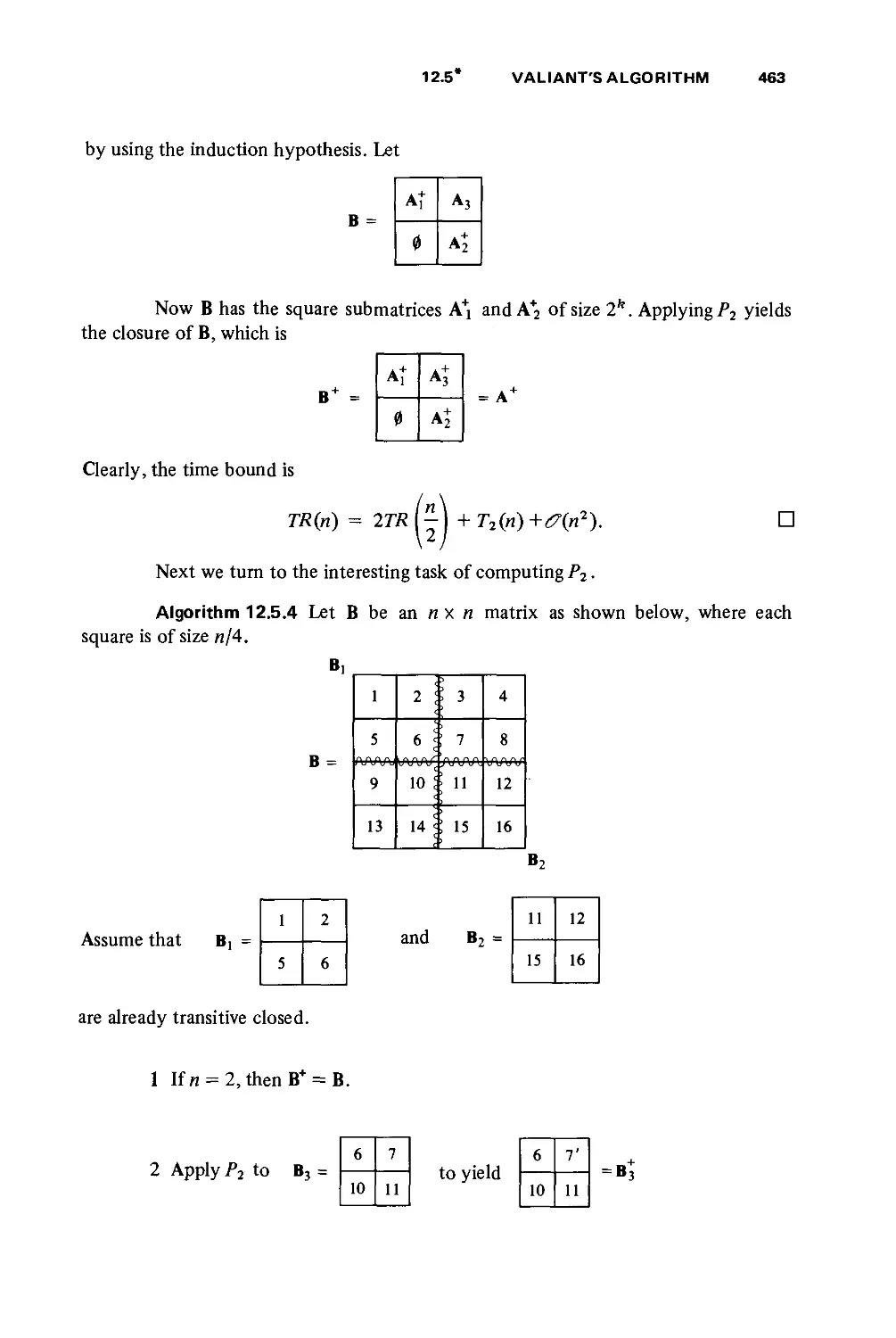
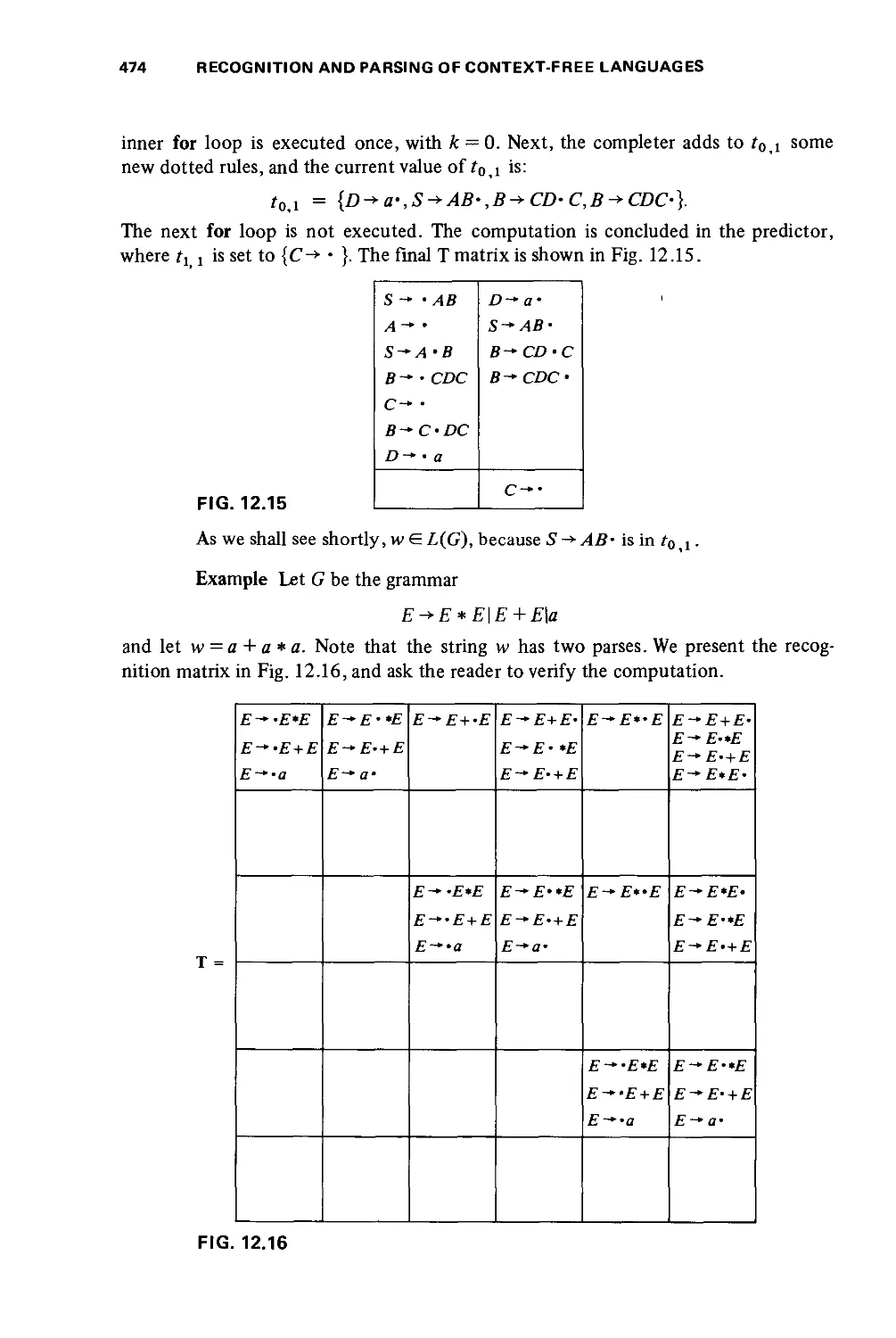
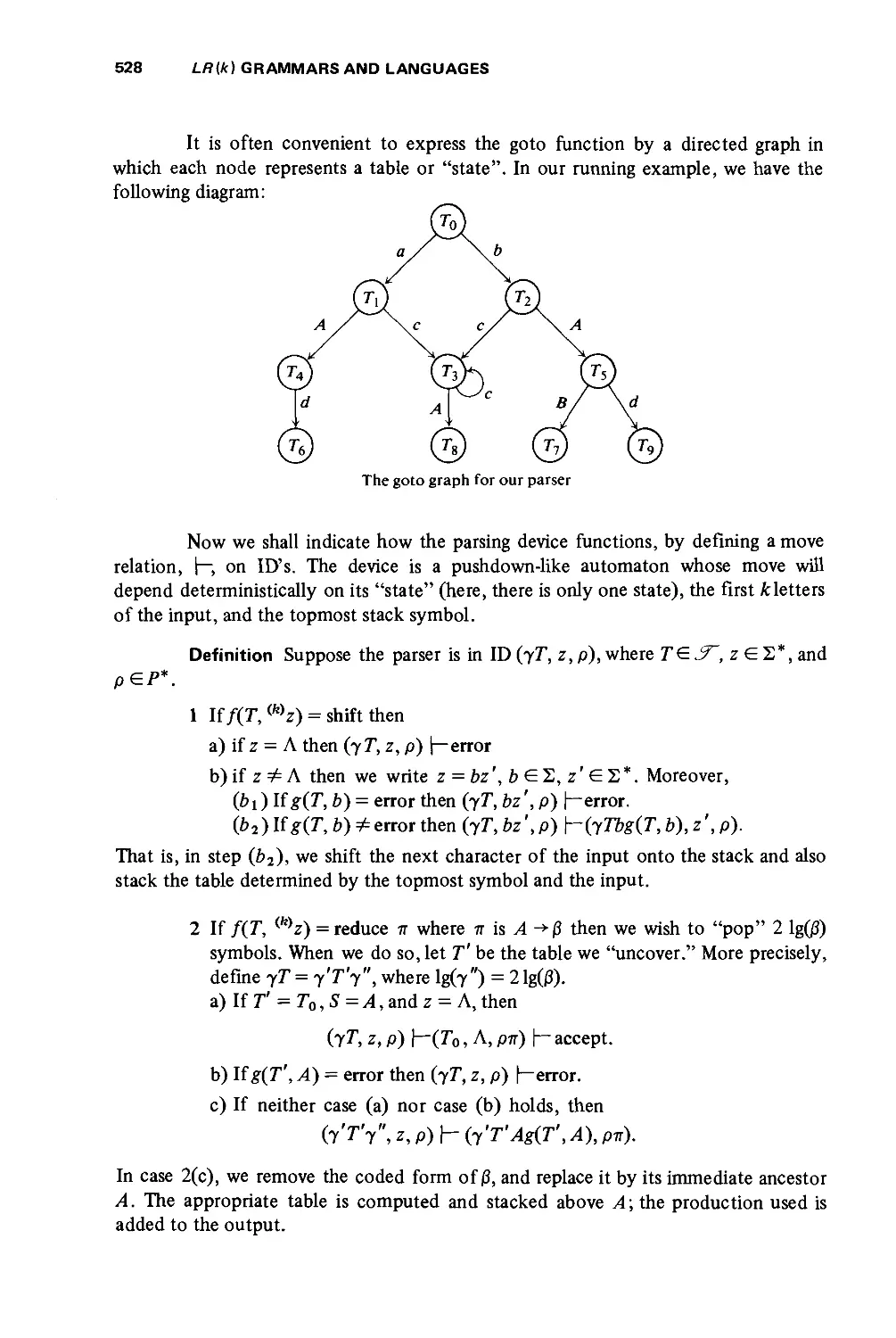
/


























































































































































































































































































































































































































































































































































































































Текст
MICHAEL A. HARRISON
|W|h|o|t| [a|r|e| | 1j h|o]s|e1 |a|n| i)m|o| I |s |
finite
state
control
MICHAEL A. HARRISON
University of California
Berkeley, California
Introduction
to Formal
_ Language
Theory
A
TT
ADDISON-WESLEY PUBLISHING COMPANY
Reading, Massachusetts
Menlo Park, California
London
Amsterdam
Don Mills, Ontario
Sydney
This book is in the
ADDISON-WESLEY SERIES IN COMPUTER SCIENCE
Consulting editor:
Michael A. Harrison
Copyright © 1978 by Addison-Wesley Publishing Company, Inc. Philippines copyright 1978 by
Addison-Wesley Publishing Company, Inc.
All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or
transmitted, in any form or by any means, electronic, mechanical, photocopying, recording, or
otherwise, without the prior written permission of the publisher. Printed in the United States of
America. Published simultaneously in Canada. Library of Congress Catalog Card No. 77-81196.
ISBN 0-201-02955-3
ABCDEFGHIJK-MA-798
To Susan and Craig
M
ace
Formal language theory was first developed in the mid 1950's in an attempt to develop
theories of natural language acquisition. It was soon realized that this theory
(particularly the context-free portion) was quite relevant to the artificial languages that had
originated in computer science. Since those days, the theory of formal languages has
been developed extensively, and has several discernible trends, which include
applications to the syntactic analysis of programming languages, program schemes, models
of biological systems, and relationships with natural languages. In addition, basic
research into the abstract properties of families of languages has continued.
The primary goal of this book is to give an account of the basic theory. My
personal interests are in those applications of the subject to syntactic analysis, and some
material on that subject is included. The temptation to write about lindenmayer
systems, program schemes, AFL's, and natural-language processing has been resisted.
There are now specialized books available on those topics.
This book is written for advanced undergraduates or graduate students. It is
assumed that the student has previously studied finite automata, Turing machines, and
computer programming. Experience has shown that the material in this book is easily
accessible to mathematics students who do not know any computer science. Although
no single academic course is prerequisite to the study of the material in this book, it
has been my experience that students who have had no background in constructing
proofs do have difficulty with the material. Any junior or senior who is majoring in
computer science should be able to read the book.
One of the problems facing any person teaching formal language theory is
how to present the results. The proofs in language theory are often constructive and the
PREFACE
verifications that the constructions work can be long. One approach is to give the
intuitive idea and omit a formal proof. This leads to an entertaining course, but some
students are unable to carry out such proofs and soon learn to claim all sorts of false
results. On the other hand, if one attempts to prove everything thoroughly, the course
goes slowly and becomes one interminable induction proof after another. The few
students who survive such a course are capable of doing research and writing proofs.
The presentation in this book is designed to help the instructor to strike a compromise
between the two extremes. When I teach the course, I try to give the intuitive versions
of the constructions and proofs in class and to depend on the text for the details. There
are a lot of exercises, particularly of the "prove something" variety, in the text and I
assign a good many of these when I teach the material. The student who wants to be
a specialist can become well versed in all the techniques; yet it is still possible to
accommodate students who have a more casual interest in the subject.
A few sections are marked with an asterisk to indicate that they may be
skimmed on a first reading. Just because a section is "starred" does not mean it is
difficult. It means that it can be omitted if an instructor becomes pressed for time.
There is enough material in the book for a two-course sequence. In a one-
quarter introductory course, the following sections should be covered:
Chapter 1, Sections 1.1,12,1.4,1.5,1.6.
Chapter 2, Section 2.5 if the students are well prepared. If not, everything.
Chapter 3, Sections 3.1—3.4.
Chapter 4, Sections 4.1—4.4,4.6.
Chapter 5, Sections 5.1—5.4.
Chapter 6, Sections 6.1,6.2,6.4,6.5,6.7.
Chapter 7, Sections 7.1,7.2.
Chapter 8, Sections 8.1-8.4.
Chapter 9.
Chapter 12, Sections 12.1,12.2,12.4,12.6,12.7.
If an instructor has additional time, a good strategy would be to choose
additional material from the non-starred sections.
Sometimes a proof will depend on an earlier exercise. However, all the proofs
needed to develop basic results are given in the book; consequently, the instructor can
feel confident that he or she will not run into an unpleasant surprise while preparing a
lecture. Not all of the exercises are straightforward and particularly difficult ones are
starred.
An attempt has been made to credit results to their authors in the historical
summaries at the end of each chapter. There are some cases in which priority is in
doubt, and then the first published paper or thesis is referenced. The literature on
formal language theory is extensive and I have limited the bibliography to papers
whose results have been used or which I have read and found interesting and/or useful.
No attempt has been made to include papers on program schemes or biologically
motivated automata theory. Some papers on AFL theory and Turing complexity have been
included. I apologize in advance to those who may feel that their work was
inadequately referenced, and hope they understand the limitations of both space and time.
PREFACE
I have had a great deal of help in the preparation of this book. Most of this
assistance came from students who took notes, read drafts, corrected error or
constructed improved proofs. I want to thank them all but especially Douglas J. Albert,
John C. Beatty, John Foderaro, Matthew M. Geller, Ivan M. Havel, Robert Henry,
Richard B. Hull, William N. Joy, Kimberly N. King, Arnaldo Moura, John D. Revelle,
Walter L. Ruzzo, Donald Sannella, Barbara Simons, Neil Wagoner, Timothy C. Winkler,
Paul Winsburg, and Amiram Yehudai.
The continuous support of the National Science Foundation is gratefully
acknowledged.
I want to express my deep appreciation to the many people at Addison Wesley
who assisted in the preparation of the book. Special thanks must go to Mary A. Cafarella
who edited the manuscript and to William B. Gruener who is the finest Computer
Science editor that I have ever known.
The special assistance of Ralph L. Coffman, Anthony M. Harrison, John E.
Hopcroft, and Joan M. Sautter made the whole project even more worthwhile.
Susan L. Graham taught from a draft of the manuscript and her suggestions
were very helpful. Ruth Suzuki typed the manuscript and course notes. Somehow she
converted a nearly illegible handwritten manuscript into beautifully typed notes so
that student feedback was possible, all in realtime. Her contribution is greatly
appreciated. Both Dorian Bikle and Caryn Dombroski helped with other aspects of the
production. Caryn also drew the cover design which is based on a pun by Susan L.
Graham.
Berkeley
May 1978
Michael A. Harrison
Contents
FOUNDATIONS OF LANGUAGE THEORY - STRINGS AND
HOW TO GENERATE THEM 1
1.1 Introduction 1
1.2 Basic definitions and notation 2
1.3 2* revisited — A combinatorial view 5
1.4 Phrase-structure grammars 13
1.5 Other families of grammars — The Chomsky hierarchy 17
1.6 Context-free grammars and trees 23
1.7* Ramsey's theorem 31
1.8* Nonrepetitive words 36
1.9 The Lagrange inversion formula and its application 40
1.10 Historical survey 44
2 FINITE AUTOMATA AND LINEAR GRAMMARS 45
2.1 Introduction 45
2.2 Elementary finite automata theory — Ultimately periodic sets 45
2.3 Transition systems 52
2.4 Kleene's theorem 57
2.5 Right linear grammars and languages 60
2.6 Two-way finite automata 65
2.7 Historical survey 71
XII
CONTENTS
3 SOME BASIC PROPERTIES OF CONTEXT-FREE LANGUAGES 73
3.1 Introduction 73
3.2 Reduced grammars 73
3.3 A technical lemma and some applications to closure properties 79
3.4 The substitution theorem 82
3.5 Regular sets and self-embedding grammars 85
3.6 Historical survey 91
4 NORMAL FORMS FOR CONTEXT-FREE GRAMMARS 93
4.1 Introduction 93
4.2 Norms, complexity issues, and reduction revisited 93
4.3 Elimination of null and chain rules 98
4.4 Chomsky normal form and its variants 103
4.5 Invertible grammars 107
4.6 Greibach normal form 111
4.7 2-standard form 116
4.8 Operator grammars 121
4.9 Formal power series and Greibach normal form 125
4.10 Historical survey 133
5 PUSHDOWN AUTOMATA 135
5.1 Introduction 135
5.2 Basic definitions 135
5.3 Equivalent forms of acceptance 143
5.4 Characterization theorems 148
5.5 A-moves in pda's and the size ofapda 159
5.6 Deterministic languages closed under complementation 163
5.7 Finite-turn pda's 179
5.8 Historical survey 184
6 THE ITERATION THEOREM, NONCLOSURE AND CLOSURE
RESULTS 185
6.1 Introduction 185
6.2 The iteration theorem 185
6.3 Context-free languages over a one-letter alphabet 194
6.4 Regular sets and sequential transducers 197
6.5 Applications of the sequential-transducer theorem 206
6.6* Partial orders on 2* 214
6.7 Programming languages are not context-free 219
i*
6.8 The proper containment of the linear context-free languages in <? 221
6.9 Semilinear sets and Parikh's theorem 225
6.10 Historical survey 231
7 AMBIGUITY AND INHERENT AMBIGUITY 233
7.1 Introduction 233
7.2 Inherently ambiguous languages exist 233
CONTENTS
XIII
7.3 The degree of ambiguity 240
7.4* The preservation of unambiguity and inherent ambiguity by
operations 243
7.5 Historical survey 246
DECISION PROBLEMS FOR CONTEXT-FREE GRAMMARS 247
8.1 Introduction 247
8.2 Solvable decision problems for context-free grammars and languages 248
8.3 Turing machines, the Post Correspondence Problem, and context-
free languages 249
8.4 Basic unsolvable problems for context-free grammars and languages 258
8.5* A powerful metatheroem 262
8.6 Historical survey 270
CONTEXT-SENSITIVE AND PHRASE-STRUCTURE LANGUAGES 271
9.1 Introduction 271
9.2 Various types of phrase-structure grammars 271
9.3 Elementary decidable and closure properties of context-sensitive
languages 275
9.4 Time- and tape-bounded Turing machines - & and ^J? 280
9.5 Machine characterizations of the context-sensitive and phrase-
structure languages 290
9.6 Historical survey 296
REPRESENTATION THEOREMS FOR LANGUAGES 299
10.1 Introduction 299
10.2* Baker's theorem 300
10.3 Deterministic languages generate recursively enumerable sets 307
10.4 The semi-Dyck set and context-free languages 312
10.5 Context-free languages and inverse homomorphisms 326
10.6 Historical survey 331
BASIC THEORY OF DETERMINISTIC LANGUAGES 333
11.1 Introduction 333
11.2 Closure of deterministic languages under right quotient by regular
sets 334
11.3 Closure and nonclosure properties of deterministic languages 341
11.4 Strict deterministic grammars 346
11.5 Deterministic pushdown automata and their relation to strict
deterministic languages 355
11.6* A hierarchy of strict deterministic languages 366
11.7 Deterministic languages and realtime computation 375
11.8* Structure of trees in strict deterministic grammars 381
11.9 Introduction to simple machines, grammars, and languages 392
11.10 The equivalence problem for simple languages 398
11.11 Historical survey 416
CONTENTS
RECOGNITION AND PARSING OF GENERAL CONTEXT-FREE
LANGUAGES 417
12.1 Introduction 417
12.2 Mathematical models of computers and a hardest context-
free language 417
12.3 Matrix multiplication, boolean matrix multiplication, and
transitive closure algorithms 426
12.4 The Cocke—Kasami—Younger algorithm 430
12.5* Valiant's algorithm 442
12.6 A good practical algorithm 470
12.7 General bounds on time and space for language recognition 489
12.8 Historical survey 500
LR(k) GRAMMARS AND LANGUAGES 501
13.1 Introduction 501
13.2 Basic definitions and properties of LR(k) grammars 501
13.3 Characterization of LR{0) languages 515
13.4 LR-sty\e parsers 525
13.5 Constructing sets of LR(k) items 530
13.6 Consistency-and parser construction 544
13.7 The relationship between LR -languages and A0 554
13.8 Historical survey 558
REFERENCES 559
INDEX
584
one
Foundations
of Language Theory-
Strings and
How to Generate Them
1.1 INTRODUCTION
Formal language theory concerns itself with sets of strings called "languages"
and different mechanisms for generating and recognizing them. Certain finitary
processes for generating these sets are called "grammars." A mathematical theory of such
objects was proposed in the latter 1950's and has been extensively developed since
that time for application both to natural languages and to computer languages. The
aim of this book is to give a fairly complete account of the basic theory and to go
beyond it somewhat into its applications to computer science.
In the present chapter, we begin in Section 1.2 by giving the basic string-
theoretic notation and concepts that will be used throughout. Section 1.3 gives a
number of useful results for dealing with strings. Many of those results will not be
needed until later and so the section has an asterisk after its number. Sections which
are starred in this manner may be read lightly. When references to a theorem from that
section occur later, the reader is advised to return to the starred section and read it
more thoroughly.
Section 1.4 introduces the family of phrase-structure grammars, which are
fundamental objects of our study. A number of examples from natural language and
programming languages help to motivate the study. Section 1.5 introduces many
other families of grammars and indicates intuitively how their languages may also
be characterized by different types of automata.
Section 1.6 is devoted to trees and their relation to context-free grammars.
The intuition developed in that section will be important in subsequent chapters.
1
2 FOUNDATIONS OF LANGUAGE THEORY
Section 1.7 is devoted to Ramsey's Theorem, which is a deep and very
general combinatorial theorem. It is used to show relationships that must hold in any
sufficiently long word. Section 1.8 is devoted to showing how to construct words
with no repeated subwords.
Section 1.9 proves a classical theorem of analysis due to Lagrange. In later
sections, this can be applied to power series generated by context-free grammars
and can be used to solve for the "degree of ambiguity."
1.2 BASIC DEFINITIONS AND NOTATION
A formalism is required to deal with strings and sets of strings. Let us fix
a finite nonempty set 2 called an alphabet. The elements of 2 are assumed to be
indivisible symbols.
Examples 2 = {0,1} or 2 = {a, b).
In certain applications to compiling, we might have an alphabet which
contains begin, end. These are assumed to be indivisible symbols in the applications.
A set X= {1,10,100} is not an alphabet since the elements of A" are made up of
other basic symbols.
Definition A wore? (or string)ovei an alphabet 2 is a finite-length 2-sequence.
A typical word can be written as x = a^ ■ ■ ■ ak, k > 0, a; £ 2 for 1 < i < k.
We allow k = 0, which gives the null (or empty) word, which is denoted by A. k is
called the length of x, written \g(x), and is the number of occurrences of letters of
2 in*.
Let 2 denote the set of all finite-length 2-sequences.
Let x and y be in 2 . Define a binary operation of concatenation, where
we form the new word xy.
Example Let 2 = {0,1} and
x = 010 7=1
Then
xy = 0101 and yx = 1010
The following proposition summarizes the basic properties of concatenation.
Proposition 1.2.1 Let 2 be an alphabet.
a) Concatenation is associative; i.e., for each x, y, z in 2*,
x(yz) = (xy)z
b) A is a two-sided identity for 2*; i.e., for each x e 2*,
xA = Ax = x
1.2
BASIC DEFINITIONS AND NOTATION
3
c) 2* is a monoid^ under concatenation and A is the identity element.
d) 2* has left and right cancellation. For each*,7,z G 2*,
i) zx — zy implies x = y, and
ii) xz =yz impliesx =y.
e) For znyx,y G 2*,
IgfoO = l«(*) + lgG0.
It is necessary to extend our operations on strings to sets. Let X, Y be sets
of words. Hereafter, one writes X, Y£_ 2*. Then the product of two sets is:
XY = {xy\xeX,y<EY}.
Exponent notation can be used in an advantageous fashion for sets. Let
X£ 2*. Define
X° = {A} and Xi+1 = XlX for all i>0.
Define monoid (or Kleene) closure of a set X £ 2* by
X* = U X\
and semigroup closure by l>0
X* = X*X = U X\
i> 1
Examples Let 2 = {0,1}. In general,
2'' ={x£2*l lg(x) = /}.
Thus*
2 = (2)*.
Note that
2+ = 2* - {A}.
Also, if
X = {A,01} and Y = {010,0},
then
XY = {0,010,01010}.
Proposition 1.2.2 For each X £ 2 ,
a) for each / > 0, X{ £ X*;
b) for each i> \,Xl£ X*;
c) AGI*;
d) AGr if and only if AGI.
t A semigroup consists of a set S with a binary associative operation • defined on S. A
monoid is a semigroup which possesses a two-sided identity. The set of functions on a
set is a monoid under the operation of functional composition.
•f The set of all 2-words can be obtained by applying the star operation to 2.
4 FOUNDATIONS OF LANGUAGE THEORY
The product, exponent, and star notation has a counterpart in the monoid
of binary relations on a set which we will mention.
Definition Let p<~ X x Y and a £ Y x Z be binary relations. The
composition of p and a is:
pa = {(x,z)\ (x,y)£p and (y,z)£o for some.)' e Y}£ Xx Z.
If we specialize to binary relations on a set - that is, p£ X x X - we can
define
p° = {(x, x)lx£I} (the equality or diagonal relation).
For each / > 0,
P''+1 = P!P.
The reflexive-transitive closure of p is:
p* = U p',
while the transitive closure of p is:
p+ = p*p = U p\
i> 1
It is easy to verify the following property of p*, which is usually taken as
the definition of reflexive—transitive closure.
Fact Let p be a binary relation on X and let x, x be in X. Then (x, x) £ p*
if and only if there exists r > 0;z0,. . . , zr in X such that:
0 x = z0;
ii) zr = *';
iii) (z,-,z1+1)Gp for each 0 </'<r.
A similar statement holds for transitive closures. Just replace "*" by "+" and
"r > 0" by "r > 1."
Another useful operation on strings is transposing or reversing them. That is,
if x = 011, then define xT = 110. A more formal definition, useful in proofs, is now
given.
Definition The transpose operator is defined on strings in 2* as follows:
AT = A
For any x in 2*, a in 2,
(xa)T = a(xT)
The notation is extended to sets in 2* "pointwise":
XT = {xT\xGX}.
1.3* Z* REVISITED- A COMBINATORIAL VIEW 5
Examples Let 2 = {a,b)andL = ab* = {ab'\ i>0}.Then
LT = b*a = {bia\ i>0}.
Also, the following sequence of containments is a good test of familiarity with the
notation".
{aWl i > 0} c a*b* = WI /, / > 0}c {a> 6}*;
/> = {wwTl wG{a, 6}*}.
F is the set of even-length "palindromes." A palindrome is a string that is the same
whether written forwards or backward. We conclude this section by giving some
natural-language examples.'
RADAR
ABLE WAS I ERE I SAW ELBA
MADAM IM ADAM
A MAN A PLAN A CANAL PANAMA
1.3* Z* REVISITED - A COMBINATORIAL VIEW
In this section, we shall take a brief, more algebraic look at the monoid 2*.
We begin by recalling some concepts from semigroup theory.
If we have some semigroup S, let T be a subset of S (not necessarily a sub-
semigroup). T is contained in at least one subsemigroup, namely S. Let T* be the least
subsemigroup containing T (i.e., the intersection of all subsemigroups of S containing
T). We say that T* is the semigroup generated by T. If T* = S, we say that T is a set
of generators for S. Similar remarks hold for monoids, except that we would write
T* instead of T+. There is another important type of generation.
Definition Let T be a set of generators of a semigroup (monoid) S. S is free
over T if each element of S has a unique representation as a product of elements
from T.
Fact 2 is free over 2.
Thus if we have x, y G 2*, where x = a^ ■ ■ ■ am, at £ 2, m > 0, and y =
bx ■ ■ ■ bn, bt G 2, n > 0, then we may have x =y if and only if m = n and a,- = b;
for all /, 1 </' < m ~n.
There is an important but simple theorem that lies at the root of the study
of equations in 2*.
Theorem 1.3.1 (Levi) Let v, w, x, and y be words in 2*. If vw =xy, then:
i) if lg(i>) >\g(x), then there exists a unique word z G2* such that v =
xz andy = zw;
ii) if lg(z») = lg(x), then v = x andw = y;
The spaces between words are included only for clarity in the last two examples.
6 FOUNDATIONS OF LANGUAGE THEORY
iii) if lg(p)<lg(x), then there exists a unique word z e 2* such that* =
vz and w = zy.
Proof The most intuitive way to deal with general problems of this type is
to draw a picture of the strings, as follows:
CASE i)
V
X | Z
w
y
From the picture, it is clear that the desired relationships hold.
The proof follows by considering whether the line between x and y in the
second row of the picture goes to the left or right of the line between v and w.
A formal proof of the result would proceed by an induction on lg(wv), and
is omitted. □
Definition Let w and y be in 2*. Write w<j, w is a prefix of y, if there
exists/ in 2* so that
y = wy'
Also, w is a suffix ofy ify =y'w for some /e2*.
This allows us to state a corollary to Theorem 1.3.1.
Corollary Let v, w, x, andj be in 2*. If vw = xy, then
x < v or v < x
As an example of the usefulness of these little results, we prove the following
easy proposition.
Proposition 1.3.1 Let w, x, y andz be in 2*. If w <y and* <yz then either
w<xoix<w.
Proof w <y and* <yz imply that there exist./ andx' so that
y = wy' (1-3-1)
yz = xx (1-3.2)
Thus (1.3.1) and (1.3.2) imply that
yz = wy'z = xx'
but w(y'z) = xx' implies that
x<w or w<x. O
A more interesting and useful result is the following.
1.3* Z* REVISITED -A COMBINATORIAL VIEW 7
Theorem 1.3.2 Let y G 2 and x, z G 2+ such that xy=yz. Then there
exist u, z>G2* andp >0 such that* = wz>, z = z>w, andy = (uv)"u = u(yu)p.
Proof We induct on the length of y.
Basis. If lg(y) = 0, we have u = A=y,v = x =z, and p = 0.
Induction step. There are two cases depending on the comparative lengths of
x and 7.
CASE1. ]g(x)>]g(y).
By Theorem 1.3.1 applied to xy = yz, we know that there is vG 2* so that
x = yv and z = vy
We may choose p = 0 and u =y and the result is proven. Note that if lg(x) = lg(y),
then v = A, but the proof is still valid.
CASE2.Ig(x)<lg(7).
Again by Theorem 1.3.1, there exists w G 2* so that
y = xw and y = wz
and lg (w) < lg (y). Since we have
xw = wz
with lg(vv) <lg(y), we can assert, by the induction hypothesis, that there exist u,
v G 2* and p > 0 so that x = uv, z = z»m, and w = {uv)pu. From the above, we have
y = xw = uvw = uv{uvfu = (MZ»y+,M.
The induction has been extended. □
Now we approach a very useful theorem which has many applications. The
sufficient condition is particularly valuable.
Theorem 1.3.3 Let u, z»G2*. u — wm and v=w" for some w G 2 , w,
n > 0, if and only if there exist p, q > 0 so that up and p" contain a common prefix
(suffix) of length lg(«) + lg(i>) — (lg(w), lg(^)), where (/', /) denotes the greatest
common divisor of / and /.
Proof Let lg(«) = x and \g(v) = t. Let
u = a0 ■■ as-! )
with ah bj G2,
v = b0 ■••bt-i J
and suppose that s <t.
Let us first suppose that the second condition is satisfied, that is, we deal
with sufficiency first. Suppose that (x, t) = 1.
8 FOUNDATIONS OF LANGUAGE THEORY
= 1.
we get:
Claim a, = b0 for each 0 < / < x. That is, all the a-, are equal and thus lg (w)
Proof We simply begin to pair off the first x + t — 1 letters of up and vq, and
i
0
1
s + t-
-2
up v"
do = b0
a, = bi
ah - bk
It is clear that
a,- = b( for each i, 0 < i < x.
Moreover, the following is true.
Fact For each /', 0 < / < x — 1,
a(iV()mods = b;.
This fact is easily seen to be true for i = 0. From that, the case of i >0 follows easily
from the form of up and vq. Now let us consider the set of letters
A = KtmodJ 0<k<s}.
Since (x, t) = 1, we have {ktmodxl 0<fc<x} = {0,1, ...,x — 1}. By this fact, every
letter in u is in A and equals b0. Thus all the letters in u are identical.
Therefore u =b% and v = b% since every letter in v is equal to some letter
inw.
To extend the result to the case where d = (x, t) > 1, simply take words of
length d and work over Sd, using the previous case.
Necessity. Let u = wm and v = wn for some wes";m,n>0. Let^
m + n — (m, n)
P =
and
Then we have
m
m + n—(m,ri)
The notation \x] denotes the "ceiling" of x, the smallest integer >x.
1.3* Z* REVISITED- A COMBINATORIAL VIEW 9
but mp>m + n—{m,n) and nq>m +n —(m,n) so that up and vq have a common
prefix of length
> lg(w)(iH +n-(m, n)) = lg(M) + lg(z>) -(lg(M), lg(i>)). □
Corollary If uv = vu, where u, !)£S", then there iswGZ* so that u = wm
and z> = w" for some w, « > 0.
Now, an application of the previous theorem will be presented.
Theorem 1.3.4 Let X={x,y}£ S+ with x ¥=y. X* is free if and only if
xy ¥=yx.
Proof If X* is free, then xy ¥=yx.
Conversely, suppose xy ¥=yx with A¥=x ¥=y¥= A. Assume, for the sake of
contradiction, that there is a nontrivial relation involving.* andy, say,
Xniyni ■ ■ ■ x"k-ly"k =ymlxm* ■ ■ ■ ymS-ixms (1.3.3)
with «;, m, > 0 for all i. [Note that (1.3.3) can be assumed to begin (end) with
different words by left (right) cancellation.] We may assume that lg(y) < lg(x). This and
(1.3.3) imply that y is a prefix of x. Thus,
x = y9t0 (1.3.4)
for some t0 G2*, where q > 1 is the largest power of y that is a prefix of x.
Substituting (1.3.4) in (1.3.3) yields:
yqt0y-y"h = ymiyqt0 ■ ■■x"1*.
By left cancellation,
t0y-y"k = ymit0 ■■■x"1*. (1.3.5) •
Note that y cannot be a prefix of t0 because, if it were, the definition of q would be
contradicted. By (1.3.5), we know that t0 is a prefix of y. Hence,
y = t0ti
for some t\ €2*. From (1.3.3) we must have that y is a suffix of x. [Recall that
lg(v) ^lg(*)] ■ Since y = t0ti is a suffix of x and lg(y) = lg(?o'i)> we must nave.
from Eq. (1.3.4), that:
y = tth = t0ti (1.3.6)
10 FOUNDATIONS OF LANGUAGE THEORY
From the Corollary to Theorem 1.3.3 and Eq. (1.3.6), we know that there exists
z G 2* so that
t0 = zp<>, tx = zp>, y = zp*
for some p0, plt p2 > 0, p0 + Pi = Pi > 0. But now we know from (1.3.4) that
* = y"t0 = (?oM%
= zP29+Po_
Since both* andy are powers of z, we know that:
Xy = yx = z<-q*')p^po
which is a contradiction. D
In certain applications, it is useful to order strings.
Definition Let S be any set. A binary relation, to be written <, is a partial
order on S if it is reflexive, antisymmetric, and transitive, that is, if for each a, b, c
in S,
1) a<a;
2) ifa<b and b<a, then a = b\
3) if a < b and b < c, then a<c.
Moreover, < is said to be a total order if it is a partial order which satisfies the
following additional property: For each a, b £S, either
a<& or b<a.
where the relation a < b is an abbreviation for a < b and aj=b.
For example, the "prefix relation" is a partial ordering of 2*. The ordinary
relation < on natural numbers is an example of a total order. Now we introduce a
mathematical counterpart to a dictionary ordering.
Definition Let 2 be any alphabet and suppose that 2 is totally ordered by
-<. Let x=X\ ■ ■ ■ xr, y = yx ■ • -ys, where r, s > 0, xu ys € 2. We say that x< y if
i) Xj = yt for 1 < / < r and r < x; or
ii) there exists & > 1 so that xt = yt for 1 < i < k and xk < yk. < is referred
to as lexicographic order.
This definition is not hard to understand:
i) says that if x is a proper prefix of y (that is, j £ {jc}2+), then x-<y;
ii) says that if there exist u, v, v G 2*; a, b, € 2 so that x = uav, y = ubv'
and a<b, then.x-<.y.
Note that if 2 = {a, b, .. . , z} and the total order is alphabetical, then the lexicographic
order on 2* is the usual dictionary order.
1.3* 2* REVISITED -A COMBINATORIAL VIEW 11
Example Consider 2 = {0,1}. We begin to enumerate the elements of 2
in lexicographic order.
A
0
00
000
01
1
11
First we justify that «< is a total order on 2*.
Proposition 1.3.2 Let*, y, zG2*.
1 lfx<y,y<z,ihenx<z.
2 Ifx^Ly andy^x, then* =y.
3 For every x, y G 2*, either x =y,x<y, or y<x.
This proposition establishes -< as a total order on 2 . Next we establish the
connection between concatenation and lexicographic order.
Proposition 1.3.3 Let*, y, zG2*. x<y if and only if zx <zy.
Next we show that things are different on the right.
Proposition 1.3.4 Concatenation is not "monotone" on the right. That is,
there exist x, y, z G 2*, such that x < y but xz-^yz.
Proof Let 2 = {0,1,2}. Choose x = 0, y = 01, and z = 2. Clearly x<y,
butxz =02>012=7z. □
Now we will state and prove one of the main properties of lexicographic
order.
Theorem 1.3.5 Let*,7 G 2 andx-<y. Either
i) x is a prefix of y, or
ii) for any z, z G 2 , xz -<yz'.
12 FOUNDATIONS OF LANGUAGE THEORV
Proof Suppose x is not a proper prefix of y. Then, since x<y, there exists
u, v, z/G2*;a, 2>G2, so that
x = uav
y = ubv'
with a < b. But xz = uavz and yz = ubv'z, so that xz <yz. □
PROBLEMS
1 Two words x and z G 2 are said to be conjugates if there exists >> G 2 so
that jry =>>z. Show that x and z are conjugate if and only if there exist u, v G 2
so that x = uv and z = Vu.
2 Show that the conjugate relation is an equivalence relation on 2 .
3 Show that, if x is conjugate to y in 2*, then x is obtained from y by a
circular permutation of letters of >>.
4 Let x, w G 2*. Show that, if x = w" for some n > 0, then every conjugate
x is of the form x = (w )" for some n > 0 and some w G 2 which is conjugate to
w.
5 Let w, z G 2 . z is a roof of w if w = z" for some n > 0. The root of w of
minimal length is a primitive root of w, and is denoted by p(w). Show that the
following proposition is true.
Proposition Let x, y G 2+. We have xy = yx if and only if p(x) = p(y).
6 Show that, for any w G 2*, we have p(wk) = p(w) for any k > 1 where
p(w) is the primitive root of w.
7 Prove Proposition 1.3.2.
8 Let -< be the lexicographic order on 2 . Prove that, if y -<x-<yz, then
there exists w G 2 such that x = yw, where w-<z.
9 Let 2 be of finite cardinality n and let co be any map of 2 onto {1, . . . , n).
This provides a standard way of totally ordering 2. Extend the order to 2 as follows:
Let x = jcj- • • Xk, jCfe G 2 for 1 < i < k. Define
For example, if 2 = {0,1} and co(0) = 1 and co( 1) = 2, then we have
co(00) = \, cj(A) = 0, co(01) = 2, co(Oll) = \.
Give maximum and minimum values of co(jc) as a function of n and k.
10 Prove that, for any strings x and>>, co(x)< co(y) if and only if x<y.
11 Suppose we redefined the cj function to be
Would Problem 10 still be valid?
12 Show that Theorem 1.3.3 is best possible by showing that the bound
\g(u) + \g(v) —(lg(«), lg(i>» cannot be improved.
1.4 PHRASE-STRUCTURE GRAMMARS 13
1.4 PHRASE-STRUCTURE GRAMMARS
There is an underlying framework for describing "grammars." Our intuitive
concept of a grammar is as a (finite) mechanism for producing sets of strings. The
following concept has proved to be very useful in linguistics, in programming languages
and even in biology.
Definition A phrase-structure grammar is a 4-tuple: G = (V, 2, P, S), where:
Fis a finite nonempty set called the total vocabulary;
2 £ V is a finite nonempty set called the terminal alphabet;
5GF— 2 = Af is called the start symbol f
Pisa finite set of rules (or productions) of the form
a-»-0 where oi<EV*NV* and (3GF*.
Some examples will help to motivate and clarify these concepts.
Example of natural language The alphabet 2 would consist of all words in
the language. Although large, 2 is finite. N would contain variables which stand for
concepts that need to be added to a grammar to understand its structure, for example*
<noun phrase) and <verb phrase). The start symbol would be Sentence) and a typical
rule might be:
Sentence) -»■ <noun phrase) <verb phrase)
Example from programming languages Here 2 would be all the symbols in
the language. For some reasonable language, it might contain
A, B, C, . . . , Z, :=, begin, end, if, then, etc.
The set of variables would contain the start symbol <program), as well as others like
<compound-statement), <block), etc. A typical rule might be as follows:
<for statement) -*■ for <control variable) := <for list) do Statement)
Example 1.4.1 (of a more abstract grammar) Let 2 = {a, b}, N = F— 2 =
{A, S} with the productions:
S -+ ab AS -+ bSb
S -»■ aASb A -»■ A
A -»■ bSb aASAb -»■ aa
Note that a phrase-structure grammar has very general rules. The only
requirement is that the lefthand side has at least one variable.
Grammars are made for "rewriting" or "generation," as given by the
following definition.
t ./V is called the set of nonterminals, or the set of variables.
For the moment only, variables are being written in angled brackets to distinguish them.
14 FOUNDATIONS OF LANGUAGE THEORY
Definition Let G = (V, 2, P, S) be a phrase-structure grammar and let
a', (3' G V*. a is said to directly generate f3', written a => (3' if there exist ax, a2,
a, (3 G F*, such that a' = at aa2, j3' = aj (3a2 and a -»■ j3 is in P. We write => for the
reflexive—transitive closure of => .
Example We use the grammar of Example 1.4.1:
S => ab
S => aASb =» aW»2> =» aftaftftft (1.4.1)
5 ^ (aft)2 ft2
A sequence like (1.4.1) is called a generation or derivation. It is convenient in
displaying derivations, to underline the subword being rewritten, as is done in (1.4.1).
Certain conventions are adopted in usage of symbols. Capital letters near the
beginning of the alphabet are used for elements of V or N. Lower-case elements like
a, b, c designate elements of 2 or SA = 2 U {A}. One uses a, j3,7,... for elements of
V* and u,v, w,. .. for elements of 2*.
Definition Let G = (V, 2, P, S) be a phrase-structure grammar. The set of
sentential forms of G, written S(G), is the set:
S(G) = {aeV*\S 5* a}.
Intuitively, a sentential form is something derivable from S. Historically,
S stood for "sentencehood" and so, potentially, a sentential form could be expanded
to a sentence. The set of sentences can be defined as the language generated by the
grammar, as is done in the following definition.
Definition Let G = (V, 2, P, 5) be a phrase-structure grammar. The language
generated by G, written L{G), is the set:
L(G) = 5(G) n 2* = {wG2*l S ^> w}.
An important concept is expressed when we say that two grammars are
"equivalent." Since there are a number of concepts of equivalence which make sense,
the term weak equivalence is sometimes used for this concept.
Definition If G and G' are phrase-structure grammars, then G is said to be
(weakly) equivalent to G' if L{G) = L(G').
Let us work more closely with a grammar in order to get a feeling for what is
involved. The example will show that these constructs do possess a certain complexity.
LetG = (K, 2, P, S), where
2 = {0, 1}, V = 2 U {A, B, C, D, S).
1.4 PHRASE-STRUCTURE GRAMMARS 15
The rules of Pare listed in Table l.l, with numbers and explanatory comments.
TABLE 1.1
Number
1
2
3
4
5
6
7
8
9
10
11
12
13
Rule
S -*
AB -*
AB -*
£»C -*
£T ->
£»0 -*
£»1 -*
£"0 -*
£1 ->
AB -*
C -*
05 -*
\B ->
/45C
0/4 £»
\AE
BOC
B\C
OD
ID
OE
IE
A )
50
fil
Comments
start
addaO
add a 1
drop a 0
drop a 1
skip right
remembering a 0
skip right
remembering a 1
terminate
move B left to
continue
What is L{G) for this grammar? At this point, the answer is not clear, and
even the intuitive comments given in the grammatical description do not help very
much. It turns out that
L(G) = {xx\xe{0,l}*}.
(1.4.2)
Even knowing the answer is of little help, since we must prove it. Proofs of this kind
are important because we must verify that:
i) xx is in L{G) for eachx E {0,1 }* ;
ii) every string in L(G) is of the form xx, where x£{0,lf.
Step (i) is not too hard in general. Step (ii) is necessary for making sure that a
construction is correct.
Let us now work out some of the propositions needed to prove (1.4.2).
Consider derivations that start from the string xABxC, where x £ {0,1} .We
will determine all the ways in which the derivation can continue and ultimately be
able to generate a sentence.
First of all, these considerations suffice to deal with (1.4.2), since
Now consider
ABC = AABAC
xABxC
How shall we continue?
CASE 1. Apply production 10 to (1.4.3). We get:
xABxC => xxC
(1.4.3)
(1.4.4)
16 FOUNDATIONS OF LANGUAGE THEORY
Our only choice is to use production 11, to get:
xxeL(G).
This is fine, since we need this string in the language.
CASE 2. Apply production 11 to (1.4.3). We get:
xABxC =*• xABx
We could again apply production 10 but that would reproduce Case 1. So we'll use
one of productions 2 or 3, say 2. Then we get:
xABx =» xOADx
Now rules 6 and 7 are applicable (depending on the structure of x). There is no way
that the D can ever be made to go away, because it will never find a C with which to
"collaborate" (as in rule 4). Thus the initial choice of rule 11 leads us to block. (The
argument would be the same if production 3 instead of production 2 had been
employed.)
CASE 3. Apply production 2 to (1.4.3). (There is an analogous argument
for production 3 by the symmetry of the rules.)
xABxC => xOADxC
* rules 6 and 7
=*• xOAxDC
=> xOAxBOC drop a 0
=* xOABxOC continue
In this case, a string was found which is one longer than x and of the same form.
The cases we have studied exhaust all possible rewritings of xABxC, and it
now follows that (1.4.2) is true. □
Doing these proofs is important because it helps to prevent errors. In the
example, note that rules 12 and 13 occur after the termination rules. The reason is
that the grammar was designed first. When the proof was carried out, it became
apparent that omissions had been made.
Writing a grammar for a problem is very much like composing a program
(in a primitive programming language). The techniques for writing an understandable
or structured program are even more useful here and should be employed.
PROBLEM
1 Give a phrase-structure grammar that generates the set
L = {aib1aibi\i,j>\}.
Explain clearly how the grammar is supposed to work, and also prove that it generates
L; i.e., every string in L (G) is in L and every string in L is in L (G).
1.5 OTHER FAMILIES OF GRAMMARS-THE CHOMSKY HIERARCHY 17
1.5 OTHER FAMILIES OF GRAMMARS - THE CHOMSKY HIERARCHY
We shall now survey some of the other families of grammars which are known,
and characterize some of them by automata. This will be a somewhat informal survey.
In later chapters, these devices will be studied in great detail and the actual
characterizations will be proved.
First, we consider some variations on phrase-structure grammars.
Definition A phrase-structure grammar G = (V, S, P, S) is said to be of
type 0 if each rule is of the form
a -» j3
whereaGAf+andj3e V*.
We shall see that type 0 and phrase-structure grammars are equivalent. This
is, in fact, a general theme that will run throughout the book. For a given family of
languages, Jz^ we will be interested in very powerful types of grammars that generate
-2? Moreover, we are very interested in the weakest family of grammars that also
generates ¥. When we have some particular set L and wish to show it is in Jz^ we use
a powerful type of grammar. On the other, if we wish to show that some given set
L' is not in Sf, then it is convenient to assume it is in Jz^and is generated by a very
constrained type of grammar. It then becomes much easier to find a contradiction.
Definition A phrase-structure grammar G = (V, 1,,P,S) is said to be
context-sensitive with erasing if each rule is of the form
where AGNand a, j3, y & V*.
Examples Consider the grammar Gx given by the following rules."
S -+ ABC
A -»■ a
aB -» b
C -+ c
This grammar is neither type 0 nor context-sensitive with erasing, but is phrase-
structure. Of course, every type 0 grammar and context-sensitive with erasing grammar
must be phrase-structure.
Now consider grammar G2 shown below:
S -+ AB A -»■ a
AB -+ BA B -+ b
G2 is type 0 but not context-sensitive with erasing. It is easy to modify Gj to obtain
a grammar G3 which is context-sensitive with erasing but not type 0. This is left to
the reader.
The next definition will lead to a different family of languages.
18 FOUNDATIONS OF LANGUAGE THEORY
Definition A phrase-structure grammar G = (V, S, P, S) is context-sensitive
if each rule is of the form
i) aAy -»■ a$y
where A E N; a, y G V*, j3 € F*; or
ii) 5 -> A
If this rule occurs, then S does not appear in the righthand side of any rule.
The motivation for the term context-sensitive comes from rules like
aAy -*■ afiy
The idea is that A is rewritten by (3 only if it occurs in the context of a on the left
and y on the right.
The purpose of the restriction (3 € V* is to ensure that when A is rewritten,
it has an effect. But this condition alone would rule out A from being a sentence.
For certain technical reasons and for certain applications, we would like to include
A. This leads to condition (ii) in the definition. We must constrain the appearance of
S in the rules; otherwise erasing could be simulated by a construction using rules
aAy -*■ aSy and S -»■ A, to yield
aAy =» aSy =» ay
Now we give a definition of context-free grammars, which will be one of the
main topics of this book.
Definition A phrase-structure grammar G = (V, 2, P, S) is a context-free
grammar if each rule is of the form
A -»■ a
where A<EN,a<EV*.
The term "context free" means that A can be replaced by a wherever it
appears, no matter the context.
Some authors given an alternative definition in which a € V+, which
prohibits A rules. The presence of A rules in our definition must be accounted for
eventually, and indeed it will be shown that, for each language L generated by a context-
free grammar with A rules, there exists a A-free, context-free grammar that generates
L — {A}. In the meantime A rules will play an important role in proofs, since they
frequently give rise to special cases that must be carefully checked. Because A rules
do cause technical problems, their omission is a common suggestion of novices and
a temptation to specialists. Systematic omission of A rules changes the class of
theorems one can prove. We shall include them.
There is an alternative form of context-free grammar which is used in the
specification of programming languages. This system is called the Backus normal
form or Backus—Naur form; in either case it is commonly abbreviated BNF. The
form uses four meta characters which are not in the working vocabulary. These are
< >
1.5 OTHER FAMILIES OF GRAMMARS-THE CHOMSKY HIERARCHY 19
D
D
D
D
-*■
-»
-»
-»
1
2
3
4
The idea is that strings (which do not contain the meta characters) are enclosed by
< and > and denote variables. The symbol .":= serves as a replacement operator just
like -*■ and I is read "or".
Example An ordinary context-free grammar for unsigned digits in a
programming language might be as follows, where D stands for the class of digits and U stands
for the class of unsigned integers:
D -> 0 D -> 5
D -> 6
D -> 7
Z> -» 8
£> -> 9
£/->£> U -+ UD
The example, when rewritten in BNF, becomes
<digit>:: = 0|l|2|3|4|5|6|7|8|9
<unsigned integer):." = <digit>|<unsigned integer) <digit>
In this book, we will adopt a blend of the two notations. We shall use | but
not the other metacharacters. This allows for the compact representation of context-
free grammars.
There are a few special classes of context-free grammars which will now be
singled out.
Definition A context-free grammar G = (V, 2, P, S) is linear if each rule is
of the form
A -> uBv or A -»■ u
where A, B&N and u, z»GS*.
In a linear grammar, there is at most one variable on the right side of each
rule.
In a linear grammar, if the one variable that appears is on the right end of
the word, the grammar is called "right linear." A left linear grammar is defined in
analogous fashion.
Definition A context-free grammar G = (V, 2, P, S) is right linear if each
rule is of the form
A -+ uB A,BGN
or
A ■+ u mGS*
Examples S -*■ aSa\bSb\ A is a linear context-free grammar for the even-length
palindromes; that is,
L(G) = {wwT\we{a,b}*}.
The grammar G' given by
S -+ aS\a
20 FOUNDATIONS OF LANGUAGE THEORY
is a right linear grammar which generates
L(G') = a*
Any of these families of grammars gives rise to a family of languages. The
following definition makes the connection more precise.
Definition A language L is said to be of type X (e.g., phrase-structure,
context-sensitive, etc.) if there exists a type-X grammar G such that L(G) = L.
For any language, there will be infinitely many grammars generating it.
Example Let Gx be the following grammar:
S -+ aSa
S -»• aa
S -» a
Clearly, L{Gl)=a+.
This example shows that a* is a linear language, but we know still more.
The previous example establishes that a* is a right linear language.
A great deal is known about these classes of languages and grammars. In the
rest of this section, we shall give an outline. To summarize the material, we use Table
1.2. The undefined terms in the table will be explained subsequently.
TABLE 1.2 The Chomsky Hierarchy
Grammars Languages Automata
Phrase-structure
Type 0
Context-sensitive
with erasing
Context-sensitive
Monotonic
Context-free
LR(k)
Linear
Right linear
Left linear
Recursively
enumerable sets
Context-sensitive
Context-free
Deterministic
context-free
Linear context-
free
Regular sets
Nondeterministic
or deterministic
Turing machines
Nondeterministic
linearly space-
bounded Turing
machines, or
lba's, for short
Nondeterministic
pushdown automata
Deterministic
pushdown automata
Two-tape
nondeterministic finite
automata of a special
type or l-turn pda's
Nondeterministic
or deterministic,
one-way or two-way
finite automata
1.5 OTHER FAMILIES OF GRAMMARS-THE CHOMSKY HIERARCHY 21
We shall now try to give some intuitive meaning to the technical terms in
this table. (This organization is sometimes called the Chomsky hierarchy.) The reader
who has trouble understanding the table should not be distressed. The definitions will
be given later in full detail, and the results will be carefully proven.
A deterministic automaton which is in a given state reading a given input
always does the same thing (i.e., transfers to the same new state, writes the same
output, etc.). On the other hand, a nondeterministic automaton may "choose" any
one of a finite set of actions. A nondeterministic automaton is said to accept a string
x if there exists some sequence of transitions which start from an initial configuration,
end in a final configuration, and are "controlled by x".
A recursive set is a set for which there exists an algorithm for deciding set
membership. That is, for any string x, the algorithm will halt in a finite amount of
time, either accepting or rejecting x. A recursively enumerable set is a set for which
there exists a procedure for recognizing the set. That is, given a string* in the set, the
procedure will halt after a finite length of time, accepting x. On the other hand, if*
is not in the set, the procedure may either halt, rejecting x, or never halt.
Recursive sets are a proper subset of the recursively enumerable sets.
A Turing machine is simply a finite-state control device with a finite but
potentially unbounded read—write tape. The sets accepted by deterministic and non-
deterministic Turing machines are the same.
A /inear founded automaton (lba) is a Turing machine with a bounded
tape. It should be noted that if the automaton is limited to n squares of tape, by
suitably enlarging its alphabet to fc-tuples, it can increase its effective tape size to kn
for any fixed k. Hence the word linear.
While many properties of context-sensitive languages and deterministic
context-sensitive languages (languages accepted by deterministic lba's) are known,
it is an open question as to whether the two families of languages are equivalent.
A pushdown automaton (pda) has a finite-state control with an input tape
and an auxiliary pushdown store (LIFO, or /ast-m, /irst-out, store). In a given state,
reading a given input and the symbol from the top of its pushdown store, it will make
a transition to a new state, writing n > 0 symbols on the top of its pushdown store
(n = 0, corresponding to erasing the top symbol of the pushdown store).
LR(k) grammars are grammars that may be parsed from left to right, with k
symbols lookahead, by working from the bottom to the top. This class of grammar is
rich enough to contain the syntax of many programming languages but restrictive
enough to be parsable in "linear" time.
The deterministic context-free languages are characterized by the
automata which accept them. It will be shown that they are a proper subset of the family
of context-free languages.
PROBLEMS
Definition A phrase-structure grammar G = (V, S, P, S) is called monotonic
if each rule is of the form:
i) a-► j3 where a G V*NV*,f3e V*, and lg(a)< lg(j3);
ii) S -* A and if this rule occurs, then S does not appear on the righthand side
of any rule in P.
22 FOUNDATIONS OF LANGUAGE THEORY
1 Given a phrase-structure (context-sensitive with erasing)
[context-sensitive] {monotonic} grammar, show that there is a phrase-structure (context-sensitive
with erasing) [context-sensitive] {monotonic} grammar G' = (v', 2, P , S') with
L(G') = L(G) and for each rule a-* j3 in p', we have a GN*.
2 Prove the following statement (if it is true; if not give a counter example).
Fact For each phrase-structure (context-sensitive with erasing) [context-
sensitive] {monotonic} grammar G = (V, 2, P, S), there is a phrase-structure
(context-sensitive with erasing) [context-sensitive] {monotonic} grammar G = (V ,
2, P',S') such that L(G') = L(G ) and each rule in P' is of the form
a -* j3
withaG/V*, j3GN*,or
y4 -* a
with /4 G N and a G 2 U {A}.
In the next few problems, we shall show that the family of monotonic languages is
coextensive with the family of context-sensitive languages.
Definition For any phrase-structure grammar G = (V, 2, P, S), let the
weight of G be max {lg (j3)l a -* j3 is in P}.
3 Prove the following fact.
Fact For each monotonic grammar G = (V, 2, P, S), there is a monotonic
grammar G' = (V', 2, P', S) of weight at most 2, so that L(G') = L(G ).
4 Prove the following statement.
Fact For each monotonic grammar G = (V, 2, P, S), there is a context-
sensitive grammar G' = (V', 2, P', 5) such that L(G') = L(G).
5 Consider the following "proof" of Problem 4:
Assume without loss of generality that the weight of G is 2.
i) If a production n G P has weight < 2, then 7r G P .
ii) If 7r = ,4.6 -* C£» and C = A or fi = D, then 7r G p'.
iii) If 7T = /li? -* CD with C =£ /I and D ¥= B, then the following productions
are in P':
AB -* (7T,/4)£
(7T,^)fi -* (7T,/4)£»
(7T, A)D -* CD
where (n, A) is a new variable.
Surely P is a finite set of context-sensitive rules, and since
AB =*, (n,A)B gf (n,A)D g CD
we have that L(G')=L(G)
a) Is this proof correct? If not, explain in detail.
b) If the proof is correct, is the argument incomplete in some way? If there
are any gaps, complete the proof.
1.6 CONTEXT-FREE GRAMMARS AND TREES 23
c) If your answer to (a) was yes and to (b) was no, then what do you think
is the point of this problem?
6 Give a context-sensitive or monotonic grammar which generates
{xx\xe{a,b}*}
Be sure to explain your grammar and prove that it works.
7 Show that the family of languages generated by context-sensitive grammars
with erasing is identical to the phrase-structure languages.
1.6 CONTEXT-FREE GRAMMARS AND TREES
The systematic use of trees to illustrate context-free derivations is an
important device that greatly sharpens our intuition. Since we use these concepts in formal
proofs, it is necessary to have precise formal definitions of the concepts. It turns out
that the usual graph-theoretic terminology is insufficient for our purposes. On the
other hand, a completely formal treatment becomes tedious and obscures the very
intuition we wish to develop. For these reasons, a semiformal approach is developed
here, which can be completely formalized. We leave a number of alternative approaches
for the exercises.
An example of a tree T is given in Fig. 1.1. It has one or more nodes (x0,
Xi, .. . ,Xio), one of which is the root (x0). We denote the relation of immediate
descendancy by r (thus, on Fig. 1.1(a), x2 Tx4 but not x2 Fxl0). The descendancy
relation is the reflexive and transitive closure r of T (now x2 T^io). If xf~ y, then
the path from x to y (or path to y if x is the root) is the sequence of all nodes
between and including x and y (for example, (x0, x2, x4, xa) is the path frornxo tox8
b B a
(b)
FIG. 1.1
24 FOUNDATIONS OF LANGUAGE THEORY
in Fig. 1.1(a)). If n is the number of nodes in one of the longest paths in T, then the
height of T is, by definition, n — 1 (the tree in Fig. 1.1(a) has height 4). A node x is
a leaf in T if for no y in T, x V y. Nodes that are not leaves are called internal.
We must pay attention to the left-right order of nodes. Let
yi,yi,---,ym, m>\ (1.6.1)
be a sequence of all the leaves in T without repetition. (There is no other restriction
on this sequence except the informal assumption that sequence (1.6.1) represents the
intuitive left-to-right orders of leaves.) Now we define a special relation L between
certain pairs of nodes in T.
For any x, y in T,
x L y
if and only if
i) x and y are not on the same path, and
ii) for some leavesyhyi+l (1 </< m) in (1.6.1) we have x [7; and 7 r yi+1.
Thus, in particular, there is no leaf "between" x and y. (Thus, for instance, we have
x2 \~x6 but not x9 \-X6 in Fig. 1.1(a).) Note that relation L is determined uniquely
by (1.6.1). The left-to-right order is then the reflexive and transitive closure \1 of |_.
Note that we have r+ D Lt = 0. On the other hand, one of the two relations |_! orT*
(or their inverses) holds between any two nodes of a tree.
Every node xGT has a label X(x) from a given finite set of labels — in our
cases it is always the set VA = VU {A}, where V is the alphabet of a given grammar.
The corresponding function X: T ►*■ VA;: x ►*■ X(x) is the labeling (thus Fig. 1.1(a)
&. Fig. 1.1 (b)). Of special importance are the root label of T, rt(7), and the frontier
of T, fr(T). The latter is defined as a concatenation of labels of leaves in (1.6.1):
fr(D = XOi)X02)--XOm)GF*.
Note that some leaves may be labeled by A and thus fr(7) may be shorter than sequence
(1.6.1) (for instance, in Fig. \.\,ix{T) = abaA).
For any internal node x in T the set {y\ y = x or x\~y} defines an
elementary subtree of T in an obvious way. A cross section in T is any maximal
sequence of nodes in T (with respect to the partial ordering obtained from the prefix
relation)
? = (xi,x2,■ ■. ,xn)
such that Xi Lx2 L • • • L xn (n > 1). Thus, in particular, sequence (1.6.1) is a cross
section in T.
Two trees T, T' are structurally isomorphic, T = T', if and only if there is a
bijection T *-T'\ x ** x , called a structural isomorphism from T to T', such that
xTy (x\-y) if and only if x \~y' (x'Ly'); (intuitively, T and T' are "identical
except for the labeling"). Where there is no danger of confusion, we write T = T'
when T= T', and the labeling is preserved (this is in agreement with the customary
understanding that T and T' are "identical," but not with the algebraic definition of
trees). Also we use the same symbols F, L, X, even for different trees.
1.6 CONTEXT-FREE GRAMMARS AND TREES 25
We now define certain trees and sets of trees related to grammars. Let G =
(V, 2, P, S) be a context-free grammar. We interpret the productions of G as trees
(of height 1) in a natural way: The production A0 + AiA2 • • ■ An corresponds to
the tree shown in Fig. 1.2 (or, formally, x0 r xlt x0 \~x2, . .., x0 t~ xm, Xi Lx2 L
• • • \-Xn, and \(x;) —Ah 0 <*'<«). We make a convention that, in this correspondence,
X(xi) = A if and only if i = n = 1 and A 0 -* A is in P.
Definition Let G = (V, 2, P, S) be a context-free grammar and let T be a
tree with labeling X: T ►* V\. T is said to be a grammatical tree of G if and only if,
for every elementary subtree T' of T, there exists a production pGP corresponding
to T'. Moreover, a derivation tree T is a grammatical tree such that fr(r) € 2*.
Consequently, the leaves in a derivation tree are precisely the nodes labeled
by letters in 2 (called the terminal nodes) or by A (the A-nodes). All other nodes
are labeled by letters in Af = V — 2 (and are accordingly called the nonterminal
nodes). Note, that in particular, a trivial tree consisting of a single node, labeled
by a € 2 or by A, is a derivation tree of G.
A, A
The tree in Fig. 1.1 may serve as an example of a grammatical tree for any
grammar with productions
S -> aAB I bBa
A -* SA
B -> A
Now let us turn to the question of relating these trees to the properties of
the relation =».
Example Let G be
then the derivation
is associated with the tree
S -* AB
A -* a
B -* b
S => AB => Ab => ab
S
A'
a i
i
>B
<b
(1.6.2)
26 FOUNDATIONS OF LANGUAGE THEORY
Note that the derivation
S => AB => aB => ab (1.6.3)
is also a derivation of ab, and the same tree is associated with it. Thus there are many
different derivations associated with the same tree.
Example If G is the grammar
S -+ aSa
S -> bSb
S -»• A
which may be compactly written
S -> aSa\bSb\A
then the derivation
5 =* aSa =* abSba =* abaSaba =* abaaba
is represented by the tree in Fig. 1.3, where the derived string may be read off by
concatenating in left-to-right order the symbols on the frontier of the tree; i.e.,
"reading the tree leaves."
Since many derivations may correspond to the same tree, we would like to
identify one of these as canonical so as to set up a one-to-one correspondence between
trees and derivations.
S
a
b
a
Definition Let G = (V, 2, P, S) be a context-free grammar and let a, j3 £ V*.
If
a => /3 (1.6.4)
then there exist ax, a2, .4, 6, so that a = ai^a2, (3 = ai0a2, and A ->■ 6 is in P. If
a2 G 2 , then (1.6.4) is called a rightmost (or canonical) generation. If ax G 2*, then
(1.6.4) is a leftmost generation. The notation
a ^ (3 or a =* 0
is used in the respective cases.
FIG. 1.3
1.6 CONTEXT-FREE GRAMMARS AND TREES 27
Note that (1.6.2) and (1.6.3) provide examples of rightmost and leftmost
derivations.
Now we can state the correspondence between trees and rightmost
derivations.
Theorem 1.6.1 Let G = (V, 2, P, S) be a context-free grammar. There is a
one-to-one correspondence between rightmost (leftmost) derivations of a string
w £ 2 and the derivation trees of w with root labeled S.
Proof The proof is obvious intuitively, the correspondence being the natural
one. A formal proof is omitted, since trees have been introduced only informally. □
The condition in Theorem 1.6.1 that w £ 2 is necessary. To illustrate this
point, consider the grammar:
S -+ ABC B -»• b
A -»• a C -»• c
The tree
b
has frontier AbC. There is no rightmost or leftmost derivation that contains that
string.
Definition Let G = {V, ~L,P,S) be a context-free grammar; a&V is a
canonical sentential form if S^ a.
xv
Not every sentential form is canonical, as the following trivial example shows.
Let G be
S ^ AA
A ->■ a
then aA £ S(G) but is not canonical.
Definition A context-free grammar G = (V, 2, P, S) is ambiguous if there
exists x £L(G) such that x has at least two rightmost generations from S. A grammar
that is not ambiguous is said to be unambiguous. Alternatively, G is unambiguous if,
for any two derivation trees Tand T' (from S), fr(!T) = fr(r') implies T= T'.
28 FOUNDATIONS OF LANGUAGE THEORY
Example Let G be S->SbS\a. Then G is ambiguous, since the string (ab)2a
has the two rightmost generations shown in Fig. 1.4.
r * 1
b /
s.
a
>
S
( • i
b
>
i
FIG. 1.4
Definition A context-free language L is unambiguous if there exists an
unambiguous context-free grammar G such that L = LOG).
It can easily be shown that the language generated by the grammar in the
preceding example is
Consider the grammar G':
Then we have
L{G) = {(ab)na\n>0}.
S -+ Ta
T -> abT\A
T f abTf (abfT f{ab)n
S =» {abfa, n>0
We have that LOG) = LOG') and hence the language L = {Oab)na \n > 0} is
unambiguous.
This discussion raises a deep question. Can ambiguity always be disposed
of by changing grammars? Assuming the worst, the following definition would be
useful.
Definition A context-free language is inherently ambiguous if L is not
unambiguous (i.e., there does not exist any unambiguous grammar G such that L =
LOG)).
In a later chapter, it will be shown that there exist inherently ambiguous
context-free languages. The following is an example.
L = {db'ck\i = / or / = k,where/',/, k> 1}
Returning to the relationship between trees and grammars we note that if
G = {V, 2,,P, S) is linear, then each rule in G is of the form
1.6 CONTEXT-FREE GRAMMARS AND TREES 29
A -»• aia2 ■ ■ ■ fl,-5fl,+ i • • • ak B&N, d(6S,
or
A ->• flifl2 "' 'flfc A: >0.
Thus trees associated with a linear grammar have a special form. At each level, at
most one node may have descendants. An example of such a tree is shown in Fig. 1.5.
Example Let G be S -*■ aSb I A, which is a "minimal linear" grammar in that
it has only one variable. Then
L(G) = tfb'\i>0}.
FIG. 1.5
Then a derivation tree is of the form shown in Fig. 1.6.
If the grammar is right linear, then the generation trees have an even more
restricted form. At each level at most one node may have descendants, and this must
be the rightmost node. Thus, Fig. 1.7 would be an example of a derivation tree for a
right linear grammar.
S
a' is *b
FIG. 1.6 I
s
"1
FIG. 1.7
ci
cm
30 FOUNDATIONS OF LANGUAGE THEORY
PROBLEMS
1 Let G be the grammar
SbS\a
and consider the tree shown in Fig. 1.8. We shall give a technique for numbering the
tree. The root will be numbered (1). The successors are numbered (1,1), (1,2), (1,3)
in order, and the numbered tree looks like Fig. 1.9.
Using this idea, construct a formal definition of generation trees.
2 Using the definition of Problem 1, prove Theorem 1.6.1.
3 Show that the generation trees, as defined in problem 1, have the following
properties:
i) there is exactly one root which no edge enters; i.e. it has in-degree 0;
ii) for each node N other than the root, there is a unique path from the root
to TV.
4 Show that if G = (K, 2, P, S) is a context-free grammar, then
for some a& V , u> G Z*, if and only if there is a grammatical tree T such that the
root is labeled by A, fr(T) = w, and a = X(§), for some cross section % in T.
5 Let T be a set. Define a "tree structure" {J, a, X, x0) over Tby the
following axioms:
i) a. and X are partial orders on T.
ii) a U X U (a U X)-1 = T x T, where for any relation p, p~l denotes the
inverse (or converse relation); that is, (x,v)Gp-1 if and only if (y, x)
Gp.
(1,3)
(1,M)
(1,1,1,1)
FIG. 1.9
(l,l,2)
(1,1,3)
(1,1,3,1)
1.7* RAMSEY'S THEOREM 31
iii) X' = a'1 X'a, where X' = X - {(*, x) I x G T}.
iv) x0 G T, and for any y E.T, x0ay.
Intuitively, xay means that x is an "ancestor" of y while x\y means x is to the left of
y. Do our grammatical trees satisfy these axioms? Do these axioms capture the essence
of "tree structures?"
6 Let T be any tree. Define a canonical cross section (of level n, for n > 0)
in T inductively as follows:
i) The sequence % = (x0) consisting of the root x0 of T, is a canonical cross
section (of level 0) in T.
ii) Let
£o — ix\, ■ ■ ■ ,xk, . . . , xm)
be a canonical cross section of level h, in which xk is the rightmost node
which is internal in T. Let y\, y2, . . . ,yr be all the immediate
descendants of xk in T and let y i L y2 I— ■ • • L ». Then the sequence
§i = (xi, . . . ,xfe _1(^i,. . . ,>v, xfe+1, . .. ,xm)
is a canonical cross section (of level h + 1) in T.
a) Show that every canonical cross section is a cross section.
b) Show that no two distinct canonical cross sections in a tree can be of the
same level.
7 Let T be a derivation tree of any grammar G, and let % = (xj, . . . , xm)
and § =(*!,..., xm') be two canonical cross sections in T, of level h and h ,
respectively. Define X(§) = X(x,) • • ■ \(xm) G K*, and similarly X(§'). Show that X(§) ^ X(§')
if 6' = h + 1. Also show that if T is a derivation tree with fr(D = S of G, then X(§) is
a canonical sentential form in G; and that, conversely, for every canonical sentential
form a, there is a grammatical tree with a canonical cross section % such that X(§) = a.
8 Prove the following useful proposition.
Proposition Let T be a derivation tree of some unambiguous grammar G and
let %, % be two canonical cross sections in T. Assume that if rt(r) = A , then S =*x A y
for some*,/ G 2*. Then X(§) = X(§') implies § = §'.
1.7* RAMSEY'S THEOREM
Let 2 = {a, b). It turns out that any string in 2* of length at least 4 has two
consecutive identical subwords. To see that, let's try to find a counterexample x.
The string x must start with a letter, say a. The second letter cannot be a for, if it were
we would have x = aa ■ • • and that would satisfy the condition. Similarly, the next
character must be an a and again the same reasoning forces the fourth letter to be b.
Thus, x begins
abab = (ab)2,
and the result is verified.
Now let us consider another more general situation. Let 2 be a nonempty
set and suppose that 2+ is partitioned into two classes; that is, 1,*=A UB with
A C\B = 0. Any string of length at least 4 has two consecutive nonempty substrings,
which are both in A or both in B. It clearly suffices to deal with a string of length 4.
Suppose w is a string of length 4, which does not have the desired property w = abed
32 FOUNDATIONS OF LANGUAGE THEORY
with a, b, c,d£S. Suppose a&A. Then we must have b 6B, cGA, and dEB. To
which set does the subword be belong? If it belongs to A, then jz,,^ is a
contradiction and if be G B then ^^ is a contradiction.
We now state a very general theorem due to Ramsey, and examine special
cases of it. The theorem will show that these examples are special cases of a more
general situation.
Theorem 1.7.1 (Ramsey) Let qlt... ,qt, r be given positive integers such
that Kr<ql,. .. ,qt. There exists a minimal positive integer N(ql,...,qt,r)
such that for all integers n ^N(gi,. .. ,qt,r), the following is true.
Let S be a set with^ \S\ = n, and suppose that Pr(S), the set of all subsets
of S of size r, is expressed as
Pr(S) = {U^S\ It/I = r} = At U • • • UA„
with j4,- n^4y = 0 for /' =£/'. Then there exists F£ S and /' such that \F\ = q;
and
PAF) 9 Aj.
The theorem is sufficiently complex that some examples may help to clarify
the result before we prove it.
Example Consider the statement when r = 1. The statement is:
Let #!,..., qr t > 1. There exists a minimum positive integer N(q x,..., q t, 1)
so that, for all integers n >N(qt,.. .,qt, 1), the following is true: If S =
Ax U • • -UAt, \S\ = n, A^Aj = 0 if i=t=j, then S has a subset T such that
Irl = qj and T1- Aj for some/.
This is a familiar statement in which we can rephrase the second part as
follows:
If there is a set of n balls and t boxes with n >N(qi,..., qt, 1), then there
is a subset of qj balls which go into box Aj.
This form is more familiar and is known as Dirichlet's principle (or the "drawer"
or "shoe box" principle).
Let us estimate N(qi,..., qt, 1). The largest case in which this would not
be true is taken:
N(.qi,...,qt,l) = ((7,-1) + ... + 07,-1).
(If <7i = .. . = qt = q, then we could have q — 1 balls in each box and the principle
would not be true.) Adding one more point gives the desired result, so:
N(qi,...,qt, 1) = 1+ £(<7,--l) = <?, +...+qt-t+l.
1=1
' For any set S, the cardinality of S, or the number of elements in S, is denoted by
ISl.
1.7* RAMSEY'S THEOREM 33
Example Consider the theorem with qx = .. .=qt=q>r>\. The
statement is roughly that, if ISI = n, which is sufficiently large, and
Pr(S) =AlU---UAt,
then there exists F£ S, \F\ = q, and Pr(F) £ A,.
The statement is equivalent to Ramsey's theorem. In one direction, this is
trivial. Conversely, suppose the assertion of this example to be valid. In the general
case 1 <r<qlt... ,qt, and define q = max {qt}. Then, by the above statement,
there is a subset F with iFl = q and Pr(F) £ Ar Take any subset F' £ F such that
|F'| = q-j, and we have that Pr(F')£ Pr(F) 9 Ajy and so Ramsey's theorem is satisfied.
Now we begin the proof of Ramsey's Theorem.
Proof We begin by induction on t.
Basis, t = 1. The result is trivial since Pr(S) = A i and we need only take
N(q1,r) = ql.
Induction step. t>2
We first show that it suffices to prove the result for t = 2. Suppose that we
can prove the theorem in that case. We will now show that the result is true for t + 1.
We can write
Pr(S) = Ax U...U^t+1 = Ax U(42U...U^t+1).
Let q2 = N(q2, ■ ■ ■ ,qt*i,r). If n^N(qi, q'i,r), then S must contain a subset F
with the property that:
i) |F| = qi andP^F)9 Ai,oi
ii) |F| = q'2 and Pr(F) £ A2 U • • • UAt+i.
If the first alternative holds, we are done. Otherwise, take S' = F so that 15'I = q\ =
N(q2,..., qt+l, r) and Pr(S') = A'2 U . .. U A't+l where A'} = Aj n Pr(S') for 2 </ <
t+l. By the induction hypothesis, there is a subset G£ S' so that IGI = <7; and
Pr(G) £ Al'k Ax for some /'. This completes the proof of sufficiency.
Next, we return to a proof of the result for t = 2. It has already been established in an
example that:
N(qi,q2,l) = qi+q2~l.
Claim 7V(<7i, r, r) = qx andN(r, q2, r) = q2.
Proof The second result follows from the first by symmetry. To see the first
result, let q2=r and n^qx. If A2 =£0, then let {ax,..., ar} be an /--combination of
A2. Then F= {ax,... ,ar} is a subset of S (since \S\ = n>qx >r) such that Pr{F) 9
A2. If A2 =0, then Pr(S) = Ax; and if S is any set with \S\ = n >otl, then any subset
Fofqi elements has Pr(F) £ A x. This completes the proof of the claim.
34 FOUNDATIONS OF LANGUAGE THEORY
The main argument with t = 2 is completed by induction. Assume that we
have 1 <r<qi,q2- The induction hypothesis asserts that there exists integers
N(qi - 1,(72, r), N{qx, q2 — l,r), and N(q'uq'2, r—\) for all q\, q\ which satisfy
1 </-— 1 <q\, q2. We shall show the existence of N{qx, q2, r). This is valid because
we can fill out the following array for each /-; for example, for r = 2, we have:
N(2, 2, 2) N(2, 3,2)
7V(3,2,2) N(3,3,2)
7V(4,2,2) 7V(4,3,2)
This will imply the existence of N(qx, q2,3), etc.
Assume the existence of pl =N(g1 ~ \, q2, r), p2 = N{qx, q2 — \, r), and
N(j)\, p2, r— 1), and we shall prove the existence of N(qlt q2, r). Moreover, it will
be shown that
N(ql,q2,r)<N(pl,p2,r-l)+l. (1.7.1)
Suppose n >N{px, p2, r— 1) + 1. Let S be a set with a65 and ISl = n.
Define T = S - {a}. Then
Pr(S) = Ai UA2,
with ^ C\A2 =0. Define
Pr-i(T) = fli UB2, (1.7.2)
where B( = {UeP^^TJlUU {fl}G^,-} for / = 1, 2.
Clearly, \T\>N(pup2,r—1), since T = S — {a}. By the induction
hypothesis, there exists a set F so that
i) IFI = p! andpr_!(F)^5i,or
ii) IFI = p2 anApr^(F)^B2.
We assume the first case. (Case (ii) is analogous.) Since px =N(ql — 1,
<72, r),Fcontains a subset G so that:
iii) IGI = <7! -1 withPr(G)£Au or
iv) \G\ = q2 with^(G)^^,
by the induction hypothesis.
If (iv) holds, then the induction is completed, so we assume that (iii) holds.
Then H = G U {a} has the property that I//1 = qx; and now we consider the
/--combinations of H. If an /--combination of// does not contain a, then it is an /--combination of
F and, by (iii), it is in A\. If an /--combination of H contains a, then it consists of a
and an (/- — l)-combination of G. But G has all its r — 1 subsets in B\. By the
definition of the 5-decomposition, our /--combination is in A \. Thus, H is a subset of
cardinality qx and Pr(H) 9 At. Thus the induction is extended and the theorem is proven.
□
1.7* RAMSEY'S THEOREM 35
There is an interesting application of Ramsey's theorem to graph theory.
In the vernacular, the following result asserts that, at a sufficiently large party, there
exist m individuals who are all strangers to each other, or a clique of m people all of
whom know each other.
Theorem 1.7.2 For any m there exists N(m) so that, if n >7V(m), any
graph with n vertices either contains a set of m isolated vertices or contains the
complete subgraph on m points.
Proof Let N(m) =N(m, m, 2) with P1(S)=Al UA2, where A2 is the set
of edges and Ax =P2(S)—A 2. n
Another important application of Ramsey's theorem concerns repeated
patterns in strings.
Theorem 1.7.3 Let Z+=Al LM2U...LMt, AiC\A} = 9, if i¥=j. For
each natural number n, there exists a minimum positive integer Nt(n) such that each
word w, where lg(vv) >Nt(n), is in Z*AfL* for some/ with 1 </ < t.
t
Proof Let Nt(n) = N{n^T.. ,n, 2) and let w = ax .. .am, at£E, m>
Nt(n). Let S = {0,1, 2,.. ., m}. For each pair (/', /), with /', / £ S and /' </, associate
a unique word w,j = ai+1 ■ • • as. Thus there is a partition on Pi(S) induced by the
A;. By Ramsey's theorem, there is a set F = {p0,.. . ,pn}£ S with Pi<pi+i such
that
WpiPjl Pt<Pj; i,j£F}£Ae.
Thus the consecutive subwords of w (the words are consecutive since /', /6f)
wn d » wn D » • • • , Wn „
Po'Pi' Pi>P2' ' Pn-i'Pn
are all in^4E, and so wG 2*^4g2*. □
Now we can estimate the number Nt(n). We begin by an example.
Example 1 N2(2) < 4. This is the example which was given before.
Example 2 Suppose 7V2(2) = 3. Then take 2 = {0, \},Ai= {0}, A2 = 2+ -
{0}. The string w = 010 fails to be in one of the desired sets, since its factorizations are
A2
'o
Ax
n2
1 ,
I1
Ai
1
0
Ax
One can study this case in more detail and show that Nt(ri) = n*.
PROBLEMS
1 Prove the following geometric proposition:
Suppose there are five points in the plane and no three of them are collinear.
Then four of the points are the vertices of a convex quadrilateral.
36 FOUNDATIONS OF LANGUAGE THEORY
2 Prove the following fact:
Let m > 4. If m points in the plane have no three points collinear, and if all
the quadrilaterals formed from the m points are convex, then the m points are the
vertices of a convex m-gon.
3 Using Problems 1 and 2, prove the following theorem:
Let m > 4. There exists a minimal positive integer Nm so that the
following is true for all n>Nm: If n points in the plane have no three points collinear,
then m of the points are the vertices of a convex w-gon.
*4 Ramsey's Theorem becomes easier to prove in the infinite case. Prove the
following form of the result:
Let t, r > 1. Let S be an infinite set and suppose that
Pr(S) = Ai U. . .UAt
with A( UAj = 0 if i ¥=/. Then there is an infinite set F^ S so that Pr(F) 9 A{ for
some i.
1.8* NONREPETITIVE WORDS
For the moment, let 2 be a binary alphabet. Any string of length at least 4
must have two identical subwords, as we argued in the last section. It turns out that
over a three-letter alphabet, one can construct strings of infinite length such that no
two consecutive subwords are identical. Such a string will now be constructed. There
are many applications of these sequences, particularly in mathematical games.
The construction is made in the following way: Define
So = a
and
for each / > 0, where 0 is the homomorphism:
(pa = abcab = a,
(pb = acabcb = (3,
0c = acbcacb = y.
The desired string is the limit of the §,'s. For instance,
So = a
Si = abcab
S2 = abcabacabcbacbcacbabcabacabcb
etc.
The argument proceeds by examining these words closely.
1.8* NONREPETITIVE WORDS 37
Proposition 1.8.1
a) Each of a, /3, and y (which will be called blocks) begins with an a and is
a product of two words, each beginning with an a (which will be called
half-blocks).
b) All blocks and half-blocks are distinct.
c) For each x in {a, /3, y}*, if x= wlauaw2, where the number of a's in
u is 0 (written #a(u) = 0), then lg(«) < 3.
d) For any x in {a, /3, y}*, if x = wlauaw2 and #a(u) = 0, then u uniquely
determines the block to which the first a belongs and whether it is the
first or second a in that block.
Proof Only (d) requires explanation. In view of (c), the only cases that may
arise are those shown in Table 1.3.
TABLE 1.3
aua
. . . aba . . .
. . . aca .. .
. .. abca . . .
. . . acba . . .
. . . abcba . . .
. . . acbca . . .
First a
belongs
a
&
a
1
&
1
to:
First or second a?
Second
First
First
Second
Second
First
□
Now we prove a key lemma.
Lemma 1.8.1 If 77 is a nonrepetitive sequence and d = 0(t?), then d is a non-
repetitive sequence.
Proof Suppose d has a repetition; that is,
0 = 00?) = wltlt2w2
where tx = t2. It will be shown that 77 has a repetition.
CASE 1. Suppose #a(ti)>2. Let X be the block to which the first a
belongs. One possible picture is shown in Fig. 1.10. More generally, X need not be
contained in ti.
1 =
FIG.
1
• '[2
.10
a
X
A
1 a
~\
1
Y
'1
'
a
X
Y
h
1 a
\
|
|
38 FOUNDATIONS OF LANGUAGE THEORY
The block X and its position in t\ (respectively, t2) is determined by the
string between the first two a's in tx. (This is cross-hatched in Fig. 1.10.)
If the two blocks were together, then we would have
ti = t2 = X and d = WiXXw2
which implies
77 = w'iddw'2
where <f>(d) = X and <A(w,') = w{ for / = 1,2. That would finish the proof.
X
y\' • -yn
'1
X
y\> • -yn '' '
'2
FIG. 1.11
Now suppose the X-blocks are not adjacent. Then the picture is shown in
Fig. 1.11, where Yx,..., Yn are the blocks between the X-blocks. Note that Yn may
overlap t2 but all the a's in Y\ • • • Yn are in tx because we singled out the first a in
ti and ti = t2. These blocks are uniquely determined by the part of t\ to the right
of X. Compare Figs. 1.8 and 1.9. The corresponding part of t2 determines the same
sequence of blocks and
77 = w\dyi ■ ■ -yndyi- • -ynw2
where 0(w,') = wh (pd = X, <S>y-} = Yjiovi= 1,2;/= 1,. . . , n.
CASE 2. #a(ti)= l.Thus
#a('2) = #a('l) = I-
Thus the two a's are consecutive in 6 = 4>(rf). Since the second a in each block is
preceded by c and since each block ends in b, the only way we can have consecutive
fl's in d is to have them following different letters in 6. The only way that this is
compatible with membership in tl and t2 is for ti and t2 to begin with a, as is shown
in Fig. 1.12.
h
1 1 a 1
v
/ \
a \ | |
'1
FIG. 1.12
Thus ti is a half-block and t2 is a subword of the following half-block. In
Table 1.4, we enumerate all the possible cases in order to determine which ones are
actually feasible.
1.8* NONREPETITIVE WORDS 39
Inspection of the table shows only two possibilities. Either:
1 ti is the second half-block of a and t2 is a subword of the first half-block
ofa;or
2 ti is the second half-block of 7 and t2 is a subword of the first half-block
of y.
In the event that (1) holds, 77 contains aa; and if (2) holds, 77 contains cc.
TABLE 1.4 Feasible matches
between tt
ti
abc
ab
ab
ab
ac
abcb
abcb
abcb
acbc
acb
acb
acb
[ and t2w2
t2w2
ab
abc
ac
acbc
abcb
abc
ac
acbc
acb
abc
ac
acbc
Feasible?
No
Yes
No
No
No
No
No
No
No
No
No
Yes
CASE 3. #a0i)=0. Then #a(t2) = 0 also. Since there are at most three
letters of the sequence between any two consecutive a's, the only possibility is that
lg(fi) = IgCa) = 1.
but this is impossible, because no two consecutive letters are equal. □
With the aid of this lemma, the main theorem follows easily.
Theorem 1.8.1 Let 2 = {a,b,c}. There is a "doubly-infinite"-length string
over 2 which is nonrepetitive; i.e., has no two consecutive identical subwords.
Proof Define the sequence
So = a,
Then
Si = 0a = a = abcab
§! = a contains a = So as a strictly proper subword [i.e., the first and last letters of
Si are not in So] ■ Repeating §2 has Si as such a subword and, in general, %n contains
S„-i as a strictly proper subword. There is a unique infinite-length 2-sequence % =
liirin^ooSn such that each prefix of S of length lg(Sfe) is %k. S does not contain any
repetition of any subword because §0 = a does not and by the Lemma. □
40 FOUNDATIONS OF LANGUAGE THEORY
PROBLEMS
*1 Generalize the result of this section to show that there exist sequences
of unbounded length over an alphabet of five letters, which are strongly nonrepetitive;
i.e., such that there are not two consecutive words t\ and t2 such that t2 is obtained
by tx by a permutation of the letters. [Hint. Let 2 = {a, b, c, d, e) and let a be the
cycle (abed e). Define a homomorphism 0 by:
4>a
4>b
0C
4>d
0e
=
=
=
=
=
bacaeacadaeadab
a (a),
a2 (a),
a3 (a),
a4 (a),
So =
*;+i =
a
«(*»),
Now define
to obtain the desired result.] Can you take the limit of the £,• to obtain an infinite
sequence?
2 Taking the sequences constructed in Problem 1, show that asymptotically
each symbol occurs with density |.
3 Show that if k < 3, any string over an alphabet of k symbols of length
greater than 2fe — 1 has two consecutive subwords, one of which is a permutation of
the other.
4 (Open problem). Do there exist infinite sequences over a four-letter
alphabet which are strongly nonrepetitive?
5 Let S be a semigroup. An element 0€S is a zero for S if sO = Os = 0
for each s65. S is nilpotent if there exists an integer k such that Sk = {0}.
Construct a semigroup S which is nonnilpotent, has three generators, and the square
of each element in S is 0.
1.9* THE LAGRANGE INVERSION FORMULA AND ITS APPLICATION
There is an old inversion formula due to Lagrange which is occasionally useful
in language theory. We sketch a derivation of the formula and omit all considerations
of convergence, as is customary in the combinatorial applications of generating
functions and power series.
Suppose that
x = yf(x), (1.9.1)
and that f(x) can be expanded as a power series in x:
fix) = 1 ftx1, (1.9.2)
1 = 0
1.9* THE LAGRANGE INVERSION FORMULA AND ITS APPLICATION 41
where f0 ¥= 0. We wish to solve not just for x as a power series in y, but for some
functiong(x). That is,one seeksa0,ai,...,such that:
g(x) = t a-j. (1.9.3)
1 = 0
Since (1.9.3) implies that x = 0 if y = 0, then a0 = g(0)- Moreover,
y = x(f(x)yl = £ bfic'. (1.9.4)
;=i
If Eq. (1.9.3) is differentiated, we get
g\x) = I ia^'1 £. (1.9.5)
Multiplying (1.9.5) by (f(x))n yields:
S ■ dv
g'(x)(f(x)f = X /^'-'(/W)"/. (1.9.6)
/=i dx
By using(1.9.1), we get:
g\x){f{x))n = 1 ia^'"-1 xn ^. (1.9.7)
i*=i ax
Let us now evaluate
J^i tfMM4-.
by using Eq. (1.9.7). Clearly, the result is:
(n - 1) ! [Coefficient of*""1 in (1.9.7)]. (1.9.8)
This gives rise to two cases.
CASE 1. i = n. The general term of (1.9.7) becomes:
iaiyi'n''xn^- =nanxn-d^, (1.9.9)
dx y dx
n ^"=1 lV"
= nflnx"'^! +CiX + c2jc2 +...).
Therefore the coefficient of*"-1 is:
nan. (1.9.11)
CASE 2. / =£ n. The general term is
• , dv \ d .
iaiXny'""-» -j- = iaiX" — \y>~n ]. (1.9.12)
dx i—ndx
nanxn !Ti ' ,. (By using (1.9.4)) (1.9.10)
42 FOUNDATIONS OF LANGUAGE THEORY
Note that there does not exist any power of x (even negative ones) which has a
derivative l/x; consequently (d/dx) \y'~n] does not contain*-1 and Case 2 contributes no
terms in x"'1.
ThuS £ ■ , dy
X idix"/-"'1 -^ = ... + nanxn~l + ..., (1.9.13)
and therefore ,n
. T^i fe'WtfW)"] = (« - 1)!«»„ = «!«„•
c?x '*=o
The expression for a„ is:
n! g?x
fl" = i tSt-i &'(*)(/(*))") I _ (1-9-14)
if n > 1 and
flo = *(0). (1.9.15)
Summarizing the above discussion, we have proved a famous theorem of
Lagrange. Actually we shall state a slightly stronger theorem than we proved, and leave
the generalization to the reader. Instead of forcing our original relation to be
homogeneous, we shall allow a constant term. The changes to the statement and theorem
are minor.
Theorem 1.9.1 Let
x = c+yf(x). (1.9.16)
Then
dn-~, g'(x)(f(x)r (1-9.17)
g(x) = g(c)+ X ^r
ixn
First, we give a purely mathematical example of the use of Lagrange's
Theorem.
Example Let
x = yex. (1.9.18)
Then (/(*))" = enx and takeg(x) = x. Computing, we get:
dx"'1
so that „
flo = 0,
a„ = nn~
and oo ..n
L—y. (i.9.i9)
n = l n\
One may check that (1.9.19) is a solution of x in terms ofy by substituting in (1.9.18)
Now let us consider an example from language theory. Consider the
grammar G:
S -> SbS\a
1.9* THE LAGRANGE INVERSION FORMULA AND ITS APPLICATION 43
The language L(G)= {(ab)na\ n>0} is ambiguously generated by G. We seek the
number of derivations of (ab)na. Let us rewrite the grammar as an equation:
S = a+SbS. (1.9.20)
One may now derive the power-series solution of (1.9.20) iteratively but we need not
do so here. If we map Eq. (1.9.20) into the ring of polynomials in the natural way
(actually mapping from the noncommutative case into the commutative one), we get
U UlUL/L/Ulgi
Thus (1.9.20) becomes:
Thus f(x) = x2. For g(x),
Now we evaluate
dn-l
dx"'1
and ,~ -.
(2n)-
an -
Therefore
S » x,
b » y,
a » 1.
x = yx2 + 1.
we choose:
g(x) = x.
(x2n) = (2n)(2n - 1) • • • (n + 7)xn + l
•■(n + 2)(n+l)! 2n\ _ (2„")
n\ (n+1)! (n+l)(n!)2 (n + 1)
*-i+i[i?y
(1.9.21)
This tells us that there are (2„")/(n + 1) derivation trees of (ab)na. One could also
derive the result from the grammar by generating function techniques, but the
present approach is easier and more general.
PROBLEMS
1 Carry out the nonhomogeneous proof of Theorem 1.9.1.
2 Was it necessary to use the nonhomogeneous form of Lagrange's theorem
in working the last example of the section?
3 Let 1 — x + yxl3= 0. Use Lagrange's theorem to solve forx" as a function
of y. By judicious choices of a and /?, a number of classical identities involving
binomial coefficients may be derived.
4 Consider the grammar
S -> aSa\bSb\aa\bb\A
Show directly that the number of strings of length i in this grammar is given by 5;,
where
0 if i is odd,
6< i ,
2* if i = 2/'.
44 FOUNDATIONS OF LANGUAGE THEORY
5 Suppose we have a triangle ABC. By placing a new point in the interior
and joining this point to each of the vertices A, B, and C, we can decompose the
triangle into three elementary triangles. This construction may be iterated with some
other triangle. The diagrams in Fig. 1.13 show the "triangulations of a triangle" with
1,3, and 5 elementary triangles. Find the number of triangulations of a triangle into
n elementary triangles. [Hint. Construct a map from triangulations to parenthesized
strings. Construct an appropriate grammar which generates these strings such that the
degree of ambiguity is the desired number.]
, A
3 A
.A A A
FIG. 1.13
1.10 HISTORICAL SURVEY
The origins of formal language theory may be found in the work of Chomsky
[1959a, 1963, 1964, 1965]. A number of important early contributions are due to
Bar-Hillel and his colleagues, and may be found in Bar-Hillel [1964]. There are a
number of other general books on this subject. Aho and Ullman [Vol. 1,1972] cover many
of the basic facets of the theory in a book oriented toward theories of translating and
compiling. Book and Greibach [1973] present the basic theory in a style oriented
towards a general abstract study. Ginsburg [1966] is a text that emphasizes the
mathematical aspects of the context-free case. Hopcroft and Ullman [1969] give a
very general coverage, as well as a number of related topics. The book by Salomaa
[1973] covers a wide variety of topics concerning formal languages, also.
Theorem 1.2.1 is from Levi [1944]. Much of the material from Section 1.3
may be found in Lentin [1972] and Schutzenberger [1967]. In particular, Theorem
1.3.3 is from Fine and Wilf [1965]. Theorem 1.7.1 is from Ramsey [1930]. The proof
given follows Ryser [1963] and Erdos and Szerkeres [1935]. The latter reference
contains the geometric results given in the problems. Theorem 1.8.1 is from Pleasants
[1970]. Our proof of the Lagrange inversion formula follows Stanton [1961].
Applications of simple language theory to compiling may be found in the
textbooks by Gries [1971] and Aho and Ullman [1977].
tWD
Finite Automata
and Linear Grammars
2.1 INTRODUCTION
In this chapter, regular events, or the sets accepted by finite automata, are
discussed. In particular they are characterized by a class of context-free grammars
as well. This fills in one of the pieces of the Chomsky Hierarchy. A number of simple
but useful results are obtained both in the text and in the exercises.
It has been assumed that the reader has had some familiarity with elementary
automata theory and so the coverage in this chapter is quite concise. Readers who
experience difficulty are advised to consult some of the general references given in
Section 2.7.
2.2 ELEMENTARY FINITE AUTOMATA THEORY - ULTIMATELY
PERIODIC SETS
The techniques and results of finite automata theory are necessary for our
development. The subject is treated very concisely here and the reader is referred to
the literature for a more leisurely discussion.
Definition A finite automaton is a 5-tuple A = (Q, 2, 8,q0, F), where:
i) Q is a finite nonempty set of states.
ii) £ is a finite nonempty set of inputs.
iii) 6 is a function from Q x 2 into Q called the direct transition function.
iv) q0^Q is the initial state.
v) f~ Qis the set of final states.
45
46 FINITE AUTOMATA AND LINEAR GRAMMARS
Next, it is necessary to extend 6 to allows! to accept sequences of inputs.
Definition Let A = (Q, 2,,8,q0, F) be a finite automaton. For each (q,a,x)
G Q x 2 x 2*, define
8(q,A) = q and 8(q,ax) = 8(8(q,a),x).
Note the following simple identities:
For each q&Q;x,y,z&'2*,
8(q,xy) = 8(8(q,x),y); (2.2.1)
8(q,x) = 8(q,y) implies S(q,xz) = 8(q,yz). (2.2.2)
The notation rp(y) = 8(q0,y), the "response" to y, is sometimes used, and
denotes the stated reaches after reading^.
Finally, A accepts a string* G 2* if A, starting in q0 at the left end of x, goes
through some computation and reads all of x, and stops in some final state. The set of
all accepted strings is denoted as 7\A). More compactly,
T(A) = (*G2*| 8(q0,x)GF}.
Definition A set L £ 2* is called regular if there is some finite automaton
A such that L = T{A).
Example Let L = {a'V| i > 0, / > 0} = a*b*. We shall show that L is regular
by constructing a finite automaton A which accepts x. To avoid excessive formalism,
we draw the "state diagram" of A as in Fig. 2.1. The initial state is q0 and the set of
final states is F = {q0, q^.
a b
0—-—^Q—-—>
FIG. 2.1
In our discussions of families of languages, we want to show that certain
sets are not definable. For this reason, we need to find a set that is not regular.
Theorem 2.2.1 The set L = \a'b'\ i ~> 0} is not regular.
Proof Suppose L = {a'b'\ i>0} is regular. Then there exists a finite
automaton A = (Q, 2, 8,q0,F) so that L = T(A). Consider the set {6(^r0, «')l i > 0}. There
are infinitely many tapes a', i > 0, and only finitely many states in Q. Therefore, there
exist i,/, with i >/, so that
Sfao.<0 = SfaoX).
2.2 ELEMENTARY FINITE AUTOMATA THEORY 47
By setting z = b' in Eq. (2.2.2), we have:
8fooV6') = SfaoX'n
If 8(q0,a'b') = q is in F, then a'b' is in T^), which is a contradiction since />/. If
# ^ F, then a'b' £ T(A), which is again a contradiction. Therefore, L cannot be regular.
□
We shall now establish a necessary condition on strings in a regular set. This
theorem and its generalization for more powerful classes of sets is an important tool
in proving that certain sets do not belong to the family in question.
Theorem 2.2.2 (Iteration theorem for regular sets) Let A = (Q, 2, 6, q0, F)
be a finite automaton with n states. Let wEJ\A) and lg(w)>m. If m>n, then
there exist x,y, z, such that w = xyz,y ¥= A, and xykz G T(A) for each k > 0.
Proof Let w = al- • am. Consider the set Q = \rp(ax • • • at)\ 0 </ <m\
We have \Q\ = m+ 1 >n = |Q|. Then there must be p, r,such that 0 <p<r<n so
that qp = qr where qt = rp(at ■ • •«,) for / > 0. Take x = ax ■ ■ ■ ap, y = ap +1 • • • ar,
z = ar+1- ■ -am. Note that lg(y) = r — p>0. Thus w = xyzET(A). Also, rp(x) =
rp(xy).
We claim that
rp(x) = rp(xyk) for each k > 0.
Proof of claim by induction on k k = 0 is trivial. Then,
rp(xyk+1) = 8(rp(xyk),y).
By the induction hypothesis,
rp(xyk+1) = 8(rp(x),y) = rp(xy) = rp(x)
and the claim is verified. Therefore
rp(w) = rp(xyz) = 8(rp(xy),z)
= 8(rp(xyklz) = rp(xykz).
Thus, if w G T(A), then xykz G rC4) for each yfc > 0. □
Next we turn to the question of dealing with regular sets over the one-letter
alphabet.
Definition 1 A set X of natural numbers is said to be ultimately periodic if
X is finite or if there exist two integers No>0,p> 1, so that if x > N0, then xGI
if and only if x + p G X.
Example The sets X\ and X2 are clearly ultimately periodic:
Xx = {10, 12, 14, 16, 18,...}, #oi=10, Pi = 2;
X2 = {5,8, 11,14, 17,...}, #02=5, p2 = 3.
48 FINITE AUTOMATA AND LINEAR GRAMMARS
Also X3 = Xi U X2 is ultimately periodic. Find N03 and p3.
It is useful to establish a canonical form for ultimately periodic sets.
Theorem 2.2.3 Let X be an ultimately periodic set with N0 and p as in the
above definition. Let
A = Xn{i\ 0<i<No}
and
B = U feCO + pfl «>o},
;'=i
where
G = fe(l),...,g(s)}
= AT>{/| N0<i<N0 + p).
Then X = A U 5.
/Voo/ First we show the following proposition.
Claim 1B=U {g(/) + p/| J > 0} = {x GXI x >#<,} = ^at0-
/V<w/ rtar 5 9 xNo Note that for any /, g(j)<=X and N0<g(j)<N0 +p.
Then *(/) G X^ and g(/) + P°G X^.
Claim 2 Hy^X andy>N0, theny + ip GI for all i, i > 0.
Proof of Claim 2 The argument is a trivial induction on i.
Returning to the proof of Claim 1, note that g(j) + ip G XN and the first
part of that proof is complete, because we have now shown that B ? XNo.
Conversely, suppose that xGXN . ThenxGl and x>N0. Consider
{x\x>N0} = U Yi,
where
Y, = {y\N0 + ip<y<N0 + (i+l)p}.
This can always be done as we are dividing an interval into a countable number of
subintervals which do not overlap.
Claim 3 If x£XN n Yh then x = g(j) + ip for some /, 1 </' < s. Moreover,
xGB.
Proof of Claim 3 The argument is an induction on i.
Basis. i = 0. x£XNo and N0<x <N0 + p. Thus, x = g(j) for some /',
1 </ < s. Therefore x = g(f) + 0 • p and the basis is complete.
Induction step. Assume the result for i = k. Suppose that x£XN and
N0 + (k+ l)p<x <N0 + (k+2)p. Subtracting p from all parts of the inequality
2.2 ELEMENTARY FINITE AUTOMATA THEORY 49
gives N0+ kp <x — p <N0 + (k + \)p. Thus* — p£XNa n Yk and, by the induction
hypothesis, x — p =g(f) + kp for some /. Now we know that x =g(j) + (k + \)p,
and the induction has been extended. Note that xGB because B contains numbers
of this form.
Now the proof of Claim 1 can be finished. Recall that we assumed that
x £X and x >N0- Then x £ Yt for some / and, by Claim 3, x = g(j) + pi for some
/, so thatxGB.
To do the main proof is now easy. Clearly, if x£A UB, then xGI, since
A'-X and by Claim 1. On the other hand, suppose xGX. If x <N0, then xGA. If
x ~> N0, then xGYt for some i, and Claim 3 implies that xGB. □
We can also discuss ultimately periodic sequences as well as sets.
Definition 1 An infinite sequence {xn} of natural numbers is ultimately
periodic if there exist integers N'0 ~> 0 and p > \ such that xn+p' = xn for each n > N'0.
Example (3, 2,1,1,2, 2,1,1, 2, 2,1, 1,2,. ..) is an ultimately periodic
sequence.
This allows us to give a second definition of ultimately periodic sets.
Definition 2 A set X of natural numbers is said to be ultimately periodic if
X is finite or if the sequence (jv1,jv2 —>"i, • • • ,yn+i ~)>n,.. .) is an ultimately periodic
sequence where (yi,y2,.. •) are the elements of X'm increasing order.
Example Consider the set X3 defined at the beginning of this section. A
simple calculation shows that the desired sequence occurs in the previous example and
so X3 is ultimately periodic.
Of course it must be shown that these definitions are equivalent.
Theorem 2.2.4 Definition 1 is equivalent to Definition 2.
Proof The argument is left to the reader.
Definition 2 is more convenient than Definition 1 in showing that particular
sets are not ultimately periodic.
Now we are ready to prove the main result about this topic.
Theorem 2.2.5 A set L £ {a}* is regular if and only if X is ultimately periodic
whereX = {i\ a'<=L}.
Proof Assume that X is an ultimately periodic set of natural numbers. By
Theorem 2.2.3, X = A UB where A is finite and
B = [}{g(j) + pi\i>0}.
Thus s
L = {al\ iGX) = {al\ i£A}U (J {ag(J)+ip\ i>0}.
50 FINITE AUTOMATA AND LINEAR GRAMMARS
The first set is regular since A is finite. The second set is the finite union of sets of
the form {ag(')+ip| i &*0} = a8(J^(cf)*, and so these are regular sets and L is regular.
Conversely, suppose that L'- {«}* is regular. L = T(A), where A = (Q,{a},
8,q0,F). Write L = {a'\ iGX}. If L is finite, then X is finite and hence ultimately
periodic, and we are done. Suppose L is infinite. Then let N0 be the least number such
that c^o^L and N0> \Q\. By the iteration theorem, we know that aN° = a'apas,
p>\, and moreover rp^0) = rp(a'(ap)"as)G F for any n>0. When n = 2, we have
rp(aN°) = rp(aN°+p).
To show that X is ultimately periodic, let i > N0 so that i = N0+ s for some
s > 0. We must show that i G X if and only if i + p €= X. We compute
/p(«'") = r/V^) = 8(rp(aN°),as)
= 8(rp(aN°+p),as) = rp(aN°+s+p)
= rp(ai+p).
Therefore / G X if and only if i' + p G X. Thus X is ultimately periodic. □
One important use of this result is to show that certain sets cannot be regular.
Example {an \ n > 1} is not regular. Let X = {n2 \ n > 1}. Suppose that X
were ultimately periodic. Then the sequence (yi,y2~yu ■ ■ •) would be ultimately
periodic. But this sequence is (1,3,5, 7,9, 11,. . . , In + 1,. . .). In order for the
sequence to be ultimately periodic, we need to have y„+i—y„ = yn+p'+i~yn+p'
for some p . This implies 2« + 1 = 2(n + p')+ 1, which implies p' = 0, which
contradicts p > 1.
PROBLEMS
1 Design a finite automaton that accepts the set
L = {u>G{a,/)}*| w does not contain the sub word bab}.
2 Let xGS*. Construct a finite automaton that accepts {x}. How many
states are there in the minimal finite automaton for this set?
3 Leti?9£x£be given. Define
HR = {flj • • -ak\ k>2, (ai,ai+l)GR{or each i, Ki<k}.
Show that HR is regular.
4 Let*, yes*. Define
XY'1 = {w\ wy<EX for somey G V}.
Show that if X is regular and Y is arbitrary, then XY'1 is regular.
5 Show that the set {xx\ x G {a, ft}*} is not regular.
6 Show that the following sets are not regular.
a) {/| n > 1} b) {a" | pis prime} c){a"l\n>l}
2.2 ELEMENTARY FINITE AUTOMATA THEORY 51
7 Let R be an equivalence relation on a set. Let rk(R), the rank of equivalence
relation R, be the number of equivalence classes induced by R. Let Ex and E2 be
equivalence relations on X. We say Ex refines E2 if Ex £ £"2 (that is, xExy implies that
xE-iy). Show that if Ex and £"2 are equivalence relations on X, it follows that, if
Ex £ e2, then rfc(£"i) > rk{E2).
8 Let Z? be an equivalence relation on 2*. R is a ng/jf congruence relation
if xRy implies that, for any word z G £*, (xz)R(yz); that is,
(x,y) (=R implies (xz,yz) (=R for all z£X*.
Furthermore let L <= 2*. Then Z? refines L iff (x, >>) G Z? implies that x G Z, if and only
if >> GZ,. That is, if xR.y, then either x and .y are both inZ, or x andy are both not in
L. Show that R refines L if and only if L is a union of some of the equivalence classes
oiR.
9 Let L 9 2*. Define Z?i; the ngTif congruence relation induced by the set L,
as follows:
(x,y)GRL if and only if for each z G 2*
[xz(=lL if and only if yz G L ].
Prove the following proposition.
Theorem
a) RL is a right congruence relation.
b) RL refines L.
c) If R is any right congruence relation that refinesL, theni? £ RL.
10 Prove the following proposition:
Theorem Let L £ £*. The following statements are equivalent.
a) L is regular.
b) There is a right congruence relation on 2* of finite rank which refines L.
c) RL has finite rank.
11 Prove Fermat's little theorem. That is, for any prime p and nonnegative
integer a, d — .'
<r = a mod p.
Let us fix £ = {0, l} and define a mapping from £* into the natural numbers, as
follows:
x »■ x
where x is the integer represented by x as a binary string. If x = an^ ■ ■ ■ a0, then
n-l
x=Y, ai2'-
For example,
1=1 101 = 5
10 = 2 A = 0
52 FINITE AUTOMATA AND LINEAR GRAMMARS
12 Prove the following facts:
a) The map x *+ x is a one-to-one map from {l}£* onto the positive integers.
b) For any x, y G £*,
xy = 2l^y)x+y.
c) For any x G £+ and fc > 1,
2fe !g(*) — J
(*fe) = x
13 Prove the following result.
->ig(*)
1
Theorem Let £ = {0, 1} and p be an odd prime. If xj.zGT, so that
2lg(y)# 1 mod p, then
xyp~xz = £z mod p.
14 Prove the following result: Let £ = {0, l}withx, y,z G£*. Letp = xykz
be an odd prime and assume 2l6(y) ^ 1 mod p. Then
xj^ ^p~'z = *y z = 0 mod p.
15 Is the hypothesis that 2lg(y) # 1 mod p actually needed in Problems 13
and 14?
Now the previous problems can be combined to show that no infinite set of prime
numbers can be regular if they are represented in this fashion.
16 Prove the following result.
Theorem Let £={0, l}. Let ^be any infinite subset of {l}£* such that
w G S6 implies that w is prime. Then S6 is not regular.
2.3 TRANSITION SYSTEMS
For our purposes it is convenient to consider a more complex type of device
than a finite automaton. Let us describe our new device by a state graph, i.e., a finite
directed labelled graph. Consider the graph shown in Fig. 2.2. Note that this graph
has two arrows labelled 0 leaving q0 and even has two initial states. Formally, we have
the following definition:
Definition A transition system is a 5-tuple A = (Q, £,6,20, F) where Q,
2, and-Fare as in a finite automaton, 0^=QO- Q and 6 is a finite subsetof Q x 2* x Q.
Note that every finite automaton is a transition system.
Definition A transition system A = (Q, 1,,8,Q0,F) accepts w^I,* if there
exist r>0,w = u1 • • • «r,«; G I,* ,q0,. . . , qr G Q such that
0 Qo^Qo,
ii) (Qi, W/+i, 4,-+i) e S for 0 < i < r,
hi) qr^F.
2.3 TRANSITION SYSTEMS 53
A F={q3}
Go = too. <7il
FIG. 2.2
Write T(A) = {w\ A accepts w). Intuitively, A accepts w if there is a path in
the graph from some initial state to some final state and the concatenation of all the
labels on the path is w.
Note that if A is a finite automaton, T(A) is the same as when A is regarded
as a transition system.
Example In the previous example, 101011 £ T(A). There are infinitely many
different paths from q0 to q3 with that label.
Since every finite automaton is a transition system, these devices accept all
the regular sets and possibly more. We now show that these devices are no more
powerful than finite automata.
Theorem 2.3.1 (Myhill) For each transition system A = (Q, 2, 6, Q0, F),
T(A) is regular.
Proof We may assume that each element of 6 is a member of Q x (2 U {A})
x Q. [For if (q,x,q')G8 with lg(x) > 1, we write x = ax ■ ■ -ak, k> 2. Delete
(q,x, q') from 6 and add to 6 the triples
(Q,ahq1)
(Qi,a2,q2)
(4fe-2,afe-l,4fe-l)
where the qt are all new state symbols.]
Define B = (2°, 2, 8B, Q'0,FB) where FB = {X9 Q\ XnF=£0}. Define
the direct spontaneous transition relation, P0, on Q by:
(q,q')£P0 if and only if (q, A, q') G6;
54 FINITE AUTOMATA AND LINEAR GRAMMARS
then let P = P% be the reflexive transitive closure of P. Define
Go = {q\ Qo pQ f°r some q0 G Go }•
Finally, for each V~ Q, define 8B(V,a)= {q'\ (v,a,w)£8, wPq for some (w, v)
G G x V}.
To complete the proof, we must argue that T(B) = T(A). It suffices to show
the following:
Claim q GSB(Go,*) if and only if there exist
r,q0t. . .,qrinQ\ bu... ,6rin£U{A}
such that:
i) x = bi ■ ■ ■ br,
ii) qo^Qo,
iii) (q,, bi+1, qi+1)G 6 for 0 < /'< r,
iv) qr = q.
The argument is an induction onm = lg(x):
Basis m = 0, x = A. Then ^G6B(Qo, A) if and only if q^Qo- Thus all
b\ = A, and the basis is established.
Induction step. Suppose the result true for all sequences x of length k. We
will show it true forxa, a G 2, which has length & + 1. Let V = S'(Go, x). Then
<7'GSB(Go,*«) = Sb(Sb(Qo,*),«) = Sb(K,jc)
= {f| (v,fl,w)G6, wft for some (w,v)£Qx V).
But dGF implies that claims (i) through (iv) hold for v. Note that wPt implies a
finite number of additional A-rules (all of type (iii)) ending at q . Thus there exists
a sequence of the desired type.
Conversely, if such a sequence occurs ending at q', we have q ^rpB(xa).
Thus the claim is verified.
Finally, we verify that T(B) = T(A):
x G T(B)
if and only if
SB(Qo,*)GFB.
This holds if and only if
8B(Q'o,x)nF=t 0.
In turn, this is equivalent to the existence of r>0,blt. . . ,br in £ U {A},q0, ■ ■ ■ ,qr
G Q such that:
i) x - bi ■ ■ ■ br,
") Qo^Qo,
2.3 TRANSITION SYSTEMS 55
iii) (qh bi+u qi+1) G 6 for 0 < / < r,
iv) qr£F.
Therefore, x G T(B) if and only if x G r(4). D
Some applications of transition systems will now be given.
Theorem 2.3.2 X is regular implies XT is regular.
Proof Let X = T(A), where A = (Q, 2,6, <y0, /0 is a finite automaton. Define
B = (Q, £,6B,F, {q0}\ where 5B = {(<?',«, <?)| <?' = 5(<?,«)}. Note that B is not
necessarily a finite automaton but is a transition system. We claim that for each
x = ct\ ■ ■ ■ am, a,- G £ for 1 < i < m, q G Q, 8(q, x) = q if and only if there exist
qu... ,4m+1sothat:
0 Qm+i = q\
ii) fa,-+i,«i,4i)GSB for 1 <i<m,
iii) qi = q.
Proof of claim by induction on lg(x).
Basis, x = A so 5(^r, A) = q. But q = q1 = q0+1 = q and the basis is verified.
Induction step. Assuming the result for all tapes of length m, we have that
8(q,xa) = 8(8(q,x),a).
By the induction hypothesis, x = at- ■ ■ am, and the definition of 8B, there exist
Qu ■ ■ ■ ,4m+iS0that:
ii) (qi+uai,qi)G8B for 1 <i<m,
iii) Qi = Q,
iv) (8(q,xa),a,8(q,x))^8B.
Taking qm+2= 8(q,xa),am+1 = a, the result follows.
It is now easy to verify that T\B) = (T(A))T = XT. Let x = ax- ■■ am with
fl,-G£ for 1 <i<m.
x G T(B) if and only if there exist #i,.. ., qm+l G Q such that
0 qi^F,
ii) (q{,ahqi+1)G6B, Ki<m,
i") 4m+i = 4o.
This holds T
if and only if 5(^0,^ ) = ?i£f,
if and only if xT G X,
if and only if x GJT.
Thus T(5) = X7 is regular. D
56 FINITE AUTOMATA AND LINEAR GRAMMARS
FIG. 2.3
a,b
— >(C'^Jl — H d ) T(A) = X
B = AT (I gQ ))< b- (q^)< ^ ( d ) T(B) = XT
FIG. 2.4
Example X= {a}*{b}, XT = {b}{a}*. X is regular, since it is recognized by
the finite automaton >1. (See Fig. 2.3.)
Construct the transition system B from A by converting all final states to
initial states, the initial state to a final state, and reversing all arrows. (See Fig. 2.4.)
Next we show closure of the regular sets under product and star.
Theorem 2.3.3 If X and Y are regular sets, then XY is regular and X* is
regular.
Proof Suppose X = T(A0, Y = T(A2), where each^,- = (ft, 2,6,-, qoh F,) for
i= 1,2 denotes a finite automaton. Assume, without loss of generality, that Qi n Qi
= 0. First we construct a new transition system^, as follows:
A = (GiUe2,£,6A,{^oi},^2),
where 8A = Sj U 62 U {(q, A,^)! q^F{\. The intuitive picture of this construction
is shown in Fig. 2.5.
Thus there is a path from q01 to a final state in F2 under w = xy if and only
if there is a path q0i to a final state in Ax under x and a path from q^ to some final
state of F2 undery. Formally, it is easily seen that
T(A) = TXAJTXAi) = XY,
and therefore XY is regular.
<70I"
State graph
of A i
State graph
Q02 0{ a,
FIG. 2.5
2.4 KLEENE'S THEOREM 57
Next we construct a transition system B which can accept X*. Let
B = (Q\V {<7o}, 2, SB, {q0}, {tfo}) where q0 is a new state not in Qx.
h = 81 U {(?o, A, <7o)} U {fo, A, $0)| <7 e^i}.
The intuitive picture is shown in Fig. 2.6.
It is easily verified that T(B) = (T(A 0)* = X* and hence X* is regular. □
FIG. 2.6
PROBLEMS
1 It is easier to design a transition system to recognize a regular set than to
do it with a finite automaton. In this problem, we shall attempt to see how much
easier. Find a regular set Xn, n>\, such that Xn can be accepted by a transition
system with n states but any ordinary finite automaton takes 2" states.
2 Show that if L £ 2* is regular and </?: 2* -> A* is a homomorphism, then
<pL = {tpx\ x ez,} is also regular.
3 Show that if L 9 A* is regular and tp: 2* -> A* is a homomorphism, then
i£-1Z, ={xeS*| i^t €= Z,} is also regular.
4 Show that the family of regular sets is closed under union.
5 Are the following propositions true or false? Support your answer by
giving proofs or counterexamples.
a) If L i U L 2 is regular and | L11 = 1, then L 2 is regular.
b) If L! UL2is regular andLl is finite, thenL2is regular.
c) If Li U L2 is regular and Li is regular, then L2 is regular.
d) If /. iZ,2 is regular and | L i \ = 1, then L2 is regular.
e) If LiL2 is regular and Li is finite, thenL2is regular.
f) MLXL2 is regular and Lx is regular, thenZ,2 is regular.
g) If L* is regular, then L is regular.
2.4 KLEENE'S THEOREM
The family of regular sets has a lovely set-theoretic characterization due to
Kleene.
Theorem 2.4.1 The family of regular sets (over 2) is the smallest family
containing {a} for each a €= 2 and which is closed under union, concatenation, and *.
58 FINITE AUTOMATA AND LINEAR GRAMMARS
a b
FIG. 2.7
Proof Let M be the family of regular sets and let Jf be the least family
containing the sets {a}, a G £, and closed under U, •, and *. Clearly JT£ <% since every
set {a} is regular and by Theorem 2.3.3 and Problem 4 of Section 2.3. Conversely,
one must show that .& £ J2T. One technique for doing this is to let A = (Q, £, B,quF)
be a finite automaton with Q = {qu ..., qn}, £ = {0,1}, and F = {qSi,qs2, ■ ■■, qsr}.
Definition For all /, /', k, with 1 </, /<« and 0<k<n, define the set
c4p inductively by:
oq) = {«G£U{A}| S(q,,a) = q,}.
Then
Example See Fig. 2.7.
= a U (b U A)(6 U A)*fl
= aUb*a = 6 V
Claim 1 Let /?f/° = {* G 2* | 8(qhx) = qj and for each x, z G £+, x =jz,
8to,-,>') = ^e implies £<yfc}. Then af)=Rfjt\ That is, c$° is the set of all words
which take A from state i to state / without going through (i.e., both entering and
leaving) any state q% with £ > k.
Proof By induction on k.
Base of induction: k = 0. The definition of <4p implies that (4j>) = {a G £
U {A}|S(/jr,-,a) = qj}. Since it is impossible to factor aG£U{A} into a = yz with
y,z(= £+, we have aft* £ Rf?\ Let x^Rfp. Then Sfa,-,*) = qr Assume that x =jz
with y,z£ £+. Then S^,-,^) = qz with £ < 0. But there is no qs G Q with £ < 0. Thus
it is impossible to factor x as above. Then x must be in £ U {A}. Therefore
x G {a G £ U {A}| 8(q,,a) = q}}= oqJ\ Thus 4P> - *kP)> so °iP) = ^P>-
Induction step. Assume a\f _1) = R\f _1) for all 1 < i, j < n. Then
aW = a^-1>U(afri>)(a<fefe-1>ra^-1>
= R$-V VR\£-1\Rgk-1'>)*R%-1'> (by induction hypothesis).
To show that c$° £ R$\ assume that x<Ea\f>. Then jce/jf/8-1* or
■^^"''(^IV0)^^0 In the first case, x^R\f\ since Rtf^ £ Rtf* (easy
consequence of definition of Rfp. In the second case, x=>'zh', where J^^^"1',
2.4 KLEENE'S THEOREM 59
zGCRflr1*)*, and w^Ri)-". Then q) = S(S(S(q,,y),z),w) = S(q,,yzw) = S(qt,x).
Now suppose x—x'x", with x\ x"G £+. An analysis of the cases lg(x')<lg(y),
lg(x') = lg(», lg(»<lg(x')<lgOz); lg(*') = lgO), and \g(yz)< \g{x) < \g(yzw)
indicates that 8(qh x) = q^ with £ = k. Thus x Gi?jyfe), which means that a\f> £ R\f>.
We must now show that R\p<~ a\f^. Assume x^RJp. Then 8(qi,x) = qj
and, for every y, z G £+, such that x=_yz, Sfa/,.}') = <7e with £<&. If for every
y, z6£+, the previous sentence holds with 9.<k, then x&R^'iy = a^fe"1> by the
induction hypothesis. Suppose this stronger condition does not hold. Then there
exist y, z£J* such that x = yz and 8(q;, y) = qk- Let us further restrict y and z so
that y is minimal in the sense that if y = uv, u, z;G £+, d(qt, u) = q% then £ < k. This
simply means that y £R$~^. Now factor z into two words z = z'z" with d(qk, z')
= 4fe and z" # A (we can always do this at first by picking z' = A, z" = z).
Furthermore, choose z' and z" so that z' is the maximal prefix of z such
that Sfafe, z') = ?fe and lg(z') < lg(z). Thus z G (RgT1*)* and z" GR§"».
Summarizing, we have shown that if jc G/?^fe), then either x ^R\f x) or else
x can be factored into x =yz'z" with.y G/?f£-1),z'G(/?j&-1))*, and z'^^"^. But
this means that jtGR},*-1' URfJ-'^-'y^"1' =o{,*). Thus /?&*>£ fljf>
implying /jj^ = a\f^ and the theorem follows by induction. The situation can be
summarized by the diagram in Fig. 2.8.
xER
(*-i)
ye tit"
"e 4*-"
z'eiRi^r
FIG. 2.8
Claim 2 Let A be a finite automaton as above. Then
|0| ifr = 0 (i.e., no final states),
T(A) =
of-"^ U <#£ U • • • U a^ otherwise.
Proof If A has no final states, then T(A) = 0. Suppose r =£ 0. By the previous
theorem,
a^n) = {jcGS*| 6(^i, x) = qj and for each x,zG£+;x =yz, 8(qhy) = qs implies £<«}
= {xGS* | 6(^,-,x) = ^-} (since £ <« for all <qrc G Q).
60 FINITE AUTOMATA AND LINEAR GRAMMARS
Now.jcGTX^)
if and only if 8(qux) = q%. for some i, 1 < i < r,
if and only if i£ a\^ for some i, 1 < i < r,
if and only if x G U a{t = aft? U • • • U a$.
1 < I < r '
Therefore,
Note that the form of the regular set obtained by this method is not unique, since it
depends upon the numbering of the states.
This argument shows that L G Si is also in Jif, so that
j? =jr;
and the proof is complete. □
PROBLEMS
1 Show that:
b)«g> = «^1>(o^-1))*;
c) ag> = (a}/-")*.
2 Give a procedure for constructing a finite automaton directly from a
"regular expression," i.e., a description of the regular set in terms of Kleene's theorem.
[Hint: Use transition systems.]
3 Let L be a regular set. Let
ml = {y\ xyzGL for some x,z G £* such that lg(x) = IgO) = lg(z)}.
Show that ML, the set of middle thirds of L, is regular.
2.5 RIGHT LINEAR GRAMMARS AND LANGUAGES
We are already in a position to characterize the right linear languages. The
argument can be broken down into two lemmas. The first deals with the "power" of
this class of grammars, and shows that any regular set can be generated by some right
linear grammar.
Lemma 2.5.1 If L is a regular set, then L = L(G) for some right linear
grammar G.
Proof Since L is regular, there exists a finite automaton
A = (Q,X,8,qi,F)
such that L = T(A). (^i has been chosen as an initial state for technical convenience.)
2.5 RIGHT LINEAR GRAMMARS AND LANGUAGES 61
Since, by a suitable renaming of Q, we can make £ n Q = 0, we can assume,
without loss of generality, that £ and Q are disjoint.
Defme G = (K,S,P,«D.
where
k = sue,
/> = {q-+a8(q,a)\ (q,a)GQxI,}U{q-*A\ q^F),
the set of variables being Q and the start symbol qx G Qi-
Since 6: (2 x £ ->Q, we have immediately that G is a right linear grammar.
All that must be shown is that L(G) = T(A).
Claim For all _y G 2*, there exists a unique derivation of the form
q\ ^ yq
with q^zQ. Moreover,q = 8(q1,y).
Proof This is an obvious consequence of the fact that y determines a unique
path through the automaton. A formal proof is included as an example of how such
proofs are carried out. Hereafter, if the proofs are straightforward, they will be left to
the reader.
The proof is by induction on lgO>).
Basis. \%{y) = 0 impliesy = A; but, by definition,
8(quA) = qx.
Therefore, q1 =>q1 = Aqx = ASfaj, A) is in P, where the derivation is unique since A
has no A-rules. Therefore,
qx => A^j uniquely.
Induction step. Assume that, for all y 6 2*, if lg(j)<«, then there exists
a unique derivation
Q\ =*■ yq
and q = 8(qlty). Let w G 2* and lg(vv) = n + 1. Then w can be written
w = ya flG£, >iGS*, IgO) = n.
By the induction hypothesis, there exists a unique derivation
Qi ^yq
and ^ = S(quy). But
Sfai.jO -" a8(8(quy),a)
is in P and is unique since 6 is a function. Therefore,
Q\ ^>yK<i\,y) ^ya8(8(quy),a).
Now, using the fact that
6(Sfai,>0,tf) = &(quya)
62 FINITE AUTOMATA AND LINEAR GRAMMARS
and
w = ya
we have „
qx =*■ w8(quw) uniquely,
which proves the claim. Therefore,
qi ^yHiuy) ^y
if and only if &(qi,y) -> A is in P. But, from the definition of P, we have
&(Qi>y) "* A is ini*
if and only if S(qri,.y) S Z7. Therefore,
qi => y if and only if 8(qlty)EF,
or, equivalently,
y e L(G) if and only if yGT(A),
which proves the lemma. □
Corollary Every regular set is an unambiguous context-free language.
Example Let G be
S -» SbS\a
We have seen that G is ambiguous. But L(G) = (ab)*a is regular, and hence there
exists an unambiguous right linear grammar G' such that LOG') = (ab)*a. For instance,
G' could be taken to be
S -> aM|a
Now we turn to the reverse direction of simulating a right linear grammar by
a finite automaton. Such a direct construction would be tedious because there is much
more "freedom" in what the grammar may do than there is in a finite automaton; but
the proof becomes transparent with the aid of transition systems.
Lemma 2.5.2 If L is generated by a right linear grammar, then L is regular.
Proof Let L = L(G), where
G = (V,2,P,S)
is a right linear grammar. Now define a transition system:
C= (G,2,6,{5},n
G = (K-2)U{?}, q$V,
F = {q},
8 = {(Qi,u, q})\ qi ->uqs is in />}U {(qhu,q)\ q-t ->« is in/>}.
Clearly, C is a transition system, and all that must be shown is L(G)= TOC). As is
typical in these constructions, it is easier to prove more.
2.5 RIGHT LINEAR GRAMMARS AND LANGUAGES 63
Claim Letr>l. S = w0^Wi =>w2^- •' =*w, = w £L(G) if and only if
there exist«,- e 2* for 0 < i < r\ qt E Q for 0 < / < r, such that:
i) W[ = «i • • • UjQi for 0 </ < r,
ii) wr = «i • • • ur
iii)'(<7/»u/+D<7/+i) is in 6 forO</<r — l.and
iv)'(<7r-i,ur,<7)isin8.
Proof of the claim It is easy to see, by induction on r, that
S = w0^wi^- ■ -^ = w&L(G)
if and only if there exist«,- S 2* for 0 < / < r; qi G 2 for 0 < / < r, such that
i) W; = «! • • • U(<7/ for 0 </ < r,
ii) wr = «!-•• «r
iii) <7,-->-Mi+i<7,-+i is inP for 0 <i<r — 1, and
iy) ^?r "*■ "r is in ^>-
But by the construction, (iii)' and (iv)' are equivalent to (iii) and (iv). But the second
half of the biconditional, together with the fact that the initial set of states is {S} and
q&F, gives us
S ^ w, we2* ifandonlyif wGT(G).
Therefore,
L(G) = T(Q.
Since C is a transition system, L(G) is regular. CD
Combining this with Lemma 2.5.2 leads to the main result of this section.
Theorem 2.5.1 L is a right linear language if and only if L is a regular set.
Corollary Every regular set is a context-free language.
Consider the grammar G with production
S -» aSb\A
G is a linear grammar with only one variable and
L(G) = {albl\ i>0}.
We know that L(G) is not regular. Therefore, there are linear languages which are not
right linear languages.
Theorem 2.5.2 The family of right linear languages (regular sets) is a proper
subfamily of the family of linear context-free languages.
Corollary The family of regular sets is properly contained in the family of
context-free languages.
We will establish other properties of these classes of grammars in later sections
when more techniques are available.
64 FINITE AUTOMATA AND LINEAR GRAMMARS
PROBLEMS
1 Show that every linear context-free language may be generated by a
context-free grammar G = (V, 2, P, S), where each rule is of the form:
A -> a
A -> aB
or
A -> Ba
where A, B GN,a GT, U {A}. This is sometimes called linear normal form.
2 Prove the following fact:
Fact L 9 2* is a linear context-free language if and only if there exists a
set 2', a regular set £/9 (2')* and two homomorphisms tfil and ip2 from (2')* into
2* so that L = Wi(w)ip2(wT)\ w S £/}.
3 Show that a language L is left linear if and only if L is regular.
4 A context-free grammar is metalinear if each rule is of the form:
S-*Al---Am A{GN-{S);
A -+ UiBui BGN — {S};ul,u2€.'Z*;
A -> u u G 2*.
A set i is metalinear if i = i(G) for some metalinear grammar. Show that L is
metalinear if and only if L is a finite union of products of linear context-free languages.
5 Consider an automaton which has a nondeterministic finite-state control,
two read-only input tapes equipped with right end markers, and which computes as
follows: It starts with input pair (u>i $, u>2$), reading the left end of both tapes. At each
instant of time, the read head of one tape (assume it is associated with the current
state) advances one square to the right and a state change occurs. The device accepts
by final state when one tape has been entirely read. We say the device accepts (x,y) if
(*$,;>$) leads to an accepting configuration. Such a device accepts a binary relation
on words. Formalize such devices. Show that if L is a relation accepted by such a
device, then
IIi(Z,) = {xS2*| (x,y)GL for somey& 2*}
is regular.
6 Show that L is a linear context-free language if every string z S L can be
represented as z = xy and the set
{(x,yT)\ z = xyGL)
is accepted by a nondeterministic two-tape finite automaton. (Cf. Problem 5.)
7 Let L 9 2*c2* with c^2. Is it true that if L is a linear context-free
language, then {x\ xcy S L for some y S 2* } is a regular set?
8 Show that, for k> 1, Lk =a* ■ ■ ■ a% may be generated by a right linear
grammar which has k variables. Show that there is no right linear grammar with fewer
than k variables that generates Lh.
2.6 TWO-WAY FINITE AUTOMATA 65
2.6 TWO-WAY FINITE AUTOMATA
We now consider finite automata which can move both ways on their input
tapes. Intuitively, such devices should be able to accept more than just regular sets,
since they can revisit certain parts of the input.
Definition A two-way finite automaton is a 5-tuple A - (Q, 2,6,^0,F),
where Q, 2, q0, F are as in a finite automaton; 6 is a map from QxS into {—1,0, 1}
xfi.
Intuitively, 8(q, a) = (d, q') means that, if A is in a state q reading input a,
then A goes to the left when d = — 1, remains stationary if d = 0, or goes to the right
if d = 1 and enters state q .
Definition Let A = (Q, X,8,q0,F)be a two-way finite automaton. Assume,
without loss of generality, that Q n 2 = 0. An instantaneous description (or ID)
of A is an element of 2*Q2*.
Example The ID ax ■ • • a,--^,- • ■ ■ an describes the machine as drawn below:
a\
"2
"i-i
at
a„
<7
Definition The move relation |— of ID's of a two-way finite automaton
A = (Q, 2, 8,q0,F) is defined as follows: For any q &Q;ax,... ,an e 2,
a! ■ • • qat ■ ■ ■ an h«i • • • Qa^d ■ ■ ■ an
if 8(q,ai) = (d,q'), where n > 1, 1 </<n, and an+l = A. Moreover, if /= 1, then
d>0.
The convention a„+1 = A allows A to leave the righthand end of its input
tape. The last condition prevents A from going left from the first square of the tape.
As usual, |— denotes the reflexive—transitive closure of |—. It is interesting
to compare the following two relationships.
a) qz )r qz,
b) xqz \~xqz.
If (a) holds, it means that A starts on the lefthand symbol of z, computes within z,
and returns to the same place. Thus, if (a) holds, one can say that (b) holds. On the
other hand, if (b) holds, A starts at the same place but the computation may involve
visitingx as well as z, and one cannot conclude that (a) holds.
Next, we can define acceptance.
Definition Let A = (Q, 2, 8,q0,F) be a two-way finite automaton. Define
T(A) = {x S 2* | qoX )r xq for some q E F}.
66 FINITE AUTOMATA AND LINEAR GRAMMARS
Example Let A be as shown in Fig. 2.9.
0 l
<7o
<7l
12
1. Qi
— 1. <7o
-1.91
-1. Qi
0, ft
1. 12
F={q2}
FIG. 2.9
Clearly,
<70011 hOflill
hO^ll
h01^2l
h-01l£|2.
Thus, 011 E 7X4). The reader should verify that 00 <£ T(A) and 00 causes,4 to go into
an infinite loop.
Since every finite automaton is a special case of a two-way finite automaton,
these new devices can accept every regular set and possibly more. Our next definition
is useful in analyzing the behavior of two-way finite automata.
Definition Let A = (A, 2,8,q0,F) be a two-way finite automaton and
suppose 0 £ Q. For each x E 2*, define a map tx from Q U {0} into Q U {0}, where:
i) lfx=x'a for some a €2 and x'qa f— x'aq', then rx(q) = q'.
Otherwise, Tx(q) = 0.
ii) If q0x \- xq', then tx(0) - q .
iii) Otherwise, tx(0) = 0.
In words, condition (i) means that A is started on the rightmost symbol of an input
x in state q. If A ultimately leaves the entire input word in a state q , then Tx(q) = q .
Otherwise, rx(q) = 0.
Condition (ii) means that if A is started on the left end of input x in state
q0 and it finally goes off the right end of x in state q , then tx(0) = q . Otherwise,
7,(0) =0.
In order to analyze the computations, we shall examine computations which
"return to the same place."
Definition Let A = (Q, 2, 6, q0, F) be a two-way finite automaton. For
each x, z S 2*; q, q'^Q define xqz r~xq'z if there exist n > 1, xt, zt E 2*, where
1 < / < n and
xtfiZi h x2q2z2 h •■• \-x„q„z„
with:
i) xtzt = xz for all /, 1 < / < n,
ii) xlqlzl =xqz,
2.6 TWO-WAY FINITE AUTOMATA 67
iii) xnqnzn =xq'z, and
iv) for all/, 1 <i<n,xt ¥=x andzt ¥=z.
Thus, xqz \— xqz describes the shortest non-null computation which starts with the
input head on the first square of z and returns to that position.
We now begin to relate the t functions to computations.
Lemma 2.6.1 Let A = (Q,X,8,q0,F) be a two-way finite automaton. For
a\[x,y S 2*, if tx =Ty, then, for any z S H*;q,q' S Q,
xqz \— xqz if and only if yqz \— yqz.
Proof Figure 2.10 illustrates computations on xz and yz if we assume that
tx =Ty. Note that xq2z \—xq3z and yq2z Y~yq$z, even though the computations
are different.
x z
<?o«-
<7l
—•—
12
H <73
I
14
<?5
<?6
V Z
<7o«-
<7l
—•-
12
—•—
<?3
14
—•—
<?5
—•—
<?6
—•—
FIG. 2.10 The traces of a computation on xz and on yz if
Tv = 7„
68 FINITE AUTOMATA AND LINEAR GRAMMARS
If x = A, then
t*(0) = q0 and Tx(q") = 0
for all q" e Q, by the definition of rx. Assume that y ¥= A; that is, y = y'a for some
u6E. Since rx =Ty, we know that Ty(0) = q0 and
Qoy f-yQo implies q^'a $- y'aq0,
which implies
Qoy a ^~y'q"a ^~ y'aq0 for some q" eg,
But then , „ , . , „.
Ty(q ) = q0 * o = Tx(q ),
which is a contradiction. Thus,.y = A.
Combining the previous argument with symmetry, we see that the following
is true:
Fact x = A if and only if y = A.
By the symmetry between x and y, it suffices to prove the result in one
direction. Suppose xqz \— xq'z. Then, by definition,
(2.6.1)
At the first step of the computation, we move left or we do not. From Eq. (2.6.1)
and this observation, there are two disjoint cases:
i) All the xt are prefixes of x, at least one of which is proper (the first move
went left);
ii) All the zt are suffixes of z (the first move had d > 0).
CASE i. Assume that all the xt are prefixes of x and at least one of them is
proper.
Let x,y ¥= A, so that x =x'a and y =y'b for some a,b&~L. Using the
assumption of Case (i) and (2.6.1), we have:
x'aqxz \—x'q2az (2.6.2)
and
x'q2a \rx'aqn = xqn. (2.6.3)
From (2.6.2), it clearly follows that:
y'bqiz \~y'q2bz, (2.6.4)
since A is deterministic. Since rx{q2) = Ty(q2), it follows from (2.6.3) that:
y'qib \ry'bqn = yqn =yq. (2.6.5)
Combining (2.6.4) and (2.6.5), we have:
yqz ^yq'z,
and Case (i) is proven.
2.6 TWO-WAY FINITE AUTOMATA 69
CASE ii. All the z; are prefixes of z. Then,
QiZi I \-Qnzn,
which implies that
yqiz | \~yqnz;
that is, +
yqz r^yq'z- n
In our next result, we extend the computations beyond merely p:
Lemma 2.6.2 Let A = (Q,~E,8,q0,F) be a two-way finite automaton. For
eachx,^ S 2*, if tx =ry, then, for each z GS'^GQ,
qoxz f~ xqz if and only if qoyz Y~ yqz.
Proof By the symmetry between x and y, it suffices to prove one direction.
Suppose q^xz \— xqz. Then either
q0x f~ xq (never use the interior of z) (2.6.6)
or * + + +
q0x F^i and xqxz \j xq2z ^ ■ ■ ■ \j xqnz (2.6.7)
for some n > 1, some qt S Q, with qn = q.
To see that these are the only two cases, examine the original computation
sequence; that is,
q0xz \~x\q\z\ \- x\q\z\ \- ■ ■ ■ \- x'mq'mz'm \- xqz. (2.6.8)
If no ID x'lq'tZ; occurs with x] =x and z\ = z, then (2.6.6) holds. Otherwise, we may
consider only the IDs in (2.6.8) with x\ = x and z\ = z and connect these by p~to get
(2.6.7).
