число обследованных изделий при принятом
методе браковки. Если наряду с уравнением (10.4.2) потребовать,
чтобы выполнялось условие J(^cp) = min, то мы получим уже вполне
определенную пару п и С, удовлетворяющую этим двум требова-
ниям, обеспечивающим заданный риск р потребителя и минимальное
число проверяемых объектов при данных qfl и qcv — q.
Процедура простой или однократной выборки аналогична проверке
гипотезы q^qa при альтернативной гипотезе
Я > Vo-
10. 4.3. Случай приемочного числа С, равного нулю. Мы рас-
смотрим случай приемочного числа С, равного нулю. В этом случае
L(q; п) — вероятность принятия партии с долей брака q=^ — выра-
жается формулой (2.1,27), Из нее мы легко получим следующее
§ 4] ПРИЕМОЧНЫЙ ПОСЛЕДУЮЩИЙ КОНТРОЛЬ 399
двустороннее неравенство:
/ М \п ! М\п
<L^ «х^-у) =(1-?л
(10.4.4)
А П
где Х = .
Математическое ожидание Q{q\ п) доли дефектных изделий
в принятых партиях, называемое обычно средним выходным качест-
вом, в данном случае, очевидно, будет равно произведению этой
доли q в партии на вероятность L (q\ п) принятия партии, т. е.
Q(q; n) = L(q; ri)q. (10.4.5)
Из (10.4.4) и (10.4.5) имеем:
Q(q-, п) <(\—q)nq. (10.4.6)
Легко проверить, что максимум функции, стоящей в правой части
(10.4.6), достигается для q = у и потому
г 1 \ге 1 пп
тахС?(^ я)=Ц1 — ^7) 7+7 = (« +1)"*’ ' (10-4-7)
При я >20 можно пользоваться следующей приближенной фор-
мулой:
гч \ 0,3679 /. 1 1 \ .лп . а.
fflaxQ(?; «)«-—(Ю.4.8)
Если допустимая доля брака будет qa, то для вероятности ошибок
первого (а) и второго ((J) родов мы будем иметь неравенства
для q^qa
а — Р (rf> Q!q <qa) < 1 -(1 -?-%)" < 1 -(1 -qa -X)n, (10.4.9)
для q>q0
P = p (d = 0 :q > q0) < (1 -q)n < (1 -qf, (10.4.10)
где % = ^-.
Задаваясь величиной p, мы по ней с помощью формулы (10.4.10)
можем легко определить значение q = qa такое, что вероятность
приемки с долей брака q~>q0 будет достаточно мала, меньше р.
Для этого нужно только взять за qa величину 1 — {/р.
Пользуясь формулой (10.4.8), можно рассчитать необходимый
объем пробы я, при котором обеспечивается заданный верхний
предел выходного качества 6. Такое я находится по формуле
(10.4.8) из приближенного равенства
maxQ(<?; я)« 6. (10.4.11)
400
МЕТОДЫ РАСЧЕТА, АНАЛИЗА И КОНТРОЛЯ ТОЧНОСТИ
{гл. х
§ 5. Приложение теории распределения крайних членов
выборки в расчетах и испытаниях прочности
10.5.1. Теория «наиболее слабого звена» и законы распре-
деления крайних членов выборки. Как известно, расчеты деталей
машин и сооружений на прочность производятся в предположении
наименее благоприятного сочетания внешних нагрузок и проч-
ностных свойств материала конструкции: нагрузки принимаются
в расчет максимальные, а прочность материалов — минимальная для
того, чтобы в эксплуатации избежать поломок и аварий. На прак-
тике как нагрузки, так и прочность материалов обнаруживают слу-
чайные вариации под воздействием многочисленных факторов, по-раз-
ному складывающихся в повторных «испытаниях». Эти вариации
как раз и учитываются коэффициентами запаса прочности, устанав-
ливаемыми большей частью по данным опыта. Выводам из подобных
массовых данных можно придать характер научных прогнозов, если
опереться на соответствующую статистическую теорию. В особенности
это можно сказать в отношении таких расчетов и испытаний, где
сама нагрузка и поведение материала подвержены влиянию ярко
выраженных случайных факторов. Так, например, при расчете гидро-
технических сооружений приходится принимать во внимание макси-
мальные расходы воды в реках, резко варьирующие из года в год;
при расчете некоторых гражданских сооружений приходится учи-
тывать максимальную силу и скорость ветра; при испытаниях мате-
риалов на усталость приходится считаться с вариациями результатов
поведения образцов при многочисленных повторных нагружениях; при
определении пробивного напряжения на зажимах конденсаторов прихо-
дится учитывать вариацию диэлектрических свойств материалов и т. д.
В этой обстановке экстремальным значениям рассматриваемых
величин (нагрузка, прочность и т. д.) естественно поставить в соот-
ветствие вероятности их получения на практике, т. е. рассматривать
распределения вероятностей этих величин. Тогда, задавшись опреде-
ленной надежностью, т. е. отбрасывая интервалы значений, вероят-
ность попадания в которые достаточно мала (например, меньше
0,05%), можно получить расчетные экстремальные значения указан-
ных величин с тем, чтобы использовать их при проектировании
соответствующих машин и сооружений.
Такой подход оказывается возможным на основе рассмотрения
законов распределения крайних членов выборки. Схематически это
можно представить в следующем виде.
Пусть мы имеем цепь, состоящую из п одинаковых звеньев. Проч-
ность Xt любого /-го звена есть величина случайная, с функцией
распределения Р [Х{ <Z х) = Р (х). Прочности звеньев не зависят друг
от друга. Спрашивается, как будет распределена прочность всей
цепи. При испытаниях на разрыв цепь будет разрушаться в том
§ 5] ТЕОРИЯ РАСПРЕДЕЛЕНИЯ КРАЙНИХ ЧЛЕНОВ ВЫБОРКИ 401
звене, которое имеет наименьшую прочность. Поэтому, обозначая
через X,, Хг, Хп прочности отдельных звеньев и через £п
прочность всей цепи, мы будем иметь
^ = min(^„ Xt, .... Хп). (10.5.1)
Найдем вероятность неравенства ±п^х. Очевидно, для того чтобы
прочностьвсей цепи была не меньше х при любом j(i=l, 2, ...,п),
должно выполняться неравенство
Х^х, (10.5.2)
причем
Р(Х,->х)=1 — Р(А;<х) = 1 — Р(х) (10.5.3)
при каждом /, так как все Xt по условию одинаково распределены
с одной и той же функцией распределения Р(х). По правилу умно-
жения для независимых событий вероятность одновременного выпол-
нения всех неравенств (10.5.2) будет:
Р(^>х) = Р(^>х; Лг>х; ...; Хп х) = [1 -Р (х)]". (10.5.4)
Отсюда
P(Sn<x) = l-[l-P(x)]n. (10.5.5)
Таким образом, закон распределения прочности всей цепи выра-
жается равенством (10.5.5).
Мы можем полученный результат формулировать в виде следу-
ющего утверждения: пусть величины (А'1, Хг, .. ., Хп) представляют
выборку из генеральной совокупности, распределенной по закону Р (х);
тогда наименьший член выборки иг „ = £п имеет распределение(10.5.5).
Аналогично наибольший член ип,п выборки будет иметь распреде-
ление, определяемое равенством:
Р(ип,п<х)^Рп(х). (10.5.6)
Легко видеть, что (10.5.6) выражает вероятность совместного вы-
полнения неравенств: JVt<;x; Xt<Zx; ...; Хп <Z X, что в свою оче-
редь, необходимо и достаточно для того, чтобы ип „<х.
Рассмотрим несколько частных случаев.
Пусть прочность каждого звена цепи заведомо больше величины а,
так что Р (ult „ <_ а) — Р (а) = 0, но может оказаться меньше а -|- h,
каково бы ни было й>0, и потому Р(а-рЛ)>0. Предположим
далее, что при малых /г>0
Р (a -I- h) = (с + еА) /г, (10.5.7)
где с>0 и ел—>0 при h—► 0. Геометрически это означает, что
кривая у = Р (х) вблизи точки а и справа от нее приближенно
описывается своей (правой) касательной в точке (а, 0), которая
представляет прямую с угловым коэффициентом с > 0. Из (10.5.5)
следует, чго прочность всей цепи наверное не меньше а, так как
402
МЕТОДЫ РАСЧЕТА, АНАЛИЗА И КОНТРОЛЯ ТОЧНОСТИ
[ГЛ. X
₽(«,. п<«) = 0 при любом п. С другой стороны, согласно (10.5.5),
при всяком постоянном /г>0 вероятность
Р „ <а Ч- А) == 1 — [1 — Р (а Л)]" (10.5.8)
будет близка к единице, если п велико, так как
1 — Р(а4-Л)<1 и [1 — Р (а h)]n—>0 при п—► оо.
Рассмотрим значение Л = — , где /> 0— постоянное число; тогда,
используя (10.5.7), будем иметь:
р(а + ^)=(с+е^4 - (10Л9>
ел = 8< —*0 при п—> оо, и из (10.5.8) и (10.5.9) получим:
п
р(«„„<а + ^) = 1- (Ю-5.10)
, t 1 _
или, полагая а-\— = х и сп — — , причем v>0, для больших п
из (10.5.10) найдем:
р («!,»<«)
при х > а,
при х <_ а.
(10.5.11)
Таким образом, в нашем случае прочность цепи подчиняется (асимпто-
тически при большом числе звеньев) показательному закону распре-
деления. Отметим, что форма этого закона определялась поведением
функции распределения вблизи точки а, описываемым с помощью
(10.5.7); в остальном закон распределения Р(х) был совершенно
произвольным. Делая вместо (10.5.7) более общее предположение:
Р(а + А) = (с-|-ед)/г’, (10.5.12)
где с>0, а>0 и цд—>0 при h—► 0, мы придем тем же путем
к асимптотическому равенству
!(х - а)а
1—е V прих>а, (Ю.5.13)
0 при х < а,
где Prri,i(x) — условное обозначение предельного закона распреде-
ления.
Заметим еще, что максимум последовательности величин совпадает
с точностью до знака с минимумом последовательности тех же
§ 5] ТЕОРИЯ РАСПРЕДЕЛЕНИЯ КРАЙНИХ ЧЛЕНОВ ВЫБОРКИ 403
величин, взятых со знаком минус, так что
«/(1>П=таХ(^«» •••• А’п) =
= —min(—— Хг, .... ~Хп) = — а'1п. (10.5.14)
Отсюда
р(««,»<*)=р(—„<х)=
= Р(< n>-x) = 1-P(tt't п<-х). (10.5.15)
Поэтому, если для минимального члена ut п выборки мы имеем
распределение (10.5.13), то при аналогичных условиях для распре-
деления, ограниченного справа значением Ь, причем Р (Ь)=1 и
P(b~ h) = 1— (с + ел)Г, (10.5.12')
где ft>0, а>0 и ей—>0 при h—> 0, мы найдем на основа-
нии (10.5.15), полагая —а=Ь для максимального члена ип п,
Р («»,»< л:) = 1—Р х)«
(ф-*)а
е v при x<b, (Ю.5.13')
1 при х> Ь,
где Рш. п(х)— условное обозначение данного закона1).
Распределения, задаваемые законами Рщ, , (х) и Рщ, п (х), назы-
ваются распределениями третьего типа для крайних членов по-
следовательности независимых величин. Они характерны для тех
случаев, когда распределения величин последовательности имеют
границы, например, когда каждая величина принимает лишь значения,
лежащие в определенном отрезке (а, Ь), причем функция распреде-
ления удовлетворяет условиям (10.5.12) и (10.5.12'). Отметим, что
эти условия ограничивают поведение функции лишь в «конечных»
точках распределения, в остальном функция Р(х) может быть со-
вершенно произвольной.
Теперь мы рассмотрим другой случай, когда величина ^ распре-
делена в бесконечном интервале и минимум или максимум ее может
принимать сколь угодно большое по абсолютной величине значение.
Пусть каждая величина Х{ подчиняется показательному закону
X
р(х) = 0 при х < 0, Р (х) = 1—е у при х>0.
’) Буква п в обозначении Р1Н п (х) служит лишь для указания того,
что при больших п имеет место (10.5.13').
404 МЕТОДЫ РАСЧЕТА, АНАЛИЗА И КОНТРОЛЯ ТОЧНОСТИ [ГЛ. X
Здесь есть единственный параметр, равный среднему значению.
В самом деле, принимая во внимание, что плотность равна
Р'(х) = |е v, найдем^
у х dx — yj е"1/dt ~ у
о о
^замена х на f = В этом случае минимум д1П величин Xt
по вероятности будет сходиться к нулю и его асимптотическое
распределение имеет вид (10.5.13), причем а=1 и <г = 0 ^так как
при а — 0 имеем Р(/г)«?у); другими словами, оно будет также
показательным. Но распределение максимума ип п величин будет
следовать закону совсем другого типа. Согласно (10.5.6) при А’ЗзО
/ —
Р(ип,п<х) = < 1—V, (10.5.16)
при х<0, конечно, Р («„, п < х) = 0. Из (10.5.16) следует, что при
любом постоянном значении х>0 при п—* оо
Р(ип>п<х)— 0 и Р(«п,п>х)-*1,
так что при п достаточно большом ип п наверное превзойдет любую
наперед заданную границу. Можно доказать, что среднее значение
величины иПзП также растет с ростом л, будучи равным
Ми„, „ = vn«Y’n«-
Полагая х= yin п -f-z, где z может иметь любой знак, найдем:
/ Z \П / 2 \ п
I — 1п П ) / л -у \
Р(«П1„<у1пл + Д) = к <10-5-17)
и ( , и \ _1,
Но как известно из анализа, II —— 1 —► е при п—» оо; поэтому
из (10.5.17) мы заключаем, что при этом же условии
Р(п„ п*<у'п л + 2)—* е~“ У- (10.5.18)
Это — так называемый двойной показательный закон, или закон
первого типа. Общий вид закона первого типа дается следующей
формулой:
Pi, п (х) = е~е~у> (10.5.18)
ТЕОРИЯ РАСПРЕДЕЛЕНИЯ КРАЙНИХ ЧЛЕНОВ ВЫБОРКИ
405
§ 51
где у = а{х—q), а>0 и q—некоторая константа. Отметим, что
асимптотически при большом п распределение иП1„ (максимального
члена выборки) будет следовать закону вида (10.5.18') всякий раз,
когда распределение Р(х) каждой из величин X^i — X, 2, п]
при х—» оо приближается к единице достаточно быстро. Так, напри-
мер, «показательное» убывание разности 1—Р(х)прих—► оо будет
иметь место при нормальном распределении величин Х-г В остальном
функция Р(х) может быть совершенно произвольной. Точно также
распределение минимума иьп в том случае, когда при х—►—оо
Р(х) достаточно быстро приближается к нулю (но не обращается в нуль
ни при каком конечном х), будет асимптотически следовать закону
Р1г1(х)=1—(10.5.19)
где по-прежнему у = а(х—q) п а>0.
Распределения Pi, i (х) и Pi, п(х) несимметричны и неограниченны,
однако при больших по абсолютным значениям у (например, при
|у (> 7) эти функции мало отличаются от нуля (при _у<(0) и от
единицы (при у>>0). Значение x — q обращает обе функции
в у ~ 0,3679, и оно отвечает модам кривых плотностей вероятностей
распределений (10.5.18') и (10.5.19). Величина у называется норми-
рованным уклонением от моды. Согласно теории крайних членов
выборки только три типа законов распределения могут выступать
в качестве предельных для крайних членов выборки при п—► оо,
а каждый из них наверное будет наблюдаться, если распределение
величин, т. е. функция Р(х), удовлетворяет определенным условиям.
Два из этих предельных типов, имеющих для приложений в технике
большое значение, как раз и представляют Pi, i (х) и PL „(х) и соот-
ветственно Рш, 1 (х) и Рщ, п (х). Заметим, что в приложениях обычно
число величин, максимумы или минимумы которых рассматриваются,
значительно, так что здесь могут быть использованы асимптотиче-
ские законы для крайних членов, и следовательно, в этом случае
не требуется детального знания функции распределения самих
величин.
10.5.2. Применение закона первого типа распределения край-
них членов для определения экстремальных расходов воды
в реках. Рассмотренные в п. 10.5.1 два типа законов распределения
крайних членов имеют многочисленные практические применения.
Здесь мы рассмотрим применение закона первого типа для расчета
экстремальных расходов воды в реках, являющихся исходными пред-
посылками при проектировании различных гидротехнических соору-
жений. Аналогичная методика, естественно, может быть применена
для изучения максимумов и минимумов атмосферного давления, наи-
больших снегопадов, наиболее низких (или наиболее высоких)годо-
вых температур, наибольшей силы ветра и т. д.
406 МЕТОДЫ РАСЧЕТА, АНАЛИЗА И КОНТРОЛЯ ТОЧНОСТИ [ГЛ. X '
В порядке приближения предполагают, что наблюдаемые годовые
максимумы или минимумы являются крайними членами
обширной последовательности независимых величин (например, днев-
ных расходов воды, температур, давлений и т. д.), следующих одному.
и тому же закону распределения. Ясно, что такие допущения лишь
весьма приближенно отвечают действительности, так как на самом
деле близкие во времени значения рассматриваемых величин обычно
зависимы между собой, а для значений, разделенных большими
промежутками времени, законы распределения, вообще говоря, могут
значительно отличаться друг от друга. Тем не менее, как показывает
опыт, закономерность, отвечающая одному из законов распределения
Pi, I (х) и Pi.nW или Рш, 1 (х) и Рш, nW, может осуществляться
довольно точно, и это обстоятельство дает возможность путем надле-
жащей обработки наблюдений делать определенные прогнозы о ве-
роятностях, с которыми годовые максимумы превосходят ту или
иную границу. Рассмотрим сначала вопрос о том, как сопоставить
данные наблюдений с теоретической функцией распределения и оце-
нить параметры последней.
В первую очередь обратимся к законам Pi, j (х) и Pi, nW,
используя процедуру, предложенную Гумбелем [125].
Эта процедура приводит к построению графика зависимости зна-
чений X исследуемых максимумов или минимумов от нормированных
отклонений у, представляющих аргументы функции е~е~у. При этом
шкалы для х и у обычно выбираются линейные (равномерные).
Значения^ откладываются по горизонтали. Параллельно основной
(линейной) шкале у дается дополнительная функциональная шкала,
на которой при исследовании максимумов значениям у отвечают зна-
чения функции ф W = е~е у, описывающей, как мы видели в п. 10.5.1,
закон Pi,„(x) первого типа распределения вероятностей максималь-
ных членов вариационного ряда. При исследовании минимумов на
дополнительной шкале откладываются значения функции ф1(_у) =
= 1—е~е у—1—<р(—j/), отвечающей закону Рщ (х) первого типа
распределения вероятностей минимальных членов вариационного ряда.
Значения функций ф(_у) и ф, (у) можно получить путем двойного
потенцирования, исходя из равенства
1g [—1g Ф (J)] — —У lg lg lge = — 0,43429 у—0,36222 (10.5.20)
(где логарифмы десятичные), или, используя значения ф(_у), приво-
димые в таблице 10.5.1 (см. также таблицу IX приложений).
Из (10.5.20) в свою очередь имеем:
.у = — 2,30261 lg[—1g ф W] —0,83405. (10.5.21)
Дополнительная шкала будет нелинейной: так, например, на ней
значению у = — 2 отвечает ф( — 2) = 0,00062, значению _у = 0 отве-
чает ф (0) = 0,36788, значению у = 6 отвечает ф (6) = 0,99752 и
§ 5]
ТЕОРИЯ РАСПРЕДЕЛЕНИЯ КРАЙНИХ ЧЛЕНОВ ВЫБОРКИ
407
Таблица 10.5.1
Значения функции <р (у}=е~е~у
Нормиро- ванное переменное Ф (0 Нормиро- ванное переменное У Ф (У) Нормиро- ванное переменное У Ф <у)
—2,00 0,00062 0,75 0,62352 3,50 0,97025
—1,75 0,00317 1,00 0,69220 3,75 0,97675
— 1,50 0,01131 1,25 0,75088 4,00 0,98185
—1,25 0,03049 1,50 0,80001 1 4,25 0,98584
—1,00 0,06599 ’ 1,75 0,84048 1 4,50 0,98895
—0,75 0,12039 2,00 0,87342 4,75 0,99138
-0,50 0,19230 2,25 0,89996 5,00 0,99329
—0,25 0,27693 2,50 0,92119 5,25 0,99477
0,00 0,36788 2,75 0,93807 5,50 0,99592
0,25 0,45896 3,00 0,95143 5,75 0,99682
0,50 0,54524 3,25 0,96197 6,00 0,99752
т. д. По вертикальной оси графика откладываются наблюденные зна-
чения х максимумов или минимумов. Совокупность точек, отвечаю-
щих на графике произведенным наблюдениям, аппроксимируется соот-
ветствующей линией, которая и позволяет прогнозировать значения
максимумов (или минимумов), отвечающие надлежащим образом вы-
бранным вероятностям. Если бы величина X максимума точно сле-
довала бы закону Р[,„(х) = <р (у), где у — а(х—q), причем а и
q — параметры распределения, и мы точно знали бы всякий раз,
какому значению вероятности Р|,,г(х) отвечает наблюденное зна-
чение х, то имели бы точную линейную зависимость у = а(х—q).
На нашем графике она изобразилась бы прямой линией. Параметры
а и q без труда определились бы, например, по координатам
(j0, х(|) и (ур xj двух каких-либо точек нашего графика. Конечно,
в действительности мы не знаем вероятности Р(,„(хй)для каждого
наблюдаемого (некоторого й-го) значения xk. Однако W значений
х, наблюденных в выборке, как можно показать, в среднем делят
ось х так, что (Л/-)-1) полученных промежутков отвечают равным
приростам функции Pi,n(x). Другими словами, расположив наблю-
денные значения xk в порядке возрастания, мы получим вариа-
ционный ряд величин х
хг<хг<.. .<xkC.. .<.xN.
(10.5.22)
Тогда вероятности Р|,п(х) в соответствующих точках будут:
Pi,и (х,) <Pi n(xt) < ... <Pl.„(xJ < ... <Pi.n (xN). (10.5.23)
Так же как и сами xk, они будут случайными величинами. Но, как
408
МЕТОДЫ РАСЧЕТА, АНАЛИЗА И КОНТРОЛЯ ТОЧНОСТИ
[ГЛ. X
было указано в п. 10.5.1, математические ожидания приростов
функции Р(х) в каждом из интервалов (— оо, хх), (хр х,), ...
...,(xy_i, Хы), (Xff, оо) будут равны между собой, т. е.
М [Pi.„ (•*>)—0] = М [Р1л (xs)-P1>n (xj] =
= M[P1,„(XS) —Р[,„(Х!)]= . . . =M[P|,n(Xjv) — Pi.n (x,v-,)].
Каждый из этих приростов равен тД—н поэтому мы будем иметь:'
/V 1
1 2
м [РI л W1 = ; м [Р1 л (*,)]=jv+T
... ; М[Р1,„(х^] = д^-г (10.5.24)
Далее, можно показать, что
Dl₽t.Wl-(4^±i5<wLjy (10.5.23)
и, следовательно, Pi л (xk) по вероятности сходится к М[Р1,л(хА)]
при N—► оо. Поэтому, приравнивая
Р1л(хА) = д^, (10.5.26)
мы сделаем случайную ошибку, почти наверное сколь угодно ма- .
лую, если /V достаточно велико. Определяя, далее, отвечающие .
k ( k \
—значения у =yk (такие, что <р (jft) = I , мы получим по-
следовательность У1<Уг<.-. <•••<>.v такую, что точки
xk)> где &=1> 2, ... , N, лежат наверное вблизи теорети-
ческой прямой у — а(х—q) или x — q-\-^ и отклоняются от нее
лишь в силу наличия случайных ошибок. Для оценки параметров •
а и q приближенной прямой применяют следующую процедуру;
1) вычисляют среднюю арифметическую х и среднее квадратиче-
ское отклонение sx по всем N наблюдениям; 2) берут вспомога-
тельные значения у^ и ст# из таблицы 10.5.2, представляющие
среднее значение и среднее квадратическое отклонение величин
у (А>=1, 2, ... , А/); 3) находят оценку 4- параметра — в урав-
а а
нении х = о4----, полагая
3-=^-; (10.5.27)
a
4) затем находят оценку q для параметра q, полагая
q — x—у,м ~ (для максимума) (10.5.Ф8)
§ 5] ТЕОРИЯ РАСПРЕДЕЛЕНИЯ КРАЙНИХ ЧЛЕНОВ ВЫБОРКИ 409
Т а б л и ц а 10.5.2
Средние значения у и и средние квадратические отклонения
величин yk(k=l, 2,..., У)
N N Sn /V °N
20 0,5236 1,0628 41 0,5442 1,1436 62 0,5527 1,1770
21 0,5252 1,0695 42 0,5448 1,1458 64 0,5533 1,1793
22 0,5268 1,0755 43 0,5453 1,1480 66 0,5538 1,1814
23 0,5282 1,0812 44 0,5458 1,1499 68 0,5543 1,1834
24 0,5296 1,0865 45 0,5463 1,1519 70 0,5548 1,1854
25 0,5309 1,0915 46 0,5468 1,1538 72 0,5552 1,1873
26 0,5320 1,0961 47 0,5473 1,1557 74 0,5557 1,1890.
27 0,5332 1,1004 48 0,5477 1,1574 76 0,5561 1,1906
28 0,5343 1,1047 49 0,5481 1,1590 78 0,5565 1,1923
29 0,5353 1,1086 50 0,5485 1,1607 80 0,5569 1,1938
30 0,5362 1,1124 51 0,5489 1,1623 82 0,5572 1,1953
31 0,5371 1,1159 52 0,5493 1,1638 84 0,5576 1,1967
32 0,5380 1,1193 53 0,5497 1,1653 86 0,5580 Г,1980
33 0,5388 1,1226 54 0,5501 1,1667 88 0,5583 1,1994
34 0,5396 1,1255 55 0,5504 1,1681 90 0,5586 1,2007
35 0,5403 1,1285 56 0,5508 1,1696 92 0,5589 1,2020
36 0,5410 1,1313 57 0,5511 1,1708 94 0,5592 1,2032
37 0,5418 1,1339 58 0,5515 1,1721 96 0,5595 1,2044
38 0,5424 1,1363 59 0,5518 1,1734 98 0,5598 1,2055
39 40 0,5430 0,5436- 1,1388 1,1413 60 0,5521 1,1747 100 0,5600 1,2065
и
= х-|-.Ул^" (для минимума). (10.5.29)
а
Уравнение выравнивающей прямой записывают в виде
х = ^4-т- (Для максимумов), (10.5.30)
а
x = q—(для минимумов). (10.5.31)
а
В качестве оценки степени согласованности эмпирической и теоре-
тической кривых при каком-либо значении хт вычисляют величину
|1ОЛ32)
при этом числитель заимствуют из таблицы 10.5.3.
„ т
Эта оценка может быть использована лишь при значениях у- } ,
не слишком близких к нулю или к единице ^0,15 < 0,85^ .
410 МЕТОДЫ РАСЧЕТА, АНАЛИЗА И КОНТРОЛЯ ТОЧНОСТИ [ГЛ. X
Таблица 10.5.3
Средние квадратические ошибки /n-ых значений для закона
распределения первого типа максимальных членов
L <г w Ту 1/ Ф ('/) а(ит)
-0,5 0,19230 1,2431 1,0 0,69220 1,8126
0,0 0,36788 1,3108 1,5 0,80001 2,2408
0,5 0,54524 1,5057 2,0 0,87342 2,8129
Величина o(Xm) используется для построения критической об-
ласти по обе стороны от теоретического значения х,
прямой, причем уровни значимости определяются по таблице
приложений. Так, например, при уровне значимости 5°/0 по
стороны от х, лежащего на прямой, откладывается по 1,96 в(Хт). ’
Таблица 10.5.4
Максимальные (по годам) расходы воды р. Нил у Асуана
в тыс. м31сек
1 од Расход X2 Год Расход X X2 Год Расход X х»
1888 7,34 53,88 1912 7,03 49,42 1936 9,24 85,38
1889 10,58 111,94 1913 4,71 22,18 1937 8,59 73,79
1890 11,29 127,46 1914 7,71 59,44 1938 10,74 115,35
1891 10,41 108,37 1915 5,73 32,83 1939 7,08 50,13
1892 13,19 173,98 1916 10,27 105,47 1940 6,94 48,16
1893 9,41 88,55 1917 10,71 114,70 1941 5,56 30,19
1894 12,04 144,96 1918 6,83 46,65 1942 7,83 61,31
1895 11,40 129,96 1919 8,03 64,48 1943 9,56 91,39
1896 11,51 132,48 1920 6,89 47,47 1944 6,92 47,89
1897 9,49 90,06 1921 7,57 57,30 1945 7,24 52,42
1898 11,13 123,88 1922 9,12 83,17 1946 10,75 115,56
1899 6,46 41,73 1923 8,28 68,56 1947 8,87 78,68
1900 8,57 73,44 1924, 8,61 74,13 1948 7,41 54,91
1901 9,39 88,17 1925 6,41 41,09 1949 7,80 60,84
1902 7,06 49,84 1926 7,95 63,20 1950 8,61 74,13
1903 9,56 91,39 1927 7,06 49,84 1951 6,86 47,06
1904 7,33 53,73 1928 7,72 59,60 1952 8,13 66,10
1905 7,55 57,00 1929 9,44 89,11 1953 8,02 64,32
1906 9,56 91,39 1930 6,83 46,65 1954 10,93 119,46
1907 6,81 46,83 1931 8,21 67,40 1955 8,68 75,34
1908 11,30 127,69 1932 8,83 77,97 1956 7,98 63,68
1909 9,94 98,80 1933 8,54 72,93 1957 8,22 67,57
1910 9,46 89,49 1934 9,16 83,91 1958 9,48 89,87
1911 8,99 80,82 1935 9,30 86,49 1959 11,27 127,01
§ 5] ТЕОРИЯ РАСПРЕДЕЛЕНИЯ КРАЙНИХ ЧЛЕНОВ ВЫБОРКИ 41 1
Рассмотрим пример. В таблице 10.5.4 приводятся данные о
максимальных по годам расходах воды реки Нил у Асуана за 72
года (1888 —1959), в ней же даны квадраты расходов, нужные
для последующих подсчетов. Требуется определить максимально
возможный расход воды в реке в указанном пункте с вероятностью,
не меньшей [Р] = 0 999
Данные таблицы 10.5.4 мы располагаем в вариационный ряд
значений xft(fe=l, 2, N), представленных в 4-м столбце таб-
лицы 10.5.5. Для каждого значения во 2-м столбце той же таблицы
k
приводятся величины определяемые по формуле (10.5.26).
Приравнивая последние значениям функции (уй), находим по таб-
лице IX приложений или по соотношению (10.5.21) значения вели-
чины yk и проставляем их в 3-м столбце таблицы 10.5.5.
Таблица 10.5.5
Вариационный ряд максимальных по годам расходов воды
р. Нил (xk) и отвечающие его членам значения накопленных
частот k и нормированных отклонений yk
! А/7 3 Ук *к /г Л/73 1/1; j XI, k л/73 1/к Хк
1 0,014 —1,451 4,71 25 0,343 —0,068 7,80 49 0,671 0,919 9,41
2 0,027 —1,284 5,56 26 0,356 —0,032 7,83 50 0,685 0,972 9,44
3 0,041 —1,161 5,73 27 0,370 +0,006 7,95 51 0,699 1,027 9,46
4 0,055 —1,065 6,41 28 0,384 +0,044 7,98 52 0,712 1,080 9,48
5 0,069 —0,983 6,46 29 0,397 0,079 8,02 53 0,726 1,139 9,49
6 0,082 -0,917 6,81 30 0,411 0,117 8,03 54 0,740 1,200 9,56
7 0,096 -0,852 6,83 31 0,425 0,156 8,13 55 0,754 1,265 9,56
8 0,110 —0,792 6,83 32 0,438 0,192 8,21 56 0,767 1,327 9,56
9 0,123 —0,740 6,86 33 0,452 0,231 8,22 57 0,721 1,398 9,94
10 0,137 —0,687 6,89 34 0,466 0,270 8,28 58 0,795 1,472 10,27
11 0,151 —0,637 6,92 35 0,480 0,309 8,54 59 0,808 1,546 10,41
12 0,164 —0,592 6,94 36 0,493 0,346 8,57 60 0,822 1,630 10,58
13 0,178 —0,546 7,03 37 0,507 0,387 8,59 61 0,836 1,720 10,71
14 0,191 —0,501 7,06 38 0,521 0,428 8,61 62 0,849 1,810 10,74
15 0,206 —0,457 7,06 39 0,535 0,469 8,61 63 0,863 1,915 10,75
16 0,219 —0,418 7,08 40 0,548 0,508 8,68 64 0,877 2,031 10,93
17 0,233 —0,376 7,24 41 0,562 0,551 8,83 65 0,891 2,159 11,13
18 0,247 —0,335 7,33 42 0,575 0,592 8,87 66 0,904 2,293 11,27
19 0,260 —0,298 7,34 43 0,589 0,6 16 8,99 67 0,918 2,459 11,29
20 0,274 —0,258 7,41 44 0,602 0,6/8 9,12 68 0,932 2,653 11,30
21 0,288 —0,219 7,55 45 0,617 0,728 9,16 69 0,945 2,872 11,40
22 0,301 —0,183 7,57 46 0,630 0,772 9,24 70 0,959 3,173 11,51
23 0,315 —0,144 7,71 47 0,644 0,821 9,29 71 0,973 3,598 12,04
24 0,329 —0,106 7,72 1 48 0,658 0,871 9,39 72 0,986 4,262 13,19
412 МЕТОДЫ РАСЧЕТА, АНАЛИЗА И КОНТРОЛЯ ТОЧНОСТИ [ГЛ. X
Данные этой таблицы мы наносим в виде точек (хд, _yft) на пост-
роенный в координатах х, у описанным выре способом график,
показанный на рис. 78.
На этот же график наносим приближенную прямую, описыва-
ющую зависимость между максимальными расходами воды(х), с одной
стороны, и отвечающими им вероятностями Pi.n(x) = <p(j) и норми-
рованными отклонениями (у), с другой. Для этого мы сначала
ределяем по данным таблицы 10.5.4 средний арифметический мак-
симум расхода х и его среднее квадратическое отклонение sx:
Далее по таблице 10.5.2 берем вспомогательные значения у,г
и а,г, отвечающие N— 72; они равны = 0,5552 и о,2 = 1,1873.
Затем находим оценки параметров 1/а и q в уравнении
х = <?-1 -i-, применяя формулы (10.5.27) и (10.5.28):
^- = г?гй=1414 и = 8657,3 —0,5552• 1414 = 7872.
а *»J*'**
Искомое уравнение будет иметь вид х= 1414.УД-7872.
Эту прямую мы наносим на наш график (рис. 78), продолжая
ее до значения ординаты, отвечающей Pi,n(x) = (p„ (_у) = 0,999.
По графику находим, что при такой ординате полученной _
прямой соответствует максимальный расход воды
«17 800 ма[сек.
Подсчитаем теперь величину а(хк) по формуле (10.5.32), поль-
зуясь таблицей 10.5.3, например, для значений у = 0, 1, 2, отве-
чающих значениям х на полученной нами прямой х = 7872, 9286
и 10700:
*(,=„„) = 1414 « 0,22-10’,
1414 « 0,30 -10‘,
а(^о гоо)= у=у 1414 « 0,47-10’.
Теперь, выбрав, например, доверительную вероятность 0,9545,
мы по таблице II приложений находим, что ей отвечает отклоне-
ние границы доверительного интервала от центра, равное 2o(Xm).
ТЕОРИЯ РАСПРЕДЕЛЕНИЯ КРАЙНИХ ЧЛЕНОВ ВЫБОРКИ
О
Рис. 78. Максимальные расходы воды в тыс. ма1сек.