Now we analyze the two cases.
CASE1. Assume (2.6.6) holds. Then
Ty(0) = tx(0) = q,
so that q0y \—yq, which implies that:
q0yz £~yqz-
CASE 2. Assume that (2.6.7) holds. By an argument identical to Case 1,
Qoyz \ryqiz- (2.6.9)
By use of Lemma 2.6.1 applied to (2.6.7), we have:
yq\Z \[jyq2z f^--- \jyqnz = yqz. (2.6.10)
Combining (2.6.9) and (2.6.10) produces:
Qoyz f-yqz,
and the proof is complete. □
70 FINITE AUTOMATA AND LINEAR GRAMMARS
Now we are ready to relate a two-way finite automaton A to the induced
right congruence relation R^^ of Problem 9 of Section 2.2.
Lemma 2.6.3 Let A = (Q, 2, 8,q0,F) by a two-way finite automaton. If
tx = Ty, where x,yGX*, then {x,y)GR^A^. Rj^A) is the right congruence relation
induced by 7X^4).
Proof Assume rx = Ty. Then, for any z G 2*,
jczG T(A) **qoXZ \~ xzqf for some qf&F,
o q0xz \— xqz,qz r~ zqf for some q S Q, qf S F,
**Qoyz \~ yqz,qz \~ zqf for some q S Q, qf S F (by Lemma 2),
** Qo)>z \~ yzQf for some qf S F,
oyzET(A).
Thus, (x,y)GRnA). D
Now we present the main theorem of this section.
Theorem 2.6.1 For each two-way finite automaton A = (Q, 2, 6,^0,F),
T(A) is a regular set.
Proof Since rx = ry implies (x,y) £RjxA), then rk(RjxA)) ^ I iTx I x S 2* }|.
If IQI =n, then the number of different tx functions is at most (n+ If**1. Thus,
RjxA) has finite rank and 1\A) is regular. □
Remark 1. The family of sets accepted by two-way finite automata with
endmarkers is the same as those accepted without endmarkers.
Proof {<} X {$} is regular if and only if X is regular. The "if part" is obvious,
and the "only if part" follows from closure under homomorphism. □
Remark 2. Let A = (Q, 2, 6, q0,F) be a two-way finite automaton. Consider
the sets „
R(A) = {x S 2* | q0x r~ xq for some q S Q — F}
and t
L(A) = {x €2*1^0* r~ xq forno^SQ}.
R(A) is the set of tapes rejected by a two-way finite automaton, in that the device
leaves the right end of the input in a nonfinal state. L(A) is the set of tapes that cause
A to never leave the input tape. Since 2* = T(A) UR(A) U L(A), we have that L(A)
= 2* —(T(A) UR(A)), since the sets are disjoint. Therefore, bothR(A) andL(A) are
regular sets.
Remark 3. If A is a nondeterministic two-way finite automaton, then T(A)
is regular and, moreover, Remarks 1 and 2 hold for A
2.7 HISTORICAL SURVEY 71
PROBLEMS
1 Let us change the formal definition of the manner in which a two-way
finite automaton A works, so that it may leave the input tape at either end. Define
TL(A) as the set of tapes A accepts by starting at the left end and going off the left
end in some final state. Show that TL(A) is regular. Can you give an algorithm for
constructing an ordinary finite automaton for this set?
2 Find a regular set Yn (n > 1) such that Yn is accepted by a two-way
finite automaton which has a linear number of states, while the reduced connected
automaton for Yn has an exponential number of states.
3 Find a family of sets Ln such that:
i) Each Ln is accepted by a cn-state transition system, where c is some
constant independent of n; and
ii) for each n > 2, no Ln is accepted by any two-way deterministic finite
automaton with fewer than dn2/log n states; d is a constant independent
of n.
2.7 HISTORICAL SURVEY
There are a number of texts that cover finite automata theory in some detail.
Salomaa [1969a] is an excellent general text. Eilenberg [1974] gives an elegant
mathematical treatment, although his terminology is unique.
The paper by Rabin and Scott [1959] is the source for the classical treatment
of finite automata and is still worth reading. Exercises 9 and 10 of Section 2.2 are
based on the work of Nerode [1958]. The material on the nonrecognizability of the
primes follows Hartmanis and Shank [1968]. Transition systems follow an idea of
Myhill [1957], and are a variation of the nondetenninistic automata of Rabin and
Scott [1959]. Kleene's theorem may be found in Kleene [1956]. Our proof uses
techniques due to McNaughton and Yamada [1960]. Theorem 2.5.1 may be essentially
found in Chomsky and Miller [1958], and Bar-Hillel and Shamir [I960]. Exercise
6 of Section 2.5 is from Rosenberg [1967]. The results of Section 2.6 follow the
paper by Shepherdson [1959].
three
Some Basic Properties
of Context-Free
Languages
3.1 INTRODUCTION
A number of basic results will be established here. It is possible to eliminate
variables that can never occur in a sentential form as well as variables that can never
generate a terminal string. A "factorization lemma" is proved for derivations, and this
lemma is used to prove a number of simple but useful little theorems.
It may be shown that substituting context-free languages into context-free
languages gives context-free languages. Another characterization of regular sets is
presented that involves self-embedding grammars.
3.2 REDUCED GRAMMARS
It can sometimes happen that grammars contain variables that cannot
generate any terminal strings. Consider the following example:
Example E -> E + E\T\F
F -* F*E\(T)\a
T -» E-T
where 2 = {a,+,*, (,),-}.
The only rule with T on the lefthand side has T also on the righthand side,
so it appears that T will never derive a terminal string. Surely such a situation is
undesirable, and an algorithm for eliminating such variables would be useful.
73
74 SOME BASIC PROPERTIES OF CONTEXT-FREE LANGUAGES
Theorem 3.2.1 For each context-free grammar G = (V, Z,P,S), one can
effectively construct a context-free grammar G' = (V', 2,i>',S) such that L(G) =
L(G'). Moreover, if L(G) = 0, then P' = 0, and if L{G) ¥=0, then for each A &N'
there exists x £S* such that
A ^ x
G
Proof The first part of the proof consists of a construction that determines
the set of variables which derive terminal strings. The proof is a paradigm for future
proofs and is given in (tedious) detail.
Define
Wi = {AeN\ A-+xisinP for some* e 2*}
Wk+l = Wku{AeN\ A-+aisinP for some aS (2 U Wk)*}.
Intuitively, Wk contains those variables that will derive some string of terminals in
a derivation tree of height less than or equal to k.
i) Wk c Wk+l, by construction.
ii) If there exists an / such that Wt = W,-+i, then
Wt = Wi+m, forallm>0.
Proof By induction on m.
Basis. Wt = Wn.0.
Induction step. Suppose Wt = Wl+m. Then
AeWi+m+1oAeWi+m or A^aismPfoTsomeaeCEUWi+m)*
oAeWt or A -> a is in P for some a S (2 U W,-)*
<>Aewi+l
oAeWi.
This completes the proof of (ii).
Note that the above proof would generalize for any sequence of sets defined
in this manner and for any predicate that depends on its predecessors in a similar
fashion.
iii) Wn = Wn+l where n= \N\.
Proof From (i) we have
W^ W2c W3t ■■■cWn9 Wn+19 ■•■.
But for all /, Wi 9 jV=>| Wt\ < \N\. Therefore, by a trivial counting argument,
Wn = Wn+l.
iv) A S Wt if and only if A =>x where x S 2* in a derivation tree of height
3.2 REDUCED GRAMMARS 75
Proof The argument is an induction on /".
Basis. / = 1. The result is immediate.
Induction step. Assume the result for /. Then by the construction,^ G HA+1
if and only if A S Wt or A -> a is in i> for some a S (2 U W/)*. The induction
hypothesis will take care of the first possibility. In the other case, let
a = u0CiUi ■ ■ -uk-iCkuk,
where k > 0, C, S Wh and «;- S 2* for all /. By the induction hypothesis, there exist
Zj S 2* such that Cj ^Zj in a tree of height < /.
If one notes that the tree in Fig. 3.1 is of height < / + 1, then we can conclude
the following: A S fV,-+1 if and only if A =>x for some x S 2* by a tree of height <
/ + 1. This completes the proof of (iv).
v) Wn = {A | A =>x for some xS 2*} where n = \N\.
Proof If A S Wn, then A is in the righthand side of (v). Conversely suppose
A =>jc. Let /be the height of a derivation tree of* from ,4. If/<«, then
Aew^ wn.
If/ > n, write i = n + m. Then, by (ii) and (iii),
and the proof of (v) is complete.
Now we can finish the proof by constructing G'. If L(G) ¥=0, define
G' = (V',Z,P',S),
V' = Wn U 2 U {S},
P' = U->a|4,ae(EU Wn)*, and A-*a\sinP}.
FIG. 3.1
76 SOME BASIC PROPERTIES OF CONTEXT-FREE LANGUAGES
In the extreme case where L(G) = 0, we'll have Stfi W„. By convention, G'
will not have any rules; that is, P' = 0. If L(G) ^ 0, then, for any A GiV', there is
x e 2* so that *
A => x
G
This follows from the construction and (v). All that remains for us to do is to show that
L(G) = L(G').
Since P' 9 P, every G' derivation is a G derivation and L(G') £ L(G).
Conversely, suppose wSL(G). ThenS =>w and w£X*. For every variable Aj that appears
in the tree, Aj =*",-, u;- S 2*. Thus >4;- S W„ by (v), and the first production used was
of the form ttj = Aj->as and it must be the case that a;S(2 U Wn)*. Therefore,
each such njEP', and hence we have a G' derivation of w. Thus L(G) 9 L(G'), and
therefore:
L(G) = L{G'). D
Example Consider the grammar
f -> £" + £*| r|F
F -+ F*E\{T)\a
T -» F-T
The algorithm works in a bottom-up fashion:
Wi = {F} since F-> a is a production;
W2 = {F, E} since F -> F is a production;
W3 = Wi-
The new grammar has rules:
E -> F + F|F
F -> F*F|a
There is another problem to be considered in examining the structure of a
grammar. The following example illustrates the problem.
Example S -*■ aBa
B -+ Sb\bCC
C -* abb
D -* aC
If S is the start symbol, then D cannot occur in a sentential form; i.e., it is
not "reachable" from S. We begin our consideration of this phenomenon by defining
reachability.
3.2 REDUCED GRAMMARS 77
Definition Let G = (V, Z,P,S) be a context-free grammar, and let AG.N
and BGV. Bis said to be reachable from A if
A ^> otBQ for some a, 0 S V*.
A construction is now given to eliminate unreachable symbols.
Theorem 3.2.2 For each context-free grammar G = (V, X,P,S), one can
effectively construct G' =(V, 2', P',S) such that L(G') = L(G) and each symbol in
V' is reachable from S.
Proof For each AGN, define
WM) = {A}\
Wk+l(A) = Wk(A)U{Cev\ there exist a,0e V* and
B e Wk(A) so that B -> aC0 is in P}.
Intuitively, Wfe(/4) contains all symbols reachable from A by a derivation
of fewer than & steps.
The Wfc(y4) have the following properties:
i) Wk(A)tWk+l(A);
ii) If Wk(A) = Wk+1(A), then for all m > 0, WfeC4) = Wfe+m04);
iii) Wn(A) = Wn+l(A) wheren = \N\;
iv) Wn(A) = {BeV\ A^>uBP, a,0SF*}.
The proof of these facts completely parallels that used in Theorem 3.2.1 and is
omitted.
To obtain G', we use Wn(S) in the following way. Let
G' = {V',1,',P\S),
V' = W„(S) and 2' = K'ni,
P' = {A-+ainP\ A<EWn(S)}.
Every symbol in V' is in Wn{S) and by (iv) is reachable from S. To complete
the proof, it must only be checked that G and G' are equivalent. Since P' £ P, any
G' derivation is a G derivation, and so L(G')9 L(G). Conversely, if w£L(G), then
Sfw (3.2.1)
Every symbol in each step is in Wn(S) and so each production used in (3.2.1) is inP'.
Thus, (3.2.1) may be written:
and L(G) £ /-(C), which completes the proof. □
Example Let us return to the previous example and consider G where P
consists of the following productions:
78 SOME BASIC PROPERTIES OF CONTEXT-FREE LANGUAGES
S -> aBa
B -» Sb\bCC
C -> abb
D -* aC
Let us compute W4(S):
W^S) = {S},
W2(S) = {S,B,a},
W3(S) = {S,B,C,a,b}= W*{S).
Thus,/) cannot be reached from S and the construction produces G', where:
2'= {a, b} N = {S,B,C}
S -> aBa
B -* Sb\bCC
C -» abb
In our discussion about reachability, our examples stressed the case of
unreachable variables. Actually, the discussion is relevant to terminal symbols that are
not reachable from S. The reader should now recheck the previous discussion to see
how that case was accommodated.
We may combine the ideas of Theorems 2.3.1 and 2.3.2 to yield the
following concept of a reduced grammar:
Definition A context-free grammar G = (V, X,P,S) is reduced if P = 0 or,
for every A G V, S =*aA(S=*-w for some a, 0 E V*, w G 2*.
The main result is that every language has a reduced grammar.
Theorem 3.2.3 For each context-free grammar G = {V,'S,P,S), one can
effectively construct a context-free grammar G' such that L(G') = L(G) and G' is
reduced.
Proof Given a grammar G, we may use Theorem 3.2.1, and we may assume
that every variable (except possibly S) produces a terminal string. Next we apply the
construction of Theorem 3.2.2. It is easily checked that this transformation does not
undo the effects of the first transformation, since we are just deleting rules. Now the
resulting grammar is equivalent to G and is reduced.
There is only one case that has not been explained. Suppose that the original
grammar G generated the empty set. Then all variables except S would be eliminated
by these transformations and all 5-productions would be eliminated by the first
transformation. G' would end up with P' = 0 and that is desirable since 0 is a context-free
language. □
By an earlier remark, a reduced grammar with P^Q has no unused symbols
whether they are terminals or variables.
3.3 A TECHNICAL LEMMA 79
PROBLEMS
1 Let us reconsider the proof of Theorem 3.2.1. Define a sequence of sets
W'o= 0,
W'k+l = {A &N\ A -xxisinP for some aS (2 U Wk)*}.
Relate the sets W'k to the Wk defined in the original proof.
2 Construct a reduced grammar equivalent to the grammar shown below.
Let G be
S -> aBa
B -> Sb\bCC\DaB
C -> abb\DD
E -> aC
3 Construct a reduced grammar for the following grammar G where G =
(V, 2,P,S) and Pis:
S -> aSM
.4 -> bBSa\bBaB
B -> ^5a^ | C
4 Can you reformulate the construction given in Theorem 3.2.2 as a transitive
closure problem?
5 Give an algorithm for deciding whether an arbitrary context-free grammar
generates the empty set.
6 Let G = (V, 2, P, S) be a context-free grammar and let a, j3 S V*. Give an
algorithm for deciding whether a=>|3. Note that when a = 5 and j3=wS2*, this
gives an algorithm for checking whether w£I(G) and shows that context-free
languages are recursive sets.
7 Show that a reduced grammar for the context-free language {A} cannot
have any rule of the form
A -> a<z|3
withae2,a,|3e K*.
3.3 A TECHNICAL LEMMA AND SOME APPLICATIONS TO CLOSURE
PROPERTIES
There is a technical lemma which is very useful in writing proofs in context-
free language theory. We will prove this easy lemma now, and use it in showing that
the context-free languages are closed under transpose.
Lemma 3.3.1 Let G = (V, 2,P,S) be a context-free grammar and let a,
j3 S V*. If a =^0 for some r > 0 and if a = a! • ■ ■ an for some n > 1, at S V* for
80 SOME BASIC PROPERTIES OF CONTEXT-FREE LANGUAGES
1 </'<«, then there exist tt>0, ft G V* for !</<« such that 0 = ft---ft,,
a; J> ft, and
n
I U = r.
Proof We induct on r, the length of the derivation.
Basis. Let a = a^ • • • a„ =>ft Then a = ft so let ft = a,- and tt - 0. Hence,
<*,■=> ft and:
£ r, = 0 = r.
Induction step. Our induction hypothesis is that if a = al ■ ■ ■ an =>/}, then
there exist tt > 0, ft e K* such that 0 = ft • • ■ ft,, a,- i£ft and 2"=1 tt = r.
Now consider
r+l „
a = ai---a„ => 0
Then there exists )SF* such that a = a^ - • ■ a„ =*7 =*0. Because G is a context-free
grammar, the rule used in a =>7 was of the form A-*%. Let ak, 1 < k < n, contain the
>4 that was rewritten in a =*• 7. Then afe = a'Atf for some a', ft S K*. Let
%■
f,
a; if/' ¥= &,
a'£ft if/' = fc.
Then at =*■ 7,- if i=£k and afe => 7fe. Thus
r
a = a! • • ■ an =* 71 • • • 7„ =*■ 0
By the induction hypothesis, there exist th ft so that 0 = 01 •••ft,, 7,-=*ft and
2"=1r,- = r. Combining the derivations, we find
0 H
at => 7,- => ft for /' ^ &
and (
<*fe => 7fe 4 ft,
Let
f ?,- if/' ^ k,
t\ =
Ufe + 1 if i = k.
Thus we know t't>0, ft S K*, so that
0= ft'"ft.
a; ^ ft
We compute S?=1r| = 1 + S?=1r, = r + 1. D
Next we turn to proving a closure property of context-free languages.
Theorem 3.3.1 If Z, is a context-free language, then
LT = {xT\xGL}
is a context-free language.
3.3 A TECHNICAL LEMMA 81
Proof Let L = L(G), where G = (V, ~L,P,S) is a context-free grammar.
Define
GT = (V, Z,PT,S),
where
i>T = {A-+aT\ A-+aisinP}.
Claim For each A &N,A =fa, ffS K* if and only if >4 =» aT.
/V00/ of claim We will show by induction on the length r of a derivation in
G that if >4 =>a, aS K* then>4 => aT. The reverse direction follows from the
observation that we could replace G by GT, and vice versa, in the proof. Note that (GT)T = G.
Basis. For any A e N, A =g A implies A=>TA.
Induction step. Assume that for all A&N, if A ^> a, aS V*, and t<r,
then A^oF.lfA r£$, then A 7? a =*/}. Let
a = uxAxu2A2 ■ ■ unAnun+i «,e2*, i4,-GiV.
Now since A => a is in P implies A =*■ aT is in i>',
>4 => aT = u^AnU^A,,^ ■ ■ -u^Aiuf
g'
But uxAxu2A2 ■ ■ ■ unAnun+t ^>(j. By the preceding lemma, there exist 7,-SK*,
tt > 0 so that >4,- 4-7,-, 0 = "i7i"272"' " 7n"n+i; and 2"=1r,- = r. Thus each tt < r and
the induction hypothesis holds forAt =^7; so that >4 =L ff ■ Therefore
G
A =t uTn^An ■ ■ Axu\ 4 i£+lT£ • • 7^ = 0T
Gl GT
which extends the induction and proves the claim.
In particular, for w S 2*,
o 73 w 11 anu uiny 11 o ~~^ vt'
Therefore
5 ^ w if and only if 5 =>, w
(L(G)f = L(GT). □
Corollary /, is a regular set if and only if/, is a left linear language.
Proof This is an immediate consequence of the following observations.
a) L is regular if and only if L is a right linear language. Cf. Theorem 2.5.1.
b) If G is right linear, then GT is left linear.
c) If/, is regular, then LT is regular. Cf. Theorem 2.3.2. □
PROBLEMS
1 Show that the language
L = {w£ {a, b}* I #a(w) = #b(w)}
is an unambiguous context-free language.
82 SOME BASIC PROPERTIES OF CONTEXT-FREE LANGUAGES
2 Is L, given in Problem 1, also linear and unambiguous?
3 Show that Lemma 3.3.1 becomes false for transitive closure (=>) rather
than =*■. That is, if we assume r> 1 and require t; > 1 for each 1 <!<«, then the
result is no longer true.
3.4 THE SUBSTITUTION THEOREM
Intuitively we know that if a context-free grammar G generates {a"bn},
then {0"1"} is also context-free, because we could go through the grammar and
replace a by 0 and b by 1. This would suggest that if we replaced a and b by any
strings x, y, and possibly by any two "reasonable" sets of strings, we would still have
a context-free language. In this section we will treat this situation in its full generality.
Definition Let 2 be a fixed alphabet. For any a S 2, let 2a be an alphabet
and let tp(a) £ 2* be a set. Such a mapping y is a substitution mapping if
m = {a}
and if for all at, 1 < / < k,
ifi(ai---ak) = tfad " ■lAak).
Note, (i) ip is a set-valued function.
(ii) If tfi(a) is a singleton, then ip reduces to the usual definition of a
semigroup homomorphism.
We extend ^ to sets in an obvious way, namely if L 9 2*,
*(L) = U tfx)-
Let us work more examples in order to understand this operation. Let
L = {anbcn\ n>\\
Define ya = Lu ipb — L2, and tpc = L3, where Lu L2, and L3 are any three fixed
context-free languages. Then
tfiL = U L"L2L^.
n > 1
Now, we shall give the main theorem of this section.
Theorem 3.4.1 If L is a context-free language and y is a substitution map
such that for every a e 2, tfi(a) is a context-free language, then y(L) is a context-free
language.
PTOof L = L{GL), GL = (VL,ZL,PL,S),
and for every a S 2L, since La — y(a) is a context-free language, let
La — L(Ga), Ga = (Va,2a,Pa,Sa).
3.4 THE SUBSTITUTION THEOREM 83
By appropriate renaming of variables we can ensure that for each a,b £2,
Na i~> Vb = 0 and Nb n KL = 0 and Ea njVx, = 0.
Therefore we can assume, without loss of generality, that these conditions hold. Now
define a mapping , .
t:Vl-*Nlu[ U {Sa}\
by
«"i
fa if aGNL,
[Sa if a G SL.
Next extend 7 to strings by letting
t(A) = A
and if x € Kj,, x —Xi ■ ■ ■ x„, x,- € Kx,, then
t(x) = t(x{)t(x2) ■ ■ ■ t(x„).
Now let
Gti = (VL;2L;PL;S),
Si' = U {sa},
aesL
Fi- = NL U Sx.',
Pi- = {4 -> 7(a) | ^ -> a is in i>}.
Claim 1 For each A € A^-, A =*• a if and only if >4 =*■ rfaV
Proof This is intuitively obvious, since 7 corresponds to a simple renaming
of "LL. A formal proof by induction on the length of the derivation, using the Lemma
3.3.1, is straightforward and is left as an exercise.
In particular we have
S§>Lar--aneL(GL) if and only ifS=>,Sai ■ ■ ■£„„, a.-GSx,, l</<«.
Now let
Claim 2 5fl] ■
(1 </< n) such that
G = (V,2,P,S),
v = vL'U ( U vA,
2 = U 2a,
'=*U(.M/-)-
■■1S,anf'wGZ,(G)£ 2* if and .
S„t => Wi&L{Ga) and w = w, ■
■w„
84 SOME BASIC PROPERTIES OF CONTEXT-FREE LANGUAGES
Proof This is a direct consequence of Lemma 3.3.1 and the fact that, since
all the grammars are disjoint,
Sa. => w( if and only if 5ai. =» wt
and, for each a £ 2,
Nanx = 0.
Claim 3 S^w, wEL(G) if and only if there exists a derivation of the form
/W/ Since PL> £ P if 5 =►, 50i ■ • -San =»w then S=fw. Conversely, let
S^w. Since all the grammars involved are disjoint, rules from different grammars
commute. Therefore we may "rearrange" the derivation 5 r> w in such a way that all
rules from PL> precede those from the Pa.. Thus there exists a derivation of the form
such that a =*w uses no rule from PL>. Since Vjj n 2 = 0 and w S 2*, all of a must
be rewritten in the derivation c
from PL', a must be of the form:
be rewritten in the derivation a^vv. Now, since this derivation contains no rules
a — SaiSa2 ■ ■ -San
which proves the claim.
Combining these three facts we have:
S|w£ L(G) if and only if 5 ^, Sa%Saj-• ■ SQn => w
if and only if there exists wt such that
Sa.=>w,&L(Ga) and
5 =f>ax ■■■anG L(GL) (by claim 2),
if and only if w £ ¥>(£).
Therefore i^>(Z,) = Z,(G), which proves the theorem. □
Corollary 1 If L\ and Z,2 are context-free languages, then
0 LiUL2,
ii) LiL2,
iii) £l
are context-free languages.
Proof (i) Let L = {a,b}, which is context-free. (Any finite set is context-
free.) Let
y(a) = Lly v(6) = L2.
Then
<p(L) = LiUL2.
3.5 REGULAR SETS AND SELF-EMBEDDING GRAMMARS 85
ii) Let L — {ab} and y be as in (i). Then
ip(L) — LiL2.
iii) Let L = {a}*. Since L is regular, it is context-free. Again let ^p(a) = Li.
Then
rf£) = L*i-
Corollary 2 If L is a context-free language and ^ is any homomorphism,
then tp(L) is a context-free language.
We already know that every regular set is context-free, by the characterization
theorem for right linear languages (Theorem 2.5.1). The substitution theorem gives us
another proof.
Corollary 3 Every regular set is context-free.
Proof By Kleene's theorem (Theorem 2.4.1), the family of regular sets is
the least collection which contains 0, {a}, a £ 2, and is closed under finite applications
of U, •, and *. Since 0 is context-free, and so is {a} for any a £ 2, we know that every
regular set is context-free, from Corollary 1. □
Now we can also show that the substitution theorem holds for the family
of regular sets.
Theorem 3.4.2 If L is a regular set and tfi is a substitution map such that for
every a £ 2, ip(a) is regular, then y(L) is regular.
Proof Using Kleene's theorem, we know that every regular set can be obtained
from 0 and {a}, a £ 2, by a finite number of applications of union, product, and star.
Since <p maps each singleton into a set that can be obtained by a finite number of
applications of union, product, and Kleene closure, replacing each {a} in the regular
expression for L by tp(a) still gives only a finite number of applications of union,
product, and closure. Hence, y{L) is regular. □
3.5 REGULAR SETS AND SELF-EMBEDDING GRAMMARS
Another grammatical characterization of regular sets can be given.
Definition A context-free grammar G = (V, 2,P,5) is self-embedding if
there exists A EN such that t
A => ocAQ
for some a, 0 £ V*. A context-free language L is self-embedding if every context-free
grammar for L is self-embedding.
This definition is equivalent to: A context-free language L is not self-
embedding if and only if there exists a context-free grammar G for L that is not self-
embedding.
86 SOME BASIC PROPERTIES OF CONTEXT-FREE LANGUAGES
If a variable is self-embedding, then
A ^>aAP (3.5.1)
and (3.5.1) may be iterated to yield
A ^ otAff for all i>0. (3.5.2)
If one further assumes a reduced grammar, then strings are produced with coordinated
substrings like
v'2v3 v\.
Sets that contain such strings give the appearance of nonregular sets. This provides
some insight for the belief that self-embedding grammars may generate nonregular
sets. That is not true in general, as the following example shows:
S -+ aSa\a\A
This grammar generates Z,(G) = a*. Our intuition is not completely wrong, as the
following theorem shows.
Theorem 3.5.1 A set L is regular if and only if L is a context-free language
and is not self-embedding.
Proof If L is regular, then L = L(G) for some right linear grammar G. Since
every production of G is one of the forms
A -»• uB
A -»• u
where A,BGN,uGX*, then G is not self-embedding.
Assume L = L(G), whence
G = (V.Z.P.S)
is a non-self-embedding, context-free grammar. Further, without loss of generality,
we may assume that G is reduced. Consider the following two cases.
CASE 1. For each A EN, there exist a, 0 in V* such that A ^-aSp. Note
that, since S =*5 is always true, any grammar with exactly one variable satisfies Case 1.
Now every production in P is of at least one of the following forms:
i) A -»• aBP
ii) A -»• aB
iii) A^-BQ
iv) A -+B
v) A^-u
where A, B G N, a, 0 G V+, and u G 2*.
Rules of type (iv) and type (v) cause no difficulty and will not be considered
further.
3.5 REGULAR SETS AND SELF-EMBEDDING GRAMMARS 87
We now prove a series of facts which show that G is either right linear or left
linear.
Fact 1 P contains no rules of type (i).
Proof Assume that P contains a production of type (i). Then
A => aBt$ a, 0 G V*.
Now, since we are in case 1,
Since G is reduced, there exist a2,02 in V* such that
S ^ a2AQ2.
Combining these, we get
A => ctB$ ^ aotiSPiP ^> ac*ia2,4020i0
But a, 0 e F+ implies ac*ia2, /32/3ij3 £ F+. The situation is depicted by Fig. 3.2. But this
is a contradiction, since G is not self-embedding. Hence P contains no productions of
type (i).
Fact 2 P does not contain productions of both type (ii) and type (iii).
Proof Assume
A -»• aB C -»• D/3 tt,|3 6F+,
are in P. Since we are in case 1, there exist c*i, 0i in V* such that
5 ^ a,5/3,
But G is reduced, and hence there exist a2,02 in F* such that
S ^ OjCPj
Similarly, there exist a3, a4, /33,04 in V* so that
£ ^ a3S03 and 5 ^> a4^/34
88 SOME BASIC PROPERTIES OF CONTEXT-FREE LANGUAGES
FIG. 3.3
Combining these we have
^aotia2a3a4A^3^2^
But again a:J6F+ implies aala2a3a4 and /34/33/3/320iS F+. The tree is shown in Fig.
3.3. This contradicts the fact that G is not self-embedding and hence G cannot have
productions of both type (ii) and type (iii).
Fact 3 If P contains a rule of type (ii) (type (iii)), A ^aB (respectively,
A -+Ba), then a G 2*.
Proof We prove this only for rules of type (ii), since the proof for rules of
type (iii) is completely symmetric.
Let ,4 -*aB and assume a £ 2*. Then there exist 7i,72G V* and C&N, such
that n
a = y\Cy2
There are two cases to consider:
a) 7! ^ A. Then
A -»• yiCy2B isinP;
3.5 REGULAR SETS AND SELF-EMBEDDING GRAMMARS 89
But 71, y2B S V+, and thus P would have a rule of type (i), which contradicts Fact 1.
b) 7! = A. Then
A -»• Cy2B isinP;
but this is a rule of type (ii) and type (iii), which contradicts Fact 2. Therefore a S 2*.
Combining these three facts, we see that G is either a right linear grammar or
a left linear grammar. In either case,/, is regular, which completes Case 1.
CASE 2. There is some A G N such that for no a, 0 e F* does
^ ^ aS0
We will show by induction on the number of variables in G that L(G) is
regular.
Basis. |An = l. Any grammar with one variable satisfies Case 1 and the
basis is vacuously satisfied.
Induction step. Assume that if \N\ = k and there exists A E A7 such that for
noa,0E V* does „
A =>aS0
then L(G) is regular.
Now consider a grammar G in which \N\ = k+ 1. Consider the following
grammars:
Gl = (V,XU{A},PUS),
Pi = {B^ainP\ BG(N-{A})}.
In Gi, we treat A as a terminal.
Now we define G2 to be like G but S is dropped and A is the new start
variable:
G2 = (V-{S},X,P2,A),
P2 = {B^ainP\ Be(N-{S}\aG(V-{S})*}.
Claim L(Gi) and L(G2) are regular.
Proof If Gi(G2) satisfies the condition of Case 1, then L(Gi) (respectively,
L(G2)) is regular. Otherwise Case 2 applies. But lA^I (and also \N2\)~ k and hence,
by the induction hypothesis, L(G{) (respectively, L(G2)) is regular.
Now let y be the substitution map
(I(G2), a = A,
[a, a G 2.
Since Z,(Gi) and L(G2) are regular, tfi(L(Gi)) is regular and all that must be shown is
rt£(G,)) = £(G).
Fact 4 For any otE V*, A^a if and only if A r* a. (Recall that this is the
fixed A in the definition of Case 2.)
90 SOME BASIC PROPERTIES OF CONTEXT-FREE LANGUAGES
Proof This is a direct consequence of the following.
a) If aS V* and A ^a then a does not contain S, since we are in Case 2.
b) P2 consists of precisely those rules that do not have an S in them.
Fact 5xS L(G) if and only if there exists a derivation of the form
S ^ uxAu2A • ■ • unAun+i J> Miw^j • • • unwnun+l
*
where x = UiWiU2 •' • unwnun+1 and A 7? w,-.
Proof Clearly if such a derivation exists, x SZ,(G). Now suppose x SZ,(G).
Then „
x G 2* and 5 s> x
Consider a new derivation obtained from this by:
a) First rewrite all variables except A and its descendants, in each case using
the same rule as was used in the original derivation.
b) Complete the derivation by using the remaining steps in exactly the same
order as they occurred in the original derivation.
Since in (a) no rules with A on the lefthand side are used, they are all in/V
Therefore, * *
S ^ uxAu2-•-Aun+1 ^x «,-6 2 .
Now by Lemma 3.3.1 there exist wt in 2* such that:
X = UiWiU2 • • • UnWnUn + i
and *
A j* Wi
or,equivalently,
This completes the proof of Claim 5. To complete the proof we have x SZ,(G) if and
only if there exists a derivation of the form
S ^ uxAu2 • • ■ unAun+i ^ x = Ui\viU2 • • ■ unwnun+l
and ' „
A J> w{ Wj,w,e2*
from Fact 5. This holds if and only if
5 ^ uxAu2 • ■ ■ unAun+l £ L(Gi)
4 =>WieL(G2),
using Fact 4. In turn, this holds if and only if
jeGrt£(G,)),
by the definition of <p. Thus L{G) = <p(JL(Gi)), and therefore L{G) is regular, by the
substitution theorem. □
and G
3.6 HISTORICAL SURVEY 91
PROBLEMS
1 Explain why the case structure of the proof of Theorem 3.5.1 is necessary.
That is, why not just induct on the number of variables, as in Case 2?
3.6 HISTORICAL SURVEY
Almost all of the results given here may be found in the fundamental paper
by Bar-Hillel, Perles, and Shamir [1961]. Theorem 3.5.1 is from Chomsky [1959a,
1959b].
bur
Normal Forms
for Context-Free
Grammars
4.1 INTRODUCTION
This chapter is devoted to showing that there are many different types of
context-free grammars which can generate all of the context-free languages. Results
of this type are of general interest because, if one wishes to show that some set is
context-free, it is easier if one can employ the full generality of context-free grammars
so that one can exploit A-rules, chain rules, left recursion, etc. On the other hand, if
one wishes to show that some property does not hold, it is convenient to be able to
restrict the type of grammar severely, since the complexity of a proof can be reduced.
We shall be interested in exhibiting a number of normal forms which generate
all the context-free languages. Moreover, we are interested in transformations for
putting a given grammar into these forms, as well as analyzing how much time and/or
space is required. As one might expect, there are some algorithms that are easy to
describe but very inefficient.
A number of the normal forms used here are important in practical
applications to parsing, while almost all of them will occur later in this book in
simplifying some proof or other.
4.2 NORMS, COMPLEXITY ISSUES, AND REDUCTION REVISITED
As we consider various normal forms for grammars, constructions will be
given for achieving these transformations. One question of interest is the efficiency
of these methods. A full discussion of these matters would take us into the theory
93
94 NORMAL FORMS FOR CONTEXT-FREE GRAMMARS
of computational complexity and the differences between Turing machines, random-
access machines (RAMs, for short), and bit vector machines. While this is not the
appropriate place for such a treatment (cf. Chapter 9), we do wish to mention enough
of the ideas to permit the reader to be aware of the issues.
In order to discuss these concepts, we need to clarify the notion of the size
of a context-free grammar.
Definition Let G = {V, ~L,P, S) be a context-free grammar. Define
\G\ = I lg04a)
A -*■ a
and in p
IIGII = \G\'log2W\
IG | is read as the size of G and IIGII the norm of G.
The size of G is simply the number of characters involved in productions.
The norm of G is a more realistic measure because it not only counts the size of the
grammar but includes a measure of the size of the alphabet used. The log occurs
because one should count the amount of information in V, or the number of bits
required to encode V.
For example, suppose we have some algorithm that scans the entire
production set and checks, for each production,
A -*■ a
in P, whether or not A EN. Should we use \G\ or IIGII in evaluating the work done?
Naturally the second measure is more realistic, since it accounts for the size of the
alphabet and if N is large, checking to see whether A EN should enter into the
accounting. On the other hand, for many purposes, | G | will suffice.
First, we estimate the relationship between | V\ and the size of a grammar
G = (V,2,P,S).
Lemma 4.2.1 For any context-free grammar G = (V,2,,P,S) such that if
L{G) =£ 0, L(G) =£ {A}, and if every letter in V occurs in at least one production, then
i) 2<m<|G|;
ii) | F| <2«/(log«), where n = ||G|| = \G\ log | V\. (All logs are to the
base 2.)
Proof Since S GN, \N\ > 1. Since 2 * 0, we have
\V\ = \N\+\-Z\>\ + \ = 2.
The upper bound of (i) follows from the assumption that each symbol of V appears
in at least one production.
From (i), we have
n = | G| log 1 K| > | K| log | K| > 2 log 2.
Consider the function
f(x) = 2v£-logx. (4.2.3)
(4.2.1)
(4.2.2)
4.2 NORMS, COMPLEXITY ISSUES, AND REDUCTION REVISITED 95
/'(*)
c =
1
1
Sn 2 ~
c \/x -
X X
1.44269...
-c
If (4.2.3) is differentiated,
where
Thus
fix) > 0
if x > c2 = 2.0813... The minimum of the function is at c2 and is/(c2) = 1.8278. ..
The function / is monotonically increasing for all x > c2. Since our concern is only
at positive integer values, the above argument shows that
fin) > /O)
for all integers n > 3. It is also true that
/(3) = 1.8791. ..> 1.8284 = /(2).
Hence
/(«)>/(2) = 2V2-1>0
or, for all n > 2,
From (4.2.4), for all n>2,
Taking logs,
2>/«-log«>0. (4.2.4)
2y/n>logn.
log(2V«)>loglog«,
log 2 + jlogH > log log h,
log 2 + log n — log log n > \ log n,
log(i^r)>ilogw-
Multiplying by (2«/(log «)) - (which is always positive in this range), we get:
2n log(^-|>n;
logH \log«
but
n>\V\\og\V\,
so ill
H log —— I > I K| log I ^|.
log« UOgH
It follows immediately that if x, y> 1 and x log* >y logy, then x>y. Taking
x = (2«/(log «)) andy = | V\, then we have shown that
log«
Many of the current investigations into the complexity of computations
give us only "order of magnitude" information about the time or the space required.
Such statements are useful, and so we introduce some terminology which is convenient.
96 NORMAL FORMS FOR CONTEXT-FREE GRAMMARS
Definition Let
£7(/(«)) = {g(n)\ There exist positive constants c,N0, such that
\g(n)\<cf(n) forall«>7V0};
n(f(nj) = {g(n)\ There exist positive constants c and iV0 such that
gin)>cf(n) for all «>#„};
©(/(«)) = {g(n)\ There exist positive constants c, c , and iV0, such that
cf(n) < g(ri) < c'f{ri) for all n > N0}.
One can read (7{f{n)) to be "order at most /(«)"; U{f(n)) as "order at least
/(«)";©(/(«)) as "order exactly /(«)".
These definitions are used in a peculiar but customary way. One writes
(;) - w>
instead of (S)S ^(«2). Using equality signs in this context requires care because =
is no longer reflexive. For instance, it is true that
1+0OT1) = <7(1),
but
0{X) = 1 + ^(«_1)
is false.
Now, let us examine the computation of W„ in the reduction algorithm,
Theorem 3.2.1.
Theorem 4.2.1 Let G = (V, 2,P, S) be a context-free grammar. The
computation of W= Wn given in Theorem 3.2.1 requires time
/Voo/ It is clear that to compute Wt requires time proportional to the size
of G. That means \G\ if that measure is used, or ||G|| if that is used. We will work
with ||G||. Moreover, the computation may take at most \N\ iterations, so the total
bound is 0(\N\- \\G\\). By Lemma4.2.1,
0{\N\-\\G\\)< ^(|F|-||G||)< ^(r^^jl. □
\log||G||/
Now we shall show how to do better. It will be assumed that we work on a
computer with a random-access memory, which we refer to as a RAM. For the reader
unfamiliar with this concept, imagine a typical general-purpose computer with an
unbounded random-access memory. Each word of memory can hold an arbitrary
number, and the instruction set is sufficient to compute any partial recursive function.
It suffices to write programs for such a machine in a high-level language. (One can read
Chapter 9 for more details about this class of machines.)
Our program will be organized as follows.
4.2 NORMS, COMPLEXITY ISSUES, AND REDUCTION REVISITED 97
Data Structures
W is a subset of TV; stack will denote a typical pushdown store, and we will
have the usual push and pop procedures. For each B&N, position{B) is a list of
positions where B appears in the righthand side of a production; nongen{A -*■ a) is an
integer for each production.
The program now follows, see Fig. 4.1.
begin
W: = 0;
stack: = 0;
for all B G TV do position(B): = 0;
for all A -*■ a in P do
begin
ifaGS* then
begin
if^^K/then
begin
W: = WU{A};
push(A)
end
end else
comment a = a^i • • • an-iBnan where n > 1, at G 2* and 5,- G TV;
begin
nongen(A -*■ a): = number of variables in a;
for all Bt, 1 </'<«, do
position(Bj): = positional) u (04 -*• a, 0}
end
end;
while stack =£ empty do
begin
B: =pop;
for all {A -*■ a, i) in position(B) do
begin
nongen{A -*■ a): = nongen(A -*■ a) — 1;
if nongen(A -*■ a) = 0 and A$W then
begin
«/: = «/U{^};
end
end
end
end.
FIG. 4.1 An Improved Program to Calculate W.
98 NORMAL FORMS FOR CONTEXT-FREE GRAMMARS
It is not difficult to see that this program always terminates and calculates
W={AEJV\A=>x for some x £ 2*}. Moreover, the time required is proportional to
the size of G, but that argument is more complicated.
PROBLEMS
1 Prove the claims made about the program given in this section.
2 In the argument of Lemma 4.2.1, Part (i), where are the hypotheses that
L(G) ^ 0, L(G) ^ {A} needed? Show that (i) is false without the hypothesis. Explain.
3 Let k> 1 and Lk = {a4 }. Show that, for any context-free grammar G
such that L(G) = Lk, we must have that \G\> 5k. The argument is rather complex
and so a sketch is given here. If the reader can prove the claims, the result will follow.
LetG = (V, 2,P,S) be a context-free grammar and let P= {^,^-a,| 1 <i<p}.
Assume G minimizes \G\.
a) If L{G) is finite, show that there is no loss of generality in assuming that
there are no recursive variables. (A =*otAfi never occurs.)
b) Show that we may assume that G is A-free if L(G) has cardinality one.
c) Show that, if L(G) = {x}, then
lg(*)<nig(a,).
i=l
d) Show that there is no context-free grammar G\ which can generate {a4}
with|G1|<5.
e) Show that there do not exist nonnegative integers p and xit 1 <r<p,
such that
i=l
and p
X (Xi+ 1)<5*.
i=l
4.3 ELIMINATION OF NULL AND CHAIN RULES
Our first goal is to show that null rules may be eliminated from a context-
free grammar. If we do this carefully, the language L(G) will not be altered if A £L(G).
If A6I(G), then we could eliminate all null rules and get a grammar forZ,(G) — {A}.
Instead, we'll eliminate all null rules except S -*■ A and further restrict the new grammar
so that S appears on no righthand side of a production.
An essential part of a proof of this result is an algorithm to determine which
variables can generate A. The first algorithm is the "classical" one due to Bar-Hillel,
Pedes, and Shamir [1961].
Theorem 4.3.1 Let G = (V, X,P,S) be a context-free grammar. There is an
algorithm for producing a context-free grammar G' = (V', X,P',S'), so that
4.3
ELIMINATION OF NULL AND CHAIN RULES
99
i)£(G') = £(G);
ii) A -»• A is in P' if and only if A G L(G) and A = S';
hi) S' does not occur on the righthand side of any production in P'.
Proof Letn= \N\ and W, = {A\ A -»• A}. For each k> 1, let
^fe+i = Wh uUl -4 ^ a is in P for some a GK/^}.
It is easy to see that:
1 Wi£ Wi+l for eachi>\\
2 If Wt = Wi+l, then W; = W,-+m for each m > 1;
3 W ^, = W •
4 Wn = {AGN\ A^A};
5 A G L{G) if and only if S G «/„.
To construct the new grammar, define G' = (FU {5'}, 2,P', S'), where
P' = {S'^S}U{S'^A\SeWn}U{A^Ai ••■Ah\k>\; AtGV;
there exist a1;... ,ak + l G K/* so that ,4 -^aiAi ... afe^4feafe + 1 is inP}.
Clearly, 5' does not appear on the righthand side of any production inP'. Moreover,
A G L(G') if and only if 5' -»• A is in P' if and only if 5 G Wn if and only if 5 ^ A if
and only if A G L(G).
It only remains for us to show that L(G') = L(G). First, we see that, for
each production A -^Ai ■ • ■ Ak in P', there must have been a production A -»a!1,41
■ • • otkAkak+i in P, where a,- G W* for 1 < i < k + 1. Thus, a, ^ A, and so
A =* alAl---otkAkotk+l =*• Ai ■■ Mfc
Thus every production in G' can be simulated in G by a derivation so that L(G')
c KG).
To see that L(G)£ L(G'), we shall prove, by induction on the length h of a
derivation, that if A ^ w, w G 2+, then A=>w.
ifas/s. A = 1. If ,4 ->• wisinP, then, since wi= A, A ->-wis inP'.
Induction step. If A=g Ax- • ■ Ak=*w, wG2+, /;</*, then, by Lemma
3.3.1, there exist wt G 2* so that w = W] ■ ■ • wh and At =g wt for some /' <h. If
w,G2+, then ,4,=*w,- by the induction hypothesis. If wt = A, then^,GK/„ and
^4 ->• ,4yj • • • Aj is in P', where l<p<fc and ,4y- ■••Aj is the subsequence of
A i • • • Ak obtained by deleting those At whose wt = A. Therefore,
*
A => Aj • ■ -A: =?■ Wj • • • W;
where wii • ■ • wj = w. □
Corollary There is an algorithm which decides whether AEL(G) for any
context-free grammar G.
100 NORMAL FORMS FOR CONTEXT-FREE GRAMMARS
Proof From (v), A G L(G) if and only if S € Wn. □
Example We can illustrate the construction with the following grammar,
where 2= {a, b,x):
S -»• aOb
O -»• P\aOb\00
P -»• x\E
E -»• A
The grammar is part of ALGOL. To see this, make the following associations:
S stands for (string);
(open string);
(proper string);
(empty);
0
p
E
a
b
X
stands for
stands for
stands for
stands for
stands for
stands for
(any sequence of basic symbols not containing")
Here we regard x as a terminal, for simplicity. We compute:
Wi = {E},
W2 = {E,P},
W3 = {E,P,0},
and Wn = W3. The new grammar is:
S' -»• S
S -»• aOb\ab
O -»• P\aOb\00\0\ab
P -»• jclf
Note that the new grammar contains many redundancies. When it is reduced it may
not even resemble the original one. Note that these changes all came merely from the
single rule E-*- A. In more complex examples, the grammars are changed drastically.
Now that we have developed this grammatical transformation, it is easy to
see how to pass from any context-free grammar G to a A-free grammar which generates
1(G)-{A}.
Example The next example will help us understand the complexity of this
algorithm.
S -»• Ai---Ak
At -»• a,|A for alii, \<i<k.
4.3 ELIMINATION OF NULL AND CHAIN RULES 101
Note that |S I = k, I V\ = 2k + 1, \G\ = 4k + 1, and ||G|| = (4k + l)log(2fc + 1). If
we compute G', we find that P' is as follows:
S' -»• S|A
5 -»• X, • • • Xk Xte {At, A} and Xx-- Xk ^ A,
Aj -»• a,- 1 </<£,
where | F \ = 2k + 2. To compute |G |, we merely count the symbols in each
production. This results in .„,. . .
|Cj | - 2 +
1 +
iLKi+O-1 + 2*
k fk\ k Ik
\G'\ = 2* + 2 + I.+I/
Thus,
= 2fc + 2 + 2fe + /t2fe-1
= (A: + 2)2fe_1 + 2A: + 2.
This algorithm takes exponential time no matter how the set of variables that derive
A is computed, because it takes that long to even write down G .
It is possible to do much better. One can in fact show that this can be done
in essentially linear time.
The next case to be considered is the elimination of "chain rules."
Definition Let G = (V, ~L,P, S) be a context-free grammar. A production
A -*■ B in P is called a chain rule if A, B&N.
Now we present an algorithm to eliminate both chain and A-rules.
Theorem 4.3.2 For each context-free grammar G = (V, 2,P, S), there is
a grammar G' = (V, 2,P',5) so that L(G') = LOG) and P' has only productions of
the form <? ->• A
A ■+ a aG(F-{5})+,lg(a)>2,
A -»• a a G2.
Proof We may assume, without loss of generality, that G = (V,2,,P,S)
satisfies the conditions of Theorem 4.3.1. Let A SN and we shall eliminate all chain
rules A -*■ B, B £ A', by the following construction. Define
WoC-4) = {A}
and, for each />0,
Wi+i(A) = Wt(A) U{B&N\ C^B is inPfor some C& Wt(A)}.
102 NORMAL FORMS FOR CONTEXT-FREE GRAMMARS
The following facts are immediate:
i) For each / > 0, Wt(A) £ Wi+l{A);
ii) If Wt(A) = Wi+l(A), then, for all m > 0, Wt(A) = WUm(A);
iii) Wn{A) = Wn+l(A),where n=\N\;
iv) Wn(A)={BeN\ A^B).
Next, we define G' = {V, 2, P', S), where
P' = {A^-a.\0L$N<Ln&B^-0LV>\nP forsometf G Wn(A)}.
It is clear that G' satisfies the conditions of the theorem. It is straightforward
to verify that L{G') = L{G). U
Example E^E+T\T
T -»• T*F\F
F -» (E)\a
Clearly, W3(F) = {F}, W3(T) = {T, F}, W3(E) = {E, T, F). The new grammar is:
E ■* E + T\T*F\{E)\a
T -» T* F\(E)\a
F -» (E)\a
Let us also consider the grammar show below.
Example Consider the grammar
At -*■ Ai+l\aiAi+l for each/, 1 </<£,
The start variable is ^41- For this grammar G, \ GI = 5k — 3 and so || G \\ = 0(k log k).
If we apply the transformation given in Theorem 4.3.2, we get G', as shown below:
Clearly,
or
At -*■ ajAj+i for each/,/, 1 </</<£,
Ai -*■ ak for each/, l</<fc.
fe-i
\G'\ = 2* + 3£/
;=1
_ k(3k+ 1)
2
Gil2
IG'H = 0(A:2logA:) = O
log||G|
This example shows that the transformation can enlarge G' by a factor of
|G||/(log||G||).
4.4
CHOMSKY NORMAL FORM AND ITS VARIANTS
103
PROBLEMS
1 Show that the nested-set algorithm given in Theorem 4.3.1 to compute
Wn takes time less than a constant times
11 Gil2
log 11G 11 '
2 Devise a new algorithm which computes Wn of Theorem 4.3.1 and which
takes a length of time that is linear in the size of the grammar. [Hint: One approach
requires a stack and for each BEN, a list of all places in the righthand sides of
productions at which B occurs. One also needs to keep a count of how many symbols in
a righthand side cannot produce A.]
3 Devise a new algorithm for computing a A-free equivalent of G which
works in linear time (using the | G | measure), assuming that Wn is computable in linear
time.
4 Prove (if it is true) that the constructions given in this section preserve the
unambiguity of the original grammar. Do these constructions change the "degree of
ambiguity" of a grammar?
5 State and prove a result for chain-rule elimination in the presence of null
rules.
6 Consider the last example of A-rule elimination in this section. Estimate
II G' || as a function of II G ||.
Let us extend our notions of complexity from grammars to languages. Define
\L |, for L a context-free language, to be:
|Z,| = min{|G|: G is a context-free grammar and L(G) = Z,}.
Although the same notation is used for the cardinality of L, we shall distinguish
between the two concepts whenever the context is not clear. A similar definition
holds for || Z,||.
7 Let us define
|Z,|A = min{|G|: G is a A-free, context-free grammar and L(G) = L},
where L is any context-free language with A(fcL. Show that for any context-free
language L with A ^ L, we have
\L\A<c\L\
for some constant c, where \L | is defined above. Would a similar result be true if we
changed our definition of | G | to be the number of productions?
4.4 CHOMSKY NORMAL FORM AND ITS VARIANTS
In a context-free grammar, there is no a priori bound on the size of a right-
hand side of a production. Many proofs can be simplified if these righthand sides are
bounded to be of length at most 2; then no grammatical tree ever has more than
binary branching. There are many ways to achieve this effect, and different normal
104 NORMAL FORMS FOR CONTEXT-FREE GRAMMARS
forms arise. We mention several of these here. There exist applications for each in
which none of the others would suffice.
Definition A context-free grammar G = {V, ~L,P,S) is said to be in canonical
two form if each rule is of the form
i) A^BCwithB,CGN
ii) A^-BmthBeN
iii) A -*■ a with a E 2
iv) S->-A
Furthermore, if 5^- A is inP, thenB, CEN— {5}in (i) and (ii).
This form guarantees that we have at most binary branching but we may still
have chains, as shown below in Fig. 4.2.
There is another normal form which eliminates that possibility.
Definition A context-free grammar G — (V, 2,P,S) is in Chomsky normal
form if each rule is of the form
i) A^BCwithB,C£N,
ii) A -*a with a E 2,
iii) S->-A.
Furthermore, if S -»• A is in P, then B, C in N — {S} in (i).
Next we show that any context-free language may be generated by a grammar
in Chomsky normal form.
Theorem 4.4.1 For each context-free grammar G — (V, 2,P, 5), there is a
grammar G' = (V', 2,P', S) so that L(G') = L{G) and G' is in Chomsky normal form.
Proof We may assume that G satisfies the conditions of Theorem 4.3.2.
Furthermore, for each production inP,A^>-Bl--Br,Bi£V,r>2,we may assume
that each Bt EN; for, if some Bj E 2, replace Bj by a new nonterminal symbol Cand
add a production C^Bj. (Recall that Bj E 2.) This is repeated for all such instances
in all the rules.
Now we can construct P'.
1 MA ->-aisinPandlg(a)<2, then ,4 ->-aisinP'.
A,
f3
a
FIG. 4.2
4.4 CHOMSKY NORMAL FORM AND ITS VARIANTS 105
is equivalent to
FIG. 4.3
2 hetA^-Bi- • Br,r>3,BjeNbemP. Then P'contains:
A -»• 5^!
Ci -»• B2C2
Cr_3 ->• i>r_2Cr_2
C7r_2 "^ Br_iBr
where Ci,. .. , Cr_2 are all new symbols. [Note that if r — 3, the rules are A ->-51C1
and Ci^-B2B3.] This transformation is illustrated in Fig. 4.3. It is now a
straightforward matter to verify that L{G') = L(G). D
Example Consider the following grammar:
5 -»• TbT
T -»• TaT\ ca
First, we eliminate terminals on the right, and produce:
5 -» TBT
T -»• TAT
T ^ CA
B -»• b
A -*■ a
C -»• c
106 NORMAL FORMS FOR CONTEXT-FREE GRAMMARS
Only the first two rules need modification to achieve Chomsky normal form. Thus we
have
T -»• CA
B -»• b
A -»• a
C -»• c
S -»• TDi
Dx -»• 5r
r -»• ro2
z>2 -»• ^r
A similar theorem may be stated for the canonical two form.
Theorem 4.4.2 For each context-free grammar G, one may effectively
construct an equivalent context-free grammar in canonical two form.
Another form may be employed in which the generation trees always have
binary branching.
Definition Let G — {V, 2,P, S) be a context-free grammar, G is said to be
in binary standard form if each rule is of the form
A -» BC
whereAeN;B,Ce V.
We leave to the reader (Problem 2, below) the task of formulating and proving
the theorem which tells how general the binary standard form is.
PROBLEMS
1 Prove Theorem 4.4.2.
2 State as general a theorem as possible about the binary standard form.
3 Place the following grammar into Chomsky normal form, canonical two
form and binary standard form.
S -»• aAC
A -»• aB\bAB
B -»• b
C -»• c
4. Let G = (V, 2, P, S) be a context-free grammar in Chomsky normal
form. Suppose w £ L(G) and S => w. Find a relationship between / and lg(vv).
5 Show that if G is an unambiguous context-free grammar and if G' is the
Chomsky normal-form grammar for G constructed by Theorem 4.4.1, then G1 is
unambiguous.
6 Suppose G — (V, 2,P, S) is a context-free grammar. Show that one can
find an equivalent grammar G1 which is in canonical two form, where every variable
in G is in G', and where \G'\ is proportional to \G\. Is the result also true for ||G||?
7 Is the result of Problem 6 also valid for Chomsky normal form?
8 Work out the relationship between \G\ (and ||G||) and \G'\ (respectively,
II G ||) where G is the binary standard form grammar of G.
4.5 INVERTIBLE GRAMMARS 107
4.5 INVERTIBLE GRAMMARS
The motivation for studying the next class of grammars comes from the
theory of bottom-up parsing. Crudely speaking, bottom-up parsing consists of (i)
successively finding phrases and (ii) reducing them to their parents. In a certain sense,
each half of this process can be made simple but only at the expense of the other.
Invertible grammars allow reduction decisions to be made simply.
Definition A context-free grammar G = {V, 2,P, S) is said to be invertible
if A -*■ a and B -*■ a in P implies A = B.
Thus invertible grammars have unique righthand sides of the productions
and the reduction phase of parsing becomes a matter of table lookup. The reason for
this name is that P~1 is a function exactly when G is invertible.
Next we show that each context-free language can be given an invertible
grammar.
Theorem 4.5.1 For each context-free grammar G = (V, 2,,P,S), there is an
invertible context-free grammar G' = (V1, X,P', S) such that L{G') = L(G).
Proof The proof is an example of trivialization. That is, there is an unnatural
argument which proves the result in such a way as to destroy the potential utility of
the theorem. Let G = {V, 2,,P,S), where N= {Aly... ,An). Let R be a new symbol
not in V and define
G' = (V',Z,P',S),
where N' =NUR and P' = {Ai^aRi\ At^-a is in P}U{R^-A}. Clearly, G' is
invertible and L{G') = L{G). U
The trivialization occurs in the previous proof because null rules are used to
encode the index of the variable in unary. We prefer to allow A-rules only if absolutely
necessary. Now we show how to prove the previous theorem without this trick. The
argument becomes more complex but the result is more useful.
Theorem 4.5.2 For each context-free grammar G = {V, X,P,S), there is an
invertible context-free grammar G' = {V', 2,,P',S') so that L(G') — L{G). Moreover
i) A -»• A is in P' if and only if A G L(G) and A = S'.
ii) S' does not appear on the righthand side of any rule in P'.
Proof Let us assume, without loss of generality, that G = {V,~L,P,S) is
A-free and chain-free. [If ASL(G), then Lx — L(G)— {A} has a grammar G' — {V\
Z,P',S'), which is A-free and chain-free. If the result has been proved for G', take
G" = (V'U{S"},I,,P",S"), where P"=P'u{S"^A, S"^S'}. Clearly, L{G")
— L{G) and G" will be invertible if G' is.]
Let G' = {V',T,,P',S') and let N' = {S'} UN", where N" consists of
all nonempty subsets of A7.
108 NORMAL FORMS FOR CONTEXT-FREE GRAMMARS
P' is defined to include exactly:
1 S' -*-A is inP' where A is any subset of TV containing S.
2 For each production B^x$\Xx ■ ■ Bnxn with n>0, Bu .. . ,Bn E.N,
and x0, ■ ■ ■ ,xn S 2*, then for each A\,. .. ,An EN' — {S1}, P' contains
A -»• x0Aixl ■ ■ Anxn
where
A = {C\ C^x0CiXi ■ • ■ Cnxn is inP for some Cu ... , Cn with each Q EAt}.
If C^y^C^i- ■ Cnyn is in P with y0,... ,jne2*,Cje V-'L, we call the string
j0 —y\ — • ■ • —yn the stencil of the production (variables replaced by dashes).
Note that P and P' have the same set of stencils if we exclude the rules of
the form (1) fromP'. Assume without loss of generality that G' is reduced.
Before embarking on a proof that L(G') = L(G), we give an example of
the construction.
Example Consider the following grammar
S -» 0A\ IB
A -» 0A\0S\ IB
B -» 1|0
Applying the construction of the theorem leads to the following grammar:
{»}- no
{A} ■* 0{S}\0{S,B}
{A,S} ■+ 0{A}\0{A,B}\0{A,S}\0{A,S,B}\1{B}\1{B,A}\1{B,A,S}\1{B,S}
S' ■* {S}\{A,S}\{B,S}\{A,B,S}
Reducing the grammar leads to
S' - {A,S}
{b}^ no
{A,S}^ 0{A,S}\l{B}
To finish the proof, note that G' is invertible. Now we begin the proof that
L(C') = L(C).
Claim 1 For each^4 SjV'and eachxS 2*,
A ^-xinG'
implies t
B => xinG for eachB eA.
Proof The argument is an induction on C, the length of a derivation in G'.
4.5 INVERTIBLE GRAMMARS 109
Basis. Suppose £ = 1. Then A =>x e 2* in G' and A -*-x is in P'. By the
construction, A = {C€.N\ C^x is in P}. Thus ,4 -*-a is in P' if and only if B-*-x is
in P for each 5 £ ,4.
Induction step. Suppose £>2 and Claim 1 holds for all derivations of
length less than £. Then suppose A ^XqAiX^ • • • Anxn =*x in G'. This implies that
for each/, 1 </<«,
At ^ yt e 2* and x0yixl • • -ynxn = x.
By the construction, for each B €.A there exist Bt £A[ so that B^XqBiX^ • • ■ Bnxn
is in P. Moreover, the induction hypothesis implies that Bt =>yt in G, and therefore
B =* x0Blxl ■ ■ Bnxn =*• x0^iX! • • -ynxn = x
Note that Claim 1 implies that
L(G')tL(G).
To complete the proof, the following result is needed.
Claim 2 For each x e 2*, let X* = {CSjV| C^x in G}. If 5 ^x in G, then
^4 =*x in G' for some ,4 such that B&A 9 X,..
Proof The argument is an induction on £, the length of a derivation in G.
Basis. £ = 1. Suppose 5 =>x S 2* so 5 -*•* is in P. Then ,4 ->• x is in />' with
BeA = {CeN\ C^-xisinP}.
Induction step. Suppose B ^XqBiXi ■ ■ ■ Bnxn ^o^i^i ■ ■ -ynxn = x S 2*
in G is a derivation of length £, where B, Bu .. . ,Bn SjV; x0,. .. ,xn, yu- • • ,yn
S 2*. There are derivations Bt =>yi, all of which have length <£. By the induction
hypothesis, there arc4( SjV' so that
Ai^yj'mG' and B^A^
By the construction, A -*X(yAxx\ ■ ■ A„x„ is in P with B &A. Thus
A => x0AiXi- Anxn ^ x0ylxl ■ ■ ynxn =xinG'.
By Claim 2, L(G') 2 L(G), and hence L(G') = L(G). D
The construction given seems to be exponential in nature. The following
example will confirm it.
Example Let A: be a positive even integer. Let 2 = {a, b, c} andN= {Ai,...,
Ak}. Let aa — (1, 2,..., k) and ab — (1,2) be two permutations written in cyclic
notation. These two permutations generate the symmetric group on ^-letters; that
is, the group of all permutations of the letters {1,..., k}. Define .P by:
Ai -*■ aAGair)\bAabiiy for each/, l</<&;
Ai -*■ c for each odd/, !</<&.
110 NORMAL FORMS FOR CONTEXT-FREE GRAMMARS
For G = (V, 2, P, A,), we have
\V\ = k + 3 and \G\ = 7k.
Now the variables of G' will be sets of variables such as {Ai,A3,. ..}. To simplify
the notation, we will write {1,3,. . .} instead. If the computation of G' is carried
out and reduced, we get N' = {B 9 N: | B | = k/2} U {S'} and
P' = {S'^B\AleB^.N, \B\ = k/2)
U{B^aB',B^bB"\ B^N, \B\ = k/2, B' = aa(B), B" = ab(B)}
U{{l,3,...,*-l}-c}.
Clearly,
One can show that
where n
\V'\ =ly2l + 4>2*"
iP'l = 2+6U+U>7-2,,!-
IC'H = O I -5- • 2"/loE " I, (4.5.1)
logH
PROBLEMS
1 Why did we assume that G was chain-free in the proof of Theorem 4.5.2?
2 If we assume that G is unambiguous, then does the following stronger
correspondence hold in the proof of Theorem 4.5.2?
Proposition B =>x in G if and only if {b}=>x in G'.
3 Show that, for any context-free grammar G, there is a context-free grammar
G' such that L(G) = L(G') which is invertible and chain-free.
4 Show that there exist context-free grammars G with A£L(G) for which
there do not exist equivalent grammars that are invertible, chain-free, and A-free.
5 Continuing the last example of Section 4.5,
a) Prove Eq. (4.5.1).
b) Find an equivalent invertible grammar of size k2.
c) Note that L{G) is regular. Find a finite automaton for L(G) of "size"
proportional to k. [The size of a finite automaton may be thought of as
the length of all its transitions when written out as a string. ]
6 There is an intimate relationship between invertibility and determinism in
the case of one-sided linear grammars. Can you expand on this insight?
4.6 GREIBACH NORMAL FORM 111
4.6 GREIBACH NORMAL FORM
In this section, another normal form is considered which has important
implications in both theory and practice.
The most important practical applications of this form are to top-down
parsing. A problem occurs in top-down parsing when we have "left recursive" variables.
Definition Let G = (V, 2,P,S) be a context-free grammar. A variable
A GA' is said to be left recursive (right recursive) if A =>Aa for some aG. V*
(respectively, A =*aA). A grammar is left (right) recursive if it has at least one left (right)
recursive variable.
In "recursive descent" parsers, the presence of left recursion causes the device
to go into an infinite loop. Thus the elimination of left recursion is of practical
importance in such parsers. It will turn out that a grammar in the form we are now
introducing is never left recursive. Thus, the main theorem of this section will solve
this looping problem in top-down parsers. We begin by considering two lemmas, even
before the normal form is introduced.
Lemma 4.6.1 Let G = (V, "L,P, S) be a context-free grammar. Let n — A -*■
axBa2 be a production in P and B-*$x\ ■ ■ • ||3r be the only BNF rule in P with B
on the lefthand side. Define Gi = (V, 2,^,5), where
Pl = (P-{ir})U{A^a1faa2\ai02a2\---\alpra2}.
ThenL(Gi) = L(G).
Proof Clearly, L(Gt) £ L(G), since if A -*-a1/3l-a2 is used in a Grderivation,
then A =g aiBa2 =g a1/3,a2 can occur in G.
Conversely, note that A -^aiBa2 is the only production of G not in Gh
MA -+ctiBa2 is used in a G-derivation of a terminal string, then B must be rewritten
by some B -*■ ft. These two steps are combined in G\. Therefore, L(G) 9 L(G{). □
The next lemma involves certain regular sets.
Lemma 4.6.2 Let G = (V, E,P, S) be a A-free, context-free grammar. Let
A -»• Aax\ ■ ■ ■ \Aar
where at =£ A for all /', 1 < i < r, be all the rules with A on the left such that the
leftmost symbol of the righthand side of the rule is ,4. Let
A -0,|---|&
be the remaining rules with A on the left. Let Gi = (VU {Z}, 2,^,5), where Z is a
new nonterminal symbol and Pi is the set of productions in P with all the productions
having A on the left replaced by
A -^Z|---IAZ|^|---|A
Z ■* a%Z\---\arZ\al\---\ar
Then L(Gd = L(G).
112 NORMAL FORMS FOR CONTEXT-FREE GRAMMARS
Proof The effect of this construction is to eliminate the left recursion in the
variable A. In each place, we have a new right recursive variable Z. Note that none of
the new A -rules are directly left recursive because none of the ft begin with ,4. Since
ft =£ A, we cannot get left recursion on A by "going through" Z. Also, note that Z
is not a left recursive variable because a,- =£ A for all i and because none of the at
begin with Z.
To complete the proof, note that the original productions in G with A on
the left generate the regular set
{/J,,..., p,}{Aalt... ,Aar,alt... , ar}* U {A}.
Moreover, this is the set generated by A (with the help of Z) in Gx. With the aid of
this remark, it is straightforward to verify that L(Gi) - L(G). We omit the details. □
Now the grammatical form is introduced.
Definition A context-free grammar G - (V, "L,P, S) is said to be in Greibach
normal form if each rule is of one of the forms
A -+ aBi- Bn
A -»• a
S -+ A
where Bu . . . ,Bn EN— {S}, a£ 2. A grammar is said to be in m-standard form if G
is in Greibach form, as above, and n <m.
Thus a grammar is in Greibach form if and only if it is in m-standard form
for some m.
There are a number of alternative definitions of Greibach form. In certain
textbooks, all rules are required to be of the form
A -*■ aa
with aGS,aGJV*. Such a definition rules out A from being in the language. In other
places, the rules may be of the form
A ^ a$
where uSS and |3S V*; that is, terminals and variables may be in ft One must be
quite careful in quoting theorems from the literature that involve this grammatical
form.
This form has a number of important implications. Ignoring S-*■ A, all other
rules have righthand sides that begin with a terminal. If G is in Greibach normal form
and w GL(G), w =£ A, then every derivation of w from S in G has exactly lg(w) steps.
The following proposition generalizes this fact and states it precisely.
Theorem 4.6.1 Let G = (V, 2,P,S) be a context-free grammar in Greibach
normal form. If w S 2*, aG A^*, and S=>wa then every derivation of S =>wa has
exactly max{l, lg(w)} steps.
We are now in a position to prove the main result.
4.6 GREIBACH NORMAL FORM 113
Theorem 4.6.2 Every context-free language may be generated by a context-
free grammar in Greibach normal form.
Proof Suppose, without loss of generality, that L = L(G), where G =
{V,H,P,S) is reduced, in Chomsky normal form, and assume (for the moment)
that G is A-free. Let N = {A x,..., Am} with 5 = A i.
We begin by modifying the grammar so that if At -*AjO. is in P, then / > i.
Suppose that this has been done for all rules starting with Ax and proceeding to Ah.
Inductively, we may suppose that Ai^AjQ. for 1 <*'<& implies/>/'. We now deal
with the rules that ha\eAk+l on the left. If^4ft+1 -+Ajais a production with/ <k + 1,
we generate a new set of productions by substituting for ,4/ the righthand side of each
of the Aj rules according to Lemma 4.6.1. By repeating this operation at most k times,
we will obtain rules of the form
4tl^Aja with C > & + 1.
The rule with £ = k + 1 are replaced according to Lemma 4.6.2 in which we introduce
a new nonterminal Zfe+1.
Repeating the construction for each original nonterminal gives rules of the
following forms:
1 Ak^ABa with C > k, a e ((N- {S}) U {Zu ... , Z„})+;
2 Afe -+ aa where a e 2, a e ((N- {S}) U {Zl,..., Z„})+;
3 Zft ^a where aE ((N- {S}) V{Zlt... ,Z„})+.
The reader should verify that the exact quantification given above is correct.
This requires a separate proof and employs the fact that G was in Chomsky normal
form.
Note that the leftmost symbol on the righthand side of any Am production
must be terminal by rule (1) and the fact that there is no higher indexed nonterminal.
For Am-i, the leftmost symbol generated is terminal or Am. If it is Am,
generate new rules by use of Lemma 4.6.1. These new rules all begin with a terminal
symbol. Repeat the process for Am-i,. . . ,A\. Finally, examine the Zu . . . ,Zn
rules. These rules begin with an At. For each Ah use Lemma 4.6.1 again. Because G
was in Chomsky normal form, the only terminal on the righthand side of any rule is
the first one.
To complete the proof, we must deal with the case where A Si. If this
occurs, let G — (V, ~L,P, S) be the Greibach normal-form grammar for L — {A}.
Define G' = (VU {S'}, I,,P',S'), where P' =PU {S' ->S}U {S' -+ A}. Use Lemma
4.6.1 once on the rule S' -*-S. Clearly, the resulting grammar G' is in Greibach normal
form and generates L. □
Corollary Every context-free language may be given a context-free grammar
which is not left recursive.
Example Consider G as shown below:
Ax -»• ^2^3
A2 ■*i4Ii42|l
A3 -+ AiA3\0
114 NORMAL FORMS FOR CONTEXT-FREE GRAMMARS
Applying Lemma4.6.1 to,42yields:
Ai -»• A2A3
A2 -»• A2A3A2\\
A3 ^ A1A3\0
Now Lemma 4.6.2 can be applied to the second production:
At -»• A2A3
A2 -» lZill
Zi -*■ A3A2Zl\A3A2
A3 -»• ^i^3|0
Focussing on A3, we use Lemma 4.6.1 to obtain:
Ai -*■ A2A3
A-i -» lZill
Z, -» A3A2ZX\A*A2
A3 "»• ^2^3^310
Now Lemma 4.6.1 is used again oxvA3,
Ax -*■ A2A3
A2 -+ IZjII
Zt -»• A3A2Zl\A3A2
A3 -» IZ1A3A3\IA3A3\0
Now it is possible to begin the process of back-substitution. A3 and A2 are already
in Greibach form, but A i is not:
Ai -+ \ZiA3\lA3
A2 -+ 1Z,|1
A3 -» \Z1A3A3\lA3A3\0
Zt -*■ A3A2Zi\A3A2
If we substitute for A 3 in the Z t rules, we obtain:
At -» \Z1A3\IA3
A2 -+ lZill
i43 -» lZii43i43|M3i43|0
Z! -* \Z}A3A3A2Zi\lA3A3A2Zi\0A2Zi\lZiA3A3A2\lA3A3A2\0A2
This grammar is in Greibach form.
4.6 GREIBACH NORMAL FORM 115
Now consider the following grammar which will help us to estimate the size
of a grammar in Greibach normal form. Let G be:
Bt -* Bi+1Bk+11Bi+1Bk+2 for all i, Ki<k,
Bk ■* a\b
Bk+i -* a
Bk+2 -» b
where 2 = {a,b}, jV= {Bu ... ,Bk+2}, and S = Bx. Then | V\ = k + 4, \G\ = 6*+ 2.
If the construction is carried out, we get G' with productions
Bk+2 -*■ b
for each a in {a,6}{5fe+1,5fe+2}'_1andforeach/, l </< k. Clearly for each /, l <j<A:,
we will have 2' righthand sides (with Bk+1_t on the left), and each such rule has length
/ + 1. Thus: k
\G'\ = 4+ £(/+ 1)2'' = 2k2k +4.
i=l
The latter equality may be easily verified by induction.
Note that G' is exponentially larger than the original grammar. Moreover, G
was not even left recursive originally. If we reduce G', we get G" shown below:
Bk+2 -+ b
Bi -»• a
for each ae {a,b}{Bk+1,Bk + 2}k'>. Thus:
\G"\ = 2fe + 5,
which is still exponential in the size of G.
PROBLEMS
1 Give an algorithm for detecting left-recursive variables.
2 Although the algorithm given in the proof of Theorem 4.6.2 starts from
Chomsky normal form, show that chain rules may occur in the middle of the
computation. Would the algorithm work if we started from canonical two form?
3 Does the construction given in this section preserve unambiguity?
4 Place the following grammar in Greibach normal form
E -»• E+ T\T
T -»• T* F\F
F -»• (£01 a
116 NORMAL FORMS FOR CONTEXT-FREE GRAMMARS
5 A context-free grammar G = (V, 2,P, S) is in reverse Greibach form if
all rules are of the form
A -»• aa ae(N-{S})*
A -»• a a€S
S -»• A
Show that any context free language has a grammar in reverse Greibach form.
6 A context-free grammar G = (V, 2,P, S) is in double Greibach form if
each rule is in one of the following forms
S -»• A
.4 -»• a aSS
/I -»• aa* a, 6 S 2; a e (N - {S})*
Show that every context-free language has a grammar in double Greibach form.
7 The following "proof" of Problem 6 has been proposed. If the sketch
presented here is correct, write a complete proof. If there is a flaw in the approach,
explain the problem in detail.
Suppose we are given a context-free grammar G; place G in Greibach
normal form and call your new grammar Gx. Define G2 as Gj, that is, if G\ =
(Vu 2, Pi, Si), define G2 = (Vu 2, P[, Si), where
P[ = {A -*aT\ A -*amPi\.
Place G2 in Greibach normal form and call the resulting grammar G3. Now form
G4 = Gj. It is claimed that L(G4) — L{G) and that G4 is in double Greibach form.
4.7 2-STANDARD FORM
In the previous section, we showed that any context-free grammar could be
placed in Greibach form or, equivalently, in m-standard form for some m. In the
present section, we shall attempt to minimize m and yet still generate all the context-
free languages. If m = 1, we would have rules of the form
A -+ aB BeN-{S]
A -»• a aSS
S -+ A
But these are right linear rules and so we can generate only regular sets. Thus, we
must have m > 2 if we are to succeed in generating all the context-free languages.
Theorem 4.7.1 For each context free grammar G= (V, 2,P, 5), there exists
a context-free grammar G' such that G' is in 2-standard form and L(G) = L(G').
Proof We may assume, without loss of generality, that G is in m-standard
4.7 2-STANDARD FORM 117
form for some m; that is, G is in Greibach form where:
A -* aa ae(N-{S})*, lg(a)<m,
A -*■ a
S -+ A
Thus it suffices to show that if G is in m-standard form for some m > 3, then we can
find a grammar G' in (m — l)-standard form such that L(G) = L(G'). Let
G = (F,2,P,5)
be in m-standard form, m > 3. Define
G' = (V',Z,,P',S),
where
V = VU{(A,B){ A,B&N)
and P' is given by
P' = {^4->-a| A -*a is inP and lg(a)<m}
U^afl, • • •5m.2(5m.1,5m)| A^aB1---Bm isinP}
U {(,4,5) -»• afi| ^ -»• a is in P and lg(a) < m - 1}
U{{A,B)-+aBi ■•■Bm.2{Bm.uB)\ A^aBx- ■ ■ Bm_x\smP}
U {(A,B)^aBl ■ ■ Bm^(Bm.2,Bm^)(Bm,B)\A ^aBl ■ ■ ■ Bm isinP}.
Definition If A -*a is a rule, then we shall call lg(a) the width of the rule.
The intuition behind the construction is not difficult. If we have a rule of
width m + 1, we replace it by a rule of width m whose last variable is a pair; see
Fig. 4.4.
Now, however, the rules with paired variables must be defined. If
5m_, -*■ a is in P
with lg(a) < m, then clearly we will have
(Bm_uBm) - aBm
If the righthand side of a is too long, more paired variables are introduced.
It is certainly clear that G' is in (m — l)-standard form, but it is less clear
that L(G') = L(G).
A
a B\ ' ' ' Bm-2 (Bm-1> Bm)
118 NORMAL FORMS FOR CONTEXT-FREE GRAMMARS
Claim 1
a) If y, a S V* and y 7* a using only rules of width less than m, then
7^a (4.7.1)
G
b) If A ^ a with aGV* using only rules of width less than m, then
(A,B) => aB
for any B G.N.
Proof To prove (a) it suffices to note that if A is some variable occurring
in 7, then since each rule used in the derivation A ^a is of width less than m, there
is a corresponding rule in P', and hence
Af,a
The generalization to (4.7.1) then follows directly from Lemma 3.3.1.
To prove (b), let the derivation A j? a be of the form
A "g y <? a' h(y)<m.
Thus the rule
A -*■ 7 is in P
and lg(7) < m — 1. Therefore the rule
(A,B) -»• yBisinP'.
Furthermore, since
by (4.7.1), we have
Combining these results gives
Claim 2 If
yta
T? a
(A,B) £ yB £ aB
A => x with x6S*,
then i) A =>, x
ii) (A,B)=>xB for anyBeN.
G
Proof Let p be the number of rules of width greater than m — 1 in the
derivation A ^> x. We induct on p.
G
Basis, p — 0. Claim 2 reduces to a special case of Claim 1 which we have
proven.
Induction step. Assume that if C <p and
Afx
4.7 2 STANDARD FORM 119
using £ rules of width greater than m — 1, then
A §x
(A,B) % xB
Now let
A =>x
using p + 1 rules of width greater than m — 1. Then the derivation is of the form
A =?yA'r, (4.7.2)
g> yaBl ■■ -Bkrj k>m — \,
*
£?■ x0axi • • 'Xkxk+i — x
where the derivation (4.7.2) uses no rules of width greater than m — 1, and hence,
by Claim 1,
A £; yA'n
Bt £ X; for each /, 1 < / < k,
V ^ xk+l
each with at most p rules of width greater than m — 1. Therefore,
7 |*o
Bt § xt 1 </<*:,
V % xk+l
by the induction hypothesis.
There are now two cases.
CASE 1 k = m — 1. In this case, the rule
A' -* aBl ■Bk isinP',
and thus, by combining the above results, we have
A g; yA'ri
g; yaBi ■■Bk'n
*
g; x0axi • • ~xkxk+l — x
CASE 2. k = m. Then the rule
A' -+ aBi- • •{Bm_uBm)ismP'.
Now, since
#m-i f" xm-i and flm §> xm
120 NORMAL FORMS FOR CONTEXT-FREE GRAMMARS
using at most p rules of width greater than m — l, by parts (ii) and (i) of the induction
hypothesis, we have:
\Pm-\'"m) q' xm-\"m q' xm-lxm
Combining these results gives
A g; yA'ri
g* 7«ifli---5m_2(5m_I,5m)Tj
*
Q> XqAXj ■ ■ XmXm + l — X
which completes the proof of (i).
To prove (ii), let the derivation A ^x be of the form
A => y ^ x
There are three cases to consider.
CASE 3. lgfr) < m - l. Then the rule
(A,B) -+ yB is inP'.
Using Lemma 3.3.1 and part (i) of Claim 2, we have
y I x
Thus
(A,B) g! yB | xB
CASE 4. lg(7) = m. Then the derivation is of the form
A ^ aBi-'-B^y f ox,-xm_,
Thus we have:
1 B{ =* x, 1< i < m - 1,
using at most p rules of width greater than m — 1, since the first rule is of
width m.
2 The rule
(A,B) ■*aBl---Bm^{Bm.l,B)
is inP'.
3 By the induction hypothesis,
Bt gt X,- 1 <i<m-2,
and
(Z?m_„Z?) | xm_,Z?
Combining gives
04, Z?) gr aBr--Bm.2(Bm.uB)
§; ox,- •xm_,xm5 = x5
4.8 OPERATOR GRAMMARS 121
CASE 5. lg(7) = m + 1. Then, similarly to Case 4, we have that
A - aBx • ■Bm.3(Bm.2,Bm.l)(Bm,B)
is in P' and t
B; g Xi 1 <i<m-3,
, * *
\"m-2>Bm-l) q' xm-2^m-l ($ xm-2xm-l
(Bm,B) f, xmB
Thus
04,Z?) f, aBl ■ ••Bm.3(Bm-2,Bm-i)(Bm,B)
g? axi • ■ -xm_2Xm-iXmB = xB
which completes the induction.
Now, taking ,4 = S in Claim 2 gives:
Claim 3. For each x in 2*, if 5 =» x, then 5 ^x. Thus
G G
£(ff)c-£(C)
Claim 4. L(G') ?/,((;).
Proof. Define a map </>: V' -*■ V, by:
0(a) = a for each a€.V,
0(04,5)) = ,45 for each (A,B)eNxN.
Now extend i/) to be a homomorphism from (V')* to V* in the natural way. It is then
straightforward to prove by induction that, for each a, 0 in (V')*,
Thus if S ^ x, x G 2 *, then
g'
if
then
G
*(a) =» *(0).
0(5) = 5 => 0(x) = x
or, equivalently,/,(£')- L(G), which completes the proof of the theorem. □
PROBLEMS
1 Estimate the size of G' as a function of the size of G. Can you improve the
construction given in Theorem 4.7.1?
2 Put the following grammar into 2-standard form:
S -»• SaA | SA | b
A -»• /IdMSalaS'lc
4.8 OPERATOR GRAMMARS
One of the most important normal forms used in precedence analysis is the
operator form.
122 NORMAL FORMS FOR CONTEXT-FREE GRAMMARS
Definition A context-free grammar G = (V, E,P,S) is said to be in operator
form if P<k N x (y* _ V*N* y*y
This means that each rule in P is of one of the following forms:
i) A^BforAeN,Be FA,or
ii) ,4-»a:flq3 where for allocs V*,B,CE V, either Be 2 or CE 2.
The main point is that there are never two adjacent variables in the righthand
side of a rule in an operator grammar.
We can now show that every context-free language has a grammar in this form.
It is not too difficult to prove this result with the aid of Greibach normal form [2-
standard form is particularly convenient]. We shall give a proof that does not use this
form because, in other applications, the construction will be needed. Note that the case
in which A £ L is handled somewhat separately because it does not generalize in the
applications to precedence parsing.
Theorem 4.8.1 Let G = (V, 2,.P, 5) be a A-free, context-free grammar.
There is a context-free grammar G - (V', 2,.P',S) in operator form such that L(G')
= UG).
Proof There is no loss of generality in assuming that G= (V, 2,.P, 5) is
A-free and in canonical two form. Define G' = (V', E,P',S) where V' = 2 U {5}
U (Nx 2). DefineP' =P1UP2UP3UP4, where
Px = {S^(S,a)a\ a £2}
P2 = {(A,a)^A\AeN;ae2;A^ainP}
P3 = {(A,a)^(B,a)\ A,BeN;ae2;A -+BinP]
P4 = {(A,a)^(B,b)b(C,a)\A,B,CeN;a,be2;A^BCinP}
The idea of the construction is to imagine that we are at some internal node
of a derivation tree of G which is labelled by A. The leading terminal of the subtree
properly to the right of A is encoded into the variable^ (cf. Fig. 4.5). Note that G'
is in operator form.
a A a
G tree G' tree
FIG. 4.5
4.8 OPERATOR GRAMMARS 123
Let us define a mapping <p from P2UP3U P4 into P as follows:
4>((A, a) -»• A) = A -»• a if (-4, a) -»• A is in P2
4>((A,a)^(B,a)) = A^B if{A,a)^{B,a)\smP3
<p((A,a) -+ (B, b)b(C,a)) = A -*BC if (A,a)^ (B, b)b(C,a) is inP4
Extend ^ to a homomorphism from (P2 U P3 U P*f into P*. We can now state the
exact correspondence between derivations in G and in G'.
Proposition For each aSS, x6S*, AG.N, and for each sequence
7Ti,..., 7r„ of productions inP,
,4 ^ xa by canonical derivation (wi,..., w„)
if and only if there exist -n\,.. ., tin in P' such that
<t>(Ti'i) — w,- for all i, 1 < i < n,
and „
by canonical derivation (wi,..., w^,).
The proof of the proposition involves an induction on n and is left to the
reader.
From the proposition it follows that for any x S 2*, a S 2,
S ^ xa by canonical derivation (wj,..., w„)
if and only if „
(5, a) =*■ x by canonical derivation (wi,. .., tt'„)
and 0(7rJ-) = 7T,-. Using a rule from Pi it follows easily that L(G) = L(G'). □
Now we consider the case in which G is not A-free.
Theorem 4.8.2 If G = (V, I,,P,S) is any context-free grammar, then there
is another grammar G' = (V', E,P',S') so that G' is in operator form and L(G') =
L(G).
Proof If A £ Z,(G), there is nothing new to prove. If A e Z,(G), then L — {A}
is context-free. Apply Theorem 4.8.1 to a A-free grammar for L — {A}, and let G" =
(V", 2,P",S) be the resulting operator grammar. Define G' = (V', 2,P',5'), where
F' = V" U {5'} and S' is a new symbol. Then P' = i>" U {S' -+ A, 5' -» 5}. Clearly, G'
is in operator form and Z,(G') = L. □
Example Let G be given as follows:
S -+ SA\SB\a
A -»• a
fl -► 6
124 NORMAL FORMS FOR CONTEXT-FREE GRAMMARS
If we apply the construction of Theorem 4.8.1 to G and then reduce it, we get the
following grammar:
S -» (S,a)a\(S,b)b
(S,a) -+ (S,a)a(A,a)\(S,b)b(A,a)\A
(S,b) - (S,a)a(B,b)\(S,b)b(B,b)
(A,a) -+ A
(B,b) -+ A
For example, we show the derivation of aab in both grammars G and G' in Fig. 4.6.
a a
(a) in G
(b) inC
FIG. 4.6
PROBLEMS
1 Prove the proposition stated in the proof of Theorem 4.8.1.
2 The construction used in proving Theorem 4.8.1 uses A-rules even when G
is A-free. Give a new construction that does not have that property.
3 Can you give a simpler proof of Theorem 4.8.1 with the aid of the 2-
standard form?
4 One can strengthen the definition of operator form by demanding that the
rules be of the following forms:
S
A
A
A
A
a
B
aBC|3
BeN-{S},
where a, 0 e (V- {S})*,B,Cev~{S}, and either
SGSorCeS.
Modify the construction to achieve this form as well.
4.9 FORMAL POWER SERIES AND GREIBACH NORMAL FORM 125
4.9 FORMAL POWER SERIES AND GREIBACH NORMAL FORM
It is possible to view a context-free grammar in terms of some traditional
mathematical concepts such as equations and formal power series. For example,
consider a grammar with the production shown below:
S -+ SbS\a
Let us rewrite this grammar as an equation:
S = a + SbS (4.9.1)
In some sense, we want to solve (4.9.1) for 5. To do this, we approximate by taking
5 to be empty. Then we get a first approximation:
a0 = 0.
A second approximation may be made by substituting a0 into (4.9.1) to obtain a\.
ax — a
Continuing, we get
a2 = a + aba
a3 — a + (a + aba)b(a + aba)
= a + aba + lababa + abababa
Now, these operations have been carried out and we have tacitly assumed a
number of properties of + and ■ such as distributivity. These were fortuitous choices,
since these conventions led to a situation where the coefficients of the term x in the
Oj were the number of derivation trees of x of height </. In the limit, a„ could be
written: v-* , \
a = a„ — i_, a{x)x,
where a(x) is the degree of ambiguity ofx, that is, the number of canonical derivations
ofx.
The example indicates that these ideas give a useful interpretation to the
action of a grammar. It is therefore worthwhile to make these definitions precise and
to understand any underlying assumptions.
Definition Let 2 be an alphabet. A formal power series is a map from 2*
into the integers and is written a:x-* a(x), or as
This is a power series in variables which are the elements of 2; they are associative but
not commutative.
The support of a formal power series a is written as supp(a) and defined by
supp(a) = {xS2*| a(x) =£ 0}.
Thus, the support gives a language from a formal power series.
126 NORMAL FORMS FOR CONTEXT-FREE GRAMMARS
Because the underlying set is the integers, it is easy to define useful operations
such as plus and product on formal power series. (This is done mainly in the exercises.)
Many other classes of power series can be defined. For instance, a power series arising
from a grammar will have coefficients that are nonnegative integers. It is worthwhile
to study power series which have negative coefficients, or even to generalize to power
series whose coefficients are in an arbitrary ring. Further applications may be found in
the exercises and the literature.
It is useful to explain the process of associating a formal power series with a
grammar. Our first example, while very intuitive, hid several issues because of its
simplicity.
Let G = (V, 2,P,5) be a context-free grammar and let N — {Alt... ,Ak]
with S = A1. For each At£N, let aj, l</<m,-, be all the righthand sides of At
rules. G may be specified by the equations:
A, = ofi+--- + a'm.
for 1 < i<&. If we assume G is A-free and chain-free, then for each x £ 2*, there
will be only a finite number of derivation trees for x. Let a(x) be this number, and
define
a = X <"(•*)*
x es*
Here a may be computed by simultaneous approximation of all variables. We shall
illustrate this by an example.
Example Ai -*Axa\A2b
A2 -*■ a\b
In the form of equations, we have:
A i — A\a +A2b
A2 = a + b
We approximate with ordered pairs of sets:
°o = (0,0) = (OouOm),
a! = (0,a + 6) = (a„, a12),
a2 = (ab + bb,a + b) - (p2\,a22),
a3 = (aba + bba + ab + bb,a + b) = (o3l, a32),
a4 = (abaa + bbaa + aba + bba + ab + bb,a + b) = (a41, a42),
To obtain a, we compute
a — lim ok = ( lim okl, lim afe2).
4.9 FORMAL POWER SERIES AND GREIBACH NORMAL FORM 127
It is easy to prove that a exists, and a procedure like this may be used in a more
general context where the underlying equations were not generated by a grammar.
Formal power series and the associated equations that they satisfy are useful
in deriving an alternative method for placing a grammar into Greibach normal form.
Let G = (V, H,P,S) be a context-free grammar. Assume that N= {Ai,. .. ,Ak],
S = Ai, and that G is A-free and chain-free. We take variable At and partition the
righthand sides associated with ,4; into those in NV+ and those in ~LV*. That is, we
write:
At ■* a}\---\a?
where 1 < i < k, nt > 0, and af e "LV* for 1 < £ < nh and for each 1 < i, / < k, we
write
Aj ■+Afl$,\---\AflfiU
where my > 0 and ay £ V+ for 1 < £ < my. To simplify the notation, we write
r„ = ajj + ■ ■ ■ + a%iJ
b, = a}+--- + a?'
where 1 < /, / < k and nt > 0, my > 0. If (say) my — 0, then ri3 = <J). Now we may
represent G as:
A = AR + b, (4.9.2)
where A = [Ai,... ,Ak], b = \b\,..., bk], and R = (ry). The rtj and bt notation
can be extended by defining
rfj = au and bf = a,-
An example will show that the process is less arcane than the notation might suggest.
Example Consider a grammar G given by:
Ax -*■ A\oAi\A2Ai|b
Ai -*■ A2d\A2Aia\aAl\c
In matrix form, this becomes
aA2
A2 d + Aia_
[Ax A2] = [A, A2)
+ [b aA j + c].
Now we are ready to state an algorithm for transforming a grammar into
Greibach normal form.
Algorithm 4.9.1 Let G = (V, I,,P,S) be a A-free and chain-free context-
free grammar. AssumeN = {Alt... ,Ak}andS = Ai.
1 Express G by equations of the form (4.9.2); that is,
A = AR + b
2 Let H = (Hy) be a kxk matrix, each of whose entries is a new variable.
128 NORMAL FORMS FOR CONTEXT-FREE GRAMMARS
Construct a new system of equations:
A = bH + b,
H = RH + R.
(4.9.3a)
(4.9.3b)
3 Replace every word in R that is in NV* by substituting the righthand
sides for the leading variables. That is, if we have a word Apol for some
1 <p < k, then, from (4.9.3a), the Ap productions are:
and
b}H,
ip
for K8<m/', K/'Ofc,
for 1 <C<mp.
"p up
This results in a new system of equations:
A = bH + b,
H = KH + K,
where K is derived from R by making the above substitution.
4 The Greibach form grammar of G is now given by Eqs. (4.9.4a) and (4.9.4b).
If we apply this algorithm to our running example, step 2 gives us
(4.9.4a)
(4.9.4b)
[Ax A
H\\ H\2
H2\ H22.
2] =
= [b
aA2
.A2
aAi + c]
0
d + Ata_
#ii
#21
H\2
#22.
H\2
H22.
+
+
b aAt + c]
aA2 0
_A2 d + Axa_
and
Note that the (2,1) and (2,2) entries of R require further modification. To
derive K from R, we carry out the substitutions, noting in advance that Hi2 must be
a useless variable. We get
H = KH + K,
where
K =
aAi
aA 1H22 + cH22 + oA, + c d + bHna + aAiH2\a + cH2ia + ba
Now the Greibach form is obtained from Eqs. (4.9.4) and gives us:
Ax^bHn\aAxH2x\cH2X\b
A2 ->■ aA lH22\cH22\aA i\c
Hn^aA2Hn\aA2
H2i^(Li1H22Hn\cH21Hi1\aA1Hn\cHn\dH21\bHuaH2i\aA1H21aH21\cH2iaH2i\baH21\
aAlH22\cH22\aAv\c
H22 -*■ dH22\bH uaH22\aA iH2laH22\cH2iaH22\baH22\d\bHna\aA 1H2ia\cH2ia\ba
The method for achieving Greibach form developed in Section 4.6 led to
grammars which were exponential in the size of G. We shall now show that this
method does much better.
4.9 FORMAL POWER SERIES AND GREIBACH NORMAL FORM 129
Theorem 4.9.1 Let G' be the Greibach normal-form grammar produced from
G by Algorithm 4.9.1. Then
\G'\<c\G?
for some constant c.
Proof Assume that the number of R words is u and their total length is 2U.
Similarly, suppose the total length of the b words is % and v is the number of such
words. The rules which arise from Eq. (4.9.2) are
At -* Affi with 1 < £ < rtiju 1 < ij < k,
and
At -► b\ withl<£<«,-, l</<jfc.
There are u rules of the first type, so At and Aj contribute 2u to \G\. The r3i
contribute £u. A similar analysis for the second type of rules yields that
|G| = £u + 2u + £„ + v. (4.9.5)
Now the productions arising from (4.9.4a) are:
Ai -+ bjHji for 1 < £ < nh 1 <i,j<k,
and
Af ^ b, fori <£<«,, Ki<k.
Each bf may appear in at most k rules of the first type and one of the second
type. The contribution of (4.9.4a) is at most:
jfc(£„ + 2v) + H„ + v. (4.9.6)
Now suppose K has w words of total length £„, and recall that K is derived
from R. In particular, each word Apa in R may be replaced by the summation of all
words bjHjPa, where 1 <£<«y, 1 </<&, and b^a, where 1 <£<«p. The number
of words in each category is at most v because each b word can appear at most once
in each type of rule. The total length of words of the first type (involving bf, Hjp,
and a) is at most:
^ + v(l+lg(a)). (4.9.7)
A similar analysis for the second type yields the bound:
% + v(l + lg(a)) + % + v < 2£„ + 2v\gtfj), (4.9.8)
since rjj = Apa and using a bound 2v for the number of words. Since such
substitutions can be made for at most u words of R,
w<2uv (4.9.9)
and
K = I 2£, + 2wlg(/fy)
U,e,
1 < B < m,7,
= 2%u + 2v X lg(4)
= 2£„m + 2i«u<4£„£i,, (4.9.10)
using u < £u and w < £„.
130 NORMAL FORMS FOR CONTEXT-FREE GRAMMARS
The contribution to \G'\ from (4.9.4b) is at most:
k(S.w + 2w) + Zw + w, (4.9.11)
as for (4.9.4a).
Finally, the size of G' is determined by (4.9.4a) and (4.9.4b), so (4.9.6) and
(4.9.11) yield:
| G' | < jfc(£„ + 2v) + 1» + v + k(2w + 2w) + Zw + w. (4.9.12)
Now, using (4.9.9) and (4.9.10), we have:
\G'\<k(%, + 2v) + % + v+ &(4£0£„ + 2 ■ 2uv) + 4£u£„ + 2uv.
It follows easily that there is some constant c so that
|G'|<cHuV
Now fiu < | G |, £„ < | G |, and k = | N\< | V\ so that
\G'\<c\G\2-\V\<c\G\* □
To see that the bound given in the previous theorem is achieved, consider
G = (V, 2,P,S), where 2 = {au .. . ,ak}, k>\, N= {Au . .. ,Ak}, S = AU and:
P= {Ai^Af+l\ Ki<k}U{Ak^aj\ 1 </<£}.
Note that | V\ = 2k and \G\ = 5k-3. Algorithm 4.9.1 will produce the
grammar:
At -+ ajHki 1 </< jfc, 1<i <k,
Ak -»• aj 1 </<&,
Hi} -+ aeHkiHt-u 2<i<k, 1 < £,/ < fc,
Hkj - asHk.hj l</<*, KKi,
Hu-i -+ aBHki 2<i<k, 1<£<k,
Clearly, | V'\ = k2 + 2k. After some work,
|C'| = 4k3+5k2 + k.
Let us reduce this grammar to see whether that changes its size substantially. We get:
A1 -+ aeHkl Kf<t,
Hv - asHkM-U j+\<i<k, j>\, 1 <£<*,
Hv ■* aaHk.u \<j<k-\, 1<«<*,
//,-,,•_! -+ a<iHki 2<i<k, 1 <£<k,
Hk.k-i ■* as 1<«<*.
Now we find that \V'\ = (k2 + k + 2)/2, and
\G'\ = 2k3 - 4k2 + 5k.
4.9
FORMAL POWER SERIES AND GREIBACH NORMAL FORM
131
Thus there are grammars for which this algorithm produces results on the order of
Id3.
Our study of the complexity of grammatical transformations has led to a
number of good algorithms but we have not yet proved a lower bound on the
complexity of a transformation. Such a bound is now derived.
Theorem 4.9.2 There is a context-free language Lk with A ^ L such that,
for any context-free grammar G in Greibach form such that L(G) = Lk, it must be
the case that: \G\> Sk\
Moreover, there is a grammar Gk for Lk such that \Gk\ = lk.
ft
Proof Let Lk = {a\,.. ., ak} . Let Gk have the productions:
Ai -* Af+i for 1 </<&,
Ak+i -»" «il •• -\ak
Clearly,
\Gk\ = 5k + 2k = lk.
This proves the last statement of the theorem.
Let G = (V, 2,P,S) be a reduced grammar in Greibach normal form which
generates L. Assume that G is a minimal grammar which generates L with respect to
\G\. The k strings a\ ,... ,a\ are all in L, so simultaneously consider a derivation
of each string. Because G is in Greibach form, the productions used in any pair of
these derivations are disjoint since the terminal strings produced involve different
letters. LstPt be the productions used in the derivation of a? . Define Gt = (V, S, Pt, S).
It is easy to see that „ .ft
L(Gj) = {af }.
ft
Thus each G{ is a Greibach-form grammar generating {a? }. By Problem 3 of Section
4.2, we have:
\Gt\>5k.
Now, since each of the k grammars Gt has pairwise disjoint productions, we know that:
\G\>Y.\Gi\>Sk\ □
PROBLEMS
Let
a = £ a(x)x and t = £ t(x)x
be formal power series and let n be an integer. Define
no = £ na(x)x,
xez*
a + T = £ (a(x) + t(x))x,
x e £*
132 NORMAL FORMS FOR CONTEXT-FREE GRAMMARS
and
ot = V p(x)x,
x e £*
where
p(x) = £ o(y)T(z).
x=yz
Thus ot is the product (or Cauchy product) of a and t.
1 Show that the set of all formal power series is a ring with respect to + and
• of power series.
2 Show that, if a and t are formal power series,
supp(a + t) = supp(a) U supp(r),
supp(ar) = supp(a) supp(r).
3 If a is a formal power series and k > 1, verify that afe is well defined.
Using that notation and assuming that a(A) = 0, define:
a+ = Urn To"1.
m=l
Here a+ is called the quasi-inverse of a. Show that:
a) a+ exists;
b) a+ satisfies a + a+a = a + aa+ = a+;
c) supp(a+) = (supp(a))+.
A collection %? of formal power series is said to be rationally closed if, for every
a G J^such that a(A) = 0, we have a* G W.
The family of (positive) rational power series is the least rationally closed
family which contains A (the power series where A(x) —I if x = A and A(x) = 0 if
x =^= A), each a G S is regarded as a power series a(x) =1 if x = a and a(x) = 0 if
x±a, and is closed under sum, product, and multiplication by (nonnegative) integers
n.
4 Show that a language L is regular if and only if L = supp(p), where p is
in the family of positive rational power series.
Let ju be any map from S into n x n matrices whose entries are nonnegative
integers. Extend ju to a homomorphism by defining:
ju(A) = I, the n x n identity matrix,
p.(ax) = ju(a)ju(x),
where a G 2 and x G S*. A power series a is said to admit a matrix representation if
there exist « > 1 and a map ju such that for all x G S+, a(x) = (p.(x))in (that is, the
(1, n) entry in fi{x)).
5 Characterize the family of formal power series that admit matrix
representations.
6 Prove that Algorithm 4.9.1 works.
7 Show that if one starts from a grammar in Chomsky normal form and
applies Algorithm 4.9.1, then the resulting grammar is in 2-standard form.
4.10 HISTORICAL SURVEY 133
4.10 HISTORICAL SURVEY
A general reference on algorithmic complexity is Aho, Hopcroft, and Ullman
[1974]. The approach adopted here is related to work by Hunt, Szymanski, and
Ullman [1974], who have been studying the complexity of many problems related
to grammars. Theorem 4.2.1 and Problem 2 of Section 4.3 are due to A. Yehudai.
Theorems 4.3.1 and 4.3.2 are from Bar-Hillel, Perles, and Shamir [1961]. Chomsky
normal form appears in Chomsky [1959a]. Canonical two-form first appeared in Gray
and Harrison [1969, 1972]. Invertibility was first studied in McNaughton [1967] for
parenthesis grammars, and Fischer [1969] for operator-precedence grammars. The
fact that it holds for all context-free grammars first appears in Gray and Harrison
[1969].
Greibach normal form and Theorem 4.6.2 are from Greibach [1965]. Our
proof of Theorem 4.7.1 follows Hopcroft and Ullman [1969]. Other proofs and
generalizations may be found in Wood [1969a, 1970]. 2-Standard form is mentioned
in Greibach [1965]. Operator form first occurs in Floyd [1963]. The material in
Section 4.9 on power series is from the work of Schiitzenberger. The matrix technique
for placing a grammar in GNF is due to Rosenkrantz [1967]. Problems 3 of Section
4.2 and 7 of Section 43 are due to Gruska. The lower bound on achieving GNF is due
to Piricka-Kemenova [1975] and to Yehudai.
five
Pushdown
Automata
5.1 INTRODUCTION
The major result of this chapter is the characterization of context-free
languages in terms of pushdown automata. This is an important and satisfying theorem,
in that our intuition about which sets are context-free will be greatly strengthened.
Whenever one is faced with some new context-free set, it is generally much easier
to describe a pushdown automation to accept it than to try to produce a grammar.
Another important family is introduced, the deterministic context-free
languages. These languages are all unambiguous and, moreover, are recognizable in linear
time. It has turned out that this family is a very practical one for compiler writers and
those interested in fast parsing techniques. The relationship between fast parsing and
this family is taken up again in Chapter 13.
An interesting family of pushdown automata is defined by bounding the
number of times the direction of a pushdown can change. Thus "finite-turn pushdown
automata" are introduced in Section 5.7 and some basic results obtained. Others
will occur later when we have additional tools at our disposal.
5.2 BASIC DEFINITIONS
There is a class of devices, called pushdown automata, which is very
important since its study leads to an important characterization of the context-free
languages. Intuitively, a pushdown automaton consists of three parts, a read-only input
tape, a read-write pushdown store, and a finite state control. (See Fig. 5.1.)
135
136 PUSHDOWN AUTOMATA
Input i
M
A
Finite =
state
control
Z
FIG. 5.1
Depending on the state the automaton is in, the input symbol it is reading,
and the symbol on the top of the pushdown store, the automaton may make a
transition to any one of a finite set of states, writing a finite number of symbols on its
pushdown store. (Writing the null string corresponds to erasing the topmost symbol.)
In addition, the automaton may make transitions and write on its store
without reading an input symbol. Such transitions will be called A-moves. Later we
will prove that A-moves do not increase the power of the automaton in the sense
that, for each automaton with A-moves, there exists an automaton without A-moves
which accepts the same set.
We will assume that there must be some symbol on the pushdown in order
for the automaton to make a move (i.e., the automaton must halt when it empties
its store). We will show that, in exactly the same sense as with A-moves, this
assumption leads to no loss of generality.
It should be noted that the automaton has a potentially unbounded memory,
and it is only the fact that its access to this memory is highly restricted that prevents
it from being equivalent to a Turing machine.
We now proceed to make these ideas precise.
where
Definition A pushdown automaton (pda for short) is a 7-tuple
A = (Q,X,r,8,q0,Z0,F),
Q is a finite nonempty set of states,
S is a finite nonempty set of input symbols,
r is a finite nonempty set of pushdown symbols,
<7o £ Q is the initial state,
Z0 £ T is the initial symbol on the pushdown store,
F ? Q is a set of final states,
8: Qx (SUA)x r-> finite subsets of Q x T*.
We will write (q', a) G 6 (q, a, Z) to indicate a particular transition.
To describe the automaton at any given time we need to know three things:
the state it is in, what remains on the input tape, and what is on the pushdown store.
5.2 BASIC DEFINITIONS 137
Definition Let A = (Q, E, F, 8,q0,Z0,F) be a pda. An instantaneous
description (abbreviated ID) of A is an element of Q x S* x V*. An j'w'ft'a/ /£) is a
member of {<70} x 2* x {Z0}.
Thus
(q.ax.aZ), qSQ, xGE*, aG2A, a G r*, and ZGT,
would be an ID for an automaton in state q, currently reading input a, and having Z
on the top of the stack.
Note that a may be A, in which case the device will make a A-move; that is,
the input is not advanced. Also, the topmost symbol on the stack will be written
at the righthand end of the third coordinate of the ID's.
Definition Let A = (ft 2,r,8,q0,Z0,F) be a pda. Define a relation \—
called the move relation by:
(q.ax.aZ) \- (q',x,a$)
if
(q',P)e8(q,a,Z)
for any q,q G Q\ any a in 2 U {A}; any xG 2*; a, j3GT*, andZGT. Let f^be the
reflexive transitive closure of |—.
Note that lg (aZ) > 1, which corresponds to the assumption that the
automaton cannot make a move if the pushdown store is empty. Moreover the case j3 = A
allows the top symbol on the pushdown to be erased.
Note that if, for some q, q G Q,x G S*; a, 0 G r*,
(q,x,a)f-(q',A,0),
then, for any y G £*,
(q,xy,a) ^ (q',y,0).
The converse is also true.
For the pushdown, the operation is slightly different. For any q, q G Q;
P,yer*,zndx,ye-Z*,[f:
(q, xy, j3) 1^ (q, y, y),
then, for any aG r*,
(q.xy.ap) K^ (q',y,ay).
Here the converse is false. The above situation is shown pictorially in Fig. 5.2. The
failure of the converse is shown in Fig. 5.3.
For future reference, we summarize these observations in a formal statement.
Proposition 5.2.1 Let A = (ft S, I\ 5, q0,Z0, 0) be a pda. Let q.q'GQ,
j3,7Gr*,;tGS*.If
fo.x,0) \^(q',A,y),
then, for any y G 2*, a G r*,
(q.xy, <*0) f-^ fa', 7,07)-
138
PUSHDOWN AUTOMATA
Pushdown
- Time, t
v
Driven by x
(a)
Pushdown
aji
ay
-> Time, t
Driven by x
(b)
FIG. 5.2
It is important to observe that the converse of Proposition 5.2.1 is false. We illustrate
this in Fig. 5.3.
The idea of Fig. 5.3 is that, in a computation (q, xy, a/3) \~(q', y, ay), it
is possible that some of a is destroyed and then rewritten. If we ran the same
computation without a on the pushdown, then the computation would "block" at point *
in Fig. 5.3.
We must now define what we mean by saying that a pda accepts a set.
own
• '
>
>
1
1
1 N
t
<
> 1
i-^ay
*■ Time, t
FIG. 5.3
5.2 BASIC DEFINITIONS 139
Definition Let A = (Q, 2, r, 6, q0, Z0, F) be a pda. Define:
7X4)= {wG2*l (<7o,w,Z0) [^ fa, A, a) for some <? GF, a G T*}
and
N(A)= {u>G2*l fa0, w,Z0) h fa, A, A) for some q&Q)
and
LC4) = {w G 2 I (<7o, w, Z0) h fa, A, A) for some q G F).
T(A) is the set accepted by automaton ^ by final state. N(A) is the set accepted by
automaton A by empty store. L(A) is the set accepted by both final state and empty
store.
Intuitively, A accepts by final state if there exists some finite sequence of
moves that exhausts the input and leaves A in a final state. (Note that, since A may
have A-moves, it may not halt even though it accepts.) On the other hand, A accepts
by empty store if there exists some finite sequence of moves that exhausts the input
and empties the pushdown store. (In this case the automaton will stop since it cannot
make any move if its store is empty.)
Finally, we would like to define a "deterministic pda." To ensure that a pda
is deterministic, not only must we restrict the "choice" of a next state to at most
one state, but we must also take into account A-moves. In order to permit the
automaton to perform operations on its pushdown store without reading its input, instead
of simply disallowing A-moves, we permit a A-move from a given state if and only if
there is no "regular" (non-A) move. Hence,
Definition Apda.4 = (Q, 2, T, 5, q0,Z0,F) is deterministic (dpda for short)
if for all (<7, a, Z) G Q x (2 U {A}) x I\
1. l5fa,a,Z)l<l;
2. If 5 fa, A, Z) =£ 0, then 5 (q, a,Z)=Q for each a G 2.
Definition A set L is called a deterministic context-free language if there is
some dpda A such that L = T(A). we say that two dpda's A and A' are equivalent if
T(A)=T(A').
Before proceeding to a mathematical analysis of pda's, we give two examples
to illustrate the ideas and notation.
Example 1 Let G be the grammar
S^aSa\bSb\c
0t may be premature to call a set a "deterministic" context-free language before the
connection between pda's and these languages has been established but we shall do
so.)
Then
Lc = L(G) = {wcwT\ we {a,b}*}.
That is, Lc is the set of palindromes with a center marker. We want to construct a
pda.4 which accepts Lc.
140 PUSHDOWN AUTOMATA
Intuitively, A will copy each symbol of its input onto its pushdown until
it encounters the center marker. It will then go into a new state, in which it will
compare the top symbol on the pushdown with the input. If they fail to match, it will
halt; otherwise it will erase the top symbol on the pushdown and repeat the process
with the next symbol of the input. Finally, if it exhausts its input and only the start
symbol remains on the pushdown, it will go into an accepting state.
Let
A = (Q.Z,r,8,q0,Z0,F),
where
Q = {<7o,<71,(72},
2 = {a,b,c},
T = {a,b,Z0},
F = {q2},
and 5 is given by:*
For allege {a, b),
8 (<70,d,Z0) = (<7o, Z0d) Stack first input letter.
8(q0,d,A) = (q0,Ad) Continue stacking.
8(q0,c,B) = (<7i,5) forall^GT Center found.
8(q1,d,d) = (<7i,A) Compare and erase.
8(qx,\,Z0) = (q2,Z0) Accept.
To show how the automaton works, consider the input aabebaa:
(q0,aabcbaa,Z0) \~ (q0,abcbaa,Z0a)
\~ (q0,bcbaa,Z0aa)
\~ (<7o, cbaa, z0aab)
\~ (qi,baa,Z0aab)
\~ (qi,aa,Z0aa)
\~ (qi,a,Z0a)
hfoi,A,Z«>)
\~ (<72,A,Z0),
at which point the machine halts, since q2 is not in the domain of 5.
Note c&Lc and (q0, c, Z0) £~ (q2, A, Z0).
The automaton is clearly deterministic, and hence Lc = T(A) is a
deterministic, context-free language.
* Note that in a dpda, we write 5 (q, a, Z) = (q',a), instead of 5 (q, a, Z) = {(q', a)}.
5.2 BASIC DEFINITIONS 141
Example 2 Let G be the grammar
S^aSa\bSb\A
Then
P = L(G) = {wwT\ we{a,b}*}
is clearly context-free. P is the set of even-length palindromes (without a center
marker).
P differs from Lc only in that there is no center marker. Hence, if we could
construct a pda which could find the center of the input, we could proceed as before.
A little thought should convince the reader that, since the input is one-way and the
length of the input is unbounded, a deterministic pda cannot find the center of the
input. (Can you prove that rigorously?) Therefore we will construct a pda that will
"guess" at where the center is and then proceed as before. Clearly, if the pda "guesses"
correctly, it will work properly. All that must be checked is that, when the automaton
makes a wrong guess, it does not accept the input.
CASE 1. If the automaton "guesses" too soon, then, although the pda
could empty its pushdown, the input would not be exhausted and hence the string
will not be accepted.
CASE 2. If the automaton "guesses" too late, then it could exhaust its
input, but the pushdown would not be empty and therefore the string will not be
accepted.
Formally, let
where
C = (<2,2,r,5,<7o,Zo,0),
Q = {<7o,<7i},
2 = {a, b),
T = {a,b,Z0},
and 5 is given by:
For allege {a, b),
8(q0,c,Z0) = {(<7o,Z0c)} Stack first letter.
8(q0,c,A) = {(q0,Ac)} Continue stacking.
8(q0,A,Z0) = {(<7i,A)} Accept A.
8(q0,c,c) = {(q0,cc),(qi, A)} Guess what to do.
5 (<71, c, c) = {(q j, A)} Compare and pop.
5(<7i,A,Z0) = {(<7i,A)} Accept.
To show how the pda works, consider the input abba. There are two possible
sequences of ID's:
142 PUSHDOWN AUTOMATA
(<7o,abba, Z0 ) \~ (q0,bba,Z0a)
(— (q0,ba,Z0ab)
\~ (qo,a,Z0abb)
\- (q0,A,Z0abba)
and
(q0,abba,Z0) \— (q0,bba,Z0a)
\— (<7o, ba, Z0ab)
\~ (,Q\,a,Z0a)
\- (<7i,A,Z0)
hfoi.A.A)
Since the second of these ends with an empty pushdown and null input, the
string is accepted. (The reader should verify that a string like abbb is not accepted.)
Thus C accepts P by empty store. It should be noted that Cis nondetermin-
istic. Later we will prove that there is no deterministic pda that accepts/'.
Before embarking on the proof of equivalence between pda and context-free
grammars, we associate timing conditions with these devices.
Definition A pda A = (Q, S, T, 5, q0, Z0, F)
i) operates with delay k,k>0, if for all q, q G Q; a, 0 G r*,
n
(q, A, a) f— (<7 , A, j3) implies n < k.
[Intuitively,^ can have at most k consecutive A-moves.]
ii) operates in quasi-realtime (is quasi-realtime) if there is k > 0 such that A
operates with delay k. [Intuitively,^ can have at most a bounded number
of A-moves.]
iii) operates in linear time if there exists &>0 such that for all q, q G Q;
a,j8Gr*,andwGS+,if
(q, w, a) p- (q', A, 0),
then n<fclg(u>). [Intuitively, every non-null input can be processed in
time proportional to its length.]
iv) is A-free if for all q G Q, Z G T,
Hq,A,Z) = 0.
v) operates in realtime if A is deterministic and operates with delay 0,
vi) is unambiguous if, for each w G S*, there is at most one computation
CohQ | hC„
where C0 is an initial ID involving w and Cn is an accepting ID. [Note
that the form of a final ID depends on whether we are dealing with
L(A),N(A), or T(A).]
5.3 EQUIVALENT FORMS OF ACCEPTANCE 143
Looking ahead to Lemma 5.6.5, we will prove the following result.
Proposition 5.2.2 Every dpda is equivalent to an unambiguous pda.
Every A-free pda operates with delay 0. Each pda that operates in quasi-real-
time operates in linear time. The converse is false. To see this, imagine a dpda A that
accepts a*b*c. As this set is regular, the dpda need not even consult its stack, but let
us suppose that A stacks all its input up to the c. Then if the input is of the proper
form, A will accept as L(A) by erasing its pushdown. This will take a number of
consecutive A-moves that is linear in the length of the input. Thus A would be a linear-
time dpda but not quasi-realtime.
Example Returning to Example 1 and examining the pda A, we note that A
is deterministic and operates with delay one. What can you say about Example 2?
PROBLEMS
1 Show that, if L 9 S*, then L = L(A) for some pda A if and only if L =
T(B) for some pda B if and only if L = N(C) for some pda C.
2 Can you modify the pda in Example 1 to work in realtime?
3 Show that the set L = {w G {a, b}*\#a(w) = #b (w)} can be accepted by a
dpda.
4 Show that the set L = {anbm | 1 < n < m < 2n} can be accepted by a pda.
5 Given any pda A, one can construct a new pda B such that if (<?', a) £
8B(q,a, Z), then lg(a)^2. That is, B never tries to add more than one character
at a time. In what sense is B "equivalent" to A1 That is, is N(B) = N(A)1 If A is
realtime, is B1 etc.
6 There is another way in which dpda's can be used to accept languages. Let
A = {Q,T,,T,b,q0,Z0,F) be a dpda. If
(q, x, a)
is an ID, we say that (q, a(1)) is the mode. We now let F be a set of modes. Show that
L = {w€ 2* I (q0,w,Z0) H1 (q,A,a) for some (q, a(1)) GF}
is a deterministic context-free language.
7 Show that every regular set accepted by a finite automaton with n states
may be accepted by
i) a dpda with n states and one pushdown symbol, or
ii) a dpda with one state and n pushdown symbols.
Be sure to state which type of acceptance is being used.
8 Show that a dpda A, with q states and t pushdown symbols and maximum
length r to be stacked, has an equivalent dpda with q states and at most one symbol
added to the stack at a time.
5.3 EQUIVALENT FORMS OF ACCEPTANCE
Given a pda A, a set may be accepted as T(A), N(A), and L(A). We shall
study the relation between sets defined in these ways.
144 PUSHDOWN AUTOMATA
Definition For a fixed alphabet 2, let:
,TZ ={ics'li = T(A) for some pda.4},
^Ts = {L 9 2* I Z, = W(d) for some pda.4},
^ = {L c 2* I L = L{A) for some pda.4}.
.y~2 is the set of languages accepted by final state, J^^, is the set of languages
accepted by empty store, and Sfz is the set of languages accepted by both final state and
empty pushdown. In this section, we prove that ^ = J^-^ = -S^.
We begin by showing that J^ 9 .T^.
Theorem 5.3.1 For each (deterministic) pda A = (Q, 2, T, 8,q0,Z0, 0),
there exists a (deterministic) pda B = ((/, 2, r',5B,<fo, i^o > {/}) such that N(A) =
T(B) = N(B) = L (B). Moreover
(q0,x, Z0) |j (q, A, A) for some q G Q
if and only if (q0, x, Y0) f^ (/, A, A).
TVoo/ Let
B = (QU{q0,f},Z,rU{Y0},8B,q0,Y0,{f})
where q0 ,/£ 0, r0 £ I\ and 5B is given by:
1 SB(<fo, A, K0)= {(<7o. Y0Z0)} Add a new bottom symbol.
2 For all (q, a, Z) G G x (2 U {A}) x T, 5B(<7, a, Z) = 5 (<7, a, Z) Simulate A.
3 SB(q, A, Y0) = {(/, A)} for all <7 G Q. Erase K0 and accept.
Note. B is deterministic if and only if A is deterministic.
Intuitively, B enters Z0 on the pushdown, simulates A until ,4's stack is
empty, and then makes a transition to/, erasing its start symbol.
We now proceed to show N(A) = T(B).
Claim 1 HxeN(A),then(q0,x, Y0) \j (f.A.A).
Proof lfxGN(A), then
(<7o,^,Z0) [j (<7,A,A) for some <7Gg.
But, since 8A £ 5B, we have
(q0,x,Z0) \~ (q, A, A).
Now, since the pushdown could only have been emptied on the last move, we have
(q0,x, Y0) fj (q0,x, Y0Z0) £ (q,A, Y0) (j </,A,A),
or, equivalently,
IfxG^U),then(«0.*. Ko) fj (/".A.A).
5.3 EQUIVALENT FORMS OF ACCEPTANCE 145
Claim 2 If (q0,x, Y0)\j(f,A,A), thenx&N(A).
Proof If (ifo, x, Y0) \^{f, A, A), then, from the construction of B, the
computation must be of the form
(q0,x, Y0) fj (q0,x, Y0Z0) £ (q,A,Y0) |j if, A, A) for some q G Q.
Now, since Y0 could not have been rewritten in the computation
(q0,x, Y0Z0) \j (q, A, Y0),
we must have *
(q0,x, Z0) [7 (<7,A,A).
This computation uses only states from Q. Therefore
(q0,x,Z0) fj (<7,A,A)
or xeN(A). Thus,
Ofo ,x. Y0) \j (f, A, A) impliesx GN(A).
Also, since / is a final state, x G L(B) and x G T(B). B empties its stack if and only if
B enters a final state. Together with Claims l and 2, we have
N(A) = T(B) = N(B) = L(B)
and
(<7o,*,Z0) fj fo, A, A) if and only if (<Fo,*, >W £ (/", A, A). D
Corollary (a) . r2 ^ J^;(b) J^£ c j^£.
Next we show that JTZ 9 J^^.
Theorem 5.3.2 If L = T(A) for some pda A, then there exists a pda B such
that L=N(B) = L(B).
Proof Let
^ = (Q,X,r,8,q0,Z0,F).
We will construct 5 from A as follows: 5 has a special stack marker Y0
(its start symbol), which can only be erased from a special state d. On a given input,
5 will
a) Place A's start symbol on the pushdown (using a A-move) from a special
initial state;
b) Simulate A until A enters a final state;
c) If A enters a final state, 5 may either (i) go into the special state d,
erase its store and halt, or (ii) continue simulating A until another final
state is reached.
Formally, we have
S=(fiU {d, q'0}, S, T U {Y0}, 8B,q'0,Y0, {d}),
whered, q0 ^Q, Y0 fc r, and 8B is given by:
1 8B(q'0,A,Y0)={(q0,Y0Z0)} Add Z0 to stack.
2 8B(q,a,Z)= 8(q,a,Z) for all (q, a,Z), q ^ F, or a =£ A. Simulate A.
146 PUSHDOWN AUTOMATA
3 If qGF, SB(q, A, Z) = 8(q, A,Z)U{(d, A)} for all ZGru{r0}. In a final
state, guess whether or not it is the end. Erase everything from d.
4 SB(d, A, Z) = {(d, A)} for all Z G T U {Y0}.
Note. B may be nondeterministic even if A is deterministic.
We now must show that N(B) = T(A).
Claim 1 T(A)£N(B).
Proof If x G T(A), then (q0, x,Z0)\j (q, A, a), for some q G F, a G T*.
Since 5 £ 5b >we have
(q0,x,Z0) f^- (<7, A, a) for some <7 GF, a G r*.
Now, since, in the above computation, B could not have annihilated its store (except
possibly on the last step), we have, by (1) above,
(q'o,x, Y0) tj (qo.x, Y0Z0) £ (q, A, Y0a).
But
j(d,A,A) if a = A
' ° ^ 1 (d, A, Y0a') if a = a'Z for some ZGT,
whence
(d,A, Y0a') \j (d,A,A).
Combining we have: If x G T{A), then {q'0,x, Y0) \j (d, A, A) or
T(A)CN(B).
Claim 2 N(B)^ T(A).
Proof If xeN(B), then
(q'o,x, Y0) fj(tf, A,A).
The above computation must end in d since it is the only state that can erase Y0.
From the construction of B, this is possible only if the computation is of the form
fa'o.x, Y0) fj (q0,x, Y0Z0)\j (<7, A, Y0a) ^ (d, A, A) forsome? GFand aGT*.
But since Y0 could not have been rewritten in the computation
(q0,x, Y0Z0) \j (q, A, Y0a),
we must have
(q0,x,Z0)^ (q,A,a), q&F.
Therefore x G N(B) implies x G T{A) or
T(A) 2 N(B).
5.3 EQUIVALENT FORMS OF ACCEPTANCE 147
Combining Claims (1) and (2), we have:
T(A) = N(B),
which proves the theorem. Also, N(B) = L(B). □
Combining these theorems with Problem 5, we have:
Theorem 5.3.3 ^\ = ^-^ = &•£. That is, acceptance by final state or by
empty store or by both simultaneously leads to the same family of accepted sets.
Proof We have actually shown that
The proof that -£^ £ S\ is left for Problem 5. □
PROBLEMS
1 Suppose that the proof of Theorem 5.3.2 were changed and a new start
state <7o was not added. [Change q'0 to q0 in (1) above.] Would the construction
still work?
2 Congratulations! You have just purchased a standard pda or dpda. The
following options are available at a slight extra cost. Which of these features increase
the power of your pda-(dpda)? Prove your answers.
a) The ability to move on input strings rather than on elements of 2A.
b) The ability to define 5 on strings from T+ instead of just T, and hence to
erase strings in one move.
c) The ability to move on A on the pushdown as well as on elements of T.
3 Design a dpda to accept the following set by empty store:
L = {a^b ■ ■ ■a;'-i6a^csa^+i \r>\,\ <i} for all/, 1 </<r, 1 <* < r}.
4 Design the simplest A-free pda you can which accepts L as defined in
Problem 3. Can you do it with a realtime dpda? Can you do it with a deterministic
multitape Turing machine that works in realtime?
5 Explain why it does not follow immediately that ¥■% £ .9"^. Now give
the necessary construction.
6 A pushdown automaton A = (Q, 2, I\ 5, q0, a, F) is said to be a counter
if Irl = 1. Show that, for each counter A, there exists a counter B such that
N(A) = L(B).
7 Let L = {a"bmc\n > m > l}. Construct a counter A such that L(A) = L.
Show that there is no counter B such that N(B) = L.
8 Show that, for counters, the families S~and J1^are incomparable.
For future reference, a counter language is any set L £ £ which is accepted as L(A)
for some counter A. Now, counter languages are very restricted because a pda may
not move on an empty store. Thus the only information we can get from the stack
is when it is empty and then the computation stops. To remedy this, we allow
detection of a zero count as well.
148 PUSHDOWN AUTOMATA
A pushdown automaton A = (Q, £, T, 5, q0, Z0, F) is an iterated counter
if T = {Z0, a}, and
8(q,b,a) S 0x {a}*
and
8(q,b,Z0)£ (QxZ0a*)U(Qx {A})
for each q (=Q and 662U {A}. Thus, an iterated counter may count down to zero
more than once. Of course, every counter language is an iterated counter language.
9 Show that, for the family of iterated counters,
jT = y = j~.
5.4 CHARACTERIZATION THEOREMS
Our purpose in studying pushdown automata is to characterize context-free
languages in terms of them. Without further ado, we begin this task.
Definition Let
^e = {£ - E I L is a context-free language}.
Then 9j; is the family of context-free languages (over £).
In the last section, we showed that JT-% = S~-z = ¥■%. In this section we
will prove that ^^ = 9^; that is, the family of context-free languages is the same as
the family of languages accepted by empty store by pda's. Thus we will have
9^ = J''£ = .9 y, = -z£.
giving a very nice characterization of the context-free languages, which we will use
extensively.
The proof that ^^ = 9"^ is very important, not only for the result
obtained, but also for the technique employed, since similar constructions occur
elsewhere in both the theory and the applications of context-free languages.
Theorem 5.4.1 For each context-free language L, there exists a pda A such
that L=N(A).
Proof Let L = L{G) for some context-free grammar
G = (V,2,P,S).
Now, construct a pda
A = ({<?}, £, V,8,q,S,0),
where 5 is given by
i) 5 (q, A, Z) = {(q, aT)\ Z -* a is in P};
ii) For each a G 2,5 (q, a, a) = {(q, A)}.
Intuitively, A performs a standard top-down parse. There is no left recursion problem
because A is nondeterministic. To illustrate this, consider:
5.4 CHARACTERIZATION THEOREMS 149
Example Let G be the grammar with
S -+ aSb IA
as productions. Then
8(q,A,S) = {(q,bSa),(q.*)},
8(q,a,a) = 8(q,b,b) = {(<?, A)}.
Now consider the string aab. The reader may easily verify that the possible
computations are
i) (q,aab,S) H1 (q,ab,b);
ii) (q, aab, S) \— (q, aab, A);
iii) (q, aab, S) H1 (q, b, bbbSa);
iv) (q, aab, S) £- (q, A, b).
Thus aab £N(A). On the other hand,
(q, ab, S) h (q, ab, bSa)
h (q, b, bS)
\- (q, b, b)
hfo.A,A).
Thus, abGN{A).
We now proceed to prove the theorem.
Claim 1 If S =>ua, with uGZ*,aG NV* U {A}, then, for each w G 2*,
(q, uw, S) \— (q, w, aT).
Proof By induction on the length of the derivation.
Basis S => S, so u = A and a = 5. Then
(<?, w, S) £~ (<7, w, S),
and the basis is complete.
Induction step. Suppose that we have a leftmost derivation of length n + 1,
n
S => M.B7 7* MX/37
where B -+ xj3 is in P, u, x G 2*, 7 S F*, and |3 S NF* U {A}. By the induction
hypothesis, we have, for any w G 2 *,
(<7, mxu>, 5) |— (<7, xw, yTB).
Since 5 -»■ x& is in P, there is a rule of type (i), so that for any w G 2
(<7, mxw, S) \— (q, xw, yTB)
h (<7, xw, 7T/3T*T)
^ (q, w, 7T/3T).
150 PUSHDOWN AUTOMATA
We were able to conclude the above computation using rules of type (ii) above, since
x &"£*. Thus the induction is extended and the claim is proven.
In particular, if S ^x S 2*, then, by taking
u = x, w = A, a = A,
we have
(q,x,S) f-(q,A,A).
Therefore
L c N{A).
Claim 2 If (q,uw,S) £-(q, w, aT), u, weZ*,ae V*, then S fwa.
Li
Proof By induction on the number of steps in the computation.
Basis. If (q, w, S) \—(q, w, S), then u = A and a = S. Therefore, S=>S
completes the basis.
Induction step. Assume that if
(q, uw, S) p- (q, w, aT), u,w£X*,a£V*,
then *
S ?> ua
Li
Now let (q, uw, S) p— (q, w, aT). There are two cases to consider.
CASE 1. The last move is type (ii). Then if we let u = u'a, with a S 2,
(q, uw, S) = (q, u'aw, S) p- (q, aw, aTa)
h (q,w,aT).
By the induction hypothesis,
* i
S r* u aa = ua
Li
CASE 2. The last move is type (i). Then
(q, uw, S) p- (q, w, f B) \- {q, w, fyT) = {q, w, aT).
By the construction, B -*■ y is in P and a = 7/3. By the induction hypothesis,
S => m5|3
Now, using 5 -* 7, we have
5 => "5/3 =* «7|3 = ««
which completes the proof of Claim 2.
In particular, if x S £* and
(<?,*, S) r-((?,A,A),
then, by taking u = x, w = A, a = A, we have
5.4 CHARACTERIZATION THEOREMS 151
Therefore, N(A) 9 L. Now, using the result of the previous claim, we get
L = N{A),
which proves the theorem. □
The construction that we have given allows us to draw some even stronger
conclusions. We shall state them here as a theorem and leave the proof for the
exercises. We will feel free to employ these facts in the future.
Theorem 5.4.2 For each context-free language L, there is a pda A = (Q, 2,
r, 5, q0, S, F) such that N(A) = L(A) = L, and
0 Ifil = 2;
ii) forall<7,<7'e0,aeZA,Zer,aer*,if
(q',a)G8(q,a,Z),
then
lg(a)<2;
iii) forallwei^.aer^ee,
(q0,w,S) F1 (<?, A,a)
implies q ^q0.
iv) If L is an unambiguous context-free language, then A is an unambiguous
pda.
v) A operates in linear time.
We shall shortly investigate the role of A-moves in pda's.
Next we turn to showing that N(A) is context-free. This construction has
many important applications.
Theorem 5.4.3 If A is an (unambiguous) pda, then N(A) is an (unambiguous)
context-free language.
Proof UtA= (Q, 2, I\ 5, q0 ,Z0, F).
We may assume without loss of generality that there exists a unique state
/S Q such that F = {/} and
(<7o.*, Z0) F^ (<7,A, A) ifandonlyif<7 =/,
since, if A does not satisfy this condition, we can construct
a' = (Gug-0,/},z,ru{y0},«',9o.i'o.{/}),
where 5 £ 8' and
8'(q0,A,Y0) = {(q0,Y0Z0)},
8'(q,A,Y0) = {(f,A)} for all? eg.
152 PUSHDOWN AUTOMATA
Clearly,/!' satisfies the condition andN(A) = N(A') = L(A')= T{A').
Now define
G = (V.E.iS),
where
V = Z U (Q x T x Q),
S = (<7o,Z0,/),
and Pis given by:
i) For all k > 1, each a G ZA, each Z, Zj,..., Zk G r, each q,p, qly...,
(q, Z, qk)^>-a(p,Zi, qi)(qu Z2, q2) • ' • fa*-2, Zfc-i, <7fe-i)faft-i> zft> <7ft)
(P, -^fe "• • zi) G 5 (<7, a, Z).
ii) fa, Z,p)^a if (p, A) e 5 fa, a, Z).
The idea of the construction is to encode information into the variables
fa, Z, p). In fa, Z, p), the first coordinate tells us that the pda is currently in state q.
The second coordinate indicates that the top of the pushdown is Z. Let us imagine
that the pda A is in state q and reading Z at the top of the pushdown. Let us
consider strings w G 2* which cause the pda to ultimately erase Z from the top of
pushdown. The third component p is a "guess" that we will be in state p when that Z is
erased as above.
Before giving a proof that L (G) = N(A), we work an example.
Example We will construct A and G for the set
L = {anbman\n,m>\}u{anbmcm\n,m>\}.
The idea behind A's processing of the set is simple.
a) Stack the a's and then b's.
b) If next input is a, erase all b's from stack and match up the remaining a's
in the input with the stacked a's.
c) If next input is c, match up the c's with the b's and then erase the a's from
the stack.
A can accept this set as
L = L(A).
Formally
a = (e,i:,r,5,o,c,{2}),
where
Q = {0, 1, 2},
z = r = {a,b,c}.
Table 5.1 gives
8:Qx (SU{A})x T^Qx T*.
5.4 CHARACTERIZATION THEOREMS 153
The second half of the table gives the productions associated with each move of A.
(Some of the unnecessary productions have been omitted.)
Let <7o = 0, Z0 = c, and
(q',a)e8(q,a,Z),
where q, q E Q, a E V*, Z S T, and a G 2.
TABLE 5.1
q a Z q' a Productions
0 a c
0 a a
0 ft a
0 ft ft
0 a b
1 A b
1 a a
1 A c
0 c b
2 c b
2 A a
2 A c
0
0
0
0
1
1
1
2
2
2
2
2
ca
aa
b
bb
A
A
A
A
A
A
A
A
(0,c, 2)->a(0,a, 1)(1, c, 2)|a(0,a, 2)(2, c, 2)
(0,a, l)->a(0,a, l)(l,«, 1) (0,a,2)->a(0,a,2)(2,a,2)
(0,a, 1)^-6(0,6, 1) (0, a, 2)^-6(0,6, 2)
(0, ft, 1) -> ft(0, ft, 1) (1, ft, 1) (0, ft, 2) -> ft(0, ft, 2) (2, ft, 2)
(0,6, l)^-a
(1,6, D-»A
(l,a, D-^a
(l.c, 2)->A
(0, ft, 2)^-c
(2, ft, 2)^c
(2, a, 2)^ A
(2,c, 2)^ A
7Vo?e. The start symbol in G is (0, c, 2).
Now consider the computation
(0, abba, c) \~ (0, bba, ca)
h (0,6a, cZ>)
h (0, a, ebb)
r-(i,A,d>)
h0,A,c)
h (2, A, A)
The corresponding (leftmost) derivation of abba in G is shown in Fig. 5.4.
The correspondence between a partial computation of A and its associated
generation can best be seen by example:
(0, abba, c) ^ (0, a, ebb).
On the other hand, concatenating the frontier of the generation tree at the third
step in the derivation gives
abb(0,b, 1)(1,6, 1)0,c,2).
The string abb is that part of the input string used and ebb (the reversal of
the string obtained by concatenating the center symbol of each variable) is the state
of the pushdown at the corresponding point in the computation.
154 PUSHDOWN AUTOMATA
<p,
:,2)
0^
(0,a, l)
®/
b
^^^
0
s©
(0,/
b. I)
©^
(0,/», D
©
(1,
:,2)
©
A
\©
(i.M)
©
FIG. 5.4
A similar statement holds in general, and it is just this statement which we
must make precise and prove to show that L(G) =N(A). Hence, we define
H= {aG(Qx rx Q)*l If a = a^q!, Zlt q\)(q2, Z2, q'2)a2, thenq\ =q2).
Thus H is a set of strings of triples where the triples are "internally linked," as shown
below.
Example Continuing from the previous example, let
a = (0,6,I)(1,6, 1X1, c, 2).
Clearly, a G H.
Next, we define a mapping <p: H^-V , where:
*(A) = A,
V(a(q, Z, q')) = Zy{a) for all a(q, Z, q) GH.
Note that, for any a, |3, we have
<p(a|3) = <p(|3)<p(a).
The purpose of <p is to decode the center components of its argument and to reverse
them.
Example Ifa = (0,Z>, l)(l,Z>, l)(l,c, 2), then ya = ebb.
Claim For each w,yG £*,eachp, q, q in Q, each a GN*, and for all n ^ 1,
if and only if
(<7, Z, q) => wa
(q, wy, Z) f^ (p, y, <p(a))
5.4 CHARACTERIZATION THEOREMS 155
and eithert
a e ({p}x r x Q)HnH(Q x r x {<?'}) n#
or
a = A and p = q .
Proof By induction on n.
Basis, n = 1; then,
(q, Z, q') => wa if and only if (q, Z,q) -*■ wot. is in P.
There are two possible cases.
CASE 1. The rule (q, Z, q') -* wa is type (i). This can occur if and only if
a e({p}x Tx Q)HnH(Qx rx{q'})nH.
Suppose
a =(p,Z1,q1)---(qk_1,Zk,q')
for some ?],... ,qk-i ^Q,ZX,. .. ,Zk S T. Thus,
(q, Z, q') => wa
if and only if
(q,Z,q) -y w(p, ZY ,qY) • • • (qk.x, Zk,q) is mP
if and only if
(p,Zk ■ ■ ■ Zj) S 5 (q, w, Z)
if and only if
(q, wy, Z) \-{p,y,Zh--- Zx).
But
<p(a) = <P((Pi,Zi, <?i)(<?i, Z2,q2)---(qk-i. zk, q')) = ZkZk _Y ■Z1.
Thus
(q, Z,q) => wa
by a rule of type (i) if and only if
(q, wy,Z) \- (p,y, «p(a))
and
ae({p}x TxQ)HC\H(Qx Tx {q'})nH.
t This condition means that either
a = (p,Zltqi)&(q2,Z2,tl')^H
for some Q\, Q2 ^ Q< Z l > ^2 £ T, and some /3 S // (that is, the first component of the
first triple is p while the last component of the last triple is q'), or
a = A and p = q'.
156 PUSHDOWN AUTOMATA
CASE 2. The rule (q, Z, q) -*■ wa is type (ii). This can happen if and only
if
a = A
Thus
(q, Z, q') =» w
if and only if
(q, Z, q') -> wisinP
if and only if
(q',A)e8(q,w,Z)
if and only if
(q,wy,Z) h (q'.y.A).
Now, since <p(a) = <p(A) = A, we have
(q,Z,q') => wa if and only if (<7, wy, Z) |— (p,.y, f>(a))
and
a = A and p = q .
Induction Step. Assume the claim holds for k < n. Note that
(q,Z,q) =*■ wa
will hold if and only if
(q,Z,q')=?w1Ya2 ^ w^iia^
where
w = wxa, a = aja^, y-^aai is in P.
Let
Y = (q",Z',p').
Now, applying the induction hypothesis, we have
(q, Z, q) => Wl y<x2
if and only if
(q, wxay, Z) f- ((7", ay, <p(ya2)) = (q", ay, <p(a2)Z'),
where the equality follows from
0(^2) = <p(a2)<p(y) = <p(a2)Z'.
By the induction hypothesis, Ka2 S ({(7"} x T x 2)// H #(2 x T x {(7'}), and hence
a) a2 = A and p = (7'
or
a2 ¥= A and Ka2 e//(2 x T x {(7'}) n//.
But this gives
b) a2 e({p'}x rx 2)//n//(2x rx fo'})n//,since y = (q",z',p).
Now, since y -* aax is in P,
y = (<?", Z', p') 4 aax
5.4 CHARACTERIZATION THEOREMS 157
Applying the induction hypothesis a second time gives
(q" , Z', p') ^ aaY
if and only if
(q", ay, Z') \~ (p,y,y(ai))
with either
c) ax = A and p = p
or
d) ax e({p}x Tx Q)HnH(Qx Tx {p'})nH.
Now, combining, we have
"' , n + l
(q, Z,q) => wa
if and only if
(q, w1ay, Z) \- (q",ay,y(a2)Z') ^ (p,y, tp(a2)^>(a1)),
where we may combine the computations by Proposition 5.2.1.
Now, using the fact that
w = wxa a = axa2
and
«p(a2)«p(ai) = «p(aia2) = <p(a),
we have
, n + l n + l
(q,Z,q) =? wa if and only if (q, wy, Z) \ (p, y, $(<*)).
To get the conditions on a, there are four cases to consider:
CASE 3. ai = a2 = A. Then, from (a) and (c) above, we have:
P = q', P = P-
Thus' a a
a = ala2 = A and p = q .
CASE 4. ai ¥= A, a2 = A. Then, from (a) and (d), we have:
a = av e({p}x Tx Q)HnH(Qx Tx {<?'}) n^-
CASE 5. C*! = A, a2 ¥= A. Then, from (b) and (c),
a = a2<=({p}x rxQ)BnH(Qx Tx {<?'}) n 7/.
CASE 6. aj ¥= A and a2 ¥= A. Then, from (b) and (d),
a = aia2e[({p}xrxQ)HnH(Qxrx{p'})nH\
1({p'} x r x Q)hhh(q x r x {<?'}) n#],
or
ae({P}x rxQ)HnH(Qx rx {<7'})ny/,
which proves the claim.
158 PUSHDOWN AUTOMATA
Now let
q = <7o, Z = Z0, a = y = A, p = q = f
in the above claim and we get
S = fao, Z0,f) ^ w G 2* if and only if (q0, w, Z0) h (/, A, A).
Therefore, L(G) = ^) = ^ = ^
By the claim, if A is unambiguous, then so is G. □
We may now combine several of our previous results to state one of the
main results of this book.
Theorem 5.4.4 Let an alphabet 2 be fixed. Then
Corollary Every deterministic context-free language is unambiguous.
PROBLEMS
1 Prove Theorem 5.4.2.
2 Is Theorem 5.4.2, part (v), true if we replace the linear time condition by
the condition of operating with delay 0; that is, if we require a A-free pda? Explain
in detail.
3 Show that the following sets are context-free
a) L = {albV| i,j>l}U {a'b'c^ i, j>l};
b) L = {alb'\i> \,i<j<7i);
c) L = {xcy\ x,y S £*,x ^y], where c^ 2.
//for. Find suitable context-free languages Lj, Z,2, L3 so that Z, =
L1 U Z,2 U Z,3, and the sets are not pairwise disjoint.
Let us generalize the concept of a pushdown automaton to allow two-way motion on
the input. Formally, a two-way nondeterministic pushdown automaton is a 7-tuple
A = (Q, Z,r,8,q0,Z0,F), where Q, V, q0, Z0, and F have their customary meanings.
2, the input alphabet, is now assumed to contain two distinguished symbols <tand $,
which serve as the left and right endmarkers, respectively. 5 is a mapping from Q x
2 x T into finite subsets of {— 1, 0, l}x Q x T*. The idea is that
(d,q, y)eS(q,a,Z)
means that the device may go into state q ', write y en the pushdown, and move right
if d = 1, move left if d = — 1, and remain stationary on the input if d = 0. If (d, q', y)
S 5 (q, a,Z) implies d > 0, then A is a one-way pda.
If \8(q,a, Z)\ < 1 for all (q,a, Z), then A is deterministic. As an abbreviation,
we can write 1-pda or 2-pda to stand for a one-way or two-way pda, and write 1-dpda
or 2-dpda to stand for one-way or two-way deterministic pushdown automata.
An ID of a 2-pda is a quadruple of the form
(q, <tw$, i, y),
5.5
A-MOVES IN PDA'S AND THE SIZE OF A PDA
159
where q G Q, w G (2 - {<fc $})*, 0 < i < lg(w) + 2, and y G T*. Thus an ID tells us
the state of the device, the location of the read head on the input, and the complete
contents of the pushdown store.
One defines
(q, <tw$, i, aZ) \~(q', <twS, i + d, ay)
if (d, q', y) G 8(q, a, Z) and 1 <z + d <«. A 2-pda >4 accepts w G (£ — {<fc $}) if
(<7o, *w$, 2, Z0) ^ (<7, <tw$, «, a)
for some q GF. Let !TC4) = {w\ A accepts w).
4 Show that any 2-pda A' may be simulated by a 2-pda A with the following
properties.
On any move which adds to the stack (there is also no loss of generality in
assuming that additions to the stack are of length 1),
a) the input head is not moved, and
b) the move is independent of the input.
More formally, if (d, q , y) G 8(q, a, Z) implies
c) y = A, or
d) y = ZZ' with Z,Z' GT,d = 0, and (d, q', y) G b(q, b, Z)
for every b G~L.
5.5 AMOVES IN PDA'S AND THE SIZE OF A PDA
We shall briefly consider the role of A-moves in pda's. One might conjecture
that every context-free language can be accepted by a A-free pda. If "accepted" is
used to mean by N(A) or L(A), then there is a minor problem with A. If AGL,
then the pda must have at least one A-move in order to erase Z0 from the pushdown
store. This argument is one justification of those authors who allow pda's to move on
empty pushdowns. We begin by assuming that A ^Z,.
Theorem 5.5.1 L9 £+ is a context-free language if and only if L = N(A)
for some A-free pda A.
Proof
a) If L =N(A) for some A-free pda, then the result follows directly from
Theorem 5.4.4.
b) Suppose L = L(G), where
G = (V,X,P,S).
We may assume, without loss of generality, that G is in Greibach normal
form. Let , ,
A = ({<?}, Z, V, 8, q, S, 0),
where
5 (q, a, Z) = {(q, aT) I Z -+ aa is in P}.
Clearly, A is A-free and the proof that N(A) = L(G) is exactly the same as in Theorem
5.4.1. □
160 PUSHDOWN AUTOMATA
Now we turn to acceptance by final state. Final states easily eliminate the
previous problem with A.
Theorem 5.5.2 L 9 £* is a context-free language if and only if L = T(A) for
some A-free pda A.
Proof If L = T(A), then L is a context-free language, by Theorem 5.4.4.
Let L = L(G), where
G = (V,I,,P,S)
is in Greibach form.
Defme A = ({<7o, <?,/}, 2, F',5, <?<>, 5', F),
where
Then
and
V = VU{A'\AGN}.
i) 8(q,a,Z) = {(q, aT)\ Z^aa is in P};
ii) 5 (q, a, Z') = {(<?, 5'aT) I Z -» aaS is in P} U {(/, A) IZ -» a is in />};
iii) 5 (<7o, a, S') = {(q, B'qT) \S -* aaS is in P} U {(/, A) 15 -* a is in P};
F ={/}U{40l S^AisinP}.
Note. The state q0 allows A6I.
The proof that L(G) - T(A) is straightforward and is left as an exercise. □
Corollary Every context-free language may be accepted by a nondetermin-
istic pda with delay 0.
We may restate these results in a still more vivid form.
Theorem 5.5.3 For each pda A, one can construct a A-free pda B so that
T(A)=T(B).
Proof Given a pda A, we use Theorem 5.4.4 to get a context-free grammar
Gi for T{A). By Theorem 5.5.2, we can find a A-free pda B so that T(B) = T(A). □
The theorems of this section are really nontrivial in spite of their short
proofs. The reason that the proofs are so simple is that the hard work was done in
the grammatical transformation. The skeptical reader may try to prove Theorem 5.5.3
directly without the aid of Greibach form.
Many pda constructions are greatly simplified by the presence of null moves.
In the future, we shall use them extensively.
In Chapter 4, we discussed the size of a grammar and now we wish to
consider the size of a pda. There are at least two different ways to define the size. By
analogy with \G\, we could define \A\ to be the length of the string which results if
all of the entries in 5 are written out as a word. The formal definition now follows.
5.5 AMOVES IN PDA'S AND THE SIZE OF A PDA 161
Definition Let A = (Q, 2, T, 5, q0, Z0, F) be a pda. Define
\A\= 2 (lg(a) + lg(a) + 3).
(q ,a)£«(W,Z)
While this is a natural definition, it is cumbersome to compute. One would
like to use a measure like \Q\ x 12 I x Irl, but this measure seems too crude. For
example, we could write down two pda's having the same Q, 2, and T, and yet one
writes long strings on each stack move while the other does not. For this reason, it
is necessary to impose a restriction on the class of pda's being considered.
Definition A pda A = (Q, 2, T, 5, q0, Z0, F) is moderate if (q', a) G
8(q,a,Z) implies lg(a) < 2.
We already know something about moderate pda's.
Theorem 5.5.4 For each (deterministic) pda A, there is a moderate
(deterministic) pda B which is equivalent to A in whichever form of acceptance is being
used.
Proof The technique of adding states works in the deterministic case as
well. □
For moderate pda's, \A\ actually grows proportionally to the number of
rules, as the following result shows.
Theorem 5.5.5 Let A — (Q, 2, T, 5, q0, Z0, F) be a moderate pda. Then
3I6KUK6I6I,
and hence
\A\ = 0(|5|).
Proof Since A is moderate, (q', a)G 8(q, a, Z)implies lg(a) < 2. Therefore
\A\ = 1 (lg(«*) + 3)<6|6|.
(n',a)e%ii,Z)
The lower bound is obvious also. □
Now we can consider another definition of size:
Definition Let A = (Q, 2, T, 5, q0, Z0, F) be a moderate pda. Let
Size (A) = 12 x 2x T|.
This is an attractive measure of size, since it is independent of 5.
Now we can begin to relate these measures to each other.
Theorem 5.5.5 There exists a constant c such that for any moderate pda
A = (Q, 2, r, 8,q0,Z0,F), where m = \Qx 2 x T| and n = \A\, we have
n<cm3,
where c depends only on the coding of the rules.
162 PUSHDOWN AUTOMATA
Proof Let \Q\ = </,|2| = s, and |T| = t. Then
m = qst.
To prove that n Kcm3, we construct the largest possible moderate pda. We include
every allowable type of rule, i.e., for each
(q',a)e8(q,a,Z)
for all q, q e Q, Z S I\ a S 2 U {A}, a S A U T U T2, we have a rule. Since A is a
moderate pda,
«<|5|(2 + 1 +3) = 6|5|,
by the definition of n = \A\. Thus
n <6|5|< 6<7(1 +t + t2)q(s+ \)t
= 6q2(t + t2 + t3)(s + \)
<6q3(3t3)2s3 = 36m3,
so c = 36 will do. □
PROBLEMS
1 Show that, for any context-free language L, there is a deterministic pda A
and a homomorphism ip such that .4 operates in realtime and ip(L(A)) = L.
2 Consider the following "proof" of Theorem 5.5.2. Explain in detail exactly
what goes wrong.
Let L = L(G), where G = (V,2,P,S) is in 2-standard form. Let A =
({<7o,<7i}, 2, V,8,q0,S,F), where F= {qi }U {^q I S -» A is in />}. Here, 5 is
defined as follows."
5(<70, a, 4) = 5(<7i, a, 4)
= {On, A) | .4 -► a is in/>}
U{(?1,5)| .4-► a£ is in P}
U {(<?!, Cfi)| .4 -► a£C is in/>}.
Clearly, A is A-free and it is straightforward to verify that T(A) = L(G).
3 Prove the following result.
Proposition For each context-free language L there is a pda A = (Q, 2,
T, 5, q0, Z0, F) such that:
a) L = {WeX*\(q0,W,Z0)\-(q,A,A)for some q S F}.
b) IfAez,,then5(<70,A,Z0) = {((7o-A)}and(7oG/;'. If A^Z,,then
5(<7o,A,2o)=0.
c) If<7Ge-{<7o}orZer-{Z0},5((7, A, Z)= 0.
d) For each (q,a,Z)GQx 2 x r, if to', a)65(?,a,Z), then lg(a) < 2.
5.6 DETERMINISTIC LANGUAGES CLOSED UNDER COMPLEMENTATION 163
4 Show that, if a finite set is recognized by a deterministic (nondeterministic)
pda with q states and t pushdown symbols, then it can be recognized by a (non)-
deterministic finite automaton with a number of states proportional to
tiitf
5 Show that, for each n > 0, there is an infinite regular set Ln which is
accepted by a reduced finite automaton that has at least 22 states but can be accepted
by a dpda of size proportional to n3.
6 Find a lower bound for m in terms of n for moderate pda's, which would
be a counterpart of Theorem 5.5.5. Are additional hypotheses required on the pda?
5.6 DETERMINISTIC LANGUAGES CLOSED UNDER
COMPLEMENTATION
Although the full family of context-free languages is not closed under
complementation (as we shall see shortly), the deterministic languages are. This important
result will often be used in the sequel, even before dpda's are studied in detail. The
proof of the result is fairly complicated.
Our intuition about how to prove this result is strong. One wishes to replace
F by Q—F and design a "complementary machine." The problem is that A-moves
complicate the action of dpda's. A dpda might go into an infinite A-cycle in the
middle of processing an input.
First we ensure that our dpda's always have a next move. This could fail to
happen either if a transition was not defined or if the pushdown were emptied
prematurely. The idea of the first lemma is to make 5 as "total as possible."
Lemma 5.6.1 Let A = (Q, 2, r,8,q0,F) be a dpda. There is an equivalent
dpda/4' = (Q\Z,r',5',(7'o,Zo,F)suchthat
1 For all (q, a, Z) in Q' x 2 x T',
\8'(q,a,Z)\ + \8'(q,A,Z)\ = 1.
2 If 8'(q, a,Z'0) = (q'f a) for some a G 2A, then a = Zo/3 for some |3 G (f)*.
Proof We construct A', in which Z'0 acts as a bottom-of-stack marker so that
the pushdown is never erased, and we add any missing transitions.
Define A' = (Q\ 2, r", 8', q'0, Z'0,F), where r' = ru{z;}, Q' = Q U
{q'o, d) and 5' is defined by four cases:
1 8'(q'0,A,Z'o) = (qo,Z'0Z0)
2 For all (q, a, Z) G dom 5,
8\q,a,Z) = 8(q,a,Z).
3 If 8(q, A, Z) = 0 and 8(q, a, Z) = 0 for some a G 2, then
8\q,a,Z) = (d,Z).
4 ForallZGr>G2,
8'{d,a,Z) = (d,Z).
164 PUSHDOWN AUTOMATA
5 For all 4 e g, a e 2,
8'(q,a,Z'0) = (d,Z'0).
Clearly,/!' is a dpda which satisfies cases (1) and (2). For any x S 2*, q^-F,
(<7o, x, Z0) fj to, A, a)
if and only if
(q'o,x,Z'0) |j, too,*, Z0Z0)
|j, to, A, Z'0a).
Therefore,
T(/l') = T(A). D
One of the problems to be dealt with concerns the possibility that a dpda
will get into a A-loop and the computation will not terminate.
Definition An ID to, A, a) of a dpda A = (Q, 2, T, 5, <70, Z0, F)is immortal
if, for all integers i, there is an ID to,-, A, ft) such that lg(ft) > lg(a) and to, A, a) r~
to,-, a, ft).
Intuitively, an ID is immortal if A can make an infinite number of A-moves
and also never shorten its pushdown below its initial height. This would mean that the
pushdown might grow infinitely, or might cycle between different strings of the same
length.
Some of the basic facts about immortal ID's are summarized in the following
proposition.
Proposition 5.6.1 Let A = (Q, 2, T, 8,q0,Z0,F) be a dpda, and let
<7e2,zer,a,a'er*.Then,
a) If to, A, a) is immortal, then for any w £ 2* and / > 0, there exist q{ S Q,
Pi e r* such that
to, w, a) \- to, w, ft).
b) For any a S T*, to, A, Z) is immortal if and only if to, A, aZ) is immortal.
toi, wi, aO F^ to, w, a) H^ to', w, a)
and to, A, a) is immortal, then w' = u>.
d) If there exists a £ 2 such that
to, a, Z) H1 to', A, aj),
then to, A, Z) is not immortal.
a) If to, A, a) is immortal, then
to, A a) ^ to;, A ft)
for some q{ S 2 and ft S T*. By Proposition 5.2.1, (a) follows.
5.6 DETERMINISTIC LANGUAGES CLOSED UNDER COMPLEMENTATION 165
b) The argument is trivial since the immortal computation never emptied
the pushdown so a would not even be read.
c) This follows from the determinism of A and the definition of immortality,
since, once an immortal ID is reached, no additional input is read.
d) This is a variant of (c), since, if a true input gets read, the ID that started
the computation could not have been immortal, by the determinism of
A. The formal details are left to the reader. □
Because of (a), it is convenient to refer to ID's of the form (q, w, a) as being
immortal also.
Before deriving an algorithm for detecting immortal ID's, we need more
definitions.
Definition Let A = (Q, 2, T, 5, q0, Z0, F) be a pda and let q G Q, Qx £ Q,
and aG r*. Define:
T(A, q, a, 20 = {wG 2* | (q, w, a) f- (q', A, |3) for some |3 G T* and some q G Q1}
and
L(A, q, a, Qx) = {w G 2*| (q, w, a) ^ (q', A, A) for some q G Qx }.
These sets are context-free, in general.
Lemma 5.6.2 Let A = (Q, 2, T, 5, q0, Z0, F) be a pda and let q G Q,
£>! Sz Q, and aGT*. Then T(A,q,a, Q^) and L(A, q, a, gj) are context-free
languages.
Proof Define BqaQi = (Q U {q'0}, 2, T, 5', q'0, Z0, Qx), where 5' is defined
as follows:
1 5'(<7o,A,Zo) = (q,a)
2 8'(p,a,Z) = 8(p,a,Z) for all (p,a, Z) in the domain of 5.
B is deterministic if A is. Clearly,
T(B) = TiA.q.a.Qi)
and
L(B) = HA,q,a,Q1)
are context-free languages. □
Now T(A, q, a, Q) and L(A, q, a, Q) are used to provide a test for immortal
configurations.
Lemma 5.6.3 Let A = (Q, 2, T, 5, q0, Z0, F) be a dpda and let q G Q and
ZG r. If A satisfies condition (1) of Lemma 5.6.1, then (q,A,Z) is immortal if and
only if
T(A,q,Z,Q)= {A}
and
A$L(A,q,Z,Q).
Moreover, this is decidable in polynomial time.
166 PUSHDOWN AUTOMATA
Proof Suppose (q, A, Z) is immortal. Then
A $ L(A, q, Z, Q)
because, if it were, then
(q, A, Z) \r fa', A, A),
which violates the immortality of (q, A, Z). Also, if there exists xGI* which is in
T(A, q, Z, Q), then
(q,x,Z) £ fa',A,/3). (5.6.1)
But, since at least one true input was used in Computation (5.6.1), then (q,x,Z)
could not have initiated an infinite A-loop; that is, (q, A, Z) is not immortal. Cf.
Proposition 5.6.1(d).
Conversely, assume that (q,A,Z) is not immortal; then there exist z'X),
<7'G(2,and 76 T*,such that
(q, A, Z) ^ fa', A, 7),
and there is no q" £ Q, y £ T* with
fa', A, y) h fa", A, 7').
This can occur in one of two cases, namely:
1 y = A, or
2 y = aZ' and 5 far', A, Z') = 0.
If (1) holds, then AEL(A, q, Z, Q). If (2) holds, then, since A satisfies the first
condition of Lemma 5.6.1, there exist a £ 2, q" £ 2,7'" £ T*, such that
5fa',a,Z') = fa"',T"'),
and consequently,
(q,a,Z) ^- fa'",A,aT'").
Then
aeT(A,q,Z,Q).
In either case, one of the conditions is violated.
To analyze the running time of the algorithm, let us proceed as follows.
The size of a pda for L(A, q, Z, Q) is proportional to the size of A. Assume that all
our pda's never add more than one symbol to the stack at a time (fa', a) in 8(q,a,Z)
implies lg(a) < 2). There is no loss of generality in this assumption because we may
break down a long addition of symbols into many additions of length 1.
To check whether A £ L(A, q, Z, Q), convert from the dpda to a context-
free grammar for the same set. The grammar G will be of size proportional to the size of
the pda. One can test whether the grammar generates A in time proportional to IIC II.
For T(A, q, Z, Q), pass to a pda C (not necessarily deterministic) which
accepts this set as N(C). The size of C is polynomial in the size of A. Again pass to a
grammar for this language. This grammar will be polynomial in the size of C. Reduce
5.6 DETERMINISTIC LANGUAGES CLOSED UNDF.R COMPLEMENTATION 167
the grammar in linear time. There exists x ¥= A in T(A, q, Z, Q) if and only if there
is a righthand side that contains a terminal. (Cf. Problem 3.2.7.) □
Now we are in a position to detect which immortal ID's go through final
states.
Lemma 5.6.4 Let A = (Q, 2, I\ 5, q0, Z0, F) be a dpda. Let d = {(q, Z)\
q GQ, ZGT, and (q, A, Z) is an immortal ID, and there exists no q 6f such that
(q, A,Z)\*-(q', A, a) for any a G V*} and C2 = {(q,Z)\q G Q,ZG r,and (q, A,Z)
is an immortal ID and (<7, A,Z) \—(q',A,a) for some q GF and a G r*}. Let(<7, A,Z)
be an immortal ID. Then
a) (q, Z) G d if and only if T(A, q,Z,F) = 0.
b) (q, Z) G d if and only if T(A, q, Z, F) = {A}.
Proof Consider T(A, q, Z, F). Since (q, A, Z) is immortal,
if(q,Z)GC1,
T(A, q,Z,F) = l
{A} if(<7,z)ed- n
Corollary There is an algorithm for testing membership in d or d in time
which is polynomial in the size of A.
Proof The proof of Lemma 5.6.3 gives a polynomial time test for the
emptiness of T(A, q, Z, F) and for membership of A. □
Before continuing, a different form of acceptance is required.
Definition Let A = (Q, 2, T, 8, go, Zq, F) be a dpda. We define a relation
H~ £ P*- as follows: For all g, q GQ, w, w G2*,and 7, 7'G T*,
07. w,7) |^ (q'.w'.y')
if and only if
i) fa, w, 7) (— (q', w, 7') and
ii) 8(q', A,7'(1 ^is undefined (in particular, if 7' = A).
Intuitively, (4, w, 7) H~ (q', w', 7') if and only if (q, w, 7) \— (q', w', 7') in a
computation which cannot be extended by A-moves. That is, A has gone as far as it could go
in computing on (g, w, 7) without reading the first symbol of w'.
The computations defined with |f— are sometimes called d-computations
(d for deterministic). We can define "d-acceptance" by
Td(A) = {w G 2*| (qQ, w, ZQ) |^- (q, A, a) for some qGF,aG V*}.
Note that a dpda A may have many different opportunities to accept w
since w = wA' for any / but only one opportunity to d-accept w.
Next we introduce a special type of dpda.
168 PUSHDOWN AUTOMATA
Definition A dpda A = (Q, 2, r, 8, q0, Z0, F) is loop-free if for all w G 2*
there exists g G 2 and a G T* such that (<70, w, Z0) IP6- fa, A, a).
The g and a in the definition of loop-free are uniquely determined by w.
Thus, a loop-free dpda always exhausts its input string and stops. Note that a loop-free
dpda cannot go into an immortal ID after the input is processed. That is, suppose
(q0,w,Z0) IF11 (q, A, a).
Could (q, A, a) be immortal, or in other words, could this computation continue
indefinitely? This could not happen because, if it did, strings like wa, where a G 2
would violate the definition of loop-free since
(q0,wa,Z0) \^- (q',A,fl)
for no q G Q and |3 G T*, so
is impossible as well.
Lemma 5.6.5 For any dpda A, there is a dpda A' which is loop-free and
T(A') = 7X4). 4' may be effectively constructed from A.
Proof We may assume, without loss of generality, that A =(Q, 2, r, 6,
q0,Z0, F) satisfies the conditions of Lemma 5.6.1. (Intuitively, A always has a next
move.) Define A' = (£>', 2, I\ 5',q0,Z0,F') where Q' = Q U {/, J}andF' = FU {/}.
5' is defined by five cases.
1 For all fa, a, Z) G (Q x 2 x T),
S'O/, a, Z) = 5(<7, a, Z).
(All moves on true inputs are simulated.)
2 For all q, Z such that (g, A, Z) is not an immortal ID, let
8'(q,A,Z) = Sfa, A, Z),
(All A-moves that terminate are included).
3 For all (q, Z) e d of Lemma 5.6.4, let
8'fo. A, Z) = (rf.Z).
(We broke an infinite A-loop in which the stack never shortened and which
never went through a final state and instead went directly to a new non-
final state.)
4 For all (q, Z) G C2 of Lemma 5.6.4, let
5'(<7,A,Z) =(f,Z).
(In this step, we broke an infinite A-loop in which the stack never
shortened and which involved a final state and instead went directly to a new
final state.)
5.6 DETERMINISTIC LANGUAGES CLOSED UNDER COMPLEMENTATION 169
5 For all (a, Z) G 2 x T,
&'{f,a,Z) = (d,Z),
8'(d,a,Z) = (d,Z).
By Lemmas 5.6.3 and 5.6.4, one can decide whether an ID is immortal or not
and test membership in C\ or C2 and so A' may be effectively constructed from A. It is
straightforward to check that A' is a dpda because A is and because C\ n C2 = 0.
Claim 1 .4' is loop-free.
/¥oo/ Suppose A' is not loop-free. There exists w0 G 2* such that, for all
q G Q and a G T*, it is not the case that
(q0, w0,Z0) ||j, fa, A, a).
Since ^' satisfies the conditions of Lemma 5.6.1, this means that, for all /> 0, there
exist qt G Q, a,- G T+, and w,-, a suffix of w0, such that
(q0, w0,Z0) [^ fa,-, wit a,).
Now lg(w,) > 0 for all / and lg(w,) is nonincreasing, so let iQ be chosen such
that for all / > i0, lg (w,) = lg(w,o). Thus, for all / > i0, wt = w,o and
(%, A, %) P2- (<7,-. A, a,).
Now for all i>i0, lg(a,)>0, so there is z'i >i0 such that for all i>il,
lg (a,) > lg (a,-,). Let Z G r and a G T* be such that
aZ = a.-
and let ft be such that
aft = a,-
for all / > z-!; it is clear that
(qh,A,Z) h^ fo,.A.ft)
andlg(ft)>l.
Since for all Z G T,
S'(rf. A- Z) = 5'(/, A, Z) = 0,
it must be true that for all i>ix, we have qt G Q. This, in turn, implies that, for all
i > ii , if
ft = PZt
and
ft+i = SIS'
for some ft, then
(^•+1,/3')e5fe,A,Z,),
because the only entries in 5' — 5 involve d and /. Thus
(</,-, A, Z) f^ fo„ A. ft).
170 PUSHDOWN AUTOMATA
This implies that (qt], Z) G Cx U C2 whence
8Xqi],A,Z)£{(d,Z),(f,Z)l
which contradicts
07i,,A.Z) |j, (<7,i + 1, A,/3,-i + 1)
since qt +lG Q. Therefore A' is loop-free after all.
Claim 2 If
(<7o, w0, 7o) Ij (<?i,wi.7i) lj " ' tj fefe-^fe-Tfe), (5.6.2)
where 70 = Z0 and no immortal ID occurs in (5.6.2) (except possibly (<7fe, wfe,7fe)),
fao, wo, 7o) lj< - - • tj' (<7fe, wfe, 7fe).
Proof The argument is a straightforward induction on k because the
construction of A' includes all the moves used in (5.6.2).
Now we consider "successful" computations of A involving immortal ID's.
Claim 3 If there exists some k > 0 such that
fao. w0, 7o) lj 07i, wi, 7i) I7 " • • I7 fa*, wfe, 7fe) h • • • (5.6.3)
where 70 =ZQ,wk = A, and (<7fe,wfe,7fe) is immortal but (^-, wj,yj) is not, for/ <fc,
then
fao. w0, 7o) tj' • • ' tj- fa. A, 7),
where
(/ if qt G F for some / > k,
d otherwise.
Proof By Claim 2,
fao, w0, 70) tj- fafe, wfe> 7fe).
By the construction of A'
(f A, 7) for some 7 GT* if ^ GFfor some/>£,
. (d, A, 7') for some 7' G T* if q} £F for all/ > k.
The proof is completed by pasting together these A' computations. D
Our next task is to relate computations in A' to those in A.
Claim 4 If there exists k > 0 such that
(<7o, wo, 70) \X' " ' tj' fafe- wfe, 7fe), (5.6.4)
where 7o = Z0, wfe = A, and qk GF U {/}, then either
0 fao, w0, 70) tj • • • Ijfafe, wfe, 7fe) with^ GFand wk = A
[i.e., no immortal ID's encountered in A], or
fafe, wfe,7fe) lj.
5.6 DETERMINISTIC LANGUAGES CLOSED UNDER COMPLEMENTATION 171
ii) there exist g G F, 7 G T* such that
too. w0,7o) tj (qk-i.Wk-i.yk-i) \j (q.^.y)
and wfe_j = A [an immortal ID in C2 encountered by A].
Proofof Claim 4 Consider (5.6.4). All the ID's of A' are ID's of A unless
an immortal ID was encountered by A' when started on (q0, w0,yo)- If none were
encountered then (i) holds. If there exists 0 < / < k such that (qh wt, y\1}) is immortal
in A, then clearly qk =/and/ = k — 1. But, by rule (4) of the construction, we have
fe-i
fao. w0,y0) hp- (qk-i, A, 7fe-i) Ij- </, A, 7fe).
(<7fe-i. 7fe-i) is in C2, and so there exist q £f, 7 G T* so that fafe-i,A, 7fe_,) h~
(4, A, 7). Therefore, fe_, ^
fao. w0, 7o) hj- (?fe-i. A, 7fe_!) h (q, A, 7).
Our last claim relates the behaviors of A and A'.
Claim 5 7'(y4')=7'(yl).
Proof By Claims 2,3, and 4. □
Note that Proposition 5.2.2 follows from the preceding theorem.
We can now put together all our results into the main theorem of this
section.
Theorem 5.6.1 If L is a deterministic context-free language, then L= 2* — L
is also a deterministic context-free language.
Proof Suppose L = T(A), where A = (Q, 2, T, 5, qQ, Z0, F) is a dpda. By
Lemma 5.6.5, there is no loss of generality in supposing that A is loop-free. Define
A' = (Q\ 2, T, 5',<7o,Z0,F'), where
e' = to, ou^g./G {0,1,2}};
0 if q0£F,
q'o = (qo.io) where z'0
1 if q0 ^F;
F' = Q x {2};
and 6' is defined by cases:
1 lf(q,a, Z)GQx 2 x T,then
8'(fo, l),a,Z) = 8'((q,2),a,Z) = ((<?',/), a)
where 6(^7, a, Z) = (g', a) and
[0 if q'£F,
(l if q'GF.
172 PUSHDOWN AUTOMATA
2 If (q, Z) G Q x T and 5 (q, A, Z) = (</, a), then
5'((<?, 1), A, Z) = ((<?', l),a)
and
5'(07,O),A,Z) = ((q',i),a)
where
0 if q'$F,
1 ifqr'GF.
3 If 5 (<7, A, Z) = 0,then
8'((q,0),A,Z) = (fo,2),Z).
The idea of the construction is to use three copies of the set of states of Q.
A state of the form (q, 0) means that A has not been in a final state since it last made
a move on a true input. A state of the form (q, 1) indicates that A has entered a final
state in that time interval. The states of the form (q, 2) are used only for final states.
The detailed argument will proceed by consideration of a number of
claims.
Claim 1 A' is a dpda and Td(A') = T(A').
Proof It is clear that A' is a dpda from the construction. It is always true
that Td(A') 9 T(A'). If w G T(A'), then
(q'o.w,Z0) |j, (fa, 2), A, a)
for some 4 G g and a G T*. But, for all q G Q, Z G r,
5(0?, 2), A, Z) = 0,
so *
(q'o,w,Z0) |tj, ((q, 2), A, a),
and therefore w€Td(A').
Claim 2 For any q, q G Q, y, y' G r*, and / > 0,
(too,a,7) k oy,i),A,7')
if and only if ;
to. a, 7) tr to'.A- ?')•
Proof The argument is an induction on /. The basis when / = 0 is trivial.
Induction step. Assume the result for all computations of length k. Now
((q, D,A,7) t^-OV, 1),A,7') (5.6.5)
if and only if there exist Z G r and y" G r* such that
((q, 1), A, 7) £. ((q", 1), A, y"Z) |j, {{q1, 1), A, 7')- (5.6.6)
Note that we know the intermediate state (q", 1) has second component 1 because
no A-move can change the 1 in (g, 1) to a 0 or a 2. By the induction hypothesis
applied to (5.6.6) and by the definition of 5', this condition holds if and only if
5.6
DETERMINISTIC LANGUAGES CLOSED UNDER COMPLEMENTATION
173
and (q,A,y) ^(q",A,y"Z) ^
8(q",A,Z) = (q',a)
and
7 = 7 a.
Thus, (5.6.7) holds if and only if
(q, A, y) (j (q", A, y"Z) (j (q, A, 7')
or fe+i ( (
07- A, 7) hj- (q , A, 7 ).
The induction has been extended.
Claim 3 For any q, q' G Q, 7,7' G T*, and / > 0,
((<?,0), A, 7) £ ((<?', 0), A, 7')
if and only if
(q,A,y) £ (q',A,y').
Proof The argument is similar to the proof of Claim 2. The difference is that
we may observe that an intermediate state must have second component 0, for if it
were a 1 or a 2 it could not be reconverted to a 0 in a A-computation.
Now we consider how the second component in the states of A' might
change.
Claim 4 For any q, q G Q, 7,7' G r*,
(0?,0), A, 7) £-, ((<?', 1), A, 7')
if and only if there exist / < /, q" G F, and 7" G T*, so that
(q,A,y) £ 0?",A,7") \~ iq',A,y').
Proof The argument is another induction on / in which the basis is omitted.
Induction step. Suppose the result holds for k and consider
(0?,0),A,7) ^ ((<?', 1), A, 7% (5.6.8)
This holds if and only if there exist q" G Q, g G {0, l}, 7" G T*, Z G T, such that
(0?, 0), A, 7) £ (0?", S), A, y"Z) fr ((q\ 1), A, 7'). (5.6.9)
Note that £ ¥= 2 since A' cannot move from a 2-state to a 1-state under A. In turn,
(5.6.9) holds if and only if
fo. A, 7) ^(q",A,y"Z) (5.6.10)
and either
or
C = 0, 8(q",A,Z) = (q',a), q G F and 7' = 7"a
8=1, 8(q",A,Z) = (q',a), y = y'a. and
07, A, 7) fj O7"', A, 7'") for some 4'" G F,/ < fc.
174 PUSHDOWN AUTOMATA
The equivalence of (5.6.9) and (5.6.10) uses the induction hypothesis and Claim 3.
Using (5.6.10) we see that (5.6.8) holds if and only if
fe,A,7) t^ fai,A,/3) ^V,A,7'),
where m = if C = 1 then / else k + 1. The values of q t and |3 may be obtained from
(5.6.10) and q\^F. This extends the induction and completes the proof of Claim 4.
Claim 5 For any q, q e Q, q $ F, y, y e T*, and i > 0,
(fa,0),A,7) ^ (fa', 2), A, 7')
if and only if
(q, A, 7) tj fa'. A, 7'), 5fa', A,(7')(1)) = 0,
and for any p^F, y" G T*,
fa,A,7)^fa,A,7").
/¥oo/ The argument is an induction on /.
Basis, i = 0. Then,
(fa,0),A,7) fr (fe', 2), A, 7')
if and only if (by rule (3))
q = q', 7 = 7' and 5fa,A,7(1)) = 0,
which holds if and only if
fa. A, 7) tjfa',A,7')
and, since q^F, then q' = q (£F, and so
fa.A,7) ^fa",A,7")
for any q" £F.
Induction step. Assume the result for i = k. Let us consider
(fa,0),A,7) ^ (fa', 2), A, 7').
This holds if and only if
(fa, 0), A, 7) k (fa"' °)> A' ?") ^T" (fa'« 2). A' V). (5-6.11)
The second state has second component 0 because if it were a 2, we could not move
further on A. If it were a 1, it would not be possible to ultimately reach a 2-state
on A's. Now (5.6.11) holds if and only if q"£F, 8(q, A, 7(1)) = fa",a), 7 = j37(1),
7' = j3a, and, by the induction hypothesis,
fa", A, 7") \~ fa', A, 7')
q $F, and 5 fa', A,(7')(1)) = 0, and for any p GF, y" e T*,
fa", A, 7") Jh (P, A, 7'").
5.6 DETERMINISTIC LANGUAGES CLOSED UNDER COMPLEMENTATION 175
This holds if and only if
fa, a, 7) Ij fa", A, 7") h fa', A, 7'),
8(q', A, (7")(1)) = 0, and for any p Gf, 7'" e r*.
fa,A,7)i^ (p,A,ym).
This extends the induction.
Claim 6 For any q, q G Q, 7, 7' G r*, and /' G {0, 1, 2}, if
(fa,/), A, 7) l£ (fa',/'), A, 7'),
then/'G {1,2}.
* 0
Proof If / = 2, then /' = 2 because |p reduces to p. If / = 1, then /' = 1
for any number of A-moves. If /= 0, then it may be changed to a 1 and would
remain so because a 1-state cannot change to a 0-state under A's. If /= 0, it may be
changed to a 2. In the only remaining case, we would have
(fa,0),A,7) Bj. (fa',0),A,7').
This holds if and only if
(0?,0), A, 7) £. ((<?', 0),A,7')
and
5'(fa',0),A,(7')(1)) - 0- (5-6.12)
But if 5fa', A, (7')(1)) = 0, then (5.6.12) is contradicted by part (3) of the
construction. On the other hand if 5fa', A, (7')(1)) =£ 0, then (5.6.12) is contradicted by part
(2) of the construction.
Claim 7 For any w G 2*, q G Q, 7 G T*, /0 £ (0, 1}, if
(fa,/o),w,7o) Itj. (fa',/),A,7),
then t
fa, w, 70) (j fa', A, 7)
and if q = q0 and y0 = Z0, then / = 1 holds if and only if w G T(A).
Proof The argument is an induction on lg (w).
Basis, lg(vv) = 0, so w — A, and we have
(fa,/0),A,7o) llj' (fa',0,A,7)-
There are several possibilities:
CASE 1 If i0 = 1, then /= 1, since a "1-state" cannot be changed to a "0-
state" under A's nor can it go to a "2-state" without becoming a "0-state" first. By
Claim 2,
fa,A,7o) \j fa', A, 7).
Since q = q0, y0 = Z0, and /0 = 1 imply q0 G F, then this in turn implies A G T(A).
This completes the proof of Case 1.
176 PUSHDOWN AUTOMATA
CASE 2 z'0 = 0. By Claim 6, / = 1 or / = 2. Assume / = 1. Then, for some
k>0,
to,0),A,7o) Itj, ((<?', 1), A, 7).
By Claim 4, there exist
07,A,7o) tj (q", A,7') \~ (q',A,y)
for some / < k, q" G F. Thus, ifq=q0,y0=Z0, then w = A G r(^).
Now assume / = 2. Then
to, 0), A, 70)^'to', 2), A, 7)
implies that there is some k > 0 such that
(07,0),A,7o) |^" to', 2), A, 7).
Note that g $ F since /0 = 0. By claim 5,
fa.A.To) lj (q',A,y),
and for no p G F, 7' G r* do we have
(^,A,7o) I7 (p,A,7').
Therefore, q = qo, 70 =Z0 implies that w^T(A). The proof of the basis is now
complete.
Induction step. Assume the result true for all w G 2* such that 0 < lg(vv) <
k. Let
((q, /o). w. 70) Ifr to'. 0, A- 7), (5-6.13)
where lg(vv) = k + 1 > 1. Then we factor this computation as
to./o),w,7o) |j, toi,/i),a,7i) (5.6.14)
and
toi,*'i),a,7i) fr (fei,»2),A,72) ft to',0,A,7), (5.6.15)
where w = w'a where w' G 2*,a G 2, and Sfa', A,7(1)) = 0, because the original
computation (5.6.13) involved It"*-.
Consider computation (5.6.14). We have
to, z'o),w',7o) tj. toi,/i),A,7iZ),
where 7! = y[Z, y[ G T*, and Z G T. Furthermore,
5'to1,/1),a>Z)^0,
so that 5'to!, /j), A, Z) = 0, since A' is deterministic. Then
to,/0),w',70) Itj. toi,*'i),A,7i),
where lg(vv') < k, so the induction hypothesis applies, to yield
O7.w',7o) £ («i,A,7i) (5.6.16)
and w' G T(A) if and only if il = 1 when q - qo and 70 = Z0.
5.6 DETERMINISTIC LANGUAGES CLOSED UNDER COMPLEMENTATION 177
Now, we consider the computation of (5.6.15). By the construction of A',
fai>«>7i) fj fa2>A,72). (5.6.17)
Since
(fo2.»2).A,72) Ifr (fo'.O. A, 7), (5-6.18)
which follows from (5.6.15), and by the construction of A', we have that
i2 = 1 if and only if q2 G F.
By the induction hypothesis applied to (5.6.18), we have:
fa2,A,72) £fa\A,7). (5.6.19)
But (5.6.16) and (5.6.17), together with (5.6.19), yield
fa, w, 7o) tj fa', A, 7).
It follows that q = qo,lo = Zo, and * — 1 hold if and only if w G T(A). D
Claim 8 For any w G 2*, ^ GQ, and 7 G T*,
fao.w, Z0) ffj fa, A, 7)
implies
(fao,'o),w, Z0) Hj, ((?,/), A, 7)
for some /.
/¥oo/ The argument is an induction on lg(w).
Basis, lg(vv) = 0. From the definition of A', /0 = 0 or /0 = 1. By Claim 6, / = 1
or /= 2. Now, every possible case that can arise is dealt with by Claims 2, 4, or 5.
Induction step. Assume the result for all w G 2 * such that 0 < lg(vv) < k. If
(qo, w,Z0) tA fa, A, 7),
where lg(vv) = k + 1, then
(q0,w,Z0) f£ fa,,tf, 7i) (j fa2,A,72) (£ fa, A, 7)
for some w' G 2*, a G 2, so that w = w'a, some qx, q2 G 2, and some yi, 72 G T .
This implies
(fao.''o).w',Z0) H^. (fai.ii), A, 71)
and z'i G {1, 2}, by the induction hypothesis. Hence
(faw'oXw.Zo) H^. (fai,/i),a,7i) lj< (fa2.'2).A,72)
with/2 = 0 or 1, by the construction of A'. Moreover,
(fo. h), A,72) ifr (fa.0,A>7)
by Claims 2,4, 5, or 6. Combining the subcomputations, we have:
(fao.'o).w,Z0) Hjt (fa,/), A, 7).
178 PUSHDOWN AUTOMATA
We now arrive at our last proposition.
Claim 9 7X4') =2* -T(A)
Proof Since A is loop-free, for any w£X , there exist q and 7 such that
{q0,w,Z0)VrA (q,A,y)
Hence, by Claim 8
) |£ (0?,/), A, 7)
By Claim 7,/=2 if and only if w$ T(A). Thus w<$ T(A) if and only if w G Td(A') =
T(A'). Therefore,
7X4') = 2*-7X4). D
PROBLEMS
Let A = (Q, 2, T, 5, q0, ZQ, F) be a dpda and let q E Q, Qx c Q, for any
aG r*. Define:
L(A,q, a, Qx) = {wG 2*| (q, w, a) £- (<?', A, A) for some q G Qx\,
Ld(A,q,a, Qx) = {wG 2*| (q, w, a) W1- {q, A, A) for some q'G Qx};
Td(A,q,a, Qt) = {wG 2*| (q, w, a) [^ (q', A, |3) for some q G Qi,|3e T*}.
1 Show that, if A is a dpda, then £d04, q, a, Qi) and Td(A, q, a, Qx) are
context-free languages. Show that one can decide whether they are nonempty and
whether a given string belongs to them in time that is polynomial in the size of A.
2 Let A = (Q, 2, T, 6, q0, Z0, F) be a dpda. Show that A is loop-free if and
only if
2* = (Td(A,q0,Z0,F) U Td(.A,qQ,ZQ,Q-F)).
3 Let A = (Q, 2, T, 5, q0, Z0, F) be a loop-free dpda. Is it true or false
that
Td(A, q0, Z0, Q-F) = 2* - 7X4)?
Justify your answer.
4 Let A = (Q, 2, T, 5, q0, F) be a dpda. A pair (q, a) with <? G Q, aG T*,
is accessible if there exists w G 2 such that
(q0, w,Z0) f— (<?, A, a).
Is there an algorithm to decide which configurations are accessible? Suppose A were
nondeterministic. Would the result still hold?
*5 Let A = (Q, 2, r, 5, q0, Z0, 0) be a dpda. Let
r = max{l,lg(7)|5(Q, a, Z) = (<?', 7)}
and let
( (/•ioi|r|-1 )/(/•-1) if r > 1,
/V =
llQliri if r= 1.
5.7 FINITE-TURN PDA'S 179
Show that (q, A, Z) is an immortal ID if and only if there exists j> N such that
(q,A,Z) f(q',h,y)
for some q' G Q, y G T*.
6 Show that in a dpda, A-moves can be essential only in computations that
cause the stack to decrease in height.
7 Show that it is never necessary for a dpda to change states in computations
where the stack is increasing in height.
8 In Lemma 5.6.5, is it true or false that:
a) Td(A') = Td(A)1 b) T(A') = Td(A)l c) T(A') = Td(A')1
9 Let L £ 2 be a deterministic context-free language and let c ^ 2.
Construct a deterministic loop-free dpda A such that
L(A) = idU) = rU) = Td(A) = £c.
10 Show that any deterministic context-free language may be accepted by
a dpda A such that for each input string w of length n, the computation of A on w
takes time proportional to n.
11 Define a pda ,4 to be a deterministic (iterated) counter if A is
deterministic and is a(n) (iterated) counter. (Counters and iterated counters are defined
in the exercises in Section 5.3.) Show that the family of deterministic iterated counter
languages is closed under complementation. Is the same result true for counter
languages?
5.7 FINITE-TURN PDA'S
We have seen that restricting pda's to be deterministic has led to a useful
family of languages. Another restriction will be considered here and some simple
implications will be derived. In later sections when more tools are available, we shall
return to this family and characterize it in several simple and elegant ways.
To illustrate the restriction we have in mind, consider the set
L = {a"b"\ n>0}{c}{anbn\ « > 0>.
A pda accepting this set might stack a's and pop on ft's and then repeat this strategy
for the second half of the set. A graph of the pushdown would look like Fig. 5.5.
We shall say that, in this computation, there were 3 "turns" or places where
the length of the pushdown reversed. The restriction we shall study is to bound the
number of turns in a computation. Formalism is needed if we are to be precise about
this restriction.
Pushdown
FIG. 5.5
Turns
-^•Time
180 PUSHDOWN AUTOMATA
Definition Let A = (Q, 2, T, 6, q0, Z0, 0) be a pda. A sweep is a
computation
fao, w, Z0 ) Pfo.A.A)
for any w£E and q E Q.
Thus a sweep is any computation that empties the pushdown. Next we
classify the moves of the pda.
Definition Let A = (Q, 2, T, 5, q0, Z0, 0) be a pda and let (q, 0) E 8(q,a,Z)
for some g G Q, a E 2 U {A}, and ZEY.k move (q, ax, aZ) {~(q', x, a/3) is called
Nondecreasing if lg (|3) > 1,
Nonincreasing if lg (|3) < 1,
Increasing if lg (|3) > 1,
or
Decreasing if |3 = A.
Next the notion of "increasing" is applied to sweeps.
Definition Let (q0, x0, y0) \ h(qk, xk, yk), where y0 = Z0, yk = A,
and xk = A, be a sweep. The concept of an increasing (decreasing) sweep is defined
recursively as follows:
i) The length of(q0, x0, y0) is defined to be increasing;
ii) Inductively, if the length at (qu xt, yt) is increasing and if the move
(47> xi> Ji) \~(qu xi+i> 7i+i) is nondecreasing (decreasing), then the
length at (^i+1, xi+l, yi+l) is said to be increasing (decreasing);
iii) If the length at (qh xv yt) is decreasing and the move (q[t xit 7,) (—
(qi+i, xi+1, 71+1) is nonincreasing (increasing), then the length at (^i+1>
xi+l, 7,-+1) is said to be decreasing (increasing).
Now, a "turn" can be precisely defined.
Definition Let A be a pda and suppose we have
(<7;. xh 7,0 h (qi+i, xi+l, y!+l).
If the length at (q{, xh 7,) is increasing (decreasing) while the length at (^,-+1, xi+i,
7i+1) is decreasing (increasing), then the length has had a turn at (qt, xh yt).
Definition A sweep is a (2k — l)-turn sweep if it has exactly (2k — 1)
turns. A pda is a (2k — \)-turn pda if every sweep has at most 2k — 1 turns. A pda
A is said to be a finite turn if there is some k > 1 so that A is a (2k — 1) turn pda.
Let us single out the sweeps with a bounded number of turns.
Definition Let A be a pda and letk> 1. Define
N2k~i (A) = {xG 2*I (q0,x, Z0) \— (q, A, A) for some q E Q is a (2/ — 1) sweep
for some / < k}.
5.7 FINITE-TURN PDA'S 181
Our first little result is to show that N2k-i(A) is always a context-free
language.
Lemma 5.7.1 For each pda A and any k > 1, there is a (2k — l)-turn pda
A' such that
N(A') = N2k_M).
Proof Let A = (Q, 2, T, 5, q0, Z0, F) be a pda. We shall construct a pda
A' with 2k copies of the states of A, which will simulate A and keep track of the
(2fc-l)-turn sweeps. Define /T = (Q', Z, T, 5',fa0, 0, 0), where Q'=Qx {/|1<
/ < 2k}. S' is given by cases:
CASE 1 ((q, i), a) E S'((q, i), a, Z) if and only if
(q, a) E 8(q, a, Z) and either / is odd and lg(a) > 1
or / is even and lg (a) < 1.
(Thus a move from (q, /') to (q, i) is nondecreasing if /' is odd and nonincreasing if
i is even.)
CASE 2 ((q', 2i), A) £ S'((q, 2/ - 1), a, Z) if and only if
(q',A)E8(q,a,Z).
(Moves from a state (g, 2/ — 1) to (q', 2i) are decreasing moves.)
CASE 3 ((q, 2/ + 1), a) E 5 \(q, 2i), a, Z) if and only if
(q, a) £ 5 (q, a, Z) and lg (a) > 2.
(Moves from (g, 2/') to fa', 2/ + 1) are increasing moves.)
It is now a straightforward matter to verify that each turn in a sweep of A'
corresponds to a move from a state of the form (q, i) to one of the form (q', i + 1).
Therefore, A' is a (2k — l)-turn pda. Note that any (2/— 1) sweep of A (where 1 <
/'<£) corresponds to a sweep of A'. Since the converse of this is also true, it follows
that
yV2fe_,C4) = N(A'). □
Corollary N2k-\ (A) is a context-free language for each pda A.
One of our ultimate goals will be to characterize the finite-turn languages
grammatically. The following definition will prove to be equivalent to these
languages but it will take some effort before the characterization is achieved.
Definition A context-free grammar G = (V, 2, P, S) is ultralinear if there
exists a finite number of (possibly empty) pairwise disjoint sets X0,.. . ,Xn such
that
n
N = V-T, = Ul;
1 = 0
182 PUSHDOWN AUTOMATA
and for each Xt and each A £1,, either
1 A -»■ w is \nP
where w£pUI0U'"U *,-_,)*, or
2 ^ -+uBv is inP
withw, i)£ 2* and B G AV
Note that every linear language is ultralinear by taking X0 = 0 and A^ = A'.
We are now ready to prove half of our characterization theorem.
Theorem 5.7.1 If A is a finite-turn pda, then N(A) is an ultralinear language.
Proof Let A = (2, 2, T, 5, ^0, Z0, 0) be a finite-turn pda. There is no loss
of generality in assuming that .4 satisfies the following properties:
0 Q = Qi u---uQ2fc with<jr0eGi-
ii) Every move from a state of (?2,-i is either a nondecreasing move to a
state of (?2i-i or a decreasing move to a state of (?2j-
iii) Every move from a state of Q21 is either a nonincreasing move to a state
of Qii or an increasing move to a state of Qi^x •
iv) fa', a) G 5fa, a, Z) for any q G g, a G 2 U {A}, and Z G T implies lg(a)
<2.
(i), (ii) and (iii) follow from Lemma 5.7.1. Property (iv) may be assumed because we
could add extra states to achieve it if necessary. Such additions would result in a new
pda A' such that N(A') = N(A), and if A is a (2k — l)-turn pda, then so is A'.
Now for any state q G Q, define v(q) — i, where q G Qr Note that v(q0) = 1
and i^fa) < 2k for all 4 G 0.
Define G - (V, 2, P, 5), where
V = 2 U {5} U U (2; x T x 2; x (r U {A})).
1 «!</«2fe
and P is given by the following productions: For all q, q , /,pGg;a£2U {A};
Y, Z, Z' G T; X G T U {A}. Then,
1 5^fa0,Z0,^', A);
2 fa.Z,?', A)^a iffa', A)G5fa,a,Z);
3 fa, Z, 4", Af) -> afa', F, 4", AT) if fa', F) G 5 fa, a, Z);
4 fa", X ?', Y) -» fa", X 4, Z)a if fa', r) e 8 fa, a, Z);
5 fa, Z, 4", Z') -» afa', F, 4", A) if fa', Z'Y) G 5 fa, a, Z);
6 fa", Z', <?', A) -> fa", Z', 4, Z)a if fa', A) G 5 fa, a, Z);
7 fa, Z, 4', AO -> fa, Z, p, F)(p, F, q, X) for all p6g such that v(q) <
v(p)<v(q')
5.7 FINITE-TURN PDA'S 183
The basic idea of the construction is embodied in the following observations
and the claim.
The first rule indicates a goal of obtaining all words in N(A). Rule 2 is a
terminal rule, which corresponds to a decreasing move of the pda and will only be
applicable when v(q) is odd and v(q') — v(q) = 1. Productions (3) and (4) correspond to
length-preserving moves of the pda. Production (5) corresponds to an increasing move
of the pda. It can occur only when v(q) is odd and v(q') <v(q"). Similarly, (6)
represents a decreasing move of the pda, which can only apply when v(q') is even and
v(q") < v(q). Rule 7 corresponds to a sequence of moves of the pda such that there
is a state p such that
v{q)<v(p)<v(q),
at which the length of the pushdown is exactly one. The following claim summarizes
the correspondence between the variables and the pda's computation.
Claim For each q, q G Q, Z G T, and Y G V U {A},
(q,Z,q', Y)^w wG 2*
if and only if
(q,w,Z) \^(q',A,Y).
Proof The argument involves an induction and case analysis in each direction
and is omitted.
It follows from the claim that
L(G) = N(A).
To complete the proof, we need only verify that G is ultralinear. Define
X[ = {(q, Z, q',Y)\ v(q) - v(q) = i} for 1 < / < 2k - 1
and
X2H = {SI
It is now easy to verify that G is ultralinear. □
Corollary If A is a one-turn pda, then N(A) is a linear language.
Proof If k = 1, then the grammar G uses no productions of type (7). Thus
G is in linear normal form (Problem 2.5.1). □
PROBLEMS
1 Complete the proof of the claim in Theorem 5.7.1.
A context-free grammar G = (V, 2, P, S) is said to be nonterminal bounded if there
exists an integer k > 1 such that, for any derivation A =^a, aG V*, the number of
occurrences of variables in a is at most k. A language is called nonterminal bounded if
it is generated by a nonterminal bounded grammar. If G is such a grammar and a G V
define p(a), the rank of a, to be the largest integer r such that there is a word |3 G V
with r occurrences of variables such that
*
184 PUSHDOWN AUTOMATA
2 Prove that:
a) For w e 2*, p(w) = 0.
b) pC4, ■■■A„)= 2 p(^i) for >!!,.. . ,^„ £ V,n>0.
1 = 1
c) p(/4)> 1 for each A G N.
d) If A is a variable of rank r, there exists a word a £ F such that:
i) A 4- a
ii) a has /■ occurrences of variables, and
iii) each variable in a has rank 1.
e) Every nonterminal bounded grammar contains variables of rank 1.
3 Prove that a context-free grammar G is ultralinear if and only if G is
nonterminal bounded.
4 Is the set L = {{anbn \ n > 0}c)* nonterminal bounded or not? Can you
prove your answer?
5 Show that if Ll and L2 are finite-turn languages, then so are
£i U L2
and
LtL2-
6 Show that every regular set is a finite-turn language.
5.8 HISTORICAL SURVEY
The close connection between context-free languages and pushdown
automata was established by Chomsky and Schiitzenberger. Cf. Chomsky [1962] and
Schiitzenberger [1963]. Another early reference is Evey [1963]. Theorem 5.6.1 is
due to Haines [1965]. The theory of deterministic context-free languages originated
in Haines [1965] and Ginsburg and Greibach [1966a]. Related results are in
Schiitzenberger [1963]. The theory of finite-turn pda's is due to Ginsburg and Spanier
[1966].
six
The Iteration Theorem,
Nonclosure
and Closure Results
6.1 INTRODUCTION
This chapter begins with an iteration theorem for context-free languages. Use
of this result allows us to give direct proofs that certain sets are not context-free. The
theorem also shows that, over the one-letter terminal alphabet, there is no difference
between context-free and regular sets. Next, the closure properties of the context-free
languages are explored. One particularly important result is that context-free languages
are closed under "sequential transducer mappings."
Section 6.6 digresses by giving a closure result whose proof is not constructive.
Section 6.7 discusses the relationship of programming languages to context-free
languages and indicates the programming language features that are incompatible with
the context-free languages. A theorem is established in Section 6.8 that enables us to
prove that there are "nonlinear" context-free languages. The proof is rather a nice
blend of the different techniques used in this chapter. A natural map of context-free
languages into n-ary relations on natural numbers is given in Section 6.9, and Parikh's
Theorem is proved.
6.2 THE ITERATION THEOREM
We will now establish one of the most important theorems of context-free
language theory. It is a necessary condition on the set of strings of a language. The
notation of Section 1.6 will be needed in our development.
185
186 THE ITERATION THEOREM. NONCLOSURE AND CLOSURE RESULTS
Definition Let wG2*. Any sequence \p = (vu . . . , vn)£ (2*)" such that
w = vt---v„
is called a factorization of w. Any integer /, 1 < / < lg(vv) is called a position of w.
Let ^ be a set of positions in w. Any factorization \p induces a "partition"
of A, which we write as
Kfr= (Ku...,Kn),
where for each /, 1 < / < n,
K, = {k£K\ lgfa, . . . , q_,) < * < lg(»,,. . . , t*)}.
Note that some A,- may be empty, so this is not a true partition.
Examples
a) Let w = ai ■ ■ • a„,at€ 2, and A = {1, . . . ,«}.
i) If we take \p = (a1,a2, ■ ■ . ,an), then
A,V = {A-,} where A", = {«}.
ii) If we take <p = (^1^2'"' anX then
A/^ = A, = A.
b) Let w = ff" 6P <■",</>= (a", 6p,c") and A = {p + 1,... ,2p};then
A, = A3 = 0, A2 = A.
Notation. To mark a set of positions we will underline them. Thus, in (b)
above, the set of positions would be written as:
ap .b". c".
We can now state and prove an iteration theorem for context-free languages.
The theorem we prove is stronger than the "pumping lemma" ("xuwvy theorem")
found in some standard texts. The additional power of the iteration theorem stems
from the use of positions. This forces the factorization of a string to be restricted and
cuts down on the number of cases that can arise.
Theorem 6.2.1 (The Iteration Theorem) Let L = L(G) be a context-free
language and G = (V,~L,P,S) be a grammar for L. There exists a number p(G) such
that for each w£L and any set A of positions in w, if |A| >p(G), then there is a
factorization
<fi = (vu ... ,vs) of w
such that:
i) There exists A&N such that
S ^> ViAvs
A => v2Av4
A => v3
6.2 THE ITERATION THEOREM 187
if) For each^XD,^ v%v3vivs€-L.
iii) lfK/*=lKl,...,Ks},tben
a) eitherKUK2,K^<}> or K3,KA,Ks=£ 0;and
b) |tf2Utf3Utf4|<p(G).
Part (iii) means, in part, that K3¥=0 and either K2 or ^f4=£0. Thus either
z>2 =£ A or z>4 =£ A. Condition (Hi) (b),
|tf2Utf3Utf4|<p(G),
is necessary in order to prohibit trivial factorizations in which w = v2v3v4.
Proof Let
r = max {2, lg(ct)| ^ -*■ a is in P},
and define
v = |7V|, p(G) = r2"+3.
Observe that one can actually compute p(G) and that it depends on the grammar.
This will be needed later when this theorem arises in certain decidability questions.
Let w be in L and let K be any set of positions in w such that \K\ >p(G).
Let T be a generation tree for S=>w and let _y1?... ,yigiW) be the sequence of non-
null terminal nodes in T. That is, using the notation from Section 1.6,
yi\lyi+i for l </<lg(w),
w = XCi)---XOig("'>)>
and
Now define two sets:
D = {jc in r| x ry-t for some / G /T},
5 = {^inr| xrx1andxrx2 for somexl,x2^D,xl ¥=x2}.
Intuitively, a node is in D if there is a path from the node to a position. A node is in
B if it has at least two immediate descendants, each of which has a path to a position.
(Nodes inZ) (B) will be referred to asD- (2?)-nodes.)
Claim 1 If every path in T, the tree for w, contains </ 5-nodes, then w has
< r' positions in K.
Proof The maximum number of positions would occur if each 5-node had
maximum "fan out" and each of the successors of a 5-node was a Z)-node. Since the
maximum "fan out" of any node in the tree is r, the maximum number of positions
in w is /■'.
Now choose a path s = (sq, . .. , st) in T such that:
a) s0 is the root of T;
b) st is a leaf;
c) s contains the maximum number of 5-nodes taken over all such paths.
188 THE ITERATION THEOREM, NONCLOSURE AND CLOSURE RESULTS
Claim 2 s contains at least (2v + 3) fi-nodes.
Proof Assume s has < (2v + 2) 5-nodes. Then, since s has a maximal number
of 5-nodes, every path in T from s0 to a leaf must have < (2v + 2) fi-nodes. By Claim
1, w would have 02"+2 positions in K; but w was chosen to have at least r20*3
positions in K. Hence s must have at least (2v + 3) 5-nodes. □
Now define a set Cs of nodes on s by.
*
ii) For each* &Cs,x\~ y,y &B imply_y S Cs;
iii) \Cs\ = 2v+3.
Intuitively, Cs contains the "lowest" (2v + 3) fi-nodes on s.
Claim 3 If Cs = CL U CR for any sets CL and CR, then either
\C^\>v+2 or \CR\>v+2.
Proof Assume that this is not the case. Then
I Ca\ < | CL| + | CR| < 2v+ 2 < 2v + 3.
But this is a contradiction. Hence, either | CR | or | CLI > v + 2.
We now define two sets
CL = {xeCglxr^ and y\lst for some y&D]
CR = {x€Ca\xFy and st\ly for somey €Z)}.
Intuitively, *GCL (respectively, CR) if it is in Cs and has an immediate
descendant y which has a descendant that is a position strictly to the left (right) of
st.
Example See Fig. 6.1.
Note. CL and CR are not necessarily disjoint.
Claim 4 CS=CL UCR.
Proof
a) CL U CR 9 Cs, by definition of CL and CR.
and
D = fi-nodes
x = positions in K
Cs = \x0,xx)
CL={xx)
CR= {x0,X\)
FIG. 6.1
6.2 THE ITERATION THEOREM 189
b) On the other hand, if x 6CS, then x has at least two descendants which
are positions in K, since x is a B-node. One of these might be st, but at
least one must lie either to the left or to the right of st. Hence, x is an
element of either CL or CR. Thus C £ CL U CR, and therefore
Cs = Cl U Cr ,
which completes the proof of Claim 4.
By Claim 3 there are now two dual cases to consider, namely
\C,\>v+2
\CR\>v+2.
We will assume that
\C,\>v+7.
The argument in the other case completely parallels this one and is omitted.
Thus we have
Cl — v*i, • ■ • ,xm\,
where +
xt r *,-+, for 1 < / < m.
Now, since m> (v+ 2), there exists/, k, and there is ,4 S TV such that
\<j<k<m
X(xj) = X(xk) = A.
and
But this gives
S =
A --
A --
This is illustrated in Fig. 6.2.
= position
□ = CL-node
ViAvs for some Vi,vs£ 2*,
v2Av4 for some v7, v4 S 2*,
v3 for some v3G 2*.
FIG. 6.2
190 THE ITERATION THEOREM, NONCLOSURE AND CLOSURE RESULTS
Now, by iterating the second sequence of productions q^O times, we get
S => vxAvs =*■ v^Avlvs ^ vxv\vzv%v^L.
SincexuXj,xk 6CL, there existyhyj, and_yfe such that i,j,k&K,and
* * *
Xiry,, XjFyj, xkFyk,
and
yt\ly}\lym\lst
(where we have also used the fact that Tis a tree).
Letting y?be the factorization
<fi = (Vi,V2,V3,Va,Vs)
and
Kh= {Kl3...,Ks},
we have
/€*,, JGK2, k&K3.
Thus, KuK2,K3^0.
Finally, since s was chosen to have the maximum number of S-nodes and
that part of the path starting at xx has exactly (2v + 3) fi-nodes, no other path starting
at xx can have more than (2v+ 3) fi-nodes. Further, any path starting at Xj can be
extended to be a path starting at xu and hence must have <(2z> + 3) B-nodes.
Thus, by Claim 1, the subtree rooted at Xj can have at most
/•w+3 = p(G) = p
positions in K. Since this subtree derives v2v3v4, we must have
\K2UK3LlK4\<p. □
Corollary {The Pumping Lemma) Let L be a context-free language generated
by G = (V, 2, />, S). There exists a number p(G) such that, if w G L and lg(w) >p(G),
then there exists a factorization
P = (Vl,V2,V3,V4,Vs) Ofw
such that:
i) There exists ,4 GN so that
S ^ ViAvs
A => z>2^4
ii) For each q>0,vlv^v3v^vsG L;
iii) vu v2, v3¥=Aot v3, v4, vs¥=A and \g(v2v3vA)<p(G).
Proof Choose every position to be distinguished. □
A careful study of these proofs reveals that we never used the fact that the
leaves were labeled by 2. (We did require that positions not be labeled by A.)
Therefore, the result is valid for sentential forms.
6.2 THE ITERATION THEOREM 191
Theorem 6.2.2 (The Iteration Theorem for Sentential Forms) Let L(G) £ S*
be a context-free language generated by G = (V, I,,P,S). There exists a number p(G)
such that, for any sentential form a of G and any set K of positions in a, if | K |> p(G),
then there is a factorization
V = (01,02,03,04, Us) °fw
such that:
i) There exists ,4 S^Vsuch that:
S 4 ft^
A 4 02,404
^ ^03
ii) For each g >0, 010203040s is a sentenial form of G;
hi) If */<* = {*,,..., Ks}, then:
a) either £ l, tf2, £3 =£ 0 or £3, tf4, £s =£ 0; and
b) |/:2u/:3u/:4i<p(G).
Using the iteration theorem, we can now show that there exist languages
that are not context-free.
Theorem 6.2.3 TV = {a"b"a" | n > 1} is not context-free.
Proof Suppose TV is context-free. Then, from the iteration theorem, there
exists a p such that conclusions of the theorem hold.
Let
w = apj£ a"
where the underlined bs are distinguished. That is,
K = {p+l,...,2p}.
Then there exists a factorization
V = (Pi, v2, ■ ■ . , 0s),
and we may assume, without loss of generality, from the symmetry of w that Kx,
K2,K3¥=<}.
Thus,
vx = apb', i>0
v2 = bJ, />0
z>3 = bkv, k>0, veb*a*.
Now consider
w2 = ^^2030405 = a"bv' for some z/ S b+a* because w2STV;
192 THE ITERATION THEOREM, NONCLOSURE AND CLOSURE RESULTS
But lg(w2) = \g(apbpap) = 3p. On the other hand,
lg(w2) = lg(w) + lg(w2^4) > 3P + l,
which is a contradiction. Hence TV is not context-free. □
It is of some interest to compare the pumping lemma with the iteration
theorem, As we shall later see, the use of positions greatly restricts the number of
possible factorizations of a string and reduces the labor involved in showing a set to
be noncontext-free. We shall now give an example of a noncontext-free language
that can be shown to be noncontext-free by the iteration theorem but not by the
pumping lemma.
Theorem 6.2.4 Let L = {a*bc}U {a"banca"\ p prime, n>0}. L is not a
context-free language, but the conclusions of the pumping lemma hold for L.
Proof The iteration theorem may be used to show that L is not context-free.
Let p be any prime larger than the constant p0 of the iteration theorem.
Consider „ „ „
w = a^ bapcap,
where the underlined a's are distinguished. All possible factorizations lead to a
contradiction. We omit the details because a more elegant proof that L is not context-free
will be given in Section 6.5.
Now let us show that the pumping lemma is too weak to show that L is not
context-free.
CASE 1. Let w = ambc, where lg(w)>p0, the constant of the pumping
lemma. Then we have a factorization:
», = a"1-1
v2 — a
v3 = be
vA = A
vs = A
Clearly, VxV%v3vivs&L for all g 5*0.
CASE 2. Let w = apba"ca", where lg(w) >p0,n> 1. Take the factorization
u, = apba"-1
v2 = a
v3 = c
vA = a
vs = a"-1
Then ViV^v3vivs G L for all q > 0. Thus the pumping lemma is satisfied. □
6.2 THE ITERATION THEOREM 193
PROBLEMS
1 Use the iteration theorem to show that the set L given in Theorem 6.2.4
is not context-free.
2 If you try to prove an iteration theorem for regular sets using right linear
grammars, what is your strongest result?
3 Prove the strongest iteration theorem you can get for the family of linear
context-free languages by specializing the argument in this section.
4 In Problem 8 of Section 2.5, it was shown that every linear context-free
language was representable as
where <pu ip2 are homomorphisms and R is regular. Can you use this characterization to
obtain an iteration theorem for the linear context-free languages?
5 Give a pda proof of the iteration theorem.
6 Using the result of Problem 5, can you find an iteration theorem for
deterministic context-free languages?
7 By the use of the iteration theorem, show that the set L given below is
noncontext-free. Show that this result cannot be obtained with the pumping lemma.
L = {aib'ck\ i^j^k^i}.
8 Is the set L given below context-free or not?
L = {albJck | i,j>\,k> max{/, /}}.
9 Let G = (V, 2,P, S) be a reduced context-free grammar. A variable A 6Af
is said to be recursive HA =±>uAvfox some u,vE2,*, where uv¥= A. Show that L(G) is
infinite if and only if G has a recursive variable.
10 Are the following sets context-free or not? Prove your answer.
L, = {aWbJ\ lj>\}\
L2 = {xx\ xe{a,b}*};
L3 = {wicw^l «i, «2e l{°> 1}*, c^{0, l}, and «i<«2 where «,•
denotes the binary number represented by «,- for i = 1, 2};
L4 = {anbna'\ n<j<2n,n>\}.
*11 Find an iteration theorem for the family of counter languages.
12 Recall from problems 13 through 16 in Section 2.2 that, if 2 = {0, l},
the map x ^x is a one-to-one map from {l}£* onto the positive integers. Prove the
following result.
Proposition Let 2 = {0, 1}, u,€{l}S*, v2, v3, vA, fls€E*, be such that
21e("2) ^ j moc[ p an(j 21b("4> ^ i moci p^ where p is an odd prime. Then
V\V2~lV3,V%~lVs = I^|^3^5 mod p.
Hint: Recall Problem 14 of Section 2.2.
194 THE ITERATION THEOREM, NONCLOSURE AND CLOSURE RESULTS
13 Prove the following result.
Proposition Let 2 = {0, 1}, z;, G{l}2*, v2, v3, v4, vs be in 2*. Let k > 0
be such that ViV2v3v4vs = p is an odd prime, 2lg("2> ^ 1 mod p and 2lg("4> ^ 1 mod p.
Then , , , _
V\v\v\ v3v%v4 vs = V\v\v$v*Vs = 0 mod p.
14 Let 2 = {0, 1}. If & is an infinite subset of {l}2* which represents
primes (i.e., w£# implies w is a prime), then ^ is not context-free.
6.3* CONTEXT-FREE LANGUAGES OVER A ONE-LETTER ALPHABET
The following theorem characterizes the context-free language over a one-
letter alphabet.
Theorem 6.3.1 Every context-free language L <L {a}* is regular.
Proof Let L 9 {a}* be a context-free language generated by some grammar
G, and let N0 = p(G) be the constant given by the iteration theorem. Then, for each
w e z,n2yv»2+,
there exists a factorization
V = (vuv2,v3,v4,vs)
such that
a) w = ViV2v3v4vs,
b) \g(v2v3v4)<N0,
c) v2v4 ¥= A.
From (b) and (c) we have
v2v4 = a' for some/, 1 </<jV0.
Further, since 2 = {a}, any two words commute:
Wk = vxv\v3vh4v% = ViV3vs(aJ)k GZ,, 0<&.
Claim 1 Let p be the least common multiple of {1,... ,N0}. Then, for all
w G Z, n 2N» 2+, we have that w(ap)* 9 Z,.
ZV00/ Each word in w(a")* is of the form
w(ap)' = ViV2v3v4vsam = ViV3v5aJap' = ViV3vsaJ+pt.
Now, since p is the least common multiple of {1,. . . ,jV0} and 1 </<jV0, / divides
p. Therefore,
/ + p/ = /(l + (p//)0,
where the second factor is an integer. Thus
w(al7" = ViVjVsa^^^ = ViV3vs(v2VAy*wiii,
which is an element of L by the iteration theorem.
6.3* CONTEXT-FREE LANGUAGES OVER A ONE-LETTER ALPHABET 195
Now define
A, = aN°+i(ap)* nL, Ki<p.
Note that A; may be empty for some /. Let yt be a word of minimal length in At if
Aj ¥= 0. Otherwise, let_y,- be undefined.
Claim2 L = Z, n U Z') Ju U y^a*)* I.
a) in |Ur|u U^TCi.
Since: i)in(Ul')Ci;
ii) ^,- GL and, by Claim 1 ,.y,(ap)* 9 Z,.
b) To show that
letx be any element ofZ,. There are two cases.
CASE 1. lflg(x)^N0, then
jcGLnlU 2'j.
CASE 2. Iflg(x)>7V0,then
lg(x) = N0 + k for some fc.
Let
k = qp + r, 1 <r<p.
Then
x = aN"+r(a"f.
Thus
i4r = (aN°+r(ap)* nL)*Q,
and^r has a minimal element^. Let
JV = aN»+r(ap)s for some s>0.
This gives
x = jvW*,
where q — sX) since j>r was minimal, which completes the proof of Claim 2.
Therefore Z, is regular, since it can be written as a regular expression. □
Recalling the definition of an ultimately periodic set from Section 2.2, we
can prove the following theorem.
196 THE ITERATION THEOREM, NONCLOSURE AND CLOSURE RESULTS
Theorem 6.3.2 For L 9 E*, where | E | = l, the following conditions are
equivalent:
1 L is a context-free language.
2 L is a regular set.
3 IL = {i\ a' G L} is an ultimately periodic set.
/Voo/ (1) implies (2) by Theorem 6.3.1. (2) implies (3) by Theorem 2.2.5.
If IL is ultimately periodic, then L is regular, by Theorem 2.2.5, and context-free
by the Corollary to Theorem 2.5.1. □
PROBLEMS
1 Show that, if L 9 E* is any context-free language, then {lgOOl xGL} is
an ultimately periodic set of natural numbers.
2 Show that L = {af(-n)\ n> 1}, where f(n) is a polynomial of degree at
least 2, is not an ultimately periodic set.
3 If L 9 a* ■ ■ ■ a^, where E = {at, . . . , a„), define
I(L) = {(/!, ...,in)\a\<-ai?eL}.
Show that, if Z, is a context-free language, then I(L) may be expressed as a finite union
of sets of the form:
{c + ilpl + • • • + impm hi, ... , im > 0}.
The symbols c, Pi,. . ., pm are n-tuples of nonnegative integers and none of the p,-
contain more than two nonzero components.
4 Let /be a function on the natural numbers and i9S*. Define
Uf) = {x&T,*\xy&L for some y G E* and lgOO = /(lg(x))}.
Here / is said to be a context-free preserving function if, for each Z, that is context-
free, /.(/) is also context-free. Show that if/is a context-free preserving function, then:
a) for each r > 0, {i'|/(0 = r} is ultimately periodic;
b) for each d> 1 and for each r<c/, {*1(/(0)mOdd = r) is ultimately
periodic; and
c) for each k > 1, {;'| /(i) < fc;'} is ultimately periodic.
5 Show that if /is a context-free preserving function, then for k > 1,
{w|/(«) = w and f(n)*^kn for somen}
is a finite set.
6 Show that /is a context-free preserving function if and only if:
a) for each r > 0, {i'|/(0 = r} is ultimately periodic;
b) for each d > 1 and each r<d, {*1(/(0)mOd d = r} is ultimately periodic;
c) for each k > 1, {m\ f(n) = m and f(n) < fc« for some n} is finite.
7 Using the result of Problem 6, show that the class of context-free preserving
functions is closed under composition, addition, multiplication, and exponentiation.
8 Is every context-free preserving function also a total recursive function?
6.4
REGULAR SETS AND SEQUENTIAL TRANSDUCERS
197
6.4 REGULAR SETS AND SEQUENTIAL TRANSDUCERS
In studying the closure properties of context-free languages, it is possible to
give very simple proofs by using pushdown automata.
We have already shown that the context-free languages are closed under union,
product, Kleene closure, substitution mapping, homomorphism, and reversal. We now
show that they are closed under intersection with a regular set. Later it will be shown
that the intersection of two context-free languages is not necessarily a context-free
language.
Theorem 6.4.1 If L is a (deterministic) {unambiguous} context-free language
and R is a regular set, then L n R is a (deterministic) {unambiguous} context-free
language.
Proof Let L = T(A) for some pda A:
A = (Q,X,r,8A,q0A,Z0,FA)
and R = T(B) for some finite automaton
B = (QB,X,8B,q0B,FB).
Let C be a pda defined by
C = (QA*QB,°Z.,T,Z,(q0A,q0B),Z0,FA xFB),
where, for each (q\,q2)&QA x 2B,eachaGSA and each ZGT,
8(fai,flfa),a,Z) = {((q',8B(q2,a)),a)\ (q ,a)e8A(q,a,Z)}.
Intuitively, C simulates^ and B in parallel and accepts if and only if they both accept.
Note that, since for each q2 6 Qb,
5b(^2, A) = q2,
the two machines remain in "synchronization."
Claim For each (qi,q2), (q\-,q2)^ QA x QB, each wGE*, and each a,
per*,
((qi,q2),w,a) £ ((q\,q2), A,0)
if and only if
(Qi,w,<x) f^" (<7i,A,0) and q2 = &B(q2,w).
Proof The proof, by induction on the number of moves, is left as an exercise.
Thus,
xe7\C) if and only if xGT(A) and xGT(B).
Therefore,
T(Q = LHR,
which proves the theorem. Note that Cis deterministic {unambiguous} if A is. □
Corollary If Z, is a (deterministic) {unambiguous} context-free language and
R is regular, then L —R is a (deterministic) {unambiguous} context-free language.
198 THE ITERATION THEOREM, NONCLOSURE AND CLOSURE RESULTS
Proof If/? is regular, then E* — R is regular. But we have
L-R = Z,n (£*-/?). □
This result does not generalize to the intersection of two deterministic
context-free languages, as the following example shows. Let
Li = {a'fcV'l i,j>\}
and . . .
L2 = {a'b'aJ\ i,j>\}.
Clearly,Lx and L2 are deterministic context-free languages. Then
L,nz,2 = {«VV| i>\)
would be context-free but this is not so. Thus we have shown:
Theorem 6.4.2 The family of (deterministic) context-free languages is not
closed under intersection. The family of context-free languages is not closed under
complement. There is a context-free language which is not deterministic.
Proof The second sentence follows because
LinL2= 2*-((2*-Z,i)U(2*-Z,2)).
If every context-free language were deterministic, the family <g would be
closed under complementation, by Theorem 5.6.1. □
In Section 3.4, the idea of a homomorphism was generalized to the concept
of a substitution. Another direction would be to have a powerful kind of transducer
into which a context-free language could be sent. Such devices will now be introduced.
Definition A sequential transducer is a 5-tuple
S = (2,2, A, 6,<?<,),
where
Q is a finite nonempty set of states,
E is a finite nonempty input alphabet,
A is a finite nonempty output alphabet,
q0 G Q is the start state, and
6 is a finite subset of Q x E* x A* x Q.
Intuitively, if (q,u,v,q')G8, the machine in state q under the influence of
input u G E* will make a transition to state q , outputting v&A*. This may be
represented graphically as:
6.4 REGULAR SETS AND SEQUENTIAL TRANSDUCERS 199
A/1
FIG. 6.3
Thus there is a natural correspondence between sequential transducers and labeled
directed graphs.
Example See Fig. 6.3.
The sequential transducer functions like a nondeterministic finite automaton
(i.e., given an input, one can follow any path through the automaton which
corresponds to that input). Thus, in the example,
S(ab) = {A}U{01*}.
We now give formal definition of the output of S.
Definition Let Q = (Q, E, A, 8,q0) be a sequential transducer. For u62*,
we say vGS(u) if and only if there exist uu ... ,uk GE*;^,... ,vk G A* ,qu .. . ,qk
G Q, such that
i) u = ul- ■ -uk,
ii) v=vx ■■■vk,
iii) (fli, ui+l, vi+l, qi+l) G 6 for each /, 0 < / < k.
IfZ,9 E*,then
S(L) = U S(tt).
u E L
Finally, if£9 A*, then
S~\L) = {wGE*| S(w)9Z,}.
Note that, if S = (Q, Z,A,8,q0)isa sequential transducer, then:
a) IfS^QxExAxQ and satisfies the condition that whenever (q, a, v, q)
G6 and (q,a,v',q")e.8, then v=v and q = q", then S corresponds to
a "sequential machine."
b) If ip: E->-A* is any homomorphism, then, if one takes the one-state
machine defined by
8 = {(<7o,a,¥>(a),<7o)l for each a G EA},
then S(x) = <p(x) for each x G E*.
200 THE ITERATION THEOREM, NONCLOSURE AND CLOSURE RESULTS
We now prove the following important theorem.
Theorem 6.4.3 (The Sequential Transducer Theorem) If L is a context-free
language (regular set) and S is a sequential transducer, then S(L) is a context-free
language (regular set).
Proof Let L = T(A) for some pda
A = (Gi,Z,rj8ljqf0jZ0,fi)
satisfying the following condition:
Forall(qr,a)G(2xEA,
if (q' ,a)G8l(q,a,Z0), then a ¥= A.
The condition ensures that the start symbol Z0 is never erased. The method of Lemma
5.6.1 may be employed here to ensure that this condition is satisfied. Let
S = (G2,2,A,62,s0).
Now let
m = max{l,lg(M),lg(z;)| (q,u, v,q) G52}
and
Sm = U Sf, Am = U A\
1 = 0 1=0
Define a new pda B, which simulates both the original pda A and the
sequential transducer S.
B = (e,A,r,6,(<7o,s0,A,A),Zo,F),
where
Q = QixQ2xZmxAm,
F = F1 x Q2 x {A} x {A},
and 6 has three types of rules:
Type 1. For all (q, Z) G Ql x T and for all s G Q2,
8((q,s,A,A),A,Z) = {(fa.s'.u,*;), Z)| (s,u,u,s')G62}.
7)'pe 2. For all (q, s, a) G Qi x Q2 X (2 U {A}), and for all (x,y) G Em x Am
such that lg(ox) < m,
8((q,s,ax,y),A,Z) = {((q',s,x,y),a)\ (q ,a)e8l(q,a,Z)}.
Type 3. For a\\(q,s,b)GQ1 xQ2x A and for ally G Am such that lg(»<m,
8((q,s,A,by),b,Z) = {((q,s, A,y),Z)}.
Although B looks rather formidable, the idea involved is simple. 1 f (q, s, u, v)
is a state, then q and s correspond to the state of A and S, respectively, at that point
in the computation, and u and v are input and output "buffers" for S (used in a
manner described below). In accepting a string, B performs the following sequence of
steps.
6.4 REGULAR SETS AND SEQUENTIAL TRANSDUCERS 201
Step 1 (Move of type 1). B "guesses" that S in state s will map u into v and
transfer to state s':
((q,s,A,A),x,P) k ((q,s',u,v),x,j}).
Note that a Type-1 move occurs only when both the input and output buffers are
empty. Also, the state of the pda, the pushdown, and the input all remain unchanged.
Step 2 (Move of type 2). B now simulates A started in state q with 0 on the
pushdown and input u:
((q,s',u,v),x,(i) £ ((q ,s',A,v),x,$').
The state of the transducer, the output buffer and the input remained unchanged
during this computation.
Step 3 (Moves of type 3). B then checks whether the output v of S generated
in Step 1 corresponds to the input string:
((q',s',A,v),vx,j}') \^ ((q',s',A,A),x,j}').
If x ¥= A, then B goes back to Step 1; otherwise the input string is accepted if and only
if q GFt. Note that the states of A andS and the pushdown store remain unchanged.
We now prove a series of claims which show that B operates as described.
Claim 1 For each q, q G<2i, each s,s' GQ2, eachz/G Sm,each vGAm, each
w, w' G A*, each a', 0 G T*, and each Z G T,
(G7,s,A,A),w,0Z) t-g- ((q',s',u,v),w\a')
by a move of Type 1 if and only if
q = q, w' = w, a' = 0Z, and (s,u,v, s')G62.
Proof Follows directly from the definition of moves of Type 1.
Claim 2 For each q,q & Qx, each s, s' G Q2; each w£Sm, each v, t'eAm,
each w, w' G A*, each 0 G T*, 0' G T+, and Z G T,
((q,s,ux,v),w,pZ) \j ((q',s',x,v'),w',P'),
using only moves of Type 2 if and only if
s' = s, v = v, w' = w, and (q,u,(lZ) |j (^',A,0').
Proof We prove the only if direction by induction on n.
Basis, n = O.Then,
((q,s,ux, v),w,PZ) [j «y,s',x,z/),w',0'),
q = q, s' = s, u = A, v = v, w = w, and 0' = 0Z.
But
(<7,M,0Z) ^ (^?,u,0Z).
202 THE ITERATION THEOREM, NONCLOSURE AND CLOSURE RESULTS
Induction step. Assume that the only if direction of the claim holds for all
computations of length n. Let
((q,s,ux,v),w,pZ) Fir ((q',s',x,v'),w',p').
Then
((q,s,u'ax,v),w,pZ) |j ((<7i,s,,ax,z>i),wi,0iZ,), (6.4.1)
\B(ftl',s,x,v'),w',PM, (6.4.2)
where
u = u'a, «eZU{A}, and 0' = 0,02.
Applying the induction hypothesis to (6.4.1) gives:
si = s, Vi = v, Wi = w, (q,u',j3Z) \^ (<7i,A,0iZ).
Now (6.4.2) is a move of Type 2. Hence,
s = si, v = vu w' = Wi, («7',j32)G6(^i,a,Z).
Combining these results gives:
s' = s, v = v, w' = w,
and
(q.u.pZ) = (q,u'a,jiZ) \j (ql,a,plZl)
|j (fl',A,AW = fo',A,A
which completes the induction.
The j/ direction follows directly from the fact that, for each move in A, there
is a corresponding Type-2 move in B. A formal proof by induction is left as Exercise 1.
Claim 3 For each q,q' GQU each s,s' G Q2, each uxG 2m,each w,w' G A*,
zyeAm,|3'er+,|3er\andzer,
((<7, s, «x, ly), w, j3Z) £ (fa', s,x,y), w', j3'),
with no moves of Type 1 if and only if s = s,w = vw',and
(q,u,pZ) \j fa', A, A
Proof The ow/j> if direction will be proved by induction on n.
Basis. \g(v) = 0. Then v = A and
((q,s,ux,y),w,pZ) £ ((q ,s',x,y),w',P').
Since only moves of Type 2 could be used, we have, by Claim 2, that
s = s, w' = w, and fa,«,0Z) |j fa',A,0').
Induction step. Assume that the only if direction of the claim holds for
\g(v) = n.
Letlg(z;) = H + l.Then,
v = v'a, aGA lgO>') = n.
6.4
REGULAR SETS AND SEQUENTIAL TRANSDUCERS
203
The computation of B must be of the form:
((q,s,UiU2x,v'ay),w,^Z) (j (07i,Si,u2*,<y), vt>i,0iZ,) (6.4.3)
Ij ((<72,s2,"2x,.y),w2,02Z2) (6.4.4)
£ te's'^Jb'.U'), (6.4.5)
where u = UyU2.
In line (6.4.3), only moves of Type 2 and Type 3 are used and lg(w') = n.
Thus, by the induction hypothesis,
Si = s, w = v'wi, and (q,uu(iZ) |j (qiy A,0iZi).
Move (6.4.4) is a Type-3 move and thus,
Q2 - Qu s2 = Si, Wi = «w2, 02Z2 = |3iZi.
Finally, (6.4.5) consists of only moves of Type 2. Again applying Claim 2 gives
s = s2, w' = w2, (q2,u2,j}2Z2) [j (q',A,j}').
Combining these results gives
s' = s, w = z/«w' = ww
and * * , ,
(<7,"i"2,0Z) \j (<72,"2,|32Z2) fj (<7,A,0),
proving this direction of Claim 3.
Conversely, it suffices to prove that, for all <7 G Qu s G Q2, u G Am, lg(«) < m,
if w = i>w', then:
(fa,s,u,vy),w,pZ) \j ((q,s,u,y),w',(}Z).
This is a straightforward proof by induction on \g(v). Then the desired result follows
directly from Claim 2.
Claim 4 For each?,?' G Qu s, s' G Q2, w,y G A*, 0 G r*,0' G r+, and Z G r,
((<7,s,A,A),wy,0Z) £ ((<?', s', A, A)^,0'),
using k > 1 moves of Type 1 if and only if there exist wu ... , wfe in A*, there exist
s0, ■ ■ ■, Sfe in Q2, there exist uu .. ., uh in E* such that
w = Wi • • • wfe,
t
S0 — S, Sfr — S ,
(s(, ui+1, w,+1, s,+1) G S2, 0 < / < k,
fa.K,•••«*,0Z) \j (<7',A,0').
Proof The argument in the only if direction is an induction on k.
Basis. k = 1. If
((<7,s,A,A),wy,0Z) £ ((<?',s', A, A),/,0'),
204 THE ITERATION THEOREM, NONCLOSURE AND CLOSURE RESULTS
using only one move of Type 1, then the computation must be of the form:
(fy,s,A,A),wy,pZ) |j(fai,Si,A,A),*i,0iZD (6-4.6)
Ij ((Q2,S2,u,v),x2J2Z2) (6.4.7)
ft(ffl',s',A,A),y,P'), (6.4.8)
where si,s2GQ2,x1,x2GA*.
The computation (6.4.6) has only Type-2 moves, since no Type-3 moves
are possible when the output buffer is empty. By Claim 2.
Si = s, Xi — wy,
and .
fa,A,0Z) [jtoi.A.ftZO.
Now (6.4.7) is the single Type-1 move, and hence, by Claim 1,
<72 = Qi, *2 = *i, j32Z2 = PiZu
(Sl,«,fl,S2)G62-
Finally, (6.4.8) has no Type-1 moves and thus, by Claim 3,
s' = s2, x2 = vy,
(q2,u,a2Z2) [j fa'.A,/}').
Combining these results gives
V = W, St = S, S2 = S ,
(s,m, w,s') 662,
(<?,«, j3Z) £ (flfi,«,PiZ,) £ fo', A,0').
Thus, by taking
s0 = s, Si = s', «i = m, and wt = w,
we will have proved the basis.
Induction step. Assume that the only if direction of the claim holds for a
computation with k > 1 moves of Type 1. Let
((<7,s,A,A),wy,0Z) £ ((<?',s', A, A),y,p'),
with A: + 1 moves of Type 1. Then
(iq,s,A,A),w'w"y,pZ) £ ((<?„/•,, A, A), w"y,^Z,) (6.4.9)
ft«tl',s,A,A),y,p'), (6.4.10)
where w = w'w" and (6.4.9) uses only k moves of Type 1. Such a "factorization" of
the computation must exist since the last move of Type 1 cannot be made unless both
the input and output buffers are empty.
6.4 REGULAR SETS AND SEQUENTIAL TRANSDUCERS 205
Thus the induction hypothesis applies to (6.4.9) and there exist
w1(. .. ,wk in A*, s0,. . . ,sk in Q2, «i,.. . ,uk in E*,
such that i
w = Wi ■ ■ ■ wk,
s0 = s, sfe = ru
(s,-, ui+u wi+l, s,+1) G 62, 0<i<k,
(q>Ul--uk,pZ) \j (q1,A,P1Z0.
But (6.4.10) uses only one move of Type 1 and thus, by the basis of the induction,
there is some u£Z* such that
(rl,u,w",sl) G62
and
foi.K.frzo [j («', a, A
Therefore, if we let
sfe+1 = s', wfe+1 = w", z/fe+1 = u,
we will have
w = w w' = wi"--w^+i,
s0 — s, Sk+} — s ,
(s,-,«,+1,w,+1,s,+i)G62, 0</<&+ 1,
(<7,«i- ■ukuk+1,pZ) ^ (fli.Ufc+i.jSiZ,)
£(<?', A, 0'),
which completes the proof of the necessity of Claim 4.
Using Claims 1, 2, and 3, the proof of the converse is straightforward and is
left as an exercise.
Now, taking
q = q0, s = s0, 0 = y = A, Z = Z0
in Claim 4 gives
(G7o,So,A,A),w,Zo) fc (to',s',A,A), A,0')
if and only if there exist wi,. .. , wfe in A*,s0,... ,sfe in Q2, Ui,... ,uk in E* such
that
W = W] • • • Wk,
(sf, «,+1, w,+1, s,+1) G 62 for 0 < i < k.
(q0,Ui ■ -Mfe.Zo) [^ to',A,0').
Thus, wG 7(5) if and only if w &S(L), which proves the theorem for context-free
languages.
For regular sets, it suffices to note that exactly the same construction works
without using the pushdown store. In this case, B will be a nondeterministic finite
automaton but T(B) is still a regular set. □
206 THE ITERATION THEOREM, NONCLOSURE AND CLOSURE RESULTS
PROBLEMS
1 Give a formal proof of the if direction in the proof of Claims 2 and 3 in
the proof of Theorem 6.4.3.
2 Show that, for each sequential transducer S = (Q, 2, A, 6, q0), there is a
sequential transducer S' - (£?', 2, A, 6', q'0) such that 6' 9 Q' x Ea x A* x Q' and
5(u) = 5'(u)foralluGE*.
It is often useful to discuss a-transducers or accepting transducers. The idea is to
define S = (Q, E, A, 6, q0, F), where F'-Q and the rest is as usual in a sequential
transducer. We change the definition to define Siw) as before, except that the
computation must end in a final state.
3 Show that, if S is an a-transducer and L is a context-free language, then
S(L) is a context-free language.
4 Show that if L is a linear context-free language and S is a sequential
transducer, then S(L) is a linear context-free language.
5 Extend the previous problem to the case where L is metalinear. Cf. Problem
4 of Section 2.5 for the definition of metalinear.
6 Give a context-free grammar proof of the sequential-transducer theorem.
7 Let G be the following linear grammar:
S -+ aSa | bSb | dSa | dSb | dS | c
Describe i(G) and show that the complement of L(G) is not context-free.
8 Let L\, i29 E*, and define the set of shuffles of Lx and L2as
shufCZ,!,/^) = {x1y1 ■ ■ -xkyk\ k> \,xy ■ ■ ■ xk &Luy1 ■ ■ ■ yk GL2, ^^eX').
Show that
shuf(Z,1UZ,2,Z,'1UZ,'2) = U shuf(/,,-, /,'•).
Ue{i,2}
Prove or disprove:
shuf(Z,!, L2) = shuf(L2,Z,i).
9 Show that, if L is context-free (regular) and R is regular, then
shut\L,R)
is context-free (regular).
10 Find two context-free languages Ll and L2 such that shuf(Z-!, L2) is not
context-free. Make Ll and L2 as "simple" as possible.
6.5 APPLICATIONS OF THE SEQUENTIAL-TRANSDUCER THEOREM
Using the sequential-transducer theorem from the previous section, we can
obtain further closure properties of context-free languages. We first define a restricted
form of the sequential transducer which is sufficiently powerful for many applications.
Definition A generalized sequential machine (gsm) is a 6-tuple
S = «2,2,A,6,A,<70)
6.5
APPLICATIONS OF THE SEQUENTIAL-TRANSDUCER THEOREM
207
where
Q is a finite nonempty set of states,
E is a finite nonempty input alphabet,
A is a finite nonempty output alphabet,
q0 G Q is the start state,
8: Q x E ->■ Q is the transition function, and
X:Qx2^A* is the output function.
The functions 6 and X are extended to 2* in the usual way, namely: For
each<7G0,xG£*,aGE,
8fa,A) = Q,
8(q,ax) = 8(8(q,a),x),
Xfa.A) = A,
\(q,ax) = Xq,a)\(8(q,a),x).
The definition of a gsm is not standardized in the literature. One must
exercise care because some authors define this device with final states.
The gsm can be thought of as a sequential machine with not necessarily
length-preserving outputs. Although many of the results for sequential machines
carry over to gsm's, some do not. For instance, given two sequential machines Afi
and Af2, then it is decidable whether or not there is an xG E+ such that Mi(x) =
M2(x) (where M(x) designates the response of Af to input x). If Mi and M2 are gsm's,
then this is no longer the case.
Also, every homomorphism can be represented by a one-state gsm.
Definition Let L £ E* and let S be a gsm. We define two sets
S(L) = {S(x)\ x&L),
and
S-\L) = {x\ S(x)eL}.
Theorem 6.5.1 If Z, is a context-free language (regular set) and S is a
generalized sequential machine, then S(L) is a context-free language (regular set).
Proof Let S = (Q, E, A,6,,0)
be a gsm. Define a sequential transducer
S' = (2,S,A,6',<70),
where
6' = {(q,a,Uq,a),8(q,a))\ for each (q,a)GQ x S}U {(q0, A, A,q0)}.
Claim S(L) = S'(L).
Proof By induction on the length of the input. The argument is left as an
exercise.
Thus, by the sequential-transducer theorem, we have completed the proof. □
208 THE ITERATION THEOREM, NONCLOSURE AND CLOSURE RESULTS
Corollary If L is a context-free language (regular set) and ip is a homomor-
phism, then \p(L) is a context-free language (regular set).
Example Let
L = {a*be} U {apba"ca" \ p prime, n>0}.
L is the noncon text-free set used in Theorem 6.2.4 to distinguish between the iteration
theorem and the pumping lemma. Now an elegant proof that L is not context-free
will be given.
Suppose that L were context-free. Then
Li = L-{a*bc}
would be context-free. Define the gsm S by:
a/a{ { q0 l
Then
S(L{) = {ap\ p prime}
would be a context-free language. This is a contradiction of Theorem 6.3.1, and shows
L to be noncontext-free.
Now, let us consider inverse gsm mappings.
Theorem 6.5.2 If L is a context-free language (regular set) and S is a gsm
mapping, then S~l(L) is a context-free language (regular set).
Proof Let
S = (Q,Z,A,8,\,q0).
Define a sequential transducer
S' = (Q,A,Z,8',q0),
where
6' = {(q,\(q,a),a,8(q,a))\ (q,a) GQ x E}u {fa0, A, A,q0)}.
Claim S'(L) = S~1(L).
Proof By induction. The argument is left as an exercise.
Thus, again applying the sequential-transducer theorem, we have the desired
result. □
Corollary If L 9 A* is a context-free language (regular set) and ip: S* ->■ A* is
a homomorphism, then ip"'(Z.) is a context-free language (regular set).
6.5 APPLICATIONS OF THE SEQUENTIAL-TRANSDUCER THEOREM 209
It turns out that the family of context-free languages is not closed under
S_1 if S is a sequential transducer.
Theorem 6.5.3 There is a deterministic context-free language L and a
sequential transducer S such that S~l(L) is not context-free. The family of context-
free languages is not closed under inverse sequential transducer mappings.
Proof Let S be the following sequential transducer.
Then, for all we{a,bf,
S(w) = {cw,dw}.
Now let
L = {ozW| i,j> l}u{c?«W| i,j>\).
Clearly,/- is a deterministic context-free language. But
S~\L) = {w\ S(w)£L}
~ {w\dwGL and cw&L}
= {aibiah\ i = /and/ = k}
= {a"b"a"\ n>\)
is not context-free. □
Next we turn to a set-theoretic operation on sets.
Definition Let A', 79 2*. Define
X~lY = {wGE*| xwGY for some xG X},
YX~l = {wGE*|wxGy for some xG X}.
YX'1 (X'1 Y) is the right (left) quotient of Y by X.
We now prove that context-free languages are closed under right quotient
with regular sets. The proof is interesting since it is based only on the closure
properties of context-free languages and hence would apply to any family of languages
that satisfy the necessary closure properties.
Theorem 6.5.4 If L is a context-free language and R is a regular set, then
LR'1 is a context-free language.
Proof Let L, R 9 E* and c $ 2. Let
S = (teo,<7i},2U{c},Z,8,flf0),
210 THE ITERATION THEOREM, NONCLOSURE AND CLOSURE RESULTS
where
6 = {(q0,a,a,q0)\aei:}u{((i0,c,A,qi)}utoi1,a,A,qd\aei:u{c}}.
Graphically, S is given by:
a denotes any letter in Z
It is easily seen that, for each xe2*jS(SU {c})*,
S(x) = x, S(xcy) = x.
Now let ifi: (S U {c})* -> S* be the homomorphism given by
a, a 6 2,
A, a = c.
Claim S(y~l(L) n E*c/?) is context-free.
vO) =
i) E*c/? is regular.
ii) Since ip is a homomorphism, ip-1 is an inverse homomorphism. Thus
ip~l(L) is context-free.
iii) <p-1(Z.) H E*c/? is context-free, since the intersection of a context-free
language with a regular set is context-free.
iv) S($~l{L) n E*c/?) is context-free, by the sequential-transducer theorem.
Claim LR'1 = S(<p'\L) n ?*cR).
Proof x eSQp~\L) n Z*cR) if and only if there is.y G S* so that
xcyGvJ_1(Z,)n2*c/?.
This holds if and only if there isy G'E* such that
xcy&tp'l{L) and y&R.
But this holds if and only if there isy G'E* such that
y&R and *p{xcy) = xyGL and y€R;
i.e., if and only if
xGLR-1. O
Corollary If Z, is a context-free language and R a regular set, then R'1L
is a context-free language.
RTlL = (LT(/?T)-')T,
and both regular sets and context-free languages are closed under reversal.
6.5 APPLICATIONS OF THE SEQUENTIAL-TRANSDUCER THEOREM 211
Corollary If L is a context-free language, then
a) init(Z,) = {u\ uv&L for some v£ E*},
b) fin(Z,) = {u\ vu&L for some !)£2*}, and
c) subwords(Z,) = {v\ uvw&L for some u,w6J*}
are context-free languages.
Proof
a) init(Z,) = Z,(E*)-1,
b) fm(L) = (E*r1L,
c) subwords(Z,) = fin(init(Z,)). D
Now we shall show that the full family of context-free languages is not closed
under quotient.
Theorem 6.5.5 There exist two deterministic context-free languages Lx and
L2 such that L[lL2 is not a context-free language.
Proof Let , . .
J Lx = a{blal\ i>\f
and . .
L2 = {a'b2,\ i>\}*.
Clearly, Lx and L2 are deterministic context-free languages, and
L\lL2 = {w\ ywGL2 for someyGLi}.
Now
weL?L2 (6.5.1)
if and only if there exist k > £ > 0, i\,. .. , ih > 1 ,j\, . . . ,/g > 1 such that
yw = a'-b^b21* - ■ •fl'*fc2i* (6.5.2)
and y = ab'iailbi*ai* ■ ■ ■ b^a^. (6.5.3)
In turn this holds if and only if there exist k > Z > 0, ilt. . . , 4 > 1, j\,. . . ,/g > 1,
such that
jr = 2r for each 1>r>\, (6.5.4)
and
ir = 2r'1 foreach£>r> 1. (6.5.5)
It now follows easily from these propositions that
(L?L2)nb+ = {b2m\ m>\).
If L\lL2 were context-free, then, by Theorem 6.4.1, {b2 \ m~> 1} would be regular;
but that would contradict Theorem 6.3.1. The result about right quotient follows
from the identity.
lxl? = (L?(LTyy. a
We shall later see that Theorem 6.5.5 is a trivially weak result. Actually any
recursively enumerable set may be obtained as the quotient of two context-free
languages.
212 THE ITERATION THEOREM, NONCLOSURE AND CLOSURE RESULTS
PROBLEMS
1 Show that, if L 9 A* is a deterministic context-free language and S is a
gsm, then S~l(L) is also a deterministic context-free language. Hence, the deterministic
context-free languages are closed under inverse gsm mappings.
2 Let L 9 A* and let S = {Q, 2, A, 6, q0) be a sequential transducer. By
definition, S~l(L) = {w\ S(w) 9 L} and it has been shown that *& is not closed under
S'1. Suppose we had defined S'1 by the following relationship:
S'HL) = {wGE*| S(w)r\L¥=Q}.
Is & now closed under 5"1?
3 Let X, Y,Z^ E* .'Show that:
a) (XZ~l)Y~l = X(YZy\
b) (X'1Y)Z~1 = X~1(YZ~1),
c) (XY)~1Z = Y~l(X~lZ).
Now we consider a-transducers, which were defined in the problems at the end of
Section 6.4.
Definition An a-transducer S — (Q, 2, A, 5, q0, F) is 1-bounded if
6 9 Q x (Z U {A}) x (A U {A}) x <2.
4 Show that, for each a-transducer S = (Q, 2, A, 6, q0, F), there is a 1-
bounded a-transducer S' = (£)', 2, A, 6 ,qo,F), such that
S'(u>) = S(u>) for each w 6 2*.
Let 5 = (Q, 2, A, 6, q0, F) be an a-transducer and let X be any function from F into
subsets of 2*. Define:
■S(X) = {«!-•• urX(qr)i>r -I'll There exist r>0,<?i, . . . ,qr,qrGF, such
that (<?,-, Mi+i,u,-+1,<jf+1)G 6 forO<i'<r}.
5 Show the following useful result.
Lemma Let S = (Q, 2, A, 8,q0, F) be an a-transducer. If for each q&F,
\(q) is a context-free language, then 5(X) is also context-free. Moreover, if each \(q)
is ultralinear, then so is 5(X).
6 Show that the class of ultralinear languages is the least family which
contains the finite sets and is closed under finitely many applications of union, product,
and 5(X) (where the image of 5(X) is contained in the family).
7 Show that a set L is ultralinear if and only if there is a finite-turn pda A
such that L = N(A).
8 Show that L is linear if and only if L is accepted by a 1-turn pda.
Let 2 and A be two alphabets and let Ri,R2 be subsets of 2* X A*. Define
RiR2 = {(x1x2,y1y2)\ (.x1,yi)eR1,(x2,y2)GR2).
Define
R° = {(A, A)},
6.5 APPLICATIONS OF THE SEQUENTIAL-TRANSDUCER THEOREM 213
and, for each k > 0, define
Rk+i = RkR
Then write
R* = U R*.
A relation R is said to be regular if R is obtained from the set
{(a, A), (A, b)\ aGZ,fcGA}
by finitely many applications of U, •, and *. Also define a transduction to be any
mapping from E* into A*, but we shall write it as a relation.
9 Prove the following important theorem.
Theorem (Nivat) A transduction from E* into A* is regular if and only if
there exists an alphabet V, a regular set R 9 T*, a homomorphism <p from T* into E*,
a homomorphism i// from T* into A* , such that, for each x G E*,
7* = iMYJ-1(x)n/0.
Let S and A be alphabets and let the members of E be interpreted as elementary
messages. The coding problem is to find suitable mappings tp from E+ into A* so that
right inverses exist, i.e., so that vV~ = 1. For our purposes, define an encoding as any
one-to-one homomorphism from E+ into A+. Define
A0 = V>(2)
and
A = ^2+).
A0 is called the set of all code words or just the code, while A is the set of all encoded
messages.
Recall that a semigroup S is freely generated by a set S0 if every element of
S has a unique representation as a product of elements of S0. S is free if there is a set
So which freely generates S.
10 Show that
a) A=A%
b) A is a free semigroup of A+ generated by A0.
11 Show that, if A is an arbitrary free semigroup of A+, then there exists a
set 2, and an encoding \p: S+ -»■ A+ such that A = v>(2+).
Let S be any semigroup and /1,B9 S. Define
^_1fl = {sGS\as&B forsomeaG/l}
and
AB 1 = {seS\saGB for some a G A }.
For Problems 12 through 14, let .40^ A+ and A = {A0)+. Define
^i = A^Aq
and i -l
An+i = A0 A„ UA„ A0
for each n > 0.
214 THE ITERATION THEOREM, NONCLOSURE AND CLOSURE RESULTS
12 Show that A is freely generated by A0 if and only if, for each n > 1,
AnHA0 = 0.
13 Show that, if An — An+k for some n, k > 1, then
An+jk + r An + r
for all/> 0 and all r, 0 < r < k.
14 Show that, if A0 is finite, then there exists a natural number 7V0 such
that, for all n > N0, there exists m<N0 such that
An — Am .
15 Show that there is an algorithm for deciding whether a regular set is a
code. Does your method work for context-free sets?
6.6* PARTIAL ORDERS ON I*
By introducing partial orders on 2*, some surprising properties will be
derived. The methods of this section will be nonconstructive and the reader should
watch for the occurrence of such techniques.
In Chapter 1, we studied various partial orders on 2*. For example, we
might write x<1j' if and only if y =yixy2, which is the familiar relation "x is a
subword ofy." (2*,<!) is a partially ordered set.
Recall that, in any partially ordered set (5,<), x and y are said to be
incomparable if x ^y and j *fex.
Example 1 The set {ab"a\ n > 1} is an infinite set of pairwise incomparable
elements of the partially ordered set (2*, <!).
Next we shall consider another partial ordering, namely that of subsequences.
Definition Let x and y be in 2*. We write x^y if x = Xi • ■ ■ xn and
y =y\X\' • 'ynxnyn-n for somen >Q,xhyj E 2*,where 1 </<« and 1 </<« + 1.
Lemma 6.6.1 (2*, <) is a partially ordered set.
Proof It is clear that < is reflexive and transitive. To prove the antisymmetric
property, assume that x <y, which implies that
X = X\ • ■ ■Xn,
and (6.6.1)
y = >'i*i • ■■ynxnyn*u
and hence that
lgC) = lg(*) + lgO'i"->'n+i) (6-6.2)
and, a fortiori,
lg00>lg(x). (6.6.3)
6.6* PARTIAL ORDERS ONZ* 215
Also assume that y < x, so that
y = y\---y'k,
II III
x — xiyi■ ■ ■*fej;fe*fe+i>
and hence that
lg(x) = \g(y) + \g(x'r--x'k+l),
and, a fortiori,
lg(x)>lgO>). (6.6.4)
But (6.6.3) and (6.6.4) imply \g(x) = lg(y), which implies (using (6.6.2)) that
lg(ji"-"J'n+i) = 0,
so thatyi • ■ -yn+i = A, and, by (6.6.1),j> =x.
The following observation will also turn out to be useful.
Fact 1 For each u E 2*, there are only finitely many x E 2* such that x < u.
Next we consider a lemma which will be applied in our main theorem.
Lemma 6.6.2 If 2 is an alphabet which has the property that every set of
pairwise incomparable elements of 2* is finite, then every infinite subset of 2* has
an infinite chain.
Proof Let L be an infinite subset of 2* and suppose that every chain in L
is finite. Consider the set X of maximum elements of maximal chains. If x, y GI,
then x and y are incomparable. By assumption X is finite and \X\ = the number of
maximal elements of L. But L is infinite, so that infinitely many distinct chains have
the same maximal element u. But we then have x<=u for infinitely many x, which
contradicts Fact 1. □
We are now ready to prove an important result.
Theorem 6.6.2 Every set of pairwise incomparable elements of (2*,<) is
finite.
Proof We induct on |2|.
Basis. | 21 = 1. The result is trivial.
Induction step . Suppose the result holds for all alphabets A with |A| = n.
Let | 21 = n + 1, and let Y = {j>1;y2,. . .} be an infinite set of pairwise incomparable
elements.
Claim 1 There is x E 2* such that x ^yt for all /.
Proof Suppose the contrary; i.e., that for each x E 2*, there is an / so that
x <yt. Consider a string x =yxa, where a E 2*. Then x ^y\ so there must be some
/>1 so that yla=x<=yj. But then J>i<*<j>;-, which contradicts the incompar-
ability of yx andy}-.
216 THE ITERATION THEOREM, NONCLOSURE AND CLOSURE RESULTS
We may assume there is a shortest x which satisfies Claim 1. Among all
infinite sets of pairwise incomparable elements, suppose that Y is chosen so that x
has minimum length.
Let
x = xt ■■-xk,
where xj 62 for 1 </ < k. Note that k =£ 0, for then x would be null and A = x <>>,■
for all /. If k= 1, then yt E (2 — {xi})* for all i> 1 [by the incomparability
condition] . But this would contradict the induction hypothesis for 2 — {xx}.
Claim 2 xx ■ ■ • xfe_i <j>; for all but finitely many /.
Proof Supposexx ■ • -xk^ <j>;- for infinitely many/, say/i,.. . Define
Yo = {yj^yj,, ■ ■ -I yH e Y and jf! • • • jcfc_! <yh).
Then y0 is an infinite set of pairwise incomparable elements which has a string x =
Xi ■ ■ -xk-i satisfying Claim 1, where \g(x') < lg(x), and that would be a contradiction,
since x was chosen to be minimal.
By relabeling subscripts of thejvt-, we may assume that
xi '' 'xk-i ^yi for all i >C.
Moreover, for each i> £, there exist unique words, jv,i, ■ ■ . ,ytk such that
yi = ynxlynx1 ■ ■ ■yik-lxk.lyik
and Xj ^yfj for all 1 </ < k; that is,ytj S (2 — {Xj})*. Moreover, we have xk ^ytk for
all i > £. [Suppose xk <yik for some OS.; then*! • • -xk =x <yt which would
contradict our choice of x.]
Claim 3 There exist infinite index sets A^,.. . ,Nk such that
a) Nj+1c Nj for Kj<k.
b) If p,q GA) for some/, 1 </<& andp <q, thenj>p;- <j>q/.
Proof Let N0 = {/| / > £}. The existence of Nj will follow from the existence
of the A^.! for 1 </<&. Let
Yj = {y^iENj.i} for K/</c. (6.6.5)
CASE 1. Yj is finite.
If Yj is finite, then, since Nj-i is infinite, we have that Iw = {i GA^I ytj = w} for
some fixed wG 2* must be infinite. In other words, from (6.6.5), as / runs through
Nj_i, infinitely many of the ytj must be the same. Define Nj to be any such Iw. Clearly,
this Nj is infinite and satisfies (a) and (b) since Nj^ did.
CASE 2. Yj is infinite.
In this case, since Yj c (2 — {xj})* the induction hypothesis applies. By Lemma 6.6.2,
Yj has an infinite chain
y.j<y.j<---. (6.6.6)
6.6* PARTIAL ORDERS ON Z* 217
Let ti, t2, . . . be an infinite strictly increasing subsequence of slt s2, ■ ■ ■ and define
Nj = {tj\ i > l}. Clearly, Nj is infinite and Nj £ Nj-i. To see (b), suppose p, q EWy and
p<q. By (6.6.6), we know that yps <>'<„. This completes the proof of Claim 3.
If p < q and p, q&Nk, then p, q EVV,- for l <f<k so that for each/, 1 </
< k,ypj ^y<u- Therefore
yP = yPiXiyP2X2 ■ • -yPk-iXk-iyPk
< yq\Xiyq2x2- ■ yqk-ixk-iyqk = yq-
But yp <j>g contradicts the definition of Y. □
Corollary (The Konig Infinity Lemma) Each set of pairwise incomparable
elements of (Nfe,<) is finite where N is the set of natural numbers and (n1;... ,nk)
< («i,.. . , n'k)if nt < n'j for each i, 1 < i < k.
Proof Consider the mapping tp: (n1;. . . ,nk)^>-a"1 ■ ■ -a1^. <p is an
isomorphism. If X is an infinite set of pairwise incomparable elements of (Nk, <) then <p(X)
is an infinite subset of {fli}* • • • {an}* <~{al,..., an}*. But if u and v are incomparable
elements of Nk, then i^(u) and ip(v) are incomparable elements of ({a,,.. . ,a„}*,<).
This contradicts Theorem 6.6.2. D
We introduce the operations of taking subsequences and supersequences of
sets.
Definition Let L £ 2* and < be the "subsequence" ordering defined at the
start of this section. Define
L = {xGI,*\ y<:X for some y in L}
and
L = {xG'E*\x<y for some y in L}.
In words, L is called the set of supersequences of L while L is the set of
subsequences of L.
Some algebraic identities concerning these sets are listed below.
Lemma 6.6.3 For any L £ 2*,
1 L£L,
2 L£L;
3 L=L.
Proof (1) and (2) are immediate from the definitions. For (3), note that
L £ L by (2). Suppose x&L. Then x <j> for some y£L. Again by the definition,
y <z for some z EL. By transitivity,x <z, so that x EL. □
Before passing to our main results, we need one more definition.
Definition Let (5, <) be any partially ordered set. x E S is said to be minimal
if y < x and y E 5 imply j> = x.
218 THE ITERATION THEOREM, NONCLOSURE AND CLOSURE RESULTS
We recall a trivial fact about minimal elements.
Fact Let (5,<) be any partially ordered set. If x and y are distinct minimal
elements, then x and y are incomparable.
Proof Immediate
Now we are ready to prove a useful lemma.
Lemma 6.6.4 Let L £ 2*.
a) There exists a finite subset F'k 2* so that L = F.
b) There exists a finite subset G £ 2* so that
L = 2*-G.
Proof a) Let F be the set of minimal elements of L. By the previous fact,
the elements of F are pairwise incomparable. By Theorem 6.6.1, F is finite. We must
prove that L = F.
Suppose x£F. Then y < x for some y&F^L. Thus, x EL and F 5 L.
Suppose xEL. Then j><x for some j>EL. There is y' £F so that
j> <j><;t. [If j' is minimal, then y'=y. If not, the definition of minimality
guarantees the existence ofy'.] Thus* GF andL 9 F. Therefore,L =F.
b) LetM=2*-L.
Claim M = M.
Proof We already know that M£M. Suppose that M%^M; i.e., there is
x EM and x ^M = 2* — L. That is, x EM and * EL. Since x EM,x >j> for some
y EM. Since x EL and x >jv, we conclude that y EL = L. But we have established
that j> E L and j>EM=2*— L, which is a contradiction. This completes the proof of
the claim.
By part (a) of the Lemma, there is a finite subset G so that M = G. However,
G = M = 2*-L = G,
so that Z
L = 2*-G. □
Now we come to our main result.
Theorem 6.6.3 For any set L 9 2*, L and L are regular sets.
Proof For any word, w E 2*, write
where w, E 2 U {A} for l < i < n. Clearly, w is regular since vv = 2*{w!}2* • • • 2*
{w„}2*. Moreover, for any finite set W^ 2*, W is regular since
W = U {w},
w <EW
and a finite union of regular sets is regular.
6.7 PROGRAMMING LANGUAGES ARE NOT CONTEXT-FREE 219
Let L £ 2* and let F and G be as given by the previous lemma. Then
L = F
is regular by the above remark and
L = 2*-G
is regular since the complement of a regular set is regular. □
This theorem is amazing because there are no constraints on the set L. It
might not even be recursive, and still L and L are regular.
PROBLEMS
Definition Let k > 1 and let x, y E 2*. We define x <fe y if x = xt ■ ■ ■ xk
and y =y\Xi ■ ■ • >'feXfej'fe+1 for somex,- andy3 in 2* where 1 </ < k and 1 </ < k + 1.
Thus x <fe y if a factorization of x into k parts occurs in y.
1 Is (2*, <fe) a partially ordered set?
2 Is a constructive proof of Theorem 6.6.3 possible if L is recursively
enumerable? If L were context-sensitive, could one construct a right linear grammar fori?
3 Show that no matter how one partitions an infinite «-ary expansion of
any real number into blocks of finite length, one block is necessarily a subsequence
of another.
6.7 PROGRAMMING LANGUAGES ARE NOT CONTEXT-FREE
Since much of the motivation for studying context-free languages came from
programming languages, it is desirable to ask whether existing languages are context-
free or not. To understand this question, one must ask "What is a programming
language?" Let us take ALGOL as an example because it was one of the earliest
languages that was carefully designed. The set of valid ALGOL programs is the set of
strings that (i) satisfies the syntactic conditions of ALGOL and (ii) satisfies the
semantic conditions. Since the syntax is written in BNF, there is no doubt that the set
of strings which satisfy (i) is context-free. The semantic conditions for ALGOL were
written in English and it is not immediately clear whether the set of strings which
satisfy (i) and (ii) is context-free. Note that there is a distinction between the
specification of a language and some implementation restriction of a compiler. In ALGOL,
an identifier has unbounded length while, in a particular compiler, the length may be
at most 10 characters. Our interest is in the language definition, not a particular
implementation.
Theorem 6.7.1 ALGOL 60 is not a context-free language.
Proof Let L be the set of (syntactically and semantically) valid ALGOL 60
programs. If L were context-free, then so would
M = Ln({beginKtealK*n;K*}*{:=K*r{end})
since it would be the intersection of a context-free language and a regular set. But
M = {begin realxl;xJ : = xk end| i = j = k,i> 1},
220 THE ITERATION THEOREM, NONCLOSURE AND CLOSURE RESULTS
x/a x/b X/a
begin/A end/A
real/A
FIG. 6.4
where the condition i=j = k follows from the semantic rule that every variable that
occurs in a valid ALGOL program must be previously declared. Also, /> 1, since
there is no bound on the length of identifiers in ALGOL. Let S be the gsm shown in
Fig. 6.4.
Then S(M) = {a"b"a"\ n~> 1}, which is a contradiction since context-free
languages are closed under sequential-transducer maps. Thus L is not context-free. □
Now let us turn to another language.
Theorem 6.7.2 FORTRAN, as specified below, is not a context-free language.
Proof Let F be the set of all valid ASA FORTRAN programs with the
assumption that there is no bound on the number of continuation cards.
Let R be the following set, where the representation of R is written on
separate lines to make it more intuitive .t
R = { WRITE (6, 1)
1 FORMAT(1}{0}*{//}{X}*{)
END}
Clearly, R is a regular set. If F were context-free, then L = FC\R would be, but we
have that
L = { WRITE (6, 1)
1 FORMAT(10"HX10")
END|w>0}
Define the homomorphism tp by <p(X) = X and <p(a) = A otherwise. Then
XL) = {x10"\ n>0}
would be context-free but it isn't. This contradiction establishes that F is not context-
free. □
Now we turn to PL/I, which is a descendant of both ALGOL and FORTRAN.
The argument used for ALGOL will not work for PL/I, since it is not necessary to
;/A
t The characters {and} are meta characters not in the FORTRAN character set.
6.8* PROPER CONTAINMENT OF LINEAR LANGUAGES IN 6 221
declare every identifier. However, the generality of structures in PL/I allows the
number of dimensions of an array to be unbounded.
Theorem 6.7.3 PL/I is not context-free.
Proof Let P be the class of valid PL/I programs and suppose P were context-
free. Consider
M = Pn ({MAH: PROCEDURE OPTIONS (MAIN): DECLARE A(l :4}{,l :4}* {);
A(2}{,2}*{) = A(3}{,3}*{;ENDMAH;})
The quantity in parentheses is regular so that M is context-free. Thus
M = {MAH: PROCEDURE OPTIONS (MAIN);
DECLARE A(l:4{, 1:4}');
A(2{,2}') = A(3{,3};);
END MAH;| i > 0}
This follows because (i) there is no bound on the number of dimensions in PL/I and
(ii) each reference to the array must have the same number of indices.
Define a homomorphism <p as follows:
tp4 = a
<p2 = b
tp3 = c
ipx = A in all other cases.
Clearly, ipM= {a'b'c'\ /> 1}, which would be context-free if P were. This
contradiction establishes that PL/I is not context-free. □
PROBLEMS
1 In Theorem 6.7.2, no bound was placed on the number of continuation
cards in FORTRAN. Suppose this quantity were bounded. Would FORTRAN be
context-free? Explain.
2 Is ALGOL 68 a context-free language?
3 Is PASCAL a context-free language?
4 Is COBOL a context-free language?
6.8* THE PROPER CONTAINMENT OF THE LINEAR CONTEXT-FREE
LANGUAGES INC
The techniques of using closure properties which have been presented in this
chapter are of great value. To illustrate this, we return to the case of linear languages
and prove a theorem from which it follows that there are context-free languages which
are not linear.
222 THE ITERATION THEOREM, NONCLOSURE AND CLOSURE RESULTS
,, „Q0 >QQ
S; -Q0 ^ ^O
a/A
c/A
a/a
c/A
FIG. 6.5 The definition of Sj and S2; a denotes any letter of 2.
Theorem 6.8.1 Let 2 be a finite nonempty set, c$ 2 andi?,X9 I,*.\fRcX
is a linear context-free language, then either R or X is regular.
#•00/ Let
L(G) = i?cX = L,
where
G = (K, 2U{c},i>,5)
is a linear context-free grammar. Assume, without loss of generality, that G is reduced.
Now define two gsm's Si and S2 by Fig. 6.5.
The reader may easily verify that
Si(RcX) = R S2(RcX) = X.
Now define a set of variables
C = {A E7V| A ^w for some w E 2*c2*}.
Since each wGL contains exactly one c,ifA =>aE V*, then either
1 a contains no c and at most one variable which belongs to C; or
2 a contains a c and no variables which belong to C.
Now we partition P into four disjoint sets
P0 = {A^u\ ueZ*}U{A^uBv\ BeN, u,uE2*},
Pi = {A ->ucv\ u,uE2*},
P2 = {A^UiCU2Bv\ BeN,uuu2,vej:*},
P3 = {A^-uBviCV2\ BeN,u,vuv2ei:*}.
The variables that occur on the righthand side of rules in P2 L)P3 are not in C, since,
if they were, one could derive a word in L with two c's.
Define three grammars:
Gi = (K,2U{c},i>0Ui'1,5),
G2 = (V,i:u{c},P0L)P2,S)
G3 = (K,2U{c},i>0Ui>3,S)
and let
^ = L(Gi), 1<*<3.
6.8* PROPER CONTAINMENT OF LINEAR LANGUAGES IN Q. 223
Again, using the fact that if w E L, it has exactly one c, we have that every derivation
in G uses exactly one rule in Px U P2 U P3. Thus
L = LiUL2UL3.
Claim 1 Si(Li), Si(L2), and S2(L3) are regular.
Proof We give a right linear grammar
G\ = (K, 2,/>;,£)
such that S^LO = L(G\). Let
Pi = {A^u\ ,4 ^u is inland «E 2*}
= L){A^uB\ A ^ uBv is in P0,BeN}
= U {A->-u\ A^- ucv is in Pi}.
To show that L(G[) = Si(Li) it suffices to prove:
Claim S^ucv if and only if S=>u.
Proof The argument is omitted.
Thus L(G\) = Sl(Ll). Since G\ is right linear, L{G'{) is regular and
therefore Si(Li) is regular.
Similar proofs show that Sl(L2) and S2(L3) are regular, which proves the
claim.
Now, since
L = RcX = LiUL2UL3,
then
R = SiiL) = SiiLJUSiiLjUSiiLs). (6.8.1)
Also since
X = S2{L) = S2(Li)US2(L2)US2(L3),
then
S2{L^X. (6.8.2)
It will suffice to prove the next claim because then we will have that R is
regular orXis.
Claim 2 EitherR=Si(L1)USi(L2) orX = S2(LZ).
Proof From (6.8.1) we have
Si(Li)USi(L2)^R.
Now suppose Si(Li) U Si(L2) J R. Then there exists a w such that
wGR-(Si(Li)USi(L2)).
Since wGR,
wcX9RcX = L. (6.8.3)
224 THE ITERATION THEOREM, NONCLOSURE AND CLOSURE RESULTS
But
wcXn^ULi) = 0, (6.8.4)
since
Si(wcX) = w$(S1(L1)USi(L2)).
From (6.8.3) and (6.8.4) and the fact that L = i1UL2UL3we have
wcX£L2.
Therefore,
S2(wcX)= X9 52(L3).
Thus, from (6.8.2), we get:
S2(L3) = X,
which proves Claim 2.
Claims 1 and 2 show that either R or X is regular, and this proves the
theorem. □
Corollary Let 2 be a finite nonempty set, c^2, and R £ 2*. If RcR is a
linear context-free language, theni? is regular.
Theorem 6.8.2 There exist context-free languages which are not linear.
Proof Let G be the context-free grammar given by
S -> TcT
T -> aTb\A
Then
L{G) = {fl'ft'l i>0}{c}{aibi\j>0}.
By the above corollary, if L(G) were linear, then
R = {flWl i>0}
would be regular. But, from Theorem 2.2.1, R is not regular. Therefore L(G) is not
linear. □
PROBLEMS
1 Let R 9 2* be a regular set and c $■ 2. Show that
L = {xcxT\ xGR}
is a linear context-free language
2 i is said to be a ucv-language if L 9 2*c2*, where c $■ 2. If L is such a
language, let u, vE. 2*, and define
/l(") = {w| «w6£},
gL(v) = {w\ wcvGL},
U(L) = {w| fL(w) ¥=9],
V(L) = {w\ gL(w) *9}.
6.9* SEMILINEAR SETS AND PARIKH'S THEOREM 225
Prove the following result.
Proposition Let L be a ucv context-free language. If, for each u E2*,/I/(w)
is finite, then V(L) is regular. If, for each uE2*, gL(v) is finite, then U(L) is regular.
3 Use the result of Problem 2 to show that if a regular set gets run into a
pda, the contents of the pushdown store is regular. More formally, let A = (Q, 2, T,
5, q0, Z0, 0) be a pda and let R £ 2* be a regular set. Show that
PR = {aer*| (q0, w,Z0) f^-fa.A.a) for someq EQ and w GR}.
[Hint: Consider Lq = {wca\ (q0, w, Z0) r~(q, A, a), where u>E2*} but watch out
for the possibly infinitely many A-moves.]
4 Show that the linear languages are not closed under product.
5 Let R, X£ 2*, and c £ 2. Show that, if R and X are linear context-free
languages and either R or X is regular, then RcX is a linear context-free language.
6 Let X'- 2* and cf£. Show that AcA" is a linear context-free language if
and only if X is regular.
7 Let G = (K, 2,/", 5) be a metalinear grammar, as defined in Problem 4 of
Section 2.5. The width of G is defined as
max {m \ S -»• .4 i ■ ■ • .4 m is in P}.
L is said to be metalinear of width k if L = L(G) for some metalinear grammar of
width k. Let X^ X* for 1 </< m,m > 2, and let c<£ 2. Show that if A^cA^ • • • cXm
is metalinear of width k > 1 and if X\ is not regular, then X2cX3 ■ ■ • cXm is metalinear
of width at most k — 1.
8 Let Xjt 2* for 1 </<w and let c<£2. Show that if X^ ■ ■ -cXm is
metalinear and of width k, then at most k of the A*,- are not regular.
9 Let X^ 2* and c<£2. Show that (A"c)*X is metalinear if and only if AT
is regular.
10 Let 2 be an alphabet and c $ 2. If L *~ 2*, then define
N(L) = {xcy\ x,y&L,x±y}.
Show that, if L is regular, then N(L) is context-free.
11 Is it true that N(L) context-free implies L is regular?
12 Show that an affirmative answer to Problem 11 gives an elegant proof
that English is not context-free. [Hint: Consider sentences like "John is more
successful as a V than Bill is as a 'z'."]
6.9* SEMILINEAR SETS AND PARIKH'S THEOREM
In this section, a natural mapping from sets of strings into sets of «-tuples
of natural numbers will be explored. The resulting theorem is a classical one in
language theory. The applications of this theorem will be found in the exercises in
future sections. We approach the proof by first stating a result which follows easily
from the Iteration Theorem.
226 THE ITERATION THEOREM, NONCLOSURE AND CLOSURE RESULTS
Lemma 6.9.1 (The Pairing Lemma) For each context-free grammar
G = (V, 2, P, S) there is an integer p such that, for any k > 1, if w E L(G) and lg(w) >
pk, then there exist strings vu v3, vs, v2l,. .. , v2k, v4l,... , v4k E 2* and A GN such
that:
i) S =>v1Avs=>vlv2iAv4lvs
^■vlv2lv22Av42v4lv5
=^1^21 • --v2kAv4k ■ --v^Vs
^Vi v2l ■ ■ ■ v2kv3v4k ■■•v/nvs = w
ii) v2iv4i =£ A for each /, 1 < i < k; and
iii) lg(u21 • • • v2kv3v4k ■ ■ ■ v4l)<pk.
Proof When k = 1, the lemma is a minor modification of the pumping
lemma. The proof of the Pairing Lemma merely follows that of the Iteration Theorem
except that, because lg(w)> pk, the crucial path in the generation tree for w has k
repetitions of some variable A. It is not necessary to even worry about positions. □
A fair amount of notation must be built up in order to state the main
theorem. Let H be the set of natural numbers as well as the commutative monoid
consisting of (^ under +. |\|" denotes the cartesian product of py with itself n times.
Let* = (jti,. . . ,xn) andj> = (yu ... ,yn)be inN" and define
x+y = (*i+j'i,...,*n+J'n)
and for m > 0, define
mx = (mxu ..., mxn).
Definition A set of the form
{a0 + n!<*! + ■ ■ • + nmam\ rij>0 for 1 </<m},
where a0,..., am are elements of N", is said to be a linear subset of Nn. A semi-
linear set is a finite union of linear sets.
Let us fix 2 = {«!, .. . ,an} and define a mapping from 2* into N" given by
HW) = (#ai(w),...,#an(w)),
where #a.(w) denotes the number of occurrences of at in the word w. Note that,
for anyx,j>£2*,
Mxy) = «h*) + My) = My) + <H*) = My*)-
\p is sometimes called a Parikh mapping. For any L 9 2*, define
i,(L) = {4/(x)\xGL}.
Sometimes </>(X) is referred to as the "commutative image" of L.
6.9* SEMILINEAR SETS AND PARIKH'S THEOREM 227
Example Let L = {a\a\\ i > 0}. Then
«H£) = {{iJ)\i>0} = {i(\,\)\i>0}.
Thus, </>(L) is a linear subset of N2.
We sometimes say that a language L 9 2* has a semilinear image if t/>(L)
is semilinear.
A mapping like \p can induce an equivalence relation on languages, as follows:
Definition Two languages Ll and L2 contained in 2* are called letter-
equivalent if i/>Li = ^L2.
The languages with a semilinear image can be characterized quite simply.
Theorem 6.9.1 A set L 9 2* has a semilinear image if and only if L is letter-
equivalent to a regular set.
Proof Suppose L has a semilinear image; that is,
\pL = MiU---UMm,
where each
Mi = {ai0 + nnan+ ■ ■■ + nir.\ ni}>0 for 1 </</•,}.
Let yi0,yn, ■ ■ ■ ,yir- be strings in 2* whose images under \p are, respectively, a,0,
an,..., air.. Then define G by the productions:
S ■+Al\---\Am
At ^ Aiyij\yi0 for all i,/, \<i<m, 1 </</•;.
Since G is left linear, L(G) is regular and, clearly,
«H£(C)) = «/,(£)•
Conversely, we shall show that any regular set has a semilinear image by
Kleene's Theorem. It is clear that
*0 = 0
and that ^{a,}is semilinear.
CASE 1. If 4/Li and t/>L2 are semilinear, then \[/Ll U t/>L2 is semilinear.
Proof If t//L,- = Ln U • • • U L,fe. for i = 1, 2, then
«H£iUL2) = U Ui,7
1 = 1 ;'=l
is a semilinear representation of Lx UL2.
CASE 2. If Li and L2 have semilinear images, then so doesLiL2.
228 THE ITERATION THEOREM, NONCLOSURE AND CLOSURE RESULTS
Proof Since concatenation distributes over union and we have closure under
union, it suffices to assume that \pLi = Mi and \jjL2 = Mi, where Mi and M2 are linear.
Let
M{ = {at + nnaji + ■•■ + nim.aim.\ nt > 0} for i = 1,2.
It is easy to verify that
4/(LiL2) = Mi+M2
= {o^ + a-2 + «i1a11+ ••• + «imialmi+«21a21+ ■ ■ ■ + n2m2a2m2\nij>0}.
The proof for * is a little tricky so it is convenient to do a special case first.
CASE 3. If 4/L is linear, then \[/L* is semilinear.
Proof Suppose
4/L = M = {a0 + nidi + ■ ■ • + nmam\ nt>0}.
Note that
4/(L*) = {0}u{ao + noao + "iai + ■ • ■ + nmam\ nt>0},
where 0 denotes the zero vector in Nn.
CASE 4. If \pL has a semilinear image, then so does \[/L*.
Proof Let L - Lx U • • • U Lk, where each L; £ 2* is a set whose image is a
linear set in Nn. By Cases 2 and 3,
I* • ■ • I*
has a semilinear image. The proof of Case 4 now follows easily from the observation
that
«/,L* = «K(£i U • • • U Lkf) = i,{LX ■ • • Li).
The converse now follows from Kleene's theorem. □
We are now ready to prove the main result of the section.
Theorem 6.9.2 (Parikh's Theorem) For each context-free language/,, \pL is
semilinear. Equivalently, each context-free language is letter-equivalent to a regular set.
Proof Let G-(V, Y.,P,S) be a context-free grammar such that L(G) = L,
and let p be the constant from the pairing lemma.
For any ae V*, define v(a) = {A eN\ a = (3Ay for some j3, y e V*}. That is,
v(a) is the set of variables that occur in a. We extend v to derivations. That is, if 6 is
a derivation,
6: a! =>•••=> a„,
define
n
K0) = U K<*<)-
6.9* SEMILINEAR SETS AND PARIKH'S THEOREM 229
Now let U be any set of variables containing S. Define Lv to be the subset
of L consisting of words derivable from S in which the only variables used were from
U. More precisely,
Lv = {weL\ Forsomefl: S =*• w,v{6) = U}.
Claim 1 It suffices to prove that each Lv has a semilinear image or, equiva-
lently, that each Lv is letter-equivalent to a regular set.
Proof There are only finitely many sets U and hence sets Lv. Moreover;
L = U Lv,
u
so that Claim 1 follows.
Consider a set Lv. Let k= \U\ and define
F = {weLu\ lg(w)<pfe}.
Now consider the set
{xy e 2* 16: A ^ xAy, v(6) 9 U, lg(xy) <pk}.
Because the length of xy is bounded, this is a finite set, so let
^1> . . . »Sm
be any fixed enumeration of the elements of the set.
Claim 2 WLu)^ UK* ■■■**„)•
Proof The argument proceeds by strong induction on lg(w), where w&Lv.
Let n0> 0 be fixed and suppose that
*(z)e *(/*:•■■**)
for all z&Lv, with lg(z)<w0. Now suppose w&Lv and lg(w) = n0. If lg(w)<pfe,
then w E F, so that \jj{w) E \jj(F,s* ■ ■ • s^).
Suppose lg(w) > p . Since w £ L,fj, there is some derivation
6: S 2* w
with v(Q)= U. Since lg(w)>pfe, the pairing lemma yields a derivation 0' such that
=* ViV2lAv4lv5
=> vxv2l ■ ■ • v2kAv4k ■ ■ ■ v4lvs
=> vlv2l • • • v2kv3v4k • ■ ■ v4lv5 = w
'fe-n
230 THE ITERATION THEOREM, NONCLOSURE AND CLOSURE RESULTS
where A G U and 1 < \g(v2l •" ■ v2kv3v4k ' ' ' v4i)^Pk ■ Certain subderivations of 9'
have been distinguished. Note that v(8') = v(d) = U. Since
fe + i
v(8') = U ii8i) = U,
each variable in U — {A} is in at least one vfOf) for some i, 0 < i < k + 1. For each
variable in U — {A }, arbitrarily choose some i, 0 < i < k + 1, such that y(0,) contains
that variable. Some values of / may be chosen more than once. Since there are only
k — 1 variables in U — {A} and k values between 1 and k, some value of i,Ki<k is
not chosen at all. Let i0 be such an index. That is, p(9t ) contains only^l. Now delete
the subdrivation 0; from 0' to yield
0": S ^ vxv2l • ■ • v2io.iV2io+1 • ■ ■ v2kv3v4k ■ ■ ■ i>4,yh*>4;0-i • • • v41v5 = w'.
From the choice of i0, every variable in U — {A} is in v(Q"). Clearly, A E v(8"), so
v(0") = U. Hence, w E Lv. Since lg(w') < lg(w) = n0,
4>(w')e4,(Fst ■■■**„)
by the induction hypothesis. Since w'v2i v4i is a permutation of w,
\l/(w) = ^(w'v2iov4io)G\l/(Fs* ■ • ■ s*mv2iv4i).
But v2iov4io is in {su . . . ,sm}, so
iKw) S ^(Fs? • • • s*mv2iv4ii) = \l/(Fs*i ■ • ■ s^n).
Claim 3 *(/*!• ••s£)c,KLu).
Proof Let wSLy, and we prove that i//(ws,-)E t//(Xi/) for any i. From the
definition of thes,-, we can write s,- = v2v4 for some v2 and u4, and there is some B&N
and some derivation t
6: B =" u25u4
with ^(0) = U. Since w E L^, there is a derivation of w in which 5 occurs; for example,
5 =*■ xBz => xyz = w
but then t
S =*■ xBz =*■ xv2Bv4z =*■ jo^j^z = w
Now w' E Lv and tZ'(w') = t/'Cws,). Thus,
^(L[;S,)9 iHLfj) for each s,-
and since
this shows that
Mwsi) = *(w') G *(/*! • • • C) ^ <H^i • • • C) ^ Wu).
By Claims 3 and 4,
*(/.„) = *(/*?•••«;,).
Since Fs* • • • s^ is clearly regular, the proof is complete. D
6.10 HISTORICAL SURVEY 231
PROBLEMS
1 Show that a set of ^-tuples of natural numbers is linear if and only if it is
a coset of a finitely generated subsemigroup of N".
2 Show that the family of semilinear sets of N" is closed under intersection
and complementation. Show that if Li'- Nm and Z,2-^™ are semilinear sets, then
L i x L 2 is a semilinear subset of Nn * m.
3 Find a set 1^2* which is not a context-free language but which has a
semilinear image.
4 Use Parikh's Theorem to show that every context-free language L 9 a*
is regular.
We begin to build a logical system involving addition and the logical connectives. The
formulas will express statements about natural numbers. The set of Presburger formulas,
&, is the least class of formulas satisfying the following conditions.
a) For given nonegative integers nt, n\, 0 < ; < m,
m m
"0+ E"i*i = "0+ Y*n'lxi
is a formula in & with free variables x\,... , xn.
b) If/>1,/>2e.#8,thensois/>1n/>2.
c) If Pu P2 S & , then so is Pi U P2.
d) If P is in &, then so is ~l P.
e) If P(xi,. .. ,xn) is in & and 1 <<<«, then (Vx,)/>(xi,. ..,*„)£.#*.
f) lfP(xi,. . . ,x„) is in & and 1 <i<«, then the formula
(3xi)P(xu. ..,xn)
is in &.
A formula with no free variables is called a sentence.
*5 Show that it is decidable whether or not a Presburger sentence is true.
If P(xi,. .. , xn) is a Presburger formula, it defines a relation as follows:
Ap = {(al5. . ., a„)\ P(ai, ... ,an) is true}.
A Presburger set A £ N" is of the form Ap for some Presburger formula P(xu ... , xn).
6 Show that the family of Presburger sets in Nn is identical with the family
of semilinear sets in Nn.
6.10 HISTORICAL SURVEY
The pumping lemma first appears in Bar-Hillel, Perles, and Shamir [1961].
The iteration theorem is from Ogden [1968]. The example used in Theorem 6.2.4 is
due to Wise. Problems 10 through 12 in Section 6.2 are from Hartmanis and Shank
[1968]. The L nR theorem is due to Bar-Hillel, Perles, and Shamir [1961], although
our machine proof is much simpler than the original argument. Theorem 6.3.1 is from
232 THE ITERATION THEOREM, NONCLOSURE AND CLOSURE RESULTS
Ginsburg and Rice [1962]. While gsm's and context-free languages were first studied
in Ginsburg and Rose [1963], our development follows Ginsburg, Greibach, and
Harrison [1967]. Problems 4-7 of Section 6.3 are from Kosaraju [1975].
Theorem 6.6.3 is from Haines [1969]. Our notation for quotient follows
that of the "French school"; cf. Eilenberg [1974]. Exercise 9 from Section 6.3 is
fromNivat [1967].
Theorem 6.8.1 is from Greibach [1966]. At the end of Section 6.8, Problem
2 is from Bar-Hillel, Perles, and Shamir [1961], and Problem 3 is from Greibach
[1967]. Parikh's theorem occurred originally in Parikh [1961] and was republished
in Parikh [1966] due to its importance and the inaccessibility of the original note.
Our proof follows Goldstine [1977].
seven
Ambiguity
and Inherent
Ambiguity
7.1 INTRODUCTION \
In earlier sections, ambiguous context-free grammars have been introduced,
and we defined a language to be inherently ambiguous if every one of its infinitely
many context-free grammars was ambiguous. Either such languages exist or for every
ambiguous grammar there is an equivalent unambiguous grammar. In either event, this
is an interesting phenomenon. It turns out that the former case holds, and in Section
7.2, this is proved with the aid of the iteration theorem.
In Section 7.3, we strengthen the above result by showing that there are
inherently ambiguous languages that have an exponential number of derivation trees in
the length of the string. Since the number of factorizations of a string of length n is
exponential in n, this is as many as possible.
Section 7.4 is devoted to showing that certain operations preserve or do not
preserve unambiguity or inherent ambiguity. While those results are simple to prove,
they turn out to be very useful.
7.2 INHERENTLY AMBIGUOUS LANGUAGES EXIST
Our earlier discussion of inherently ambiguous languages was very brief and
consisted merely of a definition. Now we shall use the iteration theorem to prove that
they exist. The first step in the proof is to examine phrases.
233
234 AMBIGUITY AND INHERENT AMBIGUITY
Definition Let G = (V,X,P,S) be a context-free grammar and suppose
17, j3G V*. ]3is said to be a phrase of 17 if there exist a, 76 V*,A EN, so that
* n
S => aAy A =*/? for some n > 1 and 17 = a/37
/3 is a simple phrase of 17 if (3 is a phrase of 17 as above, in which n = 1.
Definition Let a and /3be subwords of 7, where a,/3, 76 K .aand /3 are said
to be disjoint if there exist p,a,r& V* so that 7 = pao/Jr or 7 = pfioca.
The following simple result is needed.
Theorem 7.2.1 Let G = (V,X,P,S) be an unambiguous context-free
grammar, let x 6 L(G), and let xx and x2 be phrases of x. Either:
i) xl andx2 are disjoint,
ii) Xi is a subword of x2, or
iii) x2 is a subword of xl.
Proof Consider the (unique) rightmost derivation for x:
Since j^ in 2* is a phrase of x, there is an index i such that ]3,- = atAVi and ^4 j**!.
Since the derivation is rightmost, v{ 6 2*. Similarly, there is a number / so that j3y =
oijBVj, B=>x2 and ^ 6 2*.
There are 3 cases: /=/, />/, and /</. The third case will follow from the
second by symmetry. Let z, be the node of the tree labeled/I while z2 has label B. If
i = /', then zl =z2 and at = as,A = B, and p,- = v-r Thus xt = x2.
Now assume / < i. In the derivation for x, we have either one of two choices.
Since j3y- j*/3; or a,ify- ^> <XiAvh our two choices for subderivations of the derivation in
question are
B ^ yAy for some 7 6 K* and y 6 2*
or
(fylj^yUy for some 7' 6 K* and y 6 2*.
These cases are represented by Fig. 7.1.
CASE 1. Suppose B => yAy for some 7 e V* and .y e 2*. Then we have
Bj>yAy=> yx^^ x2
because B ^> x2 and A J> xi and both are in 2*. Therefore, Xi is a subword of x2.
CASE 2. Suppose a,- s> 7'^' for some 7' e K* and some j'' e 2*. Then
S=>oijBVj =>UjX2Vj => y'Ay'x2Vj=>y'xly'x2vj =>x
Thus,*! andx2 are disjoint phrases of x. □
Corollary Let G = (V, 2,i>,5') be a context-free grammar. Let* &L{G) and
Xi,x2 be phrases of x. If *! and x2 are incomparable (with respect to <, that is, one
7.2
INHERENTLY AMBIGUOUS LANGUAGES EXIST
235
AT] isasubwordof x2
(a)
x\ x2
a,±> y'Ay'
AT] and x2 are disjoint
(by
FIG. 7.1
is not a subword of the other) and they are not disjoint, then G is ambiguous; that is,
if*! andx2 "overlap," then G is ambiguous.
Now the idea of our proof that there exist inherently ambiguous languages
can be explained. We shall take two languages L0 and L, and show that L0 u^i is
inherently ambiguous. We will study a string z0 in L0 —Lx and determine the form of
its factorization. Another string zx in L\ — Lo will be studied in its factorization
determined. By pumping these strings we shall obtain overlapping phrases of a string in
L0 U Lx and conclude that the grammar must be ambiguous.
236 AMBIGUITY AND INHERENT AMBIGUITY
Notation LetL0 = {alblc'\i,j> ljandLj = {a'b'c1] i,j>l}-
Theorem 7.2.2 L0 U Lx = {a'b'ck \i=j or/ = fc}is an inherently ambiguous
context-free language.
Proof Since Z,0 u L\ is context-free, let p0 be the number give by the
iteration theorem. Let p = p0\ and let
z0 = a2pb2pc3p = a2"^ ^ c3p = x0u0w0v0y0
where the underlined ft's are distinguished; that is, K = {3p + I,... ,4p}, and
x0UowoVoyo is a factorization given by the iteration theorem.
We must determine the factorization of z0 6i0 ~~L\. There are two cases
according as Kx, K2, K3 # 0 or K3, K4, Ks =£ 0.
CASE 1. Suppose KX,K2,K3±$. This leads to:
x0 = a2pbp*1 />0,
u0 = bk k>0,
w0 = b"'a+k)w' k <p0<p andf+ k<p.
CASE la. Suppose v0 6 ft*. Then we would have:
x0 = a2pb"+1
"o = bh
w0 = ft8
»b = ftm
= j»-<^
C+m)_3p
/>o,
ifc>0,
£>0,
m>0,
But then
But^oH'oj'o f L0, since k>0andxowoyo ^ Lx, because £> 0 implies that:
fc + w</ + fc + e + w<p.