414
МЕТОДЫ РАСЧЕТА, АНАЛИЗА И КОНТРОЛЯ ТОЧНОСТИ
[гл. X
Используя вычисленные нами ранее значения О(Хт>, ми наносим на
график (рис. 78) границы доверительного интервала, откладывая их
вдоль оси х в обе стороны от указанных выше точек полученной
нами прямой.
10.5.3. Статистическая интерпретация результатов испытаний
материалов деталей машин на выносливость при переменных нап-
ряжениях. При периодически изменяющихся нагрузках, вызывающих
в материале деталей машин переменные напряжения, в этих де-
талях наблюдаются при определенных условиях прогрессивно
растущие характерные трещины усталости. При каждой данной
амплитуде 5 изменений напряжения за цикл по достижении не-
которого числа М циклов происходит разрушение детали. Это
число циклов до разрушения постепенно увеличивается при умень-
шении амплитуды S колебаний напряжения цикла. Эксперимен-
тальные исследования зависимости 5 от N навели на мысль о
существовании такой наибольшей величины периодически меня-
ющегося напряжения, которой материал может противостоять
практически неограниченно долго без появления трещин усталости.
Эта величина названа пределом выносливости (усталости) и, будучи
определена при напряжениях изгиба, меняющихся по симметрич-
ному циклу, она обозначается через о_, (индекс —1 представляет
частное значение коэффициента асимметрии цикла, определяющегося
отношением минимального напряжения к максимальному, т. е.
, и этот коэффициент равен—1 при omin=—omax). Естественно,
'Гщах
что эта характеристика механических свойств материала меньше
его предела прочности оЕ; она составляет для различных материа-
лов от 0,2 ов до 0,5 ов, причем это отвечает для стали значению
числа циклов примерно М=10’ и для цветных сплавов Д/ =
= (5-i-lO) 107. Многочисленные наблюдения показывают, что экспе-
риментально определяемые значения в стандартных условиях
для материала одной и той же марки существенно варьируют и
это заметно осложняет истолкование результатов важных и, вместе
с тем, длительных и трудоемких усталостных испытаний.
Для правильной научной интерпретации этих результатов в
условиях случайной их вариации естественно использовать надле-
жащую статистическую теорию.
С физической точки зрения усталостные явления можно объяс-
нить наличием в испытуемом образце (и соответственно в детали,
изготовленной из данного материала) трещин, случайно распреде-
ленных в отношении своего положения и своей величины по всему
телу образца. При действии переменных напряжений трещины
постепенно проникают в глубь деталей, поперечное сечение ослаб-
ляется все сильнее и, наконец, при случайном толчке или ударе
наступает окончательное разрушение, когда сопротивление остав-
при N>NaS,
(10.5.33)
§ 5] ТЕОРИЯ РАСПРЕДЕЛЕНИЯ КРАЙНИХ ЧЛЕНОВ ВЫБОРКИ 415
шейся части сечения оказывается недостаточным. Причиной излома
можно считать наибольшую по своим размерам трещину. Естест-
венно полагать, что число циклов N, необходимых при данном напряже -
нии 5 для разрушения образца в месте расположения той или
иной трещины, есть убывающая функция размеров данной трещины, и
оно является минимальным для наибольшей по своим размерам
трещины. Отсюда вытекает, что число N циклов до разрушения
должно подчиняться закону распределения минимального члена из
большого числа случайных независимых величин — чисел циклов,
отвечающих различным по размерам трещинам в теле образца.
Так как это число заведомо положительно, то наиболее подходящим
асимптотическим законом в такой обстановке является закон Рц (х),
который мы рассмотрели в п. 10.5.1. Обычно при анализе резуль-
татов усталостных испытаний рассматривают дополнительную веро-
ятность 1—Pni.i(x), т. е. вероятность того, что долговечность
образца превысит х циклов. Эгу вероятность неразрушения образца
для x — N циклов нагружений его при амплитуде 5 колебаний
напряжения за цикл обозначают через ls(Nr'). Согласно нашему
допущению вероятность неразрушения после N циклов можно вы-
разить следующим образом:
( е_2“
где
N-NqS
Vs — ^'oS
a NoS и У5—два параметра кривой Параметр WoS имеет
простой смысл —это наибольшее возможное число циклов, которое
при данном напряжении S не вызывает разрушения; его называют
«порогом чувствительности по циклам». Параметр Уу есть зна-
чение N, отвечающее вероятности неразрушения, равной у = 0,36788.
Параметр NoS оценивается с помощью метода моментов. В даль-
нейшем мы для простоты ограничимся случаем, когда без большой
погрешности можно принять /Vo5 = O и, следовательно,
-Г—V
/5(ДГ) = е vs/ при М>0. (10.5.34)
Если ввести вспомогательные величины
x* = ln2V,
. .. .. w N x*~lls
«5 = 1пИ5, К5=еди^=г
то (10.5.34) примет вид
;s(jV) = e-^ (10.5.35)
416 МЕТОДЫ РАСЧЕТА, АНАЛИЗА И КОНТРОЛЯ ТОЧНОСТИ (ГЛ. X’
где у = а{х*—us), так что e~eV будет представлять убывающую
функцию у.
Таким образом, вероятность примет вид закона Pi,, (х*
первого типа распределения вероятностей минимального
вариационного ряда.
Поэтому для оценки параметров вероятности и для изображе-.
ния на графике результатов усталостных испытаний можно при-
менить метод, изложенный в п. 10.5.2, с той только разницей,
вместо числа V наблюденных циклов до разрушения следует брать
их обыкновенные (десятичные) логарифмы.
Вся необходимая процедура сводится к следующим
1°. Наблюдение числа V циклов до разрушения располагают
в вариационный ряд
где п — число испытанных образцов.
2®. Вычисляют соответствующую этому вариационному ряду по-
следовательность логарифмов x = lg№):
х,<х,<...<х„<...<ха,
где x„ = lgNOT и т= 1, 2, ... , п.
3°. Каждому члену Nm (и соответственно хт) этих последова-
тельностей ставится в соответствие число
(10.5.36)
оценивающее отвечающую ему вероятность
4®. По числам рт определяют значения ут. Для этого можно
воспользоваться таблицей IX приложений или таблицей 10.5.1
функции <р(_у) и определить ут из уравнения
<?(->„) = 1-^1 (Ю.5.37)
или использовать получающуюся из двукратного логарифмирования
соотношения (10.5.35) формулу
Ут =(^1£( — ]gPJ — Ig 1g® = 2,30261 lg( — lgpm) + 0,83405.
(10.5.38)
5°. Полученные данные наносят на график. По горизонтальной
оси откладывают в натуральном масштабе числа xm~\gNm (или
сами числа Nm в логарифмическом масштабе). По вертикальной оси
‘) В данном случае десятичные логарифмы используются для удобства
вычислений.
§ 5] ТЕОРИЯ РАСПРЕДЕЛЕНИЯ КРАЙНИХ ЧЛЕНОВ ВЫБОРКИ 417
откладывают значения у —ут в натуральном масштабе или, что то
же самое, отвечающие им вероятности ls(N,n) в функциональном
масштабе. Последнее удобно делать, если заранее заготовить
соответствующую вероятностную бумагу.
Если принятая гипотеза о форме распределения числа цик-
лов оправдывается, то точки (хт, ут) будут лежать вблизи прямой
У==«д (х—us)
или
x = + (10.5.39)
где
= Vs.
6°. Для оценки параметров а5 и us вычисляют среднюю арифме-
тическую lg Nm и среднее квадратическое отклонение s(\gNm) вели-
чины х = lg 7V, а затем находят оценки параметров из соотношений
= (10.5.40)
ад а«
(10.5.41)
ад
где коэффициенты уп и о„ берутся из таблицы 10.5.2, в которой
полагают N = n, причем п — число испытанных образцов.
Прямая (10.5.39), приближенно описывающая зависимость вероят-
ности ls(N) от числа N циклов до разрушения при каждом выбран-
ном значении амплитуды S изменений напряжения за цикл, позволяет
строить прогнозы в отношении того, какие напряжения и при каких
числах циклов отвечают вероятности неразрушения образца, доста-
точно близкой к единице. А они-то, в конечном счете, и предста-
вляют практический интерес как характеристики прочности материа-
лов при периодически изменяющихся напряжениях.
Рассмотрим пример. В таблице 10.5.6 приводятся вариационный
ряд чисел Nm циклов до разрушения, последовательность отвечающих
этим числам логарифмов xm = 1gNm, подсчитанные по формуле
(10.5.36) оценки рт вероятностей и найденные по таблице IX
приложений или по формуле (10.5.38) значения величины ут на
основании результатов усталостных испытаний гладких образцов
при амплитуде колебаний напряжения за цикл 5=30 кг'мм‘. При
этом следует иметь в виду, что таблица IX приложений состав-
лена для <р(у), а потому необходимо учесть соотношение (10.5.37).
По данным таблицы 10.5.6 вычисляем:
= 112^33 = 5о8361
14 Н, В. Смирнов, И. В. Дунин-Барковский
418 МЕТОДЫ РАСЧЕТА, АНАЛИЗА И КОНТРОЛЯ ТОЧНОСТИ [ГЛ. X
Таблица 10.5.6
Результаты усталостных испытаний гладких образцов
при напряжении $ = 30 кг/лш2
т хт~Ifi 4 Pm Ут
1 0,53 4,72428 22,31882 0,9565 -3,11283
2 0,65 4,81291 23,16410 0,9130 -2,39668
3 0,76 4,88081 23,82231 0r8696 —1,96813
4 0,80 4,90309 24,04029 0,8261 -1,65528
5 0,87 4,93952 24,39886 0,7826 -1,40596
6 0,90 4,95424 24,54440 0,7391 -1,19626
7 0,90 4,95424 24,54440 0,6957 —1,01380
8 1,02 5,00860 25,08607 0,6522 —0,85003
9 1,07 5,02938 25,29470 0,6087 -0,70032
10 1,07 5,02938 25,29470 0,5652 -0,56111
11 1,09 5,03743 25,37570 0,5217 —0,42976
12 1,16 5,06446 25,64876 0,4783 -0,30447
13 1,22 5,08636 25,87106 0,4348 —0,18288
14 1,29 5,11059 26,11813 0,3913 —0,06376
15 1,40 5,14613 26,48265 0,3478 0,05461
16 1,57 5,19590 26,99738 0,3043 0,17373
17 1,59 5,20140 27,05456 0,2609 0,29536
18 1,88 5,27416 27,81676 0,2174 0,42266
19 2,07 5,31597 28,25954 0,1739 0,55920
20 2,23 5,34830 28,60431 0,1304 0,71156
21 2,38 5,37658 28,90761 0,0870 0,89276
22 2,79 5,44560 29,65456 0,0435 1,26763
2 111,83933 569,29967
и
Г^ббЭ, 29967
---------- -=0,1850
Далее по формулам (10.5.40) и (10.5.41) находим:
г-та”0’1720' “--5'8136
II
«30 = 5,08361 +0,5268-0,1720 = 5,1742,
где у22 и а22 взяты по таблице 10.5.2 при N = /z = 22; они равны
0,5268 и 1,0755.
Теперь уравнение нашей прямой будет иметь вид
у = 5,8136 (х — 5,1742).
§ 5]
ТЕОРИЯ РАСПРЕДЕЛЕНИЯ КРАЙНИХ ЧЛЕНОВ ВЫБОРКИ
419
По приведенным выше правилам мы строим график, показанный
х= lg N
Рис. 79. Вероятности /50 (Д') неразрушения образца из алюми-
ниевого сплава В-95 в зависимости от числа N циклов измене-
ний напряжения при амплитуде S = 30 кг/мм2 (по данным испы-
таний « = 22 образцам).
точки (хт, ут), а затем нашу прямую. Из рис. 79 видно, что, на-
пример, вероятности неразрушения образца /ао (Nm) = 0,995 при
напряжении <5' = 30 кг^мм2 отвечает число циклов N— 0,17-10%
14*
ГЛАВА XI
ПОНЯТИЕ О ТЕОРИИ СЛУЧАЙНЫХ ПРОЦЕССОВ
И НЕКОТОРЫХ ЕЕ ПРИЛОЖЕНИЯХ
§ 1. Случайные процессы и их характеристики
11.1.1. Понятие о случайных процессах. Мы вкратце рас-
смотрим теперь основные понятия и некоторые простейшие при-
ложения теории случайных процессов (или случайных функций) —
одного из новых разделов теории вероятностей, представляющего
большой интерес для решения многих важнейших задач в технике.
В этой теории изучаются закономерности изменения случайных вели-
чин в зависимости от изменения неслучайного параметра, например
времени, пространственной координаты и т. д. Уже в классических
предельных теоремах закона больших чисел и в теореме Ляпунова,
рассмотренных в главе V, речь шла о поведении сумм независимых
величин S„ = X, 4-Хг -|- ... 4-Хп при неограниченном возрастании
параметра л, пробегающего в данном случае значения, представляю-
щие последовательность натуральных чисел 1, 2, ..., п.
Случайные процессы различных типов давно уже изучались
в физике. Так, например, рассматривая частичку микроскопических
размеров, взвешенную в жидкой среде, мы можем следить за ее
хаотическим движением, вызванным сталкивающимися с ней молеку-
лами жидкости (броуновское движение). Пусть X (/), У(/)и Z(t)—
координаты этой частички в момент времени t. Тогда совокупность
случайных величин X(/) (или соответственно Y(t), Z(t}) для всех
значений времени t образует случайный процесс. Приращение
абсциссы за промежуток времени от момента tx до момента /2, т. е.
Х(/г)—X(/t) — Д/,/3А'(/), есть случайная величина, математическое
ожидание которой равно нулю, ибо, как показывает теория, противо-
положные направления движения имеют одинаковые вероятности;
дисперсия этой случайной величины пропорциональна промежутку
времени
= (0] = 2О2(/2-^),
где£) есть коэффициент диффузии, характерный для данной жидкости.
§ 1] СЛУЧАЙНЫЕ ПРОЦЕССЫ И ИХ ХАРАКТЕРИСТИКИ 421
Приращения
в неперекрывающихся промежутках времени {iv /2) и (t[, f)
считаются между собой независимыми. Вместе с тем приращение
координаты за конечный промежуток времени t можно рассматривать
как сумму ее приращений за сколь угодно большое число п не-
перекрывающихся промежутков времени, из которых составлен про-
межуток времени t. А это, как мы видели в п. 5.4.2, приводит
к заключению о нормальности распределения указанного прираще-
ния координаты микроскопической частички. На этих положениях
основана физическая теория броуновского движения, развитая Смо-
луховским и Эйнштейном.
В качестве другого примера, в котором случайная величина
может принимать с течением времени лишь целые значения, укажем
на процесс распада атомов радиоактивного вещества или процесс
испускания электронов раскаленным катодом электронной лампы.
Обозначая через X(t) число распавшихся атомов за время /, мы
будем иметь случайный процесс, носящий название процесса Пуас-
сона. Этот процесс встречается во многих других областях физики
и техники. Ему подчиняются, например, изменение нагрузки теле-
фонной станции, обрывы нитей в прядильных машинах и т. д.
Еще одним примером случайного процесса может служить орди-
ната Х(1} профиля обработанной поверхности, случайным образом
изменяющаяся вдоль рассматриваемой трассы в зависимости от не-
случайного параметра /—расстояния ординаты профиля от началь-
ной точки трассы.
Много более сложных примеров случайных процессов можно
было бы привести из области разнообразных систем автоматического
управления, где именно использование теории случайных процессов
для учета воздействия на работу системы всякого рода случайных
возмущений способно обеспечить помехоустойчивость автоматических
устройств.
Во всех этих примерах мы имели упорядоченные семейства слу-
чайных величин, поставленных в соответствие значениям некоторого
неслучайного параметра так, что для каждого значения t послед-
него мы имели вполне определенную случайную величину X(t)
с определенным законом распределения и, следовательно, с опре-
деленными характеристиками этого закона, такими, как математи-
ческое ожидание, дисперсия и т. д. Для уяснения нового, содер-
жащегося в понятии случайного процесса, можно подойти к нему
еще иначе.
Мы видели в главе 11, что основным понятием теории вероят-
ностей является понятие испытания с определенным множеством Q
422 ПОНЯТИЕ О ТЕОРИИ СЛУЧАЙНЫХ ПРОЦЕССОВ [гл. XI
возможных элементарных событий со —исходов данного испытания.
Случайная величина X в этом аспекте (см. п. 3.1.1) представляет
однозначную числовую функцию А’=/(со) указанных элементарных
событий со, принимающую то или иное числовое значение в зависи-
мости от реализации того или иного исхода со испытания.
Пусть теперь каждому элементу со множества Q соответствует
не одно определенное числовое значение, а определенная числовая
функция /ш(0 некоторого неслучайного параметра t (определенная,
Мб
rv
ooj *
см/сек 6)
6)
мм
о 2 см
г)
Рис. 80. Наблюденные значения случайных функ-
ч ций:
с—замирание интенсивности разносигналов, принятых
«следящей системой»; б - пульсация температуры воздуха
в точке атмосферы, в —пульсация разности скоростей
ветра в двух точках атмосферы на расстоянии 8 см друг
от друга; а —изменение диаметра ткацкой нити вдоль
длины нити.
например, в интервале Мы будем называть каждую
такую функцию /ш(/) (для различных со эти функции, вообще говоря,
различны) «.возможной реализацией-» случайного процесса X(t),
отвечающей элементарному исходу со испытания.
Совокупность всех возможных реализаций, т. е. множество функ-
ций получаемых при различных исходах со испытания, и обра-
зует случайный процесс X(t). При этом вероятностная мера, извест-
ная для различных событий, образованных из элементов со мно-
жества Q, позволяет вместе с тем определить вероятность того,
что реализация процесса будет обладать теми или инымя особен-
ностями или удовлетворять некоторым условиям.
Пусть, например, нам задано двумерное распределение двух
величин X и Ф с двумерной плотностью вероятности р (х, ср), причем
S) 1] СЛУЧАЙНЫЕ ПРОЦЕССЫ И ИХ ХАРАКТЕРИСТИКИ 423
0<х<оо и 0<ф<2л, такой, что для каждого возможного
результата испытания
х < X < х -|- Ах \
ср <Ф <ф + Дф/
.ан имеем:
„ (х <.х <Х 4 Ах\ , , л л
р(ф<ф<ф + дфЛ^^ ф)д^ф-
Множество функций u(t) вида и (t) = х cos (А/ -f-<p будет представ-
лять совокупность возможных реализаций случайного процесса
U(t) = X cos (АИФ)-
На рис. 80 показано по одной реализации четырех различных
случайных процессов. Повторяя испытания, мы по каждому из этих
процессов получим некоторое множество реализаций.
Распределение вероятностей случайного процесса X(t) можно
задавать совокупным распределением вероятностей случайных вели-
чин X^J, X(i2), ..., X(ts), отвечающих любому конечному набору
значений tt, f2, ..., ts параметра Z(s=l, 2, 3, ...).
11.1.2. Математическое ожидание, дисперсия и корреляцион-
ная функция случайного процесса. Аналогично тому, что указы-
валось в п. 3.1.2, во многих случаях практики достаточно описать
случайный процесс при помощи некоторого числа кратких характе-
ристик. Мы знаем, что такими характеристиками для случайной
величины являются математическое ожидание и дисперсия, пред-
ставляющие определенные постоянные числа. В отличие от этого
аналогичные характеристики случайного процесса будут, вообще
говоря, определенными неслучайными функциями параметра t. Вместе
с этим двух указанных характеристик обычно недостаточно даже
для самого сжатого описания случайного процесса. Дело в том, что
между случайными величинами, отвечающими разным значениям не-
случайного параметра, может существовать зависимость, а потому
для суждения о их поведении надо располагать по меньшей мере
еще характеристикой этой связи. Во многих случаях такой харак-
теристикой служит «корреляционная функция-» случайного процесса.
Познакомимся теперь с перечисленными тремя характеристиками
случайного процесса.
Математическим ожиданием случайного процесса Xif) назы-
вается неслучайная функция МХ(0, значение которой при каждом
значении / = параметра t равно математическому ожиданию МАЛ(/О)
той случайной величины Х(/о), которая отвечает этому значению
параметра.
424
ПОНЯТИЕ О ТЕОРИИ СЛУЧАЙНЫХ ПРОЦЕССОВ
[ГЛ. XI
По самому смыслу MJV(Z) представляет некоторую среднюю
функцию, около которой группируются все возможные реализа-
ции данного процесса. Так, например, математическое ожидание
профиля поверхности как случайного процесса представляет средний
профиль поверхности, показанный жирной линией на рис. 81.
тикальное 15 000х.)
Математическое ожидание случайного процесса обладает свой-
ствами, аналогичными свойствам математического ожидания слу-
чайной величины (см. п. 3.1.2 и п. 3.1.3).,
Дисперсией случайного процесса X(t) называется неслучайная
функция DX(0, значение которой при каждом значении/ = / пара-
метра t равно дисперсии DX(/0) той случайной величины х¥(^0),
которая отвечает этому значению параметра.
Квадратный корень из дисперсии представляет среднее квадра-
тическое отклонение случайного процесса, так что
0Л(о= + I- DX(t).
(11.1.1)
§ 1] СЛУЧАЙНЫЕ ПРОЦЕССЫ И ИХ ХАРАКТЕРИСТИКИ 425
Дисперсия и среднее квадратическое отклонение случайного процесса
характеризуют величину рассеивания возможных реализаций относи-
тельно среднего течения случайного процесса. На рис. 82 показаны
а)
Рис. 82. Средние квадратические отклонения неровностей поверхностей,
а—шлифованный образец 7-го класса чистоты, б — полированный образец 8-го класса
X
чистоты. (Увеличение: горизонтальное 1800 и вертикальное 15 000 .)
некоторые возможные реализации случайного процесса профиля
поверхности, причем, как и прежде, жирными линиями нанесены
математические ожидания процессов, от которых в обе стороны
426
ПОНЯТИЕ О ТЕОРИИ СЛУЧАЙНЫХ ПРОЦЕССОВ
[ГЛ. XI
отложены их средние квадратические отклонения (обозначены пунк-
тирными линиями). На верхнем графике среднее квадратическое от-
клонение больше, чем на нижнем. Поэтому ограничиваемая его зна-
чениями полоса шире. Эти полосы ограничивают зоны, в которых
со значительной вероятностью пройдут графики соответствующих
процессов.
Чтобы получить представление о третьей характеристике случай-
ного процесса, рассмотрим две случайные величины .¥(/') и X(t”),
отвечающие значениям t' и t" параметра t случайного процесса X(t\
Рис. 83. Геометрическая интерпретация’ корреля-
ционной функции Вх (t’, Г') случайного процесса.
Как известно из п. 5.2.2, связь между этими величинами может
быть охарактеризована их ковариацией
Z>’x(r', t”) = cov [X(t'), =
= м {[Х(П—мл(Г)1 И(П—мх(И]}. (и.1.2)
Заставим f и t" пробегать все возможные значения параметра t.
Ковариация будет представлять неслучайную функцию t")
двух переменных t' и t", которая графически может быть пред-
ставлена некоторой поверхностью, как это показано на рис. 83.
Функция By(f', t”) называется корреляционной функцией или,
точнее, автокорреляционной функцией процесса A'(Z)1).
’) Правильнее было бы назвать функцию Bx(t', t') ковариационной
функцией, а корреляционной функцией называть в соответствии с опре-
делением коэффициента корреляции ее отношение к произведению средних
квадратических отклонении. Однако это последнее называют нормированной
корреляционной функцией.
§ 2[
НЕКОТОРЫЕ ТИПЫ СЛУЧАЙНЫХ ПРОЦЕССОВ
427
Корреляционная функция симметрична, т. е.
B(t', t').
(11.1.3)
Это следует из ее определения. Поэтому поверхность, интерпре-
тирующая B(t', i"}, будет симметрична относительно секущей
плоскости, проходящей через биссектор координатного угла.
При i' — t" ==t корреляционная функция, как легко заметить
из (11,1.2), равна дисперсии, соответствующей данному значению
параметра t.
Корреляционная функция не изменяется от прибавления к данному
случайному процессу произвольной неслучайной функции /(/), т. е.
Bx + I(t', t") — Bx{t', t"), (И.1.4)
что легко следует из равенства
M[^(/)f/(/)] = M^(/)+/(/), (11.1.5)
а также имеем;
D[*(0 +/(()] = DX(0. (И.1.6)
§ 2. Некоторые типы случайных процессов
11.2.1. Процесс Пуассона. Рассмотрим поток случайных событий,
которые регистрируются в порядке их поступления. Это могут быть, на-
пример, вызовы абонентов, поступающие на телефонную станцию, или реги-
страция а-частиц в результате распада радиоактивного вещества, поток
электронов, испускаемых катодом электронной лампы, и т. п. Мы сделаем
следующие предположения о характере этого процесса.
1) Пусть (i0, /0 + /)—промежуток времени длительностью t, начинаю-
щийся в произвольный момент t0. Мы будем предполагать, что вероятность
того, что в этом интервале времени произойдет ровно k событий (6 = 0,
1, 2, ...), зависит лишь от длины t этого промежутка и не зависит от
начального момента /0; поэтому мы будем обозначать эту вероятность
через соА (7) (не указывая начала, а указывая лишь длину рассматриваемого
промежутка). Это свойство неизменного вероятностного режима для всех про-
межутков одинаковой длительности называют однородностью процесса.
2) Пусть /0 рассмотрим последовательные промежутки
времени
К». G). «2. t.)......(^-ъ U.
не накладывающиеся друг на друга. Через тг, тг, ..., тп обозначим числа
наступлений событий в указанных промежутках. Мы будем считать, что
числа «,(( = J, 2, ..., п) представляют случайные и притом независимые
между собой величины. Другими словами, в нашем потоке отсутствует
последействие: мы можем как угодно точно знать картину протекания
процесса в одном промежутке, и все же это не может сказаться на вероят-
ностях тех или иных результатов в неперекрывающемся с ним другом про-
межутке. Пусть Х(1)—число событий потока с начала регистрации до
момента 1,Это будет случайная функция, принимающая лишь целочисленные
значения и не убывающая с ростом аргумента 1; она остается постоянной
во всяком промежутке, в котором не произошло ни одного события. График
такой функции имеет ступенчатый вид. Приращение X (1) в произвольном
428 ПОНЯТИЕ О ТЕОРИИ СЛУЧАЙНЫХ ПРОЦЕССОВ [гл. XI
промежутке (/,, /2), очевидно, равно числу событий, появившихся в данном
промежутке. Свойство отсутствия последействия утверждает независимость
приращений нашей функции в неперекрывающихся интервалах, в то время
как свойство однородности говорит о постоянстве закона распределения
приращений нашей функции во всех интервалах равной длины.
3) Обозначим через ф (/) вероятность наступления в произвольном про-
межутке длины t не менее двух событий; другими словами,
Ф(0 = М0 + М0+-.-, (11.2.1)
а так как на основании (2.1.15)
w0 (1) + СО) (/) + со2 (/)+... = 1, (11.2.2)
то
ф (0=1--МО-МО- (11.2.3)
Будем предполагать, что ф (1) при бесконечно малых t есть бесконечно
малая высшего порядка, т. е. что
^->0 при ?->0. (11.2.4)
Это свойство называют свойством ординарности потока; конкретно оно
обозначает невозможность совмещения двух или большего числа событий
в очень малом промежутке времени.
4) Мы предположим еще, что вероятность того, что событие наступит
ровно один раз в очень малом промежутке времени t, приближенно про-
порциональна t или, более точно,
при Z->0, (11.2.5)
где X > 0.
Докажем теперь, что в предположениях 1) — 4) мы имеем:
=(И-2.6)
т. е. число появлений события в каком-нибудь промежутке длины t распре-
делено по закону Пуассона, рассмотренному в п. 3.1.6, с параметром (мате-
матическим ожиданием), равным М.
Докажем сначала (11.2.6) для случая т = 0. Наряду с промежутком
(0, 1), которому отвечает вероятность непоявления события ни одного раза
ш0 (1), рассмотрим еще более широкий промежуток (0, /-(-Д/). Ввиду то-
го, что промежутки (0, t) и (/, t -ф Д1) взаимно не перекрываются, согласно
второму свойству имеем:
ю0 (/-|-Д/) = со0 (1) ш0 (Д1). (11.2.7)
Далее, согласно (11.2.3) получим:
®11(Д/) = 1-Ю1(Л0-41(Д0. (11.2.8)
причем согласно (11.2.4) и (11.2.5) при Д1-з-0
<£>! (Д/) = (А- + е1) Д/, ф (Д0 = е2 Д£, (11.2.9)
где и е2 стремятся к нулю вместе с ДЛ
Из (11.2.8) и (11.2.9) следует:
<£>0 (Д/) = 1 — М —е2 М. (11.2.10)
§ 2] НЕКОТОРЫЕ ТИПЫ СЛУЧАЙНЫХ ПРОЦЕССОВ 429
Подставляя (11.2.10) в (11.2.7), мы найдем:
®о G "Г Д 7) =<oQ (/) {1 — [(^ + ei) / 8г1 Д^}>
откуда
(...гл.!
Устремляя в (11.2.11) Д7 к нулю, мы получим:
= (11.2.12)
Замечая еще, что соо(0) = 1, мы получим из (11.2.12)
w0(7)=e~Xt (11.2.13)
и тем самым (11.2.6) доказано для случая т = 0.
Для того чтобы в промежутке (0, 7-фД7) произошло ровно т событий,
необходимо и достаточно, чтобы сумма чисел появлений их в промежут-
ках (0, t) и (t, была равна т. Согласно допущению (11.2.2) эти сла-
гаемые независимы между собой и вероятность того, что одновременно пер-
вое из них будет равно k, а второе (т—k) (так, что сумма окажется рав-
ной т) будет (д/). При этом k может принимать значения k = m,
т—1, .... 2, 1, 0. Полная вероятность встретить т событий в промежутке
(О, Z-j-Д/) будет на основании (2.2.22) равна
(^ +Д0 = <ая» (0 % (ДО + Ю(В_1 (0 м! (Д7) + 7?, (11.2.14)
где
^==“/П-2(/)®2(Д0 + ит-з(0«з(дг) + --. +«о(0«от(Д7). (11.2.14')
Из (11.2.14') следует неравенство
0< 7? <о>2 (Д7) -{-со, (Д7) -f-... +сода (ДО < 2 “а(ДО = 'Ф(ДО> (Н.2.15)
/г=2
и так как в силу (11.2.9)
ф(д7)==е2 Д7,
то
0<:А<Ё2; (11.2.16)
где е2 0 при Д7 -+ 0.
Принимая во внимание (11.2.9) и (11.2.10), перепишем (11.2.14) в виде
<от (t + — (7) [1 —(X-f-Ej 4-е2) ДО 4-й;л__1 (7) (А. + В]) Д7 -ф/?,
откуда
сот(7 + Д7)-Мя(7) = х + + } + w (/) (Х + )+ R (1 ] 2 17)
дг at
Правая часть (11.2.17) имеет согласно (11.2.9) и (11.2.16) определенный пре-
дел при Д7 0. Поэтому при Д7 -* 0 (11.2.17) перейдете следующее равенство:
<(0 = -?^(0 + ^я_1(7), (11.2.18)
где т— 1, 2, ...
Мы имеем, таким образом, систему из бесконечного числа линейных
дифференциальных уравнений и, кроме того, начальные условия ыя(0) = 0
при mlsl, вытекающие из (11.2.9) при Д7 0.
430 ПОНЯТИЕ О ТЕОРИИ СЛУЧАЙНЫХ ПРОЦЕССОВ [гл. XI
Рассмотрим теперь вспомогательную функцию и (t, х) — производящую
функцию вероятности ат (Г), определяемую степенным рядом,
»(М)=2 МО*’- (11.2.19)
771 = 0
Ряд наверное сходится при значениях х, для которых | х | < 1, так как его
коэффициенты неотрицательны и меньше единицы. Дифференцируя этот ряд
по t, получим для производной разложение в степенной ряд по х(закон-
ность этой операции можно оправдать)
= V шт (t)xm. (11.2.20)
т=о
Согласно (11.2.18) при т^1
(0 = — (0+ (0
и при т = 0
<в' (()= — Хех,= — Хсоо (О-
Поэтому (11.2.20) можно переписать так:
^=-Хюо(О + У I — X®m (() + X®m_1(()[xm =
m = j
= —X У <оя (о хт + Хх У (1\хт~' -=
т=о tn-x
= — X«+Xxu = X(x— 1) u (х, t). (11.2.21)
Ввиду того, что
1 ди _д In и
и dt~ dt '
(11.2.21) можно написать в виде
или, интегрируя обе части (11.2.22) по t в пределах от 0 до t, получим:
In и (х, 1)— In и (х, 0) = X (х— 1) t. (11.2.23)
В силу того, что соо (0) = 1 и сот (0) = 0 при т > 0,
и(х, 0)= 2 шт(0)х“=1. (11.2.24)
т=о
Поэтому (11.2.23) дает:
In и (х, 1) = Х(х—1) t
§ 2] НЕКОТОРЫЕ ТИПЫ СЛУЧАЙНЫХ ПРОЦЕССОВ 431
или
и(х, (11.2.25)
Отсюда
и(х, f)=j-X|ew=rM (11.2.26)
т = о
Согласно (11.2.19) коэффициент при хт в разложении и(х, f) равен a>m(t).
Таким образом, из (11.2.26) следует:
что и доказывает (11.2.6).
Дифференцируя обе части (11.2.26) по х и полагая затем х = 1, найдем:
ОО
= V, -—(11.2.27)
т=о
Итак, математическое ожидание числа появлений т равно
Mm=U (11.2.28)
Дифференцируя еще раз и полагая потом х=1, получим:
e-Kt [e**^2f2]x=1 = X2f2 = т (т — 1) = М [т(т— 1)] = Мт2—М/п.
m=i
Отсюда, принимая во внимание (11.2.28), получим:
M/n3=V/2 + lf. (11.2 29)
С помощью (11.2.28) и (11.2.29) найдем дисперсию Dm:
Dm = Mm2 —(Мт)2 = )Д, (11.2.30)
и потому среднее квадратическое отклонение числа т равно
(11.2.31)
Рассмотрим теперь случайную функцию X (t). По самому определению этой
функции приращение ее в промежутке (0, t) равно Х(() — X (0) — т, а если
считать, что х(0) = 0, то Х(/) = т. Поэтому мы знаем теперь закон рас-
пределения для X (/) (при каждом фиксированном /) и его характеристики
Р[Х (<) = «]= —(11.2.32)
MX(0 = U (11.2.33)
DX(/)=Xt (11.2.34)
Рассмотрим теперь два момента времени 0 < (' и Г, причем t" > Г.
Найдем двумерное распределение величин Х((') и X (Г): для этого доста-
точно определить вероятность
Р[Х ((•') = т',
432 ПОНЯТИЕ О ТЕОРИИ СЛУЧАЙНЫХ ПРОЦЕССОВ [гл. XI
где tn' и tn” (т'чт")—два целых положительных числа. Но, очевидно,
Р[Х(/') = «', X(f') = m"] = P [Х(Г) = т', Х(Г)—Х(Г) = т"—т'],
а так как два интервала (0, /') и (/', I") не перекрываются, то величины X (/')
и Х(Г)—Х(Г) независимы и потому на основании (5.1.23)
е~и’ 1? (Г—Г)]”1"-"1'
Р [X (Г) = т', X (Г) = m"] = — -----------------~
(т'—т'у.
zn'l
(т"— т')1
(11.2.35)
(11.2.36)
п__^^пг"'~т"
(11.2.37)
Точно так же найдем для i' < I" < {'"
Р[Х(/') = т', Х(Г) = т", Х(Г)=т'"[-
ц1\Щ' ц»
, «'"(£)_ (' —t )
m'\ (m"—m')l
и аналогично мы можем получить соотношение вида (11.2.36) для любого
числа моментов времени.
Ввиду того, что X (/') и X (/")—X (/') независимы, на основании (5.2.5)
и (11.2.33) получим:
М {X (/') [X (Г)-Х (/')]} = МХ (Г) М [X (Г)-Х (/')] =
= л/'-Х(г"-Г) = /Л'(Г — t').