CASE lb. v0 6 ft+c+. The factorization is:
*o = a2pbp+1 />0,
u0 = bh k>0,
w0 = bs £>0,
_ f,P-U+h + Z)nm
y0
Vo = frP-U^Ky" B1>0,/ + ik + B<Po<P,
„3p-m
7.2 INHERENTLY AMBIGUOUS LANGUAGES EXIST 237
Then
x0ulw0vly0 = a2pbp+ib2kbibp-u+k+Z)cmbp-<-i+k+Z)cmc3p-m Ea+b+c+b+c+
and thereforex0u%w0v%y0 £ L0 UL,.
CASE lc. v0 Ec*. Then the factorization becomes:
x0 = a2pbp+i />0,
u0 = bk p-2>k>0,
w0 = ip-<J'+fc)cc k<po<p,fl>0,
v0 = cm m>0,
„ _ „3p-(C+m)
Consider x0w0y0 = a2P^p-kc^p-m ^ Xqw0y0 $ L0, since 2p — k < 2p because k > 0.
But x0w0y0 EL0 Ui, by the iteration theorem, so that x0w0y0 6L,. This implies
that 2p—k~3p—m,ov that
m = p + k.
However, let us consider
x0ulw0v20y0 = a2pb2p+kc3p+m
But x0ulw0vly0 $L0 ULj, since fc > 0, and2p + k ¥^4p+k since p >0. This shows
that Case 1 cannot hold.
CASE 2. K3,K4,KS^ 0. We must have that:
y0 = blc3p i>0,
Vo = iJ' 7>0,
w0 = w'bk k>0.
CASE 2a. u0 Eb*. Then the factorization would be:
.Vo = b'c3p
Vo = b'1
w0 = bk
u0 - b
x0 = a2pb2p-^+h+i+i)
/>0,
/>o,
Jfc>0:
Z>0,
But then
x0w0y0 = a2pb2p-«+i+k+i)bkb'c3p
_ a2PA2p-(y+E)c3p
Since/ > 0, XoWcVo £ £o u £ i , which contradicts that w0 e A*
238 AMBIGUITY AND INHERENT AMBIGUITY
CASE 2b. u0 Ga+b+. In this case,x0«Jwo v\yoea+b+a+b+c+, which would be
a contradiction.
CASE 2c. u0 Ga*. This leads to the factorization:
y0 = b'c3" i>0,
v0 = b' />0,
w0 = aeb2p-u+i) i+j<p,V>0,
h0 = ah 0<Jfc<2p-£,
x0 — a
To complete our picture of the factorization, suppose k #/. But then
x0U(jW0v0y0 —a d c
But x0u%w0v\y0 $.L0, since &=£/, andx0u\w0v\y0 f /,,, since 2p + j <3p.
Therefore, we have the following factorization, in which we have subscripted all the indices
for future applications:
x0 = «w-<A> + E.>
"o = a1" /o >0,
w0 = a^b^-Vo+M p-(i0 +/o)<Po <P.«o >0>
»o = *'° po>/o>0,
y0 = b'oc3" p-l>io>0.
Note that/o <Po, since otherwise \K^\ >Po would contradict the iteration
theorem. Thus/0|p and q0 = (p//0) + 1 is an integer. We have that
S^>x0A0y0£>x0uQ0"A0vS'>y0UXoU9oWoV9oy0 = a3pb3pc3p = z
and that
^0^m3»Wo* = ap+J° + s°b3p-'° (7.2.1)
Next we consider the word
z, = a3p£2V = a3p £ bpc2p,
where K = {3p + 1,. .. , 4p}. The problem of obtaining a factorization of z, is "dual"
to the problem of factoring z0. To see this duality, we reverse z0 and interchange a's
and c's. (Note that the symmetry of the iteration theorem under reversal plays a role
here.) Thus it follows that zx =xlulwlvlyl and Kl,K2,Ki #0. The factorization
is:
*i = a3pb'> p-i >il >0,
"i = bj> p0 >/, ^ 1,
7.2 INHERENTLY AMBIGUOUS LANGUAGES EXIST 239
Let qi = (p//j) + 1. Since/, <p0,Qi is an integer. We have that
S^XiA^i ^>xlu1'Alv9^yl £■ xlu\<wlvq<yl = a3pb3pc3p
and * ...
Al=>u91>wlvV = b3p-l'Cp+1'+k' (7.2.2)
Now let us consider the string a3pb3pc3p. We know that we may "pump up"
our factorization of z0 and z1 to get factorizations of a3pb3pcip (see Fig. 7.2). We
must now see how the phrases that derive from^40 and/I, fit into the picture. Recall
that A0^ap*i°+*°b3p-i° (7.2.3)
and
A0Z>ap+i°+*°b3p-t°
Al±>b3p-i>cp+}''+k'
S
(7.2.4)
FIG. 7.2
But it is clear that the phrases (7.2.3) and (7.2.4) overlap, since the minimum length of
the b's in the righthand side of (7.2.3) is:
3p-z'0 >3p~P = 2p,
while the minimum length of the b's on the lefthand side of (7.2.4) is:
3p — il >3p— p = 2p.
There is no way to partition (3p) i's into two classes each of which has size
greater than 2p without overlap, as can be seen from Fig. 7.2. Therefore the arbitrary
grammar G is ambiguous, and hence L0 UL, is an inherently ambiguous context-free
language. □
240 AMBIGUITY AND INHERENT AMBIGUITY
PROBLEMS
1 Show that {aaT| a 6 {a, b}*}2 is an inherently ambiguous context-free
language. (Hint. Start withz0 = aba2pbba2pbaaba3pbba3pba.)
2 Find a minimal linear language L which is inherently ambiguous among the
class of minimal linear grammars yet L has an unambiguous linear grammar.
3 Let M={a'bai+lb\i>0} and define L0 = abM* and LX =M*a*b. Show
that L0 UI, is inherently ambiguous.
4 A set L 9 2* is bounded if there exist w,, .. . , wr 6 2* so that
L 9 w* • • • w*. Settle the following question by providing a proof or a
counterexample.
For each inherently ambiguous language L, is there some bounded regular set
R £ w* • • • w* such that L O R is inherently ambiguous?
7.3 THE DEGREE OF AMBIGUITY
Now that we know that inherently ambiguous languages exist, let us take a
more refined view of ambiguous generation.
Definition Let k > 1. A context-free grammar G is ambiguous of degree k if
each string in L(G) has at most k distinct derivation trees (equivalently, leftmost
derivations). If k > 2, then L is called inherently ambiguous of degree k if L cannot be
generated by any grammar that is ambiguous of degree less than k but can be
generated by a grammar which is ambiguous of degree k. L is finitely inherently
ambiguous if there is some k and some G so that G is inherently ambiguous of degree k.
For example, L0 Ui, = {a'b'ck\ i = j or /= k} is inherently ambiguous of
degree 2. Since a grammar which is ambiguous of degree 1 is unambiguous, it only makes
sense to use the phrase "inherently ambiguous of degree k" when k>2. Also note
that if G is ambiguous of degree k, then k = sup{0(x)|x 6 2*},t where a(x) is the
coefficient of* in the formal power series, as described in Section 4.9.
Definition A context-free grammar G is infinitely ambiguous if, for each
i > 1, there exists a string in L(G) which has at least i leftmost derivations. A language
L is infinitely inherently ambiguous if every grammar generating L is infinitely
ambiguous.
Example Consider the grammar G:
s^ssw
where L(G) = {A}. G is infinitely ambiguous but L(G) is an unambiguous language.
We begin our development by reconsidering L0 U L j of Section 7.2.
t Suppose S is a partially ordered set with respect to <and S0 - S. An element sES
is an upper bound for So if So **= * for every s0 &S0- An element s* 6 S is a least upper
bound for S0 if s* <s for every upper bound s of So. We also write s* = sup(S). A
similar definition holds for lower bounds and greatest lower bounds, and the notation
used is inf(S). If i^ is a function with domain X, one writes
sup ip(x) for sup{<p(x)\x EX}.
7.3 THE DEGREE OF AMBIGUITY 241
Theorem 7.3.1 For any n > 1,(L0 U L i)" is inherently ambiguous of degree
2".
Proof Let p0 be the constant of the iteration theorem for (L0 u^i)" and
let p — p0!; by a straightforward generalization of the proof of Theorem 7.2.2, we can
prove the following: If
w2a2pbplb^ c3pw3 6(L0 UL,)n with wf+,€(£,„ UZ,,)^
for some kh i= 1,2, then:
w2a2p62pc3pw3 = x0u0w0v0y0,
where
x0 = w2a2p-(yo+«o)
m0 = a/o
u>0 = aco62p-<i0+;0) £0>0,
Wo = *y° p>po>jo>0,
y0 = &''°c3pw3 p-1 >/0>0.
Moreover, if we take q0 = (p//) + 1, then
xottfrwovfrx, = w2a3pb3pc3pw3e(L0^>L1)n.
Similarly, if we consider
w2a33plb^ibpc2pw3 =x1«1w1d,}'1,
then we find that
Xl = w2a3pb^ p-1 >/, >0,
"i = b1'' P>Po>h >0,
w, = b2p-^+>i)ch> ix +/', <p,fc, >0,
Taking g j = (p//,) + 1, we have that
je,ii?'w,»f'^, = u>2a3p£3pc3pw3e(Z,0U/,,)".
Using these factorizations, we are ready to prove the following result.
Claim For any w,+ 1 £ (/,<, ULi)fc', i = 1,2, &i, fc2 > 0, the string
w2a3p63pc3pvv3 € (/,<, U L2)" has at least two derivations.
Proof We have already seen (in the proof of Theorem 7.2.2) that the two
phrases ul°w0v%« and «?'w,i;f' overlap, so that w2a3pb3pc3pw3 has at least two
derivations.
242 AMBIGUITY AND INHERENT AMBIGUITY
If we consider the string (a3pb3pc3p)n, then we see that this string has at least
2" distinct derivations since we may generate any of the n subwords a3pb3pc3p in at
least two ways.
A straightforward argument shows that L is of degree exactly 2". □
Next we turn to showing that there is a context-free language with an
unbounded degree of inherent ambiguity.
Theorem 7.3.3 (L0UL])* is a context-free language which is infinitely
inherently ambiguous.
Proof Let p0 he the constant of the iteration theorem for (L0 u L j )* and let
P = PoU we note that the claim of the previous theorem applies in this case as well.
Therefore, for any «>0, the string (a3pb3pc3p)n has 2" trees. Since (/,<, UL,)*
contains (L0 UZ,])" for any n, we can proceed as follows. Let i be any fixed integer
and let n be such that 2" >i. Then (L0 U L2)" 9 (L0 UL,)* and has a degree of
ambiguity that is greater than i. D
PROBLEMS
1 Show that L = {wwT \ w 6 {a, b}*}2 is infinitely inherently ambiguous.
2 Let 2 be an alphabet with 121 > 2 and c $ 2. Show that
Z, = {ucvxuTv2\ u, vx, v2 6 2*}
is infinitely inherently ambiguous.
3 Is there a (minimal) linear language that is infinitely inherently ambiguous?
4 Show that, for each k>7, there exists an inherently ambiguous grammar
of degree k.
5 Let G = (V, 2, P, S) be a reduced context-free grammar. Let it denote the
production A -*Bi ■ ■ ■ Bk and letx62*. The degree of direct ambiguity of (7T, x) is
the number of different factorizations such that
A =>Bi ■Bk^>x1-xk
where for each /, 1 < / < k, Bj 6 V, and
*
Bj=>xj
and
X = X i ' ' ' Xfc
The degree of direct ambiguity of G = (V, 2, P, S) is k > 1 if k is the least integer such
that any pair (n, x) with ttEP and xEL(G) has degree of direct ambiguity < k. A
grammar has an infinite degree of direct ambiguity if for each ;', there is some pair
(n, x) with degree of direct ambiguity 5s j. Similar definitions hold for languages. Show
that the degree of direct ambiguity of a grammar is less than or equal to the degree of
ambiguity.
6 Find a linear context-free language (i.e., give its grammar) which is infinitely
ambiguous but has degree of inherent direct ambiguity equal to 1.
7 Let 2 be an alphabet, |2| > 2, and let c, d $ 2. Show that
L = {ulCVxUiU2V2du1\ul,U2,Vl,V2&^*}
7.4* PRESERVATION OF UNAMBIGUITY AND AMBIGUITY 243
is a language which is infinitely inherently directly ambiguous; i.e., every grammar for
L has an unbounded degree of direct ambiguity.
8 (Open question due to Shamir). Are there any languages whose degree of
direct ambiguity is not 1 and not infinite?
9 Extend the concept of an unambiguous pda to obtain a family of pda's
which correspond to the finitely inherently ambiguous languages.
7.4* THE PRESERVATION OF UNAMBIGUITY AND INHERENT
AMBIGUITY BY OPERATIONS
For a number of applications, it is necessary to know which operations do or
do not preserve unambiguity and inherent ambiguity. Many of the basic facts about
this have been studied when we studied the relevant closure operations, and it is a
comparatively simple problem to combine our results.
Our first proposition restates some facts which have been proven earlier in a
different form.
Proposition 7.4.1
a) If L is a context-free language whose intersection with some regular set is
inherently ambiguous, then L is inherently ambiguous.
b) If L\ and L2 are disjoint unambiguous context-free languages, then
L\ U/,2 is unambiguous.
c) If L is an unambiguous context-free language and R is a regular set, then
L~ R and L U R are both unambiguous.
d) If L is an inherently ambiguous context-free language and R is a regular
set with L n R — 0, then L U R is inherently ambiguous.
Now we study gsm's.
Theorem 7.4.1 If L is an unambiguous context-free language and S is a gsm
which is one-to-one on L, then S(L) is also an unambiguous context-free language.
Proof The argument is merely a careful re-examination of the proof of
Theorem 6.4.3 in the case where S is a gsm. Assume thatL is unambiguous so that A
(using the notation of the proof of Theorem 6.4.3) is an unambiguous pda. Moreover,
S is a gsm which is one-to-one on L. Now Qaim 4 in the proof of Theorem 6.4.3
becomes the following proposition.
Claim 4' For each q, q eQus,s' 6Q2, w,y 6 A*,(36 P\ & 6 T+, and
(Om, A, A), wy, m \j ((?', s', A, A),.y, 0'),
using k > l moves of Type 1 if and only if there exist Mj, .. ., uh in 2 such that
s0 = s,
s' = SjCs.m, •• Mfe)
S("i •••"*) = XjO.Mi •••"fe) = w,
and +
fa.ii, ■■•uk,0Z)\I(fi',A,&').
244 AMBIGUITY AND INHERENT AMBIGUITY
Using Claim 4' and the facts that 5" is one-to-one on L and that A is
unambiguous, one can show that B is an unambiguous pda so that S(L) is unambiguous. We
omit the details. □
Next, we turn to a consideration of inverse gsm's.
Theorem 7.4.2 If L is an unambiguous context-free language and 7Ms a gsm,
then r_1(L) is an unambiguous context-free language.
Proof Again, we use Theorem 6.4.3. LetL 9 A* and let the sequential
transducer of Theorem 6.4.3 be T~x as defined in the proof of Theorem 6.5.2. Claim 4,
from Theorem 6.4.3, becomes:
Claim4" For each q, q'&Qx, s,s'eQ2, wj6S*, /36T*, 0'er+, and
zer,
((<7,s,A,A),wjM3Z)£ (.(q',s',A,A),y,l5'),
using k > 1 moves of Type 1 if and only if there exist u i,.. . , uk in A* such that
s' = S2(s,u1 ■■■uk)
T(w) = \2(s,w) = «! • • -uh
and
(q,Ul •■•uk,0Z)\I(g',A,&').
From Claim 4" and the unambiguity of the pda A, it follows that B is an
unambiguous pda, so T~l (L) is unambiguous. □
Corollary 1 If L is an unambiguous context-free language and <p is a homo-
morphism, then <p~lL is an unambiguous context-free language.
Proof Every homomorphism is a one-state gsm mapping. □
Corollary 2 If L 9 2* is inherently ambiguous and S is a gsm which is
one-to-one on 2*, then S(L) is inherently ambiguous.
Proof If S(L) were unambiguous, then
S-l{S{L)) = L
would be unambiguous and that would be a contradiction. □
Corollary 3 Let L 9 S+ be an unambiguous (inherently ambiguous) context-
free language and let wGS*. Then wL and Lw are both unambiguous (inherently
ambiguous).
Proof One can design a gsm S which maps L into wL and S is one-to-one on
2*. By Theorem 7.4.1, wL is unambiguous if L is and by Corollary 2 of Theorem
7.4.2, inherent ambiguity is preserved also. The case of Lw follows that of wL by the
preservation of these properties under transpose. (Cf. Problem 1 of Section 7.4.) □
The next theorem will have an application in proving a metatheorem about
decidability.
7.4* PRESERVATION OF UNAMBIGUITY AND AMBIGUITY 245
Theorem 7.4.3
a) The finitely inherently ambiguous languages are closed under inverse gsm
mappings.
b) The finitely inherently ambiguous languages are closed under quotients
with singletons on both the left and right.
Proof The argument for (a) is an extension of the proof of Theorem 7.4.2. If
L is finitely inherently ambiguous, the pda A has a bounded number of accepting
sequences and so does the pda B.
The argument for (b) involves giving a machine construction for L{w}~1. It
will be clear that this set is finitely inherently ambiguous if L is. The details are left to
the reader. □
The previous theorem is rather weak. Since an unambiguous language is
finitely inherently ambiguous, the result only says that these operations will not
produce an infinitely inherently ambiguous language. The theorem does not even
imply that these operations preserve inherent ambiguity. (Cf. Problem 2 of Section
7.4.)
In general, any form of "recoding" destroys ambiguity and inherent
ambiguity. We prove a simple result now and leave similar cases for the problems.
Theorem 7.4.4 Neither unambiguity nor inherent ambiguity is preserved
under projections (i.e., homomorphisms <p which map 2 into A) nor under product by
a two-word set.
Proof Let M= {da'b'c'li, j> 1}U {ea'tf cf\ i,j>\}. M is clearly
unambiguous. Define a projection ip by the condition that, for all x£S,
e if* = d or x = e,
x otherwise.
Clearly, . ,_
<p(M) = e(L0 ULO = {ea'b'ck\i = j or / = k).
By Corollary 2 of Theorem 7.4.2, M is inherently ambiguous.
On the other hand, define \p such that
\px = a
for all x 6 2. Then
1KI0UIO = {a'\i>3} = a3a*.
Thus L0Ui, is inherently ambiguous and ii{L0 UL)) is unambiguous because it is
regular.
Turning to the second operation, define
TV = {a'W| i, j > 1} U {cta'Vc'l i, j > 1}.
N is surely unambiguous. Now we form
{d,d2}N
<px =
246 AMBIGUITY AND INHERENT AMBIGUITY
and assume it to be unambiguous. Note that since d2a*b*c* is a regular set, then
{d,d2}NC\(d2a*b*c*) = d2(L0^Ll)
would be unambiguous. But by Corollary 2 of Theorem 7.4.3, it is inherently
ambiguous.
Let
L' = a*b*c*Ud2d*a*b*c*Ud(L0UL1).
L' is inherently ambiguous because
i) d(L0 U Li) is inherently ambiguous, by Corollary 2 of Theorem 7.4.3;
ii) a*b*c* V d2d*a*b*c* is a regular set disjoint from d(L0 ULi);and
iii) by Proposition 7.4.1(d).
But
{d,d2}L' = d+a*b*c*
is regular and hence unambiguous. This shows nonclosure of inherent ambiguity under
product with a two-word set. □
PROBLEMS
1 Show that L is an unambiguous context-free language if and only if L is.
2 Show that, if L is inherently ambiguous and <p is a homomorphism, then
<fl (L) is not necessarily inherently ambiguous.
3 Show that there is an inherently ambiguous language L and a gsm S which
is one-to-one on L, such that S(L) is unambiguous. Actually S can even be a sequential
machine, which means that A: Q x 2 -*■ A.
4 Show that neither unambiguity nor inherent ambiguity is preserved by init
or by subwords.
5 Show that the set
L = {flp6acrrfse'| (p = q and r = s) or (q = r and s = t);p,q,r,s, r 5s l}
is an inherently ambiguous language. Moreover, L = {a, b, c, d, e}* — L is also a
context-free language.
6 Find an unambiguous context-free language L whose complement is not
context-free.
7.5 HISTORICAL SURVEY
Parikh [1961] first showed the existence of inherently ambiguous languages.
Our argument derives from the iteration theorem and uses techniques of Ogden
[1968]. The notion of direct ambiguity is due to Earley [1968]. Problem 7 of Section
7.4 is from Shamir [1971]. Most of the results from Section 7.4 are due to Ginsburg
and Ullian [1966]. Problems 5 and 6 are from Hibbard and Ullian [1966].
eight
Decision Problems
for Context-Free
Grammars
8.1 INTRODUCTION
In this chapter, we look at context-free grammars and languages from the
point of view of actually computing certain information. Do there exist algorithms to
determine (say) whether L(G) = 0 or L{G{)= 2*? Section 8.2 is devoted to some
solvable problems, i.e., ones for which algorithms exist. Regrettably, that is a short
section because most of the questions that arise do not have algorithmic solutions.
In Section 8.3, the halting problem for Turing machines is reviewed
informally. The Post correspondence problem is defined and shown to be unsolvable by
reduction to the halting problem. Then this problem is encoded into some context-free
languages.
In Section 8.4, it is shown that one can't decide whether LlC\L2 = 9 for
two context-free languages L\ and L2. One cannot decide whether L(G)= 2*. It is
not possible to decide whether a context-free grammar G is ambiguous or not. A similar
result holds for deciding whether L(G) is inherently ambiguous.
In Section 8.5, we consider problems like "given a context-free language
L{G), can we decide whether L(G) is deterministic?" That problem is unsolvable. If
we replace "deterministic" by (say) "finitely inherently ambiguous," then the answer
is the same. A general theorem is proved which deals with the decision question
concerning whether
L(G)6y, (or not),
where Sf is an appropriate family of sets.
247
248 DECISION PROBLEMS FOR CONTEXT-FREE GRAMMARS
8.2 SOLVABLE DECISION PROBLEMS FOR CONTEXT-FREE
GRAMMARS AND LANGUAGES
A number of basic decision questions about context-free grammars and
languages will be investigated. In this section, the decidable questions are considered.
It is somewhat discouraging that most natural questions are undecidable, but these
negative results are important, because they indicate which problems can have no
algorithmic solutions. Among the solvable questions, the complexity of carrying out
the basic computations will be studied.
First, we turn to the very important question of "recognition." Given a
context-free grammar G = (V, 2, P, S) and a string w 6 2", is w 6 L(G) or not? This
problem will be analyzed in great detail in a later chapter, where a variety of algorithms
will be given. These algorithms run in under cubic time as a function of n, the length
of the string to be recognized. For the moment, we content ourselves with proving
that the problem is solvable and we give a simple (but computationally terrible)
algorithm.
Theorem 8.2.1 There is an algorithm to determine, for a context-free
grammar G = (V, 2,P, S) and a string w 6 2*, whether or not w 6 L{G).
Proof Assume, without loss of generality, that G is in Chomsky normal form.
(Cf. Theorem 4.4.1.) If w = A, then w 6 L(G) if and only if S -> A is in P. Assume
w6 2+, where lg(vv) = n > 1. Then S =>w implies t <2n ~ I, since G is in Chomsky
normal form. (Cf. Problem 4 of Section 4.4.) We can decide whether w&L{G) by
enumerating all derivations of length < 2« — 1. □
We now show that there is an algorithm that can be used to decide whether
a context-free language is empty, finite, or infinite. In later sections, it will be shown
that almost all other general questions of interest about context-free languages are not
decidable.
Theorem 8.2.2 There is an algorithm to determine whether an arbitrary
context-free language is empty, finite, or infinite.
Proof Let L = L(G), where G = (V, 2, P, S); L(G) is nonempty if and only
if S 6 Wn, where Wn is the set constructed in the proof of Theorem 3.2.1.
From the pumping lemma, we know that there exists a computable number
p = p{G) such that L{G) is infinite if and only if there exists w 6 L(G) such that
lg(w)>p. Let , «
Lp = in/ (J 2'j = {weL\ lg(w)<p}.
Lp is computable since U,- < p 2' is finite.
We also know that L~Lp is a context-free language since Lp is finite. But
I L(G) | = °° if and only if L - Lp # 0.
From the first part of this theorem, we have an algorithm for determining whether
L~LP is empty. □
8.3 TURING MACHINES 249
We can also decide whether a deterministic context-free language equals a
regular set.
Theorem 8.2.3 Let L be a deterministic context-free language and let R be a
regular set. It is decidable whether or not L = R.
Proof L = R if and only if
L £ R (8.2.1)
and
R 5 L. (8.2.2)
That is, if and only if
LHR = 0 (8.2.3)
and
Lr\R = 0. (8.2.4)
But L C\R is a context-free language, since R is regular if i? is. On the other hand,
L is a deterministic context-free language, since L is, and hence LC\R\% context-free.
By Theorem 8.2.1, (8.2.3) and (8.2.4) are solvable. □
PROBLEMS
1 Let L = T(A), where A is a dpda, and let R = T(B), where B is a finite
automaton. Show that the following problems are solvable in polynomial time as a
function of I ^4 | and | B \.
a)L^R b)R£L c) L = R d)Lr\R = Q
2 Let G = (V, X,P,S) be a context-free grammar and let a, (36 V*. Show
that it is decidable whether or not a =*ft and whether or not a t*j3.
3 Let G = (V, 2,/\ S) be a context-free grammar. A variable A 6 TV is
recursive if
*
for some «, V6S* and uv=£ A. Give an algorithm which determines whether a given
variable is recursive.
4 Show directly (without using grammars) that there is an algorithm for
testing whether or not T(A) = (3, where A is a pda.
8.3 TURING MACHINES, THE POST CORRESPONDENCE PROBLEM,
AND CONTEXT-FREE LANGUAGES
Although it is assumed that Turing machines are familiar to the reader,' we
shall give a quick sketch of a proof of the halting problem for Turing machines.
Although this is a familiar example of an unsolvable problem, there is another problem
called the Post Correspondence Problem which is more natural in the context of
language theory because it involves strings of symbols.
t Chapter 9 contains some material on Turing machines and computational
complexity. It is not needed here.
250 DECISION PROBLEMS FOR CONTEXT-FREE GRAMMARS
For the purposes of the present discussion, imagine a Turing machine working
over some fixed alphabet, and let us assume that the input is regarded as a nonnegative
integer. Let us assume that we have some mapping g which is a Godel numbering;
that is, g maps from the positive integers onto the set of all Turing machines. Moreover,
g is a totally computable function. Thus, given n,g(n) denotes the nth Turing machine,
which will also be written An. If machine An is run on input*, there are two possible
outcomes: Either An(x) eventually halts and gives some output, or it runs forever.
Definition The halting problem is the problem of deciding, for any number
n, whether An(n) halts or not.
Theorem 8.3.1 The halting problem is recursively unsolvable.
Proof Suppose it were solvable. Then there would be an algorithm P which
decides the halting problem. We could define a new algorithm Q based on P as follows:
For a given n, decide whether An(n) halts, using P. If An(n) halts, then go into an
infinite loop; else stop. This procedure Q is clearly an algorithm, so that there is a
Turing machine Ak which computes Q; that is, Q(x) = Ak(x) for all x. Let us
diagonalize and examine Ak(k):
Ak(k)ha\ts implies Q(k) loops implies Ak(k) loops.
On the other hand,
Ak(k) loops implies Q(k) halts implies Ak(k) halts.
Therefore, Ak(k) halts if and only if Ak(k) loops. Clearly, this is a contradiction. □
Now we turn our attention to a problem which is very useful in language
theory.
Definition Let x = (xu... ,xn) and y = (.Vi,. . . ,yn) be two lists of nonnull
words from a common alphabet 2. The Post Correspondence Problem (PCP for short)
is to determine whether or not there exist i{,.. . ,ik, where 1 < /,- < n such that
*'.■■■*»* =yt>'--ytk
If there exists a solution to a PCP, then there are infinitely many, since one
may iterate a solution any number of times to obtain another solution.
Examples
x = (a,b2a,a2b),
1.
y = (ba,a3,ba).
In this case there is no solution, since any solution must start with some index / and
X; and^,- must have a common nonnull initial subword.
x = (b3,ab2),
2.
y = (b2,bab3).
Then (1,2, 1) is a solution since
b3ab2b3 = b2bab3b2
8.3 TURING MACHINES 251
3. x = (ba,ab2,bab),
y = (bab,b2,abb).
Any solution must have /, = 1. Then
Xi = ba
y{ = bob
Now the choice for xt must begin with a b. Therefore, i2 = 1 or 3. If i2 = 1,
then
x{x{ — baba
y{yx = babbab
which fails. Thus, i2 =£ 1. If h — 3, one gets
x{x3 = babab
y^3 = bababb
By exactly the same reasoning as above, z3 = 3, z4 = 3, etc. But the sequence will
continue indefinitely and hence there can be no solution, because the x-word cannot
catch up with the .y-word.
It is convenient to use an intermediate problem to prove that the
correspondence problem is unsolvable.
Definition Let x = (j1, ... ,xn) and y = (yu . .. ,yn) be two lists of non-
null words from some common alphabet 2. The Modified Post Correspondence
Problem (MPCP, for short) is to determine whether or not there exist i\,... ,ik
where 1 <t)<n, such that
The only difference between the MPCP and the PCP is the condition that the
first strings used in the MPCP be xx and yx.
Lemma 8.3.1 If the Post Correspondence Problem were solvable, then the
Modified Post Correspondence Problem would also be solvable.
Proof Let
X = (*!,. .. ,Xn)
and
y = Oi, • • • ,yn)
be two lists of words over some alphabet 2. Assume that this is the instance of MPCP
that we wish to solve. Now an "equivalent" PCP will be constructed. Let 2' = 2 U {$, $}
where <t and $ are new symbols. Define two homomorphisms ipL and ipR by the
conditions
(pL(a) = <ta
<pR(a) = a<t
for each a € 2. Define
i , i i -.
X — [X\, . . . ,Xn+2),
252 DECISION PROBLEMS FOR CONTEXT-FREE GRAMMARS
where
x't+i = *Pr(*,-)
for each /, 1 < / < n, and
xn+2 — 3>
Also, define
y' = (y\,---,y'n+J,
where
y\ = <PlOi)
y'ui = *h(yt)
for each /, 1 < i < n, and
yn+2 = *$
The lists x' and y' represent an instance of a PCP. We shall show that the
PCP for x' and y' has a solution if and only if the MPCP for x and y has a solution.
It is clear that if 1, il}... ,ik is a solution to the MPCP with lists x and y,
then
1, z'i + 1,. . . , ik + 1, n + 2
is a solution to the PCP with lists x' and y'.
Suppose ii,. .. , ik is a solution to the PCP with lists x' and y'. Then clearly,
i{ = 1, since that is the only index for which both terms start with <t. Also ik =n + 2,
since that is the only index for which both terms end in the same character. Let / be the
least integer such that i, = n + 2. Then, it is not hard to see that ix,...,ij is also a
solution. It should now be clear that:
1, *2 — 1 .... , //_! — 1
is a solution to the MPCP for lists x and y. Therefore, if there were an algorithm to
solve the PCP, then we could also solve the MPCP. □
Now we are ready to prove the main theorem.
Theorem 8.3.2 For | 21 > 2, the Post Correspondence Problem is unsolvable.
That is, there is no algorithm which takes x and y as input and determines whether or
not an index sequence iu . . ., ik exists such that
*f, ■■■*»* =ytl---ytk
Proof It suffices to show that if the MPCP were solvable, then the halting
problem would be solvable, by Lemma 8.3.1. Given a Turing machine A and an input
w, an instance of the MPCP will be constructed that has a solution if and only if A
halts on w.
Let A — {Q, 2, T, B, 5, q0, {^})be a Turing machine, and assume that A has a
unique "halting state," say q. The idea of the construction is that .4's halting
computation on w will look like'.t
t aqfl denotes an ID of the Turing machine A and indicates that A is in internal state
q, the tape is a|3, and A is reading the first character of |3.
8.3 TURING MACHINES
q0w h otiqiPi h • • • h OLkqk$k,
where qk = q. In that case, a solution of the MPCP will be as follows:
#q0w#alqrf1#- ■■#akqkpk #
The construction proceeds by giving the pertinent lists in Table 8.1.
TABLE 8.1 Lists for the MPCP
Number
1
2
3
4
For each q G Q -
X
#
q##
#
a
-{q}, eachq'
qa
qa
cqa
q#
cq#
q#
aqb
aq#
#qb
#q0w#
#
#
y
a for each a G 2— {B}
G Q, each a.
q'b
bq'
q'cb
bq#
q'cb#
q'b#
q
q#
#q
,6,cG2-{5},
if S(q,a) =(q',b,0)
if 8(q,a) =(q',b,l)
if S{q, a) =(q',b,-\)
if5(<?,5) = (q',b, 1)
if 5 fa, B) = {q',b,- 1)
if 8(q, B) =(<?', b,0)
In order to analyze the MPCP, the following definition is helpful.
Definition Let x and y be two lists over an alphabet 2 for an MPCP. A pair
of strings (u, v), where u, v& 2*, is said to be a partial solution to the MPCP if u is
a prefix of v, and u and v are formed by concatenating corresponding strings from x
and y, respectively. If v= uu , then u is said to be the remainder of the partial
solution (u, v).
Claim If
q0w h<*i<7i!3i h--- hafe<7fe|3fe, (8.3.1)
where none of q0,. . . , qk^ are equal to q, then there is a partial solution
(u,v) = {#q0w#alq^l#- ■ • #afe_1^fe_1|3fe-1#,#q0w#alqlPl#■ ■ ■ #akqkPk#).
(8.3.2)
Moreover, this is the only partial solution whose second coordinate is as long as lg(z>).
Proof The argument is an induction on k.
Basis. k = 0. Since this is a MPCP, we must choose the first pair and we get
(#,#q0w#).
254 DECISION PROBLEMS FOR CONTEXT-FREE GRAMMARS
Induction step. Suppose the claim is true for some k and qk ¥= q. We will
show it true for k + 1. The remainder of the partial solution (u, v) is u = ctkqkQk#.
We must match this from list x in the next move. Note that there can be at most one
pair in Table 8.1 that is consistent with this requirement. Moreover this pair
corresponds to a move of the Turing machine. The other symbols of u come from items 3
and 4 in the lists. This provides a new partial solution
(«",""afe+i<7fe+i!3fe+1#),
where this is the configuration A can reach from OLkqk$k. There is no other partial
solution whose second component is so long. This completes the induction proof.
If qk = q, then pairs from 2, 3, 4, and the last 3 items on the list may be
added to the partial solution to give a total solution to the MPCP. On the other hand,
if A never reaches q, then there are partial solutions which are not total solutions.
Therefore there is a solution to the MPCP if and only if M halts on w. But this
is unsolvable. □
Our next task is now to "code" the PCP into some languages. For ease in
the construction, we use a three-letter alphabet 2 = {a,b,c}. All of the results may
also be proved for a two-letter alphabet by suitably encoding the three-letter alphabet.
The encoding to a binary alphabet is left for the problems.
First we define three languages which will be used extensively. Let
x = (xitx2, ■ ■. ,xn), y = (yi,y2, ■ ■ ■ ,yn), xhyte{a,b}+.
Let
L(x) = {ba'kb ■ ■ ■ ba^cxix ■■■xik\k>\, 1< /,- < w, Kf<k}.
The idea behind L(x) is simple. The integers ilt. .. ,ik are encoded as blocks of a's
separated by 6's in reverse order; c acts as a "center" marker and is followed by
XhXh ' ' X'k-
Proposition 8.3.1
a) Let w be a word in Z,(x); given the part of the word up to c in w, the
remainder is uniquely determined.
b) It is possible that different index sequences give rise to the same* andy
words. That is, it is possible that
ba'k . . . faix =£ fair ■ ■ ■ fai,
and yet
•*■', '' x'k ~~ xii '' xir'
Example x = {a,b, b2)- Then
ba2ba2 ¥= ba3 but x2x2 = b1 = x3.
Next let
L(x,y) = L(x){c}(L(y)f
= {ba'k ■ ■ ba'^cx^ ■ ■ -x^cyj^ ■ ■ -yjca^b ■ ■ ■ aJ'*b\ where
M> 1, 1 <W« <n, 1 <p<k, 1 <q <il},
8.3 TURING MACHINES 255
and
Ls = {vt^cwzcw^cwfl wu w2G {a,b}+}.
Theorem 8.3.3 L(x,y) and Ls are deterministic context-free languages.
Proof We give an informal description of dpda's which accept L(x,y) and
Ls, and leave as an exercise the formal proof that the constructions are correct.
The construction for L(x, y) = L(x){c}(L(y))T now follows".
1 Copy everything up to the first c onto the stack.
2 Erase the top block of a's from the stack, counting them. This is possible
since the number of a's in a valid block is<«. If more than n a's are found,
the string is rejected.
3 Now advance on the input, checking to see whether the input is*,-., where
/} is the number determined in Step 2. Again this is possible since there
are only a finite number of x;..
4 If input symbol is not a c, go back to Step 2.
5 Copy everything up to the next c onto the stack.
6 Count the number of a's in the current block of a's, from the input.
7 Now check to see whether the top of the stack is yf., where i} is the number
of a's counted in Step 6.
8 If the stack is 20, then accept by erasing Z0 and going to a final state under
A; else return to Step 6 and continue. If the input is not exhausted, go back
to Step 6.
Now the technique for Ls = {wycw^cw^cwjl wl,w2E {a, b}+}is given:
1 Copy everything up to the second c onto the stack.
2 Compare the rest of the input with the stack. □
The next lemma plays a key role in subsequent applications.
Lemma 8.3.2 L(x, y) n Ls contains no infinite context-free language.
Proof
L(x,y)nLs = {tiCtictfctf] t{ = ba'k ■ ■ ba^;t2 =xh ■ ■ -xik =y^ ■ ■ -yik}.
Fact tx uniquely determines tlct1ct^ct{.
Proof tx uniquely determines t2 by the encoding of L(x, y).
Now suppose L is an infinite context-free language and Z,^i(x,y)n/,s.
Then, by the iteration theorem, there exists a constant p such that the conclusions of
that theorem hold.
Let
w = txctici{ct\&L
256 DECISION PROBLEMS FOR CONTEXT-FREE GRAMMARS
with \g(t2)>p. This is possible since, for L to be infinite, it must contain arbitrarily
long words and if
tx = ba'p ■ ■ -ba'',
then \g(t2) > p, since xt ¥= A, 1 < / < n.
Now let all the positions in t2 be distinguished as shown below:
w = txcti.ct\ci['.
Then, by the iteration theorem, there exists a factorization
<P = (Vl,V2,V3,V4,VS)
such that
ViV^v3v%Vs&L forall^^O,
and either KuK2, K3±0 orK3,K4,Ks^0. AssumeKuK2,K3 =£0. (The case A:3,K4,
Ks ¥= 0 is similar to this one.) Then
Vi = ^cfli for some v\,
v2 * A,
and
vxv3vs&L.
Thus
^i^3^s = fiCTl^^ei.
But, by the fact proved above,
If
tiCv\v3vseL,
then / „ „ .t /r
Therefore,
ViV2V3V4Vs = W = V{V3VS
This is a contradiction, since v2¥=A, and therefore Z, cannot be both infinite and
context-free. □
PROBLEMS
1 Extend the theorems of this section to the case of a two-letter alphabet.
Encode Z,(x, y) and Ls into a binary alphabet.
2 Show that the Post Correspondence Problem is solvable if | 2 | = 1.
Let |S | > 2 and let x = (x{, . . . ,xn) and y = (y\,...,yn) be two lists of nonnull
S-words.
3 Is the Post Correspondence Problem solvable
a) if n = 1?
b) if/? = 2?
c) if n > 1 and for each i, 1 </</?, lg(x;) = lg(.y,-)?
4 Show that there exists some positive integer n0 such that the Post
Correspondence Problem with n = n0 is unsolvable.
8.3 TURING MACHINES 257
5 Is the following problem unsolvable or not? Given | 21 > 2 and let x =
(*!, . . . ,xn) and y = (yu . . . ,yn) be lists of nonnull 2-words; do there exist k~^ 1,
%> 1, ilt . . . , ik, /i,. . . ,/s, such that Kip, jq <n for 1 <p < A:, 1 < <? < 8, and
*!,■■■*«■* = >vV
6 Is the following problem unsolvable or not? Given | 21 > 2 and let
x = (xx,. . . , xn) and y = (yu . . . ,yn) be two lists of nonnull 2-words; do there
exist k~> 1, iu . . . ,ik, ju . . . ,/fe, such that 1 </p, jq <« for 1 <p, q^k, and
**.■■■*«* = >v^k?
7 Let /I = (0, 2, r, B, 5, q0, {/}) be a Turing machine, given that B is the
blank symbol and is in 2; / is the unique "stopping state." Assume Q C\ 2 = 0. A
computation oi A is a sequence
«o h «i h ■ • ■ han,
where a; € 2*G2+ and a; f-a,-+1, as specified by 6. Let c £ 2 and define
Z,, = {ac/3Tc| a k ^}*c
and
i2 = {<?0wc| wG2*}{aTc^c| a fI0}*{W»Tl x,>> G 2*}{cc}.
Show that Lx and Z,2 are deterministic context-free languages. Are they real-time
as well?
8 Show that there is an algorithm which takes as input a Turing machine A
and produces a context-free grammar GA such that
L(GA) = 2* — {oilca2c • • • ca%kcc\ ax = q0w for some w G 2*, a2fc = xfy
and a! h a2 h • " h a2fe}.
9 Show that there is a context-free language L such that the set of prefixes
of 2* — L is not recursive but is recursively enumerable.
10 Fix 2 = {<7,6}. Construct a family {G„| n > 0}of context-free grammars
such that:
i) For each n > 0, Gn may be effectively constructed from n;
ii) A GL(Gn) for each/?;
iii) |2*-L(G„)| <l;
iv) {n| L(Gn)¥= 2*}is not recursive.
///«?: Take a Turing machine /I which accepts a nonrecursive set over 2*. Encode
(non)computations such that there is a set J(A,n) which lacks one member from
{a, b}* if and only if A accepts/?.
11 Show that every recursively enumerable set L may be represented as
Z, 1Z-2x for some context-free languages Lx and L2. Hint: Represent L = T(A) for some
Turing machine A = (Q, 2, T, B, 8, q0, {/}).
12 Refer to the proof of Theorem 8.3.2. Show that A halts on w G 2* if
and only if there exists k > 0, 3 < /[, .. . ,ik<n such that
"■i*i, ■ • -xikx2 = yiyix-- ■J',-fc>'2
258 DECISION PROBLEMS FOR CONTEXT-FREE GRAMMARS
13 Show that, for any recursive function f and for arbitrarily large integers
n, there is a context-free grammar G so that \G\ = n, L(G) is a regular set, and the
reduced finite automaton acceptingL(G) has at least f(n) states. [Hint. Cf. Problem 8.]
8.4 BASIC UNSOLVABLE PROBLEMS FOR CONTEXT-FREE
GRAMMARS AND LANGUAGES
In Section 8.3, we worked out the properties of two deterministic context-
free languages. With the aid of these sets, we shall very easily develop the basic negative
results about the context-free languages and grammars. In what follows, the results
are claimed for all alphabets with at least two symbols. In fact, the proofs are given
only for alphabets with at least three symbols. In Problem 1, the reader is asked to
extend the result to a binary alphabet.
We begin our development by noting the form of strings in i(x,y)nZ,s.
Lemma 8.4.1 It is recursively unsolvable to determine for arbitrary lists
of words x and y whether
L(x,y)nLs * 0.
Proof
L(x,y)nLs = {txct2ct\ctTx\ tx = ba'k ■ ••bai>; t2 = *,-_ ■ • *;fe = yi% ■ ■ -yik)
Therefore, L(x,y)C\Ls =£0 if and only if there exists a solution to the Post
Correspondence Problem. But the Post Correspondence Problem is recursively unsolvable,
which proves the lemma. □
This establishes the following result.
Theorem 8.4.1 Let | 21 > 2. It is recursively unsolvable to determine whether
L\ n L2 = 0 for (deterministic) context-free languages Lx and L2.
Proof Lemma 8.4.1 gives the result for | S| > 3 by taking Ll = L(x, y) and
L2 = Ls. The case | 21 > 2 is left to Exercise 1. □
Next we learn that we cannot even decide whether Lt nz,2 is context-free.
Theorem 8.4.2 Let | 21 > 2. It is recursively unsolvable to determine whether
LXC\L2 is a context-free language for arbitrary context-free languages Lx and L2.
Proof L(x, y)nis # 0
if and only if there exists a solution to the Post Correspondence Problem. By an
earlier observation, we know that if there is one solution to the Post Correspondence
Problem, there are infinitely many. But we have shown that L(x, y) n Ls contains no
infinite context-free language. Therefore Z,(x,y)Ois is a context-free language if
and only if it is empty. But by Lemma 8.4.1 this is undecidable. □
Now, we wish to show that one cannot decide whether a context-free language
is regular. To do this, we need a simple lemma.
8.4 BASIC UNSOLVABLE PROBLEMS 259
Lemma 8.4.2 Let | 21 > 2. Let M(x, y) = 2* - (L(x, y) n Z,5). Vkf(x, y) is
a context-free language and it is recursively unsolvable to determine whether or not
M(x,y) = 2*.
Proof M(x, y) = 2* - (Z.(x, y) n /.,)
= (2*-L(x,y))U(2*-Ls)
= £(x,y)U£,.
We know that Z,(x, y) and Z,s are deterministic context-free languages and so are
T(x,y) and Ls, by Theorem 5.6.1. Thus M(x,y) is a union of two deterministic
context-free languages and hence is a context-free language. But
M(x,y) = 2*
if and only if
L{x,y)(Ms = 0.
Now, using the fact that Z,(x, y) n Ls = 0 is undecidable, we have that
M(x, y) = 2* is undecidable. □
Theorem 8.4.3 Let jW(x,y) be as in Lemma 8.4.2 above. M{x,y) is regular
if and only if M(x,y) = 2*. Thus, it is recursively unsolvable to determine whether
an arbitrary context-free language over an alphabet 2,121 > 3, is regular.
Proof Again we use the fact that £(x,y)nz,s is either empty or infinite.
Since L(x,y)C\ Ls contains no infinite context-free languages, it contains no infinite
regular sets.
Recall that
M(x,y) = r-(£(x,y)n£s)
and
Z*-M(x,y) = L(x,y)nLs.
We claim that M(x, y) is regular if and only if M(x, y) = 2*. The //direction is trivial.
If M(x, y) is regular, then 2* —M(x, y) = L(x, y) n Ls is regular. Since L(x, y) n Ls
cannot be infinite, we must have £(x,y)n£s = 0, which implies M(x,y)= 2*. By
Lemma 8.4.2, one cannot decide whetherM(x, y) = 2*. □
Corollary For |2|>2, it is recursively unsolvable whether or not an
arbitrary context-free language is regular.
Proof Cf. Problem 1 at the end of this section. □
Now we shall consider the containment and equality problems for context-
free languages.
Theorem 8.4.4 Let | 21 > 2. It is recursively unsolvable to determine whether,
for arbitrary context-free languages Lx and L2,
L\ — Z,2.
260 DECISION PROBLEMS FOR CONTEXT-FREE GRAMMARS
Proof Recall that
M(x,y) = r-(I(x,y)ny.
Let
L1 = 2*
L2 = S*-(i(x,y)ny = M(x,y).
Both Lx and Z,2 are context-free languages, and
L^L2 ifandonlyifAf(x,y) = 2*.
But it is recursively unsolvable to determine whether M(x, y) = 2*.
Take Lt=M(x,y) and L2= 2*. The unsolvability of the equality problem
follows from Lemma 8.4.2. □
Next we turn to a potentially useful idea. Could we find an algorithm to
decide whether a context-free grammar is ambiguous?
Theorem 8.4.5 Let | 21 > 4. It is recursively unsolvable to determine whether
an arbitrary context-free grammar over 2 is ambiguous or not.
Proof Let
X = (Xi, . . . ,Xn),
y = (yu...,y„)
be two lists of nonnull words over {a, b}*. Consider G where
S -> Si\S2
Si -> X;Sidc' I Xidc' for 1 < /' < n,
S2 -> ytS2dc'' | ytdc'' for 1 < / < n.
Clearly,
Z,(G)= {jcji---jc1-mdc''"' ■■■dci'\m>l,xje{a,b}*, 1</,-<«, for all 1 <f<m}
u fa, • • ->V*C'P '' ■dcJ'\P> l.^fc e{fl,6}*. 1 </b<«. for all 1 <C<p}.
Moreover, the context-free languages generated by G,- = (K, 2,/*, 5,) are both
unambiguous. Thus, G is ambiguous if and only if
{*,-_ • • x^dc'™ ■ ••dc^}n{yJi ■ ■ -yjpdc'p ■ ■ -de1'} * 0.
Thus, G is ambiguous if and only if m—p\ (z'i,. . . ,zm) = Q\,. . . ,jm), and
X; ■ ■ ■ xt —y: ■ ■ ■ y-t , that is, if and only if the Post Correspondence Problem has
a solution; but the Post Correspondence Problem is recursively unsolvable. Therefore
it is recursively unsolvable to determine whether an arbitrary context-free grammar is
ambiguous. D
Lastly, we consider inherent ambiguity.
Theorem 8.4.6 There is no algorithm to decide whether a context-free
language is inherently ambiguous.
8.4 BASIC UNSOLVABLE PROBLEMS 261
Proof Let x, y be nonnull lists of words over {a, b }*. Define
L = {a'Vc'l i,J>l}{d}L(x,y)U{aibici\ i,j>\}{d}Ls.
L is surely a context-free language. Moreover, each term is an unambiguous context-
free language.
Claim L is inherently ambiguous if and only if
i(x,y)ni, # 0.
Proof of the claim If L is inherently ambiguous, then there must be some
string in each term and surely L(x,y)nZ,s#(J. If L(x, y) HLS =£0, then let
z€/,(x,y)nis. Define R — a*b*c*dz, which is a regular set. Suppose that L were
unambiguous. Then
Lr\R = L2 = {a'Vc'l i,j>\}{dz}U{atb'c'\ i,j>\}{dz} = (L0\JL{)dz
would be unambiguous, by Theorem 6.4.1. But, by Theorem 7.2.2, ijUi, is
inherently ambiguous. Applying Theorem 7.4.3,
(L0UL{){dz} = L2
is also inherently ambiguous. But this contradicts that L2 is unambiguous.
It now follows that we can decide whether L is inherently ambiguous if
and only if L(x, y)CiLs¥z0. But this is undecidable, by Lemma 8.4.1. □
There are additional questions about context-free languages which are
recursively unsolvable but which are not included here. The above theorems should be
sufficient to provide the reader with a "feel" for the types of questions which are
undecidable and the methods used in proving that a given question is undecidable.
PROBLEMS
1 Extend all the results of this section to a binary alphabet.
2 Show that, given a context-free grammar G, there is no effective way to
construct G' such that
L(G') = L(G)-{A)
and \G'\ = min{\Gl\: Z,(G,) = Z,(G)-{A}, G, is A-free}.
3 Show that it is undecidable to determine, of two context-free grammars,
whether or not they have the same set of sentential forms.
4 There is an interesting class of decision problems called "birdie" problems."
We already know that one cannot decide whether a context-free language is regular.
Suppose a birdie tells us that Z-(G) is regular. Show that one cannot construct a finite
automaton^ so that
L(G) = T(A).
[Hint: Cf. Problem 11 of Section 8.3.]
5 Is it decidable whether or not L 9 R for a context-free language L and a
regular set R1
262 DECISION PROBLEMS FOR CONTEXT-FREE GRAMMARS
6 A context-free language L is prefix-free if, for any u,i)6S*,we have that
uvGL and « G Z, imply V = A. Show that it is undecidable whether or not L is prefix-
free. [Hint: Reduce to Lx C\ L2 — 0.]
7 Show that there is an algorithm to decide whether an arbitrary pda A is
finite-turn or not (cf. Section 5.7). Show that if A is finite-turn, it is solvable to find
the least integer k0 such that each sweep of A has (2k — 1) turns for some k <k0.
8.5* A POWERFUL METATHEOREM
In the previous section, certain problems were proved to be unsolvable.
Given a context-free grammar, we cannot decide whether it is unambiguous or regular,
etc. We will consider many other questions such as, "is L(G) a deterministic context-
free language," or "unambiguous," or "precedence." These problems are often
undecidable, and the proofs are sufficiently similar that one suspects that the subject
can be unified so that proving one theorem will distill the essence of the argument.
This section is devoted to such a theorem.
We will need some properties of the "bounded sets." These sets were first
studied because it was noticed that many of our examples were of the form of subsets
of a*b*c*. It is useful to generalize the concept as follows:
Definition A set L 9 2* is bounded if there exist k> 0, wh . . . , wfe G 2*,
such that:
L £ w* ■ ■ ■ w*..
A set that is not bounded is called unbounded.
For example,
LoULi = {a'b'ck\ i = / or / = k, i,f,k>\}
is bounded. Also,
{(aba)lc(aba)l\ i>0)
is bounded but
{a,b}*
is unbounded.
We need the following lemma about unbounded regular sets and finite
automata.
Lemma 8.5.1 Let a, b G 2 and let L 9 2*, where L = T(A) for some reduced
finite automaton A = (Q, 2, 5, q0, F). Either:
1 L is bounded, or
2 There exist a ¥=b in 2,x1,x2,x3,x4in 2*, and^ EQ such that
5(<7o,*i) = Q, (8-5.1)
8(q,ax2)=q, (8.8.2)
S(q,bx3) = q, (8.8.3)
and
8(q,x4) G F. (8.5.4)
8.5» A POWERFUL METATHEOREM 263
Proof Let \Q\ = k and we induct on k.
Basis, k = 1. T(A) = 0 or T(A) = 2*. If L = T(A) = 0, then L is bounded.
If T(A) = 2*, then q0&F and .x^ = x2 = x3 = x4 = A satisfy Condition 2 of the lemma.
Induction step. Assume the result for all finite automata with k or fewer
states and assume \Q\ — k + 1. Suppose (2) is false. That is, for all xlt.. . ,x4E 2*,
the conjunction of (8.5.1), (8.5.2), (8.5.3), and (8.5.4) is false. Now choose x{ = A,
which forces qo = q- Choose any x4 such that (8.5.4) is true (why does such anx4
exist?). This means that at most one of (8.5.2) and (8.5.3) can be true; i.e., there
exists a € 2,,x = x2,such that
S(q,ax2) = 8(q0,ax) = q0.
Moreover, by choosing x to be minimal among the set of all nonnull y, so that 8(q0,y)
= q0, the string ax is unique. For each c € 2, define
Ac = (Q-fao},2,6',5(?o,c),F-te0}),
where
5' = sn((Q-{?0})xSx(s-y)).
If 6(<7o>c) = <7o> define Ac to be a one-state finite automaton which accepts 0. Now
{(ax)* U cT(Ac) Xqo$F,
I c fc 2
r04) =
((«)* c U£ c7T>U) u («)* ^ <lo e F-
By the induction hypothesis, T(AC) is a bounded set. But the bounded sets are closed
under finite union and products, so that T(A) is bounded. □
The previous lemma is employed to prove the following useful theorem.
Theorem 8.5.1 Let L be any regular set over 2 = {a, b}. The following three
conditions are equivalent.
a) L is unbounded.
b) There exist u, v,x,y in 2* such that
x{au,bv}*y 9 L.
c) There exist u, v,x,y in 2* such that
x{ua,vb}*y 9 L.
Proof Parts (b) and (c) are clearly equivalent, since L is (un)bounded if and
only if LT is (un)bounded. (Cf. Problem 1 at the end of this section.)
Next, we show that (a) implies (b). Since L is regular and unbounded, it
follows, from Lemma 8.5.1, that there exist x = xu u = x2, v = x3, andy = x4, so that
264 DECISION PROBLEMS FOR CONTEXT-FREE GRAMMARS
(8.5.1) through (8.5.4) of the lemma are satisfied. Pasting together the computation
of A in Lemma 8.5.1 gives that
x{au,bv}*y£ L.
To show that (b) implies (a), we proceed by a sequence of claims.
Claim 1
a) If L contains an unbounded set, then L is unbounded.
b) If L is unbounded, then so is {x}L, where x € 2*.
c) If Z, is unbounded, then so is {x}L{y} for x,y £ Z*.
Proof (a) follows from Problem 8.5.1 by contraposition, (b) follows by
induction on lg(x). (c) follows from (b) and the closure of the bounded sets under
reversal (Problem 1 again).
Claim 2 In order to show that (b) implies (a), it suffices to show that
{au,bv}*
is unbounded.
Proof Suppose that {au, bv}* were unbounded. By Claim 1(c),
x{au,bv}*y
is unbounded. But, by (b), if x{au, bv}*y 9 L, then Claim 1(a) implies that L is
unbounded and we would be done.
Suppose now
{au,bv}* 9 w*- ■ ■ Wfe
for some w1;. .., wk G 2*. Let £; = lg(w,-) and let £ be the least common multiple of
£1;. . . , £fe. Consider the string
daufibvff = wj> • • • wjfe (8.5.5)
and let us call a string {auf{bvf a block.
Claim 3 Each block of (8.5.5) must contain (as a subword) W; and Wj, where
Proof If not,
(aufibvf = wp for some py;
but
lg(W;)| £ lg(fl!i)
and
lg(w,-)| £ Igfbv).
Thus Fig. 8.1 describes the factorizations.
But it is clear that the first character of ws must be an a (cf. the left arrow
in Fig. 8.1). On the other hand, the first character of w; must be a b, by the second
arrow in Fig. 8.1. This contradiction establishes Claim 3.
8.5* A POWERFUL METATHEOREM 265
* I
1
a i u
i
Wj
au
au
. . .
Wj
b i v
i
Wj
. . .
bv
. . .
Wj
FIG. 8.1
To finish the proof, Claim 3 establishes the need for two distinct words in
each block. So we have k blocks, and we must assign wx- ■ -wk to the word
{{auf{bvff,
using two different wt in each block. The best way we could do this is shown below.
Block 1 Block 2 Block k -1 Block k
Assignment 1,2 2,3 k — \,k k, k + \
But we need k + 1 words w; and we have only k of them. This contradiction establishes
the result. □
In order to state our main result, it will be necessary to introduce predicates
on languages.
Definition Let X be any set. A predicate & is any function from X into
{true, false). & is nontrivial if there exist xux2&X so that ^"(x,) = true and &(x2)
= false.
Now some special predicates are introduced on a family of languages over
the alphabet {a, b).
Definition Let 2 = {a,b} and let & be a predicate on a class of languages
over 2*. Let u, v,x,y € 2*. Define the one-to-one homomorphism <p where
ifi(a) = au
ip(6) = bv
Then define
^f(^",x,u,v,y) = {L'\ L' = ip'i(W-l(x-1Ly-l)),we{au,bv}+, &>(L) = true).
Define the one-to-one homomorphism tp by
\l/(a) = ua
\l/(b) = vb
Then
&(&,x,u,v,y) = {L'\ L' = \p'l(x'lLy'l)w'l,we {ua,vb}+, 3»{L) = true).
Note that £f{JP,x,u,v,y) and ■$?(&,x,u,v,y) are in fact families of
languages over {a, b).
266 DECISION PROBLEMS FOR CONTEXT-FREE GRAMMARS
Example Suppose one has a predicate on languages, which is always false
except for the language
L = abb{aba,b4,aa}*ab.
Here* = abb,u = ba,v = b, andy = ab. Then
x~lLy-x = {aba,b\aa}*.
Then
M = {L'\ L' = w'\x'1 Ly'l),wG {aba,bb}+}
= {{aba,b\aa}*,bb{aba,b\aa}*}.
Putting the pieces together yields
&(&,x,u,v,y) = {{a,bb}*,b{a,bb}*}.
Our next technical lemma contains the essence of the proof of the main
result.
Lemma 8.5.2 Let & be any predicate on the family of context-free languages
over 2 = {a, b). If there exists a context-free language L0 and strings x, u, v, y in
{a, b}* such that either:
a) £>(L0) = true,
b) x{au, bv}*y £ L0, and
c) J?f(JP,x,u, v,y) is a proper subfamily of the context-free languages
or overE*;
d) ^{L0) = true,
e) x{ua, vb}*y 9 L0, and
f) &(&,x,u,v,y) is a proper subfamily of the context-free languages
over 2*;
then, for any arbitrary context-free grammar G, the predicate ^(L(G)) is undecidable.
Proof Let & be any predicate over the context-free languages that satisfies
(a), (b), and (c). (There is a dual proof for (d), (e), and (f), which will be omitted.)
From (c), there is a context-free language L' £ 2* that is not in £f(& ,x,u, v,y).
Define two one-to-one homomorphisms yx and <p3 by:
ifiia = au
yxb - bv
<p3a — auau
<p3b = aubv
Let G be an arbitrary context-free grammar over 2:
Lx = x*p3(L(G))bvau{au, bv}*y
L2 = x {auau, aubv}* bvauiPx(L')y
L3 - L0r\(E*—{x {auau, aubv}* bvau{au,bv}*y})
8.5* A POWERFUL METATHEOREM 267
Clearly, Lu L2, and L3 are context-free languages. Then i1UZ,2U L3is a context-free
language and let Gj be a context-free grammar such that
Ud) = iiU/,2Ui3. (8.5.6)
Since G is given, Gx can be effectively constructed.t
Claim ^(UGJ) = true if and only if L{G) = 2*.
Proof of claim Suppose
L(G) = {a, b}*.
Then
if3(L(G)) = {auau, a«6p}*
and
LiVL3 = L0.
To see (8.57), note that, if z G L3, then z G Z,0. If z G Z,1; then, since Z,j 9 x{aw, 6^}*^
£ Z-o by (b) of the lemma, so zEL0. Thus LiC\L3£ L0. Conversely, assume zGZ,0.
If z is the form in Lx, then we are done; otherwise it is in L0 n (2* — Z,j) = Z,3. This
proves (8.5.7). From (8.5.7) and the fact that L2 £ L0, we have that
LiG^ = Z,,UZ,2U/,3 = /,0U/,2 = /,„,
and so
&(L(Gi)) = true.
Conversely, assume that L(G) $ {a,b}*. Then there exists
ze{a,b}*-L(G). (8.5.8)
Then
tfi3(z)G{auau,aubv}* —<p3(L(G)).
Let
w = tfi3(z)bvau.
Clearly,
JcwE*nZ,! = 0, (8.5.9)
because if xws€.Lu then, since w = y3{z)bvau,we would have zGZ,(G), which
contradicts (8.5.8).
Define
r = {r| xwry g/.3}.
We claim that
TC\{au,bv}* = 0, (8.5.10)
because f£Tn {aw, 6p}* implies that
xw/y ex{auflu,au6^}*6^au{flu,ftz;}*j; = M,
so that
xwfy<£z,3 = L0r\(Z*-M),
which contradicts the definition of T.
t That is, there is some recursive function that produces Gj from G. However, we
don't know which recursive function does so unless we have an effective presentation
ofZ,'.
268 DECISION PROBLEMS FOR CONTEXT-FREE GRAMMARS
We claim that
w'\x''lL(Gl)y-'1) = ^(Z,')ur. (8.5.11)
To see this, suppose t € w~i(x~1L(Gl)y~i). Then
xwtyEKG^. (8.5.12)
If xwty E L3, then t&T and we are done. Assume that xwty£.L3. By (8.5.6) and
(8 5 12^
v ' ' '' xwtyeLiULi. (8.5.13)
But xwty £LX because of (8.5.9). Thus (8.5.13) leads to
xwtyGL2. (8.5.14)
From the definition of L2 and (8.5.14), we have
te^(L').
The argument can be reversed and this completes the proof of (8.5.11).
Applying, <£i' to (8.5.11) yields:
*71(w"VI/.(Gi)J'~1)) = ri'iML') U T). (8.5.15)
Since ipj is one-to-one,
<PiVi(£') = £',
and moreover
^(^ = 0,
since rG^^T) would imply <p{t e{au,bv}* n T, which contradicts (8.5.10). Thus
(8.5.15) becomes
^1(w-1(x-1L(G1)>'"1)) = L'.
If ^(^(G!)) = ftw, then L' would be in &{& ,x,u, v,y), which would be a
contradiction. Therefore, ^(L(Gi)) = false, and the proof of the claim is complete.
The predicate &(L{Gd) is undecidable because it is undecidable whether or
not L{G)— {a, b}*, by Lemma 8.4.2. But given G, one can effectively obtain Gx,
so &(L(G)) is undecidable. □
Now, we are able to state the main result of this section.
Theorem 8.5.2 Let y be any subfamily of the finitely inherently ambiguous
context-free languages over 2 = {a, b} such that there is some language L0 in Sf which
has an unbounded regular subset. For an arbitrary context-free grammar, the predicate
L{G) e ¥
is undecidable.
Proof By Theorem 7.4.3, the finitely inherently ambiguous context-free
languages are closed under inverse homomorphisms and quotients with singleton sets
on both the left and the right. Define the predicate & by
(true if Ley,
P{L) =
[false UL^y
8.5* A POWERFUL METATHEOREM 269
Then, for a\\x,u, v,y €2*, Sf(& ,x,u,v,y)is a subset of the context-free languages
of finite degree of inherent ambiguity. There exist context-free languages L' which are
infinitely inherently ambiguous, by Theorem 7.3.3; and so (c) of Lemma 8.5.2 is
satisfied. Moreover, by assumption, there exists L0E J/'with an unbounded regular
set. By Theorem 8.5.1, (b) is satisfied. Since L0E y, ^(Z,0) = true and (a) is
satisfied. Since the hypotheses of Lemma 8.5.2 are satisfied, the conclusion holds. □
We list a few corollaries of this theorem. In the future, we shall make extensive
use of the result. Note that the simplest example of an unbounded regular subset is
{a,b}*.
Theorem 8.5.3 For the following families Y of context-free languages over
2 = {a, b} and for arbitrary context-free grammars G, it is undecidable whether or not
L(G) e y.
1 the finitely inherently ambiguous context-free languages',
2 the finitely directly inherently ambiguous context-free languages;
3 for any k > 1, the context-free languages of degree of inherent ambiguity
<k;
4 the unambiguous context-free languages;
5 the regular sets;
6 the deterministic context-free languages;
7 the transpose of any of the above classes.
PROBLEMS
1 Show that the collection of bounded sets over 2 is closed under product,
transpose, and union. Show that a subset of bounded sets is bounded.
2 Show that if | 21 > 2, then 2* is not bounded.
3 Verify that Theorem 8.5.2 holds if the languages are specified by
pushdown automata rather than by context-free grammars.
4 Show that, if L0 is any fixed context-free language which contains an
unbounded regular subset, then it is undecidable whether or not L(G) = L0.
5 Show that, for any arbitrary context-free grammar G, one can decide
whether or not
L(G) = {wcwT\ we{a,b}*}.
6 Show that one cannot decide whether a given context-free language can be
parsed in linear time.
7 Show that R is a bounded regular set if and only if R belongs to the
smallest family of sets which contains all regular subsets of w*, w G 2*, and which is
closed under finite union and finite product.
8 A set L is commutative if, for all wordsx,y EL,xy = yx. Show that a set
is commutative if and only if /. 9 w*.
270 DECISION PROBLEMS FOR CONTEXT-FREE GRAMMARS
9 Let u, DGE*. Show that uv=fcvu implies {u, v}* is unbounded. This gives
another proof of Problem 2.
10 Show that every context-free language L is commutative or else L*
contains an unbounded regular set.
11 Show that it is undecidable whether or not. L(G) is linear, or metalinear,
or ultralinear.
8.6 HISTORICAL SURVEY
The basic decision questions in this chapter date back to Bar-Hillel, Perles,
and Shamir [1961]. The unsolvability of the halting problem is due to Turing [1936].
The Post Correspondence Problem is from Post [1946]. Our proof follows Hopcroft
and Ullman [1969]. Exercises 7,8, and 9 of Section 8.3 are based on Hartmanis
[1967a] .problems 10 and 11 are from Ullian [1967]. Problem 2 of Section 8.4 is from
Gruska [1975], while Problem 3 was proved by Blattner [1973], Salomaa [1973b],
and Rozenberg [1972]. "Birdie problems" like Problem 4 of Section 8.4 were
systematically studied by Ullian [1967]. Problem 6 of Section 8.4 is due to Englefriet
[1973], and Problem 7 is due to Ginsburg and Spanier [1966].
The main results of Section 8.5 are derived from the work of Hunt and
Rozenkrantz [1978]. Bounded languages were introduced by Ginsburg and Spanier
[1964]. Lemma 8.5.1 is due to Hopcroft [1969]. Problem 4 is also from Hopcroft
[1969].
nine
Context-Sensitive
and Phrase-Structure
Languages
9.1 INTRODUCTION
It is possible to characterize both the context-sensitive languages and the
phrase-structure languages in terms of Turing machines. For the context-sensitive
case, one needs to restrict attention to nondeterministic, linearly space-bounded
devices. This focuses attention on both time- and space-bounded computations of
nondeterministic as well as deterministic Turing machines. While the general topic
of machine complexity is outside the scope of this book, some of the open questions
in language theory are related to questions in machine complexity theory. The serious
student of language theory is well advised to learn this subject in more depth than can
be provided here.
In Section 9.2, we begin by considering a number of alternative forms of
phrase-structure grammars. All of these are useful in one application or another.
Section 9.3 is devoted to a study of the basic properties of the context-sensitive
languages. For instance, every context-sensitive language is recursive but there are
recursive sets that are not context-sensitive. Section 9.4 is devoted to time-and tape-
bounded Turing machines. A few of the basic theorems of machine-based complexity
theory are proved there, such as Savitch's Theorem (9.4.3), which relates space-
bounded nondeterministic and deterministic computations. In Section 9.5, machine
characterizations of the context-sensitive and phrase-structure languages are given.
9.2 VARIOUS TYPES OF PHRASE-STRUCTURE GRAMMARS
In Sections 1.4 and 1.5, a number of types of grammars were introduced
for both the context-sensitive languages and the phrase-structure languages. We shall
271
272 CONTEXT-SENSITIVE AND PHRASE-STRUCTURE LANGUAGES
now introduce one more grammatical definition. This family of grammars also
generates the phrase-structure languages.
Definition A nonterminal rewriting grammar (or NR grammar) is a 4-tuple
G = (V, 2, P, S), where V, 2, and S are as in a phrase-structure grammar. P is a finite
set of productions of the form
*0^1*l ' ' ' xn-\AnXn ~*x0&\x\ ' ' 'xn-lfinxn
with«>0,;c,G 2*,/3,-G F*,and4,. G7V.
Note that, in a nonterminal rewriting grammar, the terminals are not
displaced once they are generated.
If we abbreviate each class of grammars by its initials, Fig. 9.1 displays the
grammar class containments.
PSG
s' \ ps
/ \ TO
TOG NRG \ NR
MG CSE
CSEG / M
/ CS
CSG
FIG. 9.1
We shall now quickly show that the following classes of languages are
coextensive.
PSL = TOL = NRL = CSEL
and
CSL = ML.
To show how these families interrelate, a sequence of easy results will be
proven.
Lemma 9.2.1 For each phrase-structure (respectively, context-sensitive with
erasing, context-sensitive, monotonic,NR) grammar G= (V, 1,,P, S), there is a phrase-
structure (respectively, context-sensitive with erasing, context-sensitive, monotonic,
NR) grammar G' = (V', 2,P', S) such that
UP') = UG)
and each rule in P' is of the form
a ->■ (3
withaG7V+,/3G7V*,or
A -* a
with A G TV and a G 2.
= phrase structure
= type 0
= nonterminal
rewriting
= context-sensitive
with erasing
= monotonic
= context-sensitive
9.2 VARIOUS TYPES OF PHRASE-STRUCTURE GRAMMARS 273
Proof Let G = (V, 2, P, S) be a grammar of the desired type. Define a map
tp: v^ V' =VV{Aa\aE 2}, such that:
<*?(4) = A if A G7V,
*(«) = Aa if a G 2,
and extend «p to be a homomorphism. Define G' = (F', 1,,P', S), where
i>' = {<p(a)^<p(0)\a^0ishiP}U{Aa^a\ae2}.
It is a straightforward matter to verify that L(G') = Z,(G) and G' is of the same type
asG. D
Corollary 1 The class of phrase-structure languages equals the class of type 0
languages.
Proof G' is a type 0 grammar. □
In order to deal with the other classes, we need a reduction lemma.
Definition For any phrase-structure grammar G = (V, 2, P, S), let the weight
of a production -n = a -+ (} be lg(/3) and let the weight of G be max{lg(/3) \a -+ P is in i>}.
Lemma 9.2.2 For each type 0 (monotonic) grammar G = (V, 2,P,S), there
is a type 0 (monotonic) grammar G' = (V',2,P',S) of weight at most 2, so that
L(G') = £(G). Furthermore, if G is of type 0, then the only length-decreasing rules in
G' have the form A-*A for A G F' — 2; if G is monotonic, then every rule in G' has
the form a -► (3 for a GN+ and 0 G V*.
Proof First we must modify G so that it has no length-decreasing rules except
A-rules of the form A-*A. This step is not necessary for monotonic grammars.
Define a new grammar G' = (V\ 2, P', S), where V' = F U {i?} and i>' is
defined as follows.
1 If a -»(3 is in i> and lg (a) < lg (0), then a -> (3 is in P'.
2 UAi ■■■Am^B1 ■■■Bn is in P with Ai,..., Am &N, Bi,. . .Bn e V,
and« <w,then
A, ■■■Am^B1 ■■•BnRm-n
is in P.
3 P' contains i?-» A.
Note that a rule 45C-» A in G is transformed to ABC^-RRR in G'.
Clearly, L(G') = £(G), G' is type 0, and G' has context-free A-rules but no
other length-decreasing rules.
Now assume that we have a grammar G = (V, 2, P, S) which is monotonic
or is the result of the previous construction. In the former case, we may assume (by
Lemma 9.2.1) that every rule in P has the form a -> (3 where aEN+,0G V*.
274 CONTEXT-SENSITIVE AND PHRASE-STRUCTURE LANGUAGES
Let 7r be a production in P. If the weight of -n is less than 3, then -n is in P'.
If the weight of -n is at least 3, then
* = Ai ■■■Am^B1 ■■■Bn
where m<n and n>3. Perform the following steps.
1 If m — n, then go to step 2. Let P' contain:
Xn_! -*■ Bm • • • Bn
This rule provides either rules whose left- and righthand sides have the same length,
or rules of reduced weight.
2 For rules a = Cx ■ ■ • Cm -»£>! • ■ ■ Dm, where m>3 and eachD,-G V — 2,
P' contains:
C,C2 -> DyYoA
Ya,iCi+2 -yDi+1 YaJ+1 for 1 <i<m-2
All of these rules are of weight 2. Thus steps 1 and 2 start with a production
of weight n and produce only productions of lesser weight. Repeat the construction
until all the rules associated with the original production have weight 2. The argument
is repeated for all productions whose weight is at least 3. □
Now we may apply this result to establish an equivalence between context-
sensitive and monotonic languages.
Theorem 9.2.1 For each type 0 (monotonic) grammar G = (V, 2, P, S),
there is a context-sensitive grammar with erasing (context-sensitive grammar) G' =
(V, 2, P', S) such that L(G') = L(G).
Proof By Lemma 9.2.2, assume without loss of generality that the weight of
G is at most 2, that G contains no length-decreasing rules except those of the form
A -> A, and that every rule in P has the form a -> (3 for some a GN+ and (3 G V ■
i) If a production n GP has only one nonterminal on its lefthand side, then
ttGP';
ii) If Tr=AB^CDandC = A oiD = B, then tt G P'\
iii) If 7r = AB -> CD with (7^4 and D^B, then the following productions
are in/'':
,45 -► (tt, A)B
(tt, 4)5 -► (tt, A)(v, B)
(7T, 4)(7T, 5) -► C(7T, 5)
C(tt,.8) -► CD
where (w, 4) and (w, 5) are new variables.
9.3 ELEMENTARY PROPERTIES OF CONTEXT-SENSITIVE LANGUAGES 275
It is clear that G' is context-sensitive (with erasing if G was not monotonic).
An easy induction verifies that L(G') = L(G). □
Corollary 1 The family of context-sensitive languages with erasing equals
the family of phrase-structure languages.
Corollary 2 The family of monotonic languages equals the family of
context-sensitive languages.
Corollary 3 The family of nonterminal rewriting languages equals the family
of phrase-structure languages.
PROBLEMS
1 Show by examples that Fig. 9.1 cannot have any lines added. That is, there
is a line between two grammar classes XG and YG in Fig. 9.1 if and only if
XG £ YG where X, Y e {PS, TO, NR, CSE, M, CS}.
93 ELEMENTARY DECIDABLE AND CLOSURE PROPERTIES OF
CONTEXT-SENSITIVE LANGUAGES
There are some very simple properties of the context-sensitive grammars
that will be developed here. Since only grammatical arguments are now available,
we shall use them as much as is reasonable. There are a number of closure results
that are intuitively clear when an automaton theoretic characterization is available.
These results could be proven with grammars but would be less intuitive.
Our first goal will be to give an algorithm that tests whether a given string
belongs to a context-sensitive language.
Definition Let G = (V, 2, P, S) be a context-sensitive grammar and let
w G 2" for some n > 1. Define a sequence of sets Wt £ V* as follows:
Wo = {S}
and for each / > 0,
Wi+l = W,-U{0G F+|a=>j3inG,aGH/,-,andlg(|3)<«}.
The next claim summarizes the properties of the Wt.
Proposition 9.3.1 Let G = (V, 2, P, S), w, and the Wt be as in the previous
definition.
i) For each / > 0, W,- c wi+l;
ii) If Wk = Wk + 1 for some k > 0, then
Wk = Wk+m forallin>l;
iii) For each/^0,
Wt = {peV+\S 2>p,]g(p)<n,Z<i\;
276 CONTEXT-SENSITIVE AND PHRASE-STRUCTURE LANGUAGES
iv) There exists k < max {2\V\",n + 1} such that
Wk = Wk+l;
v) Let k be the least integer such that Wh = Wk+l. Then
Proof Part (i) is trivial. Part (ii) is a trivial induction on m. Part (iii) is clear,
or could be verified by induction on /.
To prove (iv), note that, from (iii),
n
W, c (J Vs (9.3.1)
for each /. Taking cardinalities
m <
U v'
y=i
£ Wi < max{2|Fr,« + 1}.
y=i
Cf. Problem 1. Since \V\ and « are fixed, the Wt are of uniformly bounded size; and
since W{ 9 Wi+l, it is clear that:
Wk = Wk+l
for some k where k< max {21V\", n+ l}. B
Part (v) follows easily because, if S^-p, lg(/3)<«, then 5=>|3 for some
fi > 0. If fi < k, then (3 G WB c i|/fe. if 8 > jfc, then, since WB = Wk by (ii), we know that
pew„. □
We can now show that there is an algorithm to decide whether w G L(G),
where G is an arbitrary context-sensitive grammar.
Theorem 9.3.1 Let G=(V, 2,P, S) be a context-sensitive grammar. Then
L(G) is recursive; i.e. there is an algorithm which, given any w G 2*, decides whether
or not wGZ,(G).
/W/ Let w = ai ■■ -an, n>0, a; G 2 for l</<«. If « = 0, AGZ,(G)
if and only if
5 -► A
is in P. Now assume that n>\. Let W= Wk of Proposition 9.3.1, where k is the
smallest nonnegative integer such that Wk = Wh+l. By (v) of Proposition 9.3.1, w G
L(G) if and only if w G PV. Since W is finite and has been effectively constructed, the
result follows. □
Now we shall show that the context-sensitive languages are a proper subset
of the class of recursive sets. The argument is a straightforward "diagonalization." The
reader not familiar with the technique should study it carefully, because it is very
powerful and widely applicable.
Theorem 9.3.2 There are recursive sets which are not context-sensitive
languages.
9.3 ELEMENTARY PROPERTIES OF CONTEXT-SENSITIVE LANGUAGES 277
Proof Let 2 be an alphabet. Let xt,x2,.. .be an effective enumeration
(without repetition) of 2*. Let Gx, G2,... be an effective enumeration (without
repetition) of the context-sensitive grammars with terminal alphabet 2. Define
L = {x^x^UGd}. (9.3.2)
Claim 1 L is recursive.
Proof Given wG2*, by using the effective enumeration of 2*, we can
determine the / for which xt = w.
Now using the effective enumeration of the grammars, we can find Gt.
By Theorem 9.3.1 it is decidable whether or not xt G L(Gt).
Claim 2 L is not a context-sensitive language.
Proof Assume that L is a context-sensitive language. Then
L = L(Gj) for some/ (9.3.3)
But now consider string xf,
Xj<=L
if and only if (by (9.3.3))
XjGLiGj),
which holds if and only if (by (9.3.2))
xj £ L.
We have shown that xj G L if and only if jcy ^ Z,, which is a contradiction. Therefore,
Z, is not a context-sensitive language. □
Now we turn to the second main topic of this section, elementary closure
properties of the context-sensitive languages. Our purpose here is to establish a few
easy results which are best proven by elementary grammatical constructions. Since
some of the same constructions work for phrase-structure languages, those will be
proved at the same time.
Theorem 9.3.3 The families of context-sensitive and phrase-structure
languages are closed under U, ■, *, and transpose.
Proof The arguments are all quite trivial and are omitted. Cf. Theorem 3.3.1
for similar constructions in the context-free case. □
In a later section, it will be seen that the context-sensitive languages are not
closed under homomorphisms. Moreover, it is the case where A G ip(2) that causes
problems. We now consider a restriction on homomorphisms which does allow
preservation of context-sensitive languages.
Definition A homomorphism ip on a set L £ 2* is said to be k-limited (k > 1
is an integer), if for each wGZ,, if w =xyz for some x, y,z G2* and ip(y) = A then
lgO0<*.
278 CONTEXT-SENSITIVE AND PHRASE-STRUCTURE LANGUAGES
The intuition behind this definition is that for any w G L, $ never erases more
than k adjacent letters within w.
Example Let
Lx = {apbqcr\p,q,r>\},
L2 = {apb2cq\p,q>l}
and define ip by
(A ifd = b
<pd =
{d otherwise.
Now ip is not /c-limited on Lx for any k. To see that, suppose it were. Then
consider
w = abk*xc^Lx.
Let x = a, y = bh+l, and z = c. Then tf(y) = A but lg (j>) > k. On the other hand,
V is 2-limited for L2 since no word of L2 has more than two b's.
Theorem 9.3.4 The family of context-sensitive languages is closed under
k -limited homomorphisms.
Proof Let G = (V, 1,,P, S) be a context-sensitive grammar. There is no loss
of generality in assuming that G is in the form specified by Lemma 9.2.1. Let ip
be a &-limited homomorphism on L(G). Note that ip: 2* -*■ A*. Define
r = max{&+ l,lg(0)|a->-0is inP}.
Define G = {V,1,\P',S'), where
2' - {b G A| <p(2) n A*bA* ± 0};
that is, 2' consists of all letters of A that occur in ip(2). Then,
TV' = {[a]|aGF*,lg(a)<2r},
S' = [5],
V' = N'U E',
i>' is defined as follows:
1 If S -*■ A is in P or if there exists x G L (G) such that «p (x) = A then
[5] - A
■ • n*
isinr .
2 If a =>0 in G and [a], [|3] G N', then
[a] - \p]
isinP'.
9.3 ELEMENTARY PROPERTIES OF CONTEXT-SENSITIVE LANGUAGES 279
3 For any [a], [0, ]...., [0m ] G N1 such that
a =* /J, ■ • ■ /3m in C
where lg(/3;) = r for each /, 1 <i<m, and r < lg(/3m) < 2r, then
[«] - Wi] •■•[/3m]
isinP'.
4 For any [a,], [a2], [/J,],..., [0m] in N1 such that
<*i<*2 ^ Ui ■■■ftn
where lg(ft-) = r for each /', 1 <i<m, and
r<lg(/3;)<2r and r<lg(aI),lg(a2)<2r,
then
[«i][«a] - [Ui] •■[/3m]
isinP'.
5 For each [jc] G TV', jc G E*, v?(x) ¥= A,
[x] -► ^.(ac)
isinP'.
All the rules of P' are context-free except those of (4). G' is monotonic, so
by Theorem 9.2.1, L(G'), is context-sensitive. Moreover, G' is effectively constructable
since, in part (1), we can check' to see whether there exists xEL(G) such that
ip(x) = A, because ip is k-limited on L(G) and we need check only those strings x
where lg(x) < k. This can be done by Theorem 9.3.1. The tests required in parts (2),
(3), and (4) can be carried out, so G' is effectively constructable from G.
We leave to the reader the verification that L(G') = ^p(L(G)). □
Corollary The family of context-sensitive languages is closed under A-free
homomorphisms.
PROBLEMS
1 Show that
n . [2\V\n if|K|>l,
I IKK <
hi [n+l if|K|=l.
2 In subsequent sections, we shall learn that there are phrase-structure
languages which are not recursive. Where do the proofs of Theorem 9.3.1 and
Proposition 9.3.1 break down if G was assumed to be an arbitrary phrase-structure grammar?
t Later we will see that the question L (G) = 0 is unsolvable for context-sensitive
grammars G.
280 CONTEXT-SENSITIVE AND PHRASE-STRUCTURE LANGUAGES
3 What is the recognition time of the algorithm given in Theorem 9.3.1?
Give this as a function of n, the length of the input.
4 Show that the family of phrase-structure languages is closed under
a) substitution (and hence homomorphisms);
b) gsm mappings;
c) inverse gsm mappings.
5 Show that the family of context-sensitive languages is closed under
a) A-free substitution; [ip is a A-free substitution if for each s6E, A^
b) inverse gsm mappings.
6 Complete the proof of Theorem 9.3.4 by showing that Z-(G') = *p(L(G)).
7 Formulate suitable restrictions on the type of substitution mappings under
which the context-sensitive languages are closed.
8 Give effective enumerations of 2 and of the context-sensitive grammars
over 2, as described in the proof of Theorem 9.3.2.
9 Does it matter whether or not there are repetitions in the enumerations
used in the proof of Theorem 9.3.2?
9.4 TIME-AND TAPE-BOUNDED TURING MACHINES- 9 AND JV3>
In this section, we shall take a close look at Turing machines and examine
some implications of nondeterminism versus determinism. We shall also consider time-
and tape-bounded computations, as well as two particularly important classes of sets
called & and ^V&.
Our coverage of these topics will not be thorough, as we need only a few
results for our purposes. This general topic is important and textbooks should become
available on this subject soon.
We begin with an intuitive version of a fc-tape nondeterministic Turing
machine. Such a device is illustrated in Fig. 9.2.
Finite -
state
control
Y I
• • • Tape 1
••• Tape 2
; :
• • • Tape k
FIG. 9.2
9.4 TURING MACHINES 281
In this version, the fc-work tapes are semi-infinite (to the right) and the first
tape will contain the input. It can be shown that the results to be obtained are very
insensitive to these details.
It is now necessary to give a precise definition.
Definition A k-tape nondeterministic Turing machine is a 7-tuple A =
(Q, 2, T, B, S,q0,F), where:
i) Q is a finite nonempty set of states;
ii) 2 is a finite nonempty set of input letters;
iii) T is a finite nonempty set of work symbols and 2 Q V;
iv) B € r — 2 is the blank symbol;
v) Qo e Q is the initial state;
vi) F£ Q is the set of final or accepting states;
vii) 5 is a mapping from Q x Tfe into subsets of Q x (r x {—1,0, l})fe. 5 is
called the transition function.
Such a device is called a k-tape deterministic Turing machine if
\8(q, ai,... ,ak)\ < 1 foreach^G2;a1;... ,ak G r.
Next, we define an instantaneous description or ID of a k-tape Turing
machine. Intuitively, an ID must tell us what state the device is in, the contents of each
work tape, and the head position on each tape.
Definition Let A = (Q, 2, T, B, 5, q0,F) be a fc-tape nondeterministic Turing
machine. An instantaneous description or ID of A is any element of Q(T*{\}T+)k,
where we assume that Q n r = 0 and that I" is a new symbol not in Q U T.
Thus a typical ID is of the form
^(air|31,...,afer/3fe),
which indicates that the contents of the /th tape is a,-/3,- and that the read-write head
on this tape is scanning the first letter of ft. For single-tape Turing machines, one
sometimes writes the ID as otq0.
Now we are ready to indicate how the device works. This is done by defining
a "move" relation on ID's. To avoid a surplus of notation, an informal definition
is given.
Definition Let A = (Q, 2, r,B,8,q0,F) be a fc-tape nondeterministic
Turing machine. If a is an ID of A, where
a = q{ux \alv'[,...,uk\akvl)
and
(q', (bud!),..., (bk, dk)) isin5(q,a1,... ,ak),
then A rewrites each a,- by bj and moves one position to the right (left) on tape / if
dj = + 1 (—1), while, if d{ = 0, the head position on tape /' does not change. If any
v'j = A and dt = + 1, then the contents of tape / is represented by utbi tB in 0. If 0 is
282 CONTEXT-SENSITIVE AND PHRASE-STRUCTURE LANGUAGES
the resulting ID, we write a \— (3. As usual, pMs the reflexive-transitive closure of
h.
An ID is called initial if it is of the form qo(tw, \B,..., \B), wheret
w G 2+ U {5}. An accepting ID is any element of F(F* {l~}r+)fe.
Now we can discuss acceptance by a nondeterministic Turing machine.
Definition Let A = (Q, 2, I\ B, 5, #0> -F) be a fc-tape nondeterministic
Turing machine and let w£S*U{B}J accepts w (or when w = 5, A accepts A), if
q0(\w, \B,. .. , IB) \—q(oti,.. ■ ,ak) for some q £F
and some a1,... , ak G r* {\} Y*.
We also write T(A) = {w G 2* | ^1 accepts w}.
Next, we name the sets defined by a Turing machine.
Definition A set L is said to be recursively enumerable (or r.e., for short)
if L = 7X4) for some Turing machine A.
It can easily be seen that this definition is insensitive to whether or not A
is deterministic or has multiple tapes, etc. Thus an r.e. set has the property that
there is a procedure which returns the value true if the string is in the set but, if the
string is not in the set, the procedure may return the value false or it may fail to halt.
Of course, we can't determine whether a Turing machine will stop or not.
Definition A set L is recursive if both L and L = 2 —L are r.e.
Thus, a recursive set is one for which we can determine whether or not a
given string is a member. This corresponds to our previous informal usage of the
phrase.
This formalism and the ideas involved can be appreciated by studying a
detailed example.
Example Let L = {xzyzT \x,y,zG {a, b}*, z ¥= A}. We shall design a 2-tape
nondeterministic Turing machine which accepts L. The idea is quite simple. We shall
read the input, which is on the first tape. We shall guess when z begins and ends, and
during z, we write it on tape 2. After this is done, we skip merrily along ignoring j>.
When we guess that zT begins, we compare the input against tape 2. We have 2 =
{a, b}, T = 2 U {c,B}, F = {q5}, and 5 is defined as follows.
i) For each d G 2,
8(q0,d,B) = (<7i,(rf,0),(c,l)).
Mark left end of tape 2 with a c.
t An initial ID in which w = A is represented by (\B, . . . ).
9.4 TURING MACHINES 283
ii) For each d G 2,
S(qi,d, B) = {(qi, (d, 1), (B, 0)), (q2,(d, 1), (d, 1))}.
The first alternative is a guess that the input letter is part of x and should
be skipped over. The second alternative is to assume that it is part of z
and should be written on tape 2.
iii) For each d G 2,
8(q2, d, B) = {(q2,(d, 1), (d, 1)), (q3, (d, 0), (B, - 1))}.
The first alternative continues to write z on tape 2 while the second one
prepares to consider that y is next,
iv) For each d,eG 2,
8(q3,d,e) = {(q3,(d,D,(e,0)),(q.,(d,0),(e,0))}.
Either skip over j> or prepare to check zT against tape 2.
v) For each d G 2,
8(q4,d,d) = fa4,(rf,l),(rf,-l)).
Go right on tape 1 and left on tape 2 to check for zT.
vi) Stop and accept.
8(q4,B,c) = (qs,(B,0),(c,0)).
The reader should follow several computations of this Turing machine on a
given input. For instance, it is worth checking that there is no computation sequence
that accepts ab.
There are many variants of Turing machines. One of the most common is a
Turing machine with a separate input tape which is delimited by endmarkers. This
input tape may be read but not written. Another variation concerns whether or not a
Turing machine must halt in order to accept. In some instances this is desirable, while
for other results just passing through a final state is sufficient. Halting is represented
by having a final state qf such that 5 (flf ,alt... ,ak) = 0 for all a\,... , ak G V.
Another variant in the way in which a Turing machine accepts concerns
"on-line" versus "off-line" computation. Let A be a Turing machine with a separate
read-only input tape. We equip the device with an output tape on which it may write a
zero or a one. A computation of A on input a\ • • -an is on-line HA never goes left
on the input and writes a one or zero on the output after reading a ,• (indicating whether
ai • • • a,- was accepted or rejected) but before reading a1+1. A computation is
sometimes said to be off-line if it is not on-line. It is much easier to prove lower bounds on
on-line computations, because the form that the computation takes is so restricted.
Next we deal with measuring the time or space complexity of a
computation.
Definition Let A be a &-tape Turing machine and let S and T be functions
from M into M where M denotes the set of natural numbers. A is said to be of time
complexity T(n) if, for each accepted input of length n, there exists some computa-
284 CONTEXT-SENSITIVE AND PHRASE-STRUCTURE LANGUAGES
tion sequence of at most T(n) moves which leads to an accepting ID. Similarly, A is
of space or tape complexity S(n) if, for every accepted input of length n, there is some
accepting computation in which at most S(n) different squares are scanned by any
read-write head.
Example If we return to the previous example, it is clear that T(n) = n + 4
and S(n) = n + 1.
When we have a Turing machine with a separate read-only input, we measure
only the space used on the work tapes as the input tape cannot be changed. Thus we
may talk about accepting a set in, say, log« space.
One may wonder which functions could be the space bound of a
computation.
Definition A function S from N into N is a measurable space function, or
measurable, if there is a Turing machine A which has one work tape and a read-only
input tape and which visits exactly S(n) squares on its work tape, where n is the length
of the input.
For example, it is easy to see that log« is measurable. So is any polynomial
in n or in log n, as well as functions like 2". Of course, nonmeasurable functions exist,
by a counting argument. Techniques for exhibiting them will occur in the exercises.
The first result to be proved here will be useful in estimating the tape
complexity of language recognition problems.
Theorem 9.4.1 If a set L is accepted by a deterministic A:-tape Turing
machine A with space bound S(n), then L is accepted by some deterministic one-tape
Turing machine C with space bound S(n).
Proof The proof is quite intuitive, so we content ourselves with a sketch.
In Fig. 9.3, we show what A looks like at some given time. Figure 9.4 shows how C
represents all of this information on a single tape.
A
V
a\
"2
"3
a4
"5
•
•
•
ag
j£
b\ t>2 63 b4 b5
Cl c2
FIG. 9.3 A three-tape Turing machine.
9.4
TURING MACHINES
285
"\
*1
■
■
C\
"2
h
Cl
>'
"3
*3
B
a4
b4
B
Q
V
"5
'
f
b5
B
"6
B
B
"7
B
B
"i
B
B
a9
B
B
FIG. 9.4 A single-tape Turing machine which
simulates a three-tape machine; q is only one
component of the state.
To simulate a move of A, C must visit each of the cells which are pointed
at, recording in its state the symbol scanned by each of ,4's heads. When all this
information is available, C determines ^4's move. C then goes back to each tape,
changes the symbol scanned, and moves the pointers as A would require. It should be
clear that T(C) = T(A). □
Our next development shows that constant factors do not matter in
computing space bounds. The analogous result for time is left for Exercise 2.
Theorem 9.4.2 Let e > 0 be any real number. If L is accepted by a
deterministic A:-tape Turing machine A with space complexity S(n), then there is a
deterministic A:-tape Turing machine C which accepts L and has space complexity eS(n).
Proof The argument merely involves recoding the tape alphabet of A to
use, as basic symbols, blocks of length r where r is the least integer such that re > 1.
□
In preparation for the next theorem, a lemma about space-bounded Turing
machines is useful.
Lemma 9.4.1 Let A = (Q, 2, T, B, 8, q0, F) be a &-tape Turing machine of
tape complexity S(n), and w € 2* be an input of length n.
i) The number of different ID's which can arise from w is at most cs^"\
where c is a constant independent of n.
ii) If A accepts w, then there is an accepting computation
a0 = q0(lw, IB,..., [B) |-<*i I h^-i,
where
(1) at * aj for all i */ and (2) k < cS(n).
286 CONTEXT-SENSITIVE AND PHRASE-STRUCTURE LANGUAGES
Proof Since lg(vv) = n, A can visit at most S(n) squares on any work tape.
Thus the total number of ID's which can occur during the computation is
|(2l(|r| + l)feS(">(5(«))fe,
because there are \Q\ choices for the state, and for each one of k tapes, there are at
most (|r| + l)S(n) tape contents,-!" and S(n) places for the head to be (and so a total
of (S(n))k head positions).
It is now clear that any accepting computation of A on w can be converted
to one which satisfies (ii) because any duplicate ID's involve a "loop", which can be
omitted.
Note that
IGI(|r| + l)feS(")(S(H))fe<cS(")
for a suitable constant c independent of n. The same constant may be used in both
parts of the lemma. □
It is a well-known fact that nondeterministic and deterministic Turing
machines are equivalent in accepting power, and this is proved in any course on the subject.
We prove a stronger result, namely, the relationship between the space complexity of
the nondeterministic and deterministic machines.
Theorem 9.4.3 (Savitch's Theorem) Let S(n)>n be a measurable space
function. If a set £ is accepted by a nondeterministic Turing machine A of tape
complexity S(n), then L is accepted by some deterministic Turing machine C of tape
complexity (5(«))2.
Proof Suppose we have w € T(A) and lg(vv) = n. Then
a \- y,
where a is the initial ID, y is some accepting ID, and k > 0. Now this computation
takes place if and only if there exists an ID 0 so that
Tfe/21 a ,lfe/2j
a F^- 0 h1-2- y.
Recall that \k/2] + [k/2\ = k for all k.
The idea of the proof is to check for such a 0 (there are only finitely many
of them, by part (i) of Lemma 9.4.1). If we were working on a model of computation
which allowed us to have recursive programs, the result would be trivial. As it is, we
must carry out the analysis far enough to see that all the computations can be done on
a Turing machine. Let us define a predicate P(f], a, k), which is supposed to be true if
there is a computation of A from r? to a of length k which uses at most space S(n).
P is defined for all ID's r? and a which use at most space S(n) and all k > 0, as follows."
If we used exactly S(n) squares of tape, the bound would be |r|S(n), but we could
use less, so the bound is
iri + --- + inS(")<(in + i)s(">.
9.4 TURING MACHINES 287
true if k = 0 and 77 = a,
true if k = 1 and 77 h~ a,
P(f], a,k) =\ true if k > 1, /"(r?, 0, T&/2] ) which uses no more than tape
S(n), and P(9, a, [k/2\) for some ID 9.
, false in all other cases.
It is easy to see that P may be calculated because all of the ID's which use
at most space S(n) may be enumerated.
Let f(j], a, k) be the number of intermediate ID's that must be stored in
evaluating P(f], 9, k). It is easy to check by induction that this quantity is < [log2&];
and when storage is also provided for 77 and a, the bound is 2 + [log2&].
The strategy for constructing the deterministic simulating machine C now
becomes clear. In view of Lemma 9.4.1, we can restrict ourselves to accepting
computations of length <cS(n). Cwill deterministically compute P(a, y, cS(n)) for all possible
accepting configurations which use at most S(n) tape. (We know the number of these,
by Lemma 9.4.1 again.) The number of ID's to be stored is at most
2+ <?\logcSM] = <?(S(n)).
On the other hand, the length of an ID is {7(S(n)) and the total space which will be
used is t?((S(n))2 ). Use of Theorem 9.4.2 allows all constants to be reduced to unity. □
Some notation is useful in dealing with the various classes of languages
accepted by time- and tape-bounded Turing machines. The notation facilitates the
classification of languages and the study of relationships between classes.
Definition Fix some countably infinite alphabet and assume that all the
machines which are discussed have input alphabets which are finite subsets of this
alphabet.
a) DTIME(r(«)) (respectively, NTIME(7,(«))) is the family of all sets
accepted by deterministic (respectively, nondeterministic) Turing machines
which operate within time-bound T(n).
b) DSPACE(5(«)) (respectively, NSPACE(5(«))) is defined analogously to
part (a), except that "time" is replaced by "space".
c) >#*= U DTIME(«fe)
fe = i '
&)Jr&= u NTIME(«fe)
e)^-SPACE= U DSPACE(«fe)
fe = i
For instance, Savitch's theorem asserts that
NSPACE(5(«))£ DSPACE((5(«))2).
From this, it follows that
^-SPACE = U NSPACE(«fe).
fe = i
288 CONTEXT-SENSITIVE AND PHRASE-STRUCTURE LANGUAGES
One reason for the importance of these concepts is that various problems
can be coded into languages and then we may speak of reducing one problem to
another. More precisely, we have the following.
Definition A language Lt £ 2* is polynomially reducible or p-reducible to a
language £2 - A*, written Z,x <p L2 if there is a function/: 2* -> A* computed by a
deterministic polynomially time-bounded Turing machine such that
xGIi if and only if /(x)GZ,2.
Proposition 9.4.1
a) If L2 G ^and U <p L2 then LY € >#*.
b) The relation <p is transitive; that is, if Lt <p L2 and L2 <p L3, then
Next, we define the important notions of "hard" and "complete."
Definition A set L is J^&'-hard if, for each L' € Jr&1, we have L' <p L.
L is J^S* -complete if L e ^^ and Z, is ^#* -hard.
Proposition 9.4.2
a) Let Lt be ^T^1 -complete. If L2ej^&> and Z,x<p Z,2, then Z,2 is also
J^S6 -complete.
b) Let Z, be ^T^-complete. L G J* if and only if J* = jTS6.
Part (b) focuses attention on an open question, namely, whether .#* = j^S6.
It turns out that a large number of important problems can be shown to be J^&
-complete. If any of these problems can be shown to be in >#*, then they all will be.
PROBLEMS
1 Design a deterministic Turing machine to accept L = {xzyzT \ x, y, z G
(a, b}*, z =£ A}. What time and tape complexity does your machine have?
2 Given a deterministic A:-tape Turing machine A with k > 1, which accepts
a set Z- with time complexity T(n), and given any real number e, show that there is
a A:-tape Turing machine B which accepts L and has time complexity n + eT{n).
3 Does the speed-up theorem of Problem 2 imply that a linear time
computation (T(«) = Cx« + c2) can be speeded up to a real-time computation (T(n) = «)?
4* Speed-up theorems have been extensively studied and proved in abstract
form for arbitrary measures of computations that include time and space. We state a
general version of the result below for space. Prove the result.
Theorem Let Ao, Ai,...be an enumeration of deterministic Turing
machines with a fixed input alphabet. For any recursive function r, there exists a
recursive set L such that if Aj (the ith Turing machine) accepts L in space 5,-(«), then
there exists Turing machine Aj which accepts L in space Sj{n) and
r(Sj(n))<Si(n)
almost everywhere (i.e., with only finitely many exceptions).
9.4 TURING MACHINES 289
5 Show that, for each recursive function r, there is a recursive function T
which is monotone increasing, T(n) > r{n), such that any language L recognizable in
time h(T(n)), where h is any recursive function, is also recognizable in time T(n).
This result is called the "gap theorem" because it shows that there are arbitrarily
large gaps among the recursive functions which contain no running times.
6 Give an example of a nonmeasurable space function.
7 The proof of Savitch's theorem is merely a sketch. Complete the argument
by giving a detailed construction and the necessary proof. Extend the theorem to the
case where S(n) > logn.
8 Extend Savitch's theorem to nonmeasurable space functions.
A Turing machine is said to be realtime if it is a deterministic Turing
machine with time bound T(n) = n and has a separate input tape. In problems 9—13, the
input tape is not counted among the work tapes.
9 Can a realtime Turing machine accept any deterministic context-free
language?
10 Find large classes of functions computed by realtime Turing machines.
11* Show that the set L £ 2*, where 2 = (a, b, c, d, e,f], given by
L = {uveuT \Ue{a,b}*,ve {c, d}*} U {uvfvT \ u G (a, b}*, v G {c, d}*\
can be accepted by a realtime Turing machine with two work tapes, but by no
realtime Turing machine with one work tape.
12* (Very difficult) Find a family of sets {Lk} such that Lk can be
recognized in real time by a A:-tape Turing machine but not by any (k — l)-tape realtime
Turing machine.
13* Let 2„ = {aj, . . . , a„, ax,. . . , a„}. Consider the set 0„ which encodes
the "origin-crossing problem" defined by
0„ = {w G 2* | For each i, 1 < i < n, #a.(w) = #a,(w)}.
The name of this set derives from thinking of a,- (respectively, a}) as an instruction to
take one step to the right (left) along the ith axis in n-space. Show that 0„ is real time
recognizable by a Turing machine with one work tape.
14 Consider the following set L £ 2 , where 2 = (a, b, c}:
L = (wic • • • cw2kcuic ■ ■ ■ cui\wi,Uj&{a,b}*,lg(w,) = k = lg(uy)
for all i, /; J2, k > 1; there exists some
/, 1 </ < 2fe such that uc = wj}.
Show that any on-line deterministic multitape Turing machine that accepts L requires
time T(n), where
T(n) > c(«2/(log n)2) infinitely often
for some constant c. [Hint: Count the number of different ID's which could exist
after all the w,'s are read.]
15 Show that if there exists a real number r > 1 such that DSPACE(«r) c^1,
then
&> = JT& = j^-SPACE.
290 CONTEXT-SENSITIVE AND PHRASE-STRUCTURE LANGUAGES
16 Show that there exists no pair of real numbers r and s, 1 </■<.$, such
that
DSPACE(«r)£ ■& ^ DSPACE(«S)
or
NSPACE(«r)^ &"^ NSPACE(«S).
A similar result holds for Jf&.
17 Show that, for any real number r > 1,
a) J* =£ DSPACE(«r) b) ^ =£ NSPACE(«r)
c) jr&i= DSPACE(«r) d)J^=£ NSPACE(«r)
9.5 MACHINE CHARACTERIZATIONS OF THE CONTEXT-SENSITIVE
AND PHRASE-STRUCTURE LANGUAGES
Similar characterizations of the phrase-structure and context-sensitive
languages can be given. The former family is exactly the class of sets accepted by
unrestricted Turing machines. The other family is accepted by nondeterministic linearly
space-bounded Turing machines. The proofs of the characterizations are so similar that
we shall consider them at the same time.
Definition A linear bounded automaton, or Iba, for short, is a one-tape
nondeterministic Turing machine which is (S(n) — n + l)-space bounded, which
accepts by leaving the input tape at the right end in a final state.
The fact that S(n) = n + 1 instead of S(n) = n in the space bound arises
from the fact that a Turing machine must scan the blank to the right of the last
symbol of the input in order to detect the right end of the input string.
Since we know that constants do not change a space-complexity class (by
Theorem 9.4.2), an lba has a linear amount of space at its disposal.
Our first result will be to show that each set accepted by an lba is a context-
sensitive language.
Lemma 9.5.1 For each lba C, there is a monotonic grammar G such that
L(G)=T(C).
Proof Let L = T(C), where C= (Q, 2, I\ B, 8, q0,F) is an lba. Construct
G = (F,2,P,S),where
v = {(s,a}uzux r)(rur')x r)u((gu{r})x (rur'),
with T a new symbol not in Q. r' denotes a primed copy of T. The rules of P are
given by cases.
9.5 MACHINE CHARACTERIZATIONS 291
(Tape generation) For each a&"L,P contains:
S -> (q0, a, a)A
A -> (a, a)A
A+(a',a)
S^-(q0,a',a)
5-> A if ^o isinF.
(Stay) If (q,b,0)G8 (p,a) then, for eachcG 2,/"contains
(p, a, c)->(?,&,c)
(p,a',c)^-(^,fe',c)
(Move left) If (q, b, — 1) € 6 (p, a), then, for each c€S,d,c6r,P contains
(J, e)(p,a,c) ->(q,d, c)(b, c),
(d, e)(p, a',c)->(q, d, e)(b', c)
(Move right) If (q, b, 1) G 6 (p, a), then, for each c,e&"L,d&V,P contains
(p,a,c)(d,e)^(b,c)(q,d,e)
(p, a, c)(d', e) -> (b, c)(q, d', e)
(Accept) If (q, b, 1) € 8(p, a), and q&F, then, for each c€2,P contains
(p,a',c)^(T,a,c).
(Retrieve original input) For each b,d&'L,a,c&T,P contains
(a,b)(T,c,d)^(T,a,b)(T,c,d)
and
(T,a,b)^b
Rather than give a formal proof that the construction works and L{G) =
T(C),we shall explain each phase of the construction.
1. 5 generates a string (q0, a i, ai)(a2, a2) ■ ■ -(tfc-i, ac-i)(tfc, ag). In this
string,(q0,ai , tfi) denotes that Cis scanninga\ in state q0.
2—4. These rules simply simulate the action of C on the tape. The first coordinate
of each ordered pair is used to record the changes that C makes to its tape.
5. When the device has entered a final state, we have
S => (pi.ai)-- (6c_1,ac_1)(7,,6c,ac)
6. Then T sends a signal and we get 7s throughout, that is,
(r,&,,«,) •••(r,&B,«fi).
Finally, a^ • • ■ a% is produced as the terminal string. Note that the construction is
still valid if C<1.
Note that if C "guessed wrong," the grammar will not generate anything
since it will have a string with variables in it that cannot be rewritten as terminals. □
292 CONTEXT-SENSITIVE AND PHRASE-STRUCTURE LANGUAGES
Now, we prove a similar result for r.e. sets.
Lemma 9.5.2 If L = T(A) for some Turing machine A, then there is a phrase-
structure grammar G, such that L = L(G).
Proof Let L = T(A), where A = (Q, 2, I\ B, 8, q0, F) is a Turing machine.
There is no loss of generality in assuming that A is deterministic and has one tape.
We construct a phrase-structure grammar G = (V, 2, P, S), such that L(G) — L.G will
nondeterministically generate some word in 2* and simulate the action of A on it. Let
V = 2 U ((2 U{A}) x T)U Q U {S, T, U\ P consists of the following productions.
1 S^q0T
2 r-> [a,a]T foreacha G2
3 T^U
4 U-*[A,B]U (Recall that B is the blank)
5 £/-->A
6 p [a, C] -> [a, Z>] q- for each a € 2 U {A}, ? G £, and Ce r, so that
SG?,C)=(<7,A1)
1 p[a,C]^q [a, D] for each a € 2 U {A}, q&Q, and CGT, so that
S(p,C) = (q,D,0)
8 [6, £■] p [a, C]^q [b, E] [a, D] for each a, b G 2 U {A}, £, C G r,
and q- G Q, so that 5(p, C]I = (q-, A -1)
q [a, C] -> q-aq-
?->A foreachaG 2U (A},CGr, andq-GF.
A generation must begin with rules (1) and (2), and yields
S ^ q0[ai,ai] [a2,a2] ••• [a„, an] T
with each at G 2. If A accepts a\ • • -an, then it stops and so never uses more than
some m cells to the right of the input. Next, use rule (3), then rule (4) m times,
and then rule (5). This yields
S ^<7o[«i.«i] ■■■[an,an] [A,B]m
Only rules (6), (7), and (8) are used until a final state is reached. Note that the first
components of the tape symbols are never changed. We claim the following.
Claim Ifq0ai • • • an \~Xi • • • Xr^lqXr.. .X„+m,then
q0[ai,ai][a2,a2] ••• [an, an] [A, B]m
^ [ai,Xl ] [a2, X2] •■• [ar^,Xr^]q[ar, Xr] ••• [an+m, Xn+m]
where a,- = A for /' > n and Xs G r for 1 </ < n + m.
Proof of claim The argument is a straightforward induction on the number
of moves and is omitted.
9.5 MACHINE CHARACTERIZATIONS 293
By (9), q&F implies that:
[ffi, Xi ] • • • [ar_!, Xr_! ] q [ar, Xr] ■ ■ ■ [an+m, Xn+m ] ^a, • • • an
Thus, r(^4) G L{G). The reverse argument is again an induction, which is omitted. □
Now we turn to the arguments which take us from grammars to automata.
Lemma 9.5.3 If L is a context-sensitive language, then L = T(A) for some
IbaA
Proof Let L = L(G), where G = (V, 2, P, S) is context-sensitive. The lba.4
is constructed to work in the following way. Suppose, without loss of generality,
that A has endmarkers. This is justified in Problem 1 at the end of this section. A will
work as follows:
1 (Initialization) A divides the input into two channels. Channel 1 contains
the original input string, while channel 2 is for scratch work. A writes S
on channel 2 at the lefthand end (next to the endmarker).
2 (Search) A slides back and forth across the tape until it finds some string
a on channel 2 such that a -> 0 is in P.
3 (Replace) Replace a by 0 and slide the symbols on the rest of channel 2
to the right if necessary. It will not be necessary to move symbols to the
left. (Why?) If it is necessary to move a symbol past the right endmarker,
A goes to a "dead" state and halts without accepting.
4 (Decide) A guesses whether to continue or quit. If it continues, it goes
back to 2 and repeats the cycle. Otherwise it goes to 5.
5 (Compare) A moves to the left end of the input and then compares
channels 1 and 2. If they agree, A accepts. Otherwise^ halts without accepting.
It is easily seen that this construction works and that T(A) = L. □
Combining our results leads to the following important theorem.
Theorem 9.5.1 L is a context-sensitive language if and only if there is an
lba/1 such that L = T(A).
We can define a deterministic lba in the obvious way and define a
deterministic context-sensitive language to be a set accepted by such a device. It can easily
be seen that the family of deterministic context-sensitive languages has many
attractive features. For example, it is a boolean algebra. It is not known whether or not the
deterministic and nondeterministic lba's are equivalent in computation power.
Now we finish our simulations of grammars by automata.
Lemma 9.5.4 If L is generated by a phrase-structure grammar, then L =
T(A) for some Turing machine A.
Proof The argument is quite similar to the proof of the previous lemma and
may be safely omitted. □
294 CONTEXT-SENSITIVE AND PHRASE-STRUCTURE LANGUAGES
Combining the previous results leads to a characterization of phrase-structure
languages.
Theorem 9.5.2 The following conditions are equivalent.
1 L is a phrase-structure language.
2 L is accepted as T(A) for some nondeterministic (or deterministic)
multitape (or single-tape) Turing machine A.
3 L is recursively enumerable.
Now that both the phrase-structure languages and the context-sensitive
languages have been given machine characterizations, our coverage of the Chomsky
hierarchy is complete.
There are two classical open questions about the context-sensitive languages
which should be stated. Is every context-sensitive language accepted by a deterministic
lba? In other words, is it the case that
NSPACE(«) = DSPACEfa)?
Another question of interest is whether the context-sensitive languages are
closed under complementation. We know that DSPACE(«) is closed under
complementation so that if NSPACE(«) = DSPACE(«), then we have closure of NSPACE(«)
under complementation. It could be the case that context-sensitive languages are
closed under complementation but that DSPACE(«) £ NSPACE(«).
While these problems are interesting in their own right, they can be viewed
as special cases of open problems in machine-based complexity theory. For instance,
we know of no function S(n) ^ log« such that the question
DSPACE(5(«)) = NSPACE(5(«))?
has been resolved.
PROBLEMS
1 Show that, for any (deterministic) lba A with endmarkers, there is an
equivalent lba C without endmarkers.
2 Show that every context-free language is accepted by some deterministic
lba. Symbolically,
£f£ DSPACE(m).
A stronger result will be proved later, namely, that^t DSPACE((log«)2).
3* {Open question) Is
"T^ NSPACE(log «)?
4 Show that, for each lba A, there is an lba B which is equivalent and which
always halts.
5 Work out the closure properties of the r.e. sets, the context-sensitive
languages, and the deterministic context-sensitive languages. Be sure to include nega-
9.5 MACHINE CHARACTERIZATIONS 295
tive results such as the fact that the context-sensitive languages are not closed under
homomorphism.
Let us fix an alphabet 2 with 2 = {a0, . .. ,am_j}, and use the notation xy = z to
stand for the concatenation predicate {(x, y, z)\ x, y, z G 2 and xy = z}. We
construct a formal logical system &, starting from the concatenation predicate, and
allowing the following operations:
a) If Pi and P2 are in &, then Px V P2 is in ^(disjunction).
b) If P is in ^then IP is in ^(negation).
c) If P{x\,. . . ,xn) isin SI, then
Q(yi,... ,ym)<>P(zi,... ,z„)
is in J?, where each z? is either one of theyt or a string from 2*, or even
a concatenation of such terms. This operation is called explicit
transformation and allows us to form a new predicate from an old one by
interchanging variables, identifying them, replacing a variable by a constant,
etc.
d) If P(xi,. . . , xn, y) is an (« + l)-ary predicate in^, then
(3z)z<y P(xlt. . . ,xn, z) (*)
is in $1. This is called bounded existential quantification and means that
(*) is true if and only if there is a string z G 2 such that z <;v for which
P(xi,. .. ,xn, z) holds. We interpret z <;y as follows: Since z,y G 2 ,
regard them as numbers in /n-adic notation, since < is thus the usual "less
than or equal to" relationship between natural numbers.
e) Nothing else is in Sf.
Thus J% is a formal logical system and we can define relations or sets on 2 . These
sets or relations are called rudimentary.
6 Show that each rudimentary set can be accepted by a deterministic lba.
7 Show that every regular set is rudimentary.
8 Show that any context-free language is rudimentary.
9 Show that the rudimentary sets (i.e., definable by 1-place rudimentary
predicates) are coextensive with the least family which contains the context-free
languages and is closed under boolean operations and length-preserving homomor-
phisms.
10 Give a machine characterization of the rudimentary sets.
11 Show that there is no algorithm which can determine, of a given context-
sensitive grammar G, whether or not L(G) = 0. (Thus the problem is unsolvable for
phrase-structure grammars also.)
12 Show that there is no algorithm which can determine, of a
context-sensitive grammar G, whether or not L(G) is infinite.
13 Show that there is an algorithm which takes a given context-sensitive
grammar G = (V, 2, P, S) and two strings a and |3 in V and which decides whether
or not
a 4- 0
296 CONTEXT-SENSITIVE AND PHRASE-STRUCTURE LANGUAGES
14 Show that the problem mentioned in the previous exercise becomes
unsolvable if G is a phrase-structure grammar.
15 Show that there is no algorithm which can decide whether a given
production is ever used in a derivation of a string in a context-sensitive language.
16 We can effectively enumerate the lba's over an alphabet 2 as A\,. . .
Let tp be a fixed homomorphism which maps strings in 2* into a fixed alphabet, say
{0, 1, #}*, such that lg(<p(<z)) > \rt\ for eacha G 2 and where Tr is the work alphabet
of.4;.
L0 = {#^#V(w)#|wG2*,#£2,andwGT04/)}.
Prove the following three statements.
a) L0 is a context-sensitive language.
b) L0 G DSPACE(m) if and only if NSPACE(m) = DSPACE(m).
c) L0 G NSPACE(m) if and only if the family of context-sensitive languages
is closed under complementation.
The previous problem asserts that L0 could be thought of as a "hardest
context-sensitive language" with respect to space. It is also a hardest language with respect to time.
17 Show that every context-sensitive language is in^* if and only if Lq G &.
18 Let LINEAR denote the set of linear context-free languages. Show that
LINEAR £ NSPACEdog/?).
19 Define E\ = L (G), where G is given by
S -> aiSa^a-iSa^ A
Define
L(E1)= {cxlyiZiCX2y2z2c • • ■ cxkykzkc\k> l,^2 = {a1,a2,fl1,ff2},
Vx ■ ■ -yk e*i ,x, G (2 U {c})*{c}U {A},y. G (c}(2 U {c})* U {A}. }
Show that L (Ex) is a linear context-free language.
20* Show that, for any e, 0 < e < 1, the following statements are equivalent:
a) LINEAR c DSPACE(log«)(1+e)
b) L(Et) G DSPACE(log«)(1+e)
c) NSPACE(£(«)) £ DSPACE([£(n)]1+e) for allS(n) > logn.
21 Can you find a recursive set of phrase-structure grammars^7 = {G;} such
that JS^= {L(G)\ G G ^}is exactly the family of recursive sets?
9.6 HISTORICAL SURVEY
The basic material on phrase-structure and context-sensitive grammars is due
to Chomsky [1959]. linear bounded automata were studied by Myhill [I960].
Connections with context-sensitive languages were established by Landweber [1963]
and Kuroda [1964]. Some closure results about context-sensitive languages were
9.6 HISTORICAL SURVEY 297
derived by Ginsburg and Greibach [1966b]. The importance of time- and space-
complexity classes of Turing-machine computations was first noted by Hartmanis
and Stearns [1965]. Theorem 9.4.3 is from Savitch [1970]. Cook [1971] was the
first to realize the importance of ^and J^. Karp [1972] systematically reduced
many combinatorial problems to the & = J^ question. Speed-up theorems such as
Problem 4 at the end of Section 9.4 were first proved by Blum [1967]. Problem 5 is
from Borodin [1972]. Problem 11 is from Rabin [1963], while Problem 12 is from
Aanderaa [1974]. Problem 13 is from Fischer and Rosenberg [1968]. Problem 14 is
from Hennie [1966], while Problems 15 through 17 are from Book [1972b].
Problem 6 of Section 9.5 is from Myhill [1960]. Problems 7 and 8 are from
the work of Jones [1969], while Problems 9 and 10 are due to Yu [1970]. A number
of decision questions about context-sensitive languages come from Landweber [ 1964].
Problems 16 and 17 are from Hartmanis and Hunt [1973]. Problems 18
through 20 are from the work of Sudborough [1975ab, 1976ab].
ten
Representation
Theorems
for Languages
10.1 INTRODUCTION
In this section, a number of characterization theorems for classes of
languages will be proved. All of the results are important and are used extensively.
There have been a number of papers in the literature which place various
restrictions on phrase-structure grammars or on their derivations, so that the
languages that are generated are exactly the context-free languages. Section 10.2 is
devoted to proving one theorem which captures the essential idea of such constructions.
Then, we shall obtain a number of the results from the literature as corollaries.
Section 10.3 is devoted to showing that any r.e. set L may be represented
as
L = y(Li r\L2),
where Lx and L2 are deterministic context-free languages and tp is a homomorphism.
Some applications for this result are given.
In Section 10.4, the semi-Dyck and Dyck sets are introduced. These are
sets with several types of left and right brackets, which are balanced according to
onesided or two-sided cancellation rules. It will be shown that each context-free language
L is of the form
L = y(DnR),
where D is a semi-Dyck set, R is a regular set, and y is a homomorphism.
299
300 REPRESENTATION THEOREMS FOR LANGUAGES
Section 10.5 is devoted to proving that there is one context-free language
L0 such that any other context-free language L may be written
L = tp~l L0,
where tp is a homomorphism. The importance of this result will be clear in Chapter 12
where it will be shown that L0 is a "hardest" context-free language with respect to both
time and space.
10.2* BAKER'S THEOREM
In this section, we shall start from NR grammars of Section 9.2, which are
known to generate exactly the family of phrase-structure languages. By placing
suitable restrictions on the rules, one can get context-free languages. The main theorem in
this section has, as corollaries, almost every other result of this type that is known.
Next we introduce an important property of NR grammars.
Definition Let G = (V, 2, P, S) be an NR grammar. G is terminal bounded
if each rule in P is of the form
x0AiXi ■ ■ ■xn.lAnxn -» y0Bi ■ ■ -ym-iBmym
where each xt, yt G 2*, Ab Bt G N, and either n = 1 or there is some /, 0 </ <m,
such that, for every k, 1 <k <n,\g(yj)>\g(xh).
This definition says that either a rule is context-free (n = 1) or that there is
some terminal string >>y which is strictly longer than any of the terminal strings xit
. .. , *„_!; that is, y}- is longer than any string that can appear between two variables
in the lefthand side.
Example
AaB -»• BaCbb
This is a terminal bounded rule since \g{bb) = 2 > lg(a) = 1.
Notation. For any NR grammar G = (V, 2, P, S), define
N(G)= JJpflgC*)"!).
is inP
N(G) measures the excess of symbols on the lefthand side of rules over that which
would be present in a context-free grammar with the same number of rules.
Fact Let G = (V, 2, P, S) be an NR grammar, N(G) = 0 if and only if G is
context-free.
Example If we consider the rule in the previous example as an entire
grammar, then
N(G) = 2.
We need one more definition before we can begin to prove a lemma.
10.2* BAKER'S THEOREM 301
Definition Let G = (V, 2, P, S) be an arbitrary NR grammar. Define
LG = max {0, lg(x)| xy -» 0 is in P for some y, 0 G V*, x G 2*};
/?G = max {0, lg(jc)| yx -» 0 is in P for some y, 0 G F*, jc G 2*};
BG =max{0,lg(x)| yiAixA2y2^PisinP for some xG'E*,AuA2GN,y i,y2G V*}.
Thus LG (respectively, RG) is the largest length of a terminal string appearing on the
left (right) end of a rule in P. BG is the maximum length of a string appearing
between two variables in the lefthand side of a rule in P.
We are now ready for a nontrivial lemma.
Lemma 10.2.1 Let G= (V, 2,P,S') be a terminal bounded grammar with
N(G)>0. Then there exists a terminal bounded grammar Glt a regular set R, and
a gsm S such that
L(G) = S(L(G{)nR),
and
N(Gi) < N(G).
Proof There are basically two cases in the proof.
CASE 1 LG >BG otRg >Bg.
The idea will be to take a rule of G which has in its left side a terminal string
that is too long to appear between variables in any rule, and shorten the terminal
context of this rule.
Assume, without loss of generality, that RG^LG and RG>BG. (For
LG > RG, the construction would yield a G\ symmetric to the present one.)
The idea is to consider a string AwB where wG 2* and \g(w) = RG >BG,
A,BG V. No rule of P can span AwB, so that, if some initial part of a derivation
produces w, then any later step must apply a rule to the left of w independent of what
occurs to the right of w, or to the right of w independent of what occurs to the left
of w.
We shall replace a single rule in P whose lefthand side contains a terminal
string of length RG by a rule with shorter terminal context. But this could allow
derivations in which the new rule could be applied when the old rule was not
applicable. Accordingly, a special symbol $ will be used with the new rule to flag unwanted
derivations.
Define Gj = (F1; 2 U {$}, Pu S'), where Vl = W {$}. Choose a rule yw^-
0w in P, where w G 2* and lg(vv) = RG ■ Define
Pi = (P-{yw^-$w\) U {y^QwS}.
Gt is terminal bounded since G was. Since lg(vv) = RG > 0, lg(y) < \g(yw), so that
N(Gi) < N(G).
Given a string aywp, we can use yw -*■ j3w in G to produce o&wp. w is
available as context for the further rewriting of 0 or of p. In Gx if we start with aywp
and use y -*■ j3w$ in Pi, we get o(5w$wp and again both 0 and p have the context w
302 REPRESENTATION THEOREMS FOR LANGUAGES
with which to continue. But we have to restrict the context in which 7-»0w$ is
applied and to erase the extra w$l
Let R = (V U ($w))* and define the gsm S as follows: Let w = wi • ■ • wn,
Wj G 2, and:
a/a
Q^^ . rri^Q
a*% wn/A
To complete the proof, we must prove the following claim.
Claim 1 L(G) = S(L(G1)nR).
Proof We shall only sketch the argument here but will give the essential
parts so that the details can be easily supplied. The argument proceeds by first showing
that L(G)£ S(L(Gi) nR). To prove this,it suffices to prove Claim 1(a).
Claim 1(a) For anyj> G 2*, if
5"
where n > 0, k > 0, and each
S' r? y = iiiwu2w ' • • ukwuk+i
Uiev*-v*wV*,
then there exist il7... ,ik>0 such that
S'^ z = u1(w$)''wu2(w$)'', •••ufe(w$),'*wufe+,
Proof The argument is an easy induction on n and is omitted.
Note that Claim 1(a) is sufficient to prove that L(G)£ S(L(Gi)nR) since
zGR andy=S(z).
The reverse direction is more interesting. There are derivations of strings in
L(Gi)C\R which cannot be simulated exactly in G [y->-(}w$ may be applicable to
a string while yw -*■ 0w is not]. One can show that, for each y G L(G\) n R, there is
some derivation of y in which y -*■ j3w$ is applied only when context w has already
been generated to the right of y. This derivation is "almost" a G-derivation and it is
easy to construct a G-derivation of S(y) which imitates it. The argument proceeds
in a sequence of steps.
Claim 1 (b) Ify G L(Gi)nR, then G\ has a derivation
G, ' G, G, " -^
and each a,- G /?.
/Voo/ The argument involves labeling all occurrences of $ in y and
considering where each subscripted $ was introduced. A straightforward case analysis proves
the result, and details are left to the reader.
10.2* BAKER'S THEOREM 303
Claim 1 (c) If, for some n > 0,
and each a: G R, then
S' => an =* ai => • • • => a
G, ° G, l G, G, "
ST = S(a0) f S(ai) t •'' t S(an)
Proof The argument is a straightforward induction on n.
Claims 1(a) and 1(b) prove that
S(L(Gi)nR)cL(G)
and that completes the proof of Claim 1.
CASE 2 LG <BG and/?G <BG.
The idea is similar to Case 1 except that we must consider a string w of
length BG + 1. Choose a rule
XoAiX! ■ ■ -Xn-iAnXn -+ XoJlXi ■ ■ -Xn-iJnX,,
where each xt G S*, At G N, j; G F*, and there exists/, 1 </ < n — 1, so that \g{xs)
= BG. We claim n > 2. Otherwise, n = 1 and all rules have one variable on the left,
so that BG = LG = RG = 0, and thus N(G) — 0. Since G is terminal bounded, the
righthand side of this rule has a terminal substring w of length >BG. Since BG >LG
and BG > RG, lg(vv) > lg(jc,) for any /, 0 < / < n.
Thus some part of the -y's must be included in w. Let us say that yk must be
included in w. (By symmetry, assume k < n.) We rewrite the rule as
°AkxkAk+lp ■+ 0iw02
where lg(0,) < lg(x07i ■ ■ ■ 7k-i^fe-i7fe)- Define G, = (K,, 2 U {«, $},P, ,5") where
K, = Kujt, $},andletP' = {a>lfe^/31w$,xfeylfe + 1p^xfe<|rw/32}.
Then
Pi =(P-{oAkxkAk+lP^PlWp2})UP'.
Gx is surely terminal bounded. Clearly,N(Gi )<N(G).
Let R = (V U {$xfe<tw})* and define a gsm as indicated in Fig. 10.1. Let
xk =x\ ■ ■ ■ x'p, and w = Wi • • • wr, when jcJ, Wj G 2.
FIG. 10.1
304 REPRESENTATION THEOREMS FOR LANGUAGES
Again the completion of the argument depends on the following result.
Claim 2 L(G) = S(L(Gl)nR).
Proof The argument will be sketched by giving an outline.
r n
Claim 2(a) For any y, if S =j» y then there exists z G R such that
and
S(z) = y
Proof The argument is a straightforward induction on n.
As in Gaim 1, it is the reverse direction that is more complex. Take y in
L(Gi)C\R, and index occurrences of <t and $, so that
y = 7o$i^k<t:i7i$2^'fe<te • • • 7p-i%pXk<tp7p
Claim 2(b) If>> GL(Gi) HR, then
s' t ai t • • • t an = y
such that for all/, oj first appears in ar+1 if $y first appears in o^..
Proof The argument is a case study of how symbols may be generated. The
reader should provide the details.
Claim 2(c) If
. * * *
"° G, ' G, G, m y
where, for each / <m,OLi=> ai+l by a single rule of P or via consecutive applications
of the two rules of/1', then
S' = %)^''f%)= S(y).
Proof Induction on m.
The argument above completes the proof of Claim 2. The main proof is
now complete. □
We are now going to show that terminal bounded grammars can generate only
context-free languages. Intuitively, this seems clear since the long terminal context
prevents reapplication of a rule and hence destroys the ability to transmit information.
Theorem 10.2.1 (Baker's theorem) If G = (V, 2,P, S') is a terminal bounded
grammar, then L(G) is context-free.
Proof We induct on N(G).
Basis. If N(G) = 0, then G is context-free.
Induction step. Assume the result for all grammars G' such that N(G')< k.
Consider G = (V, 2, P, S") with N(G) = k. By Lemma 10.2.1, there exists a regular
10.2* BAKER'S THEOREM 305
set R, a gsm S, and a terminal bounded grammar G\ such that N(Gi )<k and L(G) =
S(L(Gi) n /{). By the induction hypothesis, L(Gi) is context-free. Therefore
L(G) = S(L(Gi)DR)
is also context-free and the proof is complete. □
Now we begin a sequence of corollaries of this theorem. Each of the
corollaries is nontrivial and interesting in its own right.
Corollary 1 If G = (V, 2, P, S) is a phrase-structure grammar with each rule
of the form a ->■ 0 with a &N* and 0 G F* 2 F*, then £(G) is context-free.
Corollary 2 If G = (V, 2, P, S) is a context-sensitive grammar with erasing,
such that each rule is of the form a -*■ j3 with a G 2*N 2*, then £(G) is context-free.
Corollary 3 If G = (V, 2, P, S) is a context-sensitive grammar with erasing,
in which each rule is of the form xA(l-*■ xy(3, where A EN, x G 2*, 0G V*, and
lg(x) > lg(/3), then L(G) is context-free.
Corollary 4 If G = (V, 2, P, S) is a context-sensitive grammar with erasing,
such that each rule is of the form aAy -*■ o#y, where either
i) aG2* and lg(a)>lg(7)
or ii)7G2* and lg(7)>lg(a),
then L(G) is context-free.
Corollary 5 Let G = (V, 2,/\ S) be an NR grammar and let < be a partial
ordering on V. Suppose that each rule is of the form
Ax ■■■An+Bl ■Bm
where each AtGN and there is some k, 1 <A:</w, such that for all /, 1 </<«,
A;<Bk. Then L(G) is context-free.
Proof The argument is involved and is left for Problem 2 at the end of the
section, where some hints are given.
Definition Let G = (V, 2, P, S) be an NR grammar. If x G 2*, a ->• 0 is in P,
and 7 G V*, write
xorf^x&y and -yax ?f-y/fr.
Define L „ R
Left (G) = {w G 2* | S f w}
and
Two-way (G) = {wG 2*15 L=JR w},
where L^R means that each rewriting is either a leftmost one (by =*■) or a rightmost
one (by ^).
Corollary 6 If G = (V, 2, P, S) is an NR grammar, then Left (G) and
Two-way (G) are context-free.
306 REPRESENTATION THEOREMS FOR LANGUAGES
Proof We shall first construct a new terminal bounded grammar G' such that
L(G')= Two-way (G1) and $L(G')= Two-way (G), where <p is a homomorphism.
Let <7 = max {lg(a)| a ->■ |3 is in P}. Let d, £, /?, and Si be new symbols. Define G' =
(V, 2', P', 51!), where 2' = 2 U {d}, and K' = K U {d, £, R, Si}. P' is defined as
follows.
i) L -» A
R -» A
Si -» dqLSRd9
are all in P.
ii) If uoz;-»-w/k is in P and w, t>, w, *,>> G (2')*, a, 0G {A}UJV(2*A0*
with lg(>0 = q, then
yuLuv -*■ ywLfbc
uaRvy^ w$Rxy
yuLaRv ->■ ywLQRx
are all in/1'.
The idea is to add markers L and R to designate the leftmost and rightmost
variables at any point in a derivation. To also make G' terminal bounded, extra
terminal context is added on the left or right side of each rule; this terminal context does
not interfere with the application of rules, since each rule can be applied only where
there are no nonterminals on at least one side.
It is now easy to see that
L(G') = Two-way (C).
Let ip be the homomorphism given by
yd = A
ipa = a iia^d.
A straightforward argument shows that
<p(L(G')) = Two-way (G).
Since G' is terminal bounded, Two-way (G) is context-free. □
PROBLEMS
1 Show that if G is an NR grammar, then Left (G) is context-free.
2 Prove Corollary 5. Hint. Assume that < is a total order and that S is the
least element in this ordering. Also assume that, if a-*- 0 is a rule, then either 0G N*
or 0 G 2. Let d, E, and ^ be new symbols. Define 2j = 2 U {d}, Vx = V U {d, E, Si},
and let
p = max {lg (0) I a ->■ 0 is in P}.
10.3* DETERMINISTIC LANGUAGES 307
Define </> to be a homomorphism given by
ipA = Ad"'
if A G V and A is greater than exactly i elements in V. Define Pi to consist of the
following rules:
a) Si -» SdE
E^d
b) If a ->■ 0 is in P and Y G N, then add to Pi
<p(a)Y -» ^(/3)r
Show that Gi = (Vi, Si, Pi, Si) is an NR grammar and is terminal bounded. Define
a homomorphism \p: Vi -> V* by
iiA
Show that
A if.4 = d,
A otherwise.
\p(.L(Gi)) = L(G)
and hence L(G) is context-free.
10.3 DETERMINISTIC LANGUAGES GENERATE RECURSIVELY
ENUMERABLE SETS
Any recursively enumerable (or phrase-structure) language L may be
generated as
L = y(Li C\L2),
where Li and £2 are deterministic context-free languages and </> is a homomorphism.
This result turns out to be extremely useful when investigating new families of
languages. For example, if one is investigating a new family of languages that is sub-
recursive, and one knows that the family is closed under homomorphism and contains
the deterministic context-free languages, then the new family cannot be closed under
intersection.
The construction is not very hard at all. Let
G = (y,-L,P,S)
be a phrase-structure grammar. Assume that G has k rules for some k. Define
L\(G)= bioidfocylPfyfcl 7,, y2G V*, a,- -»• ft is inP, 1 </ <k}\
where dit.. . ,dk and c are new symbols, not in V.
Lemma 10.3.1 L\{G) is a deterministic context-free language for each
phrase-structure grammar G.
Proof For at ->■ ft in P, 1 </ < k, let at = aa • • • a,m(0 and ft = fti • • •
ft„(0, each au and ft,- in V.
Note. By the definition of a phrase-structure grammar, m(i) > 1 and «(/) > 0.
308 REPRESENTATION THEOREMS FOR LANGUAGES
Let A = (Q, 2', T, 6, Z0,{/})be the deterministic pda with 2' = VU {c, di,
...,dk}.Then
Q = {<7o, <7i. «2, d,f}U{Sij\ 1 </ <*, 0 </< w(0} U{rtf| 1 </ <*, 0 </ <«(/)};
and r = 2' U {Z0}, Z0 being a new symbol, and 6 defined as follows:
0 8(<7o, a, Z0) = (<7o. Z0a) for eacha in V;
6(<70, a, &) = (<70, &a) for eacha and b'mVU {d,| 1 </ <A};
8(q0, c, b) = (q!, b) for each b in V U K11 </ < A:}.
ii) 6(<7i ,a,a) = (qi, A) for each a in V;
6 (<71, A, d,-) = (s,-0, A) for each 1 < /' < k.
ui) 6 (sij, A, a,(m (0.j)) = (x,-0+ d, A) for each 1 < / < A:, 0 </ < m(i) - 1;
8fe(m(o-i),A- aa) = 0;o, A) for each 1 </ < k.
iv) 6(r;/, ft(„(0-y),a) = (r,0+1))a) for each a in VU{Z0}, Ki<k,
0</<n(0-l;
^(?i(n(0-1)' fti» a) = (<l2, a) for each 1</<A:, a in KU{Z0}, If
n(i) = 0, this becomes 6(ti0, A,a) = (q2, a).
v) 6 (q2, a, a) = (q2, A) for each a in V;
8(q2,c,Z0) = (f,Z0).
vi) S(f,A,Z0) = (q0,Z0).
vii) S(<7, a, &) = (d, b) for all (<7, a, b) not previously specified.
The dpda j4 operates as follows:
1 In (i), A copies the input onto the stack until the symbol c is read.
2 In (ii), it checks the input against the stack until some dt is read on the
stack. The d; is then erased.
3 Without moving the input, A checks in (iii) to see whether the word a,- is
on the stack (erasing a,- in the process).
4 In (iv),A sees whether ft is on the input while not altering the stack.
5 In (v), A matches the input against the stack until c is read.
6 In (v), A goes to an accepting state if c is read on the input and Z0 on the
stack.
7 In (vi), A then goes to the start state, the cycle (beginning at step (1))
being repeated.
It is a straightforward matter to verify that T(A) = L\ (G). □
The following notation is useful.
Notation. For a in 2, let a be a new symbol. Let A = A and w = Si ■ ■ ■ ak
for each w = a\ ■ ■ ■ ak, all a,- in 2. For each U9 2*, let U = {«| u in £/}. For each
phrase-structure grammar G, let Li(G) = £i (G)(2)*.
10.3* DETERMINISTIC LANGUAGES 309
Corollary L\(G) is a deterministic context-free language.
Proof Since strings over (2)* involve a new alphabet, it is clear that
L\(G) (2)* is a deterministic context-free language.
Now, a second encoding must be prepared.
Notation. Let V be a finite set containing S, k ^ 1, and let c, di,. .., dh
be k + 1 new symbols. Let
£(A:, P0={.Stf,-c|l <i<k}{ula2ca2rdJa[c\ \<j<k,ax anda2 in K*}* {/3c0Tl0in K*}.
Lemma 10.3.2 £(&, F) is a deterministic context-free language.
Proof Let ,4 be the deterministic pda (Q, 2', T, 6, <70, Z0, {/j ,/2}), where
2 = teo.?i.?2,rf,/i./2}U{s/|0</<4},
2' = KU2U{c,rfi,...,rffc},
r = fufu{z0},
Z0 being a new symbol, and 6 is defined as follows (a and b are arbitrary elements in
vy.
i) 8(q0, S, Z0) = (qi,Z0);
8(qi,d.,Z0) = (q2,Z0) forl<i<k;
8(q2,c,Z0) = (s0,Z0).
ii) S(s0) a, Z0) = (s0, Z0a);
S(s0> a, b)=(s0,ba);
8(s0,c,a) = (si,a).
iii) 5(s1(a,a) = (s2,A);
8(s1,a,a) = (s3,A).
iv) S(s2)a,a) = (s2) A);
6 (s2, dy, a) = (s4, a), 8 (s2, djt Z„ ) = (s4> Z0).
v) 603,5)fl) = 03, A);
8(s3,A,Z0) = (f1,Z0).
vi) 5(s4, a, a) = (s4, A);
S(s4) c,Z0) = (x0,Z0).
vii) 8(s0,c,Z0) = (f2,Z0);
8(f2,d„ Z0) = 04, Z0) for Ki<k.
viii) Sfa, a', Z) = (d, Z) for all (q, a', Z) in Q X 2' X Y not previously
defined.
Note that the rules in (vii) are needed in case aj a2 = A or /3 = A.
Intuitively,^ operates as follows:
1 In (i), A checks to see whether the first three input symbols are Sdtc for
some /.
310 REPRESENTATION THEOREMS FOR LANGUAGES
2 In (ii), A copies the input symbols onto the stack until the symbol c is
read.
3 In (iii) and (iv), it matches the input against the stack until some d}- is read
on the input.
4 In (iv), the dj is read on the input without altering the stack.
5 In (vi), the input is again matched against the stack until the symbol c is
read.
6 A then goes to s0 and cycles.
7 If, at step (3), a symbol 2 is read, then A goes to s3, where it compares,
in (v), S on the input with a on the stack.
8 A accepts if, after reading the input, the stack is empty except for Z0.
It is a straightforward matter to formally verify that T(A) = L(k, V). The
details are omitted. □
We now obtain the desired representation theorem for recursively enumerable
sets.
Theorem 10.3.1 For each recursively enumerable set E£ £*, there exist
deterministic context-free languages L\ and L2»and a homomorphism </> such that
E = tp(Lx C\L2).
Proof Let E = L(G), where G = (V, 2, P, S) is a phrase-structure grammar.
Let L\ = L\(G) and L2 = L(k, V), where k is the number of productions in P. Let tp
be the homomorphism defined by ${fi.) = a for each a in £ and <p(a) = A for each
a in V U {c, d\,..., dk}.
Let x be a word in E. Then there exist y^, ~fn'ae(i)^e(i^or 0</<w,
such that
701 = 702 = A, Ofto) = S, 7ml0*(m)7m2 = *,
and
T7i "tfOVto implies that 7/1 Pe<JyYj2,
with as(/) ->■ j3s(y) inP, for 0<j<m,and
for 1 </ < 7n — 1. For each 71, /, and y2, let
s(7iW', 72) = Jtj'i cyxdfoc
and
K7i.'. 72) = 7iUidnicylpT-fic.
Then
z = K7oi,^(0),7o2)K7ii»^(l),7i2)---K7mi.^('"),7m2)^
is in Z/i(G). However,
z = Sdgi0)cs(yn<xgm,g(l),712) • • • s(ymlag(m),g(m), ym2)xTcx.
10.3* DETERMINISTIC LANGUAGES 311
Therefore, z is in L(k, V); that is, z is in L\ n L2• Then x = </>(z) is in </>(/,! n£2);
that is, E£<p(L 1 n/,2).
Suppose that X is in </>(£i n£2). Thus x = tp(z) for some z in L\ n£2.
Then
z = t(y0i,g(0),y02)---t(yml,g(m),ym2)X
for some 701,7o2, • ■ ■ ,7mi, 7m2,,?(0),... ,g(m). Similarly,
z = &?W)«(|„,/(1), |12) • • ■ sttnl,/(«), |„2);cTc*
for some |n, |12,..., |nl, |„2, /(0),...,/(«). Then w = n (since there are exactly
2m + 2 and 2n + 2 occurrences of c in z). By observing the occurrences of dj in z,
we see that/0') = g(i) for 0 < /' <m. We also see that
_, 7oi = 7o2 = A, as(o) = ■?, 7n<W) = In, 7i2 = 1,2,
and
T(i-i)iPg(i-i)7(/-»2 = lnl/2 = 7ti<*gii)7i2
for 0 <i <m, and ymiPgim)ym2 = *.Thus
S =»• 7oife(o)7o2 =»• 7n^(i)7i2 =>•••=> 7miftr(m)7m2 = *;
that is,* is in E. Then ip(£i O L2) E £ and the proof is complete. □
The application that was discussed earlier can now be formalized.
Theorem 10.3.2 Let Jzf be any family of recursive sets that contains the
family of deterministic context-free languages.
a) If Jzf is closed under intersection, then Jzf is not closed under
homomorphism.
b) If -Sfis closed under homomorphism, then jgf is not closed under
intersection.
Other variations are possible as well.
Theorem 10.3.3 Let .S^be any family of recursive sets such that there is a
nonempty language inJzf. IfJzfis closed under intersection and homomorphism, then
Jzfdoes not contain the family of deterministic context-free languages.
PROBLEMS
1 Extend Theorem 10.3.1 to the following: Given 2, let S0 = 2 U {«,*},
a and b being two new symbols. There exists a homomorphism <p of Sj onto 2* with
the following property: For each recursively enumerable set E£ X*, there exist
deterministic context-free languages L\ *=. Sj and L2 E So such that E = v(Li n L2).
2 Give a Turing-machine proof of Theorem 10.3.1.
3 Let ,4 =(Q, S, A, S, <70, Z0, F) be a pdaand let L £ S*. Define
HL = {aGT*| (q0,w,Z0) h1 (<7,A,a) forsomewGL}.