С другой стороны, на основании (11.2.29)
М {X (/') [X (Г)-Х (/')]} = М [X (t')-X (/")]-—М [X (Г)]2 =
= М[Х(Г)Х(Щ-^'2-АГ.
Из (11.2.37) и (11 2.38) следует:
М [X (/')Х (/")] = «' (/"-/') + Z2r2-hW' = W l" + W.
С помощью (11.2.39) легко найдем ковариацию, или так называемую «кор-
реляционную функцию»,
В (Г, i") = cov [X (t')-X (f)] = M {[X (/') — М'] [X (f)-Xf]} =
= M [X (/') X (;")]-=
(11.2.38)
(11.2.39)
откуда
В (t', (11.2.40)
Мы считали, что V < t"; при /' > t" будем иметь аналогично В (Г, —
а при — = t
’ B(i, t) = M=DX(t).
Для коэффициента корреляции Qt,t„ между X (f) и X (Г) найдем при
cov [X (f) X (/")] _ А/'
°Л'(Г)аХ(Г)
(11.2.41)
при t > Z" имеем;
егг= ]/
§ 2]
НЕКОТОРЫЕ ТИПЫ СЛУЧАЙНЫХ ПРОЦЕССОВ
433
Эту характеристику называют еще, как мы указывали, «нормированной кор-
реляционной функцией». Таковы основные характеристики случайного про-
цесса Пуассона.
На рис. 84 показано распределение вероятностей числа т телеграмм,
поступивших на связь в промежутках времени длительностью в 1 мин., по
данным Центрального научно-исследовательского института связи1). Сплош-
ная линия на графике отвечает фактическим
данным, а пунктирная — формуле
__е-о,'170,47"‘
т\
11.2.2. Распределение длительности
промежутков между наступлениями собы-
тий в процессе Пуассона. Испытание на
надежность. Согласно результатам, полу-
ченным в и. 11.2.1, вероятность того, что
в промежутке (/0, ^-Н) ие наступит ни
одного события, будет равна соо —
(при любом ?0). Если обозначить через £
случайную длительность промежутка до
первого появления события (после момента
/0), то мы будем иметь:
Р(1>/) = е~'г
И
P;(/) = P(g</)=l-e_x‘ при t>0
Рис. 84. Распределение вероят-
ностей числа т телеграмм,
поступивших на связь в 1 мин.
(11.2.42)
и, конечно,
Р- (/) = Р(5<() = 0 при t<0.
Таким образом, длительность ожидания появления события распределена
по показательному закону (11.2.42), т. е. с плотностью вероятности
p'(O = Ae"w. (11.2.43)
Показательный закон (11.2.43) часто наблюдается в распределениях
случайных промежутков, например в распределениях сроков службы неко-
торых материалов, приборов и т. и. Параметр носящий название интен-
сивности отказов, весьма просто связан со средним значением величины
На основании соотношений (3.2.29) и (3.2.30) имеем:
M- = J-, <ь=4- . (11.2.44)
-A s А
Таким образом, средний срок безотказной работы обратно пропорционален
интенсивности отказов.
Мы отметим здесь одно свойство показательного распределения, которое
будет играть существенную роль в дальнейшем и которое ограничивает
область его приложений.
Пусть мы знаем, что в промежутке (1д, /0-Н) событие не наступило,
так что длительность ожидания заведомо больше t. Какова при этом усло-
вии вероятность его появления в промежутке (ta, + М) > 0? Другими
*) А. А. Конюс, Краткие сведения по теории вероятностей, М., 1954.
434
ПОНЯТИЕ О ТЕОРИИ СЛУЧАЙНЫХ ПРОЦЕССОВ
[ГЛ. XI
словами, нужно найти условную вероятность события t < £ < t -f- Lt при усло-
вии, что | > /. Согласно (2.2.3) мы должны вычислить отношение безусловных
вероятностей
р а < i < t + ami > •
• Vb 4
Но согласно (11.2.42) и (11.2.43)
P(Z <В</ + Д/) = А.е-А* Lt и P(l>t) = e-U.
Следовательно,
P(/<g<Z + A/|c>/) = XA/. (11.2.45)
Из сравнения (11.2.5) и (11.2.45) видно, что условная вероятность появления
события в промежутке (t, t^ + t-\-Lt) при условии, что длительность ожидания
его появления была больше t, равна по-прежнему безусловной вероят-
ности X Lt его появления, другими словами, вероятность появления совсем
не зависит от продолжительности ожидания. Применительно к распределениям
сроков службы материалов, приборов и т. п. это означает, что длительность
использования их никак не сказывается на вероятности окончания их службы
в ближайшем будущем. Хотя это свойство несколько парадоксально, однако
имеются примеры, подтверждающие, что показательное распределение срока
службы иногда на самом деле хорошо согласуется с действительностью.
Таково, например, распределение срока службы подшипников на камнях
в часах, а также некоторых видов электрических предохранителей, когда
распределение остающегося времени работы после долгого срока службы
практически такое же, как в начале их работы.
При одновременном испытании на надежность Л систем без замещения
отказавших систем возможны два варианта плана:
1) испытания ведутся до тех пор, пока не произойдут первые отказы
в т системах и время испытаний не ограничивается,
2) фиксируется продолжительность всех испытаний, равная некоторому
т > 0, и наблюдается число Л1 первых отказов систем.
В предположении, что время g до появления первого отказа каждой
из испытуемых систем подчиняется экспоненциальному закону (11.2.42),
при обоих вариантах плана требуется по результатам испытаний определить
для интенсивности отказов X доверительный интервал, отвечающий выбран-
ной доверительной вероятности 1 — у^, где q— некоторый малый процент.
Рассмотрим сначала первый вариант. Пусть
т = |,+12+-..+!„• (11.2.46)
Суммарное время безотказной работы (до первого отказа) тех т систем,
в которых за период испытаний наблюдались отказы. Величина т представ-
ляет собой сумму независимых одинаково распределенных по закону (11.2.42)
случайных величин. Для производящей функции ср. (и) величины т найдем
на основании соотношения (3.1.48) следующее выражение:
т
.SЬи .
cp,(u) = Me“x = Me!=I = (MeS;")“. (11.2.47)
При этом на основании (3.1.49) и (11.2.43) имеем:
“ с 11
Ме;г“ = Х \ е-Л'+'и<«=Х \ (Л“и| dl — г—- =—— . (11.2.48)
J J X—и и
о о * — т-
§ 2] НЕКОТОРЫЕ ТИПЫ СЛУЧАЙНЫХ ПРОЦЕССОВ 435
Из (11.2.47) и (11.2.48) найдем:
г и\~т
<p_.(U)=(j-TJ . (11.2.47')
Если вместо т мы будем рассматривать величину т' = 2тХ, то из (11.2.47')
для производящей функции величины т' получим:
<pt, (и) = <р. (2Х«) = (1 — 2«)“т. (11.2.47")
Принимая во внимание (6.3.14), на основании рассмотренной в п. 3.1.4
теоремы единственности мы можем заключить, что величина т' распределена
по закону X2 с 2m степенями свободы.
Поэтому, обозначая через Z2m верхний ^-процентный предел рас-
пределения X2, получим
Р (т < X2m, q)~ ]QQ >
ИЛИ
/ у2 \
р ( X < -~2т' 4 ) = . (11 9 49)
\ 2т / 100 u '
У 2
ТЯ Л2т, <?/юо - О и
Иными словами, величина ------— представляет собой верхний ^-процент*
ный доверительный предел для интенсивности отказов X.
Аналогичным образом, обозначив через X2m Н1|жний /-процент-
» ’ • ^ат, 1 —а'Кво
ныи предел того же распределения, найдем, что------------2т~~ является
/-процентным нижним доверительным пределом для X, т. е.
= (11.2.50)
Выбрав р5о= jog= 77 и объединив (11.2.49) и (11.2.50), получим сле-
дующий доверительный интервал для интенсивности отказов:
2m, 1— 2m, —
_^_1<Х<-^, (11.2.51)
отвечающий доверительной вероятности 1 —а.
Перейдем ко второму варианту плана испытаний на надежность.
При фиксированном времени испытаний т случайным элементом будет
число Л4 наступивших за это время отказов.
В рассматриваемых условиях число М следует закону Пуассона (11.2 6),
так что
Р(,И = т) = е- А^Т)СТ-, (11.2.52)
и задача сводится к оценке параметра а = Хт этого закона по данной чи-
сленности отказов М.
Данная задача очень близка к рассмотренной в п. 4.3.2 задаче оценки
вероятности случайного события по частоте его появления в наблюденной
серии испытаний.
436 ПОНЯТИЕ О ТЕОРИИ СЛУЧАЙНЫХ ПРОЦЕССОВ [гл. XI
Не приводя детального доказательства, дадим окончательный результат
решения поставленной задачи.
Для верхнего доверительного предела а имеем а — — %2 р , где f =
=2(Л1-|-1)— число степеней свободы распределения %2, и для нижнего
предела а получим а = гДе /,;=2/И. При этом справедливо соот-
ношение
Р(а < а <а) — рг—= Р (а<а ) — Р (а<а ).
На основании этого для оценки интенсивности отказов X при втором вари-
анте плана испытаний будем иметь следующие нижний Л и верхний А пределы:
„ (11.2.53)
2Л1, 1--
2
и
1=1 Vs
2т 2Л1+2,-
2
(11.2.54)
а 1
где -2=Р^-Рг,
откуда доверительный интервал для X, отвечающий
доверительной вероятности 1 — а, будет
X < 1 < X,
(11.2.55)
где 1 и % определяются соотношениями (11.2.53) и (11.2.54).
Можно показать, что первый вариант плана испытаний предпочтителен
при малой интенсивности отказов, так как коэффициент изменчивости 1
используемон в этом случае оценки для X стремится к конечному пределу
при X -+ 0.
Второй вариант предпочтительнее при больших интенсивностях отказов,
так как коэффициент изменчивости используемой здесь оценки для X про-
порционален ’) .
Рассмотрим два примера.
Пусть испытания на надежность велись по первому варианту плана до
первого отказа zn=12 систем без замещения отказавших систем, причем
наблюдалось суммарное время т безотказной работы всех отказавших си-
стем. В результате испытаний было получено т==4052 часа. Требуется оце-
нить интенсивность отказов X.
Выбрав доверительную вероятность 1—а —0,98, определяем по резуль-
татам наблюдений доверительный интервал для интенсивности отказов %
в предположении экспоненциального закона (11.2.42) распределения времени
безотказной работы каждой системы. На основе (11.2.51) определяем -^ =
= -—0^98_q[ и j—^ = 0,99 и при этих вероятностях Р ('X2 > '/Д) по
2 2 х ч/
’) См. Большее Л. Н., Сравнение интенсивностей простейших пото-
ков, «Теория вероятностей и ее применения», т. VII, вып. 3, 1962.
§ 2] НЕКОТОРЫЕ ТИПЫ СЛУЧАЙНЫХ ПРОЦЕССОВ 437
таблице IV приложений при числе степеней свободы k — 2m = 2-12 = 24 на-
ходим X2 а ~ 10,9 и X2 = 43,0; в результате доверительный интер-
2»1, 1--------- 2/И, —
2 2
вал для интенсивности отказов X, отвечающий доверительной вероятности
0,98, будет
10,9 43,0
2-4052 <А< 2-4052
или
0,0013 < Л < 0,0053.
Иными словами, на основании результатов испытаний можно с вероят-
ностью 0,98 утверждать, что интервал (0,0013; 0,0053) охватывает параметр X
систем, подвергавшихся испытаниям.
Пусть теперь испытания на надежность велись по второму варианту
плана в течение заранее фиксированного времени, равного т = 500 часов.
В результате испытаний первые отказы наблюдались в 14 системах. Требу-
ется определить интенсивность отказов X.
Выбрав доверительную вероятность 1— а=0,98, на основании соотно-
шений (11.2.53), (11.2.54) и (11.2.55) при ^- = -"°-'-98 = 0,01 и 1— у = 0,99
при числах степеней свободы соответственно k = 2-14 + 2 — 30 и k = 2-14 = 28,
пользуясь таблицей IV приложений, находим:
13,6 50,9
2-500 <А< 2-500
или
0,0136 <Х < 0,0509.
Таким образом, интервал (0,0136; 0,0509) с вероятностью 0,98 охватывает
интенсивность отказов X систем, подвергнутых испытаниям.
11.2.3. Понятие о процессах Маркова. Пусть X (t) есть случайный
процесс, обладающий следующим свойством: если в момент t0 известно зна-
чение X (i0), то всякий вероятностный прогноз относительно течения про-
цесса в будущем совсем не зависит от того, как протекал процесс до
момента i0; таким образом, будущее не зависит от прошлого, если известно
настоящее. Можно дать простое математическое описание этого свойства
«отсутствия последействия». Для определенности допустим, что X (/) прини-
мает лишь целые значения 0, 1, 2, ... Пусть
^0 < ^1 < ^2 < - - - < ^„—1 <
его возрастающая последовательность значений параметра t и известно,
что имели место следующие равенства:
*(U = «o> А'(;1)г=г’1- *(/„_2) = «п_г, х(/„_1) = г, (11.2.56)
где /0, г'р ..., <п_2, i — некоторые заданные целые числа. Тогда условная
вероятность равенства
(i также целое)
при условии (11.2.56) равна вероятности равенства x(tn) = j при одном
лишь условии х (/„_,) = /, т. е.
Р [X (/„) = /[X (/(,) = <;.X(Z,!_2) = I„_2, X(t„_.)=--i] =
= Р[х (/„) = /I х (/„_,) = «]. (11.2.57)
438 ПОНЯТИЕ О ТЕОРИИ СЛУЧАЙНЫХ ПРОЦЕССОВ [гл. XI
Таким образом, каковы бы ни были iit ..., знание значений, при-
нятых случайной функцией до момента tn_„ не дает нам никакой дополни-
тельной информации, если известно значение х((п_1) = (.
Пусть для любых двух моментов и tz, причем < t2, заданы услов-
ные вероятности
Р [д-(г‘2) = / !x(/I)=q=Pz/(ZI, <2), (Н.2.58)
которые называются «переходными» вероятностями процесса. Если вероят-
ности Pijitj, (2) зависят лишь от (2—tt — t так, что
Pijih, (11.2.59)
при всяком то процесс Маркова называют однородным.
Функция рц(1) задает, следовательно, вероятность за промежуток вре-
мени t перейти от значения i в начальный момент к значению / в конечный
момент этого промежутка; можно говорить также о переходе от «состояния !»
к «состоянию /» по истечении времени t. Вероятности перехода p,-j(.t) одно-
родного процесса удовлетворяют двум условиям. Первое из них описывается
соотношением
2>,-Н0=1. (11.2.60)
k
где суммирование производится при данном i по всем возможным зна-
чениям k.
Равенство (11.2.60) выражает неизбежность того, что от состояния i
процесс через время t перейдет обязательно к одному из состояний j
(j = 0, 1, 2, ...).
Второе условие основывается на формуле полной вероятности и запи-
сывается так:
PijU + n^PikWPkjlt’), (11.2.61)
k
где t и t' — два промежутка времени, причем, так же как в (11.2.60), сум-
мирование производится по всем значениям k. Равенство (11.2.61) выражает
вероятность перехода от состояния i к состоянию j за время (/ + !'), т. е.
вероятность р,-7(/+/')> причем этот переход, очевидно, может быть осу-
ществлен таким и только таким образом, что сначала за промежуток t
система переходит от состояния i к одному из вообще возможных для нее
состояний k (или остается в прежнем состоянии так, что k = i), а затем
от состояния k через промежуток I' к состоянию /. В силу основного
свойства марковских процессов вторая вероятность перехода не зависит
от начальной точки перехода (т. е. от состояния /), как это могло бы быть
в случае процесса иного типа. Для того чтобы получить полное описание
марковского процесса, следует еще знать «начальное» распределение, т. е.
вероятности pk (0), где 6=1,2, ..., нахождения в «состоянии» k в начальный
момент /(). При этом, конечно,
2рА(0)=1 (11.2.62)
k
После этого для всякого Момента времени t > 0 легко получить вероят-
ность Pk(t) того, что процесс находится в состоянии k (или, что то же,
х(() = 6).
В самом деле, по формуле (2.2.22) полной вероятности найдем:
Рл(0=2М<Ш(0. (11.2.63)
i
§ 2] НЕКОТОРЫЕ ТИПЫ СЛУЧАЙНЫХ ПРОЦЕССОВ
439
так как попасть в состояние k к моменту t можно исходя .из любого началь-
ного состояния i с вероятностью р,^(/), и аналогично (11.2.61)
+ (11.2.63')
i
Заметим, что вероятности р4(1) существенно зависят от начальных вероят-
ностей р/(0). В частности, если, например, известно заведомо, что процесс
начинается с состояние т. е. р/ (0) = 0 при i # j и ру(О)=1, то из (11.2.63)
получим:
Р*(О=Р/ИО, (11.2.64)
как и следовало ожидать.
Если вероятности р^(<) не зависят от времени, т. е. Р*(О=Р& Для
всех k, то распределение pk называется стационарным (сохраняющимся
во времени). Во многих практически важных случаях для процессов Мар-
кова наблюдается следующая важная закономерность. При возрастании t
распределение в момент t приближается к некоторому стационарному
распределению так, что
Pk (0 Pk при t оо (11.2.65)
и при любом начальном распределении.
В частности,- как это следует из (11.2.54), при любом j
Pjk У) Pk ПРИ t °0- (11.2.66)
В этом случае по истечении достаточно большого времени существует
вполне определенная, не зависящая от времени вероятность попасть в то
или иное состояние. Как показал академик А. А. Марков, для процессов
с конечным множеством состояний существование предельного стационар-
ного распределения будет обеспечено для всякого процесса, обладающего
свойством «транзитивности». Оно заключается в том, что для некоторого
достаточно большого t = T существует положительная вероятность перейти
от любого состояния к любому другому так, что для любых i и k (0 < I < /V;
0<й<Л')
Р«(Т)>о,
где N—число возможных состояний или число возможных значений слу-
чайной функции X (/).
Мы рассматривали процесс с непрерывным временем t, но ничто не
препятствует t принимать лишь дискретную последовательность значений,
например целых неотрицательных чисел t = 0, 1,2, ..., п. Такие марковские
процессы называются процессами с дискретным временем, или марковскими
цепями. Однородные марковские цепи описываются заданием вероятностей р^
перейти от состояния i к состоянию k за одно испытание. Вероятность
сделать тот же переход в результате п > 1 испытаний будет р(к (п), кото-
рые рассчитываются последовательно по формулам, аналогичным (11.2.61),
а именно,
Pik W = 2 Pij (п ~1) Pjk (11.2.67)
или
PikW = ^PijPjk^-\). (112.68)
Мы рассмотрели случай простой цепи Маркова, в которой вероятность ре-
зультата п-го испытания становится вполне определенной, если известен
результат предшествующего (п—1)-го испытания и притом независимо от
440 ПОНЯТИЕ О ТЕОРИИ СЛУЧАЙНЫХ ПРОЦЕССОВ [гл. XI
результатов (п — 2), (п — 3), .... 1 испытаний. В некоторых случаях прихо-
дится рассматривать сложные цепи, где вероятность результата n-го испы-
тания становится определенной, если учесть s(s> 1) непосредственно пред-
шествующих ему испытаний (независимо от более ранних).
В качестве примера цепных процессов приведем схему так называемого
ступенчатого выборочного приемочного контроля качества продукции.
Объем выборки, а также, вообще говоря, и допустимые числа дефектных
изделий в выборке (браковочные числа) при проверке данной партии назна-
чаются всякий раз в зависимости от результатов обследования предшествую-
щих s партий. В простейшем случае, приводящем к простой однородной
цепи Маркова с двумя состояниями (которые можно занумеровать, например,
числами 1 и 2), назначаются два возможных значения объемов выборки п,
и п2 < П], а браковочные числа полагаются равными нулю.
Контроль выборками объема /г, производится в том случае, когда пред-
шествующая партия была забракована (и объема п2, когда она была принята).
В этих условиях, опираясь на теорию цепей Маркова, можно легко рассчи-
тать верхнюю границу выходного качества и наметить рациональный объем
выборок для экономически выгодного проведения приемочного контроля1).
В приложениях мы часто встречаемся со случаем, когда множество возмож-
ных состояний не только бесконечно, но и непрерывно (континуум). В этом
случае однородный процесс описывается плотностью вероятности достиже-
ния того или иного уровня и плотностью вероятности перехода р (х, t, у)
за время t от значения х к значению у. Так, например, уровень настройки
станка, обрабатывающего некоторые изделия, качество которых проверяется
с помощью текущего предупредительного контроля, можно с некоторым
основанием считать однородным процессом Маркова, слагающимся под дей-
ствием двух основных факторов. Если за время t не производилось пере-
наладок, то разладке станка, т. е. переходу от начальной настройки х
к уровню, лежащему в интервале (у, y-j-Ay), будет отвечать некоторая
вероятность ср (х, t, у) Ay, причем плотность ф(х, t, у) будет характеризо-
вать процессы, вызывающие разладку. С другой стороны, непосредственно
после переналадки распределение уровня зависит лишь от точности произ-
веденной наладки и совсем не зависит от предшествующих значений уровня:
вероятность перехода к уровню, лежащему в интервале (у, у + Ау), в этом
случае будетф (у) Ау, где ф (у) — плотность вероятности. Но переналадки свя-
заны обычно с сигналом о выходе показателей очередной пробы за кон-
трольные границы на карте статистического контроля (построенной, напри-
мер, для средней арифметической, медианы и т. д.). Поэтому вероятность
иметь тот или иной уровень настройки после ьй настройки не зависит
от того, каков был уровень после (/ — 1)-й настройки и каковы были ре-
зультаты проверки очередной пробы, предшествующей i-й настройке. Эта
ситуация приводит к довольно сложным соотношениям. Оказывается, суще-
ствует некоторая предельная плотность распределения уровня настройки,
к которой фактическое распределение будет близко после достаточно боль-
шого числа проверок2 3 *).
11.2.4. Задача Эрланга для конечного пучка линий8). Мы рассмотрим
теперь одну из типичных задач связи, имеющую большое значение при рас-
чете телефонных сетей. Познакомимся сначала с некоторыми терминами,
') См. Кордонский X. Б., Простейшая форма контроля продукции,
«Стандартизация», № 5 (1956), 8—12.
2) См. Лурье А. Л., К построению математической теории статисти-
ческого контроля производственных процессов, Изв. АН, отд. техн, наук,
№ 2 (1956), 113-119.
3) При изложении материала этого раздела мы следуем книге [99]
X и н ч и н а А. Я., с которой рекомендуем читателю ознакомиться,
§ 2] НЕКОТОРЫЕ ТИПЫ СЛУЧАЙНЫХ ПРОЦЕССОВ 441
необходимыми для постановки задачи. Полнодоступным пучком линий
называется совокупность соединительных линий (или приборов), каждая из
которых в случае, если она свободна в данный момент, может обслужить
поступающий вызов. В дальнейшем число линий пучка мы обозначим через s.
Вызовы, поступающие на пучок, будут образовывать процесс Пуассона с па-
раметром X > О, так что среднее число вызовов, поступающих в единицу
времени, будет, как мы видели в п. 11.2.1, равно X. Следовательно, мы пре-
небрегаем наличием всякой зависимости, которая реально может обнару-
живаться между частотой вызовов в двух не перекрывающихся интервалах
времени.
Относительно продолжительности £ занятости линий мы сделаем следую-
щее предположение: эта случайная величина следует показательному закону
с параметром [1 так, что
Р(?<х) = 1-е"?я для х>0. (11.2.69)
Как мы знаем, в этом случае средняя продолжительность занятости линии
будет -р .
Обозначим теперь через X (f) число занятых линий пучка,— это будет
случайная функция,— и мы докажем, что при наших предположениях отве-
чающий ей процесс будет марковским. В самом деле, пусть в некоторый
момент t = t0 известно, что Х(/0)=Д, где I—одно из чисел 0, 1, 2, ..., s.
Посмотрим, от чего может зависеть значение x(t) в некоторый момент t > ta.
Это значение определяется однозначно:
1) моментами окончания занятостей тех i линий, которые были заняты
в момент очевидно, зная эти моменты, мы можем определить, сколько
из этих линий освободится в промежутке от Д до t\
2) моментами появления новых вызовов в промежутке (<0, I), — этим
самым определится число новых занятостей, происшедших в этом проме-
жутке;
3) продолжительностями занятостей, происшедших в промежутке (Zo, t), —
этим самым определится число тех занятостей за этот промежуток, которые
продолжаются до момента t.
Но ни один из перечисленных случайных факторов не зависит от того,
как протекал процесс до момента Д. Для моментов окончания занятостей, т. е.
для первого фактора, это вытекает из допущения о показательном распре-
делении длительности, так как мы уже видели, что длительность оставшейся
части занятия линий не зависит от того, сколько времени протекло с его
начала.
Для второго фактора независимость от прошлого объясняется свойствами
процесса Пуассона. Третий же фактор относится к обстоятельствам, имею-
щим место уже после момента /0, а не до него. Таким образом, отсутствие
последействия установлено полностью, и мы вправе здесь применять теорию
процессов Маркова. В данном случае рассматриваемый нами процесс может
находиться в одном из (s-f-1) состояний 0, 1, 2, ..., з.
Посмотрим, как будут выглядеть в нашем случае вероятности пере-
хода pik(f).
Для конечного значения I их выражение будет сложным, но, как это
бывает обычно, эти вероятности приобретают значительно более простой
вид для случая бесконечно малых промежутков времени Д£, если учитывать
только главные члены и пренебречь бесконечно малыми высшими порядка
по сравнению с А/ членами. При рассмотрении процесса Пуассона в п. 11.2.1
мы установили, что вероятность поступления хотя бы одного вызова в про-
межутке Д/ равна К St, а вероятность поступления более одного вызова равна
ф(ДО = е(Д/),
442 ПОНЯТИЕ О ТЕОРИИ СЛУЧАЙНЫХ ПРОЦЕССОВ (ГЛ. XI
где е -+ О при At -» 0, т. е. гр (АО есть величина более высокого порядка
малости по сравнению с At. В дальнейшем, чтобы пользоваться однообраз-
ным обозначением, мы будем величины высшего по сравнению с At порядка
малости обозначать через о (At). Таким образом, гр (At) = o (At). Пренебрегая
случаями с вероятностями о (At), мы будет считать, что в промежутке может
или появиться один вызов с вероятностью X At, или не появиться с вероят-
ностью 1 —X At.
Обращаясь теперь к освобождениям занятых линий, мы заметим прежде
всего, что если какая-нибудь линия занята, то вероятность того, что дли-
тельность занятия будет больше At, согласно (11.2.69), равняется е~^д/. Если
заняты k линий, то вероятность, что они не освободятся в течение проме-
жутка At, будет (е~|ЗЛ9* = и> наоборот, вероятность освобождения
по меньшей мере одной линии будет
+ j =*p At-|-o(At). (11.2.70)
Легко видеть, однако, что вероятность освобождения более одной линии
будет величиной порядка о (At). Поэтому практически в малом промежутке
времени At мы можем считаться лишь с двумя альтернативами: или прои-
зойдет освобождение одной из занятых линий, или число занятых линий не
изменится.
Теперь легко установить, что для переходных вероятностей pik (At) вся-
кий раз, когда |/ — й| > 1, и, следовательно, для соответствующего перехода
от состояния I к состоянию k требуется осуществление не менее двух эле-
ментарных событий (двух освобожденных линий или двух занятий), мы бу-
дем иметь:
to(At) = o(At). (11.2.71)
Далее,
Pft,ft+1(At)=XAt-(-o(At), (11.2.72)
так как для перехода от Л к (#4-1) занятым линиям требуется или посту-
пление одного вызова (с вероятностью X At) или поступления двух, трех
и т. д. вызовов и вместе с тем прекращения одного, двух, трех и т. д.
занятостей, т. е. наступления более чем одного элементарного события, что
имеет, как мы видели, вероятность о (At).
Точно так же при 0<#<s
pftift_1(At) = #₽At + o(AO, (11.2.73)
так как для такого перехода нужно или освобождение одной из k занятых
линий (с вероятностью k At), или совершение более одного элементарного
события (например, освобождения двух линий и появления одного вызова
и т. п.), что имеет вероятность о (At).
Из (11.2.72) и (11.2.73) следует, далее, в силу равенства
Pkk (At) +р*, j+i (At) + pfti /г_1 (At) + о (At) = 1,
что
pM(At)=l — XAt — (3# At + o(At), —1. (11.2.74)
При #=0, рассуждая аналогично, найдем:
р00 (At) = 1 —X AZ+ <? (At), (11.2.75)
а при k —a
ps,s(M)=\—s'?> At -J-o(At). (11.2.75')
§ 2]
НЕКОТОРЫЕ ТИПЫ СЛУЧАЙНЫХ ПРОЦЕССОВ
443
Применяя теперь формулу (11.2.63х), в которой заменим f через &tt будем
иметь:
Pk(i + M)= ^pm(t)pmk(M), (11.2.76)
т = а
Заменяя теперь в (11,2.76) переходные вероятности их выражениями из
(11.2.72), (11.2.73), (11.2.74) и (11.2.75), мы получим:
Р0(/ + Д<)=Р0(ОРоо(дО+Р1 (0 Рю (ДО + о(д0 == \
=Ро(О(1-^ДО+р1(ОР а* + о(О.
Pk + АО —Pk-i (0 Pft-i, k (АО + Рк (0 Ркк (АО + I
+р*+1 (0 Ра+1, k (АО 4-0 (ДО =Рй-1 (О х Д/ +
+ рк (о (1-Х Д«-₽6 до4-Pft+i (0 (6 4-1) ₽ А<4-0 (Д/),
ps (t + ^i) = ps_l (t) ps_„ s(At)+ps(t) pss(M)+o(M) =
= Pi-i(0^A^4-pH0(l—s₽ AO4-o(ДО- }
(11.2.77)
Из уравнений (11.2.77) получим простым преобразованием
р° (z + М-Ро = - хРо (о 4- Рр, (0 4- ,
рл.(£+а<)..-рИО.==х^_1 (0_(Х + %₽) pk (t) +
,дп > (11.2.78)
+ (6 4-1) ₽РА+1(0 4-^,
ML+..Ag-M9.=Xp5_i (f)_spPs (0+1^0,
где правые части стремятся к определенным пределам при Д/-+-0, так как
о (At)
все отношения вида ' стремятся при этом к нулю; следовательно, и левые
части имеют предел, т. е. существуют производные от функций, и мы будем
иметь в пределе
Ро(О=—^Ро (O + ₽Pi (О,
Рк (0 = ^Pa-i (О — (Х + 6₽) P*(04-(6 +1) Рр^+1 (О,
p's (О = ^_1(0—«₽Р^(0,
(11.2.79)
где 0 < k < s.
Решая эту систему линейных однородных дифференциальных уравнений
с постоянными коэффициентами при данных начальных условиях (например,
можно предположить, что в начальный момент система свободна: ро(О)=1,
рк (0) = 0 (k = 1, 2, ..., s)), мы найдем искомые вероятности pk(t).
Кроме уравнений (11.2.79), вероятности pk(t) должны удовлетворять еще
условию
£рИ0=1.
k=i
(11.2.79')
Но уравнения (11.2.79) определяют pk(t) лишь с точностью до постоянного
множителя, который всегда можно выбрать так, чтобы удовлетворить усло-
вию (11.2.79').
444
ПОНЯТИЕ О ТЕОРИИ СЛУЧАЙНЫХ ПРОЦЕССОВ [ГЛ. XI
Рассмотрим в качестве примера случай s=2. Уравнения (11.2.78) в этом
случае напишутся так:
р;К) = кРо(/)-а + р)Р1(0 + 2рр2(0. J (11.2.80)
pU0 = 4(0-2Pp2(0- J
Следуя обычной процедуре, ищем фундаментальную систему частных реше-
ний (11.2.80) вида
(fe-1, 2....s), (11.2.81)
где ck и р, — некоторые константы.
Подставляя (11.2.81) в (11.2.80) и сокращая на показательные множи-
тели e;xZ, придем к следующей линейной системе:
—(1-1 + ?-) со + Р С1 =0, \
со—(1х + Р) ci + 2|3 с2 = 0, >
k q—(р + 2Р)с2 = 0. )
(11.2.82)
Для того чтобы эта система имела нетривиальное решение, необходимо
и достаточно, чтобы детерминант ее
Ми)-2-
-(н-ю
X
о
был равен нулю:
Р о
-(ц+Х + р) 2р
% -(Ц + 2Р)
- - ц [(ц 4- 2Р) (р + Р) + 2Х (р + Р) + Г]
Д3 (р)=0.
(11.2.83)
Легко проверить, что уравнение (11.2.83) третьей степени относительно р
имеет корень ро = 0 и еще два действительных отрицательных корня — ц,
и —р2. Корню р0 отвечает частное решение (с0, ср с2), не зависящее от
времени. Двум другим корням отвечают решения
для p = pI
и
ф_;л4, с,е-1лЛ с*е“^1 для р = р2.
Общее решение представится в виде линейной комбинации частных решений
Ро (0 = а0с0 + ajCje-H-? 4- <z2c’e-^, А
р, (1) — аос, 4-а1с]е”1л>‘4-а2с’г~^‘, У (11.2.84)
Р2 (0 =аос24-а1с’е"'х4 4-а2ф_^(. J
Здесь константы, обозначенные буквой с, определяются из соответствующих
линейных систем типа (11.2.82) (с определенным значением р —р0,—р,,
— ц2) и константы а — из заданных начальных условий. Во всяком случае
коэффициенты а и с не зависят от времени; поэтому, переходя к пределу
при t оо в (11.2.84), мы получим:
Рч (О
Рх (О айси
Pz (О •*“ aQCZf
§ 2]
НЕКОТОРЫЕ ТИПЫ СЛУЧАЙНЫХ ПРОЦЕССОВ
445
(аосо, <z0C!, <зос2) и будет стационарным предельным распределением р”,
р”, р® вероятностей для нашего процесса, если удовлетворяется условие
а0с0 + аос, + а 0с2 — 1, (11.2.85)
т. е.
(11.2,86)
с0 “Г С1 Т с2
и, следовательно,
Для с0, сг и с2 мы имеем систему
— Лс0+ ₽ Cj =0, \
Ч-(^ + ₽)с1 + 2рс2 = 0, У (11.2.88)
Ас,— 2рс3 —0, >
которая получается из (11.2.82) при р = 0.
Из (11.2.88) получим;
X А2
Р ор2
и потому (11.2.87) дают:
A If —Y
п“=.-----!------ п®=________Р------ 0^=____2 Р _____ 111 2 89)
р0 ? v Р1 7 V > Р2 А А2’ 1 '
1+Т + 2р 1+Т + 2р
чем наша задача и решается полностью.
В общем случае произвольного s мы будем искать стационарное (не
зависящее от времени) решение системы (11.2.79) р_>, (1) —Р/У ~сА. при усло-
вии (11.2.79'). Наличие такого решения можно доказать, опираясь на тео-
рему Маркова, о которой мы говорили выше. Для этого решения левые
части (11.2.79) обращаются в нуль и система приобретает вид
О — — Ас0 + fjCp
0= Ас0—(А + р) ct + 2pc2,
0= hCk-i — (л4~|3/г) сй + (й 4-1) Рс4+1,
О— Асу_ 1
откуда последовательно
1 /А \ I П V 1 /А V „ _ 1 7 А V
С1 ЦН С” Сг—2! р J С°’ Сг”3! \.р .....s! HP С°'
Из условия нормировки
eo + Ci+...+^ = Co^l+-p-+2! (у) + • • + IT ("J) )=1
(11.2.90)
следует:
_1
+---+^Г
$
446 ПОНЯТИЕ О ТЕОРИИ СЛУЧАЙНЫХ ПРОЦЕССОВ [гл, XI
и, следовательно,
й=0, 1....s (01 = 1).
В частности, вероятность застать все линии занятыми, или, как
вероятность потери вызова, будет:
(11.2.91)
говорят,
(11.2.92)
впервые
Формулы (11.2.91) и (11.2.92) называются формулами Эрланга,
решившего данную задачу. Они лежат в основе расчетов рационального
выбора числа соединительных линий, обслуживающих приборов и т. п.
Вероятность потерь существенно зависит от двух факторов: 1) от числа
соединительных линий s и 2) от отношения , т. е. от плотности нагрузки —
среднего числа вызовов за среднее время одного соединения.
Таблица 11.2.1 дает некоторое представление о том, как убывает вероят-
ность потерь при возрастании числа линий и как возрастает она с ростом
плотности нагрузки.
Таблица 11.2.1
Вероятность потерь для разных чисел s соединительных линий
X
при различных значениях отношения плотности нагрузки
(среднее число вызовов на среднее время одного соединения)
Число линий r'
потери потери потери потери
s== 4 0,015384 0,047958 0,095238 0,187392
s = 5 0,003068 0,014183 0,036697 0,110055
S = 6 0,000511 0,003533 0,012068 0,052157
s = 7 0,000073 0,000756 0,003440 0,021864
s = 8 0,000009 0,000142 0,000859 0,008131
s» 9 0,000001 0,000024 0,000191 0,002701
s = 10 0,000000 0,000004 0,000038 0,000810
Данные таблицы получены вычислением по формуле (11.2.92) с исполь-
зованием таблицы вероятностей для распределения Пуассона’).
Для того чтобы получить представление о скорости приближения
к стационарному распределению, мы должны были бы провести такое же
исследование, какое мы провели выше для случая з=2. Мы видели, что
’) См. книгу (36], таблицу 1 приложений.
НЕКОТОРЫЕ ТИПЫ СЛУЧАЙНЫХ ПРОЦЕССОВ
447
§ 2]
в этом случае приближение идет очень быстро, так как разность между
стационарной вероятностью и соответствующей вероятностью рА(/) убы-
вает по показательному закону. То же самое можно установить и в общем
случае.
В самом деле, можно показать, что характеристическое уравнение (анало-
гичное тому, какое мы имели для s = 2)
(р + 1)-го порядка имеет: 1) простой корень ро = О, 2) все остальные корни
будут отрицательны: — p,;(i=l, 2, ..., s) (pz>0), и просты.
Данное заключение следует из равенства
Л^(ц) = (—1)'!+1Н<|(н + ₽)(ц + 2₽)...(|л + зр)-|-
+ 1 ^(ti + ₽)(H+2p)...lp + (s-l)₽] + Q )Г(^ + Р) (м+2₽)...
...[p + (S-2)p] + ... + (s^1)v-’ (jx-f-1) p+vj-.
Это доказывается на основании рекуррентного соотношения
(н) + (£ + 1 + +ц) Л* (н) + (и) = 0
методом полной индукции.
„ ч ДЛц)
С другой стороны, относительно многочлена ——— легко установить, что
все его корни действительны, отрицательны и по абсолютной величине
больше р’). Таким образом, показательные множители в выражении будут
иметь вид
где ЩЗ*Р-
11.2.5. Статистическая модель работы водохранилища. В качестве вто-
рого примера приложений процессов Маркова мы рассмотрим следующую
модель работы некоторого водохранилища вместимости К единиц (К—целое
число). Предположим, что в течение некоторого промежутка (/, /-|-1) вре-
мени (года, сезона и т. д.) водохранилище получает пополнение X (t) (х прини-
мает, так же как и t, только целые значения 0, 1, 2, ...). Мы допускаем,
что величины X (/), отвечающие различным значениям t, независимы и оди-
наково распределены:
PlX(i) = r)=Pf (г = 0, 1, 2, ...),
оо
г=о
Если к начальному моменту промежутка времени (1, Z-J-1) водохранилище
обладало запасом 7. (1) < К, причем X(/)-f-Z(t) окажется большим К, то
количество X(t) + Z(t) — К. сбрасывается и к концу промежутка (/, 1-|-1)
водохранилище заполняется полностью. Если же X (/)-(-Z (/)</(, то это
количество сохраняется. В конце интервала (t, Г-|-1) происходит потребле-
ние (расход) воды из водохранилища. Расход воды к этому моменту У (1)
подчинен следующему правилу. Если
Х(/) + 2(/)^Л1,
’) См. книгу [99] А. Я. Хинчина, §§ 31 и 32.
448 ПОНЯТИЕ О ТЕОРИИ СЛУЧАЙНЫХ ПРОЦЕССОВ [гл. XI
где М (М < К) — заданное целое число — норма потребления, то забирается М
единиц и остается Z (t -|-1) --= X (Z) Z (Z) — /И при ^(Z)^-Z(Z)<^ или
Z(t + V)=K —М, если X(t) + Z(t) = K.
Если же X (Z) + Z (Z) < Л1, то забирается вся вода и Z(Z-|-1) = O. Мы
видим, что величина Z(Z-t-l) полностью определена с вероятностной точки
зрения, если известно значение Z(Z), независимо от того, что происходило
в предшествующее время (величины X (t) независимы по предположению).
Поэтому для Z (t) мы будем иметь процесс Маркова с возможными состоя-
ниями 0, 1, 2, ..., К—М.
Рассмотрим таблицу (матрицу) переходных вероятностей
Z(Z + 1)
( 0 1 0 Ям Ям-1 1 Рм + 1 рм 2 . РЛ1 + 2 • РМ+ 1 • . К — 2М . . • РК~М • ‘ • ₽К-Л1-1 • • К-М—1 Рк-1 РК-2 к-м Х~ЧК-2
2(/) М Яо — Ро р, Рг . РК~2М • • Рк-м-1 1 ~^К-М-1
м-Н 0 Ра Ру • • РК~2 Л1-1 • • РК-М~2 '—^K-M-2
Здесь „ к—м 0 0 0 . . Ро • • Рм-i 1 fyl-1
г
Яг— 2 Р‘"'
i = l
кроме того, мы допустили, что К > 2М. Сумма вероятностей в каждой строке
равна 1 в соответствии с формулой (11.2.60).
Чтобы от Z(Z) = /-<M перейти к Z(Z-{-!) = О, нужно, чтобы приток
воды был бы не больше (Л1—г), вероятность чего равна p0+Pi + ...
... +рМ-г—ЯМ~г Если же Z(t) = M-\-r, где г > 0, то пустым водохра-
нилище не останется и соответствующие переходы невозможны. Точно также
определяются и все остальные переходные вероятности, составляющие мат-
рицу. Пользуясь ею, можно легко написать уравнение для определения ве-
роятности ps(t) равенства Z(Z) = s. В самом деле, на основании (И.2.63')
будем иметь, например, при —2/И
Ps (t + ^ = Po (0 PM + s + Pi (0 PM + s-y + Рг (О РЛ1 + 5-2-Т - • • +P2I1+S U) Р„.
(11.2.93)
Практически наиболее интересным является разыскание стационарного ре-
жима, который устанавливается в работе водохранилища по истечении
достаточно большого срока. Эта задача до конца решается лишь при до-
вольно частных предположениях относительно распределения притока воды,
т. е. относительно вероятности ps. Например, в предположении так называе-
мого геометрического распределения, которое отвечает показательному рас-
пределению в случае дискретных процессов, когда для всех значений s
ps = (l—B)BS, 0<В<1
(вероятности ps убывают в геометрической прогрессии). Можно показать, что
стационарное распределение процесса X (Г) + Z (Р) = U (Z) в случае водохрани-
лища неограниченной емкости принадлежит также к классу геометрических
§ 2] НЕКОТОРЫЕ ТИПЫ СЛУЧАЙНЫХ ПРОЦЕССОВ 449
распределений с параметром Р, определяемым из уравнения
. д 1-Р
1 —Р^м+1’
Точно так же исследована и схема непрерывного процесса Маркова с не-
прерывным расходом и приходом воды.
Здесь для нахождения функций стационарного распределения вероят-
ностей мы имеем интегральное уравнение, которое в конечной форме решается
лишь при частных предположенияхНо при каждом данном конкретном
распределении вероятностей ps мы можем последовательно вычислять
с помощью уравнений (11.2.93) вероятности ps(t) для 1 = 0, 1, 2, 3, ...,
задаваясь некоторым произвольным начальным распределением (0). Пере-
ход от вероятностей ps(t) к вероятностям ps (t + 1) называется итерацией.
Проделав достаточно большое число итераций, мы получим распределение,
наверное достаточно близкое к предельному стационарному. Средства совре-
менной вычислительной математики, вооруженной быстродействующими
электронными машинами, позволяют быстро провести такие операции. Ана-
логичная возможность имеется и для решения интегральных уравнений для
непрерывной схемы работы2).
11.2.6. Стационарные случайные процессы. На практике довольно часто
встречаются случайные процессы, протекающие в вероятностном отношении
однородно при изменении параметра t (например, времени). К числу, таких
процессов относятся шумы в ламповых схемах, работающих на установив-
шемся режиме, фэдинги, ошибки авторегулируемых и следящих систем,
работающих в неизменных условиях, и т. д. Вероятностный режим таких слу-
чайных процессов не изменяется при любом сдвиге всей группы точек
I,, /2, ..., ts вдоль числовой оси, т. е. при переходек точкам tj + т, ...
+ где т произвольно. Поэтому, прежде всего, случайная величина
X (t) для любого момента имеет одно и то же распределение и, значит,
имеет одинаковые математические ожидания и дисперсии, т. е. для процесса
в целом МХ(1) = const и DX(t) = const, а автокорреляционная функция
процесса непрерывна н зависит только от разности t"—t' — r, т. е. является
непрерывной функцией В (т) одного аргумента т. Такие случайные процессы
называются стационарными случайными процессами. Для стационарных про-
цессов в очень широких условиях доказывается сходимость по вероятности
среднего по времени от случайной функции
т
хт = ~ ^x^dt (11.2.94)
-т
к математическому ожиданию М X (/) при -Т->со.
Аналогично этому и для корреляционной функции можно показать схо-
димость по вероятности к величине
т
x(t) x(t + x)dt В (т) при Т оо. (11.2.95)
—т
’) Допускается, например, что оно следует Г-распределению с плот-
и/7
ностью вида —е~^ххр~' (0 < х < оо), р—целое.
2) Аналогичный подход к решению водохозяйственных проблем разви-
вался С. Н. Крицким и М. Ф. Менке леи (см. их книгу «Водохозяйственные
расчеты», Л., 1952).
15 Н. В. Смирнов, И. В. Дунин-Барковский
450 ПОНЯТИЕ О ТЕОРИИ СЛУЧАЙНЫХ ПРОЦЕССОВ [гл. XI
Точно так же для двух стационарных и стационарно связанных случайных
процессов X (i) и Y (t) можно доказать сходимость по вероятности к величине
т
^x(t)y(t + x)dt Bxy(i) при Т оо,
-т
если* (Z) и у (f)— возможные реализации процессов соответственно X (/)
и Y (t).
Случайные процессы (или функции) рассмотренного типа называют еще
стационарными в узком смысле в отличие от случайных функций, у кото-
рых математическое ожидание и дисперсия не зависят от неслучайного ар-
гумента, а корреляционная функция зависит только от разности I"—t~t
Случайные функции, удовлетворяющие последним трем условиям, назы-
ваются стационарными в широком смысле пли в смысле А. Я. Хинчина.
Условие постоянства математического ожидания при соблюдении осталь-
ных двух условий не является существенным, так как согласно (11.1.5)
и (11.1.6) при этом случайная функция может быть представлена суммой,
стационарной в широком смысле случайной функции с математическим ожи-
данием, равным нулю, и неслучайной функции, описывающей математиче-
ское ожидание рассматриваемой случайной функции.
Примером стационарной в широком смысле случайной функции могут
служить случайные составляющие погрешностей показаний измерительных
приборов, имеющих относительно широкие пределы изменений1). К таким
приборам принадлежит, например, индикатор часового типа, предназначен-
ный для линейных измерений. Исследование случайных функций—погреш-
ностей показаний подобных приборов необходимо для анализа точности и
надежности их работы.
Основным требованием к измерительному прибору, определяющим, рабо-
тоспособность последнего, является требование к его точности, характери-
зующейся величиной погрешности показаний. Эта погрешность служит глав-
ным параметром измерительного прибора.
Рассматриваемые при анализе надежности измерительного прибора от-
казы заключаются прежде всего в превышении погрешностью показаний
установленных норм точности. Отказы измерительного прибора бывают:
внезапными или постепенными, полными или частичными, устойчивыми пли
сбоями (в том числе перемежающимися). Часто все эти отказы бывают скры-
тыми (неявными). Исполнитель в процессе эксплуатации, как правило, их
не замечает, а выявляются они лишь при поверке измерительного прибора.
Отказы, заключающиеся в нарушении норм точности, обнаруживаются
при поверке с некоторой вероятностью безошибочности. При этом возможны
двоякого рода ошибки: ошибка I рода, представляющая выявление отказа,
которого на самом деле нет, и ошибка II рода —невыявление отказа, хотя
он фактически имеется. Между двумя соседними поверками отказ обычно
не замечается, он остается иногда незамеченным и после дальнейших пове-
рок, если имеют место ошибки II рода.
Поэтому для характеристики надежности измерительного прибора недо-
статочно таких параметров, как вероятность безотказной работы в течение
заданного времени, частота отказов и т. д. К ним необходимо еще добавить
вероятность безошибочного выявления отказа и вероятности ошибок I и II
родов при поверке прибора.
‘) См. А. Н. Карташева, О статистических критериях оценки на-
дежности поверки приборов для линейных измерений, Сб «Исследования
по методике оценки погрешностей измерений», ВНИИМ им. Менделеева,
М.— Л., Стандартгиз, 1962.
§ 2] НЕКОТОРЫЕ ТИПЫ СЛУЧАЙНЫХ ПРОЦЕССОВ
451
Данные об этих вероятностях используются для улучшения методик
поверки измерительных приборов в смысле повышения вероятности безоши-
бочного выявления отказов, причем по возможности при той же или еще
меньшей трудоемкости и сложности процедуры поверки.
Получение данных о таких вероятностях для индикаторов часового типа
связано с анализом случайных функций их погрешностей показаний.
Принципиальная схема механизма
Измерительный стержень / выполнен за
щейся в зацеплении с зубчатым колесом
с зубчатым колесом 3. Последнее в свою
очередь находится в зацеплении с зуб-
чатым колесом 4, на одной оси с кото-
рым жестко посажена стрелка С при-
бора. На одной оси с колесом 2 посажен
указатель оборотов стрелки С,
Ввиду наличия погрешностей в зуб-
чатых парах 1—2 и 3—4, а также дру-
гих погрешностей изготовления, погреш-
ность показаний индикатора Y' (х) со-
держит систематическую составляющую
МУ'(х), изменяющуюся по мере пере-
мещения измерительного стержня / от
той точки, в которой индикатор был
настроен, и случайную составляющую,
варьирующую от одного повторного
измерения к другому.
Систематическая составляющая
МУ' (х) погрешности показаний индика-
тора представляет периодическую функ-
цию. Ее хорошо описывают в совокуп-
индикатора показана на рис. 85.
одно с зубчатой рейкой, находя-
2, жестко сидящим на одной оси
ности три-четыре гармоники: первая с рис. 85. Принципиальная схема
шагом Bt — 10 мм, равным полной вели- механизма индикатора часового
чине хода измерительного стержня, типа.
вторая с шагом В2 — 5 мм, третья с
шагом Bt — -^MMH десятая с шагом В10=1 мм. Первая гармоника харак-
теризует величину кинематической погрешности первой ступени зубчатой
передачи, т е. пары 1—2. Вторая и третья гармоника возникает вслед-
ствие овальности и огранности зубчатого колеса 2 по его делительной
окружности. Десятая гармоника при передаточном отношении зубчатой пере-
дачи 3—4, равном i =10, обусловливается кинематической погрешностью
этой передачи.
На рис. 86 показано приближение эмпирической кривой, оценивающей
МУ' (х) в среднем по 14 реализациям, посредством тригонометрического
полинома вида
МУ (х) = + 7,4 sin f • х + 172° J + 1,6 sin ( 2х + 316° j +
+ 1,9 sin ^i~3x+ 189°) 4-2sin 10x4-324°) , (11.2.96)
где коэффициент при синусах (амплитуды) и свободный член в мк, а аргу-
мент х в мм.
Анализ показывает, что амплитуды более высоких, чем 10-я гармоника,
гармонических составляющих систематической погрешности индикаторов не
15*
452 ПОНЯТИЕ О ТЕОРИИ СЛУЧАЙНЫХ ПРОЦЕССОВ [гл. XI
существенны по сравнению с установленными на погрешность показаний
индикаторов нормами.
Случайная составляющая погрешности показаний индикатора, представ-
ляющая разность
Г(х) = У'(х)-МГ (х) (11.2.97)
погрешности показаний У' (х) и ее математического ожидания, характери-
зуется постоянным средним квадратическим отклонением:
0у(х) const,
(11.2.98)
причем случайные величины Ух, отвечающие каждому значению х, нор-
мально распределены с плотностью п (х. 0, а).
График автокорреляционной функции случайной функции Ух показан
на рис. 87. Из него видно, что теснота корреляционной связи между по-
грешностями показаний У и У" в различных сечениях функции У (х)
быстро падает с увеличением т —х"—х'— расстояния между сечениями, так
что при расстоянии порядка т — 0,5 лл величины У и У" можно считать
независимыми.
Ю-
7-
10
5
I
1
5-
У
3-
2-
/ -
0
Эмпирическая
кривая
МУЭД
Кривая
у упригонометри-
ческого полино*
ма
2-ягармоника
1-я гар-
моника
3-я гармоника
10~я гармоника
О
Z J 4 5 6 7 8 9 К)*мм
Перемещение измерительного стержня
Рис. 86. Приближение эмпирической кривой, оценивающей М У (х)—систе-
матическую составляющую погрешности показаний индикатора с помощью
тригонометрического полинома.
Практически предельные отклонения случайной погрешности показаний
индикатора, равные За, показаны пунктиром на рис. 88.
Сказанное позволяет считать, что погрешность показаний индикатора
на длине / участка измерений представляет разность
Д/ = МУ' (хь)-ГЛУ (хй) + /ао, (11.2.99)
где ха и хь—абсциссы положения измерительного стержня, в которых
функция МП (х) имеет соответственно минимальное и максимальное значе-
ния, te—коэффициент при а, отвечающий интервалу (—tx, tp, вероятность
§ 2]
НЕКОТОРЫЕ ТИПЫ СЛУЧАЙНЫХ ПРОЦЕССОВ
453
а попадания в который достаточно близка к единице (например, при нор-
мальном распределении /а = 6 отвечает а = 0,9973).
Интерпретация (11.2.89) погрешности показаний индикатора позволяет
дать конкретное выражение вероятности Рц,1 положительного заключения
Рис. 87. Автокорреляционная функция случайной функции Y (х) погрешно-
сти показаний индикатора.
при поверке о соответствии индикатора установленным нормам точности.
Эта вероятность, естественно, зависит от аг = МК'(х) и о.
Оперативные кривые зависимости Рц,1 от и а позволяют получить ста-
тистический критерий N качества методики поверки прибора, оценивающий
Рис. 88. Практически предельные отклонения ± ~~ погрешности показаний
индикатора и геометрическая интерпретация вероятности Р принятия гипо-
тезы о кондиционности прибора при поверке погрешности показаний Аг
в пределах участка длины I.
ха— абсцисса наименьшего минимума функции МУ'(х),
хь — абсцисса наибольшего максимума той же функции,
р7—норма на предельную погрешность показаний.
вероятность безошибочной поверки приборов по данной методике В свою
очередь, пользуясь критерием N, можно существенно улучшить методику
поверки приборов в смысле повышения ее надежности без увеличения
трудоемкости процедуры поверки.
454
ПОНЯТИЕ О ТЕОРИИ СЛУЧАЙНЫХ ПРОЦЕССОВ
[гл. XI
11.2.7. Определение «несущей поверхности» деталей машин, работаю-
щих при трении1). Для характеристики трения поверхностей деталей
машин представляет интерес определение так называемой «несущей поверх-
ности», которая получается на основе суммарной длины S (и) кусков, выре-
заемых профилем рассматриваемой поверхности из горизонтальной прямой,
располагающейся на высоте и над средней линией профиля (т. е. над пря-
мой линией, наименее отклоняющейся от точек профиля в смысле среднего
квадратического), как это показано на рис. 89.
Рис. 89. Профиль вырезает куски 1—6 из горизонтальной прямой, располо-
женной на высоте и над его средней линией. (Увеличение: горизонтальное
1800х и вертикальное 15 000х.)
Величина S (и) при фиксированном и, очевидно, является случайной
величиной, зависящей от выбранной реализации случайного процесса X(t)
профиля, т. е. от того сечения, в котором мы рассматриваем профиль.
Введем функцию
... J 1, если X (t) > и,
— ( 0, если X (0 < и,
(11.2.100)
где t лежит на интервале (0, Т).
Тогда
т
5= J r\(t)dt
о
(11.2.101)
в математическое ожидание S будет равно
MS = M
г 7
J Л (0 dt
-о
7 7
= J Мп (С л = J Р [X (0 >u]dt, (11.2.102)
о о
так как
Мп (/) = 0 Р [X (0 < и] + 1 -Р [X (0 > и].
Предположим, что при достаточно малой систематической составляющей
наш профиль X (0 представляет стационарный нормальный случайный про-
цесс с автокорреляционной функцией вида
Вх(т) = сг-а'1т|, О 0, а > 0. (11.2.103)
') См. Ю. В. Л и н н и к и А. П. Хусу, Математико-статистическое опи-
сание неровностей профиля поверхности при шлифовании, Инженерный сбор-
ник, т. XX, Отделение технических наук АН СССР (1954), 154—159.
§ 2] НЕКОТОРЫЕ ТИПЫ СЛУЧАЙНЫХ ПРОЦЕССОВ 455
Как показывают наблюдения, профили с такими автокорреляционными функ-
циями встречаются на практике в тех случаях, когда поверхность
обрабатывается шлифованием.
Из (11.2.103) видно, что случайные величины А'(/1) и Х(^ + т), отвечаю-
щие значениям ft и + t параметра t нашего процесса, слабо зависимы,
а потому при достаточно длинной трассе (0, Т) профиля в соответствии со
сказанным в п. 5.4.2 можно считать величину S (и) с большой степенью
точности нормально распределенной, в силу чего
Р[Х(0> и]=0,5—Фо
(11.2.104)
где Фо ( )—функция Лапласа, определяемая соотношением (4.2.2), и а2—дис-
персия процесса Х(0, которая, как указывалось в п. 11.2.6, постоянна.
В силу стационарности X(t) вероятность Р (Х(<) > и] не зависит от I,
а потому
(11.2.105)
что как раз и определяет математическое ожидание несущей поверхности
на уровне и.
Пусть, например, для поверхности, удовлетворяющей указанным
выше допущениям, а = 1,2 мк и требуется определить математическое ожида-
ние «несущей поверхности» на расстоянии 0,6 мк кверху от средней линии
профиля.
По формуле (11.2.105), пользуясь таблицей II приложений, находим:
MS= Го,5—Фо Т =0,30857-,
т. е. интересующая нас поверхность составляет в среднем около 31°/0 от
всей площади.
Для построения интервалов, в которых величина S(u) находилась бы
с заданной надежностью, необходимо еще знать ее дисперсию DS, которая
согласно (3.1.24) равна
DS = MS2-(MS)2.
Аналогично (11.2.102) имеем:
т т
MS! = J dt' J Р [X (7) > и, X (Г) > и] di".
о 6
(11.2.106)
(11.2.107)
Плотность вероятности р(х', х", т) двумерного распределения величин X (Г)
и X (Г") ввиду нормальности распределения X (Z) определяется соотношением
(5.2.38), где следует положить х=х' и у=х" и 6ху = 0х'У" зависит от т-
Тогда
05 05
Р[Х (<')>«, X (*")>«] = $ $ ?(*'> ^dx' dx"’ (Н.2.108)
и и
456 ПОНЯТИЕ О ТЕОРИИ СЛУЧАЙНЫХ ПРОЦЕССОВ [гл. XI
где интеграл можно вычислить, пользуясь известным разложением функции
р (х', х", т) в ряд по степеням р(т) ’):
р(х', х", = (11.2.109)
о k ' 4 7
где Ф ^Д^ = 0,5+ Ф0 и Ф|’'+,) f-У — се (у+1)-я производная.
Интегрируя этот ряд почленно, получаем разложение для вероятности
(X)
Р[Х(Г)> и, X(i")> и] = Г1 -Ф (2 + £ 11 Ф(” (-У1 > (Т). (11.2.110)
Таким образом,
«, Г Т
MS2 = р-Ф [Ф<” (т)У j j (t"—t')dt'dt". (11.2.111)
1 и и
Заменив в (11.2.111) £> (t"—i') аппроксимирующей его функцией (11.2.103),
получим:
j г I и 2 2 Г 1 I2
DS=>-A- Ф0” — ) —- т+— (е-4^— 1) (11.2.112)
v! L \ а /] vo [ va' J •
Эту формулу можно упростить, отбросив члены с множителем e~WT ввиду
их малости, и тогда будем иметь:
О5 = У Д Гф(” (— W — Т2. (11.2.113)
v! L \ ® / J w
Производные функции нормального распределения табулированы так, что
вычисления по формуле (11.2.113) не представляют большого труда.
Пусть для приведенного выше числового примера prDS=0,02T. Тогда
с вероятностью 0,95 можно считать, что
MS—1,96 KDS <S(u) <MS+1,96/DS?
т. e.
0,31 — 1,96.0,02 < УД < 0,31 + 1,96-0,02,
и окончательно
0,27 < < 0,35.
Иными словами, с вероятностью 0,95 можно считать, что «несущая поверх-
ность» на высоте « = 0,6 мк над средней линией профиля в рассматриваемом
случае составляет от 27 до 35%.
Теория стационарных случайных процессов в настоящее время широко
применяется в расчетах разнообразных систем автоматического управления.
Однако детальное изложение этих расчетов выходит за рамки данной
книги. Читатель может ознакомиться с ними по книгам [59], [70], [84].
1) См., например, книгу [48], формулу (21.12.5).
ЭЛЕМЕНТЫ СТАТИСТИКИ СЛУЧАЙНЫХ ПРОЦЕССОВ
457
§ 3]
§ 3. Элементы статистики случайных процессов
11.3.1. Определение статистических оценок математического
ожидания и корреляционной функции случайного процесса. Рас-
сматривая случайный процесс X (t) как совокупность случайных ве-
личин X(t), мы можем в отношении каждой из этих величин решать
задачу статистической оценки интересующих нас параметров, в част-
ности, математических ожиданий МА’(7) и ковариаций соу[Л(/'), -¥(/")]
общими методами, рассмотренными в главе VI данной книги. Для
этого необходимо располагать достаточным числом независимых
реализаций процесса А'(/), полученных в одинаковых условиях. Такими
реализациями могут служить, например, осциллограммы при рассмот-
рении случайного процесса протекания тока в электрической цепи
или профилограммы при анализе случайного профиля обработанной
поверхности и т. п.
Для всех реализаций мы, прежде всего, должны выбрать общее
начало отсчета по неслучайному параметру t. Таким началом может
быть какое-нибудь характерное значение неслучайного параметра,
достаточно четко различаемое на всех имеющихся реализациях. Если
параметром служит время, то началом отсчета может быть общий
для всех реализаций момент времени (по отношению к циклу рас-
сматриваемого процесса).
Далее, ось параметра t мы разбиваем на k равных интервалов,
выбирая их длину так, чтобы на ее протяжении каждая реализация
мало изменялась. При каждом значении в конце каждого интер-
вала математическое ожидание MA'(/J-) мы оцениваем по средней
арифметической x (Q из значений х(1,, х!>г, ..., х;>)1 величины полу-
ченных из п реализаций процесса.
Получив ряд средних арифметических x{i^, х(/2), ..., х (tk),
мы можем аппроксимировать его подходящей кривой (процесс пред-
полагается непрерывным) и, таким образом, получим эмпирическую
оценку x(t) функции fAX(t) — математического ожидания процесса.
При оценке ковариаций мы опять-таки пользуемся общими при-
емами статистической оценки параметров связи, изложенными в § 2
главы IX. Формула для вычисления эмпирической ковариации имеет
вид
п
^-(Л Л = 4Е[хЛЛ-х(Л][х,(Л-х(Л], (п.з.1)
v= 1
где п — число реализаций, I' и /" — выбранные значения параметра /,
xv(f') и х.Д/") — значения процесса в точках I' и t" по v-й реали-
зации.
Давая t' и t" все возможные значения, мы получим ряд значений
cov (/', I”).
458
ПОНЯТИЕ О ТЕОРИИ СЛУЧАЙНЫХ ПРОЦЕССОВ
[ГЛ. XI
Аппроксимируя эти значения подходящей поверхностью в коор-
динатной системе t", cov(/', t"), мы получим статистическую
оценку корреляционной функции.
Аналогично этому определяются эмпирические значения взаимной
корреляционной функции двух случайных процессов X(t) и Y(t).
Расчетная формула при этом имеет вид
п
П = (11.3.2)
v= 1
где у обозначают значения процесса У(/), аналогичные значениями
процесса X(t).
Легко заметить, что формулы (11.3.1) и (11.3.2) вполне анало-
гичны формулам (9.2.1).
Поясним несколько подробнее способ нахождения эмпирической
оценки автокорреляционной функции.
Пусть у нас имеется п — 120 реализаций некоторого случайного
процесса, например 120 профилограмм обработанной поверхности,
в отношении которой нет оснований предполагать «вероятностный
механизм» образования неровностей устойчивым. В соответствии
с ранее сказанным мы выбираем’на всех профилограммах одинако-
вые начала отсчетов и откладываем от них равные отрезки длины Д/
по выбранным осям. Для простоты будем считать, что у нас полу-
чилось по fe = 4 таких отрезков на каждой профилограмме (на самом
деле их бывает по нескольку десятков или даже сотен); точки на
их концах обозначим через tl,
Таблица 11.3.1
г, и г4, а отвечающие этим точ-
кам случайные величины — через
Л(^), Х(/2), X(t,) и X(it). Для
каждой из этих величин мы полу-
чим из 120 реализаций процесса
(т. е. из профилограмм) по п = 120
значений (ординат кривой микро-
профиля в указанных точках).
Теперь независимые переменные
f и Г, фигурирующие в формуле
(11.3.1), могут принять (каждое)
по четыре значения: tx, tt, и /4.
Заставляя каждую из пере-
менных Г и t" пробегать все воз-
можные для нее значения, мы
получим 16 комбинаций, приведенных в таблице' 11.3.1. Сверху
вниз по диагонали этой квадратной таблицы располагаются комби-
нации с одинаковыми I' и t", а именно: txtx, Z2/2, и /4/4. При
подстановке в формулу (11.3.1) эмпирически полученных из профи-
дограмм ординат, отвечающих этим точкам, мы, как легко заметить,
§ 3] ЭЛЕМЕНТЫ СТАТИСТИКИ СЛУЧАЙНЫХ ПРОЦЕССОВ 459
получим для этих же точек эмпирические дисперсии, задаваемые
соотношением (3.1.32). Методика их вычисления изложена в п. 3.2.3.
Далее, из (11.3.1) следует, что ковариации для комбинаций,
расположенных вверх и вниз от диагональных клеточек таблицы 11.3.1,
попарно равны между собой, а именно:
cov (ttt,) = cov (tit,,), cov (ttti)~ cov (?,/,) и т. д.
Поэтому мы получаем различные значения ковариаций лишь для
шести комбинаций:
Таблица 11.3.2
№ реа- лизации по порядку № точки
t, 6 *3
1 3,4 2,2 1,8 2,9
2 2,4 1,2 2,7 3,1
120 3,1 0,8 0,5 1,7
КЧ, У*, и
Из теории соединений известно, что эти комбинации представляют
сочетания из четырех элементов по два, а их число может быть
подсчитано по известной общей
формуле
г)-с> = 2чгаг. 'чад
где k — число получившихся
точек на оси параметра t на име-
ющихся реализациях случайного
процесса.
По профилограммам мы изме-
ряем ординаты в наших четырех
точках и получаем таблицу
11.3.2.
Беря столбцы, отвечающие
каждой из наших шести комбина-
ций точек, мы получим такие же
сопряженные исходные данные,
какие послужили для составления корреляционной таблицы 5.1.2.
Только теперь мы будем иметь шесть таких таблиц. Методика вы-
числения коэффициентов корреляции, т. е., иначе говоря, нормирован-
ных ковариаций, рассмотрена в п. 9.2.1. Аппроксимируя полученные
коэффициенты корреляции подходящей поверхностью, мы получим
статистическую оценку нормированной корреляционной функции
r(t', f").
Методика нахождения статистической оценки взаимной корреля-
ционной функции совершенно аналогична только что рассмотренной
методике.
11.3,2. Нахождение статистических оценок характеристик ста-
ционарного случайного процесса. Определение статистических оценок
стационарного случайного процесса на основании его свойства (11.2.84)
можно производить не по множеству реализаций, а путем усредне-
ния данных по неслучайному параметру i (в принципе даже по
460 ПОНЯТИЕ О ТЕОРИИ СЛУЧАЙНЫХ ПРОЦЕССОВ (гл. XI
единственной записи процесса, если она охватывает достаточно
большой интервал значений параметра t). При этом на оси t от-
кладываются п равных отрезков и в конце каждого из них опре-
деляются значения х„ х2, ..х„ по имеющейся реализации. Сред-
няя арифметическая х из этих значений дает статистическую оценку
постоянного для данного процесса математического ожидания.
Далее статистическая оценка автокорреляционной функции на-
ходится по формуле
п-ц
= (*<—х)- (11.3.4)
1=1
Оценка нормированной автокорреляционной функции находится
по формуле
п-|*
2 (xi—х)(х1 + а—х)
Аналогично этому для оценки взаимной корреляционной функции
двух стационарных случайных процессов имеем:
bXY (н) = ^37 У K +U—Х)(У1— У)- (11.3.6)
1 = 1
Рассмотрим пример нахождения статистической оценки норми-
рованной автокорреляционной функции стационарного процесса.
Рис. 90. Профиль образца чистоты поверхности 6-го класса с регулярным
профилем.
На рис. 90 показана профилограмма образца чистоты поверх-
ности с регулярным профилем, полученным при достаточной устой-
чивости «механизма, образования» неровностей. Отклонения про-
филя этого образца от заданного регулярного профиля с достаточно
хорошим приближением можно считать стационарным случайным
процессом. Таким образом, регулярный профиль образца представ-
ляет сумму стационарного случайного процесса и заданной неслу-
чайной функции параметра t. Из (11.3.4) следует, что автокорре-
§ 3] элементы статистики случайных процессов 461
ляционная функция такой суммы совпадает с автокорреляционной
функцией указанного стационарного случайного процесса.
В таблице 11.3.3 приводятся данные по вычислению статистиче-
ской оценки автокорреляционной функции указанного стационар-
ного процесса по реализации, представленной на рис. 90. Таблица
дается в сокращенном виде.
Таблица 11.3.3
Вычисление статистической оценки нормированной автокорреляционной
функции профиля образца с регулярным профилем
№ строк Зна- чения пара- метра Орди- на ты Xi-X Произведения (х,+а-Т) |
ц = 0 Ц=1 ц = 2 ц = 3 Ц=4 ц = 20
1 2 3 4 5 6 7 8 24
1 0 0,0 3,4 11,56 11,56 9,86 —1,36 —5,44 10,88
2 2 0,0 3,4 11,56 9,86 —1,36 —5,44 —6,22 11,56
3 4 —0,5 2,9 8,41 — 1,16 —4,64 —5,22 —5,80 9,57
4 6 -3,8 -0,4 0,16 —0,64 0,72 0,80 1,04 —0,96
113 224 —0,3 3,1 9,61 16,54 16,54
114 226 0,0 3,4 11,56 11,56
115 228 0,0 3,4 11,56
2 —392,8 442,58 396,85 303,54 189,07 72,94 272,30
'(и) 1,0 0,92 0,72 0,46 0,18 0,77
В столбце 2 этой таблицы проставлены ординаты нашего про-
филя, измеренные по профилограмме в
п — 115
точках. В столбцах 4—24 приводятся данные по вычислениям эмпи-
рических ковариаций при
ц = 0, 1, . . ., 20.