Thus HL is the set of all pushdown contents that can occur when L is fed into A. If L
is context-free, is HL regular or context-free? In general, describe what kind of sets can
occur as HL.
312 REPRESENTATION THEOREMS FOR LANGUAGES
4 Show that an arbitrary deterministic Turing machine may be simulated by
a deterministic device with two pushdown stores.
5 Show, with the help of the previous problem, that any deterministic Turing
machine may be simulated by a deterministic device with four iterated counters (i.e.,
they can count to zero more than once).
6 Show that a deterministic Turing machine may be simulated by a
deterministic device with two iterated counters.
7 Show that, for each Turing machine A, there exists a finite alphabet T and
two deterministic iterated counter languages L\ and L2 over T such that A halts on
some input if and only if L\ n L2 =0.
8 Show that it is undecidable whether or not L = 2* where L is an iterated
one-counter language. Thus the equality problem is unsolvable for this family of
languages.
9 Show that it is undecidable whether or not Lj £ L2 for deterministic
iterated counter languages L^ and L2.
10.4 THE SEMI-DYCK SET AND CONTEXT-FREE LANGUAGES
An algebraic characterization of the context-free languages will be obtained
in this section. It hinges on the semi-Dyck set, which is a particular deterministic
context-free language.
To motivate the semi-Dyck set, let us imagine a terminal alphabet consisting
of left and right parentheses, ( and ). Define D\ to be the set of all well-balanced
parentheses, for example,
()ez>!,
()()e/>i,
and
(()(()))€£,,
but
D\ is a (deterministic) context-free language, as we shall see very soon. An alternative
way to describe Dx is to code ( as a^ and ) as a\ [or a_x ]. Then Dx is the set of all
strings of {ai, flj}* subject to the relation
aid'i = A
[respectively, ax a _, = A].
Correspondingly, one could allow two-sided cancellation, which would give
us the "two-sided" or simply the "Dyck Set," D\.
Example ) ( G D\,
)(())(ez?i.
The last relation is more natural if we write
a\a\a\a\a\a\ &D\.
10.4 SEMI DYCK SET AND CONTEXT-FREE LANGUAGES 313
If we think of ax as the inverse of ai, it is like group theory. In the exercises, we shall
see that the analogy is appropriate.
We shall soon introduce the semi-Dyck set on r letters. Many of the results
to be given hold for D'r as well with similar proofs but these will be omitted and left
for the problems.
The terminal alphabet of Dr, the semi-Dyck set on r letters, will be 2r U 2r,
where 2r = {a\,..., ar) and 2r = {at\ at G 2r}.
We may define
2 = 2r U 2r
and consider 2* which is a free monoid. We can define relations on 2*, first defining
p0 = {(a,5i,A)|fllG2I.}u{(A,fll5i)|flJG2I.}.
Let — be the least two-sided congruence relation that contains p0. Not only is — an
equivalence relation on 2 but
xafljy — xy
for all /, 1 < / < r, and all x, y G 2*. Intuitively, if x, y G 2*, then x^y if and only
if x can be obtained from y by introducing or cancelling adjacent pairs aflj or vice
versa (meaning that y can be obtained from x in this fashion).
Example Let r = 2. Then,
a.\a.\a.\a.ia.\ — aidiaiaiaia2aiaiai-
It is convenient to have a normal form for such words.
Definition Let 2 = Sr U Sr for some r > 1. A word w G 2* is reduced (for
Dr) if w contains no consecutive pairs afit for any /, 1 < / < r. A word w is reduced
for Dr if u> contains no consecutive pairs afii or a"^,- for any /, 1 < / < r.
Given any word in (2)*, we may reduce it by cancelling consecutive pairs. We
shall now carry out this process carefully.
Definition Let 2 = 2r U 2r for some r > 1. Define a mapping /i from 2*
into 2* as follows:
m(/0 = a,
nixdi) = n(x)at for each /, 1 < / < r,
li(xya, if/u(jc)^2*«j, Ki<r,
x if n(x) = x'ar
Examples
H(A) = A,
li(at) = at,
li(ai) = a„
ix(a\aiaia\a\ai) = n(aia2a2a1di)a2 = n(aia2a2)a2 = P-fai)^ = ^1^2-
At(xa,) =
314 REPRESENTATION THEOREMS FOR LANGUAGES
We summarize the pertinent properties of 11 in the following proposition.
Proposition 10.4.1 Let 2 = 2r U 2r for some r > 1 and let u, v, w, x, y G 2*
a) /i(xaiai) = /i(x) for any /, 1 < / < r.
b) n(w) is reduced.
c) n(w) — w.
d) If u is reduced, ii{u) — u.
e) AiGi(w)) = ii(w).
f) jufoO = ^G^bO-
g) ju^) = ju(ju(jc)ju(»).
h) lfn(x) = n(y), then n(uxv) = n(uyv).
i) n(xata{y) = /u(xj>) for any /, 1 < / < r.
j) n(x) = /i(y) if and only if x —y.
k) Let wG 2*. If jv G 2*,j>is reduced andjv — w, thenj> = n(w).
Proof The proof of (a) is a straightforward induction on the length of x.
The proofs of (b) and (c) are easy inductions on the length of w. A trivial induction
on the length of u proves (d).
To show (e), let w G 2*. By (b), n(w) is reduced. By (d),
H(li(w)) = At(vv).
Now (f) will be shown by induction on y.
Basis, y = A. Then
H(x) = ii(li(x))
and the basis follows from (e).
Induction step. Assume the result for all words y and consider ya with
a G 2. There are two cases, depending on whether a G 2r or a G 2r.
CASE 1 a = ate 2r.
Ii(xya) = n(xWi)
= n(xy)at by definition of /i,
= ti(p.(x)y)ai by the induction hypothesis,
= n(n(x)yaj) by the definition of /i.
The induction is now extended in Case 1.
CASE 2 a = ate 2r.
There are two cases here, depending on whether or not
1 zb for some b^ah
za{.
H(xy) =
10.4 SEMI-DYCK SET AND CONTEXT-FREE LANGUAGES 315
CASE 2(a) n(xy) = zb, where b =£ at.
Then
n(xydi) = /i(xy)ai by definition of n,
= ii(p.(x)y)ai by the induction hypothesis.
Since ti(p.(x)y) = n(xy) = zb,bi^ ah we may invoke the definition of /i again and
H(n(x)y)at = ii(jx(x)yai),
and the induction is extended in Case 2(a).
CASE 2(b) n(xy) = zat.
H(xyat) = K(xy)ai)
= n(jx(xy)aj) by the induction hypothesis,
= liiza-fii) = ju(z) = z.
Note that zat and z are reduced because za,- is in the range of /i. The only way that
z could fail to be reduced would be to have some cancellation at the right end, but
that is impossible, by the one-sided nature of our system. On the other hand,
nQjL(x)yai) = z
because ti(p.(x)y) = n(xy) = zat; the induction is extended and the entire proof of
(f)is complete.
The proofs of (g) and (h) are left to the reader; (i) follows from (g) and (a),
because
VixdiCiiy) = n(p.(xatai)n(y))
= ii(fi(x)ii(y))
= v(xy).
The proof of (j) follows in a straightforward manner from (i). To show (k), note that
y — w implies
Ky) = J"(w)
but, since y is reduced,
li(w) = n(y) = y. □
The /x function is quite helpful in dealing with the semi-Dyck set.
Definition Let r> 1 and define Gr = (Vr, 2, P, S), where 2 = 2r U 2r,
Kr = 2 U {5}, and P consists of the following productions:
S^SaiSatS\A
for each /, 1 <i<r. The semi-Dyck set is formally defined by
Dr = L(Gr).
316 REPRESENTATION THEOREMS FOR LANGUAGES
We may think of the at, 1 <i <r, as r different kinds of left brackets, and
the dj for 1 < / < r, as their respective right brackets.
It is clear that
Dr = {wG2*Iai(w) = A}.
Our first result is that Dr is a deterministic context-free language.
Theorem 10.4.1 Dr is a deterministic context-free language.
Proof Let A = ({q0, q^}, 2, 2 U {Z0}, 6, q0, Z0, {q0}), where 2 = 2 U 2r.
Define :
6(q0, ab Z0 ) = (q1, Z0at) for each i, 1 < / <r,
6 (q1, ait a,-) = (<7i, a/a,-) stack first letter for all 1 < /,/ < r;
8 (q i, ait at) = (q 1, A) for each /, 1 < i < r; cancel a^;
8(qlt A, Z0) = (q0, Z0) accept and prepare to repeat.
Corollary Dr is an unambiguous context-free language.
Now we list some basic properties of Dr.
Proposition 10.4.2 LetZ)r be the semi-Dyck set.
a) If;c,j<GZ)r,then;c>>GZ)r.
b) If x G Dr, then a;xdi G Dr for all i, 1 < / < r.
c) For each word x G Z)r, either x = A or x = fljj'aiz for some /, 1 < / < r,
and some j, zGZ)r.
d) Ifa,ajz GZ)r, thenz GZ)r.
e) IfyzGDr and><GZ)r, then zGZ)r.
f) x£ init(Z)r) = {w G 2*1 vvy G Dr for some >< G 2*} if and only if u(x) G
2* (that is, w has no letters in 2r).
Proof Since w G Dr if and only if n(w) = A, Proposition 10.4.1 can be
used to prove (a) through (e) elegantly. As an example, consider (e).
y G Dr implies /i(y) = A,
yz G Dr implies n(yz) = A.
But
l±(yz) = ii(ti(y)z) = n(z) = A,
so
zGZ)r.
To see (f), suppose x=x1 • • -;c8, ju(jc) = jc{i '' '*ik, %>k>0, and each ^i.G2r.
Define>< =Jc,- • ' 'ic,^ , where jc,-. is a barred copy of jc,-.. Qearly,
Kxy) = ^(^(x)^) = juCjc;, • • • x;k xik ■ ■ -x-h ) = A,
so xy G Z)r, which means that x G init(Z)r). This proves the */direction.
10.4 SEMI-DYCK SET AND CONTEXT-FREE LANGUAGES 317
Conversely, suppose x G init(Z)r). There exists >< G 2* so that
xy G Dr.
We show that fi(x)& 2* by induction on the length of x. The basis is trivial.
Induction step. Assume the result for a string x. If y = A, we are done. Let
a be the first letter of j\
CASE 1 a G 2r. By the induction hypothesis, /i(;c)G 2*; and by the
definition of ii,
H(xa) = /i(x)a G 2*,
which extends the induction.
CASE 2 a £ 2r. Let a =ai. By the induction hypothesis, Ai(x)G 2*. Since
l*(xy) = A, it follows that
ju(x) = *'a;, a,- G 2„, Jt'GJ*.
But, clearly,
H(xa) = At(xOi) = iiix'aiOi) = n(n(x')n(aia,)) = x'e 2*.
The induction has been extended and the proof is complete. □
We are now in a position to state and prove the main theorem of this section,
which is a characterization of context-free languages in terms of Dr. The result says
that every context-free language L may be written as
L = <p(DrnR),
where Dr is the semi-Dyck set on r-letters, R is a regular set, and tp is a homomorphism.
Of course, for any homomorphism <p, and any regular set, it follows, that <p(Dr H7?)
is a context-free language, by our closure properties.
Theorem 10.4.2 (Chomsky-Schutzenberger Theorem) For each context-free
language L, there is an integer r, a regular set R, and a homomorphism y such that
L=<p(DrnR).
Proof Let L = L(A), where A = (Q, 2, T, 6, q0, Z0, F) is a pda satisfying
the conditions of Problem 3 of Section 5.5. That is,
a) L = L(A).
b) If AGi, then 6(<70, A, Z0)= {(<70, A)} and q0 GF; otherwise, S(<70,
A,Zo) = 0.-
c) If 9 G Q -fao}orZGT-{Z0}, then 6(9, A, Z) = 0.
d) If (q, a) G 6 fa, a, Z), then lg(a) < 2.
Assume that Q, 2, and T are pairwise disjoint and that |2 U T\ = r. The
alphabet for the semi-Dyck set will be 2rU2r; but in order to retain notational
consistency, we will write _ _
20 = (2 U D U (2 U T).
318 REPRESENTATION THEOREMS FOR LANGUAGES
Define $ as the homomorphism from 2^ into 2* determined by
y(a) = a, <p(a)= A ifaGD,
<p(Z) = ip(Z)= A ifZGT.
Let Dr be the semi-Dyck set over 20 •
Define a grammar G = (Q U 20 U {S}, 20> p> •$% where S is a new symbol
and P is given as follows:
i) S-+Z0q0isin P.
ii) If 8 too. A, Z0) = {(<?„, A)}, then
is in P.
iii) If fa', a) G 5(qr,a, Z)for q, q G Q, ,4 G 2, Z G T, a G T*, then
<7 -> aaZaq'
is in P.
iv) If? GF, then
<7 -> A
is in P.
Since G is right linear, then R = Z,(G) is regular.
It only remains for us to show that
L = <p(DrnR).
Define Gq = (Q U 20 U {S},20, i>, 9) and then L(Gq) = {t£ Sol <7 =* *}■
First we prove that L£ <p(Dr C\ R). Suppose x G L. If * = A, then, by our
assumption about the pda^4,
8(q0, A, Z0) = {(q0, A)} with q0 G F.
By rules (ii) and (iii) in the definition of P, we have
S => q0 =*• A
so A G R. Since A G Z)r, we have that
AG^(Z)rnfl).
If* =£ A, then
fao, x, Z0) p1 (qf, A, A) with qfGF.
To establish the desired result, we need the following result.
Claim 1 For any q G Q, x G 2+, a G T+, and qf G F, if
fa, x, a) p- (qf, A, A),
then
xe<p(DrnaL(Gq)).
10.4
SEMI-DYCK SET AND CONTEXT-FREE LANGUAGES
319
Proof The argument is an induction on the length of the computation
sequence.
Basis. If (q, x, a) \~(qf, A, A), then xSJU{A} and a G I\ Then A
contains the rule (qf, A) G 6 (q, x, a) with qf G F. By construction, P contains the rule
qf "* A
and
<7 -* xxaqf
Clearly,
<7 => xxuqf => xxa
Hence, cade a G Z)r n a(Z, ((?„)) and
x = ip(cwcJca)G^(Z)rna(Z,(Gq))).
Induction step. Suppose that (q, x, a) (—— (<7^, A, A) with qf€F implies
x G i£(Dr ria(Z,(Gq))). Assume (<7,a;c, aZ) |— ((7', x,aa') by the rule(<7', a')GS(<7,
a, Z) and let (qf, x, aa') |—— (qf, A, A) with n > 1, qf G F, a G 2 (by our assumption
about the pda). Then
q -> aaZolq
is in P by part (iii). Clearly,
aaZa'L(Gq-)£ L(Gq),
which implies that
uZaa~Za'L(Gq')£ aZL(Gq).
By intersecting withZ)r and applying \p, we have
<p0rnaZaaZa'L(Gq')) £ <p(Drr\(aZL(Gq))).
By the induction hypothesis,x G tp(Dr n aa'L(Gq')). So
ax G aip(Z)r n aa'Z, ((?„'))•
Now, we claim the following is true.
Claim 1(a) For each q'EQ,ae T+, a G r*. a G 2,
av(Drnaa'L(Gq-)) £ <p(Dr n aZaaZu'L(Gq')).
Proof of Claim 1(a) If j> G atp(Z)r n aa'L(Gq-)), then there is z such that
j> = aip(aa'z), with aa'zGZ)r and zGL(Gq')). Moreover, note that
y = atp(aa'z) = atp(z),
since <p(a) = <p(a') = A, because ^(P) = A. Consider
aZaaZa'z.
This string is obviously in aZaa~Za'L(Gq'), since z is in L(Gq'). It is surely in Dr
since aa'z is. But
ip(aZaaZa'z) = ^(a)a^(a')^(z) = ay(z) = a<p(aa'z) = y.
320 REPRESENTATION THEOREMS FOR LANGUAGES
Thus>< is in the righthand side.
Returning to the main proof, we have that
ax G y(Dr naZaaZa'L(Gq')) £ *(Dr n aZL(Gq)),
which completes the induction proof of Claim 1.
Using Claim 1, we can show that L £ <p(Dr C\R) as follows: If x G L and
lg(x)>0, then (q0,x,Z0) £- fay, A, A), with qfeF. By claim l,*G<p(Drn
Z0L(Gq )). Since S^-Z0q0 is always a rule of P, Z0L(Gqa)<=. L(G). Therefore,
xg<p(Dr nz0L(GQo))c ^{Dr ni(G)) = ^(Dr n7?).
We must now deal with the reverse direction. Suppose x G <p(Z)r n R); then
jc = ^(y), where y G Z)r Pi R. Since y E R, S =>y. There are two possibilities for the
generation of y. Either
1 S=*q0 ^y
01 *
2 S=>Z0q0=>y
CASE 1 If S=*q0 ^•j>andj>eZ?I.n/?,thenj> = Aand AEL.
Proof S-+q0 is in P if and only if Sfa0, A, Z0) = {fa0, A)} and q0 G F,
which implies A G L. Consider the derivation q0 =>y. Assume that y =h A. Then the
derivation begins as
<jr0 => aaZaq' => y'
where a G 2, ZG T, aG r*, and q G Q. Thus >> =aaZay' where / G £(£„•)■ But
j> is not in Dr because there is no way to cancel Z. This contradiction establishes
thatj> = A.
CASE 2 Suppose that
S => Z0q0 4- y
with y &DrC\R. We wish to show that ip(y) is in L. This is accomplished with the
following result.
Claim 2 For each q G Q, a G T*, z G 2$, if og =^az with z G £(£„), and
az G Z)r, then
fa, ip(z), a) (— fay, A, A) for some qf G F.
Proof of Claim 2 The argument is an induction on the length of a
generation of aq =>az.
Basis. Suppose aq=*az with z&L(Gq) and azGZ)r. By the definition of
Gq, we must have that q -* A is a rule of P and z = A. (This is the only string in 2*
that Gq can generate.) Then az G Dr implies a G Dr. But a G Z)r implies that a = A,
since r* n 2* = {A}. Since q -+ A is in i>, then ? G F. Thus fa, <p(z), a) = (q, A, A)
r~ fa, A, A) with q G F and the basis is complete.
Induction step. Suppose that aq => az, n > 1, zG L(Gg); then azGZ)r
implies that fa, <p(z), a) £- (qf, A, A) with qf G F.
10.4 SEMI-DYCK SET AND CONTEXT-FREE LANGUAGES 321
Suppose that
aq => aaaXa. q => az
wherea G 2;XG T;a, a'G T*;z G L(Gq), and oa GDr.Clearly,
z = aaXa'z'
where z'GZ,(Gq')-Thus
—— / i (n~i) —— / /
007 =*■ aaaXaq => aaaXaz
where z & L(Gq') and aaaXaz GZ)r. But otaaXa'z £Dr implies that there exists
|3 in T* such that a = j3X and j3a'z' GZ)r. (The form of the rules in G prevents us from
having a = 0Xy with 7 G Z)r.)
Rewriting the primary derivation again,
PXq => QXaaXa'q ^ pXaaXa'z'
where z G L(Gq>) and j3ZaaZa'z' G Dr. This implies that
j3a<7 =*■ j3az
where z'GZ(Gq') and ]3a'z'GZ)r (since pXaaXa'z' GZ>r). By the induction
hypothesis,
(<7Xz'),/to') ^(^,A,A)
with qf&F. But since we have a rule <7 -* aaXa'q in />, then (q',a')€8(q,a,X).
Therefore,
(<7, <p(z), a) = fa, y(aaXa'z'),(3X)
= (q,ap(z'),pX)
\-(q'Mz'),ptt')
IrOlf.A.A)
with qf G F. This completes the induction proof of Claim 2.
To complete the entire proof, we need only show that <p(Dr C\R)£ L.
Suppose that
S => Z0q0 ^ y
andyeDrnR. Then >< = Z0y', where/ &L{GqJ and Z0y' eDr. By Claim 2,
(Qo, V(y),Z0) \^ (qf, A, A),
which means that ^(j)G L. Hence,
<p(DrnR)CL,
and the proof is complete. □
The result can now be sharpened by coding Dr into D2 .
Theorem 10.4.3 If L is context-free, then there is a regular set R, and two
homomorphisms \pi and tp2 such that
L = <p2{<p[l{D2)C\R).
322 REPRESENTATION THEOREMS FOR LANGUAGES
Proof Let D2 be the semi-Dyck set on {0, 1, 0, 1}, and let A =
(Q, 2, T, 6, <70, Z0, F) be the pda of the previous theorem. Let 2 = {a^,..., ak } and
r = {Ai,..., Am }. Define ^ which maps (2 U r)* into {0,1,0, T }* by
for each/, 1 </<£,
<fii(a,) = 10'1
Ma}) = TO'I
^(^■)=io'+fei;
. _ } for each /, KKm.
and
^(I/) = l0''+fel
Note that t^i(tf,tf,) = <£i(^4,^4,) = A for each /. Moreover, if r = |2 U T\, then
By the proof of the previous theorem,
L = <p2(Dr n R) = <p2(^"i1 (Z)2)n R). □
PROBLEMS
1 Show that Z>r and Z>r are n°t regular sets.
2 Define —reduction, and /j.' in the case of the Dyck set, i.e., for two-sided
cancellation. Reprove all the results of this chapter for D'r noting carefully where and
how things change.
3 Note that n (and //) determine relations — and —' on 2* by
x — y if and only if n(x) = n(y).
These relations are congruence relations. What sort of algebraic structure is 2 /—?
Show that 2 /— is isomorphic to the free group on r generators. Note that Dr is
the kernel of a free group.
4 Give an unambiguous grammar for Dr and Dr. Does Gr suffice for Dr1
Prove your answer.
5 Let G be a group which is finitely presented. The word problem for (the
presentation of) G is to give an algorithm which determines whether or not a given
word in the generators of G defines the identity. Show that the word problem for
the free group with generators di, ... , ar is decidable.
6 Let G = (V, 2, P, S) be a context-free grammar. Define a homomorphism
<p: V* ^N*,
(A if A G N,
*(A) =
U ifv4G2.
Let D be any derivation of G,
D: S = a0 =*•»!=*•■ • =>an
Define the index of D as
index(D, G) = max {lg (^(a,))| 0 < i< n}.
10.4 SEMI-DYCK SET AND CONTEXT-FREE LANGUAGES 323
IfwGL(G), then define
index (w, G) = min {index (D, G)\ D is a derivation of w}.
Also, the notion can be extended to grammars by defining
index (G) = lub{u| index(w, G)<u for all w G L(G)}.
G is of /zw/?e z'wdex if index (G) is finite. Show that the following grammar for Z>i
has infinite index:
S -> S5|A| a^Sax
7 Show that, for each positive integer k, there is some context-free grammar
of index k.
8 Using Problem 6 as a guide, define the concept of "leftmost index."
Produce a context-free grammar G which is of index 2 but has infinite leftmost index.
9 Define the index of a context-free language L by
index (Z) = min {index(G)| L(G) = L}.
Show that Dx has infinite index.
10 Show that, for each positive integer k, there is some context-free language
of index k.
11 Prove that every context-free language is a homomorphic image of a
deterministic context-free language.
12 Characterize phrase-structure languages in terms of Dyck sets, homomor-
phisms, and regular sets. (There are many ways to do this.)
13 A set L £ 2* is a standard regular set if there exist two binary relations
Pi and p2 on 2 (not 2*) such that x G L if and only if
i) x G j2 nj i for some (a, b) G p2, and
ii) x ^ 2*jfe2*, where (j,i)6p2-
Show that, for every regular set L £ A , there is some alphabet 2, a homomorphism
<p: 2 ->■ A , and a standard regular set i? such that L = <p(R).
14 Show that every context-free language L may be represented as L =
(p(Dr Hi?) for some r, some homomorphism <p, and some standard regular set R.
*1S Give algebraic characterizations similar to Theorem 10.4.2 for the families
of:
a) minimal linear languages,
b) linear languages,
c) metalinear languages.
16 Let Ai ={j1,j1}. Define a mapping v(ai)— 1 and v(ai)=—l, and
extend v to be a homomorphism of Af into the integers. Define the set:
L = {x €E Ai | «c = — 1 and, for each proper prefix x' of x, wc' > 0}.
L is called the Lukasiewicz language, and it is closely related to "Polish" or
parenthesis-free notation. We can generalize to A„ = {a0,. . . ,an) and define v(at) — i—\
for each i, 0 < i < n. Then
324 REPRESENTATION THEOREMS FOR LANGUAGES
L„ = {x £ A^ | vx = — 1 and vx > 0 for each proper prefix x of x}.
Show that L„ is an iterated counter language.
17 Show that a necessary and sufficient condition for L52 to be a counter
language is that there exists a regular transduction r from {jj, a"i} into 2 such that
£ = t(Z>i).
Cf. the problems in Section 6.5 for the definition of regular transductions.
18 Show that Z>i is not a counter language.
19 Show that the family of iterated counter languages is exactly the least
family containing Z>i and closed under union, inverse homomorphism, intersection
with regular sets, concatenation, +, and arbitrary homomorphisms.
20 A language L is stack bounded of order p if there is a pda A such that
L = N(A) and each stack contents is an element of Z0Ait ■ • • A; where each Atj G
r — {Z0}. L is stack bounded if L is stack bounded of order p for some p. Show that
the set of stack bounded languages is exactly the closure of the iterated counter
languages under substitution.
*21 Show that any iterated counter language that is not nonterminal bounded
must contain an infinite regular set.
22 Show that the semi-Dyck set can be accepted by a deterministic Turing
machine with space function S(n) = log n.
*23 Extend the result in Problem 22 to the Dyck set (i.e., allow two-sided
cancellation).
Let F be a field. A linear group (over F) is any group which is isomorphic to the
group of k X k invertible matrices over F for some k > 1.
*24 Show that the word problem for finitely generated linear groups over
a field is solvable in log space (i.e., by a Turing machine which runs in space S(n) =
log n). Relate to Problems 5 and 23.
There are a number of other interesting ways to utilize parentheses in language theory.
Definition A parenthesis grammar is a grammar G = (V, 2, P, S) where
i) The symbols ( and ) are in 2, and
ii) Each rule is of the form
A -* (a)
where a e (V -{(,)})*.
A set L is a parenthesis language if L is generated by some parenthesis grammar.
25 Show that a parenthesis language may be recognized in deterministic log
space.
*26 Show that there is an algorithm to decide whether L(Gi)£L(G2),
where Gj and G2 are parenthesis grammars. Hence the equality problem is also
solvable.
10.4 SEMI-DYCK SET AND CONTEXT-FREE LANGUAGES 325
*27 Show that there is an algorithm to decide whether a given context-free
language is a parenthesis language.
A general two-type bracketed grammar is a 7-tuple G = (N, 2, /, Blt B2, S, P), and
where N, 2, / are finite nonempty sets called nonterminals, terminals, and
intermediate symbols, respectively. Bi contains only indexed square brackets while B2
contains only indexed round brackets. S £ N is the start symbol. P is a finite set of
productions of the following forms:
a) A -> 77 where A S N and 77 G (2 U N U / U flj )*
b) tt-Mf-JTUG
c) a-+],-Xj3)z-
where ttS/, J'GfJVU 2)*, ]3S / U {A}, and all square brackets are in
2?i and all round brackets are in B2.
Example G = ({S,A}, {a,b,c}, {a,j3}, {[j, [2, ] j, ]2}, {(1, (2,)i, )2}, S,P)
where P is given by
S -* [Mli a -* ]2ta)2 0 -* [2j3(2
A -* <z[2.4]2c a -* hj3), 0 -* [2(2
4 -* a[2a]2c |3 -* [,/Jd
The rules in such a grammar are used as context-free rules except that the
brackets and parentheses "commute with terminals" and "cancel each other" if
properly nested. To make this precise, define a form as any string in (N U 2 U / U
B\ U B2 )*. A form 7?2 is a normalization of a form r?i if there is a 7 £ 2?i U B2, a G 2,
and forms tj3, tj4 such that tj1=tj37jtj4 and tj2 = tj3j7TJ4. A form will be
called normalized if there is no other form which is a normalization of it (e.g., if Tjj =
a(3)3A[iaB]jc[2D]2 with a,c&~L,A,B,D&N, a normalization of it would be
V2 = 1(3)3 Aa[iB] icf2D] 2. A normalization of 772 is tj3 = a(3)3Aa[1Bc]! [2Z>]2;t73
is normalized).
A form tj2 is a reduction of a form rjj if there are forms Tfa, 774 such that
either rji = 772[,];774 or 7?i =773(^)^-774,and 772 = 773774. Note that in any case the
vanishing brackets have the same index.
A form will be called reduced if there is no other form which is a reduction
of it (e.g., if 772 = j(3)3^4j[15] ic[2Z>]2 as in the previous example, then 774 =
aAa[1B]1c[2D]2 is a reduction of 772 ,• 774 is also reduced).
A form will be said to be in canonical form if it is both normalized and
reduced.
A form I is called the canonical form of a form 6 if | is in canonical form
and there is a sequence 771,772,. .. , 77m of forms such that d = 771, i; = 77m and for
each i, 1 < i < m, 77,-+1 is either a reduction or a normalization of 77,-.
28 Show that any substring of a reduced form is also a reduced form.
29 Show that the canonical form of a form 77 is unique. It will be denoted by
cf {77}. Also show that
cf{7?iP772} = cf{771}pcf{772} ifpGIUN.
326 REPRESENTATION THEOREMS FOR LANGUAGES
A form rji which is in canonical form is said to directly derive a form rj2, written
Vi =>V2, if there is a form 773 such that 773 is obtained from r}\ by replacing a symbol
u (u G NUJ) of Tj! by the righthand side of a production in P having the symbol u
on the lefthand side, and tj2 = cf {tj3}.
30 Show that for the example grammar G defined before Problem 28, we
have
L(G) = {anbnc"\n>\}.
31 Show that every recursively enumerable set L can be generated by a
general two-type bracketed grammar.
10.5 CONTEXT-FREE LANGUAGES AND INVERSE HOMOMORPHISMS
We shall show that there is one context-free language L0 from which any
context-free language L may be obtained by an inverse homomorphism. That is, for
each context-free L £ 2*, there exists a homomorphism \p so that L = <p~l(Lo)- This
result has a number of implications that are not at all obvious. It will turn out, when
we study parsing, that L0 is a "hardest context-free language." Any context-free
language can be parsed in whatever time or space it takes to recognize L0.
The key to finding L0 is to use the semi-Dyck set. Choosing L0 = D2 could
not work because D2 is deterministic and hence unambiguous. For any
homomorphism <p, <p~1D2 is unambiguous, and we could not generate the inherently ambiguous
languages in this way. We shall choose a nondeterministic version of D2 as a
"generator."
Definition Let 2 = {a\, a2, a\, a2, <t c). Define
L0 = {A}U{^1c>'1cz1d-- -xncyncznd\n>\, yi •••>>„£ *D2,xu z(G 2*
for all/, 1 </<«,
yi^{ai,a2,aua2}*
for all / > 2}.
(Note that the x('s and z,-'s can contain c's and <t's.)
It is easy to see that L0 is context-free. Imagine a pushdown automaton
which "guesses" a substring y\ in the first block and processes it in the natural way
a pushdown automaton would work on the Dyck set (i.e., stack everything and pop
when the top of the stack is ai and the input is at). The computation is repeated for
each block as delimited by d's.
We are now ready to begin the main argument.
Theorem 10.5.1 If L is a context-free language, then there is a
homomorphism y so that L = <p'L (L0) if A G L and L = ip"1 (Z,0 ~ {A}) if A £L.
Proof There is no loss of generality in assuming that A is not in L. (If A G L,
then the argument to be given works for L — A. Since i^A = A G L0 and tpx = A if
10.5 CONTEXT-FREE LANGUAGES 327
and only if x = A for our <p, the construction also works for L.) We may also assume,
without loss of generality, that L = L(G), where G = (V, ~L,P, S) is in Greibach form.
Thus every rule ■ni of P is of the form
A -> aa,
where A G N, a G 2, and ae (TV — {5})*. Let us index N as {Ai,... ,An), where
The idea of the construction is to encode productions. We shall do this by
only encoding the variables in the production, not the terminals. Then, when $ is
defined on a terminal a, it will encode all possible productions whose righthand sides
start with a.
We begin by defining two mappings from P into 2*. If nk is A{-^a, then
Tirk = a^aiai.
If Trk is Aj -*■ aAjx • ■ • Ajm for some m > 1, then
Tirk = aiaiax a1a{mai ■ • ■a\a\xa\.
To define r, we recall that / is the index of the lefthand side and
if / ^ 1 then Ttrk = Ttrk
else Tnk = <ta1a2aiTiik
Since r and r encode only the nonterminals in the production and not the terminal,
we let Pa = {nPi,... ,np } be the set of all productions whose righthand side begins
with a G 2. We define the homomorphism tp by
<pa = ifPa^0then ct(ttPi) • • • CT(itPm)cd
else <$<$
It only remains for us to show that L = tp'1 (L0 — {A}). The following claim
is the key to the proof and gives the exact correspondence between a derivation in
G and the structure of L0.
Claim For each b\,... ,bh in 2',Atl,... ,A{r in A^ — {5}, we have that
S fbi ■■■bkAh ■■■Air
under production sequence (nPl,... ,nPk) if and only if there exist x{, yit zh 1 < /
< k, such that
i) (/>(&! • • • bk) = xlcylczld • • ■ dxkcykczkd
ii) y\ '' ')>k e init(*D2) = {x\ xw G <tZ)2 for some w G 2*}
iii) iiiyi • • •yk) = taia'Jai •••aia'jai, where, for each w, /i(w) is the
unique reduced word that can be obtained from w by cancellation;
cf. Section 10.3.
Before proving the claim, let us work an example which will illustrate the
construction.
328 REPRESENTATION THEOREMS FOR LANGUAGES
Example Consider a grammar with productions
7Ti :Ai -> aA2A2
■n2:A2 -*■ a
ir3:A2 -*■ bA2
1T4-A2 -*■ b
First we compute r:
Clearly,
Now
7(7:4) = t(7t4) = aiaiai
t(7t3) = F(7r3) = aiajh a^aU^
Code for Code for
parent A2 on the
A2 right
t(7t2) = F(7r2) = aiaiai
t(iti) = WL\a2<i\ d\a2a.\ a\a\ai aia\ai
$a = ct(tti) CT(n2)cd
yb = ct(7t3) CT(Tr4)cd
A1 =j> aabA2
under production sequence (jix, ir2, ir3). Let us verify how the derivation corresponds
to conditions of the claim:
ip(aab) = c<taia2aiaia2aiaia2aiaialaica1a2aicd
c$a\a2aiaia2aiaia\aiaia\aicaxa\~axcd
ca\a\a\aid\a\ca\a\a\cd
and (i) of the claim is clearly true. Within each block (or line), there are different
ways to choose xt, y(, and Z;. In the last line, we could choose
x3 = caxalaidialaic
x3 = axa\a\
z3 = A
or we could have chosen
x3 = c
y3 = axa\.a\axa\ai
z3 = ca1a2aic
10.5 CONTEXT-FREE LANGUAGES 329
To be concrete, choose
yx = <taia2aiaia2aiaia2aiaialai = 7(7:1)
yi = t(7t2)
and
y^ = t(jt3)
This will determine xt and zt for 1 </< 3. To check whethery\ ■ ■ -y3 G init(<fcD2),
we use part (f) of Proposition 10.4.2. So both parts (ii) and (iii) of the claim require
computing n(y\y2yi)- But that is fun, as the reader who does it will learn. The answer
is
A'O'iJ'zJ'a) = W\a\ax
Now we return to the proof and note that the claim suffices to prove the
theorem. This is because (ii) and (iii) hold if and only if yx ■ ■ -yh G<fcD2; we have
that w G L if and only if there exist xlr yt, zh 1 < / < k such that
i) ipw —x\cy\CZ\d • • • xkcykczkd
ii) y\ ■■■yk^tDi
iii) yi = rnPi G S2 for / > 2,
which holds if and only if w G L0 — {A}.
Now we shall prove the claim by induction on k.
Basis, k = 1.
CASE 1 The derivation is
Ai => a
where this production is nPi. Then, applying 7 to this production gives
■nip. = <ta1a2aia1a2ai
If ^ = {*„,...,*,„,}, we have
<pa = ct(tiPi) ■ • ■ CT(iiPm)cd = xxcyxczxd
If we let j>! = 7(7Tp.),then \i{y{) - <t and so yx G init(<tD), and all the properties of
the claim are established. Conversely, if each part of the claim is satisfied, there must
be a derivation A1 =>a and Case 1 has been verified.
CASE 2 The derivation is
A1 =>aAhAh ■■■A;,,,
where m > 1, and the production is iiPi. By definition,
THPi = <taia2aia~ia~2a1aia{ma1 ■■■a1a121a1
lfPa = {iiPl,...,iiPm},then
ya = ct(tiPi) ■ ■ ■ ct(tip )cd = xxcyxczxd
330 REPRESENTATION THEOREMS FOR LANGUAGES
satisfying property (i) of the claim. As in Case 1, we let j^ = t(hp.). Then
Hiyi) = tfl^a^ax ■■■axa)ia\
satisfying property (iii). Consequently, y^ S init (*£>), satisfying property (ii).
Conversely, if each part of the claim is satisfied, there must be a derivation
Ax =>aAhAh •■•Ahn
and the basis has been verified.
Induction step. Assume the result for k > 1. Suppose we have
S f fei ■■■bhAh ■■■Air
the production ttp is Atl -*bjt+iAjl • • ■ A-n and ${b\ • • • b^)—X\cy\CZ\d • • • dxh
cykczkd, where ju(j>i • • -yk) = W\a\rax ' • -fliai'ai • Let yk+1 = t(itp) = a^al'
fliflta^ai ■■■ala'1xai andip(bk+1)=xk + 1cyk+iczk+1cd. We compute
Kyi '••J'fe+i) = K"ia-fai •••aiai'aij'fe + i)
= a\al{a\ • • • a\a-?a\a\a}£a\ ■•■aia12'a1
while
S => bx ■■■bkAil ■■■Air =* bx ■■■bkbk+1Ah ■ ■ ■ AJtA,t ■ ■ ■ Air
This establishes one direction of the proof.
On the other hand, suppose tp(&i • • -bk) = X\cy\CZ\d ■ ■ -dxk+1cyk+1
czk+1d and n(yi ■ ■■yk+i)^ *{ai> a2}*. By the construction of y, the only way
this can happen is if
Kyi '"A) = <Wi«2rai •••aiai'ai
and .
Kyn + i) = t(iip) ~ aiaUia'Jai ■■■a1a]2'a1
where irp must be a production
X. ~ bk+1Ah ■■■Ajt (10.5.1)
But since ju^j • • 'J'fe+i)£ <t{tfi, #2}*, there must be some cancellation between
^(71 '' • a) and ju(yfe+i); that is, s = /i. By the induction hypothesis,
S fbx ■■■bkAh ■■■A(r
and by using equation (10.5.1), we have
Sfbr ■■■bhAh ■ ■ ■ AitA-H-■ ■ Air
Therefore the induction has been extended. □
Corollary 1 L0 is an inherently ambiguous language.
Proof If L0 were unambiguous, then for any homomorphism ip, ip_1(Z,0)
would be unambiguous. By the theorem, every context-free language would be
unambiguous and that contradicts Theorem 7.2.2.
Corollary 2 L0 is not a deterministic context-free language.
Proof If it were, it would be unambiguous and would contradict Corollary 1.
10.6 HISTORICAL SURVEY 331
PROBLEMS
1 Write a context-free grammar for L0.
2 How would you recognize strings of L01 Can you give a polynomial-time
algorithm for recognition of strings in L0? There is a great deal of interest in efficient
recognition of strings in L0.
**3 Find a set L0 (not context-free) with the property Vna*.&=J^?>\i and
only if L0 G &. [Hint. Take three copies of L0, shuffle them (cf. Problem 8 at the end
of Section 6.4), and find a suitable restriction on the result. Relate to the family of
sets accepted by nondeterministic Turing machines in quasi-realtime.]
10.6 HISTORICAL SURVEY
Theorem 10.2.1 is from Baker [1974]. Corollary 1 of that result is due to
Ginsburg and Greibach [1966]. Corollaries 2 and 3 are due to Book [1972]. Corollary
5 is from Hibbard [1966]. Corollary 6 was proved by Matthews [1967].
Theorem 10.3.1 is from Ginsburg, Greibach, and Harrison [1967]. Problem
6 of Section 10.3 is due to Minsky [1961].
Theorem 10.4.2 is from Chomsky and Schutzenberger [1963]. The concept
of index, and relevant results about it, appear in Yntema [1967], Nivat [1967],
Brainerd [1968], and Salomaa [1969]. Problems 13 through 15 of Section 10.4
derive from the paper by Chomsky and Schutzenberger [1963]. The exercises on
counters are from Boasson [1971, 1973, 1974] and Greibach [1969,1975 a]. Ritchie
and Springsteel [1972] appear to have been the first to recognize the semi-Dyck set
in log space. Problem 24 is from Lipton and Zalcstein [1976]. Problem 25 was
suggested by the work of Mehlhorn [1975] and Lynch [1976].
The equivalence problems for parenthesis grammars are due to McNaughton
[1967] and Knuth [1967]. Various kinds of bracketed grammars are given in Schkol-
nick [1968] and Harrison and Schkolnick [1971]. Exercise 31 is from Santos [1972].
Theorem 10.5.1 is from Greibach [1973].
eleven
Basic Theory
of Deterministic
Languages
11.1 INTRODUCTION
Deterministic context-free languages are one of the most important classes of
languages because it is possible to construct efficient parsers for them. In this chapter,
we begin a systematic study of this family.
We start by studying the closure properties of the class. It takes a great deal
of work to prove that, if L is deterministic and R is regular, then LR_1 is also
deterministic. That result implies that adding or removing a right endmarker does not affect
the class of deterministic languages.
Section 11.3 is devoted to simple closure and nonclosure results. One gains a
certain amount of advantage by studying the more tractable subfamily of strict
deterministic languages. This study is begun in Section 11.4, and machine characterizations
are obtained in Section 11.5. It turns out that a language is strict deterministic if and
only if it is both deterministic and prefix-free.
In Section 11.6, an infinite hierarchy of strict deterministic languages is
established, based on degrees or on the number of states of dpda's accepting them.
Next, the length of time required to accept deterministic languages is
considered. The real-time strict deterministic languages are defined and studied in Section
11.7; and it is shown that there are some (strict) deterministic languages that cannot
be accepted in realtime even on a multitape Turing machine.
In Section 11.8, the trees that occur in strict deterministic grammars are
characterized. Using this characterization, it is possible to prove iteration theorems for
both strict deterministic and deterministic languages.
333
334 BASIC THEORY OF DETERMINISTIC LANGUAGES
In Section 11.10, we look at the family of simple languages, i.e., those
accepted by one-state realtime dpda's which accept by empty store. It will be shown
that this family has an unsolvable inclusion problem but a solvable equivalence
problem.
11.2 CLOSURE OF DETERMINISTIC LANGUAGES UNDER RIGHT
QUOTIENT BY REGULAR SETS
Our goal is to show that if L is a deterministic context-free language andi? is
a regular set, then LR'1 is also a deterministic context-free language. The proof
proceeds in an indirect manner; and first we define tables which will be used as
pushdown symbols.
Definition Let A = 02, 2,r,8,q0,Z0,F) be a dpda and let n = \Q\. For
each a S T*, define an n x n matrix T(a), called a transition matrix for a, such that
1 if (p,w, a) \— (<7, A, A) for some wS 2*,
0 otherwise.
(T(a))PQ =
Let ^~ be the set of all such matrices for A. Note that, for a dpda ,4, there are at
2
most 2" such matrices; and our first question concerns their effective construction
from A. Note that the matrix T(A) is the n x « identity matrix.
Lemma 11.2.1 Let A = (Q, 2,r,8,q0,Z0,F) be a dpda and let .T be the
set of all transition tables for A. If/is the function from ^xT* into _f defined by
f(T(a),p) = r(a/3)
for a, |3 S r*, then /may be effectively computed from A.
Proof First, we must show that /is well defined. More precisely, we have:
Claim 1 For any a1; a2) 0 e Y* if T(a{) = T(a2), then/(r(a,), 0) = f(T(a2), 0).
Proof Assume T(a{) = T(a2), where a1; a2iz A.. The special cases where
a, = A or a2 = A may be handled separately later. For any p, q e Q if T(c*\, ff)pg = 1,
then there exists w S 2* so that
(p,w,a!0) f*-(<7,A,A).
Since at ¥= A, there exist w1; w26E*,(?'sQ such that
w = W\\v2
Moreover, we may choose wi, w2, q' such that in
(p,w,axP) ^-(q',w2,a{) (11.2.1)
no part of a! is ever read. Thus we may conclude from (11.2.1) that
(P.wufi) ^(<7',A,A).
11.2 CLOSURE OF DETERMINISTIC LANGUAGES 335
mP
But
(fl',w2,ai) ]r(q,A,A)
implies
n«iv, = i.
From T(ai) — T(a2), we have
T(a2)g-Q = 1.
Thus there exists w3 S 2* such that
(q',w3,a2) f-(q,A,A).
Hence
(p, wtw3,a2/3) f- (q\ w3, a2) f~ (q,A, A).
Therefore T(a20)pg = 1.
Conversely, if T(a2$)pq ~ 1, then Tiptop,, = 1, so that
This argument also shows that, if we have T(pi) and T(0), we may effectively compute
/(7X«),0) = 7X«».
We need only show how to compute T(a) from A, where a S T*. For any p,q G <2>
1 if{We2*|(p,w,a) ^(<7,A,A)}*0,
,0 otherwise.
We know from Section 5.6 that
L(A,p,a,q) = {w6S'|(p,W,a) f-fa.A.A)}
is a context-free language which is effectively constructible from A. Moreover, its
emptiness is decidable, so that T(a) is computable from A. □
It is important to observe that the computation of / depends on T(a) and
not on a.
Corollary Let A = (Q, 2, r,8,q0,Z0, F) be a dpda with p, q&Q. Define
Rpq = {aer*| (p,w,a) f- (q, A, A) for some we 2*}.
i?p„ is a regular set.
Proof Define a relation r on T* by
(a1;a2)er «• r(a,) = r(a2).
r is a right congruence relation on T*. r has finite rank since there are only a finite
number of such matrices. Moreover
Rp« =aeUI*[«]r.
T(a)=l
where [a]T denotes the equivalence class of a under r. Therefore, Rpq is regular.
(Cf. Problem 10 of Section 2.2.) □
336 BASIC THEORY OF DETERMINISTIC LANGUAGES
Our next result not only is useful by itself, but is an important intermediate
result in showing closure under quotient.
Theorem 11.2.1 If L 9 2* is a deterministic context-free language, then so
is init(L) = L(2*)_1.
Proof By Problem 8 of Section 5.5, if c^S, then there is a dpda
A i = (<2i, 2 U {c}, r,, 6, <7o, Fi) such that
Lc = L(4i) = {wS(2U{c})*| (<7o,w,Zo) ^ (<7, A, A) for some? 6f,}.
There is no loss of generality in assuming that
8(q,a,Z) = (q',a)
implies that lg(a) < 2.
Let S~ be the set of transition tables for A\. Let/: .Tx Y\ -> J^be the
function defined by
f(T(a)J) = Tiap)
for a, j3srj. /is well defined and is computable by Lemma 11.2.1. Construct
A2 = (G2, 2, T2,62, /•„,Z„, ^2), where
Q2 = to, 011G fii. *G {o, 1,2}} u {/•<,},
T2 = ri x JTkj {Z0} where Z0 is a new symbol,
^2 = {(<7,2)|<7e<2,}u{/-o|L^0}
62 is defined by cases as shown below.
CASE 1. For any a S 2 U {A}, if 6(<70,a,Z0) = (<7,a), then:
a) if a = A, let b2(r0, a, Z„) = ((q, 0), Z„);
b) if a = A S r,, let 62(/-0, a, Z0) = ((q, 0), Z0(4, r(A)));
c) if a =^,4,,let 62(/-o,a,Z0) = ((<?, 0),Z0(A2, T(A))(AUT(A2))).
For any a e 2 U {A}, Z e r,, let 6 fa, a, Z)= (p, a).
CASE 2 (Simulation of erase rules in (q,\) or (q, 2).) If a = A, then for all
SS J^let:
b2((q,\),a,(Z,S)) = 62(fa,2),«,(Z„S)) = ((p,0),A).
CASE 3. (Preservation of tables.) If a = Z,er,, then, for all S6i", let
62((<7,l),fl,(Z,5)) = 82((q,2),a,(Z,S)) = ((p, 0), (Z„5)).
CASE 4. (f/se transition tables to predict what will happen next.) If a =
A2AU where AUA2 e r,, then for all S e S~, let
«2((<7,l),a,(Z,5)) = 82((q,2),a,(Z,S))
= (0»,0),(X2,SXi4i,/(S,i4j)).
11.2 CLOSURE OF DETERMINISTIC LANGUAGES 337
CASE 5. (Deciding to accept.) For each A&TU S&.T, and q&Qu let
((<7,2), (A,S)) if S' = /(S,i4) and there is
pS^ such that (S')<y, = 1,
(fa, 1), 04, S)) if S' = /(S,.4) and for all
peF,(S\p = 0.
62((^,0),A,(^,5)) ={
States (#, 1) and (#, 2) are the states in which input is processed. Only
A-moves are done in states (q, 0). When in state (q,0), A2 determines whether^
would accept under some future input. If such an input exists, A2 continues in states
of the form (q, 2); and if not, it uses states of the form (q, 1).
We shall prove that the construction works, by a series of simple claims.
Claim 1 FoieacliqGQ1,n>l,AiGruwG'S*,
(q0,w,Z0) ^ (q,A,An ■■■Al)
if and only if
(r0,w,Z0) f3J-((<7,0),A,a),
where a = Z0(An, TVWAn-u KAn)) ■ ■ ■ (A2, T(A3 ■ ■ • An))(A,, T(A2 ■ ■ ■ An)).
Proof The argument is a straightforward induction on k. The basis involves
only part (1) of the construction, while the induction step uses parts (2), (3), (4), and
(5). Details are left for Problem 2 at the end of the section.
Claim 2 r0GF2 if and only if L =£ 0 if and only if A S init(L).
Claim 3 init(L) = Z,(2*)_1
- [Lc((2 U {c})*)"1] n 2*
Claim 4 T(A2)^ init(L).
Proof Let w e T(A2). If u> = A and rQGF2, then L =# 0, by Claim 2, and so
A e init(L). The case r0 fi F2 is left for the problems. Suppose w ¥= A. Then there
exist q G Qu a2 G H, A G r,, 5 e S~, such that
(/•o,H-,Z0) |j2((<7,0), A,0,(^,5)) fc; «ft,2),Ka2(A,S)).
Note that a2 = Z0 if and only if S = r(A). By Claim 1, there exists a! e rf such that
(q0,w,Z0) f-(q,A,aiA)
and
[TCaO if a, =£ A,
l^A) if a, = A.
338 BASIC THEORY OF DETERMINISTIC LANGUAGES
By Claim 1, a, = A if and only if a2 = Z0. Let S' = f(S, A). If a! = A, then a2 = Z0
and S = r(A). Thus
S' = f(S,A) = f(T(A),A) = T(A) = T{a,A).
If a! =#= A, then
S' =f{T(al),A)= TfaiA).
By part (5) of the construction of 82, if 82((q,0), A,(A,S)) = ((q,2),(A,S)), then
there exists p £ T7! so that
(«')„ = 1-
Thus there exists w' £ 2* such that
(q0,ww',Z0) \j (q,w',aiA)
ff- (p,A, A) where pGFx.
Thus
W £ Z,(j4 i)
and so
w £ [£(i4i)((S U {c})*)"1] n 2* = init(L)
by Claim 3. Therefore
T(A2) £ init(L).
Claim 5 init(L) £ T(A2)
If w £ init(L) and w = A, then L ¥= 0 and r0 £ ^2 by Claim 2. Thus w £ 7X42).
Now suppose w t^ A is in init(L). There exist w £ 2* so that
ww' £ Z,
and
ww'c £ L(A{).
Hence there exists GQupGFuA £Ti anda^Tj such that
(q0,ww'c,Z0) ^ (<7,w'c,a,y4) (11.2.2)
£ (P.A.A).
But (11.2.2) implies that
(q0,w,Z0) ^ (<7,A,a,y4)
and allows us to use Claim 1 to conclude that
(r0,w,Z0) |j (q,0),A,a2(A,S))
for some a2 £ Tj. Moreover,
(7XA) if a, = A,
S =
(TXa,) if a, + A.
11.2 CLOSURE OF DETERMINISTIC LANGUAGES 339
Again, note that ai = A if and only if a2 = Z0. Let S' = f(S, A) and so S' = T(otiA).
We already know that
,A) tr(p,A,A)
where p&F,. Thus
iS')qp = 1.
By part (5) of the construction of 62,
52((<7,0),A,(^,S)) = ((<?, 2), (4,5)),
so that w S 7X-42). Therefore, init(L) c 7T(.42).
This completes the entire proof. □
The next step in showing closure under right quotient is to show closure
under removal of the right endmarker. The idea is similar to what is done in the proof
of Theorem 11.2.1, but that construction will not work directly. We wish to consider
the computation
(q,c,aA) ^(P,A,A). (11.2.3)
There are two different ways in which (11.2.3) can occur, namely:
i) The letter c can erase A and a can be erased by the null string,
or ii) A can erase A and c can erase a.
It is necessary to generalize transition tables to keep track of these possibilities.
Definitions Let A = (Q, 2, r,8,q0,Z0,F) be a dpda. Let n = \Q\, c$ 2,
and a S T*. A c-transition table for a is an n x n matrix ^(a) defined by
(Tc(a))PQ = (/,/),
where
i =
and
/ =
1 if(p,c,a) h(<7,A,A),
0 otherwise,
1 if(p,A,a) ^(<7,A,A),
0 otherwise.
Let S~c denote all c-transition tables for A.
Given a dpda, one can effectively compute the set of transition tables.
Lemma 11.2.2 Let A = (Q, 2,r,8,q0,Z0,F) be a dpda and let S~c be the
set of all c-transition tables for A. If fc: J*~c xT*-> S~c is the function defined by
fe(Te(a),P)) = Te(a®
for a, |3 S T*, then fc is computable from A.
Proof The argument is similar to that of Lemma 11.2.1 and is left as Exercise
4 at the end of the section. □
With the aid of c-transition tables, the right endmarkers may be removed.
340 BASIC THEORY OF DETERMINISTIC LANGUAGES
Theorem 11.2.2 Let c be a letter not in 2. If L 5 2* c is a deterministic
context-free language, then so is Z,(c_1).
Proof Assume that
L = 7X^0 - rd(4,)
for some loop-free dpda^. Construct a dpda^42 such that
l = 1(40 = zp2).
By using c-transition tables and fc from Lemma 11.2.2, construct ^43 from ^42 such
that
T(A3) = Lc-\
A construction similar to that employed in the proof of Theorem 11.2.1 will work to
produce A3 from A2. D
Finally, the main result can be proved.
Theorem 11.2.3 If L is a deterministic context-free language and R is a regular
set, then LR'1 is also a deterministic context-free language.
Proof Assume L,R 9 2* and let c <fc 2. Define
<p: (2 U {c})* -> 2*
to be a homomorphism defined by
la if a e 2,
ya =
(A if a = c.
Now
I, = lp-1(L)n2*ci?
is a deterministic context-free language by Problem 1 of Sec. 6.5 and Theorem 6.4.1.
Note that
Lx = {wcy\ wy EL andy GR}.
Define
L2 = (init(Z,1))n2*c-
init(L i) is a deterministic context-free language and hence so is L2. But
L2 = {wc| wcyGLi for some j> Gi?}
= {wc\ wyGL for somey£R} = (LR~l)c.
By Theorem 11.2.3, ZJ?"1 is a deterministic context-free language since L2 — (L/?_1)c
is. □
PROBLEMS
1 Do Lemma 11.2.1 and its Corollary hold for nondeterministic pda's as
well as deterministic ones?
2 Prove Claim 1 in the proof of Theorem 11.2.1.
11.3 CLOSURE AND NONCLOSURE OF DETERMINISTIC LANGUAGES 341
3 The proof of Claim 4 in Theorem 11.2.1 does not explicitly deal with the
case where w = A and r0 £ F2. Analyze this case.
4 Prove Lemma 11.2.2.
5 Complete the details of the proof of Theorem 11.2.2.
11.3 CLOSURE AND NONCLOSURE PROPERTIES OF DETERMINISTIC
LANGUAGES
It is necessary for us to know which operations do or do not preserve
deterministic context-free languages.
We recall from Theorem 6.4.1 that if L is deterministic and R is regular, then
L n R is a deterministic context-free language. We also know that, if L is a deterministic
language and S is a gsm, then 5_1(L) is also a deterministic language. (Cf. Problem 1 at
the end of the section.) It follows as a corollary of this result that the family of
deterministic context-free languages is closed under inverse homomorphisms. The first new
operation that we shall study here is product with regular sets.
Theorem 11.3.1 If L is a deterministic context-free language and R is a
regular set, then LR is also a deterministic context-free language.
Proof Let .4, = (Q,, 2, r,6,,<7,,F,) be a dpda such that T(Al)=L. There
is no loss of generality in assuming that Ay is loop-free, by Lemma 5.6.5. Let
A2 = (G2, 2,52,q2,F2) be a finite automaton such that T(A2) = R. We construct a
dpda A3 for LR as follows. l£tAi = (Q3, 2, r, 6 3, q3,Z0,F3), where
Q3 = <2i x 2Q>,
<73 = (<7i,0),
^3 = <2i x{<2^ Qt.\Q^F2 #0}.
63 is defined by cases as shown below.
CASE1. For ZST, 4, q'eQu Q<k Q2, aST* if 8l(q,A,Z)= (q',a),
define
f(<?',fiuM,a) iff'e*"!,
«3((<7,0,A,Z) =
l((<7\G),a) iff'g*1.
As ^4i goes to a final state, place the start state of Ay into the finite
control ofy4i.
CASE 2. For Z er, q,q'eQuQ£ Q2,a GS,aer*,if S^q,a,Z)=(q',a),
then define
((07',{<72}U62(G,fl)),a) if<7'e^i,
«3((<7,G),«,Z) =
Ufa,Saffi,«)),«) if* £*"i.
342 BASIC THEORY OF DETERMINISTIC LANGUAGES
We simulate all possible computations of A2 in the second component and
continue to add the start state every time A i hits a final state.
Note that A 3 is a deterministic pda because A i is.
To complete the proof, we must show that T(A3) = LR. The argument is
given in several simple claims.
Claiml Let q, q'GQlt p&Q2, wS2*, a, j3er*, and S, S'^Q2. If
(fa, S), w, a) £ (fa', S'), A, 0) and ifpGS, then S2(p, w) G 5'.
/•too/ The argument follows easily by induction on lg(w).
The next claim states a correspondence between A\ and A3 computations.
Claim 2 For any h>i, w2e 2*, for any k, 8> 0, any q,q' &Q, any a,0e T*,
and any 5, S' 9 <22,
fai.w^.Zo) S" (<7'.w2,a) I7 fa",A,|3)
if and only if
(G7i,0), WiWa.Zo) ^(fa',5),W2,a) £ (fa",5'); A,|3).
/"too/ The argument is an induction on k + 2 and is omitted.
In our next claim, we show that LR £ T(A3);
Claim 3 LR 9 T(A3).
Proof w S LR
if and only if there exist wh w2 S 2* so that
W = WiW2
WiEL,
and
w2ER.
This holds if and only if
fai,w,,Z0) £ fa', A, a) (11.3.1)
and
8(q2,w2)eF2, (11.3.2)
where q S F^ Since A y is loop-free and because (11.3.1) holds, we have
fai,WiW2,Z0) |^ fa',w2,a) ^ fa",A,0)
for some q e Fi, some 0 e r*, and some q" e Qi. By Claim 2,
(fai,0),w,w2,Zo) |j ((q',S),w2,a) \j (fa", 5'), A,|3). (11.3.3)
■"•3 -"3
11.3 CLOSURE AND NONCLOSURE OF DETERMINISTIC LANGUAGES 343
Since q G T^, we have
q2e S
by the construction. Moreover, by Claim 1,
8(q2, w2) G S'.
But we assumed that w2 G R, so
%2,w2) G F2.
Thus
and (11.3.3) is an accepting computation of A3 on wlw2. Therefore wlw2GT(A3).
In order to prove the converse, an intermediate proposition is helpful.
Claim 4 For any k>0, u>G2*, |3er*, q'eQu S'£ Q2 if there exists
q" ES' and
((<7i,0),w,Za) tj3(fe',5'), A,|3),
then there exist wu w2 G 2*, q G Qu S 9 <22, and a G T* such that
w = w1w2
((^iJXwj^Zo) £ ((<7,S% w2)a) £ ((q',S'),A,P),
where
<72 G 5,
and
%2,w2) = <7".
Proof The argument is a straightforward induction on k and is omitted.
Claim 5 T(A3) 9 £/?.
/Voo/ Assume that w G 7X/43). Then,
((«7„0), w.Zo) £ ((<7',S'),A,|3) (11.3.4)
for some /3ST*, and some (q',S')£F3. This means that S' (~}F2¥=<I), so let
q" e 5" n F2. By Claim 4 there exist w,, w2 G E*, ? G Q,, S^ Q2, a e r*, such that
(fei^Xw^^Zo) f3((<7,.S),w2,a) £-3((<7',S'),A,0),
where # G Fi, #2 G5, and 62(<72, w2) = q". By Claim 2,
(<7i,w,,Zo) ^ (<7,A,a)
with q&Fi and
62(42, w2) = q"^F2.
Thus, h> = w! h>2 with h> i G Z, and w2 G i?, and therefore T(A 3) 9 Li?. □
Next we study product on the left with a single string.
344 BASIC THEORY OF DETERMINISTIC LANGUAGES
Lemma 11.3.1 Let 2 be an alphabet, let a S 2 and let c £ 2. The following
conditions are equivalent.
1 cL is a deterministic context-free language.
2 L is a deterministic context-free language.
3 ah is a deterministic context-free language.
/Voo/ Suppose cZ, is a deterministic context-free language. Assume, without
loss of generality, that cL = T(A), where A = (Q, T,,r,8,q0,Z0, F) is a loop-free
deterministic pda. Define B = (<2, 2 — {c}, T, 6B, q0, Z0, Z7), where
8B(q,a,Z) = 8(q,a,Z) for a\l(q,a,Z)eQ x ((2 U {A}) - {c}) x I\
The initial state ^0 and the initial symbol Z0 are determined by the condition
(q0, c, Z0) If- (<7o> A, aZ0) for some a£ T*. It is now a straightforward matter to
verify that L = r(5), which is still a deterministic language.
To prove (2) implies (3) is a trivial dpda construction and is omitted.
To show that (3) implies (1), assume that ah is a deterministic context-free
language. Define a homomorphism <p by
ipb = b iffe€2
and
ipc = a.
Then
V~l(aL) n c2* = cZ,
is deterministic by the closure of deterministic languages under inverse homomorphism
and under intersection with regular sets. D
We can use this lemma repeatedly as follows.
Theorem 11.3.2 Let L 9 2* and w S 2*. L is a deterministic context-free
language if and only if wL is.
Proof Let h> = ax- ■ ■ an, where n > 0, afe S 2 for 1 < fc < n. The proof
follows from using the lemma n times. □
Now we turn to showing that the deterministic context-free languages are
not closed under certain operations. We recall that they are not closed under union.
Theorem 11.3.3
1 The family of deterministic context-free languages, A0, is a proper
subfamily of the family of context-free languages.
2 A0 is not closed under homomorphisms. More strongly, A0 is not closed
under "projections";thatis,maps from 2 into A extended to be
homomorphisms.
3 A0 is not closed under concatenation. More strongly, A0 is not closed under
concatenation on the left by two element sets.
4 A0 is not closed under * (or + either).
5 A0 is not closed under transposition.
11.3 CLOSURE AND NONCLOSURE OF DETERMINISTIC LANGUAGES 345
Proof Since every deterministic context-free language is unambiguous, it
follows from the existence of inherently ambiguous languages that A0 is a proper
subfamily of the context-free languages.
To see (2), recall that Dr, the semi-Dyck set, is deterministic. For any regular
set R, DrCiR is deterministic; and if A0 were closed under homomorphism, then
L = ^>(DrnR)
would be deterministic. By Theorem 10.4.2, every context-free language would be
deterministic, which would contradict (1).
It is convenient to define
L0 = {«W| /,/>l},
Li = {a'ftVl i,i>\\
Recall that L2 is inherently ambiguous and hence not a deterministic context-free
language. (Cf. Section 7.2.)
To prove part (3) of the theorem, let
L = cLqUZ,!.
It is clear that L is deterministic. Let R = {c, c2}. Suppose that RL were deterministic.
Then , » „ -
RLDc2a*b*a* = c2L2
would be deterministic. Using Theorem 11.3.2 allows us to conclude that L2 is
deterministic, which is false.
To show (4), define
L = Z,oUcZaU{c}.
Suppose that L* were deterministic. Then
L*nc2a+b*a* = c2L2
would be, and that was already shown to be impossible.
To show (5), let
L = cZaUc2Z,0.
Clearly,/, is deterministic. Suppose LT were deterministic. Then
(LT{c,c2}"1)n2* =L0UL! = L2
would be deterministic by Theorem 11.2.4. But this is a contradiction. □
PROBLEMS
1 Show that if L is a deterministic context-free language and R is a regular
set, then iUi?>
L-R,
and
R -L
are all deterministic context-free languages.
346 BASIC THEORY OF DETERMINISTIC LANGUAGES
2 Let 2 be an alphabet and <t=# $ $ 2. If Lu L2£ 2*, then ^ U $i2 is
called the marked union of L\ and L2. The marked concatenation of L\ and L2 is
Lx$L2 while the marked star is (/,!$)*. Show that the family of deterministic context-
free languages is closed under marked union, marked product, and marked star.
3 Show that, if L is a deterministic context-free language and R is a regular
set then
div(L,R) = {u\ uR£ l}
is also a deterministic context-free language.
4 Find a context-free language L and a regular set R such that div(L,R) is
not even context-free. R can even be chosen to have cardinality two if L is chosen
correctly.
5 Let x, y&T,*. Recall that x<y if y = xy' for some / S 2+. Define
min(I) = {yGL\ If x <y, thenx <£/,}.
That is, j» is in min(i) if y S i and no proper prefix of j» is in L. Show that if L is a
deterministic context-free language, then so is min(i).
6 Show that, if L is a context-free language, then min(L) may not be context-
free.
7 IflS 2*, define
max(I) = (ySil Ifj><x,thenx£z,}.
Thus y S max(i) means that y£i and no continuation of y is in i. Show that, if Z,
is a deterministic context-free language, then so is max(i).
8 Give an example of a context-free language L so that max(i) is not context-
free.
9 Extend the proof of Theorem 11.3.2 to cover projections.
10 Show that, if L is a deterministic context-free language, then L — min(i)
is also a deterministic context-free language.
11 Are the deterministic context-free languages closed under left quotient
with regular sets?
12 Show that it is unsolvable to determine, of two deterministic context free
languages Lx and L2, whether or not:
a) Li U L2 is deterministic;
b) LjCl,;
c) LiL2 is deterministic;
d) L\ is deterministic.
11.4 STRICT DETERMINISTIC GRAMMARS
In this section, a new family of grammars will be introduced and related to
the deterministic languages. The intuition behind this family is technical and its use
will simplify many arguments.
11.4 STRICT DETERMINISTIC GRAMMARS 347
Notation. Let aS V* and «>0. (n)a denotes the prefix of a of length
min{«,lg(a)}. The notation a(n) is used for the suffix of a of length min{«,lg(a)}.
Definition 11.4.1 Let G = (F, 2,P, S) be a context-free grammar and let
7r be a partition of the set V of terminal and nonterminal letters of G. Such a partition
7r is called strict if:
1 2 Sir;and
2 For any ,4, ,4'SAT and a, 0, 0' e K* if,4-+a0 and ,4'-+a/3' are inland
^4 =^4' (mod w), then either:
i) both 0,0' =£ A and (1)0 = (1)0' (mod tt), or
ii) 0 = 0' = AancM=j4'.
In most cases, the partition tt will be clear from the context and we shall
write simply A =B instead of A =B(mod v), and [A] instead of [^4] n = {A' G V\
A' =A (mod w)}.
Definition Any grammar G = (V,'2,P,S) is called strict deterministic if
there exists a strict partition -n of K. A language Z, is called a sfrz'c? deterministic
language if Z, = Z,(G) for some strict deterministic grammar G.
The motivation behind this definition is that we wish to make certain
restrictions on the simultaneous occurrences of substrings in different productions.
Intuitively, if ^4->a0 is a production in our grammar, then "partial information"
about A, together with complete information about a prefix a of a0, yields similar
partial information about the next symbol of 0 when 0 =# A, or the complementary
information about A when 0 = A. In the formal definition, the intuitive notion of
"partial information" is precisely represented by means of the partition tt.
Example 1 Let Gx be a grammar with the productions
S -> aA \aB
A -> aAa\bC
B -> aB\bD
C -> bC\a
D -> bDc\c
The blocks of a strict partition are: 2, {S}, {A,B}, {C,D}. The language is
L(Gl)={anbkan,akbncn\ k,n>\).
348 BASIC THEORY OF DETERMINISTIC LANGUAGES
Example 2 Our second example is a grammar for a set of simple arithmetic
expressions (enclosed in parentheses). A natural grammar for them might have
productions
E -> E+T\T
T -> T*F\F
F -> S\a
Unfortunately, this grammar has no strict partition. However, we can find an equivalent
strict deterministic grammar G2:
S -> (E
E -> TXE\T2
Ti -> FlTl\F2
T2 - F1T2\F3
Fi -> (E *\a *
F2 -> (E + \a +
F3 -> (E)\a)
The blocks of a strict partition for G2 are 2, {S\ {E}, {Tu T2\ {Fu F2, F3).
Next, we turn to the problem of testing a grammar for the strict deterministic
property. First we introduce a convenient concept.
Definition Let a, 0 e V* and let A, B be two letters in V such that A ¥=B
and we have a = yAa1 and |3 = yB^ for some y, au /3j S V*. Then the pair (A, B) is
called the distinguishing pair of a and |3. A distinguishing pair (A, B) is said to be
terminal \fA,B&'L.
From the definition, we can make the following observation.
Fact Any two strings a, |3 S V*, have a distinguishing pair if and only if
either a is not a prefix of |3 or |3 is not a prefix of a. If they have a distinguishing pair,
then it is unique.
We shall now give our algorithm.
Algorithm 11.4.1 The algorithm takes as input any context-free grammar G
and determines whether G is strict deterministic or not. In the former case the
algorithm produces the minimal' strict partition of V.
* The partition is minimal with respect to the standard lattice ordering of partitions;
that is, 7Ti < tt2 if =i 9 =2-
11.4 STRICT DETERMINISTIC GRAMMARS 349
Assume that the productions of G are consecutively numbered; that is,
P = {Ai + attf = 1,...,\P\)
and all productions are distinct.
begin
tt= {{A}\AGN}UZ;
L:forz': = 1 to \P\-1 do
begin
for/:=z' + 1 to \P\do
begin
comment At -*■ at and Aj -*■ a,- are two distinct productions in P;
if At = Aj then
if a-, and a;- have no distinguishing pair then return (fail)
else
begin
let (B, C) be the unique distinguishing pair of a,- and a;-;
if B=tC then
ifB<£ 2 and C$2 then
begin
replace [B] and [C] inir by one new block [B] U [C];
gotoZ,
end else
begin
comment B e 2 or C G 2 but not both since B $ C;
return (fail)
end
end
end
end;
return (succeed)
end.
Proof of the correctness of the algorithm The algorithm is relatively simple
and we give only an outline of a proof of its correctness. At a later time, we will
need the properties that may prevent a grammar from being strict deterministic.
First let us check that the algorithm always halts. There are two for loops,
each of which is bounded. Variables i and / are not changed inside of these loops.
Branching inside of the for-loops is either:
i) forward,
ii) out of the loops, or
iii) restarts the loops.
The first case must terminate since the loops are bounded. The second case trivially
halts. In case (iii), the cardinality of -n is decreased. Once we get to |ir| = 2, then, if
B^C, we have B G~L or CSS (but not both). Thus the loops cannot be restarted.
350 BASIC THEORY OF DETERMINISTIC LANGUAGES
Now, let us investigate how a grammar may fail to be strict deterministic.
Under the hypothesis and notation of Definition 11.4.1, we note that, if A —A'
(in the initial stage of the algorithm) or if A =A' (as a result of preceding stages in
any subsequent stage) and if 0, 0 =# A and (1)|3, (1)|3' S N, the case (i) in Condition 2
of the definition can always be satisfied by forcing ^/Js*1*/?' (the statement
preceding the goto does the job). We do not obtain an essential failure under these
circumstances. But the following three kinds of failure are essential. Assume A =A'
(forced by preceding stages).
Failure! A -> aft
A' -> a
where /3X =# A. Taking |3 = |3i and |3' = A in Definition 11.4.1, neither (i) nor (ii) can
occur. Algorithm 1 directly returns "fail" since a/3i and a have no distinguishing pair.
Failure II A -> a
A' -> a
where A ¥=A'. Taking/3 = |3' = A, we obtain case (ii) with the contradictory requirement
A = A'. Algorithm 1 halts in the same way as in the case of Failure I.
Failure III A -> aBfa
A' -> aaf}2
where B£N and a e 2. Taking |3 = 5j3j and |3' = a/32 in Definition 11.4.1, we obtain
case (i) with the requirement B= a, which contradicts condition 1. Algorithm 1
returns "fail" from the innermost else clause.
These are all the possible ways for a grammar to fail to be strict deterministic.
If no failure occurs, G is strict deterministic. Also, Algorithm 11.4.1 cannot return
"fail" and since it always terminates, it returns "success".
The fact that the partition produced is strict and minimal follows from the
property of the algorithm that two letters are made equivalent if and only if it is
required by Definition 11.4.1. □
We need to establish some simple but important properties of strict
deterministic grammars, all of which are almost direct consequences of Definition 11.4.1.
Theorem 11.4.1 Any strict deterministic grammar is equivalent to a reduced
strict deterministic grammar.
Proof The standard construction (cf. Section 3.2) for reducing a grammar
consists only of deleting some productions. The result thus follows directly from the
following claim.
Claim Let t be a strict partition for a grammar G = (V, "L,P, S), and let
G =(K', ~L,P',S) be a reduced grammar for G constructed by the methods of
Section 3.2. Then G' is also a strict deterministic grammar.
11.4 STRICT DETERMINISTIC GRAMMARS 351
Proof of the claim In G', we have V' 9 V and P' 9 P. Let w' be the partition
obtained from -n by deleting all symbols of V — V'. Then the only way that -n' could
fail to be strict would be to have two productions Pi and p2 for which a failure occurs.
But thenpi,p2GP and the failure would occur in -n also and n would not be strict. □
The following lemma extends the property of strict partitions from
productions to certain derivations in the grammar.
Lemma 11.4.1 Let G = (V, 2,.P, S) be a context-free grammar with a strict
partition -n. Then, for any A, A' &N, a, |3, |3' S V* and n > 1, if A =>£ ofi,A' ^1 aQ'
and A =A', then either
i) both p\p-'=£ A and (1)|3=(1)p-'
or iii) |3 = |3' = A and A=A'.
Proof The argument is an induction on n. The basis is immediate since, for
n = 1, the assertion of the lemma is equivalent to condition 2 in Definition 11.4.1.
Inductive step . Assume the assertion of the lemma is true for a given n > 1
and consider the case of n + 1. We can write:
A =£ wBfa =*L wfla/J, = a/3
and
A =>L w B j3, =>L w Mi = a|3
for some B, B1 £N, w, w S 2* and |3i, j3'i, j32, j32£ K*, and assume, without loss of
generality, that lg(p2)>lg(p2).
CASE 1. 0<lg(a)<lg(w). Then both (1)0, (1)/3'S2 and thus (1)|3 = (1)/3'.
For the remaining cases we make the following claim.
Claim In the above derivations, if w is a prefix of w , or w is a prefix of
w, then h> = h>' and B = i?'.
Proof of claim Assume, without loss of generality, that w is a prefix of w;
that is, that h>' = ww" for some h>" G 2*. We have A =>L wBfii and A' =*L ww"B'$\.
Then, by the inductive hypothesis, (1)(5|3i)= (1)(w"5'|3i) and since, for any u€E,
B^a (by the property that 2 e w), we conclude that w = A, u> = u>', and B = B'.
This completes the proof of the claim.
CASE 2. lg(w) < lg(a) < lg(w/32). In other words, we have a = w7i and
02 = 7i72 f°r some 71, 72 £ K* where 729t A. w is a prefix of w , or, conversely
(because they are initial subwords of a), we have w — w' and B=B' by the claim.
Therefore we can write also |32 = 7i72 for some 72S V+ (we have used the
assumption that lg(|32) > lg(|32)). Now we have B-^-y1y2, •6'->7i72, and 72, 72^ A.By the
strictness of it (property 2(i) in Definition 11.4.1), we conclude that (1)/3= (1)72 =
(1>72=(1)P'.
352 BASIC THEORY OF DETERMINISTIC LANGUAGES
CASE 3. Ig(wj32) < lg(a) < lg(wj32|3i). Again, from the claim, we have
w = w' and B = B'. Moreoever, j32 is a prefix of j32, or conversely. By the strictness
of 7r (property 2(ii) in Definition 11.4.1), this is possible only if /32 = /32 and B = B'.
Thus wB = wB' and the result follows from the inductive hypothesis. □
The following concept will start to appear regularly.
Definition A set L9 2* is prefix-free if uv&L and u&L imply v= A.
That is, a set is prefix free if no prefix of a string in L is also in L.
The following simple theorem is important.
Theorem 11.4.2 Any strict deterministic language is prefix-free.
Proof Let G = (V, 2,,P, S) be a strict deterministic grammar, and assume
S =*L w and S =*L wu
for some w,«£ 2* and«,«'> 1. If «<«', we have
5 =*i, u> and S =*£ a =>L w« (11.4.1)
for some a S K*. On the other hand, if n < n, we have
5 =*£, a =*£, u> and S =*L wu. (11.4.2)
In either case, for any k, 0<k<\g(a), (fe>a=(fe)u> implies (fe+1)a= (fe+1)u>, by
Lemma 11.4.1. Moreover,
(fe+Da = (fe+i)w
since any terminal prefix of a is (by the definition of =*£,) a prefix of wu in (11.4.1)
or of w in (11.4.2). But this shows that a = w, and so u = A. □
Corollary If L is a strict deterministic language, then either L = {A} or A ^ L.
The following result will often be applied in the sequel.
Theorem 11.4.3 Let G = (V, ~L,P, S) be a reduced strict deterministic
grammar. Then, for any,4,.BeAfandae V*,
A =*-+ Ba implies A ^ B.
Proof Let G be as in the theorem and let A =>+ Ba for some A,B£N and
a S K*. Then, for some a' e K* and n > 1, we have
X ^ 2ta\
Assume, for the sake of contradiction, that A=B. Then, by Lemma 11.4.1, for any
A'e [A], A'=>"Lp implies (1)/3e [A], and we obtain, for arbitrarily large k>l,a
derivation
kn
A =>L |3fe where ft, SAT*. (11.4.3)
11.4 STRICT DETERMINISTIC GRAMMARS 353
By the fact that G is reduced also
A =>™ w where w£ 2* andm> 1. (11.4.4)
Applying Lemma 11.4.1 to (11.4.4) (and using the definition of =*£,), we obtain that
foranym'>m and yGV*, A=>™ y impliesy62K* or7 = A,
which contradicts (11.4.3). □
Corollary No reduced strict deterministic grammar is left recursive (i.e., for
no .4 SAT and a€ K*, does.4 =>+Aa).
We shall now prove a useful grammatical normal-form result. Other results of
this type are left for the exercises. The technique used in the proof is very instructive.
Theorem 11.4.4 Any strict deterministic grammar is equivalent to a strict
deterministic grammar in Greibach normal form.
Proof Let G = (V, Z,P,S) be a context-free grammar with strict partition tt.
If L(G) = {A}, we take the grammar with the only production S -*■ A and the result
is immediate. Assume, now, that L(G) ¥= {A} and that G is reduced and A-free. There
is no loss of generality in this assumption by Theorem 11.4.1 and Problem 3 at the end
of the section. Moreover, we may assume that G is in canonical two form by Problem 5.
We shall fix our attention upon the leftmost derivations in G; the main idea
of the proof is based on Lemma 11.4.1. First, we need the following auxiliary result.
Claim 1 For any AG.N, there is a unique integer nA > 1 such that for any
aev*.
A ^"'a implies aGNV* (11.4.5)
and
A =£A a implies a€2K*. (11.4.6)
Moreover, for any A, A' G.N,
A = A' implies nA = nA\ (11.4.7)
Proof of the claim Let A &N. By the fact that G is reduced and A-free, we
can find an integer n > 1 such that A=^lol for some a e 2K*; and with the property
that for any 0 S V*, A =?L 0 implies 0 e NV* (it is enough to find a shortest leftmost
derivation from A producing a string in 2K*). Denote nA—n. We have already
established (11.4.5). To prove (11.4.6), assume that A =>1A a for some arbitrary
a E.V*. By Lemma 11.4.1, we have immediately (1)a = (1 V (note that a' =# A), and
hence (1)a' e 2. This shows (11.4.6).
Now, let A' GN, A' =A, and assume that nA< satisfies (11.4.5) and (11.4.6)
for A'. Assume, without loss of generality, that nA< ~>nA. Then we have A =*-LA a
and A' =>£A a' =>L a", where k = nA'— nA and a, a', a"SK*. By Lemma 11.4.1,
then, (1)a=(1V and thus a'SSF*. Hence, nA><nA and we conclude that
nA = nA\ We have (11.4.7). The uniqueness of nA for a given A GNis a consequence
of (11.4.7), taking A' = A. This completes the proof of Claim 1.
354 BASIC THEORY OF DETERMINISTIC LANGUAGES
We define the following finite relation PSL N x V*,
P = {(A,a)\ A GN,aG V* and A =>"A a}.
By Claim l,(A,a)GPimplies a<E 2V*.
Let us now define a new grammar G' as follows:
G' = (V.Z.P.S).
Since P is finite, G' is well defined. Also, by (11.4.6), A-*ainG' implies aS 2K*
and therefore G' is in Greibach normal form.
Claim 2 L(G') = L(G).
Proof of the claim We have Pk =>j;G <k =>G and therefore any G '-derivation
is a (7-derivation. Thus, for any wS2*, S^G'w implies S=>G w. Hence, L(G')
k L(G). For the converse, we note that any derivation of the form
S <G w (11.4.8)
where w G 2*, can be written as a composition of one or more derivations of the form
uAp^nLAG ua& (11.4.9)
where u G 2*, A G7V, ae 2K* and |3e K*. Here (4,a)£P and thus(11.4.9)can be
written as uA(t^G' ua&- Thus (11.4.8) implies S=>G- w. Hence Z,(G)^ L(G') and the
claim is proved.
Claim 3 G' is strict deterministic.
Proof of the claim We shall show that the partition -n which is strict for G
is also strict for G'. But this is simple since the statement of Lemma 11.4.1 can be
converted to the second condition of strictness (in Definition 11.4.1) by taking
n~nA= nA' and replacing =*L by -*-G\ This proves Claim 3. □
PROBLEMS
1 Show that any strict deterministic language is unambiguous.
2 Show that there are strict deterministic grammars that do not have maximal
strict partitions. Thus the family of strict partitions on a grammar forms a semilattice
but not a lattice.
3 We know, from the Corollary to Theorem 11.4.2, that either a strict
deterministic language L has the property that L = {A} or A ^ L. Prove the following result.
Theorem Let G be a strict deterministic grammar. Then either L(G) = {A}
or there exists an equivalent A-free strict deterministic grammar G'.
You may find it more convenient not to use the standard construction.
4 Prove the following result. (Cf. Section 4.5.)
Theorem Every strict deterministic grammar G is equivalent to an invertible
strict deterministic grammar G'.
11.5 DETERMINISTIC PUSHDOWN AUTOMATA 355
5 Prove the following result. (Cf. Section 4.4)
Theorem Any strict deterministic grammar is equivalent to a strict
deterministic grammar in canonical two form.
6 Can you extend Problem 5 to use Chomsky normal form as opposed to
canonical two form?
7 Show that there is an algorithm to decide whether or not a given
deterministic context-free language is prefix-free.
11.5 DETERMINISTIC PUSHDOWN AUTOMATA AND THEIR
RELATION TO STRICT DETERMINISTIC LANGUAGES
In this section, we reconsider dpda's and note some different ways in which
they may accept languages. This will give us some characterizations of strict
deterministic languages.
Definition Let A = (Q, Z,r,8,q0,Z0,F)be a dpda and, for a given AT £ T*,
define the language 1\A,K) £ 2* as follows:
T(A, K) = {w G 2* | (<7o, w, Z0) )r (q, A, a) for some q G F and a G K}.
In particular, let
T0(A) = T(A,r*),
T,{A) = T(A,r),
and
T2(A) = T(A,A).
We shall use these definitions to define three families of languages.
Definition We define the following three families of languages for i = 0,1,2:
A,- = {1}(A)\ A is a dpda}.
A0 is our family of deterministic context-free languages. Note that A2 does
not even contain all regular events but only the prefix-free ones.
The family A! contains all regular languages. It can be shown that A! is
a subfamily of the closure of A2 under the Kleene operations.
First some simple facts about these families will be established.
Theorem 11.5.1
1 Every language in A2 is prefix-free.
2 A2£ A,c A0.
3 All inclusions in (2) are proper.
Proof Part (1) is an immediate consequence of the definition of T2(A),
since if
(q0,x,Z0) ^ (<7,A,A),
356 BASIC THEORY OF DETERMINISTIC LANGUAGES
then
(q0,xy,Z0) )r(q,y,A) f^-fa'.A.A)
is possible only if y = A (and q' = 17).
To prove A2 c Au let I€A2 and let A = (G, 2, T,5, <70, Z0, F) be a dpda
such that Z, = 72 (<4). We shall construct another dpda A' with the same behavior as
A except that A' will have an additional initial pushdown letter Z'0, which is never
overwritten. Formally, let
A' = (QU{q'0},Z,ru{Z'0},8',q'0,Z'0,F),
where q'0$. Q, Z'0$. Y, and
IS(q,a,Z) if,? GG,aG2A, and ZGT;
(<7o, ZoZ0) if <? = q'0, a = A, and Z = Zq;
undefined otherwise.
Now, for any x G 2*, first (170,x,Z'0) \^ (q0,x,Z'0Z^); and afterwards, for any q&F,
(q0,x,Z'oZ0) ^7 (<7,A,Zq) ifandonlyif (<70,x,Z0) [^ (<7,A,A).
Since q&F implies that q =£<70, we have 5'(<7, A,Zq) = 0, and therefore x G T^A')
if and only ifx G r2(yl). Hence,! = T^A').
Next, we wish to show A! f= A0. It should be clear to the reader why a
construction is necessary. Let I6Aj and let A = (Q, 2, T, 5, <70, Z0, F) be a dpda such
that L = ^(/i). We shall construct another dpda A' which possesses a special copy of
each letter in T, to be able to distinguish the bottom of the store. A' simulates^ but
accepts only with a single letter on the store. Formally, let
A' = (e',2,r',S',<7o,Zo,F),
where
F= {q\q&F},
Q' = 2UF,
f = {ZIZGT},
r' = ruf.
5' is defined by cases.
CASE 1. For each q G Q, Z G r, and a G 2 U {A},
8'(q,a,Z) = 8(q,a,Z).
CASE 2. For each qGF,Ze r, and a G 2 U {A},
8'(q,a,Z) = 5(<7,a,Z).
CASE 3. If 8(q,a,Z) = (<?', Fa) with 7GT,<7 G Q -F, then
S'fo.fl.f) = fo'.Fa).
11.5 DETERMINISTIC PUSHDOWN AUTOMATA 357
CASE 4. If 8(q,a,Z) = (q', Fa) with 7e r and ^G F, then
S\q,a,Z) = (q',Ya).
CASE 5. If qGF, then
5(<7,A,Z) = (q,Z).
It is easy to see that, for every x S 2*,
(q0,x,Z0) fa (q,x,Za)
if and only if
(q0,x,Z0) fa (<7,A,Za).
Thus, xS T\(A) if and only if a = A and qGF. In turn, this holds if and only if
(q,A,Za) fa{q,\,Z).
But this holds if and only if x e T0(A'). Therefore,! = T0(A').
To show that A2 ¥= Alt let Z,! = {a}*. ij is not prefix-free and hence L is not
in A2. It is clear that ij = Ti(A), where
A = ({<7o), {«}, {Zo},5,<7o,Z0, {<7o}) and 8(q0,a,Z0) = (q0,Z0).
To show A, ^A0, let
I2 = {anbn\ «>l}Ua*.
First, Z,2=r0U), where A = (Q, 2, r,8,q0,Z0,f) is a dpda with Q =
{<7o,4i>> 2 = {«, ft}, r = {Z0,Z1,Z2},F= {«70}, and
((q0,Z{) ifZ = Z0;
5(<7o,a,Z) =
{(q0,ZZ2) if Z¥=Z0;
and for any q€Q,
L0,A) ifZ = Z,;
5(<7,ft,Z) =
(<7,,A) ifZ = Z2;
undefined if Z = Z0.
Second, assume that Z,2 = ^(d) for some dpda A. Since there are only a finite number
of accepting configurations (q,A,Z) where qGF and Z£T, there is a sufficiently
large « such that, for some k<n,
(q0,an,Z0) ^(<7,A,Z)
(q0,ak,Z0) h(<7,A,Z),
where q eFandZer. But, since,for some q' SFand Z'€ r,
(<7o,a"ft",Z0) ^(<7,ft",Z) f-fo'.A.Z'),
358 BASIC THEORY OF DETERMINISTIC LANGUAGES
we also have
(q0,akbn,Z0) \^(q,bn,Z) \^(q',A,Z'),
and hence akbn G£2, which is a contradiction since k<n. Therefore L2£ &i- D
Our next result is quite simple but informative.
Theorem 11.5.2 L G A2 if and only if L is prefix-free and L G A0.
Thus A2 coincides with the family of prefix-free deterministic languages.
Proof The only if direction is immediate from Theorem 11.5.1.
For the if direction, let L G A0 and let A = (Q, 2, T, 5, q0, Z0, F) be a dpda
such that L = T0(A). We can construct another dpda A' which simulates.4 and erases
all its store after A accepts. If L is prefix-free then L — T2(A').
Formally, let
a' = (Gu{(?f},s,ru{y0},6,,(?0,y0,y
where q{$Q and Y0£ I\ 5' is defined as follows:
1 For each <7 G g-F and ZGT,
8'(q,a,Z) = 8(q,a,Z).
2 For each <7 GFU {<7f}and Z G T U {r0},
5'(<7,A,Z) = (<7f,A).
3 8'(q0,A,Y0) = (q0,Y0Z).
Assume that L is prefix-free. If
(q0,xy,Z0) \^(q,y,a) \^(q\A,a),
then q' G F implies q £ F or y = A. Therefore, for any xG2* and<7GF,
(<7o,x,Z0) [^ (<7, A, a) if and only if (q0,x,Y0Z0)\j,(q,A,Y0a)\j,(qt,A,A),
and thus* G ro04) if and only if x G r204'). Hence,! G A2. D
We now begin the long argument to show that every language in A2 is strict
deterministic. Our first lemma puts a dpda into a more convenient form.
Lemma 11.5.1 Let L G A2. Then L = T2(A) for some dpda .4 with a single
final state.
Proof Assume L = T2(A) for some dpda A = (Q, 2, T, 5, q0, Z0, F). Using a
similar construction as in the proof that A^ A0 in Theorem 11.5.1, we construct
another dpda A which can distinguish the bottom of the store. Otherwise, it simulates
A except that if A erases its store and accepts, A does the same by entering the single
final state.
Formally, let
A = (G,Z,r\S\<7o,.Zo,{<7f})
11.5 DETERMINISTIC PUSHDOWN AUTOMATA 359
where r' = ruf= {Z, Z\ ZGT} and qt GF is chosen arbitrarily. 5' is defined by
cases. For each q G g, a G 2, andZGT,
CASE1. &'(q,a,Z) = 8(q,a,Z);
!(q',Z'y) if 8(q,a,Z) = (q',Z'y);
(<7f,A) if5(<7,a,Z) = (<7',A)and<7'eF;
undefined otherwise.
Now, for any w G 2*,
w&T2(A') if and only if (q0, w,Z0) ^ (q, a, Z) \^ (qt, A, A)
for some a G 2A, Z G r, and q€Q,
if and only if (<70, w, Z0) \j(q,a,Z) [j fa', A, A)
for some q' 6f,
if and only if wS^i). D
The next phase in our proof is to pass from A to a grammar which generates
the same set. We shall employ the standard construction used in Section 5.4. The
reader should review that construction. We shall refer to the canonical grammar of A
denoted by G^ as defined there.
Lemma 11.5.2 For any dpda A with a single final state, the canonical
grammar G^ is strict deterministic.
Proof Let G^ be the canonical grammar as given in Theorem 5.4.3 for a
given dpda A (with a single final state). Define an equivalence relation = on F such
that:
A =B ifandonlyif A,B&l,ovA = (q,Z,q)
B = (q,Z,q") for some q,q',q" GQ,ZGF.
Let 7r = V/=. Obviously, 2 G v. Let
A = (q,Z,q')-+ay = a/3
A' = (q,Z,q")-+a'y' = a/3'
where a.a'SZU {A}, y, y G (V — 2)*. Let us make the following three observations.
Observation 1. Either a = a — A or both a, a G 2.
Observation 2. If a = a', then either 7 = 7' = A and q' = q", or we have
7 = (p,Zuq{)(quZ2,q2)- ■ ■ (qk-i,Zk,q')
y = (p,Z1><7i)(<7i,Z2>(7i)---(<7;_1,Zfc><7")
360 BASIC THEORY OF DETERMINISTIC LANGUAGES
for some p, qu q\ G Q, Z; G I\ and k > 1. In either case, lg(7) = \g(y'). (This
observation is a consequence of the construction and of the fact that 5 is single-valued.)
Observation 3. Either 0 = 0' = A or 0,0' ¥= A.
Assume that 0 = A but 0' =£ A. Then a = a0 = ay and a'7' = Q0' = 070'. Thus a' = a
and, by Observation 2, lg(y) = lg(7'). But now lg(a) = lg(a0'), which contradicts that
0'#A.
To prove the strictness of n, assume first that 0 ¥= A. Then, by the last
observation, 0' ¥= A.
CASE 1. a= A and a&~L. Then a'G2 by Observation 1 and both (1)0,
(1)0'G2.Hence,(1)0=(1)0'.
CASE 2. a = aG2A. Then a' = a = a and, by Observation 2 (note that
7*A),wehave(1)0=(p,Z1,«71) = (p,Z1,<7,)=a)0'.
CASE 3. a€2AJV+. Then again a = a' and, by Observation 2, <x(1) =
(<7,-_!, Z,-, <7;) = (<7,._,, Zj, (7J) for some /, 1 < i < k. Thus <7,- = q\ and ('}0 = (qt, Zj+,,
«,-+i)=(«t,^+i.«;+i)=(!)u'-
Now, assume that 0 = A and thus 0' = A. Then a-a and 7 = 7'. By
Observation 2,17' = q". Hence, A —A'. □
We already know that
l(ga) = r2tf)
from the proof of Theorem 5.4.3.
We now have half of our characterization theorem.
Theorem 11.5.3 A2 is a subfamily of the family of all strict deterministic
languages.
Proof Let L G A2. Then L = T2(A) for some dpda A. Then, by Lemma
11.5.1, L-T2(A) for some dpda J with a single final state. Now the canonical
grammar GA is strict deterministic by Lemma 11.5.2 and L = Z.(Ga ). Thus L is a
strict deterministic language. □
Now we turn to a proof of the converse. Although the construction we are
about to give could be simplified in some ways, it has the advantage that its state set
is in a natural correspondence with the strict partition of the grammar. This
correspondence will be exploited later.
First we introduce certain notational conventions which will simplify our
formalism.
Definition For any strict partition w on a given context-free grammar
G = (V, I,,P, S), define the size of n as
IHI = max IK; I.
V;G7T-{£}
Thus || 7r II is the cardinality of the largest non-S block of tt.
11.5 DETERMINISTIC PUSHDOWN AUTOMATA 361
For our proof, let G = {V, ~£,P, S) be a grammar with the strict partition
7T = {2, V0, Vu . . . , Vm\ (11.5.1)
where m > 0 and V0 = [S]. We use special indexed symbols Ai}- for the nonterminals
of G, so that, for all i (0 < / < wz), we have
V, = U,-o,^n,.-.,^4 (11-5.2)
where «f = | Kf| — 1. (Note that max; «,■ = || tt\\.) Moreover, let Aw = S.
Definition Let (7 = (V, ~L,P, S) be a grammar with strict partition -n for
which we use the notation from (11.5.1) and (11.5.2). We define the canonical dpda
A G for G as follows:
AG = (Q,X,r,8,q0,Z0,{qo}), (11.5.3)
where
Q = fa| 0</<||ir||},
r = Vi u r2,
Tl = {(Vi,a)\ A-+a0isinP for some,4 G K*,a,0G K*},
r2 = {(Vha, Vj)\ A+aBpismP foisameAeVt,BeVj,anda,fieV*},
Zo = (m,A) = (K0,A),
and 5 is defined by means of four types of moves, as follows. For any V„ Vk 6ir-{2),
a G K*, a G 2, and <7;- G £), we have:
TYPE 1. 5(«7o, A, (V„ a)) = (q0, (Vt, a, Vk)(Vk, A)) if A -> aBjS is in /> for
some ,4 G K;,5 G Kfe, and /J G K*;
TYPE 2. 5(<7o, a, (V,, a)) = (q0, (Vh aa)) if A -> aa/3 is in P for some ,4 G Vt
and /J G K*;
TYPE 3. 5(<7o, A, (yu a)) = fo, A) iMu -+ a is in/>;
TYPE 4. Sfo,, A, (Vk, a, K,)) = (<7o, (ffc, <fc4tf)).
Otherwise 5 is not defined. Moves of Types 1,2, and 3 are called detection moves;
a move of Type 4 is called a reduction move.
First we have to verify that our definition is correct.
Lemma 11.5.3 For any strict deterministic grammar G, the object AG is a
well-defined dpda.
Proof We have to show that 5 is single-valued and is deterministic. Assume
that we have the following two moves:
(q, a, X) (q, a', Z)
(11.5.4)
(p, a) * (p', a')
362 BASIC THEORY OF DETERMINISTIC LANGUAGES
We shall show that a¥=a (hence the single-valuedness) and, moreover,
a,a GI,.
CASE 1. Both moves in (11.5.4) are of the same type in the terminology of
the definition of AG. Then either a = a = A or a, a'S 2. Suppose a=a'. Then we
obtain (p,a) = (p,a) immediately for Types 2 and 4 or using the strictness of tt
for Types 1 and 3. Hence a =£ a' and a, a' e 2.
CASE 2. The two moves in (11.5.4) are of different types. Then neither of
them is Type 4 since that is the only type with Z € r2. Assume therefore that
q = <7o, Z = (F,-, a). Now moves of Types 1 and 2 are incompatible since B = a is not
possible for 5 e N and a S 2, and neither Type 1 nor Type 2 is compatible with Type
3 since A =A', A -*■ afi, and A' -*■ a in P imply 0 = A by the strictness of tt. Hence,
The following result is intuitively obvious but the formal proof is rather
lengthy.
Lemma 11.5.4 Let AG be the canonical dpda for a strict deterministic
grammar G. Then T2(AG) = L(G).
Proof Let us partition the yield relation |— in accordance with the four
possible moves in the definition of AG.
(q,aw,yZ) fy (q',w,ya) (11.5.5)
if and only if 8(q,a,Z) = (q',a)is amove of type /,/= 1,2,3,4.
Thus |—= U?=1 \j. Moreover, let us define
n = (hru ^r ^. (n.5.6)
(Intuitively, if we interpret AG as a parsing algorithm, \= is the detection phase and
h^-the reduction phase of the algorithm.)
Let C be the set of configurations of AG and define two sets 6?d,
£?r£ & as follows:
dd = Gx2*xr2*r,,
Gr = Qx2* xH.
Using the definition of AG, we can interpret relations fy as partial functions (|— is
single-valued) as follows:
(11.5.7)
Now (11.5.6) and (11.5.7) imply:
11.5 DETERMINISTIC PUSHDOWN AUTOMATA 363
We have the following.
Fact IfciS &d and c2e ^..then
c, \^c2 implies c, ((= tD*|=c2. (11.5.8)
Further, we will need the following claim about the contents of the store of AG.
Claim 1 For any (q,w,y), (q ,w',y')e £r (that is, 7, y &T$\ if
(<7> w, 7) |— (17', w', 7'), then 7 is not a prefix of 7'.
Proof of the claim The argument is an induction on the length of 7. (For
convenience, we use the notation 7 \~y as an abbreviation for "(<7, w,7) h-(17', w', 7')
for some q,q' eg and w, w'e 2*.")
5as/'s. The case 7 = A is vacuously true, since |— is, in this case, undefined.
Inductive step. Assume the claim proved for all 7! shorter than some 7 e r2.
Now let
7 = 7i(K,a, V') \^y'
for some (V, a, V') e r2. Then, by the definition of AG,
7i(K, a, aV) f^- 7,(^,0^4) |— 7' for some .4 e K.
Now cl4 in (V, A) cannot be changed back to a in (V, a, V') without being erased,
i.e., without an application of a move of Type 3. Hence, a necessary condition for 7
being a prefix of 7' is
ydV.a.V) \rtjyi P-V.
Since 7i ^7', we have yx \— y , By the induction hypothesis 71 is not a prefix of 7',
and hence 7 is not also. This completes the proof of Claim 1.
The following two claims are crucial in our proof.
Claim 2. Let we 2* and /, />0. If Aij=>*w then, for any .ye 2* and
7 2' foo, *y, JiV,, A)) ((= tr)* (= (qhy, T)-
Let Ci = (<7o,vvy,7(F,-,A)) and c2 = (qj,y,y). Assume A^^w. The argument is
an induction on n > 1.
.Basis, « = 1. Then Ajj-*-w and if w=£ A then for every factorization w =
Witfw2 (wi, w2 e 2* and a e 2), we have
(qo,aw2y,y(Vi,wi)) I7 (<7o, w^T^i, wi<0);
and in any event we subsequently have
(<Jo,y,y(Vi,w)) \j(qj,y,y) = c2.
Thus,Ci I7 I7 c2 or,using(11.5.6),C! |=c2.
364 BASIC THEORY OF DETERMINISTIC LANGUAGES
Inductive step. Let «>1 and assume the result proved for all «'<«. Let
a G V* such that
Aij =*• a =* w
For any prefix a! of a, we have one of the following three cases:
CASE 1. a! is followed by a G 2; that is, a = a^aa2. Then, for some suffix
w2 of w we have a2 =*■* w2 and
(<7o, aw2y, y(Vi, a,)) |y (<70, w2y, y(Vh a^)).
CASE 2. a! is followed by B&N; that is, a = aiBa2. Then, for some suffix
wBw2 of w, we have 5 =*■ wB («' <n), a2 =>* w2 and
(<7o, wBw2y, y(Vi, a,) h^-(«o, WbW2j, y(V{, a, [B] )([B], A))
(r= ^)* 1= (<7fc > w2.y, 7(7;, ai,"[5])) by the inductive
hypothesis from
B=*n'wB if B
= Aike[B],
\^(Qo,w2y>7(VhaB)).
CASE 3. a, = a. Then
(qo,y,y(Vi,<x)) \j(qj,y,y) = c2.
Now starting with configuration cx, that is, a! = A, we can combine Cases 1 and 2
depending on the form of a G (2 U AO*, until we finish with Case 3 in which c*i = a.
Therefore,
ciOiuhrChhrrhhr)*^;
hence,
using the identity (p U a)* = (p*a)*p* (cf. Problem 2);hence,
ci((=f7((=hrrri=c2,
using (11.5.6) and the identity p*p = pp*; hence,
c.(htr)*Nc2,
using the identity (pp*)* — p** = p*. This proves Claim 2.
Our last claim is essentially the converse of Claim 2.
Claim 3 Let w,y G 2*,ye rj and/,/3*0. If
(<7o, wy, T( F,-, A)) f- fay ,7,7) then A
Again, let ct = (<7o, wy. 7(^i, A)), c2 = (qhy, y), and let c, ^c2. By (11.5.8),
c\ (1= I7)" 1= c2 for some n > 0. Then, by the definition of A G and (11.5.6),
c.(N^r(hrU^)*c3^c2, (11.5.9)
11.5 DETERMINISTIC PUSHDOWN AUTOMATA 365
where c3 = (qo,y,y(Vk,y)). First, we show that Vk — Vj. Indeed, if Vk ¥= Vt, we
would have (using the notation from the proof of Claim 1),
liYu A) ^riiYuff) \jy f-^y(Vk, A) \ry(yk,a) \jy
for some 0 6 V* since this is the only way of replacing Vt by Vk in agreement with
the definition of AG. But here y \—y is contrary to Claim 1. Therefore, Vt = Vk and
from c3 fjc2 we have Ay -*■ a.
We proceed by induction on n in (11.5.9).
Basis. « = 0. Then Ci (hf u br)* c3- Moreover, no move of Type 1 can occur
(since that would increase the length of 7). Thus Ci |yc3 \jc2. This is possible only if
all letters in a are terminal or if Cj = c3, which occurs if a = A. Hence, a S 2*, a = w
and Aij -*■ w.
Inductive step. Let n > 1 and assume the result proved for all ri <«. From
(11.5.9), the definition of AG and Ay -*■ a, we conclude that, for every prefix o^ of
a, there is a unique configuration c = (q0, w2y, y(Vi, aO) such that c^ \~c f~c2 (the
uniqueness follows from Claim 1). Here w2 is a suffix of w. Let w = Wi\v2 and W]6 2*.
First we show that £*! =*•* wt by induction on the length of ax. This is immediate if
a! = A =>* A = Wx. Assume that at =*■ Wx was already proved and let a = alBa2
(B S Kand a2& V*). Let us consider two configurations
c = (.qo,w2,y(Vt,ai)),
c = (<7o,W2,7(^,ai^))-
There are two cases.
CASE 1. 5 = ae2. Then, by the definition of AG, c |yc', w2 = aw'2, and
otid =** Wia is trivial.
CASE 2. BGN. Then we have
c \j (<7o, w2>>, y{Vu au [B])([B], A))
\r fa.w'iyMVi.au [B]))
assuming that B = Aike[B]. From (11.5.8), we see that the relation |— can be
replaced by (|= (-)" \= for some ri <n. Moreover, w'2 is a suffix of w2, say w2 = w\w2.
Then by the inductive hypothesis B =*-+ w\ and therefore o^i? =>+ Wiwi. This ends the
inductive proof that a^ =>+ Wi.
Now, for a! = a we have .4y =*■£* =*•* w' where w is a prefix of w. We shall
show that w = w. For, assume w = w'w". By Claim 2, then,
Ci = (<7o,wV>,7(F,,A)) p-(q},w"y,y).
But then, to avoid 7 r~7, which would contradict Claim 1, we must have (qs, w"y, 7)
= c2 and hence w" — A. We conclude Ay =** w, as asserted. This finishes the proof of
Claim 3.
366 BASIC THEORY OF DETERMINISTIC LANGUAGES
Now, to conclude the proof of the lemma, we combine Claims 2 and 3 and
substitute y = y = A, i =j = 0 (note that S = A00 by convention). We obtain that,
for any w S 2*,
S =*-+ w if and only if (q0> w, (V0> A)) ^ (<70, A, A),
and therefore w S £(G) if and only if w S T2(A G). □
We can immediately apply the previous lemma.
Theorem 11.5.4 The family of all strict deterministic languages is a
subfamily of A2.
Proof The theorem is a direct consequence of the definition of a canonical
dpda and of Lemmas 11.5.3 and 11.5.4. □
Now, combining Theorems 11.5.2, 11.5.3, and 11.5.4, we obtain one of our
main results.
Theorem 11.5.5 The family of strict deterministic languages coincides with
the family of prefix-free deterministic languages.
TABLE 11.1 Closure Properties of A2, Alf and A0
Operations with Regular Sets
Product
Intersection
Quotient
Boolean Operations
Union
Intersection
Complement
Kleene Operations
*
Product
Marked Operations
Union
Product
Other Operations
Min
Max
Reversal
Homomorphism
Inverse gsm
LR
LvnR
LR-1
LjULj
LXC\L2
L
L*
LXL2
C\L\ U C2L2
JL1 &.L2
A2
No
Yes
No
No
No
No
No
Yes
Yes
Yes
Yes
Yes
No
No
No
At
No
Yes
No
No
No
No
No
No
Yes
Yes
Yes
Yes
No
No
Yes
Ao
Yes
Yes.
Yes
No
No
Yes
No
No
Yes
Yes
Yes
Yes
No
No
Yes
11.6* A HIERARCHY OF STRICT DPDA'S 367
PROBLEMS
1 Consider the following equivalence relation.
Definition Let L 9. 2* be a deterministic context-free language. We define
the relative right congruence relation induced by L, RL, as follows: For x, y&L,
(x,y)GRL if and only if for all zS 2*, xz&L^-yz&L.
Prove that if L G At then RL has finite rank. Can you prove the converse?
2 Prove the following identities for sets over 2* or for binary relations over
a set:
a) p*p = pp* b) (p U a)* = (p*o)*p* c) (pp*)* = p** = p*
*3—47 Table 11.1 summarizes the closure operations for A0, Ai, and A2.
Prove all entries that have not yet been done in the book.
11.6* A HIERARCHY OF STRICT DETERMINISTIC LANGUAGES
In the last section, we defined ||ir|| where t is a strict partition. We shall
relate this to the number of states of a dpda accepting the language generated by
such a grammar.
Theorem 11.6.1 Let L be any language and let n > 1. Then L = L(G) for
some strict deterministic grammar with partition tt such that ||7r|| = « if and only if
L = T2(A) for some dpda.4 with n states.
Proof The result is immediate in the only if direction from Theorem 11.5.4
and from the fact that the canonical automaton has, by definition, 1177" 11 states. For
the // direction, we first note that the construction of dpda A with |F| = 1 in the
proof of Lemma 11.5.1, doesn't change the number of states. The rest then follows
from the proof of Theorem 11.5.3, in particular, that the partition -n used for proving
the strict determinism of the canonical grammar has the property that || vr|| = | Q \. □
Let us recall from Section 11.4 that every strict deterministic grammar has
a unique partition 7r0 which is the minimal element in the semilattice of all strict
partitions of G. Also, ||7r0ll< IMI for any other strict partition G. This suggests the
following definition.
Definition Let G be a strict deterministic grammar. We define the degree of
G as the number
deg(G) = llwoll,
where it0 is the minimal strict partition for G. For any language L S A2, define its
degree as follows:
deg(Z,) = min{deg(G)| G is strict deterministic andL(G) = L).
Our next objective will be to show that strict deterministic languages form a
nontrivial hierarchy with respect to their degree or, equivalently, with respect to the
368 BASIC THEORY OF DETERMINISTIC LANGUAGES
minimal number of states of the corresponding dpda. This result can be intuitively
explained by pointing out that the main reason for having more states in a dpda is
when a greater amount of information from the top part of the store has to be
preserved while any letters beneath it are read. This consideration leads us to an
example which will serve as a basis for the formal proof of the result.
Lemma 11.6.1 Let 2 = {a, b}. Define, for any n > 1, the language
Ln = {ambkambk\ Km.KKn}.
Then Ln — T2(A) for some dpda.4 with n states.
Proof Let An = (Q, Z,r,8,q0,Z0,F) be a dpda where Q={q0,--- ,<7„-i}.
T = {Z0,0, 1,2, 3},F = {<70}, and 5 is defined as follows:
8(q0,a,Z0) = (<7o,02),
5(<7o,a, 2)= (<7o, 12),
5(<70,&,2) = (<7o,3),
S(q„b,3) = (<7m>3) for 0 < / < « - 1,
8(qha,3) = (<?,•, A) for0<i<n-l,
5(<7,-,a,l) = (<?,-, A) for0</<n-l,
8(qh b, 0) = (<?,-!, 0) for 0 </ <n - 1,
5(<7O)ft,0) = (<7o,A).
To show that T2(An) =Ln,it is enough to observe that a computation leads to
acceptance of a string w S 2* if and only if it has the following form for some m > 1, where
\<k<n:
(<7o, w,Z0) h (<7o,a_1w,02)
^1(<7o,(0"V01m-12)
h fe0,(flmft)"1w,01m-13)
^=L((7fe-1)(amftfe)-1w)01m-13)
h (<7fc_1,(«mftfcfl)-V01m-1)
Fi(<7fc_1,(fl"»ftfcflm)"1w,0)
h (fe(rtk/iVw,A).
The proof is complete. D
Next we shall prove that n states are necessary for the acceptance of Ln (as
defined in Lemma 11.6.1). The formal proof is by no means trivial since we have to
prove this for all conceivable dpda's. First we need a lemma.
11.6* A HIERARCHY OF STRICT DPDA'S 369
Lemma 11.6.2 Let A = (Q, 2, I\ 5,<70, Z0,F) be a loop-free dpda and let
uSE. Then either:
a) there exists n0>l such that for any q&Q, 7ST*, and m~>\, if
(<7o,am,Z0) \— (<7, A, 7), then lg(7)<«0 (that is, the size of the stack is
bounded); or
b) there exist m0, f> 1, q G Q, y0 G T*, 17 G T+, and Z G T such that, for
every fc > 0,
(<7o,am°+/l',Z0) ft^-fe.A.To^Z) (11.6.1)
and for any k > 0 and 7 G r*,
(q0,ak,7orihZ) f-(fi',A,i) implies 7 = 7c>tjV (H.6.2)
for some 7rGr+ (i.e., the stack is essentially ultimately periodic in some word tj).
Proof Let us assume that (a) is not satisfied. A useful claim is established first.
Claim 1 For each r > 1 there exist nr > 1, «r+1 > nr, Zr G r, qr G Q, yr G r*
with lg(7r) >r, such that:
(q0,anr, Z0) (f1 (<7r, A,TrZr) (11.6.3)
and for eachs>0,
(qr,as,Zr) \^(ps,A,8s) (11.6.4)
for some ps&Q and 0„ G r*.
iVoo/ Suppose that Claim 1 were false. Then there exists r > 1 and for each
s there exists a computation sequence
(<7„o, "«o, 7«o) h ' '' h (<7,fe,, "«fes, 7sk)> 01 -6-5)
where q^ = q0, us0 = am«, 7„o = Z0, wsfes = A, and lg(7«fes) <r. Note that, for each s,
there exists an integer ms and so there are infinitely many ID's (qsk , A, y$ks)- But
Q x T is finite,so there exist s =£ r such that
(<7«fes>TSfes) = (gtkt)ytkt). (11.6.6)
CASE 1. Suppose /n„ =mt. There is no loss of generality in assuming that
ks<kt. (If it were not so, we could switch notation.) But A is deterministic so for
eachCXi <£„,
Qsi = Qti, usi = uti, and ysi = yti.
Then
(<7so, "so, 7«o) h ' ' • h (<7sfes, wSfes, 7^
II II (11.6.7)
(<7(o,W(o,7ro) h '' ' h (<7ffes, utk$, ytkg) \- ■ ■ ■ \- (qtkt,Utkt,7tkt)-
Thus
(««,. A, ytk) \r (Qtkt, A, ytkt)- (11 -6.8)
370 BASIC THEORY OF DETERMINISTIC LANGUAGES
But from (11.6.6) and (11.6.7),
(q,ks>1sk) = (Qtkt,7tkt) = (<7tfes> Ttfej)- (11.6.9)
Thus (11.6.8) represents an infinite A-loop and
(<7o,am*,Z0) Vr(.q,A,i)
is false for all q e Q and y & V*. This proves that ms¥=mt.
CASE 2. ms¥^mt. There is no loss of generality in assuming that ms <mt.
Since A is deterministic, ks<kt, and for each 0 < i < ks,
Qsi = Qti, u$i = "ti. and ysi = yti.
But we have
(qs0,am',Zo) | h (<7sfes, A, yskg)
II II
(qto,amt,Z0) | h(<7,fes,flm'""\W h(<7^,A-W-
Thus from (11.6.9),
(<7tt,.«m'~m'.7*k,) r1 (Qtkt, K7tkt)-
Now let
n0 = max{lg(7fl-)| \<i<kt}<r.
Thus we have a uniform bound and (a) is satisfied. This contradiction proves Claim 1.
Let r > 1 and let nr, qr, and Zr be as in Claim 1. Since Q x T is finite, there
exist / </ such that Z; = Z,- and <7,- = <7y. Since .4 is deterministic,
(<7o, A"',Z0) tf- (<?,-, A,T,Z,) (11.6.10)
and
(q0,a">,Z0) |^-(<7i,A,7,TjZi)
for some tj e r*. Moreover, tj e r+, since otherwise we would be in case (a). Then,
{quanr-i,Zi) \r («?,•, A,r?Z,-). (11.6.11)
Now choose m = «,• and/= «y — «,-. For each A > 0, we have
(«7o, am+V, Z0) (t^ (<?,-, a", yiZd from (11.6.10)
ttf-(<7l,A,7,T?hZ,) from (11.6.11).
Note that (11.6.11) also implies that if A; > 0, fc > 0, and
fe.-.fl*,^^,) ^(<7',A,T),
then 7 = 7,t/17' where 7' =£ A. Therefore (b) holds and the proof is complete. □
Now, we shall start the long argument which shows that any dpda which
accepts Ln (as T2(A)) has at least n states.
Lemma 11.6.3 Let Ln be the language from Lemma 11.6.1 for some n > 1
and let A be a dpda such that T2(A) = Ln. Then A has at least n states.
11.6* A HIERARCHY OF STRICT DPDA'S 371
Proof Let A = (Q, 2,r,5,<7o,Z0,F) be a dpda satisfying the assumptions
of the lemma and assume that \Q\ <«. We assume that n > 2, since for n = 1 the
lemma is trivial. Our strategy will be to prove a sequence of claims about A which will
eventually lead to a contradiction. We shall investigate an accepting computation of
the form
(q0>ambkambk,Z0) f-(qt,A,A), (11.6.12)
where 1 </n, 1 <&<«, and qt 6f. Informally, we distinguish four phases of
computation in (11.6.12) in a natural way: In each phase one block of the same letter
(am or bk) is read. A typical history of the store is illustrated in Fig. 11.1.
First we show that the content of the store after the first phase is periodic.
Claim 1 There exist m0,f> 1,qvGQ,y0£V*, t?GT+,andZl&V such that,
for every h>0, t
(q0,am°+hf,Z0) H-fe1,A,7or/kZ1). (11.6.13)
Proof of the claim To be able to apply Lemma 11.6.2, we need the loop-free
property. Consider therefore a dpda Aa = (Q, {a}, T, 8a,q0,Z0,F) obtained from A
by restriction of input alphabet to {a}; that is, for all q G Q and Z G r,
|5(<7,tf',Z) ifa'G{a, A};
[undefined ifa' = b.
Clearly, for any m > 0, q& Q, and y G T*,
(<7o, am, Z0) Hjfl 07, A, T) if and only if (q0, am,Z0) \\j (<?, A,T). (11.6.14)
For any m>\, since am is a prefix of an acceptable string (for example, ambamb),
there exist q E Q and y G T* such that (^0, am,Z0) Hj(<7, A, T). Hence, by (11.6.14),
Aa is loop-free. We shall now apply Lemma 11.6.2 to Aa, since, for any m > 1, there
must be a different configuration (^,A,7) in (11.6.14) — otherwise we would have
ambkambk G T2(A) for some m ^m. Also, since Q and V are finite but m may be
arbitrary,thereisnobound on the length of 7. Thus we cannot have case (a) in Lemma
11.6.2 and we obtain Claim 1 as a consequence of (11.6.1).
(Store)
8a(q,a',Z)
Can't occur
by Claim 3
Input a
FIG. 11.1
372 BASIC THEORY OF DETERMINISTIC LANGUAGES
For the rest of the proof we fix symbols m0, f, y0> qt, and Z\ with the same
meaning as in Claim 1. Our next claim is that during the second phase (during the
reading of the bk), only a bounded number of tj's are erased from the store.
Claim 2 Let 1 <&<« and h >0. Then
fai, bk, Tor/%) \\^ (q2, A, yotf-'y)
for some q2 S Q, y € r* and s < n1.
Proof of the claim Let q2&Q and y G T* be such that
ci = fa, bk, y0rfZl) Vr fa, A, V). (11 -6.15)
Such q2 and 7' always exist, since otherwise A could not accept a string with the
prefix am"+hfbk (cf. (11.6.13)). It is enough to show that y0rih~s is a prefix of 7' for
somes <n2.
Assume, for the sake of contradiction, that this is not the case; that is, that
To7?71 " is not a prefix of y . However, it is a prefix of 70TjhZi in C\ and therefore
there exists a configuration c\ such that (11.6.15) can be written in the form
c\ ^ c\ (f1 Oh.A.V)
and the contents of the store in c\ is exactly 70r?/l_" (cf. Fig. 11.3). We shall
concentrate on those transitions in cx \c\ which are associated with erasing a letter
from the original contents of the store (i.e., a letter written before configuration C\
was entered; cf. thick lines in Fig. 11.2). Let us call these transitions proper erasing.
Since at most one pushdown letter can be erased at a time, there are at least
lg(rj" Zi) = n2' lg(rj) + 1 proper erasing transitions in cx \—c\. At most k of the
erasing transitions correspond to non-A-moves of A, since only k input letters are
(92-A.y')
n"2z,
,/i-n2<
yoi
FIG. 11.2
Time
11.6* A HIERARCHY OF STRICT DPDA'S 373
read in (11.6.15). Consider the sequence of consecutive transitions corresponding to
A-moves (we call them h-transitions) in C\ \~c'\ which contain the maximal number
•^max °f proper erasing transitions. Since k<n, lg(r?)> 1 and, using the fact that
Ci can be followed only by a non-A-transition (a consequence of (11.6.13)), we obtain
the inequality JV^ > n • lg(r?). Now any suffix of y0rihZ1 of length Nmax contains
at least n — \ repetitions of tj or, using the assumption that \Q\<n, it contains at
least IQI repetitions of tj. Consequently, there exist two configurations c2 and c2
such that Ci |— c2 t~c2 \~c'u where c2 \~ c'2 consists entirely of A-transitions and
exactly \Q\ repetitions of tj are erased from the store during c2 \— c2 (cf. Fig. 11.2).
Formally, we have for somep,p GQ,\ </<k, andi>\Q\,
ci\^c2 = (p,bi,70T,h-WQ{) H" (?',b>.kiP'1) = ci, (11.6.16)
where t>\Q\'lg(Tj). Therefore at least two distinct configurations occur in
c2 \—c'2 such that both have the same state and the same topmost string tj in the store.
In other words, for some p" G Q and 1 < r < | Q |,
c2 £■ c3 = (pH,bt,y0rf-irn ^ (?",*', ToTJ*"') = c\ f- c'2. (11.6.17)
But this introduces a loop and (11.6.17) must repeat until almost all the periodic
part of the store is erased:
c's ^(p'>;',7oT?r°) = c4, (11.6.18)
where r0 < r. Now let ti = h + r. Then
foo, am°+h'fbk, Z0) ft*- (<?,, b', jorf'zd by Claim 1,
^ (p",bi,y0rih'-irir) by (11.6.16) and (11.6.17),-
f- (P",b}\ yo^'V) = c3\^c4 by (11.6.17) and (11.6.18),
using h' = h + r.
Let m = m0 + hf and rri — m0 + h'f¥=m.We have
(q0,ambkambk,Z0) f- (p", b}amb\y0rir°) f-(qt,A,A)
on the one hand, and
(<?o, am'bkambk, Z0) ^ (p", bJambk, y0Vr") ^ fat, A, A)
on the other hand, contradicting that m ¥=m and am bkambk $Ln = T2(A). Thus
To7?71 " is a prefix of y which concludes the proof of Claim 2.
Thus for any h^n2, m =m0 + hf, and for any k, 1 <£<«, we have a
common prefix % = y0rih~n of any possible contents of the pushdown store after the
first two phases of the accepting computation,
(q0,ambk,Z0) tf-(q2,A,ft), (11.6.19)
where q2GQ and 7G r*. Here y is dependent only on k(cf. Fig. 11.2).
We shall turn our attention to the last two phases of the computation
(11.6.12).
374 BASIC THEORY OF DETERMINISTIC LANGUAGES
Claim 3 Let 1 < k < n andm > 1. There exist mk<m and q( ' G Q such that
(<72,amfe,lT)^ (<7<fe),A,l), (11.6.20)
where q2, ?, y are the same as in (11.6.19).
Proof of the claim We have (q2,ambk ,%y) \^(qt, A, A) since ambkambk G
r2(/l). Therefore for some prefix w of ambk we have also (q2, w, %y) \~~(<7(fe\ A, |) for
some <7<fe)GQ. It is enough to show that lg(w)</n. Suppose the converse; that is,
w = amb} for some 1 </' < k. Then we have
(qw,b"-',IO f-(qt, A, A). (11.6.21)
Here %-y0Tih~" may be an arbitrarily long string since h is arbitrarily large. An
argument similar to the proof of Claim 2 leads us to the conclusion that (11.6.21)
contains a subsequence of A-transitions erasing more than | Q \ • (k — C) occurrences
of tj in i- and therefore erasing almost all %', but, since % was not changed during the
second and third phases, we would have, as in Claim 2, that, for some m ¥=m,
(q0,am'bkambk,Z0) £- (qw,bk-j, £') ^(<?f,A,A)
(where £' differs from % only in the number of repetitions of tj; we omit the details,
which are analogous to the arguments in the proof of Claim 2). This contradicts
T2(A) = Ln and therefore w = amk for some mk </n. This completes the proof of
Claim 3.
The proof of Lemma 11.6.3 can now be completed without difficulty. Let
m> 1, 1 <k<n, and 1 <k' <n. Let qw,q(k)&Q and mk,mk' be as in Claim 3
(for k and k\ respectively). Using (11.6.19) and (11.6.20), we can write
(<7o,am6W,Z0) ^ (q«\am-m*bk,%) = c ^ (qt,A,A)
and, for m =m + mk' — mk,
(q0,ambk'am'bk,Z0) f- (qlk'\am-mkbk, %) = c .
By the assumption that \Q\<n, k and k' can be chosen in such a way that k¥=k'
but qw = q(k'\ But then we have c = c \r(.Qt, A, A) and thus ambk'am'bk G T2(A)
which is our final contradiction and establishes that A cannot have less than n states.
□
Now we can state the main theorem of this section.
Theorem 11.6.2 For any n > 1 there is a language L G A2 such that deg(Z,) = n.
Proof Let n~>\ and consider the language Ln from Lemma 11.6.1. By
Lemma 11.6.1 and Theorem 11.6.1, Ln = L(G) for a grammar G with strict partition
7r, || -7T|| = n. Since || 7r0ll < II ttII we have deg(£n) < n. Assume deg(Ln) < n. By Theorem
11.6.1 there exists a dpda for Ln with less than n states, contradicting Lemma 11.6.3. D
Theorem 11.6.2 establishes a hierarchy of strict deterministic languages under
their degree.
11.7 TIMING QUESTIONS IN OPOA'S 375
PROBLEMS
1 Check which of the transformations of strict deterministic grammars
preserve degree.
2 (Open problem) Is the degree of a strict deterministic language effectively
calculable?
11.7 DETERMINISTIC LANGUAGES AND REALTIME COMPUTATION
Our goal in this section is to investigate timing questions in dpda's. We
already know that any deterministic context-free language may be accepted in linear
time by a dpda from Problem 5.6.10. This tells us that a Turing machine would also
accomplish this in linear time. We shall show, in this section, that there is a (strict)
deterministic language L such that no realtime multitape Turing machine can accept L
in realtime.
Notation. Let L = {a^b^b • • •ai'-^bair(fai'-'+l\ r>\, \<is for all /,
1 </<r, Ks<r}.
It is clear that I6AjEA,c A0. We shall now show that L cannot be
accepted in realtime. To do this, we consider a certain equivalence relation.
Definition Let L £ S* and k>0 be given. For any x, yG'L*, define the
relation Ek(L), by the condition (x,y)GEk(L) if and only if for eachzGS* with
lg(z) < k, we have xz € L if and only if yz G L.
Clearly Eh{L) is an equivalence relation on 2*.
Next we turn to the theorem which is the basis for this type of proof.
Theorem 11.7.1 Let A = (Q,2,r,8,q0,F)be a realtime Turing machine
with m work tapes, L = T(A), and let k > 0. Then
rk(Ek(L))<\Q\\r\^k+1)m.
Proof Let x, y G2* and suppose that (x,y)fiEk(L). If we start A on x
and on y, then let ax and cty be the last ID of A's computations. Clearly, a^ =?tay.
[Otherwise, for any zG2fe, xzGL if and only if yzGL, which would contradict
that (x,y)fiEk(L).] As x, y range over 2* without limit, the number of ID's ax
and Oy grows without bound. Since A is realtime and z G2fe, we must calculate the
number of ID's that A can distinguish in k steps. This bound is
iqi in(2fe+i)m
because an ID can contain any state, and in k steps, one can only move k positions
on a work tape. Since this can involve k in either direction, we find that the number
of different contents of a work tape is | T |(2fe+1) and there are m work tapes.
To complete the argument, we note that if rk(Ek(L)) = p were greater
than the bound, then there would be p tapes which were pairwise inequivalent
mod£'fe(Z,). These must lead to p distinct ID's which is more than A can distinguish
in k steps, and leads to the contradiction that some two of them would have to be
equivalent mod Eh (L). D
376 BASIC THEORY OF DETERMINISTIC LANGUAGES
Now we are ready to prove the desired result.
Theorem 11.7.2 L, as defined above, cannot be accepted by any realtime
multitape Turing machine.
Proof Suppose, for the sake of contradiction, that L = T(A) for some
realtime multitape Turing machine with m tapes. Define
Lk = {a'lb ■ ■ ■ a'r-iba'rc'a'r-**! | r > 1,1 < z) < k, 1 </ <r, 1 < s <r}.
Thus we bound the number of successive a's to be k. Note that Lk£ L. Next we
consider the equivalence relation Ek+r(L).
Claim rk(Ek+r(L))>kr.
Proof of the claim Consider two distinct prefixes of words in Lk,
Xi = a'*b ■ ■ -a'r-lbatr
and -I,
x2 = ahb .. -a3r-iba3r,
where xl=£x2 and 1 <zp, jq <k for 1 <p, q <r. Clearly, there exists a sequence
z = csal, where s + t < k + r such that
xlzE.Lh but x2z£Lk.
Thus (xi,x2)£Ek+r(L). Thus there are at least as many classes of Ek+r(L) as there
are distinct prefixes of this form. Clearly, there are k values for each of iu ... ,ir
and each may be chosen independently. Therefore
\Ek+r(L)\>kr
and the claim has been proven.
Now to complete the proof, we employ Theorem 11.7.1. We know that
k" <rk(Ek+r(L))<\Q\\r\Wk+r)^)m. (11.7.1)
In this inequality, k and r may grow but everything else is fixed. Thus (11.7.1) reduces
to
/f<c(fe+r) (H-7.2)
for some constant c. As k and r grow, (11.7.2) is obviously violated for any constant c,
and we have a contradiction. D
Corollary There exists a strict deterministic language which is not a realtime
language.
Next we define some families of deterministic languages, recalling that quasi-
realtime pda's have a bounded number of consecutive A-moves.
Definition A language L is called At-(quasi) realtime if L = Tt(A) for some
(quasi) realtime dpda A, i = 0, 1,2.
With this definition, we can state another corollary of Theorem 11.7.2.
11.7 TIMING QUESTIONS IN OPOA'S 377
Corollary The family of Arrealtime languages is properly contained in the
family A; for/=0,1,2.
Proof Clearly, L as defined at the beginning of this section has the property
that
L£A2CA,c A0.
But it has been shown that L cannot be accepted by any realtime, on-line multitape
Turing machine. Thus, L is not a realtime A,- language for i = 0,1, 2. D
We begin to relate quasi-realtime and realtime languages. We shall do so for
A2 now.
Theorem 11.7.3 A language L is A2-quasi-realtime if and only if it is A2-real-
time or L = {A}.
Proof The if direction is a direct consequence of the definition and the fact
that {A} = T2(A) for any dpda A with a single move
6(<7o, A,Z0) = (<7f,A) for some qt e F.
This dpda is quasi-realtime {t = 1).
For the only if direction, let A = (Q, ll)r,8,q0,Z0,F)be a dpda and assume
A is quasi-realtime with time constant t. One can define an equivalent realtime dpda
A' in such a way that (i) the pushdown letters of A' are codes for n-tuples (« = 2t + 1)
of pushdown letters of A, and (ii) one move of A{ has the same effect as a sequence of
at most n moves of A. A' must simulate the writing and erasing moves of A in its finite-
state control and must transfer information to and from its pushdown storage in
blocks of size n. We shall omit the formal construction and proof and leave the details
for Problem 2 at the end of this section. D
It turns out to be valuable to have a grammatical characterization of the
A2-realtime languages.
Definition Let G = (V, 2,P, S) be a strict deterministic grammar with
minimal strict partition n. G is called a realtime strict deterministic (or simply realtime)
grammar if it is A-free and the following condition is satisfied for all A, A' ,B,B' GN
anda,0eF\
If A -*■ aB and A' -*■ aB'/} are in P, then A=A' (mod n) implies j3 = A.
(11.7.3)
Note that if G is a realtime strict deterministic grammar, then for any A,
A' GN, if A -+a.B is inP,^'->-a5'|3isinP, and .4 =A'^,then|3= A and either .4 —A'
and B = B' (so that there is but one rule involved) or B =2?'.
It is interesting to note that the requirement that n be minimal is necessary
in this definition. Consider the following example:
378 BASIC THEORY OF DETERMINISTIC LANGUAGES
S -+ aAS\b
A ■+ aB
B -+ aAB\aCA\b
C ■+ aD\c
D ■+ aAD\aCC
and let n0 = {2, {S}, {A,C}, {B,D}} and it = {2, {S}, {A,B, C,D}}. G is a realtime
grammar. If the minimality condition were dropped from the definition, G would
not be realtime with respect to it but would be with respect to n0.
It is clear from the definition that the reduced form of any realtime grammar
is also realtime.
Theorem 11.7.4 A language is a A2-realtime language if and only if it is
generated by some reduced realtime grammar.
Proof (Only if) First note that, since acceptance is by final state and empty
pushdown, one can restrict attention to a dpda with one final state and there is no loss
of time. More formally, the dpda A constructed in Lemma 11.5.1 is realtime if and
only if A is realtime. By Lemma 11.5.2, G\ is strict deterministic under partition it
defined in that proof. It is easily seen that it is minimal. Now let us recall that Gx has
productions of two types as defined in the proof of Theorem 5.4.3. By the realtime
property of A in both cases, we have a =£ A. Thus G^ is A-free and, moreover, in
Greibach normal form. To prove (11.7.3), let A -+aB and A' -+aB'B be in P and
assume A = (q, Z, q) = (q, Z, q") = A'. Gx is in Greibach normal form; hence a =£ A
and (1)a £ 2. By the determinism of A and the definition of Gx, there is a unique
7GT* (as well as q &Q) such that 6(<7,(1)a,Z) = (q',y). Consequently, lg(a5) =
lg(7) + 1 = lgM'0). Hence, 8 = A.
(If). Let L = L(G) for some reduced realtime grammar G. Our strategy will
be to modify the canonical dpda AG in such a way that the resulting equivalent
dpda A'G will be quasi-realtime. This is sufficient for a proof that L is A2-realtime
language since the A-free property of G implies that L ¥= {A}. To make it easier to
follow the proof, we shall first examine the properties of AG related to the
occurrence of A-moves. We shall use the same notation as in the proof of Theorem 11.5.3.
We have defined the 6-function of A by means of four types of moves: Types 1,3, and
4 are A-moves, and Type 2 is always a non-A-move. Accordingly, we have distinguished
four types of yield relations
(q,aw,yZ){r(q',w,ya) if and only if 8(q,a,Z) = (q',a)is amove of Type i,
where i = 1,2,3,4. Let c, c' be two configurations of AG such that
for some m > 0, where c is the result of a Type 2 move. We are interested in finding
a bound on the number m in (11.7.4). We shall see that such a bound exists after
suitable modification of AG. First we notice that (11.7.4) can be rewritten in the
following form.
11.7 TIMING QUESTIONS IN OPOA'S 379
n /*ii \ ft.
c', (11.7.5)
where £u, k2, n >0,k2 + 2"=1 (ku + 2) = /n,and n denotes composition of relations.
Claim 1 If G = (V, ~L,P,S) is a reduced realtime grammar and c, c' any two
configurations of AG satisfying a relation of the form (11.7.5), then ku = 0 for all
i and k2<\N\.
Proof of the claim By definition, a Type 1 move can be followed by a
Type 3 move if and only if there is a A-production in the grammar. Since G is A-free,
kn = 0 for all i. Also, k2 consecutive moves of Type 1 can occur if and only if
ft -l
A h- Ba for some A, B&N and a&V*; but since there are only \N\ nonterminals
and A =>Aa is not possible in a reduced strict deterministic grammar (the Corollary
to Theorem 11.4.3), k2 < IN\ (in fact, k2 < II nil). The claim is proved.
As a consequence of Claim 1, only the number n in (11.7.5) can be
unbounded. Therefore, we restrict our concern to the case c (\^ \-^)" c , or, more
conveniently,
where c, c are two configurations of AG and n >0. Directly from the definition of
moves of Types 3 and 4, we have:
Claim 2 For any q}-, qz&Q — {q0\, Vk,Vt&-n and a G V*,
(qj,A,(Vk,a,Vi))^[j(q&,A,A) (11.7.6)
if and only if Aki -*■ atAy is a productiont in G.
Let us call any letter (Vk, a, Vf) G T a saturated letter if and only if ^4 -»■ a5
is in P for some A&Vk and 5 G Kf. Denote Ts the set of all saturated letters (we
have Ts c r2).
Claim 3 If Zi = (Kfe,a, K;) is saturated and Z2 = (Kfe,a0, K;-)Gr, then
0 = A and / = /*.
Proof of the claim This claim is a consequence of property (11.7.3) of
realtime grammars: Since Z\ is saturated, we have A -*■ olB is in P for some A&Vk and
B G Vt; and since Z2 G T2, we have A' ■+ a0C0 for some A' &Vk,C& Vh and 6GV*.
Then by the strict determinism of G, 0C0=5'0' for some B'&N, 0'G F\ But
0' = A by (11.7.3), and hence C = B', 0 = A and Kf = [5'] = [C] = K;- by the strict
determinism of G. The claim is proved.
t Recall the convention V; = {Ai0,.. ., A^.} for V; G 77.
380 BASIC THEORY OF DETERMINISTIC LANGUAGES
By Claims 2 and 3, any saturated letter on the top of the store is always
erased (never rewritten) and this is realized by a transition of the form [j [j. Now,
for any saturated letter Z = (Vk, a, Vt) G rs, we can uniquely specify a partial function
fz'.QfQ, (11-7-7)
such that fz{Qj) = <7b if and only if q}, q% ¥= q0 and one or the other side of equivalence
(11.7.6) holds. We can extend (11.7.7) to:
fn-Q-^Q (H-7.8)
for tj G T, using (11.7.7) as a basis and defining inductively/^ = /,/z, that is, for any
Q G Q, fnzi.0)— /tj(/z(<7)) provided fz(q) is defined. Note that there are only a finite
number of distinct functions /„. In fact, |{/„| n G rs+}| <(|Q| + 1)IQI.
Claim 4 For any q, q G Q; y, y' G r* and n > 1,
(q,A,y)(tj\^)" (<?'.A,V) if and only if y = y'ri
for some tj G T" and (7' =fri(q).
This claim follows from Claims 2 and 3 by a straightforward induction on n.
Thus the only effect of fl-7 h^)" is erasing a saturated string of length n
from the store and changing the state of control. Claim 4 gives the basis for the
elimination of an unbounded sequence of A-moves: instead of a saturated string tj of
length > 1, on the store of the modified dpda A'G appears a single letter fn representing
the function /,,.
For the completeness we describe formally the construction ofA'G. For this,
let AG = (Q, 2, r,8,q0,Z0, {q0}) be the canonical dpda defined prior to Lemma
11.5.4. Define A'G as follows:
A'o = (e',Z,r',6',<7o,Z0,{<7o}), (11.7.9)
where Q' = Q U {qz\ Z6T,} (the new states are added for technical reasons only),
T' = T U {/„ I tj G r;} and 6' is defined as follows: If A ■+ aB is in P for some A G V,
and B G Vk, then define:
i) 5'(<7o, A, (V,,a)) = (qz,A) where Z = (V,, a, Kfc) G Ts;
ii) 8\qz, A,/„) = (.q0Jvz(Vk, A)) for all /„ G r' - T, Z = (K,, a, Kfc);
and
iii) 8'faz,A, 10 = fao, 17z(Kfc,A)), where Z = (Vha,Vk), and for all
rer.
Moreover, for any <7;- G g — {<70} and/,, GT'-T, define
iv) 5'(<?;-, A,/„) = (/,(<?), A).
In all other cases define
v) 8'(q,a,Z) = 8(q,a,Z).
Moves (i), (ii) and (iii) are new special cases of Type 1 moves of AG; move (iv) is a
special case of the Type 4 move. We observe that a saturated letter never appears in
the store, and even if some A-moves were added, A'G is quasi-realtime. It is easy to see
that T2(A'G) = T2(AG). Claim 4 suffices for that. □
11.8 STRUCTURE OF TREES 381
PROBLEMS
1 Show that the following set L1 cannot be accepted by any realtime
multitape Turing machine:
L' = {xldx2 ■ ■ ■ xr-ldxrcdkcx?-k+1\ x; G {a, b}*, 1 =*f<r, 1 =* k<r}.
2 Give a detailed proof of Theorem 11.7.2.
3 Prove the following proposition about regular sets.
Proposition Let L £ 2* be a regular language. Then there exists a number
n > 1 such that any string x&L, where lg(x) > n can be written in the form x = y \zy2,
where yu yiGZ*, z eZ+,\g,(zy2)<:n,an<l, foi all k> 0, y iZky2 &L.
4 Prove the following useful proposition:
Proposition Let G = (V, 2;JP, S) be a reduced realtime grammar. Assume
S => uAu
and
A => vA0
for some A ejV,uG2*,a6F*, fl£Z+and 06 V*. Then for any n >0 and wGZ*,
S => uv"w
implies lg(w) > n.
5 Prove the following result:
Theorem Let G be any reduced realtime grammar. Then L(G) is regular if
and only if G is not self-embedding.
Hint. Problems 3 and 4 can be helpful.
6 Show that the result in Problem 5 is best possible in the following sense.
Find a reduced, A-free, self-embedding, strict deterministic grammar G such that
L(G) is regular. Thus the result in Problem 5 cannot be extended to the full family
of strict deterministic grammars.
Let Si be the family of sets definable by realtime multitape Turing machines.
7 Show that SI is closed under union, complementation, intersection, and
product on the right with regular sets.
8 Show that 9 is not closed under product, *, transpose, homomorphism,
either left or right quotient by regular sets, or max.
11.8* STRUCTURE OF TREES IN STRICT DETERMINISTIC
GRAMMARS
In this section, the structural properties of derivation trees ih strict
deterministic grammars will be developed. In addition to the property of unambiguity, the
strict deterministic grammars have a unique "partial" tree for every prefix of a terminal
string. We utilize more general objects than derivation trees, namely, the grammatical
382 BASIC THEORY OF DETERMINISTIC LANGUAGES
trees (with roots labeled by any letter) in order to facilitate induction proofs. The
uniqueness of the "partial" trees is the content of the Left-Part Theorem. This
theorem will be also used to prove two deterministic iteration theorems.
Recall that our conventions in Section 1.6 were to use the term grammatical
tree for a tree whose frontier is in V*. A derivation tree has a frontier in 2*. For a
given grammar G, .T'q denotes the set of derivation trees of G while -3~G{A) is the
set of derivation trees whose root is A. (Cf. Section 1.6 for the rest of our notation
involving trees.)
We are now ready to define the left-part of a grammatical tree.
Definition Let T be a derivation tree of some grammar G. For any n > 0, we
define <n)r, the left n-part of T (or the left part where n is understood) as follows.
Let (xi,... ,xm) be the sequence of all terminalt nodes in T (from the left
to the right); that is, {xu ... ,xm} = \~l(I,)andxl\lx2\l- ■ -L!:xm.Then
(n'T = {x in T\ x LTxn} ifn<nz,and
(n)r = T ifn>m_
We consider (n)r to be a tree under the same relations T, L, and labeling X
as T.
Thus, for instance, the shaded area on Fig. 11.3 (including the path tox) is
the left «-part of T if x is the nth terminal node in T. Note that, in general, ^rmay
not be a derivation tree.
As immediate consequences of the definition, we have
Factl <»)7'=(»+i)7' ifandonlyif(")7,= r.
Fact 2 If (n)r= (n)r', then U)T= U)T' for any/<n.
Our principal result about the structure of derivation trees of a strict
deterministic grammar can be informally stated as follows. A reduced grammar G has a
w = uv
FIG. 11.3
t Note that the A-nodes are not being indexed.
11.8 STRUCTURE OF TREES 383
strict partition it if and only if, given any KG w,. then each prefix u of any string
w = uv G 2* generated by some symbol A&Vt uniquely determines the left partial
subtree of tree T (cf. Fig. 11.3). T corresponds to a derivation A =>w up to the path
to the terminal node (x) labeled by the first letter of v. We allow the labels of nodes
on this particular path to be determined modulo the partition it (in particular,
X(x)=2). In the case when v= A, the complete tree is specified uniquely (and
then it cannot be a proper subtree of any other tree with an equivalent root label).
For the formal statement of the theorem we first introduce the "left-part
property" of a set of derivation trees.
Definition Let S~^. JTG for some grammar G = (V, S,P,5) and let w be
an arbitrary partition on V, not necessarily strict. We say that S~ satisfies the left-part
property with respect to it if and only if, for any n > 0 and T, T' G ^"if
rt(T) = rt(r') (mod if)
and
(n)fr(D = <n)fr(7"),
then
(.n+Dj* ^ (n+l)j-» (11.8.1)
and, moreover, if x **x' is the structural isomorphism ("+1)7' o- (n-n)^ then for
every x in ("+1)T,
\(x) = X(x')ifxll^forsome7G<"+1)rorif("+1)r = <n)T (11.8.2)
and
\(x) = \(x') (mod ir) otherwise. (11.8.3)
Note that the condition "x\ly for some ;,e<"+1>:r' in (11.8.2) is equivalent to
"x is not on the rightmost path in <"+1>7"'.
An example of this kind of mapping can be obtained by considering grammar
G2 from Section 11.4. Let us consider the trees shown in Fig. 11.4.
If we let n = 2, we see that rt(7,1) = S = S = it(T2) and wfi(Ti) = (a =
(2)fr(T2). Thus (3)r! s <3)r2 and the path from 5 to + in 7^ is "equivalent modulo n"
to the path from S to ) in T2.
Tree Tx
FIG. 11.4
/FJ\
Tree T2
384 BASIC THEORY OF DETERMINISTIC LANGUAGES
Note that the left-part property is a global property of trees in distinction to
the strictness of a grammar, which is a local property of derivation trees (being a
property of their elementary subtrees).