Способ подсчета этих данных в общем понятен из таблицы. Однако
поясним, что, например, в клеточке [2,5], т. е. во второй строке
в столбце 5 проставлено произведение
3,4-2,9 = 9,86
462
ПОНЯТИЕ О ТЕОРИИ СЛУЧАЙНЫХ ПРОЦЕССОВ [ГЛ. XI
чисел, стоящих в клеточках [2,3] и [3,3], в клеточке [2,6] — произ-
ведение
3,4 • (—0,4) = —1,36
чисел, стоящих в клеточках [2,3] и [4,3], и т. д.
Легко видеть из формулы (11.3.5), что г (pi) достаточно просто
вычисляется по итогам чисел, стоящих в столбце 4 и в столбце,
Рис. 91. Автокорреляционная функция профиля образца
чистоты поверхности 6-го класса с регулярным профилем.
соответствующем рассматриваемому р,. Так, например, при р = 3
из столбцов 4 и 7 имеем:
115-3
2 (х,—х)(х,+,-х)= 189,07,
2 —хУ = 442,58 —(11,56 + 11,56 Н- 9,61) = 409,85,
i = 1
2 (х1+5—х)2 = 442,58 —(11,56 -ф 11,56-ф 8,41) = 411,05
1 = ]
и
, п, 189,07 п „
г (ц, = 3) = .- . . = 0,46.
' 1^409,85-411,05
По данным, содержащимся в таблице 11.3.3, построен график авто-
корреляционной функции, показанный на рис. 91.
ПРИЛОЖЕНИЯ
2, Таблица!
Плотность вероятности п(г; 0; 1) = 2V' (z; 0; l)= у~_е 2 нормированного
нормального распределения (см. примечания на стр 496)
Сотые доли ДЛЯ Z
0 1 2 3 1 4 5 1 6 1 7 1 8 1 9
0,0 3989-* 3989 3989 3988 3986 3984 3982 3980 3977 3973
0,1 3970" 4 3965 3961 3956 3951 3945 3939 3932 3925 3918
0,2 3910“4 3902 3894 3885 3876 3867 3857 3847 3836 3825
0,3 3814-4 3802 3790 3778 3765 3752 3739 3726 3711 3697
0,4 3683-4 3668 3653 3637 3621 3605 3589 3572 3555 3538
0,5 352 Г4 3503 3485 3467 3448 3429 3410 3391 3372 3352
0,6 3332“ 4 3312 3292 3271 3251 3230 3209 3187 3166 3144
0,7 3123—4 3101 3079 3056 3034 ЗОИ 2989 2966 2943 2920
0,8 2897-4 2874 2850 2827 2803 2780 2756 2732 2709 2685
0,9 2661~4 2637 2613 2589 2565 2541 2516 2492 2468 2444
1,0 2420-4 2396 2371 2347 2323 2299 2275 2251 2227 2203
1,1 2179-4 2155 2131 2107 2083 2059 2036 2012 1989 1965
1,2 1942"4 1919 1895 1872 1849 1826 1804 1781 1758 1736
1,3 1714“4 1691 1669 1647 1626 1604 1582 1561 1539 1518
1,4 1497-4 1476 1456 1435 1415 1394 1374 1354 1334 1315
1,5 1295'4 1276 1257 1238 1219 1200 1182 1163 1145 1127
1,6 ПОЭ-4 1092 1074 1057 1040 1023 1006 9893 9728 9566
1,7 9405 9246 9089 8933 8780 8628 8478 8329 8183 8038
1,8 7895“5 7754 7614 7477 7341 7206 7074 6943 6814 6687
1,9 6562-s 6438 6316 6195 6077 5960 5844 5730 5618 5508
2,0 5399-5 5292 5186 5082 4980 4879 4780 4682 4586 4491
2,1 4398-’ 4307 4217 4128 4041 3955 3871 3788 3706 3626
2,2 3547-’ 3470 3394 3319 3246 3174 3103 3034 2965 2898
2,3 2833"’ 2768 2705 2643 2582 2522 2463 2406 2349 2294
2,4 2239-5 2186 2134 2083 2033 1984 1936 1888 1842 1797
2,5 1753-’ 1709 1667 1625 1585 1545 1506 1468 1431 1394
2,6 1358-’ 1323 1289 1256 1223 1191 1160 ИЗО 1100 1071
2,7 1042“’ 1014 9871 9606 9347 9094 8846 8605 8370 8140
2,8 7915“’ 7697 7483 7274 7071 6873 6679 6491 6307 6127
2,9 5953“6 5782 5616 5454 5296 5143 4993 4847 4705 4567
3,0 4432-’ 4301 4173 4049 3928 3810 3695 3584 3475 3370
3,1 3267“’ 3167 3070 2975 2884 2794 2707 2623 2541 2461
3,2 2384“’ 2309 2236 2165 2096 2029 1964 1901 1840 1780
3,3 1723“’ 1667 1612 1560' 1508 1459 1411 1364 1319 1275
3,4 1232~» 1191 1151 1112 1075 1038 1003 9689“’ 9358 9037
3,5 8727“’ 8426 8135 7853 7581 7317 7061 6814 6575 6343
3,6 6119“’ 5902 5693 5490 5294 5105 4921 4744 4573 4408
3J 4248“’ 4093 3944 3800 3661 3526 3396 3271 3149 3032
3,8 2919“’ 2810 2705 2604 2506 2411 2320 2232 2147 2065
3,9 1987-’ 1910 1837 1766 1698 1633 1569 1508 1449 1393
4,0 1338"’ 1286 1235 1186 1140 1094 1051 1009 9687“8 9299
4,1 8926“8 8567 8222 7890 7570 7263 6967 6683 6410 6147
4,2 5894“8 5652 5418 5194 4979 4772 4573 4382 4199 4023
47 3854-® 3691 3535 3386 3242 3104 2972 2845 2723 2606
4,4 2494~8 2387 2284 2185 2090 1999 1912 1829 1749 1672
4,5 1598-’ 1528 1461 1396 1334 1275 1218 1164 1112 1062
4,6 1014-’ 9684"9 9248 8830 8430 8047 7681 7331 6996 6676
4,7 6370-’ 6077 5797 5530 5274 5030 4796 4573 4360 4156
4,8 3961-’ 3775 3598 3428 3267 3112 2965 2824 2690 2561
1,9 1 . 2439"9 2322 2211 2105 2003 1907 1814 1727 1643 1563
466
ПРИЛОЖЕНИЯ
Таблица II
1 С — —
Нормированная функция Лапласа Ф0(г) = -^= j е 2 dv
о
(см. примечания на стр. 496)
г Сотые доли для г
0 I 2 | 3 4 5 6 7 8 9
00 0,0 000 040 080 120 160 199 239 279 319 359
0,1 398 438 478 517 557 596 636 675 714 753
0,2 793 832 871 910 948 987 -026 064 103 141
0,3 0,1 179 217 255 293 331 368 406 443 480 517
0,4 554 591 628 664 700 736 772 808 844 879
0,5 915 950 985 019 •054 088 123 •157 •190 224
0,6 0,2 257 291 324 357 389 422 454 486 517 549
0,7 580 611 642 673 703 734 764 794 823 852
0,8 881 910 939 967 995 023 051 078 106 133
0,9 0,3 159 186 212 238 264 289 315 340 365 389
1,0 413 437 461 485 508 583 554 577 599 621
1,1 643 665 686 708 729 749 770 790 810 830
1,2 849 869 888 907 925 944 962 980 997 015
1,3 0,4 032 049 066 082 099 115 131 147 162 177
1,4 192 207 222 236 251 265 279 292 306 319
1,5 332 345 357 370 382 394 406 418 429 441
1,6 452 463 474 484 495 505 515 525 535 545
1,7 554 564 573 582 591 599 608 616 625 633
1,8 641 649 656 664 671 678 686 693 699 706
1,9 713 719 726 732 738 744 750 756 761 767
2,0 772 778 783 788 793 798 803 808 812 817
2,1 821 826 830 834 838 842 846 850 854 857
2,2 860 864 867 871 871 877 880 883 886 889
96b 474 906 263 545 755 894 962 962 §93
2,3 892 895 898 900 903 906 908 911 913 915
759 559 29и 969 581 133 625 060 437 758
2,4 918 920 922 924 926 928 930 932 934 936
025 237 397 506 564 572 531 493 309 128
2,5 937 939 941 942 944 946 947 949 950 952
903 634 323 969 574 139 664 151 ьоо 012
2,6 953 954 956 957 958 959 960 962 963 964
388 729 035 308 547 754 930 074 189 274
2," 965 966 967 968 969 970 971 971 972 973
330 358 359 333 280 202 099 972 821 646
Приложения
46?
П родолжение
г Сотыг доли для :
° 1 ’ 1 2 3 1 4 1 5 6 7 8 9
2,8 0,4974 975 975 976 977 978 978 979 980 980
449 229 988 726 443 140 818 476 116 738
2,9 981 981 982 983 983 984 984 985 985 986
342 929 498 052 589 lit 618 110 588 051
3,0 986 986 987 987 988 988 988 989 989 989
501 938 361 772 171 558 933 297 650 992
3,1 990 990 990 991 991 991 992 992 992 992
324 646 957 260 553 836 112 378 636 886
3,2 993 993 993 993 994 994 994 994 994 994
129 363 590 810 024 230 4 29 623 8 10 991
3,3 995 995 995 995 995 995 996 996 996 996
166 335 499 658 811 959 103 242 376 505
3,4 996 996 996 996 997 997 997 997 997 997
631 752 869 982 09! 197 299 398 493 585
3,5 997 997 997 997 997 998 998 998 998 998
674 759 842 922 999 074 146 215 282 347
3,6 998 998 998 998 998 998 998 998 998 998
409 469 527 583 637 689 739 787 834 879
3,7 998 998 999 999 999 999 999 999 999 999
922 964 004 043 080 116 150 184 216 247
3,8 999 999 999 999 999 999 999 999 999 999
274 305 333 359 385 409 433 456 478 499
3,9 999 999 999 999 999 999 999 999 999 999
519 539 557 575 593 609 625 641 655 670
4,0 999 999 999 999 999 999 999 999 999 999
683 696 709 721 733 744 755 765 775 784
4,1 999 999 999 999 999 999 999 999 999 999
793 802 811 819 826 834 841 848 854 861
4,2 999 999 999 999 999 999 999 999 999 999
867 872 878 883 888 893 898 902 907 911
4,3 999 999 999 999 999 999 999 999 999 999
915 918 922 925 929 932 935 938 941 943
4,4 999 999 999 999 999 999 999 999 999 999
946 948 951 953 955 957 959 961 963 964
4,5 999 999 999 999 999 999 999 999 999 999
966 968 969 971 972 973 974 976 977 978
5,0 999
997
468
приложения
Таблица III
g-процентные пределы для отношения выборочного размаха Rn
к параметру ° исходного распределения; математическое ожидание М
и среднее квадратическое отклонение о (”о?) этого же отношения в долях
параметра о исходного распределения (см. примечания на стр. 497)
м («I о а \ СУ 0 Вероятность в процентах
п ') 0,05 0,1 0,5 1 .0 2,5 5,0 10,0 20, 0 30,0
ая 3,. V/L
9 1,128 0,853 0,756 0,00 0,00 0,01 0,02 0,04 0,09 0,18 0,36 0,55
3 1,693 0,888 0,525 0,04 0,06 0,13 0,19 0,30 0,43 0,62 0,90 1,14
4 2,059 0,880 0,427 0,16 0,20 0,34 0,43 0,59 0,76 0,98 1,29 1,53
5 2,326 0,864 0,371 0. 31 0,37 0,55 0,66 0,85 1,03 1,26 1,57 1,82
6 2,534 0,848 0,335 0,47 0,54 0,75 0,87 1,06 1,25 1, 49 1,80 2,04
7 2,704 0,833 0,308 0,61 0,69 0,92 1,15 1,25 1,44 1,68 1,99 2,22
8 2,847 0,820 0,288 0,75 0,83 1,08 1,20 1,41 1,60 1,83 2,14 2,38
9 2,970 0,808 0,272 0,88 0,96 1,21 1,34 1,55 1,74 1,97 2,28 2,51
10 3,078 0.797 0,259 1,00 1,08 1,33 1,47 1,67 1,86 2,09 2,39 2,62
11 3,173 0 787 0,248 1,10 1,20 1,45 1,58 1,78 1,97 2,20 2,50 2,72
12 3,258 0,778 0,239 1,21 1,30 1,55 1,68 1,88 2 07 2,30 2,59 2,82
13 3,336 0,770 0,231 1,30 1,39 1,64 1,77 1,97 2,16 2,39 2,68 2,90
14 3,407 0,762 0,224 1,38 1,48 1,72 1,86 2,06 2,24 2,47 2,75 2,97
15 3,472 0,755 0,217 1,46 1,56 1,80 1,93 2,14 2,32 2,54 2,83 3,04
16 3,532 0,749 0,212 1,53 1,63 1,88 2,01 2,21 2,39 2,61 2,89 3,11
17 3,588 0,743 0,207 1,60 1,69 1,94 2,07 2,27 2,45 2,67 2,95 3,17
18 3,640 0,738 0,203 1,66 1,75 2,01 2,14 2,34 2,51 2,73 3,01 3,22
19 3,689 0,733 0,199 1,72 1,82 2,07 2,20 2,39 2,57 2,79 3,06 3,27
20 3,735 0,729 0,195 1,78 1,88 2,12 2,25 2,45 2,63 2,84 3,11 3,32
вероятность в лооцентах
40.0 5 С ,0 60,0 | 70,0 1 80,0 1 90,0 I 95,0 I 97,5 1 99,0 | 99 . 5 | 99,9 99,95
2 0,74 0,95 1,20 1,47 1,81 2,33 2,77 3,17 3,64 3,97 4,65 4,У2
3 1,36 1,59 1,83 2,09 2,42 2,90 3,31 3,68 4,12 4,42 5,06 5,31
4 1,76 1,98 2,21 2,47 2,78 3,24 3,63 3,98 4,40 4,69 5,31 5,56
5 2,04 2,26 2,48 2,73 3,04 3,48 3,86 4,20 4,60 4,89 5,48 5,72
6 2,26 2,47 2,69 2,94 3,23 3,66 4,03 4,36 4,76 5,03 5,62 5,86
7 2,44 2,65 2,86 3,10 3,39 3,81 4,17 4,49 4,88 5,15 5 ,73 5,96
8 2,59 2,79 3,00 3,24 3,52 3,93 4,29 4,61 4,99 5,26 5,82 6,04
9 2,71 2,92 3,12 3,35 3,63 4 04 4,39 4,70 5,08 5,34 5,90 6,12
10 2,83 3,02 3,23 3,46 3,73 4,13 4,47 4,79 5,16 5,42 5,97 6,19
И 2,93 3,12 3,32 3,55 3,82 4,21 4,55 4,86 5,23 5,49 6,04 6,25
12 3,01 3,21 3,41 3,63 3,90 4,29 4,62 4,92 5,29 5,54 6,09 6,31
13 3,09 3,29 3,48 3,70 3,97 4,35 4,69 4,99 5,35 5,60 6,14 6,36
14 3,17 3,36 3,55 3,77 4,03 4,41 4,74 5,04 5,40 5,65 6,19 6,40
15 3,23 3,42 3,62 3,83 4,09 4,47 4,80 5,09 5,45 5,70 6,23 6,45
16 3,30 3,48 3,67 3,89 4,14 4,52 4,85 5,14 5,49 5,74 6,28 6,49
17 3,35 3,54 3,73 3,94 4,19 4,57 4,89 5,18 5,54 5,79 6,32 6,52
18 3,41 3,59 3,78 3,99 4,24 4,61 4,93 5,22 5,57 5,82 6,35 6,56
19 3,46 3,64 3,83 4,03 4,29 4,65 4,97 5,26 5,61 5,86 6,38 6,59
20 3,51 3,69 3,87 4,08 4,33 4,69 5,01 5,30 5,65 5,89 6,41 6,62
ПРИЛОЖЕНИЯ
469
Таблица IV
Значения верхнего д% предела %® в зависимости от вероятности
и числа k степеней свободы ^-распределения
(см. примечания иа стр. 497)
Число степе- ней свобо- ды k Вероятность Р (%2 >
0,99 0,98 0,95 0,90 0,80 0,70 0,50 0,30
1 0,00016 0,0006 0,0039 0,016 0,064 0,148 0,455 1,07
2 0,020 0,040 0,103 0,211 0,446 0,713 1,386 2,41
3 0,115 0,185 0,352 0,584 1,005 1,424 2,366 3,66
4 0,30 0,43 0,71 1,06 1,65 2,19 3,36 4,9
5 0,55 0,75 1,14 1,61 2,34 3,00 4,35 6,1
6 0,87 1,13 1,63 2,20 3,07 3,83 5,35 7,2
7 1,24 1,56 .2,17 2,83 3,82 4,67 6,35 8,4
8 1,65 2,03 2,73 3,49 4,59 5,53 7,34 9,5
9 2,09 2,53 3,32 4,17 5,38 6,39 8,34 10,7
10 2,56 3,06 3,94 4,86 6,18 7,27 9,34 11,8
11 3,1 3,6 4,6 5,6 7,0 8,1 10,3 12,9
12 3,6 4,2 - 5,2 6,3 7,8 9,0 11,3 14,0
13 4,1 4,8 5,9 7,0 8,6 9,9 12,3 15,1
14 4,7 5,4 6,6 7,8 9,5 10,8 13,3 16,2
15 5,2 6,0 7,3 8,5 10,3 11,7 14,3 17,3
16 5,8 6,6 8,0 9,3 11,2 12,6 15,3 18,4
17 6,4 7,3 8,7 10,1 ' 12,0 13,5 16,3 19,5
18 7,0 7,9 9,4 10,9 12,9 14,4 17,3 20,6
19 7,6 8,6 10,1 Н.7 13,7 15,4 18,3 21,7
20 8,3 9,2 10,9 12,4 14,6 16,3 19,3 22,8
21 8,9 9,9 11,6 13,2 15,4 17,2 20,3 23,9
22 9,5 10,6 12,3 14,0 16,3 18,1 21,3 24,9
23 10,2 11,3 13,1 14,8 17,2 19,0 22,3 26,0
24 10,9 12,0 13,8 15,7 18,1 19,9 23,3 27,1
25 11,5 12,7 14,6 16,5 18,9 20,9 24,3 28,1
26 12,2 13,4 15,4 17,3 19,8 21,8 25,3 29,3
27 12,9 14,1 16,2 18,1 20,7 22,7 26,3 30,3
28 13,6 14,8 16,9 18,9 21,6 23,6 27,3 31,4
29 14,3 15,6 17,7 , 19,8 22,5 24,6 28,3 32,5
30 15,0 16,3 18,5 20,6 23,4 25,5 29,3 33,5
470
ПРИЛОЖЕНИЯ
П родолжение
Число степеней свободы k Вероятность Р (х2>Х^)
0,20 0,10 0,05 0,02 0,01 0,005 0,002 0,001
1 1,64 2,7 3,8 5,4 6,6 7,9 9,5 10,83
2 3,22 4,6 6,0 7,8 9,2 11,6 12,4 13,8
3 4,64 6,3 7,8 9,8 п,з 12,8 14,8 16,3
4 6,0 7,8 9,5 11,7 13,3 14,9 16,9 18,5
5 7,3 9,2 11,1 13,4 15,1 16,3 18,9 20,5
6 8,6 10,6 12,6 15,0 16,8 18,6 20,7 22,5,
7 9,8 12,0 14,1 16,6 18,5 20,3 22,6 24,3
8 11,0 13,4 15,5 18,2 20,1 21,9 24,3 26,1
9 12,2 14,7 16,9 19,7 21,7 23,6 26,1 27,9
10 13,4 16,0 18,3 21,2 23,2 25,2 27,7 29,6
11 14,6 17,3 19,7 22,6 24,7 26,8 29,4 31,3
12 15,8 18,5 21,0 24,1 26,2 28,3 31 32,9
13 17,0 19,8 22,4 25,5 27,7 29,8 32,5 34,5
14 18,2 21,1 23,7 26,9 29,1 31 34 36,1
15 19,3 22,3 25,0 28,3 30,6 32,5 35,5 37,7
16 20,5 23,5 26,3 29,6 32,0 34 37 39,2
17 21,6 24,8 27,6 31,0 33,4 35,5 38,5 40,8
18 22,8 26,0 28,9 32,3 34,8 37 40 42,3
19 23,9 27,2 30,1 33,7 36,2 38,5 41,5 43,8
20 25,0 28,4 31,4 35,0 37,6 40 43 45,3
21 26,2 29,6 32,7 36,3 38,9 41,5 44,5 46,8
22 27,3 30,8 33,9 37,7 40,3 42,5 46 48,3
23 28,4 32,0 35,2 39,0 41,6 44,0 47,5 49,7
24 29,6 33,2 36,4 40,3 43,0 45,5 48,5 51,2
25 30,7 34,4 37,7 41,6 44,3 47 50 52,6
26 31,8 35,6 £8,9 42,9 45,6 48 51,5 54,1
27 32,9 36,7 40,1 44,1 47,0 49,5 53 55,5
28 34,0 37,9 41,3 45,4 48,3 51 54,5 56,9
29 35,1 39,1 42,6 46,7 49,6 52,5 56 58,3
30 36,3 40,3 43,8 н8,0 50,9 54 57,5 59,7
для распределения Стьюдента (см. примечания на стр. 497)
Q 10,0 5,0 2,5 2,0 1,0 0,5 0;3 0,2 0,1
1 6,314 12,706 25,452 31,821 63.657 127,3 212,2 318,3 636,6
2 2,920 4,303 6,205 6,965 9,925 14,089 18,216 22,327 31,600
3 2,353 3,182 4,177 4,541 5,841 7,453 8.891 10,214 12.922
4 2,132 2,776 3,495 3,747 4,604 5,597 6,435 7,173 8,610
5 2,015 2,571 3,163 3,365 4,032 4,773 5,376 5,893 6,869
6 1,943 2,447 2,969 3,143 3,707 4,317 4,800 5,208 5,959
7 1,895 2,365 2,841 2,998 3,499 4,029 4,442 . 4,785 5,408
8 1,860 2,306 2,752 2,896 3,355 3,833 4,199 4,501 5,041
9 1,833 2,262 2,685 2,821 3,250 3,690 4,024 4,297 4,781
10 1,812 2,228 2,634 2,764 3,169 3,581 3,892 4,144 4,587
12 1,782 2,179 2,560 2,681 3,055 3,428 3,706 3,930 4,318
14 1,761 2,145 2,510 2,624 2,977 3,326 3,583 3,787 4,140
16 1,746 2,120 2,473 2,583 2,921 3,252 3,494 3,686 4,015
18 1,734 2,101 2,445 2,552 2,878 3,193 3,428 3,610 3,922
20 1,725 2,086 2,423 2,528 2,845 3,153 3,376 3,552 3,849
22 1,717 2,074 2,405 2,508 2,819 3,119 3,335 3,505 3,792
24 1,711 2,064 2,391 2,492 2,797 3,092 3,302 3,467 3,745
26 1,706 2,056 2,379 2,479 2,779 3,067 3,274 3,435 3,704
28 1,701 2,048 2,369 2,467 2,763 3,047 3,250 3,408 3,674
30 1,697 2,042 2,360 2,457 2,750 3,030 3,230 3,386 3,646
ОО 1,645 1,960 2.241 2.326 2.576 2,807 2.968 3.090 3.291
ПРИЛОЖЕНИЯ
472
ПРИЛОЖЕНИЯ
Значения пяти- и однопроцентных верхних пределов уклонения
Пятипроцентные пределы Fs, набраны
(см. примечания
*2 kt — степени свободы
1 2 3 4 5 6 7 1 9 10 12
— степени свободы для меныпей дисперсии 1 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 161 4 052 18,51 98,49 10,13 34,12 7,71 21,20 6,61 16,26 5,99 13,74 5,59 12,25 5,32 11,26 5,12 10,56 4,96 10,04 4,84 9,85 4,75 9,33 4,67 9,07 4,60 8,86 4,54 8,68 4,49 8,53 4,45 8,40 200 4 999 19,00 99,01 9,55 30,81 6,94 18,00 5,79 13,27 5,14 10,92 4,74 9,55 4,46 8,65 4,26 8,02 4,10 7,56 3,98 7,20 3,88 6,93 3,80 6,70 3,74 6,51 3,68 6,36 3,63 6,23 3,59 6,11 216 5 403 19,16 99,17 9,28 29,46 6,59 16,69 5,41 12,06 4,76 9,78 4,35 8,45 4,07 7,59 3,86 6,99 3,71 6,55 3,59 6,22 3,49 5,95 3,41 5,74 3,34 5,56 3,29 5,42 3,24 5,29 3,20 5,18 225 5 625 19,25 99,25 9,12 28,71 6,39 15,98 5,19 11,39 4,53 9,15 4,12 7,85 3,84 7,01 3,63 6,42 3,48 5,99 3,36 5,67 3,26 5,41 3,18 5,20 3,11 5,03 3,06 4,89 3,01 4,77 2,96 4,67 230 5 764 19,30 99,30 9,01 28,24 6,26 15,52 5,05 10,97 4,39 8,75 3,97 7,46 3,69 6,63 3,48 6,06 3,33 5,64 3,20 5,32 3,11 5,06 3,02 4,86 2,96 4,69 2,90 4,56 2,85 4,44 2,81 4,34 234 5 889 19,33 99,33 8,94 27,91 6,16 15,21 4,95 10,67 4,28 8,47 3,87 7,19 3,58 6,37 3,37 5,80 3,22 5,39 3,09 5,07 3,00 4,82 2,92 4,62 2,85 4,46 2,79 4,32 2,74 4,20 2,70 4,10 237 5 928 19,36 99,34 8,88 27,67 6,09 14,98 4,88 10,45 4,21 8,26 3,79 7,00 3,50 6,19 3,29 5,62 3,14 5,21 3,01 4,88 2,92 4,65 2,84 4,44 2,77 4,28 2,70 4,14 2,66 4,03 2,62 3,93 239 5 981 19,37 99,36 8,84 27,49 6,04 14,80 4,82 10,27 4,15 8,10 3,73 6,84 3,44 6,03 3,23 5,47 3,07 5,06 2,95 4,74 2,85 4,50 2,77 4,30 2,70 4,14 2,64 4,00 2,59 3,89 "2,55 3,79 241 6 022 19,38 99,38 8,81 27,34 6,00 14,66 4,78 10,15 4,10 7,98 3,68 6,71 3,39 5,91 3,18 5,35 3,02 4,95 2,90 4,63 2,80 4,39 2,72 4,19 2,65 4,03 2,59 3,89 2,54 3,78 2,50 3,68 242 6 056 19,39 99,40 8,78 27,23 5,96 14,54 4,74 10,05 4,06 7,87 3,63 6,62 3,34 5,82 3,13 5,26 2,97 4,85 2,86 4,54 2,76 4,30 2,67 4,10 2,60 3,94 2,55 3,80 2,49 3,69 2,45 3,59 243 6 082 19,40 99,41 8,76 27,13 5,93 14,45 4,70 9,96 4,03 7,79 3,60 6,54 3,31 5,74 3,10 5,18 2,94 4,78 2,82 4,46 2,72 4,22 2,63 4,02 2,56 3,86 2,51 3,73 2,45 3,61 2,41 3,52 244 6 106 19,41 99,42 8,74 27,05 5,91 14,37 4,68 9,89 4,00 7,72 3,57 6,47 3,28 5,67 3,07 5,11 2,91 4,71 2,79 4,40 2,69 4,16 2,60 3,96 2,53 3,80 2,48 3,67 2,42 3,55 2,38 3,45
ПРИЛОЖЕНИЯ
величины F в зависимости от степеней свободы kt и й2.
обычным шрифтом, однопроцентные Ft, — жирным
на стр. 497)
473
Т а б л и ц а VI
для большей дисперсии
14 16 | 20 24 30 40 50 75 | 100 200 500 СО л2
245 6 142 19,42 99,43 8,71 26,92 5,87 14,24 4,64 9,77 3,96 7,60 3,52 6,35 3,23 5,56 3,02 5,00 2,86 4,60 2,74 4,29 2,64 4,05 2,55 3,85 2,48 3,70 2,43 3,56 2,37 3,45 2,33 3,35 246 6 169 19,43 99,44 8,69 26,83 5,84 14,15 4,60 9,68 3,92 7,52 3,49 6,27 3,20 5,48 2,98 4', 92 2,82 4,52 2,70 4,21 2,60 3,98 2,51 3,78 2,44 3,62 2,39 3,48 2,33 3,37 2,29 3,27 248 6 208 19,44 99,45 8,66 26,69 5,80 14,02 4,56 9,55 3,87 7,39 3,44 6,15 3,15 5,36 2,93 4,80 2,77 4,41 2,65 4,10 2,54 3,86 2,46 3,67 2,39 3,51 2,33 3,36 2,28 3,25 2,23 3,16 249 6 234 19,45 99,46 8,64 26,60 5,77 13,93 4,53 9,47 3,84 7,31 3,41 6,07 3,12 5,28 2,90 4,73 2,74 4,33 2,61 4,02 2,50 3,78 2,42 3,59 2,35 3,43 2,29 3,29 2,24 3,18 2,19 3,08 250 6 258 19,46 99,47 8,62 26,50 5,74 13,83 4,50 9,38 3,81 7,23 3,38 5,98 3,08 5,20 2,86 4,64 2,70 4,25 2,57 3,94 2,46 3,70 2,38 3,51 2,31 3,34 2,25 3,20 2,20 3,10 2,15 3,00 251 6 286 19,47 99,48 8,60 26,41 5,71 13,74 4,46 9,29 3,77 7,14 3,34 5,90 3,05 5,11 2,82 4,56 2,67 4,17 2,53 3,86 2,42 3,61 2,34 3,42 2,27 3,26 2,21 3,12 2,16 3,01 2,11 2,92 252 6 302 19,47 99,48 8,58 26,35 5,70 13,69 4,44 9,24 3,75 7,09 3,32 5,85 3,03 5,06 2,80 4,51 2,64 4,12 2,50 3,80 2,40 3,56 2,32 3,37 2,24 3,21 2,18 3,07 2,13 2,96 2,08 2,86 • 253 6 323 19,48 99,49 8,57 26,27 5,68 13,61 4,42 9,17 3,72 7,02 3,29 5,78 3,00 5,00 2,77 4,45 2,61 4,05 2,47 3,74 2,36 3,49 2,28 3,30 2,21 3,14 2,15 3,00 2,09 2,89 2,04 2,79 253 6 334 19,49 99,49 8,56 26,23 5,66 13,57 4,40 9,13 3,71 6,99 3,28 5,75 2,98 4,96 2,76 4,41 2,59 4,01 2,45 3,70 2,35 3,46 2,26 3,27 2,19 3,11 2,12 2,97 2,07 2,86 2,02 2,76 254 6 352 19,49 99,49 8,54 26,18 5,65 13,52 4,38 9,07 3,69 6,94 3,25 5,70 2,96 4,91 2,73 4,36 2,56 3,96 2,42 3,66 2,32 3,41 2,24 3,21 2,16 3,06 2,10 2,92 2,04 2,80 1,99 2,70 254 6 361 19,50 99,50 8,54 26,14 5,64 13,48 4,37 9,04 3,68 6,90 3,24 5,67 2,94 4,88 2,72 4,33 2,55 3,93 2,41 3,62 2,31 3,38 2,22 3,18 2,14 3,02 2,08 2,89 2,02 2,77 1,97 2,67 254 6 366 19,50 99,50 8,53 26,12 5,63 13,46 4,36 9,02 3,67 6,88 3,23 5,65 2,93 4,86 2,71 4,31 2,54 3,91 2,40 3,60 2,30 3,36 2,21 3,16 2,13 3,00 2,07 2,87 2,01 2,75 1,96 2,65 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
474
ПРИЛОЖЕНИЯ
— степени свободы
1 2 3 4 5 6 7 8 9 10 11 12
| k2 — степени свободы для меньшей дисперсии 1 18 19 20 21 22 23 24 25 26 27 28 29 30 32 34 36 38 40 4,41 8,28 4,38 8,18 4,35 8,10 4,32 8,02 4,30 7,94 4,28 7,88 4,26 7,82 4,24 7,77 4,22 7,72 4,21 7,68 4,20 7,64 4,18 7,60 4,17 7,56 4,15 7,50 4,13 7,44 4,11 7,39 4,10 7,35 4,08 7,31 3,55 6,01 3,52 5,93 3,49 5,85 3,47 5,78 3,44 5,72 3,42 5,66 3,40 5,61 3,38 5,57 3,37 5,53 3,35 5,49 3,34 5,45 3,33 5,42 3,32 5,39 3,30 5,34 3,28 5,29 3,26 5,25 3,25 5,21 3,23 5,18 3,16 5,09 3,13 5,01 3,10 4,94 3,07 4,87 3,05 4,82 3,03 4,76 3,01 4,72 2,99 4,68 2,98 4,64 2,96 4,60 2,95 4,57 2,93 4,54 2,92 4,51 2,90 4,46 2,88 4,42 2,86 4,38 2,85 4,34 2,84 4,31 2,93 4,58 2,90 4,50 2,87 4,43 2,84 4,37 2,82 4,31 2,80 4,26 2,78 4,22 2,76 4,18 2,74 4,14 2,73 4,11 2,71 4,07 2,70 4,04 2,69 4,02 2,67 3,97 2,65 3,93 2,63 3,89 2,65 3,86 2,61 3,83 2,77 4,25 2,74 4,17 2,71 4,10 2,68 4,04 2,66 3,99 2,64 3,94 2,62 3,90 2,60 3,86 2,59 3,82 2,57 3,79 2,56 3,76 2,54 3,73 2,53 3,70 2,51 3,66 2,49 3,61 2,48 3,58 2,46 3,54 2,45 3,51 2,66 4,01 2,63 3,94 2,60 3,87 2,57 3,81 2,55 3,76 2,53 3,71 2,51 3,67 2,49 3,63 2,47 3,59 2,46 3,56 2,44 3,53 2,43 3,50 2,42 3,47 2,40 3,42 2,38 3,38 2,36 3,35 2,35 3,32 2,34 3,29 2,58 3,85 2,55 3,77 2,52 3,71 2,49 3,65 2,47 3,59 2,45 3,54 2,43 3,50 2,41 3,46 2,39 3,42 2,37 3,39 2,36 3,36 2,35 3,33 2,34 3,30 2,32 3,25 2,30 3,21 2,28 3,18 2,26 3,15 2,25 3,12 2,51 3,71 2,48 3,63 2,45 3,56 2,42 3,51 2,40 3,45 2,38 3,41 2,36 3,36 2,34 3,32 2,32 3,29 2,30 3,26 2,29 3,23 2,28 3,20 2,27 3,17 2,25 3,12 2,23 3,08 2,21 3,04 2,19 3,02 2,18 2,99 2,46 3,60 2,43 3,52 2,40 3,45 2,37 3,40 2,35 3,35 2,32 3,30 2,30 3,25 2,28 3,21 2,27 3,17 2,25 3,14 2,24 3,11 2,22 3,08 2,21 3,06 2,19 3,01 2,17 2,97 2, 15 2,94 2,14 2,91 2,12 2,88 2,41 3,51 2,38 3,43 2,35 3,37 2,32 3,31 2,30 3,26 2,28 3,21 2,26 3,17 2,24 3,13 2,22 3,09 2,20 3,06 2,19 3,03 2,18 3,00 2,16 2,98 2,14 2,94 2,12 2,89 2,10 2,86 2,09 2,82 2,07 2,80 2,37 3,44 2,34 3,36 2,31 3,30 2,28 3,24 2,26 3,18 2,24 3,14 2,22 3,09 2,20 3,05 2,18 3,02 2,16 2,98 2,15 2,95 2,14 2,92 2,12 2,90 2,10 2,86 2,08 2,82 2,06 2,78 2,05 2,75 2,04 2,73 2,34 3,37 2,31 3,30 2,28 3,23 2,25 3,17 2,23 3,12 2,20 3,07 2,18 3,03 2,16 2,99 2,15 2,96 2,13 2,93 2,12 2,90 2,10 2,87 2,09 2,84 2,07 2,80 2,05 2,76 2,03 2,72 2,02 2,69 2,00 2,66
ПРИЛОЖЕНИЯ
475
Продолжение
для большей дисперсии k,
14 16 20 24 30 40 50 75 100 200 500 а>
2,29 3,27 2,25 3,19 2,19 3,07 2,15 3,00 2,11 2,91 2,07 2,83 2,04 2,78 2,00 2,71 1,98 2,68 1,95 2,62 1,93 2,59 1,92 2,57 18
2,26 3,19 2,21 3,12 2,15 3,00 2,11 2,92 2,07 2,84 2,02 2,76 2,00 2,70 1,96 2,63 1,94 2,60 1,91 2,54 1,90 2,51 1,88 2,49 19
2,23 3,13 2,18 3,05 2,12 2,94 2,08 2,86 2,04 2,77 1,99 2,69 1,96 2,63 1,92 2,56 1,90 2,53 1,87 2,47 1,85 2,44 1,84 2,42 20
2,20 3,07 2,15 2,99 2,09 2,88 2,05 2,80 2,00 2,72 1,96 2,63 1,93 2,58 1,89 2,51 1,87 2,47 1,84 2,42 1,82 2,38 1,81 2,36 21
2,18 3,02 2,13 2,94 2,07 2,83 2,03 2,75 1,98 2,67 1,93 2,58 1,91 2,53 1,87 2,46 1,84 2,42 1,81 2,37 1,80 2,33 1,78 2,31 22
2,14 2,97 2,10 2,89 2,04 2,78 2,00 2,70 1,96 2,62 1,91 2,53 1,88 2,48 1,84 2,41 1,82 2,37 1,79 2,32 1,77 2,28 1,76 2,26 23
2,13 2,93 2,09 2,85 2,02 2,74 1,98 2,66 1,94 2,58 1,89 2,49 1,86 2,44 1,82 2,36 1,80 2,33 1,76 2,27 1,74 2,23 1,73 2,21 24
2,11 2,89 2,06 2,81 2,00 2,70 1,96 2,62 1,92 2,54 1,87 2,45 1,84 2,40 1,80 2,32 1,77 2,29 1,74 2,23 1,72 2.19 1,71 2,17 25
2,10 2,86 2,05 2,77 1,99 2,66 1,95 2,58 1,90 2,50 1,85 2,41 1,82 2,36 1,78 2,28 1,76 2,25 1,72 2,19 1,70 2,15 1,69 2,13 26
2,08 2,83 2,03 2,74 1,97 2,63 1,93 2,55 1,88 2,47 1,84 2,38 1,80 2,33 1,76 2,25 1,74 2,21 1,71 2,16 1,68 2,12 1,67 2,10 27
2,06 2,80 2,02 2,71 1,96 2,60 1,91 2,52 1,87 2,44 1,81 2,35 1,78 2,30 1,75 2,22 1,72 2,18 1,69 2,13 1 ,67 2,09 1,65 2,06 28
2,05 2,77 2,00 2,68 1,94 2,57 1,90 2,49 1,85 2,41 1,80 2,32 1,77 2,27 1,73 2,19 1,71 2,15 1,68 2,10 1,65 2,06 1,64 2,03 29
2,04 2,74 1,99 2,66 1,93 2,55 1,89 2,47 1,84 2,38 1,79 2,29 1,76 2,24 1,72 2,16 1,69 2,13 1,66 2,07 1,64 2.03 1,62 2,01 30
2,02 2,70 1,97 2,62 1,91 2,51 1,86 2,42 1,82 2,34 1,76 2,25 1,74 2,20 1,69 2,12 1,67 2,08 1,64 2,02 1,61 1,98 1,59 1,96 32
2,00 2,66 1,95 2,58 1,89 2,47 1,84 2,38 1,80 2,30 1,74 2,21 1,71 2,15 1,67 2,08 1,64 2,04 1,61 1,98 1,59 1,94 1,57 1,91 34
1,98 2,62 1,93 2,54 1,87 2,43 1,82 2,35 1,78 2,26 1,72 2,17 1,69 2,12 1,65 2,04 1,62 2,00 1,59 1,94 1,56 1,90 1,55 1,87 3b
1,96 2,59 1,92 2,51 1,85 2,40 1,80 2,32 1,76 2,22 1,71 2,14 1,67 2,08 1,63 2,00 1,60 1,97 1,57 1,90 1,54 1,86 1,53 1,84 38
1,95 2,56 1,90 2,49 1,84 2,37 1,79 2,29 1,74 2,20 1,69 2,11 1,66 2,05 1,61 1,97 1,59 1,94 1,55 1,88 1,53 1,84 1,51 1,81 40
476
ПРИЛОЖЕНИЯ
степени свободы для меньшей дисперсии
*2
42
44
46
48
50
55
60
65
70
80
100
125
150
200
400
1000
00
kt — степени свободы
1 4,07 3,22 3 2,83 4 2,59 6 2,44 2,32 7 2,24 8 2,17 9 2,11 1 ’ 2,06 1" 2,02 1,99
7,27 5,15 4,29 3,80 3,49 3,26 3,10 2,96 2,86 2,77 2,70 2,64
4,06 3,21 2,82 2,58 2,43 2,31 2,23 2,16 2,10 2,05 2,01 1,98
7,24 5,12 4,26 3,78 3,46 3,24 3,07 2,94 2,84 2,75 2,68 2,62
4,05 3,20 2,81 2,57 2,42 2,30 2,22 2,14 2,09 2,04 2,00 1,97
7,21 5,10 4,24 3,76 3,44 3,22 3,05 2,92 2,82 2,73 2,66 2,60
4,04 3,19 2,80 2,56 2,41 2,30 2,21 2,14 2,08 2,03 1,99 1,96
7,19 5,08 4,22 3,74 3,42 3,20 3,04 2,90 2,80 2,71 2,64 2,58
4,03 3,18 2,79 2,56 2,40 2,29 2,20 2,13 2,07 2,02 1,98 1,95
7,17 5,06 4,20 3,72 3,41 3,18 3,02 2,88 2,78 2,70 2,62 2,56
4,02 3,17 2,78 2,54 2,38 2,27 2,18 2,11 2,05 2,00 1,97 1,93
7,12 5,01 4,16 3,68 3,37 3,15 2,98 2,85 2,75 2,66 2,59 2,53
4,00 3,15 2,76 2,52 2,37 2,25 2,17 2,10 2,04 1,99 1,95 1,92
7,08 4,98 4,13 3,65 3,34 3,12 2,95 2,82 2,72 2,63 2,56 2,50
3,99 3,14 2,75 2,51 2,36 2,24 2,15 2,08 2,02 1,98 1,94 1,90
7,04 4,95 4,10 3,62 3,31 3,09 2,93 2,79 2,70 2,61 2,54 2,47
3,98 3,13 2,74 2,50 2,35 2,23 2,14 2,07 2,01 1,97 1,93 1,89
7,01 4,92 4,08 3,60 3,29 3,07 2,91 2,77 2,67 2,59 2,51 2,45
3,96 3,11 2,72 2,48 2,33 2,21 2,12 2,05 1,99 1,95 1,91 1,89
6,96 4,88 4,04 3,56 3,25 3,04 2,87 2,74 2,64 2,55 2,48 2,41
3,94 3,09 2,70 2,46 2,30 2,19 2,10 2,03 1,97 1,92 1,88 1,85
6,90 4,82 3,98 3,51 3,20 2,99 2,82 2,69 2,59 2,51 2,43 2,36
3,92 3,07 2,68 2,44 2,29 2,17 2,08 2,01 1,95 1,90 1,86 1,83
6,84 4,78 3,94 3,47 3,17 2,95 2,79 2,65 2,56 2,47 2,40 2,33
3,91 3,06 2,67 2,43 2,27 2,16 2,07 2,00 1,94 1,89 1,85 J.82
6,81 4,75 3,91 3,44 3,14 2,92 2,76 2,62 2,53 2,44 2,37 2,30
3,89 3,04 2,65 2,41 2,26 2,14 2,05 1,98 1,92 1,87 1,83 1,80
6,76 4,71 3,88 3,41 3,11 2,90 2,73 2,60 2,50 2,41 2,34 2,28
3,86 3,02 2,62 2,39 2,23 2,12 2,03 1,96 1,90 1,85 1,81 1,78
6,70 4,66 3,83 3,36 3,06 2,85 2,69 2,55 2,46 2,37 2,29 2,23
3,85 3,00 2,61 2,38 2,22 2,10 2,02 1,95 1,89 1,84 1,80 1,76
6,66 4,62 3,80 3,34 3,04 2,82 2,66 2,53 2,43 2,34 2,26 2,20
3,84 2,99 2,60 2,37 2,21 2,09 2,01 1,94 1,88 1,83 1,79 1,75
6,64 4,60 3,78 3,32 3,02 2,80 2,64 2,51 2,41 2,32 2,24 2,18
ПРИЛОЖЕНИЯ
477
Продолжение
для большей дисперсии ft 2
14 16 20 24 । 30 40 50 100 200 500 1 8
1,94 2,54 1,89 2,46 1,82 2,35 1,78 2,26 1,73 2,17 1,68 2,08 1,64 2,02 1,60 1,94 1,57 1,91 1,54 1,85 1,51 1,80 1,49 1,78 42
1,92 2,52 1,88 2,44 1,81 2,32 1,76 2,24 1,72 2,15 1,66 2,06 L.63 2,00 1,58 1,92 1,56 1,88 1,52 1,82 1,50 1,78 1,48 1,75 44
1,91 2,50 1,87 2,42 1,80 2,30 1,75 2,22 1,71 2,13 1,65 2,04 1,62 1,98 1,57 1,90 1,54 1,86 1,51 1,80 1,48 1,76 1,46 1,72 46
1,90 2,48 1,86 2,40 1,79 2,28 1,74 2,20 1,70 2,11 1,64 2,02 1,61 1 ,96 1,56 1,88 1,53 1,84 1,50 1,78 1,47 1,73 1,45 1,70 48
1,90 2,46 1,85 2,39 1,78 2,26 1,74 2,18 1,69 2,10 1,63 2,00 1,60 1,94 1,55 1,86 1,52 1,82 1.48 1,76 1,46 1,71 1,44 1,68 50
1,88 2,43 1,83 2,35 1 ,76 2,23 1,72 2,15 1 ,67 2,06 1,61 1,-96 1,58 1,90 1,52 1,82 1,50 1,78 1,46 1,71 1,43 1,66 1,41 1,64 55
1,86 2,40 1,81 2,32 1,75 2,20 1,70 2,12 1,65 2,03 1,59 1,93 1,56 1,87 1,50 1,79 1,48 1,74 1,44 1,68 1,41 1,63 1,39 1,60 60
1,85 2,37 1,80 2,30 1,73 2,18 1,68 2,09 1,63 2,00 1,57 1,90 1,54 1,84 1,49 1,76 1,46 1,71 1,42 1,64 1,39 1,60 1,37 1,56 65
1,84 2,35 1,79 2,28 1,72 2,15 1,67 2,07 1,62 1,98 1,56 1,88 1,53 1,82 1,47 1,74 1,45 1,69 1,40 1,62 1,37 1,56 1,35 1,53 70
1,82 2,32 1,77 2,24 1,70 2,11 1,65 2,03 1,60 1,94 1,54 1,84 1,51 1,78 1,45 1,70 1,42 1,65 1,38 1,57 1,35 1,52 1,32 1,49 80
1,79 2,26 1,75 2,19 1,68 2,06 1,63 1,98 1,57 1,89 1,51 1,79 1,48 1,73 1,42 1,64 1,39 1,59 1,34 1,51 1,30 1,46 1,28 1,43 100
1,77 2,23 1,72 2,15 1,65 2,03 1,60 1,94 1,55 1,85 1,49 1,75 1,45 1,68 1,39 1,59 1,36 1,54 1,31 1,46 1,27 1,40 1,25 1,37 125
1,76 2,20 1,71 2,12 1,64 2,00 1,59 1,91 1,54 1,83 1,47 1,72 1,44 1,66 1,37 1,56 1,34 1,51 1,29 1,43 1,25 1,37 1,22 1,33 150
1,74 2,17 1,69 2,09 1,62 1,97 1,57 1,88 1,52 1,79 1,45 1,69 1,42 1,62 1,35 1,53 1,32 1,48 1,26 1,39 1,22 1,33 1,19 1,28 200
1,72 2,12 1,67 2,04 1,60 1,92 1,54 1,84 1,49 1,74 1,42 1,64 1,38 1,57 1,32 1,47 1,28 1,42 1,22 1,32 1,16 1,24 1,13 1,19 400
1,70 2,09 1,65 2,01 1,58 1,89 1,53 1,81 1,47 1,71 1,41 1,61 1,36 1,54 1,30 1,44 1,26 1,38 1,19 1,28 1,13 1,19 1,08 1,11 1000
1,69 2,07 1.64 1,99 1,57 1,87 1,52 1,79 1,46 1,69 1.40 1,59 1,35 1,52 1,28 1,41 1,24 1,36 1,17 1,25 1,11 1,15 1,00 1,09 00
478
• ПРИЛОЖЕНИЯ
Таблица VII
Критические значения меньшего из чисел положительных
и отрицательных знаков разностей между значениями
учитываемого признака двух параллельно исследуемых объектов
в N опытах (см. 7.1.3) (см. примечания на стр. 497)
М Уровни значимости д% /V Уровни значимости <?%
1 5 10 25 1 5 10 25
1 46 13 15 16 18
2 47 14 16 17 19
3 0 48 14 16 17 19
4 0 49 15 17 18 19
5 0 0 50 15 17 18 20
6 0 0 1 51 15 18 19 20
7 0 0 1 52 16 18 19 21
8 0 0 1 1 53 16 18 20 21
9 0 1 1 2 54 17 19 20 22
10 0 1 1 2 55 17 19 20 22
И 0 1 2 3 56 17 20 21 23
12 1 2 2 3 57 18 20 21 23
13 1 2 3 3 58 18 21 22 24
14 1 2 3 4 59 19 21 22 24
15 2 3 3 4 60 19 - 21 23 25
16 2 3 4 5 61 20 22 23 25
17 2 4 4 5 62 20 22 24 25
18 3 4 5 6 63 20 23 24 26
19 3 4 5 6 64 21 23 24 26
20 3 5 5 6 65 21 24 25 27
21 4 5 6 7 66 22 24 25 27
22 4 5 6 7 67 22 25 26 28
23 4 6 7 8 68 22 25 26 28
24 5 6 7 8 69 23 25 27 29
25 5 7 7 9 70 23 26 27 29
26 6 7 8 9 71 24 26 28 30
27 6 7 8 10 72 24 27 28 30
28 6 8 9 10 73 25 27 28 31
29 7 8 9 10 74 25 28 29 31
30 7 9 10 11 75 25 28 29 32
31 7 9 10 11 76 26 28 30 32
32 8 9 10 12 77 26 29 30 32
33 8 10 11 12 78 27 29 31 33
34 9 10 11 13 79 27 30 31 33
35 9 и 12 13 80 28 30 32 34
36 9 11 12 14 81 28 31 32 34
37 10 12 13 14 82 28 31 33 35
38 10 12 13 14 83 29 32 33 35
39 11 12 13 15 84 29 32 33 36
40 11 13 14 15 85 30 32 34 36
41 11 13 14 16 86 30 33 34 37
42 12 14 15 16 87 31 33 35 37
43 12 14 15 17 88 31 34 35 38
44 13 15 16 17 89 31 34 36 38
45 13 15 16 18 90 32 35 36 39
Пяти- и однопроцентные пределы для отношения G; наибольшей эмпирической дисперсии к сумме k
эмпирических дисперсий, полученных из k независимых выборок объема п.
Пятипроцентные пределы напечатаны обычным шрифтом, а однопроцентные — жирным
Гем. ппимечяния ня стп 4981
к 1 2 3 4 5 6 7 8 9 10 16 36 144 СО
2 0,9985 0,999 0,9750 0,9950 0,9392 0,9794 0,9057 0,9586 0,8772 0,9373 0,8534 0,9172 0,8332 0,8988 0,8159 0,8823 0,8010 0,8674 0,7880 0,8539 0,7341 0,7949 0,6602 0,7067 0,5813 0,6062 0,5000 0,5000
3 0,9669 0,9933 0,8709 0,9423 0,7977 0,8831 0,7457 0,8335 0,7071 0,7933 0,6771 0,7606 0,6530 0,7335 0,6333 0,7107 0,6167 0,6912 0,6025 0,6743 0,5466 0,6059 0,4748 0,5153 0,4031 0,4230 0,3333 0,3333
4 0,9065 0,9676 0,7679 0,8643 0,6841 0,7814 0,6287 0,7212 0,5895 0,6761 0,5598 0,6410 0,5365 0,6129 0,5175 0,5897 0,5017 0,5702 0,4884 0,5536 0,4366 0,4884 0,3720 0,4057 0,3093 0,3251 0,2500 0,2500
5 0,8412 0,9279 0,6838 0,7885 0,5981 0,6957 0,5441 0,6329 0,5065 0,5875 0,4783 0,5531 0,4564 0,5259 0,4387 0,5037 0,4241 0,4854 0,4118 0,4697 0,3645 0,4094 0,3066 0,3351 0,2513 0,2644 0,2000 0,2000
6 0,7808 0,8828 0,6161 0,7218 0,5321 0,6258 0,4803 0,5635 0,4447 0,5195 0,4184 0,4866 0,3980 0,4608 0,3817 0,4401 0,3682 0,4229 0,3568 0,4084 0,3135 0,3529 0,2612 0,2858 0,2119 0,2229 0,1667 0,1667
7 0,7271 0,8376 0,5612 0,6644 0,4800 0,5685 0,4307 0,5080 0,3974 0,4659 0,3726 0,4347 0,3535 0,4105 0,3384 0,3911 0,3259 0,3751 0,3154 0,3616 0,2756 0,3105 0,2278 0,2494 0,1833 0,1929 0,1429 0,1429
8 0,6798 0,7945 0,5157 0,6152 0,4377 0,5209 0,3910 0,4627 0,3595 0,4226 0,3362 0,3932 0,3185 0,3704 0,3043 0,3522 0,2926 0,3373 0,2829 0,3248 0,2462 0,2779 0,2022 0,2214 0,1616 0,1700 0,1250 0,1250
9 0,6385 0,7544 0,4775 0,5727 0,4027 0,4810 0,3584 0,4251 0,3286 0,3870 0,3067 0,3592 0,2901 0,3378 0,2768 0,3207 0,2659 0,3067 0,2568 0,2950 0,2226 0,2514 0,1820 0,1992 0,1446 0,1521 0,1111 0,1111
ПРИЛОЖЕНИЯ
Продолжение
п — 1 k 1 2 3 4 5 6 7 8 9 10 16 36 144 CD
10 0,6020 0,4450 0,3733 0,3311 0,3029 0,2823 0,2666 0,2541 0,2439 0,2353 0,2032 0,1655 0,1308 0,1000
0,7175 0,5358 0,4469 0,3934 0,3572 0,3308 0,3106 0,2945 0,2813 0,2704 0,2297 0,1811 0,1376 0,1000
12 0,5410 0,3924 0,3264 0,2880 0,2624 0,2439 0,2299 0,2187 0,2098 0,2020 0,1737 0,1403 0,1100 0,8333
0,6528 0,4751 0,3919 0,3328 0,3099 0,2861 0,2680 0,2535 0,2419 0,2320 0,1961 0,1535 0,1157 0,0833
15 0,4709 0,3346 0,2758 0,2419 0,2195 0,2034 0,1911 0,1815 0,1736 0,1671 0,1429 0,1144 0,0889 0,0667
0,5747 0,4069 0,3317 0,2882 0,2593 0,2386 0,2228 0,2104 0,2002 0,1918 0,1612 0,1251 0,0934 0,0667
20 0,3894 0,2705 0,2205 0,1921 0,1735 0,1602 0,1501 0,1422 0,1357 13,1303 0,1108 0,0879 0,0675 0,0500
0,4799 0,3297 0,2654 0,2288 0,2048 0,1877 0,1748 0,1646 0,1567 0,1501 0,1248 0,0960 0,0709 0,0500
1 24 0,3434 0,2354 0,1907 0,1656 0,1493 0,1374 0,1286 0,1216 0,1160 0,1113 0,0942 0,0743 0,0567 0,0417
0,4247 0,2871 0,2295 0,1970 0,1759 0,1608 0,1495 0,1406 0,1338 0,1283 0,1060 0,0810 0,0595 0,0417
ЯП 0,2929 0,1980 0,1593 0,1377 0,1237 0,1137 0,106! 0,1002 0,0958 0,0921 0,0771 0,0604 0,0457 0,0333
0,3632 0,2412 0,1913 0,1635 0,1454 0,1327 0,1232 0,1157 0,1100 0,1054 0,0867 0,0658 0,0480 0,0333
ЛП 0,2370 0,1576 0,1259 0,1082 0,0968 0,0887 0,0827 0,0780 0,0745 0,0713 0,0595 0,0462 0,0347 0,0250
0,2940 0,1915 0,1508 0,1281 0,1135 0,1033 0,0957 0,0898 0,0853 0,0816 0,0668 0,0503 G.0363 0,0250
лл 0,1737 0,1131 0,0895 0,0765 0,0682 0,0623 0,0583 0,0552 0,0520 0,0497 0,0411 0,0316 0,0234 0,0167
0,2151 0,1371 0,1069 0,0902 0,0796 0,0722 0,0668 0,0625 0,0594 0,0567 0,0461 0,0344 0,0245 0,0167
0,0998 0,0632 0,0495 0,0419 0,0371 0,0337 0,0312 0,0292 0,0279 0,0266 0,0218 0,0165 0,0120 0,0083
IzU 0,1225 0,0759 0,0585 0,0489 0,0429 0,0387 0,0357 0,0334 0,0316 0,0302 0,0242 0,0178 0,0125 0,0083
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
ПРИЛОЖЕНИЯ
ПРИЛОЖЕНИЯ
481
Таблица IX
Нормированные отклонения у = — fge'g f—igФ(^)l + "fge- для закона
первого типа распределения крайних членов вариационного ряда
Р/ п (х) =е-г~и (см. примечания на стр. 498)
ф ('/) 1/ T(.V) и 6»
0,0000 — со 0,0025 —1,79034 —22
0,0001 -2,22033 0,0026 —.1,78377 -21
0,0002 -2,14209 0,0027 -1,77741 -19
0,0003 -2,09331 —1059* 0,0028 -1,77124 -18
0,0004 -2,05720 —663* 0,0029 -1,76525 -17
0,0005 -2,02827 -445* 0,0030 -1,75943 —16
0,0006 -2,00399 -318* 0,0031 -1,75377 -15
0,0007 -1,98299 -239* 0,0032 —1,74826 -14
0,0008 — 1,96444 -187s 0,0033 -1,74289 -13
0,0009 -1,94778 -150* 0,0034 -1,73765 -13
0,0010 -1,93264 —123* 0,0035 —1,73254 -12
0,0011 -1,91875 -103* 0,0036 —1,72754 -11
0,0012 —1,90590 —88* 0,0037 -1,72266 —И
0,0013 -1,89392 —75* 0,0038 -1,71789 -10
0,0014 —1,88271 -66* । ,0039 -1,71322 -10
0,0015 -1,87215 —58 0,0040 —1,70864 —9
0,0016 -1,86218 -51 0,0041 —1,70416 —9
0,0017 -1,85272 -46 0,0042 -1,69977 —8
0,0018 -1,84371 -41 0,0043 —1,69546 —8
0,0019 -1,83512 -37 0,0044 —1,69123 —8
0,0020 -1,82690 -34 0,0045 —1,68708 —7
0,0021 -1,81902 -31 0,0046 —1,68300 —7
0,0022 -1,81145 -28 0,0047 -1,67900 —7
0,0023 -1,80416 -26 0,0048 —1,67506 —7
0,0024 -1,79713 -24 0,0049 —1,67120 —6
16 н В Смирнов. И. В Дунин-Баркоаский
482
ПРИЛОЖЕНИЯ
П родолжение
ф (.V) У Ф (</) У 6=
0,000 — со 0,025 — 1,30532 —32
0,001 — 1,93264 0,026 — 1,29463 -29
0,002 -1,82690 0,027 — 1,28424 -27
0,003 — 1,75943 0,028 — 1,27412 -26
0,004 — 1,70864 0,029 — 1,26426 —24
0,005 — 1,66739 —596* 0,030 —1,25463 -23
0,006 — 1,63237 —429* 0,031 — 1,24524 —21
0,007 — 1,60178 -324* 0,032 -1,23606 —20
0,008 — 1,57450 —254* 0,033 -1,22708 -19
0,009 — 1,54980 —205* 0,034 -1,21829 -18
0,010 —1,52718 -169* 0,035 — 1,20968 -17
0,011 —1,50627 — 142* 0,036 —1,20124 -16
0,012 — 1,48678 — 121* 0,037 — 1,19296 — 15
0,013 -1,46852 -105* 0,038 — 1,18484 —15
, 0,014 -1,45131 -91* 0,039 — 1,17687 —14
0,015 -1,43501 —80* 0,040 — 1,16903 -13
0,016 -1,41953 —71* 0,041 -1,16133 -13
0,017 —1,40476 —64* 0,042 — 1,15376 -12
0,018 — 1,39063 —58* 0,043 — 1,14631 — 12
0,019 — 1,37708 -52* 0,044 — 1,13898 — 11
0,020 — 1,36405 —48 0,045 -1,13175 — 11
0,021 —1,35150 —44 0,046 — 1,12464 — 10
0,022 —1,33939 —40 0,047 — 1,11763 -10
0,023 —1,32767 -37 0,048 — 1,11072 — 10
0,024 — 1,31633 —34 0,049 — 1,10391 -9
ПРИЛОЖЕНИЯ
483
П родолжение
Ф (У) У ф (У) У i Ф (У) У
0,050 —1,09719 0,090 —0,87877 0,130 —0,71306
0,051 — 1,09055 0,091 -0,87418 0,131 —0,70930
0,052 -1,08401 0,092 —0,86961 0,132 -0,70555
0,053 — 1,07754 0,093 -0,86506 0,133 -0,70181
0,054 -1,07116 0,094 -0,86055 0,134 -0,69809
0,055 —1,06485 0,095 —0,85606 0,135 -0,69439
0,056 —1,05862 0,096 —0,85160 0,136 -0,69069
0,057 — 1,05246 0,097 —0,84717 0,137 —0,68702
0,058 -1,04637 0,098 -0,84276 0,138 -0,68335
0,059 — 1,04035 0,099 -0,83838 0,139 —0,67970
0,060 -1,03439 0,100 -0,83403 0,140 —0,67606
0,061 -1,02850 0,101 -0,82970 0,141 —0,67243
0,062 -1,02267 0,102 —0,82539 0,142 -0,66882
0,063 —1,01691 0,103 —0,82111 0,143 —0,66522
0,064 -1,01119 0,104 —0,81685 0,144 —0,66163
0,065 -1,00553 0,105 -0,81262 0,145 -0,65805
0,066 -0,99993 0,106 -0,80840 0,146 —0,65448
0,067 —0,99438 0,107 —0,80421 0,147 -0,65093
0,068 —0,98889 0,108 —0,80003 0,148 —0,64738
0,069 —0,98344 0,109 -0,79588 0,149 —0,64385
0,070 —0,97805 0,110 -0,79176 0,150 —0,64034
0,071 -0,97270 0,111 —0,78765 0,151 —0,63683
0,072 —0,96739 0,112 —0,78356 0,152 —0,63332
0,073 —0,96214 0,113 —0,77949 0,153 —0,62984
0,074 -0,95693 0,114 —0,77544 0,154 —0,62637
0,075 —0,95176 0,115 —0,77141 0,155 —0,62291
0,076 —0,94664 0,116 -0,76740 0,156 —0,61945
0,077 —0,94155 0,117 -0,76341 0,157 -0,61600
0,078 —0,93650 0,118 —0,75944 0,158 -0,61257
0,079 —0,93149 0,119 -0,75548 0,159 —0,60914
0,080 -0,92653 0,120 —0,75154 0,160 -0,60573
0,081 —0,92160 0,121 —0,74762 0,161 -0,60232
0,082 -0,91670 0,122 —0,74372 0,162 -0,59893
0,083 —0,91184 0,123 —0,73983 0,163 —0,59553
0,084 -0,90702 0,124 -0,73596 0,164 -0,59216
0,085 —0,90223 0,125 —0,73210 0,165 -0,58879
0,086 —0,89747 0,126 —0,72826 0,166 —0,58543
0,087 —0,89276 0,127 —0,72443 0,167 —0,58208
0,088 —0,88807 0,128 —0,72063 0,168 —0,57874
0,089 —0,88341 0,129 —0,71683 0,169 -0,57541
16*
484
ПРИЛОЖЕНИЯ
П родолжение
<р(у) У У ф (А<) У
0,170 —0,57208 0,210 —0,44509 0,250 -0,32663
0,171 —0,56877 0,211 —0,44204 0,251 —0,32375
0,172 -0,56546 0,212 —0,43900 0,252 -0,32087
0,173 —0,56216 0,213 —0,43597 0,253 —0,31799
0,174 —0,55887 0,214 —0,43294 0,254 —0,31512
0,175 —0,55559 0,215 —0,42991 0,255 —0,31224
0,176 -0,55231 0,216 —0,42688 0,256 —0,30937
0,177 —0,54905 0,217 —0,42386 0,257 —0,30651
0,178 —0,54579 0,218 —0,42085 0,258 —0,30365
0,179 —0,54254 0,219 -0,41784 0,259 -0,30079
0,180 —0,53930 0,220 —0,41483 0,260 —0,29793
0,181 —0,53606 0,221 —0,41183 0,261 -0,29507
0,182 —0,53283 0,222 —0,40884 0,262 —0,29223
0,183 —0,52961 0,223 —0,40586 0,263 —0,28938
0,184 —0,52639 0,224 —0,40287 0,264 -0,28653
0,185 —0,52318 0,225 —0,39989 0,265 —0,28369
0,186 —0,51998 0,226 —0,39691 0,266 —0,28085
0,187 —0,51679 0,227 —0,39393 0,267 —0,27801
0,188 —0,51361 0,228 —0,39097 0,268 —0,27517
0,189 —0,51043 0,229 —0,38800 0,269 —0,27234
0,190 —0,50726 0,230 -0,38504 0,270 —0,26951
0,191 —0,50409 0,231 —0,38208 '0,271 —0,26668
0,192 —0,50093 0,232 —0,37913 0,272 -0,26386
0,193 —0,49778 0,233 -0,37618 0,273 -0,26104
0,194 —0,49463 0,234 —0,37324 0,274 -0,25822
0,195 —0,49149 0,235 —0,37030 0,275 —0,25540
0,196 —0,48836 0,236 —0,36736 0,276 —0,25258
0,197 —0,48523 0,237 —0,36443 0,277 —0,24977
0,198 —0,48211 0,238 —0,36150 0,278 —0,24696
0,199 —0,47900 0,239 —0,35857 0,279 -0,24415
0,200 —0,47588 0,240 -0,35565 0,280 —0,24135
0,201 —0,47278 0,241 —0,35274 0,281 -0,23854
0,202 —0,46968 0,242 —0,34982 0,282 -0,23574
0,203 —0,46658 0,243 —0,34691 0,283 —0,23294
0,204 —0,46350 0,244 —0,34400 0,284 -0,23014
0,205 —0,46043 0,245 —0,34110 0,285 —0,22734
0,206 —0,45735 0,246 —0,33820 0,286 -0,22455
0,207 —0,45428 0,247 —0,33530 0,287 —0,22176
0,208 —0,45121 0,248 —0,33241 0,288 —0,21896
0,209 —0,44815 0,249 —0,32952 0,289 —0,21618
ПРИЛОЖЕНИЯ
485
Продолжение
ф W У ! 1 ф (У) У ф (</) У
0,290 —0,21340 0,330 -0,10315 0,370 0,00577
0,291 -0,21061 0,331 -0,10042 0,371 0,00849
0,292 —0,20783 0,332 —0,09769 0,372 0,01120
0,293 —0,20504 0,333 -0,09496 0,373 0,01392
0,294 -0,20227 0,334 -0,09222 0,374 0,01664
0,295 -0,19949 0,335 -0,08950 0,375 0,01936
0,296 —0,19672 0,336 —0,08677 0,376 0,02207
0,297 —0,19394 0,337 -0,08404 0,377 0,02480
0,298 —0,19117 0,338 —0,08131 0,378 0,02751
0,299 —0,18840 0,339 -0,07858 0,379 0,03023
0,300 —0,18563 0,340 -0,07586 0,380 0,03296
0,301 —0,18286 0,341 -0,07313 0,381 0,03568
0,302 —0,18009 0,342 -0,07041 0,382 0,03840
0,303 —0,17733 0,343 —0,06768 0,383 0,04111
0,304 —0,17456 0,344 —0,06495 0,384 0,04384
0,305 -0,17180 0,345 —0,06223 0,385 0,04656
0,306 —0,16904 0,346 —0,05951 0,386 0,04928
0,307 —0,16628 0,347 —0,05679 0,387 0,05200