Theorem 11.8.1 (The Left-Part Theorem) Let G = (V, 2,P,S)be a reduced
grammar and let w be a partition on V such that 2 G it. Then it is strict in G if and only
if the set 9~G of all derivation trees of G satisfies the left-part property with respect
to it.
Proof (The if direction) Let G and w be as in the assumption of the theorem
and assume J7~G satisfies the left-part property with respect to it. We shall show that
n is strict.
Let A, A' GjV, let A -*■ a/3 and A' -*■ a/3' be in P and assume A=A' (mod it).
Since G is reduced, we have a =*wa, |3 =»wp and |3' =*wp' for some wa, wp, wp- G 2*.
Let us consider two derivation trees T, T' corresponding to derivations A =>a(S
=*wawp and ^4' =*ot(i' =*waw'p, respectively. Let n = lg(wa). Then rt(T)=A=A' =
rt(7") and <">fr(r) = <">fr(r'). Thus (ntl)rs <"+1>r' by the left-part property of
5~G. Let x <*x' be the structural isomorphism from (n+1)rto <"+1>:r'. We distinguish
two cases:
CASE 1. wp =t= A. Let x be the (n + l)st terminal node of T (labeled by
(1)W(3) and y the (lg(a) + l)st node among the immediate descendants of the root in
T, counted from the left (that is, XQO = (1)|3). Clearly, y is in <"+1>;r and by the
structural isomorphism also / is in <"+1>r', \(y') = (1)|3'. Then (1)0 = (1)|3' by (11.8.2)
or by (11.8.3) (depending on whether y \lx or not).
CASE 2. wp = A. Then <"+1>r= (n)r and, by (11.8.2), X(x) = \(jc') for all
x in (n+1)r. Thus ("+1)r= ("+1>r. Then also in)T= <-n)T' by Fact 2 and using Fact 1
we conclude T = T'. Hence A = ^' and 0' = |3 = A.
(77z£ on/y i/ direction) Let G be a reduced grammar with strict partition it.
Let r, T' G .9^3 be two derivation trees such that
rt(r) = rt(r') (mod ?r) (11.8.4)
and
<»)fr(D= (n)fr(7") (11.8.5)
for some n>0. To show that in+1)T and <"+1)r' satisfy (11.8.1), (11.8.2), and
(11.8.3), we proceed by induction on the height h of the larger one of the two trees.
Assume, without loss of generality, that the taller tree is T.
Basis, h = 0. Then T consists of a single node labeled by some a G 2. (Note
that we cannot have a = A since, in such a case, assumption (11.8.4) would be
meaningless). Then by (11.8.4) and since 2 G 7r also, T' has a single node labeled by some
<z'G2. Thus T=T'. Clearly, a=a and, moreover, if n> 1, we have a = a from
(11.8.5).
11.8 STRUCTURE OF TREES 385
tVl wk (r)
(")tr(T)
FIG. 11.5
Inductive step. Let h > 0 and assume the result; i.e., (11.8.1), (11.8.2), and
(11.8.3), true for all trees with heights smaller than h. Let us denote this assumption
(A). Let x0 and x'0 be the roots of Tand T1, respectively,and let x0Fxu ... ,x0rxm,
x'0rx\,...,x'0Fx'm', XiL.x2\~-■-\~xm and xiLx^L • •-LxJ„' (cf. Fig. 11.5).
Let us define, for 1 < i < m and 1 </ < m ,
7j = {x in T\ xt T x],
T) = {xmT'\x'jrx}.
Clearly, all the T,- and T) are derivation trees of G and, because their heights are
smaller than h, the inductive hypothesis (A) is applicable. Denote wt = fi^r,),
w; = fr(r;).
Claim If for some k < m, no tree among Ti,... ,Tk contains the (n + l)st
terminal node of T (in particular, if no such node exists), then m'^-k and Tt = T't
for l</<*.
The argument is an induction on k. The basis (in which k = 0) is vacuously
true.
Inductive step. Assume the premise of the claim for some k > 0 and, as
inductive hypothesis (B), the conclusion for k — 1; that is, m S* k — 1 and T{ = T\
(1 < / < k — 1). Then, in particular, \(x,) = X(xJ) for 1 < / < k — 1 and by the
strictness of it, using (11.8.4), \(xk) = \(x'k). Since wi • • • wfe is a prefix of (n)fr(r) =
<n)fr(r') and since Wi • • • Wk-i = w'i ''' w'k-i by inductive hypothesis (B), either
fr(Tfe) is a prefix of fr(T'k), or conversely. But since rt(rfe) = \(xk) = \(x'k) = rt(T'k),
and using inductive hypothesis (A), we conclude that wk = w'k and Tk = T'k.
Therefore the claim follows.
Now if n > lg(fi(T)) (that is, if (n)fr(r) = fr(T)\ then by the claim, Tt = T\
(1 < i < m < m'). But then fr(r) = w1 • • • wm = w[ • • ■ w'm and by the strictness of
386 BASIC THEORY OF DETERMINISTIC LANGUAGES
tt we have m = m; and since X(x0) = X(xo), we have, again by the strictness of tt,
\(x0) = X(xo). Hence <"+1>r= T= T' = <"+1>r'.
For the rest of the proof, we assume n < lg(fr(r)) (cf. Fig. 11.3). Let y be
the (w + 1 )st terminal node in T and let k and r be such that y is the (r + 1 )st terminal
node in Tk+1. By the claim Tt = T'i(Ki<k) and thus, by the strictness of tt, m > k
and rt(7,fe+1) = X(xfe+1) = X(xfe + 1) = rt(7,fe). Moreover, w, • • • wfe = w\ • ■ • w'k and
since (r)wfe+1 isasuffix of (")fr(r) = (n)fr(r), we have (r)wfe + 1 = (r)(u4+i • • • w'm').
The only possibility which is in agreement with the induction hypothesis (A) is
Now, <n+1)T consists of jc0, Tu..., Tk, and (r+1)rfe+1; <n+1>r consists of
jco, T\,..., T'h,wA <r+1)rfe+1.Here (r+1)rfe+1 = <r+1)T'k+1 by the inductive hypothesis.
Define a function /: <"+1)r_y ("+1)7" such that / restricted to Tt is the structural
isomorphism T( »■ T\ (0<i<A:), / restricted to (r+1)rfe+1 is the structural
isomorphism (r+1)7ft+1 ** (r+1)rjj+1 and f(x0)=x'0. Now / is a structural isomorphism
<"+1)r^("+1)r'. Hence (11.8.1). Let x e(n+1)7\ If x\ly, then \(x) = \f(x), since
either x£ (r+1)rfe+1 and we can apply the inductive hypothesis; or else x£ Tt, i*^k.
Hence (11.8.2). Otherwise \{x) = ^f(x), since either x£ir+1)Tk+1 and we can again
apply the inductive hypothesis, or x=x0 and/(x) = Xo. Hence (11.8.3) and _7~G
satisfies the left-part property. □
Note that the assumption that G is reduced was not used in the only i/part
of the proof. On the other hand, in the // part, even if ^TG satisfies the left-part
property, the strictness of tt may be violated for some useless production which does
not appear in any grammatical tree. By Theorem 11.4.1, the requirement of a reduced
grammar causes no loss of generality.
For reduced grammars we have the following result:
Fact 3 Let G be a reduced grammar. The left-part property is satisfied by
JTG if and only if it is satisfied by J~G (S),the set of derivation trees in G.
The only if direction of this fact is trivial while the //direction follows from
the observation that, in a reduced grammar, every grammatical tree is a subtree of
some derivation tree.
The following two corollaries are immediate consequences of the Left-Part
Theorem.
Corollary 1 Any strict deterministic grammar is unambiguous.
Corollary 2 If w is a strict partition on G, then for every U&tt, the set
{w G 2* I A =*■ w for some A G U} is prefix-free.
Thus, in particular, L(G) is prefix-free, which we already know.
Our next objective is to give a machine-independent proof of a deterministic
iteration theorem. The reader may wish to reread Section 6.2 before continuing,
since our development will closely follow the earlier argument.
11.8
STRUCTURE OF TREES
387
Theorem 11.8.2 {Iteration Theorem for A2) Let L G A2 and L 9 2*. There is
an integer p(L) such that, for any string wGZ, and any set K of positions in w, if
I ATI ^p(L), then there is a factorization y = (z>j,..., v5) of w such that:
1 v2*A;
2 for each w, m>0, wG2*,
^^'"z^MeZ, if and only if ^t^z^m GZ,;
3 if */* = {*!,..., tf5}, then
i) KUK2,K3±Q or K3>K4,K5^(D;
ii) i/s:2u/s:3u/s:4i<p(z).
Corollary For each «>(),
Proof of the corollary Take m = l and u = v4vs in (11.8.2). This gives
z>iZ>21+1P3P4+1PsGZ, if and only if ViV2v3v4vs = wGZ,.
Now take m = 0 and « = z>5 in (11.8.2). That gives:
Vivlv^vlvs&L if and only if VxV3vs£L.
Since w = V\ ■ ■ ■ vs is in L, the Corollary follows. □
Proof of Theorem 11.8.2 The argument mirrors the proof of Theorem
6.2.1. Let G = (V, 2,P, 5) be a strict deterministic grammar generating L. Choose
p{L) = p(G) as in the proof of Theorem 6.2.1, and follow out that proof. That is,
find </? = (Vi,..., vs) satisfying the requirements of the proof.
Property (3) follows from the iteration theorem for context-free languages.
To show property (1), suppose v2 = A. Then we would have:
A ^Av4.
But left recursion is impossible in a strict deterministic grammar. Thus (3) has been
satisfied.
To establish property (2), let m, n > 0. By the iteration theorem for context-
free languages,
5 ^-v^AvTvs ^ v-,v¥*nv3vnSmVs = w^Vg (11.8.6)
where Wj = v1v™+"v3v!i G 2*. Assume now
5 £■ v1v?+nv3viu = wlU (11.8.7)
Let T, T' be two derivation trees corresponding to (11.8.6) and (11.8.7), respectively.
Let k = lg(w!). By the left-part theorem,
Let x be the node in T, which corresponds to the indicated occurrence of A in
sentential form ViV™Av™v$. Clearly, x is left of the (k + l)st terminal node in T (labeled
388 BASIC THEORY OF DETERMINISTIC LANGUAGES
with (1)z>4). By the left-part property (2), the corresponding node in T' is also labeled
with A. Therefore the following derivation corresponds to T1:
S =*• ViV™Au =*• \x>iit
Since A=*v" v3v% for any ri > 0, we have
ViV?+n'v3viuGL, anyri>0.
In particular, taking ri = 0, we obtain the only if part of property (2); taking n = 0
in (11.8.7) and ri arbitrary, we obtain the //direction of (2). □
The main purpose in proving an iteration theorem for A2 was not to use it
in showing sets to be non-strict deterministic. Our main purpose was to be able to
prove a similar result for A0. This result will be useful in showing that a number of
particular sets are not deterministic.
Theorem 11.8.3 (Iteration Theorem for A0) Let L £ 2* be a deterministic
context-free language. There is an integer p'(L) such that for every w GZ,, and every
set K of positions in w, if \K\>p'(L), then there is a factorization
<p = (vu ...,vs)
of w such that:
1 v2*A;
2 For si\n>0,v1v"v3v1vs^L;
3 ifKfo={Klt...,K5),then
i) KUK2,K3^<D or K3,K4,K5^<D,
ii) \K2VK3UK4\<p'(L);
4 if vs =£ A, then for each m, n > 0, u G 2*,
v1v™*nv3v1u&L if and only if v^v^u GZ,.
Proof Much of the previous proof and all of the proof of Theorem 6.2.1
still apply here. Thus (3) follows. Also, (2) follows easily. To complete the proof,
let Z,GA0. Then Z,$GA2 and is subject to Theorem 11.8.2. Define p'(L) = p(L$)
and let w GZ, with a set of positions K where |ATI >p'(L). Consider the factorization
^' = (^,^2,^3,^4,^5) of w$ obtained from Theorem 11.8.2 applied to L$. Since $
doesn't occupy any position from K, there are only two possibilities where it can
occur: either z>3G2+$ and u4 = f5 = A, or z>3G2+ and ^5=^5$ for some z>5G2*.
In either event, (1) holds. Assume vs^A. We can restrict ourselves to the second
possibility. Take ^ = (^1,^2,^3,^4,^5) as the factorization of w. The result is now
simple, since, for any n, m > 0 and u G 2*, we have
v1v"+mv3v1ueL if and only if vlv1*mv3v1u% GZ,$
if and only if ViV™v3u$ GZ,$
if and only if vxv™v3u€lL.
This satisfies (4), and completes the proof.
□
11.8 STRUCTURE OF TREES 389
To illustrate the importance of the last theorem, some applications will be
given.
Theorem 11.8.4 The set L = {a"b"\ n>l}u{anb2"\ w>l}is not a
deterministic context-free language.
Proof Let p = p(L) be an integer satisfying Theorem 11.8.3. Let w = apbp
and assume that all p positions which are b's are distinguished. By the theorem, there
exist vu ..., vs such that w = vt • • • vs.
and
Then
But this
Claim 1 v2 £ b*.
Proof If Vi — b' for some / > 1, then:
v1 = a"bh,
v3 = b}, ;>0,
v* = b\
v - foP-(h + i+j+k)
V!V3v5 = a"bp-<i+kyGL.
: is a contradiction since / > 0 implies
p-(i+k)<p.
Claim 2 v2£a*b*.
Proof This is clear.
Claim 3 vx = a' i>0,
v2 = aJ ;>0,
v3 = ap-ii+nbk k>0,
v4 = b>
Vs = bp-i**i)
Proof This is clear except for the fact that lg(z>2) = \g(v4). Suppose that
Vt=b' and vs = bp~ik+'\ and we shall prove that/ = /'. First, consider viv3vi =
ap-iy?-i ejr, But, if p— f = p— /", then /=/". Then, suppose 2(p— f) = p— /',
which implies that/' = 2j—p. An analysis of V\v\v3viv^L shows that either/ = /'
or ]"> p, which would contradict that v2v3v4 can have at most p distinguished
positions. Thus; =/' and now Claim 3 is proven.
To complete the proof, we note that vs must have a distinguished position,
by part 3(ii) of Theorem 11.8.3. Thus v5i=A. By condition (4) of Theorem 11.8.3,
letw =vsbp. Note that:
V]V2V3Va,U &L.
390 BASIC THEORY OF DETERMINISTIC LANGUAGES
Thus
ViV3vsbp GZ,.
But , , .
VMVsb" = a"~3b2p~' GL.
The only way that this string is in L is if
p -j = 2p -j
or if
2(p -j) = 2p -j.
Neither of tnese conditions is consistent withp > 0 and; > 0. □
Another example will be given which is an even stronger implication.
Theorem 11.8.5 The language L = {wwT\ wG{a,b}*} is not a finite union
of deterministic languages.
Proof Assume, for the sake of contradiction, that
N
L = U Lt for some N > 1 and Lt G A0.
Let !=1
P = max p'(Z,,),
wherep'(Lk)are the constants from Theorem 11.8.3 for every i<N. Consider the set
H = {(bapbf"\ n>l}9L.
H is infinite and therefore, for some Lt, \HC\L{\>2 or, more specifically, there are
two (even) numbers nu n2>2 such that bothw = (ba"b)"1 GZ,f and w' = w{bapb)n*
G L;. Applying the Iteration Theorem 11.8.3 to w, let
K = {/| (w1-l)(p + 2)</<w1(p + 2) = lg(w)}
(that is, K corresponds to the rightmost substringap in w). Clearly |ATI =p>p'(Li).
Let (yi,Vi, v3, z>4, vs) be the factorization of w from Theorem 11.8.3. By Property (3),
and since strings in L{ are palindromes, we have V\ G ba+, v5Ga+b and v^ = v4 = aq
for some q, 1 <q <p. Define u = v4vs(bapb)"'i. Now, taking m — n = 1 in 2 (note
that v5 =£ A), ViV2V3u — w' G L; implies
vlVlv3v4u = bap+qb(bapb)">-'ibap+9b(bapb)n>eLh
which is not a palindrome since q, n2 =£ 0. We have a contradiction with Z,,- 9 L. □
Since L is an unambiguous language, we have the following consequence.
Corollary There exists an unambiguous context-free language which is not
a finite union of deterministic languages.
11.8 STRUCTURE OF TREES 391
PROBLEMS
1 The proof of Theorem 11.8.2 is not completely formal. Find the "hand-
waving" part. Formulate and prove a lemma about cross sections and make the proof
completely rigorous.
2 Extend Theorem 11.8.3 in that (2) is replaced by the following statement.
(2') For each n > 0, viv"vzv1vsG. L if and only if h-GZ,.
A sequence of definitions is necessary before the next problems can be stated.
Definition A (finite) tree automaton is a system
j^= (G,2,a,F) (1)
where Q is a finite nonempty set, F^ Q, 2 is an alphabet, and a: Q* x 2 -*■ Q is a
function with the property that a~l{q) is finite for all q G Q.
Definition Let T be a tree with labels in 2 and let sf be a tree automaton
of the form (1). A function /: T-*■ Q is called a computation for T if and only if:
i) if x is a leaf in T, then f(x) = a(A, \(x)); and
ii) if x is an internal node in T and xu ... ,xn are all the immediate
descendants of x such that xxLxjL • ■ -L x„,
then/(oc) = a(f(Xl)f(x2) ■ • •/(*„), \(x)).
Define
£(j*0 = {fr(T)| T is a tree with labels in 2 and there is a computation
f.T^-Q such that f(x0) S F where x0 is the root of T}.
It is not a coincidence that the following definition reminds us of the definition of
a strict deterministic grammar.
Definition We shall say that a tree automaton sf = (fi, 2, a, F) has the
strict deterministic property if and only if \F\= 1 and there exists a partition w on
g such that, for any 77, r)h i?2G g*, quq2G Q, and a, b G 2, the following two
implications hold:
i) Ifa(77^1771,a) = a(77q2772,6),thenfl1 Sq2;
ii) If 01(7777!, a) = a(r), b), then r)i = A and (77 =£ A implies a = i»).
3 Prove the following result.
Theorem L G A2 if and only if Z, = {A} or Z, = Z,(j*0 for some tree
automaton with the strict deterministic property.
Definition A grammar G = (V, 2,/>, S) is deterministic if and only if there
is a partition it of V and a subset E £ V — 2 such that 2 G jt and for every A,
,4'G K-2anda,|3,|3'G V*,
a) if ,4 -»■ a0 is in P and a G K*£, then 0 = A and A G £;
b) if ^4 ->■ a/3 and /T ->-aj3' are in P and A =A' (mod jt), then at least one of
the following four cases is true:
392 BASIC THEORY OF DETERMINISTIC LANGUAGES
i) 0, 0' =£ A and (1)0 = (1)0' (mod w);
ii) 0 = 0' = Aand^ =^';
iii) 0 = A and A G £;
iv) 0' = Aand^'G£'.
4 Note that, in the preceding definition, condition 1 is equivalent to the
requirement
pc (VX(V-E)*)V(EX(V-E)*E),
and that we obtain a strict deterministic grammar as a special case when E = 0. Prove
the following result.
Theorem L G A0 if and only if L — L(G) for some deterministic grammar G.
11.9 INTRODUCTION TO SIMPLE MACHINES, GRAMMARS, AND
LANGUAGES
In Section 11.6, we were able to construct a nontrivial hierarchy of strict
deterministic languages. This hierarchy was based on the degree of a language, which
was related to the number of states in a dpda. In this section, we shall restrict our
attention to the "simplest" class of strict deterministic languages in the hierarchy,
i.e., to the strict deterministic languages of degree one.
First we show a convenient characterization of strict deterministic grammars
of degree 1. This characterization makes it easier to recognize these grammars.
Lemma 11.9.1 Let G be any context-free grammar. Then G is strict
deterministic of degree 1 if and only if A -+ a \ 0 in G implies that either a = 0 or a, 0 have
a terminal distinguishing pair.'
Proof Let G be strict deterministic, deg(G) = 1 and let A ■+ a \ 0 be in G,
a =£ 0. If a, 0 have no distinguishing pair, one of them is a (proper) prefix of the other,
which contradicts the strict determinism of G. Let (C,D) be the distinguishing pair of
a, 0. Then C = D. By definition of distinguishing pairs, C^D. If C,D GAT, we have a
contradiction of deg(G) = 1. Hence, C, D G 2.
Assume that G has the above property. Recall Algorithm 11.4.1, which tests
a given context-free grammar for the property of being strict deterministic. Now let us
apply that Algorithm to G. Starting in Step 1 with partition w consisting of 2 and
otherwise only of singletons, the algorithm never reaches Step 6 (Step 5 is always
followed by Step 3 since 2 G it), and thus n is not altered. The algorithm halts in Step
8 (Step 4 is never followed by Step 7 since A{=Aj implies At =Aj, which implies
(Xj =£ otj by the assumption of the indices in the algorithm). Therefore, w is strict and
llir|| = ||ir0||=l. □
t Recall the definition (given in Section 11.4) of distinguishing pair.
11.9 INTRODUCTION TO SIMPLE MACHINES 393
Now let us introduce "simple" grammars.
Definition A context-free grammar G = (V, 2,P,5) in Greibach normal form
is said to be a simple grammar (s-grammar for short) if for all A G N, a G 2, and a,
B&V*
A -+ aa and A -*■ a(i in P
imply a = |3. A simple language, or s-language, for short, is a language generated by
an s-grammar.
Example 5 ->■ a&4 | b
A -*■ a
This is clearly an s-grammar that generates the set L(G) = {anban \ n > 0}.
Consider the grammar
5 -»■ aAd\aBe
A -+ <fc4fc|fc
5 -»■ a5c|c
This grammar is not an s-grammar. The language generated is
L = {a"b"d\ n>l}U{a"c"e\ n>\).
It can be shown that L is not an s-language. L is, however, a realtime strict
deterministic language.
Next, we relate strict deterministic languages of degree one to dpda's.
Lemma 11.9.2 L is a strict deterministic language and deg(Z,) = 1 if and only
if either L = {A} or L = T2(A) for some realtime dpda A with one state.
Proof We note that {A} is of degree 1. If L = T2(A) for some dpda with one
state, then, by Theorem 11.6.1, L is strict deterministic of degree one.
Conversely, let G be a strict deterministic grammar of degree 1 and let
L(G) =£ {A}. Assume, without loss of generality, that G is A-free. We shall show that
G satisfies the main condition, from the definition of a realtime strict deterministic
grammar. But this is immediate from the assumption that deg(G) = 1; that is,
llwoll = 1, since then A =A' (mod w0) implies A =A'. If we assume A =A', and
A^-aB and A' -*■ aB '|3 are in P, then, since tt0 is strict,
B = B',
so we have B = B' by the degree 1 condition. Clearly, this implies (3 = A, by the
strictness of n0. Thus G is realtime. Clearly, L is accepted by a realtime dpda with
only one state, as can be seen by a careful check of the proof of Theorem 11.7.4. □
Next, we show that the realtime assumption is not necessary.
Lemma 11.9.3 L = T2(A') for some one-state realtime dpda A' if and only
if L = Ti(A) for some one-state dpda A and L =£ {A}.
394 BASIC THEORY OF DETERMINISTIC LANGUAGES
Proof Only the // condition needs proof. Let {A}i=L = T2(A) for some
one-state dpda A. Then L is strict deterministic of degree 1, by Theorem 11.6.1.
By Lemma 11.9.2, L = T2 (A') for some one-state realtime dpda A'. □
Now the various results can be collected into one proposition.
Theorem 11.9.1 LetZ, £ 2*. The following statements are equivalent:
a) L is simple.
b) L is strict deterministic of degree one.
c) L is accepted as T2(A) for some realtime dpda with one state or L = {A}.
d) L is accepted as T2(B) for some dpda with one state.
Proof By our lemmas, (b), (c), and (d) are already known to be equivalent.
Clearly, if L is simple, it is strict deterministic of degree one.
Assume {A}^L = T2(A) for some one-state realtime dpda A. By the proof
of Theorem 11.7.4, L = L(G), where G is realtime, in Greibach form, and since A has
one state, L is strict deterministic and of degree one. By Lemma 11.9.1, if we have
A -*■ aa and A -*■ a/3 in P
for /I G AT, a G 2, and a, |3 in AT* (and all the rules are of this form), then a = |3. □
Now we turn to an important result about s-languages. We shall show that
the inclusion question, that is, Li £ L2, is unsolvable for s-languages. There are two
reasons why this result is noteworthy. First, the s-languages are very primitive and
are contained in many of the other families of deterministic languages that have been
studied. Thus it follows, as corollaries to this result, that the inclusion problem is
unsolvable for all families that contain the s-languages.
There is a second reason why this inclusion result is important. There is an
obvious relationship between the inclusion problem and the equality problem. If the
inclusion problem is solvable, then the equality problem is also, since Lx = L2 if and
only if L\ £ L2 and Z,2- L\. In the examples we have seen, such as regular sets or
context-free languages, both problems have been solvable or both unsolvable. It
could be the case that there is some family of languages that has an unsolvable inclusion
problem but a solvable equality problem. The s-languages will turn out to be such a
family.
In the argument which follows, some simple languages will be used and will
be specified by dpda's. As we have only one state, it can be omitted from a description
of a dpda, and we need only write:
A = (2,r,5,Z0),
where
5: 2xr->r*
is a partial function, in order to specify an s-language.
Theorem 11.9.2 The inclusion problem for s-languages is recursively
unsolvable; i.e., there is no algorithm which can decide, of two s-languages Lx and L2,
whether or not Li £ L2.
11.9 INTRODUCTION TO SIMPLE MACHINES 395
Proof The argument will proceed by taking an arbitrary Turing machine A
and input w to A. Two s-languages Li and Z,2 will be constructed such that Li % Z,2 if
and only if A halts and accepts w. (This actually shows more; namely, that the inclusion
problem is not partially decidable.)
Let A = (Q, 2, T, B, 8,q0, {q}) be any Turing machine and let w G 2*. There
is no loss of generality in assuming that A is totally defined on Q — {q} and that q is
a unique final "halt" state. The idea of the proof will use the reduction from A to the
MPCP done in Section 8.3. The reader is expected to be aware of the details of those
arguments. Assume that the lists x and y given in Table 8.3.1 have been constructed.
For each integer i, 1 < i < n, let/; be a new symbol not in
A = (S-{B})UfiU {#}.
Let <t and $ be two new symbols not in A U {/,,... ,/„}. Define a homomorphism
ip: A*->(AU {$})* defined by:
<p(a) = a<t
for each a G A. Now we define the first language of interest.
Li = {fifik---fiMiy,yii---yiky2)%\ k>0,3</„...,ifc<«}.
We construct a one-state dpda Ax such that T2(A1) = Ll. Let^4! = (AU
{<t,$,/1;...,/„}, 5 ^IYZo), where
r, = {Z0,ZU C} U {[z] I z G A+, lg(z) < max {IgO,)}}
I
U {[z<t] I z G A*, lg(z) < max (IgO,)}}.
The transition function is defined by cases.
CASE 1. Read the /}'s but stack the corresponding j>;'s.
«i(/i,Z0) = Z,\y\\C,
5 lift, C) = {yj ] C for each /, 3 < / < n,
«i(A,c)= [yj].
For each a G A, z G A*, lg(z) < max, (lgO,)}.
CASE 2. 5 i(a, [za]) = [z<t]; Check whether symbols match.
CASE 3. 5,($, [z<t])= [z] ifz^A.
CASE 4. «i(^[«]) = A.
CASE 5. 51($,Z,) = A.
(3) and (4) check whether every other symbol is a $. (5) checks that the last symbol
is a $.
It is not too difficult to see that T2(A i)=L1.
The tricky part of the proof is the construction of an appropriate L2. This
set is
396 BASIC THEORY OF DETERMINISTIC LANGUAGES
Li={fifik ■ ■ -hjYP(y\y-h ■ ■ -y^yiW k>0,3<h,.. .,ih <n, Xjx,-, • • -xikx2
^y\yi,---yi^^J
where J (an abbreviation for junk) is some set such that J Pi L\ = 0. Now we construct
an appropriate machine A2 = (A U {$, $,/i,... ,/„}, r2,52,Z0), where
T2 = {Z0,ZUA,C, D,E)
U {[z] | z G A+, lg(z) < max (lg^)}
U {[z<t] | z G A*, lg(z) < max {lg(x,-)}}.
52 is defined by cases below.
CASE1. 52(/2>Z0) = Z1[x2r]C.
CASE 2. 82(fi, Q = [xf] C for each i, 3 < i < n.
CASE 3. 52(/1>0= [xj].
In steps (1) through (3), the /j are read and the corresponding xt are stacked.
For each a G A, z G A*, lg(z) < max; {lg(x,-)}.
CASE 4. 52(a, [za])= [z<t].
CASE 5. 52(<t, [<t]) = A.
CASE 6. 52(<t, [z<t]) = [z] if z =£ A.
In (4) through (6), inputs are matched against the stack and it is checked that every
other symbol in the input is a <t.
CASE 7. 52($, Zi) = E. reject if final symbol is $ and pushdown is only Zx.
For each a, b G A, a =£ b, each z, z G A*, such that
lg(z) < max {lg(x,)},
I
lg(z)<max{lg(x.)}.
CASE 8. 52(<z, [zb]) = A. If a mismatch occurs, pop the stack.
CASE 9. 52(<t, [z]) = D. If z¥=\, use <t to encode D on the stack.
CASE 10. 52(a,D) = A.
For each c G A U {$}
CASE 11. 82(c,Zi) = A.
CASE 12. 82(c,A)=A.
CASE 13. 52($,^) = A.
In (11) through (13), if the bottom of the stack was encountered when a
symbol other than A was read, the stack symbol A is used to encode that the input
will be eventually accepted when $ is finally read.
11.9
INTRODUCTION TO SIMPLE MACHINES
397
Claim 1
T2(A2) = L2
= (ii ~ {hfik ■ ■■filfi*(?cixtl • ■■xikx2)S\k>0, 3 </,,... ,/fc < n})\jJ.
where / consists of some irrelevant strings so that
Li n/ = 0
Proof The proof of this claim is long and tedious and is left for Exercise 7
at the end of this section.
Claim 2 L,9 L2 if and only if
Li H {f2fik ■ ■ ■f,if1<fi(x1xii ■ ■■xikx2)$\ h>0, 3 </„ ... ,ik <n) = 0
if and only if there is no sequence iu...,ik,k>0, with 3 </,,...,ik <n such that
*i*i, ■ ■ -^ife^2 = y\yix • ■ -yi^i-
Proof From Claim 1, write L2 = (£, — AT) U /. Now
L^L2
if and only if
Li nL2 =0 = li 0(1, -Ar)u/ = i1 0(1, nAO("1.7=1, n(r,ui) = l1nj
The second equivalence holds because of the structure of Lx and X.
Claim 3 L, £ L2 if and only if the Turing machine halts on w £ 2*.
Proof The result follows from Claim 2 and Problem 12 of Section 8.3, in
which it is shown that
*i*i, • ■ -xikx2 = y^ ■ ■ -yiky2
for some k > 0, 3 < /",,..., ik < n if and only if A halts on w. Now the proof is
complete. □
PROBLEMS
1 Let R£ 'L* be an arbitrary regular set and let $ be a new symbol not in
2. Show that R$ is a simple language.
2 Show that the family of s-languages is not closed under union, intersection,
or complementation.
3 Show that the family of s-languages is closed under product.
4 Show that the family of s-languages is not closed under reversal.
5 Let Dr be the semi-Dyck set over 2r U 2r and let $ be a new symbol not
in 2r U 2r. Show that Dr% is a simple language.
6 Show that it is undecidable to determine whether a given context-free
language is an ^-language or not.
398 BASIC THEORY OF DETERMINISTIC LANGUAGES
7 Prove that T2(A2) = L2 in the proof of Theorem 11.9.2.
8 Does Theorem 11.9.2 hold for single-turn simple machines?
9 Show that, for each .s-grammar G, there is an equivalent .s-grammar which
is in 2-standard form.
11.10 THE EQUIVALENCE PROBLEM FOR SIMPLE LANGUAGES
In this section, we will show that the equivalence problem for s-languages
is solvable. We shall assume that the two s-languages Lx and L2 are presented by
s-grammars Gx and G2. If either Lx = {A} or L2 = {A}, the problem is trivial, so we
shall henceforth assume that Gx and G2 are A-free. The algorithm to be given will
depend on the following definition of equivalence of strings.
Definition Let Gi = (Vi,'L,Pi,Si), i= 1, 2, be two context-free grammars
such that TV, n N2 = 0 and let a, 0 G (TV, U N2)*. We say that a is equivalent to 0
(written a = 0), if for each x G 2*, a =>x if and only if 0 =>x
Note that since a and 0 may have variables from each grammar, the
generations involved may employ productions from both grammars. Also note that
L(G{) = L(G2) if and only if Sx = S2.
Example Let Gx be the grammar
Si -> ab
and let G2 have productions
S2 -> Ab
A -> aB
B -> b
Note that St ffe S2. However, it is easy to see that
b\B = (J2.
Since our grammars are A-free and may be assumed to be reduced, we have
that 0 = A if and only if 0 = A.
Our first result is that = is a congruence relation.
Lemma 11.10.1 Let G; = (T;, 2,^,5,) be two context-free grammars with
Nx n N2 = 0 for / = 1,2. The relation = is a congruence relation on (Nt U 7V2)*; i.e.,
it is an equivalence relation, and furthermore, for any a, 0, 7, 5 in (NiUN2)*, if
a = 0 and 7 = 5, then
cry = 05.
Proof The proof that = is an equivalence relation is immediate. Suppose
a = 0 and 7 = 5 for arbitrary strings a, 0, 7, and 5 in (TVi U N2)*. For each x G 2*,
*
(*7 =»■ x
11.10 EQUIVALENCE PROBLEM FOR SIMPLE LANGUAGES 399
if and only if there exist y, z G 2* such that
x = yz, a => y, and y =*■ z
This holds if and only if
x = yz, 0 => j> and 5 => z
which, in turn, holds if and only if
(35 => jc
Thus 07 = 05. □
We shall always assume in what follows that the grammars to be considered
are in Greibach normal form or, equivalently, in r-standard form for some r > 2. The
lemmas we shall use in this section are being proved in a rather general form since
they can be used in proving a number of different results. In the simplest case, any
s-grammar may be placed in 2-standard form by Problem 11.9.9.
Definition Let G = (V, 2,/*, S) be any grammar in Greibach form and let
A GN and a ex. Define
R(A,a) = {y\ A -*ayisinP}.
Note that, for any grammar in standard 2-form, it is always the case that
R(A, a) £ N\. In an s-grammar,
R(A,a) = 0 or \R(A,a)\ = 1.
We shall often write R(A,a) for this unique string when no confusion can result.
We now know that the equivalence problem reduces to deciding if 5i=52.
Let us introduce some terminology which helps to determine whether or not a = 0.
Definition Let Gt = (yl,'L,Pi,Si) be two context-free grammars with
jVi n 7V2 = 0 and let a, 0 be in (7V1 U A^)*. We define the set of witnesses for a and 0 as
W(a,$) = {xGZ*| a ^ x if and only if 0 f- x).
The set of shortest witnesses is
W(a, 0) = {x G W(a, 0)| for eachy in W(a, 0), lg(x) < IgO)}.
Thus a witness is a terminal string that distinguishes a from 0.
Example Consider grammars Gx and G2 from the first example of this section
and let a = 5, and 0 = S2. Then
W(SUS2) = {ab,abb},
W(SuS2) = {ab}.
Our algorithm for deciding whether £1 = £2 will work if we first consider
S\ =S2. Several transformations will be defined which map the pair (5'1, S2 ) into a
finite set of pairs to be tested, and the process will be repeated. Since there are a
number of other algorithms of this type, we establish some preliminary lemmas which
hold for general types of transformations.
400 BASIC THEORY OF DETERMINISTIC LANGUAGES
To simplify technical definitions assume that two grammars Gt = (Vt, 2, Pt, St)
are fixed with Ni D N2 = 0. Let N = Nj U N2.
Definition A transformation Tisa partial function from N* x TV* into
{fail} V{U\ U^N* xN*, U finite and nonempty}.
If T(a, 0) = fail, we say that T failed on (a, 0). If T =£ fail and is defined, then
T(a, 0) = {(a„ 0,), • ■ •, (<*m, ftn)l a,-, ft eN* for all /, 1 < / < m, where m > 1}.
Two important properties of transformations are now introduced, which
are relevant in determining which transformations are useful in testing for equivalence.
Definition A transformation T is valid if, for each a, 0 at which 7Ms defined,
1 a = 0 implies 7,(a,0)= {(a^fa),..., (am,0m)} for some m>\ and
at = 0; for each i, 1 < i < m, and
2 a#0 implies that either T(a,Q)=fail or there exists (a,-,ft)e r(a,0)
anda,-#ft.
The next property is a little more complicated.
Definition A transformation T is monotone if, for each a, 0GA^* such that
a ffe 0 and
7X«,0) = {(a1,01),...,(am,0m)},
and if y is a shortest witness of a and 0, then there exist i, 1 </<m, and some
shortest witness x for a; and 0f such that lg(x) < lgO>).
Now we introduce one of the transformations to be used in our final
algorithm.
Definition Let Gt = (Vh 2,/";, 5f) be two s-grammars with Wj O 7V2 = 0. For
a,0G7V+,let a = Aa and 0 = 50' for some ,4, fi G N, a, 0G7V*. The A-transform-
ation, TA, is defined by:
(fail if 1^04, a)\ + \R(B, a)\ = 1 for some a G 2,
7a(<*,0) =
(. {(i?04, a)a', #(#, a)0')| a G 2, fl(,4, a) * M(5, a) * 0} otherwise.
Also, ^(a, A) and TA(A,0) are undefined.
Note that TA(a,{f) =fail if one of the sets is empty and the other is not.
Example Let G^ be the s-grammar
Si -> aABC
A -> b
B -> c
C -> aC| $
11.10 EQUIVALENCE PROBLEM FOR SIMPLE LANGUAGES 401
S,=S,
ABC=D
BC=E
C=¥
A = A
C = F
C = F
FIG. 11.6
and let G2 be the s-grammar
S2 -> aD
D -> bE
E -> cF
F -> aF\$
We begin by applying TA to (5i,52), which yields (ABC,D), and continue.
It is often helpful to represent this process by a tree, as shown in Fig. 11.6. The
process may continue indefinitely.
Lemma 11.10.2 If the underlying grammars Gx and G2 are s-grammars, then
TA is both valid and monotone.
Proof The argument is subdivided into separate claims.
Claim 1 If a = 0 and TA(a,0) is defined, then 7U(a>0)= {(<*i»0i)» • • •,
(am, 0m)} for some m > 1 and a,- = ft for each i,\<i<m.
Proof of Claim 1 Suppose a = 0. It must be the case that both a and 0 are in
N* for, if either a or 0 were A, then a = 0 = A and TA(a, 0) is undefined. Thus there
exist A, B G TV, a', 0' G N*, such that
a = /4a' and 0 = 50'.
402 BASIC THEORY OF DETERMINISTIC LANGUAGES
Next we will argue that T(a, 0) =£ fail for, if TA (a,0)= fail, then there would
exist a G 2 for which
\R(A,a)\ + \R(B,a)\ = 1.
Without loss of generality, suppose R(A,a) = 0 and R(B,a) = {7}. Then no
string that starts with a can be derived from A, and since the grammars are A-free, no
such string can be derived from a = Ad. On the other hand,
/3 = 5ft => 37/3' => axy
where 7 =>x and 0' =>y, since the grammars are both reduced. Thus axy is a string
that distinguishes a from ft, contradicting that a = ft
Hence ^(a,|3) = {(<*!,ft),... , (a^ftn)} for some m>\, and we must
now show that a; = ft for each /, 1 < / < m. Let
a, = R(A,a)d and ft = R(B,a)0,
from the definition of TA. Let a,- ^£2*. Then
a = Ad =*■ ai?(/l, a)a' => ax
But then |3 =>ax. But this latter derivation must start with
0 = 5/3' =*aR(B,a)tf ^ ax
because the grammars are s-grammars, and so
ft = R(B,a)0 ^x
The same argument applied in the other direction yields that a,- = ft, and the
proof of Claim 1 is complete.
Claim 2 If a # U and TA(a, (3) = {(a,, ft),..., (am, /3m)} for some m > 1,
then, for any y G £+, y = ay' with a £ 2 is in W(a, ft), if and only if there is some /,
1 < / < m such that y G ^(a,-, ft).
Proof of claim 2 Let
a = Ad and /3 = 5/3'
for A, B £ N; a', ft £ W*. Then
a =*•;> if and only if a = Ad =j*aR(A,a)d ^ay'
if and only if R(A, a)d =>/
A similar argument holds for ft Thus y distinguishes a from /3 if and only if there is
some i,Ki<m, such that y distinguishes R(A,d)d fromR(B,a)0. But this proves
Claim 2, by the definition of TA.
Claims 1 and 2 combine to show that TA is a valid transformation. In
addition, Claim 2 implies that, if a#/3 and TA(a,&) = {((*!, ft),. .. ,(am,/3m)} for
some m > 1 then y = a/ G W(a, 0) if and only if there is some /, 1 < i < m, such that
/ G ^(a,-, ft). It is easy to verify that j> is in W(a, fi) if and only if/ G W(a,-, ft). This
follows because, if there were a shorter witness for (af,ft) than /, there would be a
shorter witness than y for (a, ft). The argument is reversible. □
11.10 EQUIVALENCE PROBLEM FOR SIMPLE LANGUAGES 403
Next, we need a few more simple definitions.
Definition Let G = (V, 2,,P,S) be any reduced context-free grammar. For
each A £ N, define
£04) = min{lg(x)| A =^x,xG2*},
£ = max{£(4)| A GW}.
When we deal with two grammars Gt = (Vh S./'j,S,), / = 1,2, with TV, nN2 = 0, we
define
£ = max{£i, £2},
where £,- = max{£(,4)| A GN,-}.
The following facts are useful.
Lemma 11.10.3 Let Gi = (Vi,l,,Pt,St) be two reduced A-free grammars.
1. For all a £ N+ and x £ 2*, if lg(x) < lg(a), then a £ x.
2. If 0eN+, then there exists x€Z* such that 0=^* and lg(x)< £ lg(|3).
3. Let a, 0GW+. If lg(a) > £ lg(0), then a #0.
4. Given x€2* and 0eN*, define |3' to the shortest string such that
0 = 0'0" and 0' =>*7 for some 7 e W *. Then lg(j3') < lg(x).
Proof (1) is a trivial consequence of the fact that the grammars are reduced
and A-free. Part (2) is a straightforward consequence of the fact that the grammars
are reduced and A-free and using the definition of £. To show (3), we know that there
existsx62* such that 0 =*•*and
lg(x)<£lg(0)<lg(a)
by (2) and the hypothesis of (3). By (1), a f>x, and so x G W(a, 0). Therefore a ^ 0.
To show (4), we use the definition of 0' to write
P'=Bi---Bi, x = xi--xt, and B}eN,
for each /, 1 </ < /, and xs G 2* such that Bj =*Xj for each /, 1 </ < /, and B-, fxfl.
Since the grammars are A-free, we get that lg(xy) > 1 for 1 </ < /. On the other hand,
t lg(xj) = lg(x),
so that ]~l
W) = /<lg(x). D
Now the second type of transformation is introduced, the5-transformation,
Definition Let Gi = (yi,'L,Pt,S{) be two reduced A-free grammars with
N1nN2 = Q and N = NiUN2. For all a, 0GN+ with lg(a)>2 and lg(0)>£, let
404 BASIC THEORY OF DETERMINISTIC LANGUAGES
a = Aa and let x be the shortest terminal string generated by A. If 0'eW"t' is the
shortest string such that there exists 0", y&N+, with 0 = 0'0"and 0' =*xy then we
say that
rB(«,0) = {(pL',y$'),(Ay,&)}.
If no such 0' exists, then
T(a,0) = fail.
Tb is undefined elsewhere.
Note that, since lg(0) > £ and, by part (3) of Lemma 11.10.3,
lg(0')<lg(x),
it must be the case that 0" =£ A.
Note that the ^-transformation may be applied to strings a G N\ and 0 £ N\~.
The resulting string Ay is in N^N2 and this is the reason that the symbols from the
two grammars can be mixed together.
Example Let Gi be the s-grammar
5, -> aAC
A -*aB\bAB
B -> b
C -> a
and let G be as follows:
S2 -> aDE
D -> bDF\a
E -> bG
F -> b
G -> a
Let a = ABSC and 0 = DFSE. The shortest terminal string derivable from A is x = ab.
We now attempt to derive x = ab from 0
0 = DF5^ =» aFsE=*abF4E
This tells us that
p" = .DF, 0" = F*E, and 7 = A
and thus,
TB(a,(S) = p5C,F4£% 04,/^)}.
Next we show that the i?-transformation is valid and monotone for s-grammars.
Lemma 11.10.4 Let Gx and G2 be reduced A-free grammars in Greibach
normal form with Ni C\N2 = 0, N = Wi U W2, and let a, 0 GW* such that lg(a) > 2,
lg(0)>£.lf
11.10 EQUIVALENCE PROBLEM FOR SIMPLE LANGUAGES 405
i) a=Aa for some A&N such that L(A) = {w G 2* | A =»w} is prefix-
free, and if
if) 0 =*z8 for some z6S+,5 G TV*, and 5 is uniquet,
then the ^-transformation is both valid and monotone.
Proof Again the argument is subdivided into separate claims.
Claim 1 If a = 0 and TB(a,0) is defined, then TB(a,P) = {(a,,0,), (a2,02)}
anda,- = 0,- for/= 1,2.
Proof of Claim 1 Let a = 0, a = ,4a' for some A GA' and a' €N+. Let x be
a shortest terminal string derivable from A and assume that TB(a, 0) is defined. Let j>
be a shortest terminal string derived from a'. Then
A ' A
a = Aa => xy
Since a = |3, we have 0 ^xy. Moreover, the derivation may be factored as
0 f> *0'" f xy
since the grammars are in Greibach normal form. Moreover, there must exist 0', 0",
and 7 £ TV* such that
0 = 0'0" and 0'" = 70"
so that 0' 7**7. (That is, 0' is the shortest prefix of 0 which generates xy.) Therefore
TB(a,ff) = {(<*', 70"), 047,0')}.
Next, it is necessary to show that a' =70" and ,47 = 0'. The first of the conditions
is easy to check using the hypotheses of the lemma. For each;/ € 2*,
a =*y
if and only if
a = Aa =* xy
if and only if
0 = 0'0" t *y'
because a = 0. In turn, this holds if and only if
00 =* X70 f xy
if and only if
70 f /
For the second condition, assume, for the sake of contradiction, that Ay ^ 0'
and let j'' be a shortest witness for Ay and 0'.
CASE 1. Ay=£y'. Let z be a shortest terminal string derived from 0". Then
t This means that 0 f-z81 and 0 => z52 imply that 5t = 52-
406 BASIC THEORY OF DETERMINISTIC LANGUAGES
Since we already know that a' = 70", we have that
a = Ad =* y'z
and thus
0 = W t y'z
since a = 0. There must exist j>1;j>2 e 2* such that
JCiJ^ = y'z
and
0' ^ yi and 0" ^> j>2
Since z is a shortest string derivable from 0", we get lg(z) < lg(j>2). If lgO^) = lg(z),
then y2 = z and yx = y', and thus
P'fy'
which contradicts that y' is a shortest witness of Ay and 0'. If lg(j>2) > lg(z). then
lgCvi)<lg(/)andso
implies
which contradicts that Ay' generates a prefix-free set, since yx is a prefix of/.
CASE 2. 0' ^>/. Choose z as above, and obtain
Wfy'z
Then
a = ,4a =]f jez
Since a' = 70", we get
Ayfi" fy'z
The argument now parallels that of Case 1, and a similar contradiction may be easily
obtained.
Claim 2 Let a # 0 and TB(a, 0) = {(a', 70"), (d-y,0')}, where a', A, 0\_0", 7,
and x are as in the definition of TB. Then, for every / G £*, we have xy' G W^a, 0)
if and only if/ G R>(a', 70").
Proof of Claim 2 Since L(A) is prefix-free and ,4 =>x it follows that
a = Ad =* xy' = y ifandonlyif a' => /
If 0 = 0'0" =>*/, then, for some 5 G7V*,
0 = 0'0" f*5 f-x/ (11.10.1)
Now
0 = 0'0"=>*70" (11.10.2)
11.10 EQUIVALENCE PROBLEM FOR SIMPLE LANGUAGES 407
But (11.10.1) and (11.10.2), together with hypothesis (ii) of the Lemma, imply
S = 70" 4/
Conversely, suppose
7/3 => y
Then, since 0' =>xy, we have
0 = 0'0" 4 *7/3" ^ xy' = y
Thus we have shown that
a => xy' = y if and only if a' => y
and that
0 => xy' = j> if and only if 70" => /
Since a ffe 0, xy' G W^a, 0) if and only if exactly one of a or 0 generate y . This holds
if and only if exactly one of a' or 70" generates y', which holds if and only if
y' € W(a, 70"). This completes the proof of Claim 2.
Let us agree to say that two strings rj and 6 agree on all strings of length
less than or equal to k if, for each z G 2*, lg(z)<k,r) =>z if and only if 6 =>z. We
shall write tj = 6, in this case. Also let p = lg(x).
Claim 3 For any k>\, if all elements of W(a, 0) of length<p + k are not
of the form xy', then a' = 70". (That is, W(ol', 70") cannot contain any members of
length less than or equal to k.)
Proof Suppose that a'= 70" is false. Then there exists/ G £*,lg(/)<fc,
such that/ G wy,70"). By Claim 2,
xy' G W(a, 0)
but
¥*/) = P + lg(/)<P + fc,
which is a contradiction.
The next claim gives additional information about witnesses.
Claim 4 Let Gx and G2 be as before. Assume that affe0 and TB(a,ff) =
{(<*', 7/3"), (Ay, 0')}. For any k > 1, suppose a' = 70". Then, for all y G 2*, lgOO <
k + p, we have y G W(a, 0) if and only if there exist yx, y2 G 2* such that y = y\y2,
j>, G W(Ay, 0'), and 0"^j>2 =£ A.
/Voo/ Let y G 2* with IgO) < A: + p. Clearly, a 4j> if and only if
A => y
and y
y = yy
408 BASIC THEORY OF DETERMINISTIC LANGUAGES
for somey,j>" G Z*. Since
W)>Wx) = p,
it follows that
lg(/') = Wy)-W)<k + P-P = *.
Since a' = yft", we have that a =>j> if and only if
A => y
nil *. ft
7/3 =*y
and
r it
y = yy
In turn, this holds if and only if
A^y'
* II
7 ="^1
and
;e = y'y'iyi
This is all true if and only if
A *. I II
Ay =* yyi = yt
& =* yi
and
y = y\y-i
On the other hand, ft=*y if and only if there exist yu y2€ 2* such that
0' ^i, 0" 4^2, 0 = 0'0", and j> =yiy2. Since lg(0)> £,lg(0')<lg(x) < £,so lg(0") >l,
which implies y2 =£ A.
Thus we have shown that
i) a=*y if and only if Ay=*yu ft"' =*y2, and y=y\y2, with y2¥= A; and
ii) 0=>j>if and only if 0'^i,0"=^^2^: A,andj> =yiy2.
From the definition of W(a, ft), it follows that y G W^a, |3) if and only if y =y\y2,
ft" =*y2, and yx € ^(,47,0'). This completes the proof of Claim 4.
Now, the claims can be used to complete the proof of the Lemma. Let a,
0GMV+ such that T(a,ft) is defined. If a = 0, then Claim 1 proves the first part of
the validity. If a ffe ft and T(ol, ft) ^fail, then two cases may arise.
CASE 1. There exists a shortest witness of the form xy for a and ft. By
Claim 2, y is a witness of a' and 70". Thus TB is a valid transformation. To complete
the proof of monotonicity, note that lgCv') < lg(xy'), since the grammars are reduced
and A-free.
CASE 2. No shortest witness of the form xy' exists for a and ft. hety be any
shortest witness for a and ft. It must be the case that lg(y) > p, so let lg(y) = p + k for
some k>\. By Claim 3, a' = 70". By Claim 4, there exist yu y2ei,* so that
11.10 EQUIVALENCE PROBLEM FOR SIMPLE LANGUAGES 409
yx G W(Ay, |3') and |3" =>j>2 =£ A. This proves that TB is valid in this case, also. Mono-
tonicity also follows, for, if y is a shortest witness of a and 0, we have that yx is a
witness of Ay and 0. yt is a shortest witness by the if part of Claim 4. (If z were a
shorter witness of Ay and 0', then zy2 would be a shorter witness of a, 0 than y.)
Therefore, TB is guaranteed to be valid and monotone. □
Now that both TA and TB are available, we could start to use them on some
sample grammars. However, situations can arise in which neither transformation is
applicable. For example, suppose the pair ,4 = A occurs. We augment our repertoire
with two additional transformations so that for every pair in TV* x TV* — {(A, A)},
there is always at least one applicable transformation.
Definition Let Gt be our underlying grammars. If a, 0 G TV+ and lg(a) > £ lg(|3),
then
7g(a,0) = rB(U,a) = fail.
7g is undefined elsewhere.
Definition If a G TV+, then
rA(a,A) = rA(A,a) = fail.
TA is undefined elsewhere.
Lemma 11.10.5 7a and 7g are valid and monotone transformations.
Proof If a#/3 and TA(a,0) is defined, then TA(a,0) = fail. Part (1) of
validity and monotonicity are vacuous. The proof of 7g uses part (2) of Lemma
11.10.3 and is trivial. □
Now the process of using transformations to form a tree is stated precisely.
Definition Let Gt = (Vt, S,Pj,St), i= 1,2, be two reduced A-free grammars
with TVi n TV2 = 0 and TV = TVi U TV2. Let J~ be a set of transformations such that
TV* x TV*- {(A, A)} 9 U dom(T),
where dom(7') denotes the domain of T. A ^-transformation tree is a tree with a
potentially infinite number of nodes, each labeled by elements of TV* xTV* U {fail},
where each elementary subtree corresponds to an application of T G $~. If the root is
labeled (a, 0), we say that it is a ^-transformation tree for a, 0.
Note that the only nodes of the tree which can be labeled fail are leaves. Also
note that there are many different such trees for fixed G\, G2, S~, a, and 0, since the
order in which transformations may be applied is not prescribed.
In the next lemma, the properties of such trees are explored.
410 BASIC THEORY OF DETERMINISTIC LANGUAGES
Lemma 11.10.6 Let S~ be a set of valid and monotone transformations.
Suppose a ^ ft and y is a shortest witness for a and ft For any .y-tree for a and ft
there exists a finite path from the root to a leaf with successive labels
(«o,U(i),(«i,Ui),...,(«t,Ut),/flff
where a0 = a, ft0 = ft and there exist strings j> =y0,... ,yt € 2* such that
0 *<igG0;
ii) for each /, 0 < / < t, at $ ft- and yt is a shortest witness for a,- and ft; and
iii) for all /, 1 < / < t, lgOO < lgCi-i)-
iVoo/ The argument is an induction on lg(j>).
Basis. y = A. By the definition of monotonicity, any TS ^ can fail only
on a and ft Thus t = 0 < lgOO- The other conditions are trivially satisfied.
Induction step. Assume the result true whenever lg(j>)<& and k>0. Let
lgOO = k+ I, wherey is a shortest witness for a, ft By validity,either T(a,ft) = fail,
in which case the argument proceeds as in the basis; or else T(a,ft) = {(a[, ft[),...,
(a'm,ft'm)}. By monotonicity, there exists /, 1 < i < m, a- ffe ft' and (a), ft) has a shortest
witness y' such that lg(^') < lgO>). Let (au ftj) = (a,:, ft) and yx =y'. The induction
hypothesis applies to (a1( &{) with witness^! and yields the result. □
Corollary Let S~, a, ft and j> be as in Lemma 11.10.6. Then a ^"-tree for
a, ft must have a path from the root to a fail leaf with no two nodes labelled by the
same pair (a;, ft).
Proof Two different nodes on the same path have shortest witnesses of
different lengths. □
Next we show that valid transformations applied to equivalent pairs cannot
fail.
Lemma 11.10.7 Let Gi = (Vt,'L,Pl,S), /=1,2, be two grammars with
7V"1n7V2 = (8 and let N = NiUN2. Let a, /3G7V* and f be any set of valid
transformations. If a = ft then any ^"-tree for a, ft does not have a fail-leaf.
Proof The argument is an induction on the height n of a ^"-tree for a, ft
Basis, n = 0. There is one node labeled (a, ft) 4^ fail.
Induction step. Suppose the result is true for all a, ft a = ft and all (a,ft)-
trees of height n < n0, where n0 > 0. Let n = n0 + 1. Consider a leaf sn in a tree of
height n. This node is on a path (s0,... ,sn) from the root s0.
Consider the subtree rooted at slt which also contains the leaf sn. This is
the shaded subtree in Fig. 11.7. Since all ^-transformations are valid, the pair (a1( fti)
that labels Si must satisfy a! = ftx. The induction hypothesis applies to the subtree, so
sn is not labeled fail. □
11.10 EQUIVALENCE PROBLEM FOR SIMPLE LANGUAGES 411
Node at height n
FIG. 11.7
Because the transformation trees we have been studying can be infinite, it
is convenient to define a partial transformation tree as the finite tree which results by
taking a transformation tree that has a cross section if and taking everything above and
including if. An example is shown in Fig. 11.8.
There are many different ways to form partial trees. Let us fix the convention
that no path in the tree is continued if it reaches a node label that has appeared earlier.
That includes an earlier appearance as its own ancestor.
We are now ready to indicate how to solve the equivalence problem for
s-grammars. For this purpose, we fix the class of the relevant transformations.
Definition Let JTS = {TA, TB, Tz, TA). Note that N* x N* - {(A, A)}
c dom( JTS).
Now a special kind of equivalence tree is defined.
Definition Let Gt = (Vi,'L,Pi,Si) be two s-grammars which are reduced,
A-free, and in standard /--form for some r > 2. Assume NiC\N2 = 0 and N = A^ U N2.
Let a, (SGN*. An equivalence tree for a, 0 is a partial ^-transformation tree with
the following restrictions:
i) If (<*!, 00 is the label of the root of an elementary subtree and T€ JTS is
the corresponding transformation, then
FIG. 11.8
412 BASIC THEORY OF DETERMINISTIC LANGUAGES
a) if lg(aO > £ lgOJ,), (or lg(0,) > £ lg(aO), then T = Te;
b) iflg(aO>(/• - 1)£ + 2 andlg(0O>(r- 1)£ + 2,then T¥=TA;
c) if T= TB, then lg(aO < lg(/3i). (Note that TB may be applied when
lg(0i) <lg(o;i) but then the roles of a! and 0i have to be reversed.
ii) If (oil, Pi) is a label of two different nodes, then at least one of them is a
leaf. (Note then that (au 00 = Q3,, aO.)
It is important to note that the previous definition constrains how the
transformations are to be applied but does not do so uniquely. There are still a large number
of choices as to which transformation to apply.
Example Gt and G2 are given
G,
Si ->• aAC
A -+ Mfllafi
5 -+ ft
C -+ a
below.
G2
52 ->• aD£"
D -+ ftZ>F|a
£" -+ ftG
F -»• ft
G ->• a
A straightforward calculation shows that £ = 4. An equivalence tree for Si,
S2 is shown in Fig. 11.9. Note that the leaf labeled BC = E has been circled to indicate
that it has already been encountered in the tree and fully developed. There are a
number of interesting points that occur in developing this tree. The reader should
note the situation with the circled nodes, particularly A =DF, in which the repetition
occurs on the same path. This point will be clarified as additional properties of
equivalence trees are established.
Lemma 11.10.8 Let Gt = (Vt, £,P,-, S;) be two s-grammars in standard
/•-form for some r>2 with NlnN2 = $ and N = W, UN2. Let a, 0 be in N*. In any
equivalence tree for a, 0, where lg(a), \g(0)<(r— 1)(£ + 1) + 2, any node labeled
(cti, Pi) has the property that either
lg(ai) <(r-l)(«+l) + 2
or
W.) <(r-l)(«+l) + 2.
Proof The argument is an induction on the shape of the tree.
Basis. The root clearly satisfies the condition by hypothesis.
Induction step. Suppose we are at some arbitrary node that satisfies the
condition. A new node labeled (au 0i) is generated by applying some transformation
7"S ^s to the given node. If T= Te or T= 7X, the condition is vacuously satisfied.
11.10 EQUIVALENCE PROBLEM FOR SIMPLE LANGUAGES 413
ST\
a>
(J
414 BASIC THEORY OF DETERMINISTIC LANGUAGES
If T=TA, then the new node is labeled (R(A,a)a'i,R(B,a^'^), where
(*! =Aa'l and 0i = B$\. By using part 1(b) of the definition of an equivalence tree, we
get (without loss of generality by the symmetry) that
lgCa'O = lg(a,)-K(r-l)« + 2-l.
Also, lg(R(A, a)) < r, so that
lg(R(4,«)a'1)<(r-l)« + 2-l + r = (r-1)(«+ l) + 2,
and the condition holds.
If T=TB, then the resulting node is labeled either (a',7/3") or (Ay,(}'),
where $x = 0'/3", a! =Aa, /3' j*xy, and x is the shortest terminal string derived from
A. Note that
lg(<*i) < (r-l)(«+l) + 2
by (i(c)) of the definition of an equivalence tree and the hypothesis of the lemma.
Now |3' is the shortest prefix of/3 for which the above is true, so that
lg(T) < (r - 1) lg(x) + 1 < (r - 1)8 + 1. (11.10.3)
Clearly, we have
lg(a') = lg(a,) - 1 < (r - 1)(£ + 1) + 2
and
]g(4i) = lg(T) + 1< (r - 1)(« + 1) + 2
from (11.10.3). D
Corollary 1 Let Gt = (K,-, S.i';, S;), i = 1,2, be two s-grammars in standard
2-form, with NlnN2=9 and A^ = Nl UN2. If a, 0SA^+ with lg(a), lg(/3)<£ + 3,
then any node in an equivalence tree labeled (al, j}^ has either
lg(a,) < £ + 3
or
IgOSi) < £+3.
Proof This follows directly from Lemma 11.10.8 by setting r = 2. □
Corollary 2 The number of nodes in an equivalence tree which are roots of
elementary subtrees for TA or TB is at most
c|./V|(S+1)(S+3).
Proof The labels of such nodes are all distinct, by (ii) of the definition of
equivalence trees. If such a label is (a, /3), then
lg(a) < £ + 3 and lg(/3) < £(£ + 3),
or vice versa. The inequality for 0 follows from part (i(a)) of the definition of an
equivalence tree. Thus,
aSJVl+3 and /3S^6+3>.
11.10 EQUIVALENCE PROBLEM FOR SIMPLE LANGUAGES 415
There are only
|JV|g+4-l |jV|g(g+3>+1-l
\N\-l ' \N\-\
<c,|W|(6+1)(6+3)
such labels for some constant c1 if \N\> 1. If \N\ = 1, there are fewer than c2V?
such labels for some constant c2. □
Corollary 3 An equivalence tree has at most
rf|tf|<S+D<»+3)|S|
nodes, where d is a constant.
Proof For any node counted in Corollary 2, there are at most max{|£|, 2}
immediate successors obtained by applying any transformation. Each of these nodes
either is a leaf or may have one successor that is a leaf, so the number in Corollary 2
need be multiplied by at most max{2| £| + 1, 5}, as a bound on the total number of
nodes. □
Now we can state and prove the main result.
Theorem 11.10.1 Let Gf = (K,-, £,?,-,5,), i= 1,2, be two s-grammars with
N1nN2 = 0 and N = NlUN2, and let a, /3S7V*. Then a = j3 if and only if every
equivalence tree for a and /3 does not have any leaf labeled fail.
Proof Let /? be any equivalence tree for a and /3. For any leaf labeled (alt 0i),
where (alt Px) does not label any ancestor of that leaf, it must be the case that (ai, 0i)
labels an internal node elsewhere in the tree. Modify R to form a new tree /?! by
appending to the leaf in question, a copy of the subtree rooted at the internal node.
This is continued for all such leaves. The process cannot continue indefinitely since it
cannot generate paths of length more than ClAf(6+1)(6+3), by Corollary 2 to Lemma
11.10.8. R! includes every path from root to leaf of some JTS tree for a and 0 that has
no label repeated twice. Moreover,/?! has a/a//-leaf if and only if/? has a fail-leaf.
If a = P, then by Lemma 11.10.7, /?! contains no fail-leaves and/? cannot
have any. Conversely, if a ^ /3, then /?, must have a/a//-leaf, by Lemma 11.10.6. Note
the condition that no label be repeated along the path. Therefore, /? must have a
fail-leaf. □
Corollary The equivalence problem for s-grammars is solvable.
Proof Construct an equivalence tree forS^^S^ and check it for/^//-leaves.
Since the tree is finite, this is an algorithm. □
PROBLEMS
1 In the definition of TB, it was required that lg(/3) > £. It was explained in
the text that this implies /3" # A. Show that the condition /3" # A is necessary to
ensure that TB is monotone. Give an example of the application of TB where /3" = A,
416 BASIC THEORY OF DETERMINISTIC LANGUAGES
that would allow us to conclude that two strings are equivalent when in fact they
are not.
2 Could we develop a decision procedure for equality of s-grammars by
dropping Tb from our set of transformations? Prove your answer.
3 Let X, Y be nonempty sets of strings and suppose that X is prefix-free.
Show that XY is prefix-free if and only if Y is prefix-free.
4 Let X, Y, Z be nonempty sets of strings and assume X is prefix-free. Show
that if XY = XZ, then Y = Z.
5 Let X, Y, Z be nonempty sets of words and, furthermore, suppose that
Y and Z are prefix-free. Show that if YX = ZX, then Y = Z.
6 Translate Problems 4 and 5 into results about cancellation of equivalent
strings over N*. Use these identities to find more shortcuts in dealing with equivalence
trees.
7* Generalize the main result of this section by showing that it is decidable,
of two deterministic languages, one of which is an s-language, whether or not they are
equal. You should assume, for maximum generality, that the languages are presented
by arbitrary dpda's.
11.11 HISTORICAL SURVEY
The LR_1 theorem (11.2.3) was originally proved in Ginsburg and Greibach
[1966], as were many of the closure results in Section 11.3. Our proof of Theorem
11.2.3 follows Book and Greibach [1973], which in turn follows Hopcroft and
Ullman [1968a]. The material on strict deterministic grammars follows Harrison and
Havel [1972, 1973, 1974]. Problem 1 of Section 11.5 is from Geller and Harrison
[1977].
Lemma 11.6.2 is from Ginsburg and Greibach [1966]. Theorem 11.7.1 and
the exercises on realtime Turing-machine computations are derived from the work
of Rosenberg [1967,1968].
The unsolvability of the inclusion problem for simple languages is due to
Friedman [1976], while the solvability of the equivalence problem is due to Korenjak
and Hopcroft [1966]. Our proof follows Harrison, Havel, and Yehudai [1978].
twelve
Recognition and
Parsing of General
Context-Free
Languages
12.1 INTRODUCTION
One of the most important applications of language theory concerns the
recognition and parsing of context-free languages. Such recognizers are at the heart of
many programs that take their input in natural-language form. Although some of these
systems use more sophisticated types of grammars, like transformational grammars,
even these rest on a context-free base.
In the present chapter, we begin by discussing machine models for recognition
which are closer to actual computers than Turing machines. It is shown that there is a
"hardest" context-free language with respect to recognition time and space. Section
12.3 is devoted to techniques for doing elementary operations on matrices, because it
will turn out that one can reduce the recognition problem to computing the transitive
closure of a matrix. The Cocke—Kasami—Younger algorithm appears in Section 12.4
and is analyzed in some detail. In Section 12.5, recognition is reduced to boolean
matrix multiplication, in an algorithm due to Valiant. A very useful practical algorithm
is given in Section 12.6, which is due to Graham, Harrison, and Ruzzo. Section 12.7
includes other related problems such as bounds on space required for general context-
free recognition.
12.2 MATHEMATICAL MODELS OF COMPUTERS AND A HARDEST
CONTEXT-FREE LANGUAGE
In order to avoid taking some tangents in our later development, we shall give
some definitions and results here that will be used later in this chapter.
417
418 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
It will be important to determine the number of steps in a derivation of a
string of length n. We will use this result in subsequent sections to analyze the number
of steps required by certain parsing algorithms. Unless some restriction is placed on the
grammar or the derivation, the length of a derivation may be unbounded.
Our purposes will be served by restricting the grammar to be of the following
type:
Def iniition A context-free grammar G = (V, £, P, S) is cycle-free if, for each
A EN, A =M is impossible.
Now we can state a result which says that, in a cycle-free grammar, the length
of a derivation is linear in the length of the generated string.
Theorem 12.2.1 Let G = (V, ~Z,P,S) be a cycle-free, context-free grammar
and let £ = max{lg(a)|/4 -> a is in P, A & N}. There exist constants c0, Cj, and c2,
which depend only on \N\ and £ such that c\ >c2, and for all A EN, aS V*, if
A^a, lg(a) = n, then
a) if n = 0, then /<Coi
b) ifrt >0, then/<Ci« — c2.
Proof We must consider the derivations of strings whose length is at most one.
Claim 1 Suppose A =*a where lg(a) < 1. Then:
i) If a = A, no path in the derivation tree is longer than \N\.
ii) If a = a S 2, then the path from the root labeled ,4 to the leaf labeled a is
no longer than |A^|.
iii) If a = B S N, then the path from the root to the leaf labeled B is no
longer than | N | — 1.
Proof of Claim 1 Consider a path from the derivation tree of .4 =^a as shown
in Fig. 12.1.
Suppose the path from A = Ax to a is of length k. Then we have
A = A! ^M2 ^- • • ^Mfe ^a
FIG. 12.1
Since At ^-A, is not possible, we must have that all of A i,..., Ak, and a are distinct.
If a =BGN, then Ar< \N\ - 1. If a = a S2 U {A}, then fc< \N\. This completes the
proof of Claim 1.
12.2 MATHEMATICAL MODELS OF COMPUTERS 419
IJVI-1
i< I £' = c0 =
»
1
\N\
gUvi _ j
if£ = 0,
if£=l,
if P^>1
Now we are in a position to complete the analysis of A-derivations. Note that
a derivations =^Ahas a tree of height < \N\. The number of nodes at height/'in the
tree is at most V. Thus,
(12.2.1)
\ £-1
Let c0 be this constant in eq. (12.2.1) which depends only on £ and \N\. Thus we have
proved part (a) of the theorem.
Now we must work out the case where a nonterminal derives another
nonterminal.
Claim 2 Suppose A ^B, 5 6K. If the length of the path from the root A to
the leaf labelled B is k, then
/<£((£-l)c0 + 1).
Proof of Claim 2 The argument is an induction on k.
Basis k = 0 implies / = 0, and the basis is verified.
Induction step: Assume that k >0 and that the result is true for the path to
the node labeled B, of length k — 1. Then
A^AX ■■■Am
where
Ad=*B for some d, 1 <d<m,
and y
Aj=*A if/#d.
By the induction hypothesis,
'd <(*-!) ((«-l)co + l).
Moreover,
/;- < c0 if/ =£ d,
by our proof of (a). Therefore,
i = 1 + id + 1 ij
i*d
;<l+(*-l)((£-l)c0 + l) + (£-l)c0 = *((£-l)c0 + l),
using that m < £. This completes the proof of Qaim 2.
420 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
where
and
If we combine Claims 1 and 2, we have already shown the following result:
Claim 3 Suppose A ^-B, BGV. Then
[|7V|£|JV| if£>l,
/<( |Af|((£-l)c0 + l) if BGV,
((|W|-l)((«-l)co + l) if BGN.
Now we are ready for the main claim, which will complete the argument.
Claim 4 If A ±a, lg(a) = n > 0, then
/<Ci« — c2,
ci = 2\N\((t-l)c0 + l)-co
c2 = |7V|((£-l)co + l)-c0.
Proof of Claim 4 The argument is an induction on n.
Basis. n= 1. We compute
C-l-ca = M((«-l)c0 + l).
So i < Ci • 1 — c2, by the second case of Claim 3.
Induction step. Assume the result true for all strings of length at least 1 and
less than n. Suppose that A =*a, lg(a) = n > 2. The tree of this derivation must have
a node with at least two immediate descendants producing nonnuU strings, as shown
in Fig. 12.2.
A
FIG. 12.2
Let D be the highest such descendant of A. Thus we have
A'^D =►/>! ■■■Dm
Dj & a,, lg(a;) = n,
12.2 MATHEMATICAL MODELS OF COMPUTERS 421
for each/, 1 </ < m. Moreover,
m
a, •••<*„,= a and X n} = n,
and there exist /'i, /2 such that
since lg(a)>2.
To simplify the notation of the proof, assume that there is some p, 2 <p
<m, such that
a,,.. . .a^A
and
(There is no loss of generality in this assumption since, if this condition were not
satisfied, we could introduce new indexing to make it so.)
Then
m P m
i = i* + 1 + I ij = i* + 1 + I ij + I ij-
By the induction hypothesis,
P m
i< (|/V|-l)((«-l)co + l) + l + Z (cin,-c2)+ Z c0
;'=1 ;'=p + l
= (\N\-lW-l)c0 + l)+l+cln-pc2 +(m-p)c0
= Cln + (\N\ - 1)((« - l)c0 + 1) + 1 + mc0 -p[\N\((£ - l)c0 + 1) -c0 + c0]
by substituting the value of c2. Continuing,
i<dn + CUV| - 1)((« - l)c0 + 0 + 1 + mc0 -p [|A^|((£ - l)c0 + 1].
Since m < £ and p > 2,
i <c,» + (|yV| - 1)((£ - l)c0 + 0 + 1 + <k0 -2[\N\(i ~ l)c0 + 1]
= c,« -(|yV| + 1)((£ - l)c0 + 1) + £c0 + 1
= c1«-|A^|((£-l)c0 +l)-(£-l)c0 -1 +£c0 + 1
= Cin-[|yVK(«-l)c0 + D-Co]
= ci«-c2.
Since the induction has been extended, the proof of Claim 4 and the proof of the
theorem are complete. D
Because our fundamental goal in this chapter is to examine parsing and the
resources that are required for its implementation, we must discuss how to implement
it and how to compare algorithms. The usual technique is to implement algorithms on
a standard model of a computer and then to estimate the time and storage requirements
of each algorithm. For that approach, standardized models of computation must be
used. There are two models in common usage which we shall employ, the Turing
422 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
machine and the random-access machine (or RAM, for short). We already know about
the use of Turing machines as language acceptors from Chapter 9.
Although Turing machines have an important role in the theory of
computation, they are not natural models for algorithmic analysis. Turing-machine
computations require a great deal of time moving back and forth along the tapes looking for
information, and do not have the familiar random-access memory properties of
computers. This suggest that another model is needed, and has led to the use of RAM's
(named for random access memory model).
A RAM is a device of the type shown in Fig. 12.3. It has an input tape that
can be read. Unlike a Turing-machine tape, every square may contain an integer, and
there is no a priori bound on the size of the integers used. The output tape is of the
same type, except that it can be written but not read.
Read-only input tape
Registers
Program
memory
|—> (finite)
Program
counter
Write-only \_
output tape I I I I I I I I [ I I I
FIG. 12.3
The RAM has an unbounded number of registers, each of which is capable of
storing an integer. The first register is thought of as the "accumulator." There is no
bound on the size of the integers stored in a register, nor is there a bound on the
number of registers that may be utilized. There is a program in a RAM which resides in
a program memory that cannot be altered. Each register can be directly accessed by
the program. A program counter indicates which instruction is currently being
executed. The output is printed on a write-only output tape, each square of which can
hold an arbitrary integer. There is an instruction set, which can be anything that is
sufficient to compute any partial recursive function. For example, a simple instruction
set might be:
LOAD a
STORE a
SUBTRACT a
READ a
WRITE a
BRANCH ZERO £
where £ labels an instruction in the program. On the other hand, a may be (i) a non-
r0 = Accumulator
r2
12.2 MATHEMATICAL MODELS OF COMPUTERS 423
negative integer representing a register, (ii) a literal, which means that constants are
available, or (iii) a tagged nonnegative integer used for indirection. The interpretations
of these terms are familiar to those who have experience in assembly-language
programming.
We are being deliberately vague about the actual instruction set. Cf. [Aho,
Hopcroft, and Ullman [1974] ] for a number of different choices. The reason we are
vague is that we wish to use computers at a high level and so we shall write algorithms
for a RAM in an ALGOL-like dialect. It would be a straightforward task to translate
such a language into RAM code.
Example Suppose locations A0 toAn_l in our RAM each contain an integer.
We wish to write a program to sort the integers into ascending order. Let bit have the
values true or false and let swap exchange the values of its arguments.
procedure swap (x, y);
begin
t: = x;x: =y;y: = t;
comment the procedure is called by reference;
end;
begin
repeat
b: = false;
for i": = 0 to n — 2 do
if at > ai+i then begin
swap (ah ai+l);
b: = true
end
until not (b)
end.
We leave it to the reader to analyze this algorithm, but note that, in the worst
case, we might have n(n — 1) comparisons. Thus this is an algorithm that runs in
quadratic time but linear space.
In our ALGOL dialect, program labels will have no computational significance,
but will simply serve as reference points for the discussion. In addition to program
variables containing integer or boolean values, we will allow variables to take on
(unordered) sets as values. Our algorithms will often deal with two-dimensional
matrices. The matrices will use 0-origin addressing. That is, anmxn matrix will
consist of rows 0 to m — 1 and columns 0 to n — 1. We will use the following matrix
concepts. A matrix M = (mt f) is (strictly) upper triangular if it consists only of
elements mtj where i </ (i </). The principal diagonal of an n x n matrix M consists
of the elements m0 Q,ml i,... ,/«„_!_ „_i.
If we formalize what we have done in the example, the time complexity of a
program is taken to be a function /(«), which is the maximum over all inputs of size n
of the sum of the time taken by each instruction executed.
424 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
For example, we could write a machine-language RAM program to subtract
two numbers by writing:
READ1
READ 2
L0AD1
SUBTRACT 2
STORE 3
WRITE 3
HALT
There are 7 instructions executed, so the time complexity is 7. Our definition of time
complexity could be considered to be unrealistic because the result is independent of
the length of the numbers. In cases like this, it is said that the uniform-cost criterion is
being used. We could charge log N to every instruction which uses integers of <N. In
that case, the logarithmic-cost criterion is being employed. In many of our applications,
the uniform-cost criterion is appropriate and will be used.
There is another type of model that is sometimes useful, the bit-vector
machine. A bit-vector machine works like a RAM except that its memory utilizes bit
vectors (of unbounded length). It is also convenient to have index registers and indirect
addressing. A typical set of instructions for such a machine would be as follows:
Arithmetic Operations on index registers
vk: = f(vt, Vi), where /is any boolean function of two variables
extended to vectors by bitwise operation;
SHIFT L-V Shift a word left
SHIFT R_v or right
Transfer instructions
for vectors and index
registers
As defined here, bit-vector machines are very powerful because many
complex processes can be coded into very long binary strings, and a bit vector machine
can perform its operations on these long strings in one step. When we use this model,
we must argue that its use is realistic in a computational sense. For instance, if we are
doing parsing of strings of length n and we are using bit vectors whose size is of length
log n, that seems realistic because, in practice, most strings parsed are only a few
hundred characters long at most. It would certainly be unrealistic to store strings of
length n2 in a single word.
Because of the way a bit-vector machine works, it is usually assumed that
there are no input or output operations. One can recognize context-free languages on a
bit-vector machine in time (log «)3. Now, that bound is less than linear time, and
linear time is required to read the input in a reasonable model. So the method of
achieving (log n)3 must be unrealistic.
Most of the discussion in this section has been descriptive. There is a
mathematical result that we wish to establish. We wish to exhibit a single context-free
language which has the property that, if one can parse this language in time /(«) > n
12.2 MATHEMATICAL MODELS OF COMPUTERS 425
and/or space g(n) >n, then any context-free language can be parsed within these
bounds. The significance of this result is that it is unnecessary to derive general time
and space bounds for each of the parsing algorithms that will be studied. We could
show instead that these algorithms have these bounds on just one particular grammar.
We will not choose this approach, because the general techniques of algorithmic
analysis are often more informative, and they lead us to notice significant special
cases; but it is possible in principle.
Let A denote our favorite model of a computer, for instance, a random-access
machine, a bit-vector machine, or some form of Turing machine.
Theorem 12.2.2 Let A beany computational model of the type just described
that accepts L £ A* in time p(n) >n, where p is some polynomial. Let <p: 2* -*• A* be
a homomorphism. The set
can be accepted in time p(n) by a device A' of the same type as A. The same result
holds for space.
Proof We construct A' to work as follows:
1. Scan w and translate it to <pw. This takes k lg(V) steps, for some constant
k.
2. Simulate A on <^w. This takes p(lg(^w)) steps.
3. Then w may be processed in
pQgfow)) + k lg(w) < k'p(lg(w))
steps for some constant k'. Note that a similar result holds for space. □
Let us now recall a specific context-free language, namely, L0 of Section 10.5.
Let 2 = {a i, a2, ai, a2, <t, c}. Define
L0 = {A}U {xjcj/jczjd • • • dxncy„cz„d\n>l,y1 ■ ■ ■ yn&<iD2,xi,zi&-L*
for all 2, 1 <i <n,yie{ai,a2,a1,a2}* for all i>2}.D2 is the semi-Dyck set on two
generators.
Theorem 12.2.3 L0 is a "hardest" context-free language. That is, the time
and tape complexity for recognizing any context-free language is identical to the time
and tape bounds fori0-
Proof The result follows immediately from Theorem 12.2.2 and Theorem
10.5.1. □
PROBLEMS
1 A weakened statement of Theorem 12.2.1 could be that, in a cycle-free
grammar, there is a linear relationship between the length of string generated from A
and the length of the derivation. Can you give a quick proof of this result by
contradiction? If you succeed, why is the proof given in the text superior?
426 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
2 Suppose A is a fe-tape Turing machine which accepts a set L with time
complexity T(n) > n. Show that L can be accepted by a RAM program in time
proportional to
(T(n) with uniform-cost criterion,
T(n) log T(n) with the logarithmic-cost criterion.
3 Show that the converse of Problem 2 is false for the uniform-cost criterion.
That is, there is a language L accepted by some RAM program P in time T(n) under
the uniform-cost criterion. There is no Turing machine A' which accepts L in time
p(T(n)) for any polynomial p(x).
4 Let L be a language accepted by a RAM program in time T(n) under the
logarithmic-cost criterion. Find the smallest possible polynomial p(x) so that L is
accepted by a Turing machine in time p(T(n)). For example, does p(x) = x3 suffice?
5 If indirect addressing is removed as a feature in a RAM, what consequences
follow?
6 Find a simple deterministic context-free language L i such that
A0 ? DSPACE (log n)
if and only if
ij S DSPACE (log 7i).
Recall that A0 is the family of deterministic context-free languages. Simple is used in
the sense of Section 11.9.
7 Consider the set L\ in Problem 6. Is it fair to regard Lx as a hardest
deterministic context-free language?
12.3 MATRIX MULTIPLICATION, BOOLEAN MATRIX
MULTIPLICATION, AND TRANSITIVE CLOSURE ALGORITHMS
A close connection between matrix multiplication, boolean matrix
multiplication, and transitive closure algorithms will emerge in this chapter. Some classical
results in this area are now recalled.
Let us first consider multiplication of matrices over an arbitrary ring. The
key idea is to study the 2 x 2 case first, and then to reduce the general case to it.
Lemma 12.3.1 The product of two 2x2 matrices whose elements are from
any ring can be computed with seven multiplications and fifteen additions.
Proof Let
~au au
tf2l #22
bn b12
021 Z>22
Cll C\2
C21 C22
12.3 MATRIX MULTIPLICATION 427
The following computation computes the Cy. Each st term involves one addition and
each mt involves a single multiplication.
mx = anbn
Si = an—a2\
S3 = a22 — Si
m3 - s4b22
m4 = SiS5
ms = s2s6
m6 = S3S7
mn = a22Sz,
m2 = «i2^2i
S2 = #21 + #22
54 = fll2—^3
55 = b22 — b\2
s6 — b\2 — bn
s7 = s5 + Z>n
St = b2i — s7
s9 - mi + m6
<■{}■
Cn = S10 = m\ + rn2
S11 = s9 + ms
C\i - S12 = su+m3
S13 = s9 + m4
C21 = Si4 = S\z+mn
c22 = sls = s13+ms
It is a straightforward task to verify that these identities correctly compute
D
Now we shall treat general matrix multiplication in terms of the 2 x 2 case.
Theorem 12.3.2 Two n x n matrices whose elements come from an arbitrary
ring can be multiplied in time proportional to n2il.
"c„
. C2i
Cu'
C22 .
An
.A2i
A12
A22.
B„
B2i
Bn
B22
Proof Let us consider the case n = 2k. Let us write the equation C = A * B
involving nx n matrices as
(12.3.1)
where each Cy, Ay, and By is an («/2) x («/2) matrix. Thus we may regard A, B, and
C as 2 x 2 matrices over a different ring. It is this observation that will allow us to use
Lemma 12.3.1.
Let M(n) be the number of scalar multiplications necessary to multiply two
nx n matrices. Let A(n) be the number of scalar additions necessary to multiply two
nx n matrices. Let T(n) = M(n) + A(ri). Note that n2 scalar additions are needed to
add two nx n matrices. Using Eq. (12.3.1) and Lemma 12.3.1, we see that seven
428 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
multiplications of (n/2) x (n/2) matrices and 15 additions of (n/2) x (n/2) matrices
are needed; that is,
r(«) = 77f-)+15(-
Thus
M(n) = 1m(-
and 2
n = 2fe,
Using the initial conditions Af(2) = 7 and .4(2)= 15, we conclude that, if
M(n) = lh
A(n) = 5(7fe -4fe) (12.3.2)
an(i ,. u
T(n) = 6-7fe-5-4\
as the reader may easily verify by induction on k.
Note that k = log2 n so that Eq. (12.3.2) is
M(n) = 7fe = 7^" = n^7 = «2,81.
Also observe that
T{n) = 6-«2-81 -5-«2 <6-h2-81. (12.3.3)
Note that, if n is not a power of 2, one can pad the matrices out to the next
larger power of 2. This can (at worst) double n, which involves increasing the constant
by 6 in Eq. (12.3.3). □
We could instead assume, in Theorem 12.3.2, that n = 2k,h, where h is odd.
It is then possible to derive an expression of the form
T(n) = c-n2-81
where c < 6. We leave this refinement for the reader.
Thus we have an ^(«2-81) time bound for multiplication of n x n matrices
over a ring. However, the product operation of a ring is associative but our applications
will use nonassociative products. Consequently, we extend our previous result to
multiplication of boolean matrices and then reduce our new product operation to boolean
products.
Boolean matrices are n x n matrices whose elements are subsets of {0, 1}. The
associated scalar operations + and *, given by the following table for boolean addition
and multiplication satisfy all the properties of a ring except that the element 1 has no
additive inverse.
+
0 1
0 1
1 1
*
0
1
0
0
0
1
0
1
12.3 MATRIX MULTIPLICATION 429
As usual, we define matrix multiplication by the "sum of products" rule.
Example
"1 1
0 1
Since we do not have a ring, we cannot apply our technique for fast
multiplication to boolean matrices directly. Nevertheless, as the text theorem indicates, we
can multiply boolean matrices within the same time bound.
Theorem 12.3.3 The product of two n x n boolean matrices can be computed
in time proportional to «2-81 steps.
Proof Given two n x n boolean matrices A and B, compute C = A * B by the
algorithm given in Theorem 12.3.2, using Z„+i, the integers modulo (« + 1), as the
ground ring. Note that, for 1 </,/<«, 0 < citi < n. Let D be the boolean product of
A and B.
Claim djj = 1 if and only if 1 < cit;- < n.
Proof of claim If dtj = 0, then there is no k such that aikbkj = 1, and hence
cI;y = 0. If dtj= 1, then, for some value of k, aih = 1 and bkj=^ 1. Therefore
1 < Cij < n and both the claim and the theorem follow. □
PROBLEMS
Transitive closure is an important and familiar operation on relations. It
generalizes to graphs and matrices by the familiar connections among relations,
matrices and graphs.
1 Let A be an n x n boolean matrix. Show that A*=IUAUA2U--- =
(/UA)".
2 Another procedure for computing A* or A+ involves Warshall's algorithm,
shown below.
begin
comment A is an n X n boolean matrix whose closure is to be
computed. The answer is stored into B:
for 1 < i, J < n do 4°}: = A [i, j);
for k: = 1 to n do
for 1 < i, / < n do
c£>:=c£-i>Uc£-i>.c£-i>.
for 1 < i, / < n do B [i, j ]: = c\f
end.
Prove that Warshall's algorithm uses /7(n3) U and • operations on a RAM and that
B = A+. Discuss appropriate cost functions for the computation.
3 Implement Warshall's algorithm on a bit-vector machine by storing rows
(columns). What is the time bound achieved this way, and what is the appropriate cost
function?
"1
1
1"
0
1
.1
1
0_
430 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
4 By a suitable encoding, show that the algorithm of Problem 3 can be
implemented on a unit-cost RAM in time n2log n. Hint: Map (b\, . . . , bn) into:
logn
0 • • • 06,
0 • • • 0bn
n logn
12.4 THE COCKE-KASAMI-YOUNGER ALGORITHM
The algorithm to be presented requires grammars in Chomsky normal form.
As we saw in Theorem 4.4.1, there is no loss of generality in this assumption. The
string A is in a language if and only if the Chomsky normal-form grammar for the
language has a rule S-+ A, where S is the start symbol. Furthermore, the rule S-+ A
cannot be used in the derivation of any non-null strings. Consequently, without loss
of generality, we can restrict our attention to non-null input strings and A-free
grammars in Chomsky normal form.
The key to the Cocke—Kasami—Younger algorithm is to form a strictly upper
triangular matrix of size (n + 1) x (n + 1), where n is the length of the input string.
The entries in the matrix are subsets of variables. We can then determine membership
in the language by inspecting one matrix entry. We can also use the matrix to generate
a parse.
Algorithm 12.4.1 Let G = (V, ~L,P, S) be a grammar in Chomsky normal
form (without the rule S-*■ A) and let w = a\a2 ■ ■ • an, n > 1, be a string where, for
KKn,afc£E. Form the strictly upper-triangular («+l)x(«+l) recognition
matrix T as follows, where each element f,-;isasubset of V — 2 and is initially empty .t
begin
loop-1: for i: = 0 to n — 1 do
U.i+i '■ ={A\A-+ ai+l is inP};
loop-2: ford: = 2 tort do
for i: = 0 to n — d do
begin/: =d + i\
ttj: = {A | there exists k, i + 1 < k </ — 1 such that
A ->-.BC is in .P for somcBSf,- fe, C&tkJ)
end
end.
Example
S-+ SS\AA\b
w = aabb
A-+ AS\AA\a
t Recall the 0-origin addressing convention for matrices.
12.4
THE COCKE-KASAMI-YOUNGER ALGORITHM
431
The recognition matrix is
T =
A
S,A
A
S,A
A
S
A,S
A
S
S
In computing T, the superdiagonal stripe is filled in by loop 1. As the
following diagram illustrates, the remaining computation is done down the diagonals
(;' —i = d) and working up to the righthand corner as d = 2,. .. , n. Thus the rows are
filled left to right, and the columns are filled bottom to top.
1
k 3
2\
£
As shown in Fig. 12.4 the (i, ;')th element of the matrix is computed by
scanning across the 2th row and down the/th column, always to the left and below the
entry in question.
Thus we successively consider the pairs of entries
(i,i+l) (i + l,/)
(i,i + 2) (i + 2,/)
(i,;-l) (j-l,j)
Each matrix entry is a set of nonterminals. For each pair of entries, we find every
grammar rule with a right part composed of a symbol from the first entry followed by
a symbol from the second entry. The left parts of these rules constitute the (i,/)th
entry in the recognition matrix.
The next theorem and its corollary show that the algorithm is correct, in that
it recognizes all and only strings generated by the associated grammar.
Theorem 12.4.1 Let G = (V, I,,P, S) be a grammar in Chomsky normal form
(without the rule S -*■ A). Let w = aifl2 • ■ ■ a„,« > 1, be a string, where for 1 < k < n,
432 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
(0,0)
(1,1)
(i, 0
(i,i + l).
(1,7- 1)
(U)
('+1,7)
"
(7-1,7)
(7,7)
(1-1,1)
(1,1)
FIG. 12.4
ak e 2, and let T = (tt j) be the recognition matrix constructed by Algorithm 12.4.1.
Then A e tu if and only if A =^ai+lai+2 ■ ■ ■ as.
Proof Since the recognition matrix is strictly upper-triangular and (n + 1) x
(« + 1), the algorithm must set entries fy where 0 </ <n — 1, 1 </<«, and i <;'.
Consequently, 1 <;' —j<n. The first loop handles the case;' — i= 1. In the second
loop, since j = d + i, we know that d=j — i. For a given value of d, we must have
j = d + i<:n. Consequently, i<n~d. It follows that Algorithm 12.4.1 sets every
entry of the recognition matrix and each element is assigned a value only once. We
show by induction on d that the values of T correspond appropriately to derivations.
Basis, j-i = 1, so ;'- 1 =i. Clearly, after the first loop, Aetu+1 if and
only if>l =>a1+1.
Induction step. For some d = j — i,l <d<n, assume the result for all d! < d.
After the second loop, A e tu if and only if there exists k,i<k <;', such that A -*• BC
is in P for some B S tih, CS ffe y.
12.4 THE COCKE-KASAMI-YOUNGER ALGORITHM 433
Since k </, we have
k — i<j — i = d,
and the induction hypothesis applies to tiyh since k — i<d. Also, since i < k,
j — k<j — i = d,
and, since / — k<d, the induction hypothesis holds for tkj also.
+
B^U.k if and only if 5 => aI+1 • • ■ ak
Ce rfe>;- if and only if C => afe+1 • • • a;-
Combining these results, we have
A S /j j if and only if A =>BC ^ aI+1 • • • ay
This extends the induction. □
Corollary w&L (G) if and only if S £ to, „.
Algorithm 12.4.1 is an "off-line" algorithm in the sense that all of the input is
read at the beginning and the successive matrix entries computed correspond, by
Theorem 12.4.1, to sets of successively longer substrings of the entire input string. An
"on-line" algorithm would compute the matrix entries in such a way that, after
reading at, the recognition matrix would indicate which nonterminals generate
aia2 "'' ai- In fact> Algorithm 12.4.1 can be rewritten as an on-line algorithm. We
present this algorithm so that the reader can compare it with other on-line algorithms.
Algorithm 12.4.2 Let G = (V, I,,P, S) be a grammar in Chomsky normal
form (without the rule S-+ A) and let w = axa-i • ■ an, n> 1, be a string, where for
1 <j'<«, a,S 2. Form the strictly upper-triangular (« + 1) x (n + 1) recognition
matrix T as follows, where each element ttj is a subset of V — E:
begin
for /: = 1 to n do
begin
tj.-ij: = {A\A-+dj isinP};
loop-2: for i: =/ — 2 down to 0 do
tij: = {A I there exists k, i+ Kk<j— 1 such that
A -+BCis inPfor some B e tUk, C&thJ}
end
end.
Note that this algorithm fills in the matrix column by column and the column
elements are computed "bottom to top." We leave it to the reader to verify that
Algorithm 12.4.1 and Algorithm 12.4.2 yield the same recognition matrix for any
grammar and string.
Next we estimate the number of steps required by the algorithm, as a
function of the length of the string being analyzed. Observe that, for a given terminal
434 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
symbol aI+1) computation of {A\A ->-tfI+1 is in P} takes a fixed amount of time.
Similarly, for fixed i, j, and k, computation of {A\A-+ BC is in P, B e tik, Ce tkj}
takes an amount of time bounded by a constant with respect to the length of the
string being analyzed.
Theorem 12.4.2 Algorithm 12.4.1 requires 0 (n3) steps to compute the
recognition matrix.
Proof Loop 1 takes cxn steps to initialize the superdiagonal. The setting of
ttj in the-body of loop 2 takes c2(d — 1) steps, since k can take on d — 1 values.
Therefore the algorithm requires
ci«+c2 £ (d-l)(n-d+l) = cln + -2L—. = <7(n3)steps. □
d=2 6
The space required by the algorithm is determined by the number of elements
in the strictly upper-triangular matrix. Since each element contains a set of bounded
size, we get immediately the next theorem.
Theorem 12.4.3 Algorithm 12.4.1 requires n(n + l)/2 cells of memory on
a RAM.
Now that the recognition problem has been solved, a technique is needed for
parsing. Algorithm 12.43, which follows, provides a means of obtaining a parse for a
given string from its recognition matrix. The algorithm will also be used for the
recognition matrices defined using other methods of recognition.
Algorithm 12.4.3 Let G = (V, I,,P,S) be a grammar in Chomsky normal
form (without the rule S -*• A) with the productions numbered 1,2,... ,p and the rth
production designated 7r,-. Let w = aitf2 • ■ ■ a„,« > 1,be a string, where for 1 <k<n,
ah £ E and let T = (ttj) be the recognition matrix for w constructed by Algorithm
2.1.1.
In order to produce a left parse for w, define the recursive procedure
parse(i, j, A), which generates a left parse for,4 =*■ ai+1ai+2 ■ ■ ■ as by:
procedure parseQ, j, A);
begin
if/ — i = l and nm = A -*• ai+1 is in P
then output (rri)
else
if k is the least integer i<k<j such that nm = A -*• BC
is inP where B e f/jfe and Ce tkJ
then begin output (m); parse(i, k, B)
parse (k,j, C)
end
end;
12.4 THE COCKE-KASAMI-YOUNGER ALGORITHM 435
Output a left parse for w as follows:
main program: if S £ ?0 „
then parse(0,n,S)
else output ("error").
Note that Algorithm 12.4.3 produces the leftmost parse "top down" with
respect to the syntax trees. By contrast, Algorithm 12.4.1 builds the recognition matrix
"bottom up." The reader can easily modify the algorithm to produce a rightmost parse.
We next verify that Algorithm 12.4.3 works and derive its running time. The
theorem is followed by an example.
Theorem 12.4.4 Let G = (V, 2, P, S) be a grammar in Chomsky normal form
(without the rule S -*• A), with productions designated 7Ti, n2, ■ ■ ■, fp ■ If Algorithm
12.4.3 is executed with the string w = a\a2 ■ ■ ■an,n> 1, where, for 1 </ <n,a,- S 2,
then the parsing algorithm terminates. If w&L(G), then the parsing algorithm
produces a left parse; otherwise it announces error. The parsing algorithm takes time
<7(n2).
Proof We establish the theorem by a sequence of partial results.
Claim 1 Wheneverparse0',/,j4)is called, then/>/ and^l G^y.
Proof of Claim 1 The procedure parse is called once from the main program
and twice from within the body of parse. In all cases the call is conditional on the
satisfaction of this property of the arguments.
Claim 2 parse (i, j, A) terminates and produces a left parse of the derivation
A ^ai+1ai+2 ■■ -ay.
Proof of Claim 2 We induct on / — i.
Basis, j — i = 1. By claim 1, A e tu+1. It follows from Theorem 12.4.2 that
A =>ai+1 and therefore that P contains a rule nm~A -+ai+1. Clearly, the procedure
parse terminates and produces the left parse m.
Induction step. Assume the result for j — i<:d. Consider parse{i,i,A),
where f — i = d+ I. Since j — i¥=l, the else portion of the conditional statement in
parse is executed. It follows from Claim 1 and Theorem 12.4.2 that, for some B, Cm
V— 2, A=^BC=*ai+yai+2 ■ ■ • aj and, consequently, that P contains some rule
7rm =A -+BC where BStik andCe?feiy. Therefore, parse produces (m,parse(i, k, B)
parse{k,j,C)). By the induction hypothesis, parse(i,k,E) and parse(k,j,C)
terminate and produce the appropriate left parses. Consequently, the else portion of
parse terminates and produces a left parse of A ^ai+^a^ '' ■ fly.
Claim 3 For each d, 1 <d<n, a call of parse(i, },A) takes at most cd2 steps
where j — i = d and c is some constant.
436 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
Proof of Claim 3 We induct on d.
Basis. d=\. parse(i, i + 1 ,A) takes one step.
Induction step. Assume the result for/ — i<d. Suppose parse (i,j,A) is
called with j — i = d+ 1. Clearly, the else portion of the procedure is executed.
Except for calls of parse, for some constant Ci, the else portion takes at most
C\{j — i — 1) < cx (j — 0 steps, since k takes on / — i — 1 values. Therefore, if we
choose c = c\, then, including the recursive calls on parse and using the induction
hypothesis, parse requires at most c(j — i) + c(k — i)2 + c(j — k)2 steps. Let k = i + x
and; = i + x + y. Then the number of steps is
c((j-i)+(k ~i)2+(j-k)2) = c(x+y+x2 + y2).
Using the elementary relationship
-^<xy,
we get
x+y+x2 +y2<x2 +y2 + 2xy = (x + yf = (j-i)2.
This completes the induction proof of Claim 3.
Putting the partial results together, it follows, from Theorem 12.4.2, that if
w $L(G), the S $ f0, n • Clearly, the algorithm terminates and announces error in this
case. Otherwise the algorithm calls parse(0,n,S). It follows from Claim 2 that the
algorithm terminates and produces a left parse for S=>aia-2 ■ • -an=w. It follows
from Claim 3 that the algorithm takes <^{n2) steps. □
Example Continuing the previous example, we number the productions
1. S-+SS 4. A-+AS
2. S-+AA 5. A-+AA
3. S-+b 6. A-*a
The parse of w = aaab is generated in the following way:
Since S e tQ< 4, parse(0,4, S) is called.
Since 7r2 =S-+AA is in .P, ,4 €t0,i, and A S?14, we get:
(2, parse(0, 1, A), parse{\, 4, A)) = (2,6, parse(l, 4, A)).
Since ir4= A -+AS is in P, A S/li2,and5S/2>4, we get:
(2,6,4,parse(l,2,A),parse(2,4,5)) = (2, 6,4,6,parse(2,4,5)).
Since n^ =<S'->-<S'Sisin.P,1S'ef2i3, and5e?34, we get:
(2,6,4,6, l,parse(2,3,5), parse(3,4,5))
= (2,6,4,6,1,3,pawe(3,4,5))
= (2,6,4,6,1,3,3),
12.4 THE COCKE-KASAMI-YOUNGER ALGORITHM 437
which corresponds to the tree
By combining our recognition and parsing results, we get a time bound for
general context-free parsing.
Theorem 12.4.5 Every context-free language i can be parsed in time
proportional to n3 where n is the length of the string to be parsed and in space proportional
tOrt2.
Proof By Theorem 4.4.1, every context-free language L £ X* is generated by
a grammar G = (V, 2,P,5)in Chomsky normal form. For any string w = a1a2 " ~an,
if n = 0, then vv = A is in i ifS-* A is in (7. If «>0, then, by Theorem 12.4.1, we can
determine whether wSi by a computation which, by Theorem 12.4.2, requires at
most 0(n3) steps. If w Si, then, by Theorem 12.4.4, we can generate a parse for w
in another 0 («2) steps. The space bound follows from Theorem 12.4.3. □
Although we have shown how Algorithm 12.4.1 recognizes strings in time
& (n3 ) on a RAM, it does not follow that this can be done on a Turing machine within
the same time bound. It might be the case that the Turing machine cannot organize its
tapes sufficiently well to avoid many bookkeeping steps that will change the time
bound. In this section we show that, in fact, recognition can be done on a Turing
machine in time 0(n3).
Our model will consist of a Turing machine with a read-only input tape and
two work tapes.
Theorem 12.4.6 Let G = (V, X,P, S) be a A-free, context-free grammar in
Chomsky normal form and let w=a1 • ■ ■ an, at 6 2, 1<j<«. There is a Turing
machine A which computes the recognition matrix T = (ttj) in time at most en3 for
some constant c.
Proof The initial configuration of A is shown below,
Input
Tapel
Tape 2
t
«i
...
t
C|£| S|
t
T
*l
$|
«n
$
t
where <t and $ are endmarkers on the tapes and B is a "blank" symbol.
438 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
The idea of the argument will be to have the upper-triangular entries of ttj
laid out on both tapes 1 and 2. On tape 1 the entries of T will be written by rows,
while on tape 2 the entries will be by columns. The computation proceeds by filling in
the matrix by diagonals, filling entries in the same order as does Algorithm 12.4.1.
The first phase of the computation is to initialize A to the configurations
Input
c
«1
...
«n
$
Tape 1
(by rows)
Tape 2
(by columns)
0,1
« | '0,1 |
!
0,1
...
0, n
1,2
'1,2
• • •
Y V
n n—\
0,2 1,2 0, n-\
« | '0,1 |
'1,2
...
l,n
• • •
n-2
,n-
1
'n-2, n-1
n-1, n
'n-l,n
$
' n-2, n
0,n n-l,n
...
'n-2, n-1
...
'n-l,n
$
n-1
n
Since tape 1 and tape 2 each have (7(n2) entries, the initialization takes at
least <7(n2) steps. It is left to the reader to show that the initialization can be done in
time <7(n2).
We next show how to compute any element ttj where z+ 1 </<«. The
configuration just prior to the computation is shown below.
i m
Input
Tapel
Tape 2
t
i, J
••• 1 'l, 1+1
'U-l
B
...1
t
ij 0,y+l
...
B
'•+ij
• ••
'j-lj
B
...
t
The procedure to compute titl is as follows, once we are in the position
above.
Move right on tapes 1 and 2, computing ttj in the finite-state control until a
blank is encountered on tape 1. This is square (/, /) on tape 1, so write the
entry there. Move left on tape 2 to the first blank which is (/, /) and make the
entry there. This computation takes 0{j — i) steps.
Next we must get into position for the ti+l j+1 (if we weren't previously at the "end"
of the diagonal).
Move right on tape 1 to the first nonblank; since the rows are filled left to
right, this is ti+lti+2. Move right on tape 2. Since the columns are filled
bottom to top, the first blank we encounter is in square (0,/ + 1) and the
subsequent first nonblank is in position (z + 2,/ + 1).
12.4 THE COCKE-KASAMI-YOUNGER ALGORITHM 439
If we reach $ on the work tapes, then we have concluded a diagonal. Thus, the
previously computed entry was tijK. The next entry to be computed will be
(0,n + 1 —/). To position the work tapes:
1 Move to <t on both tapes 1 and 2. If no blanks were encountered along the
way, then look at the last entry ttj in the finite-state control. This was t0itl.
If S& t0 „, then halt and accept; else halt and reject.
2 If there were blanks along the way, then move the head on tape 1 to the
first square to the right of *. This is f 0, i ■ On tape 2, scan right and find the
first blank; then go one square to the right on the blank. The blank is in
position (0, n + 1 — /). The square to the right is tin+i-^. The tapes are
then positioned correctly.
To estimate the number of steps, note that the computation of any element
tjj, where i + 1 </ < n, takes at most en steps. (One can compute c from studying the
tape motion.) Since there are t7{n2) elements, at most c\n3 steps are required to
compute all the elements. In addition, we must consider the tape repositioning. To compute
the next element in a diagonal requires t9{ri) steps for repositioning. For each of the n
diagonals, we must reposition the heads over the entire work tapes. Consequently,
repositioning requires tf (n3) steps. Thus, including the initialization, the entire
computation takes
Cin3 + c2n3 +c3n2 = t7{n3) steps. □
Example Consider the grammar G used in the previous examples and shown
below. Let w = aabb.
S -+SS\AA\b
A^AS\AA\a
After initialization, the configuration of the Turing machine is
\t\a\a\b\b\%\
t
0,1 0,2 0,3 0,4 1,2 1,3 1,4 2,3 2,4 3,4
\ t \ A \ | | \A\ [ | 5 | 1 SY~T\
t
0,1 0,2 1,2 0,3 1,3 2,3 0,4 1,4 2,4 3,4
ft I A\ \ A \ I I 5 I | | | 5 |T|
t
We scan right on both tapes to compute 0,2. This is entered in the 0,2
square of tape 1, which is the current position of the tape head. On tape 2, we scan
left to the first blank to fill in the entry. Then we go right on tape 1 to the first
nonblank. On tape 2, we go right on through one or more nonblanks and then through
blanks and stop at f2,3- This computation is repeated. The following is the
configuration just before f2,4 is computed.
440 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
\t\a\a\b\b\$\
t
0,1 0,2 0,3 0,4 1,2 1,3 1,4 2,3 2,4 3,4
| t | A \S,A\ | 1 A J A | [ 5 | 1 5 | $ |
t
0, 10,2 1,2 0,3 1,3 2,3 0,4 1,4 2,4 3,4
j <t 1 A \S,A\ A 1 1 A. 1 5 1 1 1 1 5 1 $ 1
t
We compute f24 as before, and make the entry. When we go right, we reach
the endmarker and must move left. This yields:
l<t|a[a|b|H$|
t
0,1 0,2 0,3 0,4 1,2 1,3 1,4 2,3 2,4 3,4
| it j A \S,a\ I | A | A | | 5 | 5 [ 5 1 $~1
t
0,1 0,2 1,2 0,3 1,3 2,3 0,4 1,4 2,4 3,4
| it | A \S,A\ A I | A | 5 [ | | 5 | 5 | $ |
t
and so it goes....
As is true in the random-access case, the recognition matrix can be computed
on-line by a Turing machine, provided the bookkeeping is done slightly differently. We
leave this construction to the reader.
As an interesting special case, let us assume that the underlying grammar G is
linear. Recall (from Problem 2.5.1) that there is no loss of generality in assuming that
G = (V, S,P, S) is in linear normal form. That is, each rule is of one of the following
types:
S -s- A ifASL(G)
A->aB a<EZ,AeN,B<EN-{S}
A->Ba a&l,,A&N,B&N-{S)
A^-a aeZ,AeN
Now we are ready to prove that every linear context-free language can be
parsed in time 0(n2) by a form of the Cocke-Kasami-Younger algorithm. Algorithm
12.4.4 provides a variant of the recognition-matrix construction of Algorithm 12.4.1,
which handles grammars in linear normal form. (Cf. Problem 1 of Section 2.5) The
difference between the two algorithms is only in the way in which the t( /s are
computed in the second loop.
12.4 THE COCKE-KASAMI-YOUNGER ALGORITHM 441
Algorithm 12.4.4 Let G = {V, ~L,P,S) be a grammar in linear normal form
(without the rule S-*-A) and let w = aia2 ■ ■ an, n>\, be a string, where, for
l</<«, a,-SS. Form the strictly upper-triangular (n + 1) x (n + 1) recognition
matrix T as follows, where each element tjj is a subset of V — 2.
begin
loop_l: for z: = 0 to n — 1 do
>i,i+i '• = (^ 1^4 -» a,-+i is in P};
loop_2: for d: = 2 to n do
for/: =0 ton —ddo
begin/: =c? + i;
tij\ = {A \A -*■ ai+l B is in P for some B e ti+1 j]
U {A \A -» Zto,- is in P for some 5 e tij-x}
end
end.
Theorem 12.4.7 Let G = (F, S,P, 5) be a grammar in linear normal form
(without the rule S-*- A). Let w = aia2 • • man,n> l,be astrvig, where for 1 <&<«,
flfe S S, and let T = (t;j) be the recognition matrix constructed by Algorithm 12.4.1.
Then A £ t,j if and only if A =>ai+l ■ • • a-r
Proof The argument parallels the proof of Theorem 12.4.2 except that, in
analyzing a derivation, the first step is either A -+ai+lB or A -+Baj. The details are
omitted. D
In order to obtain our time bounds, we simply analyze Algorithm 12.4.4.
Theorem 12.4.8 Every linear context-free language L can be parsed in time
proportional to n2, where n is the length of the string to be parsed. Additionally, every
such language can be recognized using only a linear amount of space.
Proof By Problem 1 of Section 2.5, there is no loss of generality in assuming
that L is generated by a grammar in linear normal form. Using Algorithm 12.4.4, an
input string of length n is in the language if S £ t0, „ (or if n = 0 and S -*■ A is in the
grammar). Following the timing analysis of Theorem 12.4.2, loop 1 requires c^n steps.
Since the setting of titj in loop requires inspection of only two matrix entries, it takes
at most a constant c2 number of steps. Therefore, the algorithm requires
cYn + c2 Yj (n ~d + 1) = cxn -\ = <?(n2) steps
to construct the recognition matrix. Using Algorithm 12.4.3, it follows, from Theorem
12.4.4, that a parse can be produced in (7(n2) steps.
Since, in loop 2, each ttj is computed using only entries from the previous
diagonal, all that must be remembered for recognition are the previous diagonal (or the
input) and the current diagonal. Since the diagonals have at most n elements, this is a
linear space requirement. (However, it does not suffice if a parse is to be generated.) □
442 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
PROBLEMS
1 Complete the proof of Theorem 12.4.7.
2 Modify Algorithm 12.4.2 to obtain an on-line algorithm for recognition of
strings in a linear context-free grammar which takes quadratic time and linear space.
3 Design an algorithm which meets the requirements of Problem 2 but runs
on a Turing machine.
4 Construct an algorithm which obtains a parse from the recognition matrix
and which requires linear time for a grammar in linear normal form. What is the space
bound and which cost criterion is being used?
5 Devise a new algorithm to determine a parse of a string of length n from
the recognition matrix which takes time proportional to n log n.
6 Show how to achieve the configuration of the end of Phase 1 of the
Turing-machine computation of Theorem 12.4.6, using time proportional to n2.
7 Suppose that G is an unambiguous context-free grammar in Chomsky
normal form. Can you prove a better time bound for Algorithm 12.4.1 in this case?
8 Show how to implement the Cocke—Kasami—Younger algorithm on a
single-tape Turing machine which runs in time 0(n4). [Hint. Code the recognition
matrix onto the tape with the columns stored from left to right and from the bottom
to the top. Use symbols to mark the top of each column. In working up column /,
suppose ti+1 j has been computed and we are about to compute tt j. In computing t-x j,
the fth row of T is needed, so the earlier part of the computation stores tk}- in the
same tape square as tik. Thus, ?,-_; may be computed in a single left-to-right pass and
stored in the next empty cell, which is ?,•_,-.].
12.5* VALIANT'S ALGORITHM
The Cocke—Kasami—Younger algorithm allowed us to recognize and parse in
time proportional to n3. We are now about to give a procedure due to Valiant, which
will result in a time bound proportional to n2"81. To achieve this, we will resort to
techniques that are asymptotically superior but result in such huge constants that this
method is only of theoretical interest. It is important in that it relates matrix
multiplication, boolean matrix multiplication, transitive closure, and parsing algorithms.
We first give an overview of the ideas of the algorithm. Let G = (V, S,P, S)
be a context-free grammar in Chomsky normal form. Suppose w is a string of length
n to be parsed. Our algorithm produces the same recognition matrix as Algorithm
12.4.1, but the computation proceeds in quite a different way. We form the same
starting matrix as in the Cocke-Kasami-Younger algorithm. We note that one can
naturally define a (nonassociative) product operation on nonterminals of the grammar.
In a properly generalized sense, the recognition matrix can be found by taking the
"transitive closure" of the starting matrix. It turns out that one can do this efficiently
if one can take the "product" of two upper-triangular matrices efficiently. One can
reduce computing this product to computing ordinary boolean matrix products. This,
in turn, reduces to studying efficient methods for computing ordinary matrix products,
which we have already done.
12.5* VALIANT'S ALGORITHM 443
Given any binary operation on a set S, we can extend that operation to
matrices whose elements are subsets of S in a natural way. Suppose A = (ay), B = (fcy),
and C = (cy) are n x n matricest whose elements are subsets of S. Then we define
C = A * B by
Cij = U aik * bkj for 0 < /, / < n — 1.
fe=0
Also, by definition, A 9 B if for all i and /, atj 9 by. Of course, we define C = A U B
by
ciS = atj U bi} for 0 < /, / < n — 1.
Using any product operation for sets and ordinary set union, we define a
transitive-closure operation on matrices whose elements are sets.
Definition Let D be an n x n matrix whose elements are subsets of a set S
and let * be any binary operation on S. Let D(1) = D and, for each i > 1, let
D(i) = "u D0) * D('"y).
The transitive closure of D is defined to be D+ = D(1) U D(2) U • • • . We say that a
matrix D is transitively closed if D+ = D.
Since the underlying binary operation may be nonassociative, as is the
operation to be used for constructing the recognition matrix, we have defined D(,) so
as to include all possible associations. Although we write
D+ = D(1)UD(2)UD(()U---
as an infinite union, if S is finite, then the number of unions is always finite, as the
number of possible entries is finite and so there are only finitely many such matrices.
We leave it to the reader to find an upper bound for t in this case so that
D+ = D(1)U- ■UD(I).
Example Let S = {0,1} and define a binary product by the following table:
0
1
0
0
0
1
0
1
Let D be any matrix over S. The transitive closure of D is the "standard transitive
closure" treated in the literature. In the usual fashion, D describes a binary relation p
and D+ corresponds in the same way to the transitive closure p+ of p.
The heart of the algorithm for constructing the recognition matrix is the
following binary operation on subsets of the nonterminals of a grammar.
t Recall our convention of 0-origin addressing for matrices.
444 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
Definition Let G = (V, S,P, S) be a context-free grammar in Chomsky
normal form. Let A^,N2 9 V — 2. Define:
Nx-N2 = {CeV-Z\C-*ABisinP forsomeAeN^BeN^}.
Example Let G contain the following rules:
C->AB
D^CE
F^-BE
E->AF
There may be other rules as well but these need not concern us. Take Nt = {A},
N2 = {B},N3 = {£■}. Note that:
JVi(A^3) = {E}±{D} = {N,N2)NZ.
This establishes that this product of subsets is not associative.
Using the product operation just defined, we claim that the following
algorithm computes the Cocke—Kasami—Younger recognition matrix. Note that we
have not specified in detail how to compute D+. We leave the details for subsequent
sections.
Algorithm 12.5.1 Let G = (V, S,/5,5) be a grammar in Chomsky normal
form (without the rule S-*- A) and let w = a^a-i ■ ■ ■ an, n > 1, be a string, where, for
1 <k<n,ak S 2.
Form the strictly upper-triangular (n + 1) x (n + 1) recognition matrix T as
follows. Let D be a strictly upper-triangular (n + 1) x (n + 1) matrix, where each
element dtj is a subset of V — 2 and initially the value of each element is 0.
begin
comment D = (d£ j) is an (n + 1) x (n + 1) square matrix;
for 0 < i <} <n '- 1 do du: = 0;
for i: = 0 to n — 1 do
dii+l: = {A\A-*ai+l isinP};
T: =D+
end.
To show that the algorithm works, we establish the following result.
Theorem 12.5.1 Let G = {V, S,P,5) be a context-free grammar in Chomsky
normal form (without the rule S-»A) and let w = a.\a2 ■ ■ an, n>\, be a string,
where, for 1 <k <n, ak e 2. Let D+ be the matrix constructed by Algorithm 12.5.1
and let T be the Cocke-Kasami—Younger recognition matrix. Then D+ = T.
Proof We first prove that the only nonempty elements of D(d) are along the
fifth diagonal.
12.5* VALIANT'S ALGORITHM 445
Claim InD(d) we have
dW =.i'w if/-/ = rf,
'i,i
0 otherwise.
Proof of claim The argument is an induction on d—]—i. The basis of the
induction, namely, d = j — i= 1, is immediate.
Induction step. Consider forming the product D(d+1 \ We have
s = l fe=0
It follows from the property that, for any subset of variables 5, 5*0 = 0*5=0, the
only way we can get a nonzero entry is if there exists some s, 1 <s <d, and some
k,0<k<n, so that dffl^Q and d£j+1~s) =£<}>. It follows, from the induction
hypothesis, that, in such a case,
k — i = s
and
/-* = d+ 1 -s.
Adding the equations produces
/-i = rf+1,
which shows that d\j*1 * = 0 except if / — z = d + 1. If j — i = d + 1, it follows, from
the definition of the product operation and the induction hypothesis, that
dfd}+l) = {A\A-*BC where,foisomek,0<k<n,Betitk,CetkJ} = tu.
This completes the proof of the claim.
Next, note that, as a corollary of the claim,
D<d> = 0
if d>n. Therefore,
D+ = D(1)UD(2)U- UD(n) = T. D
Corollary 1 BG d^j if and only if
B^ a;+1 ...a-, » □
Proof d\ j = tjj and we invoke Theorem 12.4.1.
Corollary 2 w6i(G) if and only if 5 S cf^,,,.
Example
y4->y4y4|a
446 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
Let w = aaab. Thus we must form a 5 x 5 matrix D:
D
One can compute that
0 {A}
0
0
"0 {A}
0
0
{A}
0 {A}
0 {B}
TS-
{A} {A} {S}~
{A} {A} {S}
0 {A} {S}
0 {B}
0.
D+ =
Since we have established that Algorithm 12.5.1 yields the Cocke—Kasami—
Younger recognition matrix, we can, of course, use the parsing Algorithm 12.4.3 on
this matrix. Furthermore, using the proof of Theorem 12.5.1 as a guide, the reader can
verify that a straightforward computation of D+ which takes advantage of the fact that
only the product of nonempty sets yields a nonempty set, causes Algorithm 12.5.1 to
be "stepwise equivalent" to Algorithm 12.4.1. Consequently, it is easily shown that
Algorithm 12.5.1 can be carried out in <7(n3) steps. It remains to show that, when
viewed as a transitive-closure problem, the time bound for this computation can be
further improved.
We next give an algorithm which reduces matrix multiplication of the very
general kind we have been considering to boolean matrix multiplication. Let S be any
set and let * be any binary operation on subsets of S. We demand only that * satisfy
the following distributive laws.
For any X, Y, Z £ S,
X*(YUZ)
(XUY)*Z
X*YUX*Z,
X*ZUY*Z.
(Dl)
(D2)
Suppose S = {Ai, A2, • ■., As}. Let B = (btj) be a matrix whose elements
are subsets ofS. Define a set of boolean matrices B!,B2,. .., Bs, where, for 1 < k < s,
the (z — /)th element of Bfe is 1 if Ak S b(,- and 0 otherwise.
e hstS = {Al,A:
B =
}andn = 3. Then,
*0 {Ax} {Al,A2}
0 0 {A2}
0 0 0
12.5* VALIANT'S ALGORITHM 447
Then
Bi =
0 1 1
0 0 0
0 0 0
and
0 0 1
0 0 1
0 0 0
Next we give an algorithm for *-multiplication of two such matrices.
Algorithm 12.5.2 Given two n x n matrices B and C whose entries are
subsets ofS={Al,...,As}, our goal is to compute B * C.
1 Compute Bt,..., Bg and Cj,..., Cs, where these are defined as above.
2 Compute the s2 boolean products B,- * C; for 1 < i, f < s.
3 Let D = (du), where du = {E\E = {Ap}*{Aq}, where (Bp * Cq\j = 1}.
Example Let S = {Ai ,A2}, n = 3, and define * by the table:
Ax A2
Let
0
0
0
Mi)
TS-
0
Ai
A2
{A1M2}
{A2}
<*
A2 A2
Ax A2
r
, c =
0 U1M2} 0
0 0 M,
0 0 0
Then, by using the definition of boolean-matrix products,
"0 0 {A2}
D = B*C
0 0 0
By using Algorithm 12.5.2, we write:
0 1 1
Bi
C, =
0 0
0 0
0 1
0 0
0 0
0
0
0
0
0
0
0
0
0
1
0
0
1
1
0
0
0
0
448 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
Then
BiC! =
B2C!
0 0 1
0 0 0
0 0 0
0 0 0
0 0 0
0 0 0
BiC2
B2C2
0 0 0
0 0 0
0 0 0
'0 0 0
0 0 0
0 0 0
Since (B1C1)02 = 1, we have d^ =AX *AX —A2, and both computations produce
the same answer.
We leave it to the reader to verify that, for operations * satisfying distributive
laws (Dl) and (D2), Algorithm 12.5.2 computes D = B * C.
We can conclude that, if M(n) is the time necessary to multiply two n x n
matrices with elements that are subsets of some set S, and BM(n) is the time to
compute the boolean product of two n x n boolean matrices, then a relationship
between the two quantities is given by the following result.
Theorem 12.5.2 M(n) < cBM(n) for some constant c.
Having posed the recognition problem as a transitive-closure problem, and
having reduced the multiplication aspect of that problem to fast boolean-matrix
multiplication, it remains to reduce the transitive-closure problem to one with a time bound
proportional to that for boolean-matrix multiplication. This will be done shortly.
Our next goal is to prove a lemma due to Valiant, on which the construction
rests. In order to prove the lemma, it is necessary to develop a notation for nonassoci-
ative products in terms of binary trees.
In the discussion that follows, we will consider matrices whose elements are
subsets of some set S. The multiplication operation * defined on these subsets is
assumed to have only the two distributive properties (Dl) and (D2) to reduce matrix
multiplication to boolean-matrix multiplication and the additional axiom
5*0=0*5=0. (Nl)
We will restrict our attention to strictly upper-triangular matrices. It will be
convenient to use the following facts, which are immediate consequences of the
axioms.
Lemma 12.5.1 If A and B are strictly upper-triangular matrices, then A * B is
also strictly upper-triangular and
U aa
fc=0
* b
hi
,= u
ft=1+1
"i" * bki.
Proof Follows directly from Axiom Nl.
12.5* VALIANT'S ALGORITHM 449
Lemma 12.5.2 (The distributive property) Let S be any set and let * be any
binary operation on subsets of S satisfying axioms Dl and D2. Let sl5 s2,. .. ,st,
f > 1, be subsets of S, and let n(sl,s2, ■ ■ ■ ,st) denote the ordered composition of
Sx, s2,.. ■, st under * and some order of association. If / is any family of subsets of
S, then, for any 1 < k < t,
■nis^Si,.. . ,sfe_!, U i,sfe+lJ.. -,sf) = U (Si,s2>- • • >Sfe-i» i',sfe+1,. .. ,st).
i £ I i £ J
Proof Follows directly from distributive axioms Dl and D2. D
In order to describe the nonassociative products that we will deal with in
Valiant's lemma, we first introduce a set of such products called terms. We then
present a notation for terms and a sequence of propositions establishing the properties
of the notation. The verification of these propositions is straightforward and is left for
the reader.
Definition Let B = (p,-) be an n x n matrix, whose elements are subsets of
some set S. Let
0|,,i2»0|2,i3. ■ ■ ■» b{t,it+l
be any sequence of matrix elements. We say the sequence is acceptable in the case
that, for 1 </, k < t + 1, if/ < k, then i} < ik.
The composition under * of the elements of an acceptable sequence under
some order of association is called a term ofB or, more specifically,an (/1; it+i)term
with t components. The notation
denotes any one of the terms of B with components b^,^,
operation *. For example,
bu*(b23*b^)
and
(fc23*fc35)* bSi
are terms, but
b 12*^23* &34
is not a term because no order of association is given, and
^12*^22
is not a term because the indices do not increase.
Definition Two (z, /) terms are formally distinct if either they are composed
of distinct sequences of elements or they have different orders of association. Let
•rfi,)) 0*) be the set of all formally distinct (/, f) terms having exactly d components
from the matrix B. Let
n-l
^*(B) = U U ^(.d> (B)
d>i i,y-o Uj>
be the set of all formally distinct terms with components from the matrix B. (We omit
the explicit mention of B when the matrix is understood.)
,bit, it+1 under the
450 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
Proposition 12.5.1 Let B = (b{ j) be annxn matrix whose elements are
subsets of S. Then, for all 0 < i, j < n — 1,
bfl U T*
T*G5r&!o(B)
and
b\j= U U T*.
The proof is straightforward and is left for the reader. D
A natural way to describe terms of the type just introduced is to use binary
trees. For example, the (2,7) term (fc2, 3*^3,s)*^s,7 can be represented by a binary
tree, as shown below.
In order to precisely define the trees that describe terms, we introduce a
functional notation. However, we shall continue to use the trees themselves as a
descriptive device to explain the formalism.
We shall introduce functions t(x1,x2, ■.. ,xt) which denote binary trees
having t leaves labeled Xi to xt from left to right. If B = {btJ) is an n x n matrix
whose elements are subsets of some set S, then the subclass of trees t(xi ,x2 , ■.., xt)
we get by restricting Xi ,x2,... , xt to be an acceptable sequence of elements from B
will be in one-to-one correspondence with the terms of B.
For example, the terms
T*(Xl,X2,X3,X4) = (*i *X2)*(X3 *X4)
and
r$(x1,x2,x3,x4) = *! *(x2 *(*3 **4»
will correspond to the functions t1(x1,X2,x3,x4) and t2(xi,*2,*3>*4) designating
the binary trees
T, T2
X\ ^\
X\ X2 X3 X4 X2 /'^\s^
The formal definition of these functions is now given.
Definition Let X = {xl,x2,...} be a set. The class S~of binary trees
T(*i, >*!,>•••» xt), t > 1 over X, is defined inductively as follows:
12.5* VALIANT'S ALGORITHM 451
i) For any xSX, t(x) = x is in JT
ii) For any jc,- , xt in X, t(x,- , x-t ) is in S7
iii) If Ti(x{i,... ,X[ ), T2(xtp + l,... ,xit), and t3(xJi , x^) are in J?~for
some 1 < p < t, then
t(*,-, , • • ■ ,xif) = Tsfr^ ,... ,xip), T2(xip+l,... ,xif))
is in J7*.
iv) All elements of ^are constructed from (i), (ii), and (iii).
By a suitable choice of elements, we get the class of trees corresponding to
nonassociative products.
Definition Let B = (pij) be an n x n matrix, where each bij is a subset of
some set S. The acceptable class JT of binary trees over B is defined inductively by
i') For any element bitj of B, T(btij) = btj is in ^T
ii') For any acceptable sequence y i, y2, r(y i, y2) is in ^T
iii') Let Xj, x2,..., xp, xp +1,..., xt be an acceptable sequence of elements
of B. IfTi(*i, ■ ■. ,xp),t2(xp + 1, ...,xt), andT3(yi,y2) are in ^ for
some 1 <p <t, then
T(Xi,...,Xt) = T3(Ti(Xi,. .. ,Xp),T2(xp+1,.. . ,XtJ)
is in ^7
iv') All elements of ^~ are constructed from (i'), (ii'), and (iii').
Qearly, an acceptable class of binary trees over a matrix is a special case of a
class of binary trees over a set. These definitions are illustrated in Fig. 12.5. Figure
12.5(a) represents (i) or (ii). Figure 12.5(b) illustrates (iii) or (iii').
(a)
T= T3
FIG. 12.5
452 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
The t functions satisfy the following properties.
Proposition 12.5.2 Let J~ be an (acceptable) class of binary trees. For each
t(xi ,. .., xt), t > 1, in >T, there exist k, 1 < k < t, and three functions, T\, t2 , and
t3 , all in 3", such that
T(Xi,...,Xt) = T3(Ti (*!,.. .,Xk),T2(xk+1,...,Xt)).
This proposition is a restatement of the definition.
Our next principle, which is illustrated by Fig. 12.6, is familiar to us from
language theory. We may describe it as a composition principle.
T2
FIG. 12.6
Proposition 12.5.3 Let JT be an (acceptable) class of binary trees. Given
Ti(xi,.. . ,xs) and T2(ji, ■ ■ ■ ,yt) inland some k, where 1 <A; <s, then there
exists a unique t in T such that
T(^! ,...,Xk^,yi,... ,yt,Xk+l ,-.. ,XS) = Tj (X! ,. . . ,Xfe_! ,T2Ol , • • • ,yt),Xk+i ,-.. ,XS).
We next introduce the notion of a factorization for binary trees.
Definition Let S~ be an (acceptable) class of binary trees. For any
t(x! ,. .., xt) in 3~ and any p, q such that 1 < p < q < t, if, for some Tx,t2, in 3~,
T(Xi, . . . ,Xt) = Ti(Xi, . . . , Xp_1, T2(Xp, . . . , Xq), Xg+1 , . . . ,Xt),
then the quadruple (ji,T2,p, q)is a factorization of t(xi ,... ,xt).
Our next proposition is a unique factorization result for trees.
Proposition 12.5.4 Let ^be an (acceptable) class of binary trees.
1 Given t(x i,... ,xt) inland 1 <p' <<?' <?, then there exist n, t2, p,
and q such that:
a) p<p',
b) q ><jf',and
c) (ti,t2,p,q)is a factorization of t(xi,...,xt).
12.5* VALIANT'S ALGORITHM 453
2 If there also exist t\ , T2,r, and s such that:
d) r<p',
e) s>q ,and
0 0"i , tJ. , r, s) is a factorization of t (*i,..., x(),
then either:
g) r<p ands>q, or
h) p <r and<jf >s.
3 There exists a unique factorization satisfying 1(a), 1(b), and 1(c) and such
that (q — p) is minimal.
Although we have written Proposition 12.5.4 out in great detail, the intuitive
picture is shown in Fig. 12.7. By Case 2, we see that either t2 is nested inside of t2,
or vice versa.
Ti
(a)
X\ Xr Xp Xp Xq Xq xs Xj X\ Xp Xr Xp Xq Xs Xq Xj
r<k pa.nis> q p^ ra.niq> s
(b)
FIG. 12.7
This situation suggests the following definitions.
Definition A factorization of Case 3 in Proposition 12.5.4 is called the
smallest (p', q) factorization ofr.
The smallest (p',q') factorization is exemplified in Fig. 12.8. In that figure,
let us choose p = 5 and q = 9. The unique choices of p and q are p = 4, q = 9. The
454 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
*4 *5 x6 xl x% X(>
FIG. 12.8
X\ X2 X3 XW XU X\2
(b)
trees T\ and t2 are shown in Fig. 12.8. Note that the root of j2 is the least common
ancestor of xs and x9.
Now, we define a smallest tree.
Definition t(x2, ■.. ,xt) is said to be (u, v)-minimal if the smallest (u, v)
factorization of t is (/, t, 1, t), where / is the identity function of one variable, that is,
i(x) =x.
Returning to Fig. 12.8(b), we note that the tree t2(x4, ... ,x9) is
(8, 9)-minimal. In a (u, u)-minimal tree, the least common ancestor of xu and xv is the
root of the entire tree.
Now we present two lemmas concerning these minimal trees.
Lemma 12.5.3 Let
T(Xi,...,Xt) - Ti (Xi , . . . , *,._! , T2 (Xr, . . . , Xs), Xs+1 , . . . , Xt)
for some t>\, \<r<s<t. Then, for any yx,... ,^s_m , j2{yx,... ,jVm) is
(u — r + \,v~r +)-minimal if and only if (tj ,T2,r, s) is the smallest (u, v)
factorization of t.
12.5* VALIANT'S ALGORITHM 455
Proof The result follows directly from the definitions and Proposition
12.5.4. □
The next result is also an obvious property of these trees.
Lemma 12.5.4 Let J7~be an (acceptable) class of binary trees. Let Ti, t2,
t2 be in J"and\et t> 1,1 <p<q<t.Then
Tl\Xl, • . . ,Xp-i , T2\Xp, • • • , Xg),Xg + i, . . . ,Xt)
~ T\(Xi, . . . ,Xp-i, T2\Xp,. . . ,Xq), Xq+l , . . . ,Xt),
if and only if t2 = t'2 ■
Now we extend the composition principle and the factorization notion to
terms, by establishing a correspondence between trees and terms.
Proposition 12.5.5 Let B = (&,-,-) be an n x n matrix whose elements are
subsets of some set S. Let <T be an acceptable class of binary trees over B. Let * be
any binary operator on subsets ofS satisfying axioms Dl, D2, and Nl. Then there is a
one-to-one correspondence between the set of terms Jf~* and the set of trees S~. The
correspondence is defined inductively by:
i) For any element btj of B, r(b;j) *> T*(Z»,_y)
ii) For any T, (*,„,,, *,„,-,,..., bipijp) and t2 (btpttp+l ,■■■, *fcittl).
T(Ti(bilitl,..., bip-Up),T2(bipJp+l,... ,bitJt+l)) ♦->
riib,^ ,..., bip^ip)*T* (bip,ip+l,..., biuh+l).
Using this correspondence, we extend the notion of minimality to terms in
the obvious way.
Definition Let B be an n x n matrix whose elements are subsets of S. Let
T*(bix,H ,-••, bit,it+l) be a term of B. Then, for any p, q, 1 <p <q < t, t* is (ip, iq)-
minimal if the corresponding tree t is (ip, /q)-minimal.
We next introduce two concepts related to matrices which are useful in
conjunction with Valiant's Lemma and the transitive-closure algorithm. The first
concept is the notion of a central submatrix. Intuitively, as shown in Fig. 12.9, a
central submatrix is a matrix contained within a larger matrix such that the principal
diagonal of the smaller matrix lies along the principal diagonal of the larger matrix.
B =
FIG. 12.9
456 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
Definition Let B be an n x n matrix. Then A is a central submatrix if there
exists m > 0 and r, 0 < r < n — 1 such that A = (a ,-y) is an m x m matrix and for
0 < /, / < m - 1, au = bi+r-t, y+r_!.
The most important property of central submatrices for our purposes is given
by the next theorem and its corollary.
Theorem 12.5.3 (The Central Submatrix Theorem) Let B be a strictly upper-
triangular matrix. If A is a central submatrix of B, then, for any d > 1, the
corresponding central matrix of B(d) (or B+) is A(d) (or A+).
Proof Let B be an n x n matrix and A be m x m with aStt = Z»s+r_li(+r-1
for each 0 < s, t < m — 1 as the indices range over A. These are the /, / positions of B,
where r<i,f<r + m. Thus, let /'=/ —r+ 1 and/'=/ — r+ 1. We will show, by
induction on d, that
Basis, d = 1. This is immediate.
Induction step. Suppose d > 1 and the result holds for d — 1. It follows from
the definitions and Lemma 12.5.1 that
U = l fe = l + l
If we let k' = k — r + 1 and employ the induction hypothesis, then we get
d-i y'-i
b)j' - U U a(yahy -afj>.
U=l ft =1 +1
This completes the proof for B(d). For B+, note that
B+ = U B(d).
t>\
Corollary Let B be a strictly upper-triangular matrix which is transitively
closed. If A is any central submatrix of B, then A is transitively closed.
The second useful concept is that of the reduction-closure operation on a
matrix.
Definition Let C = (c,-j) be a strictly upper-triangular n x n matrix and let
n>r>n/2 > 1. Define the 2(n — r) x 2(« — r) matrix D = (d{J) to be the r-reduction
ofCif
cu if 0 < /, / < n — r — 1,
',-',; if/>«— r— l,j<n— r— 1,
i,i' if i<n—r— \,j>n—r— 1,
'/',;■ if /,/>« — r — 1,
<*U = {
12.5* VALIANT'S ALGORITHM 457
where i' = i + 2r — n,j' =j + 2r — n.
The r-reduction of C is illustrated in Fig. 12.10(a). Intuitively, we form D by
deleting the (n — r + l)st to rth rows and columns.
Using the notion of the r-reduction of a matrix, we can define the reduction
closure. Intuitively (as illustrated in Fig. 12.10(b)), we take the transitive closure of
the r-reduced matrix and then restore each element to its original place in C.
r
r<
C =
1
4
7
2
" -B i - " -
8
3
6
9
2r—n
>r
D =
1
7
3
9
(a)
D+ = E
El
E7
E3
E9
c+w
E,
4
E7
2
5
8
E3
6
E9
(b)
FIG. 12.10
458 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
1,1
Definition Let C = (c-tJ) be a strictly upper-triangular n x n matrix and let
n>r>njl>\. Let D = (d;j) be the r-reduction of C and let E = (e,-y) be the
transitive closure of D. Define the n x n matrix C+(r) = (c*Sr)) to be the reduction
closure of C, where, for 0 </,/<« — 1,
e-,j if i,j<n — r — 1,
Cij if n— r— 1 < / < r — 1
or«—r—l</<r—1,
et'j if / > r — l,/<«— r— 1,
e,-y' if / < « — r — 1, / > r — 1,
\ ei'j' if/,j>r— 1,
where /' = /— (2r —«) and/' = / —(2r —«).
Now we may begin to combine the partial results into a proof of the key
lemma.
Lemma 12.5.5 (Valiant's Lemma) Let B a strictly upper-triangular « x n
matrix, let n > r > n/2 > 1, and suppose that
2r-n
r
, •
1
4
7
2 i
ll
8
*
; 3
! 6
9
j
> r
where the r x r submatrices
1
4
2
5
5
8
6
9
and B2 = ofB
are transitively closed. Define Er as the submatrix of B given by
E, =
/ •*
0
0
0
2
0
0
0
6
0
where the shaded area above is taken from B.
ThenB+ = (BUE?)+(r).
12.5* VALIANT'S ALGORITHM 459
Proof The proof of the lemma is long and tedious. A sketch is given here
with the detailed proofs of the claims relegated to the problems.
Since B] and B2 are transitively closed, and since B is strictly upper triangular,
the only part of B+ that is unknown is region 3, in which 0</<«— r— 1 and
r</<«— 1. This follows from the Corollary to Theorem 12.5.3 on central sub-
matrices.
Let S"* be the set of terms of B and let S~ be the corresponding set of
acceptable trees.
Claim 1 Let t* be any (z'i,/f+i) term of B, where ix <n—r—\ and
zf+1>r—1. Then for some /p<«— r— 1 and iq+l >r, t* contains a unique
(n — r— l,r— l)-minimal (ip,iq+1) term t|. Moreover, either p = q or, for some
t%,t%&^~* and for some is such that«—r—1</, <r—1,
rt = T$(bipiip+1,..., */,_!,/,) * tJ(\, ig+1,..., biq, iq+1 )•
The proof of Gaim 1 is left to Problem 2(a).
For any x, y, 0<x<n-r-\ </■— 1 <^<«-l,let Ux>y(B) be the set
of all formally distinct (n — r — 1, r — l)-minimal (x, y) terms of B.
Claim 2 For any x < n — r — 1 and y > r — 1,
U t* = 6x>y U U **,.**.,*. 02.5.1)
T*et/x:y(B) s=""r
A-oo/ o/ claim By Proposition 12.5.1, Z»*s is the union of all formally
distinct (x, s) terms of B and b*Sty is the union of all formally distinct (s, y) terms of B.
Therefore, by Claim 1,
?m
, U T* = bx,y U U b+x,s*bly.
Since B] and B2 are transitively closed, Z»x>s = b*x>s and Z»s_y = b*s>y for all
jc<«—r—1,«—r<s<r—l,,y>r—1.
Note that Eq. (12.5.1) can be computed by the following procedure.
1. Matrix-multiply partitions 2 and 6 of B.
2. Form the union of the resulting (n — r) x (« — r) matrix with partition 3
ofB.
Let C be the (n — r) x (« — r) matrix which is in position 3 of B U E;?. We
proceed to analyze C.
It is clear from Claim 2 and the construction of C that the following is true.
Claim 3 For any i<n— r— 1,/>r — 1,
cu-r = U r*. (12.5.2)
T*et/W<B)
In words, c,-j_r is the union of all (n — r — 1, r — l)-minimal (/, /) terms of B.
460 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
Note that, if/ = i + 2r — n, Eq. (12.5.2) reduces to the following:
Li,i-n-r
u
= ui, i+2 r-n<P)
Let D be the r-reduction of B U Ej obtained by deleting the central 2r — n
rows and columns. D is a 2(n — r) x 2(« — r) matrix.
Clearly,
du- U U x,
from Proposition 12.5.1. Moreover, each t contains exactly one element from C. This
follows from the strict ordering of the subscripts on the terms and the method of
construction of D.
To finish the proof of the lemma requires establishing a correspondence
between the terms of D and of B.
Claim 4 Let / < n — r — l,j>r — 1, and/' =/ —2r + n. Every (/',/') term of
D is a union of some formally distinct (i, /) terms of B.
The proof of Claim 4 is left as Problem 2(b).
In the reverse direction another claim is needed.
Claim 5 Let /<«—r—l,/>r—1, and/' =/ —2r+ «. Every (/,/) term of
B occurs in the formation of a unique (i, /') term of D.
The proof of Claim 5 is relegated to Problem 2(c).
To complete the main proof, it follows from Claim 4 that d*j' is a union of
distinct (/', /) terms of B. From Claim 5, every (/,/) term of B appears in d*j'. Thus
d)j> is exactly the union of all formally distinct (/, /) terms of B. From Proposition
12.5.1,
d\f = b*tJ
for all / < n — r, j > r, and /' =/ — 2r + n. But this is exactly the region of B which
had to be verified, and the proof is complete. □
Note that since
r
_A_
EJ
0
0
0
0
0
0
2»6
0
0
12.5* VALIANT'S ALGORITHM 461
we have just shown that
J +(r)
1
4
7
2
5
8
3U2»6
6
9
This will provide a simple recursive method for the computation of B+.
Now we are ready to show how to compute D+ in less than cubic time. If D
is a strictly upper-triangular matrix whose elements are subsets of some set S and * is
an arbitrary binary operation on S which satisfies axioms Dl, D2, and Nl, we wish to
compute D+ as efficiently as possible. Since * is not necessarily associative, techniques
from the literature that assume associativity are useless here. It should be observed
that our method will be as efficient as any that is known in the associative case. In
what follows, it is convenient to assume that n is a power of 2. We shall return to this
point later and will relax this assumption.
We now introduce a family of procedures that will be useful.
Definition We define the operation Pk of taking the transitive closure of an
n x n strictly upper-triangular matrix B under the assumption that the [n — (n/k)] x
[n — (n/k)] submatrices B] and B2 (shown in Fig. 12.11) are already transitively
closed.t
n-H
B =
FIG. 12.11
_A_
B|
B2
>n-
"V"
t Recall that a matrix D is transitively closed if D+ = D.
462 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
It will turn out that we need only construct P2,P3, andP4.
Let T;(n) be the time required to compute P; for an n x n matrix. Also, let
TR(n) be the time required to compute the transitive closure of an n x n matrix.
Now we give an algorithm to compute D+ in terms of P2 ■
Algorithm 12.5.3 Let A be an n x n strictly upper-triangular matrix. We
define a procedure trans(A) which returns the transitive closure of A.
1 If n = 2, then trans(A) = A.
2 Consider D
-H
A,
0
A3
A2
If
3 Compute trans{Ai) and trans(A2).
4 LetB:
trans (A))
0
A3
trans (A2)
5 Compute ,P2(B) = A+.
Now we will argue that the algorithm works, and analyze it.
Lemma 12.5.6 Algorithm 12.5.3 correctly computes A+ and
TR(n) = 2TR ||j+ T2{n) +<7(n2).
Proof To see that ^(B) = A+, we induct on k where n = 2k. Note that the
result is true for k = 1. Suppose k > 1 and that trans works correctly for n = 2fe •
Applying the algorithm to a matrix A of size 2fe+1, we correctly compute trans{Ax)
and trans(A2) where
A,
0
A3
A2
12.5* VALIANT'S ALGORITHM 463
by using the induction hypothesis. Let
At
0
A3
A^
Now B has the square submatrices A*! and A+2 of size 2k. Applying P2 yields
the closure of B, which is
At
0
At
A}
= AT
Clearly, the time bound is
TR(n) = 2TR | - + T2(n) +<7(n2).
Next we turn to the interesting task of computing P2.
D
Algorithm 12.5.4 Let B be an n x n matrix as shown below, where each
square is of size njA.
B,
1
13
10
14
■ wwiww
11
15
8
12
16
Assume that B, =
are already transitive closed.