0,308 -0,16352 0,348 -0,05406 0,388 0,05472
0,309 -0,16077 0,349 —0,05134 0,389 0,05745
0,310 —0,15801 0,350 —0,04862 0,390 0,06017
0,311 -0,15526 0,351 —0,04590 0,391 0,06290
0,312 —0,15251 0,352 -0,04318 0,392 0,06562
0,313 -0,14976 0,353 -0,04046 0,393 0,06835
0,314 —0,14700 0,354 —0,03773 0,394 0,07107
0,315 —0,14425 0,355 —0,03501 0,395 0,07379
0,316 -0,14151 0,356 —0,03229 0,396 0,07652
0,317 -0,13876 0,357 —0,02958 0,397 0,07925
0,318 —0,13602 0,358 —0,02686 0,398 0,08197
0,319 -0,13327 0,359 —0,02414 0,399 0,08470
0,320 —0,13053 0,360 —0,02142 0,400 0,08742
0,321 —0,12779 0,361 —0,01870 0,401 0,09015
0,322 —0,12505 0,362 -0,01598 0,402 0,09288
0,323 -0,12231 0,363 -0,01326 0,403 0,09561
0,324 —0,11957 0,364 -0,01054 0,404 0,09834
0,325 -0,11683 0,365 —0,00783 0,405 0,10108
0,326 —0,11409 0,366 -0,00511 , 0,406 0,10381
0,327 —0,11136 0,367 -0,00239 0,407 0,10654
0,328 -0,10863 0,368 0,00033 0,408 0,10927
0,329 —0,10589 0,369 0,00305 0,409 0,11201
486
ПРИЛОЖЕНИЯ
Продолжение
ф(у) У Ч’('У) У <Р (?/) У
0,410 0,11474 0,450 0,22501 0,490 0,33778
0,411 0,11748 0,451 0,22780 0,491 0,34065
0,412 0,12022 0,452 0,23059 0,492 0,34351
0,413 0,12295 0,453 0,23337 0,493 0,34638
0,414 0,12569 0,454 0,23616 0,494 0,34924
0,415 0,12843 0,455 0,23895 0,495 0,35211
0,416 0,13117 0,456 0,24174 0,496 0,35500
0,417 0,13392 0,457 0,24453 0,497 0,35788
0,418 0,13666 0,458 0,24733 0,498 0,36076
0,419 0,13940 0,459 0,25012 0,499 0,36364
0,420 0,14214 0,460 0,25292 0,500 0,36651
0,421 0,14489 0,461 0,25573 0,501 0,36940
0,422 0,14764 0,462 0,25852 0,502 0,37229
0,423 0,15038 0,463 0,26132 0,503 0,37518
0,424 0,15313 0,464 0,26414 0,504 0,37808
0,425 0,15588 0,465 0,26694 0,505 0,38097
0,426 0,15863 0,466 0,26975 0,506 0,38387
0,427 0,16138 0,467 0,27257 0,507 0,38677
0,428 0,16413 0,468 0,27539 0,508 0,38968
0,429 0,16688 0,469 0,27820 0,509 0,39259
0,430 0,16964 0,470 0,28101 0,510 0,39550
0,431 0,17240 0,471 0,28383 0,511 0,39841
0,432 0,17515 0,472 0,28665 0,512 0,40133
0,433 0,17791 0,473 0,28947 0,513 0,40425
0,434 0,18067 0,474 0,29230 0,514 0,40717
0,435 0,18343 0,475 0,29512 0,515 0,41009
0,436 0,18620 0,476 0,29795 0,516 0,41302
0,437 0,18896 0,477 0,30078 0,517 0,41595
0,438 0,19172 0,478 0,30362 0,518 0,41888
0,439 0,19449 0,479 0,30646 0,519 0,42182
0,440 0,19725 0,480 0,30930 0,520 0,42476
0,441 0,20003 0,481 0,31213 0,521 0,42770
0,442 0,20280 0,482 0,31497 0,522 0,43065
0,443 0,20557 0,483 0,31782 0,523 0,43360
0,444 0,20834 0,484 0,32066 0,524 0,43655
0,445 0,21111 0,485 0,32351 0,525 0,43950
0,446 0,21389 0,486 0,32636 0,526 0,44246
0,447 0,21667 0,487 0,32921 0,527 0,44542
0,448 0,21945 0,488 0,33207 0,528 0,44838
0,449 0,22223 0,489 0,33492 0,529 0,45135
Приложений
487
Продолжение
ФО/) У ф 0/) У ф (»/) У
0,530 0,45432 0,570 0,57604 0,610 0,70462
0,531 0,45730 0,571 0,57916 0,611 0,70794
0,532 0,46027 0,572 0,58229 0,612 0,71126
0,533 0,46325 0,573 0,58542 - 0,613 0,71459
0,534 0,46624 0,574 0,58856 0,614 0,71793
0,535 0,46922 0,575 0,59170 0,615 0,72127
0,536 0,47221 0,576 0,59485 0,616 0,72462
0,537 0,47521 0,577 0,59800 0,617 0,72797
0,538 0,47820 0,578 0,60115 0,618 0,73133
0,539 0,48120 0,579 0,60431 0,619 0,73470
0,540 0,48421 0,580 0,60747 0,620 0,73807
0,541 0,48721 0,581 0,6106.4 0,621 0,74145
0,542 0,49022 0,582 0,61381 0,622 0,74483
0,543 0,49324 0,583 0,61699 0,623 0,74822
0,544 0,49626 0,584 0,62017 0,624 0,75161
0,545 0,49928 0,585 0,62335 0,625 0,75501
0,546 0,50230 0,586 0,62654 0,626 0,75842
0,547 0,50533 0,587 0,62974 0,627 0,76184
0,548 0,50836 0,588 0,63294 0,628 0,76526
0,549 0,51140 0,589 0,63614 0,629 0,76868
0,550 0,51444 0,590 0,63935 0,630 0,77211
0,551 0,51748 0,591 0,64257 0,631 0,77555
0,552 0,52053 0,592 0,64579 0,632 0,77900
0,553 0,52358 0,593 0,64901 0,633 0,78245
0,554 0,52663 0,594 0,65224 0,634 0,78591
0,555 0,52969 0,595 0,65548 0,635 0,78937
0,556 0,53275 0,596 0,65872 0,636 0,79284
0,557 0,53582 0,597 0,66196 0,637 0,79632
0,558 0,53889 0,598 0,66521 0,638 0,79980
о;559 0,54196 0,599 0,66847 0,639 0,80330
0,560 0,54504 0,600 0,67173 0,640 0,80679
0,561 0,54812 0,601 0,67499 0,641 0,81030
0,562 0,55121 0,602 0,67826 0,642 0,81381
0,563 0,55430 0,603 0,68154 0,643 0,81733
0,564 0,55739 0,604 0,68482 0,644 0,82085
0,565 0,56049 0,605 0,68811 0,645 0,82438
0,566 0,56359 0,606 0,69140 0,646 0,82792
0,567 0,56670 0,607 0,69470 0,647 0,83147
0,568 0,56981 0,608 0,69800 0,648 0,83502
0,569 0,57292 0,609 0,70131 0,649 0,83858
488
ПРИЛОЖЕНИЯ
Продолжение
ф(у) У ф (I/) У <Р (£/) У
0,650 0,84215 0,690' 0,99138 0,730 1,15610
0,651 0,84573 0,691 0,99529 0,731 1,16046
0,652 0,84931 0,692 0,99921 0,732 1,16483
0,653 0,85290 0,693 1,00314 0,733 1,16922
0,654 0,85649 0,694 1,00708 0,734 1,17362
0,655 0,86010 0,695 1,01103 0,735 1,17803
0,656 0,86371 0,696 1,01499 0,736 1,18246
0,657 0,86733 0,697 1,01896 0,737 1,18689
0,658 0,87096 0,698 1,02294 0,738 1,19135
0,659 0,87459 0,699 1,02693 0,739 1,19581
0,660 0,87824 0,700 1,03093 0,740 1,20030
0,661 0,88189 0,701 1,03494 0,741 1,20479
0,662 0,88554 0,702 1,03896 0,742 1,20930
0,663 0,88921 0,703 1,04299 0,743 1,21382
0,664 0,89288 0,704 1,04703 0,744 1,21836
0,665 0,89657 0,705 1,05109 0,745 1,22291
0,666 0,90026 0,706 1,05515 0,746 1,22748
0,667 0,90395 0,707 1,05922 0,747 1,23206
0,668 0,90766 0,708 1,06331 0,748 1,23666
0,669 0,91137 0,709 1,06741 0,749 1,24127
0,670 0,91509 0,710 1,07151 0,750 1,24590
0,671 0,91883 0,711 1,07563 0,751 1,25054
. 0,672 0,92257 0,712 1,07976 0,752 1,25520
0,673 0,92632 0,713 1,08390 0,753 1,25987
0,674 0,93007 0,714 1,08805 0,754 1,26456
0,675 0,93384 0,715 1,09221 0,755 1,26927
0,676 0,93761 0,716 1,09639 0,756 1,27399
0,677 0,94139 а,717 1,10058 0,757 1,27872
0,678 0,94518 0,718 1,10477 0,758 1,28348
0,679 0,94898 0,719 1,10898 0,759 1,28825
0,680 0,95279 0,720 1,11321 0,760 1,29303
0,681 0,95661 0,721 1,11744 0,761 1,29784
0,682 0,96044 0,722 1,12169 0,762 1,30266
0,683 0,96427 0,723 1,12594 0,763 1,30749
0,684 0,96812 0,724 1,13021 0,764 1,31235
0,685 0,97197 0,725 1,13450 0,765 1,31722
0,686 0,97583 0,726 1,13870 0,766 1,32211
0,687 0,97971 0,727 1,14310 0,767 1,32701
0,688 0,98359 0,728 1,14742 0,768 1,33194
0,689 0,98748 0,729 1,15175 0,769 1,33688
ПРИЛОЖЕНИЯ
489
Продолжение
ф (.</) У Ф (У) У 1 ф («/) У
0,770 1,34184 0,810 1,55722 0,850 1,81696
0,771 1,34682 0,811 1,56309 0,851 1,82422
0,772 1,35181 0,812 1,56899 0,852 1,83153
0,773 1,35683 0,813 1,57492 0,853 1,83888
0,774 1,36186 0,814 1,58088 0,854 1,84627
0,775 1,36691 0,815 1,58686 0,855 1,85372
0,776 1,37199 0,816 1,59287 0,856 1,86121
0,777 1,37708 0,817 -1,59891 0,857 1,86874
0,778 1,38219 0,818 1,60498 0,858 1,87633
0,779 1,38732 0,819 1,61108 0,859 1,88396
0,780 1,39247 , 0,820 1,61721 0,860 1,89165
0,781 1,39764 0,821 1,62337 '0,861 1,89938
0,782 1,40283 0,822 1,62956 0,862 1,90717
0,783 1,40804 0,823 1,63579 0,863 1,91501
0,784 1,41327 0,824 1,64204 0,864 1,92290
0,785 1,41852 0,825 1,64832 0,865 1,93084
0,786 1,42379 0,826 1,65464 0,866 1,93884
0,787 1,42909 0,827 1,66099 0,867 1,94690
0,788 1,43440 0,828 1,66737 0,868 1,95501
0,789 1,43974 0,829 1,67379 0,869 1,96317
0,790 1,44510 0,830 1,68024 0,870 1,97140
0,791 1,45048 0,831 1,68672 0,871 1,97968
0,792 1,45589 0,832 1,69324 0,872 1,98802
0,793 1,46131 0,833 1,69979 0,873 1,99643
0,794 1,46676 0,834 1,70638 0,874 2,00489
0,795 1,47223 0,835 1,71300 0,875 2,01342
0,796 1,47773 0,836 1,71966 0,876 2,02201
0,797 1,48324 0,837 1,72636 0,877 2,03066
0,798 1,48878 0,838 1,73309 0,878 2,03939
0,799 1,49435 0,839 1,73986 0,879 2,04817
0,800 1,49994 0,840 1,74667 0,880 2,05703
0,801 1,50555 0,841 1,75352 0,881 2,06595
0,802 1,51119 0,842 1,76040 0,882 2,07495
0,803 1,51686 0,843 1,76733 0,883 2,08401
0,804 1,52254 0,844 1,77430 0,884 2,09315
0,805 1,52826 0,845 1,78130 0,885 2,10236
0,806 1,53400 0,846 1,78835 0,886 2,11165
0,807 1,53976 0,847 1,79544 0,887 2,12101
0,808 1,54556 0,848 1,80257 0,888 2,13045
0,809 1,55137 0,849 1,80974 0,889 2,13997
490
ПРИЛОЖЕНИЯ
Продолжение
ф (.«/) У <У ф (У) У 62
0,890 2,14957 8 0,935 2,69995 24
0,891 2,15926 8 0,936 2,71598 24
0,892 2,16902 9 0,937 2,73226 25
0,893 2,17888 9 0,938 2,74879 26
0,894 2,18881 9 0,939 2,76558 27
0,895 2,19884 9 0,940 2,78263 28
0,896 2,20896 9 0,941 2,79997 29
0,897 2,21917 9 0,942 2,81759 30
0,898 2,22947 10 0,943 2,83550 31
0,899 2,23987 10 0,944 2,85373 32
0,900 2,25037 10 0,945 2,87227 33
0,901 2,26096 10 0,946 2,89114 34
0,902 2,27166 10 0,947 2,91036 36
0,903 2,28246 11 0,948 2,92993 37
0,904 2,29337 и 0,949 2,94987 38
0,905 2,30438 11 0,950 2,97020 40
0,906 2,31551 и 0,951 2,99092 42
0,907 2,32675 12 0,952 3,01206 43
0,908 2,33810 12 0,953 3,03363 45
0,909 2,34957 12 0,954 3,05566 47
0,910 2,36116 12 0,955 3,07816 49
0,911 2,37287 13 0,956 3,10115 52
0,912 2,38471 13 0,957 3,12466 54
0,913 2,39668 13 0,958 3,14871 57
0,914 2,40878 13 0,959 3,17332 59
0,915 2,42102 14 0,960 3,19853 62
0,916 2,43339 14 0,961 3,22437 66
0,917 2,44590 14 0,962 3,25086 69
0,918 2,45856 15 0,963 3,27805 73
0,919 2,47137 15 0,964 3,30596 77
0,920 2,48433 16 0,965 3,33465 82
0,921 2,49744 16 0,966 3,36415 86
0,922 2,51072 16 0,967 3,39452 92
0,923 2,52415 17 0,968 3,42580 98
0,924 2,53776 17 0,969 3,45806 104
0,925 2,55154 18 0,970 3,49137 111*
0,926 2,56550 18 0,971 3,52578 119*
0,927 2,57963 19 0,972 3,56138 127*
0,928 2,59396 19 0,973 3,59826 137*
0,929 2,60848 20 0,974 3,63652 148*
0,930 2,62319 20 0,975 3,67525 160*
0,931 2,63811 •21 0,976 3,71758 173*
0,932 2,65324 22 0,977 3,76065 189*
0,933 2,66859 22 0,978 3,80561 206*
0,934 2,68416 23 0,979 3,85264 226*
ПРИЛОЖЕНИЯ
491
Продолжение
Ф (.у) У | 62 ф (.У) У 63
0,980 3,90194 250- 0,9918 4,79951 15
0,981 3,95374 276* 0,9919 4,81183 15
0,982 4,00832 308* 0,9920 4,82430 16
0,983 4,06598 345* 0,9921 4,83693 16
0,984 4,12711 390* 0,9922 4,84972 16
0,985 4,19216 443* 0,9923 4,86267 17
0,986 4,26166 509* 0,9924 4,87580 17
0,987 3,33627 589* 0,9925 4,88909 18
0,988 4,41682 691* 0,9926 4,90256 18
0,9880 4,41682 7 0,9927 4,91622 19
0,9881 4,42524 7 0,9928 4,93006 19
0,9882 4,43373 7 0,9929 4,94410 20
0,9883 4,44229 7 0,9930 4,95833 20
0,9884 4,45092 7 0,9931 4,97277 21
0,9885 4,45963 8 0,9932 4,98742 22
0,9886 4,46841 8 0,9933 5,00229 22
0,9887 4,47728 8 0,9934 5,01738 23
0,9888 4,48622 8 0,9935 5,03269 24
0,9889 4,49523 8 0,9936 5,04825 24
0,9890 4,50433 8 0,9937 5,06405 25
0,9891 4,51352 8 0,9938 5,08010 26
0,9892 4,52278 9 0,9939 5,09641 27
0,9893 4,53214 9 0,9940 5,11299 28
0,9894 4,54158 9 0,9941 5,12985 29
0,9895 4,55111 9 0,9942 5,14699 30
0,9896 4,56073 9 0,9943 5,16443 31
0,9897 4,57044 9 0,9944 5,18218 32
0,9898 4,58025 10 0,9945 5,20025 33
0,9899 4,59015 10 0,9946 5,21865 34
0,9900 4,60015 10 0,9947 5,23739 36
0,9901 4,61025 10 0,9948 5,25649 37
0,9902 4,62045 10 0,9949 5,27596 38
0,9903 4,63076 И 0,9950 5,29581 40
0,9904 4,64117 11 0,9951 5,31607 42
0,9905 4,65169 11 0,9952 5,33673 43
0,9906 4,66233 И 0,9953 5,35784 45
0,9907 4,67307 12 0,9954 5,37939 47
0,9908 4,68393 12 0,9955 5,40142 49
0,9909 4,69491 12 0,9956 5,42395 52
0,9910 4,70601 12 0,9957 5,44699 54
0,9911 4,71724 13 0,9958 5,47057 57
0,9912 4,72859 13 0,9959 5,49471 60
0,9913 4,74007 13 0,9960 5,51946 63
0,9914 4,75168 14 0,9961 5,54 483 66
0,9915 4,76342 14 0,9962 5,57085 69
0,9916 4,77531 14 0,9963 5,59757 73
0,9917 4,78734 15 0,9964 5 62502 77
492
ПРИЛОЖЕНИЯ
Продолжение
<р (у) У б2 <Р (!/) У 62
0,9965 5,65324 82 0,99955 7,70604 49
0,9966 5,68228 87 0,99956 7,72852 52
0,9967 5,71218 92 0,99957 7,75151 54
0,9968 5,74300 98 0,99958 7,77505 57
0,9969 5,77480 104 0,99959 7,79915 60
0,9970 5,80764 111* 0,99960 7,82385 63
0,9971 5,84159 119* 0,99961 7,84917 66
0,9972 5,87673 127* 0,99962 7,87515 69
0,9973 5,91315 137* 0,99963 7,90182 73
0,9974 5,95094 148* 0,99964 7,92923 77
0,9975 0,9976 0,9977 0,9978 0,9979 5,99021 6,03109 6,07370 6,11820 6,16477 160* 173* ' 189* 206* 226* 0,99965 0,99966 0,99967 0,99968 0,99969 7,95740 7,98639 8,01625 8,04703 8,07878 82 87 92 98- 104*
0,99970 8,11158 111*
0,9980 6,21361 250* 0,99971 8,14548 119*
0,9981 6,26495 277* 0,99972 8,18058 127*
0,9982 6,31907 308* 0,99973 8,21695 137*
0,9983 6,37628 345* 0,99974 8,25470 148*
0,9984 6,43695 390* 0,99975 8,29392 160*
0,9985 6,50154 443* -0,99976 8,33475 173*
0,9986 6,57058 509* 0,99977 8,37732 189*
0,9987 6,64474 590* 0,99978 8,42177 206*
0,9988 6,72483 691* 0,99979 8,46830 226*
0,9989 6,81190 822* 0,99980 8,51709 250*
0,9990 6,90726 994* 0,99981 8,56839 277*
0,9991 7,01267 1225* 0,99982 8,62246 308*
0,9992 7,13050 1546* 0,99983 8,67963 345*
0,9993 7,26408 2013* 0,99984 8,74026 390*
0,9994 7,41828 2723* 0,99985 8,80480 443*
0,99940 7,41828 28 0,99986 8,87380 509*
0,99941 7 43509 29 0,99987 8,94791 590*
0,99942 7,45219 30 0,99988 9,02796 691*
0,99943 7,46959 31 0,99989 9,11498 822*
0,99944 7,48729 32 0,99990 9,21029 994*
0,99991 9,31566 1225*
0,99945 7,50532 33 0,99992 9^43344 1546*
0,99946 7,52367 34 0,99993 9,'56698 2013*
0,99947 7,54237 36 0,99994 9,72114 2723*
0,99948 0,99949 7,56142 7,58084 37 38 0,99995 0,99996 9'90346 10,12661 3879* 5911*
0,99950 7,60065 40 0,99997 10,41430 9633*
0,99951 7,62086 42 0,99998 10,81977
0,99952 7,64148 43 0,99999 11,51292
0,99953 7,66254 45 1,00000
0,99954 7,68405 47
ПРИЛОЖЕНИЯ
493
Таблица X
Обратная функция ф (х) (см. примечания на стр. 500)
р 0 1 2 3 4 5 6 7 9
0,00 — 00 —3,09 -2,88 —2,75 -2,65 —2,58 -2,51 —2,46 —2,41 —2,37
0,01 -2,33 —2,29 —2,26 —2,23 —2,20 -2,17 —2,14 —2,12 -2,10 -2,07
0,02 —2,05 -2,03 —2,01 —2,00 — 1,98 -1,96 — 1,94 -1,93 -1,91 —1,90
0,03 — 1,88 -1,87 — 1,85 —1,84 —1,83 —1,81 —1,80 -1,79 -1,77 —1,76
0,04 -1,75 -1,74 -1,73 -1,72 -1,71 —1,70 -1,68 —1,67 — 1,66 —1,65
0,05 — 1,64 — 1,64 -1,63 -1,62 -1,61 —1,60 —1,59 -1,58 -1,57 -1,56
0,06 —1,55 —1,55 — 1,54 -1,53 — 1,52 — 1,51 -1,51 -1,50 — 1,49 —1,48
0,07 — 1,48 -1,47 — 1,46 -1,45 -1,45 — 1,44 — 1,43 -1,43 — 1,42 —1,41
0,08 — 1,41 -1,40 — 1,39 -1,39 -1,38 —1,37 — 1,37 —1,36 — 1,35 —1,35
0,09 -1,34 —1,33 — 1,33 —1,32 —1,32 -1,31 —1,30 -1,30 — 1,29 -1,29
0,10 — 1,28 —1,28 -1,27 —1,26 —1,26 -1,25 — 1,25 — 1,24 —1,24 —1,23
0,11 — 1,23 -1,22 — 1,22 -1,21 — 1,21 — 1,20 — 1,20 -1,19 -1,19 —1,18
0,12 — 1,18 -1,17 — 1,17 — 1,16 -1,16 —1,15 —1,15 —1,14 — 1,14 —1,13
0,13 —1,13 -1,12 -1,12 —1,11 -1,11 -1,10 -1,10 — 1,09 — 1,09 —1,09
0,14 —1,08 -1,08 -1,07 -1,07 —1,06 —1,06 — 1,05 -1,05 -1,05 —1,04
0,15 — 1,04 -1,03 — 1,03 —1,02 —1,02 — 1,02 —1,01 -1,01 -1,00 —1,00
0,16 -0,99 —0,99 -0,99 —0,98 —0,98 —0,97 —0,97 —0,97 -0,96 —0,96
0,17 —0,95 -0,95 -0,95 -0,94 -0,94 —0,93 —0,93 —0,93 —0,92 —0,92
0,18 —0,92 —0,91 —0,91 —0,90 —0,90 —0,90 -0,89 —0,89 -0,89 —0,88
0,19 —0,88 —0,87 —0,87 -0,87 —0,86 —0,86 -0,86 —0,85 -0,85 —0,85
0,20 —0,84 —0,84 -0,83 —0,83 —0,83 —0,82 —0,82 —0,82 —0,81 —0,81
0,21 -0,81 —0,80 -0,80 —0,80 —0,79 —0,79 —0,79 —0,78 —0,78 —0,78
0,22 —0,77 —0,77 -0,77 -0,76 -0,76 —0,76 —0,75 —0,75 -0,75 —0,74
0,23 —0,74 —0,74 —0,73 -0,73 —0,73 —0,72 -0,72 —0,72 —0,71 —0,71
0,24 -0,71 —0,70 —0,70 —0,-70 —0,69 —0,69 —0,69 —0,68 —0,68 —0,68
0,25 —0,67 —0,67 —0,67 —0,67 -0,66 —0,66 —0,66 —0,65 —0,65 —0,65
0,26 —0,64 —0,64 —0,64 —0,63 —0,63 —0,63 —0,63 —0,62 —0,62 —0,62
0,27 —0,61 —0,61 —0,61 —0,60 -0,60 —0,60 -0,59 -0,59 -0,59 -0,59
0,28 -0,58 —0,58 —0,58 -0,57 —0,57 —0,57 —0,57 —0,56 -0,56 —0,56
0,29 —0,55 —0,55 -0,55 -0,54 —0,54 —0,54 —0,54 —0,53 —0,53 —0,53
0,30 —0,52 —0,52 —0,52 —0,52 —0,51 —0,51 —0,51 —0,50 —0,50 —0,50
494
ПРИЛОЖЕНИЯ
Продолжение
р 0 1 2 3 4 5 6 7 8 9
0,31 —0,50 —0,49 —0,49 —0,49 -0,48 —0,48 -0,48 —0,48 —0,47 -0,47
0,32 —0,47 —0,46 —0,46 —0,46 —0,46 —0,45 -0,45 -0,45 —0,45 —0,44
0,33 —0,44 —0,44 —0,43 -0,43 —0,43 -0,43 -0,42 -0,42 —0,42 -0,42
0,34 —0,41 —0,41 —0,41 —0,40 —0,40 —0,40 -0,40 -0,39 —0,39 -0,39
0,35 —0,39 —0,38 —0,38 -0,38 —0,37 —0,37 —0,37 —0,37 —0,36 -0,36
0,36 —0,36 —0,36 —0,35 -0,35 -0,35 —0,35 -0,34 —0,34 —0,34 —0,33
0,37 —0,33 —0,33 -0,33 -0,32 —0,32 —0,32 —0,32 -0,31 -0,31 —0,31
0,38 —0,31 —0,30 —0,30 -0,30 —0,30 —0,29 -0,29 -0,29 -0,28 -0,28
0,39 —0,28 —0,28 —0,27 —0,27 —0,27 —0,27 —0,26 —0,26 —0,26 -0,26
0,40 —0,25 —0,25 —0,25 -0,25 -0,24 —0,24 -0,24 -0,24 —0,23 -0,23
0,41 -0,23 —0,23 —0,22 -0,22 —0,22 —0,21 -0,21 -0,21 -0,21 -0,20
0,42 -0,20 —0,20 -0,20 -0,19 —0,19 —0,19 -0,19 —0,18 —0,18 —0,18
0,43 —0,18 —0,17 —0,17 —0,17 —0,17 —0,16 —0,16 —0,16 —0,16 —0,15
0,44 -0,15 —0,15 —0,15 —0,14 -0,14 —0,14 —0,13 -0,13 —0,13 -0,13
0,45 —0,13 —0,12 -0,12 —0,12 —0,12 -0,11 -0,11 -0,11 -0,11 -0,10
0,46 —0,10 —0,10 —0,10 —0,09 —0,09 -0,09 —0,09 —0,08 -0,08 -0,08
0,47 —0,08 —0,07 -0,07 —0,07 —0,07 -0,06 —0,06 -0,06 -0,06 -0,05
0,48 —0,05 —0,05 -0,05 —0,04 —0,04 -0,04 -0,04 —0,03 -0,03 -0,03
0,49 —0,03 -0,02 —0,02 -0,02 -0,02 -0,01 —0,01 —0,01 -0,0) -0,00
0,50 0,00 0,00 0,01 0,01 0,01 0,01 0,02 0,02 0,02 0,02
0,51 0,03 0,03 0,03 0,03 0,04 0,04 0,04 0,04 0,05 0,05
0,52 0,05 0,05 0,06 0,06 0,06 0,06 0,07 0,07 0,07 0,07
0,53 0,08 0,08 0,08 0,08 0,09 0,09 0,09 0,09 0,10 0,10
0,54 0,10 0,10 0,11 0,11 0,11 0,11 0,12 0,12 0,12 0,12
0,55 0,13 0,13 0,13 0,13 0,14 0,14 0,14 0,14 0,15 0,15
0,56 0,15 0,15 0,16 0,16 0,16 0,16 0,17 0,17 0,17 0,17
0,57 0,18 0,18 0,18 0,18 0,18 0,19 0,19 0,19 0,20 0,20
0,58 0,20 0,20 0,21 0,21 0,21 0,21 0,22 0,22 0,22 0,23
0,59 0,23 0,23 0,23 0,24 0,24 0,24 0,24 0,25 0,25 0,25
0,60 0,25 0,26 0,26 0,26 0,26 0,27 0,27 0,27 0,27 0,28
0,61 0,28 0,28 0,28 0,29 0,29 0,29 0,30 0,30 0,30 0,30
0,62 0,31 0,3) 0,31 0,31 0,32 0,32 0,32 0,32 0,33 0,33
ПРИЛОЖЕНИЯ
495
П родо.гжение
р 0 1 2 3 4 5 6 7 8 9
0,63 0,33 0,33 0,34 0,34 0,34 0,35 0,35 0,35 0,35 0,36
0,64 0,36 0,36 0,36 0,37 0,37 0,37 0,37 0,38 0,38 0,38
0,65 0,39 0,39 0,39 0,39 0,40 0,40 0,40 0,40 0,41 0,41
0,66 0,41 0,42 0,42 0,42 0,42 0,43 0,43 0,43 0,43 0,44
0,67 0,44 0,44 0,45 0,45 0,45 0,45 0,46 0,46 0,46 0,46
0,68 0,47 0,47 0,47 0,48 0,48 0,48 0,48 0,49 0,49 0,49
0,69 0,50 0,50 0,50 0,50 0,51 0,51 0,51 0,52 0,52 0,52
0,70 0,52 0,53 0,53 0,53 0,54 0,54 0,54 0,54 0,55 0,55
0,71 0,55 0,56 0,56 0,56 0,57 0,57 0,57 0,57 0,58 0,58
0,72 0,58 0,59 0,59 0,59 0,59 0,60 0,60 0,60 0,61 0,61
0,73 0,61 0,62 0,62 0,62 0,63 0,63 0,63 0,63 0,64 0,64
0,74 0,64 0,65 0,65 0,65 0,66 0,66 0,66 0,67 0,67 0,67
0,75 0,67 0,68 0,68 0,68 0,69 0,69 0,69 0,70 0,70 0,70
0,76 0,71 0,71 0,71 0,72 0,72 0,72 0,73 0,73 0,73 0,74
0,77 0,74 0,74 0,75 0,75 0,75 0,76 0,76 0,76 0,77 0,77
0,78 0,77 0,78 0,78 0,78 0,79 0,79 0,79 0,80 0,80 0,80
0,79 0,81 0,81 0,81 0,82 0,82 0,82 0,83 0,83 0,83 0,84
0,80 0,84 0,85 0,85 0,85 0,86 0,86 0,86 0,87 0,87 0,87
0,81 0,88 0,88 0,89 0,89 0,89 0,90 0,90 0,90 0,91 0,91
0,82 0,92 0,92 0,92 0,93 0,93 0,93 0,94 0,94 0,95 0,95
0,83 0,95 0,96 0,96 0,97 0,97 0,97 0,98 0,98 0,99 0,99
0,84 0,99 1,00 1,00 1,01 1,01 1,02 1,02 1,02 1,03 1,03
0,85 1,04 1,04 1,05 1,05 1,05 1,06 1,06 1,07 1,07 1,08
0,86 1,08 1,09 1,09 1,09 1,10 1,10 1,11 1,11 1,12 1,12
0,87 1,13 1,13 1,14 1,14 1,15 1,15 1,16 1,16 1,17 1,17
0,88 1,18 1,18 1,19 1,19 1,20 1,20 1,21 1,21 1,22 1,22
0,89 1,23 1,23 1,24 1,24 1,25 1,25 1,26 1,26 1,27 1,27
0,90 1,28 1,29 1,29 1,30 1,30 1,31 1,32 1,32 1,-33 ’1,33
0,91 1,34 1,35 1,35 1,36 1,37 1,37 1,38 1,39 1,39 1,40
0,92 1,41 1,41 1,42 1,43 1,43 1,44 1,45 1,45 1,46 1,47
0,93 1,48 1,48 1,49 1,50 1,51 1,51 1,52 1,53 1,54 1,54
0,94 1,55 1,56 1,57 1,58 1,59 1,60 1,61 1,62 1,63 1,64
0,95 1,64 1,65 1,66 1,67 1,68 1,70 1,71 1,72 1,73 1,74
0,96 1,75 1,76 1,77 1,79 1,80 1,81 1 ,83 1,84 1,85 1,87
0,97 1,88 1,90 1,91 1,93 1,94 1,96 1,98 2,00 2,01 2,03
0,98 2,05 2,07 2,10 2,12 2,14 2,17 2,20 2,23 2,26 2,29
0,99 2,33 2,37 2,41 2,46 2,51 2,58 2,65 2,75 2,88 3,09
496
ПРИЛОЖЕНИЯ
Таблица XI
Квантили распределения величины п = —- *- или
о, = ,x~^giin. (СМ примечания на стр. 500)
И 0,10 0,05 0,0С5 0,01
3 1,406 1,412 1,414 1,414
4 1,645 1,689 1,710 1,723
5 1,791 1,869 1,917 1,955
6 1,894 1,996 2,067 2,130
7 1,974 2,093 2,182 2,265
8 2,041 2,172 2,273 2,374
9 2,097 2,237 2,349 2,464
10 2,146 2,294 2,414 2,540
11 2,190 2,343 2,470 2,606
12 2,229 2,387 2,519 2,663
13 2,264 2,426 2,562 2,714
14 2,297 2,461 2,602 2,759
15 2,326 2,493 2,638 2,800 •
16 2,354 2,523 2,670 2,837
17 2,380 2,551 2,701 2,871
18 2,404 2,577 2,728 2,903
19 2,426 2,600 2,754 2,932
20 2,447 2,623 2,778 2,959
21 2,467 2.644 2,801 2,984
22 2,486 2,664 2,823 3,008
23 2,504 2,683 2,843 3,030
24 2,520 2,701 2,862 3,051
25 2,537 . 2,717 2,880 3,071
Примечания к таблицам
Таблица I. В этой таблице показатель степени при числе,
определяющем плотность вероятности л (г; 0; 1), относится к мно-
жителю 10. Например, при z = 0,9 плотность вероятности
л (0,9; 0; 1) = 2661 = 0,2661. Если у числа показатель степени
отсутствует, то им будет показатель степени у ближайшего слева
числа, имеющего этот показатель. Например, для z = 2,78 имеем
л (2,78; 0; 1) = 8370"’= 0,008370.
Пример. Требуется определить ординату нормальной кривой
распределения в точке г=1,85; имеем: л (1,85; 0; 1) — 7206“’ =
= 0,07206.
Таблица 11. В таблице заданы лишь три последних десятич-
ных знака из четырех; первый из них записан в графе «0» данной
ПРИЛОЖЕНИЯ
497
строки или выше данной. Если перед последними тремя десятич-
ными знаками стоит точка, то это означает, что первый десятичный
знак надо смотреть в графе «О» следующей строки. Например,
для z = 0,53 имеем Фо(О,53) = О,2О19 (а не 0,1019).
Для значений 2,2 ^.z^ 5,0 под основными четырьмя десятич-
ными знаками функции Ф0(г) даются мелким шрифтом еще три деся-
тичных знака. Например, при z = 3,51 находим Фо (3,51) = 0,4997,
т. е. Фо (3,51) = 0,4997759.
Пример. Требуется определить вероятность того, что нор-
мально распределенная нормированная величина Z примет значение
в интервале от 0 до 3,28. Имеем:
Р (0 < Z < 3,28) = Фо (3,28) = 0,4994810.
Таблица Ill. Требуется определить для выборки объема п = 10
математическое ожидание размаха Rn, его среднее квадратическое
отклонение и вероятность того, что размах не превысит 4,79а.
Из таблицы находим: М7?п = 3,078а; а#п = 0,797а и вероятность
Р (R„ < 4,79а) = 0,975 = 97,5°/0.
Таблица IV. Требуется для случайной величины, следующей
закону %2, с числом степеней свободы, равным 7, определить такое
отклонение, вероятность превышения которого равна 0,05 (7 = 5°/0).
Имеем: %2 = 14,1.
Таблица V. Требуется определить 10% пределы для откло-
нения выборочной средней х от генеральной средней а при объеме
15 штук, если параметр а оценивается по данным той же выборки.
Имеем:
fe = /z —1 = 15 —1 = 14, /10, м=1,761,
и потому
—1,761 -^=<х—а<+1,761 -4= .
/15 /15
Таблица VI. Требуется определить 5% и 1% пределы для
величины F отношения несмещенных оценок двух дисперсий
о?
— (<Jj>ap, если известно, что / = —1 =25 —1 =24 и й2 =
з
= л2—1 = 12—1 = 11 (nt и nt — объемы выборок, по которым на-
ходятся оценки дисперсий а® и ар. Имеем: при ^ = 5% величина
5 = 2,61 и при д=1% величина 5=4,02.
Таблица VII. Требуется определить критическое значение mN
меньшего из чисел положительных и отрицательных знаков разно-
стей между значениями учитываемого признака двух параллельно
исследуемых объектов в 70 опытах при уровне значимости <7 = 5%.
Имеем: /Ядг=26, т. е. если меньшее из чисел знаков разностей
498
ПРИЛОЖЕНИЯ
окажется меньше 26, то гипотеза об однородности распределений
объектов опровергается.
Таблица VIII. Требуется определить 5% предел отношения
наибольшей эмпирической дисперсии из 20 таких дисперсий к сумме
всех 20 дисперсий, полученных в независимых выборках объема 8
каждая. Имеем: при п —1=8—1=7 величина G,=0,1501.
Таблица IX. Здесь символом б2 обозначены вторые разности,
т. е. разности между разностями соседних значений табулированной
функции. Так, например, значению <р(_У) = 0,0015 отвечает ^в,в()П =
=—1,87215, значению ф(_у) = 0,0016 отвечает _у010016 =—1,86218
и значению ф (у) = 0,0017 отвечает значение х0 017 = —1,85272.