1
5
2
6
1 If« = 2,thenB+ = B.
and B2 =
11
15
12
16
2 Apply P2 to B3 =
6
10
7
11
to yield
6
10
7'
11
464
RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
3 Apply P3 to B4 =
4 Apply P3 to B5 =
5 Apply ^4 to
1
5
9
6
10
14
1
5
9
13
2
6
10
7'
11
15
2
6
10
14
3
7'
11
8
12
16
3'
7'
11
15
4
8'
12
16
to yield
to yield
l
5
9
2
6
10
3'
7'
11
6
10
14
7'
11
15
8'
12
16
= b;
to yield B+.
Lemma 12.5.7 The previous algorithm computes^ and
7-2(1)= r2fcj + 2r3ra + r4(«).
Proof The equation is trivial to verify.
□
To see that the algorithm works, note that we were allowed to assume that
Bi and B2 were transitively closed. Note that
0
and
QD
are transitively closed because they are central submatrices of transitively closed
matrices. (Cf. the Corollary to Theorem 12.5.3.) Thus we apply P2 to B3 to get B^.
Next consider Step 3. To apply P3 to B4, we must check to see whether
1
5
2
6
is transitively closed, and it is, by assumption. Moreover, we require that
6
10
7'
11
be transitively closed, which it is, by Step 2. Therefore,^3(84) = B4. Now we want
12.5* VALIANT'S ALGORITHM 465
to apply P3 to B5. But
6
10
7'
11
and
11
15
12
16
are transitively closed by Step 2 and our assumption.
To invoke P4 in Step 5 we need only check that B4 and B^ are transitively
closed. But this is true, from Steps 2 and 4, respectively. Thus we obtain B+. □
With the aid of Valiant's Lemma, it is easy to give algorithms for P3 and P4.
Algorithm 12.5.5 (Computation of P3) Given an nx n upper-triangular
matrix B. Let us represent B by
1
4
7
2
5
8
3
6
9
where each square is of size w/3. We may assume that
1
4
2
5
and
»2 =
5
8
6
9
= °1
1 Compute B U Er * Er = C, where r = 2«/3. Recall that
Thus
Er
0
0
0
2
0
0
0
6
0
1
4
7
2
5
8
3'
6
9
2 Compute C+ (r) for r=2n/3, using P2, which means that we compute P2 of
1
7
3'
9
466 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
This is permissible since | 1 and 9 are closed.
The algorithm for P4 is similar, with r = 3n/4.
Algorithm 12.5.6 (Computation of P4) Let B be an n x n upper-triangular
matrix, which is represented by
1
5
9
13
2
6
10
14
3
7
11
15
4
8
12
16
where each entry is a matrix of size w/4. Assume that:
1
5
9
2
6
10
3
7
11
and that:
6
10
14
7
11
15
8
12
16
1 Compute BUEr*Er = C, where r = 3w/4, so
E,=
0
0
0
0
2
0
0
0
3
0
0
0
0
8
12
0
Then
c =
1
5
9
13
2
6
10
14
3
7
11
15
4'
8
12
16
12.5 VALIANT'S ALGORITHM 467
2 Compute C+(r) for r = 3n/4, using P2; i.e., apply P2 to
1
13
4'
16
Now we begin to analyze these procedures.
Lemma 12.5.8 Algorithms 12.5.5 and 12.5.6 compute P3 and P4,
respectively. Moreover,
r3(n) = M(n) + T2 fe\ + ^(«2),
T4(n) = M(n)+T2[^)+<7(n2).
Proof Correctness follows, from Valiant's Lemma, while the equations follow
trivially. □
At this point, we have reduced the computation of the transitive closure to
the computation of the product of two upper-triangular matrices. We must estimate
the time required to do this. Let M(n) be the time necessary to multiply two such
n x n matrices.
Lemma 12.5.9 If n = 2k for some k > 1, and there is some 7 > 2 such that,
for all m,
then
T2(n)<
M(2m+i)>2yM(2m),
CiM(n) for some constant Ci if 7 > 2,
,c2M(n)\ogn for some constant c2 if 7 = 2.
Proof If we substitute the result of Lemma 12.5.8 into the result of Lemma
12.5.7, we get
T2(n) = 47-2||) + W^)+M(«)+^(«2).
By the monotonicity of M,M(3n/4) <M(k) so
T2 (h) < 4T21 j I + 3M(n) + <7(n2).
(12.5.3)
(12.5.4)
The solution of (12.5.4) is claimed to be:
logn
T2(n)< <7(n2logn) + 3M(n) £ 2(2-7)m.
(12.5.5)
468 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
If we let n = 2 , the claim becomes:
7,2(2fe)<c(^22fe) + 3M(2fe) Y, 2<2_7)"
m=0
(12.5.6)
for some constant c ^ cx /4, where cx is the constant in (12.5.4). We can verify this by
induction on fc. We shall just do the induction step here. Since M(2fe)<2~7M(2fe+1), it
follows that
T2(2k+1)<c(k + l)22(fe+1) + 3M(2fe+1)
1 + 2(2_7) Z 2(2_7)m
m=0
or
fe+1
7-2(2fe+1)<c(^+l)22(fe+1) + 3M(2fe+1) I 2(2~7)m.
m=0
From inequality (12.5.4),
7'2(2fe+1)<47'2(2fe) + 3M(2fe+1) + Ci(22k).
By the induction hypothesis,
ft
T2(2k+1)<3M(2k+1) + Cl(2*)+4c(k22k)+12M(2k) I 2(2-7)m.
m=0
Since c > c\ /4, we have
4dt + Cj < 4dt + 4c = 4c(fc + 1).
Multiplying both sides by 22fe yields:
Cl22fe +4dt2fe = Cl22fe +ck2k+2 <c(k+l)2zk+2 .
Substituting this in (12.5.7) yields:
ft
r2(2fe+1)<3M(2fe+1)+12M(2fe) £ 2(2-7)m+c(/c + l)22fe+2.
m=0
This completes the induction proof of (12.5.5) and also establishes (12.5.4).
Since the series 2 xm converges if 1*1 < 1, then the result follows.
m=0
Next we use the present result to estimate TR(n).
Theorem 12.5.4 If there exists 7 > 2 such that, for all m,
M(2m+1)>2yM(2m),
(<7(M(n)) ifT>2,
(12.5.7)
□
then
TR(n) <
<7(M(n)\ogn) ifT = 2.
12.5* VALIANT'S ALGORITHM 469
Proof For the moment, we continue to assume that n = 2k. It follows from
Eq. (12.5.3), that
T2(n)>4T2(n/2).
We claim that
logn
TR(n)<<7(n2)+T2(n) £ 2"m.
m=0
Since n = 2k, we shall show by induction on k that
ft
TR(2h)<T2(2h) X 2_m + ^(22fe).
m=0
We shall just do the induction step. Lemma 12.5.6 gives that
TR(2k+1) = 2TR(2k) + T2(2k+1)+ ^(22(fe+1)).
(12.5.8)
(12.5.9)
Applying the induction hypothesis yields
T2(2h) £ 2"m
m=0
+ ^(22(fe+1)).
77?(2fe+1)<7'2(2fe+1)+2
Since T2(2fe) < T2(2fe+1 )/4, we have
fe+i
ra(2fe+1)<r2(2fe+1) X 2""m + ^(22(fe+1)).
m=0
This completes the induction step. It follows from (12.5.9) that:
TR(n)<2T2(n)+ <7(n2).
Applying Lemma 12.5.9 gives the result if n = 2k.
Now we deal with nonpowers of 2. It may have seemed that we would run
into difficulty with assuming that n = 2k and using P3, which would seem to require
that the size of the matrix be divisible by 3. Closer observation of P2, which calls P3,
indicates that if n = 2k, P3 is applied to matrices of size3«/4 = 3-2fe_2.When we take
the "reduction by one third" operation, we deal with matrices of size 2fe"2 and there
is no problem.
To complete the proof, we merely pad out an n x n matrix to the next higher
power of 2 if n ^ 2k, which is 2 ^loe^ "^. The method of padding is illustrated in Fig.
12.12.
n
Original
matiix
0
0
0
>2'
|log2 "1
FIG. 12.12
470 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
Note that the padded matrix is still strict upper-triangular if the original one
was. Note that there is a constant c so that, for all n,
cM(n)>M(2^loenh,
and the final result now holds for all n. □
Now we can combine our various results to obtain the following important
theorem.
Theorem 12.5.5 Let 5 be a finite set and * an arbitrary binary operation on
S, which satisfies axioms Dl, D2, and Nl. If D is a strictly upper-triangular matrix
whose entries are subsets of 5, then the time required to compute D+ is 77? (w) and
(cBM(n) < en2-81 if BM(n) > n2*6 for some e > 0,
7R(n)<
(c«2logK if BM(n)<n2*e foranye>0.
Proof The result follows from Theorems 12.2.3,12.5.2, and 12.5.4. □
We can now combine our individual results, to state the main result.
Theorem 12.5.6 Let G = (V, 2, P, S) be a context-free grammar in Chomsky
normal form. The time needed to recognize a string of length n generated by G is at
most a constant times
BM(n)<n2-81 if BM(n)>n2+e for some e>0,
K2log« if BM(n)<n2+e foranye>0.
Proof Algorithm 12.5.1 requires (7(n2) steps to initialize the matrix and
TR(n + 1) steps to compute the transitive closure. It is easily shown that the binary
operation • defined in Section 4.1 satisfies axioms Dl, D2, and Nl. The time bound
then follows, from Theorem 12.5.5. □
PROBLEMS
1 Prove Proposition 12.5.1.
2 Complete the following parts of the proof of Lemma 12.5.5:
a) Claim 1 b) Claim 4 c) Claim 5
3 In one abstract formulation in this section, we started from a binary
operation * on S and extended * to work on subsets. Are the three axioms given
exactly equivalent to this situation? That is, if we start out as above, do the axioms
always hold? If the axioms hold, may * be redefined as above?
12.6 A GOOD PRACTICAL ALGORITHM
In this section, another recognition algorithm is presented that is quite
suitable for practical use. It works on any context-free grammar, so no initial
transformations of the grammar are needed. It can be shown that the simplest variant of the
12.6 A GOOD PRACTICAL ALGORITHM 471
algorithm runs in time en3, where c is proportional to ||G||. It turns out that, in
applications to the grammars which occur in natural language processing, dependence on
||G|| is more critical than dependence on n. It also turns out that this method can be
speeded up by a factor of logw.
The algorithm to be presented will construct an (n + 1) x (n + 1) upper-
triangular matrix. The entries in the matrix will be "dotted rules," which we now
define.
Definition Let G = (V, T,,P, S) be a context-free grammar and let • be a
symbol not in V. If A -*■ aQ is in P, then we say that A -> a • j3 is a dotted rule of G.
Our intuition tells us that the "dot" separates a and j8; the apart of the rule
has been found to be consistent with the input, while nothing is yet known about j3.
If A -*■ A is in P, we write the dotted rule A ->■ • and let • concatenate with A.
The matrix will be filled in by using certain operations that will now be
defined.
Definition Let G - (V, 2. P, S) be a context-free grammar. Let Q be a set of
dotted rules, and let R £ V. Define:
QxR = {A -+afi|3- y\A -+a ■ BPyismQ,P^>A, andB<ER);
Q*R = {,l^afij3-7|/l^a-5j37isme,j3^A,5^CforsomeCe#}
The idea of the x product is to extend the "product" of the Cocke—Kasami—
Younger algorithm to the case in which A-rules exist. The *-product is a method of
precomputing chain derivations. Next we extend these products to the case where
both arguments are sets of dotted rules. Note that:
Qx R£ Q*R.
Definition Let G = (V, T,,P, S) be a context-free grammar and let Q, R be
sets of dotted rules. Define
QxR = {A -+ afij3 • 7IA ->■ a • Bj5y e Q, 0 ^> A, and B ->■ tj • is in R }
and
Q*R = {A->aBp-y\A->a-BPy<EQ,P^>A,B^>CforsomeC<ENandC^ri-ismR}.
Again, note that:
Qx R£Q*R.
The algorithm that we shall give uses a predictor to guess which dotted rules
may be needed next.
Definition Let G = (V, H,P,S) be a context-free grammar and let R£ V.
Define
predict(R) = {C + y-Q C-»- y% is in P,7 =^> A,B ^> Ct\ for some B <ER and some tj e V*}.
If R is a set of dotted rules, then
predict(R) = predict({B\ A-+ a • Bj5 is in R}).
472 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
It is important to note that predict depends only on the grammar and can be
precomputed for each variable or dotted rule.
Example Consider the grammar
tQ =
1*1 A
lie
predict({S])
= {S-
= {S->- A •£}. Then
Now we can
present
S^AB
A^-A
B^CDC
C->A
D->a
•AB,S^A-B,A^--,B-
Qx{B}= {S^AB-},
Q *{D}= {S^AB'l
the main algorithm.
CDQB^-C-DC, C-
Algorithm 12.6.1 Let G = (T, 2,.P, S) be any context-free grammar. Let
w = a\ ■ ■ ■ an, where n >0 and at6S for each k, 1 <k <n, be the string to be
recognized. Form an (n + 1) X (n + 1) matrix T = (/y), as follows:
begin
*o,o: = predict({S});
for/ : = 1 to n do
begin
comment build col./', given cols. 0,
scanner:
for0</</-l do
h/- = U,j-i x {«,}:
completer:
for k: = j' — 1 down to 0 do
begin tky. = tkJ U tk>k * tkJ;
for /: = k — 1 downto 0 do
end;
predictor: / \
tjj:= predict \ U ?u
end \o <,</-i j
end.
-,/-i;
The order of computation will now be enumerated. Suppose we have built
columns 0, ...,/'— 1. To construct column/', the scanner puts partial information
into the off-diagonal part of the column. The completer works up the column from
(/-i./ t0 t0j. The computation of tkj- where 0 <&</', is done by first computing
12.6 A GOOD PRACTICAL ALGORITHM 473
A: J
<j,j
FIG. 12.13
tkj'- = th j U tk, fe * ffc_y. That is, each entry tkj is filled in by adding the *-product
of the diagonal entry of that row to the original contents of tkj. This is illustrated in
Fig. 12.13.
Next tk j is cross-multiplied against tik and the result added to ttj for all
rows above tkj. Then we continue to the next entry, which is tk-u_ This is illustrated
in Fig. 12.14. '
Only after t0j has been completed is the predictor used. The predictor fills in
Before studying the algorithm in detail, let us simply execute it on the first
example of this section, when we try to recognize the input w = a. Since we have
precomputed predict, the first executable statement yields:
'o,o = {S^-AB,A^-,S^A -B,B^- CDC, C^-• ,B ^C • DC,D ^ • a).
The outer for loop is executed once, for /' = 1. The scanner sets t0,i to {/)-*■ a•}. The
fc j
1- r
\
tk
>
J
'J. J
FIG. 12.14
474 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
inner for loop is executed once, with k = 0. Next, the completer adds to t01 some
new dotted rules, and the current value of ?0,i is:
,01 = {D^a-,S^AB-,B^CD-C,B^CDC-}.
The next for loop is not executed. The computation is concluded in the predictor,
where tx x is set to {C-> • }. The final T matrix is shown in Fig. 12.15.
S- -AB
A-~ '
S-^A'B
B - • CDC
C- •
B-~C-DC
£>— . a
D-*a'
S-"AB-
B-~CD'C
B-~CDC'
C--
FIG. 12.15
As we shall see shortly, w G /.(G), because S^-AB- is in f0,i-
Example Let G be the grammar
E^E*E\E + E\a
and let w = a + a * a. Note that the string w has two parses. We present the
recognition matrix in Fig. 12.16, and ask the reader to verify the computation.
T =
E -"E*E
E-"E + E
E-"a
E-~E-*E
E-+E- + E
E-'a-
E-'E + 'E
E — -E*E
E-"E + E
E-"a
E-'E+E-
E-'E- *E
E-'E' + E
E-'E-E
E-'E' + E
E-'a-
E-'E-E
E-~E*'E
E-"E'E
E-"E + E
E-'-a
E-'E + E-
E-'E-E
E-'E' + E
£— E*E-
E-~E*E'
E-'E-E
E-'E'+E
E-'E-E
E-'E' + E
E-'a'
FIG. 12.16
12.6 A GOOD PRACTICAL ALGORITHM 475
Since E-+E + E- is in /0,s (and E-*E *E- is in /0,s)> we conclude that
wGL(G).
Some new terminology is needed for the proof that the algorithm works.
Definition Let G = (V, 2, P, S) be a context-free grammar, let w = a\ ■ • • a„,
ak G 2 for each 1 <fc <«, let A -+aj3 be in P, and let 1 </,/<«. A dotted rule
A -* a-0 is called (/, j)-consistent if there exists 7 G F* such that
atAy
and
a => a;.
A set of dotted rules is (/, ^-consistent if each rule in the set is. A set of (/, /)-
consistent rules is (i, f)-complete if it contains all (/, f)-consistent rules.
There are only a finite number of (/,/)-consistent rules. Figure 12.17 shows the
interpretation of an (/, /)-consistent rule.
0\02 ••• a, ai+l , ,, aj
FIG. 12.17
It is convenient to prove a lemma about the preservation of consistency,
which will substantially reduce the level of detail involved in carrying out the proof
that the algorithm works.
Lemma 12.6.1 Let G = (V, 2,P, S) be a context-free grammar and let
w = ai ■ ■ ■ an,n^0, where eachafe E £ for 1 <£^n. Let 0 </,/<«.
a) U tij-i is (/,/— Inconsistent, then fJ>;-_1 x {a,-} is (/, /)-consistent.
b) If tLi and tiyj are (/,/)- and (/,/)-consistent, respectively, then tUi*tij
is (/, /)-consistent.
c) For any k, 0 < k </, if t, k and tkJ- are (i, k)- and (k, /)-consistent,
respectively, then tUh x tkJ is (/,/)-consistent.
d)
predict U tt j
is (i, /)-consistent if ttj is (/, /)-consistent, where / </.
476 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
Proof A -* aafi' y is in ttj-i x {a,} if and only if
A-+a-ajfiy is in tij-i (12.6.1)
and
^A (12.6.2)
Since t^-i is (/, /— l)-consistent,
S^ai---aiA6 for some 9GV* (12.6.3)
and
a ^a,+1 ■•■«;_! (12.6.4)
Now, *
aa;0=>a/+1 ...afi by (12.6.4),
^■ai+1 •••a/ by (12.6.2).
This, together with (12.6.3), allows us to conclude that t{j-i x {a,-} is (/'^-consistent,
and completes the proof of part (a).
Next, we turn to part (b). A -* aB(l-y is in titi * tu if and only if
A-+a • B§y is in titi
U^A (12.6.5)
B^C (12.6.6)
and
C-*rf is in /i;y.
Since ttii is (/', /')-consistent,
a=^A (12.6.7)
and *
5=>«i ■■■a,i4e (12.6.8)
for some 9. Since C-*r\m is in /1;y, we know that
T?=*a,+1---a, (12.6.9)
Combining (12.6.8) with (12.6.5), (12.5.6), (12.6.7), and (12.6.9) leads us to conclude
that
aBP^>Bp^> C^n^a,-+i • • • ay
and so A -* aBfi-y is (/', /)-consistent.
Now, we focus on part (c). A -* aBfi-y is in tiyk x tkj if and only if
A -* a • B$y is in tiM (12.6.10)
0^>A (12.6.11)
and
5-+Tj"isinffc>y. (12.6.12)
By (12.6.10) and the consistency of tik,
s£-al---aiA0 forsomeflGF* (12.6.13)
a^-ai+1--ak (12.6.14)
12.6 A GOOD PRACTICAL ALGORITHM 477
By (12.6.12) and the consistency of tkj,
T?^tffe+r • dj
We must derive some strings from aBfi. That is,
aB$^ai+l ■■■ akBp
=> ai+l ■ ■ ■ akr)P
*
=>ai+l ■ ■ -fifefife+i • • -fi/P
^ fli+i ■■■a,
by (12.6.14)
by (12.6.12)
by (12.6.15)
by (12.6.11)
(12.6.15)
This derivation, together with (12.6.13), proves that tiM x tkJ is (/,/)-consistent,
and completes the proof of part (c).
Turning to part (d) of the lemma, C-+ 6 • % is in predict(L)0<i<j titj) if and
only if there exist / </, and there is B G TV such that
(12.6.16)
(12.6.17)
(12.6.18)
(12.6.19)
(12.6.20)
6 => A
B =^> Cri for some r? G V*
A -* a • 50 is in titi.
Since /,•;- is assumed to be (r,/)-consistent,
5 => a\ ■ ■ ■ atAy for some y G V*
a ^a,+1 •• -ay
Note that
5 => ai • • • a,^7
=> ai • • ■ afliBfiy
^ ai ■■■aiai+l ■■■a]B^y
=> ai • • -ajCriPy
by (12.6.17)
by (12.6.18)
by (12.6.20)
by (12.6.17).
Using the last derivation with (12.6.16) allows us to conclude that C-+8 • % is (J, /)-
consistent, and completes the proof of the lemma. □
We are now ready to prove that the algorithm works. Understanding this
proof is the key to modifying the algorithm to improve its performance.
Theorem 12.6.1 Let G = (V, 2,P, S) be a context-free grammar and let
w = ai ■ ■ -a„, each ak G 2 for 1 <k <n. Let T be the recognition matrix produced
by Algorithm 12.6.1. Then, for any 0 </,/<«, ttj is both (/,/)-consistent and
complete. Equivalently, A -* a • 0 is in ttj if and only if there exists y G V* such that
S => ai ■ • ■ a(Ay
and
a ^> a,+1 ■■■a,
478 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
Proof The argument will be an induction on the order in which the
computation is carried out.
Basis. We must show that
predict({S}) = fM
is (O,0)-consistent and complete. It follows, from the definition of predict, that /0;o
is (0, 0)-consistent because, if C-+6 • % is in predict{{S}), then 6 =>A and S=>Cri,
and hence, C-*6 •£ is (0,0)-consistent. Conversely, if C-+8 •£ is (0,0)-consistent,
then, by the definition of (0,0)-consistency, 6 => A and there is some t? G V* such that
S => AG? = Ctj, which implies that C -* 6 • £ is in pre<#c/({S}).
Induction step. Assume that we are about to make our final assignment to
ttj as specified below. As an induction hypothesis, assume that, after final assignment
to all earlier entries /,'/, the t^j are (r',/')-consistent and complete.t We must show
that, for titj, the following propositions are true:
a) All dotted rules added to tiyJ are (/,/)-consistent.
b) If /</, then ttj will be (/,/)-complete after execution of the program
statement
tk,j '■ ~ thj U thh * tkj,
when k and/ have the values / and/, respectively.
c) The tj j will be (/,/)-complete after execution of the statement labeled
predictor.
The proof of part (a) follows immediately, because the induction hypothesis asserts
that tij-i is (/,/ — Inconsistent and Lemma 12.6.1(a) shows that
is (/,/)-consistent. That assignment is done in the scanner. Similarly, the other parts
of Lemma 12.6.1 assert that all additions to titi are (r',/)-consistent.
To show (b), let /</ and let A -*a • j3 be an (/', /)-consistent dotted rale.
By (/,/)-consistency, it is known that
a ^> ai+l ■ ■ a-j (12.6.21)
Since / </, a,+1 • • • a;- ^ A, and so there is some X&V which is the ancestor of a,- in
(12.6.21):
a = a1Ara2
for some alt a2G V*. Also there existsk,i<*k </, such that
t Our formulation of the induction step is complicated by the fact that some entries
are partially completed before the final values are assigned. It is possible to state the
exact characterization of the full matrix at any time during the execution of the
algorithm, but it is cumbersome and involves extra notation. By stating the induction
hypothesis this way, we can eliminate the extra notation.
12.6 A GOOD PRACTICAL ALGORITHM 479
c*i => a,+1 • • ak (12.6.22)
X ^>afc+1 •■■*,• (12.6.23)
a2 ^> A (12.6.24)
It is easily checked that
A -* ^ • Xa2(l
is (/, fc)-consistent. Since k </, the induction hypothesis applies, and A-*^- Xa2fi is
in'*,*.
There are now three cases to be considered.
CASE1. I6S. Then X = as and k=j-l, from (12.6.23). This case is
illustrated in Fig. 12.18. Then
A -* ai' ajOL2fi is in tU-x
so A -* axdja2 • 0 is in ttj-i x {a;}. Hence it is added to ttJ by the scanner.
ai+i
FIG. 12.18
CASE 2. XGN and i<k. This case is illustrated in Fig. 12.19. Rewriting
(12.6.23), we have:
X ^6 ^afc+1---fl,
and A"-*6 is in P. It follows easily that X-+8 • is (fc,/)-consistent and must be in
tk,h by the induction hypothesis, since i<k. But then ,4 -+a • (1 will be in tith x tkj,
so it will be added to tiyj by the completer loop immediately after the computation
of tk j is finished.
CASE 3. X GN and / = k. Now we find that (12.6.22) and (12.6.23) become:
c*i ^ A
X ^aw-aj^A (12.6.25)
480 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
"1
FIG. 12.19
a, a, ai + ] aj A
FIG. 12.20
The situation is illustrated in Fig. 12.20. Expanding (12.6.25), which is possible since
/</, we have:
X => yt ^ai+l--aj (12.6.26)
for some fiG V*. Hence, X-*nm is (/,/)-consistent. Now, however, t-tj may not be
complete when
Uj- = tuUtt.t*tij (12.6.27)
"it
"i+\
12.6 A GOOD PRACTICAL ALGORITHM 481
is executed, so the induction hypothesis does not apply directly as it did in Cases 1
and 2. Let us examine a generation tree of (12.6.26). See Fig. 12.20. There will be an
internal node in the tree, which is labeled Y and is the lowest common ancestor of
ai+1 and a,-. That is
X ^ OlY02
0, ^> A
e2 ^ a
Y -* 5isinP
This situation is illustrated in Fig. 12.21.
A ai+l — at al + i
FIG. 12.21
There is some Z EV such that
6 = 5iZ82
*
Z => afi+1 ■ ■ ■ dj
82 =*> A
Note that Z € V, so that Z = a,- is included in this case. If / + 1 =/, then C = / and
Z =>ay. But then Z is a common ancestor of a,+1 (= aj) and a;-, which is a contradiction
unless Z = a,-.
On the other hand, if / + 1 </, then / < C </, because i = i would imply
that Z is a lower common ancestor of a,+1 and a;- than F. In either case Y-+5 • is
(/, /)-consistent. Moreover, Y -* 8 • falls under Case 1 or Case 2 above, respectively
[with Y-*- 8iZ82 • in place of A -*■ diXa^ • &,Z in place of X, and C in place of k].
By the arguments used earlier, Y-* 8 • was added to titi before the statement
fi,i ■ = U,j Uf(,i* ?i,y
was executed.
for some/ <£</
482 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
Since /</ and A -*<*! • Xa2P is in ttit by the induction hypothesis and
X Z> Y
we have that A -* a1Ara2 • fi is in ti>t * ttj, so that A -* a • 0 will be in ttj after
execution of (12.6.27). This completes the proof of part (b).
To prove part (c), let C-*t) • 0 be a dotted rule that is 0',/)-consistent. By
definition,
S ^■al---ajCy (12.6.28)
for some 7 6 V* and
t? =S> A. (12.6.29)
Let the least common ancestor of a}- and C be a node labeled >1, and the production
/4 -► aflj3
is used. See Fig. 12.22. a contains an ancestor of a;- while B 6 V is an ancestor of C.
S
FIG. 12.22
Now A-*a- Bfi must be (/,/)-consistent for some / </. That is, there is some
/ so that
a 2> ai+l • ■ ■ aj
because a contains an ancestor of a,-. By the induction hypothesis,
A -* a ■ B$ is in tt j ^ U tpj.
JJ = 0
Since B is an ancestor of C (but not of aj), we have
B ^Ct
12.6 A GOOD PRACTICAL ALGORITHM 483
for some t 6 V*. Thus, C-+T)m6 must be in
predict I U tpJ ,
which completes the proof of (c) and of the theorem. □
Corollary Let G, w, T be as in Theorem 12.6.1. Then wGL(G) if and only
if S -* a • is in t0n for some a G V*.
Proof By the theorem, S -* a • is in fft„ if and only if S =>a =>ai • • • a„ = w.
a
Corollary Algorithm 12.6.1 is an on-line recognition algorithm.
Note that the algorithm would still work if * were used instead of x. This is
true because * preserves consistency, no extra dotted rules can occur, and none will
be omitted.
In order to analyze the algorithm we have given, we shall modify it
somewhat. The analysis will be simplified by using the * operation in place of the x
operation throughout the algorithm. Basically, this causes chain derivations to be handled
as soon as possible, rather than as late as possible. As we remarked earlier, replacement
of x by * preserves the correctness of the algorithm.
We use ty to denote the vector that is the /th column of T; that is, the /th
component of ty is ti j. Union of two vectors, or * of a vector by a scalar, is done
componentwise. Algorithm 12.6.1 has been recast into vector notation below.
Algorithm 12.6.2 (Vector version of Algorithm 12.6.1)
begin
v =
predict ({S})~
0
0 -
)
for/: = 1 to n do
begin
scanner:
ty: = ty_i * {fly};
computer:
for k: =/ — 1 downto 0 do
V = ty U tfe * tk j;
predictor:
Zy;: = predict I U /,-,y) ;
\0<><; J
end
end.
484 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
First, we claim that this algorithm is also correct.
Theorem 12.6.2 Algorithm 12.6.2 is correct in that A -+a-|3 is placed in
tiyj if and only if S =>fii • • • atAy for some y 6 V* and a =>ai+l ■ ■ ■ as.
Proof The present algorithm is carrying out the same computation as
Algorithm 12.6.1. Therefore, the result follows from Theorem 12.6.1. □
Now let us consider how to implement the "vector" algorithm on a bit-
vector machine. For each dotted rule A -* a • ft, let us define
V
where
1 if A -* a • 0 is in tu,
,0 otherwise.
Corresponding to each column t;- is a sequence of vectors, one for each tf^01'^.
fA-*a-l
Example We use our first example again. First, we index all the dotted rules:
0.
1.
2.
3.
4.
5.
S-+-AB
S-+A-B
S-+AB-
A-+-
B -* ■ CDC
B-+C-DC
6.
7.
8.
9.
10.
B-+CD-C
B-+CDC-
C-+-
D-+ -a
D-*a-
Then t! (the matrix appears after Algorithm 12.6.1) is represented by
ti **
0010001100 1
00000000100
The "one" in the bottom row means that C-+ • is in tlti.
Note that the array has two rows and eleven columns. Although the number
of columns is large, it depends, in general, on the grammar and not on the size of the
input. In example, the row size is n + 1, where n is the length of the input.
Consequently, each column is stored in a bit-vector "word" and we shall use as many
words as we have dotted rules.
Next, we must be able to perform operations on this representation of
columns.
Lemma 12.6.2 Let G = {V, T,,P,S) be a context-free grammar, let
w = al • • • a„, and let T = (ftf) be the matrix computed by Algorithm 12.6.2. If the
12.6 A GOOD PRACTICAL ALGORITHM 485
columns are represented as above, the following operations may be performed in
constant time which is independent of n.
a) Compute the union of t;- and tfe;
b) Compute a representation of tiyj from t};
c) Test whether A -* a • Bfi is in t;-;
d) For any sequence of vectors Q and any set' R, compute
Q*R.
Proof Carrying out these computations is a straightforward programming
exercise and will be left as Problem 2 at the end of the section. □
We are now ready to analyze the time bound for Algorithm 12.6.2.
Theorem 12.6.3 Algorithm 12.6.2 requires time <?(n2) when implemented
on a bit-vector machine and uses words whose length is n. The algorithm may be
implemented on a RAM and takes time <7(n3).
Proof By Lemma 12.6.2, all the operations used in Algorithm 12.6.2 require
only constant time. If it takes time c0 to compute tQ and time cx to execute the
scanner, and time c2 to execute the completer, then the entire program requires
Co + Lcl X c2 = co +cic2 X / = t^iri1).
;=1 \k=0 J 7=1
Since only bit vectors of length n are used, one can simulate the whole process on a
RAM in time ^(n3). □
Although the present algorithm seems quite different from the on-line version
of the Cocke—Kasami—Younger algorithm, it turns out that the two algorithms are
very closely related. The exact correspondence is brought out in the problems at the
end of this section.
We now indicate how to use our new type of recognition matrix to parse as
well as recognize. The algorithm that follows provides a means of obtaining, from the
recognition matrix, a rightmost parse for a given string. The algorithm is similar to that
used for the Cocke—Kasami—Younger recognition matrix.
Algorithm 12.6.3 Let G = (V, 2, P, S) be a cycle-free, context-free grammar
with the productions designated iri,ir2,... , irp. Let w = a\a2 ■ • a„, n > 0, be a
string, where, for 1 < / < n, a, G 2; and let T = (/,• y) be the recognition matrix for w
constructed by either Algorithm 12.6.1 or 12.6.2.
t This is to be interpreted for both the case R 9 V and R a set of dotted rules.
486 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
Define the recursive procedure parse(ij\ irm) which generates a right parse for
A =>a=>ai+l ■ ■ ■ dj, where 7rm =A -+a, as follows:
procedure parse(i,f, nm = A-^AlA2- °-4pm);
begin
output(m);f0: =/;
for £: = pm downto 1 do
if^fies
then/0: =/0 — 1
else
if k is the greatest integer / < k </0 such that for some a G V*,
Aa->-a-isintkjo and A -*AXA2 ■■ ■Aa.1-Aa ■ ■ ■ APm is in fIjfe
then begin parse(k,j0 ,Ae~*oi);
Jo- =k;
end;
end;
Output a right parse for w as follows:
mainprogram: if for some a G F ,S-+a • is in t0n
then parse(0, n,S-+a)
else output{" error").
Example Consider the second example of this section with grammar
1. E-+E*E
2. E-+E + E
3. E-+a
and string w = a + a *a. Since E-+E + E- is in /0,s, parse(0, 5, it2 = E-+E + E) is
called, yielding (2,parse(2, 5, n^ = E -+ E * E), parse(0, l,ir3 -E-*a)).Thenparse(2,
5, ir2 = E -+ E * E) generates (1, parse(4, 5, tt3 = E -* a), parse(2, 3,,7r3 = E-*a)),
which yields (1,3,3).parse(0, 1, 7T3 = £" -* a)yields 3. Thus the output of the algorithm
is (2,1,3,3,3).
If the grammar contains cycles, then Algorithm 12.6.3 may not terminate.
However, if we modify the algorithm so that, in the case that some tk j contains two
or more dotted rules A% -* a • and A% -* y •, we choose the dotted rule that was
entered first by Algorithm 12.6.1, it can be shown that Algorithm 12.6.3 always
terminates. We leave these details to the reader.
Theorem 12.6.4 Let G - (V, J,,P, S) be a cycle-free context-free grammar
with productions designated n^, n^,... , irp. If Algorithm 12.6.3 is executed with the
string w = aia2 ■ • a„, n> 0, where, for 1 </<«,af G 2, then the algorithm
terminates. If w G L(G), then the algorithm produces a right parse; otherwise it announces
error. The algorithm takes time & («2).
Proof The proof follows that of Theorem 12.4.4. We outline the proof,
giving only the details that differ significantly.
Claim 1 Whenever parse(i, j, nm = A -* a) is called, then / > i and A -* a • is
infu.
12.6 A GOOD PRACTICAL ALGORITHM 487
Claim 2 In the sequence of calls on parse during the execution of Algorithm
12.6.3, no call parse(i, j, itm=A-+AlA2-- Ap ) generates another call parse(i, j,
nm =A-+AlA2--APm).
Proof Given a call parse(j, j, nm = A-+AiA2- ■ Ap ), each call parse{k, /0,
A£-+a) directly generated has the property that r'<fc</0 and /<></. It follows
inductively that this property (namely, that successive values of/ are nonincreasing
and, for fixed values of /, successive values of / are nondecreasing) is true of the
sequence of calls generated by parse(i, j, nm=A -* A\A2- ■ Ap ). Suppose the call
parse(i, f, nm =A-*AlA2- -Ap ) directly generates the call parse(i, /, irr = B-+
BXB2- ■ -BPr). It follows that, for"some C, 1 < C <pm, Aa =B, and that A -*AXA2
■ ■ vle_! • Ae - • Ap is in titt. It follows from Claim 1 and Theorem 12.6.1 that
A =^A1A2--Ai.iAi--APm
=*AxA2-- -Ai^a^-- ajAe+l- ■ APm
Uci+i ■ ■ a}
and that A \A2- ■ vlfi_! => A and>lfi+1- • Ap =>A. Hence, >1 =>B.
Inductively, if parseQ, j, rrm = A-* AXA2- ■ 'APm) generates a call with the
same arguments, then >1 =M, contradicting the fact that G is cycle-free.
Claim 3 parse{i, j, -nm =A-+a) terminates and produces a right parse of A =>
a =>a,+1 • • -aj.
Proof Consider the sequence of calls on parse during the execution of
Algorithm 12.6.3. It follows, from the argument in Claim 2, that the sequence of values
for/ is nonincreasing and that, for fixed/, the sequence of values for / is nondecreasing.
It follows from Claim 1 that 0 </ and 0 < /. Consequently, we conclude from Claim
2 that the number of calls is finite. Clearly, if parse does not make a call, then it
terminates. Therefore the algorithm terminates. The production of a right parse then
follows, by a straightforward induction on the number of calls on parse.
Claim 4 A call of parse(i, /, nm = A -+a) takes at most c(j — i)2 steps for
some constant c if/ > /, and c steps if/ = /.
Proof We first analyze the number of steps required by the call on parse,
excluding the recursive calls. The for loop is executed, at most, q times, where q is the
length of the longest righthand side of a production. For each execution of the for
loop, if A e G 2, the number of steps is c3 for some constant c3. If A fi G N, the number
of steps, excluding recursive calls, is at most c4(j0 —Jc+ 1) for some constant c4.
Since i <fc and /0 </ for all values of k and/0 during the call, the total number of
steps, excluding recursive calls, is at most qcs(j — i+ 1), where cs =max(c3,c4).
Since each recursive call has arguments /0, k such that / < k and/0 </, each recursive
call requires at most qc$(j —i + 1) steps, excluding its recursive calls.
By Claim 3, parse(j, j, irm =A -+a) produces a right parse of A =>a =>ai+l
■ ■ -aj. Let/? be the length of that derivation.
488 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
By Theorem 12.2.1, if / = /', then p<c0 and if/>/, thenp <cl(/ —i)-c2
where c0, Ci and c2 are constants. Since a production index is printed when and only
when parse is called, this call on parse generates at most p recursive calls. Combining
results, the total number of steps for the call on parse is at most
c0qcs if / = /
and
qcs(/-i+lYci(f-0-c2) if />i. (12.6.30)
Simplifying Eq. (12.6.30) yields
qcs(j-i+ \\ci0'-i)-c2) = qcs(ci(j-i)2 + fci -c2Xj-i)-c2)
<qcs(c1U-t)2+cl(f-i))
< 2qcsci0'-i)2-
Letting c = max {c0qcs, 2qc%c\} completes the claim. □
PROBLEMS
1 Give efficient algorithms for computing x, *, and predict. Analyze the
complexity of these algorithms.
2 Write the programs needed for the proof of Lemma 12.6.2.
3 Prove the following result".
Theorem Let G — (V, 2, P, S ) be a context-free grammar in Chomsky normal
form. Let w = ai ■ ■ -an, n > 0, and a^ 6 2 for 1 < k < n. Let T = (fi;) be the matrix
for G computed by Algorithm 12.6.1. Let T' = (t'lj) be the recognition matrix
computed by the Cocke—Kasami—Younger algorithm. Then,
{A\A-*BC' or A-+a • is in t;j}£ t'tj
for each 0 </</'<«. In general, the containment is proper.
4 Let G = (V, 2, P, S) be any context-free grammar. We modify Algorithm
12.6.1 by "weakening" the predictor and changing that step of the program to be
tjj : = predict(N).
Show that the new algorithm still works and is a correct recognizer. [Hint. Prove that
A -* a ' fi is in ttj if and only if a ^ai+l ■ ■ aj.]
S* Consider the algorithm given in the previous problem. Show that the
diagonal may be eliminated from the matrix by a suitable redefinition of * and x.
What is the relationship between the resulting algorithm and the Cocke-Kasami-
Younger algorithm?
6 Modify Algorithm 12.6.2 by noting that, as n grows, it is efficient to
precompute the product of certain columns and q-tuples of sets. Show that such a
modification can be made and that the resulting algorithm works.
12.7
GENERAL BOUNDS ON TIME AND SPACE
489
7 Continuing with Problem 6, choose q so that the algorithm can run in
n2
&\ on a bit-vector machine,
\iog«;
<?|-^—I on a RAM.
time
logn
8 Let us consider how to recognize a set defined by a 2-pda A = (Q, 2, T,
6, q0, Z0, F). There is no loss of generaUty in assuming that A satisfies the conditions
of Problem 4 of Section 5.4. Form a square matrix T such that (q, Z, q ) is in ttj if and
only if « i* ,
(«,*w$,/,Z)H«,*w$,/,A).
Note that this matrix is not upper-triangular, in general. Define a suitable product
operation, and show that the problem of recognizing whether or not a string is in a
2-pda language L may be reduced to taking the transitive closure of T.
9 Show that T+ of Problem 8 may be computed in time proportional to n3
and space proportional to n2 on a RAM.
10 How fast can the operations of Problem 9 be carried out on a Turing
machine?
11 What is the computational complexity of recognizing a set accepted by a
2-dpda?
12.7 GENERAL BOUNDS ON TIME AND SPACE FOR LANGUAGE
RECOGNITION
We have considered a number of recognition algorithms, and, for each of
these, we have computed the time and space requirements. In this section, we shall
summarize the least upper bounds and greatest lower bounds now known for the time
and memory used in context-free language recognition. These algorithms are
sometimes extreme, in that time may be traded for space.
If we let R(n) be the time required to recognize (or parse) a string of length
n, then we have the following result:
Theorem 12.7.1 n <:R(n)^cBM(n).
Proof The upper bound follows from Valiant's algorithm. The lower bound is
obvious, since we must read the entire string before giving an answer. □
Let us define R'(n) to be the time required to recognize a string of length n
by an on-line Turing machine. In this case, we must formulate the problem as in
Section 9.4, to prevent the machine from copying the input to a work tape and then
proceeding as in an off-line computation.
Theorem 12.7.2 For on-line computation,
n2 _,_ , n3
<R\ri)<~<n3.
log n log n
490 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
Proof The upper bound of n3 follows from Algorithm 12.6.1 or Algorithm
12.4.2. The «3/log« result can be obtained from Problem 7 at the end of Section 12.6.
The lower bound is too complicated to be included here, but the idea can be mentioned
briefly. Let
2 = {0,1}, c,st-Z,,
L = {xyzcsuis ■ ■ ■suts\t>l,x,y,z&Z*,\g(y)>0,ujeZ* for l </<?,
and iti = yT for some z, 1 < i < t}.
It is interesting to note that L is a linear context-free language. The idea of the proof is
to find another set l! (which is not context-free) that has essentially the same
recognition time as L. It is possible to show that L' needs at least w2/logw time for on-line
recognition.
Corollary There is a single context-free language which requires at least time
d?(n2/\ogri) for on-line recognition and can be recognized on-line in time ^(w2).
Let us now concentrate on the space requirements for recognition. Let S(n)
be the space required to recognize a string of length n.
Theorem 12.7.3 log«<5(«).
Proof There is no loss of generality in dealing with single-tape Turing
machines, because of Theorem 9.4.1. Suppose we have an L(«)-tape-bounded,
deterministic Turing machine with a read-only input and a single work tape. The instantaneous
descriptions (IDs, for short) of such a machine are of the form (q, i, a), where q is a
state, a is the portion of the work tape scanned so far, and i is the cell of the work
tape being scanned (so 1 < i < lg(a)). The maximum number of IDs is
r(n) = sL(n)tLM, (12.7.1)
where s is the number of states and t> 1 is the cardinality of the work alphabet. Let
Ci,.. .,Cr(„) be an enumeration of all IDs. For each n>0 and each d€2*, with
lg(u) < n, define a transition matrix T„(v) to be an r(n) x r(n) matrix whose entries
are from the set {00,01,10,11}. Then ttj is defined as follows:
1. The first digit of tij is 1 if and only if the Turing machine, started in tape
configuration Q while scanning the first cell of v%, can reach ID Cj
without moving the input head left out of v$.
2. The second digit of ttj is 1 if and only if, when started in Q while
scanning the first cell of v%, the device can move the head left out of v$ and
can be in ID Cj the first time it does so.
Thus Tn(v) describes the behavior of the device on v when v is a suffix of the input.
Then we have the following useful lemma:
Lemma 12.7.1 If \g(uv)<n for some uv&L, where L is the language
recognized by a single-tape Turing machine M and for some v' G 2*, T„(v) = T„(v'), then
ud'GL.
12.7
GENERAL BOUNDS ON TIME AND SPACE
491
Proof The argument is a straightforward "crossing sequence" proof and is
omitted. □
Now, consider the language
L = {wcwT\ wG{0,1}*}.
We shall shortly show that any on-line Turing machine requires at least log n tape to
recognize L.
Let n be a fixed odd integer, and consider all strings in 5= {0, i}"("-D/2.
Claim 1 No two strings in S have the same transition matrix.
Proof Suppose w,w' G S with w^w' and T„(w) = T„(w'). Then wcwT G L
but, by Lemma 12.7.1, we have
wc(w')T G L,
which is a contradiction. If all such strings have distinct transition matrices and there
are 2"("~1)/2 such strings but only 4(r(n)) transition matrices, we must have
4(r(«))2 > 2"<"-1)/2 > 2("~1)/2. (12.7.2)
Taking logs of Eq. (12.7.2) yields:
n-\
2(K»))
>
2
or, using Eq. (12.7.1),
4(r(«))2 = 4(sZ,(«)^(n))2 > h - 1. (12.7.3)
If n > 1, then « - 1 > n/2. Also, for all L(n), fL(") > L(n), since f > 1; so Eq. (12.7.3)
becomes: r, ,
8sY,L(")>n. (12.7.4)
Taking logs of Eq. (12.7.4) yields:
log 8s2 + 4L(n)log t > log n.
Thus
w ^log«-log8s2 /-mo
^W^ 71—I • (12.7.5)
4 log?
If n > (8s2)2, then log n > 2 log 8s2, so Eq. (12.7.5) becomes:
w 8 log t
for n > (8s2)2. Thus, for infinitely many n (all odd n >(8s2)2), we have
L(n)>c\ogn,
where c = 1/(8 log t). Therefore,
S(n) > log n.
We note in passing that L can be recognized in log n space.
492 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
Claim 2 L = {wcwT\ wG{0,1}*} can be recognized in space logw. This
completes the proof of Theorem 12.7.3.
□
Now we turn to an upper bound for S(n). The next lemma shows a suitable
way to "factor" a derivation.
Lemma 12.7.2 Let G = (V, 2,P,S) be a context-free grammar in Chomsky
normal form. Let A GN and aG V3V*. If A =>a, then there exist B, y, 8 in V* and
B &N such that:
A ^ BB8 ^ By8 = a
where
<lg(T)<2
and n = lg(a).
#
Proof Suppose we have a derivation tree of A =*a. Each node of the tree is
to be given a weight by the following procedure:
1 Every leaf has weight 1.
2 Every other node has a weight that is the sum of the weights of its
immediate descendants.
Figure 12.23 illustrates a sample derivation and the corresponding labeling of the tree.
Example G is the grammar with productions
S -+ AS\b
A -+ SA\a
Note that the weight of the root is always n.
Now find a heaviest path s in the tree by starting at the root and taking, at
each node, the branch to the heaviest subtree until a leaf is reached. Such a path is
marked in Fig. 12.23. A path like s must start at the root with a weight of «>3
(recall a G V3 V*) and end at a leaf with weight 1.
■s£)
s
/ \
A S
© J (Da
/V
S A
I / \
b S /I
\©
V)(pb ©
^s©
© /©N S&A (2)
© i ©I in)/\ _
© S A ©
© * « ©
The circled node is the one
promised by the lemma.
FIG. 12.23
12.7
GENERAL BOUNDS ON TIME AND SPACE
493
Now trace up path s until the first node is encountered with weight > L«/3J .
This node cannot be a leaf, since a leaf has weight
-liHs
Such a node must exist since the root has weight n > \n\7>\. As we progress up the
path s, the weight at successive nodes will double (at most) since we have a Chomsky
normal-form grammar and s is through the heaviest subtrees. Hence, this first node of
weight > |_w/3j follows a node of weight < [_w/3j, and so it itself has weight < 2 |_w/3_|.
Let B be the label of this node. Its weight is lg("y), where A =*y, and we have
just shown that
fj<ig(r)<2[fj. n
Now we are in a position to prove a result that gives an upper bound on the
space complexity of all context-free languages.
Theorem 12.7.4 Every context-free language can be recognized by a
deterministic Turing machine that uses space S(n) = (log n)2.
Proof Let L = L(G), where G = (V, Z,P,S) is some context-free grammar
in Chomsky normal form. Let N = {A i,..., Am } with S = A j. The construction of
the Turing machine is quite complex, so an intuitive version is presented first.
It is necessary to determine whether A =*a, where A GN and a G V*. If the
lg(a) < 3 (for example), we can determine whether A ^a by precomputing all such
information and storing this in the finite-state control of the Turing machine.
If lg(a) = k> 3 and A ^a, then there exist B GN, 0, y, 8 G V*, such that
A ^ (356 =* 076 = a
where
<lg(7)<2
The determination of A =*a can be reduced to determining whether B =*y and
A ^>PB8.
Thus, to determine whether A =>a, the Turing machine will, for each B GN
and each possible factorization of a = 0^6 with l£/3] < lg(-y) < 2 1&/3J, attempt the
subproblem B^y. If the subproblem is solved successfully, then the algorithm will
attempt the complementary subproblem A =*066. Since
«r)>[fj
it follows that
lg(7)>^i,
494 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
and hence
lg(056) = lg(076)-lg(7) + lg(5)
k + 1
< k —- +1
3
2k+ 2
since we also know that
3
lg(7)<2
<2kL
^ 3 '
Thus, if the original goal is of size k = lg(a), then all possible subgoals are of size
<(2k + 2)/3.Foi k>3,
k
2 = 2-K2-
3
so
2k + 2 2k + §fc _ 8&
3 ^ 3 9
Thus we have proved:
Claim 1 For k > 3, any goal of size & has all of its subgoals of size at most
8*.
Next, we compute the number of levels of subgoals to break down the
problem to one of size < 3.
Claim 2 The number p of levels of subgoals needed to bring the problem
down to size < 3 satisfies
p<c\og2n,
where c= l/(log2(D).
Proof of Claim 2 After p levels, the goal of size k has been broken into
subgoals of size < (*)pk- If we set this < 3 and take logs, we get
P<, „\= c\og2k.
log2 (1)
To solve the problem at hand for an input of length n will require 0(log ri)
space to record each current subgoal, and there will be 0(log n) such subgoals, leading
to a total bound of 0((log«)2).
The work tape is divided into blocks of
Llog n\ + 1 cells.
Each such block is long enough to contain a binary number from 0 to n. Imagine
the tape split horizontally into channels or tracks. The top track of block i contains
an integer denoted by begin(i). The second track contains an integer denoted by
end(i). The third track contains an integer size(i). The fourth track contains a variable
12.7 GENERAL BOUNDS ON TIME AND SPACE 495
SGoal 1—unsatisfied
Goal 2—unsatisfied
Goal 4—?
Goal 3—satisfied
sat®
FIG. 12.24
called variable® (right justified) and a boolean variable (or bit) sat® (for satisfied).
There are some other tracks to handle arithmetic and comparison operations as needed.
The meaning of the z'th block can now be explained. Its purpose is to record
information as to whether
variable® ^ a,- ^ wbegin(i) ■ ■ ■ wend(i)
where size® = lg(a,) and each wk G 2 for begin® < k < end®. Also
true if variable® =* a,- is known to be true,
false otherwise.
The approach we shall use is to break up a possible derivation of S =* Wj • ■ ■ wn
into subderivations of nearly equal parts. If sat® = false, then all succeeding blocks
are partitions of the second half of the derivation, i.e., the inner subtree. If sat® =
true, then subsequent blocks deal with the outer subtree. This is exemplified in Fig.
12.24.
The algorithm to be given is quite complicated. We wish to determine whether
S=>w, and we generalize that to the consideration of whether A =*w'. If lg(w') < 3,
then table lookup is used; otherwise, we use recursion. The algorithm starts with the
goal of determining whether S=^ai = w. An elaborate backtracking is begun, and w
is factored into 0i7i61, where
[=|<«T.)«|f];
and a variable Bx is stored into block 1 to indicate that it is possible that B ^-y^.
Then ji is stored by writing pointers to the first and last symbols of the input. (Since
these input positions are between 1 and n, log« space is sufficient.) The determination
of Bi =*"y1 will be done recursively.
Now the process is continued on the subgoal in a similar fashion. There are
several points which are different however. Subsequent a,'s may have several variables.
For each at, we record the first and last indices of the subword of the input derived
from a,-.
496 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
We have also been vague about how the recursion will take place, since that
requires space also. The space for that is all the unused blocks to the right of the
present one. A simple calculation shows that exactly the correct number of them
exists at any time.
When it has been determined that a particular goal has failed, then the next
case is systematically generated by our backtracking mechanism.
We are now ready to give a detailed construction of the device. The device is
described by an ALGOL-like program, but all the operations can be carried out on a
Turing machine within the given space bounds.
There will be two variables s and s' which appear in the program. Assume that
these are separate procedures defined by:
j
s = size(i) — Y, (size(k)— 1)
ft =1+1
and
s = size(j) — £ (size(k) — 1).
ft=i+l
Every time that s and s' appear, imagine that they are recomputed.
In understanding the program, i is the last block for which sat(i) = false and;
is the last block.;' may decrease, but it always is the case that 1 < i <;'.
begin
step_0: i : = 1;
;: = 1;
begin(l) : = 1;
end(l) :=n\
comment n may be computed on a first pass through the input;
sz'ze(l) : = n;
variable(l) :=Au
comment A t = S;
sat(l) : = false;
if n < 3 and variable(l) =*ax- ■ -an then accept;
comment The only goal here is to determine if S =*a1 = w;
step_l: comment We are working on goal /and have finished subgoalsz'+ 1,...,;'.
Each successfully completed subgoal k, i+Kk<,j has
established that size(&) symbols in a,- can be replaced by
variable(fc). Also s is the length of af after these
replacements have been made;
if s < 3 then goto step_6;
comment We can test if goal i can be satisfied directly. Otherwise, a new
subgoal must be built;
begin{j): = begin(i)\
end(j): = begin(i) — 1;
size(J) : =0;
variableif) : =Am;
12.7
GENERAL BOUNDS ON TIME AND SPACE
497
step_2: comment advance the end pointers of subgoal/;
repeat
if end(f) = endQ) then goto step_3;
end(j) : = end(J) + 1;
if (end(f) = beginQc)) and satQc) for somet k,j' — 1 > k > 1
then endQ) = endQc);
size(J) : = size(j) + 1;
until size(j) > |//3| ;
if sizeQ) > 2 \s'/3\ then goto step_3;
satQ) : = false;
goto step_l;
step_3: comment advance begin pointer for subgoal /;
if beginQ) = beginQc) and satQc) for somet kj — \>k>\
then beginQ) : = endQc);
if beginQ) =£ endQ) then
begin
endQ) : = beginQ);
beginQ) : = endQ) + 1;
sizeQ) : = 0;
goto step_2
end;
step_4: comment advance the variable stored in block / and continue
backtracking;
if variableQ) = Ak and Qc > 1) then
begin
variableQ) :=Ak^1;
beginQ) : = beginQ);
endQ) : = beginQ) — 1;
sizeQ) : = 0;
goto step_2
end;
step_5: comment back up on block/;
if (/' = 2) and (z = 1) then quit;
comment the above condition means that w is not in L;
repeat /: = / — 1 until not satQ);
comment goal i has failed and we backtrack to a previous goal.
Since not sat(l) this will always work;
goto step_2;
t Count downwards so the largest such k is used.
498 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
step_6: comment The subgoal is now so small that it can be done with a direct
test;
r:=0;
q : = begin(i);
while q < end(i) do
begin
if q = beginQc) for some' k,j>k~> 1 andsat(k) then
begin
ar+1 : = var(k);
q : = end(k)
end
else ar+1 : = wQ;
r:=r+\;
q-=q+U
end;
ifvar(i)i>at- ■ -ar then
begin
i: = i — 1;
goto step_2
end;
comment If the test fails then we must continue backtracking. Whenever
we get here r = s < 3 and the predicate may be checked in
the finite state control;
if i = 1 then accept
else
begin
/: = /;
repeat i: = i — 1 until not sat(i);
sat (J) : = true;
goto step_l;
end
end.
The tasks of showing that the program works and that only log2 n storage
is used on a Turing machine are left to the reader. □
Combining previous results leads to the following proposition.
Theorem 12.7.5 log n < S(n) < log2 («).
The situation for on-line tape bounds is quite simple.
Theorem 12.7.6 In the on-line case,
S'(n) = n.
Proof Note that we may copy the input on a work tape and use the upper
bound of Theorem 12.7.3 for recognition. Thus, S\ri) < n.
< Count downwards so the largest k is used.
12.7
GENERAL BOUNDS ON TIME AND SPACE
499
To handle the lower bound, again let
L = {wcwT\ wG{0, 1}*}.
There are 2" words of length n for w such that wcwT GI. The ID's of the Turing
machine when scanning the c must be different; otherwise we would accept wcwT
and wc(w')T when w=£w'. But the number of different ID's would be
r(n) = sL(n)tL(n)>2n.
By an analysis similar to that in the proof of Theorem 12.7.3, we find that
L(ri)>n.
Thus,S'{n)>n, and therefore S'(«) = n. □
PROBLEMS
1 Give the best time bound you can for the recognition of any 2-pda language
on a deterministic Turing machine with a single work tape and a read-only input tape.
2 Show that there exist nonregular context-free languages that can be
accepted by a tape-bounded Turing machine which uses space S(n) = log log(n).
3 Show that, if a language L is recognizable using space S(n), and if
S(n)
inf —L— = 0,
n-*~ log log(n)
then L is a regular set.
4 Show that it is recursively undecidable how much tape is required to
recognize a nonregular context-free language. [Hint. Find a nonregular context-free
language L0 such that L0 is recognizable in space log n if Lx n L2 # 0, and in space
log log(n) if Li n Li = 0, where L1 and L2 are variants of L(x) and I(y) of Section 8.3.
5* Show that for every nonregular, deterministic context-free language
L, recognizing L or L = 2* — L requires space log(n) on a nondeterministic Turing
machine.
6 Show that the language L defined in the proof of Theorem 12.7.6 can be
recognized in linear time on a RAM.
7 Let R(n) be the time required to test whether a string w G 2" is in L,
where L is a context-free language. Let CBM(n) be the time required to check whether
AB = C where A, B, and C are n x n boolean matrices. Show that
R(n)>sJCBM(n).
[Hint. Design a context-free language i(A, B, C) whose complement consists of strings
which represent that A, B, and C are n x n matrices and AB = C. Note that the time
to recognize_Z,(A, B, C) and its complement is the same. Moreover, a reasonable
encoding of L(A, B, C) is of order n2, so that
CBMin) <R(n2) < (R(n))2,
so
R(n)>s/CBM(n).
Describe L(A, B, C), and show that it is a context-free language.
500 RECOGNITION AND PARSING OF CONTEXT-FREE LANGUAGES
8 Based on Problem 7, devise a new context-free language L(A, B) which
depends only on two n X n boolean matrices A and B. Show how an on-line recognizer
for L (A, B) may be used to compute AB = C.
9 Using Problem 8, it follows that the time required by an on-line RAM to
recognize a context-free language is:
R\n)> \/BM'(n)
where BM\n) is the time required to compute the boolean product of two matrices
"on-line" (i.e., the ;th column of the product is computed before the; + 1 column of
B is read).
10 Write a recursive program to implement the algorithm given in the proof
of Theorem 12.7.4.
12.8 HISTORICAL SURVEY
Theorem 12.2.1 is well known in one form or another. Our particularly sharp
proof is due to A. Yehudai. Greibach [1973] found a hardest context-free language
first. Problem 6 of Section 12.2 is from the work of Sudborough [1976]. The
particular algorithm for multiplying 2x2 matrices used in Lemma 12.3.1 is credited to
Winograd by Fischer and Probert [1974]. Strassen [1969] was the first to find an
w2'81 algorithm for the multiplication of n x n matrices. Problem 6 of Section 12.3 is
from Warshall [1962]. The Cocke—Kasami—Younger algorithm may be found in many
places, such as Kasami [1965] and Younger [1967]. Our version (and much of this
chapter) derives from Graham and Harrison [1976].
Problem 8 of Section 12.4 is due to Taniguchi and Kasami [1969]. The hint
given follows an unpublished construction of W.L. Ruzzo.
Section 12.5 derives from Valiant [1975]. The detailed proof of the key
lemma is due to W.L. Ruzzo. Section 12.6 presents a new algorithm reported in
Graham, Harrison, and Ruzzo [1976]. This algorithm in its simplest form is an
adaptation of Earley's algorithm [1970]. The connection between this algorithm and the
Cocke—Kasami—Younger algorithm is deeper than is hinted at in the problems of
Section 12.6. Problem 8 is due to W.L. Ruzzo again.
The lower bound of Theorem 12.7.2 is due to Gallaire [1965]. Theorem
12.7.4 is due to Lewis, Stearns, and Hartmanis [1965]. Our proof is an adaptation
of a "program" written by Ronald Hunsinger. Problem 5 of Section 12.7 is due to Alt
and Mehlhorn [1975]. Problem 9 is due to Ruzzo.
thirteen
LR(k) Grammars
and Languages
13.1 INTRODUCTION
In Chapter 12, we learned a variety of ways to parse general context-free
languages. Such methods are not usually used in compiler construction because they
require at best superlinear time. In practice, one wants a linear-time method and,
moreover, one cannot tolerate large constants. An important class of grammars is known,
called LR(k) grammars, which have the property that they can be parsed in linear time.
Also, the grammar class is large enough to allow us to accommodate "natural
grammars" for programming languages. Any deterministic language has an LR(k)
grammar so that the family of languages is nontrivial and has desirable practical
properties such as unambiguity.
In the next section, the basic definition of an LR(k) grammar is presented. It
is shown that every strict deterministic language is LR(0) and that every deterministic
language is LR(1). In Section 13.3, an important characterization theorem for LR(0)
languages is proved.
Section 13.4 begins the treatment of parsing by defining table-driven LR-
style parsers. Section 13.5 is a highly technical treatment of the generation of sets of
LR(k) items. In Section 13.6, consistency of a set of items is introduced. It is then
possible to construct LR(k) parsers and to prove exactly how they operate. Section
13.8 concludes by showing that A0 = LR.
13.2 BASIC DEFINITIONS AND PROPERTIES OF LR{k) GRAMMARS
We are about to introduce LR(k) grammars. In order to study this family, it is
convenient to work with "handles" of canonical (or rightmost) sentential forms.
501
502 LR(k) GRAMMARS AND LANGUAGES
Definition Let G = (V, 2, P, S) be a context-free grammar and let y G V*. A
handle of y is an ordered pair (p, z), where p&P and i > 0 such that there exist >4 G N,
a, 0 G K*, and w G 2*, such that:
i) Sj> aAw £ o@w = y
ii) p is A -*■ 0
iii) z" = lg(a0).
Examples Let G\ be the grammar
S^aB\ab
B^b
The string y = ab has handle (S^-ab, 2) by the derivation
On the other hand, y has handle (B -*■ b, 2) by derivation
S^aB^ab
Consider grammar G2 shown below:
S^Aa\aA
A -+a
The canonical sentential form y = aa has handles (A -+a, 1) and (A -+a, 2), as the
reader may verify.
The idea behind an LR(k) grammar is that a parsing device is reading some
canonical sentential form. We wish the device to work by finding the handle (A -*■ 0, z)
and replacing fiby A. This gives a new canonical sentential form and the action is
repeated. In order for this to work, our grammar must have the property that the handle
is uniquely determined by what we have read up to now and by the next k characters
ahead. The formal definition that follows says just this.
Definition 13.2.1 Let k>0 and G = (V, 2, P, S) be a reduced context-free
grammar such that Sj> S is impossible in G G is LR(k) if, for each w, w', x G 2*;
y,a,a',p,p'eV*,A,A'£N,if
$
i) S j* aAw j* afiw = yw (That is, yw has handle (A -*■ 0, lg (a0)).)
ii) S^a'A'x^a'fl'x = yw' (That is, yw' has handle (A'^-fl',
lg(a'0'))-)
iii)t (fe)w = <feV
then iv) (A ■* 0, lg (a©) = (A' -» 0', lg (a '0')).
Example The grammar G3 shown below is LR(0).
S^aAc
A^Abb\b
' Recall that (fe)w denotes the first k letters of w if lg(w) > k, and all of w otherwise.
13.2 LR(k) GRAMMARS 503
At this stage, we have not yet learned efficient tests for the LR(0) property. We must
enumerate all canonical sentential forms and verify that they have unique handles. The
canonical sentential forms are listed below along with the corresponding handles.
Canonical Sentential Forms Handles
aAc (S^-aAc,3)
aAb2ic (A ^ Abb, 4)
ab2i+1c (A+b,2)
Note that L(G3) = {ab2i+1c\i>0}.
Now let us consider a new grammar G4, which generates the same language.
Go, consists of:
S^aAc
A^bAb\b
Consider the canonical sentential forms
abc and abbbc.
The first form has handle (A -*■ b, 2), while the second one has handle (A -*■ b, 3);yet,
when we look back, we see y = ab and the same lookahead string, namely, A.
Therefore, G4 is not LR(0).
The conclusion in Definition 13.2.1, that is, (iv), has several implications.
1 By the definition of equality of ordered pairs, we have A =A',fS = fi', and
lg(c0) = lg(a'0').
2 y = <Mr))a>p> = a««rf»a'0' = ag(«'PV/3' = a'0\ Thus, 7 = a0 = a'jj'.
3 Since 0 = 0', from (2) we have a = a'.
4 a'fi'x =yw' implies a'fi'x = a'fi'w' impliesx = w'.
Note that, if G is LR(k), then G is LR(k') for all k' >k.
One of the properties that we wish a grammatical class to possess, in order
that it constitute a useful class for parsing, is unambiguity. We show that the LR(k)
grammars are unambiguous.
The first lemma gives an equivalent formulation for equality of handles. This
lemma does not require that the grammar be LR{k).
Lemma 13.2.1 Let G = (F, 2, P, S) be a reduced context-free grammar.
Assume that for a, a',0,0' G V*;w, w' GT,*;A,A' SN,
St> cxAw^-aBw
and h h
S^aA w jfapw = apw
Then, aAw = a'A 'w' if and only if
(,4-0,lg(o0)) = (-4'-j3',lg(a'j3')).
Proof Assume that:
(^-j3,lg(a©) = (,4'-0',lg(a'0')).
504 LR(k) GRAMMARS AND LANGUAGES
Since a'fi'w' = otfiw and lg(aj3) = lg(a'|3'), we have afi = a'|3' and w = w'. Since 0 = 0',
we have a = a'. Also,^4 = A'. Thus,a4w = a'A'w'.
Conversely, assume that aAw = a'A 'w'. By our quantification, since A and
A' are the rightmost nonterminals in aAw and a!A 'w', respectively, we have A = A',
a = a', and w = w'. Since a|3w = a'fi'w', we have 0 = 0'. Thus,
(A -0,lg(a0)) = (4'-J3',lg(a'j3')). □
The second lemma characterizes unambiguous grammars in terms of handles.
Lemma 13.2.2 Let G = (V, 2, P, S) be a reduced context-free grammar.
Then G is unambiguous if and only if every canonical sentential form has exactly one
handle except S, which has none.
Proof Assume that G is unambiguous.
Claim 1 Shas no handle.
Proof Assume, for the sake of contradiction, that S has some handle. Then,
for some a € V* and w G 2+, n>0, m>\, since G is reduced, we have
and also t
SRW
Thus G is clearly ambiguous and we have a contradiction. Therefore S has no handle.
Claim 2 Every canonical sentential form except Shas at least one handle.
Proof This follows directly from the definition of a canonical sentential form.
Claim 3 Every canonical sentential form except S has at most one handle.
Proof Assume, for the sake of contradiction, that this is not true. Then we
have, for a, a', 0,0" G V*, w, w',x G 2*, a, a' &P, p, p , p" GP* ,A ,A' GN,
P' o „ P
Sj£aAwj>a(Sw = afiw =* x
where (>4 ->0, lg(a/3)) ¥= (-4' ->0', lg(a'|3')). Since G is unambiguous, p 'op = p"a'p. It
follows that p' = p"; thus a4w = aU'w'. Therefore, by Lemma 13.2.1, (A ->-/3,
lg(a/3)) = (4' ->• 0', lg(a'/3')), giving us a contradiction. Thus, every canonical sentential
form except S has at most one handle.
Conversely, assume that every canonical sentential form has exactly one
handle except S, which has none. Assume for the sake of contradiction that G is
ambiguous. Then there exist m, n, m>n>\, ah aj&V* for 0</<«, 0</</7z,
w G 2 *, and distinct derivations of w in G
S = aog'ar • -^a„ = w
We show how these derivations differ.
13.2 LR(k) GRAMMARS 505
Claim There exists some i, 1 < i< n, such that a„_,- =£ a'
Proof Assume, for the sake of contradiction, that an _, = a^, _ ,• for 1 < i ^ n.
If m = n, the two derivations are not distinct; therefore m>n. It follows that
a0 = a'm-n, where m —n =£0. We know that a^, _„_! j*c4,_„, so a'm-„ = Shas a
handle, which is contradiction.
We now let /, 1 </<«, be the smallest integer such that a„_;- ^a^,-/. It
follows that a„-j+i =a^,_J+1. Since every canonical sentential form has at most
one handle, Lemma 13.2.1 gives us that a„_y = a'm-j, which is a contradiction. □
Now we shall apply these results to verify that every LR(k) grammar is
unambiguous.
Theorem 13.2.1 Let G = (V, 2, P, S) be an LR(k) grammar, k>0. Then G
is unambiguous.
Proof Assume, for the sake of contradiction, that G = (V, 2, P, S), an LR(k)
grammar, is ambiguous. By Lemma 13.2.2, we have either:
1 S has a handle;
2 some canonical sentential form besides S has no handle; or
3 some canonical sentential form has more than one handle.
CASE 1. Suppose S has a handle. Then, for some a G V*, x G 2*, we have
Thus S =? S in G. But this contradicts the fact that G is LR(k).
CASE 2. Assume that some canonical sentential form besides S has no
handle. This is impossible, by the definition of a canonical sentential form.
CASE 3. Assume that some canonical sentential form has more than one
handle. We have, for y, a, j3,a', 0' G V*;w, w' G I,*; A,A' GN,
S j* aAw j* a0w = yw
Sj*aU'w'j*a'j3'w' = a0w = yw
where 04 -> 0, lg(a0)) ¥= (^' -*0', lg(a'0')).
Now, we know that (fe)w = (feV. Thus, since G is L#(&), (4 ->-0,ig(a0)) =
(A' -*■ 0', lg(a'0')). But this is a contradiction. □
The following lemma tells us when a grammar is not LR(k). Consequently the
lemma is often useful in proofs by contradiction.
Lemma 13.2.3 Let k>0 and G = (V, 2, P, S) be a reduced context-free
grammar such that S j* S is impossible in G G is not LR(k) if and only if there exist
w, w',xeZ,*;A,A'GN;y', 7,a,a',0,0'G K*, such that
i) S j* a4 w j* a0w = 7W
n) Sj>a A x j>a p x =y x = yw
iii) <fe>w = <feV
506 LR(k) GRAMMARS AND LANGUAGES
/-
a
~\
P
a'P'
w
'. X
w'
FIG. 13.1 The relations between the strings.
and iv) (A -»0,lg(aj3))# (,4' -► 0', lg(a'j3')), with
v) lg(a'0')>lg(a0).
Proof If (i) through (v) hold, G is clearly not LR(k). Conversely, assume that
G is not LR(k). Then, clearly, (i) through (iv) hold.
Suppose
v') lg(T') = lg(a'0') < lg(a0) - lg(T).
We shall show how, by reversing (i) and (ii), we can satisfy (v).
Figure 13.1 illustrates the relationships between the strings in (i) and (ii).
Now, let y = W>-W»x. Clearly, y G 2 *. We now have, for x, y, w G 2 *;
y',a',a,p',peV,A',AeN,
i ) S^aA x^a p x = y x
From (i) we have:
ii')^
From (iii), we see that:
ii') Sj*aAwj*otfiw = y'yw
(fe)v
(ft)
yw
(ft)
yw
Thus iii') (fe)x = (k)yw
From (iv), we get:
iv') (A' - p\ lg(a'0')) * (,4 - 0, lg(a0)).
Thus (i') through (v') satisfy our lemma.
□
The following theorem will be extremely useful in studying the class of
LR(0) languages. It is an inductive version of the definition of an LR(k) grammar.
Theorem 13.2.2 {Extended LR(kj theorem) Suppose G = {V, 2, P, S) is an
LR(k) grammar and there exist aGK*;;c1,;c2,wG2*, such that
ii) S=>wx2
iii) ™Xl = (fe)x2
iv) x2 ¥= A, k > 0, or k = 0 and there exists no x G 2* such that &c is a
sentential form of G with a handle whose second component is 1 ;t
then v) S j* ox2 ^" wx2.
' In most cases, we will use the fact that x2 ¥= A. The other possibilities will be useful
later on and in the problems.
13.2 LR(k) GRAMMARS 507
/Voo/We assume, for the sake of contradiction, that (i), (ii), (iii), and (iv)
hold, but not (v). Suppose axi j* wx\ is a derivation of n steps, where n > 1, by the
(unique) derivation
«*! = anxl^an_lxl^ ...^axxx = wxx
with a( G V*, for 1 < / < n. Let m be the number of steps in the derivation S j* hw2 ,
and let r = min(/rz, «).
Now, suppose that the last r steps of the derivation S^> wx2 are
for some a; G V*, for 1 < / < r.
Claim There exists some £ < r such that ag ¥= ae;c2.
Proof By contradiction. Suppose ag = asx2 for all £ < r.
CASE 1. r<n. Then ar'=arx2=S. Thus ar = S and x2 = A. Since
(fe)x! = (fe)x2, we must have k = 0 or x i = A. If x i = A, then S =*■ S, which contradicts
the fact that G is LR(k). Therefore, & = 0. However, we know that ar+1jc! j*
cvti = 5xi. The handle of Sx\ has second component 1, contradicting (iv).
CASE 2. r = n. Again ar' = a^. We have S =jfar' = arx2 = anx2 = ooc2 ??
wx2. But this is (v), which is assumed to be false. Thus, we have a contradiction and
the claim is established.
Now let m be the smallest positive integer satisfying our claim. Clearly, m > 1,
since a[ = wx2 = ai*2.
Now, we know that there exist a, a', (?jGF*;l,i,6A'andy, z £2*
such that
0 s§amXi = aAyxx gofiyxx =am-1x1
ii) s^am =a'A'zj>a'fl'z = ain_l =am_lx2 =o$yx2
using the fact that a^j = am_1x2 from our minimality assumption about m.
Now let 7 = ajl We get:
i) S^aAyxl ^ ot^yx^ = yyxi
ii) Sj>a'A'z j* a'fi'z = yyx2
Now <fe)jci = (fe)x2 implies (fe)j>*i = (k)yx2 ■ Since G is Lfl(fc), we have
(A - ft lg(aj3)) = (J' - j3', lg(6'j3')).
From (ii) a^, = a 'A'z, and, using the equality of handles, we have j3 = p,A =A , and
thus a' = a and z-yx2. Thus a!m =aA~yx2 =amx2. But this contradicts our
assumption that a'm =£ amx2. D
Now we must turn to relating A2 to the family of LR(0) languages. This will
involve a detailed study of derivation trees and canonical cross sections. The reader
may wish to reread the definitions given in the problems of Section 1.6. Our next
lemma relates the canonical cross sections to the left part of a tree.
508 LR(k) GRAMMARS AND LANGUAGES
Lemma 13.2.4 Let T be a grammatical tree of some grammar, (n)r the left
part of 7 for some n >0,and % = (xlt.. . ,x^,yi,.. . ,ym) a canonical cross section
in T with exactly the nodes xx,... ,xk in (n)7\ Then 17 = (*i ,...,*&) is a canonical
cross section in (n)7\
Proof The argument is an induction on the level h of the cross section if.
Basis. The case when h = 0 is immediate, since if = 17 = (x0) where x0 is the
common root of T and (n)7\
Inductive step. Assume the lemma true for canonical cross sections of level
h > 0. Let % have level h + 1 and let if' be the (unique) canonical cross section of level
h in T. Using the inductive hypothesis, let 17' be the canonical cross section in (n)T
which consists of all the nodes of if' which are in (n)7\ Now, to obtain if from if' we
need the rightmost internal (with respect to T) node, say x, in if'. There are two cases.
If x is not in (rt>T, then none of its descendants is in (n)r and 17 = 17'. Hence, 17 is a
canonical cross section in (n)7\ On the other hand, if x is in (rt>T, then it is the
rightmost internal node not only in £' (with respect to T) but also in r\' (with respect to
(ri>T) and, by the definition of canonical cross section, we conclude that r\ is a
canonical cross section in (n)r. D
The next lemma is, in a certain sense, a converse of the previous lemma.
Lemma 13.2.5 Let T be a grammatical tree of some grammar and let (n)rbe
the left part of 7 for some n > 0. Let 17 = (xi,... ,xk) be a canonical cross section in
MT and let ^j,.. .,ym be all the leaves in T which are right of xk; that is,xfe L^i L
• • -\-ym. Then the sequence % = (xi,... ,xk,yi,... ,ym) is a canonical cross
section in T.
Proof Again the argument is an induction, this time on the level h of canonical
cross section 17.
Basis. h = 0. Let x0 be the root of MT (and of T). Then 17 = (x0) and the
only possibility for % is if = 17 = (x0). Hence, if is a canonical cross section (of level 0)
inT.
Inductive step. Assume the lemma true for canonical cross sections of level
h > 0. Under the same notation as in Lemma 13.2.4, let 17 = (xi,..., xk) be of level
h + 1 and let 17' = (x[,... ,x'k') be the (unique) canonical cross section of level h in
(n)r. By the induction hypothesis the sequence if' = (x[,... ,x'k, yjt...,ym) for
some / > 1 is a canonical cross section in 7\ Since none of the nodes yt (/ <i<m) is
an internal node in T we can conclude* from the definition that if = (xx,... ,xk,
yi. • • ■.ym) is a canonical cross section in T. □
* We need only use the following observation: If (xj, ..., xp,..., xm) is a canonical
cross section where xp+1,... , xm are leaves and if x[,. .., x'q are all the leaves in the
subtree below xp> then (xj,.. ., xp_x, x\,. .., x'q, xp+1,. .. , xm) is a canonical
cross section.
13.2 LR(k) GRAMMARS 509
We are now prepared to relate A2 and LR(0).
Theorem 13.2.3 Any reduced strict deterministic grammar is also an LR(0)
grammar.
Proof Let G = {V, 2, P, S) be a reduced strict deterministic grammar. First
observe that S j> S cannot occur in P since that would contradict the Corollary to
Theorem 11.4.3. Now, following Definition 13.2.1, assume that, for some aG V*,
w, w'G 2*,p, p' GP and ri >0, (p,lg(a)) and (p', n') are handles of aw and aw',
respectively. We want to prove that these two handles are identical. Informally
summarized, we shall prove this equivalence by first showing that each of the two
handles appears in a certain position in a left part of a given derivation tree, and
second, using the left-part theorem, that this left part is unique.
Since G is reduced, there is some u G 2 * such that a j? u. Let T, T' be two
ti
derivation trees of G corresponding to derivations
Sjfaw^uw and S^ocw'^uw'.
ti ti ti ti
Since G is unambiguous (cf. Corollary 1 after Theorem 11.8.1), each of the two trees
is unique. Moreover, since aw and aw' are canonical sentential forms (by Definition
13.2.1, this is a necessary condition for a sentential form to have a handle), there are
canonical cross sections ^ in T and ifl in T' such that A(ifi) = aw and A(ifi) = aw';
each canonical cross section is also unique in its respective tree (cf. Problem 7 of
Section 11.6). We shall study these cross sections in detail (Fig. 13.2). Assume %x is
of level h (in T) and %[ of level h' (in T'). The existence of handles implies the
existence of a canonical cross section if0 of level A — 1 in T and another canonical cross
section ifo of level h' — 1 in T'. Corresponding to the definition of canonical cross
section, let us write, for 1 < k < m,
£0 = (xi,...,xfe,...,xm)> (13.2.1)
A T
(n + i)T / J \
^3—o-
u w
FIG. 13.2
510 LR(k) GRAMMARS AND LANGUAGES
and, forr> 1,
£j = (x1,...,xk^1,y1,. ..,yr,xk+1,. ..,xm), (13.2.2)
where
X(JCi)---X(xfe_1)X0'1)---X0;r) = 7, X(xfe+1)---X(JCm) = w.
Similarly, for & and 1 <k'<m', (13.2.3)
& = (pc'i,... ,Xk',. .. ,x'm'), (13.2.4)
and for if J andr'S* 1,
%\ = (x\,...,x'h^x,y[,...,y'r\x'h\x,...,x'm'). (13.2.5)
In (13.2.1) and (13.2.4), xh and x'k< are the rightmost internal nodes in if0 and ifo,
respectively.
Next we shall apply the Left-Part Theorem to T and T'. Assume first that
w#A. Let n = lg(«) and let z be the (n + l)st terminal node in T; that is, X(z) = (1)w.
From (11.2.3), we can see that z appears both in if0 and ifi or, more specifically,
z = xq for some £ > k. We have
w/Hr) = « = (n)HT'),
and the left-part property of the derivation trees of G yields the existence of a
structural isomorphism/: <"-1>7,->•<"',■1>7,' and,moreover, for any* in T,
x\lz implies \{x) = X(/Qc)), (13.2.6)
and for z itself, X(z) = X(/(z)) = (1V. (13.2.7)
Define
t?o = (*!,. ..,xfe,...,z),
1?! = (JC1)...)JCfe_1)^1)...)^r)JCfe + 1)...,z).
(Note that xh ¥=z, but xfe+1 = z is possible.) By Lemma 13.2.4, t/0 and t/i are
canonical cross sections in ("+1)r. Because canonical cross sections are invariant under
structural isomorphism, the following are canonical cross sections in ("+1)7,r (cf. Fig.
13.2).
/too) = (/(*i),.-.,/(*fe),...,/(z)),
/(t?i) = (/(*i), . • • ,/C«fc-i),/CVi), • • • ,/0v), • • • ,/(*))•
Extending /(t/0) and /(t/j) by all the leaves in T' on the right of/(z) and using
Lemma 13.2.5, we obtain two canonical cross sections £0' and ifi' of T'. Now, by
(13.2.6) and (13.2.7), X(ifJ') = aw' = X(ifJ) and, since G is unambiguous, we have that
ifi' = £i by Problem 8 of Section 11.6.
Now yx,... ,yr in (13.2.2) are the immediate descendants of xk in T (and
thus in <"+1>r) and therefore, using the structural isomorphism ("+1)7^ ("+1)7^
f(ji), ■ ■ ■ ,/0v) are the immediate descendants of f(xk) in <n+1>7'' (and, since
f(xk)[lf(z), this is also true in T'). Moreover, f(xk)is the rightmost internal node
in /(t?0) and hence in if0'. Consequently, ifo has level h' — 1, which is possible only if
£o = %'o (cf. Problem 6(b) of Section 1.6). Therefore in (13.2.4) and (13.2.5), we have
k' = k, r =r, x'h> = f(xh), and y[ = /()>,-) for /= 1,... ,r. Using (13.2.6), we
conclude thatp' =p andlg(a) = k—\ + r = k' — 1 +r' =n'.
It remains to verify the case w = A. In that case T=T' by the Left-Part
Theorem and the result is an immediate consequence of Problem 8 of Section 1.6. □
13.2 LFHk) GRAMMARS 511
We are now in a position to prove a useful theorem. We shall show that every
A0 language has an LR(\) grammar. When we learn how to accept every LR(k)
language by a dpda and some other techniques, we shall have proved that A0 is
coextensive with the LR(k) languages.
One additional lemma is necessary.
Lemma 13.2.6. Let G be an LR(0) grammar of the form G = (KU{$},
2 U {$}, P, S) where P£ Nx (V* U V*$), L(G) £ S*$, and there is no derivation
Sf 5$ in G. Define another grammar G' = (V, 2, P', S) where P'=P1UP2,
i>! = {A -+P\A^pinPmdpe V*},
P2 = {A+P\A^P$inP}.
Then G' is an LR(1) grammar and L(G')$ = L(G).
Proof Assume, without loss of generality, that G is reduced. Clearly, there is
no derivation S j* S in G' since S^S$ cannot occur in G. We shall examine the handles
in G'. Let h = (A -+ 0, /) be a handle of y in G' where A GN, j3, y G V*, and / > 0.
There are two possibilities. If A -*■ j3 is in P1, then h is also a handle of y or 7$ in G. On
the other hand, if A -*■ j3 is in P2, then (A -*■ j3$, / + 1) is a handle of 7$ in G.
Now, following Definition 13.2.1, let 7G V*, w, w' G S*, p, p' GP', i>0,
and let h = (p, lg(7)) and h' = (p', /') be handles of yw and 7W', respectively.
Moreover, let (1)w = (1)w'. We shall show that h=h'. Assume that p and p' have the form
A -*■ j3 and >4' ->• j3', respectively, where >4, >4' GTV, )3, j3' G K*. We can distinguish four
cases.
CASE 1. p, p' Gi3!. Then h is also a handle of 7wor tw$ in G and/T is also
a handle of yw' or7w'$ in G. In all cases we have h =h' by the LR(0) property of G.
CASE 2. p,p'eP2. Then A, = (^ -»• j3$, lg(7) + 1) is a handle of yw% in G
and h[ =(^4'->-j3'$, /+ 1) is a handle of 7w'$ in G. Here (1)w = (l)w' implies
(1)(w$) = (1)(w'$) and thus hi =h[ by the LR(0) property of G. Therefore, also,
h = h'.
We shall see that the remaining two cases cannot occur. First, let us make the
following observation, which is a direct consequence of Definition 13.2.1. If h = (p,
lg(7)) is a handle of yw and if yw' is a canonical sentential form where w, w' G 2*,
then h is also a handle of 7w'. We proceed in our case analysis.
CASE 3. p&Pi, p'&P2. Then h is a handle of 71V or yw$ in G and
hi = (A' -► j3'$, i + 1) is a handle of yw'$ in G. Here yw'% is a canonical sentential
form in G (otherwise it could not have a handle) and thus h is also a handle of 7w'$
in G. Then, by the LR(0) property, h=h\. But this is not possible since $ does not
occur in j3.
CASE 4. p' GPi, pGP2. Then h' is a handle of 7w' or of 7w'$ and /i! =
(A ->• j3$, lg(7) + 1) is a handle of 7W$. The form of hi implies that w — A. Since
(1)w = (1)w', also w' = A. Now h' is a handle of 7$ (if it is a handle of 7, then it is also
512 Z_fl(fc) GRAMMARS AND LANGUAGES
a handle of 7$ since 7$ is a canonical sentential form). But also hi is a handle of 7$
and thus h' = h 1, which is again not possible.
We have proved that h = h' and therefore G' satisfies the LR{\) property.
The fact that L(G')$ = L(G) is immediate from the definition of C. □
We can now prove an important consequence of the previous result.
Theorem 13.2.4 Any deterministic language has an LR{\) grammar.
Proof Let L £ £* and L G A0. Then L$ G A2 and, by Theorem 11.5.3, there
exists a strict deterministic grammar G = (TU {$}, 2 U {$},i>, 5)such that L(G) = L%.
Using Theorem 11.4.1 and Problem 3 of Section 11.4, we may assume, without loss of
generality, that G is reduced and A-free (note that L(G) ¥= {A}). By Theorem 13.2.3, G
is LR(0). We shall check that G satisfies assumptions of Lemma 13.2.6. First,
P£ Nx {V* U V*%), or in other words, each production in Phas the form A -»-/3 or
A -+0$, where A GNand0G V*.For,if A -+0$5 where in P for some 5 =£A, the fact
that G is reduced and A-free would imply that u$vGL$ for some u, v G £* and v =£ A,
which is not possible. Second, S?>S$ is impossible in G, since that would contradict
the Corollary to Theorem 11.4.3 and the strict determinism of G. Now we can apply
Lemma 13.2.6 and obtain an LR(l) grammar G' such that L(G') = L. □
PROBLEMS
1 Is the following grammar LR(k) and, if so, what is the least k for which it
is true?
E-*E+T\T
T^-T*F\F
F^(E)\a
2 Let k > 0. Find a family of grammars Gk such that G& is not LR(k) but is
LR(k+ 1).
3 Show that the restriction against derivations of the form S^SinDefinition
13.2.1 is necessary to preserve the unambiguity of LR(k) grammars.
4 Another definition that has been proposed for LR(k) grammars in Aho and
Ullman [1972] is now given.
Definition Let k > 0 and G = (V, S, P, S) be a reduced context-free grammar.
Define the augmented grammar G' = (V', S, P', S'), where V' = V U {S'} and
P' = P U {S' -*■ S}, where S, a symbol not in V, is our new starting symbol. G is said to
be ALR(k) (augmented LR(k)) if and only if, in G',
For each w, w',* G £* ;7, a, a', 0,0'in F'*;^,^'G f'-S.if
i) S' => a4w g> a0w = 7w (That is, yw has handle U ~* P, lg(a0)))
and ii) S'ga'A'x jfa'p'x =yw! (That is, 7w' has handle U'-^',
lg(o'U')))
13.2 LR(k) GRAMMARS 513
and Hi) (fe)w = (feV
then iv) (A -» 0, lg(a0)) = (A1-* fi', lg(a'0')).
Show the following lemma.
Lemma Let G = (V, S, P, S) be a reduced context-free grammar. For each
k > 0, if G is ALR(k), then G is Z,/?(fc).
5 Prove the following partial converse of Problem 4.
Lemma Let G = (V, S, P, S) be a reduced context-free grammar. If G is
ZJ?(fc) for some k > 1, then G is ALR(k).
At this point, we know that the family of LR(k) languages and grammars is the same
for k > 1. Let us examine the case k = 0.
6 Prove the following result.
Lemma If G = (K, E, P, S) is LR(0) and S^Sw is impossible in G for any
wGS+,thenGis^Z-P.(0).
7 Prove the following lemma.
Lemma Let G = {V, 2, P, S) be an ^Z,i?(0) grammar. For any wGS*,
S ifSw is impossible in G.
8 Summarize the relationship between the families of ALR{k) and LR(k)
grammars and languages.
Now let us consider a different variation on the LR{k) definition.
Definition Let k > 0 and G = (V, S, P, S) be a reduced context-free grammar.
Define the %-augmented grammar G' = (V, £', P', S\ where K' = 7U{S', $},
S' = SU {$}, P' = P U {S' ^-S$}, where S' and $ are new symbols not in V. G is said
to be $LR(k) if and only if, in G ,
For each w, w', x G S* ; 7, a, a', 0, 0' in V'*, A, A' G JV', if
i) S1' =? aAw ^ a0w = yw (That is, yw has handle {A -+ 0, lg(a0)))
and ii) S'=>aVx^a'0';c=7w' (That is, yw' has handle U ' -+P\ lg (a '0')))
xi rv
and iii) (fe)w = (feV
then iv) {A -* 0, lg(a/3)) = (A ' ■* 0', lg(a'/3')).
9 Let G = (V, 2, P, S) be a $ZJ?(fc) grammar and fc > 0. Show that Sg> S
is impossible in G.
10 Let G = (F, £, P, S) be a reduced context-free grammar. Show that, for
each k > 0, if G is $LR(k), then G is ZJ?(fc).
11 Let G = (F, S, P, S) be a reduced context-free grammar. Show that, for
each k > 1, if G is Z,/?(fc), then G is $LR(k).
In order to work out the properties of the $LR(0) grammars, we need another
definition.
514 LR(k) GRAMMARS AND LANGUAGES
Definition Let G =(F, £, P, S) be a reduced context-free grammar. A
production p GP is pathological if:
i) there exists a T&N, w G £ *, such that
P = (7"-»>S)
and +
S^Tw^Sw
a ti
or ii) there exists an A G N, w G £ * such that
p = U ■* A)
and
12 Prove the following result.
S^S^wg'S'w
Lemma Let G = (F, £, P, S) be a reduced context-free grammar. Then G
has no pathological productions if and only if there exists no w G £* such that Sw is a
sentential form of G with a handle whose second component is 1.
13 Let G = (F, £, P, S) be a reduced context-free grammar. Show that G is
$LR(0) if and only if it is LR(0) and has no pathological productions.
14 Prove a theorem which relates the families of LR(k) and $LR(k)
grammars for all k > 0.
15 Prove a theorem which relates the families of %LR{k) and ALR(k)
grammars for all k > 0.
Finally, another variation of the LR condition is given.
Definition Let G = (V, S, P, S) be a reduced context-free grammar. Then G
is LLR{k) if and only if:
a) G is unambiguous, and
b) for all W[, w2, W3, w'3 G £*, ^4 GJV, if
i) S => wij4w3 => w»i W2W3
ii) S^wiWjWs and
iii) (fe)w3 = (fe)W3 then
iv) S=> wij4w3
16 Let G = (F, £, P, S) be a $LR(k) grammar for some k > 0. Show that G
is LLR(k).
17 Show that every LR(0) grammar is LLR{ 1).
18 Let G = (F, 2, P, S) be an LR{k) grammar, where k > 1. Show that G is
an LLR{k) grammar.
19 Show that, for any k > 0, there exists a grammar which is LLR(0) but not
LR(k).
20 Prove the following useful result.
Theorem Let G = (V, S, P, S) be a reduced context-free A-free grammar.
Then G is $Z,i?(fc) if and only if G is LLR(k).
13.3 CHARACTERIZATION OF LfHO) LANGUAGES 515
21 Prove the following lemma about canonical cross sections.
Lemma Let T be any tree and if a canonical cross section in T of level
h > 1. Let x, y be two nodes in £ such that x\l y and y is internal in T. There exists a
+
node z in Tsuch that zV x and zfy.
Now we introduce an interesting family of grammars which is closely
related to the LR grammars. In this family, the handle is uniquely determined by
looking ahead k characters and looking behind £ characters.
Definition Let G = (V, 2, P, S) be a grammar with no derivations of the
form S ^S. Let C, k > 0. Then G is called a BRC($., k) grammar (bounded right
context) if the following condition holds for all a,a',0G V*;w, w'G2*;.4 GiV;p'GP
and i' > lg(a'j3). If (A -»■ 0, lg(a|3)) and (p', /') are handles of aQw and a'/3w',
respectively, and if a(fi) = a'(fi) and (fe)w = (fe)w', then p' has the form A -*■ 0 and /' = lg(aj3).
22 Prove the following useful result.
Theorem Every strict deterministic grammar G is equivalent to some strict
deterministic BRC(C, 0) grammar G' for some S. > 0. (#wf. Let G = (7, S, P, S) be a
strict deterministic grammar with partition n. Let 7r — S = {Zi, .. . , Xm } = X, where
X,- is a representative of the rth block.) Define G' = (V U X, 2, P', S) where
P' = {X.-^AIK^mjU^^ZjaU^aisinP^GZ,}.
Show that L(G') = L(G), G' is strict deterministic, and (with the help of the previous
problem) that G' is BRC(C, 0) where fi = max{lg(a)U -»-a is inP}.
13.3 CHARACTERIZATION OF LR(0) LANGUAGES
Our main purpose in this section is to prove an important and very useful
characterization theorem for LR(0) languages.
Theorem 13.3.1 (LR(0) language characterization theorem) Let L £ 2*. The
following four statements are equivalent.
a) L is an LR(0) language.
b) LSl 2* is a deterministic context-free language and for all xG2+; w,
y G2*,if wGL, wx GI, and_y GZ-, thenyx GL.
c) There exists a dpda A - (Q, 2, T, 5, <y0, Z0, F), where F = {qt} and there
exists Zf £ r such that
/. = r(^l,Zf) = T(A,r) = {wG2*|(flo,w,Z0)r^(flf,A,Zf)}.
d) There exist strict deterministic languages L0 and L\ such that Z- = L0L*.
Proof We first prove that (a) implies (b). Assume that G = (V, 2,P, S) is an
ZJ?(0) grammar and that L = L(G). Furthermore, suppose that, for w € 2*, x G 2+,
we have wGL and wx G/,. Thus, we have, in G, the derivations
516 LR(k) GRAMMARS AND LANGUAGES
and ii) S^wx
iii) (0)A = (0)x = A
and iv) x =£ A.
By the extended LR(0) theorem (13.2.3), we get
v) S=>Sxfwx
Now we assume that, for some y G £*, we have y &L. Thus, we have S^y.
Derivation (v) gives us „ +
Sj>Sxtyx
Thusyx GL, which completes the proof that (a) implies (b).
We now prove that (b) implies (c). This is fhe.most involved part of the proof
of this theorem, since several machine constructions are involved. We begin by
considering the degeneratet languages that obey (b), namely 0 and {A}. We then consider
the prefix-free languages that satisfy (b). We next consider the languages that satisfy
(b) that are not prefix-free.
Suppose L = 0. Let A - ({q0,qfl 2, {Zt\ 0, q0,Zf, {<?,}), where q0 i=qt.
Clearly, T(A, Zf) = 0. Suppose L = {A}. Let A=({qt}, Z, {Zt}, 0, qt, Zu {qf}).
Clearly, T(A,Zt) = {A}.
Now, we shall operate under the assumption that L is not degenerate. We
know that there exists a dpda A =(Q, 2,r,8,q0,Z0,F) such that L = T(A) since L
is deterministic. We wish to modify A so that we obtain a new dpda such that L is
accepted by a new machine with only Zt on the pushdown. Our first step is to add a
new "bottom of stack" marker to our machine. We let
A' = (Q',Z,r',8',qi,Zb,F'),
where
Q = Q u {<7o}, where q'0 is a new state not in Q,
r' = T U {Zb}, where Zb is a new symbol not in T,
F' = F.
Define 5' as follows:
i) ForaU^GC,aGS,ZGr,let
S'(q,a,Z) = 5(q,a,Z).
ii) Also let
8'(qo,A,Zb) = (q0,ZbZ0).
Clearly, T(A')=T(A).
We now choose any xG£* such that xGmin(Z<). Since Z-^0, clearly,
min(L) ¥= 0. We shall now consider two cases. The first case will correspond to the
strict deterministic languages. Observe carefully, however, that this does not follow
directly from the statement of this case. Our construction will be much simpler in this
case, than in Case 2, where our language is not prefix-free.
' A language L is said to be degenerate if L = 0 or L = {A}.
13.3 CHARACTERIZATION OF Lff(O) LANGUAGES 517
CASE 1. Choose any x G 2 * such that x G min(L). For all y G 2\ xy $ L.
Claim L is strict deterministic.
Proof Assume, for the sake of contradiction, that L is not strict deterministic.
Then there exist w6E*,y6E* such that w GZ, and wy GZ, since L is not prefix-
free. Since x GL,xy GZ.,by (b). But this contradicts the supposition for Case 1,giving
us a contradiction. Thus L is strict deterministic.
We shall construct a machine that simulates the machine A' until a final state
of A' is reached. It then erases the stack until a new bottom of stack marker is reached,
and then goes to a special final state and puts the special accept symbol on the
pushdown. We let
A" = (G",S,r",5",^,Z6)F"),
where
Q" = Q',
V" = r'u{Zf}, where Zf is a new symbol not in T', our special
acceptance stack symbol,
n i
qo = qo,
F" = {qt\
and 5 " is obtained from 5' as follows:
i) For4G£'-F',aG2A,ZGr,let5"(4,a,Z) = b\q,a,Z).
ii) ForallflGF',ZGr'-Z6,welet
S"(q,A,Z) = (q,A).
iii) For q G F\ we let
8"(q,A,Zb) = (qt,Zt).
These cases have the following significance.
i) For nonfinal states, behave the same as A' behaves.
ii) When A" reaches a final configuration for A', erase the stack until:
iii) The bottom marker is reached. Then go to the final configuration by
replacing the bottom marker with the special accept symbol on the
pushdown.
Since L is strict deterministic, we define no move for this configuration, making it a
"dead configuration." Clearly,
T(A",T") = T(A",Zt) = T(A') = T(A) = L.
We now consider Case 2.
CASE 2. Let x G S* be any string such that x G min(L). For some y G £+,
xy GL. In this case, our machine cannot go to a dead configuration after reaching an
accepting configuration. We shall construct a new machine ,4", which, after accepting
518 LR(k) GRAMMARS AND LANGUAGES
any string by T(A ", Zf), will pretend that it is, in fact, x that it has just accepted. Our
first claim shows us how our machine will pretend that it has just accepted x. Our
claim concerns the behavior of A' under the assumption of Case 2.
Claim There exists aq GQ',aG(r')*,Zer', such that, for our chosenx,
(c/o,x,Zb)\^(q,A,ZbaZ),
where for some a G S, 5 '(q, a, Z) is defined.
Proof This follows directly from the hypothesis of Case 2.
We now define A " in terms of A' = (Q', 2, T', 5', q'0, Zb, F'). We let
A" = (G",S,r",5",^',Z6,F"),
where
Q" = Q' U{i7f}, where qt is a new symbol not in Q'.
r" = r' U {Zf}, whereZf is anew symbol not in r'(Zf will be our
special acceptance stack symbol),
Qo = Qo,
F" = {qt}.
We now define 5" as follows:
i) Forall^GF',ZGr'-Z6,welet
8"(q,A,Z) = for, A),
ii) Forall^GF'
a) 8"(q,A,Zb) = (quZt),
b) 8"(q,A,Zt) = (qf,Zj).
iii) 5 "(qt, A, Zf) = (qt,ZtaZ) where aZ is defined in the previous Claim,
iv) ForaUaGS,ZGr'-Zf,^G(2',aGr*,if
8\q,a,Z) = (q,a)
then
8"(qf,a,Z) = fo,a)
with q as defined in the previous Claim (note that 5 '(q, A, Z) = 0, since
,4' is deterministic).
v) Forflree'-.F\aezA,zer\<7'ee\ae(r')*,if
8\q,a,Z) = fo',a)
then let
S"(q,a,Z) = fo',a).
The sets of added rules have the following significance:
1 When an ^'-accepting configuration is reached, the stack is erased until the
bottom marker is reached.
2 When the bottom marker is reached, we go into an A "-accepting
configuration.
13.3 CHARACTERIZATION OF LfHO) LANGUAGES 519
3 The machine pretends that x has just been accepted and so adjusts its
stack.
4 The machine proceeds under the assumption that it is in fact x that has just
been accepted.
5 Otherwise,,4" proceeds as A'.
We must now show that A " is a dpda such that L = T(A ", Zf) = T(A ", r").
We leave to the reader the task of showing that A " is deterministic.
Next we must show that
L = T{A) = T(A') = T{A",Y") = T(A",Zt) = L".
First, we show that L" £ L. We assume that for some w G 2*, we have w&L". Since
w G L", we know that in A " we have
{qo,w,Zb)^r{qt,KZt).
By the determinism of A", there exist w2,..., w„ G 2+, u>i G 2 *, « > 1, where
w = Wi w2 • • • wn such that
(qo, w, ••• w„,Zb)HL(<7f,w2 •••w„,Zf) H1- •• j^fa,, A,Zf),
where our machine passes through (7f in only designated ID's. Since, in A ", we have
(qo,wuZb) \^(qt,A,Zt).
Thus W! G L(,4"). Also in A', for some a G (T')* ,q&F', we have
07o,Wi,Z„) f^fa, A,Z„a).
Thusw! Gr(,4') = /,.
Also, in A ", for 2 < / < n, we have
^ ,„ (flf,w,-,Zf) ]r(qt,A,Zt).
Thus in ,4 we have _ +
(flf>Wi,Zf) h(flf,w,-,ZfaZ) pfa,, A,Zf).
Thus, in ,4', for some q G F', 0 G (r')*, we have
foWj.ZjOZ) ^(qr.A.ZftjS),
since we have assumed that A " only passes through qt at the designated ID's, since
A" could get to the (qt, A, Zf) configuration only if A', the machine A" is emulating,
passed through a final state after reading w,-. We know that, in A',
(q'o,xwuZb) \^(q,wi,ZbuZ).
Thus xWieT(A')=L.
We now show, by induction on i, that w — Wj • • • wt G r(,4') = L, for / < n,
where Wj G 2 * and vv(- G 2+ for 2 < / < «.
5axj'x. n = 1. We have shown that wt GL.
520 LR(k) GRAMMARS AND LANGUAGES
Induction step. Suppose Wi •••w(GL. Now x&L and xwi+1 GI; thus,
since we are assuming that characterization (b) for LR(0) languages holds, we have
Wi ••• WjWf+i G L. It is thus clear that w = Wi • • • w„ G Z..
We next show that L = T(A') £ L". Assume for some wG£* that w&L.
Now, we know there exist w2,... , wn G £+; wi &l,*;n> l,w = Wi ■ ■ ■ wn, such
that Wi • • • Wj G L for all i such that 1 < / < n, and no other prefixes of w are in Z..
Now consider any i such that 2 < i < n.
Claim xWj-GZ,.
Proof Since W\ ■••wMGL,Wi • • • u>; GZ., and* GL, we knowxw,- GZ..
Therefore, in ,4' for some q G F', a G (r ')*,
(qi,xwh Z„) f- (?, w,, Z„aZ) F1 fa, A,Z„a).
In ,4 we get +
(qt, wt, Zf) p (qt, A, Zf).
Also, since W\ G Z,, we know that in A ",
fao\w,,Zb) f^fo.A.Z,).
Thus in ,4 we have
(^o, vvj •• -Wn.Z,,) FL(<7f,w2 •••w„,Zf) F1-- • \-(qt,A,Zf).
Thus w = w, • • • w„ G TC4", Zf) = /,".
By the construction of A ", we see that T(A ", Zf) = T(A ", V"). This
completes the proof that (b) implies (c).
To help prove (c) implies (d), we first show that (c) implies (b). Assume there
exists a dpda A = (Q, X,F, 8,q0, Z, F), where F = {q^ and there exists Zf G r such
that L = T(A, Zf) = T(A, T). Clearly, L G A i. By Theorem 11.5.1, L G A0. Suppose
that forx £S*;wj GS*, we have w£L,wx GZ.,and_y GZ-.Then we have
(qo,wx,Z0)\^(qt,x,Zt)\^(qt,A,Zt)
and t
m r (q0,y,Z0)f-(qt,A,Zt).
Therefore + t
(q0,yx,Z0) f-(qf,x,Zf)YL(qf,A,Zf).
Thusyx GZ.. This completes the proof that (c) implies (b).
We now prove that (c) implies (d). We assume that there exists a dpda A = (Q,
Z,r,8,q0,Z0,F), where F = {qf}and L = T(A, V) = T(A,Zf) for some Zf G V. Let
L0 = min(Z.). By Problem 11.3.5, L0 is deterministic. By the definition of min,Z,0 is
prefix-free. Thus, by Theorem 11.5.5, Z-o is strict deterministic. We now consider two
cases, when L = L0 and when L =£L0.
CASE 1. L =L0. Since L0 is strict deterministic, L = Z.o(0)*.
CASE 2. Z-^Z-o- Since L=tL0, there exist x GS*, z G£+ such fhatxGZ.
and xz&L. Let V = {y G 2* \xy GZ.}. We shall show that Z.' is deterministic, and
that L = L0L'.
13.3 CHARACTERIZATION OF LR(0) LANGUAGES 521
We now construct a dpda to accept L'. Let A' = (Q, S, I\ 8, <7f, Zf, {<7f}),
where ,4 = (2, S, I\ 8,170, Z0, F) was previously defined. Clearly, A' is deterministic.
Claim L = L0L'.
Proof We first show that Z, E L0L'. Suppose that, for some w G S*, u> €Z-.
Then, for some w0, vvx G S *, w = w0Wi, where w0 G L0 = min(Z,).
Ifwi = A, clearly, Wi GZ,';thus wGZ.0Z,'.
Suppose Wi =£ A. Since w0 GL, woWi GZ,, and x GZ,, we knowxwi GZ, by
characterization (b) of LR(0) languages. Recall that we are assuming (c), and (c)
implies (b). Thus Wi GZ,'.
Conversely, we show that L0L' <~ L.
Suppose that, for some w G £ *, w6Z0£'.Then, for some w0,Wi G £ *, we
have w = w0Wi, where w0 EL0 and Wi GZ.'. Since u>i GZ,', weknowxwi GZ,. Since
xGL, xwi GZ-, and w0 &L, we know w = u'ovv1 GZ-, by characterization (b) of
LR(0) languages. Thus Z-0Z-i 9 Z-, and therefore we see that L = LqL'.
Now, let Z-! = min(Z-' — {A}). Clearly, Z-i is strict deterministic, since L' is
deterministic.
Claim L' =L\.
We first show that L' £ L*. For some wG £*, assume that u>GZ-'. Suppose
w = A. Then, clearly, w€Z{. Assume w G £+. Then there exist n > 1, w,- G £+, for
1 < i < n, where w = Wi • • • vv„ such that in machine A',
(,qf,Wi ■ ■■w„,Zt) \*-(qt,w2 ■ ■■w„,Zt) ^(qt,w3 ■ ■ ■ w„,Zt) \^- ■ ■ F^faf, A,Zf),
where these are the only instances in which the machine A' goes through state qt.
Thus,for Ki<n, +
(qf,W;,Zf) p(qrf)A,Zf).
Thus wt G Li and hence w G L*.
We now show that L* £ /,'. For some we 2*, assume w€i{. If w = A,
clearly, wGL', by definition of L'. Assume w =£A. Since wGZ-f, there exist n~>\,
Wj-GS* such that wt GZ- for 1 <*' <«, where w = u>i • • -w„. We now have, in A',
(qt,wl • ■ ■ wn, Zt) f^faf, w2 • • • w„, Zf) h*~ • • • \^{qt, A. Zf).
This gives us that
w = Wx • • • wn GZ,'.
Therefore,
L' = L\.
Thus, we have L = L0L* with L0, Z-i G A2. This completes our proof that (c) implies
(d).
Finally, we show that (d) implies (a). We assume that
L = LqZ-i where Z-0,Z-i GA2.
522 LR(k) GRAMMARS AND LANGUAGES
We first consider the degenerate case. Suppose L0 = 0. Then L = 0 and clearly is an
LR(0) language. Suppose L t = 0 or {A}. Then L =L0. Since L0 is a strict deterministic
language, L must be an LR(0) language by Theorem 13.2.4.
Now, we handle the nondegenerate cases. We assume that
Lo,£i*0, £i*{A}-
Since Lt is a strict deterministic language, there exist strict deterministic, thus LR(0),
grammars Gt = (Vt, S,-, Pt, 5,) such that Lt =L(Gt), for i = 0, 1, with N0 n JV, = 0.
Let G = (V, S, />, 5), where F=F0UF1U{5}, Sn {K0 U K,}=0,
P = P0VPi U (5 -+55!, 5 -+ 50}, S = S0 U Si. Qearly, Z,(G) = L, since G lays down
one word of L0 followed by a series of strings of any length of words of L i. We need
only show that G is LR(Q). Since Lx =t {A}, and Lx G A2, we know A^ Z-i, by the
Corollary to Theorem 11.4.2.
We assume now, for the sake of contradiction, that G is not an LR(0)
grammar. Then, by Lemma 13.2.3,
i) There exist w, w'.x GS*;7, y',a, a', 0,0' G V*;A,A' GN, such that:
ii) 5jf a/lu>if a0w = 7W
iii) St>ol'A 'x t> a'0'x = y'x = yw'
iv) <°>u, = »V = A
where v) (A ■*0, lg(a0)) #(/!'-► 0', lg(a'0'))
and vi) lg(a'0')>lg(T).
We now expand derivations (ii) and (iii). For some yi, ■ ■ ■ ,y„,y[,... ,y„ £
Z+;y0,y'o GS*,n,w>0, (ii) gives us
S%SS1=>SyngSS1yn=>Syn_lyn=>Sy1 ■■■yn^S0yi •■•ynfyoyi •••J',,
where a/tw j? a0w are two consecutive canonical sentential forms in this derivation.
ti
(iii) gives us
S^SS1^Sy'm^SS1y^l§Sy^ly^^Sy[ ■■■y'm^S0y[ ■--y'mfy'*y[ ---y'm
where a'A 'x j* a'0'x are two consecutive canonical sentential forms in this derivation.
The productions in G come from either P0, Plt or from our two new
productions. We thus now consider two cases, namely, (1)7 = 5 and (1)7 =£ 5. In the first
case we will be working on a reduction in Po or on a new production; in the second
case, we will be working on a reduction in Pi, or on a new production.
CASE 1. (1)7 = 5. We now have two subcases, which will turn out to represent
a production in P0 or a new production.
CASE 1(a). Suppose (2)7 = 55i. Then we know that, for some SGV*, we
have 5i ^Si5. But, since Ly is strict deterministic, we must have S\ j*Si by the
Corollary to Theorem 11.4.3, since strict deterministic grammars cannot be left-
recursive. Then 7 = SSl and
C4+0,lg(a0)) = (A'+p'Ma'p')) = (5 + 55,, 2).
13.3 CHARACTERIZATION OF LR(O) LANGUAGES 523
But this is a contradiction of (v).
CASE 1(b). (2)7^55l We have, for i such that -l<*'<«-2, a,,
0, eV*,Wl GZ*,A,Al G7V,
Sjf SSrfn-i ■ ■ ■ yng S<MiW,.y„_.- ■ ■ ■ yn = aAwgaftw = yw
= Sa^lWlyn.i---yn
Also, for/such that- \<j<m-2,u[,&[ 6F*,x, &V*,A',A[ G7V,
]?SSiym-j • • • ym ]t foiAiXrfm-j ■■■ym = aAxgafrx = yw
= Sa[$[xiy'm-r--y'm
Now, for 71 £F*, let 7! = 7<te(?>~1>) that is, y without the leading S. Then, for some
w[ G S *, since lg(a'0') > lg(7),
5i if a^.Wi ^aiBiWi = 7iWi
Si jta[A[xi jta[f}[xi — y\w[
Qearly, (0)u>i = (0)w[. Thus, since d is LR(0), we have
(A, ^01,lg(a,01)) = (ylj -*Ui,lg(a;Ui)).
Now A=AU A'=A[, 0 = 0i, 0' = 0i, and a, =5a, a,'=5a'. Thus, (.4-► 0,
lg(a0)) = (-4' -+0', lg(a'0')). contradicting (v).
CASE 2. (1)7 =£ 5. Again, we have two subcases.
Case 2(a). Suppose (1)7 = 50. We know that, for some 5 G V£, we have
So |f S05. But, since L0 is strict deterministic, as before, then we must have S0 it So-
Thus, we have y = S0, and
(,4+0,lg(a0)) = (A'+p'Ma'p')) = (5^50,1),
which contradicts (v).
CASE 2(b). Suppose wy=tS0. Then, for some a,, 0iGF*, w, GS*,
,41 G TV, we have
5^50yi •••j'njfcMiW,.y1 •••yn5>ai0ivv1y1 •••>>„
Also, for some a(, 0| G V*,xx &!,* ,A[ GW, we have
S^-S0yi ■■■y„galAlxlyl ■ ■ ■ymga^lxlyl ■ ■ ■ yn
We have, for some w[ G £ *, since lg(aj 01) > lg(a! 0!).
Sai?<XiAtWt z>atBtWt = ywi
o^<Mi*i ^ai0i*i = ywi
Qearly, (0)w, = (0)w{. Since G0 is Z,tf(0), we have
04, ^01,lg(a,01)) = (>!,' -*Ui,Ig(«i'Ui')),
giving us a contradiction of (v). □
524 LR(k) GRAMMARS AND LANGUAGES
Condition (b) of the LR(0) characterization theorem will prove most useful
in checking whether or not a language is LR(0). The following corollary to
characterization (b) will be particularly useful.
Corollary Suppose L£ £* is an LR(Q) language. For u>G£*, xG£+, if
w G Z. and wx EL, then wxx GI.
As an example of the utility of this corollary, consider the language
L = {A, a). We could prove directly that L is not an LR(0) language, but the use of the
corollary makes it even easier. Choose w = A and x = a. If L were LR(0), then aa
would have to be in L, which is a contradiction.
The next theorem shows us that the factorization of an LR(Q) language, of
the form given in the LR(0) language-characterization theorem, is unique.
Recall that a language L £ S* is degenerate if L = 0 or L = {A}.
Theorem 13.3.2 {Unique Factorization of LR(0) Languages) Let L = L0L*
be a nonempty LR(0) language, where Z-o, Z-i are strict deterministic languages. If
there are two strict deterministic languages L'0, L[ such that L = L'0(L[)*, then
L0 = L'0 and either
0 L, =L[
or ii) Li,L[ are degenerate.
Proof For the sake of a contradiction, we assume that there exist strict
deterministic languages L0, Z-o, Lx, L[ such that L0L* = L'oL[*, where L0 ^Lq
orLx ¥=L[ andZ-i andZ-J are not degenerate.
CASE 1 L0¥=Lq. We assume, without loss of generality, that there exists
some x E S* such thatx£Z,J but x £ L0.This is possible since L ¥= 0 implies L0 =£0.
Since x EL'o, we have x EL'0(L[)*. Thus,* GZ. and hence x EL0L*. Then, for some
x0 G£*, xi G£+, we have x - x0Xi, where x0 EL0 and*i GZ,*. Sincex0 GZ,0, we
know x0EL0L*; therefore, x0EL. Now, we know that x0 EL'0(L[)*. Clearly
x0 £ Lq, since x0 is a proper prefix of x, x EL'o, and L'0 is prefix-free. Thus, there
exist some x2 £S*,Jt3 G£+, such thatx2 EL0,x3 GZ.J*,wherex0 -x2x3. We also
know that x =x0xl = x2(x3Xi)EL'0. Since x3 ¥= A, L0 is not prefix-free. But this
is a contradiction.
CASE 2 Z-o =Z.;. We have L=L0L* = L0L[*. We assume for the sake of
contradiction, that L\ ¥=L{ and we do not have L\ and L[ degenerate. Without loss
of generality, there exists a y G £+ such that y EL[, but y^Lx. Since Z.0 =£ 0, there
exists some x€E* such that xEL0. Clearly, xyEL0L[*, giving us xyGL0L*.
Therefore, xy =x'y', where x'EL0 and y' EL*. Clearly, x must be a prefix of x' or
x' a prefix of x. Since Z.0 is prefix-free, we must have x =x', and thus y - y'.
Therefore, we see that y EL*. Now, since y<fcLl,we know there exist yoET,* ,yx G £+
such thaty =yoy\, where y0 GZ-!. It follows that xy0 EL and, hence, xy0 EL0L'i*.
Thus jcy0 =Jc'yo where x'EL0 and j>o G/.1*. Again, since L0 is prefix-free, we
13.4 LRSTYLE PARSERS 525
have x =x' and_y0 = yi>, giving us y0 GL[*. But we know_y0 ^ ^1, since, if it were,
we would have y0GL[ and yoyi GZ.J, where yx =£ A, contradicting the fact that
L\ is prefix-free. Now, since y0GL[*, there exist _y2G£*, y3 GX+ such that
yo =72^3, wherey2 GL[. Now we have_y =y0yi = J^C^i)GZ.|. But.y3yi =£A0,
and j>2 G Z, J. But this contradicts the fact that L J is prefix-free. □
We conclude this section with an example of the use of the LR(0)
characterization theorem to show us immediately that a given language which is not strict
deterministic is LR(0). We shall show that the semi-Dyck language is contained in the
class of LR(0) languages.
Theorem 13.3.3 Let Dr£ S* be the semi-Dyck language for some r> 1.
Then Dr is an LR(0) language, but not a strict deterministic language.
Proof Dr = D is deterministic, by Theorem 10.4.1. Suppose that, for x G £+,
w, y G £*, we have wGD, wx GD, and y GD. By Proposition 10.4.2(e), we have
x GD. Since y GD and x GD, we have yx GD, by Proposition 10.4.2(a). By (b) of
the LR(Q) language characterization theorem, D is an LR(0) language. Since a.\a\ GD
andtfitfitfitfi GD,D\%xvo\ strict deterministic, since it is not prefix-free. □
PROBLEMS
All of these problems refer to concepts introduced in the problems of Section
13.2.
1 Show that L is an ALR(O) language if and only if L is strict deterministic.
2 Show that L is a %LR(0) language if and only if L is an LR(0) language.
3 Show that an LR(0) grammar can have at most one pathological
production.
4 Work out the closure properties for the LR(0) languages, as was done for
the families Af) where 0 < i < 2, in Problems 3 through 47 of Section 11.5.
5 Prove the following interesting result.
Theorem There is an algorithm to decide whether a deterministic language is
LR(0) if and only if there is an algorithm to decide whether two deterministic context-
free languages are equal.
Hint for the only if direction: Let L\, L2 £ S* be two deterministic context-free
languages, and let C\, c2, C3, $ be four new symbols not in S. Consider the following
L = c,(Z,,$)*C3(Z.2$)* Uc2(Z,2$)*c3(Z,,$)*.
6 Prove that there is an algorithm to decide whether a A! language isLR(O)
if and only if there is an algorithm to decide whether two deterministic context-free
languages are equal.
13.4 LRSTYLE PARSERS
A parser that has many desirable practical features will now be described. The
operation will be precisely specified and will depend on some special stack symbols,
526 LR(k) GRAMMARS AND LANGUAGES
which are traditionally called "tables." In subsequent subsections, the existence of
such tables will be derived for LR(k) grammars.
An "LR-style parser" has the following structure: There will be an input tape,
an output tape, a pushdown stack, and some mechanism for "looking ahead" k
characters on the input string. The pushdown symbols are alternately symbols of the
grammar being parsed and certain tables. The action of the parser will be determined
by the table at the top of the pushdown stack and the lookahead symbols. The table
on top of the pushdown stack represents all the productions upon which the device
may be working at a given stage of the parse. These tables determine whether to shift
or reduce with the given lookahead, and if we are to reduce, what to "pop" from the
top of the pushdown, and a choice of nonterminals to which we reduce. After we have
popped the given number of symbols from the pushdown, the table appearing on top
of the pushdown will uniquely tell us what reduction to make. The suitable
nonterminal will then be placed on top of the pushdown, followed by the new appropriate
table; and the number of the production being reduced by will be printed on the
output tape (see Fig. 13.3).
The parser will accept a string by halting in a special accept state with the
bottom-of-stack table on the pushdown, and with empty input tape. The parser will
reject strings by halting in a special error state. Such a parser operates "properly" on
a given grammar if, for every string over the alphabet over which the grammar is
defined, the parser halts. Moreover, it must halt in the error state given a string not
generated by the grammar. For a string generated by the grammar, the parser must
halt in the accept state with the reversed canonical derivation of the string on the
output tape.
The device shown in Fig. 13.3 is a type of deterministic pushdown
"transducer" whose moves depend on the tables that are supplied.
The simplest way to formalize the parser is to begin with an instantaneous
description (or ID). An ID of the parser is written as (7, z, p), where
Input tape
Pushdown stack
Tables (are shaded)
Symbols in V
-»indicates head direction
FIG. 13.3 An LR style parser.
13.4 Lfl-STYLE PARSERS 527
i) z £ 2* is the contents of the (as yet unread) input.
ii) 7 G To(VT)* is the contents of the pushdown store. The "top" is
assumed to be at the right. T0 is a special "initial table."
iii) p &P* is the contents of the output tape, the partial parse.
The initial ID is defined to be (T0, z, A). In addition, there are two special ID's error
and accept.
We are now ready to give a more formal description of the functions that
control the parser.
Definition 13.4.1 Let G = (V, 2, P, S) be a reduced context-free grammar
andfc^O.Let J7~ be a set of tables.t Define two functions /andg as follows:
1 /, the parsing action function, is a mapt from S~y> 2^ into {shift, error}
U {reduces|ttGP};
2 g, the goto function, is a map from J^x V into y U {error}.
Example Assume k = 1. Let G be the grammar whose numbered productions
are shown below:
1.
2.
3.
4.
5.
S-*aAd
S-*bAB
A -*cA
A -*c
B-*d
For this grammar, y= {T0,.
Table 13.4.1.
TABLE 13.4.1 The / and g functions*
T9} and the functions / and g are given in
7\)
Ti
T2
T3
T*
Ts
To
T,
T&
T9
* A
/
a b c
shift
shift
shift
shift
shift
l blank denotes error.
d A
reduce 4
shift
shift
reduce 3
reduce 1
reduce 2
reduce 5
a
Ti
b
T2
g
c d
T3
T3
T3
T6
T9
A
T4
Ts
Ta
B
Tn
S
t The construction of tables that may be used by such a parser will be given later.
* Recall that XkA = {x <E 2* |lg(x) < k}.
528 LR(k) GRAMMARS AND LANGUAGES
It is often convenient to express the goto function by a directed graph in
which each node represents a table or "state". In our running example, we have the
following diagram:
The goto graph for our parser
Now we shall indicate how the parsing device functions, by defining a move
relation, \~, on ID's. The device is a pushdown-like automaton whose move will
depend deterministically on its "state" (here, there is only one state), the first ^letters
of the input, and the topmost stack symbol.
Definition Suppose the parser is in ID (yT, z,p), where TG Sr, z G 2*, and
Pep*.
1 If f(T, (fe)z) = shift then
a) if z = A then (7 T, z, p) \-error
b) if z ¥= A then we write z = iz',662,z'G2*. Moreover,
(bi)lfg(T, b) = error then (yT, bz', p) herror.
(b2) If g(T, b) * error then (yT, bz',p) \-(yTbg(T, b),z', p).
That is, in step (b2), we shift the next character of the input onto the stack and also
stack the table determined by the topmost symbol and the input.
2 If f(T, (fe)z) = reduce it where it is A ->0 then we wish to "pop" 2 lg(j3)
symbols. When we do so, let T' be the table we "uncover." More precisely,
define yT= y'T'y", where lgfr") = 2 lg(/3).
a) If T = T0, S =A,and z = A,then
(yT, z, p) \-(T0, A, pir) h accept.
b) If g(T', A) = error then (yT, z, p) herror.
c) If neither case (a) nor case (b) holds, then
(y'T'y",z,p)\-(y'T'Ag(T',A),pir).
In case 2(c), we remove the coded form of 0, and replace it by its immediate ancestor
A. The appropriate table is computed and stacked above A; the production used is
added to the output.
13.4 L/?-STYLE PARSERS 529
3 If f(T, (fe)z) = error, then (yT, z, p) herror.
Finally, let f— (f— ) be the (reflexive) transitive closure of f—.
The action of our sample parser on the following examples may be helpful.
Let us use the parser on the string bccd, which is in L(G).
(T0, bccd, A) h (T0bT2, ccd, A)
\-(T0bT2cT3, cd, A)
\-(T0bT2cT3cT3, d, A)
\-(T0bT2cT3ATs,d,4)
\-(T0bT2AT5,d, 43)
\-(T0bT2AT5dT9, A, 43)
\-(J0bT2ATsBTn, A, 435)
h(r0,A,4352)
\— accept
Since we have reached accept, a rightmost derivation of bccd is given by 2534,
as can be seen by the following tree in Fig. 13.4.
Now, let us try to use the parser on a nonsentence, say acb. We have the
computation
(T0,acb, A)\-(T0aTucb, A)
\-(T0aTlCT3,b,A)
\— error
because f(T3, b) = error.
This kind of parser has a number of attractive features, but there is a great
deal that we do not know. Where did these tables come from? When and how can they
be constructed? We shall learn how to construct such tables shortly. To do so, certain
functions will be helpful.
Definition Let G = (V, 2, P, S) be a reduced context-free grammar. For a,
pev*, define
530 LR{k) GRAMMARS AND LANGUAGES
FIRSTfe(a) = {xG?,\\a^y for some y G 2* andx = my\
and ■ *
FOLLOWfe(0) = {jc G T,hK \S => dfa for some 0 G V* and x G FIRSTS)}.
In our running example, it is easy to compute FIRST! and FOLLOWi
although, in general, it takes some effort. Finding efficient algorithms for these tasks is
left for the problems at the end of this section.
Example FIRSTi (A) = {c} and FIRSTS) = {d}
FOLLOW! 04) = {d}
in our running example.
PROBLEMS
1 Let G = (V, 2, P, S) be a reduced context-free grammar such that L(G) # 0.
Show that:
a) foraG V*,
FIRSTfe(a) = {x£S\la^ for some^ G 2* andx = (feV);
b)for^GAT,
FOLLOWfe(^) = {x &?,\\S => aAy where y G 2 * and x = my}.
2 Derive an efficient algorithm for the computation of FIRSTfe(a) and
FOLLOWfe(a). Is it easier to determine whether some string belongs to these sets than
to generate the sets?
3 The following function appears in the literature on Li? parsing. For aG V*,
define
EFFfe(a) = {w|w G FIRSTfe(a) and there is a derivation
aJ?0i?wx where (!J=Awx for alM GAf}.
Interpret the definition of EFF in terms of generation trees and then give an efficient
algorithm for computing EFF.
13. 5 CONSTRUCTING SETS OF LR(k) ITEMS
We now begin to construct certain sets which will be necessary in forming
the tables that drive our parser.
Definition Let G — (V, 2, P, S) be a reduced context-free grammar, and let
k>0. An LR(k) item for G is a pair (A ->0! • 02) u) where A GN, 0i, 02 G V*,
u G FOLLOWS), and A -> 0!02 is in P.
The intuition behind this definition is clear. It means that, in forming our tree,
we have matched up to the dot and our lookahead is u. The situation is illustrated in
Fig. 13.5.
An algorithm is now given for constructing sets of items. This construction
will build sets that are reminiscent of the entries in the recognition matrices of Section
12.6.
13.5
CONSTRUCTING SETS OF Lft(k) ITEMS
531
Algorithm 13.5.1
Input G = (V, 2, P, 5), a reduced context-free grammar, k> 0, and 7 G F*.
Output We define the output to be a set Vk(y)J
Method
1 To construct Vk(A),
a) If, for some a G V*, S -> a is in P, add (S -> • a, A) to Ffe(A).
b)If, for some .4, BGN, a, j3G K*. «G2*, we have (A -*-Ba, u) in
Ffe(A), andfi -> 0 is in P, then, for all jc such thatt x G FIRSTfe(ow), add
(5->-0,x)toFfe(A).
c) Repeat (b) until nothing new can be added to Vk(A).
2 To construct Vk (Xi • • • X,) for some i > 1, Xj G V for 1</< i.
a) If, for some a, 0 G F*,,4 GJV,wG2*,
(yl-► a-JT^, ii) is in Kfc(JT! •••X,-1),
then add
(A -*• aX, • (3, ii) to V&Xi • • • Xt).
b)If, for some A, BGN, a, 0, 6 G F\ h G2*, U ->a-50, h) has been
placed in Ffe(X! • • • X,) and fi -> 6 is in P, then, for all x G FIRSTfe(0H),
addCtf-fr'S.^toKfcCA'i ■ ■ ■ Xt).
c) Repeat (b) until nothing new can be added to Vk (A^ • • • X;).
The algorithm clearly halts, since, for given k and G, only a finite number of
LR(k) items exist.
We now work out an example, starting with the running example of Section
13.4.
First, we compute /
\(S-*-aAd,A)
Vi(A):
((S -> • bAB, A)
* Note that we write V^Qy) when the grammar in question is clear, as an abbreviation
for V0ik(j).
t FIRST is defined in Section 13.4.
532 LR(k) GRAMMARS AND LANGUAGES
We obtain Vi{a) by applying part 2(a) of Algorithm 13.5.1 to ^(A). This adds
(S-*a-Ad, A)
to Vi(a), and allows us to use part 2(b), to add
(A -> • cA, d)
and
(A->-c,d)
This completes the construction of Vi(a). The reader should check that:
(A -> c • A, d)
(A-*c- ,d)
Vi (ac) is
(A -*• • cA, d)
(A-*-c, d)
We now study the set of items generated by Algorithm 13.5.1. Our first
lemma shows how having an item in a set of items corresponds to "moving across the
righthand side of a production."
Lemma 13.5.1 Let G = (V, 2, P, S) be a reduced context-free grammar and
k > 0. Then, for A GAT, a, fa, fa, y G V*, u G FOLLOWfe(,4),
(,4 -> • fa fa, u) G Ffe (a), where aft = 7
if and only if
(y4-► Pi •&,«)€ Kfc(7).
Proof Assume that
(A-*'fafa,u)eVk(a).
We use induction on lg(|3i).
fiasw. Let lg(0!) = 0. Clearly,
(A->fa-fa,u) = (A->-fa,u)eVk(a) = ^(afr).
Induction step. Assume that the lemma is true in this direction for
lg03O = £ > O.We show that it is true for lg(0i) = £ + 1. Let fa = $[X, where fa' G V*,
16 V. By our induction hypothesis,
(y4-► Pi •*&,«)€ Kfc(o0l).
Therefore,^->/3;X-/32,«)GFfe(a0;Ar)= Ffe(a01) by 2(a) of Algorithm 13.5.1.
Now assume, conversely, that {A -*■ fa • fa, u)GVk(y). Again induct on
lg(0i).
Basis. lg(/3i) = 0. Clearly,
(A->'fafa,u) = (A-*-fa,u)eVk(y) = Vh(a),
where a0! = 7.
13.5 CONSTRUCTING SETS OF LRik) ITEMS 533
Induction step. Assume that the lemma is true in this direction for
lg(0O = £>O. We show that it is true for lg(/31) = K+l. Let 0! = &\X, where
P[GV*,XGV. Since 0|X¥= A, clearly the item (A ->0! • 02, «) had to be added to
Vk(y) in Step 2(a) of Algorithm 13.5.1. Thus, for some y' G V* such that y = y'X, we
haVC (A-*t$[-X(i2,u)eVk(y').
Now, by our induction hypothesis, there exists some a£K* such that (A -*■ • 0i02 >")
G Vk{a), where a0| = 7'. Therefore, a$[X = a^ = y'X = 7. □
The following theorem shows that if, for one item in a set of items, 0i
precedes the dot, and for another item in this set of items, ft precedes the dot, then
either 0i is a suffix of/3( or 0j is a suffix of 0!.
Theorem 13.5.1 Let G = (V, 2, P, S) be a reduced context-free grammar and
k>0. Then, if ,4, ,4'GJV, 7, ft, ft' G F+, Ig0?l)>lg0?i), ft, 02GF*, wG
FOLLOWfeU), w' G FOLLOW,^'), and
(,4->ft-ft,w)
O4'->0i-02,w')
are in Ffe(7), then there exists an a G V* such that ft = aft.
iVoo/ Since (,4 ->ft • ft, w)G Ffe(7), by Lemma 13.5.1, there exists some
7' G V* such that 7 = 7'ft and
U->-ftft,w)isinFfe(7').
Since (A' -> ft" -j32, w') is in Vk(y), by Lemma 13.5.1, there exists some 7" G V* such
that 7 = 7 "01 and
G4'->-0i02,w')isinFfe(7").
Since 7'0! =7"0i andlg(0i)>lg(ft), we let
a = (teOS.Vigtf,)^
as shown in Fig. 13.6. Clearly, 0l = a0l4 □
Since there are only a finite number of possible LR(k) items for any fixed
grammar, there can be only a finite number of sets of items. Therefore, to compute
the collection of distinct sets of items, we could systematically compute Vk(A),
Vk(y) for all 7 such that lg(7) = 1, Vk{y) for all 7 such that lg(7) =2 Vk{y) for
all 7 such that lg(7) = £,... This algorithm will eventually terminate, since, for some
£, we will eventually get no new sets of items. The algorithm we have just described is
somewhat wasteful, since it will necessitate computing many empty sets of items. One
can avoid computing many such sets of items by building up only the collection of
nonempty sets of items.
, 1
y 1 a
y"
Pi
Pi
FIG. 13.6
534 LR{k) GRAMMARS AND LANGUAGES
Algorithm 13.5.2
Input Reduced context-free grammar G = (V, 2,P, S) and k > 0.
Output We define the output to be^g = {Vk(7) # 0I7 G F* }.
Method Initially,^ is empty.
1 If Fft(A) ^=0, place Vk(A) mYk. The set Vk(A) is initially unmarked.
2 If a set of LR(k) items Ffe(7) inJ^ is unmarked,
a) Compute Vk(yX) for each XG K. If Vk(yX) #0, add Ffe(7X) to ^
as an unmarked set of items if it is not already there.
b)Mark Vk(y).
3 Repeat Step (2) until all sets of items in^ are marked.
Again, the algorithm is guaranteed to halt since we will eventually get no new
sets of items.
We now use Algorithm 13.5.2 to compute all of the sets of items for our
running example.
Example There are ten nonempty sets of items which are as follows:
\(S-*-bAB,A)j
((S-*a-Ad,A)}
= \(A-*-cA,d)
{(A-*-c,d) J
((S-*b-AB,A)}
= I (A -> • cA, d) I
{(A-*'C,d) J
Vi(ac) =
Vi(aA) =
VdbA) =
ViiaAd) =
ViibAB) =
V^acA) =
Vt(bAd) =
(A-*cA,d)
(A->c-,d)
(A-*-cA,d)
(A-*-c,d)
{(S->aA-d,A)}
(S-*bA-B,A)\
(B-*-d,A) ]
{(S->aAd-,A)}
{(S -> bAB •, A)}
{(A->cA-,d)}
{(B->d-,A)}
13.5 CONSTRUCTING SETS OF LR(k) ITEMS 535
(S — a-Ad,A)
(A--cA,d)
(A--c,d)
(S-a-4-rf,A)
(S-a4d-,A)
(S — -aAd,K)
(S — -bAB,A)
(A~-c-A,d)
(A - c; d)
(A^-cA,d)
(A - .c, d)
(A~*cA-,d)
(S — b'AB,A)
(A~--cA,d)
(A — -c, d)
FIG. 13.7
It is an aid to our intuition to regard each set of items as a "state," and to
draw a state graph. A state Vk(y) leads to state Vk(yX) under input XG V. In our
running example, we have the graph shown in Fig. 13.7. The reader should compare
Fig. 13.7 with the goto graph in Section 13.4.
We now must show that Algorithm 13.5.2 generates the desired output.
Theorem 13.5.2 Let G = (V, 2, P, 5) be a reduced, context-free grammar
and k > 0. Let J?k be the collection of sets of items for G computed by Algorithm
13.5.2. Then
^k = {Vk(.y)*t>\yev*}.
Proof We first show that ^k £ {Vk (7) # 017 G V* }. Suppose / G ^h. Then,
for some 7GF*, /= Vk(y). By Algorithm 13.5.2, clearly, Kfc(7)#0, and thus
ie{Vk(y)¥=$\yeV*l Therefore, ^kc {Vk(y)¥=0\yGV*}.
Conversely, we must show that {Vk(y)¥=0\yev*}Q Sfh. Assume that
/ = Vk(y) G {Vk(y') *017' G V*}. We use induction on lgfr).
Basis. lg(7) = 0. Then 7= A. Since I&{Vk(y)^0\yeV*}, Ffe(A)=£0.
By (1) of Algorithm 13.5.2, /G ^fe.
Induction step. Assume that the theorem in this direction is true for
lg(7)</. We shall show that it is true for lg(7) = i+ 1. Let 7 = y'X, where X&V.
536 LR{k) GRAMMARS AND LANGUAGES
Now, we know that Vk(y) # 0. From Algorithm 13.5.1, we know that Vk(y') # 0, for
otherwise we would have Vk(y) = 0. By our induction hypothesis, Vk(y')G Sfh.
Therefore, (Ffe(7)^0l7GF*}c ^fe. D
In order to fully understand the use of these items, we must study certain
important prefixes that occur naturally.
Definition Let G = (V, 2, P, S) be a context-free grammar, y G V* is said to
be a viable prefix of G is there exist a, 0 G F*, A G TV, w G 2 *, such that
and 7 is a prefix of a/3.
We will often also use the following concept.
Definition Let G = {V, 2, P, 5) be a context-free grammar. 7G F* is a
valid prefix of G if there exist a, 0!, |32 G F*, ^ G TV, w G 2 *, such that
and 7 = 0:0!.
Thus, a valid prefix is a viable prefix that "includes all of the left context."
A valid prefix corresponds to input that has already been read and reduced by the
parser.
Viable and valid prefixes turn out to be, in fact, equivalent concepts. The
following lemma will be useful in showing the equivalence of these two concepts. The
idea of the proof is that, if we look to some earlier steps in the derivation, viable
prefixes turn out to be valid prefixes.
Lemma 13.5.2 Let G = (F, 2, P, S) be a reduced context-free grammar.
Assume that, for some A G N, a, 0,7,6 G F*, we have
S^cxAw^aBw = 76
where 7 is a proper prefix of a. Then there exist A' G.N, a', ji' G V*, w' G 2*, such
that * , , , , +
St* a'A 'w' 7? a'B'w' j? aBw
It It It
where, for some 0| G V*, fa G F+, we have that /3' = 0l02 and 7 = a'/3j.
Furthermore, if 5 G 2F*, then (1)02 G 2, and if 5 G 2*, we have (fe)5 G FIRSTfe(02w') for any
k>0.
Proof Since S £ a(3w and 7 is a proper prefix of a, we must have a # A.
Therefore +
S^aAw
It
Therefore, there exist n > 2, a,- G F* for 0 < i < n, such that
S = ao^a! £"•• 'jtan-i = otAw^a&w = an
Intuitively, let i be the smallest integer such that a,- and all succeeding
canonical sentential forms in the above derivation have 7 as a prefix. Formally, define
13.5 CONSTRUCTING SETS OF LR{k) ITEMS 537
y
a
Pi
PjAjWj
P'l
P'
w'
FIG. 13.8
i to be the least integer such that for all /', n — 1 >/' > i, there exist Aj G N, 0,- € V*,
vv,-G2*, and a,- = yfyAjWj. Qearly, such an integer exists since n — \>\ and
an_j = aAw, where lg(7) <lg(a). Since a,- = S is impossible, we see that i > 1.
Therefore, for some A' GN, a', 0' G V*, w' G 2*, we have
5j* <*,-_! = aU'w'^a'0'w' = 7/3^4,-w,- = a,- j* a4w j* a0w
By our minimality assumption, lg(7) > lg(a').
Now, since At is the rightmost variable in a'0'vv', we know that lg(yPiAi) <
lg(a'0'). Therefore, lg(7)<lg(a'0'). Thus, there exist 0[ e F*, 02 G K+, where
13' = 0l02 such that y = a'/3l. (See Fig. 13.8.)
Now assume that S G 2 F*. We shall show that (1)02 cannot be written in this
derivation. It will follow that (1)02 G 2. Since we have the rightmost derivation
702w' = 7M,-w,-^70i+i^,+iW,+1 ^ •••^70n-i^n-iW„_1 ^70n-i0vvn_1 = 76
and 0;- G F+ for all / such that n — 1 > / > /, we must have
u>pj = <Dft = (»A+1 =
= (1)ft,
(D6
Since (1)6 G 2, we have (1)02 G 2. If 5 G 2*, since we have 0jw' f- S, we must have
(fe)5G FIRSTfe(02w'). D
The following example illustrates the Lemma.
Example Consider the grammar whose productions are
S-*abA
Since
Sj>abA£abc
and a is a prefix ofabc, we have that a is a viable prefix. However, since
S^S^abA
and a is a prefix of abA, we have that a is a valid prefix. Furthermore, JGS and
mbc G FIRSTfe (bA) for any k > 0.
The following theorem shows that valid and viable prefixes are equivalent.
It will later prove extremely useful to go back and forth between these notions.
Theorem 13.5.3 Let G = (F, 2, P, S) be a reduced context-free grammar.
Then 7 G F* is a valid prefix of G if and only if 7 is a viable prefix of G.
538 LR{k) GRAMMARS AND LANGUAGES
Proof Assume that 7 G V* is a valid prefix of G. From the definitions it
follows that 7 is a viable prefix of G.
Conversely, assume that 7 G V* is a viable prefix of G. Then there exist
A GN,a,BG F*,w6S*, such that
S^aAw^-aBw
H it
and 7 is a prefix of aB.
CASE1. lg(7)>lg(a). Then, clearly, 7 is a valid prefix of G, by the
definition.
CASE 2. lg(7) < lg(a). If 7 = A, then, for some 6 G V*,
Thus A is a valid prefix of G.
Assume that 7 # A. By Lemma 13.5.2, we have, for some A' GN, a',B'G V*,
w'G2*,
Sz>aA w^apw
where, for some B[ G V*, 02 G F+, we have 0' = B[B2 and 7 = a'B[. Thus, 7 is a valid
prefix of G. □
The concept of a valid prefix leads to the corresponding notion of a valid
LR{k) item. A valid LR(k) item for some 7GF* specifies a production, and the
place in that production, at which one might be working, after reading input that has
been reduced to valid prefix 7.
Definition Let G — (V, 2, P, S) be a reduced context-free grammar and
k>0. For a, Blt B2 &V*, w, wG2*, A GN, G4->0i -B2,u) is a valid LR(k) item
for aBi if there exists a derivation in G such that
SgaAwjfoBtBiW
with w = (fe)w.
Example Again consider the sample grammar
S-*abA
A -*c
Since we have
StStabA
(S -* a • bA, A) is a valid LR(k) item for a for any k > 0.
Every valid LR(k) item for a string is an LR(k) item. Moreover, every valid
prefix has at least one corresponding valid LR(k) item, as the following theorem shows.
Theorem 13.5.4 Let G = (V, 2, P, S) be a reduced context-free grammar.
7 G F* is a valid (viable) prefix of G if and only if there is at least one valid LR(k)
item for 7.
13.5 CONSTRUCTING SETS OF LR(k) ITEMS 539
Proof The theorem follows directly from the definitions involved and
Theorem 13.5.3. □
We next show how the existence of a given production in a grammar
guarantees the existence of certain valid LR(k) items corresponding to that production.
Lemma 13.5.3 Let G = (V, 2, P, S) be a reduced context-free grammar.
Assume that, for some 0i, 02 G V*, A G.N, we have
A -> 0!02 in P and h G FOLLOWfeU).
Then, for some a G V*, (A -> 0! ■ 02,") is a valid £/?(£) item for a0!.
Proof By Problem 13.4.1, there exist a G F*, w G 2*, such that
SgaAwgaPifcw,
where h G FIRSTfe (w). Therefore, (,4 -> 0! • 02, h) is a valid Ltf(fc) item for a0!. □
Our ultimate goal in this section is to show that Algorithm 13.5.1 computes
the set of valid LR(k) items for any y G V*. However, we first must prove a result
which shows that, if some y G V* has a valid L.R(fc) item with A preceding the dot,
then there is another specified LR(k) item for y under most conditions.
Lemma 13.5.4 Let G — (V, 2, P, S) be a reduced context-free grammar and
fc>0. For a,0G V*,uGX*,A GN, (A-+-0, u) is a valid LR(k)item for a, where
either A =£S, u¥= A, or a ^ A if and only if there exists A', B0 E.N, 0j, 02 G F*,
h' G FOLLOWfe (,4') such that
1 (A' ->0| -.eo02,H') is a valid Lfl(fc) item for a. If a ¥= A, then 0l G F+
while, if a = A, thenw' = A and S =,4';
2 there exists an n>0, B-, GN, 6,G V* for KKn, with Bn -A such
that
Bo -*Bl8i
B\ -*B282
are inPand«GFIRSTfe(6„ •••S102h').
Proof We assume that there exist a, 0 G V*, A G TV, such that (.4 -> • 0, w) is a
valid LR(k) item for a, where A # S, « # A, or a =#= A. By definition, there exists a
wG 2* such that „
S^-c^4w^-a0w
where u = (fe)w.
Since either A # S,« # A, or a =#= A, we must have
S;f a^vvjf o0w
540 LR{k) GRAMMARS AND LANGUAGES
Therefore, there exist n > 2, a,- G V* for 0 < i < n — 1 such that
S = aog-a! ^-••^•a„_1 = aAw^-a&w
Now let /> 1 be the smallest integer such that there exist Aj&N, ft- G V*,
Wj G 2 * for all / such that n — l>j>i,'we have a,- = afijAjWj. Clearly, such an integer
exists since n — 1 > 1 and a„_t = a4w. Therefore, for some A' &N, a', 0' G F*,
w' G 2*, we have
S^-a,.! = aU'vv'j*a'0'w' = a^^jW,- = a; j*a4w j*a0w
By the minimality of i, lg(a) > lg(a'), provided a # A. If a = A, then a' = A and
i= 1.
Now, since At is the rightmost variable in a'0'vv', we know that Ig(a0,v4,) <
lg(a'0'). Therefore, lg(a)<lg(a'0'). Thus, there exist |3| G V*, fc'eT, where
0' = 0l02 and a = a'0j. (The situation is similart to Fig. 13.8.) Let u - (fe)w' and note
that u' G FOLLOWfe (A'). Thus (A' ->0l • 02',h') is a valid Ltf (fc) item for a. Moreover,
i)0!GF+ if a # A, and
ii) 4' = Sandw = w' = A ifa = A.
We now have „
a,- = a'0'w' = O0,>l,W,£-a0„_1,4„_1W„_1 = OtAw j> O0W
We see that BjAjGNV* for i </' < n — 1, for otherwise we would have (1)0;- G 2 for
i < / < n — 1. Therefore, (1)0„-i = (1)^4 G 2, which is a contradiction. It is necessary
to examine the sequence of derivations in which the variable immediately following a
is changed. We now choose i < i0 < ii < • • • < i6 = n — 1 such that 0,-. = A for
0 </' < £. We see, from our derivation, that At — (1)02. Therefore, for some B0 GN,
02 G V*, we have 02=5O02. We now consider the productions used in the steps
ai.^ai.+l forO</<£.
There exist 5,'. G V* for 0 </ < £ such that
is in P. Since we can write a,-.+1 = a0H.1.41-.+1w1-.+1, with ^ij+lAi.+l GNV*, we must
have w8',.eN. Therefore, there exist SJgK*, BjGN such'that b^Bfij for
0 </ < £. We also know that Bj — A^+l from our derivation. This gives us a sequence
of productions
Bo ~*^iSi
Bi ~*B282
5n->0
* Replace 02 in Fig. 13.8 by 02' and also 7 by a.
13.5
CONSTRUCTING SETS OF LR{k) ITEMS
541
From our derivation, we see that
u = (fe)wGFIRSTfe(5„ •••510»=FIRSTfe(5„ •••81p'2u').
Conversely, assume that there exist A', B0 EN, a, B[, & G V*, and u G
FOLLOWfe (A') such that (A' -> j3[ • B0Bi, «') is a valid LR(k) item for a, and there
exist n > 0, Bt G N, S; G F* for 1 < i < n, with fi„ = ,4, such that
B\ -*i?2§2
Bn~>B
areinPandwG FIRSTfe(5„ • • -b^W)-
By a definition of a valid LR(k) item, there exists a w'G2*, a'GF*,
such that a — a 'B [, and *
where u — (fe)w'.
Since u G FIRSTfe(6n • • • 61/32«') and G is reduced, there exists some w G 2*
such that
§n "" •Si&m'^vv where m = (fe)w
Now we have
■S^a'fllflo&w' = oS0/3>'
since a = a'B[. Because u — *V, we may write
w = u w
for some w" G 2*. Then the above derivation becomes
S£ aBoBiw' = oBqBiu'w" =>otB8n • • -SiB^u'w"
Since u G FIRSTfc(6„ • • • 61BW), it is easy to see that
S=>aB0B'iw"ffaBuw" = a$w
S=>a'B\B0BW%<*'B\Abn ■■■8lw'=>a'B'lAw^a'B'lBw
Therefore, (A -> • B,") is a valid LR(k) item for a. □
We are now ready to prove that Algorithm 13.5.1 computes sets of valid
LR(k) items.
Theorem 13.5.5 Let G = (F, 2, P, 5) be a reduced context-free grammar,
7 G V*, and k > 0. An item is in Ffc(7) after application of Algorithm 13.5.1 if and
only if the item is a valid LR(k) item for y.
Proof By induction on lg(7).
542 LR{k) GRAMMARS AND LANGUAGES
Basis. lg(7) = 0. Then 7 = A. Assume that there exist j3 G V*, A GN, u G 2a
such that (A -> • ft «) is in Ffc(A) after application of Algorithm 13.5.1.
CASE 1. Assume (A -> • ft h) is added to Vk(A) in Step 1(a). Then A = 5 and
h = A. Clearly, (5 -> • ft A) is a valid LR(fc) item for A.
CASE 2. Assume (A ->-ft h) is added to Fft(A) in Step 1(b). Then there
exist n > 0, £,- GN, 6,- G F* for 1< /' < «, with p2GV*,Bn=A such that
are in P and h GFIRSTfc(6n • • -S^). It follows that (S-*-B0p2, A) is added to
Ffe(A) in Step 1(a). By Lemma 13.5.4, (A -> • j3,h) is a valid Li?(fc) item for A.
Conversely, assume that (A -> • ft «) is a valid LR(fc) item for A. The case
structure given below is from Lemma 13.5.4. The symbol a comes from Lemma 13.5.4,
and a = A in the basis of the proof.
CASE 1. Assume A = S, u = A, and a = A. Then, clearly, (S-> • ft u) must
be added to Vk(A) in Step 1(a) of Algorithm 13.5.1.
CASE 2. Assume A¥=S, w=£A, or a=£A. By Lemma 13.5.4, there exist
B0 G N, fti G V* such that (S -> • B0j52, A) is a valid LR(k) item for a and there exist
ann>0,fi,G#,6;GF*for 1 </<n,withfi„ =A, such that
fii -*B2S2
Bn-*V
are in Pand h G FIRSTfc(6„ • • • Sjftz). Therefore (^ -> • ft w) will be placed in Ffc(A)in
Step 1(b) of Algorithm 13.5.1.
Induction step Assume that the theorem is true for lg(7) = /. We show that it
is true for lg(7) = / + 1. Consider some LR(k) item (A -* 0i • 02 »«) where A G TV, 0i,
02 £f',ue FOLLOWfc(,4). Two cases must be considered.
CASE 1. ft. #= A. Let j3x = P{X, where $[ G V*, XG V. We know, from the
definition of valid LR(k) items, that (A-*fii'P2, ") is a valid LR(k) item for 7 if
and only if (A -> 0i • Zfti, w) is a valid LR(k) item for 7', where 7 = 7'^. By our
induction hypothesis, (A -> j5\ 'Xp2, ") is a valid LR(k) item for 7' if and only if
13.5 CONSTRUCTING SETS OF LR{k) ITEMS 543
(A -*0j •XP2,u)eVk(y'). From Algorithm 13.5.1, it is clear that (A -»0j -X02,h)G
Ffc(7') if and only if (A -> 0! • 02, u) G Ffc(7). Thus, 04 -* 0, • 02, h) is a valid L/?(fc)
item for 7 if and only if (A ->0i •02,«)G Vk(y).
CASE 2. 0i = A. Assume that (A ->• 02, w) is a valid LR(k) item for 7.
Therefore, there exist A',B0 GJV,ai,02 G F*,0i G F+,H'GFOLLOWfc04') such that
O4'->0| -fio02, «') is a valid LR{k) item for 7 and an «>0, BtGN, SfG F* for
1 < 1 < n, with Bn= A, such that
i?i -*fi252
are inPandw G FIRSTfc(6„ • • • 6„02h')- By Case 1,
O4'->0;-fio02,")eFfc(7).
Therefore, {A -*■ • 02, u) is placed in Ffc(7), by Algorithm 13.5.1 in Step 2(b).
Conversely, assume that (A -> • 02, u) G Ffc(7). Then there exist A', B0 GN,
02 G V*, 0i G F+, u GFOLLOWfe04') such that 04' ->0i -B0&, u')GVk(y) and
there exist an n>0,B{GN, 6j;G F* for 1 <i<n,withfi„ = ,4, such that
B\ -*'fi252
5n-i ~*Bn8n
Bn->P
are in i» and u GFIRSTfc(6„ • • • Si02h'). By Case 1, (A' -»0| -fio02, "') is a valid
LR(fc) item for 7. Therefore, by Lemma 13.5.4, (A -*■ • 02, w) is a valid LR(fc) item for
7. □
The following definition is useful for dealing with the collection of sets of
items valid for the valid prefixes of a grammar.
Definition Let G = (F, 2, P, S) be a reduced context-free grammar and
let k > 0. Then the canonical collection of sets ofLR(k) items for G is defined as
{{i\i is a valid LR(k) item for 7)17 G V* is a valid prefix for G}.
We now use Algorithm 13.5.2 to get Vfc. We will now show that Algorithm
13.5.2 in fact produces the canonical collection of sets of LR(k) items for G.
Theorem 13.5.6 Let G = (F, 2, P, S) be a reduced context-free grammar,
k > 0. Then .Vfc = the canonical collection of sets of LR(k) items for G.
544 LR(k) GRAMMARS AND LANGUAGES
Proof By Theorem 13.5.2, S?k = {Vk(y) ¥=0\ye V*}. By Theorem 13.5.5,
Vk(y) =£0 if and only if y has at least one valid LR(k) item, and, by Theorem 13.5.4,
this is true if and only if 7 is a valid prefix. Therefore, yk = the canonical collection
of sets of LR(k) items for G.
PROBLEMS
1 Construct the canonical collection of sets of LR(k) items for the following
grammars:
a) k = OandS-*Sa\a
b)k = 1 and S-*aAc
A -*bAb\b
c) k = 0 and S -* aAc
A-*Abb\b
d)k= 1 and E-*E +T | T
T-> T* F\F
F-*(E)\a
2 Which of the grammars in Problem 1 are LR{k)1
3 There can be a large number of elements in 5^ •# even for a small LR(k)
grammar. Find an LR(0) grammar Gn of size which is polynomial in n and yet where
I J?o| is exponential in n.
13.6 CONSISTENCY AND PARSER CONSTRUCTION
The algorithms of the previous section may be applied to any context-free
grammar, but the results may not be useful in constructing parsers. In this section, we
shall introduce the important notion of consistency, which allows us to define parsers
from our collection of sets of items. Then it will be shown which grammars yield
parsers. It should not be a surprise to find that it is exactly the LR(k) grammars which
work.
In the parsers which were described in Section 13.4, all moves were made
deterministically. We hope to be able to use the sets Vk(y) as the tables on the stack.
In order to do so, these tables must satisfy certain conditions. For any move of our
parser:
1 There must never be a conflict between a reduce and a shift move.
2 When we have a reduce move, the reduction to be performed must be
uniquely determined.
This leads to the following definition.
Definition Let G = (V, 2, P, S) be a reduced, context-free grammar and let
k > 0. A collection £? of sets of LR(k) items for G is consistent if, for all / G S*, all
13.6 CONSISTENCY AND PARSER CONSTRUCTION 545
A, A' EN, allj3>j31,i32eF*> where (1)02 gW,and all a, 0 e 2A withh£FIRST*Qk?),
we have that
(A->P -,u)EI and (A' -»0, 'fa,v) EI imply that
(A'->^-^,v) = (A+P;u).
There are several things to note in this definition. The condition (1)02 &N
means that 02 = A or (1)02 E 2. The conclusion means that:
i) u = v
ii) A=A'
iii) 0, = 0 and 02 = A
Example Returning to our running example from Section 13.5, it is easy to
see that J?k is consistent. In fact, only the set
/
/ = Viiac) = •
(A
(A
(A
(A
■cA,d)
■c,d)
■ • cA, d)
• • c,d)
\
might cause concern. But the first item can cause no problem, since A EN. The third
and fourth cannot be inconsistent with the second because both the third and fourth
items have FIRSTi(02tf) = {c}and no conflict can exist.
Our next task is to characterize the class of grammars which produce
consistent grammars.
Theorem 13.6.1 Let G = (V, 2,P,S) be a reduced context-free grammar and
let k > 0. G is LR(k) if and only if the canonical collection of sets of LR(k) items for
G is consistent.
Proof Assume G is LR(k). Assume, for the sake of contradiction, that the
canonical collection of sets of LR(k) items for G, denoted by J^, is not consistent.
Then, for some IE S^, we have some A, B EN, 0, 0x,02 E V*,u,vEl,*, (1)02 £N,
u E FIRSTfc(02zO such that
(A-*P',u)EI and (B-*^ • p2,v)EI
where (A -*■ 0*, u) ¥= (B -> 0i • 02, v). By definition of /, there exist a, a", y E V*, w,
x E 2 * such that u = (fc)w, v = (fc)x and
5;? clAw j* a0w = yw
5^a"fix^a"0,02x
7(02*)
We are not yet ready to employ the LR(k)-ness of the grammar to force a
contradiction, since we must have 02 E 2* in order to use the LR(k) definition. We
therefore divide our proof into two cases, according to whether 02 E 2* or 02 ^ 2*.
546 LR{k) GRAMMARS AND LANGUAGES
CASE 1. 02 G 2 *. Now we have
(fc)(02x) = (fc)(02z>) = u
Since G is /,/?(£) we therefore have
(A -> 0, lg(«0)) = (B -> 0,02, lg(a"0!02)).
It follows that lg(a"0102) = lg(a0) = lg(7) = lg(a"01). Therefore 02 = A. Since
0 = 0i02, we have 0 = 0i. Also, v= (fc)x = (fc)(02x) = u. In addition, we have A = B.
Therefore
G4->0-,h) = (fl->0, .fo.p),
which contradicts our hypothesis.
CASE 2. 02 £ 2 *. We now rewrite 02 in a rightmost fashion until we have a
string of terminals. We know that there exists an x' G 2*, p GP+ such that 02 £x'
and u = ^x'x. Therefore we have
S=>yP2x§-y(x'x)
We consider the last step in this derivation, namely, there exist A' &N,
a'GF*,0',x"G2*suchthat
S=>yp2xf>ya'A'x"gya'p'x" = y(x'x)
Since (1)02 $N and 02#=A, clearly (1V = (1)02 G 2, and lg(7a'0') Mgfr). Since
G is LR(k), we now have
G4->0,lg(7)) = G4'->0',lg(7a'0'))
This is clearly a contradiction; thus the canonical collection of sets of LR(k) items for
G must be consistent.
Conversely, assume that Sf, the canonical collection of sets of LR(k) items
for G, is consistent. Assume, for the sake of contradiction, that G is not LR(k). Then,
by Lemma 13.2.3, there exist u, w, w',*G2*, 7, a, a', 0, 0' G V*, ,4, ,4'GAT such
that:
i) S;? aAw ;*• a0w = yw
tt ft
ii) 5g-aU'x^a'0'x = 7'x = 7w'
iii) «w = Ww' = „
iv) (A ->0, lg(«0)) *(A'->0', lg(a'0')), with
v) lg(a'/J')>lg(a0).
At this point, we know that if, in fact, lg(7) > lg(a'), then derivations (i) and
(ii) will give us items that will lead us to a contradiction. However, in the case where
lg(7)<lg(a'), we will have to examine an earlier step in the derivation of a'ji'x to
get our contradiction.
CASE 1. lg(a')<lg(7). Then, for some 0|,02GF*,0'=0|02 and7 = a'0i.
Let v = (fc)x Then (A -> 0 •, u) and (A' -> 0l • 02, v) are valid LR(k) items for 7 with
u = (fcV = (fc)(02x) = (fc)(02z>). Since we have consistency,
G4->0-,M) = {A'+e\-&,v).
13.6 CONSISTENCY AND PARSER CONSTRUCTION 547
a
P
a
P'
FIG. 13.9.
Therefore, A = A', &=&[,u=v and 02 = A. Since a/3 = a'0l = a'0, we have a = a'.
Therefore, (A -> 0, lg(a0)) = (A' -> 0', lg(a'0')), which contradicts (v).
CASE 2. lg(7) <lg(a'). We have the situation shown in Fig. 13.9.
By Lemma 13.5.2 there exist a",0" G V*, w" &H*,A" GN, such that
=f a ,4 w ^ a p w z>aB x = yw
ti K ti
where, for some $'l GV*, 02 G F+, we have 0"=0i'02\ h GFIRSTfc(0>") and
y = a"0{'. Since w' G 2*, (1)02 G 2+, from this production, we see that
G4"->02'02»
is a valid LR(k) item for 7 where »=(*V'and«6 FIRSTfc (02 z>). Since (A -> 0 •, u) is
also a valid LR(k) item for 7, we have
04 -><?•,«) = o4"->0;-02»
since Sf is consistent. Therefore, 02 = A. This, however, contradicts the
quantification on 02. Therefore, G must be LR(k). □
Corollary There is an algorithm which, if given a context-free grammar G and
a nonnegative integer k, decides whether or not G is LR(k).
Our next step is to build an LR parser from our sets S?k. The set of tables
that are necessary will consist of some new symbols to stand for the elements of S?k.
To be formal, define
jr= jrk = {T(J)\ 1 GVk),
where T(I) is a new symbol denoting/, ^is called the canonical collection ofLR(k)
tables for G. Next, we must define the /and g functions of the parser.
Definition Let G = (V, 2,P, S) be an LR(k) grammar and let k>0. Let
S~= JTh be the canonical collection of LR(k) tables for G and assume that S~ is
consistent. Define the parsing action function /and the goto function g as follows:
1 For each TG S~M\d «6S\, define
a) f(T, u) = shift if there is some0! G F*,02 G l,V* ,vG X\ and A GN
such that (A -> 0j • 02, v) G T and u G FIRSTfe (j32 v);
b) f(T, u) = reduce n if n is A -*j3 and (A ->0',«)isin T;
c) f{T, u) = error otherwise.
2 For each T= Vk(y) G S~m.d each ,4 G V, define
a)g(Vk(y),A) = Vk(yA)ifVk(yA)*k
b) g(Vk(y), A) = error otherwise.
548 LR{k) GRAMMARS AND LANGUAGES
It is a straightforward matter to prove the following lemma and the proof is
left for the exercises.
Lemma 13.6.1 The relations / and g defined in the previous definition
are well defined functions if S? is consistent.
Examples It is easy to see that the / and g functions in our running example
of Section 13.4 were constructed by employing this definition.
As another example, let k = 1 and G be given by
1.
2.
S-*aS
S-*a
The sets of items and the g function may be "read" from the graph in Fig. 13.10.
(S-*-aS,A)
(S—aS,A)
(S-a,A)
(S--aS,A)
(S-'fl,A)
(S-aS,A)
FIG. 13.10.
The /and g functions are given by the following table:
/
a
shift
shift
A
reduce 2
reduce 1
a
Tx
S
T2
Now our string of definitions and results are complete so that, given any
LR(k) grammar, we can use our algorithms to produce a consistent set of LR(k) tables
and an LR parser. However there is one more important task to accomplish. It must be
shown that this parser works correctly. This means that any string in the language is
accepted and, moreover, that any nonsentence is rejected in a finite time (i.e., the
parser halts). A detailed analysis of the actions of the parser on nonsentences is useful
for error recovery work.
13.6 CONSISTENCY AND PARSER CONSTRUCTION 549
We now show that, given a grammar G = (V, 2,P, S), the canonical LR(k)
parser for G does the following:
1. Given a string x £ L(G), the parser halts in the accept state and outputs
the parse for x in G.
2. Given a stringx ^ L(G), the parser halts in the error state.
The next theorem proves that our parser accepts strings in the language and
outputs the correct parse.
Theorem 13.6.2 Let G = (V, 2,P, S) be an LR(k) grammar, k > 0. Then, in
the canonical LR(k) parser for G with tables JT^, for all xGL(G), (T0, x, A) p
(To, A,p) [—accept, where S^ x.
Proof hit x&L(G). Then there exist n>0, a,-GK*, W;G2* for
0<i<n+ 1, p,-GP, Ai&N for 0</<n, a„+1 = An+l = A such that there is a
unique derivation of x in G,
5 = ao^oWo^-^oWo = axAxwx =* a^iW, =
<M2w2 J- •••£> a„0„w„ = a„+i^„+iw„+1 = x
Claim 1 For 0 < / < n, lg(a,-+1^,-+1) < lg(a,ft)-
Proof This is clear from the fact that ,4,+1 is the rightmost variable in a,-/3fw,-.
Claim 1 allows us to do the following: For the a,-ft, 0 < i < n, we order the
prefixes of the a,-j3j as follows:
Rown+1 a„+1^„+1,a„+1^„+1(1)w„+1 ,...,Wa»^i)(oB+1i4B+1wB+,)
Row n anAn< anAn(l )wn,... ,lg(0'»-i<J"-i)(cv4„w„)
Row 1 aiAi^xAi^^Wi ,.. .,alAlwl
Row 0 a0j40 = S
We index each row from zero and we associate the pair (C, ni) with the mth
element in row C.
Next, we impose a linear ordering on these elements, defined by the order in
which they have been listed, indexed from zero.
We now prepare for an induction proof, by defining SP, IP, and OP, which
stand for the stack part, input part, and output part, as follows:
For 0 < / < t, where t is the number of items ordered above, let
SP(i) = ith element in the ordering.
Assume that the pair (&,m) is associated with this element. Let SP(i) = ae,4g(m)wg.
550 LR(k) GRAMMARS AND LANGUAGES
Also let
IP(J) = We(^e)-m)
OP(j) = P„---Ps-
We now make a very strong induction hypothesis which gives us the condition
of every element of our parser at any given state of the parse.
Claim 2 After i steps, 0 < i < t, the configuration of the parser is
(T0X1 TiX2T2--- X$T$,y, p) where x = x'y for x , y G 2*, T, G S~h for 0 </ < s,
XjGVfor Kj<s,pGP* and
1 X, ■■■Xs = SP(i),
2y = IP(il
3 p = OP(i),
4 7>= 7X^(^i-•• A))) for K/<s.
/Voo/
fiasw. /' = 0. The initial ID of our parser is (x, T0, A). We see that
1 A = 5P(0),
2 y=x=IP(.0),
3 A=OP(0),and
4 Condition (4) is vacuously satisfied.
Induction step. Assume that, for i = r, (1), (2), (3), and (4)hold. Now assume
that i = r+ 1. After r moves, we have, by our induction hypothesis,
(7-0,x,A) f- (T0X1TlX2T2---XtT„y,p)
where x = x'y with x',y G 2*, 7} G J^fc for 0</<B, X, G F for K/<s, pGP*
with
1 *, ...*, = SP(r),
2 y = IP(r),
3 p = OP{r),
4 7) = 7XFfc(Jr, •••A»)forl</<s.
Assume that (£, w) is associated with element r. By definition, we have
SP(r) = <Me((mS)
//>(/•) = wj^lg("'e)-m),
OT^r) = p„---ps.
We now have two cases, one of which will amount to a shift move and the
other to a reduce move.
CASE 1. \g(SPQ-)) < lgfag-iftj-i). We know that
S => ae^ewe = afi_1j3fi_1wfi_1 = (SP(r))y
13.6
CONSISTENCY AND PARSER CONSTRUCTION
551
where SP(f) is a proper prefix of ae_i/3e_i. We claim that there exist A'&N, a,
0'GF*,w'G2*suchthat
S => a'A'w' =* a'P'w =*• afi_1j3fi_1wfi_1
where, for some 0', G V*, 0j G F+ we have 0' = 0i0i and SP(f) = a'0i. If 5P(r) is not
a proper prefix of ae_i, then this is immediate. Otherwise, it follows directly from
Lemma 13.5.2. Therefore, (A' -> 0i • 0i, (fcV) is a valid /,/?(&) item for SP(r).
Furthermore, by Lemma 13.5.2, (1)0i G 2 and (fc)y GFIRSTfc(02w').Itfollowsthat/Ts((fcV) =
shift. Clearly, ae,4g((m+1\vg) is a valid prefix of G. It follows from Lemma 13.6.1 that
the next move of our parser is well defined. Therefore
{ToXlTlX2T2---X.T„y,p)
Y-iT^T^Tr ■ ■XsTs(^y)(T(Vk(Xl ■ '■X™y))),y<My>-1\p).
Clearly,
1 X1---Xs(^y) = SP(r+\),
2 ^(lg(y)-1)=/P(/-+l),
3 p = OP(r+l),
4 Tj = HVkiXi ■ ■ ■ Xjj) for 1 </ < s + 1, where *s+1 = (1>y.
CASE 2. lgCSPC)) = lg(ae-ife-i). We have
T
S ^"fi-i^fi-iWfi-! ^ aj-A-iWt-! = ae,4ewe => x
Since Ts = T(Vk{Xx- ■ ■ Xs)), we have
(^e.1->0e_1-,(feS_1) = (Ai.l^pi.r,wy)GVk(Xr--Xt).
Therefore, /Ts((fc)X) = reduce 7r where n = (^Ig-! ->j3g_i). Clearly, ag.^g.! is a
viable prefix of G. Thus, by Lemma 13.6.1, we have the well-defined move
(T0XlTlX1.T2--XsTs,y,p)
\—(T0XlTlX2T2 ■ ■ 'Arg_ig(0g_1)7,fi_lg(pg_1).4fi_1 T ,y,pn),
where 7"' = T(Vk(Xl ■ ■ ■ -Xg-ig^g y4g_i). Therefore we have
1 Xx ■ ■ •A'e.xg^gMy4e_i = SP(r + 1),
2^=/P(r+l),
3 pTr=OP(r+ 1),
4 7} = 7XKfc(jr, • • • A})) for 1</ < £ - lg0B_,) + 1.
This completes the induction proof.
Now let / = t — 1. We have parser configuration
(r0X17Vr27V--*s7's>A,p').
1 A^i • • • Xs = SP(t — 1) = alA iWj,
2 A = IP(t-l),
552 LR(k) GRAMMARS AND LANGUAGES
3 p' = OP(t-\) = pn---Pl
4 Tj = T(Vk(X1 ■ ■ ■ Xj)) for 1</ < s.
We know, by our induction proof, that
SP(t) = ao0owo
IP(t) = A
OP{t) = p„---p0
Since p0= (£->*! • • • XS)GP, then (S-**, • • • Xs •, A)erj. Therefore/Tg(A) =
reduce n where ir = p0. Thus, by Lemma 13.6.1, the parser makes the well-defined
move
(ToX^XiTi ■ ■ -XsTs,A,p') \- (A, T0,p'«) \- accept
where S ^ x.
We now consider the behavior of our canonical LR(Jc) parser on an input
string not in the language. We wish to show that, when the parser is given a string
that is not in the language, it will halt in a special error state; and moreover the
parser will halt at the earliest step possible. That is, as soon as the input string thus
far read could not have the given lookahead string if the string were in the language,
the parser must halt and declare error. When k = 0, we must, in addition, consider
the special case when the input string is a prefix of some string in the language.
Theorem 13.6.3 Let G = (V, 2, P, S) be an LR(k) grammar, k > 0. Then in
the canonical LR(k) parser for G, with tables S'h, for all x & L(G), (T0 ,x,A) \-error.
Furthermore, the parser halts at the following point in the computation:
CASE 1. Let x = x'x", where x is the minimal-length prefix of x such that
there exists nojGS', with (fc)^ = wx" andx'y GL(G). Then
(T0,x,A) )r(7,x",p) h error
where the next-to-last move of the parser is not a reduce move.
CASE 2. If x £ L(G) and Case 1 does not hold, then, for some y G T£ V 3~h )*,
pGP*,
(T0,x,A) )r(y,A,p) \- error.
Proof We must consider two cases. In the first case, at some point the prefix
of the string we have thus far read could not have the given lookahead for any string
in the language. In the second case, the input string is a prefix of some string in the
language.
CASE 1. In this case, it is assumed that there exist x , x"G2* such that
x = x'x" where x is the minimal-length prefix of x such that there exists no y G 2*,
with wy = wx" and x'y 6i(G). We shall show that, immediately after reading the
last letter of x , the parser declares an error. Since x is the minimal-length prefix of
13.6 CONSISTENCY AND PARSER CONSTRUCTION 553
x such that there exists no y G 2* with (ky = (fc)x" and x'y GL(G), by Theorem
4.1, the configuration of the parser after reading x (or the initial configuration if
x = A) is
(T0X1TlX2T2---X.T.,x'',p)
where 7} G ^fe for 0 </ <s,X, G Vfor K/<j,p6 P* and
1 Xf-X.=SP(i),
2 x" = IP(i),
Assume, for the sake of contradiction, that
(7-0^,7-^7-2 • • -XsTs,x",p) h error
is false. Then there exist A GW, 0,, 02 G V*,« G 2*, (1)j32 £ # such that (A -> 0, • j32,«)
is a valid L/?(fc) item for Xi ■ • • Xs with (fc)x" GFIRSTfc(02H). By definition, there
exist aG V*, w G 2*, such that
S =f ovlw f- 00,02w
and « = (fc)w. By (1), a0, j*x'. Thus, for some m'G2*, a0102w^*xW. But this
contradicts the hypothesis of Case 1.
CASE 2. We therefore assume that, for some y G 2+, xy G L(G) and iky = A.
Since y G 2+ and (fc)y = A, we must have k = 0. Since xy G L, by Theorem 13.6.2 for
some 7,7 G T0{V^k)*,p,p GP*,
(7-0,xy, A) ^(7,^,P) ^(7',A,p').
Therefore, given the input x, we will have
(7-0, x, A) ^(7,A,p)
and after a finite number of steps, the parser will attempt to shift. By the definition
of our parser, since the input stream will be empty, the parser will halt and declare
error. □
PROBLEMS
1 Prove Lemma 13.6.1.
2 Prove the following proposition.
Lemma Let G = (V, 2, P, S) be a reduced context-free grammar, where
k > 0. Let 7G y, where 5? is the canonical collection of sets of LR(k) items for G.
Assume that, for some B&N, 0, G K*, 02 GNV*, z>GFOLLOWfc(£) we have
(B -> 0i-02, v) G /, witht u G EFFfc(02zO. Then there exist C G N, S G 2 K*,
«' G FOLLOWfc(C) such that
(C->-5,m')G7
and«GFIRSTfc(6«').
t EFF is defined in Problem 3 of Section 13.4 on page 530.
554 LR(k) GRAMMARS AND LANGUAGES
3 In the literature, one finds a different definition of consistency than the
one used here.
Definition Let G = {V, E,P,S) be a reduced context-free grammar and let
/fc>0. A collection S? of sets of LR(k) items for G is sf- %-consistent if, for all
/G Sf, A,A' &N,(S,(Sx,$i GK*,andall«,vG2^ with u G EFFfc (j32 v), we have that
U->/3-,«)G7 and (A' ->02 • j33, ») G7
imply that
U->/3-,«) = W'-»-02 •&,»).
Prove the following result.
Theorem Let G = (V,"E,P,S) be a reduced context-free grammar where
k > 0. ^, the canonical collection of sets of LR(k) items for G, is s/- ^-consistent
if and only if it is consistent.
4 The way in which our parser is defined in Section 13.4 is complicated.
In order for our parser to halt, three conditions must be satisfied, namely:
a) The input stream must be empty.
b) A reduction to S must be performed immediately before the parser halts.
c) After popping the stack for the final reduction, only T0 may remain on
the stack.
Show that each of these three conditions is necessary.
5 Fix k > 0. Analyze the time required to test a context-free grammar for
the LR(k) property if the consistency is checked.
*6 Find a method for testing a context-free grammar for the LR(k) property
which takes time proportional to nk+2 when k is fixed and where n = \G\.
13.7 THE RELATIONSHIP BETWEEN /.^-LANGUAGES AND A0
We have seen, in Theorems 13.2.4, that every deterministic language has an
LR(l) grammar. Our purpose here is to prove a converse and to characterize the
deterministic context-free languages by LR grammars. To do this is not very difficult.
We must merely convert the LR parser from Sections 13.4 and 13.6 into a dpda that
accepts the language in question.
Theorem 13.7.1 Every LR(k) language is a deterministic context-free
language.
Proof The idea is simply to construct a dpda from the LR parser of the
previous sections. The states of the dpda will consist of pairs, the first element of
which is the table on the top of the stack while the second is the lookahead string.
The final states will be those where the lookahead string, concatenated with a valid
prefix corresponding to the set of items, produces a word in the language. More
formally, let G = (V, 2, P, S) be an LR(k) grammar. Define a dpda A = (Q, 2, T, 6,
q0, T0, F) where
r = kux
13.7 RELATIONSHIP BETWEEN tff-LANGUAGES AND A0 555
and 3~= {^}is the set of LR(k) tables produced by Algorithm 13.5.1.
Q = (,^x(2U{A})fc)U{0,...,fc-l}x(2U{A})fc
U (2 U {A})fc x {t}}
U ^x{r2p| p = lg(a),^->aisinP},
and
f(r0,A) if* = 0,
<7o = {
1(0, A) otherwise.
The final states are defined by cases:
(To, tip) where p = lg(a), S -* a is in P if k = 0.
(/,*) ifk>l,xGL(G),andO<i<k.
F= {(T,u) \ik> l,«GSfeJ= T(I) and there is some
(A ->a-aM)e/forsomeae F*,aG2,0G V*,
»e(EU {A})fc and u G FIRSTfc+1 (a0p).
The 6 function is defined by cases:
CASE 1. For each a G 2,
(((T0, a), To) if*=l,
5((0,A),a,r0) =
\((\,a),To) if*>l.
We start to fill a buffer with the lookahead string of length k > 1.
CASE2. Iffc> l,thenforeachaG2,0",x)GQ with 1 <i<k,
8((i,x),a,T0) = ((i+l,xa),To).
CASE 3. If A: > 1 then, for each* G 2(fc_1) andaG 2,
8((k-l,x),a, To) = ((7-0,xa), T0).
Now the buffer is loaded.
CASE 4.
a) Iff f(T, u) = shift, k> 1, u = aU2-■ ■ Uk, with a G 2, each [/,• G 2, and
£(r, a) =£ error then
5((7>t/2 • • • Uk), b,T) = ((g(T,a), t/2 • • • Ukb), Tag(T,a))
for all ft G 2.
t / and g are the parsing action and goto functions associated with G and are defined
in Section 13.6. Their effect on the parser is explained in Section 13.4.
556 LR(k) GRAMMARS AND LANGUAGES
b) If k = 0 and f(T, u) = shift, then
S((T, A),a,T) = ((g(T,a), A), Tag(T,a))
for any a G 2, provided g(T, a) i= error.
CASE 5. If f(T, u) = reduce n, where 7r is A -> 0, then let p = lg(0) andt for
any w G (2 U {A})\
a) 8([T,u),A,T) = ({u,t0),T)
b) S((h, ?2l), A> r) = ((". ?2(+i). A) for each TG ^and each /, 0 < / <p.
c) 5((j/,r2i+i), A, y) = ((«,r2i+2), A) for each i, 0 <i<p, and each KG K.
d) If k > 1 and £(r', a) ^ error, then
s((u,t2p),A,T') = (a(r',^),«),rU^r'M)).
e) If fc = 0, then we have:
0 5((A,r2p),A,r') = ((r',r2p),r'),
ii) «((r', r2p), A, r') = MT',A), A), T'Ag(T',A)) provided «(7"M) ^
error.
The extra move here is to be able to accept when k = 0.
This completes the construction. Note that the accepting condition has the
property that, if the lookahead string u is concatenated to what has been read already,
we have a string in the language.
It can be shown that T(A) = L(G), but we shall not do so here because A
is so close to the parser of Section 13.4 whose operation was proved to be correct
in Section 13.6. □
The previous result can be combined with an earlier theorem to give an
important characterization.
Theorem 13.7.2 L is a deterministic context-free language if and only if L
is an LR(k) language for some k > 0.
Proof The result follows from Theorems 13.7.1 and 13.2.4. □
Now we prove a very useful theorem which shows that the LR(k) languages
do not form a hierarchy with respect to k.
Theorem 13.7.3 Every LR(k) language has an LR(l) grammar and hence is
an LR(l) language.
Proof If k = 0 or k = 1, the result is trivial. Suppose L is an LR(k) language
with k> 2. Then LGA0, by Theorem 13.7.1. By Theorem 13.2.4, L is LR(l). □
' It is intended that different states t( be used for different productions. This
dependence is not shown in the notation, in order to simplify matters.
13.7 RELATIONSHIP BETWEEN/.ff-LANGUAGES AND A„ 557
We have found an algorithm for testing whether a context-free grammar is
LR(k) when k is known. If k is not known, the problem is unsolvable.
Theorem 13.7.4 There is no algorithm which can decide, of a context free
grammar G, whether or not G is LR(k) for some k.
Proof See Knuth [1965] for the original proof, or Hunt and Szymanski
[1976] for a metatheorem which covers a number of other important cases.
□
PROBLEMS
1 Give a formal proof that T(A) = L(G) in Theorem 13.7.1.
*2 Prove Theorem 13.7.2 by giving a direct grammatical transformation.
3 Show the following interesting result:
Theorem L is a deterministic context-free language if and only if £ is a
bounded-right-context language.
Hint. Show that any LR(k) grammar is equivalent to a BRC(\,k) grammar. Use
Problem 21 of Section 13.2.
4 Prove the following result:
Theorem Every LR(k) language with k > 1 may be given an LR(l) grammar
(and, hence, LR(k)) in Greibach normal form.
5 Find an LR(0) language L for which there is no LR(0) grammar which is
in Greibach form.
6 Prove the following result. Pertinent definitions and results may be found
in the problems of Section 13.2.
Lemma Let G = (V, 2, P, S) be an LLR(k) grammar, k>0. Then there
exists an LR(l) grammar G' such that L(G) = L(G').
7 Prove the following result:
Theorem L£S* is a deterministic language if and only if L is an LLR
language.
8 Prove the following result:
Theorem L £ 2* is an LR(0) language if and only if L is an LLR(0) language.
9 Let L £ 2* be in A0. A string x £ 2* is a correct prefix of L if there exists
some )>£S* such that xy GZ,. Define I(L) = {x\ x = x'a for some a G 2, x is a
correct prefix of L but x is not}. Let A be a dpda acting as a parser for L. A has the
correct prefix property if, by changing the set of final states of A, we can produce a
recognizer for I(L). Show that the LR parser we have constructed in this chapter is a
correct prefix parser.
558 LR(k) GRAMMARS AND LANGUAGES
13.8 HISTORICAL SURVEY
LR(k) parsing was invented by Knuth [1965]. Our treatment of the
fundamental concepts in Section 13.2 is from Geller and Harrison [1977a] while Theorem
13.2.3 is due to Harrison and Havel [1974]. The characterization of LR(0) languages
is also from Geller and Harrison [1977a]. The concept of LLR(k) grammars is from
Lewis and Stearns [1968]. The family of BRC(2,k) grammars was introduced by
Floyd [1964]. Problem 22 of Section 13.2 is from Harrison and Havel [1974].
The treatment of LR parsing is essentially the canonical subcase of the
theory of characteristic parsing which is from Geller and Harrison [1977b and c].
Problem 6 of Section 13.6 is due to Hunt, Szymanski, and Ullman [1975a]. The proof
of Theorem 13.7.1 is due to M.M. Geller. Problem 3 of Section 13.7 appears in Knuth
[1965]; also see Graham [1971]. Problem 4 appears in Lomet [1973] and in Geller,
Harrison, and Havel [1977] along with Problem 6.
ReF<
eiences
AANDERAA, S.O., "On fc-tape versus (k — 1) tape real time computation,"
SIAM—AMS Colloquium on Applied Mathematics, Vol. 7, Complexity of
Computation (R. Karp, ed.), pp. 75-96, 1974.
AGUILAR, R., ed., Formal Languages and Programming, Amsterdam: North-Holland
Publishing Co., 1976.
AHO, A. V., "Indexed grammars: an extension of the context-free grammars," Journal
of the Association for Computing Machinery, 15, pp. 647—671, 1968.
AHO, A.V., "Nested-stack automata," Journal of the Association for Computing
Machinery, 16, pp. 383-406, 1969.
AHO, A.V., DENNING, P.J., AND ULLMAN, J.D., "Weak and mixed-strategy
precedence parsing," Journal of the Association for Computing Machinery, Vol. 19,
pp. 225-243, 1972.
AHO, A.V., HOPCROFT, J.E., AND ULLMAN, J.D., "Time and tape complexity of
pushdown automaton languages," Information and Control, 13, pp. 186—206, 1968.
AHO, A.V., HOPCROFT, J.E., AND ULLMAN, J.D., The Design and Analysis of
Computer Algorithms, Reading, Mass.: Addison-Wesley Publishing Co., 1974.
AHO, A.V., JOHNSON, S.C., AND ULLMAN, J.D., "Deterministic parsing of
ambiguous grammars," Communications of the Association for Computing Machinery, 18,
pp. 441-452, 1975.
AHO, A.V., AND ULLMAN, J.D., The Theory of Parsing, Translating, and Compiling,
Vols. I and II. Englewood Cliffs, N. J.: Prentice Hall, 1972 and 1973.
AHO, A.V., AND ULLMAN, J.D., "Optimization of LR(k) parsers," Journal of
Computer and System Sciences, 6, pp. 573—602, 1972.
559
560 REFERENCES
AHO, A.V., AND ULLMAN, J.D., Compiler Design, Reading, Mass.: Addison-Wesley
Publishing Co., 1977.
AHO, A.V., ULLMAN, J.D., AND HOPCROFT, J.E., "On the computational power of
pushdown automata," Journal of Computer and System Sciences, 4, pp. 129—136,
1970.
ALLEN, D., "On a characterization of the nonregular set of primes," Journal of
Computer and System Sciences, 1, pp. 464—467, 1968.
ALT, H., AND MEHLHORN, K., "Untere Schranken fur den Platzbedarf bei der
kontext-freien Analyse," Fachbereich 10, Angewandte Mathematik und Informatik der
Universitdt des Saarlandes, September 1975.
ALTMAN, E.B., AND BANERJI, R.B., "Some problems of finite representability,"
Information and Control, 8, pp. 251—263, 1965.
AMAR, V., AND PUTZOLU, G., "On a family of linear grammars," Information and
Control, 7, pp. 283-291, 1964.
AMAR, V., AND PUTZOLU, G., "Generalizations of regular events," Information and
Control, 8, pp. 56-63, 1965.
ANGLUIN, D., "The four Russians' algorithm for boolean-matrix multiplication is
optimal in its class," SIGACTNEWS, 8, pp. 29-33, 1976.
ARBIB, M.A., Theories of Abstract Automata, Englewood Cliffs, N. J.: Prentice-Hall,
1969.
ARLAZAROV, V.L., DINIC, E.A., KRONOD, M.A., AND FARADZEV, I.A., "On
economical construction of the transitive closure of an oriented graph," Doklady
Akad. Nauk SSSR, 194, pp. 487-488, 1970. Also see English translation in Soviet
Mathematics, Vol. 11, pp. 1209-1210, 1970.
BACKUS, J.W., "The syntax and semantics of the proposed international algebraic
language of the Zurich ACM—GAMM conference," Proceedings of the International
Conference on Information Processing, UNESCO, Paris, June 1959.
BAKER, B.S., AND BOOK, R.V., "Reversal-bounded multipushdown machines,"
Information and Control, 24, pp. 231-246, 1974.
BAKER, B.S. AND BOOK, R.V., "Reversal-bounded multipushdown machines,"
Journal of Computer and System Sciences, 8, pp. 315—332, 1974.
BANERJI, R.B., "Phrase-structure languages, finite machines, and channel capacity,"
Information and Control, 6, pp. 153-162, 1963.
BAR-HILLEL, Y., Language and Information, Reading, Mass.: Addison-Wesley
Publishing Co., 1964.
BAR-HILLEL, Y., PERLES, M., AND SHAMIR, E., "On formal properties of simple
phrase-structure grammars," Zeitschrift fur Phonetik, Sprachwissenschaft, und
Kommunikationsforschung, 14, pp. 143 — 177, 1961.
BAR-HILLEL, Y., AND SHAMIR, E., "Finite-state languages: formal representations
and adequacy problems," The Bulletin of the Research Council of Israel, 8F,
pp. 155-166, 1960.
BARNES, B., "A two-way automaton with fewer states than any equivalent one-way
automaton," IEEE Transactions on Computers, C-20, pp. 474-475, 1971.
BEERI, C, "An improvement on Valiant's decision procedure for equivalence of
deterministic finite-turn pushdown automata," Journal of Computer and System
Sciences, 10, pp. 317-339, 1975.
REFERENCES 561
BEERI, C, "Two-way nested-stack automata are equivalent to two-way stack
automata," Journal of Computer and System Sciences, 10, pp. 317—339, 1975.
BENNETT, J.H., "On Spectra," Ph.D. Thesis, Dept. of Mathematics, University of
Michigan, 1962.
BERSTEL, J., "Contribution a l'Etude des Proprietes Arithmetiques des Langages
Formels," Sc.D. Thesis, University of Paris VII, January 1972.
BERSTEL, J., "Sur la densite asymptotique des langages formels," in Automata,
Languages, and Programming (M. Nivat, ed.), pp. 345—358, Amsterdam North-Holland
Publishing Co., 1973.
BIRD, M., "The equivalence problem for deterministic two-tape automata," Journal of
Computer and System Sciences, 7, pp. 218-236, 1973.
BLATTNER, M., "The unsolvability of the equality problem for sentential forms of
context-free grammars," Journal of Computer and System Sciences, 7, pp. 463—468,
1973.
BLATTNER, M., "Transductions of context-free languages into sets of sentential
forms," in Automata, Languages, and Programming (J. Loeckx, ed.), 14, "Lecture Notes
in Computer Science," pp. 511-522, New York: Springer-Verlag, 1974.
BLATTNER, M., "Structural similarity in context-free grammars," Information and
Control, 30, pp. 267-294, 1976.
BLUM, E.K., "A note on free semigroups with two generators," Bulletin of the
American Mathematical Society, 71, pp. 678—679, 1965.
BLUM, M., "On the size of machines," Information and Control, 11, pp. 257—265,
1967.
BLUM, M., "A machine-independent theory of the complexity of recursive functions,"
Journal of the Association for Computing Machinery, 14, pp. 322—336, 1967.
BOASSON, L., "Cones Rationnels et Families Agreables de Langages — Application au
Langage a Compteur," Thesis, University of Paris VII, 1971.
BOASSON, L., "Two iteration theorems for some families of languages," Journal of
Computer and System Sciences, 7, pp. 583—596, 1973.
BOASSON, L., "Un critere de rationalite des langages algebriques," in Automata,
Languages, and Programming (M. Nivat, ed.), pp. 359-365, Amsterdam, North-Holland
Publishing Co., 1973.
BOASSON, L., "Paires Iterantes et Langages Algebriques," Thesis, University of Paris
VII, 1974.
BOASSON, L., "Langages algebriques, paires iterantes, et transductions rationnelles,"
Theoretical Computer Science, 2, pp. 209-224, 1976.
BOOK, R.V., "Time-bounded grammars and their languages," Journal of Computer
and System Sciences, 5, pp. 397-429, 1971.
BOOK, R.V., "Terminal context in context-sensitive grammars," SIAM Journal on
Computing, 1, pp. 20-30, 1972a.
BOOK, R.V., "On languages accepted in polynomial time," SIAN Journal on
Computing, 1, pp. 281-287, 1972b.
BOOK, R.V., "On the structure of context-sensitive grammars," Int. Journal of
Computer and Information Sciences, 2, pp. 129—139, 1973.
562 REFERENCES
BOOK, R.V., AND GREIBACH, S.A., "Quasi-real-time languages," Mathematical
Systems Theory, 4, pp. 97-111, 1970.
BOOK, R.V., AND GREIBACH, S.A., "Formal languages," unpublished manuscript,
1973.
BOOK, R.V., AND HARRISON, M.A., "Mutually divisible semigroups," Discrete
Mathematics, 9, pp. 329-332, 1974.
BORODIN, A., "Complexity classes of recursive functions and the existence of
complexity gaps," Proceedings of the First ACM Symposium on Theory of
Computing, pp. 67-78, 1969.
BORODIN, A., "Computational complexity and the existence of complexity gaps,"
Journal of the Association for Computing Machinery, 19, pp. 158—174, 1972.
BORODIN, A., AND MUNRO, I., The Computational Complexity of Algebraic and
Numeric Problems, New York: American Elsevier Publishing Co., 1975.
BOUCKAERT, M., PIROTTE, A., AND SNELLING, M., "Efficient parsing
algorithms for general context-free parsers," Information Sciences, 8, pp. 1—26,
1975.
BRAFFORT, P., AND HIRSCHBERG, D., Computer Programming and Formal
Systems, Amsterdam, North-Holland Publishing Co., 1963.
BRAINERD, W.S., "An analog of a theorem about context-free languages,"
Information and Control, 11, pp. 561-567, 1968.
BRAINERD, W.S., "Tree-generating regular systems," Information and Control,
14, pp. 217-231, 1969.
BROSGOL, B.M., "Deterministic Translation Grammars," Ph.D. Thesis, Harvard
University, 1974.
CANNON, R.L., "Phrase-structure grammars generating context-free languages,"
Information and Control, 29, pp. 252-267, 1975.
CANTOR, D.G., "On the ambiguity problem of Backus systems," Journal of the
Association for Computing Machinery, 9, pp. 477-479, 1962.
CHANDRA, A.K., AND STOCKMEYER, L.J., "Alternation," Proceedings of the 17th
Annual Symposium on Foundations of Computer Science, pp. 98—108, 1976.
CHEN, K.T., FOX, R.H., AND LYNDON, R.C., "Free differential calculus: IV. The
quotient groups of the lower central series," Annals of Mathematics, 68, pp. 81—95,
1958.
CHOMSKY, N., "Three models for the description of language,"IRE Transactions on
Information Theory, IT2, pp. 113-124, 1956.
CHOMSKY, N., "On certain formal properties of grammars," Information and
Control, 2, pp. 137-167, 1959a.
CHOMSKY, N., "A note on phrase-structure grammars," Information and Control, 2,
pp. 393-395, 1959b.
CHOMSKY, N., "Context-free grammars and pushdown storage," MIT Research Lab
of Electronics Quarterly Progress Report, 65, 1962.
CHOMSKY, N., "Formal properties of grammars," Handbook of Mathematical
Psychology, Vol. 2 (Bush, Galanter, and Luce, eds.), New York: John Wiley, 1963.
CHOMSKY, N., Syntactic Structures, The Hague: Mouton & Co., 1964.
REFERENCES 563
CHOMSKY, N., Aspects of the Theory of Syntax, Cambridge, Mass.: M.I.T. Press,
1965.
CHOMSKY, N., AND MILLER, G.A., "Finite-state languages," Information and
Control, 1, pp. 91-112, 1958.
CHOMSKY, N., AND SCHUTZENBERGER, M.P., "The algebraic theory of context-
free languages," in Computer Programming and Formal Systems (Braffort, P., and
Hirschberg, D., eds.), Amsterdam: North-Holland, pp. 118-161, 1963.
CLIFFORD, A.H., AND PRESTON, G.B., The Algebraic Theory of Semigroups, Vols. I
and II, Providence, R. I.: American Mathematical Society, 1967.
COBHAM, A., "On the base dependence of sets of numbers recognizable by finite
automata," Mathematical Systems Theory, 3, pp. 186—192, 1969.
COBHAM, A., "The instrinsic computational difficulty of functions," Proceedings of
the 1964 Congress for Logic, Mathematics, and Philosophy of Science, Amsterdam:
North-Holland Publishing Co., 1964;pp. 24-30.
COBHAM, A., "Uniform tag sequences," Mathematical Systems Theory, 6, pp. 164-
192, 1972.
COLE, S.N., "Real-time computation by iterative arrays of finite-state machines,"
Ph.D. Thesis, Harvard University, 1962.
COLE, S.N., "Deterministic pushdown store machines and real-time computation,"
Journal of the Association for Computing Machinery, 14, pp. 453—460, 1971.
COLMERAUR, A., "Total precedence relations," Journal of the Association for
Computing Machinery, 17, pp. 14-30, 1970.
CONWAY, J.H., Regular Algebra and Finite Machines. London: Chapman and Hall,
1971.
COOK, S.A., "Characterizations of pushdown machines in terms of time-bounded
computers," Journal of the Association for Computing Machinery, 18, pp. 4—18,
1971.
COOK, S.A., "The complexity of theorem-proving procedures," Proceedings of the
Third Annual ACM Symposium on Theory of Computing, pp. 151 — 158, 1971.
COOK, S.A., "An observation on time-storage tradeoff," Journal of Computer and
System Sciences, 9, pp. 308-316, 1974.
COURCELLE, B., "Une forme canonique pour les grammaires simples deterministes,"
Revue Francaise d'Automatique, Informatique, and Recherche Operationelle, Serie
rouge, 8, pp. 19-36, 1974.
COURCELLE, B., "Recursive schemes, algebraic trees, and deterministic languages,"
Proceedings of the 15th Annual Symposium on Switching and Automata Theory,
pp. 52-62, 1974.
COURCELLE, B., "Sur les ensembles algebriques d'arbres et les langages
deterministes," Ph.D. Thesis and IRIA Report, 1975.
CRESTIN, J.P., "Sur un langage quasi-rationnel d'ambiguite inherente non bornee,"
These de 3° Cycle, Faculty of Science, University of Paris, 1969.
CRESTIN, J.P., "Un langage non ambigu dont le carre est d'ambiguite non bornee,"
in Automata, Languages, and Programming (M. Nivat, ed.), pp. 377—390, Amsterdam:
North-Holland Publishing Co., 1973.
564 REFERENCES
CRESTIN, J.P., "Structure des grammaires d'ambiguite bornee," Journal of Computer
and System Sciences, 8, pp. 36—40, 1974.
CUDIA, D.F., "General problems of formal grammars," Journal of the Association for
Computing Machinery, 17, pp. 31—43, 1970.
CULIK, K., AND COHEN, R., "/.^-regular grammars - an extension of LR(k)
grammars," Journal of Computer and System Sciences, 7, pp. 66—96, 1973.
DeREMER, F., "Practical Translators for LR(k) Languages," Ph.D. Thesis and Project
MAC Technical Report TR-65, M.I.T., 1965.
DeREMER, F., "Simple LR(k) grammars," Communications of the Association for
Computing Machinery, 14, pp. 453—460, 1971.
DIKOVSKII, A. JA., "On the relationship between the class of all context-free
languages and the class of deterministic context-free languages" (in Russian), Algebra i
Logika, 8, pp. 44-64, 1969.
EARLEY, J., "An efficient context-free parsing algorithm," Communications of the
Association for Computing Machinery, 13, pp. 94—102, 1970. Also Ph.D. thesis,
Carnegie-Mellon University, 1968.
EICKEL, J., PAUL, M., BAUER, F.L., AND SAMELSON, K., "A syntax-controlled
generator of formal language processors," Communications of the Association for
Computing Machinery, 6, pp. 451—455, 1963.
EILENBERG, S., Automata, Languages, and Machines, Vol. A, New York: Academic
Press Inc., 1974.
EILENBERG, S., AND SCHUTZENBERGER, M.P., "Rational sets in commutative
monoids," Journal of Algebra, 13, pp. 173—191, 1969.
ELGOT, C.C., "Decision problems of finite-automata design and related arithmetics,"
Transactions of the American Mathematical Society, 98, pp. 21—51, 1961.
ELGOT, C.C., AND MEZEI, J.E., "On relations defined by generalized finite
automata," IBM Journal of Research and Development, 9, pp. 47—68, 1965.
ENGELFRIET, J., "Translation of simple program schemes," in Automata, Languages,
and Programming (M. Nivat, ed.), pp. 215—223, Amsterdam: North-Holland
Publishing Co., 1973.
ERDOS, P., AND SZERKERES, G., "A combinatorial problem in geometry,"
Compositio Mathematica, 2, pp. 463-470, 1935.
ESTENFELD, K., "Strukturelle Untersuchungen zur schwersten kontextfreien
Sprache," Technical Report A76/06, Saarbriicken: Universitat des Saarlandes, 1976.
EVEY, R.J., "The Theory and Application of Pushdown Store Machines," Ph.D.
Thesis and Research Report, Mathematical Linguistics and Automatic Translation
Project, Harvard University, NSF-10, May 1963.
FINE, N.J., AND WILF, H.S., "Uniqueness theorems for periodic functions,"
Proceedings of the American Mathematical Society, 16, pp. 109-114, 1965.
FISCHER, M.J., "Grammars with Macrolike Productions," Ph.D. Dissertation, Harvard
University, 1968.
FISCHER, M.J., "Two characterizations of context-sensitive languages," IEEE
Conference Record of 10th Annual Symposium on Switching and Automata Theory,
pp. 149-156, 1969.
REFERENCES 565
FISCHER, M.J., "Some properties of precedence languages," A CM Symposium on
Theory of Computing, pp. 181-190, 1969.
FISCHER, M.J., AND MEYER, A.R., "Boolean-matrix multiplication and transitive
closure," IEEE Conference Record of 12th Annual Symposium on Switching and
Automata Theory, pp. 129-131, 1971.
FISCHER, M.J., AND ROSENBERG, A.L., "Real-time solutions of the origin crossing
problem,"Mathematical Systems Theory, 2, pp. 257—263, 1968.
FISCHER, P.C., "Turing machines with restricted memory access," Information and
Control, 9, pp. 364-379, 1966.
FISCHER, P.C., AND PROBERT, R.L., "Efficient procedures for using matrix
algorithms," in Automata, Languages and Programming (J. Loeckx, ed.), Vol. 14,
"Lecture Notes in Computer Science," Berlin: Springer-Verlag, 1974; pp. 413-428.
FISCHER, P.C., AND ROSENBERG, A., "Multitape one-way nonwriting automata,"
Journal of Computer and System Sciences, 2, pp. 88—101, 1968.
FISCHER, P.C., MEYER, A.R., AND ROSENBERG, A.L., "Counter machines and
counter languages," Mathematical Systems Theory, 2, pp. 265—283, 1968.
FLIESS, M., "Transductions de series formelles," Discrete Mathematics, 10,
pp. 57-74, 1974.
FLIESS, M., "Matrices de Hankel," Journal of Pure and Applied Math, 53,
pp. 197-222, 1974.
FLOYD, R.W., "Syntactic analysis and operator precedence," Journal of the
Association for Computing Machinery, 10, pp. 313—333, 1963.
FLOYD, R.W., "Bounded-context syntactic analysis," Communications of the
Association for Computing Machinery, 7, pp. 62—66, 1964a.
FLOYD, R.W., "The syntax of programming languages," IEEE Transactions on
Electronic Computers, EC-13,pp. 346-353, 1964b.
FLOYD, R.W., "A machine-oriented recognition algorithm for context-free
languages," unpublished manuscript, April 1969.
FRIEDMAN, E.P., "Deterministic Languages and Monadic Recursion Schemes," Ph.D.
Thesis, Harvard University, Cambridge, 1974.
FRIEDMAN, E.P., "The inclusion problem for simple languages," Theoretical
Computer Science, 1, pp. 297-316, 1976.
GALIL, Z., "Some open problems in the theory of computation as questions about
two-way deterministic pushdown automaton languages," Mathematical Systems Theory,
10,pp. 211-218, 1977.
GALIL, Z., "Real-time algorithms for string matching and palindrome recognition,"
unpublished manuscript, Yorktown Heights, N.Y.: IBM Research Center, 1975.
GALIL, Z., "Two fast simulations which imply some fast string-matching and
palindrome-recognition algorithms," Information Processing Letters, 4, pp. 85—100,
1976.
GALIL, Z., AND SEIFERAS, J., "Recognizing certain repetitions and reversals within
strings," Proceedings of the 17th Annual Symposium on Foundations of Computer
Science, pp. 236-252, 1976.
GALLAIRE, H., "Recognition time of context-free languages by on-line Turing
machines," Information and Control, 15, pp. 288-295, 1969.
566 REFERENCES
GELLER, M.M., GRAHAM, S.L., AND HARRISON, M.A., "Production prefix
parsing" (extended abstract), Automata, Languages, and Programming, 2nd
Colloquium (Jacques Loeckx, ed.), University of Saarbriicken, July 29-August 2, 1974,
pp. 232-241.
GELLER, M.M., AND HARRISON, M.A., "Strict deterministic versusLR(0) parsing,"
Conference Record of the ACM Symposium on Principles of Programming Languages,
pp. 22-32, 1973.
GELLER, M.M., AND HARRISON, M.A., "Characterizations of LR(0) languages,"
Conference Record of the 14th Annual Symposium on Switching and Automata
Theory, pp. 103-108, 1973.
GELLER, M.M., AND HARRISON, M.A., "Characteristic parsing: A framework for
producing compact deterministic parsers, I," Journal of Computer and System
Sciences, 14, pp. 265-317, 1977.
GELLER, M.M., AND HARRISON, M.A., "Characteristic parsing: A framework for
producing compact deterministic parsers, II," Journal of Computer and System
Sciences, 14, pp. 318-343, 1977.
GELLER, M.M., AND HARRISON, M.A., "On LR(k) grammars and languages,"
Theoretical Computer Science, 4, pp. 245-276, 1977.
GELLER, M.M., HARRISON, M.A., AND HAVEL, I.M., "Normal forms of
deterministic grammars," Discrete Mathematics, 16, pp. 313—321, 1976.
GELLER, M.M., HUNT, H.B., SZYMANSKI, T.G., AND ULLMAN, J.D., "Economy
of description by parsers, dpda's, and pda's," Theoretical Computer Science, 4,
pp. 143-159,1977.
GINSBURG, S., The Mathematical Theory of Context-Free Languages, New York:
McGraw-Hm Book Co., 1966.
GINSBURG, S., Algebraic and Automata-Theoretic Properties of Formal Languages,
Amsterdam: North-Holland Publishing Co., 1975.
GINSBURG, S., GOLDSTINE, J., AND GREIBACH, S., "Uniformly erasable AFL,"
Journal of Computer and System Sciences, 10, pp. 165—182, 1975.
GINSBURG, S„ AND GREIBACH, S.A., "Deterministic context-free languages,"
Information and Control, 9, pp. 602—648, 1966a.
GINSBURG, S., AND GREIBACH, S.A., "Mappings which preserve context-sensitive
languages," Information and Control, 9, pp. 620—649, 1966b.
GINSBURG, S., AND GREIBACH, S.A., "Abstract families of languages," Memoirs of
the American Mathematical Society, 87, 1969.
GINSBURG, S., GREIBACH, S.A., AND HARRISON, M.A., "Stack automata and
compiling," Journal of the Association for Computing Machinery, 14, pp. 172—201,
1967.
GINSBURG, S., GREIBACH, S.A., AND HARRISON, M.A., "One-way stack
automata," Journal of the Association for Computing Machinery, 14, pp. 389—418,
1967.
GINSBURG, S., AND HARRISON, M.A., "Bracketed context-free languages,"
Journal of Computer and System Sciences, 1, pp. 1—23, 1967.
GINSBURG, S., AND HARRISON, M.A., "On the elimination of endmarkers,"
Information and Control, 12, pp. 103-115, 1968.
REFERENCES 567
GINSBURG, S., AND HARRISON, M.A., "One-way nondeterministic real-time list-
storage languages," Journal of the Association for Computing Machinery, 15,
pp. 428-446, 1968.
GINSBURG, S., AND HARRISON, M.A., "On the closure of AFL under reversal,"
Information and Control, 17, pp. 395-409, 1970.
GINSBURG, S., AND RICE, H.G., "Two families of languages related to ALGOL,"
Journal of the Association for Computing Machinery, 9, pp. 350—371, 1962.
GINSBURG, S., AND ROSE, G.F., "Some recursively unsolvable problems in ALGOL-
like languages," Journal of the Association for Computing Machinery, 10, pp. 29—47,
1963.
GINSBURG, S., AND ROSE, G.F., "Operations which preserve definability in
languages," Journal of the Association for Computing Machinery, 10, pp. 175 — 195,
1963.
GINSBURG, S., AND ROSE, G.F., "The equivalence of stack-counter acceptors and
quasi-real-time acceptors," Journal of Computer and System Sciences, 8, pp. 243—
269, 1974.
GINSBURG, S., AND SPANIER, E.H., "Quotients of context-free languages," Journal
of the Association for Computing Machinery, 10, pp. 487—492, 1963.
GINSBURG, S., AND SPANIER, E.H., "Bounded ALGOL-like languages,"
Transactions of the American Mathematical Society, 113, pp. 333—368, 1964.
GINSBURG, S., AND SPANIER, E.H., "Finite-turn pushdown automata," SIAM
Journal on Control, 4, pp. 429-453, 1966.
GINSBURG, S., AND SPANIER, E.H., "Semigroups, Presburger formulas, and
languages," Pacific Journal of Mathematics, 16, pp. 285—296, 1966.
GINSBURG, S., AND SPANIER, E.H., "Bounded regular sets," Proceedings of the
American Mathematical Society, 17, pp. 1043—1049, 1966.
GINSBURG, S., AND SPANIER, E.H., "Derivation-bounded languages," Journal of
Computer and System Sciences, 2, pp. 228—250, 1968.
GINSBURG, S., AND ULLIAN, J.S., "Preservation of unambiguity and inherent
ambiguity in context-free languages," Journal of the Association for Computing
Machinery, 13, pp. 364-368, 1966.
GINSBURG, S., AND ULLIAN, J., "Ambiguity in context-free languages," Journal of
the Association for Computing Machinery, 13, pp. 62—89, 1966.
GLADKII, A., "Grammars with linear memory," Algebri i Logika Sem., 2, pp. 43—
55, 1963.
GLADKII, A., "On the complexity of derivations in phrase-structure grammars,"
Algebri i Logika Sem., 3, pp. 29-44, 1964.
GOLDSTINE, J., "Some independent families of one-letter languages," Journal of
Computer and System Sciences, 10, pp. 351—369, 1975.
GOLDSTINE, J., "A simplified proof of Parikh's theorem," Discrete Mathematics, 19,
pp. 235-240, 1977.
GRAHAM, S.L., "Extended precedence: bounded right-context languages and
deterministic languages," Proceedings of the Eleventh Symposium on Switching and
Automata Theory, pp. 175-180, 1970.
568 REFERENCES
GRAHAM, S.L., "Precedence Languages and Bounded Right-Context Languages,"
Ph.D. Thesis and Technical Report CS—71— 223, Department of Computer Science,
Stanford University, 1971.
GRAHAM, S.L., "On bounded right-context languages and grammars," SIAM Journal
of Computing, 3, pp. 224-254, 1974.
GRAHAM, S.L., AND HARRISON, M.A., "Parsing of general context-free languages,"
in Advances in Computers, Vol. 14 (M. Yovits and M. Rubinoff, eds.), pp. 77—185,
New York: Academic Press, 1976.
GRAHAM, S.L., HARRISON, M.A., AND RUZZO, W.L., "On-line context-free
recognition in less than cubic time," Proceedings of the Eighth Annual ACM Symposium on
Theory of Computing, pp. 112-120, 1976.
GRAY, J.N., AND HARRISON, M.A., "The theory of sequential relations,"
Information and Control, 9, pp. 435—468, 1966.
GRAY, J.N., AND HARRISON, M.A., "Single-pass precedence analysis," Conference
Record of the 10th Annual Symposium on Switching and Automata Theory, pp. 106 —
117, 1969.
GRAY, J.N., AND HARRISON, M.A., "On the covering and reduction problems for
context-free grammars," Journal of the Association for Computing Machinery, 19,
pp. 675-698, 1972.
GRAY, J.N., AND HARRISON, M.A., "Canonical precedence schemes," Journal of
the Association for Computing Machinery, 20, pp. 214—234, 1973.
GRAY, J.N., HARRISON, M.A., AND IBARRA, O.H., "Two-way pushdown
automata," Information and Control, 11, pp. 30—70, 1967.
GREIBACH, S.A., "Undecidability of the ambiguity problem for minimal linear
grammars," Information and Control, 6, pp. 119—125, 1963.
GREIBACH, S.A., "A new normal-form theorem for context-free, phrase-structure
grammars," Journal of the Association for Computing Machinery, 12, pp. 42—52,
1965.
GREIBACH, S.A., "The unsolvability of the recognition of linear context-free
5-.^ languages," Journal of the Association for Computing Machinery, 13, pp. 582—587,
1966.
GREIBACH, S.A., "A note on pushdown-store automata and regular systems,"
Proceedings of the American Mathematical Society, 18, pp. 263—268, 1967.
GREIBACH, S.A., "A note on undecidable properties of formal languages,"
Mathematical Systems Theory, 2, pp. 1—6, 1968.
GREIBACH, S.A., "An infinite hierarchy of context-free languages," Journal of the
Association for Computing Machinery, 16, pp. 91 — 106, 1969.
GREIBACH, S.A., "Characteristic and ultrarealtime languages," Information and
Control, 18, pp. 65-98, 1971.
GREIBACH, S.A., "A generalization of Parikh's semilinear theorem," Discrete
Mathematics, 2, pp. 347-355, 1972.
GREIBACH, S.A., "The hardest context-free language," SIAM Journal of Computing,
2, pp. 304-310, 1973.
GREIBACH, S.A., "Jump pda's and hierarchies of deterministic context-free
languages," SIAM Journal of Computing, 3, pp. 111-127, 1974.
REFERENCES 569
GREIBACH, S.A., "One-counter languages and the IRS condition," Journal of
Computer and System Sciences, 10, pp. 237-247, 1975a.
GREIBACH, S.A., "Erasable context-free languages," Information and Control, 29,
pp. 301-326, 1975b.
GRIES, D., Compiler Construction for Digital Computers, New York: John Wiley and
Sons, 1971.
GRIFFITHS, T.V., "Some remarks on derivations in general rewriting
systems,"Information and Control, 12, pp. 27—54, 1968.
GRIFFITHS, T. V., "The unsolvability of the equivalence problem for A-free nondeter-
ministic generalized machines," Journal of the Association for Computing Machinery,
15, pp. 409-413, 1968.
GROSS, M., "Inherent ambiguity of minimal linear grammars," Information and
Control, 7, pp. 366-368, 1964.
GROSS, M., "Applications geometriques des langages formels," ICC Bulletin, 5-3,
1966.
GROSS, M., AND LENTIN, A., Notions sur les Grammaires Formelles, Paris:
Gauthier-Villars, 1967.
GRUSKA, J., "Some classifications of context-free languages," Information and
Control, 14, pp. 152-179, 1969.
GRUSKA, J., "Complexity and unambiguity of context-free grammars and languages,"
Information and Control, 18, pp. 502-519, 1971.
GRUSKA, J., "A characterization of context-free languages," Journal of Computer
and System Sciences, 5, pp. 353—364, 1971.
GRUSKA, J., "On star-height hierarchies of context-free languages," Kybernetika, 9,
pp. 231-236, 1973.
GRUSKA, J., "Grammatical levels and subgrammars of context-free grammars," Arch.
Math 1, Scripta Fac. Sci. Nat. Ujep Bruneusis, IX, pp. 19-21, 1973.
GRUSKA, J., "A note on e-rules in context-free grammars," Kybernetika, 11,
pp. 26-31, 1975.
GRZEGORCZYK, A., "Some classes of recursive functions," Rozprawy Mat-
ematyczne, IV, pp. 1—46, 1954.
HAINES, L.H., "Note on the complement of a (minimal) linear language,"
Information and Control, 7, pp. 307-314, 1964.
HAINES, L.H., "Generation and Recognition of Formal Languages," Ph.D. thesis,
M.I.T., 1965.
HAINES, L.H., "On free monoids partially ordered by embedding," Journal of
Combinatorial Theory, 6, pp. 94-98, 1969.
HAINES, L.H., "Representation theorems for context-sensitive languages,"
unpublished manuscript, University of California, Berkeley, 1970.
HARRISON, M.A., Introduction to Switching and Automata Theory, New York:
McGraw-Hill, 1965.
HARRISON, M.A., "On the relation between grammars and automata," in Advances
of Information Sciences 4 (J.T. Tou, ed.), pp. 39-92, New York: Plenum Press, 1972.
570 REFERENCES
HARRISON, M.A., AND HAVEL, I.M., "Strict deterministic grammars," Journal of
Computer and Systems Sciences, 7, pp. 237—277, 1973.
HARRISON, M.A., AND HAVEL, I.M., "On the parsing of deterministic languages,"
Journal of the Association for Computing Machinery, 21, pp. 525—548, 1974.
HARRISON, M.A., AND HAVEL, I.M., "Real-time strict deterministic languages,"
SIAM Journal of Computing, 1, pp. 333-349, 1972.
HARRISON, M.A., AND HAVEL, I.M., "On a family of deterministic grammars,"
in Automata, Languages, and Programming (M. Nivat, ed.), pp. 413-442, Amsterdam:
North-Holland Publishing Co., 1973.
HARRISON, M.A., AND IBARRA, O.H., "Multitape and multihead pushdown
automata," Information and Control, 13, pp. 433—470, 1968.
HARRISON, M.A., AND SCHKOLNICK, M., "A grammatical characterization of
oneway nondeterministic stack languages," Journal of the Association for Computing
Machinery, 18, pp. 148-172, 1971.
HARTMANIS, J., "Context-free languages and Turing-machine computations,"
Proceedings of a Symposium on Applied Mathematics, 19, Mathematical Aspects of
Computer Science, pp. 42—51. Providence: American Mathematical Society, 1967a.
HARTMANIS, J., "On memory requirements for context-free language recognition,"
Journal of the Association for Computing Machinery, 14, pp. 663—665, 1967b.
HARTMANIS, J., "Computational complexity of one-tape Turing-machine
computations," Journal of the Association for Computing Machinery, 15, pp. 325—339,
1968.
HARTMANIS, J., "On the complexity of undecidable problems in automata theory,"
Journal of the Association for Computing Machinery, 16, pp. 160—167, 1969.
HARTMANIS, J., "Computational complexity of random-access stored-program
machines," Mathematical Systems Theory, 5, pp. 232—245, 1971.
HARTMANIS, J., "On nondeterminancy in simple computing devices," Acta
Informatica, 1, pp. 336-344, 1972.
HARTMANIS, J., AND HOPCROFT, J.E., "What makes some language-theory
problems undecidable?" Journal of Computer and System Sciences, 3, 196—217,
1969.
HARTMANIS, J., AND HOPCROFT, J.E., "An overview of computational com-
plexitVjT Journal of the Association for Computing Machinery, 18, pp. 444—475,
^^T97L^
HARTMANIS, J., AND HUNT, H.B., III, "The lba problem and its importance in the
-—theory of computing," in Complexity of Computation (R. Karp, ed.), Vol. VII,
SL\M^ATstS-^roceed1ngs, 1973; pp. 27-42.
HARTMANIS, J., AND SHANK, H., "On the recognition of primes by automata,"
Journal of the Association for Computing Machinery, 15, pp. 382-389, 1968.
HARTMANIS, J., AND SHANK, H., "Two memory bounds for the recognition of
primes by automata," Mathematical Systems Theory, 3, pp. 125-129, 1969.
HARTMANIS, J., AND STEARNS, R.E., "Regularity-preserving modifications of
regular expressions,"Information and Control, 6, pp. 55-69, 1963.
REFERENCES 571
HARTMANIS, J., AND STEARNS, R.E., "On the computational complexity of
algorithms," Transactions of the American Mathematical Society, 117, pp. 285—306,
1965.
HARTMANIS, J., AND STEARNS, R.E., "Sets of numbers defined by finite
automata," American Mathematical Monthly, 74, pp. 539—542, 1967.
HARTMANIS, J., AND STEARNS, R.E., "Automata-based computational
complexity," Information Sciences, 1, pp. 173 — 184, 1969.
HENNIE, F.C., "One-tape, off-line Turing-machine computations," Information and
Control, 8, pp. 553-578, 1965.
HENNIE, F.C., "On-line Turing-machine computations," IEEE Transactions on
Electronic Computers, EC—15, pp. 35—44, 1966.
HENNIE, F.C., AND STEARNS, R.E., "Two-tape simulation of multitape Turing
machines," Journal of the Association for Computing Machinery, 13, pp. 553—546,
1966.
HIBBARD, T.N., "Scan-limited automata and context-limited grammars," Ph.D. Thesis,
Dept. of Mathematics, University of California at Los Angeles, 1966.
HIBBARD, T.N., "Context-limited grammars," Journal of the Association for
Computing Machinery, 21, pp. 446—453, 1974.
HIBBARD, T.N., AND ULLIAN, J., "The independence of inherent ambiguity from
complementedness among context-free languages," Journal of the Association for
Computing Machinery, 13, pp. 588-593, 1966.
HOPCROFT, J.E., "On the equivalence and containment problems for context-free
languages," Mathematical Systems Theory, 3, pp. 119—124, 1969.
HOPCROFT, J.E., PAUL, W., AND VALIANT, L., "On time versus space and related
problems," Proceedings of the 16th Annual Symposium on Foundations of Computer
Science, pp. 57-64, 1975.
HOPCROFT, J.E., AND ULLMAN, J.D., Formal Languages and Their Relation to
Automata, Reading, Mass.: Addison-Wesley Publishing Co., 1969.
HOPCROFT, J.E., AND ULLMAN, J.D., "An approach to a unified theory of
automata," Bell System Technical Journal, 46, pp. 1793-1829, 1967.
HOPCROFT, J.E., AND ULLMAN, J.D., "Deterministic stack automata and the
quotient operator," Journal of Computer and System Sciences, 2, pp. 1—12, 1968a.
HOPCROFT, J.E., AND ULLMAN, J.D., "Relations between time and tape
complexities," Journal of the Association for Computing Machinery, 15, pp. 414—427,
1968b.
HOTZ, G., "Sequentielle Analyse kontextfreier Sprachen," Acta Informatica, 4,
pp. 55-75, 1974.
HOTZ, G., "Normal-form transformations of context-free grammars," unpublished
manuscript, 1976.
HOTZ, G., "Der Satz von Chomsky-Schutzenberger und die schwerste kontext-
freie Sprache von S. Greibach," unpublished manuscript, 1976.
HOTZ, G., AND CLAUS, V., "Automatentheorie und Formale Sprachen," Mannheim:
Bib. Institut, 1972.
572 REFERENCES
HOTZ, G., AND MESSERSCHMIDT, J., "Dyck Sprachen sind in Bandkomplexitat log
n analysierbar," Fachbereich 10, Saarbriicken: Universitat des Saarlandes, 1975.
HUNT, H.B., III "A complexity theory of grammar problems," Conference Record of
the Third ACM Symposium on Principles of Programming Languages, pp. 12-18,
1976.
HUNT, H.B., III, "On the complexity of finite, pushdown, and stack automata,"
Mathematical Systems Theory, 10, pp. 33-52, 1976.
HUNT, H.B., III, "On the time and tape complexity of languages," Proceedings of the
5th Annual Symposium on Theory of Computing, pp. 10—19, 1973.
HUNT, H.B., III, AND RANGEL, J.L., "Decidability of equivalence, containment,
intersection, and separability of context-free languages," Proceedings of 16th Annual
Symposium on Foundations of Computer Science, pp. 144—150, 1975.
HUNT, H.B., III, AND ROSENKRANTZ, D.J., "Computational parallels between the
regular and context-free languages," SIAM Journal on Computing, 7, 1978.
HUNT, H.B., III, ROSENKRANTZ, D.J., AND SZYMANSKI, T.G., "The covering
problem for linear context-free grammars," Theoretical Computer Science, 2,
pp. 361-382, 1976.
HUNT, H.B., 111, AND ROZENKRANTZ, D.J., "On equivalence and containment
problems for formal languages," Journal of the Association for Computing Machinery,
24, pp. 387-396, 1977.
HUNT, H.B., III, AND SZYMANSKI, T.G., "Complexity metatheorems for context-
free grammar problems," Journal of Computer and System Sciences, 13, pp. 318—334,
1976.
HUNT, H.B., III, AND SZYMANSKI, T.G., "Dichotomization, reachability, and the
forbidden-subgraph problem," Proceedings of the Eighth Annual ACM Symposium on
Theory of Computing, pp. 126-135, 1976.
HUNT, H.B., III, SZYMANSKI, T.G., AND ULLMAN, J.D., "On the complexity of
LR(k) Testing," Communications of the Association for Computing Machinery, 18,
pp. 707-716, 1975a.
HUNT, H.B., III, SZYMANSKI, T.G., AND ULLMAN, J.D., "Operations on sparse
relations, with applications to grammar problems," Proceedings of the Fifteenth
Annual Symposium on Switching and Automata Theory, pp. 127-132, 1974.
HUNT, H.B., III, SZYMANSKI, T.G., AND ULLMAN, J.D., "Operations on sparse
relations," Communications of the Association for Computing Machinery, 20, pp.
171-176, 1977.
IBARRA, O.H., "On two-way multihead automata," Journal of Computer and
System Sciences, 7, pp. 28-36, 1973.
IBARRA, O.H., AND KIM, C.E., "On 3-head versus 2-head finite automata,"/!eta
Informatica, 4, pp. 193-200, 1975.
IBARRA, O.H., AND KIM, C.E., "A useful device for showing the solvability of some
decision problems," Journal of Computer and System Sciences, 13, pp. 153—160,
1976.
REFERENCES 573
ICHBIAH, J.D., AND MORSE, S.P., "A technique for generating almost optimal
Floyd—Evans productions for precedence grammars," Communications of the
Association for Computing Machinery, 13, pp. 501—508, 1970.
IGARASHI, Y., AND HONDA, N., "On the extension of Gladkij's theorem and the
hierarchy of languages," Journal of Computer and System Sciences, 7, pp. 199—217,
1973.
JACOB, G., "Sur un theoreme de Shamir," Information and Control, 27, pp. 218—
261, 1975a.
JACOB, G., "Representations et Substitutions Matricielles dans la Theorie Algebriques
des Transductions," Thesis, University of Paris VII, 1975b.
JONES, N.D., "Classes of automata and transitive closure," Information and Control,
13, pp. 207-229, 1968.
JONES, N.D., "Context-free languages and rudimentary attributes," Mathematical
Systems Theory, 3, pp. 102-109, 1969.
JONES, N.D., "Space-bounded reducibility among combinatorial problems," Journal
of Computer and System Sciences, 11, pp. 68—85, 1975.
JONES, N.D., AND LAASER, W.T., "Complete problems for deterministic
polynomial time," Theoretical Computer Science, 3, pp. 105 — 118, 1976.
JONES, N.D., LAASER, W.T., AND LIEN, Y., "New problems complete for nondeter-
ministic log space computability," Mathematical Systems Theory, 10, pp. 19—32,
1976.
JONES, N.D., AND SELMAN, A.L., "Turing machines and the spectra of first-order
formulas," Journal of Symbolic Logic, 39, pp. 139-150, 1974.
JOSHI, A.K., LEVY, L.S., AND TAKAHASHI, M., "Tree-Adjunct Grammars,"
Journal of Computer and System Sciences, 10, pp. 136—163, 1975.
KARP, R.M., "Reducibilities among combinatorial problems," in Complexity of
Computer Computations (R. Miller and J. Thatcher, eds.), New York: Plenum Press, 1972;
pp. 85-104.
KARP, R.M., "Automaton-based complexity theory," Class notes for CS 276,
Computer Science Division, University of California, Berkeley, 1975.
KASAMI, T., "An efficient recognition and syntax-analysis algorithm for context-
free languages," Science Report AFCRL—65—758, Air Force Cambridge Research
Laboratory, Bedford, Mass., 1965.
KASAMI, T., AND TORII, K., "A syntax-analysis procedure for unambiguous
context-free grammars," Journal of the Association for Computing Machinery, 16,
pp. 423-431, 1969.
KASAMI, T., "A note on computing time for recognition of languages generated by
linear grammars," Information and Control, 10, pp. 209—214, 1968.
KEMP, R., "An estimation of the set of states of the minimal LR(0) acceptor," in
Automata, Languages, and Programming (M. Nivat, ed.), pp. 563—574, Amsterdam:
North-Holland Publishing Co., 1973.
KEMP, R., "Mehrdeutigkeiten kontextfreier Grammatiken," in Automata, Languages,
and Programming (J. Loeckx, ed.), Vol. 14, Lecture notes in Computer Science,"
pp. 534-546, Berlin: Springer-Verlag, 1974.
574 REFERENCES
KEMP, R., "LR(k) Analysatoren," Technical Report A73/02, Mathematisches Institut
und Institut fiir Angewandte Mathematik, Saarbriicken, Universitat des Saarlandes,
1973.
KLEENE, S.C., "Representation of events in nerve nets," in Automata Studies (C.E.
Shannon and J. McCarthy, eds.), pp. 3—40, Princeton: Princeton University Press,
1956.
KNUTH, D.E., "On the translation of languages from left to right," Information and
Control, 8, pp. 607-639, 1965.
KNUTH, D.E., "A characterization of parenthesis languages," Information and Control,
11, pp. 269-289, 1967.
KNUTH, D.E., "Fundamental Algorithms," Vol. I of The Art of Computer
Programming, Reading, Mass.: Addison-Wesley Publishing Co., 1973.
KNUTH, D.E., "Top-down syntax analysis," Acta Informatica, 1, pp. 79-110, 1971.
KNUTH, D.E., AND BIGELOW, R.H., "Programming languages for automata,"
Journal of the Association for Computing Machinery, 14, pp. 615-635, 1967.
KNUTH, D.E., MORRIS, J.H., AND PRATT, V.R., "Fast pattern-matching in strings,"
SIAM Journal on Computing, 6, pp. 323-350, 1977.
KNUTH, D.E., "Big omicron and big omega and big theta," SIGACT NEWS, 8, pp.
18-24,1976.
KORENJAK, A.J., "A practical method for constructing LR(k) processors,"
Communications of the Association for Computing Machinery, 12, pp. 613—623, 1969.
KORENJAK, A.J., AND HOPCROFT, J.E., "Simple deterministic languages,"
Conference Record of Seventh Annual Symposium on Switching and Automata Theory,
Berkeley, pp. 36-46, 1966.
KOSARAJU, S.R., "One-way stack automaton with jumps," Journal of Computer and
System Sciences, 9, pp. 164-176, 1974.
KOSARAJU, S.R., "Speed of recognition of context-free language by array-automata,"
SIAM Journal on Computing, 4, pp. 333-340, 1975.
KOSARAJU, S.R., "Context-free preserving functions," Mathematical Systems Theory,
9, pp. 193-197,1975.
KOSARAJU, S.R., "Recognition of context-free languages by random-access machines,"
unpublished manuscript, Fall, 1975.
KOZEN, D., "On parallelism in Turing machines," Proceedings of the 17th Annual
Symposium on Foundations of Computer Science, pp. 89—97, 1976.
KRAL, J., AND DEMNER, J., "A note on the number of states of the DeRemer's
recognizer," Information Processing Letters, 2, pp. 22-23, 1973.
KREIDER, D„ AND RITCHIE, R.E., "A basis theorem for a class of two-way
automata," Zeitschrift fiir Mathematische Logik und Grundlagen der Mathematik, 12,
pp. 243-255, 1966.
KURODA, S.Y., "Classes of languages and linear-bounded automata," Information
and Control, 7, pp. 207-223, 1964.
LALONDE, W.R., "On directly constructing LR(k) parsers without chain reductions,"
Conference Record of the Third ACM Symposium on Principles of Programming
Languages, pp. 127-133, 1976.
REFERENCES 575
LANDWEBER, P.S., "Three theorems on phrase-structure grammars of type 1,"
Information and Control, 6, pp. 131-136, 1963.
LANDWEBER, P.S., "Decision problems of phase-structure grammars," IEEE
Transactions on Electronic Computers, EC-13, pp. 354—362, 1964.
LEARNER, A., AND LIM, A.L., "A note on transforming grammars to Wirth—Weber
precedence form," Computer Journal, 12, pp. 142-144, 1970.
LEHMANN, D., "LR(k) grammars and deterministic languages," Israel Journal of
Mathematics, 10, pp. 526-530, 1971.
LENTIN, A., Equations dans les Monoides Libres. Paris: Gauthier—Villars, 1972.
LENTIN, A., AND SCHUTZENBERGER, M.P., "A combinatorial problem in the
theory of free monoids," in Combinatorial Mathematics and Its Applications, pp.
128-144, 1967; Proc. of conf. at Chapel Hill, N.C., April 10-14, 1967, Ed. by R.C.
Bose and T.A. Dowling. Chapel Hill: University of No. Carolina Press, 1969.
LEVI, F.W., "On semigroups," Bulletin of the Calcutta Mathematical Society, 36, pp.
141-146,1944.
LEWIS, P.M., Ill, AND ROSENKRANTZ, D.J., "An ALGOL compiler designed using
automata theory," Proceedings of a Symposium on Computers and Automata, Vol. 21.
New York: Polytechnic Institute of Brooklyn, 1971; pp. 75-88.
LEWIS, P.M., Ill, AND STEARNS, R.E., "Syntax-directed transductions," Journal of
the Association for Computing Machinery, 15, pp. 465—488, 1968.
LEWIS, P.M., Ill, STEARNS, R.E., AND HARTMANIS, J., "Memory bounds for
recognition of context-free and context-sensitive languages," IEEE Conference Record
on Switching Circuit Theory and Logical Design, Ann Arbor, Michigan, pp. 191—202,
1965.
LIPTON, R.J., AND ZALCSTEIN, Y., "Word problems solvable in log space," Journal
of the Association for Computing Machinery, 24, pp. 522—526, 1977.
LIU, L.Y., AND WEINER, P., "A characterization of semilinear sets," Journal of
Computer and System Sciences, 4, pp. 299-307, 1970.
LOMET, D.B., "A formalization of transition diagram systems," Journal of the
Association for Computing Machinery, 20, pp. 235-237, 1973.
LYNCH, N., "Log space recognition and translation of parenthesis languages," Journal
of the Association for Computing Machinery, 24, pp. 583-590, 1977.
LYNDON, R.C, AND SCHUTZENBERGER, M.P., "The equation aM = bNcp in a free
group," Michigan Mathematical Journal, 9, pp. 289-298, 1962.
MCNAUGHTON, R., "Parentheses grammars," Journal of the Association for
Computing Machinery, 14,pp. 490-500, 1967.
MCNAUGHTON, R., AND YAMADA, H., "Regular expressions and state graphs for
automata," IEEE Transactions on Electronic Computers, EC—9, pp. 39—47, 1960.
MCWHIRTER, LP., "Substitution expressions," Journal of Computer and System
Sciences, 5, pp. 629-637, 1971.
MAIBAUM, T.S.E., "A generalized approach to formal languages," Journal of
Computer and System Sciences, 8, pp. 409-439, 1974.
MARCUS, S., Introduction Mathematique a la Linguistique Structural. Paris: Dunod,
1967.
576 REFERENCES
MATTHEWS, G., "Discontinuity and asymmetry in phrase-structure grammars,"
Information and Control, 7, pp. 137-146, 1963.
MATTHEWS, G., "A note on asymmetry in phrase-structure grammars," Information
and Control, 7, pp. 360-365, 1964.
MATTHEWS, G., "Two-way languages," Information and Control, 10, pp. 111-119,
1967.
MAURER, H.A., "A direct proof of the inherent ambiguity of a simple context-free
language," Journal of the Association for Computing Machinery, 16, pp: 256—260,
1969.
MEHLHORN, K., "Bracket languages are recognizable in logarithmic space," Technical
Report A 75/12. Saarbriicken; Universitat des Saarlandes, 1975.
MEHTA, V., "Onward and upward with the arts: John is easy to please," New Yorker,
47, pp. 44-87, May 8, 1971.
MEYER, A.R., and FISCHER, M.J., "Economy of description by automata, grammars,
and formal systems," Conference Record of 1971 Annual Symposium on Switching
and Automata Theory, pp. 188-191, 1971.
MICKUNAS, M.D., "On the complete covering problem for LR(k) grammars," Journal
of the Association for Computing Machinery, 23, pp. 17—30, 1976.
MICKUNAS, M.D., LANCASTER, R.L., AND SCHNEIDER, B.B., "Transforming
LR(k) grammars to LR(1), SLR(l), and (1, 1) bounded right-context grammars,"
Journal of the Association for Computing Machinery, 23, pp. 1 7—30, 1976.
MINSKY, M.L., "Recursive unsolvability of Post's problem of 'Tag' and other topics in
the theory of Turing machines," Annals of Mathematics, 74, pp. 437—455, 1961.
MINSKY, M.L., AND PAPERT, S., "Unrecognizable sets of numbers," Journal of the
Association for Computing Machinery, 13, pp. 281—286, 1966.
MORSE, M., AND HEDLUND, G.A., "Unending chess, symbolic dynamics, and a
problem in semigroups," Duke Mathematical Journal, 11, pp. 1—7, 1944.
MUNRO, I., "Efficient determination of the transitive closure of a directed graph,"
Information Processing Letters, l,pp. 56—58, 1971.
MYHILL, J., "Finite automata and the representation of events," WADD Technical
Report 57—624, Wright-Patterson Air Force Base, November, 1957.
MYHILL, J., "Linear bounded automata," WADD Technical Note 60-165, Wright-
Patterson Air Force Base, 1960.
NELSON, C, "One-way automata on bounded languages," Technical Report TR-14-76,
Center for Research in Computing Technology, Harvard University, July, 1976.
NERODE, A., "Linear automaton transformations," Proceedings of the American
Mathematical Society, 9, pp. 541-544, 1958.
NIVAT, M., "Transductions des Langages de Chomsky," Ph.D. Thesis, University of
Paris, 1967.
NIVAT, M., "Sur les automates a memoire pile." Institut de Programmation, 1970.
NIVAT, M„ "On some families of languages related to the Dyck language," Institut de
Programmation, 1970.
NIVAT, M., "Congruences de Thue et Mangages," StudiaScientiarum Mathematicarum
Hungarica, 6, pp. 243-249, 1971.
REFERENCES 577
NIVAT, M., "On the interpretation of recursive program schemes," Rapport de
Recherche No. 84, Institut de Recherche d'Informatique et d'Automatique, 1974.
NIVAT, M., "Extensions et restrictions des grammaires algebriques," in Formal
Languages and Programming (R. Aguilar, editor), pp. 83—96, 1976.
OGDEN, W.F., "Intercalation Theorems for Pushdown Store and Stack Languages,"
Ph.D. thesis, Stanford University, 1968.
OGDEN, W.F., "A helpful result for proving inherent ambiguity," Mathematical
Systems Theory, 2, pp. 191-194, 1968.
PAGER, D., "A fast left-to-right parser for context-free grammars," Technical Report
PE240, Information Sciences Program, University of Hawaii, January, 1972.
PAIR, C, "Trees, pushdown stores, and compilation," Rev. Franq. Traitment Infor-
matique, Chiffres 7; 3, pp. 199-216, 1964.
PAIR, C, AND QUERE, A., "Definition et etude des bilangages reguliers," Information
and Control, 13, pp. 565-593, 1968.
PARIKH, R.J., "Language-generating devices," Quarterly Progress Report, No. 60,
Research Laboratory of Electronics, M.I.T., pp. 199-212, 1961.
PARIKH, R.J., "On context-free languages," Journal of the Association for Computing
Machinery, 13, pp. 570-581, 1966.
PATERSON, M.S., "Decision problems in computational models," in Proceedings of
the ACM Conference on Proving Assertions about Programs, Las Cruces, New Mexico,
1972.
PAULL, M.C., AND UNGER, S.H., "Structural equivalence of context-free grammars,"
Journal of Computer and System Sciences, 2, pp. 427—463, 1968.
PERROT, J.F., "Monoides syntactiques des langages algebriques," ^4 eta Informatica,
7, pp. 393-413, 1977.
PERROT, J.F., AND SAKAROVITCH, J., "Langages algebriques deterministes et
groupes abe'liens," Second GI Fachtagung, Automaten theorie und formate Sprachen,
Kaiserslautern, pp. 20—30, May 1975.
PETERS, P.S., AND RITCHIE, R.W., "Context-sensitive immediate constituent
analysis — context-free languages revisited," Conference Record of the ACM
Symposium on Theory of Computing, pp. 1—8, 1969.
PILLING, D.L., "Commutative regular equations and Parikh's theorem," Journal of
the London Mathematical Society (II) 6, pp. 663-666, 1973.
PIRICKA-KELEMENOVA, A., "Greibach normal-form complexity," in Mathematical
Foundations of Computer Science 1975 (J. Becvar, ed.), Vol. 32, "Lecture Notes in
Computer Science," pp. 344-350. Berlin: Springer-Verlag, 1975.
PLEASANTS, P.A.B., "Nonrepetitive sequences," Proceedings of the Cambridge
Philosophical Society, 68, pp. 261-21 A, 1970.
POST, E.L., "A variant of a recursively unsolvable problem," Bulletin of the American
Mathematical Society, 52, pp. 264-268, 1946.
PRATT, V.R., RABIN, M.O., AND STOCKMEYER, L.J., "A characterization of the
power of vector machines," Conference Record of the Sixth ACM symposium on
Theory of Computing, pp. 122-134, 1974.
PRATT, V., "LINGOL - a progress report," Fourth International Joint Conference on
Artificial Intelligence, Tbilisi, U.S.S.R., Vol. 1; 1975; pp. 422-428.
578 REFERENCES
PRESBURGER, M., "Uber die Vollstandigkeit eines gewissen Systems der Arithmetic
ganzer Zahlen in welchem die Addition als einzige Operation hervortritt," Sprawozdanie
z I Kongresu Matematykow Krajow Slowanskieb, Warsaw, pp. 92-101, 1930.
PUTZBACH, P., "Une famille de congruences de Thue pour lesquelles le probleme de
I'equivalence est decidable. Application a I'equivalence des grammaires separees," in
Automata, Languages, and Programming (M. Nivat, ed.), pp. 3—12. Amsterdam:
North-Holland Publishing Co., 1973.
RABIN, M.O., "Degree of difficulty of computing a function and a partial ordering of
recursive sets," Applied Logic Branch, Technical Report No. 2, Hebrew University,
Jerusalem, 1960.
RABIN, M.O., "Real-time computation," Israel Journal of Mathematics, 1, pp. 203—
211, 1963.
RABIN, M.O., AND SCOTT, D., "Finite automata and their decision problems," IBM
Journal of Research and Development, 3, pp. 114—125, 1959.
RAMSEY, F.P., "On a problem of formal logic," Proceedings of the London
Mathematical Society, 2nd Series, 30, pp. 264-286, 1930.
RANEY, G.N., "Functional composition patterns and power-series reversion,"
Transactions of the American Mathematical Society, 94, pp. 441-451, 1960.
REEDY, A., AND SAVITCH, W.J., "The Turing degree of the inherent ambiguity
problem for context-free languages," Theoretical Computer Science, 1, pp. 77-79,
1975.
RIORDAN, J., Combinatorial Identities. New York: John Wiley and Sons, Inc., 1968.
RITCHIE, R.W., "Classes of predictably computable functions," Transactions of the
American Mathematical Society, 106, pp. 139—173, 1963a.
RITCHIE, R.W., "Finite automata and the set of squares," Journal of the Association
for Computing Machinery, 10, pp. 528-531, 1963b.
RITCHIE, R.W., AND SPRINGSTEEL, F.N., "Language recognition by marking
automata," Information and Control, 20, pp. 313—330, 1972.
ROGERS, H., The Theory of Recursive Functions and Effective Computability. New
York: McGraw-Hill Book Co., 1967.
ROSENBERG, A.L., "On multihead finite automata," IBM Journal of Research and
Development, 10, pp. 388-394, 1966.
ROSENBERG, A.L., "A machine realization of the linear context-free languages,"
Information and Control, 10, pp. 175-188, 1967.
ROSENBERG, A.L., "Real-time definable languages," Journal of the Association
for Computing Machinery, 14, pp. 645—662, 1967.
ROSENBERG, A.L., "On the independence of realtime definability and certain
structural properties of context-free languages," Journal of the Association for
Computing Machinery, IS, 672-679, 1968.
ROSENBERG, A.L., "A note on ambiguity of context-free languages and presentations
of semilinear sets," Journal of the Association for Computing Machinery, 17, pp.
44-50, 1970.
ROSENKRANTZ, D.J., "Matrix equations and normal forms for context-free grammar."
Journal of the Association for Computing Machinery, 14, pp. 501—507, 1967.
REFERENCES 579
ROSENKRANTZ, D.J., "Programmed grammars and classes of formal languages,"
Journal of the Association for Computing Machinery, 16, pp. 107—131, 1969.
ROSENKRANTZ, D.J., AND LEWIS, P.M., Ill, "Deterministic left-corner parsing,"
Symposium on Switching and Automata Theory, pp. 139—152, 1970.
ROSENKRATZ, D.J., AND STEARNS, R.E., "Properties of deterministic top-down
grammars," Information and Control, 17, pp. 226—255, 1970.
ROUNDS, W.C., "Mappings and grammars on trees," Mathematical Systems Theory, 4,
pp. 257-287, 1970.
ROZENBERG, G., "Direct proofs of the undecidability of the equivalence problem
for sentential forms of linear context-free grammars and the equivalence problem for
OL systems," Information Processing Letters, 1, pp. 233—235, 1972.
RUOHONEN, K., "Some combinatorial mappings of words," Annates Academiae
Scientiarum Fennicae, Sec. A, Helsinki, 1976.
RYSER, H.J., "Combinatorial Mathematics," Vol. 14, Cams Monograph Series, The
Mathematical Association of America, 1963.
SALOMAA, A., Theory of Automata. New York: Pergamon Press, 1969a.
SALOMAA, A., "On grammars with restricted use of productions." Annales Academiae
Scientiarum Fennicae, Series A.I., 454, Helsinki, 1969b.
SALOMAA, A., "On the index of a context-free grammar and language," Information
and Control, 14, pp. 474-477, 1969c.
SALOMAA, A., "On some families of formal languages obtained by regulated
derivations," Annales Academiae Scientiarum Fennicae, Series A.I., 479. Helsinki,
1970.
SALOMAA, A., Formal Languages, New York: Academic Press, 1973a.
SALOMAA, A., "On sequential forms of context-free grammars," Acta Informatica, 2,
pp. 40-49, 1973b.
SANTOS, E.S., "A note on bracketed grammars," Journal of the Association for
Computing Machinery, 19, pp. 222-224, 1972.
SAVITCH, W.J., "Relationships between nondeterministic and deterministic tape
complexities," Journal on Computer and System Sciences, 4, pp. 177—192, 1970.
SAVITCH, W.J., "How to make arbitrary grammars look like context-free grammars,"
SIAM Journal on Computing, 2, pp. 174-182, 1973.
SAVITCH, W.J., "Maze-recognizing automata and nondeterministic tape complexity,"
Journal of Computer and System Sciences, 7, pp. 389—403, 1973.
SCHEINBERG, S., "Note on the boolean properties of context-free languages,"
Information and Control, 3, pp. 372-375, 1960.
SCHKOLNICK, M., "Two-tape bracketed grammars," Proceedings of the 9th Annual
Symposium on Switching and Automata Theory, pp. 315—326, 1968.
SCHUTZENBERGER, M.P., "A remark on finite transducers," Information and
Control, 4, pp. 185-196, 1961a.
SCHUTZENBERGER, M.P., "On the definition of a family of automata," Information
and Control, 4, pp. 245-270, 1961b.
SCHUTZENBERGER, M.P., "Certain elementary families of automata," in Proceedings
of the Symposium on Mathematical Theory of Automata, Polytechnic Institute of
Brooklyn, pp. 139-153, 1962a.
580 REFERENCES
SCHUTZENBERGER, M.P., "On a theorem of R. Jungen," Proceedings of the
American Mathematical Society, 13, pp. 885-890, 1962b.
SCHUTZENBERGER, M.P., "Finite counting automata," Information and Control, 5,
pp. 91-107, 1962c.
SCHUTZENBERGER, M.P., "On context-free languages and pushdown automata,"
Information and Control, 6, pp. 246—264, 1963.
SCHUTZENBERGER, M.P., Quelques Problemes Combinatories de la Theorie des
Automata; Course notes. Paris: Institut de Programmation, 1967.
SCHUTZENBERGER, M.P., "A remark on acceptable sets of numbers," Journal of
the Association for Computing Machinery, IS, pp. 300—303, 1968.
SCHUTZENBERGER, M.P., "Le theoreme de Lagrange selon Raney," in Logiques et
Automates. Rocquencourt: Seminaires IRIA, 1971.
SCHUTZENBERGER, M.P., "Une caracterisation des parties reconnaissables," in
Formal Languages and Programming (R. Aguilar, ed.), 1.976; pp. 77—82.
SCHUTZENBERGER, M.P., "Sur une caracterisation des fonctions sequentielles,"
Research Report 176, IRIA, 1976.
SCOTT, D., "Some definitional suggestions for automata theory," Journal of Computer
and System Sciences, l,pp. 187-212, 1967.
SEIFERAS, J.I., "A note on prefixes of regular languages," ACM SIGACT News,
pp. 25-29, January 1974.
SEIFERAS, J.I., "Techniques for separating space complexity classes" and "Relating
refined space complexity classes," Journal of Computer and System Sciences, 14,
pp. 73-99 and pp. 100-129, 1977.
SEIFERAS, J.I., AND MCNAUGHTON, R., "Regularity-preserving relations,"
Theoretical Computer Science, 2, pp. 147-154, 1976.
SEKIMOTO, S., MUKAI, K., AND SUDO, M., "A method of minimizing LR(k)
parsers," Systems, Computers, and Control, 4, pp. 73—80, 1973.
SEMONOV, A.L., "Algorithmic problems for power-series and context-free grammars,"
Doklady Akademii Nauk SSSR, 212, pp. 50-52, 1973. Translated into English in
Soviet Math, 14, pp. 1319-1322, 1973.
SHAMIR, E., "A representation theorem for algebraic and context-free power series in
noncommutating variables," Information and Control, 11, pp. 239—254, 1967.
SHAMIR, E., "Some inherently ambiguous context-free languages," Information and
Control, 18, pp. 355-363, 1971.
SHEPHERDSON, J.C., "The reduction of two-way automata to one-way automata,"
IBM Journal of Research and Development, 3, pp. 198-200, 1959.
SLISENKO, A.O., "Recognition of palindromes by multihead Turing machines,"
Proceedings of the Steklov Mathematical Institute, Acad, of Sciences of the U.S.S.R.,
129, pp. 30-202,1973.
SMITH, A.R., "Real-time language recognition by one-dimensional cellular automata,"
Journal of Computer and System Sciences, 6, pp. 233—253, 1972.
SMULLYAN, R.M., Theory of Formal Systems. Princeton: Princeton University Press,
1961.
STANAT, D.F., "A homomorphism theorem for weighted context-free grammars,"
Journal of Computer and System Sciences, 6, pp. 217-232, 1972.
REFERENCES 581
STANTON, R.G., Numerical Methods for Science and Engineering. Englewood Cliffs,
N.J.: Prentice-Hall, Inc., 1961.
STEARNS, R.E., "A regularity test for pushdown machines," Information and
Control, 11, pp. 323-340, 1967.
STEARNS, R.E., HARTMANIS, J., AND LEWIS, P.M., Ill, "Hierarchies of memory-
limited computations," Conference Record on Switching Circuit Theory and Logical
Design, pp. 191-202, 1965.
STRASSEN, V., "Gaussian elimination is not optimal," Numerische Mathematik, 13,
pp. 354-456, 1969.
SUDBOROUGH, I.H., "A note on tape-bounded complexity classes and linear context-
free languages," Journal ofthe Association for Computing Machinery, 22, pp. 499—500,
1975.
SUDBOROUGH, I.H., "On tape-bounded complexity classes and multihead finite
automata." Journal of Computer and System Sciences, 10, pp. 62—76, 1975.
SUDBOROUGH, I.H., "One-way multihead writing finite automata," Information and
Control, 30, pp. 1-20, 1976.
SUDBOROUGH, I.H., "On deterministic context-free languages, multihead automata,
and the power of an auxiliary pushdown store," Proceedings of the Eighth Annual
ACM Symposium on Theory of Computing, pp. 141 — 148, 1976.
SZYMANSKI, T.G., AND ULLMAN, J.D., "Evaluating relational expressions with
dense and sparse arguments," SIAM Journal on Computing, 6, pp. 109—122, 1977.
SZYMANSKI, T.G., AND WILLIAMS, J.H., "Noncanonical extensions of bottom-up
parsing techniques," SIAM Journal on Computing, 5, pp. 231-250, 1976.
TANIGUCHI, K., AND KASAMI, T., "A note on computing time for the recognition
of context-free languages by a single-tape Turing machine," Information and Control,
14, pp. 278-284, 1969.
THATCHER, J.W., "Characterizing derivation trees of a context-free grammar through
a generalization of finite-automata theory," Journal of Computer and System
Sciences, 1, pp. 317-322, 1967.
THATCHER, J.W., "Generalized 2-sequential transducers," Journal of Computer and
System Sciences, 4, pp. 339-367, 1970.
TOWNLEY, J.G., "The Measurement of Complex Algorithms," Ph.D. Thesis, Harvard
University, Cambridge, Mass., October 1972. Also available as Report TR 14—73,
Center for Research in Computing Technology, Harvard University.
TURING, A.M., "On computable numbers with an application to the Entscheidungs-
problem," Proceedings of the London Mathematical Society, 2—42, pp. 230-265,
1936.
ULLIAN, J., "Failure of a conjecture about context-free languages," Information and
Control, 9, pp. 61-65, 1966.
ULLIAN, J.S., "Partial-algorithm problems for context-free languages," Information
and Control, 11, pp. 80-101, 1967.
ULLMAN, J.D., "Halting stack automata," Journal of the Association for Computing
Machinery, 16, pp. 550-563, 1969.
582 REFERENCES
ULLMAN, J.D., "Applications of Language Theory to Compiler Design," in Theoretical
Computer Science (A.V. Aho, ed.). Englewood Cliffs, N.J.: Prentice-Hall, 1972.
ULLMAN, J.D., Fundamental Concepts of Programming. Reading, Mass.: Addison-
Wesley Publishing Co., 1976.
URPONEN, T., "On axiom systems for regular expressions and on equations involving
languages," Annales Universitatis Turkuensis, Series A, Turku, 1971.
URPONEN, T., "Equations with a Dyck-language solution," Information and Control,
30, pp. 21-37, 1976.
VALIANT, L.G., "Decision Procedures for Families of Deterministic Pushdown
Automata," Ph.D. Thesis, Department of Computer Science, University of Warwick,
1973.
VALIANT, L., "General context-free recognition in less than cubic time," Journal of
Computer and System Sciences, 10, pp. 308-315, 1975.
VALIANT, L.G., "Regularity and related problems for deterministic pushdown
automata," Journal of the Association for Computing Machinery, 22, pp. 1 — 10, 1975.
VALIANT, L.G., "A note on the succinctness of descriptions of deterministic
languages," Information and Control, 32, pp. 139—145, 1976.
VALIANT, L.G., AND PATERSON, M.S., "Deterministic one-counter languages,"
Journal of Computer and System Sciences, 10, pp. 340-350, 1975.
VAN LEEUWEN, J., "A generalization of Parikh's theorem in formal language theory,"
in Automata, Languages, and Programming (J. Loeckx, ed.), Vol. 14, "Lecture Notes
in Computer Science," pp. 17-26. Berlin: Springer-Verlag, 1974.
VAN LEEUWEN, J., AND SMITH, C.H., "An improved bound for detecting looping
configurations in deterministic pda's," Information Processing Letters, 3, pp. 22—24,
1974.
VAN LEEUWEN, J., "Variations of a new machine model," Proceedings of the 17th
Annual Symposium on Foundations of Computer Science, pp. 228—235, 1976.
WARSHALL, S., "A theorem on boolean matrices," Journal of the Association for
Computing Machinery, 9, pp. 11 — 12, 1962.
WEGBREIT, B., "A generator of context-sensitive languages," Journal of Computer
and System Sciences, 3, pp. 456—461, 1969.
WEICKER, R., "General context-free language recognition by a RAM with uniform-
cost criterion in time n2\o%n," Technical Report No. 182, The Pennsylvania State
University, 1976.
WILLIAMS, J.H., "Bounded-context parsable grammars," Information and Control,
28, pp. 314-334, 1975.
WIRTH, N., "PL 360 - a programming language for the 360 computer," Journal of
the Association for Computing Machinery, IS, pp. 37-74, 1968.
WIRTH, N., AND WEBER, H., "EULER, a generalization of ALGOL, and its formal
definition," Communications of the Association for Computing Machinery, 9, pp.
13-25, pp. 88-89, 1966.
WISE, D.S., "Generalized overlap-resolvable grammars and their parsers," Journal of
Computer and System Sciences, 6, pp. 538—572, 1972.
REFERENCES 583
WISE, D.S., "A strong pumping lemma for context-free languages," Theoretical
Computer Science, 3, pp. 359-369, 1976.
WOOD, D., "The normal-form theorem — another proof," The Computer Journal,
12, pp. 139-147, 1969a.
WOOD, D., "A note on top-down deterministic languages," BIT, 9, pp. 387-399,
1969b.
WOOD, D., "The theory of left-factored languages," The Computer Journal, 12,
pp. 349-356, 1969c, and 13, pp. 55-62, 1970.
WOOD, D., "A generalised normal-form theorem for context-free grammars," The
Computer Journal, 13, pp. 212—211, 1970.
WOOD, D., "A further note on top-down deterministic languages," The Computer
Journal, 14, pp. 396-403, 1971.
WOOD, D., "Some remarks on the KH algorithm for j-grammars," BIT, 13, pp. 476—
489, 1973.
WOODS, W.A., "Context-sensitive parsing," Communications of the Association for
Computing Machinery, 13, pp. 437-445, 1970.
WRATHALL, C, "Subrecursive predicates and automata," Ph.D. Thesis, Harvard
University, 1975. Also Research Report 56, Dept. of Computer Science, Yale University,
1975.
YAMADA, H., "Real-time computation and recursive functions not real-time
computable," IRE Professional Group on Electronic Computers, 11, pp. 753—760, 1962.
YAO, A.C., AND RIVEST, R.L., "K + 1 heads are better than K," Proceedings of the
17th Annual Symposium on Foundations of Computer Science, pp. 67—70, 1976.
YNTEMA, M.K., "Inclusion relations among families of context-free languages,"
Information and Control, 10, pp. 572-597, 1967.
YOUNGER, D.H., "Recognition and parsing of context-free languages in time n3,"
Information and Control, 10, pp. 189-208, 1967.
YU, Y., "Rudimentary Relations and Formal Languages," Ph.D. Dissertation,
University of California, Berkeley, 1970.
ZIMMER, R., "Soft precedence," Information Processing Letters, 1, pp. 108—110,
1972.
ndex
Aanderaa, Stal, 0., 297
Accept state of an LR style parser, 526, 528,
529, 547, 552
Acceptable class of binary trees, 451, 452, 455
Acceptable sequence of matrix elements, 449,
450
Acceptance by a
finite automaton, 46
pda with empty store, 139, 143-159
pda with empty store and final state, 139,
143-147, 158
pda with final state, 139, 143-147, 158, 160
Turing machine, 282, 285
a-transducer, 206
1-bounded, 212
Accessible pair in a dpda
(See Deterministic pushdown automaton)
Addison Wesley Publishing Co., ix
Aho, Alfred V., 44, 133, 423, 512
sf- 2/ Consistency, 554
Albert, Douglas, J., ix
ALGOL, 100, 219, 220
ALGOL 60, 219, 220
ALGOL 68, 221,
Algorithm, 247
Cocke-Kasami-Younger, 412, 430-442
on-line version, 433
to compute transitive closure, 462, 500
to decide if
a generates /3 in a context free grammar,
79
a generates /3 in a context-sensitive
grammar, 295
a context-free grammar is strict
deterministic, 348-350
a context-free language is empty, 79, 248
a context-free language is finite, 248
a context-free language is infinite, 248
a deterministic context-free language is
equal to a regular set, 249
a given string is in a context-free
language, 248
a given string is in a context-sensitive
language, 276
the null string is in a context-free
language, 99
a variable is reachable, 77
to eliminate
null rules, 98, 99, 103
chain rules, 101, 102
variables which do not generate terminal
strings, 74
to obtain
a left parse from a recognition matrix,
434
the minimal strict partition of a strict
584
INDEX 585
deterministic grammar, 348-350
to place a context-free grammar into
Chomsky normal form 104, 105
Greibach normal form 111-113, 127-129
invertible form, 107, 108
2-standard form, 116, 117
operator form, 122
to reduce a context-free grammar, 78, 96,
97
to test membership in C, or C2, 167
Valiant's, 442-470
Alphabet, 2
terminal, 13
Alt, Helmut, 500
Ambiguous context-free grammar, 27, 28, 43,
233-247, 260
Ambiguous context-free grammar of degree
k, 240
Ancestor, 31
Associativity, 2
Augmented grammar, 512 ALR(k) grammar
or language, 512, 513, 514, 525
Backtracking, 495
Backus, John W., 18
Backus-Naur form, 18
Backus normal form, 18
BNF, 18, 219
Baker, Brenda S., 331
Baker's theorem, 300-307
Bar-Hillel, Yehoshua, 44, 71, 91, 98, 133,
231, 232, 270
Beatty, John C, ix
Bikle, Dorian, ix
Binary relations, 4
Binary standard form, 106
Binary trees, 450-455
Birdie problems, 261, 270
Bit vector machine, 424, 429, 484, 485, 489
Blattner, Meera, 270
Block, 37, 264
Blum, Manuel, 297
BoaSson, Luc, 331
Book, Ronald V., 44, 297, 331, 416
Boolean algebra, 293
Boolean matrix, 428, 429
Boolean matrix multiplication, 426-430, 442,
446-448, 499, 500
Borodin, Alan, 297
Bottom-up parsing, 107
Bounded existential quantification, 295
Bounded regular set, 240
Bounded right context grammar or language,
515, 557, 558
Bounded set, 240, 262, 269, 270
Brainerd, Walter S„ 331
fl-node, 187-190
Cafarella, Mary A., ix
Cancellation
left, 3
right, 3
Canonical collection of sets of LR (k) items,
543, 545, 547, 553
Canonical cross section, 31, 508, 510, 515
level of, 31
Canonical dpda, 361-366, 378, 380
Canonical form of a form, 325, 326
Canonical generation or derivation
(See Generation)
Canonical grammar, 151, 152, 359, 360
Canonical sentential form, 27, 501-505
Canonical two form, 104, 106, 115, 122, 133,
355
Cardinality of a set, 32
Cartesian product of two semilinear sets, 231
Cauchy product, 132
Ceiling, 8
Central submatrix, 455, 456, 464
Central submatrix theorem, 456
Chain in a partially ordered set, 215
Chain rules, 98, 101-103
Chain-free context-free grammar, 107, 110
Checking problem for boolean matrix
multiplication, 499
Chomsky, Noam, 17-21, 71, 91, 133, 184,
296, 331
Chomsky hierarchy, 17-21
Chomsky normal form, 103-106, 113, 115,
132, 248, 355, 430, 433, 434, 444, 470,
488, 492, 493
Chomsky-Schutzenberger Theorem, 317
Clique, 35
Closure
of Aq.A,, and A2, 366
of deterministic languages, 341-346
Kleene, 3, 56
operations
(See Operations)
reflexive-transitive 4, 23, 24, 54
semigroup, 3
transitive, 4, 82, 417, 426-430, 442, 445,
446, 448, 456, 457, 461, 462, 470, 489
COBOL, 221
Cocke, John, 500
Cocke-Kasami-Younger Algorithm, 417, 430-
432, 444, 445, 471, 481, 488
Code, 213, 214
586 INDEX
Coding problem, 213
Coffman, Ralph L., ix
Commutative image, 226
Commutative set, 269, 270
Complement of a context-free language, 198,
206, 246
Complement of a semilinear set, 231
Complementation, 296, 381, 397
Complete graph, 35
Complete set of dotted rules
(See Dotted rules)
Completer, 472, 474, 483
Composition
of functions, 196
of relations, 4
Composition principle, 452, 455
Computation
of a tree automaton, 391
Concatenation, 2, 3, 11, 24, 344
Conjugate, 12
Consistent collection of sets of LR (k) items,
544-554
Consistent set of dotted rules
(See Dotted rules)
Context-free grammar or language, 18, 20,
23-31, 60-64, 73-91, 93-133, 148-160,
162, 165, 181, 185-270, 294, 295, 304-
307, 312-331, 417-558
Context-free preserving function, 196
Context-sensitive grammar or language, 18,
20, 21, 219, 271-297
Context-sensitive grammar with erasing, 17,
20-22, 272, 274, 275, 305
Converse, 30
Cook, Stephen A., 297
Correct prefix property, 557
Coset, 231
Counter automaton
(See Pushdown automaton)
Counter Language, 147, 179, 324
Cross section of a tree, 24, 30
Cycle-free context-free grammar, 418, 425,
486
Decision problems, 247-270, 275-277
Degenerate language, 516, 524
Degree of ambiguity, 103, 125, 240
Degree of direct ambiguity
(See Direct ambiguity)
Degree of a strict deterministic grammar or
language, 367, 374, 375, 392-394
Delay k in a pda
(See Pushdown automaton)
Derivation, 14
Derivation tree, 25, 27, 31, 233
Descendant, 189
immediate, 187, 188
Detection move, 361
Determinism, 21, 110, 280
D-acceptance, 167-169, 178
D-computations, 167, 175-178
Deterministic context-free language, 20, 21,
135, 139, 143, 158, 163-179, 184, 193,
197, 198, 209, 211, 212, 247, 249, 257-
259, 269, 289, 299, 307, 309-312 316,
323, 330, 333-416, 426, 499, 501, 512,
525, 554, 556, 557
Deterministic context-sensitive language, 294
Deterministic counter
(See Pushdown automaton)
Deterministic grammar, 391
Deterministic linear bounded automaton
(See Linear bounded automaton)
Deterministic iterated counter
(See Pushdown automaton)
Deterministic iterated counter language, 312
Deterministic pushdown automaton, 20, 139-
144, 146, 147, 161-178, 249, 255, 333,
355-374, 378-380, 393, 394, 515, 557
Deterministic pushdown automaton
accessible pair, 178
loop-free, 168-171, 178, 369
mode, 143
realtime, 147, 162
DSPACE, 287, 289, 290, 294, 296, 426
DTIME, 287
Deterministic Turing machine
(See Turing machine)
Diagonal
principal, 423
Diagonal relation
(See Relation)
Diagonalization, 276
Difference of a context-free language and a
regular set, 197, 198, 243
Direct ambiguity of a context-free grammar or
language, 242, 246, 269
degree, 242, 243
infinite, 242, 243
Dirichlet's principle, 32
Disjoint subwords, 234
D-node, 187
Distinguished position
(See Position)
Distinguishing pair, 348
terminal, 348, 392
Distributive laws, 446, 448, 455
Distributive property, 449
INDEX 587
$-augmented grammar or language, 513
%LR(k) grammar or language, 513, 514, 525
Dombroski, Caryn, ix
Dotted rule, 471-479, 482, 483-485
complete set of, 475, 477, 478
consistent set of, 475-482
Double Greibach form, 116
Dpda
(See deterministic pushdown automata)
Dyckset, 299, 312, 322, 323
Earley, Jay, 246, 500
Effective enumeration, 277, 280, 288
Eilenberg, Samuel, 71, 232
Elementary subtree, 24
Empty set, 79
Encoded messages, 213
Endmarkers, 70, 294, 333, 339
Englefriet, Joost, 270
EFFA function, 530
Erdos, Pal, 44
Equality problem, 394, 416
Equality relation
(See Relation)
Equations, 125-128
Equivalence
of deterministic pushdown automata, 139
of grammars, 14
of strings, 398
weak, 14
Equivalence relation
(See Relation)
Equivalence tree, 411-415
Error state of an LR style parser, 526, 528,
529, 547, 552, 553, 556
Evey, R. J., 184
Explicit Transformation, 295
Extended LR(k) theorem, 506, 507, 516, 524
Factorization, 452, 455
smallest, 453, 454
string, 186, 187, 190, 219, 233, 234, 236,
241
Fermat, Pierre de, 51
Fin, 211
Final state, 45, 59
Fine, Nathan J., 44
Finite Automata, 20, 45-47, 50, 52, 55, 57-59,
110, 163,249,258, 262
Finite-turn pushdown automaton
(See Pushdown automaton)
Finitely inherently ambiguous context-free
language, 240, 243, 245, 247, 268, 269
FIRST* function, 530
Fischer, Michael J., 133, 297
Fischer, Patrick C, 500
Floyd, Robert W.
Foderaro, John, ix
FOLLOW* function, 530
Form, 325, 326
Formal power series, 125-133, 240
FORTRAN, 220, 221
Friedman, Emily P., 416
Frontier of a tree
(See Tree)
Gallaire, Herve, 500
Gap theorem, 289
Geller, Matthew, M., ix, 416, 558
General two-type bracketed grammar, 325,
326
Generalized sequential machine, 206-209, 232,
234, 235, 244, 246, 280, 341
Generation, 14, 26
canonical, 26, 27
leftmost, 26, 27
rightmost, 26, 27
Generation tree, 30
Generators
(See Semigroup)
Grammar
(See Type)
Ginsburg, Seymour, 49, 184, 232, 246, 270,
297, 331,416
Goldstine, Jonathan, 232
goto function, 527, 528, 547, 548, 555
Graham, Susan L., ix, 417, 500, 558
(See Susan G. Harrison)
Grammatical tree, 25, 30, 31, 508
Graphs, 35
Gray, James N., 133
Greatest lower bound, 240
Greibach, Sheila A., 44, 133, 184, 232, 297,
327, 331, 416, 500
Greibach normal form, 111-116, 122, 125-133,
159, 353, 354, 394, 399, 557
Gries, David, 44
Group
finitely presented, 322
free, 322
linear, 324
Gruener, William B., ix
Gruska, Jozef, 133, 270
Gsm
(See Generalized sequential machine)
Haines, Leonard H., 184, 232
Half-block, 37-39
588 INDEX
Halting problem, 247, 250, 254
Handle, 501-505
Hardest context-free language, 300, 326, 417,
425
Hardest context-sensitive language, 296
Hardest deterministic context-free language,
426
Harrison, Anthony M., ix
Harrison, Craig A., v
Harrison, Michael A., iv, 133, 232, 331, 416,
417,500,558
Harrison, Susan G., v
(See Susan L. Graham)
Hartmanis, Juris, 71, 231, 270, 297, 500
Havel, Ivan M., ix, 416, 558
Height, 24
Hennie, Frederick C. Ill, 297
Henry, Robert, ix
Hibbard, Thomas N., 246, 331
Hierarchy of strict deterministic languages,
366
Homomorphism, 36, 57, 82, 85, 132, 162,
193, 199, 207, 208, 213, 244, 245, 280,
299,300, 307,310,311, 317,321,323,
326, 344, 381
inverse, 57, 208, 244, 246, 326-331, 341,
344
^-limited, 277, 278
lambda-free, 279
length preserving, 295
Hopcroft, John E., ix, 44, 133, 270, 416,
423
Hull, Richard B., ix
Hunsinger, Ronald A., 500
Hunt, Harry B., Ill, 133, 270, 297, 557
ID
(See Instantaneous description)
Identity, 2, 3, 322
Immediate descendant, 23
Immortal ID
(See Instantaneous description)
Inclusion problem, 394, 416
Incomparable elements, 214, 215, 217, 218
Index
of a derivation, 322, 323
of a context-free language, 323
finite, 323
leftmost, 323
Induced right congruence relation
(See Relation)
Inf, 240
Infinitely ambiguous context-free grammar,
240
Infinitely inherently ambiguous context-free
language, 240, 242
Inherently ambiguous context-free grammar
of degree k, 240, 242
Inherently ambiguous context-free language,
28, 233-247, 260, 330
Inherently ambiguous context-free language
of degree k, 240, 241, 269
lnit, 211, 246, 316, 327, 336-339
Initial instantaneous description of a pda, 137
Initial slate, 45
Input part, 549-552
Instantaneous description
of an LR style parser, 526, 528, 529
immortal, 164-171, 179
of a pushdown automaton, 137
of a two way finite automaton, 65
of a nondeterministic Turing machine, 281,
285
accepting, 282
initial, 282
of a two way pushdown automaton, 158,
159
Instruction set, 422, 424
Intersection, 366, 381, 397
of a context-free language and a regular set,
197
of two context-free languages, 198
of two semilinear sets, 231
Inverse, 30
Inverse gsm mappings, 208, 211, 244, 245,
280, 341
Inverse homomorphism
(See Homomorphism)
Inverse sequential transducer mappings, 209,
212
lnvertible context-free grammar, 107-110,
133, 354
IP
(See Input part)
Isomorphism
structural, 24, 383
Iterated counter automaton
(See Pushdown automaton)
Iterated counter language, 148, 312, 324
Iteration theorem, 185-194, 231, 236, 238,
242, 246, 333, 387
for A0, 388
for A2, 387
for regular sets, 47
for sequential forms, 191
Jones, Neil D., 297
Joy, William N., ix
INDEX 589
Karp, Richard, M„ 297
Kasami, Tadao, 500
Kernel of a free group, 322
King, Kimberly N., ix
Kleene, Stephen C, 57, 71
Kleene Operations, 355, 366
Kleene's theorem, 57-60, 85
/c-limited homomorphism
(See Homomorphism)
Knuth, Donald E., 331, 557, 558
K6nig, Denes, 217
K6nig infinity lemma, 217
Korenjak, Allen J., 416
Kosarju, S. Rao, 232
Kuroda, S. Y. 296
Label, 24
root, 24
Lagrange, Joseph L., 40-44
Lagrange inversion formula, 40-44
Lambda free context-free grammar, 103, 110,
111, 122-124
Lambda free pushdown automaton
(See Pushdown automaton)
Lambda free substitution
(See Substitution)
Lambda moves in a pushdown automaton,
136, 147, 159-162
Lambda-rules, 18, 98-100, 103, 471
Lambda-transitions, 373
Landweber, Peter S., 296, 297
Language, 14
Leaf, 24
Least upper bound, 240
Left(G), 305, 306
Left linear context-free grammar or language,
19, 20,64, 81
Leftmost generation or derivation
(See Generation)
Left parse, 434, 435
Left part, 382, 383, 508
Left part property, 383-386
Left part Theorem, 382, 384-387, 510
Left recursion, 93, 111, 148
Left recursive
grammar, 111, 113, 353
variable, 111, 112
LR parsers, 525-530
LR parsing, 501-558
LR (k) grammar or language, 20, 21, 501-558
LR (k) items, 530-544
LR(0) grammar or language, 509-511, 513-
525, 557
LR (0) language characterization theorem,
515-524, 558
Left-to-right order
(See Tree)
Length of a word, 2
Lentin, Andre, 44
Letter-equivalent, 227, 228
Levi, F. W., 5, 44
Lewis, Philip M., Ill, 500, 558
Linear, 296
Linear bounded automaton, 20, 21, 290-294,
296
deterministic, 293-295
Linear context-free grammar or language, 19,
20, 28, 29, 64, 82, 182, 183, 193, 206,
212, 221-225, 240, 242, 270, 296, 323,
441
Linear normal form, 64, 440-442
Linear set, 226, 231
Linear-time pushdown automaton
(See Pushdown automaton)
L n R theorem, 231
Lipton, Richard J., 331
LLR (k) grammar or language, 514, 557, 558
Log space, 324, 331
Logarithmic cost function, 424, 426
Lomet, David B.
Loop-free deterministic pushdown automaton
(See Deterministic pushdown automaton)
Lower bound, 240
-Lukasiewicz, Jan, 323
-Lukasiewicz language, 323, 324
Lynch, Nancy, 331
McNaughton, Robert, 71, 133, 331
Marked operations, 346, 366
Matrices, 132, 417
Matrix
multiplication of, 426-430, 446-448
representation, 132
strictly upper triangular, 423, 448, 456, 461,
462
transitively closed, 443, 456, 458, 459, 461
upper triangular, 423
Matthews, G. H., 331
Max, 346, 366, 381
Measurable function, 284
Mehlhorn, Kurt, 331, 500
Message set, 213
Metalinear grammar or language, 64, 206,
225, 270, 323
of width k, 225
Miller, George A., 71
Min, 346, 366, 516,517
Minimal elements in a partially ordered set,
590 INDEX
217,218
Minimal linear context-free grammar or
language, 29, 240, 242, 323
Minsky, Marvin, 331
Mode of a deterministic pushdown automaton
(See Deterministic pushdown automaton)
Moderate pushdown automaton
(See Pushdown automaton)
Modified Post correspondence problem, 251-
254, 395
Monoid, 3, 5
free, 5, 313
Monotone transformations, 400, 401, 405,
409, 410, 415
Monotonic grammar or language, 20-23, 272-
275, 290
Moura, Arnaldo, ix
Move
decreasing, 180, 181
increasing, 180-182
nondecreasing, 180-182
nonincreasing, 180-182
Move relation
of a pushdown automaton, 137
of a two way finite automaton, 65
MPCP
(See Modified Post Correspondence
Problem)
Mu function for word reduction, 313-317,
322, 327, 329, 330
Myhill, John, 53, 71, 296, 297
National Science Foundation, ix
Naur, Peter, 18
Nerode, Anil, 71
Nilpotent, 40
Nivat, Maurice, 232, 331
Node, 23, 24
internal, 24
lambda, 25, 382
nonterminal, 25
terminal, 25, 382
Nonassociativity, 428, 442, 444
Nondeterminism, 21, 280
jTS1, 280, 287-289
^^■-complete, 288
^T^.hard, 288
NSPACE, 290, 294, 296
NTIME, 287
Nondeterministic Turing machine
(See Turing machine)
Nonrepetitive words, 36-39
Nonterminal, 13
Nonterminal bounded context-free grammar
or language, 183, 184, 324
Nonterminal rewriting grammar or language,
272, 275, 300, 301, 305, 307
Normal forms for context-free grammars
binary standard form, 106
canonical two form, 104, 106, 115, 122,
133, 355
Chomsky normal form, 103-106
Greibach normal form, 111-116
operator normal form, 121-124, 133
Normalization of a form, 325, 326
Norms, 93-98
Notational conventions, 14
Null rules,
elimination of, 98
Null word
(See Word)
Off-line algorithm, 433
Off-line computation, 283
Ogden, William F., 231, 246
One-bounded
(See a-Transducer)
One letter alphabet, 194-196
One turn pushdown automaton, 20
On-line algorithm, 433, 483, 500
On-line computation, 283, 289, 440, 489, 498
OP
(See Output part)
Operation
closure, 55-57, 60, 80, 85, 164-178, 277-280
Operator
transpose, 4, 277
Operator grammar, 121-124, 133
Order
lexicographic, 10-12
partial, 10, 214-219, 240, 305
total, 10-12, 306
Order of magnitude, 96
Origin-crossing problem, 289
Output part, 549-552
Pairing lemma, 226, 229
Palindrome, 5
with a center marker, 139
even length, 5, 19, 141
with a center marker, 139
Parenthesis grammar or language, 133, 324,
325, 331
Parenthesis-free notation, 323
Parikh, Rohit J., 232, 246
Parikh mapping, 226
Parikh's theorem, 185, 225-232
Parser, 333
INDEX 591
Parsing, 417-558
Parsing action function, 527-529, 547, 548,
555
Partial order
(See Order)
Partial solution to the MPCP, 253
Partial transformation tree, 411
Partition, 347, 391
strict, 347, 348, 360, 367, 378, 383, 384,
386
maximal, 354
minimal, 378
PASCAL, 221
Path, 23, 24, 30
Pathological production, 514, 525
PCP
(See Post correspondence problem)
Pda
(See pushdown automaton)
Perles, Micha A., 91, 98, 133, 231, 232, 270
Permutation, 109
Phrase, 107, 234, 239
Phrase structure grammar or language, 13-23,
271-297, 305, 323
Piricka-Kemonova, Alica, 133
Pleasants, P. A. B., 44
Polish notation, 323
■£», 280, 287-290,296,297, 331
Polynomially reducible, 288
J^-SPACE, 287, 289
Position, 186, 188, 190
Post, Emil L., 270
Post Correspondence Problem, 247, 249-252,
254, 256, 258, 260, 270
Power series, 40, 41
Precedence analysis, 121
Predicate, 265, 266, 268
nontrivial, 265
Predictor, 471-473, 475, 477, 478, 483, 488
Prefix, 6, 7, 257, 347, 352, 383
Prefix-free set, 262, 333, 352, 355, 358, 386,
416
Presburger formulae, 231
Presburger set, 231
Prime, 50-52, 193, 194
Probert, Robert L., 500
Product
of sets, 3, 56, 366, 381, 397
Productions, 13
Programming languages, 219-221, 501
PL/I, 220, 221
Projection, 245, 344, 346
Proper erasing transition, 372
Pumping lemma, 190, 192, 193, 226, 231, 248
Pushdown automaton, 20, 21, 135-184, 225,
249, 311, 340
counter, 147
deterministic counter, 179
deterministic iterated counter, 179
finite-turn, 135, 179-184, 212, 262
iterated counter, 148, 312
lambda-free, 142, 160
linear time, 142, 143, 151, 158
moderate, 161, 162
one state, realtime, deterministic, 334, 393,
394
operating with delay k, 142, 143, 158, 160
quasi-realtime, 142, 143
realtime, 142, 143, 393
size of, 160-162, 166, 167
two way deterministic, 158, 159, 489
two way nondeterministic, 158, 159, 489,
499
unambiguous, 142, 143, 151, 243, 244
Pushdown store, 21, 97, 135-138, 179-183,
225, 311,312, 526
Quasi-inverse, 132
Quasi-realtime deterministic language, 376,
377
Quasi-realtime pushdown automaton
(See Pushdown automaton)
Quotient of sets, 50, 209-211, 232, 245, 333-
340,366, 381,416
Rabin, Michael O., 71, 297
RAM
(See Random access machine)
Ramsey, Frank. P., 31-36, 44
Ramsey's Theorem, 31-36
Random access machine, 94, 96, 422, 424,
426, 429, 430, 437, 485, 489, 499
Rank
of an equivalence relation, 51, 367
of a string in a nonterminal bounded
grammar, 183, 184
Rationally closed set of formal power series,
132
Reachable symbol, 76-78
Realtime pushdown automaton
(See Pushdown automaton)
Realtime strict deterministic grammar or
language, 333, 377-381, 393, 394
Realtime Turing machine, 288, 289
Recognition matrix, 430, 432-435, 437, 441,
442, 444, 477, 485
Recognition problem, 248, 280, 417-500
Recursive descent parsers, 111
592 INDEX
Simple grammar or language, 334, 392-416,
426
Simple machines, 392-398
Simple phrase, 234
Size
of a context-free grammar, 94, 98, 106,
129, 160
of a context-free language, 103
of a finite automaton, 110
of a pushdown automaton, 160-162, 166,
167
of a strict partition, 360, 367, 374, 392
Solvability, 247-249
SP
(See Stack part)
Space bounded Turing machine
(See Turing machine)
Space complexity, 284, 285, 425
Spanier, Edwin H., 184, 270
Speed-up theorem 288, 297
Springsteel, Fred N., 331
Stack
(See Pushdown store)
Stack bounded context-free language, 324
Stack part, 549-552
/^Standard form, 112, 116, 117
2-Standard form, 116-121, 122, 124, 132, 133,
162
Stanton, Ralph G., 44
Start symbol, 13
State, 45, 535
State graph, 46, 535
Stearns, Richard E., 297, 500, 558
Stencil, 108
Strassen, Volker, 500
Strict Deterministic grammar or language,
333, 346-394, 416, 509, 512, 515, 525
Strict Deterministic property of a tree
automaton, 391
Strict partition
(See Partition)
Strictly upper triangular matrix
(See Matrix)
String, 2
(See Word)
Strongly repetitive word, 40
Subsequence, 214, 217
Substitution
mapping, 82, 85, 280
lambda-free, 280
theorem, 82-85, 90
Subtree
elementary, 24
Subwords, 211, 246
Sudborough, Ivan H., 297, 500
Suffix, 6, 7, 347
Sup, 240
Supersequence, 217
Support, 125, 132
Suzuki, Ruth, ix
Sweep, 180-182
decreasing, 180, 181
increasing, 180, 181
Szerkeres, George, 44
Szymanski, Thomas G., 133, 551
Tables for LR style parsers, 526-528
Taniguchi, Kenichi, 500
Tape complexity
(See Space complexity)
Term, 449, 455, 460
minimal, 455, 459
Terminal alphabet, 13
Terminal bounded grammar or language,
300-307
Terms
formally distinct, 449, 460
Time bounded Turing machine
(See Turing machine)
Time complexity, 283, 284, 423, 425
Transduction, 213, 324
Transformation tree, 409-411
Transformations, 400, 411, 414
Transition function, 45, 46
Transition matrix, 334-338, 490, 491
o, 339, 340
Transition systems, 52-57, 60
Transitive closure
(See Closure)
Transpose
string, 4
set, 4, 55, 80, 81, 267, 344, 381, 397
Tree, 23-31, 381-386, 391
derivation, 25, 386, 387
frontier of, 24, 383-386
generation, 30
grammatical, 25, 30, 382, 386
height of, 23
internal node of, 24
leaf, 24
left-to-right order in, 24
minimal, 454
root of, 23, 384, 386
Tree automaton, 391
Tree structures, 30, 31
Trees
structurally isomorphic, 24
structural isomorphism of, 24
INDEX 593
Recursive function
total, 196, 258, 267, 288, 289
Recursive set, 21, 79, 257, 276, 277, 279, 288,
296, 311
Recursive variable, 98, 193, 249
Recursively enumerable set, 20, 21, 257, 282,
294, 299, 307, 310, 326
Reduce move, 544, 547, 552, 556
Reduced
context-free grammar, 73-79, 96, 97, 350,
386
form, 325, 326
word, 313
Reduction
closure of a matrix, 458
move, 36
matrix, 456-458, 460
Reference
dangling, 558
Refinement of an equivalence relation, 51
Reflexive-transitive closure
(See Closure)
Register, 422
Regular expression, 60
Regular relation, 213
Regular set, 20, 46-53, 57-60, 62-64, 70, 71,
81, 85-90, 132, 143, 163, 185, 193-210,
213, 214, 222-225, 228, 243, 249, 259,
268, 269, 295, 299, 317, 321-324, 334,
335, 340, 341, 344, 345, 355, 366, 381,
397
standard, 323
Relation
binary, 4, 367
congruence, 313, 322, 398
converse of, 30
diagonal, 4
equality, 4
equivalence, 12, 51, 375, 398
induced right congruence, 51, 70
relative right congruence, 367
right congruence, 51, 355
Remainder, 253
Representation theorems, 299-331
Response, 46
Revelle, John D., ix
Reverse Greibach form, 116
Rice, H. Gordon, 232
Right congruence relation
(See Relation)
Right linear context-free grammar or
language, 19, 20, 29, 60-64, 81, 193,
223
Right parse, 485
Right recursive
grammar. 111
variable, 111
Rightmost generation or derivation
(See Generation)
Ritchie, Robert W„ 331
Root, 12
label, 24
primitive, 12
Rose, Gene F., 232
Rosenberg, Arnold L., 71, 297, 416
Rosenkrantz, Daniel J., 133, 270
Rozenberg, Grzegorz, 270
Rudimentary sets, 295
Rule
(See Production), 13
Ruzzo, Walter L., ix, 417, 500
Ryser, Herbert J., 44
Salomaa, Arto, 44, 71, 270, 331
Sannella, Donald, ix
Santos, Eugene S., 331
Saturated letter, 379, 380
Sautter, Joan M., ix
Savitch, Walter J., 297
Savitch's theorem, 271, 286, 287, 289
Scanner, 472, 479, 483
Schkolnick, Mario, 331
Schutzenberger, Marcel P., 44, 133, -184, 331
Scott, Dana, 71
Self-embedding context-free grammar or
language, 85-90, 381
Semi-Dyck set, 299, 312-322, 324, 326, 327,
331, 345, 397, 525
Semigroup, 3, 5, 40
free, 5, 9, 213, 214
generation of, 5, 213
nilpotent, 40
Semilinear image, 221, 231
Semilinear set, 225-231
Sentence
Presburger, 231
Sentential form, 14, 190, 191, 261
Sequential machine, 246
Sequential transducer, 197-213
Sequential transducer theorem, 200-205, 244
Shamir, Eliahu, 71, 91, 98, 133, 231, 232,
242, 246, 270
Shank, Herberts., 71, 231
Shepherdson, John C, 71
Shift move, 544, 547, 556
Shoe box principle, 32
Shuffle, 206, 331
Simons, Barbara B., ix
594 INDEX
Triangles, 44
Turing, Alan M., 270
Turing machine, 20, 21, 247, 249, 250, 252,
257, 271, 311, 312, 324, 395, 422, 426,
437-440, 490-499
deterministic, 20, 147, 281, 282, 284-288,
292, 294
nondeterministic, 20, 280-282, 286, 287,
294, 331, 499
realtime, 288, 289, 333, 375, 376, 381,
416
tape bounded, 280-290, 297, 493-499
time bounded, 280-290, 297
Turn, 180-183
2-Standard form, 118-121
Two way finite automaton, 65-71
Two-way(G), 305, 306
Two way pushdown automaton
(See Pushdown automaton)
Type 0 grammar or language, 17, 20, 212-215
ucivLanguage, 224, 225
Ullian, Joseph, 246, 270
Ullman, Jeffrey D., 44, 133, 270, 416, 423,
512, 558
Ultimately periodic sequence, 49-50
Ultimately periodic set, 47-50, 195, 196, 369
Ultralinear context-free grammar or language,
181-184, 212, 270
Unambiguous context-free grammar or
language, 27, 62, 81, 82, 103, 110, 115,
151, 158, 197, 233, 234, 240, 243-246,
261, 269, 322, 326, 330, 354, 386, 387,
503-505, 514
Unambiguous pushdown automaton
(See Pushdown automaton)
Unbounded set, 262, 263, 268-270
Uniform cost criterion, 424, 426
Union, 366, 381, 397
Unique factorization theorem for LR (0)
languages, 524, 525
Unsolvable problems, 250, 252, 256-261, 269,
295
Upper bound, 240
Valiant, Leslie G., 417, 442, 500
Valiant's algorithm, 442-470, 489
Valiant's lemma, 449, 455, 458-460, 465, 467
Valid LR (k) item for a string, 538-543
Valid prefix, 536-538
Valid transformation, 400, 401, 405, 409, 410
Variables, 13
Viable prefix, 536-538
Vocabulary, 13
Wagoner, Neil, ix
Warshall, Stephen, 500
Warshall's algorithm, 429
Weight
of a phrase structure grammar, 22, 273, 274
of a phrase structure production, 273, 274
Width
of a context-free rule, 117-120
of a metalinear grammar, 225
Wilf, Herbert S., 44
Winkler, Timothy C, ix
Winograd, Shmuel, 500
Wise, David S., 231
Witness, 399, 407
shortest, 399, 408-410
Wood, Derick, 133
Word, 2
empty, 2
nonrepetitive, 36-39
null, 2
strongly repetitive, 40
Word problem for groups, 322, 324
Words
conjugate, 12
Yamada, Hisao, 71
Yehudai, Amiram, ix, 133, 416, 500
Yntema, Mary K., 331
Younger, Daniel H., 500
Yu, Yth Y. Y., 297
Zalcstein, Yechezkel, 331
Zero, 40
Zero-origin addressing, 423
<sentence> —*■ <subjectxpredicate>
<subject> —> <deterrniner>
<determiner> —> they
<predicate> -» <verb phrase>
<verb phrase> -* <verb><noun phrase>
<verb> —» are
<noun phrase> —* <adjective><noun>
<odjective> -* pumping
<noun> —»lemmings
ISBN 0-201-02955-3