Первые разности будут:
60,о015,0,0о15 = -1,86218-(-1,87215) = 997.10-’
11
60>0017, 0,001в = —1,85272 —(—1,86218) = 946.10-“.
Вторая разность для ф(у) = 0,0016 равна
б\„ =(946 —997)-10-5 = —51-Ю-5.
0,0016 ' '
Это значение мы и находим в таблице.
Знак * поставлен против модифицированных (видоизмененных)
значений вторых разностей, которые, однако, используются при
интерполировании совершенно так же, как упоминавшиеся уже
простые вторые разности.
Для уточненного интерполирования следует использовать формулу
/(x) = /(.v0 + pA) =
=P/W+?/<•«.) - S; s; , (A)
где
x— заданное значение аргумента,
х0 и xt— соседние значения аргумента, имеющиеся в та-
блице IX, между которыми находится х,
h—xl — х9—интервал между х0 и х, по таблице,
р = —--------Д°ля интервала, находимая из равенства х = х0 + рй,
<у=1—р—противоположная доля интервала,
/(х0) и/(х,)— значения табулированной функции, отвечающие соот-
ветственно х0 и х,,
^/и)И^нх)—значения вторых разностей (простых или модифици-
рованных), отвечающие соответственно /(х0) и /(х,).
В таблице IX табулирована функция
/(.Г) = у = - 1g (-1g X) ,
ПРИЛОЖЕНИЯ
490
аргументом которой является
Ф(у)=х.
При линейном интерполировании используется формула (А) без
двух последних членов в правой части, множителями для которых
являются вторые разности. Его следует применять при значениях х,
попадающих между такими табличными значениями, для которых
вторые разности в таблице IX не приводятся (от х = 0,050 до
х = 0,890). Можно им пользоваться и при всех остальных значе-
ниях х, но при этом результат интерполирования будет завышен-
ным примерно на '/8 от средней (для границ соответствующего
табличного интервала) величины второй разности.
Уточненное интерполирование (в пределах от х = 0,0003 до
х — 0,050 и от х — 0,890 до х= 0,99997) производится по фор-
муле (А), используемой без сокращений.
Пример. Требуется определить значение ys7 нормированного
отклонения для 97-го члена вариационного ряда, составленного из
максимальных членов ста выборок (например, из 100 максимальных
годовых расходов воды в реке).
Приравнивая
f«”/m“№TT=0'9604’
будем, искать Л,98М =/(0,9604-).
Из таблицы IX берем
/(х0) = /(0,960) = 3,19853, /(.V,) = /(0,961) = 3,22437,
6* =б2-10-5 и 6’ =66-10-5,
О,Эво , 0,8в1 1
а потому
, А ОС1 А ПСА A АА1 0,9604--0,960 - .
h — 0,961 —0,960 = 0,001, р= —o~(jQi--=0,4
и 9=1—0,4 = 0,6.
Производя линейное интерполирование, получим;
/(0,9604) = 0,4-3,22437 + 0,6-3,19853 = 3,20887 = у0„во4.
Погрешность линейного интерполирования (в сторону увеличения
результата) будет равна примерно
" 10-5 = 0,00008.
О Z
Используя для уточненного интерполирования формулу (А) без
сокращений, будем иметь:
/(0,9604) = 0,4 -3,22437 ф 0,6 • 3,19853 —0,4 (1 ~°’42-) 66-Ю"5 —
-^6-(-'~0’6^ 62 10“5 = 3,20887 =у0) 9601.
500
ПРИЛОЖЕНИЙ
Мы видим, что, действительно, в нашем примере при линейном
интерполировании результат получился больше на 0,00008, чем
при уточненном интерполировании по формуле (А).
Таблица X, В таблице даны значения обратной функции ф (х)
для нормального распределения, т. е. величины отклонений, веро-
ятность не превзойти которые равна
x=P(ZCfQ,) = 0,5 + O0 U =
где второе слагаемое в правой части представляет нормированную
функцию Лапласа (при аргументе z = tQji), значения которой при-
ведены в таблице II приложений.
Пример. Пусть требуется найти величину отклонения ф(х) =
/у____________________________________а \
— tQn, вероятность х — Р (Z < t<?„).= Р ( —— tq,J Для нормиро-
ванной (см. п. 4.1.2) нормально распределенной (с параметрами а
и о) величины Y равна р = 0,877.
По таблице X при аргументе р = 0,877 находим ф (х) = tQn~ 1,16.
Этот же результат можно получить по таблице 11 приложений
следующим обр-азом. Находим отвечающую вероятности р — 0,856
функцию Лапласа:
Ф„ {г = /<?„) = 0,877 — 0,5 = 0,377.
По таблице II находим аргумент г, отвечающий этому значе-
нию вероятности. Он равен 1,16.
Если бы функция Лапласа при аргументе 1,16 не равнялась
числу 0,3770, оканчивающемуся на нуль, то отыскание z было бы
сопряжено с интерполяцией, от которой избавляет использование
таблицы X.
Таблица XI. Требуется найти значение ga,s- ]2 верхнего от-
клонения величины = (отклонения максимального члена
Хта^~х) а выборке объема л=12 такое, что вероятность превы-
сить это значение отклонения равна PG’>go,5;!S) = O,O5 (9 = 5%).
По таблице XI при и = 12 и Р g0,5! i2) = 0,05 находим
g»,t; 12 = 2,387.
ЛИТЕРАТУРА
1 Андерсон Т., Введение в многомерный статистический анализ, М.,
-Физматгиз, 1963.
2. Арлей Н. и Бух К., Введение в теорию вероятностей и матема-
тическую статистику, М., ИЛ, 1951.
3. Ачеркан Н. С., Статистические методы контроля, М., Машгиз, 1946.
4. Балакшин Б. С., Основы технологии машиностроения, М., Маш-
гиз, 1959.
5. Бартлетт М. С., Введение в теорию случайных процессов, М.,
ИЛ, 1958
6. Бернштейн С. Н., Теория вероятностей, М.—Л., Гостехиздат, 1946.
7. Боев Г. П., Теория вероятностей, М.—Л., Гостехиздат, 1950.
8, Болотин В. В., Статистические методы в строительной механике,
М„ 1961.
9. Бородач ев Н. А., Анализ качества и точности производства, М.,
Машгиз, 1946.
10. Бородач ев Н. А., Основные вопросы теории точности производ-
ства, М.—Л., Изд. АН СССР, 1950.
11. Боярский А. Я., Математика для экономистов, М., Госстатиздат,
1957.
12. Б р а у н л и К. А., Статистические исследования в производстве, М.,
ИЛ, 1949.
13. Бриллюэн Л., Наука и теория информации, М., Физматгиз, 1959.
14. Бруевич Н. Г., Точность механизмов, М.—Л., Гостехиздат, 1946.
15. Бунимович В. И., Флуктуационные процессы в радиоприемных
устройствах, «Советское радио», 1951.
16. Б у с л е н к о Н. П. и Ю. А. Шрейдер, Метод статистических ис-
пытаний (Монте-Карло) и его реализация на цифровых вычислитель-
ных машинах, М., Физматгиз, 1961.
17. Ван дер Варден, Математическая статистика, М., ИЛ, 1960
18. Вентце ль Е. С., Теория вероятностей М., Физматгиз, 1962.
19. Владимиров Л. П., Практическое освоение наладки, контроля
анализа производственных процессов на базе метода средних выбо-
рок, Изд. Львовск. ун-та, 1956.
20. Вудворд Ф. М., Теория вероятностей и теория информации с при-
менениями в радиолокации, «Советское радио», 1955.
21. Гливенко В. И., Курс теории вероятностей, М.—Л., ГОНТИ, 1939.
22. Гнеденко Б. В., Курс теории вероятностей, М., Физматгиз, 1961.
23. Гнеденко Б. В. и Колмогоров А. Н., Предельные распреде-
ления для сумм независимых случайных величин, М.—Л , Гостехиз-
дат, 1949.
24. Г н е ДЪ н к о Б. В. и X и н ч и н А Я., Элементарное введение в тео-
рию вероятностей, М.—Л., Гостехиздат, 1946.
25. Голдман С., Теория информации, М., ИЛ, 1957.
502
литература
26. Головинский В. В., Статистический контроль качества за рубе-
жом, М., Машгиз, 1957.
27. Гольданский В. И. и др., Статистика отсчетов при регистрации
ядерных частиц, М., 1959.
28. Гонор овск ий И. С., Основы радиотехники, М., Госсвязьиздат,
1957.
29. Гончаров В. Л., Теория вероятностей, М., Оборонгиз, 1939.
30. Гостев В Н., Модель Г. А. и Файн Ф А., Статистический
контроль методом группировок, Л., 1949.
31. Грен ан дер У., Случайные процессы и статистические выводы, М.,
ИЛ, 1961.
32. Давенпорт В. Б. и Р у т В. Л., Введение в теорию случайных сиг-
налов и шумов, М., ИЛ, 1960.
33. Длин А. М., Математическая статистика в технике, 3-е изд., М.,
«Советская наука», 1958.
34. Долу ха нов М. П., Введение в теорию передачи информации по
электрическим каналам связи, М., Госсвязьиздат, 1955.
35. Дуб Дж. Л., Вероятностные процессы, М.—Л., 1956.
36. Д у н и н - Б а р к о в с к и й И. В. и Смирнов Н. В , Теория вероят-
ностей и математическая статистика в технике (общая часть), М., Гос-
техиздат, 1955
37. Журавлев А. Н., Статистический метод контроля в машинострое-
нии, М., ВНИТОМАШ, 1948.
38. Захар ян Р. О., Вероятностные расчеты при выборе посадок в со-
пряжениях машин, Ереван, Айпетрат, 1962.
39. Идельсон Н. И., Способ наименьших квадратов, Л., 1932.
40. Казаков И Е и Д о с т у п о в Б. Г., Статистическая динамика не-
линейных автоматических систем, М., Физматгиз, 1962.
41. Калашников Н. А., Точность в машиностроении и ее законы, М.,
Машгиз, 1950.
42. Колмогоров А. Н., Основные понятия теории вероятностей, М.—Л.,
ОНТИ, 1936.
43. Колмогоров А. Н., Статистический приемочный контроль при до-
пустимом числе дефектных деталей, равном нулю. Ленингр. Дом на-
учно-технической пропаганды, 1948.
44. Колмогоров А. Н., Теория передачи информации, М., Изд. АН
СССР, 1956.
45. Кон юс А. А., Краткие сведения по теории вероятностей, М., Гос-
связьиздат, 1954.
46. Кордонский X. Б., Теория вероятностей в инженерном деле, М.,
Физматгиз, 1963.
47. Коуден Д. И., Статистические методы контроля качества, М., физ-
матгиз, 1961.
48. Крамер Г., Математические методы статистики, М., ИЛ, 1948.
49. Крицкий С. Н. и Менке ль М. Ф., Водохозяйственные расчеты,
Л., 1952.
50. Кутай А. К. и Кордонский X. Б., Анализ точности и контроль
качества в машиностроении, М., Машгиз, 1958.
51, Лебедев В. П., Случайные процессы в электрических и механиче-
ских системах, М., Физматгиз, 1958.
52. Л е в и н Б Р., Теория случайных процессов и ее применение в радио-
технике, М., «Советское радио», 1960.
53. Леонтьев Л. П., Введение в теорию надежности радиоэлектронной
аппаратуры, Рига, Изд-во АН Латв. ССР, 1963.
54, Лившиц Н. А. и П у г а ч е в В. С., Вероятностный анализ систем
автоматического управления, М., «Советское радио», 1963.
ЛИТЕРАТУРА
503
55. Линник Ю. В., Способ наименьших квадратов и основы теории
обработки наблюдений, AI., Физматгиз, 1958.
56. Л у к о м с к и й Я- И., Теория корреляции и ее приложения к ана-
лизу производства, М., Госстатиздат, 1958.
57. Луцкий В. А., Расчет надежности и эффективности радиоэлектрон-
ной аппаратуры, Киев, Изд-во АН УССР, 1963.
58. Льюис Р. Д. и Райфа X., Игры и решения, М., ИЛ, 1961.
59. Лэнинг Дж. X. и Бэтти н Р. Г., Случайные процессы в задачах
автоматического управления, М., ИЛ, 1958.
60. М а л и к о в И. М. и др., Основы теории и расчета надежности, М.,
Судпромгиз, 1960.
61. Месяцев П. П., Применение теории вероятностей и математической
статистики при конструировании и производстве радиоаппаратуры,
М., Оборонгиз, 1958.
62. Мидлтон Д„ Введение в статистическую теорию связи, М., «Со-
ветское радио», т. I, 1961, т. II, 1962.
63. Митропольский А. К., Статистическое исследование, ВЗЛИ, Л.,
кн. 1-я, 1952; кн. 2-я, 1952; кн. 3-я, 1953; кн. 4-я, 1954.
64. Морз Ф. М. и Кимбелл Д. Е., Методы исследования операций,
«Советское радио», 1956.
65. Налимов В. В., Применение математической статистики при ана-
лизе вещества, М., Физматгиз, 1960.
66. Немчинов В. С., Полиномы Чебышева и математическая статисти-
ка, М., ТСХА, 1946.
67. Новиков А. С., Применение предупредительного статистического
контроля качества продукции, М.—Л., Госэнергоиздат, 1955.
68. Определение параметров случайных процессов, Сборник статей, Пере-
вод с английского под ред. В. И. Чайковского, Киев, Гостехиздат,
УССР, 1962.
69 Пелегрэн М., Статистический расчет следящих систем, М., ИЛ,
1957.
70. П у г а ч е в В. С., Теория случайных функций и ее применение к
задачам автоматического управления, М., Гостехиздат, 1957.
71. Розенберг В. Я. и Прохоров А. И., Что такое теория массо-
вого обслуживания, М., 1962.
72. Р о м а н о в с к и й В. И., Математическая статистика, М.—Л., ГОНТИ,
1938.
73. Р о м а н о в с к и й В. И., Элементарный курс математической стати-
стики, М., Госпланиздат, 1939.
74. Р о м а н о в с к и й В. И., Основные задачи теории ошибок, М.—Л.,
Гостехиздат, 1947.
75. Р о м а н о в с к и й В. И., Применение математической статистики в
опытном деле, М.—Л., Гостехиздат, 1947.
76. Романовский В. И., Дискретные цепи Маркова, М.—Л., Гос-
техиздат, 1954.
77. Р у м ш и с к и й Л. 3., Элементы теории вероятностей, М., Физмат-
гиз, 1960.
78. Самойлов В. Ф., Статистические свойства телевизионного сигнала
и требования к пропускной способности канала, М., Госсвязьиздат,
1955.
79. Сарымсаков Т. А., Основы теории процессов Маркова, М.—Л.,
Гостехиздат, 1954.
80. Свешников А. А., Прикладные методы теории случайных функций,
М.—Л., Судпромгиз, 1961.
81. Сифоров В. И., О методах расчета надежности систем, содержа-
щих большое количество элементов, изд. АН СССР, ОТН, №6, 1954.
504
ЛИТЕРАТУРА
82. С о к о л о в с к и й А. П-, Расчеты точности обработки на металлоре-
жущих станках, М.—Л., Машгиз, 1952.
83. Соколовский А. П., Научные основы технологии машинострое-
ния, М.—Л., Машгиз, 1955.
84. Солодовников В. В., Введение в статистическую динамику си-
стем автоматического управления, М.—Л., Гостехиздат, 1952.
85. С о л о д о в н и к о в В. В., Статистическая динамика линейных си-
стем автоматического управления, М., Физматгиз, 1960.
86. С о л о д о в н и к о в В. В. и Усков А. С., Статистический анализ
объектов регулирования, М., Машгиз, 1960.
87. Статистические методы анализа и контроля качества машинострои-
тельной продукции, М.—Л., Машгиз, 1949.
88 Теория передачи электрических сигналов при наличии помех, М.,ИЛ,
1953.
89. Теория следящих систем, М., ИЛ, 1953.
90. Уиттекер Э. и Робинсон Г., Математическая обработка резуль
татов наблюдений, М.—Л., ГТТИ, 1933.
91. Уорсинг А. и Геффнер Дж., Методы обработки эксперимен-
тальных данных, М., ИЛ, 1953.
92. Файнстейн А., Основы теории информации, М., ИЛ, 1960.
93. Феллер В., Введение в теорию вероятностей и ее приложения, М.,
ИЛ, 1952.
94. Фишер Р. А., Статистические методы для исследователей, М., Гос-
статиздат, 1958.
95 Фрай Торнтон, Теория вероятностей для инженеров, М-.—Л.,
ГТТИ, 1934.
96. Хальд А., Математическая статистика с техническими приложе-
ниями, М., ИЛ, 1956.
97. X а р ке в и ч А. А., Очерки общей теории связи, М., Гостехиздат, 1955.
98. X и н ч и н А. Я., Асимптотические законы теории вероятностей, М,—Л,,
ОНТИ, 1936.
99. Хинчин А. Я., Математические методы массового обслуживания,
Труды Матем. ин-та им. Стеклова 49 (1955).
100. Хинчин А. Я., Работы по математической теории массового обслу-
живания, М., Физматгиз, 1963.
101. Ц з я н С ю э • с э н ь, Техническая кибернетика, М., ИЛ, 1956.
102. Чеботарев А. С., Способ наименьших квадратов, М„ 1936.
103. Шеффе Г., Дисперсионный анализ, М., Физматгиз, 1963.
104. Шилов П. И., Способ наименьших квадратов, М., Госгеокартиздат,
1941.
105. Шор Я. Б., Статистические методы анализа и контроля качества и
надежности, М., Изд-во «Советское радио», 1962.
106. Щукин А. Н. Теория вероятностей и экспериментальное определе-
ние характеристик сложных объектов, М.—Л., Госэнергоиздат, 1959.
107. Юл Д. Э. и К эн дэл М. Д., Теория статистики, М., Госстатиздат,
1960.
108. Яглом А. М. и Я гл ом И. М., Вероятность и информация, М.,
Физматгиз, 1960.
109 Яковлев К. П., Математическая обработка результатов измерений,
М.—Л., Гостехиздат, 1950.
ПО Я стрем ск ий Б. С., Математическая статистика, М., Госстатиздат,
1956.
111. ЯхинА. Б., Проектирование технологических процессов механиче-
ской обработки, М„ Оборонгиз, 1946.
112. В а г 11 е 11 М. S., An Introduction to Stochastic Processes, Cambridge
University Press, 1&55.
ЛИТЕРАТУРА
505
113. Bazovsky I., Reliability theory and practice, Prentice Hall, 1962.
114. В 1 a n c-L a Pierre A., Fortet R., Theorie des fonctions aleatoires,
Paris, 1953.
115. Chorafos D. N., Statistical processes and reliability engineering, New
York, 1960.
116. Cramer H., The Elements of Probability Theory, J. Wiley, New York.
117. D a v i e s O. L. (ed.), Statistical methods in research and production
with special reference to the chemical industry, London, 1957,
118. Doerffel K., Beurteilung von Analysenverfahren und ergebnissen,
Berlin, 1962.
119. Duncan A. I., Quality control and industrial statistics, Homewood,
1959.
120. Enrick N. L., Qualitatskontrolle im Industriebetrieb, Miinchen, 1961.
121. Fisz Marek, Rachunek pravdopodobienstva i statystyka matematycz-
na, Warszawa, 1958.
122. Graf U. und Henning H. I., Statistische Methoden bei textilen Unter-
suchungen, Berlin—Gottingen—Heidelberg, 1960.
123. Grenander and Rosenblatt, Statistical Analisis Stationary Time
Series.
124. Gumbel E. J., Statistics of extremes, New York, 1958.
125. Gumbel E. J., Statistical Theory of Extreme Values and Some Prac-
tical Applications, National Bureau of Standarts, Washington, 1954.
126. H a I d A., Statistical Tables and Formulas.
127. Klemm L. H. I., Riehl, Statistische Kontrollmethoden in der Textilin-
dustrie, Leipzig, 1960.
128. Lange T. H., Korrelationselektronic, Berlin, 1959.
129. Lee W., Statistical theory of communication, New York—London, 1960.
130. Paradine C. G. and Rivett В. H., Statistics for Technologiecs, Van
Nostraud Company, New York.
131. Plackett R. L., Principles of regression analysis, Oxford, 1960.
132. Rao, Advanced Statistical Methods in Biometric Resarch, New York.
133. Riordan I., Stohastic service systems, New York, 1962.
134. Sehin do w ski E. und Schurz P., Statistische Qualitatskontrolle,
Berlin, 1959
135. Sy ski R., Introduction to congestion theory in telephone systems,
London, 1960.
136. Tienstra I. M., Die Begriindung des Beobachtungskalkiils und die Me-
thode der kleinsten Quadrate, Frankfurt a. M., Munchen, 1956.
137. Tippett, The Methods of Statistics, J., Wiley, N. J.
138. Tippett, Technological Applications of Statistics.
139. Wan der Warden, .Matematische Statistik, Berlin, 1957,
140. Weber E., Grundriss der biologischen Statistik, Jena, 1961.
141. Wold H., Ausgleichsrechung nach der Methode der Kleinsten Quadrate,
Hamburg, 1961.
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
Аксиомы теории вероятностей 30
Анализ двухфакторный 306
— дисперсионный 17, 295
— — многофакторный 306
— — однофакторный 295
Асимметрия 85
— биномиального распределения 100
— нормального распределения 142
— распределения Пуассона 108
Величина дискретная случайная 73
— непрерывная случайная 112
— ограниченная 114
— случайная 27
Величины независимые 165
Вероятность 12, 19, 27
— безусловная 43
— гипотез 50
— кумулятивная 66
— процесса переходная 438
— условная 43, 159
— элементарного события 114
Выборка 22, 200
— безвозвратная 36
— однократная 396
— представительная 201
— репрезентативная 22, 201
Вычисление вероятностей при нор-
мальном распределении 144
— выборочных характеристик связи
323
Гамма-функция 223
Гипотеза нулевая 253
— о положении центра группиро-
вания 248
— простая 268
— сложная 272
Гистограмма 14, 129
Гомоскедастичность 179
Граница односторонняя критическая
Границы двусторонние критические
Границы доверительные 233, 380
График плотности вероятности Г-рас-
пределения 265
Группа событий полная 32
Диаграмма доверительных интер-
валов 378
— точечная 378
— точностная 378
Дисперсия 86, 87, 120
— величины биномиально распре-
деленной 99
— — непрерывно распределенной
121
— — нормально распределенной 141
— — распределенной гипергеомет-
рически 103
— — — по закону Пуассона 107
— выборочная 205
— разности 171
— случайного процесса 424
— средней арифметической 174
— суммы 169, 171
— условная 160, 314
— функции 176
— эмпирическая 90 , 324
Единица двоичная 55
Задача о безвозвратной выборке 36
— — телеграфном коде 53 I
— проверки гипотез 248
— регрессии 333
— теории корреляции 317
— Эрланга 440
Закон больших чисел 182, 187 -
— двойной показательный 404
— первого типа 404
— распределения крайних членов
выборки 400
— — нормальный 133
— — показательный 115
— — прочности цепи 401
— — Пуассона 104
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
507
Закон распределения Стыодента 226
— — условный 315
Законы предельные основные 185
Звено 365
— замыкающее 365
— исходное 365
— конечное 365
— отрицательное 367
— положительное 367
— составляющее 365
— увеличивающее 367
— уменьшающее 367
Значение среднее 12, 79
— — выборки 203
Интервал доверительный 154, 233
— — в случае асимптотически нор-
мальных оценок 240
— — для коэффициентов Фурье 361
— — — центра распределения при
известном о 233
— — — — — — неизвестном о 236
--------о 238
— — при неизвестной вероятности
152
Испытание 21
— материалов деталей машин на
выносливость при переменных на-
пряжениях 414
— на надежность 433
Испытания независимые 53
Исход испытания 23
Итерация 449
Качество допускное 397
— среднее выходное 399
Квантиль 111, 118
Квартиль верхний 119
— нижний 119
Ковариация 169
— эмпирическая 324
Композиция испытаний 52
— распределений 187
Континуум 111
Контроль положения центра на-
стройки машины 387
— приемочный ступенчатый выбо-
рочный 440
— статистический последующий 387,
440
— — приемочный 387
— — — последующий 395
— — текущий предупредительный
387
Корреляция 313
— линейная 321
Коэффициент асимметрии цикла 414
— вариации 85, 91
— корреляции 171, 317, 432
— — выборки 324
— регрессии 321, 324
— — приближенный 324
Кривая Гаусса 14
—распределения дифференциальная
— — интегральная 134
— — нормальная И, 114
— регрессии 314
— ступенчатая 130
— /-распределения 228
Критерий грубых ошибок наблю-
дений 284
— знаков 254
— значимости 245
— непараметрический 258
— однородности распределений 275
— принадлежности двух выборок
одной генеральной совокупности
281
— проверки 249
— соответствия 268
---м2 277
— Стьюдента 225
- X2 268
- со2 278
Линия регрессии 163, 165, 315
— скедастическая 315
Ложный нуль 131
Математическое ожидание 80, 135
— — величины, биномиально рас-
пределенной 99
— — —, непрерывно распределен-
ной 121
— — —, нормально распределенной
141
— — —, распределенной по закону
Пуассона 107
— — постоянной 82
— — произведения 83, 168
— — случайного процесса 423
— — суммы 83, 167
— — условное 159
— — функции 119, 166, 175
— — — линейной 83
— — — многих переменных 167
Медиана 111
— выборочного распределения 204
Мера эффективности оценки 210
Метод максимума — минимума 366
— моментов 216
508
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
Метод наибольшего правдоподобия
212
— наименьших квадратов 317
— расчета размерных цепей теоре-
тико-вероятностный 365
Методы анализа стабильности тех-
нологического процесса статисти-
ческие 377
—- — точности технологического про-
цесса статистические 371
— контроля качества продукции ста-
тистические 395
— математико-статистические 15
Множество данного поля основное 23
Мода 85, 120
Модель работы водохранилища ста-
тистическая 447
Момент k-ro порядка 85
— — — начальный 85, 119
— связи 170
— — эмпирический 324
— - теоретический 87
— условный 160
— центральный 87
— — ft-го порядка 87, 119
— — — — нормированного уклоне-
ния 141
— эмпирический 88
Моменты биномиального распреде-
ления центральные 100
— нормального распределения на-
чальные 141
— — — центральные 142
— распределения Пуассона 107
Мощность критерия проверки ги-
потезы 251
Надежность системы 70
Независимость событий 48
— — в совокупности 49
— — попарная 49
Неравенство Чебышева 183
Несмешенность оценки 209
Нормирование распределения 136
Область больших отрицательных от-
клонений 250
— — по абсолютной величине от-
клонений 250
— — положительных отклонений 250
— допустимых значений 246
— критическая 245
— малых по абсолютной величине
отклонений 251
Однородность процесса 427
Ожидание математическое 80, 119
Определение вероятности классиче-
ское 34
— корреляционной функции слу-
чайного процесса 457
— несущей поверхности 454
— статистических оценок матема-
тического ожидания 457
— — — характеристик стационар-
ного случайного процесса 459
Ординарность потока 428
Отклонение корреляционное 322
— — эмпирическое 330
— критическое 245
— предельное 211
— случайной величины 87
— среднее абсолютное 85, 92
— — квадратическое 12, 85, 90
— — — нормального распределения
случайной величины 141
— — — при биномиальном распре-
делении 99
— — — — распределении Пуассо-
на 108
— — — случайного процесса 424
--------фиктивного наблюдения
218
-------- функции 176
--------эмпирическое 90
— стандартное 90
Оценка, асимптотически эффектив-
ная 211
— дисперсии несмещенная 206
— достоверности коэффициента свя-
зи 331
— корреляционных характеристик
по данным выборки 323
— коэффициента корреляции 172
— наибольшего правдоподобия 213
— несмещенная 206
— параметра о 219
-------- по размахам нескольких
выборок 239
— • параметров линейной зависимости
335
---нормального распределения
214
— • состоятельная 205
— центра распределения 216
— эффективная 210
— — с минимально возможной дис-
персией 210
Оценки параметров распределения
статистические 208
Ошибка второго рода 250, 450
— первого рода 250, 450
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
509
Параметры биномиального закона 95
— нормального распределения 133
— нормальной кривой 12
Переменные свободные 231
Плотность вероятности нормальная
133
— — х2 -распределения 224
— двумерная нормального распре-
деления 177
— распределения вероятности 111
— — — условная 315
Поверхность несущая 454
— нормального распределения 180
— распределения 161
Показатель асимметрии 93
Поле событий 22
Полигон 129
Понятие «вычет» 23
— «подразделение событий» 31
— «следует» 23
Порог чувствительности по циклам
415
Правило сложения вероятности 45
— умножения вероятностей 46
— — независимых в совокупности
событий 49
— — — событий 48
Предел выносливости 414
— допустимый 242
— толерантный 242
— усталости 414
- <?% 225
Приближенное определение диспер-
сии функции 175
— — математического ожидания
функции 175
— — параметров нормального рас-
пределения 137
Применение закона первого типа
распределения крайних членов для
определения экстремальных рас-
ходов воды в реках 405
Проверка гипотез о дисперсиях 263
__ — — законе распределения 267
— гипотезы нормальности по сово-
купности малых выборок 287
— — — распределения 272
_ — — — с помощью асимметрии
и эксцесса 277
— — о положении центра группи-
рования 252
— — — равенстве двух центров
распределения 260
— — — — дисперсий 263
— — об однородности ряда диспер-
сий 266
Проверка гипотезы об отсутствии
корреляционной связи 333
— — относительно вероятности 244
Произведение событий 25
Производящая функция 96
— — биномиального распределения
— — распределения Пуассона 107
Процесс Маркова 437
— — однородный 438
— Пуассона 421, 427
— с дискретным временем 439
— случайный 420
Процессы случайные стационарные
449
-------в смысле А. Я. Хинчина 450
— — — — узком смысле 450
— — — — широком смысле 450
Прочность цепи 402
Прямая приближенной регрессии 317
— регрессии, проведенная по ме-
тоду наименьших квадратов 320
Пучок линий полнодопустимый 441
Размах варьирования 125
—- выборки 215
Распределение асимптотическое 401 —
. 405
— вероятностей биномиальное 63, 65
— выборки 202
— выборочных характеристик асимп-
тотическое 210
— генеральной совокупности 202
— гипергеометрическое 102
— двумерное 157
— двумерной величины равномерное
161
— двумодальное 120
— дискретных величин 73
— дисперсии выборки 228
— длительности промежутков меж-
ду наступлениями события в про-
цессе Пуассона 433
— для крайних членов третьего
типа 403
— крайних членов выборки 400
— — — последовательности 403
— критерия Стьюдента 232
— мгновенное 372
— наибольшего члена выборки 401
— наименьшего члена выборки 401
— непрерывных величин 111
— — — эмпирическое 73
— нормальное 133
— — двумерное 176
510
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
Распределение нормальное условное
179
— нормированное 135
— одномодальное 92
— первого типа 404
— Пуассона 106
— равномерное 114
— статистическое 75
— стационарное 439
— теоретическое 75
— трехмодальное 120
— условное 159, 162
— Фишера 228
• — эмпирическое 75
— F 228, 263
— t Стыодента 225
— %2 221, 224
Рассеивание остаточное 298
— по факторам 298
— случайное 11
Расчет размерной цепи 368
---— поверочный 365, 368
— — — проектный 365, 368
— — — теоретико-вероятностным
методом 365
— расходов воды экстремальный 405
Реализация случайного процесса
возможная 422
Регрессия 160, 313
— нормальная 179
Репрезентативность выборки 22
Ряд вариационный 125
Свойства дисперсии 89
— математического ожидания 82
— производящей функции 97—98
— условных вероятностей 44
Связь вероятностная 313
— стохастическая 313
Сложение вероятностей 31, 45
Случайная величина дискретная 73
Событие 21
— возможное 22
— достоверное 21, 24
— невозможное 21, 24
— случайное 22
— элементарное 23
События взаимно-дополнительные 24
— независимые 48
— — в совокупности 49
— попарно 49
— несовместимые 24, 31
— противоположные 24
— равновозможные 22
— совместные 24
— эквивалентные 23
Совокупность генеральная 201
Состоятельность оценки 208
Способ 12 ординат для подсчета
коэффициентов Фурье 354
Средняя арифметическая 81
— — взвешенная 217
— — выборки 203
— взвешенная 80
— условная 315
Статистика математическая 17
— случайных процессов 457
Степень свободы 224
Сумма квадратов остаточная 308
— — отклонений внутри серий 298
— — — между сериями 298
— — — общая 298
— — — полная 298
---разностей между колонками 308
— — — — строками 308
Схема двухфакторного дисперсион-
ного анализа 309
— независимых испытаний с раз-
ными вероятностями 67, 108
— однофакторного дисперсионного
анализа 300
Сходимость по вероятности 186
Таблица корреляционная 164
— распределения 75
— случайных чисел 39
Теорема Бернулли 149
— единственности 98
— Лапласа 147
— непрерывности 98
— центральная предельная 192—198
Теория вероятностей 18
— корреляции 17, 313
— надежности 122
— —, применение закона Пуассона
108
— наиболее слабого звена 400
— передачи информации 53
Уклонение от моды нормированное
405
Умножение вероятностей 44, 45
Уравнение размерной цепи основное
368
Уровень доверительный вероятности
154
— значимости 245
Формула Бейеса 51
— вероятности гипотез 51
— полной вероятности 50
Формулы Эрланга 446
1Й УКАЗАТЕЛЬ
511
Функция ковариацион
— корреляционная 42с
— Лапласа 143
— — нормированная
— нормального pacnpi
тегральная 133
— нормированная кор
426, 433
— правдоподобия 212
— производящая 95
— — композиции 192
— — нормального р
140
— — суммы 192
—- процесса автокоррел
— распределения выбс
— — генеральной сово
— — двумерной вели
тральная 161
— — дифференциальна
— — интегральная 111
— — кумулятивная т(
75
— — — эмпирическая
— — эмпирическая 20
— случайная 420
— — стационарная в с
Хинчина 450
— — — — узком СМ1
— — — — широком с
Характеристика асимм!
— оперативная 397
— эксцесса 85
Характеристики биномг
пределения 95
— выборочные 203
— рассеивания 79
— связи выборочные 3
— эмпирические 203
Центр гипергеометрического распре-
деления 103
— группирования распределения
— рассеивания 79
Цепь линейная 367
— марковская 439
— плоскостная 367
— погрешностей измерения 366
— пространственная 367
— процесса Маркова 439
— размерная 365
— подетальная 366
— сборочная 366
— технологическая 366
Частость 12, 27
— безусловная 40
— кумулятивная 130
— условная 41
Частота кумулятивная 130
— относительная 27
Число браковочное 397
— инверсий 282
— приемочное 396, 398
— случайное 38
Члены крайние 400
Широта распределения 125
Эксцесс 85, 93
— биномиального распределения
100
— нормального распределения 93,
142
— распределения Пуассона 108
Энтропия 55
Эффективность оценки 208
Николай Васильевич Смирнов
и Игорь Валерианович Лунин-Барковский
Курс теории вероятностей
и математической
статистики для технических
приложений
М., 1969 г., 512 стр. с илл.
Редактор А. Ф. Лапко.
Техн, редактор С. Я. Шкляр.
Корректор Г. С. Смоликова
Печать с матриц. Подписано к печа-
ти 25/Ш 1969 г. Бумага 60X90V16. Физ.
печ. л. 32. Условн. печ. л. 32. Уч.-изд.
л. 33,26. Тираж 40 000 экз. Цена книги
1 р. 26 к.' Заказ № 366.
Издательство «Наука».
Главная редакция
физико-математической литературы.
Москва, В-71, Ленинский проспект, 15.
Главполиграфпром Комитета по печати
при Совете Министров СССР. Отпечатано
в Ордена Трудового Красного Знамени
Ленинградской типографии № 1 «Печат-
ный Двор» им. А. М. Горького, г. Ленин-
град, Гатчинская ул., 26 с матриц Ордена
Трудового Красного Знамени Первой Об-
разцовой типографии имени А. А. Жда-
нова, Москва, Ж-54, Валовая, 28.